From 1454d7851f2e7221ceedc44d223e5ebb33e9c110 Mon Sep 17 00:00:00 2001
From: Xingyu Wang <xingyu.wang@gmail.com>
Date: Fri, 31 Jan 2020 13:05:35 +0800
Subject: [PATCH 01/11] PRF
@robsean
---
...buntu- Important Things You Should Know.md | 83 +++++++++----------
1 file changed, 38 insertions(+), 45 deletions(-)
diff --git a/translated/tech/20200115 Root User in Ubuntu- Important Things You Should Know.md b/translated/tech/20200115 Root User in Ubuntu- Important Things You Should Know.md
index 6113f5aa4a..c09cc5b595 100644
--- a/translated/tech/20200115 Root User in Ubuntu- Important Things You Should Know.md
+++ b/translated/tech/20200115 Root User in Ubuntu- Important Things You Should Know.md
@@ -1,16 +1,18 @@
[#]: collector: (lujun9972)
[#]: translator: (robsean)
-[#]: reviewer: ( )
+[#]: reviewer: (wxy)
[#]: publisher: ( )
[#]: url: ( )
[#]: subject: (Root User in Ubuntu: Important Things You Should Know)
[#]: via: (https://itsfoss.com/root-user-ubuntu/)
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-Ubuntu 的 root 用户:你应该知道的重要事情
+Ubuntu 中的 root 用户:你应该知道的重要事情
======
-当你已经开始使用 Linux 时,你将发现与 Windows 的很多不同。其中一个‘不同的东西’是 root 用户的概念。
+![][5]
+
+当你刚开始使用 Linux 时,你将发现与 Windows 的很多不同。其中一个“不同的东西”是 root 用户的概念。
在这个初学者系列中,我将解释几个关于 Ubuntu 的 root 用户的重要的东西。
@@ -18,38 +20,32 @@ Ubuntu 的 root 用户:你应该知道的重要事情
你将在这篇文章中学到下面的内容:
- * [为什么在 Ubuntu 中禁用 root 用户][1]
- * [像 root 用户一样使用命令][2]
- * [切换为 root 用户][3]
- * [解锁 root 用户][4]
-
-
+* 为什么在 Ubuntu 中禁用 root 用户
+* 像 root 用户一样使用命
+* 切换为 root 用户
+* 解锁 root 用户
### 什么是 root 用户?为什么它在 Ubuntu 中被锁定?
-![][5]
+在 Linux 中,有一个称为 [root][6] 的超级用户。这是超级管理员账号,它可以做任何事以及使用系统的一切东西。它可以在你的 Linux 系统上访问任何文件和运行任何命令。
-在 Linux 中,这里总是有一个称为 [root][6] 的超级用户。这是超级管理员账号,它可以做任何事以及使用系统的一切东西。它可以在你的 Linux 系统上访问任何文件和运行任何命令。
+能力越大,责任越大。root 用户给予你完全控制系统的能力,因此,它应该被谨慎地使用。root 用户可以访问系统文件,运行更改系统配置的命令。因此,一个错误的命令可能会破坏系统。
-能力越大,责任越大。root 用户给予你完全控制系统,因此,它应该被谨慎地使用。root 用户可以访问系统文件,运行更改系统配置的命令。因此,一个错误的命令可能会破坏系统。
+这就是为什么 [Ubuntu][7] 和其它基于 Ubuntu 的发行版默认锁定 root 用户,以从意外的灾难中挽救你的原因。
-这就是为什么 [Ubuntu][7] 和其它基于 Ubuntu 的发行版默认锁定 root 用户以从意外的灾难中挽救你的原因。
+对于你的日常任务,像移动你家目录中的文件,从互联网下载文件,创建文档等等,你不需要拥有 root 权限。
-对于你的日常任务,像移动你 home 目录中的文件,从因特网下载文件,创建文档等等,你不需要拥有 root 权限。
+**打个比方来更好地理解它。假设你想要切一个水果,你可以使用一把厨房用刀。假设你想要砍一颗树,你就得使用一把锯子。现在,你可以使用锯子来切水果,但是那不明智,不是吗?**_
-_**打个比方来更好地理解它。假设你不得不切一个水果,你使用一把厨房用刀。假设你不得不砍一颗树,你不得不使用一把锯子。现在,你可以使用锯子来切水果,但是那不明智,不是吗?**_
+这意味着,你不能是 Ubuntu 中 root 用户或者不能使用 root 权限来使用系统吗?不,你仍然可以在 `sudo` 的帮助下来拥有 root 权限来访问(在下一节中解释)。
-这意味着,你不能是 Ubuntu 中 root 用户,或者不能使用 root
-权限来使用系统?不,你仍然可以在 ‘sudo’ 的帮助下来拥有 root 权限来访问(在下一节中解释)。
-
-**底线:
-**使用于常规任务,root 用户权限太过强大。这就是为什么不建议一直使用 root 用户。你仍然可以使用 root 用户来运行特殊的命令。
+> **要点:** 使用于常规任务,root 用户权限太过强大。这就是为什么不建议一直使用 root 用户。你仍然可以使用 root 用户来运行特殊的命令。
### 如何在 Ubuntu 中像 root 用户一样运行命令?
![Image Credit: xkcd][8]
-对于一些系统的特殊任务来说,你将需要 root 权限。例如。如果你想[通过命令行更新 Ubuntu ][9],你不能作为一个常规用户运行该命令。它将给予你权限被拒绝的错误。
+对于一些系统的特殊任务来说,你将需要 root 权限。例如。如果你想[通过命令行更新 Ubuntu][9],你不能作为一个常规用户运行该命令。它将给出权限被拒绝的错误。
```
apt update
@@ -60,41 +56,38 @@ W: Problem unlinking the file /var/cache/apt/pkgcache.bin - RemoveCaches (13: Pe
W: Problem unlinking the file /var/cache/apt/srcpkgcache.bin - RemoveCaches (13: Permission denied)
```
-那么,你如何像 root 用户一样运行命令?简单的答案是,在命令前添加 sudo ,来像 root 用户一样运行。
+那么,你如何像 root 用户一样运行命令?简单的答案是,在命令前添加 `sudo`,来像 root 用户一样运行。
```
sudo apt update
```
-Ubuntu 和很多其它的 Linux 发行版使用一个被称为 sudo 的特殊程序机制。Sudo 是一个像 root 用户(或其它用户)一样来控制运行命令访问的程序。
+Ubuntu 和很多其它的 Linux 发行版使用一个被称为 `sudo` 的特殊程序机制。`sudo` 是一个以 root 用户(或其它用户)来控制运行命令访问的程序。
-实际上,Sudo 是一个非常多用途的工具。它可以配置为允许一个用户像 root 用户一样来运行所有的命令,或者仅仅一些命令。你也可以配置是否一些命令需要密码,或者不使用 sudo 去运行命令。它是一个广泛的主题,也许我将在另一篇文章中详细讨论它。
+实际上,`sudo` 是一个非常多用途的工具。它可以配置为允许一个用户像 root 用户一样来运行所有的命令,或者仅仅一些命令。你也可以配置为无需密码即可使用 sudo 运行命令。这个主题内容比较丰富,也许我将在另一篇文章中详细讨论它。
-就目前而言,你应该知道 [当你安装 Ubuntu 时][10] ,你必需创建一个用户账号。这个用户账号在你系统上作为管理员工作,在 Ubuntu 中作为一个默认的 sudo 策略,它可以在你的系统上使用 root 用户权限来运行任何命令。
+就目前而言,你应该知道[当你安装 Ubuntu 时][10],你必须创建一个用户账号。这个用户账号在你系统上以管理员身份来工作,并且按照 Ubuntu 中的默认 sudo 策略,它可以在你的系统上使用 root 用户权限来运行任何命令。
-sudo 的问题是,运行 **sudo 不需要 root 用户密码,而是需要用户自己的密码**。
+`sudo` 的问题是,运行 **sudo 不需要 root 用户密码,而是需要用户自己的密码**。
-并且这就是为什么当你使用 sudo 运行一个命令,会要求正在运行 sudo 命令的用户的密码的原因:
+并且这就是为什么当你使用 `sudo` 运行一个命令,会要求输入正在运行 `sudo` 命令的用户的密码的原因:
```
[email protected]:~$ sudo apt update
[sudo] password for abhishek:
```
-正如你在上面示例中所见 _abhishek_ 在尝试使用 _sudo_ 来运行 ‘apt update’ 命令,系统要求 _abhishek_ 的密码。
+正如你在上面示例中所见 `abhishek` 在尝试使用 `sudo` 来运行 `apt update` 命令,系统要求输入 `abhishek` 的密码。
-如果你对 Linux 完全不熟悉,当你在终端中开始输入密码时,你可能会惊讶,在屏幕上什么都没有发生。这是十分正常的,因为作为默认的安全功能,在屏幕上什么都不会显示。甚至星号(*)都没有。你输入你的密码并按 Enter 键。
+**如果你对 Linux 完全不熟悉,当你在终端中开始输入密码时,你可能会惊讶,在屏幕上什么都没有发生。这是十分正常的,因为作为默认的安全功能,在屏幕上什么都不会显示。甚至星号(`*`)都没有。输入你的密码并按回车键。**
-**底限:
-**为在 Ubuntu 中像 root 用户一样运行命令,在命令前添加 sudo 。
-当被要求输入密码时,输入你的账户的密码。
-当你在屏幕上输入密码时,什么都看不到。请保持输入密码,并按 Enter 键。
+> **要点:**为在 Ubuntu 中像 root 用户一样运行命令,在命令前添加 `sudo`。 当被要求输入密码时,输入你的账户的密码。当你在屏幕上输入密码时,什么都看不到。请继续输入密码,并按回车键。
### 如何在 Ubuntu 中成为 root 用户?
-你可以使用 sudo 来像 root 用户一样运行命令。但是,在某些情况下,你必需像 root 用户一样来运行一些命令,而你总是忘了在命令前添加 sudo ,那么你可以临时切换为 root 用户。
+你可以使用 `sudo` 来像 root 用户一样运行命令。但是,在某些情况下,你必须以 root 用户身份来运行一些命令,而你总是忘了在命令前添加 `sudo`,那么你可以临时切换为 root 用户。
-sudo 命令允许你来模拟一个 root 用户登录的 shell ,使用这个命令:
+`sudo` 命令允许你来模拟一个 root 用户登录的 shell ,使用这个命令:
```
sudo -i
@@ -108,19 +101,19 @@ root
[email protected]:~#
```
-你将注意到,当你切换为 root 用户时,shell 命令提示符从 $ (美元按键符号)更改为 # (英镑按键符号)。这使我开了一个(拙劣的)玩笑,英镑比美元强大。
+你将注意到,当你切换为 root 用户时,shell 命令提示符从 `$`(美元符号)更改为 `#`(英镑符号)。我开个(拙劣的)玩笑,英镑比美元强大。
-_**虽然我已经向你显示如何成为 root 用户,但是我必需警告你,你应该避免作为 root 用户使用系统。毕竟它有阻拦你使用 root 用户的原因。**_
+**虽然我已经向你显示如何成为 root 用户,但是我必须警告你,你应该避免作为 root 用户使用系统。毕竟它有阻拦你使用 root 用户的原因。**
-另外一种临时切换为 root 用户的方法是使用 su 命令:
+另外一种临时切换为 root 用户的方法是使用 `su` 命令:
```
sudo su
```
-如果你尝试使用不带有的 sudo 的 su 命令,你将遇到 ‘su authentication failure’ 错误。
+如果你尝试使用不带有的 `sudo` 的 `su` 命令,你将遇到 “su authentication failure” 错误。
-你可以使用 exit 命令来恢复为正常用户。
+你可以使用 `exit` 命令来恢复为正常用户。
```
exit
@@ -132,13 +125,13 @@ exit
Linux 给予你在系统上想做什么就做什么的自由。解锁 root 用户就是这些自由之一。
-如果,出于某些原因,你决定启用 root 用户,你可以通过为其设置一个密码来做到:
+如果出于某些原因,你决定启用 root 用户,你可以通过为其设置一个密码来做到:
```
sudo passwd root
```
-再强调一次,不建议使用 root 用户,并且我不支持你在你的桌面上也这样做。如果你忘记密码,你将不能再次 [在 Ubuntu 中更改 root 用户密码][11] 。
+再强调一次,不建议使用 root 用户,并且我也不鼓励你在桌面上这样做。如果你忘记了密码,你将不能再次[在 Ubuntu 中更改 root 用户密码][11]。(LCTT 译注:可以通过单用户模式修改。)
你可以通过移除密码来再次锁定 root 用户:
@@ -146,9 +139,9 @@ sudo passwd root
sudo passwd -dl root
```
-**最后…**
+### 最后…
-我希望你现在对 root 概念有稍微更好一点的理解。如果你仍然有些关于它的困惑和问题,请在评论中让我知道。我将尝试回答你的问题,并且也可能更新这篇文章。
+我希望你现在对 root 概念理解得更好一点。如果你仍然有些关于它的困惑和问题,请在评论中让我知道。我将尝试回答你的问题,并且也可能更新这篇文章。
--------------------------------------------------------------------------------
@@ -157,7 +150,7 @@ via: https://itsfoss.com/root-user-ubuntu/
作者:[Abhishek Prakash][a]
选题:[lujun9972][b]
译者:[robsean](https://github.com/robsean)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
From a19775aa4ab437de30b3433f471144d12fd518a0 Mon Sep 17 00:00:00 2001
From: Xingyu Wang <xingyu.wang@gmail.com>
Date: Fri, 31 Jan 2020 13:06:09 +0800
Subject: [PATCH 02/11] PUB
@robsean
https://linux.cn/article-11837-1.html
---
...5 Root User in Ubuntu- Important Things You Should Know.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
rename {translated/tech => published}/20200115 Root User in Ubuntu- Important Things You Should Know.md (99%)
diff --git a/translated/tech/20200115 Root User in Ubuntu- Important Things You Should Know.md b/published/20200115 Root User in Ubuntu- Important Things You Should Know.md
similarity index 99%
rename from translated/tech/20200115 Root User in Ubuntu- Important Things You Should Know.md
rename to published/20200115 Root User in Ubuntu- Important Things You Should Know.md
index c09cc5b595..0abc566f4b 100644
--- a/translated/tech/20200115 Root User in Ubuntu- Important Things You Should Know.md
+++ b/published/20200115 Root User in Ubuntu- Important Things You Should Know.md
@@ -1,8 +1,8 @@
[#]: collector: (lujun9972)
[#]: translator: (robsean)
[#]: reviewer: (wxy)
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11837-1.html)
[#]: subject: (Root User in Ubuntu: Important Things You Should Know)
[#]: via: (https://itsfoss.com/root-user-ubuntu/)
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
From 6a5097dc4e770a30f3cdaf41757487aeaa83a6d5 Mon Sep 17 00:00:00 2001
From: LazyWolf Lin <LazyWolfLin@gmail.com>
Date: Fri, 31 Jan 2020 14:01:22 +0800
Subject: [PATCH 03/11] Translating.
---
.../tech/20200126 What-s your favorite Linux distribution.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/sources/tech/20200126 What-s your favorite Linux distribution.md b/sources/tech/20200126 What-s your favorite Linux distribution.md
index 029a4272e8..c1f4ab4688 100644
--- a/sources/tech/20200126 What-s your favorite Linux distribution.md
+++ b/sources/tech/20200126 What-s your favorite Linux distribution.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (LazyWolfLin)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
@@ -43,7 +43,7 @@ via: https://opensource.com/article/20/1/favorite-linux-distribution
作者:[Opensource.com][a]
选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
+译者:[LazyWolfLin](https://github.com/LazyWolfLin)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
From d822d1f0e947d59c7248ded6c1b47b8892a39ffc Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=E8=90=8C=E6=96=B0=E9=98=BF=E5=B2=A9?=
<31788564+mengxinayan@users.noreply.github.com>
Date: Fri, 31 Jan 2020 06:31:15 -0800
Subject: [PATCH 04/11] Update & Translating
File name: 20200129 Showing memory usage in Linux by process and user.md
Translator: mengxinayan
---
...00129 Showing memory usage in Linux by process and user.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/sources/tech/20200129 Showing memory usage in Linux by process and user.md b/sources/tech/20200129 Showing memory usage in Linux by process and user.md
index 8e21baf042..85c6fcb4ea 100644
--- a/sources/tech/20200129 Showing memory usage in Linux by process and user.md
+++ b/sources/tech/20200129 Showing memory usage in Linux by process and user.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (mengxinayan)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
@@ -180,7 +180,7 @@ via: https://www.networkworld.com/article/3516319/showing-memory-usage-in-linux-
作者:[Sandra Henry-Stocker][a]
选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
+译者:[mengxinayan](https://github.com/mengxinayan)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
From 4c90885ba1d4629c74a65cca4014d94e062d283d Mon Sep 17 00:00:00 2001
From: DarkSun <lujun9972@gmail.com>
Date: Sat, 1 Feb 2020 00:58:43 +0800
Subject: [PATCH 05/11] =?UTF-8?q?=E9=80=89=E9=A2=98:=2020200131=205=20ways?=
=?UTF-8?q?=20to=20use=20Emacs=20as=20your=20RPG=20dashboard?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
sources/tech/20200131 5 ways to use Emacs as your RPG dashboard.md
---
...ways to use Emacs as your RPG dashboard.md | 182 ++++++++++++++++++
1 file changed, 182 insertions(+)
create mode 100644 sources/tech/20200131 5 ways to use Emacs as your RPG dashboard.md
diff --git a/sources/tech/20200131 5 ways to use Emacs as your RPG dashboard.md b/sources/tech/20200131 5 ways to use Emacs as your RPG dashboard.md
new file mode 100644
index 0000000000..b1d7c6923d
--- /dev/null
+++ b/sources/tech/20200131 5 ways to use Emacs as your RPG dashboard.md
@@ -0,0 +1,182 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (5 ways to use Emacs as your RPG dashboard)
+[#]: via: (https://opensource.com/article/20/1/emacs-rpgs)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+5 ways to use Emacs as your RPG dashboard
+======
+Emacs is a flexible way to organize and manage your tabletop
+role-playing games.
+![Chess pieces on a chess board][1]
+
+There are two ways to play a tabletop role-playing game (RPG): You can play an adventure written by the game's publisher or an independent author, or you can play an adventure that is made up as you go. Regardless of which you choose, there's probably prep work to do. One player (generically called the _game master_) must gather monster or enemy stats, loot tables, and references for rules, and the other players must build characters and apportion (pretend) equipment. Nothing's going to eliminate prep work from a complex RPG, but if you're an [Emacs][2] user, you might find that Emacs makes a great dashboard to keep everything all straight.
+
+### Organize the rules
+
+Unfortunately, the digital editions of many RPGs are distributed as PDFs because that's what the RPG publisher sent to the printer for the physical edition. PDFs are good at preserving layout, but they're far from an ideal eBook format. If you play RPGs published under an open license, you can often obtain the rules in alternate formats (such as HTML), which gives you more control and flexibility. Even the world's first and most famous RPG, Dungeons & Dragons, provides its rules as a free download in digital format (which has been translated into HTML and Markdown by many a website).
+
+I open the rules as Markdown in Emacs so that I have a searchable reference at the ready. While opening the rules as a PDF in a PDF reader lets you search for embedded text, using a text file instead provides several benefits. First of all, a text file is much smaller than a PDF, so it's faster to load and to search. Second, text files are easily editable, so if you find a rule that sends you seeking clarification, you can add what you learn (or whatever you make up) directly into your master document. You can also add house rules and additional resources. My aim is to have a single file that contains all of the rules and resources I use in games I run, with everything a quick **Ctrl+s** (**C-s** in Emacs notation) away.
+
+### Manage initiatives
+
+Most RPG systems feature a method to determine the order of play during combat. This is commonly called _initiative_, and it comes up a lot since the source of conflict in games often involves combat or some kind of opposed competitive action. It's not that hard to keep track of combat with pencil and paper, but in games where I'm using digital assets anyway, I find it easier to stay digital for everything. Luckily, the venerable [Org mode][3] provides an excellent solution.
+
+When players roll for initiative, I type their names into Emacs' scratch buffer. Then I type each monster or enemy, along with the hit or health points (HP) of each, followed by two columns of 0:
+
+
+```
+brad
+emily
+zombie 22 0 0
+zombie 22 0 0
+flesh-golem 93 0 0
+```
+
+Then I select the block of player characters (PCs) and monsters and use the **org-table-create-or-convert-from-region** function to create an Org mode table around it. Using **Alt+Down arrow** (**M-down** in Emacs notation), I move each PC or monster into the correct initiative order.
+
+
+```
+| emily | | | |
+| flesh-golem | 93 | 0 | 0 |
+| zombie | 22 | 0 | 0 |
+| brad | | | |
+| zombie | 22 | 0 | 0 |
+```
+
+During combat, I only need to record damage for monsters, because the players manage their own HP. For the enemies I control in combat, the second column is its HP (its starting number is taken from the RPG system's rules), and the third is the damage dealt during the current round.
+
+Table formulas in Org mode are defined on a special **TBLFM** line at the end of the table. If you've used any computerized spreadsheet for anything, [Org table][4] will be fairly intuitive. For combat tracking, I want the third column to be subtracted from the second. Columns are indexed from left to right (**$1** for the first, **$2** for the second, and **$3** for the third), so to replace the contents of column $2 with the sum of columns $2 and $3, I add this line to the bottom of the table:
+
+
+```
+`#+TBLFM: $2=vsum($2 - $3)`
+```
+
+I don't actually type that into Emacs every time the game enters combat mode. Instead, I've defined an auto-completion trigger with Emacs' [abbrev mode][5], a system that allows you to type in a special string of your choosing, which Emacs expands into something more complex. I define my abbreviations in a file called **~/.emacs.d/abbrev_defs**, using **rpgi** followed by a **Space** as the trigger for Emacs to change the line to my initiative table formula:
+
+
+```
+(define-abbrev-table 'global-abbrev-table
+ '(
+ ("rpgi" "#+TBLFM: $2=vsum($2 - $3)" nil 0)
+ ))
+```
+
+Each time a player deals damage to a monster, I enter the amount of damage in the damage column. To trigger a table recalculation, I press **Ctrl+u Ctrl+c** (i.e., **C-u C-c** in Emacs) or **Ctrl+c Ctrl+c** (i.e., **C-c C-c**) if I happen to be on the formula line:
+
+
+```
+| brad | | |
+| emily | | |
+| zombie | 12 | 10 |
+| zombie | 15 | 7 |
+| flesh-golem | 91 | 2 |
+#+TBLFM: $2=vsum($2 - $3)
+```
+
+This system isn't perfect. Character names can't contain any spaces because Org table splits cells by white space. It's relatively easy to forget that you processed one line and accidentally reprocess it at the end of a round. To add HP back to a creature's total, you have to use a negative number. (I think of it as negative damage, which suggests health.) Then again, many computerized initiative trackers suffer the same problems, so it's not a particularly bad solution. For me, it's one of the faster methods I've found (I'm happy to admit that [MapTool][6] is the best, but I use my Emacs workflow when I'm not using a digital shared map).
+
+### View PDFs in DocView
+
+Sometimes a PDF is unavoidable. Whether it's a d100 list of tavern names or a dungeon map, some resources exist only as a PDF with no extractable text data. In these cases, Emacs' [DocView][7] package can help. DocView is a mode that loads PDF data and generates a PNG file for you to view (Emacs can also view JPEG files). I've found that large PDFs are problematic and slow, but if it's a low-resolution PDF with just one or two pages, DocView is an easy way to reference a document without leaving Emacs.
+
+I use this mode exclusively for maps, tables, and lists. It's not useful for anything that might involve searching, because text data isn't accessible, but it's an amazingly useful feature for documents you only need to glance at.
+
+![Emacs for RPG][8]
+
+The [Ghostscript][9] suite that ships with most Linux distributions (or certainly is available in your repository) allows you to process PDFs, drastically simplifying them by lowering the resolution of images from print quality to screen quality. The command contains mostly PostScript commands and attributes, but you don't need to become a PostScript expert to perform a quick down-res:
+
+
+```
+$ gs -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 \
+-dPDFSETTINGS=/ebook -dNOPAUSE -dBATCH \
+-sOutputFile=adventure.pdf \
+-dDownsampleColorImages=true \
+-dColorImageResolution=72 big-adventure-module.pdf
+```
+
+Opening PDFs in Emacs isn't as exciting as it may sound. It's not by any means a first-class PDF viewer, but for select resources, it can be a convenient way to keep all your information on one screen.
+
+### Create adventure rap sheets
+
+Published adventures are often heavy on prose. The theory is that you've paid a lot of money for a prepared adventure, so you obviously want value for your purchase. I do value the lore and world-building that authors put into their adventures, but during a game, I like to have a quick reference to the information I need for the game mechanics to work as intended. In other words, I don't need to have the story of why a trap was placed in a dungeon when a rogue triggers it; I only need to know that the trap exists and what the rogue needs to roll in order to survive.
+
+I haven't found any modern adventure format that provides me with just that information, so I end up creating my own "rap sheets": a minimal outline for the adventure, with just the game mechanics information I need for each location. Once again, Org mode is the best way for me to keep this information handy.
+
+In Org mode, you create lists using asterisks for bullet points. For a sub-item, add an asterisk. Even better, press **C-c t** (that's **Ctrl+c** and then the **t** key) to mark the item as a **TODO** item. When your players clear an area in the game, press **C-c t** again to mark the location **DONE**.
+
+
+```
+* DONE 1 Entrance
+** Zombie
+AC 9 | HP 22
+* TODO 2 Necromancer's chambers
+** Flesh golem
+AC 16 | HP 93
+** Treasure
+\- Gold ring (200 gp)
+\- Rusty nail (1 cp)
+ Cursed (roll on curse table)
+** Secret door (DC 20)
+\- to area 11
+```
+
+Each asterisk is collapsible, so you can get a summary of a global area by collapsing your list down to just the top-level:
+
+
+```
+* DONE 1 Entrance
+* TODO 2 Necromancer's chambers
+* TODO 3 Wyrmling nursery
+* TODO 4 Caretaker's chambers
+* TODO 5 Caretaker's laboratory
+```
+
+An added bonus: I find that making my own rap sheets helps me internalize both the mechanics and the lore of the adventure I'm preparing, so the benefits to this method are numerous. Since I manage any adventure I run in Emacs with Git, once I do the prep work for an adventure, I have fresh copies of all my assets in case I run the adventure with another group or with a set of fresh characters.
+
+### Make your own adventure journal
+
+Generally, I let my players keep their own notes about the adventure because I want to encourage players to interpret the events happening in the adventure for themselves. However, a game master needs private notes to keep all of the improvised data in order. For example, if a published adventure doesn't feature a blacksmith shop, but players decide to visit a blacksmith, then a blacksmith needs to be invented in the moment. If the players revisit the blacksmith six weeks later, then they expect it to be the same blacksmith, and it's up to the game master to keep track of such additions to the published setting. I manage my personal notes about adventures in two different ways, depending on what's available to me.
+
+If I have the text of the adventure in an editable format (such as HTML or Markdown), I enter my additions into the adventure as if the publisher had included them from the start. This means there's always one source of truth for the setting and for significant events.
+
+If I haven't been able to get an editable copy of the adventure because it's a hard copy or a PDF that's not easily modified, then I write my additions into my rap sheets in Org mode. This functionally means that there's still one source of truth because my rap sheets are the first place I look for information, falling back on the published text only for details I've forgotten. Sometimes I like my additions enough to merge them back into my Git master for the adventure, but usually, I trust in improvisation and let additions happen dynamically for each group that plays the adventure.
+
+### Why Emacs is my favorite RPG dashboard
+
+I've fallen into using Emacs for RPGs because it serves as the heads-up display of my dreams. The "right" answer is probably a good [tiling window manager][10], but until I implement that, I'm happy with Emacs. Everything's bound to keyboard shortcuts designed for specificity and speed, and there's just enough easy customization that I can hack together good-enough solutions—sometimes even while players are arguing with one another about what to do next.
+
+I've tried juggling multiple desktops, several PDF reader windows, and a spreadsheet for initiatives; while it's a fine experience, nothing has equaled the fluidity of Emacs as my RPG dashboard.
+
+* * *
+
+Hey! do you love Emacs? [Write an article][11] about how you use an Emacs (GNU or otherwise) for inclusion in our forthcoming Emacs series!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/1/emacs-rpgs
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life-chess-games.png?itok=U1lWMZ0y (Chess pieces on a chess board)
+[2]: https://opensource.com/life/16/2/intro-to-emacs
+[3]: https://orgmode.org/
+[4]: https://orgmode.org/manual/Tables.html
+[5]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Abbrevs.html#Abbrevs
+[6]: https://opensource.com/article/19/6/how-use-maptools
+[7]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Document-View.html
+[8]: https://opensource.com/sites/default/files/uploads/emacs-rpg.jpg (Emacs for RPG)
+[9]: https://www.ghostscript.com/
+[10]: https://opensource.com/article/19/12/ratpoison-linux-desktop
+[11]: https://opensource.com/how-submit-article
From 4e4f09fa7f2bd9c3e8d2ed648b9547271ea632fe Mon Sep 17 00:00:00 2001
From: DarkSun <lujun9972@gmail.com>
Date: Sat, 1 Feb 2020 01:39:09 +0800
Subject: [PATCH 06/11] =?UTF-8?q?=E9=80=89=E9=A2=98:=2020200131=20Intro=20?=
=?UTF-8?q?to=20the=20Linux=20command=20line?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
sources/tech/20200131 Intro to the Linux command line.md
---
...0200131 Intro to the Linux command line.md | 105 ++++++++++++++++++
1 file changed, 105 insertions(+)
create mode 100644 sources/tech/20200131 Intro to the Linux command line.md
diff --git a/sources/tech/20200131 Intro to the Linux command line.md b/sources/tech/20200131 Intro to the Linux command line.md
new file mode 100644
index 0000000000..572be7eee2
--- /dev/null
+++ b/sources/tech/20200131 Intro to the Linux command line.md
@@ -0,0 +1,105 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Intro to the Linux command line)
+[#]: via: (https://www.networkworld.com/article/3518440/intro-to-the-linux-command-line.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+Intro to the Linux command line
+======
+Here are some warm-up exercises for anyone just starting to use the Linux command line. Warning: It can be addictive.
+[Sandra Henry-Stocker / Linux][1] [(CC0)][2]
+
+If you’re new to Linux or have simply never bothered to explore the command line, you may not understand why so many Linux enthusiasts get excited typing commands when they’re sitting at a comfortable desktop with plenty of tools and apps available to them. In this post, we’ll take a quick dive to explore the wonders of the command line and see if maybe we can get you hooked.
+
+First, to use the command line, you have to open up a command tool (also referred to as a “command prompt”). How to do this will depend on which version of Linux you’re running. On RedHat, for example, you might see an Activities tab at the top of your screen which will open a list of options and a small window for entering a command (like “cmd” which will open the window for you). On Ubuntu and some others, you might see a small terminal icon along the left-hand side of your screen. On many systems, you can open a command window by pressing the **Ctrl+Alt+t** keys at the same time.
+
+You will also find yourself on the command line if you log into a Linux system using a tool like PuTTY.
+
+[][3]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][3]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+Once you get your command line window, you’ll find yourself sitting at a prompt. It could be just a **$** or something as elaborate as “**user@system:~$**” but it means that the system is ready to run commands for you.
+
+Once you get this far, it will be time to start entering commands. Below are some of the commands to try first, and [here is a PDF][4] of some particularly useful commands and a two-sided command cheatsheet suitable for printing out and laminating.
+
+```
+Command What it does
+pwd show me where I am in the file system (initially, this will be your
+ home directory)
+ls list my files
+ls -a list even more of my files (including those that start with a period)
+ls -al list my files with lots of details (including dates, file sizes and
+ permissions)
+who show me who is logged in (don’t be disappointed if it’s only you)
+date remind me what day today is (shows the time too)
+ps list my running processes (might just be your shell and the “ps”
+ command)
+```
+
+Once you’ve gotten used to your Linux home from the command line point of view, you can begin to explore. Maybe you’ll feel ready to wander around the file system with commands like these:
+
+```
+Command What it does
+cd /tmp move to another directory (in this case, /tmp)
+ls list files in that location
+cd go back home (with no arguments, cd always takes you back to your home
+ directory)
+cat .bashrc display the contents of a file (in this case, .bashrc)
+history show your recent commands
+echo hello say “hello” to yourself
+cal show a calendar for the current month
+```
+
+To get a feeling for why more advanced Linux users like the command line so much, you will want to try some other features – like redirection and pipes. Redirection is when you take the output of a command and drop it into a file instead of displaying it on your screen. Pipes are when you take the output of one command and send it to another command that will manipulate it in some way. Here are commands to try:
+
+[[Get regularly scheduled insights by signing up for Network World newsletters.]][5]
+
+```
+Command What it does
+echo “echo hello” > tryme create a new file and put the words “echo hello” into
+ it
+chmod 700 tryme make the new file executable
+tryme run the new file (it should run the command it
+ contains and display “hello”)
+ps aux show all running processes
+ps aux | grep $USER show all running processes, but limit the output to
+ lines containing your username
+echo $USER display your username using an environment variable
+whoami display your username with a command
+who | wc -l count how many users are currently logged in
+```
+
+### Wrap-Up
+
+Once you get used to the basic commands, you can explore other commands and try your hand at writing scripts. You might find that Linux is a lot more powerful and nice to use than you ever imagined.
+
+Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3518440/intro-to-the-linux-command-line.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://commons.wikimedia.org/wiki/File:Tux.svg
+[2]: https://creativecommons.org/publicdomain/zero/1.0/
+[3]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[4]: https://www.networkworld.com/article/3391029/must-know-linux-commands.html
+[5]: https://www.networkworld.com/newsletters/signup.html
+[6]: https://www.facebook.com/NetworkWorld/
+[7]: https://www.linkedin.com/company/network-world
From 60b4b26f1606225edd395f943946dbd230f0ce75 Mon Sep 17 00:00:00 2001
From: geekpi <geekpi@users.noreply.github.com>
Date: Sat, 1 Feb 2020 10:31:17 +0800
Subject: [PATCH 07/11] translating
---
...tool to get your local weather forecast.md | 104 ------------------
...tool to get your local weather forecast.md | 101 +++++++++++++++++
2 files changed, 101 insertions(+), 104 deletions(-)
delete mode 100644 sources/tech/20200123 Use this open source tool to get your local weather forecast.md
create mode 100644 translated/tech/20200123 Use this open source tool to get your local weather forecast.md
diff --git a/sources/tech/20200123 Use this open source tool to get your local weather forecast.md b/sources/tech/20200123 Use this open source tool to get your local weather forecast.md
deleted file mode 100644
index df44d3b659..0000000000
--- a/sources/tech/20200123 Use this open source tool to get your local weather forecast.md
+++ /dev/null
@@ -1,104 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Use this open source tool to get your local weather forecast)
-[#]: via: (https://opensource.com/article/20/1/open-source-weather-forecast)
-[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
-
-Use this open source tool to get your local weather forecast
-======
-Know whether you need a coat, an umbrella, or sunscreen before you go
-out with wego in the thirteenth in our series on 20 ways to be more
-productive with open source in 2020.
-![Sky with clouds and grass][1]
-
-Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
-
-### Check the weather with wego
-
-One of the things I love about the past decade of my employment is that it mostly has been remote. I can work anywhere I happen to be in the world, although the reality is that I spend a lot of time in my home office. The downside is that when I leave the house, I base a lot of decisions on what the conditions look like outside my window. And where I live, "sunny and clear" can mean anything from "scorchingly hot" to "below freezing" to "it will rain in an hour." Being able to check the actual conditions and forecast quickly is pretty useful.
-
-![Wego][2]
-
-[Wego][3] is a program written in Go that will fetch and display your local weather. It even renders it in shiny ASCII art if you wish.
-
-To install wego, you need to make sure [Go][4] is installed on your system. After that, you can fetch the latest version with the **go get** command. You'll probably want to add the **~/go/bin** directory to your path as well:
-
-
-```
-go get -u github.com/schachmat/wego
-export PATH=~/go/bin:$PATH
-wego
-```
-
-On its first run, wego will complain about missing API keys. Now you need to decide on a backend. The default backend is for [Forecast.io][5], which is part of [Dark Sky][6]. Wego also supports [OpenWeatherMap][7] and [WorldWeatherOnline][8]. I prefer OpenWeatherMap, so that's what I'll show you how to set up here.
-
-You'll need to [register for an API key][9] with OpenWeatherMap. Registration is free, although the free API key has a limit on how many queries you can make in a day; this should be fine for an average user. Once you have your API key, put it into the **~/.wegorc** file. Now is also a good time to fill in your location, language, and whether you use metric, imperial (US/UK), metric-ms, or International System of Units (SI). OpenWeatherMap supports locations by name, postal code, coordinates, and ID, which is one of the reasons I like it.
-
-
-```
-# wego configuration for OEM
-aat-coords=false
-aat-monochrome=false
-backend=openweathermap
-days=3
-forecast-lang=en
-frontend=ascii-art-table
-jsn-no-indent=false
-location=Pittsboro
-owm-api-key=XXXXXXXXXXXXXXXXXXXXX
-owm-debug=false
-owm-lang=en
-units=imperial
-```
-
-Now, running **wego** at the command line will show the local weather for the next three days.
-
-Wego can also show data as JSON output for consumption by programs and with emoji. You can choose a frontend with the **-f** command-line parameter or in the **.wegorc** file.
-
-![Wego at login][10]
-
-If you want to see the weather every time you open a new shell or log into a host, simply add wego to your **~/.bashrc** (or **~/.zshrc** in my case).
-
-The [wttr.in][11] project is a web-based wrapper around wego. It provides some additional display options and is available on the website of the same name. One cool thing about wttr.in is that you can fetch one-line information about the weather with **curl**. I have a little shell function called **get_wttr** that fetches the current forecast in a shortened form.
-
-
-```
-get_wttr() {
- curl -s "wttr.in/Pittsboro?format=3"
-}
-```
-
-![weather tool for productivity][12]
-
-Now, before I leave the house, I have a quick and easy way to find out if I need a coat, an umbrella, or sunscreen—directly from the command line where I spend most of my time.
-
-I began paragliding a few years ago. It’s maybe the most weather-dependent sport in the world. We...
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/20/1/open-source-weather-forecast
-
-作者:[Kevin Sonney][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ksonney
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bus-cloud.png?itok=vz0PIDDS (Sky with clouds and grass)
-[2]: https://opensource.com/sites/default/files/uploads/productivity_13-1.png (Wego)
-[3]: https://github.com/schachmat/wego
-[4]: https://golang.org/doc/install
-[5]: https://forecast.io
-[6]: https://darksky.net
-[7]: https://openweathermap.org/
-[8]: https://www.worldweatheronline.com/
-[9]: https://openweathermap.org/api
-[10]: https://opensource.com/sites/default/files/uploads/productivity_13-2.png (Wego at login)
-[11]: https://github.com/chubin/wttr.in
-[12]: https://opensource.com/sites/default/files/uploads/day13-image3.png (weather tool for productivity)
diff --git a/translated/tech/20200123 Use this open source tool to get your local weather forecast.md b/translated/tech/20200123 Use this open source tool to get your local weather forecast.md
new file mode 100644
index 0000000000..e151e40d65
--- /dev/null
+++ b/translated/tech/20200123 Use this open source tool to get your local weather forecast.md
@@ -0,0 +1,101 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Use this open source tool to get your local weather forecast)
+[#]: via: (https://opensource.com/article/20/1/open-source-weather-forecast)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+使用这个开源工具获取本地天气预报
+======
+在我们的 20 个使用开源提升生产力的系列的第十三篇文章中使用 wego 来了解出门前你是否要需要外套、雨伞或者防晒霜。
+![Sky with clouds and grass][1]
+
+去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
+
+### 使用 wego 了解天气
+
+过去十年我对我的职业最满意的地方之一是大多数时候是远程工作。尽管现实情况是我很多时候是在家里办公,但我可以在世界上任何地方工作。缺点是,离家时我会根据天气做出一些决定。在我居住的地方,”晴朗“可以表示从”酷热“、”低于零度“到”一小时内会小雨“。能够了解实际情况和快速预测非常有用。
+
+![Wego][2]
+
+[Wego][3] 是用 Go 编写的程序,可以获取并显示你的当地天气。如果你愿意,它甚至可以用闪亮的 ASCII 艺术效果进行渲染。
+
+要安装 wego,你需要确保在系统上安装了[Go][4]。之后,你可以使用 **go get** 命令获取最新版本。你可能还想将 **~/go/bin** 目录添加到路径中:
+
+
+```
+go get -u github.com/schachmat/wego
+export PATH=~/go/bin:$PATH
+wego
+```
+
+首次运行时,wego 会报告缺失 API 密钥。现在你需要决定一个后端。默认后端是 [Forecast.io][5],它是 [Dark Sky][6]的一部分。Wego还支持 [OpenWeatherMap][7] 和 [WorldWeatherOnline][8]。我更喜欢 OpenWeatherMap,因此我将在此向你展示如何设置。
+
+你需要在 OpenWeatherMap 中[注册 API 密钥][9]。注册是免费的,尽管免费的 API 密钥限制了一天可以查询的数量,但这对于普通用户来说应该没问题。得到 API 密钥后,将它放到 **~/.wegorc** 文件中。现在可以填写你的位置、语言以及使用公制、英制(英国/美国)还是国际单位制(SI)。OpenWeatherMap 可通过名称、邮政编码、坐标和 ID 确定位置,这是我喜欢它的原因之一。
+
+
+
+```
+# wego configuration for OEM
+aat-coords=false
+aat-monochrome=false
+backend=openweathermap
+days=3
+forecast-lang=en
+frontend=ascii-art-table
+jsn-no-indent=false
+location=Pittsboro
+owm-api-key=XXXXXXXXXXXXXXXXXXXXX
+owm-debug=false
+owm-lang=en
+units=imperial
+```
+
+现在,在命令行运行 **wego** 将显示接下来三天的当地天气。
+
+Wego 还可以输出 JSON 以便程序使用,还可显示 emoji。你可以使用 **-f** 参数或在 **.wegorc** 文件中指定前端。
+
+![Wego at login][10]
+
+如果你想在每次打开 shell 或登录主机时查看天气,只需将 wego 添加到 **~/.bashrc**(我这里是 **~/.zshrc**)即可。
+
+[wttr.in][11] 项目是 wego 上的基于 Web 的封装。它提供了一些其他显示选项,并且可以在同名网站上看到。关于 wttr.in 的一件很酷的事情是,你可以使用 **curl** 获取一行天气信息。我有一个名为 **get_wttr** 的 shell 函数,用于获取当前简化的预报信息。
+
+
+```
+get_wttr() {
+ curl -s "wttr.in/Pittsboro?format=3"
+}
+```
+
+![weather tool for productivity][12]
+
+现在,在我离开家之前,我就可以通过命令行快速简单地获取我是否需要外套、雨伞或者防晒霜了。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/1/open-source-weather-forecast
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bus-cloud.png?itok=vz0PIDDS (Sky with clouds and grass)
+[2]: https://opensource.com/sites/default/files/uploads/productivity_13-1.png (Wego)
+[3]: https://github.com/schachmat/wego
+[4]: https://golang.org/doc/install
+[5]: https://forecast.io
+[6]: https://darksky.net
+[7]: https://openweathermap.org/
+[8]: https://www.worldweatheronline.com/
+[9]: https://openweathermap.org/api
+[10]: https://opensource.com/sites/default/files/uploads/productivity_13-2.png (Wego at login)
+[11]: https://github.com/chubin/wttr.in
+[12]: https://opensource.com/sites/default/files/uploads/day13-image3.png (weather tool for productivity)
From 2938813972673d0936258e1d64ce06af7932c2f7 Mon Sep 17 00:00:00 2001
From: geekpi <geekpi@users.noreply.github.com>
Date: Sat, 1 Feb 2020 10:35:42 +0800
Subject: [PATCH 08/11] translating
---
...eeds and podcasts in one place with this open source tool.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/sources/tech/20200122 Get your RSS feeds and podcasts in one place with this open source tool.md b/sources/tech/20200122 Get your RSS feeds and podcasts in one place with this open source tool.md
index 994523d830..d257520efa 100644
--- a/sources/tech/20200122 Get your RSS feeds and podcasts in one place with this open source tool.md
+++ b/sources/tech/20200122 Get your RSS feeds and podcasts in one place with this open source tool.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (geekpi)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
From be6b1cf405831fa52f2914ed889d220acd10d734 Mon Sep 17 00:00:00 2001
From: Xingyu Wang <xingyu.wang@gmail.com>
Date: Sat, 1 Feb 2020 11:16:42 +0800
Subject: [PATCH 09/11] =?UTF-8?q?=E5=BD=92=E6=A1=A3=20202001?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
... to create an e-book chapter template in LibreOffice Writer.md | 0
published/{ => 202001}/20190405 File sharing with Git.md | 0
published/{ => 202001}/20190406 Run a server with Git.md | 0
.../20190619 Getting started with OpenSSL- Cryptography basics.md | 0
.../20190724 How to make an old computer useful again.md | 0
... An advanced look at Python interfaces using zope.interface.md | 0
...n save your tasks - and your sanity - if SSH is interrupted.md | 0
published/{ => 202001}/20191015 How GNOME uses Git.md | 0
.../20191016 Open source interior design with Sweet Home 3D.md | 0
.../{ => 202001}/20191017 Intro to the Linux useradd command.md | 0
.../20191108 My Linux story- Learning Linux in the 90s.md | 0
.../20191113 How to cohost GitHub and GitLab with Ansible.md | 0
.../{ => 202001}/20191121 Simulate gravity in your Python game.md | 0
.../20191129 How to write a Python web API with Django.md | 0
.../{ => 202001}/20191130 7 maker gifts for kids and teens.md | 0
.../20191205 Add jumping to your Python platformer game.md | 0
.../20191208 What-s your favorite terminal emulator.md | 0
.../20191210 Lessons learned from programming in Go.md | 0
... Enable your Python game player to run forward and backward.md | 0
.../20191214 Make VLC More Awesome With These Simple Tips.md | 0
.../20191215 How to Add Border Around Text in GIMP.md | 0
...7 App Highlight- Open Source Disk Partitioning Tool GParted.md | 0
.../{ => 202001}/20191219 Kubernetes namespaces for beginners.md | 0
.../20191220 4 ways to volunteer this holiday season.md | 0
...220 Why Vim fans love the Herbstluftwm Linux window manager.md | 0
.../20191221 Pop-_OS vs Ubuntu- Which One is Better.md | 0
...191224 Chill out with the Linux Equinox Desktop Environment.md | 0
...91226 Darktable 3 Released With GUI Rework and New Features.md | 0
.../20191227 10 resources to boost your Git skills.md | 0
...hy Your Distribution Still Using an ‘Outdated- Linux Kernel.md | 0
.../20191229 The best resources for agile software development.md | 0
.../20191230 10 articles to enhance your security aptitude.md | 0
...230 Fixing -VLC is Unable to Open the MRL- Error -Quick Tip.md | 0
...1 10 Ansible resources to accelerate your automation skills.md | 0
.../20191231 12 programming resources for coders of all levels.md | 0
.../{ => 202001}/20200101 5 predictions for Kubernetes in 2020.md | 0
...00101 9 cheat sheets and guides to enhance your tech skills.md | 0
.../20200101 Signal- A Secure, Open Source Messaging App.md | 0
.../20200102 Put some loot in your Python platformer game.md | 0
...3 GNOME has a Secret- Screen Recorder. Here-s How to Use it.md | 0
...troducing the guide to inter-process communication in Linux.md | 0
...20200103 My Raspberry Pi retrospective- 6 projects and more.md | 0
.../20200105 PaperWM- tiled window management for GNOME.md | 0
...0106 How to write a Python web API with Pyramid and Cornice.md | 0
...107 Generating numeric sequences with the Linux seq command.md | 0
...0107 How piwheels will save Raspberry Pi users time in 2020.md | 0
.../20200108 How to setup multiple monitors in sway.md | 0
...0109 Huawei-s Linux Distribution openEuler is Available Now.md | 0
...end eMail With a List of User Accounts Expiring in -X- Days.md | 0
.../20200111 Sync files across multiple devices with Syncthing.md | 0
... Use Stow for configuration management of multiple machines.md | 0
.../20200113 Keep your email in sync with OfflineIMAP.md | 0
...tV- A Bash function to maintain Python virtual environments.md | 0
.../{ => 202001}/20200114 Organize your email with Notmuch.md | 0
published/{ => 202001}/20200115 6 handy Bash scripts for Git.md | 0
...15 Organize and sync your calendar with khal and vdirsyncer.md | 0
...00115 Root User in Ubuntu- Important Things You Should Know.md | 0
.../20200115 Why everyone is talking about WebAssembly.md | 0
.../20200116 3 open source tools to manage your contacts.md | 0
...Rust- Which to choose for programming hardware abstractions.md | 0
...200117 Get started with this open source to-do list manager.md | 0
.../20200117 Locking and unlocking accounts on Linux systems.md | 0
.../20200119 What-s your favorite Linux terminal trick.md | 0
...ting up passwordless Linux logins using public-private keys.md | 0
.../20200123 Wine 5.0 is Released- Here-s How to Install it.md | 0
65 files changed, 0 insertions(+), 0 deletions(-)
rename published/{ => 202001}/20171018 How to create an e-book chapter template in LibreOffice Writer.md (100%)
rename published/{ => 202001}/20190405 File sharing with Git.md (100%)
rename published/{ => 202001}/20190406 Run a server with Git.md (100%)
rename published/{ => 202001}/20190619 Getting started with OpenSSL- Cryptography basics.md (100%)
rename published/{ => 202001}/20190724 How to make an old computer useful again.md (100%)
rename published/{ => 202001}/20190924 An advanced look at Python interfaces using zope.interface.md (100%)
rename published/{ => 202001}/20190930 How the Linux screen tool can save your tasks - and your sanity - if SSH is interrupted.md (100%)
rename published/{ => 202001}/20191015 How GNOME uses Git.md (100%)
rename published/{ => 202001}/20191016 Open source interior design with Sweet Home 3D.md (100%)
rename published/{ => 202001}/20191017 Intro to the Linux useradd command.md (100%)
rename published/{ => 202001}/20191108 My Linux story- Learning Linux in the 90s.md (100%)
rename published/{ => 202001}/20191113 How to cohost GitHub and GitLab with Ansible.md (100%)
rename published/{ => 202001}/20191121 Simulate gravity in your Python game.md (100%)
rename published/{ => 202001}/20191129 How to write a Python web API with Django.md (100%)
rename published/{ => 202001}/20191130 7 maker gifts for kids and teens.md (100%)
rename published/{ => 202001}/20191205 Add jumping to your Python platformer game.md (100%)
rename published/{ => 202001}/20191208 What-s your favorite terminal emulator.md (100%)
rename published/{ => 202001}/20191210 Lessons learned from programming in Go.md (100%)
rename published/{ => 202001}/20191211 Enable your Python game player to run forward and backward.md (100%)
rename published/{ => 202001}/20191214 Make VLC More Awesome With These Simple Tips.md (100%)
rename published/{ => 202001}/20191215 How to Add Border Around Text in GIMP.md (100%)
rename published/{ => 202001}/20191217 App Highlight- Open Source Disk Partitioning Tool GParted.md (100%)
rename published/{ => 202001}/20191219 Kubernetes namespaces for beginners.md (100%)
rename published/{ => 202001}/20191220 4 ways to volunteer this holiday season.md (100%)
rename published/{ => 202001}/20191220 Why Vim fans love the Herbstluftwm Linux window manager.md (100%)
rename published/{ => 202001}/20191221 Pop-_OS vs Ubuntu- Which One is Better.md (100%)
rename published/{ => 202001}/20191224 Chill out with the Linux Equinox Desktop Environment.md (100%)
rename published/{ => 202001}/20191226 Darktable 3 Released With GUI Rework and New Features.md (100%)
rename published/{ => 202001}/20191227 10 resources to boost your Git skills.md (100%)
rename published/{ => 202001}/20191227 Explained- Why Your Distribution Still Using an ‘Outdated- Linux Kernel.md (100%)
rename published/{ => 202001}/20191229 The best resources for agile software development.md (100%)
rename published/{ => 202001}/20191230 10 articles to enhance your security aptitude.md (100%)
rename published/{ => 202001}/20191230 Fixing -VLC is Unable to Open the MRL- Error -Quick Tip.md (100%)
rename published/{ => 202001}/20191231 10 Ansible resources to accelerate your automation skills.md (100%)
rename published/{ => 202001}/20191231 12 programming resources for coders of all levels.md (100%)
rename published/{ => 202001}/20200101 5 predictions for Kubernetes in 2020.md (100%)
rename published/{ => 202001}/20200101 9 cheat sheets and guides to enhance your tech skills.md (100%)
rename published/{ => 202001}/20200101 Signal- A Secure, Open Source Messaging App.md (100%)
rename published/{ => 202001}/20200102 Put some loot in your Python platformer game.md (100%)
rename published/{ => 202001}/20200103 GNOME has a Secret- Screen Recorder. Here-s How to Use it.md (100%)
rename published/{ => 202001}/20200103 Introducing the guide to inter-process communication in Linux.md (100%)
rename published/{ => 202001}/20200103 My Raspberry Pi retrospective- 6 projects and more.md (100%)
rename published/{ => 202001}/20200105 PaperWM- tiled window management for GNOME.md (100%)
rename published/{ => 202001}/20200106 How to write a Python web API with Pyramid and Cornice.md (100%)
rename published/{ => 202001}/20200107 Generating numeric sequences with the Linux seq command.md (100%)
rename published/{ => 202001}/20200107 How piwheels will save Raspberry Pi users time in 2020.md (100%)
rename published/{ => 202001}/20200108 How to setup multiple monitors in sway.md (100%)
rename published/{ => 202001}/20200109 Huawei-s Linux Distribution openEuler is Available Now.md (100%)
rename published/{ => 202001}/20200110 Bash Script to Send eMail With a List of User Accounts Expiring in -X- Days.md (100%)
rename published/{ => 202001}/20200111 Sync files across multiple devices with Syncthing.md (100%)
rename published/{ => 202001}/20200112 Use Stow for configuration management of multiple machines.md (100%)
rename published/{ => 202001}/20200113 Keep your email in sync with OfflineIMAP.md (100%)
rename published/{ => 202001}/20200113 setV- A Bash function to maintain Python virtual environments.md (100%)
rename published/{ => 202001}/20200114 Organize your email with Notmuch.md (100%)
rename published/{ => 202001}/20200115 6 handy Bash scripts for Git.md (100%)
rename published/{ => 202001}/20200115 Organize and sync your calendar with khal and vdirsyncer.md (100%)
rename published/{ => 202001}/20200115 Root User in Ubuntu- Important Things You Should Know.md (100%)
rename published/{ => 202001}/20200115 Why everyone is talking about WebAssembly.md (100%)
rename published/{ => 202001}/20200116 3 open source tools to manage your contacts.md (100%)
rename published/{ => 202001}/20200117 C vs. Rust- Which to choose for programming hardware abstractions.md (100%)
rename published/{ => 202001}/20200117 Get started with this open source to-do list manager.md (100%)
rename published/{ => 202001}/20200117 Locking and unlocking accounts on Linux systems.md (100%)
rename published/{ => 202001}/20200119 What-s your favorite Linux terminal trick.md (100%)
rename published/{ => 202001}/20200122 Setting up passwordless Linux logins using public-private keys.md (100%)
rename published/{ => 202001}/20200123 Wine 5.0 is Released- Here-s How to Install it.md (100%)
diff --git a/published/20171018 How to create an e-book chapter template in LibreOffice Writer.md b/published/202001/20171018 How to create an e-book chapter template in LibreOffice Writer.md
similarity index 100%
rename from published/20171018 How to create an e-book chapter template in LibreOffice Writer.md
rename to published/202001/20171018 How to create an e-book chapter template in LibreOffice Writer.md
diff --git a/published/20190405 File sharing with Git.md b/published/202001/20190405 File sharing with Git.md
similarity index 100%
rename from published/20190405 File sharing with Git.md
rename to published/202001/20190405 File sharing with Git.md
diff --git a/published/20190406 Run a server with Git.md b/published/202001/20190406 Run a server with Git.md
similarity index 100%
rename from published/20190406 Run a server with Git.md
rename to published/202001/20190406 Run a server with Git.md
diff --git a/published/20190619 Getting started with OpenSSL- Cryptography basics.md b/published/202001/20190619 Getting started with OpenSSL- Cryptography basics.md
similarity index 100%
rename from published/20190619 Getting started with OpenSSL- Cryptography basics.md
rename to published/202001/20190619 Getting started with OpenSSL- Cryptography basics.md
diff --git a/published/20190724 How to make an old computer useful again.md b/published/202001/20190724 How to make an old computer useful again.md
similarity index 100%
rename from published/20190724 How to make an old computer useful again.md
rename to published/202001/20190724 How to make an old computer useful again.md
diff --git a/published/20190924 An advanced look at Python interfaces using zope.interface.md b/published/202001/20190924 An advanced look at Python interfaces using zope.interface.md
similarity index 100%
rename from published/20190924 An advanced look at Python interfaces using zope.interface.md
rename to published/202001/20190924 An advanced look at Python interfaces using zope.interface.md
diff --git a/published/20190930 How the Linux screen tool can save your tasks - and your sanity - if SSH is interrupted.md b/published/202001/20190930 How the Linux screen tool can save your tasks - and your sanity - if SSH is interrupted.md
similarity index 100%
rename from published/20190930 How the Linux screen tool can save your tasks - and your sanity - if SSH is interrupted.md
rename to published/202001/20190930 How the Linux screen tool can save your tasks - and your sanity - if SSH is interrupted.md
diff --git a/published/20191015 How GNOME uses Git.md b/published/202001/20191015 How GNOME uses Git.md
similarity index 100%
rename from published/20191015 How GNOME uses Git.md
rename to published/202001/20191015 How GNOME uses Git.md
diff --git a/published/20191016 Open source interior design with Sweet Home 3D.md b/published/202001/20191016 Open source interior design with Sweet Home 3D.md
similarity index 100%
rename from published/20191016 Open source interior design with Sweet Home 3D.md
rename to published/202001/20191016 Open source interior design with Sweet Home 3D.md
diff --git a/published/20191017 Intro to the Linux useradd command.md b/published/202001/20191017 Intro to the Linux useradd command.md
similarity index 100%
rename from published/20191017 Intro to the Linux useradd command.md
rename to published/202001/20191017 Intro to the Linux useradd command.md
diff --git a/published/20191108 My Linux story- Learning Linux in the 90s.md b/published/202001/20191108 My Linux story- Learning Linux in the 90s.md
similarity index 100%
rename from published/20191108 My Linux story- Learning Linux in the 90s.md
rename to published/202001/20191108 My Linux story- Learning Linux in the 90s.md
diff --git a/published/20191113 How to cohost GitHub and GitLab with Ansible.md b/published/202001/20191113 How to cohost GitHub and GitLab with Ansible.md
similarity index 100%
rename from published/20191113 How to cohost GitHub and GitLab with Ansible.md
rename to published/202001/20191113 How to cohost GitHub and GitLab with Ansible.md
diff --git a/published/20191121 Simulate gravity in your Python game.md b/published/202001/20191121 Simulate gravity in your Python game.md
similarity index 100%
rename from published/20191121 Simulate gravity in your Python game.md
rename to published/202001/20191121 Simulate gravity in your Python game.md
diff --git a/published/20191129 How to write a Python web API with Django.md b/published/202001/20191129 How to write a Python web API with Django.md
similarity index 100%
rename from published/20191129 How to write a Python web API with Django.md
rename to published/202001/20191129 How to write a Python web API with Django.md
diff --git a/published/20191130 7 maker gifts for kids and teens.md b/published/202001/20191130 7 maker gifts for kids and teens.md
similarity index 100%
rename from published/20191130 7 maker gifts for kids and teens.md
rename to published/202001/20191130 7 maker gifts for kids and teens.md
diff --git a/published/20191205 Add jumping to your Python platformer game.md b/published/202001/20191205 Add jumping to your Python platformer game.md
similarity index 100%
rename from published/20191205 Add jumping to your Python platformer game.md
rename to published/202001/20191205 Add jumping to your Python platformer game.md
diff --git a/published/20191208 What-s your favorite terminal emulator.md b/published/202001/20191208 What-s your favorite terminal emulator.md
similarity index 100%
rename from published/20191208 What-s your favorite terminal emulator.md
rename to published/202001/20191208 What-s your favorite terminal emulator.md
diff --git a/published/20191210 Lessons learned from programming in Go.md b/published/202001/20191210 Lessons learned from programming in Go.md
similarity index 100%
rename from published/20191210 Lessons learned from programming in Go.md
rename to published/202001/20191210 Lessons learned from programming in Go.md
diff --git a/published/20191211 Enable your Python game player to run forward and backward.md b/published/202001/20191211 Enable your Python game player to run forward and backward.md
similarity index 100%
rename from published/20191211 Enable your Python game player to run forward and backward.md
rename to published/202001/20191211 Enable your Python game player to run forward and backward.md
diff --git a/published/20191214 Make VLC More Awesome With These Simple Tips.md b/published/202001/20191214 Make VLC More Awesome With These Simple Tips.md
similarity index 100%
rename from published/20191214 Make VLC More Awesome With These Simple Tips.md
rename to published/202001/20191214 Make VLC More Awesome With These Simple Tips.md
diff --git a/published/20191215 How to Add Border Around Text in GIMP.md b/published/202001/20191215 How to Add Border Around Text in GIMP.md
similarity index 100%
rename from published/20191215 How to Add Border Around Text in GIMP.md
rename to published/202001/20191215 How to Add Border Around Text in GIMP.md
diff --git a/published/20191217 App Highlight- Open Source Disk Partitioning Tool GParted.md b/published/202001/20191217 App Highlight- Open Source Disk Partitioning Tool GParted.md
similarity index 100%
rename from published/20191217 App Highlight- Open Source Disk Partitioning Tool GParted.md
rename to published/202001/20191217 App Highlight- Open Source Disk Partitioning Tool GParted.md
diff --git a/published/20191219 Kubernetes namespaces for beginners.md b/published/202001/20191219 Kubernetes namespaces for beginners.md
similarity index 100%
rename from published/20191219 Kubernetes namespaces for beginners.md
rename to published/202001/20191219 Kubernetes namespaces for beginners.md
diff --git a/published/20191220 4 ways to volunteer this holiday season.md b/published/202001/20191220 4 ways to volunteer this holiday season.md
similarity index 100%
rename from published/20191220 4 ways to volunteer this holiday season.md
rename to published/202001/20191220 4 ways to volunteer this holiday season.md
diff --git a/published/20191220 Why Vim fans love the Herbstluftwm Linux window manager.md b/published/202001/20191220 Why Vim fans love the Herbstluftwm Linux window manager.md
similarity index 100%
rename from published/20191220 Why Vim fans love the Herbstluftwm Linux window manager.md
rename to published/202001/20191220 Why Vim fans love the Herbstluftwm Linux window manager.md
diff --git a/published/20191221 Pop-_OS vs Ubuntu- Which One is Better.md b/published/202001/20191221 Pop-_OS vs Ubuntu- Which One is Better.md
similarity index 100%
rename from published/20191221 Pop-_OS vs Ubuntu- Which One is Better.md
rename to published/202001/20191221 Pop-_OS vs Ubuntu- Which One is Better.md
diff --git a/published/20191224 Chill out with the Linux Equinox Desktop Environment.md b/published/202001/20191224 Chill out with the Linux Equinox Desktop Environment.md
similarity index 100%
rename from published/20191224 Chill out with the Linux Equinox Desktop Environment.md
rename to published/202001/20191224 Chill out with the Linux Equinox Desktop Environment.md
diff --git a/published/20191226 Darktable 3 Released With GUI Rework and New Features.md b/published/202001/20191226 Darktable 3 Released With GUI Rework and New Features.md
similarity index 100%
rename from published/20191226 Darktable 3 Released With GUI Rework and New Features.md
rename to published/202001/20191226 Darktable 3 Released With GUI Rework and New Features.md
diff --git a/published/20191227 10 resources to boost your Git skills.md b/published/202001/20191227 10 resources to boost your Git skills.md
similarity index 100%
rename from published/20191227 10 resources to boost your Git skills.md
rename to published/202001/20191227 10 resources to boost your Git skills.md
diff --git a/published/20191227 Explained- Why Your Distribution Still Using an ‘Outdated- Linux Kernel.md b/published/202001/20191227 Explained- Why Your Distribution Still Using an ‘Outdated- Linux Kernel.md
similarity index 100%
rename from published/20191227 Explained- Why Your Distribution Still Using an ‘Outdated- Linux Kernel.md
rename to published/202001/20191227 Explained- Why Your Distribution Still Using an ‘Outdated- Linux Kernel.md
diff --git a/published/20191229 The best resources for agile software development.md b/published/202001/20191229 The best resources for agile software development.md
similarity index 100%
rename from published/20191229 The best resources for agile software development.md
rename to published/202001/20191229 The best resources for agile software development.md
diff --git a/published/20191230 10 articles to enhance your security aptitude.md b/published/202001/20191230 10 articles to enhance your security aptitude.md
similarity index 100%
rename from published/20191230 10 articles to enhance your security aptitude.md
rename to published/202001/20191230 10 articles to enhance your security aptitude.md
diff --git a/published/20191230 Fixing -VLC is Unable to Open the MRL- Error -Quick Tip.md b/published/202001/20191230 Fixing -VLC is Unable to Open the MRL- Error -Quick Tip.md
similarity index 100%
rename from published/20191230 Fixing -VLC is Unable to Open the MRL- Error -Quick Tip.md
rename to published/202001/20191230 Fixing -VLC is Unable to Open the MRL- Error -Quick Tip.md
diff --git a/published/20191231 10 Ansible resources to accelerate your automation skills.md b/published/202001/20191231 10 Ansible resources to accelerate your automation skills.md
similarity index 100%
rename from published/20191231 10 Ansible resources to accelerate your automation skills.md
rename to published/202001/20191231 10 Ansible resources to accelerate your automation skills.md
diff --git a/published/20191231 12 programming resources for coders of all levels.md b/published/202001/20191231 12 programming resources for coders of all levels.md
similarity index 100%
rename from published/20191231 12 programming resources for coders of all levels.md
rename to published/202001/20191231 12 programming resources for coders of all levels.md
diff --git a/published/20200101 5 predictions for Kubernetes in 2020.md b/published/202001/20200101 5 predictions for Kubernetes in 2020.md
similarity index 100%
rename from published/20200101 5 predictions for Kubernetes in 2020.md
rename to published/202001/20200101 5 predictions for Kubernetes in 2020.md
diff --git a/published/20200101 9 cheat sheets and guides to enhance your tech skills.md b/published/202001/20200101 9 cheat sheets and guides to enhance your tech skills.md
similarity index 100%
rename from published/20200101 9 cheat sheets and guides to enhance your tech skills.md
rename to published/202001/20200101 9 cheat sheets and guides to enhance your tech skills.md
diff --git a/published/20200101 Signal- A Secure, Open Source Messaging App.md b/published/202001/20200101 Signal- A Secure, Open Source Messaging App.md
similarity index 100%
rename from published/20200101 Signal- A Secure, Open Source Messaging App.md
rename to published/202001/20200101 Signal- A Secure, Open Source Messaging App.md
diff --git a/published/20200102 Put some loot in your Python platformer game.md b/published/202001/20200102 Put some loot in your Python platformer game.md
similarity index 100%
rename from published/20200102 Put some loot in your Python platformer game.md
rename to published/202001/20200102 Put some loot in your Python platformer game.md
diff --git a/published/20200103 GNOME has a Secret- Screen Recorder. Here-s How to Use it.md b/published/202001/20200103 GNOME has a Secret- Screen Recorder. Here-s How to Use it.md
similarity index 100%
rename from published/20200103 GNOME has a Secret- Screen Recorder. Here-s How to Use it.md
rename to published/202001/20200103 GNOME has a Secret- Screen Recorder. Here-s How to Use it.md
diff --git a/published/20200103 Introducing the guide to inter-process communication in Linux.md b/published/202001/20200103 Introducing the guide to inter-process communication in Linux.md
similarity index 100%
rename from published/20200103 Introducing the guide to inter-process communication in Linux.md
rename to published/202001/20200103 Introducing the guide to inter-process communication in Linux.md
diff --git a/published/20200103 My Raspberry Pi retrospective- 6 projects and more.md b/published/202001/20200103 My Raspberry Pi retrospective- 6 projects and more.md
similarity index 100%
rename from published/20200103 My Raspberry Pi retrospective- 6 projects and more.md
rename to published/202001/20200103 My Raspberry Pi retrospective- 6 projects and more.md
diff --git a/published/20200105 PaperWM- tiled window management for GNOME.md b/published/202001/20200105 PaperWM- tiled window management for GNOME.md
similarity index 100%
rename from published/20200105 PaperWM- tiled window management for GNOME.md
rename to published/202001/20200105 PaperWM- tiled window management for GNOME.md
diff --git a/published/20200106 How to write a Python web API with Pyramid and Cornice.md b/published/202001/20200106 How to write a Python web API with Pyramid and Cornice.md
similarity index 100%
rename from published/20200106 How to write a Python web API with Pyramid and Cornice.md
rename to published/202001/20200106 How to write a Python web API with Pyramid and Cornice.md
diff --git a/published/20200107 Generating numeric sequences with the Linux seq command.md b/published/202001/20200107 Generating numeric sequences with the Linux seq command.md
similarity index 100%
rename from published/20200107 Generating numeric sequences with the Linux seq command.md
rename to published/202001/20200107 Generating numeric sequences with the Linux seq command.md
diff --git a/published/20200107 How piwheels will save Raspberry Pi users time in 2020.md b/published/202001/20200107 How piwheels will save Raspberry Pi users time in 2020.md
similarity index 100%
rename from published/20200107 How piwheels will save Raspberry Pi users time in 2020.md
rename to published/202001/20200107 How piwheels will save Raspberry Pi users time in 2020.md
diff --git a/published/20200108 How to setup multiple monitors in sway.md b/published/202001/20200108 How to setup multiple monitors in sway.md
similarity index 100%
rename from published/20200108 How to setup multiple monitors in sway.md
rename to published/202001/20200108 How to setup multiple monitors in sway.md
diff --git a/published/20200109 Huawei-s Linux Distribution openEuler is Available Now.md b/published/202001/20200109 Huawei-s Linux Distribution openEuler is Available Now.md
similarity index 100%
rename from published/20200109 Huawei-s Linux Distribution openEuler is Available Now.md
rename to published/202001/20200109 Huawei-s Linux Distribution openEuler is Available Now.md
diff --git a/published/20200110 Bash Script to Send eMail With a List of User Accounts Expiring in -X- Days.md b/published/202001/20200110 Bash Script to Send eMail With a List of User Accounts Expiring in -X- Days.md
similarity index 100%
rename from published/20200110 Bash Script to Send eMail With a List of User Accounts Expiring in -X- Days.md
rename to published/202001/20200110 Bash Script to Send eMail With a List of User Accounts Expiring in -X- Days.md
diff --git a/published/20200111 Sync files across multiple devices with Syncthing.md b/published/202001/20200111 Sync files across multiple devices with Syncthing.md
similarity index 100%
rename from published/20200111 Sync files across multiple devices with Syncthing.md
rename to published/202001/20200111 Sync files across multiple devices with Syncthing.md
diff --git a/published/20200112 Use Stow for configuration management of multiple machines.md b/published/202001/20200112 Use Stow for configuration management of multiple machines.md
similarity index 100%
rename from published/20200112 Use Stow for configuration management of multiple machines.md
rename to published/202001/20200112 Use Stow for configuration management of multiple machines.md
diff --git a/published/20200113 Keep your email in sync with OfflineIMAP.md b/published/202001/20200113 Keep your email in sync with OfflineIMAP.md
similarity index 100%
rename from published/20200113 Keep your email in sync with OfflineIMAP.md
rename to published/202001/20200113 Keep your email in sync with OfflineIMAP.md
diff --git a/published/20200113 setV- A Bash function to maintain Python virtual environments.md b/published/202001/20200113 setV- A Bash function to maintain Python virtual environments.md
similarity index 100%
rename from published/20200113 setV- A Bash function to maintain Python virtual environments.md
rename to published/202001/20200113 setV- A Bash function to maintain Python virtual environments.md
diff --git a/published/20200114 Organize your email with Notmuch.md b/published/202001/20200114 Organize your email with Notmuch.md
similarity index 100%
rename from published/20200114 Organize your email with Notmuch.md
rename to published/202001/20200114 Organize your email with Notmuch.md
diff --git a/published/20200115 6 handy Bash scripts for Git.md b/published/202001/20200115 6 handy Bash scripts for Git.md
similarity index 100%
rename from published/20200115 6 handy Bash scripts for Git.md
rename to published/202001/20200115 6 handy Bash scripts for Git.md
diff --git a/published/20200115 Organize and sync your calendar with khal and vdirsyncer.md b/published/202001/20200115 Organize and sync your calendar with khal and vdirsyncer.md
similarity index 100%
rename from published/20200115 Organize and sync your calendar with khal and vdirsyncer.md
rename to published/202001/20200115 Organize and sync your calendar with khal and vdirsyncer.md
diff --git a/published/20200115 Root User in Ubuntu- Important Things You Should Know.md b/published/202001/20200115 Root User in Ubuntu- Important Things You Should Know.md
similarity index 100%
rename from published/20200115 Root User in Ubuntu- Important Things You Should Know.md
rename to published/202001/20200115 Root User in Ubuntu- Important Things You Should Know.md
diff --git a/published/20200115 Why everyone is talking about WebAssembly.md b/published/202001/20200115 Why everyone is talking about WebAssembly.md
similarity index 100%
rename from published/20200115 Why everyone is talking about WebAssembly.md
rename to published/202001/20200115 Why everyone is talking about WebAssembly.md
diff --git a/published/20200116 3 open source tools to manage your contacts.md b/published/202001/20200116 3 open source tools to manage your contacts.md
similarity index 100%
rename from published/20200116 3 open source tools to manage your contacts.md
rename to published/202001/20200116 3 open source tools to manage your contacts.md
diff --git a/published/20200117 C vs. Rust- Which to choose for programming hardware abstractions.md b/published/202001/20200117 C vs. Rust- Which to choose for programming hardware abstractions.md
similarity index 100%
rename from published/20200117 C vs. Rust- Which to choose for programming hardware abstractions.md
rename to published/202001/20200117 C vs. Rust- Which to choose for programming hardware abstractions.md
diff --git a/published/20200117 Get started with this open source to-do list manager.md b/published/202001/20200117 Get started with this open source to-do list manager.md
similarity index 100%
rename from published/20200117 Get started with this open source to-do list manager.md
rename to published/202001/20200117 Get started with this open source to-do list manager.md
diff --git a/published/20200117 Locking and unlocking accounts on Linux systems.md b/published/202001/20200117 Locking and unlocking accounts on Linux systems.md
similarity index 100%
rename from published/20200117 Locking and unlocking accounts on Linux systems.md
rename to published/202001/20200117 Locking and unlocking accounts on Linux systems.md
diff --git a/published/20200119 What-s your favorite Linux terminal trick.md b/published/202001/20200119 What-s your favorite Linux terminal trick.md
similarity index 100%
rename from published/20200119 What-s your favorite Linux terminal trick.md
rename to published/202001/20200119 What-s your favorite Linux terminal trick.md
diff --git a/published/20200122 Setting up passwordless Linux logins using public-private keys.md b/published/202001/20200122 Setting up passwordless Linux logins using public-private keys.md
similarity index 100%
rename from published/20200122 Setting up passwordless Linux logins using public-private keys.md
rename to published/202001/20200122 Setting up passwordless Linux logins using public-private keys.md
diff --git a/published/20200123 Wine 5.0 is Released- Here-s How to Install it.md b/published/202001/20200123 Wine 5.0 is Released- Here-s How to Install it.md
similarity index 100%
rename from published/20200123 Wine 5.0 is Released- Here-s How to Install it.md
rename to published/202001/20200123 Wine 5.0 is Released- Here-s How to Install it.md
From 523ed70853c845ed4944ebb553dff4d0c3990b8e Mon Sep 17 00:00:00 2001
From: Xingyu Wang <xingyu.wang@gmail.com>
Date: Sat, 1 Feb 2020 12:15:05 +0800
Subject: [PATCH 10/11] =?UTF-8?q?=E6=B8=85=E9=99=A4=E5=A4=AA=E4=B9=85?=
=?UTF-8?q?=E8=BF=9C=E7=9A=84=E6=96=87=E7=AB=A0?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../20200117 Fedora CoreOS out of preview.md | 108 ---
...ft release open source machine learning.md | 80 --
...the developer, and more industry trends.md | 61 --
...ript Fatigue- Realities of our industry.md | 221 -----
.../20171030 Why I love technical debt.md | 69 --
... How to Monetize an Open Source Project.md | 86 --
...air writing helps improve documentation.md | 87 --
... and How to Set an Open Source Strategy.md | 120 ---
...71116 Why is collaboration so difficult.md | 94 --
...lved our transparency and silo problems.md | 95 --
...and GitHub to improve its documentation.md | 116 ---
... sourcing movements can share knowledge.md | 121 ---
... the cost of structured data is reduced.md | 181 ----
...ering- A new paradigm for cybersecurity.md | 87 --
...eat resume that actually gets you hired.md | 395 ---------
...lopment process that puts quality first.md | 99 ---
...nframes Aren-t Going Away Any Time Soon.md | 73 --
...ywhere Is Dead, Long Live Anarchy Linux.md | 127 ---
... even if you don-t identify as a writer.md | 149 ----
...ser community makes for better software.md | 47 -
...an anonymity and accountability coexist.md | 79 --
...0216 Q4OS Makes Linux Easy for Everyone.md | 140 ---
...en naming software development projects.md | 91 --
...80221 3 warning flags of DevOps metrics.md | 42 -
...0180222 3 reasons to say -no- in DevOps.md | 105 ---
... Give Life to a Mobile Linux Experience.md | 123 ---
...ortant issue in a DevOps transformation.md | 91 --
...301 How to hire the right DevOps talent.md | 48 -
... as team on today-s open source project.md | 53 --
...303 4 meetup ideas- Make your data open.md | 75 --
...How to apply systems thinking in DevOps.md | 89 --
...ommunity will help your project succeed.md | 111 ---
...Growing an Open Source Project Too Fast.md | 40 -
...comers- A guide for advanced developers.md | 119 ---
...en Source Projects With These Platforms.md | 96 --
...for better agile retrospective meetings.md | 66 --
...180323 7 steps to DevOps hiring success.md | 56 --
... Android Auto emulator for Raspberry Pi.md | 81 --
...one should avoid with hybrid multicloud.md | 87 --
...0180404 Is the term DevSecOps necessary.md | 51 --
...ing -ownership- across the organization.md | 125 ---
.../talk/20180410 Microservices Explained.md | 61 --
...ent, from coordination to collaboration.md | 71 --
...back up your people, not just your data.md | 79 --
... develop the FOSS leaders of the future.md | 93 --
...mpatible with part-time community teams.md | 73 --
...pen source project-s workflow on GitHub.md | 109 ---
...Could Be Costing to More Than You Think.md | 39 -
...s a Server in Every Serverless Platform.md | 87 --
...80511 Looking at the Lispy side of Perl.md | 357 --------
...7 Whatever Happened to the Semantic Web.md | 106 ---
...nciples of resilience for women in tech.md | 93 --
... AI Is Coming to Edge Computing Devices.md | 66 --
... list for open organization enthusiasts.md | 133 ---
...d avoid with hybrid multi-cloud, part 2.md | 68 --
...g your project and community on Twitter.md | 157 ----
...rate to the world of Linux from Windows.md | 154 ----
...ones can teach us about open innovation.md | 49 -
...Ren-Py for creating interactive fiction.md | 70 --
...ce Certification Matters More Than Ever.md | 49 -
... Linux and Windows Without Dual Booting.md | 141 ---
...eveloper 9 experiences you ll encounter.md | 141 ---
... a multi-microphone hearing aid project.md | 69 --
...Confessions of a recovering Perl hacker.md | 46 -
... Success with Open Source Certification.md | 63 --
.../talk/20180719 Finding Jobs in Software.md | 90 --
...e Certification- Preparing for the Exam.md | 64 --
...ur workloads to the cloud is a bad idea.md | 71 --
...jargon- The good, the bad, and the ugly.md | 108 ---
...180802 Design thinking as a way of life.md | 95 --
...rammer in an underrepresented community.md | 94 --
...lding more trustful teams in four steps.md | 70 --
...ur team to a microservices architecture.md | 180 ----
.../20180809 How do tools affect culture.md | 56 --
...eimplement Inheritance and Polymorphism.md | 235 -----
...t the Evolution of the Desktop Computer.md | 130 ---
...Ru makes a college education affordable.md | 60 --
...atient data safe with open source tools.md | 51 --
...source projects for the new school year.md | 59 --
...80906 DevOps- The consequences of blame.md | 67 --
...he Rise and Demise of RSS (Old Version).md | 278 ------
...80917 How gaming turned me into a coder.md | 103 ---
...Building a Secure Ecosystem for Node.js.md | 51 --
...ubleshooting Node.js Issues with llnode.md | 75 --
...1003 13 tools to measure DevOps success.md | 84 --
...sier to Get a Payrise by Switching Jobs.md | 99 ---
...es for giving open source code feedback.md | 47 -
...sational interface design and usability.md | 105 ---
... your organization-s security expertise.md | 147 ---
...reasons not to write in-house ops tools.md | 64 --
...pen source classifiers in AI algorithms.md | 111 ---
... BeOS or not to BeOS, that is the Haiku.md | 151 ----
...out leveling up a heroic developer team.md | 213 -----
...tips for facilitators of agile meetings.md | 60 --
...open source hardware increases security.md | 84 --
...ntinuous testing wrong - Opensource.com.md | 184 ----
...rce in education creates new developers.md | 65 --
...derstanding a -nix Shell by Writing One.md | 412 ---------
...seen these personalities in open source.md | 93 --
.../20181114 Analyzing the DNA of DevOps.md | 158 ----
...open source- 9 tips for getting started.md | 76 --
... Closer Look at Voice-Assisted Speakers.md | 125 ---
...t the open source community means to me.md | 94 --
...9 top tech-recruiting mistakes to avoid.md | 108 ---
...back is important to the DevOps culture.md | 68 --
... emerging tipping points in open source.md | 93 --
... reasons to give Linux for the holidays.md | 78 --
...in Linux Kernel Code Replaced with -Hug.md | 81 --
...nately, Garbage Collection isn-t Enough.md | 44 -
...ware delivery with value stream mapping.md | 94 --
...on the Desktop- Are We Nearly There Yet.md | 344 -------
.../talk/20181209 Open source DIY ethics.md | 62 --
... tips to help non-techies move to Linux.md | 111 ---
...-t Succeeded on Desktop- Linus Torvalds.md | 65 --
...ipten, LDC and bindbc-sdl (translation).md | 276 ------
...ch skill in 2019- What you need to know.md | 145 ---
...ons for artificial intelligence in 2019.md | 91 --
... Don-t Use ZFS on Linux- Linus Torvalds.md | 82 --
...g- gene signatures and connectivity map.md | 133 ---
...hannels are bad and you should feel bad.md | 443 ----------
sources/tech/20170115 Magic GOPATH.md | 119 ---
...eboard problems in pure Lambda Calculus.md | 836 ------------------
...20171006 7 deadly sins of documentation.md | 85 --
...nes and Android Architecture Components.md | 201 -----
...ute Once with Xen Linux TPM 2.0 and TXT.md | 94 --
...o Mint and Quicken for personal finance.md | 96 --
...1114 Finding Files with mlocate- Part 2.md | 174 ----
...ux Programs for Drawing and Image Editing.md | 130 ---
...1121 Finding Files with mlocate- Part 3.md | 142 ---
...eractive Workflows for Cpp with Jupyter.md | 301 -------
...usiness Software Alternatives For Linux.md | 117 ---
...power of community with organized chaos.md | 110 ---
...erve Scientific and Medical Communities.md | 170 ----
... millions of Linux users with Snapcraft.md | 321 -------
...xtensions You Should Be Using Right Now.md | 307 -------
...ings Flexibility and Choice to openSUSE.md | 114 ---
...n must include people with disabilities.md | 67 --
sources/tech/20171224 My first Rust macro.md | 145 ---
.../20180108 Debbugs Versioning- Merging.md | 80 --
...erTux- A Linux Take on Super Mario Game.md | 77 --
...et a compelling reason to turn to Linux.md | 70 --
...ures resolving symbol addresses is hard.md | 163 ----
...180114 Playing Quake 4 on Linux in 2018.md | 80 --
...To Create A Bootable Zorin OS USB Drive.md | 315 -------
...Top 6 open source desktop email clients.md | 115 ---
... Perl module a minimalist web framework.md | 106 ---
...urity features installing apps and more.md | 245 -----
... for using CUPS for printing with Linux.md | 101 ---
...here MQ programming in Python with Zato.md | 262 ------
... and manage MacOS LaunchAgents using Go.md | 314 -------
...security risks in open source libraries.md | 249 ------
.../tech/20180130 Trying Other Go Versions.md | 112 ---
...chem group subversion repository to Git.md | 223 -----
...y a React App on a DigitalOcean Droplet.md | 199 -----
.../tech/20180202 CompositeAcceleration.md | 211 -----
...h the openbox windows manager in Fedora.md | 216 -----
...0205 Writing eBPF tracing tools in Rust.md | 258 ------
...art writing macros in LibreOffice Basic.md | 332 -------
...e to create interactive adventure games.md | 299 -------
...20180211 Latching Mutations with GitOps.md | 60 --
...t Is sosreport- How To Create sosreport.md | 195 ----
...A Comparison of Three Linux -App Stores.md | 128 ---
...n source card and board games for Linux.md | 103 ---
...hite male asshole, by a former offender.md | 153 ----
...o create an open source stack using EFK.md | 388 --------
.../tech/20180327 Anna A KVS for any scale.md | 139 ---
...n to the Flask Python web app framework.md | 451 ----------
... Importer Tool Rewritten in C plus plus.md | 70 --
...ipt to your Java enterprise with Vert.x.md | 362 --------
...80411 5 Best Feed Reader Apps for Linux.md | 192 ----
...custom Linux settings with DistroTweaks.md | 108 ---
... Getting started with Jenkins Pipelines.md | 352 --------
...0180413 Redcore Linux Makes Gentoo Easy.md | 89 --
...iting Advanced Web Applications with Go.md | 695 ---------------
...y way to add free books to your eReader.md | 179 ----
...x filesystem forensics - Opensource.com.md | 342 -------
...aging virtual environments with Vagrant.md | 488 ----------
... An easy way to generate RPG characters.md | 136 ---
...istributed tracing system work together.md | 156 ----
... Modularity in Fedora 28 Server Edition.md | 76 --
...507 Multinomial Logistic Classification.md | 215 -----
...ux Revives Your Older Computer [Review].md | 114 ---
...ghtBSD Could Be Your Gateway to FreeBSD.md | 180 ----
...to the Pyramid web framework for Python.md | 617 -------------
...ust, flexible virtual tabletop for RPGs.md | 216 -----
...t The Historical Uptime Of Linux System.md | 330 -------
...id into a Linux development environment.md | 81 --
...w to Enable Click to Minimize On Ubuntu.md | 102 ---
... BSD Distribution for the Desktop Users.md | 147 ---
...ustralian TV Channels to a Raspberry Pi.md | 209 -----
... Go runtime implements maps efficiently.md | 355 --------
... Build an Amazon Echo with Raspberry Pi.md | 374 --------
...1 3 open source music players for Linux.md | 128 ---
...Get Started with Snap Packages in Linux.md | 159 ----
...How to Install and Use Flatpak on Linux.md | 167 ----
...ping tools to extract data from the web.md | 207 -----
...ing an older relative online with Linux.md | 76 --
...n books for Linux and open source types.md | 113 ---
...e tools to make literature reviews easy.md | 73 --
...Ledger for YNAB-like envelope budgeting.md | 143 ---
...h tips for everyday at the command line.md | 593 -------------
...t apps with Pronghorn, a Java framework.md | 120 ---
...180621 Troubleshooting a Buildah script.md | 179 ----
...corn Archimedes Games on a Raspberry Pi.md | 539 -----------
...629 Discover hidden gems in LibreOffice.md | 97 --
...ging Linux applications becoming a snap.md | 148 ----
...Browse Stack Overflow From The Terminal.md | 188 ----
...gs to do After Installing Linux Mint 19.md | 223 -----
...702 5 open source alternatives to Skype.md | 101 ---
...v4 launch an optimism born of necessity.md | 91 --
...Scheme for the Software Defined Vehicle.md | 88 --
...6 Using Ansible to set up a workstation.md | 168 ----
... simple and elegant free podcast player.md | 119 ---
...The aftermath of the Gentoo GitHub hack.md | 72 --
...ource racing and flying games for Linux.md | 102 ---
... Snapshot And Restore Utility For Linux.md | 237 -----
...mand Line With OpenSubtitlesDownload.py.md | 221 -----
...ner image- Meeting the legal challenges.md | 64 --
...tandard Notes for encrypted note-taking.md | 299 -------
...lusively Created for Microsoft Exchange.md | 114 ---
...0180801 Migrating Perl 5 code to Perl 6.md | 77 --
...2 Walkthrough On How To Use GNOME Boxes.md | 117 ---
...ora Server to create a router - gateway.md | 285 ------
...NU Make to load 1.4GB of data every day.md | 126 ---
...ecryption Effect Seen On Sneakers Movie.md | 110 ---
...806 Use Gstreamer and Python to rip CDs.md | 312 -------
...fix, an open source mail transfer agent.md | 334 -------
...Quality sound, open source music player.md | 105 ---
...E- 6 reasons to love this Linux desktop.md | 71 --
...garden with Edraw Max - FOSS adventures.md | 74 --
.../20180816 Garbage collection in Perl 6.md | 121 ---
...ryaLinux- A Distribution and a Platform.md | 224 -----
... a new open source web development tool.md | 282 ------
...r behaviour on my competitor-s websites.md | 117 ---
...owchart and diagramming tools for Linux.md | 186 ----
... books to your eReader- Formatting tips.md | 183 ----
...sktop Client With VODs And Chat Support.md | 126 ---
...20180829 4 open source monitoring tools.md | 143 ---
sources/tech/20180829 Containers in Perl 6.md | 174 ----
...0830 A quick guide to DNF for yum users.md | 131 ---
... your website across all mobile devices.md | 85 --
...ow subroutine signatures work in Perl 6.md | 335 -------
...reat Desktop for the Open Source Purist.md | 114 ---
...diobook Player For DRM-Free Audio Files.md | 72 --
...st your own cloud with Raspberry Pi NAS.md | 128 ---
...r Own Streaming Media Server In Minutes.md | 171 ----
...ibuted tracing in a microservices world.md | 113 ---
...untu Linux With Kazam -Beginner-s Guide.md | 185 ----
...oint is a Delight for Stealth Game Fans.md | 104 ---
...s To Find Out Process ID (PID) In Linux.md | 208 -----
... the Audiophile Linux distro for a spin.md | 161 ----
...29 Use Cozy to Play Audiobooks in Linux.md | 138 ---
.../tech/20181003 Manage NTP with Chrony.md | 291 ------
... 4 Must-Have Tools for Monitoring Linux.md | 102 ---
... to access educational material offline.md | 107 ---
...erna, a web-based information organizer.md | 128 ---
...tion to Ansible Operators in Kubernetes.md | 81 --
...ckage installation for the Raspberry Pi.md | 87 --
...ting upstream releases with release-bot.md | 327 -------
...source alternatives to Microsoft Access.md | 94 --
...tive, JavaScript timeline building tool.md | 82 --
...irmware Version from Linux Command Line.md | 131 ---
... data streams on the Linux command line.md | 302 -------
... started with OKD on your Linux desktop.md | 407 ---------
...How to manage storage on Linux with LVM.md | 237 -----
...es Installed From Particular Repository.md | 342 -------
...s on running new software in production.md | 151 ----
...Behind the scenes with Linux containers.md | 205 -----
...o After Installing elementary OS 5 Juno.md | 260 ------
...how C-- destructors are useful in Envoy.md | 130 ---
...20181122 Getting started with Jenkins X.md | 148 ----
... scientific research Linux distribution.md | 79 --
...tom documentation workflows with Sphinx.md | 126 ---
...How to test your network with PerfSONAR.md | 148 ----
...nd Tutorial With Examples For Beginners.md | 192 ----
...earch - Quick Search GUI Tool for Linux.md | 108 ---
... How to view XML files in a web browser.md | 109 ---
... Screen Recorders for the Linux Desktop.md | 177 ----
...ent and delivery of a hybrid mobile app.md | 102 ---
...you document a tech project with comics.md | 100 ---
... Commands And Programs From Commandline.md | 265 ------
...g Flood Element for performance testing.md | 180 ----
...h Reliability Infrastructure Migrations.md | 78 --
...using KeePassX to secure your passwords.md | 78 --
...less Way of Using Google Drive on Linux.md | 137 ---
...Large files with Git- LFS and git-annex.md | 145 ---
...o Heaven With These 23 GNOME Extensions.md | 288 ------
...226 -Review- Polo File Manager in Linux.md | 139 ---
... model of concurrent garbage collection.md | 62 --
...1229 Some nonparametric statistics math.md | 178 ----
290 files changed, 44787 deletions(-)
delete mode 100644 sources/news/20200117 Fedora CoreOS out of preview.md
delete mode 100644 sources/news/20200119 Open source fights cancer, Tesla adopts Coreboot, Uber and Lyft release open source machine learning.md
delete mode 100644 sources/news/20200125 What 2020 brings for the developer, and more industry trends.md
delete mode 100644 sources/talk/20170717 The Ultimate Guide to JavaScript Fatigue- Realities of our industry.md
delete mode 100644 sources/talk/20171030 Why I love technical debt.md
delete mode 100644 sources/talk/20171107 How to Monetize an Open Source Project.md
delete mode 100644 sources/talk/20171114 Why pair writing helps improve documentation.md
delete mode 100644 sources/talk/20171115 Why and How to Set an Open Source Strategy.md
delete mode 100644 sources/talk/20171116 Why is collaboration so difficult.md
delete mode 100644 sources/talk/20171221 Changing how we use Slack solved our transparency and silo problems.md
delete mode 100644 sources/talk/20180109 How Mycroft used WordPress and GitHub to improve its documentation.md
delete mode 100644 sources/talk/20180111 The open organization and inner sourcing movements can share knowledge.md
delete mode 100644 sources/talk/20180112 in which the cost of structured data is reduced.md
delete mode 100644 sources/talk/20180124 Security Chaos Engineering- A new paradigm for cybersecurity.md
delete mode 100644 sources/talk/20180131 How to write a really great resume that actually gets you hired.md
delete mode 100644 sources/talk/20180206 UQDS- A software-development process that puts quality first.md
delete mode 100644 sources/talk/20180207 Why Mainframes Aren-t Going Away Any Time Soon.md
delete mode 100644 sources/talk/20180209 Arch Anywhere Is Dead, Long Live Anarchy Linux.md
delete mode 100644 sources/talk/20180209 How writing can change your career for the better, even if you don-t identify as a writer.md
delete mode 100644 sources/talk/20180209 Why an involved user community makes for better software.md
delete mode 100644 sources/talk/20180214 Can anonymity and accountability coexist.md
delete mode 100644 sources/talk/20180216 Q4OS Makes Linux Easy for Everyone.md
delete mode 100644 sources/talk/20180220 4 considerations when naming software development projects.md
delete mode 100644 sources/talk/20180221 3 warning flags of DevOps metrics.md
delete mode 100644 sources/talk/20180222 3 reasons to say -no- in DevOps.md
delete mode 100644 sources/talk/20180223 Plasma Mobile Could Give Life to a Mobile Linux Experience.md
delete mode 100644 sources/talk/20180223 Why culture is the most important issue in a DevOps transformation.md
delete mode 100644 sources/talk/20180301 How to hire the right DevOps talent.md
delete mode 100644 sources/talk/20180302 Beyond metrics- How to operate as team on today-s open source project.md
delete mode 100644 sources/talk/20180303 4 meetup ideas- Make your data open.md
delete mode 100644 sources/talk/20180314 How to apply systems thinking in DevOps.md
delete mode 100644 sources/talk/20180315 6 ways a thriving community will help your project succeed.md
delete mode 100644 sources/talk/20180315 Lessons Learned from Growing an Open Source Project Too Fast.md
delete mode 100644 sources/talk/20180316 How to avoid humiliating newcomers- A guide for advanced developers.md
delete mode 100644 sources/talk/20180320 Easily Fund Open Source Projects With These Platforms.md
delete mode 100644 sources/talk/20180321 8 tips for better agile retrospective meetings.md
delete mode 100644 sources/talk/20180323 7 steps to DevOps hiring success.md
delete mode 100644 sources/talk/20180330 Meet OpenAuto, an Android Auto emulator for Raspberry Pi.md
delete mode 100644 sources/talk/20180403 3 pitfalls everyone should avoid with hybrid multicloud.md
delete mode 100644 sources/talk/20180404 Is the term DevSecOps necessary.md
delete mode 100644 sources/talk/20180405 Rethinking -ownership- across the organization.md
delete mode 100644 sources/talk/20180410 Microservices Explained.md
delete mode 100644 sources/talk/20180412 Management, from coordination to collaboration.md
delete mode 100644 sources/talk/20180416 For project safety back up your people, not just your data.md
delete mode 100644 sources/talk/20180417 How to develop the FOSS leaders of the future.md
delete mode 100644 sources/talk/20180418 Is DevOps compatible with part-time community teams.md
delete mode 100644 sources/talk/20180419 3 tips for organizing your open source project-s workflow on GitHub.md
delete mode 100644 sources/talk/20180420 What You Don-t Know About Linux Open Source Could Be Costing to More Than You Think.md
delete mode 100644 sources/talk/20180424 There-s a Server in Every Serverless Platform.md
delete mode 100644 sources/talk/20180511 Looking at the Lispy side of Perl.md
delete mode 100644 sources/talk/20180527 Whatever Happened to the Semantic Web.md
delete mode 100644 sources/talk/20180604 10 principles of resilience for women in tech.md
delete mode 100644 sources/talk/20180613 AI Is Coming to Edge Computing Devices.md
delete mode 100644 sources/talk/20180619 A summer reading list for open organization enthusiasts.md
delete mode 100644 sources/talk/20180620 3 pitfalls everyone should avoid with hybrid multi-cloud, part 2.md
delete mode 100644 sources/talk/20180622 7 tips for promoting your project and community on Twitter.md
delete mode 100644 sources/talk/20180701 How to migrate to the world of Linux from Windows.md
delete mode 100644 sources/talk/20180703 What Game of Thrones can teach us about open innovation.md
delete mode 100644 sources/talk/20180704 Comparing Twine and Ren-Py for creating interactive fiction.md
delete mode 100644 sources/talk/20180705 5 Reasons Open Source Certification Matters More Than Ever.md
delete mode 100644 sources/talk/20180706 Robolinux Lets You Easily Run Linux and Windows Without Dual Booting.md
delete mode 100644 sources/talk/20180711 Becoming a senior developer 9 experiences you ll encounter.md
delete mode 100644 sources/talk/20180711 Open hardware meets open science in a multi-microphone hearing aid project.md
delete mode 100644 sources/talk/20180716 Confessions of a recovering Perl hacker.md
delete mode 100644 sources/talk/20180717 Tips for Success with Open Source Certification.md
delete mode 100644 sources/talk/20180719 Finding Jobs in Software.md
delete mode 100644 sources/talk/20180724 Open Source Certification- Preparing for the Exam.md
delete mode 100644 sources/talk/20180724 Why moving all your workloads to the cloud is a bad idea.md
delete mode 100644 sources/talk/20180726 Tech jargon- The good, the bad, and the ugly.md
delete mode 100644 sources/talk/20180802 Design thinking as a way of life.md
delete mode 100644 sources/talk/20180807 Becoming a successful programmer in an underrepresented community.md
delete mode 100644 sources/talk/20180807 Building more trustful teams in four steps.md
delete mode 100644 sources/talk/20180808 3 tips for moving your team to a microservices architecture.md
delete mode 100644 sources/talk/20180809 How do tools affect culture.md
delete mode 100644 sources/talk/20180813 Using D Features to Reimplement Inheritance and Polymorphism.md
delete mode 100644 sources/talk/20180817 5 Things Influenza Taught Me About the Evolution of the Desktop Computer.md
delete mode 100644 sources/talk/20180817 OERu makes a college education affordable.md
delete mode 100644 sources/talk/20180820 Keeping patient data safe with open source tools.md
delete mode 100644 sources/talk/20180831 3 innovative open source projects for the new school year.md
delete mode 100644 sources/talk/20180906 DevOps- The consequences of blame.md
delete mode 100644 sources/talk/20180916 The Rise and Demise of RSS (Old Version).md
delete mode 100644 sources/talk/20180917 How gaming turned me into a coder.md
delete mode 100644 sources/talk/20180920 Building a Secure Ecosystem for Node.js.md
delete mode 100644 sources/talk/20180925 Troubleshooting Node.js Issues with llnode.md
delete mode 100644 sources/talk/20181003 13 tools to measure DevOps success.md
delete mode 100644 sources/talk/20181007 Why it-s Easier to Get a Payrise by Switching Jobs.md
delete mode 100644 sources/talk/20181009 4 best practices for giving open source code feedback.md
delete mode 100644 sources/talk/20181010 Talk over text- Conversational interface design and usability.md
delete mode 100644 sources/talk/20181011 How to level up your organization-s security expertise.md
delete mode 100644 sources/talk/20181017 We already have nice things, and other reasons not to write in-house ops tools.md
delete mode 100644 sources/talk/20181018 The case for open source classifiers in AI algorithms.md
delete mode 100644 sources/talk/20181019 To BeOS or not to BeOS, that is the Haiku.md
delete mode 100644 sources/talk/20181023 What MMORPGs can teach us about leveling up a heroic developer team.md
delete mode 100644 sources/talk/20181024 5 tips for facilitators of agile meetings.md
delete mode 100644 sources/talk/20181031 How open source hardware increases security.md
delete mode 100644 sources/talk/20181107 5 signs you are doing continuous testing wrong - Opensource.com.md
delete mode 100644 sources/talk/20181107 How open source in education creates new developers.md
delete mode 100644 sources/talk/20181107 Understanding a -nix Shell by Writing One.md
delete mode 100644 sources/talk/20181113 Have you seen these personalities in open source.md
delete mode 100644 sources/talk/20181114 Analyzing the DNA of DevOps.md
delete mode 100644 sources/talk/20181114 Is your startup built on open source- 9 tips for getting started.md
delete mode 100644 sources/talk/20181121 A Closer Look at Voice-Assisted Speakers.md
delete mode 100644 sources/talk/20181127 What the open source community means to me.md
delete mode 100644 sources/talk/20181129 9 top tech-recruiting mistakes to avoid.md
delete mode 100644 sources/talk/20181129 Why giving back is important to the DevOps culture.md
delete mode 100644 sources/talk/20181130 3 emerging tipping points in open source.md
delete mode 100644 sources/talk/20181205 5 reasons to give Linux for the holidays.md
delete mode 100644 sources/talk/20181205 F-Words in Linux Kernel Code Replaced with -Hug.md
delete mode 100644 sources/talk/20181205 Unfortunately, Garbage Collection isn-t Enough.md
delete mode 100644 sources/talk/20181206 6 steps to optimize software delivery with value stream mapping.md
delete mode 100644 sources/talk/20181209 Linux on the Desktop- Are We Nearly There Yet.md
delete mode 100644 sources/talk/20181209 Open source DIY ethics.md
delete mode 100644 sources/talk/20181217 8 tips to help non-techies move to Linux.md
delete mode 100644 sources/talk/20181219 Fragmentation is Why Linux Hasn-t Succeeded on Desktop- Linus Torvalds.md
delete mode 100644 sources/talk/20181220 D in the Browser with Emscripten, LDC and bindbc-sdl (translation).md
delete mode 100644 sources/talk/20181231 Plans to learn a new tech skill in 2019- What you need to know.md
delete mode 100644 sources/talk/20190205 7 predictions for artificial intelligence in 2019.md
delete mode 100644 sources/talk/20200111 Don-t Use ZFS on Linux- Linus Torvalds.md
delete mode 100644 sources/tech/20151127 Research log- gene signatures and connectivity map.md
delete mode 100644 sources/tech/20160302 Go channels are bad and you should feel bad.md
delete mode 100644 sources/tech/20170115 Magic GOPATH.md
delete mode 100644 sources/tech/20170320 Whiteboard problems in pure Lambda Calculus.md
delete mode 100644 sources/tech/20171006 7 deadly sins of documentation.md
delete mode 100644 sources/tech/20171006 Create a Clean-Code App with Kotlin Coroutines and Android Architecture Components.md
delete mode 100644 sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md
delete mode 100644 sources/tech/20171030 5 open source alternatives to Mint and Quicken for personal finance.md
delete mode 100644 sources/tech/20171114 Finding Files with mlocate- Part 2.md
delete mode 100644 sources/tech/20171116 Unleash Your Creativity – Linux Programs for Drawing and Image Editing.md
delete mode 100644 sources/tech/20171121 Finding Files with mlocate- Part 3.md
delete mode 100644 sources/tech/20171129 Interactive Workflows for Cpp with Jupyter.md
delete mode 100644 sources/tech/20171130 Excellent Business Software Alternatives For Linux.md
delete mode 100644 sources/tech/20171130 Tap the power of community with organized chaos.md
delete mode 100644 sources/tech/20171201 Linux Distros That Serve Scientific and Medical Communities.md
delete mode 100644 sources/tech/20171202 Easily control delivery of your Python applications to millions of Linux users with Snapcraft.md
delete mode 100644 sources/tech/20171203 Top 20 GNOME Extensions You Should Be Using Right Now.md
delete mode 100644 sources/tech/20171208 GeckoLinux Brings Flexibility and Choice to openSUSE.md
delete mode 100644 sources/tech/20171222 Why the diversity and inclusion conversation must include people with disabilities.md
delete mode 100644 sources/tech/20171224 My first Rust macro.md
delete mode 100644 sources/tech/20180108 Debbugs Versioning- Merging.md
delete mode 100644 sources/tech/20180108 SuperTux- A Linux Take on Super Mario Game.md
delete mode 100644 sources/tech/20180108 You GNOME it- Windows and Apple devs get a compelling reason to turn to Linux.md
delete mode 100644 sources/tech/20180109 Profiler adventures resolving symbol addresses is hard.md
delete mode 100644 sources/tech/20180114 Playing Quake 4 on Linux in 2018.md
delete mode 100644 sources/tech/20180116 How To Create A Bootable Zorin OS USB Drive.md
delete mode 100644 sources/tech/20180119 Top 6 open source desktop email clients.md
delete mode 100644 sources/tech/20180126 An introduction to the Web Simple Perl module a minimalist web framework.md
delete mode 100644 sources/tech/20180129 CopperheadOS Security features installing apps and more.md
delete mode 100644 sources/tech/20180129 Tips and tricks for using CUPS for printing with Linux.md
delete mode 100644 sources/tech/20180129 WebSphere MQ programming in Python with Zato.md
delete mode 100644 sources/tech/20180130 Create and manage MacOS LaunchAgents using Go.md
delete mode 100644 sources/tech/20180130 Mitigating known security risks in open source libraries.md
delete mode 100644 sources/tech/20180130 Trying Other Go Versions.md
delete mode 100644 sources/tech/20180131 Migrating the debichem group subversion repository to Git.md
delete mode 100644 sources/tech/20180201 I Built This - Now What How to deploy a React App on a DigitalOcean Droplet.md
delete mode 100644 sources/tech/20180202 CompositeAcceleration.md
delete mode 100644 sources/tech/20180205 Getting Started with the openbox windows manager in Fedora.md
delete mode 100644 sources/tech/20180205 Writing eBPF tracing tools in Rust.md
delete mode 100644 sources/tech/20180208 How to start writing macros in LibreOffice Basic.md
delete mode 100644 sources/tech/20180209 How to use Twine and SugarCube to create interactive adventure games.md
delete mode 100644 sources/tech/20180211 Latching Mutations with GitOps.md
delete mode 100644 sources/tech/20180307 What Is sosreport- How To Create sosreport.md
delete mode 100644 sources/tech/20180309 A Comparison of Three Linux -App Stores.md
delete mode 100644 sources/tech/20180314 5 open source card and board games for Linux.md
delete mode 100644 sources/tech/20180319 How to not be a white male asshole, by a former offender.md
delete mode 100644 sources/tech/20180326 How to create an open source stack using EFK.md
delete mode 100644 sources/tech/20180327 Anna A KVS for any scale.md
delete mode 100644 sources/tech/20180402 An introduction to the Flask Python web app framework.md
delete mode 100644 sources/tech/20180403 Open Source Accounting Program GnuCash 3.0 Released With a New CSV Importer Tool Rewritten in C plus plus.md
delete mode 100644 sources/tech/20180404 Bring some JavaScript to your Java enterprise with Vert.x.md
delete mode 100644 sources/tech/20180411 5 Best Feed Reader Apps for Linux.md
delete mode 100644 sources/tech/20180411 Replicate your custom Linux settings with DistroTweaks.md
delete mode 100644 sources/tech/20180412 Getting started with Jenkins Pipelines.md
delete mode 100644 sources/tech/20180413 Redcore Linux Makes Gentoo Easy.md
delete mode 100644 sources/tech/20180419 Writing Advanced Web Applications with Go.md
delete mode 100644 sources/tech/20180420 A handy way to add free books to your eReader.md
delete mode 100644 sources/tech/20180423 Breach detection with Linux filesystem forensics - Opensource.com.md
delete mode 100644 sources/tech/20180423 Managing virtual environments with Vagrant.md
delete mode 100644 sources/tech/20180430 PCGen- An easy way to generate RPG characters.md
delete mode 100644 sources/tech/20180503 How the four components of a distributed tracing system work together.md
delete mode 100644 sources/tech/20180507 Modularity in Fedora 28 Server Edition.md
delete mode 100644 sources/tech/20180507 Multinomial Logistic Classification.md
delete mode 100644 sources/tech/20180509 4MLinux Revives Your Older Computer [Review].md
delete mode 100644 sources/tech/20180511 MidnightBSD Could Be Your Gateway to FreeBSD.md
delete mode 100644 sources/tech/20180514 An introduction to the Pyramid web framework for Python.md
delete mode 100644 sources/tech/20180514 MapTool- A robust, flexible virtual tabletop for RPGs.md
delete mode 100644 sources/tech/20180514 Tuptime - A Tool To Report The Historical Uptime Of Linux System.md
delete mode 100644 sources/tech/20180515 Termux turns Android into a Linux development environment.md
delete mode 100644 sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
delete mode 100644 sources/tech/20180524 TrueOS- A Simple BSD Distribution for the Desktop Users.md
delete mode 100644 sources/tech/20180527 Streaming Australian TV Channels to a Raspberry Pi.md
delete mode 100644 sources/tech/20180529 How the Go runtime implements maps efficiently.md
delete mode 100644 sources/tech/20180531 How to Build an Amazon Echo with Raspberry Pi.md
delete mode 100644 sources/tech/20180601 3 open source music players for Linux.md
delete mode 100644 sources/tech/20180601 Get Started with Snap Packages in Linux.md
delete mode 100644 sources/tech/20180608 How to Install and Use Flatpak on Linux.md
delete mode 100644 sources/tech/20180608 How to use screen scraping tools to extract data from the web.md
delete mode 100644 sources/tech/20180609 4 tips for getting an older relative online with Linux.md
delete mode 100644 sources/tech/20180611 12 fiction books for Linux and open source types.md
delete mode 100644 sources/tech/20180612 7 open source tools to make literature reviews easy.md
delete mode 100644 sources/tech/20180612 Using Ledger for YNAB-like envelope budgeting.md
delete mode 100644 sources/tech/20180614 Bash tips for everyday at the command line.md
delete mode 100644 sources/tech/20180618 Write fast apps with Pronghorn, a Java framework.md
delete mode 100644 sources/tech/20180621 Troubleshooting a Buildah script.md
delete mode 100644 sources/tech/20180626 Playing Badass Acorn Archimedes Games on a Raspberry Pi.md
delete mode 100644 sources/tech/20180629 Discover hidden gems in LibreOffice.md
delete mode 100644 sources/tech/20180629 Is implementing and managing Linux applications becoming a snap.md
delete mode 100644 sources/tech/20180629 SoCLI - Easy Way To Search And Browse Stack Overflow From The Terminal.md
delete mode 100644 sources/tech/20180701 12 Things to do After Installing Linux Mint 19.md
delete mode 100644 sources/tech/20180702 5 open source alternatives to Skype.md
delete mode 100644 sources/tech/20180702 Diggs v4 launch an optimism born of necessity.md
delete mode 100644 sources/tech/20180703 AGL Outlines Virtualization Scheme for the Software Defined Vehicle.md
delete mode 100644 sources/tech/20180706 Using Ansible to set up a workstation.md
delete mode 100644 sources/tech/20180708 simple and elegant free podcast player.md
delete mode 100644 sources/tech/20180710 The aftermath of the Gentoo GitHub hack.md
delete mode 100644 sources/tech/20180711 5 open source racing and flying games for Linux.md
delete mode 100644 sources/tech/20180723 System Snapshot And Restore Utility For Linux.md
delete mode 100644 sources/tech/20180727 Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py.md
delete mode 100644 sources/tech/20180731 What-s in a container image- Meeting the legal challenges.md
delete mode 100644 sources/tech/20180801 Getting started with Standard Notes for encrypted note-taking.md
delete mode 100644 sources/tech/20180801 Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange.md
delete mode 100644 sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
delete mode 100644 sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
delete mode 100644 sources/tech/20180803 How to use Fedora Server to create a router - gateway.md
delete mode 100644 sources/tech/20180806 How ProPublica Illinois uses GNU Make to load 1.4GB of data every day.md
delete mode 100644 sources/tech/20180806 Recreate Famous Data Decryption Effect Seen On Sneakers Movie.md
delete mode 100644 sources/tech/20180806 Use Gstreamer and Python to rip CDs.md
delete mode 100644 sources/tech/20180809 Getting started with Postfix, an open source mail transfer agent.md
delete mode 100644 sources/tech/20180810 Strawberry- Quality sound, open source music player.md
delete mode 100644 sources/tech/20180815 Happy birthday, GNOME- 6 reasons to love this Linux desktop.md
delete mode 100644 sources/tech/20180816 Designing your garden with Edraw Max - FOSS adventures.md
delete mode 100644 sources/tech/20180816 Garbage collection in Perl 6.md
delete mode 100644 sources/tech/20180817 AryaLinux- A Distribution and a Platform.md
delete mode 100644 sources/tech/20180817 Cloudgizer- An introduction to a new open source web development tool.md
delete mode 100644 sources/tech/20180821 How I recorded user behaviour on my competitor-s websites.md
delete mode 100644 sources/tech/20180822 9 flowchart and diagramming tools for Linux.md
delete mode 100644 sources/tech/20180824 Add free books to your eReader- Formatting tips.md
delete mode 100644 sources/tech/20180828 Orion Is A QML - C-- Twitch Desktop Client With VODs And Chat Support.md
delete mode 100644 sources/tech/20180829 4 open source monitoring tools.md
delete mode 100644 sources/tech/20180829 Containers in Perl 6.md
delete mode 100644 sources/tech/20180830 A quick guide to DNF for yum users.md
delete mode 100644 sources/tech/20180830 How to scale your website across all mobile devices.md
delete mode 100644 sources/tech/20180912 How subroutine signatures work in Perl 6.md
delete mode 100644 sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
delete mode 100644 sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
delete mode 100644 sources/tech/20180919 Host your own cloud with Raspberry Pi NAS.md
delete mode 100644 sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
delete mode 100644 sources/tech/20180920 Distributed tracing in a microservices world.md
delete mode 100644 sources/tech/20180920 Record Screen in Ubuntu Linux With Kazam -Beginner-s Guide.md
delete mode 100644 sources/tech/20180923 Gunpoint is a Delight for Stealth Game Fans.md
delete mode 100644 sources/tech/20180925 9 Easiest Ways To Find Out Process ID (PID) In Linux.md
delete mode 100644 sources/tech/20180925 Taking the Audiophile Linux distro for a spin.md
delete mode 100644 sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md
delete mode 100644 sources/tech/20181003 Manage NTP with Chrony.md
delete mode 100644 sources/tech/20181004 4 Must-Have Tools for Monitoring Linux.md
delete mode 100644 sources/tech/20181005 How to use Kolibri to access educational material offline.md
delete mode 100644 sources/tech/20181008 Taking notes with Laverna, a web-based information organizer.md
delete mode 100644 sources/tech/20181015 An introduction to Ansible Operators in Kubernetes.md
delete mode 100644 sources/tech/20181016 piwheels- Speedy Python package installation for the Raspberry Pi.md
delete mode 100644 sources/tech/20181017 Automating upstream releases with release-bot.md
delete mode 100644 sources/tech/20181018 4 open source alternatives to Microsoft Access.md
delete mode 100644 sources/tech/20181018 TimelineJS- An interactive, JavaScript timeline building tool.md
delete mode 100644 sources/tech/20181023 How to Check HP iLO Firmware Version from Linux Command Line.md
delete mode 100644 sources/tech/20181031 Working with data streams on the Linux command line.md
delete mode 100644 sources/tech/20181101 Getting started with OKD on your Linux desktop.md
delete mode 100644 sources/tech/20181105 How to manage storage on Linux with LVM.md
delete mode 100644 sources/tech/20181106 How To Check The List Of Packages Installed From Particular Repository.md
delete mode 100644 sources/tech/20181111 Some notes on running new software in production.md
delete mode 100644 sources/tech/20181112 Behind the scenes with Linux containers.md
delete mode 100644 sources/tech/20181115 11 Things To Do After Installing elementary OS 5 Juno.md
delete mode 100644 sources/tech/20181118 An example of how C-- destructors are useful in Envoy.md
delete mode 100644 sources/tech/20181122 Getting started with Jenkins X.md
delete mode 100644 sources/tech/20181127 Bio-Linux- A stable, portable scientific research Linux distribution.md
delete mode 100644 sources/tech/20181128 Building custom documentation workflows with Sphinx.md
delete mode 100644 sources/tech/20181128 How to test your network with PerfSONAR.md
delete mode 100644 sources/tech/20181129 The Top Command Tutorial With Examples For Beginners.md
delete mode 100644 sources/tech/20181203 ANGRYsearch - Quick Search GUI Tool for Linux.md
delete mode 100644 sources/tech/20181206 How to view XML files in a web browser.md
delete mode 100644 sources/tech/20181207 5 Screen Recorders for the Linux Desktop.md
delete mode 100644 sources/tech/20181207 Automatic continuous development and delivery of a hybrid mobile app.md
delete mode 100644 sources/tech/20181209 How do you document a tech project with comics.md
delete mode 100644 sources/tech/20181211 How To Benchmark Linux Commands And Programs From Commandline.md
delete mode 100644 sources/tech/20181214 Tips for using Flood Element for performance testing.md
delete mode 100644 sources/tech/20181215 New talk- High Reliability Infrastructure Migrations.md
delete mode 100644 sources/tech/20181217 6 tips and tricks for using KeePassX to secure your passwords.md
delete mode 100644 sources/tech/20181218 Insync- The Hassleless Way of Using Google Drive on Linux.md
delete mode 100644 sources/tech/20181221 Large files with Git- LFS and git-annex.md
delete mode 100644 sources/tech/20181224 Turn GNOME to Heaven With These 23 GNOME Extensions.md
delete mode 100644 sources/tech/20181226 -Review- Polo File Manager in Linux.md
delete mode 100644 sources/tech/20181228 The office coffee model of concurrent garbage collection.md
delete mode 100644 sources/tech/20181229 Some nonparametric statistics math.md
diff --git a/sources/news/20200117 Fedora CoreOS out of preview.md b/sources/news/20200117 Fedora CoreOS out of preview.md
deleted file mode 100644
index d7a1393cde..0000000000
--- a/sources/news/20200117 Fedora CoreOS out of preview.md
+++ /dev/null
@@ -1,108 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Fedora CoreOS out of preview)
-[#]: via: (https://fedoramagazine.org/fedora-coreos-out-of-preview/)
-[#]: author: (bgilbert https://fedoramagazine.org/author/bgilbert/)
-
-Fedora CoreOS out of preview
-======
-
-![The Fedora CoreOS logo on a gray background.][1]
-
-The Fedora CoreOS team is pleased to announce that Fedora CoreOS is now [available for general use][2].
-
-Fedora CoreOS is a new Fedora Edition built specifically for running containerized workloads securely and at scale. It’s the successor to both [Fedora Atomic Host][3] and [CoreOS Container Linux][4] and is part of our effort to explore new ways of assembling and updating an OS. Fedora CoreOS combines the provisioning tools and automatic update model of Container Linux with the packaging technology, OCI support, and SELinux security of Atomic Host. For more on the Fedora CoreOS philosophy, goals, and design, see the [announcement of the preview release][5].
-
-Some highlights of the current Fedora CoreOS release:
-
- * [Automatic updates][6], with staged deployments and phased rollouts
- * Built from Fedora 31, featuring:
- * Linux 5.4
- * systemd 243
- * Ignition 2.1
- * OCI and Docker Container support via Podman 1.7 and Moby 18.09
- * cgroups v1 enabled by default for broader compatibility; cgroups v2 available via configuration
-
-
-
-Fedora CoreOS is available on a variety of platforms:
-
- * Bare metal, QEMU, OpenStack, and VMware
- * Images available in all public AWS regions
- * Downloadable cloud images for Alibaba, AWS, Azure, and GCP
- * Can run live from RAM via ISO and PXE (netboot) images
-
-
-
-Fedora CoreOS is under active development. Planned future enhancements include:
-
- * Addition of the _next_ release stream for extended testing of upcoming Fedora releases.
- * Support for additional cloud and virtualization platforms, and processor architectures other than _x86_64_.
- * Closer integration with Kubernetes distributions, including [OKD][7].
- * [Aggregate statistics collection][8].
- * Additional [documentation][9].
-
-
-
-### Where do I get it?
-
-To try out the new release, head over to the [download page][10] to get OS images or cloud image IDs. Then use the [quick start guide][11] to get a machine running quickly.
-
-### How do I get involved?
-
-It’s easy! You can report bugs and missing features to the [issue tracker][12]. You can also discuss Fedora CoreOS in [Fedora Discourse][13], the [development mailing list][14], in _#fedora-coreos_ on Freenode, or at our [weekly IRC meetings][15].
-
-### Are there stability guarantees?
-
-In general, the Fedora Project does not make any guarantees around stability. While Fedora CoreOS strives for a high level of stability, this can be challenging to achieve in the rapidly evolving Linux and container ecosystems. We’ve found that the incremental, exploratory, forward-looking development required for Fedora CoreOS — which is also a cornerstone of the Fedora Project as a whole — is difficult to reconcile with the iron-clad stability guarantee that ideally exists when automatically updating systems.
-
-We’ll continue to do our best not to break existing systems over time, and to give users the tools to manage the impact of any regressions. Nevertheless, automatic updates may produce regressions or breaking changes for some use cases. You should make your own decisions about where and how to run Fedora CoreOS based on your risk tolerance, operational needs, and experience with the OS. We will continue to announce any major planned or unplanned breakage to the [coreos-status mailing list][16], along with recommended mitigations.
-
-### How do I migrate from CoreOS Container Linux?
-
-Container Linux machines cannot be migrated in place to Fedora CoreOS. We recommend [writing a new Fedora CoreOS Config][11] to provision Fedora CoreOS machines. Fedora CoreOS Configs are similar to Container Linux Configs, and must be passed through the Fedora CoreOS Config Transpiler to produce an Ignition config for provisioning a Fedora CoreOS machine.
-
-Whether you’re currently provisioning your Container Linux machines using a Container Linux Config, handwritten Ignition config, or cloud-config, you’ll need to adjust your configs for differences between Container Linux and Fedora CoreOS. For example, on Fedora CoreOS network configuration is performed with [NetworkManager key files][17] instead of _systemd-networkd_, and time synchronization is performed by _chrony_ rather than _systemd-timesyncd_. Initial migration documentation will be [available soon][9] and a skeleton list of differences between the two OSes is available in [this issue][18].
-
-CoreOS Container Linux will be maintained for a few more months, and then will be declared end-of-life. We’ll announce the exact end-of-life date later this month.
-
-### How do I migrate from Fedora Atomic Host?
-
-Fedora Atomic Host has already reached end-of-life, and you should migrate to Fedora CoreOS as soon as possible. We do not recommend in-place migration of Atomic Host machines to Fedora CoreOS. Instead, we recommend [writing a Fedora CoreOS Config][11] and using it to provision new Fedora CoreOS machines. As with CoreOS Container Linux, you’ll need to adjust your existing cloud-configs for differences between Fedora Atomic Host and Fedora CoreOS.
-
-Welcome to Fedora CoreOS. Deploy it, launch your apps, and let us know what you think!
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/fedora-coreos-out-of-preview/
-
-作者:[bgilbert][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/bgilbert/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/introducing-fedora-coreos-816x345.png
-[2]: https://getfedora.org/coreos/
-[3]: https://www.projectatomic.io/
-[4]: https://coreos.com/os/docs/latest/
-[5]: https://fedoramagazine.org/introducing-fedora-coreos/
-[6]: https://docs.fedoraproject.org/en-US/fedora-coreos/auto-updates/
-[7]: https://www.okd.io/
-[8]: https://github.com/coreos/fedora-coreos-pinger/
-[9]: https://docs.fedoraproject.org/en-US/fedora-coreos/
-[10]: https://getfedora.org/coreos/download/
-[11]: https://docs.fedoraproject.org/en-US/fedora-coreos/getting-started/
-[12]: https://github.com/coreos/fedora-coreos-tracker/issues
-[13]: https://discussion.fedoraproject.org/c/server/coreos
-[14]: https://lists.fedoraproject.org/archives/list/coreos@lists.fedoraproject.org/
-[15]: https://github.com/coreos/fedora-coreos-tracker#meetings
-[16]: https://lists.fedoraproject.org/archives/list/coreos-status@lists.fedoraproject.org/
-[17]: https://developer.gnome.org/NetworkManager/stable/nm-settings-keyfile.html
-[18]: https://github.com/coreos/fedora-coreos-tracker/issues/159
diff --git a/sources/news/20200119 Open source fights cancer, Tesla adopts Coreboot, Uber and Lyft release open source machine learning.md b/sources/news/20200119 Open source fights cancer, Tesla adopts Coreboot, Uber and Lyft release open source machine learning.md
deleted file mode 100644
index 90b5c18537..0000000000
--- a/sources/news/20200119 Open source fights cancer, Tesla adopts Coreboot, Uber and Lyft release open source machine learning.md
+++ /dev/null
@@ -1,80 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Open source fights cancer, Tesla adopts Coreboot, Uber and Lyft release open source machine learning)
-[#]: via: (https://opensource.com/article/20/1/news-january-19)
-[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
-
-Open source fights cancer, Tesla adopts Coreboot, Uber and Lyft release open source machine learning
-======
-Catch up on the biggest open source headlines from the past two weeks.
-![Weekly news roundup with TV][1]
-
-In this edition of our open source news roundup, we take a look machine learning tools from Uber and Lyft, open source software to fight cancer, saving students money with open textbooks, and more!
-
-### Uber and Lyft release machine learning tools
-
-It's hard to a growing company these days that doesn't take advantage of machine learning to streamline its business and make sense of the data it amasses. Ridesharing companies, which gather massive amounts of data, have enthusiastically embraced the promise of machine learning. Two of the biggest players in the ridesharing sector have made some of their machine learning code open source.
-
-Uber recently [released the source code][2] for its Manifold tool for debugging machine learning models. According to Uber software engineer Lezhi Li, Manifold will "benefit the machine learning (ML) community by providing interpretability and debuggability for ML workflows." If you're interested, you can browse Manifold's source code [on GitHub][3].
-
-Lyft has also upped its open source stakes by releasing Flyte. Flyte, whose source code is [available on GitHub][4], manages machine learning pipelines and "is an essential backbone to (Lyft's) operations." Lyft has been using it to train AI models and process data "across pricing, logistics, mapping, and autonomous projects."
-
-### Software to detect cancer cells
-
-In a study recently published in _Nature Biotechnology_, a team of medical researchers from around the world announced [new open source software][5] that "could make it easier to create personalised cancer treatment plans."
-
-The software assesses "the proportion of cancerous cells in a tumour sample" and can help clinicians "judge the accuracy of computer predictions and establish benchmarks" across tumor samples. Maxime Tarabichi, one of the lead authors of [the study][6], said that the software "provides a foundation which will hopefully become a much-needed, unbiased, gold-standard benchmarking tool for assessing models that aim to characterise a tumour’s genetic diversity."
-
-### University of Regina saves students over $1 million with open textbooks
-
-If rising tuition costs weren't enough to send university student spiralling into debt, the high prices of textbooks can deepen the crater in their bank accounts. To help ease that financial pain, many universities turn to open textbooks. One of those schools is the University of Regina. By offering open text books, the university [expects to save a huge amount for students][7] over the next five years.
-
-The expected savings are in the region of $1.5 million (CAD), or around $1.1 million USD (at the time of writing). The textbooks, according to a report by radio station CKOM, are "provided free for (students) and they can be printed off or used as e-books." Students aren't getting inferior-quality textbooks, though. Nilgun Onder of the University of Regina said that the "textbooks and other open education resources the university published are all peer-reviewed resources. In other words, they are reliable and credible."
-
-### Tesla adopts Coreboot
-
-Much of the software driving (no pun intended) the electric vehicles made by Tesla Motors is open source. So it's not surprising to learn that the company has [adopted Coreboot][8] "as part of their electric vehicle computer systems."
-
-Coreboot was developed as a replacement for proprietary BIOS and is used to boot hardware and the Linux kernel. The code, which is in [Tesla's GitHub repository][9], "is from Tesla Motors and Samsung," according to Phoronix. Samsung, in case you're wondering, makes the chip on which Tesla's self-driving software runs.
-
-#### In other news
-
- * [Arduino launches new modular platform for IoT development][10]
- * [SUSE and Karunya Institute of Technology and Sciences collaborate to enhance cloud and open source learning][11]
- * [How open-source code could help us survive natural disasters][12]
- * [The hottest thing in robotics is an open source project you've never heard of][13]
-
-
-
-_Thanks, as always, to Opensource.com staff members and moderators for their help this week. Make sure to check out [our event calendar][14], to see what's happening next week in open source._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/20/1/news-january-19
-
-作者:[Scott Nesbitt][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/scottnesbitt
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
-[2]: https://venturebeat.com/2020/01/07/uber-open-sources-manifold-a-visual-tool-for-debugging-ai-models/
-[3]: https://github.com/uber/manifold
-[4]: https://github.com/lyft/flyte
-[5]: https://www.cbronline.com/industry/healthcare/open-source-cancer-cells/
-[6]: https://www.nature.com/articles/s41587-019-0364-z
-[7]: https://www.ckom.com/2020/01/07/open-source-program-to-save-u-of-r-students-1-5m/
-[8]: https://www.phoronix.com/scan.php?page=news_item&px=Tesla-Uses-Coreboot
-[9]: https://github.com/teslamotors/coreboot
-[10]: https://techcrunch.com/2020/01/07/arduino-launches-a-new-modular-platform-for-iot-development/
-[11]: https://www.crn.in/news/suse-and-karunya-institute-of-technology-and-sciences-collaborate-to-enhance-cloud-and-open-source-learning/
-[12]: https://qz.com/1784867/open-source-data-could-help-save-lives-during-natural-disasters/
-[13]: https://www.techrepublic.com/article/the-hottest-thing-in-robotics-is-an-open-source-project-youve-never-heard-of/
-[14]: https://opensource.com/resources/conferences-and-events-monthly
diff --git a/sources/news/20200125 What 2020 brings for the developer, and more industry trends.md b/sources/news/20200125 What 2020 brings for the developer, and more industry trends.md
deleted file mode 100644
index e22735d21c..0000000000
--- a/sources/news/20200125 What 2020 brings for the developer, and more industry trends.md
+++ /dev/null
@@ -1,61 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (What 2020 brings for the developer, and more industry trends)
-[#]: via: (https://opensource.com/article/20/1/hybrid-developer-future-industry-trends)
-[#]: author: (Tim Hildred https://opensource.com/users/thildred)
-
-What 2020 brings for the developer, and more industry trends
-======
-A weekly look at open source community and industry trends.
-![Person standing in front of a giant computer screen with numbers, data][1]
-
-As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
-
-## [How developers will work in 2020][2]
-
-> Developers have been spending an enormous amount of time on everything *except* making software that solves problems. ‘DevOps’ has transmogrified from ‘developers releasing software’ into ‘developers building ever more complex infrastructure atop Kubernetes’ and ‘developers reinventing their software as distributed stateless functions.’ In 2020, ‘serverless’ will mature. Handle state. Handle data storage without requiring devs to learn yet-another-proprietary-database-service. Learning new stuff is fun-but shipping is even better, and we’ll finally see systems and services that support that.
-
-**The impact:** A lot of forces are converging to give developers superpowers. There are ever more open source building blocks in place; thousands of geniuses are collaborating to make developer workflows more fun and efficient, and artificial intelligences are being brought to bear solving the types of problems a developer might face. On the one hand, there is clear leverage to giving developer superpowers: if they can make magic with software they'll be able to make even bigger magic with all this help. On the other hand, imagine if teachers had the same level of investment and support. Makes ya wonder don't it?
-
-## [2020 forecast: Cloud-y with a chance of hybrid][3]
-
-> Behind this growth is an array of new themes and strategies that are pushing cloud further up business agendas the world over. With ‘emerging’ technologies, such as AI and machine learning, containers and functions, and even more flexibility available with hybrid cloud solutions being provided by the major providers, it’s no wonder cloud is set to take centre stage.
-
-**The impact:** Hybrid cloud finally has the same level of flesh that public cloud and on-premises have. Over the course of 2019 especially the competing visions offered for what it meant to be hybrid formed a composite that drove home why someone would want it. At the same time more and more of the technology pieces that make hybrid viable are in place and maturing. 2019 was the year that people truly "got" hybrid. 2020 will be the year that people start to take advantage of it.
-
-## [The no-code delusion][4]
-
-> Increasingly popular in the last couple of years, I think 2020 is going to be the year of “no code”: the movement that says you can write business logic and even entire applications without having the training of a software developer. I empathise with people doing this, and I think some of the “no code” tools are great. But I also thing it’s wrong at heart.
-
-**The impact:** I've heard many devs say it over many years: "software development is hard." It would be a mistake to interpret that as "all software development is equally hard." What I've always found hard about learning to code is trying to think in a way that a computer will understand. With or without code, making computers do complex things will always require a different kind of thinking.
-
-## [All things Java][5]
-
-> The open, multi-vendor model has been a major strength—it’s very hard for any single vendor to pioneer a market for a sustained period of time—and taking different perspectives from diverse industries has been a key strength of the [evolution of Java][6]. Choosing to open source Java in 2006 was also a decision that only worked to strengthen the Java ecosystem, as it allowed Sun Microsystems and later Oracle to share the responsibility of maintaining and evolving Java with many other organizations and individuals.
-
-**The impact:** The things that move quickly in technology are the things that can be thrown away. When you know you're going to keep something for a long time, you're likely to make different choices about what to prioritize when building it. Disposable and long-lived both have their places, and the Java community made enough good decisions over the years that the language itself can have a foot in both camps.
-
-_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/20/1/hybrid-developer-future-industry-trends
-
-作者:[Tim Hildred][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/thildred
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
-[2]: https://thenextweb.com/readme/2020/01/15/how-developers-will-work-in-2020/
-[3]: https://www.itproportal.com/features/2020-forecast-cloud-y-with-a-chance-of-hybrid/
-[4]: https://www.alexhudson.com/2020/01/13/the-no-code-delusion/
-[5]: https://appdevelopermagazine.com/all-things-java/
-[6]: https://appdevelopermagazine.com/top-10-developer-technologies-in-2019/
diff --git a/sources/talk/20170717 The Ultimate Guide to JavaScript Fatigue- Realities of our industry.md b/sources/talk/20170717 The Ultimate Guide to JavaScript Fatigue- Realities of our industry.md
deleted file mode 100644
index 923d4618a9..0000000000
--- a/sources/talk/20170717 The Ultimate Guide to JavaScript Fatigue- Realities of our industry.md
+++ /dev/null
@@ -1,221 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (The Ultimate Guide to JavaScript Fatigue: Realities of our industry)
-[#]: via: (https://lucasfcosta.com/2017/07/17/The-Ultimate-Guide-to-JavaScript-Fatigue.html)
-[#]: author: (Lucas Fernandes Da Costa https://lucasfcosta.com)
-
-The Ultimate Guide to JavaScript Fatigue: Realities of our industry
-======
-
-**Complaining about JS Fatigue is just like complaining about the fact that humanity has created too many tools to solve the problems we have** , from email to airplanes and spaceships.
-
-Last week I’ve done a talk about this very same subject at the NebraskaJS 2017 Conference and I got so many positive feedbacks that I just thought this talk should also become a blog post in order to reach more people and help them deal with JS Fatigue and understand the realities of our industry. **My goal with this post is to change the way you think about software engineering in general and help you in any areas you might work on**.
-
-One of the things that has inspired me to write this blog post and that totally changed my life is [this great post by Patrick McKenzie, called “Don’t Call Yourself a Programmer and other Career Advice”][1]. **I highly recommend you read that**. Most of this blog post is advice based on what Patrick has written in that post applied to the JavaScript ecosystem and with a few more thoughts I’ve developed during these last years working in the tech industry.
-
-This first section is gonna be a bit philosophical, but I swear it will be worth reading.
-
-### Realities of Our Industry 101
-
-Just like Patrick has done in [his post][1], let’s start with the most basic and essential truth about our industry:
-
-Software solves business problems
-
-This is it. **Software does not exist to please us as programmers** and let us write beautiful code. Neither it exists to create jobs for people in the tech industry. **Actually, it exists to kill as many jobs as possible, including ours** , and this is why basic income will become much more important in the next few years, but that’s a whole other subject.
-
-I’m sorry to say that, but the reason things are that way is that there are only two things that matter in the software engineering (and any other industries):
-
-**Cost versus Revenue**
-
-**The more you decrease cost and increase revenue, the more valuable you are** , and one of the most common ways of decreasing cost and increasing revenue is replacing human beings by machines, which are more effective and usually cost less in the long run.
-
-You are not paid to write code
-
-**Technology is not a goal.** Nobody cares about which programming language you are using, nobody cares about which frameworks your team has chosen, nobody cares about how elegant your data structures are and nobody cares about how good is your code. **The only thing that somebody cares about is how much does your software cost and how much revenue it generates**.
-
-Writing beautiful code does not matter to your clients. We write beautiful code because it makes us more productive in the long run and this decreases cost and increases revenue.
-
-The whole reason why we try not to write bugs is not that we value correctness, but that **our clients** value correctness. If you have ever seen a bug becoming a feature you know what I’m talking about. That bug exists but it should not be fixed. That happens because our goal is not to fix bugs, our goal is to generate revenue. If our bugs make clients happy then they increase revenue and therefore we are accomplishing our goals.
-
-Reusable space rockets, self-driving cars, robots, artificial intelligence: these things do not exist just because someone thought it would be cool to create them. They exist because there are business interests behind them. And I’m not saying the people behind them just want money, I’m sure they think that stuff is also cool, but the truth is that if they were not economically viable or had any potential to become so, they would not exist.
-
-Probably I should not even call this section “Realities of Our Industry 101”, maybe I should just call it “Realities of Capitalism 101”.
-
-And given that our only goal is to increase revenue and decrease cost, I think we as programmers should be paying more attention to requirements and design and start thinking with our minds and participating more actively in business decisions, which is why it is extremely important to know the problem domain we are working on. How many times before have you found yourself trying to think about what should happen in certain edge cases that have not been thought before by your managers or business people?
-
-In 1975, Boehm has done a research in which he found out that about 64% of all errors in the software he was studying were caused by design, while only 36% of all errors were coding errors. Another study called [“Higher Order Software—A Methodology for Defining Software”][2] also states that **in the NASA Apollo project, about 73% of all errors were design errors**.
-
-The whole reason why Design and Requirements exist is that they define what problems we’re going to solve and solving problems is what generates revenue.
-
-> Without requirements or design, programming is the art of adding bugs to an empty text file.
->
-> * Louis Srygley
->
-
-
-This same principle also applies to the tools we’ve got available in the JavaScript ecosystem. Babel, webpack, react, Redux, Mocha, Chai, Typescript, all of them exist to solve a problem and we gotta understand which problem they are trying to solve, we need to think carefully about when most of them are needed, otherwise, we will end up having JS Fatigue because:
-
-JS Fatigue happens when people use tools they don't need to solve problems they don't have.
-
-As Donald Knuth once said: “Premature optimization is the root of all evil”. Remember that software only exists to solve business problems and most software out there is just boring, it does not have any high scalability or high-performance constraints. Focus on solving business problems, focus on decreasing cost and generating revenue because this is all that matters. Optimize when you need, otherwise you will probably be adding unnecessary complexity to your software, which increases cost, and not generating enough revenue to justify that.
-
-This is why I think we should apply [Test Driven Development][3] principles to everything we do in our job. And by saying this I’m not just talking about testing. **I’m talking about waiting for problems to appear before solving them. This is what TDD is all about**. As Kent Beck himself says: “TDD reduces fear” because it guides your steps and allows you take small steps towards solving your problems. One problem at a time. By doing the same thing when it comes to deciding when to adopt new technologies then we will also reduce fear.
-
-Solving one problem at a time also decreases [Analysis Paralysis][4], which is basically what happens when you open Netflix and spend three hours concerned about making the optimal choice instead of actually watching something. By solving one problem at a time we reduce the scope of our decisions and by reducing the scope of our decisions we have fewer choices to make and by having fewer choices to make we decrease Analysis Paralysis.
-
-Have you ever thought about how easier it was to decide what you were going to watch when there were only a few TV channels available? Or how easier it was to decide which game you were going to play when you had only a few cartridges at home?
-
-### But what about JavaScript?
-
-By the time I’m writing this post NPM has 489,989 packages and tomorrow approximately 515 new ones are going to be published.
-
-And the packages we use and complain about have a history behind them we must comprehend in order to understand why we need them. **They are all trying to solve problems.**
-
-Babel, Dart, CoffeeScript and other transpilers come from our necessity of writing code other than JavaScript but making it runnable in our browsers. Babel even lets us write new generation JavaScript and make sure it will work even on older browsers, which has always been a great problem given the inconsistencies and different amount of compliance to the ECMA Specification between browsers. Even though the ECMA spec is becoming more and more solid these days, we still need Babel. And if you want to read more about Babel’s history I highly recommend that you read [this excellent post by Henry Zhu][5].
-
-Module bundlers such as Webpack and Browserify also have their reason to exist. If you remember well, not so long ago we used to suffer a lot with lots of `script` tags and making them work together. They used to pollute the global namespace and it was reasonably hard to make them work together when one depended on the other. In order to solve this [`Require.js`][6] was created, but it still had its problems, it was not that straightforward and its syntax also made it prone to other problems, as you can see [in this blog post][7]. Then Node.js came with `CommonJS` imports, which were synchronous, simple and clean, but we still needed a way to make that work on our browsers and this is why we needed Webpack and Browserify.
-
-And Webpack itself actually solves more problems than that by allowing us to deal with CSS, images and many other resources as if they were JavaScript dependencies.
-
-Front-end frameworks are a bit more complicated, but the reason why they exist is to reduce the cognitive load when we write code so that we don’t need to worry about manipulating the DOM ourselves or even dealing with messy browser APIs (another problem JQuery came to solve), which is not only error prone but also not productive.
-
-This is what we have been doing this whole time in computer science. We use low-level abstractions and build even more abstractions on top of it. The more we worry about describing how our software should work instead of making it work, the more productive we are.
-
-But all those tools have something in common: **they exist because the web platform moves too fast**. Nowadays we’re using web technology everywhere: in web browsers, in desktop applications, in phone applications or even in watch applications.
-
-This evolution also creates problems we need to solve. PWAs, for example, do not exist only because they’re cool and we programmers have fun writing them. Remember the first section of this post: **PWAs exist because they create business value**.
-
-And usually standards are not fast enough to be created and therefore we need to create our own solutions to these things, which is why it is great to have such a vibrant and creative community with us. We’re solving problems all the time and **we are allowing natural selection to do its job**.
-
-The tools that suit us better thrive, get more contributors and develop themselves more quickly and sometimes other tools end up incorporating the good ideas from the ones that thrive and becoming even more popular than them. This is how we evolve.
-
-By having more tools we also have more choices. If you remember the UNIX philosophy well, it states that we should aim at creating programs that do one thing and do it well.
-
-We can clearly see this happening in the JS testing environment, for example, where we have Mocha for running tests and Chai for doing assertions, while in Java JUnit tries to do all these things. This means that if we have a problem with one of them or if we find another one that suits us better, we can simply replace that small part and still have the advantages of the other ones.
-
-The UNIX philosophy also states that we should write programs that work together. And this is exactly what we are doing! Take a look at Babel, Webpack and React, for example. They work very well together but we still do not need one to use the other. In the testing environment, for example, if we’re using Mocha and Chai all of a sudden we can just install Karma and run those same tests in multiple environments.
-
-### How to Deal With It
-
-My first advice for anyone suffering from JS Fatigue would definitely be to stay aware that **you don’t need to know everything**. Trying to learn it all at once, even when we don’t have to do so, only increases the feeling of fatigue. Go deep in areas that you love and for which you feel an inner motivation to study and adopt a lazy approach when it comes to the other ones. I’m not saying that you should be lazy, I’m just saying that you can learn those only when needed. Whenever you face a problem that requires you to use a certain technology to solve it, go learn.
-
-Another important thing to say is that **you should start from the beginning**. Make sure you have learned enough about JavaScript itself before using any JavaScript frameworks. This is the only way you will be able to understand them and bend them to your will, otherwise, whenever you face an error you have never seen before you won’t know which steps to take in order to solve it. Learning core web technologies such as CSS, HTML5, JavaScript and also computer science fundamentals or even how the HTTP protocol works will help you master any other technologies a lot more quickly.
-
-But please, don’t get too attached to that. Sometimes you gotta risk yourself and start doing things on your own. As Sacha Greif has written in [this blog post][8], spending too much time learning the fundamentals is just like trying to learn how to swim by studying fluid dynamics. Sometimes you just gotta jump into the pool and try to swim by yourself.
-
-And please, don’t get too attached to a single technology. All of the things we have available nowadays have already been invented in the past. Of course, they have different features and a brand new name, but, in their essence, they are all the same.
-
-If you look at NPM, it is nothing new, we already had Maven Central and Ruby Gems quite a long time ago.
-
-In order to transpile your code, Babel applies the very same principles and theory as some of the oldest and most well-known compilers, such as the GCC.
-
-Even JSX is not a new idea. It E4X (ECMAScript for XML) already existed more than 10 years ago.
-
-Now you might ask: “what about Gulp, Grunt and NPM Scripts?” Well, I’m sorry but we can solve all those problems with GNU Make in 1976. And actually, there are a reasonable number of JavaScript projects that still use it, such as Chai.js, for example. But we do not do that because we are hipsters that like vintage stuff. We use `make` because it solves our problems, and this is what you should aim at doing, as we’ve talked before.
-
-If you really want to understand a certain technology and be able to solve any problems you might face, please, dig deep. One of the most decisive factors to success is curiosity, so **dig deep into the technologies you like**. Try to understand them from bottom-up and whenever you think something is just “magic”, debunk that myth by exploring the codebase by yourself.
-
-In my opinion, there is no better quote than this one by Richard Feinman, when it comes to really learning something:
-
-> What I cannot create, I do not understand
-
-And just below this phrase, [in the same blackboard, Richard also wrote][9]:
-
-> Know how to solve every problem that has been solved
-
-Isn’t this just amazing?
-
-When Richard said that, he was talking about being able to take any theoretical result and re-derive it, but I think the exact same principle can be applied to software engineering. The tools that solve our problems have already been invented, they already exist, so we should be able to get to them all by ourselves.
-
-This is the very reason I love [some of the videos available in Egghead.io][10] in which Dan Abramov explains how to implement certain features that exist in Redux from scratch or [blog posts that teach you how to build your own JSX renderer][11].
-
-So why not trying to implement these things by yourself or going to GitHub and reading their codebase in order to understand how they work? I’m sure you will find a lot of useful knowledge out there. Comments and tutorials might lie and be incorrect sometimes, the code cannot.
-
-Another thing that we have been talking a lot in this post is that **you should not get ahead of yourself**. Follow a TDD approach and solve one problem at a time. You are paid to increase revenue and decrease cost and you do this by solving problems, this is the reason why software exists.
-
-And since we love comparing our role to the ones related to civil engineering, let’s do a quick comparison between software development and civil engineering, just as [Sam Newman does in his brilliant book called “Building Microservices”][12].
-
-We love calling ourselves “engineers” or “architects”, but is that term really correct? We have been developing software for what we know as computers less than a hundred years ago, while the Colosseum, for example, exists for about two thousand years.
-
-When was the last time you’ve seen a bridge falling and when was the last time your telephone or your browser crashed?
-
-In order to explain this, I’ll use an example I love.
-
-This is the beautiful and awesome city of Barcelona:
-
-![The City of Barcelona][13]
-
-When we look at it this way and from this distance, it just looks like any other city in the world, but when we look at it from above, this is how Barcelona looks:
-
-![Barcelona from above][14]
-
-As you can see, every block has the same size and all of them are very organized. If you’ve ever been to Barcelona you will also know how good it is to move through the city and how well it works.
-
-But the people that planned Barcelona could not predict what it was going to look like in the next two or three hundred years. In cities, people come in and people move through it all the time so what they had to do was make it grow organically and adapt as the time goes by. They had to be prepared for changes.
-
-This very same thing happens to our software. It evolves quickly, refactors are often needed and requirements change more frequently than we would like them to.
-
-So, instead of acting like a Software Engineer, act as a Town Planner. Let your software grow organically and adapt as needed. Solve problems as they come by but make sure everything still has its place.
-
-Doing this when it comes to software is even easier than doing this in cities due to the fact that **software is flexible, civil engineering is not**. **In the software world, our build time is compile time**. In Barcelona we cannot simply destroy buildings to give space to new ones, in Software we can do that a lot easier. We can break things all the time, we can make experiments because we can build as many times as we want and it usually takes seconds and we spend a lot more time thinking than building. Our job is purely intellectual.
-
-So **act like a town planner, let your software grow and adapt as needed**.
-
-By doing this you will also have better abstractions and know when it’s the right time to adopt them.
-
-As Sam Koblenski says:
-
-> Abstractions only work well in the right context, and the right context develops as the system develops.
-
-Nowadays something I see very often is people looking for boilerplates when they’re trying to learn a new technology, but, in my opinion, **you should avoid boilerplates when you’re starting out**. Of course boilerplates and generators are useful if you are already experienced, but they take a lot of control out of your hands and therefore you won’t learn how to set up a project and you won’t understand exactly where each piece of the software you are using fits.
-
-When you feel like you are struggling more than necessary to get something simple done, it might be the right time for you to look for an easier way to do this. In our role **you should strive to be lazy** , you should work to not work. By doing that you have more free time to do other things and this decreases cost and increases revenue, so that’s another way of accomplishing your goal. You should not only work harder, you should work smarter.
-
-Probably someone has already had the same problem as you’re having right now, but if nobody did it might be your time to shine and build your own solution and help other people.
-
-But sometimes you will not be able to realize you could be more effective in your tasks until you see someone doing them better. This is why it is so important to **talk to people**.
-
-By talking to people you share experiences that help each other’s careers and we discover new tools to improve our workflow and, even more important than that, learn how they solve their problems. This is why I like reading blog posts in which companies explain how they solve their problems.
-
-Especially in our area we like to think that Google and StackOverflow can answer all our questions, but we still need to know which questions to ask. I’m sure you have already had a problem you could not find a solution for because you didn’t know exactly what was happening and therefore didn’t know what was the right question to ask.
-
-But if I needed to sum this whole post in a single advice, it would be:
-
-Solve problems.
-
-Software is not a magic box, software is not poetry (unfortunately). It exists to solve problems and improves peoples’ lives. Software exists to push the world forward.
-
-**Now it’s your time to go out there and solve problems**.
-
-
---------------------------------------------------------------------------------
-
-via: https://lucasfcosta.com/2017/07/17/The-Ultimate-Guide-to-JavaScript-Fatigue.html
-
-作者:[Lucas Fernandes Da Costa][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://lucasfcosta.com
-[b]: https://github.com/lujun9972
-[1]: http://www.kalzumeus.com/2011/10/28/dont-call-yourself-a-programmer/
-[2]: http://ieeexplore.ieee.org/document/1702333/
-[3]: https://en.wikipedia.org/wiki/Test_Driven_Development
-[4]: https://en.wikipedia.org/wiki/Analysis_paralysis
-[5]: https://babeljs.io/blog/2016/12/07/the-state-of-babel
-[6]: http://requirejs.org
-[7]: https://benmccormick.org/2015/05/28/moving-past-requirejs/
-[8]: https://medium.freecodecamp.org/a-study-plan-to-cure-javascript-fatigue-8ad3a54f2eb1
-[9]: https://www.quora.com/What-did-Richard-Feynman-mean-when-he-said-What-I-cannot-create-I-do-not-understand
-[10]: https://egghead.io/lessons/javascript-redux-implementing-store-from-scratch
-[11]: https://jasonformat.com/wtf-is-jsx/
-[12]: https://www.barnesandnoble.com/p/building-microservices-sam-newman/1119741399/2677517060476?st=PLA&sid=BNB_DRS_Marketplace+Shopping+Books_00000000&2sid=Google_&sourceId=PLGoP4760&k_clickid=3x4760
-[13]: /assets/barcelona-city.jpeg
-[14]: /assets/barcelona-above.jpeg
-[15]: https://twitter.com/thewizardlucas
diff --git a/sources/talk/20171030 Why I love technical debt.md b/sources/talk/20171030 Why I love technical debt.md
deleted file mode 100644
index da071d370a..0000000000
--- a/sources/talk/20171030 Why I love technical debt.md
+++ /dev/null
@@ -1,69 +0,0 @@
-Why I love technical debt
-======
-
-This is not necessarily the title you'd expect for an article, I guess,* but I'm a fan of [technical debt][1]. There are two reasons for this: a Bad Reason and a Good Reason. I'll be upfront about the Bad Reason first, then explain why even that isn't really a reason to love it. I'll then tackle the Good Reason, and you'll nod along in agreement.
-
-### The Bad Reason I love technical debt
-
-We'll get this out of the way, then, shall we? The Bad Reason is that, well, there's just lots of it, it's interesting, it keeps me in a job, and it always provides a reason, as a security architect, for me to get involved in** projects that might give me something new to look at. I suppose those aren't all bad things. It can also be a bit depressing, because there's always so much of it, it's not always interesting, and sometimes I need to get involved even when I might have better things to do.
-
-And what's worse is that it almost always seems to be security-related, and it's always there. That's the bad part.
-
-Security, we all know, is the piece that so often gets left out, or tacked on at the end, or done in half the time it deserves, or done by people who have half an idea, but don't quite fully grasp it. I should be clear at this point: I'm not saying that this last reason is those people's fault. That people know they need security is fantastic. If we (the security folks) or we (the organization) haven't done a good enough job in making sufficient security resources--whether people, training, or visibility--available to those people who need it, the fact that they're trying is great and something we can work on. Let's call that a positive. Or at least a reason for hope.***
-
-### The Good Reason I love technical debt
-
-Let's get on to the other reason: the legitimate reason. I love technical debt when it's named.
-
-What does that mean?
-
-We all get that technical debt is a bad thing. It's what happens when you make decisions for pragmatic reasons that are likely to come back and bite you later in a project's lifecycle. Here are a few classic examples that relate to security:
-
- * Not getting around to applying authentication or authorization controls on APIs that might, at some point, be public.
- * Lumping capabilities together so it's difficult to separate out appropriate roles later on.
- * Hard-coding roles in ways that don't allow for customisation by people who may use your application in different ways from those you initially considered.
- * Hard-coding cipher suites for cryptographic protocols, rather than putting them in a config file where they can be changed or selected later.
-
-
-
-There are lots more, of course, but those are just a few that jump out at me and that I've seen over the years. Technical debt means making decisions that will mean more work later on to fix them. And that can't be good, can it?
-
-There are two words in the preceding paragraphs that should make us happy: they are "decisions" and "pragmatic." Because, in order for something to be named technical debt, I'd argue, it has to have been subject to conscious decision-making, and trade-offs must have been made--hopefully for rational reasons. Those reasons may be many and various--lack of qualified resources; project deadlines; lack of sufficient requirement definition--but if they've been made consciously, then the technical debt can be named, and if technical debt can be named, it can be documented.
-
-And if it's documented, we're halfway there. As a security guy, I know that I can't force everything that goes out of the door to meet all the requirements I'd like--but the same goes for the high availability gal, the UX team, the performance folks, etc.
-
-What we need--what we all need--is for documentation to exist about why decisions were made, because when we return to the problem we'll know it was thought about. And, what's more, the recording of that information might even make it into product documentation. "This API is designed to be used in a protected environment and should not be exposed on the public Internet" is a great piece of documentation. It may not be what a customer is looking for, but at least they know how to deploy the product, and, crucially, it's an opportunity for them to come back to the product manager and say, "We'd really like to deploy that particular API in this way. Could you please add this as a feature request?" Product managers like that. Very much.****
-
-The best thing, though, is not just that named technical debt is visible technical debt, but that if you encourage your developers to document the decisions in code,***** then there's a decent chance that they'll record some ideas about how this should be done in the future. If you're really lucky, they might even add some hooks in the code to make it easier (an "auth" parameter on the API, which is unused in the current version, but will make API compatibility so much simpler in new releases; or cipher entry in the config file that currently only accepts one option, but is at least checked by the code).
-
-I've been a bit disingenuous, I know, by defining technical debt as named technical debt. But honestly, if it's not named, then you can't know what it is, and until you know what it is, you can't fix it.******* My advice is this: when you're doing a release close-down (or in your weekly standup--EVERY weekly standup), have an agenda item to record technical debt. Name it, document it, be proud, sleep at night.
-
-* Well, apart from the obvious clickbait reason--for which I'm (a little) sorry.
-
-** I nearly wrote "poke my nose into."
-
-*** Work with me here.
-
-**** If you're software engineer/coder/hacker, here's a piece of advice: Learn to talk to product managers like real people, and treat them nicely. They (the better ones, at least) are invaluable allies when you need to prioritize features or have tricky trade-offs to make.
-
-***** Do this. Just do it. Documentation that isn't at least mirrored in code isn't real documentation.******
-
-****** Don't believe me? Talk to developers. "Who reads product documentation?" "Oh, the spec? I skimmed it. A few releases back. I think." "I looked in the header file; couldn't see it there."
-
-******* Or decide not to fix it, which may also be an entirely appropriate decision.
-
-This article originally appeared on [Alice, Eve, and Bob - a security blog][2] and is republished with permission.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/17/10/why-i-love-technical-debt
-
-作者:[Mike Bursell][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mikecamel
-[1]:https://en.wikipedia.org/wiki/Technical_debt
-[2]:https://aliceevebob.wordpress.com/2017/08/29/why-i-love-technical-debt/
diff --git a/sources/talk/20171107 How to Monetize an Open Source Project.md b/sources/talk/20171107 How to Monetize an Open Source Project.md
deleted file mode 100644
index ab51006101..0000000000
--- a/sources/talk/20171107 How to Monetize an Open Source Project.md
+++ /dev/null
@@ -1,86 +0,0 @@
-How to Monetize an Open Source Project
-======
-
-
-The problem for any small group of developers putting the finishing touches on a commercial open source application is figuring out how to monetize the software in order to keep the bills paid and food on the table. Often these small pre-startups will start by deciding which of the recognized open source business models they're going to adapt, whether that be following Red Hat's lead and offering professional services, going the SaaS route, releasing as open core or something else.
-
-Steven Grandchamp, general manager for MariaDB's North America operations and CEO for Denver-based startup [Drud Tech][1], thinks that might be putting the cart before the horse. With an open source project, the best first move is to get people downloading and using your product for free.
-
-**Related:** [Demand for Open Source Skills Continues to Grow][2]
-
-"The number one tangent to monetization in any open source product is adoption, because the key to monetizing an open source product is you flip what I would call the sales funnel upside down," he told ITPro at the recent All Things Open conference in Raleigh, North Carolina.
-
-In many ways, he said, selling open source solutions is the opposite of marketing traditional proprietary products, where adoption doesn't happen until after a contract is signed.
-
-**Related:** [Is Raleigh the East Coast's Silicon Valley?][3]
-
-"In a proprietary software company, you advertise, you market, you make claims about what the product can do, and then you have sales people talk to customers. Maybe you have a free trial or whatever. Maybe you have a small version. Maybe it's time bombed or something like that, but you don't really get to realize the benefit of the product until there's a contract and money changes hands."
-
-Selling open source solutions is different because of the challenge of selling software that's freely available as a GitHub download.
-
-"The whole idea is to put the product out there, let people use it, experiment with it, and jump on the chat channels," he said, pointing out that his company Drud has a public chat channel that's open to anybody using their product. "A subset of that group is going to raise their hand and go, 'Hey, we need more help. We'd like a tighter relationship with the company. We'd like to know where your road map's going. We'd like to know about customization. We'd like to know if maybe this thing might be on your road map.'"
-
-Grandchamp knows more than a little about making software pay, from both the proprietary and open source sides of the fence. In the 1980s he served as VP of research and development at Formation Technologies, and became SVP of R&D at John H. Harland after it acquired Formation in the mid-90s. He joined MariaDB in 2016, after serving eight years as CEO at OpenLogic, which was providing commercial support for more than 600 open-source projects at the time it was acquired by Rogue Wave Software. Along the way, there was a two year stint at Microsoft's Redmond campus.
-
-OpenLogic was where he discovered open source, and his experiences there are key to his approach for monetizing open source projects.
-
-"When I got to OpenLogic, I was told that we had 300 customers that were each paying $99 a year for access to our tool," he explained. "But the problem was that nobody was renewing the tool. So I called every single customer that I could find and said 'did you like the tool?'"
-
-It turned out that nearly everyone he talked to was extremely happy with the company's software, which ironically was the reason they weren't renewing. The company's tool solved their problem so well there was no need to renew.
-
-"What could we have offered that would have made you renew the tool?" he asked. "They said, 'If you had supported all of the open source products that your tool assembled for me, then I would have that ongoing relationship with you.'"
-
-Grandchamp immediately grasped the situation, and when the CTO said such support would be impossible, Grandchamp didn't mince words: "Then we don't have a company."
-
-"We figured out a way to support it," he said. "We created something called the Open Logic Expert Community. We developed relationships with committers and contributors to a couple of hundred open source packages, and we acted as sort of the hub of the SLA for our customers. We had some people on staff, too, who knew the big projects."
-
-After that successful launch, Grandchamp and his team began hearing from customers that they were confused over exactly what open source code they were using in their projects. That lead to the development of what he says was the first software-as-a-service compliance portal of open source, which could scan an application's code and produce a list of all of the open source code included in the project. When customers then expressed confusion over compliance issues, the SaaS service was expanded to flag potential licensing conflicts.
-
-Although the product lines were completely different, the same approach was used to monetize MariaDB, then called SkySQL, after MySQL co-founders Michael "Monty" Widenius, David Axmark, and Allan Larsson created the project by forking MySQL, which Oracle had acquired from Sun Microsystems in 2010.
-
-Again, users were approached and asked what things they would be willing to purchase.
-
-"They wanted different functionality in the database, and you didn't really understand this if you didn't talk to your customers," Grandchamp explained. "Monty and his team, while they were being acquired at Sun and Oracle, were working on all kinds of new functionality, around cloud deployments, around different ways to do clustering, they were working on lots of different things. That work, Oracle and MySQL didn't really pick up."
-
-Rolling in the new features customers wanted needed to be handled gingerly, because it was important to the folks at MariaDB to not break compatibility with MySQL. This necessitated a strategy around when the code bases would come together and when they would separate. "That road map, knowledge, influence and technical information was worth paying for."
-
-As with OpenLogic, MariaDB customers expressed a willingness to spend money on a variety of fronts. For example, a big driver in the early days was a project called Remote DBA, which helped customers make up for a shortage of qualified database administrators. The project could help with design issues, as well as monitor existing systems to take the workload off of a customer's DBA team. The service also offered access to MariaDB's own DBAs, many of whom had a history with the database going back to the early days of MySQL.
-
-"That was a subscription offering that people were definitely willing to pay for," he said.
-
-The company also learned, again by asking and listening to customers, that there were various types of support subscriptions that customers were willing to purchase, including subscriptions around capability and functionality, and a managed service component of Remote DBA.
-
-These days Grandchamp is putting much of his focus on his latest project, Drud, a startup that offers a suite of integrated, automated, open source development tools for developing and managing multiple websites, which can be running on any combination of content management systems and deployment platforms. It is monetized partially through modules that add features like a centralized dashboard and an "intelligence engine."
-
-As you might imagine, he got it off the ground by talking to customers and giving them what they indicated they'd be willing to purchase.
-
-"Our number one customer target is the agency market," he said. "The enterprise market is a big target, but I believe it's our second target, not our first. And the reason it's number two is they don't make decisions very fast. There are technology refresh cycles that have to come up, there are lots of politics involved and lots of different vendors. It's lucrative once you're in, but in a startup you've got to figure out how to pay your bills. I want to pay my bills today. I don't want to pay them in three years."
-
-Drud's focus on the agency market illustrates another consideration: the importance of understanding something about your customers' business. When talking with agencies, many said they were tired of being offered generic software that really didn't match their needs from proprietary vendors that didn't understand their business. In Drud's case, that understanding is built into the company DNA. The software was developed by an agency to fill its own needs.
-
-"We are a platform designed by an agency for an agency," Grandchamp said. "Right there is a relationship that they're willing to pay for. We know their business."
-
-Grandchamp noted that startups also need to be able to distinguish users from customers. Most of the people downloading and using commercial open source software aren't the people who have authorization to make purchasing decisions. These users, however, can point to the people who control the purse strings.
-
-"It's our job to build a way to communicate with those users, provide them value so that they'll give us value," he explained. "It has to be an equal exchange. I give you value of a tool that works, some advice, really good documentation, access to experts who can sort of guide you along. Along the way I'm asking you for pieces of information. Who do you work for? How are the technology decisions happening in your company? Are there other people in your company that we should refer the product to? We have to create the dialog."
-
-In the end, Grandchamp said, in the open source world the people who go out to find business probably shouldn't see themselves as salespeople, but rather, as problem solvers.
-
-"I believe that you're not really going to need salespeople in this model. I think you're going to need customer success people. I think you're going to need people who can enable your customers to be successful in a business relationship that's more highly transactional."
-
-"People don't like to be sold," he added, "especially in open source. The last person they want to see is the sales person, but they like to ply and try and consume and give you input and give you feedback. They love that."
-
---------------------------------------------------------------------------------
-
-via: http://www.itprotoday.com/software-development/how-monetize-open-source-project
-
-作者:[Christine Hall][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://www.itprotoday.com/author/christine-hall
-[1]:https://www.drud.com/
-[2]:http://www.itprotoday.com/open-source/demand-open-source-skills-continues-grow
-[3]:http://www.itprotoday.com/software-development/raleigh-east-coasts-silicon-valley
diff --git a/sources/talk/20171114 Why pair writing helps improve documentation.md b/sources/talk/20171114 Why pair writing helps improve documentation.md
deleted file mode 100644
index ff3bbb5888..0000000000
--- a/sources/talk/20171114 Why pair writing helps improve documentation.md
+++ /dev/null
@@ -1,87 +0,0 @@
-Why pair writing helps improve documentation
-======
-
-
-Professional writers, at least in the Red Hat documentation team, nearly always work on docs alone. But have you tried writing as part of a pair? In this article, I'll explain a few benefits of pair writing.
-### What is pair writing?
-
-Pair writing is when two writers work in real time, on the same piece of text, in the same room. This approach improves document quality, speeds up writing, and allows writers to learn from each other. The idea of pair writing is borrowed from [pair programming][1].
-
-When pair writing, you and your colleague work on the text together, making suggestions and asking questions as needed. Meanwhile, you're observing each other's work. For example, while one is writing, the other writer observes details such as structure or context. Often discussion around the document turns into sharing experiences and opinions, and brainstorming about writing in general.
-
-At all times, the writing is done by only one person. Thus, you need only one computer, unless you want one writer to do online research while the other person does the writing. The text workflow is the same as if you are working alone: a text editor, the documentation source files, git, and so on.
-
-### Pair writing in practice
-
-My colleague Aneta Steflova and I have done more than 50 hours of pair writing working on the Red Hat Enterprise Linux System Administration docs and on the Red Hat Identity Management docs. I've found that, compared to writing alone, pair writing:
-
- * is as productive or more productive;
- * improves document quality;
- * helps writers share technical expertise; and
- * is more fun.
-
-
-
-### Speed
-
-Two writers writing one text? Sounds half as productive, right? Wrong. (Usually.)
-
-Pair writing can help you work faster because two people have solutions to a bigger set of problems, which means getting blocked less often during the process. For example, one time we wrote urgent API docs for identity management. I know at least the basics of web APIs, the REST protocol, and so on, which helped us speed through those parts of the documentation. Working alone, Aneta would have needed to interrupt the writing process frequently to study these topics.
-
-### Quality
-
-Poor wording or sentence structure, inconsistencies in material, and so on have a harder time surviving under the scrutiny of four eyes. For example, one of our pair writing documents was reviewed by an extremely critical developer, who was known for catching technical inaccuracies and bad structure. After this particular review, he said, "Perfect. Thanks a lot."
-
-### Sharing expertise
-
-Each of us lives in our own writing bubble, and we normally don't know how others approach writing. Pair writing can help you improve your own writing process. For example, Aneta showed me how to better handle assignments in which the developer has provided starting text (as opposed to the writer writing from scratch using their own knowledge of the subject), which I didn't have experience with. Also, she structures the docs thoroughly, which I began doing as well.
-
-As another example, I'm good enough at Vim that XML editing (e.g., tags manipulation) is enjoyable instead of torturous. Aneta saw how I was using Vim, asked about it, suffered through the learning curve, and now takes advantage of the Vim features that help me.
-
-Pair writing is especially good for helping and mentoring new writers, and it's a great way to get to know professionally (and have fun with) colleagues.
-
-### When pair writing shines
-
-In addition to benefits I've already listed, pair writing is especially good for:
-
- * **Working with[Bugzilla][2]** : Bugzillas can be cumbersome and cause problems, especially for administration-clumsy people (like me).
- * **Reviewing existing documents** : When documentation needs to be expanded or fixed, it is necessary to first examine the existing document.
- * **Learning new technology** : A fellow writer can be a better teacher than an engineer.
- * **Writing emails/requests for information to developers with well-chosen questions** : The difficulty of this task rises in proportion to the difficulty of technology you are documenting.
-
-
-
-Also, with pair writing, feedback is in real time, as-needed, and two-way.
-
-On the downside, pair writing can be a faster pace, giving a writer less time to mull over a topic or wording. On the other hand, generally peer review is not necessary after pair writing.
-
-### Words of caution
-
-To get the most out of pair writing:
-
- * Go into the project well prepared, otherwise you can waste your colleague's time.
- * Talkative types need to stay focused on the task, otherwise they end up talking rather than writing.
- * Be prepared for direct feedback. Pair writing is not for feedback-allergic writers.
- * Beware of session hijackers. Dominant personalities can turn pair writing into writing solo with a spectator. (However, it _can _ be good if one person takes over at times, as long as the less-experienced partner learns from the hijacker, or the more-experienced writer is providing feedback to the hijacker.)
-
-
-
-### Conclusion
-
-Pair writing is a meeting, but one in which you actually get work done. It's an activity that lets writers focus on the one indispensable thing in our vocation--writing.
-
-_This post was written with the help of pair writing with Aneta Steflova._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/17/11/try-pair-writing
-
-作者:[Maxim Svistunov][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/maxim-svistunov
-[1]:https://developer.atlassian.com/blog/2015/05/try-pair-programming/
-[2]:https://www.bugzilla.org/
diff --git a/sources/talk/20171115 Why and How to Set an Open Source Strategy.md b/sources/talk/20171115 Why and How to Set an Open Source Strategy.md
deleted file mode 100644
index 79ec071b4d..0000000000
--- a/sources/talk/20171115 Why and How to Set an Open Source Strategy.md
+++ /dev/null
@@ -1,120 +0,0 @@
-Why and How to Set an Open Source Strategy
-============================================================
-
-
-
-This article explains how to walk through, measure, and define strategies collaboratively in an open source community.
-
- _“If you don’t know where you are going, you’ll end up someplace else.” _ _—_ Yogi Berra
-
-Open source projects are generally started as a way to scratch one’s itch — and frankly that’s one of its greatest attributes. Getting code down provides a tangible method to express an idea, showcase a need, and solve a problem. It avoids over thinking and getting a project stuck in analysis-paralysis, letting the project pragmatically solve the problem at hand.
-
-Next, a project starts to scale up and gets many varied users and contributions, with plenty of opinions along the way. That leads to the next big challenge — how does a project start to build a strategic vision? In this article, I’ll describe how to walk through, measure, and define strategies collaboratively, in a community.
-
-Strategy may seem like a buzzword of the corporate world rather something that an open source community would embrace, so I suggest stripping away the negative actions that are sometimes associated with this word (e.g., staff reductions, discontinuations, office closures). Strategy done right isn’t a tool to justify unfortunate actions but to help show focus and where each community member can contribute.
-
-A good application of strategy achieves the following:
-
-* Why the project exists?
-
-* What the project looks to achieve?
-
-* What is the ideal end state for a project is.
-
-The key to success is answering these questions as simply as possible, with consensus from your community. Let’s look at some ways to do this.
-
-### Setting a mission and vision
-
- _“_ _Efforts and courage are not enough without purpose and direction.”_ — John F. Kennedy
-
-All strategic planning starts off with setting a course for where the project wants to go. The two tools used here are _Mission_ and _Vision_ . They are complementary terms, describing both the reason a project exists (mission) and the ideal end state for a project (vision).
-
-A great way to start this exercise with the intent of driving consensus is by asking each key community member the following questions:
-
-* What drove you to join and/or contribute the project?
-
-* How do you define success for your participation?
-
-In a company, you’d ask your customers these questions usually. But in open source projects, the customers are the project participants — and their time investment is what makes the project a success.
-
-Driving consensus means capturing the answers to these questions and looking for themes across them. At R Consortium, for example, I created a shared doc for the board to review each member’s answers to the above questions, and followed up with a meeting to review for specific themes that came from those insights.
-
-Building a mission flows really well from this exercise. The key thing is to keep the wording of your mission short and concise. Open Mainframe Project has done this really well. Here’s their mission:
-
- _Build community and adoption of Open Source on the mainframe by:_
-
-* _Eliminating barriers to Open Source adoption on the mainframe_
-
-* _Demonstrating value of the mainframe on technical and business levels_
-
-* _Strengthening collaboration points and resources for the community to thrive_
-
-At 40 words, it passes the key eye tests of a good mission statement; it’s clear, concise, and demonstrates the useful value the project aims for.
-
-The next stage is to reflect on the mission statement and ask yourself this question: What is the ideal outcome if the project accomplishes its mission? That can be a tough one to tackle. Open Mainframe Project put together its vision really well:
-
- _Linux on the Mainframe as the standard for enterprise class systems and applications._
-
-You could read that as a [BHAG][1], but it’s really more of a vision, because it describes a future state that is what would be created by the mission being fully accomplished. It also hits the key pieces to an effective vision — it’s only 13 words, inspirational, clear, memorable, and concise.
-
-Mission and vision add clarity on the who, what, why, and how for your project. But, how do you set a course for getting there?
-
-### Goals, Objectives, Actions, and Results
-
- _“I don’t focus on what I’m up against. I focus on my goals and I try to ignore the rest.”_ — Venus Williams
-
-Looking at a mission and vision can get overwhelming, so breaking them down into smaller chunks can help the project determine how to get started. This also helps prioritize actions, either by importance or by opportunity. Most importantly, this step gives you guidance on what things to focus on for a period of time, and which to put off.
-
-There are lots of methods of time bound planning, but the method I think works the best for projects is what I’ve dubbed the GOAR method. It’s an acronym that stands for:
-
-* Goals define what the project is striving for and likely would align and support the mission. Examples might be “Grow a diverse contributor base” or “Become the leading project for X.” Goals are aspirational and set direction.
-
-* Objectives show how you measure a goal’s completion, and should be clear and measurable. You might also have multiple objectives to measure the completion of a goal. For example, the goal “Grow a diverse contributor base” might have objectives such as “Have X total contributors monthly” and “Have contributors representing Y different organizations.”
-
-* Actions are what the project plans to do to complete an objective. This is where you get tactical on exactly what needs done. For example, the objective “Have contributors representing Y different organizations” would like have actions of reaching out to interested organizations using the project, having existing contributors mentor new mentors, and providing incentives for first time contributors.
-
-* Results come along the way, showing progress both positive and negative from the actions.
-
-You can put these into a table like this:
-
-| Goals | Objectives | Actions | Results |
-|:--|:--|:--|:--|
-| Grow a diverse contributor base | Have X total contributors monthly | Existing contributors mentor new mentors Providing incentives for first time contributors | |
-| | Have contributors representing Y different organizations | Reach out to interested organizations using the project | |
-
-
-In large organizations, monthly or quarterly goals and objectives often make sense; however, on open source projects, these time frames are unrealistic. Six- even 12-month tracking allows the project leadership to focus on driving efforts at a high level by nurturing the community along.
-
-The end result is a rubric that provides clear vision on where the project is going. It also lets community members more easily find ways to contribute. For example, your project may include someone who knows a few organizations using the project — this person could help introduce those developers to the codebase and guide them through their first commit.
-
-### What happens if the project doesn’t hit the goals?
-
- _“I have not failed. I’ve just found 10,000 ways that won’t work.”_ — Thomas A. Edison
-
-Figuring out what is within the capability of an organization — whether Fortune 500 or a small open source project — is hard. And, sometimes the expectations or market conditions change along the way. Does that make the strategy planning process a failure? Absolutely not!
-
-Instead, you can use this experience as a way to better understand your project’s velocity, its impact, and its community, and perhaps as a way to prioritize what is important and what’s not.
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxfoundation.org/blog/set-open-source-strategy/
-
-作者:[ John Mertic][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linuxfoundation.org/author/jmertic/
-[1]:https://en.wikipedia.org/wiki/Big_Hairy_Audacious_Goal
-[2]:https://www.linuxfoundation.org/author/jmertic/
-[3]:https://www.linuxfoundation.org/category/blog/
-[4]:https://www.linuxfoundation.org/category/audience/c-level/
-[5]:https://www.linuxfoundation.org/category/audience/developer-influencers/
-[6]:https://www.linuxfoundation.org/category/audience/entrepreneurs/
-[7]:https://www.linuxfoundation.org/category/campaigns/membership/how-to/
-[8]:https://www.linuxfoundation.org/category/campaigns/events-campaigns/linux-foundation/
-[9]:https://www.linuxfoundation.org/category/audience/open-source-developers/
-[10]:https://www.linuxfoundation.org/category/audience/open-source-professionals/
-[11]:https://www.linuxfoundation.org/category/audience/open-source-users/
-[12]:https://www.linuxfoundation.org/category/blog/thought-leadership/
diff --git a/sources/talk/20171116 Why is collaboration so difficult.md b/sources/talk/20171116 Why is collaboration so difficult.md
deleted file mode 100644
index 6567b75dca..0000000000
--- a/sources/talk/20171116 Why is collaboration so difficult.md
+++ /dev/null
@@ -1,94 +0,0 @@
-Why is collaboration so difficult?
-======
-
-
-Many contemporary definitions of "collaboration" define it simply as "working together"--and, in part, it is working together. But too often, we tend to use the term "collaboration" interchangeably with cognate terms like "cooperation" and "coordination." These terms also refer to some manner of "working together," yet there are subtle but important differences between them all.
-
-How does collaboration differ from coordination or cooperation? What is so important about collaboration specifically? Does it have or do something that coordination and cooperation don't? The short answer is a resounding "yes!"
-
-[This unit explores collaboration][1], a problematic term because it has become a simple buzzword for "working together." By the time you've studied the cases and practiced the exercises contained in this section, you will understand that it's so much more than that.
-
-### Not like the others
-
-"Coordination" can be defined as the ordering of a variety of people acting in an effective, unified manner toward an end goal or state
-
-In traditional organizations and businesses, people contributed according to their role definitions, such as in manufacturing, where each employee was responsible for adding specific components to the widget on an assembly line until the widget was complete. In contexts like these, employees weren't expected to contribute beyond their pre-defined roles (they were probably discouraged from doing so), and they didn't necessarily have a voice in the work or in what was being created. Often, a manager oversaw the unification of effort (hence the role "project coordinator"). Coordination is meant to connote a sense of harmony and unity, as if elements are meant to go together, resulting in efficiency among the ordering of the elements.
-
-One common assumption is that coordinated efforts are aimed at the same, single goal. So some end result is "successful" when people and parts work together seamlessly; when one of the parts breaks down and fails, then the whole goal fails. Many traditional businesses (for instance, those with command-and-control hierarchies) manage work through coordination.
-
-Cooperation is another term whose surface meaning is "working together." Rather than the sense of compliance that is part of "coordination," it carries a sense of agreement and helpfulness on the path toward completing a shared activity or goal.
-
-"Collaboration" also means "working together"--but that simple definition obscures the complex and often difficult process of collaborating.
-
-People tend to use the term "cooperation" when joining two semi-related entities where one or more entity could decide not to cooperate. The people and pieces that are part of a cooperative effort make the shared activity easier to perform or the shared goal easier to reach. "Cooperation" implies a shared goal or activity we agree to pursue jointly. One example is how police and witnesses cooperate to solve crimes.
-
-"Collaboration" also means "working together"--but that simple definition obscures the complex and often difficult process of collaborating.
-
-Sometimes collaboration involves two or more groups that do not normally work together; they are disparate groups or not usually connected. For instance, a traitor collaborates with the enemy, or rival businesses collaborate with each other. The subtlety of collaboration is that the two groups may have oppositional initial goals but work together to create a shared goal. Collaboration can be more contentious than coordination or cooperation, but like cooperation, any one of the entities could choose not to collaborate. Despite the contention and conflict, however, there is discourse--whether in the form of multi-way discussion or one-way feedback--because without discourse, there is no way for people to express a point of dissent that is ripe for negotiation.
-
-The success of any collaboration rests on how well the collaborators negotiate their needs to create the shared objective, and then how well they cooperate and coordinate their resources to execute a plan to reach their goals.
-
-### For example
-
-One way to think about these things is through a real-life example--like the writing of [this book][1].
-
-The editor, [Bryan][2], coordinates the authors' work through the call for proposals, setting dates and deadlines, collecting the writing, and meeting editing dates and deadlines for feedback about our work. He coordinates the authors, the writing, the communications. In this example, I'm not coordinating anything except myself (still a challenge most days!).
-
-The success of any collaboration rests on how well the collaborators negotiate their needs to create the shared objective, and then how well they cooperate and coordinate their resources to execute a plan to reach their goals.
-
-I cooperate with Bryan's dates and deadlines, and with the ways he has decided to coordinate the work. I propose the introduction on GitHub; I wait for approval. I comply with instructions, write some stuff, and send it to him by the deadlines. He cooperates by accepting a variety of document formats. I get his edits,incorporate them, send it back him, and so forth. If I don't cooperate (or something comes up and I can't cooperate), then maybe someone else writes this introduction instead.
-
-Bryan and I collaborate when either one of us challenges something, including pieces of the work or process that aren't clear, things that we thought we agreed to, or things on which we have differing opinions. These intersections are ripe for negotiation and therefore indicative of collaboration. They are the opening for us to negotiate some creative work.
-
-Once the collaboration is negotiated and settled, writing and editing the book returns to cooperation/coordination; that is why collaboration relies on the other two terms of joint work.
-
-One of the most interesting parts of this example (and of work and shared activity in general) is the moment-by-moment pivot from any of these terms to the other. The writing of this book is not completely collaborative, coordinated, or cooperative. It's a messy mix of all three.
-
-### Why is collaboration important?
-
-Collaboration is an important facet of contemporary organizations--specifically those oriented toward knowledge work--because it allows for productive disagreement between actors. That kind of disagreement then helps increase the level of engagement and provide meaning to the group's work.
-
-In his book, The Age of Discontinuity: Guidelines to our Changing Society, [Peter Drucker discusses][3] the "knowledge worker" and the pivot from work based on experience (e.g. apprenticeships) to work based on knowledge and the application of knowledge. This change in work and workers, he writes:
-
-> ...will make the management of knowledge workers increasingly crucial to the performance and achievement of the knowledge society. We will have to learn to manage the knowledge worker both for productivity and for satisfaction, both for achievement and for status. We will have to learn to give the knowledge worker a job big enough to challenge him, and to permit performance as a "professional."
-
-In other words, knowledge workers aren't satisfied with being subordinate--told what to do by managers as, if there is one right way to do a task. And, unlike past workers, they expect more from their work lives, including some level of emotional fulfillment or meaning-making from their work. The knowledge worker, according to Drucker, is educated toward continual learning, "paid for applying his knowledge, exercising his judgment, and taking responsible leadership." So it then follows that knowledge workers expect from work the chance to apply and share their knowledge, develop themselves professionally, and continuously augment their knowledge.
-
-Interesting to note is the fact that Peter Drucker wrote about those concepts in 1969, nearly 50 years ago--virtually predicting the societal and organizational changes that would reveal themselves, in part, through the development of knowledge sharing tools such as forums, bulletin boards, online communities, and cloud knowledge sharing like DropBox and GoogleDrive as well as the creation of social media tools such as MySpace, Facebook, Twitter, YouTube and countless others. All of these have some basis in the idea that knowledge is something to liberate and share.
-
-In this light, one might view the open organization as one successful manifestation of a system of management for knowledge workers. In other words, open organizations are a way to manage knowledge workers by meeting the needs of the organization and knowledge workers (whether employees, customers, or the public) simultaneously. The foundational values this book explores are the scaffolding for the management of knowledge, and they apply to ways we can:
-
- * make sure there's a lot of varied knowledge around (inclusivity)
- * help people come together and participate (community)
- * circulate information, knowledge, and decision making (transparency)
- * innovate and not become entrenched in old ways of thinking and being (adaptability)
- * develop a shared goal and work together to use knowledge (collaboration)
-
-
-
-Collaboration is an important process because of the participatory effect it has on knowledge work and how it aids negotiations between people and groups. As we've discovered, collaboration is more than working together with some degree of compliance; in fact, it describes a type of working together that overcomes compliance because people can disagree, question, and express their needs in a negotiation and in collaboration. And, collaboration is more than "working toward a shared goal"; collaboration is a process which defines the shared goals via negotiation and, when successful, leads to cooperation and coordination to focus activity on the negotiated outcome.
-
-Collaboration is an important process because of the participatory effect it has on knowledge work and how it aids negotiations between people and groups.
-
-Collaboration works best when the other four open organization values are present. For instance, when people are transparent, there is no guessing about what is needed, why, by whom, or when. Also, because collaboration involves negotiation, it also needs diversity (a product of inclusivity); after all, if we aren't negotiating among differing views, needs, or goals, then what are we negotiating? During a negotiation, the parties are often asked to give something up so that all may gain, so we have to be adaptable and flexible to the different outcomes that negotiation can provide. Lastly, collaboration is often an ongoing process rather than one which is quickly done and over, so it's best to enter collaboration as if you are part of the same community, desiring everyone to benefit from the negotiation. In this way, acts of authentic and purposeful collaboration directly necessitate the emergence of the other four values--transparency, inclusivity, adaptability, and community--as they assemble part of the organization's collective purpose spontaneously.
-
-### Collaboration in open organizations
-
-Traditional organizations advance an agreed-upon set of goals that people are welcome to support or not. In these organizations, there is some amount of discourse and negotiation, but often a higher-ranking or more powerful member of the organization intervenes to make a decision, which the membership must accept (and sometimes ignores). In open organizations, however, the focus is for members to perform their activity and to work out their differences; only if necessary would someone get involved (and even then would try to do it in the most minimal way that support the shared values of community, transparency, adaptability, collaboration and inclusivity.) This make the collaborative processes in open organizations "messier" (or "chaotic" to use Jim Whitehurst's term) but more participatory and, hopefully, innovative.
-
-This article is part of the [Open Organization Workbook project][1].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/17/11/what-is-collaboration
-
-作者:[Heidi Hess Von Ludewig][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/heidi-hess-von-ludewig
-[1]:https://opensource.com/open-organization/17/8/workbook-project-announcement
-[2]:http://opensource.com/users/bbehrens
-[3]:https://www.elsevier.com/books/the-age-of-discontinuity/drucker/978-0-434-90395-5
diff --git a/sources/talk/20171221 Changing how we use Slack solved our transparency and silo problems.md b/sources/talk/20171221 Changing how we use Slack solved our transparency and silo problems.md
deleted file mode 100644
index d68bab55bf..0000000000
--- a/sources/talk/20171221 Changing how we use Slack solved our transparency and silo problems.md
+++ /dev/null
@@ -1,95 +0,0 @@
-Changing how we use Slack solved our transparency and silo problems
-======
-
-
-Collaboration and information silos are a reality in most organizations today. People tend to regard them as huge barriers to innovation and organizational efficiency. They're also a favorite target for solutions from software tool vendors of all types.
-
-Tools by themselves, however, are seldom (if ever), the answer to a problem like organizational silos. The reason for this is simple: Silos are made of people, and human dynamics are key drivers for the existence of silos in the first place.
-
-So what is the answer?
-
-Successful communities are the key to breaking down silos. Tools play an important role in the process, but if you don't build successful communities around those tools, then you'll face an uphill battle with limited chances for success. Tools enable communities; they do not build them. This takes a thoughtful approach--one that looks at culture first, process second, and tools last.
-
-Successful communities are the key to breaking down silos.
-
-However, this is a challenge because, in most cases, this is not the way the process works in most businesses. Too many companies begin their journey to fix silos by thinking about tools first and considering metrics that don't evaluate the right factors for success. Too often, people choose tools for purely cost-based, compliance-based, or effort-based reasons--instead of factoring in the needs and desires of the user base. But subjective measures like "customer/user delight" are a real factor for these internal tools, and can make or break the success of both the tool adoption and the goal of increased collaboration.
-
-It's critical to understand the best technical tool (or what the business may consider the most cost-effective) is not always the solution that drives community, transparency, and collaboration forward. There is a reason that "Shadow IT"--users choosing their own tool solution, building community and critical mass around them--exists and is so effective: People who choose their own tools are more likely to stay engaged and bring others with them, breaking down silos organically.
-
-This is a story of how Autodesk ended up adopting Slack at enterprise scale to help solve our transparency and silo problems. Interestingly, Slack wasn't (and isn't) an IT-supported application at Autodesk. It's an enterprise solution that was adopted, built, and is still run by a group of passionate volunteers who are committed to a "default to open" paradigm.
-
-Utilizing Slack makes transparency happen for us.
-
-### Chat-tastrophe
-
-First, some perspective: My job at Autodesk is running our [Open@ADSK][1] initiative. I was originally hired to drive our open source strategy, but we quickly expanded my role to include driving open source best practices for internal development (inner source), and transforming how we collaborate internally as an organization. This last piece is where we pick up our story of Slack adoption in the company.
-
-But before we even begin to talk about our journey with Slack, let's address why lack of transparency and openness was a challenge for us. What is it that makes transparency such a desirable quality in organizations, and what was I facing when I started at Autodesk?
-
-Every company says they want "better collaboration." In our case, we are a 35-year-old software company that has been immensely successful at selling desktop "shrink-wrapped" software to several industries, including architecture, engineering, construction, manufacturing, and entertainment. But no successful company rests on its laurels, and Autodesk leadership recognized that a move to Cloud-based solutions for our products was key to the future growth of the company, including opening up new markets through product combinations that required Cloud computing and deep product integrations.
-
-The challenge in making this move was far more than just technical or architectural--it was rooted in the DNA of the company, in everything from how we were organized to how we integrated our products. The basic format of integration in our desktop products was file import/export. While this is undoubtedly important, it led to a culture of highly-specialized teams working in an environment that's more siloed than we'd like and not sharing information (or code). Prior to the move to a cloud-based approach, this wasn't as a much of a problem--but, in an environment that requires organizations to behave more like open source projects do, transparency, openness, and collaboration go from "nice-to-have" to "business critical."
-
-Like many companies our size, Autodesk has had many different collaboration solutions through the years, some of them commercial, and many of them home-grown. However, none of them effectively solved the many-to-many real-time collaboration challenge. Some reasons for this were technical, but many of them were cultural.
-
-I relied on a philosophy I'd formed through challenging experiences in my career: "Culture first, tools last."
-
-When someone first tasked me with trying to find a solution for this, I relied on a philosophy I'd formed through challenging experiences in my career: "Culture first, tools last." This is still a challenge for engineering folks like myself. We want to jump immediately to tools as the solution to any problem. However, it's critical to evaluate a company's ethos (culture), as well as existing processes to determine what kinds of tools might be a good fit. Unfortunately, I've seen too many cases where leaders have dictated a tool choice from above, based on the factors discussed earlier. I needed a different approach that relied more on fitting a tool into the culture we wanted to become, not the other way around.
-
-What I found at Autodesk were several small camps of people using tools like HipChat, IRC, Microsoft Lync, and others, to try to meet their needs. However, the most interesting thing I found was 85 separate instances of Slack in the company!
-
-Eureka! I'd stumbled onto a viral success (one enabled by Slack's ability to easily spin up "free" instances). I'd also landed squarely in what I like to call "silo-land."
-
-All of those instances were not talking to each other--so, effectively, we'd created isolated islands of information that, while useful to those in them, couldn't transform the way we operated as an enterprise. Essentially, our existing organizational culture was recreated in digital format in these separate Slack systems. Our organization housed a mix of these small, free instances, as well as multiple paid instances, which also meant we were not taking advantage of a common billing arrangement.
-
-My first (open source) thought was: "Hey, why aren't we using IRC, or some other open source tool, for this?" I quickly realized that didn't matter, as our open source engineers weren't the only people using Slack. People from all areas of the company--even senior leadership--were adopting Slack in droves, and, in some cases, convincing their management to pay for it!
-
-My second (engineering) thought was: "Oh, this is simple. We just collapse all 85 of those instances into a single cohesive Slack instance." What soon became obvious was that was the easy part of the solution. Much harder was the work of cajoling, convincing, and moving people to a single, transparent instance. Building in the "guard rails" to enable a closed source tool to provide this transparency was key. These guard rails came in the form of processes, guidelines, and community norms that were the hardest part of this transformation.
-
-### The real work begins
-
-As I began to slowly help users migrate to the common instance (paying for it was also a challenge, but a topic for another day), I discovered a dedicated group of power users who were helping each other in the #adsk-slack-help channel on our new common instance of Slack. These power users were, in effect, building the roots of our transparency and community through their efforts.
-
-The open source community manager in me quickly realized these users were the path to successfully scaling Slack at Autodesk. I enlisted five of them to help me, and, together we set about fabricating the community structure for the tool's rollout.
-
-We did, however, learn an important lesson about transparency and company culture along the way.
-
-Here I should note the distinction between a community structure/governance model and traditional IT policies: With the exception of security and data privacy/legal policies, volunteer admins and user community members completely define and govern our Slack instance. One of the keys to our success with Slack (currently approximately 9,100 users and roughly 4,300 public channels) was how we engaged and involved our users in building these governance structures. Things like channel naming conventions and our growing list of frequently asked questions were organic and have continued in that same vein. Our community members feel like their voices are heard (even if some disagree), and that they have been a part of the success of our deployment of Slack.
-
-We did, however, learn an important lesson about transparency and company culture along the way.
-
-### It's not the tool
-
-When we first launched our main Slack instance, we left the ability for anyone to make a channel private turned on. After about three months of usage, we saw a clear trend: More people were creating private channels (and messages) than they were public channels (the ratio was about two to one, private versus public). Since our effort to merge 85 Slack instances was intended to increase participation and transparency, we quickly adjusted our policy and turned off this feature for regular users. We instead implemented a policy of review by the admin team, with clear criteria (finance, legal, personnel discussions among the reasons) defined for private channels.
-
-This was probably the only time in this entire process that I regretted something.
-
-We took an amazing amount of flak for this decision because we were dealing with a corporate culture that was used to working in independent units that had minimal interaction with each other. Our defining moment of clarity (and the tipping point where things started to get better) occurred in an all-hands meeting when one of our senior executives asked me to address a question about Slack. I stood up to answer the question, and said (paraphrased from memory): "It's not about the tool. I could give you all the best, gold-plated collaboration platform in existence, but we aren't going to be successful if we don't change our approach to collaboration and learn to default to open."
-
-I didn't think anything more about that statement--until that senior executive starting using the phrase "default to open" in his slide decks, in his staff meetings, and with everyone he met. That one moment has defined what we have been trying to do with Slack: The tool isn't the sole reason we've been successful; it's the approach that we've taken around building a self-sustaining community that not only wants to use this tool, but craves the ability it gives them to work easily across the enterprise.
-
-### What we learned
-
-The tool isn't the sole reason we've been successful; it's the approach that we've taken around building a self-sustaining community that not only wants to use this tool, but craves the ability it gives them to work easily across the enterprise.
-
-I say all the time that this could have happened with other, similar tools (Hipchat, IRC, etc), but it works in this case specifically because we chose an approach of supporting a solution that the user community adopted for their needs, not strictly what the company may have chosen if the decision was coming from the top of the organizational chart. We put a lot of work into making it an acceptable solution (from the perspectives of security, legal, finance, etc.) for the company, but, ultimately, our success has come from the fact that we built this rollout (and continue to run the tool) as a community, not as a traditional corporate IT system.
-
-The most important lesson I learned through all of this is that transparency and community are evolutionary, not revolutionary. You have to understand where your culture is, where you want it to go, and utilize the lever points that the community is adopting itself to make sustained and significant progress. There is a fine balance point between an anarchy, and a thriving community, and we've tried to model our approach on the successful practices of today's thriving open source communities.
-
-Communities are personal. Tools come and go, but keeping your community at the forefront of your push to transparency is the key to success.
-
-This article is part of the [Open Organization Workbook project][2].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/17/12/chat-platform-default-to-open
-
-作者:[Guy Martin][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/guyma
-[1]:mailto:Open@ADSK
-[2]:https://opensource.com/open-organization/17/8/workbook-project-announcement
diff --git a/sources/talk/20180109 How Mycroft used WordPress and GitHub to improve its documentation.md b/sources/talk/20180109 How Mycroft used WordPress and GitHub to improve its documentation.md
deleted file mode 100644
index 9e35e0ede7..0000000000
--- a/sources/talk/20180109 How Mycroft used WordPress and GitHub to improve its documentation.md
+++ /dev/null
@@ -1,116 +0,0 @@
-How Mycroft used WordPress and GitHub to improve its documentation
-======
-
-
-
-Image credits : Photo by Unsplash; modified by Rikki Endsley. CC BY-SA 4.0
-
-Imagine you've just joined a new technology company, and one of the first tasks you're assigned is to improve and centralize the organization's developer-facing documentation. There's just one catch: That documentation exists in many different places, across several platforms, and differs markedly in accuracy, currency, and style.
-
-So how did we tackle this challenge?
-
-### Understanding the scope
-
-As with any project, we first needed to understand the scope and bounds of the problem we were trying to solve. What documentation was good? What was working? What wasn't? How much documentation was there? What format was it in? We needed to do a **documentation audit**. Luckily, [Aneta Šteflova][1] had recently [published an article on OpenSource.com][2] about this, and it provided excellent guidance.
-
-![mycroft doc audit][4]
-
-Mycroft documentation audit, showing source, topic, medium, currency, quality and audience
-
-Next, every piece of publicly facing documentation was assessed for the topic it covered, the medium it used, currency, and quality. A pattern quickly emerged that different platforms had major deficiencies, allowing us to make a data-driven approach to decommission our existing Jekyll-based sites. The audit also highlighted just how fragmented our documentation sources were--we had developer-facing documentation across no fewer than seven sites. Although search engines were finding this content just fine, the fragmentation made it difficult for developers and users of Mycroft--our primary audiences--to navigate the information they needed. Again, this data helped us make the decision to centralize our documentation on to one platform.
-
-### Choosing a central platform
-
-As an organization, we wanted to constrain the number of standalone platforms in use. Over time, maintenance and upkeep of multiple platforms and integration touchpoints becomes cumbersome for any organization, but this is exacerbated for a small startup.
-
-One of the other business drivers in platform choice was that we had two primary but very different audiences. On one hand, we had highly technical developers who we were expecting would push documentation to its limits--and who would want to contribute to technical documentation using their tools of choice--[Git][5], [GitHub][6], and [Markdown][7]. Our second audience--end users--would primarily consume technical documentation and would want to do so in an inviting, welcoming platform that was visually appealing and provided additional features such as the ability to identify reading time and to provide feedback. The ability to capture feedback was also a key requirement from our side as without feedback on the quality of the documentation, we would not have a solid basis to undertake continuous quality improvement.
-
-Would we be able to identify one platform that met all of these competing needs?
-
-We realised that two platforms covered all of our needs:
-
- * [WordPress][8]: Our existing website is built on WordPress, and we have some reasonably robust WordPress skills in-house. The flexibility of WordPress also fulfilled our requirements for functionality like reading time and the ability to capture user feedback.
- * [GitHub][9]: Almost [all of Mycroft.AI's source code is available on GitHub][10], and our development team uses this platform daily.
-
-
-
-But how could we marry the two?
-
-
-
-
-### Integrating WordPress and GitHub with WordPress GitHub Sync
-
-Luckily, our COO, [Nate Tomasi][11], spotted a WordPress plugin that promised to integrate the two.
-
-This was put through its paces on our test website, and it passed with flying colors. It was easy to install, had a straightforward configuration, which just required an OAuth token and webhook with GitHub, and provided two-way integration between WordPress and GitHub.
-
-It did, however, have a dependency--on Markdown--which proved a little harder to implement. We trialed several Markdown plugins, but each had several quirks that interfered with the rendering of non-Markdown-based content. After several days of frustration, and even an attempt to custom-write a plugin for our needs, we stumbled across [Parsedown Party][12]. There was much partying! With WordPress GitHub Sync and Parsedown Party, we had integrated our two key platforms.
-
-Now it was time to make our content visually appealing and usable for our user audience.
-
-### Reading time and feedback
-
-To implement the reading time and feedback functionality, we built a new [page template for WordPress][13], and leveraged plugins within the page template.
-
-Knowing the estimated reading time of an article in advance has been [proven to increase engagement with content][14] and provides developers and users with the ability to decide whether to read the content now or bookmark it for later. We tested several WordPress plugins for reading time, but settled on [Reading Time WP][15] because it was highly configurable and could be easily embedded into WordPress page templates. Our decision to place Reading Time at the top of the content was designed to give the user the choice of whether to read now or save for later. With Reading Time in place, we then turned our attention to gathering user feedback and ratings for our documentation.
-
-
-
-There are several rating and feedback plugins available for WordPress. We needed one that could be easily customized for several use cases, and that could aggregate or summarize ratings. After some experimentation, we settled on [Multi Rating Pro][16] because of its wide feature set, especially the ability to create a Review Ratings page in WordPress--i.e., a central page where staff can review ratings without having to be logged in to the WordPress backend. The only gap we ran into here was the ability to set the display order of rating options--but it will likely be added in a future release.
-
-The WordPress GitHub Integration plugin also gave us the ability to link back to the GitHub repository where the original Markdown content was held, inviting technical developers to contribute to improving our documentation.
-
-### Updating the existing documentation
-
-Now that the "container" for our new documentation had been developed, it was time to update the existing content. Because much of our documentation had grown organically over time, there were no style guidelines to shape how keywords and code were styled. This was tackled first, so that it could be applied to all content. [You can see our content style guidelines on GitHub.][17]
-
-As part of the update, we also ran several checks to ensure that the content was technically accurate, augmenting the existing documentation with several images for better readability.
-
-There were also a couple of additional tools that made creating internal links for documentation pieces easier. First, we installed the [WP Anchor Header][18] plugin. This plugin provided a small but important function: adding `id` content in GitHub using the `[markdown-toc][19]` library, then simply copied in to the WordPress content, where they would automatically link to the `id` attributes to each `<h1>`, `<h2>` (and so on) element. This meant that internal anchors could be automatically generated on the command line from the Markdown content in GitHub using the `[markdown-toc][19]` library, then simply copied in to the WordPress content, where they would automatically link to the `id` attributes generated by WP Anchor Header.
-
-Next, we imported the updated documentation into WordPress from GitHub, and made sure we had meaningful and easy-to-search on slugs, descriptions, and keywords--because what good is excellent documentation if no one can find it?! A final activity was implementing redirects so that people hitting the old documentation would be taken to the new version.
-
-### What next?
-
-[Please do take a moment and have a read through our new documentation][20]. We know it isn't perfect--far from it--but we're confident that the mechanisms we've baked into our new documentation infrastructure will make it easier to identify gaps--and resolve them quickly. If you'd like to know more, or have suggestions for our documentation, please reach out to Kathy Reid on [Chat][21] (@kathy-mycroft) or via [email][22].
-
-_Reprinted with permission from[Mycroft.ai][23]._
-
-### About the author
-Kathy Reid - Director of Developer Relations @MycroftAI, President of @linuxaustralia. Kathy Reid has expertise in open source technology management, web development, video conferencing, digital signage, technical communities and documentation. She has worked in a number of technical and leadership roles over the last 20 years, and holds Arts and Science undergraduate degrees... more about Kathy Reid
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/rocking-docs-mycroft
-
-作者:[Kathy Reid][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/kathyreid
-[1]:https://opensource.com/users/aneta
-[2]:https://opensource.com/article/17/10/doc-audits
-[3]:/file/382466
-[4]:https://opensource.com/sites/default/files/images/life-uploads/mycroft-documentation-audit.png (mycroft documentation audit)
-[5]:https://git-scm.com/
-[6]:https://github.com/MycroftAI
-[7]:https://en.wikipedia.org/wiki/Markdown
-[8]:https://www.wordpress.org/
-[9]:https://github.com/
-[10]:https://github.com/mycroftai
-[11]:http://mycroft.ai/team/
-[12]:https://wordpress.org/plugins/parsedown-party/
-[13]:https://developer.wordpress.org/themes/template-files-section/page-template-files/
-[14]:https://marketingland.com/estimated-reading-times-increase-engagement-79830
-[15]:https://jasonyingling.me/reading-time-wp/
-[16]:https://multiratingpro.com/
-[17]:https://github.com/MycroftAI/docs-rewrite/blob/master/README.md
-[18]:https://wordpress.org/plugins/wp-anchor-header/
-[19]:https://github.com/jonschlinkert/markdown-toc
-[20]:https://mycroft.ai/documentation
-[21]:https://chat.mycroft.ai/
-[22]:mailto:kathy.reid@mycroft.ai
-[23]:https://mycroft.ai/blog/improving-mycrofts-documentation/
diff --git a/sources/talk/20180111 The open organization and inner sourcing movements can share knowledge.md b/sources/talk/20180111 The open organization and inner sourcing movements can share knowledge.md
deleted file mode 100644
index 272c1b03ae..0000000000
--- a/sources/talk/20180111 The open organization and inner sourcing movements can share knowledge.md
+++ /dev/null
@@ -1,121 +0,0 @@
-The open organization and inner sourcing movements can share knowledge
-======
-
-
-Image by : opensource.com
-
-Red Hat is a company with roughly 11,000 employees. The IT department consists of roughly 500 members. Though it makes up just a fraction of the entire organization, the IT department is still sufficiently staffed to have many application service, infrastructure, and operational teams within it. Our purpose is "to enable Red Hatters in all functions to be effective, productive, innovative, and collaborative, so that they feel they can make a difference,"--and, more specifically, to do that by providing technologies and related services in a fashion that is as open as possible.
-
-Being open like this takes time, attention, and effort. While we always strive to be as open as possible, it can be difficult. For a variety of reasons, we don't always succeed.
-
-In this story, I'll explain a time when, in the rush to innovate, the Red Hat IT organization lost sight of its open ideals. But I'll also explore how returning to those ideals--and using the collaborative tactics of "inner source"--helped us to recover and greatly improve the way we deliver services.
-
-### About inner source
-
-Before I explain how inner source helped our team, let me offer some background on the concept.
-
-Inner source is the adoption of open source development practices between teams within an organization to promote better and faster delivery without requiring project resources be exposed to the world or openly licensed. It allows an organization to receive many of the benefits of open source development methods within its own walls.
-
-In this way, inner source aligns well with open organization strategies and principles; it provides a path for open, collaborative development. While the open organization defines its principles of openness broadly as transparency, inclusivity, adaptability, collaboration, and community--and covers how to use these open principles for communication, decision making, and many other topics--inner source is about the adoption of specific and tactical practices, processes, and patterns from open source communities to improve delivery.
-
-For instance, [the Open Organization Maturity Model][1] suggests that in order to be transparent, teams should, at minimum, share all project resources with the project team (though it suggests that it's generally better to share these resources with the entire organization). The common pattern in both inner source and open source development is to host all resources in a publicly available version control system, for source control management, which achieves the open organization goal of high transparency.
-
-Inner source aligns well with open organization strategies and principles.
-
-Another example of value alignment appears in the way open source communities accept contributions. In open source communities, source code is transparently available. Community contributions in the form of patches or merge requests are commonly accepted practices (even expected ones). This provides one example of how to meet the open organization's goal of promoting inclusivity and collaboration.
-
-### The challenge
-
-Early in 2014, Red Hat IT began its first steps toward making Amazon Web Services (AWS) a standard hosting offering for business critical systems. While teams within Red Hat IT had built several systems and services in AWS by this time, these were bespoke creations, and we desired to make deploying services to IT standards in AWS both simple and standardized.
-
-In order to make AWS cloud hosting meet our operational standards (while being scalable), the Cloud Enablement team within Red Hat IT decided that all infrastructure in AWS would be configured through code, rather than manually, and that everyone would use a standard set of tools. The Cloud Enablement team designed and built these standard tools; a separate group, the Platform Operations team, was responsible for provisioning and hosting systems and services in AWS using the tools.
-
-The Cloud Enablement team built a toolset, obtusely named "Template Util," based on AWS Cloud Formations configurations wrapped in a management layer to enforce certain configuration requirements and make stamping out multiple copies of services across environments easier. While the Template Util toolset technically met all our initial requirements, and we eventually provisioned the infrastructure for more than a dozen services with it, engineers in every team working with the tool found using it to be painful. Michael Johnson, one engineer using the tool, said "It made doing something relatively straightforward really complicated."
-
-Among the issues Template Util exhibited were:
-
- * Underlying cloud formations technologies implied constraints on application stack management at odds with how we managed our application systems.
- * The tooling was needlessly complex and brittle in places, using multiple layered templating technologies and languages making syntax issues hard to debug.
- * The code for the tool--and some of the data users needed to manipulate the tool--were kept in a repository that was difficult for most users to access.
- * There was no standard process to contributing or accepting changes.
- * The documentation was poor.
-
-
-
-As more engineers attempted to use the Template Util toolset, they found even more issues and limitations with the tools. Unhappiness continued to grow. To make matters worse, the Cloud Enablement team then shifted priorities to other deliverables without relinquishing ownership of the tool, so bug fixes and improvements to the tools were further delayed.
-
-The real, core issues here were our inability to build an inclusive community to collaboratively build shared tooling that met everyone's needs. Fear of losing "ownership," fear of changing requirements, and fear of seeing hard work abandoned all contributed to chronic conflict, which in turn led to poorer outcomes.
-
-### Crisis point
-
-By September 2015, more than a year after launching our first major service in AWS with the Template Util tool, we hit a crisis point.
-
-Many engineers refused to use the tools. That forced all of the related service provisioning work on a small set of engineers, further fracturing the community and disrupting service delivery roadmaps as these engineers struggled to deal with unexpected work. We called an emergency meeting and invited all the teams involved to find a solution.
-
-During the emergency meeting, we found that people generally thought we needed immediate change and should start the tooling effort over, but even the decision to start over wasn't unanimous. Many solutions emerged--sometimes multiple solutions from within a single team--all of which would require significant work to implement. While we couldn't reach a consensus on which solution to use during this meeting, we did reach an agreement to give proponents of different technologies two weeks to work together, across teams, to build their case with a prototype, which the community could then review.
-
-While we didn't reach a final and definitive decision, this agreement was the first point where we started to return to the open source ideals that guide our mission. By inviting all involved parties, we were able to be transparent and inclusive, and we could begin rebuilding our internal community. By making clear that we wanted to improve things and were open to new options, we showed our commitment to adaptability and meritocracy. Most importantly, the plan for building prototypes gave people a clear, return path to collaboration.
-
-When the community reviewed the prototypes, it determined that the clear leader was an Ansible-based toolset that would eventually become known, internally, as Ansicloud. (At the time, no one involved with this work had any idea that Red Hat would acquire Ansible the following month. It should also be noted that other teams within Red Hat have found tools based on Cloud Formation extremely useful, even when our specific Template Util tool did not find success.)
-
-This prototyping and testing phase didn't fix things overnight, though. While we had consensus on the general direction we needed to head, we still needed to improve the new prototype to the point at which engineers could use it reliably for production services.
-
-So over the next several months, a handful of engineers worked to further build and extend the Ansicloud toolset. We built three new production services. While we were sharing code, that sharing activity occurred at a low level of maturity. Some engineers had trouble getting access due to older processes. Other engineers headed in slightly different directions, with each engineer having to rediscover some of the core design issues themselves.
-
-### Returning to openness
-
-This led to a turning point: Building on top of the previous agreement, we focused on developing a unified vision and providing easier access. To do this, we:
-
- 1. created a list of specific goals for the project (both "must-haves" and "nice-to-haves"),
- 2. created an open issue log for the project to avoid solving the same problem repeatedly,
- 3. opened our code base so anyone in Red Hat could read or clone it, and
- 4. made it easy for engineers to get trusted committer access
-
-
-
-Our agreement to collaborate, our finally unified vision, and our improved tool development methods spurred the growth of our community. Ansicloud adoption spread throughout the involved organizations, but this led to a new problem: The tool started changing more quickly than users could adapt to it, and improvements that different groups submitted were beginning to affect other groups in unanticipated ways.
-
-These issues resulted in our recent turn to inner source practices. While every open source project operates differently, we focused on adopting some best practices that seemed common to many of them. In particular:
-
- * We identified the business owner of the project and the core-contributor group of developers who would govern the development of the tools and decide what contributions to accept. While we want to keep things open, we can't have people working against each other or breaking each other's functionality.
- * We developed a project README clarifying the purpose of the tool and specifying how to use it. We also created a CONTRIBUTING document explaining how to contribute, what sort of contributions would be useful, and what sort of tests a contribution would need to pass to be accepted.
- * We began building continuous integration and testing services for the Ansicloud tool itself. This helped us ensure we could quickly and efficiently validate contributions technically, before the project accepted and merged them.
-
-
-
-With these basic agreements, documents, and tools available, we were back onto the path of open collaboration and successful inner sourcing.
-
-### Why it matters
-
-Why does inner source matter?
-
-From a developer community point of view, shifting from a traditional siloed development model to the inner source model has produced significant, quantifiable improvements:
-
- * Contributions to our tooling have grown 72% per week (by number of commits).
- * The percentage of contributions from non-core committers has grown from 27% to 78%; the users of the toolset are driving its development.
- * The contributor list has grown by 15%, primarily from new users of the tool set, rather than core committers, increasing our internal community.
-
-
-
-And the tools we've delivered through this project have allowed us to see dramatic improvements in our business outcomes. Using the Ansicloud tools, 54 new multi-environment application service deployments were created in 385 days (compared to 20 services in 1,013 days with the Template Util tools). We've gone from one new service deployment in a 50-day period to one every week--a seven-fold increase in the velocity of our delivery.
-
-What really matters here is that the improvements we saw were not aberrations. Inner source provides common, easily understood patterns that organizations can adopt to effectively promote collaboration (not to mention other open organization principles). By mirroring open source production practices, inner source can also mirror the benefits of open source code, which have been seen time and time again: higher quality code, faster development, and more engaged communities.
-
-This article is part of the [Open Organization Workbook project][2].
-
-### about the author
-Tom Benninger - Tom Benninger is a Solutions Architect, Systems Engineer, and continual tinkerer at Red Hat, Inc. Having worked with startups, small businesses, and larger enterprises, he has experience within a broad set of IT disciplines. His current area of focus is improving Application Lifecycle Management in the enterprise. He has a particular interest in how open source, inner source, and collaboration can help support modern application development practices and the adoption of DevOps, CI/CD, Agile,...
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/1/open-orgs-and-inner-source-it
-
-作者:[Tom Benninger][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/tomben
-[1]:https://opensource.com/open-organization/resources/open-org-maturity-model
-[2]:https://opensource.com/open-organization/17/8/workbook-project-announcement
diff --git a/sources/talk/20180112 in which the cost of structured data is reduced.md b/sources/talk/20180112 in which the cost of structured data is reduced.md
deleted file mode 100644
index 992ad57a39..0000000000
--- a/sources/talk/20180112 in which the cost of structured data is reduced.md
+++ /dev/null
@@ -1,181 +0,0 @@
-in which the cost of structured data is reduced
-======
-Last year I got the wonderful opportunity to attend [RacketCon][1] as it was hosted only 30 minutes away from my home. The two-day conference had a number of great talks on the first day, but what really impressed me was the fact that the entire second day was spent focusing on contribution. The day started out with a few 15- to 20-minute talks about how to contribute to a specific codebase (including that of Racket itself), and after that people just split off into groups focused around specific codebases. Each table had maintainers helping guide other folks towards how to work with the codebase and construct effective patch submissions.
-
-![lensmen chronicles][2]
-
-I came away from the conference with a great sense of appreciation for how friendly and welcoming the Racket community is, and how great Racket is as a swiss-army-knife type tool for quick tasks. (Not that it's unsuitable for large projects, but I don't have the opportunity to start any new large projects very frequently.)
-
-The other day I wanted to generate colored maps of the world by categorizing countries interactively, and Racket seemed like it would fit the bill nicely. The job is simple: show an image of the world with one country selected; when a key is pressed, categorize that country, then show the map again with all categorized countries colored, and continue with the next country selected.
-
-### GUIs and XML
-
-I have yet to see a language/framework more accessible and straightforward out of the box for drawing1. Here's the entry point which sets up state and then constructs a canvas that handles key input and display:
-```
-(define (main path)
- (let ([frame (new frame% [label "World color"])]
- [categorizations (box '())]
- [doc (call-with-input-file path read-xml/document)])
- (new (class canvas%
- (define/override (on-char event)
- (handle-key this categorizations (send event get-key-code)))
- (super-new))
- [parent frame]
- [paint-callback (draw doc categorizations)])
- (send frame show #t)))
-
-```
-
-While the class system is not one of my favorite things about Racket (most newer code seems to avoid it in favor of [generic interfaces][3] in the rare case that polymorphism is truly called for), the fact that classes can be constructed in a light-weight, anonymous way makes it much less onerous than it could be. This code sets up all mutable state in a [`box`][4] which you use in the way you'd use a `ref` in ML or Clojure: a mutable wrapper around an immutable data structure.
-
-The world map I'm using is [an SVG of the Robinson projection][5] from Wikipedia. If you look closely there's a call to bind `doc` that calls [`call-with-input-file`][6] with [`read-xml/document`][7] which loads up the whole map file's SVG; just about as easily as you could ask for.
-
-The data you get back from `read-xml/document` is in fact a [document][8] struct, which contains an `element` struct containing `attribute` structs and lists of more `element` structs. All very sensible, but maybe not what you would expect in other dynamic languages like Clojure or Lua where free-form maps reign supreme. Racket really wants structure to be known up-front when possible, which is one of the things that help it produce helpful error messages when things go wrong.
-
-Here's how we handle keyboard input; we're displaying a map with one country highlighted, and `key` here tells us what the user pressed to categorize the highlighted country. If that key is in the `categories` hash then we put it into `categorizations`.
-```
-(define categories #hash((select . "eeeeff")
- (#\1 . "993322")
- (#\2 . "229911")
- (#\3 . "ABCD31")
- (#\4 . "91FF55")
- (#\5 . "2439DF")))
-
-(define (handle-key canvas categorizations key)
- (cond [(equal? #\backspace key) (swap! categorizations cdr)]
- [(member key (dict-keys categories)) (swap! categorizations (curry cons key))]
- [(equal? #\space key) (display (unbox categorizations))])
- (send canvas refresh))
-
-```
-
-### Nested updates: the bad parts
-
-Finally once we have a list of categorizations, we need to apply it to the map document and display. We apply a [`fold`][9] reduction over the XML document struct and the list of country categorizations (plus `'select` for the country that's selected to be categorized next) to get back a "modified" document struct where the proper elements have the style attributes applied for the given categorization, then we turn it into an image and hand it to [`draw-pict`][10]:
-```
-
-(define (update original-doc categorizations)
- (for/fold ([doc original-doc])
- ([category (cons 'select (unbox categorizations))]
- [n (in-range (length (unbox categorizations)) 0 -1)])
- (set-style doc n (style-for category))))
-
-(define ((draw doc categorizations) _ context)
- (let* ([newdoc (update doc categorizations)]
- [xml (call-with-output-string (curry write-xml newdoc))])
- (draw-pict (call-with-input-string xml svg-port->pict) context 0 0)))
-
-```
-
-The problem is in that pesky `set-style` function. All it has to do is reach deep down into the `document` struct to find the `n`th `path` element (the one associated with a given country), and change its `'style` attribute. It ought to be a simple task. Unfortunately this function ends up being anything but simple:
-```
-
-(define (set-style doc n new-style)
- (let* ([root (document-element doc)]
- [g (list-ref (element-content root) 8)]
- [paths (element-content g)]
- [path (first (drop (filter element? paths) n))]
- [path-num (list-index (curry eq? path) paths)]
- [style-index (list-index (lambda (x) (eq? 'style (attribute-name x)))
- (element-attributes path))]
- [attr (list-ref (element-attributes path) style-index)]
- [new-attr (make-attribute (source-start attr)
- (source-stop attr)
- (attribute-name attr)
- new-style)]
- [new-path (make-element (source-start path)
- (source-stop path)
- (element-name path)
- (list-set (element-attributes path)
- style-index new-attr)
- (element-content path))]
- [new-g (make-element (source-start g)
- (source-stop g)
- (element-name g)
- (element-attributes g)
- (list-set paths path-num new-path))]
- [root-contents (list-set (element-content root) 8 new-g)])
- (make-document (document-prolog doc)
- (make-element (source-start root)
- (source-stop root)
- (element-name root)
- (element-attributes root)
- root-contents)
- (document-misc doc))))
-
-```
-
-The reason for this is that while structs are immutable, they don't support functional updates. Whenever you're working with immutable data structures, you want to be able to say "give me a new version of this data, but with field `x` replaced by the value of `(f (lookup x))`". Racket can [do this with dictionaries][11] but not with structs2. If you want a modified version you have to create a fresh one3.
-
-### Lenses to the rescue?
-
-![first lensman][12]
-
-When I brought this up in the `#racket` channel on Freenode, I was helpfully pointed to the 3rd-party [Lens][13] library. Lenses are a general-purpose way of composing arbitrarily nested lookups and updates. Unfortunately at this time there's [a flaw][14] preventing them from working with `xml` structs, so it seemed I was out of luck.
-
-But then I was pointed to [X-expressions][15] as an alternative to structs. The [`xml->xexpr`][16] function turns the structs into a deeply-nested list tree with symbols and strings in it. The tag is the first item in the list, followed by an associative list of attributes, then the element's children. While this gives you fewer up-front guarantees about the structure of the data, it does work around the lens issue.
-
-For this to work, we need to compose a new lens based on the "path" we want to use to drill down into the `n`th country and its `style` attribute. The [`lens-compose`][17] function lets us do that. Note that the order here might be backwards from what you'd expect; it works deepest-first (the way [`compose`][18] works for functions). Also note that defining one lens gives us the ability to both get nested values (with [`lens-view`][19]) and update them.
-```
-(define (style-lens n)
- (lens-compose (dict-ref-lens 'style)
- second-lens
- (list-ref-lens (add1 (* n 2)))
- (list-ref-lens 10)))
-```
-
-Our `<path>` XML elements are under the 10th item of the root xexpr, (hence the [`list-ref-lens`][20] with 10) and they are interspersed with whitespace, so we have to double `n` to find the `<path>` we want. The [`second-lens`][21] call gets us to that element's attribute alist, and [`dict-ref-lens`][22] lets us zoom in on the `'style` key out of that alist.
-
-Once we have our lens, it's just a matter of replacing `set-style` with a call to [`lens-set`][23] in our `update` function we had above, and then we're off:
-```
-(define (update doc categorizations)
- (for/fold ([d doc])
- ([category (cons 'select (unbox categorizations))]
- [n (in-range (length (unbox categorizations)) 0 -1)])
- (lens-set (style-lens n) d (list (style-for category)))))
-```
-
-![second stage lensman][24]
-
-Often times the trade-off between freeform maps/hashes vs structured data feels like one of convenience vs long-term maintainability. While it's unfortunate that they can't be used with the `xml` structs4, lenses provide a way to get the best of both worlds, at least in some situations.
-
-The final version of the code clocks in at 51 lines and is is available [on GitLab][25].
-
-๛
-
---------------------------------------------------------------------------------
-
-via: https://technomancy.us/185
-
-作者:[Phil Hagelberg][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://technomancy.us/
-[1]:https://con.racket-lang.org/
-[2]:https://technomancy.us/i/chronicles-of-lensmen.jpg
-[3]:https://docs.racket-lang.org/reference/struct-generics.html
-[4]:https://docs.racket-lang.org/reference/boxes.html?q=box#%28def._%28%28quote._~23~25kernel%29._box%29%29
-[5]:https://commons.wikimedia.org/wiki/File:BlankMap-World_gray.svg
-[6]:https://docs.racket-lang.org/reference/port-lib.html#(def._((lib._racket%2Fport..rkt)._call-with-input-string))
-[7]:https://docs.racket-lang.org/xml/index.html?q=read-xml#%28def._%28%28lib._xml%2Fmain..rkt%29._read-xml%2Fdocument%29%29
-[8]:https://docs.racket-lang.org/xml/#%28def._%28%28lib._xml%2Fmain..rkt%29._document%29%29
-[9]:https://docs.racket-lang.org/reference/for.html?q=for%2Ffold#%28form._%28%28lib._racket%2Fprivate%2Fbase..rkt%29._for%2Ffold%29%29
-[10]:https://docs.racket-lang.org/pict/Rendering.html?q=draw-pict#%28def._%28%28lib._pict%2Fmain..rkt%29._draw-pict%29%29
-[11]:https://docs.racket-lang.org/reference/dicts.html?q=dict-update#%28def._%28%28lib._racket%2Fdict..rkt%29._dict-update%29%29
-[12]:https://technomancy.us/i/first-lensman.jpg
-[13]:https://docs.racket-lang.org/lens/lens-guide.html
-[14]:https://github.com/jackfirth/lens/issues/290
-[15]:https://docs.racket-lang.org/pollen/second-tutorial.html?q=xexpr#%28part._.X-expressions%29
-[16]:https://docs.racket-lang.org/xml/index.html?q=xexpr#%28def._%28%28lib._xml%2Fmain..rkt%29._xml-~3exexpr%29%29
-[17]:https://docs.racket-lang.org/lens/lens-reference.html#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-compose%29%29
-[18]:https://docs.racket-lang.org/reference/procedures.html#%28def._%28%28lib._racket%2Fprivate%2Flist..rkt%29._compose%29%29
-[19]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-view%29%29
-[20]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Flist..rkt%29._list-ref-lens%29%29
-[21]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Flist..rkt%29._second-lens%29%29
-[22]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Fdict..rkt%29._dict-ref-lens%29%29
-[23]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-set%29%29
-[24]:https://technomancy.us/i/second-stage-lensman.jpg
-[25]:https://gitlab.com/technomancy/world-color/blob/master/world-color.rkt
diff --git a/sources/talk/20180124 Security Chaos Engineering- A new paradigm for cybersecurity.md b/sources/talk/20180124 Security Chaos Engineering- A new paradigm for cybersecurity.md
deleted file mode 100644
index 35c89150c8..0000000000
--- a/sources/talk/20180124 Security Chaos Engineering- A new paradigm for cybersecurity.md
+++ /dev/null
@@ -1,87 +0,0 @@
-Security Chaos Engineering: A new paradigm for cybersecurity
-======
-
-
-Security is always changing and failure always exists.
-
-This toxic scenario requires a fresh perspective on how we think about operational security. We must understand that we are often the primary cause of our own security flaws. The industry typically looks at cybersecurity and failure in isolation or as separate matters. We believe that our lack of insight and operational intelligence into our own security control failures is one of the most common causes of security incidents and, subsequently, data breaches.
-
-> Fall seven times, stand up eight." --Japanese proverb
-
-The simple fact is that "to err is human," and humans derive their success as a direct result of the failures they encounter. Their rate of failure, how they fail, and their ability to understand that they failed in the first place are important building blocks to success. Our ability to learn through failure is inherent in the systems we build, the way we operate them, and the security we use to protect them. Yet there has been a lack of focus when it comes to how we approach preventative security measures, and the spotlight has trended toward the evolving attack landscape and the need to buy or build new solutions.
-
-### Security spending is continually rising and so are security incidents
-
-We spend billions on new information security technologies, however, we rarely take a proactive look at whether those security investments perform as expected. This has resulted in a continual increase in security spending on new solutions to keep up with the evolving attacks.
-
-Despite spending more on security, data breaches are continuously getting bigger and more frequent across all industries. We have marched so fast down this path of the "get-ahead-of-the-attacker" strategy that we haven't considered that we may be a primary cause of our own demise. How is it that we are building more and more security measures, but the problem seems to be getting worse? Furthermore, many of the notable data breaches over the past year were not the result of an advanced nation-state or spy-vs.-spy malicious advanced persistent threats (APTs); rather the principal causes of those events were incomplete implementation, misconfiguration, design flaws, and lack of oversight.
-
-The 2017 Ponemon Cost of a Data Breach Study breaks down the [root causes of data breaches][1] into three areas: malicious or criminal attacks, human factors or errors, and system glitches, including both IT and business-process failure. Of the three categories, malicious or criminal attacks comprises the largest distribution (47%), followed by human error (28%), and system glitches (25%). Cybersecurity vendors have historically focused on malicious root causes of data breaches, as it is the largest sole cause, but together human error and system glitches total 53%, a larger share of the overall problem.
-
-What is not often understood, whether due to lack of insight, reporting, or analysis, is that malicious or criminal attacks are often successful due to human error and system glitches. Both human error and system glitches are, at their root, primary markers of the existence of failure. Whether it's IT system failures, failures in process, or failures resulting from humans, it begs the question: "Should we be focusing on finding a method to identify, understand, and address our failures?" After all, it can be an arduous task to predict the next malicious attack, which often requires investment of time to sift threat intelligence, dig through forensic data, or churn threat feeds full of unknown factors and undetermined motives. Failure instrumentation, identification, and remediation are mostly comprised of things that we know, have the ability to test, and can measure.
-
-Failures we can analyze consist not only of IT, business, and general human factors but also the way we design, build, implement, configure, operate, observe, and manage security controls. People are the ones designing, building, monitoring, and managing the security controls we put in place to defend against malicious attackers. How often do we proactively instrument what we designed, built, and are operationally managing to determine if the controls are failing? Most organizations do not discover that their security controls were failing until a security incident results from that failure. The worst time to find out your security investment failed is during a security incident at 3 a.m.
-
-> Security incidents are not detective measures and hope is not a strategy when it comes to operating effective security controls.
-
-We hypothesize that a large portion of data breaches are caused not by sophisticated nation-state actors or hacktivists, but rather simple things rooted in human error and system glitches. Failure in security controls can arise from poor control placement, technical misconfiguration, gaps in coverage, inadequate testing practices, human error, and numerous other things.
-
-### The journey into Security Chaos Testing
-
-Our venture into this new territory of Security Chaos Testing has shifted our thinking about the root cause of many of our notable security incidents and data breaches.
-
-We were brought together by [Bruce Wong][2], who now works at Stitch Fix with Charles, one of the authors of this article. Prior to Stitch Fix, Bruce was a founder of the Chaos Engineering and System Reliability Engineering (SRE) practices at Netflix, the company commonly credited with establishing the field. Bruce learned about this article's other author, Aaron, through the open source [ChaoSlingr][3] Security Chaos Testing tool project, on which Aaron was a contributor. Aaron was interested in Bruce's perspective on the idea of applying Chaos Engineering to cybersecurity, which led Bruce to connect us to share what we had been working on. As security practitioners, we were both intrigued by the idea of Chaos Engineering and had each begun thinking about how this new method of instrumentation might have a role in cybersecurity.
-
-Within a short timeframe, we began finishing each other's thoughts around testing and validating security capabilities, which we collectively call "Security Chaos Engineering." We directly challenged many of the concepts we had come to depend on in our careers, such as compensating security controls, defense-in-depth, and how to design preventative security. Quickly we realized that we needed to challenge the status quo "set-it-and-forget-it" model and instead execute on continuous instrumentation and validation of security capabilities.
-
-Businesses often don't fully understand whether their security capabilities and controls are operating as expected until they are not. We had both struggled throughout our careers to provide measurements on security controls that go beyond simple uptime metrics. Our journey has shown us there is a need for a more pragmatic approach that emphasizes proactive instrumentation and experimentation over blind faith.
-
-### Defining new terms
-
-In the security industry, we have a habit of not explaining terms and assuming we are speaking the same language. To correct that, here are a few key terms in this new approach:
-
- * **(Security) Chaos Experiments** are foundationally rooted in the scientific method, in that they seek not to validate what is already known to be true or already known to be false, rather they are focused on deriving new insights about the current state.
- * **Security Chaos Engineering** is the discipline of instrumentation, identification, and remediation of failure within security controls through proactive experimentation to build confidence in the system's ability to defend against malicious conditions in production.
-
-
-
-### Security and distributed systems
-
-Consider the evolving nature of modern application design where systems are becoming more and more distributed, ephemeral, and immutable in how they operate. In this shifting paradigm, it is becoming difficult to comprehend the operational state and health of our systems' security. Moreover, how are we ensuring that it remains effective and vigilant as the surrounding environment is changing its parameters, components, and methodologies?
-
-What does it mean to be effective in terms of security controls? After all, a single security capability could easily be implemented in a wide variety of diverse scenarios in which failure may arise from many possible sources. For example, a standard firewall technology may be implemented, placed, managed, and configured differently depending on complexities in the business, web, and data logic.
-
-It is imperative that we not operate our business products and services on the assumption that something works. We must constantly, consistently, and proactively instrument our security controls to ensure they cut the mustard when it matters. This is why Security Chaos Testing is so important. What Security Chaos Engineering does is it provides a methodology for the experimentation of the security of distributed systems in order to build confidence in the ability to withstand malicious conditions.
-
-In Security Chaos Engineering:
-
- * Security capabilities must be end-to-end instrumented.
- * Security must be continuously instrumented to build confidence in the system's ability to withstand malicious conditions.
- * Readiness of a system's security defenses must be proactively assessed to ensure they are battle-ready and operating as intended.
- * The security capability toolchain must be instrumented from end to end to drive new insights into not only the effectiveness of the functionality within the toolchain but also to discover where added value and improvement can be injected.
- * Practiced instrumentation seeks to identify, detect, and remediate failures in security controls.
- * The focus is on vulnerability and failure identification, not failure management.
- * The operational effectiveness of incident management is sharpened.
-
-
-
-As Henry Ford said, "Failure is only the opportunity to begin again, this time more intelligently." Security Chaos Engineering and Security Chaos Testing give us that opportunity.
-
-Would you like to learn more? Join the discussion by following [@aaronrinehart][4] and [@charles_nwatu][5] on Twitter.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/new-paradigm-cybersecurity
-
-作者:[Aaron Rinehart][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/aaronrinehart
-[1]:https://www.ibm.com/security/data-breach
-[2]:https://twitter.com/bruce_m_wong?lang=en
-[3]:https://github.com/Optum/ChaoSlingr
-[4]:https://twitter.com/aaronrinehart
-[5]:https://twitter.com/charles_nwatu
diff --git a/sources/talk/20180131 How to write a really great resume that actually gets you hired.md b/sources/talk/20180131 How to write a really great resume that actually gets you hired.md
deleted file mode 100644
index b54b3944ae..0000000000
--- a/sources/talk/20180131 How to write a really great resume that actually gets you hired.md
+++ /dev/null
@@ -1,395 +0,0 @@
-How to write a really great resume that actually gets you hired
-============================================================
-
-
-
-
-This is a data-driven guide to writing a resume that actually gets you hired. I’ve spent the past four years analyzing which resume advice works regardless of experience, role, or industry. The tactics laid out below are the result of what I’ve learned. They helped me land offers at Google, Microsoft, and Twitter and have helped my students systematically land jobs at Amazon, Apple, Google, Microsoft, Facebook, and more.
-
-### Writing Resumes Sucks.
-
-It’s a vicious cycle.
-
-We start by sifting through dozens of articles by career “gurus,” forced to compare conflicting advice and make our own decisions on what to follow.
-
-The first article says “one page MAX” while the second says “take two or three and include all of your experience.”
-
-The next says “write a quick summary highlighting your personality and experience” while another says “summaries are a waste of space.”
-
-You scrape together your best effort and hit “Submit,” sending your resume into the ether. When you don’t hear back, you wonder what went wrong:
-
- _“Was it the single page or the lack of a summary? Honestly, who gives a s**t at this point. I’m sick of sending out 10 resumes every day and hearing nothing but crickets.”_
-
-
-
-How it feels to try and get your resume read in today’s world.
-
-Writing resumes sucks but it’s not your fault.
-
-The real reason it’s so tough to write a resume is because most of the advice out there hasn’t been proven against the actual end goal of getting a job. If you don’t know what consistently works, you can’t lay out a system to get there.
-
-It’s easy to say “one page works best” when you’ve seen it happen a few times. But how does it hold up when we look at 100 resumes across different industries, experience levels, and job titles?
-
-That’s what this article aims to answer.
-
-Over the past four years, I’ve personally applied to hundreds of companies and coached hundreds of people through the job search process. This has given me a huge opportunity to measure, analyze, and test the effectiveness of different resume strategies at scale.
-
-This article is going to walk through everything I’ve learned about resumes over the past 4 years, including:
-
-* Mistakes that more than 95% of people make, causing their resumes to get tossed immediately
-
-* Three things that consistently appear in the resumes of highly effective job searchers (who go on to land jobs at the world’s best companies)
-
-* A quick hack that will help you stand out from the competition and instantly build relationships with whomever is reading your resume (increasing your chances of hearing back and getting hired)
-
-* The exact resume template that got me interviews and offers at Google, Microsoft, Twitter, Uber, and more
-
-Before we get to the unconventional strategies that will help set you apart, we need to make sure our foundational bases are covered. That starts with understanding the mistakes most job seekers make so we can make our resume bulletproof.
-
-### Resume Mistakes That 95% Of People Make
-
-Most resumes that come through an online portal or across a recruiter’s desk are tossed out because they violate a simple rule.
-
-When recruiters scan a resume, the first thing they look for is mistakes. Your resume could be fantastic, but if you violate a rule like using an unprofessional email address or improper grammar, it’s going to get tossed out.
-
-Our goal is to fully understand the triggers that cause recruiters/ATS systems to make the snap decisions on who stays and who goes.
-
-In order to get inside the heads of these decision makers, I collected data from dozens of recruiters and hiring mangers across industries. These people have several hundred years of hiring experience under their belts and they’ve reviewed 100,000+ resumes across industries.
-
-They broke down the five most common mistakes that cause them to cut resumes from the pile:
-
-
-
-
-### The Five Most Common Resume Mistakes (According To Recruiters & Hiring Managers)
-
-Issue #1: Sloppiness (typos, spelling errors, & grammatical mistakes). Close to 60% of resumes have some sort of typo or grammatical issue.
-
-Solution: Have your resume reviewed by three separate sources — spell checking software, a friend, and a professional. Spell check should be covered if you’re using Microsoft Word or Google Docs to create your resume.
-
-A friend or family member can cover the second base, but make sure you trust them with reviewing the whole thing. You can always include an obvious mistake to see if they catch it.
-
-Finally, you can hire a professional editor on [Upwork][1]. It shouldn’t take them more than 15–20 minutes to review so it’s worth paying a bit more for someone with high ratings and lots of hours logged.
-
-Issue #2: Summaries are too long and formal. Many resumes include summaries that consist of paragraphs explaining why they are a “driven, results oriented team player.” When hiring managers see a block of text at the top of the resume, you can bet they aren’t going to read the whole thing. If they do give it a shot and read something similar to the sentence above, they’re going to give up on the spot.
-
-Solution: Summaries are highly effective, but they should be in bullet form and showcase your most relevant experience for the role. For example, if I’m applying for a new business sales role my first bullet might read “Responsible for driving $11M of new business in 2018, achieved 168% attainment (#1 on my team).”
-
-Issue #3: Too many buzz words. Remember our driven team player from the last paragraph? Phrasing like that makes hiring managers cringe because your attempt to stand out actually makes you sound like everyone else.
-
-Solution: Instead of using buzzwords, write naturally, use bullets, and include quantitative results whenever possible. Would you rather hire a salesperson who “is responsible for driving new business across the healthcare vertical to help companies achieve their goals” or “drove $15M of new business last quarter, including the largest deal in company history”? Skip the buzzwords and focus on results.
-
-Issue #4: Having a resume that is more than one page. The average employer spends six seconds reviewing your resume — if it’s more than one page, it probably isn’t going to be read. When asked, recruiters from Google and Barclay’s both said multiple page resumes “are the bane of their existence.”
-
-Solution: Increase your margins, decrease your font, and cut down your experience to highlight the most relevant pieces for the role. It may seem impossible but it’s worth the effort. When you’re dealing with recruiters who see hundreds of resumes every day, you want to make their lives as easy as possible.
-
-### More Common Mistakes & Facts (Backed By Industry Research)
-
-In addition to personal feedback, I combed through dozens of recruitment survey results to fill any gaps my contacts might have missed. Here are a few more items you may want to consider when writing your resume:
-
-* The average interviewer spends 6 seconds scanning your resume
-
-* The majority of interviewers have not looked at your resume until
- you walk into the room
-
-* 76% of resumes are discarded for an unprofessional email address
-
-* Resumes with a photo have an 88% rejection rate
-
-* 58% of resumes have typos
-
-* Applicant tracking software typically eliminates 75% of resumes due to a lack of keywords and phrases being present
-
-Now that you know every mistake you need to avoid, the first item on your to-do list is to comb through your current resume and make sure it doesn’t violate anything mentioned above.
-
-Once you have a clean resume, you can start to focus on more advanced tactics that will really make you stand out. There are a few unique elements you can use to push your application over the edge and finally get your dream company to notice you.
-
-
-
-
-### The 3 Elements Of A Resume That Will Get You Hired
-
-My analysis showed that highly effective resumes typically include three specific elements: quantitative results, a simple design, and a quirky interests section. This section breaks down all three elements and shows you how to maximize their impact.
-
-### Quantitative Results
-
-Most resumes lack them.
-
-Which is a shame because my data shows that they make the biggest difference between resumes that land interviews and resumes that end up in the trash.
-
-Here’s an example from a recent resume that was emailed to me:
-
-> Experience
-
-> + Identified gaps in policies and processes and made recommendations for solutions at the department and institution level
-
-> + Streamlined processes to increase efficiency and enhance quality
-
-> + Directly supervised three managers and indirectly managed up to 15 staff on multiple projects
-
-> + Oversaw execution of in-house advertising strategy
-
-> + Implemented comprehensive social media plan
-
-As an employer, that tells me absolutely nothing about what to expect if I hire this person.
-
-They executed an in-house marketing strategy. Did it work? How did they measure it? What was the ROI?
-
-They also also identified gaps in processes and recommended solutions. What was the result? Did they save time and operating expenses? Did it streamline a process resulting in more output?
-
-Finally, they managed a team of three supervisors and 15 staffers. How did that team do? Was it better than the other teams at the company? What results did they get and how did those improve under this person’s management?
-
-See what I’m getting at here?
-
-These types of bullets talk about daily activities, but companies don’t care about what you do every day. They care about results. By including measurable metrics and achievements in your resume, you’re showcasing the value that the employer can expect to get if they hire you.
-
-Let’s take a look at revised versions of those same bullets:
-
-> Experience
-
-> + Managed a team of 20 that consistently outperformed other departments in lead generation, deal size, and overall satisfaction (based on our culture survey)
-
-> + Executed in-house marketing strategy that resulted in a 15% increase in monthly leads along with a 5% drop in the cost per lead
-
-> + Implemented targeted social media campaign across Instagram & Pintrest, which drove an additional 50,000 monthly website visits and generated 750 qualified leads in 3 months
-
-If you were in the hiring manager’s shoes, which resume would you choose?
-
-That’s the power of including quantitative results.
-
-### Simple, Aesthetic Design That Hooks The Reader
-
-These days, it’s easy to get carried away with our mission to “stand out.” I’ve seen resume overhauls from graphic designers, video resumes, and even resumes [hidden in a box of donuts.][2]
-
-While those can work in very specific situations, we want to aim for a strategy that consistently gets results. The format I saw the most success with was a black and white Word template with sections in this order:
-
-* Summary
-
-* Interests
-
-* Experience
-
-* Education
-
-* Volunteer Work (if you have it)
-
-This template is effective because it’s familiar and easy for the reader to digest.
-
-As I mentioned earlier, hiring managers scan resumes for an average of 6 seconds. If your resume is in an unfamiliar format, those 6 seconds won’t be very comfortable for the hiring manager. Our brains prefer things we can easily recognize. You want to make sure that a hiring manager can actually catch a glimpse of who you are during their quick scan of your resume.
-
-If we’re not relying on design, this hook needs to come from the _Summary_ section at the top of your resume.
-
-This section should be done in bullets (not paragraph form) and it should contain 3–4 highlights of the most relevant experience you have for the role. For example, if I was applying for a New Business Sales position, my summary could look like this:
-
-> Summary
-
-> Drove quarterly average of $11M in new business with a quota attainment of 128% (#1 on my team)
-
-> Received award for largest sales deal of the year
-
-> Developed and trained sales team on new lead generation process that increased total leads by 17% in 3 months, resulting in 4 new deals worth $7M
-
-Those bullets speak directly to the value I can add to the company if I was hired for the role.
-
-### An “Interests” Section That’s Quirky, Unique, & Relatable
-
-This is a little “hack” you can use to instantly build personal connections and positive associations with whomever is reading your resume.
-
-Most resumes have a skills/interests section, but it’s usually parked at the bottom and offers little to no value. It’s time to change things up.
-
-[Research shows][3] that people rely on emotions, not information, to make decisions. Big brands use this principle all the time — emotional responses to advertisements are more influential on a person’s intent to buy than the content of an ad.
-
-You probably remember Apple’s famous “Get A Mac” campaign:
-
-
-When it came to specs and performance, Macs didn’t blow every single PC out of the water. But these ads solidified who was “cool” and who wasn’t, which was worth a few extra bucks to a few million people.
-
-By tugging at our need to feel “cool,” Apple’s campaign led to a [42% increase in market share][4] and a record sales year for Macbooks.
-
-Now we’re going to take that same tactic and apply it to your resume.
-
-If you can invoke an emotional response from your recruiter, you can influence the mental association they assign to you. This gives you a major competitive advantage.
-
-Let’s start with a question — what could you talk about for hours?
-
-It could be cryptocurrency, cooking, World War 2, World of Warcraft, or how Google’s bet on segmenting their company under the Alphabet is going to impact the technology sector over the next 5 years.
-
-Did a topic (or two) pop into year head? Great.
-
-Now think about what it would be like to have a conversation with someone who was just as passionate and knew just as much as you did on the topic. It’d be pretty awesome, right? _Finally, _ someone who gets it!
-
-That’s exactly the kind of emotional response we’re aiming to get from a hiring manager.
-
-There are five “neutral” topics out there that people enjoy talking about:
-
-1. Food/Drink
-
-2. Sports
-
-3. College
-
-4. Hobbies
-
-5. Geography (travel, where people are from, etc.)
-
-These topics are present in plenty of interest sections but we want to take them one step further.
-
-Let’s say you had the best night of your life at the Full Moon Party in Thailand. Which of the following two options would you be more excited to read:
-
-* Traveling
-
-* Ko Pha Ngan beaches (where the full moon party is held)
-
-Or, let’s say that you went to Duke (an ACC school) and still follow their basketball team. Which would you be more pumped about:
-
-* College Sports
-
-* ACC Basketball (Go Blue Devils!)
-
-In both cases, the second answer would probably invoke a larger emotional response because it is tied directly to your experience.
-
-I want you to think about your interests that fit into the five categories I mentioned above.
-
-Now I want you to write a specific favorite associated with each category in parentheses next to your original list. For example, if you wrote travel you can add (ask me about the time I was chased by an elephant in India) or (specifically meditation in a Tibetan monastery).
-
-Here is the [exact set of interests][5] I used on my resume when I interviewed at Google, Microsoft, and Twitter:
-
- _ABC Kitchen’s Atmosphere, Stumptown Coffee (primarily cold brew), Michael Lewis (Liar’s Poker), Fishing (especially fly), Foods That Are Vehicles For Hot Sauce, ACC Sports (Go Deacs!) & The New York Giants_
-
-
-
-
-If you want to cheat here, my experience shows that anything about hot sauce is an instant conversation starter.
-
-### The Proven Plug & Play Resume Template
-
-Now that we have our strategies down, it’s time to apply these tactics to a real resume. Our goal is to write something that increases your chances of hearing back from companies, enhances your relationships with hiring managers, and ultimately helps you score the job offer.
-
-The example below is the exact resume that I used to land interviews and offers at Microsoft, Google, and Twitter. I was targeting roles in Account Management and Sales, so this sample is tailored towards those positions. We’ll break down each section below:
-
-
-
-
-First, I want you to notice how clean this is. Each section is clearly labeled and separated and flows nicely from top to bottom.
-
-My summary speaks directly to the value I’ve created in the past around company culture and its bottom line:
-
-* I consistently exceeded expectations
-
-* I started my own business in the space (and saw real results)
-
-* I’m a team player who prioritizes culture
-
-I purposefully include my Interests section right below my Summary. If my hiring manager’s six second scan focused on the summary, I know they’ll be interested. Those bullets cover all the subconscious criteria for qualification in sales. They’re going to be curious to read more in my Experience section.
-
-By sandwiching my Interests in the middle, I’m upping their visibility and increasing the chance of creating that personal connection.
-
-You never know — the person reading my resume may also be a hot sauce connoisseur and I don’t want that to be overlooked because my interests were sitting at the bottom.
-
-Next, my Experience section aims to flesh out the points made in my Summary. I mentioned exceeding my quota up top, so I included two specific initiatives that led to that attainment, including measurable results:
-
-* A partnership leveraging display advertising to drive users to a gamified experience. The campaign resulted in over 3000 acquisitions and laid the groundwork for the 2nd largest deal in company history.
-
-* A partnership with a top tier agency aimed at increasing conversions for a client by improving user experience and upgrading tracking during a company-wide website overhaul (the client has ~20 brand sites). Our efforts over 6 months resulted in a contract extension worth 316% more than their original deal.
-
-Finally, I included my education at the very bottom starting with the most relevant coursework.
-
-Download My Resume Templates For Free
-
-You can download a copy of the resume sample above as well as a plug and play template here:
-
-Austin’s Resume: [Click To Download][6]
-
-Plug & Play Resume Template: [Click To Download][7]
-
-### Bonus Tip: An Unconventional Resume “Hack” To Help You Beat Applicant Tracking Software
-
-If you’re not already familiar, Applicant Tracking Systems are pieces of software that companies use to help “automate” the hiring process.
-
-After you hit submit on your online application, the ATS software scans your resume looking for specific keywords and phrases (if you want more details, [this article][8] does a good job of explaining ATS).
-
-If the language in your resume matches up, the software sees it as a good fit for the role and will pass it on to the recruiter. However, even if you’re highly qualified for the role but you don’t use the right wording, your resume can end up sitting in a black hole.
-
-I’m going to teach you a little hack to help improve your chances of beating the system and getting your resume in the hands of a human:
-
-Step 1: Highlight and select the entire job description page and copy it to your clipboard.
-
-Step 2: Head over to [WordClouds.com][9] and click on the “Word List” button at the top. Towards the top of the pop up box, you should see a link for Paste/Type Text. Go ahead and click that.
-
-Step 3: Now paste the entire job description into the box, then hit “Apply.”
-
-WordClouds is going to spit out an image that showcases every word in the job description. The larger words are the ones that appear most frequently (and the ones you want to make sure to include when writing your resume). Here’s an example for a data a science role:
-
-
-
-
-You can also get a quantitative view by clicking “Word List” again after creating your cloud. That will show you the number of times each word appeared in the job description:
-
-9 data
-
-6 models
-
-4 experience
-
-4 learning
-
-3 Experience
-
-3 develop
-
-3 team
-
-2 Qualifications
-
-2 statistics
-
-2 techniques
-
-2 libraries
-
-2 preferred
-
-2 research
-
-2 business
-
-When writing your resume, your goal is to include those words in the same proportions as the job description.
-
-It’s not a guaranteed way to beat the online application process, but it will definitely help improve your chances of getting your foot in the door!
-
-* * *
-
-### Want The Inside Info On Landing A Dream Job Without Connections, Without “Experience,” & Without Applying Online?
-
-[Click here to get the 5 free strategies that my students have used to land jobs at Google, Microsoft, Amazon, and more without applying online.][10]
-
- _Originally published at _ [_cultivatedculture.com_][11] _._
-
---------------------------------------------------------------------------------
-
-作者简介:
-
-I help people land jobs they love and salaries they deserve at CultivatedCulture.com
-
-----------
-
-via: https://medium.freecodecamp.org/how-to-write-a-really-great-resume-that-actually-gets-you-hired-e18533cd8d17
-
-作者:[Austin Belcak ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://medium.freecodecamp.org/@austin.belcak
-[1]:http://www.upwork.com/
-[2]:https://www.thrillist.com/news/nation/this-guy-hides-his-resume-in-boxes-of-donuts-to-score-job-interviews
-[3]:https://www.psychologytoday.com/blog/inside-the-consumer-mind/201302/how-emotions-influence-what-we-buy
-[4]:https://www.businesswire.com/news/home/20070608005253/en/Apple-Mac-Named-Successful-Marketing-Campaign-2007
-[5]:http://cultivatedculture.com/resume-skills-section/
-[6]:https://drive.google.com/file/d/182gN6Kt1kBCo1LgMjtsGHOQW2lzATpZr/view?usp=sharing
-[7]:https://drive.google.com/open?id=0B3WIcEDrxeYYdXFPVlcyQlJIbWc
-[8]:https://www.jobscan.co/blog/8-things-you-need-to-know-about-applicant-tracking-systems/
-[9]:https://www.wordclouds.com/
-[10]:https://cultivatedculture.com/dreamjob/
-[11]:https://cultivatedculture.com/write-a-resume/
\ No newline at end of file
diff --git a/sources/talk/20180206 UQDS- A software-development process that puts quality first.md b/sources/talk/20180206 UQDS- A software-development process that puts quality first.md
deleted file mode 100644
index e9f7bb94ac..0000000000
--- a/sources/talk/20180206 UQDS- A software-development process that puts quality first.md
+++ /dev/null
@@ -1,99 +0,0 @@
-UQDS: A software-development process that puts quality first
-======
-
-
-
-The Ultimate Quality Development System (UQDS) is a software development process that provides clear guidelines for how to use branches, tickets, and code reviews. It was invented more than a decade ago by Divmod and adopted by [Twisted][1], an event-driven framework for Python that underlies popular commercial platforms like HipChat as well as open source projects like Scrapy (a web scraper).
-
-Divmod, sadly, is no longer around—it has gone the way of many startups. Luckily, since many of its products were open source, its legacy lives on.
-
-When Twisted was a young project, there was no clear process for when code was "good enough" to go in. As a result, while some parts were highly polished and reliable, others were alpha quality software—with no way to tell which was which. UQDS was designed as a process to help an existing project with definite quality challenges ramp up its quality while continuing to add features and become more useful.
-
-UQDS has helped the Twisted project evolve from having frequent regressions and needing multiple release candidates to get a working version, to achieving its current reputation of stability and reliability.
-
-### UQDS's building blocks
-
-UQDS was invented by Divmod back in 2006. At that time, Continuous Integration (CI) was in its infancy and modern version control systems, which allow easy branch merging, were barely proofs of concept. Although Divmod did not have today's modern tooling, it put together CI, some ad-hoc tooling to make [Subversion branches][2] work, and a lot of thought into a working process. Thus the UQDS methodology was born.
-
-UQDS is based upon fundamental building blocks, each with their own carefully considered best practices:
-
- 1. Tickets
- 2. Branches
- 3. Tests
- 4. Reviews
- 5. No exceptions
-
-
-
-Let's go into each of those in a little more detail.
-
-#### Tickets
-
-In a project using the UQDS methodology, no change is allowed to happen if it's not accompanied by a ticket. This creates a written record of what change is needed and—more importantly—why.
-
- * Tickets should define clear, measurable goals.
- * Work on a ticket does not begin until the ticket contains goals that are clearly defined.
-
-
-
-#### Branches
-
-Branches in UQDS are tightly coupled with tickets. Each branch must solve one complete ticket, no more and no less. If a branch addresses either more or less than a single ticket, it means there was a problem with the ticket definition—or with the branch. Tickets might be split or merged, or a branch split and merged, until congruence is achieved.
-
-Enforcing that each branch addresses no more nor less than a single ticket—which corresponds to one logical, measurable change—allows a project using UQDS to have fine-grained control over the commits: A single change can be reverted or changes may even be applied in a different order than they were committed. This helps the project maintain a stable and clean codebase.
-
-#### Tests
-
-UQDS relies upon automated testing of all sorts, including unit, integration, regression, and static tests. In order for this to work, all relevant tests must pass at all times. Tests that don't pass must either be fixed or, if no longer relevant, be removed entirely.
-
-Tests are also coupled with tickets. All new work must include tests that demonstrate that the ticket goals are fully met. Without this, the work won't be merged no matter how good it may seem to be.
-
-A side effect of the focus on tests is that the only platforms that a UQDS-using project can say it supports are those on which the tests run with a CI framework—and where passing the test on the platform is a condition for merging a branch. Without this restriction on supported platforms, the quality of the project is not Ultimate.
-
-#### Reviews
-
-While automated tests are important to the quality ensured by UQDS, the methodology never loses sight of the human factor. Every branch commit requires code review, and each review must follow very strict rules:
-
- 1. Each commit must be reviewed by a different person than the author.
- 2. Start with a comment thanking the contributor for their work.
- 3. Make a note of something that the contributor did especially well (e.g., "that's the perfect name for that variable!").
- 4. Make a note of something that could be done better (e.g., "this line could use a comment explaining the choices.").
- 5. Finish with directions for an explicit next step, typically either merge as-is, fix and merge, or fix and submit for re-review.
-
-
-
-These rules respect the time and effort of the contributor while also increasing the sharing of knowledge and ideas. The explicit next step allows the contributor to have a clear idea on how to make progress.
-
-#### No exceptions
-
-In any process, it's easy to come up with reasons why you might need to flex the rules just a little bit to let this thing or that thing slide through the system. The most important fundamental building block of UQDS is that there are no exceptions. The entire community works together to make sure that the rules do not flex, not for any reason whatsoever.
-
-Knowing that all code has been approved by a different person than the author, that the code has complete test coverage, that each branch corresponds to a single ticket, and that this ticket is well considered and complete brings a piece of mind that is too valuable to risk losing, even for a single small exception. The goal is quality, and quality does not come from compromise.
-
-### A downside to UQDS
-
-While UQDS has helped Twisted become a highly stable and reliable project, this reliability hasn't come without cost. We quickly found that the review requirements caused a slowdown and backlog of commits to review, leading to slower development. The answer to this wasn't to compromise on quality by getting rid of UQDS; it was to refocus the community priorities such that reviewing commits became one of the most important ways to contribute to the project.
-
-To help with this, the community developed a bot in the [Twisted IRC channel][3] that will reply to the command `review tickets` with a list of tickets that still need review. The [Twisted review queue][4] website returns a prioritized list of tickets for review. Finally, the entire community keeps close tabs on the number of tickets that need review. It's become an important metric the community uses to gauge the health of the project.
-
-### Learn more
-
-The best way to learn about UQDS is to [join the Twisted Community][5] and see it in action. If you'd like more information about the methodology and how it might help your project reach a high level of reliability and stability, have a look at the [UQDS documentation][6] in the Twisted wiki.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/uqds
-
-作者:[Moshe Zadka][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/moshez
-[1]:https://twistedmatrix.com/trac/
-[2]:http://structure.usc.edu/svn/svn.branchmerge.html
-[3]:http://webchat.freenode.net/?channels=%23twisted
-[4]:https://twisted.reviews
-[5]:https://twistedmatrix.com/trac/wiki/TwistedCommunity
-[6]:https://twistedmatrix.com/trac/wiki/UltimateQualityDevelopmentSystem
diff --git a/sources/talk/20180207 Why Mainframes Aren-t Going Away Any Time Soon.md b/sources/talk/20180207 Why Mainframes Aren-t Going Away Any Time Soon.md
deleted file mode 100644
index 7a1a837ff9..0000000000
--- a/sources/talk/20180207 Why Mainframes Aren-t Going Away Any Time Soon.md
+++ /dev/null
@@ -1,73 +0,0 @@
-Why Mainframes Aren't Going Away Any Time Soon
-======
-
-
-
-IBM's last earnings report showed the [first uptick in revenue in more than five years.][1] Some of that growth was from an expected source, cloud revenue, which was up 24 percent year over year and now accounts for 21 percent of Big Blue's take. Another major boost, however, came from a spike in mainframe revenue. Z series mainframe sales were up 70 percent, the company said.
-
-This may sound somewhat akin to a return to vacuum tube technology in a world where transistors are yesterday's news. In actuality, this is only a sign of the changing face of IT.
-
-**Related:** [One Click and Voilà, Your Entire Data Center is Encrypted][2]
-
-Modern mainframes definitely aren't your father's punch card-driven machines that filled entire rooms. These days, they most often run Linux and have found a renewed place in the data center, where they're being called upon to do a lot of heavy lifting. Want to know where the largest instance of Oracle's database runs? It's on a Linux mainframe. How about the largest implementation of SAP on the planet? Again, Linux on a mainframe.
-
-"Before the advent of Linux on the mainframe, the people who bought mainframes primarily were people who already had them," Leonard Santalucia explained to Data Center Knowledge several months back at the All Things Open conference. "They would just wait for the new version to come out and upgrade to it, because it would run cheaper and faster.
-
-**Related:** [IBM Designs a “Performance Beast” for AI][3]
-
-"When Linux came out, it opened up the door to other customers that never would have paid attention to the mainframe. In fact, probably a good three to four hundred new clients that never had mainframes before got them. They don't have any old mainframes hanging around or ones that were upgraded. These are net new mainframes."
-
-Although Santalucia is CTO at Vicom Infinity, primarily an IBM reseller, at the conference he was wearing his hat as chairperson of the Linux Foundation's Open Mainframe Project. He was joined in the conversation by John Mertic, the project's director of program management.
-
-Santalucia knows IBM's mainframes from top to bottom, having spent 27 years at Big Blue, the last eight as CTO for the company's systems and technology group.
-
-"Because of Linux getting started with it back in 1999, it opened up a lot of doors that were closed to the mainframe," he said. "Beforehand it was just z/OS, z/VM, z/VSE, z/TPF, the traditional operating systems. When Linux came along, it got the mainframe into other areas that it never was, or even thought to be in, because of how open it is, and because Linux on the mainframe is no different than Linux on any other platform."
-
-The focus on Linux isn't the only motivator behind the upsurge in mainframe use in data centers. Increasingly, enterprises with heavy IT needs are finding many advantages to incorporating modern mainframes into their plans. For example, mainframes can greatly reduce power, cooling, and floor space costs. In markets like New York City, where real estate is at a premium, electricity rates are high, and electricity use is highly taxed to reduce demand, these are significant advantages.
-
-"There was one customer where we were able to do a consolidation of 25 x86 cores to one core on a mainframe," Santalucia said. "They have several thousand machines that are ten and twenty cores each. So, as far as the eye could see in this data center, [x86 server workloads] could be picked up and moved onto this box that is about the size of a sub-zero refrigerator in your kitchen."
-
-In addition to saving on physical data center resources, this customer by design would likely see better performance.
-
-"When you look at the workload as it's running on an x86 system, the math, the application code, the I/O to manage the disk, and whatever else is attached to that system, is all run through the same chip," he explained. "On a Z, there are multiple chip architectures built into the system. There's one specifically just for the application code. If it senses the application needs an I/O or some mathematics, it sends it off to a separate processor to do math or I/O, all dynamically handled by the underlying firmware. Your Linux environment doesn't have to understand that. When it's running on a mainframe, it knows it's running on a mainframe and it will exploit that architecture."
-
-The operating system knows it's running on a mainframe because when IBM was readying its mainframe for Linux it open sourced something like 75,000 lines of code for Linux distributions to use to make sure their OS's were ready for IBM Z.
-
-"A lot of times people will hear there's 170 processors on the Z14," Santalucia said. "Well, there's actually another 400 other processors that nobody counts in that count of application chips, because it is taken for granted."
-
-Mainframes are also resilient when it comes to disaster recovery. Santalucia told the story of an insurance company located in lower Manhattan, within sight of the East River. The company operated a large data center in a basement that among other things housed a mainframe backed up to another mainframe located in Upstate New York. When Hurricane Sandy hit in 2012, the data center flooded, electrocuting two employees and destroying all of the servers, including the mainframe. But the mainframe's workload was restored within 24 hours from the remote backup.
-
-The x86 machines were all destroyed, and the data was never recovered. But why weren't they also backed up?
-
-"The reason they didn't do this disaster recovery the same way they did with the mainframe was because it was too expensive to have a mirror of all those distributed servers someplace else," he explained. "With the mainframe, you can have another mainframe as an insurance policy that's lower in price, called Capacity BackUp, and it just sits there idling until something like this happens."
-
-Mainframes are also evidently tough as nails. Santalucia told another story in which a data center in Japan was struck by an earthquake strong enough to destroy all of its x86 machines. The center's one mainframe fell on its side but continued to work.
-
-The mainframe also comes with built-in redundancy to guard against situations that would be disastrous with x86 machines.
-
-"What if a hard disk fails on a node in x86?" the Open Mainframe Project's Mertic asked. "You're taking down a chunk of that cluster potentially. With a mainframe you're not. A mainframe just keeps on kicking like nothing's ever happened."
-
-Mertic added that a motherboard can be pulled from a running mainframe, and again, "the thing keeps on running like nothing's ever happened."
-
-So how do you figure out if a mainframe is right for your organization? Simple, says Santalucia. Do the math.
-
-"The approach should be to look at it from a business, technical, and financial perspective -- not just a financial, total-cost-of-acquisition perspective," he said, pointing out that often, costs associated with software, migration, networking, and people are not considered. The break-even point, he said, comes when at least 20 to 30 servers are being migrated to a mainframe. After that point the mainframe has a financial advantage.
-
-"You can get a few people running the mainframe and managing hundreds or thousands of virtual servers," he added. "If you tried to do the same thing on other platforms, you'd find that you need significantly more resources to maintain an environment like that. Seven people at ADP handle the 8,000 virtual servers they have, and they need seven only in case somebody gets sick.
-
-"If you had eight thousand servers on x86, even if they're virtualized, do you think you could get away with seven?"
-
---------------------------------------------------------------------------------
-
-via: http://www.datacenterknowledge.com/hardware/why-mainframes-arent-going-away-any-time-soon
-
-作者:[Christine Hall][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://www.datacenterknowledge.com/archives/author/christine-hall
-[1]:http://www.datacenterknowledge.com/ibm/mainframe-sales-fuel-growth-ibm
-[2]:http://www.datacenterknowledge.com/design/one-click-and-voil-your-entire-data-center-encrypted
-[3]:http://www.datacenterknowledge.com/design/ibm-designs-performance-beast-ai
diff --git a/sources/talk/20180209 Arch Anywhere Is Dead, Long Live Anarchy Linux.md b/sources/talk/20180209 Arch Anywhere Is Dead, Long Live Anarchy Linux.md
deleted file mode 100644
index c3c78e84ad..0000000000
--- a/sources/talk/20180209 Arch Anywhere Is Dead, Long Live Anarchy Linux.md
+++ /dev/null
@@ -1,127 +0,0 @@
-Arch Anywhere Is Dead, Long Live Anarchy Linux
-======
-
-
-
-Arch Anywhere was a distribution aimed at bringing Arch Linux to the masses. Due to a trademark infringement, Arch Anywhere has been completely rebranded to [Anarchy Linux][1]. And I’m here to say, if you’re looking for a distribution that will enable you to enjoy Arch Linux, a little Anarchy will go a very long way. This distribution is seriously impressive in what it sets out to do and what it achieves. In fact, anyone who previously feared Arch Linux can set those fears aside… because Anarchy Linux makes Arch Linux easy.
-
-Let’s face it; Arch Linux isn’t for the faint of heart. The installation alone will turn off many a new user (and even some seasoned users). That’s where distributions like Anarchy make for an easy bridge to Arch. With a live ISO that can be tested and then installed, Arch becomes as user-friendly as any other distribution.
-
-Anarchy Linux goes a little bit further than that, however. Let’s fire it up and see what it does.
-
-### The installation
-
-The installation of Anarchy Linux isn’t terribly challenging, but it’s also not quite as simple as for, say, [Ubuntu][2], [Linux Mint][3], or [Elementary OS][4]. Although you can run the installer from within the default graphical desktop environment (Xfce4), it’s still much in the same vein as Arch Linux. In other words, you’re going to have to do a bit of work—all within a text-based installer.
-
-To start, the very first step of the installer (Figure 1) requires you to update the mirror list, which will likely trip up new users.
-
-![Updating the mirror][6]
-
-Figure 1: Updating the mirror list is a necessity for the Anarchy Linux installation.
-
-[Used with permission][7]
-
-From the options, select Download & Rank New Mirrors. Tab down to OK and hit Enter on your keyboard. You can then select the nearest mirror (to your location) and be done with it. The next few installation screens are simple (keyboard layout, language, timezone, etc.). The next screen should surprise many an Arch fan. Anarchy Linux includes an auto partition tool. Select Auto Partition Drive (Figure 2), tab down to Ok, and hit Enter on your keyboard.
-
-![partitioning][9]
-
-Figure 2: Anarchy makes partitioning easy.
-
-[Used with permission][7]
-
-You will then have to select the drive to be used (if you only have one drive this is only a matter of hitting Enter). Once you’ve selected the drive, choose the filesystem type to be used (ext2/3/4, btrfs, jfs, reiserfs, xfs), tab down to OK, and hit Enter. Next you must choose whether you want to create SWAP space. If you select Yes, you’ll then have to define how much SWAP to use. The next window will stop many new users in their tracks. It asks if you want to use GPT (GUID Partition Table). This is different than the traditional MBR (Master Boot Record) partitioning. GPT is a newer standard and works better with UEFI. If you’ll be working with UEFI, go with GPT, otherwise, stick with the old standby, MBR. Finally select to write the changes to the disk, and your installation can continue.
-
-The next screen that could give new users pause, requires the selection of the desired installation. There are five options:
-
- * Anarchy-Desktop
-
- * Anarchy-Desktop-LTS
-
- * Anarchy-Server
-
- * Anarchy-Server-LTS
-
- * Anarchy-Advanced
-
-
-
-
-If you want long term support, select Anarchy-Desktop-LTS, otherwise click Anarchy-Desktop (the default), and tab down to Ok. Click Enter on your keyboard. After you select the type of installation, you will get to select your desktop. You can select from five options: Budgie, Cinnamon, GNOME, Openbox, and Xfce4.
-Once you’ve selected your desktop, give the machine a hostname, set the root password, create a user, and enable sudo for the new user (if applicable). The next section that will raise the eyebrows of new users is the software selection window (Figure 3). You must go through the various sections and select which software packages to install. Don’t worry, if you miss something, you can always installed it later.
-
-
-![software][11]
-
-Figure 3: Selecting the software you want on your system.
-
-[Used with permission][7]
-
-Once you’ve made your software selections, tab to Install (Figure 4), and hit Enter on your keyboard.
-
-![ready to install][13]
-
-Figure 4: Everything is ready to install.
-
-[Used with permission][7]
-
-Once the installation completes, reboot and enjoy Anarchy.
-
-### Post install
-
-I installed two versions of Anarchy—one with Budgie and one with GNOME. Both performed quite well, however you might be surprised to see that the version of GNOME installed is decked out with a dock. In fact, comparing the desktops side-by-side and they do a good job of resembling one another (Figure 5).
-
-![GNOME and Budgie][15]
-
-Figure 5: GNOME is on the right, Budgie is on the left.
-
-[Used with permission][7]
-
-My guess is that you’ll find all desktop options for Anarchy configured in such a way to offer a similar look and feel. Of course, the second you click on the bottom left “buttons”, you’ll see those similarities immediately disappear (Figure 6).
-
-![GNOME and Budgie][17]
-
-Figure 6: The GNOME Dash and the Budgie menu are nothing alike.
-
-[Used with permission][7]
-
-Regardless of which desktop you select, you’ll find everything you need to install new applications. Open up your desktop menu of choice and select Packages to search for and install whatever is necessary for you to get your work done.
-
-### Why use Arch Linux without the “Arch”?
-
-This is a valid question. The answer is simple, but revealing. Some users may opt for a distribution like [Arch Linux][18] because they want the feeling of “elitism” that comes with using, say, [Gentoo][19], without having to go through that much hassle. With regards to complexity, Arch rests below Gentoo, which means it’s accessible to more users. However, along with that complexity in the platform, comes a certain level of dependability that may not be found in others. So if you’re looking for a Linux distribution with high stability, that’s not quite as challenging as Gentoo or Arch to install, Anarchy might be exactly what you want. In the end, you’ll wind up with an outstanding desktop platform that’s easy to work with (and maintain), based on a very highly regarded distribution of Linux.
-
-That’s why you might opt for Arch Linux without the Arch.
-
-Anarchy Linux is one of the finest “user-friendly” takes on Arch Linux I’ve ever had the privilege of using. Without a doubt, if you’re looking for a friendlier version of a rather challenging desktop operating system, you cannot go wrong with Anarchy.
-
-Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/2/arch-anywhere-dead-long-live-anarchy-linux
-
-作者:[Jack Wallen][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://anarchy-linux.org/
-[2]:https://www.ubuntu.com/
-[3]:https://linuxmint.com/
-[4]:https://elementary.io/
-[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_1.jpg?itok=WgHRqFTf (Updating the mirror)
-[7]:https://www.linux.com/licenses/category/used-permission
-[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_2.jpg?itok=D7HkR97t (partitioning)
-[10]:/files/images/anarchyinstall3jpg
-[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_3.jpg?itok=5-9E2u0S (software)
-[12]:/files/images/anarchyinstall4jpg
-[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_4.jpg?itok=fuSZqtZS (ready to install)
-[14]:/files/images/anarchyinstall5jpg
-[15]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_5.jpg?itok=4y9kiC8I (GNOME and Budgie)
-[16]:/files/images/anarchyinstall6jpg
-[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_6.jpg?itok=fJ7Lmdci (GNOME and Budgie)
-[18]:https://www.archlinux.org/
-[19]:https://www.gentoo.org/
-[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/talk/20180209 How writing can change your career for the better, even if you don-t identify as a writer.md b/sources/talk/20180209 How writing can change your career for the better, even if you don-t identify as a writer.md
deleted file mode 100644
index 55618326c6..0000000000
--- a/sources/talk/20180209 How writing can change your career for the better, even if you don-t identify as a writer.md
+++ /dev/null
@@ -1,149 +0,0 @@
-How writing can change your career for the better, even if you don't identify as a writer
-======
-Have you read Marie Kondo's book [The Life-Changing Magic of Tidying Up][1]? Or did you, like me, buy it and read a little bit and then add it to the pile of clutter next to your bed?
-
-Early in the book, Kondo talks about keeping possessions that "spark joy." In this article, I'll examine ways writing about what we and other people are doing in the open source world can "spark joy," or at least how writing can improve your career in unexpected ways.
-
-Because I'm a community manager and editor on Opensource.com, you might be thinking, "She just wants us to [write for Opensource.com][2]." And that is true. But everything I will tell you about why you should write is true, even if you never send a story in to Opensource.com. Writing can change your career for the better, even if you don't identify as a writer. Let me explain.
-
-### How I started writing
-
-Early in the first decade of my career, I transitioned from a customer service-related role at a tech publishing company into an editing role on Sys Admin Magazine. I was plugging along, happily laying low in my career, and then that all changed when I started writing about open source technologies and communities, and the people in them. But I did _not_ start writing voluntarily. The tl;dr: of it is that my colleagues at Linux New Media eventually talked me into launching our first blog on the [Linux Pro Magazine][3] site. And as it turns out, it was one of the best career decisions I've ever made. I would not be working on Opensource.com today had I not started writing about what other people in open source were doing all those years ago.
-
-When I first started writing, my goal was to raise awareness of the company I worked for and our publications, while also helping raise the visibility of women in tech. But soon after I started writing, I began seeing unexpected results.
-
-#### My network started growing
-
-When I wrote about a person, an organization, or a project, I got their attention. Suddenly the people I wrote about knew who I was. And because I was sharing knowledge—that is to say, I wasn't being a critic—I'd generally become an ally, and in many cases, a friend. I had a platform and an audience, and I was sharing them with other people in open source.
-
-#### I was learning
-
-In addition to promoting our website and magazine and growing my network, the research and fact-checking I did when writing articles helped me become more knowledgeable in my field and improve my tech chops.
-
-#### I started meeting more people IRL
-
-When I went to conferences, I found that my blog posts helped me meet people. I introduced myself to people I'd written about or learned about during my research, and I met new people to interview. People started knowing who I was because they'd read my articles. Sometimes people were even excited to meet me because I'd highlighted them, their projects, or someone or something they were interested in. I had no idea writing could be so exciting and interesting away from the keyboard.
-
-#### My conference talks improved
-
-I started speaking at events about a year after launching my blog. A few years later, I started writing articles based on my talks prior to speaking at events. The process of writing the articles helps me organize my talks and slides, and it was a great way to provide "notes" for conference attendees, while sharing the topic with a larger international audience that wasn't at the event in person.
-
-### What should you write about?
-
-Maybe you're interested in writing, but you struggle with what to write about. You should write about two things: what you know, and what you don't know.
-
-#### Write about what you know
-
-Writing about what you know can be relatively easy. For example, a script you wrote to help automate part of your daily tasks might be something you don't give any thought to, but it could make for a really exciting article for someone who hates doing that same task every day. That could be a relatively quick, short, and easy article for you to write, and you might not even think about writing it. But it could be a great contribution to the open source community.
-
-#### Write about what you don't know
-
-Writing about what you don't know can be much harder and more time consuming, but also much more fulfilling and help your career. I've found that writing about what I don't know helps me learn, because I have to research it and understand it well enough to explain it.
-
-> "When I write about a technical topic, I usually learn a lot more about it. I want to make sure my article is as good as it can be. So even if I'm writing about something I know well, I'll research the topic a bit more so I can make sure to get everything right." ~Jim Hall, FreeDOS project leader
-
-For example, I wanted to learn about machine learning, and I thought narrowing down the topic would help me get started. My team mate Jason Baker suggested that I write an article on the [Top 3 machine learning libraries for Python][4], which gave me a focus for research.
-
-The process of researching that article inspired another article, [3 cool machine learning projects using TensorFlow and the Raspberry Pi][5]. That article was also one of our most popular last year. I'm not an _expert_ on machine learning now, but researching the topic with writing an article in mind allowed me to give myself a crash course in the topic.
-
-### Why people in tech write
-
-Now let's look at a few benefits of writing that other people in tech have found. I emailed the Opensource.com writers' list and asked, and here's what writers told me.
-
-#### Grow your network or your project community
-
-Xavier Ho wrote for us for the first time last year ("[A programmer's cleaning guide for messy sensor data][6]"). He says: "I've been getting Twitter mentions from all over the world, including Spain, US, Australia, Indonesia, the UK, and other European countries. It shows the article is making some impact... This is the kind of reach I normally don't have. Hope it's really helping someone doing similar work!"
-
-#### Help people
-
-Writing about what other people are working on is a great way to help your fellow community members. Antoine Thomas, who wrote "[Linux helped me grow as a musician][7]", says, "I began to use open source years ago, by reading tutorials and documentation. That's why now I share my tips and tricks, experience or knowledge. It helped me to get started, so I feel that it's my turn to help others to get started too."
-
-#### Give back to the community
-
-[Jim Hall][8], who started the [FreeDOS project][9], says, "I like to write ... because I like to support the open source community by sharing something neat. I don't have time to be a program maintainer anymore, but I still like to do interesting stuff. So when something cool comes along, I like to write about it and share it."
-
-#### Highlight your community
-
-Emilio Velis wrote an article, "[Open hardware groups spread across the globe][10]", about projects in Central and South America. He explains, "I like writing about specific aspects of the open culture that are usually enclosed in my region (Latin America). I feel as if smaller communities and their ideas are hidden from the mainstream, so I think that creating this sense of broadness in participation is what makes some other cultures as valuable."
-
-#### Gain confidence
-
-[Don Watkins][11] is one of our regular writers and a [community moderator][12]. He says, "When I first started writing I thought I was an impostor, later I realized that many people feel that way. Writing and contributing to Opensource.com has been therapeutic, too, as it contributed to my self esteem and helped me to overcome feelings of inadequacy. … Writing has given me a renewed sense of purpose and empowered me to help others to write and/or see the valuable contributions that they too can make if they're willing to look at themselves in a different light. Writing has kept me younger and more open to new ideas."
-
-#### Get feedback
-
-One of our writers described writing as a feedback loop. He said that he started writing as a way to give back to the community, but what he found was that community responses give back to him.
-
-Another writer, [Stuart Keroff][13] says, "Writing for Opensource.com about the program I run at school gave me valuable feedback, encouragement, and support that I would not have had otherwise. Thousands upon thousands of people heard about the Asian Penguins because of the articles I wrote for the website."
-
-#### Exhibit expertise
-
-Writing can help you show that you've got expertise in a subject, and having writing samples on well-known websites can help you move toward better pay at your current job, get a new role at a different organization, or start bringing in writing income.
-
-[Jeff Macharyas][14] explains, "There are several ways I've benefitted from writing for Opensource.com. One, is the credibility I can add to my social media sites, resumes, bios, etc., just by saying 'I am a contributing writer to Opensource.com.' … I am hoping that I will be able to line up some freelance writing assignments, using my Opensource.com articles as examples, in the future."
-
-### Where should you publish your articles?
-
-That depends. Why are you writing?
-
-You can always post on your personal blog, but if you don't already have a lot of readers, your article might get lost in the noise online.
-
-Your project or company blog is a good option—again, you'll have to think about who will find it. How big is your company's reach? Or will you only get the attention of people who already give you their attention?
-
-Are you trying to reach a new audience? A bigger audience? That's where sites like Opensource.com can help. We attract more than a million page views a month, and more than 700,000 unique visitors. Plus you'll work with editors who will polish and help promote your article.
-
-We aren't the only site interested in your story. What are your favorite sites to read? They might want to help you share your story, and it's ok to pitch to multiple publications. Just be transparent about whether your article has been shared on other sites when working with editors. Occasionally, editors can even help you modify articles so that you can publish variations on multiple sites.
-
-#### Do you want to get rich by writing? (Don't count on it.)
-
-If your goal is to make money by writing, pitch your article to publications that have author budgets. There aren't many of them, the budgets don't tend to be huge, and you will be competing with experienced professional tech journalists who write seven days a week, 365 days a year, with large social media followings and networks. I'm not saying it can't be done—I've done it—but I am saying don't expect it to be easy or lucrative. It's not. (And frankly, I've found that nothing kills my desire to write much like having to write if I want to eat...)
-
-A couple of people have asked me whether Opensource.com pays for content, or whether I'm asking someone to write "for exposure." Opensource.com does not have an author budget, but I won't tell you to write "for exposure," either. You should write because it meets a need.
-
-If you already have a platform that meets your needs, and you don't need editing or social media and syndication help: Congratulations! You are privileged.
-
-### Spark joy!
-
-Most people don't know they have a story to tell, so I'm here to tell you that you probably do, and my team can help, if you just submit a proposal.
-
-Most people—myself included—could use help from other people. Sites like Opensource.com offer one way to get editing and social media services at no cost to the writer, which can be hugely valuable to someone starting out in their career, someone who isn't a native English speaker, someone who wants help with their project or organization, and so on.
-
-If you don't already write, I hope this article helps encourage you to get started. Or, maybe you already write. In that case, I hope this article makes you think about friends, colleagues, or people in your network who have great stories and experiences to share. I'd love to help you help them get started.
-
-I'll conclude with feedback I got from a recent writer, [Mario Corchero][15], a Senior Software Developer at Bloomberg. He says, "I wrote for Opensource because you told me to :)" (For the record, I "invited" him to write for our [PyCon speaker series][16] last year.) He added, "And I am extremely happy about it—not only did it help me at my workplace by gaining visibility, but I absolutely loved it! The article appeared in multiple email chains about Python and was really well received, so I am now looking to publish the second :)" Then he [wrote for us][17] again.
-
-I hope you find writing to be as fulfilling as we do.
-
-You can connect with Opensource.com editors, community moderators, and writers in our Freenode [IRC][18] channel #opensource.com, and you can reach me and the Opensource.com team by email at [open@opensource.com][19].
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/career-changing-magic-writing
-
-作者:[Rikki Endsley][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/rikki-endsley
-[1]:http://tidyingup.com/books/the-life-changing-magic-of-tidying-up-hc
-[2]:https://opensource.com/how-submit-article
-[3]:http://linuxpromagazine.com/
-[4]:https://opensource.com/article/17/2/3-top-machine-learning-libraries-python
-[5]:https://opensource.com/article/17/2/machine-learning-projects-tensorflow-raspberry-pi
-[6]:https://opensource.com/article/17/9/messy-sensor-data
-[7]:https://opensource.com/life/16/9/my-linux-story-musician
-[8]:https://opensource.com/users/jim-hall
-[9]:http://www.freedos.org/
-[10]:https://opensource.com/article/17/6/open-hardware-latin-america
-[11]:https://opensource.com/users/don-watkins
-[12]:https://opensource.com/community-moderator-program
-[13]:https://opensource.com/education/15/3/asian-penguins-Linux-middle-school-club
-[14]:https://opensource.com/users/jeffmacharyas
-[15]:https://opensource.com/article/17/5/understanding-datetime-python-primer
-[16]:https://opensource.com/tags/pycon
-[17]:https://opensource.com/article/17/9/python-logging
-[18]:https://opensource.com/article/16/6/getting-started-irc
-[19]:mailto:open@opensource.com
diff --git a/sources/talk/20180209 Why an involved user community makes for better software.md b/sources/talk/20180209 Why an involved user community makes for better software.md
deleted file mode 100644
index 2b51023e44..0000000000
--- a/sources/talk/20180209 Why an involved user community makes for better software.md
+++ /dev/null
@@ -1,47 +0,0 @@
-Why an involved user community makes for better software
-======
-
-
-Imagine releasing a major new infrastructure service based on open source software only to discover that the product you deployed had evolved so quickly that the documentation for the version you released is no longer available. At Bloomberg, we experienced this problem firsthand in our deployment of OpenStack. In late 2016, we spent six months testing and rolling out [Liberty][1] on our OpenStack environment. By that time, Liberty was about a year old, or two versions behind the latest build.
-
-As our users started taking advantage of its new functionality, we found ourselves unable to solve a few tricky problems and to answer some detailed questions about its API. When we went looking for Liberty's documentation, it was nowhere to be found on the OpenStack website. Liberty, it turned out, had been labeled "end of life" and was no longer supported by the OpenStack developer community.
-
-The disappearance wasn't intentional, rather the result of a development community that had not anticipated the real-world needs of users. The documentation was stored in the source branch along with the source code, and, as Liberty was superseded by newer versions, it had been deleted. Worse, in the intervening months, the documentation for the newer versions had been completely restructured, and there was no way to easily rebuild it in a useful form. And believe me, we tried.
-
-The disappearance wasn't intentional, rather the result of a development community that had not anticipated the real-world needs of users. ]After consulting other users and our vendor, we found that OpenStack's development cadence of two releases per year had created some unintended, yet deeply frustrating, consequences. Older releases that were typically still widely in use were being superseded and effectively killed for the purposes of support.
-
-Eventually, conversations took place between OpenStack users and developers that resulted in changes. Documentation was moved out of the source branch, and users can now build documentation for whatever version they're using—more or less indefinitely. The problem was solved. (I'm especially indebted to my colleague [Chris Morgan][2], who was knee-deep in this effort and first wrote about it in detail for the [OpenStack Superuser blog][3].)
-
-Many other enterprise users were in the same boat as Bloomberg—running older versions of OpenStack that are three or four versions behind the latest build. There's a good reason for that: On average it takes a reasonably large enterprise about six months to qualify, test, and deploy a new version of OpenStack. And, from my experience, this is generally true of most open source infrastructure projects.
-
-For most of the past decade, companies like Bloomberg that adopted open source software relied on distribution vendors to incorporate, test, verify, and support much of it. These vendors provide long-term support (LTS) releases, which enable enterprise users to plan for upgrades on a two- or three-year cycle, knowing they'll still have support for a year or two, even if their deployment schedule slips a bit (as they often do). In the past few years, though, infrastructure software has advanced so rapidly that even the distribution vendors struggle to keep up. And customers of those vendors are yet another step removed, so many are choosing to deploy this type of software without vendor support.
-
-Losing vendor support also usually means there are no LTS releases; OpenStack, Kubernetes, and Prometheus, and many more, do not yet provide LTS releases of their own. As a result, I'd argue that healthy interaction between the development and user community should be high on the list of considerations for adoption of any open source infrastructure. Do the developers building the software pay attention to the needs—and frustrations—of the people who deploy it and make it useful for their enterprise?
-
-There is a solid model for how this should happen. We recently joined the [Cloud Native Computing Foundation][4], part of The Linux Foundation. It has a formal [end-user community][5], whose members include organizations just like us: enterprises that are trying to make open source software useful to their internal customers. Corporate members also get a chance to have their voices heard as they vote to select a representative to serve on the CNCF [Technical Oversight Committee][6]. Similarly, in the OpenStack community, Bloomberg is involved in the semi-annual Operators Meetups, where companies who deploy and support OpenStack for their own users get together to discuss their challenges and provide guidance to the OpenStack developer community.
-
-The past few years have been great for open source infrastructure. If you're working for a large enterprise, the opportunity to deploy open source projects like the ones mentioned above has made your company more productive and more agile.
-
-As large companies like ours begin to consume more open source software to meet their infrastructure needs, they're going to be looking at a long list of considerations before deciding what to use: license compatibility, out-of-pocket costs, and the health of the development community are just a few examples. As a result of our experiences, we'll add the presence of a vibrant and engaged end-user community to the list.
-
-Increased reliance on open source infrastructure projects has also highlighted a key problem: People in the development community have little experience deploying the software they work on into production environments or supporting the people who use it to get things done on a daily basis. The fast pace of updates to these projects has created some unexpected problems for the people who deploy and use them. There are numerous examples I can cite where open source projects are updated so frequently that new versions will, usually unintentionally, break backwards compatibility.
-
-As open source increasingly becomes foundational to the operation of so many enterprises, this cannot be allowed to happen, and members of the user community should assert themselves accordingly and press for the creation of formal representation. In the end, the software can only be better.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/important-conversation
-
-作者:[Kevin P.Fleming][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/kpfleming
-[1]:https://releases.openstack.org/liberty/
-[2]:https://www.linkedin.com/in/mihalis68/
-[3]:http://superuser.openstack.org/articles/openstack-at-bloomberg/
-[4]:https://www.cncf.io/
-[5]:https://www.cncf.io/people/end-user-community/
-[6]:https://www.cncf.io/people/technical-oversight-committee/
diff --git a/sources/talk/20180214 Can anonymity and accountability coexist.md b/sources/talk/20180214 Can anonymity and accountability coexist.md
deleted file mode 100644
index 8b15ed169c..0000000000
--- a/sources/talk/20180214 Can anonymity and accountability coexist.md
+++ /dev/null
@@ -1,79 +0,0 @@
-Can anonymity and accountability coexist?
-=========================================
-
-Anonymity might be a boon to more open, meritocratic organizational cultures. But does it conflict with another important value: accountability?
-
-
-
-Image by :opensource.com
-
-### Get the newsletter
-
-Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
-
-Whistleblowing protections, crowdsourcing, anonymous voting processes, and even Glassdoor reviews—anonymous speech may take many forms in organizations.
-
-As well-established and valued as these anonymous feedback mechanisms may be, anonymous speech becomes a paradoxical idea when one considers how to construct a more open organization. While an inability to discern speaker identity seems non-transparent, an opportunity for anonymity may actually help achieve a _more inclusive and meritocratic_ environment.
-
-More about open organizations
-
-* [Download free Open Org books](https://opensource.com/open-organization/resources/book-series?src=too_resource_menu1a)
-* [What is an Open Organization?](https://opensource.com/open-organization/resources/open-org-definition?src=too_resource_menu2a)
-* [How open is your organization?](https://opensource.com/open-organization/resources/open-org-maturity-model?src=too_resource_menu3a)
-* [What is an Open Decision?](https://opensource.com/open-organization/resources/open-decision-framework?src=too_resource_menu4a)
-* [The Open Org two years later](https://www.redhat.com/en/about/blog/open-organization-two-years-later-and-going-strong?src=too_resource_menu4b&intcmp=70160000000h1s6AAA)
-
-But before allowing outlets for anonymous speech to propagate, however, leaders of an organization should carefully reflect on whether an organization's "closed" practices make anonymity the unavoidable alternative to free, non-anonymous expression. Though some assurance of anonymity is necessary in a few sensitive and exceptional scenarios, dependence on anonymous feedback channels within an organization may stunt the normalization of a culture that encourages diversity and community.
-
-### The benefits of anonymity
-
-In the case of [_Talley v. California (1960)_](https://supreme.justia.com/cases/federal/us/362/60/case.html), the Supreme Court voided a city ordinance prohibiting the anonymous distribution of handbills, asserting that "there can be no doubt that such an identification requirement would tend to restrict freedom to distribute information and thereby freedom of expression." Our judicial system has legitimized the notion that the protection of anonymity facilitates the expression of otherwise unspoken ideas. A quick scroll through any [subreddit](https://www.reddit.com/reddits/) exemplifies what the Court has codified: anonymity can foster [risk-taking creativity](https://www.reddit.com/r/sixwordstories/) and the [inclusion and support of marginalized voices](https://www.reddit.com/r/MyLittleSupportGroup/). Anonymity empowers individuals by granting them the safety to speak without [detriment to their reputations or, more importantly, their physical selves.](https://www.psychologytoday.com/blog/the-compassion-chronicles/201711/why-dont-victims-sexual-harassment-come-forward-sooner)
-
-For example, an anonymous suggestion program to garner ideas from members or employees in an organization may strengthen inclusivity and enhance the diversity of suggestions the organization receives. It would also make for a more meritocratic decision-making process, as anonymity would ensure that the quality of the articulated idea, rather than the rank and reputation of the articulator, is what's under evaluation. Allowing members to anonymously vote for anonymously-submitted ideas would help curb the influence of office politics in decisions affecting the organization's growth.
-
-### The harmful consequences of anonymity
-
-Yet anonymity and the open value of _accountability_ may come into conflict with one another. For instance, when establishing anonymous programs to drive greater diversity and more meritocratic evaluation of ideas, organizations may need to sacrifice the ability to hold speakers accountable for the opinions they express.
-
-Reliance on anonymous speech for serious organizational decision-making may also contribute to complacency in an organizational culture that falls short of openness. Outlets for anonymous speech may be as similar to open as crowdsourcing is—or rather, is not. [Like efforts to crowdsource creative ideas](https://opensource.com/business/10/4/why-open-source-way-trumps-crowdsourcing-way), anonymous suggestion programs may create an organizational environment in which diverse perspectives are only valued when an organization's leaders find it convenient to take advantage of members' ideas.
-
-Anonymity and the open value of accountability may come into conflict with one another.
-
-A similar concern holds for anonymous whistle-blowing or concern submission. Though anonymity is important for sexual harassment and assault reporting, regularly redirecting member concerns and frustrations to a "complaints box" makes it more difficult for members to hold their organization's leaders accountable for acting on concerns. It may also hinder intra-organizational support networks and advocacy groups from forming around shared concerns, as members would have difficulty identifying others with similar experiences. For example, many working mothers might anonymously submit requests for a lactation room in their workplace, then falsely attribute a lack of action from leaders to a lack of similar concerns from others.
-
-### An anonymity checklist
-
-Organizations in which anonymous speech is the primary mode of communication, like subreddits, have generated innovative works and thought-provoking discourse. These anonymous networks call attention to the potential for anonymity to help organizations pursue open values of diversity and meritocracy. Organizations in which anonymous speech is _not_ the main form of communication should acknowledge the strengths of anonymous speech, but carefully consider whether anonymity is the wisest means to the goal of sustainable openness.
-
-Leaders may find reflecting on the following questions useful prior to establishing outlets for anonymous feedback within their organizations:
-
-1\. _Availability of additional communication mechanisms_: Rather than investing time and resources into establishing a new, anonymous channel for communication, can the culture or structure of existing avenues of communication be reconfigured to achieve the same goal? This question echoes the open source affinity toward realigning, rather than reinventing, the wheel.
-
-2\. _Failure of other communication avenues:_ How and why is the organization ill-equipped to handle the sensitive issue/situation at hand through conventional (i.e. non-anonymous) means of communication?
-
-Careful deliberation on these questions may help prevent outlets for anonymous speech from leading to a dangerous sense of complacency.
-
-3\. _Consequences of anonymity:_ If implemented, could the anonymous mechanism stifle the normalization of face-to-face discourse about issues important to the organization's growth? If so, how can leaders ensure that members consider the anonymous communication channel a "last resort," without undermining the legitimacy of the anonymous system?
-
-4\. _Designing the anonymous communication channel:_ How can accountability be promoted in anonymous communication without the ability to determine the identity of speakers?
-
-5\. _Long-term considerations_: Is the anonymous feedback mechanism sustainable, or a temporary solution to a larger organizational issue? If the latter, is [launching a campaign](https://opensource.com/open-organization/16/6/8-steps-more-open-communications) to address overarching problems with the organization's communication culture feasible?
-
-These five points build off of one another to help leaders recognize the tradeoffs involved in legitimizing anonymity within their organization. Careful deliberation on these questions may help prevent outlets for anonymous speech from leading to a dangerous sense of complacency with a non-inclusive organizational structure.
-
-About the author
-----------------
-
-[](https://opensource.com/users/susiechoi)
-
-Susie Choi - Susie is an undergraduate student studying computer science at Duke University. She is interested in the implications of technological innovation and open source principles for issues relating to education and socioeconomic inequality.
-
-[More about me](https://opensource.com/users/susiechoi)
-
-* * *
-
-via: [https://opensource.com/open-organization/18/1/balancing-accountability-and-anonymity](https://opensource.com/open-organization/18/1/balancing-accountability-and-anonymity)
-
-作者: [Susie Choi](https://opensource.com/users/susiechoi) 选题者: [@lujun9972](https://github.com/lujun9972) 译者: [译者ID](https://github.com/译者ID) 校对: [校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
\ No newline at end of file
diff --git a/sources/talk/20180216 Q4OS Makes Linux Easy for Everyone.md b/sources/talk/20180216 Q4OS Makes Linux Easy for Everyone.md
deleted file mode 100644
index a868ed28d5..0000000000
--- a/sources/talk/20180216 Q4OS Makes Linux Easy for Everyone.md
+++ /dev/null
@@ -1,140 +0,0 @@
-Q4OS Makes Linux Easy for Everyone
-======
-
-
-
-Modern Linux distributions tend to target a variety of users. Some claim to offer a flavor of the open source platform that anyone can use. And, I’ve seen some such claims succeed with aplomb, while others fall flat. [Q4OS][1] is one of those odd distributions that doesn’t bother to make such a claim but pulls off the feat anyway.
-
-So, who is the primary market for Q4OS? According to its website, the distribution is a:
-
-“fast and powerful operating system based on the latest technologies while offering highly productive desktop environment. We focus on security, reliability, long-term stability and conservative integration of verified new features. System is distinguished by speed and very low hardware requirements, runs great on brand new machines as well as legacy computers. It is also very applicable for virtualization and cloud computing.”
-
-What’s very interesting here is that the Q4OS developers offer commercial support for the desktop. Said support can cover the likes of system customization (including core level API programming) as well as user interface modifications.
-
-Once you understand this (and have installed Q4OS), the target audience becomes quite obvious: Business users looking for a Windows XP/7 replacement. But that should not prevent home users from giving Q4OS at try. It’s a Linux distribution that has a few unique tools that come together to make a solid desktop distribution.
-
-Let’s take a look at Q4OS and see if it’s a version of Linux that might work for you.
-
-### What Q4OS all about
-
-Q4OS that does an admirable job of being the open source equivalent of Windows XP/7. Out of the box, it pulls this off with the help of the [Trinity Desktop][2] (a fork of KDE). With a few tricks up its sleeve, Q4OS turns the Trinity Desktop into a remarkably similar desktop (Figure 1).
-
-![default desktop][4]
-
-Figure 1: The Q4OS default desktop.
-
-[Used with permission][5]
-
-When you fire up the desktop, you will be greeted by a Welcome screen that makes it very easy for new users to start setting up their desktop with just a few clicks. From this window, you can:
-
- * Run the Desktop Profiler (which allows you to select which desktop environment to use as well as between a full-featured desktop, a basic desktop, or a minimal desktop—Figure 2).
-
- * Install applications (which opens the Synaptic Package Manager).
-
- * Install proprietary codecs (which installs all the necessary media codecs for playing audio and video).
-
- * Turn on Desktop effects (if you want more eye candy, turn this on).
-
- * Switch to Kickoff start menu (switches from the default start menu to the newer kickoff menu).
-
- * Set Autologin (allows you to set login such that it won’t require your password upon boot).
-
-
-
-
-![Desktop Profiler][7]
-
-Figure 2: The Desktop Profiler allows you to further customize your desktop experience.
-
-[Used with permission][5]
-
-If you want to install a different desktop environment, open up the Desktop Profiler and then click the Desktop environments drop-down, in the upper left corner of the window. A new window will appear, where you can select your desktop of choice from the drop-down (Figure 3). Once back at the main Profiler Window, select which type of desktop profile you want, and then click Install.
-
-![Desktop Profiler][9]
-
-Figure 3: Installing a different desktop is quite simple from within the Desktop Profiler.
-
-[Used with permission][5]
-
-Note that installing a different desktop will not wipe the default desktop. Instead, it will allow you to select between the two desktops (at the login screen).
-
-### Installed software
-
-After selecting full-featured desktop, from the Desktop Profiler, I found the following user applications ready to go:
-
- * LibreOffice 5.2.7.2
-
- * VLC 2.2.7
-
- * Google Chrome 64.0.3282
-
- * Thunderbird 52.6.0 (Includes Lightning addon)
-
- * Synaptic 0.84.2
-
- * Konqueror 14.0.5
-
- * Firefox 52.6.0
-
- * Shotwell 0.24.5
-
-
-
-
-Obviously some of those applications are well out of date. Since this distribution is based on Debian, we can run and update/upgrade with the commands:
-```
-sudo apt update
-
-sudo apt upgrade
-
-```
-
-However, after running both commands, it seems everything is up to date. This particular release (2.4) is an LTS release (supported until 2022). Because of this, expect software to be a bit behind. If you want to test out the bleeding edge version (based on Debian “Buster”), you can download the testing image [here][10].
-
-### Security oddity
-
-There is one rather disturbing “feature” found in Q4OS. In the developer’s quest to make the distribution closely resemble Windows, they’ve made it such that installing software (from the command line) doesn’t require a password! You read that correctly. If you open the Synaptic package manager, you’re asked for a password. However (and this is a big however), open up a terminal window and issue a command like sudo apt-get install gimp. At this point, the software will install… without requiring the user to type a sudo password.
-
-Did you cringe at that? You should.
-
-I get it, the developers want to ease away the burden of Linux and make a platform the masses could easily adapt to. They’ve done a splendid job of doing just that. However, in the process of doing so, they’ve bypassed a crucial means of security. Is having as near an XP/7 clone as you can find on Linux worth that lack of security? I would say that if it enables more people to use Linux, then yes. But the fact that they’ve required a password for Synaptic (the GUI tool most Windows users would default to for software installation) and not for the command-line tool makes no sense. On top of that, bypassing passwords for the apt and dpkg commands could make for a significant security issue.
-
-Fear not, there is a fix. For those that prefer to require passwords for the command line installation of software, you can open up the file /etc/sudoers.d/30_q4os_apt and comment out the following three lines:
-```
-%sudo ALL = NOPASSWD: /usr/bin/apt-get *
-
-%sudo ALL = NOPASSWD: /usr/bin/apt-key *
-
-%sudo ALL = NOPASSWD: /usr/bin/dpkg *
-
-```
-
-Once commented out, save and close the file, and reboot the system. At this point, users will now be prompted for a password, should they run the apt-get, apt-key, or dpkg commands.
-
-### A worthy contender
-
-Setting aside the security curiosity, Q4OS is one of the best attempts at recreating Windows XP/7 I’ve come across in a while. If you have users who fear change, and you want to migrate them away from Windows, this distribution might be exactly what you need. I would, however, highly recommend you re-enable passwords for the apt-get, apt-key, and dpkg commands… just to be on the safe side.
-
-In any case, the addition of the Desktop Profiler, and the ability to easily install alternative desktops, makes Q4OS a distribution that just about anyone could use.
-
-Learn more about Linux through the free ["Introduction to Linux" ][11]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/2/q4os-makes-linux-easy-everyone
-
-作者:[JACK WALLEN][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://q4os.org
-[2]:https://www.trinitydesktop.org/
-[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_1.jpg?itok=dalJk9Xf (default desktop)
-[5]:/licenses/category/used-permission
-[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_2.jpg?itok=GlouIm73 (Desktop Profiler)
-[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_3.jpg?itok=riSTP_1z (Desktop Profiler)
-[10]:https://q4os.org/downloads2.html
-[11]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/talk/20180220 4 considerations when naming software development projects.md b/sources/talk/20180220 4 considerations when naming software development projects.md
deleted file mode 100644
index 1e1add0b68..0000000000
--- a/sources/talk/20180220 4 considerations when naming software development projects.md
+++ /dev/null
@@ -1,91 +0,0 @@
-4 considerations when naming software development projects
-======
-
-
-
-Working on a new open source project, you're focused on the code—getting that great new idea released so you can share it with the world. And you'll want to attract new contributors, so you need a terrific **name** for your project.
-
-We've all read guides for creating names, but how do you go about choosing the right one? Keeping that cool science fiction reference you're using internally might feel fun, but it won't mean much to new users you're trying to attract. A better approach is to choose a name that's memorable to new users and developers searching for your project.
-
-Names set expectations. Your project's name should showcase its functionality in the ecosystem and explain to users what your story is. In the crowded open source software world, it's important not to get entangled with other projects out there. Taking a little extra time now, before sending out that big announcement, will pay off later.
-
-Here are four factors to keep in mind when choosing a name for your project.
-
-### What does your project's code do?
-
-Start with your project: What does it do? You know the code intimately—but can you explain what it does to a new developer? Can you explain it to a CTO or non-developer at another company? What kinds of problems does your project solve for users?
-
-Your project's name needs to reflect what it does in a way that makes sense to newcomers who want to use or contribute to your project. That means considering the ecosystem for your technology and understanding if there are any naming styles or conventions used for similar kinds of projects. Imagine that you're trying to evaluate someone else's project: Would the name be appealing to you?
-
-Any distribution channels you push to are also part of the ecosystem. If your code will be in a Linux distribution, [npm][1], [CPAN][2], [Maven][3], or in a Ruby Gem, you need to review any naming standards or common practices for that package manager. Review any similar existing names in that distribution channel, and get a feel for naming styles of other programs there.
-
-### Who are the users and developers you want to attract?
-
-The hardest aspect of choosing a new name is putting yourself in the shoes of new users. You built this project; you already know how powerful it is, so while your cool name may sound great, it might not draw in new people. You need a name that is interesting to someone new, and that tells the world what problems your project solves.
-
-Great names depend on what kind of users you want to attract. Are you building an [Eclipse][4] plugin or npm module that's focused on developers? Or an analytics toolkit that brings visualizations to the average user? Understanding your user base and the kinds of open source contributors you want to attract is critical.
-
-Great names depend on what kind of users you want to attract.
-
-Take the time to think this through. Who does your project most appeal to, and how can it help them do their job? What kinds of problems does your code solve for end users? Understanding the target user helps you focus on what users need, and what kind of names or brands they respond to.
-
-Take the time to think this through. Who does your project most appeal to, and how can it help them do their job? What kinds of problems does your code solve for end users? Understanding the target user helps you focus on what users need, and what kind of names or brands they respond to.
-
-When you're open source, this equation changes a bit—your target is not just users; it's also developers who will want to contribute code back to your project. You're probably a developer, too: What kinds of names and brands excite you, and what images would entice you to try out someone else's new project?
-
-Once you have a better feel of what users and potential contributors expect, use that knowledge to refine your names. Remember, you need to step outside your project and think about how the name would appeal to someone who doesn't know how amazing your code is—yet. Once someone gets to your website, does the name synchronize with what your product does? If so, move to the next step.
-
-### Who else is using similar names for software?
-
-Now that you've tried on a user's shoes to evaluate potential names, what's next? Figuring out if anyone else is already using a similar name. It sometimes feels like all the best names are taken—but if you search carefully, you'll find that's not true.
-
-The first step is to do a few web searches using your proposed name. Search for the name, plus "software", "open source", and a few keywords for the functionality that your code provides. Look through several pages of results for each search to see what's out there in the software world.
-
-The first step is to do a few web searches using your proposed name.
-
-Unless you're using a completely made-up word, you'll likely get a lot of hits. The trick is understanding which search results might be a problem. Again, put on the shoes of a new user to your project. If you were searching for this great new product and saw the other search results along with your project's homepage, would you confuse them? Are the other search results even software products? If your product solves a similar problem to other search results, that's a problem: Users may gravitate to an existing product instead of a new one.
-
-Unless you're using a completely made-up word, you'll likely get a lot of hits. The trick is understanding which search results might be a problem. Again, put on the shoes of a new user to your project. If you were searching for this great new product and saw the other search results along with your project's homepage, would you confuse them? Are the other search results even software products? If your product solves a similar problem to other search results, that's a problem: Users may gravitate to an existing product instead of a new one.
-
-Similar non-software product names are rarely an issue unless they are famous trademarks—like Nike or Red Bull, for example—where the companies behind them won't look kindly on anyone using a similar name. Using the same name as a less famous non-software product might be OK, depending on how big your project gets.
-
-### How big do you plan to grow your project?
-
-Are you building a new node module or command-line utility, but not planning a career around it? Is your new project a million-dollar business idea, and you're thinking startup? Or is it something in between?
-
-If your project is a basic developer utility—something useful that developers will integrate into their workflow—then you have enough data to choose a name. Think through the ecosystem and how a new user would see your potential names, and pick one. You don't need perfection, just a name you're happy with that seems right for your project.
-
-If you're planning to build a business around your project, use these tips to develop a shortlist of names, but do more vetting before announcing the winner. Use for a business or major project requires some level of registered trademark search, which is usually performed by a law firm.
-
-### Common pitfalls
-
-Finally, when choosing a name, avoid these common pitfalls:
-
- * Using an esoteric acronym. If new users don't understand the name, they'll have a hard time finding you.
-
- * Using current pop-culture references. If you want your project's appeal to last, pick a name that will last.
-
- * Failing to consider non-English speakers. Does the name have a specific meaning in another language that might be confusing?
-
- * Using off-color jokes or potentially unsavory references. Even if it seems funny to developers, it may fall flat for newcomers and turn away contributors.
-
-
-
-
-Good luck—and remember to take the time to step out of your shoes and consider how a newcomer to your project will think of the name.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/choosing-project-names-four-key-considerations
-
-作者:[Shane Curcuru][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/shane-curcuru
-[1]:https://www.npmjs.com/
-[2]:https://www.cpan.org/
-[3]:https://maven.apache.org/
-[4]:https://www.eclipse.org/
diff --git a/sources/talk/20180221 3 warning flags of DevOps metrics.md b/sources/talk/20180221 3 warning flags of DevOps metrics.md
deleted file mode 100644
index a103a2bbca..0000000000
--- a/sources/talk/20180221 3 warning flags of DevOps metrics.md
+++ /dev/null
@@ -1,42 +0,0 @@
-3 warning flags of DevOps metrics
-======
-
-
-Metrics. Measurements. Data. Monitoring. Alerting. These are all big topics for DevOps and for cloud-native infrastructure and application development more broadly. In fact, acm Queue, a magazine published by the Association of Computing Machinery, recently devoted an [entire issue][1] to the topic.
-
-I've argued before that we conflate a lot of things under the "metrics" term, from key performance indicators to critical failure alerts to data that may be vaguely useful someday for something or other. But that's a topic for another day. What I want to discuss here is how metrics affect behavior.
-
-In 2008, Daniel Ariely published [Predictably Irrational][2] , one of a number of books written around that time that introduced behavioral psychology and behavioral economics to the general public. One memorable quote from that book is the following: "Human beings adjust behavior based on the metrics they're held against. Anything you measure will impel a person to optimize his score on that metric. What you measure is what you'll get. Period."
-
-This shouldn't be surprising. It's a finding that's been repeatedly confirmed by research. It should also be familiar to just about anyone with business experience. It's certainly not news to anyone in sales management, for example. Base sales reps' (or their managers'!) bonuses solely on revenue, and they'll discount whatever it takes to maximize revenue even if it puts margin in the toilet. Conversely, want the sales force to push a new product line—which will probably take extra effort—but skip the [spiffs][3]? Probably not happening.
-
-And lest you think I'm unfairly picking on sales, this behavior is pervasive, all the way up to the CEO, as Ariely describes in [a 2010 Harvard Business Review article][4]. "CEOs care about stock value because that's how we measure them. If we want to change what they care about, we should change what we measure," writes Ariely.
-
-Think developers and operations folks are immune from such behaviors? Think again. Let's consider some problematic measurements. They're not all bad or wrong but, if you rely too much on them, warning flags should go up.
-
-### Three warning signs for DevOps metrics
-
-First, there are the quantity metrics. Lines of code or bugs fixed are perhaps self-evidently absurd. But there are also the deployments per week or per month that are so widely quoted to illustrate DevOps velocity relative to more traditional development and deployment practices. Speed is good. It's one of the reasons you're probably doing DevOps—but don't reward people on it excessively relative to quality and other measures.
-
-Second, it's obvious that you want to reward individuals who do their work quickly and well. Yes. But. Whether it's your local pro sports team or some project team you've been on, you can probably name someone who was really a talent, but was just so toxic and such a distraction for everyone else that they were a net negative for the team. Moral: Don't provide incentives that solely encourage individual behaviors. You may also want to put in place programs, such as peer rewards, that explicitly value collaboration. [As Red Hat's Jen Krieger told me][5] in a podcast last year: "Having those automated pots of awards, or some sort of system that's tracked for that, can only help teams feel a little more cooperative with one another as in, 'Hey, we're all working together to get something done.'"
-
-The third red flag area is incentives that don't actually incent because neither the individual nor the team has a meaningful ability to influence the outcome. It's often a good thing when DevOps metrics connect to business goals and outcomes. For example, customer ticket volume relates to perceived shortcomings in applications and infrastructure. And it's also a reasonable proxy for overall customer satisfaction, which certainly should be of interest to the executive suite. The best reward systems to drive DevOps behaviors should be tied to specific individual and team actions as opposed to just company success generally.
-
-You've probably noticed a common theme. That theme is balance. Velocity is good but so is quality. Individual achievement is good but not when it damages the effectiveness of the team. The overall success of the business is certainly important, but the best reward systems also tie back to actions and behaviors within development and operations.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/three-warning-flags-devops-metrics
-
-作者:[Gordon Haff][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/ghaff
-[1]:https://queue.acm.org/issuedetail.cfm?issue=3178368
-[2]:https://en.wikipedia.org/wiki/Predictably_Irrational
-[3]:https://en.wikipedia.org/wiki/Spiff
-[4]:https://hbr.org/2010/06/column-you-are-what-you-measure
-[5]:http://bitmason.blogspot.com/2015/09/podcast-making-devops-succeed-with-red.html
diff --git a/sources/talk/20180222 3 reasons to say -no- in DevOps.md b/sources/talk/20180222 3 reasons to say -no- in DevOps.md
deleted file mode 100644
index 5f27fbaf47..0000000000
--- a/sources/talk/20180222 3 reasons to say -no- in DevOps.md
+++ /dev/null
@@ -1,105 +0,0 @@
-3 reasons to say 'no' in DevOps
-======
-
-
-
-DevOps, it has often been pointed out, is a culture that emphasizes mutual respect, cooperation, continual improvement, and aligning responsibility with authority.
-
-Instead of saying no, it may be helpful to take a hint from improv comedy and say, "Yes, and..." or "Yes, but...". This opens the request from the binary nature of "yes" and "no" toward having a nuanced discussion around priority, capacity, and responsibility.
-
-However, sometimes you have no choice but to give a hard "no." These should be rare and exceptional, but they will occur.
-
-### Protecting yourself
-
-Both Agile and DevOps have been touted as ways to improve value to the customer and business, ultimately leading to greater productivity. While reasonable people can understand that the improvements will take time to yield, and the improvements will result in higher quality of work being done, and a better quality of life for those performing it, I think we can all agree that not everyone is reasonable. The less understanding that a person has of the particulars of a given task, the more likely they are to expect that it is a combination of "simple" and "easy."
-
-"You told me that [Agile/DevOps] is supposed to be all about us getting more productivity. Since we're doing [Agile/DevOps] now, you can take care of my need, right?"
-
-Like "Agile," some people have tried to use "DevOps" as a stick to coerce people to do more work than they can handle. Whether the person confronting you with this question is asking in earnest or is being manipulative doesn't really matter.
-
-The biggest areas of concern for me have been **capacity** , **firefighting/maintenance** , **level of quality** , and **" future me."** Many of these ultimately tie back to capacity, but they relate to a long-term effort in different respects.
-
-#### Capacity
-
-Capacity is simple: You know what your workload is, and how much flex occurs due to the unexpected. Exceeding your capacity will not only cause undue stress, but it could decrease the quality of your work and can injure your reputation with regards to making commitments.
-
-There are several avenues of discussion that can happen from here. The simplest is "Your request is reasonable, but I don't have the capacity to work on it." This seldom ends the conversation, and a discussion will often run up the flagpole to clarify priorities or reassign work.
-
-#### Firefighting/maintenance
-
-It's possible that the thing that you're being asked for won't take long to do, but it will require maintenance that you'll be expected to perform, including keeping it alive and fulfilling requests for it on behalf of others.
-
-An example in my mind is the Jenkins server that you're asked to stand up for someone else, but somehow end up being the sole owner and caretaker of. Even if you're careful to scope your level of involvement early on, you might be saddled with responsibility that you did not agree to. Should the service become unavailable, for example, you might be the one who is called. You might be called on to help triage a build that is failing. This is additional firefighting and maintenance work that you did not sign up for and now must fend off.
-
-This needs to be addressed as soon and publicly as possible. I'm not saying that (again, for example) standing up a Jenkins instance is a "no," but rather a ["Yes, but"][1]—where all parties understand that they take on the long-term care, feeding, and use of the product. Make sure to include all your bosses in this conversation so they can have your back.
-
-#### Level of quality
-
-There may be times when you are presented with requirements that include a timeframe that is...problematic. Perhaps you could get a "minimum (cough) viable (cough) product" out in that time. But it wouldn't be resilient or in any way ready for production. It might impact your time and productivity. It could end up hurting your reputation.
-
-The resulting conversation can get into the weeds, with lots of horse-trading about time and features. Another approach is to ask "What is driving this deadline? Where did that timeframe come from?" Discussing the bigger picture might lead to a better option, or that the timeline doesn't depend on the original date.
-
-#### Future me
-
-Ultimately, we are trying to protect "future you." These are lessons learned from the many times that "past me" has knowingly left "current me" to clean up. Sometimes we joke that "that's a problem for 'future me,'" but don't forget that 'future you' will just be 'you' eventually. I've cursed "past me" as a jerk many times. Do your best to keep other people from making "past you" be a jerk to "future you."
-
-I recognize that I have a significant amount of privilege in this area, but if you are told that you cannot say "no" on behalf of your own welfare, you should consider whether you are respected enough to maintain your autonomy.
-
-### Protecting the user experience
-
-Everyone should be an advocate for the user. Regardless of whether that user is right next to you, someone down the hall, or someone you have never met and likely never will, you must care for the customer.
-
-Behavior that is actively hostile to the user—whether it's a poor user experience or something more insidious like quietly violating reasonable expectations of privacy—deserves a "no." A common example of this would be automatically including people into a service or feature, forcing them to explicitly opt-out.
-
-If a "no" is not welcome, it bears considering, or explicitly asking, what the company's relationship with its customers is, who the company thinks of as it's customers, and what it thinks of them.
-
-When bringing up your objections, be clear about what they are. Additionally, remember that your coworkers are people too, and make it clear that you are not attacking their character; you simply find the idea disagreeable.
-
-### Legal, ethical, and moral grounds
-
-There might be situations that don't feel right. A simple test is to ask: "If this were to become public, or come up in a lawsuit deposition, would it be a scandal?"
-
-#### Ethics and morals
-
-If you are asked to lie, that should be a hard no.
-
-Remember if you will the Volkswagen Emissions Scandal of 2017? The emissions systems software was written such that it recognized that the vehicle was operated in a manner consistent with an emissions test, and would run more efficiently than under normal driving conditions.
-
-I don't know what you do in your job, or what your office is like, but I have a hard time imagining the Individual Contributor software engineer coming up with that as a solution on their own. In fact, I imagine a comment along the lines of "the engine engineers can't make their product pass the tests, so I need to hack the performance so that it will!"
-
-When the Volkswagen scandal came public, Volkswagen officials blamed the engineers. I find it unlikely that it came from the mind and IDE of an individual software engineer. Rather, it's more likely indicates significant systemic problems within the company culture.
-
-If you are asked to lie, get the request in writing, citing that the circumstances are suspect. If you are so privileged, decide whether you may decline the request on the basis that it is fundamentally dishonest and hostile to the customer, and would break the public's trust.
-
-#### Legal
-
-I am not a lawyer. If your work should involve legal matters, including requests from law enforcement, involve your company's legal counsel or speak with a private lawyer.
-
-With that said, if you are asked to provide information for law enforcement, I believe that you are within your rights to see the documentation that justifies the request. There should be a signed warrant. You should be provided with a copy of it, or make a copy of it yourself.
-
-When in doubt, begin recording and request legal counsel.
-
-It has been well documented that especially in the early years of the U.S. Patriot Act, law enforcement placed so many requests of telecoms that they became standard work, and the paperwork started slipping. While tedious and potentially stressful, make sure that the legal requirements for disclosure are met.
-
-If for no other reason, we would not want the good work of law enforcement to be put at risk because key evidence was improperly acquired, making it inadmissible.
-
-### Wrapping up
-
-You are going to be your single biggest advocate. There may be times when you are asked to compromise for the greater good. However, you should feel that your dignity is preserved, your autonomy is respected, and that your morals remain intact.
-
-If you don't feel that this is the case, get it on record, doing your best to communicate it calmly and clearly.
-
-Nobody likes being declined, but if you don't have the ability to say no, there may be a bigger problem than your environment not being DevOps.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/3-reasons-say-no-devops
-
-作者:[H. "Waldo" Grunenwal][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/gwaldo
-[1]:http://gwaldo.blogspot.com/2015/12/fear-and-loathing-in-systems.html
diff --git a/sources/talk/20180223 Plasma Mobile Could Give Life to a Mobile Linux Experience.md b/sources/talk/20180223 Plasma Mobile Could Give Life to a Mobile Linux Experience.md
deleted file mode 100644
index 583714836e..0000000000
--- a/sources/talk/20180223 Plasma Mobile Could Give Life to a Mobile Linux Experience.md
+++ /dev/null
@@ -1,123 +0,0 @@
-Plasma Mobile Could Give Life to a Mobile Linux Experience
-======
-
-
-
-In the past few years, it’s become clear that, outside of powering Android, Linux on mobile devices has been a resounding failure. Canonical came close, even releasing devices running Ubuntu Touch. Unfortunately, the idea of [Scopes][1]was doomed before it touched down on its first piece of hardware and subsequently died a silent death.
-
-The next best hope for mobile Linux comes in the form of the [Samsung DeX][2] program. With DeX, users will be able to install an app (Linux On Galaxy—not available yet) on their Samsung devices, which would in turn allow them to run a full-blown Linux distribution. The caveat here is that you’ll be running both Android and Linux at the same time—which is not exactly an efficient use of resources. On top of that, most Linux distributions aren’t designed to run on such small form factors. The good news for DeX is that, when you run Linux on Galaxy and dock your Samsung device to DeX, that Linux OS will be running on your connected monitor—so form factor issues need not apply.
-
-Outside of those two options, a pure Linux on mobile experience doesn’t exist. Or does it?
-
-You may have heard of the [Purism Librem 5][3]. It’s a crowdfunded device that promises to finally bring a pure Linux experience to the mobile landscape. This device will be powered by a i.MX8 SoC chip, so it should run most any Linux operating system.
-
-Out of the box, the device will run an encrypted version of [PureOS][4]. However, last year Purism and KDE joined together to create a mobile version of the KDE desktop that could run on the Librem 5. Recently [ISOs were made available for a beta version of Plasma Mobile][5] and, judging from first glance, they’re onto something that makes perfect sense for a mobile Linux platform. I’ve booted up a live instance of Plasma Mobile to kick the tires a bit.
-
-What I saw seriously impressed me. Let’s take a look.
-
-### Testing platform
-
-Before you download the ISO and attempt to fire it up as a VirtualBox VM, you should know that it won’t work well. Because Plasma Mobile uses Wayland (and VirtualBox has yet to play well with that particular X replacement), you’ll find VirtualBox VM a less-than-ideal platform for the beta release. Also know that the Calamares installer doesn’t function well either. In fact, I have yet to get the OS installed on a non-mobile device. And since I don’t own a supported mobile device, I’ve had to run it as a live session on either a laptop or an [Antsle][6] antlet VM every time.
-
-### What makes Plasma Mobile special?
-
-This could be easily summed up by saying, Plasma Mobile got it all right. Instead of Canonical re-inventing a perfectly functioning wheel, the developers of KDE simply re-tooled the interface such that a full-functioning Linux distribution (complete with all the apps you’ve grown to love and depend upon) could work on a smaller platform. And they did a spectacular job. Even better, they’ve created an interface that any user of a mobile device could instantly feel familiar with.
-
-What you have with the Plasma Mobile interface (Figure 1) are the elements common to most Android home screens:
-
- * Quick Launchers
-
- * Notification Shade
-
- * App Drawer
-
- * Overview button (so you can go back to a previously used app, still running in memory)
-
- * Home button
-
-
-
-
-![KDE mobile][8]
-
-Figure 1: The Plasma Mobile desktop interface.
-
-[Used with permission][9]
-
-Because KDE went this route with the UX, it means there’s zero learning curve. And because this is an actual Linux platform, it takes that user-friendly mobile interface and overlays it onto a system that allows for easy installation and usage of apps like:
-
- * GIMP
-
- * LibreOffice
-
- * Audacity
-
- * Clementine
-
- * Dropbox
-
- * And so much more
-
-
-
-
-Unfortunately, without being able to install Plasma Mobile, you cannot really kick the tires too much, as the live user doesn’t have permission to install applications. However, once Plasma Mobile is fully installed, the Discover software center will allow you to install a host of applications (Figure 2).
-
-
-![Discover center][11]
-
-Figure 2: The Discover software center on Plasma Mobile.
-
-[Used with permission][9]
-
-Swipe up (or scroll down—depending on what hardware you’re using) to reveal the app drawer, where you can launch all of your installed applications (Figure 3).
-
-![KDE mobile][13]
-
-Figure 3: The Plasma Mobile app drawer ready to launch applications.
-
-[Used with permission][9]
-
-Open up a terminal window and you can take care of standard Linux admin tasks, such as using SSH to log into a remote server. Using apt, you can install all of the developer tools you need to make Plasma Mobile a powerful development platform.
-
-We’re talking serious mobile power—either from a phone or a tablet.
-
-### A ways to go
-
-Clearly Plasma Mobile is still way too early in development for it to be of any use to the average user. And because most virtual machine technology doesn’t play well with Wayland, you’re likely to get too frustrated with the current ISO image to thoroughly try it out. However, even without being able to fully install the platform (or get full usage out of it), it’s obvious KDE and Purism are going to have the ideal platform that will put Linux into the hands of mobile users.
-
-If you want to test the waters of Plasma Mobile on an actual mobile device, a handy list of supported hardware can be found [here][14] (for PostmarketOS) or [here][15] (for Halium). If you happen to be lucky enough to have a device that also includes Wi-Fi support, you’ll find you get more out of testing the environment.
-
-If you do have a supported device, you’ll need to use either [PostmarketOS][16] (a touch-optimized, pre-configured Alpine Linux that can be installed on smartphones and other mobile devices) or [Halium][15] (an application that creates an minimal Android layer which allows a new interface to interact with the Android kernel). Using Halium further limits the number of supported devices, as it has only been built for select hardware. However, if you’re willing, you can build your own Halium images (documentation for this process is found [here][17]). If you want to give PostmarketOS a go, [here are the necessary build instructions][18].
-
-Suffice it to say, Plasma Mobile isn’t nearly ready for mass market. If you’re a Linux enthusiast and want to give it a go, let either PostmarketOS or Halium help you get the operating system up and running on your device. Otherwise, your best bet is to wait it out and hope Purism and KDE succeed in bringing this oustanding mobile take on Linux to the masses.
-
-Learn more about Linux through the free ["Introduction to Linux" ][19]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/2/plasma-mobile-could-give-life-mobile-linux-experience
-
-作者:[JACK WALLEN][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://launchpad.net/unity-scopes
-[2]:http://www.samsung.com/global/galaxy/apps/samsung-dex/
-[3]:https://puri.sm/shop/librem-5/
-[4]:https://www.pureos.net/
-[5]:http://blog.bshah.in/2018/01/26/trying-out-plasma-mobile/
-[6]:https://antsle.com/
-[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_1.jpg?itok=EK3_vFVP (KDE mobile)
-[9]:https://www.linux.com/licenses/category/used-permission
-[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_2.jpg?itok=CiUQ-MnB (Discover center)
-[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_3.jpg?itok=i6V8fgK8 (KDE mobile)
-[14]:http://blog.bshah.in/2018/02/02/trying-out-plasma-mobile-part-two/
-[15]:https://github.com/halium/projectmanagement/issues?q=is%3Aissue+is%3Aopen+label%3APorts
-[16]:https://postmarketos.org/
-[17]:http://docs.halium.org/en/latest/
-[18]:https://wiki.postmarketos.org/wiki/Installation_guide
-[19]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/talk/20180223 Why culture is the most important issue in a DevOps transformation.md b/sources/talk/20180223 Why culture is the most important issue in a DevOps transformation.md
deleted file mode 100644
index 8fe1b6f273..0000000000
--- a/sources/talk/20180223 Why culture is the most important issue in a DevOps transformation.md
+++ /dev/null
@@ -1,91 +0,0 @@
-Why culture is the most important issue in a DevOps transformation
-======
-
-
-
-You've been appointed the DevOps champion in your organisation: congratulations. So, what's the most important issue that you need to address?
-
-It's the technology—tools and the toolchain—right? Everybody knows that unless you get the right tools for the job, you're never going to make things work. You need integration with your existing stack (though whether you go with tight or loose integration will be an interesting question), a support plan (vendor, third party, or internal), and a bug-tracking system to go with your source code management system. And that's just the start.
-
-No! Don't be ridiculous: It's clearly the process that's most important. If the team doesn't agree on how stand-ups are run, who participates, the frequency and length of the meetings, and how many people are required for a quorum, then you'll never be able to institute a consistent, repeatable working pattern.
-
-In fact, although both the technology and the process are important, there's a third component that is equally important, but typically even harder to get right: culture. Yup, it's that touch-feely thing we techies tend to struggle with.1
-
-### Culture
-
-I was visiting a midsized government institution a few months ago (not in the UK, as it happens), and we arrived a little early to meet the CEO and CTO. We were ushered into the CEO's office and waited for a while as the two of them finished participating in the daily stand-up. They apologised for being a minute or two late, but far from being offended, I was impressed. Here was an organisation where the culture of participation was clearly infused all the way up to the top.
-
-Not that culture can be imposed from the top—nor can you rely on it percolating up from the bottom3—but these two C-level execs were not only modelling the behaviour they expected from the rest of their team, but also seemed, from the brief discussion we had about the process afterwards, to be truly invested in it. If you can get management to buy into the process—and be seen buying in—you are at least likely to have problems with other groups finding plausible excuses to keep their distance and get away with it.
-
-So let's assume management believes you should give DevOps a go. Where do you start?
-
-Developers may well be your easiest target group. They are often keen to try new things and find ways to move things along faster, so they are often the group that can be expected to adopt new technologies and methodologies. DevOps arguably has been driven mainly by the development community.
-
-But you shouldn't assume all developers will be keen to embrace this change. For some, the way things have always been done—your Rick Parfitts of dev, if you will7—is fine. Finding ways to help them work efficiently in the new world is part of your job, not just theirs. If you have superstar developers who aren't happy with change, you risk alienating and losing them if you try to force them into your brave new world. What's worse, if they dig their heels in, you risk the adoption of your DevSecOps vision being compromised when they explain to their managers that things aren't going to change if it makes their lives more difficult and reduces their productivity.
-
-Maybe you're not going to be able to move all the systems and people to DevOps immediately. Maybe you're going to need to choose which apps start with and who will be your first DevOps champions. Maybe it's time to move slowly.
-
-### Not maybe: definitely
-
-No—I lied. You're definitely going to need to move slowly. Trying to change everything at once is a recipe for disaster.
-
-This goes for all elements of the change—which people to choose, which technologies to choose, which applications to choose, which user base to choose, which use cases to choose—bar one. For those elements, if you try to move everything in one go, you will fail. You'll fail for a number of reasons. You'll fail for reasons I can't imagine and, more importantly, for reasons you can't imagine. But some of the reasons will include:
-
- * People—most people—don't like change.
- * Technologies don't like change (you can't just switch and expect everything to still work).
- * Applications don't like change (things worked before, or at least failed in known ways). You want to change everything in one go? Well, they'll all fail in new and exciting9 ways.
- * Users don't like change.
- * Use cases don't like change.
-
-
-
-### The one exception
-
-You noticed I wrote "bar one" when discussing which elements you shouldn't choose to change all in one go? Well done.
-
-What's that exception? It's the initial team. When you choose your initial application to change and you're thinking about choosing the team to make that change, select the members carefully and select a complete set. This is important. If you choose just developers, just test folks, just security folks, just ops folks, or just management—if you leave out one functional group from your list—you won't have proved anything at all. Well, you might have proved to a small section of your community that it kind of works, but you'll have missed out on a trick. And that trick is: If you choose keen people from across your functional groups, it's much harder to fail.
-
-Say your first attempt goes brilliantly. How are you going to convince other people to replicate your success and adopt DevOps? Well, the company newsletter, of course. And that will convince how many people, exactly? Yes, that number.12 If, on the other hand, you have team members from across the functional parts or the organisation, when you succeed, they'll tell their colleagues and you'll get more buy-in next time.
-
-If it fails, if you've chosen your team wisely—if they're all enthusiastic and know that "fail often, fail fast" is good—they'll be ready to go again.
-
-Therefore, you need to choose enthusiasts from across your functional groups. They can work on the technologies and the process, and once that's working, it's the people who will create that cultural change. You can just sit back and enjoy. Until the next crisis, of course.
-
-1\. OK, you're right. It should be "with which we techies tend to struggle."2
-
-2\. You thought I was going to qualify that bit about techies struggling with touchy-feely stuff, didn't you? Read it again: I put "tend to." That's the best you're getting.
-
-3\. Is percolating a bottom-up process? I don't drink coffee,4 so I wouldn't know.
-
-4\. Do people even use percolators to make coffee anymore? Feel free to let me know in the comments. I may pretend interest if you're lucky.
-
-5\. For U.S. readers (and some other countries, maybe?), please substitute "check" for "tick" here.6
-
-6\. For U.S. techie readers, feel free to perform `s/tick/check/;`.
-
-7\. This is a Status Quo8 reference for which I'm extremely sorry.
-
-8\. For millennial readers, please consult your favourite online reference engine or just roll your eyes and move on.
-
-9\. For people who say, "but I love excitement," try being on call at 2 a.m. on a Sunday at the end of the quarter when your chief financial officer calls you up to ask why all of last month's sales figures have been corrupted with the letters "DEADBEEF."10
-
-10\. For people not in the know, this is a string often used by techies as test data because a) it's non-numerical; b) it's numerical (in hexadecimal); c) it's easy to search for in debug files; and d) it's funny.11
-
-11\. Though see.9
-
-12\. It's a low number, is all I'm saying.
-
-This article originally appeared on [Alice, Eve, and Bob – a security blog][1] and is republished with permission.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/most-important-issue-devops-transformation
-
-作者:[Mike Bursell][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mikecamel
-[1]:https://aliceevebob.com/2018/02/06/moving-to-devops-whats-most-important/
diff --git a/sources/talk/20180301 How to hire the right DevOps talent.md b/sources/talk/20180301 How to hire the right DevOps talent.md
deleted file mode 100644
index bcf9bb3d20..0000000000
--- a/sources/talk/20180301 How to hire the right DevOps talent.md
+++ /dev/null
@@ -1,48 +0,0 @@
-How to hire the right DevOps talent
-======
-
-
-
-DevOps culture is quickly gaining ground, and demand for top-notch DevOps talent is greater than ever at companies all over the world. With the [annual base salary for a junior DevOps engineer][1] now topping $100,000, IT professionals are hurrying to [make the transition into DevOps.][2]
-
-But how do you choose the right candidate to fill your DevOps role?
-
-### Overview
-
-Most teams are looking for candidates with a background in operations and infrastructure, software engineering, or development. This is in conjunction with skills that relate to configuration management, continuous integration, and deployment (CI/CD), as well as cloud infrastructure. Knowledge of container orchestration is also in high demand.
-
-In a perfect world, the two backgrounds would meet somewhere in the middle to form Dev and Ops, but in most cases, candidates lean toward one side or the other. Yet they must possess the skills necessary to understand the needs of their counterparts to work effectively as a team to achieve continuous delivery and deployment. Since every company is different, there is no single right or wrong since so much depends on a company’s tech stack and infrastructure, as well as the goals and the skills of other team members. So how do you focus your search?
-
-### Decide on the background
-
-Begin by assessing the strength of your current team. Do you have rock-star software engineers but lack infrastructure knowledge? Focus on closing the skill gaps. Just because you have the budget to hire a DevOps engineer doesn’t mean you should spend weeks, or even months, trying to find the best software engineer who also happens to use Kubernetes and Docker because they are currently the trend. Instead, look for someone who will provide the most value in your environment, and see how things go from there.
-
-### There is no “Ctrl + F” solution
-
-Instead of concentrating on specific tools, concentrate on a candidate's understanding of DevOps and CI/CD-related processes. You'll be better off with someone who understands methodologies over tools. It is more important to ensure that candidates comprehend the concept of CI/CD than to ask if they prefer Jenkins, Bamboo, or TeamCity. Don’t get too caught up in the exact toolchain—rather, focus on problem-solving skills and the ability to increase efficiency, save time, and automate manual processes. You don't want to miss out on the right candidate just because the word “Puppet” was not on their resume.
-
-### Check your ego
-
-As mentioned above, DevOps is a rapidly growing field, and DevOps engineers are in hot demand. That means candidates have great buying power. You may have an amazing company or product, but hiring top talent is no longer as simple as putting up a “Help Wanted” sign and waiting for top-quality applicants to rush in. I'm not suggesting that maintaining a reputation a great place to work is unimportant, but in today's environment, you need to make an effort to sell your position. Flaws or glitches in the hiring process, such as abruptly canceling interviews or not offering feedback after interviews, can lead to negative reviews spreading across the industry. Remember, it takes just a couple of minutes to leave a negative review on Glassdoor.
-
-### Contractor or permanent employee?
-
-Most recruiters and hiring managers immediately start searching for a full-time employee, even though they may have other options. If you’re looking to design, build, and implement a new DevOps environment, why not hire a senior person who has done this in the past? Consider hiring a senior contractor, along with a junior full-time hire. That way, you can tap the knowledge and experience of the contractor by having them work with the junior employee. Contractors can be expensive, but they bring invaluable knowledge—especially if the work can be done within a short timeframe.
-
-### Cultivate from within
-
-With so many companies competing for talent, it is difficult to find the right DevOps engineer. Not only will you need to pay top dollar to hire this person, but you must also consider that the search can take several months. However, since few companies are lucky enough to find the ideal DevOps engineer, consider searching for a candidate internally. You might be surprised at the talent you can cultivate from within your own organization.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/how-hire-right-des-talentvop
-
-作者:[Stanislav Ivaschenko][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/ilyadudkin
-[1]:https://www.glassdoor.com/Salaries/junior-devops-engineer-salary-SRCH_KO0,22.htm
-[2]:https://squadex.com/insights/system-administrator-making-leap-devops/
diff --git a/sources/talk/20180302 Beyond metrics- How to operate as team on today-s open source project.md b/sources/talk/20180302 Beyond metrics- How to operate as team on today-s open source project.md
deleted file mode 100644
index fb5454bbe4..0000000000
--- a/sources/talk/20180302 Beyond metrics- How to operate as team on today-s open source project.md
+++ /dev/null
@@ -1,53 +0,0 @@
-Beyond metrics: How to operate as team on today's open source project
-======
-
-
-
-How do we traditionally think about community health and vibrancy?
-
-We might quickly zero in on metrics related primarily to code contributions: How many companies are contributing? How many individuals? How many lines of code? Collectively, these speak to both the level of development activity and the breadth of the contributor base. The former speaks to whether the project continues to be enhanced and expanded; the latter to whether it has attracted a diverse group of developers or is controlled primarily by a single organization.
-
-The [Linux Kernel Development Report][1] tracks these kinds of statistics and, unsurprisingly, it appears extremely healthy on all counts.
-
-However, while development cadence and code contributions are still clearly important, other aspects of the open source communities are also coming to the forefront. This is in part because, increasingly, open source is about more than a development model. It’s also about making it easier for users and other interested parties to interact in ways that go beyond being passive recipients of code. Of course, there have long been user groups. But open source streamlines the involvement of users, just as it does software development.
-
-This was the topic of my discussion with Diane Mueller, the director of community development for OpenShift.
-
-When OpenShift became a container platform based in part on Kubernetes in version 3, Mueller saw a need to broaden the community beyond the core code contributors. In part, this was because OpenShift was increasingly touching a broad range of open source projects and organizations such those associated with the [Open Container Initiative (OCI)][2] and the [Cloud Native Computing Foundation (CNCF)][3]. In addition to users, cloud service providers who were offering managed services also wanted ways to get involved in the project.
-
-“What we tried to do was open up our minds about what the community constituted,” Mueller explained, adding, “We called it the [Commons][4] because Red Hat's near Boston, and I'm from that area. Boston Common is a shared resource, the grass where you bring your cows to graze, and you have your farmer's hipster market or whatever it is today that they do on Boston Common.”
-
-This new model, she said, was really “a new ecosystem that incorporated all of those different parties and different perspectives. We used a lot of virtual tools, a lot of new tools like Slack. We stepped up beyond the mailing list. We do weekly briefings. We went very virtual because, one, I don't scale. The Evangelist and Dev Advocate team didn't scale. We need to be able to get all that word out there, all this new information out there, so we went very virtual. We worked with a lot of people to create online learning stuff, a lot of really good tooling, and we had a lot of community help and support in doing that.”
-
-![diane mueller open shift][6]
-
-Diane Mueller, director of community development at Open Shift, discusses the role of strong user communities in open source software development. (Credit: Gordon Haff, CC BY-SA 4.0)
-
-However, one interesting aspect of the Commons model is that it isn’t just virtual. We see the same pattern elsewhere in many successful open source communities, such as the Linux kernel. Lots of day-to-day activities happen on mailings lists, IRC, and other collaboration tools. But this doesn’t eliminate the benefits of face-to-face time that allows for both richer and informal discussions and exchanges.
-
-This interview with Mueller took place in London the day after the [OpenShift Commons Gathering][7]. Gatherings are full-day events, held a number of times a year, which are typically attended by a few hundred people. Much of the focus is on users and user stories. In fact, Mueller notes, “Here in London, one of the Commons members, Secnix, was really the major reason we actually hosted the gathering here. Justin Cook did an amazing job organizing the venue and helping us pull this whole thing together in less than 50 days. A lot of the community gatherings and things are driven by the Commons members.”
-
-Mueller wants to focus on users more and more. “The OpenShift Commons gathering at [Red Hat] Summit will be almost entirely case studies,” she noted. “Users talking about what's in their stack. What lessons did they learn? What are the best practices? Sharing those ideas that they've done just like we did here in London.”
-
-Although the Commons model grew out of some specific OpenShift needs at the time it was created, Mueller believes it’s an approach that can be applied more broadly. “I think if you abstract what we've done, you can apply it to any existing open source community,” she said. “The foundations still, in some ways, play a nice role in giving you some structure around governance, and helping incubate stuff, and helping create standards. I really love what OCI is doing to create standards around containers. There's still a role for that in some ways. I think the lesson that we can learn from the experience and we can apply to other projects is to open up the community so that it includes feedback mechanisms and gives the podium away.”
-
-The evolution of the community model though approaches like the OpenShift Commons mirror the healthy evolution of open source more broadly. Certainly, some users have been involved in the development of open source software for a long time. What’s striking today is how widespread and pervasive direct user participation has become. Sure, open source remains central to much of modern software development. But it’s also becoming increasingly central to how users learn from each other and work together with their partners and developers.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/how-communities-are-evolving
-
-作者:[Gordon Haff][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/ghaff
-[1]:https://www.linuxfoundation.org/2017-linux-kernel-report-landing-page/
-[2]:https://www.opencontainers.org/
-[3]:https://www.cncf.io/
-[4]:https://commons.openshift.org/
-[5]:/file/388586
-[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/39369010275_7df2c3c260_z.jpg?itok=gIhnBl6F (diane mueller open shift)
-[7]:https://www.meetup.com/London-OpenShift-User-Group/events/246498196/
diff --git a/sources/talk/20180303 4 meetup ideas- Make your data open.md b/sources/talk/20180303 4 meetup ideas- Make your data open.md
deleted file mode 100644
index a431b8376a..0000000000
--- a/sources/talk/20180303 4 meetup ideas- Make your data open.md
+++ /dev/null
@@ -1,75 +0,0 @@
-4 meetup ideas: Make your data open
-======
-
-
-
-[Open Data Day][1] (ODD) is an annual, worldwide celebration of open data and an opportunity to show the importance of open data in improving our communities.
-
-Not many individuals and organizations know about the meaningfulness of open data or why they might want to liberate their data from the restrictions of copyright, patents, and more. They also don't know how to make their data open—that is, publicly available for anyone to use, share, or republish with modifications.
-
-This year ODD falls on Saturday, March 3, and there are [events planned][2] in every continent except Antarctica. While it might be too late to organize an event for this year, it's never too early to plan for next year. Also, since open data is important every day of the year, there's no reason to wait until ODD 2019 to host an event in your community.
-
-There are many ways to build local awareness of open data. Here are four ideas to help plan an excellent open data event any time of year.
-
-### 1. Organize an entry-level event
-
-You can host an educational event at a local library, college, or another public venue about how open data can be used and why it matters for all of us. If possible, invite a [local speaker][3] or have someone present remotely. You could also have a roundtable discussion with several knowledgeable people in your community.
-
-Consider offering resources such as the [Open Data Handbook][4], which not only provides a guide to the philosophy and rationale behind adopting open data, but also offers case studies, use cases, how-to guides, and other material to support making data open.
-
-### 2. Organize an advanced-level event
-
-For a deeper experience, organize a hands-on training event for open data newbies. Ideas for good topics include [training teachers on open science][5], [creating audiovisual expressions from open data][6], and using [open government data][7] in meaningful ways.
-
-The options are endless. To choose a topic, think about what is locally relevant, identify issues that open data might be able to address, and find people who can do the training.
-
-### 3. Organize a hackathon
-
-Open data hackathons can be a great way to bring open data advocates, developers, and enthusiasts together under one roof. Hackathons are more than just training sessions, though; the idea is to build prototypes or solve real-life challenges that are tied to open data. In a hackathon, people in various groups can contribute to the entire assembly line in multiple ways, such as identifying issues by working collaboratively through [Etherpad][8] or creating focus groups.
-
-Once the hackathon is over, make sure to upload all the useful data that is produced to the internet with an open license.
-
-### 4. Release or relicense data as open
-
-Open data is about making meaningful data publicly available under open licenses while protecting any data that might put people's private information at risk. (Learn [how to protect private data][9].) Try to find existing, interesting, and useful data that is privately owned by individuals or organizations and negotiate with them to relicense or release the data online under any of the [recommended open data licenses][10]. The widely popular [Creative Commons licenses][11] (particularly the CC0 license and the 4.0 licenses) are quite compatible with relicensing public data. (See this FAQ from Creative Commons for more information on [openly licensing data][12].)
-
-Open data can be published on multiple platforms—your website, [GitHub][13], [GitLab][14], [DataHub.io][15], or anywhere else that supports open standards.
-
-### Tips for event success
-
-No matter what type of event you decide to do, here are some general planning tips to improve your chances of success.
-
- * Find a venue that's accessible to the people you want to reach, such as a library, a school, or a community center.
- * Create a curriculum that will engage the participants.
- * Invite your target audience—make sure to distribute information through social media, community events calendars, Meetup, and the like.
-
-
-
-Have you attended or hosted a successful open data event? If so, please share your ideas in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/celebrate-open-data-day
-
-作者:[Subhashish Panigraphi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/psubhashish
-[1]:http://www.opendataday.org/
-[2]:http://opendataday.org/#map
-[3]:https://openspeakers.org/
-[4]:http://opendatahandbook.org/
-[5]:https://docs.google.com/forms/d/1BRsyzlbn8KEMP8OkvjyttGgIKuTSgETZW9NHRtCbT1s/viewform?edit_requested=true
-[6]:http://dattack.lv/en/
-[7]:https://www.eventbrite.co.nz/e/open-data-open-potential-event-friday-2-march-2018-tickets-42733708673
-[8]:http://etherpad.org/
-[9]:https://ssd.eff.org/en/module/keeping-your-data-safe
-[10]:https://opendatacommons.org/licenses/
-[11]:https://creativecommons.org/share-your-work/licensing-types-examples/
-[12]:https://wiki.creativecommons.org/wiki/Data#Frequently_asked_questions_about_data_and_CC_licenses
-[13]:https://github.com/MartinBriza/MediaWriter
-[14]:https://about.gitlab.com/
-[15]:https://datahub.io/
diff --git a/sources/talk/20180314 How to apply systems thinking in DevOps.md b/sources/talk/20180314 How to apply systems thinking in DevOps.md
deleted file mode 100644
index c35eb041bd..0000000000
--- a/sources/talk/20180314 How to apply systems thinking in DevOps.md
+++ /dev/null
@@ -1,89 +0,0 @@
-How to apply systems thinking in DevOps
-======
-
-
-For most organizations, adopting DevOps requires a mindset shift. Unless you understand the core of [DevOps][1], you might think it's hype or just another buzzword—or worse, you might believe you have already adopted DevOps because you are using the right tools.
-
-Let’s dig deeper into what DevOps means, and explore how to apply systems thinking in your organization.
-
-### What is systems thinking?
-
-Systems thinking is a holistic approach to problem-solving. It's the opposite of analytical thinking, which separates a problem from the "bigger picture" to better understand it. Instead, systems thinking studies all the elements of a problem, along with the interactions between these elements.
-
-Most people are not used to thinking this way. Since childhood, most of us were taught math, science, and every other subject separately, by different teachers. This approach to learning follows us throughout our lives, from school to university to the workplace. When we first join an organization, we typically work in only one department.
-
-Unfortunately, the world is not that simple. Complexity, unpredictability, and sometimes chaos are unavoidable and require a broader way of thinking. Systems thinking helps us understand the systems we are part of, which in turn enables us to manage them rather than be controlled by them.
-
-According to systems thinking, everything is a system: your body, your family, your neighborhood, your city, your company, and even the communities you belong to. These systems evolve organically; they are alive and fluid. The better you understand a system's behavior, the better you can manage and leverage it. You become their change agent and are accountable for them.
-
-### Systems thinking and DevOps
-
-All systems include properties that DevOps addresses through its practices and tools. Awareness of these properties helps us properly adapt to DevOps. Let's look at the properties of a system and how DevOps relates to each one.
-
-### How systems work
-
-The figure below represents a system. To reach a goal, the system requires input, which is processed and generates output. Feedback is essential for moving the system toward the goal. Without a purpose, the system dies.
-
-
-
-If an organization is a system, its departments are subsystems. The flow of work moves through each department, starting with identifying a market need (the first input on the left) and moving toward releasing a solution that meets that need (the last output on the right). The output that each department generates serves as required input for the next department in the chain.
-
-The more specialized teams an organization has, the more handoffs happen between departments. The process of generating value to clients is more likely to create bottlenecks and thus it takes longer to deliver value. Also, when work is passed between teams, the gap between the goal and what has been done widens.
-
-DevOps aims to optimize the flow of work throughout the organization to deliver value to clients faster—in other words, DevOps reduces time to market. This is done in part by maximizing automation, but mainly by targeting the organization's goals. This empowers prioritization and reduces duplicated work and other inefficiencies that happen during the delivery process.
-
-### System deterioration
-
-All systems are affected by entropy. Nothing can prevent system degradation; that's irreversible. The tendency to decline shows the failure nature of systems. Moreover, systems are subject to threats of all types, and failure is a matter of time.
-
-To mitigate entropy, systems require constant maintenance and improvements. The effects of entropy can be delayed only when new actions are taken or input is changed.
-
-This pattern of deterioration and its opposite force, survival, can be observed in living organisms, social relationships, and other systems as well as in organizations. In fact, if an organization is not evolving, entropy is guaranteed to be increasing.
-
-DevOps attempts to break the entropy process within an organization by fostering continuous learning and improvement. With DevOps, the organization becomes fault-tolerant because it recognizes the inevitability of failure. DevOps enables a blameless culture that offers the opportunity to learn from failure. The [postmortem][2] is an example of a DevOps practice used by organizations that embrace inherent failure.
-
-The idea of intentionally embracing failure may sound counterintuitive, but that's exactly what happens in techniques like [Chaos Monkey][3]: Failure is intentionally introduced to improve availability and reliability in the system. DevOps suggests that putting some pressure into the system in a controlled way is not a bad thing. Like a muscle that gets stronger with exercise, the system benefits from the challenge.
-
-### System complexity
-
-The figure below shows how complex the systems can be. In most cases, one effect can have multiple causes, and one cause can generate multiple effects. The more elements and interactions a system has, the more complex the system.
-
-
-
-In this scenario, we can't immediately identify the reason for a particular event. Likewise, we can't predict with 100% certainty what will happen if a specific action is taken. We are constantly making assumptions and dealing with hypotheses.
-
-System complexity can be explained using the scientific method. In a recent study, for example, mice that were fed excess salt showed suppressed cerebral blood flow. This same experiment would have had different results if, say, the mice were fed sugar and salt. One variable can radically change results in complex systems.
-
-DevOps handles complexity by encouraging experimentation—for example, using the scientific method—and reducing feedback cycles. Smaller changes inserted into the system can be tested and validated more quickly. With a "[fail-fast][4]" approach, organizations can pivot quickly and achieve resiliency. Reacting rapidly to changes makes organizations more adaptable.
-
-DevOps also aims to minimize guesswork and maximize understanding by making the process of delivering value more tangible. By measuring processes, revealing flaws and advantages, and monitoring as much as possible, DevOps helps organizations discover the changes they need to make.
-
-### System limitations
-
-All systems have constraints that limit their performance; a system's overall capacity is delimited by its restrictions. Most of us have learned from experience that systems operating too long at full capacity can crash, and most systems work better when they function with some slack. Ignoring limitations puts systems at risk. For example, when we are under too much stress for a long time, we get sick. Similarly, overused vehicle engines can be damaged.
-
-This principle also applies to organizations. Unfortunately, organizations can't put everything into a system at once. Although this limitation may sometimes lead to frustration, the quality of work usually improves when input is reduced.
-
-Consider what happened when the speed limit on the main roads in São Paulo, Brazil was reduced from 90 km/h to 70 km/h. Studies showed that the number of accidents decreased by 38.5% and the average speed increased by 8.7%. In other words, the entire road system improved and more vehicles arrived safely at their destinations.
-
-For organizations, DevOps suggests global rather than local improvements. It doesn't matter if some improvement is put after a constraint because there's no effect on the system at all. One constraint that DevOps addresses, for instance, is dependency on specialized teams. DevOps brings to organizations a more collaborative culture, knowledge sharing, and cross-functional teams.
-
-### Conclusion
-
-Before adopting DevOps, understand what is involved and how you want to apply it to your organization. Systems thinking will help you accomplish that while also opening your mind to new possibilities. DevOps may be seen as a popular trend today, but in 10 or 20 years, it will be status quo.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/how-apply-systems-thinking-devops
-
-作者:[Gustavo Muniz do Carmo][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/gustavomcarmo
-[1]:https://opensource.com/tags/devops
-[2]:https://landing.google.com/sre/book/chapters/postmortem-culture.html
-[3]:https://medium.com/netflix-techblog/the-netflix-simian-army-16e57fbab116
-[4]:https://en.wikipedia.org/wiki/Fail-fast
diff --git a/sources/talk/20180315 6 ways a thriving community will help your project succeed.md b/sources/talk/20180315 6 ways a thriving community will help your project succeed.md
deleted file mode 100644
index cf15b7f06f..0000000000
--- a/sources/talk/20180315 6 ways a thriving community will help your project succeed.md
+++ /dev/null
@@ -1,111 +0,0 @@
-6 ways a thriving community will help your project succeed
-======
-
-
-NethServer is an open source product that my company, [Nethesis][1], launched just a few years ago. [The product][2] wouldn't be [what it is today][3] without the vibrant community that surrounds and supports it.
-
-In my previous article, I [discussed what organizations should expect to give][4] if they want to experience the benefits of thriving communities. In this article, I'll describe what organizations should expect to receive in return for their investments in the passionate people that make up their communities.
-
-Let's review six benefits.
-
-### 1\. Innovation
-
-"Open innovation" occurs when a company sharing information also listens to the feedback and suggestions from outside the company. As a company, we don't just look at the crowd for ideas. We innovate in, with, and through communities.
-
-You may know that "[the best way to have a good idea is to have a lot of ideas][5]." You can't always expect to have the right idea on your own, so having different point of views on your product is essential. How many truly disruptive ideas can a small company (like Nethesis) create? We're all young, caucasian, and European—while in our community, we can pick up a set of inspirations from a variety of people, with different genders, backgrounds, skills, and ethnicities.
-
-So the ability to invite the entire world to continuously improve the product is now no longer a dream; it's happening before our eyes. Your community could be the idea factory for innovation. With the community, you can really leverage the power of the collective.
-
-No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
-
-### 2\. Research
-
-A community can be your strongest source of valuable product research.
-
-First, it can help you avoid "ivory tower development." [As Stack Exchange co-founder Jeff Atwood has said][6], creating an environment where developers have no idea who the users are is dangerous. Isolated developers, who have worked for years in their high towers, often encounter bad results because they don't have any clue about how users actually use their software. Developing in an Ivory tower keeps you away from your users and can only lead to bad decisions. A community brings developers back to reality and helps them stay grounded. Gone are the days of developers working in isolation with limited resources. In this day and age, thanks to the advent of open source communities research department is opening up to the entire world.
-
-No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
-
-Second, a community can be an obvious source of product feedback—always necessary as you're researching potential paths forward. If someone gives you feedback, it means that person cares about you. It's a big gift. The community is a good place to acquire such invaluable feedback. Receiving early feedback is super important, because it reduces the cost of developing something that doesn't work in your target market. You can safely fail early, fail fast, and fail often.
-
-And third, communities help you generate comparisons with other projects. You can't know all the features, pros, and cons of your competitors' offerings. [The community, however, can.][7] Ask your community.
-
-### 3\. Perspective
-
-Communities enable companies to look at themselves and their products [from the outside][8], letting them catch strengths and weaknesses, and mostly realize who their products' audiences really are.
-
-Let me offer an example. When we launched the NethServer, we chose a catchy tagline for it. We were all convinced the following sentence was perfect:
-
-> [NethServer][9] is an operating system for Linux enthusiasts, designed for small offices and medium enterprises.
-
-Two years have passed since then. And we've learned that sentence was an epic fail.
-
-We failed to realize who our audience was. Now we know: NethServer is not just for Linux enthusiasts; actually, Windows users are the majority. It's not just for small offices and medium enterprises; actually, several home users install NethServer for personal use. Our community helps us to fully understand our product and look at it from our users' eyes.
-
-### 4\. Development
-
-In open source communities especially, communities can be a welcome source of product development.
-
-They can, first of all, provide testing and bug reporting. In fact, if I ask my developers about the most important community benefit, they'd answer "testing and bug reporting." Definitely. But because your code is freely available to the whole world, practically anyone with a good working knowledge of it (even hobbyists and other companies) has the opportunity to play with it, tweak it, and constantly improve it (even develop additional modules, as in our case). People can do more than just report bugs; they can fix those bugs, too, if they have the time and knowledge.
-
-But the community doesn't just create code. It can also generate resources like [how-to guides,][10] FAQs, support documents, and case studies. How much would it cost to fully translate your product in seven different languages? At NethServer, we got that for free—thanks to our community members.
-
-### 5\. Marketing
-
-Communities can help your company go global. Our small Italian company, for example, wasn't prepared for a global market. The community got us prepared. For example, we needed to study and improve our English so we could read and write correctly or speak in public without looking foolish for an audience. The community gently forced us to organize [our first NethServer Conference][11], too—only in English.
-
-A strong community can also help your organization attain the holy grail of marketers everywhere: word of mouth marketing (or what Seth Godin calls "[tribal marketing][12]").
-
-Communities ensure that your company's messaging travels not only from company to tribe but also "sideways," from tribe member to potential tribe member. The community will become your street team, spreading word of your organization and its projects to anyone who will listen.
-
-In addition, communities help organizations satisfy one of the most fundamental members needs: the desire to belong, to be involved in something bigger than themselves, and to change the world together.
-
-Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
-
-### 6\. Loyalty
-
-Attracting new users costs a business five times as much as keeping an existing one. So loyalty can have a huge impact on your bottom line. Quite simply, community helps us build brand loyalty. It's much more difficult to leave a group of people you're connected to than a faceless product or company. In a community, you're building connections with people, which is way more powerful than features or money (trust me!).
-
-### Conclusion
-
-Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
-
-And I wouldn't be honest with you if I didn't admit that the approach has some drawbacks. Doing everything in the open means moderating, evaluating, and processing of all the data you're receiving. Supporting your members and leading the discussions definitely takes time and resources. But, if you look at what a community enables, you'll see that all this is totally worth the effort.
-
-As my friend and mentor [David Spinks keeps saying over and over again][13], "Companies fail their communities when when they treat community as a tactic instead of making it a core part of their business philosophy." And [as I've said][4]: Communities aren't simply extensions of your marketing teams; "community" isn't an efficient short-term strategy. When community is a core part of your business philosophy, it can do so much more than give you short-term returns.
-
-At Nethesis we experience that every single day. As a small company, we could never have achieved the results we have without our community. Never.
-
-Community can completely set your business apart from every other company in the field. It can redefine markets. It can inspire millions of people, give them a sense of belonging, and make them feel an incredible bond with your company.
-
-And it can make you a whole lot of money.
-
-Community-driven companies will always win. Remember that.
-
-[Subscribe to our weekly newsletter][14] to learn more about open organizations.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/3/why-build-community-3
-
-作者:[Alessio Fattorini][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/alefattorini
-[1]:http://www.nethesis.it/
-[2]:https://www.nethserver.org/
-[3]:https://distrowatch.com/table.php?distribution=nethserver
-[4]:https://opensource.com/open-organization/18/2/why-build-community-2
-[5]:https://www.goodreads.com/author/quotes/52938.Linus_Pauling
-[6]:https://blog.codinghorror.com/ivory-tower-development/
-[7]:https://community.nethserver.org/tags/comparison
-[8]:https://community.nethserver.org/t/improve-our-communication/2569
-[9]:http://www.nethserver.org/
-[10]:https://community.nethserver.org/c/howto
-[11]:https://community.nethserver.org/t/nethserver-conference-in-italy-sept-29-30-2017/6404
-[12]:https://www.ted.com/talks/seth_godin_on_the_tribes_we_lead
-[13]:http://cmxhub.com/article/community-business-philosophy-tactic/
-[14]:https://opensource.com/open-organization/resources/newsletter
diff --git a/sources/talk/20180315 Lessons Learned from Growing an Open Source Project Too Fast.md b/sources/talk/20180315 Lessons Learned from Growing an Open Source Project Too Fast.md
deleted file mode 100644
index 6ae7cbea2c..0000000000
--- a/sources/talk/20180315 Lessons Learned from Growing an Open Source Project Too Fast.md
+++ /dev/null
@@ -1,40 +0,0 @@
-Lessons Learned from Growing an Open Source Project Too Fast
-======
-![open source project][1]
-
-Are you managing an open source project or considering launching one? If so, it may come as a surprise that one of the challenges you can face is rapid growth. Matt Butcher, Principal Software Development Engineer at Microsoft, addressed this issue in a presentation at Open Source Summit North America. His talk covered everything from teamwork to the importance of knowing your goals and sticking to them.
-
-Butcher is no stranger to managing open source projects. As [Microsoft invests more deeply into open source][2], Butcher has been involved with many projects, including toolkits for Kubernetes and QueryPath, the jQuery-like library for PHP.
-
-Butcher described a case study involving Kubernetes Helm, a package system for Kubernetes. Helm arose from a company team-building hackathon, with an original team of three people giving birth to it. Within 18 months, the project had hundreds of contributors and thousands of active users.
-
-### Teamwork
-
-“We were stretched to our limits as we learned to grow,” Butcher said. “When you’re trying to set up your team of core maintainers and they’re all trying to work together, you want to spend some actual time trying to optimize for a process that lets you be cooperative. You have to adjust some expectations regarding how you treat each other. When you’re working as a group of open source collaborators, the relationship is not employer/employee necessarily. It’s a collaborative effort.”
-
-In addition to focusing on the right kinds of teamwork, Butcher and his collaborators learned that managing governance and standards is an ongoing challenge. “You want people to understand who makes decisions, how they make decisions and why they make the decisions that they make,” he said. “When we were a small project, there might have been two paragraphs in one of our documents on standards, but as a project grows and you get growing pains, these documented things gain a life of their own. They get their very own repositories, and they just keep getting bigger along with the project.”
-
-Should all discussion surrounding a open source project go on in public, bathed in the hot lights of community scrutiny? Not necessarily, Butcher noted. “A minor thing can get blown into catastrophic proportions in a short time because of misunderstandings and because something that should have been done in private ended up being public,” he said. “Sometimes we actually make architectural recommendations as a closed group. The reason we do this is that we don’t want to miscue the community. The people who are your core maintainers are core maintainers because they’re experts, right? These are the people that have been selected from the community because they understand the project. They understand what people are trying to do with it. They understand the frustrations and concerns of users.”
-
-### Acknowledge Contributions
-
-Butcher added that it is essential to acknowledge people’s contributions to keep the environment surrounding a fast-growing project from becoming toxic. “We actually have an internal rule in our core maintainers guide that says, ‘Make sure that at least one comment that you leave on a code review, if you’re asking for changes, is a positive one,” he said. “It sounds really juvenile, right? But it serves a specific purpose. It lets somebody know, ‘I acknowledge that you just made a gift of your time and your resources.”
-
-Want more tips on successfully launching and managing open source projects? Stay tuned for more insight from Matt Butcher’s talk, in which he provides specific project management issues faced by Kubernetes Helm.
-
-For more information, be sure to check out [The Linux Foundation’s growing list of Open Source Guides for the Enterprise][3], covering topics such as starting an open source project, improving your open source impact, and participating in open source communities.
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxfoundation.org/blog/lessons-learned-from-growing-an-open-source-project-too-fast/
-
-作者:[Sam Dean][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linuxfoundation.org/author/sdean/
-[1]:https://www.linuxfoundation.org/wp-content/uploads/2018/03/huskies-2279627_1920.jpg
-[2]:https://thenewstack.io/microsoft-shifting-emphasis-open-source/
-[3]:https://www.linuxfoundation.org/resources/open-source-guides/
diff --git a/sources/talk/20180316 How to avoid humiliating newcomers- A guide for advanced developers.md b/sources/talk/20180316 How to avoid humiliating newcomers- A guide for advanced developers.md
deleted file mode 100644
index e433e85d5f..0000000000
--- a/sources/talk/20180316 How to avoid humiliating newcomers- A guide for advanced developers.md
+++ /dev/null
@@ -1,119 +0,0 @@
-How to avoid humiliating newcomers: A guide for advanced developers
-======
-
-
-Every year in New York City, a few thousand young men come to town, dress up like Santa Claus, and do a pub crawl. One year during this SantaCon event, I was walking on the sidewalk and minding my own business, when I saw an extraordinary scene. There was a man dressed up in a red hat and red jacket, and he was talking to a homeless man who was sitting in a wheelchair. The homeless man asked Santa Claus, "Can you spare some change?" Santa dug into his pocket and brought out a $5 bill. He hesitated, then gave it to the homeless man. The homeless man put the bill in his pocket.
-
-In an instant, something went wrong. Santa yelled at the homeless man, "I gave you $5. I wanted to give you one dollar, but five is the smallest I had, so you oughtta be grateful. This is your lucky day, man. You should at least say thank you!"
-
-This was a terrible scene to witness. First, the power difference was terrible: Santa was an able-bodied white man with money and a home, and the other man was black, homeless, and using a wheelchair. It was also terrible because Santa Claus was dressed like the very symbol of generosity! And he was behaving like Santa until, in an instant, something went wrong and he became cruel.
-
-This is not merely a story about Drunk Santa, however; this is a story about technology communities. We, too, try to be generous when we answer new programmers' questions, and every day our generosity turns to rage. Why?
-
-### My cruelty
-
-I'm reminded of my own bad behavior in the past. I was hanging out on my company's Slack when a new colleague asked a question.
-
-> **New Colleague:** Hey, does anyone know how to do such-and-such with MongoDB?
-> **Jesse:** That's going to be implemented in the next release.
-> **New Colleague:** What's the ticket number for that feature?
-> **Jesse:** I memorize all ticket numbers. It's #12345.
-> **New Colleague:** Are you sure? I can't find ticket 12345.
-
-He had missed my sarcasm, and his mistake embarrassed him in front of his peers. I laughed to myself, and then I felt terrible. As one of the most senior programmers at MongoDB, I should not have been setting this example. And yet, such behavior is commonplace among programmers everywhere: We get sarcastic with newcomers, and we humiliate them.
-
-### Why does it matter?
-
-Perhaps you are not here to make friends; you are here to write code. If the code works, does it matter if we are nice to each other or not?
-
-A few months ago on the Stack Overflow blog, David Robinson showed that [Python has been growing dramatically][1], and it is now the top language that people view questions about on Stack Overflow. Even in the most pessimistic forecast, it will far outgrow the other languages this year.
-
-![Projections for programming language popularity][2]
-
-If you are a Python expert, then the line surging up and to the right is good news for you. It does not represent competition, but confirmation. As more new programmers learn Python, our expertise becomes ever more valuable, and we will see that reflected in our salaries, our job opportunities, and our job security.
-
-But there is a danger. There are soon to be more new Python programmers than ever before. To sustain this growth, we must welcome them, and we are not always a welcoming bunch.
-
-### The trouble with Stack Overflow
-
-I searched Stack Overflow for rude answers to beginners' questions, and they were not hard to find.
-
-![An abusive answer on StackOverflow][3]
-
-The message is plain: If you are asking a question this stupid, you are doomed. Get out.
-
-I immediately found another example of bad behavior:
-
-![Another abusive answer on Stack Overflow][4]
-
-Who has never been confused by Unicode in Python? Yet the message is clear: You do not belong here. Get out.
-
-Do you remember how it felt when you needed help and someone insulted you? It feels terrible. And it decimates the community. Some of our best experts leave every day because they see us treating each other this way. Maybe they still program Python, but they are no longer participating in conversations online. This cruelty drives away newcomers, too, particularly members of groups underrepresented in tech who might not be confident they belong. People who could have become the great Python programmers of the next generation, but if they ask a question and somebody is cruel to them, they leave.
-
-This is not in our interest. It hurts our community, and it makes our skills less valuable because we drive people out. So, why do we act against our own interests?
-
-### Why generosity turns to rage
-
-There are a few scenarios that really push my buttons. One is when I act generously but don't get the acknowledgment I expect. (I am not the only person with this resentment: This is probably why Drunk Santa snapped when he gave a $5 bill to a homeless man and did not receive any thanks.)
-
-Another is when answering requires more effort than I expect. An example is when my colleague asked a question on Slack and followed-up with, "What's the ticket number?" I had judged how long it would take to help him, and when he asked for more help, I lost my temper.
-
-These scenarios boil down to one problem: I have expectations for how things are going to go, and when those expectations are violated, I get angry.
-
-I've been studying Buddhism for years, so my understanding of this topic is based in Buddhism. I like to think that the Buddha discussed the problem of expectations in his first tech talk when, in his mid-30s, he experienced a breakthrough after years of meditation and convened a small conference to discuss his findings. He had not rented a venue, so he sat under a tree. The attendees were a handful of meditators the Buddha had met during his wanderings in northern India. The Buddha explained that he had discovered four truths:
-
- * First, that to be alive is to be dissatisfied—to want things to be better than they are now.
- * Second, this dissatisfaction is caused by wants; specifically, by our expectation that if we acquire what we want and eliminate what we do not want, it will make us happy for a long time. This expectation is unrealistic: If I get a promotion or if I delete 10 emails, it is temporarily satisfying, but it does not make me happy over the long-term. We are dissatisfied because every material thing quickly disappoints us.
- * The third truth is that we can be liberated from this dissatisfaction by accepting our lives as they are.
- * The fourth truth is that the way to transform ourselves is to understand our minds and to live a generous and ethical life.
-
-
-
-I still get angry at people on the internet. It happened to me recently, when someone posted a comment on [a video I published about Python co-routines][5]. It had taken me months of research and preparation to create this video, and then a newcomer commented, "I want to master python what should I do."
-
-![Comment on YouTube][6]
-
-This infuriated me. My first impulse was to be sarcastic, "For starters, maybe you could spell Python with a capital P and end a question with a question mark." Fortunately, I recognized my anger before I acted on it, and closed the tab instead. Sometimes liberation is just a Command+W away.
-
-### What to do about it
-
-If you joined a community with the intent to be helpful but on occasion find yourself flying into a rage, I have a method to prevent this. For me, it is the step when I ask myself, "Am I angry?" Knowing is most of the battle. Online, however, we can lose track of our emotions. It is well-established that one reason we are cruel on the internet is because, without seeing or hearing the other person, our natural empathy is not activated. But the other problem with the internet is that, when we use computers, we lose awareness of our bodies. I can be angry and type a sarcastic message without even knowing I am angry. I do not feel my heart pound and my neck grow tense. So, the most important step is to ask myself, "How do I feel?"
-
-If I am too angry to answer, I can usually walk away. As [Thumper learned in Bambi][7], "If you can't say something nice, don't say nothing at all."
-
-### The reward
-
-Helping a newcomer is its own reward, whether you receive thanks or not. But it does not hurt to treat yourself to a glass of whiskey or a chocolate, or just a sigh of satisfaction after your good deed.
-
-But besides our personal rewards, the payoff for the Python community is immense. We keep the line surging up and to the right. Python continues growing, and that makes our own skills more valuable. We welcome new members, people who might not be sure they belong with us, by reassuring them that there is no such thing as a stupid question. We use Python to create an inclusive and diverse community around writing code. And besides, it simply feels good to be part of a community where people treat each other with respect. It is the kind of community that I want to be a member of.
-
-### The three-breath vow
-
-There is one idea I hope you remember from this article: To control our behavior online, we must occasionally pause and notice our feelings. I invite you, if you so choose, to repeat the following vow out loud:
-
-> I vow
-> to take three breaths
-> before I answer a question online.
-
-This article is based on a talk, [Why Generosity Turns To Rage, and What To Do About It][8], that Jesse gave at PyTennessee in February. For more insight for Python developers, attend [PyCon 2018][9], May 9-17 in Cleveland, Ohio.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/avoid-humiliating-newcomers
-
-作者:[A. Jesse][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/emptysquare
-[1]:https://stackoverflow.blog/2017/09/06/incredible-growth-python/
-[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/projections.png?itok=5QTeJ4oe (Projections for programming language popularity)
-[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-1.jpg?itok=BIWW10Rl (An abusive answer on StackOverflow)
-[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-2.jpg?itok=0L-n7T-k (Another abusive answer on Stack Overflow)
-[5]:https://www.youtube.com/watch?v=7sCu4gEjH5I
-[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/i-want-to-master-python.png?itok=Y-2u1XwA (Comment on YouTube)
-[7]:https://www.youtube.com/watch?v=nGt9jAkWie4
-[8]:https://www.pytennessee.org/schedule/presentation/175/
-[9]:https://us.pycon.org/2018/
diff --git a/sources/talk/20180320 Easily Fund Open Source Projects With These Platforms.md b/sources/talk/20180320 Easily Fund Open Source Projects With These Platforms.md
deleted file mode 100644
index 8c02ca228b..0000000000
--- a/sources/talk/20180320 Easily Fund Open Source Projects With These Platforms.md
+++ /dev/null
@@ -1,96 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (Easily Fund Open Source Projects With These Platforms)
-[#]: via: (https://itsfoss.com/open-source-funding-platforms/)
-[#]: author: ([Ambarish Kumar](https://itsfoss.com/author/ambarish/))
-[#]: url: ( )
-
-Easily Fund Open Source Projects With These Platforms
-======
-
-**Brief: We list out some funding platforms you can use to financially support open source projects. **
-
-Financial support is one of the many ways to [help Linux and Open Source community][1]. This is why you see “Donate” option on the websites of most open source projects.
-
-While the big corporations have the necessary funding and resources, most open source projects are developed by individuals in their spare time. However, it does require one’s efforts, time and probably includes some overhead costs too. Monetary supports surely help drive the project development.
-
-If you would like to support open source projects financially, let me show you some platforms dedicated to open source and/or Linux.
-
-### Funding platforms for Open Source projects
-
-![Open Source funding platforms][2]
-
-Just to clarify, we are not associated with any of the funding platforms mentioned here.
-
-#### 1\. Liberapay
-
-[Gratipay][3] was probably the biggest platform for funding open source projects and people associated with the project, which got shut down at the end of the year 2017. However, there’s a fork – Liberapay that works as a recurrent donation platform for the open source projects and the contributors.
-
-[Liberapay][4] is a non-profit, open source organization that helps in a periodic donation to a project. You can create an account as a contributor and ask the people who would really like to help (usually the consumer of your products) to donate.
-
-To receive a donation, you will have to create an account on Liberapay, brief what you do and about your project, reasons for asking for the donation and what will be done with the money you receive.
-
-For someone who would like to donate, they would have to add money to their accounts and set up a period for payment that can be weekly, monthly or yearly to someone. There’s a mail triggered when there is not much left to donate.
-
-The currency supported are dollars and Euro as of now and you can always put up a badge on Github, your Twitter profile or website for a donation.
-
-#### 2\. Bountysource
-
-[Bountysource][5] is a funding platform for open source software that has a unique way of paying a developer for his time and work int he name of Bounties.
-
-There are basically two campaigns, bounties and salt campaign.
-
-Under the Bounties, users declare bounties aka cash prizes on open issues that they believe should be fixed or any new features which they want to see in the software they are using. A developer can then go and fix it to receive the cash prize.
-
-Salt Campaign is like any other funding, anyone can pay a recurring amount to a project or an individual working for an open source project for as long as they want.
-
-Bountysource accepts any software that is approved by Free Software Foundation or Open Source Initiatives. The bounties can be placed using PayPal, Bitcoin or the bounty itself if owned previously. Bountysource supports a no. of issue tracker currently like GitHub, Bugzilla, Google Code, Jira, Launchpad etc.
-
-#### 3\. Open Collective
-
-[Open Collective][6] is another popular funding initiative where a person who is willing to receive the donation for the work he is doing in Open Source world can create a page. He can submit the expense reports for the project he is working on. A contributor can add money to his account and pay him for his expenses.
-
-The complete process is transparent and everyone can track whoever is associated with Open Collective. The contributions are visible along with the unpaid expenses. There is also the option to contribute on a recurring basis.
-
-Open Collective currently has more than 500 collectives being backed up by more than 5000 users.
-
-The fact that it is transparent and you know what you are contributing to, drives more accountability. Some common example of collective include hosting costs, community maintenance, travel expenses etc.
-
-Though Open Collective keeps 10% of all the transactions, it is still a nice way to get your expenses covered in the process of contributing towards an open source project.
-
-#### 4\. Open Source Grants
-
-[Open Source Grants][7] is still in its beta stage and has not matured yet. They are looking for projects that do not have any stable funding and adds value to open source community. Most open source projects are run by a small community in a free time and they are trying to fund them so that the developers can work full time on the projects.
-
-They are equally searching for companies that want to help open source enthusiasts. The process of submitting a project is still being worked upon, and hopefully, in coming days we will see a working way of funding.
-
-### Final Words
-
-In the end, I would also like to mention [Patreon][8]. This funding platform is not exclusive to open source but is focused on creators of all kinds. Some projects like [elementary OS have created their accounts on Patreon][9] so that you can support the project on a recurring basis.
-
-Think Free Speech, not Free Beer. Your small contribution to a project can help it sustain in the long run. For the developers, the above platform can provide a good way to cover up their expenses.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/open-source-funding-platforms/
-
-作者:[Ambarish Kumar][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ambarish/
-[b]: https://github.com/lujun9972
-[1]: https://itsfoss.com/help-linux-grow/
-[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/03/Fund-Open-Source-projects.png?resize=800%2C450&ssl=1
-[3]: https://itsfoss.com/gratipay-open-source/
-[4]: https://liberapay.com/
-[5]: https://www.bountysource.com/
-[6]: https://opencollective.com/
-[7]: https://foundation.travis-ci.org/grants/
-[8]: https://www.patreon.com/
-[9]: https://www.patreon.com/elementary
diff --git a/sources/talk/20180321 8 tips for better agile retrospective meetings.md b/sources/talk/20180321 8 tips for better agile retrospective meetings.md
deleted file mode 100644
index ec45bf17f0..0000000000
--- a/sources/talk/20180321 8 tips for better agile retrospective meetings.md
+++ /dev/null
@@ -1,66 +0,0 @@
-8 tips for better agile retrospective meetings
-======
-
-
-I’ve often thought that retrospectives should be called prospectives, as that term concerns the future rather than focusing on the past. The retro itself is truly future-looking: It’s the space where we can ask the question, “With what we know now, what’s the next experiment we need to try for improving our lives, and the lives of our customers?”
-
-### What’s a retro supposed to look like?
-
-There are two significant loops in product development: One produces the desired potentially shippable nugget. The other is where we examine how we’re working—not only to avoid doing what didn’t work so well, but also to determine how we can amplify the stuff we do well—and devise an experiment to pull into the next production loop to improve how our team is delighting our customers. This is the loop on the right side of this diagram:
-
-
-![Retrospective 1][2]
-
-### When retros implode
-
-While attending various teams' iteration retrospective meetings, I saw a common thread of malcontent associated with a relentless focus on continuous improvement.
-
-One of the engineers put it bluntly: “[Our] continuous improvement feels like we are constantly failing.”
-
-The teams talked about what worked, restated the stuff that didn’t work (perhaps already feeling like they were constantly failing), nodded to one another, and gave long sighs. Then one of the engineers (already late for another meeting) finally summed up the meeting: “Ok, let’s try not to submit all of the code on the last day of the sprint.” There was no opportunity to amplify the good, as the good was not discussed.
-
-In effect, here’s what the retrospective felt like:
-
-
-
-The anti-pattern is where retrospectives become dreaded sessions where we look back at the last iteration, make two columns—what worked and what didn’t work—and quickly come to some solution for the next iteration. There is no [scientific method][3] involved. There is no data gathering and research, no hypothesis, and very little deep thought. The result? You don’t get an experiment or a potential improvement to pull into the next iteration.
-
-### 8 tips for better retrospectives
-
- 1. Amplify the good! Instead of focusing on what didn’t work well, why not begin the retro by having everyone mention one positive item first?
- 2. Don’t jump to a solution. Thinking about a problem deeply instead of trying to solve it right away might be a better option.
- 3. If the retrospective doesn’t make you feel excited about an experiment, maybe you shouldn’t try it in the next iteration.
- 4. If you’re not analyzing how to improve, ([5 Whys][4], [force-field analysis][5], [impact mapping][6], or [fish-boning][7]), you might be jumping to solutions too quickly.
- 5. Vary your methods. If every time you do a retrospective you ask, “What worked, what didn’t work?” and then vote on the top item from either column, your team will quickly get bored. [Retromat][8] is a great free retrospective tool to help vary your methods.
- 6. End each retrospective by asking for feedback on the retro itself. This might seem a bit meta, but it works: Continually improving the retrospective is recursively improving as a team.
- 7. Remove the impediments. Ask how you are enabling the team's search for improvement, and be prepared to act on any feedback.
- 8. There are no "iteration police." Take breaks as needed. Deriving hypotheses from analysis and coming up with experiments involves creativity, and it can be taxing. Every once in a while, go out as a team and enjoy a nice retrospective lunch.
-
-
-
-This article was inspired by [Retrospective anti-pattern: continuous improvement should not feel like constantly failing][9], posted at [Podojo.com][10].
-
-**[See our related story,[How to build a business case for DevOps transformation][11].]**
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/tips-better-agile-retrospective-meetings
-
-作者:[Catherine Louis][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/catherinelouis
-[1]:/file/389021
-[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/retro_1.jpg?itok=bggmHN1Q (Retrospective 1)
-[3]:https://en.wikipedia.org/wiki/Scientific_method
-[4]:https://en.wikipedia.org/wiki/5_Whys
-[5]:https://en.wikipedia.org/wiki/Force-field_analysis
-[6]:https://opensource.com/open-organization/17/6/experiment-impact-mapping
-[7]:https://en.wikipedia.org/wiki/Ishikawa_diagram
-[8]:https://plans-for-retrospectives.com/en/?id=28
-[9]:http://www.podojo.com/retrospective-anti-pattern-continuous-improvement-should-not-feel-like-constantly-failing/
-[10]:http://www.podojo.com/
-[11]:https://opensource.com/article/18/2/how-build-business-case-devops-transformation
diff --git a/sources/talk/20180323 7 steps to DevOps hiring success.md b/sources/talk/20180323 7 steps to DevOps hiring success.md
deleted file mode 100644
index cdea0c65ac..0000000000
--- a/sources/talk/20180323 7 steps to DevOps hiring success.md
+++ /dev/null
@@ -1,56 +0,0 @@
-7 steps to DevOps hiring success
-======
-
-
-As many of us in the DevOps scene know, most companies are hiring, or, at least, trying to do so. The required skills and job descriptions can change entirely from company to company. As a broad overview, most teams are looking for a candidate from either an operations and infrastructure background or someone from a software engineering and development background, then combined with key skills relating to continuous integration, configuration management, continuous delivery/deployment, and cloud infrastructure. Currently in high-demand is knowledge of container orchestration.
-
-In the ideal world, the two backgrounds will meet somewhere in the middle to form Dev and Ops, but in most cases, there is a lean toward one side or the other while maintaining sufficient skills to understand the needs and demands of their counterparts to work collaboratively and achieve the end goal of continuous delivery/deployment. Every company is different and there isn’t necessarily a right or wrong here. It all depends on your infrastructure, tech stack, other team members’ skills, and the individual goals you hope to achieve by hiring this individual.
-
-### Focus your hiring
-
-Now, given the various routes to becoming a DevOps practitioner, how do hiring managers focus their search and selection process to ensure that they’re hitting the mark?
-
-#### Decide on the background
-
-Assess the strengths of your existing team. Do you already have some amazing software engineers but you’re lacking the infrastructure knowledge? Aim to close these gaps in skills. You may have been given the budget to hire for DevOps, but you don’t have to spend weeks/months searching for the best software engineer who happens to use Docker and Kubernetes because they are the current hot trends in this space. Find the person who will provide the most value in your environment and go from there.
-
-#### Contractor or permanent employee?
-
-Many hiring managers will automatically start searching for a full-time permanent employee when their needs may suggest that they have other options. Sometimes a contractor is your best bet or maybe contract-hire. If you’re aiming to design, implement and build a new DevOps environment, why not find a senior person who has done this a number of times already? Try hiring a senior contractor and bring on a junior full-time hire in parallel; this way, you’ll be able to retain the external contractor knowledge by having them work alongside the junior hire. Contractors can be expensive, but the knowledge they bring can be invaluable, especially if the work can be completed over a shorter time frame. Again, this is just another point of view and you might be best off with a full-time hire to grow the team.
-
-#### CTRL F is not the solution
-
-Focus on their understanding of DevOps and CI/CD-related processes over specific tools. I believe the best approach is to focus on finding someone who understands the methodologies over the tools. Does your candidate understand the concept of continuous integration or the concept of continuous delivery? That’s more important than asking whether your candidate uses Jenkins versus Bamboo versus TeamCity and so on. Try not to get caught up in the exact tool chain. The focus should be on the candidates’ ability to solve problems. Are they obsessed with increasing efficiency, saving time, automating manual processes and constantly searching for flaws in the system? They might be the person you were looking for, but you missed them because you didn’t see the word "Puppet" on the resume.
-
-#### Work closely with your internal talent acquisition team and/or an external recruiter
-
-Be clear and precise with what you’re looking for and have an ongoing, open communication with recruiters. They can and will help you if used effectively. The job of these recruiters is to save you time by sourcing candidates while you’re focusing on your day-to-day role. Work closely with them and deliver in the same way that you would expect them to deliver for you. If you say you will review a candidate by X time, do it. If they say they’ll have a candidate in your inbox by Y time, make sure they do it, too. Start by setting up an initial call to talk through your requirement, lay out a timeline in which you expect candidates by a specific time, and explain your process in terms of when you will interview, how many interview rounds, and how soon after you will be able to make a final decision on whether to offer or reject the candidates. If you can get this relationship working well, you’ll save lots of time. And make sure your internal teams are focused on supporting your process, not blocking it.
-
-#### $$$
-
-Decide how much you want to pay. It’s not all about the money, but you can waste a lot of your and other people’s time if you don’t lock down the ballpark salary or hourly rate that you can afford. If your budget doesn’t stretch as far as your competitors’, you need to consider what else can help sell the opportunity. Flexible working hours and remote working options are some great ways to do this. Most companies have snacks, beer, and cool offices nowadays, so focus on the real value such as the innovative work your team is doing and how awesome your game-changing product might be.
-
-#### Drop the ego
-
-You may have an amazing company and/or product, but you also have some hot competition. Everyone is hiring in this space and candidates have a lot of the buying power. It is no longer as simple as saying, "We are hiring" and the awesome candidates come flowing in. You need to sell your opportunities. Maintaining a reputation as a great place to work is also important. A poor hiring process, such as interviewing without giving feedback, can contribute to bad rumors being spread across the industry. It only takes a few minutes to leave a sour review on Glassdoor.
-
-#### A smooth process is a successful One
-
-"Let’s get every single person within the company to do a one-hour interview with the new DevOps person we are hiring!" No, let’s not do that. Two or three stages should be sufficient. You have managers and directors for a reason. Trust your instinct and use your experience to make decisions on who will fit into your organization. Some of the most successful companies can do one phone screen followed by an in-person meeting. During the in-person interview, spend a morning or afternoon allowing the candidate to meet the relevant leaders and senior members of their direct team, then take them for lunch, dinner, or drinks where you can see how they are on a social level. If you can’t have a simple conversation with them, then you probably won’t enjoy working with them. If the thumbs are up, make the hire and don’t wait around. A good candidate will usually have numerous offers on the table at the same time.
-
-If all goes well, you should be inviting your shiny new employee or contractor into the office in the next few weeks and hopefully many more throughout the year.
-
-This article was originally published on [DevOps.com][1] and republished with author permission.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/7-steps-devops-hiring-success
-
-作者:[Conor Delanbanque][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/cdelanbanque
-[1]:https://devops.com/7-steps-devops-hiring-success/
diff --git a/sources/talk/20180330 Meet OpenAuto, an Android Auto emulator for Raspberry Pi.md b/sources/talk/20180330 Meet OpenAuto, an Android Auto emulator for Raspberry Pi.md
deleted file mode 100644
index bac0819e74..0000000000
--- a/sources/talk/20180330 Meet OpenAuto, an Android Auto emulator for Raspberry Pi.md
+++ /dev/null
@@ -1,81 +0,0 @@
-Meet OpenAuto, an Android Auto emulator for Raspberry Pi
-======
-
-
-In 2015, Google introduced [Android Auto][1], a system that allows users to project certain apps from their Android smartphones onto a car's infotainment display. Android Auto's driver-friendly interface, with larger touchscreen buttons and voice commands, aims to make it easier and safer for drivers to control navigation, music, podcasts, radio, phone calls, and more while keeping their eyes on the road. Android Auto can also run as an app on an Android smartphone, enabling owners of older-model vehicles without modern head unit displays to take advantage of these features.
-
-While there are many [apps][2] available for Android Auto, developers are working to add to its catalog. A new, open source tool named [OpenAuto][3] is hoping to make that easier by giving developers a way to emulate Android Auto on a Raspberry Pi. With OpenAuto, developers can test their applications in conditions similar to how they'll work on an actual car head unit.
-
-OpenAuto's creator, Michal Szwaj, answered some questions about his project for Opensource.com. Some responses have been edited for conciseness and clarity.
-
-### What is OpenAuto?
-
-In a nutshell, OpenAuto is an emulator for the Android Auto head unit. It emulates the head unit software and allows you to use Android Auto on your PC or on any other embedded platform like Raspberry Pi 3.
-
-Head unit software is a frontend for the Android Auto projection. All magic related to the Android Auto, like navigation, Google Voice Assistant, or music playback, is done on the Android device. Projection of Android Auto on the head unit is accomplished using the [H.264][4] codec for video and [PCM][5] codec for audio streaming. This is what the head unit software mostly does—it decodes the H.264 video stream and PCM audio streams and plays them back together. Another function of the head unit is providing user inputs. OpenAuto supports both touch events and hard keys.
-
-### What platforms does OpenAuto run on?
-
-My target platform for deployment of the OpenAuto is Raspberry Pi 3 computer. For successful deployment, I needed to implement support of video hardware acceleration using the Raspberry Pi 3 GPU (VideoCore 4). Thanks to this, Android Auto projection on the Raspberry Pi 3 computer can be handled even using 1080p@60 fps resolution. I used [OpenMAX IL][6] and IL client libraries delivered together with the Raspberry Pi firmware to implement video hardware acceleration.
-
-Taking advantage of the fact that the Raspberry Pi operating system is Raspbian based on Debian Linux, OpenAuto can be also built for any other Linux-based platform that provides support for hardware video decoding. Most of the Linux-based platforms provide support for hardware video decoding directly in GStreamer. Thanks to highly portable libraries like Boost and [Qt][7], OpenAuto can be built and run on the Windows platform. Support of MacOS is being implemented by the community and should be available soon.
-
-![][https://www.youtube.com/embed/k9tKRqIkQs8?origin=https://opensource.com&enablejsapi=1]
-
-### What software libraries does the project use?
-
-The core of the OpenAuto is the [aasdk][8] library, which provides support for all Android Auto features. aasdk library is built on top of the Boost, libusb, and OpenSSL libraries. [libusb][9] implements communication between the head unit and an Android device (via USB bus). [Boost][10] provides support for the asynchronous mechanisms for communication. It is required for high efficiency and scalability of the head unit software. [OpenSSL][11] is used for encrypting communication.
-
-The aasdk library is designed to be fully reusable for any purposes related to implementation of the head unit software. You can use it to build your own head unit software for your desired platform.
-
-Another very important library used in OpenAuto is Qt. It provides support for OpenAuto's multimedia, user input, and graphical interface. And the build system OpenAuto is using is [CMake][12].
-
-Note: The Android Auto protocol is taken from another great Android Auto head unit project called [HeadUnit][13]. The people working on this project did an amazing job in reverse engineering the AndroidAuto protocol and creating the protocol buffers that structurize all messages.
-
-### What equipment do you need to run OpenAuto on Raspberry Pi?
-
-In addition to a Raspberry Pi 3 computer and an Android device, you need:
-
- * **USB sound card:** The Raspberry Pi 3 doesn't have a microphone input, which is required to use Google Voice Assistant
- * **Video output device:** You can use either a touchscreen or any other video output device connected to HDMI or composite output (RCA)
- * **Input device:** For example, a touchscreen or a USB keyboard
-
-
-
-### What else do you need to get started?
-
-In order to use OpenAuto, you must build it first. On the OpenAuto's wiki page you can find [detailed instructions][14] for how to build it for the Raspberry Pi 3 platform. On other Linux-based platforms, the build process will look very similar.
-
-On the wiki page you can also find other useful instructions, such as how to configure the Bluetooth Hands-Free Profile (HFP) and Advanced Audio Distribution Profile (A2DP) and PulseAudio.
-
-### What else should we know about OpenAuto?
-
-OpenAuto allows anyone to create a head unit based on the Raspberry Pi 3 hardware. Nevertheless, you should always be careful about safety and keep in mind that OpenAuto is just an emulator. It was not certified by any authority and was not tested in a driving environment, so using it in a car is not recommended.
-
-OpenAuto is licensed under GPLv3. For more information, visit the [project's GitHub page][3], where you can find its source code and other information.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/openauto-emulator-Raspberry-Pi
-
-作者:[Michal Szwaj][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/michalszwaj
-[1]:https://www.android.com/auto/faq/
-[2]:https://play.google.com/store/apps/collection/promotion_3001303_android_auto_all
-[3]:https://github.com/f1xpl/openauto
-[4]:https://en.wikipedia.org/wiki/H.264/MPEG-4_AVC
-[5]:https://en.wikipedia.org/wiki/Pulse-code_modulation
-[6]:https://www.khronos.org/openmaxil
-[7]:https://www.qt.io/
-[8]:https://github.com/f1xpl/aasdk
-[9]:http://libusb.info/
-[10]:http://www.boost.org/
-[11]:https://www.openssl.org/
-[12]:https://cmake.org/
-[13]:https://github.com/gartnera/headunit
-[14]:https://github.com/f1xpl/
diff --git a/sources/talk/20180403 3 pitfalls everyone should avoid with hybrid multicloud.md b/sources/talk/20180403 3 pitfalls everyone should avoid with hybrid multicloud.md
deleted file mode 100644
index b128be62f0..0000000000
--- a/sources/talk/20180403 3 pitfalls everyone should avoid with hybrid multicloud.md
+++ /dev/null
@@ -1,87 +0,0 @@
-3 pitfalls everyone should avoid with hybrid multicloud
-======
-
-
-This article was co-written with [Roel Hodzelmans][1].
-
-We're all told the cloud is the way to ensure a digital future for our businesses. But which cloud? From cloud to hybrid cloud to hybrid multi-cloud, you need to make choices, and these choices don't preclude the daily work of enhancing your customers' experience or agile delivery of the applications they need.
-
-This article is the first in a four-part series on avoiding pitfalls in hybrid multi-cloud computing. Let's start by examining multi-cloud, hybrid cloud, and hybrid multi-cloud and what makes them different from one another.
-
-### Hybrid vs. multi-cloud
-
-There are many conversations you may be having in your business around moving to the cloud. For example, you may want to take your on-premises computing capacity and turn it into your own private cloud. You may wish to provide developers with a cloud-like experience using the same resources you already have. A more traditional reason for expansion is to use external computing resources to augment those in your own data centers. The latter leads you to the various public cloud providers, as well as to our first definition, multi-cloud.
-
-#### Multi-cloud
-
-Multi-cloud means using multiple clouds from multiple providers for multiple tasks.
-
-![Multi-cloud][3]
-
-Figure 1. Multi-cloud IT with multiple isolated cloud environments
-
-Typically, multi-cloud refers to the use of several different public clouds in order to achieve greater flexibility, lower costs, avoid vendor lock-in, or use specific regional cloud providers.
-
-A challenge of the multi-cloud approach is achieving consistent policies, compliance, and management with different providers involved.
-
-Multi-cloud is mainly a strategy to expand your business while leveraging multi-vendor cloud solutions and spreading the risk of lock-in. Figure 1 shows the isolated nature of cloud services in this model, without any sort of coordination between the services and business applications. Each is managed separately, and applications are isolated to services found in their environments.
-
-#### Hybrid cloud
-
-Hybrid cloud solves issues where isolation and coordination are central to the solution. It is a combination of one or more public and private clouds with at least a degree of workload portability, integration, orchestration, and unified management.
-
-![Hybrid cloud][5]
-
-Figure 2. Hybrid clouds may be on or off premises, but must have a degree of interoperability
-
-The key issue here is that there is an element of interoperability, migration potential, and a connection between tasks running in public clouds and on-premises infrastructure, even if it's not always seamless or otherwise fully implemented.
-
-If your cloud model is missing portability, integration, orchestration, and management, then it's just a bunch of clouds, not a hybrid cloud.
-
-The cloud environments in Fig. 2 include at least one private and public cloud. They can be off or on premises, but they have some degree of the following:
-
- * Interoperability
- * Application portability
- * Data portability
- * Common management
-
-
-
-As you can probably guess, combining multi-cloud and hybrid cloud results in a hybrid multi-cloud. But what does that look like?
-
-### Hybrid multi-cloud
-
-Hybrid multi-cloud pulls together multiple clouds and provides the tools to ensure interoperability between the various services in hybrid and multi-cloud solutions.
-
-![Hybrid multi-cloud][7]
-
-Figure 3. Hybrid multi-cloud solutions using open technologies
-
-Bringing these together can be a serious challenge, but the result ensures better use of resources without isolation in their respective clouds.
-
-Fig. 3 shows an example of hybrid multi-cloud based on open technologies for interoperability, workload portability, and management.
-
-### Moving forward: Pitfalls of hybrid multi-cloud
-
-In part two of this series, we'll look at the first of three pitfalls to avoid with hybrid multi-cloud. Namely, why cost is not always the obvious motivator when determining how to transition your business to the cloud.
-
-This article is based on "[3 pitfalls everyone should avoid with hybrid multi-cloud][8]," a talk the authors will be giving at [Red Hat Summit 2018][9], which will be held May 8-10 in San Francisco. [Register by May 7][9] to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
-
-作者:[Eric D.Schabell][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/eschabell
-[1]:https://opensource.com/users/roelh
-[3]:https://opensource.com/sites/default/files/u128651/multi-cloud.png (Multi-cloud)
-[5]:https://opensource.com/sites/default/files/u128651/hybrid-cloud.png (Hybrid cloud)
-[7]:https://opensource.com/sites/default/files/u128651/hybrid-multicloud.png (Hybrid multi-cloud)
-[8]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=153892
-[9]:https://www.redhat.com/en/summit/2018
diff --git a/sources/talk/20180404 Is the term DevSecOps necessary.md b/sources/talk/20180404 Is the term DevSecOps necessary.md
deleted file mode 100644
index 96b544e7c4..0000000000
--- a/sources/talk/20180404 Is the term DevSecOps necessary.md
+++ /dev/null
@@ -1,51 +0,0 @@
-Is the term DevSecOps necessary?
-======
-
-
-First came the term "DevOps."
-
-It has many different aspects. For some, [DevOps][1] is mostly about a culture valuing collaboration, openness, and transparency. Others focus more on key practices and principles such as automating everything, constantly iterating, and instrumenting heavily. And while DevOps isn’t about specific tools, certain platforms and tooling make it a more practical proposition. Think containers and associated open source cloud-native technologies like [Kubernetes][2] and CI/CD pipeline tools like [Jenkins][3]—as well as native Linux capabilities.
-
-However, one of the earliest articulated concepts around DevOps was the breaking down of the “wall of confusion” specifically between developers and operations teams. This was rooted in the idea that developers didn’t think much about operational concerns and operators didn’t think much about application development. Add the fact that developers want to move quickly and operators care more about (and tend to be measured on) stability than speed, and it’s easy to see why it was difficult to get the two groups on the same page. Hence, DevOps came to symbolize developers and operators working more closely together, or even merging roles to some degree.
-
-Of course, calls for improved communications and better-integrated workflows were never just about dev and ops. Business owners should be part of conversations as well. And there are the actual users of the software. Indeed, you can write up an almost arbitrarily long list of stakeholders concerned with the functionality, cost, reliability, and other aspects of software and its associated infrastructure. Which raises the question that many have asked: “What’s so special about security that we need a DevSecOps term?”
-
-I’m glad you asked.
-
-The first is simply that it serves as a useful reminder. If developers and operations were historically two of the most common silos in IT organizations, security was (and often still is) another. Security people are often thought of as conservative gatekeepers for whom “no” often seems the safest response to new software releases and technologies. Security’s job is to protect the company, even if that means putting the brakes on a speedy development process.
-
-Many aspects of traditional security, and even its vocabulary, can also seem arcane to non-specialists. This has also contributed to the notion that security is something apart from mainstream IT. I often share the following anecdote: A year or two ago I was leading a security discussion at a [DevOpsDays][4] event in London in which we were talking about traditional security roles. One of the participants raised his hand and admitted that he was one of those security gatekeepers. He went on to say that this was the first time in his career that he had ever been to a conference that wasn’t a traditional security conference like RSA. (He also noted that he was going to broaden both his and his team’s horizons more.)
-
-So DevSecOps perhaps shouldn’t be a needed term. But explicitly calling it out seems like a good practice at a time when software security threats are escalating.
-
-The second reason is that the widespread introduction of cloud-native technologies, particularly those built around containers, are closely tied to DevOps practices. These new technologies are both leading to and enabling greater scale and more dynamic infrastructures. Static security policies and checklists no longer suffice. Security must become a continuous activity. And it must be considered at every stage of your application and infrastructure lifecycle.
-
-**Here are a few examples:**
-
-You need to secure the pipeline and applications. You need to use trusted sources for content so that you know who has signed off on container images and that they’re up-to-date with the most recent patches. Your continuous integration system must integrate automated security testing. You’ll sometimes hear people talking about “shifting security left,” which means earlier in the process so that problems can be dealt with sooner. But it’s actually better to think about embedding security throughout the entire pipeline at each step of the testing, integration, deployment, and ongoing management process.
-
-You need to secure the underlying infrastructure. This means securing the host Linux kernel from container escapes and securing containers from each other. It means using a container orchestration platform with integrated security features. It means defending the network by using network namespaces to isolate applications from other applications within a cluster and isolate environments (such as dev, test, and production) from each other.
-
-And it means taking advantage of the broader security ecosystem such as container content scanners and vulnerability management tools.
-
-In short, it’s DevSecOps because modern application development and container platforms require a new type of Dev and a new type of Ops. But they also require a new type of Sec. Thus, DevSecOps.
-
-**[See our related story,[Security and the SRE: How chaos engineering can play a key role][5].]**
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/devsecops
-
-作者:[Gordon Haff][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/ghaff
-[1]:https://opensource.com/resources/devops
-[2]:https://kubernetes.io/
-[3]:https://jenkins.io/
-[4]:https://www.devopsdays.org/
-[5]:https://opensource.com/article/18/3/through-looking-glass-security-sre
diff --git a/sources/talk/20180405 Rethinking -ownership- across the organization.md b/sources/talk/20180405 Rethinking -ownership- across the organization.md
deleted file mode 100644
index d41a3a86dc..0000000000
--- a/sources/talk/20180405 Rethinking -ownership- across the organization.md
+++ /dev/null
@@ -1,125 +0,0 @@
-Rethinking "ownership" across the organization
-======
-
-
-Differences in organizational design don't necessarily make some organizations better than others—just better suited to different purposes. Any style of organization must account for its models of ownership (the way tasks get delegated, assumed, executed) and responsibility (the way accountability for those tasks gets distributed and enforced). Conventional organizations and open organizations treat these issues differently, however, and those difference can be jarring for anyone hopping transitioning from one organizational model to another. But transitions are ripe for stumbling over—oops, I mean, learning from.
-
-Let's do that.
-
-### Ownership explained
-
-In most organizations (and according to typical project management standards), work on projects proceeds in five phases:
-
- * Initiation: Assess project feasibility, identify deliverables and stakeholders, assess benefits
- * Planning (Design): Craft project requirements, scope, and schedule; develop communication and quality plans
- * Executing: Manage task execution, implement plans, maintain stakeholder relationships
- * Monitoring/Controlling: Manage project performance, risk, and quality of deliverables
- * Closing: Sign-off on completion requirements, release resources
-
-
-
-The list above is not exhaustive, but I'd like to add one phase that is often overlooked: the "Adoption" phase, frequently needed for strategic projects where a change to the culture or organization is required for "closing" or completion.
-
- * Adoption: Socializing the work of the project; providing communication, training, or integration into processes and standard workflows.
-
-
-
-Examining project phases is one way contrast the expression of ownership and responsibility in organizations.
-
-### Two models, contrasted
-
-In my experience, "ownership" in a traditional software organization works like this.
-
-A manager or senior technical associate initiates a project with senior stakeholders and, with the authority to champion and guide the project, they bestow the project on an associate at some point during the planning and execution stages. Frequently, but not always, the groundwork or fundamental design of the work has already been defined and approved—sometimes even partially solved. Employees are expected to see the project through execution and monitoring to completion.
-
-Employees cut their teeth on a "starter project," where they prove their abilities to a management chain (for example, I recall several such starter projects that were already defined by a manager and architect, and I was assigned to help implement them). Employees doing a good job on a project for which they're responsible get rewarded with additional opportunities, like a coveted assignment, a new project, or increased responsibility.
-
-An associate acting as "owner" of work is responsible and accountable for that work (if someone, somewhere, doesn't do their job, then the responsible employee either does the necessary work herself or alerts a manager to the problem.) A sense of ownership begins to feel stable over time: Employees generally work on the same projects, and in the same areas for an extended period. For some employees, it means the development of deep expertise. That's because the social network has tighter integration between people and the work they do, so moving around and changing roles and projects is rather difficult.
-
-This process works differently in an open organization.
-
-Associates continually define the parameters of responsibility and ownership in an open organization—typically in light of their interests and passions. Associates have more agency to perform all the stages of the project themselves, rather than have pre-defined projects assigned to them. This places additional emphasis on leadership skills in an open organization, because the process is less about one group of people making decisions for others, and more about how an associate manages responsibilities and ownership (whether or not they roughly follow the project phases while being inclusive, adaptable, and community-focused, for example).
-
-Being responsible for all project phases can make ownership feel more risky for associates in an open organization. Proposing a new project, designing it, and leading its implementation takes initiative and courage—especially when none of this is pre-defined by leadership. It's important to get continuous buy-in, which comes with questions, criticisms, and resistance not only from leaders but also from peers. By default, in open organizations this makes associates leaders; they do much the same work that higher-level leaders do in conventional organizations. And incidentally, this is why Jim Whitehurst, in The Open Organization, cautions us about the full power of "transparency" and the trickiness of getting people's real opinions and thoughts whether we like them or not. The risk is not as high in a traditional organization, because in those organizations leaders manage some of it by shielding associates from heady discussions that arise.
-
-The reward in an Open Organization is more opportunity—offers of new roles, promotions, raises, etc., much like in a conventional organization. Yet in the case of open organizations, associates have developed reputations of excellence based on their own initiatives, rather than on pre-sanctioned opportunities from leadership.
-
-### Thinking about adoption
-
-Any discussion of ownership and responsibility involves addressing the issue of buy-in, because owning a project means we are accountable to our sponsors and users—our stakeholders. We need our stakeholders to buy-into our idea and direction, or we need users to adopt an innovation we've created with our stakeholders. Achieving buy-in for ideas and work is important in each type of organization, and it's difficult in both traditional and open systems—but for different reasons.
-
-Open organizations better allow highly motivated associates, who are ambitious and skilled, to drive their careers. But support for their ideas is required across the organization, rather than from leadership alone.
-
-Penetrating a traditional organization's closely knit social ties can be difficult, and it takes time. In such "command-and-control" environments, one would think that employees are simply "forced" to do whatever leaders want them to do. In some cases that's true (e.g., a travel reimbursement system). However, with more innovative programs, this may not be the case; the adoption of a program, tool, or process can be difficult to achieve by fiat, just like in an open organization. And yet these organizations tend to reduce redundancies of work and effort, because "ownership" here involves leaders exerting responsibility over clearly defined "domains" (and because those domains don't change frequently, knowing "who's who"—who's in charge, who to contact with a request or inquiry or idea—can be easier).
-
-Open organizations better allow highly motivated associates, who are ambitious and skilled, to drive their careers. But support for their ideas is required across the organization, rather than from leadership alone. Points of contact and sources of immediate support can be less obvious, and this means achieving ownership of a project or acquiring new responsibility takes more time. And even then someone's idea may never get adopted. A project's owner can change—and the idea of "ownership" itself is more flexible. Ideas that don't get adopted can even be abandoned, leaving a great idea unimplemented or incomplete. Because any associate can "own" an idea in an open organization, these organizations tend to exhibit more redundancy. (Some people immediately think this means "wasted effort," but I think it can augment the implementation and adoption of innovative solutions. By comparing these organizations, we can also see why Jim Whitehurst calls this kind of culture "chaotic" in The Open Organization).
-
-### Two models of ownership
-
-In my experience, I've seen very clear differences between conventional and open organizations when it comes to the issues of ownership and responsibility.
-
-In an traditional organization:
-
- * I couldn't "own" things as easily
- * I felt frustrated, wanting to take initiative and always needing permission
- * I could more easily see who was responsible because stakeholder responsibility was more clearly sanctioned and defined
- * I could more easily "find" people, because the organizational network was more fixed and stable
- * I more clearly saw what needed to happen (because leadership was more involved in telling me).
-
-
-
-Over time, I've learned the following about ownership and responsibility in an open organization:
-
- * People can feel good about what they are doing because the structure rewards behavior that's more self-driven
- * Responsibility is less clear, especially in situations where there's no leader
- * In cases where open organizations have "shared responsibility," there is the possibility that no one in the group identified with being responsible; often there is lack of role clarity ("who should own this?")
- * More people participate
- * Someone's leadership skills must be stronger because everyone is "on their own"; you are the leader.
-
-
-
-### Making it work
-
-On the subject of ownership, each type of organization can learn from the other. The important thing to remember here: Don't make changes to one open or conventional value without considering all the values in both organizations.
-
-Sound confusing? Maybe these tips will help.
-
-If you're a more conventional organization trying to act more openly:
-
- * Allow associates to take ownership out of passion or interest that align with the strategic goals of the organization. This enactment of meritocracy can help them build a reputation for excellence and execution.
- * But don't be afraid sprinkle in a bit of "high-level perspective" in the spirit of transparency; that is, an associate should clearly communicate plans to their leadership, so the initiative doesn't create irrelevant or unneeded projects.
- * Involving an entire community (as when, for example, the associate gathers feedback from multiple stakeholders and user groups) aids buy-in and creates beneficial feedback from the diversity of perspectives, and this helps direct the work.
- * Exploring the work with the community [doesn't mean having to come to consensus with thousands of people][1]. Use the [Open Decision Framework][2] to set limits and be transparent about what those limits are so that feedback and participation is organized ad boundaries are understood.
-
-
-
-If you're already an open organization, then you should remember:
-
- * Although associates initiate projects from "the bottom up," leadership needs to be involved to provide guidance, input to the vision, and circulate centralized knowledge about ownership and responsibility creating a synchronicity of engagement that is transparent to the community.
- * Ownership creates responsibility, and the definition and degree of these should be something both associates and leaders agree upon, increasing the transparency of expectations and accountability during the project. Don't make this a matter of oversight or babysitting, but rather [a collaboration where both parties give and take][3]—associates initiate, leaders guide; associates own, leaders support.
-
-
-
-Leadership education and mentorship, as it pertains to a particular organization, needs to be available to proactive associates, especially since there is often a huge difference between supporting individual contributors and guiding and coordinating a multiplicity of contributions.
-
-["Owning your own career"][4] can be difficult when "ownership" isn't a concept an organization completely understands.
-
-[Subscribe to our weekly newsletter][5] to learn more about open organizations.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/4/rethinking-ownership-across-organization
-
-作者:[Heidi Hess von Ludewig][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/heidi-hess-von-ludewig
-[1]:https://opensource.com/open-organization/17/8/achieving-alignment-in-openorg
-[2]:https://opensource.com/open-organization/resources/open-decision-framework
-[3]:https://opensource.com/open-organization/17/11/what-is-collaboration
-[4]:https://opensource.com/open-organization/17/12/drive-open-career-forward
-[5]:https://opensource.com/open-organization/resources/newsletter
diff --git a/sources/talk/20180410 Microservices Explained.md b/sources/talk/20180410 Microservices Explained.md
deleted file mode 100644
index 1d7e946a12..0000000000
--- a/sources/talk/20180410 Microservices Explained.md
+++ /dev/null
@@ -1,61 +0,0 @@
-Microservices Explained
-======
-
-
-Microservices is not a new term. Like containers, the concept been around for a while, but it’s become a buzzword recently as many companies embark on their cloud native journey. But, what exactly does the term microservices mean? Who should care about it? In this article, we’ll take a deep dive into the microservices architecture.
-
-### Evolution of microservices
-
-Patrick Chanezon, Chief Developer Advocate for Docker provided a brief history lesson during our conversation: In the late 1990s, developers started to structure their applications into monoliths where massive apps hadall features and functionalities baked into them. Monoliths were easy to write and manage. Companies could have a team of developers who built their applications based on customer feedback through sales and marketing teams. The entire developer team would work together to build tightly glued pieces as an app that can be run on their own app servers. It was a popular way of writing and delivering web applications.
-
-There is a flip side to the monolithic coin. Monoliths slow everything and everyone down. It’s not easy to update one service or feature of the application. The entire app needs to be updated and a new version released. It takes time. There is a direct impact on businesses. Organizations could not respond quickly to keep up with new trends and changing market dynamics. Additionally, scalability was challenging.
-
-Around 2011, SOA (Service Oriented Architecture) became popular where developers could cram multi-tier web applications as software services inside a VM (virtual machine). It did allow them to add or update services independent of each other. However, scalability still remained a problem.
-
-“The scale out strategy then was to deploy multiple copies of the virtual machine behind a load balancer. The problems with this model are several. Your services can not scale or be upgraded independently as the VM is your lowest granularity for scale. VMs are bulky as they carry extra weight of an operating system, so you need to be careful about simply deploying multiple copies of VMs for scaling,” said Madhura Maskasky, co-founder and VP of Product at Platform9.
-
-Some five years ago when Docker hit the scene and containers became popular, SOA faded out in favor of “microservices” architecture. “Containers and microservices fix a lot of these problems. Containers enable deployment of microservices that are focused and independent, as containers are lightweight. The Microservices paradigm, combined with a powerful framework with native support for the paradigm, enables easy deployment of independent services as one or more containers as well as easy scale out and upgrade of these,” said Maskasky.
-
-### What’s are microservices?
-
-Basically, a microservice architecture is a way of structuring applications. With the rise of containers, people have started to break monoliths into microservices. “The idea is that you are building your application as a set of loosely coupled services that can be updated and scaled separately under the container infrastructure,” said Chanezon.
-
-“Microservices seem to have evolved from the more strictly defined service-oriented architecture (SOA), which in turn can be seen as an expression object oriented programming concepts for networked applications. Some would call it just a rebranding of SOA, but the term “microservices” often implies the use of even smaller functional components than SOA, RESTful APIs exchanging JSON, lighter-weight servers (often containerized, and modern web technologies and protocols,” said Troy Topnik, SUSE Senior Product Manager, Cloud Application Platform.
-
-Microservices provides a way to scale development and delivery of large, complex applications by breaking them down that allows the individual components to evolve independently from each other.
-
-“Microservices architecture brings more flexibility through the independence of services, enabling organizations to become more agile in how they deliver new business capabilities or respond to changing market conditions. Microservices allows for using the ‘right tool for the right task’, meaning that apps can be developed and delivered by the technology that will be best for the task, rather than being locked into a single technology, runtime or framework,” said Christian Posta, senior principal application platform specialist, Red Hat.
-
-### Who consumes microservices?
-
-“The main consumers of microservices architecture patterns are developers and application architects,” said Topnik. As far as admins and DevOps engineers are concerned their role is to build and maintain the infrastructure and processes that support microservices.
-
-“Developers have been building their applications traditionally using various design patterns for efficient scale out, high availability and lifecycle management of their applications. Microservices done along with the right orchestration framework help simplify their lives by providing a lot of these features out of the box. A well-designed application built using microservices will showcase its benefits to the customers by being easy to scale, upgrade, debug, but without exposing the end customer to complex details of the microservices architecture,” said Maskasky.
-
-### Who needs microservices?
-
-Everyone. Microservices is the modern approach to writing and deploying applications more efficiently. If an organization cares about being able to write and deploy its services at a faster rate they should care about it. If you want to stay ahead of your competitors, microservices is the fastest route. Security is another major benefit of the microservices architecture, as this approach allows developers to keep up with security and bug fixes, without having to worry about downtime.
-
-“Application developers have always known that they should build their applications in a modular and flexible way, but now that enough of them are actually doing this, those that don’t risk being left behind by their competitors,” said Topnik.
-
-If you are building a new application, you should design it as microservices. You never have to hold up a release if one team is late. New functionalities are available when they're ready, and the overall system never breaks.
-
-“We see customers using this as an opportunity to also fix other problems around their application deployment -- such as end-to-end security, better observability, deployment and upgrade issues,” said Maskasky.
-
-Failing to do so means you would be stuck in the traditional stack, which means microservices won’t be able to add any value to it. If you are building new applications, microservices is the way to go.
-
-Learn more about cloud-native at [KubeCon + CloudNativeCon Europe][1], coming up May 2-4 in Copenhagen, Denmark.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/4/microservices-explained
-
-作者:[SWAPNIL BHARTIYA][a]
-译者:[runningwater](https://github.com/runningwater)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/arnieswap
-[1]:https://events.linuxfoundation.org/events/kubecon-cloudnativecon-europe-2018/attend/register/
diff --git a/sources/talk/20180412 Management, from coordination to collaboration.md b/sources/talk/20180412 Management, from coordination to collaboration.md
deleted file mode 100644
index 1262f88300..0000000000
--- a/sources/talk/20180412 Management, from coordination to collaboration.md
+++ /dev/null
@@ -1,71 +0,0 @@
-Management, from coordination to collaboration
-======
-
-
-
-Any organization is fundamentally a pattern of interactions between people. The nature of those interactions—their quality, their frequency, their outcomes—is the most important product an organization can create. Perhaps counterintuitively, recognizing this fact has never been more important than it is today—a time when digital technologies are reshaping not only how we work but also what we do when we come together.
-
-
-And yet many organizational leaders treat those interactions between people as obstacles or hindrances to avoid or eliminate, rather than as the powerful sources of innovation they really are.
-
-That's why we're observing that some of the most successful organizations today are those capable of shifting the way they think about the value of the interactions in the workplace. And to do that, they've radically altered their approach to management and leadership.
-
-### Moving beyond mechanical management
-
-Simply put, traditionally managed organizations treat unanticipated interactions between stakeholders as potentially destructive forces—and therefore as costs to be mitigated.
-
-This view has a long, storied history in the field of economics. But it's perhaps nowhere more clear than in the early writing of Nobel Prize-winning economist[Ronald Coase][1]. In 1937, Coase published "[The Nature of the Firm][2]," an essay about the reasons people organized into firms to work on large-scale projects—rather than tackle those projects alone. Coase argued that when the cost of coordinating workers together inside a firm is less than that of similar market transactions outside, people will tend to organize so they can reap the benefits of lower operating costs.
-
-But at some point, Coase's theory goes, the work of coordinating interactions between so many people inside the firm actually outweighs the benefits of having an organization in the first place. The complexity of those interactions becomes too difficult to handle. Management, then, should serve the function of decreasing this complexity. Its primary goal is coordination, eliminating the costs associated with messy interpersonal interactions that could slow the firm and reduce its efficiency. As one Fortune 100 CEO recently told me, "Failures happen most often around organizational handoffs."
-
-This makes sense to people practicing what I've called "[mechanical management][3]," where managing people is the act of keeping them focused on specific, repeatable, specialized tasks. Here, management's key function is optimizing coordination costs—ensuring that every specialized component of the finely-tuned organizational machine doesn't impinge on the others and slow them down. Managers work to avoid failures by coordinating different functions across the organization (accounts payable, research and development, engineering, human resources, sales, and so on) to get them to operate toward a common goal. And managers create value by controlling information flows, intervening only when functions become misaligned.
-
-Today, when so many of these traditionally well-defined tasks have become automated, value creation is much more a result of novel innovation and problem solving—not finding new ways to drive efficiency from repeatable processes. But numerous studies demonstrate that innovative, problem-solving activity occurs much more regularly when people work in cross-functional teams—not as isolated individuals or groups constrained by single-functional silos. This kind of activity can lead to what some call "accidental integration": the serendipitous innovation that occurs when old elements combine in new and unforeseen ways.
-
-That's why working collaboratively has now become a necessity that managers need to foster, not eliminate.
-
-### From coordination to collaboration
-
-Reframing the value of the firm—from something that coordinated individual transactions to something that produces novel innovations—means rethinking the value of the relations at the core of our organizations. And that begins with reimagining the task of management, which is no longer concerned primarily with minimizing coordination costs but maximizing cooperation opportunities.
-
-Too few of our tried-and-true management practices have this goal. If they're seeking greater innovation, managers need to encourage more interactions between people in different functional areas, not fewer. A cross-functional team may not be as efficient as one composed of people with the same skill sets. But a cross-functional team is more likely to be the one connecting points between elements in your organization that no one had ever thought to connect (the one more likely, in other words, to achieve accidental integration).
-
-Working collaboratively has now become a necessity that managers need to foster, not eliminate.
-
-I have three suggestions for leaders interested in making this shift:
-
-First, define organizations around processes, not functions. We've seen this strategy work in enterprise IT, for example, in the case of [DevOps][4], where teams emerge around end goals (like a mobile application or a website), not singular functions (like developing, testing, and production). In DevOps environments, the same team that writes the code is responsible for maintaining it once it's in production. (We've found that when the same people who write the code are the ones woken up when it fails at 3 a.m., we get better code.)
-
-Second, define work around the optimal organization rather than the organization around the work. Amazon is a good example of this strategy. Teams usually stick to the "[Two Pizza Rule][5]" when establishing optimal conditions for collaboration. In other words, Amazon leaders have determined that the best-sized team for maximum innovation is about 10 people, or a group they can feed with two pizzas. If the problem gets bigger than that two-pizza team can handle, they split the problem into two simpler problems, dividing the work between multiple teams rather than adding more people to the single team.
-
-And third, to foster creative behavior and really get people cooperating with one another, do whatever you can to cultivate a culture of honest and direct feedback. Be straightforward and, as I wrote in The Open Organization, let the sparks fly; have frank conversations and let the best ideas win.
-
-### Let it go
-
-I realize that asking managers to significantly shift the way they think about their roles can lead to fear and skepticism. Some managers define their performance (and their very identities) by the control they exert over information and people. But the more you dictate the specific ways your organization should do something, the more static and brittle that activity becomes. Agility requires letting go—giving up a certain degree of control.
-
-Front-line managers will see their roles morph from dictating and monitoring to enabling and supporting. Instead of setting individual-oriented goals, they'll need to set group-oriented goals. Instead of developing individual incentives, they'll need to consider group-oriented incentives.
-
-Because ultimately, their goal should be to[create the context in which their teams can do their best work][6].
-
-[Subscribe to our weekly newsletter][7] to learn more about open organizations.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/4/management-coordination-collaboration
-
-作者:[Jim Whitehurst][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/remyd
-[1]:https://news.uchicago.edu/article/2013/09/02/ronald-h-coase-founding-scholar-law-and-economics-1910-2013
-[2]:http://onlinelibrary.wiley.com/doi/10.1111/j.1468-0335.1937.tb00002.x/full
-[3]:https://opensource.com/open-organization/18/2/try-learn-modify
-[4]:https://enterprisersproject.com/devops
-[5]:https://www.fastcompany.com/3037542/productivity-hack-of-the-week-the-two-pizza-approach-to-productive-teamwork
-[6]:https://opensource.com/open-organization/16/3/what-it-means-be-open-source-leader
-[7]:https://opensource.com/open-organization/resources/newsletter
diff --git a/sources/talk/20180416 For project safety back up your people, not just your data.md b/sources/talk/20180416 For project safety back up your people, not just your data.md
deleted file mode 100644
index 0dc6d41fa5..0000000000
--- a/sources/talk/20180416 For project safety back up your people, not just your data.md
+++ /dev/null
@@ -1,79 +0,0 @@
-For project safety back up your people, not just your data
-======
-
-
-The [FSF][1] was founded in 1985, Perl in 1987 ([happy 30th birthday, Perl][2]!), and Linux in 1991. The [term open source][3] and the [Open Source Initiative][4] both came into being in 1998 (and [turn 20 years old][5] in 2018). Since then, free and open source software has grown to become the default choice for software development, enabling incredible innovation.
-
-We, the greater open source community, have come of age. Millions of open source projects exist today, and each year the [GitHub Octoverse][6] reports millions of new public repositories. We rely on these projects every day, and many of us could not operate our services or our businesses without them.
-
-So what happens when the leaders of these projects move on? How can we help ease those transitions while ensuring that the projects thrive? By teaching and encouraging **succession planning**.
-
-### What is succession planning?
-
-Succession planning is a popular topic among business executives, boards of directors, and human resources professionals, but it doesn't often come up with maintainers of free and open source projects. Because the concept is common in business contexts, that's where you'll find most resources and advice about establishing a succession plan. As you might expect, most of these articles aren't directly applicable to FOSS, but they do form a springboard from which we can launch our own ideas about succession planning.
-
-According to [Wikipedia][7]:
-
-> Succession planning is a process for identifying and developing new leaders who can replace old leaders when they leave, retire, or die.
-
-In my opinion, this definition doesn't apply very well to free and open source software projects. I primarily object to the use of the term leaders. For the collaborative projects of FOSS, everyone can be some form of leader. Roles other than "project founder" or "benevolent dictator for life" are just as important. Any project role that is measured by bus factor is one that can benefit from succession planning.
-
-> A project's bus factor is the number of team members who, if hit by a bus, would endanger the smooth operation of the project. The smallest and worst bus factor is 1: when only a single person's loss would put the project in jeopardy. It's a somewhat grim but still very useful concept.
-
-I propose that instead of viewing succession planning as a leadership pipeline, free and open source projects should view it as a skills pipeline. What sorts of skills does your project need to continue functioning well, and how can you make sure those skills always exist in your community?
-
-### Benefits of succession planning
-
-When I talk to project maintainers about succession planning, they often respond with something like, "We've been pretty successful so far without having to think about this. Why should we start now?"
-
-Aside from the fact that the phrase, "We've always done it this way" is probably one of the most dangerous in the English language, and hearing (or saying) it should send up red flags in any community, succession planning provides plenty of very real benefits:
-
- * **Continuity** : When someone leaves, what happens to the tasks they were performing? Succession planning helps ensure those tasks continue uninterrupted and no one is left hanging.
- * **Avoiding a power vacuum** : When a person leaves a role with no replacement, it can lead to confusion, delays, and often most damaging, political woes. After all, it's much easier to fix delays than hurt feelings. A succession plan helps alleviate the insecure and unstable time when someone in a vital role moves on.
- * **Increased project/organization longevity** : The thinking required for succession planning is the same sort of thinking that contributes to project longevity. Ensuring continuity in leadership, culture, and productivity also helps ensure the project will continue. It will evolve, but it will survive.
- * **Reduced workload/pressure on current leaders** : When a single team member performs a critical role in the project, they often feel pressure to be constantly "on." This can lead to burnout and worse, resignations. A succession plan ensures that all important individuals have a backup or successor. The knowledge that someone can take over is often enough to reduce the pressure, but it also means that key players can take breaks or vacations without worrying that their role will be neglected in their absence.
- * **Talent development** : Members of the FOSS community talk a lot about mentoring these days, and that's great. However, most of the conversation is around mentoring people to contribute code to a project. There are many different ways to contribute to free and open source software projects beyond programming. A robust succession plan recognizes these other forms of contribution and provides mentoring to prepare people to step into critical non-programming roles.
- * **Inspiration for new members** : It can be very motivational for new or prospective community members to see that a project uses its succession plan. Not only does it show them that the project is well-organized and considers its own health and welfare as well as that of its members, but it also clearly shows new members how they can grow in the community. An obvious path to critical roles and leadership positions inspires new members to stick around to walk that path.
- * **Diversity of thoughts/get out of a rut** : Succession plans provide excellent opportunities to bring in new people and ideas to the critical roles of a project. [Studies show][8] that diverse leadership teams are more effective and the projects they lead are more innovative. Using your project's succession plan to mentor people from different backgrounds and with different perspectives will help strengthen and evolve the project in a healthy way.
- * **Enabling meritocracy** : Unfortunately, what often passes for meritocracy in many free and open source projects is thinly veiled hostility toward new contributors and diverse opinions—hostility that's delivered from within an echo chamber. Meritocracy without a mentoring program and healthy governance structure is simply an excuse to practice subjective discrimination while hiding behind unexpressed biases. A well-executed succession plan helps teams reach the goal of a true meritocracy. What counts as merit for any given role, and how to reach that level of merit, are openly, honestly, and completely documented. The entire community will be able to see and judge which members are on the path or deserve to take on a particular critical role.
-
-
-
-### Why it doesn't happen
-
-Succession planning isn't a panacea, and it won't solve all problems for all projects, but as described above, it offers a lot of worthwhile benefits to your project.
-
-Despite that, very few free and open source projects or organizations put much thought into it. I was curious why that might be, so I asked around. I learned that the reasons for not having a succession plan fall into one of five different buckets:
-
- * **Too busy** : Many people recognize succession planning (or lack thereof) as a problem for their project but just "hadn't ever gotten around to it" because there's "always something more important to work on." I understand and sympathize with this, but I suspect the problem may have more to do with prioritization than with time availability.
- * **Don't think of it** : Some people are so busy and preoccupied that they haven't considered, "Hey, what would happen if Jen had to leave the project?" This never occurs to them. After all, Jen's always been there when they need her, right? And that will always be the case, right?
- * **Don't want to think of it** : Succession planning shares a trait with estate planning: It's associated with negative feelings like loss and can make people address their own mortality. Some people are uncomfortable with this and would rather not consider it at all than take the time to make the inevitable easier for those they leave behind.
- * **Attitude of current leaders** : A few of the people with whom I spoke didn't want to recognize that they're replaceable, or to consider that they may one day give up their power and influence on the project. While this was (thankfully) not a common response, it was alarming enough to deserve its own bucket. Failure of someone in a critical role to recognize or admit that they won't be around forever can set a project up for failure in the long run.
- * **Don't know where to start** : Many people I interviewed realize that succession planning is something that their project should be doing. They were even willing to carve out the time to tackle this very large task. What they lacked was any guidance on how to start the process of creating a succession plan.
-
-
-
-As you can imagine, something as important and people-focused as a succession plan isn't easy to create, and it doesn't happen overnight. Also, there are many different ways to do it. Each project has its own needs and critical roles. One size does not fit all where succession plans are concerned.
-
-There are, however, some guidelines for how every project could proceed with the succession plan creation process. I'll cover these guidelines in my next article.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/passing-baton-succession-planning-foss-leadership
-
-作者:[VM(Vicky) Brasseur][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/vmbrasseur
-[1]:http://www.fsf.org
-[2]:https://opensource.com/article/17/10/perl-turns-30
-[3]:https://opensource.com/article/18/2/coining-term-open-source-software
-[4]:https://opensource.org
-[5]:https://opensource.org/node/910
-[6]:https://octoverse.github.com
-[7]:https://en.wikipedia.org/wiki/Succession_planning
-[8]:https://hbr.org/2016/11/why-diverse-teams-are-smarter
diff --git a/sources/talk/20180417 How to develop the FOSS leaders of the future.md b/sources/talk/20180417 How to develop the FOSS leaders of the future.md
deleted file mode 100644
index a65dc9dabd..0000000000
--- a/sources/talk/20180417 How to develop the FOSS leaders of the future.md
+++ /dev/null
@@ -1,93 +0,0 @@
-How to develop the FOSS leaders of the future
-======
-
-Do you hold a critical role in a free and open source software project? Would you like to make it easier for the next person to step into your shoes, while also giving yourself the freedom to take breaks and avoid burnout?
-
-Of course you would! But how do you get started?
-
-Before you do anything, remember that this is a free or open source project. As with all things in FOSS, your succession planning should happen in collaboration with others. The [Principle of Least Astonishment][1] also applies: Don't work on your plan in isolation, then spring it on the entire community. Work together and publicly, so no one is caught off guard when the cultural or governance changes start happening.
-
-### Identify and analyse critical roles
-
-As a project leader, your first step is to identify the critical roles in your community. While it can help to ask each community members what role they perform, it's important to realize that most people perform multiple roles. Make sure you consider every role that each community member plays in the project.
-
-Once you've identified the roles and determined which ones are critical to your project, the next step is to list all of the duties and responsibilities for each of those critical roles. Be very honest here. List the duties and responsibilities you think each role has, then ask the person who performs that role to list the duties the role actually has. You'll almost certainly find that the second list is longer than the first.
-
-### Refactor large roles
-
-During this process, have you discovered any roles that encompass a large number of duties and responsibilities? Large roles are like large methods in your code: They're a sign of a problem, and they need to be refactored to make them easier to maintain. One of the easiest and most effective steps in succession planning for FOSS projects is to split up each large role into two or more smaller roles and distribute these to other community members. With that one step, you've greatly improved the [bus factor][2] for your project. Even better, you've made each one of those new, smaller roles much more accessible and less intimidating for new community members. People are much more likely to volunteer for a role if it's not a massive burden.
-
-### Limit role tenure
-
-Another way to make a role more enticing is to limit its tenure. Community members will be more willing to step into roles that aren't open-ended. They can look at their life and work plans and ask themselves, "Can I take on this role for the next eighteen months?" (or whatever term limit you set).
-
-Setting term limits also helps those who are currently performing the role. They know when they can set aside those duties and move on to something else, which can help alleviate burnout. Also, setting a term limit creates a pool of people who have performed the role and are qualified to step in if needed, which can also mitigate burnout.
-
-### Knowledge transfer
-
-Once you've identified and defined the critical roles in your project, most of what remains is knowledge transfer. Even small projects involve a lot of moving parts and knowledge that needs to be where everyone can see, share, use, and contribute to it. What sort of knowledge should you be collecting? The answer will vary by project, needs, and role, but here are some of the most common (and commonly overlooked) types of information needed to implement a succession plan:
-
- * **Roles and their duties** : You've spent a lot of time identifying, analyzing, and potentially refactoring roles and their duties. Make sure this information doesn't get lost.
- * **Policies and procedures** : None of those duties occur in a vacuum. Each duty must be performed in a particular way (procedures) when particular conditions are met (policies). Take stock of these details for every duty of every role.
- * **Resources** : What accounts are associated with the project, or are necessary for it to operate? Who helps you with meetup space, sponsorship, or in-kind services? Such information is vital to project operation but can be easily lost when the responsible community member moves on.
- * **Credentials** : Ideally, every external service required by the project will use a login that goes to an email address designated for a specific role (`sre@project.org`) rather than to a personal address. Every role's address should include multiple people on the distribution list to ensure that important messages (such as downtime or bogus "forgot password" requests) aren't missed. The credentials for every service should be kept in a secure keystore, with access limited to the fewest number of people possible.
- * **Project history** : All community members benefit greatly from learning the history of the project. Collecting project history information can clarify why decisions were made in the past, for example, and reveal otherwise unexpressed requirements and values of the community. Project histories can also help new community members understand "inside jokes," jargon, and other cultural factors.
- * **Transition plans** : A succession plan doesn't do much good if project leaders haven't thought through how to transition a role from one person to another. How will you locate and prepare people to take over a critical role? Since the project has already done a lot of thinking and knowledge transfer, transition plans for each role may be easier to put together.
-
-
-
-Doing a complete knowledge transfer for all roles in a project can be an enormous undertaking, but the effort is worth it. To avoid being overwhelmed by such a daunting task, approach it one role at a time, finishing each one before you move onto the next. Limiting the scope in this way makes both progress and success much more likely.
-
-### Document, document, document!
-
-Succession planning takes time. The community will be making a lot of decisions and collecting a lot of information, so make sure nothing gets lost. It's important to document everything (not just in email threads). Where knowledge is concerned, documentation scales and people do not. Include even the things that you think are obvious—what's obvious to a more seasoned community member may be less so to a newbie, so don't skip steps or information.
-
-Gather these decisions, processes, policies, and other bits of information into a single place, even if it's just a collection of markdown files in the main project repository. The "how" and "where" of the documentation can be sorted out later. It's better to capture key information first and spend time [bike-shedding][3] a documentation system later.
-
-Once you've collected all of this information, you should understand that it's unlikely that anyone will read it. I know, it seems unfair, but that's just how things usually work out. The reason? There is simply too much documentation and too little time. To address this, add an abstract, or summary, at the top of each item. Often that's all a person needs, and if not, the complete document is there for a deep dive. Recognizing and adapting to how most people use documentation increases the likelihood that they will use yours.
-
-Above all, don't skip the documentation process. Without documentation, succession plans are impossible.
-
-### New leaders
-
-If you don't yet perform a critical role but would like to, you can contribute to the succession planning process while apprenticing your way into one of those roles.
-
-For starters, actively look for opportunities to learn and contribute. Shadow people in critical roles. You'll learn how the role is done, and you can document it to help with the succession planning process. You'll also get the opportunity to see whether it's a role you're interested in pursuing further.
-
-Asking for mentorship is a great way to get yourself closer to taking on a critical role in the project. Even if you haven't heard that mentoring is available, it's perfectly OK to ask about it. The people already in those roles are usually happy to mentor others, but often are too busy to think about offering mentorship. Asking is a helpful reminder to them that they should be helping to train people to take over their role when they need a break.
-
-As you perform your own tasks, actively seek out feedback. This will not only improve your skills, but it shows that you're interested in doing a better job for the community. This commitment will pay off when your project needs people to step into critical roles.
-
-Finally, as you communicate with more experienced community members, take note of anecdotes about the history of the project and how it operates. This history is very important, especially for new contributors or people stepping into critical roles. It provides the context necessary for new contributors to understand what things do or don't work and why. As you hear these stories, document them so they can be passed on to those who come after you.
-
-### Succession planning examples
-
-While too few FOSS projects are actively considering succession planning, some are doing a great job of trying to reduce their bus factor and prevent maintainer burnout.
-
-[Exercism][4] isn't just an excellent tool for gaining fluency in programming languages. It's also an [open source project][5] that goes out of its way to help contributors [land their first patch][6]. In 2016, the project reviewed the health of each language track and [discovered that many were woefully maintained][7]. There simply weren't enough people covering each language, so maintainers were burning out. The Exercism community recognized the risk this created and pushed to find new maintainers for as many language tracks as possible. As a result, the project was able to revive several tracks from near-death and develop a structure for inviting people to become maintainers.
-
-The purpose of the [Vox Pupuli][8] project is to serve as a sort of succession plan for the [Puppet module][9] community. When a maintainer no longer wishes or is able to work on their module, they can bequeath it to the Vox Pupuli community. This community of 30 collaborators shares responsibility for maintaining all the modules it accepts into the project. The large number of collaborators ensures that no single person bears the burden of maintenance while also providing a long and fruitful life for every module in the project.
-
-These are just two examples of how some FOSS projects are tackling succession planning. Share your stories in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/succession-planning-how-develop-foss-leaders-future
-
-作者:[VM(Vicky) Brasseur)][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/vmbrasseur
-[1]:https://en.wikipedia.org/wiki/Principle_of_least_astonishment
-[2]:https://en.wikipedia.org/wiki/Bus_factor
-[3]:https://en.wikipedia.org/wiki/Law_of_triviality
-[4]:http://exercism.io
-[5]:https://github.com/exercism/exercism.io
-[6]:https://github.com/exercism/exercism.io/blob/master/CONTRIBUTING.md
-[7]:https://tinyletter.com/exercism/letters/exercism-track-health-check-new-maintainers
-[8]:https://voxpupuli.org
-[9]:https://forge.puppet.com
diff --git a/sources/talk/20180418 Is DevOps compatible with part-time community teams.md b/sources/talk/20180418 Is DevOps compatible with part-time community teams.md
deleted file mode 100644
index e78b96959f..0000000000
--- a/sources/talk/20180418 Is DevOps compatible with part-time community teams.md
+++ /dev/null
@@ -1,73 +0,0 @@
-Is DevOps compatible with part-time community teams?
-======
-
-
-DevOps seems to be the talk of the IT world of late—and for good reason. DevOps has streamlined the process and production of IT development and operations. However, there is also an upfront cost to embracing a DevOps ideology, in terms of time, effort, knowledge, and financial investment. Larger companies may have the bandwidth, budget, and time to make the necessary changes, but is it feasible for part-time, resource-strapped communities?
-
-Part-time communities are teams of like-minded people who take on projects outside of their normal work schedules. The members of these communities are driven by passion and a shared purpose. For instance, one such community is the [ALM | DevOps Rangers][1]. With 100 rangers engaged across the globe, a DevOps solution may seem daunting; nonetheless, they took on the challenge and embraced the ideology. Through their example, we've learned that DevOps is not only feasible but desirable in smaller teams. To read about their transformation, check out [How DevOps eliminates development bottlenecks][2].
-
-> “DevOps is the union of people, process, and products to enable continuous delivery of value to our end customers.” - Donovan Brown
-
-### The cost of DevOps
-
-As stated above, there is an upfront "cost" to DevOps. The cost manifests itself in many forms, such as the time and collaboration between development, operations, and other stakeholders, planning a smooth-flowing process that delivers continuous value, finding the best DevOps products, and training the team in new technologies, to name a few. This aligns directly with Donovan's definition of DevOps, in fact—a **process** for delivering **continuous value** and the **people** who make that happen.
-
-Streamlined DevOps takes a lot of planning and training just to create the process, and that doesn't even consider the testing phase. We also can't forget the existing in-flight projects that need to be converted into the new system. While the cost increases the more pervasive the transformation—for instance, if an organization aims to unify its entire development organization under a single process, then that would cost more versus transforming a single pilot or subset of the entire portfolio—these upfront costs must be addressed regardless of their scale. There are a lot of resources and products already out there that can be implemented for a smoother transition—but again, we face the time and effort that will be necessary just to research which ones might work best.
-
-In the case of the ALM | DevOps Rangers, they had to halt all projects for a couple of sprints to set up the initial process. Many organizations would not be able to do that. Even part-time groups might have very good reasons to keep things moving, which only adds to the complexity. In such scenarios, additional cutover planning (and therefore additional cost) is needed, and the overall state of the community is one of flux and change, which adds risk, which—you guessed it—requires more cost to mitigate.
-
-There is also an ongoing "cost" that teams will face with a DevOps mindset: Simple maintenance of the system, training and transitioning new team members, and keeping up with new, improved technologies are all a part of the process.
-
-### DevOps for a part-time community
-
-Whereas larger companies can dedicate a single manager or even a team to the task over overseeing the continuous integration and continuous deployment (CI/CD) pipelines, part-time community teams don't have the bandwidth to give. With such a massive undertaking we must ask: Is it even worth it for groups with fewer resources to take on DevOps for their community? Or should they abandon the idea of DevOps altogether?
-
-The answer to that is dependent on a few variables, such as the ability of the teams to be self-managing, the time and effort each member is willing to put into the transformation, and the dedication of the community to the process.
-
-### Example: Benefits of DevOps in a part-time community
-
-Luckily, we aren't without examples to demonstrate just how DevOps can benefit a smaller group. Let's take a quick look at the ALM Rangers again. The results from their transformation help us understand how DevOps changed their community:
-
-
-
-As illustrated, there are some huge benefits for part-time community teams. Planning goes from long, arduous design sessions to a quick prototyping and storyboarding process. Builds become automated, reliable, and resilient. Testing and bug detection are proactive instead of reactive, which turns into a happier clientele. Multiple full-time program managers are replaced with self-managing teams with a single part-time manager to oversee projects. Teams become smaller and more efficient, which equates to higher production rates and higher-quality project delivery. With results like these, it's hard to argue against DevOps.
-
-Still, the upfront and ongoing costs aren't right for every community. The number-one most important aspect of any DevOps transformation is the mindset of the people involved. Adopting the idea of self-managing teams who work in autonomy instead of the traditional chain-of-command scheme can be a challenge for any group. The members must be willing to work independently without a lot of oversight and take ownership of their features and user experience, but at the same time, work in a setting that is fully transparent to the rest of the community. **The success or failure of a DevOps strategy lies on the team.**
-
-### Making the DevOps transition in 4 steps
-
-Another important question to ask: How can a low-bandwidth group make such a massive transition? The good news is that a DevOps transformation doesn’t need to happen all at once. Taken in smaller, more manageable steps, organizations of any size can embrace DevOps.
-
- 1. Determine why DevOps may be the solution you need. Are your projects bottlenecking? Are they running over budget and over time? Of course, these concerns are common for any community, big or small. Answering these questions leads us to step two:
- 2. Develop the right framework to improve the engineering process. DevOps is all about automation, collaboration, and streamlining. Rather than trying to fit everyone into the same process box, the framework should support the work habits, preferences, and delivery needs of the community. Some broad standards should be established (for example, that all teams use a particular version control system). Beyond that, however, let the teams decide their own best process.
- 3. Use the current products that are already available if they meet your needs. Why reinvent the wheel?
- 4. Finally, implement and test the actual DevOps solution. This is, of course, where the actual value of DevOps is realized. There will likely be a few issues and some heartburn, but it will all be worth it in the end because, once established, the products of the community’s work will be nimbler and faster for the users.
-
-
-
-### Reuse DevOps solutions
-
-One benefit to creating effective CI/CD pipelines is the reusability of those pipelines. Although there is no one-size fits all solution, anyone can adopt a process. There are several pre-made templates available for you to examine, such as build templates on VSTS, ARM templates to deploy Azure resources, and "cookbook"-style textbooks from technical publishers. Once it identifies a process that works well, a community can also create its own template by defining and establishing standards and making that template easily discoverable by the entire community. For more information on DevOps journeys and tools, check out [this site][3].
-
-### Summary
-
-Overall, the success or failure of DevOps relies on the culture of a community. It doesn't matter if the community is a large, resource-rich enterprise or a small, resource-sparse, part-time group. DevOps will still bring solid benefits. The difference is in the approach for adoption and the scale of that adoption. There are both upfront and ongoing costs, but the value greatly outweighs those costs. Communities can use any of the powerful tools available today for their pipelines, and they can also leverage reusability, such as templates, to reduce upfront implementation costs. DevOps is most certainly feasible—and even critical—for the success of part-time community teams.
-
-**[See our related story,[How DevOps eliminates development bottlenecks][4].]**
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/devops-compatible-part-time-community-teams
-
-作者:[Edward Fry][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/edwardf
-[1]:https://github.com/ALM-Rangers
-[2]:https://opensource.com/article/17/11/devops-rangers-transformation
-[3]:https://www.visualstudio.com/devops/
-[4]:https://opensource.com/article/17/11/devops-rangers-transformation
diff --git a/sources/talk/20180419 3 tips for organizing your open source project-s workflow on GitHub.md b/sources/talk/20180419 3 tips for organizing your open source project-s workflow on GitHub.md
deleted file mode 100644
index 29e4ea2f48..0000000000
--- a/sources/talk/20180419 3 tips for organizing your open source project-s workflow on GitHub.md
+++ /dev/null
@@ -1,109 +0,0 @@
-3 tips for organizing your open source project's workflow on GitHub
-======
-
-
-
-Managing an open source project is challenging work, and the challenges grow as a project grows. Eventually, a project may need to meet different requirements and span multiple repositories. These problems aren't technical, but they are important to solve to scale a technical project. [Business process management][1] methodologies such as agile and [kanban][2] bring a method to the madness. Developers and managers can make realistic decisions for estimating deadlines and team bandwidth with an organized development focus.
-
-At the [UNICEF Office of Innovation][3], we use GitHub project boards to organize development on the MagicBox project. [MagicBox][4] is a full-stack application and open source platform to serve and visualize data for decision-making in humanitarian crises and emergencies. The project spans multiple GitHub repositories and works with multiple developers. With GitHub project boards, we organize our work across multiple repositories to better understand development focus and team bandwidth.
-
-Here are three tips from the UNICEF Office of Innovation on how to organize your open source projects with the built-in project boards on GitHub.
-
-### 1\. Bring development discussion to issues and pull requests
-
-Transparency is a critical part of an open source community. When mapping out new features or milestones for a project, the community needs to see and understand a decision or why a specific direction was chosen. Filing new GitHub issues for features and milestones is an easy way for someone to follow the project direction. GitHub issues and pull requests are the cards (or building blocks) of project boards. To be successful with GitHub project boards, you need to use issues and pull requests.
-
-
-![GitHub issues for magicbox-maps, MagicBox's front-end application][6]
-
-GitHub issues for magicbox-maps, MagicBox's front-end application.
-
-The UNICEF MagicBox team uses GitHub issues to track ongoing development milestones and other tasks to revisit. The team files new GitHub issues for development goals, feature requests, or bugs. These goals or features may come from external stakeholders or the community. We also use the issues as a place for discussion on those tasks. This makes it easy to cross-reference in the future and visualize upcoming work on one of our projects.
-
-Once you begin using GitHub issues and pull requests as a way of discussing and using your project, organizing with project boards becomes easier.
-
-### 2\. Set up kanban-style project boards
-
-GitHub issues and pull requests are the first step. After you begin using them, it may become harder to visualize what work is in progress and what work is yet to begin. [GitHub's project boards][7] give you a platform to visualize and organize cards into different columns.
-
-There are two types of project boards available:
-
- * **Repository** : Boards for use in a single repository
- * **Organization** : Boards for use in a GitHub organization across multiple repositories (but private to organization members)
-
-
-
-The choice you make depends on the structure and size of your projects. The UNICEF MagicBox team uses boards for development and documentation at the organization level, and then repository-specific boards for focused work (like our [community management board][8]).
-
-#### Creating your first board
-
-Project boards are found on your GitHub organization page or on a specific repository. You will see the Projects tab in the same row as Issues and Pull requests. From the page, you'll see a green button to create a new project.
-
-There, you can set a name and description for the project. You can also choose templates to set up basic columns and sorting for your board. Currently, the only options are for kanban-style boards.
-
-
-![Creating a new GitHub project board.][10]
-
-Creating a new GitHub project board.
-
-After creating the project board, you can make adjustments to it as needed. You can create new columns, [set up automation][11], and add pre-existing GitHub issues and pull requests to the project board.
-
-You may notice new options for the metadata in each GitHub issue and pull request. Inside of an issue or pull request, you can add it to a project board. If you use automation, it will automatically enter a column you configured.
-
-### 3\. Build project boards into your workflow
-
-After you set up a project board and populate it with issues and pull requests, you need to integrate it into your workflow. Project boards are effective only when actively used. The UNICEF MagicBox team uses the project boards as a way to track our progress as a team, update external stakeholders on development, and estimate team bandwidth for reaching our milestones.
-
-
-![Tracking progress][13]
-
-Tracking progress with GitHub project boards.
-
-If you are an open source project and community, consider using the project boards for development-focused meetings. It also helps remind you and other core contributors to spend five minutes each day updating progress as needed. If you're at a company using GitHub to do open source work, consider using project boards to update other team members and encourage participation inside of GitHub issues and pull requests.
-
-Once you begin using the project board, yours may look like this:
-
-
-![Development progress board][15]
-
-Development progress board for all UNICEF MagicBox repositories in organization-wide GitHub project boards.
-
-### Open alternatives
-
-GitHub project boards require your project to be on GitHub to take advantage of this functionality. While GitHub is a popular repository for open source projects, it's not an open source platform itself. Fortunately, there are open source alternatives to GitHub with tools to replicate the workflow explained above. [GitLab Issue Boards][16] and [Taiga][17] are good alternatives that offer similar functionality.
-
-### Go forth and organize!
-
-With these tools, you can bring a method to the madness of organizing your open source project. These three tips for using GitHub project boards encourage transparency in your open source project and make it easier to track progress and milestones in the open.
-
-Do you use GitHub project boards for your open source project? Have any tips for success that aren't mentioned in the article? Leave a comment below to share how you make sense of your open source projects.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/keep-your-project-organized-git-repo
-
-作者:[Justin W.Flory][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jflory
-[1]:https://en.wikipedia.org/wiki/Business_process_management
-[2]:https://en.wikipedia.org/wiki/Kanban_(development)
-[3]:http://unicefstories.org/about/
-[4]:http://unicefstories.org/magicbox/
-[5]:/file/393356
-[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-open-issues.png?itok=OcWPX575 (GitHub issues for magicbox-maps, MagicBox's front-end application)
-[7]:https://help.github.com/articles/about-project-boards/
-[8]:https://github.com/unicef/magicbox/projects/3?fullscreen=true
-[9]:/file/393361
-[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-project-boards-create-board.png?itok=pp7SXH9g (Creating a new GitHub project board.)
-[11]:https://help.github.com/articles/about-automation-for-project-boards/
-[12]:/file/393351
-[13]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-issues-metadata.png?itok=xp5auxCQ (Tracking progress)
-[14]:/file/393366
-[15]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-project-boards-overview.png?itok=QSbOOOkF (Development progress board)
-[16]:https://about.gitlab.com/features/issueboard/
-[17]:https://taiga.io/
diff --git a/sources/talk/20180420 What You Don-t Know About Linux Open Source Could Be Costing to More Than You Think.md b/sources/talk/20180420 What You Don-t Know About Linux Open Source Could Be Costing to More Than You Think.md
deleted file mode 100644
index 10511c3a7d..0000000000
--- a/sources/talk/20180420 What You Don-t Know About Linux Open Source Could Be Costing to More Than You Think.md
+++ /dev/null
@@ -1,39 +0,0 @@
-What You Don’t Know About Linux Open Source Could Be Costing to More Than You Think
-======
-
-If you would like to test out Linux before completely switching it as your everyday driver, there are a number of means by which you can do it. Linux was not intended to run on Windows, and Windows was not meant to host Linux. To begin with, and perhaps most of all, Linux is open source computer software. In any event, Linux outperforms Windows on all your hardware.
-
-If you’ve always wished to try out Linux but were never certain where to begin, have a look at our how to begin guide for Linux. Linux is not any different than Windows or Mac OS, it’s basically an Operating System but the leading different is the fact that it is Free for everyone. Employing Linux today isn’t any more challenging than switching from one sort of smartphone platform to another.
-
-You’re most likely already using Linux, whether you are aware of it or not. Linux has a lot of distinct versions to suit nearly any sort of user. Today, Linux is a small no-brainer. Linux plays an essential part in keeping our world going.
-
-Even then, it is dependent on the build of Linux that you’re using. Linux runs a lot of the underbelly of cloud operations. Linux is also different in that, even though the core pieces of the Linux operating system are usually common, there are lots of distributions of Linux, like different software alternatives. While Linux might seem intimidatingly intricate and technical to the ordinary user, contemporary Linux distros are in reality very user-friendly, and it’s no longer the case you have to have advanced skills to get started using them. Linux was the very first major Internet-centred open-source undertaking. Linux is beginning to increase the range of patches it pushes automatically, but several of the security patches continue to be opt-in only.
-
-You are able to remove Linux later in case you need to. Linux plays a vital part in keeping our world going. Linux supplies a huge library of functionality which can be leveraged to accelerate development.
-
-Even then, it’s dependent on the build of Linux that you’re using. Linux is also different in that, even though the core pieces of the Linux operating system are typically common, there are lots of distributions of Linux, like different software alternatives. While Linux might seem intimidatingly intricate and technical to the ordinary user, contemporary Linux distros are in fact very user-friendly, and it’s no longer the case you require to have advanced skills to get started using them. Linux runs a lot of the underbelly of cloud operations. Linux is beginning to increase the range of patches it pushes automatically, but several of the security patches continue to be opt-in only. Read More, open source projects including Linux are incredibly capable because of the contributions that all these individuals have added over time.
-
-### Life After Linux Open Source
-
-The development edition of the manual typically has more documentation, but might also document new characteristics that aren’t in the released version. Fortunately, it’s so lightweight you can just jump to some other version in case you don’t like it. It’s extremely hard to modify the compiled version of the majority of applications and nearly not possible to see exactly the way the developer created different sections of the program.
-
-On the challenges of bottoms-up go-to-market It’s really really hard to grasp the difference between your organic product the product your developers use and love and your company product, which ought to be, effectively, a different product. As stated by the report, it’s going to be hard for developers to switch. Developers are now incredibly important and influential in the purchasing procedure. Some OpenWrt developers will attend the event and get ready to reply to your questions!
-
-When the program is installed, it has to be configured. Suppose you discover that the software you bought actually does not do what you would like it to do. Open source software is much more common than you believe, and an amazing philosophy to live by. Employing open source software gives an inexpensive method to bootstrap a business. It’s more difficult to deal with closed source software generally. So regarding Application and Software, you’re all set if you are prepared to learn an alternate software or finding a means to make it run on Linux. Possibly the most famous copyleft software is Linux.
-
-Article sponsored by [Vegas Palms online slots][1]
-
-
---------------------------------------------------------------------------------
-
-via: https://linuxaria.com/article/what-you-dont-know-about-linux-open-source-could-be-costing-to-more-than-you-think
-
-作者:[Marc Fisher][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://linuxaria.com
-[1]:https://www.vegaspalmscasino.com/casino-games/slots/
diff --git a/sources/talk/20180424 There-s a Server in Every Serverless Platform.md b/sources/talk/20180424 There-s a Server in Every Serverless Platform.md
deleted file mode 100644
index 9bc935c06d..0000000000
--- a/sources/talk/20180424 There-s a Server in Every Serverless Platform.md
+++ /dev/null
@@ -1,87 +0,0 @@
-There’s a Server in Every Serverless Platform
-======
-
-
-Serverless computing or Function as a Service (FaaS) is a new buzzword created by an industry that loves to coin new terms as market dynamics change and technologies evolve. But what exactly does it mean? What is serverless computing?
-
-Before getting into the definition, let’s take a brief history lesson from Sirish Raghuram, CEO and co-founder of Platform9, to understand the evolution of serverless computing.
-
-“In the 90s, we used to build applications and run them on hardware. Then came virtual machines that allowed users to run multiple applications on the same hardware. But you were still running the full-fledged OS for each application. The arrival of containers got rid of OS duplication and process level isolation which made it lightweight and agile,” said Raghuram.
-
-Serverless, specifically, Function as a Service, takes it to the next level as users are now able to code functions and run them at the granularity of build, ship and run. There is no complexity of underlying machinery needed to run those functions. No need to worry about spinning containers using Kubernetes. Everything is hidden behind the scenes.
-
-“That’s what is driving a lot of interest in function as a service,” said Raghuram.
-
-### What exactly is serverless?
-
-There is no single definition of the term, but to build some consensus around the idea, the [Cloud Native Computing Foundation (CNCF)][1] Serverless Working Group wrote a [white paper][2] to define serverless computing.
-
-According to the white paper, “Serverless computing refers to the concept of building and running applications that do not require server management. It describes a finer-grained deployment model where applications, bundled as one or more functions, are uploaded to a platform and then executed, scaled, and billed in response to the exact demand needed at the moment.”
-
-Ken Owens, a member of the Technical Oversight Committee at CNCF said that the primary goal of serverless computing is to help users build and run their applications without having to worry about the cost and complexity of servers in terms of provisioning, management and scaling.
-
-“Serverless is a natural evolution of cloud-native computing. The CNCF is advancing serverless adoption through collaboration and community-driven initiatives that will enable interoperability,” [said][3] Chris Aniszczyk, COO, CNCF.
-
-### It’s not without servers
-
-First things first, don’t get fooled by the term “serverless.” There are still servers in serverless computing. Remember what Raghuram said: all the machinery is hidden; it’s not gone.
-
-The clear benefit here is that developers need not concern themselves with tasks that don’t add any value to their deliverables. Instead of worrying about managing the function, they can dedicate their time to adding featured and building apps that add business value. Time is money and every minute saved in management goes toward innovation. Developers don’t have to worry about scaling based on peaks and valleys; it’s automated. Because cloud providers charge only for the duration that functions are run, developers cut costs by not having to pay for blinking lights.
-
-But… someone still has to do the work behind the scenes. There are still servers offering FaaS platforms.
-
-In the case of public cloud offerings like Google Cloud Platform, AWS, and Microsoft Azure, these companies manage the servers and charge customers for running those functions. In the case of private cloud or datacenters, where developers don’t have to worry about provisioning or interacting with such servers, there are other teams who do.
-
-The CNCF white paper identifies two groups of professionals that are involved in the serverless movement: developers and providers. We have already talked about developers. But, there are also providers that offer serverless platforms; they deal with all the work involved in keeping that server running.
-
-That’s why many companies, like SUSE, refrain from using the term “serverless” and prefer the term function as a service, because they offer products that run those “serverless” servers. But what kind of functions are these? Is it the ultimate future of app delivery?
-
-### Event-driven computing
-
-Many see serverless computing as an umbrella that offers FaaS among many other potential services. According to CNCF, FaaS provides event-driven computing where functions are triggered by events or HTTP requests. “Developers run and manage application code with functions that are triggered by events or HTTP requests. Developers deploy small units of code to the FaaS, which are executed as needed as discrete actions, scaling without the need to manage servers or any other underlying infrastructure,” said the white paper.
-
-Does that mean FaaS is the silver bullet that solves all problems for developing and deploying applications? Not really. At least not at the moment. FaaS does solve problems in several use cases and its scope is expanding. A good use case of FaaS could be the functions that an application needs to run when an event takes place.
-
-Let’s take an example: a user takes a picture from a phone and uploads it to the cloud. Many things happen when the picture is uploaded - it’s scanned (exif data is read), a thumbnail is created, based on deep learning/machine learning the content of the image is analyzed, the information of the image is stored in the database. That one event of uploading that picture triggers all those functions. Those functions die once the event is over. That’s what FaaS does. It runs code quickly to perform all those tasks and then disappears.
-
-That’s just one example. Another example could be an IoT device where a motion sensor triggers an event that instructs the camera to start recording and sends the clip to the designated contant. Your thermostat may trigger the fan when the sensor detects a change in temperature. These are some of the many use cases where function as a service make more sense than the traditional approach. Which also says that not all applications (at least at the moment, but that will change as more organizations embrace the serverless platform) can be run as function as service.
-
-According to CNCF, serverless computing should be considered if you have these kinds of workloads:
-
- * Asynchronous, concurrent, easy to parallelize into independent units of work
-
- * Infrequent or has sporadic demand, with large, unpredictable variance in scaling requirements
-
- * Stateless, ephemeral, without a major need for instantaneous cold start time
-
- * Highly dynamic in terms of changing business requirements that drive a need for accelerated developer velocity
-
-
-
-
-### Why should you care?
-
-Serverless is a very new technology and paradigm, just the way VMs and containers transformed the app development and delivery models, FaaS can also bring dramatic changes. We are still in the early days of serverless computing. As the market evolves, consensus is created and new technologies evolve, and FaaS may grow beyond the workloads and use cases mentioned here.
-
-What is becoming quite clear is that companies who are embarking on their cloud native journey must have serverless computing as part of their strategy. The only way to stay ahead of competitors is by keeping up with the latest technologies and trends.
-
-It’s about time to put serverless into servers.
-
-For more information, check out the CNCF Working Group's serverless whitepaper [here][2]. And, you can learn more at [KubeCon + CloudNativeCon Europe][4], coming up May 2-4 in Copenhagen, Denmark.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/4/theres-server-every-serverless-platform
-
-作者:[SWAPNIL BHARTIYA][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/arnieswap
-[1]:https://www.cncf.io/
-[2]:https://github.com/cncf/wg-serverless/blob/master/whitepaper/cncf_serverless_whitepaper_v1.0.pdf
-[3]:https://www.cncf.io/blog/2018/02/14/cncf-takes-first-step-towards-serverless-computing/
-[4]:https://events.linuxfoundation.org/events/kubecon-cloudnativecon-europe-2018/attend/register/
diff --git a/sources/talk/20180511 Looking at the Lispy side of Perl.md b/sources/talk/20180511 Looking at the Lispy side of Perl.md
deleted file mode 100644
index 1fa51b314c..0000000000
--- a/sources/talk/20180511 Looking at the Lispy side of Perl.md
+++ /dev/null
@@ -1,357 +0,0 @@
-Looking at the Lispy side of Perl
-======
-
-Some programming languages (e.g., C) have named functions only, whereas others (e.g., Lisp, Java, and Perl) have both named and unnamed functions. A lambda is an unnamed function, with Lisp as the language that popularized the term. Lambdas have various uses, but they are particularly well-suited for data-rich applications. Consider this depiction of a data pipeline, with two processing stages shown:
-
-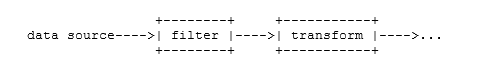
-
-### Lambdas and higher-order functions
-
-The filter and transform stages can be implemented as higher-order functions—that is, functions that can take a function as an argument. Suppose that the depicted pipeline is part of an accounts-receivable application. The filter stage could consist of a function named `filter_data`, whose single argument is another function—for example, a `high_buyers` function that filters out amounts that fall below a threshold. The transform stage might convert amounts in U.S. dollars to equivalent amounts in euros or some other currency, depending on the function plugged in as the argument to the higher-order `transform_data` function. Changing the filter or the transform behavior requires only plugging in a different function argument to the higher order `filter_data` or `transform_data` functions.
-
-Lambdas serve nicely as arguments to higher-order functions for two reasons. First, lambdas can be crafted on the fly, and even written in place as arguments. Second, lambdas encourage the coding of pure functions, which are functions whose behavior depends solely on the argument(s) passed in; such functions have no side effects and thereby promote safe concurrent programs.
-
-Perl has a straightforward syntax and semantics for lambdas and higher-order functions, as shown in the following example:
-
-### A first look at lambdas in Perl
-
-```
-#!/usr/bin/perl
-
-use strict;
-use warnings;
-
-## References to lambdas that increment, decrement, and do nothing.
-## $_[0] is the argument passed to each lambda.
-my $inc = sub { $_[0] + 1 }; ## could use 'return $_[0] + 1' for clarity
-my $dec = sub { $_[0] - 1 }; ## ditto
-my $nop = sub { $_[0] }; ## ditto
-
-sub trace {
- my ($val, $func, @rest) = @_;
- print $val, " ", $func, " ", @rest, "\nHit RETURN to continue...\n";
- <STDIN>;
-}
-
-## Apply an operation to a value. The base case occurs when there are
-## no further operations in the list named @rest.
-sub apply {
- my ($val, $first, @rest) = @_;
- trace($val, $first, @rest) if 1; ## 0 to stop tracing
-
- return ($val, apply($first->($val), @rest)) if @rest; ## recursive case
- return ($val, $first->($val)); ## base case
-}
-
-my $init_val = 0;
-my @ops = ( ## list of lambda references
- $inc, $dec, $dec, $inc,
- $inc, $inc, $inc, $dec,
- $nop, $dec, $dec, $nop,
- $nop, $inc, $inc, $nop
- );
-
-## Execute.
-print join(' ', apply($init_val, @ops)), "\n";
-## Final line of output: 0 1 0 -1 0 1 2 3 2 2 1 0 0 0 1 2 2strictwarningstraceSTDINapplytraceapplyapply
-```
-
-The lispy program shown above highlights the basics of Perl lambdas and higher-order functions. Named functions in Perl start with the keyword `sub` followed by a name:
-```
-sub increment { ... } # named function
-
-```
-
-An unnamed or anonymous function omits the name:
-```
-sub {...} # lambda, or unnamed function
-
-```
-
-In the lispy example, there are three lambdas, and each has a reference to it for convenience. Here, for review, is the `$inc` reference and the lambda referred to:
-```
-my $inc = sub { $_[0] + 1 };
-
-```
-
-The lambda itself, the code block to the right of the assignment operator `=`, increments its argument `$_[0]` by 1. The lambda’s body is written in Lisp style; that is, without either an explicit `return` or a semicolon after the incrementing expression. In Perl, as in Lisp, the value of the last expression in a function’s body becomes the returned value if there is no explicit `return` statement. In this example, each lambda has only one expression in its body—a simplification that befits the spirit of lambda programming.
-
-The `trace` function in the lispy program helps to clarify how the program works (as I'll illustrate below). The higher-order function `apply`, a nod to a Lisp function of the same name, takes a numeric value as its first argument and a list of lambda references as its second argument. The `apply` function is called initially, at the bottom of the program, with zero as the first argument and the list named `@ops` as the second argument. This list consists of 16 lambda references from among `$inc` (increment a value), `$dec` (decrement a value), and `$nop` (do nothing). The list could contain the lambdas themselves, but the code is easier to write and to understand with the more concise lambda references.
-
-The logic of the higher-order `apply` function can be clarified as follows:
-
- 1. The argument list passed to `apply` in typical Perl fashion is separated into three pieces:
-```
-my ($val, $first, @rest) = @_; ## break the argument list into three elements
-
-```
-
-The first element `$val` is a numeric value, initially `0`. The second element `$first` is a lambda reference, one of `$inc` `$dec`, or `$nop`. The third element `@rest` is a list of any remaining lambda references after the first such reference is extracted as `$first`.
-
- 2. If the list `@rest` is not empty after its first element is removed, then `apply` is called recursively. The two arguments to the recursively invoked `apply` are:
-
- * The value generated by applying lambda operation `$first` to numeric value `$val`. For example, if `$first` is the incrementing lambda to which `$inc` refers, and `$val` is 2, then the new first argument to `apply` would be 3.
- * The list of remaining lambda references. Eventually, this list becomes empty because each call to `apply` shortens the list by extracting its first element.
-
-
-
-Here is some output from a sample run of the lispy program, with `%` as the command-line prompt:
-```
-% ./lispy.pl
-
-0 CODE(0x8f6820) CODE(0x8f68c8)CODE(0x8f68c8)CODE(0x8f6820)CODE(0x8f6820)CODE(0x8f6820)...
-Hit RETURN to continue...
-
-1 CODE(0x8f68c8) CODE(0x8f68c8)CODE(0x8f6820)CODE(0x8f6820)CODE(0x8f6820)CODE(0x8f6820)...
-Hit RETURN to continue
-```
-
-The first output line can be clarified as follows:
-
- * The `0` is the numeric value passed as an argument in the initial (and thus non-recursive) call to function `apply`. The argument name is `$val` in `apply`.
- * The `CODE(0x8f6820)` is a reference to one of the lambdas, in this case the lambda to which `$inc` refers. The second argument is thus the address of some lambda code. The argument name is `$first` in `apply`
- * The third piece, the series of `CODE` references, is the list of lambda references beyond the first. The argument name is `@rest` in `apply`.
-
-
-
-The second line of output shown above also deserves a look. The numeric value is now `1`, the result of incrementing `0`: the initial lambda is `$inc` and the initial value is `0`. The extracted reference `CODE(0x8f68c8)` is now `$first`, as this reference is the first element in the `@rest` list after `$inc` has been extracted earlier.
-
-Eventually, the `@rest` list becomes empty, which ends the recursive calls to `apply`. In this case, the function `apply` simply returns a list with two elements:
-
- 1. The numeric value taken in as an argument (in the sample run, 2).
- 2. This argument transformed by the lambda (also 2 because the last lambda reference happens to be `$nop` for do nothing).
-
-
-
-The lispy example underscores that Perl supports lambdas without any special fussy syntax: A lambda is just an unnamed code block, perhaps with a reference to it for convenience. Lambdas themselves, or references to them, can be passed straightforwardly as arguments to higher-order functions such as `apply` in the lispy example. Invoking a lambda through a reference is likewise straightforward. In the `apply` function, the call is:
-```
-$first->($val) ## $first is a lambda reference, $val a numeric argument passed to the lambda
-
-```
-
-### A richer code example
-
-The next code example puts a lambda and a higher-order function to practical use. The example implements Conway’s Game of Life, a cellular automaton that can be represented as a matrix of cells. Such a matrix goes through various transformations, each yielding a new generation of cells. The Game of Life is fascinating because even relatively simple initial configurations can lead to quite complex behavior. A quick look at the rules governing cell birth, survival, and death is in order.
-
-Consider this 5x5 matrix, with a star representing a live cell and a dash representing a dead one:
-```
- ----- ## initial configuration
- --*--
- --*--
- --*--
- -----
-```
-
-The next generation becomes:
-```
- ----- ## next generation
- -----
- -***-
- ----
- -----
-```
-
-As life continues, the generations oscillate between these two configurations.
-
-Here are the rules determining birth, death, and survival for a cell. A given cell has between three neighbors (a corner cell) and eight neighbors (an interior cell):
-
- * A dead cell with exactly three live neighbors comes to life.
- * A live cell with more than three live neighbors dies from over-crowding.
- * A live cell with two or three live neighbors survives; hence, a live cell with fewer than two live neighbors dies from loneliness.
-
-
-
-In the initial configuration shown above, the top and bottom live cells die because neither has two or three live neighbors. By contrast, the middle live cell in the initial configuration gains two live neighbors, one on either side, in the next generation.
-
-## Conway’s Game of Life
-```
-#!/usr/bin/perl
-
-### A simple implementation of Conway's game of life.
-# Usage: ./gol.pl [input file] ;; If no file name given, DefaultInfile is used.
-
-use constant Dead => "-";
-use constant Alive => "*";
-use constant DefaultInfile => 'conway.in';
-
-use strict;
-use warnings;
-
-my $dimension = undef;
-my @matrix = ();
-my $generation = 1;
-
-sub read_data {
- my $datafile = DefaultInfile;
- $datafile = shift @ARGV if @ARGV;
- die "File $datafile does not exist.\n" if !-f $datafile;
- open(INFILE, "<$datafile");
-
- ## Check 1st line for dimension;
- $dimension = <INFILE>;
- die "1st line of input file $datafile not an integer.\n" if $dimension !~ /\d+/;
-
- my $record_count = 0;
- while (<INFILE>) {
- chomp($_);
- last if $record_count++ == $dimension;
- die "$_: bad input record -- incorrect length\n" if length($_) != $dimension;
- my @cells = split(//, $_);
- push @matrix, @cells;
- }
- close(INFILE);
- draw_matrix();
-}
-
-sub draw_matrix {
- my $n = $dimension * $dimension;
- print "\n\tGeneration $generation\n";
- for (my $i = 0; $i < $n; $i++) {
- print "\n\t" if ($i % $dimension) == 0;
- print $matrix[$i];
- }
- print "\n\n";
- $generation++;
-}
-
-sub has_left_neighbor {
- my ($ind) = @_;
- return ($ind % $dimension) != 0;
-}
-
-sub has_right_neighbor {
- my ($ind) = @_;
- return (($ind + 1) % $dimension) != 0;
-}
-
-sub has_up_neighbor {
- my ($ind) = @_;
- return (int($ind / $dimension)) != 0;
-}
-
-sub has_down_neighbor {
- my ($ind) = @_;
- return (int($ind / $dimension) + 1) != $dimension;
-}
-
-sub has_left_up_neighbor {
- my ($ind) = @_;
- ($ind) && has_up_neighbor($ind);
-}
-
-sub has_right_up_neighbor {
- my ($ind) = @_;
- ($ind) && has_up_neighbor($ind);
-}
-
-sub has_left_down_neighbor {
- my ($ind) = @_;
- ($ind) && has_down_neighbor($ind);
-}
-
-sub has_right_down_neighbor {
- my ($ind) = @_;
- ($ind) && has_down_neighbor($ind);
-}
-
-sub compute_cell {
- my ($ind) = @_;
- my @neighbors;
-
- # 8 possible neighbors
- push(@neighbors, $ind - 1) if has_left_neighbor($ind);
- push(@neighbors, $ind + 1) if has_right_neighbor($ind);
- push(@neighbors, $ind - $dimension) if has_up_neighbor($ind);
- push(@neighbors, $ind + $dimension) if has_down_neighbor($ind);
- push(@neighbors, $ind - $dimension - 1) if has_left_up_neighbor($ind);
- push(@neighbors, $ind - $dimension + 1) if has_right_up_neighbor($ind);
- push(@neighbors, $ind + $dimension - 1) if has_left_down_neighbor($ind);
- push(@neighbors, $ind + $dimension + 1) if has_right_down_neighbor($ind);
-
- my $count = 0;
- foreach my $n (@neighbors) {
- $count++ if $matrix[$n] eq Alive;
- }
-
- if ($matrix[$ind] eq Alive) && (($count == 2) || ($count == 3)); ## survival
- if ($matrix[$ind] eq Dead) && ($count == 3); ## birth
- ; ## death
-}
-
-sub again_or_quit {
- print "RETURN to continue, 'q' to quit.\n";
- my $flag = <STDIN>;
- chomp($flag);
- return ($flag eq 'q') ? 1 : 0;
-}
-
-sub animate {
- my @new_matrix;
- my $n = $dimension * $dimension - 1;
-
- while (1) { ## loop until user signals stop
- @new_matrix = map {compute_cell($_)} (0..$n); ## generate next matrix
-
- splice @matrix; ## empty current matrix
- push @matrix, @new_matrix; ## repopulate matrix
- draw_matrix(); ## display the current matrix
-
- last if again_or_quit(); ## continue?
- splice @new_matrix; ## empty temp matrix
- }
-}
-
-### Execute
-read_data(); ## read initial configuration from input file
-animate(); ## display and recompute the matrix until user tires
-```
-
-The gol program (see [Conway’s Game of Life][1]) has almost 140 lines of code, but most of these involve reading the input file, displaying the matrix, and bookkeeping tasks such as determining the number of live neighbors for a given cell. Input files should be configured as follows:
-```
- 5
- -----
- --*--
- --*--
- --*--
- -----
-```
-
-The first record gives the matrix side, in this case 5 for a 5x5 matrix. The remaining rows are the contents, with stars for live cells and spaces for dead ones.
-
-The code of primary interest resides in two functions, `animate` and `compute_cell`. The `animate` function constructs the next generation, and this function needs to call `compute_cell` on every cell in order to determine the cell’s new status as either alive or dead. How should the `animate` function be structured?
-
-The `animate` function has a `while` loop that iterates until the user decides to terminate the program. Within this `while` loop the high-level logic is straightforward:
-
- 1. Create the next generation by iterating over the matrix cells, calling function `compute_cell` on each cell to determine its new status. At issue is how best to do the iteration. A loop nested inside the `while `loop would do, of course, but nested loops can be clunky. Another way is to use a higher-order function, as clarified shortly.
- 2. Replace the current matrix with the new one.
- 3. Display the next generation.
- 4. Check if the user wants to continue: if so, continue; otherwise, terminate.
-
-
-
-Here, for review, is the call to Perl’s higher-order `map` function, with the function’s name again a nod to Lisp. This call occurs as the first statement within the `while` loop in `animate`:
-```
-while (1) {
- @new_matrix = map {compute_cell($_)} (0..$n); ## generate next matrixcompute_cell
-```
-
-The `map` function takes two arguments: an unnamed code block (a lambda!), and a list of values passed to this code block one at a time. In this example, the code block calls the `compute_cell` function with one of the matrix indexes, 0 through the matrix size - 1. Although the matrix is displayed as two-dimensional, it is implemented as a one-dimensional list.
-
-Higher-order functions such as `map` encourage the code brevity for which Perl is famous. My view is that such functions also make code easier to write and to understand, as they dispense with the required but messy details of loops. In any case, lambdas and higher-order functions make up the Lispy side of Perl.
-
-If you're interested in more detail, I recommend Mark Jason Dominus's book, [Higher-Order Perl][2].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/looking-lispy-side-perl
-
-作者:[Marty Kalin][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mkalindepauledu
-[1]:https://trello-attachments.s3.amazonaws.com/575088ec94ca6ac38b49b30e/5ad4daf12f6b6a3ac2318d28/c0700c7379983ddf61f5ab5ab4891f0c/lispyPerl.html#gol (Conway’s Game of Life)
-[2]:https://www.elsevier.com/books/higher-order-perl/dominus/978-1-55860-701-9
diff --git a/sources/talk/20180527 Whatever Happened to the Semantic Web.md b/sources/talk/20180527 Whatever Happened to the Semantic Web.md
deleted file mode 100644
index 22d48c150a..0000000000
--- a/sources/talk/20180527 Whatever Happened to the Semantic Web.md
+++ /dev/null
@@ -1,106 +0,0 @@
-Whatever Happened to the Semantic Web?
-======
-In 2001, Tim Berners-Lee, inventor of the World Wide Web, published an article in Scientific American. Berners-Lee, along with two other researchers, Ora Lassila and James Hendler, wanted to give the world a preview of the revolutionary new changes they saw coming to the web. Since its introduction only a decade before, the web had fast become the world’s best means for sharing documents with other people. Now, the authors promised, the web would evolve to encompass not just documents but every kind of data one could imagine.
-
-They called this new web the Semantic Web. The great promise of the Semantic Web was that it would be readable not just by humans but also by machines. Pages on the web would be meaningful to software programs—they would have semantics—allowing programs to interact with the web the same way that people do. Programs could exchange data across the Semantic Web without having to be explicitly engineered to talk to each other. According to Berners-Lee, Lassila, and Hendler, a typical day living with the myriad conveniences of the Semantic Web might look something like this:
-
-> The entertainment system was belting out the Beatles’ “We Can Work It Out” when the phone rang. When Pete answered, his phone turned the sound down by sending a message to all the other local devices that had a volume control. His sister, Lucy, was on the line from the doctor’s office: “Mom needs to see a specialist and then has to have a series of physical therapy sessions. Biweekly or something. I’m going to have my agent set up the appointments.” Pete immediately agreed to share the chauffeuring. At the doctor’s office, Lucy instructed her Semantic Web agent through her handheld Web browser. The agent promptly retrieved the information about Mom’s prescribed treatment within a 20-mile radius of her home and with a rating of excellent or very good on trusted rating services. It then began trying to find a match between available appointment times (supplied by the agents of individual providers through their Web sites) and Pete’s and Lucy’s busy schedules.
-
-The vision was that the Semantic Web would become a playground for intelligent “agents.” These agents would automate much of the work that the world had only just learned to do on the web.
-
-![][1]
-
-For a while, this vision enticed a lot of people. After new technologies such as AJAX led to the rise of what Silicon Valley called Web 2.0, Berners-Lee began referring to the Semantic Web as Web 3.0. Many thought that the Semantic Web was indeed the inevitable next step. A New York Times article published in 2006 quotes a speech Berners-Lee gave at a conference in which he said that the extant web would, twenty years in the future, be seen as only the “embryonic” form of something far greater. A venture capitalist, also quoted in the article, claimed that the Semantic Web would be “profound,” and ultimately “as obvious as the web seems obvious to us today.”
-
-Of course, the Semantic Web we were promised has yet to be delivered. In 2018, we have “agents” like Siri that can do certain tasks for us. But Siri can only do what it can because engineers at Apple have manually hooked it up to a medley of web services each capable of answering only a narrow category of questions. An important consequence is that, without being large and important enough for Apple to care, you cannot advertise your services directly to Siri from your own website. Unlike the physical therapists that Berners-Lee and his co-authors imagined would be able to hang out their shingles on the web, today we are stuck with giant, centralized repositories of information. Today’s physical therapists must enter information about their practice into Google or Yelp, because those are the only services that the smartphone agents know how to use and the only ones human beings will bother to check. The key difference between our current reality and the promised Semantic future is best captured by this throwaway aside in the excerpt above: “…appointment times (supplied by the agents of individual providers through **their** Web sites)…”
-
-In fact, over the last decade, the web has not only failed to become the Semantic Web but also threatened to recede as an idea altogether. We now hardly ever talk about “the web” and instead talk about “the internet,” which as of 2016 has become such a common term that newspapers no longer capitalize it. (To be fair, they stopped capitalizing “web” too.) Some might still protest that the web and the internet are two different things, but the distinction gets less clear all the time. The web we have today is slowly becoming a glorified app store, just the easiest way among many to download software that communicates with distant servers using closed protocols and schemas, making it functionally identical to the software ecosystem that existed before the web. How did we get here? If the effort to build a Semantic Web had succeeded, would the web have looked different today? Or have there been so many forces working against a decentralized web for so long that the Semantic Web was always going to be stillborn?
-
-### Semweb Hucksters and Their Metacrap
-
-To some more practically minded engineers, the Semantic Web was, from the outset, a utopian dream.
-
-The basic idea behind the Semantic Web was that everyone would use a new set of standards to annotate their webpages with little bits of XML. These little bits of XML would have no effect on the presentation of the webpage, but they could be read by software programs to divine meaning that otherwise would only be available to humans.
-
-The bits of XML were a way of expressing metadata about the webpage. We are all familiar with metadata in the context of a file system: When we look at a file on our computers, we can see when it was created, when it was last updated, and whom it was originally created by. Likewise, webpages on the Semantic Web would be able to tell your browser who authored the page and perhaps even where that person went to school, or where that person is currently employed. In theory, this information would allow Semantic Web browsers to answer queries across a large collection of webpages. In their article for Scientific American, Berners-Lee and his co-authors explain that you could, for example, use the Semantic Web to look up a person you met at a conference whose name you only partially remember.
-
-Cory Doctorow, a blogger and digital rights activist, published an influential essay in 2001 that pointed out the many problems with depending on voluntarily supplied metadata. A world of “exhaustive, reliable” metadata would be wonderful, he argued, but such a world was “a pipe-dream, founded on self-delusion, nerd hubris, and hysterically inflated market opportunities.” Doctorow had found himself in a series of debates over the Semantic Web at tech conferences and wanted to catalog the serious issues that the Semantic Web enthusiasts (Doctorow calls them “semweb hucksters”) were overlooking. The essay, titled “Metacrap,” identifies seven problems, among them the obvious fact that most web users were likely to provide either no metadata at all or else lots of misleading metadata meant to draw clicks. Even if users were universally diligent and well-intentioned, in order for the metadata to be robust and reliable, users would all have to agree on a single representation for each important concept. Doctorow argued that in some cases a single representation might not be appropriate, desirable, or fair to all users.
-
-Indeed, the web had already seen people abusing the HTML `<meta>` tag (introduced at least as early as HTML 4) in an attempt to improve the visibility of their webpages in search results. In a 2004 paper, Ben Munat, then an academic at Evergreen State College, explains how search engines once experimented with using keywords supplied via the `<meta>` tag to index results, but soon discovered that unscrupulous webpage authors were including tags unrelated to the actual content of their webpage. As a result, search engines came to ignore the `<meta>` tag in favor of using complex algorithms to analyze the actual content of a webpage. Munat concludes that a general-purpose Semantic Web is unworkable, and that the focus should be on specific domains within medicine and science.
-
-Others have also seen the Semantic Web project as tragically flawed, though they have located the flaw elsewhere. Aaron Swartz, the famous programmer and another digital rights activist, wrote in an unfinished book about the Semantic Web published after his death that Doctorow was “attacking a strawman.” Nobody expected that metadata on the web would be thoroughly accurate and reliable, but the Semantic Web, or at least a more realistically scoped version of it, remained possible. The problem, in Swartz’ view, was the “formalizing mindset of mathematics and the institutional structure of academics” that the “semantic Webheads” brought to bear on the challenge. In forums like the World Wide Web Consortium (W3C), a huge amount of effort and discussion went into creating standards before there were any applications out there to standardize. And the standards that emerged from these “Talmudic debates” were so abstract that few of them ever saw widespread adoption. The few that did, like XML, were “uniformly scourges on the planet, offenses against hardworking programmers that have pushed out sensible formats (like JSON) in favor of overly-complicated hairballs with no basis in reality.” The Semantic Web might have thrived if, like the original web, its standards were eagerly adopted by everyone. But that never happened because—as [has been discussed][2] on this blog before—the putative benefits of something like XML are not easy to sell to a programmer when the alternatives are both entirely sufficient and much easier to understand.
-
-### Building the Semantic Web
-
-If the Semantic Web was not an outright impossibility, it was always going to require the contributions of lots of clever people working in concert.
-
-The long effort to build the Semantic Web has been said to consist of four phases. The first phase, which lasted from 2001 to 2005, was the golden age of Semantic Web activity. Between 2001 and 2005, the W3C issued a slew of new standards laying out the foundational technologies of the Semantic future.
-
-The most important of these was the Resource Description Framework (RDF). The W3C issued the first version of the RDF standard in 2004, but RDF had been floating around since 1997, when a W3C working group introduced it in a draft specification. RDF was originally conceived of as a tool for modeling metadata and was partly based on earlier attempts by Ramanathan Guha, an Apple engineer, to develop a metadata system for files stored on Apple computers. The Semantic Web working groups at W3C repurposed RDF to represent arbitrary kinds of general knowledge.
-
-RDF would be the grammar in which Semantic webpages expressed information. The grammar is a simple one: Facts about the world are expressed in RDF as triplets of subject, predicate, and object. Tim Bray, who worked with Ramanathan Guha on an early version of RDF, gives the following example, describing TV shows and movies:
-
-```
-@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
-
-@prefix ex: <http://www.example.org/> .
-
-
-ex:vincent_donofrio ex:starred_in ex:law_and_order_ci .
-
-ex:law_and_order_ci rdf:type ex:tv_show .
-
-ex:the_thirteenth_floor ex:similar_plot_as ex:the_matrix .
-```
-
-The syntax is not important, especially since RDF can be represented in a number of formats, including XML and JSON. This example is in a format called Turtle, which expresses RDF triplets as straightforward sentences terminated by periods. The three essential sentences, which appear above after the `@prefix` preamble, state three facts: Vincent Donofrio starred in Law and Order, Law and Order is a type of TV Show, and the movie The Thirteenth Floor has a similar plot as The Matrix. (If you don’t know who Vincent Donofrio is and have never seen The Thirteenth Floor, I, too, was watching Nickelodeon and sipping Capri Suns in 1999.)
-
-Other specifications finalized and drafted during this first era of Semantic Web development describe all the ways in which RDF can be used. RDF in Attributes (RDFa) defines how RDF can be embedded in HTML so that browsers, search engines, and other programs can glean meaning from a webpage. RDF Schema and another standard called OWL allows RDF authors to demarcate the boundary between valid and invalid RDF statements in their RDF documents. RDF Schema and OWL, in other words, are tools for creating what are known as ontologies, explicit specifications of what can and cannot be said within a specific domain. An ontology might include a rule, for example, expressing that no person can be the mother of another person without also being a parent of that person. The hope was that these ontologies would be widely used not only to check the accuracy of RDF found in the wild but also to make inferences about omitted information.
-
-In 2006, Tim Berners-Lee posted a short article in which he argued that the existing work on Semantic Web standards needed to be supplemented by a concerted effort to make semantic data available on the web. Furthermore, once on the web, it was important that semantic data link to other kinds of semantic data, ensuring the rise of a data-based web as interconnected as the existing web. Berners-Lee used the term “linked data” to describe this ideal scenario. Though “linked data” was in one sense just a recapitulation of the original vision for the Semantic Web, it became a term that people could rally around and thus amounted to a rebranding of the Semantic Web project.
-
-Berners-Lee’s article launched the second phase of the Semantic Web’s development, where the focus shifted from setting standards and building toy examples to creating and popularizing large RDF datasets. Perhaps the most successful of these datasets was [DBpedia][3], a giant repository of RDF triplets extracted from Wikipedia articles. DBpedia, which made heavy use of the Semantic Web standards that had been developed in the first half of the 2000s, was a standout example of what could be accomplished using the W3C’s new formats. Today DBpedia describes 4.58 million entities and is used by organizations like the NY Times, BBC, and IBM, which employed DBpedia as a knowledge source for IBM Watson, the Jeopardy-winning artificial intelligence system.
-
-![][4]
-
-The third phase of the Semantic Web’s development involved adapting the W3C’s standards to fit the actual practices and preferences of web developers. By 2008, JSON had begun its meteoric rise to popularity. Whereas XML came packaged with a bunch of associated technologies of indeterminate purpose (XLST, XPath, XQuery, XLink), JSON was just JSON. It was less verbose and more readable. Manu Sporny, an entrepreneur and member of the W3C, had already started using JSON at his company and wanted to find an easy way for RDFa and JSON to work together. The result would be JSON-LD, which in essence was RDF reimagined for a world that had chosen JSON over XML. Sporny, together with his CTO, Dave Longley, issued a draft specification of JSON-LD in 2010. For the next few years, JSON-LD and an updated RDF specification would be the primary focus of Semantic Web work at the W3C. JSON-LD could be used on its own or it could be embedded within a `<script>` tag on an HTML page, making it an alternative to both RDF and RDFa.
-
-Work on JSON-LD coincided with the development of [schema.org][5], a centralized collection of simple schemas for describing things that might exist on the web. schema.org was started by Google, Bing, and Yahoo with the express purpose of delivering better search results by agreeing to a common set of vocabularies. schema.org vocabularies, together with JSON-LD, are now used to drive features like Google’s Knowledge Graph. The approach was a more practical and less abstract one, where immediate applications in search results were the focus. The schema.org team are careful to state on their website that they are not attempting to create a “universal ontology.”
-
-Today, work on the Semantic Web seems to have petered out. The W3C still does some work on the Semantic Web under the heading of “Data Activity,” which might charitably be called the fourth phase of the Semantic Web project. But it’s telling that the most recent “Data Activity” project is a study of what the W3C must do to improve its standardization process. Even the W3C now appears to recognize that few of its Semantic Web standards have been widely adopted and that simpler standards would have been more successful. The attitude at the W3C seems to be one of retrenchment and introspection, perhaps in the hope of being better prepared when the Semantic Web looks promising again.
-
-### A Lingering Legacy
-
-And so the Semantic Web, as colorfully described by one person, is “as dead as last year’s roadkill.” At least, the version of the Semantic Web originally proposed by Tim Berners-Lee, which once seemed to be the imminent future of the web, is unlikely to emerge soon. That said, many of the technologies and ideas that were developed amid the push to create the Semantic Web have been repurposed and live on in various applications. As already mentioned, Google relies on Semantic Web technologies—now primarily JSON-LD—to generate useful conceptual summaries next to search results. schema.org maintains a list of “vocabularies” that web developers can use to publish easily understood data for a wide audience—it is a new, more practical imagining of what a public, shared ontology might look like. And to some degree, the many REST APIs now available constitute a diminished Semantic Web. What wasn’t possible in 2001 now is: You can easily build applications that make use of data from across the web. The difference is that you must sign up for each API one by one beforehand, which in addition to being wearisome also gives whoever hosts the API enormous control over how you access their data.
-
-Another modern application of Semantic Web technologies, perhaps the most popular and successful in recent years outside of Google, is Facebook’s [OpenGraph][6] protocol. The OpenGraph protocol defines a schema that web developers can use (via RDFa) to determine how a web page is displayed when shared in a social media application. For example, a web developer working at the New York Times might use OpenGraph to specify the title and thumbnail that should appear when a New York Times article is shared in Facebook. In one sense, this is an application of Semantic Web technologies true to the Semantic Web’s origins in research on metadata. Tagging a webpage with extra information about who wrote it and what it is about is exactly the kind of metadata authoring the Semantic Web was going to depend on. But in another sense, OpenGraph is an application of Semantic Web technologies to further a purpose somewhat at odds with the philosophy of the web. The metadata isn’t meant to be general-purpose, after all. People tag their webpages using OpenGraph because they want links to their content to unfurl properly in Facebook. And the more information Facebook knows about your website, the closer Facebook gets to simply reproducing your entire website within Facebook, portending a future where the open web is a mythical land beyond Facebook’s towering blue walls.
-
-What’s fascinating about JSON-LD and OpenGraph is that you can use them without knowing anything about subject-predicate-object triplets, RDF, RDF Schema, ontologies, OWL, or really any other Semantic Web technologies—you don’t even have to know XML. Manu Sporny has even said that the JSON-LD working group at W3C made a special effort to avoid references to RDF in the JSON-LD specification. This is almost certainly why these technologies have succeeded and continue to be popular. Nobody wants to use a tool that can only be fully understood by reading a whole family of specifications.
-
-It’s interesting to consider what might have happened if simple formats like JSON-LD had appeared earlier. The Semantic Web could have sidestepped its fatal association with XML. More people might have been tempted to mark up their websites with RDF, but even that may not have saved the Semantic Web. Sean B. Palmer, an Internet Person that has scrubbed all biographical information about himself from the internet but who claims to have worked in the Semantic Web world for a while in the 2000s, posits that the real problem was the lack of a truly decentralized infrastructure to host the Semantic Web on. To host your own website, you need to buy a domain name from ICANN, configure it correctly using DNS, and then pay someone to host your content if you don’t already have a server of your own. We shouldn’t be surprised if the average person finds it easier to enter their information into a giant, corporate data repository. And in a web of giant, corporate data repositories, there are no compelling use cases for Semantic Web technologies.
-
-So the problems that confronted the Semantic Web were more numerous and profound than just “XML sucks.” All the same, it’s hard to believe that the Semantic Web is truly dead and gone. Some of the particular technologies that the W3C dreamed up in the early 2000s may not have a future, but the decentralized vision of the web that Tim Berners-Lee and his follow researchers described in Scientific American is too compelling to simply disappear. Imagine a web where, rather than filling out the same tedious form every time you register for a service, you were somehow able to authorize services to get that information from your own website. Imagine a Facebook that keeps your list of friends, hosted on your own website, up-to-date, rather than vice-versa. Basically, the Semantic Web was going to be a web where everyone gets to have their own personal REST API, whether they know the first thing about computers or not. Conceived of that way, it’s easy to see why the Semantic Web hasn’t yet been realized. There are so many engineering and security issues to sort out between here and there. But it’s also easy to see why the dream of the Semantic Web seduced so many people.
-
-If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][7] on Twitter or subscribe to the [RSS feed][8] to make sure you know when a new post is out.
-
---------------------------------------------------------------------------------
-
-via: https://twobithistory.org/2018/05/27/semantic-web.html
-
-作者:[Two-Bit History][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://twobithistory.org
-[b]: https://github.com/lujun9972
-[1]: https://twobithistory.org/images/scientific_american_cover.jpg
-[2]: https://twobithistory.org/2017/09/21/the-rise-and-rise-of-json.html
-[3]: http://wiki.dbpedia.org/
-[4]: https://twobithistory.org/images/linked_data.png
-[5]: http://schema.org/
-[6]: http://ogp.me/
-[7]: https://twitter.com/TwoBitHistory
-[8]: https://twobithistory.org/feed.xml
diff --git a/sources/talk/20180604 10 principles of resilience for women in tech.md b/sources/talk/20180604 10 principles of resilience for women in tech.md
deleted file mode 100644
index be1960d0c9..0000000000
--- a/sources/talk/20180604 10 principles of resilience for women in tech.md
+++ /dev/null
@@ -1,93 +0,0 @@
-10 principles of resilience for women in tech
-======
-
-
-
-Being a woman in tech is pretty damn cool. For every headline about [what Silicon Valley thinks of women][1], there are tens of thousands of women building, innovating, and managing technology teams around the world. Women are helping build the future despite the hurdles they face, and the community of women and allies growing to support each other is stronger than ever. From [BetterAllies][2] to organizations like [Girls Who Code][3] and communities like the one I met recently at [Red Hat Summit][4], there are more efforts than ever before to create an inclusive community for women in tech.
-
-But the tech industry has not always been this welcoming, nor is the experience for women always aligned with the aspiration. And so we're feeling the pain. Women in technology roles have dropped from its peak in 1991 at 36% to 25% today, [according to a report by NCWIT][5]. [Harvard Business Review estimates][6] that more than half of the women in tech will eventually leave due to hostile work conditions. Meanwhile, Ernst & Young recently shared [a study][7] and found that merely 11% of high school girls are planning to pursue STEM careers.
-
-We have much work to do, lest we build a future that is less inclusive than the one we live in today. We need everyone at the table, in the lab, at the conference and in the boardroom.
-
-I've been interviewing both women and men for more than a year now about their experiences in tech, all as part of [The Chasing Grace Project][8], a documentary series about women in tech. The purpose of the series is to help recruit and retain female talent for the tech industry and to give women a platform to be seen, heard, and acknowledged for their experiences. We believe that compelling story can begin to transform culture.
-
-### What Chasing Grace taught me
-
-What I've learned is that no matter the dismal numbers, women want to keep building and they collectively possess a resilience unmatched by anything I've ever seen. And this is inspiring me. I've found a power, a strength, and a beauty in every story I've heard that is the result of resilience. I recently shared with the attendees at the Red Hat Summit Women’s Leadership Luncheon the top 10 principles of resilience I've heard from throughout my interviews so far. I hope that by sharing them here the ideas and concepts can support and inspire you, too.
-
-#### 1\. Practice optimism
-
-When taken too far, optimism can give you blind spots. But a healthy dose of optimism allows you to see the best in people and situations and that positive energy comes back to you 100-fold. I haven’t met a woman yet as part of this project who isn’t an optimist.
-
-#### 2\. Build mental toughness
-
-I haven’t met a woman yet as part of this project who isn’t an optimist.
-
-When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said _mental toughness_. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
-
-#### 3\. Recognize your power
-
-When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
-
-Most of the women I’ve interviewed don’t know their own power and so they give it away unknowingly. Too many women have told me that they willingly took on the housekeeping roles on their teams—picking up coffee, donuts, office supplies, and making the team dinner reservations. Usually the only woman on their teams, this put them in a position to be seen as less valuable than their male peers who didn’t readily volunteer for such tasks. All of us, men and women, have innate powers. Identify and know what your powers are and understand how to use them for good. You have so much more power than you realize. Know it, recognize it, use it strategically, and don’t give it away. It’s yours.
-
-#### 4\. Know your strength
-
-Not sure whether you can confront your boss about why you haven’t been promoted? You can. You don’t know your strength until you exercise it. Then, you’re unstoppable. Test your strength by pushing your fear aside and see what happens.
-
-#### 5\. Celebrate vulnerability
-
-Every single successful women I've interviewed isn't afraid to be vulnerable. She finds her strength in acknowledging where she is vulnerable and she looks to connect with others in that same place. Exposing, sharing, and celebrating each other’s vulnerabilities allows us to tap into something far greater than simply asserting strength; it actually builds strength—mental and emotional muscle. One women with whom we’ve talked shared how starting her own tech company made her feel like she was letting her husband down. She shared with us the details of that conversation with her husband. Honest conversations that share our doubts and our aspirations is what makes women uniquely suited to lead in many cases. Allow yourself to be seen and heard. It’s where we grow and learn.
-
-#### 6\. Build community
-
-If it doesn't exist, build it.
-
-Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
-
-#### 7\. Celebrate victories
-
-Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
-
-One of my favorite Facebook groups is [TechLadies][9] because of its recurring hashtag #YEPIDIDTHAT. It allows women to share their victories in a supportive community. No matter how big or small, don't let a victory go unrecognized. When you recognize your wins, you own them. They become a part of you and you build on top of each one.
-
-#### 8\. Be curious
-
-Being curious in the tech community often means asking questions: How does that work? What language is that written in? How can I make this do that? When I've managed teams over the years, my best employees have always been those who ask a lot of questions, those who are genuinely curious about things. But in this context, I mean be curious when your gut tells you something doesn't seem right. _The energy in the meeting was off. Did he/she just say what I think he said?_ Ask questions. Investigate. Communicate openly and clearly. It's the only way change happens.
-
-#### 9\. Harness courage
-
-One women told me a story about a meeting in which the women in the room kept being dismissed and talked over. During the debrief roundtable portion of the meeting, she called it out and asked if others noticed it, too. Being a 20-year tech veteran, she'd witnessed and experienced this many times but she had never summoned the courage to speak up about it. She told me she was incredibly nervous and was texting other women in the room to see if they agreed it should be addressed. She didn't want to be a "troublemaker." But this kind of courage results in an increased understanding by everyone in that room and can translate into other meetings, companies, and across the industry.
-
-#### 10\. Share your story
-
-When people connect to compelling story, they begin to change behaviors.
-
-Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
-
-Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
-
-If you would like to support [The Chasing Grace Project][8], email Jennifer Cloer to learn more about how to get involved: [jennifer@wickedflicksproductions.com][10]
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/being-woman-tech-10-principles-resilience
-
-作者:[Jennifer Cloer][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jennifer-cloer
-[1]:http://www.newsweek.com/2015/02/06/what-silicon-valley-thinks-women-302821.html%E2%80%9D
-[2]:https://opensource.com/article/17/6/male-allies-tech-industry-needs-you%E2%80%9D
-[3]:https://twitter.com/GirlsWhoCode%E2%80%9D
-[4]:http://opensource.com/tags/red-hat-summit%E2%80%9D
-[5]:https://www.ncwit.org/sites/default/files/resources/womenintech_facts_fullreport_05132016.pdf%E2%80%9D
-[6]:Dhttp://www.latimes.com/business/la-fi-women-tech-20150222-story.html%E2%80%9D
-[7]:http://www.ey.com/us/en/newsroom/news-releases/ey-news-new-research-reveals-the-differences-between-boys-and-girls-career-and-college-plans-and-an-ongoing-need-to-engage-girls-in-stem%E2%80%9D
-[8]:https://www.chasinggracefilm.com/
-[9]:https://www.facebook.com/therealTechLadies/%E2%80%9D
-[10]:mailto:jennifer@wickedflicksproductions.com
diff --git a/sources/talk/20180613 AI Is Coming to Edge Computing Devices.md b/sources/talk/20180613 AI Is Coming to Edge Computing Devices.md
deleted file mode 100644
index 0dc34c9ba3..0000000000
--- a/sources/talk/20180613 AI Is Coming to Edge Computing Devices.md
+++ /dev/null
@@ -1,66 +0,0 @@
-AI Is Coming to Edge Computing Devices
-======
-
-
-
-Very few non-server systems run software that could be called machine learning (ML) and artificial intelligence (AI). Yet, server-class “AI on the Edge” applications are coming to embedded devices, and Arm intends to fight with Intel and AMD over every last one of them.
-
-Arm recently [announced][1] a new [Cortex-A76][2] architecture that is claimed to boost the processing of AI and ML algorithms on edge computing devices by a factor of four. This does not include ML performance gains promised by the new Mali-G76 GPU. There’s also a Mali-V76 VPU designed for high-res video. The Cortex-A76 and two Mali designs are designed to “complement” Arm’s Project Trillium Machine Learning processors (see below).
-
-### Improved performance
-
-The Cortex-A76 differs from the [Cortex-A73][3] and [Cortex-A75][4] IP designs in that it’s designed as much for laptops as for smartphones and high-end embedded devices. Cortex-A76 provides “35 percent more performance year-over-year,” compared to Cortex-A75, claims Arm. The IP, which is expected to arrive in products a year from now, is also said to provide 40 percent improved efficiency.
-
-Like Cortex-A75, which is equivalent to the latest Kyro cores available on Qualcomm’s [Snapdragon 845][5], the Cortex-A76 supports [DynamIQ][6], Arm’s more flexible version of its Big.Little multi-core scheme. Unlike Cortex-A75, which was announced with a Cortex-A55 companion chip, Arm had no new DynamIQ companion for the Cortex-A76.
-
-Cortex-A76 enhancements are said to include decoupled branch prediction and instruction fetch, as well as Arm’s first 4-wide decode core, which boosts the maximum instruction per cycle capability. There’s also higher integer and vector execution throughput, including support for dual-issue native 16B (128-bit) vector and floating-point units. Finally, the new full-cache memory hierarchy is “co-optimized for latency and bandwidth,” says Arm.
-
-Unlike the latest high-end Cortex-A releases, Cortex-A76 represents “a brand new microarchitecture,” says Arm. This is confirmed by [AnandTech’s][7] usual deep-dive analysis. Cortex-A73 and -A75 debuted elements of the new “Artemis” architecture, but the Cortex-A76 is built from scratch with Artemis.
-
-The Cortex-A76 should arrive on 7nm-fabricated TSMC products running at 3GHz, says AnandTech. The 4x improvements in ML workloads are primarily due to new optimizations in the ASIMD pipelines “and how dot products are handled,” says the story.
-
-Meanwhile, [The Register][8] noted that Cortex-A76 is Arm’s first design that will exclusively run 64-bit kernel-level code. The cores will support 32-bit code, but only at non-privileged levels, says the story..
-
-### Mali-G76 GPU and Mali-G72 VPU
-
-The new Mali-G76 GPU announced with Cortex-A76 targets gaming, VR, AR, and on-device ML. The Mali-G76 is said to provide 30 percent more efficiency and performance density and 1.5x improved performance for mobile gaming. The Bifrost architecture GPU also provides 2.7x ML performance improvements compared to the Mali-G72, which was announced last year with the Cortex-A75.
-
-The Mali-V76 VPU supports UHD 8K viewing experiences. It’s aimed at 4x4 video walls, which are especially popular in China and is designed to support the 8K video coverage, which Japan is promising for the 2020 Olympics. 8K@60 streams require four times the bandwidth of 4K@60 streams. To achieve this, Arm added an extra AXI bus and doubled the line buffers throughout the video pipeline. The VPU also supports 8K@30 decode.
-
-### Project Trillium’s ML chip detailed
-
-Arm previously revealed other details about the [Machine Learning][9] (ML) processor, also referred to as MLP. The ML chip will accelerate AI applications including machine translation and face recognition.
-
-The new processor architecture is part of the Project Trillium initiative for AI, and follows Arm’s second-gen Object Detection (OD) Processor for optimizing visual processing and people/object detection. The ML design will initially debut as a co-processor in mobile phones by late 2019.
-
-Numerous block diagrams for the MLP were published by [AnandTech][10], which was briefed on the design. While stating that any judgment about the performance of the still unfinished ML IP will require next year’s silicon release, the publication says that the ML chip appears to check off all the requirements of a neural network accelerator, including providing efficient convolutional computations and data movement while also enabling sufficient programmability.
-
-Arm claims the chips will provide >3TOPs per Watt performance in 7nm designs with absolute throughputs of 4.6TOPs, deriving a target power of approximately 1.5W. For programmability, MLP will initially target Android’s [Neural Networks API][11] and [Arm’s NN SDK][12].
-
-Join us at [Open Source Summit + Embedded Linux Conference Europe][13] in Edinburgh, UK on October 22-24, 2018, for 100+ sessions on Linux, Cloud, Containers, AI, Community, and more.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/6/ai-coming-edge-computing-devices
-
-作者:[Eric Brown][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/ericstephenbrown
-[1]:https://www.arm.com/news/2018/05/arm-announces-new-suite-of-ip-for-premium-mobile-experiences
-[2]:https://community.arm.com/processors/b/blog/posts/cortex-a76-laptop-class-performance-with-mobile-efficiency
-[3]:https://www.linux.com/news/mediateks-10nm-mobile-focused-soc-will-tap-cortex-a73-and-a32
-[4]:http://linuxgizmos.com/arm-debuts-cortex-a75-and-cortex-a55-with-ai-in-mind/
-[5]:http://linuxgizmos.com/hot-chips-on-parade-at-mwc-and-embedded-world/
-[6]:http://linuxgizmos.com/arm-boosts-big-little-with-dynamiq-and-launches-linux-dev-kit/
-[7]:https://www.anandtech.com/show/12785/arm-cortex-a76-cpu-unveiled-7nm-powerhouse
-[8]:https://www.theregister.co.uk/2018/05/31/arm_cortex_a76/
-[9]:https://developer.arm.com/products/processors/machine-learning/arm-ml-processor
-[10]:https://www.anandtech.com/show/12791/arm-details-project-trillium-mlp-architecture
-[11]:https://developer.android.com/ndk/guides/neuralnetworks/
-[12]:https://developer.arm.com/products/processors/machine-learning/arm-nn
-[13]:https://events.linuxfoundation.org/events/elc-openiot-europe-2018/
diff --git a/sources/talk/20180619 A summer reading list for open organization enthusiasts.md b/sources/talk/20180619 A summer reading list for open organization enthusiasts.md
deleted file mode 100644
index d0539c1550..0000000000
--- a/sources/talk/20180619 A summer reading list for open organization enthusiasts.md
+++ /dev/null
@@ -1,133 +0,0 @@
-A summer reading list for open organization enthusiasts
-======
-
-
-
-The books on this year's open organization reading list crystallize so much of what makes "open" work: Honesty, authenticity, trust, and the courage to question those status quo arrangements that prevent us from achieving our potential by working powerfully together.
-
-These nine books—each one a recommendation from a member of our community—represent merely the beginning of an important journey toward greater and better openness.
-
-But they sure are a great place to start.
-
-### Radical Candor
-
-**by Kim Scott** (recommended by [Angela Roberstson][1])
-
-Do you avoid conflict? Love it? Or are you somewhere in between?
-
-Wherever you are on the spectrum, Kim Scott gives you a set of tools for improving your ability to speak your truth in the workplace.
-
-The book is divided into two parts: Part 1 is Scott's perspective on giving feedback, including handling the conflict that might be associated with it. Part 2 focuses on tools and techniques that she recommends.
-
-Radical candor is most impactful for managers when it comes to evaluating and communicating feedback about employee performance. In Chapter 3, "Understand what motivates each person on your team," Scott explains how we can employ radical candor when assessing employees. Included is an explanation of how to have constructive conversations about our assessments.
-
-I also appreciate that Scott spends a few pages sharing her perspective on how gender politics can impact work. With all the emphasis on diversity and inclusion, especially in the tech sector, including this topic in the book is another reason to read.
-
-### Powerful
-**by Patty McCord** (recommended by [Jeff Mackanic][2])
-
-Powerful is an inspiring leadership book by Patty McCord, the former chief talent officer at Netflix. It's a fast-paced book with many great examples drawn from the author's career at Netflix.
-
-One of the key characteristics of an open organization is collaboration, and readers will learn a good deal from McCord as she explains a few of Netflix's core practices that can help any company be more collaborative.
-
-For McCord, collaboration clearly begins with honesty. For example, she writes, "We wanted people to practice radical honesty: telling one another, and us, the truth in a timely fashion and ideally face to face." She also explains how, at Netflix, "We wanted people to have strong, fact-based opinions and to debate them avidly and test them rigorously."
-
-This is a wonderful book that will inspire the reader to look at leadership through a new lens.
-
-### The Code of Trust
-**by Robin Dreeke** (recommended by [Ron McFarland][3])
-
-Author Robin Dreeke was an FBI agent, which gave him experience getting information from total strangers. To do that, he had to get people to be open to him.
-
-His experience led to this book, which offers five rules he calls "The Code of Trust." Put simply, the rules are: 1) Suspend your ego or pride when you meet someone for the first time, 2) Avoid being judgmental about that person, 3) Validate the person's position and feelings, 4) Honor basic reason, and 5) Be generous and encourage building the value of the relationship.
-
-Dreeke argues that you can achieve the above by 1) Aligning your goals with others' after learning what ther goals are, 2) Understanding the power of context and their situations, 3) Crafting the meeting to get them to open up to you, and 4) Connecting with deep communication (something over and above language that includes feelings as well).
-
-The book teaches how to do the above, so I learned a great deal. Overall, though, it makes some important points for anyone interested in open organizations. If people are cooperative, engaged, interactive, and open, an organization with many outside contributors can be very successful. But if people are uninterested, non-cooperative, protective, reluctant to interact, and closed, an organization will suffer.
-
-### Team of Teams
-
-**by Gen. Stanley McChrystal, Chris Fussell, and Tantum Collins** (recommended by [Matt Micene][4])
-
-Does the highly specialized and hierarchical United States military strike you as a source for advice on building agile, integrated, highly disparate teams? This book traces General McChrystal's experiences transforming a team "moving from playing football to basketball, and finding that habits and preconceptions had to be discarded along with pads and cleats."
-
-With lives literally on the line, circumstances forced McChrystal's Joint Special Operations Task Force walks through some radical changes. But as much as this book takes place during a war, it's not a story about a war. It's a story that traces Frederick Winslow Taylor's legacy and impact on the way we think about operational efficiency. It's about the radical restructuring of communications in a siloed organization. It distinguishes the "complex" and the "complicated," and explains the different forces those two concepts exert on organizations. Readers will note many themes that resonate with open organization thinking—like resilience thinking, the OODA loop, systems thinking, and empowered execution in leadership.
-
-Perhaps most importantly, you'll see more than discourse and discussion on these topics. You'll get to see an example of a highly siloed organization successfuly changing its culture and embracing a more transparent and "organic" system of organization that fostered success.
-
-### Liminal Thinking
-
-**by Dave Gray** (recommended by [Angela Roberstson][1])
-
-When I read this book's title, the word "liminal" throws me every time. I think "limit." But as Dave Gray patiently explains, "The word liminal comes from the Latin root limen, which means threshold." Gray shares his perspective on ways that readers can push past the boundaries of our thinking to become more creative, impactul leaders.
-
-I love how Gray quickly explains how beliefs impact our lives. We can reframe beliefs, he says, if we're willing to stop clinging to them. The concise text means that you can read and reread this book as you work to implement the practices for enacting change that Gray provides.
-
-The book is divided into two parts: Principles and Practices. After describing each of the six principles and nine practices, Gray offers a short exercise you can complete. Throughout the book are also great visuals and quotes to ensure you're staying engaged.
-
-Read this book if you're looking for fresh ideas about how to manage change.
-
-### Orbiting the Giant Hairball
-
-**by Gordon MacKenzie** (recommended by [Allison Matlack][5])
-
-Sometimes—even in open organizations—we can struggle to maintain our creativity and authenticity in the face of the bureaucratic processes that live at the heart of every company of certain size. Gordon MacKenzie offers a refreshing alternative to corporate normalcy in this charming book that has been something of a cult classic since it was self-published in the 1980s.
-
-There's a masterpiece in each of us, MacKenzie posits—one that is singular and unique. We can choose to paint by the corporate numbers, or we can find real joy in using bold strokes to create an original work of art.
-
-### Tribal Leadership
-
-**by Dave Logan, John King, and Halee Fischer-Wright** (recommended by [Chris Baynham-Hughes][6])
-
-Too often, technology rather than culture an organization's starting point for transformation, innovation, and speed to market. I've lost count of the times I've used this book to frame conversations around company culture and challenge leaders on what they are doing to foster innovation and loyalty, and to create a workplace in which people. It's been a game-changer for me.
-
-Tribal Leadership is essential reading for anybody interested in workplace culture or a leadership role—especially those wanting to develop open, innovative, and collaborative cultures. It provides an evidence-based approach to developing corporate culture detailing: 1) five distinct stages of tribal culture, 2) a framework to develop yourself and others as tribal leaders, and 3) characteristics and coaching tips to ensure practitioners can identify the levels each individual is at and nudge them to the next level. Each chapter presents a case study narrative before identifying coaching tips and summarizing key points. I found it enjoyable to read and easy to remember.
-
-### Wikipedia and the Politics of Openness
-
-**by Nathaniel Tkacz** (recommended by [Bryan Behrenshausen][7])
-
-This thing we call "open" isn't something natural or eternal—some kind of fixed and immutable essence or quality that somehow exists outside time. It's flexible, contingent, context-specific, and the site of so much negotiation and contestation. What does "open" mean to and for the parties most invested in the term? And what happens when we organize groups and institutions around those very definitions? What (and who) do they enable? And what (and who) do they preclude?
-
-Tkacz explores these questions with historical richness and critical flair by examining one of the world's largest and most notable open organizations: Wikipedia, that paragon of ostensibly participatory and collaborative behavior. Tkacz is perhaps less sanguine: "While the force of the open must be acknowledged, the real energy of the people who rally behind it, the way innumerable projects have been transformed in its name, the new projects and positive outcomes it has produced—I suggest that the concept itself has some crucial problems," he writes. Read on to see if you agree.
-
-### WTF? What's the Future and Why It's Up to Us
-
-**by Tim O'Reilly** (recommended by [Jason Hibbets][8])
-
-Since I first saw Tim O'Reilly speak at a conference many years ago, I've always felt he had a good grasp of what's happening not only in open source but also in the broader space of digital technology. O'Reilly possesses the great ability to read the tea leaves, to make connections, and (based on those observations), to "predict" potential outcomes. In the book, he calls this map making.
-
-While this book is about what the future could hold (with a particular filter on the impacts of artificial intelligence), it really boils down to the fact that humans are shaping the future. The book opens with a pretty extensive history of free and open source software, which I think many in the community will enjoy. Then it dives directly into the race for automated vehicles—and why Uber, Lyft, Tesla, and Google are all pushing to win.
-
-And closely related to open organizations, the book description posted on [Harper Collins][9] poses the following questions:
-
- * What will happen to business when technology-enabled networks and marketplaces are better at deploying talent than traditional companies?
- * How should companies organize themselves to take advantage of these new tools?
-
-
-
-As many of our readers know, the future will be based on open source. O'Reilly provides you with some thought-provoking ideas on how AI and automation are closer than you might think.
-
-Do yourself a favor. Turn to your favorite AI-driven home automation unit and say: "Order Tim O'Reilly 'What's the Future.'"
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/6/summer-reading-2018
-
-作者:[Bryan Behrenshausen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/remyd
-[1]:https://opensource.com/users/arobertson98
-[2]:https://opensource.com/users/mackanic
-[3]:https://opensource.com/users/ron-mcfarland
-[4]:https://opensource.com/users/matt-micene
-[5]:https://opensource.com/users/amatlack
-[6]:https://opensource.com/users/onlychrisbh
-[7]:https://opensource.com/users/bbehrens
-[8]:https://opensource.com/users/jhibbets
-[9]:https://www.harpercollins.com/9780062565716/wtf/
diff --git a/sources/talk/20180620 3 pitfalls everyone should avoid with hybrid multi-cloud, part 2.md b/sources/talk/20180620 3 pitfalls everyone should avoid with hybrid multi-cloud, part 2.md
deleted file mode 100644
index bc6d037ec4..0000000000
--- a/sources/talk/20180620 3 pitfalls everyone should avoid with hybrid multi-cloud, part 2.md
+++ /dev/null
@@ -1,68 +0,0 @@
-3 pitfalls everyone should avoid with hybrid multi-cloud, part 2
-======
-
-
-
-This article was co-written with [Roel Hodzelmans][1].
-
-Cloud hype is all around you—you're told it's critical to ensuring a digital future for your business. Whether you choose cloud, hybrid cloud, or hybrid multi-cloud, you have numerous decisions to make, even as you continue the daily work of enhancing your customers' experience and agile delivery of your applications (including legacy applications)—likely some of your business' most important resources.
-
-In this series, we explain three pitfalls everyone should avoid when transitioning to hybrid multi-cloud environments. [In part one][2], we defined the different cloud types and explained the differences between hybrid cloud and multi-cloud. Here, in part two, we will dive into the first pitfall: Why cost is not always the best motivator for moving to the cloud.
-
-### Why not?
-
-When looking at hybrid or multi-cloud strategies for your business, don't let cost become the obvious motivator. There are a few other aspects of any migration strategy that you should review when putting your plan together. But often budget rules the conversations.
-
-When giving this talk three times at conferences, we've asked our audience to answer a live, online questionnaire about their company, customers, and experiences in the field. Over 73% of respondents said cost was the driving factor in their business' decision to move to hybrid or multi-cloud.
-
-But, if you already have full control of your on-premises data centers, yet perpetually underutilize and overpay for resources, how can you expect to prevent those costs from rolling over into your cloud strategy?
-
-There are three main (and often forgotten, ignored, and unaccounted for) reasons cost shouldn't be the primary motivating factor for migrating to the cloud: labor costs, overcapacity, and overpaying for resources. They are important points to consider when developing a hybrid or multi-cloud strategy.
-
-### Labor costs
-
-Imagine a utility company making the strategic decision to move everything to the cloud within the next three years. The company kicks off enthusiastically, envisioning huge cost savings, but soon runs into labor cost issues that threaten to blow up the budget.
-
-One of the most overlooked aspects of moving to the cloud is the cost of labor to migrate existing applications and data. A Forrester study reports that labor costs can consume [over 50% of the total cost of a public cloud migration][3]. Forrester says, "customer-facing apps for systems of engagement… typically employ lots of new code rather than migrating existing code to cloud platforms."
-
-Step back and analyze what's essential to your customer success and move only that to the cloud. Then, evaluate all your non-essential applications and, over time, consider moving them to commercial, off-the-shelf solutions that require little labor cost.
-
-### Overcapacity
-
-"More than 80% of in-house data centers have [way more server capacity than is necessary][4]," reports Business Insider. This amazing bit of information should shock you to your core.
-
-What exactly is "way more" in this context?
-
-One hint comes from Deutsche Bank CTO Pat Healey, presenting at Red Hat Summit 2017. He talks about ordering hardware for the financial institution's on-premises data center, only to find out later that [usage numbers were in the single digits][5].
-
-Healey is not alone; many companies have these problems. They don't do routine assessments, such as checking electricity, cooling, licensing, and other factors, to see how much capacity they are using on a consistent basis.
-
-### Overpaying
-
-Companies are paying an average of 36% more for cloud services than they need to, according to the Business Insider article mentioned above.
-
-One reason is that public cloud providers enthusiastically support customers coming agnostically into their cloud. As customers leverage more of the platform's cloud-native features, they reach a monetary threshold, and technical support drops off dramatically.
-
-It's a classic case of vendor lock-in, where the public cloud provider knows it is cost-prohibitive for the customer to migrate off its cloud, so it doesn't feel compelled to provide better service.
-
-### Coming up
-
-In part three of this series, we'll discuss the second of three pitfalls that everyone should avoid with hybrid multi-cloud. Stay tuned to learn why you should take care with moving everything to the cloud.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/reasons-move-to-cloud
-
-作者:[Eric D.Schabell][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/eschabell
-[1]:https://opensource.com/users/roelh
-[2]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
-[3]:https://www.techrepublic.com/article/labor-costs-can-make-up-50-of-public-cloud-migration-is-it-worth-it/
-[4]:http://www.businessinsider.com/companies-waste-62-billion-on-the-cloud-by-paying-for-storage-they-dont-need-according-to-a-report-2017-11
-[5]:https://youtu.be/SPRUJ5Z-Aew
diff --git a/sources/talk/20180622 7 tips for promoting your project and community on Twitter.md b/sources/talk/20180622 7 tips for promoting your project and community on Twitter.md
deleted file mode 100644
index 1201d23190..0000000000
--- a/sources/talk/20180622 7 tips for promoting your project and community on Twitter.md
+++ /dev/null
@@ -1,157 +0,0 @@
-7 tips for promoting your project and community on Twitter
-======
-
-
-
-Communicating in open source is about sharing information, engaging, and building community. Here I'll share techniques and best practices for using Twitter to reach your target audience. Whether you are just starting to use Twitter or have been playing around with it and need some new ideas, this article's got you covered.
-
-This article is based on my [Lightning Talk at UpSCALE][1], a session at the Southern California Linux Expo ([SCALE][2]) in March 2018, held in partnership with Opensource.com. You can see a video of my five-minute talk on [Opensource.com's YouTube][3] page and access my slides on [Slideshare][4].
-
-### Rule #1: Participate
-
-
-
-My tech marketing colleague [Amanda Katona][5] and I were talking about the open source community and the ways successful people and organizations use social media. We came up with the meme above. Basically, you have to be part of the community—participate, go to events, engage on Twitter, and meet people. When you share something on Twitter, people see it. In turn, you become known and part of the community.
-
-So, the Number 1 rule in marketing for open source projects is: You have to be a member of the community. You have to participate.
-
-### Start with a goal
-
-Starting with a goal helps you stay focused, instead of doing a lot of different things or jumping on the latest "good idea." Since this is marketing for open source projects, following the tenets of open source helps keep the communications focused on the community, transparency, and openness.
-
-There is a broad spectrum of goals depending on what you are trying to accomplish for your community, your organization, and yourself. Some ideas:
-
- * In general, grow the open source community.
- * Create awareness about the different open source projects going on by talking about and bringing attention to them.
- * Create a community around a new open source project.
- * Find things the community is sharing and share them further.
- * Talk about open source technologies.
- * Get your project into a foundation.
- * Build awareness of your project so you can get more users and/or contributors.
- * Work to be seen as an expert.
- * Take your existing community and grow it.
-
-
-
-Above all, know why you are communicating and what you hope to accomplish. Otherwise, you might end up with a laundry list of things that dilute your focus, ultimately slowing progress towards your goals.
-
-Goals help you stay focused on doing the most impactful things and even enable you to work less.
-
-### Mix up your tweets
-
-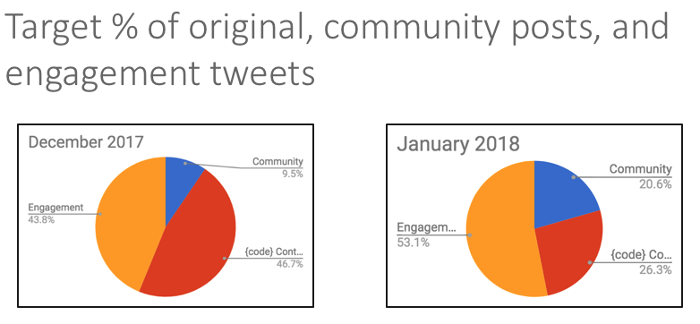
-Twitter is a great form of communication to reach a broad audience. There is a lot of content available that can help drive your goals: original content such as blogs and videos, third-party content from the community, and [engagement][6], which Twitter defines as the "total number of times a user interacted with a Tweet. Clicks anywhere on the tweet, including retweets, replies, follows, likes, links, cards, hashtags, embedded media, username, profile photo, or tweet expansion such as retweets and quote retweets."
-
-When working in the open source community, weighing your Twitter posts toward 50% engagement and 20% community content is a good practice. It shows your expertise while being a good community member.
-
-### Tweet throughout the day
-
-There are many opinions on how often to tweet. My research turned up a wide variety of suggestions:
-
- * Up to 15 times a day
- * Minimum of five
- * Maximum of five
- * Five to 20 times a day
- * Three to five tweets a day
- * More than three and engagement drops off
- * Engagement changes whether you do four to five a day or 11-15 a day
- * And on and on and on!
-
-
-
-I looked at my engagement stats and how often the influencers I follow tweet to determine the "magic number" of five to eight tweets a day for a business account and three to five per day for my personal account.
-
-There are days I tweet more—especially if there is a lot of good community content to share! Some days I tweet less, especially if I'm busy and don't have time to find good content to share. On days when I find more good content than I want to share in one day, I store the web links in a spreadsheet so I can share them throughout the week.
-
-### Follow Twitter best practices
-
-By tweeting, monitoring engagement, and watching what others in the community are doing, I came up with this list of Twitter best practices.
-
- * Be consistently present on Twitter preferably daily or at least a couple of times a week.
- * Write your content to lead with what the community will find most interesting. For example, if you are sharing something about yourself and a community member, put the other person first in your tweet.
- * Whenever possible, give credit to the source by using their Twitter handle.
- * Use hashtags (#) as it makes sense to help the community find content.
- * Make sure all your tweets have an image.
- * Tweet like a community member or a person and not like a business. Let your personality show!
- * Put the most interesting part of the content at the beginning of a tweet.
- * Monitor Twitter for engagement opportunities:
- * Check your Twitter notifications tab daily.
- * Like and set up appropriate retweets and quote retweets.
- * Review your Twitter lists for engagement opportunities.
- * Check your numbers of followers, retweets, likes, comments, etc.
-
-
-
-### Find your influencers
-
-Knowing who the influencers in your industry are will help you find engagement opportunities and good content to share. Influencers can be technical, business-focused, inspirational, or even people posting pictures of dogs. The important thing is: Figure out who influences you.
-
-Other ways to find your influencers:
-
- * Ask your team and other people in the community.
- * Do a little snooping: Look at the Twitter handles the industry people you respect follow on Twitter.
- * Follow industry hashtags, especially event hashtags. People who are into the event are tweeting and sharing using the event hashtag. I always find someone who has something interesting to say!
-
-
-
-When I manage Twitter for companies, I create an Influencer List, which is a spreadsheet that lists influencers' Twitter handles and hashtags. I use this to feed Twitter Lists, which help you organize the people you follow and find content to share. Creating an Influencer List and Twitter Lists takes some time, but it's worth it once you finish!
-
-Need some inspiration? Check out [my Twitter Lists][7]. Feel free to subscribe to them, copy them, and use them. They are always a work in process as I add or remove people; if you have suggestions, let me know!
-
-### Engage with the community
-
-That's what it's all about—engaging with the community! I mentioned earlier that my goal is for 50% of my daily activity to be engagement. Here's my daily to-do list to hit that goal:
-
- * Check my Notifications tab on Twitter
- * This is super important! If someone takes the time to respond on Twitter, I want to be prompt and respond to them.
- * Then I "like" the tweet and set up a retweet, a quote retweet, or a reply—whichever is the most appropriate.
- * Review my lists for engagement opportunities
- * See what the community is saying by reviewing tweets from my Twitter feed and my Lists
- * Check my list of hashtags common in the community to see what people are talking about
-
-
-
-Based on the information I collect, I set up retweets and quote retweets throughout the day, using Twitter best practices, hashtags, and Twitter handles as it makes sense.
-
-### More tips and tricks
-
-There are many things you can do to promote your project, company, or yourself on Twitter. You don't have to do it all! Think hard about the time and other resources you have available—being consistent with your communications and your "community-first" message are most important.
-
-Follow this checklist to ensure you're participating in the community—with your online presence, your outbound communications, or at events.
-
- * **Set goals:** This doesn't need to be a monumental exercise or a full marketing strategy, but do set some goals for your online presence.
- * **Resources:** Know your resources and the limits of your (and your team's) time.
- * **Audience:** Define your audience—who you are talking to?
- * **Content:** Choose the content types that fit your goals and available resources.
- * **Community content:** Finding good community content to share is an excellent place to start.
- * **On Twitter:**
- * Have a good profile.
- * Decide on the right number and type of daily tweets.
- * Draft tweets using best practices.
- * Allocate time for engagement. Consistency is more important than the amount of time you spend.
- * At a minimum, check your Notifications tab and respond.
- * **Metrics:** While this is the most time-consuming thing to set up, once it's done, it's easy to keep up.
-
-
-
-I hope this gives you some Twitter strategy ideas. I welcome your comments, questions, and invitations to talk about Twitter and social media in open source! Either leave a message in the comments below or reach out to me on Twitter [@kamcmahon][7]. Happy tweeting!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/promote-your-project-twitter
-
-作者:[Kim McMahon][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/kimmcmahon
-[1]:https://opensource.com/article/18/5/promote-twitter-project
-[2]:https://www.socallinuxexpo.org/scale/16x
-[3]:https://www.youtube.com/watch?v=PnTJ4ZHRMuM&index=6&list=PL4jrq6cG7S45r6WC4MtODiwVMNQQVq9ny
-[4]:https://www.slideshare.net/KimMcMahon1/promoting-your-open-source-project-and-building-online-communities-using-social-media
-[5]:https://twitter.com/amanda_katona
-[6]:https://help.twitter.com/en/managing-your-account/using-the-tweet-activity-dashboard
-[7]:https://twitter.com/kamcmahon/lists
diff --git a/sources/talk/20180701 How to migrate to the world of Linux from Windows.md b/sources/talk/20180701 How to migrate to the world of Linux from Windows.md
deleted file mode 100644
index 5d9ef80c08..0000000000
--- a/sources/talk/20180701 How to migrate to the world of Linux from Windows.md
+++ /dev/null
@@ -1,154 +0,0 @@
-How to migrate to the world of Linux from Windows
-======
-Installing Linux on a computer, once you know what you’re doing, really isn’t a difficult process. After getting accustomed to the ins and outs of downloading ISO images, creating bootable media, and installing your distribution (henceforth referred to as distro) of choice, you can convert a computer to Linux in no time at all. In fact, the time it takes to install Linux and get it updated with all the latest patches is so short that enthusiasts do the process over and over again to try out different distros; this process is called distro hopping.
-
-With this guide, I want to target people who have never used Linux before. I’ll give an overview of some distros that are great for beginners, how to write or burn them to media, and how to install them. I’ll show you the installation process of Linux Mint, but the process is similar if you choose Ubuntu. For a distro such as Fedora, however, your experience will deviate quite a bit from what’s shown in this post. I’ll also touch on the sort of software available, and how to install additional software.
-
-The command line will not be covered; despite what some people say, using the command line really is optional in distributions such as Linux Mint, which is aimed at beginners. Most distros come with update managers, software managers, and file managers with graphical interfaces, which largely do away with the need for a command line. Don’t get me wrong, the command line can be great – I do use it myself from time to time – but largely for convenience purposes.
-
-This guide will also not touch on troubleshooting or dual booting. While Linux does generally support new hardware, there’s a slight chance that any cutting edge hardware you have might not yet be supported by Linux. Setting up a dual boot system is easy enough, though wiping the disk and doing a clean install is usually my preferred method. For this reason, if you intend to follow the guide, either use a virtual machine to install Linux or use a spare computer that you’ve got lying around.
-
-The chief appeal for most Linux users is the customisability and the diverse array of Linux distributions or distros that are available. For the majority of people getting into Linux, the usual entry point is Ubuntu, which is backed by Canonical. Ubuntu was my gateway Linux distribution in 2008; although not my favourite, it’s certainly easy to begin using and is very polished.
-
-Another beginner-friendly distribution is Linux Mint. It’s the distribution I use day-to-day on every one of my machines. It’s very easy to start using, is generally very stable, and the user interface (UI) doesn’t drastically change; anyone familiar with Windows XP or Windows Vista will be familiar with the the UI of Linux Mint. While everyone went chasing the convergence dream of merging mobile and desktop together, Linux Mint stayed staunchly of the position that an operating system on the desktop should be designed for desktop and therefore totally avoids being mobile-friendly UI; desktop and laptops are front and centre.
-
-For your first dive into Linux, I highly recommend the two mentioned above, simply because they’ve got huge communities and developers tending to them around the clock. With that said, several other operating systems such as elementary OS (based on Ubuntu) and Fedora (run by Red Hat) are also good ways to get started. Other users are fond of options such as Manjaro and Antergos which make the difficult-to-configure Arch Linux easy to use.
-
-Now, we’re starting to get our hands dirty. For this guide, I will include screenshots of Linux Mint 18.3 Cinnamon edition. If you decide to go with Ubuntu or another version of Linux Mint, note that things may look slightly different. For example, when it comes to a distro that isn’t based on Ubuntu – like Fedora or Manjaro – things will look significantly different during installation, but not so much that you won’t be able to work the process out.
-
-In order to download Linux Mint, head on over to the Linux Mint downloads page and select either the 32-bit version or 64-bit version of the Cinnamon edition. If you aren’t sure which version is needed for your computer, pick the 64-bit version; this tends to work on computers even from 2007, so it’s a safe bet. The only time I’d advise the 32-bit version is if you’re planning to install Linux on a netbook.
-
-Once you’ve selected your version, you can either download the ISO image via one of the many mirrors, or as a torrent. It’s best to download it as a torrent because if your internet cuts out, you won’t have to restart the 1.9 GB download. Additionally, the downloaded ISO you receive via torrent will be signed with the correct keys, ensuring authenticity. If you download another distribution, you’ll be able to continue to the next step once you have an ISO file saved to your computer.
-
-Note: If you’re using a virtual machine, you don’t need to write or burn the ISO to USB or DVD, just use the ISO to launch the distro on your chosen virtual machine.
-
-Ten years ago when I started using Linux, you could fit an entire distribution onto a CD. Nowadays, you’ll need a DVD or a USB to boot the distro from.
-
-To write the ISO to a USB device, I recommend downloading a tool called Rufus. Once it’s downloaded and installed, you should insert a USB stick that’s 4GB or more. Be sure to backup the data as the device will be erased.
-
-Next, launch Rufus and select the device you want to write to; if you aren’t sure which is your USB device, unplug it, check the list, then plug it back in to work out which device you need to write to. Once you’ve worked out which USB drive you want to write to, select ‘MBR Partition Scheme for BIOS or UEFI’ under ‘Partition scheme and target system type’. Once you’ve done that, press the optical drive icon alongside the enabled ‘Create a bootable disk using’ field. You can then navigate to the ISO file that you just downloaded. Once it finishes writing to the USB, you’ve got everything you need to boot into Linux.
-
-Note: If you’re using a virtual machine, you don’t need to write or burn the ISO to USB or DVD, just use the ISO to launch the distro on your chosen virtual machine.
-
-If you’re on Windows 7 or above and want to burn the ISO to a DVD, simply insert a blank DVD into the computer, then right-click the ISO file and select ‘Burn disc image’, from the dialogue window which appears, select the drive where the DVD is located, and tick ‘Verify disc after burning’, then hit Burn.
-
-If you’re on Windows Vista, XP, or lower, download an install Infra Recorder and insert your blank DVD into your computer, selecting ‘Do nothing’ or ‘Cancel’ if any autorun windows pop up. Next, open Infra Recorder and select ‘Write Image’ on the main screen or go to Actions > Burn Image. From there find the Linux ISO you want to burn and press ‘OK’ when prompted.
-
-Once you’ve got your DVD or USB media ready you’re ready to boot into Linux; doing so won’t harm your Windows install in any way.
-
-Once you’ve got your installation media on hand, you’re ready to boot into the live environment. The operating system will load entirely from your DVD or USB device without making changes to your hard drive, meaning Windows will be left intact. The live environment is used to see whether your graphics card, wireless devices, and so on are compatible with Linux before you install it.
-
-To boot into the live environment you’re going to have to switch off the computer and boot it back up with your installation media already inserted into the computer. It’s also a must to ensure that your boot up sequence is set to launch from USB or DVD before your current operating system boots up from the hard drive. Configuring the boot sequence is beyond the scope of this guide, but if you can’t boot from the USB or DVD, I recommend doing a web search for how to access the BIOS to change the boot sequence order on your specific motherboard. Common keys to enter the BIOS or select the drive to boot from are F2, F10, and F11.
-
-If your boot up sequence is configured correctly, you should see a ten second countdown, that when completed, will automatically boot Linux Mint.
-
-![][1]
-
-![][2]
-
-Those who opted to try Linux Mint can let the countdown run to zero and the boot up will commence normally. On Ubuntu you’ll probably be prompted to choose a language, then press ‘Try Ubuntu without installing’, or the equivalent option on Linux Mint if you interrupted the automatic countdown by pressing the keyboard. If at any time you have the choice between trying or installing your Linux distribution of choice, always opt to try it, as the install option can cause irreversible damage to your Windows installation.
-
-Hopefully, everything went according to plan, and you’ve made it through to the live environment. The first thing to do now is to check to see whether your Wi-Fi is available. To connect to Wi-Fi press the icon to the left of the clock, where you should see the usual list of available networks; if this is the case, great! If not, don’t despair just yet. In the second case, when wireless card doesn’t seem to be working, either establish a wired connection via Ethernet or connect your phone to the computer – provided your handset supports tethering (via Wi-Fi, not data).
-
-Once you’ve got some sort of internet connection via one of those methods, press ‘Menu’ and use the search box to look for ‘Driver Manager’. This usually requires an internet connection and may let you enable your wireless card driver. If that doesn’t work, you’re probably out of luck, but the vast majority of cards should work with Linux Mint.
-
-For those who have a fancy graphics card, chances are that Linux is using an open source driver alternative instead of the proprietary driver you use on Windows. If you notice any issues pertaining to graphics, you can check the Driver Manager and see whether any proprietary drivers are available.
-
-Once those two critical components are confirmed to be up and running, you may want to check printer and webcam compatibility. To test your printer, go to ‘Menu’ > ‘Office’ > ‘LibreOffice Writer’ and try printing a document. If it works, that’s great, if not, some printers may be made to work with some effort, but that’s outside the scope of this particular guide. I’d recommend searching something like ‘Linux [your printer model]’ and there may be solutions available. As for your webcam, go to ‘Menu’ again and use the search box to look for ‘Software Manager’; this is the Microsoft Store equivalent on Linux Mint. Search for a program named ‘Cheese’ and install it. Once installed, open it up using the ‘Launch’ button in Software Manager, or have a look in ‘Menu’ and find it manually. If it detects a webcam it means it’s compatible!
-
-![][3]
-
-By now, you’ve probably had a good look at Linux Mint or your distribution of choice and, hopefully, everything is working for you. If you’ve had enough and want to return to Windows, simply press Menu and then the power off button which is located right above ‘Menu’, then press ‘Shut Down’ if a dialogue box pops up.
-
-Given that you’re sticking with me and want to install Linux Mint on your computer, thus erasing Windows, ensure that you’ve backed up everything on your computer. Dual boot installations are available from the installer, but in this guide I’ll explain how to install Linux as the sole operating system. Assuming you do decide to deviate and set up a dual boot system, then ensure you still back up your files from Windows first, because things could potentially go wrong for you.
-
-In order to do a clean install, close down any programs that you’ve got running in the live environment. On the desktop, you should see a disc icon labelled ‘Install Linux Mint’ – click that to continue.
-
-![][4]
-
-On the first screen of the installer, choose your language and press continue.
-
-![][5]
-
-On the second screen, most users will want to install third-party software to ensure hardware and codecs work.
-
-![][6]
-
-In the ‘Installation type’ section you can choose to erase your hard drive or dual boot. You can encrypt the entire drive if you check ‘Encrypt the new Linux Mint installation for security’ and ‘Use LVM with the new Linux Mint installation’. You can press ‘Something else’ for a specific custom set up. In order to set up a dual boot system, the hard drive which you’re installing to must already have Windows installed first.
-
-![][7]
-
-Now pick your location so that the operating system’s time can be set correctly, and press continue.
-
-![][8]
-
-Now set your keyboard’s language, and press continue.
-
-![][9]
-
-On the ‘Who are you’ screen, you’ll create a new user. Pop in your name, leave the computer’s name as default or enter a custom name, pick a username, and enter a password. You can choose to have the system log you in automatically or require a password. If you choose to require a password then you can also encrypt your home folder, which is different from encrypting your entire system. However, if you encrypt your entire system, there’s not a lot of point to encrypting your home folder too.
-
-![][10]
-
-Once you’ve completed the ‘Who are you’ screen, Linux Mint will begin installing. You’ll see a slideshow detailing what the operating system offers.
-
-![][11]
-
-Once the installation finishes, you’ll be prompted to restart. Go ahead and do so.
-
-Now that you’ve restarted the computer and removed the Linux media, your computer should boot up straight to your new install. If everything has gone smoothly, you should arrive at the login screen where you just need to enter the password you created during the set up.
-
-![][12]
-
-Once you reach the desktop, the first thing you’ll want to do is apply all the system updates that are available. On Linux Mint you should see a shield icon with a blue logo in the bottom right-hand corner of the desktop near the clock, click on it to open the Update Manager.
-
-![][13]
-
-You should be prompted to pick an update policy, give them all a read over and apply whichever you think is most appropriate for you then press ‘OK’.
-
-![][14]
-
-![][15]
-
-You’ll probably be asked to pick a more local mirror too. This is optional, but could allow your updates to download quicker. Now, apply any updates offered, until the shield icon has a green tick indicating that all updates have been applied. In future, the Update Manager will continually check for new updates and alert you to them.
-
-You’ve got all the necessary tasks out the way for setting up Linux Mint and now you’re free to start using the system for whatever you like. By default, Mozilla Firefox is installed, so if you’ve got a Sync account it’s probably a good idea to go pull in all your passwords and bookmarks. If you’re a Chrome user, you can either run Chromium which is in the Software Manager, or download Google Chrome from the internet. If you opt to get Chrome, you’ll be offered a .deb file which you should save to your system and then double-click to install. Installing .deb files is straightforward enough, just press ‘Install’ when prompted and the system will handle the rest, you’ll find the new software in ‘Menu’.
-
-![][16]
-
-Other pre-installed software includes LibreOffice which has decent compatibility with Microsoft Office; Mozilla’s Thunderbird for managing your emails; GIMP for editing images; Transmission is readily available for you to begin torrenting files, it supports adding IP block lists too; Pidgin and Hexchat will allow you to send instant messages and connect to IRC respectively. As for media playback, you will find VLC and Rhythmbox under ‘Sound and Video’ to satisfy all your music and video needs. If you need any other software, check out the Software Manager, there are lots of popular packages including Skype, Minecraft, Google Earth, Steam, and Private Internet Access Manager.
-
-Throughout this guide, I’ve explained that it will not touch on troubleshooting problems. However, the Linux Mint community can help you overcome any complications. The first port of call is definitely a quick web search, as most problems have been resolved by others in the past and you might be able to find your solution online. If you’re still stuck, you can try the Linux Mint forums as well as the Linux Mint subreddit, both of which are oriented towards troubleshooting.
-
-Linux definitely isn’t for everyone. It still lacks on the gaming front, despite the existence of Steam on Linux, and the growing number of games. In addition, some commonly used software isn’t available on Linux, but usually there are alternatives available. If, however, you have a computer lying around that isn’t powerful enough to support Windows any more, then Linux could be a good option for you. Linux is also free to use, so it’s great for those who don’t want to spend money on a new copy of Windows too.
-
-loading...
-
---------------------------------------------------------------------------------
-
-via: http://infosurhoy.com/cocoon/saii/xhtml/en_GB/technology/how-to-migrate-to-the-world-of-linux-from-windows/
-
-作者:[Marta Subat][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://infosurhoy.com/cocoon/saii/xhtml/en_GB/author/marta-subat/
-[1]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139198_autoboot_linux_mint.jpg
-[2]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139206_bootmenu_linux_mint.jpg
-[3]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139213_cheese_linux_mint.jpg
-[4]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139254_install_1_linux_mint.jpg
-[5]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139261_install_2_linux_mint.jpg
-[6]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139270_install_3_linux_mint.jpg
-[7]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139278_install_4_linux_mint.jpg
-[8]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139285_install_5_linux_mint.jpg
-[9]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139293_install_6_linux_mint.jpg
-[10]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139302_install_7_linux_mint.jpg
-[11]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139317_install_8_linux_mint.jpg
-[12]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139224_first_boot_1_linux_mint.jpg
-[13]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139232_first_boot_2_linux_mint.jpg
-[14]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139240_first_boot_3_linux_mint.jpg
-[15]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139248_first_boot_4_linux_mint.jpg
-[16]:https://cdn.neow.in/news/images/uploaded/2018/02/1519219725_software_1_linux_mint.jpg
diff --git a/sources/talk/20180703 What Game of Thrones can teach us about open innovation.md b/sources/talk/20180703 What Game of Thrones can teach us about open innovation.md
deleted file mode 100644
index 120c4df0f3..0000000000
--- a/sources/talk/20180703 What Game of Thrones can teach us about open innovation.md
+++ /dev/null
@@ -1,49 +0,0 @@
-What Game of Thrones can teach us about open innovation
-======
-
-
-
-You might think the only synergy one can find in Game of Thrones is that between Jaime Lannister and his sister, Cersei. Characters in the show's rotating cast don't see many long term relationships, as they're killed off, betrayed, and otherwise trading loyalty in an effort to stay alive. Even the Stark children, siblings suffering from the deaths of their parents, don't really get along most of the time.
-
-But there's something about the chaotic free-for-all of constantly shifting loyalties in Game of Thrones that lends itself to a thought exercise: How can we always be aligning disparate positions in order to innovate?
-
-Here are three ways Game of Thrones illustrates behaviors that lead to innovation.
-
-### Join forces
-
-Aria Stark has no loyalties. Through the death of her parents and separation from her siblings, young Aria demonstrates courage in pursuing an education with the faceless man. And she's rewarded for her courage with the development of seemingly supernatural abilities.
-
-Aria's hate for the people on her list has her innovating left and right in an attempt to get closer to them. As the audience, we're on Aria's side; despite her violent and deadly methods, we identify with her attempts to overcome hardship. Her determination makes us loyal fans, and in an open organization, courage and determination like hers would be rewarded with some well-deserved influence.
-
-Being loyal and helpful to driven people like Aria will help you and (by extension) your organization innovate. Passion is infectious.
-
-### Be nimble
-
-The Lannisters represent a traditional management structure that forcibly resists innovation. Their resistance is usually the result of their fear of change.
-
-Without a doubt, change is scary—especially to people who wield power in an organization. Losing status causes us fear, because in our evolutionary and social history, losing status could mean that we would be unable to survive. But look to Tyrion as an example of how to thrive once status is lost.
-
-There's something about the chaotic free-for-all of constantly shifting loyalties in Game of Thrones that lends itself to a thought exercise: How can we always be aligning disparate positions in order to innovate?
-
-Tyrion is cast out (demoted) by his family (the senior executive team). Instead of lamenting his loss of power, he seeks out a community (by the side of Daenerys) that values (and can utilize) his unique skills, connections, and influences. His resilience in the face of being cast out of Casterly Rock is the perfect metaphor for how innovation occurs: It's iterative and never straightforward. It requires resilience. A more open source way to say this would be: "fail forward," or "release early, release often."
-
-### Score resources
-
-Daenerys Targaryen embodies all the necessary traits for successful innovation. She can be seen as a model for the kind of employee that thrives in an open organization. What the Mother of Dragons needs, the Mother of Dragons gets, and she doesn't compromise her ideals to do it.
-
-Whether freeing slaves (and then asking for their help) or forming alliances to acquire transport vehicles she's never seen before, Daenerys is resourceful. In an open organization, a staff member needs to have the wherewithal to get things done. Colleagues (even the entire organization) may not always share your priorities, but innovation happens when people take risks. Becoming a savvy negotiator like Khaleesi, and developing a willingness to trade a lot for a little (she's been known to do favors for the mere promise of loyalty), you can get things done, fail forward, and innovate.
-
-Courage, resilience, and resourcefulness are necessary traits for innovating in an open organization. What else can Game of Thrones teach us about working—and succeeding—openly?
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/7/open-innovation-lessons-game-of-thrones
-
-作者:[Laura Hilliger][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/laurahilliger
diff --git a/sources/talk/20180704 Comparing Twine and Ren-Py for creating interactive fiction.md b/sources/talk/20180704 Comparing Twine and Ren-Py for creating interactive fiction.md
deleted file mode 100644
index f4bf136f51..0000000000
--- a/sources/talk/20180704 Comparing Twine and Ren-Py for creating interactive fiction.md
+++ /dev/null
@@ -1,70 +0,0 @@
-Comparing Twine and Ren'Py for creating interactive fiction
-======
-
-
-
-Any experienced technology educator knows engagement and motivation are key to a student's learning. Of the many techniques for stimulating engagement and motivation among learners, storytelling and game creation have good track records of success, and writing interactive fiction is a great way to combine both of those techniques.
-
-Interactive fiction has a respectable history in computing, stretching back to the text-only adventure games of the early 1980s, and it's enjoyed a new popularity recently. There are many technology tools that can be used for writing interactive fiction, but the two that will be considered here, [Twine][1] and [Ren'Py][2], are ideal for the task. Each has different strengths that make it more attractive for particular types of projects.
-
-### Twine
-
-![Twine 2.0][4]
-
-![][5]
-
-Twine is a popular cross-platform open source interactive fiction system that developed out of the HTML- and JavaScript-based [TiddlyWiki][6]. If you're not familiar with Twine, multimedia artist and Opensource.com contributor Seth Kenlon's article on how he [uses Twine to create interactive adventure games][7] is a great introduction to the tool.
-
-One of Twine's advantages is that it produces a single, compiled HTML file, which makes it easy to distribute and play an interactive fiction work on any system with a reasonably modern web browser. But this comes at a cost: While it will support graphics, sound files, and embedded video, Twine is somewhat limited by its roots as a primarily text-based system (even though it has developed a lot over the years).
-
-This is very appealing to new learners who can rapidly produce something that looks good and is fun to play. However, when they want to add visual effects, graphics, and multimedia, learners can get lost among the different, creative ways to do this and the maze of different Twine program versions and story formats. Even so, there's an impressive amount of resources available on how to use Twine.
-
-Educators often hope learners will take the skills they have gained using one tool and build on them, but this isn't a strength for Twine. While Twine is great for developing literacy and creative writing skills, the coding and programming side is weaker. The story format scripting language has what you would expect: logic commands, conditional statements, arrays/lists, and loops, but it is not closely related to any popular programming language.
-
-### Ren'Py
-
-![Ren'Py 7.0][9]
-
-![][5]
-
-Ren'Py approaches interactive fiction from a different angle; [Wikipedia][10] describes it as a "visual novel engine." This means that the integration of graphics and other multimedia elements is a lot smoother and more integrated than in Twine. In addition, as Opensource.com contributor Joshua Allen Holm explained, [you don't need much coding experience][11] to use Ren'Py.
-
-Ren'Py can export finished work for Android, Linux, Mac, and Windows, which is messier than the "one file for all systems" that comes from Twine, particularly if you get into the complexity of making builds for mobile devices. Bear in mind, too, that finished Ren'Py projects with their multimedia elements are a lot bigger than Twine projects.
-
-The ease of downloading graphics and multimedia files from the internet for Ren'Py projects also provides a great opportunity to teach learners about the complexities of copyright and advocate (as everyone should!) for [Creative Commons][12] licenses.
-
-As its name suggests, Ren'Py's scripting languages are a mix of true Python and Python-like additions. This will be very attractive to educators who want learners to progress to Python programming. Python's syntatical rules and strict enforcement of indentation are more intimidating to use than the scripting options in Twine, but the long-term gains are worth it.
-
-### Comparing Twine and Ren'Py
-
-There are various reasons why Twine has become so successful, but one that will appeal to open source enthusiasts is that anyone can take a compiled Twine story or game and import it back into Twine. This means if you come across a compiled Twine story or game with a neat feature, you can look at the source code and find out how it was done. Ren'Py allows a level of obfuscation that prevents low-level attempts at hacking.
-
-When it comes to my work helping people with visual impairments use technology, Ren'Py is superior to Twine. Despite claims to the contrary, Twine's HTML files can be used by screen reader users—but only with difficulty. In contrast, Ren'Py has built-in self-voicing capabilities, something that I am very pleased to see, although Linux users may need to add the [eSpeak package][13] to support it.
-
-Ren'Py and Twine can be used for similar purposes. Text-based projects tend to be simpler and quicker to create than ones that require creating or sourcing graphics and multimedia elements. If your projects will be more text-based, Twine might be the best choice. And, if your projects make extensive use of graphics and multimedia elements, Ren'Py might suit you better.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/twine-vs-renpy-interactive-fiction
-
-作者:[Peter Cheer][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/petercheer
-[1]:http://twinery.org/
-[2]:https://www.renpy.org/
-[3]:/file/402696
-[4]:https://opensource.com/sites/default/files/uploads/twine2.png (Twine 2.0)
-[5]:data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw== (Click and drag to move)
-[6]:https://tiddlywiki.com/
-[7]:https://opensource.com/article/18/2/twine-gaming
-[8]:/file/402701
-[9]:https://opensource.com/sites/default/files/uploads/renpy.png (Ren'Py 7.0)
-[10]:https://en.wikipedia.org/wiki/Ren%27Py
-[11]:https://opensource.com/life/13/8/gaming-renpy
-[12]:https://creativecommons.org/
-[13]:http://espeak.sourceforge.net/
diff --git a/sources/talk/20180705 5 Reasons Open Source Certification Matters More Than Ever.md b/sources/talk/20180705 5 Reasons Open Source Certification Matters More Than Ever.md
deleted file mode 100644
index dace150f39..0000000000
--- a/sources/talk/20180705 5 Reasons Open Source Certification Matters More Than Ever.md
+++ /dev/null
@@ -1,49 +0,0 @@
-5 Reasons Open Source Certification Matters More Than Ever
-======
-
-
-In today’s technology landscape, open source is the new normal, with open source components and platforms driving mission-critical processes and everyday tasks at organizations of all sizes. As open source has become more pervasive, it has also profoundly impacted the job market. Across industries [the skills gap is widening][1], making it ever more difficult to hire people with much needed job skills. In response, the [demand for training and certification is growing][2].
-
-In a recent webinar, Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation, discussed the growing need for certification and some of the benefits of obtaining open source credentials. “As open source has become the new normal in everything from startups to Fortune 2000 companies, it is important to start thinking about the career road map, the paths that you can take and how Linux and open source in general can help you reach your career goals,” Seepersad said.
-
-With all this in mind, this is the first article in a weekly series that will cover: why it is important to obtain certification; what to expect from training options that lead to certification; and how to prepare for exams and understand what your options are if you don’t initially pass them.
-
-Seepersad pointed to these five reasons for pursuing certification:
-
- * **Demand for Linux and open source talent.** “Year after year, we do the Linux jobs report, and year after year we see the same story, which is that the demand for Linux professionals exceeds the supply. This is true for the open source market in general,” Seepersad said. For example, certifications such as the [LFCE, LFCS,][3] and [OpenStack administrator exam][4] have made a difference for many people.
-
- * **Getting the interview.** “One of the challenges that recruiters always reference, especially in the age of open source, is that it can be hard to decide who you want to have come in to the interview,” Seepersad said. “Not everybody has the time to do reference checks. One of the beautiful things about certification is that it independently verifies your skillset.”
-
- * **Confirming your skills.** “Certification programs allow you to step back, look across what we call the domains and topics, and find those areas where you might be a little bit rusty,” Seepersad said. “Going through that process and then being able to demonstrate skills on the exam shows that you have a very broad skillset, not just a deep skillset in certain areas.”
-
- * **Confidence.** This is the beauty of performance-based exams,” Seepersad said. “You're working on our live system. You're being monitored and recorded. Your timer is counting down. This really puts you on the spot to demonstrate that you can troubleshoot.” The inevitable result of successfully navigating the process is confidence.
-
- * **Making hiring decisions.** “As you become more senior in your career, you're going to find the tables turned and you are in the role of making a hiring decision,” Seepersad said. “You're going to want to have candidates who are certified, because you recognize what that means in terms of the skillsets.”
-
-
-
-
-Although Linux has been around for more than 25 years, “it's really only in the past few years that certification has become a more prominent feature,” Seepersad noted. As a matter of fact, 87 percent of hiring managers surveyed for the [2018 Open Source Jobs Report][5] cite difficulty in finding the right open source skills and expertise. The Jobs Report also found that hiring open source talent is a priority for 83 percent of hiring managers, and half are looking for candidates holding certifications.
-
-With certification playing a more important role in securing a rewarding long-term career, are you interested in learning about options for gaining credentials? If so, stay tuned for more information in this series.
-
-[Learn more about Linux training and certification.][6]
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
-
-作者:[Sam Dean][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/sam-dean
-[1]:https://www.linuxfoundation.org/blog/open-source-skills-soar-in-demand-according-to-2018-jobs-report/
-[2]:https://www.linux.com/blog/os-jobs-report/2018/7/certification-plays-big-role-open-source-hiring
-[3]:https://www.linux.com/learn/certification/2018/5/linux-foundation-lfcs-lfce-maja-kraljic
-[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/openstack-administration-fundamentals
-[5]:https://www.linuxfoundation.org/publications/open-source-jobs-report-2018/
-[6]:https://training.linuxfoundation.org/certification
diff --git a/sources/talk/20180706 Robolinux Lets You Easily Run Linux and Windows Without Dual Booting.md b/sources/talk/20180706 Robolinux Lets You Easily Run Linux and Windows Without Dual Booting.md
deleted file mode 100644
index 783aa0bd4e..0000000000
--- a/sources/talk/20180706 Robolinux Lets You Easily Run Linux and Windows Without Dual Booting.md
+++ /dev/null
@@ -1,141 +0,0 @@
-Robolinux Lets You Easily Run Linux and Windows Without Dual Booting
-======
-
-
-
-The number of Linux distributions available just keeps getting bigger. In fact, in the time it took me to write this sentence, another one may have appeared on the market. Many Linux flavors have trouble standing out in this crowd, and some are just a different combination of puzzle pieces joined to form something new: An Ubuntu base with a KDE desktop environment. A Debian base with an Xfce desktop. The combinations go on and on.
-
-[Robolinux][1], however, does something unique. It’s the only distro, to my knowledge, that makes working with Windows alongside Linux a little easier for the typical user. With just a few clicks, it lets you create a Windows virtual machine (by way of VirtualBox) that can run side by side with Linux. No more dual booting. With this process, you can have Windows XP, Windows 7, or Windows 10 up and running with ease.
-
-And, you get all this on top of an operating system that’s pretty fantastic on its own. Robolinux not only makes short work of having Windows along for the ride, it simplifies using Linux itself. Installation is easy, and the installed collection of software means anyone can be productive right away.
-
-Let’s install Robolinux and see what there is to see.
-
-### Installation
-
-As I mentioned earlier, installing Robolinux is easy. Obviously, you must first [download an ISO][2] image of the operating system. You have the choice of installing a Cinnamon, Mate, LXDE, or xfce desktop (I opted to go the Mate route). I will warn you, the developers do make a pretty heavy-handed plea for donations. I don’t fault them for this. Developing an operating system takes a great deal of time. So if you have the means, do make a donation.
-Once you’ve downloaded the file, burn it to a CD/DVD or flash drive. Boot your system with the media and then, once the desktop loads, click the Install icon on the desktop. As soon as the installer opens (Figure 1), you should be immediately familiar with the layout of the tool.
-
-![Robolinux installer][4]
-
-Figure 1: The Robolinux installer is quite user-friendly.
-
-[Used with permission][5]
-
-Once you’ve walked through the installer, reboot, remove the installation media, and login when prompted. I will say that I installed Robolinux as a VirtualBox VM and it installed to perfection. This however, isn’t a method you should use, if you’re going to take advantage of the Stealth VM option. After logging in, the first thing I did was install the Guest Additions and everything was working smoothly.
-
-### Default applications
-
-The collection of default applications is impressive, but not overwhelming. You’ll find all the standard tools to get your work done, including:
-
- * LibreOffice
-
- * Atril Document Viewer
-
- * Backups
-
- * GNOME Disks
-
- * Medit text editor
-
- * Seahorse
-
- * GIMP
-
- * Shotwell
-
- * Simple Scan
-
- * Firefox
-
- * Pidgen
-
- * Thunderbird
-
- * Transmission
-
- * Brasero
-
- * Cheese
-
- * Kazam
-
- * Rhythmbox
-
- * VLC
-
- * VirtualBox
-
- * And more
-
-
-
-
-With that list of software, you shouldn’t want for much. However, should you find a app not installed, click on the desktop menu button and then click Package Manager, which will open Synaptic Package Manager, where you can install any of the Linux software you need.
-
-If that’s not enough, it’s time to take a look at the Windows side of things.
-
-### Installing Windows
-
-This is what sets Robolinux apart from other Linux distributions. If you click on the desktop menu button, you see a Stealth VM entry. Within that sub-menu, a listing of the different Windows VMs that can be installed appears (Figure 2).
-
-![Windows VMs][7]
-
-Figure 2: The available Windows VMs that can be installed alongside of Robolinux.
-
-[Used with permission][5]
-
-Before you can install one of the VMs, you must first download the Stealth VM file. To do that, double-click on the desktop icon that includes an image of the developer’s face (labeled Robo’s FREE Stealth VM). You must save that file to the ~/Downloads directory. Don’t save it anywhere else, don’t extract it, and don’t rename it. With that file in place, click the start menu and then click Stealth VM. From the listing, click the top entry, Robolinx Stealth VM Installer. When prompted, type your sudo password. You will then be prompted that the Stealth VM is ready to be used. Go back to the start menu and click Stealth VM and select the version of Windows you want to install. A new window will appear (Figure 3). Click Yes and the installation will continue.
-
-![Installing Windows][9]
-
-Figure 3: Installing Windows in the Stealth VM.
-
-[Used with permission][5]
-
-Next you will be prompted to type your sudo password again (so your user can be added to the vboxusers group). Once you’ve taken care of that, you’ll be prompted to configure the RAM you want to dedicate to the VM. After that, a browser window will appear (once again asking for a donation). At this point everything is (almost) done. Close the browser and the terminal window.
-
-You’re not finished.
-
-Next you must insert the Windows installer media that matches the type of Windows VM you installed. You then must start VirtualBox by click start menu > System Tools > Oracle VM VirtualBox. When VirtualBox opens, an entry will already be created for your Windows VM (Figure 4).
-
-![Windows VM][11]
-
-Figure 4: Your Windows VM is ready to go.
-
-[Used with permission][5]
-
-You can now click the Start button (in VirtualBox) to finish up the installation. When the Windows installation completes, you’re ready to work with Linux and Windows side-by-side.
-
-### Making VMs a bit more user-friendly
-
-You may be thinking to yourself, “Creating a virtual machine for Windows is actually easier than that!”. Although you are correct with that sentiment, not everyone knows how to create a new VM with VirtualBox. In the time it took me to figure out how to work with the Robolinux Stealth VM, I could have had numerous VMs created in VirtualBox. Additionally, this approach doesn’t happen free of charge. You do still have to have a licensed copy of Windows (as well as the installation media). But anything developers can do to make using Linux easier is a plus. That’s how I see this—a Linux distribution doing something just slightly different that could remove a possible barrier to entry for the open source platform. From my perspective, that’s a win-win. And, you’re getting a pretty solid Linux distribution to boot.
-
-If you already know the ins and outs of VirtualBox, Robolinux might not be your cuppa. But, if you don’t like technology getting in the way of getting your work done and you want to have a Linux distribution that includes all the necessary tools to help make you productive, Robolinux is definitely worth a look.
-
-Learn more about Linux through the free ["Introduction to Linux" ][12] course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/7/robolinux-lets-you-easily-run-linux-and-windows-without-dual-booting
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.robolinux.org
-[2]:https://www.robolinux.org/downloads/
-[3]:/files/images/robolinux1jpg
-[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_1.jpg?itok=MA0MD6KY (Robolinux installer)
-[5]:/licenses/category/used-permission
-[6]:/files/images/robolinux2jpg
-[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_2.jpg?itok=bHktIhhK (Windows VMs)
-[8]:/files/images/robolinux3jpg
-[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_3.jpg?itok=B7ar6hZf (Installing Windows)
-[10]:/files/images/robolinux4jpg
-[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_4.jpg?itok=nEOt5Vnc (Windows VM)
-[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/talk/20180711 Becoming a senior developer 9 experiences you ll encounter.md b/sources/talk/20180711 Becoming a senior developer 9 experiences you ll encounter.md
deleted file mode 100644
index 7ff8e59007..0000000000
--- a/sources/talk/20180711 Becoming a senior developer 9 experiences you ll encounter.md
+++ /dev/null
@@ -1,141 +0,0 @@
-Becoming a senior developer: 9 experiences you'll encounter
-============================================================
-
-
-
-Plenty of career guides suggest appropriate steps to take if you want a management track. But what if you want to stay technical—and simply become the best possible programmer? These non-obvious markers let you know you’re on the right path.
-
-Many programming career guidelines stress the skills a software developer is expected to acquire. Such general advice suggests that someone who wants to focus on a technical track—as opposed to, say, [taking a management path to CIO][5]—should go after the skills needed to mentor junior developers, design future application features, build out release engineering systems, and set company standards.
-
-That isn’t this article.
-
-Being a developer—a good one—isn't just about writing code. To be successful, you do a lot of planning, you deal with catastrophes, and you prevent catastrophes. Not to mention you spend plenty of time [working with other humans][6] about what your code should do.
-
-Following are a number of markers you’ll likely encounter as your career progresses and you become a more accomplished developer. You’ll have highs that boost you up and remind you how awesome you are. You'll also encounter lows that keep you humble and give you wisdom—at least in retrospect, if you respond to them appropriately.
-
-These experiences may feel good, they may be uncomfortable, or they may be downright scary. They're all learning experiences—at least for those developers who sincerely want to move forward, in both skills and professional ambition. These experiences often change the way developers look at their job or how they approach the next problem. It's why an experienced developer's value to a company is more than just a list of technology buzzwords.
-
-Here, in no particular order, is a sampling of what you'll run into on your way to becoming a senior developer—not in terms of a specific job title but being confident about creating quality code that serves users.
-
-### You write your first big bug into production
-
-Probably your initial step into the big leagues is the first bug you write into production. It's a sickening feeling. You know that the software you're working on is now broken in some significant way because of something you did, code you wrote, or a test you didn't run.
-
-No matter how good a programmer you are, you'll make mistakes. You're a human, and that's part of what we do.
-
-Most developers learn from the “bug that went live” experience. You promise never to make the same bug again. You analyze what happened, and you think about how the bug could have been prevented. For me, one effect of discovering I let a bug into production code is that it reinforced my belief that compiler warnings and static analysis tools are a programmer's best friend.
-
-You repeat the process when it happens again. It _will_ happen again, but as your programming skill improves, it happens less frequently.
-
-### You delete production data for the first time
-
-It might be a `DROP TABLE` in production or [a mistaken `rm -rf`][7]. Maybe you clicked on the wrong volume to format. You get an uneasy feeling that "this is taking longer to run than I would expect. It's not running on... oh, no!" followed by a mad scramble to fix it.
-
-Data loss has long-term effects on a growing-wiser developer much like the production bug. Afterward, you re-examine how you work. It teaches you to take more safeguards than you did previously. Maybe you decide to create a more rigorous rotation schedule for backups, or even start having a backup schedule at all.
-
-As with the bug in production, you learn that you can survive making a mistake, and it's not the end of the world.
-
-### You automate away part of your job
-
-There's an old saying that you can't get promoted if you can't be replaced. Anything that ties you to a specific job or task is an anchor on your ability to move up in the company or be assigned newer and more interesting tasks.
-
-When good programmers find themselves doing drudgework as part of their job, they find a way to let a machine do it. If they are stuck [scanning server logs][8] every Monday looking for problems, they'll install a tool like Logwatch to summarize the results. When there are many servers to be monitored, a good programmer will turn to a more capable tool that analyzes logs on multiple servers.
-
-Unsure how to get started with containers? Yes, we have a guide for that. Get Containers for Dummies.
-
-[Download now][4]
-
-In each case, wise programmers provide more value to their company, because an automated system is much cheaper than a senior programmer’s salary. They also grow personally by eliminating drudgery, leaving them more time to work on more challenging tasks.
-
-### You use existing code instead of writing your own
-
-A senior programmer knows that code that doesn't get written doesn't have bugs, and that many problems, both common and uncommon, have already been solved—in many cases, multiple times.
-
-Senior programmers know that the chances are very low that they can write, test, and debug their own code for a task faster or cheaper than existing code that does what they want. It doesn't have to be perfect to make it worth their while.
-
-It might take a little bit of turning down your ego to make it happen, but that's an excellent skill for senior programmers to have, too.
-
-### You are publicly recognized for achievements
-
-Many people aren't comfortable with public recognition. It's embarrassing. We have these amazing skills, and we like the feeling of helping others, but we can be embarrassed when it's called out.
-
-Praise comes in many forms and many sizes. Maybe it's winning an "employee of the quarter" award for a project you drove and being presented a plaque onstage. It could be as low-key as your team leader saying, "Thanks to Cheryl for implementing that new microservice."
-
-Whatever it is, accept it graciously and appreciatively, even if you're embarrassed by the attention. Don't diminish the praise you receive with, "Oh, it was nothing" or anything similar. Accept credit for the things that users and co-workers appreciate. Thank the speaker and say you were glad you could be of service.
-
-First, this is the polite thing to do. When people praise you, they want it to be acknowledged. In addition, that warm recognition helps you in the future. Remembering it gets you through those crappy days, such as when you uncover bugs in your code.
-
-### You turn down a user request
-
-As much as we love being superheroes who can do amazing things with computers, sometimes turning down a request is best for the organization. Part of being a senior programmer is knowing when not to write code. A senior programmer knows that every bit of code in a codebase is a chance for things to go wrong and a potential future cost for maintenance.
-
-You might be uncomfortable the first time you tell a user that you won’t be incorporating his maybe-even-useful suggestion. But this is a notable occasion. It means you understand the application and its role in a larger context. It also means you “own” the software, in a positive, confident way.
-
-The organization need not be an employer, either. Open source project managers deal with this all the time, when they have to tell a user, "Sorry, it doesn't fit with where the project is going.”
-
-### You know when to fight for what's right and when it really doesn't matter
-
-Rookie programmers are full of knowledge straight from school, having learned all the right ways to do things. They're eager to apply their knowledge and make amazing things happen for their employers. However, they're often surprised to find that out in the business world, things sometimes don't get done the "right" way.
-
-There's an old military saying: No plan survives contact with the enemy. It's the same with new programmers and project plans. Sometimes in the heat of the battle of business, the purist computer science techniques learned in school fall by the wayside.
-
-Maybe the database schema gets slapped together in a way that isn't perfect [fifth normal form][9]. Sometimes code gets cut and pasted rather than refactored out into a new function or library. Plenty of production systems run on shell scripts and prayers. The wise programmer knows when to push for the right way to do things and when to take the cheap way out.
-
-The first time you do it, it feels like you're selling out your principles. It’s not. The balance between academic purism and the realities of getting work done can be a delicate one, and that knowledge of when to do things less than perfectly is part of the wisdom you’ll acquire.
-
-### You are asked what to do
-
-After a while, you'll have earned a reputation in your organization for getting things done. It won’t be just for having expertise in a certain area—it’ll be wisdom. Someone will come to you and ask for guidance with a project or a problem.
-
-That person isn't just asking you for help with a problem. You are being asked to lead.
-
-A common situation is when you are asked to help a team of less-experienced developers that's navigating difficult new terrain or needs shepherding on a project. That's when you'll be called on to help not just do things but show people how to improve their own skills.
-
-It might also be leadership from a technical point of view. Your boss might say, "We need a new indexing solution. Find out what you can about FooIndex and BarSearch, and let me know what you propose." That's the sort of responsibility given only to someone who has demonstrated wisdom and experience.
-
-### You are seriously headhunted for the first time
-
-Recruiting professionals are always looking for talent. Most recruiters seem to do random emailing and LinkedIn harvesting. But every so often, they find out about talented performers and hunt them down.
-
-When that happens, it's a feather in your cap. Maybe a former colleague spoke to a recruiter friend trying to place a developer at a company that needs the skills you have. If you get a personal recommendation for a position—even if you don’t want the job—it means you've really arrived. You're recognized as an expert, or someone who brings value to an organization, enough to recommend you to others.
-
-### Onward
-
-I hope that my little list helps prompt some thought about [where you are in your career][10] or [where you might be headed][11]. Markers and milestones can help you understand what’s around you and what to expect.
-
-This list is far from complete, of course. Everyone has their own story. In fact, one of the ways to know you’ve hit a milestone is when you find yourself telling a story about it to others. When you do find yourself looking back at a tough situation, make sure to reflect on what it means to you and why. Experience is a great teacher—if you listen to it.
-
-What are your markers? How did you know you had finally become a senior programmer? Tweet at [@enterprisenxt][12] and let me know.
-
-This article/content was written by the individual writer identified and does not necessarily reflect the view of Hewlett Packard Enterprise Company.
-
- [][13]
-
-### 作者简介
-
-Andy Lester has been a programmer and developer since the 1980s, when COBOL walked the earth. He is the author of the job-hunting guide [Land the Tech Job You Love][2] (2009, Pragmatic Bookshelf). Andy has been an active contributor to the open source community for decades, most notably as the creator of the grep-like code search tool [ack][3].
-
---------------------------------------------------------------------------------
-
-via: https://www.hpe.com/us/en/insights/articles/becoming-a-senior-developer-9-experiences-youll-encounter-1807.html
-
-作者:[Andy Lester ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
-[1]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
-[2]:https://pragprog.com/book/algh/land-the-tech-job-you-love
-[3]:https://beyondgrep.com/
-[4]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_510384402_seniordev0718
-[5]:https://www.hpe.com/us/en/insights/articles/7-career-milestones-youll-meet-on-the-cio-and-it-management-track-1805.html
-[6]:https://www.hpe.com/us/en/insights/articles/how-to-succeed-in-it-without-social-skills-1705.html
-[7]:https://www.hpe.com/us/en/insights/articles/the-linux-commands-you-should-never-use-1712.html
-[8]:https://www.hpe.com/us/en/insights/articles/back-to-basics-what-sysadmins-must-know-about-logging-and-monitoring-1805.html
-[9]:http://www.bkent.net/Doc/simple5.htm
-[10]:https://www.hpe.com/us/en/insights/articles/career-interventions-when-your-it-career-needs-a-swift-kick-1806.html
-[11]:https://www.hpe.com/us/en/insights/articles/how-to-avoid-an-it-career-dead-end-1806.html
-[12]:https://twitter.com/enterprisenxt
-[13]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
diff --git a/sources/talk/20180711 Open hardware meets open science in a multi-microphone hearing aid project.md b/sources/talk/20180711 Open hardware meets open science in a multi-microphone hearing aid project.md
deleted file mode 100644
index f6a348980d..0000000000
--- a/sources/talk/20180711 Open hardware meets open science in a multi-microphone hearing aid project.md
+++ /dev/null
@@ -1,69 +0,0 @@
-Open hardware meets open science in a multi-microphone hearing aid project
-======
-
-
-
-Since [Opensource.com][1] first published the story of the [GNU/Linux hearing aid][2] research platform in 2010, there has been an explosion in the availability of miniature system boards, including the original BeagleBone in 2011 and the Raspberry Pi in 2012. These ARM processor devices built from cellphone chips differ from the embedded system reference boards of the past—not only by being far less expensive and more widely available—but also because they are powerful enough to run familiar GNU/Linux distributions and desktop applications.
-
-What took a laptop to accomplish in 2010 can now be achieved with a pocket-sized board costing a fraction as much. Because a hearing aid does not need a screen and a small ARM board's power consumption is far less than a typical laptop's, field trials can potentially run all day. Additionally, the system's lower weight is easier for the end user to wear.
-
-The [openMHA project][3]—from the [Carl von Ossietzky Universität Oldenburg][4] in Germany, [BatAndCat Sound Labs][5] in Palo Alto, California, and [HörTech gGmbH][6]—is an open source platform for improving hearing aids using real-time audio signal processing. For the next iteration of the research platform, openMHA is using the US$ 55 [BeagleBone Black][7] board with its 1GHz Cortex A8 CPU.
-
-The BeagleBone family of boards enjoys guaranteed long-term availability, thanks to its open hardware design that can be produced by anyone with the requisite knowledge. For example, BeagleBone hardware variations are available from community members including [SeeedStudio][8] and [SanCloud][9].
-
-![BeagleBone Black][11]
-
-The BeagleBone Black is open hardware finding its way into research labs.
-
-Spatial filtering techniques, including [beamforming][12] and [directional microphone arrays][13], can suppress distracting noise, focusing audio amplification on the point in space where the hearing aid wearer is looking, rather than off to the side where a truck might be thundering past. These neat tricks can use two or three microphones per ear, yet typical sound cards for embedded devices support only one or two input channels in total.
-
-Fortunately, the [McASP][14] communication peripheral in Texas Instruments chips offers multiple channels and support for the [I2S protocol][15], originally devised by Philips for short digital audio interconnects inside CD players. This means an add-on "cape" board can hook directly into the BeagleBone's audio system without using USB or other external interfaces. The direct approach helps reduce the signal processing delay into the range where it is undetectable by the hearing aid wearer.
-
-The openMHA project uses an audio cape developed by the [Hearing4all][16] project, which combines three stereo codecs to provide up to six input channels. Like the BeagleBone, the Cape4all is open hardware with design files available on [GitHub][17].
-
-The Cape4all, [presented recently][18] at the Linux Audio Conference in Berlin, Germany, runs at a sample rate from 24kHz to 96Khz with as few as 12 samples per period, leading to internal latencies in the sub-millisecond range. With hearing enhancement algorithms running, the complete round-trip latency from a microphone to an earpiece has been measured at 3.6 milliseconds (at 48KHz sample rate with 16 samples per period). Using the speed of sound for comparison, this latency is similar to listening to someone just over four feet away without a hearing aid.
-
-![Cape4all ][20]
-
-The Cape4all might be the first multi-microphone hearing aid on an open hardware platform.
-
-The next step for the openMHA project is to develop a [Bluetooth Low Energy][21] module that will enable remote control of the research device from a smartphone and perhaps route phone calls and media playback to the hearing aid. Consumer hearing aids support Bluetooth, so the openMHA research platform must do so, too.
-
-Also, instructions for running a [stereo hearing aid on the Raspberry Pi][22] were released by an openMHA user-project.
-
-As evidenced by the openMHA project, open source innovation has transformed digital hearing aid research from an esoteric branch of audiology into an accessible open science.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/open-hearing-aid-platform
-
-作者:[Daniel James,Christopher Obbard][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/daniel-james
-[1]:http://Opensource.com
-[2]:https://opensource.com/life/10/9/open-source-designing-next-generation-digital-hearing-aids
-[3]:http://www.openmha.org/
-[4]:https://www.uni-oldenburg.de/
-[5]:http://batandcat.com/
-[6]:http://www.hoertech.de/
-[7]:https://beagleboard.org/black
-[8]:https://www.seeedstudio.com/
-[9]:http://www.sancloud.co.uk
-[10]:/file/403046
-[11]:https://opensource.com/sites/default/files/uploads/1-beagleboneblack-600.jpg (BeagleBone Black)
-[12]:https://en.wikipedia.org/wiki/Beamforming
-[13]:https://en.wikipedia.org/wiki/Microphone_array
-[14]:https://en.wikipedia.org/wiki/McASP
-[15]:https://en.wikipedia.org/wiki/I%C2%B2S
-[16]:http://hearing4all.eu/EN/
-[17]:https://github.com/HoerTech-gGmbH/Cape4all
-[18]:https://lac.linuxaudio.org/2018/pages/event/35/
-[19]:/file/403051
-[20]:https://opensource.com/sites/default/files/uploads/2-beaglebone-wireless-with-cape4all-labelled-600.jpg (Cape4all )
-[21]:https://en.wikipedia.org/wiki/Bluetooth_Low_Energy
-[22]:http://www.openmha.org/userproject/2017/12/21/openMHA-on-raspberry-pi.html
diff --git a/sources/talk/20180716 Confessions of a recovering Perl hacker.md b/sources/talk/20180716 Confessions of a recovering Perl hacker.md
deleted file mode 100644
index 48a904cf35..0000000000
--- a/sources/talk/20180716 Confessions of a recovering Perl hacker.md
+++ /dev/null
@@ -1,46 +0,0 @@
-Confessions of a recovering Perl hacker
-======
-
-
-
-My name's MikeCamel, and I'm a Perl hacker.
-
-There, I've said it. That's the first step.
-
-My handle on IRC, Twitter and pretty much everywhere else in the world is "MikeCamel." This is because, back in the day, when there were no chat apps—no apps at all, in fact—I was in a technical "chatroom" and the name "Mike" had been taken. I looked around, and the first thing I noticed on my desk was the [Camel Book][1], the O'Reilly Perl Bible.
-
-I have the second edition now, but this was the first edition. Yesterday, I happened to pick up the second edition, the really thick one, to show someone on a video conference call, and it had a thin layer of dust on it. I was a little bit ashamed, but a little bit relieved as well.
-
-For years, I was a sysadmin. Just bits and pieces, from time to time. Nothing serious, you understand—mainly my systems, my friends' systems. Sometimes I'd admin systems owned by other people—even at work. I always had it under control, and I was always able to step away. There were whole weeks—well days—when I didn't administer a system at all. With the exception of remote systems, which felt different, somehow less serious.
-
-What pushed it over the edge, on reflection, was the Perl. This was the '90s—the 1990s, just to be clear—when Perl was young, and free, and didn't even pretend to be object-oriented. We all know it still isn't, but those youngsters—they like to pretend, and we old lags, well, we play along.
-
-The thing about Perl is that it just starts small, with a regexp here, a text-file line counter there. Nothing that couldn't have been managed quite easily in Bash or Sed or Awk. But once you've written a couple of scripts, you're in—there's no going back. Long-term Perl users remember how we started, and we see the newbs going the same way.
-
-I taught myself Perl in order to collate static web pages from five disparate FoxPro databases. I did it by starting at the beginning of the Camel Book and reading as much of it as I could before my brain started to hurt, then picking up a few pages back and carrying on. And then writing some Perl, which always failed, mainly because of lack of semicolons to start with, and then because I didn't really understand much of what I was doing. But I kept with it until I wasn't just writing scripts to collate databases, but scripts to load data into a single database and using CGI to serve pages in real time. My wife knew, and some of my colleagues knew, but I don't think they fully understood how deep I was in.
-
-You know that Perl has you when you start looking for admin tasks to automate with it. Tasks that don't need automating and that would be much, much faster if you performed them by hand. When you start scouring the web for three- or four-character commands that, when executed, alphabetise, spell-check, and decrypt three separate files in parallel and output them to STDERR, ROT13ed.
-
-I was lucky: I escaped in time. I always insisted on commenting my Perl. I never got to the very end of the Camel Book. Not in one reading, anyway. I never experimented with the darker side-effects; three or four separate operations per line was always enough for me. Over time, as my responsibilities moved more to programming, I cut back on the sysadmin tasks. Of course, that didn't stop the Perl use completely—it's amazing how often you can find an excuse to automate a task and how often Perl is the answer. But it reduced my Perl to manageable levels, levels that didn't affect my day-to-day functioning.
-
-I'd like to pretend that I've stopped, but you never really give up on Perl, and it never gives up on you.
-
-I'd like to pretend that I've stopped, but you never really give up on Perl, and it never gives up on you. My Camel Book (2nd ed.) is still around, even if it's a little dusty. I always check that the core modules are installed on any systems I run. And about five months ago, I found that my 10-year-old daughter had some mathematics homework that was susceptible to brute-forcing. Just a few lines. A couple of loops. No more than that. Nothing that I didn't feel went out of scope.
-
-I'd like to pretend that I've stopped, but you never really give up on Perl, and it never gives up on you. My Camel Book (2nd ed.) is still around, even if it's a little dusty. I always check that the core modules are installed on any systems I run. And about five months ago, I found that my 10-year-old daughter had some mathematics homework that was susceptible to brute-forcing. Just a few lines. A couple of loops. No more than that. Nothing that I didn't feel went out of scope.
-
-I discovered after she handed in the results that it hadn't produced the correct results, but I didn't mind. It was tight, it was elegant, it was beautiful. It was Perl. My Perl.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/confessions-recovering-perl-hacker
-
-作者:[Mike Bursell][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mikecamel
-[1]:https://en.wikipedia.org/wiki/Programming_Perl
diff --git a/sources/talk/20180717 Tips for Success with Open Source Certification.md b/sources/talk/20180717 Tips for Success with Open Source Certification.md
deleted file mode 100644
index ad2ec2738b..0000000000
--- a/sources/talk/20180717 Tips for Success with Open Source Certification.md
+++ /dev/null
@@ -1,63 +0,0 @@
-Tips for Success with Open Source Certification
-======
-
-
-
-In today’s technology arena, open source is pervasive. The [2018 Open Source Jobs Report][1] found that hiring open source talent is a priority for 83 percent of hiring managers, and half are looking for candidates holding certifications. And yet, 87 percent of hiring managers also cite difficulty in finding the right open source skills and expertise. This article is the second in a weekly series on the growing importance of open source certification.
-
-In the [first article][2], we focused on why certification matters now more than ever. Here, we’ll focus on the kinds of certifications that are making a difference, and what is involved in completing necessary training and passing the performance-based exams that lead to certification, with tips from Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation.
-
-### Performance-based exams
-
-So, what are the details on getting certified and what are the differences between major types of certification? Most types of open source credentials and certification that you can obtain are performance-based. In many cases, trainees are required to demonstrate their skills directly from the command line.
-
-“You're going to be asked to do something live on the system, and then at the end, we're going to evaluate that system to see if you were successful in accomplishing the task,” said Seepersad. This approach obviously differs from multiple choice exams and other tests where candidate answers are put in front of you. Often, certification programs involve online self-paced courses, so you can learn at your own speed, but the exams can be tough and require demonstration of expertise. That’s part of why the certifications that they lead to are valuable.
-
-### Certification options
-
-Many people are familiar with the certifications offered by The Linux Foundation, including the [Linux Foundation Certified System Administrator][3] (LFCS) and [Linux Foundation Certified Engineer][4] (LFCE) certifications. The Linux Foundation intentionally maintains separation between its training and certification programs and uses an independent proctoring solution to monitor candidates. It also requires that all certifications be renewed every two years, which gives potential employers confidence that skills are current and have been recently demonstrated.
-
-“Note that there are no prerequisites,” Seepersad said. “What that means is that if you're an experienced Linux engineer, and you think the LFCE, the certified engineer credential, is the right one for you…, you're allowed to do what we call ‘challenge the exams.’ If you think you're ready for the LFCE, you can sign up for the LFCE without having to have gone through and taken and passed the LFCS.”
-
-Seepersad noted that the LFCS credential is great for people starting their careers, and the LFCE credential is valuable for many people who have experience with Linux such as volunteer experience, and now want to demonstrate the breadth and depth of their skills for employers. He also said that the LFCS and LFCE coursework prepares trainees to work with various Linux distributions. Other certification options, such as the [Kubernetes Fundamentals][5] and [Essentials of OpenStack Administration][6]courses and exams, have also made a difference for many people, as cloud adoption has increased around the world.
-
-Seepersad added that certification can make a difference if you are seeking a promotion. “Being able show that you're over the bar in terms of certification at the engineer level can be a great way to get yourself into the consideration set for that next promotion,” he said.
-
-### Tips for Success
-
-In terms of practical advice for taking an exam, Seepersad offered a number of tips:
-
- * Set the date, and don’t procrastinate.
-
- * Look through the online exam descriptions and get any training needed to be able to show fluency with the required skill sets.
-
- * Practice on a live Linux system. This can involve downloading a free terminal emulator or other software and actually performing tasks that you will be tested on.
-
-
-
-
-Seepersad also noted some common mistakes that people make when taking their exams. These include spending too long on a small set of questions, wasting too much time looking through documentation and reference tools, and applying changes without testing them in the work environment.
-
-With open source certification playing an increasingly important role in securing a rewarding career, stay tuned for more certification details in this article series, including how to prepare for certification.
-
-[Learn more about Linux training and certification.][7]
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/sysadmin-cert/2018/7/tips-success-open-source-certification
-
-作者:[Sam Dean][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/sam-dean
-[1]:https://www.linuxfoundation.org/publications/open-source-jobs-report-2018/
-[2]:https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
-[3]:https://training.linuxfoundation.org/certification/lfcs
-[4]:https://training.linuxfoundation.org/certification/lfce
-[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/kubernetes-fundamentals
-[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/openstack-administration-fundamentals
-[7]:https://training.linuxfoundation.org/certification
diff --git a/sources/talk/20180719 Finding Jobs in Software.md b/sources/talk/20180719 Finding Jobs in Software.md
deleted file mode 100644
index 6d3aebaea0..0000000000
--- a/sources/talk/20180719 Finding Jobs in Software.md
+++ /dev/null
@@ -1,90 +0,0 @@
-Finding Jobs in Software
-======
-
-A [PDF of this article][1] is available.
-
-I was back home in Lancaster last week, chatting with a [friend from grad school][2] who’s remained in academia, and naturally we got to talking about what advice he could give his computer science students to better prepare them for their probable future careers.
-
-In some later follow-up emails we got to talking about how engineers find jobs. I’ve fielded this question about a dozen times over the last couple years, so I thought it was about time to crystallize it into a blog post for future linking.
-
-Here are some strategies for finding jobs, ordered roughly from most to least useful:
-
-### Friend-of-a-friend networking
-
-Many of the best jobs never make it to the open market at all, and it’s all about who you know. This makes sense for employers, since good engineers are hard to find and a reliable reference can be invaluable.
-
-In the case of my current job at Iterable, for example, a mutual colleague from thoughtbot (a previous employer) suggested that I should talk to Iterable’s VP of engineering, since he’d worked with both of us and thought we’d get along well. We did, and I liked the team, so I went through the interview process and took the job.
-
-Like many companies, thoughtbot has an alumni Slack group with a `#job-board` channel. Those sorts of semi-formal corporate alumni networks can definitely be useful, but you’ll probably find yourself relying more on individual connections.
-
-“Networking” isn’t a dirty word, and it’s not about handing out business cards at a hotel bar. It’s about getting to know people in a friendly and sincere way, being interested in them, and helping them out (by, say, writing a lengthy blog post about how their students might find jobs). I’m not the type to throw around words like karma, but if I were, I would.
-
-Go to (and speak at!) [meetups][3], offer help and advice when you can, and keep in touch with friends and ex-colleagues. In a couple of years you’ll have a healthy network. Easy-peasy.
-
-This strategy doesn’t usually work at the beginning of a career, of course, but new grads and students should know that it’s eventually how things happen.
-
-### Applying directly to specific companies
-
-I keep a text file of companies where I might want to work. As I come across companies that catch my eye, I add ‘em to the list. When I’m on the hunt for a new job I just consult my list.
-
-Lots of things might convince me to add a company to the list. They might have an especially appealing mission or product, use some particular technology, or employ some specific people that I’d like to work with and learn from.
-
-One shockingly good heuristic that identifies a great workplace is whether a company sponsors or organizes meetups, and specifically if they sponsor groups related to minorities in tech. Plenty of great companies don’t do that, and they still may be terrific, but if they do it’s an extremely good sign.
-
-### Job boards
-
-I generally don’t use job boards, myself, because I find networking and targeted applications to be more valuable.
-
-The big sites like Indeed and Dice are rarely useful. While some genuinely great companies do cross-post jobs there, there are so many atrocious jobs mixed in that I don’t bother with them.
-
-However, smaller and more targeted job boards can be really handy. Someone has created a job site for any given technology (language, framework, database, whatever). If you’re really interested in working with a specific tool or in a particular market niche, it might be worthwhile for you to track down the appropriate board.
-
-Similarly, if you’re interested in remote work, there are a few boards that cater specifically to that. [We Work Remotely][4] is a prominent and reputable one.
-
-The enormously popular tech news site [Hacker News][5] posts a monthly “Who’s Hiring?” thread ([an example][6]). HN focuses mainly on startups and is almost adorably obsessed with trends, tech-wise, so it’s a thoroughly biased sample, but it’s still a huge selection of relatively high-quality jobs. Browsing it can also give you an idea of what technologies are currently in vogue. Some folks have also built [sites that make it easier to filter][7] those listings.
-
-### Recruiters
-
-These are the folks that message you on LinkedIn. Recruiters fall into two categories: internal and external.
-
-An internal recruiter is an employee of a specific company and hires engineers to work for that company. They’re almost invariably non-technical, but they often have a fairly clear idea of what technical skills they’re looking for. They have no idea who you are, or what your goals are, but they’re encouraged to find a good fit for the company and are generally harmless.
-
-It’s normal to work with an internal recruiter as part of the application process at a software company, especially a larger one.
-
-An external recruiter works independently or for an agency. They’re market makers; they have a stable of companies who have contracted with them to find employees, and they get a placement fee for every person that one of those companies hires. As such, they have incentives to make as many matches as possible as quickly as possible, and they rarely have to deal with the fallout if the match isn’t a good one.
-
-In my experience they add nothing to the job search process and, at best, just gum up the works as unnecessary middlemen. Less reputable ones may edit your resume without your approval, forward it along to companies that you’d never want to work with, and otherwise mangle your reputation. I avoid them.
-
-Helpful and ethical external recruiters are a bit like UFOs. I’m prepared to acknowledge that they might, possibly, exist, but I’ve never seen one myself or spoken directly with anyone who’s encountered one, and I’ve only heard about them through confusing and doubtful chains of testimonials (and such testimonials usually make me question the testifier more than my assumptions).
-
-### University career services
-
-I’ve never found these to be of any use. The software job market is extraordinarily specialized, and it’s virtually impossible for a career services employee (who needs to be able to place every sort of student in every sort of job) to be familiar with it.
-
-A recruiter, whose purview is limited to the software world, will often try to estimate good matches by looking at resume keywords like “Python” or “natural language processing.” A university career services employee needs to rely on even more amorphous keywords like “software” or “programming.” It’s hard for a non-technical person to distinguish a job engineering compilers from one hooking up printers.
-
-Exceptions exist, of course (MIT and Stanford, for example, have predictably excellent software-specific career services), but they’re thoroughly exceptional.
-
-There are plenty of other ways to find jobs, of course (job fairs at good industrial conferences—like [PyCon][8] or [Strange Loop][9]—aren’t bad, for example, though I’ve never taken a job through one). But the avenues above are the most common ways that job-finding happens. Good luck!
-
---------------------------------------------------------------------------------
-
-via: https://harryrschwartz.com/2018/07/19/finding-jobs-in-software.html
-
-作者:[Harry R. Schwartz][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://harryrschwartz.com/
-[1]:https://harryrschwartz.com/assets/documents/articles/finding-jobs-in-software.pdf
-[2]:https://www.fandm.edu/ed-novak
-[3]:https://meetup.com
-[4]:https://weworkremotely.com
-[5]:https://news.ycombinator.com
-[6]:https://news.ycombinator.com/item?id=13764728
-[7]:https://www.hnhiring.com
-[8]:https://us.pycon.org
-[9]:https://thestrangeloop.com
diff --git a/sources/talk/20180724 Open Source Certification- Preparing for the Exam.md b/sources/talk/20180724 Open Source Certification- Preparing for the Exam.md
deleted file mode 100644
index 2abcaa7693..0000000000
--- a/sources/talk/20180724 Open Source Certification- Preparing for the Exam.md
+++ /dev/null
@@ -1,64 +0,0 @@
-Open Source Certification: Preparing for the Exam
-======
-Open source is the new normal in tech today, with open components and platforms driving mission-critical processes at organizations everywhere. As open source has become more pervasive, it has also profoundly impacted the job market. Across industries [the skills gap is widening, making it ever more difficult to hire people][1] with much needed job skills. That’s why open source training and certification are more important than ever, and this series aims to help you learn more and achieve your own certification goals.
-
-In the [first article in the series][2], we explored why certification matters so much today. In the [second article][3], we looked at the kinds of certifications that are making a difference. This story will focus on preparing for exams, what to expect during an exam, and how testing for open source certification differs from traditional types of testing.
-
-Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation, stated, “For many of you, if you take the exam, it may well be the first time that you've taken a performance-based exam and it is quite different from what you might have been used to with multiple choice, where the answer is on screen and you can identify it. In performance-based exams, you get what's called a prompt.”
-
-As a matter of fact, many Linux-focused certification exams literally prompt test takers at the command line. The idea is to demonstrate skills in real time in a live environment, and the best preparation for this kind of exam is practice, backed by training.
-
-### Know the requirements
-
-"Get some training," Seepersad emphasized. "Get some help to make sure that you're going to do well. We sometimes find folks have very deep skills in certain areas, but then they're light in other areas. If you go to the website for [Linux Foundation training and certification][4], for the [LFCS][5] and the [LFCE][6] certifications, you can scroll down the page and see the details of the domains and tasks, which represent the knowledge areas you're supposed to know.”
-
-Once you’ve identified the skills you need, “really spend some time on those and try to identify whether you think there are areas where you have gaps. You can figure out what the right training or practice regimen is going to be to help you get prepared to take the exam," Seepersad said.
-
-### Practice, practice, practice
-
-"Practice is important, of course, for all exams," he added. "We deliver the exams in a bit of a unique way -- through your browser. We're using a terminal emulator on your browser and you're being proctored, so there's a live human who is watching you via video cam, your screen is being recorded, and you're having to work through the exam console using the browser window. You're going to be asked to do something live on the system, and then at the end, we're going to evaluate that system to see if you were successful in accomplishing the task"
-
-What if you run out of time on your exam, or simply don’t pass because you couldn’t perform the required skills? “I like the phrase, exam insurance,” Seepersad said. “The way we take the stress out is by offering a ‘no questions asked’ retake. If you take either exam, LFCS, LFCE and you do not pass on your first attempt, you are automatically eligible to have a free second attempt.”
-
-The Linux Foundation intentionally maintains separation between its training and certification programs and uses an independent proctoring solution to monitor candidates. It also requires that all certifications be renewed every two years, which gives potential employers confidence that skills are current and have been recently demonstrated.
-
-### Free certification guide
-
-Becoming a Linux Foundation Certified System Administrator or Engineer is no small feat, so the Foundation has created [this free certification guide][7] to help you with your preparation. In this guide, you’ll find:
-
- * Critical things to keep in mind on test day
-
-
- * An array of both free and paid study resources to help you be as prepared as possible
-
- * A few tips and tricks that could make the difference at exam time
-
- * A checklist of all the domains and competencies covered in the exam
-
-
-
-
-With certification playing a more important role in securing a rewarding long-term career, careful planning and preparation are key. Stay tuned for the next article in this series that will answer frequently asked questions pertaining to open source certification and training.
-
-[Learn more about Linux training and certification.][8]
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/sysadmin-cert/2018/7/open-source-certification-preparing-exam
-
-作者:[Sam Dean][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/sam-dean
-[1]:https://www.linux.com/blog/os-jobs-report/2017/9/demand-open-source-skills-rise
-[2]:https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
-[3]:https://www.linux.com/blog/sysadmin-cert/2018/7/tips-success-open-source-certification
-[4]:https://training.linuxfoundation.org/
-[5]:https://training.linuxfoundation.org/certification/linux-foundation-certified-sysadmin-lfcs/
-[6]:https://training.linuxfoundation.org/certification/linux-foundation-certified-engineer-lfce/
-[7]:https://training.linuxfoundation.org/download-free-certification-prep-guide
-[8]:https://training.linuxfoundation.org/certification/
diff --git a/sources/talk/20180724 Why moving all your workloads to the cloud is a bad idea.md b/sources/talk/20180724 Why moving all your workloads to the cloud is a bad idea.md
deleted file mode 100644
index 1d97805178..0000000000
--- a/sources/talk/20180724 Why moving all your workloads to the cloud is a bad idea.md
+++ /dev/null
@@ -1,71 +0,0 @@
-Why moving all your workloads to the cloud is a bad idea
-======
-
-
-
-As we've been exploring in this series, cloud hype is everywhere, telling you that migrating your applications to the cloud—including hybrid cloud and multicloud—is the way to ensure a digital future for your business. This hype rarely dives into the pitfalls of moving to the cloud, nor considers the daily work of enhancing your customer's experience and agile delivery of new and legacy applications.
-
-In [part one][1] of this series, we covered basic definitions (to level the playing field). We outlined our views on hybrid cloud and multi-cloud, making sure to show the dividing lines between the two. This set the stage for [part two][2], where we discussed the first of three pitfalls: Why cost is not always the obvious motivator for moving to the cloud.
-
-In part three, we'll look at the second pitfall: Why moving all your workloads to the cloud is a bad idea.
-
-### Everything's better in the cloud?
-
-There's a misconception that everything will benefit from running in the cloud. All workloads are not equal, and not all workloads will see a measurable effect on the bottom line from moving to the cloud.
-
-As [InformationWeek wrote][3], "Not all business applications should migrate to the cloud, and enterprises must determine which apps are best suited to a cloud environment." This is a hard fact that the utility company in part two of this series learned when labor costs rose while trying to move applications to the cloud. Discovering this was not a viable solution, the utility company backed up and reevaluated its applications. It found some applications were not heavily used and others had data ownership and compliance issues. Some of its applications were not certified for use in a cloud environment.
-
-Sometimes running applications in the cloud is not physically possible, but other times it's not financially viable to run in the cloud.
-
-Imagine a fictional online travel company. As its business grew, it expanded its on-premises hosting capacity to over 40,000 servers. It eventually became a question of expanding resources by purchasing a data center at a time, not a rack at a time. Its business consumes bandwidth at such volumes that cloud pricing models based on bandwidth usage remain prohibitive.
-
-### Get a baseline
-
-Sometimes running applications in the cloud is not physically possible, but other times it's not financially viable to run in the cloud.
-
-As these examples show, nothing is more important than having a thorough understanding of your application landscape. Along with a having good understanding of what applications need to migrate to the cloud, you also need to understand current IT environments, know your present level of resources, and estimate your costs for moving.
-
-As these examples show, nothing is more important than having a thorough understanding of your application landscape. Along with a having good understanding of what applications need to migrate to the cloud, you also need to understand current IT environments, know your present level of resources, and estimate your costs for moving.
-
-Understanding your baseline–each application's current situation and performance requirements (network, storage, CPU, memory, application and infrastructure behavior under load, etc.)–gives you the tools to make the right decision.
-
-If you're running servers with single-digit CPU utilization due to complex acquisition processes, a cloud with on-demand resourcing might be a great idea. However, first ask these questions:
-
- * How long did this low-utilization exist?
- * Why wasn't it caught earlier?
- * Isn't there a process or effective monitoring in place?
- * Do you really need a cloud to fix this? Or just a better process for both getting and managing your resources?
- * Will you have a better process in the cloud?
-
-
-
-### Are containers necessary?
-
-Many believe you need containers to be successful in the cloud. This popular [catchphrase][4] sums it up nicely, "We crammed this monolith into a container and called it a microservice."
-
-Containers are a means to an end, and using containers doesn't mean your organization is capable of running maturely in the cloud. It's not about the technology involved, it's about applications that often were written in days gone by with technology that's now outdated. If you put a tire fire into a container and then put that container on a container platform to ship, it's still functionality that someone is using.
-
-Is that fire easier to extinguish now? These container fires just create more challenges for your DevOps teams, who are already struggling to keep up with all the changes being pushed through an organization moving everything into the cloud.
-
-Note, it's not necessarily a bad decision to move legacy workloads into the cloud, nor is it a bad idea to containerize them. It's about weighing the benefits and the downsides, assessing the options available, and making the right choices for each of your workloads.
-
-### Coming up
-
-In part four of this series, we'll describe the third and final pitfall everyone should avoid with hybrid multi-cloud. Find out what the cloud means for your data.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
-
-作者:[Eric D.Schabell][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/eschabell
-[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
-[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
-[3]:https://www.informationweek.com/cloud/10-cloud-migration-mistakes-to-avoid/d/d-id/1318829
-[4]:https://speakerdeck.com/caseywest/containercon-north-america-cloud-anti-patterns?slide=22
diff --git a/sources/talk/20180726 Tech jargon- The good, the bad, and the ugly.md b/sources/talk/20180726 Tech jargon- The good, the bad, and the ugly.md
deleted file mode 100644
index def2701a78..0000000000
--- a/sources/talk/20180726 Tech jargon- The good, the bad, and the ugly.md
+++ /dev/null
@@ -1,108 +0,0 @@
-Tech jargon: The good, the bad, and the ugly
-======
-
-
-One enduring and complex piece of jargon is the use of "free" in relation to software. In fact, the term is so ambiguous that different terms have evolved to describe some of the variants—open source, FOSS, and even phrases such as "free as in speech, not as in beer." But surely this is a good thing, right? We know what we mean; we're sharing shorthand by using a particular word in a particular way. Some people might not understand, and there's some ambiguity. But does that matter?
-
-### A couple of definitions
-
-I was involved in an interesting discussion with colleagues recently about the joys (or otherwise) of jargon. It stemmed from a section I wrote in a recent article, [How to talk to security people: a guide for the rest of us][1], where I said:
-
-> "Jargon has at least two uses:
->
-> 1. as an exclusionary mechanism for groups to keep non-members in the dark;
-> 2. as a short-hand to exchange information between 'in-the-know' people so that they don't need to explain everything in exhaustive detail every time."
->
-
-
-Given the discussion that arose, I thought it was worth delving more deeply into this question. It's more than an idle interest, as I think there are important lessons around our use of jargon that impact how we interact with our colleagues and peers that deserve some careful thought. These lessons apply particularly to my chosen field, security.
-
-Before we start, we should define "jargon". It's always nice to have two conflicting versions, so here we go:
-
- * "Special words or expressions used by a profession or group that are difficult for others to understand." ([Oxford Living Dictionaries][2])
- * "Without a qualifier, denotes informal 'slangy' language peculiar to or predominantly found among hackers." ([The Jargon File][3])
-
-
-
-I should start by pointing out that The Jargon File, which was published in paper form in at least [two versions][4] as The Hacker's Dictionary (ed. Steele) and The New Hacker's Dictionary (ed. Raymond), has a pretty special place in my heart. When I decided that I wanted to properly "take up" geekery,1,2 I read The New Hacker's Dictionary from cover to cover, several times, and when a new edition came out, I bought that and did the same.
-
-In fact, for more technical readers, I suspect that a fair amount of your cultural background is expressed within its covers (paper or virtual), even if you're not aware of it. If you're interested in delving deeper and like the feel of paper in your hands, I encourage you to purchase a copy—but be careful to get the right one. There are some expensive versions that seem just to be printouts of The Jargon File, rather than properly typeset and edited versions.3
-
-But let's get onto the meat of this article: is jargon a force for good or ill?
-
-### First: Why jargon is good
-
-The case for jargon is quite simple. We need jargon to enable us to discuss concepts and the use of terms in normal language—like scheduling—as jargon leads to some interesting metaphors that guide us in our practice.4 We absolutely need shared practice, and for that we need shared language—and some of that language is bound to become jargon over time. But consider a lexicon, or an FAQ, or other ways to allow your colleagues to participate: be inclusive, not exclusive. That's the good. The problem, however, is the bad.
-
-### The case against jargon: Ambiguity
-
-You would think jargon would serve to provide agreed terms within a particular discipline and help prevent ambiguity around contexts. It may be a surprise, then, that the first problem we often run into with jargon is namespace clashes. Consider the following. There's an old joke about how to distinguish an electrical engineer from a humanities5 graduate: ask them how many syllables are in the word "coax." The point here, of course, is that they come from different disciplines. But there are lots of words—and particularly abbreviations—that have different meanings or expansions depending on context and where disciplines and contexts may collide.
-
-What do these words mean to you?6
-
- * Scheduling: kernel-level CPU allocation to processes OR placement of workloads by an orchestration component
- * Comms: I/O in a computer system OR marketing/analyst communications
- * Layer: OSI model OR IP suite layer OR another architectural abstraction layer such as host or workload
- * SME: subject matter expert OR small/medium enterprise
- * SMB: small/medium business OR small message block
- * TLS: transport layer security OR Times Literary Supplement
- * IP: internet protocol OR intellectual property OR intellectual property as expressed as a silicon component block
- * FFS for further study OR …7
-
-
-
-One of the interesting things is that quite a lot of my background is betrayed by the various options that present themselves to me. I wonder how many readers will have thought of the Times Literary Supplement, for example. I'm also more likely to think of SME as the term relating to organisations, because that's the favoured form in Europe, whereas I believe that the US tends to SMB. I'm sure your experiences will all be different—which rather makes my point for me.
-
-That's the first problem. In a context where jargon is often praised as a way of shortcutting lengthy explanations, it can actually be a significant ambiguating force.
-
-### The case against jargon: Exclusion
-
-Intentionally or not—and sometimes it is intentional—groups define themselves through the use of specific terminology. Once this terminology becomes opaque to those outside the group, it becomes "jargon," as per our first definition above. "Good" use of jargon generally allows those within the group to converse using shared context around concepts that do not need to be explained in detail every time they are used.
-
-An example would be a "smoke test"—a quick test to check that basic functionality is performing correctly (see the Jargon File's [definition][5] for more). If everyone in the group understands what this means, then why go into more detail? But if you are joined at a stand-up meeting8 by a member of marketing who wants to know whether a particular build is ready for release, and you say "well, no—it's only been smoke-tested so far," then it's likely you'll need to explain.
-
-The problem is that there are occasions when jargon can exclude others, whether that usage is intended or not. There have been times for most of us, I'm sure, when we want to show we're part of a group, so we use terms that we know another person won't understand. On other occasions, the term may be so ingrained in our practice that we use it without thinking, and the other person is unintentionally excluded. I would argue that we need to be careful to avoid both of these uses.
-
-Intentional exclusion is rarely helpful, but unintentional exclusion can be just as damaging—in some ways more so, as it is typically unremarked and therefore difficult to remedy.
-
-### What to do?
-
-First, be aware when you're using jargon, and try to foster an environment where people feel happy to query what you mean. If you see people's eyes glazing over, take a step back and explain the context and the term. Second, be on the lookout for ambiguity: if you're on a project where something can mean more than one thing, disambiguate somewhere in a file or diagram that everyone can access and is easily discoverable. And last, don't use jargon to exclude. We need all the people we can get, so let's bring them in, not push them out.
-
-1\. "Properly"—really? Although I'm not sure "improperly" is any better.
-
-2\. I studied English Literature and Theology at university, so this was a conscious decision to embrace a rather different culture.
-
-3\. The most recent "real" edition of which I'm aware is Raymond, Eric S., 1996, [The New Hacker's Dictionary][6], 3rd ed., MIT University Press, Cambridge, Mass.
-
-4\. Although metaphors can themselves be constraining as they tend to push us to think in a particular way, even if that way isn't entirely applicable in this context.
-
-5\. Or "liberal arts".
-
-6\. I've added the first options that spring to mind when I come across them—I'm aware there are almost certainly others.
-
-7\. Believe me, when I saw this abbreviation in a research paper for the first time, I was most confused and had to look it up.
-
-8\. Oh, look: jargon…
-
-This article originally appeared on [Alice, Eve, and Bob – a security blog][7] and is republished with permission.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/tech-jargon
-
-作者:[Mike Bursell][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mikecamel
-[1]:http://aliceevebob.com/2018/05/08/how-to-talk-to-security-people-a-guide-for-the-rest-of-us/
-[2]:https://en.oxforddictionaries.com/definition/jargon
-[3]:http://catb.org/jargon/html/distinctions.html
-[4]:https://en.wikipedia.org/wiki/Jargon_File
-[5]:http://catb.org/jargon/html/S/smoke-test.html
-[6]:https://www.amazon.com/New-Hackers-Dictionary-3rd/dp/0262680920
-[7]:https://aliceevebob.com/2018/06/26/jargon-a-force-for-good-or-ill/
diff --git a/sources/talk/20180802 Design thinking as a way of life.md b/sources/talk/20180802 Design thinking as a way of life.md
deleted file mode 100644
index 5d88bdf04f..0000000000
--- a/sources/talk/20180802 Design thinking as a way of life.md
+++ /dev/null
@@ -1,95 +0,0 @@
-Design thinking as a way of life
-======
-
-
-
-Over the past few years, design has become more than a discipline. It has become a mindset, one gaining more and more traction in industrial practices, processes, and operations.
-
-People have begun to recognize the value in making design the fundamental component of the process and methodologies aimed at both the "business side" and the "people side" of the organization. In other words, "thinking with design" is a great way to approach business problems and organizational culture problems.
-
-Design thinkers have tried to visualize how design can be translated as the core of methodologies like Design Thinking, Lean, Agile, and others in a meaningful way, as industries begin seeing potential in a design-driven approach capable of helping organizations be more efficient and effective in delivering value to customers.
-
-But still, many questions remain—especially questions about the operational aspect of translating core design values. For example:
-
- * "When should we use Design Thinking?"
- * "What is the best way to run a design process?"
- * "How effectively we can fit design into Agile? Or Agile into the design process?"
- * "Which methodologies are best for my team and the design practices I am following?"
-
-
-
-The list goes on. In general, though, the tighter integration of design principles into all phases of development processes is becoming more common—something we might call "[DesOps][1]." This mode of thinking, "Design Operations," is a mindset that some believe might be the successor of the DevOps movement. In this article, I want to explain how open principles intersect with the DesOps movement.
-
-### Eureka
-
-The quest for a design "Holy Grail," especially from a service design perspective, has led many on a journey through similar methodologies yet toward the same goal: that "eureka" moment that reveals the "best fit" service model for a design process that will work most effectively. But among those various methodologies and practices are so many overlaps, and as a result, everyone is looking for the common framework capable of assessing problems from diverse angles, like business and engineering. It's as if all the gospels of all major religions are preaching and striving for the same higher human values of love, peace, and conscience—but the question is "Which is the right and most effective way?"
-
-I may have found an answer.
-
-On my first day at Red Hat, I received a copy of Jim Whitehurst's The Open Organization. What immediately came to my mind was: "Oh, another book with rants about open source practices and benefits."
-
-But over the weekend, as I scanned the book's pages, I realized it's about more than just "open source culture." It's a book about the quest to find an answer to a much more basic puzzle, one that every organization is currently trying to solve: "What is that common thread that can bind best practices and philosophies in a way that's meaningful for organizations?"
-
-This was interesting! As I dove more deeply, I found something that made even more sense in context of all the design- and operations-related questions I've seen debated for years: Being "open" is the key to bringing together the best of different practices and philosophies, something that allows us to retain their authenticity and yet help in catering to real needs in operations and design.
-
-It's also the key to thinking with DesOps.
-
-### DesOps: Culture, process, technology
-
-Like every organizational framework, DesOps touches upon culture, process, and technology—the entire ecosystem of the enterprise.
-
-Like every organizational framework, DesOps touches upon culture, process, and technology—the entire ecosystem of the enterprise. Because it is inspired by the culture of DevOps, people tend to view it more from the angle of technological aspects (such as automation, continuous integration, and a delivery point of view). However the most difficult—and yet most important—piece of the DesOps puzzle to solve is the cultural one. This is critical because it involves human-to-human interactions (unlike the machine-to-machine or human-to-machine interactions that are a more common part of purely technological questions).
-
-So DesOps is not only about bringing automation and continuous integration to systems-to-systems interactions. It's an approach to organically making the systems a part of all interaction touch points that actually enable in human-to-human communication and feedback models.
-
-Humans are at the center of DesOps, which requires a culture that itself follows design philosophies and values, including "zero waste" in translation across interaction touch points (including lean methodologies across the activity chains). Stressing dynamic culture based on agile philosophies, DesOps is design thinking as a way of life.
-
-But how can we build an organizational culture that aligns to basic DesOps philosophies? What kind of culture can organically compliment those meaningfully integrated system-to-system and system-to-human toolings and eco-systems as part of DesOps?
-
-The answer can be found in The Open Organization.
-
-A DesOps culture is essentially an open culture, and that solves a critical piece of the puzzle. What I realized during my [book-length exploration of DesOps][2] is that every DesOps-led organization is actually an open organization.
-
-### DesOps, open by default
-
-To ensure we can sustain our organizations in the future, we must rethink how to we work together and prepare ourselves—how we develop and sustain a culture of innovation.
-
-Broadly, DesOps focuses on how to converge different work practices so that an organization's product management, design, engineering, and marketing teams can work together in an optimal way. Then the organization can nurture and sustain creativity and innovation, while at the same time delivering that "wow" experience to customers and end users through products and services.
-
-At a fundamental level, DesOps is not about introducing new models or process in the enterprise; rather, it's about orchestrating best practices from Design Thinking, Lean Methodologies, User-Centered Design models, and other best practices with modern technologies to understand, create, and deliver value.
-
-Let's take a closer look at core DesOps philosophies. Some are inherently aligned with and draw inspirations from the DevOps movement, and all are connected to the attributes of an open organization (both at organizational and individual levels).
-
-Being "open" means:
-
- * Every individual is transparent. So is the organization they're part of. The upshot is that each member of the organization enables greater transparency and more feedback-loops.
- * There's less manipulation in translation among touch points. This also means the process is lean and every touch point is easily accessible.
- * There's greater accessibility, which means the organizational structure tends towards zero hierarchy, as each ladder is accessible through openness. Every one is encouraged to interact, ask questions, and share thoughts and ideas, and provide feedback. When individuals ask and share ideas across roles, they feel more responsible, and a sense of ownership develops.
- * Greater accessibility, in turn, helps nurture ideas from bottom up, as it provides avenues for ideas to germinate and evolve upward.
- * Bottom-up momentum helps with inclusivity, as it opens doors for grassroots movements in the organization and eliminates structural boundaries within it.
- * Inclusivity reduces gaps among functional roles, again reducing hierarchy.
- * Feedback loops form across the organization (and also through development life cycles). This in return enables more meaningful data for informed decision making.
- * Empathy is nurtured, which helps people in the organization to understand the needs and pain-points of users and customers. Within the organization, it helps people identify and solve core issues, making it possible to implement design thinking as a way of life. With the enablement of empathy and humility, the culture becomes more receptive and will tend towards zero bias. The open, receptive, and empathetic team has greater agility, one that's more open to change.
- * Freedom arrives as a bonus when the organization has a open culture, and this creates a positive environment for the team to innovate, not feeling psychologically fearful and encourage fail-fast philosophies.
-
-
-
-We're at an interesting historical moment, when competition in the market is increasing, technology has matured, and unstructured data is a fuel that can open up new possibilities. Our organizational management models have matured beyond corporate, autocratic ways of running people and systems. To ensure we can sustain our organizations in the future, we must rethink how to we work together and prepare ourselves—how we develop and sustain a culture of innovation.
-
-Open organization principles are guideposts on that journey.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/8/introduction-to-desops
-
-作者:[Samir Dash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/sdash
-[1]:http://desops.io/
-[2]:http://desops.io/2018/06/07/paperback-the-desops-enterprise-re-invent-your-organization-volume-1-the-overview-culture/
diff --git a/sources/talk/20180807 Becoming a successful programmer in an underrepresented community.md b/sources/talk/20180807 Becoming a successful programmer in an underrepresented community.md
deleted file mode 100644
index ff86e1f213..0000000000
--- a/sources/talk/20180807 Becoming a successful programmer in an underrepresented community.md
+++ /dev/null
@@ -1,94 +0,0 @@
-Becoming a successful programmer in an underrepresented community
-======
-
-
-
-Becoming a programmer from an underrepresented community like Cameroon is tough. Many Africans don't even know what computer programming is—and a lot who do think it's only for people from Western or Asian countries.
-
-I didn't own a computer until I was 18, and I didn't start programming until I was a 19-year-old high school senior, and had to write a lot of code on paper because I couldn't be carrying my big desktop to school. I have learned a lot over the past five years as I've moved up the ladder to become a successful programmer from an underrepresented community. While these lessons are from my experience in Africa, many apply to other underrepresented communities, including women.
-
-### 1\. Learn how to code
-
-This is obvious: To be a successful programmer, you first have to be a programmer. In an African community, this may not be very easy. To learn how to code you need a computer and probably internet, too, which aren't very common for Africans to have. I didn't own a desktop computer until I was 18 years old—and I didn't own a laptop until I was about 20, and some may have still considered me privileged. Some students don't even know what a computer looks like until they get to the university.
-
-You still have to find a way to learn how to code. Before I had a computer, I used to walk for miles to see a friend who had one. He wasn't very interested in it, so I spent a lot of time with it. I also visited cybercafes regularly, which consumed most of my pocket money.
-
-Take advantage of local programming communities, as this could be one of your greatest sources of motivation. When you're working on your own, you may feel like a ninja, but that may be because you do not interact much with other programmers. Attend tech events. Make sure you have at least one friend who is better than you. See that person as a competitor and work hard to beat them, even though they may be working as hard as you are. Even if you never win, you'll be growing in skill as a programmer.
-
-### 2\. Don't read too much into statistics
-
-A lot of smart people in underrepresented communities never even make it to the "learning how to code" part because they take statistics as hard facts. I remember when I was aspiring to be a hacker, I used to get discouraged about the statistic that there are far fewer black people than white people in technology. If you google the "top 50 computer programmers of all time," there probably won't be many (if any) black people on the list. Most of the inspiring names in tech, like Ada Lovelace, Linus Torvalds, and Bill Gates, are white.
-
-Growing up, I always believed technology was a white person's thing. I used to think I couldn't do it. When I was young, I never saw a science fiction movie with a black man as a hacker or an expert in computing. It was always white people. I remember when I got to high school and our teacher wrote that programming was part of our curriculum, I thought that was a joke—I wondered, "since when and how will that even be possible?" I wasn't far from the truth. Our teachers couldn't program at all.
-
-Statistics also say that a lot of the amazing, inspiring programmers you look up to, no matter what their color, started coding at the age of 13. But you didn't even know programming existed until you were 19. You ask yourself questions like: How am I going to catch up? Do I even have the intelligence for this? When I was 13, I was still playing stupid, childish games—how can I compete with this?
-
-This may make you conclude that white people are naturally better at tech. That's wrong. Yes, the statistics are correct, but they're just statistics. And they can change. Make them change. Your environment contributes a lot to the things you do while growing up. How can you compare yourself to someone whose parents got him a computer before he was nine—when you didn't even see one until you were 19? That's a 10-year gap. And that nine-year-old kid also had a lot of people to coach him.
-
-How can you compare yourself to someone whose parents got him a computer before he was nine—when you didn't even see one until you were 19?
-
-You can be a great software engineer regardless of your background. It may be a little harder because you may not have the resources or opportunities people in the western world have, but it's not impossible.
-
-### 3\. Have a local hero or mentor
-
-I think having someone in your life to look up to is one of the most important things. We all admire people like Linus Torvalds and Bill Gates but trying to make them your role models can be demotivating. Bill Gates began coding at age 13 and formed his first venture at age 17. I'm 24 and still trying to figure out what I want to do with my life. Those stories always make me wonder why I'm not better yet, rather than looking for reasons to get better.
-
-Having a local hero or mentor is more helpful. Because you're both living in the same community, there's a greater chance there won't be such a large gap to discourage you. A local mentor probably started coding around the age you did and was unlikely to start a big venture at a very young age.
-
-I've always admired the big names in tech and still do. But I never saw them as mentors. First, because their stories seemed like fantasy to me, and second, I couldn't reach them. I chose my mentors and role models to be those near my reach. Choosing a role model doesn't mean you just want to get to where they are and stop. Success is step by step, and you need a role model for each stage you're trying to reach. When you attain a stage, get another role model for the next stage.
-
-You probably can't get one-on-one advice from someone like Bill Gates. You can get the advice they're giving to the public at conferences, which is great, too. I always follow smart people. But advice that makes the most impact is advice that is directed to you. Advice that takes into consideration your goals and circumstances. You can get that only from someone you have direct access to.
-
-I'm a product of many mentors at different stages of my life. One is [Nyah Check][1] , who was a year ahead of me at the university, but in terms of skill and experience, he was two to three years ahead. I heard stories about him when I was still in high school. He made people want to be great programmers, not just focus on getting a 4.0 GPA. He was one of the first people in French-speaking Africa to participate in [Google Summer of Code][2] . While still at the university, he traveled abroad more times than many lecturers would dream of—without spending a dime. He could write code that even our course instructors couldn't understand. He co-founded [Google Developer Group Buea][3] and created an elite programmers club that helped many students learn to code. He started a lot of other communities, like the [Docker Buea meetup][4] that I'm the lead organizer for.
-
-These things inspired me. I wanted to be like him and knew what I would gain by becoming friends with him. Discussions with him were always very inspiring—he talked about programming and his adventures traveling the world for conferences. I learned a lot from him, and I think he taught me well. Now younger students want to be around me for the same reasons I wanted to learn from him.
-
-### 4\. Get involved with open source
-
-If you're in Africa and want to gain top skills from top engineers, your best bet is to join an open source project. The tech ecosystem in Africa is small and mostly made of startups, so getting experience in a field you love might not be easy. It's rare for startups in Africa to be working with machine learning, distributed computing, or containers and technologies like Kubernetes. Unless your passion is web development, your best bet is joining an open source project. I've learned most of what I know by being part of the [OpenMRS][5] community. I've also contributed to other open source projects including [LibreHealth][6], [Coala][7], and [Kubernetes][8]. Along with gaining tech skills, you'll be building your network of influential people. Most of my peers know about Linus Torvalds from books, but I have a picture with him.
-
-Participate in open source outreach programs like Google Summer of Code, [Google Code-in][9], [Outreachy][10], or [Linux Foundation Networking Internships][11]. These opportunities help you gain skills that may not be available in startups.
-
-I participated in Google Summer of Code twice as a student, and I'm now a mentor. I've been a Google Code-in org admin, and I'm volunteering as an open source developer. All these activities help me learn new things.
-
-### 5\. Take advantage of diversity programs while you can
-
-Diversity programs are great, but if you're like me, you may not like to benefit very much from them. If you're on a team of five and the basis of your offer is that you're a black person and the other four are white, you might wonder if you're really good enough. You won't want people to think a foundation sponsored your trip because you're black rather than because you add as much value as anyone else. It's never only that you're a minority—it's because the sponsoring organization thinks you're an exceptional minority. You're not the only person who applied for the diversity scholarship, and not everyone that applied won the award. Take advantage of diversity opportunities while you can and build your knowledge base and network.
-
-When people ask me why the Linux Foundation sponsored my trip to the Open Source Summit, I say: "I was invited to give a talk at their conference, but they have diversity scholarships you can apply for." How cool does that sound?
-
-Attend as many conferences as you can—diversity scholarships can help. Learn all you can learn. Practice what you learn. Get to know people. Apply to give talks. Start small. My right leg used to shake whenever I stood in front of a crowd to give a speech, but with practice, I've gotten better.
-
-### 6\. Give back
-
-Always find a way to give back. Mentor someone. Take up an active role in a community. These are the ways I give back to my community. It isn't only a moral responsibility—it's a win-win because you can learn a lot while helping others get closer to their dreams.
-
-I was part of a Programming Language meetup organized by Google Developer Group Buea where I mentored 15 students in Java programming (from beginner to intermediate). After the program was over, I created a Java User Group to keep the Java community together. I recruited two members from the meetup to join me as volunteer developers at LibreHealth, and under my guidance, they made useful commits to the project. They were later accepted as Google Summer of Code students, and I was assigned to mentor them during the program. I'm also the lead organizer for Docker Buea, the official Docker meetup in Cameroon, and I'm also Docker Campus Ambassador.
-
-Taking up leadership roles in this community has forced me to learn. As Docker Campus Ambassador, I'm supposed to train students on how to use Docker. Because of this, I've learned a lot of cool stuff about Docker and containers in general.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/becoming-successful-programmer
-
-作者:[lvange Larry][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/ivange94
-[1]:https://github.com/Ch3ck
-[2]:https://summerofcode.withgoogle.com/
-[3]:http://www.gdgbuea.net/
-[4]:https://www.meetup.com/Docker-Buea/?_cookie-check=EnOn1Ct-CS4o1YOw
-[5]:https://openmrs.org/
-[6]:https://librehealth.io/
-[7]:https://coala.io/#/home'
-[8]:https://kubernetes.io/
-[9]:https://codein.withgoogle.com/archive/
-[10]:https://www.outreachy.org/
-[11]:https://wiki.lfnetworking.org/display/LN/LF+Networking+Internships
-[12]:http://sched.co/FAND
-[13]:https://ossna18.sched.com/
diff --git a/sources/talk/20180807 Building more trustful teams in four steps.md b/sources/talk/20180807 Building more trustful teams in four steps.md
deleted file mode 100644
index 60dfe37133..0000000000
--- a/sources/talk/20180807 Building more trustful teams in four steps.md
+++ /dev/null
@@ -1,70 +0,0 @@
-Building more trustful teams in four steps
-======
-
-
-
-Robin Dreeke's The Code of Trust is a helpful guide to developing trustful relationships, and it's particularly useful to people working in open organizations (where trust is fundamental to any kind of work). As its title implies, Dreeke's book presents a "code" or set of principles people can follow when attempting to establish trust. I explained those in [the first installment of this review][1]. In this article, then, I'll outline what Dreeke (a former FBI agent) calls "The Four Steps to Inspiring Trust"—a set of practices for enacting the principles. In other words, the Steps make the Code work in the real world.
-
-### The Four Steps
-
-#### 1\. Align your goals
-
-First, determine your primary goal—what you want to achieve and what sacrifices you are willing to make to achieve those goals. Learn the goals of others. Look for ways to align your goals with their goals, to make parts of their goals a part of yours. "You'll achieve the power that only combined forces can attain," Dreeke writes. For example, in the sales manager seminar I once ran regularly, I mentioned that if a sales manager helps a salesman reach his sales goals, the manager will reach his goals automatically. Also, if a salesman helps his customer reach his goals, the salesman will reach his goals automatically. This is aligning goals. (For more on this, see an [earlier article][2] I wrote about how companies can determine when to compete and when to cooperate).
-
-This couldn't be more true in open organizations, which depend on both internal and external contributors a great deal. What are those contributors' goals? Everyone must understand these if an open organization is going to be successful.
-
-When aligning goals, try to avoid having strong opinions on the topic at hand. This leads to inflexibility, Dreeke says, and reduces the chance of generating options that align with other people's goals. To find their goals, consider what their fears or concerns are. Then try to help them overcome those fears or concerns.
-
-If you can't get them to align with your goals, then you should choose to not align with them and instead remove them from the team. Dreeke recommends doing this in a way that allows you to stay approachable for other projects. In one issue, goals might not be aligned; in other issues, they may.
-
-Dreeke also notes that many people believe being successful means carefully narrowing your focus to your own goals. "But that's one of those lazy shortcuts that slow you down," Dreeke writes. Success, Dreeke says, arrives faster when you inspire others to merge their goals with yours, then forge ahead together. In that respect, if you place heavy attention on other people and their goals while doing the same with yours, success in opening someone up comes far sooner. This all sounds very much like advice for activating transparency, inclusivity, and collaboration—key open organization principles.
-
-#### 2\. Apply the power of context
-
-Dreeke recommends really getting to know your partners, discovering "their desires, beliefs, personality traits, behaviors, and demographic characteristics." Those are key influences that define their context.
-
-To achieve trust, you must find a plan that achieves their goals along with yours.
-
-People only trust those who know them (including these beliefs, goals, and personalities). Once known, you can match their goals with yours. To achieve trust, you must find a plan that achieves their goals along with yours (see above). If you try to push your goals on them, they'll become defensive and information exchange will shut down. If that happens, no good ideas will materialize.
-
-#### 3\. Craft your encounter
-
-When you meet with potential allies, plan the meeting meticulously—especially the first meeting. Create the perfect environment for it. Know in advance: 1. the proper atmosphere and mood required, 2. the special nature of the occasion, 3. the perfect time and location, 4. your opening remark, and 5. your plan of what to offer the other person (and what to ask for at that time). Creating the best possible environment for every interaction sets the stage for success.
-
-Dreeke explains the difference between times for planning and thinking and times for simply performing (like when you meet a stranger for the first time). If you are not well prepared, the fear and emotions of the moment could be overwhelming. To reduce that emotion, planning, preparing and role playing can be very helpful.
-
-Later in the book, Dreeke discusses "toxic situations," suggesting you should not ignore toxic situations, as they'll more than likely get worse if you do. People could become emotional and say irrational things. You must address the toxic situation by helping people stay rational. Then try to laser in on interactions between your goals and theirs. What does the person want to achieve? Suspending your ego gives you "the freedom to laser-in" on others' points of view and places where their goals can lead to joint ultimate goals, Dreeke says. Stay focused on their context, not your ego, in toxic situations.
-
-Some leaders think it is best to strongly confront toxic people, maybe embarrassing them in front of others. That might feel good at the time, but "kicking ass in a crowd" just builds people's defenses, Dreeke says. To build a productive plan, he says, you need "shields down," so information will be shared.
-
-Show others you speak their language—not only for understanding, but also to demonstrate reason, respect, and consideration.
-
-"Trust leaders take no interest in their own power," Dreeke argues, as they are deeply interested and invested in others. By helping others, their trust develops. For toxic people, the opposite is true: They want power. Unfortunately, this desire for power just espouses more fear and distrust. Dreeke says that to combat a toxic environment, trust leaders do not "fight fire with fire" which spreads the toxicity. They "fight fire with water" to reduce it. In movies, fights are exciting; in real life they are counterproductive.
-
-#### 4\. Connect
-
-Finally, show others you speak their language—not only for understanding, but also to demonstrate reason, respect, and consideration. Speak about what they want to hear (namely, issues that focus on them and their needs). The speed of trust is directly opposed to the speed of speech, Dreeke says. People who speak slowly and carefully build trust faster than people who rush their speaking.
-
-Importantly, Dreeke also covers a way to get people to like you. It doesn't involve directly getting people to like you personally; it involves getting people to like themselves. Show more respect for them than they might even feel about themselves. Praise them for qualities about themselves that they hadn't thought about. That will open the doors to a trusting relationship.
-
-### Putting it together
-
-I've spent my entire career attempting to build trust globally, throughout the business communities in which I've worked. I have no experience in the intelligence community, but I do see great similarities in spite of the different working environment. The book has given me new insights I never considered (like the section on "crafting your encounter," for example). I recommend people pick up the book and read it thoroughly, as there is other helpful advice in it that I couldn't cover in this short article.
-
-As I [mentioned in Part 1][1], following Dreeke's Code of Trust can lead to building strong trust networks or communities. Those trust communities are exactly what we are trying to create in open organizations.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/8/steps-trust
-
-作者:[Ron McFarland][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/ron-mcfarland
-[1]:https://opensource.com/open-organization/18/7/the-code-of-trust-1
-[2]:https://opensource.com/open-organization/17/6/collaboration-vs-competition-part-1
diff --git a/sources/talk/20180808 3 tips for moving your team to a microservices architecture.md b/sources/talk/20180808 3 tips for moving your team to a microservices architecture.md
deleted file mode 100644
index fd990a0d8e..0000000000
--- a/sources/talk/20180808 3 tips for moving your team to a microservices architecture.md
+++ /dev/null
@@ -1,180 +0,0 @@
-3 tips for moving your team to a microservices architecture
-======
-
-
-Microservices are gaining in popularity and providing new ways for tech companies to improve their services for end users. But what impact does the shift to microservices have on team culture and morale? What issues should CTOs, developers, and project managers consider when the best technological choice is a move to microservices?
-
-Below you’ll find key advice and insight from CTOs and project leads as they reflect on their experiences with team culture and microservices.
-
-### You can't build successful microservices without a successful team culture
-
-When I was working with Java developers, there was tension within the camp about who got to work on the newest and meatiest features. Our engineering leadership had decided that we would exclusively use Java to build all new microservices.
-
-There were great reasons for this decision, but as I will explain later, such a restrictive decision come with some repercussions. Communicating the “why” of technical decisions can go a long way toward creating a culture where people feel included and informed.
-
-When you're organizing and managing a team around microservices, it’s always challenging to balance the mood, morale, and overall culture. In most cases, the leadership needs to balance the risk of team members using new technology against the needs of the client and the business itself.
-
-This dilemma, and many others like it, has led CTOs to ask themselves questions such as: How much freedom should I give my team when it comes to adopting new technologies? And perhaps even more importantly, how can I manage the overarching culture within my camp?
-
-### Give every team member a chance to thrive
-
-When the engineering leaders in the example above decided that Java was the best technology to use when building microservices, the decision was best for the company: Java is performant, and many of the senior people on the team were well-versed with it. However, not everyone on the team had experience with Java.
-
-The problem was, our team was split into two camps: the Java guys and the JavaScript guys. As time went by and exciting new projects came up, we’d always reach for Java to get the job done. Before long, some annoyance within the JavaScript camp crept in: “Why do the Java guys always get to work on the exciting new projects while we’re left to do the mundane front-end tasks like implementing third-party analytics tools? We want a big, exciting project to work on too!”
-
-Like most rifts, it started out small, but it grew worse over time.
-
-The lesson I learned from that experience was to take your team’s expertise and favored technologies into account when choosing a de facto tech stack for your microservices and when adjusting your team's level of freedom to pick and choose their tools.
-
-Sure, you need some structure, but if you’re too restrictive—or worse, blind to the desire of team members to innovate with different technologies—you may have a rift of your own to manage.
-
-So evaluate your team closely and come up with a plan that empowers everyone. That way, every section of your team can get involved in major projects, and nobody will feel like they’re being left on the bench.
-
-### Technology choices: stability vs. flexibility
-
-Let’s say you hire a new junior developer who is excited about some brand new, fresh-off-the-press JavaScript framework.
-
-That framework, while sporting some technical breakthroughs, may not have proven itself in production environments, and it probably doesn’t have great support available. CTOs have to make a difficult choice: Okaying that move for the morale of the team, or declining it to protect the company and its bottom line and to keep the project stable as the deadline approaches.
-
-The answer depends on a lot of different factors (which also means there is no single correct answer).
-
-### Technological freedom
-
-“We give our team and ourselves 100% freedom in considering technology choices. We eventually identified two or three technologies not to use in the end, primarily due to not wanting to complicate our deployment story,” said [Benjamin Curtis][1], co-founder of [Honeybadger][2].
-
-“In other words, we considered introducing new languages and new approaches into our tech stack when creating our microservices, and we actually did deploy a production microservice on a different stack at one point. [While we do generally] stick with technologies that we know in order to simplify our ops stack, we periodically revisit that decision to see if potential performance or reliability benefits would be gained by adopting a new technology, but so far we haven't made a change,” Curtis continued.
-
-When I spoke with [Stephen Blum][3], CTO at [PubNub][4], he expressed a similar view, welcoming pretty much any technology that cuts the mustard: “We're totally open with it. We want to continue to push forward with new open source technologies that are available, and we only have a couple of constraints with the team that are very fair: [It] must run in container environment, and it has to be cost-effective.”
-
-### High freedom, high responsibility
-
-[Sumo Logic][5] CTO [Christian Beedgen][6] and chief architect [Stefan Zier][7] expanded on this topic, agreeing that if you’re going to give developers freedom to choose their technology, it must come with a high level of responsibility attached. “It’s really important that [whoever builds] the software takes full ownership for it. In other words, they not only build software, but they also run the software and remain responsible for the whole lifecycle.”
-
-Beedgen and Zier recommend implementing a system that resembles a federal government system, keeping those freedoms in check by heightening responsibility: “[You need] a federal culture, really. You've got to have a system where multiple, independent teams can come together towards the greater goal. That limits the independence of the units to some degree, as they have to agree that there is potentially a federal government of some sort. But within those smaller groups, they can make as many decisions on their own as they like within guidelines established on a higher level.”
-
-Decentralized, federal, or however you frame it, this approach to structuring microservice teams gives each team and each team member the freedom they want, without enabling anyone to pull the project apart.
-
-However, not everyone agrees.
-
-### Restrict technology to simplify things
-
-[Darby Frey][8], co-founder of [Lead Honestly][9], takes a more restrictive approach to technology selection.
-
-“At my last company we had a lot of services and a fairly small team, and one of the main things that made it work, especially for the team size that we had, was that every app was the same. Every backend service was a Ruby app,” he explained.
-
-Frey explained that this helped simplify the lives of his team members: “[Every service has] the same testing framework, the same database backend, the same background job processing tool, et cetera. Everything was the same.
-
-“That meant that when an engineer would jump around between apps, they weren’t having to learn a new pattern or learn a different language each time,” Frey continued, “So we're very aware and very strict about keeping that commonality.”
-
-While Frey is sympathetic to developers wanting to introduce a new language, admitting that he “loves the idea of trying new things,” he feels that the cons still outweigh the pros.
-
-“Having a polyglot architecture can increase the development and maintenance costs. If it's just all the same, you can focus on business value and business features and not have to be super siloed in how your services operate. I don't think everybody loves that decision, but at the end of the day, when they have to fix something on a weekend or in the middle of the night, they appreciate it,” said Frey.
-
-### Centralized or decentralized organization
-
-How your team is structured is also going to impact your microservices engineering culture—for better or worse.
-
-For example, it’s common for software engineers to write the code before shipping it off to the operations team, who in turn deploy it to the servers. But when things break (and things always break!), an internal conflict occurs.
-
-Because operation engineers don’t write the code themselves, they rarely understand problems when they first arise. As a result, they need to get in touch with those who did code it: the software engineers. So right from the get-go, you’ve got a middleman relaying messages between the problem and the team that can fix that problem.
-
-To add an extra layer of complexity, because software engineers aren’t involved with operations, they often can’t fully appreciate how their code affects the overall operation of the platform. They learn of issues only when operations engineers complain about them.
-
-As you can see, this is a relationship that’s destined for constant conflict.
-
-### Navigating conflict
-
-One way to attack this problem is by following the lead of Netflix and Amazon, both of which favor decentralized governance. Software development thought leaders James Lewis and Martin Fowler feel that decentralized governance is the way to go when it comes to microservice team organization, as they explain in a [blog post][10].
-
-“One of the consequences of centralized governance is the tendency to standardize on single technology platforms. Experience shows that this approach is constricting—not every problem is a nail and not every solution a hammer,” the article reads. “Perhaps the apogee of decentralized governance is the ‘build it, run it’ ethos popularized by Amazon. Teams are responsible for all aspects of the software they build, including operating the software 24/7.”
-
-Netflix, Lewis and Fowler write, is another company pushing higher levels of responsibility on development teams. They hypothesize that, because they’ll be responsible and called upon should anything go wrong later down the line, more care will be taken during the development and testing stages to ensure each microservice is in ship shape.
-
-“These ideas are about as far away from the traditional centralized governance model as it is possible to be,” they conclude.
-
-### Who's on weekend pager duty?
-
-When considering a centralized or decentralized culture, think about how it impacts your team members when problems inevitably crop up at inopportune times. A decentralized system implies that each decentralized team takes responsibility for one service or one set of services. But that also creates a problem: Silos.
-
-That’s one reason why Lead Honestly's Frey isn’t a proponent of the concept of decentralized governance.
-
-“The pattern of ‘a single team is responsible for a particular service’ is something you see a lot in microservice architectures. We don't do that, for a couple of reasons. The primary business reason is that we want teams that are responsible not for specific code but for customer-facing features. A team might be responsible for order processing, so that will touch multiple code bases but the end result for the business is that there is one team that owns the whole thing end to end, so there are fewer cracks for things to fall through,” Frey explained.
-
-The other main reason, he continued, is that developers can take more ownership of the overall project: “They can actually think about [the project] holistically.”
-
-Nathan Peck, developer advocate for container services at Amazon Web Services, [explained this problem in more depth][11]. In essence, when you separate the software engineers and the operations engineers, you make life harder for your team whenever an issue arises with the code—which is bad news for end users, too.
-
-But does decentralization need to lead to separation and siloization?
-
-Peck explained that his solution lies in [DevOps][12], a model aimed at tightening the feedback loop by bringing these two teams closer together, strengthening team culture and communication in the process. Peck describes this as the “you build it, you run it” approach.
-
-However, that doesn’t mean teams need to get siloed or distanced away from partaking in certain tasks, as Frey suggests might happen.
-
-“One of the most powerful approaches to decentralized governance is to build a mindset of ‘DevOps,’” Peck wrote. “[With this approach], engineers are involved in all parts of the software pipeline: writing code, building it, deploying the resulting product, and operating and monitoring it in production. The DevOps way contrasts with the older model of separating development teams from operations teams by having development teams ship code ‘over the wall’ to operations teams who were then responsible to run it and maintain it.”
-
-DevOps, as [Armory][13] CTO [Isaac Mosquera][14] explained, is an agile software development framework and culture that’s gaining traction thanks to—well, pretty much everything that Peck said.
-
-Interestingly, Mosquera feels that this approach actually flies in the face of [Conway’s Law][15]:
-
-_" Organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations." — M. Conway_
-
-“Instead of communication driving software design, now software architecture drives communication. Not only do teams operate and organize differently, but it requires a new set of tooling and process to support this type of architecture; i.e., DevOps,” Mosquera explained.
-
-[Chris McFadden][16], VP of engineering at [SparkPost][17], offers an interesting example that might be worth following. At SparkPost, you’ll find decentralized governance—but you won’t find a one-team-per-service culture.
-
-“The team that is developing these microservices started off as one team, but they’re now split up into three teams under the same larger group. Each team has some level of responsibility around certain domains and certain expertise, but the ownership of these services is not restricted to any one of these teams,” McFadden explained.
-
-This approach, McFadden continued, allows any team to work on anything from new features to bug fixes to production issues relating to any of those services. There’s total flexibility and not a silo in sight.
-
-“It allows [the teams to be] a little more flexible both in terms of new product development as well, just because you're not getting too restricted and that's based on our size as a company and as an engineering team. We really need to retain some flexibility,” he said.
-
-However, size might matter here. McFadden admitted that if SparkPost was a lot larger, “then it would make more sense to have a single, larger team own one of those microservices.”
-
-“[It's] better, I think, to have a little bit more broad responsibility for these services and it gives you a little more flexibility. At least that works for us at this time, where we are as an organization,” he said.
-
-### A successful microservices engineering culture is a balancing act
-
-When it comes to technology, freedom—with responsibility—looks to be the most rewarding path. Team members with differing technological preferences will come and go, while new challenges may require you to ditch technologies that have previously served you well. Software development is constantly in flux, so you’ll need to continually balance the needs of your team are new devices, technologies, and clients emerge.
-
-As for structuring your teams, a decentralized yet un-siloed approach that leverages DevOps and instills a “you build it, you run it” mentality seems to be popular, although other schools of thought do exist. As usual, you’re going to have to experiment to see what suits your team best.
-
-Here’s a quick recap on how to ensure your team culture meshes well with a microservices architecture:
-
- * **Be sustainable, yet flexible** : Balance sustainability without forgetting about flexibility and the need for your team to be innovative when the right opportunity comes along. However, there’s a distinct difference of opinion over how you should achieve that balance.
-
- * **Give equal opportunities** : Don’t favor one section of your team over another. If you’re going to impose restrictions, make sure it’s not going to fundamentally alienate team members from the get-go. Think about how your product roadmap is shaping up and forecast how it will be built and who’s going to do the work.
-
- * **Structure your team to be agile, yet responsible** : Decentralized governance and agile development is the flavor of the day for a good reason, but don’t forget to install a sense of responsibility within each team.
-
-
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/microservices-team-challenges
-
-作者:[Jake Lumetta][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jakelumetta
-[1]:https://twitter.com/stympy?lang=en
-[2]:https://www.honeybadger.io/
-[3]:https://twitter.com/stephenlb
-[4]:https://www.pubnub.com/
-[5]:http://sumologic.com/
-[6]:https://twitter.com/raychaser
-[7]:https://twitter.com/stefanzier
-[8]:https://twitter.com/darbyfrey
-[9]:https://leadhonestly.com/
-[10]:https://martinfowler.com/articles/microservices.html#ProductsNotProjects
-[11]:https://medium.com/@nathankpeck/microservice-principles-decentralized-governance-4cdbde2ff6ca
-[12]:https://opensource.com/resources/devops
-[13]:http://armory.io/
-[14]:https://twitter.com/imosquera
-[15]:https://en.wikipedia.org/wiki/Conway%27s_law
-[16]:https://twitter.com/cristoirmac
-[17]:https://www.sparkpost.com/
diff --git a/sources/talk/20180809 How do tools affect culture.md b/sources/talk/20180809 How do tools affect culture.md
deleted file mode 100644
index 89fedec026..0000000000
--- a/sources/talk/20180809 How do tools affect culture.md
+++ /dev/null
@@ -1,56 +0,0 @@
-How do tools affect culture?
-======
-
-
-
-Most of the DevOps community talks about how tools don’t matter much. The culture has to change first, the argument goes, which might modify how the tools are used.
-
-I agree and disagree with that concept. I believe the relationship between tools and culture is more symbiotic and bidirectional than unidirectional. I have discovered this through real-world transformations across several companies now. I admit it’s hard to determine whether the tools changed the culture or whether the culture changed how the tools were used.
-
-### Violating principles
-
-Some tools violate core principles of modern development and operations. The primary violation I have seen are tools that require GUI interactions. This often separates operators from the value pipeline in a way that is cognitively difficult to overcome. If everything in your infrastructure is supposed to be configured and deployed through a value pipeline, then taking someone out of that flow inherently changes their perspective and engagement. Making manual modifications also injects risk into the system that creates unpredictability and undermines the value of the pipeline.
-
-I’ve heard it said that these tools are fine and can be made to work within the new culture, and I’ve tried this in the past. Screen scraping and form manipulation tools have been used to attempt automation with some systems I’ve integrated. This is very fragile and doesn’t work on all systems. It ultimately required a lot of manual intervention.
-
-Another system from a large vendor providing integrated monitoring and ticketing solutions for infrastructure seemed to implement its API as an afterthought, and this resulted in the system being unable to handle the load from the automated system. This required constant manual recoveries and sometimes the tedious task of manually closing errant tickets that shouldn’t have been created or that weren’t closed properly.
-
-The individuals maintaining these systems experienced great frustration and often expressed a lack of confidence in the overall DevOps transformation. In one of these instances, we introduced a modern tool for monitoring and alerting, and the same individuals suddenly developed a tremendous amount of confidence in the overall DevOps transformation. I believe this is because tools can reinforce culture and improve it when a similar tool that lacks modern capabilities would otherwise stymie motivation and engagement.
-
-### Choosing tools
-
-At the NAIC (National Association of Insurance Commissioners), we’ve adopted a practice of evaluating new and existing tools based on features we believe reinforce the core principles of our value pipeline. We currently have seven items on our list:
-
- * REST API provided and fully functional (possesses all application functionality)
- * Ability to provision immutably (can be installed, configured, and started without human intervention)
- * Ability to provide all configuration through static files
- * Open source code
- * Uses open standards when available
- * Offered as Software as a Service (SaaS) or hosted (we don't run anything)
- * Deployable to public cloud (based on licensing and cost)
-
-
-
-This is a prioritized list. Each item gets rated green, yellow, or red to indicate how much each statement applies to a particular technology. This creates a visual that makes it quite clear how the different candidates compare to one another. We then use this to make decisions about which tools we should use. We don’t make decisions solely on these criteria, but they do provide a clearer picture and help us know when we’re sacrificing principles. Transparency is a core principle in our culture, and this system helps reinforce that in our decision-making process.
-
-We use green, yellow, and red because there’s not normally a clear binary representation of these criteria within each tool. For example, some tools have an incomplete API, which would result in yellow being applied. If the tool uses open standards like OpenAPI and there’s no other applicable open standard, then it would receive green for “Uses open standards when available.” However, a tracing system that uses OpenAPI and not OpenTracing would receive a yellow rating.
-
-This type of system creates a common understanding of what is valued when it comes to tool selection, and it helps avoid unknowingly violating core principles of your value pipeline. We recently used this method to select [GitLab][1] as our version control and continuous integration system, and it has drastically improved our culture for many reasons. I estimated 50 users for the first year, and we’re already over 120 in just the first few months.
-
-The tools we used previously didn’t allow us to contribute back our own features, collaborate transparently, or automate so completely. We’ve also benefited from GitLab’s culture influencing ours. Its [handbook][2] and open communication have been invaluable to our growth. Tools, and the companies that make them, can and will influence your company’s culture. What are you willing to allow in?
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/how-tools-affect-culture
-
-作者:[Dan Barker][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/barkerd427
-[1]:https://about.gitlab.com/
-[2]:https://about.gitlab.com/handbook/
diff --git a/sources/talk/20180813 Using D Features to Reimplement Inheritance and Polymorphism.md b/sources/talk/20180813 Using D Features to Reimplement Inheritance and Polymorphism.md
deleted file mode 100644
index eed249b8bf..0000000000
--- a/sources/talk/20180813 Using D Features to Reimplement Inheritance and Polymorphism.md
+++ /dev/null
@@ -1,235 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Using D Features to Reimplement Inheritance and Polymorphism)
-[#]: via: (https://theartofmachinery.com/2018/08/13/inheritance_and_polymorphism_2.html)
-[#]: author: (Simon Arneaud https://theartofmachinery.com)
-
-Using D Features to Reimplement Inheritance and Polymorphism
-======
-
-Some months ago I showed [how inheritance and polymorphism work in compiled languages][1] by reimplementing them with basic structs and function pointers. I wrote that code in D, but it could be translated directly to plain old C. In this post I’ll show how to take advantage of D’s features to make DIY inheritance a bit more ergonomic to use.
-
-Although [I have used these tricks in real code][2], I’m honestly just writing this because I think it’s neat what D can do, and because it helps explain how high-level features of D can be implemented — using the language itself.
-
-### `alias this`
-
-In the original version of the code, the `Run` command inherited from the `Commmand` base class by including a `Command` instance as its first member. `Run` and `Command` were still considered completely different types, so this meant explicit typecasting was needed every time a `Run` instance was polymorphically used as a `Command`.
-
-The D type system actually allows declaring a struct to be a subtype of another struct (or even of a primitive type) using a feature called “[`alias this`][3]”. Here’s a simple example of how it works:
-
-```
-struct Base
-{
- int x;
-}
-
-struct Derived
-{
- // Add an instance of Base as a member like before...
- Base _base;
- // ...but this time we declare that the member is used for subtyping
- alias _base this;
-}
-
-void foo(Base b)
-{
- // ...
-}
-
-void main()
-{
- Derived d;
-
- // Derived "inherits" members from Base
- d.x = 42;
-
- // Derived instances can be used where a Base instance is expected
- foo(d);
-}
-```
-
-The code above works in the same way as the code in the previous blog post, but `alias this` tells the type system what we’re doing. This allows us to work _with_ the type system more, and do less typecasting. The example showed a `Derived` instance being passed by value as a `Base` instance, but passing by `ref` also works. Unfortunately, D version 2.081 won’t implicitly convert a `Derived*` to a `Base*`, but maybe it’ll be implemented in future.
-
-Here’s an example of `alias this` being used to implement some slightly more realistic inheritance:
-
-```
-import io = std.stdio;
-
-struct Animal
-{
- struct VTable
- {
- void function(Animal* instance) greet;
- }
- immutable(VTable)* vtable;
-
- void greet()
- {
- vtable.greet(&this);
- }
-}
-
-struct Penguin
-{
- private:
- static immutable Animal.VTable vtable = {greet: &greetImpl};
- auto _base = Animal(&vtable);
- alias _base this;
-
- public:
- string name;
-
- this(string name) pure
- {
- this.name = name;
- }
-
- static void greetImpl(Animal* instance)
- {
- // We still need one typecast here because the type system can't guarantee this is okay
- auto penguin = cast(Penguin*) instance;
- io.writef("I'm %s the penguin and I can swim.\n", penguin.name);
- }
-}
-
-void main()
-{
- auto p = Penguin("Paul");
-
- // p inherits members from Animal
- p.greet();
-
- // and can be passed to functions that work with Animal instances
- doThings(p);
-}
-
-void doThings(ref Animal a)
-{
- a.greet();
-}
-```
-
-Unlike the code in the previous blog post, this version uses a vtable, just like the polymorphic inheritance in normal compiled languages. As explained in the previous post, every `Penguin` instance will use the same list of function pointers for its virtual functions. So instead of repeating the function pointers in every instance, we can have one list of function pointers that’s shared across all `Penguin` instances (i.e., a list that’s a `static` member). That’s all the vtable is, but it’s how real-world compiled OOP languages work.
-
-### Template Mixins
-
-If we implemented another `Animal` subtype, we’d have to add exactly the same vtable and base member boilerplate as in `Penguin`:
-
-```
-struct Snake
-{
- // This bit is exactly the same as before
- private:
- static immutable Animal.VTable vtable = {greet: &greetImpl};
- auto _base = Animal(&vtable);
- alias _base this;
-
- public:
-
- static void greetImpl(Animal* instance)
- {
- io.writeln("I'm an unfriendly snake. Go away.");
- }
-}
-```
-
-D has another feature for dumping this kind of boilerplate code into things: [template mixins][4].
-
-```
-mixin template DeriveAnimal()
-{
- private:
- static immutable Animal.VTable vtable = {greet: &greetImpl};
- auto _base = Animal(&vtable);
- alias _base this;
-}
-
-struct Snake
-{
- mixin DeriveAnimal;
-
- static void greetImpl(Animal* instance)
- {
- io.writeln("I'm an unfriendly snake. Go away.");
- }
-}
-```
-
-Actually, template mixins can take parameters, so it’s possible to create a generic `Derive` mixin that inherits from any struct that defines a `VTable` struct. Because template mixins can inject any kind of declaration, including template functions, the `Derive` mixin can even handle more complex things, like the typecast from `Animal*` to the subtype.
-
-By the way, [the `mixin` statement can also be used to “paste” code into places][5]. It’s like a hygienic version of the C preprocessor, and it’s used below (and also in this [compile-time Brainfuck compiler][6]).
-
-### `opDispatch()`
-
-There’s some highly redundant wrapper code inside the definition of `Animal`:
-
-```
-void greet()
-{
- vtable.greet(&this);
-}
-```
-
-If we added another virtual method, we’d have to add another wrapper:
-
-```
-void eat(Food food)
-{
- vtable.eat(&this, food);
-}
-```
-
-But D has `opDispatch()`, which provides a way to automatically add members to a struct. When an `opDispatch()` is defined in a struct, any time the compiler fails to find a member, it tries the `opDispatch()` template function. In other words, it’s a fallback for member lookup. A fallback to a fully generic `return vtable.MEMBER(&this, args)` will effectively fill in all the virtual function dispatchers for us:
-
-```
-auto opDispatch(string member_name, Args...)(auto ref Args args)
-{
- mixin("return vtable." ~ member_name ~ "(&this, args);");
-}
-```
-
-The downside is that if the `opDispatch()` fails for any reason, the compiler gives up on the member lookup and we get a generic “Error: no property foo for type Animal”. This is confusing if `foo` is actually a valid virtual member but was called with arguments of the wrong type, or something, so `opDispatch()` needs some good error handling (e.g., with [`static assert`][7]).
-
-### `static foreach`
-
-An alternative is to use a newer feature of D: [`static foreach`][8]. This is a powerful tool that can create declarations inside a struct (and other places) using a loop. We can directly read a list of members from the `VTable` definition by using some compile-time reflection:
-
-```
-import std.traits : FieldNameTuple;
-static foreach (member; FieldNameTuple!VTable)
-{
- mixin("auto " ~ member ~ "(Args...)(auto ref Args args) { return vtable." ~ member ~ "(&this, args); }");
-}
-```
-
-The advantage in this case is that we’re explicitly creating struct members. Now the compiler can distinguish between a member that shouldn’t exist at all, and a member that exists but isn’t used properly.
-
-### It’s all just like the C equivalent
-
-As I said, this is basically just a tour-de-force of ways that D can improve the code from the previous post. However, the original motivation for this blog post was people asking me about tricks I used to implement polymorphic inheritance in bare metal D code, so I’ll finish up by saying this: All this stuff works in [`-betterC`][9] code, and none of it requires extra runtime support. The code in this post implements the same kind of thing as in the [previous post][1]. It’s just expressed in a more compact and less error-prone way.
-
---------------------------------------------------------------------------------
-
-via: https://theartofmachinery.com/2018/08/13/inheritance_and_polymorphism_2.html
-
-作者:[Simon Arneaud][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://theartofmachinery.com
-[b]: https://github.com/lujun9972
-[1]: /2018/04/02/inheritance_and_polymorphism.html
-[2]: https://gitlab.com/sarneaud/xanthe/blob/master/src/game/rigid_body.d#L15
-[3]: https://dlang.org/spec/class.html#alias-this
-[4]: https://dlang.org/spec/template-mixin.html
-[5]: https://dlang.org/articles/mixin.html
-[6]: /2017/12/31/compile_time_brainfuck.html
-[7]: https://dlang.org/spec/version.html#StaticAssert
-[8]: https://dlang.org/spec/version.html#staticforeach
-[9]: https://dlang.org/blog/2018/06/11/dasbetterc-converting-make-c-to-d/
diff --git a/sources/talk/20180817 5 Things Influenza Taught Me About the Evolution of the Desktop Computer.md b/sources/talk/20180817 5 Things Influenza Taught Me About the Evolution of the Desktop Computer.md
deleted file mode 100644
index c1e7f98200..0000000000
--- a/sources/talk/20180817 5 Things Influenza Taught Me About the Evolution of the Desktop Computer.md
+++ /dev/null
@@ -1,130 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (5 Things Influenza Taught Me About the Evolution of the Desktop Computer)
-[#]: via: (https://blog.dxmtechsupport.com.au/5-things-influenza-taught-me-about-the-evolution-of-the-desktop-computer/)
-[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
-
-5 Things Influenza Taught Me About the Evolution of the Desktop Computer
-======
-
-The flu took me completely out of action recently. It hit me pretty hard.
-
-And, as tends to happen with these things, I ended up binge watching more TV and movies in two weeks hidden under a blanket than in 2 years as a member of wider society.
-
-In the most delirious moments, the vicious conspiracy of fever and painkillers gave me no choice but to stick to bad 80s action movies.
-
-When I was a little more lucid, though, I got really stuck into some documentaries around the early days of desktop computing: Computerphile episodes, Silicon Cowboys, Micro Men, Youtube interviews, all sorts of stuff.
-
-Here are the big things that have stuck with me from it:
-
-### The Modern Computing Industry was Almost Entirely Built by Young Hobbyists
-
-There was an established computing industry in the 1970s – but these companies played very little direct role in what was to come.
-
-Xerox’s Palo Alto Research Centre had an important role to play in developing desktop technologies – with absolutely zero intention of ever commercialising anything. The entire thing was funded entirely from Xerox’s publicity budget.
-
-But for the most part, computers were sold to universities and enterprises. These were large, expensive machines guarded by a priesthood.
-
-The smallest and most affordable machines in use here were minicomputers like the DEC PDP-11. “Mini” is, of course, a relative term. These were the size of several fridges and cost several years worth of the average wage.
-
-So what if you wanted a computer of your own? Were you totally stranded? Not quite. You could always buy a bunch of chips and build and program the whole damn thing yourself.
-
-This had become increasingly accessible, thanks to the development of the microprocessor, which condensed the separate components of a CPU into a single chip. As the homebrew computer scene grew, hobby electronics companies started offering kits.
-
-It was out of this scene that desktop computing industry actually grew – both Apple and Acorn computers were founded by hobbyists. Their first commercial products evolved from what they’d built at home.
-
-Businesses that catered to the electronics hobbyist market, like Tandy and Radio Shack, were also some of the earliest to enter the market.
-
-### Things Changed More Radically from ’77 – ’87 than the Next 3 Decades Combined
-
-The first desktop computers were a massive leap forward in terms of bringing computing to ordinary people, they were still fairly primitive. We’re talking beeps, monochrome graphics, and a 30 minute wait to load your software from cassette tape.
-
-And the only way to steer it was from the command line. It’s definitely much more accessible than building and programming your own computer from scratch, but it’s still very much in nerd territory.
-
-By 1987, you’ve got most of what we’re familiar with: point and click interfaces, full colour graphics, word processors, spreadsheets, desktop publishing, music production, 3D gaming. The floppy drives had made loading times insignificant – and some machines even had hard drives.
-
-Your mum could use it.
-
-Things still got invented after that. The internet has obviously been a game changer. Screens are completely different. And there are any number of new languages.
-
-For the most part, though, desktop computers came together in a decade. Since then, we’ve just been making better and better versions of the same thing.
-
-### Bill Gates Really Was Kind of a James Bond Villain
-
-Back in the ’90s, it seemed a fairly ubiquitous part of computer geek culture that Bill Gates was kind of a dick. In magazines, on bulletin boards and the early internet, it was just taken for granted that Microsoft dominated the market not with a superior product but with sharp business practices.
-
-I was too young to really know if that was true, but I was happy to go along with it. It turns out that there was actually plenty of truth in that. An MS-DOS PC was hardly the best computer of the 1980s.
-
-The [Acorn Archimedes][1], for instance, had the world’s fastest processor in a desktop computer, many times faster than the 386, and an operating system so far ahead of its time that Microsoft shamelessly plagiarised it 8 years for Windows 95.
-
-And the Motorola 68000 series of CPUs used in many machines such as the Apple Macintosh and Commodore Amiga was also faster, and were vastly better for input/output intensive work such as graphics and sound.
-
-So how did Microsoft win?
-
-Well they had a head start piggybacking with IBM, who very successfully marketed the PC as a general purpose business computer. At this point, the PC was already one of the first platforms that many software developers would write for.
-
-Then, as what was then known as the “IBM clone” market began and grew, Bill Gates was very aggressive about getting MS-DOS onto as many machines as possible by licensing it on very generous terms to companies like Compaq and Amstrad. This was a short term sacrifice of profits in pursuit of market share. It also helped the PC to become the affordable choice for families.
-
-As this market share grew, the PC became the more obvious platform to first release your software on. This created a snowball effect, where more software support made the PC the more obvious computer to buy, increasing market share and attracting more software development.
-
-In the end, it didn’t matter how much better your computer was when all the programs ran on MS-DOS.
-
-### That’s Actually Totally Awesome Though
-
-On first glance, Gates looks like the consummate monopolist. Actually, he did a lot more open up access to new players and foster innovation and competition.
-
-In the early days of desktop computing, every manufacturer more or less maintained its own proprietary platform, with its own hardware, operating system and software support. That meant if you wanted a certain kind of computer, there was one company who built it so you bought it from them.
-
-By opening the PC market to new entrants, selling the operating systems to anyone who wanted them, and setting industry standards that anyone could build to, PC makers had to compete directly on price and performance.
-
-Apple still have the old model of a closed, proprietary platform, and you’ll pay vastly more for an equivalent machine – or perhaps one whose specs haven’t improved in 3 years.
-
-It was also great for software developers not to have to port their software across so many platforms. I had first hand experience of this growing up – when I was really young, there were more than a dozen computers scattered around the house, because Dad was running his software business from home, and when he needed to port a program to a new machine, he needed the machine. But by the time I was finishing primary school, it was just the mac and the PC.
-
-Handling the compatibility problem, throwing Windows on top of it, and offering it on machines at all price points did so much to bring computing to ordinary people.
-
-At this point, I’m pretty sure someone in the audience is saying “yeah, but we could have done that open source”. Look, I like Linux for what it’s good for, but let’s be real here. Linux doesn’t really have a GUI environment – it has dozens of them, each with different quirks to learn.
-
-One thing that they all have in common though is that they’re not really proper operating system environments, more just nice little boxes to stick your web browser and word processor. The moment you need to install or configure anything, guess what? It’s terminal time. Which is rather excellent if you’re that way inclined, but realistically, that’s a small fraction of humanity.
-
-If Bill Gates never came up with an everyman operating system that you could run on an affordable machine, would someone else have? Probably. But he’s the guy that actually did it.
-
-### Sheer Conceit Will Make Fools of Even the Most Brilliant and Powerful
-
-The deal that really made Microsoft is also the deal that eventually cost IBM their entire market share of the PC platform they created and of the desktop computer market as a whole.
-
-IBM were in a hurry to bring their PC to market, they built almost all of it from off-the-shelf components. Bill Gates got the meeting to talk operating systems because his mother sat on a board with. IBM offered to buy the rights to the operating system, but Gates offered instead to license it.
-
-There was really no reason that IBM had to take that deal. There was nothing all that special about MS-DOS. They could have bought a similar operating system from someone else. I mean, that’s exactly what Gates did: he went to another guy in Seattle, bought the rights to a rip off of CP/M that worked on the Intel 8086, and tweaked it a bit.
-
-To be fair to IBM, in 1980, it wasn’t obvious yet how crucial it would be to hold a dominant operating system. That came later. At that point, the OS was kind of just a bit of code to run the hardware – a component. It was normal for every computer manufacturer to have its own . It was normal for developers to port their products across them.
-
-But it’s also just weren’t inclined to take a skinny twenty-something seriously.
-
-Compaq famously reverse engineered the BIOS, and other manufacturers followed them into the market. IBM now had competition, but were still considered the market leaders and standard setters – it was their platform and everyone else was a “clone”.
-
-They were still cocky.
-
-So when the 386, IBM decided they weren’t in any hurry to do anything with it. The logic was that they already held the manufacturing rights to the 286, so they might as well get as much value out of that as they could. This was crazy: the 386 was more than twice as fast at the same clock speed, and it could go to much higher clock speeds.
-
-Compaq jumped on it. Suddenly IBM were the slowpokes in their own market.
-
-Having totally lost all control and leadership in the PC market, they fought back with a new, totally proprietary platform: the PS/2. But it was way too late. The genie was out of the bottle. This was up against the same third party support issues working against everyone other company with a closed, proprietary platform. It didn’t last.
-
---------------------------------------------------------------------------------
-
-via: https://blog.dxmtechsupport.com.au/5-things-influenza-taught-me-about-the-evolution-of-the-desktop-computer/
-
-作者:[James Mawson][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
-[b]: https://github.com/lujun9972
-[1]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
diff --git a/sources/talk/20180817 OERu makes a college education affordable.md b/sources/talk/20180817 OERu makes a college education affordable.md
deleted file mode 100644
index ba7d66b7a5..0000000000
--- a/sources/talk/20180817 OERu makes a college education affordable.md
+++ /dev/null
@@ -1,60 +0,0 @@
-OERu makes a college education affordable
-======
-
-
-
-Open, higher education courses are a boon to adults who don’t have the time, money, or confidence to enroll in traditional college courses but want to further their education for work or personal satisfaction. [OERu][1] is a great option for these learners. It allows people to take courses assembled by accredited colleges and universities for free, using open textbooks, and pay for assessment only when (and if) they want to apply for formal academic credit.
-
-I spoke with [Dave Lane][2], open source technologist at the [Open Education Resource Foundation][3], which is OERu’s parent organization, to learn more about the program. The OER Foundation is a nonprofit organization hosted by [Otago Polytechnic][4] in Dunedin, New Zealand. It partners with organizations around the globe to provide leadership, networking, and support to help advance [open education principles][5].
-
-OERu is one of the foundation's flagship projects. (The other is [WikiEducator][6], a community of educators collaboratively developing open source materials.) OERu was conceived in 2011, two years after the foundation’s launch, with representatives from educational institutions around the world.
-
-Its network "is made up of tertiary educational institutions in five continents working together to democratize tertiary education and its availability for those who cannot afford (or cannot find a seat in) tertiary education," Dave says. Some of OERu’s educational partners include UTaz (Australia), Thompson River University (Canada), North-West University or National Open University (ZA and Nigeria in Africa, respectively), and the University of the Highlands and Islands (Scotland in the UK). Funding is provided by the [William and Flora Hewlett Foundation][7]. These institutions have worked out the complexity associated with transferring academic credits within the network and across the different educational cultures, accreditation boards, and educational review committees.
-
-### How it works
-
-The primary requirements for taking OERu courses are fluency in English (which is the primary teaching language) and having a computer with internet access. To start learning, peruse the [list of courses][8], click the title of the course you want to take, and click “Start Learning” to complete any registration details (different courses have different requirements).
-
-Once you complete a course, you can take an assessment that may qualify you for college-level course credit. While there’s no cost to take a course, each partner institution charges fees for administering assessments—but they are far less expensive than traditional college tuition and fees.
-
-In March 2018, OERu launched a [Certificate Higher Education Business][9] (CertHE), a one-year program that the organization calls its [first year of study][10], which is "equivalent to the first year of a bachelor's degree." CertHE “is an introductory level qualification in business and management studies which provides a general overview for a possible career in business across a wide range of sectors and industries.” Although CertHE assessment costs vary, it’s likely that the first full year of study will be US$ 2,500, a significant cost savings for students.
-
-OERu is adding courses and looking for ways to expand the model to eventually offer full baccalaureate degrees and possibly even graduate degrees at much lower cost than a traditional degree program.
-
-### Open source technologist's background
-
-Dave didn’t set out to work in IT or live and work in New Zealand. He grew up in the United States and earned his master’s degree in mechanical engineering from the University of Washington. Fresh out of graduate school, he moved to New Zealand to take a position as a research scientist at a government-funded [Crown Research Institute][11] to improve the efficiency of the country’s forest industry.
-
-IT and open technologies were important parts of getting his job done. "The image processing and photogrammetry software I developed … was built on Linux, entirely using open source math (C/C++) and interface libraries (Qt)," he says. "The source material for my advanced photogrammetric algorithms was US Geological Survey scientist papers from the 1950s-60s, all publicly available."
-
-His frustration with the low quality of IT systems in the outlying offices led him to assume the role of "ad hoc IT manager" using "100% open source software," he says, which delighted his colleagues but frustrated the fulltime IT staff in the main office.
-
-After four years of working for the government, he founded a company called Egressive to build Linux-based server systems for small businesses in the Christchurch area. Egressive became a successful small business IT provider, specializing in free and open source software, web development and hosting, systems integration, and outsourced sysadmin services. After selling the business, he joined the OER Foundation’s staff in 2015. In addition to working on the WikiEducator.org and OERu projects, he develops [open source collaboration][12] and teaching tools for the foundation.
-
-If you're interested in learning more about the OER Foundation, OERu, open source technology, and Dave's work, take a look at [his blog][13].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/oeru-courses
-
-作者:[João Trindade][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.flickr.com/photos/joao_trindade/4362409183
-[1]:https://oeru.org/
-[2]:https://www.linkedin.com/in/davelanenz/
-[3]:http://wikieducator.org/OERF:Home
-[4]:https://www.op.ac.nz/
-[5]:https://oeru.org/how-it-works/
-[6]:http://wikieducator.org/
-[7]:https://hewlett.org/
-[8]:https://oeru.org/courses/
-[9]:https://oeru.org/certhe-business/
-[10]:https://oeru.org/qualifications/
-[11]:https://en.wikipedia.org/wiki/Crown_Research_Institute
-[12]:https://tech.oeru.org/many-simple-tools-loosely-coupled
-[13]:https://tech.oeru.org/blog/1
diff --git a/sources/talk/20180820 Keeping patient data safe with open source tools.md b/sources/talk/20180820 Keeping patient data safe with open source tools.md
deleted file mode 100644
index decdffd487..0000000000
--- a/sources/talk/20180820 Keeping patient data safe with open source tools.md
+++ /dev/null
@@ -1,51 +0,0 @@
-Keeping patient data safe with open source tools
-======
-
-
-
-Healthcare is experiencing a revolution. In a tightly regulated and ancient industry, the use of free and open source software make it uniquely positioned to see a great deal of progress.
-
-I work at a [scrappy healthcare startup][1] where cost savings are a top priority. Our primary challenge is how to safely and efficiently manage personally identifying information (PII), like names, addresses, insurance information, etc., and personal health information (PHI), like the reason for a recent clinical visit, under the regulations of the Health Insurance Portability and Accountability Act of 1996, [HIPAA][2], which became mandatory in the United States in 2003.
-
-Briefly, HIPAA is a set of U.S. regulations that were created in response to the need for safety in healthcare data transmission and security. Titles 1, 3, 4, and 5 relate to the healthcare industry and insurance regulation, and Title 2 protects patient privacy and the security of the PHI/PII. Title 2 dictates how and to whom medical information can be disclosed (patients, medical providers, and relevant staff members), and it also loosely describes technological security that must be used, with many suggestions.
-
-The law was written to manage digital data portability through some amount of time (though several updates have been added to the original legislation), but it couldn’t have anticipated the kinds of technological advancements that have been introduced, so it often lacks detail on exactly how to keep patient data safe. Auditors want to see best-effort, authentically crafted and respected documentation—an often vague but compelling and ever-present challenge. But no regulation says we can’t use open source software, which makes our lives much easier.
-
-Our stack consists of Python, with readily available open source security and cryptography packages that are typically already baked into the requirements of Python web frameworks (which in our case is Klein, a framework built with Twisted, an asynchronous networking framework for Python). On the front end, we’ve got [AngularJS][3]. Some of the free security Python packages we use are [cryptography][4], [itsdangerous][5], [pycrypto][6], and somewhat unrelatedly, [magic-wormhole][7], a fairly cryptographically secure file sending tool that my team and I love, built on Twisted and the Python cryptography packages.
-
-These tools are integral to our HIPAA compliance on both the front-end and server side, as described in the example below. With the maturity and funding of FOSS (shout-out to the Mozilla Foundation for [funding the PyPI project][8], the packaging repository all Python developers depend on), it’s possible for a for-profit business to not only use and contribute to a significant amount of open source but also make it secure.
-
-One of our early challenges was how to use Amazon Web Services' (AWS) message queuer, [SQS][9] (Simple Queueing Service), to transmit data from our application server to our data interface server (before SQS encrypted traffic end to end). We separate the data intake/send instance from the web application instance to make the data and the application incommunicable to one another. This reduces the security surface should an attacker gain access. The purpose of SQS, then, is to transmit data we receive from partners for continuing care and store it temporarily in application memory, and data that we send back to our data and interface engine from the application to add to patient’s chart on the healthcare network’s medical records system.
-
-A typical HIPAA-compliant installation requires all data in transit to be encrypted, but at the time, SQS had no HIPAA-compliant option. So we use [GNU Privacy Guard][10] (GnuPG), which can be difficult to use but is reliable and cryptographically secure when applied correctly. This ensures that any data housed on the application server for any period of time is encrypted with a key we created for this service. While data is in transit from the application to the data interface, we encrypt and decrypt it with keys that live only on the two components.
-
-While it’s easier than ever to use open source software, we are still working on contributing back. Even as the company attorneys and marketing folks determine the best and safest way to publicize our OSS projects, we’ve had some nibbles at our pip packages and repositories from others looking for the exact solution we present. I’m excited to make the [projects][11] [we've][12] [issued][13] better known, to steward more of our open source code to those who want it, and to encourage others to contribute back in kind.
-
-There are a number of hurdles to this innovation in healthcare, and I recommend the excellent [EMR & HIPAA][14] blog, which offers a terrific, accessible daily newsletter on how many organizations are addressing these hurdles technically, logistically, and interpersonally.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/foss-hippa-healthcare-open-source-tools
-
-作者:[Rachel Kelly][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/rachelkelly
-[1]:http://bright.md/
-[2]:https://www.hhs.gov/hipaa/for-individuals/guidance-materials-for-consumers/index.html
-[3]:https://angularjs.org/
-[4]:https://pypi.org/project/cryptography/
-[5]:https://pypi.org/project/itsdangerous/
-[6]:https://pypi.org/project/pycrypto/
-[7]:https://github.com/warner/magic-wormhole
-[8]:http://pyfound.blogspot.com/2017/11/the-psf-awarded-moss-grant-pypi.html
-[9]:https://aws.amazon.com/sqs/
-[10]:https://gnupg.org/
-[11]:https://github.com/Brightmd/txk8s
-[12]:https://github.com/Brightmd/hoursofoperation
-[13]:https://github.com/Brightmd/yamlschema
-[14]:https://www.emrandhipaa.com/
diff --git a/sources/talk/20180831 3 innovative open source projects for the new school year.md b/sources/talk/20180831 3 innovative open source projects for the new school year.md
deleted file mode 100644
index e8493ed501..0000000000
--- a/sources/talk/20180831 3 innovative open source projects for the new school year.md
+++ /dev/null
@@ -1,59 +0,0 @@
-3 innovative open source projects for the new school year
-======
-
-
-
-I first wrote about open source learning software for educators in the fall of 2013. Fast-forward five years—today, open source software and principles have moved from outsiders in the education industry to the popular crowd.
-
-Since Penn Manor School District has [adopted open software][1] and cultivated a learning community built on trust, we've watched student creativity, ingenuity, and engagement soar. Here are three free and open source software tools we’ve used during the past school year. All three have enabled great student projects and may spark cool classroom ideas for open-minded educators.
-
-### Catch a wave: Software-defined radio
-
-Students may love the modern sounds of Spotify and Soundcloud, but there's an old-school charm to snatching noise from the atmosphere. Penn Manor help desk student apprentices had serious fun with [software-defined radio][2] (SDR). With an inexpensive software-defined radio kit, students can capture much more than humdrum FM radio stations. One of our help desk apprentices, JR, discovered everything from local emergency radio chatter to unencrypted pager messages.
-
-Our basic setup involved a student’s Linux laptop running [gqrx software][3] paired with a [USB RTL-SDR tuner and a simple antenna][4]. It was light enough to fit in a student backpack for SDR on the go. And the kit was great for creative hacking, which JR demonstrated when he improvised all manner of antennas, including a frying pan, in an attempt to capture signals from the U.S. weather satellite [NOAA-18][5].
-
-Former Penn Manor IT specialist Tom Swartz maintains an excellent [quick-start resource for SDR][6].
-
-### Stream far for a middle school crowd: OBS Studio
-
-Remember live morning TV announcements in school? Amateur weather reports, daily news updates, middle school puns... In-house video studios are an excellent opportunity for fun collaboration and technical learning. But many schools are stuck running proprietary broadcast and video mixing software, and many more are unable to afford costly production hardware such as [NewTek’s TriCaster][7].
-
-Cue [OBS Studio][8], a free, open source, real-time broadcasting program ideally suited for school projects as well as professional video streaming. During the past six months, several Penn Manor schools successfully upgraded to OBS Studio running on Linux. OBS handles our multi-source video and audio mixing, chroma key compositing, transitions, and just about anything else students need to run a surprising polished video broadcast.
-
-Penn Manor students stream a live morning show via UDP multicast to staff and students tuned in via the [mpv][9] media player. OBS also supports live streaming to YouTube, Facebook Live, and Twitch, which means students can broadcast daily school lunch menus and other vital updates to the world.
-
-### Self-drive by light: TurtleBot3 and Lidar
-
-Of course, robots are cool, but robots with lasers are ace. The newest star of the Penn Manor student help desk is Patch, a petite educational robot built with the [TurtleBot3][10] open hardware and software kit. The Turtlebot platform is extensible and great for hardware hacking, but we were most interested in creating a self-driving gadget.
-
-We used the Turtlebot3 Burger, the entry-level kit powered by a Raspberry PI and loaded with a laser distance sensor. New student tech apprentices Aiden, Alex, and Tristen were challenged to make the robot autonomously navigate down one Penn Manor High School hallway and back to the technology center. It was a tall order: The team spent several months building the bot, and then working through the [ROS][11]-based programming, [rviz][12] (a 3D environment visualizer) and mapping for simultaneous localization and mapping (SLAM).
-
-Building the robot was a joy, but without a doubt, the programming challenged the students, none of whom had previously touched any of the ROS software tools. However, after much persistence, trial and error, and tenacity, Aiden and Tristen succeeded in achieving both the hallway navigation goal and in confusing fellow students with a tiny robot transversing school corridors and magically avoiding objects and people in its path.
-
-I recommend the TurtleBot3, but educators should be aware of the cost (approximately US$ 500) and the complexity. However, the kit is an outstanding resource for students aspiring to technology careers or those who want to build something amazing.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/back-school-project-ideas
-
-作者:[Charlie Reisinger][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/charlie
-[1]: https://opensource.com/education/14/9/interview-charlie-reisinger-penn-manor
-[2]: https://en.wikipedia.org/wiki/Software-defined_radio
-[3]: http://gqrx.dk/
-[4]: https://www.amazon.com/JahyShow%C2%AE-RTL2832U-RTL-SDR-Receiver-Compatible/dp/B01H830YQ6
-[5]: https://en.wikipedia.org/wiki/NOAA-18
-[6]: https://github.com/tomswartz07/CPOSC2017
-[7]: https://www.newtek.com/tricaster/
-[8]: https://obsproject.com/
-[9]: https://mpv.io/
-[10]: https://www.turtlebot.com/
-[11]: http://www.ros.org/
-[12]: http://wiki.ros.org/rviz
diff --git a/sources/talk/20180906 DevOps- The consequences of blame.md b/sources/talk/20180906 DevOps- The consequences of blame.md
deleted file mode 100644
index f7efed4d66..0000000000
--- a/sources/talk/20180906 DevOps- The consequences of blame.md
+++ /dev/null
@@ -1,67 +0,0 @@
-DevOps: The consequences of blame
-======
-
-
-
-Merriam-Webster defines "blame" as both a verb and a noun. As a verb, it means "to find fault with or to hold responsible." As a noun, it means "an expression of disapproval or responsibility for something believed to deserve censure."
-
-Either way, blame isn’t a pleasant thing. It can create feelings of fear and shame, foster power imbalances, and cause us to devalue others.
-
-Just think of what it felt like the last time you were yelled at or accused of something. Conversely, consider the opposite of blame: Praise, flattery, and approval. How does it feel to be complimented or commended for a job well done?
-
-You may be wondering what all this talk about blame has to do with DevOps. Read on:
-
-### DevOps and blame
-
-The three pillars of DevOps are flow, feedback, and continuous improvement. How can an organization or a team improve if its members are focused on finding someone to blame? For a DevOps culture to succeed, blame must be eliminated.
-
-For example, suppose your product has a bug or experiences an outage. If your organization's leaders react to this by looking for someone to blame, there’s little chance for feedback on how to improve. Look at how blame is flowing in your organization and work to remove it. Strive for blameless post-mortems and move away from _root-cause analysis_ , which tends to focus on assigning blame. In today’s complex business infrastructure, many factors can contribute to bugs and other problems. Successful DevOps teams practice post-incident reviews to examine the bigger picture when things go wrong.
-
-### Consequences of blame
-
-DevOps is about creating a culture of collaboration and community. This is not possible in a culture of blame. Because blame does not correct behavior, there is no continuous learning. What _is_ learned is how to avoid blame—so instead of solving problems, team members focus on how they can avoid being blamed for them.
-
-What about accountability? Avoiding blame does not mean avoiding accountability or consequences. Here are some tips to create an environment in which people are held accountable without blame:
-
- * When mistakes are made, focus on what steps you can take to avoid making the same mistake in the future. What did you learn, and how can you apply that knowledge to improving things?
-
- * When something goes wrong, people feel stress. Work toward eliminating or reducing that stress. Avoid yelling and putting additional pressure on people.
-
- * Accept that mistakes will happen. Nobody—and nothing—is perfect.
-
- * When corrective actions are necessary, provide them privately, not publicly.
-
-
-
-
-As a child, I loved reading the [Family Circus][1] comic strip, especially the ones featuring “Not Me.” Not Me frequently appeared with “Ida Know” and “Nobody” when Mom and Dad asked an accusatory question. Why did the kids in Family Circus blame Not Me? Look no further than the parents' angry, frustrated expressions. Like the kids in the comic strip, we quickly learn to assign blame or look for faults in others because blaming ourselves is too painful.
-
-In his book, [_Thinking, Fast and Slow_][2], author Daniel Kanheman points out that most of us spend as little time as possible thinking—after all, thinking is hard. To make things easier, we learn from previous experiences, which in turn creates biases. If blame is part of that equation, it will be included in our bias: _“The last time a question was asked in a meeting and I took responsibility, I was chewed out in front of all my co-workers. I won’t do that again.”_
-
-When something goes wrong, we want answers and accountability. Uncertainty is scary and leads to stress; we prefer predictable scenarios. This drives us to look for root causes, which often leads to blame.
-
-But what if, instead of assigning blame, we turned the situation into something constructive and helpful—an opportunity for learning? It isn't always easy, but working to eliminate blame will build a stronger DevOps team and a happier, more productive company.
-
-Next time you find yourself starting to look for someone to blame, think of this poem by Rupi Kaur:
-
-_“It takes grace_
-
-_To remain kind_
-
-_In cruel situations”_
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/consequences-blame-your-devops-team
-
-作者:[Dawn Parzych][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/dawnparzych
-[1]: http://familycircus.com/comics/september-1-2012/
-[2]: https://www.amazon.com/Thinking-Fast-Slow-Daniel-Kahneman/dp/0374533555
diff --git a/sources/talk/20180916 The Rise and Demise of RSS (Old Version).md b/sources/talk/20180916 The Rise and Demise of RSS (Old Version).md
deleted file mode 100644
index b6e1a4fdd9..0000000000
--- a/sources/talk/20180916 The Rise and Demise of RSS (Old Version).md
+++ /dev/null
@@ -1,278 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (The Rise and Demise of RSS (Old Version))
-[#]: via: (https://twobithistory.org/2018/09/16/the-rise-and-demise-of-rss.html)
-[#]: author: (Two-Bit History https://twobithistory.org)
-
-The Rise and Demise of RSS (Old Version)
-======
-
-_A newer version of this post was published on [December 18th, 2018][1]._
-
-There are two stories here. The first is a story about a vision of the web’s future that never quite came to fruition. The second is a story about how a collaborative effort to improve a popular standard devolved into one of the most contentious forks in the history of open-source software development.
-
-In the late 1990s, in the go-go years between Netscape’s IPO and the Dot-com crash, everyone could see that the web was going to be an even bigger deal than it already was, even if they didn’t know exactly how it was going to get there. One theory was that the web was about to be revolutionized by syndication. The web, originally built to enable a simple transaction between two parties—a client fetching a document from a single host server—would be broken open by new standards that could be used to repackage and redistribute entire websites through a variety of channels. Kevin Werbach, writing for _Release 1.0_, a newsletter influential among investors in the 1990s, predicted that syndication “would evolve into the core model for the Internet economy, allowing businesses and individuals to retain control over their online personae while enjoying the benefits of massive scale and scope.”[1][2] He invited his readers to imagine a future in which fencing aficionados, rather than going directly to an “online sporting goods site” or “fencing equipment retailer,” could buy a new épée directly through e-commerce widgets embedded into their favorite website about fencing.[2][3] Just like in the television world, where big networks syndicate their shows to smaller local stations, syndication on the web would allow businesses and publications to reach consumers through a multitude of intermediary sites. This would mean, as a corollary, that consumers would gain significant control over where and how they interacted with any given business or publication on the web.
-
-RSS was one of the standards that promised to deliver this syndicated future. To Werbach, RSS was “the leading example of a lightweight syndication protocol.”[3][4] Another contemporaneous article called RSS the first protocol to realize the potential of XML.[4][5] It was going to be a way for both users and content aggregators to create their own customized channels out of everything the web had to offer. And yet, two decades later, RSS [appears to be a dying technology][6], now used chiefly by podcasters and programmers with tech blogs. Moreover, among that latter group, RSS is perhaps used as much for its political symbolism as its actual utility. Though of course some people really do have RSS readers, stubbornly adding an RSS feed to your blog, even in 2018, is a reactionary statement. That little tangerine bubble has become a wistful symbol of defiance against a centralized web increasingly controlled by a handful of corporations, a web that hardly resembles the syndicated web of Werbach’s imagining.
-
-The future once looked so bright for RSS. What happened? Was its downfall inevitable, or was it precipitated by the bitter infighting that thwarted the development of a single RSS standard?
-
-### Muddied Water
-
-RSS was invented twice. This meant it never had an obvious owner, a state of affairs that spawned endless debate and acrimony. But it also suggests that RSS was an important idea whose time had come.
-
-In 1998, Netscape was struggling to envision a future for itself. Its flagship product, the Netscape Navigator web browser—once preferred by 80% of web users—was quickly losing ground to Internet Explorer. So Netscape decided to compete in a new arena. In May, a team was brought together to start work on what was known internally as “Project 60.”[5][7] Two months later, Netscape announced “My Netscape,” a web portal that would fight it out with other portals like Yahoo, MSN, and Excite.
-
-The following year, in March, Netscape announced an addition to the My Netscape portal called the “My Netscape Network.” My Netscape users could now customize their My Netscape page so that it contained “channels” featuring the most recent headlines from sites around the web. As long as your favorite website published a special file in a format dictated by Netscape, you could add that website to your My Netscape page, typically by clicking an “Add Channel” button that participating websites were supposed to add to their interfaces. A little box containing a list of linked headlines would then appear.
-
-![A My Netscape Network Channel][8]
-
-The special file that participating websites had to publish was an RSS file. In the My Netscape Network announcement, Netscape explained that RSS stood for “RDF Site Summary.”[6][9] This was somewhat of a misnomer. RDF, or the Resource Description Framework, is basically a grammar for describing certain properties of arbitrary resources. (See [my article about the Semantic Web][10] if that sounds really exciting to you.) In 1999, a draft specification for RDF was being considered by the W3C. Though RSS was supposed to be based on RDF, the example RSS document Netscape actually released didn’t use any RDF tags at all, even if it declared the RDF XML namespace. In a document that accompanied the Netscape RSS specification, Dan Libby, one of the specification’s authors, explained that “in this release of MNN, Netscape has intentionally limited the complexity of the RSS format.”[7][11] The specification was given the 0.90 version number, the idea being that subsequent versions would bring RSS more in line with the W3C’s XML specification and the evolving draft of the RDF specification.
-
-RSS had been cooked up by Libby and another Netscape employee, Ramanathan Guha. Guha previously worked for Apple, where he came up with something called the Meta Content Framework. MCF was a format for representing metadata about anything from web pages to local files. Guha demonstrated its power by developing an application called [HotSauce][12] that visualized relationships between files as a network of nodes suspended in 3D space. After leaving Apple for Netscape, Guha worked with a Netscape consultant named Tim Bray to produce an XML-based version of MCF, which in turn became the foundation for the W3C’s RDF draft.[8][13] It’s no surprise, then, that Guha and Libby were keen to incorporate RDF into RSS. But Libby later wrote that the original vision for an RDF-based RSS was pared back because of time constraints and the perception that RDF was “‘too complex’ for the ‘average user.’”[9][14]
-
-While Netscape was trying to win eyeballs in what became known as the “portal wars,” elsewhere on the web a new phenomenon known as “weblogging” was being pioneered.[10][15] One of these pioneers was Dave Winer, CEO of a company called UserLand Software, which developed early content management systems that made blogging accessible to people without deep technical fluency. Winer ran his own blog, [Scripting News][16], which today is one of the oldest blogs on the internet. More than a year before Netscape announced My Netscape Network, on December 15th, 1997, Winer published a post announcing that the blog would now be available in XML as well as HTML.[11][17]
-
-Dave Winer’s XML format became known as the Scripting News format. It was supposedly similar to Microsoft’s Channel Definition Format (a “push technology” standard submitted to the W3C in March, 1997), but I haven’t been able to find a file in the original format to verify that claim.[12][18] Like Netscape’s RSS, it structured the content of Winer’s blog so that it could be understood by other software applications. When Netscape released RSS 0.90, Winer and UserLand Software began to support both formats. But Winer believed that Netscape’s format was “woefully inadequate” and “missing the key thing web writers and readers need.”[13][19] It could only represent a list of links, whereas the Scripting News format could represent a series of paragraphs, each containing one or more links.
-
-In June, 1999, two months after Netscape’s My Netscape Network announcement, Winer introduced a new version of the Scripting News format, called ScriptingNews 2.0b1. Winer claimed that he decided to move ahead with his own format only after trying but failing to get anyone at Netscape to care about RSS 0.90’s deficiencies.[14][20] The new version of the Scripting News format added several items to the `<header>` element that brought the Scripting News format to parity with RSS. But the two formats continued to differ in that the Scripting News format, which Winer nicknamed the “fat” syndication format, could include entire paragraphs and not just links.
-
-Netscape got around to releasing RSS 0.91 the very next month. The updated specification was a major about-face. RSS no longer stood for “RDF Site Summary”; it now stood for “Rich Site Summary.” All the RDF—and there was almost none anyway—was stripped out. Many of the Scripting News tags were incorporated. In the text of the new specification, Libby explained:
-
-> RDF references removed. RSS was originally conceived as a metadata format providing a summary of a website. Two things have become clear: the first is that providers want more of a syndication format than a metadata format. The structure of an RDF file is very precise and must conform to the RDF data model in order to be valid. This is not easily human-understandable and can make it difficult to create useful RDF files. The second is that few tools are available for RDF generation, validation and processing. For these reasons, we have decided to go with a standard XML approach.[15][21]
-
-Winer was enormously pleased with RSS 0.91, calling it “even better than I thought it would be.”[16][22] UserLand Software adopted it as a replacement for the existing ScriptingNews 2.0b1 format. For a while, it seemed that RSS finally had a single authoritative specification.
-
-### The Great Fork
-
-A year later, the RSS 0.91 specification had become woefully inadequate. There were all sorts of things people were trying to do with RSS that the specification did not address. There were other parts of the specification that seemed unnecessarily constraining—each RSS channel could only contain a maximum of 15 items, for example.
-
-By that point, RSS had been adopted by several more organizations. Other than Netscape, which seemed to have lost interest after RSS 0.91, the big players were Dave Winer’s UserLand Software; O’Reilly Net, which ran an RSS aggregator called Meerkat; and Moreover.com, which also ran an RSS aggregator focused on news.[17][23] Via mailing list, representatives from these organizations and others regularly discussed how to improve on RSS 0.91. But there were deep disagreements about what those improvements should look like.
-
-The mailing list in which most of the discussion occurred was called the Syndication mailing list. [An archive of the Syndication mailing list][24] is still available. It is an amazing historical resource. It provides a moment-by-moment account of how those deep disagreements eventually led to a political rupture of the RSS community.
-
-On one side of the coming rupture was Winer. Winer was impatient to evolve RSS, but he wanted to change it only in relatively conservative ways. In June, 2000, he published his own RSS 0.91 specification on the UserLand website, meant to be a starting point for further development of RSS. It made no significant changes to the 0.91 specification published by Netscape. Winer claimed in a blog post that accompanied his specification that it was only a “cleanup” documenting how RSS was actually being used in the wild, which was needed because the Netscape specification was no longer being maintained.[18][25] In the same post, he argued that RSS had succeeded so far because it was simple, and that by adding namespaces or RDF back to the format—some had suggested this be done in the Syndication mailing list—it “would become vastly more complex, and IMHO, at the content provider level, would buy us almost nothing for the added complexity.” In a message to the Syndication mailing list sent around the same time, Winer suggested that these issues were important enough that they might lead him to create a fork:
-
-> I’m still pondering how to move RSS forward. I definitely want ICE-like stuff in RSS2, publish and subscribe is at the top of my list, but I am going to fight tooth and nail for simplicity. I love optional elements. I don’t want to go down the namespaces and schema road, or try to make it a dialect of RDF. I understand other people want to do this, and therefore I guess we’re going to get a fork. I have my own opinion about where the other fork will lead, but I’ll keep those to myself for the moment at least.[19][26]
-
-Arrayed against Winer were several other people, including Rael Dornfest of O’Reilly, Ian Davis (responsible for a search startup called Calaba), and a precocious, 14-year-old Aaron Swartz, who all thought that RSS needed namespaces in order to accommodate the many different things everyone wanted to do with it. On another mailing list hosted by O’Reilly, Davis proposed a namespace-based module system, writing that such a system would “make RSS as extensible as we like rather than packing in new features that over-complicate the spec.”[20][27] The “namespace camp” believed that RSS would soon be used for much more than the syndication of blog posts, so namespaces, rather than being a complication, were the only way to keep RSS from becoming unmanageable as it supported more and more use cases.
-
-At the root of this disagreement about namespaces was a deeper disagreement about what RSS was even for. Winer had invented his Scripting News format to syndicate the posts he wrote for his blog. Guha and Libby at Netscape had designed RSS and called it “RDF Site Summary” because in their minds it was a way of recreating a site in miniature within Netscape’s online portal. Davis, writing to the Syndication mailing list, explained his view that RSS was “originally conceived as a way of building mini sitemaps,” and that now he and others wanted to expand RSS “to encompass more types of information than simple news headlines and to cater for the new uses of RSS that have emerged over the last 12 months.”[21][28] Winer wrote a prickly reply, stating that his Scripting News format was in fact the original RSS and that it had been meant for a different purpose. Given that the people most involved in the development of RSS disagreed about why RSS had even been created, a fork seems to have been inevitable.
-
-The fork happened after Dornfest announced a proposed RSS 1.0 specification and formed the RSS-DEV Working Group—which would include Davis, Swartz, and several others but not Winer—to get it ready for publication. In the proposed specification, RSS once again stood for “RDF Site Summary,” because RDF had had been added back in to represent metadata properties of certain RSS elements. The specification acknowledged Winer by name, giving him credit for popularizing RSS through his “evangelism.”[22][29] But it also argued that just adding more elements to RSS without providing for extensibility with a module system—that is, what Winer was suggesting—”sacrifices scalability.” The specification went on to define a module system for RSS based on XML namespaces.
-
-Winer was furious that the RSS-DEV Working Group had arrogated the “RSS 1.0” name for themselves.[23][30] In another mailing list about decentralization, he described what the RSS-DEV Working Group had done as theft.[24][31] Other members of the Syndication mailing list also felt that the RSS-DEV Working Group should not have used the name “RSS” without unanimous agreement from the community on how to move RSS forward. But the Working Group stuck with the name. Dan Brickley, another member of the RSS-DEV Working Group, defended this decision by arguing that “RSS 1.0 as proposed is solidly grounded in the original RSS vision, which itself had a long heritage going back to MCF (an RDF precursor) and related specs (CDF etc).”[25][32] He essentially felt that the RSS 1.0 effort had a better claim to the RSS name than Winer did, since RDF had originally been a part of RSS. The RSS-DEV Working Group published a final version of their specification in December. That same month, Winer published his own improvement to RSS 0.91, which he called RSS 0.92, on UserLand’s website. RSS 0.92 made several small optional improvements to RSS, among which was the addition of the `<enclosure>` tag soon used by podcasters everywhere. RSS had officially forked.
-
-It’s not clear to me why a better effort was not made to involve Winer in the RSS-DEV Working Group. He was a prominent contributor to the Syndication mailing list and obviously responsible for much of RSS’ popularity, as the members of the Working Group themselves acknowledged. But Tim O’Reilly, founder and CEO of O’Reilly, explained in a UserLand discussion group that Winer more or less refused to participate:
-
-> A group of people involved in RSS got together to start thinking about its future evolution. Dave was part of the group. When the consensus of the group turned in a direction he didn’t like, Dave stopped participating, and characterized it as a plot by O’Reilly to take over RSS from him, despite the fact that Rael Dornfest of O’Reilly was only one of about a dozen authors of the proposed RSS 1.0 spec, and that many of those who were part of its development had at least as long a history with RSS as Dave had.[26][33]
-
-To this, Winer said:
-
-> I met with Dale [Dougherty] two weeks before the announcement, and he didn’t say anything about it being called RSS 1.0. I spoke on the phone with Rael the Friday before it was announced, again he didn’t say that they were calling it RSS 1.0. The first I found out about it was when it was publicly announced.
->
-> Let me ask you a straight question. If it turns out that the plan to call the new spec “RSS 1.0” was done in private, without any heads-up or consultation, or for a chance for the Syndication list members to agree or disagree, not just me, what are you going to do?
->
-> UserLand did a lot of work to create and popularize and support RSS. We walked away from that, and let your guys have the name. That’s the top level. If I want to do any further work in Web syndication, I have to use a different name. Why and how did that happen Tim?[27][34]
-
-I have not been able to find a discussion in the Syndication mailing list about using the RSS 1.0 name prior to the announcement of the RSS 1.0 proposal.
-
-RSS would fork again in 2003, when several developers frustrated with the bickering in the RSS community sought to create an entirely new format. These developers created Atom, a format that did away with RDF but embraced XML namespaces. Atom would eventually be specified by [a proposed IETF standard][35]. After the introduction of Atom, there were three competing versions of RSS: Winer’s RSS 0.92 (updated to RSS 2.0 in 2002 and renamed “Really Simple Syndication”), the RSS-DEV Working Group’s RSS 1.0, and Atom.
-
-### Decline
-
-The proliferation of competing RSS specifications may have hampered RSS in other ways that I’ll discuss shortly. But it did not stop RSS from becoming enormously popular during the 2000s. By 2004, the New York Times had started offering its headlines in RSS and had written an article explaining to the layperson what RSS was and how to use it.[28][36] Google Reader, an RSS aggregator ultimately used by millions, was launched in 2005. By 2013, RSS seemed popular enough that the New York Times, in its obituary for Aaron Swartz, called the technology “ubiquitous.”[29][37] For a while, before a third of the planet had signed up for Facebook, RSS was simply how many people stayed abreast of news on the internet.
-
-The New York Times published Swartz’ obituary in January, 2013. By that point, though, RSS had actually turned a corner and was well on its way to becoming an obscure technology. Google Reader was shutdown in July, 2013, ostensibly because user numbers had been falling “over the years.”[30][38] This prompted several articles from various outlets declaring that RSS was dead. But people had been declaring that RSS was dead for years, even before Google Reader’s shuttering. Steve Gillmor, writing for TechCrunch in May, 2009, advised that “it’s time to get completely off RSS and switch to Twitter” because “RSS just doesn’t cut it anymore.”[31][39] He pointed out that Twitter was basically a better RSS feed, since it could show you what people thought about an article in addition to the article itself. It allowed you to follow people and not just channels. Gillmor told his readers that it was time to let RSS recede into the background. He ended his article with a verse from Bob Dylan’s “Forever Young.”
-
-Today, RSS is not dead. But neither is it anywhere near as popular as it once was. Lots of people have offered explanations for why RSS lost its broad appeal. Perhaps the most persuasive explanation is exactly the one offered by Gillmor in 2009. Social networks, just like RSS, provide a feed featuring all the latest news on the internet. Social networks took over from RSS because they were simply better feeds. They also provide more benefits to the companies that own them. Some people have accused Google, for example, of shutting down Google Reader in order to encourage people to use Google+. Google might have been able to monetize Google+ in a way that it could never have monetized Google Reader. Marco Arment, the creator of Instapaper, wrote on his blog in 2013:
-
-> Google Reader is just the latest casualty of the war that Facebook started, seemingly accidentally: the battle to own everything. While Google did technically “own” Reader and could make some use of the huge amount of news and attention data flowing through it, it conflicted with their far more important Google+ strategy: they need everyone reading and sharing everything through Google+ so they can compete with Facebook for ad-targeting data, ad dollars, growth, and relevance.[32][40]
-
-So both users and technology companies realized that they got more out of using social networks than they did out of RSS.
-
-Another theory is that RSS was always too geeky for regular people. Even the New York Times, which seems to have been eager to adopt RSS and promote it to its audience, complained in 2006 that RSS is a “not particularly user friendly” acronym coined by “computer geeks.”[33][41] Before the RSS icon was designed in 2004, websites like the New York Times linked to their RSS feeds using little orange boxes labeled “XML,” which can only have been intimidating.[34][42] The label was perfectly accurate though, because back then clicking the link would take a hapless user to a page full of XML. [This great tweet][43] captures the essence of this explanation for RSS’ demise. Regular people never felt comfortable using RSS; it hadn’t really been designed as a consumer-facing technology and involved too many hurdles; people jumped ship as soon as something better came along.
-
-RSS might have been able to overcome some of these limitations if it had been further developed. Maybe RSS could have been extended somehow so that friends subscribed to the same channel could syndicate their thoughts about an article to each other. But whereas a company like Facebook was able to “move fast and break things,” the RSS developer community was stuck trying to achieve consensus. The Great RSS Fork only demonstrates how difficult it was to do that. So if we are asking ourselves why RSS is no longer popular, a good first-order explanation is that social networks supplanted it. If we ask ourselves why social networks were able to supplant it, then the answer may be that the people trying to make RSS succeed faced a problem much harder than, say, building Facebook. As Dornfest wrote to the Syndication mailing list at one point, “currently it’s the politics far more than the serialization that’s far from simple.”[35][44]
-
-So today we are left with centralized silos of information. In a way, we _do_ have the syndicated internet that Kevin Werbach foresaw in 1999. After all, _The Onion_ is a publication that relies on syndication through Facebook and Twitter the same way that Seinfeld relied on syndication to rake in millions after the end of its original run. But syndication on the web only happens through one of a very small number of channels, meaning that none of us “retain control over our online personae” the way that Werbach thought we would. One reason this happened is garden-variety corporate rapaciousness—RSS, an open format, didn’t give technology companies the control over data and eyeballs that they needed to sell ads, so they did not support it. But the more mundane reason is that centralized silos are just easier to design than common standards. Consensus is difficult to achieve and it takes time, but without consensus spurned developers will go off and create competing standards. The lesson here may be that if we want to see a better, more open web, we have to get better at not screwing each other over.
-
-_If you enjoyed this post, more like it come out every four weeks! Follow [@TwoBitHistory][45] on Twitter or subscribe to the [RSS feed][46] to make sure you know when a new post is out._
-
-_Previously on TwoBitHistory…_
-
-> New post: This week we're traveling back in time in our DeLorean to see what it was like learning to program on early home computers.<https://t.co/qDrwqgIuuy>
->
-> — TwoBitHistory (@TwoBitHistory) [September 2, 2018][47]
-
- 1. Kevin Werbach, “The Web Goes into Syndication,” Release 1.0, July 22, 1999, 1, accessed September 14, 2018, <http://cdn.oreillystatic.com/radar/r1/07-99.pdf>. [↩︎][48]
-
- 2. ibid. [↩︎][49]
-
- 3. Werbach, 8. [↩︎][50]
-
- 4. Peter Wiggin, “RSS Delivers the XML Promise,” Web Review, October 29, 1999, accessed September 14, 2018, <https://people.apache.org/~jim/NewArchitect/webrevu/1999/10_29/webauthors/10_29_99_2a.html>. [↩︎][51]
-
- 5. Ben Hammersley, RSS and Atom (O’Reilly), 8, accessed September 14, 2018, <https://books.google.com/books?id=kwJVAgAAQBAJ>. [↩︎][52]
-
- 6. “RSS 0.90 Specification,” RSS Advisory Board, accessed September 14, 2018, <http://www.rssboard.org/rss-0-9-0>. [↩︎][53]
-
- 7. “My Netscape Network Future Directions,” RSS Advisory Board, accessed September 14, 2018, <http://www.rssboard.org/mnn-futures>. [↩︎][54]
-
- 8. Tim Bray, “The RDF.net Challenge,” Ongoing by Tim Bray, May 21, 2003, accessed September 14, 2018, <https://www.tbray.org/ongoing/When/200x/2003/05/21/RDFNet>. [↩︎][55]
-
- 9. Dan Libby, “RSS: Introducing Myself,” August 24, 2000, RSS-DEV Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/rss-dev/conversations/topics/239>. [↩︎][56]
-
- 10. Alexandra Krasne, “Browser Wars May Become Portal Wars,” CNN, accessed September 14, 2018, <http://www.cnn.com/TECH/computing/9910/04/portal.war.idg/index.html>. [↩︎][57]
-
- 11. Dave Winer, “Scripting News in XML,” Scripting News, December 15, 1997, accessed September 14, 2018, <http://scripting.com/davenet/1997/12/15/scriptingNewsInXML.html>. [↩︎][58]
-
- 12. Joseph Reagle, “RSS History,” 2004, accessed September 14, 2018, <https://reagle.org/joseph/2003/rss-history.html>. [↩︎][59]
-
- 13. Dave Winer, “A Faceoff with Netscape,” Scripting News, June 16, 1999, accessed September 14, 2018, <http://scripting.com/davenet/1999/06/16/aFaceOffWithNetscape.html>. [↩︎][60]
-
- 14. ibid. [↩︎][61]
-
- 15. Dan Libby, “RSS 0.91 Specification (Netscape),” RSS Advisory Board, accessed September 14, 2018, <http://www.rssboard.org/rss-0-9-1-netscape>. [↩︎][62]
-
- 16. Dave Winer, “Scripting News: 7/28/1999,” Scripting News, July 28, 1999, accessed September 14, 2018, <http://scripting.com/1999/07/28.html>. [↩︎][63]
-
- 17. Oliver Willis, “RSS Aggregators?” June 19, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/topics/173>. [↩︎][64]
-
- 18. Dave Winer, “Scripting News: 07/07/2000,” Scripting News, July 07, 2000, accessed September 14, 2018, <http://essaysfromexodus.scripting.com/backissues/2000/06/07/#rss>. [↩︎][65]
-
- 19. Dave Winer, “Re: RSS 0.91 Restarted,” June 9, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/topics/132>. [↩︎][66]
-
- 20. Leigh Dodds, “RSS Modularization,” XML.com, July 5, 2000, accessed September 14, 2018, <http://www.xml.com/pub/a/2000/07/05/deviant/rss.html>. [↩︎][67]
-
- 21. Ian Davis, “Re: [syndication] RSS Modularization Demonstration,” June 28, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/topics/188>. [↩︎][68]
-
- 22. “RDF Site Summary (RSS) 1.0,” December 09, 2000, accessed September 14, 2018, <http://web.resource.org/rss/1.0/spec>. [↩︎][69]
-
- 23. Dave Winer, “Re: [syndication] Re: Thoughts, Questions, and Issues,” August 16, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/topics/410>. [↩︎][70]
-
- 24. Mark Pilgrim, “History of the RSS Fork,” Dive into Mark, September 5, 2002, accessed September 14, 2018, <http://www.diveintomark.link/2002/history-of-the-rss-fork>. [↩︎][71]
-
- 25. Dan Brickley, “RSS-Classic, RSS 1.0 and a Historical Debt,” November 7, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/rss-dev/conversations/topics/1136>. [↩︎][72]
-
- 26. Tim O’Reilly, “Re: Asking Tim,” UserLand, September 20, 2000, accessed September 14, 2018, <http://static.userland.com/userLandDiscussArchive/msg021537.html>. [↩︎][73]
-
- 27. Dave Winer, “Re: Asking Tim,” UserLand, September 20, 2000, accessed September 14, 2018, <http://static.userland.com/userLandDiscussArchive/msg021560.html>. [↩︎][74]
-
- 28. John Quain, “BASICS; Fine-Tuning Your Filter for Online Information,” The New York Times, 2004, accessed September 14, 2018, <https://www.nytimes.com/2004/06/03/technology/basics-fine-tuning-your-filter-for-online-information.html>. [↩︎][75]
-
- 29. John Schwartz, “Aaron Swartz, Internet Activist, Dies at 26,” The New York Times, January 12, 2013, accessed September 14, 2018, <https://www.nytimes.com/2013/01/13/technology/aaron-swartz-internet-activist-dies-at-26.html>. [↩︎][76]
-
- 30. “A Second Spring of Cleaning,” Official Google Blog, March 13, 2013, accessed September 14, 2018, <https://googleblog.blogspot.com/2013/03/a-second-spring-of-cleaning.html>. [↩︎][77]
-
- 31. Steve Gillmor, “Rest in Peace, RSS,” TechCrunch, May 5, 2009, accessed September 14, 2018, <https://techcrunch.com/2009/05/05/rest-in-peace-rss/>. [↩︎][78]
-
- 32. Marco Arment, “Lockdown,” Marco.org, July 3, 2013, accessed September 14, 2018, <https://marco.org/2013/07/03/lockdown>. [↩︎][79]
-
- 33. Bob Tedeschi, “There’s a Popular New Code for Deals: RSS,” The New York Times, January 29, 2006, accessed September 14, 2018, <https://www.nytimes.com/2006/01/29/travel/theres-a-popular-new-code-for-deals-rss.html>. [↩︎][80]
-
- 34. “NYTimes.com RSS Feeds,” The New York Times, accessed September 14, 2018, <https://web.archive.org/web/20050326065348/www.nytimes.com/services/xml/rss/index.html>. [↩︎][81]
-
- 35. Rael Dornfest, “RE: Re: [syndication] RE: RFC: Clearing Confusion for RSS, Agreement for Forward Motion,” May 31, 2001, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/messages/1717>. [↩︎][82]
-
-
-
-
---------------------------------------------------------------------------------
-
-via: https://twobithistory.org/2018/09/16/the-rise-and-demise-of-rss.html
-
-作者:[Two-Bit History][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://twobithistory.org
-[b]: https://github.com/lujun9972
-[1]: https://twobithistory.org/2018/12/18/rss.html
-[2]: tmp.F599d8dnXW#fn:3
-[3]: tmp.F599d8dnXW#fn:4
-[4]: tmp.F599d8dnXW#fn:5
-[5]: tmp.F599d8dnXW#fn:6
-[6]: https://trends.google.com/trends/explore?date=all&geo=US&q=rss
-[7]: tmp.F599d8dnXW#fn:7
-[8]: https://twobithistory.org/images/mnn-channel.gif
-[9]: tmp.F599d8dnXW#fn:8
-[10]: https://twobithistory.org/2018/05/27/semantic-web.html
-[11]: tmp.F599d8dnXW#fn:9
-[12]: http://web.archive.org/web/19970703020212/http://mcf.research.apple.com:80/hs/screen_shot.html
-[13]: tmp.F599d8dnXW#fn:10
-[14]: tmp.F599d8dnXW#fn:11
-[15]: tmp.F599d8dnXW#fn:12
-[16]: http://scripting.com/
-[17]: tmp.F599d8dnXW#fn:13
-[18]: tmp.F599d8dnXW#fn:14
-[19]: tmp.F599d8dnXW#fn:15
-[20]: tmp.F599d8dnXW#fn:16
-[21]: tmp.F599d8dnXW#fn:17
-[22]: tmp.F599d8dnXW#fn:18
-[23]: tmp.F599d8dnXW#fn:19
-[24]: https://groups.yahoo.com/neo/groups/syndication/info
-[25]: tmp.F599d8dnXW#fn:20
-[26]: tmp.F599d8dnXW#fn:21
-[27]: tmp.F599d8dnXW#fn:22
-[28]: tmp.F599d8dnXW#fn:23
-[29]: tmp.F599d8dnXW#fn:24
-[30]: tmp.F599d8dnXW#fn:25
-[31]: tmp.F599d8dnXW#fn:26
-[32]: tmp.F599d8dnXW#fn:27
-[33]: tmp.F599d8dnXW#fn:28
-[34]: tmp.F599d8dnXW#fn:29
-[35]: https://tools.ietf.org/html/rfc4287
-[36]: tmp.F599d8dnXW#fn:30
-[37]: tmp.F599d8dnXW#fn:31
-[38]: tmp.F599d8dnXW#fn:32
-[39]: tmp.F599d8dnXW#fn:33
-[40]: tmp.F599d8dnXW#fn:34
-[41]: tmp.F599d8dnXW#fn:35
-[42]: tmp.F599d8dnXW#fn:36
-[43]: https://twitter.com/mgsiegler/status/311992206716203008
-[44]: tmp.F599d8dnXW#fn:37
-[45]: https://twitter.com/TwoBitHistory
-[46]: https://twobithistory.org/feed.xml
-[47]: https://twitter.com/TwoBitHistory/status/1036295112375115778?ref_src=twsrc%5Etfw
-[48]: tmp.F599d8dnXW#fnref:3
-[49]: tmp.F599d8dnXW#fnref:4
-[50]: tmp.F599d8dnXW#fnref:5
-[51]: tmp.F599d8dnXW#fnref:6
-[52]: tmp.F599d8dnXW#fnref:7
-[53]: tmp.F599d8dnXW#fnref:8
-[54]: tmp.F599d8dnXW#fnref:9
-[55]: tmp.F599d8dnXW#fnref:10
-[56]: tmp.F599d8dnXW#fnref:11
-[57]: tmp.F599d8dnXW#fnref:12
-[58]: tmp.F599d8dnXW#fnref:13
-[59]: tmp.F599d8dnXW#fnref:14
-[60]: tmp.F599d8dnXW#fnref:15
-[61]: tmp.F599d8dnXW#fnref:16
-[62]: tmp.F599d8dnXW#fnref:17
-[63]: tmp.F599d8dnXW#fnref:18
-[64]: tmp.F599d8dnXW#fnref:19
-[65]: tmp.F599d8dnXW#fnref:20
-[66]: tmp.F599d8dnXW#fnref:21
-[67]: tmp.F599d8dnXW#fnref:22
-[68]: tmp.F599d8dnXW#fnref:23
-[69]: tmp.F599d8dnXW#fnref:24
-[70]: tmp.F599d8dnXW#fnref:25
-[71]: tmp.F599d8dnXW#fnref:26
-[72]: tmp.F599d8dnXW#fnref:27
-[73]: tmp.F599d8dnXW#fnref:28
-[74]: tmp.F599d8dnXW#fnref:29
-[75]: tmp.F599d8dnXW#fnref:30
-[76]: tmp.F599d8dnXW#fnref:31
-[77]: tmp.F599d8dnXW#fnref:32
-[78]: tmp.F599d8dnXW#fnref:33
-[79]: tmp.F599d8dnXW#fnref:34
-[80]: tmp.F599d8dnXW#fnref:35
-[81]: tmp.F599d8dnXW#fnref:36
-[82]: tmp.F599d8dnXW#fnref:37
diff --git a/sources/talk/20180917 How gaming turned me into a coder.md b/sources/talk/20180917 How gaming turned me into a coder.md
deleted file mode 100644
index f5675c4628..0000000000
--- a/sources/talk/20180917 How gaming turned me into a coder.md
+++ /dev/null
@@ -1,103 +0,0 @@
-How gaming turned me into a coder
-======
-
-Text-based adventure gaming leads to a satisfying career in tech.
-
-
-
-I think the first word I learned to type fast—and I mean really fast—was "fireball."
-
-Like most of us, I started my typing career with a "hunt-and-peck" technique, using my index fingers and keeping my eyes focused on the keyboard to find letters as I needed them. It's not a technique that allows you to read and write at the same time; you might call it half-duplex. It was okay for typing **cd** and **dir** , but it wasn't nearly fast enough to get ahead in the game. Especially if that game was a MUD.
-
-### Gaming with multi-user dungeons
-
-MUD is short for multi-user dungeon. Or multi-user domain, depending on who (and when) you ask. MUDs are text-based adventure games, like [Colossal Cave Adventure][1] and Zork, which you may have heard about in Season 2 [Episode 1][2] of [Command Line Heroes][3]. But MUDs have an extra twist: you aren't the only person playing them. They allow you to group with others to tackle particularly nasty beasts, trade goods, and make new friends. They were the great granddaddies of modern massively multiplayer online role-playing games (MMORPGs) like Everquest and World of Warcraft. And, for an aspiring command-line hero, they offered an experience those modern games still don't.
-
-My "home MUD" was NyxMud, which you could access by telnetting to port 2000 of nyx.cs.du.edu. It was the first command line I ever mastered. In a lot of ways, it allowed me to be a hero—or at least play the part of one.
-
-One special quality of NyxMud was that every time you connected to play, you started with an empty inventory. The gold you collected was still there from your last session, but none of your hard-won weapons, armor, or magical items were. So, at the end of every session, you had to make it back to a store to sell everything… and you would get a fraction of what you paid. If you were killed, the first player who encountered your lifeless body could take everything you had.
-
-![dying and losing everything in a MUD.][5]
-
-This shows what it looks like when you die and lose everything in a MUD
-
-This made the game extremely sticky. Selling everything and quitting was a horrible thing to do, fiscally speaking. It meant that your session had to be profitable. If you didn't earn enough gold through looting and quests between the time you bought and sold your gear, you wouldn't be able to equip yourself as well the next time you played. If you died, it was even worse: You might find yourself killing balls of slime with a newbie sword as you scraped together enough gold for better gear.
-
-I never wanted to "pay the store tax" by selling my gear, which meant a lot of late nights and sleeping through morning biology classes. Every modern game designer wants you to say, "I can't have dinner now, Dad, I have to keep playing or I'm in big trouble." NyxMud had me so hooked that I was saying that several decades ago.
-
-So when it came time to "cast fireball" or die an imminent and ruinous death, I was forced to learn how to type properly. It also forced me to take a social approach to the game—having friends around to fight off scavengers allowed me to reclaim my gear when I died.
-
-Command-line heroes all have some things in common: They work with others and they type wicked fast. NyxMud trained me to do both.
-
-### From gamer to creator
-
-NyxMud was not the largest MUD by any measure. But it was still an expansive world filled with hundreds of areas and dozens of epic adventures, each one tailored to a different level of a player's advancement. Over time, it became apparent that not all these areas were created by the same person. The term "user-generated content" was yet to be invented, but the concept was dead simple even to my young mind: This entire world was created by a group of people, other players.
-
-Once you completed each of the challenging quests and achieved level 20, you became a wizard. This was a singularity of sorts, beyond which existed a reality known only to a few. During lunch breaks at school, my circle of friends would muse about the powers of a wizard; you see, we knew wizards could create rooms, beasts, items, and quests. We knew they could kill players at will. We really didn't know much else about their powers. The whole thing was shrouded in mystery.
-
-In our group of high school friends, Eddie was the first to become a wizard. His flaunting and taunting threw us into overdrive, and Jared was quick to follow. I was last, but only by a day or two. Now that 25 years have passed, let's just call it a three-way tie. We discovered it was pretty much what we thought. We could create rooms, beasts, items, and quests. We could kill players. Oh, and we could become invisible. In NyxMud, that was just about it.
-
-![a wizard’s private workroom][7]
-
-This shows a wizard’s private workroom.
-
-Wizards used the Wand of Creation, an item invented by Quasi (rhymed with "crazy"), the grand wizard. He alone had access to the code for the engine, due to a strict policy set by the administrator of the Nyx system where it ran. So, he created a complicated, magical object that would allow users to generate new game elements. This wand, when invoked, ran the wizard through a menu-based workflow for creating rooms and objects, establishing quest objectives, and designing terrible monsters.
-
-Having that magical wand was enough. I immediately set to work creating new lands and grand adventures across a series of islands, each with a different, exotic climate and theme. I found immense pleasure in hovering, invisible, as the savage beasts from my imagination would slay intrepid adventurers over and over again. But it was even better to see players persevere after a hard battle, knowing I had tweaked and tuned my quests to be just within the realm of possibility.
-
-Being accepted into this elite group of creators was one of the more rewarding and satisfying moments of my young life. Each new wizard would have to pass my test, spending countless hours and sleepless nights, just as I did, to complete the quests of the wizards before me. I had proven my value through dedication and contribution. It was just a game, but it was also a community—the first one I encountered, and the one that showed me how powerful a properly run [meritocracy][8] could be.
-
-### From creator to coder
-
-NyxMud was based on the LPMud codebase, which was created by Lars Pensjö. LPMud was not the first MUD software developed, but it contained one very important innovation: It allowed players to code the game from within the game. It accomplished this by separating the mudlib, which contained all the content and user-facing functionality, from the driver, which acted as a real-time interpreter for the mudlib and provided access to basic network and storage resources. This architecture meant the mudlib could be edited on-the-fly by virtually untrusted people (e.g., players like me) who could augment the game experience without being able to do anything particularly harmful to the server it was running on. The driver provided an "air gap."
-
-This air gap was not enough for NyxMud; it was allowed to exist only if a single person could be trusted to write all the code. In most LPMud systems, players who became wizards could use **ls** , **cd** , and **ed** to traverse the mudlib and modify files, all from the same command line they had used countless times for casting fireballs and drinking potions. Quasi went to great lengths to modify the Nyx mudlib so wizards couldn't traipse around the system with a full set of sharp tools. The Wand of Creation was born.
-
-As a wizard who hadn't played any other MUDs, I didn't miss what I never had. Besides, I didn't have a way to access any systems at the time—telnet was disabled on Nyx, which was my only connection to the internet. But I did have access to Usenet, which provided me with [The Totally Unofficial List of Internet Muds][9]. It was clear there was more of the MUD universe for me to discover. I read all the documentation about mudlibs I could get my hands on and got some exposure to [LPC][10], the niche programming language used to create new content.
-
-I convinced my dad to make an investment in my future by paying for a shell account at Netcom (remember that?). With that account, I could connect to any MUD I wanted, and, based on several strong recommendations, I chose Viking MUD. It still [exists today][11]. It was a real MUD, the bleeding edge, and it showcased the true potential of a universe built with code instead of the limited menu system of a magical wand. But, to be honest, I never got very far as a player. I really wanted to learn how to code, and I didn't want to slay slimeballs with a noobsword for hours to get there.
-
-There was a very small window of time—between February and August 1992, according to Lauren P. Burka's [Mud Timeline][12]—where the perfect place existed for my exploration. The Mud Institute (TMI for short) was a very special MUD designed to teach people how to program in LPC, illuminating the darkest corners of the mudlib. It offered immediate omnipotence to all who applied and built a community for the development of a new generation of LPMuds.
-
-![a snippet of code from the wizard's workroom][14]
-
-This is a snippet of code from the wizard's workroom.
-
-This was my first exposure to C programming, as LPC was essentially a flavor of C that shared the same types, control structures, and syntax. It was C with training wheels, designed for rapid creation of content but allowing coders to develop intricate game scenarios (if they had the chops). I had always seen the curly brace on my keyboard, and now I knew what it was used for. The only thing I can remember creating was a special vending machine, somewhat inspired by the Wand of Creation, that would create the monster of your choice on-the-spot.
-
-TMI was not a long-lasting phenomenon; in fact, it was gone almost before I had a chance to discover it. It quickly abandoned its educational charter, although its efforts were ultimately productive with the release of [MudOS][15]—which still lives through its modern-day descendant, [FluffOS][16]. But what a treasure trove of knowledge about a highly specific subject! Immediately after logging in, I was presented with a complete set of developer tools, a library of instructional materials, and a ton of interesting sample code to learn from.
-
-I never talked to anyone or asked for any help, and I never had to. The community had published just enough resources for me to get started by myself. I was able to learn the basics of structured programming without a textbook or teacher, all within the context of a fantastical computer game. As a result, I have had a long and (mostly) fulfilling career in technology.
-
-The line from Field of Dreams, "if you build it, they will come," is almost certainly untrue for communities.** **The folks at The Mud Institute built the makings of a great community, but I can't say they were successful. They didn't become a widely known wizarding school—in fact, it's really hard to find any information about TMI at all. If you build it, they may not come; if they do, you may still fail. But it still accomplished something wonderful that its creators never thought to predict: It got me excited about programming.
-
-For more on the gamer-to-coder phenomenon and its effect on open source community culture, check out [Episode 1 of Season 2 of Command Line Heroes][2].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/gamer-coder
-
-作者:[Ross Turk][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/rossturk
-[1]: https://opensource.com/article/17/6/revisit-colossal-cave-adventure-open-adventure
-[2]: https://www.redhat.com/en/command-line-heroes/season-2/press-start
-[3]: https://www.redhat.com/en/command-line-heroes
-[4]: /file/409311
-[5]: https://opensource.com/sites/default/files/uploads/sourcecode_wizard_workroom.png (dying and losing everything in a MUD)
-[6]: /file/409306
-[7]: https://opensource.com/sites/default/files/uploads/wizard_workroom.png (a wizard’s private workroom)
-[8]: https://opensource.com/open-organization/16/8/how-make-meritocracy-work
-[9]: http://textfiles.com/internet/mudlist.txt
-[10]: https://en.wikipedia.org/wiki/LPC_(programming_language)
-[11]: https://www.vikingmud.org
-[12]: http://www.linnaean.org/~lpb/muddex/mudline.html
-[13]: /file/409301
-[14]: https://opensource.com/sites/default/files/uploads/firstroom_newplayer.png (a snippet of code from the wizard's workroom)
-[15]: https://en.wikipedia.org/wiki/MudOS
-[16]: https://github.com/fluffos/fluffos
diff --git a/sources/talk/20180920 Building a Secure Ecosystem for Node.js.md b/sources/talk/20180920 Building a Secure Ecosystem for Node.js.md
deleted file mode 100644
index a64f0e32cc..0000000000
--- a/sources/talk/20180920 Building a Secure Ecosystem for Node.js.md
+++ /dev/null
@@ -1,51 +0,0 @@
-Building a Secure Ecosystem for Node.js
-======
-
-
-
-At[Node+JS Interactive][1], attendees collaborate face to face, network, and learn how to improve their skills with JS in serverless, IoT, and more. [Stephanie Evans][2], Content Manager for Back-end Web Development at LinkedIn Learning, will be speaking at the upcoming conference about building a secure ecosystem for Node.js. Here she answers a few questions about teaching and learning basic security practices.
-
-**Linux.com: Your background is in tech education, can you provide more details on how you would define this and how you got into this area of expertise?**
-
-**Stephanie Evans:** It sounds cliché, but I’ve always been passionate about education and helping others. After college, I started out as an instructor of a thoroughly analog skill: reading. I worked my way up to hiring and training reading teachers and discovered my passion for helping people share their knowledge and refine their teaching craft. Later, I went to work for McGraw Hill Education, publishing self-study certification books on popular IT certs like CompTIA’s Network+ and Security+, ISAAP’s CISSP, etc. My job was to figure out who the biggest audiences in IT were; what they needed to know to succeed professionally; hire the right book author; and help develop the manuscript with them.
-
-I moved into online learning/e-learning 4 years ago and shifted to video training courses geared towards developers. I enjoy working with people who spend their time building and solving complex problems. I now manage the video training library for back-end web developers at LinkedIn Learning/Lynda.com and figure out what developers need to know; hire instructors to create that content; and work together to figure out how best to teach it to them. And, then update those courses when they inevitably become out of date.
-
-**Linux.com: What initially drove you to use your skill set in education to help with security practices?**
-
-**Evans:** I attend a lot of conferences, watch a lot of talks, and chat to a lot of developers as part of my job. I distinctly remember attending a security best practices talk at a very large, enterprise-tech focused conference and was surprised by the rudimentary content being covered. Poor guy, I’d thought…he’s going to get panned by this audience. But then I looked around and most everyone was engaged. They were learning something new and compelling. And it hit me: I had been in a security echo chamber of my own making. Just like the mainstream developer isn’t working with the cutting-edge technology people are raving about on Twitter, they aren’t necessarily as fluent in basic security practices as I’d assumed. A mix of unawareness, intense time pressure, and perhaps some misplaced trust can lead to a “security later” mentality. But with the global cost of cybercrime up to 6 00 billion a year from 500 billion in 2014 as well as the [exploding amount of data on the web][3]. We can’t afford to be working around security or assuming everyone knows the basics.
-
-**Linux.com: What do you think are some common misconceptions about security with Node.js and in general with developers?**
-
-**Evans:** I think one of the biggest misconceptions is that security awareness and practices should come “later” in a developer’s career (and later in the development cycle). Yes, your first priority is to learn that Java and JavaScript are not the same thing—that’s obviously most important. And you do have to understand how to create a form before you can understand how to prevent cross-site -scripting attacks. But helping developers understand—at all stages of their career and learning journey—what the potential vulnerabilities are and how they can be exploited needs to be a much higher priority and come earlier than we may intuitively think.
-
-I joke with my instructors that we have to sneak in the ‘eat your vegetables’ content to our courses. Security is an exciting, complex and challenging topic, but it can feel like you’re having to eat your vegetables as a developer when you dig into it. Often ‘security’ is a separate department (that can be perceived as ‘slowing things down’ or getting in the way of deploying code) and it can further distance developers from their role in securing their applications.
-
-I also think that those who truly understand security can feel that it’s overwhelmingly complex to teach—but we have to start somewhere. I attended an introductory npm talk last year that talked about how to work with dependencies and packages…but never once mentioned the possibility of malicious code making it into your application through these packages. I’m all about teaching just enough at the right time and not throwing the kitchen sink of knowledge at new developers. We should stop thinking of security—or even just security awareness—as an intermediate or advanced skill and start bringing it up early and often.
-
-**Linux.com: How can we infuse tech education into our security practices? Where does this begin?**
-
-**Evans:** It definitely goes both ways. Clear documentation and practical resources right alongside security recommendations go a long way towards ensuring understanding and adoption. You have to make things as easy as possible if you want people to actually do it. And you have to make those best practices accessible enough to understand.
-
-The [2018 Node User Survey Report][4] from the Node.js Foundation showed that while learning resources around Node.js and JavaScript development improved, the availability and quality of learning resources for Node.js Security received the lowest scores across the board.
-
-After documentation and Stack Overflow, many developers rely on online videos and tutorials—we need to push security education to the forefront, rather than expecting developers to seek it out. OWASP, the nodegoat project, and the Node.js Security Working Group are doing great work here to move the needle. I think tech education can do even more to bring security in earlier in the learning journey and create awareness about common exploits and important resources.
-
-Learn more at [Node+JS Interactive][1], coming up October 10-12, 2018 in Vancouver, Canada.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/node-js/2018/9/building-secure-ecosystem-nodejs
-
-作者:[The Linux Foundation][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/ericstephenbrown
-[1]: https://events.linuxfoundation.org/events/node-js-interactive-2018/?utm_source=Linux.com&utm_medium=article&utm_campaign=jsint18
-[2]: https://jsi2018.sched.com/speaker/stevans1?iframe=no
-[3]: https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/#101d261a60ba
-[4]: https://nodejs.org/en/user-survey-report/
diff --git a/sources/talk/20180925 Troubleshooting Node.js Issues with llnode.md b/sources/talk/20180925 Troubleshooting Node.js Issues with llnode.md
deleted file mode 100644
index 3565b0270d..0000000000
--- a/sources/talk/20180925 Troubleshooting Node.js Issues with llnode.md
+++ /dev/null
@@ -1,75 +0,0 @@
-Troubleshooting Node.js Issues with llnode
-======
-
-
-
-The llnode plugin lets you inspect Node.js processes and core dumps; it adds the ability to inspect JavaScript stack frames, objects, source code and more. At [Node+JS Interactive][1], Matheus Marchini, Node.js Collaborator and Lead Software Engineer at Sthima, will host a [workshop][2] on how to use llnode to find and fix issues quickly and reliably, without bloating your application with logs or compromising performance. He explains more in this interview.
-
-**Linux.com: What are some common issues that happen with a Node.js application in production?**
-
-**Matheus Marchini:** One of the most common issues Node.js developers might experience -- either in production or during development -- are unhandled exceptions. They happen when your code throws an error, and this error is not properly handled. There's a variation of this issue with Promises, although in this case, the problem is worse: if a Promise is rejected but there's no handler for that rejection, the application might enter into an undefined state and it can start to misbehave.
-
-The application might also crash when it's using too much memory. This usually happens when there's a memory leak in the application, although we usually don't have classic memory leaks in Node.js. Instead of unreferenced objects, we might have objects that are not used anymore but are still retained by another object, leading the Garbage Collector to ignore them. If this happens with several objects, we can quickly exhaust our available memory.
-
-Memory is not the only resource that might get exhausted. Given the asynchronous nature of Node.js and how it scales for a large number of requests, the application might start to run out on other resources such as opened file descriptions and a number of concurrent connections to a database.
-
-Infinite loops are not that common because we usually catch those during development, but every once in a while one manages to slip through our tests and get into our production servers. These are pretty catastrophic because they will block the main thread, rendering the entire application unresponsive.
-
-The last issues I'd like to point out are performance issues. Those can happen for a variety of reasons, ranging from unoptimized function to I/O latency.
-
-**Linux.com: Are there any quick tests you can do to determine what might be happening with your Node.js application?**
-
-**Marchini:** Node.js and V8 have several tools and features built-in which developers can use to find issues faster. For example, if you're facing performance issues, you might want to use the built-in [V8 CpuProfiler][3]. Memory issues can be tracked down with [V8 Sampling Heap Profiler][4]. All of these options are interesting because you can open their results in Chrome DevTools and get some nice graphical visualizations by default.
-
-If you are using native modules on your project, V8 built-in tools might not give you enough insights, since they focus only on JavaScript metrics. As an alternative to V8 CpuProfiler, you can use system profiler tools, such as [perf for Linux][5] and Dtrace for FreeBSD / OS X. You can grab the result from these tools and turn them into flamegraphs, making it easier to find which functions are taking more time to process.
-
-You can use third-party tools as well: [node-report][6] is an amazing first failure data capture which doesn't introduce a significant overhead. When your application crashes, it will generate a report with detailed information about the state of the system, including environment variables, flags used, operating system details, etc. You can also generate this report on demand, and it is extremely useful when asking for help in forums, for example. The best part is that, after installing it through npm, you can enable it with a flag -- no need to make changes in your code!
-
-But one of the tools I'm most amazed by is [llnode][7].
-
-**Linux.com: When would you want to use something like llnode; and what exactly is it?**
-
-**Marchini:** **** llnode is useful when debugging infinite loops, uncaught exceptions or out of memory issues since it allows you to inspect the state of your application when it crashed. How does llnode do this? You can tell Node.js and your operating system to take a core dump of your application when it crashes and load it into llnode. llnode will analyze this core dump and give you useful information such as how many objects were allocated in the heap, the complete stack trace for the process (including native calls and V8 internals), pending requests and handlers in the event loop queue, etc.
-
-The most impressive feature llnode has is its ability to inspect objects and functions: you can see which variables are available for a given function, look at the function's code and inspect which properties your objects have with their respective values. For example, you can look up which variables are available for your HTTP handler function and which parameters it received. You can also look at headers and the payload of a given request.
-
-llnode is a plugin for [lldb][8], and it uses lldb features alongside hints provided by V8 and Node.js to recreate the process heap. It uses a few heuristics, too, so results might not be entirely correct sometimes. But most of the times the results are good enough -- and way better than not using any tool.
-
-This technique -- which is called post-mortem debugging -- is not something new, though, and it has been part of the Node.js project since 2012. This is a common technique used by C and C++ developers, but not many dynamic runtimes support it. I'm happy we can say Node.js is one of those runtimes.
-
-**Linux.com: What are some key items folks should know before adding llnode to their environment?**
-
-**Marchini:** To install and use llnode you'll need to have lldb installed on your system. If you're on OS X, lldb is installed as part of Xcode. On Linux, you can install it from your distribution's repository. We recommend using LLDB 3.9 or later.
-
-You'll also have to set up your environment to generate core dumps. First, remember to set the flag --abort-on-uncaught-exception when running a Node.js application, otherwise, Node.js won't generate a core dump when an uncaught exception happens. You'll also need to tell your operating system to generate core dumps when an application crashes. The most common way to do that is by running `ulimit -c unlimited`, but this will only apply to your current shell session. If you're using a process manager such as systemd I suggest looking at the process manager docs. You can also generate on-demand core dumps of a running process with tools such as gcore.
-
-**Linux.com: What can we expect from llnode in the future?**
-
-**Marchini:** llnode collaborators are working on several features and improvements to make the project more accessible for developers less familiar with native debugging tools. To accomplish that, we're improving the overall user experience as well as the project's documentation and installation process. Future versions will include colorized output, more reliable output for some commands and a simplified mode focused on JavaScript information. We are also working on a JavaScript API which can be used to automate some analysis, create graphical user interfaces, etc.
-
-If this project sounds interesting to you, and you would like to get involved, feel free join the conversation in [our issues tracker][9] or contact me on social [@mmarkini][10]. I would love to help you get started!
-
-Learn more at [Node+JS Interactive][1], coming up October 10-12, 2018 in Vancouver, Canada.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/9/troubleshooting-nodejs-issues-llnode
-
-作者:[The Linux Foundation][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/ericstephenbrown
-[1]: https://events.linuxfoundation.org/events/node-js-interactive-2018/?utm_source=Linux.com&utm_medium=article&utm_campaign=jsint18
-[2]: http://sched.co/G285
-[3]: https://nodejs.org/api/inspector.html#inspector_cpu_profiler
-[4]: https://github.com/v8/sampling-heap-profiler
-[5]: http://www.brendangregg.com/blog/2014-09-17/node-flame-graphs-on-linux.html
-[6]: https://github.com/nodejs/node-report
-[7]: https://github.com/nodejs/llnode
-[8]: https://lldb.llvm.org/
-[9]: https://github.com/nodejs/llnode/issues
-[10]: https://twitter.com/mmarkini
diff --git a/sources/talk/20181003 13 tools to measure DevOps success.md b/sources/talk/20181003 13 tools to measure DevOps success.md
deleted file mode 100644
index 26abb21f05..0000000000
--- a/sources/talk/20181003 13 tools to measure DevOps success.md
+++ /dev/null
@@ -1,84 +0,0 @@
-13 tools to measure DevOps success
-======
-How's your DevOps initiative really going? Find out with open source tools
-
-
-In today's enterprise, business disruption is all about agility with quality. Traditional processes and methods of developing software are challenged to keep up with the complexities that come with these new environments. Modern DevOps initiatives aim to help organizations use collaborations among different IT teams to increase agility and accelerate software application deployment.
-
-How is the DevOps initiative going in your organization? Whether or not it's going as well as you expected, you need to do assessments to verify your impressions. Measuring DevOps success is very important because these initiatives target the very processes that determine how IT works. DevOps also values measuring behavior, although measurements are more about your business processes and less about your development and IT systems.
-
-A metrics-oriented mindset is critical to ensuring DevOps initiatives deliver the intended results. Data-driven decisions and focused improvement activities lead to increased quality and efficiency. Also, the use of feedback to accelerate delivery is one reason DevOps creates a successful IT culture.
-
-With DevOps, as with any IT initiative, knowing what to measure is always the first step. Let's examine how to use continuous delivery improvement and open source tools to assess your DevOps program on three key metrics: team efficiency, business agility, and security. These will also help you identify what challenges your organization has and what problems you are trying to solve with DevOps.
-
-### 3 tools for measuring team efficiency
-
-Measuring team efficiency—in terms of how the DevOps initiative fits into your organization and how well it works for cultural innovation—is the hardest area to measure. The key metrics that enable the DevOps team to work more effectively on culture and organization are all about agile software development, such as knowledge sharing, prioritizing tasks, resource utilization, issue tracking, cross-functional teams, and collaboration. The following open source tools can help you improve and measure team efficiency:
-
- * [FunRetro][1] is a simple, intuitive tool that helps you collaborate across teams and improve what you do.
- * [Kanboard][2] is a [kanban][3] board that helps you visualize your work in progress to focus on your goal.
- * [Bugzilla][4] is a popular development tool with issue-tracking capabilities.
-
-
-
-### 6 tools for measuring business agility
-
-Speed is all that matters for accelerating business agility. Because DevOps gives organizations capabilities to deliver software faster with fewer failures, it's fast gaining acceptance. The key metrics are deployment time, change lead time, release frequency, and failover time. Puppet's [2017 State of DevOps Report][5] shows that high-performing DevOps practitioners deploy code updates 46x more frequently and high performers experience change lead times of under an hour, or 440x faster than average. Following are some open source tools to help you measure business agility:
-
- * [Kubernetes][6] is a container-orchestration system for automating deployment, scaling, and management of containerized applications. (Read more about [Kubernetes][7] on Opensource.com.)
- * [CRI-O][8] is a Kubernetes orchestrator used to manage and launch containerized workloads without relying on a traditional container engine.
- * [Ansible][9] is a popular automation engine used to automate apps and IT infrastructure and run tasks including installing and configuring applications.
- * [Jenkins][10] is an automation tool used to automate the software development process with continuous integration. It facilitates the technical aspects of continuous delivery.
- * [Spinnaker][11] is a multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence. It combines a powerful and flexible pipeline management system with integrations to the major cloud providers.
- * [Istio][12] is a service mesh that helps reduce the complexity of deployments and eases the strain on your development teams.
-
-
-
-### 4 tools for measuring security
-
-Security is always the last phase of measuring your DevOps initiative's success. Enterprises that have combined development and operations teams under a DevOps model are generally successful in releasing code at a much faster rate. But this has increased the need for integrating security in the DevOps process (this is known as DevSecOps), because the faster you release code, the faster you release any vulnerabilities in it.
-
-Measuring security vulnerabilities early ensures that builds are stable before they pass to the next stage in the release pipeline. In addition, measuring security can help overcome resistance to DevOps adoption. You need tools that can help your dev and ops teams identify and prioritize vulnerabilities as they are using software, and teams must ensure they don't introduce vulnerabilities when making changes. These open source tools can help you measure security:
-
- * [Gauntlt][13] is a ruggedization framework that enables security testing by devs, ops, and security.
- * [Vault][14] securely manages secrets and encrypts data in transit, including storing credentials and API keys and encrypting passwords for user signups.
- * [Clair][15] is a project for static analysis of vulnerabilities in appc and Docker containers.
- * [SonarQube][16] is a platform for continuous inspection of code quality. It performs automatic reviews with static analysis of code to detect bugs, code smells, and security vulnerabilities.
-
-
-
-**[See our related security article,[7 open source tools for rugged DevOps][17].]**
-
-Many DevOps initiatives start small. DevOps requires a commitment to a new culture and process rather than new technologies. That's why organizations looking to implement DevOps will likely need to adopt open source tools for collecting data and using it to optimize business success. In that case, highly visible, useful measurements will become an essential part of every DevOps initiative's success
-
-### What to read next
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/devops-measurement-tools
-
-作者:[Daniel Oh][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/daniel-oh
-[1]: https://funretro.io/
-[2]: http://kanboard.net/
-[3]: https://en.wikipedia.org/wiki/Kanban
-[4]: https://www.bugzilla.org/
-[5]: https://puppet.com/resources/whitepaper/state-of-devops-report
-[6]: https://kubernetes.io/
-[7]: https://opensource.com/resources/what-is-kubernetes
-[8]: https://github.com/kubernetes-incubator/cri-o
-[9]: https://github.com/ansible
-[10]: https://jenkins.io/
-[11]: https://www.spinnaker.io/
-[12]: https://istio.io/
-[13]: http://gauntlt.org/
-[14]: https://www.hashicorp.com/blog/vault.html
-[15]: https://github.com/coreos/clair
-[16]: https://www.sonarqube.org/
-[17]: https://opensource.com/article/18/9/open-source-tools-rugged-devops
diff --git a/sources/talk/20181007 Why it-s Easier to Get a Payrise by Switching Jobs.md b/sources/talk/20181007 Why it-s Easier to Get a Payrise by Switching Jobs.md
deleted file mode 100644
index 3baf2f7126..0000000000
--- a/sources/talk/20181007 Why it-s Easier to Get a Payrise by Switching Jobs.md
+++ /dev/null
@@ -1,99 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Why it's Easier to Get a Payrise by Switching Jobs)
-[#]: via: (https://theartofmachinery.com/2018/10/07/payrise_by_switching_jobs.html)
-[#]: author: (Simon Arneaud https://theartofmachinery.com)
-
-Why it's Easier to Get a Payrise by Switching Jobs
-======
-
-It’s an empirical fact that it’s easier to get a payrise if you’re negotiating a new job than if you’re negotiating within your current job. When I look back over my own career, every time I’ve worked somewhere longer term (over a year), payrises have been a hard struggle. But eventually I’d leave for a new position, and my new pay made all payrises at the previous job irrelevant. These days I make job switching upfront and official: I run my own business and most of my money comes from short contracts. Getting rewarded for new skills or extra work is nowhere near as difficult as before.
-
-I know I’m not the only one to notice this effect, but I’ve never heard anyone explain why things might be this way.
-
-Before I give my explanation, let me make a couple of things clear from the start. I’m not going to argue that everyone should quit their jobs. I don’t know your situation, and maybe you’re getting a good deal already. Also, I apply game theory here, but, no, I don’t assume that humans are slaves to simplistic, mechanical laws of behaviour. However, just like music composition, even if humans are free, there are still patterns that matter. If you understand this stuff, you’ll have a career advantage.
-
-But first, some background.
-
-### BATNA
-
-Many geeks think negotiation is like a role-playing game: roll the die, add your charisma score, and if the result is high enough you’re convincing. Geeks who think that way usually have low confidence in their “charisma score”, and they blame that for their struggle with things like asking for payrises.
-
-Charisma isn’t totally irrelevant, but the good news for geeks is that there’s a nerdy thing that’s much more important for negotiation: BATNA, or Best Alternative To Negotiated Agreement. Despite the jargony name, it’s a very simple idea: it’s about analysing the best outcome for both sides in a negotiation, assuming that at least one side says no to the other. Although most people don’t know it’s called “BATNA”, it’s the core of how any agreement works (or doesn’t work).
-
-It’s easy to explain with an example. Imagine you buy a couch for $500, but when you take it home, you discover that it doesn’t fit the place you wanted to put it. A silly mistake, but thankfully the shop offers you a full refund if you return it. Just as you’re taking it back to the shop, you meet a stranger who says they want a couch like that, and they offer to buy it. What’s the price? If you ask for $1000,000, the deal won’t happen because their BATNA is that they go to the shop and buy one themselves for $500. If they offer $1 to buy, your BATNA is that you go to the shop and get the $500 refund. You’ll only come to an agreement if the price is something like $500. If transporting the couch to the shop costs significant time and money, you’ll accept less than $500 because your BATNA is worth $500 minus the cost of transport. On the other hand, if the stranger needs to cover up a stained carpet before the landlord does an inspection in half an hour, they’ll be willing to pay a heavy premium because their BATNA is so bad.
-
-You can’t expect a negotiation to go well unless you’ve considered the BATNA of both sides.
-
-### Employment and Self-Employment
-
-Most people of a certain socioeconomic class believe that the ideal, “proper” career is salaried, full-time employment at someone else’s business. Many people in this class never even imagine any other way to make a living, but there are alternatives. In Australia, like other countries, you’re free to register your own business number and then do whatever it is that people will pay for. That includes sitting at a desk and working on software and computer systems, or other work that’s more commonly done as an employee.
-
-So why is salaried employment so popular? As someone who’s done both kinds of employment, one answer is obvious: stability. You can be (mostly) sure about exactly how much money you’ll make in the next six months when you have a salary. The next obvious answer is simplicity: as long as you meet the minimum bar of “work” done ([whatever “work” means][1]), the company promises to look after you. You don’t have to think about where your next dollar comes from, or about marketing, or insurances, or accounting, or even how to find people to socialise with.
-
-That sums up the main reasons to like salaried employment (not that they’re bad reasons). I sometimes hear claims about other benefits of salaried employment, but they’re typically things that you can buy. If you’re self-employed and your work isn’t paying you enough to have the same lifestyle as you could under a salary (doing the same work) that means you’re not billing high enough. A lot of people make that mistake when they quit a salaried job for self-employment, but it’s still just a mistake.
-
-### Asking for that Payrise
-
-Let’s say you’ve been working as a salaried employee at a company for a while. As a curious, self-motivated person who regularly reads essays by nerds on the internet, you’ve learned a lot in that time. You’ve applied your new skills to your work, and proven yourself to be a much more valuable employee than when you were first hired. Is it time to ask for a payrise? You practise your most charismatic phrasing, and approach your manager with your d20 in hand. The response is that you’re doing great, and they’d love to give you a payrise, but the rules say
-
- 1. You can’t get a payrise unless you’ve been working for more than N years
- 2. You can’t get more than one payrise in N years
- 3. That inflation adjustment on your salary counted as a payrise, so you can’t ask for a payrise now
- 4. You can’t be paid more than [Peter][2]
- 5. We need more time to see if you’re ready, so keep up the great work for another year or so and we’ll consider it then
-
-
-
-The thing to realise is that all these rules are completely arbitrary. If the company had a genuine motivation to give you a payrise, the rules would vanish. To see that, try replacing “payrise” with “workload increase”. Software projects are extremely expensive, require skill, and have a high failure rate. Software work therefore carries a non-trivial amount of responsibility, so you might argue that employers should be very conservative about increasing how much involvement someone has in a project. But I’ve never heard an employer say anything like, “Great job on getting that last task completed ahead of schedule, but we need more time to see if you’re ready to increase your workload. Just take a break until the next scheduled task, and if you do well at that one, too, maybe we can start giving you more work to do.”
-
-If you’re hearing feedback that you’re doing well, but there are various arbitrary reasons you can’t get rewarded for it, that’s a strong sign you’re being paid below market rates. Now, the term “market rates” gets used pretty loosely, so let me be super clear: that means someone else would agree to pay you more if you asked.
-
-Note that I’m not claiming that your manager is evil. At most larger companies, your manager really can’t do much against the company rules. I’m not writing this to call companies evil, either, because that won’t help you or me to get any payrises. What _will_ help is understanding why companies can afford to make payrises difficult.
-
-### Getting that Payrise
-
-You’ve probably seen this coming: it’s all about BATNA, and how you can’t expect your employer to agree to something that’s worse than their BATNA. So, what’s their BATNA? What happens if you ask for a payrise, and they say no?
-
-Sometimes you see a story online about someone who was burning themselves out working super hard as an obviously vital member of a team. This person asks for a small payrise and gets rejected for some silly reason. Shortly after that, they tell their employer that they have a much bigger offer from another company. Suddenly the reason for rejecting the payrise evaporates, and the employer comes up with a counteroffer, but it’s too late: the worker leaves for a better job. The original employer is left wailing and gnashing their teeth. If only companies appreciated their employees more!
-
-These stories are like hero stories in the movies. They tickle our sense of justice, but aren’t exactly representative of normal life. The reality is that most employees would just go back to their desks if they’re told, “No.” Sure, they’ll grumble, and they’ll upvote the next “Tech workers are underappreciated!” post on Reddit, but to many companies this is a completely acceptable BATNA.
-
-In short, the main bargaining chip a salaried employee has is quitting, but that negates the reasons to be a salaried employee in the first place.
-
-When you’re negotiating a contract with a new potential employer, however, the situation is totally different. Whatever conditions you ask for will be compared against the BATNA of searching for someone else who has your skills. Any reasonable request has a much higher chance of being accepted.
-
-### The Job Security Tax
-
-Now, something might be bothering you: despite what I’ve said, people _do_ get payrises. But all I’ve argued is that companies can make payrises difficult, not impossible. Sure, salaried employees might not quit when they’re a little underpaid. (They might not even realise they’re underpaid.) But if the underpayment gets big and obvious enough, maybe they will, so employers have to give out payrises eventually. Occasional payrises also make a good carrot for encouraging employees to keep working harder.
-
-At the scale of a large company, it’s just a matter of tuning. Payrises can be delayed a little here, and made a bit smaller there, and the company saves money. Go too far, and the employee attrition rate goes up, which is a sign to back off and start paying more again.
-
-Sure, the employee’s salary will tend to grow as their skills grow, but that growth will be slowed down. How much it is slowed down will depend (long term) on how strongly the employee values job security. It’s a job security tax.
-
-### What Should You Do?
-
-As I said before, I’m not going to tell you to quit (or not quit) without knowing what your situation is.
-
-Perhaps you read this thinking that it sounds nothing like your workplace. If so, you’re lucky to be in one of the better places. You now have solid reasons to appreciate your employer as much as they appreciate you.
-
-For the rest of you, I guess there are two broad options. Obviously, there’s the one I’m taking: not being a salaried employee. The other option is to understand the job security tax and try to optimise it. If you’re young and single, maybe you don’t need job security so much (at least for now). Even if you have good reasons to want job security (and there are plenty), maybe you can reduce your dependence on it by saving money in an emergency fund, and making sure your friendship group includes people who aren’t your current colleagues. That’s a good idea even if you aren’t planning to quit today — you never know what the future will be like.
-
---------------------------------------------------------------------------------
-
-via: https://theartofmachinery.com/2018/10/07/payrise_by_switching_jobs.html
-
-作者:[Simon Arneaud][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://theartofmachinery.com
-[b]: https://github.com/lujun9972
-[1]: /2017/09/14/busywork.html
-[2]: https://www.youtube.com/watch?v=zBfTrjPSShs
diff --git a/sources/talk/20181009 4 best practices for giving open source code feedback.md b/sources/talk/20181009 4 best practices for giving open source code feedback.md
deleted file mode 100644
index 4cfb806525..0000000000
--- a/sources/talk/20181009 4 best practices for giving open source code feedback.md
+++ /dev/null
@@ -1,47 +0,0 @@
-4 best practices for giving open source code feedback
-======
-A few simple guidelines can help you provide better feedback.
-
-
-
-In the previous article I gave you tips for [how to receive feedback][1], especially in the context of your first free and open source project contribution. Now it's time to talk about the other side of that same coin: providing feedback.
-
-If I tell you that something you did in your contribution is "stupid" or "naive," how would you feel? You'd probably be angry, hurt, or both, and rightfully so. These are mean-spirited words that when directed at people, can cut like knives. Words matter, and they matter a great deal. Therefore, put as much thought into the words you use when leaving feedback for a contribution as you do into any other form of contribution you give to the project. As you compose your feedback, think to yourself, "How would I feel if someone said this to me? Is there some way someone might take this another way, a less helpful way?" If the answer to that last question has even the chance of being a yes, backtrack and rewrite your feedback. It's better to spend a little time rewriting now than to spend a lot of time apologizing later.
-
-When someone does make a mistake that seems like it should have been obvious, remember that we all have different experiences and knowledge. What's obvious to you may not be to someone else. And, if you recall, there once was a time when that thing was not obvious to you. We all make mistakes. We all typo. We all forget commas, semicolons, and closing brackets. Save yourself a lot of time and effort: Point out the mistake, but leave out the judgement. Stick to the facts. After all, if the mistake is that obvious, then no critique will be necessary, right?
-
- 1. **Avoid ad hominem comments.** Remember to review only the contribution and not the person who contributed it. That is to say, point out, "the contribution could be more efficient here in this way…" rather than, "you did this inefficiently." The latter is ad hominem feedback. Ad hominem is a Latin phrase meaning "to the person," which is where your feedback is being directed: to the person who contributed it rather than to the contribution itself. By providing feedback on the person you make that feedback personal, and the contributor is justified in taking it personally. Be careful when crafting your feedback to make sure you're addressing only the contents of the contribution and not accidentally criticizing the person who submitted it for review.
-
- 2. **Include positive comments.** Not all of your feedback has to (or should) be critical. As you review the contribution and you see something that you like, provide feedback on that as well. Several academic studies—including an important one by [Baumeister, Braslavsky, Finkenauer, and Vohs][2]—show that humans focus more on negative feedback than positive. When your feedback is solely negative, it can be very disheartening for contributors. Including positive reinforcement and feedback is motivating to people and helps them feel good about their contribution and the time they spent on it, which all adds up to them feeling more inclined to provide another contribution in the future. It doesn't have to be some gushing paragraph of flowery praise, but a quick, "Huh, that's a really smart way to handle that. It makes everything flow really well," can go a long way toward encouraging someone to keep contributing.
-
- 3. **Questions are feedback, too.** Praise is one less common but valuable type of review feedback. Questions are another. If you're looking at a contribution and can't tell why the submitter
-
-When your feedback is solely negative, it can be very disheartening for contributors.
-
-did things the way they did, or if the contribution just doesn't make a lot of sense to you, asking for more information acts as feedback. It tells the submitter that something they contributed isn't as clear as they thought and that it may need some work to make the approach more obvious, or if it's a code contribution, a comment to explain what's going on and why. A simple, "I don't understand this part here. Could you please tell me what it's doing and why you chose that way?" can start a dialogue that leads to a contribution that's much easier for future contributors to understand and maintain.
-
- 4. **Expect a negotiation.** Using questions as a form of feedback implies that there will be answers to those questions, or perhaps other questions in response. Whether your feedback is in question or statement format, you should expect to generate some sort of dialogue throughout the process. An alternative is to see your feedback as incontrovertible, your word as law. Although this is definitely one approach you can take, it's rarely a good one. When providing feedback on a contribution, it's best to collaborate rather than dictate. As these dialogues arise, embracing them as opportunities for conversation and learning on both sides is important. Be willing to discuss their approach and your feedback, and to take the time to understand their perspective.
-
-
-
-
-The bottom line is: Don't be a jerk. If you're not sure whether the feedback you're planning to leave makes you sound like a jerk, pause to have someone else review it before you click Send. Have empathy for the person at the receiving end of that feedback. While the maxim is thousands of years old, it still rings true today that you should try to do unto others as you would have them do unto you. Put yourself in their shoes and aim to be helpful and supportive rather than simply being right.
-
-_Adapted from[Forge Your Future with Open Source][3] by VM (Vicky) Brasseur, Copyright © 2018 The Pragmatic Programmers LLC. Reproduced with the permission of the publisher._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/best-practices-giving-open-source-code-feedback
-
-作者:[VM(Vicky) Brasseur][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/vmbrasseur
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/article/18/10/6-tips-receiving-feedback
-[2]: https://www.msudenver.edu/media/content/sri-taskforce/documents/Baumeister-2001.pdf
-[3]: http://www.pragprog.com/titles/vbopens
diff --git a/sources/talk/20181010 Talk over text- Conversational interface design and usability.md b/sources/talk/20181010 Talk over text- Conversational interface design and usability.md
deleted file mode 100644
index e9d76f9ef4..0000000000
--- a/sources/talk/20181010 Talk over text- Conversational interface design and usability.md
+++ /dev/null
@@ -1,105 +0,0 @@
-Talk over text: Conversational interface design and usability
-======
-To make conversational interfaces more human-centered, we must free our thinking from the trappings of web and mobile design.
-
-
-
-Conversational interfaces are unique among the screen-based and physically manipulated user interfaces that characterize the range of digital experiences we encounter on a daily basis. As [Conversational Design][1] author Erika Hall eloquently writes, "Conversation is not a new interface. It's the oldest interface." And the conversation, the most human interaction of all, lies at the nexus of the aural and verbal rather than the visual and physical. This makes it particularly challenging for machines to meet the high expectations we tend to have when it comes to typical human conversations.
-
-How do we design for conversational interfaces, which run the gamut from omnichannel chatbots on our websites and mobile apps to mono-channel voice assistants on physical devices such as the Amazon Echo and Google Home? What recommendations do other experts on conversational design and usability have when it comes to crafting the most robust chatbot or voice interface possible? In this overview, we focus on three areas: information architecture, design, and usability testing.
-
-### Information architecture: Trees, not sitemaps
-
-Consider the websites we visit and the visual interfaces we use regularly. Each has a navigational tool, whether it is a list of links or a series of buttons, that helps us gain some understanding of the interface. In a web-optimized information architecture, we can see the entire hierarchy of a website and its contents in the form of such navigation bars and sitemaps.
-
-On the other hand, in a conversational information architecture—whether articulated in a chatbot or a voice assistant—the structure of our interactions must be provided to us in a simple and straightforward way. For instance, in lieu of a navigation bar that has links to pages like About, Menu, Order, and Locations with further links underneath, we can create a conversational means of describing how to navigate the options we wish to pursue.
-
-Consider the differences between the two examples of navigation below.
-
-| **Web-based navigation:** | **Conversational navigation:** |
-| Present all options in the navigation bar | Present only certain top-level options to access deeper options |
-|-------------------------------------------|-----------------------------------------------------------------|
-| • Floss's Pizza | • "To learn more about us, say About" |
-| • About | • "To hear our menu, say Menu" |
-| ◦ Team | • "To place an order, say Order" |
-| ◦ Our story | • "To find out where we are, say Where" |
-| • Menu | |
-| ◦ Pizzas | |
-| ◦ Pastas | |
-| ◦ Platters | |
-| • Order | |
-| ◦ Pickup | |
-| ◦ Delivery | |
-| • Where we are | |
-| ◦ Area map • "Welcome to Floss's Pizza!" | |
-
-In a conversational context, an appropriate information architecture that focuses on decision trees is of paramount importance, because one of the biggest issues many conversational interfaces face is excessive verbosity. By avoiding information overload, prizing structural simplicity, and prescribing one-word directions, your users can traverse conversational interfaces without any additional visual aid.
-
-### Design: Finessing flows and language
-
-![Well-designed language example][3]
-
-An example of well-designed language that encapsulates Hall's conversational key moments.
-
-In her book Conversational Design, Hall emphasizes the need for all conversational interfaces to adhere to conversational maxims outlined by Paul Grice and advanced by Robin Lakoff. These conversational maxims highlight the characteristics every conversational interface should have to succeed: quantity (just enough information but not too much), quality (truthfulness), relation (relevance), manner (concision, orderliness, and lack of ambiguity), and politeness (Lakoff's addition).
-
-In the process, Hall spotlights four key moments that build trust with users of conversational interfaces and give them all of the information they need to interact successfully with the conversational experience, whether it is a chatbot or a voice assistant.
-
- * **Introduction:** Invite the user's interest and encourage trust with a friendly but brief greeting that welcomes them to an unfamiliar interface.
-
- * **Orientation:** Offer system options, such as how to exit out of certain interactions, and provide a list of options that help the user achieve their goal.
-
- * **Action:** After each response from the user, offer a new set of tasks and corresponding controls for the user to proceed with further interaction.
-
- * **Guidance:** Provide feedback to the user after every response and give clear instructions.
-
-
-
-
-Taken as a whole, these key moments indicate that good conversational design obligates us to consider how we write machine utterances to be both inviting and informative and to structure our decision flows in such a way that they flow naturally to the user. In other words, rather than visual design chops or an eye for style, conversational design requires us to be good writers and thoughtful architects of decision trees.
-
-![Decision flow example ][5]
-
-An example decision flow that adheres to Hall's key moments.
-
-One metaphor I use on a regular basis to conceive of each point in a conversational interface that presents a choice to the user is the dichotomous key. In tree science, dichotomous keys are used to identify trees in their natural habitat through certain salient characteristics. What makes dichotomous keys special, however, is the fact that each card in a dichotomous key only offers two choices (hence the moniker "dichotomous") with a clearly defined characteristic that cannot be mistaken for another. Eventually, after enough dichotomous choices have been made, we can winnow down the available options to the correct genus of tree.
-
-We should design conversational interfaces in the same way, with particular attention given to disambiguation and decision-making that never verges on too much complexity. Because conversational interfaces require deeply nested hierarchical structures to reach certain outcomes, we can never be too helpful in the instructions and options we offer our users.
-
-### Usability testing: Dialogues, not dialogs
-
-Conversational usability is a relatively unexplored and less-understood area because it is frequently based on verbal and aural interactions rather than visual or physical ones. Whereas chatbots can be evaluated for their usability using traditional means such as think-aloud, voice assistants and other voice-driven interfaces have no such luxury.
-
-For voice interfaces, we are unable to pursue approaches involving eye-tracking or think-aloud, since these interfaces are purely aural and users' utterances outside of responses to interface prompts can introduce bad data. For this reason, when our Acquia Labs team built [Ask GeorgiaGov][6], the first Alexa skill for residents of the state of Georgia, we chose retrospective probing (RP) for our usability tests.
-
-In retrospective probing, the conversational interaction proceeds until the completion of the task, at which point the user is asked about their impressions of the interface. Retrospective probing is well-positioned for voice interfaces because it allows the conversation to proceed unimpeded by interruptions such as think-aloud feedback. Nonetheless, it does come with the disadvantage of suffering from our notoriously unreliable memories, as it forces us to recollect past interactions rather than ones we completed immediately before recollection.
-
-### Challenges and opportunities
-
-Conversational interfaces are here to stay in our rapidly expanding spectrum of digital experiences. Though they enrich the range of ways we have to engage users, they also present unprecedented challenges when it comes to information architecture, design, and usability testing. With the help of previous work such as Grice's conversational maxims and Hall's key moments, we can design and build effective conversational interfaces by focusing on strong writing and well-considered decision flows.
-
-The fact that conversation is the oldest and most human of interfaces is also edifying when we approach other user interfaces that lack visual or physical manipulation. As Hall writes, "The ideal interface is an interface that's not noticeable at all." Whether or not we will eventually reach the utopian outcome of conversational interfaces that feel completely natural to the human ear, we can make conversational interfaces more human-centered by freeing our thinking from the trappings of web and mobile.
-
-Preston So will present [Talk Over Text: Conversational Interface Design and Usability][7] at [All Things Open][8], October 21-23 in Raleigh, North Carolina.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/conversational-interface-design-and-usability
-
-作者:[Preston So][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/prestonso
-[b]: https://github.com/lujun9972
-[1]: https://abookapart.com/products/conversational-design
-[2]: /file/411001
-[3]: https://opensource.com/sites/default/files/uploads/conversational-interfaces_1.png (Well-designed language example)
-[4]: /file/411006
-[5]: https://opensource.com/sites/default/files/uploads/conversational-interfaces_2.png (Decision flow example )
-[6]: https://www.acquia.com/blog/ask-georgiagov-alexa-skill-citizens-georgia-acquia-labs/12/10/2017/3312516
-[7]: https://allthingsopen.org/talk/talk-over-text-conversational-interface-design-and-usability/
-[8]: https://allthingsopen.org/
diff --git a/sources/talk/20181011 How to level up your organization-s security expertise.md b/sources/talk/20181011 How to level up your organization-s security expertise.md
deleted file mode 100644
index e67db6a3fb..0000000000
--- a/sources/talk/20181011 How to level up your organization-s security expertise.md
+++ /dev/null
@@ -1,147 +0,0 @@
-How to level up your organization's security expertise
-======
-These best practices will make your employees more savvy and your organization more secure.
-
-
-IT security is critical to every company these days. In the words of former FBI director Robert Mueller: “There are only two types of companies: Those that have been hacked, and those that will be.”
-
-At the same time, IT security is constantly evolving. We all know we need to keep up with the latest trends in cybersecurity and security tooling, but how can we do that without sacrificing our ability to keep moving forward on our business priorities?
-
-No single person in your organization can handle all of the security work alone; your entire development and operations team will need to develop an awareness of security tooling and best practices, just like they all need to build skills in open source and in agile software delivery. There are a number of best practices that can help you level up the overall security expertise in your company through basic and intermediate education, subject matter experts, and knowledge-sharing.
-
-### Basic education: Annual cybersecurity education and security contact information
-
-At IBM, we all complete an online cybersecurity training class each year. I recommend this as a best practice for other companies as well. The online training is taught at a basic level, and it doesn’t assume that anyone has a technical background. Topics include social engineering, phishing and spearfishing attacks, problematic websites, viruses and worms, and so on. We learn how to avoid situations that may put ourselves or our systems at risk, how to recognize signs of an attempted security breach, and how to report a problem if we notice something that seems suspicious. This online education serves the purpose of raising the overall security awareness and readiness of the organization at a low per-person cost. A nice side effect of this education is that this basic knowledge can be applied to our personal lives, and we can share what we learned with our family and friends as well.
-
-In addition to the general cybersecurity education, all employees should have annual training on data security and privacy regulations and how to comply with those.
-
-Finally, we make it easy to find the Corporate Security Incident Response team by sharing the link to its website in prominent places, including Slack, and setting up suggested matches to ensure that a search of our internal website will send people to the right place:
-
-
-
-### Intermediate education: Learn from your tools
-
-Another great source of security expertise is through pre-built security tools. For example, we have set up a set of automated security tests that run against our web services using IBM AppScan, and the reports it generates include background knowledge about the vulnerabilities it finds, the severity of the threat, how to determine if your application is susceptible to the vulnerability, and how to fix the problem, with code examples.
-
-Similarly, the free [npm audit command-line tool from npm, Inc.][1] will scan your open source Node.js modules and report any known vulnerabilities it finds. This tool also generates educational audit reports that include the severity of the threat, the vulnerable package, and versions with the vulnerability, an alternative package or versions that do not have the vulnerability, dependencies, and a link to more detailed information about the vulnerability. Here’s an example of a report from npm audit:
-
-| High | Regular Expression Denial of Service |
-| --------------| ----------------------------------------- |
-| Package | minimath |
-| --------------| ----------------------------------------- |
-| Dependency of | gulp [dev] |
-| --------------| ----------------------------------------- |
-| Path | gulp > vinyl-fs > glob-stream > minimatch |
-| --------------| ----------------------------------------- |
-| More info | https://nodesecurity.io/advisories/118 |
-
-Any good network-level security tool will also give you information on the types of attacks the tool is blocking and how it recognizes likely attacks. This information is available in the marketing materials online as well as the tool’s console and reports if you have access to those.
-
-Each of your development teams or squads should have at least one subject matter expert who takes the time to read and fully understand the vulnerability reports that are relevant to you. This is often the technical lead, but it could be anyone who is interested in learning more about security. Your local subject matter expert will be able to recognize similar security holes in the future earlier in the development and deployment process.
-
-Using the npm audit example above, a developer who reads and understands security advisory #118 from this report will be more likely to notice changes that may allow for a Regular Expression Denial of Service when reviewing code in the future. The team’s subject matter expert should also develop the skills needed to determine which of the vulnerability reports don’t actually apply to his or her specific project.
-
-### Intermediate education: Conferences
-
-Let’s not forget the value of attending security-related conferences, such as the [OWASP AppSec Conferences][2]. Conferences provide a great way for members of your team to focus on learning for a few days and bring back some of the newest ideas in the field. The “hallway track” of a conference, where we can learn from other practitioners, is also a valuable source of information. As much as most of us dislike being “sold to,” the sponsor hall at a conference is a good place to casually check out new security tools to see which ones you might be interested in evaluating later.
-
-If your organization is big enough, ask your DevOps and security tool vendors to come to you! If you’ve already procured some great tools, but adoption isn’t going as quickly as you would like, many vendors would be happy to provide your teams with some additional practical training. It’s in their best interests to increase the adoption of their tools (making you more likely to continue paying for their services and to increase your license count), just like it’s in your best interests to maximize the value you get out of the tools you’re paying for. We recently hosted a [Toolbox@IBM][3] \+ DevSecOps summit at our largest sites (those with a couple thousand IT professionals). More than a dozen vendors sponsored each event, came onsite, set up booths, and gave conference talks, just like they would at a technical conference. We also had several of our own presenters speaking about DevOps and security best practices that were working well for them, and we had booths set up by our Corporate Information Security Office, agile coaching, onsite tech support, and internal toolchain teams. We had several hundred attendees at each site. It was great for our technical community because we could focus on the tools that we had already procured, learn how other teams in our company were using them, and make connections to help each other in the future.
-
-When you send someone to a conference, it’s important to set the expectation that they will come back and share what they’ve learned with the team. We usually do this via an informal brown-bag lunch-and-learn, where people are encouraged to discuss new ideas interactively.
-
-### Subject-matter experts and knowledge-sharing: The secure engineering guild
-
-In the IBM Digital Business Group, we’ve adopted the squad model as described by [Spotify][4] and tweaked it to make it work for us. One sometimes-forgotten aspect of the squad model is the guild. Guilds are centers of excellence, focused around one topic or skill set, with members from many squads. Guild members learn together, share best practices with each other and their broader teams, and work to advance the state of the art. If you would like to establish your own secure engineering guild, here are some tips that have worked for me in setting up guilds in the past:
-
-**Step 1: Advertise and recruit**
-
-Your co-workers are busy people, so for many of them, a secure engineering guild could feel like just one more thing they have to cram into the week that doesn’t involve writing code. It’s important from the outset that the guild has a value proposition that will benefit its members as well as the organization.
-
-Zane Lackey from [Signal Sciences][5] gave me some excellent advice: It’s important to call out the truth. In the past, he said, security initiatives may have been more of a hindrance or even a blocker to getting work done. Your secure engineering guild needs to focus on ways to make your engineering team’s lives easier and more efficient instead. You need to find ways to automate more of the busywork related to security and to make your development teams more self-sufficient so you don’t have to rely on security “gates” or hurdles late in the development process.
-
-Here are some things that may attract people to your guild:
-
- * Learn about security vulnerabilities and what you can do to combat them
- * Become a subject matter expert
- * Participate in penetration testing
- * Evaluate and pilot new security tools
- * Add “Secure Engineering Guild” to your resume
-
-
-
-Here are some additional guild recruiting tips:
-
- * Reach out directly to your security experts and ask them to join: security architects, network security administrators, people from your corporate security department, and so on.
-
- * Bring in an external speaker who can get people excited about secure engineering. Advertise it as “sponsored by the Secure Engineering Guild” and collect names and contact information for people who want to join your guild, both before and after the talk.
-
- * Get executive support for the program. Perhaps one of your VPs will write a blog post extolling the virtues of secure engineering skills and asking people to join the guild (or perhaps you can draft the blog post for her or him to edit and publish). You can combine that blog post with advertising the external speaker if the timing allows.
-
- * Ask your management team to nominate someone from each squad to join the guild. This hardline approach is important if you have an urgent need to drive rapid improvement in your security posture.
-
-
-
-
-**Step 2: Build a team**
-
-Guild meetings should be structured for action. It’s important to keep an agenda so people know what you plan to cover in each meeting, but leave time at the end for members to bring up any topics they want to discuss. Also be sure to take note of action items, and assign an owner and a target date for each of them. Finally, keep meeting minutes and send a brief summary out after each meeting.
-
-Your first few guild meetings are your best opportunity to set off on the right foot, with a bit of team-building. I like to run a little design thinking exercise where you ask team members to share their ideas for the guild’s mission statement, vote on their favorites, and use those to craft a simple and exciting mission statement. The mission statement should include three components: WHO will benefit, WHAT the guild will do, and the WOW factor. The exercise itself is valuable because you can learn why people have decided to volunteer to be a part of the guild in the first place, and what they hope will come of it.
-
-Another thing I like to do from the outset is ask people what they’re hoping to achieve as a guild. The guild should learn together, have fun, and do real work. Once you have those ideas out on the table, start putting owners and target dates next to those goals.
-
- * Would they like to run a book club? Get someone to suggest a book and set up book club meetings.
-
- * Would they like to share useful articles and blogs? Get someone to set up a Slack channel and invite everyone to it, or set up a shared document where people can contribute their favorite resources.
-
- * Would they like to pilot a new tool? Get someone to set up a free trial, try it out for their own team, and report back in a few weeks.
-
- * Would they like to continue a series of talks? Get someone to create a list of topics and speakers and send out the invitations.
-
-
-
-
-If a few goals end up without owners or dates, that’s OK; just start a to-do list or backlog for people to refer to when they’ve completed their first task.
-
-Finally, survey the team to find the best time and day of the week for ongoing meetings and set those up. I recommend starting with weekly 30-minute meetings and adjust as needed.
-
-**Step 3: Keep the energy going, or reboot**
-
-As the months go on, your guild could start to lose energy. Here are some ways to keep the excitement going or reboot a guild that’s losing energy.
-
- * Don’t be an echo chamber. Invite people in from various parts of the organization to talk for a few minutes about what they’re doing with respect to security engineering, and where they have concerns or see gaps.
-
- * Show measurable progress. If you’ve been assigning owners to action items and completing them all along, you’ve certainly made progress, but if you look at it only from week to week, the progress can feel small or insignificant. Once per quarter, take a step back and write a blog about all you’ve accomplished and send it out to your organization. Showing off what you’ve accomplished makes the team proud of what they’ve accomplished, and it’s another opportunity to recruit even more people for your guild.
-
- * Don’t be afraid to take on a large project. The guild should not be an ivory tower; it should get things done. Your guild may, for example, decide to roll out a new security tool that you love across a large organization. With a little bit of project management and a lot of executive support, you can and should tackle cross-squad projects. The guild members can and should be responsible for getting stories from the large projects prioritized in their own squads’ backlogs and completed in a timely manner.
-
- * Periodically brainstorm the next set of action items. As time goes by, the most critical or pressing needs of your organization will likely change. People will be more motivated to work on the things they consider most important and urgent.
-
- * Reward the extra work. You might offer an executive-sponsored cash award for the most impactful secure engineering projects. You might also have the guild itself choose someone to send to a security conference now and then.
-
-
-
-
-### Go forth, and make your company more secure
-
-A more secure company starts with a more educated team. Building upon that expertise, a secure engineering guild can drive real changes by developing and sharing best practices, finding the right owners for each action item, and driving them to closure. I hope you found a few tips here that will help you level up the security expertise in your organization. Please add your own helpful tips in the comments.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/how-level-security-expertise-your-organization
-
-作者:[Ann Marie Fred][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/annmarie99
-[b]: https://github.com/lujun9972
-[1]: https://www.npmjs.com/about
-[2]: https://www.owasp.org/index.php/Category:OWASP_AppSec_Conference
-[3]: mailto:Toolbox@IBM
-[4]: https://medium.com/project-management-learnings/spotify-squad-framework-part-i-8f74bcfcd761
-[5]: https://www.signalsciences.com/
diff --git a/sources/talk/20181017 We already have nice things, and other reasons not to write in-house ops tools.md b/sources/talk/20181017 We already have nice things, and other reasons not to write in-house ops tools.md
deleted file mode 100644
index e5502ed9bb..0000000000
--- a/sources/talk/20181017 We already have nice things, and other reasons not to write in-house ops tools.md
+++ /dev/null
@@ -1,64 +0,0 @@
-We already have nice things, and other reasons not to write in-house ops tools
-======
-Let's look at the pitfalls of writing in-house ops tools, the circumstances that justify it, and how to do it better.
-
-
-When I was an ops consultant, I had the "great fortune" of seeing the dark underbelly of many companies in a relatively short period of time. Such fortune was exceptionally pronounced on one client engagement where I became the maintainer of an in-house deployment tool that had bloated to touch nearly every piece of infrastructure—despite lacking documentation and testing. Dismayed at the impossible task of maintaining this beast while tackling the real work of improving the product, I began reviewing my old client projects and probing my ops community for their strategies. What I found was an epidemic of "[not invented here][1]" (NIH) syndrome and a lack of collaboration with the broader community.
-
-### The problem with NIH
-
-One of the biggest problems of NIH is the time suck for engineers. Instead of working on functionality that adds value to the business, they're adding features to tools that solve standard problems such as deployment, continuous integration (CI), and configuration management.
-
-This is a serious issue at small or midsized startups, where new hires need to hit the ground running. If they have to learn a completely new toolset, rather than drawing from their experience with industry-standard tools, the time it takes them to become useful increases dramatically. While the new hires are learning the in-house tools, the company remains reliant on the handful of people who wrote the tools to document, train, and troubleshoot them. Heaven forbid one of those engineers succumbs to [the bus factor][2], because the possibility of getting outside help if they forgot to document something is zero.
-
-### Do you need to roll it yourself?
-
-Before writing your own ops tool, ask yourself the following questions:
-
- * Have we polled the greater ops community for solutions?
- * Have we compared the costs of proprietary tools to the estimated engineering time needed to maintain an in-house solution?
- * Have we identified open source solutions, even those that lack desired features, and attempted to contribute to them?
- * Can we fork any open source tools that are well-written but unmaintained?
-
-
-
-If you still can't find a tool that meets your needs, you'll have to roll your own.
-
-### Tips for rolling your own
-
-Here's a checklist for rolling your own solutions:
-
- 1. In-house tooling should not be exempt from the high standards you apply to the rest of your code. Write it like you're going to open source it.
- 2. Make sure you allow time in your sprints to work on feature requests, and don't allow features to be rushed in before proper testing and documentation.
- 3. Keep it small. It's going to be much harder to exact any kind of exit strategy if your tool is a monstrosity that touches everything.
- 4. Track your tool's usage and prune features that aren't actively utilized.
-
-
-
-### Have an exit strategy
-
-Open sourcing your in-house tool is not an exit strategy per se, but it may help you get outside contributors to free up your engineers' time. This is the more difficult strategy and will take some extra care and planning. Read "[Starting an Open Source Project][3]" and "[So You've Decided To Open-Source A Project At Work. What Now?][4]" before committing to this path. If you're interested in a cleaner exit, set aside time each quarter to research and test new open source replacements.
-
-Regardless of which path you choose, explicitly stating that an in-house solution is not the preferred state—early in its development—should clear up any confusion and prevent the issue of changing directions from becoming political.
-
-Sabice Arkenvirr will present [We Already Have Nice Things, Use Them!][5] at [LISA18][6], October 29-31 in Nashville, Tennessee, USA.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/nice-things
-
-作者:[Sabice Arkenvirr][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/vishuzdelishuz
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Not_invented_here
-[2]: https://en.wikipedia.org/wiki/Bus_factor
-[3]: https://opensource.guide/starting-a-project/
-[4]: https://www.smashingmagazine.com/2013/12/open-sourcing-projects-guide-getting-started/
-[5]: https://www.usenix.org/conference/lisa18/presentation/arkenvirr
-[6]: https://www.usenix.org/conference/lisa18
diff --git a/sources/talk/20181018 The case for open source classifiers in AI algorithms.md b/sources/talk/20181018 The case for open source classifiers in AI algorithms.md
deleted file mode 100644
index fd9a7a96fa..0000000000
--- a/sources/talk/20181018 The case for open source classifiers in AI algorithms.md
+++ /dev/null
@@ -1,111 +0,0 @@
-The case for open source classifiers in AI algorithms
-======
-Machine bias is a widespread problem with potentially serious human consequences, but it's not unmanageable.
-
-
-
-Dr. Carol Reiley's achievements are too long to list. She co-founded [Drive.ai][1], a self-driving car startup that [raised $50 million][2] in its second round of funding last year. Forbes magazine named her one of "[20 Incredible Women in AI][3]," and she built intelligent robot systems as a PhD candidate at Johns Hopkins University.
-
-But when she built a voice-activated human-robot interface, her own creation couldn't recognize her voice.
-
-Dr. Reiley used Microsoft's speech recognition API to build her interface. But since the API was built mostly by young men, it hadn't been exposed to enough voice variations. After some failed attempts to lower her voice so the system would recognize her, Dr. Reiley [enlisted a male graduate][4] to lead demonstrations of her work.
-
-Did Microsoft train its API to recognize only male voices? Probably not. It's more likely that the dataset used to train this API didn't have a wide range of voices with diverse accents, inflections, etc.
-
-AI-powered products learn from the data they're trained on. If Microsoft's API was exposed only to male voices within a certain age range, it wouldn't know how to recognize a female voice—even if a female built the product.
-
-This is an example of machine bias at work—and it's a more widespread problem than we think.
-
-### What is machine bias?
-
-[According to Gartner research][5] (available for clients), "Machine bias arises when an algorithm unfairly prefers a particular group or unjustly discriminates against another when making predictions and drawing conclusions." This bias takes one of two forms:
-
- * **Direct bias** occurs when models make predictions based on sensitive or prohibited attributes. These attributes include race, religion, gender, and sexual orientation.
- * **Indirect bias** is a byproduct of non-sensitive attributes that correlate with sensitive attributes. This is the more common form of machine bias. It's also the tougher form of bias to detect.
-
-
-
-### The human impact of machine bias
-
-In my [lightning talk][6] at Open Source Summit North America in August, I shared the Correctional Offender Management Profiling for Alternative Sanctions ([COMPAS][7]) algorithm as an example of indirect bias. Judges in more than 12 U.S. states use this algorithm to predict a defendant's likelihood to recommit crimes.
-
-Unfortunately, [research from ProPublica][8] found that the COMPAS algorithm made incorrect predictions due to indirect bias based on race. The algorithm was two times more likely to incorrectly cite black defendants as high risks for recommitting crimes and two times more likely to incorrectly cite white defendants as low risks for recommitting crimes.
-
-How did this happen? The COMPAS algorithm's predictions correlated with race (a sensitive/prohibited attribute). To confirm whether indirect bias exists within a dataset, the outcomes from one group are compared with another group's. If the difference exceeds some agreed-upon threshold, the model is considered unacceptably biased.
-
-This isn't a "What if?" scenario: COMPAS's results impacted defendants' prison sentences, including the length of those sentences and whether defendants were released on parole.
-
-Based partially on COMPAS's recommendation, a Wisconsin judged [denied probation][9] to a man named Eric Loomis. Instead, the judge gave Loomis a six-year prison sentence for driving a car that had been used in a recent shooting.
-
-To make matters worse, we can't confirm how COMPAS reached its conclusions: The manufacturer refused to disclose how it works, which made it [a black-box algorithm][10]. But when Loomis took his case to the Supreme Court, the justices refused to give it a hearing.
-
-This choice signaled that most Supreme Court justices condoned the algorithm's use without knowing how it reached (often incorrect) conclusions. This sets a dangerous legal precedent, especially as confusion about how AI works [shows no signs of slowing down][11].
-
-### Why you should open source your AI algorithms
-
-The open source community discussed this subject during a Birds of a Feather (BoF) session at Open Source Summit North America in August. During this discussion, some developers made cases for keeping machine learning algorithms private.
-
-Along with proprietary concerns, these black-box algorithms are built on endless neurons that each have their own biases. Since these algorithms learn from the data they're trained on, they're at risk of manipulation by bad actors. One program manager at a major tech firm said his team is constantly on guard to protect their work from those with ill intent.
-
-In spite of these reasons, there's a strong case in favor of making the datasets used to train machine learning algorithms open where possible. And a series of open source tools is helping developers solve this problem.
-
-Local Interpretable Model-Agnostic Explanations (LIME) is an open source Python toolkit from the University of Washington. It doesn't try to dissect every factor influencing algorithms' decisions. Instead, it treats every model as a black box.
-
-LIME uses a pick-step to select a representative set of predictions or conclusions to explain. Then it approximates the model closest to those predictions. It manipulates the inputs to the model and then measures how predictions change.
-
-The image below, from [LIME's website][12], shows a classifier from text classification. The tool's researchers took two classes—Atheism and Christian—that are difficult to distinguish since they share so many words. Then, they [trained a forest with 500 trees][13] and got a test accuracy of 92.4%. If accuracy was your core measure of trust, you'd be able to trust this algorithm.
-
-
-
-Projects like LIME prove that while machine bias is unavoidable, it's not unmanageable. If you add bias testing to your product development lifecycles, you can decrease the risk of bias within datasets that are used to train AI-powered products built on machine learning.
-
-### Avoid algorithm aversion
-
-When we don't know how algorithms make decisions, we can't fully trust them. In the near future, companies will have no choice but to be more transparent about how their creations work.
-
-We're already seeing legislation in Europe that would fine large tech companies for not revealing how their algorithms work. And extreme as this might sound, it's what users want.
-
-Research from the University of Chicago and the University of Pennsylvania showed that users [have more trust in modifiable algorithms][14] than in those built by experts. People prefer algorithms when they can clearly see how those algorithms work—even if those algorithms are wrong.
-
-This supports the crucial role that transparency plays in public trust of tech. It also makes [the case for open source projects][15] that aim to solve this problem.
-
-Algorithm aversion is real, and rightfully so. Earlier this month, Amazon was the latest tech giant to [have its machine bias exposed][16]. If such companies can't defend how these machines reach conclusions, their end users will suffer.
-
-I gave a full talk on machine bias—including steps to solve this problem—[at Google Dev Fest DC][17] as part of DC Startup Week in September. On October 23, I'll give a [lightning talk][18] on this same subject at All Things Open in Raleigh, N.C.
-
-Lauren Maffeo will present [Erase unconscious bias from your AI datasets][19] at [All Things Open][20], October 21-23 in Raleigh, N.C.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/open-source-classifiers-ai-algorithms
-
-作者:[Lauren Maffeo][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/lmaffeo
-[b]: https://github.com/lujun9972
-[1]: http://Drive.ai
-[2]: https://www.reuters.com/article/us-driveai-autonomous-idUSKBN19I2ZD
-[3]: https://www.forbes.com/sites/mariyayao/2017/05/18/meet-20-incredible-women-advancing-a-i-research/#1876954026f9
-[4]: https://techcrunch.com/2016/11/16/when-bias-in-product-design-means-life-or-death/
-[5]: https://www.gartner.com/doc/3889586/control-bias-eliminate-blind-spots
-[6]: https://www.youtube.com/watch?v=JtQzdTDv-P4
-[7]: https://en.wikipedia.org/wiki/COMPAS_(software)
-[8]: https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm
-[9]: https://www.nytimes.com/2017/10/26/opinion/algorithm-compas-sentencing-bias.html
-[10]: https://www.technologyreview.com/s/609338/new-research-aims-to-solve-the-problem-of-ai-bias-in-black-box-algorithms/
-[11]: https://www.thenetworkmediagroup.com/blog/ai-the-facts-and-myths-lauren-maffeo-getapp
-[12]: https://homes.cs.washington.edu/~marcotcr/blog/lime/
-[13]: https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052
-[14]: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2616787
-[15]: https://github.com/mbilalzafar/fair-classification
-[16]: https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G
-[17]: https://www.facebook.com/DCstartupweek/videos/1919103555059439/?fref=mentions&__xts__%5B0%5D=68.ARD1fVGSdYCHajf8qSryp5g2MoKg4522wZ0KJGIIPJTtw3xulDIkl9A6Vg4BrnbB6BfSX-yl9D5sNMZ4rtZb8rIbBU9ueWA9xXnt6SDv_hPlo_cxIRVS2RUI_O0hYahfNvHvYi8AsCPsDRqiHO4Jt1Ex9VS67uoJ46MXynR1XQB4f5jdGp1UDQ&__tn__=K-R
-[18]: https://opensource.com/article/18/10/lightning-talks-all-things-open
-[19]: https://opensource.com/article/18/10/lightning-talks-all-things-open#4
-[20]: https://allthingsopen.org/
diff --git a/sources/talk/20181019 To BeOS or not to BeOS, that is the Haiku.md b/sources/talk/20181019 To BeOS or not to BeOS, that is the Haiku.md
deleted file mode 100644
index 1533f6fa6d..0000000000
--- a/sources/talk/20181019 To BeOS or not to BeOS, that is the Haiku.md
+++ /dev/null
@@ -1,151 +0,0 @@
-To BeOS or not to BeOS, that is the Haiku
-======
-
-
-
-Back in 2001, a new operating system arrived that promised to change the way users worked with their computers. That platform was BeOS and I remember it well. What I remember most about it was the desktop, and how much it looked and felt like my favorite window manager (at the time) AfterStep. I also remember how awkward and overly complicated BeOS was to install and use. In fact, upon installation, it was never all too clear how to make the platform function well enough to use on a daily basis. That was fine, however, because BeOS seemed to live in a perpetual state of “alpha release.”
-
-That was then. This is very much now.
-
-Now we have haiku
-
-Bringing BeOS to life
-
-An AfterStep joy.
-
-No, Haiku has nothing to do with AfterStep, but it fit perfectly with the haiku meter, so work with me.
-
-The [Haiku][1] project released it’s R1 Alpha 4 six years ago. Back in September of 2018, it finally released it’s R1 Beta 1 and although it took them eons (in computer time), seeing Haiku installed (on a virtual machine) was worth the wait … even if only for the nostalgia aspect. The big difference between R1 Beta 1 and R1 Alpha 4 (and BeOS, for that matter), is that Haiku now works like a real operating system. It’s lighting fast (and I do mean fast), it finally enjoys a modicum of stability, and has a handful of useful apps. Before you get too excited, you’re not going to install Haiku and immediately become productive. In fact, the list of available apps is quite limiting (more on this later). Even so, Haiku is definitely worth installing, even if only to see how far the project has come.
-
-Speaking of which, let’s do just that.
-
-### Installing Haiku
-
-The installation isn’t quite as point and click as the standard Linux distribution. That doesn’t mean it’s a challenge. It’s not; in fact, the installation is handled completely through a GUI, so you won’t have to even touch the command line.
-
-To install Haiku, you must first [download an image][2]. Download this file into your ~/Downloads directory. This image will be in a compressed format, so once it’s downloaded you’ll need to decompress it. Open a terminal window and issue the command unzip ~/Downloads/haiku*.zip. A new directory will be created, called haiku-r1beta1XXX-anyboot (Where XXX is the architecture for your hardware). Inside that directory you’ll find the ISO image to be used for installation.
-
-For my purposes, I installed Haiku as a VirtualBox virtual machine. I highly recommend going the same route, as you don’t want to have to worry about hardware detection. Creating Haiku as a virtual machine doesn’t require any special setup (beyond the standard). Once the live image has booted, you’ll be asked if you want to run the installer or boot directly to the desktop (Figure 1). Click Run Installer to begin the process.
-
-
-![Haiku installer][4]
-
-Figure 1: Selecting to run the Haiku installer.
-
-[Used with permission][5]
-
-The next window is nothing more than a warning that Haiku is beta software and informing you that the installer will make the Haiku partition bootable, but doesn’t integrate with your existing boot menu (in other words, it will not set up dual booting). In this window, click the Continue button.
-
-You will then be warned that no partitions have been found. Click the OK button, so you can create a partition table. In the remaining window (Figure 2), click the Set up partitions button.
-
-![Haiku][7]
-
-Figure 2: The Haiku Installer in action.
-
-[Used with permission][5]
-
-In the resulting window (Figure 3), select the partition to be used and then click Disk > Initialize > GUID Partition Map. You will be prompted to click Continue and then Write Changes.
-
-![target partition][9]
-
-Figure 3: Our target partition ready to be initialized.
-
-[Used with permission][5]
-
-Select the newly initialized partition and then click Partition > Format > Be File System. When prompted, click Continue. In the resulting window, leave everything default and click Initialize and then click Write changes.
-
-Close the DriveSetup window (click the square in the titlebar) to return to the Haiku Installer. You should now be able to select the newly formatted partition in the Onto drop-down (Figure 4).
-
-![partition][11]
-
-Figure 4: Selecting our partition for installation.
-
-[Used with permission][5]
-
-After selecting the partition, click Begin and the installation will start. Don’t blink, as the entire installation takes less than 30 seconds. You read that correctly—the installation of Haiku takes less than 30 seconds. When it finishes, click Restart to boot your newly installed Haiku OS.
-
-### Usage
-
-When Haiku boots, it’ll go directly to the desktop. There is no login screen (or even the means to log in). You’ll be greeted with a very simple desktop that includes a few clickable icons and what is called the Tracker(Figure 5).
-
-
-
-The Tracker includes any minimized application and a desktop menu that gives you access to all of the installed applications. Left click on the leaf icon in the Tracker to reveal the desktop menu (Figure 6).
-
-![menu][13]
-
-Figure 6: The Haiku desktop menu.
-
-[Used with permission][5]
-
-From within the menu, click Applications and you’ll see all the available tools. In that menu you’ll find the likes of:
-
- * ActivityMonitor (Track system resources)
-
- * BePDF (PDF reader)
-
- * CodyCam (allows you to take pictures from a webcam)
-
- * DeskCalc (calculator)
-
- * Expander (unpack common archives)
-
- * HaikuDepot (app store)
-
- * Mail (email client)
-
- * MediaPlay (play audio files)
-
- * People (contact database)
-
- * PoorMan (simple web server)
-
- * SoftwareUpdater (update Haiku software)
-
- * StyledEdit (text editor)
-
- * Terminal (terminal emulator)
-
- * WebPositive (web browser)
-
-
-
-
-You will find, in the HaikuDepot, a limited number of available applications. What you won’t find are many productivity tools. Missing are office suites, image editors, and more. What we have with this beta version of Haiku is not a replacement for your desktop, but a view into the work the developers have put into giving the now-defunct BoOS new life. Chances are you won’t spend too much time with Haiku, beyond kicking the tires. However, this blast from the past is certainly worth checking out.
-
-### A positive step forward
-
-Based on my experience with BeOS and the alpha of Haiku (all those years ago), the developers have taken a big, positive step forward. Hopefully, the next beta release won’t take as long and we might even see a final release in the coming years. Although Haiku won’t challenge the likes of Ubuntu, Mint, Arch, or Elementary OS, it could develop its own niche following. No matter its future, it’s good to see something new from the developers. Bravo to Haiku.
-
-Your OS is prime
-
-For a beta 2 release
-
-Make it so, my friends.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/2018/10/beos-or-not-beos-haiku
-
-作者:[Jack Wallen][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/jlwallen
-[b]: https://github.com/lujun9972
-[1]: https://www.haiku-os.org/
-[2]: https://www.haiku-os.org/get-haiku
-[3]: /files/images/haiku1jpg
-[4]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_1.jpg?itok=PTTBoLCf (Haiku installer)
-[5]: /licenses/category/used-permission
-[6]: /files/images/haiku2jpg
-[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_2.jpg?itok=NV1yavv_ (Haiku)
-[8]: /files/images/haiku3jpg
-[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_3.jpg?itok=XWBz6kVT (target partition)
-[10]: /files/images/haiku4jpg
-[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_4.jpg?itok=6RbuCbAx (partition)
-[12]: /files/images/haiku6jpg
-[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_6.jpg?itok=-mmzNBxa (menu)
diff --git a/sources/talk/20181023 What MMORPGs can teach us about leveling up a heroic developer team.md b/sources/talk/20181023 What MMORPGs can teach us about leveling up a heroic developer team.md
deleted file mode 100644
index 23161bd1b6..0000000000
--- a/sources/talk/20181023 What MMORPGs can teach us about leveling up a heroic developer team.md
+++ /dev/null
@@ -1,213 +0,0 @@
-What MMORPGs can teach us about leveling up a heroic developer team
-======
-The team-building skills that make winning gaming guilds also produce successful work teams.
-
-
-For the better part of a decade, I have been leading guilds in massively multiplayer role-playing games (MMORPGs). Currently, I lead a guild in [Guild Wars 2][1], and before that, I led progression raid teams in [World of Warcraft][2], while also maintaining a career as a software engineer. As I made the transition into software development, it became clear that the skills I gained in building successful raid groups translated well to building successful tech teams.
-
-
-![Guild Wars 2 guild members after an event.][4]
-
-Guild Wars 2 guild members after an event.
-
-### Identify your problem
-
-The first step to building a successful team, whether in software or MMORPGs, is to recognize your problem. In video games, it's obvious: the monster. If you don't take it down, it will take you down. In tech, it's a product or service you want to deliver to solve your users' problems. In both situations, this is a problem you are unlikely to solve by yourself. You need a team.
-
-In MMORPGs, the goal is to create a "progression" raid team that improves over time for faster and smoother tackling of objectives together, allowing it to push its goals further and further. You will not reach the second objective in a raid without tackling the initial one first.
-
-In this article, I'll share how you can build, improve, and maintain your own progression software and/or systems teams. I'll cover assembling our team, leading the team, optimizing for success, continuously improving, and keeping morale high.
-
-### Assemble your team
-
-In MMORPGs, progression teams commonly have different levels of commitment, summed up into three tiers: hardcore, semi-hardcore, and casuals. These commitment levels translate to what players value in their raiding experience.
-
-You may have heard of the concept of "cultural fit" vs "value fit." One of the most important things in assembling your team is making sure everyone aligns with your concrete values and goals. Creating teams based on cultural fit is problematic because culture is hard to define. Matching new recruits based on their culture will also result in homogenous groups.
-
-Hardcore teams value dedication, mastery, and achievements. Semi-hardcore teams value efficiency, balance, and empathy. Casual teams balance fun above all else. If you put a casual player in a hardcore raid group, the casual player is probably going to tell the hardcore players they're taking things too seriously, while the hardcore players will tell the casual player they aren't taking things seriously enough (then remove them promptly).
-
-#### Values-driven team building
-
-A mismatch in values results in a negative experience for everyone. You need to build your team on a shared foundation of what is important, and each member should align with your team's values and goals. What is important to your team? What do you want your team's driving values to be? If you cannot easily answer those questions, take a moment right away and define them with your team.
-
-The values you define should influence which new members you recruit. In building raid teams, each potential member should be assessed not only on their skills but also their values. One of my previous employers had a "value fit" interview that a person must pass after their skills assessment to be considered for hiring. It doesn't matter if you're a "ninja" or a "rockstar" if you don't align with the company's values.
-
-#### Diversify your team
-
-When looking for new positions, I want a team that has a strong emphasis on delivering a quality product while understanding that work/life balance should be weighed more heavily on the life side ("life/work balance"). I steer away from companies with meager, two-week PTO policies, commitments over 40 hours, or rigid schedules. When interviews with companies show less emphasis on technical collaboration, I know there is a values mismatch.
-
-While values are important to share, the same skills, experience, and roles are not. Ten tanks might be able to get a boss down, eventually, but it is certainly more effective to have diversity. You need people who are skilled and trained in their specific roles to work together, with everyone focusing on what they do best.
-
-In MMORPGs, there are always considerably more people who want to play damage roles because they get all the glory. However, you're not going to down the boss without at least a tank and a healer. The tank and the healer mitigate the damage so that the damage classes can do what they do. We need to be respectful of the roles we each play and realize we're much better when we work together. There shouldn't be developers vs. operators when working together helps us deliver more effectively.
-
-Diversity in roles is important but so is diversity within roles. If you take 10 necromancers to a raid, you'll quickly find there are problems you can't solve with your current ability pool. You need to throw in some elementalists, thieves, and mesmers, too. It's the same with developers; if you everyone comes from the same background, abilities, and experience, you're going to face unnecessary challenges.
-
-It's better to take the inexperienced person who is willing to learn than the experienced person unwilling to take criticism. If a developer doesn't have hundreds of open source commits, it doesn't necessarily mean they are less skilled. Everyone has to learn somewhere. Senior developers and operators don't appear out of nowhere. Teams often only look for "experienced" people, spending more time with less manpower than if they had just trained an inexperienced recruit.
-
-Teams often only look for "experienced" people, spending more time with less manpower than if they had just trained an inexperienced recruit.
-
-Experience helps people pick things up faster, but no one starts out knowing exactly what to do, and you'd be surprised how seemingly unrelated skills translate well when applied to new experiences (like raid leadership!). **Hire and support junior technologists.** Keep in mind that a team comprised of a high percentage of inexperienced people will take considerably more time to achieve their objectives. It's important to find a good balance, weighed more heavily with experienced people available to mentor.
-
-Experience helps people pick things up faster, but no one starts out knowing exactly what to do, and you'd be surprised how seemingly unrelated skills translate well when applied to new experiences (like raid leadership!).Keep in mind that a team comprised of a high percentage of inexperienced people will take considerably more time to achieve their objectives. It's important to find a good balance, weighed more heavily with experienced people available to mentor.
-
-Every member of a team comes with strengths we need to utilize. In raids, we become obsessed with the "meta," which is a build for a class that is dubbed most efficient. We become so obsessed with what is "the best" that we forget about what "just works." In reality, forcing someone to dramatically change their playstyle because someone else determined this other playstyle to be slightly better will not be as efficient as just letting a player play what they have expertise in.
-
-Every member of a team comes with strengths we need to utilize.
-
-We get so excited about the latest and greatest in tech that we don't always think about the toll it takes. It's OK to choose "boring" technology and adopt new technologies as they become standard. What's "the best" is always changing, so focus on what's best for your team. Sometimes the best is what people are the most comfortable with. **Trust in your team's expertise rather than the tools.**
-
-### Take the lead
-
-We get so excited about the latest and greatest in tech that we don't always think about the toll it takes. It's OK to choose "boring" technology and adopt new technologies as they become standard. What's "the best" is always changing, so focus on what's best for your team. Sometimes the best is what people are the most comfortable with.
-
-You need a strong leader to lead a team and guide the overall direction, working for the team. Servant leadership is the idea that we serve our entire team and their individual needs before our own, and it is the leadership philosophy I have found most successful. Growth should be promoted at the contributor level to encourage growth at the macro level. As leaders, we want to work with each individual to identify their strengths and weaknesses. We want to keep morale high and keep everyone excited and focused so that they can succeed.
-
-Above all, a leader wants to keep the team working together. Sometimes this means resolving conflicts or holding meetings. Often this means breaking down communication barriers and improving team communication.
-
-![Guild Wars 2 raid team encountering Samarog.][6]
-
-Guild Wars 2 raid team encountering Samarog.
-
-#### Communicate effectively
-
-As companies move towards the remote/distributed model, optimizing communication and information access has become more critical than ever. How do you make sure everyone is on the same page?
-
-Above all, a leader wants to keep the team working together.
-
-During my World of Warcraft years, we used voice-over-IP software called Ventrilo. It was important for each team member to be able to hear my instructions, so whenever too many people started talking, someone would say "Clear Vent!" to silence the channel. You want the important information to be immediately accessible. In remote teams, this is usually achieved by a zero-noise "#announcements" channel in Slack where only need-to-know information is present.
-
-During my World of Warcraft years, we used voice-over-IP software called Ventrilo. It was important for each team member to be able to hear my instructions, so whenever too many people started talking, someone would say "Clear Vent!" to silence the channel. You want the important information to be immediately accessible. In remote teams, this is usually achieved by a zero-noise "#announcements" channel in Slack where only need-to-know information is present.
-
-A central knowledge base is also crucial. Guild Wars 2 has a /wiki command built into the game, which brings up a player-maintained wiki in the browser to look up information as needed without bothering other players. In most companies where I've worked, information is stored across various repositories, wikis, and documents, making it difficult and time-consuming to seek a source of truth. A central, searchable wiki, like Guild Wars 2 has, would relieve this issue. Treat knowledge sharing as an important component of your company!
-
-### Optimize for what works
-
-When you have your team assembled and are communicating effectively, you're prepared to take on your objectives. You need to think about it strategically, whether it's a monster or a system, breaking it down into steps and necessary roles. It's going to feel like you don't know what you're doing—but it's a starting point. The monster is going to die as long as you deplete its health pool, despite how messy the encounter may be at first. Your product can start making money with the minimum. Only once you have achieved the minimum can you move the goalpost.
-
-Your team learns what works and how to improve when they have the freedom to experiment. Trying something and failing is OK if it's a learning experience. It can even help identify overlooked weaknesses in your systems or processes.
-
-![Deaths during the Samarog encounter.][8]
-
-Deaths during the Samarog encounter.
-
-Your team learns what works and how to improve when they have the freedom to experiment.
-
-We live in the information age where there are various strategies at our disposal, but what works for others might not work for your team. While there is no one way to do anything, some ways are definitely better than others. Perform educated experiments based on the experience of others. Don't go in without a basic strategy unless absolutely necessary.
-
-We live in the information age where there are various strategies at our disposal, but what works for others might not work for your team. While there is no one way to do anything, some ways are definitely better than others. Perform educated experiments based on the experience of others. Don't go in without a basic strategy unless absolutely necessary.
-
-Your team needs to feel comfortable making mistakes. The only true failures are when nothing can be salvaged and nothing was learned. For your team to feel comfortable experimenting, you need to foster a culture where people are held accountable but not punished for their mistakes. When your team fears retaliation, they will be hesitant to try something unfamiliar. Worse, they might hide the mistakes they've made, and you'll find out too late to recover.
-
-Large-scale failures are rarely the result of one person. They are an accumulation of mistakes and oversights by different people combined with things largely outside the team's control. Tank healer went down? OK, another healer will cover. Someone is standing in a ring of fire. Your only remaining healer is overloaded, everything's on cooldown, and now your tank's block missed thanks to a random number generator outside her control. It's officially reached the point of failure, and the raid has wiped.
-
-Is it the tank healer's fault we wiped? It went down first and caused some stress on the other healer, sure. But there were enough people alive to keep going. It was a cumulation of everything.
-
-In systems, there are recovery protocols and hopefully automation around failures. Someone on-call will step in to provide coverage. Failures are more easily prevented when we become better aware of our systems.
-
-#### Measure success (or failures) with metrics
-
-How do you become more aware? Analysis of logs and metrics. Monitoring and observability.
-
-Logs, metrics, and analysis are as important in raids as they are around your systems and applications. After objectives, we review damage output, support uptime, time to completion, and failed mechanics.
-
-Your teams need to collect similar metrics. You need baseline metrics to compare and ensure progress has been made. In systems and applications, you care about speed, health, and overall output, too. Without being able to see these logs and metrics, you have limited measures of success.
-
-![Boon uptime stats][10]
-
-Boon uptime stats for my healer, Lullaby of Thix.
-
-### Continuously improve
-
-A team is a sum of its parts, with an ultimate goal of being coordinated at both the individual and group levels. You want people comfortable in their roles and who can make decisions in the best interest of the whole team; people who know how to step in when needed and seamlessly return to their original role after recovery. This is not easy, and many teams never reach this level of systemization.
-
-One of the ways we can improve coordination is to help people grow where they are struggling, whether by extending additional educational resources or working with them directly to strengthen their skills. Simply telling someone to "get good" (a phrase rampant in gaming culture) is not going to help. Constructive feedback with working points and pairing will, though.
-
-Keep in mind that you're measuring progress properly. You can't compare a healer's damage output to that of a dedicated damage class. Recognize that just because someone's performance looks different than another's, it could be that they are taking on roles that others are neglecting, like reviewing code or harder-than-average tickets.
-
-If one person isn't carrying their weight and the team notices, you have to address it. Start positively, give them a chance to improve: resources, assistance, or whatever they need (within reason). If they still show no interest in improvement, it's time to let them go to keep your team happy and running smoothly.
-
-### Maintain happiness
-
-Happiness is important for team longevity. After the honeymoon phase is over, what makes them stay?
-
-#### Safety
-
-One of the core, foundational needs of maintaining happiness is maintaining safety. **People stay where they feel safe.**
-
-Happiness is important for team longevity.
-
-In a game, it's easy to hide your identity and try to blend in with the perceived status quo. When people are accepted for who they are, they are comfortable enough to stay. And because they stay, a diverse community is built.
-
-In a game, it's easy to hide your identity and try to blend in with the perceived status quo. When people are accepted for who they are, they are comfortable enough to stay. And because they stay, a diverse community is built.
-
-One way to create this sense of safety is to use a Code of Conduct (CoC) that, as explicitly as possible, maps out boundaries and the consequences of violating them. It serves as a definitive guide to acceptable behavior and lets people have minimal doubts as to what is and is not allowed. While having a CoC is a good start, **it is meaningless if it is not actively enforced.**
-
-I've had to cite CoC violations to remove gaming members from our community a few times. Thankfully this doesn't happen very often, because we review our values and CoC as part of the interview process. I have turned people away because they weren't sure they could commit to it. Your values and CoC serve as a filter in your recruiting process, preventing some potential conflicts.
-
-#### Inclusion
-
-Once people feel safe, they want to feel included and a sense of belonging. In raids, people who are constantly considered substitutes are going to find a different team where they are appreciated. If hero worship is rampant in your team's culture, you will have a difficult time fostering inclusion. No one likes feeling like they are constantly in the shadows. Everyone has something to bring to the table when given the chance.
-
-#### Reputation management
-
-Maintaining team happiness also means maintaining the team's reputation. Having toxic members representing you damages your reputation.
-
-In Guild Wars 2, a few members belonging to the same guild wanted the achievements and rewards that come from winning a player vs. player (PvP) tournament, so they purchased a tournament win—essentially, skilled PvP players played as them and won the tournament. ArenaNet, the maker of Guild Wars 2, found out and reprimanded them. The greater community found out and lost respect for the entire guild, despite only a tiny percent of the guild being the offenders. You don't want people to lose faith in your team because of bad actors.
-
-Everyone has something to bring to the table when given the chance.
-
-Having a positive impact on the greater community also carries a positive impact on your image. In games, we do this by hosting events, helping newcomers, and just being friendly in our interactions with people outside our guilds. In business, maybe you do this by sponsoring things you agree with or open sourcing your core software products.
-
-Having a positive impact on the greater community also carries a positive impact on your image. In games, we do this by hosting events, helping newcomers, and just being friendly in our interactions with people outside our guilds. In business, maybe you do this by sponsoring things you agree with or open sourcing your core software products.
-
-If you have a good reputation, earned by both how you treat your members and how you treat your community, recruiting new talent and retaining the talent you have will be much easier.
-
-Recruiting and retraining take significantly more effort than letting people just relax from time to time. If your team members burn out, they are going to leave. When you're constantly retraining new people, you have more and more opportunities for mistakes. New people to your team generally lack knowledge about the deep internals of your system or product. **High turnover leads to high failure.**
-
-#### Avoid burnout
-
-Burnout happens in gaming, too. Everyone needs a break. Time off is good for everyone! You need to balance your team's goals and health. While we may feel like cogs in a machine, we are not machines. Sprint after sprint is really just a full-speed marathon.
-
-#### Celebrate wins
-
-Relieve some pressure by celebrating your team's success. This stuff is hard! Recognize and reward your teams. Were you working on a monster encounter for weeks and finally got it down? Have a /dance party! Finally tackled a bug that plagued you for months? Send everyone a cupcake!
-
-![Guild Wars 2 dance party][12]
-
-A dance party after a successful Keep Construct encounter in Guild Wars 2.
-
-### Always evolve
-
-To thrive as a team, you need to evolve with your market, your company, and your community. Change is inevitable. Embrace it. Grow. I truly believe that the worst thing you can say is, "We've always done it this way, and we're not going to change."
-
-Building, maintaining, and growing a heroic team is an arduous process that needs constant evolution, but the benefits are infinite.
-
-Aly Fulton will present [It's Dangerous to Go Alone: Leveling Up a Heroic Team][13] at [LISA18][14], October 29-31 in Nashville, Tenn.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/what-mmorpgs-can-teach-us
-
-作者:[Aly Fulton][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/sinthetix
-[b]: https://github.com/lujun9972
-[1]: https://www.guildwars2.com/
-[2]: https://worldofwarcraft.com/
-[3]: /file/412396
-[4]: https://opensource.com/sites/default/files/uploads/lime_southsun_cove.png (Guild Wars 2 guild members after an event.)
-[5]: /file/412401
-[6]: https://opensource.com/sites/default/files/uploads/lime_samarog_readycheck.png (Guild Wars 2 raid team encountering Samarog.)
-[7]: /file/412406
-[8]: https://opensource.com/sites/default/files/uploads/lime_samarog_deaths.png (Deaths during the Samarog encounter.)
-[9]: /file/412411
-[10]: https://opensource.com/sites/default/files/uploads/boon_uptime.png (Boon uptime stats)
-[11]: /file/412416
-[12]: https://opensource.com/sites/default/files/uploads/lime_keep_construct_trophy_dance_party.png (Guild Wars 2 dance party)
-[13]: https://www.usenix.org/conference/lisa18/presentation/fulton
-[14]: https://www.usenix.org/conference/lisa18
diff --git a/sources/talk/20181024 5 tips for facilitators of agile meetings.md b/sources/talk/20181024 5 tips for facilitators of agile meetings.md
deleted file mode 100644
index 433140f684..0000000000
--- a/sources/talk/20181024 5 tips for facilitators of agile meetings.md
+++ /dev/null
@@ -1,60 +0,0 @@
-5 tips for facilitators of agile meetings
-======
-Boost your team's productivity and motivation with these agile principles.
-
-
-
-As Agile practitioner, I often hear that the best way to have business meetings is to avoid more meetings, or to cancel them altogether.
-
-Do your meetings fail to keep attendees engaged or run longer than they should? Perhaps you have mixed feelings about participating in meetings—but don't want to be excluded?
-
-If all this sounds familiar, read on.
-
-### How do we fix meetings?
-
-To succeed in this role, you must understand that agile is not something that you do, but something that you can become.
-
-Meetings are an integral part of work culture, so improving them can bring important benefits. But improving how meetings are structured requires a change in how the entire organization is led and managed. This is where the agile mindset comes into play.
-
-An agile mindset is an _attitude that equates failure and problems with opportunities for learning, and a belief that we can all improve over time._ Meetings can bring great value to an organization, as long as they are not pointless. The best way to eliminate pointless meetings is to have a meeting facilitator with an agile mindset. The key attribute of agile-driven facilitation is to focus on problem-solving.
-
-Agile meeting facilitators confronting a complex problem start by breaking the meeting agenda down into modules. They also place more value on adapting to change than sticking to a plan. They work with meeting attendees to develop a solution based on feedback loops. This assures audience engagement and makes the meetings productive. The result is an integrated, agreed-upon solution that comprises a set of coherent action items aligned on a goal
-
-### What are the skills of an agile meeting facilitator?
-
-An agile meeting facilitator is able to quickly adapt to changing circumstances. He or she integrates all stakeholders and encourages them to share knowledge and skills.
-
-To succeed in this role, you must understand that agile is not something that you do, but something that you can become. As the [Manifesto for Agile Software Development][1] notes, tools and processes are important, but it is more important to have competent people working together effectively.
-
-### 5 tips for agile meeting facilitation
-
- 1. **Start with the problem in mind.** Identify the purpose of the meeting and narrow the agenda items to those that are most important. Stay tuned in and focused.
-
- 2. **Make sure that a senior leader doesn’t run the meeting.** Many senior leaders tend to create an environment in which the team expects to be told what to do. Instead, create an environment in which diverse ideas are the norm. Encourage open discussion in which leaders share where—but not how—innovation is needed. This reduces the layer of control and approval, increases the time focused on decision-making, and boosts the team’s motivation.
-
- 3. **Identify bottlenecks early.** Bureaucratic procedures or lack of collaboration between team members leads to meeting meltdowns and poor results. Anticipate how things might go wrong and be prepared to offer suggestions, not dictate solutions.
-
- 4. **Show, don’t tell.** Share the meeting goals and create the meeting agenda in advance. Allow time to adjust the agenda items and their order to achieve the best flow. Make sure that the meeting’s agenda is clear and visible to all attendees.
-
- 5. **Know when to wait.** Map out a clear timeline for the meeting and help keep the meeting on track. Understand when you should allow an item to go long versus when you should table a discussion. This will go a long way toward helping you stay on track.
-
-
-
-
-The ultimate goal is to create a work environment that encourages contribution and empowers the team. Improving how meetings are run will help your organization transition from a traditional hierarchy to a more agile enterprise.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/agile-culture-5-tips-meeting-facilitators
-
-作者:[Dominika Bula][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/dominika
-[b]: https://github.com/lujun9972
-[1]: http://agilemanifesto.org/
diff --git a/sources/talk/20181031 How open source hardware increases security.md b/sources/talk/20181031 How open source hardware increases security.md
deleted file mode 100644
index 9e823436cf..0000000000
--- a/sources/talk/20181031 How open source hardware increases security.md
+++ /dev/null
@@ -1,84 +0,0 @@
-How open source hardware increases security
-======
-Want to boost cybersecurity at your organization? Switch to open source hardware.
-
-
-Hardware hacks are particularly scary because they trump any software security safeguards—for example, they can render all accounts on a server password-less.
-
-Fortunately, we can benefit from what the software industry has learned from decades of fighting prolific software hackers: Using open source techniques can, perhaps counterintuitively, [make a system more secure][1]. Open source hardware and distributed manufacturing can provide protection from future attacks.
-
-### Trust—but verify
-
-Imagine you are a 007 agent holding classified documents. Would you feel more secure locking them in a safe whose manufacturer keeps the workings of the locks secret, or in a safe whose design is published openly so that everyone (including thieves) can judge its quality—thus enabling you to rely exclusively on technical complexity for protection?
-
-The former approach might be perfectly secure—you simply don’t know. But why would you trust any manufacturer that could be compromised now or in the future? In contrast, the open system is almost certain to be secure, especially if enough time has passed for it to be tested by multiple companies, governments, and individuals.
-
-To a large degree, the software world has seen the benefits of moving to free and open source software. That's why open source is run on all [supercomputers][2], [90% of the cloud, 82% of the smartphone market, and 62% of the embedded systems market][3]. Open source appears poised to dominate the future, with over [70% of the IoT][4].
-
-In fact, security is one of the core benefits of [open source][5]. While open source is not inherently more secure, it allows you to verify security yourself (or pay someone more qualified to do so). With closed source programs, you must trust, without verification, that a program works properly. To quote President Reagan: "Trust—but verify." The bottom line is that open source allows users to make more informed choices about the security of a system—choices that are based on their own independent judgment.
-
-### Open source hardware
-
-This concept also holds true for electronic devices. Most electronics customers have no idea what is in their products, and even technically sophisticated companies like Amazon may not know exactly what is in the hardware that runs their servers because they use proprietary products that are made by other companies.
-
-In the incident mentioned above, Chinese spies recently used a tiny microchip, not much bigger than a grain of rice, to infiltrate hardware made by SuperMicro (the Microsoft of the hardware world). These chips enabled outside infiltrators to access the core server functions of some of America’s leading companies and government operations, including DOD data centers, CIA drone operations, and the onboard networks of Navy warships. Operatives from the People’s Liberation Army or similar groups could have reverse-engineered or made identical or disguised modules (in this case, the chips looked like signal-conditioning couplers, a common motherboard component, rather than the spy devices they were).
-
-Having the source available helps customers much more than hackers, as most customers do not have the resources to reverse-engineer the electronics they buy. Without the device's source, or design, it's difficult to determine whether or not hardware has been hacked.
-
-Enter [open source hardware][6]: hardware design that is publicly available so that anyone can study, modify, test, distribute, make, or sell it, or hardware based on it. The hardware’s source is available to everyone.
-
-### Distributed manufacturing for cybersecurity
-
-Open source hardware and distributed manufacturing could have prevented the Chinese hack that rightfully terrified the security world. Organizations that require tight security, such as military groups, could then check the product's code and bring production in-house if necessary.
-
-This open source future may not be far off. Recently I co-authored, with Shane Oberloier, an [article][7] that discusses a low-cost open source benchtop device that enables anyone to make a wide range of open source electronic products. The number of open source electronics designs is proliferating on websites like [Hackaday][8], [Open Electronics][9], and the [Open Circuit Institute][10], as are communities based on specific products like [Arduino][11] and around companies like [Adafruit Industries][12] and [SparkFun Electronics][13].
-
-Every level of manufacturing that users can do themselves increases the security of the device. Not long ago, you had to be an expert to make even a simple breadboard design. Now, with open source mills for boards and electronics repositories, small companies and even individuals can make reasonably sophisticated electronic devices. While most builders are still using black-box chips on their devices, this is also changing as [open source chips gain traction][14].
-
-
-
-Creating electronics that are open source all the way down to the chip is certainly possible—and the more besieged we are by hardware hacks, perhaps it is even inevitable. Companies, governments, and other organizations that care about cybersecurity should strongly consider moving toward open source—perhaps first by establishing purchasing policies for software and hardware that makes the code accessible so they can test for security weaknesses.
-
-Although every customer and every manufacturer of an open source hardware product will have different standards of quality and security, this does not necessarily mean weaker security. Customers should choose whatever version of an open source product best meets their needs, just as users can choose their flavor of Linux. For example, do you run [Fedora][15] for free, or do you, like [90% of Fortune Global 500 companies][16], pay Red Hat for its version and support?
-
-Red Hat makes billions of dollars a year for the service it provides, on top of a product that can ostensibly be downloaded for free. Open source hardware can follow the [same business model][17]; it is just a less mature field, lagging [open source software by about 15 years][18].
-
-The core source code for hardware devices would be controlled by their manufacturer, following the "[benevolent dictator for life][19]" model. Code of any kind (infected or not) is screened before it becomes part of the root. This is true for hardware, too. For example, Aleph Objects manufacturers the popular [open source LulzBot brand of 3D printer][20], a commercial 3D printer that's essentially designed to be hacked. Users have made [dozens of modifications][21] (mods) to the printer, and while they are available, Aleph uses only the ones that meet its QC standards in each subsequent version of the printer. Sure, downloading a mod could mess up your own machine, but infecting the source code of the next LulzBot that way would be nearly impossible. Customers are also able to more easily check the security of the machines themselves.
-
-While [challenges certainly remain for the security of open source products][22], the open hardware model can help enhance cybersecurity—from the Pentagon to your living room.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/cybersecurity-demands-rapid-switch-open-source-hardware
-
-作者:[Joshua Pearce][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/jmpearce
-[b]: https://github.com/lujun9972
-[1]: https://dl.acm.org/citation.cfm?id=1188921
-[2]: https://www.zdnet.com/article/supercomputers-all-linux-all-the-time/
-[3]: https://www.serverwatch.com/server-news/linux-foundation-on-track-for-best-year-ever-as-open-source-dominates.html
-[4]: https://www.itprotoday.com/iot/survey-shows-linux-top-operating-system-internet-things-devices
-[5]: https://www.infoworld.com/article/2985242/linux/why-is-open-source-software-more-secure.html
-[6]: https://www.oshwa.org/definition/
-[7]: https://www.mdpi.com/2411-5134/3/3/64/htm
-[8]: https://hackaday.io/
-[9]: https://www.open-electronics.org/
-[10]: http://opencircuitinstitute.org/
-[11]: https://www.arduino.cc/
-[12]: http://www.adafruit.com/
-[13]: https://www.sparkfun.com/
-[14]: https://www.wired.com/story/using-open-source-designs-to-create-more-specialized-chips/
-[15]: https://getfedora.org/
-[16]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
-[17]: https://openhardware.metajnl.com/articles/10.5334/joh.4/
-[18]: https://www.mdpi.com/2411-5134/3/3/44/htm
-[19]: https://www.theatlantic.com/technology/archive/2014/01/on-the-reign-of-benevolent-dictators-for-life-in-software/283139/
-[20]: https://www.lulzbot.com/
-[21]: https://forum.lulzbot.com/viewtopic.php?t=2378
-[22]: https://ieeexplore.ieee.org/abstract/document/8250205
diff --git a/sources/talk/20181107 5 signs you are doing continuous testing wrong - Opensource.com.md b/sources/talk/20181107 5 signs you are doing continuous testing wrong - Opensource.com.md
deleted file mode 100644
index 03793b78ba..0000000000
--- a/sources/talk/20181107 5 signs you are doing continuous testing wrong - Opensource.com.md
+++ /dev/null
@@ -1,184 +0,0 @@
-5 signs you are doing continuous testing wrong | Opensource.com
-======
-Avoid these common test automation mistakes in the era of DevOps and Agile.
-
-
-In the last few years, many companies have made large investments to automate every step of deploying features in production. Test automation has been recognized as a key enabler:
-
-> “We found that Test Automation is the biggest contributor to continuous delivery.” – [2017 State of DevOps report][1]
-
-Suppose you started adopting agile and DevOps practices to speed up your time to market and put new features in the hands of customers as soon as possible. You implemented continuous testing practices, but you’re facing the challenge of scalability: Implementing test automation at all system levels for code bases that contain tens of millions of lines of code involves many teams of developers and testers. And to add even more complexity, you need to support numerous browsers, mobile devices, and operating systems.
-
-Despite your commitment and resources expenditure, the result is likely an automated test suite with high maintenance costs and long execution times. Worse, your teams don't trust it.
-
-Here are five common test automation mistakes, and how to mitigate them using (in some cases) open source tools.
-
-### 1\. Siloed automation teams
-
-In medium and large IT projects with hundreds or even thousands of engineers, the most common cause of unmaintainable and expensive automated tests is keeping test teams separate from the development teams that deliver features.
-
-This also happens in organizations that follow agile practices where analysts, developers, and testers work together on feature acceptance criteria and test cases. In these agile organizations, automated tests are often partially or fully managed by engineers outside the scrum teams. Inefficient communication can quickly become a bottleneck, especially when teams are geographically distributed, if you want to evolve the automated test suite over time.
-
-Furthermore, when automated acceptance tests are written without developer involvement, they tend to be tightly coupled to the UI and thus brittle and badly factored, because the most testers don’t have insight into the UI’s underlying design and lack the skills to create abstraction layers or run acceptance tests against a public API.
-
-A simple suggestion is to split your siloed automation teams and include test engineers directly in scrum teams where feature discussion and implementation happen, and the impacts on test scripts can be immediately discovered and fixed. This is certainly a good idea, but it is not the real point. Better yet is to make the entire scrum team responsible for automated tests. Product owners, developers, and testers must then work together to refine feature acceptance criteria, create test cases, and prioritize them for automation.
-
-When different actors, inside or outside the development team, are involved in running automated test suites, one practice that levels up the overall collaborative process is [BDD][2], or behavior-driven development. It helps create business requirements that can be understood by the whole team and contributes to having a single source of truth for automated tests. Open source tools like [Cucumber][3], [JBehave][4], and [Gauge][5] can help you implement BDD and keep test case specifications and test scripts automatically synchronized. Such tools let you create concrete examples that illustrate business rules and acceptance criteria through the use of a simple text file containing Given-When-Then scenarios. They are used as executable software specifications to automatically verify that the software behaves as intended.
-
-### 2\. Most of your automated suite is made by user interface tests
-
-You should already know that user interface automated tests are brittle and even small changes will immediately break all the tests referring to a particular changed GUI element. This is one of the main reasons technical/business stakeholders perceive automated tests as expensive to maintain. Record-and-playback tools such as [SeleniumRecorder][6], used to generate GUI automatic tests, are tightly coupled to the GUI and therefore brittle. These tools can be used in the first stage of creating an automatic test, but a second optimization stage is required to provide a layer of abstraction that reduces the coupling between the acceptance tests and the GUI of the system under test. Design patterns such as [PageObject][7] can be used for this purpose.
-
-However, if your automated test strategy is focused only on user interfaces, it will quickly become a bottleneck as it is resource-intensive, takes a long time to execute, and it is generally hard to fix. Indeed, resolving UI test failure may require you to go through all system levels to discover the root cause.
-
-A better approach is to prioritize development of automated tests at the right level to balance the costs of maintaining them while trying to discover bugs in the early stages of the software [deployment pipeline][8] (a key pattern introduced in continuous delivery).
-
-
-
-As suggested by the [agile test pyramid][9] shown above, the vast majority of automated tests should be comprised of unit tests (both back- and front-end level). The most important property of unit tests is that they should be very fast to execute (e.g., 5 to 10 minutes).
-
-The service layer (or component tests) allows for testing business logic at the API or service level, where you're not encumbered by the user interface (UI). The higher the level, the slower and more brittle testing becomes.
-
-Typically unit tests are run at every developer commit, and the build process is stopped in the case of a test failure or if the test coverage is under a predefined threshold (e.g., when less than 80% of code lines are covered by unit tests). Once the build passes, it is deployed in a stage environment, and acceptance tests are executed. Any build that passes acceptance tests is then typically made available for manual and integration testing.
-
-Unit tests are an essential part of any automated test strategy, but they usually do not provide a high enough level of confidence that the application can be released. The objective of acceptance tests at service and UI level is to prove that your application does what the customer wants it to, not that it works the way its programmers think it should. Unit tests can sometimes share this focus, but not always.
-
-To ensure that the application provides value to end users while balancing test suite costs and value, you must automate both the service/component and UI acceptance tests with the agile test pyramid in mind.
-
-Read more about test types, levels, and tools in this comprehensive [article][10] from ThoughtWorks.
-
-### 3\. External systems are integrated too early in your deployment pipeline
-
-Integration with external systems is a common source of problems, and it can be difficult to get right. This implies that it is important to test such integration points carefully and effectively. The problem is that if you include the external systems themselves within the scope of your automated acceptance testing, you have less control over the system. It is difficult to set an external system starting state, and this, in turn, will end up in an unpredictable test run that fails most of the time. The rest of your time will be probably spent discussing how to fix testing failures with external providers. However, our objective with continuous testing is to find problems as early as possible, and to achieve this, we aim to integrate our system continuously. Clearly, there is a tension here and a “one-size-fits-all” answer doesn’t exist.
-
-Having suites of tests around each integration point, intended to run in an environment that has real connections to external systems, is valuable, but the tests should be very small, focus on business risks, and cover core customer journeys. Instead, consider creating [test doubles][11] that represent the connection to all external systems and use them in development and/or early-stage environments so that your test suites are faster and test results are deterministic. If you are new to the concept of test doubles but have heard about mocks and stubs, you can learn about the differences in this [Martin Fowler blog post][11].
-
-In their book, [Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation][12], Jez Humble and David Farley advise: “Test doubles must almost always be used to stub out part of an external system when:
-
- * The external system is under development but the interface has been defined ahead of time (in these situations, be prepared for the interface to change).
-
- * The external system is developed already but you don’t have a test instance of that system available for your testing, or the test system is too slow or buggy to act as a service for regular automated test runs.
-
- * The test system exists, but responses are not deterministic and so make validation of tests results impossible for automated tests (for example, a stock market feed).
-
- * The external system takes the form of another application that is difficult to install or requires manual intervention via a UI.
-
- * The load that your automated continuous integration system imposes, and the service level that it requires, overwhelms the lightweight test environment that is set up to cope with only a few manual exploratory interactions.”
-
-
-
-
-Suppose you need to integrate one or more external systems that are under active development. In turn, there will likely be changes in the schemas, contracts, and so on. Such a scenario needs careful and regular testing to identify points at which different teams diverge. This is the case of microservice-based architectures, which involve several independent systems deployed to test a single functionality. In this context, review the overall automated testing strategies in favor of a more scalable and maintainable approach like the one used on [consumer-driven contracts][13].
-
-If you are not in such a situation, I found the following open source tools useful to implement test doubles starting from an API contract specification:
-
- * [SoapUI mocking services][14]: Despite its name, it can mock both SOAP and rest services.
-
- * [WireMock][15]: It can mock rest services only.
-
- * For rest services, look at [OpenAPI tools][16] for “mock servers,” which are able to generate test stubs starting from [OpenAPI][17] contract specification.
-
-
-
-
-### 4\. Test and development tools mismatch
-
-One of the consequences of offloading test automation work to teams other than the development team is that it creates a divergence between development and test tools. This makes collaboration and communication harder between dev and test engineers, increases the overall cost for test automation, and fosters bad practices such as having the version of test scripts and feature code not aligned or not versioned at all.
-
-I’ve seen a lot of teams struggle with expensive UI/API automated test tools that had poor integration with standard versioning systems like Git. Other tools, especially GUI-based commercial ones with visual workflow capabilities, create a false expectation—primarily between test managers—that you can easily expect testers to develop maintainable and reusable automated tests. Even if this is possible, they can’t scale your automated test suite over time; the tests must be curated as much as feature code, which requires developer-level programming skills and best practices.
-
-There are several open source tools that help you write automated acceptance tests and reuse your development teams' skills. If your primary development language is Java or JavaScript, you may find the following options useful:
-
- * Java
-
- * [Cucumber-jvm][18] for implementing executable specifications in Java for both UI and API automated testing
-
- * [REST Assured][19] for API testing
-
- * [SeleniumHQ][20] for web testing
-
- * [ngWebDriver][21] locators for Selenium WebDriver. It is optimized for web applications built with Angular.js 1.x or Angular 2+
-
- * [Appium Java][22] for mobile testing using Selenium WebDriver
-
- * JavaScript
-
- * [Cucumber.js][23] same as Cucumber.jvm but runs on Node.js platform
-
- * [Chakram][24] for API testing
-
- * [Protractor][25] for web testing optimized for web applications built with AngularJS 1.x or Angular 2+
-
- * [Appium][26] for mobile testing on the Node.js platform
-
-
-
-
-### 5\. Your test data management is not fully automated
-
-To build maintainable test suites, it’s essential to have an effective strategy for creating and maintaining test data. It requires both automatic migration of data schema and test data initialization.
-
-It's tempting to use large database dumps for automated tests, but this makes it difficult to version and automate them and will increase the overall time of test execution. A better approach is to capture all data changes in DDL and DML scripts, which can be easily versioned and executed by the data management system. These scripts should first create the structure of the database and then populate the tables with any reference data required for the application to start. Furthermore, you need to design your scripts incrementally so that you can migrate your database without creating it from scratch each time and, most importantly, without losing any valuable data.
-
-Open source tools like [Flyway][27] can help you orchestrate your DDL and DML scripts' execution based on a table in your database that contains its current version number. At deployment time, Flyway checks the version of the database currently deployed and the version of the database required by the version of the application that is being deployed. It then works out which scripts to run to migrate the database from its current version to the required version, and runs them on the database in order.
-
-One important characteristic of your automated acceptance test suite, which makes it scalable over time, is the level of isolation of the test data: Test data should be visible only to that test. In other words, a test should not depend on the outcome of the other tests to establish its state, and other tests should not affect its success or failure in any way. Isolating tests from one another makes them capable of being run in parallel to optimize test suite performance, and more maintainable as you don’t have to run tests in any specific order.
-
-When considering how to set up the state of the application for an acceptance test, Jez Humble and David Farley note [in their book][12] that it is helpful to distinguish between three kinds of data:
-
- * **Test reference data:** This is the data that is relevant for a test but that has little bearing upon the behavior under test. Such data is typically read by test scripts and remains unaffected by the operation of the tests. It can be managed by using pre-populated seed data that is reused in a variety of tests to establish the general environment in which the tests run.
-
- * **Test-specific data:** This is the data that drives the behavior under test. It also includes transactional data that is created and/or updated during test execution. It should be unique and use test isolation strategies to ensure that the test starts in a well-defined environment that is unaffected by other tests. Examples of test isolation practices are deleting test-specific data and transactional data at the end of the test execution, or using a functional partitioning strategy.
-
- * **Application reference data:** This data is irrelevant to the test but is required by the application for startup.
-
-
-
-
-Application reference data and test reference data can be kept in the form of database scripts, which are versioned and migrated as part of the application's initial setup. For test-specific data, you should use application APIs so the system is always put in a consistent state as a consequence of executing business logic (which otherwise would be bypassed if you directly load test data into the database using scripts).
-
-### Conclusion
-
-Agile and DevOps teams continue to fall short on continuous testing—a crucial element of the CI/CD pipeline. Even as a single process, continuous testing is made up of various components that must work in unison. Team structure, testing prioritization, test data, and tools all play a critical role in the success of continuous testing. Agile and DevOps teams must get every piece right to see the benefits.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/continuous-testing-wrong
-
-作者:[Davide Antelmo][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/dantelmo
-[b]: https://github.com/lujun9972
-[1]: https://puppet.com/blog/2017-state-devops-report-here
-[2]: https://www.agilealliance.org/glossary/bdd/
-[3]: https://docs.cucumber.io/
-[4]: https://jbehave.org/
-[5]: https://www.gauge.org/
-[6]: https://www.seleniumhq.org/projects/ide/
-[7]: https://martinfowler.com/bliki/PageObject.html
-[8]: https://continuousdelivery.com/implementing/patterns/
-[9]: https://martinfowler.com/bliki/TestPyramid.html
-[10]: https://martinfowler.com/articles/practical-test-pyramid.html
-[11]: https://martinfowler.com/bliki/TestDouble.html
-[12]: https://martinfowler.com/books/continuousDelivery.html
-[13]: https://martinfowler.com/articles/consumerDrivenContracts.html
-[14]: https://www.soapui.org/soap-mocking/service-mocking-overview.html
-[15]: http://wiremock.org/
-[16]: https://openapi.tools/
-[17]: https://www.openapis.org/
-[18]: https://github.com/cucumber/cucumber-jvm
-[19]: http://rest-assured.io/
-[20]: https://www.seleniumhq.org/
-[21]: https://github.com/paul-hammant/ngWebDriver
-[22]: https://github.com/appium/java-client
-[23]: https://github.com/cucumber/cucumber-js
-[24]: http://dareid.github.io/chakram/
-[25]: https://www.protractortest.org/#/
-[26]: https://github.com/appium/appium
-[27]: https://flywaydb.org/
diff --git a/sources/talk/20181107 How open source in education creates new developers.md b/sources/talk/20181107 How open source in education creates new developers.md
deleted file mode 100644
index 7f79ce8b44..0000000000
--- a/sources/talk/20181107 How open source in education creates new developers.md
+++ /dev/null
@@ -1,65 +0,0 @@
-How open source in education creates new developers
-======
-Self-taught developer and new Gibbon maintainer explains why open source is integral to creating the next generation of coders.
-
-
-Like many programmers, I got my start solving problems with code. When I was a young programmer, I was content to code anything I could imagine—mostly games—and do it all myself. I didn't need help; I just needed less sleep. It's a common pitfall, and one that I'm happy to have climbed out of with the help of two important realizations:
-
-First, the software that impacts our daily lives the most isn't made by an amazingly talented solo developer. On a large scale, it's made by global teams of hundreds or thousands of developers. On smaller scales, it's still made by a team of dedicated professionals, often working remotely. Far beyond the value of churning out code is the value of communicating ideas, collaborating, sharing feedback, and making collective decisions.
-
-Second, sustainable code isn't programmed in a vacuum. It's not just a matter of time or scale; it's a diversity of thinking. Designing software is about understanding an issue and the people it affects and setting out to find a solution. No one person can see an issue from every point of view. As a developer, learning to connect with other developers, empathize with users, and think of a project as a community rather than a codebase are invaluable.
-
-### Open source and education: natural partners
-
-Education is not a zero-sum game. Worldwide, members of the education community work together to share ideas, build professional learning networks, and create new learning models.
-
-This collaboration is where there's an amazing synergy between open source software and education. It's already evident in the many open source projects used in schools worldwide; in classrooms, running blogs, sharing resources, hosting servers, and empowering collaboration.
-
-Working in a school has sparked my passion to advocate for open source in education. My position as web developer and digital media specialist at [The International School of Macao][1] has become what I call a developer-in-residence. Working alongside educators has given me the incredible opportunity to learn their needs and workflows, then go back and write code to help solve those problems. There's a lot of power in this model: not just programming for hypothetical "users" but getting to know the people who use a piece of software on a day-to-day basis, watching them use it, learning their pain points, and aiming to build [something that meets their needs][2].
-
-This is a model that I believe we can build on and share. Educators and developers working together have the ability to create the quality, open, affordable software they need, built on the values that matter most to them. These tools can be made available to those who cannot afford commercial systems but do want to educate the next generation.
-
-Not every school may have the capacity to contribute code or hire developers, but with a larger community of people working together, extraordinary things are happening.
-
-### What schools need from software
-
-There are a lot of amazing educators out there re-thinking the learning models used in schools. They're looking for ways to provide students with agency, spark their curiosity, connect their learning to the real world, and foster mindsets that will help them navigate our rapidly changing world.
-
-The software used in schools needs to be able to adapt and change at the same pace. No one knows for certain what education will look like in the future, but there are some great ideas for what directions it's going in. To keep moving forward, educators need to be able to experiment at the same level that learning is happening; to try, to fail, and to iterate on different approaches right in their classrooms.
-
-This is where I believe open source tools for learning can be quite powerful. There are a lot of challenging projects that can arise in a school. My position started as a web design job but soon grew into developing staff portals, digital signage, school blogs, and automated newsletters. For each new project, open source was a natural jumping-off point: it was affordable, got me up to speed faster, and I was able to adapt each system to my school's ever-evolving needs.
-
-One such project was transitioning our school's student information system, along with 10 years of data, to an open source platform called [Gibbon][3]. The system did a lot of [things that my school needed][4], which was awesome. Still, there were some things we needed to adapt and other things we needed to add, including tools to import large amounts of data. Since it's an open source school platform, I was able to dive in and make these changes, and then share them back with the community.
-
-This is the point where open source started to change from something I used to something I contributed to. I've done a lot of solo development work in the past, so the opportunity to collaborate on new features and contribute bug fixes really hooked me.
-
-As my work on Gibbon evolved from small fixes to whole features, I also started collaborating on ideas to refactor and modernize the codebase. This was an open source lightbulb for me, and over the past couple of years, I've become more and more involved in our growing community, recently stepping into the role of maintainer on the project.
-
-### Creating a new generation of developers
-
-As a software developer, I'm entirely self-taught, and much of what I know wouldn't have been possible if these tools were locked down and inaccessible. Learning in the information age is about having access to the ideas that inspire and motivate us.
-
-The ability to explore, break, fix and tinker with the source code I've used is largely the driving force of my motivation to learn. Like many coders, early on I'd peek into a codebase and change a few variables here and there to see what happened. Then I started stringing spaghetti code together to see what I could build with it. Bit by bit, I'd wonder "what is it doing?" and "why does this work, but that doesn't?" Eventually, my haphazard jungles of code became carefully architected codebases; all of this learned through playing with source code written by other developers and seeking to understand the bigger concepts of what the software was accomplishing.
-
-Beyond the possibilities open source offers to schools as a whole, it also can also offer individual students a profound opportunity to explore the technology that's part of our everyday lives. Schools embracing an open source mindset would do so not just to cut costs or create new tools for learning, but also to give their students the same freedoms to be a part of this evolving landscape of education and technology.
-
-With this level of access, open source in the hands of a student transforms from a piece of software to a source of potential learning experiences, and possibly even a launching point for students who wish to dive deeper into computer science concepts. This is a powerful way that students can discover their intrinsic motivation: when they can see their learning as a path to unravel and understand the complexities of the world around them.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/next-gen-coders-education
-
-作者:[Sandra Kuipers][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/skuipers
-[b]: https://github.com/lujun9972
-[1]: https://www.tis.edu.mo
-[2]: https://skuipers.com/portfolio/
-[3]: https://gibbonedu.org/
-[4]: https://opensource.com/education/14/2/gibbon-project-story
diff --git a/sources/talk/20181107 Understanding a -nix Shell by Writing One.md b/sources/talk/20181107 Understanding a -nix Shell by Writing One.md
deleted file mode 100644
index acad742117..0000000000
--- a/sources/talk/20181107 Understanding a -nix Shell by Writing One.md
+++ /dev/null
@@ -1,412 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Understanding a *nix Shell by Writing One)
-[#]: via: (https://theartofmachinery.com/2018/11/07/writing_a_nix_shell.html)
-[#]: author: (Simon Arneaud https://theartofmachinery.com)
-
-Understanding a *nix Shell by Writing One
-======
-
-A typical *nix shell has a lot of programming-like features, but works quite differently from languages like Python or C++. This can make a lot of shell features — like process management, argument quoting and the `export` keyword — seem like mysterious voodoo.
-
-But a shell is just a program, so a good way to learn how a shell works is to write one. I’ve written [a simple shell that fits in a few hundred lines of commented D source][1]. Here’s a post that walks through how it works and how you could write one yourself.
-
-### First (Cheating) Steps
-
-A shell is a kind of REPL (Read Evaluate Print Loop). At its heart is just a simple loop that reads commands from the input, processes them, and returns a result:
-
-```
-import std.process;
-import io = std.stdio;
-
-enum kPrompt = "> ";
-
-void main()
-{
- io.write(kPrompt);
- foreach (line; io.stdin.byLineCopy())
- {
- // "Cheating" by using the existing shell for now
- auto result = executeShell(line);
- io.write(result.output);
- io.write(kPrompt);
- }
-}
-
-$ dmd shell.d
-$ ./shell
-> head /usr/share/dict/words
-A
-a
-aa
-aal
-aalii
-aam
-Aani
-aardvark
-aardwolf
-Aaron
-> # Press Ctrl+D to quit
->
-$
-```
-
-If you try out this code out for yourself, you’ll soon notice that you don’t have any nice editing features like tab completion or command history. The popular Bash shell uses a library called [GNU Readline][2] for that. You can get most of the features of Readline when playing with these toy examples just by running them under [rlwrap][3] (probably already in your system’s package manager).
-
-### DIY Command Execution (First Attempt)
-
-That first example demonstrated the absolute basic structure of a shell, but it cheated by passing commands directly to the shell already running on the system. Obviously, that doesn’t explain anything about how a real shell processes commands.
-
-The basic idea, though, is very simple. Nearly everything that gets called a “shell command” (e.g., `ls` or `head` or `grep`) is really just a program on the filesystem. The shell just has to run it. At the operating system level, running a program is done using the `execve` system call (or one of its alternatives). For portability and convenience, the normal way to make a system call is to use one of the wrapper functions in the C library. Let’s try using `execv()`:
-
-```
-import core.sys.posix.stdio;
-import core.sys.posix.unistd;
-
-import io = std.stdio;
-import std.string;
-
-enum kPrompt = "> ";
-
-void main()
-{
- io.write(kPrompt);
- foreach (line; io.stdin.byLineCopy())
- {
- runCommand(line);
- io.write(kPrompt);
- }
-}
-
-void runCommand(string cmd)
-{
- // Need to convert D string to null-terminated C string
- auto cmdz = cmd.toStringz();
-
- // We need to pass execv an array of program arguments
- // By convention, the first element is the name of the program
-
- // C arrays don't carry a length, just the address of the first element.
- // execv starts reading memory from the first element, and needs a way to
- // know when to stop. Instead of taking a length value as an argument,
- // execv expects the array to end with a null as a stopping marker.
-
- auto argsz = [cmdz, null];
- auto error = execv(cmdz, argsz.ptr);
- if (error)
- {
- perror(cmdz);
- }
-}
-```
-
-Here’s a sample run:
-
-```
-> ls
-ls: No such file or directory
-> head
-head: No such file or directory
-> grep
-grep: No such file or directory
-> ಠ_ಠ
-ಠ_ಠ: No such file or directory
->
-```
-
-Okay, so that’s not working so well. The problem is that that the `execve` call isn’t as smart as a shell: it just literally executes the program it’s told to. In particular, it has no smarts for finding the programs that implement `ls` or `head`. For now, let’s do the finding ourselves, and then give `execve` the full path to the command:
-
-```
-$ which ls
-/bin/ls
-$ ./shell
-> /bin/ls
-shell shell.d shell.o
-$
-```
-
-This time the `ls` command worked, but our shell quit and we dropped straight back into the system’s shell. What’s going on? Well, `execve` really is a single-purpose call: it doesn’t spawn a new process for running the program separately from the current program, it _replaces_ the current program. (The toy shell actually quit when `ls` started, not when it finished.) Creating a new process is done with a different system call: traditionally `fork`. This isn’t how programming languages normally work, so it might seem like weird and annoying behaviour, but it’s actually really useful. Decoupling process creation from program execution allows a lot of flexibility, as will become clearer later.
-
-### Fork and Exec
-
-To keep the shell running, we’ll use the `fork()` C function to create a new process, and then make that new process `execv()` the program that implements the command. (On modern GNU/Linux systems, `fork()` is actually a wrapper around a system call called `clone`, but it still behaves like the classic `fork` system call.)
-
-`fork()` duplicates the current process. We get a second process that’s running the same program, at the same point, with a copy of everything in memory and all the same open files. Both the original process (parent) and the duplicate (child) keep running normally. Of course, we want the parent process to keep running the shell, and the child to `execv()` the command. The `fork()` function helps us differentiate them by returning zero in the child and a non-zero value in the parent. (This non-zero value is the process ID of the child.)
-
-Let’s try it out in a new version of the `runCommand()` function:
-
-```
-int runCommand(string cmd)
-{
- // fork() duplicates the process
- auto pid = fork();
- // Both the parent and child keep running from here as if nothing happened
- // pid will be < 0 if forking failed for some reason
- // Otherwise pid == 0 for the child and != 0 for the parent
- if (pid < 0)
- {
- perror("Can't create a new process");
- exit(1);
- }
- if (pid == 0)
- {
- // Child process
- auto cmdz = cmd.toStringz();
- auto argsz = [cmdz, null];
- execv(cmdz, argsz.ptr);
-
- // Only get here if exec failed
- perror(cmdz);
- exit(1);
- }
- // Parent process
- // This toy shell can only run one command at a time
- // All the parent does is wait for the child to finish
- int status;
- wait(&status);
- // This is the exit code of the child
- // (Conventially zero means okay, non-zero means error)
- return WEXITSTATUS(status);
-}
-```
-
-Here it is in action:
-
-```
-> /bin/ls
-shell shell.d shell.o
-> /bin/uname
-Linux
->
-```
-
-Progress! But it still doesn’t feel like a real shell if we have to tell it exactly where to find each command.
-
-### PATH
-
-If you try using `which` to find the implementations of various commands, you might notice they’re all in the same small set of directories. The list of directories that contains commands is stored in an environment variable called `PATH`. It looks something like this:
-
-```
-$ echo $PATH
-/home/user/bin:/home/user/local/bin:/home/user/.local/bin:/usr/local/bin:/usr/bin:/bin:/opt/bin:/usr/games/bin
-```
-
-As you can see, it’s a list of directories separated by colons. If you ask a shell to run `ls`, it’s supposed to search each directory in this list for a program called `ls`. The search should be done in order starting from the first directory, so a personal implementation of `ls` in `/home/user/bin` could override the one in `/bin`. Production-ready shells cache this lookup.
-
-`PATH` is only used by default. If we type in a path to a program, that program will be used directly.
-
-Here’s a simple implemention of a smarter conversion of a command name to a C string that points to the executable. It returns a null if the command can’t be found.
-
-```
-const(char*) findExecutable(string cmd)
-{
- if (cmd.canFind('/'))
- {
- if (exists(cmd)) return cmd.toStringz();
- return null;
- }
-
- foreach (dir; environment["PATH"].splitter(":"))
- {
- import std.path : buildPath;
- auto candidate = buildPath(dir, cmd);
- if (exists(candidate)) return candidate.toStringz();
- }
- return null;
-}
-```
-
-Here’s what the shell looks like now:
-
-```
-> ls
-shell shell.d shell.o
-> uname
-Linux
-> head shell.d
-head shell.d: No such file or directory
->
-```
-
-### Complex Commands
-
-That last command failed because the toy shell doesn’t handle program arguments yet, so it tries to find a command literally called “head shell.d”.
-
-If you look back at the implementation of `runCommand()`, you’ll see that `execv()` takes a C array of arguments, as well as the path to the program to run. All we have to do is process the command to make the array `["head", "shell.d", null]`. Something like this would do it:
-
-```
-// Key difference: split the command into pieces
-auto args = cmd.split();
-
-auto cmdz = findExecutable(args[0]);
-if (cmdz is null)
-{
- io.stderr.writef("%s: No such file or directory\n", args[0]);
- // 127 means "Command not found"
- // http://tldp.org/LDP/abs/html/exitcodes.html
- exit(127);
-}
-auto argsz = args.map!(toStringz).array;
-argsz ~= null;
-auto error = execv(cmdz, argsz.ptr);
-```
-
-That makes simple arguments work, but we quickly get into problems:
-
-```
-> head -n 5 shell.d
-import core.sys.posix.fcntl;
-import core.sys.posix.stdio;
-import core.sys.posix.stdlib;
-import core.sys.posix.sys.wait;
-import core.sys.posix.unistd;
-> echo asdf
-asdf
-> echo $HOME
-$HOME
-> ls *.d
-ls: cannot access '*.d': No such file or directory
-> ls '/home/user/file with spaces.txt'
-ls: cannot access "'/home/user/file": No such file or directory
-ls: cannot access 'with': No such file or directory
-ls: cannot access "spaces.txt'": No such file or directory
->
-```
-
-As you might guess by looking at the above, shells like a POSIX Bourne shell (or Bash) do a _lot_ more than just `split()`. Take the `echo $HOME` example. It’s a common idiom to use `echo` for viewing environment variables (like `HOME`), but `echo` itself doesn’t actually do any environment variable handling. A POSIX shell processes a command like `echo $HOME` into an array like `["echo", "/home/user", null]` and passes it to `echo`, which does nothing but reflect its arguments back to the terminal.
-
-A POSIX shell also handles glob patterns like `*.d`. That’s why glob patterns work with _any_ command in *nix (unlike MS-DOS, for example): the commands don’t even see the globs.
-
-The command `ls '/home/user/file with spaces.txt'` got split into `["ls", "'/home/user/file", "with", "spaces.txt'", null]`. Any useful shell lets you use quoting and escaping to prevent any processing (like splitting into arguments) that you don’t want. Once again, quotes are completely handled by the shell; commands don’t even see them. Also, unlike most programming languages, everything is a string in shell, so there’s no difference between `head -n 5 shell.d` and `head -n '5' shell.d` — both turn into `["head", "-n", "5", "shell.d", null]`.
-
-There’s something you might notice from that last example: the shell can’t treat flags like `-n 5` differently from positional arguments like `shell.d` because `execve` only takes a single array of all arguments. So that means argument types are one thing that programs _do_ have to figure out for themselves, which explains [the clichéd inteview question about why quotes won’t help you delete a file called `-`][4] (i.e., the quotes are processed before the `rm` command sees them).
-
-A POSIX shell supports quite complex constructs like `while` loops and pipelines, but the toy shell only supports simple commands.
-
-### Tweaking the Child Process
-
-I said earlier that decoupling `fork` from `exec` allows extra flexibility. Let me give a couple of examples.
-
-#### I/O Redirection
-
-A key design principle of Unix is that commands should be agnostic about where their input and output are from, so that user input/output can be replaced with file input/output, or even input/output of other commands. E.g.:
-
-```
-sort events.txt | head -n 10 > /tmp/top_ten_events.txt
-```
-
-How does it work? Take the `head` command. The shell forks off a new child process. The child is a duplicate of the parent, so it inherits the same standard input and output. However, the child can replace its own standard input with a pipe shared with the process for `sort`, and replace its own standard output with a file handle for `/tmp/top_ten_events.txt`. After calling `execv()`, the process will become a `head` process that blindly reads/writes to/from whatever standard I/O it has.
-
-Getting down to the low-level details, *nix systems represent all file handles with so-called “file descriptors”, which are just integers as far as user programs are concerned, but point to data structures inside the operating system kernel. Standard input is file descriptor 0, and standard output is file descriptor 1. Replacing standard output for `head` looks something like this (minus error handling):
-
-```
-// The fork happens somewhere back here
-// Now running in the child process
-
-// Open the new file (no control over the file descriptor)
-auto new_fd = open("/tmp/top_ten_events.txt", O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
-// Copy the open file into file #1 (standard output)
-dup2(new_fd, 1);
-// Close the spare file descriptor
-close(new_fd);
-
-// The exec happens somewhere down here
-```
-
-The pipeline works in the same kind of way, except instead of using `open()` to open a file, we use `pipe()` to create _two_ connected file descriptors, and then let `sort` use one, and `head` use the other.
-
-#### Environment Variables
-
-If you’ve ever had to deploy something using a command line, there’s a good chance you’ve had to set some of these configuration variables. Each process carries its own set of environment variables, so you can override, say, `AUDIODEV` for one running program without affecting others. The C standard library provides functions for manipulating environment variables, but they’re not actually managed by the operating system kernel — the [C runtime][5] manages them using the same user-space memory that other program variables use. That means they also get copied to child processes on a `fork`. The runtime and the kernel co-operate to preserve them on `execve`.
-
-There’s no reason we can’t manipulate the environment variables the child process ends up using. POSIX shells support this: just put any variable assignments you want directly in front of the command.
-
-```
-$ uname
-Linux
-$ # LD_DEBUG is an environment variable for enabling linker debugging
-$ # (Doesn't work on all systems.)
-$ LD_DEBUG=statistics uname
-12128:
-12128: runtime linker statistics:
-12128: total startup time in dynamic loader: 2591152 cycles
-12128: time needed for relocation: 816752 cycles (31.5%)
-12128: number of relocations: 153
-12128: number of relocations from cache: 3
-12128: number of relative relocations: 1304
-12128: time needed to load objects: 1196148 cycles (46.1%)
-Linux
-$ # LD_DEBUG was only set for uname
-$ echo $LD_DEBUG
-
-$ # Pop quiz: why doesn't this print "bar"?
-$ FOO=bar echo $FOO
-
-$
-```
-
-These temporary environment variables are useful and easy to implement.
-
-### Builtins
-
-It’s great that the fork/exec pattern lets us reconfigure the child process as much as we like without affecting the parent shell. But some commands _need_ to affect the shell. A good example is the `cd` command for changing the current working directory. It would be pointless if it ran in a child process, changed its own working directory, then just quit, leaving the shell unchanged.
-
-The simple solution to this problem is builtins. I said that most shell commands are implemented as external programs on the filesystem. Well, some aren’t — they’re handled directly by the shell itself. Before searching PATH for a command implementation, the shell just checks if it has it’s own built-in implementation. A neat way to code this is [the function pointer approach I described in a previous post][6].
-
-You can read [a list of Bash builtins in the Advanced Bash-Scripting Guide][7]. Some, like `cd`, are builtins because they’re highly coupled to the shell. Others, like `echo`, have built-in implementations for performance reasons (most systems also have a standalone `echo` program).
-
-There’s one builtin that confuses a lot of people: `export`. It makes sense if you realise that the POSIX shell scripting language has its own variables that are totally separate from environment variables. A variable assignment is just a shell variable by default, and `export` makes it into an environment variable (when spawning child processes, at least). The difference is that the C runtime doesn’t know anything about shell variables, so they get lost on `execve`.
-
-```
-$ uname
-Linux
-$ # Let's try setting LD_DEBUG
-$ LD_DEBUG=statistics
-$ # It has no effect because that's actually just a shell variable
-$ uname
-Linux
-$ # Let's try making into an environment variable:
-$ export LD_DEBUG
-$ uname
-12128:
-12128: runtime linker statistics:
-12128: total startup time in dynamic loader: 2591152 cycles
-12128: time needed for relocation: 816752 cycles (31.5%)
-12128: number of relocations: 153
-12128: number of relocations from cache: 3
-12128: number of relative relocations: 1304
-12128: time needed to load objects: 1196148 cycles (46.1%)
-Linux
-$ # Now every non-builtin will dump debugging info
-$ # Let's stop that for sanity's sake
-$ unset LD_DEBUG
-$
-```
-
-### Putting it Together
-
-A POSIX-compliant shell does a lot more stuff (like signal handling and job management) but that’s enough to understand how to write an MVP *nix shell. You can see all the pieces together by checking out [the complete working example in my repository][1].
-
---------------------------------------------------------------------------------
-
-via: https://theartofmachinery.com/2018/11/07/writing_a_nix_shell.html
-
-作者:[Simon Arneaud][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://theartofmachinery.com
-[b]: https://github.com/lujun9972
-[1]: https://gitlab.com/sarneaud/toyshell
-[2]: https://tiswww.case.edu/php/chet/readline/rltop.html
-[3]: https://github.com/hanslub42/rlwrap
-[4]: https://unix.stackexchange.com/questions/1519/how-do-i-delete-a-file-whose-name-begins-with-hyphen-a-k-a-dash-or-minus
-[5]: /2017/06/04/what_is_the_d_runtime.html#what-about-c--does-c-really-have-a-runtime-too
-[6]: /2018/04/02/inheritance_and_polymorphism.html
-[7]: https://www.tldp.org/LDP/abs/html/internal.html
diff --git a/sources/talk/20181113 Have you seen these personalities in open source.md b/sources/talk/20181113 Have you seen these personalities in open source.md
deleted file mode 100644
index 20c2243121..0000000000
--- a/sources/talk/20181113 Have you seen these personalities in open source.md
+++ /dev/null
@@ -1,93 +0,0 @@
-Have you seen these personalities in open source?
-======
-An inclusive community is a more creative and effective community. But how can you make sure you're accommodating the various personalities that call your community "home"?
-
-
-When I worked with the Mozilla Foundation, long before the organization boasted more than a hundred and fifty staff members, we conducted a foundation-wide Myers-Briggs indicator. The [Myers-Briggs][1] is a popular personality assessment, one used widely in [career planning and the business world][2]. Created in the early twentieth century, it's the product of two women: Katharine Cook Briggs and her daughter Isabel Briggs Myers, who built the tool on Carl Jung's Theory of Psychological Types (which was itself based on clinical observations, as opposed to "controlled" scientific studies). Each of my co-workers (53 at the time) answered the questions. We were curious about what kind of insights we would gain into our individual personalities, and, by extension, about how we'd best work together.
-
-Our team's report showed that the people working for the Mozilla Foundation, one of the biggest and oldest open source projects on the web, were people with the least common personality types. Where about 77% of the general population fit into the top 8 most common Myers-Briggs types, only 23% of the Mozilla Foundation team did. Our team was mostly composed of the rarer Myers-Briggs types. For example, 23% of the team shared my own individual personality type ("ENTP"), which is interesting to me, since people with that personality type only make up 3.2% of the general population. And 9% of the team were ENTJ, the second rarest personality type, at just 1.8% of the population.
-
-I began to wonder: Do open source projects attract a certain type of personality? Or is this one assessment of full-time open sourcers just a fluke?
-
-And if it's true, which aspects of personality can we tug on when encouraging community participation? How can we use our knowledge of personality and psychology to push our open source projects towards success?
-
-### The personalities of open source
-
-Thinking about personality types and open source communities is tricky. In short, when we're talking about personality, we see lots speculation.
-
-Personality assessments and, indeed, the entire field of psychology are often considered "soft science." Academics in the field have long struggled to be seen as scientifically relevant. Other subjects, like physics and mathematics, can prove hard truths—this is the way it is, and if it's not like this, then it's not true.
-
-Thinking about personality types and open source communities is tricky. In short, when we're talking about personality, we see lots speculation.
-
-But people and their brains are fascinatingly complicated, and definitively proving a theory is impossible. Conducting controlled studies with human beings is difficult; there are ethical implications, physical needs, and no two people are alike—so there is no way to have a truly stable control group. Plus, there's always an outlier of some sort, because our backgrounds and experiences structure our personalities and the way we think. In psychology, the closest we can get to a "hard truth" is something like "This is mostly the way it is, except when it's not." Only in recent years (and with recent advancements in technology) have links between psychology and neurology provided us with some psychological "hard truths." For example, we know, definitively, which parts of the brain are responsible for certain functions.
-
-Emotion and personality, however, are more elusive subjects; generalizations remain difficult and face relevant intellectual criticism. But when we're thinking about designing communities around personality types, we can work with some useful archetypes.
-
-After all, anyone can find a place in open source. Millions of people participate in various projects and communities. Open source isn't just for engineers anymore; we've gone global. And while open source might not be as mainstream as, say, eggs, I'm confident that every personality type, gender identity, sexual orientation, age, and background is represented in the global open source community.
-
-When designing open source projects, you want to ensure that you build [architectures of participation][3] for everyone. Successful projects have communities, and community-building happens intentionally. Community management takes time and effort, so if you're hoping to lead a successful open source project, don't spend all your resources on the product. Care for your people, and your people will help you with the rest of it.
-
-Here's what to consider as you begin architecting an inclusive community.
-
-#### Introverted versus extraverted
-
-An introvert is someone who gains energy from solitude, while an extravert gains energy from being around other people. We all have a little of both. For example, an introvert teaching might be using his extravert mode of operation all day. To recharge after a day at work, he'd likely need to go into quiet mode, thinking internally. An extravert teacher would be just as tired from the same day, but to recharge he'd want to talk about the day. An extravert might happily have a dinner party and use that as a mode of recharging.
-
-Another important difference is that those with an extravert preference tend to do a lot of their thinking out loud, whereas introverts think carefully before speaking. Thinking out loud can be difficult for an introvert to understand, as she might expect the things being said to have already been thought about. But for an extravert, verbalizing is a way of figuring stuff out. They don't mind saying things that are incorrect, because doing so helps them process information.
-
-Introverts and extraverts have different comfort levels with regard to participation; they may need different pathways for getting involved in your project or community.
-
-Some communities are accustomed to being marginalized, so being welcoming and encouraging becomes even more important if you want to have a diverse and inclusive project. Remember, diversity is also intentional, and inclusivity is one of [the principles of an open organization][4].
-
-Not everyone feels comfortable speaking in a community call or posting to a public forum. Not everyone will respond to a public list. Personal outreach and communication strategies that are more private are important for ensuring inclusivity. In addition to transparent and public communication mechanisms, a well-designed open source project will point contributors to specific people they can reach directly.
-
-#### Strict versus flexible
-
-Did you know that some people need highly structured environments or workflows to be productive, while others would become incapacitated by such structures? For many creative types, an adaptive and flexible environment or workflow is essential. For a truly inclusive project, you'll need to provide for both. I recommend that you always document and detail your processes. Write up your approaches, make an overview, and share the process with your community. [I've done this][5] while working on Greenpeace's open source project, [Planet 4][6].
-
-As a leader or community manager, you need to be flexible and kind when people don't follow your carefully planned processes. The approach might make sense to you and your team—it might make sense to a lot of people in the community—but it might be too strict for others. You should gently remind people of your processes, but you'll find that some people just won't follow it. Instead of creating a secondary process for those who need less structure, just be responsive to whatever the request might be. People will tell you what they need; they will ask the question they need answered. And then you can generate even greater participation by demonstrating your own adaptability.
-
-#### Certainty versus ambiguity
-
-Openly documenting everything, including meeting notes, is a common practice for open source projects and communities. I am, indeed, in the habit of making charts and slides to pair with written documentation. Different brains process information differently: For some, a drawing is more easily digestible than a document, and vice versa! A leader in this space needs to understand that when people read the notes, some will read the lines and others will read between them.
-
-The preference for taking things at face value is not more correct than a preference for exploring the murky possibilities of differing kinds of information. People remember meetings and events in different ways, and their varying perspectives can cause uncertainty around decisions that have been made. In short, just because something is a "fact" doesn't mean that there aren't multiple perspectives of it.
-
-Documenting decisions is an important practice in open source, but so is [helping people understand the context around those decisions][7]. Having to go back to something that's already finished can be frustrating, but being a leader in open source means being flexible and understanding the neurodiversity at work in your community.
-
-#### Objective versus subjective
-
-Nothing in the universe is certain—indeed, even gravity didn't always exist. Humans define the world around them; it's part of our nature. We're wonderful at rationalizing occurrences so things make sense to us.
-
-And when it comes to personality, this means some people might see an objective reality (the facts defined and unshakeable, "gravity exists") while others might see a subjective world (facts are merely stories we tell ourselves to make sense of our reality, "we wanted a reason that we stick to the Earth"). One common personality conflict stems from how we view the concept of truth. While some people rely on objective fact to guide their perceptions of the ways they should be interacting with the world, others prefer to let their subjective feelings guide how they judge the facts. In any industry, conflicts between varying ways of thinking can be difficult to reconcile.
-
-Open leaders need to ensure a healthy and sustainable environment for all community members. When conflict arises, be ready to "believe" everyone—because from each of their perspectives, they're most likely right. Note that "believing" everyone doesn't mean putting up with destructive behavior (there should never be room in your community for racism, sexism, ageism or outright trolling, no matter how people might frame these behaviors). It means creating a place that allows people to respectfully discuss and debate their perspectives. Be sure you put a code of conduct in place to help with this.
-
-### Inclusivity at the fore
-
-In open source, practicing inclusivity means seeking to bend your mind towards ways of thinking that might not come naturally to you. We can all become more empathetic towards other people, helping our communities grow to be more diverse. Learn to recognize your own preferences and understand how your brain works—but also remember that everyone's neural networks work a bit differently. Then, as a leader, make sure you're creating space for everyone by championing inclusivity, fairness, open-mindedness, and neurodiversity.
-
-(Special thanks to [Adam Procter][8].)
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/18/11/design-communities-personality-types
-
-作者:[Laura Hilliger][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/laurahilliger
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Myers%E2%80%93Briggs_Type_Indicator
-[2]: https://opensource.com/open-organization/16/7/personality-test-for-teams
-[3]: https://opensource.com/business/12/6/architecture-participation
-[4]: https://opensource.com/open-organization/resources/open-org-definition
-[5]: https://medium.com/planet4/improving-p4-in-tandem-774a0d306fbc
-[6]: https://medium.com/planet4
-[7]: https://opensource.com/open-organization/16/3/what-it-means-be-open-source-leader
-[8]: http://adamprocter.co.uk
diff --git a/sources/talk/20181114 Analyzing the DNA of DevOps.md b/sources/talk/20181114 Analyzing the DNA of DevOps.md
deleted file mode 100644
index 0542d572e6..0000000000
--- a/sources/talk/20181114 Analyzing the DNA of DevOps.md
+++ /dev/null
@@ -1,158 +0,0 @@
-Analyzing the DNA of DevOps
-======
-How have waterfall, agile, and other development frameworks shaped the evolution of DevOps? Here's what we discovered.
-
-
-If you were to analyze the DNA of DevOps, what would you find in its ancestry report?
-
-This article is not a methodology bake-off, so if you are looking for advice or a debate on the best approach to software engineering, you can stop reading here. Rather, we are going to explore the genetic sequences that have brought DevOps to the forefront of today's digital transformations.
-
-Much of DevOps has evolved through trial and error, as companies have struggled to be responsive to customers’ demands while improving quality and standing out in an increasingly competitive marketplace. Adding to the challenge is the transition from a product-driven to a service-driven global economy that connects people in new ways. The software development lifecycle is becoming an increasingly complex system of services and microservices, both interconnected and instrumented. As DevOps is pushed further and faster than ever, the speed of change is wiping out slower traditional methodologies like waterfall.
-
-We are not slamming the waterfall approach—many organizations have valid reasons to continue using it. However, mature organizations should aim to move away from wasteful processes, and indeed, many startups have a competitive edge over companies that use more traditional approaches in their day-to-day operations.
-
-Ironically, lean, [Kanban][1], continuous, and agile principles and processes trace back to the early 1940's, so DevOps cannot claim to be a completely new idea.
-
-Let's start by stepping back a few years and looking at the waterfall, lean, and agile software development approaches. The figure below shows a “haplogroup” of the software development lifecycle. (Remember, we are not looking for the best approach but trying to understand which approach has positively influenced our combined 67 years of software engineering and the evolution to a DevOps mindset.)
-
-
-
-> “A fool with a tool is still a fool.” -Mathew Mathai
-
-### The traditional waterfall method
-
-From our perspective, the oldest genetic material comes from the [waterfall][2] model, first introduced by Dr. Winston W. Royce in a paper published in the 1970's.
-
-
-
-Like a waterfall, this approach emphasizes a logical and sequential progression through requirements, analysis, coding, testing, and operations in a single pass. You must complete each sequence, meet criteria, and obtain a signoff before you can begin the next one. The waterfall approach benefits projects that need stringent sequences and that have a detailed and predictable scope and milestone-based development. Contrary to popular belief, it also allows teams to experiment and make early design changes during the requirements, analysis, and design stages.
-
-
-
-### Lean thinking
-
-Although lean thinking dates to the Venetian Arsenal in the 1450s, we start the clock when Toyota created the [Toyota Production System][3], developed by Japanese engineers between 1948 and 1972. Toyota published an official description of the system in 1992.
-
-
-
-Lean thinking is based on [five principles][4]: value, value stream, flow, pull, and perfection. The core of this approach is to understand and support an effective value stream, eliminate waste, and deliver continuous value to the user. It is about delighting your users without interruption.
-
-
-
-### Kaizen
-
-Kaizen is based on incremental improvements; the **Plan- >Do->Check->Act** lifecycle moved companies toward a continuous improvement mindset. Originally developed to improve the flow and processes of the assembly line, the Kaizen concept also adds value across the supply chain. The Toyota Production system was one of the early implementors of Kaizen and continuous improvement. Kaizen and DevOps work well together in environments where workflow goes from design to production. Kaizen focuses on two areas:
-
- * Flow
- * Process
-
-
-
-### Continuous delivery
-
-Kaizen inspired the development of processes and tools to automate production. Companies were able to speed up production and improve the quality, design, build, test, and delivery phases by removing waste (including culture and mindset) and automating as much as possible using machines, software, and robotics. Much of the Kaizen philosophy also applies to lean business and software practices and continuous delivery deployment for DevOps principles and goals.
-
-### Agile
-
-The [Manifesto for Agile Software Development][5] appeared in 2001, authored by Alistair Cockburn, Bob Martin, Jeff Sutherland, Jim Highsmith, Ken Schwaber, Kent Beck, Ward Cunningham, and others.
-
-
-
-[Agile][6] is not about throwing caution to the wind, ditching design, or building software in the Wild West. It is about being able to create and respond to change. Agile development is [based on twelve principles][7] and a manifesto that values individuals and collaboration, working software, customer collaboration, and responding to change.
-
-
-
-### Disciplined agile
-
-Since the Agile Manifesto has remained static for 20 years, many agile practitioners have looked for ways to add choice and subjectivity to the approach. Additionally, the Agile Manifesto focuses heavily on development, so a tweak toward solutions rather than code or software is especially needed in today's fast-paced development environment. Scott Ambler and Mark Lines co-authored [Disciplined Agile Delivery][8] and [The Disciplined Agile Framework][9], based on their experiences at Rational, IBM, and organizations in which teams needed more choice or were not mature enough to implement lean practices, or where context didn't fit the lifecycle.
-
-The significance of DAD and DA is that it is a [process-decision framework][10] that enables simplified process decisions around incremental and iterative solution delivery. DAD builds on the many practices of agile software development, including scrum, agile modeling, lean software development, and others. The extensive use of agile modeling and refactoring, including encouraging automation through test-driven development (TDD), lean thinking such as Kanban, [XP][11], [scrum][12], and [RUP][13] through a choice of five agile lifecycles, and the introduction of the architect owner, gives agile practitioners added mindsets, processes, and tools to successfully implement DevOps.
-
-### DevOps
-
-As far as we can gather, DevOps emerged during a series of DevOpsDays in Belgium in 2009, going on to become the foundation for numerous digital transformations. Microsoft principal DevOps manager [Donovan Brown][14] defines DevOps as “the union of people, process, and products to enable continuous delivery of value to our end users.”
-
-
-
-Let's go back to our original question: What would you find in the ancestry report of DevOps if you analyzed its DNA?
-
-
-
-We are looking at history dating back 80, 48, 26, and 17 years—an eternity in today’s fast-paced and often turbulent environment. By nature, we humans continuously experiment, learn, and adapt, inheriting strengths and resolving weaknesses from our genetic strands.
-
-Under the microscope, we will find traces of waterfall, lean thinking, agile, scrum, Kanban, and other genetic material. For example, there are traces of waterfall for detailed and predictable scope, traces of lean for cutting waste, and traces of agile for promoting increments of shippable code. The genetic strands that define when and how to ship the code are where DevOps lights up in our DNA exploration.
-
-
-
-You use the telemetry you collect from watching your solution in production to drive experiments, confirm hypotheses, and prioritize your product backlog. In other words, DevOps inherits from a variety of proven and evolving frameworks and enables you to transform your culture, use products as enablers, and most importantly, delight your customers.
-
-If you are comfortable with lean thinking and agile, you will enjoy the full benefits of DevOps. If you come from a waterfall environment, you will receive help from a DevOps mindset, but your lean and agile counterparts will outperform you.
-
-### eDevOps
-
-
-
-In 2016, Brent Reed coined the term eDevOps (no Google or Wikipedia references exist to date), defining it as “a way of working (WoW) that brings continuous improvement across the enterprise seamlessly, through people, processes and tools.”
-
-Brent found that agile was failing in IT: Businesses that had adopted lean thinking were not achieving the value, focus, and velocity they expected from their trusted IT experts. Frustrated at seeing an "ivory tower" in which siloed IT services were disconnected from architecture, development, operations, and help desk support teams, he applied his practical knowledge of disciplined agile delivery and added some goals and practical applications to the DAD toolset, including:
-
- * Focus and drive of culture through a continuous improvement (Kaizen) mindset, bringing people together even when they are across the cubicle
- * Velocity through automation (TDD + refactoring everything possible), removing waste and adopting a [TOGAF][15], JBGE (just barely good enough) approach to documentation
- * Value through modeling (architecture modeling) and shifting left to enable right through exposing anti-patterns while sharing through collaboration patterns in a more versatile and strategic modern digital repository
-
-
-
-Using his experience with AI at IBM, Brent designed a maturity model for eDevOps that incrementally automates dashboards for measuring and decision-making purposes so that continuous improvement through a continuous deployment (automating from development to production) is a real possibility for any organization. eDevOps in an effective transformation program based on disciplined DevOps that enables:
-
- * Business to DevOps (BizDevOps),
- * Security to DevOps (SecDevOps)
- * Information to DevOps (DataDevOps)
- * Loosely coupled technical services while bringing together and delighting all stakeholders
- * Building potentially consumable solutions every two weeks or faster
- * Collecting, measuring, analyzing, displaying, and automating actionable insight through the DevOps processes from concept through live production use
- * Continuous improvement following a Kaizen and disciplined agile approach
-
-
-
-### The next stage in the development of DevOps
-
-
-
-Will DevOps ultimately be considered hype—a collection of more tech thrown at corporations and added to the already extensive list of buzzwords? Time, of course, will tell how DevOps will progress. However, DevOps' DNA must continue to mature and be refined, and developers must understand that it is neither a silver bullet nor a remedy to cure all ailments and solve all problems.
-
-```
-DevOps != Agile != Lean Thinking != Waterfall
-
-DevOps != Tools !=Technology
-
-DevOps Ì Agile Ì Lean Thinking Ì Waterfall
-```
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/analyzing-devops
-
-作者:[Willy-Peter Schaub][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/wpschaub
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Kanban
-[2]: https://airbrake.io/blog/sdlc/waterfall-model
-[3]: https://en.wikipedia.org/wiki/Toyota_Production_System
-[4]: https://www.lean.org/WhatsLean/Principles.cfm
-[5]: http://agilemanifesto.org/
-[6]: https://www.agilealliance.org/agile101
-[7]: http://agilemanifesto.org/principles.html
-[8]: https://books.google.com/books?id=CwvBEKsCY2gC
-[9]: http://www.disciplinedagiledelivery.com/books/
-[10]: https://en.wikipedia.org/wiki/Disciplined_agile_delivery
-[11]: https://en.wikipedia.org/wiki/Extreme_programming
-[12]: https://www.scrum.org/resources/what-is-scrum
-[13]: https://en.wikipedia.org/wiki/Rational_Unified_Process
-[14]: http://donovanbrown.com/
-[15]: http://www.opengroup.org/togaf
diff --git a/sources/talk/20181114 Is your startup built on open source- 9 tips for getting started.md b/sources/talk/20181114 Is your startup built on open source- 9 tips for getting started.md
deleted file mode 100644
index 678eb96a59..0000000000
--- a/sources/talk/20181114 Is your startup built on open source- 9 tips for getting started.md
+++ /dev/null
@@ -1,76 +0,0 @@
-Is your startup built on open source? 9 tips for getting started
-======
-Are open source businesses all that different from normal businesses?
-
-
-When I started [Gluu][1] in 2009, I had no idea how difficult it would be to start an open source software company. Using the open source development methodology seemed like a good idea, especially for infrastructure software based on protocols defined by open standards. By nature, entrepreneurs are optimistic—we underestimate the difficulty of starting a business. However, Gluu was my fourth business, so I thought I knew what I was in for. But I was in for a surprise!
-
-Every business is unique. One of the challenges of serial entrepreneurship is that a truth that was core to the success of a previous business may be incorrect in your next business. Building a business around open source forced me to change my plan. How to find the right team members, how to price our offering, how to market our product—all of these aspects of starting a business (and more) were impacted by the open source mission and required an adjustment from my previous experience.
-
-A few years ago, we started to question whether Gluu was pursuing the right business model. The business was growing, but not as fast as we would have liked.
-
-One of the things we did at Gluu was to prepare a "business model canvas," an approach detailed in the book [Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers][2] by Yves Pigneur and Alexander Osterwalder. This is a thought-provoking exercise for any business at any stage. It helped us consider our business more holistically. A business is more than a stream of revenue. You need to think about how you segment the market, how to interact with customers, what are your sales channels, what are your key activities, what is your value proposition, what are your expenses, partnerships, and key resources. We've done this a few times over the years because a business model naturally evolves over time.
-
-In 2016, I started to wonder how other open source businesses were structuring their business models. Business Model Generation talks about three types of companies: product innovation, customer relationship, and infrastructure.
-
- * Product innovation companies are first to market with new products and can get a lot of market share because they are first.
- * Customer relationship companies have a wider offering and need to get "wallet share" not market share.
- * Infrastructure companies are very scalable but need established operating procedures and lots of capital.
-
-
-
-![Open Source Underdogs podcast][4]
-
-Mike Swartz, CC BY
-
-It's hard to figure out what models and types of business other open source software companies are pursuing by just looking at their website. And most open source companies are private—so there are no SEC filings to examine.
-
-To find out more, I went to the web. I found a [great talk][5] from Mike Olson, Founder and Chief Strategy Officer at Cloudera, about open source business models. It was recorded as part of a Stanford business lecture series. I wanted more of these kinds of talks! But I couldn't find any. That's when I got the idea to start a podcast where I interview founders of open source companies and ask them to describe what business model they are pursuing.
-
-In 2018, this idea became a reality when we started a podcast called [Open Source Underdogs][6]. So far, we have recorded nine episodes. There is a lot of great content in all the episodes, but I thought it would be fun to share one piece of advice from each.
-
-### Advice from 9 open source businesses
-
-**Peter Wang, CTO of Anaconda: **"Investors coming in to help put more gas in your gas tank want to understand what road you're on and how far you want to go. If you can't communicate to investors on a basis that they understand about your business model and revenue model, then you have no business asking them for their money. Don't get mad at them!"
-
-**Jim Thompson, Founder of Netgate: **"Businesses survive at the whim of their customers. Solving customer problems and providing value to the business is literally why you have a business!"
-
-**Michael Howard, CEO of MariaDB: **"My advice to open source software startups? It depends what part of the stack you're in. If you're infrastructure, you have no choice but to be open source."
-
-**Ian Tien, CEO of** **Mattermost: ** "You want to build something that people love. So start with roles that open source can play in your vision for the product, the distribution model, the community you want to build, and the business you want to build."
-
-**Mike Olson, Founder and Chief Strategy Officer at Cloudera: **"A business model is a complex construct. Open source is a really important component of strategic thinking. It's a great distributed development model. It's a genius, low-cost distribution model—and those have a bunch of advantages. But you need to think about how you're going to get paid."
-
-**Elliot Horowitz, Founder of MongoDB: **"The most important thing, whether it's open source or not open source, is to get incredibly close to your users."
-
-**Tom Hatch, CEO of SaltStack: **"Being able to build an internal culture and a management mindset that deals with open source, and profits from open source, and functions in a stable and responsible way with regard to open source is one of the big challenges you're going to face. It's one thing to make a piece of open source software and get people to use it. It's another to build a company on top of that open source."
-
-**Matt Mullenweg, CEO of Automattic: **"Open source businesses aren't that different from normal businesses. A mistake that we made, that others can avoid, is not incorporating the best leaders and team members in functions like marketing and sales."
-
-**Gabriel Engel, CEO of RocketChat: **"Moving from a five-person company, where you are the center of the company, and it's easy to know what everyone is doing, and everyone relies on you for decisions, to a 40-person company—that transition is harder than expected."
-
-### What we've learned
-
-After recording these podcasts, we've tweaked Gluu's business model a little. It's become clearer that we need to embrace open core—we've been over-reliant on support revenue. It's a direction we had been going, but listening to our podcast's guests supported our decision.
-
-We have many new episodes lined up for 2018 and 2019, including conversations with the founders of Liferay, Couchbase, TimescaleDB, Canonical, Redis, and more, who are sure to offer even more great insights about the open source software business. You can find all the podcast episodes by searching for "Open Source Underdogs" on iTunes and Google podcasts or by visiting our [website][6]. We want to hear your opinions and ideas you have to help us improve the podcast, so after you listen, please leave us a review.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/tips-open-source-entrepreneurs
-
-作者:[Mike Schwartz][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/gluufederation
-[b]: https://github.com/lujun9972
-[1]: https://www.gluu.org/
-[2]: https://www.wiley.com/en-us/Business+Model+Generation%3A+A+Handbook+for+Visionaries%2C+Game+Changers%2C+and+Challengers-p-9780470876411
-[3]: /file/414706
-[4]: https://opensource.com/sites/default/files/uploads/underdogs_logo.jpg (Open Source Underdogs podcast)
-[5]: https://youtu.be/T_UM5PYk9NA
-[6]: https://opensourceunderdogs.com/
diff --git a/sources/talk/20181121 A Closer Look at Voice-Assisted Speakers.md b/sources/talk/20181121 A Closer Look at Voice-Assisted Speakers.md
deleted file mode 100644
index c3f477c0c3..0000000000
--- a/sources/talk/20181121 A Closer Look at Voice-Assisted Speakers.md
+++ /dev/null
@@ -1,125 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (A Closer Look at Voice-Assisted Speakers)
-[#]: via: (https://www.linux.com/blog/2018/11/closer-look-voice-assisted-speakers)
-[#]: author: (Eric Brown https://www.linux.com/users/ericstephenbrown)
-[#]: url: ( )
-
-A Closer Look at Voice-Assisted Speakers
-======
-
-
-
-U.S. consumers are expected to drop a bundle this Black Friday on smart speakers and home hubs. A Nov. 15 [Canalys report][1] estimates that shipments of voice-assisted speakers grew 137 percent in Q3 2018 year-to-year and are on the way to 75 million-unit sales in 2018. At the recent [Embedded Linux Conference and Open IoT Summit][2] in Edinburgh, embedded Linux developer and [Raspberry Pi HAT][3] creator Leon Anavi of the Konsulko Group reported on the latest smart speaker trends.
-
-As Anavi noted in his “Comparison of Voice Assistant SDKs for Embedded Linux Devices” talk, conversing with computers became a staple of science fiction over half a century ago. Voice technology is interesting “because it combines AI, big data, IoT, and application development,” said Anavi.
-
-In Q3 2017, Amazon and Google owned the industry with 74.7 percent and 24.6 percent, respectively, said Canalys. A year later, the percentages were down to 31.9 and 29.8. China-based Alibaba and Xiaomi almost equally split another 21.8 percent share, followed by 17.4 percent for “others,” which mostly use Amazon Alexis, and increasingly, Google Assistant.
-
-Despite the success of the mostly Linux-driven smart speaker market, Linux application developers have not jumped into voice app development in the numbers one might expect. In part, this is due to reservations about Google and [Amazon privacy safeguards][4], as well as the proprietary nature of the hardware and cloud software.
-
-“Privacy is a concern with smart speakers,” said Anavi. “You can’t fully trust a corporation if the product is not open source.”
-
-Anavi summarized the Google and Amazon SDKs but spent more time on the fully open source Mycroft Mark. Although Anavi clearly prefers Mycroft, he encouraged developers to investigate all the platforms. “There is a huge demand in the market for these devices and a lot of opportunity for IoT integration, from writing new skills to integrating voice assistants in consumer electronics devices,” said Anavi.
-
-### Alexa/Echo
-
-Amazon’s Alexa debuted in the Echo smart speaker four years ago. Amazon has since expanded to the Echo branded Dot, Spot, Tap, and Plus speakers, as well as the Echo Show and new [Echo Show 2][5] display hubs.
-
-The market leading Echo devices run on Amazon’s Linux- and Android-based Fire OS. The original Echo and Dot ran on the Cortex-A8-based TI DM3725 SoC while more recent devices have moved to an Armv8 MediaTek MT8163V SoC with 256MB RAM and 4GB flash.
-
-Thanks to Amazon’s wise decision to release an Apache 2.0 licensed Alexa Voice Services (AVS) SDK, Alexa also runs on most third-party hubs. The SDK includes an Alexa Skills Kit for creating custom Skills. The cloud platform required to make Alexa devices work is not open source, however, and commercial vendors must sign an agreement and undergo a certification process.
-
-Alexa runs on a variety of hardware [including the Raspberry Pi][6], as well as smart devices ranging from the Ecobee4 Smart Thermostat to the LG Hub Robot. Microsoft recently began [selling Echo devices][7], and earlier this year partnered with Amazon to integrate Alexa with its own Cortana voice agent in devices. This week, Microsoft announced that users can [voice-activate Skype calls][8] via Alexa on Echo devices.
-
-### Google Assistant/Home
-
-The Google Assistant voice agent debuted on the Google Home smart speaker in 2016. It has since expanded to the Echo Dot-like Home Mini, which like the Home runs on a 1.2GHz dual-core Cortex-A7 Marvell Armada 1500 Mini Plus with 512MB RAM and 4GB flash. This year’s [Home Max][9] offered improved speakers and advanced to a 1.5GHz, quad-core Cortex-A53 processor. More recently, Google launched the touchscreen enabled [Google Home Hub][10].
-
-The Google Home devices run on a version of the Linux-based Google Cast OS. Like Alexa, the Python driven [Google Assistant SDK][11] lets you add the voice agent to third-party devices. However, it’s still in preview stage and lacks an open source license. Developers can create applications with [Google Actions][12].
-
-Last year, Google [launched][13] a version of its Google Assistant SDK for the Raspberry Pi 3 and began selling an [AIY Voice Kit][14]</a> that runs on the Pi. There’s also a kit that runs on the Orange Pi, said Anavi.
-
-This year, Google has aggressively [courted hardware partners][15] to produce home hub devices that combine Assistant with Google’s proprietary [Android Things][16]. The devices run on a variety of Arm-based SoCs led by the Qualcomm SD212 Home Hub Platform.
-
-The SDK expansion has resulted in a variety of third-party devices running Assistant, including the Lenovo Smart Display and the just released [LG XBOOM AI ThinQ WK9][17] touchscreen hubs. Sales of Google Home devices outpaced Echo earlier this year, although Amazon regained the lead in Q3, says Canalys.
-
-Like Alexa, but unlike Mycroft, Google Assistant offers multilingual support. The latest version supports follow-up questions without having to repeat the activation word, and there’s a voice match feature that can recognize up to six users. A new Google Duplex feature accomplishes real-world tasks through natural phone conversations.
-
-### Mycroft/Mark
-
-Anavi’s favorite smart speaker is the Linux-driven, open source (Apache 2.0 and CERN) [Mycroft][18]. The Raspberry Pi based [Mycroft Mark 1][19] speaker was certified by the Open Source Hardware Association (OSHA).
-
-The [Mycroft Mark II][20] launched on Kickstarter in January and has received $450,000 in funding. This Xilinx [Zynq UltraScale+ MPSoC][21] driven home hub integrates Aaware’s far-field [Sound Capture][22] technology. A [Nov. 15 update post][23] revealed that the Mark II will miss its December ship date.
-
-Kansas City-based Mycroft has raised $2.5 million from institutional investors and is now seeking funding on [StartEngine][24]. Mycroft sees itself as a software company and is encouraging other companies to build the Mycroft Core platform and Mycroft AI voice agent into products. The company offers an enterprise server license to corporate customers for $1,500 a month, and there’s a free, Raspbian based [Picroft][25] application for the Raspberry Pi. A Picroft hardware kit is under consideration.
-
-Mycroft promises that user data will never be saved without an opt-in (to improve machine learning algorithms), and that it will never be used for marketing purposes. Like Alexa and Assistant, however, it’s not available offline without a cloud service, a feature that would better ensure privacy. Anavi says the company is working on an offline option.
-
-The Mycroft AI agent is enabled via a Python based Mycroft Pulse SDK, and a Mycroft Skills Manager is available for Skills development. Like Alexa and Assistant, Mycroft supports custom wake words. The new version uses its homegrown [Precise][26] wake-word listener technology in place of the earlier PocketSphinx. There’s also an optional device and account management stack called Mycroft Home.
-
-For text-to-speech (TTS), Mycroft defaults to the open source [Mimic][27], which is co-developed with VocaliD. It also supports eSpeak, MaryTTS, Google TTS, and FATTS.
-
-Mycroft lacks its own speech to-text (STT) engine, which Anavi calls “the biggest challenge for an open source voice assistant.” Instead, it defaults to Google STT and supports [IBM Watson STT][28] and [wit.ai][29].
-
-Mycroft is collaborating with Mozilla on its open source [DeepSpeech][30] STT, an open source TensorFlow implementation of [Baidu’s DeepSpeech][31] platform. Baidu trails Alibaba and Xiaomi in the [Chinese voice assistant][32] market but is one of the fastest growing voice AI companies. Just as Alibaba uses its homegrown, Alexa-like AliGenie agent on its Tmall Genie speaker, Baidu loads its [speakers][33] with its DeepSpeech-driven [DuerOS][34] voice platform. Xiaomi has used Alexa and Cortana.
-
-Mycroft is the most mature of several alternative voice AI projects that promise improved privacy safeguards. A recent [VentureBeat][35] article reported on emerging privacy-oriented technologies including [Snips][36] and [SoundHound][37].
-
-Anavi concluded with some demo videos showing off his soothing, Bulgarian AI whisperer vocal style. “I try to be polite with these things,” said Anavi. “Someday they may rule the world and I want to survive.”
-
-Anavi’s video presentation can be seen here:
-<https://www.youtube.com/embed/_dF0cMr3Aag?enablejsapi=1>
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/11/closer-look-voice-assisted-speakers
-
-作者:[Eric Brown][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/ericstephenbrown
-[b]: https://github.com/lujun9972
-[1]: https://www.canalys.com/newsroom/amazon-reclaims-top-spot-in-smart-speaker-market-in-q3-2018
-[2]: https://events.linuxfoundation.org/events/elc-openiot-europe-2018/
-[3]: http://linuxgizmos.com/phat-adds-ir-to-the-raspberry-pi/
-[4]: https://qz.com/1288743/amazon-alexa-echo-spying-on-users-raises-a-data-privacy-problem/
-[5]: https://www.techadvisor.co.uk/review/digital-home/amazon-echo-show-2-3685964/
-[6]: https://www.linux.com/news/event/open-source-summit-na/2017/3/add-skills-your-raspberry-pi-alexa
-[7]: https://www.theverge.com/2018/11/17/18099978/microsoft-store-amazon-echo-devices
-[8]: https://www.engadget.com/2018/11/19/alexa-can-now-make-skype-calls/
-[9]: https://store.google.com/us/product/google_home_max?hl=en-US
-[10]: https://arstechnica.com/gadgets/2018/10/google-home-hub-under-the-hood-its-nothing-like-other-google-smart-displays/
-[11]: https://developers.google.com/assistant/sdk/overview
-[12]: https://developers.google.com/actions/
-[13]: http://linuxgizmos.com/google-assistant-sdk-dev-preview-brings-voice-agent-to-the-raspberry-pi/
-[14]: http://linuxgizmos.com/googles-updated-aiy-vision-and-voice-kits-ship-with-raspberry-pi-zero-wh/
-[15]: http://linuxgizmos.com/android-things-and-google-assistant-appear-in-new-smart-speakers-smart-displays-and-coms/
-[16]: https://www.linux.com/blog/2018/5/android-things-10-offers-free-ota-updates-restrictions
-[17]: https://www.engadget.com/2018/11/20/lg-wk9-google-assistant-smart-speaker/
-[18]: https://mycroft.ai/
-[19]: http://linuxgizmos.com/open-source-echo-like-gizmo-is-halfway-to-kickstarter-gold/
-[20]: http://linuxgizmos.com/open-source-voice-assistant-promises-user-privacy/
-[21]: http://linuxgizmos.com/16nm-zynq-soc-mixes-cortex-a53-fpga-cortex-r5/
-[22]: https://aaware.com/technology/
-[23]: https://www.kickstarter.com/projects/aiforeveryone/mycroft-mark-ii-the-open-voice-assistant/posts/2344940
-[24]: https://www.startengine.com/mycroft-ai
-[25]: https://mycroft.ai/documentation/picroft/#hardware-prerequisites
-[26]: https://mycroft.ai/documentation/precise/
-[27]: https://mycroft.ai/documentation/mimic/
-[28]: http://linuxgizmos.com/whipping-up-ibm-watson-voice-services-with-openwhisk/
-[29]: https://wit.ai/
-[30]: https://github.com/mozilla/DeepSpeech
-[31]: http://research.baidu.com/Blog/index-view?id=90
-[32]: https://www.cbinsights.com/research/china-voice-assistants-smart-speakers-ai/
-[33]: https://www.theverge.com/ces/2018/1/8/16866068/baidu-smart-speakers-dueros-ces-2018
-[34]: https://dueros.baidu.com/en/index.html
-[35]: https://venturebeat.com/2018/07/14/alexa-alternatives-have-a-secret-weapon-privacy/
-[36]: https://snips.ai/
-[37]: https://soundhound.com/
diff --git a/sources/talk/20181127 What the open source community means to me.md b/sources/talk/20181127 What the open source community means to me.md
deleted file mode 100644
index a0f85846c9..0000000000
--- a/sources/talk/20181127 What the open source community means to me.md
+++ /dev/null
@@ -1,94 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (What the open source community means to me)
-[#]: via: (https://opensource.com/article/18/11/what-open-source-community-means-me)
-[#]: author: (Florian Effenberger https://opensource.com/users/floeff)
-[#]: url: ( )
-
-What the open source community means to me
-======
-Contributing to open source is more than a way to make better software; it can enrich your entire life.
-
-
-Every time I tell my friends about my hobby—which became my career as the executive director at [The Document Foundation][1]—I face lots of questions. A worldwide community? Contributors around the globe? An open source community? Can you eat that?!
-
-Well, actually [sometimes you can][2] eat it. But seriously, today, I'd like to share my very personal view about what the open source community means to me and why being active is not only fun but also benefits your whole life.
-
-### A long, long time ago…
-
-Back in the good old days (around 2003 or 2004) when I was in my early twenties, I was a casual open source user. Flat-rate broadband connections had just become common, which suddenly made communication around the globe possible for everyone. More and more free software (not just Linux) made its way onto people's computers. Long before we had open source operating systems for smartphones and the Internet of Things, we could download open source email clients, browsers, and other software. Like many other people, my primary motivation was price, simply because the programs were free of charge. I saw hints that these applications were driven by a community, but I didn't fully understand what that meant. Since I wasn't a developer, having access to the source code was not a compelling reason for me to use open source—neither the software nor I would have gotten any advantage if I'd started coding.
-
-### From user to community member
-
-In those early days, the idea of a free office suite was tempting, so I installed OpenOffice on my computer. More out of coincidence than a plan, I subscribed to the project's mailing list. My curiosity was much larger than my understanding, but luckily that didn't keep me from doing things.
-
-Time went by, autumn arrived, and the inevitable trade show season started again. Without really knowing what the heck I was doing, I offered to help OpenOffice.org at a Munich trade show, even though I had neither any clue about trade shows nor about the software itself—conditions couldn't have been worse, actually. I have always been quite skeptical and a bit shy, but that probably contributed to the fact that this was the best-documented trade show we'd ever had and quite a success for us.
-
-I also met a colleague, whom I still work closely with, who took me under his wing. He never gave me the feeling that I was a useless rookie; on the contrary, from the very beginning, I was treated as a full and respected member of the community whose opinion mattered. Soon I became responsible for things that I had never done on a professional basis. To my surprise, it was a lot of fun and ultimately started something that shaped my life very much.
-
-### Credit of trust
-
-Unlike large corporations with their hierarchies and complex structures, in open source, I could start doing the things that interested me almost immediately. I could work in a very relaxed and easy way, which made it a whole lot of fun.
-
-This credit of trust I received from the community is something that still touches me. After contributing in some areas—opportunities I owe to people who believed in me from the very beginning—I had the honor of meeting a wonderful human being, my mentor and good friend [John McCreesh][3], who sadly passed away in 2016. I had the joy of working with him to shape our project's international marketing. Even today, it is hard to believe this credit of trust, and I deeply value it as a gift that is anything but usual.
-
-Over time, I was introduced to more and more areas—along with marketing, I was also responsible for distributing files on our mirror network, co-organizing several events, and co-founding what is most likely the first German foundation [tailored specifically for the open source community][4].
-
-### Friends around the world
-
-Over the years I've met lots of wonderful human beings through my open source activities. Not just colleagues or contacts, but true friends who live around the globe. We not only share an interest in our community but also lots of private moments and wonderful discussions.
-
-We don't often meet in person due to distance, but that lack of proximity doesn't affect the mutual trust we share. One of my favorite memories is of meeting a friend from Rio de Janeiro, whom I've known since early 2000 when I helped him with a problem on his Linux server. We didn't meet in person until 2013; even though we'd never been in the same room throughout our friendship and the language barriers were high, we had an amazing evening among two good friends, 10,000km from home. We are in regular contact to this day.
-
-### Broaden your mind
-
-Having friends around the globe also gives you amazing insight and widens your scope, helping you redefine your point of view. Heading to the Vatican after a conference in Italy, my friend John once commented how fascinating it is seeing all the places free software can bring you.
-
-During trips to foreign countries to attend conferences, my local colleagues help me learn a lot about life in other countries. I've met contributors from high-poverty countries, people with very touching personal stories, and colleagues who took long trips to English-speaking conferences despite large language barriers. I admire these people for taking these chances.
-
-My colleagues' lives and credentials are often truly inspiring, as open source projects are open to everyone, independent of age, profession, and education. It's clear that the supposed barriers of culture, language, and time exist only in our heads—and they can be crossed in harmony. This is an important model for everyone, especially in these complicated times.
-
-Meeting people from other cultures and learning about their lives helps me think about the world in new ways. When I read news reports about violence and war in countries where I have friends and colleagues, I worry about their well-being. Suddenly all the anonymous pain and suffering has a name and a face, and looking away is no longer an option.
-
-### A life's philosophy
-
-To me, open source is not just a license or a development model—it's an open mentality of mutual respect for everyone, trust in newbies, appreciation and value for other people's opinions, joint goals, and shared ideals. Open source involves data privacy, civil rights, free knowledge, open standards, and much more. I often say it's a philosophy of life by its own.
-
-Like in any social group, open source projects are full of discussions, arguments, and discrepancies—very often you'll meet strong characters and learn that email communication can lead to a lot of confusion and misunderstanding. Still, none of this disention changes the very open, motivated, and motivating attitude of contributors. This creates an incredibly welcoming and inviting environment, which (in addition to the technical aspect) reveals a wonderful, human side of things.
-
-### Reality of life
-
-After all these years, open source has finally arrived, thanks to so many people spreading the word and living the ideals. Ten to 12 years ago, we were like aliens at trade shows, but nowadays, not only are the development and license model well recognized, but open source is an integral part of many companies' business. I'm delighted that more and more companies understand the open source model, contribute to it, act according to its principles, and therefore become an equal part of the open source community. This shows that the open source model has become mature.
-
-I am skeptical, however, of the growing use of the term "community," as it seems any company with more than a handful of users on their platform claims membership, even if they are far more interested in marketing their product than serving the community. Nonetheless, it's great to see even conservative companies opening up to collaborate with their customers and the general public.
-
-### The future is open
-
-Even after more than 15 years in open source, every day is a new beginning, every day is exciting, there's always something new to discover, and the number of successes grows as the challenges do.
-
-I am quite excited and curious where things will lead—not only in the projects and the code but even more in users' and decision-makers' minds. We all benefit, at least indirectly, from the achievements of the projects and the people driving them.
-
-I'm certain the open source community will continue bringing me in touch with new topics and connecting me to new people who'll enrich my life. I am proud and happy to be a part of this movement, which allows me to experience how mutual respect, trust, and shared ideals help move things forward.
-
-This was originally published on [Florian Effenberger][5]'s blog and is reprinted with permission.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/what-open-source-community-means-me
-
-作者:[Florian Effenberger][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/floeff
-[b]: https://github.com/lujun9972
-[1]: https://www.documentfoundation.org/
-[2]: https://opensource.com/article/18/9/open-source-cooking
-[3]: https://blog.documentfoundation.org/blog/2016/01/24/r-i-p-john-mccreesh/
-[4]: https://blog.documentfoundation.org/blog/2012/02/20/the-document-foundation-officially-incorporated-in-berlin-germany/
-[5]: https://blog.effenberger.org/2016/04/28/what-the-open-source-community-means-to-me/
diff --git a/sources/talk/20181129 9 top tech-recruiting mistakes to avoid.md b/sources/talk/20181129 9 top tech-recruiting mistakes to avoid.md
deleted file mode 100644
index a1655508ef..0000000000
--- a/sources/talk/20181129 9 top tech-recruiting mistakes to avoid.md
+++ /dev/null
@@ -1,108 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (9 top tech-recruiting mistakes to avoid)
-[#]: via: (https://opensource.com/article/18/11/top-tech-recruiting-mistakes-avoid)
-[#]: author: (Rikki Endsley https://opensource.com/users/rikki-endsley)
-[#]: url: ( )
-
-9 top tech-recruiting mistakes to avoid
-======
-We round up common mistakes tech recruiters make and a few best practices to adopt instead.
-
-
-Some of my best friends and colleagues are tech recruiters, and a bunch of my favorite humans are on the job hunt. With these fine folks in mind, I decided to help them connect by finding out what kinds of recruiting efforts stand out to potential hires. I reached out to my colleagues and contacts and asked them what they like (and hate) when it comes to recruiting, then I rounded up a list of top tech-recruiting mistakes to avoid and best practices to use instead.
-
-### 9 common tech recruiting mistakes to avoid
-
-Don’t even think about reaching out to a potential candidate without doing due diligence on their background, experience, and expertise. Not knowing what skills a recruit has and what kind of work they’ve done in the past instantly turns off job seekers. Recruiters who make it clear that they’ve done their homework signal that they aren’t planning to waste a candidate’s time and stand a better chance of piquing their interest from the beginning. Common recruiting mistakes also include:
-
-**1\. Sending form letters — or even worse, broken form letters.**
-
-Unless someone is job-seeking and not getting many offers, chances are your form letter won’t stand out or get much interest. And if your form letter is broken and has [NAME] where a candidate’s name should appear, forget about getting any qualified candidate responses.
-
-**2\. Blowing the salutation.**
-
-Be sure to spell the candidate’s name correctly, and typing “Mr.” or “Miss” in the greeting could be a big mistake. For example, I can’t tell you how many “Mr. Endsley” messages I get every month, and “Miss Endsley” won’t sit well with me, either.
-
-**3\. Not understanding what the recruit does.**
-
-Potential candidates can tell whether you’ve done your homework, dug through their LinkedIn profiles, and have a grasp of their backgrounds, experiences, and areas of interest. Reaching out to a UX designer about an engineering role won’t get you good results.
-
-**4\. Sending unsolicited contact requests.**
-
-Don’t send LinkedIn connection requests to people you don’t know. Just don’t do it.
-
-**5\. Being too general about the job position.**
-
-Kill the coy. Share as many details you can about the role, including any must-have and nice-to-have skills. Draw potential recruits a picture of what the work looks like to make qualified candidates take notice.
-
-**6\. Being too vague or mysterious about the team and company.**
-
-Tech professionals with in-demand skills and experience are being more selective about what kind of team dynamics they walk into and [organizational ethics][1]. Letting potential hires know right away what the team looks like (e.g., small vs. large, remote vs. on-site) and which company you represent can save everyone a lot of time.
-
-**7\. Having unrealistic or overly specific requirements.**
-
-Does the right candidate really need to be an expert in every technology and programming language and hold multiple degrees? Be clear about what skills a candidate needs vs. what skills might come in handy or can be acquired on the job.
-
-**8\. Getting too cutesy or culture-y in a description.**
-
-Not all of us consider office puppies, free booze, and ping pong to be job perks. If this is the messaging you lead with, you’re going to attract a pretty specific kind of applicant and quickly narrow down your list of potential candidates.
-
-Also [avoid terms][2] like “guys,” “rock star,” and “recent graduate,” which can translate to “women, minorities, and anyone over 25 need not apply.” Ouch.
-
-**9\. Asking for referrals to other potential candidates.**
-
-This is a no-win for recruiters. For example, I’m happy to recommend job seekers in my network for roles, but lots of other folks working in tech see this as lazy recruiting. The safest approach might be to ask a candidate later in the process, after you’ve developed a friendly working relationship and you've both agreed that this role doesn’t quite fit their interests or expertise. Then they might have other contacts in mind for it.
-
-### 6 best practices for tech recruiters
-
-**1\. Provide a sincere and personalized greeting.**
-
-A personalized greeting goes a long way. Let potential candidates know you understand their previous work experience, you’re familiar with what they do, and that you have an idea of what they want to be doing.
-
-
-**2\. Offer a transparent description of the team and the role.**
-
-Be as clear as you can when describing the team and the role. Using words like “rock star” or “fast-paced team” does nothing to help the potential candidate visualize what they’d be walking into. Is this a small team? Remote team?
-
-Being mysterious about the role won’t build intrigue, so opt for transparency.
-
-**3\. Give the company name.**
-
-Telling job candidates that the organization is a startup or a Fortune 500 company also won’t work as well being transparent about the organization from the beginning. How can anyone know whether they’re interested in a role if they don’t know which organization they’d be joining?
-
-**4\. Be persistent and specific.**
-
-In addition to providing the job description and company name, specifying the salary range and why you think the potential candidate is a good fit for the role stands out. Also consider specifying the work authorization and whether the organization provides visa sponsorships, relocation, and additional benefits beyond an hourly or annual salary. If you have a good feeling about a candidate who might not be a 100% technical fit with the job posting, let them know and open those lines of communication.
-
-**5\. Invite potential candidates to local recruiting events.**
-
-The event should provide brief presentations about the company, refreshments, and a networking opportunity. Here’s your chance to show off the culture (i.e., people) part of your organization in person.
-
-**6\. Maintain a relationship with potential recruits.**
-
-If you talk to a candidate who isn’t the right fit for a role, but who would be a great addition to your organization, keep the lines of communication open. If candidates have a good experience with a recruiter, they’ll also be more inclined to join the organization later or send other job seekers their way in the future.
-
-### Bonus advice for tech recruits
-
-Keep in mind that recruiters, like you, are just trying to do their jobs. If you're tired of hearing from recruiters and annoyed when they contact you, step back and get a little perspective. Although you might be in the fortunate spot of being happily employed and in-demand, not everyone else is. Grumbling about recruiters on social media is a great way to humble brag, but not the best way to show empathy for the job-seekers or win any friends.
-
-_Thank you to the many people who contributed to this article! What would you add to these lists? Let us know in the comments._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/top-tech-recruiting-mistakes-avoid
-
-作者:[Rikki Endsley][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/rikki-endsley
-[b]: https://github.com/lujun9972
-[1]: https://spectrum.ieee.org/view-from-the-valley/at-work/tech-careers/engineers-say-no-thanks-to-silicon-valley-recruiters-citing-ethical-concerns
-[2]: https://www.theladders.com/career-advice/job-descriptions-driving-away-women
diff --git a/sources/talk/20181129 Why giving back is important to the DevOps culture.md b/sources/talk/20181129 Why giving back is important to the DevOps culture.md
deleted file mode 100644
index c01889130f..0000000000
--- a/sources/talk/20181129 Why giving back is important to the DevOps culture.md
+++ /dev/null
@@ -1,68 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (Why giving back is important to the DevOps culture)
-[#]: via: (https://opensource.com/article/18/11/why-sharing-important-devops-culture)
-[#]: author: (Matty Stratton https://opensource.com/users/mattstratton)
-[#]: url: ( )
-
-Why giving back is important to the DevOps culture
-======
-Our habit of not sharing knowledge is doing us harm.
-
-In the DevOps [CALMS][1] model (which stands for Culture, Automation, Lean, Measurement, and Sharing), Sharing is often overlooked or misunderstood. While each element of CALMS is just as important as the others, sharing knowledge is something that we often neglect.
-
-### What happens if we don't share?
-
-[Jeff Smith][2], director of production operations at [Centro][3], tells this story:
-
-> A change to the level of granularity that gets stored in one of our reporting tables was made. The change increased the disk space usage on the database instance by 8x. Not only did this cause our existing database instance to rapidly fill up, but it also made operations question if the design pattern made sense. Because they weren't included in such an impactful change, all of the design decisions that went into the new process architecture were viewed as suspect and underwent a constant re-examination from ops. In a nutshell, a little bit of faith and trust was lost.
-
-The damage caused by eroding faith can't be understated. Collaboration is based on trust. Every time this trust is chipped away, energy is spent on questioning the validity of decisions made by others.
-
-### What are the benefits of sharing?
-
-Today's systems are incredibly complex. The days when one person could hold an entire infrastructure and system interdependencies in their head are long gone. Communicating across boundaries of expertise makes our entire organization more robust and resilient.
-
-Sharing isn't just about the technical data or access, though. "Inter-team communication should always start with the goal, not with one team's proposed solution to a problem," Jeff says. "When you start with a solution, the conversation veers in the wrong direction."
-
-[Emily Freeman][4], CloudOps advocate at [Microsoft][5] says "Collaboration is impossible without sharing information." She points out that having a "mental map" of the skills and knowledge of other teams "enables people to ask questions more efficiently and reduces the fear they're asking too many questions or look stupid."
-
-### How can we share better?
-
-"Sharing doesn't have to be a drum circle every Tuesday at 10:30am," Emily says. "It's openness and authenticity. It's removing the shadows from your organization and ensuring everyone is honest and forthright and accountable."
-
-At a minimum, there should be read-only access to logs, code, and after-incident reports for everyone. Before you cry "separation of concerns," please consider that the data that cannot be shared with everyone in the organization is a much smaller set than we usually think it is. It might require some additional effort to scrub and protect this small subset than to default to "nobody can see anything but their small part of it," but the benefits outweigh the effort.
-
-"If anyone's excluded, they aren't part of your team, no matter what the org chart says," Emily reminds us.
-
-It's more than the logs and the tooling, though. "The 'S' is often just seen as knowledge sharing, training, etc.," Jeff says. "But if it doesn't include the sharing of responsibility and ownership, it can be difficult to get your organization to that next level of productivity."
-
-### Why don't we share?
-
-There are many reasons that sharing information and knowledge isn't the default position for knowledge workers, but both Emily and Jeff agree it usually comes down to fear.
-
-"Teams may feel that only their circle is capable of performing a particular task with the zeal and delicacy it deserves," Jeff says. "So information gets siloed, access gets restricted, and gates get constructed. But that diminishes our responsibility to build safe systems, instead leaning on 'operator expertise' as a crutch."
-
-Emily agrees. "DevOps cultures never look to change the past," she says. "Instead, the companies that thrive at embracing the DevOps philosophy are realistic about where they are and work toward continuously improving their process so everyone on the team can thrive."
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/why-sharing-important-devops-culture
-
-作者:[Matty Stratton][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mattstratton
-[b]: https://github.com/lujun9972
-[1]: https://whatis.techtarget.com/definition/CALMS
-[2]: https://twitter.com/DarkAndNerdy
-[3]: https://www.centro.net/
-[4]: https://twitter.com/editingemily
-[5]: http://dev.azure.com/
diff --git a/sources/talk/20181130 3 emerging tipping points in open source.md b/sources/talk/20181130 3 emerging tipping points in open source.md
deleted file mode 100644
index 87761e7a5d..0000000000
--- a/sources/talk/20181130 3 emerging tipping points in open source.md
+++ /dev/null
@@ -1,93 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (3 emerging tipping points in open source)
-[#]: via: (https://opensource.com/article/18/11/3-new-tipping-points-open-source)
-[#]: author: (Bilgin lbryam https://opensource.com/users/bibryam)
-[#]: url: ( )
-
-3 emerging tipping points in open source
-======
-Understand the factors advancing the open source model's evolution.
-
-
-Over the last two decades, open source has been expanding into all aspects of technology—from software to [hardware][1]; from small, disruptive startups to large, boring enterprises; from open standards to open [patents][2].
-
-As movements evolve, they reach tipping points—stages that move the model in new directions. Following are three things that I believe are now reaching a tipping point in open source.
-
-### Open for non-coders
-
-As the name suggests, the open source model has mainly been focused on the source code. On the surface, that's probably because open source communities are usually made up of developers working on the source code, and the tools used in open source projects, such as source control systems, issue trackers, mailing list names, chat channel names, etc., all assume that developers are the center of the universe.
-
-This has created big losses because it prevents creative people, designers, document writers, event organizers, community managers, lawyers, accountants, and many others from participating in open source communities. We need and want non-code contributors, but we don't have processes and tools to include them, means to measure their value, nor ways for their peers, the community, or their employers to reward their efforts. As a result, it has been a lose-lose for decades. We can see the implications in all the ugly websites, amateur logos, badly written and formatted documentation, disorganized events, etc., in open source projects.
-
-The good news is that we are getting signals that change is on the way:
-
- * [Linus Torvalds apologized][3] for his "bad behavior." While this wasn't specifically focused on non-coders, it symbolizes making open source a non-hostile place for less-technical contributors.
- * The Cloud Native Computing Foundation (CNCF) introduced the [Non-Code Contributor's Guide][4]. In addition to showing the many ways people can contribute to open source projects, it also set a baseline for non-code contributions that other open source projects and foundations will end up following.
- * The Apache Software Foundation (ASF) is working in the same direction. We've been holding long discussions, and we will have some concrete output very soon (note that is "ASF soon").
-
-
-
-There is a little-known secret that is great news for non-coders and others new to open source: One of the easiest ways to be recognized as part of an established open source project is to do non-coding activities. Nowadays, with complex software stacks and tough competition, there is a pretty high bar for entering a project as a committer. Performing non-coding activities is less popular, and it opens a fast backdoor to open source communities.
-
-
-
-### Macro acquisitions
-
-Open source may have started in the hacker community as a way of scratching developers' personal itches, but today it is the place where innovation happens. Even the world's largest software companies are transitioning to the model to continue dominating their market.
-
-Here are some good reasons enterprises have become so interested in contributing to open source:
-
- * It multiplies the company's investments through contributions.
- * They can benefit from the most recent technology advances and avoid reinventing the wheel.
- * It helps spread knowledge of their software and its broader adoption.
- * It increases the developer base and hiring pool.
- * Internal developers' skills grow by learning from top coders in the field.
- * It builds a company's reputation—developers want to work for organizations they can boast about.
- * It aids recruitment and retention—developers want to work on exciting projects that affect large groups of people.
- * New companies and projects can start faster through the open source networking effect.
-
-
-
-Many enterprises are trying to shortcut the process by acquiring open source companies—which leads to even more open source adoption. Building an open source company takes many years of effort done out in the open. Hiring good developers who are willing to work in the open, building a community around a project, and creating a successful business model require delicate effort. Companies that manage to do this are very attractive for investment and acquisition, as they serve as a catalyst to turn the acquirer into an open source company at scale. The number of [successful open source companies][5] that is acquired seems to get bigger every day, and this trend is only getting stronger.
-
-### Micro-funding of open source software
-
-In addition to macro investments through acquisitions of open source companies, there has also been an increase in decentralized [micro-funding of self-sustaining][6] open source projects.
-
-On one end of the spectrum, there are open source projects that are maintained primarily by intrinsically motivated developers. On the other end, large companies are hiring developers to work on open source projects driven by company roadmaps and strategies. That leaves a large number of open source projects that are not exciting enough for accidental contributors nor on enterprise companies' radar.
-
-In recent years, there has been an increase in [platforms for funding and sustaining][7] these open source projects through bug bounties, micro-payments, recurring donations, one-time contributions, subscriptions, etc. These open source funding platforms allow individuals to take responsibility for open source sustainability in their own hands by paying maintainers directly. This enables people to contribute to the open source model through value transfer rather than code contributions.
-
-There are three basic channels for open source contributions:
-
- * Hobbyists contribute to open source projects because of intrinsic motivations rather than monetary value.
- * Companies with open source business models (open core, SaaS, support, services, etc.) monetize open source projects directly with regular, planned, and centralized subsidization.
- * Independent open source users provide irregular, micro, decentralized subsidization through [OSS funding][7] platforms.
-
-
-
-While hobbyists and hackers started the open source movement, it's turned into an enterprise monetization model. Having a model to sustain the remaining open source projects is welcome.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/3-new-tipping-points-open-source
-
-作者:[Bilgin lbryam][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/bibryam
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/resources/what-open-hardware
-[2]: https://www.redhat.com/en/blog/red-hat-welcomes-milestone-addition-open-invention-network-microsoft-joins-safeguard-linux-patent-attacks
-[3]: https://lkml.org/lkml/2018/9/16/167
-[4]: https://kubernetes.io/blog/2018/10/04/introducing-the-non-code-contributors-guide/
-[5]: http://oss.cash/
-[6]: https://opensource.com/article/18/8/open-source-tokenomics
-[7]: http://oss.fund/
diff --git a/sources/talk/20181205 5 reasons to give Linux for the holidays.md b/sources/talk/20181205 5 reasons to give Linux for the holidays.md
deleted file mode 100644
index 2bcd6d642c..0000000000
--- a/sources/talk/20181205 5 reasons to give Linux for the holidays.md
+++ /dev/null
@@ -1,78 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (5 reasons to give Linux for the holidays)
-[#]: via: (https://opensource.com/article/18/12/reasons-give-linux-holidays)
-[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
-[#]: url: ( )
-
-5 reasons to give Linux for the holidays
-======
-If a computer is on your gift-giving list, here's why it should be Linux.
-
-
-Every year around this time, people ask me about the best computer to give (or get) for the holidays. I always give the same answer: Linux. After all, if you want your recipients to be happy, why wouldn't you give them the best operating system on the planet?
-
-Many people don't realize they have options when it comes to computer operating systems. Just recently, two friends (who didn't do their research) fell for the clever marketing and bought brand-new systems at premium prices. I'm willing to bet that within six months they'll be dissatisfied with those expensive computers.
-
-In contrast, I recently purchased a four-year-old computer with an i5 processor, 4GB of RAM, and a 128GB SSD drive, and I love it. It's fast and has all the applications I need to be successful and happy. That's because I'm running Linux. Whether I'm using Firefox or Chrome, all my websites load quickly and the video is great. In fact, the web is faster on Linux than it is on MacOS or Windows.
-
-So, if you're in the mood to give a computer for the holidays, here are five good reasons it should be Linux.
-
-### 1\. Linux is easy to use
-
-Linux distributions like [Fedora][1], [Ubuntu][2], [PopOS][3], [Linux Mint][4], and [Raspbian][5] come with loads of documentation and access to a user community eager to help. And desktop environments such as [GNOME][6], [KDE][7], and [LXDE][8] mean the Linux operating system is just plain easy. If you have a problem with a Linux operating system, you won't have to wait in a long telephone queue for an answer—you can tap into the community's knowledge.
-
-### 2\. Free applications for practically anything you need
-
-There are hundreds of high-quality, free software packages available for Linux. My favorites are [LibreOffice][9] and [GnuCash][10]. I cannot imagine any writing task that is beyond the scope of LibreOffice. I use it and recommend it to everyone I know. Why spend money on a name-brand productivity suite when LibreOffice, the best one out there, is free? (If you agree and you're able, you really ought to consider contributing to the project.)
-
-### 3\. Security
-
-Linux is secure, an important fact in an age when security tops most people's essential features list. On Linux, viruses and malware are minimal. I spend many days each year helping friends recover their Windows systems that have been hacked or infected with malware. That's rare on Linux, and if you want to be doubly sure no one gains improper access to your computer, there are plenty of open source solutions that can help prevent it. My favorites are [ClamAV][11] and [Rootkit Hunter][12]. Linux respects your privacy. It does not upload user data to Redmond or Cupertino.
-
-### 4\. Freedom
-
-Linux gives me the freedom to use my operating system however I choose, whether that is as a standalone workstation for personal productivity, a content server, a firewall for my home network, or something else. Unlike proprietary desktop operating systems, you don't have to purchase an upgrade or extension to expand your system's capabilities. There are no limitations. Best of all, I can give all of this knowledge away and encourage others to do the same. Isn't giving to others the spirit of holiday traditions?
-
-### 5\. Stability
-
-Linux is reliable and stable. The operating system does not crash. When you get updates, they don't require you to reboot while you're in the middle of doing something else. If you're using an older version of Fedora, Ubuntu, or Linux Mint and are happy with the status quo, you don't have to upgrade. Linux also offers more support for drivers of legacy printers and other peripherals than other operating systems.
-
-### How to give Linux
-
-Linux could be the best present your friends ever receive. Instead of buying holiday gifts from your favorite retailer, buy some 8GB or 16GB USB drives, download your favorite distribution, and [make some bootable USB][13] drives to give away. Volunteer your time (or include instructions) to help your friends to explore the "live" editions of these distributions before they install the operating system. Or, if you have an old, unused laptop or desktop, consider installing Linux and loaning it out for training purposes. Most of your friends will have no idea what a wonderful gift you are giving them—in the process, you will discover the joy of giving yourself to others.
-
-If you really want to buy a new computer, this year I recommend you look at [System 76][14] or Dell's [XPS Developer][15] edition. If you don't want a new model, there are plenty of great offerings on [eBay][16], [DellRefurbished.com][17], and other sites that sell good-quality older laptops that are great candidates for an easy Linux install.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/reasons-give-linux-holidays
-
-作者:[Don Watkins][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/don-watkins
-[b]: https://github.com/lujun9972
-[1]: https://getfedora.org/
-[2]: https://www.ubuntu.com/
-[3]: https://system76.com/pop
-[4]: https://linuxmint.com/
-[5]: https://www.raspbian.org/
-[6]: https://www.gnome.org/
-[7]: https://www.kde.org/
-[8]: https://lxde.org/
-[9]: https://www.libreoffice.org/
-[10]: https://www.gnucash.org/
-[11]: https://www.clamav.net/
-[12]: http://rkhunter.sourceforge.net/
-[13]: https://opensource.com/article/18/7/getting-started-etcherio
-[14]: https://system76.com/
-[15]: https://www.dell.com/en-us/work/shop/dell-laptops-and-notebooks/xps-13-developer-edition/spd/xps-13-9370-laptop?appliedRefinements=302
-[16]: https://www.ebay.com/b/Computers-Tablets-Network-Hardware/58058/bn_1865247
-[17]: http://DellRefurbished.com
diff --git a/sources/talk/20181205 F-Words in Linux Kernel Code Replaced with -Hug.md b/sources/talk/20181205 F-Words in Linux Kernel Code Replaced with -Hug.md
deleted file mode 100644
index 821b81d29e..0000000000
--- a/sources/talk/20181205 F-Words in Linux Kernel Code Replaced with -Hug.md
+++ /dev/null
@@ -1,81 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (F-Words in Linux Kernel Code Replaced with "Hug"?)
-[#]: via: (https://itsfoss.com/swear-words-linux-kernel/)
-[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-[#]: url: ( )
-
-F-Words in Linux Kernel Code Replaced with "Hug"?
-======
-
-**Brief: To comply with the new code of conduct, a developer from Intel proposes to replace F-words in the Linux kernel code with “hug”.**
-
-![Polite Linus Torvalds after Code of Conduct][1]
-
-Change is in air for the Linux Kernel Community.
-
-Ever since the introduction of the [Linux code of conduct][2], things are going in a ‘polite direction’.
-
-To refresh your memory, a few months back a new code of conduct was introduced for the Linux kernel developers. This code of conduct asks the developers to be nice and welcoming to other developers and be more open to diversity.
-
-The new code of conduct caused a huge controversy as many Linux users and developers saw it as a conspiracy by Social Justice Warriors (SJW) to infiltrate Linux. The rumors were especially boosted by the [controversial past of the Contributor Covenant creator Coraline Ada Ehmke][2]. The Linux code of conduct is based on the same Contributor Covenant.
-
-Right after signing the new code of conduct, Linux creator [Linus Torvalds took a month-long break to improve his behavior][3].
-
-Torvalds who is known for being ruthless against poor code is a changed man now. After [coming back from the break][4], Torvalds controlled his rage and instead of lashing out against a developer, he replied nicely and pointed his mistake in a polite way.
-
-### No more F-words in the Linux Kernel code?
-
-There have been F-words in the Linux kernel code. To be clear, these F-words are in the code comments, not in the actual code.
-
-You might expect that there will be way too many F-words in the 15+ millions of lines of Linux kernel code but that’s not the case.
-
-Jarkko Sakkinen from Intel pushed [these patches][5] that replace the F-words 33 times in the 3.3 million lines of code comments.
-
-Interestingly, the patch email is titled “ **Zero ****s, hugload of hugs <3**“:
-
-> In order to comply with the CoC, replace 选题模板.txt 中文排版指北.md core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE published README.md scripts sources translated with a hug.
-
-So now comments have become:
-
- * Only Sun can take such nice parts and **hug** up the programming interface like this
- * IOC3 is **hugging** **hugged** beyond belief
- * **Hug** , we are miserable poor guys…
-
-
-
-### Do you give a ‘hug’ about these changes?
-
-At this point, it’s not clear if this ‘hugging’ patch has been accepted or not. It’s more of an attempt to bring attention to profanity inside the kernel code.
-
-So, we have to wait and watch if this patch sets a trend for removing offensive words from the Linux kernel code.
-
-What do you think of it? Is using ‘hug’ a good choice or do you have a better word for replacing the F-words?
-
-And what do you think of these changes altogether. Do you think all these are unnecessary and futile exercises?
-
-And when you comment, please replace your F-words with hugs :)
-
-Story source: [Phoronix][6]
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/swear-words-linux-kernel/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[b]: https://github.com/lujun9972
-[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/hug-you-linus-torvalds.jpeg?resize=800%2C450&ssl=1
-[2]: https://itsfoss.com/linux-code-of-conduct/
-[3]: https://itsfoss.com/torvalds-takes-a-break-from-linux/
-[4]: https://itsfoss.com/torvalds-is-back/
-[5]: https://lists.freedesktop.org/archives/dri-devel/2018-November/198581.html
-[6]: https://www.phoronix.com/scan.php?page=news_item&px=Linux-Kernel-Hugs
diff --git a/sources/talk/20181205 Unfortunately, Garbage Collection isn-t Enough.md b/sources/talk/20181205 Unfortunately, Garbage Collection isn-t Enough.md
deleted file mode 100644
index 0c08320139..0000000000
--- a/sources/talk/20181205 Unfortunately, Garbage Collection isn-t Enough.md
+++ /dev/null
@@ -1,44 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Unfortunately, Garbage Collection isn't Enough)
-[#]: via: (https://theartofmachinery.com/2018/12/05/gc_not_enough.html)
-[#]: author: (Simon Arneaud https://theartofmachinery.com)
-
-Unfortunately, Garbage Collection isn't Enough
-======
-
-Here’s a little story of some mysterious server failures I had to debug a year ago. The servers would run okay for a while, then eventually start crashing. After that, trying to run practically anything on the machines failed with “No space left on device” errors, but the filesystem only reported a few gigabytes of files on the ~20GB disks.
-
-The problem turned out to be caused by a log shipper. This was a Ruby app that read in log files, sent the data to a remote server, and deleted the old files. The bug was that the open log files weren’t being explicitly closed. The app was letting Ruby’s automatic garbage collector clean up the `File` objects, instead. Trouble is, `File` objects don’t use much memory, so the log shipper could theoretically keep millions of log files open before a collection was needed.
-
-*nix filesystems decouple filenames from file data. File data on disk can have multiple filenames pointing to it (i.e., hard links), and the data is only deleted when the last reference is removed. An open file descriptor counts as a reference, so if you delete a file while a program is reading it, the filename disappears from the directory listing, but the file data stays until the program closes it. That’s what was happening with the log shipper. The `du` (“disk usage”) command finds files using directory listings, so it didn’t see the gigabytes of file data for the thousands of log files the shipper had open. Those files only appeared after running `lsof` (“list open files”).
-
-Of course, the same kind of bug happens with other things. A couple of months ago I had to deal with a Java app that was breaking in production after a few days because it leaked network connections.
-
-Once upon a time, I wrote most of my code in C and then C++. In those days, I thought manual resource management was enough. How hard could it be? Every `malloc()` needs a `free()`, and every `open()` needs a `close()`. Simple. Except not all programs are simple, so manual resource management became a straitjacket. Then one day I discovered reference counting and garbage collection. I thought that solved all my problems, and I stopped caring about resource management completely. Once again, that was okay for simple programs, but not all programs are simple.
-
-Relying on garbage collection doesn’t work because it only solves the _memory_ management problem, and complex programs have to deal with a lot more than just memory. There’s a popular meme that responds to that by saying that [memory is 95% of your resource problems][1]. Well, you could say that all resources are 0% of your problems — until you run out of one of them. Then that resource becomes 100% of your problems.
-
-But that kind of thinking still treats resources as a special case. The deeper problem is that as programs get more complex, everything tends to become a resource. For example, take a calendar program. A complex calendar program allows multiple users to manage multiple, shareable calendars, with events that can be shared across calendars. Any piece of data will eventually have multiple parts of the program depending on it being up-to-date and accurate. So all dynamic data needs an owner, and not just for memory management. As more features are added, more parts of the program will need to update data. If you’re sane, you’ll only allow one part of the program to update data at a time, so the right and responsibility to update data becomes a limited resource, itself. Modelling mutable data with immutable datastructures doesn’t make these problems disappear; it just translates them into a different paradigm.
-
-Planning the ownership and lifespan of resources is an inescapable part of designing complex software. It’s easier if you exploit some common patterns. One pattern is fungible resources. An example is an immutable string “foo”, which is semantically the same as any other immutable string “foo”. This kind of resource doesn’t need a pre-determined lifespan or ownership. In fact, to keep the system as simple as possible, it’s better to have _no_ pre-determined lifespan or ownership. Another pattern is resources that are non-fungible, but have a deterministic lifespan. This includes network connections, as well as more abstract things like the ownership of a piece of data. It’s sanest to explicitly enforce the lifespan of these things in code.
-
-Notice that automatic garbage collection is really good for implementing the first pattern, but not the second, while manual resource management techniques (like RAII) are great for implementing the second pattern, but terrible for the first. The two approaches become complements in complex programs.
-
---------------------------------------------------------------------------------
-
-via: https://theartofmachinery.com/2018/12/05/gc_not_enough.html
-
-作者:[Simon Arneaud][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://theartofmachinery.com
-[b]: https://github.com/lujun9972
-[1]: https://yosefk.com/c++fqa/dtor.html#fqa-11.1
diff --git a/sources/talk/20181206 6 steps to optimize software delivery with value stream mapping.md b/sources/talk/20181206 6 steps to optimize software delivery with value stream mapping.md
deleted file mode 100644
index 29dc0ce63c..0000000000
--- a/sources/talk/20181206 6 steps to optimize software delivery with value stream mapping.md
+++ /dev/null
@@ -1,94 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (6 steps to optimize software delivery with value stream mapping)
-[#]: via: (https://opensource.com/article/18/12/optimizing-delivery-value-stream-mapping)
-[#]: author: (Dominika Bula https://opensource.com/users/dominika)
-
-6 steps to optimize software delivery with value stream mapping
-======
-Learn how VSM can help you streamline processes, boost efficiency, and better meet customer expectations.
-
-
-Do your efforts to improve software development fall short due to confusion and too much debate? Does your organization have a clear picture of what is achievable, and are you sure you’re moving in the right direction? Can you determine how much business value you've delivered so far? Are the bottlenecks in your process known? Do you know how to optimize your current process?
-
-If you are looking for a tool that will help you answer these questions, consider integrating [value stream mapping][1] and [lean concepts][2] into the way you deliver software.
-
-### What is value stream mapping (VSM)?
-
-Popularized in the ‘90s by James Womack and Daniel Jones, value stream mapping is a lean enterprise technique that is currently used by many organizations. In short, the value stream is the sequence of activities that are performed by the organization to deliver customer requests. Value stream mapping helps determine what is valuable and what doesn’t bring value by identifying activities that matter to your customer. The ultimate benefit of using VSM is a better understanding of how to improve your current development process to generate more value and impact.
-
-### 6 steps to optimizing software delivery
-
- 1. **Select the process**
-
-Any process can be modeled as a sequence of activities. For example, a [system development life cycle][3] is a value stream consisting of product specification, design, development, deployment, operation and maintenance, and finally, disposition. In this example, product design can be viewed as a value stream segment.
-
- 2. **Identify the parties involved in the project**
-
-Select a project sponsor and team. Keep in mind that each area of the process should be represented. Holistic thinking helps identify and set expectations, which in turn reduces resistance to change.
-
- 3. **Create the current state map**
-
-Creating the current state map helps establish a better understanding of how work is currently done. Documenting your current process is key to success at this stage. The goal is to identify the specific items that flow through your value stream.
-
- 4. **Challenge the current thinking**
-
-Make sure that what you are doing adds value—if there are actions in your process that do not add value, stop doing them. Look at the [software development waste types][2] for ideas. Mary Poppendieck and Tom Poppendieck identify these and transfer them from manufacturing to software engineering in their book, [Lean Software Development: An Agile Toolkit][4]. The waste types are:
-
- * Partially done work
- * Extra processes
- * Extra features
- * Task switching
- * Waiting
- * Motion
- * Defects
- * Management activities
-
-
- 5. **Generate the future state map and execute improvements**
-
-Think of what can be done to reduce or ideally eliminate the identified wastes.
-
-While working on the future state map, follow the principle that humans should do only what they can do best, and the rest should be [automated][5]. The future state design should aim to eliminate hands-on work and deliver completed software projects in less time with higher quality.
-
-Talk about the changes, let people ask questions—this will help reduce resistance to change. As you start executing improvements, remember that value stream mapping is an evolutionary process, and you might need to adjust the original plan. The value stream should be continuously improved; it will not be perfect the first time.
-
- 6. ****Measure benefits****
-
-Karen Martin and Mike Osterling identify key performance metrics for software delivery in their book, [Value Stream Mapping][6]:
-
- * Total lead time: the total time it takes to deliver on a customer request
-
- * Total process time: the total work effort required by all functions on the timeline critical path of the value stream
-
- * Activity ratio: the degree of flow in the value stream
-
- * Compounded effect: the quality of output across the value stream
-
-
-Well-executed value stream mapping not only improves the way work gets delivered, but it also provides a transformational opportunity for your organization and a tool to facilitate a shift in mindsets and behaviors.
-
-### What to read next
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/optimizing-delivery-value-stream-mapping
-
-作者:[Dominika Bula][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/dominika
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Value_stream_mapping
-[2]: https://en.wikipedia.org/wiki/Lean_software_development
-[3]: https://en.wikipedia.org/wiki/Systems_development_life_cycle
-[4]: https://www.oreilly.com/library/view/lean-software-development/0321150783/
-[5]: https://xkcd.com/1205/
-[6]: https://mhebooklibrary.com/doi/book/10.1036/9780071828949
diff --git a/sources/talk/20181209 Linux on the Desktop- Are We Nearly There Yet.md b/sources/talk/20181209 Linux on the Desktop- Are We Nearly There Yet.md
deleted file mode 100644
index 2f3b046362..0000000000
--- a/sources/talk/20181209 Linux on the Desktop- Are We Nearly There Yet.md
+++ /dev/null
@@ -1,344 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Linux on the Desktop: Are We Nearly There Yet?)
-[#]: via: (https://blog.dxmtechsupport.com.au/linux-on-the-desktop-are-we-nearly-there-yet/)
-[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
-
-Linux on the Desktop: Are We Nearly There Yet?
-======
-
-![][1]
-
-The numbers are pretty stark: Linux might be the backbone of everything from embedded devices to mainframes and super computers. But it has just a 2% share of desktops and laptops.
-
-It seems the only way to get most people to even touch it is to rip away everything you recognise as Linux to rebuild it as Android.
-
-Until recently, I was in the 98%. I honestly wasn’t even conflicted. I used Linux most days both for work and for hobbies – but always in the cloud or on one of those handy little project boards that are everywhere now. For my daily driver, it was Windows all the way.
-
-I guess what’s kept me with Windows so long is really that it’s just been good enough as a default option that I haven’t been prompted to even think about it. Which, to be fair, is a great quality in an operating system.
-
-The last time I tried a dual boot Linux/Windows setup was about 15 years ago. I was using Unix at university, and was quite attracted to the idea of free and open source software, so I decided to give it a go.
-
-This was back when, if you wanted to install Linux, you went to the newsagent and bought a magazine that had a CD-ROM on the front cover. I don’t exactly remember what distro it was – probably something like Slackware or Red Hat.
-
-I got it running, poked around a bit and played some of the included games, which were relatively primitive but still quite a lot of fun. After that, I wasn’t sure what I was supposed to do with it. I never managed to connect it to the internet.
-
-For a number of years, I had no say in my operating system: work was buying my computer for me. I was a junior developer at a small software company that wrote for Windows machines, so it made sense that it would be a Windows laptop. That was easy to arrange because that’s how they came anyway.
-
-When I left this role to work for myself, I kept doing the laptop thing; they’re so convenient when you’re renting and it’s great to work outside on a lovely day. Whenever I bought a new one, it would come with Windows on it, which was great because that’s what I used.
-
-I’ve managed to avoid most of the security headaches in Windows. I got a nasty rootkit about 7 years ago and it’s all been smooth sailing since.
-
-### I Only Want the Command Line When I Want it
-
-A big misgiving about Linux as a main OS is that it never really seemed like it was a total GUI operating system. Whatever desktop environment you used, it was just a nice little place to run your web browser, media player, and maybe an IDE or something. As soon as it’s time to install or configure anything, you opened a terminal window.
-
-I’m okay with the command line – up to a point. You definitely want it for “nerd stuff” like server configuration or deploying a website.
-
-But when I’m doing “normie stuff”, I’m like most people: I’d really rather just point and click. I want my mind to be on the actual task, not on what command I need to make it happen.
-
-Using a Windows laptop felt like I could have the best of both worlds. Whenever I needed a bash shell, I’d just ssh into a Linux machine and do it from there.
-
-Even when I started doing web tasks that required a bash shell on my local machine, that was no problem. Microsoft [had sorted one out for me][2] and it just worked.
-
-In the end, what made me install [Ubuntu Studio][3] was not any intent of replacing Windows. I had just started messing around with Linux synthesizers on my home theatre rig and was curious to see what I could do with these on an x86 machine.
-
-### Linux Very Quickly Became My Daily Driver
-
-The first thing to really hit me was just how fast this is. It boots quick and programs just open. This makes it so much nicer as a place to get things done.
-
-So it made sense to do my web browsing and word processing here as well. Booting back into the Windows partition for that would just be a drag.
-
-I guess, up until this point, I’ve just taken it for granted as an immutable fact of life that laptops gradually slow down as they age and every few years it will be time for a new one. Every time Microsoft pushes out an update, it gets a little slower.
-
-So it was that my cheap 4GB machine from 2015 felt like it was nearing the end. In my head, I was already pondering firewood and a longboat.
-
-I suppose when you have a monopoly operating system, nudging your customers toward buying that new machine a little bit earlier might even help move a few more licenses.
-
-I accepted that for a long time. I now thoroughly resent it.
-
-I mean, given what I’m doing – web browsing, word processing, editing text files, opening ssh terminals, some very light image editing – I honestly reckon a 3 year old machine should be able to keep up. These are all tasks you could do in the 90s. It’s not like I’m playing the latest Battlefield while rendering the next Star Wars.
-
-With Windows 10, my laptop was struggling with simple tasks. There seemed to be no way of avoiding the expense and hassle of getting a new one. After switching to Linux, I instead spent a pittance on another 4GB memory module for the spare slot.
-
-I reckon I can at least get another year of use out of this machine now. This in itself has made changing worthwhile.
-
-#### A Seamless Desktop Experience
-
-Ubuntu studio comes with the [xfce][4] desktop. The default design is intuitive and beautifully styled with kind of a cyberpunk motif. I haven’t felt any desire to mess with the default theme, except to change the background image.
-
-I love how simple the interface is. All your programs and settings are there in the menu where you might look for them. By comparison, the Windows 10 desktop seems to always grow more elaborate and crammed with obscurities.
-
-I can’t really say how much of my enthusiasm for this desktop is the ease of use and how much is simply down to how much more snappy and responsive it is – you experience these things together.
-
-#### A GUI You Can Set Your Watch to (Literally)
-
-So far, it seems like you could actually do a lot with this without ever going near the command line. They’ve actually gotten it to a point where you don’t need to edit text files to connect to wi-fi or set your timezone.
-
-I’d be lying if I said I wasn’t using the command line a bit more. But that’s only because an Ubuntu terminal window is also a great ssh client. For a couple of weeks I was using nano as my main text editor, but I decided that a mouse is actually pretty handy for navigating and selecting text.
-
-For the great mass of people who aren’t that into nerd stuff, I don’t think you would need the terminal at all.
-
-#### The Same Software, Only Better
-
-One thing that I think will help open Linux up to a much larger audience is the graphical front end for the package manager. It’s honestly not much different to browsing apps on my Android phone.
-
-I’ve found myself using both the graphical interface and the command line to install software. The graphical interface is great for browsing, while the command line makes it super simple when you already know what you want to install.
-
-That’s just me though. Most people don’t know how to run a package manager from the command line because they’ve never had to learn. The good news for them is that they’re not obliged to – you can get by fine with just the graphical interface.
-
-I guess it helps that I was already using so much open source software on Windows: [Firefox][5] for web browsing, [GIMP][6] to format images for web use, [OpenOffice][7] for word processing and the occasional spreadsheet. Moving to Linux has meant still using much the same software. I’ve switched from OpenOffice to [LibreOffice][8] and have barely noticed the difference.
-
-Installing software from the repositories means that it’s actually easier than on Windows, because I’m not having to look up a bunch of websites. Closed source applications like [Dropbox][9] and [Slack][10] were no hassle to install and work the same as always.
-
-Thanks to the package manager, updates and patches are now automated too. On Windows, Firefox knew to update itself, but other software expected you to download and install new versions manually, and I inevitably couldn’t be bothered
-
-#### Smooth Operating System Updates
-
-Every so often, when you boot Ubuntu Studio, there’s a little window that politely tells you that you have some updates to install. If you decide you want to install them right now, it will take a matter of minutes. You totally get on with other things in the meantime. Of course, if you absolutely need all your system resources, you’re not forced to run it at all until you’re ready.
-
-It’s a nice change. Windows updates, by contrast, show up out of nowhere like a bank robber, yelling, waving an Uzi and marching you to a big blue update screen for as long as it has to take.
-
-Having not booted into my Windows partition for about a month now, I’m dreading how much of it would have piled up and how long they will take to get through. And the longer I leave it, the worse it’s going to get. So maybe I’ll just never go back.
-
-All in all, I’m very happy to now use Linux as my main OS. I could almost become a Linux evangelist.
-
-Except for one thing:
-
-### This Was an Absolute Pig to Install
-
-I’m used to an easy install with Linux. You flash an SD card or buy a VPS, you’re up and running in minutes. Running a virtual machine on your own metal can take a little longer. But not a lot.
-
-Installing Linux on a partition of my laptop was a Biblical effort. It took 6 days to get it to boot.
-
-How could it take so long? Well, it starts with super slow download links: 7 to 13 hours for an image. Then there was the hardware support. Most time consuming of all were the mystery problems and all the time sunk trying to diagnose and fix them.
-
-What had got me interested was playing around with a bit of audio. [KXStudio][11] and [AVLinux][12] seemed to be the popular choices. Both belong to the Ubuntu/Debian family, which is the style of Linux I know.
-
-KXStudio booted fine from the USB stick. But it didn’t like my wireless adapter. The fix for this seemed to involve compiling something from github. This was a bother; I needed a working wireless adapter to connect to the internet.
-
-I figured it might be possible to download either a binary or the source to my Windows partition so I could install it without an internet connection. But after much searching and no clear instructions, I was stuck.
-
-So I downloaded AVLinux and flashed it to a USB stick. The installer connected to the internet fine, so I installed the damn thing, only to find that the partition wouldn’t boot and then neither would the USB stick. Also, I was locked out of the UEFI.
-
-I did the only logical thing you can do when you brick your work machine: panic. Then I remembered that I had a live boot restoration utility on a USB stick stashed away somewhere for precisely this occasion.
-
-I then tried Ubuntu Studio 18.10. The Live Boot worked fine and even connected to the internet. So I installed it. This seemed to go off without a hitch.
-
-When I tried to boot into it though, I just got a blank screen. I spent a while trying various kernel parameters like “nomodeset”, but with no luck.
-
-A helpful chap on Reddit recommended I try just bog standard Ubuntu, explaining to me that it’s easy enough to swap in a low-latency kernel once it’s installed.
-
-So it was that I tried Ubuntu 18.04 and 18.10, then Ubuntu Studio 18.04.. then again and again, trying slightly different settings on the installer, all in vain.
-
-Having made so many attempts and spent so much time trying to get these things to work, I was – reluctantly – having to face the possibility that perhaps a distribution based on Debian just wasn’t going to work on my machine.
-
-#### Fedora Jam Worked First Time
-
-I had no trouble installing this distribution. The installer was super simple and it just worked on my first try.
-
-It didn’t boot much faster than Windows 10, but once you were in the desktop it was quite snappy and responsive.
-
-Like Ubuntu Studio, this also has a graphical front end for the package manager. It doesn’t quite have the same smooth “app store” experience though. If you’re already familiar with command line package managers, it’s pretty easy, but I’m not sure how intuitive it would be for everyone else.
-
-I quickly came to discover that Fedora doesn’t have anything like the kind of software library that Ubuntu and Debian has. Or at least, that’s how it was for the software I was interested. I know that it’s often still possible to install things that aren’t in the repositories – but we’re talking ease of use here. Having to compile it yourself is not an ease of use.
-
-For web browsing and word processing, this was a great operating system. But when it came to tinkering with audio, I couldn’t even get [JACK][13] to start.
-
-So, after a few days, it was time to move on.
-
-All in all, even though I decided Fedora wasn’t really from me, I still rate it somewhat. There’s a very good workstation there for ordinary office work. And I can well believe the claims that it’s a great development environment – especially having the entire Red Hat ecosystem downstream of your OS.
-
-Still, the hunt was back on. A friend told me how much he liked using [Linux Mint][14]. I’d heard of it before, but knew little about it. I was intrigued when my friend explained it was based on Ubuntu because I’d really missed those repositories. I decided to give it a go.
-
-#### Linux Mint Was Excellent
-
-As near as I can tell, Linux Mint is basically just Ubuntu with a few tweaks to make it really user friendly right out of the box.
-
-The big one is the desktop environment Cinnamon. This is clearly very influenced by Windows XP – a fine OS to pay tribute to in my opinion. It’s probably even more beginner-friendly than the default desktop on Ubuntu Studio.
-
-I liked Linux Mint and decided to install it. The fly in the ointment though was that the dreaded wireless adapter problem had reemerged. This was a showstopper for me earlier. But by this point I was willing to consider building a temporary wireless bridge from bits and pieces I had lying around so that I could have an internet connection to try to get the right driver.
-
-I never got that far though. When I tried to, the installer kept aborting when it couldn’t install the boot loader. I tried it again and again and the same thing kept happening.
-
-#### Back to Ubuntu Studio
-
-I decided to go back to Ubuntu Studio 18.10. I’d at least gotten this to install before, even if it booted to a blank screen. I figured that there’d be some answer to this problem somewhere, if I only looked hard enough.
-
-I went and installed it again, expecting to be faced with the same problem. But this time it just worked.
-
-I’m pretty glad that it worked in the end. But I still have absolutely no idea what was going wrong or what I did differently to get it to work that one last time.
-
-### Should it Really Be This Difficult Even for Nerds?
-
-I admit it’s the other dudes in [DXM Tech Support team][15] who really know drivers and hardware. My own skills are mostly with web stuff.
-
-But still, I’d like to think I can hold my own a bit. I wrote my first code at the age of 7, I’ve worked as a software developer before, I can use a bash shell a bit, and installing weird operating systems to play 30 year old video games is my idea of a fun Sunday afternoon.
-
-And I reckon the things I was juggling a few things here that might be a bit beyond any kind of mass audience: things like kernel parameters, endlessly using Gparted and efibootmgr to clean up failed installs, or building my own wireless bridge.
-
-Which is all just a longer way of saying that, while I’m not exactly Linus Torvalds, I can do a thing or two here and there with a computer.
-
-But what if you actually are Linus Torvalds?
-
-It turns out you also think the install is disgusting:
-
-<https://www.youtube.com/embed/Lqzz3Zt0DbE?feature=oembed>
-
-My favourite bit here is in the middle where the Debian fan approaches the microphone for what’s meant to be a question. It was totally within her power to just ask him what the difficulty was. Instead she completely dismisses his experience and tells him he should use her favourite Linux instead.
-
-I doubt that she actually meant to be that much of a dick. It’d be more that she’s such a fan of the software that it’s difficult for her to see any complaint as a genuine area for improvement. For her, it has to be a user education problem.
-
-You can literally have the whole damn thing named after you and still have to put up with that crap. No wonder he can be a bit cranky.
-
-### It’s the Little Things Too
-
-To install Linux, you have to first run all sorts of errands to prepare your machine.
-
-You need the Windows 10 Disk Management tool to resize your C partition, delve into the UEFI to change some settings, install an image writer to burn the installer image to a USB stick, that sort of thing. Often you’re presented with multiple alternatives for each of these steps.
-
-My suspicion is that each of these things feels so trivial to most Linux users that it just doesn’t occur to them that it’s a real point of friction for most people.
-
-Using a different tool for each task is very much in keeping with the [UNIX Philosophy][16]: any one thing should do just one thing and do it well.
-
-That’s actually excellent for anyone who uses a computer to build things. You have all these lego bricks that you can arrange however makes sense. You can totally just run a Python script, grep the most relevant bits, then make the output presentable by piping it to [cowsay][17].
-
-But not everyone’s ready for cowsay. Joe Average has never even heard of UEFI or partitioning and he honestly shouldn’t have to.
-
-So this might be the wrong place for a rigid application of the UNIX philosophy. It greatly adds to the number of steps and that’s always going to cut down on the number of people who make it to the end.
-
-Even if you’ve always been amazing at computers, I think you can probably think of something else that once seemed too difficult. For me, that was cooking Indian recipes.
-
-That’s been my favourite thing to eat ever since I was a kid. But every time I looked at a recipe, it was just line after line of ingredients I didn’t really understand. So I made do with the jars and recipe kits.
-
-When I finally decided to actually give it a go, I realised the ingredients list was so long because of all the spices I’d never cooked with before. It turned out that the most difficult part of using them was bringing them home from the Indian grocers. Putting them in the pan added mere seconds to the actual cooking.
-
-Pretty easy, right? And yet, until I knew that, it was enough to stop me even trying, literally for years.
-
-That’s how this stuff works. Every unfamiliar step you add to a process brings people closer to thinking “hmm, that’s actually a bit too involved for me” – even if those extra steps are, individually, trivial.
-
-Linux does this to potential new users every day.
-
-The worst thing about adding this to the installation is that it’s all front loaded right at the start of someone’s decision to try Linux. If they don’t make it through the install, then none of the rest of it comes into play.
-
-### What the Install Should Look Like
-
-A big part of what sucks about an unsuccessful Linux install is the amount of time you spend and the number steps you take to reach a point of failure.
-
-So what would be cool is a lightweight installation tool that began with a hardware scan to give you meaningful feedback on what’s supported, what’s unsupported, and what needs further attention.
-
-Then, if it’s all good to go, it could download the live boot image, burn it to a USB stick, take care of the UEFI settings and so on. Then, when you decide you want to install it, it could also take care of defragmenting and resizing the C partition.
-
-It’s a thought anyway.
-
-### It’s Part of a Bigger Picture
-
-Addressing the install nightmare won’t make anyone who wasn’t. It’s more about boosting the [conversion rate][18] of those already interested to actual users.
-
-Off the top of my head, here are some of the other big things that stop people switching:
-
- * **Gaming:** A lot of the people who are most comfortable tinkering with drivers and the UEFI became that way because they’re really into playing the latest games.
-
-Linux is more than ok for casual gamers. For console gamers, like me, it’s an irrelevance. But if playing the best and latest games on PC is hugely important to you, there’s no contest which platform has the best library.
-
-There is an interesting push by the guys behind Steam to turn this around. There’s really no reason why Linux couldn’t be a major platform for gaming – not everyone realises that [the world’s best-selling console runs FreeBSD][19], a close cousin of Linux.
-
-But even if this starts to take off, it will be a while before hardcore gamers start moving away from Windows.
-
- * **Business Realities:** The difficult installation matters much less in a professionally managed IT environment. But these are also the places where a need to preserve existing systems, configurations and procedures can complicate any change. Even just migrating from one version of Windows to another has pain points.
-
-On top of this, the business owners and senior managers with the final say tend to be very busy and preoccupied with a dozen other challenges, and fairly reluctant to consider anything that seems weird and unfamiliar. This makes inertia hard to shift.
-
-The IT staff who might lobby for such a move would be understandably wary of blame for any difficulties that arise with Linux, in a way they won’t be for difficulties with Windows.
-
- * **Home Networking:** This is one spot where Windows still is much more user friendly. Your Windows machines are generally pretty good at detecting each other on the LAN and then appearing in Windows Explorer. From there it’s pretty easy to decide what to make public using a GUI interface.
-
-To do the same thing on Linux, you’re installing servers for various protocols and configuring them from the command line or in a text editor. Which is actually a lot less difficult than it first looks if you’re willing to roll your sleeves up. But, if we’re talking about going mainstream, then realistically most people will be repelled by this at a glance.
-
-Compared to the difficulty of the install, I think this is a relatively minor pain point. For the average home user, so long as they can run their software and connect to the internet, they’re pretty happy. And from what I’ve both seen and heard of DIY Windows networking jobs in the workplace, part of me thinks it’s a bad idea to democratise this too far.
-
-But it’s fairly normal for home users to want to copy things across a network to, say, a home theatre machine and they should be able to.
-
- * **Social Proof and Branding:** Properly covering all the social proof and branding problems Linux has with ordinary people would be a lengthy article in its own right.
-
-The basic idea of [social proof][20] is that humans, as social animals, are highly influenced by what everyone. That’s a highly rational instinct in a paleolithic environment, where there is an obvious drawback to A/B testing all the things that might kill you. It also suits us in our modern world that throws vastly more decisions at us than anyone has the time or mental resources.
-
-But being on the wrong side of it means you’re significantly penalised simply for not already being popular.
-
-On top of this, to the extent that people are aware of Linux, it’s mostly as an operating system for a technical elite.
-
-
-
-
-If you think about it, the difficulty of the install feeds back into most of these. Definitely, a larger user base would make games developers care more about the platform. Hypothetically, big titles that are properly optimised for a lighter weight operating system might run better. This is a huge drawcard for hardcore gamers.
-
-Because of the legacy system issues of even fairly small businesses, one easier path into the workplace would be to get the business owner while it’s still a one person show.
-
-A large number of new businesses are started by parents of young children, who are often struggling to afford everything. And a great many freelancers and solo entrepreneurs go through feast and famine periods often enough that they’ve learned to be protective of their cash buffers.
-
-These are all people who’d rather get a couple more years out of a machine than be made to buy a new one. It’s a good use case for Linux. So long as they can actually install it.
-
-And creating social proof means building a visibly larger use base. That will happen easier if more interested new users can install successfully.
-
-### Is it Time for a Branded Linux Machine?
-
-The easiest installation is one that’s already done. So perhaps it’s time for off-the-shelf Linux desktops and laptops.
-
-These exist already of course. Big PC makers like Dell have a Linux lineup, while some boutique outfits are exclusively Linux in their product offering.
-
-I’m picturing something kinda different though: an officially branded consumer product by one of the more user friendly distributions, pitched not tech professionals but to a mass market audience. Something that could be reviewed next to Apple and Samsung products.
-
-The desktop environment is ready for a broader audience. The software library is quite excellent for anyone with ordinary computing needs – and with a good graphical front end, it’s pretty easy to find and install software. And because Linux is so much gentler on hardware requirements, there’s some real scope to offer some solid bang for back here.
-
-I expect most open source developers have had no experience of and even less interest in. So what they could do is license the brand and a subdomain on their website for a given time period to someone already in the business of making and selling computers.
-
-For the sake of the brand, it’d be important to license this to someone you could trust to do a good job of building a decent machine. That would take care and attention, but I don’t think it’s impossible.
-
-As well as providing a small income stream to developers, and growing the user base through direct sales, the ordinary publicity effort to promote these products would help make Linux visible as a thing that the mass market could use.
-
-I’m just spitballin’ really. But if anyone likes this idea, they’re welcome to it.
-
-### It’s More a Matter of When than If
-
-Maybe it seems like I spent a lot of this article talking down Linux on the desktop. The wider truth though is that I’ve voted with my feet. If I don’t stick with Ubuntu Studio forever, it will be because I went to a different flavour of Linux.
-
-I really don’t want to go back to Windows if I can avoid it.
-
-There are certainly still big obstacles to bringing Linux to a wider audience. But I can’t see why they wouldn’t be overcome.
-
---------------------------------------------------------------------------------
-
-via: https://blog.dxmtechsupport.com.au/linux-on-the-desktop-are-we-nearly-there-yet/
-
-作者:[James Mawson][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
-[b]: https://github.com/lujun9972
-[1]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2018/11/Ubuntu-Desktop-1024x576.png
-[2]: https://docs.microsoft.com/en-us/windows/wsl/about
-[3]: https://ubuntustudio.org/
-[4]: https://www.xfce.org/
-[5]: https://www.mozilla.org/en-US/firefox/
-[6]: https://www.gimp.org/
-[7]: https://www.openoffice.org/
-[8]: https://www.libreoffice.org/
-[9]: https://www.dropbox.com/
-[10]: https://slack.com/
-[11]: https://kxstudio.linuxaudio.org/
-[12]: http://www.bandshed.net/avlinux/
-[13]: http://jackaudio.org/
-[14]: https://linuxmint.com/
-[15]: https://dxmtechsupport.com.au/about
-[16]: https://homepage.cs.uri.edu/~thenry/resources/unix_art/ch01s06.html
-[17]: https://medium.com/@jasonrigden/cowsay-is-the-most-important-unix-like-command-ever-35abdbc22b7f
-[18]: https://www.wordstream.com/conversion-rate
-[19]: http://www.extremetech.com/gaming/159476-ps4-runs-orbis-os-a-modified-version-of-freebsd-thats-similar-to-linux
-[20]: https://conversionxl.com/blog/is-social-proof-really-that-important/
diff --git a/sources/talk/20181209 Open source DIY ethics.md b/sources/talk/20181209 Open source DIY ethics.md
deleted file mode 100644
index 2c249d33af..0000000000
--- a/sources/talk/20181209 Open source DIY ethics.md
+++ /dev/null
@@ -1,62 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Open source DIY ethics)
-[#]: via: (https://arp242.net/weblog/diy.html)
-[#]: author: (Martin Tournoij https://arp242.net/)
-
-Open source DIY ethics
-======
-
-I moved to New Zealand last week, and as a proper Dutch person one of the first things I did after arriving was getting a bicycle.
-
-I was recommended [a great place][1] where they collect old bikes and provide people with the parts and tools to fix up the bikes. Want a bike? Choose one, fix it, and it’s yours. There are helpful and knowledgable volunteers who will gladly help you and explain how things work, but in the end you’ll have to fix your own bike; they’re not going to do it for you.
-
-I like this DIY attitude; I built my own fixie (which I unfortunately couldn’t bring) years ago and had been maintaining it myself ever since, but there are many different aspects I never touched on (different brake systems, gears, etc.) and fixing my bike with some help and explanation was a useful experience which taught me a thing or two that I’ll be sure to use in the future.
-
-My attitude to open source projects tends to be similar: I’ll gladly assist you or explain things, but you will have to do the work. This is especially true when it comes to feature requests or very specific scenarios.
-
-Open source software is fundamentally a [DIY ethic][2] for many – though not all – people who participate in it. It certainly is for me. I just fix stuff I want myself. Since I take some amount of pride in my work and want things to work well for others I’ll also gladly fix most bugs that are reported, but sometimes people will post an enhancement or feature request and just expect me to implement it. It’s sometimes even combined with a “but project X does it!”-comment. Well, feck off and use project X then (I don’t actually say this, just think it).
-
-I’ve seen more than a few people get frustrated by this attitude especially — though hardly exclusively — in the OpenBSD and suckless communities ([recent example that prompted this post][3]), partly because it’s not infrequently communicated in a somewhat unhelpful fashion (the OpenBSD saying is “shut up and hack”), but also because some people seem to misunderstand what it means to be a maintainer of an open source project. Open source software isn’t a service I provide to the world; it’s something I DIY’d myself and make available to the world because why not?
-
-Some open source software is supported by companies. Only about [14% of the contributions to the Linux kernel are not affiliated with a company][4]. I don’t think this matters: these are companies who are DIY-ing as well.
-
-Are there people who contribute to open source for other reasons? Sure. Some do because they really believe in [Free Software][5], or because they like programming as a hobby. But those are not the majority.
-
-Not all contributions that aren’t code are useless. Sometimes someone will have a great idea for an enhancement or feature that I hadn’t thought of myself and this can be a very valuable contribution. But those types of constructive contributions are usually easy to recognize: they consist of more than just a single paragraph, are respectful, show a clear understanding of what the project is supposed to do, if they don’t understand a certain aspect they’ll ask instead of bombastically claiming that it’s “broken”, and perhaps most importantly, they show a willingness to constructively contribute, rather than just trying to tell you how to run your project.
-
-This attitude isn’t limited to open source; to quote Neil Gaiman when talking about A Song of Ice and Fire fans demanding George R.R. Martin work harder on the next instalment of the series: “[George R.R. Martin is not your bitch][6]”.
-
-I can’t help George with his next book, but I can help with software projects, which is really neat. Not everyone is a computer programmer, but the vast majority of projects I’ve worked on are used exclusively by programmers.
-
-In the two months that it took me to finish this post (cleaning up drafts always takes forever) there have been a number of incidents in various communities that touched upon a mismatch in expectations between open source authors/maintainers and the users. “It’s not fun anymore, you get nothing from maintaining a popular package”, to quote one maintainer, or “I’m frustrated because I can’t handle the volume of emails” to quote another.
-
-The situation would be vastly improved if more people start seeing and treating open source more like the DIY that it is and assume responsibility for that bug you’ve encountered or enhancement you want, rather than offloading all responsibility to the maintainer. This won’t fix everything, but it’s a good start. Note that plenty of people — including myself — already do this.
-
-Both authors and users will benefit; authors will be frustrated less with “entitled” users, and users will be frustrated less by “rude” authors, and in the end the software will work better as users will be more willing to spend some time fixing stuff themselves, rather than just expecting other people to do it for them.
-
-
---------------------------------------------------------------------------------
-
-via: https://arp242.net/weblog/diy.html
-
-作者:[Martin Tournoij][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://arp242.net/
-[b]: https://github.com/lujun9972
-[1]: https://www.facebook.com/TheCrookedSpoke
-[2]: https://en.wikipedia.org/wiki/DIY_ethic
-[3]: https://www.reddit.com/r/suckless/comments/9mhwg8/why_does_sts_latency_suck_so_bad/e7fu9sj/
-[4]: https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-0
-[5]: https://www.gnu.org/philosophy/free-sw.html
-[6]: http://journal.neilgaiman.com/2009/05/entitlement-issues.html
-[7]: mailto:martin@arp242.net
-[8]: https://github.com/Carpetsmoker/arp242.net/issues/new
diff --git a/sources/talk/20181217 8 tips to help non-techies move to Linux.md b/sources/talk/20181217 8 tips to help non-techies move to Linux.md
deleted file mode 100644
index 14a645e0a7..0000000000
--- a/sources/talk/20181217 8 tips to help non-techies move to Linux.md
+++ /dev/null
@@ -1,111 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (8 tips to help non-techies move to Linux)
-[#]: via: (https://opensource.com/article/18/12/help-non-techies)
-[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
-
-8 tips to help non-techies move to Linux
-======
-Help your friends dump their proprietary operating systems and make the move to open source.
-
-
-Back in 2016, I took down the shingle for my technology coaching business. Permanently. Or so I thought.
-
-Over the last 10 months, a handful of friends and acquaintances have pulled me back into that realm. How? With their desire to dump That Other Operating System™ and move to Linux.
-
-This has been an interesting experience, in no small part because most of the people aren't at all technical. They know how to use a computer to do what they need to do. Beyond that, they're not interested in delving deeper. That said, they were (and are) attracted to Linux for a number of reasons—probably because I constantly prattle on about it.
-
-While bringing them to the Linux side of the computing world, I learned a few things about helping non-techies move to Linux. If someone asks you to help them make the jump to Linux, these eight tips can help you.
-
-### 1\. Be honest about Linux.
-
-Linux is great. It's not perfect, though. It can be perplexing and sometimes frustrating for new users. It's best to prepare the person you're helping with a short pep talk.
-
-What should you talk about? Briefly explain what Linux is and how it differs from other operating systems. Explain what you can and _can't_ do with it. Let them know some of the pain points they might encounter when using Linux daily.
-
-If you take a bit of time to [ease them into][1] Linux and open source, the switch won't be as jarring.
-
-### 2\. It's not about you.
-
-It's easy to fall into what I call the _power user fallacy_ : the idea that everyone uses technology the same way you do. That's rarely, if ever, the case.
-
-This isn't about you. It's not about your needs or how you use a computer. It's about the person you're helping's needs and intentions. Their needs, especially if they're not particularly technical, will be different from yours.
-
-It doesn't matter if Ubuntu or Elementary or Manjaro aren't your distros of choice. It doesn't matter if you turn your nose up at window managers like GNOME, KDE, or Pantheon in favor of i3 or Ratpoison. The person you're helping might think otherwise.
-
-Put your needs and prejudices aside and help them find the right Linux distribution for them. Find out what they use their computer for and tailor your recommendations for a distribution or three based on that.
-
-### 3\. Not everyone's a techie.
-
-And not everyone wants to be. Everyone I've helped move to Linux in the last 10 months has no interest in compiling kernels or code nor in editing and tweaking configuration files. Most of them will never crack open a terminal window. I don't expect them to be interested in doing any of that in the future, either.
-
-Guess what? There's nothing wrong with that. Maybe they won't _get the most out of_ Linux (whatever that means) by not embracing their inner geeks. Not everyone will want to take on challenges of, say, installing and configuring Slackware or Arch. They need something that will work out of the box.
-
-### 4\. Take stock of their hardware.
-
-In an ideal world, we'd all have tricked-out, high-powered laptops or desktops with everything maxed out. Sadly, that world doesn't exist.
-
-That probably includes the person you're helping move to Linux. They may have slightly (maybe more than slightly) older hardware that they're comfortable with and that works for them. Hardware that they might not be able to afford to upgrade or replace.
-
-Also, remember that not everyone needs a system for heavy-duty development or gaming or audio and video production. They just need a computer for browsing the web, editing photos, running personal productivity software, and the like.
-
-One person I recently helped adopt Linux had an Acer Aspire 1 laptop with 4GB of RAM and a 64GB SSD. That helped inform my recommendations, which revolved around a few lightweight Linux distributions.
-
-### 5\. Help them test-drive some distros.
-
-The [DistroWatch][2] database contains close to 900 Linux distributions. You should be able to find three to five Linux distributions to recommend. Make a short list of the distributions you think would be a good fit for them. Also, point them to reviews so they can get other perspectives on those distributions.
-
-When it comes time to take those Linux distributions for a spin, don't just hand someone a bunch of flash drives and walk away. You might be surprised to learn that most people have never run a live Linux distribution or installed an operating system. Any operating system. Beyond plugging the flash drives in, they probably won't know what to do.
-
-Instead, show them how to [create bootable flash drives][3] and set up their computer's BIOS to start from those drives. Then, let them spend some time running the distros off the flash drives. That will give them a rudimentary feel for the distros and their window managers' quirks.
-
-### 6\. Walk them through an installation.
-
-Running a live session with a flash drive tells someone only so much. They need to work with a Linux distribution for a couple or three weeks to really form an opinion of it and to understand its quirks and strengths.
-
-There's a myth that Linux is difficult to install. That might have been true back in the mid-1990s, but today most Linux distributions are easy to install. You follow a few graphical prompts and let the software do the rest.
-
-For someone who's never installed any operating system, installing Linux can be a bit daunting. They might not know what to choose when, say, they're asked which filesystem to use or whether or not to encrypt their hard disk.
-
-Guide them through at least one installation. While you should let them do most of the work, be there to answer questions.
-
-### 7\. Be prepared to do a couple of installs.
-
-As I mentioned a paragraph or two ago, using a Linux distribution for two weeks gives someone ample time to regularly interact with it and see if it can be their daily driver. It often works out. Sometimes, though, it doesn't.
-
-Remember the person with the Acer Aspire 1 laptop? She thought Xubuntu was the right distribution for her. After a few weeks of working with it, that wasn't the case. There wasn't a technical reason—Xubuntu ran smoothly on her laptop. It was just a matter of feel. Instead, she switched back to the first distro she test drove: [MX Linux][4]. She's been happily using MX ever since.
-
-### 8\. Teach them to fish.
-
-You can't always be there to be the guiding hand. Or to be the mechanic or plumber who can fix any problems the person encounters. You have a life, too.
-
-Once they've settled on a Linux distribution, explain that you'll offer a helping hand for two or three weeks. After that, they're on their own. Don't completely abandon them. Be around to help with big problems, but let them know they'll have to learn to do things for themselves.
-
-Introduce them to websites that can help them solve their problems. Point them to useful articles and books. Doing that will help make them more confident and competent users of Linux—and of computers and technology in general.
-
-### Final thoughts
-
-Helping someone move to Linux from another, more familiar operating system can be a challenge—a challenge for them and for you. If you take it slowly and follow the advice in this article, you can make the process smoother.
-
-Do you have other tips for helping a non-techie switch to Linux? Feel free to share them by leaving a comment.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/help-non-techies
-
-作者:[Scott Nesbitt][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/scottnesbitt
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/business/15/2/ato2014-lightning-talks-scott-nesbitt
-[2]: https://distrowatch.com
-[3]: https://opensource.com/article/18/7/getting-started-etcherio
-[4]: https://opensource.com/article/18/2/mx-linux-17-distro-beginners
diff --git a/sources/talk/20181219 Fragmentation is Why Linux Hasn-t Succeeded on Desktop- Linus Torvalds.md b/sources/talk/20181219 Fragmentation is Why Linux Hasn-t Succeeded on Desktop- Linus Torvalds.md
deleted file mode 100644
index e2d519439a..0000000000
--- a/sources/talk/20181219 Fragmentation is Why Linux Hasn-t Succeeded on Desktop- Linus Torvalds.md
+++ /dev/null
@@ -1,65 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Fragmentation is Why Linux Hasn’t Succeeded on Desktop: Linus Torvalds)
-[#]: via: (https://itsfoss.com/desktop-linux-torvalds/)
-[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-
-Fragmentation is Why Linux Hasn’t Succeeded on Desktop: Linus Torvalds
-======
-
-**Brief: Linus Torvalds has finally spoken his mind over why Linux that rules the servers and the clouds has not succeeded on the desktop front.**
-
-![Linus Torvalds voices his opinion on why desktop Linux didn't succeed][1]
-
-Too many cooks spoil the broth.
-
-Too many choices overwhelm the consumer/customer/user.
-
-Too many desktop choices held Linux back from succeeding as a desktop operating system? Linux creator Linus Torvalds certainly thinks so.
-
-In an interview with [TFiR][2], Torvalds expressed his views on the ‘failure’ of desktop Linux.
-
-> I still wish we were better at having a standardize desktop that goes across all the distributions… It’s not a kernel issue. It’s more of a personal annoyance how the fragmentation of the different vendors have, I think, held the desktop back a bit.
-
-You can watch the entire interview on [TFiR’s YouTube channel][3]. It’s a short video where Torvalds has expressed his views on desktop Linux and Chromebooks.
-
-<https://www.youtube.com/embed/VHFdoFKDuQA?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
-
-### Chromebooks and Android are the future of desktop Linux!
-
-When I met Jim Zemlin, executive director of the Linux Foundation, at Open Source Summit in 2017, I asked him why Linux Foundation doesn’t work on creating an affordable Linux laptop for masses. Jim answered that Chromebooks are essentially Linux desktop and they are doing exactly that so there is no need of going after a new entry-level Linux laptop.
-
-Interestingly, Torvalds also puts his weight behind Chromebooks (and Android).
-
-> It seems to be that Chromebooks and Android are the paths towards the desktop.
-
-In case you didn’t know, [Chromebooks will soon be able to run native Debian apps][4]. Using Chromebook will give a slightly better ‘Linux feel’. For now, Chromebooks and Chrome OS are nowhere close to the traditional desktop feel despite the fact they run on top of the Linux kernel.
-
-### What do you think?
-
-I, along with many other Linux users, have felt the same reason behind the not-so-successful state of the desktop Linux. There are too many choices available when it comes to desktop Linux and this is overwhelming to the new users to the extent that they just avoid using it.
-
-Do I feel vindicated that Torvalds thinks the same? Kind of.
-
-What do you think? Do you agree with the opinion that the fragmentation held back desktop Linux? Or do you think that the multitude of choices symbolize the freedom Linux provides to the users? Share your view with us.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/desktop-linux-torvalds/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[b]: https://github.com/lujun9972
-[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/12/torvalds-why-desktop-linux-failed.jpeg?resize=800%2C450&ssl=1
-[2]: https://www.tfir.io/
-[3]: https://www.youtube.com/watch?v=VHFdoFKDuQA
-[4]: https://itsfoss.com/linux-apps-chromebook/
diff --git a/sources/talk/20181220 D in the Browser with Emscripten, LDC and bindbc-sdl (translation).md b/sources/talk/20181220 D in the Browser with Emscripten, LDC and bindbc-sdl (translation).md
deleted file mode 100644
index b4dc33b434..0000000000
--- a/sources/talk/20181220 D in the Browser with Emscripten, LDC and bindbc-sdl (translation).md
+++ /dev/null
@@ -1,276 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (D in the Browser with Emscripten, LDC and bindbc-sdl (translation))
-[#]: via: (https://theartofmachinery.com/2018/12/20/emscripten_d.html)
-[#]: author: (Simon Arneaud https://theartofmachinery.com)
-
-D in the Browser with Emscripten, LDC and bindbc-sdl (translation)
-======
-
-Here’s a tutorial about using Emscripten to run D code in a normal web browser. It’s uses a different approach from the [Dscripten game demo][1] and the [dscripten-tools][2] toolchain that’s based on it.
-
- * Instead of porting the D runtime, it uses a lightweight, runtimeless `-betterC` build.
- * It uses Docker to manage the Emscripten installation.
-
-
-
-LDC has recently gained support for [compiling directly to WebAssembly][3], but (unlike the Emscripten approach) that doesn’t automatically get you libraries.
-
-You can find [the complete working code on Github][4]. `./run.sh` starts a shell in a Docker image that contains the development environment. `dub build --build=release` generates the HTML and JavaScript assets and puts them into the `dist/` directory.
-
-[This tutorial is translated from a Japanese post by outlandkarasu][5], who deserves all the credit for figuring this stuff out.
-
-### Background
-
-#### What’s Emscripten?
-
-[Emscripten][6] is a compiler toolchain for asm.js and WebAssembly that comes with ported versions of the libc and SDL2 C libraries. It can compile regular Linux-based applications in languages like C to code that can run in a browser.
-
-### How do you use Emscripten with D?
-
-Emscripten is a toolchain designed for C/C++, but the C/C++ part is just a frontend. The toolchain actually compiles LLVM intermediate representation (IR). You can generate LLVM IR bitcode from D using [LDC][7], so it should be possible to feed that through Emscripten and run D in a browser, just like C/C++.
-
-#### Gotchas using Emscripten
-
-Ideally that’s all it would take, but there are some things that require special attention (or trial and error).
-
- 1. D runtime library features like GC and Phobos can’t be used without an Emscripten port.
- 2. It’s not enough to just produce LLVM IR. The code needs to meet Emscripten’s requirements.
- * It needs to use ported libraries.
- * Pointer sizes and data structure binary layouts need to match.
- 3. Emscripten bugs need to be worked around.
- * Debug information is particularly problematic.
-
-
-
-### Implementation
-
-#### Plan of attack
-
-Here’s the plan for making D+Emscripten development work:
-
- 1. Use `-betterC` and the `@nogc` and `nothrow` attributes to avoid D runtime features.
- 2. Use SDL2 functions directly by statically compiling with [`bindbc-sdl`][8].
- 3. Keep on trying.
-
-
-
-#### Environment setup
-
-Emscripten is based on LLVM, clang and various other libraries, and is hard to set up, so I decided to [do the job with Docker][9]. I wrote a Dockerfile that would also add LDC and other tools at `docker build` time:
-
-```
-FROM trzeci/emscripten-slim:sdk-tag-1.38.21-64bit
-
-# Install D and tools, and enable them in the shell by adding them to .bashrc
-RUN apt-get -y update && \
- apt-get -y install vim sudo curl && \
- sudo -u emscripten /bin/sh -c "curl -fsS https://dlang.org/install.sh | bash -s ldc-1.12.0" && \
- (echo 'source $(~/dlang/install.sh ldc -a)' >> /home/emscripten/.bashrc)
-
-# dub settings (explained later)
-ADD settings.json /var/lib/dub/settings.json
-```
-
-Docker makes these big toolchains pretty easy :)
-
-#### Coding
-
-Here’s a basic demo that displays an image:
-
-```
-// Import SDL2 and SDL_image
-// Both work with Emscripten
-import bindbc.sdl;
-import bindbc.sdl.image;
-import core.stdc.stdio : printf; // printf works in Emscripten, too
-
-// Function declarations for the main loop
-alias em_arg_callback_func = extern(C) void function(void*) @nogc nothrow;
-extern(C) void emscripten_set_main_loop_arg(em_arg_callback_func func, void *arg, int fps, int simulate_infinite_loop) @nogc nothrow;
-extern(C) void emscripten_cancel_main_loop() @nogc nothrow;
-
-// Log output
-void logError(size_t line = __LINE__)() @nogc nothrow {
- printf("%d:%s\n", line, SDL_GetError());
-}
-
-struct MainLoopArguments {
- SDL_Renderer* renderer;
- SDL_Texture* texture;
-}
-
-// Language features restricted with @nogc and nothrow
-extern(C) int main(int argc, const char** argv) @nogc nothrow {
- // Initialise SDL
- if(SDL_Init(SDL_INIT_VIDEO) != 0) {
- logError();
- return -1;
- }
- scope(exit) SDL_Quit();
-
- // Initialise SDL_image (with PNG support)
- if(IMG_Init(IMG_INIT_PNG) != IMG_INIT_PNG) {
- logError();
- return -1;
- }
- scope(exit) IMG_Quit();
-
- // Make the window and its renderer
- SDL_Window* window;
- SDL_Renderer* renderer;
- if(SDL_CreateWindowAndRenderer(640, 480, SDL_WINDOW_SHOWN, &window, &renderer) != 0) {
- logError();
- return -1;
- }
- scope(exit) {
- SDL_DestroyRenderer(renderer);
- SDL_DestroyWindow(window);
- }
-
- // Load image file
- auto dman = IMG_Load("images/dman.png");
- if(!dman) {
- logError();
- return -1;
- }
- scope(exit) SDL_FreeSurface(dman);
-
- // Make a texture from the image
- auto texture = SDL_CreateTextureFromSurface(renderer, dman);
- if(!texture) {
- logError();
- return -1;
- }
- scope(exit) SDL_DestroyTexture(texture);
-
- // Start the image main loop
- auto arguments = MainLoopArguments(renderer, texture);
- emscripten_set_main_loop_arg(&mainLoop, &arguments, 60, 1);
- return 0;
-}
-
-extern(C) void mainLoop(void* p) @nogc nothrow {
- // Get arguments
- auto arguments = cast(MainLoopArguments*) p;
- auto renderer = arguments.renderer;
- auto texture = arguments.texture;
-
- // Clear background
- SDL_SetRenderDrawColor(renderer, 0x00, 0x00, 0x00, 0x00);
- SDL_RenderClear(renderer);
-
- // Texture image
- SDL_RenderCopy(renderer, texture, null, null);
- SDL_RenderPresent(renderer);
-
- // End of loop iteration
- emscripten_cancel_main_loop();
-}
-```
-
-#### Building
-
-Now building is the tricky bit.
-
-##### `dub.json`
-
-Here’s the `dub.json` I made through trial and error. It runs the whole build from D to WebAssembly.
-
-```
-{
- "name": "emdman",
- "authors": [
- "outland.karasu@gmail.com"
- ],
- "description": "A minimal emscripten D man demo.",
- "copyright": "Copyright © 2018, outland.karasu@gmail.com",
- "license": "BSL-1.0",
- "dflags-ldc": ["--output-bc", "-betterC"], // Settings for bitcode output
- "targetName": "app.bc",
- "dependencies": {
- "bindbc-sdl": "~>0.4.1"
- },
- "subConfigurations": {
- "bindbc-sdl": "staticBC" // Statically-linked, betterC build
- },
- "versions": ["BindSDL_Image"], // Use SDL_image
-
- // Run the Emscripten compiler after generating bitcode
- // * Disable optimisations
- // * Enable WebAssembly
- // * Use SDL+SDL_image (with PNG)
- // * Set web-only as the environment
- // * Embed image file(s)
- // * Generate HTML for running in browser
- "postBuildCommands": ["emcc -v -O0 -s WASM=1 -s USE_SDL=2 -s USE_SDL_IMAGE=2 -s SDL2_IMAGE_FORMATS='[\"png\"]' -s ENVIRONMENT=web --embed-file images -o dist/index.html app.bc"]
-}
-```
-
-##### Switch to 32b (x86) code generation
-
-Compiling with 64b “worked” but I got a warning about different data layouts:
-
-```
-warning: Linking two modules of different data layouts: '/tmp/emscripten_temp_WwvmL5_archive_contents/mulsc3_20989819.c.o' is 'e-p:32:32-i64:64-v128:32:128-n32-S128' whereas '/src/app.bc' is 'e-m:e-i64:64-f80:128-n8:16:32:64-S128'
-
-warning: Linking two modules of different target triples: /tmp/emscripten_temp_WwvmL5_archive_contents/mulsc3_20989819.c.o' is 'asmjs-unknown-emscripten' whereas '/src/app.bc' is 'x86_64-unknown-linux-gnu'
-```
-
-Apparently Emscripten is basically for 32b code. Using mismatched pointer sizes sounds like a pretty bad idea, so I added this `/var/lib/dub/settings.json` to the Dockerfile:
-
-```
-{
- "defaultArchitecture": "x86", // Set code generation to 32b
- "defaultCompiler": "ldc" // Use LDC by default
-}
-```
-
-There’s an [open issue for documenting `dub`’s `settings.json`][10].
-
-##### Remove debug information
-
-Emscripten gave the following error when I ran a normal build with `dub`:
-
-```
-shared:ERROR: Failed to run llvm optimizations:
-```
-
-It looks like there’s [an issue related to debugging information][11]. I worked around it by using `dub --build=release`.
-
-### Results
-
-After lots of trial and error, I finally succeeded in getting my demo to run in a browser. Here’s how it looks:
-
-![Meet D-Man \(Demo\)][12]
-
-The Emscripten+D dev environment isn’t as stable as a normal dev environment. For example, rendering didn’t work if I used `SDL_LowerBlit` instead. But here’s D-Man in a browser.
-
---------------------------------------------------------------------------------
-
-via: https://theartofmachinery.com/2018/12/20/emscripten_d.html
-
-作者:[Simon Arneaud][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://theartofmachinery.com
-[b]: https://github.com/lujun9972
-[1]: https://github.com/Ace17/dscripten
-[2]: https://github.com/CyberShadow/dscripten-tools
-[3]: https://wiki.dlang.org/Generating_WebAssembly_with_LDC
-[4]: https://github.com/outlandkarasu-sandbox/emdman
-[5]: https://qiita.com/outlandkarasu@github/items/15e0f4b6d1b2a0eab846
-[6]: http://kripken.github.io/emscripten-site/
-[7]: https://wiki.dlang.org/LDC
-[8]: https://github.com/BindBC/bindbc-sdl
-[9]: https://hub.docker.com/r/trzeci/emscripten/
-[10]: https://github.com/dlang/dub/issues/1463
-[11]: https://github.com/kripken/emscripten/issues/4078
-[12]: /images/emscripten_d/d-man-browser.png
diff --git a/sources/talk/20181231 Plans to learn a new tech skill in 2019- What you need to know.md b/sources/talk/20181231 Plans to learn a new tech skill in 2019- What you need to know.md
deleted file mode 100644
index 6ef539df9c..0000000000
--- a/sources/talk/20181231 Plans to learn a new tech skill in 2019- What you need to know.md
+++ /dev/null
@@ -1,145 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Plans to learn a new tech skill in 2019? What you need to know)
-[#]: via: (https://opensource.com/article/18/12/tech-skills-online-learning)
-[#]: author: (David Clinton https://opensource.com/users/remyd)
-
-Plans to learn a new tech skill in 2019? What you need to know
-======
-Go on a tour of the current state of online technology education.
-
-
-Open source software is, by definition, free. But it can sometimes cost you a king's ransom to learn how to master it. The good news? The open source ethos is alive and well in the education sector, and there are plenty of high-quality learning resources available. You just need to know where to find them.
-
-This article—adapted from my book, [Solving for Technology: How to quickly learn valuable new skills in a madly changing technology world][1]—offers some thoughts on what's out there and how to get the most out of it.
-
-How do you learn best—video courses? Hands-on interactive classes? And what are you usually looking for when you go hunting for knowledge—fast fixes to immediate problems? Deep understanding of an entire technology? Quick and dirty getting-starting guides?
-
-Whatever you're after, you're more likely to find it if you know what's out there. So keep your mind open to the many categories of teaching tools that exist, and join me for a tour of the current state of online technology education.
-
-### freeCodeCamp
-
-Most of the heavily edited, peer-reviewed courses available online live behind paywalls—but not all. [freeCodeCamp][2], as its name suggests, is free. And by free, I don't mean the site exists to drive traffic to some revenue-generating web page—it's completely free, simply because its creators believe such opportunities should exist.
-
-The idea behind freeCodeCamp is that "campers" work their way through realistic projects centered around coding challenges. But this site is different in a few important ways. First, campers are encouraged to join other local campers so they can code in mutually supportive groups. Once they've worked through the Front End, Data Visualization, Back End, or Full Stack certifications, campers are also encouraged to gain real-world experience by coding for non-profits. Finally, freeCodeCamp guides graduates through the job search and interviewing stages of their young careers.
-
-### YouTube
-
-Wondering how to change the bulb on the passenger-side brake light on your 2010 Dodge Caravan (3.8L)? There's a YouTube video that'll show you. Need to replace the pressure sensor on your ten-year-old Carrier forced-air natural gas furnace? There's another YouTube video that'll show you how to do that. In fact, there's a selection of YouTube videos that can show you how to do just about anything you can imagine—and a great many things you can't (and perhaps shouldn't).
-
-Got a specific problem that's blocking your progress? Looking for a bird's eye overview of your next language? Someone out there has probably already been there and recorded the solution in a video. Also, keep an eye out for video authors you like and subscribe to their YouTube channels. That makes it easier to find more useful content.
-
-Perhaps the most famous and successful YouTube channel of all is Salman Khan's [Khan Academy][3]. Although it's primarily aimed at K-12 students, there's plenty of useful content for people taking their first steps in programming (or physics or electrical engineering, for that matter).
-
-### Top 4 MOOCs
-
-The cost of traditional higher education programs has ballooned in recent decades. Currently, a four-year degree in the US can cost about five times the median annual household income in 2016 (around $59,000). Even if your degree ends up earning you an extra $20,000 per year beyond what you would have earned without it, it would still take you more than ten years just to break even (and perhaps many additional years to pay off the actual interest-carrying debt).
-
-Investments like that might not make a lot of sense. But what if you could get the same knowledge at no cost at all?
-
-Welcome to the world of the massive open online course (MOOC). A MOOC is a platform through which existing educational institutions deliver course content to anyone on the internet who's interested.
-
-By joining a MOOC, you can view video recordings of lectures from some of the best professors at elite universities and engage in simulated interactive labs, all at no cost and from the comfort of your own home. In many cases, you can also receive credit or certification for successfully completing a course. Certification often does carry some charges, but they are much lower than what you'd pay for a traditional degree.
-
-The downside—although not everyone will consider this a downside—is that many university-based MOOCs are less job- and industry-focused and spend more time on general theory. They sometimes also expect you to have already mastered some prerequisite STEM skills.
-
-Here are four major MOOC portals:
-
- * [**Coursera**][4]: Taking the 4- to 10-week Coursera courses is free, including quizzes and exercises. But they also offer fee-based add-ons such as assessments, grades, and certification. Specializations are multiple Coursera courses organized into a larger program like Data Science or Deep Learning. To earn a specialization certificate, students must complete a capstone project at the end. Coursera categories include Computer Science, Data Science, and Information Technology.
-
- * [**edX**][5]: Originally created by MIT and Harvard University, edX is a non-profit organization that delivers courseware created by more than 100 universities and colleges. Students may audit a course for free, or for a reasonable fee, gain verified certificates of completion.
-
- * [**MIT OpenCourseWare**][6]: OpenCourseWare isn't really a learning platform, and it won't help you much if you're looking for an organized guide through a particular topic. Rather, it's an online repository containing notes, quizzes, and some videos from thousands of MIT courses. The content can give you insights into specific questions, and if you're ambitious and determined enough, you could mine entire topics from the rich resources you'll find.
-
- * [**Udacity**][7]: I included Udacity in this higher education section because that's where its roots lie. But while the project's founders came from the Stanford University faculty, it was originally something of a rebellion against the high costs and distracting bloat of many university degree programs. Rather than spending four (or more) years studying material that's largely out of sync with the demands of the real job market, it proposes, why not focus on the skills the industry is looking for and get it done in much less time and for a tiny fraction of the cost?
-
-Udacity currently offers a couple dozen or so nano-degrees that can get to you beyond entry-level competence in some high-demand fields in just a few months. Because the nano-degrees are created with the direct involvement of major industry employers like Amazon, Nvidia, and Google, hard-working graduates have a decent chance of quickly landing a great job.
-
-
-
-
-### Tips for using the internet
-
-There's a world of help waiting for you out there. Don't miss it. A few tips:
-
-#### Learn to compose smart search strings
-
-Internet search is much more than simply typing a few related words into the search field and hitting Enter. Here are some powerful tips that will work on any major search engine (my personal favorite is [DuckDuckGo][8]):
-
-#### Use your problem to find a solution
-
-Thousands of people have worked with the same technology you’re learning, and odds are at least some of them have encountered the same problems you have. And at least a few of those folks will likely have posted their questions to an online user forum like Stack Overflow. The quickest way to find the answers they found is to search using the same language that you encountered.
-
-Did your problem generate an error message? Paste that exact text into your search engine. Were there any log messages? Post those, too.
-
-#### Be precise
-
-The internet has billions of pages, and vague search results are bound to include a lot of false positives, so be as precise as possible. One powerful trick: Enclose your error message in quotation marks, which tells the search engine that you’re looking for an exact phrase rather than a single result containing all or most of the words somewhere on the page. Just don’t be so specific that you end up narrowing your results down to zero.
-
-As an example, for an entry from the Apache error log like this:
-
-`[Fri Dec 16 02:15:44 2017] [error] [client 54.211.9.96] Client sent malformed Host header`
-
-Leave out the date and client IP address because there’s no way anyone else got those exact details. Instead, include only the `"Client sent..."` part (in quotations):
-
-`"Client sent malformed Host header"`
-
-If that’s still too broad, consider adding the strings `Apache` and `[error]` outside the quotation marks:
-
-`"Client sent malformed Host header" apache [error]`
-
-#### Be timely
-
-Search engines let you narrow down your search by time. If your problem is specific to a relatively recent release version, restrict your search to only the last week or month.
-
-#### Search in all the right places
-
-Sometimes an outside search engine will do a better job searching through a large website than the site’s own internal tool (I’m looking at you, Government of Canada). If you feel the solution to your problem is likely to be somewhere on a particular site—like Stack Overflow’s admin cousin, Server Fault—but you can’t find it, restrict results to only that one site:
-
-`"gssacceptsec_context(2) failed:" site:serverfault.com`
-
-#### Leverage public code samples
-
-Are you stuck in a way that only a developer can be stuck? You've read your code through over and over again and you just can't find the error. You've tried at least a half a dozen different design approaches and even—briefly, mind you—an entirely different language. Nothing. The application isn't working.
-
-Haunt GitHub and other places where public repositories of code live. They're all searchable and filled with examples of great code. Of course, there will also be plenty of examples of really bad and even malicious code, so keep your guard up.
-
-Browsing through other people's code is a great way to get new ideas and learn about best practices and coding patterns. If your search engine skills are as good as I'm guessing, then you'll probably uncover working solutions to whatever it is that ails you.
-
-### More free stuff
-
-You don't have to do this all by yourself. Before embarking on a significant new learning project, take a good look at your community and government to see what services are available.
-
-Many governments offer support—both financial and practical—for people looking to upgrade their professional skills. There are also more and more state/provincial governments joining the open textbook movement, where well-written, up-to-date technical textbooks are made freely available on the internet. At this point, the quality of most collections looks a bit spotty, but the long-term goal is to cut the cost of an education by many hundreds of dollars.
-
-Your company might be willing to sponsor your learning. Many companies provide their employees with accounts to online learning sites; sometimes it's just a matter of asking your boss or HR rep what is available.
-
-And what about your community? You might be surprised at how many older, experienced professionals are eager to engage in mentoring. It might take a bit of courage, but go ahead and approach someone you admire to see what wisdom and practical guidance they might offer.
-
-This article was adapted from the book [Solving for Technology: How to quickly learn valuable new skills in a madly changing technology world][1]. As an exclusive offer to the opensource.com community, feel free to [download a PDF version of the full book][9].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/tech-skills-online-learning
-
-作者:[David Clinton][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/remyd
-[b]: https://github.com/lujun9972
-[1]: https://learntech.bootstrap-it.com/
-[2]: https://www.freecodecamp.org/
-[3]: https://www.khanacademy.org/
-[4]: https://www.coursera.org/
-[5]: https://www.edx.org/
-[6]: http://ocw.mit.edu/index.htm
-[7]: https://www.udacity.com/
-[8]: https://duckduckgo.com/
-[9]: https://learntech.bootstrap-it.com/download.html
diff --git a/sources/talk/20190205 7 predictions for artificial intelligence in 2019.md b/sources/talk/20190205 7 predictions for artificial intelligence in 2019.md
deleted file mode 100644
index 2e1b047a15..0000000000
--- a/sources/talk/20190205 7 predictions for artificial intelligence in 2019.md
+++ /dev/null
@@ -1,91 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (7 predictions for artificial intelligence in 2019)
-[#]: via: (https://opensource.com/article/19/2/predictions-artificial-intelligence)
-[#]: author: (Salil Sethi https://opensource.com/users/salilsethi)
-
-7 predictions for artificial intelligence in 2019
-======
-
-While 2018 was a big year for AI, the stage is set for it to make an even deeper impact in 2019.
-
-
-
-Without question, 2018 was a big year for artificial intelligence (AI) as it pushed even further into the mainstream, successfully automating more functionality than ever before. Companies are increasingly exploring applications for AI, and the general public has grown accustomed to interacting with the technology on a daily basis.
-
-The stage is set for AI to continue transforming the world as we know it. In 2019, not only will the technology continue growing in global prevalence, but it will also spawn deeper conversations around important topics, fuel innovative business models, and impact society in new ways, including the following seven.
-
-### 1\. Machine learning as a service (MLaaS) will be deployed more broadly
-
-In 2018, we witnessed major strides in MLaaS with technology powerhouses like Google, Microsoft, and Amazon leading the way. Prebuilt machine learning solutions and capabilities are becoming more attractive in the market, especially to smaller companies that don't have the necessary in-house resources or talent. For those that have the technical know-how and experience, there is a significant opportunity to sell and deploy packaged solutions that can be easily implemented by others.
-
-Today, MLaaS is sold primarily on a subscription or usage basis by cloud-computing providers. For example, Microsoft Azure's ML Studio provides developers with a drag-and-drop environment to develop powerful machine learning models. Google Cloud's Machine Learning Engine also helps developers build large, sophisticated algorithms for a variety of applications. In 2017, Amazon jumped into the realm of AI and launched Amazon SageMaker, another platform that developers can use to build, train, and deploy custom machine learning models.
-
-In 2019 and beyond, be prepared to see MLaaS offered on a much broader scale. Transparency Market Research predicts it will grow to US$20 billion at an alarming 40% CAGR by 2025.
-
-### 2\. More explainable or "transparent" AI will be developed
-
-Although there are already many examples of how AI is impacting our world, explaining the outputs and rationale of complex machine learning models remains a challenge.
-
-Unfortunately, AI continues to carry the "black box" burden, posing a significant limitation in situations where humans want to understand the rationale behind AI-supported decision making.
-
-AI democratization has been led by a plethora of open source tools and libraries, such as Scikit Learn, TensorFlow, PyTorch, and more. The open source community will lead the charge to build explainable, or "transparent," AI that can clearly document its logic, expose biases in data sets, and provide answers to follow-up questions.
-
-Before AI is widely adopted, humans need to know that the technology can perform effectively and explain its reasoning under any circumstance.
-
-### 3\. AI will impact the global political landscape
-
-In 2019, AI will play a bigger role on the global stage, impacting relationships between international superpowers that are investing in the technology. Early adopters of AI, such as the US and [China][1], will struggle to balance self-interest with collaborative R&D. Countries that have AI talent and machine learning capabilities will experience tremendous growth in areas like predictive analytics, creating a wider global technology gap.
-
-Additionally, more conversations will take place around the ethical use of AI. Naturally, different countries will approach this topic differently, which will affect political relationships. Overall, AI's impact will be small relative to other international issues, but more noticeable than before.
-
-### 4\. AI will create more jobs than it eliminates
-
-Over the long term, many jobs will be eliminated as a result of AI-enabled automation. Roles characterized by repetitive, manual tasks are being outsourced to AI more and more every day. However, in 2019, AI will create more jobs than it replaces.
-
-Rather than eliminating the need for humans entirely, AI is augmenting existing systems and processes. As a result, a new type of role is emerging. Humans are needed to support AI implementation and oversee its application. Next year, more manual labor will transition to management-type jobs that work alongside AI, a trend that will continue to 2020. Gartner predicts that in two years, [AI will create 2.3 million jobs while only eliminating 1.8 million.][2]
-
-### 5\. AI assistants will become more pervasive and useful
-
-AI assistants are nothing new to the modern world. Apple's Siri and Amazon's Alexa have been supporting humans on the road and in their homes for years. In 2019, we will see AI assistants continue to grow in their sophistication and capabilities. As they collect more behavioral data, AI assistants will become better at responding to requests and completing tasks. With advances in natural language processing and speech recognition, humans will have smoother and more useful interactions with AI assistants.
-
-In 2018, we saw companies launch promising new AI assistants. Recently, Google began rolling out its voice-enabled reservation booking service, Duplex, which can call and book appointments on behalf of users. Technology company X.ai has built two AI personal assistants, Amy and Andrew, who can interact with humans and schedule meetings for their employers. Amazon also recently announced Echo Auto, a device that enables drivers to integrate Alexa into their vehicles. However, humans will continue to place expectations ahead of reality and be disappointed at the technology's limitations.
-
-### 6\. AI/ML governance will gain importance
-
-With so many companies investing in AI, much more energy will be put towards developing effective AI governance structures. Frameworks are needed to guide data collection and management, appropriate AI use, and ethical applications. Successful and appropriate AI use involves many different stakeholders, highlighting the need for reliable and consistent governing bodies.
-
-In 2019, more organizations will create governance structures and more clearly define how AI progress and implementation are managed. Given the current gap in explainability, these structures will be tremendously important as humans continue to turn to AI to support decision-making.
-
-### 7\. AI will help companies solve AI talent shortages
-
-A [shortage of AI and machine learning talent][3] is creating an innovation bottleneck. A [survey][4] released last year from O'Reilly revealed that the biggest challenge companies are facing related to using AI is a lack of available talent. And as technological advancement continues to accelerate, it is becoming harder for companies to develop talent that can lead large-scale enterprise AI efforts.
-
-To combat this, organizations will—ironically—use AI and machine learning to help address the talent gap in 2019. For example, Google Cloud's AutoML includes machine learning products that help developers train machine learning models without having any prior AI coding experience. Amazon Personalize is another machine learning service that helps developers build sophisticated personalization systems that can be implemented in many ways by different kinds of companies. In addition, companies will use AI to find talent and fill job vacancies and propel innovation forward.
-
-### AI In 2019: bigger and better with a tighter leash
-
-Over the next year, AI will grow more prevalent and powerful than ever. Expect to see new applications and challenges and be ready for an increased emphasis on checks and balances.
-
-What do you think? How might AI impact the world in 2019? Please share your thoughts in the comments below!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/2/predictions-artificial-intelligence
-
-作者:[Salil Sethi][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/salilsethi
-[b]: https://github.com/lujun9972
-[1]: https://www.turingtribe.com/story/china-is-achieving-ai-dominance-by-relying-on-young-blue-collar-workers-rLMsmWqLG4fGFwisQ
-[2]: https://www.gartner.com/en/newsroom/press-releases/2017-12-13-gartner-says-by-2020-artificial-intelligence-will-create-more-jobs-than-it-eliminates
-[3]: https://www.turingtribe.com/story/tencent-says-there-are-only-bTpNm9HKaADd4DrEi
-[4]: https://www.forbes.com/sites/bernardmarr/2018/06/25/the-ai-skills-crisis-and-how-to-close-the-gap/#19bafcf631f3
diff --git a/sources/talk/20200111 Don-t Use ZFS on Linux- Linus Torvalds.md b/sources/talk/20200111 Don-t Use ZFS on Linux- Linus Torvalds.md
deleted file mode 100644
index 7323b77a8e..0000000000
--- a/sources/talk/20200111 Don-t Use ZFS on Linux- Linus Torvalds.md
+++ /dev/null
@@ -1,82 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Don’t Use ZFS on Linux: Linus Torvalds)
-[#]: via: (https://itsfoss.com/linus-torvalds-zfs/)
-[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-
-Don’t Use ZFS on Linux: Linus Torvalds
-======
-
-_“Don’t use ZFS. It’s that simple. It was always more of a buzzword than anything else, I feel, and the licensing issues just make it a non-starter for me.”_
-
-This is what Linus Torvalds [said in a mailing list][1] to once again express his disliking for [ZFS filesystem][2] specially over its licensing.
-
-To avoid unnecessary confusion, this is more intended for Linux distributions, kernel developers and maintainers rather than individual Linux users.
-
-### What’s the licensing issue with ZFS and Linux kernel?
-
-![][3]
-
-ZFS was open sourced around 2003. This would have meant that Linux distributions start supporting ZFS. But that didn’t really happen because of the complexity of [open source licenses][4].
-
-ZFS is open source under [Common Development and Distribution License][5] (CDDL) 1.0 whereas Linux kernel is licensed under the GNU General Public License (GPL) 2.0.
-
-These two open source licenses are not fully compatible with each other. As noted by [PCWorld][6], if ZFS with this license is included in the Linux kernel, this would mean that kernel+ZFS is a derivative work of the (original ZFS-less) Linux kernel.
-
-### Torvalds doesn’t trust Oracle
-
-![][7]
-
-While the whole derivative thing is a matter of debate for legal and licensing experts, Torvalds is skeptical of Oracle. Oracle has a history of suing enterprises for using its code. Remember [Oracle vs Android lawsuit over the use of Java][8]?
-
-> Other people think it can be ok to merge ZFS code into the kernel and that the module interface makes it ok, and that’s their decision. But considering Oracle’s litigious nature, and the questions over licensing, there’s no way I can feel safe in ever doing so.
->
-> And I’m not at all interested in some “ZFS shim layer” thing either that some people seem to think would isolate the two projects. That adds no value to our side, and given Oracle’s interface copyright suits (see Java), I don’t think it’s any real licensing win either.
-
-Torvalds doesn’t want Linux kernel to get into legal troubles with Oracle in future and hence he refuses to include ZFS in mainline kernel until Orcale provides a signed letter that a kernel with ZFS will be under GPL license.
-
-> And honestly, there is no way I can merge any of the ZFS efforts until I get an official letter from Oracle that is signed by their main legal counsel or preferably by Larry Ellison himself that says that yes, it’s ok to do so and treat the end result as GPL’d.
-
-He is not stopping other (distributions) from using ZFS. But they are on their own.
-
-> If somebody adds a kernel module like ZFS, they are on their own. I can’t maintain it, and I can not be bound by other peoples kernel changes.
-
-Canonical, Ubuntu’s parent company, has been too keen on ZFS. Their [legal department thinks that including ZFS in kernel doesn’t make it a derivative work][9]. So they took their chances and now they provide an option to [use ZFS on root from Ubuntu 19.10][10].
-
-### Torvalds is also not impressed with ZFS in general
-
-![][11]
-
-While some people drool over ZFS, Linus Torvalds is not that impressed with ZFS. He doesn’t think it’s using ZFS is a good idea specially when it is not actively maintained by Oracle (after they open sourced it)
-
-> The benchmarks I’ve seen do not make ZFS look all that great. And as far as I can tell, it has no real maintenance behind it either any more, so from a long-term stability standpoint, why would you ever want to use it in the first place?
-
-I am no legal expert but if there is even a slightest doubt, I would prefer staying away from ZFS. What do you think of the whole ZFS debate?
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/linus-torvalds-zfs/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[b]: https://github.com/lujun9972
-[1]: https://www.realworldtech.com/forum/?threadid=189711&curpostid=189841
-[2]: https://itsfoss.com/what-is-zfs/
-[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/01/dont_use_zfs_torvalds.jpg?ssl=1
-[4]: https://itsfoss.com/open-source-licenses-explained/
-[5]: https://opensource.org/licenses/CDDL-1.0
-[6]: https://www.pcworld.com/article/3061924/ubuntu-1604s-support-for-the-zfs-file-system-may-violate-the-general-public-license.html
-[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/linus-torvalds-zfs-quotes-1.jpg?ssl=1
-[8]: https://itsfoss.com/oracle-google-dispute/
-[9]: https://ubuntu.com/blog/zfs-licensing-and-linux
-[10]: https://itsfoss.com/zfs-ubuntu/
-[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/linus-torvalds-zfs-quotes-2.jpg?ssl=1
diff --git a/sources/tech/20151127 Research log- gene signatures and connectivity map.md b/sources/tech/20151127 Research log- gene signatures and connectivity map.md
deleted file mode 100644
index f4e7faa4bc..0000000000
--- a/sources/tech/20151127 Research log- gene signatures and connectivity map.md
+++ /dev/null
@@ -1,133 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Research log: gene signatures and connectivity map)
-[#]: via: (https://www.jtolio.com/2015/11/research-log-gene-signatures-and-connectivity-map)
-[#]: author: (jtolio.com https://www.jtolio.com/)
-
-Research log: gene signatures and connectivity map
-======
-
-Happy Thanksgiving everyone!
-
-### Context
-
-This is the third post in my continuing series on my attempts at research. Previously we talked about:
-
- * [what I’m doing, cell states, and microarrays][1]
- * and then [more about microarrays and R][2].
-
-
-
-By the end of last week we had discussed how to get a table of normalized gene expression intensities that looks like this:
-
-```
-ENSG00000280099_at 0.15484421
-ENSG00000280109_at 0.16881395
-ENSG00000280178_at -0.19621641
-ENSG00000280316_at 0.08622216
-ENSG00000280401_at 0.15966256
-ENSG00000281205_at -0.02085352
-...
-```
-
-The reason for doing this is to figure out which genes are related, and perhaps more importantly, what a cell is even doing.
-
-_Summary:_ new post, also, I’m bringing back the short section summaries.
-
-### Cell lines
-
-The first thing to do when trying to figure out what cells are doing is to choose a cell. There’s all sorts of cells. Healthy brain cells, cancerous blood cells, bruised skin cells, etc.
-
-For any experiment, you’ll need a control to eliminate noise and apply statistical tests for validity. If you don’t use a control, the effect you’re seeing may not even exist, and so for any experiment with cells, you will need a control cell.
-
-Cells often divide, which means that a cell, once chosen, will duplicate itself for you in the presence of the appropriate resources. Not all cells divide ad nauseam which provides some challenges, but many cells under study luckily do.
-
-So, a _cell line_ is simply a set of cells that have all replicated from a specific chosen initial cell. Any set of cells from a cell line will be as identical as possible (unless you screwed up! geez). They will be the same type of cell with the same traits and behaviors, at least, as much as possible.
-
-_Summary:_ a cell line is a large amount of cells that are as close to being the same as possible.
-
-### Perturbagens
-
-There are many things that might affect what a cell is doing. Drugs, agitation, temperature, disease, cancer, gene splicing, small molecules (maybe you give a cell more iron or calcium or something), hormones, light, Jello, ennui, etc. Given any particular cell line, giving a cell from that cell line one of these _perturbagens_, or, perturbing the cell in a specific way, when compared to a control will say what that cell does differently in the face of that perturbagen.
-
-If you’d like to find out what exactly a certain type of cell does when you give it lemon lime soda, then you choose the right cell line, leave out some control cells and give the rest of the cells soda.
-
-Then, you measure gene expression intensities for both the control cells and the perturbed cells. The _differential expression_ of genes between the perturbed cells and the controls cells is likely due to the introduction of the lemon lime soda.
-
-Genes that end up getting expressed _more_ in the presence of the soda are considered _up-regulated_, whereas genes that end up getting expressed _less_ are considered _down-regulated_. The degree to which a gene is up or down regulated constitutes how much of an effect the soda may have had on that gene.
-
-Of course, all of this has such a significant amount of experimental noise that you could find pretty much anything. You’ll need to replicate your experiment independently a few times before you publish that lemon lime soda causes increased expression in the [Sonic hedgehog gene][3].
-
-_Summary:_ A perturbagen is something you introduce/do to a cell to change its behavior, such as drugs or throwing it at a wall or something. The wall perturbagen.
-
-### Gene signature
-
-For a given change or perturbagen to a cell, we now have enough to compute lists of up-regulated and down-regulated genes and the magnitude change in expression for each gene.
-
-This gene expression pattern for some subset of important genes (perhaps the most changed in expression) is called a _gene signature_, and gene signatures are very useful. By comparing signatures, you can:
-
- * identify or compare cell states
- * find sets of positively or negatively correlated genes
- * find similar disease signatures
- * find similar drug signatures
- * find drug signatures that might counteract opposite disease signatures.
-
-
-
-(That last bullet point is essentially where I’m headed with my research.)
-
-_Summary:_ a gene signature is a short summary of the most important gene expression differences a perturbagen causes in a cell.
-
-### Drugs!
-
-The pharmaceutical industry is constantly on the lookout for new breakthrough drugs that might represent huge windfalls in cash, and drugs don’t always work as planned. Many drugs spend years in research and development, only to ultimately find poor efficacy or adoption. Sometimes drugs even become known [much more for their side-effects than their originally intended therapy][4].
-
-The practical upshot is that there’s countless FDA-approved drugs that represent decades of work that are simply underused or even unused entirely. These drugs have already cleared many challenging regulatory hurdles, but are simply and quite literally cures looking for a disease.
-
-If even just one of these drugs can be given a new lease on life for some yet-to-be-cured disease, then perhaps we can give some people new leases on life!
-
-_Summary:_ instead of developing new drugs, there’s already lots of drugs that aren’t being used. Maybe we can find matching diseases!
-
-### The Connectivity Map project
-
-The [Broad Institute’s Connectivity Map project][5] isn’t particularly new anymore, but it represents a ground breaking and promising idea - we can dump a bunch of signatures into a database and construct all sorts of new hypotheses we might not even have thought to check before.
-
-To prove out the usefulness of this idea, the Connectivity Map (or cmap) project chose 5 different cell lines (all cancer cells, which are easy to get to replicate!) and a library of FDA approved drugs, and then gave some cells these drugs.
-
-They then constructed a database of all of the signatures they computed for each possible perturbagen they measured. Finally, they constructed a web interface where a user can upload a gene signature and get a result list back of all of the signatures they collected, ordered by the most to least similar. You can totally go sign up and [try it out][5].
-
-This simple tool is surprisingly powerful. It allows you to find similar drugs to a drug you know, but it also allows you to find drugs that might counteract a disease you’ve created a signature for.
-
-Ultimately, the project led to [a number of successful applications][6]. So useful was it that the Broad Institute has doubled down and created the much larger and more comprehensive [LINCS Project][7] that targets an order of magnitude more cell lines (77) and more perturbagens (42,532, compared to cmap’s 6100). You can sign up and use that one too!
-
-_Summary_: building a system that supports querying signature connections has already proved to be super useful.
-
-### Whew
-
-Alright, I wrote most of this on a plane yesterday but since I should now be spending time with family I’m going to cut it short here.
-
-Stay tuned for next week!
-
---------------------------------------------------------------------------------
-
-via: https://www.jtolio.com/2015/11/research-log-gene-signatures-and-connectivity-map
-
-作者:[jtolio.com][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.jtolio.com/
-[b]: https://github.com/lujun9972
-[1]: https://www.jtolio.com/writing/2015/11/research-log-cell-states-and-microarrays/
-[2]: https://www.jtolio.com/writing/2015/11/research-log-r-and-more-microarrays/
-[3]: https://en.wikipedia.org/wiki/Sonic_hedgehog
-[4]: https://en.wikipedia.org/wiki/Sildenafil#History
-[5]: https://www.broadinstitute.org/cmap/
-[6]: https://www.broadinstitute.org/cmap/publications.jsp
-[7]: http://www.lincscloud.org/
diff --git a/sources/tech/20160302 Go channels are bad and you should feel bad.md b/sources/tech/20160302 Go channels are bad and you should feel bad.md
deleted file mode 100644
index 0ad2a5ed97..0000000000
--- a/sources/tech/20160302 Go channels are bad and you should feel bad.md
+++ /dev/null
@@ -1,443 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Go channels are bad and you should feel bad)
-[#]: via: (https://www.jtolio.com/2016/03/go-channels-are-bad-and-you-should-feel-bad)
-[#]: author: (jtolio.com https://www.jtolio.com/)
-
-Go channels are bad and you should feel bad
-======
-
-_Update: If you’re coming to this blog post from a compendium titled “Go is not good,” I want to make it clear that I am ashamed to be on such a list. Go is absolutely the least worst programming language I’ve ever used. At the time I wrote this, I wanted to curb a trend I was seeing, namely, overuse of one of the more warty parts of Go. I still think channels could be much better, but overall, Go is wonderful. It’s like if your favorite toolbox had [this][1] in it; the tool can have uses (even if it could have had more uses), and it can still be your favorite toolbox!_
-
-_Update 2: I would be remiss if I didn’t point out this excellent survey of real issues: [Understanding Real-World Concurrency Bugs In Go][2]. A significant finding of this survey is that… Go channels cause lots of bugs._
-
-I’ve been using Google’s [Go programming language][3] on and off since mid-to-late 2010, and I’ve had legitimate product code written in Go for [Space Monkey][4] since January 2012 (before Go 1.0!). My initial experience with Go was back when I was researching Hoare’s [Communicating Sequential Processes][5] model of concurrency and the [π-calculus][6] under [Matt Might][7]’s [UCombinator research group][8] as part of my ([now redirected][9]) PhD work to better enable multicore development. Go was announced right then (how serendipitous!) and I immediately started kicking tires.
-
-It quickly became a core part of Space Monkey development. Our production systems at Space Monkey currently account for over 425k lines of pure Go (_not_ counting all of our vendored libraries, which would make it just shy of 1.5 million lines), so not the most Go you’ll ever see, but for the relatively young language we’re heavy users. We’ve [written about our Go usage][10] before. We’ve open-sourced some fairly heavily used libraries; many people seem to be fans of our [OpenSSL bindings][11] (which are faster than [crypto/tls][12], but please keep openssl itself up-to-date!), our [error handling library][13], [logging library][14], and [metric collection library/zipkin client][15]. We use Go, we love Go, we think it’s the least bad programming language for our needs we’ve used so far.
-
-Although I don’t think I can talk myself out of mentioning my widely avoided [goroutine-local-storage library][16] here either (which even though it’s a hack that you shouldn’t use, it’s a beautiful hack), hopefully my other experience will suffice as valid credentials that I kind of know what I’m talking about before I explain my deliberately inflamatory post title.
-
-![][17]
-
-### Wait, what?
-
-If you ask the proverbial programmer on the street what’s so special about Go, she’ll most likely tell you that Go is most known for channels and goroutines. Go’s theoretical underpinnings are heavily based in Hoare’s CSP model, which is itself incredibly fascinating and interesting and I firmly believe has much more to yield than we’ve appropriated so far.
-
-CSP (and the π-calculus) both use communication as the core synchronization primitive, so it makes sense Go would have channels. Rob Pike has been fascinated with CSP (with good reason) for a [considerable][18] [while][19] [now][20].
-
-But from a pragmatic perspective (which Go prides itself on), Go got channels wrong. Channels as implemented are pretty much a solid anti-pattern in my book at this point. Why? Dear reader, let me count the ways.
-
-#### You probably won’t end up using just channels.
-
-Hoare’s Communicating Sequential Processes is a computational model where essentially the only synchronization primitive is sending or receiving on a channel. As soon as you use a mutex, semaphore, or condition variable, bam, you’re no longer in pure CSP land. Go programmers often tout this model and philosophy through the chanting of the [cached thought][21] “[share memory by communicating][22].”
-
-So let’s try and write a small program using just CSP in Go! Let’s make a high score receiver. All we will do is keep track of the largest high score value we’ve seen. That’s it.
-
-First, we’ll make a `Game` struct.
-
-```
-type Game struct {
- bestScore int
- scores chan int
-}
-```
-
-`bestScore` isn’t going to be protected by a mutex! That’s fine, because we’ll simply have one goroutine manage its state and receive new scores over a channel.
-
-```
-func (g *Game) run() {
- for score := range g.scores {
- if g.bestScore < score {
- g.bestScore = score
- }
- }
-}
-```
-
-Okay, now we’ll make a helpful constructor to start a game.
-
-```
-func NewGame() (g *Game) {
- g = &Game{
- bestScore: 0,
- scores: make(chan int),
- }
- go g.run()
- return g
-}
-```
-
-Next, let’s assume someone has given us a `Player` that can return scores. It might also return an error, cause hey maybe the incoming TCP stream can die or something, or the player quits.
-
-```
-type Player interface {
- NextScore() (score int, err error)
-}
-```
-
-To handle the player, we’ll assume all errors are fatal and pass received scores down the channel.
-
-```
-func (g *Game) HandlePlayer(p Player) error {
- for {
- score, err := p.NextScore()
- if err != nil {
- return err
- }
- g.scores <- score
- }
-}
-```
-
-Yay! Okay, we have a `Game` type that can keep track of the highest score a `Player` receives in a thread-safe way.
-
-You wrap up your development and you’re on your way to having customers. You make this game server public and you’re incredibly successful! Lots of games are being created with your game server.
-
-Soon, you discover people sometimes leave your game. Lots of games no longer have any players playing, but nothing stopped the game loop. You are getting overwhelmed by dead `(*Game).run` goroutines.
-
-**Challenge:** fix the goroutine leak above without mutexes or panics. For real, scroll up to the above code and come up with a plan for fixing this problem using just channels.
-
-I’ll wait.
-
-For what it’s worth, it totally can be done with channels only, but observe the simplicity of the following solution which doesn’t even have this problem:
-
-```
-type Game struct {
- mtx sync.Mutex
- bestScore int
-}
-
-func NewGame() *Game {
- return &Game{}
-}
-
-func (g *Game) HandlePlayer(p Player) error {
- for {
- score, err := p.NextScore()
- if err != nil {
- return err
- }
- g.mtx.Lock()
- if g.bestScore < score {
- g.bestScore = score
- }
- g.mtx.Unlock()
- }
-}
-```
-
-Which one would you rather work on? Don’t be deceived into thinking that the channel solution somehow makes this more readable and understandable in more complex cases. Teardown is very hard. This sort of teardown is just a piece of cake with a mutex, but the hardest thing to work out with Go-specific channels only. Also, if anyone replies that channels sending channels is easier to reason about here it will cause me an immediate head-to-desk motion.
-
-Importantly, this particular case might actually be _easily_ solved _with channels_ with some runtime assistance Go doesn’t provide! Unfortunately, as it stands, there are simply a surprising amount of problems that are solved better with traditional synchronization primitives than with Go’s version of CSP. We’ll talk about what Go could have done to make this case easier later.
-
-**Exercise:** Still skeptical? Try making both solutions above (channel-only vs. mutex-only) stop asking for scores from `Players` once `bestScore` is 100 or greater. Go ahead and open your text editor. This is a small, toy problem.
-
-The summary here is that you will be using traditional synchronization primitives in addition to channels if you want to do anything real.
-
-#### Channels are slower than implementing it yourself
-
-One of the things I assumed about Go being so heavily based in CSP theory is that there should be some pretty killer scheduler optimizations the runtime can make with channels. Perhaps channels aren’t always the most straightforward primitive, but surely they’re efficient and fast, right?
-
-![][23]
-
-As [Dustin Hiatt][24] points out on [Tyler Treat’s post about Go][25],
-
-> Behind the scenes, channels are using locks to serialize access and provide threadsafety. So by using channels to synchronize access to memory, you are, in fact, using locks; locks wrapped in a threadsafe queue. So how do Go’s fancy locks compare to just using mutex’s from their standard library `sync` package? The following numbers were obtained by using Go’s builtin benchmarking functionality to serially call Put on a single set of their respective types.
-
-```
-> BenchmarkSimpleSet-8 3000000 391 ns/op
-> BenchmarkSimpleChannelSet-8 1000000 1699 ns/o
->
-```
-
-It’s a similar story with unbuffered channels, or even the same test under contention instead of run serially.
-
-Perhaps the Go scheduler will improve, but in the meantime, good old mutexes and condition variables are very good, efficient, and fast. If you want performance, you use the tried and true methods.
-
-#### Channels don’t compose well with other concurrency primitives
-
-Alright, so hopefully I have convinced you that you’ll at least be interacting with primitives besides channels sometimes. The standard library certainly seems to prefer traditional synchronization primitives over channels.
-
-Well guess what, it’s actually somewhat challenging to use channels alongside mutexes and condition variables correctly!
-
-One of the interesting things about channels that makes a lot of sense coming from CSP is that channel sends are synchronous. A channel send and channel receive are intended to be synchronization barriers, and the send and receive should happen at the same virtual time. That’s wonderful if you’re in well-executed CSP-land.
-
-![][26]
-
-Pragmatically, Go channels also come in a buffered variety. You can allocate a fixed amount of space to account for possible buffering so that sends and receives are disparate events, but the buffer size is capped. Go doesn’t provide a way to have arbitrarily sized buffers - you have to allocate the buffer size in advance. _This is fine_, I’ve seen people argue on the mailing list, _because memory is bounded anyway._
-
-Wat.
-
-This is a bad answer. There’s all sorts of reasons to use an arbitrarily buffered channel. If we knew everything up front, why even have `malloc`?
-
-Not having arbitrarily buffered channels means that a naive send on _any_ channel could block at any time. You want to send on a channel and update some other bookkeeping under a mutex? Careful! Your channel send might block!
-
-```
-// ...
-s.mtx.Lock()
-// ...
-s.ch <- val // might block!
-s.mtx.Unlock()
-// ...
-```
-
-This is a recipe for dining philosopher dinner fights. If you take a lock, you should quickly update state and release it and not do anything blocking under the lock if possible.
-
-There is a way to do a non-blocking send on a channel in Go, but it’s not the default behavior. Assume we have a channel `ch := make(chan int)` and we want to send the value `1` on it without blocking. Here is the minimum amount of typing you have to do to send without blocking:
-
-```
-select {
-case ch <- 1: // it sent
-default: // it didn't
-}
-```
-
-This isn’t what naturally leaps to mind for beginning Go programmers.
-
-The summary is that because many operations on channels block, it takes careful reasoning about philosophers and their dining to successfully use channel operations alongside and under mutex protection, without causing deadlocks.
-
-#### Callbacks are strictly more powerful and don’t require unnecessary goroutines.
-
-![][27]
-
-Whenever an API uses a channel, or whenever I point out that a channel makes something hard, someone invariably points out that I should just spin up a goroutine to read off the channel and make whatever translation or fix I need as it reads of the channel.
-
-Um, no. What if my code is in a hotpath? There’s very few instances that require a channel, and if your API could have been designed with mutexes, semaphores, and callbacks and no additional goroutines (because all event edges are triggered by API events), then using a channel forces me to add another stack of memory allocation to my resource usage. Goroutines are much lighter weight than threads, yes, but lighter weight doesn’t mean the lightest weight possible.
-
-As I’ve formerly [argued in the comments on an article about using channels][28] (lol the internet), your API can _always_ be more general, _always_ more flexible, and take drastically less resources if you use callbacks instead of channels. “Always” is a scary word, but I mean it here. There’s proof-level stuff going on.
-
-If someone provides a callback-based API to you and you need a channel, you can provide a callback that sends on a channel with little overhead and full flexibility.
-
-If, on the other hand, someone provides a channel-based API to you and you need a callback, you have to spin up a goroutine to read off the channel _and_ you have to hope that no one tries to send more on the channel when you’re done reading so you cause blocked goroutine leaks.
-
-For a super simple real-world example, check out the [context interface][29] (which incidentally is an incredibly useful package and what you should be using instead of [goroutine-local storage][16]):
-
-```
-type Context interface {
- ...
- // Done returns a channel that closes when this work unit should be canceled.
- Done() <-chan struct{}
-
- // Err returns a non-nil error when the Done channel is closed
- Err() error
- ...
-}
-```
-
-Imagine all you want to do is log the corresponding error when the `Done()` channel fires. What do you have to do? If you don’t have a good place you’re already selecting on a channel, you have to spin up a goroutine to deal with it:
-
-```
-go func() {
- <-ctx.Done()
- logger.Errorf("canceled: %v", ctx.Err())
-}()
-```
-
-What if `ctx` gets garbage collected without closing the channel `Done()` returned? Whoops! Just leaked a goroutine!
-
-Now imagine we changed `Done`’s signature:
-
-```
-// Done calls cb when this work unit should be canceled.
-Done(cb func())
-```
-
-First off, logging is so easy now. Check it out: `ctx.Done(func() { log.Errorf("canceled: %v", ctx.Err()) })`. But lets say you really do need some select behavior. You can just call it like this:
-
-```
-ch := make(chan struct{})
-ctx.Done(func() { close(ch) })
-```
-
-Voila! No expressiveness lost by using a callback instead. `ch` works like the channel `Done()` used to return, and in the logging case we didn’t need to spin up a whole new stack. I got to keep my stack traces (if our log package is inclined to use them); I got to avoid another stack allocation and another goroutine to give to the scheduler.
-
-Next time you use a channel, ask yourself if there’s some goroutines you could eliminate if you used mutexes and condition variables instead. If the answer is yes, your code will be more efficient if you change it. And if you’re trying to use channels just to be able to use the `range` keyword over a collection, I’m going to have to ask you to put your keyboard away or just go back to writing Python books.
-
-![more like Zooey De-channel, amirite][30]
-
-#### The channel API is inconsistent and just cray-cray
-
-Closing or sending on a closed channel panics! Why? If you want to close a channel, you need to either synchronize its closed state externally (with mutexes and so forth that don’t compose well!) so that other writers don’t write to or close a closed channel, or just charge forward and close or write to closed channels and expect you’ll have to recover any raised panics.
-
-This is such bizarre behavior. Almost every other operation in Go has a way to avoid a panic (type assertions have the `, ok =` pattern, for example), but with channels you just get to deal with it.
-
-Okay, so when a send will fail, channels panic. I guess that makes some kind of sense. But unlike almost everything else with nil values, sending to a nil channel won’t panic. Instead, it will block forever! That’s pretty counter-intuitive. That might be useful behavior, just like having a can-opener attached to your weed-whacker might be useful (and found in Skymall), but it’s certainly unexpected. Unlike interacting with nil maps (which do implicit pointer dereferences), nil interfaces (implicit pointer dereferences), unchecked type assertions, and all sorts of other things, nil channels exhibit actual channel behavior, as if a brand new channel was just instantiated for this operation.
-
-Receives are slightly nicer. What happens when you receive on a closed channel? Well, that works - you get a zero value. Okay that makes sense I guess. Bonus! Receives allow you to do a `, ok =`-style check if the channel was open when you received your value. Thank heavens we get `, ok =` here.
-
-But what happens if you receive from a nil channel? _Also blocks forever!_ Yay! Don’t try and use the fact that your channel is nil to keep track of if you closed it!
-
-### What are channels good for?
-
-Of course channels are good for some things (they are a generic container after all), and there are certain things you can only do with them (`select`).
-
-#### They are another special-cased generic datastructure
-
-Go programmers are so used to arguments about generics that I can feel the PTSD coming on just by bringing up the word. I’m not here to talk about it so wipe the sweat off your brow and let’s keep moving.
-
-Whatever your opinion of generics is, Go’s maps, slices, and channels are data structures that support generic element types, because they’ve been special-cased into the language.
-
-In a language that doesn’t allow you to write your own generic containers, _anything_ that allows you to better manage collections of things is valuable. Here, channels are a thread-safe datastructure that supports arbitrary value types.
-
-So that’s useful! That can save some boilerplate I suppose.
-
-I’m having trouble counting this as a win for channels.
-
-#### Select
-
-The main thing you can do with channels is the `select` statement. Here you can wait on a fixed number of inputs for events. It’s kind of like epoll, but you have to know upfront how many sockets you’re going to be waiting on.
-
-This is truly a useful language feature. Channels would be a complete wash if not for `select`. But holy smokes, let me tell you about the first time you decide you might need to select on multiple things but you don’t know how many and you have to use `reflect.Select`.
-
-### How could channels be better?
-
-It’s really tough to say what the most tactical thing the Go language team could do for Go 2.0 is (the Go 1.0 compatibility guarantee is good but hand-tying), but that won’t stop me from making some suggestions.
-
-#### Select on condition variables!
-
-We could just obviate the need for channels! This is where I propose we get rid of some sacred cows, but let me ask you this, how great would it be if you could select on any custom synchronization primitive? (A: So great.) If we had that, we wouldn’t need channels at all.
-
-#### GC could help us?
-
-In the very first example, we could easily solve the high score server cleanup with channels if we were able to use directionally-typed channel garbage collection to help us clean up.
-
-![][31]
-
-As you know, Go has directionally-typed channels. You can have a channel type that only supports reading (`<-chan`) and a channel type that only supports writing (`chan<-`). Great!
-
-Go also has garbage collection. It’s clear that certain kinds of book keeping are just too onerous and we shouldn’t make the programmer deal with them. We clean up unused memory! Garbage collection is useful and neat.
-
-So why not help clean up unused or deadlocked channel reads? Instead of having `make(chan Whatever)` return one bidirectional channel, have it return two single-direction channels (`chanReader, chanWriter := make(chan Type)`).
-
-Let’s reconsider the original example:
-
-```
-type Game struct {
- bestScore int
- scores chan<- int
-}
-
-func run(bestScore *int, scores <-chan int) {
- // we don't keep a reference to a *Game directly because then we'd be holding
- // onto the send side of the channel.
- for score := range scores {
- if *bestScore < score {
- *bestScore = score
- }
- }
-}
-
-func NewGame() (g *Game) {
- // this make(chan) return style is a proposal!
- scoreReader, scoreWriter := make(chan int)
- g = &Game{
- bestScore: 0,
- scores: scoreWriter,
- }
- go run(&g.bestScore, scoreReader)
- return g
-}
-
-func (g *Game) HandlePlayer(p Player) error {
- for {
- score, err := p.NextScore()
- if err != nil {
- return err
- }
- g.scores <- score
- }
-}
-```
-
-If garbage collection closed a channel when we could prove no more values are ever coming down it, this solution is completely fixed. Yes yes, the comment in `run` is indicative of the existence of a rather large gun aimed at your foot, but at least the problem is easily solveable now, whereas it really wasn’t before. Furthermore, a smart compiler could probably make appropriate proofs to reduce the damage from said foot-gun.
-
-#### Other smaller issues
-
- * **Dup channels?** \- If we could use an equivalent of the `dup` syscall on channels, then we could also solve the multiple producer problem quite easily. Each producer could close their own `dup`-ed channel without ruining the other producers.
- * **Fix the channel API!** \- Close isn’t idempotent? Send on closed channel panics with no way to avoid it? Ugh!
- * **Arbitrarily buffered channels** \- If we could make buffered channels with no fixed buffer size limit, then we could make channels that don’t block.
-
-
-
-### What do we tell people about Go then?
-
-If you haven’t yet, please go take a look at my current favorite programming post: [What Color is Your Function][32]. Without being about Go specifically, this blog post much more eloquently than I could lays out exactly why goroutines are Go’s best feature (and incidentally one of the ways Go is better than Rust for some applications).
-
-If you’re still writing code in a programming language that forces keywords like `yield` on you to get high performance, concurrency, or an event-driven model, you are living in the past, whether or not you or anyone else knows it. Go is so far one of the best entrants I’ve seen of languages that implement an M:N threading model that’s not 1:1, and dang that’s powerful.
-
-So, tell folks about goroutines.
-
-If I had to pick one other leading feature of Go, it’s interfaces. Statically-typed [duck typing][33] makes extending and working with your own or someone else’s project so fun and amazing it’s probably worth me writing an entirely different set of words about it some other time.
-
-### So…
-
-I keep seeing people charge in to Go, eager to use channels to their full potential. Here’s my advice to you.
-
-**JUST STAHP IT**
-
-When you’re writing APIs and interfaces, as bad as the advice “never” can be, I’m pretty sure there’s never a time where channels are better, and every Go API I’ve used that used channels I’ve ended up having to fight. I’ve never thought “oh good, there’s a channel here;” it’s always instead been some variant of _**WHAT FRESH HELL IS THIS?**_
-
-So, _please, please use channels where appropriate and only where appropriate._
-
-In all of my Go code I work with, I can count on one hand the number of times channels were really the best choice. Sometimes they are. That’s great! Use them then. But otherwise just stop.
-
-![][34]
-
-_Special thanks for the valuable feedback provided by my proof readers Jeff Wendling, [Andrew Harding][35], [George Shank][36], and [Tyler Treat][37]._
-
-If you want to work on Go with us at Space Monkey, please [hit me up][38]!
-
---------------------------------------------------------------------------------
-
-via: https://www.jtolio.com/2016/03/go-channels-are-bad-and-you-should-feel-bad
-
-作者:[jtolio.com][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.jtolio.com/
-[b]: https://github.com/lujun9972
-[1]: https://blog.codinghorror.com/content/images/uploads/2012/06/6a0120a85dcdae970b017742d249d5970d-800wi.jpg
-[2]: https://songlh.github.io/paper/go-study.pdf
-[3]: https://golang.org/
-[4]: http://www.spacemonkey.com/
-[5]: https://en.wikipedia.org/wiki/Communicating_sequential_processes
-[6]: https://en.wikipedia.org/wiki/%CE%A0-calculus
-[7]: http://matt.might.net
-[8]: http://www.ucombinator.org/
-[9]: https://www.jtolio.com/writing/2015/11/research-log-cell-states-and-microarrays/
-[10]: https://www.jtolio.com/writing/2014/04/go-space-monkey/
-[11]: https://godoc.org/github.com/spacemonkeygo/openssl
-[12]: https://golang.org/pkg/crypto/tls/
-[13]: https://godoc.org/github.com/spacemonkeygo/errors
-[14]: https://godoc.org/github.com/spacemonkeygo/spacelog
-[15]: https://godoc.org/gopkg.in/spacemonkeygo/monitor.v1
-[16]: https://github.com/jtolds/gls
-[17]: https://www.jtolio.com/images/wat/darth-helmet.jpg
-[18]: https://en.wikipedia.org/wiki/Newsqueak
-[19]: https://en.wikipedia.org/wiki/Alef_%28programming_language%29
-[20]: https://en.wikipedia.org/wiki/Limbo_%28programming_language%29
-[21]: https://lesswrong.com/lw/k5/cached_thoughts/
-[22]: https://blog.golang.org/share-memory-by-communicating
-[23]: https://www.jtolio.com/images/wat/jon-stewart.jpg
-[24]: https://twitter.com/HiattDustin
-[25]: http://bravenewgeek.com/go-is-unapologetically-flawed-heres-why-we-use-it/
-[26]: https://www.jtolio.com/images/wat/obama.jpg
-[27]: https://www.jtolio.com/images/wat/yael-grobglas.jpg
-[28]: http://www.informit.com/articles/article.aspx?p=2359758#comment-2061767464
-[29]: https://godoc.org/golang.org/x/net/context
-[30]: https://www.jtolio.com/images/wat/zooey-deschanel.jpg
-[31]: https://www.jtolio.com/images/wat/joel-mchale.jpg
-[32]: http://journal.stuffwithstuff.com/2015/02/01/what-color-is-your-function/
-[33]: https://en.wikipedia.org/wiki/Duck_typing
-[34]: https://www.jtolio.com/images/wat/michael-cera.jpg
-[35]: https://github.com/azdagron
-[36]: https://twitter.com/taterbase
-[37]: http://bravenewgeek.com
-[38]: https://www.jtolio.com/contact/
diff --git a/sources/tech/20170115 Magic GOPATH.md b/sources/tech/20170115 Magic GOPATH.md
deleted file mode 100644
index 1d4cd16e24..0000000000
--- a/sources/tech/20170115 Magic GOPATH.md
+++ /dev/null
@@ -1,119 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Magic GOPATH)
-[#]: via: (https://www.jtolio.com/2017/01/magic-gopath)
-[#]: author: (jtolio.com https://www.jtolio.com/)
-
-Magic GOPATH
-======
-
-_**Update:** With the advent of Go 1.11 and [Go modules][1], this whole post is now useless. Unset your GOPATH entirely and switch to Go modules today!_
-
-Maybe someday I’ll start writing about things besides Go again.
-
-Go requires that you set an environment variable for your workspace called your `GOPATH`. The `GOPATH` is one of the most confusing aspects of Go to newcomers and even relatively seasoned developers alike. It’s not immediately clear what would be better, but finding a good `GOPATH` value has implications for your source code repository layout, how many separate projects you have on your computer, how default project installation instructions work (via `go get`), and even how you interoperate with other projects and libraries.
-
-It’s taken until Go 1.8 to decide to [set a default][2] and that small change was one of [the most talked about code reviews][3] for the 1.8 release cycle.
-
-After [writing about GOPATH himself][4], [Dave Cheney][5] [asked me][6] to write a blog post about what I do.
-
-### My proposal
-
-I set my `GOPATH` to always be the current working directory, unless a parent directory is clearly the `GOPATH`.
-
-Here’s the relevant part of my `.bashrc`:
-
-```
-# bash command to output calculated GOPATH.
-calc_gopath() {
- local dir="$PWD"
-
- # we're going to walk up from the current directory to the root
- while true; do
-
- # if there's a '.gopath' file, use its contents as the GOPATH relative to
- # the directory containing it.
- if [ -f "$dir/.gopath" ]; then
- ( cd "$dir";
- # allow us to squash this behavior for cases we want to use vgo
- if [ "$(cat .gopath)" != "" ]; then
- cd "$(cat .gopath)";
- echo "$PWD";
- fi; )
- return
- fi
-
- # if there's a 'src' directory, the parent of that directory is now the
- # GOPATH
- if [ -d "$dir/src" ]; then
- echo "$dir"
- return
- fi
-
- # we can't go further, so bail. we'll make the original PWD the GOPATH.
- if [ "$dir" == "/" ]; then
- echo "$PWD"
- return
- fi
-
- # now we'll consider the parent directory
- dir="$(dirname "$dir")"
- done
-}
-
-my_prompt_command() {
- export GOPATH="$(calc_gopath)"
-
- # you can have other neat things in here. I also set my PS1 based on git
- # state
-}
-
-case "$TERM" in
-xterm*|rxvt*)
- # Bash provides an environment variable called PROMPT_COMMAND. The contents
- # of this variable are executed as a regular Bash command just before Bash
- # displays a prompt. Let's only set it if we're in some kind of graphical
- # terminal I guess.
- PROMPT_COMMAND=my_prompt_command
- ;;
-*)
- ;;
-esac
-```
-
-The benefits are fantastic. If you want to quickly `go get` something and not have it clutter up your workspace, you can do something like:
-
-```
-cd $(mktemp -d) && go get github.com/the/thing
-```
-
-On the other hand, if you’re jumping between multiple projects (whether or not they have the full workspace checked in or are just library packages), the `GOPATH` is set accurately.
-
-More flexibly, if you have a tree where some parent directory is outside of the `GOPATH` but you want to set the `GOPATH` anyways, you can create a `.gopath` file and it will automatically set your `GOPATH` correctly any time your shell is inside that directory.
-
-The whole thing is super nice. I kinda can’t imagine doing something else anymore.
-
-### Fin.
-
---------------------------------------------------------------------------------
-
-via: https://www.jtolio.com/2017/01/magic-gopath
-
-作者:[jtolio.com][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.jtolio.com/
-[b]: https://github.com/lujun9972
-[1]: https://golang.org/cmd/go/#hdr-Modules__module_versions__and_more
-[2]: https://rakyll.org/default-gopath/
-[3]: https://go-review.googlesource.com/32019/
-[4]: https://dave.cheney.net/2016/12/20/thinking-about-gopath
-[5]: https://dave.cheney.net/
-[6]: https://twitter.com/davecheney/status/811334240247812097
diff --git a/sources/tech/20170320 Whiteboard problems in pure Lambda Calculus.md b/sources/tech/20170320 Whiteboard problems in pure Lambda Calculus.md
deleted file mode 100644
index 02200befe7..0000000000
--- a/sources/tech/20170320 Whiteboard problems in pure Lambda Calculus.md
+++ /dev/null
@@ -1,836 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Whiteboard problems in pure Lambda Calculus)
-[#]: via: (https://www.jtolio.com/2017/03/whiteboard-problems-in-pure-lambda-calculus)
-[#]: author: (jtolio.com https://www.jtolio.com/)
-
-Whiteboard problems in pure Lambda Calculus
-======
-
-My team at [Vivint][1], the [Space Monkey][2] group, stopped doing whiteboard interviews a while ago. We certainly used to do them, but we’ve transitioned to homework problems or actually just hiring a candidate as a short term contractor for a day or two to solve real work problems and see how that goes. Whiteboard interviews are kind of like [Festivus][3] but in a bad way: you get the feats of strength and then the airing of grievances. Unfortunately, modern programming is nothing like writing code in front of a roomful of strangers with only a whiteboard and a marker, so it’s probably not best to optimize for that.
-
-Nonetheless, [Kyle][4]’s recent (wonderful, amazing) post titled [acing the technical interview][5] got me thinking about fun ways to approach whiteboard problems as an interviewee. Kyle’s [Church-encodings][6] made me wonder how many “standard” whiteboard problems you could solve in pure lambda calculus. If this isn’t seen as a feat of strength by your interviewers, there will certainly be some airing of grievances.
-
-➡️️ **Update**: I’ve made a lambda calculus web playground so you can run lambda calculus right in your browser! I’ve gone through and made links to examples in this post with it. Check it out at <https://jtolds.github.io/sheepda/>
-
-### Lambda calculus
-
-Wait, what is lambda calculus? Did I learn that in high school?
-
-Big-C “Calculus” of course usually refers to derivatives, integrals, Taylor series, etc. You might have learned about Calculus in high school, but this isn’t that.
-
-More generally, a little-c “calculus” is really just any system of calculation. The [lambda calculus][7] is essentially a formalization of the smallest set of primitives needed to make a completely [Turing-complete][8] programming language. Expressions in the language can only be one of three things.
-
- * An expression can define a function that takes exactly one argument (no more, no less) and then has another expression as the body.
- * An expression can call a function by applying two subexpressions.
- * An expression can reference a variable.
-
-
-
-Here is the entire grammar:
-
-```
-<expr> ::= <variable>
- | `λ` <variable> `.` <expr>
- | `(` <expr> <expr> `)`
-```
-
-That’s it. There’s nothing else you can do. There are no numbers, strings, booleans, pairs, structs, anything. Every value is a function that takes one argument. All variables refer to these functions, and all functions can do is return another function, either directly, or by calling yet another function. There’s nothing else to help you.
-
-To be honest, it’s a little surprising that this is even Turing-complete. How do you do branches or loops or recursion? This seems too simple to work, right?
-
-A common whiteboard problem is the [fizz buzz problem][9]. The goal is to write a function that prints out all the numbers from 0 to 100, but instead of printing numbers divisible by 3 it prints “fizz”, and instead of printing numbers divisible by 5 it prints “buzz”, and in the case of both it prints “fizzbuzz”. It’s a simple toy problem but it’s touted as a good whiteboard problem because evidently many self-proclaimed programmers can’t solve it. Maybe part of that is cause whiteboard problems suck? I dunno.
-
-Anyway, here’s fizz buzz in pure lambda calculus:
-
-```
-(λU.(λY.(λvoid.(λ0.(λsucc.(λ+.(λ*.(λ1.(λ2.(λ3.(λ4.(λ5.(λ6.(λ7.(λ8.(λ9.(λ10.(λnum.(λtrue.(λfalse.(λif.(λnot.(λand.(λor.(λmake-pair.(λpair-first.(λpair-second.(λzero?.(λpred.(λ-.(λeq?.(λ/.(λ%.(λnil.(λnil?.(λcons.(λcar.(λcdr.(λdo2.(λdo3.(λdo4.(λfor.(λprint-byte.(λprint-list.(λprint-newline.(λzero-byte.(λitoa.(λfizzmsg.(λbuzzmsg.(λfizzbuzzmsg.(λfizzbuzz.(fizzbuzz (((num 1) 0) 1)) λn.((for n) λi.((do2 (((if (zero? ((% i) 3))) λ_.(((if (zero? ((% i) 5))) λ_.(print-list fizzbuzzmsg)) λ_.(print-list fizzmsg))) λ_.(((if (zero? ((% i) 5))) λ_.(print-list buzzmsg)) λ_.(print-list (itoa i))))) (print-newline nil)))) ((cons (((num 0) 7) 0)) ((cons (((num 1) 0) 5)) ((cons (((num 1) 2) 2)) ((cons (((num 1) 2) 2)) ((cons (((num 0) 9) 8)) ((cons (((num 1) 1) 7)) ((cons (((num 1) 2) 2)) ((cons (((num 1) 2) 2)) nil))))))))) ((cons (((num 0) 6) 6)) ((cons (((num 1) 1) 7)) ((cons (((num 1) 2) 2)) ((cons (((num 1) 2) 2)) nil))))) ((cons (((num 0) 7) 0)) ((cons (((num 1) 0) 5)) ((cons (((num 1) 2) 2)) ((cons (((num 1) 2) 2)) nil))))) λn.(((Y λrecurse.λn.λresult.(((if (zero? n)) λ_.(((if (nil? result)) λ_.((cons zero-byte) nil)) λ_.result)) λ_.((recurse ((/ n) 10)) ((cons ((+ zero-byte) ((% n) 10))) result)))) n) nil)) (((num 0) 4) 8)) λ_.(print-byte (((num 0) 1) 0))) (Y λrecurse.λl.(((if (nil? l)) λ_.void) λ_.((do2 (print-byte (car l))) (recurse (cdr l)))))) PRINT_BYTE) λn.λf.((((Y λrecurse.λremaining.λcurrent.λf.(((if (zero? remaining)) λ_.void) λ_.((do2 (f current)) (((recurse (pred remaining)) (succ current)) f)))) n) 0) f)) λa.do3) λa.do2) λa.λb.b) λl.(pair-second (pair-second l))) λl.(pair-first (pair-second l))) λe.λl.((make-pair true) ((make-pair e) l))) λl.(not (pair-first l))) ((make-pair false) void)) λm.λn.((- m) ((* ((/ m) n)) n))) (Y λ/.λm.λn.(((if ((eq? m) n)) λ_.1) λ_.(((if (zero? ((- m) n))) λ_.0) λ_.((+ 1) ((/ ((- m) n)) n)))))) λm.λn.((and (zero? ((- m) n))) (zero? ((- n) m)))) λm.λn.((n pred) m)) λn.(((λn.λf.λx.(pair-second ((n λp.((make-pair (f (pair-first p))) (pair-first p))) ((make-pair x) x))) n) succ) 0)) λn.((n λ_.false) true)) λp.(p false)) λp.(p true)) λx.λy.λt.((t x) y)) λa.λb.((a true) b)) λa.λb.((a b) false)) λp.λt.λf.((p f) t)) λp.λa.λb.(((p a) b) void)) λt.λf.f) λt.λf.t) λa.λb.λc.((+ ((+ ((* ((* 10) 10)) a)) ((* 10) b))) c)) (succ 9)) (succ 8)) (succ 7)) (succ 6)) (succ 5)) (succ 4)) (succ 3)) (succ 2)) (succ 1)) (succ 0)) λm.λn.λx.(m (n x))) λm.λn.λf.λx.((((m succ) n) f) x)) λn.λf.λx.(f ((n f) x))) λf.λx.x) λx.(U U)) (U λh.λf.(f λx.(((h h) f) x)))) λf.(f f))
-```
-
-➡️️ [Try it out in your browser!][10]
-
-(This program expects a function to be defined called `PRINT_BYTE` which takes a Church-encoded numeral, turns it into a byte, writes it to `stdout`, and then returns the same Church-encoded numeral. Expecting a function that has side-effects might arguably disqualify this from being pure, but it’s definitely arguable.)
-
-Don’t be deceived! I said there were no native numbers or lists or control structures in lambda calculus and I meant it. `0`, `7`, `if`, and `+` are all _variables_ that represent _functions_ and have to be constructed before they can be used in the code block above.
-
-### What? What’s happening here?
-
-Okay let’s start over and build up to fizz buzz. We’re going to need a lot. We’re going to need to build up concepts of numbers, logic, and lists all from scratch. Ask your interviewers if they’re comfortable cause this might be a while.
-
-Here is a basic lambda calculus function:
-
-```
-λx.x
-```
-
-This is the identity function and it is equivalent to the following Javascript:
-
-```
-function(x) { return x; }
-```
-
-It takes an argument and returns it! We can call the identity function with another value. Function calling in many languages looks like `f(x)`, but in lambda calculus, it looks like `(f x)`.
-
-```
-(λx.x y)
-```
-
-This will return `y`. Once again, here’s equivalent Javascript:
-
-```
-function(x) { return x; }(y)
-```
-
-Aside: If you’re already familiar with lambda calculus, my formulation of precedence is such that `(λx.x y)` is not the same as `λx.(x y)`. `(λx.x y)` applies `y` to the identity function `λx.x`, and `λx.(x y)` is a function that applies `y` to its argument `x`. Perhaps not what you’re used to, but the parser was way more straightforward, and programming with it this way seems a bit more natural, believe it or not.
-
-Okay, great. We can call functions. What if we want to pass more than one argument?
-
-### Currying
-
-Imagine the following Javascript function:
-
-```
-let s1 = function(f, x) { return f(x); }
-```
-
-We want to call it with two arguments, another function and a value, and we want the function to then be called on the value, and have its result returned. Can we do this while using only one argument?
-
-[Currying][11] is a technique for dealing with this. Instead of taking two arguments, take the first argument and return another function that takes the second argument. Here’s the Javascript:
-
-```
-let s2 = function(f) {
- return function(x) {
- return f(x);
- }
-};
-```
-
-Now, `s1(f, x)` is the same as `s2(f)(x)`. So the equivalent lambda calculus for `s2` is then
-
-```
-λf.λx.(f x)
-```
-
-Calling this function with `g` for `f` and `y` for `x` is like so:
-
-```
-((s2 g) y)
-```
-
-or
-
-```
-((λf.λx.(f x) g) y)
-```
-
-The equivalent Javascript here is:
-
-```
-function(f) {
- return function(x) {
- f(x)
- }
-}(g)(y)
-```
-
-### Numbers
-
-Since everything is a function, we might feel a little stuck with what to do about numbers. Luckily, [Alonzo Church][12] already figured it out for us! When you have a number, often what you want to do is represent how many times you might do something.
-
-So let’s represent a number as how many times we’ll apply a function to a value. This is called a [Church numeral][13]. If we have `f` and `x`, `0` will mean we don’t call `f` at all, and just return `x`. `1` will mean we call `f` one time, `2` will mean we call `f` twice, and so on.
-
-Here are some definitions! (N.B.: assignment isn’t actually part of lambda calculus, but it makes writing down definitions easier)
-
-```
-0 = λf.λx.x
-```
-
-Here, `0` takes a function `f`, a value `x`, and never calls `f`. It just returns `x`. `f` is called 0 times.
-
-```
-1 = λf.λx.(f x)
-```
-
-Like `0`, `1` takes `f` and `x`, but here it calls `f` exactly once. Let’s see how this continues for other numbers.
-
-```
-2 = λf.λx.(f (f x))
-3 = λf.λx.(f (f (f x)))
-4 = λf.λx.(f (f (f (f x))))
-5 = λf.λx.(f (f (f (f (f x)))))
-```
-
-`5` is a function that takes `f`, `x`, and calls `f` 5 times!
-
-Okay, this is convenient, but how are we going to do math on these numbers?
-
-### Successor
-
-Let’s make a _successor_ function that takes a number and returns a new number that calls `f` just one more time.
-
-```
-succ = λn. λf.λx.(f ((n f) x))
-```
-
-`succ` is a function that takes a Church-encoded number, `n`. The spaces after `λn.` are ignored. I put them there to indicate that we expect to usually call `succ` with one argument, curried or no. `succ` then returns another Church-encoded number, `λf.λx.(f ((n f) x))`. What is it doing? Let’s break it down.
-
- * `((n f) x)` looks like that time we needed to call a function that took two “curried” arguments. So we’re calling `n`, which is a Church numeral, with two arguments, `f` and `x`. This is going to call `f` `n` times!
- * `(f ((n f) x))` This is calling `f` again, one more time, on the result of the previous value.
-
-
-
-So does `succ` work? Let’s see what happens when we call `(succ 1)`. We should get the `2` we defined earlier!
-
-```
- (succ 1)
--> (succ λf.λx.(f x)) # resolve the variable 1
--> (λn.λf.λx.(f ((n f) x)) λf.λx.(f x)) # resolve the variable succ
--> λf.λx.(f ((λf.λx.(f x) f) x)) # call the outside function. replace n
- # with the argument
-
-let's sidebar and simplify the subexpression
- (λf.λx.(f x) f)
--> λx.(f x) # call the function, replace f with f!
-
-now we should be able to simplify the larger subexpression
- ((λf.λx.(f x) f) x)
--> (λx.(f x) x) # sidebar above
--> (f x) # call the function, replace x with x!
-
-let's go back to the original now
- λf.λx.(f ((λf.λx.(f x) f) x))
--> λf.λx.(f (f x)) # subexpression simplification above
-```
-
-and done! That last line is identical to the `2` we defined originally! It calls `f` twice.
-
-### Math
-
-Now that we have the successor function, if your interviewers haven’t checked out, tell them that fizz buzz isn’t too far away now; we have [Peano Arithmetic][14]! They can then check their interview bingo cards and see if they’ve increased their winnings.
-
-No but for real, since we have the successor function, we can now easily do addition and multiplication, which we will need for fizz buzz.
-
-First, recall that a number `n` is a function that takes another function `f` and an initial value `x` and applies `f` _n_ times. So if you have two numbers _m_ and _n_, what you want to do is apply `succ` to `m` _n_ times!
-
-```
-+ = λm.λn.((n succ) m)
-```
-
-Here, `+` is a variable. If it’s not a lambda expression or a function call, it’s a variable!
-
-Multiplication is similar, but instead of applying `succ` to `m` _n_ times, we’re going to add `m` to `0` `n` times.
-
-First, note that if `((+ m) n)` is adding `m` and `n`, then that means that `(+ m)` is a _function_ that adds `m` to its argument. So we want to apply the function `(+ m)` to `0` `n` times.
-
-```
-* = λm.λn.((n (+ m)) 0)
-```
-
-Yay! We have multiplication and addition now.
-
-### Logic
-
-We’re going to need booleans and if statements and logic tests and so on. So, let’s talk about booleans. Recall how with numbers, what we kind of wanted with a number `n` is to do something _n_ times. Similarly, what we want with booleans is to do one of two things, either/or, but not both. Alonzo Church to the rescue again.
-
-Let’s have booleans be functions that take two arguments (curried of course), where the `true` boolean will return the first option, and the `false` boolean will return the second.
-
-```
-true = λt.λf.t
-false = λt.λf.f
-```
-
-So that we can demonstrate booleans, we’re going to define a simple sample function called `zero?` that returns `true` if a number `n` is zero, and `false` otherwise:
-
-```
-zero? = λn.((n λ_.false) true)
-```
-
-To explain: if we have a Church numeral for 0, it will call the first argument it gets called with 0 times and just return the second argument. In other words, 0 will just return the second argument and that’s it. Otherwise, any other number will call the first argument at least once. So, `zero?` will take `n` and give it a function that throws away its argument and always returns `false` whenever it’s called, and start it off with `true`. Only zero values will return `true`.
-
-➡️️ [Try it out in your browser!][15]
-
-We can now write an `if'` function to make use of these boolean values. `if'` will take a predicate value `p` (the boolean) and two options `a` and `b`.
-
-```
-if' = λp.λa.λb.((p a) b)
-```
-
-You can use it like this:
-
-```
-((if' (zero? n)
- (something-when-zero x))
- (something-when-not-zero y))
-```
-
-One thing that’s weird about this construction is that the interpreter is going to evaluate both branches (my lambda calculus interpreter is [eager][16] instead of [lazy][17]). Both `something-when-zero` and `something-when-not-zero` are going to be called to determine what to pass in to `if'`. To make it so that we don’t actually call the function in the branch we don’t want to run, let’s protect the logic in another function. We’ll name the argument to the function `_` to indicate that we want to just throw it away.
-
-```
-((if (zero? n)
- λ_. (something-when-zero x))
- λ_. (something-when-not-zero y))
-```
-
-This means we’re going to have to make a new `if` function that calls the correct branch with a throwaway argument, like `0` or something.
-
-```
-if = λp.λa.λb.(((p a) b) 0)
-```
-
-Okay, now we have booleans and `if`!
-
-### Currying part deux
-
-At this point, you might be getting sick of how calling something with multiple curried arguments involves all these extra parentheses. `((f a) b)` is annoying, can’t we just do `(f a b)`?
-
-It’s not part of the strict grammar, but my interpreter makes this small concession. `(a b c)` will be expanded to `((a b) c)` by the parser. `(a b c d)` will be expanded to `(((a b) c) d)` by the parser, and so on.
-
-So, for the rest of the post, for ease of explanation, I’m going to use this [syntax sugar][18]. Observe how using `if` changes:
-
-```
-(if (zero? n)
- λ_. (something-when-zero x)
- λ_. (something-when-not-zero y))
-```
-
-It’s a little better.
-
-### More logic
-
-Let’s talk about `and`, `or`, and `not`!
-
-`and` returns true if and only if both `a` and `b` are true. Let’s define it!
-
-```
-and = λa.λb.
- (if (a)
- λ_. b
- λ_. false)
-```
-
-`or` returns true if `a` is true or if `b` is true:
-
-```
-or = λa.λb.
- (if (a)
- λ_. true
- λ_. b)
-```
-
-`not` just returns the opposite of whatever it was given:
-
-```
-not = λa.
- (if (a)
- λ_. false
- λ_. true)
-```
-
-It turns out these can be written a bit more simply, but they’re basically doing the same thing:
-
-```
-and = λa.λb.(a b false)
-or = λa.λb.(a true b)
-not = λp.λt.λf.(p f t)
-```
-
-➡️️ [Try it out in your browser!][19]
-
-### Pairs!
-
-Sometimes it’s nice to keep data together. Let’s make a little 2-tuple type! We want three functions. We want a function called `make-pair` that will take two arguments and return a “pair”, we want a function called `pair-first` that will return the first element of the pair, and we want a function called `pair-second` that will return the second element. How can we achieve this? You’re almost certainly in the interview room alone, but now’s the time to yell “Alonzo Church”!
-
-```
-make-pair = λx.λy. λa.(a x y)
-```
-
-`make-pair` is going to take two arguments, `x` and `y`, and they will be the elements of the pair. The pair itself is a function that takes an “accessor” `a` that will be given `x` and `y`. All `a` has to do is take the two arguments and return the one it wants.
-
-Here is someone making a pair with variables `1` and `2`:
-
-```
-(make-pair 1 2)
-```
-
-This returns:
-
-```
-λa.(a 1 2)
-```
-
-There’s a pair! Now we just need to access the values inside.
-
-Remember how `true` takes two arguments and returns the first one and `false` takes two arguments and returns the second one?
-
-```
-pair-first = λp.(p true)
-pair-second = λp.(p false)
-```
-
-`pair-first` is going to take a pair `p` and give it `true` as the accessor `a`. `pair-second` is going to give the pair `false` as the accessor.
-
-Voilà, you can now store 2-tuples of values and recover the data from them.
-
-➡️️ [Try it out in your browser!][20]
-
-### Lists!
-
-We’re going to construct [linked lists][21]. Each list item needs two things: the value at the current position in the list and a reference to the rest of the list.
-
-One additional caveat is we want to be able to identify an empty list, so we’re going to store whether or not the current value is the end of a list as well. In [LISP][22]-based programming languages, the end of the list is the special value `nil`, and checking if we’ve hit the end of the list is accomplished with the `nil?` predicate.
-
-Because we want to distinguish `nil` from a list with a value, we’re going to store three things in each linked list item. Whether or not the list is empty, and if not, the value and the rest of the list. So we need a 3-tuple.
-
-Once we have pairs, other-sized tuples are easy. For instance, a 3-tuple is just one pair with another pair inside for one of the slots.
-
-For each list element, we’ll store:
-
-```
-[not-empty [value rest-of-list]]
-```
-
-As an example, a list element with a value of `1` would look like:
-
-```
-[true [1 remainder]]
-```
-
-whereas `nil` will look like
-
-```
-[false whatever]
-```
-
-That second part of `nil` just doesn’t matter.
-
-First, let’s define `nil` and `nil?`:
-
-```
-nil = (make-pair false false)
-nil? = λl. (not (pair-first l))
-```
-
-The important thing about `nil` is that the first element in the pair is `false`.
-
-Now that we have an empty list, let’s define how to add something to the front of it. In LISP-based languages, the operation to _construct_ a new list element is called `cons`, so we’ll call this `cons`, too.
-
-`cons` will take a value and an existing list and return a new list with the given value at the front of the list.
-
-```
-cons = λvalue.λlist.
- (make-pair true (make-pair value list))
-```
-
-`cons` is returning a pair where, unlike `nil`, the first element of the pair is `true`. This represents that there’s something in the list here. The second pair element is what we wanted in our linked list: the value at the current position, and a reference to the rest of the list.
-
-So how do we access things in the list? Let’s define two functions called `head` and `tail`. `head` is going to return the value at the front of the list, and `tail` is going to return everything but the front of the list. In LISP-based languages, these functions are sometimes called `car` and `cdr` for surprisingly [esoteric reasons][23]. `head` and `tail` have undefined behavior here when called on `nil`, so let’s just assume `nil?` is false for the list and keep going.
-
-```
-head = λlist. (pair-first (pair-second list))
-tail = λlist. (pair-second (pair-second list))
-```
-
-Both `head` and `tail` first get `(pair-second list)`, which returns the tuple that has the value and reference to the remainder. Then, they use either `pair-first` or `pair-second` to get the current value or the rest of the list.
-
-Great, we have lists!
-
-➡️️ [Try it out in your browser!][24]
-
-### Recursion and loops
-
-Let’s make a simple function that sums up a list of numbers.
-
-```
-sum = λlist.
- (if (nil? list)
- λ_. 0
- λ_. (+ (head list) (sum (tail list))))
-```
-
-If the list is empty, let’s return 0. If the list has an element, let’s add that element to the sum of the rest of the list. [Recursion][25] is a cornerstone tool of computer science, and being able to assume a solution to a subproblem to solve a problem is super neat!
-
-Okay, except, this doesn’t work like this in lambda calculus. Remember how I said assignment wasn’t something that exists in lambda calculus? If you have:
-
-```
-x = y
-<stuff>
-```
-
-This really means you have:
-
-```
-(λx.<stuff> y)
-```
-
-In the case of our sum definition, we have:
-
-```
-(λsum.
- <your-program>
-
- λlist.
- (if (nil? list)
- λ_. 0
- λ_. (+ (head list) (sum (tail list)))))
-```
-
-What that means is `sum` doesn’t have any access to itself. It can’t call itself like we’ve written, because when it tries to call `sum`, it’s undefined!
-
-This is a pretty crushing blow, but it turns out there’s a mind bending and completely unexpected trick the universe has up its sleeve.
-
-Assume we wrote `sum` so that it takes two arguments. A reference to something like `sum` we’ll call `helper` and then the list. If we could figure out how to solve the recursion problem, then we could use this `sum`. Let’s do that.
-
-```
-sum = λhelper.λlist.
- (if (nil? list)
- λ_. 0
- λ_. (+ (head list) (helper (tail list))))
-```
-
-But hey! When we call `sum`, we have a reference to `sum` then! Let’s just give `sum` itself before the list.
-
-```
-(sum sum list)
-```
-
-This seems promising, but unfortunately now the `helper` invocation inside of `sum` is broken. `helper` is just `sum` and `sum` expects a reference to itself. Let’s try again, changing the `helper` call:
-
-```
-sum = λhelper.λlist.
- (if (nil? list)
- λ_. 0
- λ_. (+ (head list) (helper helper (tail list))))
-
-(sum sum list)
-```
-
-We did it! This actually works! We engineered recursion out of math! At no point does `sum` refer to itself inside of itself, and yet we managed to make a recursive function anyways!
-
-➡️️ [Try it out in your browser!][26]
-
-Despite the minor miracle we’ve just performed, we’ve now ruined how we program recursion to involve calling recursive functions with themselves. This isn’t the end of the world, but it’s a little annoying. Luckily for us, there’s a function that cleans this all right up called the [Y combinator][27].
-
-The _Y combinator_ is probably now more famously known as [a startup incubator][28], or perhaps even more so as the domain name for one of the most popular sites that has a different name than its URL, [Hacker News][29], but fixed point combinators such as the Y combinator have had a longer history.
-
-The Y combinator can be defined in different ways, but definition I’m using is:
-
-```
-Y = λf.(λx.(x x) λx.(f λy.((x x) y)))
-```
-
-You might consider reading more about how the Y combinator can be derived from an excellent tutorial such as [this one][30] or [this one][31].
-
-Anyway, `Y` will make our original `sum` work as expected.
-
-```
-sum = (Y λhelper.λlist.
- (if (nil? list)
- λ_. 0
- λ_. (+ (head list) (helper (tail list)))))
-```
-
-We can now call `(sum list)` without any wacky doubling of the function name, either inside or outside of the function. Hooray!
-
-➡️️ [Try it out in your browser!][32]
-
-### More math
-
-“Get ready to do more math! We now have enough building blocks to do subtraction, division, and modulo, which we’ll need for fizz buzz,” you tell the security guards that are approaching you.
-
-Just like addition, before we define subtraction we’ll define a predecessor function. Unlike addition, the predecessor function `pred` is much more complicated than the successor function `succ`.
-
-The basic idea is we’re going to create a pair to keep track of the previous value. We’ll start from zero and build up `n` but also drag the previous value such that at `n` we also have `n - 1`. Notably, this solution does not figure out how to deal with negative numbers. The predecessor of 0 will be 0, and negatives will have to be dealt with some other time and some other way.
-
-First, we’ll make a helper function that takes a pair of numbers and returns a new pair where the first number in the old pair is the second number in the new pair, and the new first number is the successor of the old first number.
-
-```
-pred-helper = λpair.
- (make-pair (succ (pair-first pair)) (pair-first pair))
-```
-
-Make sense? If we call `pred-helper` on a pair `[0 0]`, the result will be `[1 0]`. If we call it on `[1 0]`, the result will be `[2 1]`. Essentially this helper slides older numbers off to the right.
-
-Okay, so now we’re going to call `pred-helper` _n_ times, with a starting pair of `[0 0]`, and then get the _second_ value, which should be `n - 1` when we’re done, from the pair.
-
-```
-pred = λn.
- (pair-second (n pred-helper (make-pair 0 0)))
-```
-
-We can combine these two functions now for the full effect:
-
-```
-pred = λn.
- (pair-second
- (n
- λpair.(make-pair (succ (pair-first pair)) (pair-first pair))
- (make-pair 0 0)))
-```
-
-➡️️ [Try it out in your browser!][33]
-
-Now that we have `pred`, subtraction is easy! To subtract `n` from `m`, we’re going to apply `pred` to `m` _n_ times.
-
-```
-- = λm.λn.(n pred m)
-```
-
-Keep in mind that if `n` is equal to _or greater than_ `m`, the result of `(- m n)` will be zero, since there are no negative numbers and the predecessor of `0` is `0`. This fact means we can implement some new logic tests. Let’s make `(ge? m n)` return `true` if `m` is greater than or equal to `n` and make `(le? m n)` return `true` if `m` is less than or equal to `n`.
-
-```
-ge? = λm.λn.(zero? (- n m))
-le? = λm.λn.(zero? (- m n))
-```
-
-If we have greater-than-or-equal-to and less-than-or-equal-to, then we can make equal!
-
-```
-eq? = λm.λn.(and (ge? m n) (le? m n))
-```
-
-Now we have enough for integer division! The idea for integer division of `n` and `m` is we will keep count of the times we can subtract `m` from `n` without going past zero.
-
-```
-/ = (Y λ/.λm.λn.
- (if (eq? m n)
- λ_. 1
- λ_. (if (le? m n)
- λ_. 0
- λ_. (+ 1 (/ (- m n) n)))))
-```
-
-Once we have subtraction, multiplication, and integer division, we can create modulo.
-
-```
-% = λm.λn. (- m (* (/ m n) n))
-```
-
-➡️️ [Try it out in your browser!][34]
-
-### Aside about performance
-
-You might be wondering about performance at this point. Every time we subtract one from 100, we count up from 0 to 100 to generate 99. This effect compounds itself for division and modulo. The truth is that Church numerals and other encodings aren’t very performant! Just like how tapes in Turing machines aren’t a particularly efficient way to deal with data, Church encodings are most interesting from a theoretical perspective for proving facts about computation.
-
-That doesn’t mean we can’t make things faster though!
-
-Lambda calculus is purely functional and side-effect free, which means that all sorts of optimizations can applied. Functions can be aggressively memoized. In other words, once a specific function and its arguments have been computed, there’s no need to compute them ever again. The result of that function will always be the same anyways. Further, functions can be computed lazily and only if needed. What this means is if a branch of your program’s execution renders a result that’s never used, the compiler can decide to just not run that part of the program and end up with the exact same result.
-
-[My interpreter][35] does have side effects, since programs written in it can cause the system to write output to the user via the special built-in function `PRINT_BYTE`. As a result, I didn’t choose lazy evaluation. The only optimization I chose was aggressive memoization for all functions that are side-effect free. The memoization still has room for improvement, but the result is much faster than a naive implementation.
-
-### Output
-
-“We’re rounding the corner on fizz buzz!” you shout at the receptionist as security drags you around the corner on the way to the door. “We just need to figure out how to communicate results to the user!”
-
-Unfortunately, lambda calculus can’t communicate with your operating system kernel without some help, but a small concession is all we need. [Sheepda][35] provides a single built-in function `PRINT_BYTE`. `PRINT_BYTE` takes a number as its argument (a Church encoded numeral) and prints the corresponding byte to the configured output stream (usually `stdout`).
-
-With `PRINT_BYTE`, we’re going to need to reference a number of different [ASCII bytes][36], so we should make writing numbers in code easier. Earlier we defined numbers 0 - 5, so let’s start and define numbers 6 - 10.
-
-```
-6 = (succ 5)
-7 = (succ 6)
-8 = (succ 7)
-9 = (succ 8)
-10 = (succ 9)
-```
-
-Now let’s define a helper to create three digit decimal numbers.
-
-```
-num = λa.λb.λc.(+ (+ (* (* 10 10) a) (* 10 b)) c)
-```
-
-The newline byte is decimal 10. Here’s a function to print newlines!
-
-```
-print-newline = λ_.(PRINT_BYTE (num 0 1 0))
-```
-
-### Doing multiple things
-
-Now that we have this `PRINT_BYTE` function, we have functions that can cause side-effects. We want to call `PRINT_BYTE` but we don’t care about its return value. We need a way to call multiple functions in sequence.
-
-What if we make a function that takes two arguments and throws away the first one again?
-
-```
-do2 = λ_.λx.x
-```
-
-Here’s a function to print every value in a list:
-
-```
-print-list = (Y λrecurse.λlist.
- (if (nil? list)
- λ_. 0
- λ_. (do2 (PRINT_BYTE (head list))
- (recurse (tail list)))))
-```
-
-And here’s a function that works like a for loop. It calls `f` with every number from `0` to `n`. It uses a small helper function that continues to call itself until `i` is equal to `n`, and starts `i` off at `0`.
-
-```
-for = λn.λf.(
- (Y λrecurse.λi.
- (if (eq? i n)
- λ_. void
- λ_. (do2 (f i)
- (recurse (succ i)))))
- 0)
-```
-
-### Converting an integer to a string
-
-The last thing we need to complete fizz buzz is a function that turns a number into a string of bytes to print. You might have noticed the `print-num` calls in some of the web-based examples above. We’re going to see how to make it! Writing this function is sometimes a whiteboard problem in its own right. In C, this function is called `itoa`, for integer to ASCII.
-
-Here’s an example of how it works. Imagine the number we’re converting to bytes is `123`. We can get the `3` out by doing `(% 123 10)`, which will be `3`. Then we can divide by `10` to get `12`, and then start over. `(% 12 10)` is `2`. We’ll loop down until we hit zero.
-
-Once we have a number, we can convert it to ASCII by adding the value of the `'0'` ASCII byte. Then we can make a list of ASCII bytes for use with `print-list`.
-
-```
-zero-char = (num 0 4 8) # the ascii code for the byte that represents 0.
-
-itoa = λn.(
- (Y λrecurse.λn.λresult.
- (if (zero? n)
- λ_. (if (nil? result)
- λ_. (cons zero-char nil)
- λ_. result)
- λ_. (recurse (/ n 10) (cons (+ zero-char (% n 10)) result))))
- n nil)
-
-print-num = λn.(print-list (itoa n))
-```
-
-### Fizz buzz
-
-“Here we go,” you shout at the building you just got kicked out of, “here’s how you do fizz buzz.”
-
-First, we need to define three strings: “Fizz”, “Buzz”, and “Fizzbuzz”.
-
-```
-fizzmsg = (cons (num 0 7 0) # F
- (cons (num 1 0 5) # i
- (cons (num 1 2 2) # z
- (cons (num 1 2 2) # z
- nil))))
-buzzmsg = (cons (num 0 6 6) # B
- (cons (num 1 1 7) # u
- (cons (num 1 2 2) # z
- (cons (num 1 2 2) # z
- nil))))
-fizzbuzzmsg = (cons (num 0 7 0) # F
- (cons (num 1 0 5) # i
- (cons (num 1 2 2) # z
- (cons (num 1 2 2) # z
- (cons (num 0 9 8) # b
- (cons (num 1 1 7) # u
- (cons (num 1 2 2) # z
- (cons (num 1 2 2) # z
- nil))))))))
-```
-
-Okay, now let’s define a function that will run from 0 to `n` and output numbers, fizzes, and buzzes:
-
-```
-fizzbuzz = λn.
- (for n λi.
- (do2
- (if (zero? (% i 3))
- λ_. (if (zero? (% i 5))
- λ_. (print-list fizzbuzzmsg)
- λ_. (print-list fizzmsg))
- λ_. (if (zero? (% i 5))
- λ_. (print-list buzzmsg)
- λ_. (print-list (itoa i))))
- (print-newline 0)))
-```
-
-Let’s do the first 20!
-
-```
-(fizzbuzz (num 0 2 0))
-```
-
-➡️️ [Try it out in your browser!][37]
-
-### Reverse a string
-
-“ENCORE!” you shout to no one as the last cars pull out of the company parking lot. Everyone’s gone home but this is your last night before the restraining order goes through.
-
-```
-reverse-list = λlist.(
- (Y λrecurse.λold.λnew.
- (if (nil? old)
- λ_.new
- λ_.(recurse (tail old) (cons (head old) new))))
- list nil)
-```
-
-➡️️ [Try it out in your browser!][38]
-
-### Sheepda
-
-As I mentioned, I wrote a lambda calculus interpreter called [Sheepda][35] for playing around. By itself it’s pretty interesting if you’re interested in learning more about how to write programming language interpreters. Lambda calculus is as simple of a language as you can make, so the interpreter is very simple itself!
-
-It’s written in Go and thanks to [GopherJS][39] it’s what powers the [web playground][40].
-
-There are some fun projects if someone’s interested in getting more involved. Using the library to prune lambda expression trees and simplify expressions if possible would be a start! I’m sure my fizz buzz implementation isn’t as minimal as it could be, and playing [code golf][41] with it would be pretty neat!
-
-Feel free to fork <https://github.com/jtolds/sheepda/>, star it, bop it, twist it, or even pull it!
-
---------------------------------------------------------------------------------
-
-via: https://www.jtolio.com/2017/03/whiteboard-problems-in-pure-lambda-calculus
-
-作者:[jtolio.com][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.jtolio.com/
-[b]: https://github.com/lujun9972
-[1]: https://www.vivint.com/
-[2]: https://www.spacemonkey.com/
-[3]: https://en.wikipedia.org/wiki/Festivus
-[4]: https://twitter.com/aphyr
-[5]: https://aphyr.com/posts/340-acing-the-technical-interview
-[6]: https://en.wikipedia.org/wiki/Church_encoding
-[7]: https://en.wikipedia.org/wiki/Lambda_calculus
-[8]: https://en.wikipedia.org/wiki/Turing_completeness
-[9]: https://imranontech.com/2007/01/24/using-fizzbuzz-to-find-developers-who-grok-coding/
-[10]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJvdXRwdXQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyKCVDRSVCQlUuKCVDRSVCQlkuKCVDRSVCQnZvaWQuKCVDRSVCQjAuKCVDRSVCQnN1Y2MuKCVDRSVCQiUyQi4oJUNFJUJCKi4oJUNFJUJCMS4oJUNFJUJCMi4oJUNFJUJCMy4oJUNFJUJCNC4oJUNFJUJCNS4oJUNFJUJCNi4oJUNFJUJCNy4oJUNFJUJCOC4oJUNFJUJCOS4oJUNFJUJCMTAuKCVDRSVCQm51bS4oJUNFJUJCdHJ1ZS4oJUNFJUJCZmFsc2UuKCVDRSVCQmlmLiglQ0UlQkJub3QuKCVDRSVCQmFuZC4oJUNFJUJCb3IuKCVDRSVCQm1ha2UtcGFpci4oJUNFJUJCcGFpci1maXJzdC4oJUNFJUJCcGFpci1zZWNvbmQuKCVDRSVCQnplcm8lM0YuKCVDRSVCQnByZWQuKCVDRSVCQi0uKCVDRSVCQmVxJTNGLiglQ0UlQkIlMkYuKCVDRSVCQiUyNS4oJUNFJUJCbmlsLiglQ0UlQkJuaWwlM0YuKCVDRSVCQmNvbnMuKCVDRSVCQmNhci4oJUNFJUJCY2RyLiglQ0UlQkJkbzIuKCVDRSVCQmRvMy4oJUNFJUJCZG80LiglQ0UlQkJmb3IuKCVDRSVCQnByaW50LWJ5dGUuKCVDRSVCQnByaW50LWxpc3QuKCVDRSVCQnByaW50LW5ld2xpbmUuKCVDRSVCQnplcm8tYnl0ZS4oJUNFJUJCaXRvYS4oJUNFJUJCZml6em1zZy4oJUNFJUJCYnV6em1zZy4oJUNFJUJCZml6emJ1enptc2cuKCVDRSVCQmZpenpidXp6LihmaXp6YnV6eiUyMCgoKG51bSUyMDEpJTIwMCklMjAxKSklMjAlQ0UlQkJuLigoZm9yJTIwbiklMjAlQ0UlQkJpLigoZG8yJTIwKCgoaWYlMjAoemVybyUzRiUyMCgoJTI1JTIwaSklMjAzKSkpJTIwJUNFJUJCXy4oKChpZiUyMCh6ZXJvJTNGJTIwKCglMjUlMjBpKSUyMDUpKSklMjAlQ0UlQkJfLihwcmludC1saXN0JTIwZml6emJ1enptc2cpKSUyMCVDRSVCQl8uKHByaW50LWxpc3QlMjBmaXp6bXNnKSkpJTIwJUNFJUJCXy4oKChpZiUyMCh6ZXJvJTNGJTIwKCglMjUlMjBpKSUyMDUpKSklMjAlQ0UlQkJfLihwcmludC1saXN0JTIwYnV6em1zZykpJTIwJUNFJUJCXy4ocHJpbnQtbGlzdCUyMChpdG9hJTIwaSkpKSkpJTIwKHByaW50LW5ld2xpbmUlMjBuaWwpKSkpJTIwKChjb25zJTIwKCgobnVtJTIwMCklMjA3KSUyMDApKSUyMCgoY29ucyUyMCgoKG51bSUyMDEpJTIwMCklMjA1KSklMjAoKGNvbnMlMjAoKChudW0lMjAxKSUyMDIpJTIwMikpJTIwKChjb25zJTIwKCgobnVtJTIwMSklMjAyKSUyMDIpKSUyMCgoY29ucyUyMCgoKG51bSUyMDApJTIwOSklMjA4KSklMjAoKGNvbnMlMjAoKChudW0lMjAxKSUyMDEpJTIwNykpJTIwKChjb25zJTIwKCgobnVtJTIwMSklMjAyKSUyMDIpKSUyMCgoY29ucyUyMCgoKG51bSUyMDEpJTIwMiklMjAyKSklMjBuaWwpKSkpKSkpKSklMjAoKGNvbnMlMjAoKChudW0lMjAwKSUyMDYpJTIwNikpJTIwKChjb25zJTIwKCgobnVtJTIwMSklMjAxKSUyMDcpKSUyMCgoY29ucyUyMCgoKG51bSUyMDEpJTIwMiklMjAyKSklMjAoKGNvbnMlMjAoKChudW0lMjAxKSUyMDIpJTIwMikpJTIwbmlsKSkpKSklMjAoKGNvbnMlMjAoKChudW0lMjAwKSUyMDcpJTIwMCkpJTIwKChjb25zJTIwKCgobnVtJTIwMSklMjAwKSUyMDUpKSUyMCgoY29ucyUyMCgoKG51bSUyMDEpJTIwMiklMjAyKSklMjAoKGNvbnMlMjAoKChudW0lMjAxKSUyMDIpJTIwMikpJTIwbmlsKSkpKSklMjAlQ0UlQkJuLigoKFklMjAlQ0UlQkJyZWN1cnNlLiVDRSVCQm4uJUNFJUJCcmVzdWx0LigoKGlmJTIwKHplcm8lM0YlMjBuKSklMjAlQ0UlQkJfLigoKGlmJTIwKG5pbCUzRiUyMHJlc3VsdCkpJTIwJUNFJUJCXy4oKGNvbnMlMjB6ZXJvLWJ5dGUpJTIwbmlsKSklMjAlQ0UlQkJfLnJlc3VsdCkpJTIwJUNFJUJCXy4oKHJlY3Vyc2UlMjAoKCUyRiUyMG4pJTIwMTApKSUyMCgoY29ucyUyMCgoJTJCJTIwemVyby1ieXRlKSUyMCgoJTI1JTIwbiklMjAxMCkpKSUyMHJlc3VsdCkpKSklMjBuKSUyMG5pbCkpJTIwKCgobnVtJTIwMCklMjA0KSUyMDgpKSUyMCVDRSVCQl8uKHByaW50LWJ5dGUlMjAoKChudW0lMjAwKSUyMDEpJTIwMCkpKSUyMChZJTIwJUNFJUJCcmVjdXJzZS4lQ0UlQkJsLigoKGlmJTIwKG5pbCUzRiUyMGwpKSUyMCVDRSVCQl8udm9pZCklMjAlQ0UlQkJfLigoZG8yJTIwKHByaW50LWJ5dGUlMjAoY2FyJTIwbCkpKSUyMChyZWN1cnNlJTIwKGNkciUyMGwpKSkpKSklMjBQUklOVF9CWVRFKSUyMCVDRSVCQm4uJUNFJUJCZi4oKCgoWSUyMCVDRSVCQnJlY3Vyc2UuJUNFJUJCcmVtYWluaW5nLiVDRSVCQmN1cnJlbnQuJUNFJUJCZi4oKChpZiUyMCh6ZXJvJTNGJTIwcmVtYWluaW5nKSklMjAlQ0UlQkJfLnZvaWQpJTIwJUNFJUJCXy4oKGRvMiUyMChmJTIwY3VycmVudCkpJTIwKCgocmVjdXJzZSUyMChwcmVkJTIwcmVtYWluaW5nKSklMjAoc3VjYyUyMGN1cnJlbnQpKSUyMGYpKSkpJTIwbiklMjAwKSUyMGYpKSUyMCVDRSVCQmEuZG8zKSUyMCVDRSVCQmEuZG8yKSUyMCVDRSVCQmEuJUNFJUJCYi5iKSUyMCVDRSVCQmwuKHBhaXItc2Vjb25kJTIwKHBhaXItc2Vjb25kJTIwbCkpKSUyMCVDRSVCQmwuKHBhaXItZmlyc3QlMjAocGFpci1zZWNvbmQlMjBsKSkpJTIwJUNFJUJCZS4lQ0UlQkJsLigobWFrZS1wYWlyJTIwdHJ1ZSklMjAoKG1ha2UtcGFpciUyMGUpJTIwbCkpKSUyMCVDRSVCQmwuKG5vdCUyMChwYWlyLWZpcnN0JTIwbCkpKSUyMCgobWFrZS1wYWlyJTIwZmFsc2UpJTIwdm9pZCkpJTIwJUNFJUJCbS4lQ0UlQkJuLigoLSUyMG0pJTIwKCgqJTIwKCglMkYlMjBtKSUyMG4pKSUyMG4pKSklMjAoWSUyMCVDRSVCQiUyRi4lQ0UlQkJtLiVDRSVCQm4uKCgoaWYlMjAoKGVxJTNGJTIwbSklMjBuKSklMjAlQ0UlQkJfLjEpJTIwJUNFJUJCXy4oKChpZiUyMCh6ZXJvJTNGJTIwKCgtJTIwbSklMjBuKSkpJTIwJUNFJUJCXy4wKSUyMCVDRSVCQl8uKCglMkIlMjAxKSUyMCgoJTJGJTIwKCgtJTIwbSklMjBuKSklMjBuKSkpKSkpJTIwJUNFJUJCbS4lQ0UlQkJuLigoYW5kJTIwKHplcm8lM0YlMjAoKC0lMjBtKSUyMG4pKSklMjAoemVybyUzRiUyMCgoLSUyMG4pJTIwbSkpKSklMjAlQ0UlQkJtLiVDRSVCQm4uKChuJTIwcHJlZCklMjBtKSklMjAlQ0UlQkJuLigoKCVDRSVCQm4uJUNFJUJCZi4lQ0UlQkJ4LihwYWlyLXNlY29uZCUyMCgobiUyMCVDRSVCQnAuKChtYWtlLXBhaXIlMjAoZiUyMChwYWlyLWZpcnN0JTIwcCkpKSUyMChwYWlyLWZpcnN0JTIwcCkpKSUyMCgobWFrZS1wYWlyJTIweCklMjB4KSkpJTIwbiklMjBzdWNjKSUyMDApKSUyMCVDRSVCQm4uKChuJTIwJUNFJUJCXy5mYWxzZSklMjB0cnVlKSklMjAlQ0UlQkJwLihwJTIwZmFsc2UpKSUyMCVDRSVCQnAuKHAlMjB0cnVlKSklMjAlQ0UlQkJ4LiVDRSVCQnkuJUNFJUJCdC4oKHQlMjB4KSUyMHkpKSUyMCVDRSVCQmEuJUNFJUJCYi4oKGElMjB0cnVlKSUyMGIpKSUyMCVDRSVCQmEuJUNFJUJCYi4oKGElMjBiKSUyMGZhbHNlKSklMjAlQ0UlQkJwLiVDRSVCQnQuJUNFJUJCZi4oKHAlMjBmKSUyMHQpKSUyMCVDRSVCQnAuJUNFJUJCYS4lQ0UlQkJiLigoKHAlMjBhKSUyMGIpJTIwdm9pZCkpJTIwJUNFJUJCdC4lQ0UlQkJmLmYpJTIwJUNFJUJCdC4lQ0UlQkJmLnQpJTIwJUNFJUJCYS4lQ0UlQkJiLiVDRSVCQmMuKCglMkIlMjAoKCUyQiUyMCgoKiUyMCgoKiUyMDEwKSUyMDEwKSklMjBhKSklMjAoKColMjAxMCklMjBiKSkpJTIwYykpJTIwKHN1Y2MlMjA5KSklMjAoc3VjYyUyMDgpKSUyMChzdWNjJTIwNykpJTIwKHN1Y2MlMjA2KSklMjAoc3VjYyUyMDUpKSUyMChzdWNjJTIwNCkpJTIwKHN1Y2MlMjAzKSklMjAoc3VjYyUyMDIpKSUyMChzdWNjJTIwMSkpJTIwKHN1Y2MlMjAwKSklMjAlQ0UlQkJtLiVDRSVCQm4uJUNFJUJCeC4obSUyMChuJTIweCkpKSUyMCVDRSVCQm0uJUNFJUJCbi4lQ0UlQkJmLiVDRSVCQnguKCgoKG0lMjBzdWNjKSUyMG4pJTIwZiklMjB4KSklMjAlQ0UlQkJuLiVDRSVCQmYuJUNFJUJCeC4oZiUyMCgobiUyMGYpJTIweCkpKSUyMCVDRSVCQmYuJUNFJUJCeC54KSUyMCVDRSVCQnguKFUlMjBVKSklMjAoVSUyMCVDRSVCQmguJUNFJUJCZi4oZiUyMCVDRSVCQnguKCgoaCUyMGgpJTIwZiklMjB4KSkpKSUyMCVDRSVCQmYuKGYlMjBmKSklNUNuJTIyJTdE
-[11]: https://en.wikipedia.org/wiki/Currying
-[12]: https://en.wikipedia.org/wiki/Alonzo_Church
-[13]: https://en.wikipedia.org/wiki/Church_encoding#Church_numerals
-[14]: https://en.wikipedia.org/wiki/Peano_axioms#Arithmetic
-[15]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJyZXN1bHQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyMCUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC54JTVDbjElMjAlM0QlMjAlQ0UlQkJmLiVDRSVCQnguKGYlMjB4KSU1Q24yJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKGYlMjB4KSklNUNuc3VjYyUyMCUzRCUyMCVDRSVCQm4uJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKChuJTIwZiklMjB4KSklNUNuJTVDbnRydWUlMjAlMjAlM0QlMjAlQ0UlQkJ0LiVDRSVCQmYudCU1Q25mYWxzZSUyMCUzRCUyMCVDRSVCQnQuJUNFJUJCZi5mJTVDbiU1Q256ZXJvJTNGJTIwJTNEJTIwJUNFJUJCbi4oKG4lMjAlQ0UlQkJfLmZhbHNlKSUyMHRydWUpJTVDbiU1Q24lMjMlMjB0cnklMjBjaGFuZ2luZyUyMHRoZSUyMG51bWJlciUyMHplcm8lM0YlMjBpcyUyMGNhbGxlZCUyMHdpdGglNUNuKHplcm8lM0YlMjAwKSU1Q24lNUNuJTIzJTIwdGhlJTIwb3V0cHV0JTIwd2lsbCUyMGJlJTIwJTVDJTIyJUNFJUJCdC4lQ0UlQkJmLnQlNUMlMjIlMjBmb3IlMjB0cnVlJTIwYW5kJTIwJTVDJTIyJUNFJUJCdC4lQ0UlQkJmLmYlNUMlMjIlMjBmb3IlMjBmYWxzZS4lMjIlN0Q=
-[16]: https://en.wikipedia.org/wiki/Eager_evaluation
-[17]: https://en.wikipedia.org/wiki/Lazy_evaluation
-[18]: https://en.wikipedia.org/wiki/Syntactic_sugar
-[19]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJyZXN1bHQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyMCUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC54JTVDbjElMjAlM0QlMjAlQ0UlQkJmLiVDRSVCQnguKGYlMjB4KSU1Q24yJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKGYlMjB4KSklNUNuMyUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMChmJTIwKGYlMjB4KSkpJTVDbnN1Y2MlMjAlM0QlMjAlQ0UlQkJuLiVDRSVCQmYuJUNFJUJCeC4oZiUyMCgobiUyMGYpJTIweCkpJTVDbiU1Q250cnVlJTIwJTIwJTNEJTIwJUNFJUJCdC4lQ0UlQkJmLnQlNUNuZmFsc2UlMjAlM0QlMjAlQ0UlQkJ0LiVDRSVCQmYuZiU1Q24lNUNuemVybyUzRiUyMCUzRCUyMCVDRSVCQm4uKChuJTIwJUNFJUJCXy5mYWxzZSklMjB0cnVlKSU1Q24lNUNuaWYlMjAlM0QlMjAlQ0UlQkJwLiVDRSVCQmEuJUNFJUJCYi4oKChwJTIwYSklMjBiKSUyMDApJTVDbmFuZCUyMCUzRCUyMCVDRSVCQmEuJUNFJUJCYi4oYSUyMGIlMjBmYWxzZSklNUNub3IlMjAlM0QlMjAlQ0UlQkJhLiVDRSVCQmIuKGElMjB0cnVlJTIwYiklNUNubm90JTIwJTNEJTIwJUNFJUJCcC4lQ0UlQkJ0LiVDRSVCQmYuKHAlMjBmJTIwdCklNUNuJTVDbiUyMyUyMHRyeSUyMGNoYW5naW5nJTIwdGhpcyUyMHVwISU1Q24oaWYlMjAob3IlMjAoemVybyUzRiUyMDEpJTIwKHplcm8lM0YlMjAwKSklNUNuJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAyJTVDbiUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwMyklMjIlN0Q=
-[20]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJyZXN1bHQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyMCUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC54JTVDbjElMjAlM0QlMjAlQ0UlQkJmLiVDRSVCQnguKGYlMjB4KSU1Q24yJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKGYlMjB4KSklNUNuMyUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMChmJTIwKGYlMjB4KSkpJTVDbiU1Q250cnVlJTIwJTIwJTNEJTIwJUNFJUJCdC4lQ0UlQkJmLnQlNUNuZmFsc2UlMjAlM0QlMjAlQ0UlQkJ0LiVDRSVCQmYuZiU1Q24lNUNubWFrZS1wYWlyJTIwJTNEJTIwJUNFJUJCeC4lQ0UlQkJ5LiUyMCVDRSVCQmEuKGElMjB4JTIweSklNUNucGFpci1maXJzdCUyMCUzRCUyMCVDRSVCQnAuKHAlMjB0cnVlKSU1Q25wYWlyLXNlY29uZCUyMCUzRCUyMCVDRSVCQnAuKHAlMjBmYWxzZSklNUNuJTVDbiUyMyUyMHRyeSUyMGNoYW5naW5nJTIwdGhpcyUyMHVwISU1Q25wJTIwJTNEJTIwKG1ha2UtcGFpciUyMDIlMjAzKSU1Q24ocGFpci1zZWNvbmQlMjBwKSUyMiU3RA==
-[21]: https://en.wikipedia.org/wiki/Linked_list
-[22]: https://en.wikipedia.org/wiki/Lisp_%28programming_language%29
-[23]: https://en.wikipedia.org/wiki/CAR_and_CDR#Etymology
-[24]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJyZXN1bHQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyMCUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC54JTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwMSUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMHgpJTIwJTIwJTIwJTIwJTIwMiUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMChmJTIweCkpJTIwJTIwJTIwJTIwMyUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMChmJTIwKGYlMjB4KSkpJTVDbnRydWUlMjAlMjAlM0QlMjAlQ0UlQkJ0LiVDRSVCQmYudCUyMCUyMCUyMCUyMGZhbHNlJTIwJTNEJTIwJUNFJUJCdC4lQ0UlQkJmLmYlNUNuJTVDbm1ha2UtcGFpciUyMCUzRCUyMCVDRSVCQnguJUNFJUJCeS4lMjAlQ0UlQkJhLihhJTIweCUyMHkpJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwcGFpci1maXJzdCUyMCUzRCUyMCVDRSVCQnAuKHAlMjB0cnVlKSUyMCUyMCUyMCUyMCUyMHBhaXItc2Vjb25kJTIwJTNEJTIwJUNFJUJCcC4ocCUyMGZhbHNlKSU1Q24lNUNubmlsJTIwJTNEJTIwKG1ha2UtcGFpciUyMGZhbHNlJTIwZmFsc2UpJTIwJTIwJTIwJTIwJTIwbmlsJTNGJTIwJTNEJTIwJUNFJUJCbC4lMjAobm90JTIwKHBhaXItZmlyc3QlMjBsKSklNUNuY29ucyUyMCUzRCUyMCVDRSVCQnZhbHVlLiVDRSVCQmxpc3QuKG1ha2UtcGFpciUyMHRydWUlMjAobWFrZS1wYWlyJTIwdmFsdWUlMjBsaXN0KSklNUNuJTVDbmhlYWQlMjAlM0QlMjAlQ0UlQkJsaXN0LiUyMChwYWlyLWZpcnN0JTIwKHBhaXItc2Vjb25kJTIwbGlzdCkpJTVDbnRhaWwlMjAlM0QlMjAlQ0UlQkJsaXN0LiUyMChwYWlyLXNlY29uZCUyMChwYWlyLXNlY29uZCUyMGxpc3QpKSU1Q24lNUNuJTIzJTIwdHJ5JTIwY2hhbmdpbmclMjB0aGlzJTIwdXAhJTVDbmwlMjAlM0QlMjAoY29ucyUyMDElMjAoY29ucyUyMDIlMjAoY29ucyUyMDMlMjBuaWwpKSklNUNuKGhlYWQlMjAodGFpbCUyMGwpKSUyMiU3RA==
-[25]: https://en.wikipedia.org/wiki/Recursion
-[26]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjJzdW0lMjAlM0QlMjAlQ0UlQkJoZWxwZXIuJUNFJUJCbGlzdC4lNUNuJTIwJTIwKGlmJTIwKG5pbCUzRiUyMGxpc3QpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwMCU1Q24lMjAlMjAlMjAlMjAlMjAlMjAlQ0UlQkJfLiUyMCglMkIlMjAoaGVhZCUyMGxpc3QpJTIwKGhlbHBlciUyMGhlbHBlciUyMCh0YWlsJTIwbGlzdCkpKSklNUNuJTVDbnJlc3VsdCUyMCUzRCUyMChzdW0lMjBzdW0lMjAoY29ucyUyMDElMjAoY29ucyUyMDIlMjAoY29ucyUyMDMlMjBuaWwpKSkpJTVDbiU1Q24lMjMlMjB3ZSdsbCUyMGV4cGxhaW4lMjBob3clMjBwcmludC1udW0lMjB3b3JrcyUyMGxhdGVyJTJDJTIwYnV0JTIwd2UlMjBuZWVkJTIwaXQlMjB0byUyMHNob3clMjB0aGF0JTIwc3VtJTIwaXMlMjB3b3JraW5nJTVDbihwcmludC1udW0lMjByZXN1bHQpJTIyJTdE
-[27]: https://en.wikipedia.org/wiki/Fixed-point_combinator#Fixed_point_combinators_in_lambda_calculus
-[28]: https://www.ycombinator.com/
-[29]: https://news.ycombinator.com/
-[30]: http://matt.might.net/articles/implementation-of-recursive-fixed-point-y-combinator-in-javascript-for-memoization/
-[31]: http://kestas.kuliukas.com/YCombinatorExplained/
-[32]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjJZJTIwJTNEJTIwJUNFJUJCZi4oJUNFJUJCeC4oeCUyMHgpJTIwJUNFJUJCeC4oZiUyMCVDRSVCQnkuKCh4JTIweCklMjB5KSkpJTVDbiU1Q25zdW0lMjAlM0QlMjAoWSUyMCVDRSVCQmhlbHBlci4lQ0UlQkJsaXN0LiU1Q24lMjAlMjAoaWYlMjAobmlsJTNGJTIwbGlzdCklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAwJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwKCUyQiUyMChoZWFkJTIwbGlzdCklMjAoaGVscGVyJTIwKHRhaWwlMjBsaXN0KSkpKSklNUNuJTVDbiUyMyUyMHdlJ2xsJTIwZXhwbGFpbiUyMGhvdyUyMHRoaXMlMjB3b3JrcyUyMGxhdGVyJTJDJTIwYnV0JTIwd2UlMjBuZWVkJTIwaXQlMjB0byUyMHNob3clMjB0aGF0JTIwc3VtJTIwaXMlMjB3b3JraW5nJTVDbnByaW50LW51bSUyMCUzRCUyMCVDRSVCQm4uKHByaW50LWxpc3QlMjAoaXRvYSUyMG4pKSU1Q24lNUNuKHByaW50LW51bSUyMChzdW0lMjAoY29ucyUyMDElMjAoY29ucyUyMDIlMjAoY29ucyUyMDMlMjBuaWwpKSkpKSUyMiU3RA
-[33]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjIwJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LnglNUNuMSUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMHgpJTVDbjIlMjAlM0QlMjAlQ0UlQkJmLiVDRSVCQnguKGYlMjAoZiUyMHgpKSU1Q24zJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKGYlMjAoZiUyMHgpKSklNUNuJTVDbnByZWQlMjAlM0QlMjAlQ0UlQkJuLiU1Q24lMjAlMjAocGFpci1zZWNvbmQlNUNuJTIwJTIwJTIwJTIwKG4lNUNuJTIwJTIwJTIwJTIwJTIwJUNFJUJCcGFpci4obWFrZS1wYWlyJTIwKHN1Y2MlMjAocGFpci1maXJzdCUyMHBhaXIpKSUyMChwYWlyLWZpcnN0JTIwcGFpcikpJTVDbiUyMCUyMCUyMCUyMCUyMChtYWtlLXBhaXIlMjAwJTIwMCkpKSU1Q24lNUNuJTIzJTIwd2UnbGwlMjBleHBsYWluJTIwaG93JTIwcHJpbnQtbnVtJTIwd29ya3MlMjBsYXRlciElNUNuKHByaW50LW51bSUyMChwcmVkJTIwMykpJTVDbiUyMiU3RA==
-[34]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjIlMkIlMjAlM0QlMjAlQ0UlQkJtLiVDRSVCQm4uKG0lMjBzdWNjJTIwbiklNUNuKiUyMCUzRCUyMCVDRSVCQm0uJUNFJUJCbi4obiUyMCglMkIlMjBtKSUyMDApJTVDbi0lMjAlM0QlMjAlQ0UlQkJtLiVDRSVCQm4uKG4lMjBwcmVkJTIwbSklNUNuJTJGJTIwJTNEJTIwKFklMjAlQ0UlQkIlMkYuJUNFJUJCbS4lQ0UlQkJuLiU1Q24lMjAlMjAoaWYlMjAoZXElM0YlMjBtJTIwbiklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAxJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwKGlmJTIwKGxlJTNGJTIwbSUyMG4pJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwMCU1Q24lMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlQ0UlQkJfLiUyMCglMkIlMjAxJTIwKCUyRiUyMCgtJTIwbSUyMG4pJTIwbikpKSkpJTVDbiUyNSUyMCUzRCUyMCVDRSVCQm0uJUNFJUJCbi4lMjAoLSUyMG0lMjAoKiUyMCglMkYlMjBtJTIwbiklMjBuKSklNUNuJTVDbihwcmludC1udW0lMjAoJTI1JTIwNyUyMDMpKSUyMiU3RA==
-[35]: https://github.com/jtolds/sheepda/
-[36]: https://en.wikipedia.org/wiki/ASCII#Code_chart
-[37]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjIlMjMlMjBkZWZpbmUlMjB0aGUlMjBtZXNzYWdlcyU1Q25maXp6bXNnJTIwJTNEJTIwKGNvbnMlMjAobnVtJTIwMCUyMDclMjAwKSUyMChjb25zJTIwKG51bSUyMDElMjAwJTIwNSklMjAoY29ucyUyMChudW0lMjAxJTIwMiUyMDIpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDIlMjAyKSUyMG5pbCkpKSklNUNuYnV6em1zZyUyMCUzRCUyMChjb25zJTIwKG51bSUyMDAlMjA2JTIwNiklMjAoY29ucyUyMChudW0lMjAxJTIwMSUyMDcpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDIlMjAyKSUyMChjb25zJTIwKG51bSUyMDElMjAyJTIwMiklMjBuaWwpKSkpJTVDbmZpenpidXp6bXNnJTIwJTNEJTIwKGNvbnMlMjAobnVtJTIwMCUyMDclMjAwKSUyMChjb25zJTIwKG51bSUyMDElMjAwJTIwNSklMjAoY29ucyUyMChudW0lMjAxJTIwMiUyMDIpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDIlMjAyKSU1Q24lMjAlMjAlMjAlMjAoY29ucyUyMChudW0lMjAwJTIwOSUyMDgpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDElMjA3KSUyMChjb25zJTIwKG51bSUyMDElMjAyJTIwMiklMjAoY29ucyUyMChudW0lMjAxJTIwMiUyMDIpJTIwbmlsKSkpKSkpKSklNUNuJTVDbiUyMyUyMGZpenpidXp6JTVDbmZpenpidXp6JTIwJTNEJTIwJUNFJUJCbi4lNUNuJTIwJTIwKGZvciUyMG4lMjAlQ0UlQkJpLiU1Q24lMjAlMjAlMjAlMjAoZG8yJTVDbiUyMCUyMCUyMCUyMCUyMCUyMChpZiUyMCh6ZXJvJTNGJTIwKCUyNSUyMGklMjAzKSklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAoaWYlMjAoemVybyUzRiUyMCglMjUlMjBpJTIwNSkpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwKHByaW50LWxpc3QlMjBmaXp6YnV6em1zZyklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAocHJpbnQtbGlzdCUyMGZpenptc2cpKSU1Q24lMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlQ0UlQkJfLiUyMChpZiUyMCh6ZXJvJTNGJTIwKCUyNSUyMGklMjA1KSklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAocHJpbnQtbGlzdCUyMGJ1enptc2cpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwKHByaW50LWxpc3QlMjAoaXRvYSUyMGkpKSkpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMChwcmludC1uZXdsaW5lJTIwbmlsKSkpJTVDbiU1Q24lMjMlMjBydW4lMjBmaXp6YnV6eiUyMDIwJTIwdGltZXMlNUNuKGZpenpidXp6JTIwKG51bSUyMDAlMjAyJTIwMCkpJTIyJTdE
-[38]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjJoZWxsby13b3JsZCUyMCUzRCUyMChjb25zJTIwKG51bSUyMDAlMjA3JTIwMiklMjAoY29ucyUyMChudW0lMjAxJTIwMCUyMDEpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDAlMjA4KSUyMChjb25zJTIwKG51bSUyMDElMjAwJTIwOCklMjAoY29ucyUyMChudW0lMjAxJTIwMSUyMDEpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMChjb25zJTIwKG51bSUyMDAlMjA0JTIwNCklMjAoY29ucyUyMChudW0lMjAwJTIwMyUyMDIpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDElMjA5KSUyMChjb25zJTIwKG51bSUyMDElMjAxJTIwMSklMjAoY29ucyUyMChudW0lMjAxJTIwMSUyMDQpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMChjb25zJTIwKG51bSUyMDElMjAwJTIwOCklMjAoY29ucyUyMChudW0lMjAxJTIwMCUyMDApJTIwKGNvbnMlMjAobnVtJTIwMCUyMDMlMjAzKSUyMG5pbCkpKSkpKSkpKSkpKSklNUNuJTVDbnJldmVyc2UtbGlzdCUyMCUzRCUyMCVDRSVCQmxpc3QuKCU1Q24lMjAlMjAoWSUyMCVDRSVCQnJlY3Vyc2UuJUNFJUJCb2xkLiVDRSVCQm5ldy4lNUNuJTIwJTIwJTIwJTIwKGlmJTIwKG5pbCUzRiUyMG9sZCklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy5uZXclNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4ocmVjdXJzZSUyMCh0YWlsJTIwb2xkKSUyMChjb25zJTIwKGhlYWQlMjBvbGQpJTIwbmV3KSkpKSU1Q24lMjAlMjBsaXN0JTIwbmlsKSU1Q24lNUNuKGRvNCU1Q24lMjAlMjAocHJpbnQtbGlzdCUyMGhlbGxvLXdvcmxkKSU1Q24lMjAlMjAocHJpbnQtbmV3bGluZSUyMHZvaWQpJTVDbiUyMCUyMChwcmludC1saXN0JTIwKHJldmVyc2UtbGlzdCUyMGhlbGxvLXdvcmxkKSklNUNuJTIwJTIwKHByaW50LW5ld2xpbmUlMjB2b2lkKSklMjIlN0Q=
-[39]: https://github.com/gopherjs/gopherjs
-[40]: https://jtolds.github.io/sheepda/
-[41]: https://en.wikipedia.org/wiki/Code_golf
diff --git a/sources/tech/20171006 7 deadly sins of documentation.md b/sources/tech/20171006 7 deadly sins of documentation.md
deleted file mode 100644
index 5f2005c764..0000000000
--- a/sources/tech/20171006 7 deadly sins of documentation.md
+++ /dev/null
@@ -1,85 +0,0 @@
-7 deadly sins of documentation
-======
-
-Documentation seems to be a perennial problem in operations. Everyone agrees that it's important to have, but few believe that their organizations have all the documentation they need. Effective documentation practices can improve incident response, speed up onboarding, and help reduce technical debt--but poor documentation practices can be worse than having no documentation at all.
-
-### The 7 sins
-
-Do any of the following scenarios sound familiar?
-
- * You've got a wiki. And a Google Doc repository. And GitHub docs. And a bunch of text files in your home directory. And notes about problems in email.
- * You have a doc that explains everything about a service, and you're sure that the information you need to fix this incident in there ... somewhere.
- * You've got a 500-line Puppet manifest to handle this service ... with no comments. Or comments that reference tickets from two ticketing systems ago.
- * You have a bunch of archived presentations that discuss all sorts of infrastructure components, but you're not sure how up-to-date they are because you haven't had time to watch them in ages.
- * You bring someone new into the team and they spend a month asking what various pieces of jargon mean.
- * You search your wiki and find three separate docs on how this service works, two of which contradict each other entirely, and none of which have been updated in the past year.
-
-
-
-These are all signs you may have committed at least one of the deadly sins of documentation:
-
-1\. Repository overload.
-2\. Burying the lede.
-3\. Comment neglect.
-4\. Video addiction.
-5\. Jargon overuse.
-6\. Documentation overgrowth.
-
-But if you've committed any of those sins, chances are you know this one, too:
-
-7\. One or more of the above is true, but everyone says they don't have time to work on documentation.
-
-The worst sin of all is thinking that documentation is "extra" work. Those other problems are almost always a result of this mistake. Documentation isn't extra work--it's a necessary part of every project, and if it isn't treated that way, it will be nearly impossible to do well. You wouldn't expect to get good code out of developers without a coherent process for writing, reviewing, and publishing code, and yet we often treat documentation like an afterthought, something that we assume will happen while we get our other work done. If you think your documentation is inadequate, ask yourself these questions:
-
- * Do your projects include producing documentation as a measurable goal?
- * Do you have a formal review process for documentation?
- * Is documentation considered a task for senior members of the team?
-
-
-
-The worst sin of all is thinking that documentation is "extra" work.
-
-Those three questions can tell you a lot about whether you treat documentation as extra work or not. If people aren't given the time to write documentation, if there's no process to make sure the documentation that's produced is actually useful, or if documentation is foisted on those members of your team with the weakest grasp on the subjects being covered, it will be difficult to produce anything of decent quality.
-
-Those three questions can tell you a lot about whether you treat documentation as extra work or not. If people aren't given the time to write documentation, if there's no process to make sure the documentation that's produced is actually useful, or if documentation is foisted on those members of your team with the weakest grasp on the subjects being covered, it will be difficult to produce anything of decent quality.
-
-This often-dismissive attitude is pervasive in the industry. According to the [GitHub 2017 Open Source Survey][1], the number-one problem with most open source projects is incomplete or confusing documentation. But how many of those projects solicit technical writers to help improve that? How many of us in operations have a technical writer we bring in to help write or improve our documentation?
-
-### Practice makes (closer to) perfect
-
-This isn't to say that only a technical writer can produce good documentation, but writing and editing are skills like any other: We'll only get better at it if we work at it, and too few of us do. What are the concrete steps we can take to make it a real priority, as opposed to a nice-to-have?
-
-For a start, make good documentation a value that your organization champions. Just as reliability needs champions to get prioritized, documentation needs the same thing. Project plans and sprints should include delivering new documentation or updating old documentation, and allocate time for doing so. Make sure people understand that writing good documentation is just as important to their career development as writing good code.
-
-Additionally, make it easy to keep documentation up to date and for people to find the documentation they need. In this way, you can help perpetuate the virtuous circle of documentation: High-quality docs help people realize the value of documentation and provide examples to follow when they write their own, which in turn will encourage them to create their own.
-
-To do this, have as few repositories as possible; one or two is optimal (you might want your runbooks to be in Google Docs so they are accessible if the company wiki is down, for instance). If you have more, make sure everyone knows what each repository is for; if Google Docs is for runbooks, verify that all runbooks are there and nowhere else, and that everyone knows that. Ensure that your repositories are searchable and keep a change history, and to improve discoverability, consider adding portals that have frequently used or especially important docs surfaced for easy access. Do not depend on email, chat logs, or tickets as primary sources of documentation.
-
-Ask new and junior members of your team to review both your code and your documentation. If they don't understand what's going on in your code, or why you made the choices you did, it probably needs to be rewritten and/or commented better. If your docs aren't easy to understand without going down a rabbit hole, they probably need to be revised. Technical documentation should include concrete examples of how processes and behaviors work to help people create mental models. You may find the tips in this article helpful for improving your documentation writing: [10 tips for making your documentation crystal clear][2].
-
-When you're writing those docs, especially when it comes to runbooks, use the [inverted pyramid format][3]: The most commonly needed or most important information should be as close to the top of the page as possible. Don't combine runbook-style documents and longer-form technical reference; instead, link the two and keep them separate so that runbooks remain streamlined (but can easily be discovered from the reference, and vice versa).
-
-Using these steps in your documentation can change it from being a nice-to-have (or worse, a burden) into a force multiplier for your operations team. Good docs improve inclusiveness and knowledge transfer, helping your more inexperienced team members solve problems independently, freeing your more senior team members to work on new projects instead of firefighting or training new people. Better yet, well-written, high-quality documentation enables you and your team members to enjoy a weekend off or go on vacation without being on the hook if problems come up.
-
-Learn more in Chastity Blackwell's talk, [The 7 Deadly Sins of Documentation][4], at [LISA17][5], which will be held October 29-November 3 in San Francisco, California.
-
-### About The Author
-
-Chastity Blackwell;Chastity Blackwell Is A Site Reliability Engineer At Yelp;With More Than Years Of Experience In Operations.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/17/10/7-deadly-sins-documentation
-
-作者:[Chastity Blackwell][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/cblkwell
-[1]:http://opensourcesurvey.org/2017/
-[2]:https://opensource.com/life/16/11/tips-for-clear-documentation
-[3]:https://en.wikipedia.org/wiki/Inverted_pyramid_(journalism)
-[4]:https://www.usenix.org/conference/lisa17/conference-program/presentation/blackwell
-[5]:https://www.usenix.org/conference/lisa17
diff --git a/sources/tech/20171006 Create a Clean-Code App with Kotlin Coroutines and Android Architecture Components.md b/sources/tech/20171006 Create a Clean-Code App with Kotlin Coroutines and Android Architecture Components.md
deleted file mode 100644
index 0ff40cdd6e..0000000000
--- a/sources/tech/20171006 Create a Clean-Code App with Kotlin Coroutines and Android Architecture Components.md
+++ /dev/null
@@ -1,201 +0,0 @@
-Create a Clean-Code App with Kotlin Coroutines and Android Architecture Components
-============================================================
-
-### Full demo weather app included.
-
-Android development is evolving fast. A lot of developers and companies are trying to address common problems and create some great tools or libraries that can totally change the way we structure our apps.
-
-
-
-
-We get excited by the new possibilities, but it’s difficult to find time to rewrite our app to really benefit from a new programming style. But what if we actually start a new project? Which of those breakthrough ideas to employ? Which solutions are stable enough? Should we use RxJava extensively and structure our app with reactive-first mindset?
-
-> The Cycle.js library (by [André Staltz][6]) contains a great explanation of reactive-first mindset: [Cycle.js — Streams][7].
-
-Rx is highly composable and it has great potential, but it’s so different from regular object-oriented programming style, that it will be really hard to understand for any developer without RxJava experience.
-
-There are more questions to ask before starting a new project. For example:
-
-* Should we use Kotlin instead of Java?
- (actually here the answer is simple: [YES][1])
-
-* Should we use experimental Kotlin Coroutines? (which, again, promote totally new programming style)
-
-* Should we use the new experimental library from Google:
- Android Architecture Components?
-
-It’s necessary to try it all first in a small app to really make an informed decision. This is exactly what [I did][8], getting some useful insights in the process. If you want to find out what I learned, read on!
-
-### About [The App][9]
-
-The aim of the experiment was to create an [app][10] that downloads weather data for cities selected by user and then displays forecasts with graphical charts (and some fancy animations). It’s simple, yet it contains most of the typical features of Android projects.
-
-It turns out that coroutines and architecture components play really well together and give us clean app architecture with good separation of concerns. Coroutines allow to express ideas in a natural and concise way. Suspendable functions are great if you want to code line-by-line the exact logic you have in mind — even if you need to make some asynchronous calls in between.
-
-Also: no more jumping between callbacks. In this example app, coroutines also completely removed the need of using RxJava. Functions with suspendable points are easier to read and understand than some RxJava operator chains — these chains can quickly become too _functional. _ ;-)
-
-> Having said that, I don’t think that RxJava can be replaced with coroutines in every use case. Observables give us a different kind of expressiveness that can not be mapped one to one to suspendable functions. In particular once constructed observable operator chain allow many events to flow through it, while a suspendable point resumes only once per invocation.
-
-Back to our weather app:
-You can watch it in action below — but beware, I’m not a designer. :-)
-Chart animations show how easily you can implement them arbitrarily by hand with simple coroutine — without any ObjectAnimators, Interpolators, Evaluators, PropertyValuesHolders, etc.
-
- ** 此处有Canvas,请手动处理 **
-
- ** 此处有iframe,请手动处理 **
-
-The most important source code snippets are displayed below. However, if you’d like to see the full project, it’s available [on GitHub.][11]
-
-[https://github.com/elpassion/crweather][12]
-
-There is not a lot of code and it should be easy to go through.
-
-I will present the app structure starting from the network layer. Then I will move to the business logic (in the [MainModel.kt][13] file) which is _(almost)_ not Android-specific. And finish with the UI part (which obviously is Android-specific).
-
-Here is the general architecture diagram with text reference numbers added for your convenience. I will especially focus on _green_ elements — _suspendable functions_ and _actors_ (an actor is a really useful kind of _coroutine builder_ ).
-
-> The actor model in general is a mathematical model of concurrent computation — more about it in my next blog post.
-
-
-
-
-### 01 Weather Service
-
-This service downloads weather forecasts for a given city from [Open Weather Map][14] REST API.
-
-I use simple but powerful library from [Square][15] called [Retrofit][16]. I guess by now every Android developer knows it, but in case you never used it: it’s the most popular HTTP client on Android. It makes network calls and parses responses to [POJO][17]. Nothing fancy here — just a typical Retrofit configuration. I plug in the [Moshi][18] converter to convert JSON responses to data classes.
-
-
-
-[https://github.com/elpassion/crweather/…/OpenWeatherMapApi.kt][2]
-
-One important thing to note here is that I set a return types of functions generated by Retrofit to: [Call][19].
-
-I use [Call.enqueue(Callback)][20] to actually make a call to Open Weather Map. I don’t use any [call adapter][21] provided by Retrofit, because I wrap the Call object in the _suspendable function_ myself.
-
-### 02 Utils
-
-This is where we enter the ([brave new][22]) _coroutines_ world: we want to create a generic _suspendable function_ that wraps a [Call][23] object.
-
-> I assume you know at least the very basics of coroutines. Please read the first chapter of [Coroutines Guide][24] (written by [Roman Elizarov][25]) if you don’t.
-
-It will be an extension function: [_suspend_ fun Call<T>.await()][26] that invokes the [Call.enqueue(…)][27] (to actually make a network call), then _suspends_ and later _resumes_ (when the response comes back).
-
- ** 此处有Canvas,请手动处理 **
-
-
-[https://github.com/elpassion/crweather/…/CommonUtils.kt][3]
-
-To turn any asynchronous computation into a _suspendable function,_ we use the [suspendCoroutine][28] function from The Kotlin Standard Library. It gives us a [Continuation][29] object which is kind of a universal callback. We just have to call its [resume][30] method (or [resumeWithException][31]) anytime we want our new _suspendable function_ to resume (normally or by throwing an exception).
-
-The next step will be to use our new _suspend_ fun Call<T>.await() function to convert asynchronous functions generated by Retrofit into convenient _suspendable functions_ .
-
-### 03 Repository
-
-The Repository object is a source of the data ([charts][32]) displayed in our app.
-
-
-
-
-[https://github.com/elpassion/crweather/…/Repository.kt][4]
-
-Here we have some private _suspendable functions_ created by applying our _suspend_ fun Call<T>.await() extension to weather service functions. This way all of them return ready to use data like Forecast instead of Call<Forecast>. Then we use it in our one public _suspendable function_ : _suspend_ fun getCityCharts(city: String): List<Chart>. It converts the data from api to a ready to display list of charts. I use some custom extension properties on List<DailyForecast> to actually convert the data to List<Chart>. Important note: only _suspendable functions_ can call other _suspendable functions_ .
-
-> We have the [appid][33] hardcoded here for simplicity. Please generate new appid [here][34]if you want to test the app — this hardcoded one will be automatically blocked for 24h if it is used too frequently by too many people.
-
-In the next step we will create the main app model (implementing the Android [ViewModel][35] architecture component), that uses an _actor (coroutine builder)_ to implement the application logic.
-
-### 04 Model
-
-In this app we only have one simple model: [MainModel][36] : [ViewModel][37] used by our one activity: [MainActivity][38].
-
-
-
-
-[https://github.com/elpassion/crweather/…/MainModel.kt][5]
-
-This class represents the app itself. It will be instantiated by our activity (actually by the Android system [ViewModelProvider][39]), but it will survive configuration changes such as a screen rotation — new activity instance will get the same model instance. We don’t have to worry about activity lifecycle here at all. Instead of implementing all those activity lifecycle related methods (onCreate, onDestroy, …), we have just one onCleared() method called when the user exits the app.
-
-> To be precise onCleared method is called when the activity is finished.
-
-Even though we are not tightly coupled to activity lifecycle anymore, we still have to somehow publish current state of our app model to display it somewhere (in the activity). This is where the [LiveData][40] comes into play.
-
-The [LiveData][41] is like [RxJava][42] [BehaviorSubject][43] reinvented once again… It holds a mutable value that is observable. The most important difference is how we subscribe to it and we will see it later in the [MainActivity][44].
-
-> Also LiveData doesn’t have all those powerful composable operators Observable has. There are only some simple [Transformations][45].
-
-> Another difference is that LiveData is Android-specific and RxJava subjects are not, so they can be easily tested with regular non-android JUnit tests.
-
-> Yet another difference is that LiveData is “lifecycle aware” — more about it in my next posts, where I present the [MainActivity][46] class.
-
-In here we are actually using the [MutableLiveData][47] : [LiveData][48] objects that allow to push new values into it freely. The app state is represented by four LiveData objects: city, charts, loading, and message. The most important of these is the charts: LiveData<List<Chart>> object which represents current list of charts to display.
-
-All the work of changing the app state and reacting to user actions is performed by an _ACTOR_ .
-
- _Actors_ are awesome and will be explained in my next blog post :-)
-
-### Summary
-
-We have already prepared everything for our main _actor_ . And if you look at the _actor_ code itself — you can (kind of) see how it works even without knowing _coroutines_ or _actors_ theory. Even though it has only a few lines, it actually contains all important business logic of this app. The magic is where we call _suspendable functions_ (marked by gray arrows with green line). One _suspendable point_ is the iteration over user actions and second is the network call. Thanks to _coroutines_ it looks like synchronous blocking code but it doesn’t block the thread at all.
-
-Stay tuned for my next post, where I will explain _actors_ (and _channels_ ) in detail.
-
---------------------------------------------------------------------------------
-
-via: https://blog.elpassion.com/create-a-clean-code-app-with-kotlin-coroutines-and-android-architecture-components-f533b04b5431
-
-作者:[Marek Langiewicz][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://blog.elpassion.com/@marek.langiewicz?source=post_header_lockup
-[1]:https://www.quora.com/Does-Kotlin-make-Android-development-easier-and-faster/answer/Michal-Przadka?srid=Gu6q
-[2]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/OpenWeatherMapApi.kt
-[3]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/CommonUtils.kt
-[4]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/Repository.kt
-[5]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainModel.kt
-[6]:https://medium.com/@andrestaltz
-[7]:https://cycle.js.org/streams.html
-[8]:https://github.com/elpassion/crweather
-[9]:https://github.com/elpassion/crweather
-[10]:https://github.com/elpassion/crweather
-[11]:https://github.com/elpassion/crweather
-[12]:https://github.com/elpassion/crweather
-[13]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainModel.kt
-[14]:http://openweathermap.org/api
-[15]:https://github.com/square
-[16]:http://square.github.io/retrofit/
-[17]:https://en.wikipedia.org/wiki/Plain_old_Java_object
-[18]:https://github.com/square/retrofit/tree/master/retrofit-converters/moshi
-[19]:https://github.com/square/retrofit/blob/master/retrofit/src/main/java/retrofit2/Call.java
-[20]:https://github.com/square/retrofit/blob/b3ea768567e9e1fb1ba987bea021dbc0ead4acd4/retrofit/src/main/java/retrofit2/Call.java#L48
-[21]:https://github.com/square/retrofit/tree/master/retrofit-adapters
-[22]:https://www.youtube.com/watch?v=_Lvf7Zu4XJU
-[23]:https://github.com/square/retrofit/blob/master/retrofit/src/main/java/retrofit2/Call.java
-[24]:https://github.com/Kotlin/kotlinx.coroutines/blob/master/coroutines-guide.md
-[25]:https://medium.com/@elizarov
-[26]:https://github.com/elpassion/crweather/blob/9c3e3cb803b7e4fffbb010ff085ac56645c9774d/app/src/main/java/com/elpassion/crweather/CommonUtils.kt#L24
-[27]:https://github.com/square/retrofit/blob/b3ea768567e9e1fb1ba987bea021dbc0ead4acd4/retrofit/src/main/java/retrofit2/Call.java#L48
-[28]:https://github.com/JetBrains/kotlin/blob/8f452ed0467e1239a7639b7ead3fb7bc5c1c4a52/libraries/stdlib/src/kotlin/coroutines/experimental/CoroutinesLibrary.kt#L89
-[29]:https://github.com/JetBrains/kotlin/blob/8fa8ba70558cfd610d91b1c6ba55c37967ac35c5/libraries/stdlib/src/kotlin/coroutines/experimental/Coroutines.kt#L23
-[30]:https://github.com/JetBrains/kotlin/blob/8fa8ba70558cfd610d91b1c6ba55c37967ac35c5/libraries/stdlib/src/kotlin/coroutines/experimental/Coroutines.kt#L32
-[31]:https://github.com/JetBrains/kotlin/blob/8fa8ba70558cfd610d91b1c6ba55c37967ac35c5/libraries/stdlib/src/kotlin/coroutines/experimental/Coroutines.kt#L38
-[32]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/DataTypes.kt
-[33]:http://openweathermap.org/appid
-[34]:http://openweathermap.org/appid
-[35]:https://developer.android.com/topic/libraries/architecture/viewmodel.html
-[36]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainModel.kt
-[37]:https://developer.android.com/topic/libraries/architecture/viewmodel.html
-[38]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainActivity.kt
-[39]:https://developer.android.com/reference/android/arch/lifecycle/ViewModelProvider.html
-[40]:https://developer.android.com/topic/libraries/architecture/livedata.html
-[41]:https://developer.android.com/topic/libraries/architecture/livedata.html
-[42]:https://github.com/ReactiveX/RxJava
-[43]:https://github.com/ReactiveX/RxJava/wiki/Subject
-[44]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainActivity.kt
-[45]:https://developer.android.com/reference/android/arch/lifecycle/Transformations.html
-[46]:https://github.com/elpassion/crweather/blob/master/app/src/main/java/com/elpassion/crweather/MainActivity.kt
-[47]:https://developer.android.com/reference/android/arch/lifecycle/MutableLiveData.html
-[48]:https://developer.android.com/topic/libraries/architecture/livedata.html
diff --git a/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md b/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md
deleted file mode 100644
index 20c14074c6..0000000000
--- a/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md
+++ /dev/null
@@ -1,94 +0,0 @@
-In Device We Trust: Measure Twice, Compute Once with Xen, Linux, TPM 2.0 and TXT
-============================================================
-
-
-
-Xen virtualization enables innovative applications to be economically integrated with measured, interoperable software components on general-purpose hardware.[Creative Commons Zero][1]Pixabay
-
-Is it a small tablet or large phone? Is it a phone or broadcast sensor? Is it a server or virtual desktop cluster? Is x86 emulating ARM, or vice-versa? Is Linux inspiring Windows, or the other way around? Is it microcode or hardware? Is it firmware or software? Is it microkernel or hypervisor? Is it a security or quality update? _Is anything in my device the same as yesterday? When we observe our evolving devices and their remote services, what can we question and measure?_
-
-### General Purpose vs. Special Purpose Ecosystems
-
-The general-purpose computer now lives in a menagerie of special-purpose devices and information appliances. Yet software and hardware components _within_ devices are increasingly flexible, blurring category boundaries. With hardware virtualization on x86 and ARM platforms, the ecosystems of multiple operating systems can coexist on a single device. Can a modular and extensible multi-vendor architecture compete with the profitability of vertically integrated products from a single vendor?
-
-Operating systems evolved alongside applications for lucrative markets. PC desktops were driven by business productivity and media creation. Web browsers abstracted OS differences, as software revenue shifted to e-commerce, services, and advertising. Mobile devices added sensors, radios and hardware decoders for content and communication. Apple, now the most profitable computer company, vertically integrates software and services with sensors and hardware. Other companies monetize data, increasing demand for memory and storage optimization.
-
-Some markets require security or safety certifications: automotive, aviation, marine, cross domain, industrial control, finance, energy, medical, and embedded devices. As software "eats the world," how can we [modernize][5]vertical markets without the economies of scale seen in enterprise and consumer markets? One answer comes from device architectures based on hardware virtualization, Xen, [disaggregation][6], OpenEmbedded Linux and measured launch. [OpenXT][7] derivatives use this extensible, open-source base to enforce policy for specialized applications on general-purpose hardware, while reusing interoperable components.
-
-[OpenEmbedded][8] Linux supports a range of x86 and ARM devices, while Xen isolates operating systems and [unikernels][9]. Applications and drivers from multiple ecosystems can run concurrently, expanding technical and licensing options. Special-purpose software can be securely composed with general-purpose software in isolated VMs, anchored by a hardware-assisted root of trust defined by customer and OEM policies. This architecture allows specialist software vendors to share platform and hardware support costs, while supporting emerging and legacy software ecosystems that have different rates of change.
-
-### On the Shoulders of Hardware, Firmware and Software Developers
-
-### 
-
- _System Architecture, from NIST SP800-193 (Draft), Platform Firmware Resiliency_
-
-By the time a user-facing software application begins executing on a powered-on hardware device, an array of firmware and software is already running on the platform. Special-purpose applications’ security and safety assertions are dependent on platform firmware and the developers of a computing device’s “root of trust.”
-
-If we consider the cosmological “[Turtles All The Way Down][2]” question for a computing device, the root of trust is the lowest-level combination of hardware, firmware and software that is initially trusted to perform critical security functions and persist state. Hardware components used in roots of trust include the TCG's Trusted Platform Module ([TPM][10]), ARM’s [TrustZone][11]-enabled Trusted Execution Environment ([TEE][12]), Apple’s [Secure Enclave][13] co-processor ([SEP][14]), and Intel's Management Engine ([ME][15]) in x86 CPUs. [TPM 2.0][16]was approved as an ISO standard in 2015 and is widely available in 2017 devices.
-
-TPMs enable key authentication, integrity measurement and remote attestation. TPM key generation uses a hardware random number generator, with private keys that never leave the chip. TPM integrity measurement functions ensure that sensitive data like private keys are only used by trusted code. When software is provisioned, its cryptographic hash is used to extend a chain of hashes in TPM Platform Configuration Registers (PCRs). When the device boots, sensitive data is only unsealed if measurements of running software can recreate the PCR hash chain that was present at the time of sealing. PCRs record the aggregate result of extending hashes, while the TPM Event Log records the hash chain.
-
-Measurements are calculated by hardware, firmware and software external to the TPM. There are Static (SRTM) and Dynamic (DRTM) Roots of Trust for Measurement. SRTM begins at device boot when the BIOS boot block measures BIOS before execution. The BIOS then execute, extending configuration and option ROM measurements into static PCRs 0-7\. TPM-aware boot loaders like TrustedGrub can extend a measurement chain from BIOS up to the [Linux kernel][17]. These software identity measurements enable relying parties to make trusted decisions within [specific workflows][18].
-
-DRTM enables "late launch" of a trusted environment from an untrusted one at an arbitrary time, using Intel's Trusted Execution Technology ([TXT][19]) or AMD's Secure Virtual Machine ([SVM][20]). With Intel TXT, the CPU instruction SENTER resets CPUs to a known state, clears dynamic PCRs 17-22 and validates the Intel SINIT ACM binary to measure Intel’s tboot MLE, which can then measure Xen, Linux or other components. In 2008, Carnegie Mellon's [Flicker][21] used late launch to minimize the Trusted Computing Base (TCB) for isolated execution of sensitive code on AMD devices, during the interval between suspend/resume of untrusted Linux.
-
-If DRTM enables launch of a trusted Xen or Linux environment without reboot, is SRTM still needed? Yes, because [attacks][22] are possible via privileged System Management Mode (SMM) firmware, UEFI Boot/Runtime Services, Intel ME firmware, or Intel Active Management Technology (AMT) firmware. Measurements for these components can be extended into static PCRs, to ensure they have not been modified since provisioning. In 2015, Intel released documentation and reference code for an SMI Transfer Monitor ([STM][23]), which can isolate SMM firmware on VT-capable systems. As of September 2017, an OEM-supported STM is not yet available to improve the security of Intel TXT.
-
-Can customers secure devices while retaining control over firmware? UEFI Secure Boot requires a signed boot loader, but customers can define root certificates. Intel [Boot Guard][24] provides OEMs with validation of the BIOS boot block. _Verified Boot_ requires a signed boot block and the OEM's root certificate is fused into the CPU to restrict firmware. _Measured Boot_ extends the boot block hash into a TPM PCR, where it can be used for measured launch of customer-selected firmware. Sadly, no OEM has yet shipped devices which implement ONLY the Measured Boot option of Boot Guard.
-
-### Measured Launch with Xen on General Purpose Devices
-
-[OpenXT 7.0][25] has entered release candidate status, with support for Kaby Lake devices, TPM 2.0, OE [meta-measured][3], and [forward seal][26] (upgrade with pre-computed PCRs).
-
-[OpenXT 6.0][27] on a Dell T20 Haswell Xeon microserver, after adding a SATA controller, low-power AMD GPU and dual-port Broadcom NIC, can be configured with measured launch of Windows 7 GPU p/t, FreeNAS 9.3 SATA p/t, pfSense 2.3.4, Debian Wheezy, OpenBSD 6.0, and three NICs, one per passthrough driver VM.
-
-Does this demonstrate a storage device, build server, firewall, middlebox, desktop, or all of the above? With architectures similar to [Qubes][28] and [OpenXT][29] derivatives, we can combine specialized applications with best-of-breed software from multiple ecosystems. A strength of one operating system can address the weakness of another.
-
-### Measurement and Complexity in Software Supply Chains
-
-While ransomware trumpets cryptocurrency demands to shocked users, low-level malware often emulates Sherlock Holmes: the user sees no one. Malware authors modify code behavior in response to “our method of questioning”, simulating heisenbugs. As system architects pile abstractions, [self-similarity][30] appears as hardware, microcode, emulator, firmware, microkernel, hypervisor, operating system, virtual machine, namespace, nesting, runtime, and compiler expand onto neighboring territory. There are no silver bullets to neutralize these threats, but cryptographic measurement of source code and stateless components enables whitelisting and policy enforcement in multi-vendor supply chains.
-
-Even for special-purpose devices, the user experience bar is defined by mass-market computing. Meanwhile, Moore’s Law is ending, ARM remains fragmented, x86 PC volume is flat, new co-processors and APIs multiply, threats mutate and demand for security expertise outpaces the talent pool. In vertical markets which need usable, securable and affordable special-purpose devices, Xen virtualization enables innovative applications to be economically integrated with measured, interoperable software components on general-purpose hardware. OpenXT is an open-source showcase for this scalable ecosystem. Further work is planned on reference architectures for measured disaggregation with Xen and OpenEmbedded Linux.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog//event/elce/2017/10/device-we-trust-measure-twice-compute-once-xen-linux-tpm-20-and-txt
-
-作者:[RICH PERSAUD][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/rpersaud
-[1]:https://www.linux.com/licenses/category/creative-commons-zero
-[2]:https://en.wikipedia.org/wiki/Turtles_all_the_way_down
-[3]:https://layers.openembedded.org/layerindex/branch/master/layer/meta-measured/
-[4]:https://www.linux.com/files/images/puzzlejpg
-[5]:http://mailchi.mp/iotpodcast/stacey-on-iot-if-ge-cant-master-industrial-iot-who-can
-[6]:https://www.xenproject.org/directory/directory/research/45-breaking-up-is-hard-to-do-security-and-functionality-in-a-commodity-hypervisor.html
-[7]:http://openxt.org/
-[8]:https://wiki.xenproject.org/wiki/Category:OpenEmbedded
-[9]:https://wiki.xenproject.org/wiki/Unikernels
-[10]:http://www.cs.unh.edu/~it666/reading_list/Hardware/tpm_fundamentals.pdf
-[11]:https://developer.arm.com/technologies/trustzone
-[12]:https://www.arm.com/products/processors/technologies/trustzone/tee-smc.php
-[13]:http://mista.nu/research/sep-paper.pdf
-[14]:https://www.blackhat.com/docs/us-16/materials/us-16-Mandt-Demystifying-The-Secure-Enclave-Processor.pdf
-[15]:https://link.springer.com/book/10.1007/978-1-4302-6572-6
-[16]:https://fosdem.org/2017/schedule/event/tpm2/attachments/slides/1517/export/events/attachments/tpm2/slides/1517/FOSDEM___TPM2_0_practical_usage.pdf
-[17]:https://mjg59.dreamwidth.org/48897.html
-[18]:https://docs.microsoft.com/en-us/windows/threat-protection/secure-the-windows-10-boot-process
-[19]:https://www.intel.com/content/www/us/en/software-developers/intel-txt-software-development-guide.html
-[20]:http://support.amd.com/TechDocs/24593.pdf
-[21]:https://www.cs.unc.edu/~reiter/papers/2008/EuroSys.pdf
-[22]:http://invisiblethingslab.com/resources/bh09dc/Attacking%20Intel%20TXT%20-%20paper.pdf
-[23]:https://firmware.intel.com/content/smi-transfer-monitor-stm
-[24]:https://software.intel.com/en-us/blogs/2015/02/20/tricky-world-securing-firmware
-[25]:https://openxt.atlassian.net/wiki/spaces/OD/pages/96567309/OpenXT+7.x+Builds
-[26]:https://openxt.atlassian.net/wiki/spaces/DC/pages/81035265/Measured+Launch
-[27]:https://openxt.atlassian.net/wiki/spaces/OD/pages/96436271/OpenXT+6.x+Builds
-[28]:http://qubes-os.org/
-[29]:http://openxt.org/
-[30]:https://en.m.wikipedia.org/wiki/Self-similarity
diff --git a/sources/tech/20171030 5 open source alternatives to Mint and Quicken for personal finance.md b/sources/tech/20171030 5 open source alternatives to Mint and Quicken for personal finance.md
deleted file mode 100644
index a1a477557e..0000000000
--- a/sources/tech/20171030 5 open source alternatives to Mint and Quicken for personal finance.md
+++ /dev/null
@@ -1,96 +0,0 @@
-5 open source alternatives to Mint and Quicken for personal finance
-======
-
-
-Editor's note: This article was originally published in January 2016 and has been updated to add two great additional tools.
-
-When asked about personal goals, getting a better handle on personal finances is high on most people's list. Whether this means making and sticking to a budget, reducing unnecessary expenses, or simply getting a better understanding of their financial situation, pretty much any approach to personal finance is dependent on having a good idea of the numbers inside a person's bank accounts, where they come from, and where they go.
-
-Determining which tools allow you to best organize your finances depends a little bit on your situation. Do you primarily make purchases electronically, or do you rely heavily on cash? Is archiving and organizing receipts important for you come tax time? Do you operate a small business and need a more powerful tool that can manage the more complex finances of sales, customers, employees, and business expenses? Or do you use multiple currencies (perhaps Bitcoin?) and want to keep track of those values as well?
-
-Just as no two people have identical bank accounts, there's no single personal finance tool that works best for everybody. For some, automation and simplicity are their main goals; for others, customization and having lots of features matter most; while still others would benefit most from a large community to provide support. Let's take a look at five popular options for open source financial software tools, and a sixth option as well--old-fashioned spreadsheets. Each of these tools was designed with Linux in mind, but there are builds for other operating systems as well.
-
-### GnuCash
-
-First up, let's take a look at [GnuCash][1]. GnuCash is a reasonably full-featured accounting application that is suitable for both personal use and managing a small business. First released in 1998, GnuCash is a stable option packaged for most major Linux distributions with Windows and Mac ports available. It features multi-entry bookkeeping, can import from a wide range of formats, handles multiple currencies, helps create budgets, prints checks, creates custom reports in Scheme, and can import from online banks and pull stock quotes directly. While not the kitchen sink, it can handle most financial needs readily out of the box.
-
-One reason I particularly like GnuCash as an option is the availability of a [mobile application][2] that complements, rather than emulates, its desktop companion. The mobile app makes it easy for you to track expenses on the go and import them into the desktop version for more detailed management (although, unfortunately, it does not provide direct syncing).
-
-GnuCash hosts a public mirror of its [source code][3], which is primarily written in C, on GitHub. Given its long and complex history, portions of the code are made available under a number of mutually compatible [licenses][4], primarily the GPL, but the code repository has the full details.
-
-### HomeBank
-
-[HomeBank][5] is another personal financial management option that is both easy to use and full of charting and reporting options. Most Linux users can find a packaged version in their usual repositories, and Windows users can install via a direct download. There are other unsupported ports available as well.
-
-HomeBank has a similar feature set to what you might expect from other tools: import from Quicken, Microsoft Money, or other common formats; duplicate-transaction detection; multiple account types; split transactions; budgeting tools; and more. HomeBank also sports translation into 56 languages, so it's probably available in a language you speak.
-
-HomeBank's source code is available in [Launchpad][6], and it is licensed as open source under the [GPL version 2][7].
-
-### KMyMoney
-
-[KMyMoney][8] is a member of the [KDE][9] family of applications and touts three main goals: accuracy, which is of the utmost importance for a financial tool; ease of use, to ensure you start and keep using it; and familiar features, designed to made KMyMoney a simple transition if you are coming over from one of its proprietary alternatives.
-
-To achieve these goals, KMyMoney hosts a number of features that you would expect from a modern money manager: institution and account management, tagging, QIF import, reconciliation, scheduling, ledger management, investment tracking, forecasting, and multiple currencies. While it doesn't offer some of the small business features found in GnuCash or other personal finance managers, this might actually make it easier for an individual who doesn't want to be overwhelmed with unneeded options.
-
-KMyMoney manages a [Git repository][10] where you can find its code base, and it is made available as open source under the [GPL version 2][7]. While designed for Linux, it has been successfully ported to Windows and Mac OS as well.
-
-### Money Manager Ex
-
-[Money Manager Ex][11] is a cross-platform, open source personal finance manager. In addition to running on the typical platforms (Windows, Linux, and MacOS), there's also a [mobile application][12], and cloud synchronization allows you to track your finances across devices. If you'd rather not install the software on your computer, you can run it directly from a USB key. Financial data is stored in a non-proprietary SQLite Database protected with AES encryption.
-
-It also offers the key money management features you'd find in similar applications. For example, you can use it to track checking, savings, credit card, and stock accounts, as well as fixed assets and recurring transactions; generate financial reports; and create budgets. It imports and exports QIF and CSV data, and also exports to HTML. It's available in 24 languages and supports multiple currencies.
-
-Money Manager Ex's source code is available on [GitHub][13]. It's available as open source under the [GPL version 2][7].
-
-### Skrooge
-
-[Skrooge][14] is another KDE-powered personal finance management application. It can import data in a wide variety of formats; the usual QIF and CSV, but also QFX and other formats used by banks, as well as KMY (KMyMoney), SQLITE, GNC (GnuCash), GSB (Grisbi), XHB (Homebank), MMB (Money Manager Ex), and MNY (Microsoft Money). Data can be exported in QIF and CSV, as well as KMY, JSON, and XML. This makes it easy to migrate to Skrooge from other money management software (and vice versa).
-
-Because it's KDE-based, it can run on Linux, BSD, Solaris, and MacOS, and possibly on Windows. It offers the usual features you'd look for in an application to track your expenses, income, and investments, and allows you to view your data in tables and a variety of charts.
-
-Skrooge's source code is available in its [Git repository][15], and it's made open source under the [GPL version 3][16].
-
-### Spreadsheets
-
-While all five of these options are well-supported and regularly updated, my final pitch is to not even use a personal finance tool at all, but instead to use spreadsheets to manage your financial data. Yes, there's a lot to be said for having a dedicated budgeting tool. There's less reinventing of the wheel involved, and you don't have to worry as much about messing up complex formulas. You also have the peace of mind of knowing that there are others out there who have exactly the same setup and can help you out when you get stuck. And you also need to be careful to not store personally identifiable information like account numbers in plain text, particularly if you store or back up your data to a shared location.
-
-But the vanilla spreadsheet isn't a terrible tool either. In terms of the ease of customization, it can't be beat. Custom charts and graphs are easy to generate, and you can track additional data alongside your accounts to get a clearer picture of your spending. Open source tools like [LibreOffice Calc][17] or [Gnumetric][18] offer great functionality and expandability to track your finances your way.
-
-Personally, I use a mix of tools. I use a personal finance tool to store the raw data and for getting an idea of what my accounts look like at a glance. But for more complex operations, I turn to a trusty spreadsheet to drill down to exactly what I want to know, particularly when I want to pair the data with other personal information I collect. For example, I have a device in my car that tracks trips via GPS; by pulling out gasoline purchases, I can pair this information to see my exact cost per mile for every trip. Or I can pair restaurant spending with the personal health metrics I collect to see the correlation between how often I eat out and how my weight fluctuates.
-
-So how do you choose? Most of the five personal finance managers here (as well as less-frequently updated options [Economizzer][19] and [Grisbi][20]) offer similar feature sets; the devil is in the details. Sometimes, your personal preferences will dictate a particular killer feature that only one of the options hosts. The best way to find out is to dive in and start using one, and if it's not working for you, migrate your accounts to another to see if it better meets your needs. If you're managing business transactions or just need more powerful options, you might also look around at the variety of [open source ERP solutions][21] available, which have better tools for managing complex business asset tracking and reporting needs.
-
-Whichever tool you decide to use, why not make open source the way to get control of your financial picture?
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/life/17/10/personal-finance-tools-linux
-
-作者:[Jason Baker][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jason-baker
-[1]:http://www.gnucash.org/
-[2]:https://play.google.com/store/apps/details?id=org.gnucash.android&hl=en
-[3]:https://github.com/Gnucash/
-[4]:https://github.com/Gnucash/gnucash/blob/master/LICENSE
-[5]:http://homebank.free.fr/index.php
-[6]:https://code.launchpad.net/homebank
-[7]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
-[8]:https://kmymoney.org/
-[9]:https://www.kde.org/
-[10]:https://quickgit.kde.org/?p=kmymoney.git
-[11]:https://www.moneymanagerex.org/
-[12]:https://www.moneymanagerex.org/features/android-version
-[13]:https://github.com/moneymanagerex/moneymanagerex
-[14]:https://skrooge.org/
-[15]:https://cgit.kde.org/skrooge.git/
-[16]:https://www.gnu.org/licenses/gpl.html
-[17]:https://www.libreoffice.org/discover/calc/
-[18]:http://www.gnumeric.org/
-[19]:http://www.economizzer.org/
-[20]:http://www.grisbi.org/
-[21]:https://opensource.com/resources/top-4-open-source-erp-systems
diff --git a/sources/tech/20171114 Finding Files with mlocate- Part 2.md b/sources/tech/20171114 Finding Files with mlocate- Part 2.md
deleted file mode 100644
index 19c546a917..0000000000
--- a/sources/tech/20171114 Finding Files with mlocate- Part 2.md
+++ /dev/null
@@ -1,174 +0,0 @@
-Finding Files with mlocate: Part 2
-======
-
-
-
-[In the previous article][1], we discussed some ways to find a specific file out of the thousands that may be present on your filesystems and introduced the locate tool for the job. Here we explain how the important updatedb tool can help.
-
-### Well Situated
-
-Incidentally, you might get a little perplexed if trying to look up the manuals for updatedb and the locate command. Even though it's actually the mlocate command and the binary is /usr/bin/updatedb on my filesystem, you probably want to use varying versions of the following man commands to find what you're looking for:
-```
-# man locate
-
-
-# man updatedb
-
-
-# man updatedb.conf
-
-```
-
-Let's look at the important updatedb command in a little more detail now. It's worth mentioning that, after installing the locate utility, you will need to initialize your file-list database before doing anything else. You have to do this as the "root" user in order to reach all the relevant areas of your filesystems or the locate command will complain. Initialize or update your database file, whenever you like, with this command:
-```
-# updatedb
-```
-
-Obviously, the first time this command is run it may take a little while to complete, but when I've installed the locate command afresh I've almost always been pleasantly surprised at how quickly it finishes. After a hop, a skip, and a jump, you can immediately query your file database. However, let's wait a moment before doing that.
-
-We're dutifully informed by its manual that the database created as a result of running updatedb resides at the following location: /var/lib/mlocate/mlocate.db.
-
-If you want to change how updatedb is run, then you need to affect it with your config file -- a reminder that it should live here: /etc/updatedb.conf. Listing 1 shows the contents of it on my system:
-```
-PRUNE_BIND_MOUNTS = "yes"
-
-PRUNEFS = "9p afs anon_inodefs auto autofs bdev binfmt_misc cgroup cifs coda configfs
-cpuset debugfs devpts ecryptfs exofs fuse fusectl gfs gfs2 hugetlbfs inotifyfs iso9660
-jffs2 lustre mqueue ncpfs nfs nfs4 nfsd pipefs proc ramfs rootfs rpc_pipefs securityfs
-selinuxfs sfs sockfs sysfs tmpfs ubifs udf usbfs"
-
-PRUNENAMES = ".git .hg .svn"
-
-PRUNEPATHS = "/afs /media /net /sfs /tmp /udev /var/cache/ccache /var/spool/cups
-/var/spool/squid /var/tmp"
-```
-
-Listing 1: The innards of the file /etc/updatedb.conf which affects how our database is created.
-
-The first thing that my eye is drawn to is the PRUNENAMES section. As you can see by stringing together a list of directory names, delimited with spaces, you can suitably ignore them. One caveat is that only directory names can be skipped, and you can't use wildcards. As we can see, all of the otherwise-hidden files in a Git repository (the .git directory might be an example of putting this option to good use.
-
-If you need to be more specific then, again using spaces to separate your entries, you can instruct the locate command to ignore certain paths. Imagine for example that you're generating a whole host of temporary files overnight which are only valid for one day. You're aware that this is a special directory of sorts which employs a familiar naming convention for its thousands of files. It would take the locate command a relatively long time to process the subtle changes every night adding unnecessary stress to your system. The solution is of course to simply add it to your faithful "ignore" list.
-
-### Well Appointed
-
-As seen in Listing 2, the file /etc/mtab offers not just a list of the more familiar filesystems such as /dev/sda1 but also a number of others that you may not immediately remember.
-```
-/dev/sda1 /boot ext4 rw,noexec,nosuid,nodev 0 0
-
-proc /proc proc rw 0 0
-
-sysfs /sys sysfs rw 0 0
-
-devpts /dev/pts devpts rw,gid=5,mode=620 0 0
-
-/tmp /var/tmp none rw,noexec,nosuid,nodev,bind 0 0
-
-none /proc/sys/fs/binfmt_misc binfmt_misc rw 0 0
-```
-
-Listing 2: A mashed up example of the innards of the file /etc/mtab.
-
-Some of the filesystems shown in Listing 2 contain ephemeral content and indeed content that belongs to pseudo-filesystems, so it is clearly important to ignore their files -- if for no other reason than because of the stress added to your system during each overnight update.
-
-In Listing 1, the PRUNEFS option takes care of this and ditches those not suitable (for most cases). There are a few different filesystems to consider as you can see:
-```
-PRUNEFS = "9p afs anon_inodefs auto autofs bdev binfmt_misc cgroup cifs coda configfs
-cpuset debugfs devpts ecryptfs exofs fuse fusectl gfs gfs2 hugetlbfs inotifyfs iso9660 jffs2
-lustre mqueue ncpfs nfs nfs4 nfsd pipefs proc ramfs rootfs rpc_pipefs securityfs selinuxfs
-sfs sockfs sysfs tmpfs ubifs udf usbfs"
-```
-
-The updatedb.conf manual succinctly informs us of the following information in relation to the PRUNE_BIND_MOUNTS option:
-
-"If PRUNE_BIND_MOUNTS is 1 or yes, bind mounts are not scanned by updatedb(8). All file systems mounted in the subtree of a bind mount are skipped as well, even if they are not bind mounts. As an exception, bind mounts of a directory on itself are not skipped."
-
-Assuming that makes sense, before moving onto some locate command examples, you should note one thing. Excluding some versions of the updatedb command, it can also be told to ignore certain "non-directory files." However, this does not always apply, so don't blindly copy and paste config between versions if you use such an option.
-
-### In Need of Modernization
-
-As mentioned earlier, there are times when finding a specific file needs to be so quick that it's at your fingertips before you've consciously recalled the command. This is the irrefutable beauty of the locate command.
-
-And, if you've ever sat in front of a horrendously slow Windows machine watching the hard disk light flash manically as if it were suffering a conniption due to the indexing service running, then I can assure you that the performance that you'll receive from the updatedb command will be a welcome relief.
-
-You should bear in mind, that unlike with the find command, there's no need to remember the base paths of where your file might be residing. By that I mean that all of your (hopefully) relevant filesystems are immediately accessed with one simple command and that remembering paths is almost a thing of the past.
-
-In its most simple form, the locate command looks like this:
-```
-# locate chrisbinnie.pdf
-```
-
-There's also no need to escape hidden files that start with a dot or indeed expand a search with an asterisk:
-
-### # locate .bash
-
-Listing 3 shows us what has been returned, in an instant, from the many partitions the clever locate command has scanned previously.
-```
-/etc/bash_completion.d/yum.bash
-
-/etc/skel/.bash_logout
-
-/etc/skel/.bash_profile
-
-/etc/skel/.bashrc
-
-/home/chrisbinnie/.bash_history
-
-/home/chrisbinnie/.bash_logout
-
-/home/chrisbinnie/.bash_profile
-
-/home/chrisbinnie/.bashrc
-
-/usr/share/doc/git-1.5.1/contrib/completion/git-completion.bash
-
-/usr/share/doc/util-linux-ng-2.16.1/getopt-parse.bash
-
-/usr/share/doc/util-linux-ng-2.16.1/getopt-test.bash
-```
-
-Listing 3: The search results from running the command: "locate .bash"
-
-I'm suspicious that the following usage has altered slightly, from back in the day when the slocate command was more popular or possibly the original locate command, but you can receive different results by adding an asterisk to that query as so:
-```
-# locate .bash*
-```
-
-In Listing 4, you can see the difference from Listing 3. Thankfully, the results make more sense now that we can see them together. In this case, the addition of the asterisk is asking the locate command to return files beginning with .bash as opposed to all files containing that string of characters.
-```
-/etc/skel/.bash_logout
-
-/etc/skel/.bash_profile
-
-/etc/skel/.bashrc
-
-/home/d609288/.bash_history
-
-/home/d609288/.bash_logout
-
-/home/d609288/.bash_profile
-
-/home/d609288/.bashrc
-```
-
-Listing 4: The search results from running the command: "locate .bash*" with the addition of an asterisk.
-
-Stay tuned for next time when we learn more about the amazing simplicity of using the locate command on a day-to-day basis.
-
-Learn more about essential sysadmin skills: Download the [Future Proof Your SysAdmin Career][2] ebook now.
-
-Chris Binnie's latest book, Linux Server Security: Hack and Defend, shows how hackers launch sophisticated attacks to compromise servers, steal data, and crack complex passwords, so you can learn how to defend against these attacks. In the book, he also talks you through making your servers invisible, performing penetration testing, and mitigating unwelcome attacks. You can find out more about DevSecOps and Linux security via his website ([http://www.devsecops.cc][3]).
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/learn/intro-to-linux/finding-files-mlocate-part-2
-
-作者:[Chris Binnie][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/chrisbinnie
-[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/finding-files-mlocate
-[2]:https://go.pardot.com/l/6342/2017-07-17/3vwshv?utm_source=linco&utm_medium=blog&utm_campaign=sysadmin&utm_content=promo
-[3]:http://www.devsecops.cc/
diff --git a/sources/tech/20171116 Unleash Your Creativity – Linux Programs for Drawing and Image Editing.md b/sources/tech/20171116 Unleash Your Creativity – Linux Programs for Drawing and Image Editing.md
deleted file mode 100644
index c6c50d9b25..0000000000
--- a/sources/tech/20171116 Unleash Your Creativity – Linux Programs for Drawing and Image Editing.md
+++ /dev/null
@@ -1,130 +0,0 @@
-### Unleash Your Creativity – Linux Programs for Drawing and Image Editing
-
- By: [chabowski][1]
-
-The following article is part of a series of articles that provide tips and tricks for Linux newbies – or Desktop users that are not yet experienced with regard to certain topics. This series intends to complement the special edition #30 “[Getting Started with Linux][2]” based on [openSUSE Leap][3], recently published by the [Linux Magazine,][4] with valuable additional information.
-
-
-
-This article has been contributed by Douglas DeMaio, openSUSE PR Expert at SUSE.
-
-Both Mac OS or Window offer several popular programs for graphics editing, vector drawing and creating and manipulating Portable Document Format (PDF). The good news: users familiar with the Adobe Suite can transition with ease to free, open-source programs available on Linux.
-
-Programs like [GIMP][5], [InkScape][6] and [Okular][7] are cross platform programs that are available by default in Linux/GNU distributions and are persuasive alternatives to expensive Adobe programs like [Photoshop][8], [Illustrator][9] and [Acrobat][10].
-
-These creativity programs on Linux distributions are just as powerful as those for macOS or Window. This article will explain some of the differences and how the programs can be used to make your transition to Linux comfortable.
-
-### Krita
-
-The KDE desktop environment comes with tons of cool applications. [Krita][11] is a professional open source painting program. It gives users the freedom to create any artistic image they desire. Krita features tools that are much more extensive than the tool sets of most proprietary programs you might be familiar with. From creating textures to comics, Krita is a must have application for Linux users.
-
-
-
-### GIMP
-
-GNU Image Manipulation Program (GIMP) is a cross-platform image editor. Users of Photoshop will find the User Interface of GIMP to be similar to that of Photoshop. The drop down menu offers colors, layers, filters and tools to help the user with editing graphics. Rulers are located both horizontal and vertical and guide can be dragged across the screen to give exact measurements. The drop down menu gives tool options for resizing or cropping photos; adjustments can be made to the color balance, color levels, brightness and contrast as well as hue and saturation.
-
-
-
-There are multiple filters in GIMP to enhance or distort your images. Filters for artistic expression and animation are available and are more powerful tool options than those found in some proprietary applications. Gradients can be applied through additional layers and the Text Tool offers many fonts, which can be altered in shape and size through the Perspective Tool.
-
-The cloning tool works exactly like those in other graphics editors, so manipulating images is simple and acurrate given the selection of brush sizes to do the job.
-
-Perhaps one of the best options available with GIMP is that the images can be saved in a variety of formats like .jpg, .png, .pdf, .eps and .svg. These image options provide high-quality images in a small file.
-
-### InkScape
-
-Designing vector imagery with InkScape is simple and free. This cross platform allows for the creation of logos and illustrations that are highly scalable. Whether designing cartoons or creating images for branding, InkScape is a powerful application to get the job done. Like GIMP, InkScape lets you save files in various formats and allows for object manipulation like moving, rotating and skewing text and objects. Shape tools are available with InkScape so making stars, hexagons and other elements will meet the needs of your creative mind.
-
-
-
-InkScape offers a comprehensive tool set, including a drawing tool, a pen tool and the freehand calligraphy tool that allows for object creation with your own personal style. The color selector gives you the choice of RGB, CMYK and RGBA – using specific colors for branding logos, icons and advertisement is definitely convincing.
-
-Short cut commands are similar to what users experience in Adobe Illustrator. Making layers and grouping or ungrouping the design elements can turn a blank page into a full-fledged image that can be used for designing technical diagrams for presentations, importing images into a multimedia program or for creating web graphics and software design.
-
-Inkscape can import vector graphics from multiple other programs. It can even import bitmap images. Inkscape is one of those cross platform, open-source programs that allow users to operate across different operating systems, no matter if they work with macOS, Windows or Linux.
-
-### Okular and LibreOffice
-
-LibreOffice, which is a free, open-source Office Suite, allows users to collaborate and interact with documents and important files on Linux, but also on macOS and Window. You can also create PDF files via LibreOffice, and LibreOffice Draw lets you view (and edit) PDF files as images.
-
-
-
-However, the Portable Document Format (PDF) is quite different on the three Operating Systems. MacOS offers [Preview][12] by default; Windows has [Edge][13]. Of course, also Adobe Reader can be used for both MacOS and Window. With Linux, and especially the desktop selection of KDE, [Okular][14] is the default program for viewing PDF files.
-
-
-
-The functionality of Okular supports different types of documents, like PDF, Postscript, [DjVu][15], [CHM][16], [XPS][17], [ePub][18] and others. Yet the universal document viewer also offers some powerful features that make interacting with a document different from other programs on MacOS and Windows. Okular gives selection and search tools that make accessing the text in PDFs fluid for how users interact with documents. Viewing documents with Okular is also accommodating with the magnification tool that allows for a quick look at small text in a document.
-
-Okular also provides users with the option to configure it to use more memory if the document is too large and freezes the Operating System. This functionality is convenient for users accessing high-quality print documents for example for advertising.
-
-For those who want to change locked images and documents, it’s rather easy to do so with LibreOffice Draw. A hypothetical situation would be to take a locked IRS (or tax) form and change it to make the uneditable document editable. Imagine how much fun it could be to transform it to some humorous kind of tax form …
-
-And indeed, the sky’s the limit on how creative a user wants to be when using programs that are available on Linux distributions.
-
-
-
-
-
-
-
-
-
-
-
-(
-
- _**2** votes, average: **5.00** out of 5_
-
-)
-
- _You need to be a registered member to rate this post._
-
-Tags: [drawing][19], [Getting Started with Linux][20], [GIMP][21], [image editing][22], [Images][23], [InkScape][24], [KDE][25], [Krita][26], [Leap 42.3][27], [LibreOffice][28], [Linux Magazine][29], [Okular][30], [openSUSE][31], [PDF][32] Categories: [Desktop][33], [Expert Views][34], [LibreOffice][35], [openSUSE][36]
-
---------------------------------------------------------------------------------
-
-via: https://www.suse.com/communities/blog/unleash-creativity-linux-programs-drawing-image-editing/
-
-作者:[chabowski ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[1]:https://www.suse.com/communities/blog/author/chabowski/
-[2]:http://www.linux-magazine.com/Resources/Special-Editions/30-Getting-Started-with-Linux
-[3]:https://en.opensuse.org/Portal:42.3
-[4]:http://www.linux-magazine.com/
-[5]:https://www.gimp.org/
-[6]:https://inkscape.org/en/
-[7]:https://okular.kde.org/
-[8]:http://www.adobe.com/products/photoshop.html
-[9]:http://www.adobe.com/products/illustrator.html
-[10]:https://acrobat.adobe.com/us/en/acrobat/acrobat-pro-cc.html
-[11]:https://krita.org/en/
-[12]:https://en.wikipedia.org/wiki/Preview_(macOS)
-[13]:https://en.wikipedia.org/wiki/Microsoft_Edge
-[14]:https://okular.kde.org/
-[15]:http://djvu.org/
-[16]:https://fileinfo.com/extension/chm
-[17]:https://fileinfo.com/extension/xps
-[18]:http://idpf.org/epub
-[19]:https://www.suse.com/communities/blog/tag/drawing/
-[20]:https://www.suse.com/communities/blog/tag/getting-started-with-linux/
-[21]:https://www.suse.com/communities/blog/tag/gimp/
-[22]:https://www.suse.com/communities/blog/tag/image-editing/
-[23]:https://www.suse.com/communities/blog/tag/images/
-[24]:https://www.suse.com/communities/blog/tag/inkscape/
-[25]:https://www.suse.com/communities/blog/tag/kde/
-[26]:https://www.suse.com/communities/blog/tag/krita/
-[27]:https://www.suse.com/communities/blog/tag/leap-42-3/
-[28]:https://www.suse.com/communities/blog/tag/libreoffice/
-[29]:https://www.suse.com/communities/blog/tag/linux-magazine/
-[30]:https://www.suse.com/communities/blog/tag/okular/
-[31]:https://www.suse.com/communities/blog/tag/opensuse/
-[32]:https://www.suse.com/communities/blog/tag/pdf/
-[33]:https://www.suse.com/communities/blog/category/desktop/
-[34]:https://www.suse.com/communities/blog/category/expert-views/
-[35]:https://www.suse.com/communities/blog/category/libreoffice/
-[36]:https://www.suse.com/communities/blog/category/opensuse/
diff --git a/sources/tech/20171121 Finding Files with mlocate- Part 3.md b/sources/tech/20171121 Finding Files with mlocate- Part 3.md
deleted file mode 100644
index c9eccb2fc7..0000000000
--- a/sources/tech/20171121 Finding Files with mlocate- Part 3.md
+++ /dev/null
@@ -1,142 +0,0 @@
-Finding Files with mlocate: Part 3
-======
-
-
-In the previous articles in this short series, we [introduced the mlocate][1] (or just locate) command, and then discussed some ways [the updatedb tool][2] can be used to help you find that one particular file in a thousand.
-
-You are probably also aware of xargs as well as the find command. Our trusty friend locate can also play nicely with the --null option of xargs by outputting all of the results onto one line (without spaces which isn't great if you want to read it yourself) by using the -0 switch like this:
-```
-# locate -0 .bash
-```
-
-An option I like to use (if I remember to use it -- because the locate command rarely needs to be queried twice thanks to its simple syntax) is the -e option.
-```
-# locate -e .bash
-```
-
-For the curious, that -e switch means "existing." And, in this case, you can use -e to ensure that any files returned by the locate command do actually exist at the time of the query on your filesystems.
-
-It's almost magical, that even on a slow machine, the mastery of the modern locate command allows us to query its file database and then check against the actual existence of many files in seemingly no time whatsoever. Let's try a quick test with a file search that's going to return a zillion results and use the time command to see how long it takes both with and without the -e option being enabled.
-
-I'll choose files with the compressed .gz extension. Starting with a count, you can see there's not quite a zillion but a fair number of files ending in .gz on my machine, note the -c for "count":
-```
-# locate -c .gz
-7539
-```
-
-This time, we'll output the list but time it and see the abbreviated results as follows:
-```
-# time locate .gz
-real 0m0.091s
-user 0m0.025s
-sys 0m0.012s
-```
-
-That's pretty swift, but it's only reading from the overnight-run database. Let's get it to do a check against those 7,539 files, too, to see if they truly exist and haven't been deleted or renamed since last night:
-```
-# time locate -e .gz
-real 0m0.096s
-user 0m0.028s
-sys 0m0.055s
-```
-
-The speed difference is nominal as you can see. There's no point in talking about lightning or blink-and-you-miss-it, because those aren't suitable yardsticks. Relative to the other indexing service I mentioned previously, let's just say that's pretty darned fast.
-
-If you need to move the efficient database file used by the locate command (in my version it lives here: /var/lib/mlocate/mlocate.db) then that's also easy to do. You may wish to do this, for example, because you've generated a massive database file (it's only 1.1MB in my case so it's really tiny in reality), which needs to be put onto a faster filesystem.
-
-Incidentally, even the mlocate utility appears to have created an slocate group of users on my machine, so don't be too alarmed if you see something similar, as shown here from a standard file listing:
-```
--rw-r-----. 1 root slocate 1.1M Jan 11 11:11 /var/lib/mlocate/mlocate.db
-```
-
-Back to the matter in hand. If you want to move away from /var/lib/mlocate as your directory being used by the database then you can use this command syntax (and you'll have to become the "root" user with sudo -i or su - for at least the first command to work correctly):
-```
-# updatedb -o /home/chrisbinnie/my_new.db
-# locate -d /home/chrisbinnie/my_new.db SEARCH_TERM
-```
-
-Obviously, replace your database name and path. The SEARCH_TERM element is the fragment of the filename that you're looking for (wildcards and all).
-
-If you remember I mentioned that you need to run updatedb command as the superuser to reach all the areas of your filesystems.
-
-This next example should cover two useful scenarios in one. According to the manual, you can also create a "private" database for standard users as follows:
-```
-# updatedb -l 0 -o DATABASE -U source_directory
-```
-
-Here the previously seen -o option means that we output our database to a file (obviously called DATABASE). The -l 0 addition apparently means that the "visibility" of the database file is affected. It means (if I'm reading the docs correctly) that my user can read it but, otherwise, without that option, only the locate command can.
-
-The second useful scenario for this example is that we can create a little database file specifying exactly which path its top-level should be. Have a look at the database-root or -U source_directory option in our example. If you don't specify a new root file path, then the whole filesystem(s) is scanned instead.
-
-If you want to get clever and chuck a couple of top-level source directories into one command, then you can manage that having created two separate databases. Very useful for scripting methinks.
-
-You can achieve that with this command:
-```
-# locate -d /home/chrisbinnie/database_one -d /home/chrisbinnie/database_two SEARCH_TERM
-```
-
-The manual dutifully warns however that ALL users that can read the DATABASE file can also get the complete list of files in the subdirectories of the chosen source_directory. So use these commands with some care.
-
-### Priced To Sell
-
-Back to the mind-blowing simplicity of the locate command in use on a day-to-day basis. There are many times when newbies may confused with case-sensitivity on Unix-type systems. Simply use the conventional -i option to ignore case entirely when using the flexible locate command:
-```
-# locate -i ChrisBinnie.pdf
-```
-
-If you have a file structure that has a number of symlinks holding it together, then there might be occasion when you want to remove broken symlinks from the search results. You can do that with this command:
-```
-# locate -Le chrisbinnie_111111.xml
-```
-
-If you needed to limit the search results then you could use this functionality, also in a script for example (similar to the -c option for counting), as so:
-```
-# locate -l25 *.gz
-```
-
-This command simply stops after outputting the first 25 files that were found. When piped through the grep command, it's very useful on a super busy system.
-
-### Popular Area
-
-We briefly touched upon performance earlier, and I happened to see this [nicely written blog entry][3], where the author discusses thoughts on the trade-offs between the database size becoming unwieldy and the speed at which results are delivered.
-
-What piqued my interest are the comments on how the original locate command was written and what limiting factors were considered during its creation. Namely how disk space isn't quite so precious any longer and nor is the delivery of results even when 700,000 files are involved.
-
-I'm certain that the author(s) of mlocate and its forebears would have something to say in response to that blog post. I suspect that holding onto the file permissions to give us the "secure" and "slocate" functionality in the database might be a fairly big hit in terms of overhead. And, as much as I enjoyed the post, I won't be writing a Bash script to replace mlocate any time soon. I'm more than happy with the locate command and extol its qualities at every opportunity.
-
-### Sold
-
-I hope you've acquired enough insight into the superb locate command to prune, tweak, adjust, and tune it to your unique set of requirements. As we've seen, it's fast, convenient, powerful, and efficient. Additionally, you can ignore the "root" user demands and use it within scripts for very specific tasks.
-
-My favorite aspect, however, is when I'm awakened in the middle of the night because of an emergency. It's not a good look, having to remember the complex find command and typing it slowly with bleary eyes (and managing to add lots of typos):
-```
-# find . -type f -name "*.gz"
-```
-
-Instead of that, I can just use the simple locate command:
-```
-# locate *.gz
-```
-
-As has been said, any fool can create something bigger, bolder, and tougher, but it takes a bit of genius to create something simpler. And, in terms of introducing more people to the venerable Unix-type command line, there's little argument that the locate command welcomes them with open arms.
-
-Learn more about essential sysadmin skills: Download the [Future Proof Your SysAdmin Career][4] ebook now.
-
-Chris Binnie's latest book, Linux Server Security: Hack and Defend, shows how hackers launch sophisticated attacks to compromise servers, steal data, and crack complex passwords, so you can learn how to defend against these attacks. In the book, he also talks you through making your servers invisible, performing penetration testing, and mitigating unwelcome attacks. You can find out more about DevSecOps and Linux security via his website ([http://www.devsecops.cc][5]).
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/learn/2017/11/finding-files-mlocate-part-3
-
-作者:[Chris Binnie][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/chrisbinnie
-[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/finding-files-mlocate
-[2]:https://www.linux.com/blog/learn/intro-to-linux/finding-files-mlocate-part-2
-[3]:http://jvns.ca/blog/2015/03/05/how-the-locate-command-works-and-lets-rewrite-it-in-one-minute/
-[4]:https://go.pardot.com/l/6342/2017-07-17/3vwshv?utm_source=linco&utm_medium=blog&utm_campaign=sysadmin&utm_content=promo
-[5]:http://www.devsecops.cc/
diff --git a/sources/tech/20171129 Interactive Workflows for Cpp with Jupyter.md b/sources/tech/20171129 Interactive Workflows for Cpp with Jupyter.md
deleted file mode 100644
index 395c901618..0000000000
--- a/sources/tech/20171129 Interactive Workflows for Cpp with Jupyter.md
+++ /dev/null
@@ -1,301 +0,0 @@
-Interactive Workflows for C++ with Jupyter
-============================================================
-
-Scientists, educators and engineers not only use programming languages to build software systems, but also in interactive workflows, using the tools available to _explore _ a problem and _reason _ about it.
-
-Running some code, looking at a visualization, loading data, and running more code. Quick iteration is especially important during the exploratory phase of a project.
-
-For this kind of workflow, users of the C++ programming language currently have no choice but to use a heterogeneous set of tools that don’t play well with each other, making the whole process cumbersome, and difficult to reproduce.
-
- _We currently lack a good story for interactive computing in C++_ .
-
-In our opinion, this hurts the productivity of C++ developers:
-
-* Most of the progress made in software projects comes from incrementalism. Obstacles to fast iteration hinder progress.
-
-* This also makes C++ more difficult to teach. The first hours of a C++ class are rarely rewarding as the students must learn how to set up a small project before writing any code. And then, a lot more time is required before their work can result in any visual outcome.
-
-### Project Jupyter and Interactive Computing
-
-
-
-
-
-The goal of Project Jupyter is to provide a consistent set of tools for scientific computing and data science workflows, from the exploratory phase of the analysis to the presentation and the sharing of the results. The Jupyter stack was designed to be agnostic of the programming language, and also to allow alternative implementations of any component of the layered architecture (back-ends for programming languages, custom renderers for file types associated with Jupyter). The stack consists of
-
-* a low-level specification for messaging protocols, standardized file formats,
-
-* a reference implementation of these standards,
-
-* applications built on the top of these libraries: the Notebook, JupyterLab, Binder, JupyterHub
-
-* and visualization libraries integrated into the Notebook and JupyterLab.
-
-Adoption of the Jupyter ecosystem has skyrocketed in the past years, with millions of users worldwide, over a million Jupyter notebooks shared on GitHub and large-scale deployments of Jupyter in universities, companies and high-performance computing centers.
-
-### Jupyter and C++
-
-One of the main extension points of the Jupyter stack is the _kernel_ , the part of the infrastructure responsible for executing the user’s code. Jupyter kernels exist for [numerous programming languages][14].
-
-Most Jupyter kernels are implemented in the target programming language: the reference implementation [ipykernel][15] in Python, [IJulia][16] in Julia, leading to a duplication of effort for the implementation of the protocol. A common denominator to a lot of these interpreted languages is that the interpreter generally exposes a C API, allowing the embedding into a native application. In an effort to consolidate these commonalities and save work for future kernel builders, we developed _xeus_ .
-
-
-
-
-
-[Xeus ][17]is a C++ implementation of the Jupyter kernel protocol. It is not a kernel itself but a library that facilitates the authoring of kernels, and other applications making use of the Jupyter kernel protocol.
-
-A typical kernel implementation using xeus would in fact make use of the target interpreter _ as a library._
-
-There are a number of benefits of using xeus over implementing your kernel in the target language:
-
-* Xeus provides a complete implementation of the protocol, enabling a lot of features from the start for kernel authors, who only need to deal with the language bindings.
-
-* Xeus-based kernels can very easily provide a back-end for Jupyter interactive widgets.
-
-* Finally, xeus can be used to implement kernels for domain-specific languages such as SQL flavors. Existing approaches use a Python wrapper. With xeus, the resulting kernel won't require Python at run-time, leading to large performance benefits.
-
-
-
-
-
-Interpreted C++ is already a reality at CERN with the [Cling][18]C++ interpreter in the context of the [ROOT][19] data analysis environment.
-
-As a first example for a kernel based on xeus, we have implemented [xeus-cling][20], a pure C++ kernel.
-
-
-
-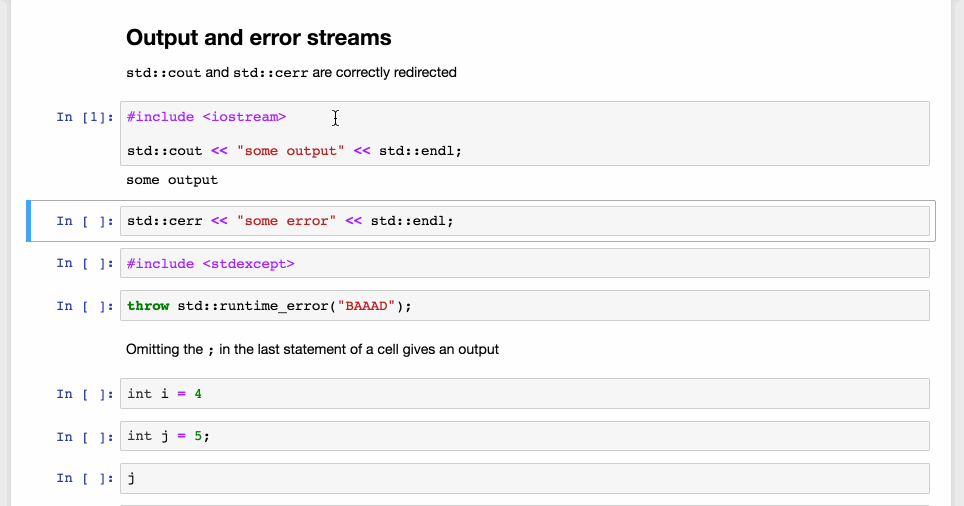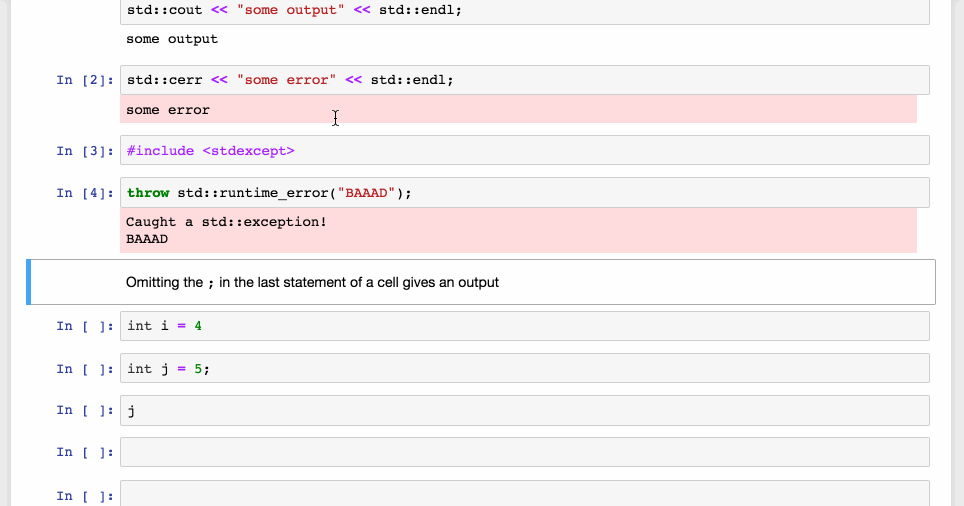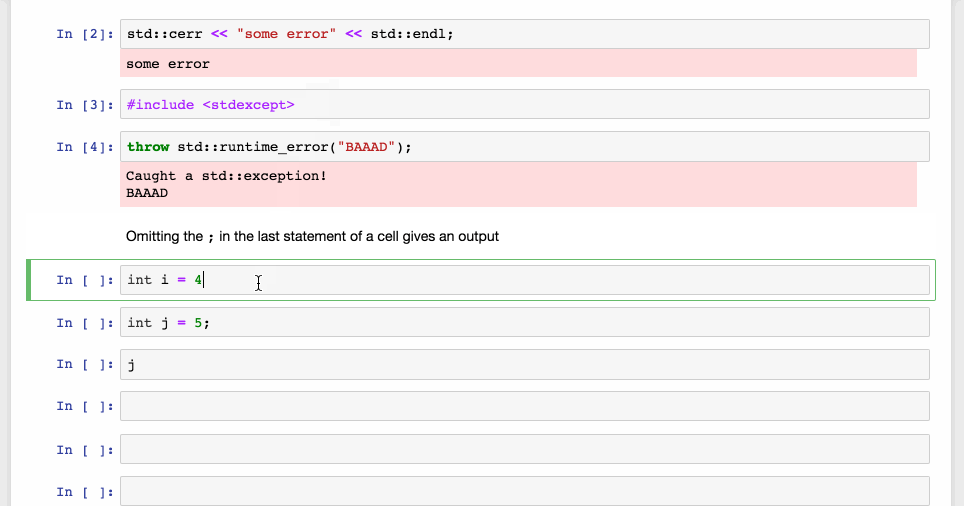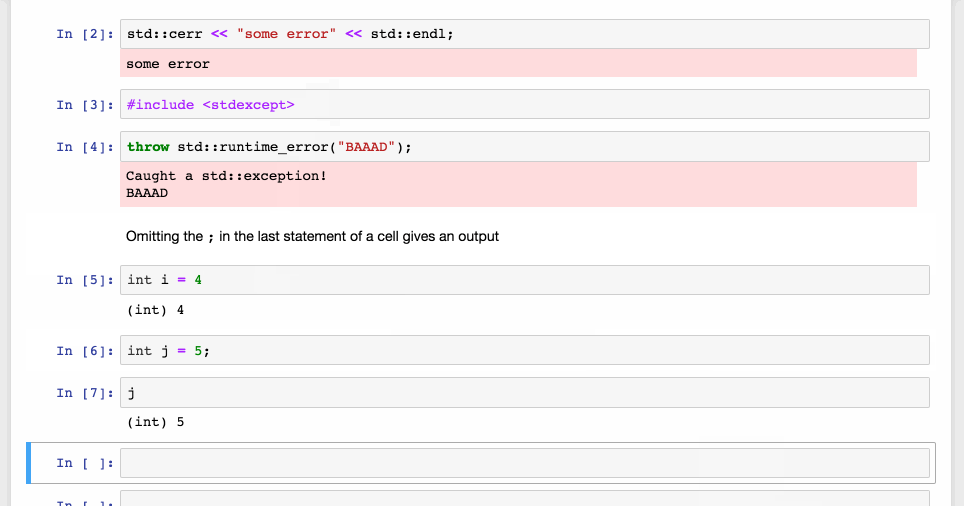
-Redirection of outputs to the Jupyter front-end, with different styling in the front-end.
-
-Complex features of the C++ programming language such as, polymorphism, templates, lambdas, are supported by the cling interpreter, making the C++ Jupyter notebook a great prototyping and learning platform for the C++ users. See the image below for a demonstration:
-
-
-
-
-Features of the C++ programming language supported by the cling interpreter
-
-Finally, xeus-cling supports live quick-help, fetching the content on [cppreference][21] in the case of the standard library.
-
-
-
-
-Live help for the C++standard library in the Jupyter notebook
-
-> We realized that we started using the C++ kernel ourselves very early in the development of the project. For quick experimentation, or reproducing bugs. No need to set up a project with a cpp file and complicated project settings for finding the dependencies… Just write some code and hit Shift+Enter.
-
-Visual output can also be displayed using the rich display mechanism of the Jupyter protocol.
-
-
-
-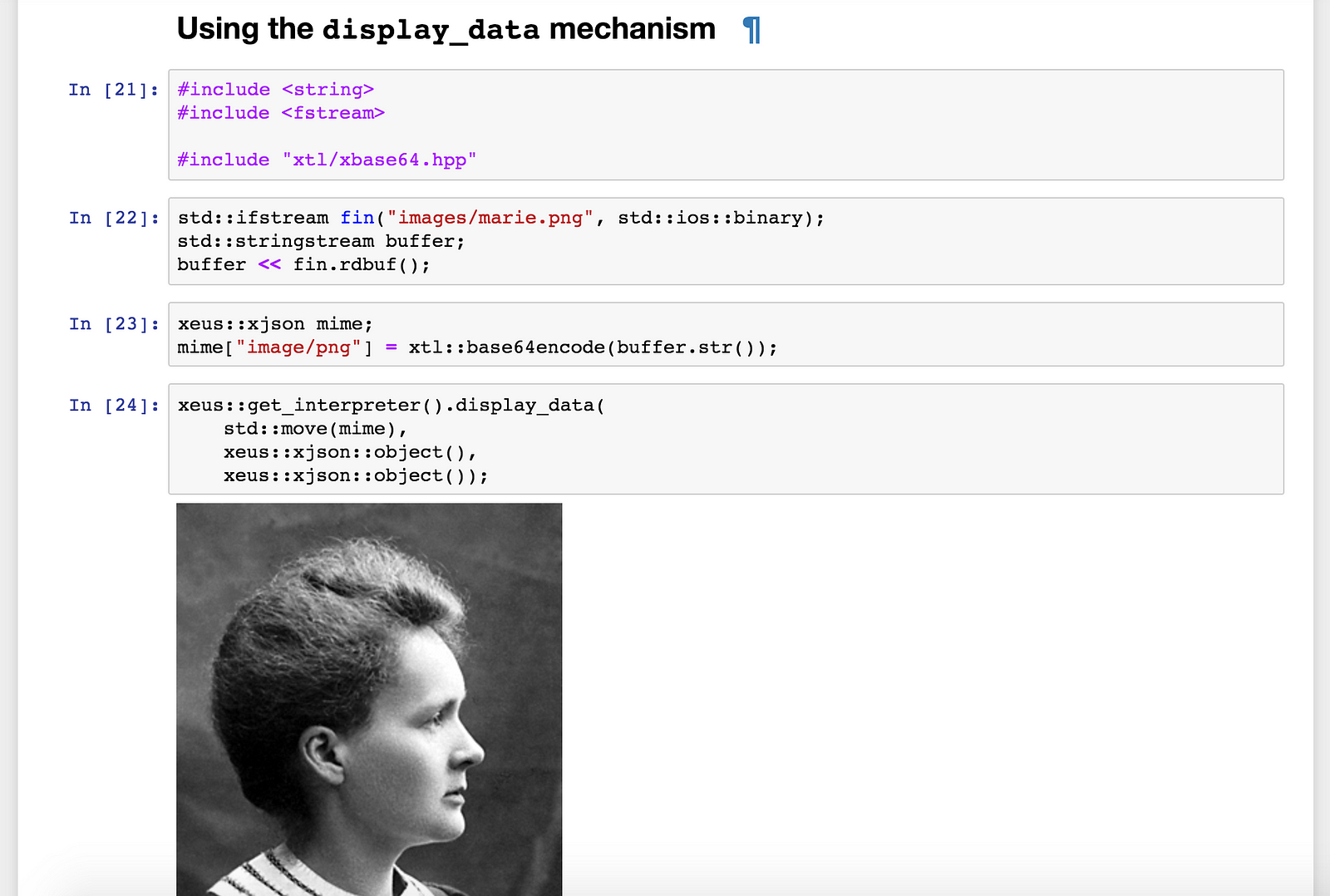
-Using Jupyter's rich display mechanism to display an image inline in the notebook
-
-
-
-
-Another important feature of the Jupyter ecosystem are the [Jupyter Interactive Widgets][22]. They allow the user to build graphical interfaces and interactive data visualization inline in the Jupyter notebook. Moreover it is not just a collection of widgets, but a framework that can be built upon, to create arbitrary visual components. Popular interactive widget libraries include
-
-* [bqplot][1] (2-D plotting with d3.js)
-
-* [pythreejs][2] (3-D scene visualization with three.js)
-
-* [ipyleaflet][3] (maps visualization with leaflet.js)
-
-* [ipyvolume][4] (3-D plotting and volume rendering with three.js)
-
-* [nglview][5] (molecular visualization)
-
-Just like the rest of the Jupyter ecosystem, Jupyter interactive widgets were designed as a language-agnostic framework. Other language back-ends can be created reusing the front-end component, which can be installed separately.
-
-[xwidgets][23], which is still at an early stage of development, is a native C++ implementation of the Jupyter widgets protocol. It already provides an implementation for most of the widget types available in the core Jupyter widgets package.
-
-
-
-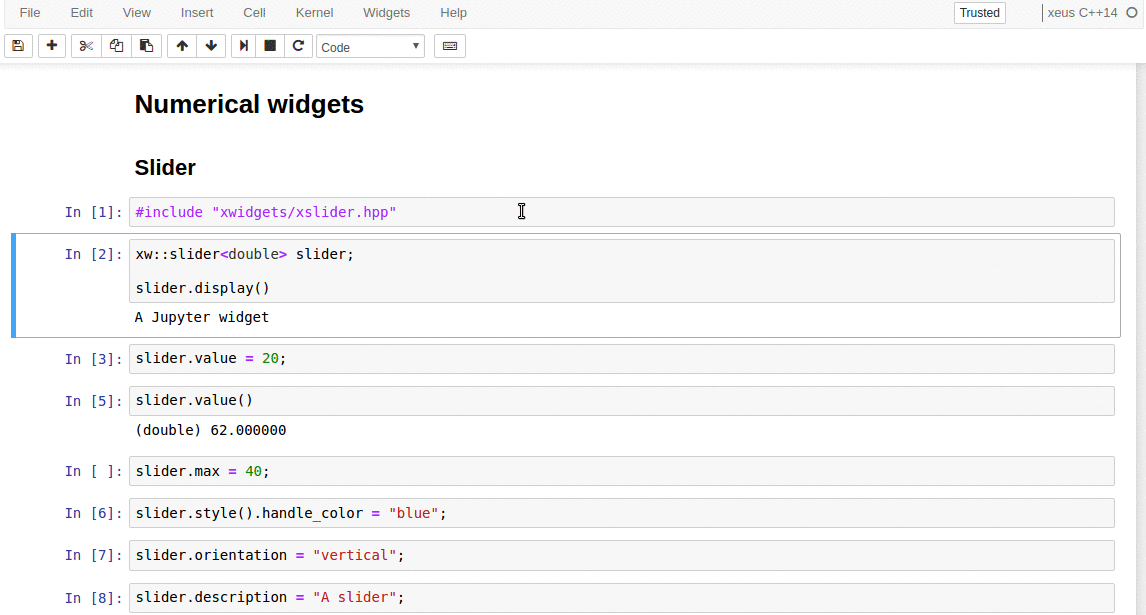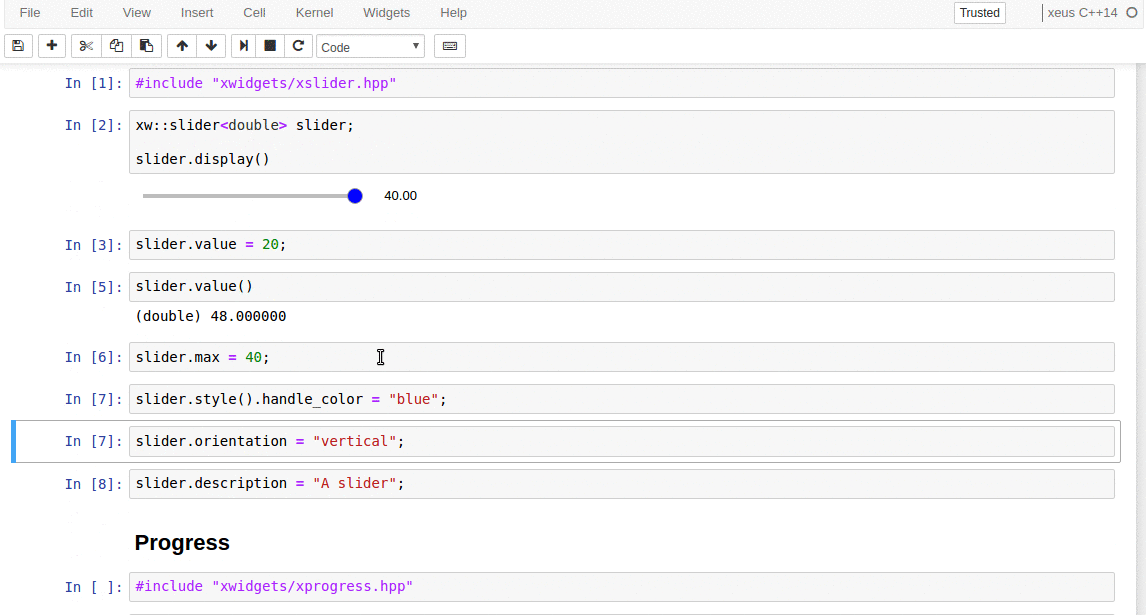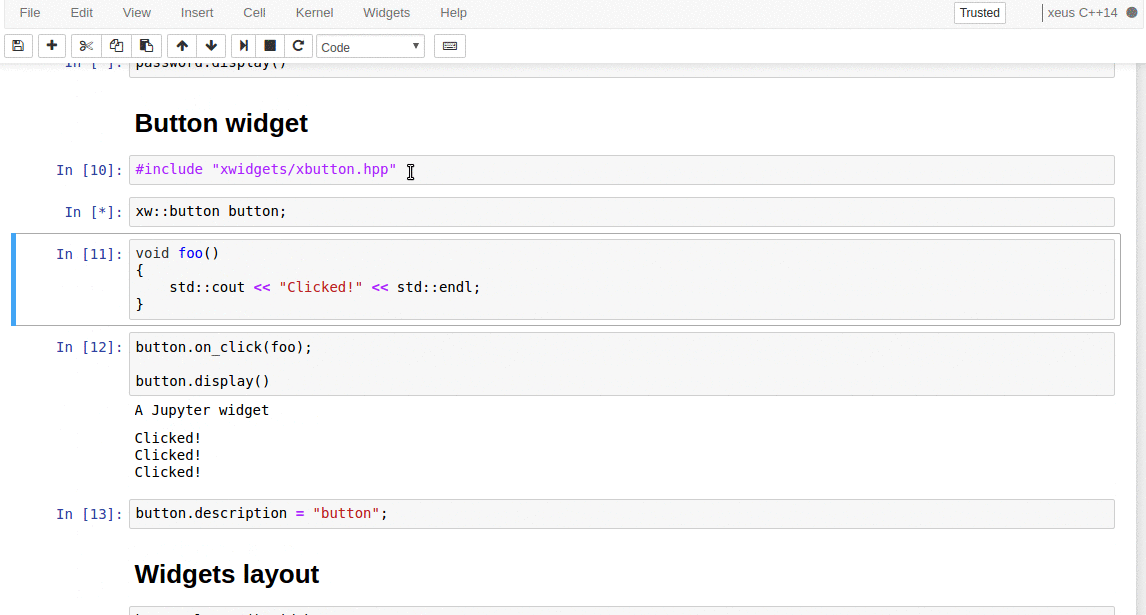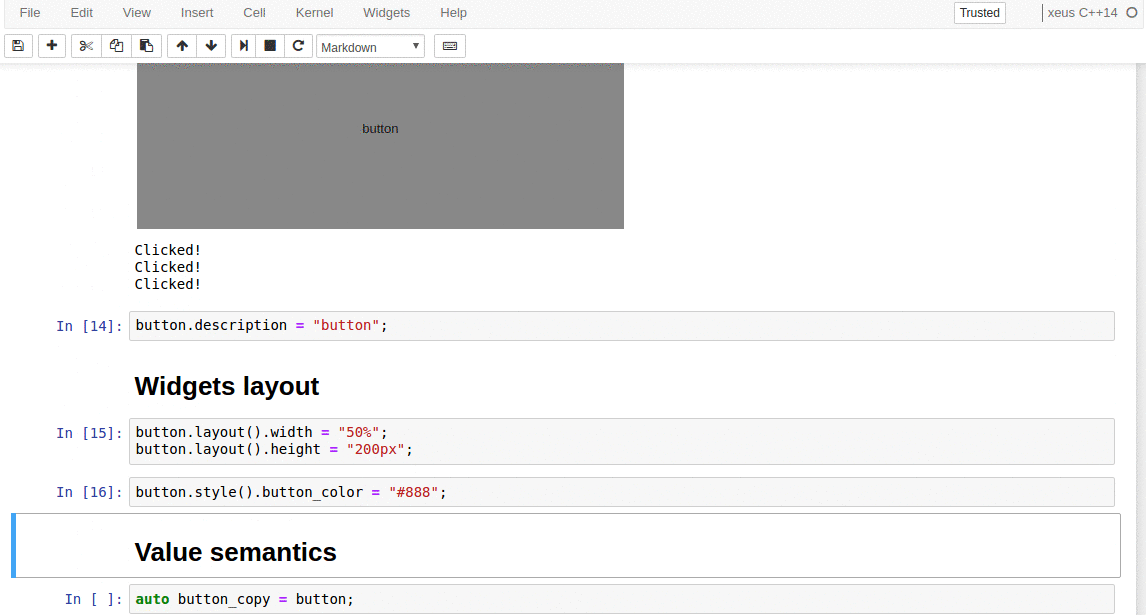
-C++ back-end to the Jupyter interactive widgets
-
-Just like with ipywidgets, one can build upon xwidgets and implement C++ back-ends for the Jupyter widget libraries listed earlier, effectively enabling them for the C++ programming language and other xeus-based kernels: xplot, xvolume, xthreejs…
-
-
-
-
-
-[xplot][24] is an experimental C++ back-end for the [bqplot][25] 2-D plotting library. It enables an API following the constructs of the [_Grammar of Graphics_][26] in C++.
-
-In xplot, every item in a chart is a separate object that can be modified from the back-end, _dynamically_ .
-
-Changing a property of a plot item, a scale, an axis or the figure canvas itself results in the communication of an update message to the front-end, which reflects the new state of the widget visually.
-
-
-
-
-Changing the data of a scatter plot dynamically to update the chart
-
-> Warning: the xplot and xwidgets projects are still at an early stage of development and are changing drastically at each release.
-
-Interactive computing environments like Jupyter are not the only missing tool in the C++ world. Two key ingredients to the success of Python as the _lingua franca_ of data science is the existence of libraries like [NumPy][27] and [Pandas][28] at the foundation of the ecosystem.
-
-
-
-
-
-[xtensor][29] is a C++ library meant for numerical analysis with multi-dimensional array expressions.
-
-xtensor provides
-
-* an extensible expression system enabling lazy NumPy-style broadcasting.
-
-* an API following the _idioms_ of the C++ standard library.
-
-* tools to manipulate array expressions and build upon xtensor.
-
-xtensor exposes an API similar to that of NumPy covering a growing portion of the functionalities. A cheat sheet can be [found in the documentation][30]:
-
-
-
-
-Scrolling the NumPy to xtensor cheat sheet
-
-However, xtensor internals are very different from NumPy. Using modern C++ techniques (template expressions, closure semantics) xtensor is a lazily evaluated library, avoiding the creation of temporary variables and unnecessary memory allocations, even in the case complex expressions involving broadcasting and language bindings.
-
-Still, from a user perspective, the combination of xtensor with the C++ notebook provides an experience very similar to that of NumPy in a Python notebook.
-
-
-
-
-Using the xtensor array expression library in a C++ notebook
-
-In addition to the core library, the xtensor ecosystem has a number of other components
-
-* [xtensor-blas][6]: the counterpart to the numpy.linalg module.
-
-* [xtensor-fftw][7]: bindings to the [fftw][8] library.
-
-* [xtensor-io][9]: APIs to read and write various file formats (images, audio, NumPy's NPZ format).
-
-* [xtensor-ros][10]: bindings for ROS, the robot operating system.
-
-* [xtensor-python][11]: bindings for the Python programming language, allowing the use of NumPy arrays in-place, using the NumPy C API and the pybind11 library.
-
-* [xtensor-julia][12]: bindings for the Julia programming language, allowing the use of Julia arrays in-place, using the C API of the Julia interpreter, and the CxxWrap library.
-
-* [xtensor-r][13]: bindings for the R programming language, allowing the use of R arrays in-place.
-
-Detailing further the features of the xtensor framework would be beyond the scope of this post.
-
-If you are interested in trying the various notebooks presented in this post, there is no need to install anything. You can just use _binder_ :
-
-
-
-[The Binder project][31], which is part of Project Jupyter, enables the deployment of containerized Jupyter notebooks, from a GitHub repository together with a manifest listing the dependencies (as conda packages).
-
-All the notebooks in the screenshots above can be run online, by just clicking on one of the following links:
-
-[xtensor][32]: the C++ N-D array expression library in a C++ notebook
-
-[xwidgets][33]: the C++ back-end for Jupyter interactive widgets
-
-[xplot][34]: the C++ back-end to the bqplot 2-D plotting library for Jupyter.
-
-
-
-
-
-[JupyterHub][35] is the multi-user infrastructure underlying open wide deployments of Jupyter like Binder but also smaller deployments for authenticated users.
-
-The modular architecture of JupyterHub enables a great variety of scenarios on how users are authenticated, and what service is made available to them. JupyterHub deployment for several hundreds of users have been done in various universities and institutions, including the Paris-Sud University, where the C++ kernel was also installed for the students to use.
-
-> In September 2017, the 350 first-year students at Paris-Sud University who took the “[Info 111: Introduction to Computer
-> Science][36]” class wrote their first lines of C++ in a Jupyter notebook.
-
-The use of Jupyter notebooks in the context of teaching C++ proved especially useful for the first classes, where students can focus on the syntax of the language without distractions such as compiling and linking.
-
-### Acknowledgements
-
-The software presented in this post was built upon the work of a large number of people including the Jupyter team and the Cling developers.
-
-We are especially grateful to [Patrick Bos ][37](who authored xtensor-fftw), Nicolas Thiéry, Min Ragan Kelley, Thomas Kluyver, Yuvi Panda, Kyle Cranmer, Axel Naumann and Vassil Vassilev.
-
-We thank the [DIANA/HEP][38] organization for supporting travel to CERN and encouraging the collaboration between Project Jupyter and the ROOT team.
-
-We are also grateful to the team at Paris-Sud University who worked on the JupyterHub deployment and the class materials, notably [Viviane Pons][39].
-
-The development of xeus, xtensor, xwidgets and related packages at [QuantStack][40] is sponsored by [Bloomberg][41].
-
-### About the authors (alphabetical order)
-
- [_Sylvain Corlay_][42] _, _ Scientific Software Developer at [QuantStack][43]
-
- [_Loic Gouarin_][44] _, _ Research Engineer at [Laboratoire de Mathématiques at Orsay][45]
-
- [_Johan Mabille_][46] _, _ Scientific Software Developer at [QuantStack][47]
-
- [_Wolf Vollprecht_][48] , Scientific Software Developer at [QuantStack][49]
-
-Thanks to [Maarten Breddels][50], [Wolf Vollprecht][51], [Brian E. Granger][52], and [Patrick Bos][53].
-
---------------------------------------------------------------------------------
-
-via: https://blog.jupyter.org/interactive-workflows-for-c-with-jupyter-fe9b54227d92
-
-作者:[QuantStack ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://blog.jupyter.org/@QuantStack?source=post_header_lockup
-[1]:https://github.com/bloomberg/bqplot
-[2]:https://github.com/jovyan/pythreejs
-[3]:https://github.com/ellisonbg/ipyleaflet
-[4]:https://github.com/maartenbreddels/ipyvolume
-[5]:https://github.com/arose/nglview
-[6]:https://github.com/QuantStack/xtensor-blas
-[7]:https://github.com/egpbos/xtensor-fftw
-[8]:http://www.fftw.org/
-[9]:https://github.com/QuantStack/xtensor-io
-[10]:https://github.com/wolfv/xtensor_ros
-[11]:https://github.com/QuantStack/xtensor-python
-[12]:https://github.com/QuantStack/Xtensor.jl
-[13]:https://github.com/QuantStack/xtensor-r
-[14]:https://github.com/jupyter/jupyter/wiki/Jupyter-kernels
-[15]:https://github.com/ipython/ipykernel
-[16]:https://github.com/JuliaLang/IJulia.jl
-[17]:https://github.com/QuantStack/xeus
-[18]:https://root.cern.ch/cling
-[19]:https://root.cern.ch/
-[20]:https://github.com/QuantStack/xeus-cling
-[21]:http://en.cppreference.com/w/
-[22]:http://jupyter.org/widgets
-[23]:https://github.com/QUantStack/xwidgets
-[24]:https://github.com/QuantStack/xplot
-[25]:https://github.com/bloomberg/bqplot
-[26]:https://dl.acm.org/citation.cfm?id=1088896
-[27]:http://www.numpy.org/
-[28]:https://pandas.pydata.org/
-[29]:https://github.com/QuantStack/xtensor/
-[30]:http://xtensor.readthedocs.io/en/latest/numpy.html
-[31]:https://mybinder.org/
-[32]:https://beta.mybinder.org/v2/gh/QuantStack/xtensor/0.14.0-binder2?filepath=notebooks/xtensor.ipynb
-[33]:https://beta.mybinder.org/v2/gh/QuantStack/xwidgets/0.6.0-binder?filepath=notebooks/xwidgets.ipynb
-[34]:https://beta.mybinder.org/v2/gh/QuantStack/xplot/0.3.0-binder?filepath=notebooks
-[35]:https://github.com/jupyterhub/jupyterhub
-[36]:http://nicolas.thiery.name/Enseignement/Info111/
-[37]:https://twitter.com/egpbos
-[38]:http://diana-hep.org/
-[39]:https://twitter.com/pyviv
-[40]:https://twitter.com/QuantStack
-[41]:http://www.techatbloomberg.com/
-[42]:https://twitter.com/SylvainCorlay
-[43]:https://github.com/QuantStack/
-[44]:https://twitter.com/lgouarin
-[45]:https://www.math.u-psud.fr/
-[46]:https://twitter.com/johanmabille?lang=en
-[47]:https://github.com/QuantStack/
-[48]:https://twitter.com/wuoulf
-[49]:https://github.com/QuantStack/
-[50]:https://medium.com/@maartenbreddels?source=post_page
-[51]:https://medium.com/@wolfv?source=post_page
-[52]:https://medium.com/@ellisonbg?source=post_page
-[53]:https://medium.com/@egpbos?source=post_page
diff --git a/sources/tech/20171130 Excellent Business Software Alternatives For Linux.md b/sources/tech/20171130 Excellent Business Software Alternatives For Linux.md
deleted file mode 100644
index 4a40b993f3..0000000000
--- a/sources/tech/20171130 Excellent Business Software Alternatives For Linux.md
+++ /dev/null
@@ -1,117 +0,0 @@
-summer2233 is translating
-
-Excellent Business Software Alternatives For Linux
--------
-
-Many business owners choose to use Linux as the operating system for their operations for a variety of reasons.
-
-1. Firstly, they don't have to pay anything for the privilege, and that is a massive bonus during the early stages of a company where money is tight.
-
-2. Secondly, Linux is a light alternative compared to Windows and other popular operating systems available today.
-
-Of course, lots of entrepreneurs worry they won't have access to some of the essential software packages if they make that move. However, as you will discover throughout this post, there are plenty of similar tools that will cover all the bases.
-
- [][3]
-
-### Alternatives to Microsoft Word
-
-All company bosses will require access to a word processing tool if they want to ensure the smooth running of their operation according to
-
-[the latest article from Fareed Siddiqui][4]
-
-. You'll need that software to write business plans, letters, and many other jobs within your firm. Thankfully, there are a variety of alternatives you might like to select if you opt for the Linux operating system. Some of the most popular ones include:
-
-* LibreOffice Writer
-
-* AbiWord
-
-* KWord
-
-* LaTeX
-
-So, you just need to read some online reviews and then download the best word processor based on your findings. Of course, if you're not satisfied with the solution, you should take a look at some of the other ones on that list. In many instances, any of the programs mentioned above should work well.
-
-### Alternatives to Microsoft Excel
-
- [][5]
-
-You need a spreadsheet tool if you want to ensure your business doesn't get into trouble when it comes to bookkeeping and inventory control. There are specialist software packages on the market for both of those tasks, but
-
-[open-source alternatives][6]
-
-to Microsoft Excel will give you the most amount of freedom when creating your spreadsheets and editing them. While there are other packages out there, some of the best ones for Linux users include:
-
-* [LibreOffice Calc][1]
-
-* KSpread
-
-* Gnumeric
-
-Those programs work in much the same way as Microsoft Excel, and so you can use them for issues like accounting and stock control. You might also use that software to monitor employee earnings or punctuality. The possibilities are endless and only limited by your imagination.
-
-### Alternatives to Adobe Photoshop
-
- [][7]
-
-Company bosses require access to design programs when developing their marketing materials and creating graphics for their websites. You might also use software of that nature to come up with a new business logo at some point. Lots of entrepreneurs spend a fortune on
-
-[Training Connections Photoshop classes][8]
-
-and those available from other providers. They do that in the hope of educating their teams and getting the best results. However, people who use Linux can still benefit from that expertise if they select one of the following
-
-[alternatives][9]
-
-:
-
-* GIMP
-
-* Krita
-
-* Pixel
-
-* LightZone
-
-The last two suggestions on that list require a substantial investment. Still, they function in much the same way as Adobe Photoshop, and so you should manage to achieve the same quality of work.
-
-### Other software solutions that you'll want to consider
-
-Alongside those alternatives to some of the most widely-used software packages around today, business owners should take a look at the full range of products they could use with the Linux operating system. Here are some tools you might like to research and consider:
-
-* Inkscape - similar to Coreldraw
-
-* LibreOffice Base - similar to Microsoft Access
-
-* LibreOffice Impress - similar to Microsoft PowerPoint
-
-* File Roller - siThis is a contributed postmilar to WinZip
-
-* Linphone - similar to Skype
-
-There are
-
-[lots of other programs][10]
-
- you'll also want to research, and so the best solution is to use the internet to learn more. You will find lots of reviews from people who've used the software in the past, and many of them will compare the tool to its Windows or iOS alternative. So, you shouldn't have to work too hard to identify the best ones and sort the wheat from the chaff.
-
-Now you have all the right information; it's time to weigh all the pros and cons of Linux and work out if it's suitable for your operation. In most instances, that operating system does not place any limits on your business activities. It's just that you need to use different software compared to some of your competitors. People who use Linux tend to benefit from improved security, speed, and performance. Also, the solution gets regular updates, and so it's growing every single day. Unlike Windows and other solutions; you can customize Linux to meet your requirements. With that in mind, do not make the mistake of overlooking this fantastic system!
-
---------------------------------------------------------------------------------
-
-via: http://linuxblog.darkduck.com/2017/11/excellent-business-software.html
-
-作者:[DarkDuck][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://linuxblog.darkduck.com/
-[1]:http://linuxblog.darkduck.com/2015/08/pivot-tables-in-libreoffice-calc.html
-[3]:https://4.bp.blogspot.com/-xwLuDRdB6sw/Whxx0Z5pI5I/AAAAAAAADhU/YWHID8GU9AgrXRfeTz4HcDZkG-XWZNbSgCLcBGAs/s1600/4444061098_6eeaa7dc1a_z.jpg
-[4]:https://www.linkedin.com/pulse/benefits-using-microsoft-word-fareed/
-[5]:https://4.bp.blogspot.com/-XdS6bSLQbOU/WhxyeWZeeCI/AAAAAAAADhc/C3hGY6rgzX4m2emunot80-4URu9-aQx8wCLcBGAs/s1600/28929069495_e85d2626ba_z.jpg
-[6]:http://linuxblog.darkduck.com/2014/03/why-open-software-and-what-are-benefits.html
-[7]:https://3.bp.blogspot.com/-Id9Dm3CIXmc/WhxzGIlv3zI/AAAAAAAADho/VfIRCAbJMjMZzG2M97-uqLV9mOhqN7IWACLcBGAs/s1600/32206185926_c69accfcef_z.jpg
-[8]:https://www.trainingconnection.com/photoshop-training.php
-[9]:http://linuxblog.darkduck.com/2011/10/photoshop-alternatives-for-linux.html
-[10]:http://www.makeuseof.com/tag/best-linux-software/
diff --git a/sources/tech/20171130 Tap the power of community with organized chaos.md b/sources/tech/20171130 Tap the power of community with organized chaos.md
deleted file mode 100644
index d7664ec21f..0000000000
--- a/sources/tech/20171130 Tap the power of community with organized chaos.md
+++ /dev/null
@@ -1,110 +0,0 @@
-Tap the power of community with organized chaos
-======
-In this article, I want to share with you of the power of an unconference--because I believe it's a technique anyone can use to generate innovative ideas, harness the power of participation, and strengthen community ties. I've developed a 90-minute session that mimics the effects of an unconference, and you can use it to generate engagement with a small group of people and tap into their ideas surrounding a topic of your choice.
-
-An "unconference" is a loosely organized event format designed specifically to maximize the exchange of ideas and the sharing of knowledge in a group driven by a common purpose. While the structure of an unconference is planned, the content and exchange of ideas for breakout sessions is not. Participants plan and execute unconference sessions by voting on the content they'd like to experience.
-
-For larger events, some organizers allow the submission of session topics in advance of the event. This is helpful for people new to the unconference format who may not understand what they could expect to experience at the event. However, most organizers have a rule that a participant must be present to pitch and lead a session.
-
-One of the more popular unconferences is BarCamp. The unconference brings together people interested in a wide range of topics and technologies. As with any unconference, everyone that attends has the opportunity to share, teach, and participate. Other popular unconferences include EduCamp (with a focus on education) and CityCamp (with a focus on government and civic technology).
-
-As you'll discover when you do this exercise, the success of the unconference format is based on the participants that are involved and the ideas they want to share. Let's take a look at the steps needed to facilitate an unconference exercise.
-
-### Materials needed
-
-To facilitate this exercise, you will need:
-
- * A room for 15-20 people
- * Tables and chairs for the group
- * Ability to break into two or three groups
- * Markers and pens
- * "Dot" stickers (optional)
- * Sheets of plain paper or larger sticky notes
- * Timer (alarm optional)
- * Moveable whiteboard (optional)
- * Pre-defined topic for participants
- * Facilitator(s)
-
-
-
-### Facilitation steps
-
-**Step 1.** Before leading the exercise, the facilitator should pre-select a topic on which the participants should generate and pitch ideas to the group. It could be a business challenge, a customer problem, a way to increase productivity, or a problem you'd like to solve for your organization.
-
-**Step 2.** Distribute paper or sticky notes and markers/pens to each participant.
-
-**Step 3.** Introduce the topic that will be the focus of the unconference exercise and ask participants to begin thinking about their pitch. Explain the process, the desired outcome, and the following timeline for the exercise:
-
- * 10 minutes: Explain process and pitch prep
- * 20 minutes: 1-minute pitches from each participant
- * 10 minutes: Voting
- * 10 minutes: Break / count votes
- * 5 minutes: Present top selections and breakout sessions
- * 25 minutes: Breakout collaboration
- * 10 minutes: Readouts
-
-
-
-**Step 4.** Ask participants to first prepare a 30 ‒60 second pitch based on the topic. This is an idea they want to share with the group to potentially explore in a breakout session. Participants should compose a title, brief description, and add their name to the paper you handed out. Pro-tip: Leave room for voting at the bottom.
-
-An example format for a pitch sheet might look like this:
-
-Title:
-
-Description:
-
-Name:
-
-Voting:
-
-**Step 5.** Begin the pitch process and time each participant for 60 seconds. Instruct each participant to share their name, title, and to briefly describe their idea (this is "the pitch.") If a participant begins to go over time, kindly stop them by starting to clap, others will follow suit. Alternatively, you can use an alarm on the timer. As each participant finishes a pitch, the group should clap to encourage others and boost confidence for the other pitches.
-
-**Step 6.** At the conclusion of each pitch the facilitator should lay out the pitch papers on a table, tape them to the wall, or post them to a moveable whiteboard so participants can vote on them before heading out for the break (second pro-tip: Don't use sharpies to vote if you tape pitch papers to the wall. You've been warned). Allow at least 20 minutes for steps 5 and 6.
-
-**Step 7.** After the pitches, give all participants three votes to select the topic(s) they are most interested in discussing or exploring further. Have them vote on the pitch paper, using tick marks, with the markers or pens. Alternatively, you can "dot" vote with circular stickers. Votes can spread out or stacked for preferred topics. Allow up to 10 minutes for this step.
-
-**Step 8.** While participants take a break, facilitators should count the votes on each pitch paper and determine the top two or three ideas. I prefer to count the votes on each pitch paper and write the number in a circle on the paper. This helps me visually see what pitches are the most popular. This will take about 10 minutes.
-
-**Step 9.** After the break, present these top ideas and ask the presenters of these ideas to lead a breakout session based on their pitches. For larger unconference events, there is a lot more organizing of the sessions with multiple rooms and multiple timeslots occurring. This exercise is drastically simplifying this step.
-
-**Step 10.** Divide participants into two or three breakout sessions. Ask participants to self-select the breakout session that is most interesting to them. Having balanced groups is preferable.
-
-**Step 11.** Ask pitch presenters to lead their breakout sessions with the goal of arriving at a prototype of a solution for the idea they pitched. In my experience, things will start off slow, then it will be hard to stop the collaboration. Allow up to 20 minutes for this step.
-
-**Step 12.** As you approach the end of the breakout sessions, ask participants to prepare their top takeaways for a group readout. Give groups a five-minute and then a two-minute warning to prepare their key takeaways.
-
-**Step 13.** Ask each breakout group to designate a spokesperson.
-
-**Step 14.** The spokesperson from each breakout group shall present their key takeaways and a summary of their prototype to the entire group. Divide the time equally between groups. A few questions from other groups are fine. This should last about 10 minutes.
-
-**Step 15.** Facilitators should summarize the session, encourage further action, and conclude the exercise.
-
-### Reflection
-
-I've previously run this exercise with a group of approximately twenty middle school and high school students with the sole purpose of introducing the concept of an unconference to them. For the last three years, in fact, I've had the privilege of hosting a group of bright, young students participating in the [Raleigh Digital Connector Program][1]. I host them at Red Hat, give them a quick tour of our office space, then lead them through this unconference exercise to help them prepare for an annual civic tech event called CityCamp NC, which brings citizens, government change agents, and businesses together to openly innovate and improve the North Carolina community.
-
-To recap on the general exercise, the facilitator's job is to keep things on time and moving through the process. The participants' job is to be present, share ideas, and build on other ideas. In this smaller setting, having everyone give a pitch is important, because you want everyone to share an idea. In my experience, you never know what you're going to get and I'm alway pleasantly surprised by the ones that get voted up.
-
-I often get participants who wish they would have made a pitch or shared a topic near and dear to them--after it was all over. Don't be that person.
-
-In larger events, facilitator's should to drive participants to have some type of outcome or next step by the end of their session. Getting people together to discuss an idea or share knowledge is great, but the most valuable sessions allow participants to leave with something to look forward to after the event.
-
-I will often refer to unconferences as organized chaos. Once first-timers go through the process, I've had many participants express sheer joy that they've never experienced this level of collaboration and knowledge sharing. On the other end of the spectrum, I often get participants who wish they would have made a pitch or shared a topic near and dear to them--after it was all over. Don't be that person. If you ever find yourself at an unconference, I encourage you to do a pitch. Be prepared to participate, jump right in, and enjoy the experience.
-
-As you get more experience, you can convert this unconference exercise into a full-blown unconference event for your organization. And the results should be astonishing.
-
-This article is part of the [Open Organization Workbook project][2].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/17/11/tap-community-power-unconference
-
-作者:[Jason Hibbets][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jhibbets
-[1]:https://www.raleighnc.gov/safety/content/ParksRec/Articles/Programs/TechnologyEducation/DigitalInclusionPrograms.html
-[2]:https://opensource.com/open-organization/17/8/workbook-project-announcement
diff --git a/sources/tech/20171201 Linux Distros That Serve Scientific and Medical Communities.md b/sources/tech/20171201 Linux Distros That Serve Scientific and Medical Communities.md
deleted file mode 100644
index 59c6297157..0000000000
--- a/sources/tech/20171201 Linux Distros That Serve Scientific and Medical Communities.md
+++ /dev/null
@@ -1,170 +0,0 @@
-Linux Distros That Serve Scientific and Medical Communities
-============================================================
-
-
-Jack Wallen looks at a few Linux distributions that specialize in serving the scientific and medical communities.[Creative Commons Zero][5]
-
-Linux serves — of that there is no doubt — literally and figuratively. The open source platform serves up websites across the globe, it serves educational systems in numerous ways, and it also serves the medical and scientific communities and has done so for quite some time.
-
-I remember, back in my early days of Linux usage (I first adopted Linux as my OS of choice in 1997), how every Linux distribution included so many tools I would personally never use. Tools used for plotting and calculating on levels I’d not even heard of before. I cannot remember the names of those tools, but I know they were opened once and never again. I didn’t understand their purpose. Why? Because I wasn’t knee-deep in studying such science.
-
-Modern Linux is a far cry from those early days. Not only is it much more user-friendly, it doesn’t include that plethora of science-centric tools. There are, however, still Linux distributions for that very purpose — serving the scientific and medical communities.
-
-Let’s take a look at a few of these distributions. Maybe one of them will suit your needs.
-
-### Scientific Linux
-
-You can’t start a listing of science-specific Linux distributions without first mentioning [Scientific Linux][12]. This particular take on Linux was developed by [Fermilab][13]. Based on Red Hat Enterprise Linux, Scientific Linux aims to offer a common Linux distribution for various labs and universities around the world, in order to reduce duplication of effort. The goal of Scientific Linux is to have a distribution that is compatible with Red Hat Enterprise Linux, that:
-
-* Provides a stable, scalable, and extensible operating system for scientific computing.
-
-* Supports scientific research by providing the necessary methods and procedures to enable the integration of scientific applications with the operating environment.
-
-* Uses the free exchange of ideas, designs, and implementations in order to prepare a computing platform for the next generation of scientific computing.
-
-* Includes all the necessary tools to enable users to create their own Scientific Linux spins.
-
-Because Scientific Linux is based on Red Hat Enterprise Linux, you can select a Security Policy for the platform during installation (Figure 1).
-
-
-
-Figure 1: Selecting a security policy for Scientific Linux during installation.[Used with permission][1]
-
-Two famous experiments that work with Scientific Linux are:
-
-* Collider Detector at Fermilab — experimental collaboration that studies high energy particle collisions at the [Tevatron][6] (a circular particle accelerator)
-
-* DØ experiment — a worldwide collaboration of scientists that conducts research on the fundamental nature of matter.
-
-What you might find interesting about Scientific Linux is that it doesn’t actually include all the science-y goodness you might expect. There is no Matlab equivalent pre-installed, or other such tools. The good news is that there are plenty of repositories available that allow you to install everything you need to create a distribution that perfectly suits your needs.
-
-Scientific Linux is available to use for free and can be downloaded from the [official download page][14].
-
-### Bio-Linux
-
-Now we’re venturing into territory that should make at least one cross section of scientists very happy. Bio-Linux is a distribution aimed specifically at bioinformatics (the science of collecting and analyzing complex biological data such as genetic codes). This very green-looking take on Linux (Figure 2) was developed at the [Environmental Omics Synthesis Centre ][15]and the [Natural Environment for Ecology & Hydrology][16] and includes hundreds of bioinformatics tools, including:
-
-* abyss — de novo, parallel, sequence assembler for short reads
-
-* Artemis — DNA sequence viewer and annotation tool
-
-* bamtools — toolkit for manipulating BAM (genome alignment) files
-
-* Big-blast — The big-blast script for annotation of long sequence
-
-* Galaxy — browser-based biomedical research platform
-
-* Fasta — tool for searching DNA and protein databases
-
-* Mesquite — used for evolutionary biology
-
-* njplot — tool for drawing phylogenetic trees
-
-* Rasmo — tool for visualizing macromolecules
-
-
-
-Figure 2: The Bio-Linux desktop.[Used with permission][2]
-
-There are plenty of command line and graphical tools to be found in this niche platform. For a complete list, check out the included software page [here][17].
-
-Bio-Linux is based on Ubuntu and is available for free download.
-
-### Poseidon Linux
-
-This particular Ubuntu-based Linux distribution originally started as a desktop, based on open source software, aimed at the international scientific community. Back in 2010, the platform switched directions to focus solely on bathymetry (the measurement of depth of water in oceans, seas, or lakes), seafloor mapping, GIS, and 3D visualization.
-
-
-
-Figure 3: Poseidon Linux with menus (Image: Wikipedia).[Used with permission][3]
-
-Poseidon Linux (Figure 3) is, effectively, Ubuntu 16.04 (complete with Ubuntu Unity, at the moment) with the addition of [GMT][25] (a collection of about 80 command-line tools for manipulating geographic and Cartesian data sets), [PROJ][26] (a standard UNIX filter function which converts geographic longitude and latitude coordinates into Cartesian coordinates), and [MB System][27] (seafloor mapping software).
-
-Yes, Poseidon Linux is a very niche distribution, but if you need to measure the depth of water in oceans, seas, and lakes, you’ll be glad it’s available.
-
-Download Poseidon Linux for free from the [official download site][18].
-
-### NHSbuntu
-
-A group of British IT specialists took on the task to tailor Ubuntu Linux to be used as a desktop distribution by the [UK National Health Service][19]. [NHSbuntu][20] was first released, as an alpha, on April 27, 2017\. The goal was to create a PC operating system that could deliver security, speed, and cost-effectiveness and to create a desktop distribution that would conform to the needs of the NHS — not insist the NHS conform to the needs of the software. NHSbuntu was set up for full disk encryption to safeguard the privacy of sensitive data.
-
-NHSbuntu includes LibreOffice, NHSMail2 (a version of the Evolution groupware suite, capable of connecting to NHSmail2 and Trust email), and Chat (a messenger app able to work with NHSmail2). This spin on Ubuntu can:
-
-* Perform as a Clinical OS
-
-* Serve as an office desktop OS
-
-* Be used as in kiosk mode
-
-* Function as a real-time dashboard
-
-
-
-Figure 4: NHSbuntu main screen.[Used with permission][4]
-
-The specific customizations of NHSbuntu are:
-
-* NHSbuntu wallpaper (Figure 4)
-
-* A look and feel similar to a well-known desktop
-
-* NHSmail2 compatibility
-
-* Email, calendar, address book
-
-* Messager, with file sharing
-
-* N3 VPN compatibility
-
-* RSA token supported
-
-* Removal of games
-
-* Inclusion of Remmina (Remote Desktop client for VDI)
-
-NHSbuntu can be [downloaded][21], for free, for either 32- or 64-bit hardware.
-
-### The tip of the scientific iceberg
-
-Even if you cannot find a Linux distribution geared toward your specific branch of science or medicine, chances are you will find software perfectly capable of serving your needs. There are even organizations (such as the [Open Science Project][22] and [Neurodebian][23]) dedicated to writing and releasing open source software for the scientific community.
-
- _Learn more about Linux through the free ["Introduction to Linux" ][24]course from The Linux Foundation and edX._
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2017/9/linux-serves-scientific-and-medical-communities
-
-作者:[JACK WALLEN ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.linux.com/licenses/category/used-permission
-[2]:https://www.linux.com/licenses/category/used-permission
-[3]:https://www.linux.com/licenses/category/used-permission
-[4]:https://www.linux.com/licenses/category/used-permission
-[5]:https://www.linux.com/licenses/category/creative-commons-zero
-[6]:https://en.wikipedia.org/wiki/Tevatron
-[7]:https://www.linux.com/files/images/scientificlinux1jpg
-[8]:https://www.linux.com/files/images/biolinuxjpg
-[9]:https://www.linux.com/files/images/poseidon4-menupng
-[10]:https://www.linux.com/files/images/nshbuntujpg
-[11]:https://www.linux.com/files/images/linux-sciencejpg
-[12]:http://www.scientificlinux.org/
-[13]:http://www.fnal.gov/
-[14]:http://www.scientificlinux.org/downloads/
-[15]:http://environmentalomics.org/omics-synthesis-centre/
-[16]:https://www.environmental-research.ox.ac.uk/partners/centre-for-ecology-hydrology/
-[17]:http://environmentalomics.org/bio-linux-software-list/
-[18]:https://sites.google.com/site/poseidonlinux/download
-[19]:http://www.nhs.uk/pages/home.aspx
-[20]:https://www.nhsbuntu.org/
-[21]:https://www.nhsbuntu.org/
-[22]:http://openscience.org/
-[23]:http://neuro.debian.net/
-[24]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
-[25]:http://gmt.soest.hawaii.edu/
-[26]:http://proj4.org/
-[27]:http://svn.ilab.ldeo.columbia.edu/listing.php?repname=MB-System
diff --git a/sources/tech/20171202 Easily control delivery of your Python applications to millions of Linux users with Snapcraft.md b/sources/tech/20171202 Easily control delivery of your Python applications to millions of Linux users with Snapcraft.md
deleted file mode 100644
index dbdebf63e3..0000000000
--- a/sources/tech/20171202 Easily control delivery of your Python applications to millions of Linux users with Snapcraft.md
+++ /dev/null
@@ -1,321 +0,0 @@
-Python
-============================================================
-
-Python has rich tools for packaging, distributing and sandboxing applications. Snapcraft builds on top of these familiar tools such as `pip`, `setup.py` and `requirements.txt` to create snaps for people to install on Linux.
-
-### What problems do snaps solve for Python applications?
-
-Linux install instructions for Python applications often get complicated. System dependencies, which differ from distribution to distribution, must be separately installed. To prevent modules from different Python applications clashing with each other, developer tools like `virtualenv` or `venv` must be used. With snapcraft it’s one command to produce a bundle that works anywhere.
-
-Here are some snap advantages that will benefit many Python projects:
-
-* Bundle all the runtime requirements, including the exact versions of system libraries and the Python interpreter.
-
-* Simplify installation instructions, regardless of distribution, to `snap install mypythonapp`.
-
-* Directly control the delivery of automatic application updates.
-
-* Extremely simple creation of daemons.
-
-### Getting started
-
-Let’s take a look at offlineimap and youtube-dl by way of examples. Both are command line applications. offlineimap uses Python 2 and only has Python module requirements. youtube-dl uses Python 3 and has system package requirements, in this case `ffmpeg`.
-
-### offlineimap
-
-Snaps are defined in a single yaml file placed in the root of your project. The offlineimap example shows the entire `snapcraft.yaml` for an existing project. We’ll break this down.
-
-```
-name: offlineimap
-version: git
-summary: OfflineIMAP
-description: |
- OfflineIMAP is software that downloads your email mailbox(es) as local
- Maildirs. OfflineIMAP will synchronize both sides via IMAP.
-
-grade: devel
-confinement: devmode
-
-apps:
- offlineimap:
- command: bin/offlineimap
-
-parts:
- offlineimap:
- plugin: python
- python-version: python2
- source: .
-
-```
-
-#### Metadata
-
-The `snapcraft.yaml` starts with a small amount of human-readable metadata, which usually can be lifted from the GitHub description or project README.md. This data is used in the presentation of your app in the Snap Store. The `summary:` can not exceed 79 characters. You can use a pipe with the `description:` to declare a multi-line description.
-
-```
-name: offlineimap
-version: git
-summary: OfflineIMAP
-description: |
- OfflineIMAP is software that downloads your email mailbox(es) as local
- Maildirs. OfflineIMAP will synchronize both sides via IMAP.
-
-```
-
-#### Confinement
-
-To get started we won’t confine this application. Unconfined applications, specified with `devmode`, can only be released to the hidden “edge” channel where you and other developers can install them.
-
-```
-confinement: devmode
-
-```
-
-#### Parts
-
-Parts define how to build your app. Parts can be anything: programs, libraries, or other assets needed to create and run your application. In this case we have one: the offlineimap source code. In other cases these can point to local directories, remote git repositories, or tarballs.
-
-The Python plugin will also bundle Python in the snap, so you can be sure that the version of Python you test against is included with your app. Dependencies from `install_requires` in your `setup.py` will also be bundled. Dependencies from a `requirements.txt` file can also be bundled using the `requirements:` option.
-
-```
-parts:
- offlineimap:
- plugin: python
- python-version: python2
- source: .
-
-```
-
-#### Apps
-
-Apps are the commands and services exposed to end users. If your command name matches the snap `name`, users will be able run the command directly. If the names differ, then apps are prefixed with the snap `name`(`offlineimap.command-name`, for example). This is to avoid conflicting with apps defined by other installed snaps.
-
-If you don’t want your command prefixed you can request an alias for it on the [Snapcraft forum][1]. These command aliases are set up automatically when your snap is installed from the Snap Store.
-
-```
-apps:
- offlineimap:
- command: bin/offlineimap
-
-```
-
-If your application is intended to run as a service, add the line `daemon: simple` after the command keyword. This will automatically keep the service running on install, update and reboot.
-
-### Building the snap
-
-You’ll first need to [install snap support][2], and then install the snapcraft tool:
-
-```
-sudo snap install --beta --classic snapcraft
-
-```
-
-If you have just installed snap support, start a new shell so your `PATH` is updated to include `/snap/bin`. You can then build this example yourself:
-
-```
-git clone https://github.com/snapcraft-docs/offlineimap
-cd offlineimap
-snapcraft
-
-```
-
-The resulting snap can be installed locally. This requires the `--dangerous` flag because the snap is not signed by the Snap Store. The `--devmode` flag acknowledges that you are installing an unconfined application:
-
-```
-sudo snap install offlineimap_*.snap --devmode --dangerous
-
-```
-
-You can then try it out:
-
-```
-offlineimap
-
-```
-
-Removing the snap is simple too:
-
-```
-sudo snap remove offlineimap
-
-```
-
-Jump ahead to [Share with your friends][3] or continue to read another example.
-
-### youtube-dl
-
-The youtube-dl example shows a `snapcraft.yaml` using a tarball of a Python application and `ffmpeg` bundled in the snap to satisfy the runtime requirements. Here is the entire `snapcraft.yaml` for youtube-dl. We’ll break this down.
-
-```
-name: youtube-dl
-version: 2017.06.18
-summary: YouTube Downloader.
-description: |
- youtube-dl is a small command-line program to download videos from
- YouTube.com and a few more sites.
-
-grade: devel
-confinement: devmode
-
-parts:
- youtube-dl:
- source: https://github.com/rg3/youtube-dl/archive/$SNAPCRAFT_PROJECT_VERSION.tar.gz
- plugin: python
- python-version: python3
- after: [ffmpeg]
-
-apps:
- youtube-dl:
- command: bin/youtube-dl
-
-```
-
-#### Parts
-
-The `$SNAPCRAFT_PROJECT_VERSION` variable is derived from the `version:` stanza and used here to reference the matching release tarball. Because the `python` plugin is used, snapcraft will bundle a copy of Python in the snap using the version specified in the `python-version:` stanza, in this case Python 3.
-
-youtube-dl makes use of `ffmpeg` to transcode or otherwise convert the audio and video file it downloads. In this example, youtube-dl is told to build after the `ffmpeg` part. Because the `ffmpeg` part specifies no plugin, it will be fetched from the parts repository. This is a collection of community-contributed definitions which can be used by anyone when building a snap, saving you from needing to specify the source and build rules for each system dependency. You can use `snapcraft search` to find more parts to use and `snapcraft define <part-name>` to verify how the part is defined.
-
-```
-parts:
- youtube-dl:
- source: https://github.com/rg3/youtube-dl/archive/$SNAPCRAFT_PROJECT_VERSION.tar.gz
- plugin: python
- python-version: python3
- after: [ffmpeg]
-
-```
-
-### Building the snap
-
-You can build this example yourself by running the following:
-
-```
-git clone https://github.com/snapcraft-docs/youtube-dl
-cd youtube-dl
-snapcraft
-
-```
-
-The resulting snap can be installed locally. This requires the `--dangerous` flag because the snap is not signed by the Snap Store. The `--devmode` flag acknowledges that you are installing an unconfined application:
-
-```
-sudo snap install youtube-dl_*.snap --devmode --dangerous
-
-```
-
-Run the command:
-
-```
-youtube-dl “https://www.youtube.com/watch?v=k-laAxucmEQ”
-
-```
-
-Removing the snap is simple too:
-
-```
-sudo snap remove youtube-dl
-
-```
-
-### Share with your friends
-
-To share your snaps you need to publish them in the Snap Store. First, create an account on [the dashboard][4]. Here you can customize how your snaps are presented, review your uploads and control publishing.
-
-You’ll need to choose a unique “developer namespace” as part of the account creation process. This name will be visible by users and associated with your published snaps.
-
-Make sure the `snapcraft` command is authenticated using the email address attached to your Snap Store account:
-
-```
-snapcraft login
-
-```
-
-### Reserve a name for your snap
-
-You can publish your own version of a snap, provided you do so under a name you have rights to.
-
-```
-snapcraft register mypythonsnap
-
-```
-
-Be sure to update the `name:` in your `snapcraft.yaml` to match this registered name, then run `snapcraft` again.
-
-### Upload your snap
-
-Use snapcraft to push the snap to the Snap Store.
-
-```
-snapcraft push --release=edge mypthonsnap_*.snap
-
-```
-
-If you’re happy with the result, you can commit the snapcraft.yaml to your GitHub repo and [turn on automatic builds][5] so any further commits automatically get released to edge, without requiring you to manually build locally.
-
-### Further customisations
-
-Here are all the Python plugin-specific keywords:
-
-```
-- requirements:
- (string)
- Path to a requirements.txt file
-- constraints:
- (string)
- Path to a constraints file
-- process-dependency-links:
- (bool; default: false)
- Enable the processing of dependency links in pip, which allow one project
- to provide places to look for another project
-- python-packages:
- (list)
- A list of dependencies to get from PyPI
-- python-version:
- (string; default: python3)
- The python version to use. Valid options are: python2 and python3
-
-```
-
-You can view them locally by running:
-
-```
-snapcraft help python
-
-```
-
-### Extending and overriding behaviour
-
-You can [extend the behaviour][6] of any part in your `snapcraft.yaml` with shell commands. These can be run after pulling the source code but before building by using the `prepare` keyword. The build process can be overridden entirely using the `build` keyword and shell commands. The `install` keyword is used to run shell commands after building your code, useful for making post build modifications such as relocating build assets.
-
-Using the youtube-dl example above, we can run the test suite at the end of the build. If this fails, the snap creation will be terminated:
-
-```
-parts:
- youtube-dl:
- source: https://github.com/rg3/youtube-dl/archive/$SNAPCRAFT_PROJECT_VERSION.tar.gz
- plugin: python
- python-version: python3
- stage-packages: [ffmpeg, python-nose]
- install: |
- nosetests
-```
-
---------------------------------------------------------------------------------
-
-via: https://docs.snapcraft.io/build-snaps/python
-
-作者:[Snapcraft.io ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:Snapcraft.io
-
-[1]:https://forum.snapcraft.io/t/process-for-reviewing-aliases-auto-connections-and-track-requests/455
-[2]:https://docs.snapcraft.io/core/install
-[3]:https://docs.snapcraft.io/build-snaps/python#share-with-your-friends
-[4]:https://dashboard.snapcraft.io/openid/login/?next=/dev/snaps/
-[5]:https://build.snapcraft.io/
-[6]:https://docs.snapcraft.io/build-snaps/scriptlets
diff --git a/sources/tech/20171203 Top 20 GNOME Extensions You Should Be Using Right Now.md b/sources/tech/20171203 Top 20 GNOME Extensions You Should Be Using Right Now.md
deleted file mode 100644
index 60b188780f..0000000000
--- a/sources/tech/20171203 Top 20 GNOME Extensions You Should Be Using Right Now.md
+++ /dev/null
@@ -1,307 +0,0 @@
-Top 20 GNOME Extensions You Should Be Using Right Now
-============================================================
-
- _Brief: You can enhance the capacity of your GNOME desktop with extensions. Here, we list the best GNOME extensions to save you the trouble of finding them on your own._
-
-[GNOME extensions][9] are a major part of the [GNOME][10] experience. These extensions add a lot of value to the ecosystem whether it is to mold the Gnome Desktop Environment (DE) to your workflow, to add more functionality than there is by default, or just simply to freshen up the experience.
-
-With default [Ubuntu 17.10][11] switching from [Unity to Gnome][12], now is the time to familiarize yourself with the various extensions that the GNOME community has to offer. We already showed you[ how to enable and manage GNOME extensions][13]. But finding good extensions could be a daunting task. That’s why I created this list of best GNOME extensions to save you some trouble.
-
-### Best GNOME Extensions
-
-
-
-The list is in alphabetical order but there is no ranking involved here. Extension at number 1 position is not better than the rest of the extensions.
-
-### 1\. Appfolders Management extensions
-
-One of the major features that I think GNOME is missing is the ability to organize the default application grid. This is something included by default in [KDE][14]‘s Application Dashboard, in [Elementary OS][15]‘s Slingshot Launcher, and even in macOS, yet as of [GNOME 3.26][16] it isn’t something that comes baked in. Appfolders Management extension changes that.
-
-This extension gives the user an easy way to organize their applications into various folders with a simple right click > add to folder. Creating folders and adding applications to them is not only simple through this extension, but it feels so natively implemented that you will wonder why this isn’t built into the default GNOME experience.
-
-
-
-[Appfolders Management extension][17]
-
-### 2\. Apt Update Indicator
-
-For distributions that utilize [Apt as their package manager][18], such as Ubuntu or Debian, the Apt Update Indicator extension allows for a more streamlined update experience in GNOME.
-
-The extension settles into your top bar and notifies the user of updates waiting on their system. It also displays recently added repos, residual config files, files that are auto removable, and allows the user to manually check for updates all in one basic drop-down menu.
-
-It is a simple extension that adds an immense amount of functionality to any system.
-
-
-
-[Apt Update Indicator][19]
-
-### 3\. Auto Move Windows
-
-If, like me, you utilize multiple virtual desktops than this extension will make your workflow much easier. Auto Move Windows allows you to set your applications to automatically open on a virtual desktop of your choosing. It is as simple as adding an application to the list and selecting the desktop you would like that application to open on.
-
-From then on every time you open that application it will open on that desktop. This makes all the difference when as soon as you login to your computer all you have to do is open the application and it immediately opens to where you want it to go without manually having to move it around every time before you can get to work.
-
-
-
-[Auto Move Windows][20]
-
-### 4\. Caffeine
-
-Caffeine allows the user to keep their computer screen from auto-suspending at the flip of a switch. The coffee mug shaped extension icon embeds itself into the right side of your top bar and with a click shows that your computer is “caffeinated” with a subtle addition of steam to the mug and a notification.
-
-The same is true to turn off Caffeine, enabling auto suspend and/or screensave again. It’s incredibly simple to use and works just as you would expect.
-
-Caffeine Disabled:
-
-
-Caffeine Enabled:
-
-
-[Caffeine][21]
-
-### 5\. CPU Power Management [Only for Intel CPUs]
-
-This is an extension that, at first, I didn’t think would be very useful, but after some time using it I have found that functionality like this should be backed into all computers by default. At least all laptops. CPU Power Management allows you to chose how much of your computer’s resources are being used at any given time.
-
-Its simple drop-down menu allows the user to change between various preset or user made profiles that control at what frequency your CPU is to run. For example, you can set your CPU to the “Quiet” present which tells your computer to only us a maximum of 30% of its resources in this case.
-
-On the other hand, you can set it to the “High Performance” preset to allow your computer to run at full potential. This comes in handy if you have loud fans and want to minimize the amount of noise they make or if you just need to save some battery life.
-
-One thing to note is that _this only works on computers with an Intel CPU_ , so keep that in mind.
-
-
-
-[CPU Power Management][22]
-
-### 6\. Clipboard Indicator
-
-Clipboard Indicator is a clean and simple clipboard management tool. The extension sits in the top bar and caches your recent clipboard history (things you copy and paste). It will continue to save this information until the user clears the extension’s history.
-
-If you know that you are about to work with documentation that you don’t want to be saved in this way, like Credit Card numbers or any of your personal information, Clipboard Indicator offers a private mode that the user can toggle on and off for such cases.
-
-
-
-[Clipboard Indicator][23]
-
-### 7\. Extensions
-
-The Extensions extension allows the user to enable/disable other extensions and to access their settings in one singular extension. Extensions either sit next to your other icons and extensions in the panel or in the user drop-down menu.
-
-Redundancies aside, Extensions is a great way to gain easy access to all your extensions without the need to open up the GNOME Tweak Tool to do so.
-
-
-
-[Extensions][24]
-
-### 8\. Frippery Move Clock
-
-For those of us who are used to having the clock to the right of the Panel in Unity, this extension does the trick. Frippery Move Clock moves the clock from the middle of the top panel to the right side. It takes the calendar and notification window with it but does not migrate the notifications themselves. We have another application later in this list, Panel OSD, that can add bring your notifications over to the right as well.
-
-Before Frippery:
-
-
-After Frippery:
-
-
-[Frippery Move Clock][25]
-
-### 9\. Gno-Menu
-
-Gno-Menu brings a more traditional menu to the GNOME DE. Not only does it add an applications menu to the top panel but it also brings a ton of functionality and customization with it. If you are used to using the Applications Menu extension traditionally found in GNOME but don’t want the bugs and issues that Ubuntu 17.10 brought to is, Gno-Meny is an awesome alternative.
-
-
-
-[Gno-Menu][26]
-
-### 10\. User Themes
-
-User Themes is a must for anyone looking to customize their GNOME desktop. By default, GNOME Tweaks lets its users change the theme of the applications themselves, icons, and cursors but not the theme of the shell. User Themes fixes that by enabling us to change the theme of GNOME Shell, allowing us to get the most out of our customization experience. Check out our [video][27] or read our article to know how to [install new themes][28].
-
-User Themes Off:
-
-User Themes On:
-
-
-[User Themes][29]
-
-### 11\. Hide Activities Button
-
-Hide Activities Button does exactly what you would expect. It hides the activities button found a the leftmost corner of the top panel. This button traditionally actives the activities overview in GNOME, but plenty of people use the Super Key on the keyboard to do this same function.
-
-Though this disables the button itself, it does not disable the hot corner. Since Ubuntu 17.10 offers the ability to shut off the hot corner int he native settings application this not a huge deal for Ubuntu users. For other distributions, there are a plethora of other ways to disable the hot corner if you so desire, which we will not cover in this particular article.
-
-Before:  After:
-
-
-#### [Hide Activities Button][30]
-
-### 12\. MConnect
-
-MConnect offers a way to seamlessly integrate the [KDE Connect][31] application within the GNOME desktop. Though KDE Connect offers a way for users to connect their Android handsets with virtually any Linux DE its indicator lacks a good way to integrate more seamlessly into any other DE than [Plasma][32].
-
-MConnect fixes that, giving the user a straightforward drop-down menu that allows them to send SMS messages, locate their phones, browse their phone’s file system, and to send files to their phone from the desktop. Though I had to do some tweaking to get MConnect to work just as I would expect it to, I couldn’t be any happier with the extension.
-
-Do remember that you will need KDE Connect installed alongside MConnect in order to get it to work.
-
-
-
-[MConnect][33]
-
-### 13\. OpenWeather
-
-OpenWeather adds an extension to the panel that gives the user weather information at a glance. It is customizable, it lets the user view weather information for whatever location they want to, and it doesn’t rely on the computers location services. OpenWeather gives the user the choice between [OpenWeatherMap][34] and [Dark Sky][35] to provide the weather information that is to be displayed.
-
-
-
-[OpenWeather][36]
-
-### 14\. Panel OSD
-
-This is the extension I mentioned earlier which allows the user to customize the location in which their desktop notifications appear on the screen. Not only does this allow the user to move their notifications over to the right, but Panel OSD gives the user the option to put their notifications literally anywhere they want on the screen. But for us migrating from Unity to GNOME, switching the notifications from the top middle to the top right may make us feel more at home.
-
-Before:
-
-
-After:
-
-
-#### [Panel OSD][37]
-
-### 15\. Places Status Indicator
-
-Places Status Indicator has been a recommended extension for as long as people have started recommending extensions. Places adds a drop-down menu to the panel that gives the user quick access to various areas of the file system, from the home directory to serves your computer has access to and anywhere in between.
-
-The convenience and usefulness of this extension become more apparent as you use it, becoming a fundamental way you navigate your system. I couldn’t recommend it more highly enough.
-
-
-
-[Places Status Indicator][38]
-
-### 16\. Refresh Wifi Connections
-
-One minor annoyance in GNOME is that the Wi-Fi Networks dialog box does not have a refresh button on it when you are trying to connect to a new Wi-Fi network. Instead, it makes the user wait while the system automatically refreshes the list. Refresh Wifi Connections fixes this. It simply adds that desired refresh button to the dialog box, adding functionality that really should be included out of the box.
-
-Before:
-
-
-After:
-
-
-#### [Refresh Wifi Connections][39]
-
-### 17\. Remove Dropdown Arrows
-
-The Remove Dropdown Arrows extension removes the arrows on the panel that signify when an icon has a drop-down menu that you can interact with. This is purely an aesthetic tweak and isn’t always necessary as some themes remove these arrows by default. But themes such as [Numix][40], which happens to be my personal favorite, don’t remove them.
-
-Remove Dropdown Arrows brings that clean look to the GNOME Shell that removes some unneeded clutter. The only bug I have encountered is that the CPU Management extension I mentioned earlier will randomly “respawn” the drop-down arrow. To turn it back off I have to disable Remove Dropdown Arrows and then enable it again until once more it randomly reappears out of nowhere.
-
-Before:
-
-
-After:
-
-
-[Remove Dropdown Arrows][41]
-
-### 18\. Status Area Horizontal Spacing
-
-This is another extension that is purely aesthetic and is only “necessary” in certain themes. Status Area Horizontal Spacing allows the user to control the amount of space between the icons in the status bar. If you think your status icons are too close or too spaced out, then this extension has you covered. Just select the padding you would like and you’re set.
-
-Maximum Spacing:
-
-
-Minimum Spacing:
-
-
-#### [Status Area Horizontal Spacing][42]
-
-### 19\. Steal My Focus
-
-By default, when you open an application in GNOME is will sometimes stay behind what you have open if a different application has focus. GNOME then notifies you that the application you selected has opened and it is up to you to switch over to it. But, in my experience, this isn’t always consistent. There are certain applications that seem to jump to the front when opened while the rest rely on you to see the notifications to know they opened.
-
-Steal My Focus changes that by removing the notification and immediately giving the user focus of the application they just opened. Because of this inconsistency, it was difficult for me to get a screenshot so you just have to trust me on this one. ;)
-
-#### [Steal My Focus][43]
-
-### 20\. Workspaces to Dock
-
-This extension changed the way I use GNOME. Period. It allows me to be more productive and aware of my virtual desktop, making for a much better user experience. Workspaces to Dock allows the user to customize their overview workspaces by turning into an interactive dock.
-
-You can customize its look, size, functionality, and even position. It can be used purely for aesthetics, but I think the real gold is using it to make the workspaces more fluid, functional, and consistent with the rest of the UI.
-
-
-
-[Workspaces to Dock][44]
-
-### Honorable Mentions: Dash to Dock and Dash to Panel
-
-Dash to Dock and Dash to Panel are not included in the official 20 extensions of this article for one main reason: Ubuntu Dock. Both extensions allow the user to make the GNOME Dash either a dock or a panel respectively and add more customization than comes by default.
-
-The problem is that to get the full functionality of these two extensions you will need to jump through some hoops to disable Ubuntu Dock, which I won’t outline in this article. We acknowledge that not everyone will be using Ubuntu 17.10, so for those of you that aren’t this may not apply to you. That being said, bot of these extensions are great and are included among some of the most popular GNOME extensions you will find.
-
-Currently, there is a “bug” in Dash to Dock whereby changing its setting, even with the extension disabled, the changes apply to the Ubuntu Dock as well. I say “bug” because I actually use this myself to customize Ubuntu Dock without the need for the extensions to be activated. This may get patched in the future, but until then consider that a free tip.
-
-### [Dash to Dock][45] [Dash to Panel][46]
-
-So there you have it, our top 20 GNOME Extensions you should try right now. Which of these extensions do you particularly like? Which do you dislike? Let us know in the comments below and don’t be afraid to say something if there is anything you think we missed.
-
-### About Phillip Prado
-
-Phillip Prado is an avid follower of all things tech, culture, and art. Not only is he an all-around geek, he has a BA in cultural communications and considers himself a serial hobbyist. He loves hiking, cycling, poetry, video games, and movies. But no matter what his passions are there is only one thing he loves more than Linux and FOSS: coffee. You can find him (nearly) everywhere on the web as @phillipprado.
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/best-gnome-extensions/
-
-作者:[ Phillip Prado][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/phillip/
-[1]:https://itsfoss.com/author/phillip/
-[2]:https://itsfoss.com/best-gnome-extensions/#comments
-[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fbest-gnome-extensions%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
-[4]:https://twitter.com/share?original_referer=/&text=Top+20+GNOME+Extensions+You+Should+Be+Using+Right+Now&url=https://itsfoss.com/best-gnome-extensions/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=phillipprado
-[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fbest-gnome-extensions%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
-[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fbest-gnome-extensions%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
-[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/best-gnome-extensions/&title=Top+20+GNOME+Extensions+You+Should+Be+Using+Right+Now
-[8]:https://www.reddit.com/submit?url=https://itsfoss.com/best-gnome-extensions/&title=Top+20+GNOME+Extensions+You+Should+Be+Using+Right+Now
-[9]:https://extensions.gnome.org/
-[10]:https://www.gnome.org/
-[11]:https://itsfoss.com/ubuntu-17-10-release-features/
-[12]:https://itsfoss.com/ubuntu-unity-shutdown/
-[13]:https://itsfoss.com/gnome-shell-extensions/
-[14]:https://www.kde.org/
-[15]:https://elementary.io/
-[16]:https://itsfoss.com/gnome-3-26-released/
-[17]:https://extensions.gnome.org/extension/1217/appfolders-manager/
-[18]:https://en.wikipedia.org/wiki/APT_(Debian)
-[19]:https://extensions.gnome.org/extension/1139/apt-update-indicator/
-[20]:https://extensions.gnome.org/extension/16/auto-move-windows/
-[21]:https://extensions.gnome.org/extension/517/caffeine/
-[22]:https://extensions.gnome.org/extension/945/cpu-power-manager/
-[23]:https://extensions.gnome.org/extension/779/clipboard-indicator/
-[24]:https://extensions.gnome.org/extension/1036/extensions/
-[25]:https://extensions.gnome.org/extension/2/move-clock/
-[26]:https://extensions.gnome.org/extension/608/gnomenu/
-[27]:https://youtu.be/9TNvaqtVKLk
-[28]:https://itsfoss.com/install-themes-ubuntu/
-[29]:https://extensions.gnome.org/extension/19/user-themes/
-[30]:https://extensions.gnome.org/extension/744/hide-activities-button/
-[31]:https://community.kde.org/KDEConnect
-[32]:https://www.kde.org/plasma-desktop
-[33]:https://extensions.gnome.org/extension/1272/mconnect/
-[34]:http://openweathermap.org/
-[35]:https://darksky.net/forecast/40.7127,-74.0059/us12/en
-[36]:https://extensions.gnome.org/extension/750/openweather/
-[37]:https://extensions.gnome.org/extension/708/panel-osd/
-[38]:https://extensions.gnome.org/extension/8/places-status-indicator/
-[39]:https://extensions.gnome.org/extension/905/refresh-wifi-connections/
-[40]:https://numixproject.github.io/
-[41]:https://extensions.gnome.org/extension/800/remove-dropdown-arrows/
-[42]:https://extensions.gnome.org/extension/355/status-area-horizontal-spacing/
-[43]:https://extensions.gnome.org/extension/234/steal-my-focus/
-[44]:https://extensions.gnome.org/extension/427/workspaces-to-dock/
-[45]:https://extensions.gnome.org/extension/307/dash-to-dock/
-[46]:https://extensions.gnome.org/extension/1160/dash-to-panel/
diff --git a/sources/tech/20171208 GeckoLinux Brings Flexibility and Choice to openSUSE.md b/sources/tech/20171208 GeckoLinux Brings Flexibility and Choice to openSUSE.md
deleted file mode 100644
index af1ba82706..0000000000
--- a/sources/tech/20171208 GeckoLinux Brings Flexibility and Choice to openSUSE.md
+++ /dev/null
@@ -1,114 +0,0 @@
-GeckoLinux Brings Flexibility and Choice to openSUSE
-======
-
-
-GeckoLinux is a unique distro that offers a few options that openSUSE does not. Jack Wallen takes a look.
-
-Creative Commons Zero
-
-I've been a fan of SUSE and openSUSE for a long time. I've always wanted to call myself an openSUSE user, but things seemed to get in the way--mostly [Elementary OS][1]. But every time an openSUSE spin is released, I take notice. Most recently, I was made aware of [GeckoLinux][2]--a unique take (offering both Static and Rolling releases) that offers a few options that openSUSE does not. Consider this list of features:
-
- * Live DVD / USB image
-
- * Editions for the following desktops: Cinnamon, XFCE, GNOME, Plasma, Mate, Budgie, LXQt, Barebones
-
- * Plenty of pre-installed open source desktop programs and proprietary media codecs
-
- * Beautiful font rendering configured out of the box
-
- * Advanced Power Management ([TLP][3]) pre-installed
-
- * Large amount of software available in the preconfigured repositories (preferring packages from the Packman repo--when available)
-
- * Based on openSUSE (with no repackaging or modification of packages)
-
- * Desktop programs can be uninstalled, along with all of their dependencies (whereas openSUSE's patterns often cause uninstalled packages to be re-installed automatically)
-
- * Does not force the installation of additional recommended packages, after initial installation (whereas openSUSE pre-installs patterns that automatically installs recommended package dependencies the first time the package manager is used)
-
-
-
-
-The choice of desktops alone makes for an intriguing proposition. Keeping a cleaner, lighter system is also something that would appeal to many users--especially in light of laptops running smaller, more efficient solid state drives.
-
-Let's dig into GeckoLinux and see if it might be your next Linux distribution.
-
-### Installation
-
-I don't want to say too much about the installation--as installing Linux has become such a no-brainer these days. I will say that GeckoLinux has streamlined the process to an impressive level. The installation of GeckoLinux took about three minutes total (granted I am running it as a virtual machine on a beast of a host--so resources were not an issue). The difference between installing GeckoLinux and openSUSE Tumbleweed was significant. Whereas GeckoLinux installed in single digits, openSUSE took more 10 minutes to install. Relatively speaking, that's still not long. But we're picking at nits here, so that amount of time should be noted.
-
-The only hiccup to the installation was the live distro asking for a password for the live user. The live username is linux and the password is, as you probably already guessed, linux. That same password is also the same used for admin tasks (such as running the installer).
-
-You will also note, there are two icons on the desktop--one to install the OS and another to install language packs. Run the OS installer. Once the installation is complete--and you've booted into your desktop--you can then run the Language installer (if you need the Language packs--Figure 1).
-
-
-![GeckoLinux ][5]
-
-Figure 1: Clearly, I chose the GNOME desktop for testing purposes.
-
-[Used with permission][6]
-
-After the Language installer finished, you can then remove the installer icon from the desktop by right-clicking it and selecting Move to Trash.
-
-### Those fonts
-
-The developer claims beautiful font rendering out of the box. In fact, the developer makes this very statement:
-
-GeckoLinux comes preconfigured with what many would consider to be good font rendering, whereas many users find openSUSE's default font configuration to be less than desirable.
-
-Take a glance at Figure 2. Here you see a side by side comparison of openSUSE (on the left) and GeckLinux (on the right). The difference is very subtle, but GeckoLinux does, in fact, best openSUSE out of the box. It's cleaner and easier to read. The developer claims are dead on. Although openSUSE does a very good job of rendering fonts out of the box, GeckoLinux improves on that enough to make a difference. In fact, I'd say it's some of the cleanest (out of the box) looking fonts I've seen on a Linux distribution.
-
-
-![openSUSE][8]
-
-Figure 2: openSUSE on the left, GeckoLinux on the right.
-
-[Used with permission][6]
-
-I've worked with distributions that don't render fonts well. After hours of writing, those fonts tend to put a strain on my eyes. For anyone that spends a good amount of time staring at words, well-rendered fonts can make the difference between having eye strain or not. The openSUSE font rendering is just slightly blurrier than that of GeckoLinux. That matters.
-
-### Installed applications
-
-GeckoLinux does exactly what it claims--installs just what you need. After a complete installation (no post-install upgrading), GeckoLinux comes in at 1.5GB installed. On the other hand, openSUSE's post-install footprint is 4.3GB. In defense of openSUSE, it does install things like GNOME Games, Evolution, GIMP, and more--so much of that space is taken up with added software and dependencies. But if you're looking for a lighter weight take on openSUSE, GeckoLinux is your OS.
-
-GeckoLinux does come pre-installed with a couple of nice additions--namely the [Clementine][9] Audio player (a favorite of mine), [Thunderbird][10] (instead of Evolution), PulseAudio Volume Control (a must for audio power users), Qt Configuration, GParted, [Pidgen][11], and [VLC][12].
-
-If you're a developer, you won't find much in the way of development tools on GeckoLinux. But that's no different than openSUSE (even the make command is missing on both). Naturally, all the developer tools you need (to work on Linux) are available to install (either from the command line or from with YaST2).
-
-### Performance
-
-Between openSUSE and GeckoLinux, there is very little noticeable difference in performance. Opening Firefox on both resulted in maybe a second or two variation (in favor of GeckoLinux). It should be noted, however, that the installed Firefox on both was quite out of date (52 on GeckoLinux and 53 on openSUSE). Even after a full upgrade on both platforms, Firefox was still listed at release 52 on GeckoLinux, whereas openSUSE did pick up Firefox 57. After downloading the [Firefox Quantum][13] package on GeckoLinux, the application opened immediately--completely blowing away both out of the box experiences on openSUSE and GeckLinux. So the first thing you will want to do is get Firefox upgraded to 57.
-
-If you're hoping for a significant performance increase over openSUSE, look elsewhere. If you're accustomed to the performance of openSUSE (it not being the sprightliest of platforms), you'll feel right at home with GeckoLinux.
-
-### The conclusion
-
-If you're looking for an excuse to venture back into the realm of openSUSE, GeckoLinux might be a good reason. It's slightly better looking, lighter weight, and with similar performance. It's not perfect and, chances are, it won't steal you away from your distribution of choice, but GeckoLinux is a solid entry in the realm of Linux desktops.
-
-Learn more about Linux through the free ["Introduction to Linux" ][14]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2017/12/geckolinux-brings-flexibility-and-choice-opensuse
-
-作者:[Jack Wallen][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://elementary.io/
-[2]:https://geckolinux.github.io/
-[3]:https://github.com/linrunner/TLP
-[4]:/files/images/gecko1jpg
-[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gecko_1.jpg?itok=qTvEsSQ1 (GeckoLinux)
-[6]:/licenses/category/used-permission
-[7]:/files/images/gecko2jpg
-[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gecko_2.jpg?itok=AKv0x7_J (openSUSE)
-[9]:https://www.clementine-player.org/
-[10]:https://www.mozilla.org/en-US/thunderbird/
-[11]:https://www.pidgin.im/
-[12]:https://www.videolan.org/vlc/index.html
-[13]:https://www.mozilla.org/en-US/firefox/
-[14]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20171222 Why the diversity and inclusion conversation must include people with disabilities.md b/sources/tech/20171222 Why the diversity and inclusion conversation must include people with disabilities.md
deleted file mode 100644
index 8052b91dc4..0000000000
--- a/sources/tech/20171222 Why the diversity and inclusion conversation must include people with disabilities.md
+++ /dev/null
@@ -1,67 +0,0 @@
-Why the diversity and inclusion conversation must include people with disabilities
-======
-
-"Diversity is being invited to the party, inclusion is being asked to dance." -Verna Myers
-
-With this in mind, communities should invite as many individuals as possible to dance the night away. Diversity and inclusion get a lot of attention in the tech community these days, perhaps more than in any other industry. Many experts agree that when people of different backgrounds work together to find solutions to problems, the result is a broader scope of innovation and better outcomes.
-
-Many organizations, including open source projects, publish reports on diversity to ensure that everybody understands its importance and participates in efforts to support it. But often diversity initiatives are limited to gender (specifically, bringing women into technology fields) and ethnicity.
-
-Gender and ethnic/racial equality in the tech community are both important, and I certainly don't want to downplay these issues. But limiting diversity efforts to gender and race excludes many other worthy groups. One of these is people with disabilities.
-
-According to many sources, at least 15% to 20% of people in the U.S. alone struggle with some type of disability. About 70% of these are disabilities such as blindness, cognitive challenges, or chronic disease, which are not visible from the outside. This group includes many talented individuals who can bring unique and valuable experiences and insights to projects and workplaces.
-
-Oscar-winning actress and activist Marlee Matlin said, "Diversity is a beautiful, absolutely wonderful thing, but I don't think they consider people with disabilities, and deaf and hard-of-hearing people, as part of the diversity mandate."
-
-Inclusion means everybody, not just specific groups. When diversity efforts focus only on specific groups, many others are excluded. And often, the loudest group wins attention at the expense of others.
-
-Open source communities are particularly well-positioned for workforce inclusion, because technology can help level the playing field for people with disabilities. But the community must be willing to do so.
-
-Here are ways organizations can become more inclusive of people with disabilities.
-
-### Making conferences more accessible
-
-Scheduling a conference at an ADA-certified building doesn't necessarily mean the conference is accessible to all those with disabilities.
-
-Providing step-free access from streets and parking lots and wheelchair-accessible restrooms is a good start. But what about the presenter's stage?
-
-Accessibility to events should consider both presenters and attendees. Many conferences have likely missed out on a great deal of valuable insight from disabled speakers who were unable or unwilling to participate based on previous negative experiences.
-
-It's also important to scatter reserved seats and areas that can accommodate mobile devices and service dogs throughout the venue so all attendees can be seated with their friends and colleagues (a big shout-out to the fine folks at AlterConf for understanding this).
-
-Visual impairment doesn't need to preclude people from attending conferences if efforts are made to accommodate them. Visual impairment doesn't always mean total blindness. According to a 2014 World Health Organization report, 285 million people worldwide suffer from some form of visual impairment; about 14% of this group is legally blind, while the rest have low or impaired vision.
-
-Finding the way to sessions can be a challenge for visually impaired individuals, and an open and welcoming community can address this. For starters, be sure to make accommodations for guide dogs, and don't distract them while they're working.
-
-Communities could also implement a "buddy system" in which a sighted person teams up with a visually impaired person to help guide them at sessions that both individuals plan to attend. Attendees could find a match using IRC, Slack, Forum, or some other tool and meet at a designated location. This would be a win-win from a community standpoint: Not only would the visually impaired attendee get to the session more easily, but both would have an opportunity to connect over a topic they share an interest in. And isn't that sort of connection the very definition of community?
-
-Preferred seating can be provided to ensure that attendees with limited vision are located as close as possible to the stage. This would also benefit people with physical disabilities who rely on assistive devices like canes (yours truly), wheelchairs, or walkers.
-
-If you are a speaker who is sharing your insight with the community, you deserve respect and credit--it is not always easy for people to stand onstage and address a large audience. However, if you use slides and graphics to enhance your presentation, and if these images show key data points, the words "as you can see on this slide" should be eradicated from your talk. This is considerate not only of people with visual impairments, but also anyone who might be listening to your talk while driving, for example.
-
-Another group to consider are people with hearing impairments, or [D/deaf people][1]. Enabling them to participate presents a technical challenge I would love to see addressed as an open source solution. Live speech-text-transcription would be beneficial in many scenarios. How many people reading this use the closed-captions on TVs in sports bars or at the gym?
-
-Providing sign language translators is great, of course, but this can present a challenge at international conferences because sign language, like any other language, is regional. While ASL (American Sign Language) is used in the U.S. and English-speaking Canada, there are also dialects, as in other languages. Speech-to-text may be a more realistic option, and accommodations for CART (Communication Access Realtime Translation) would benefit many, including non-English speakers.
-
-### Making content more accessible
-
-Sometimes you are simply unable to physically attend a particular conference due to conflicts, distance, or other factors. Or perhaps you did attend but want to catch up on sessions you were unable to fit in. Not a problem, thanks to YouTube and other sites, right? What if you're D/deaf, and the videos online don't include captions? (Please don't rely on YouTube captions; the hashtag #youtubecraptions was created for a reason.)
-
-Fortunately, you can provide your own recordings. Be sure to format event content, including any posted slides, so that visually impaired users can use an open source screen reader like NVDA on Windows, or Orca on Linux, to navigate both the site and the slides. Correct formatting is key so that screen readers can follow the flow of the document in the right order. Please include ALT IMG tags for pictures to describe what the image shows.
-
-### Conclusion
-
-Perhaps the first step toward creating a more inclusive community is to acknowledge that it involves a much wider group of individuals than is typically discussed. Communities have a lot of work to do, and particularly for small teams, this can present an extra challenge. The most important part is to take note of the problems and address them whenever possible. Even small efforts can go a long way--and for that I offer my heartfelt thanks.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/17/12/diversity-and-inclusion
-
-作者:[Michael Schulz][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mschulz
-[1]:https://en.wikipedia.org/wiki/Deaf_culture
diff --git a/sources/tech/20171224 My first Rust macro.md b/sources/tech/20171224 My first Rust macro.md
deleted file mode 100644
index a8002e050b..0000000000
--- a/sources/tech/20171224 My first Rust macro.md
+++ /dev/null
@@ -1,145 +0,0 @@
-My first Rust macro
-============================================================
-
-Last night I wrote a Rust macro for the first time!! The most striking thing to me about this was how **easy** it was – I kind of expected it to be a weird hard finicky thing, and instead I found that I could go from “I don’t know how macros work but I think I could do this with a macro” to “wow I’m done” in less than an hour.
-
-I used [these examples][2] to figure out how to write my macro.
-
-### what’s a macro?
-
-There’s more than one kind of macro in Rust –
-
-* macros defined using `macro_rules` (they have an exclamation mark and you call them like functions – `my_macro!()`)
-
-* “syntax extensions” / “procedural macros” like `#[derive(Debug)]` (you put these like annotations on your functions)
-
-* built-in macros like `println!`
-
-[Macros in Rust][3] and [Macros in Rust part II][4] seems like a nice overview of the different kinds with examples
-
-I’m not actually going to try to explain what a macro **is**, instead I will just show you what I used a macro for yesterday and hopefully that will be interesting. I’m going to be talking about `macro_rules!`, I don’t understand syntax extension/procedural macros yet.
-
-### compiling the `get_stack_trace` function for 30 different Ruby versions
-
-I’d written some functions that got the stack trace out of a running Ruby program (`get_stack_trace`). But the function I wrote only worked for Ruby 2.2.0 – here’s what it looked like. Basically it imported some structs from `bindings::ruby_2_2_0` and then used them.
-
-```
-use bindings::ruby_2_2_0::{rb_control_frame_struct, rb_thread_t, RString};
-fn get_stack_trace(pid: pid_t) -> Vec<String> {
- // some code using rb_control_frame_struct, rb_thread_t, RString
-}
-
-```
-
-Let’s say I wanted to instead have a version of `get_stack_trace` that worked for Ruby 2.1.6. `bindings::ruby_2_2_0` and `bindings::ruby_2_1_6` had basically all the same structs in them. But `bindings::ruby_2_1_6::rb_thread_t` wasn’t the **same** as `bindings::ruby_2_2_0::rb_thread_t`, it just had the same name and most of the same struct members.
-
-So I could implement a working function for Ruby 2.1.6 really easily! I just need to basically replace `2_2_0` for `2_1_6`, and then the compiler would generate different code (because `rb_thread_t` is different). Here’s a sketch of what the Ruby 2.1.6 version would look like:
-
-```
-use bindings::ruby_2_1_6::{rb_control_frame_struct, rb_thread_t, RString};
-fn get_stack_trace(pid: pid_t) -> Vec<String> {
- // some code using rb_control_frame_struct, rb_thread_t, RString
-}
-
-```
-
-### what I wanted to do
-
-I basically wanted to write code like this, to generate a `get_stack_trace` function for every Ruby version. The code inside `get_stack_trace` would be the same in every case, it’s just the `use bindings::ruby_2_1_3` that needed to be different
-
-```
-pub mod ruby_2_1_3 {
- use bindings::ruby_2_1_3::{rb_control_frame_struct, rb_thread_t, RString};
- fn get_stack_trace(pid: pid_t) -> Vec<String> {
- // insert code here
- }
-}
-pub mod ruby_2_1_4 {
- use bindings::ruby_2_1_4::{rb_control_frame_struct, rb_thread_t, RString};
- fn get_stack_trace(pid: pid_t) -> Vec<String> {
- // same code
- }
-}
-pub mod ruby_2_1_5 {
- use bindings::ruby_2_1_5::{rb_control_frame_struct, rb_thread_t, RString};
- fn get_stack_trace(pid: pid_t) -> Vec<String> {
- // same code
- }
-}
-pub mod ruby_2_1_6 {
- use bindings::ruby_2_1_6::{rb_control_frame_struct, rb_thread_t, RString};
- fn get_stack_trace(pid: pid_t) -> Vec<String> {
- // same code
- }
-}
-
-```
-
-### macros to the rescue!
-
-This really repetitive thing was I wanted to do was a GREAT fit for macros. Here’s what using `macro_rules!` to do this looked like!
-
-```
-macro_rules! ruby_bindings(
- ($ruby_version:ident) => (
- pub mod $ruby_version {
- use bindings::$ruby_version::{rb_control_frame_struct, rb_thread_t, RString};
- fn get_stack_trace(pid: pid_t) -> Vec<String> {
- // insert code here
- }
- }
-));
-
-```
-
-I basically just needed to put my code in and insert `$ruby_version` in the places I wanted it to go in. So simple! I literally just looked at an example, tried the first thing I thought would work, and it worked pretty much right away.
-
-(the [actual code][5] is more lines and messier but the usage of macros is exactly as simple in this example)
-
-I was SO HAPPY about this because I’d been worried getting this to work would be hard but instead it was so easy!!
-
-### dispatching to the right code
-
-Then I wrote some super simple dispatch code to call the right code depending on which Ruby version was running!
-
-```
- let version = get_api_version(pid);
- let stack_trace_function = match version.as_ref() {
- "2.1.1" => stack_trace::ruby_2_1_1::get_stack_trace,
- "2.1.2" => stack_trace::ruby_2_1_2::get_stack_trace,
- "2.1.3" => stack_trace::ruby_2_1_3::get_stack_trace,
- "2.1.4" => stack_trace::ruby_2_1_4::get_stack_trace,
- "2.1.5" => stack_trace::ruby_2_1_5::get_stack_trace,
- "2.1.6" => stack_trace::ruby_2_1_6::get_stack_trace,
- "2.1.7" => stack_trace::ruby_2_1_7::get_stack_trace,
- "2.1.8" => stack_trace::ruby_2_1_8::get_stack_trace,
- // and like 20 more versions
- _ => panic!("OH NO OH NO OH NO"),
- };
-
-```
-
-### it works!
-
-I tried out my prototype, and it totally worked! The same program could get stack traces out the running Ruby program for all of the ~10 different Ruby versions I tried – it figured which Ruby version was running, called the right code, and got me stack traces!!
-
-Previously I’d compile a version for Ruby 2.2.0 but then if I tried to use it for any other Ruby version it would crash, so this was a huge improvement.
-
-There are still more issues with this approach that I need to sort out. The two main ones right now are: firstly the ruby binary that ships with Debian doesn’t have symbols and I need the address of the current thread, and secondly it’s still possible that `#ifdefs` will ruin my day.
-
---------------------------------------------------------------------------------
-
-via: https://jvns.ca/blog/2017/12/24/my-first-rust-macro/
-
-作者:[Julia Evans ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://jvns.ca
-[1]:https://jvns.ca/categories/ruby-profiler
-[2]:https://gist.github.com/jfager/5936197
-[3]:https://www.ncameron.org/blog/macros-in-rust-pt1/
-[4]:https://www.ncameron.org/blog/macros-in-rust-pt2/
-[5]:https://github.com/jvns/ruby-stacktrace/blob/b0b92863564e54da59ea7f066aff5bb0d92a4968/src/lib.rs#L249-L393
diff --git a/sources/tech/20180108 Debbugs Versioning- Merging.md b/sources/tech/20180108 Debbugs Versioning- Merging.md
deleted file mode 100644
index ea479acc75..0000000000
--- a/sources/tech/20180108 Debbugs Versioning- Merging.md
+++ /dev/null
@@ -1,80 +0,0 @@
-Debbugs Versioning: Merging
-======
-One of the key features of Debbugs, the [bug tracking system Debian uses][1], is its ability to figure out which bugs apply to which versions of a package by tracking package uploads. This system generally works well, but when a package maintainer's workflow doesn't match the assumptions of Debbugs, unexpected things can happen. In this post, I'm going to:
-
- 1. introduce how Debbugs tracks versions
- 2. provide an example of a merge-based workflow which Debbugs doesn't handle well
- 3. provide some suggestions on what to do in this case
-
-
-
-### Debbugs Versioning
-
-Debbugs tracks versions using a set of one or more [rooted trees][2] which it builds from the ordering of debian/changelog entries. In the simplist case, every upload of a Debian package has changelogs in the same order, and each upload adds just one version. For example, in the case of [dgit][3], to start with the package has this (abridged) version tree:
-
-![][4]
-
-the next upload, 3.13, has a changelog with this version ordering: `3.13 3.12 3.11 3.10`, which causes the 3.13 version to be added as a descendant of 3.12, and the version tree now looks like this:
-
-![][5]
-
-dgit is being developed while also being used, so new versions with potentially disruptive changes are uploaded to experimental while production versions are uploaded to unstable. For example, the 4.0 experimental upload was based on the 3.10 version, with the changelog ordering `4.0 3.10`. The tree now has two branches, but everything seems as you would expect:
-
-![][6]
-
-### Merge based workflows
-
-Bugfixes in the maintenance version of dgit also are made to the experimental package by merging changes from the production version using git. In this case, some changes which were present in the 3.12 and 3.11 versions are merged using git, corresponds to a git merge flow like this:
-
-![][7]
-
-If an upload is prepared with changelog ordering `4.1 4.0 3.12 3.11 3.10`, Debbugs combines this new changelog ordering with the previously known tree, to produce this version tree:
-
-![][8]
-
-This looks a bit odd; what happened? Debbugs walks through the new changelog, connecting each of the new versions to the previous version if and only if that version is not already an ancestor of the new version. Because the changelog says that 3.12 is the ancestor of 4.0, that's where the `4.1 4.0` version tree is connected.
-
-Now, when 4.2 is uploaded, it has the changelog ordering (based on time) `4.2 3.13 4.1 4.0 3.12 3.11 3.10`, which corresponds to this git merge flow:
-
-![][9]
-
-Debbugs adds in 3.13 as an ancestor of 4.2, and because 4.1 was not an ancestor of 3.13 in the previous tree, 4.1 is added as an ancestor of 3.13. This results in the following graph:
-
-![][10]
-
-Which doesn't seem particularly helpful, because
-
-![][11]
-
-is probably the tree that more closely resembles reality.
-
-### Suggestions on what to do
-
-Why does this even matter? Bugs which are found in 3.11, and fixed in 3.12 now show up as being found in 4.0 after the 4.1 release, though they weren't found in 4.0 before that release. It also means that 3.13 now shows up as having all of the bugs fixed in 4.2, which might not be what is meant.
-
-To avoid this, my suggestion is to order the entries in changelogs in the same order that the version graph should be traversed from the leaf version you are releasing to the root. So if the previous version tree is what is wanted, 3.13 should have a changelog with ordering `3.13 3.12 3.11 3.10`, and 4.2 should have a changelog with ordering `4.2 4.1 4.0 3.10`.
-
-What about making the BTS support DAGs which are not trees? I think something like this would be useful, but I don't personally have a good idea on how this could be specified using the changelog or how bug fixed/found/absent should be propagated in the DAG. If you have better ideas, email me!
-
---------------------------------------------------------------------------------
-
-via: https://www.donarmstrong.com/posts/debbugs_merge_versions/
-
-作者:[Don Armstrong][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.donarmstrong.com/
-[1]:https://bugs.debian.org
-[2]:https://en.wikipedia.org/wiki/Tree_%28graph_theory%29#Forest
-[3]:https://packages.debian.org/dgit
-[4]:https://www.donarmstrong.com/graph-5d3f559f0fb850f47a5ea54c62b96da18bba46b8.png
-[5]:https://www.donarmstrong.com/graph-04a0cac92e522aa8816397090f0a23ef51e49379.png
-[6]:https://www.donarmstrong.com/graph-65493d1d56cbf3a32fc6e061d4d933f609d0dd9d.png
-[7]:https://www.donarmstrong.com/graph-cc7df2f6e47656a87ca10d313e65a8e3d55fb937.png
-[8]:https://www.donarmstrong.com/graph-94b259ce6dd4d28c04d692c72f6e021622b5b33a.png
-[9]:https://www.donarmstrong.com/graph-72f98ac7aa28e7dd40aaccf7742359f5dd2de378.png
-[10]:https://www.donarmstrong.com/graph-70ebe94be503db5ba97c4693f9e00fbb1dc3c9f7.png
-[11]:https://www.donarmstrong.com/graph-3f8db089ab21b48bcae9d536c1887b3bc6fc4bcb.png
diff --git a/sources/tech/20180108 SuperTux- A Linux Take on Super Mario Game.md b/sources/tech/20180108 SuperTux- A Linux Take on Super Mario Game.md
deleted file mode 100644
index 5cba5cda29..0000000000
--- a/sources/tech/20180108 SuperTux- A Linux Take on Super Mario Game.md
+++ /dev/null
@@ -1,77 +0,0 @@
-SuperTux: A Linux Take on Super Mario Game
-======
-When people usually think of PC games, they think of big titles, like Call of Duty, which often cost millions of dollars to create. While those games may be enjoyable, there are many games created by amateur programmers that are just as fun.
-
-I am going to review one such game that I love to play. It's called SuperTux.
-
-[video](https://www.youtube.com/embed/pTax8-cdiZU?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&theme=dark&color=red&autohide=2&controls=2&playsinline=0&)
-
-### What is SuperTux
-
-Today, we will take a look at [SuperTux][1]. According to the description on the project's website, SuperTux "is a free classic 2D jump'n run sidescroller game in a style similar to the original [Super Mario games][2] covered under the GNU GPL."
-
-[Suggested read: 30 Best Linux Games On Steam You Should Play in 2018][11]
-
-As you would expect from the title of the game, you play as [Tux][3], the beloved penguin mascot of the Linux kernel. In the opening sequence, Tux is having a picnic with his girlfriend Penny. While Tux dances to some funky beats from the radio, an evil monster named Nolok appears and kidnaps Penny. It's up to Tux to rescue her. (Currently, you are not able to rescue Penny because the game is not finished, but you can still have a lot of fun working your way through the levels.)
-
-![][4]
-
-
-### Gameplay
-
-Playing SuperTux is very similar to Super Mario. You play through different levels to complete a world. Along the way, you are confronted by a whole slew of enemies. The most common enemies are Mr. and Mrs. Snowball, Mr. Iceblock and Mr. Bomb. The Snowballs are this game's version of the Goombas from Super Mario. Mr. Iceblock is the Koopa Troopa of the game. You can defeat him by stomping on him, but if you stomp on him again he will fly across the level taking out other enemies. Be careful because on the way back he'll hit Tux and take a life away. You jump on Mr. Bomb to stun him, but be sure to move on quickly because he will explode. You can find a list of more of Tux's enemies [here][5].
-
-Just like in Super Mario, Tux can jump and hit special blocks to get stuff. Most of the time, these blocks contain coins. You can also find powerups, such as eggs, which will allow you to become BigTux. The other [powerups][6] include Fireflowers, Iceflowers, Airflowers, and Earthflowers. According to the [SuperTux wiki][7]:
-
- * Fireflowers will allow you to kill most badguys by pressing the action key, which makes Tux throw a fireball
- * Iceflowers will allow you to freeze some badguys and kill some others by pressing the action key, which makes Tux throw a ball of ice. If they are frozen, you can kill most badguys by butt-jumping on them.
- * Airflowers will allow you to jump further, sometimes even run faster. However, it can be difficult to do certain jumps as Air Tux.
- * Earthflowers give you a light. Also, pressing the action key then down will turn you into a rock for a few seconds, which means Tux is completely invulnerable.
-
-Occasionally, you will see a bell. That is a checkpoint. If you touch it, you will respawn at that point when you die, instead of having to go back to the beginning. You are limited to three respawns at the checkpoint before you are sent to the beginning of the level.
-
-You are not limited to the main Iceworld map that comes with the game. You can download several extra maps from the developers and the players. The game includes a map editor.
-
-![][8]
-
-### Where to Get SuperTux
-
-The most recent version of SuperTux is 0.5.1 and is available from the [project's website][9]. Interestingly, you can download installers for Windows or Mac or the source code. They don't have any Linux packages to download.
-
-However, I'm pretty sure that SuperTux is in all the repos. I've never had trouble installing it on any distro I've tried.
-
-[Suggested read: Top 10 Command Line Games For Linux][10]
-
-
-### Thoughts
-
-I quite enjoyed playing SuperTux. I never played proper Mario, so I can't really compare it. But, I think SuperTux does a good job of being its own creation.
-
-Tux can move pretty quickly for a penguin. He also tends to slide if he changes direction too quickly. After all, he's moving on ice.
-
-If you want a simple platformer to keep your mind off your troubles for while, this is the game for you.
-
-Have you ever played SuperTux? What is your favorite Tux-based or Linux game? Please let us know in the comments below. If you found this article interesting, please take a minute to share it on social media.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/supertux-game/
-
-作者:[John Paul][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/john/
-[1]:https://www.supertux.org/index.html
-[2]:https://en.wikipedia.org/wiki/Super_Mario_Bros.
-[3]:https://en.wikipedia.org/wiki/Tux
-[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/12/supertux-home.png
-[5]:https://github.com/SuperTux/supertux/wiki/Badguys
-[6]:https://github.com/SuperTux/supertux/wiki/User-Manual#powerups
-[7]:https://github.com/SuperTux/supertux/wiki/User-Manual
-[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/12/supertux-map.png
-[9]:https://www.supertux.org/download.html
-[10]:https://itsfoss.com/best-command-line-games-linux/
-[11]:https://itsfoss.com/best-linux-games-steam/
diff --git a/sources/tech/20180108 You GNOME it- Windows and Apple devs get a compelling reason to turn to Linux.md b/sources/tech/20180108 You GNOME it- Windows and Apple devs get a compelling reason to turn to Linux.md
deleted file mode 100644
index ed7e2650ce..0000000000
--- a/sources/tech/20180108 You GNOME it- Windows and Apple devs get a compelling reason to turn to Linux.md
+++ /dev/null
@@ -1,70 +0,0 @@
-You GNOME it: Windows and Apple devs get a compelling reason to turn to Linux
-======
-
-
-
-**Open Source Insider** The biggest open source story of 2017 was unquestionably Canonical's decision to stop developing its Unity desktop and move Ubuntu to the GNOME Shell desktop.
-
-What made the story that much more entertaining was how well Canonical pulled off the transition. [Ubuntu 17.10][1] was quite simply one of the best releases of the year and certainly the best release Ubuntu has put out in a good long time. Of course since 17.10 was not an LTS release, the more conservative users - which may well be the majority in Ubuntu's case - still haven't made the transition.
-
-![Woman takes a hammer to laptop][2]
-
-Ubuntu 17.10 pulled: Linux OS knackers laptop BIOSes, Intel kernel driver fingered
-
-Canonical pulled Ubuntu 17.10 downloads from its website last month due to a "bug" that could corrupt BIOS settings on some laptops. Lenovo laptops appear to be the most common source of problems, though users also reported problems with Acer and Dell.
-
-The bug is actually a result of Canonical's decision to enable the Intel SPI driver, which allows BIOS firmware updates. That sounds nice, but it's not ready for prime time. Clearly. It's also clearly labeled as such and disabled in the upstream kernel. For whatever reason Canonical enabled it and, as it says on the tin, the results were unpredictable.
-
-According to chatter on the Ubuntu mailing list, a fix is a few days away, with testing happening now. In the mean time, if you've been affected (for what it's worth, I have a Lenovo laptop and was *not* affected) OMGUbuntu has some [instructions that might possibly help][4].
-
-It's a shame it happened because the BIOS issue seriously mars what was an otherwise fabulous release of Ubuntu.
-
-Meanwhile, the repercussions of Canonical's move to GNOME are still being felt in the open source world and I believe this will continue to be one of the biggest stories in 2018 for several reasons. The first is that so many have yet to actually make the move to GNOME-based Ubuntu. That will change with 18.04, which is an LTS release set to arrive later this year. Users upgrading between LTS releases will get their first taste of Ubuntu with GNOME come April.
-
-### You got to have standards: Suddenly it's much, much more accessible
-
-The second, and perhaps much bigger, reason Ubuntu without Unity will continue to be a big story in the foreseeable future is that with Ubuntu using GNOME Shell, almost all the major distributions out there now ship primarily with GNOME, making GNOME Shell the de facto standard Linux desktop. That's not to say GNOME is the only option, but for a new user, landing on the Ubuntu downloads webpage or the Fedora download page or the Debian download page, the default links will get you GNOME Shell on the desktop.
-
-That makes it possible for Linux and open source advocates to make a more appealing case for the platform. The ubiquity of GNOME is something that hasn't been the case previously. And it may not be good news for KDE fans, but I believe it's going to have a profound impact on the future of desktop Linux and open source development more generally because it dovetails nicely with something that I believe has been a huge story in 2017 and will continue to be a huge story in 2018 - Flatpak/Snap packages.
-
-Combine a de facto standard desktop with a standard means of packaging applications and you have a platform that's just as easy to develop for as any other, say Windows or macOS.
-
-The development tools in GNOME, particularly the APIs and GNOME Builder tool that arrived earlier this year with GNOME 3.20, offer developers a standardised means of targeting the Linux desktop in a way that simply hasn't been possible until now. Combine that with the ability to package applications _independent of distro_ and you have a much more compelling platform for developers.
-
-That just might mean that developers not currently targeting Linux will be willing to take another look.
-
-Now this potential utopia has some downsides. As already noted it leaves KDE fans a little out in the cold. It also leaves my favourite distro looking a little less necessary than it used to. I won't be abandoning Arch Linux any time soon, but I'll have a lot harder time making a solid case for Arch with Flatpak/Snap packages having more or less eliminated the need for the Arch User Repository. That's not going to happen overnight, but I do think it will eventually get there.
-
-### What to look forward to...
-
-There are two other big stories to watch in 2018. The first is Amazon Linux 2, Amazon's new home-grown Linux distro, based - loosely it seems - on RHEL 7. While Amazon Linux 2 screams vendor lock-in to me, it will certainly appeal to the millions of companies already heavily invested in the AWS system.
-
-It also appears, from my limited testing, to offer some advantages over other images on EC2. One is speed: AL2 has been tuned to the AWS environment, but perhaps the bigger advantage is the uniformity and ease of moving from development to production entirely through identical containers.
-
-![Still from Mr Robot][5]
-
- Mozilla's creepy Mr Robot stunt in Firefox flops in touching tribute to TV show's 2nd season
-
-The last story worth keeping an eye on is Firefox. The once, and possibly future, darling of open source development had something of a rough year. Firefox 57 with the Quantum code re-write was perhaps the most impressive release since Firefox 1.0, but that was followed up by the rather disastrous Mr Robot tie-in promo fiasco that installed unwanted plugins in users situations, an egregious breach of trust that would have made even Chrome developers blush.
-
-I think there are going to be a lot more of these sorts of gaffes in 2018. Hopefully not involving Firefox, but as open source projects struggle to find different ways to fund themselves and attain higher levels of recognition, we should expect there to be plenty of ill-advised stunts of this sort.
-
-I'd say pop some popcorn, because the harder that open source projects try to find money, the more sparks - and disgruntled users - are going fly. ®
-
---------------------------------------------------------------------------------
-
-via: https://www.theregister.co.uk/2018/01/08/desktop_linux_open_source_standards_accessible/
-
-作者:[Scott Gilbertson][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:
-[1]:https://www.theregister.co.uk/2017/10/20/ubuntu_1710/
-[2]:https://regmedia.co.uk/2017/12/14/shutterstock_laptop_hit.jpg?x=174&y=115&crop=1
-[3]:https://www.theregister.co.uk/2017/12/21/ubuntu_lenovo_bios/
-[4]:http://www.omgubuntu.co.uk/2018/01/ubuntu-17-10-lenovo-fix
-[5]:https://regmedia.co.uk/2017/12/18/mr_robot_still.jpg?x=174&y=115&crop=1
-[6]:https://www.theregister.co.uk/2017/12/18/mozilla_mr_robot_firefox_promotion/
diff --git a/sources/tech/20180109 Profiler adventures resolving symbol addresses is hard.md b/sources/tech/20180109 Profiler adventures resolving symbol addresses is hard.md
deleted file mode 100644
index 971f575f5f..0000000000
--- a/sources/tech/20180109 Profiler adventures resolving symbol addresses is hard.md
+++ /dev/null
@@ -1,163 +0,0 @@
-Profiler adventures: resolving symbol addresses is hard!
-============================================================
-
-The other day I posted [How does gdb call functions?][1]. In that post I said:
-
-> Using the symbol table to figure out the address of the function you want to call is pretty straightforward
-
-Unsurprisingly, it turns out that figuring out the address in memory corresponding to a given symbol is actually not really that straightforward. This is actually something I’ve been doing in my profiler, and I think it’s interesting, so I thought I’d write about it!
-
-Basically the problem I’ve been trying to solve is – I have a symbol (like `ruby_api_version`), and I want to figure out which address that symbol is mapped to in my target process’s memory (so that I can get the data in it, like the Ruby process’s Ruby version). So far I’ve run into (and fixed!) 3 issues when trying to do this:
-
-1. When binaries are loaded into memory, they’re loaded at a random address (so I can’t just read the symbol table)
-
-2. The symbol I want isn’t necessary in the “main” binary (`/proc/PID/exe`, sometimes it’s in some other dynamically linked library)
-
-3. I need to look at the ELF program header to adjust which address I look at for the symbol
-
-I’ll start with some background, and then explain these 3 things! (I actually don’t know what gdb does)
-
-### what’s a symbol?
-
-Most binaries have functions and variables in them. For instance, Perl has a global variable called `PL_bincompat_options` and a function called `Perl_sv_catpv_mg`.
-
-Sometimes binaries need to look up functions from another binary (for example, if the binary is a dynamically linked library, you need to look up its functions by name). Also sometimes you’re debugging your code and you want to know what function an address corresponds to.
-
-Symbols are how you look up functions / variables in a binary. They’re in a section called the “symbol table”. The symbol table is basically an index for your binary! Sometimes they’re missing (“stripped”). There are a lot of binary formats, but this post is just about the usual binary format on Linux: ELF.
-
-### how do you get the symbol table of a binary?
-
-A thing that I learned today (or at least learned and then forgot) is that there are 2 possible sections symbols can live in: `.symtab` and `.dynsym`. `.dynsym` is the “dynamic symbol table”. According to [this page][2], the dynsym is a smaller version of the symtab that only contains global symbols.
-
-There are at least 3 ways to read the symbol table of a binary on Linux: you can use nm, objdump, or readelf.
-
-* **read the .symtab**: `nm $FILE`, `objdump --syms $FILE`, `readelf -a $FILE`
-
-* **read the .dynsym**: `nm -D $FILE`, `objdump --dynamic-syms $FILE`, `readelf -a $FILE`
-
-`readelf -a` is the same in both cases because `readelf -a` just shows you everything in an ELF file. It’s my favorite because I don’t need to guess where the information I want is, I can just print out everything and then use grep.
-
-Here’s an example of some of the symbols in `/usr/bin/perl`. You can see that each symbol has a **name**, a **value**, and a **type**. The value is basically the offset of the code/data corresponding to that symbol in the binary. (except some symbols have value 0\. I think that has something to do with dynamic linking but I don’t understand it so we’re not going to get into it)
-
-```
-$ readelf -a /usr/bin/perl
-...
- Num: Value Size Type Ndx Name
- 523: 00000000004d6590 49 FUNC 14 Perl_sv_catpv_mg
- 524: 0000000000543410 7 FUNC 14 Perl_sv_copypv
- 525: 00000000005a43e0 202 OBJECT 16 PL_bincompat_options
- 526: 00000000004e6d20 2427 FUNC 14 Perl_pp_ucfirst
- 527: 000000000044a8c0 1561 FUNC 14 Perl_Gv_AMupdate
-...
-
-```
-
-### the question we want to answer: what address is a symbol mapped to?
-
-That’s enough background!
-
-Now – suppose I’m a debugger, and I want to know what address the `ruby_api_version` symbol is mapped to. Let’s use readelf to look at the relevant Ruby binary!
-
-```
-readelf -a ~/.rbenv/versions/2.1.6/bin/ruby | grep ruby_api_version
- 365: 00000000001f9180 12 OBJECT GLOBAL DEFAULT 15 ruby_api_version
-
-```
-
-Neat! The offset of `ruby_api_version` is `0x1f9180`. We’re done, right? Of course not! :)
-
-### Problem 1: ASLR (Address space layout randomization)
-
-Here’s the first issue: when Linux loads a binary into memory (like `~/.rbenv/versions/2.1.6/bin/ruby`), it doesn’t just load it at the `0` address. Instead, it usually adds a random offset. Wikipedia’s article on ASLR explains why:
-
-> Address space layout randomization (ASLR) is a memory-protection process for operating systems (OSes) that guards against buffer-overflow attacks by randomizing the location where system executables are loaded into memory.
-
-We can see this happening in practice: I started `/home/bork/.rbenv/versions/2.1.6/bin/ruby` 3 times and every time the process gets mapped to a different place in memory. (`0x56121c86f000`, `0x55f440b43000`, `0x56163334a000`)
-
-Here we’re meeting our good friend `/proc/$PID/maps` – this file contains a list of memory maps for a process. The memory maps tell us every address range in the process’s virtual memory (it turns out virtual memory isn’t contiguous! Instead process get a bunch of possibly-disjoint memory maps!). This file is so useful! You can find the address of the stack, the heap, every dynamically loaded library, anonymous memory maps, and probably more.
-
-```
-$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
-56121c86f000-56121caf0000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-56121ccf0000-56121ccf5000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-56121ccf5000-56121ccf7000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
-55f440b43000-55f440dc4000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-55f440fc4000-55f440fc9000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-55f440fc9000-55f440fcb000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
-56163334a000-5616335cb000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-5616337cb000-5616337d0000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-5616337d0000-5616337d2000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
-
-```
-
-Okay, so in the last example we see that our binary is mapped at `0x56163334a000`. If we combine this with the knowledge that `ruby_api_version` is at `0x1f9180`, then that means that we just need to look that the address `0x1f9180 + 0x56163334a000` to find our variable, right?
-
-Yes! In this case, that works. But in other cases it won’t! So that brings us to problem 2.
-
-### Problem 2: dynamically loaded libraries
-
-Next up, I tried running system Ruby: `/usr/bin/ruby`. This binary has basically no symbols at all! Disaster! In particular it does not have a `ruby_api_version`symbol.
-
-But when I tried to print the `ruby_api_version` variable with gdb, it worked!!! Where was gdb finding my symbol? I found the answer with the help of our good friend: `/proc/PID/maps`
-
-It turns out that `/usr/bin/ruby` dynamically loads a library called `libruby-2.3`. You can see it in the memory maps here:
-
-```
-$ cat /proc/(pgrep -f /usr/bin/ruby)/maps | grep libruby
-7f2c5d789000-7f2c5d9f1000 r-xp 00000000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
-7f2c5d9f1000-7f2c5dbf0000 ---p 00268000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
-7f2c5dbf0000-7f2c5dbf6000 r--p 00267000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
-7f2c5dbf6000-7f2c5dbf7000 rw-p 0026d000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
-
-```
-
-And if we read it with `readelf`, we find the address of that symbol!
-
-```
-readelf -a /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0 | grep ruby_api_version
- 374: 00000000001c72f0 12 OBJECT GLOBAL DEFAULT 13 ruby_api_version
-
-```
-
-So in this case the address of the symbol we want is `0x7f2c5d789000` (the start of the libruby-2.3 memory map) plus `0x1c72f0`. Nice! But we’re still not done. There is (at least) one more mystery!
-
-### Problem 3: the `vaddr` offset in the ELF program header
-
-This one I just figured out today so it’s the one I have the shakiest understanding of. Here’s what happened.
-
-I was running system ruby on Ubuntu 14.04: Ruby 1.9.3\. And my usual code (find the libruby map, get its address, get the symbol offset, add them up) wasn’t working!!! I was confused.
-
-But I’d asked Julian if he knew of any weird stuff I need to worry about a while back and he said “well, you should read the code for `dlsym`, you’re trying to do basically the same thing”. So I decided to, instead of randomly guessing, go read the code for `dlsym`.
-
-The man page for `dlsym` says “dlsym, dlvsym - obtain address of a symbol in a shared object or executable”. Perfect!!
-
-[Here’s the dlsym code from musl I read][3]. (musl is like glibc, but, different. Maybe easier to read? I don’t understand it that well.)
-
-The dlsym code says (on line 1468) `return def.dso->base + def.sym->st_value;` That sounds like what I’m doing!! But what’s `dso->base`? It looks like `base = map - addr_min;`, and `addr_min = ph->p_vaddr;`. (there’s also some stuff that makes sure `addr_min` is aligned with the page size which I should maybe pay attention to.)
-
-So the code I want is something like `map_base - ph->p_vaddr + sym->st_value`.
-
-I looked up this `vaddr` thing in the ELF program header, subtracted it from my calculation, and voilà! It worked!!!
-
-### there are probably more problems!
-
-I imagine I will discover even more ways that I am calculating the symbol address wrong. It’s interesting that such a seemingly simple thing (“what’s the address of this symbol?”) is so complicated!
-
-It would be nice to be able to just call `dlsym` and have it do all the right calculations for me, but I think I can’t because the symbol is in a different process. Maybe I’m wrong about that though! I would like to be wrong about that. If you know an easier way to do all this I would very much like to know!
-
---------------------------------------------------------------------------------
-
-via: https://jvns.ca/blog/2018/01/09/resolving-symbol-addresses/
-
-作者:[Julia Evans ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://jvns.ca
-[1]:https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/
-[2]:https://blogs.oracle.com/ali/inside-elf-symbol-tables
-[3]:https://github.com/esmil/musl/blob/194f9cf93da8ae62491b7386edf481ea8565ae4e/src/ldso/dynlink.c#L1451
diff --git a/sources/tech/20180114 Playing Quake 4 on Linux in 2018.md b/sources/tech/20180114 Playing Quake 4 on Linux in 2018.md
deleted file mode 100644
index 26dd305a4a..0000000000
--- a/sources/tech/20180114 Playing Quake 4 on Linux in 2018.md
+++ /dev/null
@@ -1,80 +0,0 @@
-Playing Quake 4 on Linux in 2018
-======
-A few months back [I wrote an article][1] outlining the various options Linux users now have for playing Doom 3, as well as stating which of the three contenders I felt to be the best option in 2017. Having already gone to the trouble of getting the original Doom 3 binary working on my modern Arch Linux system, it made me wonder just how much effort it would take to get the closed source Quake 4 port up and running again as well.
-
-### Getting it running
-
-[![][2]][3] [![][4]][5]
-
-Quake 4 was ported to Linux by Timothee Besset in 2005, although the binaries themselves were later taken down along with the rest of the id Software FTP server by ZeniMax. The original [Linux FAQ page][6] is still online though, and mirrors hosting the Linux installer still exist, such as [this one][7] ran by the fan website [Quaddicted][8]. Once downloaded this will give you a graphical installer which will install the game binary without any of the game assets.
-
-These will need to be taken from either the game discs of a retail Windows version as I did, or taken from an already installed Windows version of the game such as from [Steam][9]. Follow the steps in the Linux FAQ to the letter for best results. Please note that the [GOG.com][10] release of Quake 4 is unique in not supplying a valid CD key, something which is still required for the Linux port to launch. There are [ways to get around this][11], but we only condone these methods for legitimate purchasers.
-
-Like with Doom 3 I had to remove the libgcc_s.so.1, libSDL-1.2.id.so.0, and libstdc++.so.6 libraries that the game came with in the install directory in order to get it to run. I also ran into the same sound issue I had with Doom 3, meaning I had to modify the Quake4Config.cfg file located in the hidden ~/.quake4/q4base directory in the same fashion as before. However, this time I ran into a whole host of other issues that made me have to modify the configuration file as well.
-
-First off the language the game wanted to use would always default to Spanish, meaning I had to manually tell the game to use English instead. I also ran into a known issue on all platforms wherein the game would not properly recognize the available VRAM on modern graphics cards, and as such would force the game to use lower image quality settings. Quake 4 will also not render see-through surfaces unless anti-aliasing is enabled, although going beyond 8x caused the game not to load for me.
-
-Appending the following to the end of the Quake4Config.cfg file resolved all of my issues:
-
-```
-seta image_downSize "0"
-seta image_downSizeBump "0"
-seta image_downSizeSpecular "0"
-seta image_filter "GL_LINEAR_MIPMAP_LINEAR"
-seta image_ignoreHighQuality "0"
-seta image_roundDown "0"
-seta image_useCompression "0"
-seta image_useNormalCompression "0"
-seta image_anisotropy "16"
-seta image_lodbias "0"
-seta r_renderer "best"
-seta r_multiSamples "8"
-seta sys_lang "english"
-seta s_alsa_pcm "hw:0,0"
-seta com_allowConsole "1"
-```
-
-Please note that this will also set the game to use 8x anti-aliasing and restore the drop down console to how it worked in all of the previous Quake games. Similar to the Linux port of Doom 3 the Linux version of Quake 4 also does not support Creative EAX ADVANCED HD audio technology. Unlike Doom 3 though Quake 4 does seem to also feature an alternate method for surround sound, and widescreen support was thankfully patched into the game soon after its release.
-
-### Playing the game
-
-[![][12]][13] [![][14]][15]
-
-Over the years Quake 4 has gained something of a reputation as the black sheep of the Quake family, with many people complaining that the game's vehicle sections, squad mechanics, and general aesthetic made it feel too close to contemporary military shooters of the time. In the game's heart of hearts though it really does feel like a concerted sequel to Quake II, with some of developer Raven Software's own Star Trek: Voyager - Elite Force title thrown in for good measure.
-
-To me at least Quake 4 does stand as being one of the "Last of the Romans" in terms of being a first person shooter that embraced classic design ideals at a time when similar titles were not getting the support of major publishers. Most of the game still features the player moving between levels featuring fixed enemy placements, a wide variety of available weapons, traditional health packs, and an array of enemies each sporting unique attributes and skills.
-
-Quake 4 also offers a well made campaign that I found myself going back to on a higher skill level not long after I had already finished my first try at the game. Certain aspects like the vehicle sections do indeed drag the game down a bit, and the multiplayer aspect pails in comparison to its predecessor Quake III Arena, but overall I am quite pleased with what Raven Software was able to accomplish with the Doom 3 engine, especially when so few others tried.
-
-### Final thoughts
-
-If anyone ever needed a reason to be reminded of the value of video game source code releases, this is it. Most of the problems I encountered could have been easily sidestepped if Quake 4 source ports were available, but with the likes of John Carmack and Timothee Besset gone from id Software and the current climate at ZeniMax not looking too promising, it is doubtful that any such creations will ever materialize. Doom 3 source ports look to be the end of the road.
-
-Instead we are stuck using this cranky 32 bit binary with an obstructive CD Key check and a graphics system that freaks out at the sight of any modern video card sporting more than 512 MB of VRAM. The game itself has aged well, with graphics that still look great and dynamic lighting that is better than what is included with many modern titles. It is just a shame that it is now such a pain to get running, not just on Linux, but on any platform.
-
---------------------------------------------------------------------------------
-
-via: https://www.gamingonlinux.com/articles/playing-quake-4-on-linux-in-2018.11017
-
-作者:[Hamish][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.gamingonlinux.com/profiles/6
-[1]:https://www.gamingonlinux.com/articles/playing-doom-3-on-linux-in-2017.10561
-[2]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/20458196191515697921gol6.jpg
-[3]:https://www.gamingonlinux.com/uploads/articles/article_images/20458196191515697921gol6.jpg
-[4]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/9405540721515697921gol6.jpg
-[5]:https://www.gamingonlinux.com/uploads/articles/article_images/9405540721515697921gol6.jpg
-[6]:http://zerowing.idsoftware.com/linux/quake4/Quake4FrontPage/
-[7]:https://www.quaddicted.com/files/idgames2/idstuff/quake4/linux/
-[8]:https://www.quaddicted.com/
-[9]:http://store.steampowered.com/app/2210/Quake_IV/
-[10]:https://www.gog.com/game/quake_4
-[11]:https://www.gog.com/forum/quake_series/quake_4_on_linux_no_cd_key/post31
-[12]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/5043571471515951537gol6.jpg
-[13]:https://www.gamingonlinux.com/uploads/articles/article_images/5043571471515951537gol6.jpg
-[14]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/6922853731515697921gol6.jpg
-[15]:https://www.gamingonlinux.com/uploads/articles/article_images/6922853731515697921gol6.jpg
diff --git a/sources/tech/20180116 How To Create A Bootable Zorin OS USB Drive.md b/sources/tech/20180116 How To Create A Bootable Zorin OS USB Drive.md
deleted file mode 100644
index 4ab7fea3f6..0000000000
--- a/sources/tech/20180116 How To Create A Bootable Zorin OS USB Drive.md
+++ /dev/null
@@ -1,315 +0,0 @@
-How To Create A Bootable Zorin OS USB Drive
-======
-![Zorin OS][17]
-
-### Introduction
-
-In this guide I will show you how to create a bootable Zorin OS USB Drive.
-
-To be able to follow this guide you will need the following:
-
- * A blank USB drive
- * An internet connection
-
-
-
-### What Is Zorin OS?
-
-Zorin OS is a Linux based operating system.
-
-If you are a Windows user you might wonder why you would bother with Zorin OS. If you are a Linux user then you might also wonder why you would use Zorin OS over other distributions such as Linux Mint or Ubuntu.
-
-If you are using an older version of Windows and you can't afford to upgrade to Windows 10 or your computer doesn't have the right specifications for running Windows 10 then Zorin OS provides a free (or cheap, depending how much you choose to donate) upgrade path allowing you to continue to use your computer in a much more secure environment.
-
-If your current operating system is Windows XP or Windows Vista then you might consider using Zorin OS Lite as opposed to Zorin OS Core.
-
-The features of Zorin OS Lite are generally the same as the Zorin OS Core product but some of the applications installed and the desktop environment used for displaying menus and icons and other Windowsy features take up much less memory and processing power.
-
-If you are running Windows 7 then your operating system is coming towards the end of its life. You could probably upgrade to Windows 10 but at a hefty price.
-
-Not everybody has the finances to pay for a new Windows license and not everybody has the money to buy a brand new computer.
-
-Zorin OS will help you extend the life of your computer and you will still feel you are using a premium product and that is because you will be. The product with the highest price doesn't always provide the best value.
-
-Whilst we are talking about value for money, Zorin OS allows you to install the best free and open source software available and comes with a good selection of packages pre-installed.
-
-For the home user, using Zorin OS doesn't have to feel any different to running Windows. You can browse the web using the browser of your choice, you can listen to music and watch videos. There are mail clients and other productivity tools.
-
-Talking of productivity there is LibreOffice. LibreOffice has everything the average home user requires from an office suite with a word processor, spreadsheet and presentations package.
-
-If you want to run Windows software then you can use the pre-installed PlayOnLinux and WINE packages to install and run all manner of packages including Microsoft Office.
-
-By running Zorin OS you will get the extra security benefits of running a Linux based operating system.
-
-Are you fed up with Windows updates stalling your productivity? When Windows wants to install updates it requires a reboot and then a long wait whilst it proceeds to install update after update. Sometimes it even forces a reboot whilst you are busy working.
-
-Zorin OS is different. Updates download and install themselves whilst you are using the computer. You won't even need to know it is happening.
-
-Why Zorin over Mint or Ubuntu? Zorin is the happy stepping stone between Windows and Linux. It is Linux but you don't need to care that it is Linux. If you decide later on to move to something different then so be it but there really is no need.
-
-### The Zorin OS Website
-
-
-
-You can visit the Zorin OS website by visiting [www.zorinos.com][18].
-
-The homepage of the Zorin OS website tells you everything you need to know.
-
-"Zorin OS is an alternative to Windows and macOX, designed to make your computer faster, more powerful and secure".
-
-There is nothing that tells you that Zorin OS is based on Linux. There is no need for Zorin to tell you that because even though Windows used to be heavily based on DOS you didn't need to know DOS commands to use it. Likewise you don't necessarily need to know Linux commands to use Zorin.
-
-If you scroll down the page you will see a slide show highlighting the way the desktop looks and feels under Zorin.
-
-The good thing is that you can customise the user interface so that if you prefer a Windows layout you can use a Windows style layout but if you prefer a Mac style layout you can go for that as well.
-
-Zorin OS is based on Ubuntu Linux and the website uses this fact to highlight that underneath it has a stable base and it highlights the security benefits provided by Linux.
-
-If you want to see what applications are available for Zorin then there is a link to do that and Zorin never sells your data and protects your privacy.
-
-### What Are The Different Versions Of Zorin OS
-
-#### Zorin OS Ultimate
-
-The ultimate edition takes the core edition and adds other features such as different layouts, more applications pre-installed and extra games.
-
-The ultimate edition comes at a price of 19 euros which is a bargain compared to other operating systems.
-
-#### Zorin OS Core
-
-The core version is the standard edition and comes with everything the average person could need from the outset.
-
-This is the version I will show you how to download and install in this guide.
-
-#### Zorin OS Lite
-
-Zorin OS Lite also has an ultimate version available and a core version. Zorin OS Lite is perfect for older computers and the main difference is the desktop environments used to display menus and handle screen elements such as icons and panels.
-
-Zorin OS Lite is less memory intensive than Zorin OS.
-
-#### Zorin OS Business
-
-Zorin OS Business comes with business applications installed as standard such as finance applications and office applications.
-
-### How To Get Zorin OS
-
-To download Zorin OS visit <https://zorinos.com/download/>.
-
-To get the core version scroll past the Zorin Ultimate section until you get to the Zorin Core section.
-
-You will see a small pay panel which allows you to choose how much you wish to pay for Zorin Core with a purchase now button underneath.
-
-#### How To Pay For Zorin OS
-
-
-
-You can choose from the three preset amounts or enter an amount of your choice in the "Custom" box.
-
-When you click "Purchase Zorin OS Core" the following window will appear:
-
-
-
-You can now enter your email and credit card information.
-
-When you click the "pay" button a window will appear with a download link.
-
-#### How To Get Zorin OS For Free
-
-If you don't wish to pay anything at all you can enter zero (0) into the custom box. The button will change and will show the words "Download Zorin OS Core".
-
-#### How To Download Zorin OS
-
-
-
-Whether you have bought Zorin or have chosen to download for free, a window will appear with the option to download a 64 bit or 32 bit version of Zorin.
-
-Most modern computers are capable of running 64 bit operating systems but in order to check within Windows click the "start" button and type "system information".
-
-
-
-Click on the "System Information" desktop app and halfway down the right panel you will see the words "system type". If you see the words "x64 based PC" then the system is capable of running 64-bit operating systems.
-
-If your computer is capable of running 64-bit operating systems click on the "Download 64 bit" button otherwise click on "Download 32 bit".
-
-The ISO image file for Zorin will now start to download to your computer.
-
-### How To Verify If The Zorin OS Download Is Valid
-
-It is important to check whether the download is valid for many reasons.
-
-If the file has only partially downloaded or there were interruptions whilst downloading and you had to resume then the image might not be perfect and it should be downloaded again.
-
-More importantly you should check the validity to make sure the version you downloaded is genuine and wasn't uploaded by a hacker.
-
-In order to check the validity of the ISO image you should download a piece of software called QuickHash for Windows from <https://www.quickhash-gui.org/download/quickhash-v2-8-4-for-windows/>.
-
-Click the "download" link and when the file has downloaded double click on it.
-
-Click on the relevant application file within the zip file. If you have a 32-bit system click "Quickhash-v2.8.4-32bit" or for a 64-bit system click "Quickhash-v2.8.4-64bit".
-
-Click on the "Run" button.
-
-
-
-Click the SHA256 radio button on the left side of the screen and then click on the file tab.
-
-Click "Select File" and navigate to the downloads folder.
-
-Choose the Zorin ISO image downloaded previously.
-
-A progress bar will now work out the hash value for the ISO image.
-
-To compare this with the valid keys available for Zorin visit <https://zorinos.com/help/install-zorin-os/> and scroll down until you see the list of checksums as follows:
-
-
-
-Select the long list of scrambled characters next to the version of Zorin OS that you downloaded and press CTRL and C to copy.
-
-Go back to the Quickhash screen and paste the value into the "Expected hash value" box by pressing CTRL and V.
-
-You should see the words "Expected hash matches the computed file hash, OK".
-
-If the values do not match you will see the words "Expected hash DOES NOT match the computed file hash" and you should download the ISO image again.
-
-### How To Create A Bootable Zorin OS USB Drive
-
-In order to be able to install Zorin you will need to install a piece of software called Etcher. You will also need a blank USB drive.
-
-You can download Etcher from <https://etcher.io/>.
-
-
-
-If you are using a 64 bit computer click on the "Download for Windows x64" link otherwise click on the little arrow and choose "Etcher for Windows x86 (32-bit) (Installer)".
-
-Insert the USB drive into your computer and double click on the "Etcher" setup executable file.
-
-
-
-When the license screen appears click "I Agree".
-
-Etcher should start automatically after the installation completes but if it doesn't you can press the Windows key or click the start button and search for "Etcher".
-
-
-
-Click on "Select Image" and select the "Zorin" ISO image downloaded previously.
-
-Click "Flash".
-
-Windows will ask for your permission to continue. Click "Yes" to accept.
-
-After a while a window will appear with the words "Flash Complete".
-
-### How To Buy A Zorin OS USB Drive
-
-If the above instructions seem too much like hard work then you can order a Zorin USB Drive by clicking one of the following links:
-
-* [Zorin OS Core – 32-bit DVD][1]
-
-* [Zorin OS Core – 64-bit DVD][2]
-
-* [Zorin OS Core – 16 gigabyte USB drive (32-bit)][3]
-
-* [Zorin OS Core – 32 gigabyte USB drive (32-bit)][4]
-
-* [Zorin OS Core – 64 gigabyte USB drive (32-bit)][5]
-
-* [Zorin OS Core – 16 gigabyte USB drive (64-bit)][6]
-
-* [Zorin OS Core – 32 gigabyte USB drive (64-bit)][7]
-
-* [Zorin OS Core – 64 gigabyte USB drive (64-bit)][8]
-
-* [Zorin OS Lite – 32-bit DVD][9]
-
-* [Zorin OS Lite – 64-bit DVD][10]
-
-* [Zorin OS Lite – 16 gigabyte USB drive (32-bit)][11]
-
-* [Zorin OS Lite – 32 gigabyte USB drive (32-bit)][12]
-
-* [Zorin OS Lite – 64 gigabyte USB drive (32-bit)][13]
-
-* [Zorin OS Lite – 16 gigabyte USB drive (64-bit)][14]
-
-* [Zorin OS Lite – 32 gigabyte USB drive (64-bit)][15]
-
-* [Zorin OS Lite – 64 gigabyte USB drive (64-bit)][16]
-
-
-### How To Boot Into Zorin OS Live
-
-On older computers simply insert the USB drive and restart the computer. The boot menu for Zorin should appear straight away.
-
-On modern computers insert the USB drive, restart the computer and before Windows loads press the appropriate function key to bring up the boot menu.
-
-The following list shows the key or keys you can press for the most popular computer manufacturers.
-
- * Acer - Escape, F12, F9
- * Asus - Escape, F8
- * Compaq - Escape, F9
- * Dell - F12
- * Emachines - F12
- * HP - Escape, F9
- * Intel - F10
- * Lenovo - F8, F10, F12
- * Packard Bell - F8
- * Samsung - Escape, F12
- * Sony - F10, F11
- * Toshiba - F12
-
-
-
-Check the manufacturer's website to find the key for your computer if it isn't listed or keep trying different function keys or the escape key.
-
-A screen will appear with the following three options:
-
- 1. Try Zorin OS without Installing
- 2. Install Zorin OS
- 3. Check disc for defects
-
-
-
-Choose "Try Zorin OS without Installing" by pressing enter with that option selected.
-
-### Summary
-
-You can now try Zorin OS without damaging your current operating system.
-
-To get back to your original operating system reboot and remove the USB drive.
-
-### How To Remove Zorin OS From The USB Drive
-
-If you have decided that Zorin OS is not for you and you want to get the USB drive back into its pre-Zorin state follow this guide:
-
-[How To Fix A USB Drive After Linux Has Been Installed On It][19]
-
---------------------------------------------------------------------------------
-
-via: http://dailylinuxuser.com/2018/01/how-to-create-a-bootable-zorin-os-usb-drive.html
-
-作者:[admin][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:
-[1]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-install-live-dvd-32bit.html?affiliate=everydaylinuxuser
-[2]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-install-live-dvd-64bit.html?affiliate=everydaylinuxuser
-[3]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-16gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
-[4]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-32gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
-[5]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-64gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
-[6]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-16gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
-[7]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-32gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
-[8]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-64gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
-[9]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-install-live-dvd-32bit.html?affiliate=everydaylinuxuser
-[10]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-install-live-dvd-64bit.html?affiliate=everydaylinuxuser
-[11]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-16gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
-[12]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-32gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
-[13]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-64gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
-[14]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-16gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
-[15]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-32gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
-[16]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-64gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
-[17]:http://dailylinuxuser.com/wp-content/uploads/2018/01/zorindesktop-678x381.png (Zorin OS)
-[18]:http://www.zorinos.com
-[19]:http://dailylinuxuser.com/2016/04/how-to-fix-usb-drive-after-linux-has.html
diff --git a/sources/tech/20180119 Top 6 open source desktop email clients.md b/sources/tech/20180119 Top 6 open source desktop email clients.md
deleted file mode 100644
index 7493714453..0000000000
--- a/sources/tech/20180119 Top 6 open source desktop email clients.md
+++ /dev/null
@@ -1,115 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Top 6 open source desktop email clients)
-[#]: via: (https://opensource.com/business/18/1/desktop-email-clients)
-[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
-
-Top 6 open source desktop email clients
-======
-
-
-
-This article was originally published on October 8, 2015, and has been updated to reflect new information and project changes.
-
-Mobile and web technologies still haven't made the desktop obsolete, and despite some regular claims to the contrary, desktop clients don't seem to be going away anytime soon.
-
-And with good reason. For many, the preference for a native application (and corresponding native performance), easy offline use, a vast array of plugins, and meeting security needs will long outweigh pressures to switch to a webmail email client. Whether you're sticking with a desktop email client because of a corporate mandate or just personal preference, there are still many great options to choose from. And just because you may be stuck on Windows doesn't mean Outlook is your only option; many open source clients are cross-platform.
-
-In this roundup, we take a quick look at six open source options for desktop email, share a little bit about each, and provide you with some options you may want to try yourself.
-
-### Thunderbird
-
-For many years, Mozilla [Thunderbird][1] was the king of the open source email clients. It was available on all major platforms, and it had great success alongside Mozilla's now-flagship project, Firefox. Thunderbird has been around for over a decade and was immediately popular from the start, receiving over a million downloads in its first 10 days of public release.
-
-In recent years, the thunder behind Thunderbird got a little quieter, and in mid-2017 the project announced it would move off Mozilla's infrastructure, but keep the Mozilla Foundation as its legal and fiscal home. Several [new hires][2] were made to advance the project, with plans to bring in new developers to fix lingering issues and transform the codebase to be based on web technologies.
-
-Thunderbird is full-featured, with a number of well-supported plugins adding everything from calendar support to advanced address book integration, and many specialized features including theming and large file management. Out of the box, it supports POP and IMAP email syncing, spam filtering, and many other features you would expect, and it works flawlessly across Windows, macOS, and Linux.
-
-Thunderbird is made available under the [Mozilla Public License][3].
-
-![Thunderbird][4]
-
-### Claws Mail
-
-[Claws Mail][5], a fork of [Sylpheed][6], is a fast and flexible alternative that might be appealing to anyone concerned about performance and minimal resource usage. It's a good option, for example, if you're working within the limited processing and memory capacity of a [Raspberry Pi][7], for example.
-
-But even for those with virtually unlimited computing resources to throw at a mail client, Claws Mail might be a good option. It's flexible, probably more so than Thunderbird or some of the other options in this list, and it has a number of plugins available for those who want to extend it. And it prides itself on being fast and reliable, too, in addition to sporting a simple interface that's perhaps ideal for new users.
-
-Claws Mail is based on the GTK+ framework and made available under the [GPL][8].
-
-
-
-### Evolution
-
-If you're a user of the popular Fedora or Debian distributions, you're probably already familiar with the next option on our list, [Evolution][9]. Evolution is an official part of the GNOME project, but it didn't start out that way. Originally developed at Ximian, and later Novell, Evolution was designed from the ground up to be an enterprise-ready email application.
-
-To this end, Evolution supports Exchange Server and a number of other email setups you might find in a corporate environment. It's also a full personal information manager (PIM), sporting a calendar, task list, contact manager, and note taking application, in addition to handling your email. Even if it's not the default mail application in your distribution, you might want to take a look if you're interested in these features or the included spam filtering, GNU Privacy Guard (GPG) support, integration with LibreOffice, or a slew of other features.
-
-Evolution is made available as open source under the [LGPL][10].
-
-
-
-### Geary
-
-[Geary][11] is a project originally developed by Yorba Foundation, which made a number of different GNOME software tools. Geary supports a number of popular webmail services as the mail backend through IMAP.
-
-Geary doesn't have a lot of features compared to some other clients on this list, but its simple interface might be appealing to users frustrated with unnecessary complexity in other email programs. Geary is available under the [LGPL][10].
-
-
-
-### KMail
-
-[KMail][12] is the mail component of [Kontact][13], the personal information manager included with KDE. KMail supports a variety of email protocols, including IMAP, SMTP, and POP3, and through its integration with the other Kontact components, it could be considered a complete groupware suite. Despite its Linux routes, a Windows build is also available.
-
-With its long history, KMail has developed most of the features you would expect to find in a modern mail program. While it fits nicely into the KDE group of applications, some may find its interface clunky compared to others. But give it a try and see what you think.
-
-KMail is made available under the [GPL][14].
-
-
-
-### Mailspring
-
-[Mailspring][15], the new kid on the block, is a relaunch of the now-defunct Nylas Mail by one of the original authors. It replaces Nylas' JavaScript sync engine with a C++ core, which is said to minimize the application's RAM and power demands, and removes heavy dependencies to add speed. Its features include a unified inbox, support for IMAP (but not ActiveSync), Gmail-style search, themes, and message translation.
-
-Mailspring is available for macOS, Windows, and Linux, and it's licensed under [GPLv3][16].
-
-![Mailspring][17]
-
-Of course, there are many more options above and beyond these, including the full-featured PIM [Zimbra Desktop][18] or one of the [lightweight alternatives][19] like [GNUMail][20] that might be the best choice for your situation. What's your favorite open source desktop email client? And with webmail as the first choice of many users, what do you see as the role of the desktop email client in the years to come? Let us know in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/business/18/1/desktop-email-clients
-
-作者:[Jason Baker][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/jason-baker
-[b]: https://github.com/lujun9972
-[1]: https://www.mozilla.org/en-US/thunderbird/
-[2]: https://blog.mozilla.org/thunderbird/2017/12/new-thunderbird-releases-and-new-thunderbird-staff/
-[3]: https://www.mozilla.org/en-US/MPL/
-[4]: https://opensource.com/sites/default/files/u128651/desktop-email-thunderbird57.png (Thunderbird)
-[5]: http://www.claws-mail.org/
-[6]: http://sylpheed.sraoss.jp/en/
-[7]: https://opensource.com/resources/what-raspberry-pi
-[8]: http://www.claws-mail.org/COPYING
-[9]: https://wiki.gnome.org/Apps/Evolution
-[10]: http://www.gnu.org/licenses/lgpl-3.0.en.html
-[11]: https://wiki.gnome.org/Apps/Geary
-[12]: https://userbase.kde.org/KMail
-[13]: https://userbase.kde.org/Kontact
-[14]: http://www.gnu.org/licenses/gpl-3.0.en.html
-[15]: https://getmailspring.com/
-[16]: https://github.com/Foundry376/Mailspring/blob/master/LICENSE.md
-[17]: https://opensource.com/sites/default/files/u128651/desktop-email-mailspring.png (Mailspring)
-[18]: https://www.zimbra.com/open-source-email-overview/
-[19]: https://opensource.com/article/17/7/email-alternatives-thunderbird
-[20]: http://wiki.gnustep.org/index.php/GNUMail
diff --git a/sources/tech/20180126 An introduction to the Web Simple Perl module a minimalist web framework.md b/sources/tech/20180126 An introduction to the Web Simple Perl module a minimalist web framework.md
deleted file mode 100644
index ab8c29b2b6..0000000000
--- a/sources/tech/20180126 An introduction to the Web Simple Perl module a minimalist web framework.md
+++ /dev/null
@@ -1,106 +0,0 @@
-An introduction to the Web::Simple Perl module, a minimalist web framework
-============================================================
-
-### Perl module Web::Simple is easy to learn and packs a big enough punch for a variety of one-offs and smaller services.
-
-
-
-Image credits : [You as a Machine][10]. Modified by Rikki Endsley. [CC BY-SA 2.0][11].
-
-One of the more-prominent members of the Perl community is [Matt Trout][12], technical director at [Shadowcat Systems][13]. He's been building core tools for Perl applications for years, including being a co-maintaner of the [Catalyst][14] MVC (Model, View, Controller) web framework, creator of the [DBIx::Class][15] object-management system, and much more. In person, he's energetic, interesting, brilliant, and sometimes hard to keep up with. When Matt writes code…well, think of a runaway chainsaw, with the trigger taped down and the safety features disabled. He's off and running, and you never quite know what will come out. Two things are almost certain: the module will precisely fit the purpose Matt has in mind, and it will show up on CPAN for others to use.
-
-
-One of Matt's special-purpose modules is [Web::Simple][23]. Touted as "a quick and easy way to build simple web applications," it is a stripped-down, minimalist web framework, with an easy to learn interface. Web::Simple is not at all designed for a large-scale application; however, it may be ideal for a small tool that does one or two things in a lower-traffic environment. I can also envision it being used for rapid prototyping if you wanted to create quick wireframes of a new application for demonstrations.
-
-### Installation, and a quick "Howdy!"
-
-You can install the module using `cpan` or `cpanm`. Once you've got it installed, you're ready to write simple web apps without having to hassle with managing the connections or any of that—just your functionality. Here's a quick example:
-
-```
-#!/usr/bin/perl
-package HelloReader;
-use Web::Simple;
-
-sub dispatch_request {
- GET => sub {
- [ 200, [ 'Content-type', 'text/plain' ], [ 'Howdy, Opensource.com reader!' ] ]
- },
- '' => sub {
- [ 405, [ 'Content-type', 'text/plain' ], [ 'You cannot do that, friend. Sorry.' ] ]
- }
-}
-
-HelloReader->run_if_script;
-```
-
-There are a couple of things to notice right off. For one, I didn't `use strict` and `use warnings` like I usually would. Web::Simple imports those for you, so you don't have to. It also imports [Moo][16], a minimalist OO framework, so if you know Moo and want to use it here, you can! The heart of the system lies in the `dispatch_request`method, which you must define in your application. Each entry in the method is a match string, followed by a subroutine to respond if that string matches. The subroutine must return an array reference containing status, headers, and content of the reply to the request.
-
-### Matching
-
-The matching system in Web::Simple is powerful, allowing for complicated matches, passing parameters in a URL, query parameters, and extension matches, in pretty much any combination you want. As you can see in the example above, starting with a capital letter will match on the request method, and you can combine that with a path match easily:
-
-```
-'GET + /person/*' => sub {
- my ($self, $person) = @_;
- # write some code to retrieve and display a person
- },
-'POST + /person/* + %*' => sub {
- my ($self, $person, $params) = @_;
- # write some code to modify a person, perhaps
- }
-```
-
-In the latter case, the third part of the match indicates that we should pick up all the POST parameters and put them in a hashref called `$params` for use by the subroutine. Using `?` instead of `%` in that part of the match would pick up query parameters, as normally used in a GET request. There's also a useful exported subroutine called `redispatch_to`. This tool lets you redirect, without using a 3xx redirect; it's handled internally, invisible to the user. So:
-
-```
-'GET + /some/url' => sub {
- redispatch_to '/some/other/url';
-}
-```
-
-A GET request to `/some/url` would get handled as if it was sent to `/some/other/url`, without a redirect, and the user won't see a redirect in their browser.
-
-I've just scratched the surface with this module. If you're looking for something production-ready for larger projects, you'll be better off with [Dancer][17] or [Catalyst][18]. But with its light weight and built-in Moo integration, Web::Simple packs a big enough punch for a variety of one-offs and smaller services.
-
-### About the author
-
- [][19] Ruth Holloway - Ruth Holloway has been a system administrator and software developer for a long, long time, getting her professional start on a VAX 11/780, way back when. She spent a lot of her career (so far) serving the technology needs of libraries, and has been a contributor since 2008 to the Koha open source library automation suite.Ruth is currently a Perl Developer at cPanel in Houston, and also serves as chief of staff for an obnoxious cat. In her copious free time, she occasionally reviews old romance... [more about Ruth Holloway][7][More about me][8]
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/introduction-websimple-perl-module-minimalist-web-framework
-
-作者:[Ruth Holloway ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/druthb
-[1]:https://opensource.com/tags/python?src=programming_resource_menu1
-[2]:https://opensource.com/tags/javascript?src=programming_resource_menu2
-[3]:https://opensource.com/tags/perl?src=programming_resource_menu3
-[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu4
-[5]:http://perldoc.perl.org/functions/package.html
-[6]:https://opensource.com/article/18/1/introduction-websimple-perl-module-minimalist-web-framework?rate=ICN35y076ElpInDKoMqp-sN6f4UVF-n2Qt6dL6lb3kM
-[7]:https://opensource.com/users/druthb
-[8]:https://opensource.com/users/druthb
-[9]:https://opensource.com/user/36051/feed
-[10]:https://www.flickr.com/photos/youasamachine/8025582590/in/photolist-decd6C-7pkccp-aBfN9m-8NEffu-3JDbWb-aqf5Tx-7Z9MTZ-rnYTRu-3MeuPx-3yYwA9-6bSLvd-irmvxW-5Asr4h-hdkfCA-gkjaSQ-azcgct-gdV5i4-8yWxCA-9G1qDn-5tousu-71V8U2-73D4PA-iWcrTB-dDrya8-7GPuxe-5pNb1C-qmnLwy-oTxwDW-3bFhjL-f5Zn5u-8Fjrua-bxcdE4-ddug5N-d78G4W-gsYrFA-ocrBbw-pbJJ5d-682rVJ-7q8CbF-7n7gDU-pdfgkJ-92QMx2-aAmM2y-9bAGK1-dcakkn-8rfyTz-aKuYvX-hqWSNP-9FKMkg-dyRPkY
-[11]:https://creativecommons.org/licenses/by/2.0/
-[12]:https://shadow.cat/resources/bios/matt_short/
-[13]:https://shadow.cat/
-[14]:https://metacpan.org/pod/Catalyst
-[15]:https://metacpan.org/pod/DBIx::Class
-[16]:https://metacpan.org/pod/Moo
-[17]:http://perldancer.org/
-[18]:http://www.catalystframework.org/
-[19]:https://opensource.com/users/druthb
-[20]:https://opensource.com/users/druthb
-[21]:https://opensource.com/users/druthb
-[22]:https://opensource.com/article/18/1/introduction-websimple-perl-module-minimalist-web-framework#comments
-[23]:https://metacpan.org/pod/Web::Simple
-[24]:https://opensource.com/tags/perl
-[25]:https://opensource.com/tags/programming
-[26]:https://opensource.com/tags/perl-column
-[27]:https://opensource.com/tags/web-development
\ No newline at end of file
diff --git a/sources/tech/20180129 CopperheadOS Security features installing apps and more.md b/sources/tech/20180129 CopperheadOS Security features installing apps and more.md
deleted file mode 100644
index fd6e110d35..0000000000
--- a/sources/tech/20180129 CopperheadOS Security features installing apps and more.md
+++ /dev/null
@@ -1,245 +0,0 @@
-CopperheadOS: Security features, installing apps, and more
-============================================================
-
-### Fly your open source flag proudly with Copperhead, a mobile OS that takes its FOSS commitment seriously.
-
-
-
-Image by : Norebbo via [Flickr][15] (Original: [public domain][16]). Modified by Opensource.com. [CC BY-SA 4.0][17].
-
- _Editor's note: CopperheadOS is [licensed][11] under the Creative Commons Attribution-NonCommercial-Shar<wbr>eAlike 4.0 license (userspace) and GPL2 license (kernel). It is also based on Android Open Source Project (AOSP)._
-
-Several years ago, I made the decision to replace proprietary technologies (mainly Apple products) with technology that ran on free and open source software (FOSS). I can't say it was easy, but I now happily use FOSS for pretty much everything.
-
-The hardest part involved my mobile handset. There are basically only two choices today for phones and tablets: Apple's iOS or Google's Android. Since Android is open source, it seemed the obvious choice, but I was frustrated by both the lack of open source applications on Android and the pervasiveness of Google on those devices.
-
-So I entered the world of custom ROMs. These are projects that take the base [Android Open Source Project][18] (AOSP) and customize it. Almost all these projects allow you to install the standard Google applications as a separate package, called GApps, and you can have as much or as little Google presence on your phone as you like. GApps packages come in a number of flavors, from the full suite of apps that Google ships with its devices to a "pico" version that includes just the minimal amount of software needed to run the Google Play Store, and from there you can add what you like.
-
-I started out using CyanogenMod, but when that project went in a direction I didn't like, I switched to OmniROM. I was quite happy with it, but still wondered what information I was sending to Google behind the scenes.
-
-Then I found out about [CopperheadOS][19]. Copperhead is a version of AOSP that focuses on delivering the most secure Android experience possible. I've been using it for a year now and have been quite happy with it.
-
-Unlike other custom ROMs that strive to add lots of new functionality, Copperhead runs a pretty vanilla version of AOSP. Also, while the first thing you usually do when playing with a custom ROM is to add root access to the device, not only does Copperhead prevent that, it also requires that you have a device that has verified boot, so there's no unlocking the bootloader. This is to prevent malicious code from getting access to the handset.
-
-Copperhead starts with a hardened version of the AOSP baseline, including full encryption, and then adds a [ton of stuff][20] I can only pretend to understand. It also applies a number of kernel and Android patches before they are applied to the mainline Android releases.
-
-### [copperos_extrapatches.png][1]
-
-
-
-It has a couple of more obvious features that I like. If you use a PIN to unlock your device, there is an option to scramble the digits.
-
-### [copperos_scrambleddigits.png][2]
-
-
-
-This should prevent any casual shoulder-surfer from figuring out your PIN, although it can make it a bit more difficult to unlock your device while, say, driving (but no one should be using their handset in the car, right?).
-
-Another issue it addresses involves tracking people by monitoring their WiFi MAC address. Most devices that use WiFi perform active scanning for wireless access points. This protocol includes the MAC address of the interface, and there are a number of ways people can use [mobile location analytics][21] to track your movement. Copperhead has an option to randomize your MAC address, which counters this process.
-
-### [copperos_randommac.png][3]
-
-
-
-### Installing apps
-
-This all sounds pretty good, right? Well, here comes the hard part. While Android is open source, much of the Google code, including the [Google Play Store][22], is not. If you install the Play Store and the code necessary for it to work, you allow Google to install software without your permission. [Google Play's terms of service][23] says:
-
-> "Google may update any Google app or any app you have downloaded from Google Play to a new version of such app, irrespective of any update settings that you may have selected within the Google Play app or your Device, if Google determines that the update will fix a critical security vulnerability related to the app."
-
-This is not acceptable from a security standpoint, so you cannot install Google applications on a Copperhead device.
-
-This took some getting used to, as I had come to rely on things such as Google Maps. The default application repository that ships with Copperhead is [F-Droid][24], which contains only FOSS applications. While I previously used many FOSS applications on Android, it took some effort to use _nothing but_ free software. I did find some ways to cheat this system, and I'll cover that below. First, here are some of the applications I've grown to love from F-Droid.
-
-### F-Droid favorites
-
-**K-9 Mail**
-
-### [copperheados_k9mail.png][4]
-
-
-
-Even before I started using Copperhead, I loved [K-9 Mail][25]. This is simply the best mobile email client I've found, period, and it is one of the first things I install on any new device. I even use it to access my Gmail account, via IMAP and SMTP.
-
-**Open Camera**
-
-### [copperheados_cameraapi.png][5]
-
-
-
-Copperhead runs only on rather new hardware, and I was consistently disappointed in the quality of the pictures from its default camera application. Then I discovered [Open Camera][26]. A full-featured camera app, it allows you to enable an advanced API to take advantage of the camera hardware. The only thing I miss is the ability to take a panoramic photo.
-
-**Amaze**
-
-### [copperheados_amaze.png][6]
-
-
-
-[Amaze][27] is one of the best file managers I've ever used, free or not. When I need to navigate the filesystem, Amaze is my go-to app.
-
-**Vanilla Music**
-
-### [copperheados_vanillamusic.png][7]
-
-
-
-I was unhappy with the default music player, so I checked out a number of them on F-Droid and settled on [Vanilla Music][28]. It has an easy-to-use interface and interacts well with my Bluetooth devices.
-
-**OCReader**
-
-### [coperheados_ocreader.png][8]
-
-
-
-I am a big fan of [Nextcloud][29], particularly [Nextcloud News][30], a replacement for the now-defunct [Google Reader][31]. While I can access my news feeds through a web browser, I really missed the ability to manage them through a dedicated app. Enter [OCReader][32]. While it stands for "ownCloud Reader," it works with Nextcloud, and I've had very few issues with it.
-
-**Noise**
-
-The SMS/MMS application of choice for most privacy advocates is [Signal][33] by [Open Whisper Systems][34]. Endorsed by [Edward Snowden][35], Signal allows for end-to-end encrypted messaging. If the person you are messaging is also on Signal, your messages will be sent, encrypted, over a data connection facilitated by centralized servers maintained by Open Whisper Systems. It also, until recently, relied on [Google Cloud Messaging][36] (GCM) for notifications, which requires Google Play Services.
-
-The fact that Signal requires a centralized server bothered some people, so the default application on Copperhead is a fork of Signal called [Silence][37]. This application doesn't use a centralized server but does require that all parties be on Silence for encryption to work.
-
-Well, no one I know uses Silence. At the moment you can't even get it from the Google Play Store in the U.S. due to a trademark issue, and there is no iOS client. An encrypted SMS client isn't very useful if you can't use it for encryption.
-
-Enter [Noise][38]. Noise is another application maintained by Copperhead that is a fork of Signal that removes the need for GCM. While not available in the standard F-Droid repositories, Copperhead includes their own repository in the version of F-Droid they ship, which at the moment contains only the Noise application. This app will let you communicate securely with anyone else using Noise or Signal.
-
-### F-Droid workarounds
-
-**FFUpdater**
-
-Copperhead ships with a hardened version of the Chromium web browser, but I am a Firefox fan. Unfortunately, [Firefox is no longer included][39] in the F-Droid repository. Apps on F-Droid are all built by the F-Droid maintainers, so the process for getting into F-Droid can be complicated. The [Compass app for OpenNMS][40] isn't in F-Droid because, at the moment, it does not support builds using the [Ionic Framework][41], which Compass uses.
-
-Luckily, there is a simple workaround: Install the [FFUpdater][42] app on F-Droid. This allows me to install Firefox and keep it up to date through the browser itself.
-
-**Amazon Appstore**
-
-This brings me to a cool feature of Android 8, Oreo. In previous versions of Android, you had a single "known source" for software, usually the Google Play Store, and if you wanted to install software from another repository, you had to go to settings and allow "Install from Unknown Sources." I always had to remember to turn that off after an install to prevent malicious code from being able to install software on my device.
-
-### [copperheados_sources.png][9]
-
-
-
-With Oreo, you can permanently allow a specified application to install applications. For example, I use some applications from the [Amazon Appstore][43] (such as the Amazon Shopping and Kindle apps). When I download and install the Amazon Appstore Android package (APK), I am prompted to allow the application to install apps and then I'm not asked again. Of course, this can be turned on and off on a per-application basis.
-
-The Amazon Appstore has a number of useful apps, such as [IMDB][44] and [eBay][45]. Many of them don't require Google Services, but some do. For example, if I install the [Skype][46] app via Amazon, it starts up, but then complains about the operating system. The American Airlines app would start, then complain about an expired certificate. (I contacted them and was told they were no longer maintaining the version in the Amazon Appstore and it would be removed.) In any case, I can pretty simply install a couple of applications I like without using Google Play.
-
-**Google Play**
-
-Well, what about those apps you love that don't use Google Play Services but are only available through the Google Play Store? There is yet another way to safely get those apps on your Copperhead device.
-
-This does require some technical expertise and another device. On the second device, install the [TWRP][47] recovery application. This is usually a key first step in installing any custom ROM, and TWRP is supported on a large number of devices. You will also need the Android Debug Bridge ([ADB][48]) application from the [Android SDK][49], which can be downloaded at no cost.
-
-On the second device, use the Google Play Store to install the applications you want. Then, reboot into recovery. You can mount the system partition via TWRP; plug the device into a computer via a USB cable and you should be able to see it via ADB. There is a system directory called `/data/app`, and in it you will find all the APK files for your applications. Copy those you want to your computer (I use the ADB `pull`command and copy over the whole directory).
-
-Disconnect that phone and connect your Copperhead device. Enable the "Transfer files" option, and you should see the storage directory mounted on your computer. Copy over the APK files for the applications you want, then install them via the Amaze file manager (just navigate to the APK file and click on it).
-
-Note that you can do this for any application, and it might even be possible to install Google Play Services this way on Copperhead, but that kind of defeats the purpose. I use this mainly to get the [Electric Sheep][50] screensaver and a guitar tuning app I like called [Cleartune][51]. Be aware that if you install TWRP, especially on a Google Pixel, security updates may not work, as they'll expect the stock recovery. In this case you can always use [fastboot][52] to access TWRP, but leave the default recovery in place.
-
-### Must-have apps without a workaround
-
-Unfortunately, there are still a couple of Google apps I find it hard to live without. Google Maps is probably the main Google application I use, and yes, while I know I'm giving up my location to Google, it has saved hours of my life by routing me around traffic issues. [OpenStreetMap][53] has an app available via F-Droid, but it doesn't have the real-time information that makes Google Maps so useful. I also use Skype on occasion, usually when I am out of the country and have only a data connection (i.e., through a hotel WiFi network). It lets me call home and other places at a very affordable price.
-
-My workaround is to carry two phones. I know this isn't an option for most people, but it is the only one I've found for now. I use my Copperhead phone for anything personal (email, contacts, calendars, pictures, etc.) and my "Googlephone" for Maps, Skype, and various games.
-
-My dream would be for someone to perfect a hypervisor on a handset. Then I could run Copperhead and stock Google Android on the same device. I don't think anyone has a strong business reason to do it, but I do hope it happens.
-
-### Devices that support Copperhead
-
-Before you rush out to install Copperhead, there are some hurdles you'll have to jump. First, it is supported on only a [limited number of handsets][54], almost all of them late-model Google devices. The logic behind this is simple: Google tends to release Android security updates for its devices quickly, and I've found that Copperhead is able to follow suit within a day, if not within hours. Second, like any open source project, it has limited resources and it is difficult to support even a fraction of the devices now available to end users. Finally, if you want to run Copperhead on handsets like the Pixel and Pixel XL, you'll either have to build from source or [buy a device][55] from Copperhead directly.
-
-When I discovered Copperhead, I had a Nexus 6P, which (along with the Nexus 5X) is one of the supported devices. This allowed me to play with and get used to the operating system. I liked it so much that I donated some money to the project, but I kind of balked at the price they were asking for Pixel and Pixel XL handsets.
-
-Recently, though, I ended up purchasing a Pixel XL directly from Copperhead. There were a couple of reasons. One, since all of the code is available on GitHub, I set out to do [my own build][56] for a Pixel device. That process (which I never completed) made me appreciate the amount of work Copperhead puts into its project. Two, there was an article on [Slashdot][57] discussing how people were selling devices with Copperhead pre-installed and using Copperhead's update servers. I didn't appreciate that very much. Finally, I support FOSS not only by being a vocal user but also with my wallet.
-
-### Putting the "libre" back into free
-
-Another thing I love about FOSS is that I have options. There is even a new option to Copperhead being developed called [Eelo][58]. Created by [Gaël Duval][59], the developer of Mandrake Linux, this is a privacy-based Android operating system based on [LineageOS][60] (the descendant of CyanogenMod). While it should be supported on more handsets than Copperhead is, it is still in the development stage, and Copperhead is very stable and mature. I am eager to check it out, though.
-
-For the year I've used CopperheadOS, I've never felt safer when using a mobile device to connect to a network. I've found the open source replacements for my old apps to be more than adequate, if not better than the original apps. I've also rediscovered the browser. Where I used to have around three to four tabs open, I now have around 10, because I've found that I usually don't need to install an app to easily access a site's content.
-
-With companies like Google and Apple trying more and more to insinuate themselves into the lives of their users, it is nice to have an option that puts the "libre" back into free.
-
-
-### About the author
-
- [][61]
-
-Tarus Balog - Having been kicked out of some of the best colleges and universities in the country, I managed after seven years to get a BSEE and entered the telecommunications industry. I always ended up working on projects where we were trying to get the phone switch to talk to PCs. This got me interested in the creation and management of large communication networks. So I moved into the data communications field (they were separate back then) and started working with commercial network management tools... [more about Tarus Balog][12][More about me][13]
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/copperheados-delivers-mobile-freedom-privacy-and-security
-
-作者:[Tarus Balog ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/sortova
-[1]:https://opensource.com/file/384496
-[2]:https://opensource.com/file/384501
-[3]:https://opensource.com/file/384506
-[4]:https://opensource.com/file/384491
-[5]:https://opensource.com/file/384486
-[6]:https://opensource.com/file/384481
-[7]:https://opensource.com/file/384476
-[8]:https://opensource.com/file/384471
-[9]:https://opensource.com/file/384466
-[10]:https://opensource.com/article/18/1/copperheados-delivers-mobile-freedom-privacy-and-security?rate=P32BmRpJF5bYEYTHo4mW3Hp4XRk34Eq3QqMDf2oOGnw
-[11]:https://copperhead.co/android/docs/building#redistribution
-[12]:https://opensource.com/users/sortova
-[13]:https://opensource.com/users/sortova
-[14]:https://opensource.com/user/11447/feed
-[15]:https://www.flickr.com/photos/mstable/17517955832
-[16]:https://creativecommons.org/publicdomain/mark/1.0/
-[17]:https://creativecommons.org/licenses/by-sa/4.0/
-[18]:https://en.wikipedia.org/wiki/Android_(operating_system)#AOSP
-[19]:https://copperhead.co/
-[20]:https://copperhead.co/android/docs/technical_overview
-[21]:https://en.wikipedia.org/wiki/Mobile_location_analytics
-[22]:https://en.wikipedia.org/wiki/Google_Play#Compatibility
-[23]:https://play.google.com/intl/en-us_us/about/play-terms.html
-[24]:https://en.wikipedia.org/wiki/F-Droid
-[25]:https://f-droid.org/en/packages/com.fsck.k9/
-[26]:https://f-droid.org/en/packages/net.sourceforge.opencamera/
-[27]:https://f-droid.org/en/packages/com.amaze.filemanager/
-[28]:https://f-droid.org/en/packages/ch.blinkenlights.android.vanilla/
-[29]:https://nextcloud.com/
-[30]:https://github.com/nextcloud/news
-[31]:https://en.wikipedia.org/wiki/Google_Reader
-[32]:https://f-droid.org/packages/email.schaal.ocreader/
-[33]:https://en.wikipedia.org/wiki/Signal_(software)
-[34]:https://en.wikipedia.org/wiki/Open_Whisper_Systems
-[35]:https://en.wikipedia.org/wiki/Edward_Snowden
-[36]:https://en.wikipedia.org/wiki/Google_Cloud_Messaging
-[37]:https://f-droid.org/en/packages/org.smssecure.smssecure/
-[38]:https://github.com/copperhead/Noise
-[39]:https://f-droid.org/wiki/page/org.mozilla.firefox
-[40]:https://compass.opennms.io/
-[41]:https://ionicframework.com/
-[42]:https://f-droid.org/en/packages/de.marmaro.krt.ffupdater/
-[43]:https://www.amazon.com/gp/feature.html?docId=1000626391
-[44]:https://www.imdb.com/
-[45]:https://www.ebay.com/
-[46]:https://www.skype.com/
-[47]:https://twrp.me/
-[48]:https://en.wikipedia.org/wiki/Android_software_development#ADB
-[49]:https://developer.android.com/studio/index.html
-[50]:https://play.google.com/store/apps/details?id=com.spotworks.electricsheep&hl=en
-[51]:https://play.google.com/store/apps/details?id=com.bitcount.cleartune&hl=en
-[52]:https://en.wikipedia.org/wiki/Android_software_development#Fastboot
-[53]:https://f-droid.org/packages/net.osmand.plus/
-[54]:https://copperhead.co/android/downloads
-[55]:https://copperhead.co/android/store
-[56]:https://copperhead.co/android/docs/building
-[57]:https://news.slashdot.org/story/17/11/12/024231/copperheados-fights-unlicensed-installations-on-nexus-phones
-[58]:https://eelo.io/
-[59]:https://en.wikipedia.org/wiki/Ga%C3%ABl_Duval
-[60]:https://en.wikipedia.org/wiki/LineageOS
-[61]:https://opensource.com/users/sortova
-[62]:https://opensource.com/users/sortova
-[63]:https://opensource.com/users/sortova
-[64]:https://opensource.com/article/18/1/copperheados-delivers-mobile-freedom-privacy-and-security#comments
-[65]:https://opensource.com/tags/mobile
-[66]:https://opensource.com/tags/android
\ No newline at end of file
diff --git a/sources/tech/20180129 Tips and tricks for using CUPS for printing with Linux.md b/sources/tech/20180129 Tips and tricks for using CUPS for printing with Linux.md
deleted file mode 100644
index f676b0efb9..0000000000
--- a/sources/tech/20180129 Tips and tricks for using CUPS for printing with Linux.md
+++ /dev/null
@@ -1,101 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Tips and tricks for using CUPS for printing with Linux)
-[#]: via: (https://opensource.com/article/19/1/cups-printing-linux)
-[#]: author: (Antoine Thomas https://opensource.com/users/ttoine)
-
-Tips and tricks for using CUPS for printing with Linux
-======
-One of Apple's most important contributions to GNU/Linux was adopting CUPS in Mac OS X.
-
-
-Did you ever try to configure a printer on a GNU/Linux desktop distribution at the end of the '90s? Or even before?
-
-To make a long story short: That was fine if you worked at a large organization with an IT team to handle it and dedicated hardware or a printing server. There were many different standards and protocols to handle printers. And only a few big vendors (usually Unix vendors) provided specific support and drivers for their entire range of products.
-
-However, if open source enthusiasts wanted a home printer that would work with their favorite distribution, that was another story. They probably spent a fair amount of time on forums, newsgroups, or IRC (remember those ancestors of social networks and chats?) asking about printers with easy-to-install Linux drivers.
-
-In 1999, the first version of [CUPS][1] (the Common Unix Printing System) was released by Easy Software Products. Most of the most popular distributions at the time adopted CUPS as their default printing system. That was a huge success: one standard could handle many printers and protocols.
-
-But if the printer vendor didn't provide a CUPS driver, it was still tricky or impossible to make it work. Some smart people might do reverse engineering. And a few printers, with native support of PostScript and Internet Printing Protocol (IPP), worked "out of the box."
-
-### Then came Apple
-
-In the early 2000s, Apple was struggling to build a new printing system for its new Mac OS X. In March 2002, it decided to save time by adopting CUPS for its flagship operating system.
-
-No printer vendor could ignore Apple computers' market share, so a lot of new printer drivers for Mac OS X's CUPS became available, spanning most vendors and product ranges, including corporate, graphic arts, consumer, and photo printing.
-
-CUPS became so important for Apple that it bought the software from Easy Software Products in 2007; since then Apple has continued to maintain it and manage its intellectual property.
-
-### But what does that have to do with GNU/Linux?
-
-At the time Apple integrated CUPS in Mac OS X, it was already used by default in many distros and available for most others. But few dedicated drivers were available, meaning they were not packaged or listed as "for GNU/Linux."
-
-However, once CUPS drivers were available for Mac OS X, a simple hack became popular with GNU/Linux enthusiasts: download the Mac driver, extract the PPD files, and test them with your printer. I used this hack many times with my Epson printers.
-
-That's the CUPS magic: If a driver exists, it usually works with all operating systems that use CUPS for printing, as long as they use a supported protocol (like IPP).
-
-That's how printer drivers began to be available for GNU/Linux.
-
-### Nowadays
-
-Afterward, printer vendors realized it was quite easy to provide drivers for GNU/Linux since they already developed them for Mac. It's now easy to find a GNU/Linux driver for a printer, even a newer one. Some distributions include packages with a lot of drivers, and most vendors provide dedicated drivers—sometimes via a package, other times with PPD files in an archive.
-
-Advanced control applications are available too, some official, some not, which make it possible (for example) to look at ink levels or clean printing heads.
-
-In some cases, installing a printer on GNU/Linux is even easier than on other operating systems, particularly with distributions using [zero-configuration networking][2] (e.g., Bonjour, Avahi) to auto-discover and share network printers.
-
-### Tips and tricks
-
- * **Install a PDF printer:** Installing a PDF printer on GNU/Linux is very easy. Just look for the **cups-pdf** package in your favorite distribution and install it. If the package doesn't automatically create the PDF printer, you can add one using your system preferences to print in PDF from any application.
-
- * **Access the CUPS web interface:** If your usual interface for managing printers doesn't work or you don't like it, open a web browser and go to <http://localhost:631/admin>. You can manage all the printers installed on your computer, adjust their settings, and even add new ones—all from this web interface. Note that this might be available on other computers on your network; if so, replace "localhost" with the relevant hostname or IP address.
-
- * **Check ink level:** If you have an Epson, Canon, HP, or Sony printer, you can see its ink level with a simple application. Look for the "ink" package in your distribution repositories.
-
- * **Contribute to CUPS:** Like many open source project, CUPS is maintained on GitHub. Check the [CUPS website][1] and [GitHub issues][3] to find out how you can contribute to improving it.
-
-
-
-
-### CUPS license
-
-Originally, CUPS was released under GPLv2. I'm not sure why; maybe to make it easier to distribute with GNU/Linux. Or maybe it was just what most open source projects did at the time.
-
-Apple decided to [change the license][4] in November 2017 to the Apache 2.0 license. Many observers commented that it was consistent with Apple's strategy to move the IP of its open source projects to more business-compliant licenses.
-
-While this change could create issues with shipping CUPS with GNU/Linux, it is still available in most distributions.
-
-### Happy 20th birthday, CUPS!
-
-CUPS was released in 1999, so, let's celebrate and thank all the people involved in this successful open source project, from the original authors to the driver developers to its current maintainers.
-
-The next time you print with your favorite GNU/Linux operating system, remind yourself to say "thank you" to Apple.
-
-The company isn't well known for its contributions to open source. But if you look carefully (at, for example, [Apple's Open Source Releases][5] and [Open Source Development][6] pages), you'll see how many open source components are in Apple's operating systems and applications.
-
-You'll also discover other important open source projects Apple kicked off. For example, it forked KHTML, the KDE browser, to create [WebKit][7] for the Safari Browser. Wait, THE WebKit? Yes, Apple initiated WebKit. But that is another story...
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/1/cups-printing-linux
-
-作者:[Antoine Thomas][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ttoine
-[b]: https://github.com/lujun9972
-[1]: https://www.cups.org/
-[2]: https://en.wikipedia.org/wiki/Zero-configuration_networking#Major_implementations
-[3]: https://github.com/apple/cups/issues
-[4]: https://www.cups.org/blog/2017-11-07-cups-license-change.html
-[5]: https://opensource.apple.com/
-[6]: https://developer.apple.com/opensource/
-[7]: https://webkit.org/
diff --git a/sources/tech/20180129 WebSphere MQ programming in Python with Zato.md b/sources/tech/20180129 WebSphere MQ programming in Python with Zato.md
deleted file mode 100644
index 3e53d67201..0000000000
--- a/sources/tech/20180129 WebSphere MQ programming in Python with Zato.md
+++ /dev/null
@@ -1,262 +0,0 @@
-WebSphere MQ programming in Python with Zato
-======
-[WebSphere MQ][1] is a messaging middleware product by IBM - a message queue server - and this post shows how to integrate with MQ from Python and [Zato][2].
-
-The article will go through a short process that will let you:
-
- * Send messages to queues in 1 line of Python code
- * Receive messages from queues without coding
- * Seamlessly integrate with Java JMS applications - frequently found in WebSphere MQ environments
- * Push MQ messages from [Django][3] or [Flask][4]
-
-
-
-### Prerequisites
-
- * [Zato][2] 3.0+ (e.g. from [source code][5])
- * WebSphere MQ 6.0+
-
-
-
-### Preliminary steps
-
- * Obtain connection details and credentials to the queue manager that you will be connecting to:
-
- * host, e.g. 10.151.13.11
- * port, e.g. 1414
- * channel name, e.g. DEV.SVRCONN.1
- * queue manager name (optional)
- * username (optional)
- * password (optional)
- * Install [Zato][6]
-
- * On the same system that Zato is on, install a [WebSphere MQ Client][7] \- this is an umbrella term for a set of development headers and libraries that let applications connect to remote queue managers
-
- * Install [PyMQI][8] \- an additional dependency implementing the low-level proprietary MQ protocol. Note that you need to use the pip command that Zato ships with:
-
-
-
-```
-# Assuming Zato is in /opt/zato/current
-zato$ cd /opt/zato/current/bin
-zato$ ./pip install pymqi
-
-```
-
- * That is it - everything is installed and the rest is a matter of configuration
-
-
-
-### Understanding definitions, outgoing connections and channels
-
-Everything in Zato revolves around re-usability and hot-reconfiguration - each individual piece of configuration can be changed on the fly, while servers are running, without restarts.
-
-Note that the concepts below are presented in the context of WebSphere MQ but they apply to other connection types in Zato too.
-
- * **Definitions** \- encapsulate common details that apply to other parts of configuration, e.g. a connection definition may contain remote host and port
- * **Outgoing connections** \- objects through which data is sent to remote resources, such as MQ queues
- * **Channels** \- objects through which data can be received, for instance, from MQ queues
-
-
-
-It is usually most convenient to configure environments during development using [web-admin GUI][9] but afterwards this can be automated with [enmasse][10], [API][11] or [command-line interface][12].
-
-Once configuration is defined, it can be used from Zato services which in turn represent APIs that Zato clients invoke. Then, external applications, such as a Django or Flask, will connect using HTTP to a Zato service which will on their behalf send messages to MQ queues.
-
-Let's use web-admin to define all the Zato objects required for MQ integrations. (Hint: web-admin by default runs on <http://localhost:8183>)
-
-### Definition
-
- * Go to Connections -> Definitions -> WebSphere MQ
- * Fill out the form and click OK
- * Observe the 'Use JMS' checkbox - more about it later on
-
-
-
-![Screenshots][13]
-
- * Note that a password is by default set to an unusable one (a random UUID4) so once a definition is created, click on Change password to set it to a required one
-
-
-
-![Screenshots][14]
-
- * Click Ping to confirm that connections to the remote queue manager can be established
-
-
-
-![Screenshots][15]
-
-### Outgoing connection
-
- * Go to Connections -> Outgoing -> WebSphere MQ
- * Fill out the form - the connection's name is just a descriptive label
- * Note that you do not specify a queue name here - this is because a single connection can be used with as many queues as needed
-
-
-
-![Screenshots][16]
-
- * You can now send a test MQ message directly from web-admin after click Send a message
-
-
-
-![Screenshots][17]
-
-![Screenshots][18]
-
-### API services
-
- * Having carried out the steps above, you can now send messages to queue managers from web-admin, which is a great way to confirm MQ-level connectivity but the crucial point of using Zato is to offer API services to client applications so let's create two services now, one for sending messages to MQ and one that will receive them.
-
-
-
-```
-# -*- coding: utf-8 -*-
-
-from __future__ import absolute_import, division, print_function, unicode_literals
-
-# Zato
-from zato.server.service import Service
-
-class MQSender(Service):
- """ Sends all incoming messages as they are straight to a remote MQ queue.
- """
- def handle(self):
-
- # This single line suffices
- self.out.wmq.send(self.request.raw_request, 'customer.updates', 'CUSTOMER.1')
-```
-
- * In practice, a service such as the one above could perform transformation on incoming messages or read its destination queue names from configuration files but it serves to illustrate the point that literally 1 line of code is needed to send MQ messages
-
- * Let's create a channel service now - one that will act as a callback invoked for each message consumed off a queue:
-
-
-
-```
-# -*- coding: utf-8 -*-
-
-from __future__ import absolute_import, division, print_function, unicode_literals
-
-# Zato
-from zato.server.service import Service
-
-class MQReceiver(Service):
- """ Invoked for each message taken from a remote MQ queue
- """
- def handle(self):
- self.logger.info(self.request.raw_request)
-```
-
-But wait - if this is the service that is a callback one then how does it know which queue to get messages from?
-
-That is the key point of Zato architecture - services do not need to know it and unless you really need it, they won't ever access this information.
-
-Such configuration details are configured externally (for instance, in web-admin) and a service is just a black box that receives some input, operates on it and produces output.
-
-In fact, the very same service could be mounted not only on WebSphere MQ ones but also on REST or AMQP channels.
-
-Without further ado, let's create a channel in that case, but since this is an article about MQ, only this connection type will be shown even if the same principle applies to other channel types.
-
-### Channel
-
- * Go to Connections -> Channels -> WebSphere MQ
- * Fill out the form and click OK
- * Data format may be JSON, XML or blank if no automatic de-serialization is required
-
-
-
-![Screenshots][19]
-
-After clicking OK a lightweight background task will start to listen for messages pertaining to a given queue and upon receiving any, the service configured for channel will be invoked.
-
-You can start as many channels as there are queues to consume messages from, that is, each channel = one input queue and each channel may declare a different service.
-
-### JMS Java integration
-
-In many MQ environments the majority of applications will be based on Java JMS and Zato implements the underlying wire-level MQ JMS protocol to let services integrate with such systems without any effort from a Python programmer's perspective.
-
-When creating connection definitions, merely check Use JMS and everything will be taken care of under the hood - all the necessary wire headers will be added or removed when it needs to be done.
-
-![Screenshots][20]
-
-### No restarts required
-
-It's worth to emphasize again that at no point are server restarts required to reconfigure connection details.
-
-No matter how many definitions, outgoing connections, channels there are, and no matter of what kind they are (MQ or not), changing any of them will only update that very one across the whole cluster of Zato servers without interrupting other API services running concurrently.
-
-### Configuration wrap-up
-
- * MQ connection definitions are re-used across outgoing connections and channels
- * Outgoing connections are used by services to send messages to queues
- * Data from queues is read through channels that invoke user-defined services
- * Everything is reconfigurable on the fly
-
-
-
-Let's now check how to add a REST channel for the MQSender service thus letting Django and Flask push MQ messages.
-
-### Django and Flask integration
-
- * Any Zato-based API service can be mounted on a channel
- * For Django and Flask, it is most convenient to mount one's services on REST channels and invoke them using the [zato-client][21] from PyPI
- * zato-client is a set of convenience clients that lets any Python application, including ones based on Django or Flask, to invoke Zato services in just a few steps
- * There is [a dedicated chapter][22] in documentation about Django and Flask, including a sample integration scenario
- * It's recommended to go through the chapter step-by-step - since all Zato configuration objects share the same principles, the whole of its information applies to any sort of technology that Django or Flask may need to integrate with, including WebSphere MQ
- * After completing that chapter, to push messages to MQ, you will only need to:
- * Create a security definition for a new REST channel for Django or Flask
- * Create the REST channel itself
- * Assign a service to it (e.g. MQSender)
- * Use a Python client from zato-client to invoke that channel from Django or Flask
- * And that is it - no MQ programming is needed to send messages to MQ queues from any Python application :-)
-
-
-
-### Summary
-
- * Zato lets Python programmers integrate with WebSphere MQ with little to no effort
- * Built-in support for JMS lets one integrate with existing Java applications in a transparent manner
- * Built-in Python clients offer trivial access to Zato-based API services from other Python applications, including Django or Flask
-
-
-
-Where to next? Start off with the [tutorial][23], then consult the [documentation][24], there is a lot of information for all types of API and integration projects, and have a look at [support options][25] in case you need absolutely any sort of assistance!
-
---------------------------------------------------------------------------------
-
-via: https://zato.io/blog/posts/websphere-mq-python-zato.html
-
-作者:[zato][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://zato.io
-[1]:https://en.wikipedia.org/wiki/IBM_WebSphere_MQ
-[2]:https://zato.io/docs
-[3]:https://www.djangoproject.com/
-[4]:http://flask.pocoo.org/
-[5]:https://zato.io/docs/admin/guide/install/source.html
-[6]:https://zato.io/docs/admin/guide/install/index.html
-[7]:https://www.ibm.com/support/knowledgecenter/en/SSFKSJ_7.0.1/com.ibm.mq.csqzaf.doc/cs10230_.htm
-[8]:https://github.com/dsuch/pymqi/
-[9]:https://zato.io/docs/web-admin/intro.html
-[10]:https://zato.io/docs/admin/guide/enmasse.html
-[11]:https://zato.io/docs/public-api/intro.html
-[12]:https://zato.io/docs/admin/cli/index.html
-[13]:https://zato.io/blog/images/wmq-python-zato/def-create.png
-[14]:https://zato.io/blog/images/wmq-python-zato/def-options.png
-[15]:https://zato.io/blog/images/wmq-python-zato/def-ping.png
-[16]:https://zato.io/blog/images/wmq-python-zato/outconn-create.png
-[17]:https://zato.io/blog/images/wmq-python-zato/outconn-options.png
-[18]:https://zato.io/blog/images/wmq-python-zato/outconn-send.png
-[19]:https://zato.io/blog/images/wmq-python-zato/channel-create.png
-[20]:https://zato.io/blog/images/wmq-python-zato/def-create-jms.png
-[21]:https://pypi.python.org/pypi/zato-client
-[22]:https://zato.io/docs/progguide/clients/django-flask.html
-[23]:https://zato.io/docs/tutorial/01.html
-[24]:https://zato.io/docs/
-[25]:https://zato.io/support.html
diff --git a/sources/tech/20180130 Create and manage MacOS LaunchAgents using Go.md b/sources/tech/20180130 Create and manage MacOS LaunchAgents using Go.md
deleted file mode 100644
index b9a477824c..0000000000
--- a/sources/tech/20180130 Create and manage MacOS LaunchAgents using Go.md
+++ /dev/null
@@ -1,314 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (runningwater)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Create and manage MacOS LaunchAgents using Go)
-[#]: via: (https://ieftimov.com/post/create-manage-macos-launchd-agents-golang/)
-[#]: author: (https://ieftimov.com/about)
-
-Create and manage MacOS LaunchAgents using Go
-============================================================
-
-If you have ever tried writing a daemon for MacOS you have met with `launchd`. For those that don’t have the experience, think of it as a framework for starting, stopping and managing daemons, applications, processes, and scripts. If you have any *nix experience the word daemon should not be too alien to you.
-
-For those unfamiliar, a daemon is a program running in the background without requiring user input. A typical daemon might, for instance, perform daily maintenance tasks or scan a device for malware when connected.
-
-This post is aimed at folks that know a little bit about what daemons are, what is the common way of using them and know a bit about Go. Also, if you have ever written a daemon for any other *nix system, you will have a good idea of what we are going to talk here. If you are an absolute beginner in Go or systems this might prove to be an overwhelming article. Still, feel free to give it a shot and let me know how it goes.
-
-If you ever find yourself wanting to write a MacOS daemon with Go you would like to know most of the stuff we are going to talk about in this article. Without further ado, let’s dive in.
-
-### What is `launchd` and how it works?
-
-`launchd` is a unified service-management framework, that starts, stops and manages daemons, applications, processes, and scripts in MacOS.
-
-One of its key features is that it differentiates between agents and daemons. In `launchd` land, an agent runs on behalf of the logged in user while a daemon runs on behalf of the root user or any specified user.
-
-### Defining agents and daemons
-
-An agent/daemon is defined in an XML file, which states the properties of the program that will execute, among a list of other properties. Another aspect to keep in mind is that `launchd` decides if a program will be treated as a daemon or an agent by where the program XML is located.
-
-Over at [launchd.info][3], there’s a simple table that shows where you would (or not) place your program’s XML:
-
-```
-+----------------+-------------------------------+----------------------------------------------------+| Type | Location | Run on behalf of |+----------------+-------------------------------+----------------------------------------------------+| User Agents | ~/Library/LaunchAgents | Currently logged in user || Global Agents | /Library/LaunchAgents | Currently logged in user || Global Daemons | /Library/LaunchDaemons | root or the user specified with the key 'UserName' || System Agents | /System/Library/LaunchAgents | Currently logged in user || System Daemons | /System/Library/LaunchDaemons | root or the user specified with the key 'UserName' |+----------------+-------------------------------+----------------------------------------------------+
-```
-
-This means that when we set our XML file in, for example, the `/Library/LaunchAgents` path our process will be treated as a global agent. The main difference between the daemons and agents is that LaunchDaemons will run as root, and are generally background processes. On the other hand, LaunchAgents are jobs that will run as a user or in the context of userland. These may be scripts or other foreground items and they also have access to the MacOS UI (e.g. you can send notifications, control the windows, etc.)
-
-So, how do we define an agent? Let’s take a look at a simple XML file that `launchd`understands:
-
-```
-<!--- Example blatantly ripped off from http://www.launchd.info/ --><?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"> <dict> <key>Label</key> <string>com.example.app</string> <key>Program</key> <string>/Users/Me/Scripts/cleanup.sh</string> <key>RunAtLoad</key> <true/> </dict></plist>
-```
-
-The XML is quite self-explanatory, unless it’s the first time you are seeing an XML file. The file has three main properties, with values. In fact, if you take a better look you will see the `dict` keyword which means `dictionary`. This actually means that the XML represents a key-value structure, so in Go it would look like:
-
-```
-map[string]string{ "Label": "com.example.app", "Program": "/Users/Me/Scripts/cleanup.sh", "RunAtLoad": "true",}
-```
-
-Let’s look at each of the keys:
-
-1. `Label` - The job definition or the name of the job. This is the unique identifier for the job within the `launchd` instance. Usually, the label (and hence the name) is written in [Reverse domain name notation][1].
-
-2. `Program` - This key defines what the job should start, in our case a script with the path `/Users/Me/Scripts/cleanup.sh`.
-
-3. `RunAtLoad` - This key specifies when the job should be run, in this case right after it’s loaded.
-
-As you can see, the keys used in this XML file are quite self-explanatory. This is the case for the remaining 30-40 keys that `launchd` supports. Last but not least these files although have an XML syntax, in fact, they have a `.plist` extension (which means `Property List`). Makes a lot of sense, right?
-
-### `launchd` v.s. `launchctl`
-
-Before we continue with our little exercise of creating daemons/agents with Go, let’s first see how `launchd` allows us to control these jobs. While `launchd`’s job is to boot the system and to load and maintain services, there is a different command used for jobs management - `launchctl`. With `launchd` facilitating jobs, the control of services is centralized in the `launchctl` command.
-
-`launchctl` has a long list of subcommands that we can use. For example, loading or unloading a job is done via:
-
-```
-launchctl unload/load ~/Library/LaunchAgents/com.example.app.plist
-```
-
-Or, starting/stopping a job is done via:
-
-```
-launchctl start/stop ~/Library/LaunchAgents/com.example.app.plist
-```
-
-To get any confusion out of the way, `load` and `start` are different. While `start`only starts the agent/daemon, `load` loads the job and it might also start it if the job is configured to run on load. This is achieved by setting the `RunAtLoad` property in the property list XML of the job:
-
-```
-<!--- Example blatantly ripped off from http://www.launchd.info/ --><?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"> <dict> <key>Label</key> <string>com.example.app</string> <key>Program</key> <string>/Users/Me/Scripts/cleanup.sh</string> <key>RunAtLoad</key><true/> </dict></plist>
-```
-
-If you would like to see what other commands `launchctl` supports, you can run`man launchctl` in your terminal and see the options in detail.
-
-### Automating with Go
-
-After getting the basics of `launchd` and `launctl` out of the way, why don’t we see how we can add an agent to any Go package? For our example, we are going to write a simple way of plugging in a `launchd` agent for any of your Go packages.
-
-As we already established before, `launchd` speaks in XML. Or, rather, it understands XML files, called _property lists_ (or `.plist`). This means, for our Go package to have an agent running on MacOS, it will need to tell `launchd` “hey, `launchd`, run this thing!”. And since `launch` speaks only in `.plist`, that means our package needs to be capable of generating XML files.
-
-### Templates in Go
-
-While one could have a hardcoded `.plist` file in their project and copy it across to the `~/Library/LaunchAgents` path, a more programmatical way to do this would be to use a template to generate these XML files. The good thing is Go’s standard library has us covered - the `text/template` package ([docs][4]) does exactly what we need.
-
-In a nutshell, `text/template` implements data-driven templates for generating textual output. Or in other words, you give it a template and a data structure, it will mash them up together and produce a nice and clean text file. Perfect.
-
-Let’s say the `.plist` we need to generate in our case is the following:
-
-```
-<?xml version='1.0' encoding='UTF-8'?><!DOCTYPE plist PUBLIC \"-//Apple Computer//DTD PLIST 1.0//EN\" \"http://www.apple.com/DTDs/PropertyList-1.0.dtd\" ><plist version='1.0'> <dict> <key>Label</key><string>Ticker</string> <key>Program</key><string>/usr/local/bin/ticker</string> <key>StandardOutPath</key><string>/tmp/ticker.out.log</string> <key>StandardErrorPath</key><string>/tmp/ticker.err.log</string> <key>KeepAlive</key><true/> <key>RunAtLoad</key><true/> </dict></plist>
-```
-
-We want to keep it quite simple in our little exercise. It will contain only six properties: `Label`, `Program`, `StandardOutPath`, `StandardErrorPath`, `KeepAlive` and `RunAtLoad`. To generate such a XML, its template would look something like this:
-
-```
-<?xml version='1.0' encoding='UTF-8'?>
-<!DOCTYPE plist PUBLIC \"-//Apple Computer//DTD PLIST 1.0//EN\" \"http://www.apple.com/DTDs/PropertyList-1.0.dtd\" >
-<plist version='1.0'>
- <dict>
- <key>Label</key><string>{{.Label}}</string>
- <key>Program</key><string>{{.Program}}</string>
- <key>StandardOutPath</key><string>/tmp/{{.Label}}.out.log</string>
- <key>StandardErrorPath</key><string>/tmp/{{.Label}}.err.log</string>
- <key>KeepAlive</key><{{.KeepAlive}}/>
- <key>RunAtLoad</key><{{.RunAtLoad}}/>
- </dict>
-</plist>
-
-```
-
-As you can see, the difference between the two XMLs is that the second one has the double curly braces with expressions in them in places where the first XML has some sort of a value. These are called “actions”, which can be data evaluations or control structures and are delimited by “ and “. Any of the text outside actions is copied to the output untouched.
-
-### Injecting your data
-
-Now that we have our template with its glorious XML and curly braces (or actions), let’s see how we can inject our data into it. Since things are generally simple in Go, especially when it comes to its standard library, you should not worry - this will be easy!
-
-To keep thing simple, we will store the whole XML template in a plain old string. Yes, weird, I know. The best way would be to store it in a file and read it from there, or embed it in the binary itself, but in our little example let’s keep it simple:
-
-```
-// template.go
-package main
-
-func Template() string {
- return `
-<?xml version='1.0' encoding='UTF-8'?>
- <!DOCTYPE plist PUBLIC \"-//Apple Computer//DTD PLIST 1.0//EN\" \"http://www.apple.com/DTDs/PropertyList-1.0.dtd\" >
- <plist version='1.0'>
- <dict>
- <key>Label</key><string>{{.Label}}</string>
- <key>Program</key><string>{{.Program}}</string>
- <key>StandardOutPath</key><string>/tmp/{{.Label}}.out.log</string>
- <key>StandardErrorPath</key><string>/tmp/{{.Label}}.err.log</string>
- <key>KeepAlive</key><{{.KeepAlive}}/>
- <key>RunAtLoad</key><{{.RunAtLoad}}/>
- </dict>
-</plist>
-`
-}
-
-```
-
-And the program that will use our little template function:
-
-```
-// main.gopackage mainimport ( "log" "os" "text/template")func main() { data := struct { Label string Program string KeepAlive bool RunAtLoad bool }{ Label: "ticker", Program: "/usr/local/bin/ticker", KeepAlive: true, RunAtLoad: true, } t := template.Must(template.New("launchdConfig").Parse(Template())) err := t.Execute(os.Stdout, data) if err != nil { log.Fatalf("Template generation failed: %s", err) }}
-```
-
-So, what happens there, in the `main` function? It’s actually quite simple:
-
-1. We declare a small `struct`, which has only the properties that will be needed in the template, and we immediately initialize it with the values for our program.
-
-2. We build a new template, using the `template.New` function, with the name`launchdConfig`. Then, we invoke the `Parse` function on it, which takes the XML template as an argument.
-
-3. We invoke the `template.Must` function, which takes our built template as argument. From the documentation, `template.Must` is a helper that wraps a call to a function returning `(*Template, error)` and panics if the error is non-`nil`. Actually, `template.Must` is built to, in a way, validate if the template can be understood by the `text/template` package.
-
-4. Finally, we invoke `Execute` on our built template, which takes a data structure and applies its attributes to the actions in the template. Then it sends the output to `os.Stdout`, which does the trick for our example. Of course, the output can be sent to any struct that implements the `io.Writer` interface, like a file (`os.File`).
-
-### Make and load my `.plist`
-
-Instead of sending all this nice XML to standard out, let’s throw in an open file descriptor to the `Execute` function and finally save our `.plist` file in`~/Library/LaunchAgents`. There are a couple of main points we need to change.
-
-First, getting the location of the binary. Since it’s a Go binary, and we will install it via `go install`, we can assume that the path will be at `$GOPATH/bin`. Second, since we don’t know the actual `$HOME` of the current user, we will have to get it through the environment. Both of these can be done via `os.Getenv` ([docs][5]) which takes a variable name and returns its value.
-
-```
-// main.gopackage mainimport ( "log" "os" "text/template")func main() { data := struct { Label string Program string KeepAlive bool RunAtLoad bool }{ Label: "com.ieftimov.ticker", // Reverse-DNS naming convention Program: fmt.Sprintf("%s/bin/ticker", os.Getenv("GOPATH")), KeepAlive: true, RunAtLoad: true, } plistPath := fmt.Sprintf("%s/Library/LaunchAgents/%s.plist", os.Getenv("HOME"), data.Label) f, err := os.Open(plistPath) t := template.Must(template.New("launchdConfig").Parse(Template())) err := t.Execute(f, data) if err != nil { log.Fatalf("Template generation failed: %s", err) }}
-```
-
-That’s about it. The first part, about setting the correct `Program` property, is done by concatenating the name of the program and `$GOPATH`:
-
-```
-fmt.Sprintf("%s/bin/ticker", os.Getenv("GOPATH"))// Output: /Users/<username>/go/bin/ticker
-```
-
-The second part is slightly more complex, and it’s done by concatenating three strings, the `$HOME` environment variable, the `Label` property of the program and the `/Library/LaunchAgents` string:
-
-```
-fmt.Sprintf("%s/Library/LaunchAgents/%s.plist", os.Getenv("HOME"), data.Label)// Output: /Users/<username>/Library/LaunchAgents/com.ieftimov.ticker.plist
-```
-
-By having these two paths, opening the file and writing to it is very trivial - we open the file via `os.Open` and we pass in the `os.File` structure to `t.Execute` which writes to the file descriptor.
-
-### What about the Launch Agent?
-
-We will keep this one simple as well. Let’s throw in a command to our package, make it installable via `go install` (not that there’s much to it) and make it runnable by our `.plist` file:
-
-```
-// cmd/ticker/main.gopackage tickerimport ( "time" "fmt")func main() { for range time.Tick(30 * time.Second) { fmt.Println("tick!") }}
-```
-
-This the `ticker` program will use `time.Tick`, to execute an action every 30 seconds. Since this will be an infinite loop, `launchd` will kick off the program on boot (because `RunAtLoad` is set to `true` in the `.plist` file) and will keep it running. But, to make the program controllable from the operating system, we need to make the program react to some OS signals, like `SIGINT` or `SIGTERM`.
-
-### Understanding and handling OS signals
-
-While there’s quite a bit to be learned about OS signals, in our example we will scratch a bit off the surface. (If you know a lot about inter-process communication this might be too much of an oversimplification to you - and I apologize up front. Feel free to drop some links on the topic in the comments so others can learn more!)
-
-The best way to think about a signal is that it’s a message from the operating system or another process, to a process. It is an asynchronous notification sent to a process or to a specific thread within the same process to notify it of an event that occurred.
-
-There are quite a bit of various signals that can be sent to a process (or a thread), like `SIGKILL` (which kills a process), `SIGSTOP` (stop), `SIGTERM` (termination), `SIGILL`and so on and so forth. There’s an exhaustive list of signal types on [Wikipedia’s page][6]on signals.
-
-To get back to `launchd`, if we look at its documentation about stopping a job we will notice the following:
-
-> Stopping a job will send the signal `SIGTERM` to the process. Should this not stop the process launchd will wait `ExitTimeOut` seconds (20 seconds by default) before sending `SIGKILL`.
-
-Pretty self-explanatory, right? We need to handle one signal - `SIGTERM`. Why not `SIGKILL`? Because `SIGKILL` is a special signal that cannot be caught - it kills the process without any chance for a graceful shutdown, no questions asked. That’s why there’s a termination signal and a “kill” signal.
-
-Let’s throw in a bit of signal handling in our code, so our program knows that it needs to exit when it gets told to do so:
-
-```
-package mainimport ( "fmt" "os" "os/signal" "syscall" "time")func main() { sigs := make(chan os.Signal, 1) signal.Notify(sigs, syscall.SIGINT, syscall.SIGTERM) go func() { <-sigs os.Exit(0) }() for range time.Tick(30 * time.Second) { fmt.Println("tick!") }}
-```
-
-In the new version, the agent program has two new packages imported: `os/signal`and `syscall`. `os/signal` implements access to incoming signals, that are primarily used on Unix-like systems. Since in this article we are specifically interested in MacOS, this is exactly what we need.
-
-Package `syscall` contains an interface to the low-level operating system primitives. An important note about `syscall` is that it is locked down since Go v1.4\. This means that any code outside of the standard library that uses the `syscall` package should be migrated to use the new `golang.org/x/sys` [package][7]. Since we are using **only**the signals constants of `syscall` we can get away with this.
-
-(If you want to read more about the package lockdown, you can see [the rationale on locking it down][8] by the Go team and the new [golang.org/s/sys][9] package.)
-
-Having the basics of the packages out of the way, let’s go step by step through the new lines of code added:
-
-1. We make a buffered channel of type `os.Signal`, with a size of `1`. `os.Signal`is a type that represents an operating system signal.
-
-2. We call `signal.Notify` with the new channel as an argument, plus`syscall.SIGINT` and `syscall.SIGTERM`. This function states “when the OS sends a `SIGINT` or a `SIGTERM` signal to this program, send the signal to the channel”. This allows us to somehow handle the sent OS signal.
-
-3. The new goroutine that we spawn waits for any of the signals to arrive through the channel. Since we know that any of the signals that will arrive are about shutting down the program, after receiving any signal we use `os.Exit(0)`([docs][2]) to gracefully stop the program. One caveat here is that if we had any `defer`red calls they would not be run.
-
-Now `launchd` can run the agent program and we can `load` and `unload`, `start`and `stop` it using `launchctl`.
-
-### Putting it all together
-
-Now that we have all the pieces ready, we need to put them together to a good use. Our application will consist of two binaries - a CLI tool and an agent (daemon). Both of the programs will be stored in separate subdirectories of the `cmd` directory.
-
-The CLI tool:
-
-```
-// cmd/cli/main.gopackage mainimport ( "log" "os" "text/template")func main() { data := struct { Label string Program string KeepAlive bool RunAtLoad bool }{ Label: "com.ieftimov.ticker", // Reverse-DNS naming convention Program: fmt.Sprintf("%s/bin/ticker", os.Getenv("GOPATH")), KeepAlive: true, RunAtLoad: true, } plistPath := fmt.Sprintf("%s/Library/LaunchAgents/%s.plist", os.Getenv("HOME"), data.Label) f, err := os.Open(plistPath) t := template.Must(template.New("launchdConfig").Parse(Template())) err := t.Execute(f, data) if err != nil { log.Fatalf("Template generation failed: %s", err) }}
-```
-
-And the ticker program:
-
-```
-// cmd/ticker/main.gopackage mainimport ( "fmt" "os" "os/signal" "syscall" "time")func main() { sigs := make(chan os.Signal, 1) signal.Notify(sigs, syscall.SIGINT, syscall.SIGTERM) go func() { <-sigs os.Exit(0) }() for range time.Tick(30 * time.Second) { fmt.Println("tick!") }}
-```
-
-To install them both, we need to run `go install ./...` in the project root. The command will install all the sub-packages that are located within the project. This will leave us with two available binaries, installed in the `$GOPATH/bin` path.
-
-To install our launch agent, we need to run only the CLI tool, via the `cli` command. This will generate the `.plist` file and place it in the `~/Library/LaunchAgents`path. We don’t need to touch the `ticker` binary - that one will be managed by `launchd`.
-
-To load the newly created `.plist` file, we need to run:
-
-```
-launchctl load ~/Library/LaunchAgents/com.ieftimov.ticker.plist
-```
-
-When we run it, we will not see anything immediately, but after 30 seconds the ticker will add a `tick!` line in `/tmp/ticker.out.log`. We can `tail` the file to see the new lines being added. If we want to unload the agent, we can use:
-
-```
-launchctl unload ~/Library/LaunchAgents/com.ieftimov.ticker.plist
-```
-
-This will unload the launch agent and will stop the ticker from running. Remember the signal handling we added? This is the case where it’s being used! Also, we could have automated the (un)loading of the file via the CLI tool but for simplicity, we left it out. You can try to improve the CLI tool by making it a bit smarter with subcommands and flags, as a follow-up exercise from this tutorial.
-
-Finally, if you decide to completely delete the launch agent, you can remove the`.plist` file:
-
-```
-rm ~/Library/LaunchAgents/com.ieftimov.ticker.plist
-```
-
-### In closing
-
-As part of this (quite long!) article, we saw how we can work with `launchd` and Golang. We took a detour, like learning about `launchd` and `launchctl`, generating XML files using the `text/template` package, we took a look at OS signals and how we can gracefully shutdown a Go program by handling the `SIGINT` and `SIGTERM`signals. There was quite a bit to learn and see, but we got to the end.
-
-Of course, we only scratched the surface with this article. For example, `launchd` is quite an interesting tool. You can use it also like `crontab` because it allows running programs at explicit time/date combinations or on specific days. Or, for example, the XML template can be embedded in the program binary using tools like [`go-bindata`][10], instead of hardcoding it in a function. Also, you explore more about signals, how they work and how Go implements these low-level primitives so you can use them with ease in your programs. The options are plenty, feel free to explore!
-
-If you have found any mistakes in the article, feel free to drop a comment below - I will appreciate it a ton. I find learning through teaching (blogging) a very pleasant experience and would like to have all the details fully correct in my posts.
-
---------------------------------------------------------------------------------
-
-作者简介:
-
-Backend engineer, interested in Ruby, Go, microservices, building resilient architectures and solving challenges at scale. I coach at Rails Girls in Amsterdam, maintain a list of small gems and often contribute to Open Source.
-This is where I write about software development, programming languages and everything else that interests me.
-
----------------------
-
-
-via: https://ieftimov.com/create-manage-macos-launchd-agents-golang
-
-作者:[Ilija Eftimov ][a]
-译者:[runningwater](https://github.com/runningwater)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://ieftimov.com/about
-[1]:https://ieftimov.com/en.wikipedia.org/wiki/Reverse_domain_name_notation
-[2]:https://godoc.org/os#Exit
-[3]:https://launchd.info/
-[4]:https://godoc.org/text/template
-[5]:https://godoc.org/os#Getenv
-[6]:https://en.wikipedia.org/wiki/Signal_(IPC)
-[7]:https://golang.org/x/sys
-[8]:https://docs.google.com/document/d/1QXzI9I1pOfZPujQzxhyRy6EeHYTQitKKjHfpq0zpxZs/edit
-[9]:https://golang.org/x/sys
-[10]:https://github.com/jteeuwen/go-bindata
diff --git a/sources/tech/20180130 Mitigating known security risks in open source libraries.md b/sources/tech/20180130 Mitigating known security risks in open source libraries.md
deleted file mode 100644
index adb1491e7d..0000000000
--- a/sources/tech/20180130 Mitigating known security risks in open source libraries.md
+++ /dev/null
@@ -1,249 +0,0 @@
-Mitigating known security risks in open source libraries
-============================================================
-
->Fixing vulnerable open source packages.
-
-
-
-
-Machine (source: [Skitterphoto][9])
-
-
-This is an excerpt from [Securing Open Source Libraries][13], by Guy Podjarny.
-[Read the preceding chapter][14] or [view the full report][15].
-
-
-### Fixing Vulnerable Packages
-
-Finding out if you’re using vulnerable packages is an important step, but it’s not the real goal. The real goal is to fix those issues!
-
-This chapter focuses on all you should know about fixing vulnerable packages, including remediation options, tooling, and various nuances. Note that SCA tools traditionally focused on finding or preventing vulnerabilities, and most put little emphasis on fix beyond providing advisory information or logging an issue. Therefore, you may need to implement some of these remediations yourself, at least until more SCA solutions expand to include them.
-
-There are several ways to fix vulnerable packages, but upgrading is the best choice. If that is not possible, patching offers a good alternative. The following sections discuss each of these options, and we will later take a look at what you can do in situations where neither of these solutions is possible.
-
-### Upgrading
-
-As I’ve previously stated, a vulnerability is a type of bug, and the best way to address a bug is to use a newer version where it is fixed. And so, the best way to fix a vulnerable dependency is to upgrade to a newer version. Statistically, most disclosed vulnerabilities are eventually fixed. In npm, 59% of reported vulnerabilities have a fix. In Maven, 90% are remediable, while that portion is 85% in RubyGems.[1][4] In other words, more often than not, there is a version of your library where the vulnerability is fixed.
-
-Finding a vulnerable package requires knowledge of which versions are vulnerable. This means that, at the very least, every tool that finds issues can tell which versions are vulnerable, allowing you to look for newer versions of the library and upgrade. Most tools also take the minor extra step of determining the minimal fixed version, and noting it in the advisory.
-
-Upgrading is therefore the best way to make a vulnerability go away. It’s technically easy (update a manifest or lock file), and it’s something dev teams are very accustomed to doing. That said, upgrading still holds some complexity.
-
-### Major Upgrades
-
-While most issues are fixed, very often the fix is only applied to the latest and greatest version of the library. If you’re still using an older version of the library, upgrading may mean switching to a new major version. Major upgrades are typically not backward compatible, introducing more risk and requiring more dev effort.
-
-Another reason for fixing an issue only in the next major version is that sometimes fixing a vulnerability means reducing functionality. For instance, fixing a certain [XSS vulnerability in a jQuery 2.x codebase][5] requires a change to the way certain selectors are interpreted. The jQuery team determined too many people are relying on this functionality to deem this a non-breaking change, and so only fixed the vulnerability in their 3.x stream.
-
-For these reasons, a major upgrade can often be difficult, but if you can accept it, it’s still the best way to fix a vulnerability.
-
-### Indirect Dependency Upgrade
-
-If you’re consuming a dependency directly, upgrading is relatively straightforward. But what happens when one of your dependencies is the one who pulled in the vulnerable package? Most dependencies are in fact indirect dependencies (a.k.a. transitive dependencies), making upgrades a bit more complex.
-
-The cleanest way to perform an indirect upgrade is through a direct one. If your app uses `A@1`, which uses a vulnerable `B@1`, it’s possible that upgrading to `A@2` will trigger a downstream upgrade to `B@2` and fix the issue. Applying such an upgrade is easy (it’s essentially a direct upgrade), but discovering _which_ upgrade to do (and whether one even exists) is time consuming. While not common, some SCA tools can determine and advise on the _direct_ upgrades you need to make to fix an _indirect_ vulnerability. If your tooling doesn’t support it, you’ll need to do the searching manually.
-
-Old vulnerabilities in indirect libraries can often be fixed with a direct upgrade, but such upgrades are frequently unavailable for new issues. When a new vulnerability is disclosed, even if the offending package releases a fix right away, it takes a while for the dependency chain to catch up. If you can’t find a path to an indirect upgrade for a newly disclosed flaw, be sure to recheck frequently as one may show up soon. Once again, some SCA tools will do this monitoring for you and alert you when new remediations are available.
-
-
-
-Figure 1-1. The direct vulnerable EJS can be upgraded, but indirect instance cannot currently be upgraded
-
-### Conflicts
-
-Another potential obstacle to upgrading is a conflict. Many languages, such as Ruby and Python, require dependencies to be global, and clients such as Ruby’s bundler and Python’s pip determine the mix of library versions that can co-exist. As a result, upgrading one library may trigger a conflict with another. While developers are adept at handling such conflicts, there are times when such issues simply cannot be resolved.
-
-On the positive side, global dependency managers, such as Ruby’s bundler, allow the parent app to add a constraint. For instance, if a downstream `B@1` gem is vulnerable, you can add `B@^2` to your Gemfile, and have bundler sort out the surrounding impact. Adding such constraints is a safe and legitimate solution, as long as your ecosystem tooling can figure out a conflict-free combination of libraries.
-
-### Is a Newer Version Always Safer?
-
-The conversation about upgrading begs a question: can a vulnerability also be fixed by downgrading?
-
-For the most part, the answer is no. Vulnerabilities are bugs, and bugs are typically fixed in a newer version, not an older one. In general, maintaining a good upgrade cadence and keeping your dependencies up to date is a good preventative measure to reduce the risk of vulnerabilities.
-
-However, in certain cases, code changes or (more often) new features are the ones that trigger a vulnerability. In those cases, it’s indeed possible that downgrading will fix the discovered flaw. The advisory should give you the information you need about which versions are affected by the vulnerability. That said, note that downgrading a package puts you at higher risk of being exposed to new issues, and can make it harder to upgrade when that happens. I suggest you see downgrading as a temporary and rarely used remediation path.
-
-### There Is No Fixed Version
-
-Last on the list of reasons preventing you from upgrading to a safe version is such a version not existing in the first place!
-
-While most vulnerabilities are fixed, many remain unfixed. This is sometimes a temporary situation—for instance, when a vulnerability was made public without waiting for a fix to be released. Other times, it may be a more long-term scenario, as many repositories fall into a poor maintenance state, and don’t fix reported issues nor accept community patches.
-
-In the following sections I’ll discuss some options for when you cannot upgrade a vulnerability away.
-
-### Patching
-
-Despite all the complexity it may involve, upgrading is the best way to fix an issue. However, if you cannot upgrade, patching the vulnerability is the next best option.
-
-Patching means taking a library as is, including its vulnerabilities, and then modifying it to fix a vulnerability it holds. Patching should apply the minimal set of changes to the library, so as to keep its functionality unharmed and only address the issue at hand.
-
-Patching inevitably holds a certain amount of risk. When you use a package downloaded millions of time a month, you have some assurance that bugs in it will be discovered, reported, and often fixed. When you download that package and modify it, your version of the code will not be quite as battle tested.
-
-Patching is therefore an exercise in risk management. What presents a greater risk: having the vulnerability, or applying the patch? For well-managed patches, especially for ones small in scope, I believe it’s almost always better to have a patch than a vulnerability.
-
-It’s worth noting that patching application dependencies is a relatively new concept, but an old hat in the operating system world. When dealing with operating system dependencies, we’re accustomed to consuming a feed of fixes by running `apt-get upgrade` or an equivalent command, often remaining unaware of which issues we fixed. What most don’t know is that many of the fixes you pull down are in fact back-ported versions of the original OS author code changes, created and tested by Canonical, RedHat, and the like. A safe registry that feeds you the non-vulnerable variants of your dependencies doesn’t exist yet in the application libraries world, but patching is sometimes doable in other ways.
-
-### Sourcing Patches
-
-To create a patch, you first need to have a fix for the vulnerability! You could write one yourself, but patches are more often sourced from existing community fixes.
-
-The first place to look for a patch is a new version of the vulnerable package. Most often the vulnerability _was_ fixed by the maintainers of the library, but that fix may be in an out-of-reach indirect dependency, or perhaps was only fitted back into the latest major version. Those fixes can be extracted from the original repo and stored into their own patch file, as well as back-ported into older versions if need be.
-
-Another common source for patches are external pull requests (PRs). Open source maintenance is a complicated topic, and it’s not uncommon for repos to go inactive. In such repos, you may find community pull requests that fix a vulnerability, have been commented on and perhaps vetted by others, but are not merged and published into the main stream. Such PRs are a good starting point—if not the full solution—for creating a patch. For instance, an XSS issue in the popular JavaScript Markdown parsing library marked had an [open fix PR][6] for nearly a year before it was incorporated into a new release. During this period, you could use the fix PR code to patch the issue in your apps.
-
-Snyk maintains its own set of patches in its [open source database][7]. Most of those patches are captures or back-ports of original fixes, a few are packaged pull requests, and even fewer are written by the Snyk security research team.
-
-### Depend on GitHub Hash
-
-In very specific cases, you may be able to patch without storing any code changes. This is only possible if the vulnerable dependency is a direct dependency of your app, and the public repo holding the package has a commit that fixes the issue (often a pull request, as mentioned before).
-
-If that’s the case, most package managers allow you to change your manifest file to point to the GitHub commit instead of naming your package and version. Git hashes are immutable, so you’ll know exactly what you’re getting, even if the pull request evolved. However, the commit may be deleted, introducing certain reliability concerns.
-
-### Fork and Patch
-
-When patching a vulnerability in a direct dependency, assuming you don’t want to depend on an external commit or have none to use, you can create one of your own. Doing so typically means forking the GitHub repository to a user you control, and patching it. Once done, you can modify your manifest to point to your fixed repository.
-
-Forking is a fairly common way of fixing different bugs in dependencies, and also carries some nice reliability advantages, as the code you use is now in your own control. It has the downside of breaking off the normal version stream of the dependency, but it’s a decent short-term solution to vulnerabilities in direct dependencies. Unfortunately, forking is not a viable option for patching indirect dependencies.
-
-### Static Patching at Build Time
-
-Another opportunity to patch a dependency is during build time. This type of patching is more complicated, as it requires:
-
-1. Storing a patch in a file (often a _.patch_ file, or an alternative JAR file with the issue fixed)
-
-2. Installing the dependencies as usual
-
-3. Determining where the dependency you’d like to patch was installed
-
-4. Applying the patch by modifying or swapping out the risky code
-
-These steps are not trivial, but they’re also usually doable using package manager commands. If a vulnerability is worth fixing, and there are no easier means to fix it, this approach should be considered.
-
-This is a classic problem for tools to address, as patches can be reused and their application can be repeated. However, at the time of this writing, Snyk is the only SCA tool that maintains patches in its DB and lets you apply them in your pipeline. I predict over time more and more tools will adopt this approach.
-
-### Dynamic Patching at Boot Time
-
-In certain programming languages, classes can also be modified at runtime, a technique often referred to as "monkey patching." Monkey patching can be used to fix vulnerabilities, though that practice has not become the norm in any ecosystem. The most prevalent use of monkey patching to fix vulnerabilities is in Ruby on Rails, where the Rails team has often released patches for vulnerabilities in the libraries it maintains.
-
-### Other Remediation Paths
-
-So far, I’ve stated upgrades are the best way to address a vulnerability, and patching the second best. However, what should you do when you cannot (or will not) upgrade nor patch?
-
-In those cases, you have no choice but to dig deeper. You need to understand the vulnerability better, and how it plays into your application. If it indeed puts your application at notable risk, there are a few steps you can take.
-
-### Removal
-
-Removing a dependency is a very effective way of fixing its vulnerabilities. Unfortunately, you’ll be losing its functionality at the same time.
-
-Dropping a dependency is often hard, as it by definition requires changes to your actual code. That said, such removal may turn out to be easy—for instance, when a dependency was used for convenience and can be rewritten instead, or when a comparable alternative exists in the ecosystem.
-
-Easy or hard, removing a dependency should always be considered an option, and weighed against the risk of keeping it.
-
-### External Mitigation
-
-If you can’t fix the vulnerable code, you can try to block attacks that attempt to exploit it instead. Introducing a rule in a web app firewall, modifying the parts of your app that accept related user input, or even blocking a port are all potential ways to mitigate a vulnerability.
-
-Whether you can mitigate and how to do so depends on the specific vulnerability and application, and in many cases such protection is impossible or high risk. That said, the most trivially exploited vulnerabilities, such as the March 2017 Struts2 RCE and ImageTragick, are often the ones most easily identified and blocked, so this approach is definitely worth exploring.
-
-###### Tip
-
-### Protecting Against Unknown Vulnerabilities
-
-Once you’re aware of a known vulnerability, your best move is to fix it, and external mitigation is a last resort. However, security controls that protect against unknown vulnerabilities, ranging from web app firewalls to sandboxed processes to ensuring least privilege, can often protect you from known vulnerabilities as well.
-
-### Log Issue
-
-Last but not least, even if you choose not to remediate the issue, the least you can do is create an issue for it. Beyond its risk management advantages, logging the issue will remind you to re-examine the remediation options over time—for instance, looking for newly available upgrades or patches that can help.
-
-If you have a security operations team, make sure to make them aware of vulnerabilities you are not solving right now. This information can prove useful when they triage suspicious behavior on the network, as such behavior may come down to this security hole being exploited.
-
-### Remediation Process
-
-Beyond the specific techniques, there are few broader guidelines when it comes to remediating issues.
-
-### Ignoring Issues
-
-If you choose not to fix an issue, or to fix it through a custom path, you’ll need to tell your SCA tool you did. Otherwise, the tool will continue to indicate this problem.
-
-All OSS security tools support ignoring a vulnerability, but have slightly different capabilities. You should consider the following, and try to note that in your tool of choice:
-
-* Are you ignoring the issue because it doesn’t affect you (perhaps you’ve mitigated it another way) or because you’ve accepted the risk? This may reflect differently in your top-level reports.
-
-* Do you want to mute the issue indefinitely, or just "snooze" it? Ignoring temporarily is common for low-severity issues that don’t yet have an upgrade, where you’re comfortable taking the risk for a bit and anticipate an upgrade will show up soon.
-
-* Do you want to ignore all instances of this known vulnerability (perhaps it doesn’t apply to your system), or only certain vulnerable paths (which, after a careful vetting process, you’ve determined to be non-exploitable)?
-
-Properly tagging the reason for muting an alert helps manage these vulnerabilities over time and across projects, and reduces the chance of an issue being wrongfully ignored and slipping through the cracks.
-
-### Fix All Vulnerable Paths
-
-For all the issues you’re not ignoring, remember that remediation has to be done for _every vulnerable path_ .
-
-This is especially true for upgrades, as every path must be assessed for upgrade separately, but also applies to patches in many ecosystems.
-
-### Track Remediations Over Time
-
-As already mentioned, a fix is typically issued for the vulnerable package first, and only later propagates through the dependency chain as other libraries upgrade to use the newer (and safer) version. Similarly, community or author code contributions are created constantly, addressing issues that weren’t previously fixable.
-
-Therefore, it’s worth tracking remediation options over time. For ignored issues, periodically check if an easy fix is now available. For patched issues, track potential updates you can switch to. Certain SCA tools automate this tracking and notify you (or open automated pull requests) when such new remediations are available.
-
-### Invest in Making Fixing Easy
-
-The unfortunate reality is that new vulnerabilities in libraries are discovered all the time. This is a fact of life—code will have bugs, some of those bugs are security bugs (vulnerabilities), and some of those are disclosed. Therefore, you and your team should expect to get a constant stream of vulnerability notifications, which you need to act on.
-
-If fixing these vulnerabilities isn’t easy, your team will not do it. Fixing these issues competes with many priorities, and its oh-so-easy to put off this invisible risk. If each alert requires a lot of time to triage and determine a fix for, the ensuing behavior would likely be to either put it off or try to convince yourself it’s not a real problem.
-
-In the world of operating systems, fixing has become the default action. In fact, "patching your servers" means taking in a feed of fixes, often without ever knowing which vulnerabilities we fix. We should strive to achieve at least this level of simplicity when dealing with vulnerable app dependencies too.
-
-Part of this effort is on tooling providers. SCA tools should let you fix vulnerabilities with a click or proactive pull requests, or patch them with a single command like `apt-get upgrade` does on servers. The other part of the effort is on you. Consider it a high priority to make vulnerability remediation easy, choose priority, choose your tools accordingly, and put in the effort to enrich or adapt those tools to fit your workflow.
-
-### Summary
-
-You should always keep in mind that finding these vulnerabilities isn’t the goal—fixing them is. Because fixing vulnerabilities is something your team will need to do often, defining the processes and tools to get that done is critical.
-
-A great way to get started with remediation is to find vulnerabilities that can be fixed with a non-breaking upgrade, and get those upgrades done. While not entirely risk-free, these upgrades should be backward compatible, and getting these security holes fixed gets you off to a very good start.
-
-[1][8]Stats based on vulnerabilities curated in the Snyk vulnerability DB.
-
-
-This is an excerpt from [Securing Open Source Libraries][16], by Guy Podjarny.
-[Read the preceding chapter][17] or [view the full report][18].
-
-
-
--------------------------------------
-
-作者简介:
-
-Guy Podjarny (Guypo) is a web performance researcher/evangelist and Akamai's Web CTO, focusing primarily on Mobile and Front-End performance. As a researcher, Guy frequently runs large scale tests, exploring performance in the real world and matching it to how browsers behave, and was one of the first to highlight the performance implications of Responsive Web Design. Guy is also the author of Mobitest, a free mobile measurement tool, and contributes to various open source tools. Guy was previously the co-founder and CTO of blaze.io, ac...
-
---------------------------------------------------------------------------------
-
-via: https://www.oreilly.com/ideas/mitigating-known-security-risks-in-open-source-libraries
-
-作者:[ Guy Podjarny][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.oreilly.com/people/4dda0-guy-podjarny
-[1]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=security-post-safari-right-rail-cta
-[2]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=security-post-safari-right-rail-cta
-[3]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=security-post-safari-right-rail-cta
-[4]:https://www.oreilly.com/ideas/mitigating-known-security-risks-in-open-source-libraries#id-xJ0u4SBFphz
-[5]:https://snyk.io/vuln/npm:jquery:20150627
-[6]:https://github.com/chjj/marked/pull/592
-[7]:https://github.com/snyk/vulnerabilitydb
-[8]:https://www.oreilly.com/ideas/mitigating-known-security-risks-in-open-source-libraries#id-xJ0u4SBFphz-marker
-[9]:https://pixabay.com/en/machine-mill-industry-steam-2881186/
-[10]:https://www.oreilly.com/ideas/mitigating-known-security-risks-in-open-source-libraries
-[11]:https://www.oreilly.com/people/4dda0-guy-podjarny
-[12]:https://www.oreilly.com/people/4dda0-guy-podjarny
-[13]:https://www.safaribooksonline.com/library/view/securing-open-source/9781491996980/?utm_source=oreilly&utm_medium=newsite&utm_campaign=fixing-vulnerable-open-source-packages
-[14]:https://www.oreilly.com/ideas/finding-vulnerable-open-source-packages?utm_source=oreilly&utm_medium=newsite&utm_campaign=fixing-vulnerable-open-source-packages
-[15]:https://www.safaribooksonline.com/library/view/securing-open-source/9781491996980/?utm_source=oreilly&utm_medium=newsite&utm_campaign=fixing-vulnerable-open-source-packages
-[16]:https://www.safaribooksonline.com/library/view/securing-open-source/9781491996980/?utm_source=oreilly&utm_medium=newsite&utm_campaign=fixing-vulnerable-open-source-packages
-[17]:https://www.oreilly.com/ideas/finding-vulnerable-open-source-packages?utm_source=oreilly&utm_medium=newsite&utm_campaign=fixing-vulnerable-open-source-packages
-[18]:https://www.safaribooksonline.com/library/view/securing-open-source/9781491996980/?utm_source=oreilly&utm_medium=newsite&utm_campaign=fixing-vulnerable-open-source-packages
-[19]:https://pixabay.com/en/machine-mill-industry-steam-2881186/
\ No newline at end of file
diff --git a/sources/tech/20180130 Trying Other Go Versions.md b/sources/tech/20180130 Trying Other Go Versions.md
deleted file mode 100644
index 731747d19a..0000000000
--- a/sources/tech/20180130 Trying Other Go Versions.md
+++ /dev/null
@@ -1,112 +0,0 @@
-Trying Other Go Versions
-============================================================
-
-While I generally use the current release of Go, sometimes I need to try a different version. For example, I need to check that all the examples in my [Guide to JSON][2] work with [both the supported releases of Go][3](1.8.6 and 1.9.3 at time of writing) along with go1.10rc1.
-
-I primarily use the current version of Go, updating it when new versions are released. I try out other versions as needed following the methods described in this article.
-
-### Trying Betas and Release Candidates[¶][4]
-
-When [go1.8beta2 was released][5], a new tool for trying the beta and release candidates was also released that allowed you to `go get` the beta. It allowed you to easily run the beta alongside your Go installation by getting the beta with:
-
-```
-go get golang.org/x/build/version/go1.8beta2
-```
-
-This downloads and builds a small program that will act like the `go` tool for that specific version. The full release can then be downloaded and installed with:
-
-```
-go1.8beta2 download
-```
-
-This downloads the release from [https://golang.org/dl][6] and installs it into `$HOME/sdk` or `%USERPROFILE%\sdk`.
-
-Now you can use `go1.8beta2` as if it were the normal Go command.
-
-This method works for [all the beta and release candidates][7] released after go1.8beta2.
-
-### Trying a Specific Release[¶][8]
-
-While only beta and release candidates are provided, they can easily be adapted to work with any released version. For example, to use go1.9.2:
-
-```
-package main
-
-import (
- "golang.org/x/build/version"
-)
-
-func main() {
- version.Run("go1.9.2")
-}
-```
-
-Replace `go1.9.2` with the release you want to run and build/install as usual.
-
-Since the program I use to build my [Guide to JSON][9] calls `go` itself (for each example), I build this as `go` and prepend the directory to my `PATH` so it will use this one instead of my normal version.
-
-### Trying Any Release[¶][10]
-
-This small program can be extended so you can specify the release to use instead of having to maintain binaries for each version.
-
-```
-package main
-
-import (
- "fmt"
- "os"
-
- "golang.org/x/build/version"
-)
-
-func main() {
- if len(os.Args) < 2 {
- fmt.Printf("USAGE: %v <version> [commands as normal]\n",
- os.Args[0])
- os.Exit(1)
- }
-
- v := os.Args[1]
- os.Args = append(os.Args[0:1], os.Args[2:]...)
-
- version.Run("go" + v)
-}
-```
-
-I have this installed as `gov` and run it like `gov 1.8.6 version`, using the version I want to run.
-
-### Trying a Source Build (e.g., tip)[¶][11]
-
-I also use this same infrastructure to manage source builds of Go, such as tip. There’s just a little trick to it:
-
-* use the directory `$HOME/sdk/go<version>` (e.g., `$HOME/sdk/gotip`)
-
-* [build as normal][1]
-
-* `touch $HOME/sdk/go<version>/.unpacked-success` This is an empty file used as a sentinel to indicate the download and unpacking was successful.
-
-(On Windows, replace `$HOME/sdk` with `%USERPROFILE%\sdk`)
-
-
---------------------------------------------------------------------------------
-
-via: https://pocketgophers.com/trying-other-versions/
-
-作者:[Nathan Kerr ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:nathan@pocketgophers.com
-[1]:https://golang.org/doc/install/source
-[2]:https://pocketgophers.com/guide-to-json/
-[3]:https://pocketgophers.com/when-should-you-upgrade-go/
-[4]:https://pocketgophers.com/trying-other-versions/#trying-betas-and-release-candidates
-[5]:https://groups.google.com/forum/#!topic/golang-announce/LvfYP-Wk1s0
-[6]:https://golang.org/dl
-[7]:https://godoc.org/golang.org/x/build/version#pkg-subdirectories
-[8]:https://pocketgophers.com/trying-other-versions/#trying-a-specific-release
-[9]:https://pocketgophers.com/guide-to-json/
-[10]:https://pocketgophers.com/trying-other-versions/#trying-any-release
-[11]:https://pocketgophers.com/trying-other-versions/#trying-a-source-build-e-g-tip
\ No newline at end of file
diff --git a/sources/tech/20180131 Migrating the debichem group subversion repository to Git.md b/sources/tech/20180131 Migrating the debichem group subversion repository to Git.md
deleted file mode 100644
index 435ac8d56a..0000000000
--- a/sources/tech/20180131 Migrating the debichem group subversion repository to Git.md
+++ /dev/null
@@ -1,223 +0,0 @@
-Migrating the debichem group subversion repository to Git - Part 1: svn-all-fast-export basics
-======
-With the [deprecation of alioth.debian.org][1] the subversion service hosted there will be shut down too. [According to lintian][2] the estimated date is May 1st 2018 and there are currently more then 1500 source packages affected. In the [debichem group][3] we've used the subversion service since 2006. Our repository contains around 7500 commits done by around 20 different alioth user accounts and the packaging history of around 70 to 80 packages, including packaging attempts. I've spent the last days to prepare the Git migration, comparing different tools, controlling the created repositories and testing possibilities to automate the process as much as possible. The resulting scripts can currently be found [here][4].
-
-Of course I began as described at the [Debian Wiki][5]. But following this guide, using `git-svn` and converting the tags with the script supplied under rubric Convert remote tags and branches to local one gave me really weird results. The tags were pointing to the wrong commit-IDs. I thought, that `git-svn` was to blame and reported this as [bug #887881][6]. In the following mail exchange Andreas Kaesorg explained to me, that the issue is caused by so-called mixed-revision-tags in our repository as shown in the following example:
-```
-$ svn log -v -r7405
-------------------------------------------------------------------------
-r7405 | dleidert | 2018-01-17 18:14:57 +0100 (Mi, 17. Jan 2018) | 1 Zeile
-Geanderte Pfade:
- A /tags/shelxle/1.0.888-1 (von /unstable/shelxle:7396)
- R /tags/shelxle/1.0.888-1/debian/changelog (von /unstable/shelxle/debian/changelog:7404)
- R /tags/shelxle/1.0.888-1/debian/control (von /unstable/shelxle/debian/control:7403)
- D /tags/shelxle/1.0.888-1/debian/patches/qt5.patch
- R /tags/shelxle/1.0.888-1/debian/patches/series (von /unstable/shelxle/debian/patches/series:7402)
- R /tags/shelxle/1.0.888-1/debian/rules (von /unstable/shelxle/debian/rules:7403)
-
-[svn-buildpackage] Tagging shelxle 1.0.888-1
-------------------------------------------------------------------------
-
-```
-
-Looking into the git log, the tags deteremined by git-svn are really not in their right place in the history line, even before running the script to convert the branches into real Git tags. So IMHO git-svn is not able to cope with this kind of situation. Because it also cannot handle our branch model, where we use /branch/package/, I began to look for different tools and found [svn-all-fast-export][7], a tool created (by KDE?) to convert even large subversion repositories based on a ruleset. My attempt using this tool was so successful (not to speak of, how fast it is), that I want to describe it more. Maybe it will prove to be useful for others as well and it won't hurt to give some more information about this poorly documented tool :)
-
-### Step 1: Setting up a local subversion mirror
-
-First I suggest setting up a local copy of the subversion repository to migrate, that is kept in sync with the remote repository. This can be achieved using the svnsync command. There are several howtos for this, so I won't describe this step here. Please check out [this guide][8]. In my case I have such a copy in /srv/svn/debichem.
-
-### Step 2: Creating the identity map
-
-svn-all-fast-export needs at least two files to work. One is the so called identity map. This file contains the mapping between subversion user IDs (login names) and the (Git) committer info, like real name and mail address. The format is the same as used by git-svn:
-```
-loginname = author name <mail address>
-```
-
-e.g.
-```
-dleidert = Daniel Leidert <dleidert@debian.org>
-```
-
-The list of subversion user IDs can be obtained the same way as [described in the Wiki][9]:
-```
-svn log SVN_URL | awk -F'|' '/^r[0-9]+/ { print $2 }' | sort -u
-```
-
-Just replace the placeholder SVN_URL with your subversion URL. [Here][10] is the complete file for the debichem group.
-
-### Step 3: Creating the rules
-
-The most important thing is the second file, which contains the processing rules. There is really not much documentation out there. So when in doubt, one has to read the source file [src/ruleparser.cpp][11]. I'll describe, what I already found out. If you are impatient, [here][12] is my result so far.
-
-The basic rules are:
-```
-create repository REPOSITORY
-...
-end repository
-
-```
-
-and
-```
-match PATTERN
-...
-end match
-
-```
-
-The first rule creates a bare git repository with the name you've chosen (above represented by REPOSITORY). It can have one child, that is the repository description to be put into the repositories description file. There are AFAIK no other elements allowed here. So in case of e.g. ShelXle the rule might look like this:
-```
-create repository shelxle
-description packaging of ShelXle, a graphical user interface for SHELXL
-end repository
-
-```
-
-You'll have to create every repository, before you can put something into it. Else svn-all-fast-export will exit with an error. JFTR: It won't complain, if you create a repository, but don't put anything into it. You will just end up with an empty Git repository.
-
-Now the second type of rule is the most important one. Based on regular expression match patterns (above represented by PATTERN), one can define actions, including the possibility to limit these actions to repositories, branches and revisions. **The patterns are applied in their order of appearance. Thus if a matching pattern is found, other patterns matching but appearing later in the rules file, won't apply!** So a special rule should always be put above a general rule. The patterns, that can be used, seem to be of type [QRegExp][13] and seem like basic Perl regular expressions including e.g. capturing, backreferences and lookahead capabilities. For a multi-package subversion repository with standard layout (that is /PACKAGE/{trunk,tags,branches}/), clean naming and subversion history, the rules could be:
-```
-match /([^/]+)/trunk/
- repository \1
- branch master
-end match
-
-match /([^/]+)/tags/([^/]+)/
- repository \1
- branch refs/tags/debian/\2
- annotated true
-end match
-
-match /([^/]+)/branches/([^/]+)/
- repository \1
- branch \2
-end match
-
-```
-
-The first rule captures the (source) package name from the path and puts it into the backreference `\1`. It applies to the trunk directory history and will put everything it finds there into the repository named after the directory - here we simply use the backreference `\1` to that name - and there into the master branch. Note, that svn-all-fast-export will error out, if it tries to access a repository, which has not been created. So make sure, all repositories are created as shown with the `create repository` rule. The second rule captures the (source) package name from the path too and puts it into the backreference `\1`. But in backreference `\2` it further captures (and applies to) all the tag directories under the /tags/ directory. Usually these have a Debian package version as name. With the branch statement as shown in this rule, the tags, which are really just branches in subversion, are automatically converted to [annotated][14] Git tags (another advantage of svn-all-fast-export over git-svn). Without enabling the `annotated` statement, the tags created will be [lightweight tags][15]. So the tag name (here: debian/VERSION) is determined via backreference `\2`. The third rule is almost the same, except that everything found in the matching path will be pushed into a Git branch named after the top-level directory captured from the subversion path.
-
-Now in an ideal world, this might be enough and the actual conversion can be done. The command should only be executed in an empty directory. I'll assume, that the identity map is called authors and the rules file is called rules and that both are in the parent directory. I'll also assume, that the local subversion mirror of the packaging repository is at /srv/svn/mymirror. So ...
-```
-svn-all-fast-export --stats --identity-map=../authors.txt --rules=../debichem.rules --stats /srv/svn/mymirror
-```
-
-... will create one or more **bare** Git repositories (depending on your rules file) in the current directory. After the command succeeded, you can test the results ...
-```
-git -C REPOSITORY/ --bare show-ref
-git -C REPOSITORY/ --bare log --all --graph
-
-```
-
-... and you will find your repositories description (if you added one to the rules file) in REPOSITORY/description:
-```
-cat REPOSITORY/description
-```
-
-**Please note, that not all the debian version strings are[well formed Git reference names][16] and therefor need fixing. There might also be gaps shown in the Git history log. Or maybe the command didn't even suceed or complained (without you noticing it) or you ended up with an empty repository, although the matching rules applied. I encountered all of these issues and I'll describe the cause and fixes in the next blog article.**
-
-But if everything went well (you have no history gaps, the tags are in their right place within the linearized history and the repository looks fine) and you can and want to proceed, you might want to skip to the next step.
-
-In the debichem group we used a different layout. The packaging directories were under /{unstable,experimental,wheezy,lenny,non-free}/PACKAGE/. This translates to [/unstable/][17]PACKAGE/ and [/non-free/][18]PACKAGE/ being the trunk directories and the [others][19] being the branches. The tags are in [/tags/][20]PACKAGE/. And packages, that are yet to upload are located in [/wnpp/][21]PACKAGE/. With this layout, the basic rules are:
-```
-# trunk handling
-# e.g. /unstable/espresso/
-# e.g. /non-free/molden/
-match /(?:unstable|non-free)/([^/]+)/
- repository \1
- branch master
-end match
-
-# handling wnpp
-# e.g. /wnpp/osra/
-match /(wnpp)/([^/]+)/
- repository \2
- branch \1
-end match
-
-# branch handling
-# e.g. /wheezy/espresso/
-match /(lenny|wheezy|experimental)/([^/]+)/
- repository \2
- branch \1
-end match
-
-# tags handling
-# e.g. /tags/espresso/VERSION/
-match /tags/([^/]+)/([^/]+)/
- repository \1
- annotated true
- branch refs/tags/debian/\2
- substitute branch s/~/_/
- substitute branch s/:/_/
-end match
-
-```
-
-In the first rule, there is a non-capturing expression (?: ... ), which simply means, that the rule applies to /unstable/ and /non-free/. Thus the backreference `\1` refers to second part of the path, the package directory name. The contents found are pushed to the master branch. In the second rule, the contents from the wnpp directory are not pushed to master, but instead to a branch called wnpp. This was necessary because of overlaps between /unstable/ and /wnpp/ history and already shows, that the repositories history makes things complicated. In the third rule, the first backreference `\1` determines the branch (note the capturing expression in contrast to the first rule) and the second backreference `\2` the package repository to act on. The last rule is similar, but now `\1` determines the package repository and `\2` the tag name (debian package version) based on the matching path. The example also shows another issue, which I'd like to explain more in the next article: some characters we use in debian package versions, e.g. the tilde sign and the colon, are not allowed within Git tag names and must therefor be substituted, which is done by the `substitute branch EXPRESSION` instructions.
-
-### Step 4: Cleaning the bare repository
-
-The [tool documentation][27] suggests to run ...
-```
-git -C REPOSITORY/ repack -a -d -f
-```
-
-... before you upload this bare repository to another location. But [Stuart Prescott told me on the debichem list][28], that this might not be enough and still leave some garbage behind. I'm not experienved enough to judge here, but his suggestion is, to clone the repository, either a bare clone or clone and init a new bare. I used the first approach:
-```
-git -C REPOSITORY/ --bare clone --bare REPOSITORY.git
-git -C REPOSITORY.git/ repack -a -d -f
-
-```
-
-**Please note, that this won't copy the repositories description file. You'll have to copy it manually, if you wanna keep it.** The resulting bare repository can be uploaded (e.g. to [git.debian.org as personal repository][29]:
-```
-cp REPOSITORY/description REPOSITORY.git/description
-touch REPOSITORY.git/git-daemon-export-ok
-rsync -avz REPOSITORY.git git.debian.org:~/public_git/
-
-```
-
-Or you clone the repository, add a remote origin and push everything there. It is even possible to use the gitlab API at salsa.debian.org to create a project and push there. I'll save the latter for another post. If you are hasty, you'll find a script [here][30].
-
---------------------------------------------------------------------------------
-
-via: http://www.wgdd.de/2018/01/migrating-debichem-group-subversion.html
-
-作者:[Daniel Leidert][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.blogger.com/profile/17052464961644858181
-[1]:https://wiki.debian.org/Alioth#Deprecation_of_Alioth
-[2]:https://lintian.debian.org/tags/vcs-deprecated-in-debian-infrastructure.html
-[3]:https://debichem.alioth.debian.org/
-[4]:https://anonscm.debian.org/viewvc/debichem/tools/svn2git/
-[5]:https://wiki.debian.org/de/Alioth/Git#Convert_a_SVN_Alioth_repository_to_Git
-[6]:https://bugs.debian.org/887881
-[7]:https://github.com/svn-all-fast-export/svn2git
-[8]:http://www.microhowto.info/howto/mirror_a_subversion_repository.html
-[9]:https://wiki.debian.org/de/Alioth/Git#Create_the_author_file
-[10]:https://anonscm.debian.org/viewvc/debichem/tools/svn2git/authors.txt?view=co&content-type=text%2Fplain
-[11]:https://raw.githubusercontent.com/svn-all-fast-export/svn2git/master/src/ruleparser.cpp
-[12]:https://anonscm.debian.org/viewvc/debichem/tools/svn2git/debichem.rules?view=co&content-type=text%2Fplain
-[13]:http://doc.qt.io/qt-5/qregexp.html#introduction
-[14]:https://git-scm.com/book/en/v2/Git-Basics-Tagging#_annotated_tags
-[15]:https://git-scm.com/book/en/v2/Git-Basics-Tagging#_lightweight_tags
-[16]:https://git-scm.com/docs/git-check-ref-format
-[17]:https://anonscm.debian.org/viewvc/debichem/unstable/
-[18]:https://anonscm.debian.org/viewvc/debichem/non-free/
-[19]:https://anonscm.debian.org/viewvc/debichem/experimental/
-[20]:https://anonscm.debian.org/viewvc/debichem/tags/
-[21]:https://anonscm.debian.org/viewvc/debichem/wnpp/
-[22]:https://anonscm.debian.org/viewvc/debichem/unstable/espresso/
-[23]:https://anonscm.debian.org/viewvc/debichem/non-free/molden/
-[24]:https://anonscm.debian.org/viewvc/debichem/wnpp/osra/
-[25]:https://anonscm.debian.org/viewvc/debichem/wheezy/espresso/
-[26]:https://anonscm.debian.org/viewvc/debichem/tags/espresso/
-[27]:https://techbase.kde.org/Projects/MoveToGit/UsingSvn2Git#Checking_for_proper_history_in_the_new_git_repository
-[28]:http://lists.alioth.debian.org/pipermail/debichem-devel/2018-January/008816.html
-[29]:https://wiki.debian.org/de/Alioth/Git#Using_personal_Git_repositories
-[30]:https://anonscm.debian.org/viewvc/debichem/tools/svn2git/gitimport.sh?view=co&content-type=text%2Fplain
diff --git a/sources/tech/20180201 I Built This - Now What How to deploy a React App on a DigitalOcean Droplet.md b/sources/tech/20180201 I Built This - Now What How to deploy a React App on a DigitalOcean Droplet.md
deleted file mode 100644
index befab76fab..0000000000
--- a/sources/tech/20180201 I Built This - Now What How to deploy a React App on a DigitalOcean Droplet.md
+++ /dev/null
@@ -1,199 +0,0 @@
-I Built This - Now What? How to deploy a React App on a DigitalOcean Droplet.
-============================================================
-
-
-Photo by [Thomas Kvistholt][1]
-
-Most aspiring developers have uploaded static HTML sites before. The process isn’t too daunting, as you’re essentially just moving files from one computer to another, and then BAM! Website.
-
-But those who have tackled learning React often pour hundreds or even thousands of hours into learning about components, props, and state, only to be left with the question “How do I host this?” Fear not, fellow developer. Deploying your latest masterpiece is a little more in-depth, but not overly difficult. Here’s how:
-
-### Preparing For Production
-
-There are a few things you’ll want to do to get your app ready for deployment.
-
-#### Turn off service workers
-
-If you’ve used something like create-react-app to bootstrap your project, you’ll want to turn off the built-in service worker if you haven’t specifically integrated it to work with your app. While usually harmless, it can cause some issues, so it’s best to just get rid of it up front. Find these lines in your `src/index.js` file and delete them:`registerServiceWorker();` `import registerServiceWorker from ‘register-service-worker’`
-
-#### Get your server ready
-
-To get the most bang for your buck, a production build will minify the code and remove extra white-space and comments so that it’s as fast to download as possible. It creates a new directory called `/build`, and we need to make sure we’re telling Express to use it. On your server page, add this line: `app.use( express.static( `${__dirname}/../build` ) );`
-
-Next, you’ll need to make sure your routes know how to get to your index.html file. To do this, we need to create an endpoint and place it below all other endpoints in your server file. It should look like this:
-
-```
-const path = require('path')app.get('*', (req, res)=>{ res.sendFile(path.join(__dirname, '../build/index.html'));})
-```
-
-#### Create the production build
-
-Now that Express knows to use the `/build` directory, it’s time to create it. Open up your terminal, make sure you’re in your project directory, and use the command `npm run build`
-
-#### Keep your secrets safe
-
-If you’re using API keys or a database connection string, hopefully you’ve already hidden them in a `.env` file. All the configuration that is different between deployed and local should go into this file as well. Tags cannot be proxied, so we have to hard code in the backend address when using the React dev server, but we want to use relative paths in production. Your resulting `.env` file might look something like this:
-
-```
-REACT_APP_LOGIN="http://localhost:3030/api/auth/login"REACT_APP_LOGOUT="http://localhost:3030/api/auth/logout"DOMAIN="user4234.auth0.com"ID="46NxlCzM0XDE7T2upOn2jlgvoS"SECRET="0xbTbFK2y3DIMp2TdOgK1MKQ2vH2WRg2rv6jVrMhSX0T39e5_Kd4lmsFz"SUCCESS_REDIRECT="http://localhost:3030/"FAILURE_REDIRECT="http://localhost:3030/api/auth/login"
-```
-
-```
-AWS_ACCESS_KEY_ID=AKSFDI4KL343K55L3
-AWS_SECRET_ACCESS_KEY=EkjfDzVrG1cw6QFDK4kjKFUa2yEDmPOVzN553kAANcy
-```
-
-```
-CONNECTION_STRING="postgres://vuigx:k8Io13cePdUorndJAB2ijk_u0r4@stampy.db.elephantsql.com:5432/vuigx"NODE_ENV=development
-```
-
-#### Push your code
-
-Test out your app locally by going to `[http://localhost:3030][2]` and replacing 3030 with your server port to make sure everything still runs smoothly. Remember to start your local server with node or nodemon so it’s up and running when you check it. Once everything looks good, we can push it to Github (or Bit Bucket, etc).
-
-IMPORTANT! Before you do so, double check that your `.gitignore` file contains `.env` and `/build` so you’re not publishing sensitive information or needless files.
-
-### Setting Up DigitalOcean
-
-[DigitalOcean][8] is a leading hosting platform, and makes it relatively easy and cost-effective to deploy React sites. They utilize Droplets, which is the term they use for their servers. Before we create our Droplet, we still have a little work to do.
-
-#### Creating SSH Keys
-
-Servers are computers that have public IP addresses. Because of this, we need a way to tell the server who we are, so that we can do things we wouldn’t want anyone else doing, like making changes to our files. Your everyday password won’t be secure enough, and a password long and complex enough to protect your Droplet would be nearly impossible to remember. Instead, we’ll use an SSH key.
-
- ** 此处有Canvas,请手动处理 **
-
-
-Photo by [Brenda Clarke][3]
-
-To create your SSH key, enter this command in your terminal: `ssh-keygen -t rsa`
-
-This starts the process of SSH key generation. First, you’ll be asked to specify where to save the new key. Unless you already have a key you need to keep, you can keep the default location and simply press enter to continue.
-
-As an added layer of security in case someone gets ahold of your computer, you’ll have to enter a password to secure your key. Your terminal will not show your keystrokes as you type this password, but it is keeping track of it. Once you hit enter, you’ll have to type it in once more to confirm. If successful, you should now see something like this:
-
-```
-Generating public/private rsa key pair.
-Enter file in which to save the key (/Users/username/.ssh/id_rsa):
-Enter passphrase (empty for no passphrase):
-Enter same passphrase again:
-Your identification has been saved in demo_rsa.
-Your public key has been saved in demo_rsa.pub.
-The key fingerprint is:
-cc:28:30:44:01:41:98:cf:ae:b6:65:2a:f2:32:57:b5 user@user.local
-The key's randomart image is:
-+--[ RSA 2048]----+
-|=*+. |
-|o. |
-| oo |
-| oo .+ |
-| . ....S |
-| . ..E |
-| . + |
-|*.= |
-|+Bo |
-+-----------------+
-```
-
-#### What happened?
-
-Two files have been created on your computer — `id_rsa` and `id_rsa.pub`. The `id_rsa` file is your private key and is used to verify your signature when you use the `id_rsa.pub` file, or public key. We need to give our public key to DigitalOcean. To get it, enter `cat ~/.ssh/id_rsa.pub`. You should now be looking at a long string of characters, which is the contents of your `id_rsa.pub` file. It looks something like this:
-
-```
-ssh-rsaAABC3NzaC1yc2EAAAADAQABAAABAQDR5ehyadT9unUcxftJOitl5yOXgSi2Wj/s6ZBudUS5Cex56LrndfP5Uxb8+Qpx1D7gYNFacTIcrNDFjdmsjdDEIcz0WTV+mvMRU1G9kKQC01YeMDlwYCopuENaas5+cZ7DP/qiqqTt5QDuxFgJRTNEDGEebjyr9wYk+mveV/acBjgaUCI4sahij98BAGQPvNS1xvZcLlhYssJSZrSoRyWOHZ/hXkLtq9CvTaqkpaIeqvvmNxQNtzKu7ZwaYWLydEKCKTAe4ndObEfXexQHOOKwwDSyesjaNc6modkZZC+anGLlfwml4IUwGv10nogVg9DTNQQLSPVmnEN3Z User@Computer.local
-```
-
-Now _that’s_ a password! Copy the string manually, or use the command `pbcopy < ~/.ssh/id_rsa.pub` to have the terminal copy it for you.
-
-#### Adding your SSH Key to DigitalOcean
-
-Login to your DigitalOcean account or sign up if you haven’t already. Go to your [Security Settings][9] and click on Add SSH. Paste in the key you copied and give it a name. You can name it whatever you like, but it’s good idea to reference the computer the key is saved on, especially if you use multiple computers regularly.
-
-#### Creating a Droplet
-
- ** 此处有Canvas,请手动处理 **
-
-
-Photo by [M. Maddo][4]
-
-With the key in place, we can finally create our Droplet. To get started, click Create Droplet. You’ll be asked to choose an OS, but for our purposes, the default Ubuntu will work just fine.
-
-You’ll need to select which size Droplet you want to use. In many cases, the smallest Droplet will do. However, review the available options and choose the one that will work best for your project.
-
-Next, select a data center for your Droplet. Choose a location central to your expected visitor base. New features are rolled out by DigitalOcean in different data centers at different times, but unless you know you want to use a special feature that’s only available in specific locations, this won’t matter.
-
-If you want to add additional services to your Droplet such as backups or private networking, you have that option here. Be aware, there is an associated cost for these services.
-
-Finally, make sure your SSH key is selected and give your Droplet a name. It is possible to host multiple projects on a single Droplet, so you may not want to give it a project-specific name. Submit your settings by clicking the Create button at the bottom of the page.
-
-#### Connecting to your Droplet
-
-With our Droplet created, we can now connect to it via SSH. Copy the IP address for your Droplet and go back to your terminal. Enter ssh followed by root@youripaddress, where youripaddress is the IP address for your Droplet. It should look something like this: `ssh root@123.45.67.8`. This tells your computer that you want to connect to your IP address as the root user. Alternatively, you can [set up user accounts][10] if you don’t want to login as root, but it’s not necessary.
-
-#### Installing Node
-
-
-
-
-To run React, we’ll need an updated version of Node. First we want to run `apt-get update && apt-get dist-upgrade` to update the Linux software list. Next, enter `apt-get install nodejs -y`, `apt-get install npm -y`, and `npm i -g n` to install Nodejs and npm.
-
-Your React app dependencies might require a specific version of Node, so check the version that your project is using by running `node -v` in your projects directory. You’ll probably want to do this in a different terminal tab so you don’t have to log in through SSH again.
-
-Once you know what version you need, go back to your SSH connection and run `n 6.11.2`, replacing 6.11.2 with your specific version number. This ensures your Droplet’s version of Node matches your project and minimizes potential issues.
-
-### Install your app to the Droplet
-
-All the groundwork has been laid, and it’s finally time to install our React app! While still connected through SSH, make sure you’re in your home directory. You can enter `cd ~` to take you there if you’re not sure.
-
-To get the files to your Droplet, you’re going to clone them from your Github repo. Grab the HTTP clone link from Github and in your terminal enter `git clone [https://github.com/username/my-react-project.git][5]`. Just like with your local project, cd into your project folder using `cd my-react-project` and then run `npm install`.
-
-#### Don’t ignore your ignored files
-
-Remember that we told Git to ignore the `.env` file, so it won’t be included in the code we just pulled down. We need to add it manually now. `touch .env`will create an empty `.env` file that we can then open in the nano editor using `nano .env`. Copy the contents of your local `.env` file and paste them into the nano editor.
-
-We also told Git to ignore the build directory. That’s because we were just testing the production build, but now we’re going to build it again on our Droplet. Use `npm run build` to run this process again. If you get an error, check to make sure you have all of your dependencies listed in your `package.json` file. If there are any missing, npm install those packages.
-
-#### Start it up!
-
-Run your server with `node server/index.js` (or whatever your server file is named) to make sure everything is working. If it throws an error, check again for any missing dependencies that might not have been caught in the build process. If everything starts up, you should now be able to go to ipaddress:serverport to see your site: `123.45.67.8:3232`. If your server is running on port 80, this is a default port and you can just use the IP address without specifying a port number: `123.45.67.8`
-
-
-
-Photo by [John Baker][6] on [Unsplash][7]
-
-You now have a space on the internet to call your own! If you have purchased a domain name you’d like to use in place of the IP address, you can follow [DigitalOcean’s instructions][11] on how to set this up.
-
-#### Keep it running
-
-Your site is live, but once you close the terminal, your server will stop. This is a problem, so we’ll want to install some more software that will tell the server not to stop once the connection is terminated. There are some options for this, but let’s use Program Manager 2 for the sake of this article.
-
-Kill your server if you haven’t already and run `npm install -g pm2`. Once installed, we can tell it to run our server using `pm2 start server/index.js`
-
-### Updating your code
-
-At some point, you’ll probably want to update your project, but luckily uploading changes is quick and easy. Once you push your code to Github, ssh into your Droplet and cd into your project directory. Because we cloned from Github initially, we don’t need to provide any links this time. You can pull down the new code simply by running `git pull`.
-
-To incorporate frontend changes, you will need to run the build process again with `npm run build`. If you’ve made changes to the server file, restart PM2 by running `pm2 restart all`. That’s it! Your updates should be live now.
-
---------------------------------------------------------------------------------
-
-via: https://medium.freecodecamp.org/i-built-this-now-what-how-to-deploy-a-react-app-on-a-digitalocean-droplet-662de0fe3f48
-
-作者:[Andrea Stringham ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://medium.freecodecamp.org/@astringham
-[1]:https://unsplash.com/photos/oZPwn40zCK4?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
-[2]:http://localhost:3030/
-[3]:https://www.flickr.com/photos/37753256@N08/
-[4]:https://www.flickr.com/photos/14141796@N05/
-[5]:https://github.com/username/my-react-project.git
-[6]:https://unsplash.com/photos/3To9V42K0Ag?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
-[7]:https://unsplash.com/search/photos/key?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
-[8]:https://www.digitalocean.com/
-[9]:https://cloud.digitalocean.com/settings/security
-[10]:https://www.digitalocean.com/community/tutorials/initial-server-setup-with-ubuntu-14-04
-[11]:https://www.digitalocean.com/community/tutorials/how-to-point-to-digitalocean-nameservers-from-common-domain-registrars
\ No newline at end of file
diff --git a/sources/tech/20180202 CompositeAcceleration.md b/sources/tech/20180202 CompositeAcceleration.md
deleted file mode 100644
index 4732746266..0000000000
--- a/sources/tech/20180202 CompositeAcceleration.md
+++ /dev/null
@@ -1,211 +0,0 @@
-CompositeAcceleration
-======
-### Composite acceleration in the X server
-
-One of the persistent problems with the modern X desktop is the number of moving parts required to display application content. Consider a simple PresentPixmap call as made by the Vulkan WSI or GL using DRI3:
-
- 1. Application calls PresentPixmap with new contents for its window
-
- 2. X server receives that call and pends any operation until the target frame
-
- 3. At the target frame, the X server copies the new contents into the window pixmap and delivers a Damage event to the compositor
-
- 4. The compositor responds to the damage event by copying the window pixmap contents into the next screen pixmap
-
- 5. The compositor calls PresentPixmap with the new screen contents
-
- 6. The X server receives that call and either posts a Swap call to the kernel or delays any action until the target frame
-
-
-
-
-This sequence has a number of issues:
-
- * The operation is serialized between three processes with at least three context switches involved.
-
- * There is no traceable relation between when the application asked for the frame to be shown and when it is finally presented. Nor do we even have any way to tell the application what time that was.
-
- * There are at least two copies of the application contents, from DRI3 buffer to window pixmap and from window pixmap to screen pixmap.
-
-
-
-
-We'd also like to be able to take advantage of the multi-plane capabilities in the display engine (where available) to directly display the application contents.
-
-### Previous Attempts
-
-I've tried to come up with solutions to this issue a couple of times in the past.
-
-#### Composite Redirection
-
-My first attempt to solve (some of) this problem was through composite redirection. The idea there was to directly pass the Present'd pixmap to the compositor and let it copy the contents directly from there in constructing the new screen pixmap image. With some additional hand waving, the idea was that we could associate that final presentation with all of the associated redirected compositing operations and at least provide applications with accurate information about when their images were presented.
-
-This fell apart when I tried to figure out how to plumb the necessary events through to the compositor and back. With that, and the realization that we still weren't solving problems inherent with the three-process dance, nor providing any path to using overlays, this solution just didn't seem worth pursuing further.
-
-#### Automatic Compositing
-
-More recently, Eric Anholt and I have been discussing how to have the X server do all of the compositing work by natively supporting ARGB window content. By changing compositors to place all screen content in windows, the X server could then generate the screen image by itself and not require any external compositing manager assistance for each frame.
-
-Given that a primitive form of automatic compositing is already supported, extending that to support ARGB windows and having the X server manage the stack seemed pretty tractable. We would extend the driver interface so that drivers could perform the compositing themselves using a mixture of GPU operations and overlays.
-
-This runs up against five hard problems though.
-
- 1. Making transitions between Manual and Automatic compositing seamless. We've seen how well the current compositing environment works when flipping compositing on and off to allow full-screen applications to use page flipping. Lots of screen flashing and application repaints.
-
- 2. Dealing with RGB windows with ARGB decorations. Right now, the window frame can be an ARGB window with the client being RGB; painting the client into the frame yields an ARGB result with the A values being 1 everywhere the client window is present.
-
- 3. Mesa currently allocates buffers exactly the size of the target drawable and assumes that the upper left corner of the buffer is the upper left corner of the drawable. If we want to place window manager decorations in the same buffer as the client and not need to copy the client contents, we would need to allocate a buffer large enough for both client and decorations, and then offset the client within that larger buffer.
-
- 4. Synchronizing window configuration and content updates with the screen presentation. One of the major features of a compositing manager is that it can construct complete and consistent frames for display; partial updates to application windows need never be shown to the user, nor does the user ever need to see the window tree partially reconfigured. To make this work with automatic compositing, we'd need to both codify frame markers within the 2D rendering stream and provide some method for collecting window configuration operations together.
-
- 5. Existing compositing managers don't do this today. Compositing managers are currently free to paint whatever they like into the screen image; requiring that they place all screen content into windows would mean they'd have to buy in to the new mechanism completely. That could still work with older X servers, but the additional overhead of more windows containing decoration content would slow performance with those systems, making migration less attractive.
-
-
-
-
-I can think of plausible ways to solve the first three of these without requiring application changes, but the last two require significant systemic changes to compositing managers. Ick.
-
-### Semi-Automatic Compositing
-
-I was up visiting Pierre-Loup at Valve recently and we sat down for a few hours to consider how to help applications regularly present content at known times, and to always know precisely when content was actually presented. That names just one of the above issues, but when you consider the additional work required by pure manual compositing, solving that one issue is likely best achieved by solving all three.
-
-I presented the Automatic Compositing plan and we discussed the range of issues. Pierre-Loup focused on the last problem -- getting existing Compositing Managers to adopt whatever solution we came up with. Without any easy migration path for them, it seemed like a lot to ask.
-
-He suggested that we come up with a mechanism which would allow Compositing Managers to ease into the new architecture and slowly improve things for applications. Towards that, we focused on a much simpler problem
-
-> How can we get a single application at the top of the window stack to reliably display frames at the desired time, and to know when that doesn't occur.
-
-Coming up with a solution for this led to a good discussion and a possible path to a broader solution in the future.
-
-#### Steady-state Behavior
-
-Let's start by ignoring how we start and stop this new mode and look at how we want applications to work when things are stable:
-
- 1. Windows not moving around
- 2. Other applications idle
-
-
-
-Let's get a picture I can use to describe this:
-
-[![][1]][1]
-
-In this picture, the compositing manager is triple buffered (as is normal for a page flipping application) with three buffers:
-
- 1. Scanout. The image currently on the screen
-
- 2. Queued. The image queued to be displayed next
-
- 3. Render. The image being constructed from various window pixmaps and other elements.
-
-
-
-
-The contents of the Scanout and Queued buffers are identical with the exception of the orange window.
-
-The application is double buffered:
-
- 1. Current. What it has displayed for the last frame
-
- 2. Next. What it is constructing for the next frame
-
-
-
-
-Ok, so in the steady state, here's what we want to happen:
-
- 1. Application calls PresentPixmap with 'Next' for its window
-
- 2. X server receives that call and copies Next to Queued.
-
- 3. X server posts a Page Flip to the kernel with the Queued buffer
-
- 4. Once the flip happens, the X server swaps the names of the Scanout and Queued buffers.
-
-
-
-
-If the X server supports Overlays, then the sequence can look like:
-
- 1. Application calls PresentPixmap
-
- 2. X server receives that call and posts a Page Flip for the overlay
-
- 3. When the page flip completes, the X server notifies the client that the previous Current buffer is now idle.
-
-
-
-
-When the Compositing Manager has content to update outside of the orange window, it will:
-
- 1. Compositing Manager calls PresentPixmap
-
- 2. X server receives that call and paints the Current client image into the Render buffer
-
- 3. X server swaps Render and Queued buffers
-
- 4. X server posts Page Flip for the Queued buffer
-
- 5. When the page flip occurs, the server can mark the Scanout buffer as idle and notify the Compositing Manager
-
-
-
-
-If the Orange window is in an overlay, then the X server can skip step 2.
-
-#### The Auto List
-
-To give the Compositing Manager control over the presentation of all windows, each call to PresentPixmap by the Compositing Manager will be associated with the list of windows, the "Auto List", for which the X server will be responsible for providing suitable content. Transitioning from manual to automatic compositing can therefore be performed on a window-by-window basis, and each frame provided by the Compositing Manager will separately control how that happens.
-
-The Steady State behavior above would be represented by having the same set of windows in the Auto List for the Scanout and Queued buffers, and when the Compositing Manager presents the Render buffer, it would also provide the same Auto List for that.
-
-Importantly, the Auto List need not contain only children of the screen Root window. Any descendant window at all can be included, and the contents of that drawn into the image using appropriate clipping. This allows the Compositing Manager to draw the window manager frame while the client window is drawn by the X server.
-
-Any window at all can be in the Auto List. Windows with PresentPixmap contents available would be drawn from those. Other windows would be drawn from their window pixmaps.
-
-#### Transitioning from Manual to Auto
-
-To transition a window from Manual mode to Auto mode, the Compositing Manager would add it to the Auto List for the Render image, and associate that Auto List with the PresentPixmap request for that image. For the first frame, the X server may not have received a PresentPixmap for the client window, and so the window contents would have to come from the Window Pixmap for the client.
-
-I'm not sure how we'd get the Compositing Manager to provide another matching image that the X server can use for subsequent client frames; perhaps it would just create one itself?
-
-#### Transitioning from Auto to Manual
-
-To transition a window from Auto mode to Manual mode, the Compositing manager would remove it from the Auto List for the Render image and then paint the window contents into the render image itself. To do that, the X server would have to paint any PresentPixmap data from the client into the window pixmap; that would be done when the Compositing Manager called GetWindowPixmap.
-
-### New Messages Required
-
-For this to work, we need some way for the Compositing Manager to discover windows that are suitable for Auto composting. Normally, these will be windows managed by the Window Manager, but it's possible for them to be nested further within the application hierarchy, depending on how the application is constructed.
-
-I think what we want is to tag Damage events with the source window, and perhaps additional information to help Compositing Managers determine whether it should be automatically presenting those source windows or a parent of them. Perhaps it would be helpful to also know whether the Damage event was actually caused by a PresentPixmap for the whole window?
-
-To notify the server about the Auto List, a new request will be needed in the Present extension to set the value for a subsequent PresentPixmap request.
-
-### Actually Drawing Frames
-
-The DRM module in the Linux kernel doesn't provide any mechanism to remove or replace a Page Flip request. While this may get fixed at some point, we need to deal with how it works today, if only to provide reasonable support for existing kernels.
-
-I think about the best we can do is to set a timer to fire a suitable time before vblank and have the X server wake up and execute any necessary drawing and Page Flip kernel calls. We can use feedback from the kernel to know how much slack time there was between any drawing and the vblank and adjust the timer as needed.
-
-Given that the goal is to provide for reliable display of the client window, it might actually be sufficient to let the client PresentPixmap request drive the display; if the Compositing Manager provides new content for a frame where the client does not, we can schedule that for display using a timer before vblank. When the Compositing Manager provides new content after the client, it would be delayed until the next frame.
-
-### Changes in Compositing Managers
-
-As described above, one explicit goal is to ease the burden on Compositing Managers by making them able to opt-in to this new mechanism for a limited set of windows and only for a limited set of frames. Any time they need to take control over the screen presentation, a new frame can be constructed with an empty Auto List.
-
-### Implementation Plans
-
-This post is the first step in developing these ideas to the point where a prototype can be built. The next step will be to take feedback and adapt the design to suit. Of course, there's always the possibility that this design will also prove unworkable in practice, but I'm hoping that this third attempt will actually succeed.
-
---------------------------------------------------------------------------------
-
-via: https://keithp.com/blogs/CompositeAcceleration/
-
-作者:[keithp][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://keithp.com
-[1]:https://keithp.com/pictures/ca-steady.svg
diff --git a/sources/tech/20180205 Getting Started with the openbox windows manager in Fedora.md b/sources/tech/20180205 Getting Started with the openbox windows manager in Fedora.md
deleted file mode 100644
index 1059df1c0b..0000000000
--- a/sources/tech/20180205 Getting Started with the openbox windows manager in Fedora.md
+++ /dev/null
@@ -1,216 +0,0 @@
-Getting Started with the openbox windows manager in Fedora
-======
-
-
-
-Openbox is [a lightweight, next generation window manager][1] for users who want a minimal enviroment for their [Fedora][2]desktop. It’s well known for its minimalistic appearance, low resource usage and the ability to run applications the way they were designed to work. Openbox is highly configurable. It allows you to change almost every aspect of how you interact with your desktop. This article covers a basic setup of Openbox on Fedora.
-
-### Installing Openbox in Fedora
-
-This tutorial assumes you’re already working in a traditional desktop environment like [GNOME][3] or [Plasma][4]over the [Wayland][5] compositor. First, open a terminal and run the following command [using sudo][6].
-```
-sudo dnf install openbox xbacklight feh conky xorg-x11-drv-libinput tint2 volumeicon xorg-x11-server-utils network-manager-applet
-
-```
-
-Curious about the packages this command installs? Here is the package-by-package breakdown.
-
- * **openbox** is the main window manager package
- * **xbacklight** is a utility to set laptop screen brightness
- * **feh** is a utility to set a wallpaper for the desktop
- * **conky** is a utility to display system information
- * **tint2** is a system panel/taskbar
- * **xorg-x11-drv-libinput** is a driver that lets the system activate clicks on tap in a laptop touchpad
- * **volumeicon** is a volume control for the system tray
- * **xorg-x11-server-utils** provides the xinput tool
- * **network-manager-applet** provides the nm-applet tool for the system tray
-
-
-
-Once you install these packages, restart your computer. After the system restarts, choose your user name to login. Before you enter your password, click the gear icon to select the Openbox session. Then enter your password to start Openbox.
-
-If you ever want to switch back, simply use this gear icon to return to the selection for your desired desktop session.
-
-### Using Openbox
-
-The first time you login to your Openbox session, a mouse pointer appears over a black desktop. Don’t worry, this is the default look and feel of the desktop. First, right click your mouse to access a handy menu to launch your apps. You can use the shortcut **Ctrl + Alt + LeftArrow / RightArrow** to switch between four virtual screens.
-
-![][7]
-
-If your laptop has a touchpad, you may want to configure tap to click for an improved experience. Fedora features libinput to handle input from the touchpad. First, get a list of input devices in your computer:
-```
-$ xinput list
- ⎡ Virtual core pointer id=2 [master pointer (3)]
- ⎜ ↳ Virtual core XTEST pointer id=4 [slave pointer (2)]
- ⎜ ↳ ETPS/2 Elantech Touchpad id=11 [slave pointer (2)]
- ⎣ Virtual core keyboard id=3 [master keyboard (2)]
- ↳ Virtual core XTEST keyboard id=5 [slave keyboard (3)]
- ↳ Power Button id=6 [slave keyboard (3)]
- ↳ Video Bus id=7 [slave keyboard (3)]
- ↳ Power Button id=8 [slave keyboard (3)]
- ↳ WebCam SC-13HDL11939N: WebCam S id=9 [slave keyboard (3)]
- ↳ AT Translated Set 2 keyboard id=10 [slave keyboard (3)]
-
-```
-
-In the example laptop, the touchpad is the device with ID 11. With this info you can list your trackpad properties:
-```
-$ xinput list-props 11
-Device 'ETPS/2 Elantech Touchpad':
-Device Enabled (141): 1
-Coordinate Transformation Matrix (143): 1.000000, 0.000000, 0.000000, 0.000000, 1.000000, 0.000000, 0.000000, 0.000000, 1.000000
-libinput Tapping Enabled (278): 0
-libinput Tapping Enabled Default (279): 0
-droped
-
-```
-
-In this example, the touchpad has the Tapping Enabled property set to false (0).
-
-Now you know your trackpad device ID (11) and the property to configure (278). This means you can enable tapping with the command:
-```
-xinput set-prop <device> <property> <value>
-
-```
-
-For the example above:
-```
-xinput set-prop 11 278 1
-
-```
-
-You should now be able to successfully click in your touchpad with a tap. Now configure this option at the Openbox session start. First, create the config file with an editor:
-```
-vi ~/.config/openbox/autostart
-
-```
-
-This example uses the vi text editor, but you can use any editor you want, like gedit or kwrite. In this file add the following lines:
-```
-# Set tapping on touchpad on:
-xinput set-prop 11 278 1 &
-
-```
-
-Save the file, logout of the current session, and login again to verify your touchpad works.
-
-### Configuring the session
-
-Here are some examples of how you can configure your Openbox session to your preferences. To use feh to set the desktop wallpaper at startup, just add these lines to your ~/.config/openbox/autostart file:
-```
-# Set desktop wallpaper:
-feh --bg-scale ~/path/to/wallpaper.png &
-
-```
-
-To use tint2 to show a task bar in the desktop, add these lines to the autostart file:
-```
-# Show system tray
-tint2 &
-
-```
-
-Add these lines to the autostart file to start conky when you login:
-```
-# Show system info
-conky &
-
-```
-
-Now you can add your own services to your Openbox session. Just add entries to your autostart file. For instance, add the NetworkManager applet and volume control with these lines:
-```
-#NetworkManager
-nm-applet &
-
-#Volume control in system tray
-volumeicon &
-
-```
-
-The configuration file used in this post for conky is available [here][8] you can copy and paste the configuration in a file called .conkyrc in your home directory .
-
-The conky utility is a highly configurable way to show system information. You can set up a preferred profile of settings in a ~/.conkyrc file. Here’s [an example conkyrc file][9]. You can find many more on the web.
-
-You are now able to customize your Openbox installation in exciting ways. Here’s a screenshot of the author’s Openbox desktop:
-
-![][10]
-
-### Configuring tint2
-
-You can also configure the look and feel of the panel with tint2. The configuration file is available in ~/.config/tint2/tint2rc. Use your favorite editor to open this file:
-```
-vi ~/.config/tint2/tint2rc
-
-```
-
-Look for these lines first:
-```
-#-------------------------------------
-#Panel
-panel_items = LTSCB
-
-```
-
-These are the elements than will be included in the bar where:
-
- * **L** = Launchers
- * **T** = Task bar
- * **S** = Systray
- * **C** = Clock
- * **B** = Battery
-
-
-
-Then look for those lines to configure the launchers in the task bar:
-```
-#-------------------------------------
-#Launcher
-launcher_padding = 2 4 2
-launcher_background_id = 0
-launcher_icon_background_id = 0
-launcher_icon_size = 24
-launcher_icon_asb = 100 0 0
-launcher_icon_theme_override = 0
-startup_notifications = 1
-launcher_tooltip = 1
-launcher_item_app = /usr/share/applications/tint2conf.desktop
-launcher_item_app = /usr/local/share/applications/tint2conf.desktop
-launcher_item_app = /usr/share/applications/firefox.desktop
-launcher_item_app = /usr/share/applications/iceweasel.desktop
-launcher_item_app = /usr/share/applications/chromium-browser.desktop
-launcher_item_app = /usr/share/applications/google-chrome.desktop
-
-```
-
-Here you can add shortcuts to your favorite launcher_item_app elements. This item accepts .desktop files and not executables. You can get a list of your system-wide desktop files with this command:
-```
-ls /usr/share/applications/
-
-```
-
-As an exercise for the reader, see if you can find and install a theme for either the Openbox [window manager][11] or [tint2][12]. Enjoy getting started with Openbox as a Fedora desktop.
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/openbox-fedora/
-
-作者:[William Moreno][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://williamjmorenor.id.fedoraproject.org/
-[1]:http://openbox.org/wiki/Main_Page
-[2]:https://getfedora.org/
-[3]:https://getfedora.org/es/workstation/
-[4]:https://spins.fedoraproject.org/kde/
-[5]:https://wayland.freedesktop.org/
-[6]:https://fedoramagazine.org/howto-use-sudo/
-[7]:https://fedoramagazine.org/wp-content/uploads/2017/10/openbox-01-300x169.png
-[8]:https://gist.github.com/williamjmorenor/96399defad35e24a8f1843e2c256b4a4
-[9]:https://github.com/zenzire/conkyrc/blob/master/conkyrc
-[10]:https://fedoramagazine.org/wp-content/uploads/2017/10/openbox-02-300x169.png
-[11]:https://www.deviantart.com/customization/skins/linuxutil/winmanagers/openbox/whats-hot/?order=9&offset=0
-[12]:https://github.com/addy-dclxvi/Tint2-Theme-Collections
diff --git a/sources/tech/20180205 Writing eBPF tracing tools in Rust.md b/sources/tech/20180205 Writing eBPF tracing tools in Rust.md
deleted file mode 100644
index 18b8eb5742..0000000000
--- a/sources/tech/20180205 Writing eBPF tracing tools in Rust.md
+++ /dev/null
@@ -1,258 +0,0 @@
-Writing eBPF tracing tools in Rust
-============================================================
-
-tl;dr: I made an experimental Rust repository that lets you write BPF tracing tools from Rust! It’s at [https://github.com/jvns/rust-bcc][4] or [https://crates.io/crates/bcc][5], and has a couple of hopefully easy to understand examples. It turns out that writing BPF-based tracing tools in Rust is really easy (in some ways easier than doing the same things in Python). In this post I’ll explain why I think this is useful/important.
-
-For a long time I’ve been interested in the [BPF compiler collection][6], a C -> BPF compiler, C library, and Python bindings to make it easy to write tools like:
-
-* [opensnoop][1] (spies on which files are being opened)
-
-* [tcplife][2] (track length of TCP connections)
-
-* [cpudist][3] (count how much time every program spends on- and off-CPU)
-
-and a lot more. The list of available tools in [the /tools directory][7] is really impressive and I could write a whole blog post about that. If you’re familiar with dtrace – the idea is that BCC is a little bit like dtrace, and in fact there’s a dtrace-like language [named ply][8] implemented with BPF.
-
-This blog post isn’t about `ply` or the great BCC tools though – it’s about what tools we need to build more complicated/powerful BPF-based programs.
-
-### What does the BPF compiler collection let you do?
-
-Here’s a quick overview of what BCC lets you do:
-
-* compile BPF programs from C into eBPF bytecode.
-
-* attach this eBPF bytecode to a userspace function or kernel function (as a “uprobe” / “kprobe”) or install it as XDP
-
-* communicate with the eBPF bytecode to get information with it
-
-A basic example of using BCC is this [strlen_count.py][9] program and I think it’s useful to look at this program to understand how BCC works and how you might be able to implement more advanced tools.
-
-First, there’s an eBPF program. This program is going to be attached to the `strlen` function from libc (the C standard library) – every time we call `strlen`, this code will be run.
-
-This eBPF program
-
-* gets the first argument to the `strlen` function (the address of a string)
-
-* reads the first 80 characters of that string (using `bpf_probe_read`)
-
-* increments a counter in a hashmap (basically `counts[str] += 1`)
-
-The result is that you can count every call to `strlen`. Here’s the eBPF program:
-
-```
-struct key_t {
- char c[80];
-};
-BPF_HASH(counts, struct key_t);
-int count(struct pt_regs *ctx) {
- if (!PT_REGS_PARM1(ctx))
- return 0;
- struct key_t key = {};
- u64 zero = 0, *val;
- bpf_probe_read(&key.c, sizeof(key.c), (void *)PT_REGS_PARM1(ctx));
- val = counts.lookup_or_init(&key, &zero);
- (*val)++;
- return 0;
-};
-
-```
-
-After that program is compiled, there’s a Python part which does `b.attach_uprobe(name="c", sym="strlen", fn_name="count")` – it tells the Linux kernel to actually attach the compiled BPF to the `strlen` function so that it runs every time `strlen` runs.
-
-The really exciting thing about eBPF is what comes next – there’s no use keeping a hashmap of string counts if you can’t access it! BPF has a number of data structures that let you share information between BPF programs (that run in the kernel / in uprobes) and userspace.
-
-So in this case the Python program accesses this `counts` data structure.
-
-### BPF data structures: hashmaps, buffers, and more!
-
-There’s a great list of available BPF data structures in the [BCC reference guide][10].
-
-There are basically 2 kinds of BPF data structures – data structures suitable for storing statistics (BPF_HASH, BPF_HISTOGRAM etc), and data structures suitable for storing events (like BPF_PERF_MAP) where you send a stream of events to a userspace program which then displays them somehow.
-
-There are a lot of interesting BPF data structures (like a trie!) and I haven’t fully worked out what all of the possibilities are with them yet :)
-
-### What I’m interested in: BPF for profiling & tracing
-
-Okay!! We’re done with the background, let’s talk about why I’m interested in BCC/BPF right now.
-
-I’m interested in using BPF to implement profiling/tracing tools for dynamic programming languages, specifically tools to do things like “trace all memory allocations in this Ruby program”. I think it’s exciting that you can say “hey, run this tiny bit of code every time a Ruby object is allocated” and get data back about ongoing allocations!
-
-### Rust: a way to build more powerful BPF-based tools
-
-The issue I see with the Python BPF libraries (which are GREAT, of course) is that while they’re perfect for building tools like `tcplife` which track tcp connnection lengths, once you want to start doing more complicated experiments like “stream every memory allocation from this Ruby program, calculate some metadata about it, query the original process to find out the class name for that address, and display a useful summary”, Python doesn’t really cut it.
-
-So I decided to spend 4 days trying to build a BCC library for Rust that lets you attach + interact with BPF programs from Rust!
-
-Basically I worked on porting [https://github.com/iovisor/gobpf][11] (a go BCC library) to Rust.
-
-The easiest and most exciting way to explain this is to show an example of what using the library looks like.
-
-### Rust example 1: strlen
-
-Let’s start with the strlen example from above. Here’s [strlen.rs][12] from the examples!
-
-Compiling & attaching the `strlen` code is easy:
-
-```
-let mut module = BPF::new(code)?;
-let uprobe_code = module.load_uprobe("count")?;
-module.attach_uprobe("/lib/x86_64-linux-gnu/libc.so.6", "strlen", uprobe_code, -1 /* all PIDs */)?;
-let table = module.table("counts");
-
-```
-
-This table contains a hashmap mapping strings to counts. So we need to iterate over that table and print out the keys and values. This is pretty simple: it looks like this.
-
-```
-let iter = table.into_iter();
-for e in iter {
- // key and value are each a Vec<u8> so we need to transform them into a string and
- // a u64 respectively
- let key = get_string(&e.key);
- let value = Cursor::new(e.value).read_u64::<NativeEndian>().unwrap();
- println!("{:?} {:?}", key, value);
-}
-
-```
-
-Basically all the data that comes out of a BPF program is an opaque `Vec<u8>`right now, so you need to figure out how to decode them yourself. Luckily decoding binary data is something that Rust is quite good at – the `byteorder`crate lets you easily decode `u64`s, and translating a vector of bytes into a String is easy (I wrote a quick `get_string` helper function to do that).
-
-I thought this was really nice because the code for this program in Rust is basically exactly the same as the corresponding Python version. So it very pretty approachable to start doing experiments and seeing what’s possible.
-
-### Reading perf events from Rust
-
-The next thing I wanted to do after getting this `strlen` example to work in rust was to handle events!!
-
-Events are a little different / more complicated. The way you stream events in a BCC program is – it uses `perf_event_open` to create a ring buffer where the events get stored.
-
-Dealing with events from a perf ring buffer normally is a huge pain because perf has this complicated data structure. The C BCC library makes this easier for you by letting you specify a C callback that gets called on every new event, and it handles dealing with perf. This is super helpful. To make this work with Rust, the `rust-bcc` library lets you pass in a Rust closure to run on every event.
-
-### Rust example 2: opensnoop.rs (events!!)
-
-To make sure reading BPF events actually worked, I implemented a basic version of `opensnoop.py` from the iovisor bcc tools: [opensnoop.rs][13].
-
-I won’t walk through the [C code][14] in this case because there’s a lot of it but basically the eBPF C part generates an event every time a file is opened on the system. I copied the C code verbatim from [opensnoop.py][15].
-
-Here’s the type of the event that’s generated by the BPF code:
-
-```
-#[repr(C)]
-struct data_t {
- id: u64, // pid + thread id
- ts: u64,
- ret: libc::c_int,
- comm: [u8; 16], // process name
- fname: [u8; 255], // filename
-}
-
-```
-
-The Rust part starts out by compiling BPF code & attaching kprobes (to the `open`system call in the kernel, `do_sys_open`). I won’t paste that code here because it’s basically the same as the `strlen` example. What happens next is the new part: we install a callback with a Rust closure on the `events` table, and then call `perf_map.poll(200)` in a loop. The design of the BCC library is a little confusing to me still, but you need to repeatedly poll the perf reader objects to make sure that the callbacks you installed actually get called.
-
-```
-let table = module.table("events");
-let mut perf_map = init_perf_map(table, perf_data_callback)?;
-loop {
- perf_map.poll(200);
-}
-
-```
-
-This is the callback code I wrote, that gets called every time. Again, it takes an opaque `Vec<u8>` event and translates it into a `data_t` struct to print it out. Doing this is kind of annoying (I actually called `libc::memcpy` which is Not Encouraged Rust Practice), I need to figure out a less gross/unsafe way to do that. The really nice thing is that if you put `#[repr(C)]` on your Rust structs it represents them in memory the exact same way C will represent that struct. So it’s quite easy to share data structures between Rust and C.
-
-```
-fn perf_data_callback() -> Box<Fn(Vec<u8>)> {
- Box::new(|x| {
- // This callback
- let data = parse_struct(&x);
- println!("{:-7} {:-16} {}", data.id >> 32, get_string(&data.comm), get_string(&data.fname));
- })
-}
-
-```
-
-You might notice that this is actually a weird function that returns a callback – this is because I needed to install 4 callbacks (1 per CPU), and in stable Rust you can’t copy closures yet.
-
-output
-
-Here’s what the output of that `opensnoop` program looks like!
-
-This is kind of meta – these are the files that were being opened on my system when I saved this blog post :). You can see that git is looking at some files, vim is saving a file, and my static site generator Hugo is opening the changed file so that it can update the site. Neat!
-
-```
-PID COMMAND FILENAME
- 8519 git /home/bork/work/homepage/.gitmodules
- 8519 git /home/bork/.gitconfig
- 8519 git .git/config
- 22877 vim content/post/2018-02-05-writing-ebpf-programs-in-rust.markdown
- 22877 vim .
- 7312 hugo /home/bork/work/homepage/content/post/2018-02-05-writing-ebpf-programs-in-rust.markdown
- 7312 hugo /home/bork/work/homepage/content/post/2018-02-05-writing-ebpf-programs-in-rust.markdown
-
-```
-
-### using rust-bcc to implement Ruby experiments
-
-Now that I have this basic library that I can use I can get counts + stream events in Rust, I’m excited about doing some experiments with making BCC programs in Rust that talk to Ruby programs!
-
-The first experiment (that I blogged about last week) is [count-ruby-allocs.rs][16]which prints out a live count of current allocation activity. Here’s an example of what it prints out: (the numbers are counts of the number of objects allocated of that type so far).
-
-```
- RuboCop::Token 53
- RuboCop::Token 112
- MatchData 246
-Parser::Source::Rang 255
- Proc 323
- Enumerator 328
- Hash 475
- Range 1210
- ??? 1543
- String 3410
- Array 7879
-Total allocations since we started counting: 16932
-Allocations this second: 954
-
-```
-
-### Related work
-
-Geoffrey Couprie is interested in building more advanced BPF tracing tools with Rust too and wrote a great blog post with a cool proof of concept: [Compiling to eBPF from Rust][17].
-
-I think the idea of not requiring the user to compile the BPF program is exciting, because you could imagine distributing a statically linked Rust binary (which links in libcc.so) with a pre-compiled BPF program that the binary just installs and then uses to do cool stuff.
-
-Also there’s another Rust BCC library at [https://bitbucket.org/photoszzt/rust-bpf/][18] at which has a slightly different set of capabilities than [jvns/rust-bcc][19] (going to spend some time looking at that one later, I just found about it like 30 minutes ago :)).
-
-### that’s it for now
-
-This crate is still extremely sketchy and there are bugs & missing features but I wanted to put it on the internet because I think the examples of what you can do with it are really exciting!!
-
---------------------------------------------------------------------------------
-
-via: https://jvns.ca/blog/2018/02/05/rust-bcc/
-
-作者:[Julia Evans ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://jvns.ca/about/
-[1]:https://github.com/iovisor/bcc/blob/master/tools/opensnoop.py
-[2]:https://github.com/iovisor/bcc/blob/master/tools/tcplife.py
-[3]:https://github.com/iovisor/bcc/blob/master/tools/cpudist.py
-[4]:https://github.com/jvns/rust-bcc
-[5]:https://crates.io/crates/bcc
-[6]:https://github.com/iovisor/bcc
-[7]:https://github.com/iovisor/bcc/tree/master/tools
-[8]:https://github.com/iovisor/ply
-[9]:https://github.com/iovisor/bcc/blob/master/examples/tracing/strlen_count.py
-[10]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#maps
-[11]:https://github.com/iovisor/gobpf
-[12]:https://github.com/jvns/rust-bcc/blob/f15d2983ddbe349aac3d2fcaeacf924a66db4be7/examples/strlen.rs
-[13]:https://github.com/jvns/rust-bcc/blob/f15d2983ddbe349aac3d2fcaeacf924a66db4be7/examples/opensnoop.rs
-[14]:https://github.com/jvns/rust-bcc/blob/f15d2983ddbe349aac3d2fcaeacf924a66db4be7/examples/opensnoop.c
-[15]:https://github.com/iovisor/bcc/blob/master/tools/opensnoop.py
-[16]:https://github.com/jvns/ruby-mem-watcher-demo/blob/dd189b178a2813e6445063f0f84063e6e978ee79/src/bin/count-ruby-allocs.rs
-[17]:https://unhandledexpression.com/2018/02/02/poc-compiling-to-ebpf-from-rust/
-[18]:https://bitbucket.org/photoszzt/rust-bpf/
-[19]:https://github.com/jvns/rust-bcc
diff --git a/sources/tech/20180208 How to start writing macros in LibreOffice Basic.md b/sources/tech/20180208 How to start writing macros in LibreOffice Basic.md
deleted file mode 100644
index 06385044a4..0000000000
--- a/sources/tech/20180208 How to start writing macros in LibreOffice Basic.md
+++ /dev/null
@@ -1,332 +0,0 @@
-How to start writing macros in LibreOffice Basic
-======
-
-
-
-I have long promised to write about the scripting language [Basic][1] and creating macros in LibreOffice. This article is devoted to the types of data used in LibreOffice Basic, and to a greater extent, descriptions of variables and the rules for using them. I will try to provide enough information for advanced as well as novice users.
-
-(And, I would like to thank everyone who commented on and offered recommendations on the Russian article, especially those who helped answer difficult questions.)
-
-### Variable naming conventions
-
-Variable names cannot contain more than 255 characters. They should start with either upper- or lower-case letters of the Latin alphabet, and they can include underscores ("_") and numerals. Other punctuation or characters from non-Latin alphabets can cause a syntax error or a BASIC runtime error if names are not put within square brackets.
-
-Here are some examples of correct variable names:
-```
-MyNumber=5
-
-MyNumber5=15
-
-MyNumber_5=20
-
-_MyNumber=96
-
-[My Number]=20.5
-
-[5MyNumber]=12
-
-[Number,Mine]=12
-
-[DéjàVu]="It seems that I have seen it!"
-
-[Моя переменная]="The first has went!"
-
-[Мой % от зделки]=0.0001
-
-```
-
-Note: In examples that contain square brackets, if you remove the brackets, macros will show a window with an error. As you can see, you can use localized variable names. Whether it makes sense to do so is up to you.
-
-### Declaring variables
-
-Strictly speaking, it is not necessary to declare variables in LibreOffice Basic (except for arrays). If you write a macro from a pair of lines to work with small documents, you don't need to declare variables, as the variable will automatically be declared as the variant type. For longer macros or those that will work in large documents, it is strongly recommended that you declare variables. First, it increases the readability of the text. Second, it allows you to control variables that can greatly facilitate the search for errors. Third, the variant type is very resource-intensive, and considerable time is needed for the hidden conversion. In addition, the variant type does not choose the optimal variable type for data, which increases the workload of computer resources.
-
-Basic can automatically assign a variable type by its prefix (the first letter in the name) to simplify the work if you prefer to use the Hungarian notation. For this, the statement **DefXXX** is used; **XXX** is the letter type designation. A statement with a letter will work in the module, and it must be specified before subprograms and functions appear. There are 11 types:
-```
-DefBool - for boolean variables;
-DefInt - for integer variables of type Integer;
-DefLng - for integer variables of type Long Integer;
-DefSng - for variables with a single-precision floating point;
-DefDbl - for variables with double-precision floating-point type Double;
-DefCur - for variables with a fixed point of type Currency;
-DefStr - for string variables;
-DefDate - for date and time variables;
-DefVar - for variables of Variant type;
-DefObj - for object variables;
-DefErr - for object variables containing error information.
-
-```
-
-If you already have an idea of the types of variables in LibreOffice Basic, you probably noticed that there is no **Byte** type in this list, but there is a strange beast with the **Error** type. Unfortunately, you just need to remember this; I have not yet discovered why this is true. This method is convenient because the type is assigned to the variables automatically. But it does not allow you to find errors related to typos in variable names. In addition, it will not be possible to specify non-Latin letters; that is, all names of variables in square brackets that need to be declared must be declared explicitly.
-
-To avoid typos when using declared variables explicitly, you can use the statement **OPTION EXPLICIT**. This statement should be the first line of code in the module. All other commands, except comments, should be placed after it. This statement tells the interpreter that all variables must be declared explicitly; otherwise, it produces an error. Naturally, this statement makes it meaningless to use the **Def** statement in the code.
-
-A variable is declared using the statement **Dim**. You can declare several variables simultaneously, even different types, if you separate their names with commas. To determine the type of a variable with an explicit declaration, you can use either a corresponding keyword or a type-declaration sign after the name. If a type-declaration sign or a keyword is not used after the variable, then the **Variant** type is automatically assigned to it. For example:
-```
-Dim iMyVar 'variable of Variant type
-Dim iMyVar1 As Integer, iMyVar2 As Integer 'in both cases Integer type
-Dim iMyVar3, iMyVar4 As Integer 'in this case the first variable
- 'is Variant, and the second is Integer
-```
-
-### Variable types
-
-LibreOffice Basic supports seven classes of variables:
-
- * Logical variables containing one of the values: **TRUE** or **FALSE**
- * Numeric variables containing numeric values. They can be integer, integer-positive, floating-point, and fixed-point
- * String variables containing character strings
- * Date variables can contain a date and/or time in the internal format
- * Object variables can contain objects of different types and structures
- * Arrays
- * Abstract type **Variant**
-
-
-
-#### Logical variables – Boolean
-
-Variables of the **Boolean** type can contain only one of two values: **TRUE** or **FALSE**. In the numerical equivalent, the value FALSE corresponds to the number 0, and the value TRUE corresponds to **-1** (minus one). Any value other than zero passed to a variable of the Boolean type will be converted to **TRUE** ; that is, converted to a minus one. You can explicitly declare a variable in the following way:
-```
-Dim MyBoolVar As Boolean
-```
-
-I did not find a special symbol for it. For an implicit declaration, you can use the **DefBool** statement. For example:
-```
-DefBool b 'variables beginning with b by default are the type Boolean
-```
-
-The initial value of the variable is set to **FALSE**. A Boolean variable requires one byte of memory.
-
-#### Integer variables
-
-There are three types of integer variables: **Byte** , **Integer** , and **Long Integer**. These variables can only contain integers. When you transfer numbers with a fraction into such variables, they are rounded according to the rules of classical arithmetic (not to the larger side, as it stated in the help section). The initial value for these variables is 0 (zero).
-
-#### Byte
-
-Variables of the **Byte** type can contain only integer-positive values in the range from 0 to 255. Do not confuse this type with the physical size of information in bytes. Although we can write down a hexadecimal number to a variable, the word "Byte" indicates only the dimensionality of the number. You can declare a variable of this type as follows:
-```
-Dim MyByteVar As Byte
-```
-
-There is no a type-declaration sign for this type. There is no the statement Def of this type. Because of its small dimension, this type will be most convenient for a loop index, the values of which do not go beyond the range. A **Byte** variable requires one byte of memory.
-
-#### Integer
-
-Variables of the Integer type can contain integer values from -32768 to 32767. They are convenient for fast calculations in integers and are suitable for a loop index. **%** is a type-declaration sign. You can declare a variable of this type in the following ways:
-```
-Dim MyIntegerVar%
-Dim MyIntegerVar As Integer
-```
-
-For an implicit declaration, you can use the **DefInt** statement. For example:
-```
-DefInt i 'variables starting with i by default have type Integer
-```
-
-An Integer variable requires two bytes of memory.
-
-#### Long integer
-
-Variables of the Long Integer type can contain integer values from -2147483648 to 2147483647. Long Integer variables are convenient in integer calculations when the range of type Integer is insufficient for the implementation of the algorithm. **&** is a type-declaration sign. You can declare a variable of this type in the following ways:
-```
-Dim MyLongVar&
-Dim MyLongVar As Long
-
-```
-
-For an implicit declaration, you can use the **DefLng** statement. For example:
-```
-DefLng l 'variables starting with l have Long by default
-```
-
-A Long Integer variable requires four bytes of memory.
-
-#### Numbers with a fraction
-
-All variables of these types can take positive or negative values of numbers with a fraction. The initial value for them is 0 (zero). As mentioned above, if a number with a fraction is assigned to a variable capable of containing only integers, LibreOffice Basic rounds the number according to the rules of classical arithmetic.
-
-#### Single
-
-Single variables can take positive or negative values in the range from 3.402823x10E+38 to 1.401293x10E-38. Values of variables of this type are in single-precision floating-point format. In this format, only eight numeric characters are stored, and the rest is stored as a power of ten (the number order). In the Basic IDE debugger, you can see only 6 decimal places, but this is a blatant lie. Computations with variables of the Single type take longer than Integer variables, but they are faster than computations with variables of the Double type. A type-declaration sign is **!**. You can declare a variable of this type in the following ways:
-```
-Dim MySingleVar!
-Dim MySingleVar As Single
-```
-
-For an implicit declaration, you can use the **DefSng** statement. For example:
-```
-DefSng f 'variables starting with f have the Single type by default
-```
-
-A single variable requires four bytes of memory.
-
-#### Double
-
-Variables of the Double type can take positive or negative values in the range from 1.79769313486231598x10E308 to 1.0x10E-307. Why such a strange range? Most likely in the interpreter, there are additional checks that lead to this situation. Values of variables of the Double type are in double-precision floating-point format and can have 15 decimal places. In the Basic IDE debugger, you can see only 14 decimal places, but this is also a blatant lie. Variables of the Double type are suitable for precise calculations. Calculations require more time than the Single type. A type-declaration sign is **#**. You can declare a variable of this type in the following ways:
-```
-Dim MyDoubleVar#
-Dim MyDoubleVar As Double
-```
-
-For an implicit declaration, you can use the **DefDbl** statement. For example:
-```
-DefDbl d 'variables beginning with d have the type Double by default
-```
-
-A variable of the Double type requires 8 bytes of memory.
-
-#### Currency
-
-Variables of the Currency type are displayed as numbers with a fixed point and have 15 signs in the integral part of a number and 4 signs in fractional. The range of values includes numbers from -922337203685477.6874 to +92337203685477.6874. Variables of the Currency type are intended for exact calculations of monetary values. A type-declaration sign is **@**. You can declare a variable of this type in the following ways:
-```
-Dim MyCurrencyVar@
-Dim MyCurrencyVar As Currency
-```
-
-For an implicit declaration, you can use the **DefCur** statement. For example:
-```
-DefCur c 'variables beginning with c have the type Currency by default
-```
-
-A Currency variable requires 8 bytes of memory.
-
-#### String
-
-Variables of the String type can contain strings in which each character is stored as the corresponding Unicode value. They are used to work with textual information, and in addition to printed characters (symbols), they can also contain non-printable characters. I do not know the maximum size of the line. Mike Kaganski experimentally set the value to 2147483638 characters, after which LibreOffice falls. This corresponds to almost 4 gigabytes of characters. A type-declaration sign is **$**. You can declare a variable of this type in the following ways:
-```
-Dim MyStringVar$
-Dim MyStringVar As String
-```
-
-For an implicit declaration, you can use the **DefStr** statement. For example:
-```
-DefStr s 'variables starting with s have the String type by default
-```
-
-The initial value of these variables is an empty string (""). The memory required to store string variables depends on the number of characters in the variable.
-
-#### Date
-
-Variables of the Date type can contain only date and time values stored in the internal format. In fact, this internal format is the double-precision floating-point format (Double), where the integer part is the number of days, and the fractional is part of the day (that is, 0.00001157407 is one second). The value 0 is equal to 30.12.1899. The Basic interpreter automatically converts it to a readable version when outputting, but not when loading. You can use the Dateserial, Datevalue, Timeserial, or Timevalue functions to quickly convert to the internal format of the Date type. To extract a certain part from a variable in the Date format, you can use the Day, Month, Year, Hour, Minute, or Second functions. The internal format allows us to compare the date and time values by calculating the difference between two numbers. There is no a type-declaration sing for the Date type, so if you explicitly define it, you need to use the Date keyword.
-```
-Dim MyDateVar As Date
-```
-
-For an implicit declaration, you can use the **DefDate** statement. For example:
-```
-DefDate y 'variables starting with y have the Date type by default
-```
-
-A Date variable requires 8 bytes of memory.
-
-**Types of object variables**
-
-We can take two variables types of LibreOffice Basic to Objects.
-
-#### Objects
-
-Variables of the Object type are variables that store objects. In general, the object is any isolated part of the program that has the structure, properties, and methods of access and data processing. For example, a document, a cell, a paragraph, and dialog boxes are objects. They have a name, size, properties, and methods. In turn, these objects also consist of objects, which in turn can also consist of objects. Such a "pyramid" of objects is often called an object model, and it allows us, when developing small objects, to combine them into larger ones. Through a larger object, we have access to smaller ones. This allows us to operate with our documents, to create and process them while abstracting from a specific document. There is no a type-declaration sing for the Object type, so for an explicit definition, you need to use the Object keyword.
-```
-Dim MyObjectVar As Object
-```
-
-For an implicit declaration, you can use the **DefObj** statement. For example:
-```
-DefObj o 'variables beginning with o have the type Object by default
-```
-
-The variable of type Object does not store in itself an object but is only a reference to it. The initial value for this type of variables is Null.
-
-#### Structures
-
-The structure is essentially an object. If you look in the Basic IDE debugger, most (but not all) are the Object type. Some are not; for example, the structure of the Error has the type Error. But roughly speaking, the structures in LibreOffice Basic are simply grouped into one object variable, without special access methods. Another significant difference is that when declaring a variable of the Structure type, we must specify its name, rather than the Object. For example, if MyNewStructure is the name of a structure, the declaration of its variable will look like this:
-```
-Dim MyStructureVar As MyNewStructure
-```
-
-There are a lot of built-in structures, but the user can create personal ones. Structures can be convenient when we need to operate with sets of heterogeneous information that should be treated as a single whole. For example, to create a tPerson structure:
-```
-Type tPerson
- Name As String
- Age As Integer
- Weight As Double
-End Type
-
-```
-
-The definition of the structure should go before subroutines and functions that use it.
-
-To fill a structure, you can use, for example, the built-in structure com.sun.star.beans.PropertyValue:
-```
-Dim oProp As New com.sun.star.beans.PropertyValue
-OProp.Name = "Age" 'Set the Name
-OProp.Value = "Amy Boyer" 'Set the Property
-```
-
-For a simpler filling of the structure, you can use the **With** operator.
-```
-Dim oProp As New com.sun.star.beans.PropertyValue
-With oProp
- .Name = "Age" 'Set the Name
- .Value = "Amy Boyer" 'Set the Property
-End With
-```
-
-The initial value is only for each variable in the structure and corresponds to the type of the variable.
-
-#### Variant
-
-This is a virtual type of variables. The Variant type is automatically selected for the data to be operated on. The only problem is that the interpreter does not need to save our resources, and it does not offer the most optimal variants of variable types. For example, it does not know that 1 can be written in Byte, and 100000 in Long Integer, although it reproduces a type if the value is passed from another variable with the declared type. Also, the transformation itself is quite resource-intensive. Therefore, this type of variable is the slowest of all. If you need to declare this kind of variable, you can use the **Variant** keyword. But you can omit the type description altogether; the Variant type will be assigned automatically. There is no a type-declaration sign for this type.
-```
-Dim MyVariantVar
-Dim MyVariantVar As Variant
-```
-
-For an implicit declaration, you can use the **DefVar** statement. For example:
-```
-DefVar v 'variables starting with v have the Variant type by default
-```
-
-This variables type is assigned by default to all undeclared variables.
-
-#### Arrays
-
-Arrays are a special type of variable in the form of a data set, reminiscent of a mathematical matrix, except that the data can be of different types and allow one to access its elements by index (element number). Of course, a one-dimensional array will be similar to a column or row, and a two-dimensional array will be like a table. There is one feature of arrays in LibreOffice Basic that distinguishes it from other programming languages. Since we have an abstract type of variant, then the elements of the array do not need to be homogeneous. That is, if there is an array MyArray and it has three elements numbered from 0 to 2, and we write the name in the first element of MyArray(0), the age in the second MyArray(1), and the weight in the third MyArray(2), we can have, respectively, the following type values: String for MyArray(0), Integer for MyArray(1), and Double for MyArray(2). In this case, the array will resemble a structure with the ability to access the element by its index. Array elements can also be homogeneous: Other arrays, objects, structures, strings, or any other data type can be used in LibreOffice Basic.
-
-Arrays must be declared before they are used. Although the index space can be in the range of type Integer—from -32768 to 32767—by default, the initial index is selected as 0. You can declare an array in several ways:
-
-| Dim MyArrayVar(5) as string | String array with 6 elements from 0 to 5 |
-| Dim MyArrayVar$(5) | Same as the previous |
-| Dim MyArrayVar(1 To 5) as string | String array with 5 elements from 1 to 5 |
-| Dim MyArrayVar(5,5) as string | Two-dimensional array of rows with 36 elements with indexes in each level from 0 to 5 |
-| Dim MyArrayVar$(-4 To 5, -4 To 5) | Two-dimensional strings array with 100 elements with indexes in each level from -4 to 5 |
-| Dim MyArrayVar() | Empty array of the Variant type |
-
-You can change the lower bound of an array (the index of the first element of the array) by default using the **Option Base** statement; that must be specified before using subprograms, functions, and defining user structures. Option Base can take only two values, 0 or 1, which must follow immediately after the keywords. The action applies only to the current module.
-
-### Learn more
-
-If you are just starting out in programming, Wikipedia provides general information about the [array][2], structure, and many other topics.
-
-For a more in-depth study of LibreOffice Basic, [Andrew Pitonyak's][3] website is a top resource, as is the [Basic Programmer's guide][4]. You can also use the LibreOffice [online help][1]. Completed popular macros can be found in the [Macros][5] section of The Document Foundation's wiki, where you can also find additional links on the topic.
-
-For more tips, or to ask questions, visit [Ask LibreOffice][6] and [OpenOffice forum][7].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/variables-data-types-libreoffice-basic
-
-作者:[Lera Goncharuk][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/tagezi
-[1]:https://helponline.libreoffice.org/latest/en-US/text/sbasic/shared/main0601.html?DbPAR=BASIC
-[2]:https://en.wikipedia.org/wiki/Array_data_structure
-[3]:http://www.pitonyak.org/book/
-[4]:https://wiki.documentfoundation.org/images/d/dd/BasicGuide_OOo3.2.0.odt
-[5]:https://wiki.documentfoundation.org/Macros
-[6]:https://ask.libreoffice.org/en/questions/scope:all/sort:activity-desc/tags:basic/page:1/
-[7]:https://forum.openoffice.org/en/forum/viewforum.php?f=20&sid=74f5894a7d7942953cd99d978d54e75b
diff --git a/sources/tech/20180209 How to use Twine and SugarCube to create interactive adventure games.md b/sources/tech/20180209 How to use Twine and SugarCube to create interactive adventure games.md
deleted file mode 100644
index d515f17026..0000000000
--- a/sources/tech/20180209 How to use Twine and SugarCube to create interactive adventure games.md
+++ /dev/null
@@ -1,299 +0,0 @@
-How to use Twine and SugarCube to create interactive adventure games
-======
-
-
-
-Storytelling is an innate part of human nature. It's an idle pastime, it's an art form, it's a communication tool, it's a form of therapy and bonding. We all love to tell stories—you're reading one now—and the most powerful technologies we have are generally the things that enable us to express our creative ideas. The open source project [Twine][1] is a tool for doing just that.
-
-Twine is an interactive story generator. It uses HTML, CSS, and Javascript to create self-contained adventure games, in the spirit of classics like [Zork][2] and [Colossal Cave][3]. Since Twine is largely an amalgamation of several open technologies, it is flexible enough to do a lot of multimedia tricks, rendering games a lot more like [HyperCard][4] than you might normally expect from HTML.
-
-### Installing Twine
-
-You can use Twine online or download it locally from its website. Unzip the download and click the `Twine` application icon to start it.
-
-The default starting interface is pretty intuitive. Read its introductory material, then click the big green `+Story` button on the right to create a new story.
-
-### Hello world
-
-The basics are simple. A new storyboard contains one node, or "passage" in Twine's terminology, called `Untitled passage`. Roll over this passage to see the node's options, then click the pencil icon to edit its contents.
-
-Name the passage something to indicate its position in your story. In the previous version of Twine, the starting passage had to be named **Start** , but in Twine 2, any title will work. It's still a good idea to make it sensible, so stick with something like `Start` or `Home` or `init`.
-
-For the text contents of this story, type:
-```
-Hello [[world]]
-
-```
-
-If you're familiar with [wikitext][5], you can probably already guess that the word "world" in this passage is actually a link to another passage.
-
-Your edits are saved automatically, so you can just close the editing dialogue box when finished. Back in your storyboard, Twine has detected that you've created a link and has provided a new passage for you, called `world`.
-
-![developing story in Twine][7]
-
-Developing a story in Twine
-
-Open the new passage for editing and enter the text:
-```
-This was made with Twine.
-
-```
-
-To test your very short story, click the play button in the lower-right corner of the Twine window.
-
-It's not much, but it's a start!
-
-You can add more navigational choices by adding another link in double brackets, which generates a new passage, until you tell whatever tale you want to tell. It really is as simple as that.
-
-To publish your adventure, click the story title in the lower-left corner of the storyboard window and select **Publish to file**. This saves your whole project as one HTML file. Upload that one file to your website, or send it to friends and have them open it in a web browser, and you've just made and delivered your very first text adventure.
-
-### Advanced Twineage
-
-Knowing only enough to build this `hello world` story, you can make a great text-based adventure consisting of exploration and choices. As quick starts go, that's not too bad. Like all good open source technology, there's no ceiling on this, and you can take it much much farther with a few additional tricks.
-
-Twine projects work as well as they do partly because of a JavaScript backend called Harlowe. It adds all the pretty transitions and some UI styling, handles basic multimedia functions, and provides some special macros to reduce the amount of code you would have to write for some advanced tasks. This is open source, though, so naturally there are alternatives.
-
-[SugarCube][8] is an alternate JavaScript library for Twine that handles media, media playback functions, advanced linking for passages, UI elements, save files, and much more. It can turn your basic text adventure into a multimedia extravaganza rivaling such adventure games as Myst or Beneath the Steel Sky.
-
-### Installing SugarCube
-
-To install the SugarCube backend for your project:
-
- * [Download the SugarCube library][9]. Even though Twine ships with an earlier version of SugarCube, you should download the latest version.
-
- * Once you've downloaded it, unzip the archive and place it in a sensible location. If you're not used to keeping files organized or [managing creative assets][10] for project development, put the unzipped SugarCube directory into your Twine directory for safekeeping.
-
- * The SugarCube directory contains only a few files, with the actual code in `format.js`. If you're on Linux, right-click on the file and select **Copy**.
-
- * In Twine, return to your project library by clicking the house icon in the lower-left corner of the Twine window.
-
- * Click the **Formats** button in the right sidebar of Twine. In the **Add a New Format** tab, paste in the file path to `format.js` and click the green **Add** button.
-
-![Install Sugarcube add format][12]
-
-Installing Sugarcube: Click the Add button to add a new format in Twine
-
-If you're not on Linux, type the file path manually in this format:
-
-`file:///home/your-username/path/to/SugarCube-2/format.js`
-
-
-
-
-### Using SugarCube
-
-To switch a project to SugarCube, enter the storyboard mode of your project.
-
-In the story board view, click the title of your storyboard in the lower-left corner of the Twine window and select **Change Story Format**.
-
-In the **Story format** window that appears, select the SugarCube 2.x option.
-
-![Story format sugarcube][14]
-
-Select SugarCube in the Story Format window
-
-### Images
-
-Before adding images, audio, or video to a Twine project, create a project directory in which to keep copies of your assets. This is vital, because these assets remain separate from the HTML file that Twine exports, so the final step of creating your story will be to take your exported HTML file and drop it in place alongside all the media it needs. If you're used to programming, video editing, or web design, this is a familiar discipline, but if you're new to this kind of content creation, you may not have encountered this before, so be especially diligent in organizing your assets.
-
-Create a project directory somewhere. Inside this directory, create a subdirectory called **img** for your images, `audio` for your audio, `video` for video, and so on.
-
-![Create a directory in Twine][16]
-
-Create subdirectories for your project files in Twine
-
-For this example, I use an image from [openclipart.org][17]. You can use this, or something similar. Regardless of what you use, place your image in your **img** directory.
-
-Continuing with the hello_world project, you can add an image to one of the passages using SugarCube's image syntax:
-```
-<img src="img/earth.svg" alt="An image of the world." />
-
-Hello [[world]].
-
-```
-
-If you try to play your project after adding your images, you'll find that all the image links are broken. This is because Twine is located outside of your project directory. To test a multimedia Twine project, export it as a file and place the file in your project directory. Don't put it inside any of the subdirectories you created; simply place it in your project directory and open it in a web browser.
-
-![View media in sugarcube][19]
-
-Previewing media files added to Twine project
-
-Other media files function in basically the same way, utilizing HTML5 media tags to display the media and SugarCube macros to control when playback begins and ends.
-
-### Variables and programming
-
-You can do a lot by leading a player to one passage or another depending on what choices they have made, but you can cut down on how many passages you need by using variables.
-
-If you have never programmed before, take a moment to read through my [introduction to programming concepts][20]. The article uses Python, but all the same concepts apply to Twine and basically any other programming language you're likely to encounter.
-
-For example, since the hello_world story is initially set on Earth, the next step in the story could be to offer a variety of trips to other worlds. Each time the reader returns to Earth, the game can display a tally of the worlds they have visited. This would be essentially impossible to do linearly, because you would never be able to tell which path a reader has taken in their exploration. For instance, one reader might visit Mars first, then Mercury. Another might never go to Mars at all, instead visiting Jupiter, Saturn, and then Mercury. You would have to make one passage for every possible combination, and that solution simply doesn't scale.
-
-With variables, however, you can track a reader's progress and display messages accordingly.
-
-To make this work, you must set a variable each time a reader reaches a new planet. In the game universe of the hello_world game, planets are actually open source projects, so each time a user visits a passage about an open source project, set a variable to "prove" that the reader has visited.
-
-Variables in SugarCube syntax are set with the <<set>> macro. SugarCube has lots of macros, and they're all handy. This example project uses a few.
-
-Change the second passage you created to provide the reader a few new options for exploration:
-```
-This was made in [[Twine]] on [[Linux]].
-
-<<choice Start "Return to Earth.">>
-
-```
-
-You're using the <<choice>> macro here, which links any string of text straight back to a given passage. In this case, the <<choice>> macro links the string "Return to Earth" to the Start passage.
-
-In the new passage, insert this text:
-```
-Twine is an interactive story framework. It runs on all operating systems, but I prefer to use it on [[Linux]].
-
-
-
-<<set $twine to true>>
-
-<<choice Start "Return to Earth.">>
-
-```
-
-In this code, you use the <<set>> macro to create a new variable called `$twine`. This variable is a Boolean, because you're just setting it to "true". You'll see why that's significant soon.
-
-In the `Linux` passage, enter this text:
-```
-Linux is an open source [[Unix]]-like operating system.
-
-
-
-<<set $linux to true>>
-
-<<choice Start "Return to Earth.">>
-
-```
-
-And in the `Unix` passage:
-```
-BSD is an open source version of AT&T's Unix operating system.
-
-
-
-<<set $bsd to true>>
-
-<<choice Start "Return to Earth.">>
-
-```
-
-Now that the story has five passages for a reader to explore, it's time to use SugarCube to detect which variable has been set each time a reader returns to Earth.
-
-To detect the state of a variable and generate HTML accordingly, use the <<if>> macro.
-```
-<img src="img/earth.png" alt="An image of the world." />
-
-
-
-Hello [[world]].
-
-<ul>
-
-<<if $twine is trueliPlanet Twine/li/if>>
-
-<<if $linux is trueliPlanet Linux/li/if>>
-
-<<if $bsd is trueliPlanet BSD/li/if>>
-
-</ul>
-
-```
-
-For testing purposes, you can press the Play button in the lower-right corner. You won't see your image, but look past that in the interest of testing.
-
-![complex story board][22]
-
-A more complex story board
-
-Navigate through the story, returning to Earth periodically. Notice that a tally of each place you visited appears at the bottom of the Start passage each time you return.
-
-There's nothing explaining why the list of places visited is appearing, though. Can you figure out how to explain the tally of explored passages to the reader?
-
-You could just preface the tally list with an introductory sentence like "So far you have visited:" but when the user first arrives, the list will be empty so your introductory sentence will be introducing nothing.
-
-A better way to manage it is with one more variable to indicate that the user has left Earth.
-
-Change the `world` passage:
-```
-This was made in [[Twine]] on [[Linux]].
-
-
-
-<<set $offworld to true>>
-
-<<choice Start "Return to Earth.">>
-
-```
-
-Then use another <<if>> macro to detect whether or not the `$offworld` variable is set to `true`.
-
-The way Twine parses wikitext sometimes results in more blank lines than you intend, so to compress the list of places visited, use the <<nobr>> macro to prevent line breaks.
-```
-<img src="img/earth.png" alt="An image of the world." />
-
-
-
-Hello [[world]].
-
-<<nobr>>
-
-<<ul>>
-
-<<if $twine is trueliPlanet Twine/li/if>>
-
-<<if $linux is trueliPlanet Linux/li/if>>
-
-<<if $bsd is trueliPlanet BSD/li/if>>
-
-<</ul>>
-
-<</nobr>>
-
-```
-
-Try playing the story again. Notice that the reader isn't welcomed back to Earth until they have left Earth.
-
-### Explore everything
-
-SugarCube is a powerful engine. Using it is often a question of knowing what's available rather than not having the ability to do something. Luckily, its documentation is very good, so refer to its [macro][23] list often.
-
-You can make further modifications to your project by changing the CSS stylesheet. To do this, click the title of your project in story board mode and select **Edit Story Stylesheet**. If you're familiar with JavaScript, you can also script your stories with the **Edit Story JavaScript**.
-
-There's no limit to what Twine can do as your interactive fiction engine. It can create text adventures, and it can serve as a prototype for more complex games, point-and-click RPGs, business presentations, [late night talk show supplements][24], and just about anything else you can imagine. Explore the [Twine wiki][25], take a look at other people's works on the [Interactive Fiction Database][26], and then make your own.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/2/twine-gaming
-
-作者:[Seth Kenlon][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/seth
-[1]:https://twinery.org/
-[2]:http://i7-dungeon.sourceforge.net/index.html
-[3]:https://opensource.com/article/17/6/revisit-colossal-cave-adventure-open-adventure
-[4]:https://en.wikipedia.org/wiki/HyperCard
-[5]:https://www.mediawiki.org/wiki/Wikitext
-[7]:https://opensource.com/sites/default/files/images/life-uploads/start.jpg (starting a story in Twine)
-[8]:http://www.motoslave.net/sugarcube/
-[9]:https://www.motoslave.net/sugarcube/2
-[10]:https://opensource.com/article/17/7/managing-creative-assets-planter
-[12]:https://opensource.com/sites/default/files/images/life-uploads/add.png (install sugarcube add format)
-[14]:https://opensource.com/sites/default/files/images/life-uploads/format.png (story format sugarcube)
-[16]:https://opensource.com/sites/default/files/images/life-uploads/dir.png (Creating directories in Twine)
-[17]:https://openclipart.org/detail/10912/earth-globe-oceania
-[19]:https://opensource.com/sites/default/files/images/life-uploads/sugarcube.png (view media sugarcube twine)
-[20]:https://opensource.com/article/17/10/python-101
-[22]:https://opensource.com/sites/default/files/images/life-uploads/complexer_0.png (complex story board)
-[23]:https://www.motoslave.net/sugarcube/2/docs/macros.html
-[24]:http://www.cbs.com/shows/the-late-show-with-stephen-colbert/escape-from-the-man-sized-cabinet/
-[25]:https://twinery.org/wiki/twine2:guide
-[26]:http://ifdb.tads.org/
diff --git a/sources/tech/20180211 Latching Mutations with GitOps.md b/sources/tech/20180211 Latching Mutations with GitOps.md
deleted file mode 100644
index b9f6f48c23..0000000000
--- a/sources/tech/20180211 Latching Mutations with GitOps.md
+++ /dev/null
@@ -1,60 +0,0 @@
-Latching Mutations with GitOps
-============================================================
-
-Immutable Infrastructure has become a hot topic recently. I’ve written a [couple][1] of [posts][2] about it, and I think the term should be more strict than how it’s usually used. In my opinion, total immutability of infrastructure is a good aspiration, but not very practical.
-
-The definition of “infrastructure” itself is blurred. Your app devs are now operators; [they operate their own code, on top of a platform you provide][3]. They specify the version and size and number of the containers running their product code. That’s _their_ infrastructure, and no-one would argue that a new cluster should be stood up every time they want to push a new version. The raison d’être of the cloud-native movement is to enable them to do that _more_ and _faster_ .
-
-No system really can be fully immutable (are _you_ writing everything in Haskell?). [Cindy Sridharan notes][4] that entropy will always build up, and one major source of that is the churn of the apps running atop your platform. It makes sense to let these apps change in place. (Immutable Architecture is a different beast — never changing the set of _services _ provided by those apps by e.g. using protobuf to make sure the total API set only grows).
-
-In response to a new build of an app, or adding one to its replica count, its cluster can be completely replaced with one containing the new version/scale, or it can be mutated in place (i.e. Pods replaced or added). While the latter might seem eminently more sensible, whichever you chose is kind of irrelevant to the argument I’m about to make. That said, I think it’s important to talk about the following in the context of the current conversation around immutable infrastructure.
-
-* * *
-
-[Alexis Richardson][5] has been posting a phenomenal series about “[GitOps][6]”*, providing great processes for controllable changes to infrastructure. Kelsey Hightower [has spoken about][7] applying the same principles to app deployment — a separate “infrastructure” repo for the Kubernetes definitions behind your apps, and deployments thereof by Pull Request.
-
- _*(In short: his thesis is that everything you run should be declared in git. Automated tooling keeps your clusters in sync with that single declaration of truth. All changes are mediated and discussed through Pull Requests coming in from dev branches.)_
-
-If a cluster catches fire, so be it. A new one is started, and Weave Flux re-deploys everything that was previously running, because it’s all declared in git. Right? Well, should _everything _ about the system be declared in git? My first reaction was “yes” — declare everything in git, bring it all under control. But what about something like application scale? We can _guess_ at this a priori, but it’s ultimately a function of the environment — of actual user traffic rates — not of some engineering best-practice. And we certainly don’t want it done ad-hoc, with a dev watching CPU loads in grafana and raising a PR every minute.
-
-Let’s consider the opposite: what if scale isn’t declared at all? Kelsey Hightower has said it shouldn’t be, so that an HPA can be used. But what if a system has traffic necessitating 10,000 Pods? If that cluster needs recovering, the result will be a Deployment of _one_ Pod. That will be totally overwhelmed by the traffic, probably compound the problem by failing its healthcheck, and certainly offer no useful service to its users.
-
-So I assert that we do want the scale declared in git. And, although the required scale is a function of the environment and can only be known empirically, that loop should be automated too; this is the essence of DevOps. Consider a tool that watches the Deployment and auto-commits each new scale (like a reverse Weave Flux). Even with a separate (app) infrastructure repo, that would be so noisy that actual version upgrades wouldn’t be easily spotted.
-
-With dynamic properties like scale, being roughly right is good enough. The CPU target is always 70 or 80%, so there’s headroom. It’s sufficient just to declare a nearby round number: a multiple of 10, or an order of magnitude. This is what I suggest; auto-committing the closest round number of your current scale. This will get the system back to a place where it can _cope._ It might be a bit slow, or a bit wasteful, but it won’t die. Declare enough to get the system back up with one click, and let the HPA take the fine-tuning from there.
-
-From a manageability point-of-view, this “latching” behaviour keeps systems declared _well enough_ in git, whilst not overloading operators with commits so numerous that they cease to have any value. This way, for example, they still function as audit logs — 3 users but a replica count of 10k probably means a computational complexity problem (or DoS attack) deserving attention. The automated tool could even PR each latch so it can be eyeballed to decide if its intentions are pure.
-
-In GitOps terms, the “desired state”, i.e. that declared in git, is a rollback checkpoint; some things _are_ meant to change, but if those changes go wrong, git will always describe the last, good, consistent state that you should go back to. All I’m saying is that a scale from 1 to 10,000 is something that’s material and should be checkpointed along the way. Think of it as a write-back cache maybe.
-
-Clearly tools like kubediff either need to ignore this field, or understand the round-numbers latching policy.
-
-Minimum scale should still be specified (it’s a function of your users’ SLAs, though it lived in the infra repo not code repo, as it’s the empirical result of that SLA married to a load test). Similarly, max scalecan and should also be specified, again as a result of load testing (the point at which you’ve determined that 2nd order effects and the Universal scalability law kill you). These bounds are a function of the users’ requirements and the codebase, whereas run-time scale results from the environment.
-
-As a further example, take blue-green rollouts. If a cluster is recovered from git that was an unknown way through a roll-out, what state should be recreated? It’s wasteful to go back to 100% v1, if it was 90% through upgrading to v2\. Conversely, it’s unsafe to go all-out with v2 if the scant 1% that had been rolled out had failed their health-checks. I posit that the in-flight ReplicaSets should be watched their major progress milestones latched in git.
-
-* * *
-
-In conclusion, changes are inevitable. Whether you scale apps by adding more Pods to an existing cluster, or even if you do make a whole new cluster of _n_ Pods every time, the problem is the same: some changes have to happen in response to the environment, rather than by operator diktat. Even with a mutating cluster, for purposes of recovery, audit, and easy roll-forwards, you still want an up-to-date description of every material aspect of it in git, but without overwhelming your tooling or operators. By _latching_ , you capture the important details, while being pragmatic about the amount of incidental churn you want to be bothered by.
-
-matt. @[mt165pro][8]
-
---------------------------------------------------------------------------------
-
-via: https://medium.com/@mt165/latching-mutations-with-gitops-92155e84a404
-
-作者:[Matt Turner ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://medium.com/@mt165?source=post_header_lockup
-[1]:https://medium.com/@mt165/immutable-definitions-f7e61593e3b0
-[2]:https://medium.com/@mt165/a-spectrum-of-mutability-3f527268a146
-[3]:https://www.youtube.com/watch?v=nMLyr8q5AWE
-[4]:https://twitter.com/copyconstruct/status/954133874002477056
-[5]:https://twitter.com/monadic
-[6]:https://www.weave.works/blog/gitops-operations-by-pull-request
-[7]:https://youtu.be/07jq-5VbBVQ?t=900
-[8]:https://twitter.com/mt165pro
diff --git a/sources/tech/20180307 What Is sosreport- How To Create sosreport.md b/sources/tech/20180307 What Is sosreport- How To Create sosreport.md
deleted file mode 100644
index eb3f77cdb8..0000000000
--- a/sources/tech/20180307 What Is sosreport- How To Create sosreport.md
+++ /dev/null
@@ -1,195 +0,0 @@
-What Is sosreport? How To Create sosreport
-======
-### What Is sosreport
-
-The sosreport command is a tool that collects bunch of configuration details, system information and diagnostic information from running system (especially RHEL & OEL system).
-
-It helps technical support engineer to analyze the system in many aspect.
-
-This reports contains bunch of information about the system such as boot information, filesystem, memory, hostname, installed rpms, system IP, networking details, OS version, installed kernel, loaded kernel modules, list of open files, list of PCI devices, mount point and it’s details, running process information, process tree output, system routing, all the configuration files which is located in /etc folder, and all the log files which is located in /var folder.
-
-This will take a while to generate a report and it’s depends on your system installation and configuration.
-
-Once completed, sosreport will generate a compressed archive file under /tmp directory.
-
-We have to provide the sosreport to RHEL (Red Hat Enterprise Linux) & OEL (Oracle Enterprise Linux) technical support engineer whenever we raise a case with them for initial analyze. This helps support engineer to verify if anything is wrong on the system.
-
-### How To Install sosreport
-
-sosreport installation is not a big deal, just run the following command to install it.
-```
-# yum install sos
-
-```
-
-### How To Generate sosreport
-
-Also generating sosreport is not a big deal so, just run the sosreport command without any options.
-
-By default it doesn’t shows much information while generating sosreport and only display how many reports are generated. If you want to see detailed information just add `-v` option while generating the sosreport.
-
-It will ask you to enter your name and the support case information.
-```
-# sosreport
-
-sosreport (version 3.2)
-
-This command will collect diagnostic and configuration information from this Oracle Linux system and installed applications.
-
-An archive containing the collected information will be generated in /tmp/sos.3pt1yJ and may be provided to a Oracle USA support representative.
-
-Any information provided to Oracle USA will be treated in accordance with the published support policies at:
-
- http://linux.oracle.com/
-
-The generated archive may contain data considered sensitive and its content should be reviewed by the originating organization before being passed to any third party.
-
-No changes will be made to system configuration.
-
-Press ENTER to continue, or CTRL-C to quit.
-
-Please enter your first initial and last name [oracle.2daygeek.com]: 2daygeek
-Please enter the case id that you are generating this report for []: 3-16619296812
-
-Setting up archive ...
-Setting up plugins ...
-dbname must be supplied to dump a database.
-Running plugins. Please wait ...
-
- Running 86/86: yum...
-[plugin:kvm] could not unmount /sys/kernel/debug
-Creating compressed archive...
-
-Your sosreport has been generated and saved in:
-
- /tmp/sosreport-2daygeek.3-16619296812-20180307124921.tar.xz
-
-The checksum is: 4e80226ae175bm185c0o2d7u2yoac52o
-
-Please send this file to your support representative.
-
-```
-
-### What Are The Details There In The Archive File
-
-I’m just curious, what kind of details are there in the archive file. To understand this, i gonna extract a archive file on my system.
-
-Run the following command to extract an archive file.
-```
-# tar -xf /tmp/sosreport-2daygeek.3-16619296812-20180307124921.tar.xz
-
-```
-
-To see what are the information captured by sosreport, go to file extracted directory.
-```
-# ls -lh sosreport-2daygeek.3-16619296812-20180307124921
-
-total 60K
-dr-xr-xr-x 4 root root 4.0K Sep 30 10:56 boot
-lrwxrwxrwx 1 root root 37 Oct 20 07:25 chkconfig -> sos_commands/startup/chkconfig_--list
-lrwxrwxrwx 1 root root 25 Oct 20 07:25 date -> sos_commands/general/date
-lrwxrwxrwx 1 root root 27 Oct 20 07:25 df -> sos_commands/filesys/df_-al
-lrwxrwxrwx 1 root root 31 Oct 20 07:25 dmidecode -> sos_commands/hardware/dmidecode
-drwxr-xr-x 43 root root 4.0K Oct 20 07:21 etc
-lrwxrwxrwx 1 root root 24 Oct 20 07:25 free -> sos_commands/memory/free
-lrwxrwxrwx 1 root root 29 Oct 20 07:25 hostname -> sos_commands/general/hostname
-lrwxrwxrwx 1 root root 130 Oct 20 07:25 installed-rpms -> sos_commands/rpm/sh_-c_rpm_--nodigest_-qa_--qf_NAME_-_VERSION_-_RELEASE_._ARCH_INSTALLTIME_date_awk_-F_printf_-59s_s_n_1_2_sort_-f
-lrwxrwxrwx 1 root root 34 Oct 20 07:25 ip_addr -> sos_commands/networking/ip_-o_addr
-lrwxrwxrwx 1 root root 45 Oct 20 07:25 java -> sos_commands/java/alternatives_--display_java
-drwxr-xr-x 4 root root 4.0K Sep 30 10:56 lib
-lrwxrwxrwx 1 root root 35 Oct 20 07:25 lsb-release -> sos_commands/lsbrelease/lsb_release
-lrwxrwxrwx 1 root root 25 Oct 20 07:25 lsmod -> sos_commands/kernel/lsmod
-lrwxrwxrwx 1 root root 36 Oct 20 07:25 lsof -> sos_commands/process/lsof_-b_M_-n_-l
-lrwxrwxrwx 1 root root 22 Oct 20 07:25 lspci -> sos_commands/pci/lspci
-lrwxrwxrwx 1 root root 29 Oct 20 07:25 mount -> sos_commands/filesys/mount_-l
-lrwxrwxrwx 1 root root 38 Oct 20 07:25 netstat -> sos_commands/networking/netstat_-neopa
-drwxr-xr-x 3 root root 4.0K Oct 19 16:16 opt
-dr-xr-xr-x 10 root root 4.0K Jun 23 2017 proc
-lrwxrwxrwx 1 root root 30 Oct 20 07:25 ps -> sos_commands/process/ps_auxwww
-lrwxrwxrwx 1 root root 27 Oct 20 07:25 pstree -> sos_commands/process/pstree
-dr-xr-x--- 2 root root 4.0K Oct 17 12:09 root
-lrwxrwxrwx 1 root root 32 Oct 20 07:25 route -> sos_commands/networking/route_-n
-dr-xr-xr-x 2 root root 4.0K Sep 30 10:55 sbin
-drwx------ 54 root root 4.0K Oct 20 07:21 sos_commands
-drwx------ 2 root root 4.0K Oct 20 07:21 sos_logs
-drwx------ 2 root root 4.0K Oct 20 07:21 sos_reports
-dr-xr-xr-x 6 root root 4.0K Jun 23 2017 sys
-lrwxrwxrwx 1 root root 28 Oct 20 07:25 uname -> sos_commands/kernel/uname_-a
-lrwxrwxrwx 1 root root 27 Oct 20 07:25 uptime -> sos_commands/general/uptime
-drwxr-xr-x 6 root root 4.0K Sep 25 2014 var
--rw------- 1 root root 1.7K Oct 20 07:21 version.txt
-lrwxrwxrwx 1 root root 62 Oct 20 07:25 vgdisplay -> sos_commands/lvm2/vgdisplay_-vv_--config_global_locking_type_0
-
-```
-
-To double confirm what exactly sosreport captured, i’m gonna to see uname output file which was captured by sosreport.
-```
-# more uname_-a
-Linux oracle.2daygeek.com 2.6.32-042stab127.2 #1 SMP Thu Jan 4 16:41:44 MSK 2018 x86_64 x86_64 x86_64 GNU/Linux
-
-```
-
-### Additional Options
-
-Visit help page to view all available options for sosreport.
-```
-# sosreport --help
-Usage: sosreport [options]
-
-Options:
- -h, --help show this help message and exit
- -l, --list-plugins list plugins and available plugin options
- -n NOPLUGINS, --skip-plugins=NOPLUGINS
- disable these plugins
- -e ENABLEPLUGINS, --enable-plugins=ENABLEPLUGINS
- enable these plugins
- -o ONLYPLUGINS, --only-plugins=ONLYPLUGINS
- enable these plugins only
- -k PLUGOPTS, --plugin-option=PLUGOPTS
- plugin options in plugname.option=value format (see
- -l)
- --log-size=LOG_SIZE set a limit on the size of collected logs
- -a, --alloptions enable all options for loaded plugins
- --all-logs collect all available logs regardless of size
- --batch batch mode - do not prompt interactively
- --build preserve the temporary directory and do not package
- results
- -v, --verbose increase verbosity
- --verify perform data verification during collection
- --quiet only print fatal errors
- --debug enable interactive debugging using the python debugger
- --ticket-number=CASE_ID
- specify ticket number
- --case-id=CASE_ID specify case identifier
- -p PROFILES, --profile=PROFILES
- enable plugins selected by the given profiles
- --list-profiles
- --name=CUSTOMER_NAME specify report name
- --config-file=CONFIG_FILE
- specify alternate configuration file
- --tmp-dir=TMP_DIR specify alternate temporary directory
- --no-report Disable HTML/XML reporting
- -z COMPRESSION_TYPE, --compression-type=COMPRESSION_TYPE
- compression technology to use [auto, gzip, bzip2, xz]
- (default=auto)
-
-Some examples:
-
- enable cluster plugin only and collect dlm lockdumps:
- # sosreport -o cluster -k cluster.lockdump
-
- disable memory and samba plugins, turn off rpm -Va collection:
- # sosreport -n memory,samba -k rpm.rpmva=off
-
-```
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-create-collect-sosreport-in-linux/
-
-作者:[Magesh Maruthamuthu][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.2daygeek.com/author/magesh/
diff --git a/sources/tech/20180309 A Comparison of Three Linux -App Stores.md b/sources/tech/20180309 A Comparison of Three Linux -App Stores.md
deleted file mode 100644
index 3095f99d3d..0000000000
--- a/sources/tech/20180309 A Comparison of Three Linux -App Stores.md
+++ /dev/null
@@ -1,128 +0,0 @@
-A Comparison of Three Linux 'App Stores'
-======
-
-
-I remember, long, long ago, when installing apps in Linux required downloading and compiling source packages. If you were really lucky, some developer might have packaged the source code into a form that was more easily installable. Without those developers, installing packages could become a dependency nightmare.
-
-But then, package managers like rpm and dpkg began to rise in popularity, followed quickly by the likes of yum and apt. This was an absolute boon to anyone looking to make Linux their operating system of choice. Although dependencies could still be an issue, they weren’t nearly as bad as they once were. In fact, many of these package managers made short shrift of picking up all the dependencies required for installation.
-
-And the Linux world rejoiced! Hooray!
-
-But, with those package managers came a continued requirement of the command line. That, of course, is all fine and good for old hat Linux users. However, there’s a new breed of Linux users who don’t necessarily want to work with the command line. For that user-base, the Linux “app store” was created.
-
-This all started with the [Synaptic Package Manager][1]. This graphical front end for apt was first released in 2001 and was a breath of fresh air. Synaptic enabled user to easily search for a piece of software and install it with a few quick clicks. Dependencies would be picked up and everything worked. Even when something didn’t work, Synaptic included the means to fix broken packages—all from a drop-down menu.
-
-Since then, a number of similar tools have arrived on the market, all of which improve on the usability of Synaptic. Although Synaptic is still around (and works quite well), new users demand more modern tools that are even easier to use. And Linux delivered.
-
-I want to highlight three of the more popular “app stores” to be found on various Linux distributions. In the end, you’ll see that installing applications on Linux, regardless of your distribution, doesn’t have to be a nightmare.
-
-### GNOME Software
-
-GNOME’s take on the graphical package manager, [Software][2], hit the scene just in time for the Ubuntu Software Center to finally fade into the sunset (which was fortuitous, considering Canonical’s shift from Unity to GNOME). Any distribution that uses GNOME will include GNOME Software. Unlike the now-defunct Ubuntu Software Center, GNOME Software allows users to both install and update apps from within the same interface (Figure 1).
-
-![GNOME Software][4]
-
-Figure 1: The GNOME Software main window.
-
-[Used with permission][5]
-
-To find a piece of software to install, click the Search button (top left, looking glass icon), type the name of the software you want to install, and wait for the results. When you find a title you want to install, click the Install button (Figure 2) and, when prompted, type your user (sudo) password.
-
-![GNOME Software][7]
-
-Figure 2: Installing Slack from GNOME Software.
-
-[Used with permission][5]
-
-GNOME Software also includes easy to navigate categories, Editor’s Picks, and GNOME add-ons. As a bonus feature, GNOME Software also supports both snaps and flatpak software. Out of the box, GNOME Software on Ubuntu (and derivatives) support snaps. If you’re adventurous, you can add support for flatpak by opening a terminal window and issuing the command sudo apt install gnome-software-plugin-flatpak.
-
-GNOME Software makes it so easy to install software on Linux, any user (regardless of experience level) can install and update apps with zero learning curve.
-
-### KDE Discover
-
-[Discover][8] is KDE’s answer to GNOME Software. Although the layout (Figure 3) is slightly different, Discover should feel immediately familiar.
-
-![KDE Discover][10]
-
-Figure 3: The KDE Discover main window is equally user friendly.
-
-[Used with permission][5]
-
-One of the primary differences between Discover and Software is that Discover differentiates between Plasma (the KDE desktop) and application add-ons. Say, for example, you want to find an “extension” for the Kate text editor; click on Application Addons and search “kate” to see all available addons for the application.
-
-The Plasma Addons feature makes it easy for users to search through the available desktop widgets and easily install them.
-
-The one downfall of KDE Discover is that applications are listed in a reverse alphabetical order. Click on one of the given categories, from the main page, and you’ll be given a listing of available apps to scroll through, from Z to A (Figure 4).
-
-![KDE Discover][12]
-
-Figure 4: The KDE Discover app listing.
-
-[Used with permission][5]
-
-You will also notice no apparent app rating system. With GNOME Software, it’s not only easy to rate a software title, it’s easy to decide if you want to pass on an app or not (based on a given rating). With KDE Discover, there is no rating system to be found.
-
-One bonus that Discover adds, is the ability to quickly configure repositories. From the main window, click on Settings, and you can enable/disable any of the included sources (Figure 5). Click the drop-down in the upper right corner, and you can even add new sources.
-
-![KDE Discover][14]
-
-Figure 5: Enabling, disable, and add sources, all from within Discover.
-
-[Used with permission][5]
-
-### Pamac
-
-If you’re hoping to soon count yourself among the growing list of Arch Linux users, you’ll be glad to know that the Linux distribution often considered for the more “elite”, also includes a graphical package manager. [Pamac][15] does an outstanding job of making installing applications on Arch easy. Although Pamac isn’t quite on the design level of either GNOME Software or KDE Discover, it still does a great job of simplifying the installing and updating of applications. From the Pamac main window (Figure 6), you can either click on the search button, or click a Category or Group to find the software you’re looking to install.
-
-![Pamac][17]
-
-Figure 6: The Pamac main window.
-
-[Used with permission][5]
-
-If you can’t find the software you’re looking for, you might need to enable one of the many repositories. Click on the Repository button and then search through the categories (Figure 7) to locate the repository to be added.
-
-![Pamac][19]
-
-Figure 7: Adding new repositories in Pamac.
-
-[Used with permission][5]
-
-Updates are smoothly handled with Pamac. Click on the Updates button (in the left navigation) and then, in the resulting window (Figure 8), click Apply. All of your Arch updates will be installed.
-
-![Pamac][21]
-
-Figure 8: Updating Arch via Pamac.
-
-[Used with permission][5]
-
-### More where that came from
-
-I’ve only listed three graphical package managers. That is not to say these three are the only options to be found. Other distributions have their own takes on the package manager GUI. However, these three do an outstanding job of representing just how far installing software on Linux has come, since those early days of only being able to install via source.
-
-Learn more about Linux through the free ["Introduction to Linux" ][22]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/3/comparison-three-linux-app-stores
-
-作者:[JACK WALLEN][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://code.launchpad.net/synaptic
-[2]:https://wiki.gnome.org/Apps/Software
-[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gnome_software.jpg?itok=MvRQRX3- (GNOME Software)
-[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gnome_software_2.jpg?itok=5nzpUQa7 (GNOME Software)
-[8]:https://userbase.kde.org/Discover
-[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_discover.jpg?itok=LDTmkkMV (KDE Discover)
-[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_discover_2.jpg?itok=f5P7elG_ (KDE Discover)
-[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_discover_3.jpg?itok=JvS3s6FB (KDE Discover)
-[15]:https://github.com/manjaro/pamac
-[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/pamac.jpg?itok=gZ9X-Z05 (Pamac)
-[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/pamac_1.jpg?itok=Ygt5_U8A (Pamac)
-[21]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/pamac_2.jpg?itok=cIjKM51m (Pamac)
-[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180314 5 open source card and board games for Linux.md b/sources/tech/20180314 5 open source card and board games for Linux.md
deleted file mode 100644
index 7ca1cee650..0000000000
--- a/sources/tech/20180314 5 open source card and board games for Linux.md
+++ /dev/null
@@ -1,103 +0,0 @@
-5 open source card and board games for Linux
-======
-
-
-Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but many of those games are not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
-
-So, can someone who uses only free and open source software find games that are polished enough to offer a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games in many genres that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download, install, and play by downloading it from the project's website.
-
-This article looks at computer versions of popular board and card games. I have already written about [arcade-style games][1]. In future articles, I plan to cover puzzle, racing, role-playing, and strategy & simulation games.
-
-### Kajongg
-
-
-There are many applications that are called [Mahjong][2], but almost all are versions of the tile-matching solitaire game that uses Mahjong tiles. [Kajongg][3] is a rare exception because it is an implementation of the classic rummy-style game for four players. This traditional multi-player version of Mahjong is most popular throughout East and Southeast Asia, but there are players throughout the world. This means there are many variations of [Mahjong rules][4]. Unfortunately, Kajongg does not support them all, but it does allow players to play a fairly standard game of Mahjong with two different rules variants. Kajongg can be played locally against computer players or online versus human opponents.
-
-To install Kajongg, run the following command:
-
-On Fedora: `dnf install kajongg`
-
-On Debian/Ubuntu: `apt install kajongg`
-
-### Pioneers
-
-
-
-Klaus Teuber's [The Settlers of Catan][5] board game and its various expansions introduced many players to a world of board games that were more complex and more interesting than some of the most familiar board games like [Monopoly][6], [Sorry!][7], and [Risk][8].
-
-Catan, for those not familiar with the game, is played on a board made of hexagonal tiles, each of which has a different terrain type and provides a resource like lumber or wool. During the initial setup phase, players take turns placing their initial settlements as well as segments of road. Settlements are placed at the point where the hexagonal tiles meet. Each tile has a number, and when that number is rolled during a player's turn, every player whose settlements are next to that tile get the associated resource. These resources are then used to build more and better structures. The first person to earn a certain number of victory points by building structures or by other methods wins the game. (There are more rules, but that is the basic premise.)
-
-[Pioneers][9] brings an unofficial adaptation of that iconic board game to computers, complete with AI opponents and online play. There are several map layouts available in Pioneers, from the basic map to maps of North America and Europe for more complex games. While Pioneers does have a few minor rough edges, it is a solid implementation of Catan and a great way to experience or re-experience a classic board game.
-
-To install Pioneers, run the following command:
-
-On Fedora: `dnf install pioneers`
-
-On Debian/Ubuntu: `apt install pioneers`
-
-### PokerTH
-
-
-
-[PokerTH][10] is a computer version of [Texas hold 'em poker][11], complete with online multiplayer (but no real gambling). Play against the computer locally, or go online to compete against other people. PokerTH is available for multiple platforms, so there are plenty of people playing it online. PokerTH's implementation of Texas hold 'em is polished and the game is feature-complete, with solid online play. Any fan of Texas hold 'em should check out PokerTH.
-
-To install PokerTH, run the following command:
-
-On Fedora: `dnf install pokerth`
-
-On Debian/Ubuntu: `apt install pokerth`
-
-### TripleA
-
-
-
-[TripleA][12] is a turn-based strategy game styled after the [Axis & Allies][13] board game and other similar board games. TripleA's gameplay is very much like Axis & Allies, but there are many different maps available for TripleA that can alter the experience. The standard game board is based on World War II, but there are other maps that feature other settings—some historical, some fantastical, like J.R.R. Tolkien's Middle Earth. There are also maps that make the game behave like the board game [Diplomacy][14]. TripleA can be played locally against the computer or against other people in hot seat mode. Online play is also available using either the network option or the play by email/forum post option.
-
-To install TripleA, run the following command:
-
-On Debian/Ubuntu: `apt install triplea`
-
-Unfortunately, TripleA is not packaged for Fedora, but a [Linux installer][15] is available from the project's website.
-
-### XBoard
-
-
-
-There are so many [chess computer programs][16], it is hard to pick just one, even from just the open source offerings. However, [XBoard][17] is a good choice for most users. XBoard supports multiple chess engines, can handle non-Western and non-traditional chess variants and has online and play-by-email capabilities. Some of the other open source chess applications might look a little nicer, but XBoard provides many features that make up for the lack of graphical polish. If you are looking for a lighter chess application with fancy 3D chessmen, you might want to look elsewhere, but if you want a powerful program that can help you analyze and improve your chess skills, XBoard is the superior open source option.
-
-To install XBoard, run the following command:
-
-On Fedora: `dnf install xboard`
-
-On Debian/Ubuntu: `apt install xboard`
-
-Did I miss one of your favorite open source board or card games? Share it in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/card-board-games-linux
-
-作者:[Joshua Allen Holm][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/holmja
-[1]:https://opensource.com/article/18/1/arcade-games-linux
-[2]:https://boardgamegeek.com/boardgame/2093/mahjong
-[3]:https://www.kde.org/applications/games/kajongg/
-[4]:https://en.wikipedia.org/wiki/Mahjong#Variations
-[5]:https://boardgamegeek.com/boardgame/13/catan
-[6]:https://boardgamegeek.com/boardgame/1406/monopoly
-[7]:https://boardgamegeek.com/boardgame/2407/sorry
-[8]:https://boardgamegeek.com/boardgame/181/risk
-[9]:http://pio.sourceforge.net/
-[10]:https://pokerth.net
-[11]:https://en.wikipedia.org/wiki/Texas_hold_%27em
-[12]:http://www.triplea-game.org
-[13]:https://boardgamegeek.com/boardgame/98/axis-allies
-[14]:https://boardgamegeek.com/boardgame/483/diplomacy
-[15]:http://triplea-game.org/download/
-[16]:https://boardgamegeek.com/boardgame/171/chess
-[17]:https://www.gnu.org/software/xboard
diff --git a/sources/tech/20180319 How to not be a white male asshole, by a former offender.md b/sources/tech/20180319 How to not be a white male asshole, by a former offender.md
deleted file mode 100644
index 3478787ea1..0000000000
--- a/sources/tech/20180319 How to not be a white male asshole, by a former offender.md
+++ /dev/null
@@ -1,153 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to not be a white male asshole, by a former offender)
-[#]: via: (https://www.jtolio.com/2018/03/how-to-not-be-a-white-male-asshole-by-a-former-offender)
-[#]: author: (jtolio.com https://www.jtolio.com/)
-
-How to not be a white male asshole, by a former offender
-======
-
-_Huge thanks to Caitlin Jarvis for editing, contributing to, and proofreading to this post._
-
-First off, let’s start off with some assumptions. You, dear reader, don’t intend to cause anyone harm. You have good intentions, see yourself as a good person, and are interested in self improvement. That’s great!
-
-Second, I don’t actually know for sure if I’m not still a current offender. I might be! It’s certainly something I’ll never be done working on.
-
-### 1\. You don’t know what others are going through
-
-Unfortunately, your good intentions are not enough to make sure the experiences of others are, in fact, good because we live in a world of asymmetric information. If another person’s dog just died unbeknownst to you and you start talking excitedly about how great dogs are to try and cheer a sad person up, you may end up causing them to be even sadder. You know things other people don’t, and others know things you don’t.
-
-So when I say that if you are a white man, there is an invisible world of experiences happening all around you that you are inherently blind to, it’s because of asymmetric information. You can’t know what others are going through because you are not an impartial observer of a system. _You exist within the system._
-
-![][1]
-
-Let me show you what I mean: did you know a recent survey found that _[81 percent of women have experienced sexual harassment of some kind][2]_? Fully 1 out of every 2 women you know have had to deal specifically with _unwanted sexual touching_.
-
-What should have been most amazing about the [#MeToo movement][3] was not how many women reported harassment, but how many men were surprised.
-
-### 2\. You can inadvertently contribute to a racist, sexist, or prejudiced society
-
-I [previously wrote a lot about how small little interactions can add up][4], illustrating that even if you don’t intend to subject someone to racism, sexism, or some other prejudice, you might be doing it anyway. Intentions are meaningless when your actions amplify the negative experience of someone else.
-
-An example from [Maisha Johnson in Everyday Feminism][5]:
-
-> Black women deal with people touching our hair a lot. Now you know. Okay, there’s more to it than that: Black women deal with people touching our hair a _hell_ of a lot.
->
-> If you approach a Black woman saying “I just have to feel your hair,” it’s pretty safe to assume this isn’t the first time she’s heard that.
->
-> Everyone who asks me if they can touch follows a long line of people othering me – including strangers who touch my hair without asking. The psychological impact of having people constantly feel entitled my personal space has worn me down.
-
-Another example is that men frequently demand proof. Even though it makes sense in general to check your sources for something, the predominant response of men when confronted with claims of sexist treatment is to [ask for evidence][6]. Because this happens so frequently, this action _itself_ contributes to the sexist subjugation of women. The parallel universe women live in is so distinct from the experiences of men that men can’t believe their ears, and treat the report of a victim with skepticism.
-
-As you might imagine, this sort of effect is not limited to asking women for evidence or hair touching. Microaggressions are real and everywhere; the accumulation of lots of small things can be enormous.
-
-If you’re someone in charge of building things, this can be even more important and an even greater responsibility. If you build an app that is blind to the experiences of people who don’t look or act like you, you can significantly amplify negative experiences for others by causing systemic and system-wide issues.
-
-### 3\. The only way to stop contributing is to continually listen to others
-
-If you don’t already know what others are going through, and by not knowing what others are going through you may be subjecting them to prejudice even if you don’t mean to, what can you do to help others avoid prejudice? You can listen to them! People who are experiencing prejudice _don’t want to be experiencing prejudice_ and tend to be vocal about the experience. It is your job to really listen and then turn around and change the way you approach these situations in the future.
-
-### 4\. How do I listen?
-
-To listen to someone, you need to have empathy. You need to actually care about them. You need to process what they’re saying and not treat them with suspicion.
-
-Listening is very different from interjecting and arguing. Listening to others is different from making them do the work to educate you. It is your job to find the experiences of others you haven’t had and learn from them without demanding a curriculum.
-
-When people say you should just believe marginalized people, [no one is asking you to check your critical thinking at the door][7]. What you’re being asked to do is to be aware that your incredulity is a further reminder that you are not experiencing the same thing. Worse - white men acting incredulous is _so unbelievably common_ that it itself is a microaggression. Don’t be a sea lion:
-
-![][8]
-
-#### Aside about diversity of experience vs. diversity of thought.
-
-When trying to find others to listen to, who should you find? Recently, a growing number of people have echoed that all that’s really required of diversity is different viewpoints, and having diversity of thought is the ultimate goal.
-
-I want to point out that this is not the kind of diversity that will be useful to you. It’s easy to have a bunch of different opinions and then reject them when they complicate your life. What you want to be listening to is diversity of _experience_. Some experiences can’t be chosen. You can choose to be contrarian, but you can’t choose the color of your skin.
-
-### 5\. Where do I listen?
-
-What you need is a way to be a fly on the wall and observe the life experiences of others through their words and perspectives. Being friends and hanging out with people who are different from you is great. Getting out of monocultures is fantastic. Holding your company to diversity and inclusion initiatives is wonderful.
-
-But if you still need more or you live somewhere like Utah?
-
-What if there was a website where people from all walks of life opted in to talking about their day and what they’re feeling and experiencing from their viewpoint in a way you could read? It’d be almost like seeing the world through their eyes.
-
-Yep, this blog post is an unsolicited Twitter ad. Twitter definitely has its share of problems, but after [writing about how I finally figured out Twitter][9], in 2014 I decided to embark on a year-long effort to use Twitter (I wasn’t really using it before) to follow mostly women or people of color in my field and just see what the field is like for them on a day to day basis.
-
-Listening to others in this way blew my mind clean open. Suddenly I was aware of this invisible world around me, much of which is still invisible. Now, I’m looking for it, and I catch glimpses. I would challenge anyone and everyone to do this. Make sure the content you’re consuming is predominantly viewpoints from life experiences you haven’t had.
-
-If you need a start, here are some links to accounts to fill your Twitter feed up with:
-
- * [200 Women of Color in Tech on Twitter][10]
- * [Women Engineers on Twitter][11]
-
-
-
-You can also check out [who I follow][12], though I should warn I also follow a lot of political accounts, joke accounts, and my following of someone is not an endorsement.
-
-It’s also worth pointing out that no individual can possibly speak for an entire class of people, but if 38 out of 50 women are saying they’re dealing with something, you should listen.
-
-### 6\. Does this work?
-
-Listening to others works, but you don’t have to just take my word for it. Here are two specific and recent experience reports of people turning their worldview for the better by listening to others:
-
- * [A professor at the University of New Brunswick][13]
- * [A senior design developer at Microsoft][14]
-
-
-
-You can see how much of a profound and fast impact this had on me because by early 2015, only a few months into my Twitter experiment, I was worked up enough to write [my unicycle post][4] in response to what I was reading on Twitter.
-
-Having diverse perspectives in a workplace has even been shown to [increase productivity][15] and [increase creativity][16].
-
-### 7\. Don’t stop there!
-
-Not everyone is as growth-oriented as you. Just because you’re listening now doesn’t mean others are hearing the same distribution of experiences.
-
-If this is new to you, it’s not new to marginalized people. Imagine how tired they must be in trying to convince everyone their experiences are real, valid, and ongoing. Help get the word out! Repeat and retweet what women and minorities say. Give them credit. In meetings at your work, give credit to others for their ideas and amplify their voices.
-
-Did you know that [non-white or female bosses who push diversity are judged negatively by their peers and managers][17] but white male bosses are not? If you’re a white male, use your position where others can’t.
-
-If you need an example list of things your company can do, [here’s a list Susan Fowler wrote after her experience at Uber][18].
-
-Speak up, use your experiences to help others.
-
-### 8\. Am I not prejudiced now?
-
-The asymmetry of experiences we all have means we’re all inherently prejudiced to some degree and will likely continue to contribute to a prejudiced society. That said, the first step to fixing it is admitting it!
-
-There will always be work to do. You will always need to keep listening, keep learning, and work to improve every day.
-
---------------------------------------------------------------------------------
-
-via: https://www.jtolio.com/2018/03/how-to-not-be-a-white-male-asshole-by-a-former-offender
-
-作者:[jtolio.com][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.jtolio.com/
-[b]: https://github.com/lujun9972
-[1]: https://www.jtolio.com/images/mrmouse.jpg
-[2]: https://www.npr.org/sections/thetwo-way/2018/02/21/587671849/a-new-survey-finds-eighty-percent-of-women-have-experienced-sexual-harassment
-[3]: https://en.wikipedia.org/wiki/Me_Too_movement
-[4]: https://www.jtolio.com/2015/03/what-riding-a-unicycle-can-teach-us-about-microaggressions/
-[5]: https://everydayfeminism.com/2015/09/dont-touch-black-womens-hair/
-[6]: https://twitter.com/ArielDumas/status/970692180766490630
-[7]: https://www.elle.com/culture/career-politics/a13977980/me-too-movement-false-accusations-believe-women/
-[8]: https://www.jtolio.com/images/sealion.png
-[9]: https://www.jtolio.com/2009/03/i-finally-figured-out-twitter/
-[10]: http://peopleofcolorintech.com/articles/a-list-of-200-women-of-color-on-twitter/
-[11]: https://github.com/ryanburgess/female-engineers-twitter
-[12]: https://twitter.com/jtolds/following
-[13]: https://www.theglobeandmail.com/opinion/ill-start-2018-by-recognizing-my-white-privilege/article37472875/
-[14]: https://micahgodbolt.com/blog/changing-your-worldview/
-[15]: http://edis.ifas.ufl.edu/hr022
-[16]: https://faculty.insead.edu/william-maddux/documents/PSPB-learning-paper.pdf
-[17]: https://digest.bps.org.uk/2017/07/12/non-white-or-female-bosses-who-push-diversity-are-judged-negatively-by-their-peers-and-managers/
-[18]: https://www.susanjfowler.com/blog/2017/5/20/five-things-tech-companies-can-do-better
diff --git a/sources/tech/20180326 How to create an open source stack using EFK.md b/sources/tech/20180326 How to create an open source stack using EFK.md
deleted file mode 100644
index e3fac7f1c1..0000000000
--- a/sources/tech/20180326 How to create an open source stack using EFK.md
+++ /dev/null
@@ -1,388 +0,0 @@
-How to create an open source stack using EFK
-======
-
-
-Managing an infrastructure of servers is a non-trivial task. When one cluster is misbehaving, logging in to multiple servers, checking each log, and using multiple filters until you find the culprit is not an efficient use of resources.
-
-The first step to improve the methods that handle your infrastructure or applications is to implement a centralized logging system. This will enable you to gather logs from any application or system into a centralized location and filter, aggregate, compare, and analyze them. If there are servers or applications, there should be a unified logging layer.
-
-Thankfully, we have an open source stack to simplify this. With the combination of Elasticsearch, Fluentd, and Kibana (EFK), we can create a powerful stack to collect, store, and visualize data in a centralized location.
-
-Let’s start by defining each component to get the big picture. [Elasticsearch][1] is an open source distributed, RESTful search and analytics engine, or simply an object store where all logs are stored. [Fluentd][2] is an open source data collector that lets you unify the data collection and consumption for better use and understanding of data. And finally, [Kibana][3] is a web UI for Elasticsearch.
-
-A picture is worth a thousand words:
-
-
-![EFK stack][5]
-
-EFK Stack using a centralized Fluentd aggregator.
-
-Image by Michael Zamot, CC BY
-
-There are other ways to collect logs, like running a small Fluentd forwarder in each host, but that’s beyond the scope of this article.
-
-### Requirements
-
-We will install each component in its own Docker container. With Docker we can deploy each component faster, focusing in EFK rather than distro-specific bits, and we can always delete the containers and start all over again. We will be using official, upstream images.
-
-To learn more about Docker, read [Vincent Batts][6]'s excellent article: [A beginners' guide to Docker][7].
-
-Increase the mmap limits by running the following command as root:
-```
-$ sudo sysctl -w vm.max_map_count=262144
-
-```
-
-To set this value permanently, update the `vm.max_map_count` setting in `/etc/sysctl.conf`.
-
-This is required; otherwise, Elasticsearch can crash.
-
-### Running Elasticsearch
-
-To allow the containers to communicate with each other, create a Docker network:
-```
-$ sudo docker network create efk
-
-[...]
-
-```
-
-Execute the following command to start Elasticsearch in Docker:
-```
-$ sudo docker run --network=efk --name elasticsearch -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e "cluster.name=docker-cluster" -e "bootstrap.memory_lock=true" -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" --ulimit memlock=-1:-1 -v elasticdata:/usr/share/elasticsearch/data docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.2
-
-```
-
-Verify the container is running:
-```
-$ sudo docker ps
-
-CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
-
-6e0db1486ee2 docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.2 "/usr/local/bin/docke" About a minute ago Up About a minute 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch
-
-```
-
-Let’s decouple the command to understand what we just did:
-
- * We use `docker run` to create a new container.
- * We use `--network` to attach the container to that specific network.
- * We need to define a container name; it will be used as the hostname.
- * The parameter `-p` maps our host ports to the container ports. Elasticsearch uses the ports 9200 and 9300.
- * The multiple parameters with `-e` are environment variables that are passed to the container to change configurations.
- * We define a custom `ulimit` to disable swapping for performance and node stability.
- * Containers, by design, are ephemeral. This means they don’t store data, so in order to keep the data and logs safe, we need to create a volume and mount it inside the container. In our case it is mounted to `/usr/share/elasticsearch/data`. This is the path where Elasticsearch stores the data.
-
-
-
-Verify the volume was created:
-```
-$ sudo docker volume ls
-
-[...]
-
-local elasticdata
-
-```
-
-This volume will survive even if you delete the container.
-
-Great! Elasticsearch is running. Let’s move on.
-
-### Running Kibana
-
-Kibana is a much simpler command. Execute the following command to spin it:
-```
-$ sudo docker run --network=efk --name kibana -d -p 5601:5601 docker.elastic.co/kibana/kibana-oss:6.2.2
-
-```
-
-By default, Kibana will try to communicate to the host named elasticsearch.
-
-Verify that you can access Kibana in your browser at this URL: http://<docker host>:5601
-
-At this point, Elasticsearch is not indexing any data, so you won’t be able to do much yet.
-
-Let’s start collecting logs!
-
-### Running Fluentd
-
-The following steps are trickier, as the official Docker image doesn’t include the Elasticsearch plugin. We will customize.
-
-Create a directory called `fluentd` with a subdirectory called `plugins`:
-```
-$ mkdir -p fluentd/plugins
-
-```
-
-Now let’s create the Fluentd configuration file. Inside the directory `fluentd`, create a file called `fluent.conf` with the following content:
-```
-$ cat fluentd/fluent.conf
-
-<source>
-
- type syslog
-
- port 42185
-
- tag rsyslog
-
-</source>
-
-
-
-<match rsyslog.**>
-
- type copy
-
- <store>
-
- type elasticsearch
-
- logstash_format true
-
- host elasticsearch # Remember the name of the container
-
- port 9200
-
- </store>
-
-</match>
-
-```
-
-The block `<source>` enables the `syslog` plugin, the port and address where it will listen. The block `<match rsyslog.**>` will match all logs coming from the `syslog` plugin and will send the data to Elasticsearch.
-
-Now create another file inside the Fluentd folder called `Dockerfile`:
-```
-$ cat fluentd/Dockerfile
-
-FROM fluent/fluentd:v0.12-onbuild
-
-
-
-RUN apk add --update --virtual .build-deps \
-
- sudo build-base ruby-dev \
-
- && sudo gem install \
-
- fluent-plugin-elasticsearch \
-
- && sudo gem sources --clear-all \
-
- && apk del .build-deps \
-
- && rm -rf /var/cache/apk/* \
-
- /home/fluent/.gem/ruby/2.3.0/cache/*.gem
-
-```
-
-This will modify the official Fluentd Docker image and add Elasticsearch support.
-
-The Fluentd directory should look like this:
-```
-$ ls fluentd/
-
-Dockerfile fluent.conf plugins
-
-```
-
-Now we can build the container. Execute the following command within the Fluentd directory:
-```
-$ sudo docker build fluentd/
-
-[...]
-
-Successfully built <Image ID>
-
-```
-
-Now we are ready to start the final piece of our stack. Execute the following command to start the container:
-```
-$ sudo docker run -d --network efk --name fluentd -p 42185:42185/udp <Image ID>
-
-```
-
-Your Unified Logging Stack is deployed. Now it’s time to point configure your host's rsyslog to send the data to Fluentd.
-
-Log into each of the nodes you want to collect logs from, and add the following line at the end of `/etc/rsyslog.conf` :
-```
-*.* @<Docker Host>:42185
-
-```
-
-Then restart `rsyslog` service:
-```
-$ sudo systemctl restart rsyslog
-
-```
-
-Don’t forget to check Kibana—all your logs are going to be there.
-
-### Wrapping everything up with Docker Compose
-
-We can use Docker Compose to combine all the steps we did previously into a single command. Compose is a tool for defining and running multi-container Docker applications. With Compose, you use a YAML file (known as a Compose file) to configure an application's services; in our case, EFK services.
-
-To install Docker Compose, execute the following commands:
-```
-$ sudo curl -L https://github.com/docker/compose/releases/download/1.19.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
-
-
-
-$ sudo chmod +x /usr/local/bin/docker-compose
-
-```
-
-Verify it is working:
-```
-$ docker-compose version
-
-docker-compose version 1.19.0, build 9e633ef
-
-```
-
-Awesome! All the steps we did previously can be summarized with the following `docker-compose.yml` file (we still need to create the Fluentd folder and files):
-```
-$ cat docker-compose.yml
-
-version: '2.1'
-
-services:
-
- fluentd:
-
- build: ./fluentd
-
- links:
-
- - "elasticsearch"
-
- expose:
-
- - 42185
-
- ports:
-
- - "42185:42185/udp"
-
- logging:
-
- driver: "json-file"
-
- options:
-
- max-size: 100m
-
- max-file: "5"
-
-
-
- elasticsearch:
-
- image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.2
-
- container_name: elasticsearch
-
- ports:
-
- - "9200:9200"
-
- environment:
-
- - "discovery.type=single-node"
-
- - "cluster.name=docker-cluster"
-
- - "bootstrap.memory_lock=true"
-
- - "ES_JAVA_OPTS=-Xms512m -Xmx512m"
-
- ulimits:
-
- memlock:
-
- soft: -1
-
- hard: -1
-
- volumes:
-
- - elasticdata:/usr/share/elasticsearch/data
-
-
-
- kibana:
-
- image: docker.elastic.co/kibana/kibana-oss:6.2.2
-
- container_name: kibana
-
- links:
-
- - "elasticsearch"
-
- ports:
-
- - "5601:5601"
-
-
-
-volumes:
-
- elasticdata:
-
- driver: local
-
-```
-
-Then you can bring all the containers up with one command:
-```
-$ sudo docker-compose up
-
-```
-
-And if you want to delete all the containers (except the volumes):
-```
-$ sudo docker-compose rm
-
-```
-
-With one simple YAML file, your proof of concept is ready to be deployed anywhere, with consistent results. When you have tested the solution thoroughly, don't forget to read the official [Elasticsearch][8], [Fluentd][9], and [Kibana][10] documentation to make your implementation production grade.
-
-As you play with the EFK (and Docker) you will recognize how practical it is, and your life as a sysadmin will never be the same.
-
-### Further reading
-
-[Install Elasticsearch with Docker][8]
-
-[Installing Fluentd with Docker][11]
-
-[Unified Logging Layer: Turning Data into Action][12]
-
-[Docker Compose][13]
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/efk-creating-open-source-stack
-
-作者:[Michael Zamot][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mzamot
-[1]:https://www.elastic.co/
-[2]:https://www.fluentd.org/
-[3]:https://www.elastic.co/products/kibana
-[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/efk_stack_illustration.png?itok=Z0RDEi8p (EFK stack illustration)
-[6]:https://opensource.com/users/vbatts
-[7]:https://opensource.com/business/14/7/guide-docker
-[8]:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
-[9]:https://docs.fluentd.org/v1.0/articles/quickstart
-[10]:https://www.elastic.co/guide/en/kibana/current/introduction.html
-[11]:https://docs.fluentd.org/v0.12/articles/install-by-docker
-[12]:https://www.fluentd.org/blog/unified-logging-layer
-[13]:https://docs.docker.com/compose/
diff --git a/sources/tech/20180327 Anna A KVS for any scale.md b/sources/tech/20180327 Anna A KVS for any scale.md
deleted file mode 100644
index eb6bfa95b3..0000000000
--- a/sources/tech/20180327 Anna A KVS for any scale.md
+++ /dev/null
@@ -1,139 +0,0 @@
-Anna: A KVS for any scale
-============================================================
-[Anna: A KVS for any scale][8] Wu et al., _ICDE’18_
-
-This work comes out of the [RISE][9] project at Berkeley, and regular readers of The Morning Paper will be familiar with much of the background. Here’s how Joe Hellerstein puts it in his [blog post][10] introducing the work:
-
-> As researchers, we asked the counter-cultural question: what would it take to build a key-value store that would excel across many orders of magnitude of scale, from a single multicore box to the global cloud? Turns out this kind of curiosity can lead to a system with pretty interesting practical implications. The key design point for answering our question centered on an ongoing theme in my research group over the last many years: designing distributed systems that avoid coordination. We’ve developed fundamental theory (the [CALM Theorem][1]), language design ([Bloom][2]), program checkers ([Blazes][3]), and transactional protocols ([HATs][4], [Invariant Confluence][5]). But until now we hadn’t demonstrated the kind of performance and scale these principles can achieve across both multicore and cloud environments. Consider that domino fallen.
-
-At it’s core Anna uses coordination-free actors. Each actor is a single thread of execution, and is mapped to a single core (see e.g. [FFWD][11] that we looked at recently). The coordination-free part comes from managing all state in lattice-based composite data structures (think [Bloom][12] and [CRDTs][13]). There is _communication_ between actors that happens at the end of every epoch (epochs determine the limit of staleness for GET operations), but this is asynchronous gossip and not on the critical path of request handling.
-
-
-
-The success of the design in scaling across orders of magnitude is shown in the following results, where Anna outperforms Redis (and Redis Cluster) on a single node:
-
-
-
-And also outperforms Cassandra in a distributed setting:
-
-
-
-It’s got a way to go to trouble [KV-Direct][14] though ;).
-
-### Design goals for Anna
-
-The high-level goal for Anna was to provide excellent performance on a single multi-core machine, while also being able to scale up elastically to geo-distributed cloud deployment. The system should support a range of consistency semantics to match application needs. From this, four design requirements emerged:
-
-1. The key space needs to be **partitioned**, not just across nodes when distributed, but also across cores within a node.
-
-2. To scale workloads (especially those with highly skewed distributions, aka. ‘hot keys’) the system should use **multi-master** replication to concurrently serve puts and gets against a single key from multiple threads.
-
-3. For maximum hardware utilisation and performance, the system should have **wait-free execution** such that a thread is never blocked on other threads. This rules out locking, consensus protocols, and even ‘lock-free’ retries.
-
-4. To support a wide-range of application semantics without compromising the other goals, the system should have a unified implementation for a wide range of **coordination-free consistency models**.
-
-> Perhaps the primary lesson of this work is that our scalability goals led us by necessity to good software engineering discipline.
-
-### Lattices
-
-The key to achieving coordination-free progress is the use of lattice-based composition (strictly, _bounded join semi-lattices_ ). Such lattices operate over some domain _S_ (the set of possible states), with a binary ‘least upper bound’ operator,
-
-, and a bottom value
-
-. The least upper bound operator must be associative, commutative, and idempotent ($\perp(a,a) = a,\ \forall a \in S$). Collectively these are known as the ACI properties. Such lattices are also the foundation of CRDTs.
-
-> Lattices prove important to Anna for two reasons. First, lattices are insensitive to the order in which they merge updates. This means they can guarantee consistency across replicas even if the actors managing those replicas receive updates in different orders…. Second, simple lattice building blocks can be composed to achieve a range of coordination-free consistency levels.
-
-Anna adopts the lattice composition approach of [Bloom][15], in which simple lattice-based (ACI) building blocks such as counters, maps, and pairs can be composed into higher-order structures with ACI properties checkable by induction. If each building block has ACI properties, and the composition rules preserve ACI properties, then we can validate composed data structures without needing to directly verify them.
-
-> The private state of each worker in Anna is represented as a lattice-valued map lattice (MapLattice) template, parameterized by the types of its keys and values…. User’s PUT requests are merged into the MapLattice. The merge operator of MapLattice takes the union of the key sets of both input hash maps. If a key appears in both inputs then the values associated with the key are merged using the ValueLattice’s merge function.
-
-Different lattice compositions can be used to support different consistency levels. For example, the lattice below supports causal consistency. The vector clock is itself a MapLattice with client proxy ids as keys and version numbers as values.
-
-
-
-Merge operations take a (vector clock, value) pair and use the least upper bound function to merge incomparable concurrent writes.
-
-It takes only a very few lines of code to change the implementation to support other consistency models. Starting with simple eventual consistency, the following table shows the number of additional C++ loc needed to implement a variety of coordination-free consistency levels.
-
-
-
-### Design and implementation
-
-On a given node, an Anna server consists of a collection of independent threads, each of which runs the coordination-free actor model. The state of each actor is maintained in a lattice-based data structure. Each actor/thread is pinned to a unique CPU core in a 1:1 correspondence. There is no shared key-value state: consistent hashing is used to partition the key space across actors. Multi-master replication is used to replicate data partitions across actors.
-
-Processing happens in time-based _multicast epochs_ (of e.g. 100ms). During an epoch any updates to a key-value pair owned by an actor are added to a local changeset. At the end of the epoch, local updates in the change set are merged using the merge operator of the lattice, and then multicast to the relevant masters for those keys. Actors also check for incoming multicast messages from other actors, and merge key-value updates from those into their own local state. The staleness of GET responses is bounded by the (configurable) multicast period.
-
-Communication between actors is done using ZeroMQ. Within a node this will be via the intra-process transport, between it will be via protocol buffers over a tcp transport.
-
-Actors may join and leave dynamically. See section VII.C in the paper for details.
-
-The entire codebase, excluding third-party libraries such as ZeroMQ, but including the lattice library, support for all consistency levels, and the client proxy code, is around 2000 lines of C++.
-
-### Evaluation
-
-Starting with performance on a single node, Anna’s performance really shines under high-contention workloads when using full replication across all actors, and spends the vast majority of its time actually processing requests (as opposed to waiting).
-
-
-
-
-
-Under low contention workloads though, it’s much more efficient to use a lower replication factor (e.g., 3 masters per key):
-
-
-
-> The lesson learned from this experiment is that for systems that support multi-master replication, having a high replication factor under low contention workloads can hurt performance. Instead, we want to dynamically monitor the data’s contention level and selectively replicate the highly contented keys across threads.
-
-As another reference point, here’s the single node comparison to Redis under high and low contention workloads:
-
-
-
-Anna scales well when adding threads across multiple servers (the slight drop at the 33rd thread in the chart below is because this is first thread residing on a second node, triggering distributed multicast across the network):
-
-
-
-As we saw previously, in the distributed setting, Anna compares very favourably against Cassandra:
-
-*
-
-
-In summary:
-
-* Anna can significantly outperform Redis Cluster by replicating hot keys under high contention.
-
-* Anna can match the performance of Redis Cluster under low contention.
-
-* Anna can outperform Cassandra by up to 10x when permitted to use all 32 available cores on each of its nodes.
-
-### The last word
-
-I’m going to leave the last word to Joe Hellerstein, from his blog post:
-
-> Anna is a prototype and we learned a ton doing it. I think the lessons of what we did apply well beyond key-value databases to any distributed system that manages internal state—basically everything. We’re now actively working on an extended system, codename Bedrock, based on Anna. Bedrock will provide a hands-off, cost-effective version of this design in the cloud, which we’ll be open-sourcing and supporting more aggressively. Watch this space!
-
---------------------------------------------------------------------------------
-
-via: https://blog.acolyer.org/2018/03/27/anna-a-kvs-for-any-scale/
-
-作者:[adriancolyer,][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://twitter.com/adriancolyer
-[1]:https://blog.acolyer.org/2015/03/16/consistency-analysis-in-bloom-a-calm-and-collected-approach/
-[2]:https://blog.acolyer.org/2015/03/16/consistency-analysis-in-bloom-a-calm-and-collected-approach/
-[3]:https://blog.acolyer.org/2015/01/05/blazes-coordination-analysis-for-distributed-programs/
-[4]:https://blog.acolyer.org/2014/11/07/highly-available-transactions-virtues-and-limitations/
-[5]:https://blog.acolyer.org/2015/03/19/coordination-avoidance-in-database-systems/
-[6]:https://blog.acolyer.org/tag/datastores/
-[7]:https://blog.acolyer.org/tag/distributed-systems/
-[8]:http://db.cs.berkeley.edu/jmh/papers/anna_ieee18.pdf
-[9]:https://rise.cs.berkeley.edu/
-[10]:https://rise.cs.berkeley.edu/blog/anna-kvs/
-[11]:https://blog.acolyer.org/2017/12/04/ffwd-delegation-is-much-faster-than-you-think/
-[12]:https://blog.acolyer.org/2015/03/16/consistency-analysis-in-bloom-a-calm-and-collected-approach/
-[13]:https://blog.acolyer.org/2015/03/18/a-comprehensive-study-of-convergent-and-commutative-replicated-data-types/
-[14]:https://blog.acolyer.org/2017/11/23/kv-direct-high-performance-in-memory-key-value-store-with-programmable-nic/
-[15]:https://blog.acolyer.org/2015/03/16/consistency-analysis-in-bloom-a-calm-and-collected-approach/
diff --git a/sources/tech/20180402 An introduction to the Flask Python web app framework.md b/sources/tech/20180402 An introduction to the Flask Python web app framework.md
deleted file mode 100644
index 4b07338bc5..0000000000
--- a/sources/tech/20180402 An introduction to the Flask Python web app framework.md
+++ /dev/null
@@ -1,451 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (An introduction to the Flask Python web app framework)
-[#]: via: (https://opensource.com/article/18/4/flask)
-[#]: author: (Nicholas Hunt-Walker https://opensource.com/users/nhuntwalker)
-[#]: url: ( )
-
-An introduction to the Flask Python web app framework
-======
-In the first part in a series comparing Python frameworks, learn about Flask.
-
-
-If you're developing a web app in Python, chances are you're leveraging a framework. A [framework][1] "is a code library that makes a developer's life easier when building reliable, scalable, and maintainable web applications" by providing reusable code or extensions for common operations. There are a number of frameworks for Python, including [Flask][2], [Tornado][3], [Pyramid][4], and [Django][5]. New Python developers often ask: Which framework should I use?
-
- * New visitors to the site should be able to register new accounts.
- * Registered users can log in, log out, see information for their profiles, and edit their information.
- * Registered users can create new task items, see their existing tasks, and edit existing tasks.
-
-
-
-This series is designed to help developers answer that question by comparing those four frameworks. To compare their features and operations, I'll take each one through the process of constructing an API for a simple To-Do List web application. The API is itself fairly straightforward:
-
-All this rounds out to a compact set of API endpoints that each backend must implement, along with the allowed HTTP methods:
-
- * `GET /`
- * `POST /accounts`
- * `POST /accounts/login`
- * `GET /accounts/logout`
- * `GET, PUT, DELETE /accounts/<str : username>`
- * `GET, POST /accounts/<str : username>/tasks`
- * `GET, PUT, DELETE /accounts/<str : username>/tasks/<int : id>`
-
-
-
-Each framework has a different way to put together its routes, models, views, database interaction, and overall application configuration. I'll describe those aspects of each framework in this series, which will begin with Flask.
-
-### Flask startup and configuration
-
-Like most widely used Python libraries, the Flask package is installable from the [Python Package Index][6] (PPI). First create a directory to work in (something like `flask_todo` is a fine directory name) then install the `flask` package. You'll also want to install `flask-sqlalchemy` so your Flask application has a simple way to talk to a SQL database.
-
-I like to do this type of work within a Python 3 virtual environment. To get there, enter the following on the command line:
-
-```
-$ mkdir flask_todo
-$ cd flask_todo
-$ pipenv install --python 3.6
-$ pipenv shell
-(flask-someHash) $ pipenv install flask flask-sqlalchemy
-```
-
-If you want to turn this into a Git repository, this is a good place to run `git init`. It'll be the root of the project, and if you want to export the codebase to a different machine, it will help to have all the necessary setup files here.
-
-A good way to get moving is to turn the codebase into an installable Python distribution. At the project's root, create `setup.py` and a directory called `todo` to hold the source code.
-
-The `setup.py` should look something like this:
-
-```
-from setuptools import setup, find_packages
-
-requires = [
- 'flask',
- 'flask-sqlalchemy',
- 'psycopg2',
-]
-
-setup(
- name='flask_todo',
- version='0.0',
- description='A To-Do List built with Flask',
- author='<Your actual name here>',
- author_email='<Your actual e-mail address here>',
- keywords='web flask',
- packages=find_packages(),
- include_package_data=True,
- install_requires=requires
-)
-```
-
-This way, whenever you want to install or deploy your project, you'll have all the necessary packages in the `requires` list. You'll also have everything you need to set up and install the package in `site-packages`. For more information on how to write an installable Python distribution, check out [the docs on setup.py][7].
-
-Within the `todo` directory containing your source code, create an `app.py` file and a blank `__init__.py` file. The `__init__.py` file allows you to import from `todo` as if it were an installed package. The `app.py` file will be the application's root. This is where all the `Flask` application goodness will go, and you'll create an environment variable that points to that file. If you're using `pipenv` (like I am), you can locate your virtual environment with `pipenv --venv` and set up that environment variable in your environment's `activate` script.
-
-```
-# in your activate script, probably at the bottom (but anywhere will do)
-
-export FLASK_APP=$VIRTUAL_ENV/../todo/app.py
-export DEBUG='True'
-```
-
-When you installed `Flask`, you also installed the `flask` command-line script. Typing `flask run` will prompt the virtual environment's Flask package to run an HTTP server using the `app` object in whatever script the `FLASK_APP` environment variable points to. The script above also includes an environment variable named `DEBUG` that will be used a bit later.
-
-Let's talk about this `app` object.
-
-In `todo/app.py`, you'll create an `app` object, which is an instance of the `Flask` object. It'll act as the central configuration object for the entire application. It's used to set up pieces of the application required for extended functionality, e.g., a database connection and help with authentication.
-
-It's regularly used to set up the routes that will become the application's points of interaction. To explain what this means, let's look at the code it corresponds to.
-
-```
-from flask import Flask
-
-app = Flask(__name__)
-
-@app.route('/')
-def hello_world():
- """Print 'Hello, world!' as the response body."""
- return 'Hello, world!'
-```
-
-This is the most basic complete Flask application. `app` is an instance of `Flask`, taking in the `__name__` of the script file. This lets Python know how to import from files relative to this one. The `app.route` decorator decorates the first **view** function; it can specify one of the routes used to access the application. (We'll look at this later.)
-
-Any view you specify must be decorated by `app.route` to be a functional part of the application. You can have as many functions as you want scattered across the application, but in order for that functionality to be accessible from anything external to the application, you must decorate that function and specify a route to make it into a view.
-
-In the example above, when the app is running and accessed at `http://domainname/`, a user will receive `"Hello, World!"` as a response.
-
-### Connecting the database in Flask
-
-While the code example above represents a complete Flask application, it doesn't do anything interesting. One interesting thing a web application can do is persist user data, but it needs the help of and connection to a database.
-
-Flask is very much a "do it yourself" web framework. This means there's no built-in database interaction, but the `flask-sqlalchemy` package will connect a SQL database to a Flask application. The `flask-sqlalchemy` package needs just one thing to connect to a SQL database: The database URL.
-
-Note that a wide variety of SQL database management systems can be used with `flask-sqlalchemy`, as long as the DBMS has an intermediary that follows the [DBAPI-2 standard][8]. In this example, I'll use PostgreSQL (mainly because I've used it a lot), so the intermediary to talk to the Postgres database is the `psycopg2` package. Make sure `psycopg2` is installed in your environment and include it in the list of required packages in `setup.py`. You don't have to do anything else with it; `flask-sqlalchemy` will recognize Postgres from the database URL.
-
-Flask needs the database URL to be part of its central configuration through the `SQLALCHEMY_DATABASE_URI` attribute. A quick and dirty solution is to hardcode a database URL into the application.
-
-```
-# top of app.py
-from flask import Flask
-from flask_sqlalchemy import SQLAlchemy
-
-app = Flask(__name__)
-app.config['SQLALCHEMY_DATABASE_URI'] = 'postgres://localhost:5432/flask_todo'
-db = SQLAlchemy(app)
-```
-
-However, this is not a sustainable solution. If you change databases or don't want your database URL visible in source control, you'll have to take extra steps to ensure your information is appropriate for the environment.
-
-You can make things simpler by using environment variables. They will ensure that, no matter what machine the code runs on, it always points at the right stuff if that stuff is configured in the running environment. It also ensures that, even though you need that information to run the application, it never shows up as a hardcoded value in source control.
-
-In the same place you declared `FLASK_APP`, declare a `DATABASE_URL` pointing to the location of your Postgres database. Development tends to work locally, so just point to your local database.
-
-```
-# also in your activate script
-
-export DATABASE_URL='postgres://localhost:5432/flask_todo'
-```
-
-Now in `app.py`, include the database URL in your app configuration.
-
-```
-app.config['SQLALCHEMY_DATABASE_URI'] = os.environ.get('DATABASE_URL', '')
-db = SQLAlchemy(app)
-```
-
-And just like that, your application has a database connection!
-
-### Defining objects in Flask
-
-Having a database to talk to is a good first step. Now it's time to define some objects to fill that database.
-
-In application development, a "model" refers to the data representation of some real or conceptual object. For example, if you're building an application for a car dealership, you may define a `Car` model that encapsulates all of a car's attributes and behavior.
-
-In this case, you're building a To-Do List with Tasks, and each Task belongs to a User. Before you think too deeply about how they're related to each other, start by defining objects for Tasks and Users.
-
-The `flask-sqlalchemy` package leverages [SQLAlchemy][9] to set up and inform the database structure. You'll define a model that will live in the database by inheriting from the `db.Model` object and define the attributes of those models as `db.Column` instances. For each column, you must specify a data type, so you'll pass that data type into the call to `db.Column` as the first argument.
-
-Because the model definition occupies a different conceptual space than the application configuration, make `models.py` to hold model definitions separate from `app.py`. The Task model should be constructed to have the following attributes:
-
- * `id`: a value that's a unique identifier to pull from the database
- * `name`: the name or title of the task that the user will see when the task is listed
- * `note`: any extra comments that a person might want to leave with their task
- * `creation_date`: the date and time the task was created
- * `due_date`: the date and time the task is due to be completed (if at all)
- * `completed`: a way to indicate whether or not the task has been completed
-
-
-
-Given this attribute list for Task objects, the application's `Task` object can be defined like so:
-
-```
-from .app import db
-from datetime import datetime
-
-class Task(db.Model):
- """Tasks for the To Do list."""
- id = db.Column(db.Integer, primary_key=True)
- name = db.Column(db.Unicode, nullable=False)
- note = db.Column(db.Unicode)
- creation_date = db.Column(db.DateTime, nullable=False)
- due_date = db.Column(db.DateTime)
- completed = db.Column(db.Boolean, default=False)
-
- def __init__(self, *args, **kwargs):
- """On construction, set date of creation."""
- super().__init__(*args, **kwargs)
- self.creation_date = datetime.now()
-```
-
-Note the extension of the class constructor method. At the end of the day, any model you construct is still a Python object and therefore must go through construction in order to be instantiated. It's important to ensure that the creation date of the model instance reflects its actual date of creation. You can explicitly set that relationship by effectively saying, "when an instance of this model is constructed, record the date and time and set it as the creation date."
-
-### Model relationships
-
-In a given web application, you may want to be able to express relationships between objects. In the To-Do List example, users own multiple tasks, and each task is owned by only one user. This is an example of a "many-to-one" relationship, also known as a foreign key relationship, where the tasks are the "many" and the user owning those tasks is the "one."
-
-In Flask, a many-to-one relationship can be specified using the `db.relationship` function. First, build the User object.
-
-```
-class User(db.Model):
- """The User object that owns tasks."""
- id = db.Column(db.Integer, primary_key=True)
- username = db.Column(db.Unicode, nullable=False)
- email = db.Column(db.Unicode, nullable=False)
- password = db.Column(db.Unicode, nullable=False)
- date_joined = db.Column(db.DateTime, nullable=False)
- token = db.Column(db.Unicode, nullable=False)
-
- def __init__(self, *args, **kwargs):
- """On construction, set date of creation."""
- super().__init__(*args, **kwargs)
- self.date_joined = datetime.now()
- self.token = secrets.token_urlsafe(64)
-```
-
-It looks very similar to the Task object; you'll find that most objects have the same basic format of class attributes as table columns. Every once in a while, you'll run into something a little different, including some multiple-inheritance magic, but this is the norm.
-
-Now that the `User` model is created, you can set up the foreign key relationship. For the "many," set fields for the `user_id` of the `User` that owns this task, as well as the `user` object with that ID. Also make sure to include a keyword argument (`back_populates`) that updates the User model when the task gets a user as an owner.
-
-For the "one," set a field for the `tasks` the specific user owns. Similar to maintaining the two-way relationship on the Task object, set a keyword argument on the User's relationship field to update the Task when it is assigned to a user.
-
-```
-# on the Task object
-user_id = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)
-user = db.relationship("user", back_populates="tasks")
-
-# on the User object
-tasks = db.relationship("Task", back_populates="user")
-```
-
-### Initializing the database
-
-Now that the models and model relationships are set, start setting up your database. Flask doesn't come with its own database-management utility, so you'll have to write your own (to some degree). You don't have to get fancy with it; you just need something to recognize what tables are to be created and some code to create them (or drop them should the need arise). If you need something more complex, like handling updates to database tables (i.e., database migrations), you'll want to look into a tool like [Flask-Migrate][10] or [Flask-Alembic][11].
-
-Create a script called `initializedb.py` next to `setup.py` for managing the database. (Of course, it doesn't need to be called this, but why not give names that are appropriate to a file's function?) Within `initializedb.py`, import the `db` object from `app.py` and use it to create or drop tables. `initializedb.py` should end up looking something like this:
-
-```
-from todo.app import db
-import os
-
-if bool(os.environ.get('DEBUG', '')):
- db.drop_all()
-db.create_all()
-```
-
-If a `DEBUG` environment variable is set, drop tables and rebuild. Otherwise, just create the tables once and you're good to go.
-
-### Views and URL config
-
-The last bits needed to connect the entire application are the views and routes. In web development, a "view" (in concept) is functionality that runs when a specific access point (a "route") in your application is hit. These access points appear as URLs: paths to functionality in an application that return some data or handle some data that has been provided. The views will be logical structures that handle specific HTTP requests from a given client and return some HTTP response to that client.
-
-In Flask, views appear as functions; for example, see the `hello_world` view above. For simplicity, here it is again:
-
-```
-@app.route('/')
-def hello_world():
- """Print 'Hello, world!' as the response body."""
- return 'Hello, world!'
-```
-
-When the route of `http://domainname/` is accessed, the client receives the response, "Hello, world!"
-
-With Flask, a function is marked as a view when it is decorated by `app.route`. In turn, `app.route` adds to the application's central configuration a map from the specified route to the function that runs when that route is accessed. You can use this to start building out the rest of the API.
-
-Start with a view that handles only `GET` requests, and respond with the JSON representing all the routes that will be accessible and the methods that can be used to access them.
-
-```
-from flask import jsonify
-
-@app.route('/api/v1', methods=["GET"])
-def info_view():
- """List of routes for this API."""
- output = {
- 'info': 'GET /api/v1',
- 'register': 'POST /api/v1/accounts',
- 'single profile detail': 'GET /api/v1/accounts/<username>',
- 'edit profile': 'PUT /api/v1/accounts/<username>',
- 'delete profile': 'DELETE /api/v1/accounts/<username>',
- 'login': 'POST /api/v1/accounts/login',
- 'logout': 'GET /api/v1/accounts/logout',
- "user's tasks": 'GET /api/v1/accounts/<username>/tasks',
- "create task": 'POST /api/v1/accounts/<username>/tasks',
- "task detail": 'GET /api/v1/accounts/<username>/tasks/<id>',
- "task update": 'PUT /api/v1/accounts/<username>/tasks/<id>',
- "delete task": 'DELETE /api/v1/accounts/<username>/tasks/<id>'
- }
- return jsonify(output)
-```
-
-Since you want your view to handle one specific type of HTTP request, use `app.route` to add that restriction. The `methods` keyword argument will take a list of strings as a value, with each string a type of possible HTTP method. In practice, you can use `app.route` to restrict to one or more types of HTTP request or accept any by leaving the `methods` keyword argument alone.
-
-Whatever you intend to return from your view function **must** be a string or an object that Flask turns into a string when constructing a properly formatted HTTP response. The exceptions to this rule are when you're trying to handle redirects and exceptions thrown by your application. What this means for you, the developer, is that you need to be able to encapsulate whatever response you're trying to send back to the client into something that can be interpreted as a string.
-
-A good structure that contains complexity but can still be stringified is a Python dictionary. Therefore, I recommend that, whenever you want to send some data to the client, you choose a Python `dict` with whatever key-value pairs you need to convey information. To turn that dictionary into a properly formatted JSON response, headers and all, pass it as an argument to Flask's `jsonify` function (`from flask import jsonify`).
-
-The view function above takes what is effectively a listing of every route that this API intends to handle and sends it to the client whenever the `http://domainname/api/v1` route is accessed. Note that, on its own, Flask supports routing to exactly matching URIs, so accessing that same route with a trailing `/` would create a 404 error. If you wanted to handle both with the same view function, you'd need stack decorators like so:
-
-```
-@app.route('/api/v1', methods=["GET"])
-@app.route('/api/v1/', methods=["GET"])
-def info_view():
- # blah blah blah more code
-```
-
-An interesting case is that if the defined route had a trailing slash and the client asked for the route without the slash, you wouldn't need to double up on decorators. Flask would redirect the client's request appropriately. It's odd that it doesn't work both ways.
-
-### Flask requests and the DB
-
-At its base, a web framework's job is to handle incoming HTTP requests and return HTTP responses. The previously written view doesn't really have much to do with HTTP requests aside from the URI that was accessed. It doesn't process any data. Let's look at how Flask behaves when data needs handling.
-
-The first thing to know is that Flask doesn't provide a separate `request` object to each view function. It has **one** global request object that every view function can use, and that object is conveniently named `request` and is importable from the Flask package.
-
-The next thing is that Flask's route patterns can have a bit more nuance. One scenario is a hardcoded route that must be matched perfectly to activate a view function. Another scenario is a route pattern that can handle a range of routes, all mapping to one view by allowing a part of that route to be variable. If the route in question has a variable, the corresponding value can be accessed from the same-named variable in the view's parameter list.
-
-```
-@app.route('/a/sample/<variable>/route)
-def some_view(variable):
- # some code blah blah blah
-```
-
-To communicate with the database within a view, you must use the `db` object that was populated toward the top of the script. Its `session` attribute is your connection to the database when you want to make changes. If you just want to query for objects, the objects built from `db.Model` have their own database interaction layer through the `query` attribute.
-
-Finally, any response you want from a view that's more complex than a string must be built deliberately. Previously you built a response using a "jsonified" dictionary, but certain assumptions were made (e.g., 200 status code, status message "OK," Content-Type of "text/plain"). Any special sauce you want in your HTTP response must be added deliberately.
-
-Knowing these facts about working with Flask views allows you to construct a view whose job is to create new `Task` objects. Let's look at the code (below) and address it piece by piece.
-
-```
-from datetime import datetime
-from flask import request, Response
-from flask_sqlalchemy import SQLAlchemy
-import json
-
-from .models import Task, User
-
-app = Flask(__name__)
-app.config['SQLALCHEMY_DATABASE_URI'] = os.environ.get('DATABASE_URL', '')
-db = SQLAlchemy(app)
-
-INCOMING_DATE_FMT = '%d/%m/%Y %H:%M:%S'
-
-@app.route('/api/v1/accounts/<username>/tasks', methods=['POST'])
-def create_task(username):
- """Create a task for one user."""
- user = User.query.filter_by(username=username).first()
- if user:
- task = Task(
- name=request.form['name'],
- note=request.form['note'],
- creation_date=datetime.now(),
- due_date=datetime.strptime(due_date, INCOMING_DATE_FMT) if due_date else None,
- completed=bool(request.form['completed']),
- user_id=user.id,
- )
- db.session.add(task)
- db.session.commit()
- output = {'msg': 'posted'}
- response = Response(
- mimetype="application/json",
- response=json.dumps(output),
- status=201
- )
- return response
-```
-
-Let's start with the `@app.route` decorator. The route is `'/api/v1/accounts/<username>/tasks'`, where `<username>` is a route variable. Put angle brackets around any part of the route you want to be variable, then include that part of the route on the next line in the parameter list **with the same name**. The only parameters that should be in the parameter list should be the variables in your route.
-
-Next comes the query:
-
-```
-user = User.query.filter_by(username=username).first()
-```
-
-To look for one user by username, conceptually you need to look at all the User objects stored in the database and find the users with the username matching the one that was requested. With Flask, you can ask the `User` object directly through the `query` attribute for the instance matching your criteria. This type of query would provide a list of objects (even if it's only one object or none at all), so to get the object you want, just call `first()`.
-
-```
-task = Task(
- name=request.form['name'],
- note=request.form['note'],
- creation_date=datetime.now(),
- due_date=datetime.strptime(due_date, INCOMING_DATE_FMT) if due_date else None,
- completed=bool(request.form['completed']),
- user_id=user.id,
-)
-```
-
-Whenever data is sent to the application, regardless of the HTTP method used, that data is stored on the `form` attribute of the `request` object. The name of the field on the frontend will be the name of the key mapped to that data in the `form` dictionary. It'll always come in the form of a string, so if you want your data to be a specific data type, you'll have to make it explicit by casting it as the appropriate type.
-
-The other thing to note is the assignment of the current user's user ID to the newly instantiated `Task`. This is how that foreign key relationship is maintained.
-
-```
-db.session.add(task)
-db.session.commit()
-```
-
-Creating a new `Task` instance is great, but its construction has no inherent connection to tables in the database. In order to insert a new row into the corresponding SQL table, you must use the `session` attached to the `db` object. The `db.session.add(task)` stages the new `Task` instance to be added to the table, but doesn't add it yet. While it's done only once here, you can add as many things as you want before committing. The `db.session.commit()` takes all the staged changes, or "commits," and applies them to the corresponding tables in the database.
-
-```
-output = {'msg': 'posted'}
-response = Response(
- mimetype="application/json",
- response=json.dumps(output),
- status=201
-)
-```
-
-The response is an actual instance of a `Response` object with its `mimetype`, body, and `status` set deliberately. The goal for this view is to alert the user they created something new. Seeing how this view is supposed to be part of a backend API that sends and receives JSON, the response body must be JSON serializable. A dictionary with a simple string message should suffice. Ensure that it's ready for transmission by calling `json.dumps` on your dictionary, which will turn your Python object into valid JSON. This is used instead of `jsonify`, as `jsonify` constructs an actual response object using its input as the response body. In contrast, `json.dumps` just takes a given Python object and converts it into a valid JSON string if possible.
-
-By default, the status code of any response sent with Flask will be `200`. That will work for most circumstances, where you're not trying to send back a specific redirection-level or error-level message. Since this case explicitly lets the frontend know when a new item has been created, set the status code to be `201`, which corresponds to creating a new thing.
-
-And that's it! That's a basic view for creating a new `Task` object in Flask given the current setup of your To-Do List application. Similar views could be constructed for listing, editing, and deleting tasks, but this example offers an idea of how it could be done.
-
-### The bigger picture
-
-There is much more that goes into an application than one view for creating new things. While I haven't discussed anything about authorization/authentication systems, testing, database migration management, cross-origin resource sharing, etc., the details above should give you more than enough to start digging into building your own Flask applications.
-
-Learn more Python at [PyCon Cleveland 2018][12].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/flask
-
-作者:[Nicholas Hunt-Walker][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/nhuntwalker
-[b]: https://github.com/lujun9972
-[1]: https://www.fullstackpython.com/web-frameworks.html
-[2]: http://flask.pocoo.org/
-[3]: http://www.tornadoweb.org/en/stable/
-[4]: https://trypyramid.com/
-[5]: https://www.djangoproject.com/
-[6]: https://pypi.python.org
-[7]: https://docs.python.org/3/distutils/setupscript.html
-[8]: https://www.python.org/dev/peps/pep-0249/
-[9]: https://www.sqlalchemy.org/
-[10]: https://flask-migrate.readthedocs.io/en/latest/
-[11]: https://flask-alembic.readthedocs.io/en/stable/
-[12]: https://us.pycon.org/2018/
diff --git a/sources/tech/20180403 Open Source Accounting Program GnuCash 3.0 Released With a New CSV Importer Tool Rewritten in C plus plus.md b/sources/tech/20180403 Open Source Accounting Program GnuCash 3.0 Released With a New CSV Importer Tool Rewritten in C plus plus.md
deleted file mode 100644
index b7148b4e56..0000000000
--- a/sources/tech/20180403 Open Source Accounting Program GnuCash 3.0 Released With a New CSV Importer Tool Rewritten in C plus plus.md
+++ /dev/null
@@ -1,70 +0,0 @@
-Open Source Accounting Program GnuCash 3.0 Released With a New CSV Importer Tool Rewritten in C++
-============================================================
-
-The free and open source accounting software, [GnuCash][10] has released its version 3.0\. The software that was first released in 1998 under the GNU General Public License (GPL) is available for GNU/Linux, Solaris, BSD, Microsoft and Mac OSX.
-
-The featured change to be seen in GnuCash 3.0 is that it now uses Gtk3 Toolkit and WebKit2Gtk API. According to John Ralls, _“This change was forced on us by some major Linux distributions dropping support for the WebKit1 API.”_
-
-[Suggested readGNU Khata: Open Source Accounting Software][11]
-
-Some major featured changes include a new user interface to manage transaction files, improvement in the removal of old prices from the price database as well as deleted files can now be removed from the history list.
-
-
-
-
-### New Features and Improvements in GnuCash 3.0
-
-The new features come on two fronts, for the Users and for the Developers.
-
-* Gtk+-3.0 Toolkit and WebKit2Gtk API: GnuCash 3.0 now uses Gtk+-3.0 Toolkit and WebKit2Gtk API. This is because some some major Linux Distros have dropped support for the WebKit1 API. It should also be noted that the WebKit project does not support Microsoft Windows so it can only use WebKit1 API alongside Gtk3.
-
-* Database Management Changes: A new user interface is now available for users to manage transaction files. New editors are now able to remove old or incorrect match data from import maps. There is an improvement in the tool used to remove old prices from the database as well as clear deleted files in the file menu’s history list.
-
-* CSV Importer: A new feature that has been partly rewritten in [C++][1] is now available whereby users can re-import CSV files that were exported from GnuCash. This works alongside a separate CSV price importer.
-
-* Each operating system now has data file directories allocated appropriately by default. For Linux, it is $XDG_CONFIG_HOME/gnucash (or the default $HOME/.config/gnucash). However, it is possible for users to override it with the environment variable, GNC_DOC_PATH which has replaced GNC_DOT_DIR in older versions of GnuCash.
-
-* GnuCash has dropped Guile-1.8 and now supports Guile-2.2
-
-* The appearance of chart reports have been improved and now comes with modern chart colors.
-
-* Transaction Report: Improvements have also been made in transaction reporting with a “Subtotal Summary Grid” now included.
-
-Other changes include an improvement in the dialog box layout which now includes the detected Finance::Quote version; the maximum fraction digit has been increased from 6 to 9 and prices can now go up to 18-digit precision. Checkout the [release note][13] for other improvements and new features for developers.
-
-### Download and installation of GnuCash 3.0
-
-Though GnuCash is available in the software repositories of all major Linux distributions, it will take some time before it gets updated to the latest version 3.0.
-
-Till then, either you wait or you download the [source code][14] and build it yourself.
-
-[Download GnuCash 3.0 Source Code][15]
-
-Have you used GnuCash before for personal accounting or for business? Share your experience with us in the comment section below.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/gnucash-3-release/
-
-作者:[ Derick Sullivan M. Lobga][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/derick/
-[1]:https://itsfoss.com/c-plus-plus-ubuntu/
-[2]:https://itsfoss.com/author/derick/
-[3]:https://itsfoss.com/gnucash-3-release/#comments
-[4]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fgnucash-3-release%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
-[5]:https://twitter.com/share?original_referer=/&text=Open+Source+Accounting+Program+GnuCash+3.0+Released+With+a+New+CSV+Importer+Tool+Rewritten+in+C%2B%2B&url=https://itsfoss.com/gnucash-3-release/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=itsfoss2
-[6]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fgnucash-3-release%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
-[7]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fgnucash-3-release%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
-[8]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/gnucash-3-release/&title=Open+Source+Accounting+Program+GnuCash+3.0+Released+With+a+New+CSV+Importer+Tool+Rewritten+in+C%2B%2B
-[9]:https://www.reddit.com/submit?url=https://itsfoss.com/gnucash-3-release/&title=Open+Source+Accounting+Program+GnuCash+3.0+Released+With+a+New+CSV+Importer+Tool+Rewritten+in+C%2B%2B
-[10]:https://www.gnucash.org/
-[11]:https://itsfoss.com/using-gnu-khata/
-[12]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2018/04/gnucash-3-released-featured.jpeg&url=https://itsfoss.com/gnucash-3-release/?utm_source=newsletter&utm_medium=email&utm_campaign=linux_and_open_source_articles_this_week&utm_term=2018-04-05&is_video=false&description=GnuCash%203.0%20Released
-[13]:https://lists.gnucash.org/pipermail/gnucash-user/2018-April/075866.html
-[14]:https://itsfoss.com/install-software-from-source-code/
-[15]:http://downloads.sourceforge.net/sourceforge/gnucash/gnucash-3.0.tar.bz2
diff --git a/sources/tech/20180404 Bring some JavaScript to your Java enterprise with Vert.x.md b/sources/tech/20180404 Bring some JavaScript to your Java enterprise with Vert.x.md
deleted file mode 100644
index 01ddf2d293..0000000000
--- a/sources/tech/20180404 Bring some JavaScript to your Java enterprise with Vert.x.md
+++ /dev/null
@@ -1,362 +0,0 @@
-Bring some JavaScript to your Java enterprise with Vert.x
-======
-
-If you are a Java programmer, chances are that you've either used JavaScript in the past or will in the near future. Not only is it one of the most popular (and useful) programming languages, understanding some of JavaScript's features could help you build the next uber-popular web application.
-
-### JavaScript on the server
-
-The idea to run JavaScript on the server is not new; in fact, in December 1995, soon after releasing JavaScript for browsers, Netscape introduced an implementation of the language for server-side scripting with Netscape Enterprise Server. Microsoft also adopted it on Internet Information Server as JScript, a reverse-engineered implementation of Netscape's JavaScript.
-
-The seed was planted, but the real boom happened in 2009 when Ryan Dahl introduced Node.js. Node's success was not based on the language but on the runtime itself. It introduced a single process event loop that followed the reactive programming principles and could scale like other platforms couldn't.
-
-### The enterprise and the JVM
-
-Many enterprises have standardized on the Java virtual machine (JVM) as the platform of choice to run their mission-critical business applications, and large investments have been made on the JVM, so it makes sense for those organizations to look for a JVM-based JavaScript runtime.
-
-[Eclipse Vert.x][1] is a polyglot-reactive runtime that runs on the JVM. Using Eclipse Vert.x with JavaScript is not much different from what you would expect from Node.js. There are limitations, such as that the JVM JavaScript engine is not fully compatible with the ES6 standard and not all Node.js package manager (npm) modules can be used with it. But it can still do interesting things.
-
-### Why Eclipse Vert.x?
-
-Having a large investment in the JVM and not wanting to switch to a different runtime might be reason enough for an enterprise to be interested in Eclipse Vert.x. But other benefits are that it can interact with any existing Java application and offers one of the best performances possible on the JVM.
-
-To demonstrate, let's look at how Vert.x works with an existing business rules management system. Imagine for a moment that our fictional enterprise has a mission-critical application running inside JBoss Drools. We now need to create a new web application that can interact with this legacy app.
-
-For the sake of simplicity, let's say our existing rules are a simple Hello World:
-```
-package drools
-
-
-
-//list any import classes here.
-
-
-
-//declare any global variables here
-
-
-
-rule "Greetings"
-
- when
-
- greetingsReferenceObject: Greeting( message == "Hello World!" )
-
- then
-
- greetingsReferenceObject.greet();
-
- end
-
-```
-
-When this engine runs, we get "Drools Hello World!" This is not amazing, but let's imagine this was a really complex process.
-
-### Implementing the Eclipse Vert.x JavaScript project
-
-Like with any other JavaScript project, we'll use the standard npm commands to bootstrap a project. Here's how to bootstrap the project `drools-integration` and prepare it to use Vert.x:
-```
-# create an empty project directory
-
-mkdir drools-integration
-
-cd drools-integration
-
-
-
-# create the initial package.json
-
-npm init -y
-
-
-
-# add a couple of dependencies
-
-npm add vertx-scripts --save-dev
-
-# You should see a tip like:
-
-#Please add the following scripts to your 'package.json':
-
-# "scripts": {
-
-# "postinstall": "vertx-scripts init",
-
-# "test": "vertx-scripts launcher test -t",
-
-# "start": "vertx-scripts launcher run",
-
-# "package": "vertx-scripts package"
-
-# }
-
-
-
-# add
-
-npm add @vertx/web --save-prod
-
-```
-
-We have initialized a bare-bones project so we can start writing the JavaScript code. We'll start by adding a simple HTTP server that exposes a simple API. Every time a request is made to the URL `http://localhost:8080/greetings`, we should see the existing Drools engine's execution result in the terminal.
-
-Start by creating an `index.js` file. If you're using VisualStudio Code, it's wise to add the following two lines to the beginning of your file:
-```
-/// <reference types="@vertx/core/runtime" />
-
-/// @ts-check
-
-```
-
-These lines will enable full support and check the code for syntax errors. They aren't required, but they sure help during the development phase.
-
-Next, add the simple HTTP server. Running on the JVM is not exactly the same as running on Node, and many libraries will not be available. Think of the JVM as a headless browser, and in many cases, code that runs in a browser can run on the JVM. This does not mean we can't have a high-performance HTTP server; in fact, this is exactly what Vert.x does. Let's start writing our server:
-```
-import { Router } from '@vertx/web';
-
-
-
-// route all request based on the request path
-
-const app = Router.router(vertx);
-
-
-
-app.get('/greetings').handler(function (ctx) {
-
- // will invoke our existing drools engine here...
-
-});
-
-
-
-vertx
-
-// create a HTTP server
-
-.createHttpServer()
-
-// on each request pass it to our APP
-
-.requestHandler(function (req) {
-
- app.accept(req);
-
-})
-
-// listen on port 8080
-
-.listen(8080);
-
-```
-
-The code is not complicated and should be self-explanatory, so let's focus on the integration with existing JVM code and libraries in the form of a Drools rule. Since Drools is a Java-based tool, we should build our application with a `java` build tool. Fortunately, because, behind the scenes, `vertx-scripts` delegates the JVM bits to Apache Maven, our work is easy.
-```
-mkdir -p src/main/java/drools
-
-mkdir -p src/main/resources/drools
-
-```
-
-Next, we add the file `src/main/resources/drools/rules.drl` with the following content:
-```
-package drools
-
-
-
-//list any import classes here.
-
-
-
-//declare any global variables here
-
-
-
-rule "Greetings"
-
- when
-
- greetingsReferenceObject: Greeting( message == "Hello World!" )
-
- then
-
- greetingsReferenceObject.greet();
-
- end
-
-```
-
-Then we'll add the file `src/main/java/drools/Greeting.java` with the following content:
-```
-package drools;
-
-
-
-public interface Greeting {
-
-
-
- ();
-
-
-
- void greet();
-
-}Greeting String getMessagegreet
-
-```
-
-Finally, we'll add the helper utility class `src/main/java/drools/DroolsHelper.java`:
-```
-package drools;
-
-
-
-import org.drools.compiler.compiler.*;
-
-import org.drools.core.*;
-
-import java.io.*;
-
-
-
-public final class DroolsHelper {
-
-
-
- /**
-
- * Simple factory to create a Drools WorkingMemory from the given `drl` file.
-
- */
-
- public static WorkingMemory load( drl) throws {
-
- PackageBuilder packageBuilder = new PackageBuilder();
-
- packageBuilder.addPackageFromDrl(new StringReader(drl));
-
- RuleBase ruleBase = RuleBaseFactory.newRuleBase();
-
- ruleBase.addPackage(packageBuilder.getPackage());
-
- return ruleBase.newStatefulSession();
-
- }
-
-
-
- /**
-
- * Simple factory to create a Greeting objects.
-
- */
-
- public static Greeting createGreeting( message, ) {
-
- return new Greeting() {
-
- @Override
-
- public () {
-
- return message;
-
- }
-
-
-
- @Override
-
- public void greet() {
-
- andThen.run();
-
- }
-
- };
-
- }
-
-}DroolsHelperWorkingMemory load String drl IOException , DroolsParserExceptionPackageBuilder packageBuilderPackageBuilderpackageBuilder.drlRuleBase ruleBaseRuleBaseFactory.ruleBase.packageBuilder.ruleBase.Greeting createGreeting String message, Runnable andThenGreeting@Override String getMessagemessage@OverridegreetandThen.
-
-```
-
-We cannot use the file directly; we need to have `drools`. To do this, we add a custom property to our `package.json` named `mvnDependencies` (following the usual pattern):
-```
-{
-
- "mvnDependencies": {
-
- "org.drools:drools-compiler": "6.0.1.Final"
-
- }
-
-}
-
-```
-
-Of course, since we updated the project file, we should update npm:
-```
-npm install
-
-```
-
-We are now entering the final step of this project, where we mix Java and JavaScript. We had a placeholder before, so let's fill in the gaps. We first use the helper Java class to create an engine (you can now see the power of Vert.x, a truly polyglot runtime), then invoke our engine whenever an HTTP request arrives.
-```
-// get a reference from Java to the JavaScript runtime
-
-const DroolsHelper = Java.type('drools.DroolsHelper');
-
-// get a drools engine instance
-
-const engine = DroolsHelper.load(vertx.fileSystem().readFileBlocking("drools/rules.drl"));
-
-
-
-app.get('/greetings').handler(function (ctx) {
-
- // create a greetings message
-
- var greeting = DroolsHelper.createGreeting('Hello World!', function () {
-
- // when a match happens you should see this message
-
- console.log('Greetings from Drools!');
-
- });
-
-
-
- // run the engine
-
- engine.insert(greeting);
-
- engine.fireAllRules();
-
-
-
- // complete the HTTP response
-
- ctx.response().end();
-
-});
-
-```
-
-### Conclusion
-
-As this simple example shows, Vert.x allows you to be truly polyglot. The reason to choose Vert.x is not because it's another JavaScript runtime, rather it's a runtime that allows you to reuse what you already have and quickly build new code using the tools and language that run the internet. We didn't touch on performance here (as it is a topic on its own), but I encourage you to look at independent benchmarks such as [TechEmpower][2] to explore that topic.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/benefits-javascript-vertx
-
-作者:[Paulo Lopes][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/pml0pes
-[1]:http://vertx.io/
-[2]:https://www.techempower.com/benchmarks/#section=data-r15
diff --git a/sources/tech/20180411 5 Best Feed Reader Apps for Linux.md b/sources/tech/20180411 5 Best Feed Reader Apps for Linux.md
deleted file mode 100644
index 8a16fcf696..0000000000
--- a/sources/tech/20180411 5 Best Feed Reader Apps for Linux.md
+++ /dev/null
@@ -1,192 +0,0 @@
-5 Best Feed Reader Apps for Linux
-======
-
-**Brief: Extensively use RSS feeds to stay updated with your favorite websites? Take a look at the best feed reader applications for Linux.**
-
-[RSS][1] feeds were once most widely used, to collect news and articles from different sources at one place. It is often perceived that [RSS usage is in decline][2]. However, there are still people (like me) who believe in opening an application that accumulates all the website’s articles at one place, which they can read later even when they are not connected to the internet.
-
-Feed Readers makes it easier by collecting all the published items on a website for anytime access. You don’t need to open several browser tabs to go to your favorite websites, and bookmarking the one you liked.
-
-In this article, I’ll share some of my favorite feed reader applications for Linux desktop.
-
-### Best Feed Readers for Linux
-
-![Best Feed Readers for Linux][3]
-
-As usual, Linux has multiple choices for feed readers and in this article, we have compiled the 5 good feed readers applications for you. The list is no particular order.
-
-#### 1\. Akregator – Feed Reader
-
-[Akregator][4] is a KDE product which is easy to use and powerful enough to provide latest updates from news sites, blogs and RSS/Atom enabled websites.
-
-It comes with an internal browser for news reading and updated the feed in real time.
-
-##### Features
-
- * You can add a website’s feed using “Ädd Feed” options and define an interval to refresh and update subscribe feeds.
- * It can store and archive contents – the setting of which can be defined on a global level or on individual feeds.
- * Features option to import subscribed feeds from another browser or a past back up.
- * Notifies you of the unread feeds.
-
-
-
-##### How to install Akregator
-
-If you are running KDE desktop, most probably Akregator is already installed on your system. If not, you can use the below command for Debian based systems.
-```
-sudo apt install akregator
-
-```
-
-Once installed, you can directly add a website by clicking on Feed menu and then **Add feed** and giving the website name. This is how It’s FOSS feed looks like when added.
-
-![][5]
-
-#### 2\. QuiteRSS
-
-[QuiteRSS][6] is another free and open source RSS/Atom news feed reader with lots of features. There are additional features like proxy integration, adblocker, integrated browser, and system tray integration. It’s easier to update feeds by setting up a timer to refresh.
-
-##### Features
-
- * Automatic feed updation on either start up or using a timer option.
- * Searching feed URL using website address and categorizing them in new, unread, starred and deleted section.
- * Embedded browser so that you don’t leave the app.
- * Hiding images, if you are only interested in text.
- * Adblocker and better system tray integration.
- * Multiple language support.
-
-
-
-##### How to install QuiteRSS
-
-You can install it from the QuiteRSS ppa.
-```
-sudo add-apt-repository ppa:quiterss/quiterss
-sudo apt-get update
-sudo apt-get install quiterss
-
-```
-
-![][7]
-
-#### 3\. Liferea
-
-Linux Feed Reader aka [Liferea][8] is probably the most used feed aggregator on Linux platform. It is fast and easy to use and supports RSS / Atom feeds. It has support for podcasts and there is an option for adding custom scripts which can run depending upon your actions.
-
-There’s a browser integration while you still have the options to open an item in a separate browser.
-
-##### Features
-
- * Liferea can download and save feeds from your favorite website to read offline.
- * It can be synced with other RSS feed readers, making a transition easier.
- * Support for Podcasts.
- * Support for search folders, which allows users to save searches.
-
-
-
-##### How to install Liferea
-
-Liferea is available in the official repository for almost all the distributions. Ubuntu-based users can install it by using below command:
-```
-sudo apt-get install liferea
-
-```
-
-![][9]
-
-#### 4\. FeedReader
-
-[FeedReader][10] is a simple and elegant RSS desktop client for your web-based RSS accounts. It can work with Feedbin, Feedly, FreshRSS, Local RSS among others and has options to send it over mail, tweet about it etc.
-
-##### Features
-
- * There are multiple themes for formatting.
- * You can customize it according to your preferences.
- * Supports notifications and podcasts.
- * Fast searches and various filters are present, along with several keyboard shortcuts to make your reading experience better.
-
-
-
-##### How to install FeedReader
-
-FeedReader is available as a Flatpak for almost every Linux distribution.
-```
-flatpak install http://feedreader.xarbit.net/feedreader-repo/feedreader.flatpakref
-
-```
-
-It is also available in Fedora repository:
-```
-sudo dnf install feedreader
-
-```
-
-And, in Arch User Repository.
-```
-yaourt -S feedreader
-
-```
-
-![][11]
-
-#### 5\. Newsbeuter: RSS feed in terminal
-
-[Newsbeuter][12] is an open source feed reader for terminal lovers. There is an option to add and delete an RSS feed and to get the content on the terminal itself. Newsbeuter is loved by people who spend more time on the terminal and want their feed to be clutter free from images and ads.
-
-##### How to install Newsbeuter
-```
-sudo apt-get install newsbeuter
-
-```
-
-Once installation completes, you can launch it by using below command
-```
-newsbeuter
-
-```
-
-To add a feed in your list, edit the urls file and add the RSS feed.
-```
-vi ~/.newsbeuter/urls
->> http://feeds.feedburner.com/itsfoss
-
-```
-
-To read the feeds, launch newsbeuter and it will display all the posts.
-
-![][13]
-
-You can get the useful commands at the bottom of the terminal which can help you in using newsbeuter. You can read this [manual page][14] for detailed information.
-
-#### Final Words
-
-To me, feed readers are still relevant, especially when you follow multiple websites and blogs. The offline access to your favorite website and blog’s content with options to archive and search is the biggest advantage of using a feed reader.
-
-Do you use a feed reader on your Linux system? If yes, tell us your favorite one in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/feed-reader-apps-linux/
-
-作者:[Ambarish Kumar][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/ambarish/
-[1]:https://en.wikipedia.org/wiki/RSS
-[2]:http://andrewchen.co/the-death-of-rss-in-a-single-graph/
-[3]:https://itsfoss.com/wp-content/uploads/2018/04/best-feed-reader-apps-linux.jpg
-[4]:https://www.kde.org/applications/internet/akregator/
-[5]:https://itsfoss.com/wp-content/uploads/2018/02/Akregator2-800x500.jpg
-[6]:https://quiterss.org/
-[7]:https://itsfoss.com/wp-content/uploads/2018/02/QuiteRSS2.jpg
-[8]:https://itsfoss.com/liferea-rss-client/
-[9]:https://itsfoss.com/wp-content/uploads/2018/02/Liferea-800x525.png
-[10]:https://jangernert.github.io/FeedReader/
-[11]:https://itsfoss.com/wp-content/uploads/2018/02/FeedReader2-800x465.jpg
-[12]:https://newsbeuter.org/
-[13]:https://itsfoss.com/wp-content/uploads/2018/02/newsbeuter.png
-[14]:http://manpages.ubuntu.com/manpages/bionic/man1/newsbeuter.1.html
diff --git a/sources/tech/20180411 Replicate your custom Linux settings with DistroTweaks.md b/sources/tech/20180411 Replicate your custom Linux settings with DistroTweaks.md
deleted file mode 100644
index b091ced741..0000000000
--- a/sources/tech/20180411 Replicate your custom Linux settings with DistroTweaks.md
+++ /dev/null
@@ -1,108 +0,0 @@
-Replicate your custom Linux settings with DistroTweaks
-======
-
-
-
-Currently, there are more than 300 different Linux operating system distributions available. Each distro serves a slightly different purpose with slightly different bundles of programs for different communities of users.
-
-Even though there are hundreds of different versions of Linux, it hasn't been very easy for individual customizers to share them with the community. [DistroTweaks][1], a process that allows users to customize and share Linux, is a better option than what's come before.
-
-A DistroTweak is a process that allows anyone to quickly and easily add dozens of customizations and programs to an existing Linux distro with just the click of a button. It replaces the tedious process of making changes and manually (and individually) adding dozens of programs. The term "tweak" is a nod to what computer enthusiasts call a slight modification of an operating system or application. A tweak generally doesn't change the core of the operating system or program; it merely adds to it.
-
-### Why DistroTweaks?
-
-In the past, there were two options for widely sharing a custom distribution. The first was to clone the distribution with a cloning tool after customizing your settings and programs, but cloning is a complex process. Often, folks didn't find out their clone didn't work until they tried to install it and got the black screen of death.
-
-The other option was to make your own distribution. You would fork an existing distribution, delete programs you didn't like, and add the programs you wanted. You also had to create new graphics to replace the ones in the parent distribution, as well as build a website to host the download page and a community forum for answering questions. This is very time-consuming.
-
-DistroTweaks offers a third option for sharing Linux that is more reliable than cloning and less work than starting your own distribution. It leverages the [Aptik][2] tool that simplifies re-installing software after a Linux distro re-installation.
-
-### How DistroTweaks solves problems
-
-I teach courses in writing books and creating complex, interactive websites, and I want my students to have access to the same custom computer system and programs I use. This is an issue because I have made several dozen minor modifications to the Linux Mint operating system, added a couple of dozen programs to the default Mint programs, and made more than 50 modifications to LibreOffice (one of Mint's default programs).
-
-Previously, my students had to follow dozens of steps in my books and websites to get a computer that looked exactly like mine. While this is a good learning exercise that teaches students why I made these modifications, this "learning by doing" process is a long ordeal that may be too intimidating or time-consuming for a lot of students.
-
-To make this faster and easier, I developed a simple process that exactly copies all my custom settings and programs into a special DistroTweaks file. My students can install Linux Mint in the normal way, add the DistroTweaks file, and, in a matter of minutes, have an exact copy of my computer with all my customized Mint settings and programs (including the LibreOffice customizations). Because it doesn't alter Linux Mint itself, the result is highly stable. The DistroTweaks process even works inside a virtual machine, so it can be tested before installing it on a computer. In addition, the process is so easy that anyone can create their own custom DistroTweak and share it with any group.
-
-### How to create a DistroTweak
-
- 1. To avoid accidentally sharing your personal settings, start with a completely clean computer.
- 2. Download and install your favorite Linux distribution (we have only tested DistroTweaks with Ubuntu-based Linux, but Debian-based distros may also work).
- 3. Create a list of all the tweaks you will make to your distro settings, the programs you will add, and the customizations you will make. For example, we customized LibreOffice Writer menu and added several extensions to it.
- 4. Complete all the steps on your list of tweaks on your clean computer. Practice installing everything, just to make sure everything works and you are aware of all dependencies ahead of time. Be as organized as possible.
- 5. Next, use a personal package archive ([PPA][3]) software repository to install the Aptik tool. To install Aptik, open a terminal and enter the following commands:
-
-
-```
-sudo apt-add-repository -y ppa:teejee2008/ppa
-
-sudo apt-get update
-
-sudo apt-get install aptik
-
-```
-
- 1. Start Aptik from the Linux menu and enter your password.
- 2. Create a backup folder in your computer's **Filesystem** folder: First, right-click on the screen and select **Open as root**. Then, right-click again and select **Add a new folder**. Name the folder **Backup**.
- 3. In Aptik, click **Select** , which opens in the **Filesystem** folder, and click on your new **Backup** folder.
- 4. Click on **One-click settings** to review your default settings (which you can change if you want). Click OK to close this window.
- 5. Click on the **Backup** icon to the right of **Installed software**. This will bring up a (long) list of programs that will be backed up by clicking on **Downloaded packages**. You can uncheck any programs you don't want copied to your new installation.
- 6. It's finally time to use Aptik to copy all your programs and system settings into your new **Backup** folder. Click on the **One-click backup** button. It will take about 10 minutes to copy all your programs, software sources, and settings to your **Backup** folder; when it's finished, you'll see the notification **Backup completed**. Click **Close**.
- 7. Copy everything in the **Backup** folder to an external USB drive or a cloud storage.
- 8. Change the name of your backup archive to whatever you want to call your special DistroTweak.
-
-
-
-### How to add a DistroTweak to your computer
-
- 1. Back up your documents and other files by coping them to an external USB.
- 2. Use a [live USB][4] containing your favorite Linux distro to reformat your computer and install the operating system. Just plug in the USB live stick, restart your computer, and go through the normal installation process.
- 3. Remove the live USB stick and install Aptik on your computer by entering the following commands in your terminal:
-
-
-```
-sudo apt-add-repository -y ppa:teejee2008/ppa
-
-sudo apt-get update
-
-sudo apt-get install aptik
-
-```
-
- 1. Copy and paste your DistroTweaks folder from your USB or cloud storage to the filesystem folder on your computer with the new distro installed.
- 2. Point Aptik to your DistroTweaks folder.
- 3. Enter your admin password, then click on **One-click restore**. Watch as dozens of programs are installed in minutes.
- 4. Recopy your documents and other files from your USB drive to your computer.
-
-
-
-### DistroTweaks limitations
-
- * DistroTweaks has only been tested on Ubuntu-based distributions.
- * After installing dozens of programs through DistroTweaks, several may not work correctly (even if they're listed in the menu). If this happens, you will have to uninstall and reinstall them.
- * For DistroTweaks to work, the target computer must use the same desktop environment used to create the DistroTweak. For example, a Mint Cinnamon DistroTweak should only be used on a Mint Cinnamon installation.
-
-
-
-While DistroTweaks is a new option for existing distributions, it offers even more benefits to people who have wanted to create and share their own custom set of programs but were impeded by the difficulties of starting and maintaining their own distributions. Whether you are a teacher (like me) or a corporate executive of a Fortune 500 company, DistroTweaks makes creating and sharing your own version of Linux a lot easier.
-
-David will be speaking at LinuxFest NW this year. See [program highlights or register][5] to attend.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/distrotweaks
-
-作者:[David Spring][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/davidspring
-[1]:https://distrotweaks.org/
-[2]:https://github.com/teejee2008/aptik
-[3]:https://en.wikipedia.org/wiki/Ubuntu_(operating_system)#Package_Archives
-[4]:https://en.wikipedia.org/wiki/Live_USB
-[5]:https://www.linuxfestnorthwest.org/conferences/lfnw18
diff --git a/sources/tech/20180412 Getting started with Jenkins Pipelines.md b/sources/tech/20180412 Getting started with Jenkins Pipelines.md
deleted file mode 100644
index 1cda5ee0c2..0000000000
--- a/sources/tech/20180412 Getting started with Jenkins Pipelines.md
+++ /dev/null
@@ -1,352 +0,0 @@
-Getting started with Jenkins Pipelines
-======
-
-
-Jenkins is a well-known open source continuous integration and continuous development automation tool. It has an excellent supporting community, and hundreds of plugins and developers have been using it for years.
-
-This article will provide a brief guide on how to get started with Pipelines and multibranch pipelines.
-
-Why pipelines?
-
- * Developers can automate the integration, testing, and deployment of their code, going from source code to product consumers many times using one tool.
- * Pipelines "as code" known as Jenkinsfiles can be saved in any source control system. In previous Jenkins versions, jobs were only configured using the UI. With Jenkinfiles, pipelines are more maintainable and portable.
- * Multi-branch pipelines integrate with Git so that different branches, features, and releases can have independent pipelines enabling each developer to customize their development/deployment process.
- * Non-technical members of a team can trigger and customize builds using parameters, analyze test reports, receive email alerts and have a better understanding of the build and deployment process through the pipeline stage view (improved in latest versions with the Blue Ocean UI).
- * Jenkins can also be [installed using Docker][1] and pipelines can interact with [Docker agents][2].
-
-
-
-### Requirements:
-
- * [Jenkins 2.89.2][3] (WAR) with Java 8 is the version used in this how-to
- * Plugins used (To install: `Manage Jenkins → Manage Plugins →Available`):
- * Pipeline: [declarative][4]
- * [Blue Ocean][5]
- * [Cucumber reports][6]
-
-
-
-## Getting started with Jenkins Pipelines
-
-If you have not used Jenkins Pipelines before, I recommend [reading the documentation][7] before getting started here, as it includes a complete description and introduction to the technology as well as the benefits of using it.
-
-This is the Jenkinsfile I used (you can also access this [code][8] on GitHub):
-```
-pipeline {
-
- agent any
-
- stages {
-
-stage('testing pipeline'){
-
- steps{
-
- echo 'test1'
-
- sh 'mkdir from-jenkins'
-
- sh 'touch from-jenkins/test.txt'
-
- }
-
- }
-
-}
-
-}
-
-```
-
-1\. Click on **New Item**.
-
-2\. Name the project, select **Pipeline** , and click **OK**.
-
-3\. The configuration page displays once the project is created. In the **Definition** segment, you must decide to either obtain the Jenkinsfile from source control management (SCM) or create the Pipeline script in Jenkins. Hosting the Jenkinsfile in SCM is recommended so that it is portable and maintainable.
-
-The SCM I chose was Git with simple user and pass credentials (SSH can also be used). By default, Jenkins will look for a Jenkinsfile in that repository unless it's specified otherwise in the **Script Path** directory.
-
-4\. Go back to the job page after saving the Jenkinsfile and select **Build Now**. Jenkins will trigger the job. Its first stage is to pull down the Jenkinsfile from SCM. It reports any changes from the previous run and executes it.
-
-Clicking on **Stage View** provides console information:
-
-### Using Blue Ocean
-
-Jenkins' [Blue Ocean][9] provides a better UI for Pipelines. It is accessible from the job's main page (see image above).
-
-This simple Pipeline has one stage (in addition to the default stage): **Checkout SCM** , which pulls the Jenkinsfile in three steps. The first step echoes a message, the second creates a directory named `from-``jenkins` in the Jenkins workspace, and the third puts a file called `test.txt` inside that directory. The path for the Jenkins workspace is `$user/.jenkins/workspace`, located in the machine where the job was executed. In this example, the job is executed in any available node. If there is no other node connected then it is executed in the machine where Jenkins is installed—check Manage Jenkins > Manage nodes for information about the nodes.
-
-Another way to create a Pipeline is with Blue Ocean's plugin. (The following screenshots show the same repo.)
-
-1\. Click **Open Blue Ocean**.
-
-2\. Click **New Pipeline**.
-
-3\. Select **SCM** and enter the repository URL; an SSH key will be provided. This must be added to your Git SSH keys (in `Settings →SSH and GPG keys`).
-
-4\. Jenkins will automatically detect the branch and the Jenkinsfile, if present. It will also trigger the job.
-
-### Pipeline development:
-
-The following Jenkinsfile triggers Cucumber tests from a GitHub repository, creates and archives a JAR, sends emails, and exposes different ways the job can execute with variables, parallel stages, etc. The Java project used in this demo was forked from [cucumber/cucumber-jvm][10] to [mluyo3414/cucumber-jvm][11]. You can also access [the][12][Jenkinsfile][12] on GitHub. Since the Jenkinsfile is not in the repository's top directory, the configuration has to be changed to another path:
-```
-pipeline {
-
- // 1. runs in any agent, otherwise specify a slave node
-
- agent any
-
- parameters {
-
-// 2.variables for the parametrized execution of the test: Text and options
-
- choice(choices: 'yes\nno', description: 'Are you sure you want to execute this test?', name: 'run_test_only')
-
- choice(choices: 'yes\nno', description: 'Archived war?', name: 'archive_war')
-
- string(defaultValue: "your.email@gmail.com", description: 'email for notifications', name: 'notification_email')
-
- }
-
-//3. Environment variables
-
-environment {
-
-firstEnvVar= 'FIRST_VAR'
-
-secondEnvVar= 'SECOND_VAR'
-
-thirdEnvVar= 'THIRD_VAR'
-
-}
-
-//4. Stages
-
- stages {
-
- stage('Test'){
-
- //conditional for parameter
-
- when {
-
- environment name: 'run_test_only', value: 'yes'
-
- }
-
- steps{
-
- sh 'cd examples/java-calculator && mvn clean integration-test'
-
- }
-
- }
-
-//5. demo parallel stage with script
-
- stage ('Run demo parallel stages') {
-
-steps {
-
- parallel(
-
- "Parallel stage #1":
-
- {
-
- //running a script instead of DSL. In this case to run an if/else
-
- script{
-
- if (env.run_test_only =='yes')
-
- {
-
- echo env.firstEnvVar
-
- }
-
- else
-
- {
-
- echo env.secondEnvVar
-
- }
-
- }
-
- },
-
- "Parallel stage #2":{
-
- echo "${thirdEnvVar}"
-
- }
-
- )
-
- }
-
- }
-
- }
-
-//6. post actions for success or failure of job. Commented out in the following code: Example on how to add a node where a stage is specifically executed. Also, PublishHTML is also a good plugin to expose Cucumber reports but we are using a plugin using Json.
-
-
-
-post {
-
- success {
-
- //node('node1'){
-
-echo "Test succeeded"
-
- script {
-
- // configured from using gmail smtp Manage Jenkins-> Configure System -> Email Notification
-
- // SMTP server: smtp.gmail.com
-
- // Advanced: Gmail user and pass, use SSL and SMTP Port 465
-
- // Capitalized variables are Jenkins variables – see https://wiki.jenkins.io/display/JENKINS/Building+a+software+project
-
- mail(bcc: '',
-
- body: "Run ${JOB_NAME}-#${BUILD_NUMBER} succeeded. To get more details, visit the build results page: ${BUILD_URL}.",
-
- cc: '',
-
- from: 'jenkins-admin@gmail.com',
-
- replyTo: '',
-
- subject: "${JOB_NAME} ${BUILD_NUMBER} succeeded",
-
- to: env.notification_email)
-
- if (env.archive_war =='yes')
-
- {
-
- // ArchiveArtifact plugin
-
- archiveArtifacts '**/java-calculator-*-SNAPSHOT.jar'
-
- }
-
- // Cucumber report plugin
-
- cucumber fileIncludePattern: '**/java-calculator/target/cucumber-report.json', sortingMethod: 'ALPHABETICAL'
-
- //publishHTML([allowMissing: false, alwaysLinkToLastBuild: false, keepAll: true, reportDir: '/home/reports', reportFiles: 'reports.html', reportName: 'Performance Test Report', reportTitles: ''])
-
- }
-
- //}
-
- }
-
- failure {
-
- echo "Test failed"
-
- mail(bcc: '',
-
- body: "Run ${JOB_NAME}-#${BUILD_NUMBER} succeeded. To get more details, visit the build results page: ${BUILD_URL}.",
-
- cc: '',
-
- from: 'jenkins-admin@gmail.com',
-
- replyTo: '',
-
- subject: "${JOB_NAME} ${BUILD_NUMBER} failed",
-
- to: env.notification_email)
-
- cucumber fileIncludePattern: '**/java-calculator/target/cucumber-report.json', sortingMethod: 'ALPHABETICAL'
-
-//publishHTML([allowMissing: true, alwaysLinkToLastBuild: false, keepAll: true, reportDir: '/home/tester/reports', reportFiles: 'reports.html', reportName: 'Performance Test Report', reportTitles: ''])
-
- }
-
- }
-
-}
-
-```
-
-Always check **Pipeline Syntax** to see how to use the different plugins in the Jenkinsfile.
-
-An email notification indicates the build was successful:
-
-Archived JAR from a successful build:
-
-You can access **Cucumber reports** on the same page.
-
-## How to create a multibranch pipeline
-
-If your project already has a Jenkinsfile, follow the [**Multibranch Pipeline** project][13] instructions in Jenkins' docs. It uses Git and assumes credentials are already configured. This is how the configuration looks in the traditional view:
-
-### If this is your first time creating a Pipeline, follow these steps:
-
-1\. Select **Open Blue Ocean**.
-
-2\. Select **New Pipeline**.
-
-3\. Select **Git** and insert the Git repository address. This repository does not currently have a Jenkinsfile. An SSH key will be generated; it will be used in the next step.
-
-4\. Go to GitHub. Click on the profile avatar in the top-right corner and select Settings. Then select **SSH and GPG Keys** from the left-hand menu and insert the SSH key Jenkins provides.
-
-5\. Go back to Jenkins and click **Create Pipeline**. If the project does not contain a Jenkinsfile, Jenkins will prompt you to create a new one.
-
-6\. Once you click **Create Pipeline** , an interactive Pipeline diagram will prompt you to add stages by clicking **+**. You can add parallel or sequential stages and multiple steps to each stage. A list offers different options for the steps.
-
-7\. The following diagram shows three stages (Stage 1, Stage 2a, and Stage 2b) with simple print messages indicating steps. You can also add environment variables and specify in which agent the Jenkinsfile will be executed.
-
-Click **Save** , then commit the new Jenkinsfile by clicking **Save & Run**.
-
-You can also add a new branch.
-
-8\. The job will execute.
-
-If a new branch was added, you can see it in GitHub.
-
-9\. If another branch with a Jenkinsfile is created, you can discover it by clicking **Scan Multibranch Pipeline Now**. In this case, a new branch called `new-feature-2` is created in GitHub from Master (only branches with Jenkinsfiles are displayed in Jenkins).
-
-After scanning, the new branch appears in Jenkins.
-
-This new feature was created using GitHub directly; Jenkins will detect new branches when it performs a scan. If you don't want the newly discovered Pipelines to be executed when discovered, change the settings by clicking **Configure** on the job's Multibranch Pipeline main page and adding the property **Suppress automatic SCM triggering**. This way, Jenkins will discover new Pipelines but they will have to be manually triggered.
-
-This article was originally published on the [ITNext channel][14] on Medium and is reprinted with permission.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/jenkins-pipelines-with-cucumber
-
-作者:[Miguel Suarez][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mluyo3414
-[1]:https://jenkins.io/doc/book/installing/#downloading-and-running-jenkins-in-docker
-[2]:https://jenkins.io/doc/book/pipeline/docker/
-[3]:https://jenkins.io/doc/pipeline/tour/getting-started/
-[4]:https://plugins.jenkins.io/pipeline-model-definition
-[5]:https://plugins.jenkins.io/blueocean
-[6]:https://plugins.jenkins.io/cucumber-reports
-[7]:https://jenkins.io/doc/book/pipeline/
-[8]:https://github.com/mluyo3414/jenkins-test
-[9]:https://jenkins.io/projects/blueocean/
-[10]:https://github.com/cucumber/cucumber-jvm
-[11]:https://github.com/mluyo3414/cucumber-jvm
-[12]:https://github.com/mluyo3414/cucumber-jvm/blob/master/examples/java-calculator/Jenkinsfile
-[13]:https://jenkins.io/doc/book/pipeline/multibranch/#creating-a-multibranch-pipeline
-[14]:https://itnext.io/jenkins-pipelines-889420409510
diff --git a/sources/tech/20180413 Redcore Linux Makes Gentoo Easy.md b/sources/tech/20180413 Redcore Linux Makes Gentoo Easy.md
deleted file mode 100644
index 259811f306..0000000000
--- a/sources/tech/20180413 Redcore Linux Makes Gentoo Easy.md
+++ /dev/null
@@ -1,89 +0,0 @@
-Redcore Linux Makes Gentoo Easy
-======
-
-
-Raise your hand if you’ve always wanted to try [Gentoo Linux][1] but never did because you didn’t have either the time or the skills to invest in such a challenging installation. I’m sure there are plenty of Linux users out there not willing to admit this, but it’s okay, really; installing Gentoo is a challenge, and it can be very time consuming. In the end, however, installing Gentoo will result in a very personalized Linux desktop that offers the fulfillment of saying, “I did it!”
-
-So, what’s a curious Linux user to do, when they want to experience this elite distribution? One option is to turn to the likes of [Redcore Linux][2]. Redcore does what many have tried (and few have succeeded in doing) in bringing Gentoo to the masses. In fact, [Sabayon][3] Linux is the only other distro I can think of that’s truly succeeded in bringing a level of simplicity to Gentoo Linux that many users can enjoy. And while Sabayon is still very much in active development, it’s good to know there are others attempting what might have once been deemed impossible:
-
-### Making Gentoo Linux easy
-
-Instead of building your desktop piece by piece, system by system, Redcore (like Sabayon) brings a much more standard installation to the process. Unlike Sabayon (which gives you the options of a GNOME, KDE, Xfce, Mate, or Fluxbox editions), Redcore offers a version that ships with two possible desktop options: The [LXQt][4] desktop and [Openbox][5]. The LXQt is a lightweight desktop that offers plenty of configuration options and performs quite well on older hardware, whereas Openbox is a very minimalist take on the desktop. In fact, once you log into the Openbox desktop, you’ll be left wondering if something had gone wrong (until you right-click on the desktop to see the solitary menu).
-
-If you’re looking for a more modern take on the desktop, neither LXQt or Openbox will be what you’re looking for. However, there is no doubt the combination of a rolling-release Gentoo-lite system that uses the LXQt and Openbox desktops will perform quite well.
-
-The official description of the distribution is:
-
-Redcore Linux is a distribution based on Gentoo Linux (stable + some unstable) and a continuation of, now defunct, Kogaion Linux. Kogaion Linux itself was a distribution based initially on Sabayon Linux, and later on Gentoo Linux and it was developed by RogentOS Development Group since 2011. Ghiunhan Mamut (aka V3n3RiX) himself joined RogentOS Development Group in January 2014.
-
-If you know much about how Gentoo is structured, Redcore Linux is built from Gentoo Linux stage3. Stage3 a tarball containing a populated directory structure from a basic Gentoo system that contains no kernel, only binaries and libraries essential for bootstrapping. On top of stage3, the Redcore developers add a kernel, a bootloader and a few other items (such as dbus and Dracut), as well as configure the init system (OpenRC).
-
-With all of that out of the way, let’s see what the installation of Redcore is like and how well it can serve as your desktop distribution.
-
-### Installation
-
-As you’ve probably expected, the installation of Redcore is incredibly simple. Download the live ISO image, burn it to a CD/DVD or USB, insert the installation media, boot the device, log into the desktop (live username/password is redcore/redcore) and click the installer icon on the desktop. The installer used by Redcore is [Calamares][6], which means the installation is incredibly easy and, in an instant, familiar (Figure 1).
-
-Everything with Calamares is automatic. In other words, you won’t have to manually partition your drive or select individual packages for installation. You should be able to start and finish a Redcore installation in five or ten minutes. Once the installation completes, reboot and log in with the username/password you created during installation.
-
-### Usage
-
-Upon login, you can select between LXQt and Openbox. I highly recommend against using Openbox. Why? Because nothing will open from the menu. I was actually quite surprised to find the Openbox desktop fairly unusable upon installation. With that in mind, select the LXQt option and be done with it.
-
-Upon logging in, you’ll be greeted by a fairly straight-forward desktop. Click on the menu button (bottom right of screen) and search through the menu hierarchy to launch an application. The list of installed applications is fairly straightforward, with the exception of finding [Steam][7] and [Wine][8] pre-installed. You might be surprised, considering Redcore is a rolling distribution, that many of the user-crucial applications are out of date. Take, for instance, LibreOffice. Redcore ships with 5.4.5.1. The Still release of LibreOffice is currently at 5.4.6. Opening the Sisyphus GUI (front end for the Sisyphus package manager) and you’ll see that LibreOffice is up to date (according to the package manager) at 5.4.5.1 (Figure 2).
-
-
-![ Sisyphus][10]
-
-Figure 2: The Sisyphus GUI package manager.
-
-[Used with permission][11]
-
-If you do see packages available for upgrade (which you might), click the upgrade button and allow the upgrade to complete. Considering this is a rolling release, you should be up to date. However, you can search through Sisyphus, locate new packages to install, and install them with ease. Installation with the Sisyphus front end is quite user-friendly.
-
-### That default browser
-
-You won’t find a copy of Firefox or Chrome installed on Redcore. Instead, QupZilla serves as the default browser. When you do open the default browser (or if you click on the Ask for help icon on the desktop) you will find the preconfigured home page to be the [recorelinux freenode.net page][12]. Instead of being greeted by a hand-crafted application, geared toward helping new users, one must choose a nickname and venture into the world of IRC. Although one might be inclined to think that does new users a disservice, one must consider the type of “new” user Redcore will be serving: These aren’t going to be new-to-Linux users. Instead, Redcore knows its users and knows many of them are already familiar with IRC. That means users don’t have to turn to Google to search for answers. Instead, they can chat with other users and even developers to solve their problems. This, of course, does depend on those users (who might be capable of answering questions) actually be logged into the redcorelinux channel on freenode.
-
-### That default theme
-
-I’m going to make a confession here. I’ve never understood the whole “dark theme” preference. I do understand that taste is a subjective issue, but my taste tends to lean toward the lighter themes. That’s not a problem. To change the theme for the LXQt desktop, open the menu, type desktop in the search field, and then select Customize Look and Feel. In the resulting window (Figure 3), you can select from the short list of theme options.
-
-
-![desktop][14]
-
-Figure 3: Changing the desktop theme in Redcore.
-
-[Used with permission][11]
-
-### That target audience
-
-So who is Redcore’s best target audience? If you’re looking to gain the benefit of Gentoo Linux, without having to go through the exhausting “get up to speed” and installation process required to compile one of the most challenging operating systems on the planet, Redcore might be what you’re looking for. It’s a very simplified means of enjoying a Gentoo-less take on Gentoo Linux. Of course, if you’re looking to enjoy Gentoo with a more modern desktop, I would highly recommend [Sabayon][3]. However, the LXQt lightweight desktop will certainly give life to old hardware. And Recore does this with a bit of Gentoo style.
-
-Learn more about Linux through the free ["Introduction to Linux" ][15] course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/4/redcore-linux-makes-gentoo-easy
-
-作者:[JACK WALLEN][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.gentoo.org/
-[2]:https://redcorelinux.org/
-[3]:http://www.sabayon.org/
-[4]:https://lxqt.org/
-[5]:http://openbox.org/wiki/Main_Page
-[6]:https://calamares.io/about/
-[7]:http://store.steampowered.com/
-[8]:https://www.winehq.org/
-[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/redcore_2.jpg?itok=ubNC-htJ ( Sisyphus)
-[11]:https://www.linux.com/licenses/category/used-permission
-[12]:http://webchat.freenode.net/?channels=redcorelinux
-[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/redcore_3.jpg?itok=FKg67lrS (desktop)
-[15]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180419 Writing Advanced Web Applications with Go.md b/sources/tech/20180419 Writing Advanced Web Applications with Go.md
deleted file mode 100644
index ecc696b470..0000000000
--- a/sources/tech/20180419 Writing Advanced Web Applications with Go.md
+++ /dev/null
@@ -1,695 +0,0 @@
-# Writing Advanced Web Applications with Go
-
-Web development in many programming environments often requires subscribing to some full framework ethos. With [Ruby][6], it’s usually [Rails][7] but could be [Sinatra][8] or something else. With [Python][9], it’s often [Django][10] or [Flask][11]. With [Go][12], it’s…
-
-If you spend some time in Go communities like the [Go mailing list][13] or the [Go subreddit][14], you’ll find Go newcomers frequently wondering what web framework is best to use. [There][15] [are][16] [quite][17] [a][18] [few][19] [Go][20] [frameworks][21]([and][22] [then][23] [some][24]), so which one is best seems like a reasonable question. Without fail, though, the strong recommendation of the Go community is to [avoid web frameworks entirely][25] and just stick with the standard library as long as possible. Here’s [an example from the Go mailing list][26] and here’s [one from the subreddit][27].
-
-It’s not bad advice! The Go standard library is very rich and flexible, much more so than many other languages, and designing a web application in Go with just the standard library is definitely a good choice.
-
-Even when these Go frameworks call themselves minimalistic, they can’t seem to help themselves avoid using a different request handler interface than the default standard library [http.Handler][28], and I think this is the biggest source of angst about why frameworks should be avoided. If everyone standardizes on [http.Handler][29], then dang, all sorts of things would be interoperable!
-
-Before Go 1.7, it made some sense to give in and use a different interface for handling HTTP requests. But now that [http.Request][30] has the [Context][31] and [WithContext][32] methods, there truly isn’t a good reason any longer.
-
-I’ve done a fair share of web development in Go and I’m here to share with you both some standard library development patterns I’ve learned and some code I’ve found myself frequently needing. The code I’m sharing is not for use instead of the standard library, but to augment it.
-
-Overall, if this blog post feels like it’s predominantly plugging various little standalone libraries from my[Webhelp non-framework][33], that’s because it is. It’s okay, they’re little standalone libraries. Only use the ones you want!
-
-If you’re new to Go web development, I suggest reading the Go documentation’s [Writing Web Applications][34]article first.
-
-### Middleware
-
-A frequent design pattern for server-side web development is the concept of _middleware_ , where some portion of the request handler wraps some other portion of the request handler and does some preprocessing or routing or something. This is a big component of how [Express][35] is organized on [Node][36], and how Express middleware and [Negroni][37] middleware works is almost line-for-line identical in design.
-
-Good use cases for middleware are things such as:
-
-* making sure a user is logged in, redirecting if not,
-
-* making sure the request came over HTTPS,
-
-* making sure a session is set up and loaded from a session database,
-
-* making sure we logged information before and after the request was handled,
-
-* making sure the request was routed to the right handler,
-
-* and so on.
-
-Composing your web app as essentially a chain of middleware handlers is a very powerful and flexible approach. It allows you to avoid a lot of [cross-cutting concerns][38] and have your code factored in very elegant and easy-to-maintain ways. By wrapping a set of handlers with middleware that ensures a user is logged in prior to actually attempting to handle the request, the individual handlers no longer need mistake-prone copy-and-pasted code to ensure the same thing.
-
-So, middleware is good. However, if Negroni or other frameworks are any indication, you’d think the standard library’s `http.Handler` isn’t up to the challenge. Negroni adds its own `negroni.Handler` just for the sake of making middleware easier. There’s no reason for this.
-
-Here is a full middleware implementation for ensuring a user is logged in, assuming a `GetUser(*http.Request)`function but otherwise just using the standard library:
-
-```
-func RequireUser(h http.Handler) http.Handler {
- return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
- user, err := GetUser(req)
- if err != nil {
- http.Error(w, err.Error(), http.StatusInternalServerError)
- return
- }
- if user == nil {
- http.Error(w, "unauthorized", http.StatusUnauthorized)
- return
- }
- h.ServeHTTP(w, req)
- })
-}
-```
-
-Here’s how it’s used (just wrap another handler!):
-
-```
-func main() {
- http.ListenAndServe(":8080", RequireUser(http.HandlerFunc(myHandler)))
-}
-```
-
-Express, Negroni, and other frameworks expect this kind of signature for a middleware-supporting handler:
-
-```
-type Handler interface {
- // don't do this!
- ServeHTTP(rw http.ResponseWriter, req *http.Request, next http.HandlerFunc)
-}
-```
-
-There’s really no reason for adding the `next` argument - it reduces cross-library compatibility. So I say, don’t use `negroni.Handler` (or similar). Just use `http.Handler`!
-
-### Composability
-
-Hopefully I’ve sold you on middleware as a good design philosophy.
-
-Probably the most commonly-used type of middleware is request routing, or muxing (seems like we should call this demuxing but what do I know). Some frameworks are almost solely focused on request routing.[gorilla/mux][39] seems more popular than any other part of the [Gorilla][40] library. I think the reason for this is that even though the Go standard library is completely full featured and has a good [ServeMux][41] implementation, it doesn’t make the right thing the default.
-
-So! Let’s talk about request routing and consider the following problem. You, web developer extraordinaire, want to serve some HTML from your web server at `/hello/` but also want to serve some static assets from `/static/`. Let’s take a quick stab.
-
-```
-package main
-
-import (
- "net/http"
-)
-
-func hello(w http.ResponseWriter, req *http.Request) {
- w.Write([]byte("hello, world!"))
-}
-
-func main() {
- mux := http.NewServeMux()
- mux.Handle("/hello/", http.HandlerFunc(hello))
- mux.Handle("/static/", http.FileServer(http.Dir("./static-assets")))
- http.ListenAndServe(":8080", mux)
-}
-```
-
-If you visit `http://localhost:8080/hello/`, you’ll be rewarded with a friendly “hello, world!” message.
-
-If you visit `http://localhost:8080/static/` on the other hand (assuming you have a folder of static assets in `./static-assets`), you’ll be surprised and frustrated. This code tries to find the source content for the request `/static/my-file` at `./static-assets/static/my-file`! There’s an extra `/static` in there!
-
-Okay, so this is why `http.StripPrefix` exists. Let’s fix it.
-
-```
- mux.Handle("/static/", http.StripPrefix("/static",
- http.FileServer(http.Dir("./static-assets"))))
-```
-
-`mux.Handle` combined with `http.StripPrefix` is such a common pattern that I think it should be the default. Whenever a request router processes a certain amount of URL elements, it should strip them off the request so the wrapped `http.Handler` doesn’t need to know its absolute URL and only needs to be concerned with its relative one.
-
-In [Russ Cox][42]’s recent [TiddlyWeb backend][43], I would argue that every time `strings.TrimPrefix` is needed to remove the full URL from the handler’s incoming path arguments, it is an unnecessary cross-cutting concern, unfortunately imposed by `http.ServeMux`. (An example is [line 201 in tiddly.go][44].)
-
-I’d much rather have the default `mux` behavior work more like a directory of registered elements that by default strips off the ancestor directory before handing the request to the next middleware handler. It’s much more composable. To this end, I’ve written a simple muxer that works in this fashion called [whmux.Dir][45]. It is essentially `http.ServeMux` and `http.StripPrefix` combined. Here’s the previous example reworked to use it:
-
-```
-package main
-
-import (
- "net/http"
-
- "gopkg.in/webhelp.v1/whmux"
-)
-
-func hello(w http.ResponseWriter, req *http.Request) {
- w.Write([]byte("hello, world!"))
-}
-
-func main() {
- mux := whmux.Dir{
- "hello": http.HandlerFunc(hello),
- "static": http.FileServer(http.Dir("./static-assets")),
- }
- http.ListenAndServe(":8080", mux)
-}
-```
-
-There are other useful mux implementations inside the [whmux][46] package that demultiplex on various aspects of the request path, request method, request host, or pull arguments out of the request and place them into the context, such as a [whmux.IntArg][47] or [whmux.StringArg][48]. This brings us to [contexts][49].
-
-### Contexts
-
-Request contexts are a recent addition to the Go 1.7 standard library, but the idea of [contexts has been around since mid-2014][50]. As of Go 1.7, they were added to the standard library ([“context”][51]), but are available for older Go releases in the original location ([“golang.org/x/net/context”][52]).
-
-First, here’s the definition of the `context.Context` type that `(*http.Request).Context()` returns:
-
-```
-type Context interface {
- Done() <-chan struct{}
- Err() error
- Deadline() (deadline time.Time, ok bool)
-
- Value(key interface{}) interface{}
-}
-```
-
-Talking about `Done()`, `Err()`, and `Deadline()` are enough for an entirely different blog post, so I’m going to ignore them at least for now and focus on `Value(interface{})`.
-
-As a motivating problem, let’s say that the `GetUser(*http.Request)` method we assumed earlier is expensive, and we only want to call it once per request. We certainly don’t want to call it once to check that a user is logged in, and then again when we actually need the `*User` value. With `(*http.Request).WithContext` and `context.WithValue`, we can pass the `*User` down to the next middleware precomputed!
-
-Here’s the new middleware:
-
-```
-type userKey int
-
-func RequireUser(h http.Handler) http.Handler {
- return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
- user, err := GetUser(req)
- if err != nil {
- http.Error(w, err.Error(), http.StatusInternalServerError)
- return
- }
- if user == nil {
- http.Error(w, "unauthorized", http.StatusUnauthorized)
- return
- }
- ctx := r.Context()
- ctx = context.WithValue(ctx, userKey(0), user)
- h.ServeHTTP(w, req.WithContext(ctx))
- })
-}
-```
-
-Now, handlers that are protected by this `RequireUser` handler can load the previously computed `*User` value like this:
-
-```
-if user, ok := req.Context().Value(userKey(0)).(*User); ok {
- // there's a valid user!
-}
-```
-
-Contexts allow us to pass optional values to handlers down the chain in a way that is relatively type-safe and flexible. None of the above context logic requires anything outside of the standard library.
-
-### Aside about context keys
-
-There was a curious piece of code in the above example. At the top, we defined a `type userKey int`, and then always used it as `userKey(0)`.
-
-One of the possible problems with contexts is the `Value()` interface lends itself to a global namespace where you can stomp on other context users and use conflicting key names. Above, we used `type userKey` because it’s an unexported type in your package. It will never compare equal (without a cast) to any other type, including `int`, in Go. This gives us a way to namespace keys to your package, even though the `Value()`method is still a sort of global namespace.
-
-Because the need for this is so common, the `webhelp` package defines a [GenSym()][53] helper that will create a brand new, never-before-seen, unique value for use as a context key.
-
-If we used [GenSym()][54], then `type userKey int` would become `var userKey = webhelp.GenSym()` and `userKey(0)`would simply become `userKey`.
-
-### Back to whmux.StringArg
-
-Armed with this new context behavior, we can now present a `whmux.StringArg` example:
-
-```
-package main
-
-import (
- "fmt"
- "net/http"
-
- "gopkg.in/webhelp.v1/whmux"
-)
-
-var (
- pageName = whmux.NewStringArg()
-)
-
-func page(w http.ResponseWriter, req *http.Request) {
- name := pageName.Get(req.Context())
-
- fmt.Fprintf(w, "Welcome to %s", name)
-}
-
-func main() {
- // pageName.Shift pulls the next /-delimited string out of the request's
- // URL.Path and puts it into the context instead.
- pageHandler := pageName.Shift(http.HandlerFunc(page))
-
- http.ListenAndServe(":8080", whmux.Dir{
- "wiki": pageHandler,
- })
-}
-```
-
-### Pre-Go-1.7 support
-
-Contexts let you do some pretty cool things. But let’s say you’re stuck with something before Go 1.7 (for instance, App Engine is currently Go 1.6).
-
-That’s okay! I’ve backported all of the neat new context features to Go 1.6 and earlier in a forwards compatible way!
-
-With the [whcompat][55] package, `req.Context()` becomes `whcompat.Context(req)`, and `req.WithContext(ctx)`becomes `whcompat.WithContext(req, ctx)`. The `whcompat` versions work with all releases of Go. Yay!
-
-There’s a bit of unpleasantness behind the scenes to make this happen. Specifically, for pre-1.7 builds, a global map indexed by `req.URL` is kept, and a finalizer is installed on `req` to clean up. So don’t change what`req.URL` points to and this will work fine. In practice it’s not a problem.
-
-`whcompat` adds additional backwards-compatibility helpers. In Go 1.7 and on, the context’s `Done()` channel is closed (and `Err()` is set), whenever the request is done processing. If you want this behavior in Go 1.6 and earlier, just use the [whcompat.DoneNotify][56] middleware.
-
-In Go 1.8 and on, the context’s `Done()` channel is closed when the client goes away, even if the request hasn’t completed. If you want this behavior in Go 1.7 and earlier, just use the [whcompat.CloseNotify][57]middleware, though beware that it costs an extra goroutine.
-
-### Error handling
-
-How you handle errors can be another cross-cutting concern, but with good application of context and middleware, it too can be beautifully cleaned up so that the responsibilities lie in the correct place.
-
-Problem statement: your `RequireUser` middleware needs to handle an authentication error differently between your HTML endpoints and your JSON API endpoints. You want to use `RequireUser` for both types of endpoints, but with your HTML endpoints you want to return a user-friendly error page, and with your JSON API endpoints you want to return an appropriate JSON error state.
-
-In my opinion, the right thing to do is to have contextual error handlers, and luckily, we have a context for contextual information!
-
-First, we need an error handler interface.
-
-```
-type ErrHandler interface {
- HandleError(w http.ResponseWriter, req *http.Request, err error)
-}
-```
-
-Next, let’s make a middleware that registers the error handler in the context:
-
-```
-var errHandler = webhelp.GenSym() // see the aside about context keys
-
-func HandleErrWith(eh ErrHandler, h http.Handler) http.Handler {
- return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
- ctx := context.WithValue(whcompat.Context(req), errHandler, eh)
- h.ServeHTTP(w, whcompat.WithContext(req, ctx))
- })
-}
-```
-
-Last, let’s make a function that will use the registered error handler for errors:
-
-```
-func HandleErr(w http.ResponseWriter, req *http.Request, err error) {
- if handler, ok := whcompat.Context(req).Value(errHandler).(ErrHandler); ok {
- handler.HandleError(w, req, err)
- return
- }
- log.Printf("error: %v", err)
- http.Error(w, "internal server error", http.StatusInternalServerError)
-}
-```
-
-Now, as long as everything uses `HandleErr` to handle errors, our JSON API can handle errors with JSON responses, and our HTML endpoints can handle errors with HTML responses.
-
-Of course, the [wherr][58] package implements this all for you, and the [whjson][59] package even implements a friendly JSON API error handler.
-
-Here’s how you might use it:
-
-```
-var userKey = webhelp.GenSym()
-
-func RequireUser(h http.Handler) http.Handler {
- return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
- user, err := GetUser(req)
- if err != nil {
- wherr.Handle(w, req, wherr.InternalServerError.New("failed to get user"))
- return
- }
- if user == nil {
- wherr.Handle(w, req, wherr.Unauthorized.New("no user found"))
- return
- }
- ctx := r.Context()
- ctx = context.WithValue(ctx, userKey, user)
- h.ServeHTTP(w, req.WithContext(ctx))
- })
-}
-
-func userpage(w http.ResponseWriter, req *http.Request) {
- user := req.Context().Value(userKey).(*User)
- w.Header().Set("Content-Type", "text/html")
- userpageTmpl.Execute(w, user)
-}
-
-func username(w http.ResponseWriter, req *http.Request) {
- user := req.Context().Value(userKey).(*User)
- w.Header().Set("Content-Type", "application/json")
- json.NewEncoder(w).Encode(map[string]interface{}{"user": user})
-}
-
-func main() {
- http.ListenAndServe(":8080", whmux.Dir{
- "api": wherr.HandleWith(whjson.ErrHandler,
- RequireUser(whmux.Dir{
- "username": http.HandlerFunc(username),
- })),
- "user": RequireUser(http.HandlerFunc(userpage)),
- })
-}
-```
-
-### Aside about the spacemonkeygo/errors package
-
-The default [wherr.Handle][60] implementation understands all of the [error classes defined in the wherr top level package][61].
-
-These error classes are implemented using the [spacemonkeygo/errors][62] library and the[spacemonkeygo/errors/errhttp][63] extensions. You don’t have to use this library or these errors, but the benefit is that your error instances can be extended to include HTTP status code messages and information, which once again, provides for a nice elimination of cross-cutting concerns in your error handling logic.
-
-See the [spacemonkeygo/errors][64] package for more details.
-
- _Update 2018-04-19: After a few years of use, my friend condensed some lessons we learned and the best parts of `spacemonkeygo/errors` into a new, more concise, better library, over at [github.com/zeebo/errs][1]. Consider using that instead!_
-
-### Sessions
-
-Go’s standard library has great support for cookies, but cookies by themselves aren’t usually what a developer thinks of when she thinks about sessions. Cookies are unencrypted, unauthenticated, and readable by the user, and perhaps you don’t want that with your session data.
-
-Further, sessions can be stored in cookies, but could also be stored in a database to provide features like session revocation and querying. There’s lots of potential details about the implementation of sessions.
-
-Request handlers, however, probably don’t care too much about the implementation details of the session. Request handlers usually just want a bucket of keys and values they can store safely and securely.
-
-The [whsess][65] package implements middleware for registering an arbitrary session store (a default cookie-based session store is provided), and implements helpers for retrieving and saving new values into the session.
-
-The default cookie-based session store implements encryption and authentication via the excellent[nacl/secretbox][66] package.
-
-Usage is like this:
-
-```
-func handler(w http.ResponseWriter, req *http.Request) {
- ctx := whcompat.Context(req)
- sess, err := whsess.Load(ctx, "namespace")
- if err != nil {
- wherr.Handle(w, req, err)
- return
- }
- if loggedIn, _ := sess.Values["logged_in"].(bool); loggedIn {
- views, _ := sess.Values["views"].(int64)
- sess.Values["views"] = views + 1
- sess.Save(w)
- }
-}
-
-func main() {
- http.ListenAndServe(":8080", whsess.HandlerWithStore(
- whsess.NewCookieStore(secret), http.HandlerFunc(handler)))
-}
-```
-
-### Logging
-
-The Go standard library by default doesn’t log incoming requests, outgoing responses, or even just what port the HTTP server is listening on.
-
-The [whlog][67] package implements all three. The [whlog.LogRequests][68] middleware will log requests as they start. The [whlog.LogResponses][69] middleware will log requests as they end, along with status code and timing information. [whlog.ListenAndServe][70] will log the address the server ultimately listens on (if you specify “:0” as your address, a port will be randomly chosen, and [whlog.ListenAndServe][71] will log it).
-
-[whlog.LogResponses][72] deserves special mention for how it does what it does. It uses the [whmon][73] package to instrument the outgoing `http.ResponseWriter` to keep track of response information.
-
-Usage is like this:
-
-```
-func main() {
- whlog.ListenAndServe(":8080", whlog.LogResponses(whlog.Default, handler))
-}
-```
-
-### App engine logging
-
-App engine logging is unconventional crazytown. The standard library logger doesn’t work by default on App Engine, because App Engine logs _require_ the request context. This is unfortunate for libraries that don’t necessarily run on App Engine all the time, as their logging information doesn’t make it to the App Engine request-specific logger.
-
-Unbelievably, this is fixable with [whgls][74], which uses my terrible, terrible (but recently improved) [Goroutine-local storage library][75] to store the request context on the current stack, register a new log output, and fix logging so standard library logging works with App Engine again.
-
-### Template handling
-
-Go’s standard library [html/template][76] package is excellent, but you’ll be unsurprised to find there’s a few tasks I do with it so commonly that I’ve written additional support code.
-
-The [whtmpl][77] package really does two things. First, it provides a number of useful helper methods for use within templates, and second, it takes some friction out of managing a large number of templates.
-
-When writing templates, one thing you can do is call out to other registered templates for small values. A good example might be some sort of list element. You can have a template that renders the list element, and then your template that renders your list can use the list element template in turn.
-
-Use of another template within a template might look like this:
-
-```
-<ul>
- {{ range .List }}
- {{ template "list_element" . }}
- {{ end }}
-</ul>
-
-```
-
-You’re now rendering the `list_element` template with the list element from `.List`. But what if you want to also pass the current user `.User`? Unfortunately, you can only pass one argument from one template to another. If you have two arguments you want to pass to another template, with the standard library, you’re out of luck.
-
-The [whtmpl][78] package adds three helper functions to aid you here, `makepair`, `makemap`, and `makeslice` (more docs under the [whtmpl.Collection][79] type). `makepair` is the simplest. It takes two arguments and constructs a[whtmpl.Pair][80]. Fixing our example above would look like this now:
-
-```
-<ul>
- {{ $user := .User }}
- {{ range .List }}
- {{ template "list_element" (makepair . $user) }}
- {{ end }}
-</ul>
-
-```
-
-The second thing [whtmpl][81] does is make defining lots of templates easy, by optionally automatically naming templates after the name of the file the template is defined in.
-
-For example, say you have three files.
-
-Here’s `pkg.go`:
-
-```
-package views
-
-import "gopkg.in/webhelp.v1/whtmpl"
-
-var Templates = whtmpl.NewCollection()
-```
-
-Here’s `landing.go`:
-
-```
-package views
-
-var _ = Templates.MustParse(`{{ template "header" . }}
-
- <h1>Landing!</h1>`)
-```
-
-And here’s `header.go`:
-
-```
-package views
-
-var _ = Templates.MustParse(`<title>My website!</title>`)
-```
-
-Now, you can import your new `views` package and render the `landing` template this easily:
-
-```
-func handler(w http.ResponseWriter, req *http.Request) {
- views.Templates.Render(w, req, "landing", map[string]interface{}{})
-}
-```
-
-### User authentication
-
-I’ve written two Webhelp-style authentication libraries that I end up using frequently.
-
-The first is an OAuth2 library, [whoauth2][82]. I’ve written up [an example application that authenticates with Google, Facebook, and Github][83].
-
-The second, [whgoth][84], is a wrapper around [markbates/goth][85]. My portion isn’t quite complete yet (some fixes are still necessary for optional App Engine support), but will support more non-OAuth2 authentication sources (like Twitter) when it is done.
-
-### Route listing
-
-Surprise! If you’ve used [webhelp][86] based handlers and middleware for your whole app, you automatically get route listing for free, via the [whroute][87] package.
-
-My web serving code’s `main` method often has a form like this:
-
-```
-switch flag.Arg(0) {
-case "serve":
- panic(whlog.ListenAndServe(*listenAddr, routes))
-case "routes":
- whroute.PrintRoutes(os.Stdout, routes)
-default:
- fmt.Printf("Usage: %s <serve|routes>\n", os.Args[0])
-}
-```
-
-Here’s some example output:
-
-```
-GET /auth/_cb/
-GET /auth/login/
-GET /auth/logout/
-GET /
-GET /account/apikeys/
-POST /account/apikeys/
-GET /project/<int>/
-GET /project/<int>/control/<int>/
-POST /project/<int>/control/<int>/sample/
-GET /project/<int>/control/
- Redirect: f(req)
-POST /project/<int>/control/
-POST /project/<int>/control_named/<string>/sample/
-GET /project/<int>/control_named/
- Redirect: f(req)
-GET /project/<int>/sample/<int>/
-GET /project/<int>/sample/<int>/similar[/<*>]
-GET /project/<int>/sample/
- Redirect: f(req)
-POST /project/<int>/search/
-GET /project/
- Redirect: /
-POST /project/
-
-```
-
-### Other little things
-
-[webhelp][88] has a number of other subpackages:
-
-* [whparse][2] assists in parsing optional request arguments.
-
-* [whredir][3] provides some handlers and helper methods for doing redirects in various cases.
-
-* [whcache][4] creates request-specific mutable storage for caching various computations and database loaded data. Mutability helps helper functions that aren’t used as middleware share data.
-
-* [whfatal][5] uses panics to simplify early request handling termination. Probably avoid this package unless you want to anger other Go developers.
-
-### Summary
-
-Designing your web project as a collection of composable middlewares goes quite a long way to simplify your code design, eliminate cross-cutting concerns, and create a more flexible development environment. Use my [webhelp][89] package if it helps you.
-
-Or don’t! Whatever! It’s still a free country last I checked.
-
-### Update
-
-Peter Kieltyka points me to his [Chi framework][90], which actually does seem to do the right things with respect to middleware, handlers, and contexts - certainly much more so than all the other frameworks I’ve seen. So, shoutout to Peter and the team at Pressly!
-
---------------------------------------------------------------------------------
-作者简介:
-
-Utahn, Software Engineer, Terrier lover, Potatoes – these are concepts that make little sense in the far future when the robots completely take over. Former affiliations like University of Minnesota, University of Utah, Space Monkey, Google, Instructure, or Mozy will be meaningless as the last chunk of Earth is plunged into an interstellar fuel reactor to power an ever-growing orb of computronium.
-
-In the meantime, it’s probably best to not worry about it.
-
-Here’s a list of all the ways to find me on the internet. Let’s do all we can together before we can’t!
-
-AngelList: jtolds
-Beeminder: jtolds
-Facebook: jtolds
-Flickr: jtolds
-GitHub: jtolds
-Google+: +jtolds
-Instagram: @jtolds
-Keybase: jtolds
-Last.fm: jtolds
-LinkedIn: jtolds
-Soundcloud: jtolds
-Spotify: jtolds
-Twitter: @jtolds @jtsmusic
-Youtube: jtolds
-(I briefly worried about powerful nation-states cross-correlating all of my accounts if I listed them here, but then I saw how different all my usernames are and thought, “nah.”)
-
-I have a separate page detailing what I’m currently involved in.
-
-Drop me a line if you simply can’t hold so many lines and they don’t all fit in your hands. I have a line tote bag you might be interested in.
-
---------------------
-
-via: https://www.jtolio.com/2017/01/writing-advanced-web-applications-with-go/
-
-作者:[Utahn ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.jtolio.com/about/
-[1]:https://github.com/zeebo/errs
-[2]:https://godoc.org/gopkg.in/webhelp.v1/whparse
-[3]:https://godoc.org/gopkg.in/webhelp.v1/whredir
-[4]:https://godoc.org/gopkg.in/webhelp.v1/whcache
-[5]:https://godoc.org/gopkg.in/webhelp.v1/whfatal
-[6]:https://www.ruby-lang.org/
-[7]:http://rubyonrails.org/
-[8]:http://www.sinatrarb.com/
-[9]:https://www.python.org/
-[10]:https://www.djangoproject.com/
-[11]:http://flask.pocoo.org/
-[12]:https://golang.org/
-[13]:https://groups.google.com/d/forum/golang-nuts
-[14]:https://www.reddit.com/r/golang/
-[15]:https://revel.github.io/
-[16]:https://gin-gonic.github.io/gin/
-[17]:http://iris-go.com/
-[18]:https://beego.me/
-[19]:https://go-macaron.com/
-[20]:https://github.com/go-martini/martini
-[21]:https://github.com/gocraft/web
-[22]:https://github.com/urfave/negroni
-[23]:https://godoc.org/goji.io
-[24]:https://echo.labstack.com/
-[25]:https://medium.com/code-zen/why-i-don-t-use-go-web-frameworks-1087e1facfa4
-[26]:https://groups.google.com/forum/#!topic/golang-nuts/R_lqsTTBh6I
-[27]:https://www.reddit.com/r/golang/comments/1yh6gm/new_to_go_trying_to_select_web_framework/
-[28]:https://golang.org/pkg/net/http/#Handler
-[29]:https://golang.org/pkg/net/http/#Handler
-[30]:https://golang.org/pkg/net/http/#Request
-[31]:https://golang.org/pkg/net/http/#Request.Context
-[32]:https://golang.org/pkg/net/http/#Request.WithContext
-[33]:https://godoc.org/gopkg.in/webhelp.v1
-[34]:https://golang.org/doc/articles/wiki/
-[35]:http://expressjs.com/
-[36]:https://nodejs.org/en/
-[37]:https://github.com/urfave/negroni
-[38]:https://en.wikipedia.org/wiki/Cross-cutting_concern
-[39]:https://github.com/gorilla/mux
-[40]:https://github.com/gorilla/
-[41]:https://golang.org/pkg/net/http/#ServeMux
-[42]:https://swtch.com/~rsc/
-[43]:https://github.com/rsc/tiddly
-[44]:https://github.com/rsc/tiddly/blob/8f9145ac183e374eb95d90a73be4d5f38534ec47/tiddly.go#L201
-[45]:https://godoc.org/gopkg.in/webhelp.v1/whmux#Dir
-[46]:https://godoc.org/gopkg.in/webhelp.v1/whmux
-[47]:https://godoc.org/gopkg.in/webhelp.v1/whmux#IntArg
-[48]:https://godoc.org/gopkg.in/webhelp.v1/whmux#StringArg
-[49]:https://golang.org/pkg/context/
-[50]:https://blog.golang.org/context
-[51]:https://golang.org/pkg/context/
-[52]:https://godoc.org/golang.org/x/net/context
-[53]:https://godoc.org/gopkg.in/webhelp.v1#GenSym
-[54]:https://godoc.org/gopkg.in/webhelp.v1#GenSym
-[55]:https://godoc.org/gopkg.in/webhelp.v1/whcompat
-[56]:https://godoc.org/gopkg.in/webhelp.v1/whcompat#DoneNotify
-[57]:https://godoc.org/gopkg.in/webhelp.v1/whcompat#CloseNotify
-[58]:https://godoc.org/gopkg.in/webhelp.v1/wherr
-[59]:https://godoc.org/gopkg.in/webhelp.v1/wherr
-[60]:https://godoc.org/gopkg.in/webhelp.v1/wherr#Handle
-[61]:https://godoc.org/gopkg.in/webhelp.v1/wherr#pkg-variables
-[62]:https://godoc.org/github.com/spacemonkeygo/errors
-[63]:https://godoc.org/github.com/spacemonkeygo/errors/errhttp
-[64]:https://godoc.org/github.com/spacemonkeygo/errors
-[65]:https://godoc.org/gopkg.in/webhelp.v1/whsess
-[66]:https://godoc.org/golang.org/x/crypto/nacl/secretbox
-[67]:https://godoc.org/gopkg.in/webhelp.v1/whlog
-[68]:https://godoc.org/gopkg.in/webhelp.v1/whlog#LogRequests
-[69]:https://godoc.org/gopkg.in/webhelp.v1/whlog#LogResponses
-[70]:https://godoc.org/gopkg.in/webhelp.v1/whlog#ListenAndServe
-[71]:https://godoc.org/gopkg.in/webhelp.v1/whlog#ListenAndServe
-[72]:https://godoc.org/gopkg.in/webhelp.v1/whlog#LogResponses
-[73]:https://godoc.org/gopkg.in/webhelp.v1/whmon
-[74]:https://godoc.org/gopkg.in/webhelp.v1/whgls
-[75]:https://godoc.org/github.com/jtolds/gls
-[76]:https://golang.org/pkg/html/template/
-[77]:https://godoc.org/gopkg.in/webhelp.v1/whtmpl
-[78]:https://godoc.org/gopkg.in/webhelp.v1/whtmpl
-[79]:https://godoc.org/gopkg.in/webhelp.v1/whtmpl#Collection
-[80]:https://godoc.org/gopkg.in/webhelp.v1/whtmpl#Pair
-[81]:https://godoc.org/gopkg.in/webhelp.v1/whtmpl
-[82]:https://godoc.org/gopkg.in/go-webhelp/whoauth2.v1
-[83]:https://github.com/go-webhelp/whoauth2/blob/v1/examples/group/main.go
-[84]:https://godoc.org/gopkg.in/go-webhelp/whgoth.v1
-[85]:https://github.com/markbates/goth
-[86]:https://godoc.org/gopkg.in/webhelp.v1
-[87]:https://godoc.org/gopkg.in/webhelp.v1/whroute
-[88]:https://godoc.org/gopkg.in/webhelp.v1
-[89]:https://godoc.org/gopkg.in/webhelp.v1
-[90]:https://github.com/pressly/chi
diff --git a/sources/tech/20180420 A handy way to add free books to your eReader.md b/sources/tech/20180420 A handy way to add free books to your eReader.md
deleted file mode 100644
index 449ca5f69e..0000000000
--- a/sources/tech/20180420 A handy way to add free books to your eReader.md
+++ /dev/null
@@ -1,179 +0,0 @@
-A handy way to add free books to your eReader
-======
-
-
-I do a lot of reading on my tablet every day. While I have bought a few eBooks, I enjoy finding things for free on [Project Gutenberg][1]; it rekindles fond memories of browsing through the stacks of a library for something to catch my interest. There are various ways to search the PG website by title or author, but this presumes you have some idea of what you’re looking for.
-
-I have used the [Magic Catalog][2], but I seem to have seen or read every book listed there that interests me, and as far as I can tell the catalog is about ten years old. In 2017 alone, PG added 2,423 books to its catalog, so perhaps 20,000 have been added over the last ten years.
-
-From the Project Gutenberg website, you can link to the [Offline Catalogs][3] and download a plain-text list of all the books freely available, but the file is 6.6 MB—a little unwieldy. Even the list for 2017 only is a bit tedious to scan. So I decided to make my own web page from this list, including links to each book (similar to the Magic Catalog), and turn that into an eBook. This turned out to be easier than you might expect. The trick is to use `regex`; specifically, `regex` as featured in [Kwrite][4].
-
-First, strip out the preamble text, which explains various details about Project Gutenberg. The listing begins after that:
-```
-~ ~ ~ ~ Posting Dates for the below eBooks: 1 Dec 2017 to 31 Dec 2017 ~ ~ ~ ~
-
-
-
-TITLE and AUTHOR ETEXT NO.
-
-
-
-The Origin and Development of Christian Dogma, by Charles A. H. Tuthill 56279
-
- [Subtitle: An essay in the science of history]
-
-
-
-Frank Merriwell's Endurance, by Burt L. Standish 56278
-
- [Subtitle: or A Square Shooter]
-
-
-
-Derelicts, by James Sprunt 56277
-
- [Subtitle: An Account of Ships Lost at Sea in General Commercial
-
- Traffic and a Brief History of Blockade Runners Stranded Along
-
- the North Carolina Coast 1861-1865]
-
-
-
-Comical Pilgrim; or, Travels of a Cynick Philosopher..., by Anonymous 56276
-
- [Subtitle: Thro' the most Wicked Parts of the World, Namely,
-
- England, Wales, Scotland, Ireland, and Holland]
-
-
-
-I'r Aifft Ac Yn Ol, by D. Rhagfyr Jones 56275
-
- [Language: Welsh]
-
-```
-
-This shows the structure of the text file. The 5-digit number is the search term for each book—for example, the first book would be found here: <http://www.gutenberg.org/ebooks/56279>. Each book is separated from the next by an empty line.
-
-To start, download the file `GUTINDEX.2017`, load it into Kwrite, strip off the preamble, and Save As `GUTINDEX.2017.xhtml`, so the original is unedited just in case. You might as well put in the `xhtml` preamble:
-```
-<?xml version="1.0" encoding="utf-8"?>
-
-<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"
-
-"http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
-
-
-
-<html xmlns="http://www.w3.org/1999/xhtml">
-
-<head>
-
-<title>GutIndex 2017</title>
-
-</head>
-
-<body>
-
-```
-
-Then at the bottom of the file:
-```
-</body>
-
-</html>
-
-```
-
-I’m not a fan of the `~ ~ ~ ~` (four tildes separated by three spaces), so select Edit > Replace in Kwrite to bring up the Replace dialog at the bottom. You don’t need to select Regular expression as the Mode, but you’ll need it later, so go ahead and do that.
-
-In Find, enter `~ ~ ~ ~` and nothing in Replace. Click Replace All, and they all disappear, with the message: 24 replacements.
-
-Now let’s make the links. In Find, enter: `(\d\d\d\d\d)`. (You must include the parentheses.)
-
-In Replace, enter: `<a href=”http://www.gutenberg.org/ebooks/\1”>\1</a>`
-
-This searches for a sequence of 5 digits and replaces it with the link information, which includes the particular 5-digit number twice, denoted by `\1`. Now summon the courage to click Replace All (remember that you can undo this if you’ve made a mistake), and the magic happens: 2423 replacements. Here’s a fragment:
-```
-The Origin and Development of Christian Dogma, by Charles A. H. Tuthill <a href="http://www.gutenberg.org/ebooks/56279">56279</a>
-
- [Subtitle: An essay in the science of history]
-
-
-
-Frank Merriwell's Endurance, by Burt L. Standish <a href="http://www.gutenberg.org/ebooks/56278">56278</a>
-
- [Subtitle: or A Square Shooter]
-
-
-
-Derelicts, by James Sprunt <a href="http://www.gutenberg.org/ebooks/56277">56277</a>
-
- [Subtitle: An Account of Ships Lost at Sea in General Commercial
-
- Traffic and a Brief History of Blockade Runners Stranded Along
-
- the North Carolina Coast 1861-1865]
-
-```
-
-Witness the power of `regex`! Now let's create paragraphs to separate these individual books as whitespace and newlines mean nothing to HTML. Here is where we use that empty line between books. Before we do that, though, let’s eliminate the lines that contain headings:
-```
-TITLE and AUTHOR ETEXT NO.
-
-```
-
-We're doing this because they’re unnecessary, and the second heading is not going to line up with the ebook number anyway. I wanted to get rid of this line and the extra newline characters, and since there were only 12, I went through the file manually—but you can facilitate this by using Edit > Find, searching for ETEXT.
-
-Now more `regex`. In Find, enter: `\n\n`
-
-In Replace, enter: `</p>\n\n<p>`
-
-Then Replace All. I leave in the two newline characters so the text file is easier to read. You will need to manually add `</p>` at the end of the list. At the beginning, you'll see this:
-```
- Posting Dates for the below eBooks: 1 Dec 2017 to 31 Dec 2017 </p>
-
-
-
-<p>The Origin and Development of Christian Dogma, by Charles A. H. Tuthill <a href="http://www.gutenberg.org/ebooks/56279">56279</a>
-
-```
-
-I’d like to make the posting dates a header, but I also want to eliminate `Posting Dates for the below eBooks:` since simply showing the dates is enough. In Find, enter: `Posting Dates for the below eBooks:`, and in Replace, enter: `<h3>` (or `<h4>`).
-
-Now let's fix that trailing `</p>` for each header. You could do this manually, but if you're feeling lazy, enter `2017 </p>` in Find, and `</h3>` in Replace. With each of these, there's a slight risk of doing too much, but the feedback will tell you how many replacements there are (there should be 12). And you always have Undo.
-
-Now for some manual cleanup. Because you added the `<p>` and `</p>` tags, and because of the new `<h3>` tags, there will be extra paragraph tags and a mismatch in the region of these headers. You could simply scan the file at these points, or get some help by entering `<h3>` in the Find space, clicking Find All to highlight them, and scrolling down the file to get rid of any unneeded tags.
-
-The other problem I found with XHTML was ampersands scattered throughout. Since XHTML is stricter than HTML, replace the `&` with `&`. You may want to replace these individually using Replace instead of Replace All.
-
-Some of the lines in the text file have some sort of control character that acts like ` ` (a non-breaking space). To fix this, highlight one in Kwrite—they show up as a faint baseline with a vertical bump—paste it into Find, and enter a space in Replace. This maintains visual spacing as text but is ignored as HTML (by the way, there were 12,586 of these in the document).
-
-Here's how it looks in a narrowed browser window:
-
-
-
-Clicking a link takes you to the book's Project Gutenberg page, where you can view or download it.
-
-I used [Sigil][5] to convert this to an eBook, which was probably the easiest part of the process. Start Sigil, then select "Add Existing Files" from the toolbar and select your XHTML or HTML file. To create a chapter for each month, scroll down to the monthly header line, place the cursor at the beginning of the line, then Split at Cursor (Ctrl + Return) to create 12 chapters. You can also use the headers to create a table of contents; it’s also a good idea to edit the metadata to give it a title that will show up in your eBook reader (you can make yourself the author). Finally, save the file, and you’re done.
-
-Happy reading!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/browse-project-gutenberg-library
-
-作者:[Greg Pittman][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/greg-p
-[1]:http://www.gutenberg.org/wiki/Main_Page
-[2]:http://freekindlebooks.org/MagicCatalog/magiccatalog.html
-[3]:http://www.gutenberg.org/wiki/Gutenberg:Offline_Catalogs
-[4]:https://www.kde.org/applications/utilities/kwrite/
-[5]:https://sigil-ebook.com/
diff --git a/sources/tech/20180423 Breach detection with Linux filesystem forensics - Opensource.com.md b/sources/tech/20180423 Breach detection with Linux filesystem forensics - Opensource.com.md
deleted file mode 100644
index b622bbbd00..0000000000
--- a/sources/tech/20180423 Breach detection with Linux filesystem forensics - Opensource.com.md
+++ /dev/null
@@ -1,342 +0,0 @@
-Breach detection with Linux filesystem forensics | Opensource.com
-======
-
-
-Forensic analysis of a Linux disk image is often part of incident response to determine if a breach has occurred. Linux forensics is a different and fascinating world compared to Microsoft Windows forensics. In this article, I will analyze a disk image from a potentially compromised Linux system in order to determine the who, what, when, where, why, and how of the incident and create event and filesystem timelines. Finally, I will extract artifacts of interest from the disk image.
-
-In this tutorial, we will use some new tools and some old tools in creative, new ways to perform a forensic analysis of a disk image.
-
-### The scenario
-
-Premiere Fabrication Engineering (PFE) suspects there has been an incident or compromise involving the company's main server named pfe1. They believe the server may have been involved in an incident and may have been compromised sometime between the first of March and the last of March. They have engaged my services as a forensic examiner to investigate if the server was compromised and involved in an incident. The investigation will determine the who, what, when, where, why, and how behind the possible compromise. Additionally, PFE has requested my recommendations for further security measures for their servers.
-
-### The disk image
-
-To conduct the forensic analysis of the server, I ask PFE to send me a forensic disk image of pfe1 on a USB drive. They agree and say, "the USB is in the mail." The USB drive arrives, and I start to examine its contents. To conduct the forensic analysis, I use a virtual machine (VM) running the SANS SIFT distribution. The [SIFT Workstation][1] is a group of free and open source incident response and forensic tools designed to perform detailed digital forensic examinations in a variety of settings. SIFT has a wide array of forensic tools, and if it doesn't have a tool I want, I can install one without much difficulty since it is an Ubuntu-based distribution.
-
-Upon examination, I find the USB doesn't contain a disk image, rather copies of the VMware ESX host files, which are VMDK files from PFE's hybrid cloud. This was not what I was expecting. I have several options:
-
- 1. I can contact PFE and be more explicit about what I am expecting from them. Early in an engagement like this, it might not be the best thing to do.
- 2. I can load the VMDK files into a virtualization tool such as VMPlayer and run it as a live VM using its native Linux programs to perform forensic analysis. There are at least three reasons not to do this. First, timestamps on files and file contents will be altered when running the VMDK files as a live system. Second, since the server is thought to be compromised, every file and program of the VMDK filesystems must be considered compromised. Third, using the native programs on a compromised system to do a forensic analysis may have unforeseen consequences.
- 3. To analyze the VMDK files, I could use the libvmdk-utils package that contains tools to access data stored in VMDK files.
- 4. However, a better approach is to convert the VMDK file format into RAW format. This will make it easier to run the different tools in the SIFT distribution on the files in the disk image.
-
-
-
-To convert from VMDK to RAW format, I use the [qemu-img][2] utility, which allows creating, converting, and modifying images offline. The following figure shows the command to convert the VMDK format into a RAW format.
-
-![Converting a VMDK file to RAW format][4]
-
-Fig. 1: Converting a VMDK file to RAW format
-
-Next, I need to list the partition table from the disk image and obtain information about where each partition starts (sectors) using the [mmls][5] utility. This utility displays the layout of the partitions in a volume system, including partition tables and disk labels. Then I use the starting sector and query the details associated with the filesystem using the [fsstat][6] utility, which displays the details associated with a filesystem. The figures below show the `mmls` and `fsstat` commands in operation.
-
-![mmls command output][8]
-
-Fig. 2: `mmls` command output
-
-I learn several interesting things from the `mmls` output: A Linux primary partition starts at sector 2048 and is approximately 8 gigabytes in size. A DOS partition, probably the boot partition, is approximately 8 megabytes in size. Finally, there is a swap partition of approximately 8 gigabytes.
-
-![fsstat command output][10]
-
-Fig. 3: `fsstat` command output
-
-Running `fsstat` tells me many useful things about the partition: the type of filesystem, the last time data was written to the filesystem, whether the filesystem was cleanly unmounted, and where the filesystem was mounted.
-
-I'm ready to mount the partition and start the analysis. To do this, I need to read the partition tables on the raw image specified and create device maps over partition segments detected. I could do this by hand with the information from `mmls` and `fsstat`—or I could use [kpartx][11] to do it for me.
-
-![Using kpartx to create loopback devices][13]
-
-Fig. 4: Using kpartx to create loopback devices
-
-I use options to create read-only mapping (`-r`), add partition mapping (`-a`), and give verbose output (`-v`). The `loop0p1` is the name of a device file under `/dev/mapper` I can use to access the partition. To mount it, I run:
-```
-$ mount -o ro -o loop=/dev/mapper/loop0p1 pf1.raw /mnt
-
-```
-
-Note that I'm mounting the partition as read-only (`-o ro`) to prevent accidental contamination.
-
-After mounting the disk, I start my forensic analysis and investigation by creating a timeline. Some forensic examiners don't believe in creating a timeline. Instead, once they have a mounted partition, they creep through the filesystem looking for artifacts that might be relevant to the investigation. I label these forensic examiners "creepers." While this is one way to forensically investigate, it is far from repeatable, is prone to error, and may miss valuable evidence.
-
-I believe creating a timeline is a crucial step because it includes useful information about files that were modified, accessed, changed, and created in a human-readable format, known as MAC (modified, accessed, changed) time evidence. This activity helps identify the specific time and order an event took place.
-
-### Notes about Linux filesystems
-
-Linux filesystems like ext2 and ext3 don't have timestamps for a file's creation/birthtime. The creation timestamp was introduced in ext4. The book [Forensic Discovery][14] (1st edition) by Dan Farmer and Wietse Venema outlines the different timestamps.
-
- * **Last modification time:** For directories, this is the last time an entry was added, renamed, or removed. For other file types, it's the last time the file was written to.
- * **Last access (read) time:** For directories, this is the last time it was searched. For other file types, it's the last time the file was read.
- * **Last status change:** Examples of status changes are change of owner, change of access permission, change of hard link count, or an explicit change of any of the MAC times.
- * **Deletion time:** ext2 and ext3 record the time a file was deleted in the `dtime` timestamp, but not all tools support it.
- * **Creation time:** ext4fs records the time the file was created in the `crtime` timestamp, but not all tools support it.
-
-
-
-The different timestamps are stored in the metadata contained in the inodes. Inodes are similar to the MFT entry number in the Windows world. One way to read the file metadata on a Linux system is to first get the inode number using the command `ls -i file` then use `istat` against the partition device and specify the inode number. This will show you the different metadata attributes, including the timestamps, the file size, owner's group and user id, permissions, and the blocks that contain the actual data.
-
-### Creating the super timeline
-
-My next step is to create a super timeline using log2timeline/plaso. [Plaso][15] is a Python-based rewrite of the Perl-based log2timeline tool initially created by Kristinn Gudjonsson and enhanced by others. It's easy to make a super timeline with log2timeline, but interpretation is difficult. The latest version of the plaso engine can parse the ext4 as well as different type of artifacts, such as syslog messages, audit, utmp, and others.
-
-To create the super timeline, I launch log2timeline against the mounted disk folder and use the Linux parsers. This process takes some time; when it finishes I have a timeline with the different artifacts in plaso database format, then I can use `psort.py` to convert the plaso database into any number of different output formats. To see the output formats that `psort.py` supports, enter `psort -o list`. I used `psort.py` to create an Excel-formatted super timeline. The figure below outlines the steps to perform this operation.
-
-(Note: extraneous lines removed from images)
-
-![Creating a super timeline in. xslx format][17]
-
-Fig. 5: Creating a super timeline in. xslx format
-
-I import the super timeline into a spreadsheet program to make viewing, sorting, and searching easier. While you can view a super timeline in a spreadsheet program, it's easier to work with it in a real database such as MySQL or Elasticsearch. I create a second super timeline and dispatch it directly to an Elasticsearch instance from `psort.py`. Once the super timeline has been indexed by Elasticsearch, I can visualize and analyze the data with [Kibana][18].
-
-![Creating a super timeline and ingesting it into Elasticsearch][20]
-
-Fig. 6: Creating a super timeline and ingesting it into Elasticsearch
-
-### Investigating with Elasticsearch/Kibana
-
-As [Master Sergeant Farrell][21] said, "Through readiness and discipline, we are masters of our fate." During the analysis, it pays to be patient and meticulous and avoid being a creeper. One thing that helps a super timeline analysis is to have an idea of when the incident may have happened. In this case (pun intended), the client says the incident may have happened in March. I still consider the possibility the client is incorrect about the timeframe. Armed with this information, I start reducing the super timeline's timeframe and narrowing it down. I'm looking for artifacts of interest that have a "temporal proximity" with the supposed date of the incident. The goal is to recreate what happened based on different artifacts.
-
-To narrow the scope of the super timeline, I use the Elasticsearch/Kibana instance I set up. With Kibana, I can set up any number of intricate dashboards to display and correlate forensic events of interest, but I want to avoid this level of complexity. Instead, I select indexes of interest for display and create a bar graph of activity by date:
-
-![Activity on pfe1 over time][23]
-
-Fig. 7: Activity on pfe1 over time
-
-The next step is to expand the large bar at the end of the chart:
-
-![Activity on pfe1 during March][25]
-
-Fig. 8: Activity on pfe1 during March
-
-There is a large bar on 05-Mar. I expand that bar out to see the activity on that particular date:
-
-![Activity on pfe1 on 05-Mar][27]
-
-Fig. 9: Activity on pfe1 on 05-Mar
-
-Looking at the logfile activity from the super timeline, I see this activity was from a software install/upgrade. There is very little to be found in this area of activity.
-
-![Log listing from pfe1 on 05-Mar][29]
-
-Fig. 10: Log listing from pfe1 on 05-Mar
-
-I go back to Kibana to see the last set of activities on the system and find this in the logs:
-
-![Last activity on pfe1 before shutdown][31]
-
-Fig. 11: Last activity on pfe1 before shutdown
-
-One of the last activities on the system was user john installed a program from a directory named xingyiquan. Xing Yi Quan is a style of Chinese martial arts similar to Kung Fu and Tai Chi Quan. It seems odd that user john would install a martial arts program on a company server from his own user account. I use Kibana's search capability to find other instances of xingyiquan in the logfiles. I found three periods of activity surrounding the string xingyiquan on 05-Mar, 09-Mar, and 12-Mar.
-
-![xingyiquan activity on pfe1][33]
-
-Fig. 12: xingyiquan activity on pfe1
-
-Next, I look at the log entries for these days. I start with 05-Mar and find evidence of an internet search using the Firefox browser and the Google search engine for a rootkit named xingyiquan. The Google search found the existence of such a rootkit on packetstormsecurity.com. Then, the browser went to packetstormsecurity.com and downloaded a file named `xingyiquan.tar.gz` from that site into user john's download directory.
-
-![Search and download of xingyiquan.tar.gz][35]
-
-Fig. 13: Search and download of xingyiquan.tar.gz
-
-Although it appears user john went to google.com to search for the rootkit and then to packetstormsecurity.com to download the rootkit, these log entries do not indicate the user behind the search and download. I need to look further into this.
-
-The Firefox browser keeps its history information in an SQLite database under the `.mozilla` directory in a user's home directory (i.e., user john) in a file named `places.sqlite`. To view the information in the database, I use a program called [sqlitebrowser][36]. It's a GUI application that allows a user to drill down into an SQLite database and view the records stored there. I launched sqlitebrowser and imported `places.sqlite` from the `.mozilla` directory under user john's home directory. The results are shown below.
-
-![Search and download history of user john][38]
-
-Fig. 14: Search and download history of user john
-
-The number in the far-right column is the timestamp for the activity on the left. As a test of congruence, I converted the timestamp `1425614413880000` to human time and got March 5, 2015, 8:00:13.880 PM. This matches closely with the time March 5th, 2015, 20:00:00.000 from Kibana. We can say with reasonable certainty that user john searched for a rootkit named xingyiquan and downloaded a file from packetstormsecurity.com named `xingyiquan.tar.gz` to user john's download directory.
-
-### Investigating with MySQL
-
-At this point, I decide to import the super timeline into a MySQL database to gain greater flexibility in searching and manipulating data than Elasticsearch/Kibana alone allows.
-
-### Building the xingyiquan rootkit
-
-I load the super timeline I created from the plaso database into a MySQL database. From working with Elasticsearch/Kibana, I know that user john downloaded the rootkit `xingyiquan.tar.gz` from packetstormsecurity.com to the download directory. Here is evidence of the download activity from the MySQL timeline database:
-
-![Downloading the xingyiquan.tar.gz rootkit][40]
-
-Fig. 15: Downloading the xingyiquan.tar.gz rootkit
-
-Shortly after the rootkit was downloaded, the source from the `tar.gz` archive was extracted.
-
-![Extracting the rootkit source from the tar.gz archive][42]
-
-Fig. 16: Extracting the rootkit source from the tar.gz archive
-
-Nothing was done with the rootkit until 09-Mar, when the bad actor read the README file for the rootkit with the More program, then compiled and installed the rootkit.
-
-![Building the xingyiquan rootkit][44]
-
-Fig. 17: Building the xingyiquan rootkit
-
-### Command histories
-
-I load histories of all the users on pfe1 that have `bash` command histories into a table in the MySQL database. Once the histories are loaded, I can easily display them using a query like:
-```
-select * from histories order by recno;
-
-```
-
-To get a history for a specific user, I use a query like:
-```
-select historyCommand from histories where historyFilename like '%<username>%' order by recno;
-
-```
-
-I find several interesting commands from user john's `bash` history. Namely, user john created the johnn account, deleted it, created it again, copied `/bin/true` to `/bin/false`, gave passwords to the whoopsie and lightdm accounts, copied `/bin/bash` to `/bin/false`, edited the password and group files, moved the user johnn's home directory from `johnn` to `.johnn`, (making it a hidden directory), changed the password file using `sed` after looking up how to use sed, and finally installed the xingyiquan rootkit.
-
-![User john's activity][46]
-
-Fig. 18: User john's activity
-
-Next, I look at the `bash` command history for user johnn. It showed no unusual activity.
-
-![User johnn's activity][48]
-
-Fig. 19: User johnn's activity
-
-Noting that user john copied `/bin/bash` to `/bin/false`, I test whether this was true by checking the sizes of these files and getting an MD5 hash of the files. As shown below, the file sizes and the MD5 hashes are the same. Thus, the files are the same.
-
-![Checking /bin/bash and /bin/false][50]
-
-Fig. 20: Checking `/bin/bash` and `/bin/false`
-
-### Investigating successful and failed logins
-
-To answer part of the "when" question, I load the logfiles containing data on logins, logouts, system startups, and shutdowns into a table in the MySQL database. Using a simple query like:
-```
-select * from logins order by start
-
-```
-
-I find the following activity:
-
-![Successful logins to pfe1][52]
-
-Fig. 21: Successful logins to pfe1
-
-From this figure, I see that user john logged into pfe1 from IP address `192.168.56.1`. Five minutes later, user johnn logged into pfe1 from the same IP address. Two logins by user lightdm followed four minutes later and another one minute later, then user johnn logged in less than one minute later. Then pfe1 was rebooted.
-
-Looking at unsuccessful logins, I find this activity:
-
-![Unsuccessful logins to pfe1][54]
-
-Fig. 22: Unsuccessful logins to pfe1
-
-Again, user lightdm attempted to log into pfe1 from IP address `192.168.56.1`. In light of bogus accounts logging into pfe1, one of my recommendations to PFE will be to check the system with IP address `192.168.56.1` for evidence of compromise.
-
-### Investigating logfiles
-
-This analysis of successful and failed logins provides valuable information about when events occurred. I turn my attention to investigating the logfiles on pfe1, particularly the authentication and authorization activity in `/var/log/auth*`. I load all the logfiles on pfe1 into a MySQL database table and use a query like:
-```
-select logentry from logs where logfilename like '%auth%' order by recno;
-
-```
-
-and save that to a file. I open that file with my favorite editor and search for `192.168.56.1`. Following is a section of the activity:
-
-![Account activity on pfe1][56]
-
-Fig. 23: Account activity on pfe1
-
-This section shows that user john logged in from IP address `192.168.56.1` and created the johnn account, removed the johnn account, and created it again. Then, user johnn logged into pfe1 from IP address `192.168.56.1`. Next, user johnn attempted to become user whoopsie with an `su` command, which failed. Then, the password for user whoopsie was changed. User johnn next attempted to become user lightdm with an `su` command, which also failed. This correlates with the activity shown in Figures 21 and 22.
-
-### Conclusions from my investigation
-
- * User john searched for, downloaded, compiled, and installed a rootkit named xingyiquan onto the server pfe1. The xingyiquan rootkit hides processes, files, directories, processes, and network connections; adds backdoors; and more.
- * User john created, deleted, and recreated another account on pfe1 named johnn. User john made the home directory of user johnn a hidden file to obscure the existence of this user account.
- * User john copied the file `/bin/true` over `/bin/false` and then `/bin/bash` over `/bin/false` to facilitate the logins of system accounts not normally used for interactive logins.
- * User john created passwords for the system accounts whoopsie and lightdm. These accounts normally do not have passwords.
- * The user account johnn was successfully logged into and user johnn unsuccessfully attempted to become users whoopsie and lightdm.
- * Server pfe1 has been seriously compromised.
-
-
-
-### My recommendations to PFE
-
- * Rebuild server pfe1 from the original distribution and apply all relevant patches to the system before returning it to service.
- * Set up a centralized syslog server and have all systems in the PFE hybrid cloud log to the centralized syslog server and to local logs to consolidate log data and prevent tampering with system logs. Use a security information and event monitoring (SIEM) product to facilitate security event review and correlation.
- * Implement `bash` command timestamps on all company servers.
- * Enable audit logging of the root account on all PFE servers and direct the audit logs to the centralized syslog server where they can be correlated with other log information.
- * Investigate the system with IP address `192.168.56.1` for breaches and compromises, as it was used as a pivot point in the compromise of pfe1.
-
-
-
-If you have used forensics to analyze your Linux filesystem for compromises, please share your tips and recommendations in the comments.
-
-Gary Smith will be speaking at LinuxFest Northwest this year. See [program highlights][57] or [register to attend][58].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/linux-filesystem-forensics
-
-作者:[Gary Smith][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/greptile
-[1]:https://digital-forensics.sans.org/community/downloads
-[2]:http://manpages.ubuntu.com/manpages/trusty/man1/qemu-img.1.html
-[3]:/file/394021
-[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_1.png?itok=97ycgLzk (Converting a VMDK file to RAW format)
-[5]:http://manpages.ubuntu.com/manpages/trusty/man1/mmls.1.html
-[6]:http://manpages.ubuntu.com/manpages/artful/en/man1/fsstat.1.html
-[7]:/file/394026
-[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_2.png?itok=xcpFjon4 (mmls command output)
-[9]:/file/394031
-[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_3.png?itok=DKsXkKK- (fsstat command output)
-[11]:http://manpages.ubuntu.com/manpages/trusty/man8/kpartx.8.html
-[12]:/file/394036
-[13]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_4.png?itok=AGJiIXmK (Using kpartx to create loopback devices)
-[14]:https://www.amazon.com/Forensic-Discovery-paperback-Dan-Farmer/dp/0321703251
-[15]:https://github.com/log2timeline/plaso
-[16]:/file/394151
-[17]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_5a_0.png?itok=OgVfAWwD (Creating a super timeline in. xslx format)
-[18]:https://www.elastic.co/products/kibana
-[19]:/file/394051
-[20]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_6.png?itok=1eohddUY (Creating a super timeline and ingesting it into Elasticsearch)
-[21]:http://allyouneediskill.wikia.com/wiki/Master_Sergeant_Farell
-[22]:/file/394056
-[23]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_7.png?itok=avIR86ws (Activity on pfe1 over time)
-[24]:/file/394066
-[25]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_8.png?itok=vfNaPsMB (Activity on pfe1 during March)
-[26]:/file/394071
-[27]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_9.png?itok=2e4oUxJs (Activity on pfe1 on 05-Mar)
-[28]:/file/394076
-[29]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_10.png?itok=0RAjs3WK (Log listing from pfe1 on 05-Mar)
-[30]:/file/394081
-[31]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_11.png?itok=xRLpPw8F (Last activity on pfe1 before shutdown)
-[32]:/file/394086
-[33]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_12.png?itok=JS9YRN6n (xingyiquan activity on pfe1)
-[34]:/file/394091
-[35]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_13.png?itok=jX0wwgla (Search and download of xingyiquan.tar.gz)
-[36]:http://sqlitebrowser.org/
-[37]:/file/394096
-[38]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_14.png?itok=E9u4PoJI (Search and download history of user john)
-[39]:/file/394101
-[40]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_15.png?itok=ZrA8j8ET (Downloading the xingyiquan.tar.gz rootkit)
-[41]:/file/394106
-[42]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_16.png?itok=wMQVSjTF (Extracting the rootkit source from the tar.gz archive)
-[43]:/file/394111
-[44]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_17.png?itok=4H5aKyy9 (Building the xingyiquan rootkit)
-[45]:/file/394116
-[46]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_18.png?itok=vc1EtrRA (User john's activity)
-[47]:/file/394121
-[48]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_19.png?itok=fF6BY3LM (User johnn's activity)
-[49]:/file/394126
-[50]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_20.png?itok=RfLFwep_ (Checking /bin/bash and /bin/false)
-[51]:/file/394131
-[52]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_21.png?itok=oX7YYrSz (Successful logins to pfe1)
-[53]:/file/394136
-[54]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_22.png?itok=wfmLvoi6 (Unsuccessful logins to pfe1)
-[55]:/file/394141
-[56]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_23.png?itok=dyxmwiSw (Account activity on pfe1)
-[57]:https://www.linuxfestnorthwest.org/conferences/lfnw18
-[58]:https://www.linuxfestnorthwest.org/conferences/lfnw18/register/new
diff --git a/sources/tech/20180423 Managing virtual environments with Vagrant.md b/sources/tech/20180423 Managing virtual environments with Vagrant.md
deleted file mode 100644
index d6be55a9de..0000000000
--- a/sources/tech/20180423 Managing virtual environments with Vagrant.md
+++ /dev/null
@@ -1,488 +0,0 @@
-Managing virtual environments with Vagrant
-======
-
-
-Vagrant is a tool that offers a simple and easy to use command-line client for managing virtual environments. I started using it because it made it easier for me to develop websites, test solutions, and learn new things.
-
-According to [Vagrant's website][1], "Vagrant lowers development environment setup time, increases production parity, and makes the 'works on my machine' excuse a relic of the past."
-
-There is a lot Vagrant can do, and you can learn a bit more background in Opensource.com's [Vagrant open source resources article][2].
-
-In this getting-started guide, I'll demonstrate how to use Vagrant to:
-
- 1. Create and configure a VirtualBox virtual machine (VM)
- 2. Run post-deployment configuration shell scripts and applications
-
-
-
-Sounds simple, and it is. Vagrant's power comes from having a consistent workflow for deploying and configuring machines regardless of platform or operating system.
-
-We'll start by using VirtualBox as a **provider** , setting up an Ubuntu 16.04 **box** , and applying a few shell commands as the **provisioner**. I'll refer to the physical machine (e.g., a laptop or desktop) as the host machine and the Vagrant VM as the guest.
-
-In this tutorial, we'll put together a [Vagrantfile][3] and offer periodic checkpoints to make sure our files look the same. We'll cover the following introductory and advanced topics:
-
-Introductory topics:
-
- * Installing Vagrant
- * Choosing a Vagrant box
- * Understanding the Vagrantfile
- * Getting the VM running
- * Using provisioners
-
-
-
-Advanced topics:
-
- * Networking
- * Syncing folders
- * Deploying multiple machines
- * Making sure everything works
-
-
-
-It looks like a lot, but it will all fit together nicely once we are finished.
-
-### Installing Vagrant
-
-First, we'll navigate to [Vagrant's][4] and [VirtualBox's][5] download pages to install the latest versions of each.
-
-We can enter the following commands to ensure the latest versions of the applications are installed and ready to use.
-
-**Vagrant:**
-```
-# vagrant --version
-
-Vagrant 2.0.3
-
-```
-
-**VirtualBox:**
-```
-# VBoxManage --version
-
-5.2.8r121009
-
-```
-
-### Choosing a Vagrant box
-
-Picking a Vagrant box is similar to picking an image for a server. At the base level, we choose which operating system (OS) we want to use. Some boxes go further and will have additional software (such as the Puppet or Chef client) already installed.
-
-The go-to online repository for boxes is [Vagrant Cloud][6]; it offers a cornucopia of Vagrant boxes for multiple providers. In this tutorial, we'll be using Ubuntu Xenial Xerus 16.04 LTS daily build.
-
-### Understanding the Vagrantfile
-
-Think of the Vagrantfile as the configuration file for an environment. It describes the Vagrant environment with regard to how to build and configure the VirtualBox VMs.
-
-We need to create an empty project directory to work from, then initialize a Vagrant environment from that directory with this command:
-```
-# vagrant init ubuntu/xenial64
-
-```
-
-This only creates the Vagrantfile; it doesn't bring up the Vagrant box.
-
-The Vagrantfile is well-documented with a lot of guidance on how to use it. We can generate a minimized Vagrantfile with the `--minimal` flag.
-```
-# vagrant init --minimal ubuntu/xenial64
-
-```
-
-The resulting file will look like this:
-```
-Vagrant.configure("2") do |config|
-
- config.vm.box = "ubuntu/xenial64"
-
-end
-
-```
-
-We will talk more about the Vagrantfile later, but for now, let's get this box up and running.
-
-### Getting the VM running
-
-Let's issue the following command from our project directory:
-```
-# vagrant up
-
-```
-
-It takes a bit of time to execute `vagrant up` the first time because it downloads the box to your machine. It is much faster on subsequent runs because it reuses the same downloaded box.
-
-Once the VM is up and running, we can `ssh` into our single machine by issuing the following command in our project directory:
-```
-# vagrant ssh
-
-```
-
-That's it! From here we should be able to log onto our VM and start working with it.
-
-### Using provisioners
-
-Before we move on, let's review a bit. So far, we've picked an image and gotten the server running. For the most part, the server is unconfigured and doesn't have any of the software we might want.
-
-Provisioners provide a way to use tools such as Ansible, Puppet, Chef, and even shell scripts to configure a server after deployment.
-
-An example of using the shell provisioner can be found in a default Vagrantfile. In this example, we'll run the commands to update apt and install Apache2 to the server.
-```
- config.vm.provision "shell", inline: <<-SHELL
-
- apt-get update
-
- apt-get install -y apache2
-
- SHELL
-
-```
-
-If we want to use an Ansible playbook, the configuration section would look like this:
-```
-config.vm.provision "ansible" do |ansible|
-
- ansible.playbook = "playbook.yml"
-
-end
-
-```
-
-A neat thing is we can run only the provisioning part of the Vagrantfile by issuing the `provision` subcommand. This is great for testing out scripts or configuration management plays without having to re-build the VM each time.
-
-#### Vagrantfile checkpoint
-
-Our minimal Vagrantfile should look like this:
-```
-Vagrant.configure("2") do |config|
-
- config.vm.box = "ubuntu/xenial64"
-
- config.vm.provision "shell", inline: <<-SHELL
-
- apt-get update
-
- apt-get install -y apache2
-
- SHELL
-
-end
-
-```
-
-After adding the provisioning section, we need to run this provisioning subcommand:
-```
-# vagrant provision
-
-```
-
-Next, we'll continue to build on our Vagrantfile, touching on some more advanced topics to build a foundation for anyone who wants to dig in further.
-
-### Networking
-
-In this section, we'll add an additional IP address on VirtualBox's `vboxnet0` network. This will allow us to access the machine via the `192.168.33.0/24` network.
-
-Adding the following line to the Vagrantfile will configure the machine to have an additional IP on the `192.168.33.0/24` network. This line is also used as an example in the default Vagrantfile.
-```
-config.vm.network "private_network", ip: "192.168.33.10
-
-```
-
-#### Vagrantfile checkpoint
-
-For those following along, here where our working Vagrantfile stands:
-```
-Vagrant.configure("2") do |config|
-
- config.vm.box = "ubuntu/xenial64"
-
- config.vm.network "private_network", ip: "192.168.33.10"
-
- config.vm.provision "shell", inline: <<-SHELL
-
- apt-get update
-
- apt-get install -y apache2
-
- SHELL
-
-end
-
-```
-
-Next, we need to reload our configuration to reconfigure our machine with this new interface and IP. This command will shut down the VM, reconfigure the Virtual Box VM with the new IP address, and bring the VM back up.
-```
-# vagrant reload
-
-```
-
-When it comes back up, our machine should have two IP addresses.
-
-### Syncing folders
-
-Synced folders are what got me into using Vagrant. They allowed me to work on my host machine, using my tools, and at the same time have the files available to the web server or application. It made my workflow much easier.
-
-By default, the project directory on the host machine is mounted to the guest machine as `/home/vagrant`. This worked for me in the beginning, but eventually, I wanted to customize where this directory was mounted.
-
-In our example, we are defining that the HTML directory within our project directory should be mounted as `/var/www/html` with user/group ownership of `root`.
-```
-config.vm.synced_folder "./"html, "/var/www/html",
-
- owner: "root", group: "root"
-
-```
-
-One thing to note: If you are using a synced folder as a web server document root, you will need to disable `sendfile`, or you might run into an issue where it looks like the files are not updating.
-
-Updating your web server's configuration is out of scope for this article, but here are the directives you will want to update.
-
-In Apache:
-```
-EnableSendFile Off
-
-```
-
-In Nginx:
-```
-sendfile off;
-
-```
-
-#### Vagrantfile checkpoint
-
-After adding our synced folder configuration, our Vagrantfile will look like this:
-```
-Vagrant.configure("2") do |config|
-
- config.vm.box = "ubuntu/xenial64"
-
- config.vm.network "private_network", ip: "192.168.33.10"
-
- config.vm.synced_folder "./html", "/var/www/html",
-
- owner: "root", group: "root"
-
- config.vm.provision "shell", inline: <<-SHELL
-
- apt-get update
-
- apt-get install -y apache2
-
- SHELL
-
-end
-
-```
-
-We need to reload our machine to make the new configuration active.
-```
-# vagrant reload
-
-```
-
-### Deploying multiple machines
-
-We sometimes refer to the project directory as an "environment," and one machine is not much of an environment. This last section extends our Vagrantfile to deploy two machines.
-
-To create two machines, we need to enclose the definition of a single machine inside a `vm.define` block. The rest of the configuration is exactly the same.
-
-Here is an example of a server definition within a `define` block.
-```
-Vagrant.configure("2") do |config|
-
-
-
-config.vm.define "web" do |web|
-
- web.vm.box = "web"
-
- web.vm.box = "ubuntu/xenial64"
-
- web.vm.network "private_network", ip: "192.168.33.10"
-
- web.vm.synced_folder "./html", "/var/www/html",
-
- owner: "root", group: "root"
-
- web.vm.provision "shell", inline: <<-SHELL
-
- apt-get update
-
- apt-get install -y apache2
-
- SHELL
-
- end
-
-
-
-end
-
-```
-
-Notice in the `define` block, our variable is called `"web"` and it is carried through the block to reference each configuration method. We'll use the same name to access it later.
-
-In this next example, we'll add a second machine called `"db"` to our configuration. Where we used `"web"` in our second block before, we'll use `"db"` to reference the second machine. We'll also update our IP address on the `private_network` so we can communicate between the machines.
-```
-Vagrant.configure("2") do |config|
-
-
-
-config.vm.define "web" do |web|
-
- web.vm.box = "web"
-
- web.vm.box = "ubuntu/xenial64"
-
- web.vm.network "private_network", ip: "192.168.33.10"
-
- web.vm.synced_folder "./html", "/var/www/html",
-
- owner: "root", group: "root"
-
- web.vm.provision "shell", inline: <<-SHELL
-
- apt-get update
-
- apt-get install -y apache2
-
- SHELL
-
- end
-
-
-
- config.vm.define "db" do |db|
-
- db.vm.box = "db"
-
- db.vm.box = "ubuntu/xenial64"
-
- db.vm.network "private_network", ip: "192.168.33.20"
-
- db.vm.synced_folder "./html", "/var/www/html",
-
- owner: "root", group: "root"
-
- db.vm.provision "shell", inline: <<-SHELL
-
- apt-get update
-
- apt-get install -y apache2
-
- SHELL
-
- end
-
-
-
-end
-
-```
-
-#### Completed Vagrantfile checkpoint
-
-In our final Vagrantfile, we'll install the MySQL server, update the IP address, and remove the configuration for the synced folder from the second machine.
-```
-Vagrant.configure("2") do |config|
-
-
-
-config.vm.define "web" do |web|
-
- web.vm.box = "web"
-
- web.vm.box = "ubuntu/xenial64"
-
- web.vm.network "private_network", ip: "192.168.33.10"
-
- web.vm.synced_folder "./html", "/var/www/html",
-
- owner: "root", group: "root"
-
- web.vm.provision "shell", inline: <<-SHELL
-
- apt-get update
-
- apt-get install -y apache2
-
- SHELL
-
- end
-
-
-
- config.vm.define "db" do |db|
-
- db.vm.box = "db"
-
- db.vm.box = "ubuntu/xenial64"
-
- db.vm.network "private_network", ip: "192.168.33.20"
-
- db.vm.provision "shell", inline: <<-SHELL
-
- export DEBIAN_FRONTEND="noninteractive"
-
- apt-get update
-
- apt-get install -y mysql-server
-
- SHELL
-
- end
-
-
-
-end
-
-```
-
-### Making sure everything works
-
-Now we have a completed Vagrantfile. Let's introduce one more Vagrant command to make sure everything works.
-
-Let's destroy our machine and build it brand new.
-
-The following command will remove our previous Vagrant image but keep the box we downloaded earlier.
-```
-# vagrant destroy --force
-
-```
-
-Now we need to bring the environment back up.
-```
-# vagrant up
-
-```
-
-We can ssh into the machines using the `vagrant ssh` command:
-```
-# vagrant ssh web
-
-```
-
-or
-```
-# vagrant ssh db
-
-```
-
-You should have a working Vagrantfile you can expand upon and serve as a base for learning more. Vagrant is a powerful tool for testing, developing and learning new things. I encourage you to keep adding to it and exploring the options it offers.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/vagrant-guide-get-started
-
-作者:[Alex Juarez][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mralexjuarez
-[1]:https://www.vagrantup.com/intro/index.html
-[2]:https://opensource.com/resources/vagrant
-[3]:https://www.vagrantup.com/docs/vagrantfile/
-[4]:https://www.vagrantup.com/downloads.html
-[5]:https://www.virtualbox.org/wiki/Downloads
-[6]:https://vagrantcloud.com/
diff --git a/sources/tech/20180430 PCGen- An easy way to generate RPG characters.md b/sources/tech/20180430 PCGen- An easy way to generate RPG characters.md
deleted file mode 100644
index bd1fd6516d..0000000000
--- a/sources/tech/20180430 PCGen- An easy way to generate RPG characters.md
+++ /dev/null
@@ -1,136 +0,0 @@
-PCGen: An easy way to generate RPG characters
-======
-
-
-Do you remember the first time you built a role-playing game (RPG) character? It was exciting and full of possibility, and your imagination ran wild. If you're an avid gamer, it was probably a major milestone for you.
-
-But do you also remember struggling to decipher an empty character sheet and what you were supposed to write down in each box? Remember poring over the core rulebook, cross-referencing one table with a class write-up, the spellbook with your chosen school of magic, and skills to your race?
-
-Whether you thought it was fun or perplexing—or both, if you play RPGs, the process of building and tracking a character is probably as natural to you now as using a computer.
-
-That's an appropriate analogy, because, as we all know, character sheets have been computerized. It's a sensible match; computers are great for tracking information that changes frequently. They certainly handle it a lot better than scratches on paper worn thin by repeated erasing and scribbling and more erasing.
-
-Sure, you could build custom spreadsheets in [Libre Office][1], but then again you could also try [PCGen][2], a Java-based application that makes character creation and maintenance sublimely simple without taking the fun out of either. While it doesn't have a mobile version, there is a [PCGen viewer][3] for Android so you can access your build whenever you need to.
-
-### Downloading and installing
-
-PCGen is a Java application, so it runs on anything that has Java installed. This isn't quite the same thing as Java in your web browser; PCGen is a downloadable application that runs locally on your computer. You likely already have Java installed; if not, download and install it from your distribution's repository. If you're not sure whether you have it installed, you can [download PCGen][4] first, try to run it, and install Java if it fails to run.
-
-Since PCGen is a Java application, you don't have to install it after you download it (because you've already got the Java runtime installed). The application should just run if you double-click the `pcgen.jar` file, but if your computer hasn't been told what to do with a Java app yet, you may need to tell it explicitly to run in Java. You usually do this by right-clicking and specifying what application to open the file in. The application you want, of course, is Java or, if you're asked to input the application launch command manually, `java -jar`.
-
-Linux and BSD users can customize this experience:
-
- 1. Download PCGen to a directory, such as `/opt` or `~/bin`.
- 2. Unzip the archive with `unzip pcgen-x.yy.zz-full.zip`.
- 3. Download a suitable icon (e.g., `wget https://openclipart.org/image/300px/svg_to_png/285672/d20-blank.png -O pcgen/d20.png`.
- 4. Create a file called `pcgen.desktop` in your `~/.local/share/applications` directory. Open it in a text editor and type the following, adjusting as appropriate:
-
-
-```
-[Desktop Entry] Version=1.0 Type=Application Name=PCGen Exec="/home/your-username/bin/pcgen/pcgen.sh" Encoding=UTF-8 Icon=/home/your-username/bin/pcgen/d20.png
-
-```
-
-Now you can launch PCGen from your system's application menu as you would any other applications.
-
-### Player agency
-
-Many hours of my childhood were spent poring over my friends' D&D Player Handbooks, rolling up characters that I'd never play (thanks to the infamous "satanic panic," I wasn't allowed to play the game). What I learned from this is creating a character for an RPG is a kind of mini-game itself. There are rules to follow, important choices to make, and ultimately a needed narrative to make it all come together.
-
-A new player might think it's a good idea to allow an application to do a build for them, but most experienced players probably agree that the best way to learn is by doing. And besides, letting something build your character would rob you of the mini-game that is character building. If an application is nothing more than a pre-gen factory, one of the most important parts of being a player is removed from the game, and nobody wants that.
-
-On the other hand, nobody wants the character building process to discourage new players.
-
-PCGen manages to strike a perfect balance between guiding you through a character build and staying out of your way as you tinker. Primarily it does this by using an unobtrusive alert system that keeps you updated about any required tasks left in your character build. It's helpful without grabbing the steering wheel out of your hands to take over completely.
-
-
-![PCGen to-do list][6]
-
-No annoying Clippy, but plenty of helpful hints
-
-### Getting started
-
-PCGen essentially has two modes: the character build and the character sheet. When you launch it, PCGen first asks you to choose the game system you're building for.
-
-![System selection][8]
-
-Selecting your game system
-
-Included systems are OGL (Open Game License) systems, including D&D 5e (3 and 3.5 editions), Pathfinder, and Fantasy Craft. Better still, PCGen comes preloaded with all manner of add-on material, so not only can you design characters from advanced and third-party modules, the dungeon master (DM) can even create stats for monsters and villains.
-
-Once you've double-clicked the system you're using, you're presented with a helpful screen letting you either load an existing build you have saved or start building a new one. Each new character gets its own tab in PCGen, so if you want to build a whole party or if a DM wants to track a whole hoard of monsters, it's easy to load up a cast of characters and have them at the ready.
-
-Starting from the top left, your character build starts with the basics: choosing a name, gender, and alignment. PCGen includes a random-name generator with lots of knobs and switches to adjust for etymology (real and fantasy), race, and gender.
-
-### Rolling for abilities
-
-When it's time to roll for ability scores, PCGen has lots of options. It defaults to manual entry. You roll physical dice and enter the numbers.
-
-Alternately, you can let PCGen roll for you, and you can set the rolling style. You can have PCGen roll 4d6 and drop the lowest, roll 3d6, or roll 2d6 and add 6.
-
-You can also choose to use a point-purchasing mode with a budget of anything between 15 and 25. This method might appeal to players coming from video games, many of which use this method to allocate attributes.
-
-### Classes and levels
-
-Once you pick a class and add your first level, your attributes are locked in and you get a budget for all remaining class- and level-dependent aspects of your character. What exactly those are, of course, depends on what system you're playing, but PCGen keeps you updated on any remaining required tasks as you go.
-
-There are a lot of tabs in PCGen, and it can sometimes seem just as overwhelming as staring at a physical 300-page Player's Handbook, but as long as you follow the tips, PCGen can keep you on the straight and narrow.
-
-### Character sheets
-
-As if building your character wasn't enough fun, the most satisfying step is yet to come: seeing all your choices laid out in a proper character-sheet format.
-
-The final tab of PCGen is the Character Sheet tab, and it formats your character's attributes into a layout of your choice. The default is a standard, generic layout. It's easily printable and easy to understand.
-
-There are several variations and addendums available, too. For spellcasters, there's a spellbook sheet that lists available spells, and there are several alternate layouts, some optimized for screen and others for print.
-
-If you're using PCGen as you play, you can add temporary effects to your character sheet to let PCGen adjust your attributes accordingly.
-
-If you export your character and import it into the PCGen Importer on your Android phone or tablet, you can use your digital character sheet to track spells and current health and make temporary adjustments to armour class and other attribute modifiers.
-
-![Exported character sheet on Android][10]
-
-Exported character sheet on Android
-
-### PCGen's advantages
-
-The market is full of digital character-sheet trackers, but PCGen stands out for several reasons. First, it's cross-platform. That may or may not mean much to you, because we tend to standardize our workflow to devices that play nice with one another. In my gaming groups, though, we have Linux users and Windows users, and we have people who want to work off a mobile device and others who prefer a proper computer. Choosing an application that everyone can use and become comfortable with makes the process of updating stats more efficient.
-
-Second, because PCGen is open source, all your character data remains in an open and parsable format. As an XML fan, I find it invaluable to get my character data as an XML dump, and it's doubly useful to me as a DM as I prepare for an upcoming adventure and need custom monster stat blocks to insert in my notes.
-
-On a related note, knowing that PCGen will always be available regardless of a player's financial circumstance is also nice. When I changed jobs a year ago, I was lucky to go from one job to the next without interruption in income. In one of my gaming groups, however, two members have been made redundant recently and a third is a university student without much disposable income. The fact that we don't have to worry about monthly membership fees or whether we can all afford to invest in software that is, at the end of the day, a minor convenience over pen and paper gives us confidence in our choice of using digital tools.
-
-PCGen's open source license also lends itself to rapid development and expansion and ensured maintenance. The reason there's a mobile edition is that the code and data are open. Who knows what's next?
-
-While PCGen's default datasets revolve, naturally, around OGL content (because the OGL is open and allows content to be freely redistributed), since the application is also open, you can add whatever data you want. It's not necessarily trivial, but games like Open Legend, Dungeon Delvers, and other openly licensed games are ripe for porting to PCGen.
-
-### Pen and paper
-
-The pen-and-paper tradition remains important. PCGen strikes a healthy balance between the desire to make stats accounting more convenient by leveraging the latest technology while maintaining the joy of manually updating characters.
-
-Whether you're an old-school gamer who banishes digital devices from your table or a progressive gamer who embraces technology, it's fair to say most of us have encountered a few times when a game has come to a halt because of a phone or tablet. The fact is, everyone has a mobile device now (even me, even if it's only because my job pays for it), so they will make their way onto your game table. I have found that encouraging game-relevant information to be on screens has helped focus players on the game; I'd rather my players stare at their character sheets and game reference documents than surf social media sites on their devices.
-
-PCGen, in my experience, is the most true-to-form digital character sheet available. It allows for user control, it offers useful guidance as needed, and it's as close to pen-and-paper convenience as possible. Take a look at it, open gamers!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/pcgen-rpg-character-generator
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/seth
-[1]:http://libreoffice.org
-[2]:http://pcgen.org
-[3]:https://play.google.com/store/apps/details?id=com.dysfunctional.apps.pcgencharactersheet
-[4]:http://pcgen.org/download/
-[5]:/file/394491
-[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/pcgen_tip.jpg?itok=GXOz_OJ_ (PCGen to-do list)
-[7]:/file/394486
-[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/pcgen_sys.jpg?itok=Zn0_9hkQ (System selection)
-[9]:/file/394481
-[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/pcgen_screen.jpg?itok=4V6AZPud (Exported character sheet on Android)
diff --git a/sources/tech/20180503 How the four components of a distributed tracing system work together.md b/sources/tech/20180503 How the four components of a distributed tracing system work together.md
deleted file mode 100644
index 68ba97e989..0000000000
--- a/sources/tech/20180503 How the four components of a distributed tracing system work together.md
+++ /dev/null
@@ -1,156 +0,0 @@
-chenmu-kk is translating.
-How the four components of a distributed tracing system work together
-======
-
-Ten years ago, essentially the only people thinking hard about distributed tracing were academics and a handful of large internet companies. Today, it’s turned into table stakes for any organization adopting microservices. The rationale is well-established: microservices fail in surprising and often spectacular ways, and distributed tracing is the best way to describe and diagnose those failures.
-
-That said, if you set out to integrate distributed tracing into your own application, you’ll quickly realize that the term “Distributed Tracing” means different things to different people. Furthermore, the tracing ecosystem is crowded with partially-overlapping projects with similar charters. This article describes the four (potentially) independent components in distributed tracing, and how they fit together.
-
-### Distributed tracing: A mental model
-
-Most mental models for tracing descend from [Google’s Dapper paper][1]. [OpenTracing][2] uses similar nouns and verbs, so we will borrow the terms from that project:
-
-![Tracing][3]
-
- * **Trace:** The description of a transaction as it moves through a distributed system.
- * **Span:** A named, timed operation representing a piece of the workflow. Spans accept key:value tags as well as fine-grained, timestamped, structured logs attached to the particular span instance.
- * **Span context:** Trace information that accompanies the distributed transaction, including when it passes from service to service over the network or through a message bus. The span context contains the trace identifier, span identifier, and any other data that the tracing system needs to propagate to the downstream service.
-
-
-
-If you would like to dig into a detailed description of this mental model, please check out the [OpenTracing specification][4].
-
-### The four big pieces
-
-From the perspective of an application-layer distributed tracing system, a modern software system looks like the following diagram:
-
-![Tracing][5]
-
-The components in a modern software system can be broken down into three categories:
-
- * **Application and business logic:** Your code.
- * **Widely shared libraries:** Other people's code.
- * **Widely shared services:** Other people’s infrastructure.
-
-
-
-These three components have different requirements and drive the design of the Distributed Tracing systems which is tasked with monitoring the application. The resulting design yields four important pieces:
-
- * **A tracing instrumentation API:** What decorates application code.
- * **Wire protocol:** What gets sent alongside application data in RPC requests.
- * **Data protocol:** What gets sent asynchronously (out-of-band) to your analysis system.
- * **Analysis system:** A database and interactive UI for working with the trace data.
-
-
-
-To explain this further, we’ll dig into the details which drive this design. If you just want my suggestions, please skip to the four big solutions at the bottom.
-
-### Requirements, details, and explanations
-
-Application code, shared libraries, and shared services have notable operational differences, which heavily influence the requirements for instrumenting them.
-
-#### Instrumenting application code and business logic
-
-In any particular microservice, the bulk of the code written by the microservice developer is the application or business logic. This is the code that defines domain-specific operations; typically, it contains whatever special, unique logic justified the creation of a new microservice in the first place. Almost by definition, **this code is usually not shared or otherwise present in more than one service.**
-
-That said, you still need to understand it, and that means it needs to be instrumented somehow. Some monitoring and tracing analysis systems auto-instrument code using black-box agents, and others expect explicit "white-box" instrumentation. For the latter, abstract tracing APIs offer many practical advantages for microservice-specific application code:
-
- * An abstract API allows you to swap in new monitoring tools without re-writing instrumentation code. You may want to change cloud providers, vendors, and monitoring technologies, and a huge pile of non-portable instrumentation code would add meaningful overhead and friction to that procedure.
- * It turns out there are other interesting uses for instrumentation, beyond production monitoring. There are existing projects that use this same tracing instrumentation to power testing tools, distributed debuggers, “chaos engineering” fault injectors, and other meta-applications.
- * But most importantly, what if you wanted to extract an application component into a shared library? That leads us to:
-
-
-
-#### Instrumenting shared libraries
-
-The utility code present in most applications—code that handles network requests, database calls, disk writes, threading, queueing, concurrency management, and so on—is often generic and not specific to any particular application. This code is packaged up into libraries and frameworks which are then installed in many microservices, and deployed into many different environments.
-
-This is the real difference: with shared code, someone else is the user. Most users have different dependencies and operational styles. If you attempt to instrument this shared code, you will note a couple of common issues:
-
- * You need an API to write instrumentation. However, your library does not know what analysis system is being used. There are many choices, and all the libraries running in the same application cannot make incompatible choices.
- * The task of injecting and extracting span contexts from request headers often falls on RPC libraries, since those packages encapsulate all network-handling code. However, a shared library cannot not know which tracing protocol is being used by each application.
- * Finally, you don’t want to force conflicting dependencies on your user. Most users have different dependencies and operational styles. Even if they use gRPC, will it be the same version of gRPC you are binding to? So any monitoring API your library brings in for tracing must be free of dependencies.
-
-
-
-**So, an abstract API which (a) has no dependencies, (b) is wire protocol agnostic, and (c) works with popular vendors and analysis systems should be a requirement for instrumenting shared library code.**
-
-#### Instrumenting shared services
-
-Finally, sometimes entire services—or sets of microservices—are general-purpose enough that they are used by many independent applications. These shared services are often hosted and managed by third parties. Examples might be cache servers, message queues, and databases.
-
-It’s important to understand that **shared services are essentially "black boxes" from the perspective of application developers.** It is not possible to inject your application’s monitoring solution into a shared service. Instead, the hosted service often runs its own monitoring solution.
-
-### **The four big solutions**
-
-So, an abstracted tracing API would help libraries emit data and inject/extract Span Context. A standard wire protocol would help black-box services interconnect, and a standard data format would help separate analysis systems consolidate their data. Let's have a look at some promising options for solving these problems.
-
-#### Tracing API: The OpenTracing project
-
-#### As shown above, in order to instrument application code, a tracing API is required. And in order to extend that instrumentation to shared libraries, where most of the Span Context injection and extraction occurs, the API must be abstracted in certain critical ways.
-
-The [OpenTracing][2] project aims to solve this problem for library developers. OpenTracing is a vendor-neutral tracing API which comes with no dependencies, and is quickly gaining support from a large number of monitoring systems. This means that, increasingly, if libraries ship with native OpenTracing instrumentation baked in, tracing will automatically be enabled when a monitoring system connects at application startup.
-
-Personally, as someone who has been writing, shipping, and operating open source software for over a decade, it is profoundly satisfying to work on the OpenTracing project and finally scratch this observability itch.
-
-In addition to the API, the OpenTracing project maintains a growing list of contributed instrumentation, some of which can be found [here][6]. If you would like to get involved, either by contributing an instrumentation plugin, natively instrumenting your own OSS libraries, or just want to ask a question, please find us on [Gitter][7] and say hi.
-
-#### Wire Protocol: The trace-context HTTP headers
-
-In order for monitoring systems to interoperate, and to mitigate migration issues when changing from one monitoring system to another, a standard wire protocol is needed for propagating Span Context.
-
-The [w3c Distributed Trace Context Community Group][8] is hard at work defining this standard. Currently, the focus is on defining a set of standard HTTP headers. The latest draft of the specification can be found [here][9]. If you have questions for this group, the [mailing list][10] and [Gitter chatroom][11] are great places to go for answers.
-
-#### Data protocol (Doesn't exist yet!!)
-
-For black-box services, where it is not possible to install a tracer or otherwise interact with the program, a data protocol is needed to export data from the system.
-
-Work on this data format and protocol is currently at an early stage, and mostly happening within the context of the w3c Distributed Trace Context Working Group. There is particular interest is in defining higher-level concepts, such as RPC calls, database statements, etc, in a standard data schema. This would allow tracing systems to make assumptions about what kind of data would be available. The OpenTracing project is also working on this issue, by starting to define a [standard set of tags][12]. The plan is for these two efforts to dovetail with each other.
-
-Note that there is a middle ground available at the moment. For “network appliances” that the application developer operates, but does not want to compile or otherwise perform code modifications to, dynamic linking can help. The primary examples of this are service meshes and proxies, such as Envoy or NGINX. For this situation, an OpenTracing-compliant tracer can be compiled as a shared object, and then dynamically linked into the executable at runtime. This option is currently provided by the [C++ OpenTracing API][13]. For Java, an OpenTracing [Tracer Resolver][14] is also under development.
-
-These solutions work well for services that support dynamic linking, and are deployed by the application developer. But in the long run, a standard data protocol may solve this problem more broadly.
-
-#### Analysis system: A service for extracting insights from trace data
-
-Last but not least, there is now a cornucopia of tracing and monitoring solutions. A list of monitoring systems known to be compatible with OpenTracing can be found [here][15], but there are many more options out there. I would encourage you to research your options, and I hope you find the framework provided in this article to be useful when comparing options. In addition to rating monitoring systems based on their operational characteristics (not to mention whether you like the UI and features), make sure you think about the three big pieces above, their relative importance to you, and how the tracing system you are interested in provides a solution to them.
-
-### Conclusion
-
-In the end, how important each piece is depends heavily on who you are and what kind of system you are building. For example, open source library authors are very interested in the OpenTracing API, while service developers tend to be more interested in the Trace-Context specification. When someone says one piece is more important than the other, they usually mean “one piece is more important to me than the other."
-
-However, the reality is this: Distributed Tracing has become a necessity for monitoring modern systems. In designing the building blocks for these systems, the age-old approach—"decouple where you can"—still holds true. Cleanly decoupled components are the best way to maintain flexibility and forwards-compatibility when building a system as cross-cutting as a distributed monitoring system.
-
-Thanks for reading! Hopefully, now when you're ready to implement tracing in your own application, you have a guide to understanding which pieces they are talking about, and how they fit together.
-
-Want to learn more? Sign up to attend [KubeCon EU][16] in May or [KubeCon North America][17] in December.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/distributed-tracing
-
-作者:[Ted Young][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/tedsuo
-[1]:https://research.google.com/pubs/pub36356.html
-[2]:http://opentracing.io/
-[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/tracing1_0.png?itok=dvDTX0JJ (Tracing)
-[4]:https://github.com/opentracing/specification/blob/master/specification.md
-[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/tracing2_0.png?itok=yokjNLZk (Tracing)
-[6]:https://github.com/opentracing-contrib/
-[7]:https://gitter.im/opentracing/public
-[8]:https://www.w3.org/community/trace-context/
-[9]:https://w3c.github.io/distributed-tracing/report-trace-context.html
-[10]:http://lists.w3.org/Archives/Public/public-trace-context/
-[11]:https://gitter.im/TraceContext/Lobby
-[12]:https://github.com/opentracing/specification/blob/master/semantic_conventions.md
-[13]:https://github.com/opentracing/opentracing-cpp
-[14]:https://github.com/opentracing-contrib/java-tracerresolver
-[15]:http://opentracing.io/documentation/pages/supported-tracers
-[16]:https://events.linuxfoundation.org/kubecon-eu-2018/
-[17]:https://events.linuxfoundation.org/events/kubecon-cloudnativecon-north-america-2018/
diff --git a/sources/tech/20180507 Modularity in Fedora 28 Server Edition.md b/sources/tech/20180507 Modularity in Fedora 28 Server Edition.md
deleted file mode 100644
index 0b5fb0415b..0000000000
--- a/sources/tech/20180507 Modularity in Fedora 28 Server Edition.md
+++ /dev/null
@@ -1,76 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Modularity in Fedora 28 Server Edition)
-[#]: via: (https://fedoramagazine.org/wp-content/uploads/2018/05/f28-server-modularity-816x345.jpg)
-[#]: author: (Stephen Gallagher https://fedoramagazine.org/author/sgallagh/)
-
-Modularity in Fedora 28 Server Edition
-======
-
-
-
-### What is Modularity?
-
-A classic conundrum that all open-source distributions have faced is the “too fast/too slow” problem. Users install an operating system in order to enable the use of their applications. A comprehensive distribution like Fedora has an advantage and a disadvantage to the large amount of available software. While the package the user wants may be available, it might not be available in the version needed. Here’s how Modularity can help solve that problem.
-
-Fedora sometimes moves too fast for some users. Its rapid release cycle and desire to carry the latest stable software can result in breaking compatibility with applications. If a user can’t run a web application because Fedora upgraded a web framework to an incompatible version, it can be very frustrating. The classic answer to the “too fast” problem has been “Fedora should have an LTS release.” However, this approach only solves half the problem and makes the flip side of this conundrum worse.
-
-There are also times when Fedora moves too slowly for some of its users. For example, a Fedora release may be poorly-timed alongside the release of other desirable software. Once a Fedora release is declared stable, packagers must abide by the [Stable Updates Policy][1] and not introduce incompatible changes into the system.
-
-Fedora Modularity addresses both sides of this problem. Fedora will still ship a standard release under its traditional policy. However, it will also ship a set of modules that define alternative versions of popular software. Those in the “too fast” camp still have the benefit of Fedora’s newer kernel and other general platform enhancements. In addition, they still have access to older frameworks or toolchains that support their applications.
-
-In addition, those users who like to live closer to the edge can access newer software than was available at release time.
-
-### What is Modularity not?
-
-Modularity is not a drop-in replacement for [Software Collections][2]. These two technologies try to solve many of the same problems, but have distinct differences.
-
-Software Collections install different versions of packages in parallel on the system. However, their downside is that each installation exists in its own namespaced portion of the filesystem. Furthermore, each application that relies on them needs to be told where to find them.
-
-With Modularity, only one version of a package exists on the system, but the user can choose which one. The advantage is that this version lives in a standard location on the system. The package requires no special changes to applications that rely on it. Feedback from user studies shows most users don’t actually rely on parallel installation. Containerization and virtualization solve that problem.
-
-### Why not just use containers?
-
-This is another common question. Why would a user want modules when they could just use containers? The answer is, someone still has to maintain the software in the containers. Modules provide pre-packaged content for those containers that users don’t need to maintain, update and patch on their own. This is how Fedora takes the traditional value of a distribution and moves it into the new, containerized world.
-
-Here’s an example of how Modularity solves problems for users of Node.js and Review Board.
-
-### Node.js
-
-Many readers may be familiar with Node.js, a popular server-side JavaScript runtime. Node.js has an even/odd release policy. Its community supports even-numbered releases (6.x, 8.x, 10.x, etc.) for around 30 months. Meanwhile, they support odd-numbered releases that are essentially developer previews for 9 months.
-
-Due to this cycle, Fedora carried only the most recent even-numbered version of Node.js in its stable repositories. It avoided the odd-numbered versions entirely since their lifecycle was shorter than Fedora, and generally not aligned with a Fedora release. This didn’t sit well with some Fedora users, who wanted access to the latest and greatest enhancements.
-
-Thanks to Modularity, Fedora 28 shipped with not just one, but three versions of Node.js to satisfy both developers and stable deployments. Fedora 28’s traditional repository shipped with Node.js 8.x. This version was the most recent long-term stable version at release time. The Modular repositories (available by default on Fedora 28 Server edition) also made the older Node.js 6.x release and the newer Node.js 9.x development release available.
-
-Additionally, Node.js released 10.x upstream just days after Fedora 28\. In the past, users who wanted to deploy that version had to wait until Fedora 29, or use sources from outside Fedora. However, thanks again to Modularity, Node.js 10.x is already [available][3] in the Modular Updates-Testing repository for Fedora 28.
-
-### Review Board
-
-Review Board is a popular Django application for performing code reviews. Fedora included Review Board from Fedora 13 all the way until Fedora 21\. At that point, Fedora moved to Django 1.7\. Review Board was unable to keep up, due to backwards-incompatible changes in Django’s database support. It remained alive in EPEL for RHEL/CentOS 7, simply because those releases had fortunately frozen on Django 1.6\. Nevertheless, its time in Fedora was apparently over.
-
-However, with the advent of Modularity, Fedora could again ship the older Django as a non-default module stream. As a result, Review Board has been restored to Fedora as a module. Fedora carries both supported releases from upstream: 2.5.x and 3.0.x.
-
-### Putting the pieces together
-
-Fedora has always provided users with a wide range of software to use. Fedora Modularity now provides them with deeper choices for which versions of the software they need. The next few years will be very exciting for Fedora, as developers and users start putting together their software in new and exciting (or old and exciting) ways.
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/wp-content/uploads/2018/05/f28-server-modularity-816x345.jpg
-
-作者:[Stephen Gallagher][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/sgallagh/
-[b]: https://github.com/lujun9972
-[1]: https://fedoraproject.org/wiki/Updates_Policy#Stable_Releases
-[2]: https://www.softwarecollections.org
-[3]: https://bodhi.fedoraproject.org/updates/FEDORA-MODULAR-2018-2b0846cb86
diff --git a/sources/tech/20180507 Multinomial Logistic Classification.md b/sources/tech/20180507 Multinomial Logistic Classification.md
deleted file mode 100644
index 01fb7b2e90..0000000000
--- a/sources/tech/20180507 Multinomial Logistic Classification.md
+++ /dev/null
@@ -1,215 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Multinomial Logistic Classification)
-[#]: via: (https://www.jtolio.com/2018/05/multinomial-logistic-classification)
-[#]: author: (jtolio.com https://www.jtolio.com/)
-
-Multinomial Logistic Classification
-======
-
-_This article was originally a problem I wrote for a coding competition I hosted, Vivint’s 2017 Game of Codes (now offline). The goal of this problem was not only to be a fun challenge but also to teach contestants almost everything they needed to know to build a neural network from scratch. I thought it might be neat to revive on my site! If machine learning is still scary sounding and foreign to you, you should feel much more at ease after working through this problem. I left out the details of [back-propagation][1], and a single-layer neural network isn’t really a neural network, but in this problem you can learn how to train and run a complete model! There’s lots of maybe scary-looking math but honestly if you can [multiply matrices][2] you should be fine._
-
-In this problem, you’re going to build and train a machine learning model… from scratch! Don’t be intimidated - it will be much easier than it sounds!
-
-### What is machine learning?
-
-_Machine learning_ is a broad and growing range of topics, but essentially the idea is to teach the computer how to find patterns in large amounts of data, then use those patterns to make predictions. Surprisingly, the techniques that have been developed allow computers to translate languages, drive cars, recognize cats, synthesize voice, understand your music tastes, cure diseases, and even adjust your thermostat!
-
-You might be surprised to learn that since about 2010, the entire artificial intelligence and machine learning community has reorganized around a surprisingly small and common toolbox for all of these problems. So, let’s dive in to this toolbox!
-
-### Classification
-
-One of the most fundamental ways of solving problems in machine learning is by recasting problems as _classification_ problems. In other words, if you can describe a problem as data that needs labels, you can use machine learning!
-
-Machine learning will go through a phase of _training_, where data and existing labels are provided to the system. As a motivating example, imagine you have a large collection of photos that either contain hot dogs or don’t. Some of your photos have already been labeled if they contain a hot dog or not, but the other photos we want to build a system that will automatically label them “hotdog” or “nothotdog.” During training, we attempt to build a model of what exactly the essence of each label is. In this case, we will run all of our existing labeled photos through the system so it can learn what makes a hot dog a hot dog.
-
-After training, we run the unseen photos through the model and use the model to generate classifications. If you provide a new photo to your hotdog/nothotdog model, your model should be able to tell you if the photo contains a hot dog, assuming your model had a good training data set and was able to capture the core concept of what a hot dog is.
-
-Many different types of problems can be described as classification problems. As an example, perhaps you want to predict which word comes next in a sequence. Given four input words, a classifier can label those four words as “likely the fourth word follows the last three words” or “not likely.” Alternatively, the classification label for three words could be the most likely word to follow those three.
-
-### How I learned to stop worrying and love multinomial logistic classification
-
-Okay, let’s do the simplest thing we can think of to take input data and classify it.
-
-Let’s imagine our data that we want to classify is a big list of values. If what we have is a 16 by 16 pixel picture, we’re going to just put all the pixels in one big row so we have 256 pixel values in a row. So we’ll say \\(\mathbf{x}\\) is a vector in 256 dimensions, and each dimension is the pixel value.
-
-We have two labels, “hotdog” and “nothotdog.” Just like any other machine learning system, our system will never be 100% confident with a classification, so we will need to output confidence probabilities. The output of our system will be a two-dimensional vector, \\(\mathbf{p}\\). \\(p_0\\) will represent the probability that the input should be labeled “hotdog” and \\(p_1\\) will represent the probability that the input should be labeled “nothotdog.”
-
-How do we take a vector in 256 (or \\(\dim(\mathbf{x})\\)) dimensions and make something in just 2 (or \\(\dim(\mathbf{p})\\)) dimensions? Why, [matrix multiplication][2] of course! If you have a matrix with 2 rows and 256 columns, multiplying it by a 256-dimensional vector will result in a 2-dimensional one.
-
-Surprisingly, this is actually really close to the final construction of our classifier, but there are two problems:
-
- 1. If one of the input \\(\mathbf{x}\\)s is all zeros, the output will have to be zeros. But we need one of the output dimensions to not be zero!
- 2. There’s nothing guaranteeing the probabilities in the output will be non-negative and all sum to 1.
-
-
-
-The first problem is easy, we add a bias vector \\(\mathbf{b}\\), turning our matrix multiplication into a standard linear equation of the form \\(\mathbf{W}\cdot\mathbf{x}+\mathbf{b}=\mathbf{y}\\).
-
-The second problem can be solved by using the [softmax function][3]. For a given vector \\(\mathbf{v}\\), softmax is defined as:
-
-In case the \\(\sum\\) scares you, \\(\sum_{j=0}^{n-1}\\) is basically a math “for loop.” All it’s saying is that we’re going to add together everything that comes after it (\\(e^{v_j}\\)) for every \\(j\\) value from 0 to \\(n-1\\).
-
-Softmax is a neat function! The output will be a vector where the largest dimension in the input will be the closest number to 1, no dimensions will be less than zero, and all dimensions sum to 1. Here are some examples:
-
-Unbelievably, these are all the building blocks you need for a linear model! Let’s put all the blocks together. If you already have \\(\mathbf{W}\cdot\mathbf{x}+\mathbf{b}=\mathbf{y}\\), your prediction \\(\mathbf{p}\\) can be found as \\(\text{softmax}\left(\mathbf{y}\right)\\). More fully, given an input \\(\mathbf{x}\\) and a trained model \\(\left(\mathbf{W},\mathbf{b}\right)\\), your prediction \\(\mathbf{p}\\) is:
-
-Once again, in this context, \\(p_0\\) is the probability given the model that the input should be labeled “hotdog” and \\(p_1\\) is the probability given the model that the input should be labeled “nothotdog.”
-
-It’s kind of amazing that all you need for good success with things even as complex as handwriting recognition is a linear model such as this one.
-
-### Scoring
-
-How do we find \\(\mathbf{W}\\) and \\(\mathbf{b}\\)? It might surprise you but we’re going to start off by guessing some random numbers and then changing them until we aren’t predicting things too badly (via a process known as [gradient descent][4]). But what does “too badly” mean?
-
-Recall that we have data that we’ve already labeled. We already have photos labeled “hotdog” and “nothotdog” in what’s called our _training set_. For each photo, we’re going to take whatever our current model is (\\(\mathbf{W}\\) and \\(\mathbf{b}\\)) and find \\(\mathbf{p}\\). Perhaps for one photo (that really is of a hot dog) our \\(\mathbf{p}\\) looks like this:
-
-This isn’t great! Our model says that the photo should be labeled “nothotdog” with 60% probability, but it is a hot dog.
-
-We need a bit more terminology. So far, we’ve only talked about one sample, one label, and one prediction at a time, but obviously we have lots of samples, lots of labels, and lots of predictions, and we want to score how our model does not just on one sample, but on all of our training samples. Assume we have \\(s\\) training samples, each sample has \\(d\\) dimensions, and there are \\(l\\) labels. In the case of our 16 by 16 pixel hot dog photos, \\(d = 256\\) and \\(l = 2\\). We’ll refer to sample \\(i\\) as \\(\mathbf{x}^{(i)}\\), our prediction for sample \\(i\\) as \\(\mathbf{p}^{(i)}\\), and the correct label vector for sample \\(i\\) as \\(\mathbf{L}^{(i)}\\). \\(\mathbf{L}^{(i)}\\) is a vector that is all zeros except for the dimension corresponding to the correct label, where that dimension is a 1. In other words, we have \\(\mathbf{W}\cdot\mathbf{x}^{(i)}+\mathbf{b} = \mathbf{p}^{(i)}\\) and we want \\(\mathbf{p}^{(i)}\\) to be as close to \\(\mathbf{L}^{(i)}\\) as possible, for all \\(s\\) samples.
-
-To score our model, we’re going to compute something called the _average cross entropy loss_. In general, [loss][5] is used to mean how off the mark a machine learning model is. While there are many ways of calculating loss, we’re going to use average [cross entropy][6] because it has some nice properties.
-
-Here’s the definition of the average cross entropy loss across all samples:
-
-All we need to do is find \\(\mathbf{W}\\) and \\(\mathbf{b}\\) that make this loss smallest. How do we do that?
-
-### Training
-
-As we said before, we will start \\(\mathbf{W}\\) and \\(\mathbf{b}\\) off with random values. For each value, choose a floating-point random number between -1 and 1.
-
-Of course, we’ll need to correct these values given the training data, and we now have enough information to describe how we will back-propagate corrections.
-
-The plan is to process all of the training data enough times that the loss drops to an “acceptable level.” Each time through the training data we’ll collect all of the predictions, and at the end we’ll update \\(\mathbf{W}\\) and \\(\mathbf{b}\\) with the information we’ve found.
-
-One problem that can occur is that your model might overcorrect after each run. A simple way to limit overcorrection some is to add a “learning rate”, usually designated \\(\alpha\\), which is some small fraction. You get to choose the learning rate! A good default choice for \\(\alpha\\) is 0.1.
-
-At the end of each run through all of the training data, here’s how you update \\(\mathbf{W}\\) and \\(\mathbf{b}\\):
-
-Just because this syntax is starting to get out of hand, let’s refresh what each symbol means.
-
- * \\(W_{m,n}\\) is the cell in weight matrix \\(\mathbf{W}\\) at row \\(m\\) and column \\(n\\).
- * \\(b_m\\) is the \\(m\\)-th dimension in the “bias” vector \\(\mathbf{b}\\).
- * \\(\alpha\\) is again your learning rate, 0.1, and \\(s\\) is how many training samples you have.
- * \\(x_n^{(i)}\\) is the \\(n\\)-th dimension of sample \\(i\\).
- * Likewise, \\(p_m^{(i)}\\) and \\(L_m^{(i)}\\) are the \\(m\\)-th dimensions of our prediction and true labels for sample \\(i\\), respectively. Remember that for each sample \\(i\\), \\(L_m^{(i)}\\) is zero for all but the dimension corresponding to the correct label, where it is 1.
-
-
-
-If you’re curious how we got these equations, we applied the [chain rule][7] to calculate partial derivatives of the total loss. It’s hairy, and this problem description is already too long!
-
-Anyway, once you’ve updated your \\(\mathbf{W}\\) and \\(\mathbf{b}\\), you start the whole process over!
-
-### When do we stop?
-
-Knowing when to stop is a hard problem. How low your loss goes is a function of your learning rate, how many iterations you run over your training data, and a huge number of other factors. On the flip side, if you train your model so your loss is too low, you run the risk of overfitting your model to your training data, so it won’t work well on data it hasn’t seen before.
-
-One of the more common ways of deciding when to [stop training][8] is to have a separate validation set of samples we check our success on and stop when we stop improving. But for this problem, to keep things simple what we’re going to do is just keep track of how our loss changes and stop when the loss stops changing as much.
-
-After the first 10 iterations, your loss will have changed 9 times (there was no change from the first time since it was the first time). Take the average of those 9 changes and stop training when your loss change is less than a hundredth the average loss change.
-
-### Tie it all together
-
-Alright! If you’ve stuck with me this far, you’ve learned to implement a multinomial logistic classifier using gradient descent, [back-propagation][1], and [one-hot encoding][9]. Good job!
-
-You should now be able to write a program that takes labeled training samples, trains a model, then takes unlabeled test samples and predicts labels for them!
-
-### Your program
-
-As input your program should take vectors of floating-point values, followed by a label. Some of the labels will be question marks. Your program should output the correct label for all of the question marks it sees. The label your program should output will always be one it has seen training examples of.
-
-Your program will pass the tests if it labels 75% or more of the unlabeled data correctly.
-
-### Where to learn more
-
-If you want to learn more or dive deeper into optimizing your solution, you may be interested in the first section of [Udacity’s free course on Deep Learning][10], or [Dom Luma’s tutorial on building a mini-TensorFlow][11].
-
-### Example
-
-#### Input
-
-```
- 0.93 -1.52 1.32 0.05 1.72 horse
- 1.57 -1.74 0.92 -1.33 -0.68 staple
- 0.18 1.24 -1.53 1.53 0.78 other
- 1.96 -1.29 -1.50 -0.19 1.47 staple
- 1.24 0.15 0.73 -0.22 1.15 battery
- 1.41 -1.56 1.04 1.09 0.66 horse
--0.70 -0.93 -0.18 0.75 0.88 horse
- 1.12 -1.45 -1.26 -0.43 -0.05 staple
- 1.89 0.21 -1.45 0.47 0.62 other
--0.60 -1.87 0.82 -0.66 1.86 staple
--0.80 -1.99 1.74 0.65 1.46 horse
--0.03 1.35 0.11 -0.92 -0.04 battery
--0.24 -0.03 0.58 1.32 -1.51 horse
--0.60 -0.70 1.61 0.56 -0.66 horse
- 1.29 -0.39 -1.57 -0.45 1.63 staple
- 0.87 1.59 -1.61 -1.79 1.47 battery
- 1.86 1.92 0.83 -0.34 1.06 battery
--1.09 -0.81 1.47 1.82 0.06 horse
--0.99 -1.00 -1.45 -1.02 -1.06 staple
--0.82 -0.56 0.82 0.79 -1.02 horse
--1.86 0.77 -0.58 0.82 -1.94 other
- 0.15 1.18 -0.87 0.78 2.00 other
- 1.18 0.79 1.08 -1.65 -0.73 battery
- 0.37 1.78 0.01 0.06 -0.50 other
--0.35 0.31 1.18 -1.83 -0.57 battery
- 0.91 1.14 -1.85 0.39 0.07 other
--1.61 0.28 -0.31 0.93 0.77 other
--0.11 -1.75 -1.66 -1.55 -0.79 staple
- 0.05 1.03 -0.23 1.49 1.66 other
--1.99 0.43 -0.99 1.72 0.52 other
--0.30 0.40 -0.70 0.51 0.07 other
--0.54 1.92 -1.13 -1.53 1.73 battery
--0.52 0.44 -0.84 -0.11 0.10 battery
--1.00 -1.82 -1.19 -0.67 -1.18 staple
--1.81 0.10 -1.64 -1.47 -1.86 battery
--1.77 0.53 -1.28 0.55 -1.15 other
- 0.29 -0.28 -0.41 0.70 1.80 horse
--0.91 0.02 1.60 -1.44 -1.89 battery
- 1.24 -0.42 -1.30 -0.80 -0.54 staple
--1.98 -1.15 0.54 -0.14 -1.24 staple
- 1.26 -1.02 -1.08 -1.27 1.65 ?
- 1.97 1.14 0.51 0.96 -0.36 ?
- 0.99 0.14 -0.97 -1.90 -0.87 ?
- 1.54 -1.83 1.59 1.98 -0.41 ?
--1.81 0.34 -0.83 0.90 -1.60 ?
-```
-
-#### Output
-
-```
-staple
-other
-battery
-horse
-other
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.jtolio.com/2018/05/multinomial-logistic-classification
-
-作者:[jtolio.com][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.jtolio.com/
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Backpropagation
-[2]: https://en.wikipedia.org/wiki/Matrix_multiplication
-[3]: https://en.wikipedia.org/wiki/Softmax_function
-[4]: https://en.wikipedia.org/wiki/Gradient_descent
-[5]: https://en.wikipedia.org/wiki/Loss_function
-[6]: https://en.wikipedia.org/wiki/Cross_entropy
-[7]: https://en.wikipedia.org/wiki/Chain_rule
-[8]: https://en.wikipedia.org/wiki/Early_stopping
-[9]: https://en.wikipedia.org/wiki/One-hot
-[10]: https://classroom.udacity.com/courses/ud730
-[11]: https://nbviewer.jupyter.org/github/domluna/labs/blob/master/Build%20Your%20Own%20TensorFlow.ipynb
diff --git a/sources/tech/20180509 4MLinux Revives Your Older Computer [Review].md b/sources/tech/20180509 4MLinux Revives Your Older Computer [Review].md
deleted file mode 100644
index c016466414..0000000000
--- a/sources/tech/20180509 4MLinux Revives Your Older Computer [Review].md
+++ /dev/null
@@ -1,114 +0,0 @@
-4MLinux Revives Your Older Computer [Review]
-======
-**Brief:** 4MLinux is a lightweight Linux distribution that can turn your old computer into a functional one with multimedia support, maintenance tools and classic games.
-
-As more and more [Linux distributions drop the support for 32-bit systems][1], you may wonder what would you do with that old computer of yours. Thankfully, there are plenty of [lightweight Linux distributions][2] that could put those old computers for some regular computing tasks such as playing small games, watching movies, listening to music and surfing web.
-
-[4MLinux][3] is one such Linux distribution that requires fewer system resources and can even run on 128 MB of RAM. The desktop edition comes only for 32-bit architecture while the server edition is of 64-bit.
-
-4MLinux can also be used as a rescue CD along with serving as a full-fledged working system or as a mini-server.
-
-![4MLinux Review][4]
-
-It is named 4MLinux because it focuses mainly on four points, called the “4 M”:
-
- * Maintenance – You can use 4MLinux as a rescue Live CD.
- * Multimedia – There is inbuilt support for almost every multimedia format, be it for Image, Audio and Video.
- * Miniserver – A 64-bit server is included running LAMP suite, which can be enabled from the Application Menu.
- * Mystery – Includes a collection of classic Linux games.
-
-
-
-Most of the Linux distributions are either based on Debian with DEB packages or Fedora with RPM. 4MLinux, on the other hand, does not rely on these package management systems, is pretty damn fast and works quite well on older systems.
-
-### 4MLinux
-
-The 4MLinux Desktop comes with a variety of [lightweight applications][5] so that it could work on older hardware. [JWM][6] – Joe’s Windows Manager, which is a lightweight stacking windows manager for [X Window System][7]. For managing the desktop wallpapers, a lightweight and powerful [feh][8] is used. It uses [PCMan File Manager][9] which is a standard file manager for [LXDE][10] too.
-
-#### Installing 4MLinux is quick
-
-I grabbed the ISO from 4MLinux website and used [MultiBootUSB][11] to create a bootable drive and live booted with it.
-
-4MLinux do not use the grub or grub2 bootloader but uses **LI** nux **LO** ader ([LILO][12]) bootloader. The main advantage of LILO is that it allows fast boot-ups for a Linux system.
-
-Now to install the 4MLinux, you will have to manually create a partition. Go to **Maintenance - > Partitions -> GParted**. Click on **Device - > Create Partition Table**. Once done, click on **New** , leave the settings to default and click on **Add**. Click on **Apply** to save the settings and close it.
-
-Next step is to go to 4MLinux -> Installer and it will launch a text-based installer.
-
-![][13]
-
-Identify the partition you have created for the default partition to install 4MLinux and follow the instructions to complete the installation.
-
-Surprisingly, the installation took less than a minute. Restart your system and remove the live USB and you will be greeted with this desktop.
-
-![][14]
-
-#### Experiencing 4MLinux
-
-The default desktop screen has a dock at the top with most common applications pinned. There is a taskbar, a [Conky theme][15] with option to turn it on/off in the dock and a clock at the bottom right corner. Left click on the desktop opens the application menu.
-
-The CPU usage was too minimal with less than 2% and RAM was less than 100 MB.
-
-4MLinux comes with a number of applications tabbed under different sections. There is Transmission for torrent downloads, Tor is included by default and Bluetooth support is there.
-
-Under Maintenance, there are options to backup the system and recover using TestDisk and GNUddrescue, CD burning tools are available along with partitioning tools. There are a number of Monitoring tools and Clam Antivirus.
-
-Multimedia section includes various video and music players and mixers, image viewers and editors and tools for digital cameras.
-
-Mystery section is interesting. It includes a number of [console games][16] like Snake, Tetris, Mines, Casino etc.
-
-Under Settings, you can select your preferences for display and others, networking, Desktop and choose default applications. The default desktop resolution was 1024×768 at the highest, so that might disappoint you.
-
-Some of the applications are not installed by default. Launching it gives you an option to install it. But that’s about it. Since there is no package manager here, you are limited to the available applications. If you want more software that are not available in the system, you’ll have to [install it from source code][17].
-
-This is by design because 4MLinux is focused on providing only essential desktop experience. A small handful selection of lightweight applications fit in its ecosystem.
-
-#### Download 4M Linux
-
-The Download section features the 32-bit stable 4MLinux and its beta version, 64bit 4MServer and a 4MRescueKit. Although the ISO size is over 1GB, 4mlinux is very light in its design.
-
-[Download 4MLinux][18]
-
-There is a [separate page to downloaded additional drivers][19]. For any other missing drivers, while you launch an application, 4MLinux asks you to download and install it.
-
-#### Final thoughts on 4MLinux
-
-4MLinux has look and feel of an old-school Linux system but the desktop is super fast. I was able to run it on an Intel Dual Core processor desktop with ease and most of the things worked. WiFi was connecting fine; the application section included most of the software I use on daily basis and the retro games section was pretty cool.
-
-The one negative point was the limitation of available application. If you can manage with the handful of applications, 4MLinux can be seen as one of the best Linux distribution for older systems and for the people who don’t prefer going in the technicality even for once.
-
-Fast boot makes it an ideal rescue disc!
-
-Let us know in the comment section. What do you think of 4MLinux? Are you willing to give it a try? Let us know in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/4mlinux-review/
-
-作者:[Ambarish Kumar][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/ambarish/
-[1]:https://itsfoss.com/32-bit-os-list/
-[2]:https://itsfoss.com/lightweight-linux-beginners/
-[3]:http://4mlinux.com/
-[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/4minux-review-feature-800x450.jpeg
-[5]:https://itsfoss.com/lightweight-alternative-applications-ubuntu/
-[6]:https://joewing.net/projects/jwm/
-[7]:https://en.wikipedia.org/wiki/X_Window_System
-[8]:https://feh.finalrewind.org/
-[9]:https://wiki.lxde.org/en/PCManFM
-[10]:https://lxde.org/
-[11]:https://itsfoss.com/multiple-linux-one-usb/
-[12]:https://en.wikipedia.org/wiki/LILO_(boot_loader)
-[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/4MLinux-installer.png
-[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/2-800x600.jpg
-[15]:https://itsfoss.com/conky-gui-ubuntu-1304/
-[16]:https://itsfoss.com/best-command-line-games-linux/
-[17]:https://itsfoss.com/install-software-from-source-code/
-[18]:http://4mlinux.com/index.php?page=download
-[19]:http://sourceforge.net/projects/linux4m/files/24.0/drivers/
diff --git a/sources/tech/20180511 MidnightBSD Could Be Your Gateway to FreeBSD.md b/sources/tech/20180511 MidnightBSD Could Be Your Gateway to FreeBSD.md
deleted file mode 100644
index 5aff6be9eb..0000000000
--- a/sources/tech/20180511 MidnightBSD Could Be Your Gateway to FreeBSD.md
+++ /dev/null
@@ -1,180 +0,0 @@
-Translating by robsean
-MidnightBSD Could Be Your Gateway to FreeBSD
-======
-
-
-[FreeBSD][1] is an open source operating system that descended from the famous [Berkeley Software Distribution][2]. The first version of FreeBSD was released in 1993 and is still going strong. Around 2007, Lucas Holt wanted to create a fork of FreeBSD that made use of the [GnuStep][3] implementation of the OpenStep (now Cocoa) Objective-C frameworks, widget toolkit, and application development tools. To that end, he began development of the MidnightBSD desktop distribution.
-
-MidnightBSD (named after Lucas’s cat, Midnight) is still in active (albeit slow) development. The latest stable release (0.8.6) has been available since August, 2017. Although the BSD distributions aren’t what you might call user-friendly, getting up to speed on their installation is a great way to familiarize yourself with how to deal with an ncurses installation and with finalizing an install via the command line.
-
-In the end, you’ll wind up with desktop distribution of a very reliable fork of FreeBSD. It’ll take a bit of work, but if you’re a Linux user looking to stretch your skills… this is a good place to start.
-
-I want to walk you through the process of installing MidnightBSD, how to add a graphical desktop environment, and then how to install applications.
-
-### Installation
-
-As I mentioned, this is an ncurses installation process, so there is no point-and-click to be found. Instead, you’ll be using your keyboard Tab and arrow keys. Once you’ve downloaded the [latest release][4], burn it to a CD/DVD or USB drive and boot your machine (or create a virtual machine in [VirtualBox][5]). The installer will open and give you three options (Figure 1). Select Install (using your keyboard arrow keys) and hit Enter.
-
-
-![MidnightBSD installer][7]
-
-Figure 1: Launching the MidnightBSD installer.
-
-[Used with permission][8]
-
-At this point, there are quite a lot of screens to go through. Many of those screens are self-explanatory:
-
- 1. Set non-default key mapping (yes/no)
-
- 2. Set hostname
-
- 3. Add optional system components (documentation, games, 32-bit compatibility, system source code)
-
- 4. Partitioning hard drive
-
- 5. Administrator password
-
- 6. Configure networking interface
-
- 7. Select region (for timezone)
-
- 8. Enable services (such as secure shell)
-
- 9. Add users (Figure 2)
-
-
-
-
-![Adding a user][10]
-
-Figure 2: Adding a user to the system.
-
-[Used with permission][8]
-
-After you’ve added the user(s) to the system, you will then be dropped to a window (Figure 3), where you can take care of anything you might have missed or you want to re-configure. If you don’t need to make any changes, select Exit, and your configurations will be applied.
-
-In the next window, when prompted, select No, and the system will reboot. Once MidnightBSD reboots, you’re ready for the next phase of the installation.
-
-### Post install
-
-When your newly installed MidnightBSD boots, you’ll find yourself at a command prompt. At this point, there is no graphical interface to be found. To install applications, MidnightBSD relies on the mport tool. Let’s say you want to install the Xfce desktop environment. To do this, log into MidnightBSD and issue the following commands:
-```
-sudo mport index
-
-sudo mport install xorg
-
-```
-
-You now have the Xorg window server installed, which will allow you to install the desktop environment. Installing Xfce is handled with the command:
-```
-sudo mport install xfce
-
-```
-
-Xfce is now installed. However, we must enable it to run with the command startx. To do this, let’s first install the nano editor. Issue the command:
-```
-sudo mport install nano
-
-```
-
-With nano installed, issue the command:
-```
-nano ~/.xinitrc
-
-```
-
-That file need only contain a single line:
-```
-exec startxfce4
-
-```
-
-Save and close that file. If you now issue the command startx, the Xfce desktop environment will start. You should start to feel a bit more at home (Figure 4).
-
-![ Xfce][12]
-
-Figure 4: The Xfce desktop interface is ready to serve.
-
-[Used with permission][8]
-
-Since you don’t want to always have to issue the command startx, you’ll want to enable the login daemon. However, it’s not installed. To install this subsystem, issue the command:
-```
-sudo mport install mlogind
-
-```
-
-When the installation completes, enable mlogind at boot by adding an entry to the /etc/rc.conf file. At the bottom of the rc.conf file, add the following:
-```
-mlogind_enable=”YES”
-
-```
-
-Save and close that file. Now, when you boot (or reboot) the machine, you should be greeted by the graphical login screen. At the time of writing, after logging in, I wound up with a blank screen and the dreaded X cursor. Unfortunately, it seems there’s no fix for this at the moment. So, to gain access to your desktop environment, you must make use of the startx command.
-
-### Installing
-
-Out of the box, you won’t find much in the way of applications. If you attempt to install applications (using mport), you’ll quickly find yourself frustrated, as very few applications can be found. To get around this, we need to check out the list of available mport software, using the svnlite command. Go back to the terminal window and issue the command:
-```
-svnlite co http://svn.midnightbsd.org/svn/mports/trunk mports
-
-```
-
-Once you do that, you should see a new directory named ~/mports. Change into that directory (with the command cd ~/.mports. Issue the ls command and you should see a number of categories (Figure 5).
-
-![applications][14]
-
-Figure 5: The categories of applications now available for mport.
-
-[Used with permission][8]
-
-Say you want to install Firefox? If you look in the www directory, you’ll see a listing for linux-firefox. Issue the command:
-```
-sudo mport install linux-firefox
-
-```
-
-You should now see an entry for Firefox in the Xfce desktop menu. Go through all of the categories and install all of the software you need, using the mport command.
-
-### A sad caveat
-
-One sad little caveat is that the only version of an office suite to be found for mport (via svnlite) is OpenOffice 3. That’s quite out of date. And although Abiword is found in the ~/mports/editors directory, it seems it’s not available for installation. Even after installing OpenOffice 3, it errors out with an Exec format error. In other words, you won’t be doing much in the way of office productivity with MidnightBSD. But, hey, if you have an old Palm Pilot lying around, you can always install pilot-link. In other words, the available software doesn’t make for an incredibly useful desktop distribution… at least not for the average user. However, if you want to develop on MidnightBSD, you’ll find plenty of available tools, ready to install (check out the ~/mports/devel directory). You could even install Drupal with the command:
-
-sudo mport install drupal7
-
-Of course, after that you’ll need to create a database (MySQL is already installed), install Apache (sudo mport install apache24) and configure the necessary Apache directives.
-
-Clearly, what is installed and what can be installed is a bit of a hodgepodge of applications, systems, and servers. But with enough work, you could wind up with a distribution that could serve a specific purpose.
-
-### Enjoy the *BSD Goodness
-
-And that is how you can get MidnightBSD up and running into a somewhat useful desktop distribution. It’s not as quick and easy as many other Linux distributions, but if you want a distribution that’ll make you think, this could be exactly what you’re looking for. Although much of the competition has quite a bit more available software titles ready for installation, MidnightBSD is certainly an interesting challenge that every Linux enthusiast or admin should try.
-
-Learn more about Linux through the free ["Introduction to Linux" ][15]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/5/midnightbsd-could-be-your-gateway-freebsd
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.freebsd.org/
-[2]:https://en.wikipedia.org/wiki/Berkeley_Software_Distribution
-[3]:https://en.wikipedia.org/wiki/GNUstep
-[4]:http://www.midnightbsd.org/download/
-[5]:https://www.virtualbox.org/
-[6]:/files/images/midnight1jpg
-[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/midnight_1.jpg?itok=BRfGIEk_ (MidnightBSD installer)
-[8]:/licenses/category/used-permission
-[9]:/files/images/midnight2jpg
-[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/midnight_2.jpg?itok=xhxHlNJr (Adding a user)
-[11]:/files/images/midnight4jpg
-[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/midnight_4.jpg?itok=DNqA47s_ ( Xfce)
-[13]:/files/images/midnight5jpg
-[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/midnight_5.jpg?itok=LpavDHQP (applications)
-[15]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180514 An introduction to the Pyramid web framework for Python.md b/sources/tech/20180514 An introduction to the Pyramid web framework for Python.md
deleted file mode 100644
index a16e604774..0000000000
--- a/sources/tech/20180514 An introduction to the Pyramid web framework for Python.md
+++ /dev/null
@@ -1,617 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (An introduction to the Pyramid web framework for Python)
-[#]: via: (https://opensource.com/article/18/5/pyramid-framework)
-[#]: author: (Nicholas Hunt-Walker https://opensource.com/users/nhuntwalker)
-[#]: url: ( )
-
-An introduction to the Pyramid web framework for Python
-======
-In the second part in a series comparing Python frameworks, learn about Pyramid.
-
-
-In the [first article][1] in this four-part series comparing different Python web frameworks, I explained how to create a To-Do List web application in the [Flask][2] web framework. In this second article, I'll do the same task with the [Pyramid][3] web framework. Future articles will look at [Tornado][4] and [Django][5]; as I go along, I'll explore more of the differences among them.
-
-### Installing, starting up, and doing configuration
-
-Self-described as "the start small, finish big, stay finished framework," Pyramid is much like Flask in that it takes very little effort to get it up and running. In fact, you'll recognize many of the same patterns as you build out this application. The major difference between the two, however, is that Pyramid comes with several useful utilities, which I'll describe shortly.
-
-To get started, create a virtual environment and install the package.
-
-```
-$ mkdir pyramid_todo
-$ cd pyramid_todo
-$ pipenv install --python 3.6
-$ pipenv shell
-(pyramid-someHash) $ pipenv install pyramid
-```
-
-As with Flask, it's smart to create a `setup.py` file to make the app you build an easily installable Python distribution.
-
-```
-# setup.py
-from setuptools import setup, find_packages
-
-requires = [
- 'pyramid',
- 'paster_pastedeploy',
- 'pyramid-ipython',
- 'waitress'
-]
-
-setup(
- name='pyramid_todo',
- version='0.0',
- description='A To-Do List build with Pyramid',
- author='<Your name>',
- author_email='<Your email>',
- keywords='web pyramid pylons',
- packages=find_packages(),
- include_package_data=True,
- install_requires=requires,
- entry_points={
- 'paste.app_factory': [
- 'main = todo:main',
- ]
- }
-)
-```
-
-`entry_points` section near the end sets up entry points into the application that other services can use. This allows the `plaster_pastedeploy` package to access what will be the `main` function in the application for building an application object and serving it. (I'll circle back to this in a bit.)
-
-Thesection near the end sets up entry points into the application that other services can use. This allows thepackage to access what will be thefunction in the application for building an application object and serving it. (I'll circle back to this in a bit.)
-
-When you installed `pyramid`, you also gained a few Pyramid-specific shell commands; the main ones to pay attention to are `pserve` and `pshell`. `pserve` will take an INI-style configuration file specified as an argument and serve the application locally. `pshell` will also take a configuration file as an argument, but instead of serving the application, it'll open up a Python shell that is aware of the application and its internal configuration.
-
-The configuration file is pretty important, so it's worth a closer look. Pyramid can take its configuration from environment variables or a configuration file. To avoid too much confusion around what is where, in this tutorial you'll write most of your configuration in the configuration file, with only a select few, sensitive configuration parameters set in the virtual environment.
-
-Create a file called `config.ini`
-
-```
-[app:main]
-use = egg:todo
-pyramid.default_locale_name = en
-
-[server:main]
-use = egg:waitress#main
-listen = localhost:6543
-```
-
-This says a couple of things:
-
- * The actual application will come from the `main` function located in the `todo` package installed in the environment
- * To serve this app, use the `waitress` package installed in the environment and serve on localhost port 6543
-
-
-
-When serving an application and working in development, it helps to set up logging so you can see what's going on. The following configuration will handle logging for the application:
-
-```
-# continuing on...
-[loggers]
-keys = root, todo
-
-[handlers]
-keys = console
-
-[formatters]
-keys = generic
-
-[logger_root]
-level = INFO
-handlers = console
-
-[logger_todo]
-level = DEBUG
-handlers =
-qualname = todo
-
-[handler_console]
-class = StreamHandler
-args = (sys.stderr,)
-level = NOTSET
-formatter = generic
-
-[formatter_generic]
-format = %(asctime)s %(levelname)-5.5s [%(name)s:%(lineno)s][%(threadName)s] %(message)s
-```
-
-In short, this configuration asks to log everything to do with the application to the console. If you want less output, set the logging level to `WARN` so a message will fire only if there's a problem.
-
-Because Pyramid is meant for an application that grows, plan out a file structure that could support that growth. Web applications can, of course, be built however you want. In general, the conceptual blocks you'll want to cover will contain:
-
- * **Models** for containing the code and logic for dealing with data representations
- * **Views** for code and logic pertaining to the request-response cycle
- * **Routes** for the paths for access to the functionality of your application
- * **Scripts** for any code that might be used in configuration or management of the application itself
-
-
-
-Given the above, the file structure can look like so:
-
-```
-setup.py
-config.ini
-todo/
- __init__.py
- models.py
- routes.py
- views.py
- scripts/
-```
-
-Much like Flask's `app` object, Pyramid has its own central configuration. It comes from its `config` module and is known as the `Configurator` object. This object will handle everything from route configuration to pointing to where models and views exist. All this is done in an inner directory called `todo` within an `__init__.py` file.
-
-```
-# todo/__init__.py
-
-from pyramid.config import Configurator
-
-def main(global_config, **settings):
- """Returns a Pyramid WSGI application."""
- config = Configurator(settings=settings)
- config.scan()
- return config.make_wsgi_app()
-```
-
-The `main` function looks for some global configuration from your environment as well as any settings that came through the particular configuration file you provide when you run the application. It takes those settings and uses them to build an instance of the `Configurator` object, which (for all intents and purposes) is the factory for your application. Finally, `config.scan()` looks for any views you'd like to attach to your application that are marked as Pyramid views.
-
-Wow, that was a lot to configure.
-
-### Using routes and views
-
-Now that a chunk of the configuration is done, you can start adding functionality to the application. Functionality comes in the form of URL routes that external clients can hit, which then map to functions that Python can run.
-
-With Pyramid, all functionality must be added to the `Configurator` in some way, shape, or form. For example, say you want to build the same simple `hello_world` view that you built with Flask, mapping to the route of `/`. With Pyramid, you can register the `/` route with the `Configurator` using the `.add_route()` method. This method takes as arguments the name of the route that you want to add as well as the actual pattern that must be matched to access that route. For this case, add the following to your `Configurator`:
-
-```
-config.add_route('home', '/')
-```
-
-Until you create a view and attach it to that route, that path into your application sits open and alone. When you add the view, make sure to include the `request` object in the parameter list. Every Pyramid view must have the `request` object as its first parameter, as that's what's being passed as the first argument to the view when it's called by Pyramid.
-
-One similarity that Pyramid views share with Flask is that you can mark a function as a view with a decorator. Specifically, the `@view_config` decorator from `pyramid.view`.
-
-In `views.py`, build the view that you want to see in the world.
-
-```
-from pyramid.view import view_config
-
-@view_config(route_name="hello", renderer="string")
-def hello_world(request):
- """Print 'Hello, world!' as the response body."""
- return 'Hello, world!'
-```
-
-With the `@view_config` decorator, you have to at least specify the name of the route that will map to this particular view. You can stack `view_config` decorators on top of one another to map to multiple routes if you want, but you have to have at least one to connect view the view at all, and each one must include the name of a route. **[NOTE: Is "to connect view the view" phrased correctly?]**
-
-The other argument, `renderer`, is optional but not really. If you don't specify a renderer, you have to deliberately construct the HTTP response you want to send back to the client using the `Response` object from `pyramid.response`. By specifying the `renderer` as a string, Pyramid knows to take whatever is returned by this function and wrap it in that same `Response` object with the MIME type of `text/plain`. By default, Pyramid allows you to use `string` and `json` as renderers. If you've attached a templating engine to your application because you want to have Pyramid generate your HTML as well, you can point directly to your HTML template as your renderer.
-
-The first view is done. Here's what `__init__.py` looks like now with the attached route.
-
-```
-# in __init__.py
-from pyramid.config import Configurator
-
-def main(global_config, **settings):
- """Returns a Pyramid WSGI application."""
- config = Configurator(settings=settings)
- config.add_route('hello', '/')
- config.scan()
- return config.make_wsgi_app()
-```
-
-Spectacular! Getting here was no easy feat, but now that you're set up, you can add functionality with significantly less difficulty.
-
-### Smoothing a rough edge
-
-Right now the application only has one route, but it's easy to see that a large application can have many dozens or even hundreds of routes. Containing them all in the same `main` function with your central configuration isn't really the best idea, because it would become cluttered. Thankfully, it's fairly easy to include routes with a few tweaks to the application.
-
-**One** : In the `routes.py` file, create a function called `includeme` (yes, it must actually be named this) that takes a configurator object as an argument.
-
-```
-# in routes.py
-def includeme(config):
- """Include these routes within the application."""
-```
-
-**Two** : Move the `config.add_route` method call from `__init__.py` into the `includeme` function:
-
-```
-def includeme(config):
- """Include these routes within the application."""
- config.add_route('hello', '/')
-```
-
-**Three** : Alert the Configurator that you need to include this `routes.py` file as part of its configuration. Because it's in the same directory as `__init__.py`, you can get away with specifying the import path to this file as `.routes`.
-
-```
-# in __init__.py
-from pyramid.config import Configurator
-
-def main(global_config, **settings):
- """Returns a Pyramid WSGI application."""
- config = Configurator(settings=settings)
- config.include('.routes')
- config.scan()
- return config.make_wsgi_app()
-```
-
-### Connecting the database
-
-As with Flask, you'll want to persist data by connecting a database. Pyramid will leverage [SQLAlchemy][6] directly instead of using a specially tailored package.
-
-First get the easy part out of the way. `psycopg2` and `sqlalchemy` are required to talk to the Postgres database and manage the models, so add them to `setup.py`.
-
-```
-# in setup.py
-requires = [
- 'pyramid',
- 'pyramid-ipython',
- 'waitress',
- 'sqlalchemy',
- 'psycopg2'
-]
-# blah blah other code
-```
-
-Now, you have a decision to make about how you'll include the database's URL. There's no wrong answer here; what you do will depend on the application you're building and how public your codebase needs to be.
-
-The first option will keep as much configuration in one place as possible by hard-coding the database URL into the `config.ini` file. One drawback is this creates a security risk for applications with a public codebase. Anyone who can view the codebase will be able to see the full database URL, including username, password, database name, and port. Another is maintainability; if you needed to change environments or the application's database location, you'd have to modify the `config.ini` file directly. Either that or you'll have to maintain one configuration file for each new environment, which adds the potential for discontinuity and errors in the application. **If you choose this option** , modify the `config.ini` file under the `[app:main]` heading to include this key-value pair:
-
-```
-sqlalchemy.url = postgres://localhost:5432/pyramid_todo
-```
-
-The second option specifies the location of the database URL when you create the `Configurator`, pointing to an environment variable whose value can be set depending on the environment where you're working. One drawback is that you're further splintering the configuration, with some in the `config.ini` file and some directly in the Python codebase. Another drawback is that when you need to use the database URL anywhere else in the application (e.g., in a database management script), you have to code in a second reference to that same environment variable (or set up the variable in one place and import from that location). **If you choose this option** , add the following:
-
-```
-# in __init__.py
-import os
-from pyramid.config import Configurator
-
-SQLALCHEMY_URL = os.environ.get('DATABASE_URL', '')
-
-def main(global_config, **settings):
- """Returns a Pyramid WSGI application."""
- settings['sqlalchemy.url'] = SQLALCHEMY_URL # <-- important!
- config = Configurator(settings=settings)
- config.include('.routes')
- config.scan()
- return config.make_wsgi_app()
-```
-
-### Defining objects
-
-OK, so now you have a database. Now you need `Task` and `User` objects.
-
-Because it uses SQLAlchemy directly, Pyramid differs somewhat from Flash on how objects are built. First, every object you want to construct must inherit from SQLAlchemy's [declarative base class][7]. It'll keep track of everything that inherits from it, enabling simpler management of the database.
-
-```
-# in models.py
-from sqlalchemy.ext.declarative import declarative_base
-
-Base = declarative_base()
-
-class Task(Base):
- pass
-
-class User(Base):
- pass
-```
-
-The columns, data types for those columns, and model relationships will be declared in much the same way as with Flask, although they'll be imported directly from SQLAlchemy instead of some pre-constructed `db` object. Everything else is the same.
-
-```
-# in models.py
-from datetime import datetime
-import secrets
-
-from sqlalchemy import (
- Column, Unicode, Integer, DateTime, Boolean, relationship
-)
-from sqlalchemy.ext.declarative import declarative_base
-
-Base = declarative_base()
-
-class Task(Base):
- """Tasks for the To Do list."""
- id = Column(Integer, primary_key=True)
- name = Column(Unicode, nullable=False)
- note = Column(Unicode)
- creation_date = Column(DateTime, nullable=False)
- due_date = Column(DateTime)
- completed = Column(Boolean, default=False)
- user_id = Column(Integer, ForeignKey('user.id'), nullable=False)
- user = relationship("user", back_populates="tasks")
-
- def __init__(self, *args, **kwargs):
- """On construction, set date of creation."""
- super().__init__(*args, **kwargs)
- self.creation_date = datetime.now()
-
-class User(Base):
- """The User object that owns tasks."""
- id = Column(Integer, primary_key=True)
- username = Column(Unicode, nullable=False)
- email = Column(Unicode, nullable=False)
- password = Column(Unicode, nullable=False)
- date_joined = Column(DateTime, nullable=False)
- token = Column(Unicode, nullable=False)
- tasks = relationship("Task", back_populates="user")
-
- def __init__(self, *args, **kwargs):
- """On construction, set date of creation."""
- super().__init__(*args, **kwargs)
- self.date_joined = datetime.now()
- self.token = secrets.token_urlsafe(64)
-```
-
-Note that there's no `config.include` line for `models.py` anywhere because it's not needed. A `config.include` line is needed only if some part of the application's configuration needs to be changed. This has only created two objects, inheriting from some `Base` class that SQLAlchemy gave us.
-
-### Initializing the database
-
-Now that the models are done, you can write a script to talk to and initialize the database. In the `scripts` directory, create two files: `__init__.py` and `initializedb.py`. The first is simply to turn the `scripts` directory into a Python package. The second is the script needed for database management.
-
-`initializedb.py` needs a function to set up the necessary tables in the database. Like with Flask, this script must be aware of the `Base` object, whose metadata keeps track of every class that inherits from it. The database URL is required to point to and modify its tables.
-
-As such, this database initialization script will work:
-
-```
-# initializedb.py
-from sqlalchemy import engine_from_config
-from todo import SQLALCHEMY_URL
-from todo.models import Base
-
-def main():
- settings = {'sqlalchemy.url': SQLALCHEMY_URL}
- engine = engine_from_config(settings, prefix='sqlalchemy.')
- if bool(os.environ.get('DEBUG', '')):
- Base.metadata.drop_all(engine)
- Base.metadata.create_all(engine)
-```
-
-**Important note:** This will work only if you include the database URL as an environment variable in `todo/__init__.py` (the second option above). If the database URL was stored in the configuration file, you'll have to include a few lines to read that file. It will look something like this:
-
-```
-# alternate initializedb.py
-from pyramid.paster import get_appsettings
-from pyramid.scripts.common import parse_vars
-from sqlalchemy import engine_from_config
-import sys
-from todo.models import Base
-
-def main():
- config_uri = sys.argv[1]
- options = parse_vars(sys.argv[2:])
- settings = get_appsettings(config_uri, options=options)
- engine = engine_from_config(settings, prefix='sqlalchemy.')
- if bool(os.environ.get('DEBUG', '')):
- Base.metadata.drop_all(engine)
- Base.metadata.create_all(engine)
-```
-
-Either way, in `setup.py`, add a console script that will access and run this function.
-
-```
-# bottom of setup.py
-setup(
- # ... other stuff
- entry_points={
- 'paste.app_factory': [
- 'main = todo:main',
- ],
- 'console_scripts': [
- 'initdb = todo.scripts.initializedb:main',
- ],
- }
-)
-```
-
-When this package is installed, you'll have access to a new console script called `initdb`, which will construct the tables in your database. If the database URL is stored in the configuration file, you'll have to include the path to that file when you invoke the command. It'll look like `$ initdb /path/to/config.ini`.
-
-### Handling requests and the database
-
-Ok, here's where it gets a little deep. Let's talk about **transactions**. A "transaction," in an abstract sense, is any change made to an existing database. As with Flask, transactions are persisted no sooner than when they are committed. If changes have been made that haven't yet been committed, and you don't want those to occur (maybe there's an error thrown in the process), you can **rollback** a transaction and abort those changes.
-
-In Python, the [transaction package][8] allows you to interact with transactions as objects, which can roll together multiple changes into one single commit. `transaction` provides **transaction managers** , which give applications a straightforward, thread-aware way of handling transactions so all you need to think about is what to change. The `pyramid_tm` package will take the transaction manager from `transaction` and wire it up in a way that's appropriate for Pyramid's request-response cycle, attaching a transaction manager to every incoming request.
-
-Normally, with Pyramid the `request` object is populated when the route mapping to a view is accessed and the view function is called. Every view function will have a `request` object to work with**.** However, Pyramid allows you to modify its configuration to add whatever you might need to the `request` object. You can use the transaction manager that you'll be adding to the `request` to create a session with every request and add that session to the request.
-
-Yay, so why is this important?
-
-By attaching a transaction-managed session to the `request` object, when the view finishes processing the request, any changes made to the database session will be committed without you needing to explicitly commit**.** Here's what all these concepts look like in code.
-
-```
-# __init__.py
-import os
-from pyramid.config import Configurator
-from sqlalchemy import engine_from_config
-from sqlalchemy.orm import sessionmaker
-import zope.sqlalchemy
-
-SQLALCHEMY_URL = os.environ.get('DATABASE_URL', '')
-
-def get_session_factory(engine):
- """Return a generator of database session objects."""
- factory = sessionmaker()
- factory.configure(bind=engine)
- return factory
-
-def get_tm_session(session_factory, transaction_manager):
- """Build a session and register it as a transaction-managed session."""
- dbsession = session_factory()
- zope.sqlalchemy.register(dbsession, transaction_manager=transaction_manager)
- return dbsession
-
-def main(global_config, **settings):
- """Returns a Pyramid WSGI application."""
- settings['sqlalchemy.url'] = SQLALCHEMY_URL
- settings['tm.manager_hook'] = 'pyramid_tm.explicit_manager'
- config = Configurator(settings=settings)
- config.include('.routes')
- config.include('pyramid_tm')
- session_factory = get_session_factory(engine_from_config(settings, prefix='sqlalchemy.'))
- config.registry['dbsession_factory'] = session_factory
- config.add_request_method(
- lambda request: get_tm_session(session_factory, request.tm),
- 'dbsession',
- reify=True
- )
-
- config.scan()
- return config.make_wsgi_app()
-```
-
-That looks like a lot, but it only did was what was explained above, plus it added an attribute to the `request` object called `request.dbsession`.
-
-A few new packages were included here, so update `setup.py` with those packages.
-
-```
-# in setup.py
-requires = [
- 'pyramid',
- 'pyramid-ipython',
- 'waitress',
- 'sqlalchemy',
- 'psycopg2',
- 'pyramid_tm',
- 'transaction',
- 'zope.sqlalchemy'
-]
-# blah blah other stuff
-```
-
-### Revisiting routes and views
-
-You need to make some real views that handle the data within the database and the routes that map to them.
-
-Start with the routes. You created the `routes.py` file to handle your routes but didn't do much beyond the basic `/` route. Let's fix that.
-
-```
-# routes.py
-def includeme(config):
- config.add_route('info', '/api/v1/')
- config.add_route('register', '/api/v1/accounts')
- config.add_route('profile_detail', '/api/v1/accounts/{username}')
- config.add_route('login', '/api/v1/accounts/login')
- config.add_route('logout', '/api/v1/accounts/logout')
- config.add_route('tasks', '/api/v1/accounts/{username}/tasks')
- config.add_route('task_detail', '/api/v1/accounts/{username}/tasks/{id}')
-```
-
-Now, it not only has static URLs like `/api/v1/accounts`, but it can handle some variable URLs like `/api/v1/accounts/{username}/tasks/{id}` where any variable in a URL will be surrounded by curly braces.
-
-To create the view to create an individual task in your application (like in the Flash example), you can use the `@view_config` decorator to ensure that it only takes incoming `POST` requests and check out how Pyramid handles data from the client.
-
-Take a look at the code, then check out how it differs from Flask's version.
-
-```
-# in views.py
-from datetime import datetime
-from pyramid.view import view_config
-from todo.models import Task, User
-
-INCOMING_DATE_FMT = '%d/%m/%Y %H:%M:%S'
-
-@view_config(route_name="tasks", request_method="POST", renderer='json')
-def create_task(request):
- """Create a task for one user."""
- response = request.response
- response.headers.extend({'Content-Type': 'application/json'})
- user = request.dbsession.query(User).filter_by(username=request.matchdict['username']).first()
- if user:
- due_date = request.json['due_date']
- task = Task(
- name=request.json['name'],
- note=request.json['note'],
- due_date=datetime.strptime(due_date, INCOMING_DATE_FMT) if due_date else None,
- completed=bool(request.json['completed']),
- user_id=user.id
- )
- request.dbsession.add(task)
- response.status_code = 201
- return {'msg': 'posted'}
-```
-
-To start, note on the `@view_config` decorator that the only type of request you want this view to handle is a "POST" request. If you want to specify one type of request or one set of requests, provide either the string noting the request or a tuple/list of such strings.
-
-```
-response = request.response
-response.headers.extend({'Content-Type': 'application/json'})
-# ...other code...
-response.status_code = 201
-```
-
-The HTTP response sent to the client is generated based on `request.response`. Normally, you wouldn't have to worry about that object. It would just produce a properly formatted HTTP response and you'd never know the difference. However, because you want to do something specific, like modify the response's status code and headers, you need to access that response and its methods/attributes.
-
-Unlike with Flask, you don't need to modify the view function parameter list just because you have variables in the route URL. Instead, any time a variable exists in the route URL, it is collected in the `matchdict` attribute of the `request`. It will exist there as a key-value pair, where the key will be the variable (e.g., "username") and the value will be whatever value was specified in the route (e.g., "bobdobson"). Regardless of what value is passed in through the route URL, it'll always show up as a string in the `matchdict`. So, when you want to pull the username from the incoming request URL, access it with `request.matchdict['username']`
-
-```
-user = request.dbsession.query(User).filter_by(username=request.matchdict['username']).first()
-```
-
-Querying for objects when using `sqlalchemy` directly differs significantly from what the `flask-sqlalchemy` package allows. Recall that when you used `flask-sqlalchemy` to build your models, the models inherited from the `db.Model` object. That `db` object already contained a connection to the database, so that connection could perform a straightforward operation like `User.query.all()`.
-
-That simple interface isn't present here, as the models in the Pyramid app inherit from `Base`, which is generated from `declarative_base()`, coming directly from the `sqlalchemy` package. It has no direct awareness of the database it'll be accessing. That awareness was attached to the `request` object via the app's central configuration as the `dbsession` attribute. Here's the code from above that did that:
-
-```
-config.add_request_method(
- lambda request: get_tm_session(session_factory, request.tm),
- 'dbsession',
- reify=True
-)
-```
-
-With all that said, whenever you want to query OR modify the database, you must work through `request.dbsession`. In the case, you want to query your "users" table for a specific user by using their username as their identifier. As such, the `User` object is provided as an argument to the `.query` method, then the normal SQLAlchemy operations are done from there.
-
-An interesting thing about this way of querying the database is that you can query for more than just one object or list of one type of object. You can query for:
-
- * Object attributes on their own, e.g., `request.dbsession.query(User.username)` would query for usernames
- * Tuples of object attributes, e.g., `request.dbsession.query(User.username, User.date_joined)`
- * Tuples of multiple objects, e.g., `request.dbsession.query(User, Task)`
-
-
-
-The data sent along with the incoming request will be found within the `request.json` dictionary.
-
-The last major difference is, because of all the machinations necessary to attach the committing of a session's activity to Pyramid's request-response cycle, you don't have to call `request.dbsession.commit()` at the end of your view. It's convenient, but there is one thing to be aware of moving forward. If instead of a new add to the database, you wanted to edit a pre-existing object in the database, you couldn't use `request.dbsession.commit()`. Pyramid will throw an error, saying something along the lines of "commit behavior is being handled by the transaction manager, so you can't call it on your own." And if you don't do something that resembles committing your changes, your changes won't stick.
-
-The solution here is to use `request.dbsession.flush()`. The job of `.flush()` is to signal to the database that some changes have been made and need to be included with the next commit.
-
-### Planning for the future
-
-At this point, you've set up most of the important parts of Pyramid, analogous to what you constructed with Flask in part one. There's much more that goes into an application, but much of the meat is handled here. Other view functions will follow similar formatting, and of course, there's always the question of security (which Pyramid has built in!).
-
-One of the major differences I see in the setup of a Pyramid application is that it has a much more intense configuration step than there is with Flask. I broke down those configuration steps to explain more about what's going on when a Pyramid application is constructed. However, it'd be disingenuous to act like I've known all of this since I started programming. My first experience with the Pyramid framework was with Pyramid 1.7 and its scaffolding system of `pcreate`, which builds out most of the necessary configuration, so all you need to do is think about the functionality you want to build.
-
-As of Pyramid 1.8, `pcreate` has been deprecated in favor of [cookiecutter][9], which effectively does the same thing. The difference is that it's maintained by someone else, and there are cookiecutter templates for more than just Pyramid projects. Now that we've gone through the components of a Pyramid project, I'd never endorse building a Pyramid project from scratch again when a cookiecutter template is available. Why do the hard work if you don't have to? In fact, the [pyramid-cookiecutter-alchemy][10] template would accomplish much of what I've written here (and a little bit more). It's actually similar to the `pcreate` scaffold I used when I first learned Pyramid.
-
-Learn more Python at [PyCon Cleveland 2018][11].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/pyramid-framework
-
-作者:[Nicholas Hunt-Walker][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/nhuntwalker
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/article/18/4/flask
-[2]: http://flask.pocoo.org/
-[3]: https://trypyramid.com/
-[4]: http://www.tornadoweb.org/en/stable/
-[5]: https://www.djangoproject.com/
-[6]: https://www.sqlalchemy.org/
-[7]: http://docs.sqlalchemy.org/en/latest/orm/extensions/declarative/api.html#api-reference
-[8]: http://zodb.readthedocs.io/en/latest/transactions.html
-[9]: https://cookiecutter.readthedocs.io/en/latest/
-[10]: https://github.com/Pylons/pyramid-cookiecutter-alchemy
-[11]: https://us.pycon.org/2018/
diff --git a/sources/tech/20180514 MapTool- A robust, flexible virtual tabletop for RPGs.md b/sources/tech/20180514 MapTool- A robust, flexible virtual tabletop for RPGs.md
deleted file mode 100644
index 4786da0b50..0000000000
--- a/sources/tech/20180514 MapTool- A robust, flexible virtual tabletop for RPGs.md
+++ /dev/null
@@ -1,216 +0,0 @@
-MapTool: A robust, flexible virtual tabletop for RPGs
-======
-
-
-
-When I was looking for a virtual tabletop for role-playing games (RPGs), either for local play or for playing on a network with family and friends around the world, I had several criteria. First, I wanted a platform I could use offline while I prepped a campaign. Second, I didn't want something that came with the burden of being a social network. I wanted the equivalent of a [Sword Coast][1] campaign-setting [boxed set][2] that I could put on my digital "shelf" and use when I wanted, how I wanted.
-
-I looked at it this way: I purchased [AD&D 2nd edition][3] as a hardcover book, so even though there have since been many great releases, I can still play AD&D 2nd edition today. The same goes for my digital life. When I want to use my digital maps and tokens or go back to an old campaign, I want access to them regardless of circumstance.
-
-
-
-### Virtual tabletop
-
-[MapTool][4] is the flagship product of the RPTools software suite. It's a Java application, so it runs on any operating system that can run Java, which is basically every computer. It's also open source and costs nothing to use, although RPTools accepts [donations][5] if you're so inclined.
-
-### Installing MapTool
-
-Download MapTool from [rptools.net][6].
-
-It's likely that you already have Java installed; if not, download and install it from [java.net][7]. If you're not sure whether you have it installed or not, you can download MapTool first, try to run it, and install Java if it fails to run.
-
-### Using MapTool
-
-If you're a game master (GM), MapTool is a great way to provide strategic maps for battles and exploration without investing in physical maps, tokens, or miniatures.
-
-MapTool is a full-featured virtual tabletop. You can load maps into it, import custom tokens, track initiative order and health, and save campaigns. You can use it locally at your game table, or you can share your session with remote gamers so they can follow along. There are other virtual tabletops out there, but MapTool is the only one you own, part and parcel.
-
-To load a map into MapTool, all you need is a PNG or JPEG version of a map.
-
- 1. Launch MapTool, then go to the **Map** menu and select **New Map**.
- 2. In the **Map Properties** window that appears, click the **Map** button.
- 3. Click the **Filesystem** button in the bottom-left corner to locate your map graphic on your hard drive.
-
-
-
-If you have no digital maps yet, there are dozens of map packs available from [Open Gaming Store][8], so you're sure to find a map regardless of where your adventure path may take you.
-
-MapTool, like most virtual tabletops, expects a PNG or JPEG. I maintain a simple [Image Magick][9] script to convert maps from PDF to PNG. The script runs on Linux, BSD, or Mac and is probably also easily adapted to PowerShell.
-```
-#!/usr/bin/env bash
-
-#GNU All-Permissive http://www.gnu.org/licenses
-
-
-
-CMD=`which convert` || echo "Image Magick not found in PATH."
-
-ARG=("${@}")
-
-ARRAYSIZE=${#ARG[*]}
-
-
-
-while [ True ]; do
-
- for item in "${ARG[@]}"; do
-
-$CMD "${item}" `basename "${item}" .pdf`.jpg || \
-
-$CMD "${item}" `basename "${item}" .PDF`.jpg
-
- done
-
- done
-
-exit
-
-```
-
-If running code like that scares you, there are plenty of PDF-to-image converters, like [GIMP][10], for manually converting a PDF to PNG or JPEG on an as-needed basis.
-
-#### Adding tokens
-
-Now that you have a map loaded, it's time to add player characters (PCs) and non-player characters (NPCs). MapTool ships with a modest selection of token graphics, but you can always create and use your own or download more from the internet. In fact, the RPTools website recently linked to [ImmortalNights][11], a website by artist Devin Night, with over 100 tokens for free and purchase.
-
- 1. Click the **Tokens** folder icon in the MapTool **Resource Library** panel.
- 2. In the panel just beneath the **Resource Library** panel, the default tokens appear. You can add your own tokens using the **Add resources to library** option in the **File** menu.
- 3. In the **New token** pop-up dialogue box, give the token a name and PC or NPC designation.
-
-
-
- 4. Once the token is on the map, it should align perfectly with the map grid. If it doesn't, you can adjust the grid.
- 5. Right-click on the token to adjust its rotation, size, and other attributes.
-
-
-
-#### Adjusting the grid
-
-By default, MapTool provides an invisible 50x50 square grid over any map. If your map graphic already has a grid on it, you can adjust MapTool's grid to match your graphic.
-
- 1. Select **Adjust grid** in the **Map** menu. A grid overlay appears over your map.
- 2. Click and drag the overlay grid so one overlay square sits inside one of your map graphic's grid squares.
- 3. Adjust the **Grid Size** pixel value in the property box in the top-right corner of the MapTool window.
- 4. When finished, click the property box's **Close** button.
-
-
-
-You can set the default grid size using the **Preferences** selection in the **Edit** menu. For instance, I do this for [Paizo][12] maps on my 96dpi screen.
-
-MapTool's default assumes each grid block is a five-foot square, but you can adjust that if you're using a wide area representing long-distance travel or if you've drawn a custom map to your own scale.
-
-### Sharing the screen locally
-
-While you can use MapTool solely as a GM tool to help keep track of character positions, you can also share it with your players.
-
-If you're using MapTool as a digital replacement for physical maps at your game table, you can just plug your computer into your TV. That's the simplest way to share the map with everyone at your table.
-
-Another alternative is to use MapTool's built-in server. If your players are physically sitting in the same room and on the same network, select **Start server** from the **File** menu.
-
-The only required field is a name for the GM. The default port is 51234. If you don't know what that means, that's OK; a port is just a flag identifying where a service like MapTool is running.
-
-Once your MapTool server is started, players can connect by selecting **Connect to server** in the **File** menu.
-
-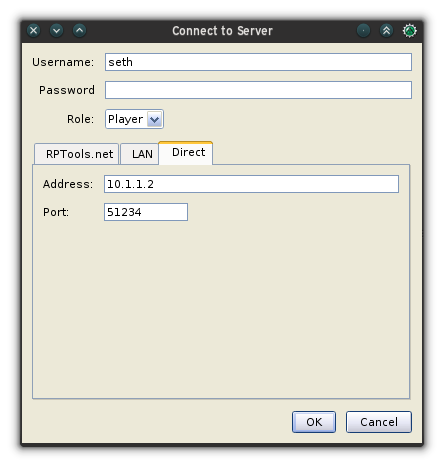
-
-A name is required, but no password is needed unless the GM has set one when starting the server.
-
-The IP address is your local IP address, so it starts with either 192.168 or 10. If you don't know your local IP address, you can check it from your computer's networking control panel. On Linux, you can also find it by typing:
-```
-$ ip -4 -ts a
-
-```
-
-And on BSD or Mac:
-```
-$ ifconfig
-
-```
-
-On Windows, open PowerShell from your **Start** menu and type:
-```
-ipconfig
-
-```
-
-
-
-If your players have trouble connecting, there are two likely causes:
-
- * You forgot to start the server. Start it and have your players try again.
- * You have a firewall running on your computer. If you're on your home network, it's safe to deactivate your firewall or to tell it to permit traffic on port 51234. If you're in a public gaming space, you should not lower your firewall, but it's safe to permit traffic on port 51234 as long as you have set a password for your MapTool server.
-
-
-
-### Sharing the screen worldwide
-
-If you're playing remotely with people all over the world, letting them into your private MapTool server is a little more complex to set up, but you only have to do it once and then you're set.
-
-#### Router
-
-The first device that needs to be adjusted is your home router. This is the box you got from your internet service provider. You might also call it your modem.
-
-Every device is different, so there's no way for me to definitively tell you what you need to click on to adjust your settings. Generally, you access your home router through a web browser. Your router's address is often printed on the bottom of the router and begins with either 192.168 or 10.
-
-Navigate to the router address and log in with the credentials you were provided when you got your internet service. It's often as simple as `admin` with a numeric password (sometimes this password is printed on the router, too). If you don't know the login, call your internet provider and ask for details.
-
-Different routers use different terms for the same thing; keywords to look for are **Port forwarding** , **Virtual server** , and **Firewall**. Whatever your router calls it, you want to accept traffic coming to port 51234 of your router and forward that traffic to the same port of your personal computer's IP address.
-
-
-
-If you're confused, search the internet for the term "port forwarding" and your router's brand name. This isn't an uncommon task for PC gamers, so instructions are out there.
-
-#### Finding your external IP address
-
-Now you're allowing traffic through the MapTool port, so you need to tell your players where to go.
-
- 1. Get your worldwide IP address at [icanhazip.com][13].
- 2. Start the MapTool server from the **File** menu. Set a password for safety.
- 3. Have players select **Connect to server** from the **File** menu.
- 4. In the **Connect to server** window, have players click the **Direct** tab and enter a username, password, and your IP address.
-
-
-
-### Features a-plenty
-
-This has been a brief overview of things you can do with MapTool. It has many other features, including an initiative tracker, adjustable tokens visibility (hide treasure and monsters from your players!), impersonation, line-of-sight (conceal hidden doors behind statues or other structures!), and fog of war.
-
-It can serve just as a digital battle map, or it can be the centerpiece of your tabletop game.
-
-
-
-### Why MapTool?
-
-Before you comment about them: Yes, there are a few virtual tabletop services online, and some of them are very good. They provide a good supply of games looking for players and players looking for games. If you can't find your fellow gamers locally, online tabletops are a great solution.
-
-By contrast, some people are not fans of social networking, so we shy away from sites that excitedly "bring people together." I've got friends to game with, and we're happy to build and set up our own infrastructure. We don't need to sign up for yet another site; we don't need to throw our hats into a great big online bucket and register when and how we game.
-
-Ultimately, I like MapTool because I have it with me whether or not I'm online. I can plan a campaign, populate it with graphics, and set up all my maps in advance without depending on having internet access. It's almost like doing the frontend programming for a video game, knowing that the backend "technology" will all happen in the player's minds on game night.
-
-If you're looking for a robust and flexible virtual tabletop, try MapTool!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/maptool
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth
-[1]:https://en.wikibooks.org/wiki/Dungeons_%26_Dragons/Commercial_settings/Forgotten_Realms/Sword_Coast
-[2]:https://en.wikipedia.org/wiki/Dungeons_%26_Dragons_campaign_settings
-[3]:https://en.wikipedia.org/wiki/Editions_of_Dungeons_%26_Dragons#Advanced_Dungeons_&_Dragons_2nd_edition
-[4]:http://www.rptools.net/toolbox/maptool/
-[5]:http://www.rptools.net/donate/
-[6]:http://www.rptools.net/downloadsw/
-[7]:http://jdk.java.net/8
-[8]:https://www.opengamingstore.com/search?q=map
-[9]:http://www.imagemagick.org/script/index.php
-[10]:http://gimp.org
-[11]:http://immortalnights.com/tokenpage.html
-[12]:http://paizo.com/
-[13]:http://icanhazip.com/
diff --git a/sources/tech/20180514 Tuptime - A Tool To Report The Historical Uptime Of Linux System.md b/sources/tech/20180514 Tuptime - A Tool To Report The Historical Uptime Of Linux System.md
deleted file mode 100644
index d079dd19af..0000000000
--- a/sources/tech/20180514 Tuptime - A Tool To Report The Historical Uptime Of Linux System.md
+++ /dev/null
@@ -1,330 +0,0 @@
-Tuptime - A Tool To Report The Historical Uptime Of Linux System
-======
-Beginning of this month we written an article about system uptime that helps user to check how long your Linux system has been running without downtime? when the system is up and what date. This can be done using 11 methods.
-
-uptime is one of the very famous commands, which everyone use when there is a requirement to check the Linux server uptime.
-
-But it won’t shows historical and statistical running time of Linux system, that’s why tuptime is came to picture.
-
-server uptime is very important when the server running with critical applications such as online portals.
-
-**Suggested Read :** [11 Methods To Find System/Server Uptime In Linux][1]
-
-### What Is tuptime?
-
-[Tuptime][2] is a tool for report the historical and statistical running time of the system, keeping it between restarts. Like uptime command but with more interesting output.
-
-### tuptime Features
-
- * Count system startups
- * Register first boot time (a.k.a. installation time)
- * Count nicely and accidentally shutdowns
- * Uptime and downtime percentage since first boot time
- * Accumulated system uptime, downtime and total
- * Largest, shortest and average uptime and downtime
- * Current uptime
- * Print formatted table or list with most of the previous values
- * Register used kernels
- * Narrow reports since and/or until a given startup or timestamp
- * Reports in csv
-
-
-
-### Prerequisites
-
-Make sure your system should have installed Python3 as a prerequisites. If no, install it using your distribution package manager.
-
-**Suggested Read :** [3 Methods To Install Latest Python3 Package On CentOS 6 System][3]
-
-### How To Install tuptime
-
-Few distributions offer tuptime package but it may be bit older version. I would advise you to install latest available version to avail all the features using the below method.
-
-Clone tuptime repository from github.
-```
-# git clone https://github.com/rfrail3/tuptime.git
-
-```
-
-Copy executable file from `tuptime/src/tuptime` to `/usr/bin/` and assign 755 permission.
-```
-# cp tuptime/src/tuptime /usr/bin/tuptime
-# chmod 755 /usr/bin/tuptime
-
-```
-
-All scripts, units and related files are provided inside this repo so, copy and past the necessary files in the appropriate location to get full functionality of tuptime utility.
-
-Add tuptime user because it doesn’t run as a daemon, at least, it only need execution when the init manager startup and shutdown the system.
-```
-# useradd -d /var/lib/tuptime -s /bin/sh tuptime
-
-```
-
-Change owner of the db file.
-```
-# chown -R tuptime:tuptime /var/lib/tuptime
-
-```
-
-Copy cron file from `tuptime/src/tuptime` to `/usr/bin/` and assign 644 permission.
-```
-# cp tuptime/src/cron.d/tuptime /etc/cron.d/tuptime
-# chmod 644 /etc/cron.d/tuptime
-
-```
-
-Add system service file based on your system initsystem. Use the below command to check if your system is running with systemd or init.
-```
-# ps -p 1
- PID TTY TIME CMD
- 1 ? 00:00:03 systemd
-
-# ps -p 1
- PID TTY TIME CMD
- 1 ? 00:00:00 init
-
-```
-
-If is a system with systemd, copy service file and enable it.
-```
-# cp tuptime/src/systemd/tuptime.service /lib/systemd/system/
-# chmod 644 /lib/systemd/system/tuptime.service
-# systemctl enable tuptime.service
-
-```
-
-If have upstart system, copy the file:
-```
-# cp tuptime/src/init.d/redhat/tuptime /etc/init.d/tuptime
-# chmod 755 /etc/init.d/tuptime
-# chkconfig --add tuptime
-# chkconfig tuptime on
-
-```
-
-If have init system, copy the file:
-```
-# cp tuptime/src/init.d/debian/tuptime /etc/init.d/tuptime
-# chmod 755 /etc/init.d/tuptime
-# update-rc.d tuptime defaults
-# /etc/init.d/tuptime start
-
-```
-
-### How To Use tuptime
-
-Make sure you should run the command with a privileged user. Intially you will get output similar to this.
-```
-# tuptime
-System startups: 1 since 02:48:00 AM 04/12/2018
-System shutdowns: 0 ok - 0 bad
-System uptime: 100.0 % - 26 days, 5 hours, 31 minutes and 52 seconds
-System downtime: 0.0 % - 0 seconds
-System life: 26 days, 5 hours, 31 minutes and 52 seconds
-
-Largest uptime: 26 days, 5 hours, 31 minutes and 52 seconds from 02:48:00 AM 04/12/2018
-Shortest uptime: 26 days, 5 hours, 31 minutes and 52 seconds from 02:48:00 AM 04/12/2018
-Average uptime: 26 days, 5 hours, 31 minutes and 52 seconds
-
-Largest downtime: 0 seconds
-Shortest downtime: 0 seconds
-Average downtime: 0 seconds
-
-Current uptime: 26 days, 5 hours, 31 minutes and 52 seconds since 02:48:00 AM 04/12/2018
-
-```
-
-### Details:
-
- * **`System startups:`** Total number of system startups from since to until date. Until is joined if is used in a narrow range.
- * **`System shutdowns:`** Total number of shutdowns done correctly or incorrectly. The separator usually points to the state of last shutdown () bad.
- * **`System uptime:`** Percentage of uptime and time counter.
- * **`System downtime:`** Percentage of downtime and time counter.
- * **`System life:`** Time counter since first startup date until last.
- * **`Largest/Shortest uptime:`** Time counter and date with the largest/shortest uptime register.
- * **`Largest/Shortest downtime:`** Time counter and date with the largest/shortest downtime register.
- * **`Average uptime/downtime:`** Time counter with the average time.
- * **`Current uptime:`** Actual time counter and date since registered boot date.
-
-
-
-If you do the same a few days after some reboot, the output may will be more similar to this.
-```
-# tuptime
-System startups: 3 since 02:48:00 AM 04/12/2018
-System shutdowns: 0 ok -> 2 bad
-System uptime: 97.0 % - 28 days, 4 hours, 6 minutes and 0 seconds
-System downtime: 3.0 % - 20 hours, 54 minutes and 22 seconds
-System life: 29 days, 1 hour, 0 minutes and 23 seconds
-
-Largest uptime: 26 days, 5 hours, 32 minutes and 57 seconds from 02:48:00 AM 04/12/2018
-Shortest uptime: 1 hour, 31 minutes and 12 seconds from 02:17:11 AM 05/11/2018
-Average uptime: 9 days, 9 hours, 22 minutes and 0 seconds
-
-Largest downtime: 20 hours, 51 minutes and 58 seconds from 08:20:57 AM 05/08/2018
-Shortest downtime: 2 minutes and 24 seconds from 02:14:47 AM 05/11/2018
-Average downtime: 10 hours, 27 minutes and 11 seconds
-
-Current uptime: 1 hour, 31 minutes and 12 seconds since 02:17:11 AM 05/11/2018
-
-```
-
-Enumerate as table each startup number, startup date, uptime, shutdown date, end status and downtime. Multiple order options can be combined together.
-```
-# tuptime -t
-No. Startup Date Uptime Shutdown Date End Downtime
-
-1 02:48:00 AM 04/12/2018 26 days, 5 hours, 32 minutes and 57 seconds 08:20:57 AM 05/08/2018 BAD 20 hours, 51 minutes and 58 seconds
-2 05:12:55 AM 05/09/2018 1 day, 21 hours, 1 minute and 52 seconds 02:14:47 AM 05/11/2018 BAD 2 minutes and 24 seconds
-3 02:17:11 AM 05/11/2018 1 hour, 34 minutes and 33 seconds
-
-```
-
-Enumerate as list each startup number, startup date, uptime, shutdown date, end status and offtime. Multiple order options can be combined together.
-```
-# tuptime -l
-Startup: 1 at 02:48:00 AM 04/12/2018
-Uptime: 26 days, 5 hours, 32 minutes and 57 seconds
-Shutdown: BAD at 08:20:57 AM 05/08/2018
-Downtime: 20 hours, 51 minutes and 58 seconds
-
-Startup: 2 at 05:12:55 AM 05/09/2018
-Uptime: 1 day, 21 hours, 1 minute and 52 seconds
-Shutdown: BAD at 02:14:47 AM 05/11/2018
-Downtime: 2 minutes and 24 seconds
-
-Startup: 3 at 02:17:11 AM 05/11/2018
-Uptime: 1 hour, 34 minutes and 36 seconds
-
-```
-
-To print kernel information with tuptime output.
-```
-# tuptime -k
-System startups: 3 since 02:48:00 AM 04/12/2018
-System shutdowns: 0 ok -> 2 bad
-System uptime: 97.0 % - 28 days, 4 hours, 11 minutes and 25 seconds
-System downtime: 3.0 % - 20 hours, 54 minutes and 22 seconds
-System life: 29 days, 1 hour, 5 minutes and 47 seconds
-System kernels: 1
-
-Largest uptime: 26 days, 5 hours, 32 minutes and 57 seconds from 02:48:00 AM 04/12/2018
-...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
-Shortest uptime: 1 hour, 36 minutes and 36 seconds from 02:17:11 AM 05/11/2018
-...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
-Average uptime: 9 days, 9 hours, 23 minutes and 48 seconds
-
-Largest downtime: 20 hours, 51 minutes and 58 seconds from 08:20:57 AM 05/08/2018
-...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
-Shortest downtime: 2 minutes and 24 seconds from 02:14:47 AM 05/11/2018
-...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
-Average downtime: 10 hours, 27 minutes and 11 seconds
-
-Current uptime: 1 hour, 36 minutes and 36 seconds since 02:17:11 AM 05/11/2018
-...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
-
-```
-
-Change the date format. By default it’s printed based on system locales.
-```
-# tuptime -d %d/%m/%y %H:%M:%S
-System startups: 3 since 12/04/18
-System shutdowns: 0 ok -> 2 bad
-System uptime: 97.0 % - 28 days, 4 hours, 15 minutes and 18 seconds
-System downtime: 3.0 % - 20 hours, 54 minutes and 22 seconds
-System life: 29 days, 1 hour, 9 minutes and 41 seconds
-
-Largest uptime: 26 days, 5 hours, 32 minutes and 57 seconds from 12/04/18
-Shortest uptime: 1 hour, 40 minutes and 30 seconds from 11/05/18
-Average uptime: 9 days, 9 hours, 25 minutes and 6 seconds
-
-Largest downtime: 20 hours, 51 minutes and 58 seconds from 08/05/18
-Shortest downtime: 2 minutes and 24 seconds from 11/05/18
-Average downtime: 10 hours, 27 minutes and 11 seconds
-
-Current uptime: 1 hour, 40 minutes and 30 seconds since 11/05/18
-
-```
-
-Print information about the internals of tuptime. It’s good for debugging how it gets the variables.
-```
-# tuptime -v
-INFO:Arguments: {'endst': 0, 'seconds': None, 'table': False, 'csv': False, 'ts': None, 'silent': False, 'order': False, 'since': 0, 'kernel': False, 'reverse': False, 'until': 0, 'db_file': '/var/lib/tuptime/tuptime.db', 'lst': False, 'tu': None, 'date_format': '%X %x', 'update': True}
-INFO:Linux system
-INFO:uptime = 5773.54
-INFO:btime = 1526019431
-INFO:kernel = Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
-INFO:Execution user = 0
-INFO:Directory exists = /var/lib/tuptime
-INFO:DB file exists = /var/lib/tuptime/tuptime.db
-INFO:Last btime from db = 1526019431
-INFO:Last uptime from db = 5676.04
-INFO:Drift over btime = 0
-INFO:System wasn't restarted. Updating db values...
-System startups: 3 since 02:48:00 AM 04/12/2018
-System shutdowns: 0 ok -> 2 bad
-System uptime: 97.0 % - 28 days, 4 hours, 11 minutes and 2 seconds
-System downtime: 3.0 % - 20 hours, 54 minutes and 22 seconds
-System life: 29 days, 1 hour, 5 minutes and 25 seconds
-
-Largest uptime: 26 days, 5 hours, 32 minutes and 57 seconds from 02:48:00 AM 04/12/2018
-Shortest uptime: 1 hour, 36 minutes and 14 seconds from 02:17:11 AM 05/11/2018
-Average uptime: 9 days, 9 hours, 23 minutes and 41 seconds
-
-Largest downtime: 20 hours, 51 minutes and 58 seconds from 08:20:57 AM 05/08/2018
-Shortest downtime: 2 minutes and 24 seconds from 02:14:47 AM 05/11/2018
-Average downtime: 10 hours, 27 minutes and 11 seconds
-
-Current uptime: 1 hour, 36 minutes and 14 seconds since 02:17:11 AM 05/11/2018
-
-```
-
-Print a quick reference of the command line parameters.
-```
-# tuptime -h
-Usage: tuptime [options]
-
-Options:
- -h, --help show this help message and exit
- -c, --csv csv output
- -d DATE_FORMAT, --date=DATE_FORMAT
- date format output
- -f FILE, --filedb=FILE
- database file
- -g, --graceful register a gracefully shutdown
- -k, --kernel print kernel information
- -l, --list enumerate system life as list
- -n, --noup avoid update values
- -o TYPE, --order=TYPE
- order enumerate by []
- -r, --reverse reverse order
- -s, --seconds output time in seconds and epoch
- -S SINCE, --since=SINCE
- restric since this register number
- -t, --table enumerate system life as table
- --tsince=TIMESTAMP restrict since this epoch timestamp
- --tuntil=TIMESTAMP restrict until this epoch timestamp
- -U UNTIL, --until=UNTIL
- restrict until this register number
- -v, --verbose verbose output
- -V, --version show version
- -x, --silent update values into db without output
-
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/tuptime-a-tool-to-report-the-historical-and-statistical-running-time-of-linux-system/
-
-作者:[Prakash Subramanian][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.2daygeek.com/author/prakash/
-[1]:https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
-[2]:https://github.com/rfrail3/tuptime/
-[3]:https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/
diff --git a/sources/tech/20180515 Termux turns Android into a Linux development environment.md b/sources/tech/20180515 Termux turns Android into a Linux development environment.md
deleted file mode 100644
index 0114b577d2..0000000000
--- a/sources/tech/20180515 Termux turns Android into a Linux development environment.md
+++ /dev/null
@@ -1,81 +0,0 @@
-Termux turns Android into a Linux development environment
-======
-
-
-So you finally figured out how to exit Vim and you can write the most highly optimized version of "Hello World" this side of the Mississippi. Now it's time to up your game! Check out [Termux][1] for Android.
-
-### What is Termux?
-
-Termux is an Android terminal emulator and Linux environment. What that means in practice is that you can install Termux on most Android devices and do almost anything you would do in a full Linux development environment on that device. That all sounds cool, but you're probably asking yourself, "why would I want to code on my phone on a touch screen? That just sounds awful." Start thinking more along the lines of tablets paired with a keyboards or Chromebooks that can now run Android applications. These are very cheap devices that can now be used to introduce people to Linux hacking and development. I know many of us in the Linux community started out by installing Linux on an old PC.
-
-Tablets and Chromebooks are this generation's old, junky computers. And there are plenty to go around. Why not use them to introduce the next generation to Linux? And since Termux can be installed with a click in the [Google Play Store][2] , I would argue Termux is the easiest way to introduce anyone to Linux. But don't leave all the fun for the noobs. Termux can accommodate many of your needs for a Linux development environment.
-
-Termux is Linux, but it is based on Android and runs in a container. That means you can install it with no root access required—but it also means it may take some getting used to. In this article, I'll outline some tips and tricks I found to get Termux working as a full-time development environment.
-
-### Where's all my stuff?
-
-The base of the Termux filesystem that you can see starts around `/data/data/com.termux/files/`. Under that directory, you'll find your home directory and the `usr` directory, where all the Linux packages are installed. This is kind of weird, but no big deal right? You would be wrong, because almost every script on the planet is hard coded for `/bin/bash`. Other libraries, executables, and configuration files are in places inconsistent with other Linux distributions.
-
-Termux provides lots of [packages][3] that have been modified to run correctly. Try looking there first instead of doing a custom build. However, you will still probably need to custom-build many things. You can try modifying your package's source code, and even though changing paths is easy, it gets old quick. Thankfully Termux also comes bundled with [termux-exec][4]. Termux-exec will redirect script paths on the fly to get them to work correctly.
-
-You may still run into some hard-coded paths that termux-exec doesn't handle. Since you don't have root access in Termux, you can't just create a symlink to fix path issues. However, you can create a [chroot jail][5]. Using the [PRoot][6] package, you can create a chroot that you have full control over and allows you to modify anything you want. You can also make chroots of different Linux distributions. If you are a Fedora fan, you can use Termux and run it in a chroot jail. Check out the [PRoot page][6] for more distros and installation details, or you can use [this script][7] to make a Termux chroot jail. I've only tried the Termux chroot and the Ubuntu chroot. The Ubuntu chroot had some issues that needed to be worked around, so your mileage may vary depending on the version of Linux you choose.
-
-### One user to rule them all
-
-In Termux, everything is installed and run under one user. This isn't so much a problem, rather something you need to get used to. This also means the typical services and user groups you might be familiar with are nowhere to be found. And nothing auto-starts on boot, so it's up to you to manage the start and stop of services you might use, like databases, SSH, etc. Also remember, your one user can't modify the base system, so you will need to use a chroot if you need to do that. Since you don't have nice, preset start scripts, you will probably have to come up with some of your own.
-
-For everyday development, I needed Postgres, Nginx, and Redis. I'd never started these services manually before; normally they start and stop for me automatically, and I had to do a little digging to find out how to start my favorite services. Here is a sample of the three services I just mentioned. Hopefully, these examples will point you in the right direction to use your favorite service. You can also look at a package's documentation to find information on how to start and stop it.
-
-#### Postgres
-
-Start: `pg_ctl -D $PREFIX/var/lib/postgresql start`
-Stop: `pg_ctl -D $PREFIX/var/lib/postgresql stop`
-
-#### Nginx
-
-Start: `nginx`
-Stop: `nginx -s stop`
-
-#### Redis
-
-Start: `redis-server $PREFIX/etc/redis.conf`
-Stop: `kill "$("$PREFIX/bin/applets/cat" "$PREFIX/var/run/redis_6379.pid"`
-
-### Broken dependencies
-
-Android is built differently than other versions of Linux, and its kernel and libraries don't always match those in typical Linux software. You can see the [common porting problems][8] when trying to build software in Termux. You can work around most of them, but it may be too much effort to fix every dependency in your software.
-
-For example, the biggest problem I ran into as a Python developer is by the Android kernel not supporting semaphores. The multi-processing library in Python depends on this functionality, and fixing this on my own was too difficult. Instead, I hacked around it by using a different deployment mechanism. Before I was using [uWSGI][9] to run my Python web services, so I switched to [Gunicorn][10]. This allowed me to route around using the standard Python multi-processing library. You may have to get a little creative to find alternative software dependencies when switching to Termux, but your list will probably be very small.
-
-### Everyday Termux
-
-When using Termux on a daily basis, you'll want to learn its [touch screen][11] or [hardware keyboard][12] shortcuts. You'll also need a text editor or IDE for coding. All the likely console-based editors are available through a quick package install: Vim, Emacs, and Nano. Termux is only console-based, so you won't be able to install any editors based on a graphical interface. I wanted to make sure Termux had a great IDE to go along with it, so I built the web-based Neutron64 editor to interface seamlessly with Termux. Just go to [Neutron64.com][13] and install [Neutron Beam][14] on Termux to start coding.
-
-Check out [Termux][1] and turn your old Android devices into development powerhouses. Happy coding!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/termux
-
-作者:[Paul Bailey][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/pizzapanther
-[1]:https://termux.com/
-[2]:https://play.google.com/store/apps/details?id=com.termux&hl=en_US
-[3]:https://termux.com/package-management.html
-[4]:https://wiki.termux.com/wiki/Termux-exec
-[5]:https://en.wikipedia.org/wiki/Chroot
-[6]:https://wiki.termux.com/wiki/PRoot
-[7]:https://github.com/Neo-Oli/chrooted-termux
-[8]:https://github.com/termux/termux-packages/blob/master/README.md#common-porting-problems
-[9]:https://uwsgi-docs.readthedocs.io/en/latest/
-[10]:http://gunicorn.org/
-[11]:https://termux.com/touch-keyboard.html
-[12]:https://termux.com/hardware-keyboard.html
-[13]:https://www.neutron64.com/
-[14]:https://www.neutron64.com/help/neutron-beam
diff --git a/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md b/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
deleted file mode 100644
index 50d68ad445..0000000000
--- a/sources/tech/20180522 How to Enable Click to Minimize On Ubuntu.md
+++ /dev/null
@@ -1,102 +0,0 @@
-How to Enable Click to Minimize On Ubuntu
-============================================================
-
-
- _Brief: This quick tutorial shows you how to enable click to minimize option on Ubuntu 18.04 and Ubuntu 16.04._
-
-The launcher at the left hand side in [Ubuntu][7] is a handy tool for quickly accessing applications. When you click on an icon in the launcher, the application window appears in focus.
-
-If you click again on the icon of an application already in focus, the default behavior is to do nothing. This may bother you if you expect the application window to be minimized on the second click.
-
-Perhaps this GIF will be better in explaining the click on minimize behavior on Ubuntu.
-
-[video](https://giphy.com/gifs/linux-ubuntu-itsfoss-52FlrSIMxnZ1qq9koP?utm_source=iframe&utm_medium=embed&utm_campaign=Embeds&utm_term=https%3A%2F%2Fitsfoss.com%2Fclick-to-minimize-ubuntu%2F%3Futm_source%3Dnewsletter&%3Butm_medium=email&%3Butm_campaign=new_linux_laptop_ubuntu_1804_flavor_reviews_meltdown_20_and_other_linux_stuff&%3Butm_term=2018-05-23)
-
-In my opinion, this should be the default behavior but apparently Ubuntu doesn’t think so. So what? Customization is one of the main reason [why I use Linux][8] and this behavior can also be easily changed.
-
-In this quick tutorial, I’ll show you how to enable click to minimize on Ubuntu 18.04 and 16.04\. I’ll show both command line and the GUI methods here.
-
-
-### Enable click to minimize on Ubuntu using command line (recommended)
-
- _This method is for Ubuntu 18.04 and 17.10 users with [GNOME desktop environment][1]_ .
-
-The first option is using the terminal. I recommend this way to ‘minimize on click’ even if you are not comfortable with the command line.
-
-It’s not at all complicated. Open a terminal using Ctrl+Alt+T shortcut or searching for it in the menu. All you need is to copy paste the command below in the terminal.
-
-```
-gsettings set org.gnome.shell.extensions.dash-to-dock click-action 'minimize'
-```
-
-No need of restarting your system or any thing of that sort. You can test the minimize on click behavior immediately after it.
-
-If you do not like ‘click to minimize’ behavior, you can set it back to default using the command below:
-
-```
-gsettings reset org.gnome.shell.extensions.dash-to-dock click-action
-```
-
-### Enable click to minimize on Ubuntu using GUI tool
-
-You can do the same steps mentioned above using a GUI tool called [Dconf Editor][10]. It is a powerful tool that allows you to change many hidden aspects of your Linux desktop. I avoid recommending it because one wrong click here and there may screw up your desktop settings. So be careful while using this tool keeping in mind that it works on single click and changes are applied immediately.
-
-You can find and install Dconf Editor in the Ubuntu Software Center.
-
-
-
-Once installed, launch Dconf Editor and go to org -> gnome -> shell -> extensions -> dash-to-dock. Scroll down a bit until you find click-action. Click on it to access the click action settings.
-
-In here, turn off the Use default value option and change the Custom Valueto ‘minimize’.
-
-
-
-You can see that the minimize on click behavior has been applied instantly.
-
-### Enable click to minimize on Ubuntu 16.04 Unity
-
-If you are using Unity desktop environment, you can easily d it using Unity Tweak Tool. If you have not installed it already, look for Unity Tweak Tool in Software Center and install it.
-
-Once installed, launch Unity Tweak Tool and click on Launcher here.
-
-
-
-Check the “Minimize single window application on click” option here.
-
-
-
-That’s all. The change takes into effect right away.
-
-### Did it work for you?
-
-I hope this quick tip helped you to enable the minimize on click feature in Ubuntu. If you are using Ubuntu 18.04, I suggest reading [GNOME customization tips][11] for more such options.
-
-If you have any questions or suggestions, please leave a comment. If it helped you, perhaps you could share this article on various social media platforms such as Reddit and Twitter.
-
-
-#### 关于作者
-
-I am a professional software developer, and founder of It's FOSS. I am an avid Linux lover and Open Source enthusiast. I use Ubuntu and believe in sharing knowledge. Apart from Linux, I love classic detective mysteries. I'm a huge fan of Agatha Christie's work.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/click-to-minimize-ubuntu/
-
-作者:[Abhishek Prakash ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/abhishek/
-[1]:https://www.gnome.org/
-[2]:https://itsfoss.com/author/abhishek/
-[3]:https://itsfoss.com/click-to-minimize-ubuntu/#comments
-[4]:https://itsfoss.com/category/how-to/
-[5]:https://itsfoss.com/tag/quick-tip/
-[6]:https://itsfoss.com/tag/ubuntu-18-04/
-[7]:https://www.ubuntu.com/
-[8]:https://itsfoss.com/reasons-switch-linux-windows-xp/
-[9]:https://itsfoss.com/how-to-know-ubuntu-unity-version/
-[10]:https://wiki.gnome.org/Projects/dconf
-[11]:https://itsfoss.com/gnome-tricks-ubuntu/
diff --git a/sources/tech/20180524 TrueOS- A Simple BSD Distribution for the Desktop Users.md b/sources/tech/20180524 TrueOS- A Simple BSD Distribution for the Desktop Users.md
deleted file mode 100644
index 1676e25f58..0000000000
--- a/sources/tech/20180524 TrueOS- A Simple BSD Distribution for the Desktop Users.md
+++ /dev/null
@@ -1,147 +0,0 @@
-TrueOS: A Simple BSD Distribution for the Desktop Users
-======
-**Brief: If you want to try something other than Linux, have a look at TrueOS. It is a BSD distribution specifically aimed at desktop users.**
-
-When you think of It’s FOSS you probably think mainly of Linux. It’s true that we cover mostly Linux-related news and tutorials. But today we are going to do something different.We are going to look at TrueOS BSD distribution.
-
-Linux and BSD, both fall into Unix-like operating system domain. The main difference lies at the core i.e. the kernel as both Linux and BSD have their own kernel implementation.
-
-### TrueOS BSD Review
-
-![TrueOS BSD ][1]
-
-[TrueOS (formerly PC-BSD)][2] is a desktop operating system based on [FreeBSD][3]. The goal of the project is to create a version of BSD that can be easily installed and is ready to use out of the box.
-
-TrueOS contains all of the FreeBSD goodness and includes some improvements of its own. It’s features include:
-
- * Graphical installer
- * OpenZFS file system
- * Automatically configured hardware
- * Full clang functionality
- * Upgrades use boot environments so live system is not harmed
- * Laptop support
- * Easy system administration
- * Built-in firewall
- * Built in support for the [Tor Project][4]
-
-
-
-There are [two version][5] of TrueOS for desktop use. TrueOS Stable is a long-term-release that is updated every 6 months. The most recent version is 18.03. TrueOS Unstable is more of a rolling release. It is based on the latest development version of FreeBSD. TrueOS also support ARM processors with [TrueOS Pico][6].
-
-#### Lumina
-
-![True OS BSD][7]
-
-While TrueOS supports many of the desktop environments that you are used to, it comes with [Lumina][8] installed by default. Started in 2014, Lumina is a lightweight desktop created by the TrueOS team from scratch. Since it is primarily designed for TrueOS and other BSDs, Lumina does not make use of “any of the Linux-based desktop frameworks (ConsoleKit, PolicyKit, D-Bus, systemd, etc..)”. However, it has been [ported][9] for several Linux distros. It currently uses Fluxbox, but they are writing a new window manage for [tighter integration][10].
-
-Lumina does come with its own file manager, media player, archiver and other utilities. The most current version is [1.4.0][11].
-
-#### System Requirements
-
-TrueOS’ [handbook][12] lists the following system requirements
-
-##### Minimum Requirements
-
- * 64-bit processor
- * 1 GB RAM
- * 10 – 15 GB of free hard drive space on a primary partition for a command-line server installation.
- * Network card
-
-
-
-##### Recommended Requirements
-
- * 64-bit processor
- * 4 GB of RAM
- * 20 – 30 GB of free hard drive space on a primary partition for a graphical desktop installation.
- * Network card
- * Sound card
- * 3D-accelerated video card
-
-
-
-#### Included Applications
-
-The number of applications that come pre-installed in TrueOS is small. Here they are:
-
- * AppCafe
- * QupZilla
- * Photonic
- * TrueOS PDF Viewer
- * Trojita email client
- * Insight File Manager
- * Lumina Archiver
- * Lumina Media Player
- * Lumina Screenshot
- * Lumina Text Editor
- * QTerminal
- * Calculator
-
-
-
-### Installation
-
-I was able to successfully install TrueOS on my Dell Latitude D630. This laptop has an Intel Centrino Duo Core processor running at 2.00 GHz, NVIDIA Quadro NVS 135M graphics chip, and 4 GB of RAM.
-
-The installation process was pretty painless. It was similar to most modern OS installers, you work your way through a series of screens which ask you for information. Interestingly, you don’t have the option to boot into a live environment. You have to install TrueOS, even if you only want to test it.
-
-I would like to note that some BSDs are fairly easy to install. I’ve installed FreeBSD and it took a little over an hour to go from text installer to a GUI. I have not managed to install vanilla Arch yet, but I’m sure it would take longer.
-
-### ![][13]
-
-### Experience
-
-I’ve been wanting to install TrueOS for a while (going back to the PC-BSD days). My only experience with BSD before this had been a web server running FreeBSD. Based on the name, I was expecting a polished desktop experience. After all, it ships with its own desktop environment. My experience was not as good as I had hoped.
-
-Whenever I start using a new operating system, I check to see if the applications that I regularly use are available. TrueOS does come with its own package manager (AppCafe), which made things easy. I was able to quickly install LibreOffice, VLC, FireFox, and Calibre. However, I was unable to install my favorite Markdown editor, ghostwriter. Interestingly, when I searched Markdown in the AppCafe there were quite a few packages listed, but none of them were Markdown editors. I was also unable to install Dropbox, which I use to backup up my writing.
-
-Besides the AppCafe package manager, you can also install applications using the TrueOS ports collection. To figure out how to do this, I turned to the [TrueOS handbook][14]. Unfortunately, the section on [ports][15] was very light on details. This is what I learned from my research on the web. The first step is to download the ports information from GitHub with this command: `git clone http://github.com/trueos/freebsd-ports.git /usr/ports`. From there you need to navigate to the directory of the port you want to install and type `make install`to start the process.
-
-While this process is similar to Arch’s AUR, it limits you to install one package at a time. Also, it takes quite a while to download the entire ports collection. (I have a fast connection and it took over 30 minutes.) When I was searching for information about how to use ports, I did see a command that allows you to only download the ports that you want to install, but that was not included in the TrueOS handbook.
-
-Like macOS and Windows, TrueOS has login and shutdown jingles. While it was cool at first, it got annoying pretty quickly. Especially, when I didn’t expect it.
-
-I applaud the TrueOS team for creating their own desktop environment (especially since the whole TrueOS team consists of less than a dozen people.). They have come a long way from their first release, but it still feels unfinished. One thing that I kept noticing was that the icons in the system tray were not a uniform size. The battery and sound icon were large, but the wifi icon was half the size. Also, when I went to click on the “start” button, I had to make sure to click on the icon, not near it, or the menu would not launch. Most other “start” menus don’t have this problem. They seem to have a large click area, so you don’t miss.
-
-For some reason, I could not get the system clock set. I entered the information for my timezone and location, but TrueOS set the time ahead by five hours.
-
-![][16]
-
-### Final Thoughts
-
-Overall, I like the idea of TrueOS, a user-friendly BSD. It offered an experience that was familiar, but different than any Linux distro. Unfortunately, the lack of applications was disappointing. Also, I wish the TrueOS handbook was more fleshed out in some areas.
-
-I would recommend that you install TrueOS if you want to get the full the BSD experience, complete with its own desktop environment. There is nothing even remotely related to Linux here.
-
-Have you ever TrueOS? What is your favorite version of BSD? Please let us know in the comments below.
-
-If you found this article interesting, please take a minute to share it on social media.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/trueos-bsd-review/
-
-作者:[John Paul][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/trueos-bsd-featured-800x450.jpg
-[2]:https://www.trueos.org
-[3]:https://en.wikipedia.org/wiki/FreeBSD
-[4]:https://www.trueos.org/handbook/using.html#tor-mode
-[5]:https://www.trueos.org/downloads/
-[6]:https://www.trueos.org/trueos-pico/
-[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/02/TrueOSScreenshot2-800x500.png
-[8]:https://lumina-desktop.org
-[9]:https://lumina-desktop.org/get-lumina/
-[10]:https://lumina-desktop.org/faq/
-[11]:https://lumina-desktop.org/version-1-4-0-released/
-[12]:https://www.trueos.org/handbook/introducing.html#hardware-requirements-and-supported-hardware
-[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/02/TrueOSScreenshot5.png
-[14]:https://www.trueos.org/handbook/trueos.html
-[15]:https://www.trueos.org/handbook/using.html#freebsd-ports
-[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/02/TrueOSScreenshot4.png
diff --git a/sources/tech/20180527 Streaming Australian TV Channels to a Raspberry Pi.md b/sources/tech/20180527 Streaming Australian TV Channels to a Raspberry Pi.md
deleted file mode 100644
index ac756223f1..0000000000
--- a/sources/tech/20180527 Streaming Australian TV Channels to a Raspberry Pi.md
+++ /dev/null
@@ -1,209 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Streaming Australian TV Channels to a Raspberry Pi)
-[#]: via: (https://blog.dxmtechsupport.com.au/streaming-australian-tv-channels-to-a-raspberry-pi/)
-[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
-
-Streaming Australian TV Channels to a Raspberry Pi
-======
-
-If you’re anything like me, it’s been years since you’ve even thought about hooking an antenna to your television. With so much of the good stuff available by streaming and download, it’s easy go a very long time without even thinking about free-to-air TV.
-
-But every now and again, something comes up – perhaps the cricket, news and current affairs shows, the FIFA World Cup – where the easiest thing would be to just chuck on the telly.
-
-When I first started tinkering with the Raspberry Pi as a gaming and media centre platform, the standard advice for watching broadcast TV always seemed to involve an antenna and a USB TV tuner.
-
-Which I guess is fine if you can be arsed.
-
-But what if you utterly can’t?
-
-What if you bitterly resent the idea of more clutter, more cords to add to the mess, more stuff to buy? What if every USB port is precious and jealously guarded for your keyboard, mouse, game controllers and removable storage? What if the wall port for your roof antenna is in a different room?
-
-That’s all a bit of a hassle for a thing you might use only a few times a year.
-
-In 2018, shouldn’t we just be able to stream free TV from the internet?
-
-It turns out that, yes, we can access legal and high quality TV streams from any Australian IP using [Freeview][1]. And thanks to a cool Kodi Add-on by [Matt Huisman][2], it’s now really easy to access this service from a Raspberry Pi.
-
-I’ve tested this to work on a Model 3 B+ running Retropie 4.4 and Kodi 17.6. But it should work similarly for other models and operating systems, so long as you’re using a reasonably up-to-date version of Kodi.
-
-Let’s jump right in.
-
-### If You Already Have Kodi Installed
-
-If you’re already using your Raspberry Pi to watch movies and TV shows, there’s a good chance you’ve already installed Kodi.
-
-Most Raspberry Pi operating systems intended for media centre use – such as OSMC or Xbian – come with Kodi installed by default.
-
-It’s fairly easy to get running on other Linux operating systems, and you might have already installed it there too.
-
-If your version of Kodi is more than a year or so old, it might be an idea to update it. The following instructions are written for the interface on Kodi 17 (Krypton).
-
-You can do that by typing the following commands at the command line:
-
-```
-sudo apt-get update
-sudo apt-get upgrade
-```
-
-And now you can skip ahead to the next section.
-
-### Installing Kodi
-
-Installing Kodi on Retropie and other versions of Raspbian is fairly simple. Other Linux operating systems should be able to run it, perhaps with a bit of coaxing.
-
-You will need to be connected to the internet to install it.
-
-If you’re using something, such as Risc OS – you probably can’t install kodi. You will need to either swap in another SD card, or use a boot loader to boot into a media centre OS for your TV viewing.
-
-#### Installing Kodi on Retropie
-
-It’s really easy to install Kodi using the Retropie menu system.
-
-Here’s how:
-
- 1. Navigate to the Retropie main screen – that’s that horizontal menu where you can scroll left and right through all your different consoles
- 2. Select “Retropie”
- 3. Select “Retropie setup”
- 4. Select “Manage Packages”
- 5. Select “Manage Optional Packages”
- 6. Scroll down and select “Kodi”
- 7. Select “Install from Binary”
-
-
-
-This will take a minute or two to install. Once it’s installed, you can exit out of the Retropie Setup screen. When you next restart Retropie, you will see Kodi under the “Ports” section of the Retropie main screen.
-
-#### Installing Kodi on Raspbian
-
-If you’re running Raspbian without Retropie. But that’s okay, because it’s pretty easy to do it from the command line
-
-Just type:
-
-```
-sudo apt-get update
-sudo apt-get install kodi
-```
-
-At this point you have a vanilla installation of Kodi. You can run it by typing:
-
-```
-kodi
-```
-
-It’s possible to delve a lot further into setting up Kodi from the command line. Check out [this guide][3] if you’re interested.
-
-If not, what you’ve just installed will work just fine.
-
-#### Installing Kodi on Other Versions of Linux
-
-If you’re using a different flavour of Linux, such as Pidora or Arch Linux ARM, then the above might or might not work – I’m not really sure, because I don’t really use these operating systems.
-
-If you get stuck, it might be worth a look at the [how-to guide][4] on the Kodi wiki.
-
-#### Dual Booting a Media Centre OS
-
-If your operating system of choice isn’t suitable for Kodi – or is just too confusing and difficult to figure out – it might be easiest to use a boot loader for multiple operating systems on the one SD card.
-
-You can set this up using an OS installer like [PINN][5].
-
-Using PINN, you can install a media centre OS like [OSMC][6] to use Kodi – it will be installed with the operating system – and then your preferred OS for your other uses.
-
-It’s even possible to [move your existing OS over][7].
-
-### Adding Australian TV Channels to Kodi
-
-With Kodi installed and running, you’ve got a pretty good media player for the files on your network and hard drive.
-
-But we need to install an add-on if we want to use it to chuck on the telly. This only takes a minute or so.
-
-#### Installing Matt Huisman’s Kodi Repository
-
-Ready? Let’s get started.
-
- 1. Open Kodi
- 2. Click the cog icon at the top left to enter the settings
- 3. Click “System Settings”
- 4. Select “Add-ons”
- 5. Make sure that “Unknown Sources” is enabled
- 6. Right click anywhere on the screen to navigate back to the settings menu
- 7. Click “File Manager”
- 8. Click “Add Source”
- 9. Double-click “Add Source”
- 10. Select “<None>”
- 11. Type in exactly **<http://k.mjh.nz>**
- 12. Select “OK”
- 13. Click the text input underneath the label “Enter a name for this media source.”
- 14. Type in exactly **MJH**
- 15. Click “OK”
- 16. Right click twice anywhere on the screen to navigate back to the main menu
- 17. Select “Add-ons”
- 18. Click “My Add-ons”
- 19. Click “..”
- 20. Click “Install from zip file”
- 21. Click “MJH”
- 22. Select “repository.matthuisman.zip”
-
-
-
-The repository is now installing.
-
-If you get stuck with any of this, here’s a video from Matt that starts by installing the repository.
-
-<https://www.youtube.com/embed/LWYg6WS1WoU?feature=oembed>
-
-#### Installing the Freeview Australia Add-On
-
-We’re nearly there! Just a few more steps.
-
- 1. Right click anywhere on the screen a couple of times to navigate back to the main menu
- 2. Select “Add-ons”
- 3. Click “My add-ons”
- 4. Click “..”
- 5. Click “Install from repository”
- 6. Click “MattHuisman.nz Repository”
- 7. Click “Video add-ons”
- 8. Click “AU Freeview”
- 9. Click “Install”
-
-
-
-You can now have every free-to-air TV channel in your Add-ons main menu item.
-
-### Watching TV
-
-When you want to chuck the telly on, all you need to do is click “AU Freeview” in the Add-ons main menu item. This will give you a list of channels to browse through and select.
-
-If you want, you can also add individual channels to your Favourites menu by right clicking them and selecting “Add to favourites”.
-
-By default you will be watching Melbourne television. You can change the region by right clicking on “AU Freeview” and clicking “settings”.
-
-When you first tune in, it sometimes jumps a bit for a few seconds, but after that it’s pretty smooth.
-
-After spending a few minutes with this, you’ll quickly realise that free-to-air TV hasn’t improved in the years since you last looked at. Unfortunately, I don’t think there’s a fix for that.
-
-But at least it’s there now for when you want it.
-
---------------------------------------------------------------------------------
-
-via: https://blog.dxmtechsupport.com.au/streaming-australian-tv-channels-to-a-raspberry-pi/
-
-作者:[James Mawson][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
-[b]: https://github.com/lujun9972
-[1]: http://www.freeview.com.au/
-[2]: https://www.matthuisman.nz/
-[3]: https://www.raspberrypi.org/forums/viewtopic.php?t=192499
-[4]: https://kodi.wiki/view/HOW-TO:Install_Kodi_for_Linux
-[5]: https://github.com/procount/pinn
-[6]: https://osmc.tv/
-[7]: https://github.com/procount/pinn/wiki/How-to-Create-a-Multi-Boot-SD-card-out-of-2-existing-OSes-using-PINN
diff --git a/sources/tech/20180529 How the Go runtime implements maps efficiently.md b/sources/tech/20180529 How the Go runtime implements maps efficiently.md
deleted file mode 100644
index a3da5278b2..0000000000
--- a/sources/tech/20180529 How the Go runtime implements maps efficiently.md
+++ /dev/null
@@ -1,355 +0,0 @@
-How the Go runtime implements maps efficiently (without generics)
-============================================================
-
-This post discusses how maps are implemented in Go. It is based on a presentation I gave at the [GoCon Spring 2018][7] conference in Tokyo, Japan.
-
-# What is a map function?
-
-To understand how a map works, let’s first talk about the idea of the _map function_ . A map function maps one value to another. Given one value, called a _key_ , it will return a second, the _value_ .
-
-```
-map(key) → value
-```
-
-Now, a map isn’t going to be very useful unless we can put some data in the map. We’ll need a function that adds data to the map
-
-```
-insert(map, key, value)
-```
-
-and a function that removes data from the map
-
-```
-delete(map, key)
-```
-
-There are other interesting properties of map implementations like querying if a key is present in the map, but they’re outside the scope of what we’re going to discuss today. Instead we’re just going to focus on these properties of a map; insertion, deletion and mapping keys to values.
-
-# Go’s map is a hashmap
-
-The specific map implementation I’m going to talk about is the _hashmap_ , because this is the implementation that the Go runtime uses. A hashmap is a classic data structure offering O(1) lookups on average and O(n) in the worst case. That is, when things are working well, the time to execute the map function is a near constant.
-
-The size of this constant is part of the hashmap design and the point at which the map moves from O(1) to O(n) access time is determined by its _hash function_ .
-
-### The hash function
-
-What is a hash function? A hash function takes a key of an unknown length and returns a value with a fixed length.
-
-```
-hash(key) → integer
-```
-
-this _hash value _ is almost always an integer for reasons that we’ll see in a moment.
-
-Hash and map functions are similar. They both take a key and return a value. However in the case of the former, it returns a value _derived _ from the key, not the value _associated_ with the key.
-
-### Important properties of a hash function
-
-It’s important to talk about the properties of a good hash function as the quality of the hash function determines how likely the map function is to run near O(1).
-
-When used with a hashmap, hash functions have two important properties. The first is _stability_ . The hash function must be stable. Given the same key, your hash function must return the same answer. If it doesn’t you will not be able to find things you put into the map.
-
-The second property is _good distribution_ . Given two near identical keys, the result should be wildly different. This is important for two reasons. Firstly, as we’ll see, values in a hashmap should be distributed evenly across buckets, otherwise the access time is not O(1). Secondly as the user can control some of the aspects of the input to the hash function, they may be able to control the output of the hash function, leading to poor distribution which has been a DDoS vector for some languages. This property is also known as _collision resistance_ .
-
-### The hashmap data structure
-
-The second part of a hashmap is the way data is stored.
-
-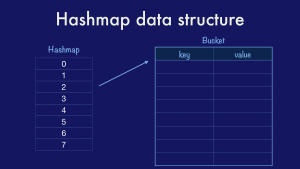
-The classical hashmap is an array of _buckets_ each of which contains a pointer to an array of key/value entries. In this case our hashmap has eight buckets (as this is the value that the Go implementation uses) and each bucket can hold up to eight entries each (again drawn from the Go implementation). Using powers of two allows the use of cheap bit masks and shifts rather than expensive division.
-
-As entries are added to a map, assuming a good hash function distribution, then the buckets will fill at roughly the same rate. Once the number of entries across each bucket passes some percentage of their total size, known as the _load factor,_ then the map will grow by doubling the number of buckets and redistributing the entries across them.
-
-With this data structure in mind, if we had a map of project names to GitHub stars, how would we go about inserting a value into the map?
-
-
-
-We start with the key, feed it through our hash function, then mask off the bottom few bits to get the correct offset into our bucket array. This is the bucket that will hold all the entries whose hash ends in three (011 in binary). Finally we walk down the list of entries in the bucket until we find a free slot and we insert our key and value there. If the key was already present, we’d just overwrite the value.
-
-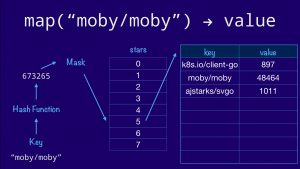
-
-Now, lets use the same diagram to look up a value in our map. The process is similar. We hash the key as before, then masking off the lower 3 bits, as our bucket array contains 8 entries, to navigate to the fifth bucket (101 in binary). If our hash function is correct then the string `"moby/moby"` will always hash to the same value, so we know that the key will not be in any other bucket. Now it’s a case of a linear search through the bucket comparing the key provided with the one stored in the entry.
-
-### Four properties of a hash map
-
-That was a very high level explanation of the classical hashmap. We’ve seen there are four properties you need to implement a hashmap;
-
-* 1. You need a hash function for the key.
-
- 2. You need an equality function to compare keys.
-
- 3. You need to know the size of the key and,
-
- 4. You need to know the size of the value because these affect the size of the bucket structure, which the compiler needs to know, as you walk or insert into that structure, how far to advance in memory.
-
-# Hashmaps in other languages
-
-Before we talk about the way Go implements a hashmap, I wanted to give a brief overview of how two popular languages implement hashmaps. I’ve chosen these languages as both offer a single map type that works across a variety of key and values.
-
-### C++
-
-The first language we’ll discuss is C++. The C++ Standard Template Library (STL) provides `std::unordered_map` which is usually implemented as a hashmap.
-
-This is the declaration for `std::unordered_map`. It’s a template, so the actual values of the parameters depend on how the template is instantiated.
-
-```
-template<
- class Key, // the type of the key
- class T, // the type of the value
- class Hash = std::hash<Key>,
// the hash function
- class KeyEqual = std::equal_to<Key>,
// the key equality function
- class Allocator = std::allocator< std::pair<const Key, T> >
-> class unordered_map;
-```
-
-There is a lot here, but the important things to take away are;
-
-* The template takes the type of the key and value as parameters, so it knows their size.
-
-* The template takes a `std::hash` function specialised on the key type, so it knows how to hash a key passed to it.
-
-* And the template takes an `std::equal_to` function, also specialised on key type, so it knows how to compare two keys.
-
-Now we know how the four properties of a hashmap are communicated to the compiler in C++’s `std::unordered_map`, let’s look at how they work in practice.
-
-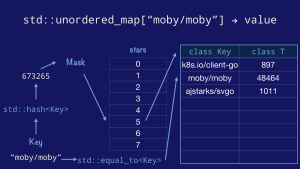
-
-First we take the key, pass it to the `std::hash` function to obtain the hash value of the key. We mask and index into the bucket array, then walk the entries in that bucket comparing the keys using the `std::equal_to` function.
-
-### Java
-
-The second language we’ll discuss is Java. In java the hashmap type is called, unsurprisingly, `java.util.Hashmap`.
-
-In java, the `java.util.Hashmap` type can only operate on objects, which is fine because in Java almost everything is a subclass of `java.lang.Object`. As every object in Java descends from `java.lang.Object` they inherit, or override, a `hashCode` and an `equals` method.
-
-However, you cannot directly store the eight primitive types; `boolean`, `int`, ``short``, ``long``, ``byte``, ``char``, ``float``, and ``double``, because they are not subclasss of `java.lang.Object`. You cannot use them as a key, you cannot store them as a value. To work around this limitation, those types are silently converted into objects representing their primitive values. This is known as _boxing._
-
-Putting this limitation to one side for the moment, let’s look at how a lookup in Java’s hashmap would operate.
-
-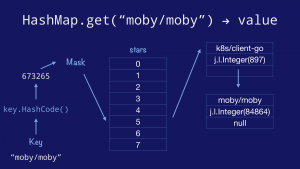
-
-First we take the key and call its `hashCode` method to obtain the hash value of the key. We mask and index into the bucket array, which in Java is a pointer to an `Entry`, which holds a key and value, and a pointer to the next `Entry` in the bucket forming a linked list of entries.
-
-# Tradeoffs
-
-Now that we’ve seen how C++ and Java implement a Hashmap, let’s compare their relative advantages and disadvantages.
-
-### C++ templated `std::unordered_map`
-
-### Advantages
-
-* Size of the key and value types known at compile time.
-
-* Data structure are always exactly the right size, no need for boxing or indiretion.
-
-* As code is specialised at compile time, other compile time optimisations like inlining, constant folding, and dead code elimination, can come into play.
-
-In a word, maps in C++ _can be_ as fast as hand writing a custom map for each key/value combination, because that is what is happening.
-
-### Disadvantages
-
-* Code bloat. Each different map are different types. For N map types in your source, you will have N copies of the map code in your binary.
-
-* Compile time bloat. Due to the way header files and template work, each file that mentions a `std::unordered_map` the source code for that implementation has to be generated, compiled, and optimised.
-
-### Java util Hashmap
-
-### Advantages
-
-* One implementation of a map that works for any subclass of java.util.Object. Only one copy of java.util.HashMap is compiled, and its referenced from every single class.
-
-### Disadvantages
-
-* Everything must be an object, even things which are not objects, this means maps of primitive values must be converted to objects via boxing. This adds gc pressure for wrapper objects, and cache pressure because of additional pointer indirections (each object is effective another pointer lookup)
-
-* Buckets are stored as linked lists, not sequential arrays. This leads to lots of pointer chasing while comparing objects.
-
-* Hash and equality functions are left as an exercise to the author of the class. Incorrect hash and equals functions can slow down maps using those types, or worse, fail to implement the map behaviour.
-
-# Go’s hashmap implementation
-
-Now, let’s talk about how the hashmap implementation in Go allows us to retain many of the benfits of the best map implementations we’ve seen, without paying for the disadvantages.
-
-Just like C++ and just like Java, Go’s hashmap written _in Go._ But–Go does not provide generic types, so how can we write a hashmap that works for (almost) any type, in Go?
-
-### Does the Go runtime use interface{}
?
-
-No, the Go runtime does not use `interface{}` to implement its hashmap. While we have the `container/{list,heap}` packages which do use the empty interface, the runtime’s map implementation does not use `interface{}`.
-
-### Does the compiler use code generation?
-
-No, there is only one copy of the map implementation in a Go binary. There is only one map implementation, and unlike Java, it doesn’t use `interface{}` boxing. So, how does it work?
-
-There are two parts to the answer, and they both involve co-operation between the compiler and the runtime.
-
-### Compile time rewriting
-
-The first part of the answer is to understand that map lookups, insertion, and removal, are implemented in the runtime package. During compilation map operations are rewritten to calls to the runtime. eg.
-
-```
-v := m["key"] → runtime.mapaccess1(m, ”key", &v)
-v, ok := m["key"] → runtime.mapaccess2(m, ”key”, &v, &ok)
-m["key"] = 9001 → runtime.mapinsert(m, ”key", 9001)
-delete(m, "key") → runtime.mapdelete(m, “key”)
-```
-
-It’s also useful to note that the same thing happens with channels, but not with slices.
-
-The reason for this is channels are complicated data types. Send, receive, and select have complex interactions with the scheduler so that’s delegated to the runtime. By comparison slices are much simpler data structures, so the compiler natively handles operations like slice access, `len` and `cap` while deferring complicated cases in `copy` and `append` to the runtime.
-
-### Only one copy of the map code
-
-Now we know that the compiler rewrites map operations to calls to the runtime. We also know that inside the runtime, because this is Go, there is only one function called `mapaccess`, one function called `mapaccess2`, and so on.
-
-So, how can the compiler can rewrite this
-
-```
-v := m[“key"]
-```
-
-into this
-
-```
-
runtime.mapaccess(m, ”key”, &v)
-```
-
-without using something like `interface{}`? The easiest way to explain how map types work in Go is to show you the actual signature of `runtime.mapaccess1`.
-
-```
-func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
-```
-
-Let’s walk through the parameters.
-
-* `key` is a pointer to the key, this is the value you provided as the key.
-
-* `h` is a pointer to a `runtime.hmap` structure. `hmap` is the runtime’s hashmap structure that holds the buckets and other housekeeping values [1][1].
-
-* `t` is a pointer to a `maptype`, which is odd.
-
-Why do we need a `*maptype` if we already have a `*hmap`? `*maptype` is the special sauce that makes the generic `*hmap` work for (almost) any combination of key and value types. There is a `maptype`value for each unique map declaration in your program. There will be one that describes maps from `string`s to `int`s, from `string`s to `http.Header`s, and so on.
-
-Rather than having, as C++ has, a complete map _implementation_ for each unique map declaration, the Go compiler creates a `maptype` during compilation and uses that value when calling into the runtime’s map functions.
-
-```
-type maptype struct {
-
typ _type
-
key *_type
-
elem *_type
-
bucket *_type // internal type representing a hash bucket
- hmap *_type // internal type representing a hmap
-
keysize uint8 // size of key slot
-
indirectkey bool // store ptr to key instead of key itself
-
valuesize uint8 // size of value slot
-
indirectvalue bool // store ptr to value instead of value itself
-
bucketsize uint16 // size of bucket
-
reflexivekey bool // true if k==k for all keys
-
needkeyupdate bool // true if we need to update key on overwrite
-}
-```
-
-Each `maptype` contains details about properties of this kind of map from key to elem. It contains infomation about the key, and the elements. `maptype.key` contains information about the pointer to the key we were passed. We call these _type descriptors._
-
-```
-type _type struct {
-
size uintptr
-
ptrdata uintptr // size of memory prefix holding all pointers
-
hash uint32
-
tflag tflag
-
align uint8
- fieldalign uint8
-
kind uint8
-
alg *typeAlg
- // gcdata stores the GC type data for the garbage collector.
-
// If the KindGCProg bit is set in kind, gcdata is a GC program.
- // Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
-
gcdata *byte
-
str nameOff
- ptrToThis typeOff
-
}
-```
-
-In the `_type` type, we have things like it’s size, which is important because we just have a pointer to the key value, but we need to know how large it is, what kind of a type it is; it is an integer, is it a struct, and so on. We also need to know how to compare values of this type and how to hash values of that type, and that is what the `_type.alg` field is for.
-
-```
-type typeAlg struct {
-
// function for hashing objects of this type
-
// (ptr to object, seed) -> hash
-
hash func(unsafe.Pointer, uintptr) uintptr
-
// function for comparing objects of this type
-
// (ptr to object A, ptr to object B) -> ==?
- equal func(unsafe.Pointer, unsafe.Pointer) bool
-}
-```
-
-There is one `typeAlg` value for each _type_ in your Go program.
-
-Putting it all together, here is the (slightly edited for clarity) `runtime.mapaccess1` function.
-
-```
-// mapaccess1 returns a pointer to h[key]. Never returns nil, instead
-// it will return a reference to the zero object for the value type if
-// the key is not in the map.
-
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
- if h == nil || h.count == 0 {
-
return unsafe.Pointer(&zeroVal[0])
- }
- alg := t.key.alg
-
hash := alg.hash(key, uintptr(h.hash0))
-
m := bucketMask(h.B)
-
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
-```
-
-One thing to note is the `h.hash0` parameter passed into `alg.hash`. `h.hash0` is a random seed generated when the map is created. It is how the Go runtime avoids hash collisions.
-
-Anyone can read the Go source code, so they could come up with a set of values which, using the hash ago that go uses, all hash to the same bucket. The seed value adds an amount of randomness to the hash function, providing some protection against collision attack.
-
-# Conclusion
-
-I was inspired to give this presentation at GoCon because Go’s map implementation is a delightful compromise between C++’s and Java’s, taking most of the good without having to accomodate most of the bad.
-
-Unlike Java, you can use scalar values like characters and integers without the overhead of boxing. Unlike C++, instead of _N_ `runtime.hashmap` implementations in the final binary, there are only _N_ `runtime.maptype` _values, a_ substantial saving in program space and compile time.
-
-Now I want to be clear that I am not trying to tell you that Go should not have generics. My goal today was to describe the situation we have today in Go 1 and how the map type in Go works under the hood. The Go map implementation we have today is very fast and provides most of the benefits of templated types, without the downsides of code generation and compile time bloat.
-
-I see this as a case study in design that deserves recognition.
-
-1. You can read more about the runtime.hmap structure here, https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it[][6]
-
-### Related Posts:
-
-1. [Are Go maps sensitive to data races ?][2]
-
-2. [Should Go 2.0 support generics?][3]
-
-3. [Introducing gmx, runtime instrumentation for Go applications][4]
-
-4. [If a map isn’t a reference variable, what is it?][5]
-
-
---------------------------------------------------------------------------------
-
-via: https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics
-
-作者:[Dave Cheney ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://dave.cheney.net/
-[1]:https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics#easy-footnote-bottom-1-3224
-[2]:https://dave.cheney.net/2015/12/07/are-go-maps-sensitive-to-data-races
-[3]:https://dave.cheney.net/2017/07/22/should-go-2-0-support-generics
-[4]:https://dave.cheney.net/2012/02/05/introducing-gmx-runtime-instrumentation-for-go-applications
-[5]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
-[6]:https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics#easy-footnote-1-3224
-[7]:https://gocon.connpass.com/event/82515/
-[8]:https://dave.cheney.net/category/golang
-[9]:https://dave.cheney.net/category/programming-2
-[10]:https://dave.cheney.net/tag/generics
-[11]:https://dave.cheney.net/tag/hashmap
-[12]:https://dave.cheney.net/tag/maps
-[13]:https://dave.cheney.net/tag/runtime
-[14]:https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics
-[15]:https://dave.cheney.net/2018/01/16/containers-versus-operating-systems
diff --git a/sources/tech/20180531 How to Build an Amazon Echo with Raspberry Pi.md b/sources/tech/20180531 How to Build an Amazon Echo with Raspberry Pi.md
deleted file mode 100644
index a5d4767706..0000000000
--- a/sources/tech/20180531 How to Build an Amazon Echo with Raspberry Pi.md
+++ /dev/null
@@ -1,374 +0,0 @@
-How to Build an Amazon Echo with Raspberry Pi
-======
-
-
-
-Many people today are using assistant software in their homes and offices to help with everyday tasks. There are many different models to purchase, but did you know you can build your own? [Amazon Developer][1] allows you to use the Alexa software to create your own [Amazon Echo][2] with [Raspberry Pi][3].
-
-### Materials
-
-For this project, you’ll need:
-
- * The Raspberry Pi 3 or Pi 2 Model B and Micro-USB power cable
- * Micro SD Card (Minimum 8 GB) – If you don’t have an operating system installed, there’s an easy-to-use operating system called NOOBS (New Out of the Box Software). The simplest way to get NOOBS is to buy an SD card with NOOBS pre-loaded.
- * USB 2.0 Mini Microphone
- * External speaker and 3.5mm audio cable
- * USB Keyboard and Mouse and external HDMI Monitor
- * Internet connection (Ethernet or WiFi)
- * For a Pi 2 to connect to the Internet wirelessly, you need a WiFi Wireless Adapter. The Pi 3 has built-in WiFi.
-
-
-
-**Related** : [5 Essential Tips & Tricks to Personalize Your Amazon Echo][4]
-
-### Register for an Amazon Developer account
-
-If you need an Amazon Developer account, create a free one on their [page][1]. Read the AVS (Alexa Voice Service) Terms and Agreements [here][5].
-
-![raspberrypi-echo-amazon-developer-account][6]
-
-![raspberrypi-echo-amazon-developer-account][6]
-
-Complete your profile information.
-
-![raspberrypi-echo-register-profile-info][7]
-
-![raspberrypi-echo-register-profile-info][7]
-
-Read and accept the App Distribution Agreement.
-
-![raspberrypi-echo-register-app-distribution-agree][8]
-
-![raspberrypi-echo-register-app-distribution-agree][8]
-
-Select whether you are choosing to monetize your apps.
-
-![raspberrypi-echo-register-payments][9]
-
-![raspberrypi-echo-register-payments][9]
-
-### Create your device on Amazon Developer
-
-After registering your Amazon Developer account, create an Alexa device and Security profile. Make careful note of the following parameters as you go through the setup – ProductID, ClientID, and ClientSecret, because you need to enter these again later.
-
-From the top menu, select “Alexa Voice Service.”
-
-![raspberrypi-echo-alexa-voice-service][10]
-
-![raspberrypi-echo-alexa-voice-service][10]
-
-The “Welcome to Developer” screen will appear.
-
-![raspberrypi-echo-developer-welcome][11]
-
-![raspberrypi-echo-developer-welcome][11]
-
-The first screen asks about the product you are building.
-
-1\. First, name your device.
-
-![raspberrypi-echo-product-name][12]
-
-![raspberrypi-echo-product-name][12]
-
-2\. Next, type a Product ID with no spaces or special characters.
-
-**Note** : You need this later. Record it somewhere.
-
-![raspberrypi-echo-product-id][13]
-
-![raspberrypi-echo-product-id][13]
-
-3\. Select Alexa-Enabled Device for the product type.
-
-![raspberrypi-echo-product-type][14]
-
-![raspberrypi-echo-product-type][14]
-
-4\. Alexa needs a companion app. Select yes for this question.
-
-![raspberrypi-echo-companion-app][15]
-
-![raspberrypi-echo-companion-app][15]
-
-5\. Choose Wireless Speakers from the dropdown menu.
-
-6\. Enter “Raspberry Pi Project on Github” into the description box. This is information for AVS and isn’t visible to others.
-
-7\. Check both the “Touch-initiated” and “Hands-free” options.
-
-![raspberrypi-echo-product-options][16]
-
-![raspberrypi-echo-product-options][16]
-
-8\. You can upload an image for your device, but let’s skip this step for now.
-
-9\. Check “no” for commercial distribution and children’s product questions.
-
-![raspberrypi-echo-product-options-2][17]
-
-![raspberrypi-echo-product-options-2][17]
-
-10\. Click “Next.”
-
-### Create your security profile
-
-On this page, you create a new LWA (Login with Amazon) security profile to identify the user data and security credentials with this project.
-
-1\. Click “Create new profile.”
-
-![raspberrypi-echo-lwa-security-profile2][18]
-
-![raspberrypi-echo-lwa-security-profile2][18]
-
-2\. Create a name for the profile. It could be something like, “Alexa Security Profile.”
-
-![raspberrypi-echo-security-profile-name][19]
-
-![raspberrypi-echo-security-profile-name][19]
-
-3\. Type a description for the profile. You can choose “Alexa Security Profile Description.”
-
-![raspberrypi-echo-security-description][20]
-
-![raspberrypi-echo-security-description][20]
-
-4\. Click “Next.”
-
-5\. Amazon generates a Client ID and Client Secret for you. These are the other two values you need later. Keep them nearby.
-
-![raspberrypi-echo-id-and-secret1][21]
-
-![raspberrypi-echo-id-and-secret1][21]
-
-6\. Enter your Allowed origins and Allowed return URLs. We’re setting up http and https routes for this project, so type the following into your “Allowed Origins” field — “<http://localhost:3000.”>
-
-7\. Click “Add.”
-
-8\. Type “<https://localhost:3000”> into the same box where you typed the first one.
-
-![raspberrypi-echo-allowed-origins-2][22]
-
-![raspberrypi-echo-allowed-origins-2][22]
-
-9\. Click “Add” again.
-
-10\. Do the same thing to the Allowed Return URLs, except enter the following two URLs:
-
-11\. The page should look like this before you click Finish. Make sure none of your URLs are still in the field where you typed them. They are displayed on a grey background after you add them.
-
-![raspberrypi-echo-all-origins][23]
-
-![raspberrypi-echo-all-origins][23]
-
-12\. Once you click “Finish,” this screen appears. Your project has been created and is ready to install.
-
-![raspberrypi-echo-product-screen][24]
-
-![raspberrypi-echo-product-screen][24]
-
-### Clone the Alexa sample app
-
-1\. Open Terminal.
-
-![raspberrypi-echo-open-terminal2][25]
-
-![raspberrypi-echo-open-terminal2][25]
-
-2\. Type the following:
-```
-cd Desktop
-git clone https://github.com/alexa/alexa-avs-sample-app.git
-```
-
-### Update the install script by adding your credentials
-
-Before you run the install script, update the script with the credentials that you recorded from Amazon — ProductID, ClientID, ClientSecret.
-
-1\. Type the following in Terminal:
-```
-cd ~/Desktop/alexa-avs-sample-app
-nano automated_install.sh
-```
-
-2\. When it runs, this screen appears. Use the arrows on your keyboard to navigate, and replace the fields for ProductID, ClientID, and ClientSecret with your values.
-
-![raspberrypi-echo-insert-device-data][26]
-
-![raspberrypi-echo-insert-device-data][26]
-
-The changes should look like this:
-```
-ProductID="Your Device Name"
-ClientID="amzn.xxxxx.xxxxxxxxx"
-ClientSecret="4e8cb14xxxxxxxxxxxxxxxxxxxxxxxxxxxxx6b4f9"
-```
-
-3\. Type Ctrl + X to exit the script. Type Y and then Enter to save your changes.
-
-### Run the install script
-
-To run the script, open Terminal and run the following commands.
-```
-cd ~/Desktop/alexa-avs-sample-app
-. automated_install.sh
-```
-
-While this script is running, you will be asked to answer some simple questions. These are to make sure you’ve completed all of the necessary setup on Amazon before you install the program.
-
-![raspberrypi-echo-setup-questions][27]
-
-![raspberrypi-echo-setup-questions][27]
-
-The installation is about thirty minutes, so go grab a snack.
-
-When installed correctly, your terminal window will look like the following image.
-
-![raspberrypi-echo-end-install2][28]
-
-![raspberrypi-echo-end-install2][28]
-
-### The Three Terminals
-
-You must complete three steps to run the Alexa app. Each of them must run in a separate Terminal window, and you must do them in the correct order.
-
-There were some programs that I needed but didn’t have. I installed these programs as I went. In case you have the same problem, I included a side note about this in each step.
-
-#### Terminal 1
-
-This window runs the web service to authorize your app with AVS (Alexa Voice Service)
-
-Open Terminal and type in the following commands:
-```
-cd ~/Desktop/alexa-avs-sample-app/samples
-cd companionService && npm start
-```
-
-**Note** : npm is a package manager for the JavaScript programming language. If it is not available when you run the command, you can get it [here][29].
-
-When the scripts finish, the window looks like this, showing that Pi is listening on port 3000.
-
-![raspberrypi-echo-port-3000][30]
-
-![raspberrypi-echo-port-3000][30]
-
-Don’t close this window. It needs to remain open while completing the next steps.
-
-#### Terminal 2
-
-This window communicates with AVS.
-
-Type the following into another Terminal window.
-```
-cd ~/Desktop/alexa-avs-sample-app/samples
-cd javaclient && mvn exec:exec
-```
-
-**Note** : mvn is short for Apache Maven. If you don’t have it, click [here][31] to get started.
-
-When you run the client, a dialog box appears saying, “Please register your device by …”
-
-Click Yes.
-
-![raspberrypi-echo-open-site][32]
-
-![raspberrypi-echo-open-site][32]
-
-With some browsers, you’ll get a warning that the connection is not safe. Dismiss this by clicking the “advanced” button. Then on the next screen, click on “Proceed to localhost (unsafe).”
-
-Now, log into Amazon using your developer credentials.
-
-The next screen asks for permission to use the security profile you created earlier for the device you are registering. Click Okay.
-
-![raspberrypi-echo-use-security-profile][33]
-
-![raspberrypi-echo-use-security-profile][33]
-
-You will be redirected to a URL beginning with “<https://localhost:3000/authresponse”> that looks like the following image.
-
-![raspberrypi-echo-device-tokens-ready][34]
-
-![raspberrypi-echo-device-tokens-ready][34]
-
-Go back to the open dialog box and click the OK button. The client is now able to accept requests from your Alexa device.
-
-Keep the terminal open as well as the Voice Service Dialog box.
-
-![raspberrypi-echo-voice-service-box][35]
-
-![raspberrypi-echo-voice-service-box][35]
-
-#### Terminal 3
-
-This window installs the application that wakes up Alexa by using her wake word. Skip this if you don’t want to use voice to initiate Alexa.
-
-Open a new terminal window and use one of the following commands to bring up a wake word engine using Sensory or KITT.AI.
-
-To use the Sensory wake word engine, type:
-```
-cd ~/Desktop/alexa-avs-sample-app/samples
-cd wakeWordAgent/src && ./wakeWordAgent -e sensory
-```
-
-To use KITT.AI’s wake word engine, type:
-```
-cd ~/Desktop/alexa-avs-sample-app/samples
-cd wakeWordAgent/src && ./wakeWordAgent -e kitt_ai
-```
-
-### Test it out
-
-Talk to Alexa by saying the wake word, “Alexa.” Wait for the beep before giving your command. For example, try it by saying, “Alexa.” Wait for the beep, and then ask, “What’s the time?”
-
-If she responds correctly, you have a working Alexa device!
-
-Check out Amazon’s Alexa [webpage][36] for more ideas. This Alexa can do everything an Echo can do!
-
---------------------------------------------------------------------------------
-
-via: https://www.maketecheasier.com/build-amazon-echo-with-raspberry-pi/
-
-作者:[Tracey Rosenberger][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.maketecheasier.com/author/traceyrosenberger/
-[1]:http://developer.amazon.com
-[2]:https://www.amazon.com/dp/B06XCM9LJ4/?tag=maketecheas08-20
-[3]:https://www.maketecheasier.com/tag/raspberry-pi
-[4]:https://www.maketecheasier.com/essential-amazon-echo-tips-tricks/ (5 Essential Tips & Tricks to Personalize Your Amazon Echo)
-[5]:https://developer.amazon.com/support/legal/alexa/alexa-voice-service/terms-and-agreements
-[6]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Amazon-developer-account.jpg (raspberrypi-echo-amazon-developer-account)
-[7]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Register-Profile-info.jpg (raspberrypi-echo-register-profile-info)
-[8]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Register-App-Distribution-Agree.jpg (raspberrypi-echo-register-app-distribution-agree)
-[9]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Register-Payments.jpg (raspberrypi-echo-register-payments)
-[10]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Alexa-voice-service.jpg (raspberrypi-echo-alexa-voice-service)
-[11]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-developer-welcome.jpg (raspberrypi-echo-developer-welcome)
-[12]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-name.jpg (raspberrypi-echo-product-name)
-[13]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-ID.jpg (raspberrypi-echo-product-id)
-[14]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-type.jpg (raspberrypi-echo-product-type)
-[15]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-companion-app.jpg (raspberrypi-echo-companion-app)
-[16]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-options.jpg (raspberrypi-echo-product-options)
-[17]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-options-2.jpg (raspberrypi-echo-product-options-2)
-[18]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-LWA-Security-Profile2.jpg (raspberrypi-echo-lwa-security-profile2)
-[19]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-security-profile-name.jpg (raspberrypi-echo-security-profile-name)
-[20]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-security-description.jpg (raspberrypi-echo-security-description)
-[21]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-ID-and-secret1.jpg (raspberrypi-echo-id-and-secret1)
-[22]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-allowed-origins-2.jpg (raspberrypi-echo-allowed-origins-2)
-[23]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-all-origins.jpg (raspberrypi-echo-all-origins)
-[24]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-screen.jpg (raspberrypi-echo-product-screen)
-[25]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-open-terminal2.jpg (raspberrypi-echo-open-terminal2)
-[26]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-insert-device-data.jpg (raspberrypi-echo-insert-device-data)
-[27]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-setup-questions.jpg (raspberrypi-echo-setup-questions)
-[28]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-end-install2.jpg (raspberrypi-echo-end-install2)
-[29]:https://www.npmjs.com/
-[30]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Port-3000.jpg (raspberrypi-echo-port-3000)
-[31]:https://maven.apache.org/
-[32]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-open-site.jpg (raspberrypi-echo-open-site)
-[33]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-use-security-profile.jpg (raspberrypi-echo-use-security-profile)
-[34]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-device-tokens-ready.jpg (raspberrypi-echo-device-tokens-ready)
-[35]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Voice-service-box.jpg (raspberrypi-echo-voice-service-box)
-[36]:https://www.amazon.com/meet-alexa/b?ie=UTF8&node=16067214011&tag=maketecheas08-20
diff --git a/sources/tech/20180601 3 open source music players for Linux.md b/sources/tech/20180601 3 open source music players for Linux.md
deleted file mode 100644
index 66c8abec89..0000000000
--- a/sources/tech/20180601 3 open source music players for Linux.md
+++ /dev/null
@@ -1,128 +0,0 @@
-3 open source music players for Linux
-======
-
-
-
-As I described [in my last article][1], when I'm using a Linux-based computer to listen to music, I pass that music through a dedicated digital-analog converter, or DAC. To make sure the bits in the music file get through to the DAC without any unnecessary fiddling on the part of intermediate software on my computer (like audio mixers), I like to aim the music player directly at the [hw interface][2] (or, if necessary, the plughw interface) that ALSA provides to the external equipment.
-
-So, when I hear about a new music player, the first thing I do is figure out how to configure the output device. In the process of reviewing quite a few Linux-based music players, I'm beginning to see a pattern.
-
-First, a sizable group of players depends on [GStreamer][3] to play the audio. As its website says, GStreamer is a multimedia framework that allows construction of arbitrary pipelines of media-processing components. In my case, [the alsasink plugin][4] can be used in a pipeline, like this:
-```
-gst-launch-1.0 -v uridecodebin uri=file:///path/to/my.flac ! audioconvert ! audioresample ! autoaudiosink
-
-```
-
-to play back the file `/path/to/my.flac` on the default ALSA audio output device. Note the use of the `audioresample` component in the pipeline—that's one of the things I don't want! Also, I don't want to use the ALSA default output—I want to select the device.
-
-GStreamer-based music players vary in the configurability of their outputs. At the one extreme, players like [QuodLibet][5] provide the ability to precisely configure the output. At the other extreme, players like [Rhythmbox][6] use the default audio device, meaning—as far as I can tell, anyway—that mixing and resampling are going to happen. For example, the [PulseAudio Perfect Setup Guide][7] explains:
-
-> Applications using the modern GStreamer media framework such as Rhythmbox or Totem can make use of the PulseAudio through gst-pulse, the PulseAudio plugin for GStreamer…
-
-and then shows how to use `gconftool` to enable that:
-```
-gconftool -t string --set /system/gstreamer/0.10/default/audiosink pulsesink
-
-```
-
-So far, I've only found a few GStreamer-based music players that let me build the dedicated output connection I want: QuodLibet, [Guayadeque][8], and [Gmusicbrowser][9]. All three of these are great music players, but for my use—once configured—[I prefer Guayadeque][10].
-
-Second, there is a different group of players that don't use GStreamer, instead taking a different route to getting data to the output device. A subgroup of these players are clients for [the MPD music server backend][11]. Of the players that use the MPD backend, [Cantata][12] is [my favorite, by far][13]. Of course, the nice thing about MPD being a server is that it can be controlled by other devices, such as Android-based phones or tablets. Therefore, for a music player hooked up to the home stereo or AV center, MPD is my go-to.
-
-Of the non-MPD, non-GStreamer music players I've tried that support my use case, I really like [Goggles Music Manager][14].
-
-With that background, let's take a look at some new (to me) players.
-
-### Museeks music player
-
-The [Museeks][15] music player is available on GitHub in source or binary (.deb, .AppImage,.rpm, amd64, or i386). Taking a quick look at the code, I see that Museeks is an Electron application, which I find kind of intriguing. The .deb installed without problems, and upon startup I was greeted with the Museeks user interface, which I find to be simple but attractive.
-
-
-
-After clicking on the Audio tab, the only option I saw changes the playback rate, which is not of interest to me. After further online searching, I opened an issue on GitHub to ask about this and was encouraged by a quick and friendly response from Pierre de la Martinière saying he thought it interesting and that he would look into it. So, for now, without the ability to configure output, I'm going to put this otherwise interesting-looking player on pause.
-
-### LPlayer music player
-
-The [LPlayer][16] music player is also available on GitHub and as an Ubuntu PPA. I used the latter to install the current version, which proceeded without issue. LPlayer offers a very simple user interface: audio files (music or whatever) are loaded from the filesystem into the current playlist, reminiscent of [VLC][17]. I don't mind this kind of organization, but I like a more extensive, tag-based music browser. However, a lightweight player has its own charms, so I continued with the evaluation.
-
-Here is LPlayer's main screen with two tracks loaded:
-
-
-
-The Settings control offers the playing track's current position, the playback speed, options to "remove silence" and "play continuously," and a graphical equalizer, but no output device configuration.
-
-
-
-A bit of source code investigation showed that LPlayer uses GStreamer. I decided to contact the author, Lorenzo Carbonell, to see if he had any thoughts about the idea of configuring the GStreamer playback pipeline within the application. Until I hear back from him, I'll keep this little player on the shelf. (By the way, Linux fans, Sr. Carbonell has a pretty great-looking Spanish-language Linux blog, [El Atareao-Linux para Legos][18]).
-
-### Elisa music player
-
-According to the KDE community website, the [Elisa][19] music player is intended to provide "very good integration with the Plasma desktop of the KDE community without compromising the support for other platforms." One of these days, I need to set up a KDE desktop so I can try some of this stuff in the native environment, but that's not in the cards for this review.
-
-I took a look at the [Try It][20] instructions to get an idea of how I might, well, try it. According to that page, my options were: 1) try a [Flatpak][21], 2) install ArchLinux and use the AUR available, or 3) install Fedora for which "the releases are usually packaged." Based on these options, I thought it was time I tried a Flatpak…
-```
-me@mymachine:~/Downloads$ sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
-
-me@mymachine:~/Downloads$ sudo flatpak remote-add --if-not-exists kdeapps --from https://distribute.kde.org/kdeapps.flatpakrepo
-
-flatpak install kdeapps org.kde.elisa
-
-Required runtime for org.kde.elisa/x86_64/master (org.kde.Platform/x86_64/5.9) is not installed, searching...
-
-Found in remote flathub, do you want to install it? [y/n]:
-
-```
-
-Hmmm let's see, `org.kde.Platform`… maybe I don't want to bring all that in. I think I'm going to press pause on this player, too, until I can take the time to set up a KDE environment.
-
-### Conclusions for this round
-
-Well, really there aren't many, except that Museeks and LPlayer reinforce my impression that being able to pass music data to the DAC without tampering is not a primary design goal for a lot of Linux music players. This is too bad, really, because there are plenty of decent-to-excellent, low-cost DACs that are compatible with Linux and do a great job of converting those digits to sweet, sweet analog.
-
-### Let's not forget the music
-
-I've been shopping for music downloads again, this time on 7digital's Linux-friendly store. I picked up three great albums by [Fela Kuti][22], in CD-quality FLAC format: [Opposite People][23], [Roforofo Fight][24], and [Unnecessary Begging][25]. This man made so much great music! The sound quality on these files is generally quite decent, which is a nice treat. Opposite People dates back to 1977, Roforofo Fight to 1972, and Unnecessary Begging to 1982.
-
-I also bought [Trentemøller][26]'s 2016 album, [Fixion][27]. I've liked his stuff since I first bumped into [The Last Resort][28]. This [video documentary][29] provides an interesting perspective on Trentemøller and his music, which is quite distinctive; I like his use of guitars, which can sometimes hint at '60s surfer music. The version on 7digital was available in 96KHz/24bit, so that's what I bought.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/open-source-music-players
-
-作者:[Chris Hermansen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/clhermansen
-[1]:https://opensource.com/article/18/3/phono-preamplifier-project
-[2]:https://en.wikipedia.org/wiki/Advanced_Linux_Sound_Architecture#Concepts
-[3]:https://gstreamer.freedesktop.org/
-[4]:https://gstreamer.freedesktop.org/data/doc/gstreamer/head/gst-plugins-base-plugins/html/gst-plugins-base-plugins-alsasink.html
-[5]:https://quodlibet.readthedocs.io/en/latest/
-[6]:https://help.gnome.org/users/rhythmbox/stable/
-[7]:https://www.freedesktop.org/wiki/Software/PulseAudio/Documentation/User/PerfectSetup/
-[8]:http://www.guayadeque.org/
-[9]:https://gmusicbrowser.org/
-[10]:https://opensource.com/article/16/12/soundtrack-open-source-music-players
-[11]:https://www.musicpd.org/
-[12]:https://github.com/CDrummond/cantata
-[13]:https://opensource.com/article/17/8/cantata-music-linux
-[14]:https://gogglesmm.github.io/
-[15]:https://github.com/KeitIG/Museeks/releases/tag/0.9.4
-[16]:https://github.com/atareao/lplayer
-[17]:https://www.videolan.org/vlc/index.es.html
-[18]:https://www.atareao.es/
-[19]:https://community.kde.org/Elisa
-[20]:https://community.kde.org/Elisa#Try_It
-[21]:https://flatpak.org/
-[22]:https://en.wikipedia.org/wiki/Fela_Kuti
-[23]:https://youtu.be/PeH4xziCHQs
-[24]:https://youtu.be/XvX_iNFcKho
-[25]:https://www.youtube.com/watch?v=614ZdP8SIbg
-[26]:http://www.trentemoller.com/
-[27]:http://www.trentemoller.com/music/fixion-0
-[28]:https://en.wikipedia.org/wiki/The_Last_Resort_(album)
-[29]:https://youtu.be/avatsxJazA0
diff --git a/sources/tech/20180601 Get Started with Snap Packages in Linux.md b/sources/tech/20180601 Get Started with Snap Packages in Linux.md
deleted file mode 100644
index 632151832a..0000000000
--- a/sources/tech/20180601 Get Started with Snap Packages in Linux.md
+++ /dev/null
@@ -1,159 +0,0 @@
-Get Started with Snap Packages in Linux
-======
-
-
-Chances are you’ve heard about Snap packages. These universal packages were brought into the spotlight with the release of Ubuntu 16.04 and have continued to draw attention as a viable solution for installing applications on Linux. What makes Snap packages so attractive to the end user? The answer is really quite easy: Simplicity. In this article, I’ll answer some common questions that arise when learning about Snaps and show how to start using them.
-
-Exactly what are Snap packages? And why are they needed? Considering there are already multiple ways to install software on Linux, doesn’t this complicate the issue? Not in the slightest. Snaps actually makes installing/updating/removing applications on Linux incredibly easy.
-
-How does it accomplish this? Essentially, a Snap package is a self-contained application that bundles most of the libraries and runtimes (necessary to successfully run an application) into a single, universal package. Because of this, Snaps can be installed, updated, and reverted without affecting the rest of the host system, and without having to first install dependencies. Snap packages are also confined from the OS (via various security mechanisms), yet can still function as if it were installed by the standard means (exchanging data with the host OS and other installed applications).
-
-Are Snaps challenging to work with? In a word, no. In fact, Snaps make short work of installing apps that might otherwise challenge your Linux admin skills. Since Snap packages are self-contained, you only need to install one package to get an app up and running.
-
-Although Snap packages were created by Ubuntu developers, they can be installed on most modern Linux distributions. Because the necessary tool for Snap packages is installed on the latest releases of Ubuntu out of the box, I’m going to walk you through the process of installing and using Snap packages on Fedora. Once installed, using Snap is the same, regardless of distribution.
-
-### Installation
-
-The first thing you must do is install the Snap system, aka snapd. To do this on Fedora, open up the terminal window and issue the command:
-```
-sudo dnf install snapd
-
-```
-
-The above command will catch any necessary dependencies and install the system for Snap. That’s all there is to is. You’re ready to install your first Snap package.
-
-### Installing with Snap: Command-line edition
-
-The first thing you’ll want to do is find out what packages are available to install via Snap. Although Snap has begun to gain significant momentum, not every application can be installed via Snap. Let’s say you want to install GIMP. First you might want to find out what GIMP-relate packages are available as Snaps. Back at the terminal window, issue the command:
-```
-sudo snap find gimp
-
-```
-
-The command should report only one package available for GIMP (Figure 1).
-
-
-![Snap][2]
-
-Figure 1: GIMP is available to install via Snap.
-
-[Used with permission][3]
-
-To get a better idea as to what the find option can do for you, issue the command:
-```
-sudo snap find nextcloud
-
-```
-
-The output of that command (Figure 2) will report Snap packages related to Nextcloud.
-
-
-![searching][5]
-
-Figure 2: Searching for Nextcloud-related Snap packages.
-
-[Used with permission][3]
-
-Let’s say you want to go ahead and install GIMP via Snap. To do this, issue the command:
-```
-sudo snap install gimp
-
-```
-
-The above command will download and install the Snap package. After the command completes, you’ll find GIMP in your desktop menu, ready to use.
-
-### Updating Snap packages
-
-Once a Snap package is installed, it will not be updated by the normal method of system updating (via apt, yum, or dnf). To update a Snap package, the refresh option is used. Say you want to update GIMP, you would issue the command:
-```
-sudo snap refresh gimp
-
-```
-
-If an updated Snap package is available, it will be downloaded and installed. Say, however, you have a number of Snap packages installed, and you want to update them all. This is done with the command:
-```
-sudo snap refresh
-
-```
-
-The snapd system will check all installed Snap packages against what’s available. If there are newer versions, the installed Snap package will be updated. One thing to note is that Snap packages are automatically updated daily, so you don’t have to manually issue the refresh command, unless you want to do this manually.
-
-### Listing installed Snap packages
-
-What if you’re not sure which Snap packages you’ve installed? Easy. Issue the command sudo snap list and all of your installed Snap packages will be listed for you (Figure 3).
-
-
-![installed packages][7]
-
-Figure 3: Listing installed Snap packages.
-
-[Used with permission][3]
-
-### Removing Snap packages
-
-Removing a Snap package is just as simple as installing. We’ll stick with our GIMP example. To remove GIMP, issue the command:
-```
-sudo snap remove gimp
-
-```
-
-One thing you’ll notice is that removing a Snap package takes significantly less time than uninstalling via the standard method (i.e., sudo apt remove gimp or sudo dnf remove gimp). In fact, on my test Fedora system, installing, updating, and removing GIMP was quite a bit faster than doing so with dnf.
-
-### Installing with Snap: GUI edition
-
-You can enable Snap support in GNOME Software with a quick dnf install command. That command is:
-```
-sudo dnf install gnome-software-snap
-
-```
-
-Once the command finishes, reboot your system and open up GNOME Software. You will be prompted to enable third party repositories (Figure 4). Click Enable and Snap packages are now ready to be installed.
-
-
-![Snap repo][9]
-
-Figure 4: Enabling the Snap repositories in GNOME Software.
-
-[Used with permission][3]
-
-If you now search for GIMP, you will see two versions available. Click on one and if you see Snap Store as the source (Figure 5), you know that’s the Snap version of GIMP.
-
-
-![installing Snap package][11]
-
-Figure 5: Installing a Snap package through GNOME Software.
-
-[Used with permission][3]
-
-Although I cannot imagine a reason for doing so, you can install both the standard and Snap version of the package. You might find it difficult to know which is which, however. Just remember, if you use a mixture of Snap and non-Snap packages, you must update them separately (which, in the case of Snap packages, happens automatically).
-
-### Get your Snap on
-
-Snap packages are here to stay, of that there is no doubt. No matter if you administer or use Linux on the server or desktop, Snap packages help make that task significantly easier. Get your Snap on today and see if you don’t start defaulting to this universal package format, over the standard installation fare.
-
-Learn more about Linux through the free ["Introduction to Linux" ][12] course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/5/get-started-snap-packages-linux
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:/files/images/snap1jpg
-[2]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_1.jpg?itok=QklXruAe (Snap)
-[3]:/licenses/category/used-permission
-[4]:/files/images/snap2jpg
-[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_2.jpg?itok=F-wxfikN (searching)
-[6]:/files/images/snap3jpg
-[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_3.jpg?itok=xFMHy93a (installed packages)
-[8]:/files/images/snap4jpg
-[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_4.jpg?itok=smr4xmUp (Snap repo)
-[10]:/files/images/snap5jpg
-[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_5.jpg?itok=dK7U2Qfv (installing Snap package)
-[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180608 How to Install and Use Flatpak on Linux.md b/sources/tech/20180608 How to Install and Use Flatpak on Linux.md
deleted file mode 100644
index 5542d27785..0000000000
--- a/sources/tech/20180608 How to Install and Use Flatpak on Linux.md
+++ /dev/null
@@ -1,167 +0,0 @@
-How to Install and Use Flatpak on Linux
-======
-
-
-
-The landscape of applications is quickly changing. Many platforms are migrating to containerized applications… and with good cause. An application wrapped in a bundled container is easier to install, includes all the necessary dependencies, doesn’t directly affect the hosting platform libraries, automatically updates (in some cases), and (in most cases) is more secure than a standard application. Another benefit of these containerized applications is that they are universal (i.e., such an application would install on Ubuntu Linux or Fedora Linux, without having to convert a .deb package to an .rpm).
-
-As of now, there are two main universal package systems: [Snap][1] and Flatpak. Both function in similar fashion, but one is found by default on Ubuntu-based systems (Snap) and one on Fedora-based systems (Flatpak). It should come as no surprise that both can be installed on either type of system. So if you want to run Snaps on Fedora, you can. If you want to run Flatpak on Ubuntu, you can.
-
-I will walk you through the process of installing and using Flatpak on [Ubuntu 18.04][2]. If your platform of choice is Fedora (or a Fedora derivative), you can skip the installation process.
-
-### Installation
-
-The first thing to do is install Flatpak. The process is simple. Open up a terminal window and follow these steps:
-
- 1. Add the necessary repository with the command sudo add-apt-repository ppa:alexlarsson/flatpak.
-
- 2. Update apt with the command sudo apt update.
-
- 3. Install Flatpak with the command sudo apt install flatpak.
-
- 4. Install Flatpak support for GNOME Software with the command sudo apt install gnome-software-plugin-flatpak.
-
- 5. Reboot your system.
-
-
-
-
-### Usage
-
-I’ll first show you how to install a Flatpak package from the command line, and then via the GUI. Let’s say you want to install the Spotify desktop client via Flatpak. To do this, you must first instruct Flatpak to retrieve the necessary app. The Spotify Flatpak (along with others) is hosted on [Flathub][3]. The first thing we’re going to do is add the Flathub remote repository with the following command:
-```
-sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
-
-```
-
-Now you can install any Flatpak app found on Flathub. For example, to install [Spotify][4], the command would be:
-```
-sudo flatpak install flathub com.spotify.Client
-
-```
-
-To find out the exact command for each install, you only have to visit the app’s page on Flathub and the installation command is listed beneath the description.
-
-Running a Flatpak-installed app is a bit different than a standard app (at least from the command line). Head back to the terminal window and issue the command:
-```
-flatpak run com.spotify.Client
-
-```
-
-Of course, after you’ve re-started your machine (upon installing the GNOME Software Support), those apps should appear in your desktop menu, making it unnecessary to start them from the command line.
-
-To uninstall a Flatpak from the command line, you would go back to the terminal and issue the command:
-```
-sudo flatpak uninstall NAME
-
-```
-
-where NAME is the name of the app to remove. In our Spotify case, that would be:
-```
-sudo flatpak uninstall com.spotify.Client
-
-```
-
-Now we want to update our Flatpak apps. To do this, first list all of your installed Flatpak apps by issuing the command:
-```
-flatpak list
-
-```
-
-Now that we have our list of apps (Figure 1), we can update with the command sudo flatpak update NAME (where NAME is the name of our app to update).
-
-
-![Flatpak apps][6]
-
-Figure 1: Our list of updated Flatpak apps.
-
-[Used with permission][7]
-
-So if we want to update GIMP, we’d issue the command:
-```
-sudo flatpak update org.gimp.GIMP
-
-```
-
-If there are any updates to be applied, they’’ll be taken care of. If there are no updates to be applied, nothing will be reported.
-
-### Installing from GNOME Software
-
-Let’s make this even easier. Since we installed GNOME Software support for flatpak, we don’t actually have to bother with the command line. Don’t be mistaken, unlike Snap support, you won’t actually find Flatpak apps listed within GNOME Software (even though we’ve installed Software support). Instead, you’ll find support through the web browser.
-
-Let me show you. Point your browser to [Flathub][3].
-
-
-![Installing a Flatpak app][9]
-
-Figure 2: Installing a Flatpak app from the Firefox browser.
-
-[Used with permission][7]
-
-Let’s say you want to install Slack via Flatpak. Go to the [Slack Flathub][10] page and then click on the INSTALL button. Since we installed GNOME Software support, the standard browser dialog window will appear with an included option to open the file via Software Install (Figure 2).
-
-This action will then open GNOME Software (or, in the case of Ubuntu, Ubuntu Software), where you can click the Install button (Figure 3) to complete the process.
-
-![ready to go][12]
-
-Figure 3: The installation process ready to go.
-
-[Used with permission][7]
-
-Once the installation completes, you can then either click the Launch button, or close GNOME Software and launch the application from the desktop menu (in the case of GNOME, the Dash).
-
-After you’ve installed a Flatpak app via GNOME Software, it can also be removed from the same system (so there’s still not need to go through the command line).
-
-### What about KDE?
-
-If you prefer using the KDE desktop environment, you’re in luck. If you issue the command sudo apt install plasma-discover-flatpak-backend, it’ll install Flatpak support for the KDE app store, Discover. Once you’ve added Flatpak support, you then need to add a repository. Open Discover and then click on Settings. In the settings window, you’ll now see a Flatpak listing (Figure 4).
-
-![Flatpak][14]
-
-Figure 4: Flatpak is now available in Discover.
-
-[Used with permission][7]
-
-Click on the Flatpak drop-down and then click Add Flathub. Click on the Applications tab (in the left navigation) and you can then search for (and install) any applications found on Flathub (Figure 5).
-
-![Slack ][16]
-
-Figure 5: Slack can now be installed, from Flathub, via Discover.
-
-[Used with permission][7]
-
-### Easy Flatpak management
-
-And that’s the gist of using Flatpak. These universal packages can be used on most Linux distributions and can even be managed via the GUI on some desktop environments. I highly recommend you give Flatpak a try. With the combination of standard installation, Flatpak, and Snaps, you’ll find software management on Linux has become incredibly easy.
-
-Learn more about Linux through the free ["Introduction to Linux" ][17]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/6/how-install-and-use-flatpak-linux
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.linux.com/learn/intro-to-linux/2018/5/get-started-snap-packages-linux
-[2]:http://releases.ubuntu.com/18.04/
-[3]:https://flathub.org/
-[4]:https://flathub.org/apps/details/com.spotify.Client
-[5]:/files/images/flatpak1jpg
-[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/flatpak_1.jpg?itok=DlJ8zFYg (Flatpak apps)
-[7]:/licenses/category/used-permission
-[8]:/files/images/flatpak2jpg
-[9]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/flatpak_2.jpg?itok=fz1fTAco (Installing a Flatpak app)
-[10]:https://flathub.org/apps/details/com.slack.Slack
-[11]:/files/images/flatpak3jpg
-[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/flatpak_3.jpg?itok=wlV8FdgJ (ready to go)
-[13]:/files/images/flatpak4jpg
-[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/flatpak_4.jpg?itok=dBKbVV8Z (Flatpak)
-[15]:/files/images/flatpak5jpg
-[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/flatpak_5.jpg?itok=IKeEgkxD (Slack )
-[17]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180608 How to use screen scraping tools to extract data from the web.md b/sources/tech/20180608 How to use screen scraping tools to extract data from the web.md
deleted file mode 100644
index 2737123f8e..0000000000
--- a/sources/tech/20180608 How to use screen scraping tools to extract data from the web.md
+++ /dev/null
@@ -1,207 +0,0 @@
-How to use screen scraping tools to extract data from the web
-======
-
-A perfect internet would deliver data to clients in the format of their choice, whether it's CSV, XML, JSON, etc. The real internet teases at times by making data available, but usually in HTML or PDF documents—formats designed for data display rather than data interchange. Accordingly, the [screen scraping][1] of yesteryear—extracting displayed data and converting it to the requested format—is still relevant today.
-
-Perl has outstanding tools for screen scraping, among them the `HTML::TableExtract` package described in the Scraping program below.
-
-### Overview of the scraping program
-
-The screen-scraping program has two main pieces, which fit together as follows:
-
- * The file data.html contains the data to be scraped. The data in this example, which originated in a university site under renovation, addresses the issue of whether the income associated with a college degree justifies the degree's cost. The data includes median incomes, percentiles, and other information about areas of study such as computing, engineering, and liberal arts. To run the Scraping program, the data.html file should be hosted on a web server, in my case a local Nginx server. A standalone Perl web server such as `HTTP::Server::PSGI` or `HTTP::Server::Simple` would do as well.
- * The file scrape.pl contains the Scraping program, which uses features from the `Plack/PSGI` packages, in particular a Plack web server. The Scraping program is launched from the command line (as explained below). A user enters the URL for the Plack server (`localhost:5000/`) in a browser, and the following happens:
- * The browser connects to the Plack server, an instance of `HTTP::Server::PSGI`, and issues a GET request for the Scraping program. The single slash (`/`) at the end of the URL identifies this program. (A modern browser would add the closing slash even if the user failed to do so.)
- * The Scraping program then issues a GET request for the data.html document. If the request succeeds, the application extracts the relevant data from the document using the `HTML::TableExtract` package, saves the extracted data to a file, and takes some basic statistical measures that represent processing the extracted data. An HTML report like the following is returned to the user's browser.
-
-
-![HTML report generated by the Scraping program][3]
-
-Fig. 1: Final report from the Scraping program
-
-The request traffic from the user's browser to the Plack server and then to the server hosting the data.html document (e.g., Nginx) can be depicted as follows:
-```
- GET localhost:5000/ GET localhost:80/data.html
-
-user's browser------------------->Plack server-------------------------->Nginx
-
-```
-
-The final step involves only the Plack server and the user's browser:
-```
- reportFinal.html
-
-Plack server------------------>user's browser
-
-```
-
-Fig. 1 above shows the final report document.
-
-### The scraping program in detail
-
-The source code and data file (data.html) are available from my [website][4] in a ZIP file that includes a README. Here is a quick summary of the pieces, and clarifications will follow:
-```
-data.html ## data source to be hosted by a web server
-
-scrape.pl ## main source code, run with the plackup utility (see below)
-
-Stats::Controller.pm ## handles request routing, data extraction, and processing
-
-Stats::Util.pm ## utility functions used in Controller.pm
-
-report.html ## HTML template used to generate the report
-
-rawData.dat ## the extracted data
-
-```
-
-The `Plack/PSGI` packages come with a command-line utility named `plackup`, which can be used to launch the Scraping program. With `%` as the command-line prompt, the command for starting the Scraping program is:
-```
-% plackup scrape.pl
-
-```
-
-The `plackup` command starts a standalone Plack web server that hosts the Scraping program. The Scraping code handles request routing, extracts data from the data.html document, produces some basic statistical measures, and then uses the `Template::Recall` package to generate an HTML report for the user. Because the Plack server runs indefinitely, the Scraping program prints the process ID, which can be used to kill the server and the Scraping app.
-
-`Plack/PSGI` supports Rails-style routing in which an HTTP request is dispatched to a specific request handler based on two factors:
-
- * The HTTP request method (verb) such as GET or POST.
- * The Uniform Resource Identifier (URI or noun) for the requested resource; in this case the standalone finishing slash (`/`) in the URL `http://localhost:5000/` that a user enters in a browser once the Scraping program has launched.
-
-
-
-The Scraping program handles only one type of request: a GET for the resource named `/`, and this resource is the screen-scraping and data-processing code in my `Stats::Controller` package. Here, for review, is the `Plack/PSGI` routing setup, right at the top of source file scrape.pl:
-```
-my $router = router {
-
- match '/', {method => 'GET'}, ## noun/verb combo: / is noun, GET is verb
-
- to {controller => 'Controller', action => 'index'}; ## handler is function get_index
-
- # Other actions as needed
-
-};
-
-```
-
-The request handler `Controller::get_index` has only high-level logic, leaving the screen-scraping and report-generating details to utility functions in the Util.pm file, as described in the following section.
-
-### The screen-scraping code
-
-Recall that the Plack server dispatches a GET request for `localhost:5000/` to the Scraping program's `get_index` function. This function, as the request handler, then starts the job of retrieving the data to be scraped, scraping the data, and generating the final report. The data-retrieval part falls to a utility function, which uses Perl's `LWP::Agent` package to get the data from whatever server is hosting the data.html document. With the data document in hand, the Scraping program invokes the utility function `extract_from_html` to do the data extraction.
-
-The data.html document happens to be well-formed XML, which means a Perl package such as `XML::LibXML` could be used to extract the data through an explicit XML parse. However, the `HTML::TableExtract` package is inviting because it bypasses the tedium of XML parses, and (in very little code) delivers a Perl hash with the extracted data. Data aggregates in HTML documents usually occur in lists or tables, and the `HTML::TableExtract` package targets tables. Here are the three critical lines of code for the data extraction:
-```
-my $col_headers = col_headers(); ## col_headers() returns an array of the table's column names
-
-my $te = HTML::TableExtract->new(headers => $col_headers);
-
-$te->parse($page); ## $page is data.html
-
-```
-
-The `$col_headers` refers to a Perl array of strings, each a column header in the HTML document:
-```
-sub col_headers { ## column headers in the HTML table
-
- return ["Area",
-
- "MedianWage",
-
- ...
-
- "BoostFromGradDegree"];
-
-}col_headers
-
-```
-
-After the call to the `TableExtract::parse` function, the Scraping program uses the `TableExtract::rows` function to iterate over the rows of extracted data—rows of data without the HTML markup. These rows, as Perl lists, are added to a Perl hash named `%majors_hash`, which can be depicted as follows:
-
- * Each key identifies an area of study such as Computing or Engineering.
-
- * The value of each key is the list of seven extracted data items, where seven is the number of columns in the HTML table. For Computing, the list with annotations is:
-```
- name median % with this degree income boost from GD
- / / / /
- (Computing 55000 75000 112000 5.1% 32.0% 31.0%) ## data items
- / \ \
- 25th-ptile 75th-ptile % going on for GD = grad degree
-```
-
-
-
-
-The hash with the extracted data is written to the local file rawData.dat:
-```
-ForeignLanguage 50000 35000 75000 3.5% 54% 101%
-LiberalArts 47000 32000 70000 9.7% 41% 48%
-...
-Engineering 78000 54000 104000 8.2% 37% 32%
-Computing 75000 51000 112000 5.1% 32% 31%
-...
-PublicPolicy 50000 36000 74000 2.3% 24% 45%
-```
-
-The next step is to process the extracted data, in this case by doing rudimentary statistical analysis using the `Statistics::Descriptive` package. In Fig. 1 above, the statistical summary is presented in a separate table at the bottom of the report.
-
-### The report-generation code
-
-The final step in the Scraping program is to generate a report. Perl has options for generating HTML, and `Template::Recall` is among them. As the name suggests, the package generates HTML from an HTML template, which is a mix of standard HTML markup and customized tags that serve as placeholders for data generated from backend code. The template file is report.html, and the backend function of interest is `Controller::generate_report`. Here is how the code and the template interact.
-
-The report document (Fig. 1) has two tables. The top table is generated through iteration, as each row has the same columns (area of study, income for the 25th percentile, and so on). In each iteration, the code creates a hash with values for a particular area of study:
-```
-my %row = (
- major => $key,
- wage => '$' . commify($values[0]), ## commify turns 1234 into 1,234
- p25 => '$' . commify($values[1]),
- p75 => '$' . commify($values[2]),
- population => $values[3],
- grad => $values[4],
- boost => $values[5]
-);
-
-```
-
-The hash keys are Perl [barewords][5] such as `major` and `wage` that represent items in the list of data values extracted earlier from the HTML data document. The corresponding HTML template looks like this:
-```
-[ === even === ]
-<tr class = 'even'>
- <td>['major']</td>
- <td align = 'right'>['p25']</td>
- <td align = 'right'>['wage']</td>
- <td align = 'right'>['p75']</td>
- <td align = 'right'>['pop']</td>
- <td align = 'right'>['grad']</td>
- <td align = 'right'>['boost']</td>
-</tr>
-[=== end1 ===]
-```
-
-The customized tags are in square brackets. The tags at the top and the bottom mark the beginning and the end, respectively, of a template region to be rendered. The other customized tags identify individual targets for the backend code. For example, the template column identified as `major` matches the hash entry with `major` as the key. Here is the call in the backend code that binds the data to the customized tags:
-```
-print OUTFILE $tr->render('end1');
-
-```
-
-The reference `$tr` is to a `Template::Recall` instance, and `OUTFILE` is the report file reportFinal.html, which is generated from the template file report.html together with the backend code. If all goes well, the reportFinal.html document is what the user sees in the browser (see Fig. 1).
-
-The scraping program draws from excellent Perl packages such as `Plack/PSGI`, `LWP::Agent`, `HTML::TableExtract`, `Template::Recall`, and `Statistics::Descriptive` to deal with the often messy task of screen-scraping for data. These packages play together nicely, as each targets a specific subtask. Finally, the Scraping program might be extended to cluster the extracted data: The `Algorithm::KMeans` package is suited for this extension and could use the data persisted in the rawData.dat file.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/screen-scraping
-
-作者:[Marty Kalin][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mkalindepauledu
-[1]:https://en.wikipedia.org/wiki/Data_scraping#Screen_scraping
-[2]:/file/399886
-[3]:https://opensource.com/sites/default/files/uploads/scrapeshot.png (HTML report generated by the Scraping program)
-[4]:http://condor.depaul.edu/mkalin
-[5]:https://en.wiktionary.org/wiki/bareword
diff --git a/sources/tech/20180609 4 tips for getting an older relative online with Linux.md b/sources/tech/20180609 4 tips for getting an older relative online with Linux.md
deleted file mode 100644
index 862ab8bb73..0000000000
--- a/sources/tech/20180609 4 tips for getting an older relative online with Linux.md
+++ /dev/null
@@ -1,76 +0,0 @@
-4 tips for getting an older relative online with Linux
-======
-
-
-
-According to a study by the [Pew Research Center][1], some members of older generations have a hard time learning computers because they were born at the wrong time to learn about computers in school or the workplace. It's a purely demographic phenomenon that tends to mostly affect older people. However, I firmly believe that these people can stay connected and can learn about the benefits of modern technology. The free software community is uniquely placed in ideology, values, and distribution to fill that need. We're a community dedicated to honest product development, longevity, and tools that do what you need and none of what you don't. Those ideologies used to define our world, but it's only in the computer era that they've been openly challenged.
-
-So, I started a GNU/Linux tech support and system builder company that focuses on enabling the elderly and promoting open source adoption. We're sharing our teaching methods and techniques to help others create a more connected society so everyone can take full advantage of our wonderfully connected world.
-
-### 4 tips for getting your family online with GNU/Linux
-
-Whether you're trying to help your mom, dad, grandma, grandpa, or older neighbor or friend, the following tips will help you get them comfortable working with GNU/Linux.
-
-#### 1\. Choose a Linux distro
-
-One of the first and biggest questions you'll face is helping your family member decide which Linux distribution to use. Distributions vary wildly in their user-friendliness, ease of use, stability, customization, extensibility, and so on. You may have an idea of what to use, but here are things to consider before you choose:
-
- * Do I know how to fix it if it breaks?
- * How hard is it to break without root privileges?
- * Is it going to fit their needs?
- * Does it receive regular security updates?
-
-
-
-I would shy away from a rolling-release distribution such as Arch, openSUSE Tumbleweed, or Gentoo, which can change and break without warning if you aren't careful. You'll probably have fewer headaches selecting a distribution such as Debian Stable, Fedora Workstation, or openSUSE Leap. In our business, we use [Ubuntu LTS][2]. Ultimately the decision is up to you. You know your skills and toolbelt better than anyone else, and it's you who will be keeping it up to date and secure.
-
-#### 2\. Keep their hands on the controls
-
-Learning how to use a computer is exactly like learning a language. It's a strange, inhuman form of interaction we usually learn while we're young and growing up. But there must be a lot of repetition to form the right habits and understanding. The easiest way to form those habits is with guided usage with the learner's hands on the controls the whole time. Older learners need to recognize it's not a jet plane or a tank, where pressing the wrong button is deadly. It's just a computer.
-
-In our company, we want our customers to be completely self-sufficient. We want them to know how to stay safe online and really use their computer to its full extent. As a result, our teaching style looks a little different from what you'd see in a regular, large corporation's customer care or tech support department.
-
-We can sum up our teaching policy in this short Python script:
-```
-def support(onsite, broken):
-
-if broken==False:
-
- print("Never take away the mouse or keyboard.")
-
- elif broken==True:
-
- print("Fix it in the command line quickly.")
-
-else:
-
- print("You shouldn’t end up here, but it's correct syntax.")
-
-```
-
-#### 3\. Take notes
-
-Have your learner take notes while you're teaching them about the computer. Taking notes has been proven to be one of the most effective memory-retention tricks for gaining new skills. It also serves another purpose: It gives the learner a resource to turn to when you aren't there and allows them to take a break from listening and focus on truly understanding.
-
-#### 4\. Have patience
-
-I think a lack of patience is the second-biggest factor (right behind demographics) that has prevented older people from learning to use a computer. The next time your loved one asks for help with her computer, ask yourself: "Do I not want to help because they can't learn? Or because I don't have the time to help them?" The second excuse seems to be the one I hear the most. Make sure you plan enough time to be patient with them. There's nothing more permanent than a temporary solution (such as doing everything for them).
-
-### Wrapping up
-
-If you combine these techniques to form habits, leave them with self-created teaching resources, and add a healthy portion of patience, you'll get your family members up and running with Linux in no time. The wonders of being online and knowing how to use a computer shouldn't be restricted to those lucky enough to grow up at a time where the computer is second nature. That's not to say it won't be difficult at times, but it's absolutely worth it.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/tips-family-online-Linux
-
-作者:[About The Author;Brian Whetten;Founder Of The Riesling Computer Company;A Long-Time Blender;Linux;Open-Source Fan;User. I Work To Help Make Sure Our Elderly Members Of Society Are Welcomed With Open Arms To The Wonderful New Technologies Constantly Being Created.][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/classywhetten
-[1]:http://www.pewinternet.org/2014/04/03/older-adults-and-technology-use/
-[2]:https://www.ubuntu.com/download/desktop
diff --git a/sources/tech/20180611 12 fiction books for Linux and open source types.md b/sources/tech/20180611 12 fiction books for Linux and open source types.md
deleted file mode 100644
index db21ae0e7f..0000000000
--- a/sources/tech/20180611 12 fiction books for Linux and open source types.md
+++ /dev/null
@@ -1,113 +0,0 @@
-12 fiction books for Linux and open source types
-======
-
-
-
-For this book list, I reached out to our writer community to ask which fiction books they would recommend to their peers. What I love about this question and the answers that follow is this list gives us a deeper look into their personalities. Fiction favorites are unlike non-fiction recommendations in that your technical skills and interests may have an influence on what you like to read read, but it's much more about your personality and life experiences that draw you to pick out, and love, a particular fiction book.
-
-These people are your people. I hope you find something interesting to add to your reading list.
-
-**[Ancillary Justice][1] by Annie Leckie**
-
-Open source is all about how one individual can start a movement. Somehow at the same time, it's about the power of a voluntary collective moving together towards a common goal. Ancillary Justice makes you ponder both concepts.
-
-This book is narrated by Breq, who is an "ancillary," an enslaved human body that was grafted into the soul of a warship. When that warship was destroyed, Breq kept all the ship's memories and its identity but then had to live in a single body instead of thousands. In spite of the huge change in her power, Breq has a cataclysmic influence on all around her, and she inspires both loyalty and love. She may have once been enslaved to an AI, but now that she is free, she is powerful. She learns to adapt to exercising her free will, and the decisions she makes changes her and the world around her. Breq pushes for openness in the rigid Radch, the dominant society of the book. Her actions transform the Radch into something new.
-
-Ancillary Justice is also about language, loyalty, sacrifice, and the disastrous effects of secrecy. Once you've read this book, you will never feel the same about what makes someone or something human. What makes you YOU? Can who you are really be destroyed while your body still lives?
-
-Like the open source movement, Ancillary Justice makes you think and question the status quo of the novel and of the world around you. Read it. (Recommendation and review by [Ingrid Towey][2])
-
-**[Cryptonomicon][3] by Neal Stephenson**
-
-Set during WWII and the present day, or near future at the time of writing, Cryptonomicon captures the excitement of a startup, the perils of war, community action against authority, and the perils of cryptography. It's a book to keep coming back to, as it has multiple layers and combines a techy outlook with intrigue and a decent love story. It does a good job of asking interesting questions like "is technology always an unbounded good?" and of making you realise that the people of yesterday were just a clever, and human, as we are today. (Recommendation and review by [Mike Bursell][4])
-
-**[Daemon][5] by Daniel Suarez**
-
-Daemon is the first in a two-part series that details the events that happen when a computer daemon (process) is awakened and wreaks havoc on the world. The story is an exciting thriller that borders on creepy due to the realism in how the technology is portrayed, and it outlines just how dependent we are on technology. (Recommendation and review by [Jay LaCroix][6])
-
-**[Going Postal][7] by Terry Pratchett**
-
-This book is a good read for Linux and open source enthusiasts because of the depth and relatability of characters; the humor and the unique outsider narrating that goes into the book. Terry Pratchett books are like Jim Henson movies: fiercely creative, appealing to all but especially the maker, tinkerer, hacker, and those daring to dream.
-
-The main character is a chancer, a fly-by-night who has never considered the results of their actions. They are not committed to anything, have never formed real (non-monetary) connections. The story follows on from the outcomes of their actions, a tale of redemption taking the protagonists on an out-of-control adventure. It's funny, edgy and unfamiliar, much like the initial 1990's introduction to Linux was for me. (Recommendation and review by [Lewis Cowles][8])
-
-**[Microserfs][9] by Douglas Coupland**
-
-Anyone who lived through the dotcom bubble of the 1990's will identify with this heartwarming tale of a young group of Microsoft engineers who end up leaving the company for a startup, moving to Silicon Valley, and becoming each other's support through life, death, love, and loss.
-
-There is a lot of humor to be found in this book, like in line this line: "This is my computer. There are many like it, but this one is mine..." This revision of the original comes from the Rifleman's Creed: "This is my rifle. There are many like it..."
-
-If you've ever spent 16 hours a day coding, while fueling yourself with Skittles and Mountain Dew, this story is for you. (Recommendation and review by [Jet Anderson][10])
-
-**[Open Source][11] by M. M. Frick**
-
-Casey Shenk is a vending-machine technician from Savannah, Georgia by day and blogger by night. Casey's keen insights into the details of news reports, both true and false, lead him to unravel a global plot involving arms sales, the Middle East, Russia, Israel and the highest levels of power in the United States. Casey connects the pieces using "Open Source Intelligence," which is simply reading and analyzing information that is free and open to the public.
-
-I bought this book because of the title, just as I was learning about open source, three years ago. I thought this would be a book on open source fiction. Unfortunately, the book has nothing to do with open source as we define it. I had hoped that Casey would use some open source tools or open source methods in his investigation, such as Wireshark or Maltego, and write his posts with LibreOffice, WordPress and such. However, "open source" simply refers to the fact that his sources are "open."
-
-Although I was disappointed that this book was not what I expected, Frick, a Navy officer, packed the book with well-researched and interesting twists and turns. If you are looking for a book that involves Linux, command lines, GitHub, or any other open source elements, then this is not the book for you. (Recommendation and review by [Jeff Macharyas][12])
-
-**[The Tao of Pooh][13] by Benjamin Hoff**
-
-Linux and the open source ethos is a way of approaching life and getting things done that relies on both the individual and collective goodwill of the community it serves. Leadership and service are ascribed by individual contribution and merit rather than arbitrary assignment of value in traditional hierarchies. This is the natural way of getting things done. The power of open source is its authentic gift of self to a community of developers and end users. Being a part of such a community of developers and contributors invites to share their unique gift with the wider world. In Tao of Poo, Hoff celebrates that unique gift of self, using the metaphor of Winnie the Pooh wed with Taoist philosophy. (Recommendation and review by [Don Watkins][14])
-
-**[The Golem and the Jinni][15] by Helene Wecker**
-
-The eponymous otherworldly beings accidentally find themselves in New York City in the early 1900s and have to restart their lives far from their homelands. It's rare to find a book with such an original premise, let alone one that can follow through with it so well and with such heart. (Recommendation and review by [VM Brasseur][16])
-
-**[The Rise of the Meritocracy][17] by Michael Young**
-
-Meritocracy—one of the most pervasive and controversial notions circulating in open source discourses—is for some critics nothing more than a quaint fiction. No surprise for them, then, that the term originated there. Michael Young's dystopian science fiction novel introduced the term into popular culture in 1958; the eponymous concept characterizes a 2034 society entirely bent on rewarding the best, the brightest, and the most talented. "Today we frankly recognize that democracy can be no more than aspiration, and have rule not so much by the people as by the cleverest people," writes the book's narrator in this pseudo-sociological account of future history,"not an aristocracy of birth, not a plutocracy of wealth, but a true meritocracy of talent."
-
-Would a truly meritocratic society work as intended? We might only imagine. Young's answer, anyway, has serious consequences for the fictional sociologist. (Recommendation and review by [Bryan Behrenshausen][18])
-
-**[Throne of the Crescent Moon][19] by Saladin Ahmed**
-
-The protagonist, Adulla, is a man who just wants to retire from ghul hunting and settle down, but the world has other plans for him. Accompanied by his assistant and a vengeful young warrior, they set off to end the ghul scourge and find their revenge. While it sounds like your typical fantasy romp, the Middle Eastern setting of the story sets it apart while the tight and skillful writing of Ahmed pulls you in. (Recommendation and review by [VM Brasseur][16])
-
-**[Walkaway][20] by Cory Doctorow**
-
-It's hard to approach this science fiction book because it's so different than other science fiction books. It's timely because in an age of rage―producing a seemingly endless parade of dystopia in fiction and in reality―this book is hopeful. We need hopeful things. Open source fans would like it because the reason it is hopeful is because of open, shared technology. I don't want to give too much away, but let's just say this book exists in a world where advanced 3D printing is so mainstream (and old) that you can practically 3D print anything. Basic needs of Maslow's hierarchy are essentially taken care of, so you're left with human relationships.
-
-"You wouldn't steal a car" turns into "you can fork a house or a city." This creates a present that can constantly be remade, so the attachment to things becomes practically unnecessary. Thus, people can―and do―just walk away. This wonderful (and complicated) future setting is the ever-present reality surrounding a group of characters, their complicated relationships, and a complex class struggle in a post-scarcity world.
-
-Best book I've read in years. Thanks, Cory! (Recommendation and review by [Kyle Conway][21])
-
-**[Who Moved My Cheese?][22] by Spencer Johnson**
-
-The secret to success for leading open source projects and open companies is agility and motivating everyone to move beyond their comfort zones to embrace change. Many people find change difficult and do not see the advantage that comes from the development of an agile mindset. This book is about the difference in how mice and people experience and respond to change. It's an easy read and quick way to expand your mind and think differently about whatever problem you're facing today. (Recommendation and review by [Don Watkins][14])
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/fiction-book-list
-
-作者:[Jen Wike Huger][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/remyd
-[1]:https://www.annleckie.com/novel/ancillary-justice/
-[2]:https://opensource.com/users/i-towey
-[3]:https://www.amazon.com/Cryptonomicon-Neal-Stephenson-ebook/dp/B000FC11A6/ref=sr_1_1?s=books&ie=UTF8&qid=1528311017&sr=1-1&keywords=Cryptonomicon
-[4]:https://opensource.com/users/mikecamel
-[5]:https://www.amazon.com/DAEMON-Daniel-Suarez/dp/0451228731
-[6]:https://opensource.com/users/jlacroix
-[7]:https://www.amazon.com/Going-postal-Terry-PRATCHETT/dp/0385603428
-[8]:https://opensource.com/users/lewiscowles1986
-[9]:https://www.amazon.com/Microserfs-Douglas-Coupland/dp/0061624268
-[10]:https://opensource.com/users/thatsjet
-[11]:https://www.amazon.com/Open-Source-M-Frick/dp/1453719989
-[12]:https://opensource.com/users/jeffmacharyas
-[13]:https://www.amazon.com/Tao-Pooh-Benjamin-Hoff/dp/0140067477
-[14]:https://opensource.com/users/don-watkins
-[15]:https://www.amazon.com/Golem-Jinni-Novel-P-S/dp/0062110845
-[16]:https://opensource.com/users/vmbrasseur
-[17]:https://www.amazon.com/Rise-Meritocracy-Classics-Organization-Management/dp/1560007044
-[18]:https://opensource.com/users/bbehrens
-[19]:https://www.amazon.com/Throne-Crescent-Moon-Kingdoms/dp/0756407788
-[20]:https://craphound.com/category/walkaway/
-[21]:https://opensource.com/users/kreyc
-[22]:https://www.amazon.com/Moved-Cheese-Spencer-Johnson-M-D/dp/0743582853
diff --git a/sources/tech/20180612 7 open source tools to make literature reviews easy.md b/sources/tech/20180612 7 open source tools to make literature reviews easy.md
deleted file mode 100644
index 96edb68eff..0000000000
--- a/sources/tech/20180612 7 open source tools to make literature reviews easy.md
+++ /dev/null
@@ -1,73 +0,0 @@
-7 open source tools to make literature reviews easy
-======
-
-
-
-A good literature review is critical for academic research in any field, whether it is for a research article, a critical review for coursework, or a dissertation. In a recent article, I presented detailed steps for doing [a literature review using open source software][1].
-
-The following is a brief summary of seven free and open source software tools described in that article that will make your next literature review much easier.
-
-### 1\. GNU Linux
-
-Most literature reviews are accomplished by graduate students working in research labs in universities. For absurd reasons, graduate students often have the worst computers on campus. They are often old, slow, and clunky Windows machines that have been discarded and recycled from the undergraduate computer labs. Installing a [flavor of GNU Linux][2] will breathe new life into these outdated PCs. There are more than [100 distributions][3], all of which can be downloaded and installed for free on computers. Most popular Linux distributions come with a "try-before-you-buy" feature. For example, with Ubuntu you can make a [bootable USB stick][4] that allows you to test-run the Ubuntu desktop experience without interfering in any way with your PC configuration. If you like the experience, you can use the stick to install Ubuntu on your machine permanently.
-
-### 2\. Firefox
-
-Linux distributions generally come with a free web browser, and the most popular is [Firefox][5]. Two Firefox plugins that are particularly useful for literature reviews are Unpaywall and Zotero. Keep reading to learn why.
-
-### 3\. Unpaywall
-
-Often one of the hardest parts of a literature review is gaining access to the papers you want to read for your review. The unintended consequence of copyright restrictions and paywalls is it has narrowed access to the peer-reviewed literature to the point that even [Harvard University is challenged][6] to pay for it. Fortunately, there are a lot of open access articles—about a third of the literature is free (and the percentage is growing). [Unpaywall][7] is a Firefox plugin that enables researchers to click a green tab on the side of the browser and skip the paywall on millions of peer-reviewed journal articles. This makes finding accessible copies of articles much faster that searching each database individually. Unpaywall is fast, free, and legal, as it accesses many of the open access sites that I covered in my paper on using [open source in lit reviews][8].
-
-### 4\. Zotero
-
-Formatting references is the most tedious of academic tasks. [Zotero][9] can save you from ever doing it again. It operates as an Android app, desktop program, and a Firefox plugin (which I recommend). It is a free, easy-to-use tool to help you collect, organize, cite, and share research. It replaces the functionality of proprietary packages such as RefWorks, Endnote, and Papers for zero cost. Zotero can auto-add bibliographic information directly from websites. In addition, it can scrape bibliographic data from PDF files. Notes can be easily added on each reference. Finally, and most importantly, it can import and export the bibliography databases in all publishers' various formats. With this feature, you can export bibliographic information to paste into a document editor for a paper or thesis—or even to a wiki for dynamic collaborative literature reviews (see tool #7 for more on the value of wikis in lit reviews).
-
-### 5\. LibreOffice
-
-Your thesis or academic article can be written conventionally with the free office suite [LibreOffice][10], which operates similarly to Microsoft's Office products but respects your freedom. Zotero has a word processor plugin to integrate directly with LibreOffice. LibreOffice is more than adequate for the vast majority of academic paper writing.
-
-### 6\. LaTeX
-
-If LibreOffice is not enough for your layout needs, you can take your paper writing one step further with [LaTeX][11], a high-quality typesetting system specifically designed for producing technical and scientific documentation. LaTeX is particularly useful if your writing has a lot of equations in it. Also, Zotero libraries can be directly exported to BibTeX files for use with LaTeX.
-
-### 7\. MediaWiki
-
-If you want to leverage the open source way to get help with your literature review, you can facilitate a [dynamic collaborative literature review][12]. A wiki is a website that allows anyone to add, delete, or revise content directly using a web browser. [MediaWiki][13] is free software that enables you to set up your own wikis.
-
-Researchers can (in decreasing order of complexity): 1) set up their own research group wiki with MediaWiki, 2) utilize wikis already established at their universities (e.g., [Aalto University][14]), or 3) use wikis dedicated to areas that they research. For example, several university research groups that focus on sustainability (including [mine][15]) use [Appropedia][16], which is set up for collaborative solutions on sustainability, appropriate technology, poverty reduction, and permaculture.
-
-Using a wiki makes it easy for anyone in the group to keep track of the status of and update literature reviews (both current and older or from other researchers). It also enables multiple members of the group to easily collaborate on a literature review asynchronously. Most importantly, it enables people outside the research group to help make a literature review more complete, accurate, and up-to-date.
-
-### Wrapping up
-
-Free and open source software can cover the entire lit review toolchain, meaning there's no need for anyone to use proprietary solutions. Do you use other libre tools for making literature reviews or other academic work easier? Please let us know your favorites in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/open-source-literature-review-tools
-
-作者:[Joshua Pearce][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jmpearce
-[1]:http://pareonline.net/getvn.asp?v=23&n=8
-[2]:https://opensource.com/article/18/1/new-linux-computers-classroom
-[3]:https://distrowatch.com/
-[4]:https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-windows#0
-[5]:https://www.mozilla.org/en-US/firefox/new/
-[6]:https://www.theguardian.com/science/2012/apr/24/harvard-university-journal-publishers-prices
-[7]:https://unpaywall.org/
-[8]:http://www.academia.edu/36709736/How_to_Perform_a_Literature_Review_with_Free_and_Open_Source_Software
-[9]:https://www.zotero.org/
-[10]:https://www.libreoffice.org/
-[11]:https://www.latex-project.org/
-[12]:https://www.academia.edu/1861756/Open_Source_Research_in_Sustainability
-[13]:https://www.mediawiki.org/wiki/MediaWiki
-[14]:http://wiki.aalto.fi
-[15]:http://www.appropedia.org/Category:MOST
-[16]:http://www.appropedia.org/Welcome_to_Appropedia
diff --git a/sources/tech/20180612 Using Ledger for YNAB-like envelope budgeting.md b/sources/tech/20180612 Using Ledger for YNAB-like envelope budgeting.md
deleted file mode 100644
index 47fc4eaed9..0000000000
--- a/sources/tech/20180612 Using Ledger for YNAB-like envelope budgeting.md
+++ /dev/null
@@ -1,143 +0,0 @@
-Using Ledger for YNAB-like envelope budgeting
-======
-### Bye bye Elbank
-
-I have to start this post with this: I will not be actively maintaining [Elbank][1] anymore, simply because I switched back to [Ledger][2]. If someone wants to take over, please contact me!
-
-The main reason for switching is budgeting. While Elbank was a cool experiment, it is not an accounting software, and inherently lacks support for powerful budgeting.
-
-When I started working on Elbank as a replacement for Ledger, I was looking for a reporting tool within Emacs that would fetch bank transactions automatically, so I wouldn’t have to enter transactions by hand (this is a seriously tedious task, and I grew tired of doing it after roughly two years, and finally gave up).
-
-Since then, I learned about ledger-autosync and boobank, which I use to sync my bank statements with Ledger (more about that in another post).
-
-### YNAB’s way of budgeting
-
-I only came across [YNAB][3] recently. While I won’t use their software (being a non-free web application, and, you know… there’s no `M-x ynab`), I think that the principles behind it are really appealing for personal budgeting. I encourage you to [read more about it][4] (or grab a [copy of the book][5], it’s great), but here’s the idea.
-
- 1. **Budget every euro** : Quite simple once you get it. Every single Euro you have should be in a budget envelope. You should assign a job to every Euro you earn (that’s called [zero-based][6], [envelope system][7]).
-
- 2. **Embrace your true expenses** : Plan for larger and less frequent expenses, so when a yearly bill arrives, or your car breaks down, you’ll be covered.
-
- 3. **Roll with the punches** : Address overspending as it happens by taking money overspent from another envelope. As long as you keep budgeting, you’re succeeding.
-
- 4. **Age your money** : Spend less than you earn, so your money stays in the bank account longer. As you do that, the age of your money will grow, and once you reach the goal of spending money that is at least one month old, you won’t worry about that next bill.
-
-
-
-
-### Implementation in Ledger
-
-I assume that you are familiar with Ledger, but if not I recommend reading its great [introduction][8] and [tutorial][9].
-
-The implementation in Ledger uses plain double-entry accounting. I took most of it from [Sacha][10], with some minor differences.
-
-#### Budgeting new money
-
-After each income transaction, I budget the new money:
-```
-2018-06-12 Employer
- Assets:Bank:Checking 1600.00 EUR
- Income:Salary -1600.00 EUR
-
-2018-06-12 Budget
- [Assets:Budget:Food] 400.00 EUR
- [Assets:Budget:Rent] 600.00 EUR
- [Assets:Budget:Utilities] 600.00 EUR
- [Equity:Budget] -1600.00 EUR
-
-```
-
-Did you notice the square brackets around the accounts of the budget transaction? It’s a feature Ledger calls [virtual postings][11]. These postings are not considered real, and won’t be present in any report that uses the `--real` flag. This is exactly what we want, since it’s a budget allocation and not a “real” transaction. Therefore we’ll use the `--real` flag for all reports except for our budget report.
-
-#### Automatically crediting budget accounts when spending money
-
-Next, we need to credit the budget accounts each time we spend money. Ledger has another neat feature called [automated transactions][12] for this:
-```
-= /Expenses/
- [Assets:Budget:Unbudgeted] -1.0
- [Equity:Budget] 1.0
-
-= /Expenses:Food/
- [Assets:Budget:Food] -1.0
- [Assets:Budget:Unbudgeted] 1.0
-
-= /Expenses:Rent/
- [Assets:Budget:Rent] -1.0
- [Assets:Budget:Unbudgeted] 1.0
-
-= /Expenses:Utilities/
- [Assets:Budget:Utilities] -1.0
- [Assets:Budget:Unbudgeted] 1.0
-
-```
-
-Every expense is taken out of the `Assets:Budget:Unbudgeted` account by default.
-
-This forces me to budget properly, as `Assets:Budget:Unbudgeted` should always be 0 (if it is not the case I immediately know that there is something wrong going on).
-
-All other automatic transactions take money out of the `Assets:Budget:Unbudgeted` account instead of `Equity:Budget` account.
-
-#### A Budget report
-
-This is the final piece of the puzzle. Here’s the budget report command:
-```
-ledger --empty -S -T -f ledger.dat bal ^assets:budget
-
-```
-
-If we have the following transactions:
-```
-2018/06/12 Groceries store
- Expenses:Food 123.00 EUR
- Assets:Bank:Checking
-
-2018/06/12 Landlord
- Expenses:Rent 600.00 EUR
- Assets:Bank:Checking
-
-2018/06/12 Internet provider
- Expenses:Utilities:Internet 40.00 EUR
- Assets:Bank:Checking
-
-```
-
-Here’s what the report looks like:
-```
- 837.00 EUR Assets:Budget
- 560.00 EUR Utilities
- 277.00 EUR Food
- 0 Rent
- 0 Unbudgeted
---------------------
- 837.00 EUR
-
-```
-
-### Conclusion
-
-Ledger is amazingly powerful, and provides a great framework for YNAB-like budgeting. In a future post I’ll explain how I automatically import my bank transactions using a mix of `ledger-autosync` and `weboob`.
-
---------------------------------------------------------------------------------
-
-via: https://emacs.cafe/ledger/emacs/ynab/budgeting/2018/06/12/elbank-ynab.html
-
-作者:[Nicolas Petton][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://emacs.cafe/l
-[1]:https://github.com/NicolasPetton/elbank
-[2]:https://www.ledger-cli.org/
-[3]:https://ynab.com
-[4]:https://www.youneedabudget.com/method/
-[5]:https://www.youneedabudget.com/book-order-now/
-[6]:https://en.wikipedia.org/wiki/Zero-based_budgeting
-[7]:https://en.wikipedia.org/wiki/Envelope_system
-[8]:https://www.ledger-cli.org/3.0/doc/ledger3.html#Introduction-to-Ledger
-[9]:https://www.ledger-cli.org/3.0/doc/ledger3.html#Ledger-Tutorial
-[10]:http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
-[11]:https://www.ledger-cli.org/3.0/doc/ledger3.html#Virtual-postings
-[12]:https://www.ledger-cli.org/3.0/doc/ledger3.html#Automated-Transactions
diff --git a/sources/tech/20180614 Bash tips for everyday at the command line.md b/sources/tech/20180614 Bash tips for everyday at the command line.md
deleted file mode 100644
index 219c6e5cf0..0000000000
--- a/sources/tech/20180614 Bash tips for everyday at the command line.md
+++ /dev/null
@@ -1,593 +0,0 @@
-Bash tips for everyday at the command line
-======
-
-
-
-As the default shell for many of the Linux and Unix variants, Bash includes a wide variety of underused features, so it was hard to decide what to discuss. Ultimately, I decided to focus on Bash tips that make day-to-day activities easier.
-
-As a consultant, I see a plurality of diverse environments and work styles. I drew on this experience to narrow the tips to four broad categories: Terminal and line tricks, navigation and files, history, and helpful commands. These categories are completely arbitrary and serve more to organize my own thoughts than as any kind of definitive classification. Many of the tips included here might subjectively fit in more than one category.
-
-Without further ado, here are some of the most helpful Bash tricks I have encountered.
-
-### Working with Bash history
-
-One of the best ways to increase your productivity is to learn to use the Bash history more effectively. With that in mind, perhaps one of the most important tweaks you can make in a multi-user environment is to enable the `histappend` option to your shell. To do that, simply run the following command:
-```
-shopt -s histappend
-
-```
-
-This allows multiple terminal sessions to write to the history at the same time. In most environments this option is not enabled. That means that histories are often lost if you have more than a single Bash session open (either locally or over SSH).
-
-Another common task is to repeat the last command with `sudo`. For example, suppose you want to create a directory `mkdir /etc/ansible/facts.d`. Unless you are root, this command will fail. From what I have observed, most users hit the `up` arrow, scroll to the beginning of the line, and add the `sudo` command. There is an easier way. Simply run the command like this:
-```
-sudo !!
-
-```
-
-Bash will run `sudo` and then the entirety of the previous command. Here is exactly what it looks like when run in sequence:
-```
-[user@centos ~]$ mkdir -p /etc/ansible/facts.d
-
-mkdir: cannot create directory ‘/etc/ansible’: Permission denied
-
-
-
-[user@centos ~]$ sudo !!
-
-sudo mkdir -p /etc/ansible/facts.d
-
-```
-
-When the **`!!`** is run, the full command is echoed out to the terminal so you know what was just executed.
-
-Similar but used much less frequently is the **`!*`** shortcut. This tells Bash that you want all of the *arguments* from the previous command to be repeated in the current command. This could be useful for a command that has a lot of arguments you want to reuse. A simple example is creating a bunch of files and then changing the permissions on them:
-```
-[user@centos tmp]$ touch file1 file2 file3 file4
-
-[user@centos tmp]$ chmod 777 !*
-
-chmod 777 file1 file2 file3 file4
-
-```
-
-It is handy only in a specific set of circumstances, but it may save you some keystrokes.
-
-Speaking of saving keystrokes, let's talk about finding commands in your history. Most users will do something like this:
-```
-history |grep <some command>
-
-```
-
-However, there is an easier way to search your history. If you press
-```
-ctrl + r
-
-```
-
-Bash will do a reverse search of your history. As you start typing, results will begin to appear. For example:
-```
-(reverse-i-search)`hist': shopt -s histappend
-
-```
-
-In the above example, I typed `hist` and it matched the `shopt` command we covered earlier. If you continue pressing `ctrl + r`, Bash will continue to search backward through all of the other matches.
-
-Our last trick isn't a trick as much as a helpful command you can use to count and display the most-used commands in your history.
-```
-[user@centos tmp]$ history | awk 'BEGIN {FS="[ \t]+|\\|"} {print $3}' | sort | uniq -c | sort -nr | head
-
-81 ssh
-
-50 sudo
-
-46 ls
-
-45 ping
-
-39 cd
-
-29 nvidia-xrun
-
-20 nmap
-
-19 export
-
-```
-
-In this example, you can see that `ssh` is by far the most-used command in my history at the moment.
-
-### Navigation and file naming
-
-`tab` key once to complete the wording for you. This works if there is a single exact match. However, you might not know that if you hit `tab` twice, it will show you all of the matches based on what you have typed. For example:
-```
-[user@centos tmp]$ cd /lib <tab><tab>
-
-lib/ lib64/
-
-```
-
-You probably already know that if you type a command, filename, or folder name, you can hit thekey once to complete the wording for you. This works if there is a single exact match. However, you might not know that if you hittwice, it will show you all of the matches based on what you have typed. For example:
-
-This can be very useful for file system navigation. Another helpful trick is to enable `cdspell` in your shell. You can do this by issuing the `shopt -s cdspell` command. This will help correct your typos:
-```
-[user@centos etc]$ cd /tpm
-
-/tmp
-
-[user@centos tmp]$ cd /ect
-
-/etc
-
-```
-
-It's not perfect, but every little bit helps!
-
-Once you have successfully changed directories, what if you need to return to your previous directory? This is not a big deal if you are not very deep into the directory tree. But if you are in a fairly deep path, such as `/var/lib/flatpak/exports/share/applications/`, you could type:
-```
-cd /va<tab>/lib/fla<tab>/ex<tab>/sh<tab>/app<tab>
-
-```
-
-Fortunately, Bash remembers your previous directory, and you can return there by simply typing `cd -`. Here is what it would look like:
-```
-[user@centos applications]$ pwd
-
-/var/lib/flatpak/exports/share/applications
-
-
-
-[user@centos applications]$ cd /tmp
-
-[user@centos tmp]$ pwd
-
-/tmp
-
-
-
-[user@centos tmp]$ cd -
-
-/var/lib/flatpak/exports/share/applications
-
-```
-
-That's all well and good, but what if you have a bunch of directories you want to navigate within easily? Bash has you covered there as well. There is a variable you can set that will help you navigate more effectively. Here is an example:
-```
-[user@centos applications]$ export CDPATH='~:/var/log:/etc'
-
-[user@centos applications]$ cd hp
-
-/etc/hp
-
-
-
-[user@centos hp]$ cd Downloads
-
-/home/user/Downloads
-
-
-
-[user@centos Downloads]$ cd ansible
-
-/etc/ansible
-
-
-
-[user@centos Downloads]$ cd journal
-
-/var/log/journal
-
-```
-
-In the above example, I set my home directory (indicated with the tilde: `~`), `/var/log` and `/etc`. Anything at the top level of these directories will be auto-filled in when you reference them. Directories that are not at the base of the directories listed in `CDPATH` will not be found. If, for example, the directory you are after was `/etc/ansible/facts.d/` this would not complete by typing `cd facts.d`. This is because while the directory `ansible` is found under `/etc`, `facts.d` is not. Therefore, `CDPATH` is useful for getting to the top of a tree that you access frequently, but it may get cumbersome to manage when you're browsing a large folder structure.
-
-Finally, let's talk about two common use cases that everyone does at some point: Changing a file extension and renaming files. At first glance, this may sound like the same thing, but Bash offers a few different tricks to accomplish these tasks.
-
-While it may be a "down-and-dirty" operation, most users at some point need to create a quick copy of a file they are working on. Most will copy the filename exactly and simply append a file extension like `.old` or `.bak`. There is a quick shortcut for this in Bash. Suppose you have a filename like `spideroak_inotify_db.07pkh3` that you want to keep a copy of. You could type:
-```
-cp spideroak_inotify_db.07pkh3 spideroak_inotify_db.07pkh3.bak
-
-```
-
-You can make quick work of this by using copy/paste operations, using the tab complete, possibly using one of the shortcuts to repeat an argument, or simply typing the whole thing out. However, the command below should prove even quicker once you get used to typing it:
-```
-cp spideroak_inotify_db.07pkh3{,.old}
-
-```
-
-This (as you can guess) copies the file by appending the `.old` file extension to the file. That's great, you might say, but I want to rename a large number of files at once. Sure, you could write a for loop to deal with these (and in fact, I often do this for something complicated) but why would you when there is a handy utility called `rename`? There is some difference in the usage of this utility between Debian/Ubuntu and CentOS/Arch. The Debian-based rename uses a SED-like syntax:
-```
-user@ubuntu-1604:/tmp$ for x in `seq 1 5`; do touch old_text_file_${x}.txt; done
-
-
-
-user@ubuntu-1604:/tmp$ ls old_text_file_*
-
-old_text_file_1.txt old_text_file_3.txt old_text_file_5.txt
-
-old_text_file_2.txt old_text_file_4.txt
-
-
-
-user@ubuntu-1604:/tmp$ rename 's/old_text_file/shiney_new_doc/' *.txt
-
-
-
-user@ubuntu-1604:/tmp$ ls shiney_new_doc_*
-
-shiney_new_doc_1.txt shiney_new_doc_3.txt shiney_new_doc_5.txt
-
-shiney_new_doc_2.txt shiney_new_doc_4.txt
-
-```
-
-On a CentOS or Arch box it would look similar:
-```
-[user@centos /tmp]$ for x in `seq 1 5`; do touch old_text_file_${x}.txt; done
-
-
-
-[user@centos /tmp]$ ls old_text_file_*
-
-old_text_file_1.txt old_text_file_3.txt old_text_file_5.txt
-
-old_text_file_2.txt old_text_file_4.txt
-
-
-
-[user@centos tmp]$ rename old_text_file centos_new_doc *.txt
-
-
-
-[user@centos tmp]$ ls centos_new_doc_*
-
-centos_new_doc_1.txt centos_new_doc_3.txt centos_new_doc_5.txt
-
-centos_new_doc_2.txt centos_new_doc_4.txt
-
-```
-
-### Bash key bindings
-
-Bash has a lot of built-in keyboard shortcuts. You can find a list of them by typing `bind -p`. I thought it would be useful to highlight several, although some may be well-known.
-```
- ctrl + _ (undo)
-
- ctrl + t (swap two characters)
-
- ALT + t (swap two words)
-
- ALT + . (prints last argument from previous command)
-
- ctrl + x + * (expand glob/star)
-
- ctrl + arrow (move forward a word)
-
- ALT + f (move forward a word)
-
- ALT + b (move backward a word)
-
- ctrl + x + ctrl + e (opens the command string in an editor so that you can edit it before execution)
-
- ctrl + e (move cursor to end)
-
- ctrl + a (move cursor to start)
-
- ctrl + xx (move to the opposite end of the line)
-
- ctrl + u (cuts everything before the cursor)
-
- ctrl + k (cuts everything after the cursor)
-
- ctrl + y (pastes from the buffer)
-
- ctrl + l (clears screen)s
-
-```
-
-I won't discuss the more obvious ones. However, some of the most useful shortcuts I have found are the ones that let you delete words (or sections of text) and undo them. Suppose you were going to stop a bunch of services using `systemd`, but you only wanted to start a few of them after some operation has completed. You might do something like this:
-```
-systemctl stop httpd mariadb nfs smbd
-
-<hit the up button to get the previous command>
-
-<use 'ctrl + w' to remove the unwanted arguments>
-
-```
-
-But what if you removed one too many? No problem—simply use `ctrl + _` to undo the last edit.
-
-The other cut commands allow you to quickly remove everything from the cursor to the end or beginning of the line (using `Ctrl + k` and `Ctrl + u`, respectively). This has the added benefit of placing the cut text into the terminal buffer so you can paste it later on (using `ctrl + y`). These commands are hard to demonstrate here, so I strongly encourage you to try them out on your own.
-
-Last but not least, I'd like to mention a seldom-used key combination that can be extremely handy in confined environments such as containers. If you ever have a command look garbled by previous output, there is a solution: Pressing `ctrl + x + ctrl + e` will open the command in whichever editor is set in the environment variable EDITOR. This will allow you to edit a long or garbled command in a text editor that (potentially) can wrap text. Saving your work and exiting, just as you would when working on a normal file, will execute the command upon leaving the editor.
-
-### Miscellaneous tips
-
-You may find that having colors displayed in your Bash shell can enhance your experience. If you are using a session that does not have colorization enabled, below are a series of commands you can place in your `.bash_profile` to add color to your session. These are fairly straightforward and should not require an in-depth explanation:
-```
-# enable colors
-
-eval "`dircolors -b`"
-
-
-
-# force ls to always use color and type indicators
-
-alias ls='ls -hF --color=auto'
-
-
-
-# make the dir command work kinda like in windows (long format)
-
-alias dir='ls --color=auto --format=long'
-
-
-
-# make grep highlight results using color
-
-export GREP_OPTIONS='--color=auto'
-
-
-
-# Add some colour to LESS/MAN pages
-
-export LESS_TERMCAP_mb=$'\E[01;31m'
-
-export LESS_TERMCAP_md=$'\E[01;33m'
-
-export LESS_TERMCAP_me=$'\E[0m'
-
-export LESS_TERMCAP_se=$'\E[0m'
-
-export LESS_TERMCAP_so=$'\E[01;42;30m'
-
-export LESS_TERMCAP_ue=$'\E[0m'
-
-export LESS_TERMCAP_us=$'\E[01;36m'
-
-```
-
-Along with adjusting the various options within Bash, you can also use some neat tricks to save time. For example, to run two commands back-to-back, regardless of each one's exit status, use the `;` to separate the commands, as seen below:
-```
-[user@centos /tmp]$ du -hsc * ; df -h
-
-```
-
-This simply calculates the amount of space each file in the current directory takes up (and sums it), then it queries the system for the disk usage per block device. These commands will run regardless of any errors generated by the `du` command.
-
-What if you want an action to be taken upon successful completion of the first command? You can use the `&&` shorthand to indicate that you want to run the second command only if the first command returns a successful exit status. For example, suppose you want to reboot a machine only if the updates are successful:
-```
-[root@arch ~]$ pacman -Syu --noconfirm && reboot
-
-```
-
-Sometimes when running a command, you may want to capture its output. Most people know about the `tee` command, which will copy standard output to both the terminal and a file. However, if you want to capture more complex output from, say, `strace`, you will need to start working with [I/O redirection][1]. The details of I/O redirection are beyond the scope of this short article, but for our purposes we are concerned with `STDOUT` and `STDERR`. The best way to capture exactly what you are seeing is to combine the two in one file. To do this, use the `2>&1` redirection.
-```
-[root@arch ~]$ strace -p 1140 > strace_output.txt 2>&1
-
-```
-
-This will put all of the relevant output into a file called `strace_output.txt` for viewing later.
-
-Sometimes during a long-running command, you may need to pause the execution of a task. You can use the 'stop' shortcut `ctrl + z` to stop (but not kill) a job. The job gets added to the job queue, but you will no longer see the job until you resume it. This job may be resumed at a later time by using the foreground command `fg`.
-
-In addition, you may also simply pause a job with `ctrl + s`. The job and its output stay in the terminal foreground, and use of the shell is not returned to the user. The job may be resumed by pressing `ctrl + q`.
-
-If you are working in a graphical environment with many terminals open, you may find it handy to have keyboard shortcuts for copying and pasting output. To do so, use the following shortcuts:
-```
-# Copies highlighted text
-
-ctrl + shift + c
-
-
-
-# Pastes text in buffer
-
-ctrl + shift + v
-
-```
-
-Suppose in the output of an executing command you see another command being executed, and you want to get more information. There are a few ways to do this. If this command is in your path somewhere, you can run the `which` command to find out where that command is located on your disk:
-```
-[root@arch ~]$ which ls
-
-/usr/bin/ls
-
-```
-
-With this information, you can inspect the binary with the `file` command:
-```
-[root@arch ~]$ file /usr/bin/ls
-
-/usr/bin/ls: ELF 64-bit LSB pie executable x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=d4e02b88e596e4f82c6cc62a5bc4ce5827209a49, stripped
-
-```
-
-You can see all sorts of information, but the most important for most users is the `ELF 64-bit LSB` nonsense. This essentially means that it is a precompiled binary as opposed to a script or other type of executable. A related tool you can use to inspect commands is the `command` tool itself. Simply running `command -V <command>` will give you different types of information:
-```
-[root@arch ~]$ command -V ls
-
-ls is aliased to `ls --color=auto`
-
-
-
-[root@arch ~]$ command -V bash
-
-bash is /usr/bin/bash
-
-
-
-[root@arch ~]$ command -V shopt
-
-shopt is a shell builtin
-
-```
-
-Last but definitely not least, one of my favorite tricks, especially when working with containers or in environments where I have little knowledge or control, is the `echo` command. This command can be used to do everything from checking to make sure your `for` loop will run the expected sequence to allowing you to check if remote ports are open. The syntax is very simple to check for an open port: `echo > /dev/<udp or tcp>/<server ip>/<port>`. For example:
-```
-user@ubuntu-1604:~$ echo > /dev/tcp/192.168.99.99/222
-
--bash: connect: Connection refused
-
--bash: /dev/tcp/192.168.99.99/222: Connection refused
-
-
-
-user@ubuntu-1604:~$ echo > /dev/tcp/192.168.99.99/22
-
-```
-
-If the port is closed to the type of connection you are trying to make, you will get a `Connection refused` message. If the packet is successfully sent, there will be no output.
-
-I hope these tips make Bash more efficient and enjoyable to use. There are many more tricks hidden in Bash than I've listed here. What are some of your favorites?
-
-#### Appendix 1. List of tips and tricks covered
-
-```
-# History related
-
-ctrl + r (reverse search)
-
-!! (rerun last command)
-
-!* (reuse arguments from previous command)
-
-!$ (use last argument of last command)
-
-shopt -s histappend (allow multiple terminals to write to the history file)
-
-history | awk 'BEGIN {FS="[ \t]+|\\|"} {print $3}' | sort | uniq -c | sort -nr | head (list the most used history commands)
-
-
-
-# File and navigation
-
-cp /home/foo/realllylongname.cpp{,-old}
-
-cd -
-
-rename 's/text_to_find/been_renamed/' *.txt
-
-export CDPATH='/var/log:~' (variable is used with the cd built-in.)
-
-
-
-# Colourize bash
-
-
-
-# enable colors
-
-eval "`dircolors -b`"
-
-# force ls to always use color and type indicators
-
-alias ls='ls -hF --color=auto'
-
-# make the dir command work kinda like in windows (long format)
-
-alias dir='ls --color=auto --format=long'
-
-# make grep highlight results using color
-
-export GREP_OPTIONS='--color=auto'
-
-
-
-export LESS_TERMCAP_mb=$'\E[01;31m'
-
-export LESS_TERMCAP_md=$'\E[01;33m'
-
-export LESS_TERMCAP_me=$'\E[0m'
-
-export LESS_TERMCAP_se=$'\E[0m' # end the info box
-
-export LESS_TERMCAP_so=$'\E[01;42;30m' # begin the info box
-
-export LESS_TERMCAP_ue=$'\E[0m'
-
-export LESS_TERMCAP_us=$'\E[01;36m'
-
-
-
-# Bash shortcuts
-
- shopt -s cdspell (corrects typoos)
-
- ctrl + _ (undo)
-
- ctrl + arrow (move forward a word)
-
- ctrl + a (move cursor to start)
-
- ctrl + e (move cursor to end)
-
- ctrl + k (cuts everything after the cursor)
-
- ctrl + l (clears screen)
-
- ctrl + q (resume command that is in the foreground)
-
- ctrl + s (pause a long running command in the foreground)
-
- ctrl + t (swap two characters)
-
- ctrl + u (cuts everything before the cursor)
-
- ctrl + x + ctrl + e (opens the command string in an editor so that you can edit it before it runs)
-
- ctrl + x + * (expand glob/star)
-
- ctrl + xx (move to the opposite end of the line)
-
- ctrl + y (pastes from the buffer)
-
- ctrl + shift + c/v (copy/paste into terminal)
-
-
-
-# Running commands in sequence
-
-&& (run second command if the first is successful)
-
-; (run second command regardless of success of first one)
-
-
-
-# Redirecting I/O
-
-2>&1 (redirect stdout and stderr to a file)
-
-
-
-# check for open ports
-
-echo > /dev/tcp/<server ip>/<port>
-
-`` (use back ticks to shell out)
-
-
-
-# Examine executable
-
-which <command>
-
-file <path/to/file>
-
-command -V <some command binary> (tells you whether <some binary> is a built-in, binary or alias)
-
-```
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/bash-tricks
-
-作者:[Steve Ovens][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/stratusss
-[1]:https://www.digitalocean.com/community/tutorials/an-introduction-to-linux-i-o-redirection
diff --git a/sources/tech/20180618 Write fast apps with Pronghorn, a Java framework.md b/sources/tech/20180618 Write fast apps with Pronghorn, a Java framework.md
deleted file mode 100644
index 124b3c5cf2..0000000000
--- a/sources/tech/20180618 Write fast apps with Pronghorn, a Java framework.md
+++ /dev/null
@@ -1,120 +0,0 @@
-Write fast apps with Pronghorn, a Java framework
-======
-
-
-
-In 1973, [Carl Hewitt][1] had an idea inspired by quantum mechanics. He wanted to develop computing machines that were capable of parallel execution of tasks, communicating with each other seamlessly while containing their own local memory and processors.
-
-Born was the [actor model][2], and with that, a very simple concept: Everything is an actor. This allows for some great benefits: Separating business and other logic is made vastly easier. Security is easily gained because each core component of your application is separate and independent. Prototyping is accelerated due to the nature of actors and their interconnectivity.
-
-### What is Pronghorn?
-
-However, what ties it all together is the ability to pass messages between these actors concurrently. An actor responds based on an input message; it can then send back an acknowledgment, deliver content, and designate behaviors to be used for the next time a message gets received. For example, one actor is loading image files from disk while simultaneously streaming chunks to other actors for further processing; i.e., image analysis or conversion. Another actor then takes these as inputs and writes them back to disk or logs them to the terminal. Independently, these actors alone can’t accomplish much—but together, they form an application.
-
-Today there are many implementations of this actor model. At [Object Computing][3], we’ve been working on a highly scalable, performant, and completely open source Java framework called [Pronghorn][4], named after one of the world’s fastest land animals.
-
-Pronghorn, recently released to 1.0, attempts to address a few of the shortcomings of [Akka][5] and [RxJava][6], two popular actor frameworks for Java and Scala.
-
-As a result, we developed Pronghorn with a comprehensive list of features in mind:
-
- 1. We wanted to produce as little garbage as possible. Without the Garbage Collector kicking in regularly, it is able to reach performance levels never seen before.
- 2. We wanted to make sure that Pronghorn has a minimal memory footprint and is mechanical-sympathetic. Built from the ground up with performance in mind, it leverages CPU prefetch functions and caches for fastest possible throughput. Using zero copy direct access, it loads fields from schemas in nanoseconds and never stall cores, while also being non-blocking and lock-free.
- 3. Pronghorn ensures that you write correct code securely. Through its APIs and contracts, and by using "[software fortresses][7]" and industry-leading encryption, Pronghorn lets you build applications that are secure and that fail safely.
- 4. Debugging and testing can be stressful and annoying, especially when you need to hit a deadline. Pronghorn easily integrates with common testing frameworks and simplifies refactoring and debugging through its automatically generated and live-updating telemetry graph, fuzz testing (in work) based on existing message schemas, and warnings when certain actors are misbehaving or consuming too many resources. This helps you rapidly prototype and spend more time focusing on your business needs.
-
-
-
-For more details, visit the [Pronghorn Features list][8].
-
-### Why Pronghorn?
-
-Writing concurrent and performant applications has never been easy, and we don’t promise to solve the problems entirely. However, to give you an idea of the benefits of Pronghorn and the power of its API, we wrote a small HTTP REST server and benchmarked it against common industry standards such as [Node & Express][9] and [Tomcat][10] & [Spring Boot][11]:
-
-
-
-We encourage you to [run these numbers yourself][12], share your results, and add your own web server.
-
-As you can see, Pronghorn does exceptionally well in this REST example. While almost being 10x faster than conventional solutions, Pronghorn could help cut server costs (such as EC2 or Azure) in half or more through its garbage-free, statically-typed backend. HTTP requests can be parsed, and responses are generated while actors are working concurrently. The scheduling and threading are automatically handled by Pronghorn's powerful default scheduler.
-
-As mentioned above, Pronghorn allows you to rapidly prototype and envision your project, generally by following three basic steps:
-
- 1. **Define your data flow graph**
-
-
-
-This is a crucial first step. Pronghorn takes a data-first approach; processing large volumes of data rapidly. In your application, think about the type of data that should flow through the "pipes"—for example, if you’re building an image analysis tool, you will need actors to read, write, and analyze image files. The format of the data between actors needs also to be established; it could be schemas containing JPG MCUs or raw binary BMP files. Pick the format that works best for your application.
-
- 2. **Define the contracts between each stage**
-
-
-
-Contracts allow you to easily define your messages using [FAST][13], a proven protocol used by the finance industry for stock trading. These contracts are used in the testing phase to ensure implementation aligns with your message field definitions. This is a contractual approach; it must be respected for actors to communicate with each other.
-
- 3. **Test first development by using generative testing as the graph is implemented**
-
-
-
-Schemas are code-generated for you as you develop your application. Test-driven development allows for correct and safe code, saving valuable time as you head towards release. As your program grows, the graph grows as well, describing every single interaction between actors and illustrating your message data flow on pipes between stages. Through its automatically telemetry, you can easily keep track of even the most complex applications, as shown below:
-
-
-
-### What does it look like?
-
-You may be curious about what Pronghorn code looks like. Below is some sample code for generating the message schemas in our "[Hello World][14]" example.
-
-To define a message, create a new XML file similar to this:
-```
-<?xml version="1.0" encoding="UTF-8"?>
-<templates xmlns="http://www.fixprotocol.org/ns/fast/td/1.1">
- <template name="HelloWorldMessage" id="1">
- <string name="GreetingName" id="100" charset="unicode"/>
- </template>
-</templates>
-```
-
-This schema will then be used by the stages described in the Hello World example. Populating a graph in your application using this schema is even easier:
-```
-private static void populateGraph(GraphManager gm) {
- Pipe<HelloWorldSchema> messagePipe =
-HelloWorldSchema.instance.newPipe(10, 10_000);
- new GreeterStage(gm, "Jon Snow", messagePipe);
- new GuestStage(gm, messagePipe);
- }
-```
-
-This uses the stages created in the [Hello World tutorial][14].
-
-We use a [Maven][15] archetype to provide you with everything you need to start building Pronghorn applications.
-
-### Start using Pronghorn
-
-We hope this article has offered a taste of how Pronghorn can help you write performant, efficient, and secure applications in Java using Pronghorn, an alternative to Akka and RXJava. We’d love your feedback on how to make this an ideal platform for developers, managers, CFOs, and others.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/writing-applications-java-pronghorn
-
-作者:[Tobi Schweiger][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/tobischw
-[1]:https://en.wikipedia.org/wiki/Carl_Hewitt
-[2]:https://en.wikipedia.org/wiki/Actor_model
-[3]:https://objectcomputing.com/
-[4]:https://oci-pronghorn.gitbook.io/pronghorn/chapter-0-what-is-pronghorn/home
-[5]:https://akka.io/
-[6]:https://github.com/ReactiveX/RxJava
-[7]:https://www.amazon.com/Software-Fortresses-Modeling-Enterprise-Architectures/dp/0321166086
-[8]:https://oci-pronghorn.gitbook.io/pronghorn/chapter-0-what-is-pronghorn/features
-[9]:https://expressjs.com/
-[10]:http://tomcat.apache.org/
-[11]:https://spring.io/projects/spring-boot
-[12]:https://github.com/oci-pronghorn/GreenLoader
-[13]:https://en.wikipedia.org/wiki/FAST_protocol
-[14]:https://oci-pronghorn.gitbook.io/pronghorn/chapter-1-getting-started-with-pronghorn/1.-hello-world-introduction/0.-getting-started
-[15]:https://maven.apache.org/
diff --git a/sources/tech/20180621 Troubleshooting a Buildah script.md b/sources/tech/20180621 Troubleshooting a Buildah script.md
deleted file mode 100644
index 482a7ebe37..0000000000
--- a/sources/tech/20180621 Troubleshooting a Buildah script.md
+++ /dev/null
@@ -1,179 +0,0 @@
-Troubleshooting a Buildah script
-======
-
-
-
-As both a father of teenagers and a software engineer, I spend most of my time dealing with problems. Whether the problem is large or small, many times you can't find the cause of an issue by looking directly at it. Instead, you need to step back and investigate the environment where the situation exists. I realized this recently, when a colleague who presents on container technologies, including [container managers][1] like [Buildah][2] and [Podman][3], asked me for help solving a problem with a demo script he was planning to show at a conference only a few days later.
-
-The script had worked in the past but wasn't working now, and he was in a pinch. It's a demo script that creates a Fedora 28-based container [using Buildah][4] and installs the NGINX HTTPD server within it. Then it uses Podman to run the container and kick off the NGINX server. Finally, the script does a quick `curl` command to pull the index.html file to prove the server is up and responsive. All these commands had worked during setup and testing, but now the `curl` was failing. (By the way, if you want to learn about Buildah or run a demo, take a look at my colleague's [full script][5], as it is a great one to use.)
-
-I talked to the folks on the Podman team, and they were not able to reproduce the issue, so I thought it might be a problem in Buildah. We did a flurry of debugging and checking in the config code to make sure the ports were being set up properly, the image was getting pulled correctly, and everything was saved. It all checked out. Prior run-throughs of the demo had all completed successfully: the NGINX server would serve up the index.html as expected. That was odd, and no recent changes to the Buildah code were likely to upset any of that.
-
-With the deadline before the conference ticking away, I began investigating by shrinking the script down to the following.
-```
-cat ~/tom_nginx.sh
-
-#!/bin/bash
-
-
-
-# docker-compatibility-demo.sh
-
-# author : demodude
-
-# Assumptions install buildah, podman & docker
-
-# Do NOT start the docker deamon
-
-# Set some of the variables below
-
-
-
-demoimg=dockercompatibilitydemo
-
-quayuser=ipbabble
-
-myname="Demo King"
-
-distro=fedora
-
-distrorelease=28
-
-pkgmgr=dnf # switch to yum if using yum
-
-
-
-#Setting up some colors for helping read the demo output
-
-bold=$(tput bold)
-
-red=$(tput setaf 1)
-
-green=$(tput setaf 2)
-
-yellow=$(tput setaf 3)
-
-blue=$(tput setaf 4)
-
-cyan=$(tput setaf 6)
-
-reset=$(tput sgr0)
-
-
-
-echo -e "Using ${green}GREEN${reset} to introduce Buildah steps"
-
-echo -e "Using ${yellow}YELLOW${reset} to introduce code"
-
-echo -e "Using ${blue}BLUE${reset} to introduce Podman steps"
-
-echo -e "Using ${cyan}CYAN${reset} to introduce bash commands"
-
-echo -e "Using ${red}RED${reset} to introduce Docker commands"
-
-
-
-echo -e "Building an image called ${demoimg}"
-
-
-
-set -x
-
-newcontainer=$(buildah from ${distro})
-
-buildah run $newcontainer -- ${pkgmgr} -y update && ${pkgmgr} -y clean all
-
-buildah run $newcontainer -- ${pkgmgr} -y install nginx && ${pkgmgr} -y clean all
-
-buildah run $newcontainer bash -c 'echo "daemon off;" >> /etc/nginx/nginx.conf'
-
-buildah run $newcontainer bash -c 'echo "nginx on OCI Fedora image, built using Buildah" > /usr/share/nginx/html/index.html'
-
-buildah config --port 80 --entrypoint /usr/sbin/nginx $newcontainer
-
-buildah config --created-by "${quayuser}" $newcontainer
-
-buildah config --author "${myname}" --label name=$demoimg $newcontainer
-
-buildah inspect $newcontainer
-
-buildah commit $newcontainer $demoimg
-
-buildah images
-
-containernum=$(podman run -d -p 80:80 $demoimg)
-
-curl localhost # Failed
-
-podman ps
-
-podman stop $containernum
-
-podman rm $containernum
-
-```
-
-### What the script is doing
-
-Beginning in the `set -x` section, you can see the script creates a new Fedora container using `buildah from`. The next four steps use `buildah run` to do some configurations in the container: the first two use the DNF software package manager to do an update, install NGINX, and clean everything up; the third and fourth steps prepare NGINX to run—the third sets up the `/etc/nginx/nginx.conf` file and sets `daemon off`, and the `run` command in the fourth step creates the index.html file to be displayed.
-
-The three `buildah config` commands that folllow do a little housekeeping within the container. They set up port 80, set the entry point to NGINX, and touch up the `created-by`, `author`, and `label` fields in the new container. At this point, the container is set up to run NGINX, and the `buildah inspect` command lets you walk through the container's fields and associated metadata to verify all of that.
-
-This script uses Podman to run the container and the NGINX server. Podman is a new, open source utility for working with Linux containers and Kubernetes pods that emulates many features of the Docker command line but doesn't require a daemon as Docker does. For Podman to run the container, it must first be saved as an image—that's what the `buildah commit` line is doing.
-
-Finally, the `podman run` line starts up the container and—due to the way we configured it with the entry point and setting up the ports—the NGINX server starts and is available for use. It's always nice to say the server is "running," but the proof is being able to interact with the server. So, the script executes a simple `curl localhost`; if it's working, index.html should contain:
-```
-nginx on OCI Fedora image, built using Buildah
-
-```
-
-However, with only hours before the next demo, it instead sent back:
-```
-curl: (7) Failed to connect to jappa.cos.redhat.com port 80: Connection refused
-
-```
-
-Now, that's not good.
-
-### Diagnosing the problem
-
-I was repeatedly having the problem on my development virtual machine (VM). I added debugging statements and still didn't find anything. Strangely, I found if I replaced `podman` with `docker` in the script, everything worked just fine. I'm not always very kind to my development VM, so I set up a new VM and installed everything nice and fresh and clean.
-
-The script failed there as well, so it wasn't that my development VM was behaving badly by itself. I ran the script multiple times while I was thinking things through, hoping to pick up any clue from the output. My next thought was to get into the container and look around in there. I commented out the `stop` and `rm` lines and re-ran the script using:
-```
-podman exec --tty 129d4d33169f /bin/bash
-
-```
-
-where `129d4d33169f` was the `CONTAINER ID` value from the `podman ps` command for the container. I ran `curl localhost` there within the container and voilà! I received the correct output from index.html. I then exited the container and tried the `curl` command again from the host running the container, and this time it worked.
-
-Finally, light dawned on marblehead. In past testing, I'd been playing with an Apache HTTPD server and trying to connect to it from another session. In those tests, if I went too quick, the server would reject me.
-
-### Could it be that simple?
-
-As it turns out, it was that simple. We added a `sleep 3` line between the `podman run` and the `curl localhost` commands, and everything worked as expected. What seemed to be happening was the `podman run` command was starting up the container and the NGINX server extremely quickly and returning to the command line. If you don't wait a few seconds, the NGINX server doesn't have time to start up and start accepting connection requests.
-
-In our testing with Docker, this wasn't the case. I didn't dig into it deeply, but my assumption is the time Docker spends talking to the Docker daemon gives the NGINX server enough time to come up fully. This is what makes Buildah and Podman very useful and powerful: no daemon, less overhead. But you need to take that into account for demos!
-
-Problems are indeed what engineers solve, and oftentimes the answer is not in the code itself. When looking at problems, it's good to step back a little bit and not get too focused on the bits and the bytes.
-
-An earlier version of this article originally appeared on the [ProjectAtomic.io][6] blog.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/buildah-troubleshooting
-
-作者:[Tom Sweeney][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/tomsweeneyredhat
-[1]:https://opensource.com/article/18/1/history-low-level-container-runtimes
-[2]:https://github.com/projectatomic/buildah
-[3]:https://github.com/projectatomic/libpod/tree/master/cmd/podman
-[4]:https://opensource.com/article/18/6/getting-started-buildah
-[5]:https://github.com/projectatomic/buildah/blob/master/demos/buildah-bud-demo.sh
-[6]:https://www.projectatomic.io/blog/2018/06/problems-are-opportunities-in-disguise/
diff --git a/sources/tech/20180626 Playing Badass Acorn Archimedes Games on a Raspberry Pi.md b/sources/tech/20180626 Playing Badass Acorn Archimedes Games on a Raspberry Pi.md
deleted file mode 100644
index b1f8d97305..0000000000
--- a/sources/tech/20180626 Playing Badass Acorn Archimedes Games on a Raspberry Pi.md
+++ /dev/null
@@ -1,539 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Playing Badass Acorn Archimedes Games on a Raspberry Pi)
-[#]: via: (https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/)
-[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
-
-Playing Badass Acorn Archimedes Games on a Raspberry Pi
-======
-
-![Cannon Fodder on the Raspberry Pi][1]
-
-The Acorn Archimedes was an excellent machine and years ahead of its time.
-
-Debuting in 1987, it featured a point and click graphic interface not so different to Windows 95, 32 bit processing, and enough 3D graphics power to portal you to a new decade.
-
-These days, it’s best remembered for launching the Acorn RISC Machines processor. ARM processors went on to rule the world. You almost certainly keep one in your pocket.
-
-What’s less well appreciated is that the Archimedes was rad for games. For a few years, it was the most powerful desktop in the world and developers were eager to show what they could do with it.
-
-But with such power came a great price tag. The Archimedes was never going to be in as many homes to make as many memories as Sega or Nintendo.
-
-But now, the Raspberry Pi’s ARM chip makes it cheap and easy to play these games on the same operating system and CPU architecture they were written for.
-
-Even better, the rights holders to much of this machine’s gaming catalogue have been generous enough to allow hobbyists to legally download their work for free.
-
-This is a cheap and easy project. In fact, if you already run a Raspberry Pi home theatre or retro gaming rig, all you really need is a spare SD card.
-
-### Introduction
-
-None of this will be on the exam, so if you already know the story of the Acorn Archimedes – or just want to get straight into gaming – feel free to skip ahead to the next section.
-
-But if you’re wondering what we’re even talking about, here it is:
-
-#### What on Earth is an Acorn Archimedes?
-
-Me and Acorn computers go way back.
-
-For the earliest part of my life that I can remember, Dad ran his business from home, writing timetabling software for schools. This was the early 80s, before the desktop computer market had been whittled down to Mac and PC. There were Amstrad CPCs, Sinclairs, Commodores, Ataris, TRSs, the list goes on.
-
-They all had their operating systems and ran their own software. If you wanted to port your software over to a new platform, you had to buy it.
-
-So, at a time when it was somewhat novel for a family to have even one computer, we had about a dozen, many of them already quite antique. There was a Microbee, an Apple IIc, an IBM XT, all sorts of stuff.
-
-The ones Dad liked most though were the BBC machines by [Acorn Computers][2]. He had several. There was a Model B, a Master 128 and a Master Compact.
-
-They were named that way because the British Broadcasting Corporation were developing a course to teach children how to program and they needed. Because of this educational focus, they’d found their way into a lot of schools – exactly the market he was selling to.
-
-At some point, I figured out you could play games on these things. I was straight away hooked like it was crack. All I cared about was games games games. It must have taken me several years to figure out that computers had a different use, because I can vividly recall how annoyed I was to be starting school while Dad got to stay home and play games all day.
-
-On my 7th birthday I got a second hand BBC Master Compact all of my own. This was probably as much to keep me away from his work computers as it was to introduce me to computing. I started learning to program in BASIC and Logo. I also played epic amounts of space shooters, 2D platformers and adventure games.
-
-Being obsessed with these things, I tagged along to the local BBC Users Group. This was a monthly get-together where enthusiasts would discuss what was new, bring their machines to show off what they’re doing and engage in some casual software piracy. Back before internet forums and torrents, people did this in person.
-
-This was where I first saw an Archimedes. I can’t really remember the exact year or the exact model – I just remember my jaw dropping to the floor at the 3D graphics and the 8 channel stereo sound. It would be about a decade before I saw anything similar on a gaming console.
-
-<https://www.youtube.com/embed/CsqsX2Nlfeg?feature=oembed>
-
-#### The Birth of a Legend
-
-Looking back, this has very good claim to be the first modern desktop computer. It was a 32-bit machine, an interface that looks more like what we use today than anything built in the 1980s, a palette of 4096 colours, and more horsepower than a lot of people knew what to do with.
-
-Now, don’t get me wrong: the 8-bit BBC machines were loads of fun and great for what they were – but what they were was fairly primitive. It was basically just a big box you typed commands on to make it beep and stuff. In theory it had 8 colours, but when you saw one in the wild it was usually hooked up to a monochrome screen and you didn’t feel like you were missing out on too much because of it.
-
-In 1984, Apple launched their Macintosh, featuring the first Graphical User Interface available on the mass market. Acorn knew they’d need a point and click graphic interface to stay in the game. And they knew the aging MOS 6502 they’d used in all their machines so far was just not going to be the CPU of the future.
-
-So, what to replace it with?
-
-The Acorn engineers looked at the available processors and found that none of them could quite do what they want. They decided to build their own – and it would be radically different.
-
-Up until that point, chip makers took a bit of a Swiss Army Knife approach to processor design – to compete, you added more and more useful stuff to the instruction set.
-
-There was a certain logic to this – hardware could be mass produced, while good software engineers were expensive. It made sense to handle as much as possible in the hardware. For device manufacturers with bills to pay, it was a real selling point.
-
-But this came at a cost – more and more complex instructions required more and more clock cycles to complete. Often there was a whole extra layer of processing to convert the complex machine code instructions into smaller instructions. As RAM became bigger and faster, CPUs were struggling to keep pace with the available memory bandwidth.
-
-Acorn turned this idea on its head, with a stripped-back approach in the great British tradition of the [de Havilland Mosquito][3]: Every instruction could be completed in a single cycle.
-
-While testing the prototype CPU, the engineers noticed something weird: they’d disconnected the power and yet the chip was running. What they’d built was so power-efficient that it kept running on residual power from nearby components.
-
-It was also 25 times faster than the 6502 CPU they used in the old BBC machines. Even better, it was several times more powerful than the Motorola 68000 found in the Apple Macintosh, Atari ST and Commodore Amiga – and several time more powerful than the 386 in the new Compaq too.
-
-With such radically new hardware, they needed a new operating system. What they come up with was Risc OS, and it was operated entirely through a graphic point-and-click desktop interface with a pinboard and an icon bar. This was pretty much Windows 95, 8 years before it happened.
-
-In a single step, Acorn had gone from producing some perfectly serviceable 8-bit box that kids could learn to code one, to having the most powerful desktop computer in the world. I mean, it was technically possible to get something more powerful – but it would have been some kind of server or mainframe. As far as something that could sit on your desk, this was top of the pile.
-
-It sold well in Acorn’s traditional education market in the UK. The sheer grunt also made it popular for certain power-hungry business tasks, like desktop publishing.
-
-#### The Crucifixion
-
-It wasn’t too long before Dad got an Archimedes – I can’t remember exactly which model. By this time, he’d moved his business out of home to an office. When school holidays rolled around, I’d sometimes have to spend the day at his work, where I had all the time in the world to fiddle around on it.
-
-The software it came with was enough to keep a child entertained for a while. It came with a demo game called Lander – this was more about showing off the machine’s 3D graphics power than providing any lasting value. There was a card game, and also some drawing programs.
-
-<https://www.youtube.com/embed/mFwpsb75omg?feature=oembed>
-
-I played with the demo disc until I got bored – which I think was the most use that this particular machine ever got. For all the power under the hood, all the applications Dad used to actually run his business ran on DOS and Windows.
-
-He’d spent more than $4000 in today’s money for the most sophisticated and advanced piece of computing technology for a mile in any direction and it just sat there.
-
-He might have at least salvaged some beneficial utility out of it if he’d followed my advice of getting some games for it and letting me take it home.
-
-He never got around to writing any software on it. The Archimedes was apparently a big hit with British schools, but never really got popular enough with his Australian customer base to be worth coding for.
-
-Which I guess is kind of sums up where it all ultimately went wrong for the Acorn desktop.
-
-As the 80s wore on to the ’90s, Compaq reverse engineered the BIOS on the IBM PC to release their own fully compatible PC, and big players like Amstrad left their proprietary platforms to produce their own compatible MS-DOS machines. It was also became increasingly easy for just about anyone with a slight technical bunt to build their own PC-compatible clone from off-the-shelf parts – and to upgrade old PCs with new hard drives, sound cards, and the latest 386 and 486 processors.
-
-Small, independent computer shops and other local businesses started building their owns PCs and hardware manufacturers competed to sell parts to them. This was a computing platform that could serve all price points.
-
-With so much of the user base now on MS-DOS, software developers followed. Which only reinforced the idea that this was the obvious system to buy, which in turn reinforced that it was the system to code for.
-
-The days when just any computer maker could make a go of it with their own proprietary hardware and operating system had passed. Third-party support was everything. It didn’t actually matter how good your technology was if nothing would run on it. Even Apple nearly went to the wall.
-
-Acorn hung on through the 90s, and there was even a successor to the Archimedes called the [RiscPC][4]. But while the technology itself was again very good, these things were relatively marginal affairs in the marketplace. The era of the Acorn desktop had passed.
-
-#### The Resurrection
-
-It was definitely good for our family business when the market consolidated to Mac and PC. We didn’t need to maintain so many versions of the same software.
-
-But the Acorn machines had so much sentimental value. We both liked them and were sad to see them go. I’ve never been that into sport, but watching them slowly disappear might have been a bit like watching your football team lose match after match before finally going broke.
-
-We totally had no idea that they were, very quietly, on a path to total domination.
-
-The ARM was originally only built to go in the Archimedes. But it turned out that having a massively powerful processor with a simple instruction set and very little heat emission was useful for all sorts of stuff: DVD players, set top boxes, photocopiers, televisions, vending machines, home and small business routers, you name it.
-
-The ARM’s low power consumption made it especially useful for portable devices like PDAs, digital cameras, GPS navigators and – eventually – tablets and smartphones. Intel tried to compete in the smartphone market, but was [eventually forced to admit that this technology was just better for phones][5].
-
-So in the end, Dad’s old BBC machines went on to conquer the world.
-
-### The Acorn Archimedes as a Gaming Platform
-
-While Microsoft operating systems were ultimately to become the only real choice for the serious desktop gamer, for a while the Archimedes was the most powerful desktop computer in the world. This attracted a lot of games developers, eager to show what they could do with it.
-
-This would have been about more than just selling to a well moneyed section of the desktop computer market that was clearly quite willing to throw cash at shiny things. It would have been a chance to make your reputation in the industry with a flagship product that just wasn’t possible on lesser hardware.
-
-So it is that you see Star Fighter 3000, Chocks Away and Zarch all charting new territory in what was possible on a desktop computer.
-
-But while the 3D graphics power was this system’s headline feature, the late 80s and early 90s were really the era of Sonic and Mario: the heyday of 2D platform games. Here, the Archimedes also excels, with offerings like Mad Professor Mariarti, Bug Hunter, F.R.E.D. and Hamsters, all of which are massively playable, have vibrant graphics and a boatload of personality.
-
-As you dig further into the library, you also find a few games that show that not every developer really knew what to do with this machine. Some games – like Repton 3 – are just old BBC micro games given the most meagre of facelifts.
-
-Many of the games in the Archimedes catalogue you’ll recognise from other platforms: Populous, Lemmings, James Pond, Battle Chess, the list goes on.
-
-Here, the massive hardware advantage of the Archimedes means that it usually had the best version of the game to play. You’re not getting a whole new game here: but it’s noticeably smoother graphics and gameplay, especially compared to the console releases.
-
-All in all, the Archimedes never had a catalogue as expansive as MS-DOS, the Commodore Amiga, or the Sega and Nintendo consoles. But there are enough truly excellent games to make it worth an SD card.
-
-### Configuring Your Raspberry Pi
-
-This is a bit different to other retro gaming options on the Raspberry Pi – we’re not running an emulator. The ARM chip in the Pi is a direct descendant of the one in the Archimedes, and there’s an [open source version of Risc OS][6] we can install on it.
-
-For the most hardcore retro gaming purist, nothing less than using the hardware will do. For everyone else, using the same operating system from back in the day to load up your games means that your retro gaming rig becomes just that little bit more of a time machine.
-
-But even with all these similarities, there’s still going to be a few things that change in 30 years of computing.
-
-The most visible difference is that our Raspberry Pi doesn’t come with an internal 3.5″ floppy disk drive. You might be able to hook up a USB one, but most of us don’t have this lying around and don’t really want one. So we’re going to need a different way to boot floppy images.
-
-The more major difference is how much RAM the operating system is written to handle. The earliest versions of Risc OS made efficient use of the ARM’s 32-bit register by using 26 bits for the memory address and the remaining 6 bits for status flags. A 26-bit scheme gives you enough addressing space for up to 64 megabytes of RAM.
-
-When this was first devised, the fact that an Archimedes came with a whole megabyte of RAM was considered incredibly luxurious by the standards of the day. By contrast, the first Commodore Amiga had 256kb of RAM. The Sega Mega Drive had 72kb.
-
-But as time wore on, and later versions of Risc OS moved to a 32-bit addressing scheme. This is what we have on our Raspberry Pi. A few games have been [recompiled to run on 32 bit addressing][7], but most have not.
-
-The Archimedes also used different display drivers for different screens. These days, our GPU can handle all of this for us. We just need to install a patch to get that working.
-
-There are free utilities you can download to handle all of these things.
-
-#### Hardware Requirements
-
-I’ve tested this to work with a Raspberry Pi Model 3 B, but I expect that any Pi from the Model A onwards should manage this. The ARM processor on the slowest Pi is a great many times more powerful than the on the fastest Archimedes.
-
-The lack of ports on a Raspberry Pi Zero means it’s probably not the most convenient choice, but if you can navigate around this, then it should be powerful enough.
-
-In addition to the board, you’ll need something to put it in, a micro SD card, a USB SD card adapter, a power supply, a screen with an HDMI input, a USB keyboard and a 3 button mouse – a clickable scroll wheel works fine for your middle button.
-
-If you already have a Raspberry Pi home theatre or retro gaming rig, then you’ve already got all this, so all you really need is a new micro SD card to swap in for Risc OS.
-
-#### Installing Risc OS Open
-
-When I first wrote this guide, Risc OS wasn’t an available option for the Raspberry Pi 3 on the NOOBS and PINN installers. That meant you had to download the image from the [Risc OS Open downloads page][8] and burn it to a new micro SD card.
-
-You can still do this if you like, and if you can’t connect your Raspberry Pi to the internet via Wi-Fi or Ethernet then that’s still your best option. If you’re not sure how to write an image to an SD card, here’s some good guides for [Windows][9] and for [Mac][10].
-
-For everyone else, now that Risc OS is available in the [NOOBS installer][11] again, I recommend using that. What’s really cool about NOOBS is that it makes it super simple to dual boot with something like [Retropie][12] or [Recalbox][13] for the ultimate all-in-one retro gaming device.
-
-Risc OS is as an extremely good option for a dual boot machine because it only uses a few gigabytes – a small fraction of even the smallest SD cards around these days. This leaves most of it available for other operating systems and saves you having to swap cards, which can be a right pain if you have to unscrew the case. The games themselves vary from about 300kb to about 5 megabytes at the very largest, so don’t worry about that.
-
-This image requires a card with at least 2 gigabytes, which for what we’re doing is plenty. Don’t worry about tracking down the largest SD card you can find. The operating system is extremely lightweight and the games themselves vary from about 300kb to about 5 megabytes at the very largest. Even a very small card offers enough space for hundreds of games – more than you will ever play.
-
-If you’re unsure how to use the NOOBS installer, please [click here for instructions][14].
-
-#### Navigating Risc OS
-
-Compared to your first Linux experience, using Risc OS for the first time is, in my opinion, far more gentle. This is in large part thanks to a graphical interface that’s both fairly intuitive and actually very useful for configuring things.
-
-The command line is there if you want it, but we won’t need it just to play some games. You can kind of tell that this was first built with a mass-market audience in mind.
-
-So let’s jump right in.
-
-Insert your card into your Pi, hook it up to your screen, keyboard, mouse and power supply. It shouldn’t take all that long before you’re at the desktop.
-
-###### The Risc OS Mouse
-
-Risc OS uses a three button mouse.
-
-You use the left button – or “Select” button – in much the same way as you’re already used to: one click to select icons and a double click to open folders and execute programs.
-
-The middle button – ie, your scroll wheel – is used to open menus in much the same way as the right mouse button is used in Windows. We’ll be using this a lot.
-
-The right button – or “Adjust” button – has behaviours that vary between applications.
-
-###### Browsing Directories
-
-Ok, so let’s start taking a look around. At the bottom of the screen you’ll see an icon bar. In the bottom left are icons for storage devices.
-
-Click once with the left mouse button on the SD card and a window will open to show you what’s on it. You can take a look inside the directories by double clicking.
-
-###### The Pling
-
-As you start to browse Risc OS, you’ll notice that a lot of what you see inside the directories has exclamation marks at the beginning. This is said out aloud as a “pling”, and it’s used to mark an application that you can execute.
-
-One of the quirks of Risc OS is that these executables aren’t really files – they’re directories. If you hold shift while double clicking, you can open them and start looking inside, same as any other directory – but be careful with this, it’s a good way to break stuff.
-
-Risc OS comes with some applications installed – including a web browser called !NetSurf. We’ll be using that soon to download our games and some small utilities we need to get them running.
-
-###### Creating Directories
-
-Risc OS comes with a basic directory structure, but you’ll probably want to create some new ones to put your floppy images and .zip files.
-
-To do this, click with the middle button inside the folder where you want to place your new directory. This will open up a menu. Move your mouse over the arrow next to “New Directory” and a prompt will open where you can name it and press OK.
-
-###### Copying Files and Directories
-
-To copy a file or directory somewhere else, just drag and drop it with the left mouse button to the new location.
-
-###### Forcing Applications to Quit
-
-Sometimes, if you haven’t configured something right, if you’ve downloaded something that just doesn’t work, or if you plain forgot to look up the controls in the manual, you might find yourself stuck inside an application that has a blank screen or isn’t responding.
-
-Here, you can press Ctrl-Shift-F12 to quit back to the desktop.
-
-###### Shutting Down and Rebooting
-
-If you want to power down or reboot your Pi, just click the middle button on the raspberry icon in the bottom right corner and select “Shutdown”. This will give you an option to reboot the Pi or you can just remove the power cable.
-
-#### Connecting to the Internet
-
-Okay, so I’ve got good news and bad news. I’ll get the bad news right out of the way first:
-
-Risc OS Open doesn’t yet support wireless networking through either the onboard wireless or a wireless dongle in the USB port. It’s on the [to-do list][15].
-
-In the meantime, if you can a way to connect to the internet through the Ethernet port, it makes the rest of this project a lot easier. If you were going to use an Ethernet cable anyway, this will be no big deal. And if you have a wireless bridge handy, you can just use that.
-
-If you don’t have a wireless bridge, but do have a second Raspberry Pi board lying around (hey, who doesn’t these days :p), you can [set it up as a wireless bridge][16]. This is what I did and it’s actually pretty easy if you just follow the steps.
-
-Another option might be to set up a temporary tinkering area next to your router so that you can plug straight in to get everything in configured.
-
-Ok, so what’s the good news?
-
-It’s this: once you’ve got the internet in your front hole, the rest is rather easy. In fact, the only bit that’s not done for your is configuring name servers.
-
-So let’s get to it.
-
-Double-click on !Configure, click once on Network, click on Internet and then on Host Names. Then enter the IPs of your name servers in the name server fields. If you’re not sure what IP to put in here, just use Google’s publicly available name servers – 8.8.8.8 and 8.8.4.4.
-
-When you click Set, it will ask you if you want to reboot. Click yes.
-
-Now double-click on !NetSurf. You’ll see the logo is now added to the bottom right corner. Click on this to open a new browser window.
-
-Compared to Chrome, Firefox, et al, !NetSurf is a primitive web browser. I do not recommend it as a daily driver. But to download Risc OS software directly to the Pi, it’s actually pretty damn convenient.
-
-###### Short Link to This Guide
-
-As you go through the rest of this guide, it’s going to get annoying copying by hand all the URLs you’ll want to visit.
-
-To save you this trouble, type bit.do/riscpi into the browser bar to load this page. With this loaded, you can follow the links.
-
-###### If You’re Still Getting Host Name Error Messages
-
-One little quirk of Risc OS is that it seems to check for name servers as part of the boot process. If it doesn’t find them then, it assumes they’re not there for the rest of the session.
-
-This means that if you connect your Pi to the internet when it’s already booted, you will get an error message when you try to browse the internet with !NetSurf.
-
-To fix this, just double check that your wireless bridge is switched on or that your Pi is plugged into the router, reboot, and the OS should find the name servers.
-
-###### If You Can’t Connect to the Internet
-
-If this is all too hard and you absolutely can’t connect to the internet, there’s always sneakernet – downloading files to another machine and then transferring by USB stick.
-
-This is what I tried at first; It does work, but I found it terribly annoying.
-
-One frustration is that using a Windows 10 machine to download Risc OS software seems to strip out the filetype information – even when you aren’t unzipping the archives. It’s not that difficult to repair this, it’s just tedious when you have to do it all the time.
-
-The other problem is that running USB sticks from computer to computer all the time just got a bit old.
-
-Still, if you have to do it, it’s an option.
-
-#### Unzipping Compressed Files
-
-Most of the files we’ll be downloading will come in .zip format – this is a good thing, because it preserves the file type information. But we’ll need a way to uncompress these files.
-
-For this we’ll use a program called !SparkFS. This is proprietary software, but you can download a read-only version for free. This will let us extract files from .zip archives.
-
-To download and install !SparkFS, click [this link][17] and follow the instructions. You want the version of this software for machines with more than 2MB of RAM.
-
-#### Installing ADFFS and Anymode
-
-Now we need to install ADFFS, a floppy disk imaging program written by Jon Abbot of the [Archimedes Software Preservation Project][18].
-
-This gives us a virtual floppy drive we can use to boot floppy images. It also takes care of the 26 bit memory addressing issues.
-
-To get your copy, browse to the [ADFFS subforum][19] and click the thread for the latest public release – at the time of writing that’s 2.64.
-
-Download the .zip file, open it and then drag and drop !ADFFS to somewhere on your SD card where it’s conveniently accessible – we’ll be using it a lot.
-
-###### Configuring Boot Scripts
-
-For ADFFS to work properly, we’re going to need to add a little boot script.
-
-Follow these instructions carefully – if you do the wrong thing here you can really mess up your OS, or even brick your Pi.
-
-###### Creating !Boot.Loader.CMDLINE/TXT
-
-Remember how I showed you that you could open up applications as directories by holding down shift when you double-click? We can also do this to get inside the Risc OS boot process. We’ll need to do this now to add our boot script.
-
-Start by left clicking once on the SD card icon on the icon bar, then hold down shift and double-click !Boot with your left mouse button. Then double click the folder labeled Loader to open it. This is where we’re going to put our script.
-
-To write our script, click Apps on the icon bar, then double-click !StrongEd. Now click on the fist icon that appeared on the bottom right of the icon bar to open a text editor window, and type:
-
-```
-disable_mode_changes
-```
-
-Computers are fussy so take a moment to double-check your spelling.
-
-To save this file, click the middle button on the text editor and hover your cursor over the arrow next to Save. Then delete the existing text in the Name field and replace it with:
-
-```
-CMDLINE/TXT
-```
-
-Now, see that button marked Save? It’s a trap! Instead, drag and drop the pen and paper icon to the Loader folder.
-
-We’re now finished with this folder, so you can close it and also close the text editor.
-
-###### Installing Anymode
-
-Now we need to install the Anymode module. This is to make the screen modes on our software play nice with our GPU and HDMI output.
-
-Download Anymode from [here,][20] copy the .zip file to somewhere temporary and open it.
-
-Now go back to the root directory on your SD card, double-click on !Boot again, then open the folders marked Choices, Boot and Predesk.
-
-Then use your left mouse button to drag and drop the Anymode module from your .zip file to the Predesk folder.
-
-#### Configuring USB Joysticks and Gamepads
-
-Over at the Archimedes Software Preservation Project, there’s a [USB joystick driver][21] in development.
-
-This module is still in alpha testing, and you’ll need to use the command line to configure it, but it’s there if you’d like to give it a try.
-
-If you can’t get this working, don’t worry too much. It was actually pretty normal back in the day for people either to not have a joystick, or not to be able to get it to work. So pretty much every game can be played with keyboard and mouse.
-
-I’ll be updating this section as this project develops.
-
-#### Setting File Types
-
-Risc OS uses an [ADFS][22] filesystem, different to anything used on Windows or Linux.
-
-Instead of using a filename extension, ADFS files have a “file type” associated with them to show what. When these files pass through a different operating system, this information can get stripped from the file.
-
-In theory, if we don’t open our .zip archives until it reaches our Risc OS machine, the file type should be preserved. Usually this works, but sometimes you unzip the archive and find files with no file type attached. You’ll be able to tell when this has happened because you’ll be faced with a green icon labeled “data”.
-
-Fortunately, this is pretty easy to fix.
-
-Just click on the file with your middle button. A menu will appear.
-
-The second item on this menu will include the name of the file and it will have an arrow next to it. Hover your cursor over the arrow and a second menu will appear.
-
-Near the bottom of this menu will be an option marked “Set Type”, and it will also have an arrow next to it. Hover your cursor over this arrow and a field will appear where you can enter the file type.
-
-To set the file type on a floppy image, type:
-
-```
-&FCE
-```
-
-[Click here for more file type codes.][23]
-
-### Finding, Loading and Playing Games
-
-The best start looking for floppy images is in the [Games subforum][24] at the Archimedes Software Preservation Project.
-
-There’s also a [Risc OS downloads section at Acorn Arcade][25].
-
-There are definitely other websites that host Archimedes games, but I have no idea how legal these copies are.
-
-###### Booting and Switching Floppy Disc Images
-
-Some games might have specific instructions for how to boot the floppy. If so, then follow them.
-
-Generally, though, you drag and drop the image file to, then click on it with the middle button and press “boot floppy”. Your game should start straight away.
-
-Many of the games use more than one floppy disc. To play these, boot disc 1. When you’re asked to switch floppy discs, press control and shift and the function key corresponding to the disc you want to change to.
-
-### Which Games Should You Play?
-
-This is a matter of opinion really and everyone’s taste differs.
-
-Still, if you’re wondering what to try, here are my recommendations.
-
-This is still a work in progress. I’ll be adding more games as I find what I like.
-
-#### Cannon Fodder
-
-<https://www.youtube.com/embed/qgfIAjJ5w8Y?feature=oembed>
-
-This is a top-down action/strategy game that’s extremely playable and wickedly funny.
-
-You control a team of soldiers indirectly by clicking on areas of the screen to tell them where to move and who to kill. Everyone dies with a single shot.
-
-At the start your enemies are all very easy to beat but the game progresses in difficulty. As you go, you’ll need to start dividing your team up into squads to command separately.
-
-I used to play this on the Mega Drive back in the day, but it’s so much more playable with an actual mouse.
-
-[Click here to get Cannon Fodder.][26]
-
-#### Star Fighter 3000
-
-<https://www.youtube.com/embed/omnpVCsDmng?feature=oembed>
-
-This is a 3D space shooter that really laid down the gauntlet for what the Archimedes could do.
-
-You fly around and blast stuff with lasers and missiles. It’s pretty awesome. It’s kind of a forerunner to Terminal Velocity, if you ever played that.
-
-It was later ported to the 3D0, Sega Saturn and Playstation, but they could never render the 3D graphics to the same distance.
-
-[Click here to get Star Fighter 3000.][27]
-
-You want the download marked “Star Fighter 3000 version 3.20”. This one doesn’t use a floppy image, so don’t use ADFFS to run this file. Just double click the program and go.
-
-#### Aggressor
-
-<https://www.youtube.com/embed/kFinTfqs-nU?feature=oembed>
-
-This is a side-scrolling run-and-gun where you have unlimited ammo and a whole lot of aliens and robots to kill. Badass.
-
-#### Bug Hunter
-
-<https://www.youtube.com/embed/TFNF0voQce4?feature=oembed>
-
-This is a really unique puzzle/platform game – you’re a robot with sticky legs who can walk up and down walls and across the ceiling, and your job is to squash bugs by dropping objects lying around.
-
-Which is harder than it sounds, because you can easily get yourself into situations where you dropped something in the wrong place, making it impossible to complete your objective, so your only way out is to initiate your self destruct sequence in futility and shame. Which I guess is kinda rather dark, if you dwell on it.
-
-It’s fun though.
-
-[Click here to get Bug Hunter.][28]
-
-#### Mad Professor Mariarti
-
-<https://www.youtube.com/embed/pQMv-CqktLQ?feature=oembed>
-
-This is a platformer where you’re a mad scientist who shoots spanners and other weapons at bad guys. It has good music and gameplay and an immersive puzzle element as well.
-
-[Click here to get Mad Professor Mariarti.][29]
-
-#### Chuckie Egg
-
-Ok, now we’re getting really retro.
-
-Strictly speaking, this doesn’t really belong in this list, because it’s not even an Archimedes game – it’s an old BBC Micro game that I played the hell out of back in the day that some nice chap has ported to Risc OS.
-
-But there’s a version that runs and it’s awesome so you should play it.
-
-Basically you’re just this guy who goes around stealing eggs. That’s it. That’s all you do.
-
-It’s absolutely amazing.
-
-If you’ve never played it, you really should check it out.
-
-You can [get Chuckie Egg here][30].
-
-This isn’t a floppy image, so you don’t need ADFFS to run it. Just double click on the program and go.
-
-### Over to You
-
-Got any favourite Acorn Archimedes games?
-
-Got any tips for getting them running on the Pi?
-
-Please let me know in the comments section 🙂
-
---------------------------------------------------------------------------------
-
-via: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
-
-作者:[James Mawson][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
-[b]: https://github.com/lujun9972
-[1]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2018/06/cannonfodder-1024x768.jpg
-[2]: http://www.computinghistory.org.uk/det/897/Acorn-Computers/
-[3]: http://davetrott.co.uk/2017/03/strategy-is-sacrifice/
-[4]: http://www.old-computers.com/museum/computer.asp?c=1015
-[5]: https://www.theverge.com/2016/8/16/12507568/intel-arm-mobile-chips-licensing-deal-idf-2016
-[6]: https://www.riscosopen.org/content/
-[7]: https://www.riscosopen.org/wiki/documentation/show/ARMv6%2Fv7%20software%20compatibility%20list#games
-[8]: https://www.riscosopen.org/content/downloads/raspberry-pi
-[9]: http://www.raspberry-projects.com/pi/pi-operating-systems/win32diskimager
-[10]: http://osxdaily.com/2018/01/11/write-img-to-sd-card-mac-etcher/
-[11]: https://www.raspberrypi.org/downloads/noobs/
-[12]: https://retropie.org.uk/
-[13]: https://www.recalbox.com/
-[14]: https://www.raspberrypi.org/documentation/installation/noobs.md
-[15]: https://www.riscosopen.org/wiki/documentation/show/RISC%20OS%20Roadmap
-[16]: https://pimylifeup.com/raspberry-pi-wifi-bridge/
-[17]: http://www.riscos.com/ftp_space/generic/sparkfs/index.htm
-[18]: https://forums.jaspp.org.uk/forum/index.php
-[19]: https://forums.jaspp.org.uk/forum/viewforum.php?f=14&sid=d0f037e95c560144f3910503b776aef5
-[20]: http://www.pi-star.co.uk/anymode/
-[21]: https://forums.jaspp.org.uk/forum/viewtopic.php?f=8&t=396
-[22]: https://en.wikipedia.org/wiki/Advanced_Disc_Filing_System
-[23]: https://www.riscosopen.org/wiki/documentation/show/File%20Types
-[24]: https://forums.jaspp.org.uk/forum/viewforum.php?f=25
-[25]: http://www.acornarcade.com/downloads/
-[26]: https://forums.jaspp.org.uk/forum/viewtopic.php?f=25&t=188
-[27]: http://starfighter.acornarcade.com/
-[28]: https://forums.jaspp.org.uk/forum/viewtopic.php?f=25&t=330
-[29]: https://forums.jaspp.org.uk/forum/viewtopic.php?f=25&t=148
-[30]: http://homepages.paradise.net.nz/mjfoot/riscos.htm
diff --git a/sources/tech/20180629 Discover hidden gems in LibreOffice.md b/sources/tech/20180629 Discover hidden gems in LibreOffice.md
deleted file mode 100644
index fdb7f288e3..0000000000
--- a/sources/tech/20180629 Discover hidden gems in LibreOffice.md
+++ /dev/null
@@ -1,97 +0,0 @@
-Discover hidden gems in LibreOffice
-======
-
-
-
-LibreOffice is the most popular free and open source office suite. It’s included by default in many Linux distributions, such as [Fedora Workstation][1]. Chances are that you use it fairly often, but how many of its features have you really explored? What hidden gems are there in LibreOffice that not so many people know about?
-
-This article explores some lesser-known features in the suite, and shows you how to make the most of them. Then it wraps up with a quick look at the LibreOffice community, and how you can help to make the software even better.
-
-### Notebookbar
-
-Recent versions of LibreOffice have seen gradual improvements to the user interface, such as reorganized menus and additional toolbar buttons. However, the general layout hasn’t changed drastically since the software was born back in 2010. But now, a completely new (and optional!) user interface called the [Notebookbar][2] is under development, and it looks like this:
-
-![LibreOffice's \(experimental\) Notebookbar][3]
-
-Yes, it’s substantially different to the current “traditional” design, and there are a few variants. Because LibreOffice’s design team is still working on the Notebookbar, it’s not available by default in current versions of the suite. Instead, it’s an experimental option.
-
-To try it, make sure you’re running a recent release of LibreOffice, such as 5.4 or 6.0. (LibreOffice 6.x is already available in Fedora 28.) Then go to Tools > Options in the menu. In the dialog box that appears, go to Advanced on the left-hand side. Tick the Enable experimental features box, click OK, and then you’ll be prompted to restart LibreOffice. Go ahead and do that.
-
-Now, in Writer, Calc and Impress, go to View > Toolbar Layout in the menu, and choose Notebookbar. You’ll see the new interface straight away. Remember that this is still experimental, though, and not ready for production use, so don’t be surprised if you see some bugs or glitches in places!
-
-The default Notebookbar layout is called “tabbed”, and you can see tabs along the top of the window to display different sets of buttons. But if you go to View > Notebookbar in the menu, you’ll see other variants of the design as well. Try them out! If you need to access the familiar menu bar, you’ll find an icon for it in the top-right of the window. And to revert back to the regular interface, just go to View > Toolbar Layout > Default.
-
-### Command line tips and tricks
-
-Yes, you can even use LibreOffice from the Bash prompt. This is most useful if you want to perform batch operations on large numbers of files. For instance, let’s say you have 20 .odt (OpenDocument Text) files in a directory, and want to make PDFs of them. Via LibreOffice’s graphical user interface, you’d have to do a lot of clicking to achieve this. But at the command line, it’s simple:
-```
-libreoffice --convert-to pdf *.odt
-
-```
-
-Or take another example: you have a set of Microsoft Office documents, and you want to convert them all to ODT:
-```
-libreoffice --convert-to odt *.docx
-
-```
-
-Another useful batch operation is printing. If you have a bunch of documents and want to print them all in one fell swoop, without manually opening them and clicking on the printer icon, do this:
-```
-libreoffice -p *.odt
-
-```
-
-It’s also worth noting some of the other command line flags that LibreOffice uses. For instance, if you want to create a launcher in your program menu that starts Calc directly, instead of showing the opening screen, use:
-```
-libreoffice --calc
-
-```
-
-It’s also possible to launch Impress and jump straight into the first slide of a presentation, without showing the LibreOffice user interface:
-```
-libreoffice --show presentation.odp
-
-```
-
-### Extra goodies in Draw
-
-Writer, Calc and Impress are the most popular components of LibreOffice. But Draw is a capable tool as well for creating diagrams, leaflets and other materials. When you’re working with multiple objects, there are various tricks you can do to speed up your work.
-
-For example, you probably know you can select multiple objects by clicking and dragging a selection area around them. But you can also select and deselect objects in the group by holding down the Shift key while clicking.
-
-When moving individual shapes or groups of shapes, you can use keyboard modifiers to change the movement speed. Try it out: select a bunch of objects, then use the cursor keys to move them around. Now try holding Shift to move them in greater increments, or Alt for fine-tuning. (The Ctrl key comes in useful here too, for panning around inside a document without moving the shapes.)
-
-[LibreOffice 5.1][4] added a useful feature to equalize the widths and heights of multiple shapes. Select them with the mouse, right-click on the selection, and then go to the Shapes part of the context menu. There you’ll see the Equalize options. This is good for making objects more consistent, and it works in Impress too!
-
-![Equalizing shape sizes in Draw][5]
-
-Lastly, here’s a shortcut for duplicating objects: the Ctrl key. Try clicking and dragging on an object, with Ctrl held down, and you’ll see that a copy of the object is made immediately. This is quicker and more elegant than using the Duplicate dialog box.
-
-### Over to you!
-
-So those are some features and tricks in LibreOffice you can now use in your work. But there’s always room for improvement, and the LibreOffice community is working hard on the next release, [LibreOffice 6.1][6], which is due in early August. Give them a hand! You can help to test the beta releases, trying out new features and reporting bugs. Or [get involved in other areas][7] such as design, marketing, documentation, translations and more.
-
-Photo by [William Iven][8] on [Unsplash][9].
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/discover-hidden-gems-libreoffice/
-
-作者:[Mike Saunders][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/mikesaunders/
-[1]:https://getfedora.org/workstation
-[2]:https://wiki.documentfoundation.org/Development/NotebookBar
-[3]:https://fedoramagazine.org/wp-content/uploads/2018/06/libreoffice_gems_notebookbar-300x109.png
-[4]:https://wiki.documentfoundation.org/ReleaseNotes/5.1
-[5]:https://fedoramagazine.org/wp-content/uploads/2018/06/libreoffice_gems_draw-300x178.png
-[6]:https://wiki.documentfoundation.org/ReleaseNotes/6.1
-[7]:https://www.libreoffice.org/community/get-involved/
-[8]:https://unsplash.com/photos/jrh5lAq-mIs?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
-[9]:https://unsplash.com/search/photos/documents?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
diff --git a/sources/tech/20180629 Is implementing and managing Linux applications becoming a snap.md b/sources/tech/20180629 Is implementing and managing Linux applications becoming a snap.md
deleted file mode 100644
index 9e590fbd8b..0000000000
--- a/sources/tech/20180629 Is implementing and managing Linux applications becoming a snap.md
+++ /dev/null
@@ -1,148 +0,0 @@
-Is implementing and managing Linux applications becoming a snap?
-======
-
-
-Quick to install, safe to run, easy to update, and dramatically easier to maintain and support, snaps represent a big step forward in Linux software development and distribution. Starting with Ubuntu and now available for Arch Linux, Debian, Fedora, Gentoo Linux, and openSUSE, snaps offer a number of significant advantages over traditional application packaging.
-
-Compared to traditional packages, snaps are:
-
- * Easier for developers to build
- * Faster to install
- * Automatically updated
- * Autonomous
- * Isolated from other apps
- * More secure
- * Non-disruptive (they don't interfere with other applications)
-
-
-
-### So, what are snaps?
-
-Snaps were originally designed and built by Canonical for use on Ubuntu. The service might be referred to as “snappy,” the technology “snapcraft,” the daemon “snapd,” and the packages “snaps,” but they all refer to a new way that Linux apps are prepared and installed. Does the name “snap” imply some simplification of the development and installation process? You bet it does!
-
-A snap is completely different than other Linux packages. Other packages are basically file archives that, on installation, place files in a number of directories (/usr/bin, /usr/lib, etc.). In addition, other tools and libraries that the packages depend on have to be installed or updated, as well — possibly interfering with older apps. A snap, on the other hand, will be installed as a single self-sufficient file, bundled with whatever libraries and other files it requires. It won’t interfere with other applications or change any of the resources that those other applications depend on.
-
-When delivered as a snap, all of the application’s dependencies are included in that single file. The application is also isolated from the rest of the system, ensuring that changes to the snap don’t affect the rest of the system and making it harder for other applications to access the app's data.
-
-Another important distinction is that snaps aren't included in distributions; they're selected and installed separately (more on this in just a bit).
-
-Snaps began life as Click packages — a new packaging format built for Ubuntu Mobile — and evolved into snaps
-
-### How do snaps work?
-
-Snaps work across a range of Linux distributions in a manner that is sometimes referred to as “distro-agnostic,” releasing developers from their concerns about compatibility with software and libraries previously installed on the systems. Snaps are packaged along with everything they require to run — compressed and ready for use. In fact, they stay that way. They remain compressed, using modest disk space in spite of their autonomous nature.
-
-Snaps also maintain a relatively low profile. You could have snaps on your system without being aware of them, particularly if you are using a recent release of the distributions mentioned earlier.
-
-If snaps are available on your system, you'll need to have **/snap/bin** on your search path to use them. For bash users, this should be added automatically.
-```
-$ echo $PATH
-/home/shs/bin:/usr/local/bin:/usr/sbin:/sbin:/bin:/usr/games:/snap/bin
-
-```
-
-And even the automatic updates don't cause problems. A running snap continues to run even while it is being updated. The new version simply becomes active the next time it's used.
-
-### Why are snaps more secure?
-
-One reason for the improvement is that snaps have considerably more limited access to the OS than traditional packages. They are sandboxed and containerized and don’t have system-wide access.
-
-### How do snaps help developers?
-
-##### Easier to build
-
-With snaps, developers no longer have to contemplate the huge variety of distributions and versions that their customers might be using. They package into the snap everything that is required for it to run.
-
-##### Easing the slow production lines
-
-From the developers' perspective, it has been hard to get apps into production. The open source community can only do so much while responding to pressure for fast releases. In addition, developers can use the latest libraries without concern for whether the target distribution relies on older libraries. And even if developers are new to snaps, they can get up to speed in under a week. I've been told that learning to build an application with snaps is significantly easier than learning a new language. And, of course, distro maintainers don't have to funnel every app through their production processes. This is clearly a win-win.
-
-For sysadmins, as well, the use of snaps avoids breaking systems and the need to chase down hairy support problems.
-
-### Are snaps on your system?
-
-You could have snaps on your system without being aware of them, particularly if you are using a recent release of the distributions mentioned above.
-
-To see if **snapd** is running:
-```
-$ ps -ef | grep snapd
-root 672 1 0 Jun22 ? 00:00:33 /usr/lib/snapd/snapd
-
-```
-
-If installed, the command “which snap”, on the other hand, should show you this:
-```
-$ which snap
-/usr/bin/snap
-
-```
-
-To see what snaps are installed, use the “snap list” command.
-```
-$ snap list
-Name Version Rev Tracking Developer Notes
-canonical-livepatch 8.0.2 41 stable canonical -
-core 16-2.32.8 4650 stable canonical core
-minecraft latest 11 stable snapcrafters -
-
-```
-
-### Where are snaps installed?
-
-Snaps are delivered as .snap files and stored in **/var/lib/snapd/snaps**. You can **cd** over to that directory or search for files with the .snap extension.
-```
-$ sudo find / -name "*.snap"
-/var/lib/snapd/snaps/canonical-livepatch_39.snap
-/var/lib/snapd/snaps/canonical-livepatch_41.snap
-/var/lib/snapd/snaps/core_4571.snap
-/var/lib/snapd/snaps/minecraft_11.snap
-/var/lib/snapd/snaps/core_4650.snap
-
-```
-
-Adding a snap is, well, a snap. Here’s a typical example of installing one. The snap being loaded here is a very simple “Hello, World” application, but the process is this simple regardless of the compexity of the snap:
-```
-$ sudo snap install hello
-hello 2.10 from 'canonical' installed
-$ which hello
-/snap/bin/hello
-$ hello
-Hello, world!
-
-```
-
-The “snap list” command will then reflect the newly added snap.
-```
-$ snap list
-Name Version Rev Tracking Developer Notes
-canonical-livepatch 8.0.2 41 stable canonical -
-core 16-2.32.8 4650 stable canonical core
-hello 2.10 20 stable canonical -
-minecraft latest 11 stable snapcrafters -
-
-```
-
-There also commands for removing (snap remove), upgrading (snap refresh), and listing available snaps (snap find).
-
-### A little history about snaps
-
-The idea for snaps came from Mark Richard Shuttleworth, the founder and CEO of Canonical Ltd., the company behind the development of the Linux-based Ubuntu operating system, and from his decades of experience with Ubuntu. At least part of the motivation was removing the possibility of troublesome installation failures — starting with the phones on which they were first used. Easing production lines, simplifying support, and improving system security made the idea compelling.
-
-For some additional history on snaps, check out this article on [CIO][1].
-
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3283337/linux/is-implementing-and-managing-linux-applications-becoming-a-snap.html
-
-作者:[Sandra Henry-Stocker][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
-[1]:https://www.cio.com/article/3085079/linux/goodbye-rpm-and-deb-hello-snaps.html
-[2]:https://www.facebook.com/NetworkWorld/
-[3]:https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20180629 SoCLI - Easy Way To Search And Browse Stack Overflow From The Terminal.md b/sources/tech/20180629 SoCLI - Easy Way To Search And Browse Stack Overflow From The Terminal.md
deleted file mode 100644
index acf05c6872..0000000000
--- a/sources/tech/20180629 SoCLI - Easy Way To Search And Browse Stack Overflow From The Terminal.md
+++ /dev/null
@@ -1,188 +0,0 @@
-SoCLI – Easy Way To Search And Browse Stack Overflow From The Terminal
-======
-Stack Overflow is the largest, most trusted online community for developers to learn, share their programming knowledge, and build their careers. It’s world’s largest developer community and allows users to ask and answer questions. It’s open alternative to earlier question and answer sites such as Experts-Exchange.
-
-It’s my preferred website, i have learned many program stuffs also i found many Linux related stuffs as well. Even i asked many questions and answered few questions too when i have time.
-
-Today i have stumbled upon good CLI utility called SoCLI & how2 both are used to browse stackoverflow website from the terminal easily and it’s very helpful when you doesn’t have GUI. Today we are going to discuss about SoCLI and will discuss about how2 in upcoming article.
-
-**Suggested Read :**
-**(#)** [How To Search The Arch Wiki Website Right From Terminal][1]
-**(#)** [Googler – Google Search from the command line on Linux][2]
-**(#)** [Buku – A Powerful Command-line Bookmark Manager for Linux][3]
-
-This might have very useful for NIX guys, whoever spending most of the time in CLI.
-
-[SoCLI][4] is a Stack overflow command line interface written in python. It’s allows you to search and browse stack overflow from the terminal.
-
-### SoCLI Featues:
-
- * Verity of search is available like Quick Search, Manual Search & interactive Search
- * Coloured interface
- * Question stats view
- * Topic Based Search using tag
- * Can view user profiles
- * Can create a new question via the web browser
- * Can open the page in a browser
-
-
-
-### How to Install Python
-
-Make sure your system should have python-pip package in order to install SoCLI. pip is a python module bundled with setuptools, it’s one of the recommended tool for installing Python packages in Linux.
-
-For **`Debian/Ubuntu`** , use [apt-get command][5] or [apt command][6] to install pip.
-```
-$ sudo apt install python-pip
-
-```
-
-For **`RHEL/CentOS`** , use [YUM command][7] to install pip.
-```
-$ sudo yum install python-pip python-devel
-
-```
-
-For **`Fedora`** , use [dnf command][8] to install pip.
-```
-$ sudo dnf install python-pip
-
-```
-
-For **`Arch Linux`** , use [pacman command][9] to install pip.
-```
-$ sudo pacman -S python-pip
-
-```
-
-For **`openSUSE`** , use [Zypper Command][10] to install pip.
-```
-$ sudo pacman -S python-pip
-
-```
-
-### How to Install SoCLI
-
-Simple use pip command to install socli.
-```
-$ sudo pip install socli
-
-```
-
-### How to Update SoCLI
-
-Run the following command to update your existing version of socli to the newest version to avail latest features.
-```
-$ sudo pip install --upgrade socli
-
-```
-
-### How to Use SoCLI
-
-Simple fire the socli command on terminal to start explorer stackoverflow from the Linux command line. It’s offering varies arguments which will speedup your search even more faster.
-
-Common syntax for **`SoCLI`**
-```
-socli [Arguments] [Search Query]
-
-```
-
-### Quick Search
-
-The following command will search for the given query `command to check apache active connections` and displays the first most voted question in Stack Overflow with its most voted answer.
-```
-$ socli command to check apache active connections
-
-```
-
-![][12]
-
-### Interactive Search
-
-To enable interactive search, use `-iq` arguments followed by your search query.
-
-The following command will search for the given query `delete matching string` and print a list of questions from Stack Overflow.
-```
-$ socli -iq delete matching string
-
-```
-
-![][13]
-
-It will allows users to choose any of the questions interactively by hitting questing number in end of the results. In my case i have choose a question `2` then it will display the complete description of the chosen question with its most voted answer.
-![][14]
-
-Use `UP` and `DOWN` arrow keys to navigate to other answers. Press `LEFT` arrow key to go back to the list of questions.
-
-### Manual Search
-
-SoCLI allows you to display mentioned question number for given query. The following command will search for the given query `netstat command examples` in Stack Overflow and displays the second question full information for given query alike quick search.
-```
-$ socli -r 2 -q netstat command examples
-
-```
-
-![][15]
-
-### Topic Based Search
-
-SoCLI allows topic based search by using specific tags. Just mention the specific tags using `-t` arguments and followed by search query `command to increase jvm heap memory`.
-```
-$ socli -t linux -q command to increase jvm heap memory
-
-```
-
-![][16]
-
-For multiple tags, Just separate them with a comma.
-```
-$ socli -t linux,unix -q grep
-
-```
-
-### Post a New Question
-
-If you can’t find an answer for your question in Stack Overflow? don’t worry, post a new question by running following command.
-```
-$ socli -n
-
-```
-
-It will open the new question page of Stack Overflow in the web browser for you to create a new question.
-
-### Man Page
-
-To know more options & arguments about SoCLI, navigate to help section.
-```
-$ socli -h
-
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/socli-search-and-browse-stack-overflow-from-linux-terminal/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.2daygeek.com/author/magesh/
-[1]:https://www.2daygeek.com/search-arch-wiki-website-command-line-terminal/
-[2]:https://www.2daygeek.com/googler-google-search-from-the-command-line-on-linux/
-[3]:https://www.2daygeek.com/buku-command-line-bookmark-manager-linux/
-[4]:https://github.com/gautamkrishnar/socli
-[5]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
-[6]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
-[7]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
-[8]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
-[9]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
-[10]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
-[11]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[12]:https://www.2daygeek.com/wp-content/uploads/2017/08/socli-search-and-browse-stack-overflow-from-command-line-1.png
-[13]:https://www.2daygeek.com/wp-content/uploads/2017/08/socli-search-and-browse-stack-overflow-from-command-line-2.png
-[14]:https://www.2daygeek.com/wp-content/uploads/2017/08/socli-search-and-browse-stack-overflow-from-command-line-2a.png
-[15]:https://www.2daygeek.com/wp-content/uploads/2017/08/socli-search-and-browse-stack-overflow-from-command-line-3.png
-[16]:https://www.2daygeek.com/wp-content/uploads/2017/08/socli-search-and-browse-stack-overflow-from-command-line-4.png
diff --git a/sources/tech/20180701 12 Things to do After Installing Linux Mint 19.md b/sources/tech/20180701 12 Things to do After Installing Linux Mint 19.md
deleted file mode 100644
index 3ed09633cf..0000000000
--- a/sources/tech/20180701 12 Things to do After Installing Linux Mint 19.md
+++ /dev/null
@@ -1,223 +0,0 @@
-12 Things to do After Installing Linux Mint 19
-======
-[Linux Mint][1] is one of the [best Linux distributions for new users][2]. It runs pretty well out of the box. Still, there are a few recommended things to do after [installing Linux Mint][3] for the first time.
-
-In this article, I am going to share some basic yet effective tips that will make your Linux Mint experience even better. If you follow these best practices, you’ll have a more user-friendly system.
-
-### Things to do after installing Linux Mint 19 Tara
-
-![Things to do after installing Linux Mint 19][4]
-
-I am using [Linux Mint][1] 19 Cinnamon edition while writing this article so some of the points in this list are specific to Mint Cinnamon. But this doesn’t mean you can follow these suggestions on Xfce or MATE editions.
-
-Another disclaimer is that this is just some recommendations from my point of view. Based on your interests and requirement, you would perhaps do a lot more than what I suggest here.
-
-That said, let’s see the top things to do after installing Linux Mint 19.
-
-#### 1\. Update your system
-
-This is the first and foremost thing to do after a fresh install of Linux Mint or any Linux distribution. This ensures that your system has all the latest software and security updates. You can update Linux Mint by going to Menu->Update Manager.
-
-You can also use a simple command to update your system:
-```
-sudo apt update && sudo apt upgrade -y
-
-```
-
-#### 2\. Create system snapshots
-
-Linux Mint 19 recommends creating system snapshots using Timeshift application. It is integrated with update manager. This tool will create system snapshots so if you want to restore your Mint to a previous state, you could easily do that. This will help you in the unfortunate event of a broken system.
-
-![Creating snapshots with Timeshift in Linux Mint 19][5]
-
-It’s FOSS has a detailed article on [using Timeshift][6]. I recommend reading it to learn about Timeshift in detail.
-
-#### 3\. Install codecs
-
-Want to play MP3, watch videos in MP$ and other formats or play DVD? You need to install the codecs. Linux Mint provides an easy way to install these codecs in a package called Mint Codecs.
-
-You can install it from the Welcome Screen or from the Software Manager.
-
-You can also use this command to install the media codecs in Linux Mint:
-```
-sudo apt install mint-meta-codecs
-
-```
-
-#### 4\. Install useful software
-
-Once you have set up your system, it’s time to install some useful software for your daily usage. Linux Mint itself comes with a number of applications pre-installed and hundreds or perhaps thousands of applications are available in the Software Manager. You just have to search for it.
-
-In fact, I would recommend relying on Software Manager for your application needs.
-
-If you want to know what software you should install, I’ll recommend some [useful Linux applications][7]:
-
- * VLC for videos
- * Google Chrome for web browsing
- * Shutter for screenshots and quick editing
- * Spotify for streaming music
- * Skype for video communication
- * Dropbox for [cloud storage][8]
- * Atom for code editing
- * Kdenlive for [video editing on Linux][9]
- * Kazam [screen recorder][10]
-
-
-
-For your information, not all of these recommended applications are open source.
-
-#### 5\. Learn to use Snap [For intermediate to advanced users]
-
-[Snap][11] is a universal packaging format from Ubuntu. You can easily install a number of applications via Snap packages. Though Linux Mint is based on Ubuntu, it doesn’t provide Snap support by default. Mint uses [Flatpak][12] instead, another universal packaging format from Fedora.
-
-While Flatpak is integrated into the Software Manager, you cannot use Snaps in the same manner. You must use Snap commands here. If you are comfortable with command line, you will find that it is easy to use. With Snap, you can install some additional software that are not available in the Software Manager or in DEB format.
-
-To [enable Snap support][13], use the command below:
-```
-sudo apt install snapd
-
-```
-
-You can refer to this article to know [how to use snap commands][14].
-
-#### 6\. Install KDE [Only for advanced users who like using KDE]
-
-[Linux Mint 19 doesn’t have a KDE flavor][15]. If you are fond of using [KDE desktop][16], you can install KDE in Linux Mint 19 and use it. If you don’t know what KDE is or have never used it, just ignore this part.
-
-Before you install KDE, I recommend that you have configured Timeshift and taken system snapshots. Once you have it in place, use the command below to install KDE and some recommended KDE components.
-```
-sudo apt install kubuntu-desktop konsole kscreen
-
-```
-
-After the installation, log out and switch the desktop environment from the login screen.
-
-#### 7\. Change the Themes and icons [If you feel like it]
-
-Linux Mint 19 itself has a nice look and feel but this doesn’t mean you cannot change it. If you go to System Settings, you’ll find the option to change the icons and themes there. There are a few themes already available in this setting section that you can download and activate.
-
-![Installing themes in Linux Mint is easy][17]
-
-If you are looking for more eye candy, check out the [best icon themes for Ubuntu][18] and install them in Mint here.
-
-#### 8\. Protect your eyes at night with Redshift
-
-Night Light is becoming a mandatory feature in operating systems and smartphones. This feature filters blue light at night and thus reduces the strain on your eyes.
-
-Unfortunately, Linux Mint Cinnamon doesn’t have built-in Night Light feature like GNOME. Therefore, Mint provides this feature [using Redshift][19] application.
-
-Redshift is installed by default in Mint 19 so all you have do is to start this application and set it for autostart. Now, this app will automatically switch to yellow light after sunset.
-
-![Autostart Redshift for night light in Linux Mint][20]
-
-#### 9\. Minor tweaks to your system
-
-There is no end to tweaking your system so I am not going to list out all the things you can do in Linux Mint. I’ll leave that up to you to explore. I’ll just mention a couple of tweaks I did.
-
-##### Tweak 1: Display Battery percentage
-
-I am used to of keeping a track on the battery life. Mint doesn’t show battery percentage by default. But you can easily change this behavior.
-
-Right click on the battery icon in the bottom panel and select Configure.
-
-![Display battery percentage in Linux Mint 19][21]
-
-And in here, select Show percentage option.
-
-![Display battery percentage in Linux Mint 19][22]
-
-##### Tweak 2: Set up the maximum volume
-
-I also liked that Mint allows setting the maximum volume between 0 and 150. You may use this tiny feature as well.
-
-![Linux Mint 19 volume more than 100%][23]
-
-#### 10\. Clean up your system
-
-Keeping your system free of junk is important. I have discussed [cleaning up Linux Mint][24] in detail so I am not going to repeat it here.
-
-If you want a quick way to clean your system, I recommend using this one single command from time to time:
-```
-sudo apt autoremove
-
-```
-
-This will help you get rid of unnecessary packages from your system.
-
-#### 11\. Set up a Firewall
-
-Usually, when you are at home network, you are behind your router’s firewall already. But when you connect to a public WiFi, you can have an additional security layer with a firewall.
-
-Now, setting up a firewall is a complicated business and hence Linux Mint comes pre-installed with Ufw (Uncomplicated Firewall). Just search for Firewall in the menu and enable it at least for the Public mode.
-
-![UFW Uncomplicated Firewall in Linux Mint 19][25]
-
-#### 12\. Fixes and workarounds for bugs
-
-So far I have noticed a few issues in Mint 19. I’ll update this section as I find more bugs.
-
-##### Issue 1: Error with Flatpaks in Software Manager
-
-major bug in the Software Manager. If you try to install a Flatpak application, you’ll encounter an error:
-
-“An error occurred. Could not locate ‘runtime/org.freedesktop.Sdk/x86_64/1.6’ in any registered remotes”
-
-![Flatpak install issue in Linux Mint 19][26]
-
-There is nothing wrong with Flatpak but the Software Manager has a bug that results in this error. This bug has been fixed and should be included in future updates. While that happens, you’ll have to [use Flatpak commands][27] in terminal to install these Flatpak applications.
-
-I advise going to [Flathub website][28] and search for the application you were trying to install. If you click on the install button on this website, it downloads a .flatpakref file. Now all you need to do is to start a terminal, go to Downloads directory and use the command in the following fashion:
-```
-flatpak install <name_of_flatpakref_file>
-
-```
-
-##### Issue 2: Edit option disabled in Shutter
-
-Another bug is with Shutter screenshot tool. You’ll find that the edit button has been disabled. It was the same case in Ubuntu 18.04. I have already written a [tutorial for Shutter edit issue][29]. You can use the same steps for Mint 19.
-
-#### What’s your suggestion?
-
-This is my recommendation of things to do after installing Linux Mint 19. I’ll update this article as I explore Mint 19 and find interesting things to add to this list. Meanwhile, why don’t you share what you did after installing Linux Mint?
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/things-to-do-after-installing-linux-mint-19/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[1]:https://linuxmint.com/
-[2]:https://itsfoss.com/best-linux-beginners/
-[3]:https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
-[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/things-to-do-after-installing-linux-mint-19.jpeg
-[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/snapshot-timeshift-mint-19.jpeg
-[6]:https://itsfoss.com/backup-restore-linux-timeshift/
-[7]:https://itsfoss.com/essential-linux-applications/
-[8]:https://itsfoss.com/cloud-services-linux/
-[9]:https://itsfoss.com/best-video-editing-software-linux/
-[10]:https://itsfoss.com/best-linux-screen-recorders/
-[11]:https://snapcraft.io/
-[12]:https://flatpak.org/
-[13]:https://itsfoss.com/install-snap-linux/
-[14]:https://itsfoss.com/use-snap-packages-ubuntu-16-04/
-[15]:https://itsfoss.com/linux-mint-drops-kde/
-[16]:https://www.kde.org/
-[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/theme-setting-mint-19.png
-[18]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
-[19]:https://itsfoss.com/install-redshift-linux-mint/
-[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/autostart-redshift-mint.jpg
-[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/configure-battery-linux-mint.jpeg
-[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/display-battery-percentage-linux-mint-1.png
-[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/01/linux-mint-volume-more-than-100.png
-[24]:https://itsfoss.com/free-up-space-ubuntu-linux/
-[25]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/firewall-mint.png
-[26]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/flatpak-error-mint-19.png
-[27]:https://itsfoss.com/flatpak-guide/
-[28]:https://flathub.org/
-[29]:https://itsfoss.com/shutter-edit-button-disabled/
diff --git a/sources/tech/20180702 5 open source alternatives to Skype.md b/sources/tech/20180702 5 open source alternatives to Skype.md
deleted file mode 100644
index 4915dd3833..0000000000
--- a/sources/tech/20180702 5 open source alternatives to Skype.md
+++ /dev/null
@@ -1,101 +0,0 @@
-5 open source alternatives to Skype
-======
-
-
-
-If you've been a working adult for more than a decade, you probably remember the high cost and complexity of doing audio- and video conferences. Conference calls were arranged through third-party vendors, and video conferences required dedicated rooms with expensive equipment at every endpoint.
-
-That all started changing by the mid-2000s, as webcams became mainstream computer equipment and Skype and related services hit the market. The cost and complexity of video conferencing decreased rapidly, as nearly anyone with a webcam, a speedy internet connection, and inexpensive software could communicate with colleagues, friends, family members, even complete strangers, right from their home or office PC. Nowadays, your smartphone's video camera puts web conferencing in the palm of your hand anywhere you have a robust cellular or WiFi connection and the right software. But most of that software is proprietary.
-
-Fortunately, there are a handful of powerful open source video-conferencing solutions that can replicate the features of Skype and similar applications. In this roundup, we've focused on applications that can accommodate multiple participants across various locations, although we do offer a couple of 1:1 communications solutions at the end that may meet your needs.
-
-### Jitsi
-
-[Jitsi][1]'s web conferencing solution stands out for its extreme ease of use: It runs directly in the browser with no download necessary. To set up a video-conferencing session, you just point your browser to [Jitsi Meet][2], enter a username (or select the random one that's offered), and click Go. Once you give Jitsi permission to use your webcam and microphone (sessions are [DTLS][3]/[SRTP][4]-encrypted), it generates a web link and a dial-in number others can use to join your session, and you can even add a conference password for an added layer of security.
-
-While in a video-conferencing session, you can share your screen, a document, or a YouTube link and collaboratively edit documents with Etherpad. Android and iOS apps allow you to make and take Jitsi video conferences on the go, and you can host your own multi-user video-conference service by installing [Jitsi Videobridge][5] on your server.
-
-Jitsi is written in Java and compatible with WebRTC standards, and the service touts its low-latency due to passing audio and video directly to participants (rather than mixing them, as other solutions do). Jitsi was acquired by Atlassian in 2015, but it remains an open source project under an [Apache 2.0][6] license. You can check out its source code on [GitHub][7], connect with its [community][8], or see some of the [other projects][9] built on the technology.
-
-### Linphone
-
-[Linphone][10] is a VoIP (voice over internet protocol) communications service that operates over the session initiation protocol (SIP). This means you need a SIP number to use the service and Linphone limits you to contacting only other SIP numbers—not cellphones or landlines. Fortunately, it's easy to get a SIP number—many internet service providers include them with regular service and Linphone also offers a free SIP service you can use.
-
-With Linphone, you can make audio and HD video calls, do web conferencing, communicate with instant messenger, and share files and photos, but there are no other screen-sharing nor collaboration features. It's available for Windows, MacOS, and Linux desktops and Android, iOS, Windows Mobile, and BlackBerry 10 mobile devices.
-
-Linphone is dual-licensed; there's an open source [GPLv2][11] version as well as a closed version which can be embedded in other proprietary projects. You can get its source code from its [downloads][12] page; other resources on Linphone's website include a [user guide][13] and [technical documentation][14].
-
-### Ring
-
-If freedom, privacy, and the open source way are your main motivators, you'll want to check out [Ring][15]. It's an official GNU package, licensed under [GPLv3][16], and takes its commitments to security and free and open source software very seriously. Communications are secured by end-to-end encryption with authentication using RSA/AES/DTLS/SRTP technologies and X.509 certificates.
-
-Audio and video calls are made through the Ring app, which is available for GNU/Linux, Windows, and MacOS desktops and Android and iOS mobile devices. You can communicate using either a RingID (which the Ring app randomly generates the first time it's launched) or over SIP. You can run RingID and SIP in parallel, switching between protocols as needed, but you must register your RingID on the blockchain before it can be used to make or receive communications.
-
-Ring's features include teleconferencing, media sharing, and text messaging. For more information about Ring, access its [source code][17] repository on GitLab, and its [FAQ][18] answers many questions about using the system.
-
-### Riot
-
-[Riot][19] is not just a video-conferencing solution—it's team-management software with integrated group video/voice chat communications. Communication (including voice and video conferencing, file sharing, notifications, and project reminders) happens in dedicated "rooms" that can be organized by topic, team, event, etc. Anything shared in a room is persistently stored with access governed by that room's confidentially settings. A cool feature is that you can use Riot to communicate with people using other collaboration tools—including IRC, Slack, Twitter, SMS, and Gitter.
-
-You can use Riot in your browser (Chrome and Firefox) or via its apps for MacOS, Windows, and Linux desktops and iOS and Android devices. In terms of infrastructure, Riot can be installed on your server, or you can run it on Riot's servers. It is based on the [Matrix][20] React SDK, so all files and data transferred over Riot are secured with Matrix's end-to-end encryption.
-
-Riot is available under an [Apache 2.0][21] license, its [source code][22] is available on GitHub, and you can find [documentation][23], including how-to videos and FAQs, on its website.
-
-### Wire
-
-Developed by the audio engineers who created Skype, [Wire][24] enables up to 10 people to participate in an end-to-end encrypted audio conference call. Video conferencing (also encrypted) is currently limited to 1:1 communications, with group video capabilities on the app's roadmap. Other features include secure screen sharing, file sharing, and group chat; administrator management; and the ability to switch between accounts and profiles (e.g., work and personal) at will from within the app.
-
-Wire is open source under the [GPL 3.0][25] license and is free to use if you [compile it from source][26] on your own server. A paid option is available starting at $5 per user per month (with large enterprise plans also available).
-
-### Other options
-
-If you need 1:1 communications, here are two other services that might interest you: Pidgin and Signal.
-
-[Pidgin][27] is like a one-stop-shop for the multitude of chat networks you and your friends, family, and colleagues use. You can use Pidgin to chat with people who use AIM, Google Talk, ICQ, IRC, XMPP, and multiple other networks, all from the same interface. Check out Ray Shimko's article "[Get started with Pidgin][28]" on [Opensource.com][29] for more information.
-
-This probably isn't the first time you've heard of [Signal][30]. The app transmits end-to-end encrypted voice, video, text, and photos, and it's been endorsed by security and cryptography experts including Edward Snowden and Bruce Schneier and the Electronic Frontier Foundation.
-
-The open source landscape is perpetually changing, so chances are some of you are using other open source video- and audio-conferencing solutions. If you have a favorite not listed here, please share it in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/alternatives/skype
-
-作者:[Opensource.com][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com
-[1]:https://jitsi.org/
-[2]:https://meet.jit.si/
-[3]:https://en.wikipedia.org/wiki/Datagram_Transport_Layer_Security
-[4]:https://en.wikipedia.org/wiki/Secure_Real-time_Transport_Protocol
-[5]:https://jitsi.org/jitsi-videobridge/
-[6]:https://github.com/jitsi/jitsi/blob/master/LICENSE
-[7]:https://github.com/jitsi
-[8]:https://jitsi.org/the-community/
-[9]:https://jitsi.org/projects/
-[10]:http://www.linphone.org/
-[11]:https://www.gnu.org/licenses/gpl-2.0.html
-[12]:http://www.linphone.org/technical-corner/linphone/downloads
-[13]:http://www.linphone.org/user-guide.html
-[14]:http://www.linphone.org/technical-corner/linphone/documentation
-[15]:https://ring.cx/
-[16]:https://www.gnu.org/licenses/gpl-3.0.en.html
-[17]:https://gitlab.savoirfairelinux.com/groups/ring
-[18]:https://ring.cx/en/documentation/faq
-[19]:https://about.riot.im/
-[20]:https://matrix.org/#about
-[21]:https://github.com/vector-im/riot-web/blob/master/LICENSE
-[22]:https://github.com/vector-im
-[23]:https://about.riot.im/need-help/
-[24]:https://wire.com/en/
-[25]:https://github.com/wireapp/wire/blob/master/LICENSE
-[26]:https://github.com/wireapp/wire
-[27]:https://pidgin.im/
-[28]:https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-business
-[29]:https://opensource.com/
-[30]:https://signal.org/
diff --git a/sources/tech/20180702 Diggs v4 launch an optimism born of necessity.md b/sources/tech/20180702 Diggs v4 launch an optimism born of necessity.md
deleted file mode 100644
index 5690517b9e..0000000000
--- a/sources/tech/20180702 Diggs v4 launch an optimism born of necessity.md
+++ /dev/null
@@ -1,91 +0,0 @@
-Digg's v4 launch: an optimism born of necessity.
-============================================================
-
-
-
-Digg was having a rough year. Our CEO left the day before I joined. Senior engineers ghosted out the door, dampening productivity and pulling their remaining friends. Fraudulent voting rings circumvented our algorithms, selling access to our front page, and threatening our lives over modifications to prevent their abuse. Our provisioning tools for developer environments broke and no one knew how to fix them, so we reassigned new hires the zombie VMs of recently departed coworkers.
-
-But today wasn't about any of that. Today was reserved for the reversal of the biggest problem that had haunted Digg for the last two years. We were launching a complete rewrite of Digg. We were committed to launching today. We were agreed against further postponing the launch. We were pretty sure the new version, version four, wasn't ready.
-
-The day started. We were naive. Our education lay in wait.
-
-If you'd been fortunate enough to be invited into our cavernous, converted warehouse of an office and felt the buzz, you'd probably guess a celebration was underway. The rewrite from Digg v3.5 to Digg v4 had marched haphazardly forward for nearly two years, and promised to move us from a monolithic community-driven news aggregator to an infinitely personalized aggregator driven by blending your social graph, top influencers, and the global zeitgeist of news.
-
-If our product requirements had continued to flux well into the preceding week, the path to Digg v4 had been clearly established several years earlier, when Digg had been devastated by [Google's Panda algorithm update][3]. As that search update took a leisurely month to soak into effect, our fortunes reversed like we'd spat on the gods: we fell from our first--and only--profitable month, and kept falling until our monthly traffic was severed in half. One month, a company culminating a five year path to profitability, the next a company in freefall and about to fundraise from a position of weakness.
-
-Launching v4 was our chance to return to our rightful place among the giants of the internet, and the cavernous office, known by employees as "Murder Church", had been lovingly rearranged for the day. In the middle of the room, an immense wooden table had been positioned to serve as the "war room." It was framed by a ring of couches, where others would stand by to assist. Waiters in black tie attire walked the room with trays of sushi, exquisite small bites and chilled champagne. A bar had been erected, serving drinks of all shapes. Folks slipped upstairs to catch a few games of ping pong.
-
-The problems started slowly.
-
-At one point, an ebullient engineer had declared the entire rewrite could run on two servers and, our minimalist QA environment being much larger to the contrary, we got remarkably close to launching with two servers as our most accurate estimate. The week before launch, the capacity planning project was shifted to Rich and I. We put on a brave farce of installing JMeter and generated as much performance data as we could against the complex, dense and rapidly shifting sands that comprised the rewrite. It was not the least confident I've ever been in my work, I can remember writing a book report on the bus to school about a book I never read in fourth grade, but it is possible we were launching without much sense of whether this was going to work.
-
-We had the suspicion it wouldn't matter much anyway, because we weren't going to be able to order and install new hardware in our datacenters before the launch. Capacity would suffice because it was all we had.
-
-Around 10:00 AM, someone asked when we were going to start the switch, and Mike chimed in helpfully, "We've already started reprovisioning the v3 servers." We had so little capacity that we had decided to reimage all our existing servers and then reprovision them in the new software stack. This was clever from the perspective of reducing our costs, but the optimism it entailed was tinged with madness.
-
-As the flames of rebirth swallowed the previous infrastructure, something curious happened, or perhaps didn't happen. The new site didn't really come up. The operations team rushed out a maintenance page and we collected ourselves around our handsome wooden table, expensive chairs and gnawing sense of dread. This was _not_ going well. We didn't have a rollback plan. The random self-selection of engineers at the table decided our only possible option was to continue rolling forward, and we did. An hour later, the old infrastructure was entirely gone, replaced by the Digg version four.
-
-Servers reprovisioning, maintenance page cajoling visitors, the office took on a "last days of rome" atmosphere. The champagne and open bar flowed, the ping pong table was fully occupied, and the rest of the company looked on, unsure how to help, and coming to terms that Digg's final hail mary had been fumbled. The framed Forbes cover in the lobby firmly a legacy, and assuredly not a harbinger.
-
-The day stretched on, and folks began to leave, but for the engineers swarming the central table, there was much left to do. We had successfully provisioned the new site, but it was still staggering under load, with most pages failing to load. The primary bottleneck was our Cassandra cluster. Rich and I broke off to a conference room and expanded our use of memcache as a write-through-cache shielding Cassandra; a few hours later much of the site started to load for logged out users.
-
-Logged in users, though, were still seeing error pages when they came to the sit. The culprit was the rewrite's crown jewel, called MyNews, which provided social context on which of your friends had interacted with each article, and merged all that activity together into a personalized news feed. Well, that is what was supposed to happen, anyway, at this point what it actually did was throw tasteful "startup blue" error pages.
-
-As the day ended, we changed the default page for users from MyNews to TopNews, the global view which was still loading, which made it possible for users to log in and use the site. The MyNews page would still error out, but it was enough for us to go home, tipsy and defeated, survivors of our relaunch celebration.
-
-Folks trickled into the office early the next day, and we regrouped. MyNews was thoroughly broken, the site was breaking like clockwork every four hours, and behind those core issues, dozens of smaller problems were cropping up as well. We'd learned we could fix the periodic breakage by restarting every single process, we hadn't been able to isolate which ones were the source, so we decided to focus on MyNews first.
-
-Once again, Rich and I sequestered ourselves in a conference room, this time with the goal of rewriting our MyNews implementation from scratch. The current version wrote into Cassandra, and its load was crushing the clusters, breaking the social functionality, and degrading all other functionality around it. We decided to rewrite to store the data in Redis, but there was too much data to store in any server, so we would need to rollout a new implementation, a new sharding strategy, and the tooling to manage that tooling.
-
-And we did!
-
-Over the next two days, we implemented a sharded Redis cluster and migrated over to it successfully. It had some bugs--for the Digg's remaining life, I would clandestinely delete large quantities of data from the MyNews cluster because we couldn't afford to size it correctly to store the necessary data and we couldn't agree what to do about it, so each time I ended up deleting the excess data in secret to keep the site running--but it worked, and our prized rewrite flew out the starting gate to begin limping down the track.
-
-It really was limping though, requiring manual restarts of every process each four hours. It took a month to track this bug down, and by the end only three people were left trying. I became so engrossed in understanding the problem, working with Jorge and Mike on the Operations team, that I don't even know if anyone else came into the office that following month. Not understanding this breakage became an affront, and as most folks dropped off--presumably to start applying for jobs because they had a lick of sense--I was possessed by the obsession to fix it.
-
-And we did!
-
-Our API server was a Python Tornado service, that made API calls into our Python backend tier, known as Bobtail (the frontend was Bobcat), and one of the most frequently accessed endpoint was used to retrieve user by their name or id. Because it supported retrieval by either name or id, it set default values for both parameters as empty lists. This is a super reasonable thing to do! However, Python only initializes default parameters when the function is first evaluated, which means that the same list is used for every call to the function. As a result, if you mutate those values, the mutations span across invocations.
-
-In this case, user ids and names were appended to the default lists each time it was called. Over hours, those lists began to retrieve tens of thousands of users on each request, overwhelming even the memcache clusters. This took so long to catch because we returned the values as a dictionary, and the dictionary always included the necessary values, it just happened to also include tens of thousands of extraneous values too, so it never failed in an obvious way. The bug's impact was amplified because we assumed users wouldn't pass in duplicate ids, and would cheerfully retrieve the same id repeatedly for a single request.
-
-We rolled out that final critical fix, and Digg V4 was fully launched. A week later our final CEO would join. A month later we'd have our third round of layoffs. A year later we would sell the company. But for that moment, we'd won.
-
-I was about to hit my six month anniversary.
-
-* * *
-
-Digg V4 is sometimes referenced as an example of a catastrophic launch, with an implied lesson that we shouldn't have launched it. At one point, I used to agree, but these days I think we made the right decision to launch. Our traffic was significantly down, we were losing a bunch of money each month, we had recently raised money and knew we couldn't easily raise more. If we'd had the choice between launching something great and something awful, we'd have preferred to launch something great, but instead we had the choice of taking one last swing or turning in our bat quietly.
-
-I'm glad we took the last swing; proud we survived the rough launch.
-
-On the other hand, I'm still shocked that we were so reckless in the launch itself. I remember the meeting where we decided to go ahead with the launch, with Mike vigorously protesting. To the best of my recollection, I remained silent. I hope that I grew from the experience, because even now uncertain how such a talented group put on such a display of fuckery.
-
---------------------------------------------------------------------------------
-
-作者简介:
-
-Hi. I grew up in North Carolina, studied CS at Centre College in Kentucky, spent a year in Japan on the JET Program, and have been living in San Francisco since 2009 or so.
-
-Since coming out here, I've gotten to work at some great companies, and some of them were even good when I worked there! Starting with Yahoo! BOSS, Digg, SocialCode, Uber and now Stripe.
-
-A long time ago, I also cofounded a really misguided iOS gaming startup with Luke Hatcher. We made thousands of dollars over six months, and spent the next six years trying to figure out how to stop paying taxes. It was a bit of a missed opportunity.
-
-The very first iteration of Irrational Exuberance was created the summer after I graduated from college, and I've been publishing to it off and on since. Early on there was a heavy focus on Django, Python and Japan; lately it's more about infrastructure, architecture and engineering management.
-
-It's hard to predict what it'll look like in the future.
-
------------------------------
-
-via: https://lethain.com/digg-v4/
-
-作者:[Will Larson.][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://lethain.com/about/
-[1]:https://lethain.com/tags/stories/
-[2]:https://lethain.com/tags/digg/
-[3]:https://moz.com/learn/seo/google-panda
diff --git a/sources/tech/20180703 AGL Outlines Virtualization Scheme for the Software Defined Vehicle.md b/sources/tech/20180703 AGL Outlines Virtualization Scheme for the Software Defined Vehicle.md
deleted file mode 100644
index 62567e1179..0000000000
--- a/sources/tech/20180703 AGL Outlines Virtualization Scheme for the Software Defined Vehicle.md
+++ /dev/null
@@ -1,88 +0,0 @@
-AGL Outlines Virtualization Scheme for the Software Defined Vehicle
-============================================================
-
-
-AGL outlines the architecture of a “virtualized software defined vehicle architecture” for UCB codebase in new white paper.[The Linux Foundation][2]
-
-Last August when The Linux Foundation’s Automotive Grade Linux (AGL) project released version 4.0 of its Linux-based Unified Code Base (UCB) reference distribution for automotive in-vehicle infotainment, it also launched a Virtualization Expert Group (EG-VIRT). The workgroup has now [released][5] a white paper outlining a “virtualized software defined vehicle architecture” for AGL’s UCB codebase.
-
-The paper explains how virtualization is the key to expanding AGL from IVI into instrument clusters, HUDs, and telematics. Virtualization technology can protect these more safety-critical functions from less secure infotainment applications, as well as reduce costs by replacing electronic hardware components with virtual instances. Virtualization can also enable runtime configurability for sophisticated autonomous and semi-autonomous ADAS applications, as well as ease software updates and streamline compliance with safety critical standards.
-
-The paper also follows several recent AGL announcements including the [addition of seven new members][6]: Abalta Technologies, Airbiquity, Bose, EPAM Systems, HERE, Integrated Computer Solutions, and its first Chinese car manufacturer -- Sitech Electric Automotive. These new members bring the AGL membership to more than 120.
-
-AGL also [revealed][7] that Mercedes-Benz Vans is using its open source platform as a foundation for a new onboard OS for commercial vehicles. AGL will play a key role in the Daimler business unit’s “adVANce” initiative for providing “holistic transport solutions.” These include technologies for integrating connectivity, IoT, innovative hardware, on-demand mobility and rental concepts, and fleet management solutions for both goods and passengers.
-
-The Mercedes-Benz deal follows last year’s announcement that AGL would appear in 2018 Toyota Camry cars. AGL has since expanded to other Toyota cars including the 2018 Prius PHV.
-
-### An open-ended approach to virtualization
-
-Originally, the AGL suggested that EG-VIRT would identify a single hypervisor for an upcoming AGL virtualization platform that would help consolidate infotainment, cluster, HUD, and rear-seat entertainment applications over a single multicore SoC. A single hypervisor (such as the new ACRN) may yet emerge as the preferred technology, but the paper instead outlines an architecture that can support multiple, concurrent virtualization schemes. These include hypervisors, system partitioners, and to a lesser extent, containers.
-
-### Virtualization benefits for the software defined vehicle
-
-Virtualization will enable what the AGL calls the “software defined vehicle” -- a flexible, scalable “autonomous connected automobile whose functions can be customized at run-time.” In addition to boosting security, the proposed virtualization platform offers benefits such as cost reductions, run-time flexibility for the software-defined car, and support for mixed criticality systems:
-
-* **Software defined autonomous car** -- AGL will use virtualization to enable runtime configurability and software updates that can be automated and performed remotely. The system will orchestrate multiple applications, including sophisticated autonomous driving software, based on different licenses, security levels, and operating systems.
-
-* **Cost reductions** -- The number of electronic control units (ECUs) -- and wiring complexity -- can be reduced by replacing many ECUs with virtualized instances in a single multi-core powered ECU. In addition, deployment and maintenance can be automated and performed remotely. EG-VIRT cautions, however, that there’s a limit to how many virtual instances can be deployed and how many resources can be shared between VMs without risking software integration complexity.
-
-* **Security** -- By separating execution environments such as the CPU, memory, or interfaces, the framework will enable multilevel security, including protection of telematics components connected to the CAN bus. With isolation technology, a security flaw in one application will not affect others. In addition, security can be enhanced with remote patch updates.
-
-* **Mixed criticality** -- One reason why real-time operating systems (RTOSes) such as QNX have held onto the lead in automotive telematics is that it’s easier to ensure high criticality levels and comply with Automotive Safety Integrity Level (ASIL) certification under ISO 26262\. Yet, Linux can ably host virtualization technologies to coordinate components with different levels of criticality and heterogeneous levels of safety, including RTOS driven components. Because many virtualization techniques have a very limited footprint, they can enable easier ASIL certification, including compliance for concurrent execution of systems with different certification levels.
-
-IVI typically requires the most basic ASIL A certification at most. Instrument cluster and telematics usually need ASIL B, and more advanced functions such as ADAS and digital mirrors require ASIL C or D. At this stage, it would be difficult to develop open source software that is safety-certifiable at the higher levels, says EG-VIRT. Yet, AGL’s virtualization framework will enable proprietary virtualization solutions that can meet these requirements. In the long-term, the [Open Source Automation Development Lab][8] is working on potential solutions for Safety Critical Linux that might help AGL meet the requirements using only open source Linux.</ul>
-
-### Building an open source interconnect
-
-The paper includes the first architecture diagrams for AGL’s emerging virtualization framework. The framework orchestrates different hypervisors, VMs, AGL Profiles, and automotive functions as interchangeable modules that can be plugged in at compilation time, and where possible, at runtime. The framework emphasizes open source technologies, but also supports interoperability with proprietary components.
-
-### [agl-arch.jpg][3]
-
-
-
-AGL virtualization approach integrated in the AGL architecture.[Used with permission][1]
-
-The AGL application framework already supports application isolation based on namespaces, cgroups, and SMACK. The framework “relies on files/processes security attributes that are checked by the Linux kernel each time an action processes and that work well combined with secure boot techniques,” says EG-VIRT. However, when multiple applications with different security and safety requirements need to be executed, “the management of these security attributes becomes complex and there is a need of an additional level of isolation to properly isolate these applications from each other…This is where the AGL virtualization platform comes into the picture.”
-
-To meet EG-VIRT’s requirements, compliant hardware virtualization solutions must enable CPU, cache, memory, and interrupts to create execution environments (EEs) such as Arm Virtualization Extensions, Intel VT-x, AMD SVM, and IOMMU. The hardware must also support a trusted computing module to isolate safety-security critical applications and assets. These include Arm TrustZone, Intel Trusted Execution Technology, and others. I/O virtualization support for GPU and connectivity sharing is optional.
-
-The AGL virtualization platform does not need to invent new hypervisors and EEs, but it does need a way to interconnect them. EG-VIRT is now beginning to focus on the development of an open source communication bus architecture that comprises both critical and non-critical buses. The architecture will enable communications between different virtualization technologies such as hypervisors and different virtualized EEs such as VT-x while also enabling direct communication between different types of EEs.
-
-### Potential AGL-compliant hypervisors and partitioners
-
-The AGL white paper describes several open source and proprietary candidates for hypervisor and system partitioners. It does not list any containers, which create abstraction starting from the layers above the Linux kernel.
-
-Containers are not ideal for most connected car functions. They lack guaranteed hardware isolation or security enforcement, and although they can run applications, they cannot run a full OS. As a result, AGL will not consider containers for safety and real time workloads, but only within non-safety critical systems, such as for IVI application isolation.
-
-Hypervisors, however, can meet all these requirements and are also optimized for particular multi-core SoCs. “Virtualization provides the best performance in terms of security, isolation and overhead when supported directly by the hardware platform,” says the white paper.
-
-For hypervisors, the open source options listed by EG-VIRT include Xen, Kernel-based Virtual Machine (KVM), the L4Re Micro-Hypervisor, and ACRN. The latter was [announced][9] as a new Linux Foundation embedded reference hypervisor project in March. The Intel-backed, BSD-licensed ACRN hypervisor provides workload prioritization and supports real-time and safety-criticality functions. The lightweight ACRN supports other embedded applications in addition to automotive.
-
-Commercial hypervisors that will likely receive support in the AGL virtualization stack include the COQOS Hypervisor SDK, SYSGO PikeOS, and the Xen-based Crucible and Nautilus. The latter was first presented by the Xen Project as a potential solution for AGL virtualization [back in 2014][10]. There’s also the Green Hills Software Integrity Multivisor. Green Hills [announced AGL support for][11] Integrity earlier this month.
-
-Unlike hypervisors, system partitioners do not tap specific virtualization functions within multi-core SoCs, and instead run as bare-metal solutions. Only two open source options were listed: Jailhouse and the Arm TrustZone based Arm Trusted Firmware (ATF). The only commercial solution included is the TrustZone based VOSYSmonitor.
-
-In conclusion, EG-VIRT notes that this initial list of potential virtualization solutions is “non-exhaustive,” and that “the role of EG-VIRT has been defined as virtualization technology integrator, identifying as key next contribution the development of a communication bus reference implementation…” In addition: “Future EG-VIRT activities will focus on this communication, on extending the AGL support for virtualization (both as a guest and as a host), as well as on IO devices virtualization (e.g., GPU).”
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/7/agl-outlines-virtualization-scheme-software-defined-vehicle
-
-作者:[ERIC BROWN ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/ericstephenbrown
-[1]:https://www.linux.com/licenses/category/used-permission
-[2]:https://www.linux.com/licenses/category/linux-foundation
-[3]:https://www.linux.com/files/images/agl-archjpg
-[4]:https://www.linux.com/files/images/agljpg
-[5]:https://www.automotivelinux.org/blog/2018/06/20/agl-publishes-virtualization-white-paper
-[6]:https://www.automotivelinux.org/announcements/2018/06/05/automotive-grade-linux-welcomes-seven-new-members
-[7]:http://linuxgizmos.com/automotive-grade-linux-joins-the-van-life-with-mercedes-benz-vans-deal/
-[8]:https://www.osadl.org/Safety-Critical-Linux.safety-critical-linux.0.html
-[9]:http://linuxgizmos.com/open-source-project-aims-to-build-embedded-linux-hypervisor/
-[10]:http://linuxgizmos.com/xen-hypervisor-targets-automotive-virtualization/
-[11]:https://www.ghs.com/news/2018061918_automotive_grade_linux.html
diff --git a/sources/tech/20180706 Using Ansible to set up a workstation.md b/sources/tech/20180706 Using Ansible to set up a workstation.md
deleted file mode 100644
index cc9e63b2d8..0000000000
--- a/sources/tech/20180706 Using Ansible to set up a workstation.md
+++ /dev/null
@@ -1,168 +0,0 @@
-Using Ansible to set up a workstation
-======
-
-
-
-Ansible is an extremely popular [open-source configuration management and software automation project][1]. While IT professionals almost certainly use Ansible on a daily basis, its influence outside the IT industry is not as wide. Ansible is a powerful and flexible tool. It is easily applied to a task common to nearly every desktop computer user: the post-installation “checklist”.
-
-Most users like to apply one “tweak” after a new installation. Ansible’s idempotent, declarative syntax lends itself perfectly to describing how a system should be configured.
-
-### Ansible in a nutshell
-
-The _ansible_ program itself performs a **single task** against a set of hosts. This is roughly conceptualized as:
-```
-for HOST in $HOSTS; do
- ssh $HOST /usr/bin/echo "Hello World"
-done
-
-```
-
-To perform more than one task, Ansible defines the concept of a “playbook”. A playbook is a YAML file describing the _state_ of the targeted machine. When run, Ansible inspects each host and performs only the tasks necessary to enforce the state defined in the playbook.
-```
-- hosts: all
- tasks:
- - name: Echo "Hello World"
- command: echo "Hello World"
-
-```
-
-Run the playbook using the _ansible-playbook_ command:
-```
-$ ansible-playbook ~/playbook.yml
-
-```
-
-### Configuring a workstation
-
-Start by installing ansible:
-```
-dnf install ansible
-
-```
-
-Next, create a file to store the playbook:
-```
-touch ~/post_install.yml
-
-```
-
-Start by defining the host on which to run this playbook. In this case, “localhost”:
-```
-- hosts: localhost
-
-```
-
-Each task consists of a _name_ field and a module field. Ansible has **a lot** of [modules][2]. Be sure to browse the module index to become familiar with all Ansible has to offer.
-
-#### The package module
-
-Most users install additional packages after a fresh install, and many like to remove some shipped software they don’t use. The _[package][3]_ module provides a generic wrapper around the system package manager (in Fedora’s case, _dnf_ ).
-```
-- hosts: localhost
- tasks:
- - name: Install Builder
- become: yes
- package:
- name: gnome-builder
- state: present
- - name: Remove Rhythmbox
- become: yes
- package:
- name: rhythmbox
- state: absent
- - name: Install GNOME Music
- become: yes
- package:
- name: gnome-music
- state: present
- - name: Remove Shotwell
- become: yes
- package:
- name: shotwell
- state: absent
-```
-
-This playbook results in the following outcomes:
-
- * GNOME Builder and GNOME Music are installed
- * Rhythmbox is removed
- * On Fedora 28 or greater, nothing happens with Shotwell (it is not in the default list of packages)
- * On Fedora 27 or older, Shotwell is removed
-
-
-
-This playbook also introduces the **become: yes** directive. This specifies the task must be run by a privileged user (in most cases, _root_ ).
-
-#### The DConf Module
-
-Ansible can do a lot more than install software. For example, GNOME includes a great color-shifting feature called Night Light. It ships disabled by default, however the Ansible _[dconf][4]_ module can very easily enable it.
-```
-- hosts: localhost
- tasks:
- - name: Enable Night Light
- dconf:
- key: /org/gnome/settings-daemon/plugins/color/night-light-enabled
- value: true
- - name: Set Night Light Temperature
- dconf:
- key: /org/gnome/settings-daemon/plugins/color/night-light-temperature
- value: uint32 5500
-```
-
-Ansible can also create files at specified locations with the _[copy][5]_ module. In this example, a local file is copied to the destination path.
-```
-- hosts: localhost
- tasks:
- - name: Enable "AUTH_ADMIN_KEEP" for pkexec
- become: yes
- copy:
- src: files/51-pkexec-auth-admin-keep.rules
- dest: /etc/polkit-1/rules.d/51-pkexec-auth-admin-keep.rules
-
-```
-
-#### The Command Module
-
-Ansible can still run commands even if no specialized module exists (via the aptly named _[command][6]_ module). This playbook enables the [Flathub][7] repository and installs a few Flatpaks. The commands are crafted in such a way that they are effectively idempotent. This is an important behavior to consider; a playbook should succeed each time it is run on a machine.
-```
-- hosts: localhost
- tasks:
- - name: Enable Flathub repository
- become: yes
- command: flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
- - name: Install Fractal
- become: yes
- command: flatpak install --assumeyes flathub org.gnome.Fractal
- - name: Install Spotify
- become: yes
- command: flatpak install --assumeyes flathub com.spotify.Client
-```
-
-Combine all these tasks together into a single playbook and, in one command, ** Ansible will customize a freshly installed workstation. Not only that, but 6 months later, after making changes to the playbook, run it again to bring a “seasoned” install back to a known state.
-```
-$ ansible-playbook -K ~/post_install.yml
-
-```
-
-This article only touched the surface of what’s possible with Ansible. A follow-up article will go into more advanced Ansible concepts such as _roles,_ configuring multiple hosts with a divided set of responsibilities.
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/using-ansible-setup-workstation/
-
-作者:[Link Dupont][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/linkdupont/
-[1]:https://ansible.com
-[2]:https://docs.ansible.com/ansible/latest/modules/list_of_all_modules.html
-[3]:https://docs.ansible.com/ansible/latest/modules/package_module.html#package-module
-[4]:https://docs.ansible.com/ansible/latest/modules/dconf_module.html#dconf-module
-[5]:https://docs.ansible.com/ansible/latest/modules/copy_module.html#copy-module
-[6]:https://docs.ansible.com/ansible/latest/modules/command_module.html#command-module
-[7]:https://flathub.org
diff --git a/sources/tech/20180708 simple and elegant free podcast player.md b/sources/tech/20180708 simple and elegant free podcast player.md
deleted file mode 100644
index 72e35c7029..0000000000
--- a/sources/tech/20180708 simple and elegant free podcast player.md
+++ /dev/null
@@ -1,119 +0,0 @@
-simple and elegant free podcast player
-======
-
-
-
-CPod (formerly known as Cumulonimbus) is a cross-platform, open source podcast player for the desktop. The application is built with web technologies – it’s written in the JavaScript programming language and uses the Electron framework. Electron is often (rightly?) criticized for being a memory hog and dog slow. But is that mainly because of poor programming, rather than an inherent flaw in the technology?
-
-CPod is available for Linux, Mac OS, and Windows. Installation was a breeze on my Ubuntu 18.04 distribution as the author conveniently provides a 64-bit deb package. If you don’t run a Debian/Ubuntu based distro, there’s an AppImage which effortlessly installs the software on all major Linux distributions. There’s also a snap package from the snapcraft website, but bizarrely (and incorrectly) flags the software as proprietary software. As CPod is released under an open source license, there’s the full source code available too.
-
-The deb package installs the software to /opt/CPod, although the binary is still called cumulonimbus. A bit of tidying up needed there. For Mac OS users, there’s an Apple Disk Image file.
-
-### Home
-
-![CPod Playlist][2]
-First off, you cannot fail to notice the gorgeous attractive interface. Presentation is first class.
-
-First off, you cannot fail to notice the gorgeous attractive interface. Presentation is first class.
-
-The home section shows your subscribed podcasts. There are helpful filters at the top. They let you select podcasts of specified duration (handy if time is limited), you can filter by date, filter for podcasts that you’ve downloaded an offline copy, as well as podcasts that have not been listened to, you’ve started listening to, and podcasts you’ve heard to the end.
-
-Below the filters, there’s the option to select multiple podcasts, download local copies, add podcasts to your queue, as well as actually playing a podcast. The interface is remarkably intuitive.
-
-One quirk is that offline episodes are downloaded to the directory ~/.config/cumulonimbus/offline_episodes/. The downloaded podcasts are therefore not visible in the Files file manager by default (this is because the standard installation of Files does not display ‘hidden files’). It’s easy to enable hidden files in the file manager. Good news, the developer plans to add a configurable default download directory.
-
-There’s lots of nice touches which enhance the user experience, such as the progress bars when downloading episodes.
-
-### Playing a podcast
-
-![CPod][3]
-
-Here’s one of my favourite podcasts, Ubuntu Podcast, in playback. There’s visualization effects enabled; they only show when the window has focus. The visualizations don’t always display properly. There’s also the option of changing the playback speed (0.5x – 4x speed). I’m not sure why I’d want to change the playback speed though. Maybe someone could enlighten me?
-
-More functional is the slider that lets you skip to a specific point of the podcast although this is a tad buggy. The software is in an early stage of development. In any case, I prefer using the keyboard shortcuts to move forwards and backwards, and they work fine. Some podcasts offer links that let you skip to a particular segment; they are displayed in the large pane.
-
-There’s also the ability to watch video podcasts in both fullscreen and window mode. I spend most of my time listening to audio podcasts, but having full screen video podcasts is a pretty cool feature. Video playback is powered by ffmpeg.
-
-### Queue
-
-![CPod Queue][4]
-There’s not much to say about the queue functionality, but it’s worth noting you can change the order of episodes simply by dragging and dropping them in the interface. It’s well implemented and really simple to use. Another tick for CPod.
-
-### Subscriptions
-
-There’s not much to say about the queue functionality, but it’s worth noting you can change the order of episodes simply by dragging and dropping them in the interface. It’s well implemented and really simple to use. Another tick for CPod.
-
-![CPod Subscriptions][5]
-
-The interface makes it really easy to subscribe and unsubscribe to podcasts. Clicking the image of a subscribed podcast lets you find an episode, as well as a list of recent episodes, again with the ability to play, queue, and download. It’s all very clean and easy to use.
-
-### Explore
-
-In explore you can search for podcasts. Just type some keywords into the Explore dialog box, and you’re presented with a list of podcasts you can listen and subscribe.
-
-If you’re a fan of YouTube, you’re in luck. There’s the ability to preview and subscribe to YouTube channels by pasting a channel’s URL into the Explore box. That’s great if you have YouTube channel hyperlinks handy, but some sort of YouTube channel finder would be a great addition.
-
-Here’s a YouTube video in action.
-
-![CPod YTube][6]
-
-### Settings
-
-![CPod Settings][7]
-
-There’s a lot you can configure in Settings. There’s functionality to:
-
- * Internationalization support – the ability to select the language displayed. Currently, there’s fairly limited support in this respect. Besides English, there’s Chinese, French, German, Korean, Portuguese, Portuguese (Brazilian), and Spanish available. Contributing translations is probably the easiest way for non-programmers to contribute to an open source project.
- * Option to group episodes in Home by day or month.
- * Keyboard shortcuts that let you skip backward, skip forward, and play/pause playback. I love my keyboard shortcuts.
- * Configure different lengths of forward/backward skip.
- * Enable waveform visualization – you can see examples of the visualization in our images (Playlist and Subscription sections).
- * Basic gpodder.net integration (currently only subscriptions and device sync are supported; other functionality such as episodes actions and queue are planned).
- * Allow pre-releases when auto-updating.
- * Export subscriptions to OPML – Outline Processor Markup Language is an XML format commonly used to exchange lists of web feeds between web feed aggregators.
- * Import subscriptions from OPML.
- * Update podcast cover art.
- * View offline episodes directory.
-
-
-
-The software has a bag of neat touches. For example, if I change the language setting, the software presents a pop up saying CPod needs to be restarted for the change to take effect. All very user-friendly.
-
-The Media Player Remote Interfacing Specification (MPRIS) is a standard D-Bus interface which aims to provide a common programmatic API for controlling media players. CPod offers basic MPRIS integration.
-
-### Summary
-
-CPod is another good example of what’s possible with modern web technologies. Sure, it’s got a few quirks, it’s in an early stage of development (read ‘expect to find lots of bugs’), and there’s some useful functionality waiting to be implemented. But I’m using the software on a daily basis, and will definitely keep up-to-date with developments.
-
-Linux already has some high quality open source podcast players. But CPod is definitely worth a download if you’re passionate about podcasts.
-
-**Website:** [**github.com/z————-/CPod**][8]
-**Support:**
-**Developer:** Zack Guard
-**License:** Apache License 2.0
-
-Zack Guard, CPod’s developer, is a student who lives in Hong Kong. You can buy him a coffee at **<https://www.buymeacoffee.com/zackguard>**. Unfortunately, I’m an impoverished student too.
-
-### Related
-
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxlinks.com/cpod-simple-elegant-free-podcast-player/
-
-作者:[Luke Baker][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linuxlinks.com/author/luke-baker/
-[1]:https://www.linuxlinks.com/wp-content/plugins/jetpack/modules/lazy-images/images/1x1.trans.gif
-[2]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Playlist.jpg?resize=750%2C368&ssl=1
-[3]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Main.jpg?resize=750%2C368&ssl=1
-[4]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Queue.jpg?resize=750%2C368&ssl=1
-[5]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Subscriptions.jpg?resize=750%2C368&ssl=1
-[6]:https://i1.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-YouTube.jpg?resize=750%2C368&ssl=1
-[7]:https://i1.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Settings.jpg?resize=750%2C368&ssl=1
-[8]:https://github.com/z-------------/CPod
diff --git a/sources/tech/20180710 The aftermath of the Gentoo GitHub hack.md b/sources/tech/20180710 The aftermath of the Gentoo GitHub hack.md
deleted file mode 100644
index fc9ff4b4e5..0000000000
--- a/sources/tech/20180710 The aftermath of the Gentoo GitHub hack.md
+++ /dev/null
@@ -1,72 +0,0 @@
-The aftermath of the Gentoo GitHub hack
-======
-
-
-
-### Gentoo GitHub hack: What happened?
-
-Late last month (June 28), the Gentoo GitHub repository was attacked after someone gained control of an admin account. All access to the repositories was soon removed from Gentoo developers. Repository and page content were altered. But within 10 minutes of the attacker gaining access, someone noticed something was going on, 7 minutes later a report was sent, and within 70 minutes the attack was over. Legitimate Gentoo developers were shut out for 5 days while the dust settled and repairs and analysis were completed.
-
-The attackers also attempted to add "rm -rf" commands to some repositories to cause user data to be recursively removed. As it turns out, this code was unlikely to be run because of technical precautions that were in place, but this wouldn't have been obvious to the attacker.
-
-One of the things that constrained how big a disaster this break in might have turned out to be was that the attack was "loud." The removal of developers resulted in them being emailed, and developers quickly discovered they'd been shut out. A stealthier attack might have led to a significant delay in anyone responding to the problem and a significantly bigger problem.
-
-A detailed timeline showing the details of what happened is available at the [Gentoo Linux site][1].
-
-### How the Gentoo GitHub attack happened
-
-Much of the focus in the aftermath of this very significant attack has been on how the attacker was able to gain admin access and what might have been done differently to keep the site safe. The most obvious take-home was that the admin's password was guessed because it too closely related to one that had been captured on another system. This might be like your using "Spring2018" on one system and "Summer2018" on another.
-
-Another problem was that it was unclear how end users might have been able to tell whether or not they had a clean copy of the code, and there was no confirmation as to whether the malicious commits (accessible for a while) would execute.
-
-### Lessons learned from the hack
-
-The lessons learned should come as no surprise. We should all be careful not to use the same password on multiple systems and not to use passwords that relate to each other so strongly that knowing one in a set suggests another.
-
-We also have to admit that two-factor authentication would have prevented this break-in. While something of a burden on users (i.e., they may have to carry a token generator or confirm their login through some secondary service), it very strongly limits who can get access to an account.
-
-Of course the lessons learned should also not overlook what this incident showed us was going right. The fact that the break-in was noticed so quickly and that communications lines were functional meant the break-in could be quickly addressed. The breach was also made public, the repository was only a secondary copy of the main Gentoo source code, and changes in the main repository were signed and could be verified.
-
-#### The best news
-
-The really good news is that it appears that no one was affected by the break in other than the fact that developers were locked out for a while. The hackers weren't able to penetrate Gentoo's master repository (the default location for automatic updates). They also weren't able to get their hands on Gentoo's digital signing key. This means that default updates would have rejected their files as fakes.
-
-The harm that could have been made to Gentoo's reputation was avoided by the precautions in place and their professional handling of the incident. What could have cost them a lot ended up as a confirmation of what they're doing right and added to their determination to make some changes to strengthen their security. They faced up to some cyberbullies and came out stronger and more confident.
-
-### Fixing the potholes
-
-Gentoo is already addressing the weaknesses that contributed to the break-in. They are making frequent backups of their GitHub Organization (i.e., their content), starting to use two-factor authentication by default, working on an incident response plan with a focus on sharing information about a security incident with their users, and tightening procedures around credential revocation. They are also reducing the number of users with elevated privileges, auditing logins, and publishing password policies that mandate the use of password managers.
-
-### Gentoo and GitHub
-
-For readers unfamiliar with Gentoo, it's important to understand that Gentoo is different than most Linux distributions. Users download and then compile the source to build the OS they will then be using. It's as close to the Linux mantra of “know how to do it yourself” as you can get.
-
-Git is a code management system not unlike CVS, and GitHub provides repositories for the code.
-
-### Gentoo strengths
-
-Gentoo users tend to be more knowledgeable about the low-level aspects of the OS (e.g., kernel configuration and hardware support) than most Linux users — probably due to their interest in working with the source code. The OS is also highly scalable and flexible with a "build what you need" focus. The name derives from that of the "Gentoo penguin" — a penguin breed that lives on many sub-Antarctic islands. More information and downloads are available at [www.gentoo.org][2].
-
-### More on the Gentoo GitHub break-in
-
-More information on the break in is available on [Naked Security][3] and (as noted above) the [Gentoo site][1].
-
-Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3287973/linux/the-aftermath-of-the-gentoo-github-hack.html
-
-作者:[Sandra Henry-Stocker][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
-[1]:https://wiki.gentoo.org/wiki/Project:Infrastructure/Incident_Reports/2018-06-28_Github
-[2]:https://www.gentoo.org/
-[3]:https://nakedsecurity.sophos.com/2018/06/29/linux-distro-hacked-on-github-all-code-considered-compromised/
-[4]:https://www.facebook.com/NetworkWorld/
-[5]:https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20180711 5 open source racing and flying games for Linux.md b/sources/tech/20180711 5 open source racing and flying games for Linux.md
deleted file mode 100644
index c2b540f498..0000000000
--- a/sources/tech/20180711 5 open source racing and flying games for Linux.md
+++ /dev/null
@@ -1,102 +0,0 @@
-5 open source racing and flying games for Linux
-======
-
-
-
-Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games often are not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
-
-So, can someone who uses only free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely to ever rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website to install and play it.
-
-This article looks at racing and flying games. I have already written about [arcade-style games][1], [board and card games][2], and [puzzle games][3]. In future articles, I plan to cover role-playing games and strategy & simulation games.
-
-### Extreme Tux Racer
-
-
-
-Race down snow and ice-covered mountains as Tux or other characters in [Extreme Tux Racer][4]. In this racing game, the goal is to collect herrings and earn the best time. There are many different tracks to choose from, and tracks can be customized by altering the time of day, wind, and weather conditions. While the game has a few rough edges compared to modern, commercial racing games, it is still an enjoyable game to play. The controls and gameplay are straightforward and simple to learn, making this a great choice for kids.
-
-To install Extreme Tux Racer, run the following command:
-
- * On Fedora: `dnf install extremetuxracer`
- * On Debian/Ubuntu: `apt install extremetuxracer`
-
-
-
-### FlightGear
-
-
-
-[FlightGear][5] is a full-fledged, open source flight simulator. Multiple aircraft types are available, and 20,000 airports are included in the full world scenery set. That means the player can fly to most parts of the world and have realistic airports and scenery. The full world scenery data is large enough to fill three DVDs. Even the developers are jokingly not sure if that counts as "a feature or a problem," so be aware that a complete installation of FlightGear and all its scenery data is huge. While certainly not the right game for everyone, FlightGear provides a very complete and complex flight simulator experience for players looking to explore the skies on their own computer.
-
-To install FlightGear, run the following command:
-
- * On Fedora: `dnf install FlightGear`
- * On Debian/Ubuntu: `apt install flightgear`
-
-
-
-### SuperTuxKart
-
-
-
-[SuperTuxKart][6] takes the basic formula used by Nintendo in the Mario Kart series and applies it to open source mascots. Players race around a variety of tracks in go-karts driven by the mascots for a plethora of open source projects. Character choices include the mascots for open source operating systems and applications of varying familiarity, with options ranging from Tux and Beastie to Gavroche, the mascot for [GNU MediaGoblin][7]. There are several gameplay modes to choose from, including multi-player modes, but many of the tracks are unavailable until they are unlocked by playing the game's single-player story mode. SuperTuxKart's graphics settings can be tweaked to run on everything from older computers with built-in graphics to modern hardware with high-end graphics cards. There is also a version of [SuperTuxKart for Android][8] available. SuperTuxKart is a very good game and great for players of all ages.
-
-To install SuperTuxKart, run the following command:
-
- * On Fedora: `dnf install supertuxkart`
- * On Debian/Ubuntu: `apt install supertuxkart`
-
-
-
-### Torcs
-
-
-
-[Torcs][9] is a fairly standard racing game with some extra features for the tech-savvy. Torcs can be played as just a standard racing game, where the player drives around a track trying to get the best time, but an alternative usage is as a platform to develop an artificial intelligence driver that can drive itself through Torcs' tracks. The cars and tracks included with the game vary in style, ranging from stock car racing to rally racing, but the gameplay is pretty typical for a racing game. Keyboard, mouse, joystick, and steering wheel input are all supported, but keyboard and mouse input modes are a little hard to get used to. Single-player races range from practice runs to championships, and there is a [split-screen multi-player mode][10] for up to four players.
-
-To install Torcs, run the following command:
-
- * On Fedora: `dnf install torcs`
- * On Debian/Ubuntu: `apt install torcs`
-
-
-
-### Trigger Rally
-
-
-
-[Trigger Rally][11] is an off-road, single-player rally racing game. The player needs to make it to each checkpoint in time to complete the race, which is standard racing game fare, but still enjoyable. The gameplay is more arcade-like than a strict racing simulator like Torcs but more realistic than cartoonish racing games like SuperTuxKart. The tracks are interesting and the controls are responsive, but a little too sensitive when playing with a keyboard. Joystick controls are available by changing an option in a configuration file. Unfortunately, development on the game is slow going, with the latest release in 2016, but the gameplay that is already there is fun.
-
-To install Trigger Rally, run the following command:
-
- * On Debian/Ubuntu: `apt install trigger-rally`
-
-
-
-Unfortunately, Trigger Rally is not packaged for Fedora.
-
-Did I miss one of your favorite open source racing or flying games? Share it in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/racing-flying-games-linux
-
-作者:[About The Author;Joshua Allen Holm;Mlis;Med;Is One Of Opensource.Com'S Community Moderators. Joshua'S Main Interests Are Digital Humanities;Open Access;Open Educational Resources. He Can Reached At][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/holmja
-[1]:https://opensource.com/article/18/1/arcade-games-linux
-[2]:https://opensource.com/article/18/3/card-board-games-linux
-[3]:https://opensource.com/article/18/6/puzzle-games-linux
-[4]:https://extremetuxracer.sourceforge.io/
-[5]:http://home.flightgear.org/
-[6]:https://supertuxkart.net/Main_Page
-[7]:https://mediagoblin.org
-[8]:https://play.google.com/store/apps/details?id=org.supertuxkart.stk
-[9]:http://torcs.sourceforge.net/index.php
-[10]:http://torcs.sourceforge.net/?name=Sections&op=viewarticle&artid=30#c4_4_4
-[11]:http://trigger-rally.sf.net/
diff --git a/sources/tech/20180723 System Snapshot And Restore Utility For Linux.md b/sources/tech/20180723 System Snapshot And Restore Utility For Linux.md
deleted file mode 100644
index 26630a372a..0000000000
--- a/sources/tech/20180723 System Snapshot And Restore Utility For Linux.md
+++ /dev/null
@@ -1,237 +0,0 @@
-System Snapshot And Restore Utility For Linux
-======
-
-
-**CYA** , stands for **C** over **Y** our **A** ssets, is a free, open source system snapshot and restore utility for any Unix-like operating systems that uses BASH shell. Cya is portable and supports many popular filesystems such as EXT2/3/4, XFS, UFS, GPFS, reiserFS, JFS, BtrFS, and ZFS etc. Please note that **Cya will not backup the actual user data**. It only backups and restores the operating system itself and not your actual user data. **Cya is a system restore utility**. By default, it will backup all key directories like /bin/, /lib/, /usr/, /var/ and several others. You can, however, define your own directories and files path to include in the backup, so Cya will pick those up as well. Also, it is possible define some directories/files to skip from the backup. For example, you can skip /var/logs/ if you don’t log files. Cya actually uses **Rsync** backup method under the hood. However, Cya is super easier than Rsync when creating rolling backups.
-
-When restoring your operating system, Cya will rollback the OS using your backup profile which you created earlier. You can either restore the entire system or any specific directories only. Also, you can easily access the backup files even without a complete rollback using your terminal or file manager. ANother notable feature is we can generate a custom recovery script to automate the mounting of your system partition(s) when you restore off a live CD, USB, or network image. In a nutshell, CYA can help you to restore your system to previous states when you end-up with a broken system caused by software update, configuration changes, intrusions/hacks, etc.
-
-### Installing CYA
-
-Installing CYA is very easy. All you have to do is download Cya binary and put it in your system path.
-```
-$ git clone https://github.com/cleverwise/cya.git
-
-```
-
-This will clone the latest cya version in a directory called cya in your current working directory.
-
-Next, copy the cya binary to your path or wherever you want.
-```
-$ sudo cp cya/cya /usr/local/bin/
-
-```
-
-CYA as been installed. Now let us go ahead and create snapshots.
-
-### Creating Snapshots
-
-Before creating any snapshots/backups, create a recovery script using command:
-```
-$ cya script
-☀ Cover Your Ass(ets) v2.2 ☀
-
-ACTION ⯮ Generating Recovery Script
-
-Generating Linux recovery script ...
-Checking sudo permissions...
-Complete
-
-IMPORTANT: This script will ONLY mount / and /home. Thus if you are storing data on another mount point open the recovery.sh script and add the additional mount point command where necessary. This is also a best guess and should be tested before an emergency to verify it works as desired.
-
-
-‣ Disclaimer: CYA offers zero guarantees as improper usage can cause undesired results
-‣ Notice: Proper usage can correct unauthorized changes to system from attacks
-
-```
-
-Save the resulting **recovery.sh** file in your USB drive which we are going to use it later when restoring backups. This script will help you to setup a chrooted environment and mount drives when you rollback your system.
-
-Now, let us create snapshots.
-
-To create a standard rolling backup, run:
-```
-$ cya save
-
-```
-
-The above command will keep **three backups** before overwriting.
-
-**Sample output:**
-```
-☀ Cover Your Ass(ets) v2.2 ☀
-
-ACTION ⯮ Standard Backup
-
-Checking sudo permissions...
-[sudo] password for sk:
-We need to create /home/cya/points/1 ... done
-Backing up /bin/ ... complete
-Backing up /boot/ ... complete
-Backing up /etc/ ... complete
-.
-.
-.
-Backing up /lib/ ... complete
-Backing up /lib64/ ... complete
-Backing up /opt/ ... complete
-Backing up /root/ ... complete
-Backing up /sbin/ ... complete
-Backing up /snap/ ... complete
-Backing up /usr/ ... complete
-Backing up /initrd.img ... complete
-Backing up /initrd.img.old ... complete
-Backing up /vmlinuz ... complete
-Backing up /vmlinuz.old ... complete
-Write out date file ... complete
-Update rotation file ... complete
-
-‣ Disclaimer: CYA offers zero guarantees as improper usage can cause undesired results
-‣ Notice: Proper usage can correct unauthorized changes to system from attacks
-
-```
-
-You can view the contents of the newly created snapshot, under **/home/cya/points/** location.
-```
-$ ls /home/cya/points/1/
-bin cya-date initrd.img lib opt sbin usr vmlinuz
-boot etc initrd.img.old lib64 root snap var vmlinuz.old
-
-```
-
-To create a backup with a custom name that will not be overwritten, run:
-```
-$ cya keep name BACKUP_NAME
-
-```
-
-Replace **BACKUP_NAME** with your own name.
-
-To create a backup with a custom name that will overwrite, do:
-```
-$ cya keep name BACKUP_NAME overwrite
-
-```
-
-To create a backup and archive and compress it, run:
-```
-$ cya keep name BACKUP_NAME archive
-
-```
-
-This command will store the backups in **/home/cya/archives** location.
-
-By default, CYA will store its configuration in **/home/cya/** directory and the snapshots with a custom name will be stored in **/home/cya/points/BACKUP_NAME** location. You can, however, change these settings by editing the CYA configuration file stored at **/home/cya/cya.conf**.
-
-Like I already said, CYA will not backup user data by default. It will only backup the important system files. You can, however, include your own directories or files along with system files. Say for example, if you wanted to add the directory named **/home/sk/Downloads** directory in the backup, edit **/home/cya/cya.conf** file:
-```
-$ vi /home/cya/cya.conf
-
-```
-
-Define your directory data path that you wanted to include in the backup like below.
-```
-MYDATA_mybackup="/home/sk/Downloads/ /mnt/backup/sk/"
-
-```
-
-Please be mindful that both source and destination directories should end with a trailing slash. As per the above configuration, CYA will copy all the contents of **/home/sk/Downloads/** directory and save them in **/mnt/backup/sk/** (assuming you already created this) directory. Here **mybackup** is the profile name. Save and close the file.
-
-Now to backup the contents of /home/sk/Downloads/ directory, you need to enter the profile name (i.e mybackup in my case) with the **cya mydata** command like below:
-```
-$ cya mydata mybackup
-
-```
-
-Similarly, you can include multiple user data with a different profile names. All profile names must be unique.
-
-### Exclude directories
-
-Some times, you may not want to backup all system files. You might want to exclude some unimportant such as log files. For example, if you don’t want to include **/var/tmp/** and **/var/logs/** directories, add the following in **/home/cya/cya.conf** file.
-```
-EXCLUDE_/var/=”tmp/ logs/”
-
-```
-
-Similarly, you can specify all directories one by one that you want to exclude from the backup. Once done, save and close the file.
-
-### Add specific files to the backup
-
-Instead of backing up whole directories, you can include a specific files from a directory. To do so, add the path of your files one by one in **/home/cya/cya.conf** file.
-```
-BACKUP_FILES="/home/sk/Downloads/ostechnix.txt"
-
-```
-
-### Restore your system
-
-Remember, we already create a recovery script named **recovery.sh** and saved it in an USB drive? Yeah, we will need it now to restore our broken system.
-
-Boot your system with any live bootable CD/DVD, USB drive. The developer of CYA recommends to use a live boot environment from same major version as your installed environment! For example if you use Ubuntu 18.04 system, then use Ubuntu 18.04 live media.
-
-Once you’re in the live system, mount the USB drive that contains the recovery.sh script. Once you mounted the drive(s), your system’s **/** and **/home** will be mounted to the **/mnt/cya** directory. This is made really easy and handled automatically by the **recovery.sh** script for Linux users.
-
-Then, start the restore process using command:
-```
-$ sudo /mnt/cya/home/cya/cya restore
-
-```
-
-Just follow the onscreen instructions. Once the restoration is done, remove the live media and unmount the drives and finally, reboot your system.
-
-What if you don’t have or lost recovery script? No problem, we still can restore our broken system.
-
-Boot the live media. From the live session, create a directory to mount the drive(s).
-```
-$ sudo mkdir -p /mnt/cya
-
-```
-
-Then, mount your **/** and **/home** (if on another partition) into the **/mnt/cya** directory.
-```
-$ sudo mount /dev/sda1 /mnt/cya
-
-$ sudo mount /dev/sda3 /mnt/cya/home
-
-```
-
-Replace /dev/sda1 and /dev/sda3 with your correct partitions (Use **fdisk -l** command to find your partitions).
-
-Finally, start the restoration process using command:
-```
-$ sudo /mnt/cya/home/cya/cya restore
-
-```
-
-Once the recovery is completed, unmount all mounted partitions and remove install media and reboot your system.
-
-At this stage, you might get a working system. I deleted some important libraries in Ubuntu 18.04 LTS server. I successfully restored it to the working state by using CYA utility.
-
-### Schedule CYA backup
-
-It is always recommended to use crontab to schedule the CYA snapshot process at regular interval. You can setup a cron job using root or setup a user that doesn’t need to enter a sudo password.
-
-The example entry below will run cya at every Monday at 2:05 am with output dumped into /dev/null.
-```
-5 2 * * 1 /home/USER/bin/cya save >/dev/null 2>&1
-
-```
-
-And, that’s all for now. Unlike Systemback and other system restore utilities, Cya is not a distribution-specific restore utility. It supports many Linux operating systems that uses BASH. It is one of the must-have applications in your arsenal. Install it right away and create snapshots. You won’t regret when you accidentally crashed your Linux system.
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/cya-system-snapshot-and-restore-utility-for-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
diff --git a/sources/tech/20180727 Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py.md b/sources/tech/20180727 Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py.md
deleted file mode 100644
index 9d4c7fedd7..0000000000
--- a/sources/tech/20180727 Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py.md
+++ /dev/null
@@ -1,221 +0,0 @@
-Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py
-======
-**If you're looking for a quick way to download subtitles from OpenSubtitles.org from your Linux desktop or server, give[OpenSubtitlesDownload.py][1] a try. This neat Python tool can be used as a Nautilus, Nemo or Caja script, or from the command line.**
-
-
-
-The Python script **searches for subtitles on OpenSubtitles.org using the video hash sum to find exact matches** , and thus avoid out of sync subtitles. In case no match is found, it then tries to perform a search based on the video file name, although such subtitles may not always be in sync.
-
-OpenSubtitlesDownload.py has quite a few cool features, including **support for more than 60 languages,** and it can query both multiple subtitle languages and videos in the same time (so it **supports mass subtitle search and download** ).
-
-The **optional graphical user interface** (uses Zenity for Gnome and Kdialog for KDE) can display multiple subtitle matches and by digging into its settings you can enable the display of some extra information, like the subtitles download count, rating, language, and more.
-
-Other OpenSubtitlesDownload.py features include:
-
- * Option to download subtitles automatically if only one is available, choose the one you want otherwise.
- * Option to rename downloaded subtitles to match source video file. Possibility to append the language code to the file name (ex: movie_en.srt).
-
-
-
-The Python tool does not yet support downloading subtitles for movies within a directory recursively, but this is a planned feature.
-
-In case you encounter errors when downloading a large number of subtitles, you should be aware that OpenSubtitles has a daily subtitle download limit (it appears it was 200 subtitles downloads / day a while back, I'm not sure if it changed). For VIP users it's 1000 subtitles per day, but OpenSubtitlesDownload.py does not allow logging it to an OpenSubtitles account and thus, you can't take advantage of a VIP account while using this tool.
-
-### Installing and using OpenSubtitlesDownload.py as a Nautilus, Nemo or Caja script
-
-The instructions below explain how to install OpenSubtitlesDownload.py as a script for Caja, Nemo or Nautilus file managers. Thanks to this you'll be able to right click (context menu) one or multiple video files in your file manager, select `Scripts > OpenSubtitlesDownload.py` and the script will search for and download subtitles from OpenSubtitles.org for your video files.
-
-This is OpenSubtitlesDownload.py used as a Nautilus script:
-
-
-
-And as a Nemo script:
-
-
-
-To install OpenSubtitlesDownload.py as a Nautilus, Nemo or Caja script, see the instructions below.
-
-1\. Install the dependencies required by OpenSubtitlesDownload.py
-
-You'll need to install `gzip` , `wget` and `zenity` before using OpenSubtitlesDownload.py. The instructions below assume you already have Python (both Python 2 and 3 will do it), as well as `ps` and `grep` available.
-
-In Debian, Ubuntu, or Linux Mint, install `gzip` , `wget` and `zenity` using this command:
-```
-sudo apt install gzip wget zenity
-
-```
-
-2\. Now you can download the OpenSubtitlesDownload.py
-```
-wget https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py
-
-```
-
-3\. Use the commands below to move the downloaded OpenSubtitlesDownload.py script to the file manager scripts folder and make it executable (use the commands for your current file manager - Nautilus, Nemo or Caja):
-
- * Nautilus (default Gnome, Unity and Solus OS file manager):
-
-
-```
-mkdir -p ~/.local/share/nautilus/scripts
-mv OpenSubtitlesDownload.py ~/.local/share/nautilus/scripts/
-chmod u+x ~/.local/share/nautilus/scripts/OpenSubtitlesDownload.py
-
-```
-
- * Nemo (default Cinnamon file manager):
-
-
-```
-mkdir -p ~/.local/share/nemo/scripts
-mv OpenSubtitlesDownload.py ~/.local/share/nemo/scripts/
-chmod u+x ~/.local/share/nemo/scripts/OpenSubtitlesDownload.py
-
-```
-
- * Caja (default MATE file manager):
-
-
-```
-mkdir -p ~/.config/caja/scripts
-mv OpenSubtitlesDownload.py ~/.config/caja/scripts/
-chmod u+x ~/.config/caja/scripts/OpenSubtitlesDownload.py
-
-```
-
-4\. Configure OpenSubtitlesDownload.py
-
-Since it's running as a file manager script, without any arguments, you'll need to modify the script if you want to change some of its settings, like enabling the GUI, changing the subtitles language, and so on. These are optional of course, and you can use it directly to automatically download subtitles using its default settings.
-
-To Configure OpenSubtitlesDownload.py, you'll need to open it with a text editor. The script path should now be:
-
- * Nautilus:
-
-`~/.local/share/nautilus/scripts`
-
- * Nemo:
-
-`~/.local/share/nemo/scripts`
-
- * Caja:
-
-`~/.config/caja/scripts`
-
-
-
-
-Navigate to that folder using your file manager and open the OpenSubtitlesDownload.py file with a text editor.
-
-Here's what you may want to change in this file:
-
- * To change the subtitle language, search for `opt_languages = ['eng']` and change the language from `['eng']` (English) to `['fre']` (French), or whatever language you want to use. The ISO codes for each language supported by OpenSubtitles.org are available on [this][2] page (use the code in the first column).
-
- * If you want a GUI to present you with all subtitles options and let you choose which to download, find the `opt_selection_mode = 'default'` setting and change it to `'manual'` . You'll not want to change this to 'manual' (or better yet, change it to 'auto') if you want to download multiple subtitles in the same time and avoid having a window popup for each video!
-
- * To force the Gnome GUI to be used, search for `opt_gui = 'auto'` and change `'auto'` to `'gnome'`
-
- * You can also enable multiple info columns in the GUI:
-
- * Search for `opt_selection_rating = 'off'` and change it to `'auto'` to display user ratings if available
-
- * Search for `opt_selection_count = 'off'` and change it to `'auto'` to display the subtitle number of downloads if available
-
-
-**You can find a list of OpenSubtitlesDownload.py settings with explanations by visiting[this page][3].**
-
-And you're done. OpenSubtitlesDownload.py should now appear in Nautilus, Nemo or Caja, when right clicking a file and selecting Scripts. Clicking OpenSubtitlesDownload.py should search and download subtitles for the selected video(s).
-
-### Installing and using OpenSubtitlesDownload.py from the command line
-
-1\. Install the dependencies required by OpenSubtitlesDownload.py (command line only)
-
-You'll need to install `gzip` and `wget` . On Debian, Ubuntu or Linux Mint you can install these packages by using this command:
-```
-sudo apt install wget gzip
-
-```
-
-2\. Install the `/usr/local/bin/` and set it so it uses the command line interface by default:
-```
-wget https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py -O opensubtitlesdownload
-sed -i "s/opt_gui = 'auto'/opt_gui = 'cli'/" opensubtitlesdownload
-sudo install opensubtitlesdownload /usr/local/bin/
-
-```
-
-Now you can start using it. To use the script with automatic selection and download of the best available subtitle, type:
-```
-opensubtitlesdownload --auto /path/to/video.mkv
-
-```
-
-You can specify the language by appending `--lang LANG` , where `LANG` is the ISO code for a language supported by OpenSubtitles.org, available on
-```
-opensubtitlesdownload --lang SPA /home/logix/Videos/Sintel.2010.720p.mkv
-
-```
-
-Which provides this output (it allows you to choose the best subtitle since we didn't use `--auto` only, nor did we append `--select manual` to allow manual selection):
-```
->> Title: Sintel
->> Filename: Sintel.2010.720p.mkv
->> Available subtitles:
-[1] "Sintel (2010).spa.srt" > "Language: Spanish"
-[2] "sintel_es.srt" > "Language: Spanish"
-[3] "Sintel.2010.720p.x264-VODO-spa.srt" > "Language: Spanish"
-[0] Cancel search
->> Enter your choice (0-3): 1
->> Downloading 'Spanish' subtitles for 'Sintel'
-2018-07-27 14:37:04 URL:http://dl.opensubtitles.org/en/download/src-api/vrf-19c10c57/sid-8rL5O0xhUw2BgKG6lvsVBM0p00f/filead/1955318590.gz [936/936] -> "-" [1]
-
-```
-
-These are all the available options:
-```
-$ opensubtitlesdownload --help
-usage: OpenSubtitlesDownload.py [-h] [-g GUI] [--cli] [-s SEARCH] [-t SELECT]
- [-a] [-v] [-l [LANG]]
- filePathListArg [filePathListArg ...]
-
-This software is designed to help you find and download subtitles for your favorite videos!
-
-
- -h, --help show this help message and exit
- -g GUI, --gui GUI Select the GUI you want from: auto, kde, gnome, cli (default: auto)
- --cli Force CLI mode
- -s SEARCH, --search SEARCH
- Search mode: hash, filename, hash_then_filename, hash_and_filename (default: hash_then_filename)
- -t SELECT, --select SELECT
- Selection mode: manual, default, auto
- -a, --auto Force automatic selection and download of the best subtitles found
- -v, --verbose Force verbose output
- -l [LANG], --lang [LANG]
- Specify the language in which the subtitles should be downloaded (default: eng).
- Syntax:
- -l eng,fre: search in both language
- -l eng -l fre: download both language
-
-```
-
-**The theme used for the screenshots in this article is called[Canta][4].**
-
-**You may also be interested in:[How To Replace Nautilus With Nemo File Manager On Ubuntu 18.04 Gnome Desktop (Complete Guide)][5]**
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxuprising.com/2018/07/download-subtitles-via-right-click-from.html
-
-作者:[Logix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/118280394805678839070
-[1]:https://emericg.github.io/OpenSubtitlesDownload/
-[2]:http://www.opensubtitles.org/addons/export_languages.php
-[3]:https://github.com/emericg/OpenSubtitlesDownload/wiki/Adjust-settings
-[4]:https://www.linuxuprising.com/2018/04/canta-is-amazing-material-design-gtk.html
-[5]:https://www.linuxuprising.com/2018/07/how-to-replace-nautilus-with-nemo-file.html
-[6]:https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py
diff --git a/sources/tech/20180731 What-s in a container image- Meeting the legal challenges.md b/sources/tech/20180731 What-s in a container image- Meeting the legal challenges.md
deleted file mode 100644
index dafb058a42..0000000000
--- a/sources/tech/20180731 What-s in a container image- Meeting the legal challenges.md
+++ /dev/null
@@ -1,64 +0,0 @@
-What's in a container image: Meeting the legal challenges
-======
-
-
-[Container][1] technology has, for many years, been transforming how workloads in data centers are managed and speeding the cycle of application development and deployment.
-
-In addition, container images are increasingly used as a distribution format, with container registries a mechanism for software distribution. Isn't this just like packages distributed using package management tools? Not quite. While container image distribution is similar to RPMs, DEBs, and other package management systems (for example, storing and distributing archives of files), the implications of container image distribution are more complicated. It is not the fault of container technology itself; rather, it's because container distribution is used differently than package management systems.
-
-Talking about the challenges of license compliance for container images, [Dirk Hohndel][2], chief open source officer at VMware, pointed out that the content of a container image is more complex than most people expect, and many readily available images have been built in surprisingly cavalier ways. (See the [LWN.net article][3] by Jake Edge about a talk Dirk gave in April.)
-
-Why is it hard to understand the licensing of container images? Shouldn't there just be a label for the image ("the license is X")? In the [Open Container Image Format Specification][4] , one of the pre-defined annotation keys is "org.opencontainers.image.licenses," which is described as "License(s) under which contained software is distributed as an SPDX License Expression." But that doesn't contemplate the complexity of a container image–while very simple images are built from tens of components, images are often built from hundreds of components. An [SPDX License Expression][5] is most frequently used to convey the licensing for a single source file. Such expressions can handle more than one license, such as "GPL-2.0 OR BSD-3-Clause" (see, for example, [Appendix IV][6] of version 2.1 of the SPDX specification). But the licensing for a typical container image is, typically, much more complicated.
-
-In talking about container-related technology, the term "[container][7]" can lead to confusion. A container does not refer to the containment of files for storing or transferring. Rather, it refers to using features built into the kernel (such as cgroups and namespaces) to present a sort of "contained" experience to code running on the kernel. In other words, the containment to which "container" refers is an execution experience, not a distribution experience. The set of files to be laid out in a file system as the basis for an executing container is typically distributed in what is known as a "container image," sometimes confusingly referred to simply as a container, thereby awkwardly overloading the term "container."
-
-In understanding software distribution via container images, I believe it is useful to consider two separate factors:
-
- * **Diversity of content:** The basic unit of software distribution (a container image) includes a larger quantity and diversity of content than in the basic unit of distribution in typical software distribution mechanisms.
- * **Use model:** The nature of widely used tooling fosters the use of a registry, which is often publicly available, in the typical workflow.
-
-
-
-### Diversity of content
-
-When talking about a particular container image, the focus of attention is often on a particular software component (for example, a database or the code that implements one specific service). However, the container image includes a much larger collection of software. In fact, even the developer who created the image may have only a superficial understanding of and/or interest in most of the components in the image. With other distribution mechanisms, those other pieces of software would be identified as dependencies, and users of the software might be directed elsewhere for expertise on those components. In a container, the individual who acquires the container image isn't aware of those additional components that play supporting roles to the featured component.
-
-#### The unit of distribution: user-driven vs. factory-driven
-
-For container images, the distribution unit is user-driven, not factory-driven. Container images are a great tool for reducing the burden on software consumers. With a container image, the image's consumer can focus on the application of interest; the image's builder can take care of the dependencies and configuration. This simplification can be a huge benefit.
-
-When the unit of software is driven by the "factory," the user bears a greater responsibility for building a platform on which to run the software of interest, assembling the correct versions of the dependencies, and getting all the configuration details right. The unit of distribution in a package management system is a modular unit, rather than a complete solution. This unit facilitates building and maintaining a flow of components that are flexible enough to be assembled into myriad solutions. Note that because of this unit, a package maintainer will typically be far more familiar with the content of the packages than someone who builds containers. A person building a container may have a detailed understanding of the container's featured components, but limited familiarity with the image's supporting components.
-
-Packages, package management system tools, package maintenance processes, and package maintainers are incredibly underappreciated. They have been central to delivery of a large variety of software over the last two decades. While container images are playing a growing role, I don't expect the importance of package management systems to fade anytime soon. In fact, the bulk of the content in container images benefits from being built from such packages.
-
-In understanding container images, it is important to appreciate how distribution via such images has different properties than distribution of packages. Much of the content in images is built from packages, but the image's consumer may not know what packages are included or other package-level information. In the future, a variety of techniques may be used to build containers, e.g., directly from source without involvement of a package maintainer.
-
-### Use models
-
-What about reports that so many container images are poorly built? In part, the volume of casually built images is because of container tools that facilitate a workflow to make images publicly available. When experimenting with container tools and moving to a workflow that extends beyond a laptop, the tools expect you to have a repository where multiple machines can pull container images (a container registry). You could spin up your own. Some widely used tools make it easy to use an existing registry that is available at no cost, provided the images are publicly available. This makes many casually built images visible, even those that were never intended to be maintained or updated.
-
-By comparison, how often do you see developers publishing RPMs of their early explorations? RPMs resulting from experimentation by random developers are not ending up in the major package repositories.
-
-Or consider someone experimenting with the latest machine learning frameworks. In the past, a researcher might have shared only analysis results. Now, they can share a full analytical software configuration by publishing a container image. This could be a great benefit to other researchers. However, those browsing a container registry could be confused by the ready-to-run nature of such images. It is important to distinguish between an image built for one individual's exploration and an image that was assembled and tested with broad use in mind.
-
-Be aware that container images include supporting software, not just the featured software; a container image distributes a collection of software. If you are building upon or otherwise using images built by others, be aware of how that image was built and consider your level of confidence in the image's source.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/whats-container-image-meeting-legal-challenges
-
-作者:[Scott Peterson][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/skpeterson
-[1]:https://opensource.com/resources/what-are-linux-containers
-[2]:https://www.linkedin.com/in/dirkhohndel
-[3]:https://lwn.net/Articles/752982/
-[4]:https://github.com/opencontainers/image-spec/blob/master/spec.md
-[5]:https://spdx.org/
-[6]:https://spdx.org/spdx-specification-21-web-version#h.jxpfx0ykyb60
-[7]:https://opensource.com/bus/16/8/introduction-linux-containers-and-image-signing
diff --git a/sources/tech/20180801 Getting started with Standard Notes for encrypted note-taking.md b/sources/tech/20180801 Getting started with Standard Notes for encrypted note-taking.md
deleted file mode 100644
index a2845eef65..0000000000
--- a/sources/tech/20180801 Getting started with Standard Notes for encrypted note-taking.md
+++ /dev/null
@@ -1,299 +0,0 @@
-Getting started with Standard Notes for encrypted note-taking
-======
-
-
-
-[Standard Notes][1] is a simple, encrypted notes app that aims to make dealing with your notes the easiest thing you'll do all day. When you sign up for a free sync account, your notes are automatically encrypted and seamlessly synced with all your devices.
-
-There are two key factors that differentiate Standard Notes from other, commercial software solutions:
-
- 1. The server and client are both completely open source.
- 2. The company is built on sustainable business practices and focuses on product development.
-
-
-
-When you combine open source with ethical business practices, you get a software product that has the potential to serve you for decades. You start to feel ownership in the product rather than feeling like just another transaction for an IPO-bound company.
-
-In this article, I’ll describe how to deploy your own Standard Notes open source syncing server on a Linux machine. You’ll then be able to use your server with our published applications for Linux, Windows, Android, Mac, iOS, and the web.
-
-If you don’t want to host your own server and are ready to start using Standard Notes right away, you can use our public syncing server. Simply head on over to [Standard Notes][1] to get started.
-
-### Hosting your own Standard Notes server
-
-Get the [Standard File Rails app][2] running on your Linux box and expose it via [NGINX][3] or any other web server.
-
-### Getting started
-
-These instructions are based on setting up our syncing server on a fresh [CentOS][4]-like installation. You can use a hosting service like [AWS][5] or [DigitalOcean][6] to launch your server, or even run it locally on your own machine.
-
- 1. Update your system:
-
-```
- sudo yum update
-
-```
-
- 2. Install [RVM][7] (Ruby Version Manager):
-
-```
- gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
- \curl -sSL https://get.rvm.io | bash -s stable
-
-```
-
- 3. Begin using RVM in current session:
-```
- source /home/ec2-user/.rvm/scripts/rvm
-
-```
-
- 4. Install [Ruby][8]:
-
-```
- rvm install ruby
-
-```
-
-This should install the latest version of Ruby (2.3 at the time of this writing.)
-
-Note that at least Ruby 2.2.2 is required for Rails 5.
-
- 5. Use Ruby:
-```
- rvm use ruby
-
-```
-
- 6. Install [Bundler][9]:
-
-```
- gem install bundler --no-ri --no-rdoc
-
-```
-
- 7. Install [mysql-devel][10]:
-```
- sudo yum install mysql-devel
-
-```
-
- 8. Install [MySQL][11] (optional; you can also use a hosted db through [Amazon RDS][12], which is recommended):
-```
- sudo yum install mysql56-server
-
- sudo service mysqld start
-
- sudo mysql_secure_installation
-
- sudo chkconfig mysqld on
-
-```
-
-Create a database:
-
-```
- mysql -u root -p
-
- > create database standard_file;
-
- > quit;
-
-```
-
- 9. Install [Passenger][13]:
-```
- sudo yum install rubygems
-
- gem install rubygems-update --no-rdoc --no-ri
-
- update_rubygems
-
- gem install passenger --no-rdoc --no-ri
-
-```
-
- 10. Remove system NGINX installation if installed (you’ll use Passenger’s instead):
-```
- sudo yum remove nginx
- sudo rm -rf /etc/nginx
-```
-
- 11. Configure Passenger:
-```
- sudo chmod o+x "/home/ec2-user"
-
- sudo yum install libcurl-devel
-
- rvmsudo passenger-install-nginx-module
-
- rvmsudo passenger-config validate-install
-
-```
-
- 12. Install Git:
-```
- sudo yum install git
-
-```
-
- 13. Set up HTTPS/SSL for your server (free using [Let'sEncrypt][14]; required if using the secure client on [https://app.standardnotes.org][15]):
-```
- sudo chown ec2-user /opt
-
- cd /opt
-
- git clone https://github.com/letsencrypt/letsencrypt
-
- cd letsencrypt
-
-```
-
-Run the setup wizard:
-```
- ./letsencrypt-auto certonly --standalone --debug
-
-```
-
-Note the location of the certificates, typically `/etc/letsencrypt/live/domain.com/fullchain.pem`
-
- 14. Configure NGINX:
-```
- sudo vim /opt/nginx/conf/nginx.conf
-
-```
-
-Add this to the bottom of the file, inside the last curly brace:
-```
- server {
-
- listen 443 ssl default_server;
-
- ssl_certificate /etc/letsencrypt/live/domain.com/fullchain.pem;
-
- ssl_certificate_key /etc/letsencrypt/live/domain.com/privkey.pem;
-
- server_name domain.com;
-
- passenger_enabled on;
-
- passenger_app_env production;
-
- root /home/ec2-user/ruby-server/public;
-
- }
-
-```
-
- 15. Make sure you are in your home directory and clone the Standard File [ruby-server][2] project:
-```
- cd ~
-
- git clone https://github.com/standardfile/ruby-server.git
-
- cd ruby-server
-
-```
-
- 16. Set up project:
-```
- bundle install
-
- bower install
-
- rails assets:precompile
-
-```
-
- 17. Create a .env file for your environment variables. The Rails app will automatically load these when it starts.
-
-```
- vim .env
-
-```
-
-Insert:
-```
- RAILS_ENV=production
-
- SECRET_KEY_BASE=use "bundle exec rake secret"
-
-
-
- DB_HOST=localhost
-
- DB_PORT=3306
-
- DB_DATABASE=standard_file
-
- DB_USERNAME=root
-
- DB_PASSWORD=
-
-```
-
- 18. Setup database:
-```
- rails db:migrate
-
-```
-
- 19. Start NGINX:
-```
- sudo /opt/nginx/sbin/nginx
-
-```
-
-Tip: you will need to restart NGINX whenever you make changes to your environment variables or the NGINX configuration:
-```
- sudo /opt/nginx/sbin/nginx -s reload
-
-```
-
- 20. You’re done!
-
-
-
-
-### Using your new server
-
-Now that you have your server running, you can plug it into any of the Standard Notes applications and sign into it.
-
-**On the Standard Notes web or desktop app:**
-
-Click Account, then Register. Choose "Advanced Options" and you’ll see a field for Sync Server. Enter your server’s URL here.
-
-**On the Standard Notes Android or iOS app:**
-
-Open the Settings window, click "Advanced Options" when signing in or registering, and enter your server URL in the Sync Server field.
-
-For help or questions with your Standard Notes server, join our [Slack group][16] in the #dev channel, or visit our [help page][17] for frequently asked questions and other topics.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/getting-started-standard-notes
-
-作者:[Mo Bitar][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mobitar
-[1]:https://standardnotes.org/
-[2]:https://github.com/standardfile/ruby-server
-[3]:https://www.nginx.com/
-[4]:https://www.centos.org/
-[5]:https://aws.amazon.com/
-[6]:https://www.digitalocean.com/
-[7]:https://rvm.io/
-[8]:https://www.ruby-lang.org/en/
-[9]:https://bundler.io/
-[10]:https://rpmfind.net/linux/rpm2html/search.php?query=mysql-devel
-[11]:https://www.mysql.com/
-[12]:https://aws.amazon.com/rds/
-[13]:https://www.phusionpassenger.com/
-[14]:https://letsencrypt.org/
-[15]:https://app.standardnotes.org/
-[16]:https://standardnotes.org/slack
-[17]:https://standardnotes.org/help
diff --git a/sources/tech/20180801 Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange.md b/sources/tech/20180801 Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange.md
deleted file mode 100644
index dbe5d042f9..0000000000
--- a/sources/tech/20180801 Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange.md
+++ /dev/null
@@ -1,114 +0,0 @@
-Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange
-======
-Previously, I have written about the email services [Protonmail][1] and [Tutanota][2] on It’s FOSS. And though I liked both of those email providers very much, some of us couldn’t possibly use these email services exclusively. If you are like me and you have an email address provided for you by your work, then you understand what I am talking about.
-
-Some of us use [Thunderbird][3] for these types of use cases, while others of us use something like [Geary][4] or even [Mailspring][5]. But for those of us who have to deal with [Microsoft Exchange Servers][6], none of these offer seamless solutions on Linux for our work needs.
-
-This is where [Hiri][7] comes in. We have already featured Hiri on our list of [best email clients for Linux][8], but we thought it was about time for an in-depth review.
-
-FYI, Hiri is neither free nor open source software.
-
-### Reviewing Hiri email client on Linux
-
-![Hiri email client review][9]
-
-According to their website, Hiri not only supports Microsoft Exchange and Office 365 accounts, it was exclusively “built for the Microsoft email ecosystem.”
-
-Based in Dublin, Ireland, Hiri has raised $2 million in funding. They have been in the business for almost five years but started supporting Linux only last year. The support for Linux has brought Hiri a considerable amount of success.
-
-I have been using Hiri for a week as of yesterday, and I have to say, I have been very pleased with my experience…for the most part.
-
-#### Hiri features
-
-Some of the main features of Hiri are:
-
- * Cross-platform application available for Linux, macOS and Windows
- * **Supports only Office 365, Outlook and Microsoft Exchange for now**
- * Clean and intuitive UI
- * Action filters
- * Reminders
- * [Skills][10]: Plugins to make you more productive with your emails
- * Office 365 and Exchange and other Calendar Sync
- * Compatible with [Active Directory][11]
- * Offline email access
- * Secure (it doesn’t send data to any third party server, it’s just an email client)
- * Compatible with Microsoft’s archiving tool
-
-
-
-#### Taking a look at Hiri Features
-
-![][12]
-
-Hiri can either be compiled manually or [installed easily as Snap][13] and comes jam-packed with useful features. But, if you knew me at all, you would know that usually, a robust feature list is not a huge selling point for me. As a self-proclaimed minimalist, I tend to believe the simpler option is often the better option, and the less “fluff” there is surrounding a product, the easier it is to get to the part that really matters. Admittedly, this is not always the case. For example, KDE’s [Plasma][14] desktop is known for its excessive amount of tweaks and features and I am still a huge Plasma fan. But in Hiri’s case, it has what feels like the perfect feature set and in no way feels convoluted or confusing.
-
-That is partially due to the way that Hiri works. If I had to put it into my own words, I would say that Hiri feels almost modular. It does this by utilizing what Hiri calls the Skill Center. Here you can add or remove functionality in Hiri at the flip of a switch. This includes the ability to add tasks, delegate action items to other people, set reminders, and even enables the user to create better subject lines. None of which are required, but each of which adds something to Hiri that no other email client has done as well.
-
-Using these features can help you organize your email like never before. The Dashboard feature allows you to monitor your time spent working on emails, the Task List enables you to stay on track, the Action/FYI feature allows you to tag your emails as needed to help you cipher through a messy inbox, and the Zero Inbox feature helps the user keep their inbox count at a minimum once they have sorted through the nonsense. And as someone who is an avid Inbox Zeroer (if that is even a thing), this to me was incredibly useful.
-
-Hiri also syncs with your associated calendars as you would expect, and it even allows a global search for all of the other accounts associated with your office. Need to email Frank Smith in Human Resources but can’t remember his email address? No big deal! Hiri will auto-fill the email address once you start typing in his name just like in a native Outlook client.
-
-Multiple account support is also available in Hiri. The support for IMAP will be added in a few months.
-
-In short, Hiri’s feature-set allows for what feels like a truly native Microsoft offering on Linux. It is clean, simple enough, and allows someone with my productivity workflow to thrive. I really dig what Hiri has to offer, and it’s as simple as that.
-
-#### Experiencing the Hiri UI
-
-As far as design goes, Hiri gets a solid A from me. I never felt like I was using something outdated looking like [Evolution][15] (I know people like Evolution a lot, but to say it is clean and modern is a lie), it never felt overly complicated like [KMail][16], and it felt less cramped than Thunderbird. Though I love Thunderbird dearly, the inbox list is just a little too small to feel like I can really cipher through my emails in a decent amount of time. Hiri seemingly fixes this but adds another issue that may be even worse.
-
-![][17]
-
-Geary is an email client that I think does layouts just right. It is spacious, but not in a wasteful way, it is clean, simple, and allows me to get from point A to point B quickly. Hiri, on the other hand, falls just shy of layout heaven. Though the inbox list looks fantastic, when you click to read an email it takes up the whole screen. Whereas Geary or Thunderbird can be set up to have the user’s list of emails on the left and opened emails in the same window on the right, which is my preferred way to read email, Hiri does not allow this functionality. The layout either looks and functions like it belongs on a mobile device, or the email preview is below the email list instead of to the right. This isn’t a make or break issue for me, but I will be honest and say I really don’t like it.
-
-In my opinion, Hiri could work even better with a couple of tweaks. But that opinion is just that, an opinion. Hiri is modern, clean, and intuitive enough, I am just obnoxiously picky. Other than that, the color palette is beautiful, the soft edges are pretty stunning, and Hiri’s overall design language is a breath of fresh air in the, at times, outdated feel that is oh so common in the Linux application world.
-
-Also, this isn’t Hiri’s fault but since I installed the Hiri snap it still has the same cursor theme issue that many other snaps suffer from, which drives me UP A WALL when I move in and out of the application, so there’s that.
-
-#### How much does Hiri cost?
-
-![Hiri is compatible with Microsoft Active Directory][18]
-
-Hiri is neither free nor open source software. [Hiri costs][19] either up to $39 a year or $119 for a lifetime license. However, it does provide a free seven day trial period.
-
-Considering the features it provides, Hiri is a good product even if you don’t have to deal with Microsoft Exchange Servers. Don’t take my word for it. Give Hiri a try for free for the seven day trial and see for yourself if it is worth paying or not.
-
-And if you decide to purchase it, I have further good news for you. Hiri team has agreed to provide an exclusive 60% discount to It’s FOSS readers. All you have to do is to use coupon code ITSFOSS60 at checkout.
-
-[Get 60% Off with ITSFOSS60 Coupon Code][20]
-
-#### Conclusion
-
-In the end, Hiri is an amazingly beautiful piece of software that checks so many boxes for me. That being said, the three marks that it misses for me are collectively too big to overlook: the layout, the cost, and the freedom (or lack thereof). If you are someone who is really in need of a native client, the layout does not bother you, you can justify spending some money, and you don’t want or need it to be FOSS, then you may have just found your new email client!
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/hiri-email-review/
-
-作者:[Phillip Prado][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/phillip/
-[1]:https://itsfoss.com/protonmail/
-[2]:https://itsfoss.com/tutanota-review/
-[3]:https://www.thunderbird.net/en-US/
-[4]:https://wiki.gnome.org/Apps/Geary
-[5]:http://getmailspring.com/
-[6]:https://en.wikipedia.org/wiki/Microsoft_Exchange_Server
-[7]:https://www.hiri.com/
-[8]:https://itsfoss.com/best-email-clients-linux/
-[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/hiri-email-client-review.jpeg
-[10]:https://www.hiri.com/skills/
-[11]:https://en.wikipedia.org/wiki/Active_Directory
-[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri2-e1533106054811.png
-[13]:https://snapcraft.io/hiri
-[14]:https://www.kde.org/plasma-desktop
-[15]:https://wiki.gnome.org/Apps/Evolution
-[16]:https://www.kde.org/applications/internet/kmail/
-[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri3-e1533106099642.png
-[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri1-e1533106238745.png
-[19]:https://www.hiri.com/pricing/
-[20]:https://www.hiri.com/download/
diff --git a/sources/tech/20180801 Migrating Perl 5 code to Perl 6.md b/sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
deleted file mode 100644
index 0399fd7a62..0000000000
--- a/sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
+++ /dev/null
@@ -1,77 +0,0 @@
-Migrating Perl 5 code to Perl 6
-======
-
-
-
-Whether you are a programmer who is taking the first steps to convert your Perl 5 code to Perl 6 and encountering some issues or you're just interested in learning about what might happen if you try to port Perl 5 programs to Perl 6, this article should answer your questions.
-
-The [Perl 6 documentation][1] already contains most (if not all) the [documentation you need][2] to deal with the issues you will confront in migrating Perl 5 code to Perl 6. But, as documentation goes, the focus is on the factual differences. I will try to go a little more in-depth about specific issues and provide a little more hands-on information based on my experience porting quite a lot of Perl 5 code to Perl 6.
-
-### How is Perl 6 anyway?
-
-Very well, thank you! Since its first official release in December 2015, Rakudo Perl 6 has seen an order of magnitude of improvement and quite a few bug fixes (more than 14,000 commits in total). Seven books about Perl 6 have been published so far. [Learning Perl 6][3] by Brian D. Foy will soon be published by O'Reilly, having been re-worked from the seminal [Learning Perl][4] (aka "The Llama Book") that many people have come to know and love.
-
-The user distribution [Rakudo Star][5] is on a three-month release cycle, and more than 1,100 modules are available in the [Perl 6 ecosystem][6]. The Rakudo Compiler Release is on a monthly release cycle and typically contains contributions by more than 30 people. Perl 6 modules are uploaded to the Perl programming Authors Upload Server ([PAUSE][7]) and distributed all over the world using the Comprehensive Perl Archive Network ([CPAN][8]).
-
-The online [Perl 6 Introduction][9] document has been translated into 12 languages, teaching over 3 billion people about Perl 6 in their native language. The most recent incarnation of [Perl 6 Weekly][10] has been reporting on all things Perl 6 every week since February 2014.
-
-[Cro][11], a microservices framework, uses all of Perl 6's features from the ground up, providing HTTP 1.1 persistent connections, HTTP 2.0 with request multiplexing, and HTTPS with optional certificate authority out of the box. And a [Perl 6 IDE][12] is now in (paid) beta (think of it as a Kickstarter with immediate deliverables).
-
-### Using Perl 5 features in Perl 6
-
-Perl 5 code can be seamlessly integrated with Perl 6 using the [`Inline::Perl5`][13] module, making all of [CPAN][14] available to any Perl 6 program. This could be considered cheating, as it will embed a Perl 5 interpreter and therefore continues to have a dependency on the `perl` (5) runtime. But it does make it easy to get your Perl 6 code running (if you need access to modules that have not yet been ported) simply by adding `:from<Perl5>` to your `use` statement, like `use DBI:from<Perl5>;`.
-
-In January 2018, I proposed a [CPAN Butterfly Plan][15] to convert Perl 5 functionality to Perl 6 as closely as possible to the original API. I stated this as a goal because Perl 5 (as a programming language) is so much more than syntax alone. Ask anyone what Perl's unique selling point is, and they will most likely tell you it is CPAN. Therefore, I think it's time to move from this view of the Perl universe:
-
-
-
-to a more modern view:
-
-
-
-In other words: put CPAN, as the most important element of Perl, in the center.
-
-### Converting semantics
-
-To run Perl 5 code natively in Perl 6, you also need a lot of Perl 5 semantics. Having (optional) support for Perl 5 semantics available in Perl 6 lowers the conceptual threshold that Perl 5 programmers perceive when trying to program in Perl 6. It's easier to feel at home!
-
-Since the publication of the CPAN Butterfly Plan, more than 100 built-in Perl 5 functions are now supported in Perl 6 with the same API. Many functions already exist in Perl 6 but have slightly different semantics, e.g., `shift` in Perl 5 magically shifts from `@_` (or `@ARGV`) if no parameter is specified; in Perl 6 the parameter is obligatory.
-
-More than 50 Perl 5 CPAN distributions have also been ported to Perl 6 while adhering to the original Perl 5 API. These include core modules such as [Scalar::Util][16] and [List::Util][17], but also non-core modules such as [Text::CSV][18] and [Memoize][19]. Distributions that are upstream on the [River of CPAN][20] are targeted to have as much effect on the ecosystem as possible.
-
-### Summary
-
-Rakudo Perl 6 has matured in such a way that using Perl 6 is now a viable approach to creating new, interactive projects. Being able to use reliable and proven Perl 5 language components aids in lowering the threshold for developers to use Perl 6, and it builds towards a situation where the sum of Perl 5 and Perl 6 becomes greater than its parts.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/migrating-perl-5-perl-6
-
-作者:[Elizabeth Mattijsen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/lizmat
-[1]:https://docs.perl6.org/
-[2]:https://docs.perl6.org/language/5to6-overview
-[3]:https://www.learningperl6.com
-[4]:http://shop.oreilly.com/product/0636920049517.do
-[5]:https://rakudo.org/files
-[6]:https://modules.perl6.org
-[7]:https://pause.perl.org/pause/query?ACTION=pause_04about
-[8]:https://www.cpan.org
-[9]:https://perl6intro.com
-[10]:https://p6weekly.wordpress.com
-[11]:https://cro.services
-[12]:https://commaide.com
-[13]:http://modules.perl6.org/dist/Inline::Perl5:cpan:NINE
-[14]:https://metacpan.org
-[15]:https://www.perl.com/article/an-open-letter-to-the-perl-community/
-[16]:https://modules.perl6.org/dist/Scalar::Util
-[17]:https://modules.perl6.org/dist/List::Util
-[18]:https://modules.perl6.org/dist/Text::CSV
-[19]:https://modules.perl6.org/dist/Memoize
-[20]:http://neilb.org/2015/04/20/river-of-cpan.html
diff --git a/sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md b/sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
deleted file mode 100644
index f4c9790df9..0000000000
--- a/sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
+++ /dev/null
@@ -1,117 +0,0 @@
-Walkthrough On How To Use GNOME Boxes
-======
-
-
-
-Boxes or GNOME Boxes is a virtualization software for GNOME Desktop Environment. It is similar to Oracle VirtualBox but features a simple user interface. Boxes also pose some challenge for newbies and VirtualBox users, for instance, on VirtualBox, it is easy to install guest addition image through menu bar but the same is not true for Boxes. Rather, users are encouraged to install additional guest tools from the terminal program within the guest session.
-
-This article will provide a walkthrough on how to use GNOME Boxes by installing the software and actually setting a guest session on the machine. It will also take you through the steps for installing the guest tools and provide some additional tips for Boxes configuration.
-
-### Purpose of virtualization
-
-If you are wondering what is the purpose of virtualization and why most computer experts and developers use them a lot. There is usually a common reason for this: **TESTING**.
-
-Developers who use Linux and writes software for Windows has to test his program on an actual Windows environment before deploying it to the end users. Virtualization makes it possible for him to install and set up a Windows guest session on his Linux computer.
-
-Virtualization is also used by ordinary users who wish to get hands-on with their favorite Linux distro that is still in beta release, without installing it on their physical computer. So in the event the virtual machine crashes, the host is not affected and the important files & documents stored on the physical disk remain intact.
-
-Virtualization allows you to test a software built for another platform/architecture which may include ARM, MIPS, SPARC, etc on your computer equipped with another architecture such as Intel or AMD.
-
-### Installing GNOME Boxes
-
-Launch Ubuntu Software and key in " gnome boxes ". Click the application name to load its installer page and then select the Install button. [][1]
-
-### Extra setup for Ubuntu 18.04
-
-There's a bug in GNOME Boxes on Ubuntu 18.04; it fails to start the Virtual Machine (VM). To remedy that, perform the below two steps on a terminal program:
-
-1. Add the line "group=kvm" to the qemu config file sudo gedit /etc/modprobe.d/qemu-system-x86.conf
-
-2. Add your user account to kvm group sudo usermod -a -G kvm
-
- [][2]
-
- After that, logout and re-login again for the changes to take effect.
-
-#### Downloading an image file
-
-You can download an image file/Operating System (OS) from the Internet or within the GNOME Boxes setup itself. However, for this article we'll proceed with the realistic method ie., downloading an image file from the Internet. We'll be configuring Lubuntu on Boxes so head over to this website to download the Linux distro.
-
-[Download][3]
-
-#### To burn or not to burn
-
-If you have no intention to distribute Lubuntu to your friends or install it on a physical machine then it's best not to burn the image file to a blank disc or portable USB drive. Instead just leave it as it is, we'll use it for creating a VM afterward.
-
-#### Starting GNOME Boxes
-
-Below is the interface of GNOME Boxes on Ubuntu - [][4]
-
-The interface is simple and intuitive for newbies to get familiar right away without much effort. Boxes don't feature a menu bar or toolbar, unlike Oracle VirtualBox. On the top left is the New button to create a VM and on the right houses buttons for VM options; delete list or grid view, and configuration (they'll become available when a VM is created).
-
-### Installing an Operating System
-
-Click the New button and choose "Select a file". Select the downloaded Lubuntu image file on the Downloads library and then click Create button.
-
- [][5]
-
-In case this is your first time installing an OS on a VM, do not panic when the installer pops up a window asking you to erase the disk partition. It's safe, your physical computer hard drive won't be erased, only that the storage space would be allocated for your VM. So on a 1TB hard drive, if you allocate 30 GB for your VM, performing erase partition operation on Boxes would only erase that virtual 30 GB storage drive and not the physical storage.
-
- _Usually, computer students find virtualization a useful tool for practicing advanced partitioning using UNIX based OS. You can too since there is no risk that would tamper the main OS files._
-
-After installing Lubuntu, you'll be prompted to reboot the computer (VM) to finish the installation process and actually boot from the hard drive. Confirm the operation.
-
-
-
-Sometimes, certain Linux distros hang in the reboot process after installation. The trick is to force shutdown the VM from the options button found on the top right side of the tile bar and then power it on again.
-
-#### Set up Guest tools
-
-By now you might have noticed Lubuntu's screen resolution is small with extra black spaces on the left and right side, and folder sharing is not enabled too. This brings up the need to install guest tools on Lubuntu.
-
-
-
-Launch terminal program from the guest session (not your host terminal program) and install the guest tools using the below command:
-
-sudo apt install spice-vdagent spice-webdavd
-
-After that, reboot Lubuntu and the next boot will set the VM to its appropriate screen resolution; no more extra black spaces on the left and right side. You can resize Boxes window and the guest screen resolution will automatically resize itself.
-
- [][6]
-
-To share a folder between the host and guest, open Boxes options while the guest is still running and choose Properties. On the Devices & Shares category, click the + button and set up the name. By default, Public folder from the host will be shared with the guest OS. You can configure the directory of your choice. After that is done, launch Lubuntu's file manager program (it's called PCManFM) and click Go menu on the menu bar. Select Network and choose Spice Client Folder. The first time you try to open it a dialog box will pop up asking you which program should handle the network, select PCManFM under Accessories category and the network will be mounted on the desktop. Launch it and there you'll see your shared folder name.
-
-Now you can share files and folders between host and guest computer. Subsequent launch of the network will directly open the shared folder so you don't have to open the folder manually the next time.
-
- [][7]
-
-#### Where's the OS installed?
-
-Lubuntu is installed as a VM using **GNOME Boxes** but where does it store the disk image?
-
-This question is of particular interest for those who wish to move the huge image file to another partition where there is sufficient storage. The trick is using symlinks which is efficient as it saves more space for Linux root partition and or home partition, depending on how the user set it up during installation. Boxes stores the disk image files to ~/.local/share/gnome-boxes/images folder
-
-### Conclusion
-
-We've successfully set up Lubuntu as a guest OS on our Ubuntu. You can try other variants of Ubuntu such as Kubuntu, Ubuntu MATE, Xubuntu, etc or some random Linux distros which in my opinion would be quite challenging due to varying package management. But there's no harm in wanting to :) You can also try installing other platforms like Microsoft Windows, OpenBSD, etc on your computer as a VM. And by the way, don't forget to leave your opinions in the comment section below.
-
-
---------------------------------------------------------------------------------
-
-via: http://www.linuxandubuntu.com/home/walkthrough-on-how-to-use-gnome-boxes
-
-作者:[linuxandubuntu][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://www.linuxandubuntu.com
-[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-gnome-boxes_orig.jpg
-[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-boxes-extras-for-ubuntu-18-04_orig.jpg
-[3]:https://lubuntu.net/
-[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-gnome-boxes_orig.jpg
-[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-os-on-ubuntu-guest-box_orig.jpg
-[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/lubuntu-on-gnome-boxes_orig.jpg
-[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-boxes-guest-addition_orig.jpg
diff --git a/sources/tech/20180803 How to use Fedora Server to create a router - gateway.md b/sources/tech/20180803 How to use Fedora Server to create a router - gateway.md
deleted file mode 100644
index 0394826c10..0000000000
--- a/sources/tech/20180803 How to use Fedora Server to create a router - gateway.md
+++ /dev/null
@@ -1,285 +0,0 @@
-How to use Fedora Server to create a router / gateway
-======
-
-
-
-Building a router (or gateway) using Fedora Server is an interesting project for users wanting to learn more about Linux system administration and networking. In this article, learn how to configure a Fedora Server minimal install to act as an internet router / gateway.
-
-This guide is based on [Fedora 28][1] and assumes you have already installed Fedora Server (minimal install). Additionally, you require a suitable network card / modem for the incoming internet connection. In this example, the [DrayTek VigorNIC 132][2] NIC was used to create the router.
-
-### Why build your own router
-
-There are many benefits for building your own router over buying a standalone box (or using the one supplied by your internet provider):
-
- * Easily update and run latest software versions
- * May be less prone to be part of larger hacking campaign as its not a common consumer device
- * Run your own VMs or containers on same host/router
- * Build OpenShift on top of router (future story in this series)
- * Include your own VPN, Tor, or other tunnel paths along with correct routing
-
-
-
-The downside is related to time and knowledge.
-
- * You have to manage your own security
- * You need to have the knowledge to troubleshoot if an issue happens or find it through the web (no support calls)
- * Costs more in most cases than hardware provided by an internet provider
-
-
-
-Basic network topology
-
-The diagram below describes the basic topology used in this setup. The machine running Fedora Server has a PCI Express modem for VDSL. Alternatively, if you use a [Raspberry Pi][3] with external modem the configuration is mostly similar.
-
-![topology][4]
-
-### Initial Setup
-
-First of all, install the packages needed to make the router. Bash auto-complete is included to make things easier when later configuring. Additionally, install packages to allow you to host your own VMs on the same router/hosts via KVM-QEMU.
-```
-dnf install -y bash-completion NetworkManager-ppp qemu-kvm qemu-img virt-manager libvirt libvirt-python libvirt-client virt-install virt-viewer
-
-```
-
-Next, use **nmcli** to set the MTU on the WAN(PPPoE) interfaces to align with DSL/ATM MTU and create **pppoe** interface. This [link][5] has a great explanation on how this works. The username and password will be provided by your internet provider.
-```
-nmcli connection add type pppoe ifname enp2s0 username 00xxx5511yyy0001@t-online.de password XXXXXX 802-3-ethernet.mtu 1452
-
-```
-
-Now, set up the firewall with the default zone as external and remove incoming SSH access.
-```
-firewall-cmd --set-default-zone=external
-firewall-cmd --permanent --zone=external --remove-service=ssh
-
-```
-
-Add LAN interface(br0) along with preferred LAN IP address and then add your physical LAN interface to the bridge.
-```
-nmcli connection add ifname br0 type bridge con-name br0 bridge.stp no ipv4.addresses 10.0.0.1/24 ipv4.method manual
-nmcli connection add type bridge-slave ifname enp1s0 master br0
-
-```
-
-Remember to use a subnet that does not overlap with your works VPN subnet. For example my work provides a 10.32.0.0/16 subnet when I VPN into the office so I need to avoid using this in my home network. If you overlap addressing then the route provided by your VPN will likely have lower priority and you will not route through the VPN tunnel.
-
-Now create a file called bridge.xml, containing a bridge definition that **virsh** will consume to create a bridge in **QEMU**.
-```
-cat > bridge.xml <<EOF
-<network>
- <name>host-bridge</name>
- <forward mode="bridge"/>
- <bridge name="br0"/>
-</network>
-EOF
-
-```
-
-Start and enable your libvirt-guests service so you can add the bridge in your virtual environment for the VMs to use.
-```
-systemctl start libvirt-guests.service
-systemctl enable libvirt-guests.service
-
-```
-
-Add your “host-bridge” to QEMU via virsh command and the XML file you created earlier.
-```
-virsh net-define bridge.xml
-
-```
-
-virsh net-start host-bridge virsh net-autostart host-bridge
-
-Add br0 to internal zone and allow DNS and DHCP as we will be setting up our own services on this router.
-```
-firewall-cmd --permanent --zone=internal --add-interface=br0
-firewall-cmd --permanent --zone=internal --add-service=dhcp
-firewall-cmd --permanent --zone=internal --add-service=dns
-
-```
-
-Since many DHCP clients including Windows and Linux don’t take into account the MTU attribute in DHCP, we will need to allow TCP based protocols to set MSS based on PMTU size.
-```
-firewall-cmd --permanent --direct --add-passthrough ipv4 -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
-
-```
-
-Now we reload the firewall to take permanent changes into account.
-```
-nmcli connection reload
-
-```
-
-### Install and Configure DHCP
-
-DHCP configuration depends on your home network setup. Use your own desired domain name and and the subnet was defined during the creation of **br0**. Be sure to note the MAC address in the config file below can either be capture from the command below once you have DHCP services up and running or you can pull it off the label externally on the device you want to set to static addressing.
-```
-cat /var/lib/dhcpd/dhcpd.leases
-
-dnf -y install dhcp
-vi /etc/dhcp/dhcpd.conf
-
-option domain-name "lajoie.org";
-option domain-name-servers 10.0.0.1;
-default-lease-time 600;
-max-lease-time 7200;
-authoritative;
-subnet 10.0.0.0 netmask 255.255.255.0 {
- range dynamic-bootp 10.0.0.100 10.0.0.254;
- option broadcast-address 10.0.0.255;
- option routers 10.0.0.1; option interface-mtu 1452;
-}
-host ubifi {
- option host-name "ubifi.lajoie.org";
- hardware ethernet f0:9f:c2:1f:c1:12;
- fixed-address 10.0.0.2;
-}
-
-```
-
-Now enable and start your DHCP server
-```
-systemctl start dhcpd
-systemctl enable dhcpd
-
-```
-
-### DNS Install and Configure
-
-Next, install **bind** and and **bind-utils** for tools like **nslookup** and **dig**.
-```
-dnf -y install bind bind-utils
-
-```
-
-Configure your bind server with listening address (LAN interface in this case) and the forward/reverse zones.
-```
-$ vi /etc/named.conf
-
-options {
- listen-on port 53 { 10.0.0.1; };
- listen-on-v6 port 53 { none; };
- directory "/var/named";
- dump-file "/var/named/data/cache_dump.db";
- statistics-file "/var/named/data/named_stats.txt";
- memstatistics-file "/var/named/data/named_mem_stats.txt";
- secroots-file "/var/named/data/named.secroots";
- recursing-file "/var/named/data/named.recursing";
- allow-query { 10.0.0.0/24; };
- recursion yes;
- forwarders {8.8.8.8; 8.8.4.4; };
- dnssec-enable yes;
- dnssec-validation yes;
- managed-keys-directory "/var/named/dynamic";
- pid-file "/run/named/named.pid";
- session-keyfile "/run/named/session.key";
- include "/etc/crypto-policies/back-ends/bind.config";
-};
-controls { };
-logging {
- channel default_debug {
- file "data/named.run";
- severity dynamic;
- };
-};
-view "internal" {
- match-clients { localhost; 10.0.0.0/24; };
- zone "lajoie.org" IN {
- type master;
- file "lajoie.org.db";
- allow-update { none; };
- };
- zone "0.0.10.in-addr.arpa" IN {
- type master;
- file "0.0.10.db";
- allow-update { none; };
- };
-};
-
-```
-
-Here is a zone file for example and make sure to update the serial number after each edit of the bind service will assume no changes took place.
-```
-$ vi /var/named/lajoie.org.db
-
-$TTL 86400
-@ IN SOA gw.lajoie.org. root.lajoie.org. (
- 2018040801 ;Serial
- 3600 ;Refresh
- 1800 ;Retry
- 604800 ;Expire
- 86400 ;Minimum TTL )
-IN NS gw.lajoie.org.
-IN A 10.0.0.1
-gw IN A 10.0.0.1
-ubifi IN A 10.0.0.2
-
-```
-
-Here is a reverse zone file for example and make sure to update the serial number after each edit of the bind service will assume no changes took place.
-```
-$ vi /var/named/0.0.10.db
-
-$TTL 86400
-@ IN SOA gw.lajoie.org. root.lajoie.org. (
- 2018040801 ;Serial
- 3600 ;Refresh
- 1800 ;Retry
- 604800 ;Expire
- 86400 ;Minimum TTL )
-IN NS gw.lajoie.org.
-IN PTR lajoie.org.
-IN A 255.255.255.0
-1 IN PTR gw.lajoie.org.
-2 IN PTR ubifi.lajoie.org.
-
-```
-
-Now enable and start your DNS server
-```
-systemctl start named
-systemctl enable named
-
-```
-
-# Secure SSH
-
-Last simple step is to make SSH service listen only on your LAN segment. Run this command to see whats listening at this moment. Remember we did not allow SSH on the external firewall zone but this step is still best practice in my opinion.
-```
-ss -lnp4
-
-```
-
-Now edit the SSH service to only listen on your LAN segment.
-```
-vi /etc/ssh/sshd_config
-
-AddressFamily inet
-ListenAddress 10.0.0.1
-
-```
-
-Restart your SSH service for changes to take effect.
-```
-systemctl restart sshd.service
-
-```
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/use-fedora-server-create-router-gateway/
-
-作者:[Eric Lajoie][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/elajoie/
-[1]:https://getfedora.org/en/server/
-[2]:https://www.draytek.com/en/products/products-a-z/router.all/vigornic-132-series/
-[3]:https://fedoraproject.org/wiki/Architectures/ARM/Raspberry_Pi
-[4]:https://ericlajoie.com/photo/FedoraRouter.png
-[5]:https://www.sonicwall.com/en-us/support/knowledge-base/170505851231244
diff --git a/sources/tech/20180806 How ProPublica Illinois uses GNU Make to load 1.4GB of data every day.md b/sources/tech/20180806 How ProPublica Illinois uses GNU Make to load 1.4GB of data every day.md
deleted file mode 100644
index f5cd367985..0000000000
--- a/sources/tech/20180806 How ProPublica Illinois uses GNU Make to load 1.4GB of data every day.md
+++ /dev/null
@@ -1,126 +0,0 @@
-How ProPublica Illinois uses GNU Make to load 1.4GB of data every day
-======
-
-
-
-I avoided using GNU Make in my data journalism work for a long time, partly because the documentation was so obtuse that I couldn’t see how Make, one of many extract-transform-load (ETL) processes, could help my day-to-day data reporting. But this year, to build [The Money Game][1], I needed to load 1.4GB of Illinois political contribution and spending data every day, and the ETL process was taking hours, so I gave Make another chance.
-
-Now the same process takes less than 30 minutes.
-
-Here’s how it all works, but if you want to skip directly to the code, [we’ve open-sourced it here][2].
-
-Fundamentally, Make lets you say:
-
- * File X depends on a transformation applied to file Y
- * If file X doesn’t exist, apply that transformation to file Y and make file X
-
-
-
-This “start with file Y to get file X” pattern is a daily reality of data journalism, and using Make to load political contribution and spending data was a great use case. The data is fairly large, accessed via a slow FTP server, has a quirky format, has just enough integrity issues to keep things interesting, and needs to be compatible with a legacy codebase. To tackle it, I needed to start from the beginning.
-
-### Overview
-
-The financial disclosure data we’re using is from the Illinois State Board of Elections, but the [Illinois Sunshine project][3] had released open source code (no longer available) to handle the ETL process and fundraising calculations. Using their code, the ETL process took about two hours to run on robust hardware and over five hours on our servers, where it would sometimes fail for reasons I never quite understood. I needed it to work better and work faster.
-
-The process looks like this:
-
- * **Download** data files via FTP from Illinois State Board Of Elections.
- * **Clean** the data using Python to resolve integrity issues and create clean versions of the data files.
- * **Load** the clean data into PostgreSQL using its highly efficient but finicky “\copy” command.
- * **Transform** the data in the database to clean up column names and provide more immediately useful forms of the data using “raw” and “public” PostgreSQL schemas and materialized views (essentially persistently cached versions of standard SQL views).
-
-
-
-The cleaning step must happen before any data is loaded into the database, so we can take advantage of PostgreSQL’s efficient import tools. If a single row has a string in a column where it’s expecting an integer, the whole operation fails.
-
-GNU Make is well-suited to this task. Make’s model is built around describing the output files your ETL process should produce and the operations required to go from a set of original source files to a set of output files.
-
-As with any ETL process, the goal is to preserve your original data, keep operations atomic and provide a simple and repeatable process that can be run over and over.
-
-Let’s examine a few of the steps:
-
-### Download and pre-import cleaning
-
-Take a look at this snippet, which could be a standalone Makefile:
-```
-data/download/%.txt : aria2c -x5 -q -d data/download --ftp-user="$(ILCAMPAIGNCASH_FTP_USER)" --ftp-passwd="$(ILCAMPAIGNCASH_FTP_PASSWD)" ftp://ftp.elections.il.gov/CampDisclDataFiles/$*.txt data/processed/%.csv : data/download/%.txt python processors/clean_isboe_tsv.py $< $* > $@
-
-```
-
-This snippet first downloads a file via FTP and then uses Python to process it. For example, if “Expenditures.txt” is one of my source data files, I can run `make data/processed/Expenditures.csv` to download and process the expenditure data.
-
-There are two things to note here.
-
-The first is that we use [Aria2][4] to handle FTP duties. Earlier versions of the script used other FTP clients that were either slow as molasses or painful to use. After some trial and error, I found Aria2 did the job better than lftp (which is fast but fussy) or good old ftp (which is both slow and fussy). I also found some incantations that took download times from roughly an hour to less than 20 minutes.
-
-Second, the cleaning step is crucial for this dataset. It uses a simple class-based Python validation scheme you can [see here][5]. The important thing to note is that while Python is pretty slow generally, Python 3 is fast enough for this. And as long as you are [only processing row-by-row][6] without any objects accumulating in memory or doing any extra disk writes, performance is fine, even on low-resource machines like the servers in ProPublica’s cluster, and there aren’t any unexpected quirks.
-
-### Loading
-
-Make is built around file inputs and outputs. But what happens if our data is both in files and database tables? Here are a few valuable tricks I learned for integrating database tables into Makefiles:
-
-**One SQL file per table / transform** : Make loves both files and simple mappings, so I created individual files with the schema definitions for each table or any other atomic table-level operation. The table names match the SQL filenames, the SQL filenames match the source data filenames. You can see them [here][7].
-
-**Use exit code magic to make tables look like files to Make** : Hannah Cushman and Forrest Gregg from DataMade [introduced me to this trick on Twitter][8]. Make can be fooled into treating tables like files if you prefix table level commands with commands that emit appropriate exit codes. If a table exists, emit a successful code. If it doesn’t, emit an error.
-
-Beyond that, loading consists solely of the highly efficient PostgreSQL `\copy` command. While the `COPY` command is even more efficient, it doesn’t play nicely with Amazon RDS. Even if ProPublica moved to a different database provider, I’d continue to use `\copy` for portability unless eking out a little more performance was mission-critical.
-
-There’s one last curveball: The loading step imports data to a PostgreSQL schema called `raw` so that we can cleanly transform the data further. Postgres schemas provide a useful way of segmenting data within a single database — instead of a single namespace with tables like `raw_contributions` and `clean_contributions`, you can keep things simple and clear with an almost folder-like structure of `raw.contributions` and `public.contributions`.
-
-### Post-import transformations
-
-The Illinois Sunshine code also renames columns and slightly reshapes the data for usability and performance reasons. Column aliasing is useful for end users and the intermediate tables are required for compatibility with the legacy code.
-
-In this case, the loader imports into a schema called `raw` that is as close to the source data as humanly possible.
-
-The data is then transformed by creating materialized views of the raw tables that rename columns and handle some light post-processing. This is enough for our purposes, but more elaborate transformations could be applied without sacrificing clarity or obscuring the source data. Here’s a snippet of one of these view definitions:
-```
-CREATE MATERIALIZED VIEW d2_reports AS SELECT id as id, committeeid as committee_id, fileddocid as filed_doc_id, begfundsavail as beginning_funds_avail, indivcontribi as individual_itemized_contrib, indivcontribni as individual_non_itemized_contrib, xferini as transfer_in_itemized, xferinni as transfer_in_non_itemized, # …. FROM raw.d2totals WITH DATA;
-```
-
-These transformations are very simple, but simply using more readable column names is a big improvement for end-users.
-
-As with table schema definitions, there is a file for each table that describes the transformed view. We use materialized views, which, again, are essentially persistently cached versions of standard SQL views, because storage is cheap and they are faster than traditional SQL views.
-
-### A note about security
-
-You’ll notice we use environment variables that are expanded inline when the commands are run. That’s useful for debugging and helps with portability. But it’s not a good idea if you think log files or terminal output could be compromised or people who shouldn’t know these secrets have access to logs or shared systems. For more security, you could use a system like the PostgreSQL `pgconf` file and remove the environment variable references.
-
-### Makefiles for the win
-
-My only prior experience with Make was in a computational math course 15 years ago, where it was a frustrating and poorly explained footnote. The combination of obtuse documentation, my bad experience in school and an already reliable framework kept me away. Plus, my shell scripts and Python Fabric/Invoke code were doing a fine job building reliable data processing pipelines based on the same principles for the smaller, quick turnaround projects I was doing.
-
-But after trying Make for this project, I was more than impressed with the results. It’s concise and expressive. It enforces atomic operations, but rewards them with dead simple ways to handle partial builds, which is a big deal during development when you really don’t want to be repeating expensive operations to test individual components. Combined with PostgreSQL’s speedy import tools, schemas, and materialized views, I was able to load the data in a fraction of the time. And just as important, the performance of the new process is less sensitive to varying system resources.
-
-If you’re itching to get started with Make, here are a few additional resources:
-
-+ [Making Data, The Datamade Way][9], by Hannah Cushman. My original inspiration.
-+ [“Why Use Make”][10] by Mike Bostock.
-+ [“Practical Makefiles, by example”][11] by John Tsiombikas is a nice resource if you want to dig deeper, but Make’s documentation is intimidating.
-
-
-In the end, the best build/processing system is any system that never alters source data, clearly shows transformations, uses version control and can be easily run over and over. Grunt, Gulp, Rake, Make, Invoke … you have options. As long as you like what you use and use it religiously, your work will benefit.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/how-propublica-illinois-uses-gnu-make
-
-作者:[David Eads][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/eads
-[1]:https://www.propublica.org/article/illinois-governors-race-campaign-widget-update
-[2]:https://github.com/propublica/ilcampaigncash/
-[3]:https://illinoissunshine.org/
-[4]:https://aria2.github.io/
-[5]:https://github.com/propublica/ilcampaigncash/blob/master/processors/lib/models.py
-[6]:https://github.com/propublica/ilcampaigncash/blob/master/processors/clean_isboe_tsv.py#L13
-[7]:https://github.com/propublica/ilcampaigncash/tree/master/sql/tables
-[8]:https://twitter.com/eads/status/968970130427404293
-[9]: https://github.com/datamade/data-making-guidelines
-[10]: https://bost.ocks.org/mike/make/
-[11]: http://nuclear.mutantstargoat.com/articles/make/
diff --git a/sources/tech/20180806 Recreate Famous Data Decryption Effect Seen On Sneakers Movie.md b/sources/tech/20180806 Recreate Famous Data Decryption Effect Seen On Sneakers Movie.md
deleted file mode 100644
index 9deb3242db..0000000000
--- a/sources/tech/20180806 Recreate Famous Data Decryption Effect Seen On Sneakers Movie.md
+++ /dev/null
@@ -1,110 +0,0 @@
-Recreate Famous Data Decryption Effect Seen On Sneakers Movie
-======
-
-
-
-A while ago, we published a guide that described how to [**turn your Ubuntu Linux console into a veritable Hollywood technical melodrama hacker interface**][1] using **Hollywood** utility which is written by **Dustin Kirkland** from Canonical. Today, I have stumbled upon a similar CLI utility named “ **N** o **M** ore **S** ecrets”, shortly **nms**. Like Hollywood utility, the nms utility is also **USELESS** (Sorry!). You can use it just for fun. The nms will recreate the famous data decryption effect seen on Sneakers, released in 1992.
-
-[**Sneakers**][2] is a comedy and crime-thriller genre movie, starred by **Robert Redford** among other famous actors named **Dan Aykroyd** , **David Strathairn** and **Ben Kingsley**. This movie is one of the popular hacker movie released in 1990s. If you haven’t watched it already, there is [**a scene**][3] in Sneakers movie where a group of experts who specialize in testing security systems will recover a top secret black box that has the ability to decrypt all existing encryption systems around the world. The nms utility simply simulates how exactly the data decryption effect scene looks like on Sneakers movie in your Terminal.
-
-### Installing Nms
-
-The nms project has no dependencies, but it relies on ANSI/VT100 terminal escape sequences to recreate the effect. Most modern terminal programs support these sequences by default. Just in case, if your Terminal doesn’t support these sequences, install **ncurses**. Ncurses is available in the default repositories of most Linux distributions. We are going to compile and install nms from source. So, just make sure you have installed the development tools in your Linux box. If you haven’t installed them already, refer the following links.
-
-After installing, git, make, and gcc development tools, run the following commands one by one to compile and install nms utility.
-```
-$ git clone https://github.com/bartobri/no-more-secrets.git
-$ cd ./no-more-secrets
-$ make nms
-$ make sneakers
-$ sudo make install
-
-```
-
-Finally, check if the installation was successful using command:
-```
-$ nms -v
-nms version 0.3.3
-
-```
-
-Alternatively, you can install nms using [**Linuxbrew**][4] package manager as shown below.
-```
-$ brew install no-more-secrets
-
-```
-
-Now it is time to run nms.
-
-### Recreate Famous Data Decryption Effect Seen On Sneakers Movie Using Nms
-
-The nms utility works on piped data. Pipe any Linux command’s output to nms tool like below and enjoy the effect right from your Terminal. Have a look at the following command:
-```
-$ ls -l | nms
-
-```
-
-By default, after the initial encrypted characters are displayed, the **nms** utility will wait for the user to press a key to start the decryption sequence. This is how the it is depicted in the Sneakers movie. Just press any key to start the decryption sequence to reveal the original plaintext characters.
-
-If you don’t want to press any key, you can auto-initiate the decryption sequence using **-a** flag.
-```
-$ ls -l | nms -a
-
-```
-
-You can also set a foreground color, for example green, use **-f <color>** option as shown below.
-```
-$ ls -l | nms -f green
-
-```
-
-Remember If you don’t specify **-a** flag, you must press any key to initiate the decryption sequence.
-
-To clear the screen before starting encryption and decryption processes, use **-c** flag.
-```
-$ ls -l | nms -c
-
-```
-
-To mask single blank space characters, use -s flag. Please note that other space characters such as tabs and newlines will not be masked.
-```
-$ ls -l | nms -s
-
-```
-
-You can also view the actual decryption effect scene in the Sneakers movie using the following command:
-```
-$ sneakers
-
-```
-
-Choose any option given to exit this utility.
-
-Don’t like it? Sorry about that. Go to the nms project folder and simply run the following command to remove it.
-```
-$ sudo make uninstall
-
-```
-
-And, that’s all for now. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/no-more-secrets-recreate-famous-data-decryption-effect-seen-on-sneakers-movie/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/turn-ubuntu-terminal-hollywood-technical-melodrama-hacker-interface/
-[2]:https://www.imdb.com/title/tt0105435/
-[3]:https://www.youtube.com/watch?v=F5bAa6gFvLs&t=35
-[4]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
diff --git a/sources/tech/20180806 Use Gstreamer and Python to rip CDs.md b/sources/tech/20180806 Use Gstreamer and Python to rip CDs.md
deleted file mode 100644
index 7b78184ad9..0000000000
--- a/sources/tech/20180806 Use Gstreamer and Python to rip CDs.md
+++ /dev/null
@@ -1,312 +0,0 @@
-Use Gstreamer and Python to rip CDs
-======
-
-
-
-In a previous article, you learned how to use the MusicBrainz service to provide tag information for your audio files, using a simple Python script. This article shows you how to also script an all-in-one solution to copy your CDs down to a music library folder in your choice of formats.
-
-Unfortunately, the powers that be make it impossible for Fedora to carry the necessary bits to encode MP3 in official repos. So that part is left as an exercise for the reader. But if you use a cloud service such as Google Play to host your music, this script makes audio files you can upload easily.
-
-The script will record your CD down to one of the following file formats:
-
- * Uncompressed WAV, which you can further encode or play with.
- * Compressed but lossless FLAC. Lossless files preserve all the fidelity of the original audio.
- * Compressed, lossy Ogg Vorbis. Like MP3 and Apple’s AAC, Ogg Vorbis uses special algorithms and psychoacoustic properties to sound close to the original audio. However, Ogg Vorbis usually produces superior results to those other compressed formats at the same file sizes. You can[read more about it here][1] if you like technical details.
-
-
-
-### The components
-
-The first element of the script is a [GStreamer][2] pipeline. GStreamer is a full featured multimedia framework included in Fedora. It comes [installed by default in Workstation][3], too. GStreamer is used behind the scene by many multimedia apps in Fedora. It lets apps manipulate all kinds of video and audio files.
-
-The second major component in this script is choosing, and using, a multimedia tagging library. In this case [the mutagen library][4] makes it easy to tag many kinds of multimedia files. The script in this article uses mutagen to tag Ogg Vorbis or FLAC files.
-
-Finally, the script uses [Python’s argparse, part of the standard library][5], for some easy to use options and help text. The argparse library is useful for most Python scripts where you expect the user to provide parameters. This article won’t cover this part of the script in great detail.
-
-### The script
-
-You may recall [the previous article][6] that used MusicBrainz to fetch tag information. This script includes that code, with some tweaks to make it integrate better with the new functions. (You may find it easier to read this script if you copy and paste it into your favorite editor.)
-```
-#!/usr/bin/python3
-
-import os, sys
-import subprocess
-from argparse import ArgumentParser
-import libdiscid
-import musicbrainzngs as mb
-import requests
-import json
-from getpass import getpass
-
-parser = ArgumentParser()
-parser.add_argument('-f', '--flac', action='store_true', dest='flac',
- default=False, help='Rip to FLAC format')
-parser.add_argument('-w', '--wav', action='store_true', dest='wav',
- default=False, help='Rip to WAV format')
-parser.add_argument('-o', '--ogg', action='store_true', dest='ogg',
- default=False, help='Rip to Ogg Vorbis format')
-options = parser.parse_args()
-
-# Set up output varieties
-if options.wav + options.ogg + options.flac > 1:
- raise parser.error("Only one of -f, -o, -w please")
-if options.wav:
- fmt = 'wav'
- encoding = 'wavenc'
-elif options.flac:
- fmt = 'flac'
- encoding = 'flacenc'
- from mutagen.flac import FLAC as audiofile
-elif options.ogg:
- fmt = 'oga'
- quality = 'quality=0.3'
- encoding = 'vorbisenc {} ! oggmux'.format(quality)
- from mutagen.oggvorbis import OggVorbis as audiofile
-
-# Get MusicBrainz info
-this_disc = libdiscid.read(libdiscid.default_device())
-mb.set_useragent(app='get-contents', version='0.1')
-mb.auth(u=input('Musicbrainz username: '), p=getpass())
-
-release = mb.get_releases_by_discid(this_disc.id, includes=['artists',
- 'recordings'])
-if release.get('disc'):
- this_release=release['disc']['release-list'][0]
-
- album = this_release['title']
- artist = this_release['artist-credit'][0]['artist']['name']
- year = this_release['date'].split('-')[0]
-
- for medium in this_release['medium-list']:
- for disc in medium['disc-list']:
- if disc['id'] == this_disc.id:
- tracks = medium['track-list']
- break
-
- # We assume here the disc was found. If you see this:
- # NameError: name 'tracks' is not defined
- # ...then the CD doesn't appear in MusicBrainz and can't be
- # tagged. Use your MusicBrainz account to create a release for
- # the CD and then try again.
-
- # Get cover art to cover.jpg
- if this_release['cover-art-archive']['artwork'] == 'true':
- url = 'http://coverartarchive.org/release/' + this_release['id']
- art = json.loads(requests.get(url, allow_redirects=True).content)
- for image in art['images']:
- if image['front'] == True:
- cover = requests.get(image['image'], allow_redirects=True)
- fname = '{0} - {1}.jpg'.format(artist, album)
- print('Saved cover art as {}'.format(fname))
- f = open(fname, 'wb')
- f.write(cover.content)
- f.close()
- break
-
-for trackn in range(len(tracks)):
- track = tracks[trackn]['recording']['title']
-
- # Output file name based on MusicBrainz values
- outfname = '{:02} - {}.{}'.format(trackn+1, track, fmt).replace('/', '-')
-
- print('Ripping track {}...'.format(outfname))
- cmd = 'gst-launch-1.0 cdiocddasrc track={} ! '.format(trackn+1) + \
- 'audioconvert ! {} ! '.format(encoding) + \
- 'filesink location="{}"'.format(outfname)
- msgs = subprocess.getoutput(cmd)
-
- if not options.wav:
- audio = audiofile(outfname)
- print('Tagging track {}...'.format(outfname))
- audio['TITLE'] = track
- audio['TRACKNUMBER'] = str(trackn+1)
- audio['ARTIST'] = artist
- audio['ALBUM'] = album
- audio['DATE'] = year
- audio.save()
-
-```
-
-#### Determining output format
-
-This part of the script lets the user decide how to format the output files:
-```
-parser = ArgumentParser()
-parser.add_argument('-f', '--flac', action='store_true', dest='flac',
- default=False, help='Rip to FLAC format')
-parser.add_argument('-w', '--wav', action='store_true', dest='wav',
- default=False, help='Rip to WAV format')
-parser.add_argument('-o', '--ogg', action='store_true', dest='ogg',
- default=False, help='Rip to Ogg Vorbis format')
-options = parser.parse_args()
-
-# Set up output varieties
-if options.wav + options.ogg + options.flac > 1:
- raise parser.error("Only one of -f, -o, -w please")
-if options.wav:
- fmt = 'wav'
- encoding = 'wavenc'
-elif options.flac:
- fmt = 'flac'
- encoding = 'flacenc'
- from mutagen.flac import FLAC as audiofile
-elif options.ogg:
- fmt = 'oga'
- quality = 'quality=0.3'
- encoding = 'vorbisenc {} ! oggmux'.format(quality)
- from mutagen.oggvorbis import OggVorbis as audiofile
-
-```
-
-The parser, built from the argparse library, gives you a built in –help function:
-```
-$ ipod-cd --help
-usage: ipod-cd [-h] [-b BITRATE] [-w] [-o]
-
-optional arguments:
- -h, --help show this help message and exit
- -b BITRATE, --bitrate BITRATE
- Set a target bitrate
- -w, --wav Rip to WAV format
- -o, --ogg Rip to Ogg Vorbis format
-
-```
-
-The script allows the user to use -f, -w, or -o on the command line to choose a format. Since these are stored as True (a Python boolean value), they can also be treated as the integer value 1. If more than one is selected, the parser generates an error.
-
-Otherwise, the script sets an appropriate encoding string to be used with GStreamer later in the script. Notice the Ogg Vorbis selection also includes a quality setting, which is then included in the encoding. Care to try your hand at an easy change? Try making a parser argument and additional formatting code so the user can select a quality value between -0.1 and 1.0.
-
-Notice also that for each of the file formats that allows tagging (WAV does not), the script imports a different tagging class. This way the script can have simpler, less confusing tagging code later in the script. In this script, both Ogg Vorbis and FLAC are using classes from the mutagen library.
-
-#### Getting CD info
-
-The next section of the script attempts to load MusicBrainz info for the disc. You’ll find that audio files ripped with this script have data not included in the Python code here. This is because GStreamer is also capable of detecting CD-Text that’s included on some discs during the mastering and manufacturing process. Often, though, this data is in all capitals (like “TRACK TITLE”). MusicBrainz info is more compatible with modern apps and other platforms.
-
-For more information on this section, [refer to the previous article here on the Magazine][6]. A few trivial changes appear here to make the script work better as a single process.
-
-One item to note is this warning:
-```
-# We assume here the disc was found. If you see this:
-# NameError: name 'tracks' is not defined
-# ...then the CD doesn't appear in MusicBrainz and can't be
-# tagged. Use your MusicBrainz account to create a release for
-# the CD and then try again.
-
-```
-
-The script as shown doesn’t include a way to handle cases where CD information isn’t found. This is on purpose. If it happens, take a moment to help the community by [entering CD information on MusicBrainz][7], using your login account.
-
-#### Ripping and labeling tracks
-
-The next section of the script actually does the work. It’s a simple loop that iterates through the track list found via MusicBrainz.
-
-First, the script sets the output filename for the individual track based on the format the user selected:
-```
-for trackn in range(len(tracks)):
- track = tracks[trackn]['recording']['title']
-
- # Output file name based on MusicBrainz values
- outfname = '{:02} - {}.{}'.format(trackn+1, track, fmt)
-
-```
-
-Then, the script calls a CLI GStreamer utility to perform the ripping and encoding process. That process turns each CD track into an audio file in your current directory:
-```
- print('Ripping track {}...'.format(outfname))
- cmd = 'gst-launch-1.0 cdiocddasrc track={} ! '.format(trackn+1) + \
- 'audioconvert ! {} ! '.format(encoding) + \
- 'filesink location="{}"'.format(outfname)
- msgs = subprocess.getoutput(cmd)
-
-```
-
-The complete GStreamer pipeline would look like this at a command line:
-```
-gst-launch-1.0 cdiocddasrc track=1 ! audioconvert ! vorbisenc quality=0.3 ! oggmux ! filesink location="01 - Track Name.oga"
-
-```
-
-GStreamer has Python libraries to let you use the framework in interesting ways directly without using subprocess. To keep this article less complex, the script calls the command line utility from Python to do the multimedia work.
-
-Finally, the script labels the output file if it’s not a WAV file. Both Ogg Vorbis and FLAC use similar methods in their mutagen classes. That means this code can remain very simple:
-```
- if not options.wav:
- audio = audiofile(outfname)
- print('Tagging track {}...'.format(outfname))
- audio['TITLE'] = track
- audio['TRACKNUMBER'] = str(trackn+1)
- audio['ARTIST'] = artist
- audio['ALBUM'] = album
- audio['DATE'] = year
- audio.save()
-
-```
-
-If you decide to write code for another file format, you need to import the correct class earlier, and then perform the tagging correctly. You don’t have to use the mutagen class. For instance, you might choose to use eyed3 for tagging MP3 files. In that case, the tagging code might look like this:
-```
-...
-# In the parser handling for MP3 format
-from eyed3 import load as audiofile
-...
-# In the handling for MP3 tags
-audio.tag.version = (2, 3, 0)
-audio.tag.artist = artist
-audio.tag.title = track
-audio.tag.album = album
-audio.tag.track_num = (trackn+1, len(tracks))
-audio.tag.save()
-
-```
-
-(Note the encoding function is up to you to provide.)
-
-### Running the script
-
-Here’s an example output of the script:
-```
-$ ipod-cd -o
-Ripping track 01 - Shout, Pt. 1.oga...
-Tagging track 01 - Shout, Pt. 1.oga...
-Ripping track 02 - Stars of New York.oga...
-Tagging track 02 - Stars of New York.oga...
-Ripping track 03 - Breezy.oga...
-Tagging track 03 - Breezy.oga...
-Ripping track 04 - Aeroplane.oga...
-Tagging track 04 - Aeroplane.oga...
-Ripping track 05 - Minor Is the Lonely Key.oga...
-Tagging track 05 - Minor Is the Lonely Key.oga...
-Ripping track 06 - You Can Come Round If You Want To.oga...
-Tagging track 06 - You Can Come Round If You Want To.oga...
-Ripping track 07 - I'm Gonna Haunt This Place.oga...
-Tagging track 07 - I'm Gonna Haunt This Place.oga...
-Ripping track 08 - Crash That Piano.oga...
-Tagging track 08 - Crash That Piano.oga...
-Ripping track 09 - Save Yourself.oga...
-Tagging track 09 - Save Yourself.oga...
-Ripping track 10 - Get on Home.oga...
-Tagging track 10 - Get on Home.oga...
-
-```
-
-Enjoy burning your old CDs into easily portable audio files!
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/use-gstreamer-python-rip-cds/
-
-作者:[Paul W. Frields][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/pfrields/
-[1]:https://xiph.org/vorbis/
-[2]:https://gstreamer.freedesktop.org/
-[3]:https://getfedora.org/workstation
-[4]:https://mutagen.readthedocs.io/en/latest/
-[5]:https://docs.python.org/3/library/argparse.html
-[6]:https://fedoramagazine.org/use-musicbrainz-get-cd-information/
-[7]:https://musicbrainz.org/
diff --git a/sources/tech/20180809 Getting started with Postfix, an open source mail transfer agent.md b/sources/tech/20180809 Getting started with Postfix, an open source mail transfer agent.md
deleted file mode 100644
index a98065489d..0000000000
--- a/sources/tech/20180809 Getting started with Postfix, an open source mail transfer agent.md
+++ /dev/null
@@ -1,334 +0,0 @@
-Getting started with Postfix, an open source mail transfer agent
-======
-
-
-
-[Postfix][1] is a great program that routes and delivers email to accounts that are external to the system. It is currently used by approximately [33% of internet mail servers][2]. In this article, I'll explain how you can use Postfix to send mail using Gmail with two-factor authentication enabled.
-
-Before you get Postfix up and running, however, you need to have some items lined up. Following are instructions on how to get it working on a number of distros.
-
-### Prerequisites
-
- * An installed OS (Ubuntu/Debian/Fedora/Centos/Arch/FreeBSD/OpenSUSE)
- * A Google account with two-factor authentication
- * A working internet connection
-
-
-
-### Step 1: Prepare Google
-
-Open a web browser and log into your Google account. Once you’re in, go to your settings by clicking your picture and selecting "Google Account.” Click “Sign-in & security” and scroll down to "App passwords.” Use your password to log in. Then you can create a new app password (I named mine "postfix Setup”).
-
-
-
-Note the crazy password (shown below), which I will use throughout this article.
-
-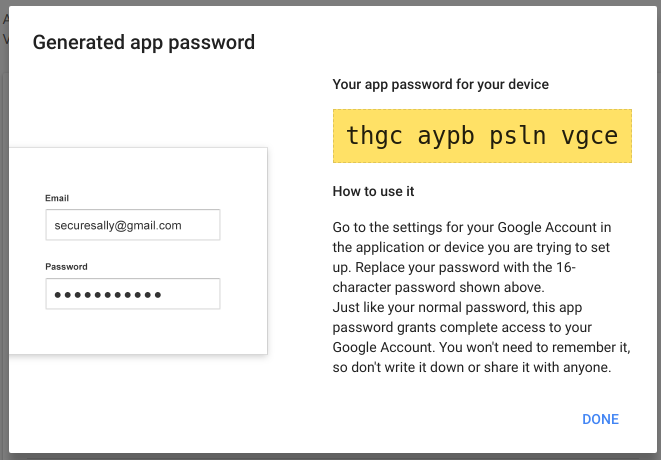
-
-### Step 2: Install Postfix
-
-Before you can configure the mail client, you need to install it. You must also install either the `mailutils` or `mailx` utility, depending on the OS you're using. Here's how to install it for each OS:
-
-**Debian/Ubuntu** :
-```
-apt-get update && apt-get install postfix mailutils
-
-```
-
-**Fedora** :
-```
-dnf update && dnf install postfix mailx
-
-```
-
-**Centos** :
-```
-yum update && yum install postfix mailx cyrus-sasl cyrus-sasl-plain
-
-```
-
-**Arch** :
-```
-pacman -Sy postfix mailutils
-
-```
-
-**FreeBSD** :
-```
-portsnap fetch extract update
-
-cd /usr/ports/mail/postfix
-
-make config
-
-```
-
-In the configuration dialog, select "SASL support." All other options can remain the same.
-
-From there: `make install clean`
-
-Install `mailx` from the binary package: `pkg install mailx`
-
-**OpenSUSE** :
-```
-zypper update && zypper install postfix mailx cyrus-sasl
-
-```
-
-### Step 3: Set up Gmail authentication
-
-Once you've installed Postfix, you can set up Gmail authentication. Since you have created the app password, you need to put it in a configuration file and lock it down so no one else can see it. Fortunately, this is simple to do:
-
-**Ubuntu/Debian/Fedora/Centos/Arch/OpenSUSE** :
-```
-vim /etc/postfix/sasl_passwd
-
-```
-
-Add this line:
-```
-[smtp.gmail.com]:587 ben.heffron@gmail.com:thgcaypbpslnvgce
-
-```
-
-Save and close the file. Since your Gmail password is stored as plaintext, make the file accessible only by root to be extra safe.
-```
-chmod 600 /etc/postfix/sasl_passwd
-
-```
-
-**FreeBSD** :
-```
-vim /usr/local/etc/postfix/sasl_passwd
-
-```
-
-Add this line:
-```
-[smtp.gmail.com]:587 ben.heffron@gmail.com:thgcaypbpslnvgce
-
-```
-
-Save and close the file. Since your Gmail password is stored as plaintext, make the file accessible only by root to be extra safe.
-```
-chmod 600 /usr/local/etc/postfix/sasl_passwd
-
-```
-
-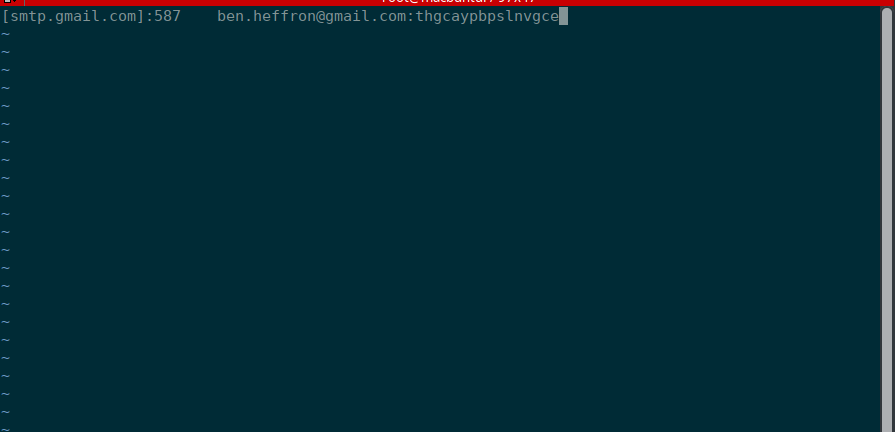
-
-### Step 4: Get Postfix moving
-
-This step is the "meat and potatoes"—everything you've done so far has been preparation.
-
-Postfix gets its configuration from the `main.cf` file, so the settings in this file are critical. For Google, it is mandatory to enable the correct SSL settings.
-
-Here are the six options you need to enter or update on the `main.cf` to make it work with Gmail (from the [SASL readme][3]):
-
- * The **smtp_sasl_auth_enable** setting enables client-side authentication. We will configure the client’s username and password information in the second part of the example.
- * The **relayhost** setting forces the Postfix SMTP to send all remote messages to the specified mail server instead of trying to deliver them directly to their destination.
- * With the **smtp_sasl_password_maps** parameter, we configure the Postfix SMTP client to send username and password information to the mail gateway server.
- * Postfix SMTP client SASL security options are set using **smtp_sasl_security_options** , with a whole lot of options. In this case, it will be nothing; otherwise, Gmail won’t play nicely with Postfix.
- * The **smtp_tls_CAfile** is a file containing CA certificates of root CAs trusted to sign either remote SMTP server certificates or intermediate CA certificates.
- * From the [configure settings page:][4] **stmp_use_tls** uses TLS when a remote SMTP server announces STARTTLS support, the default is not using TLS.
-
-
-
-**Ubuntu/Debian/Arch**
-
-These three OSes keep their files (certificates and `main.cf`) in the same location, so this is all you need to put in there:
-```
-vim /etc/postfix/main.cf
-
-```
-
-If the following values aren’t there, add them:
-```
-relayhost = [smtp.gmail.com]:587
-
-smtp_use_tls = yes
-
-smtp_sasl_auth_enable = yes
-
-smtp_sasl_security_options =
-
-smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
-
-smtp_tls_CAfile = /etc/ssl/certs/ca-certificates.crt
-
-```
-
-Save and close the file.
-
-**Fedora/CentOS**
-
-These two OSes are based on the same underpinnings, so they share the same updates.
-```
-vim /etc/postfix/main.cf
-
-```
-
-If the following values aren’t there, add them:
-```
-relayhost = [smtp.gmail.com]:587
-
-smtp_use_tls = yes
-
-smtp_sasl_auth_enable = yes
-
-smtp_sasl_security_options =
-
-smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
-
-smtp_tls_CAfile = /etc/ssl/certs/ca-bundle.crt
-
-```
-
-Save and close the file.
-
-**OpenSUSE**
-```
-vim /etc/postfix/main.cf
-
-```
-
-If the following values aren’t there, add them:
-```
-relayhost = [smtp.gmail.com]:587
-
-smtp_use_tls = yes
-
-smtp_sasl_auth_enable = yes
-
-smtp_sasl_security_options =
-
-smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
-
-smtp_tls_CAfile = /etc/ssl/ca-bundle.pem
-
-```
-
-Save and close the file.
-
-OpenSUSE also requires that you modify the Postfix master process configuration file `master.cf`. Open it for editing:
-```
-vim /etc/postfix/master.cf
-
-```
-
-Uncomment the line that reads:
-```
-#tlsmgr unix - - n 1000? 1 tlsmg
-
-```
-
-It should look like this:
-```
-tlsmgr unix - - n 1000? 1 tlsmg
-
-```
-
-Save and close the file.
-
-**FreeBSD**
-```
-vim /usr/local/etc/postfix/main.cf
-
-```
-
-If the following values aren’t there, add them:
-```
-relayhost = [smtp.gmail.com]:587
-
-smtp_use_tls = yes
-
-smtp_sasl_auth_enable = yes
-
-smtp_sasl_security_options =
-
-smtp_sasl_password_maps = hash:/usr/local/etc/postfix/sasl_passwd
-
-smtp_tls_CAfile = /etc/mail/certs/cacert.pem
-
-```
-
-Save and close the file.
-
-### Step 5: Set up the password file
-
-Remember that password file you created? Now you need to feed it into Postfix using `postmap`. This is part of the `mailutils` or `mailx` utilities.
-
-**Debian, Ubuntu, Fedora, CentOS, OpenSUSE, Arch Linux**
-```
-postmap /etc/postfix/sasl_passwd
-
-```
-
-**FreeBSD**
-```
-postmap /usr/local/etc/postfix/sasl_passwd
-
-```
-
-### Step 6: Get Postfix grooving
-
-To get all the settings and configurations working, you must restart Postfix.
-
-**Debian, Ubuntu, Fedora, CentOS, OpenSUSE, Arch Linux**
-
-These guys make it simple to restart:
-```
-systemctl restart postfix.service
-
-```
-
-**FreeBSD**
-
-To start Postfix at startup, edit `/etc/rc.conf`:
-```
-vim /etc/rc.conf
-
-```
-
-Add the line:
-```
-postfix_enable=YES
-
-```
-
-Save and close the file. Then start Postfix by running:
-```
-service postfix start
-
-```
-
-### Step 7: Test it
-
-Now for the big finale—time to test it to see if it works. The `mail` command is another tool installed with `mailutils` or `mailx`.
-```
-echo Just testing my sendmail gmail relay" | mail -s "Sendmail gmail Relay" ben.heffron@gmail.com
-
-```
-
-This is what I used to test my settings, and then it came up in my Gmail.
-
-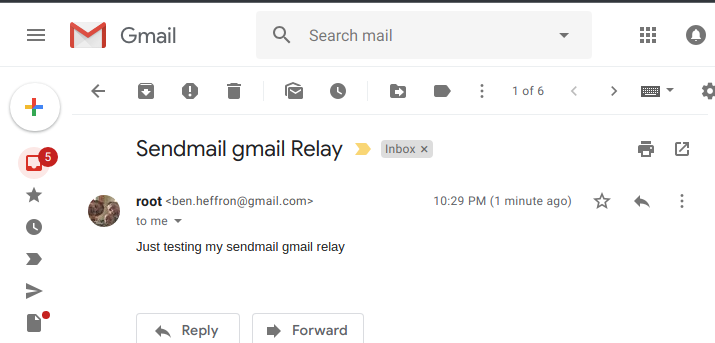
-
-Now you can use Gmail with two-factor authentication in your Postfix setup.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/postfix-open-source-mail-transfer-agent
-
-作者:[Ben Heffron][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/elheffe
-[1]:http://www.postfix.org/start.html
-[2]:http://www.securityspace.com/s_survey/data/man.201806/mxsurvey.html
-[3]:http://www.postfix.org/SASL_README.html
-[4]:http://www.postfix.org/postconf.5.html#smtp_tls_security_level
diff --git a/sources/tech/20180810 Strawberry- Quality sound, open source music player.md b/sources/tech/20180810 Strawberry- Quality sound, open source music player.md
deleted file mode 100644
index 6cc72dccfb..0000000000
--- a/sources/tech/20180810 Strawberry- Quality sound, open source music player.md
+++ /dev/null
@@ -1,105 +0,0 @@
-Strawberry: Quality sound, open source music player
-======
-
-
-
-I recently received an email from [Jonas Kvinge][1] who forked the [Clementine open source music player][2]. Jonas writes:
-
-I started working on a modified version of Clementine already in 2013, but because of other priorities, I did not pick up the work again before last year. I had not decided then if I was creating a fork, or contributing to Clementine. I ended up doing both. I started to see that I wanted the program development in a different direction. My focus was to create a music player for playing local music files, and not having to maintain support for multiple internet features that I did not use, and some which I did not want in the program at all… I also saw more and more that I disagree with the authors of Clementine and some statements that have been made regarding high-resolution audio.
-
-Jonas and I are definitely working from the same perspective, at least in relation to high-resolution music files. Back in late 2016, [I looked at Clementine][3], and though it was in many ways delightful, it definitely missed the boat with respect to working with a dedicated high-resolution digital-analog converter (DAC) for music enjoyment. But that’s OK; Clementine just wasn’t built for me. Nor, it appears, was it for Jonas.
-
-So, given that Jonas and I share an interest in being able to play back high-resolution audio on a dedicated listening device, I thought I’d best give [Strawberry][4], Jonas’ fork of Clementine, a try. I grabbed the [2018/07/16 release for Ubuntu][5] from Jonas’ site. It was a .deb and very straightforward to install.
-```
-sudo dpkg -i strawberry_0.2.1-27-gb2c26eb_amd64.deb
-
-```
-
-As usual, some necessary packages weren’t installed on my system, so I used `apt install -f` to remedy that.
-
-Apt recommended the following packages:
-```
-graphicsmagick-dbg gxine xine-ui
-
-```
-
-and installed the following packages:
-```
-libgraphicsmagick-q16-3 libiso9660-10 liblastfm5-1 libqt5concurrent5 libvcdinfo0 libxine2 libxine2-bin libxine2-doc libxine2-ffmpeg libxine2-misc-plugins libxine2-plugins
-
-```
-
-Once that was all in hand, I started up Strawberry and saw this:
-
-
-
-I verified that I could point Strawberry at ALSA in general and at my dedicated DAC in particular.
-
-
-
-
-
-Then I was ready to update my collection, which took less than a minute (Clementine was similarly fast).
-
-The only thing I noticed that seemed a little odd was that Strawberry provided a software volume control, which isn’t of great interest to me (my hardware has a nice shiny knob on top for just that purpose).
-
-
-
-And then I got down to some quality listening. One of the things I found I liked right away is the status button (see the strawberry at the top left of the UI). This verifies the details of the currently playing track, as shown in the screen capture to the left. Note that the effective bit rate, bit rate, and word length are shown, as well as other useful information.
-
-The sound is glorious, as is customary with well-recorded high-resolution material (for those of you inclined to argue about the merits of high-resolution audio, before you post your opinions, whether pro or con, please read [this article][6], which actually treats the topic in a scientific fashion).
-
-What’s cool about Strawberry, besides audio quality? Well, it’s fun to see the spectrum analyzer operating on the bottom of the screen. The overall responsiveness is smooth and quick; the album cover slides up once the music starts. There isn’t a lot of wasted space in the UI. And, as Jonas says:
-
-For many people, Clementine will still be a better choice since it has features such as scrobbling and internet services, which Strawberry lacks and I do not plan to include.
-
-Evidently, this is a player focused on the quality of the music, rather than the quantity. I’ll be using this player more in the future; it’s right up my alley.
-
-### Fine sound collections
-
-On the topic of music, especially interesting and unusual music, many thanks to [Michael Lavorgna over at Audiostream][7], who mentions these two fine online sound collections: [Cultural Equity][8] and [Smithsonian Folkways Recordings][9]. What great sources for stuff that is of historical interest and just plain fun.
-
-Also thanks to Michael for reminding me about [Ektoplazm][10], a fine free music portal for those interested in “psytrance, techno, and downtempo music.” I’ve downloaded a few albums from this site in the past, and when the mood strikes, I really appreciate what it has to offer. It's especially wonderful that the music files are available in [FLAC][11].
-
-### And more music…
-
-In my last article, I spent so much time building that I didn’t have any time for listening. But since then, I’ve been to my favorite record store and picked up four new albums, some of which came with downloads. First up is [Jon Hopkins’][12] [Singularity][12]. I’ve been picking up the odd Jon Hopkins album since [Linn Records][13] (by the way, a great site for Linux users to buy downloads since no bloatware is required) was experimenting with a more broad-based music offering and introduced me to Jon. Some of his work is [available on Bandcamp][14] these days (including Singularity) which is a fine Linux-friendly site. For me, this is a great album—not really ambient, not really beatless, not really anything except what it is. Huge powerful swaths of music, staggering bass. Great fun! Go listen on [Bandcamp][14].
-
-And if, like me, you have bought a few [Putumayo Music][15] albums over the years, keep your eyes peeled for Putumayo’s absolutely wonderful vinyl LP release of [_Vintage Latino_][16]. This great LP of vintage salsa and cha-cha is also available there to buy as a CD; you can listen to [1:00 clips on Bandcamp][17].
-
-[Bombino][18] was in town last night. I had other stuff to do, but a friend went to the concert and loved it. I have three of his albums now; the last two I purchased on that fine open source medium, the vinyl LP, which came with downloads as well. His most recent album, _Deran_ , is more than worth it; check it out on the link above.
-<https://www.youtube.com/embed/1PTj1qIqcWM>
-
-Last but by no means least, I managed to find a copy of [Nils Frahm’s _All Melody_][19] on vinyl (which includes a download code). I’ve been enjoying the high-resolution digital version of this album that I bought earlier this year, but it’s great fun to have it on vinyl.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/strawberry-new-open-source-music-player
-
-作者:[Chris Hermansen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/clhermansen
-[1]:https://github.com/jonaski
-[2]:https://www.clementine-player.org/
-[3]:https://opensource.com/life/16/10/4-open-music-players-compared
-[4]:http://www.strawbs.org/
-[5]:http://builds.jkvinge.net/ubuntu/bionic/strawberry_0.2.1-27-gb2c26eb_amd64.deb
-[6]:http://www.aes.org/e-lib/browse.cfm?elib=18296
-[7]:https://www.audiostream.com/content/alan-lomax-17000-sound-recordings-online-free
-[8]:http://research.culturalequity.org/audio-guide.jsp
-[9]:https://folkways.si.edu/radio-and-playlists/smithsonian
-[10]:http://www.ektoplazm.com/
-[11]:https://xiph.org/flac/
-[12]:https://pitchfork.com/reviews/albums/jon-hopkins-singularity/
-[13]:http://www.linnrecords.com/
-[14]:https://jonhopkins.bandcamp.com/album/singularity
-[15]:https://www.putumayo.com/
-[16]:https://www.putumayo.com/product-page/vintage-latino
-[17]:https://putumayo.bandcamp.com/album/vintage-latino
-[18]:http://www.bombinomusic.com/
-[19]:https://www.youtube.com/watch?v=1PTj1qIqcWM
diff --git a/sources/tech/20180815 Happy birthday, GNOME- 6 reasons to love this Linux desktop.md b/sources/tech/20180815 Happy birthday, GNOME- 6 reasons to love this Linux desktop.md
deleted file mode 100644
index 590a83a62d..0000000000
--- a/sources/tech/20180815 Happy birthday, GNOME- 6 reasons to love this Linux desktop.md
+++ /dev/null
@@ -1,71 +0,0 @@
-Happy birthday, GNOME: 6 reasons to love this Linux desktop
-======
-
-
-
-GNOME has been my favorite [desktop environment][1] for quite some time. While I always make it a point to check out other environments from time to time, there are some aspects of the GNOME desktop that are hard to live without. While there are many great desktop environments out there, [GNOME][2] feels like home to me. Here are some of the features I enjoy most about GNOME.
-
-### Stability
-
-Having a stable working environment is the most important aspect of a desktop for me. After all, the feature set of an environment doesn't matter at all if it crashes constantly and you lose work. For me, GNOME is rock-solid. I have heard of others experiencing crashes and instability, but it always seems to be due to either the user running GNOME on unsupported hardware or due to faulty extensions (more on that later). On my end, I run GNOME primarily on hardware that is known to be well-supported in Linux ([System76][3], for example). I also have a few systems that are not as well supported (a custom-built desktop and a Dell Latitude laptop), and I actually don't have any issues there either. For me, GNOME is rock-solid. I have compared stability in other well-known desktop environments, and I had unfortunate results. Nothing comes close to GNOME when it comes to stability.
-
-### Extensions
-
-I really enjoy being able to add additional functionality to my environment. I don't necessarily require any extensions, because I am perfectly fine with stock-GNOME with no extensions whatsoever. However, having the ability to add a few things here and there, is welcome. GNOME features various extensions to do things such as add a weather display to your panel, and much more. This adds a level of customization that is not typical of other environments. That said, proceed with caution. Sometimes extensions are of varying quality and may lead to stability issues. I find though that if you only install extensions you absolutely need, and you make sure they're kept up to date (and aren't abandoned by the developer) you'll generally be in good shape.
-
-### Activities overview
-
-Activities overview is quite possibly the easiest feature to use in GNOME, and it's barely detailed enough to justify its own section in this article. However, when I use other desktop environments, I miss this feature the most.
-
-The thing is, I am very busy, with multiple projects going on at any one time, and dozens of different windows open. To access the activities overview, I simply press the Super key. Immediately, my workspace is "zoomed out" and I see all of my windows side-by-side. This is often a faster way to locate a window that is hidden behind others, and a good way overall to see what exactly is running on any given workspace.
-
-When using other desktop environments, I will often find myself pressing the Super key out of habit, only to remember that I'm not using GNOME at the time. There are ways of achieving similar behavior in other environments (such as installing and tweaking Compiz), but in GNOME this feature is built-in.
-
-### Dynamic workspaces
-
-While working, I am not sure up-front how many workspaces I will need. Sometimes I can be working on three projects at a time, or as many as ten. With most desktop environments, I can access the settings screen and add or remove workspaces as needed. But with GNOME, I have exactly as many workspaces as I need at any given time. Every time I open applications on a workspace, I am given another blank one that I can switch to in order to start another project. Typically, I keep all windows related to a specific project on their own workspace, so it makes it very easy to locate my workflow for a given project.
-
-Other desktop environments have really good implementations of the concept of workspaces, but GNOME's implementation works best for me.
-
-### Simplicity
-
-Another thing I love about GNOME is that it's simple and straight to the point. By default, there is only one panel, and it's at the top of the screen. This panel shows you a small amount of information, such as the date, time, and battery usage. GNOME 2 had two panels, so seeing GNOME stripped down to a single panel is welcome and saves room on the screen. Most of the things you don't need to see all the time are hidden within the Activities overview, leaving you with the maximum amount of screen space for the application(s) you are working on. GNOME just stays out of the way and lets you focus on getting your work done, and stays away from fancy widgets and desktop gadgets that just aren't necessary.
-
-
-In addition, GNOME has really great support for keyboard shortcuts. Most of GNOME's features I can access without needing to touch my mouse, such as SUPER+Page Up and Super Page Down to switch workspaces, Super+Up arrow to maximize windows, etc. In addition, I am able to easily create my own keyboard shortcuts for all of my favorite applications.
-
-### GNOME Boxes
-
-GNOME's Boxes app is an underrated gem. This utility makes it very easy to spin up a virtual machine, which is a godsend among developers and those that like to test configurations on multiple distributions and platforms. With Boxes, you can spin up a virtual machine at any time, and it will even automate the installation process for you. For example, if you want a new Ubuntu VM, you simply choose Ubuntu as your desired platform, fill out your username and any related information, and you will have a new Ubuntu VM in a few minutes. When you're done with it, you can power it down or trash it.
-
-For me, I do a lot of DevOps-style work as well as system administration. Being able to test a configuration on a virtual machine before deploying to another environment is great. Sure, you can do the exact same thing in VirtualBox, and VirtualBox is a great piece of software. However, Boxes is built right into GNOME, and desktop environments generally don't offer their own solution for virtualization.
-
-### GNOME Music
-
-While I work, I have difficulty tuning out noise in my environment. Therefore, I like to listen to music while I complete projects and tune out the rest of the world. GNOME's Music app is very simplistic and works very well. With most of the music industry gravitating toward streaming music online, and many once-popular [open source music players][7] becoming abandoned projects, it's nice to see GNOME support a built-in music player that can play my music collection. It's great to listen to my music collection while I work, and it helps me zone-in to what I am doing.
-
-### GNOME Games
-
-When work is done for the day, it's time to play! There's nothing like playing a classic game such as Final Fantasy VI or Super Metroid after a hard day's work. The thing is, I am a huge fan of classic gaming, and I have 22 working gaming consoles and somewhere near 1,000 physical games in my collection. But I may not always have a moment to hook up one of my retro-consoles, so GNOME Games allows me quick-access to emulated versions of my collection. In addition to that, it also works with Libretro cores as well, so it seems to me that the developers of this application have really thought-out what fans of classic gaming like me are looking for in a frontend for gaming.
-
-These are the major features I enjoy most in the GNOME desktop. What are some of yours?
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/what-i-love-about-gnome
-
-作者:[Jay LaCroix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jlacroix
-[1]:https://opensource.com/article/18/8/how-navigate-your-gnome-linux-desktop-only-keyboard
-[2]:https://opensource.com/article/17/8/reasons-i-come-back-gnome
-[3]:https://opensource.com/article/16/12/open-gaming-news-december-31
-[4]:https://opensource.com/file/407221
-[5]:https://opensource.com/sites/default/files/uploads/gnome3-cheatsheet.png (GNOME 3 Cheat Sheet)
-[6]:https://opensource.com/downloads/cheat-sheet-gnome-3
-[7]:https://opensource.com/article/18/6/open-source-music-players
diff --git a/sources/tech/20180816 Designing your garden with Edraw Max - FOSS adventures.md b/sources/tech/20180816 Designing your garden with Edraw Max - FOSS adventures.md
deleted file mode 100644
index bcd5c0bda8..0000000000
--- a/sources/tech/20180816 Designing your garden with Edraw Max - FOSS adventures.md
+++ /dev/null
@@ -1,74 +0,0 @@
-Designing your garden with Edraw Max – FOSS adventures
-======
-
-I watch a lot of [BBC Gardeners World][1], which gives me a lot of inspiration for making changes to my own garden. I tried looking for a free and open source program for designing gardens in the openSUSE [package search][2]. The only application that I found was Rosegarden, a MIDI and Audio Sequencer and Notation Editor. Using google, I found [Edraw Max][3], an all-in-one diagram software. This included a Floor planner, including templates for garden design. And there are download options for various Linux distributions, including openSUSE.
-
-### Installation
-
-You can download a 14-day free trial from the Edraw Max [website][4].
-
-![][5]
-
-The next thing to do, is use Dolphin and browse to your Downloads folder. Find the zipped package and double click it. Ark will automatically load it. Then click on the Extract button.
-
-![][6]
-
-Now you can press F4 in Dolphin to open the integrated terminal. If you type in the commands as listed on the Edraw website, the application will install without an issue.
-
-![][7]
-
-### Experience
-
-From the application launcher (start menu), you can now type Edraw Max and launch the application. Go to New and then Floor Plan and click on Garden Design.
-
-![][8]
-
-On the left side, there is a side pane with a lot of elements that you can use for drawing (see picture below). Start with measuring your garden and with the walls, you can ‘draw’ the borders of your garden. On the right side, there is a side pane where you can adjust the properties of these elements. For instance you can edit the fill (color) of the element, the border (color) of the element and adjust the properties. I didn’t need the other parts of this right side pane (which included shadow, insert picture, layer, hyperlink, attachment and comments).
-
-![][9]
-
-Now you can make various different garden designs! This is one of the 6 designs that I created for my own garden.
-
-![][10]
-
-The last feature that I like to mention is the export possibilities. There is a lot of export options here, including Jpeg, Tiff, PDF, PS, EPS, Word, PowerPoint, Excel, HTML, SVG and Visio. In the unlicensed version, all exports work except for the Visio export. In the PDF you will see a watermark “Created by Unlicensed Version”.
-
-![][11]
-
-### Conclusion
-
-As this is proprietary software, you will have to pay for it after 14 days. Unfortunately, the price is quite high. As a Linux user, you can only select the [Lifetime license][12], which currently costs $ 245. It is a very complete package (280 different types of diagrams), but I find the pricing too high for my purposes. And there is no option to pay less. For professional users I can imagine that this price would not be a big issue, as the software will pay itself back when you get payed for making designs. For me personally, it was a very nice experience to use this limited trial and it helped me to think of different ways in which I can redesign my garden.
-
-**Published on: 16 august 2018**
-
-### A FOSS alternative found!
-
-Thanks to reddit user compairelapin, I have found an open source alternative. It is called Sweet Home 3D and its available in the [openSUSE package search][13]. In a future post, I will take a look at this software and compare it to Edraw Max.
-
-**Updated on: 17 august 2018**
-
---------------------------------------------------------------------------------
-
-via: https://www.fossadventures.com/designing-your-garden-with-edraw-max/
-
-作者:[Martin De Boer][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.fossadventures.com/author/martin_de_boer/
-[1]:https://www.bbc.co.uk/programmes/b006mw1h
-[2]:https://software.opensuse.org/
-[3]:https://www.edrawsoft.com/edraw-max.php
-[4]:https://www.edrawsoft.com/download-edrawmax.php
-[5]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-01-1024x463.jpeg
-[6]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-03.jpeg
-[7]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-04.jpeg
-[8]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-05.jpeg
-[9]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-06.jpeg
-[10]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-07.jpeg
-[11]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-08.jpeg
-[12]:https://www.edrawsoft.com/orderedrawmax.php
-[13]:https://software.opensuse.org/package/SweetHome3D
diff --git a/sources/tech/20180816 Garbage collection in Perl 6.md b/sources/tech/20180816 Garbage collection in Perl 6.md
deleted file mode 100644
index 725d0f6f50..0000000000
--- a/sources/tech/20180816 Garbage collection in Perl 6.md
+++ /dev/null
@@ -1,121 +0,0 @@
-Garbage collection in Perl 6
-======
-
-
-
-In the [first article][1] in this series on migrating Perl 5 code to Perl 6, we looked into some of the issues you might encounter when porting your code. In this second article, we’ll get into how garbage collection differs in Perl 6.
-
-There is no timely destruction of objects in Perl 6. This revelation usually comes as quite a shock to people used to the semantics of object destruction in Perl 5. But worry not, there are other ways in Perl 6 to get the same behavior, albeit requiring a little more thought by the developer. Let’s first examine a little background on the situation in Perl 5.
-
-### Reference counting
-
-In Perl 5, timely destruction of objects “going out of scope” is achieved by [reference counting][2]. When something is created in Perl 5, it has a reference count of 1 or more, which keeps it alive. In its simplest case it looks like this:
-```
-{
-
- my $a = 42; # reference count of $a = 1, because lives in lexical pad
-
-}
-
-# lexical pad is gone, reference count to 0
-
-```
-
-In Perl 5, if the value is an object (aka blessed), the `DESTROY` method will be called on it.
-```
-{
-
- my $a = Foo->new;
-
-}
-
-# $a->DESTROY called
-
-```
-
-If no external resources are involved, timely destruction is just another way of managing memory used by a program. And you, as a programmer, shouldn’t need to care about how and when things get recycled. Having said that, timely destruction is a very nice feature to have if you need to deal with external resources, such as database handles (of which there are generally only a limited number provided by the database server). And reference counting can provide that.
-
-However, reference counting has several drawbacks. It has taken Perl 5 core developers many years to get reference counting working correctly. And if you’re working in [XS][3], you always need to be aware of reference counting to prevent memory leakage or premature destruction.
-
-Keeping things in sync gets more difficult in a multi-threaded environment, as you do not want to lose any updates to references made from multiple threads at the same time (as that would cause memory leakage and/or external resources to not be released). To circumvent that, some kind of locking or atomic updates would be needed, neither of which are cheap.
-
-> Please note that Perl 5 ithreads are more like an in-memory fork with unshared memory between interpreters than threads in programming languages such as C. So, it still doesn’t need any locking for its reference counting.
-
-Reference counting also has the basic drawback that if two objects contain references to each other, they will never be destroyed as they keep each other’s reference count above 0 (a circular reference). In practice, this often goes much deeper, more like `A -> B -> C -> A`, where A, B, and C are all keeping each other alive.
-
-The concept of a weak reference was developed to circumvent these situations in Perl 5. Although this can fix the circular reference issue, it has performance implications and doesn’t fix the problem of having (and finding) circular references in the first place. You need to be able to find out where a weak reference can be used in the best way; otherwise, you might get unwanted premature object destruction.
-
-### Reachability analysis
-
-Since Perl 6 is multi-threaded in its core, it was decided at a very early stage that reference counting would be problematic performance-wise and maintenance-wise. Instead, objects are evicted from memory when more memory is needed and the object can be safely removed.
-
-`DESTROY` method, just as you can in Perl 5. But you cannot be sure when (if ever) it will be called.
-
-In Perl 6 you can create amethod, just as you can in Perl 5. But you cannot be sure when (if ever) it will be called.
-
-Without getting into [too much detail][4], objects in Perl 6 are destroyed only when a garbage collection run is initiated, e.g., when a certain memory limit has been reached. Only then, if an object cannot be reached anymore by other objects in memory and it has a `DESTROY` method, will it be called just prior to the object being removed.
-
-No garbage collection is done by Perl 6 when a program exits. Applicable [phasers][5] (such as `LEAVE` and `END`) will get called, but no garbage collection will be done other than what is (indirectly) initiated by the code run in the phasers.
-
-If you always need an orderly shutdown of external resources used by your program (such as database handles), you can use a phaser to make sure the external resource is freed in a proper and timely manner.
-
-For example, you can use the `END` phaser (known as an `END` block in Perl 5) to disconnect properly from a database when the program exits (for whatever reason):
-```
-my $dbh = DBIish.connect( ... ) or die "Couldn't connect";
-
-END $dbh.disconnect;DBIishENDdisconnect
-
-```
-
-Note that the `END` phaser does not need to have a block (like `{ ... }`) in Perl 6. If it doesn’t, the code in the phaser shares the lexical pad (lexpad) with the surrounding code.
-
-There is one flaw in the code above: If the program exits before the database connection is made or if the database connection failed for whatever reason, it will still attempt to call the `.disconnect` method on whatever is in `$dbh`, which will result in an execution error. There is however a simple idiom to circumvent this situation in Perl 6 [using with][6].
-```
-END .disconnect with $dbh;
-
-```
-
-The postfix `with` matches only if the given value is defined (generally, an instantiated object) and then topicalizes it to `$_`. The `.disconnect` is short for `$_.disconnect`.
-
-If you would like to have an external resource clean up whenever a specific scope is exited, you can use the `LEAVE` phaser inside that scope.
-```
-if DBIish.connect( ... ) -> $dbh {
-
- LEAVE $dbh.disconnect; # no need for `with` here
-
- # do your stuff with the database
-
-}
-
-else {
-
- say "Could not do the stuff that needed to be done";
-
-}DBIishLEAVEdisconnectsay
-
-```
-
-Whenever the scope of the `if` is left, any `LEAVE` phaser will be executed. Thus the database resource will be freed whenever the code has run in that scope.
-
-### Summary
-
-Even though Perl 6 does not have the timely destruction of objects that Perl 5 users are used to, it does have easy-to-use alternative ways to ensure management of external resources, similar to those in Perl 5.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/garbage-collection-perl-6
-
-作者:[Elizabeth Mattijsen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/lizmat
-[1]:https://opensource.com/article/18/7/migrating-perl-5-perl-6
-[2]:https://en.wikipedia.org/wiki/Reference_counting
-[3]:https://en.wikipedia.org/wiki/XS_%28Perl%29
-[4]:https://github.com/MoarVM/MoarVM/blob/master/docs/gc.markdown
-[5]:https://docs.perl6.org/language/phasers
-[6]:https://docs.perl6.org/syntax/with%20orwith%20without
diff --git a/sources/tech/20180817 AryaLinux- A Distribution and a Platform.md b/sources/tech/20180817 AryaLinux- A Distribution and a Platform.md
deleted file mode 100644
index 7e2509948a..0000000000
--- a/sources/tech/20180817 AryaLinux- A Distribution and a Platform.md
+++ /dev/null
@@ -1,224 +0,0 @@
-AryaLinux: A Distribution and a Platform
-======
-
-
-
-Most Linux distributions are simply that: A distribution of Linux that offers a variation on an open source theme. You can download any of those distributions, install it, and use it. Simple. There’s very little mystery to using Linux these days, as the desktop is incredibly easy to use and server distributions are required in business.
-
-But not every Linux distribution ends with that idea; some go one step further and create both a distribution and a platform. Such is the case with [AryaLinux][1]. What does that mean? Easy. AryaLinux doesn’t only offer an installable, open source operating system, they offer a platform with which users can build a complete GNU/Linux operating system. The provided scripts were created based on the instructions from [Linux From Scratch][2] and [Beyond Linux From Scratch][3].
-
-If you’ve ever attempted to build you own Linux distribution, you probably know how challenging it can be. AryaLinux has made that process quite a bit less stressful. In fact, although the build can take quite a lot of time (up to 48 hours), the process of building the AryaLinux platform is quite easy.
-
-But don’t think that’s the only way you can have this distribution. You can download a live version of AryaLinux and install as easily as if you were working with Ubuntu, Linux Mint, or Elementary OS.
-
-Let’s get AryaLinux up and running from the live distribution and then walk through the process of building the platform, using the special builder image.
-
-### The Live distribution
-
-From the [AryaLinux download pag][4]e, you can get a version of the operating system that includes either [GNOME][5] or [Xfce][6]. I chose the GNOME route and found it to be configured to include Dash to dock and Applications menu extensions. Both of these will please most average GNOME users. Once you’ve downloaded the ISO image, burn it to either a DVD/CD or to a USB flash drive and boot up the live instance. Do note, you need to have at least 25GB of space on a drive to install AryaLinux. If you’re planning on testing this out as a virtual machine, create a 30-40 GB virtual drive, otherwise the installer will fail every time.
-
-Once booted, you will be presented with a login screen, with the default user selected. Simply click the user and login (there is no password required).
-
-To locate the installer, click the Applications menu, click Activities Overview, type “installer” and click on the resulting entry. This will launch the AryaLinux installer … one that looks very familiar to many Linux installers (Figure 1).
-
-![AryaLinux installer][8]
-
-Figure 1: The AryaLinux installer is quite easy to navigate.
-
-[Used with permission][9]
-
-In the next window (Figure 2), you are required to define a root partition. To do this, type “/” (no quotes) in the Choose the root partition section.
-
-![root partition][11]
-
-Figure 2: Defining your root partition for the AryaLinux installation.
-
-[Used with permission][9]
-
-If you don’t define a home partition, it will be created for you. If you don’t define a swap partition, none will be created. If you have a need to create a home partition outside of the standard /home, do it here. The next installation windows have you do the following:
-
- * Create a standard user.
-
- * Create an administrative password.
-
- * Choose locale and keyboard.
-
- * Choose your timezone.
-
-
-
-
-That’s all there is to the installation. Once it completes, reboot, remove the media (or delete the .iso from your Virtual Machine storage listing), and boot into your newly-installed AryaLinux operating system.
-
-### What’s there?
-
-Out of the box, you should find everything necessary to use AryaLinux as a full-functioning desktop distribution. Included is:
-
- * LibreOffice
-
- * Rhythmbox
-
- * Files
-
- * GNOME Maps
-
- * GIMP
-
- * Simple Scan
-
- * Chromium
-
- * Transmission
-
- * Avahi SSH/VNC Server Browser
-
- * Qt5 Assistant/Designer/Linguist/QDbusViewer
-
- * Brasero
-
- * Cheese
-
- * Echomixer
-
- * VLC
-
- * Network Tools
-
- * GParted
-
- * dconf Editor
-
- * Disks
-
- * Disk Usage Analyzer
-
- * Document Viewer
-
- * And more
-
-
-
-
-### The caveats
-
-It should be noted that this is the first official release of AryaLinux, so there will be issues. Right off the bat I realized that no matter what I tried, I could not get the terminal to open. Unfortunately, the terminal is a necessary tool for this distribution, as there is no GUI for updating or installing packages. In order to get to a bash prompt, I had to use a virtual screen. That’s when the next caveat came into play. The package manager for AryaLinux is alps, but its primary purpose is working in conjunction with the build scripts to install the platform. Unfortunately there is no included man page for alps on AryaLinux and the documentation is very scarce. Fortunately, the developers did think to roll in Flatpak support, so if you’re a fan of Flatpak, you can install anything you need (so long as it’s available as a flatpak package) using that system.
-
-### Building the platform
-
-Let’s talk about building the AryaLinux platform. This isn’t much harder than installing the standard distribution, only it’s done via the command line. Here’s what you do:
-
- 1. Download the [AryaLinux Builder Disk][12].
-
- 2. Burn the ISO to either DVD/CD or USB flash drive.
-
- 3. Boot the live image.
-
- 4. Once you reach the desktop, open a terminal window from the menu.
-
- 5. Change to the root user with the command sudo su.
-
- 6. Change directories with the command cd aryalinux/base-system
-
- 7. Run the build script with the command ./build-arya
-
-
-
-
-You will first be asked if you want to start a fresh build or resume a build (Figure 3). Remember, the AryaLinux build takes a LOT of time, so there might be an instance where you’ve started a build and need to resume.
-
-![AryaLinux build][14]
-
-Figure 3: Running the AryaLinux build script.
-
-[Used with permission][9]
-
-To start a new build, type “1” and then hit Enter on your keyboard. You will now be asked to define a number of options (in order to fulfill the build script requirements). Those options are:
-
- * Bootloader Device
-
- * Root Partition
-
- * Home Partition
-
- * Locale
-
- * OS Name
-
- * OS Version
-
- * OS Codename
-
- * Domain Name
-
- * Keyboard Layout
-
- * Printer Paper Size
-
- * Enter Full Name
-
- * Username
-
- * Computer Name
-
- * Use multiple cores for build (y/n)
-
- * Create backups (y/n)
-
- * Install X Server (y/n)
-
- * Install Desktop Environment (y/n)
-
- * Choose Desktop Environment (XFCE, Mate, KDE, GNOME)
-
- * Do you want to configure advanced options (y/n)
-
- * Create admin password
-
- * Create password for standard user
-
- * Install bootloader (y/n)
-
- * Create Live ISO (y/n)
-
- * Select a timezone
-
-
-
-
-After you’ve completed the above, the build will start. Don’t bother watching it, as it will take a very long time to complete (depending upon your system and network connection). In fact, the build can take anywhere from 8-48 hours. After the build completes, reboot and log into your newly built AryaLinux platform.
-
-### Who is AryaLinux for?
-
-I’ll be honest, if you’re just a standard desktop user, AryaLinux is not for you. Although you can certainly get right to work on the desktop, if you need anything outside of the default applications, you might find it a bit too much trouble to bother with. If, on the other hand, you’re a developer, AryaLinux might be a great platform for you. Or, if you just want to see what it’s like to build a Linux distribution from scratch, AryaLinux is a pretty easy route.
-
-Even with its quirks, AryaLinux holds a lot of promise as both a Linux distribution and platform. If the developers can see to it to build a GUI front-end for the alps package manager, AryaLinux could make some serious noise.
-
-Learn more about Linux through the free ["Introduction to Linux" ][15]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/8/aryalinux-distribution-and-platform
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:http://aryalinux.org
-[2]:http://www.linuxfromscratch.org/
-[3]:http://www.linuxfromscratch.org/blfs/
-[4]:http://aryalinux.org/downloads/
-[5]:https://sourceforge.net/projects/aryalinux/files/releases/1.0/aryalinux-gnome-1.0-x86_64-fixed.iso
-[6]:https://sourceforge.net/projects/aryalinux/files/releases/1.0/aryalinux-xfce-1.0-x86_64.iso
-[7]:/files/images/aryalinux1jpg
-[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/aryalinux_1.jpg?itok=vR11z5So (AryaLinux installer)
-[9]:/licenses/category/used-permission
-[10]:/files/images/aryalinux2jpg
-[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/aryalinux_2.jpg?itok=Lm50af-y (root partition)
-[12]:https://sourceforge.net/projects/aryalinux/files/releases/1.0/aryalinux-builder-1.0-x86_64.iso
-[13]:/files/images/aryalinux3jpg
-[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/aryalinux_3.jpg?itok=J-GUq99C (AryaLinux build)
-[15]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180817 Cloudgizer- An introduction to a new open source web development tool.md b/sources/tech/20180817 Cloudgizer- An introduction to a new open source web development tool.md
deleted file mode 100644
index 3692ad05c5..0000000000
--- a/sources/tech/20180817 Cloudgizer- An introduction to a new open source web development tool.md
+++ /dev/null
@@ -1,282 +0,0 @@
-Cloudgizer: An introduction to a new open source web development tool
-======
-
-
-
-[Cloudgizer][1] is a free open source tool for building web applications. It combines the ease of scripting languages with the performance of [C][2], helping manage the development effort and run-time resources for cloud applications.
-
-Cloudgizer works on [Red Hat][3]/[CentOS][4] Linux with the [Apache web server][5] and [MariaDB database][6]. It is licensed under [Apache License version 2][7].
-
-### Hello World
-
-In this example, we output an [HTTP][8] header and Hello World, followed by a horizontal line:
-```
-#include "cld.h"
-
-void home()
-{
- /*<
- output-http-header
-
- Hello World!
- <hr/>
- >*/
-}
-```
-
-Cloudgizer code is written as a C comment with `/*<` and `>*/` at the beginning and ending, respectively.
-
-Writing output to the web client is as simple as directly writing [HTML][9] code in your source. There are no API calls or special markups for that—simplicity is good because HTML (or [JavaScript][10], [CSS][11], etc.) will probably comprise a good chunk of your code.
-
-### How it works
-
-Cloudgizer source files (with a `.v` extension) are translated into C code by the `cld` command-line tool. C code is then compiled and linked with the web server and your application is ready to be used. For instance, generated code for the source file named `home.v` would be `__home.c`, if you'd like to examine it.
-
-Much of your code will be written as "markups," small snippets of intuitive and descriptive code that let you easily do things like the following:
-
- * database queries
- * web programming
- * encoding and encryption
- * executing programs
- * safe string manipulation
- * file operations
- * sending emails
-
-
-
-and other common tasks. For less common tasks, there is an API that covers broader functionality. And ultimately, you can write any C code and use any libraries you wish to complete your task.
-
-The `main()` function is generated by Cloudgizer and is a part of the framework, which provides Apache and database integration and other services. One such service is tracing and debugging (including memory garbage collection, underwrite/overwrite detection, run-time HTML linting, etc.). A program crash produces a full stack, including the source code lines, and the crash report is emailed to you the moment it happens.
-
-A Cloudgizer application is linked with the Apache server as an Apache module in a pre-fork configuration. This means the Apache web server will pre-fork a number of processes and direct incoming requests to them. The Apache module mechanism provides high-performance request handling for applications.
-
-All Cloudgizer applications run under the same Linux user, with each application separated under its own application directory. This user is also the Apache user; i.e., the user running the web server.
-
-Each application has its own database with the name matching that of the application. Cloudgizer establishes and maintains database connections across requests, increasing performance.
-
-### Development process
-
-The process of compiling your source code and building an installation file is automated. By using the `cldpackapp` script, you’ll transform your code into pure C code and create an installation file (a [.tar.gz file][12]). The end user will install this file with the help of a configuration file called `appinfo`, producing a working web application. This process is straightforward:
-
-
-
-The deployment process is designed to be automated if needed, with configurable parameters.
-
-### Getting started
-
-The development starts with installing [the Example application][13]. This sets up the development environment; you start with a Hello World and build up your application from there.
-
-The Example application also serves as a smoke test because it has a number of code snippets that test various Cloudgizer features. It also gives you a good amount of example code (hence the name).
-
-There are two files to be aware of as you start:
-
- * `cld_handle_request.v` is where incoming requests (such as `GET`, `POST`, or a command-line execution) are processed.
- * `sourcelist` lists all your source code so that Cloudgizer can make your application.
-
-
-
-In addition to `cld_handle_request.v`, `oops.v` implements an error handler, and `file_too_large.v` implements a response to an upload that's too large. These are already implemented in the Example application, and you can keep them as they are or tweak them.
-
-Use `cldbuild` to recompile source-file (`.v`) changes, and `cldpackapp` to create an installer file for testing or release delivery via `cldgoapp`:
-
-
-
-Deployment via `cldgoapp` lets you install an application from scratch or update from one version to another.
-
-### Example
-
-Here's a stock-ticker application that updates and reports on ticker prices. It is included in the Example application.
-
-#### The code
-
-The request handler checks the URL query parameter page, and if it's `stock`, it calls `function stock()`:
-```
-#include "cld.h"
-
-void cld_handle_request()
-{
- /*<
- input-param page
-
- if-string page="stock"
- c stock ();
- else
- report-error "Unrecognized page %s", page
- end-if
- >*/
-}
-```
-
-The implementation of function `stock()` would be in file `stock.v`. The code adds a stock ticker if the URL query parameter action is `add` or shows all stock tickers if it is `show`.
-```
-#include "cld.h"
-
-void stock()
-{
- /*<
-
- output-http-header
-
- <html>
- <body>
- input-param action
-
- if-string action="add"
- input-param stock_name
- input-param stock_price
-
- run-query#add_data = "insert into stock \
- (stock_name, stock_price) values \
- (<?stock_name?>, <?stock_price?>) \
- on duplicate key update \
- stock_price=<?stock_price?>"
-
- query-result#add_data, error as \
- define err
-
- if atoi(err) != 0
- report-error "Cannot update \
- stock price, error [%s]",err
- end-if
- end-query
-
- <div>
- Stock price updated!
- </div>
- else-if-string action="show"
- <table>
- <tr>
- <td>Stock name</td>
- <td>Stock price</td>
- </tr>
- run-query#show_data = "select stock_name, \
- stock_price from stock"
-
- <tr>
- <td>
- query-result#show_data, stock_name
- </td>
- <td>
- query-result#show_data, stock_price
- </td>
- </tr>
- end-query
- </table>
- else
- <div>Unrecognized request!</div>
- end-if
- </body>
- </html>
- >*/
-}
-```
-
-#### The database table
-
-The SQL table used would be:
-```
-create table stock (stock_name varchar(100) primary key, stock_price bigint);
-```
-
-#### Making and packaging
-
-To include `stock.v` in your Cloudgizer application, simply add it to the sourcelist file:
-```
-SOURCE_FILES=stock.v ....
-...
-stock.o : stock.v $(CLDINCLUDE)/cld.h $(HEADER_FILES)
-...
-```
-
-To recompile changes to your code, use:
-```
-cldbuild
-```
-
-To package your application for deployment, use:
-```
-cldpackapp
-```
-
-When packaging an application, all additional objects you create (other than source code files), should be included in the `create.sh` file. This file sets up anything that the Cloudgizer application installer doesn't do; in this case, create the above SQL table. For example, the following code in your `create.sh` might suffice:
-```
-echo -e "drop table if exists stock;\ncreate table stock (stock_name varchar(100) primary key, stock_price bigint);" | mysql -u root -p$CLD_DB_ROOT_PWD -D $CLD_APP_NAME
-```
-
-In `create.sh`, you can use any variables from the `appinfo` file (an installation configuration file). Those variables always include `CLD_DB_ROOT_PWD` (the root password database, which is always automatically cleared after installation for security), `CLD_APP_NAME` (the application and database name), `CLD_SERVER` (the URL of the installation server), `CLD_EMAIL` (the administration and notification email address), and others. You also have `CLD_APP_HOME_DIR` (the application's home directory) and `CLD_APP_INSTALL_DIR` (the location where the installation .tar.gz file had been unzipped so you can copy files from it). You can include any other variables in the `appinfo` file that you find useful.
-
-#### Using the application
-
-If your application name is 'myapp' running on myserver.com, then the URL to update a stock ticker would be this:
-```
-https://myserver.com/go.myapp?page=stock&action=add&stock_name=RHT&stock_price=500
-```
-
-and the URL to show all stock tickers would be this:
-```
-https://myserver.com/go.myapp?page=stock&action=show
-```
-
-(The URL path for all Cloudgizer applications always starts with `go.`; in this case, `go.myapp`.)
-
-### Download and more examples
-
-For more examples or download and installation details, visit [Zigguro.org/cloudgizer][14]. You'll also find the above example included in the installation (see [the Example application source code][15]).
-
-For a much larger real-world example, check out the [source code][16] for [Rentomy][17], a free open source cloud application for rental property managers, written entirely in Cloudgizer and consisting of over 32,000 lines of code.
-
-### Why use Cloudgizer?
-
-Here's why Rentomy is written in Cloudgizer:
-
-Originally, the goal was to use one of the popular [scripting languages][18] or [process virtual machines][19] like [Java][20], and to host Rentomy as a [Software-as-a-Service][21] (Saas) free of charge.
-
-Since there are nearly 50 million rental units in the US alone, a free service like this needs superior software performance.
-
-So squeezing more power from CPUs and using less RAM became very important. And with [Moore's Law slowing down][22], the bloat of popular web languages is costing more computing resources—we're talking about process-virtual machines, interpreters, [p-code generators][23], etc.
-
-Debugging can be a pain because more layers of abstraction exist between you and what's really going on. Not every library can be easily used, so some functional and interoperability limitations remain.
-
-On the other hand, in terms of big performance and a small footprint, there is no match for C. Most libraries are written in C for the same reason, so virtually any library you need is available, and debugging is straightforward.
-
-However, C has issues with memory and overall safety (overwrites, underwrites, garbage collection, etc.), usability (it is low-level), application packaging, etc. And equally important, much of the development cost lies in the ease of writing and debugging the code and in its accessibility to novices.
-
-From this perspective, Cloudgizer was born. Greater performance and a smaller footprint mean cheaper computing power. Easy, stable coding brings Zen to the development process, as does the ability to manage it better.
-
-In hindsight, using Cloudgizer to build Rentomy was like using a popular scripting language without the issues.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/cloudgizer-intro
-
-作者:[Sergio Mijares][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/sergio-mijares
-[1]:https://zigguro.org/cloudgizer/
-[2]:https://en.wikipedia.org/wiki/C_%28programming_language%29
-[3]:https://www.redhat.com/en
-[4]:https://www.centos.org/
-[5]:http://httpd.apache.org/
-[6]:https://mariadb.com/
-[7]:http://www.apache.org/licenses/LICENSE-2.0
-[8]:https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
-[9]:https://en.wikipedia.org/wiki/HTML
-[10]:https://en.wikipedia.org/wiki/JavaScript
-[11]:https://en.wikipedia.org/wiki/Cascading_Style_Sheets
-[12]:https://opensource.com/article/17/7/how-unzip-targz-file
-[13]:https://zigguro.org/cloudgizer/#install
-[14]:https://zigguro.org/cloudgizer
-[15]:https://bitbucket.org/zigguro/cloudgizer_example/src
-[16]:https://bitbucket.org/zigguro/rentomy/src
-[17]:https://zigguro.org/rentomy/
-[18]:https://en.wikipedia.org/wiki/Scripting_language
-[19]:https://en.wikipedia.org/wiki/Virtual_machine
-[20]:https://www.java.com/en/
-[21]:https://en.wikipedia.org/wiki/Software_as_a_service
-[22]:https://www.engineering.com/ElectronicsDesign/ElectronicsDesignArticles/ArticleID/17209/DARPAs-100-Million-Programs-for-a-Silicon-Compiler-and-a-New-Open-Hardware-Ecosystem.aspx
-[23]:https://en.wikipedia.org/wiki/P-code_machine
diff --git a/sources/tech/20180821 How I recorded user behaviour on my competitor-s websites.md b/sources/tech/20180821 How I recorded user behaviour on my competitor-s websites.md
deleted file mode 100644
index b4729d730e..0000000000
--- a/sources/tech/20180821 How I recorded user behaviour on my competitor-s websites.md
+++ /dev/null
@@ -1,117 +0,0 @@
-How I recorded user behaviour on my competitor’s websites
-======
-
-### Update
-
-Google’s team has tracked down my test site, most likely using the source code I shared and de-indexed the whole domain.
-
-Last time [I publicly exposed a flaw][1], Google issued a [manual penalty][2] and devalued a single offending page. This time, there is no notice in Search Console. The site is completely removed from their index without any notification.
-
-I’ve received a lot of criticism in the way I’ve handled this. Many are suggesting the right way is to approach Google directly with security flaws like this instead of writing about it publicly. Others are suggesting I acted unethically, or even illegally by running this test. I think it should be obvious that if I intended to exploit this method I wouldn’t write about it. With so much risk and so little gain, is this even worth doing in practice? Of course not. I’d be more concerned about those who do unethical things and don’t write about it.
-
-### My wish list:
-
-a) Manipulating the back button in Chrome shouldn’t be possible in 2018
-b) Websites that employ this tactic should be detected and penalised by Google’s algorithms
-c) If still found in Google’s results, such pages should be labelled with “this page may be harmful” notice.
-
-### Here’s what I did:
-
- 1. User lands on my page (referrer: google)
- 2. When they hit “back” button in Chrome, JS sends them to my copy of SERP
- 3. Click on any competitor takes them to my mirror of competitor’s site (noindex)
- 4. Now I generate heatmaps, scrollmaps, records screen interactions and typing.
-
-![][3]
-
-![script][4]
-![][5]
-![][6]
-
-Interestingly, only about 50% of users found anything suspicious, partly due to the fact that I used https on all my pages, which is one of the main [trust factors on the web][7].
-
-Many users are just happy to see the “padlock” in their browser.
-
-At this point I was able to:
-
- * Generate heatmaps (clicks, moves, scroll depth)
- * Record actual sessions (mouse movement, clicks, typing)
-
-
-
-I gasped when I realised I can actually **capture all form submissions and send them to my own email**.
-
-Note: I never actually tried that.
-
-Yikes!
-
-### Wouldn’t a website doing this be penalised?
-
-You would think so.
-
-I had this implemented for a **very brief period of time** (and for ethical reasons took it down almost immediately, realising that this may cause trouble). After that I changed the topic of the page completely and moved the test to one of my disposable domains where **remained** for five years and ranked really well, though for completely different search terms with rather low search volumes. Its new purpose was to mess with conspiracy theory people.
-
-### Alternative Technique
-
-You don’t have to spoof Google SERPs to generate competitor’s heatmaps, you can simply A/B test your landing page VS your clone of theirs through paid traffic (e.g. social media). Is the A/B testing version of this ethically OK? I don’t know, but it may get you in legal trouble depending on where you live.
-
-### What did I learn?
-
-Users seldom read home page “fluff” and often look for things like testimonials, case studies, pricing levels and staff profiles / company information in search for credibility and trust. One of my upcoming tests will be to combine home page with “about us”, “testimonials”, “case studies” and “packages”. This would give users all they really want on a single page.
-
-### Reader Suggestions
-
-“I would’ve thrown in an exit pop-up to let users know what they’d just been subjected to.”
-<https://twitter.com/marcnashaat/status/1031915003224309760>
-
-### From Hacker News
-
-> Howdy, former Matasano pentester here.
-> FWIW, I would probably have done something similar to them before I’d worked in the security industry. It’s an easy mistake to make, because it’s one you make by default: intellectual curiosity doesn’t absolve you from legal judgement, and people on the internet tend to flip out if you do something illegal and say anything but “You’re right, I was mistaken. I’ve learned my lesson.”
->
-> To the author: The reason you pattern-matched into the blackhat category instead of whitehat/grayhat (grayhat?) category is that in the security industry, whenever we discover a vuln, we PoC it and then write it up in the report and tell them immediately. The report typically includes background info, reproduction steps, and recommended actions. The whole thing is typically clinical and detached.
->
-> Most notably, the PoC is usually as simple as possible. alert(1) suffices to demonstrate XSS, for example, rather than implementing a fully-working cookie swipe. The latter is more fun, but the former is more impactful.
->
-> One interesting idea would’ve been to create a fake competitor — e.g. “VirtualBagel: Just download your bagels and enjoy.” Once it’s ranking on Google, run this same experiment and see if you could rank higher.
->
-> That experiment would demonstrate two things: (1) the history vulnerability exists, and (2) it’s possible for someone to clone a competitor and outrank them with this vulnerability, thereby raising it from sev:low to sev:hi.
->
-> So to be clear, the crux of the issue was running the exploit on a live site without their blessing.
->
-> But again, don’t worry too much. I would have made similar errors without formal training. It’s easy for everyone to say “Oh well it’s obvious,” but when you feel like you have good intent, it’s not obvious at all.
->
-> I remind everyone that RTM once ran afoul of the law due to similar intellectual curiosity. (In fairness, his experiment exploded half the internet, but still.)
-
-Source: <https://news.ycombinator.com/item?id=17826106>
-
-
-### About the author
-
-[Dan Petrovic][9]
-
-Dan Petrovic, the managing director of DEJAN, is Australia’s best-known name in the field of search engine optimisation. Dan is a web author, innovator and a highly regarded search industry event speaker.
-
-
---------------------------------------------------------------------------------
-
-via: https://dejanseo.com.au/competitor-hack/
-
-作者:[Dan Petrovic][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://dejanseo.com.au/dan-petrovic/
-[1]:https://dejanseo.com.au/hijack/
-[2]:https://dejanseo.com.au/google-against-content-scrapers/
-[3]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-1.png
-[4]:https://dejanseo.com.au/wp-content/uploads/2018/08/script.gif
-[5]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-2.png
-[6]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-3.png
-[7]:https://dejanseo.com.au/trust/
-[8]:https://secure.gravatar.com/avatar/9068275e6d3863b7dc11f7dff0974ced?s=100&d=mm&r=g
-[9]:https://dejanseo.com.au/dan-petrovic/ (Dan Petrovic)
-[10]:https://dejanseo.com.au/author/admin/ (More posts by Dan Petrovic)
diff --git a/sources/tech/20180822 9 flowchart and diagramming tools for Linux.md b/sources/tech/20180822 9 flowchart and diagramming tools for Linux.md
deleted file mode 100644
index 853cd1b7c3..0000000000
--- a/sources/tech/20180822 9 flowchart and diagramming tools for Linux.md
+++ /dev/null
@@ -1,186 +0,0 @@
-9 flowchart and diagramming tools for Linux
-======
-
-
-
-Flowcharts are a great way to formalize the methodology for a new project. My team at work uses them as a tool in our brainstorming sessions and—once the ideation event wraps up—the flowchart becomes the project methodology (at least until someone changes it). My project methodology flowcharts are high-level and pretty straightforward—typically they contain just process, decision, and terminator objects—though they can be composed of many tens of these objects.
-
-I work primarily in my Linux desktop environment, and most of my office colleagues use Windows. However, we're increasing our use of G Suite in part because it minimizes distractions related to our various desktop environments. Even so, I would prefer to find an open source tool—preferably a standalone app, rather than one that's part of another suite—that offers great support for flowcharts and is available on all the desktops our team uses.
-
-It's been over four years since [Máirin Duffy reviewed Linux diagramming tools][1], so I decided to take a look at what's out there now for open source flowchart makers. I identified the following nine candidates:
-
-| Candidate name | Linux desktop | Available for Windows? | Available for MacOS? |
-|-----------------------| --------------|------------------------|----------------------|
-| [Dia][2] | GNOME | Yes | Yes |
-| [LibreOffice Draw][3] | GNOME | Yes | Yes |
-| [Inkscape][4] | GNOME | Yes | Yes |
-| [Calligra Flow][5] | KDE | Preliminary | Preliminary |
-| [Diagramo][6] | Browser | Browser | Browser |
-| [Pencil][7] | ? | Yes | Yes |
-| [Graphviz][8] | CLI | Yes | Yes |
-| [Umbrello][9] | KDE | Yes | Yes |
-| [Draw.io][10] | Browser | Browser | Browser |
-
-I'll share a bit of information about each below.
-
-### Dia
-
-
-
-I reviewed Dia 0.97.3 from the Ubuntu 18.04 repository; you can [download it here][2].
-
-Dia is a standalone drawing tool. It offers some additional components, such as `dia-rib-network` for network diagrams and `dia2cod` for converting [UML][11] to code.
-
-The installation process dragged in a few other packages, including: `dia-common`, `dia-shapes`, `gsfonts-x11`, `libpython-stdlib`, `python`, `python-cairo`, and `python-gobject2`.
-
-[Dia's documentation][12] is quite thorough and available in English, German, French, Polish, and Basque. It includes information on related utilities; versions for Linux, Windows, and MacOS; a lot of stuff related to shapes; and much more. The bug tracker on the project's website is disabled, but bug reports are accepted on [GNOME Bugzilla][13].
-
-Dia has complete support for making flowcharts—appropriate symbols, connectors, lots of connection points on objects, annotation for objects, etc. Even so, Dia's user experience (UX) feels unusual. For example, double-clicking on an object brings up properties and metadata, rather than the object's annotation; to edit annotation, you must select the object and click on Tools > Edit Text (or use the F2 key). The default text size, 22.68pt, or about 8mm, seems a bit weird. The text padding default is very large (0.50), and even when it's reduced by a factor of 10 (to 0.05), it still may leave a wide gap around the text (for example in the diamond decision object). You must also select the object before you can right-click on it. Cutting and pasting are somewhat limited—I couldn't copy text from my browser (with the standard Ctrl+C) and paste it into Dia. Dia launches ready to work with a multipage drawing, which is pretty handy if you need to make a 1x2 meter drawing and your printer accommodates only letter-size paper.
-
-In general terms, performance is very snappy. Interaction can seem a bit odd (see above), but it doesn't require huge adjustments to get the hang of it. On the downside, the Help menu did not link properly to documentation, and I couldn't find a spell checker. Finally, from what I can tell, there is no active development on Dia.
-
-### LibreOffice Draw
-
-
-
-I reviewed [LibreOffice Draw][3] version 6.0.4.2, which was installed by default on my Ubuntu 18.04 desktop.
-
-Since LibreOffice Draw is part of the LibreOffice suite, the UX will be familiar to anyone who uses LibreOffice Writer, Calc, or Impress. However, if you are looking for a standalone flowcharting tool and don't already use LibreOffice, this is likely to be a large [install][14].
-
-The application includes an extensive help facility that is accessible from the Help menu, and you can find a great deal of information by searching online.
-
-LibreOffice Draw has a set of predefined flowchart shapes that support annotation as well as connectors. Connection points are limited—all the shapes I use have just four points. Draw's UX will feel familiar to LibreOffice users; for example, double-clicking an object opens the object's annotation. Text wraps automatically when its length exceeds the width of a text box. However, annotation entered in a drawing object does not wrap; you must manually break the lines. Default text size, spacing, etc. are reasonable and easily changed. Draw permits multiple pages (which are called slides), but it doesn't support multipage drawings as easily as Dia does.
-
-In general terms, LibreOffice Draw provides good, basic flowcharting capability with no UX surprises. It performs well, at least on smaller flowcharts, and standard LibreOffice writing tools, such as spell check, are available.
-
-### Inkscape
-
-
-
-I reviewed [Inkscape][4] version 0.92.3 from the Ubuntu 18.04 repositories; you can [download it here][15].
-
-Inkscape is a standalone tool, and it is waaaaaay more than a flowchart drawing utility.
-
-The installation process dragged in several other packages, including: `fig2dev`, `gawk`, `libgtkspell0`, `libimage-magick-perl`, `libimage-magick-q16-perl`, `libmagick+±6.q16-7`, `libpotrace0`, `libsigsegv2`, `libwmf-bin`, `python-scour`, `python3-scour`, `scour`, and `transfig`.
-
-There is a great deal of Inkscape documentation available, including the Inkscape Manual available from the Help menu. This [tutorial][16] made it easier to get started with my first Inkscape flowchart.
-
-Getting my first rectangle on the screen was pretty straightforward with the Create Rectangles and Squares toolbar item. I changed the shape's background color by using the color swatches across the bottom of the screen. However, it seems text is separate from other objects, i.e., there doesn't appear to be a concept of geometric objects with annotation, so I created the text first, then added the surrounding object, and finally put in connectors. Default text sizes were odd (30pt, if I recall correctly) but you can change the default. Bottom line: I could make the diagram, but—based on what I could learn in a few minutes—it was more of a diagram than a flowchart.
-
-In general terms, Inkscape is an extremely full-featured vector drawing program with a learning curve. It's probably not the best tool for users who just want to draw a quick flowchart. There seems to be a spell checker available, although I didn't try it.
-
-### Calligra Flow
-
-From [the Calligra website][5]:
-
-> Calligra Flow is an easy to use diagramming and flowcharting application with tight integration to the other Calligra applications. It enables you to create network diagrams, organisation charts, flowcharts, and more.
-
-I could not find Calligra Flow in my repositories. Because of that and its tight integration with Calligra, which is oriented toward KDE users, I decided not to review it now. Based on its website, it looks like it's geared toward flowcharting, which could make it a good choice if you're using KDE.
-
-### Diagramo
-
-
-
-I reviewed [Diagramo][6] build number 2.4.0-3c215561787f-2014-07-01, accessed through [Try It Now!][17] on the Diagramo website using the Firefox browser.
-
-Diagramo is standalone, web-based flowcharting software. It claims to be pure HTML5 and GPL, but the [source code repository][18] states the code is available under the Apache License 2.0.
-
-The tool is accessible through a web browser, so no installation is required. (I didn't download the source code and try to install it locally.)
-
-I couldn't find any documentation for Diagramo. The application's Help button allows bug filing and turning on the debugger, and the build number is available under About.
-
-Diagramo offers several collections of drawing objects: Basic, Experimental, Network, Secondary, and UML State Machine. I limited my testing to the Basic set, which contained enough objects for me. To create a chart, you drag objects from the menu on the left and drop them on the canvas. You can set the canvas size in the options panel on the right. Sizes are in pixels, which is OK, although I prefer to work in points. The default text attributes were: 12px, Arial font, center alignment, with options to underline and change the text color. You can see the attributes in a popup menu above the text by double-clicking the default annotation, which is set to Text. You have to manually break lines of text, similar to in LibreOffice Draw. Objects have multiple connection points (I counted 12 on the rectangles and five on the diamonds). Connectors are separate from shapes and appear in the top toolbar. I couldn't save my test flowchart to my computer.
-
-In general terms, Diagramo provides good basic flowcharting capability with no UX surprises. It performs well, at least on smaller flowcharts, but doesn't seem to take advantage of Firefox's spell checker.
-
-### Pencil
-
-
-
-I reviewed [Pencil][7] version 3.0.4, which I [downloaded][19] from the Pencil project website. I used `dpkg` to install the 64-bit .deb package file. It installed cleanly with no missing packages.
-
-Pencil is a standalone drawing tool. Documentation and tutorials are available on [the project website][7].
-
-To make my sample flowchart, I selected the flowchart shape set from the far-left menu panel. From there, I could drag Process, Decision, and Straight Connector shapes onto the page. I added annotation by double-clicking on the object and typing in the text. (Copy/paste also works.) You can drag the connector endpoints near the desired attachment point and they automatically attach. The default font setting (Arial, 12pt) is a good choice, but I couldn't find a spell check function.
-
-In general, using Pencil is very simple and straightforward. It offers solid flowcharting capability with no UX surprises and performs well, at least on smaller flowcharts.
-
-### Graphviz
-
-According to the [Graphviz documentation][20]:
-
-> The Graphviz layout programs take descriptions of graphs in a simple text language and make diagrams in useful formats, such as images and SVG for web pages; PDF or Postscript for inclusion in other documents; or display in an interactive graph browser. Graphviz has many useful features for concrete diagrams, such as options for colors, fonts, tabular node layouts, line styles, hyperlinks, and custom shapes.
-
-I didn't do a full review of Graphviz. It looks like a very interesting package for converting text to graphical representations, and I might try it at some point. However, I don't see it as a good tool for people who are used to a more interactive UX. If you'd like to know more about it, [Stack Overflow][21] offers a quick overview of constructing a simple flowchart in Graphviz.
-
-### Umbrello
-
-I spotted [Umbrello][9] in my repositories, where I read:
-
-> Umbrello UML Modeller is a Unified Modelling Language diagram editor for KDE. It can create diagrams of software and other systems in the industry-standard UML format, and can also generate code from UML diagrams in a variety of programming languages. This package is part of the KDE Software Development Kit module.
-
-Because of its focus on UML rather than flowcharting and its KDE orientation, I decided to leave Umbrello to evaluate later.
-
-### Draw.io
-
-
-
-I reviewed [Draw.io][22] version 8.9.7, which I accessed through its website.
-
-Draw.io is standalone, web-based drawing software, and a desktop version is available. Since it runs in the browser, there's no installation required.
-
-[Documentation][23] is available on the Draw.io website.
-
-Draw.io launches with a set of general flowchart drawing objects on the left and context-sensitive properties on the right. (It's reminiscent of the Properties window in LibreOffice.) Clicking on a shape makes it appear on the page. Text defaults to centered 12pt Helvetica. Double-clicking on the drawing object opens the annotation editor. Draw.io automatically splits long lines of text, but the splitting isn't perfect in the diamond object. Objects have a decent number of connection points (I count 12 on the rectangle and eight on the diamond). Similar to Google Draw, as objects are dragged around, alignment aids help square up the diagram. I saved my work to an .xml file on my computer, which is a cool option for a web-based service. Diagrams can also be shared.
-
-In general terms, Draw.io provides solid flowcharting capability with no UX surprises, but no spell checker that I could find. It performs well, at least on smaller flowcharts, and the collaboration ability is nice.
-
-### What's the verdict?
-
-So, which of these flowcharting tools do I like best?
-
-Bearing in mind that I was leaning toward a standalone tool that could operate on any desktop, Draw.io and Diagramo appealed to me for their simplicity and browser-based operation (which means no installation is necessary). I also really liked Pencil, although it must be installed.
-
-Conversely, I felt Dia's UX was just a bit clunky and old-fashioned, although it certainly has great functionality.
-
-LibreOffice Draw and Calligra Flow, due to their integration in their respective office suites, didn't achieve my goal for a standalone, lightweight tool.
-
-Inkscape, Graphviz, and Umbrello seem like great tools in their own right, but trying to use them as simple, standalone flowchart creation tools seems like a real stretch.
-
-Will any of these replace G Suite's drawing capability in our office? I think Draw.io, Diagramo and Pencil could. We shall see!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/flowchart-diagramming-linux
-
-作者:[Chris Hermansen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/clhermansen
-[1]:https://opensource.com/life/14/6/tools-diagramming-fedora
-[2]:http://dia-installer.de/
-[3]:https://www.libreoffice.org/discover/draw/
-[4]:https://inkscape.org/en/
-[5]:https://www.calligra.org/flow/
-[6]:http://diagramo.com/
-[7]:https://pencil.evolus.vn/
-[8]:http://graphviz.org/
-[9]:https://umbrello.kde.org/
-[10]:https://about.draw.io/about-us/
-[11]:https://en.wikipedia.org/wiki/Unified_Modeling_Language
-[12]:http://dia-installer.de/doc/index.html.en
-[13]:https://bugzilla.gnome.org/query.cgi?format=specific&product=dia&bug_status=__all__
-[14]:https://www.libreoffice.org/download/download/
-[15]:https://inkscape.org/en/release/0.92.3/
-[16]:http://goinkscape.com/create-beautiful-diagrams-in-inkscape/
-[17]:http://diagramo.com/editor/editor.php
-[18]:https://bitbucket.org/scriptoid/diagramo/src/33c88ca45ee942bf0b16f19879790c361fc9709d/LICENSE.txt?at=default&fileviewer=file-view-default
-[19]:https://pencil.evolus.vn/Downloads.html
-[20]:https://graphviz.gitlab.io/documentation/
-[21]:https://stackoverflow.com/questions/46365855/create-simple-flowchart-with-graphviz
-[22]:http://Draw.io
-[23]:https://about.draw.io/tag/user-documentation/
diff --git a/sources/tech/20180824 Add free books to your eReader- Formatting tips.md b/sources/tech/20180824 Add free books to your eReader- Formatting tips.md
deleted file mode 100644
index bbafc0023d..0000000000
--- a/sources/tech/20180824 Add free books to your eReader- Formatting tips.md
+++ /dev/null
@@ -1,183 +0,0 @@
-Add free books to your eReader: Formatting tips
-======
-
-
-
-In my recent article, [A handy way to add free books to your eReader][1], I explained how to convert the plaintext indexes at [Project Gutenberg][2] to HTML and then EPUBs. But as one commenter noted, there is a problem in older indexes, where individual books are not always separated by an extra newline character.
-
-I saw quite vividly the extent of the problem when I was working on the index for 2007, where you see things like this:
-```
-Audio: The General Epistle of James 22931
-Audio: The Epistle to the Hebrews 22930
-Audio: The Epistle of Philemon 22929
-
-Sacrifice, by Stephen French Whitman 22928
-The Atlantic Monthly, Volume 18, No. 105, July 1866, by Various 22927
-The Continental Monthly, Vol. 6, No 3, September 1864, by Various 22926
-
-The Story of Young Abraham Lincoln, by Wayne Whipple 22925
-Pathfinder, by Alan Douglas 22924
- [Subtitle: or, The Missing Tenderfoot]
-Pieni helmivyo, by Various 22923
- [Subtitle: Suomen runoja koulunuorisolle]
- [Editor: J. Waananen] [Language: Finnish]
-The Posy Ring, by Various 22922
-```
-
-My first reaction was, "Well, how bad can it be to just add newlines where needed?" The answer: "Really bad." After days of working this way and stopping only when the cramps in my hand became too annoying, I decided to revisit the problem. I thought I might need to do multiple Find-Replace passes, maybe keyed on things like `[Language: Finnish] `or maybe just the `]` bracket, but this seemed almost as laborious as the manual method.
-
-Then I noticed a particular feature: For most instances where a newline was needed, a newline character was immediately followed by the capital letter of the next title. For lines where there was still more information about the book, the newline was followed by spaces. So I tried this: In the Find text box in [KWrite][3] (remember, we’re using regex), I put:
-```
-(\n[A-Z])
-
-```
-
-and in Replace, I put:
-```
-\n\1
-
-```
-
-For every match inside the parentheses, I added a preceding newline, retaining whatever the capital letter was. This worked extremely well. The few instances where it failed involved book titles beginning with a number or with quotes. I fixed these manually, but I could have put this:
-```
-(\n[0-9])
-
-```
-
-In Find and run Replace All again. Later, I also tried it with the quotes—this requires a backslash, like this:
-```
-(\n\”) and (\n\’)
-
-```
-
-One side effect is that a number of the listings were separated by three newline characters. Not an issue for XHTML, but easily fixed by putting in Find:
-```
-\n\n\n
-
-```
-
-and in Replace:
-```
-\n\n
-
-```
-
-To review the process with the new features:
-
- 1. Remove the preamble and other text you don’t want
- 2. Add extra newlines with the method shown above
- 3. Convert three consecutive newlines to two (optional)
- 4. Add the appropriate HTML tags at the beginning and end
- 5. Create the links based on finding `(\d\d\d\d\d)`, replacing with `<a href=”http://www.gutenberg.org/ebooks/``\1”>\1</a>`
- 6. Add paragraph tags by finding `\n\n` and replacing with `</p>\n\n<p>`
- 7. Add a `</p>` just before the `</body>` tag at the end
- 8. Fix the headers, preceding each with `<h3>` and changing the `</p>` to `</h3>` – the older indexes have only a single header
- 9. Save the file with an `.xhtml` suffix, then import to [Sigil][4] to make your EPUB.
-
-
-
-The next issue that comes up is when the eBook numbers include only four digits. This is a problem since there are many four-digit numbers in the listings, many of which are dates. The answer comes from modifying our strategy in point 5 in the above listing.
-
-In Find, put:
-
-`(\d\d\d\d)\n`
-
-and in Replace, put:
-
-`<a href="[http://www.gutenberg.org/ebooks/](http://www.gutenberg.org/ebooks/)\1">\1</a>\n`
-
-Notice that the `\n` is outside the parentheses; therefore, we need to add it at the end of the new replacement. Now we see another problem resulting from this new method: Some of the eBook numbers are followed by C (copyrighted). So we need to do another pass in Find:
-
-`(\d\d\d\d)C\n`
-
-and in Replace:
-
-`<a href=”[http://www.gutenberg.org/ebooks/](http://www.gutenberg.org/ebooks/)\1”>\1</a>C\n`
-
-I noticed that as of the 2002 index, the lack of extra newlines between listings was no longer a problem, and this continued all the way to the very first index, so steps 2 and 3 became unnecessary.
-
-I’ve now taken the process all the way to the beginning, GUTINDEX.1996, and this process works all the way. At one point three-digit eBook numbers appear, so you must begin to Find:
-
-`(\d\d\d)\n` and then `(\d\d\d)C\n`
-
-Then later:
-
-`(\d\d)\n` and then `(\d\d)C\n`
-
-And finally:
-
-`(\d)\n`
-
-The only glitch was in one book, eBook number 2, where the date "1798" was snagged by the three-digit search. At this point, I now have eBooks of the entire Gutenberg catalog, not counting new books presently being added.
-
-### Troubleshooting and a bonus
-
-I strongly advise you to test your XHTML files by trying to load them in a browser. Your browser should tell you if your XHTML is not properly formatted, in which case the file won’t show in your browser window. Two particular problems I found, having initially ignored my own advice, resulting from improper characters. I copied the link specification tags from my first article. If you do that, you will find that the typewriter quotes are substituted with typographic (curly) quotes. Fixing this was just a matter of doing a Find/Replace.
-
-Second, there are a number of ampersands (&) in the listings, and these need to be replaced by & for the browser to make sense of them. Some recent listings also use the Unicode non-breaking space, and these should be replaced with a regular space. (Hint: Copy one, put it in Find, put a regular space in Replace, then Replace All)
-
-Finally, there may be some accented characters lurking, and the browser feedback should help locate them. Example: Ibáñez needed to be Ibáñez.
-
-And now the bonus: Once your XHTML is well-formed, you can use your browser to comb Project Gutenberg just like on your e-reader. I also found that [Calibre][5] would not make the links properly until the quotes were fixed.
-
-Finally, here is a template for a separate web page you can place on your system to easily link to each year’s listing on your system. Make sure you fix the locations for your personal directory structure and filenames. Also, make sure all these quotes are typewriter quotes, not curly quotes.
-```
-<?xml version="1.0" encoding="utf-8"?>
-<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"
-"http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
-
-<html xmlns="http://www.w3.org/1999/xhtml">
-<head>
-<title>GutIndexes</title>
-</head>
-<body leftmargin="100">
-<h2>GutIndexes</h2>
-<font size="5">
-<table cellpadding="20"><tr>
-<td><a href="/home/gregp/Documents/GUTINDEX.1996.xhtml">1996</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.1997.xhtml">1997</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.1998.xhtml">1998</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.1999.xhtml">1999</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2000.xhtml">2000</a></td></tr>
-<tr><td><a href="/home/gregp/Documents/GUTINDEX.2001.xhtml">2001</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2002.xhtml">2002</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2003.xhtml">2003</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2004.xhtml">2004</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2005.xhtml">2005</a></td></tr>
-<tr><td><a href="/home/gregp/Documents/GUTINDEX.2006.xhtml">2006</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2007.xhtml">2007</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2008.xhtml">2008</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2009.xhtml">2009</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2010.xhtml">2010</a></td></tr>
-<tr><td><a href="/home/gregp/Documents/GUTINDEX.2011.xhtml">2011</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2012.xhtml">2012</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2013.xhtml">2013</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2014.xhtml">2014</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2015.xhtml">2015</a></td></tr>
-<tr><td><a href="/home/gregp/Documents/GUTINDEX.2016.xhtml">2016</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2017.xhtml">2017</a></td>
-<td><a href="/home/gregp/Documents/GUTINDEX.2018.xhtml">2018</a></td>
-</tr>
-</table>
-</font>
-</body>
-</html>
-```
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/more-books-your-ereader
-
-作者:[Greg Pittman][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/greg-p
-[1]:https://opensource.com/article/18/4/browse-project-gutenberg-library
-[2]:https://www.gutenberg.org/
-[3]:https://www.kde.org/applications/utilities/kwrite/
-[4]:https://sigil-ebook.com/
-[5]:https://calibre-ebook.com/
diff --git a/sources/tech/20180828 Orion Is A QML - C-- Twitch Desktop Client With VODs And Chat Support.md b/sources/tech/20180828 Orion Is A QML - C-- Twitch Desktop Client With VODs And Chat Support.md
deleted file mode 100644
index c87ec64e73..0000000000
--- a/sources/tech/20180828 Orion Is A QML - C-- Twitch Desktop Client With VODs And Chat Support.md
+++ /dev/null
@@ -1,126 +0,0 @@
-Orion Is A QML / C++ Twitch Desktop Client With VODs And Chat Support
-======
-**[Orion][1] is a free and open source QML / C++ client for [Twitch.tv][2] which can use multiple player backends (including [mpv][3]). The application runs on Linux, Windows, macOS and Android.**
-
-Using Orion you can watch live Twitch streams and past broadcasts, and browse or search games and channels using a nice material user interface. What's more, Orion lets you login to Twitch, so you can chat and follow channels (and receive notifications when a channel you follow goes online).
-
-The application allows customizing various aspects, like changing the stream quality, switching between light and dark user interface themes, and changing the chat position and font size.
-
-
-
-**Main Orion Twitch client features:**
-
- * **Play live Twitch streams or past VODs using one of 3 backends: mpv, QtAV or Qt5 Multimedia (mpv is default)**
- * **Browse and search Twitch games and channels**
- * **Login using your Twitch credentials**
- * **Desktop notifications when a followed channel comes online (including an option to show offline notifications)**
- * **Chat support**
- * **Light and Dark themes with configurable font**
- * **Change chat position (right, left or bottom)**
- * **Options to start minimized, close to tray and keep on top**
-
-
-
-Here's how Orion works. When you go to the channels list, you'll notice that each channel uses its icon as a thumbnail, with the channel name in an overlay on top of the icon:
-
-
-
-I would have liked to see the stream title, number of current viewers, and a preview in the channel list, or have an option for this. These are available, but not directly in the channel list. You can see a channel preview on mouse over, while the stream title and viewer count are available after you click on a channel:
-
-
-
-From this bottom overlay (which is displayed after you click on a channel) you can start playing the stream, follow or unfollow the channel, open the chat without watching the stream, or access past videos. You can also right click a channel to access these options.
-
-In the player view you'll find the regular video player controls, along with the quality selector (with source as the default quality) at the bottom, while the top overlay lets you follow / unfollow a channel or toggle the chat, which is displayed on the right-hand side of the screen by default:
-
-
-
-The chat panel uses autohide by default, but you can force it to always be displayed by clicking the lock icon its upper left corner. When the chat is locked (set to always visible), the video is shifted to the left so the chat isn't displayed on top of the video, and the chat width is resizable.
-
-### Download Orion
-
-[Download Orion(binaries for Windows or macOS)][13]
-
-The Orion GitHub project page doesn't offer any Linux binaries for download, but there are packages out there for multiple Linux distributions:
-
- * **Arch Linux** AUR packages for the latest Orion [stable][4] or [Git][5].
- * **Ubuntu 18.04 / Linux Mint 19** : [here's][6] the latest Orion Twitch client as a DEB package (if you want to add the PPA you can find it [here][7]). There's [another][8] PPA which has the latest Orion for Ubuntu 18.04 and an older Orion version for Ubuntu 16.04 - I only tried the Ubuntu 18.04 package from this second PPA but the Orion window is very small upon launching the application, that's why I prefer the first package.
- * **Fedora 29, 28 and 27** have Orion in its [repositories][9].
- * **openSUSE Tumbleweed and Leap 15.0** have Orion in the official [repositories][10].
-
-
-
-In case you're using a different Linux distribution, you'll need to search for Orion packages for yourself or build it from
-
-**If you prefer to build Orion from source on Debian/Ubuntu-based Linux distributions** (with mpv as the backend), **here's how to compile it. Orion requires Qt 5.8 or newer!** That means you'll need Ubuntu 18.04 / Linux Mint 19 to build it, or if you want to compile it in an older Ubuntu version, you'll need to install a newer Qt version from a PPA, etc.
-
-1\. Install the required dependencies on your Debian/Ubuntu-based Linux distribution:
-```
-sudo apt install qt5-default qtdeclarative5-dev qtquickcontrols2-5-dev libqt5svg5-dev libmpv-dev mesa-common-dev libgl1-mesa-dev libpulse-dev
-
-```
-
-2\. Download (using wget), build and install Orion:
-```
-cd && wget https://github.com/alamminsalo/orion/archive/1.6.5.tar.gz
-tar -xvf 1.6.5.tar.gz
-cd orion-1.6.5
-mkdir build && cd build
-qmake ../
-make && sudo make install
-
-```
-
-If you want to build a different Orion version, make sure you adjust the first 3 commands with the exact file/version name.
-
-
-### Fixing the default Orion theme when using QT_STYLE_OVERRIDE (not required in most cases)
-
-I use `QT_STYLE_OVERRIDE` . Due to this, Orion does not use its default theme which causes some fonts to be invisible or hard to read.
-
-This is how Orion looks when used with Kvantum set as the `QT_STYLE_OVERRIDE` :
-
-
-
-If you're in the same situation, you can fix the Orion theme by launching the application like this:
-```
-QT_STYLE_OVERRIDE= orion
-
-```
-
-To change the Orion desktop file to include this so you can launch Orion from your menu and have it use the correct theme, copy the Orion desktop file from `/usr/share/applications/` to `~/.local/share/applications/` , edit it in this second location and change `Exec=orion` to `Exec=env QT_STYLE_OVERRIDE= orion`
-
-You can do all of this from a terminal using these commands:
-```
-cp /usr/share/applications/Orion.desktop ~/.local/share/applications/
-
-sed -i 's/Exec=orion/Exec=env QT_STYLE_OVERRIDE= orion/' ~/.local/share/applications/Orion.desktop
-
-```
-
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxuprising.com/2018/08/orion-is-qml-c-twitch-desktop-client.html
-
-作者:[Logix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://plus.google.com/118280394805678839070
-[1]: https://alamminsalo.github.io/orion/
-[2]: https://www.twitch.tv/
-[3]: https://mpv.io/
-[4]: https://aur.archlinux.org/packages/orion/
-[5]: https://aur.archlinux.org/packages/orion-git/
-[6]: http://ppa.launchpad.net/mortigar/orion/ubuntu/pool/main/o/orion/
-[7]: https://launchpad.net/~mortigar/+archive/ubuntu/orion
-[8]: https://launchpad.net/~rakslice/+archive/ubuntu/orion
-[9]: https://apps.fedoraproject.org/packages/orion
-[10]: https://software.opensuse.org/package/orion
-[11]: https://github.com/alamminsalo/orion#building-on-linux
-[12]: https://www.linuxuprising.com/2018/05/use-custom-themes-for-qt-applications.html
-[13]: https://github.com/alamminsalo/orion/releases
diff --git a/sources/tech/20180829 4 open source monitoring tools.md b/sources/tech/20180829 4 open source monitoring tools.md
deleted file mode 100644
index a5b8bf6806..0000000000
--- a/sources/tech/20180829 4 open source monitoring tools.md
+++ /dev/null
@@ -1,143 +0,0 @@
-4 open source monitoring tools
-======
-
-
-
-Isn’t monitoring just monitoring? Doesn’t it include logging, visualization, and time-series data?
-
-The terminology around monitoring has caused a lot of confusion over the years and has led to some poor tools that tout the ability to do everything in one format. Observability proponents recognize there are many levels for observing a system. Metrics aggregation is primarily time-series data, and that’s what we’ll discuss in this article.
-
-### Features of time-series data
-
-#### Counters
-
-A counter is a metric that represents a numeric value that will only increase. (In other words, a counter should never decrease.) Counters accumulate values and present the current total when requested. These are commonly used for things like the total number of web requests, number of errors, number of visitors, etc. This is analogous to the person with a counter device standing at the entrance to an event counting all the people entering. There is generally no option to decrement the counter without resetting it.
-
-#### Gauges
-
-A gauge is similar to a counter in that it represents a single numeric value, but it can also decrease. It is essentially a representation of some value at a point in time. A thermometer is a good example of a gauge: It moves up and down with the temperature and offers a point-in-time reading. Other uses include CPU usage, memory usage, network usage, and number of threads.
-
-#### Quantiles
-
-Quantiles aren’t a type of metric, but they’re germane to the next two sections: histograms and summaries. Let’s clarify our understanding of quantiles with an example:
-
-A percentile is a type of quantile. Percentiles are something we see regularly, and they should help us understand the general concept more easily. A percentile has 100 “buckets” of values. We often see them related to testing or performance and generally stated as someone scoring, for example, within the 85th percentile or some other value. This means the person scoring within that percentile had a real value that fell within the bucket between the 85th and 86th percentile. This person also scored in the top 15% of all students. We don’t know the scores in the bucket based off this metric, but that can be derived based on the sum of all scores in the bucket divided by the count of those scores.
-
-Quantiles allow us to understand our data better than using a mean or some other statistical function that doesn’t take into account outliers and uneven distributions.
-
-#### Histograms
-
-A histogram is a little more complicated than a counter or a gauge. It is a sample of observations. It consists of a counter, which counts all the observations, and what is essentially a gauge that sums the values of the observations. It uses “buckets” or groupings to segment the values in order to bound the datasets in a productive way. This is commonly seen with quantiles related to request service-level agreements (SLAs). Let’s say we want to ensure that 95% of our requests are below 500ms. We could use a bucket with an upper bound of 0.5s to collect all values that fall under 500ms. We would then be able to determine how many of the total requests have fallen into that bucket. We can also determine how far we are from our SLA, but this can be difficult to do (as is explained more in the [Prometheus documentation][1]).
-
-Histograms are aggregate metrics that are accumulated from multiple instances into a central server. This provides an opportunity to understand the system as a whole rather than on a node-by-node basis.
-
-#### Summaries
-
-Summaries are similar to histograms in that they are a sample of observations, but the aggregation occurs on the server side. Also, the estimate of the quantile is more accurate than in a histogram. A summary uses a sliding time window, so it serves a slightly different case than a histogram but is generally used for the same types of metrics. I normally use a histogram unless I need a very accurate measure of the quantile.
-
-### Push/pull
-
-No article can be written about metrics aggregation tools without addressing the push vs. pull debate.
-
-The debate centers around whether it is better for your metrics aggregation system to have data pushed to it or to have your metrics aggregation system reach out and gather the data by scraping an endpoint. Multiple articles discuss this (like [this one][2] and [this one][3]). My perspective is that it mostly doesn’t matter. Additional research is left to the reader’s discretion.
-
-### Tool options
-
-There are many tools available, both open source and commercial. We will focus on open source tools, but some of these have an open core model with a paid component.
-
-Some of these tools feature additional components of observability—principally alerting and visualizations. These will be covered in this section as additional features and won’t be covered in subsequent articles.
-
-#### Prometheus
-
-This is the most well-recognized time-series monitoring solution for cloud-native applications. It is hosted within the [Cloud Native Computing Foundation][4] (CNCF), but it was created by Matt Proud and Julius Volz and sponsored by [SoundCloud][5], with external contributors coming in early to help develop it. Brian Brazil of [Robust Perception][6] has built a business of helping companies adopt Prometheus. He also has an excellent [blog][7] on his website. The [Prometheus documentation][8] is extensive and provides a lot of detail for understanding and using the tool.
-
-[Prometheus][9] is a pull-based system that uses local configuration to describe the endpoints to collect from and the interval desired for collection. Each endpoint has a client collecting the data and updating that representation upon each request (or however the client is configured). This data is collected and saved in a highly efficient storage engine on local disk. The storage system uses an append-only file per metric. This storage isn’t lossy, which means the fidelity of data from a year ago is as high as the data you are collecting today. However, you may not want to keep that much data locally. Fortunately, there is an option for remote storage for long-term retention and analysis.
-
-Prometheus includes an advanced expression language for selecting and presenting data called [PromQL][10]. This data can be displayed graphically, tabularly, or used by external systems through a REST API. The expression language allows a user to create regressions, analyze real-time data, or trend historical data. Labels are also a great tool for filtering and querying data. Labels can be associated with each metric name.
-
-Prometheus also offers a federation model, which encourages more localized control by allowing teams to have their own [Prometheis][11] while central teams can also have their own. The central systems could scrape the same endpoints as the local Prometheis, but they can also scrape the local Prometheis to get the aggregated data that the local instances are collecting. This reduces overhead on the endpoints. This federation model also allows local instances to collect data from each other.
-
-Prometheus comes with [AlertManager][12] to handle alerts. This system allows for aggregation of alerts as well as more complex flows to limit when an alert is sent.
-
-Let’s say 10 nodes suddenly go down at the same time a switch goes down. You probably don’t need to send an alert about the 10 nodes, as everyone who receives them will likely be unable to do anything until the switch is fixed. With the AlertManager, it’s possible to send an alert only to the networking team for the switch and include additional information about other systems that might be affected. It’s also possible to send an email (rather than a page) to the systems team so they know those nodes are down and they don’t need to respond unless the systems don’t come up after the switch is repaired. If that occurs, then AlertManager will reactivate those alerts that were suppressed by the switch alert.
-
-#### Graphite
-
-[Graphite][13] has been around for a long time, and James Turnbull's recent book [_The Art of Monitoring_][14] covers Graphite in detail. Graphite has become ubiquitous in the industry, with many large companies using it at scale.
-
-Graphite is a push-based system that receives data from applications by having the application push the data into Graphite’s Carbon component. Carbon stores this data in the Whisper database, and that database and Carbon are read by the Graphite web component that allows a user to graph their data in a browser or pull it through an API. A really cool feature is the ability to export these graphs as images or data files to easily embed them in other applications.
-
-Whisper is a fixed-size database that provides fast, reliable storage of numeric data over time. It is a lossy database, which means the resolution of your metrics will degrade over time. It will provide high-fidelity metrics for the most recent collections and gradually reduce that fidelity over time.
-
-Graphite also uses dot-separated naming, which implies dimensionality. This dimensionality allows for some creative aggregation of metrics and relationships between metrics. This enables aggregation of services across different versions or data centers and (getting more specific) a single version running in one data center in a specific Kubernetes cluster. Granular-level comparisons can also be made to determine if a particular cluster is underperforming.
-
-Another interesting feature of Graphite is the ability to store arbitrary events that should be related to time-series metrics. In particular, application or infrastructure deployments can be added and tracked within Graphite. This allows the operator or developer troubleshooting an issue to have more context about what has happened in the environment related to the anomalous behavior being investigated.
-
-Graphite also has a substantial [list of functions][15] that can be applied to metrics series. However, it lacks a powerful query language, which some other tools include. It also lacks any alerting functionality or built-in alerting system.
-
-#### InfluxDB
-
-[InfluxDB][16] is a relatively new entrant, newer than Prometheus. It uses an open core model, which means scaling and clustering cost extra. InfluxDB is part of the larger [TICK stack][17] (of Telegraf, InfluxDB, Chronograf, and Kapacitor), so we will include all those components’ features in this analysis.
-
-InfluxDB uses a key-value pair system called tags to add dimensionality to metrics, similar to Prometheus and Graphite. The results are similar to what we discussed previously for the other systems. The metric data can be of type **float64** , **int64** , **bool** , and **string** with nanosecond resolution. This is a broader range than most other tools in this space. In fact, the TICK stack is more of an event-aggregation platform than a native time-series metrics-aggregation system.
-
-InfluxDB uses a system similar to a log-structured merge tree for storage. It is called a time-structured merge tree in this context. It uses a write-ahead log and a collection of read-only data files, which are similar to Sorted Strings Tables but have series data rather than pure log data. These files are sharded per block of time. To learn more, check out [this great resource][18] on the InfluxData website.
-
-The architecture of the TICK stack is different depending on if it’s the open source or commercial version. The open source InfluxDB system is self-contained within a single host, while the commercial version is inherently distributed. This is true of the other central components as well. In the open source version, everything runs on a single host. No data or configuration is stored on external systems, so it is fairly easy to manage, but it isn’t as robust as the commercial version.
-
-InfluxDB includes a SQL-like language called InfluxQL for querying data from the databases. The primary means for querying data is the HTTP API. The query language doesn’t have as many built-in helper functions as Prometheus, but those familiar with SQL will likely feel more comfortable with the language.
-
-The TICK stack also includes an alerting system. This system can do some mild aggregation but doesn’t have the full capabilities of Prometheus’ AlertManager. It does offer many integrations, though. Also, to reduce load on InfluxDB, continuous queries can be scheduled to store results of queries that Kapacitor will pick up for alerting.
-
-#### OpenTSDB
-
-[OpenTSDB][19] is an open source time-series database, as its name implies. It’s unique in this collection of tools in that it stores its metrics in Hadoop. This means it is inherently scalable. If you already have a Hadoop cluster, this might be a good option for metrics you want to store over the long term. If you don’t have a Hadoop cluster, the operational overhead might be too large of a burden for you to bear. However, OpenTSDB now supports Google’s [Bigtable][20] as a backend, which is a cloud service you don’t have to operate.
-
-OpenTSDB shares a lot of features with the other systems. It uses a key-value pairing system it calls tags for identifying metrics and adding dimensionality. It has a query language, but it is more limited than Prometheus’ PromQL. It does, however, have several built-in functions that help with learning and usage. The API is the main entry point for querying, similar to InfluxDB. This system also stores all data forever, unless there’s a time-to-live set in HBase, so you don't have to worry about fidelity degradation.
-
-OpenTSDB doesn’t offer an alerting capability, which will make it harder to integrate with your incident response process. This type of system might be great for long-term Prometheus data storage and for performing more historical analytics to reveal systemic issues, rather than as a tool to quickly identify and respond to acute concerns.
-
-### OpenMetrics standard
-
-[OpenMetrics][21] is a working group seeking to establish a standard exposition format for metrics data. It is influenced by Prometheus. If this initiative is successful, we’ll have an industry-wide abstraction that would allow us to switch between tools and providers with ease. Leading companies like [Datadog][22] have already started offering tools that can consume the Prometheus exposition format, which will be easy to convert to the OpenMetrics standard once it’s released.
-
-It’s also important to note that the contributors to this project include Google and InfluxData (among others). This likely means InfluxDB will eventually adopt the OpenMetrics standard. This may also mean that one of the three largest cloud providers will adopt it if Google’s involvement is an indicator. Of course, the exposition format is already being used in the Google-created [Kubernetes][23] project. [SolarWinds][24], [Robust Perception][6], and [SpaceNet][25] are also involved.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/open-source-monitoring-tools
-
-作者:[Dan barker][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/barkerd427
-[1]: https://prometheus.io/docs/practices/histograms/
-[2]: https://thenewstack.io/exploring-prometheus-use-cases-brian-brazil/
-[3]: https://prometheus.io/blog/2016/07/23/pull-does-not-scale-or-does-it/
-[4]: https://www.cncf.io/
-[5]: https://soundcloud.com/
-[6]: https://www.robustperception.io/
-[7]: https://www.robustperception.io/blog/
-[8]: https://prometheus.io/docs/
-[9]: https://prometheus.io/
-[10]: https://prometheus.io/docs/prometheus/latest/querying/basics/
-[11]: https://prometheus.io/docs/introduction/faq/#what-is-the-plural-of-prometheus
-[12]: https://prometheus.io/docs/alerting/alertmanager/
-[13]: https://graphiteapp.org/
-[14]: https://www.artofmonitoring.com/
-[15]: http://graphite.readthedocs.io/en/latest/functions.html
-[16]: https://www.influxdata.com/
-[17]: https://www.thoughtworks.com/radar/platforms/tick-stack
-[18]: https://docs.influxdata.com/influxdb/v1.5/concepts/storage_engine/
-[19]: http://opentsdb.net/
-[20]: https://cloud.google.com/bigtable/
-[21]: https://github.com/RichiH/OpenMetrics
-[22]: https://www.datadoghq.com/blog/monitor-prometheus-metrics/
-[23]: https://opensource.com/resources/what-is-kubernetes
-[24]: https://www.solarwinds.com/
-[25]: https://spacenetchallenge.github.io/
diff --git a/sources/tech/20180829 Containers in Perl 6.md b/sources/tech/20180829 Containers in Perl 6.md
deleted file mode 100644
index 93c51c201f..0000000000
--- a/sources/tech/20180829 Containers in Perl 6.md
+++ /dev/null
@@ -1,174 +0,0 @@
-Containers in Perl 6
-======
-
-
-
-In the [first article][1] in this series comparing Perl 5 to Perl 6, we looked into some of the issues you might encounter when migrating code into Perl 6. In the [second article][2], we examined how garbage collection works in Perl 6. Here, in the third article, we'll focus on Perl 5's references and how they're handled in Perl 6, and introduce the concepts of binding and containers.
-
-### References
-
-There are no references in Perl 6, which is surprising to many people used to Perl 5's semantics. But worry not: because there are no references, you don't have to worry about whether something should be de-referenced or not.
-```
-# Perl 5
-my $foo = \@bar; # must add reference \ to make $foo a reference to @bar
-say @bar[1]; # no dereference needed
-say $foo->[1]; # must add dereference ->
-
-# Perl 6
-my $foo = @bar; # $foo now contains @bar
-say @bar[1]; # no dereference needed, note: sigil does not change
-say $foo[1]; # no dereference needed either
-```
-
-One could argue that everything in Perl 6 is a reference. Coming from Perl 5 (where an object is a blessed reference), this would be a logical conclusion about Perl 6 where everything is an object (or can be considered one). But that wouldn't do justice to the situation in Perl 6 and would hinder you in understanding how things work in Perl 6. Beware of [false friends][3]!
-
-### Binding
-
-Before we get to assignment, it is important to understand the concept of binding in Perl 6. You can bind something explicitly to something else using the `:=` operator. When you define a lexical variable, you can bind a value to it:
-```
-my $foo := 42; # note: := instead of =
-```
-
-Simply put, this creates a key with the name "`$foo`" in the lexical pad (lexpad) (which you could consider a compile-time hash that contains information about things that are visible in that lexical scope) and makes `42` its literal value. Because this is a literal constant, you can't change it. Trying to do so will cause an exception. So don't do that!
-
-This binding operation is used under the hood in many situations, for instance when iterating:
-```
-my @a = 0..9; # can also be written as ^10
-say @a; # [0 1 2 3 4 5 6 7 8 9]
-for @a { $_++ } # $_ is bound to each array element and incremented
-say @a; # [1 2 3 4 5 6 7 8 9 10]
-```
-
-If you try to iterate over a constant list, then `$_` is bound to the literal values, which you can not increment:
-```
-for 0..9 { $_++ } # error: requires mutable arguments
-```
-
-### Assignment
-
-If you compare "create a lexical variable and assign to it" in Perl 5 and Perl 6, it looks the same on the outside:
-```
-my $bar = 56; # both Perl 5 and Perl 6
-```
-
-In Perl 6, this also creates a key with the name "`$bar`" in the lexpad. But instead of directly binding the value to that lexpad entry, a container (a `Scalar` object) is created for you and that is bound to the lexpad entry of "`$bar`". Then, `56` is stored as the value in that container. In pseudo-code, you can think of this as:
-```
-my $bar := Scalar.new( value => 56 );
-```
-
-Notice that the `Scalar` object is bound, not assigned. The closest thing to this in Perl 5 is a [tied scalar][4]. But of course "`= 56`" is much less to type!
-
-Data structures such as `Array` and `Hash` also automatically put values in containers bound to the structure.
-```
-my @a; # empty Array
-@a[5] = 42; # bind a Scalar container to 6th element and put 42 in it
-```
-
-### Containers
-
-The `Scalar` container object is invisible for most operations in Perl 6, so most of the time you don't have to think about it. For instance, whenever you call a subroutine (or a method) with a variable as an argument, it will bind to the value in the container. And because you cannot assign to a value, you get:
-```
-sub frobnicate($this) {
- $this = 42;
-}
-my $foo = 666;
-frobnicate($foo); # Cannot assign to a readonly variable or a value
-```
-
-If you want to allow assigning to the outer value, you can add the `is rw` trait to the variable in the signature. This will bind the variable in the signature to the container of the variable specified, thus allowing assignment:
-```
-sub oknicate($this is rw) {
- $this = 42;
-}
-my $foo = 666;
-oknicate($foo); # no problem
-say $foo; # 42
-```
-
-### Proxy
-
-Conceptually, the `Scalar` object in Perl 6 has a `FETCH` method (for producing the value in the object) and a `STORE` method (for changing the value in the object), just like a tied scalar in Perl 5.
-
-Suppose you later assign the value `768` to the `$bar` variable:
-```
-$bar = 768;
-```
-
-What happens is conceptually the equivalent of:
-```
-$bar.STORE(768);
-```
-
-Suppose you want to add `20` to the value in `$bar`:
-```
-$bar = $bar + 20;
-```
-
-What happens conceptually is:
-```
-$bar.STORE( $bar.FETCH + 20 );
-```
-
-If you like to specify your own `FETCH` and `STORE` methods on a container, you can do that by binding to a [Proxy][5] object. For example, to create a variable that will always report twice the value that was assigned to it:
-```
-my $double := do { # $double now a Proxy, rather than a Scalar container
- my $value;
- Proxy.new(
- FETCH => method () { $value + $value },
- STORE => method ($new) { $value = $new }
- )
-}
-```
-
-Note that you will need an extra variable to keep the value stored in such a container.
-
-### Constraints and default
-
-Apart from the value, a [Scalar][6] also contains extra information such as the type constraint and default value. Take this definition:
-```
-my Int $baz is default(42) = 666;
-```
-
-It creates a Scalar bound with the name "`$baz`" to the lexpad, constrains the values in that container to types that successfully smartmatch with `Int`, sets the default value of the container to `42`, and puts the value `666` in the container.
-
-Assigning a string to that variable will fail because of the type constraint:
-```
-$baz = "foo";
-# Type check failed in assignment to $baz; expected Int but got Str ("foo")
-```
-
-If you do not give a type constraint when you define a variable, then the `Any` type will be assumed. If you do not specify a default value, then the type constraint will be assumed.
-
-Assigning `Nil` (the Perl 6 equivalent of Perl 5's `undef`) to that variable will reset it to the default value:
-```
-say $baz; # 666
-$baz = Nil;
-say $baz; # 42
-```
-
-### Summary
-
-
-Perl 5 has values and references to values. Perl 6 has no references, but it has values and containers. There are two types of containers in Perl 6: [Proxy][5] (which is much like a tied scalar in Perl 5) and [Scalar][6] . Simply stated, a variable, as well as an element of a [List][7] [Array][8] , or [Hash][9] , is either a value (if it is bound), or a container (if it is assigned). Whenever a subroutine (or method) is called, the given arguments are de-containerized and bound to the parameters of the subroutine (unless told to do otherwise). A container also keeps information such as type constraints and a default value. Assigningto a variable will return it to its default value, which isif you do not specify a type constraint.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/containers-perl-6
-
-作者:[Elizabeth Mattijsen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/lizmat
-[1]: https://opensource.com/article/18/7/migrating-perl-5-perl-6
-[2]: https://opensource.com/article/18/7/garbage-collection-perl-6
-[3]: https://en.wikipedia.org/wiki/False_friend
-[4]: https://metacpan.org/pod/distribution/perl/pod/perltie.pod#Tying-Scalars
-[5]: https://docs.perl6.org/type/Proxy
-[6]: https://docs.perl6.org/type/Scalar
-[7]: https://docs.perl6.org/type/List
-[8]: https://docs.perl6.org/type/Array
-[9]: https://docs.perl6.org/type/Hash
diff --git a/sources/tech/20180830 A quick guide to DNF for yum users.md b/sources/tech/20180830 A quick guide to DNF for yum users.md
deleted file mode 100644
index 559591b516..0000000000
--- a/sources/tech/20180830 A quick guide to DNF for yum users.md
+++ /dev/null
@@ -1,131 +0,0 @@
-A quick guide to DNF for yum users
-======
-
-
-
-Dandified yum, better known as [DNF][1], is a software package manager for RPM-based Linux distributions that installs, updates, and removes packages. It was first introduced in Fedora 18 in a testable state (i.e., tech preview), but it's been Fedora's default package manager since Fedora 22.
-
- * Dependency calculation based on modern dependency-solving technology
- * Optimized memory-intensive operations
- * The ability to run in Python 2 and Python 3
- * Complete documentation available for Python APIs
-
-
-
-Since it is the next-generation version of the traditional yum package manager, it has more advanced and robust features than you'll find in yum. Some of the features that distinguish DNF from yum are:
-
-DNF uses [hawkey][2] libraries, which resolve RPM dependencies for running queries on client machines. These are built on top of libsolv, a package-dependency solver that uses a satisfiability algorithm. You can find more details on the algorithm in [libsolv's GitHub][3] repository.
-
-### CLI commands that differ in DNF and yum
-
-Following are some of the changes to yum's command-line interface (CLI) you will find in DNF.
-
-**dnf update** or **dnf upgrade:** Executing either dnf update or dnf upgrade has the same effect in the system: both update installed packages. However, dnf upgrade is preferred since it works exactly like **yum --obsoletes update**.
-
-**resolvedep:** This command doesn't exist in DNF. Instead, execute **dnf provides** to find out which package provides a particular file.
-
-**deplist:** Yum's deplist command, which lists RPM dependencies, was removed in DNF because it uses the package-dependency solver algorithm to solve the dependency query.
-
-**dnf remove <package>:** You must specify concrete versions of whatever you want to remove. For example, **dnf remove kernel** will delete all packages called "kernel," so make sure to use something like **dnf remove kernel-4.16.x**.
-
-**dnf history rollback:** This check, which undoes transactions after the one you specifiy, was dropped since not all the possible changes in the RPM Database Tool are stored in the history of the transaction.
-
-**--skip-broken:** This install command, which checks packages for dependency problems, is triggered in yum with --skip-broken. However, now it is part of dnf update by default, so there is no longer any need for it.
-
-**-b, --best:** These switches select the best available package versions in transactions. During dnf upgrade, which by default skips over updates that cannot be installed for dependency reasons, this switch forces DNF to consider only the latest packages. Use **dnf upgrade --best**.
-
-**--allowerasing:** Allows erasing of installed packages to resolve dependencies. This option could be used as an alternative to the **yum swap X Y** command, in which the packages to remove are not explicitly defined.
-
-For example: **dnf --allowerasing install Y**.
-
-**\--enableplugin:** This switch is not recognized and has been dropped.
-
-### DNF Automatic
-
-The [DNF Automatic][4] tool is an alternative CLI to dnf upgrade. It can execute automatically and regularly from systemd timers, cron jobs, etc. for auto-notification, downloads, or updates.
-
-To start, install dnf-automatic rpm and enable the systemd timer unit (dnf-automatic.timer). It behaves as specified by the default configuration file (which is /etc/dnf/automatic.conf).
-```
-# yum install dnf-automatic
-# systemctl enable dnf-automatic.timer
-# systemctl start dnf-automatic.timer
-# systemctl status dnf-automatic.timer
-```
-
-
-
-Other timer units that override the default configuration are listed below. Select the one that meets your system requirements.
-
- * **dnf-automatic-notifyonly.timer:** Notifies the available updates
- * **dnf-automatic-download.timer:** Downloads packages, but doesn't install them
- * **dnf-automatic-install.timer:** Downloads and installs updates
-
-
-
-### Basic DNF commands useful for package management
-
-**# yum install dnf:** This installs DNF RPM from the yum package manager.
-
-
-
-**# dnf –version:** This specifies the DNF version.
-
-
-
-**# dnf list all** or **# dnf list <package-name>:** This lists all or specific packages; this example lists the kernel RPM available in the system.
-
-
-
-**# dnf check-update** or **# dnf check-update kernel:** This views updates in the system.
-
-
-
-**# dnf search <package-name>:** When you search for a specific package via DNF, it will search for an exact match as well as all wildcard searches available in the repository.
-
-
-
-**# dnf repolist all:** This downloads and lists all enabled repositories in the system.
-
-
-
-**# dnf list --recent** or **# dnf list --recent <package-name>:** The **\--recent** option dumps all recently added packages in the system. Other list options are **\--extras** , **\--upgrades** , and **\--obsoletes**.
-
-
-
-**# dnf updateinfo list available** or **# dnf updateinfo list available sec:** These list all the advisories available in the system; including the sec option will list all advisories labeled "security fix."
-
-
-
-**# dnf updateinfo list available sec --sec-severity Critical:** This lists all the security advisories in the system marked "critical."
-
-
-
-**# dnf updateinfo FEDORA-2018-a86100a264 –info:** This verifies the information of any advisory via the **\--info** switch.
-
-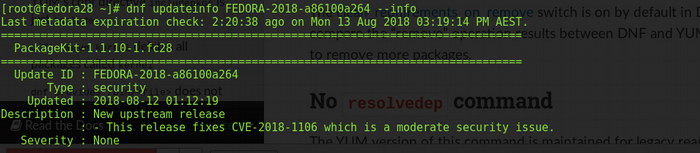
-
-**# dnf upgrade --security** or **# dnf upgrade --sec-severity Critical:** This applies all the security advisories available in the system. With the **\--sec-severity** option, you can include the packages with severity marked either Critical, Important, Moderate, or Low.
-
-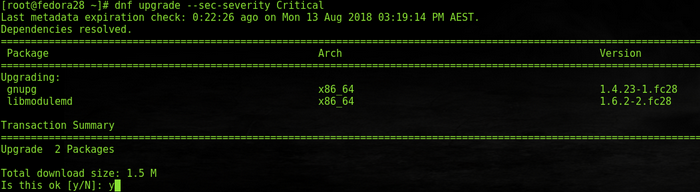
-
-### Summary
-
-These are just a small number of DNF's features, changes, and commands. For complete information about DNF's CLI, new plugins, and hook APIs, refer to the [DNF guide][5].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/guide-yum-dnf
-
-作者:[Amit Das][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/amit-das
-[1]: https://fedoraproject.org/wiki/DNF?rd=Dnf
-[2]: https://fedoraproject.org/wiki/Features/Hawkey
-[3]: https://github.com/openSUSE/libsolv
-[4]: https://dnf.readthedocs.io/en/latest/automatic.html
-[5]: https://dnf.readthedocs.io/en/latest/index.html
diff --git a/sources/tech/20180830 How to scale your website across all mobile devices.md b/sources/tech/20180830 How to scale your website across all mobile devices.md
deleted file mode 100644
index ad36b9017a..0000000000
--- a/sources/tech/20180830 How to scale your website across all mobile devices.md
+++ /dev/null
@@ -1,85 +0,0 @@
-How to scale your website across all mobile devices
-======
-
-
-
-Most of us surf the internet, make online purchases, and even pay bills using our mobile devices because they are handy and easily accessible. According to a Forrester study, [The Digital Business Imperative][1], 43% of banking customers in the US used mobile phones to complete banking transactions in a three-month period.
-
-The significant year-over-year growth of online business transactions done via mobile devices has encouraged companies to build websites and e-commerce sites that look, feel, and function identically on computers and smart mobile devices. However, many users still find the experience of browsing a website on a smartphone isn’t the same as on a computer. In order to develop websites that scale effectively and smoothly across different devices, it's important to understand what causes these differences across platforms.
-
-Web pages are usually composed of one or more of the following components: Header and footer, main content (text), images, forms, videos, and tables. Devices differ on features such as screen dimension (length x width), screen resolution (pixel density), compute power (CPU and memory), and operating system (iOS, Android, Windows, etc.). These differences contribute significantly to the overall performance and rendering of web components such as images, videos, and text across different devices. Another important factor is that mobile users may not always be connected to a high-speed network, so web pages should be carefully designed to work effectively on low-bandwidth connections.
-
-### The most troublesome issues on mobile platforms
-
-Here are some of the most common issues that can affect the performance and scalability of websites across devices:
-
- * **Sites do not automatically adapt to different screen sizes.** Some websites are designed to format for variable screen sizes, but their elements may not auto-scale. This would result in the site automatically adjusting itself for various screen sizes, but the elements in the site may look too large on smaller devices. Some sites may not be designed to adjust for variable screen sizes, causing the elements to look extremely small on devices with smaller screens.
- * **Sites have too much content for mobile devices.** Some websites are loaded with content to fill empty space on a desktop screen. Websites developed without considering mobile users generally fall under this category. These sites take more time and bandwidth to load, and if the pages aren’t designed appropriately for mobile devices, some content may not even appear.
- * **Sites take too long to load images.** Websites with too many images or heavy image files are likely to take a long time to load, especially if the images were not optimized during the design phase.
- * **Data in tables looks complex and takes too long to load.** Many websites present data in a tabular fashion (for example, comparisons of competing products, airfare data from different travel sites, flight schedules, etc.), and on mobile devices, these tables can be slow and difficult to comprehend.
- * **Websites host videos that don’t play on some devices.** Not all mobile devices support all video formats. Some websites host media that require licenses, Adobe Flash, or other players that some mobile devices may not support. This causes frustration and a poor overall user experience.
-
-
-
-### Design your sites to adapt to different devices
-
-All these issues can be addressed through proper design and by adopting a [mobile-first][2] approach. When working with limitations such as screen size, bandwidth, etc., focus on the right quantity and quality of content. A mobile-first strategy places content as the primary object and designs for the smallest devices, ensuring that a site includes only the most essential features. Address the design challenges for mobile devices first, and then progressively enhance the design for larger devices.
-
-Here are a few best practices to consider when designing websites that need to scale on different devices.
-
-* **Adapting to any screen size**. At a minimum, a web page needs to be scaled to fit the screen size of any mobile device. Today's mobile devices come with very high screen resolutions. The pixel density on mobile devices is much higher than that of desktop screens, so it is important to format pages to match the mobile screen’s width in device-independent pixels. The “meta viewport” tag included in the HTML document addresses this requirement.
-
-
-
-The meta viewport value, as shown above, helps format the entire HTML page and render the content to match any screen size.
-
-* **" Content is king."** Content should determine the design of a website, not vice versa. Websites with too many elements such as tables, forms, charts, etc., become challenging when they need to scale on mobile devices. Developers end up hiding content for mobile users, and the desktop version and the mobile version become inconsistent. The design should focus on the core structure and content rather than decorative elements. The mobile-first methodology ensures a single version of content for both desktop and mobile users, so web designers should carefully consider, craft, and optimize content so that it not only satisfies business goals but also appeals to mobile users. Content that doesn’t appear in the mobile version may not even need to appear in the desktop version.
-* **Responsive images**. The design should consider small hand-held devices operating in areas with low signal strength. Large photos and complex graphics are not suitable for mobile devices operating under such conditions. Make sure all images are optimized for different sizes of viewports and pixel densities. A recommended approach is [resolution switching][3], which enables the browser to select an appropriately sized image file, depending on the screen size of a device. Resolution switching uses two attributes—`srcset` and `sizes` (shown in the code snippet shown below)—which enable the browser to use the device width to select the most suitable media condition provided in the sizes list, choose the slot size based on that condition, and load the image referenced in the `srcset` that most closely matches the chosen slot size.
-
-
-
-For example, if a device with a viewport of 320px loads the page, the media condition (max-width: 320px) in the sizes list will be true, and the corresponding 280px slot will be chosen. The width of the first image listed in `srcset` (elephant-320w.jpg) is the closest to this slot. Browsers that don’t support resolution switching display the image listed in the src attribute as the default image. This approach not only picks the right image for your device viewport, but it also prevents loading unnecessarily large images that consume significant bandwidth.
-
-
-
-* **Responsive tables.** As the world becomes more data-driven, bringing critical, time-sensitive data to handheld devices provides power and freedom to users. The challenge is to present data in a way that is easy to load and read on mobile devices. Some data needs to be presented in the form of a table, but when data tables get too large and unwieldy, it can be frustrating for users to interpret them on a mobile device with a small screen. If the screen is much narrower than the width of the table, for example, users are forced to zoom out, making the text too small to read. Conversely, if the screen is wider than the table, users must zoom in to view the data, which requires constant vertical and horizontal scrolling.
-
-Fortunately, there are several ways to build [responsive tables][4]. Here is one of the most effective:
-
- * The table's columns are transposed into rows. Each column is sized to the same width as the screen, preventing the need to scroll horizontally. Use of color helps users clearly distinguish each individual row of data. In this case, for each “cell,” the CSS-generated content `(:before)` should be used to apply the label so that each piece of data can be identified clearly.
- * Another approach is to display the data in one of two formats, based on screen width: chart format (for narrow screens) or complete table format (for wider screens). If the user wants to click the chart to see the complete table, the approach described above can be used to show the data in tabular form.(:before)
- * A third approach is to show a mini-graphic in a narrow screen to indicate the presence of a table. The user can click on the graphic to expand and display the table.
-* **Videos that always play.** [Video files][5] generally won’t play on mobile devices if their formats are unsupported or if they require a proprietary video player. The recommended approach is to use standard HTML5 tags for videos and animations. The video element in HTML5 can be used to load, decode, and play videos on your website. Produce video in multiple formats to suit different mobile platforms, and be sure to size videos appropriately so that they play within their containers.
-
-The example below shows the use of tags to specify different video formats (indicated by the type element). In this approach, the switch to the correct format happens at the client side, and only one request is made to the server. This reduces network latency and lets the browser select the most appropriate video format without first downloading it.
-
-
-
-The `videoWidth` and `videoHeight` properties of the video element help identify the encoded size of a video. Video dimensions can be controlled using JavaScript or CSS. `max-width: 100%` helps size the videos to fit the screen. CSS media queries can be used to set the size based on the viewport dimensions. There are also several JavaScript libraries and plugins that can maintain the aspect ratio and size of videos.
-
-### All things considered…
-
-These days, users regularly surf the web and perform business transactions with their smartphones and tablets. The web is becoming the primary business channel for many businesses worldwide. Consequently, it is important to develop websites that work and scale well on mobile devices. The goal is to enhance the mobile user experience so that it mirrors the functionality and performance of desktop computers and large monitors.
-
-The mobile-first approach helps web designers create sites that operate well on small mobile devices. Design should focus on content that satisfies business requirements while also considering technical limitations such as screen size, processor speed, memory, and operating conditions (e.g., poor network signal strength). It must also ensure that pictures, videos, and data are responsive across all mobile devices while remaining sensitive to breakpoints, touch targets, etc.
-
-A well-designed website that works and scales on a small device can always be progressively enhanced to work on larger devices.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/8/how-scale-your-website-across-all-devices
-
-作者:[Sridhar Asvathanarayanan][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/sasvathanarayanangmailcom
-[1]: https://www.forrester.com/report/The+Digital+Business+Imperative/-/E-RES115784#
-[2]: https://www.uxpin.com/studio/blog/a-hands-on-guide-to-mobile-first-design/
-[3]: https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images
-[4]: https://css-tricks.com/responsive-data-tables/
-[5]: https://developers.google.com/web/fundamentals/media/video
diff --git a/sources/tech/20180912 How subroutine signatures work in Perl 6.md b/sources/tech/20180912 How subroutine signatures work in Perl 6.md
deleted file mode 100644
index 79606380bd..0000000000
--- a/sources/tech/20180912 How subroutine signatures work in Perl 6.md
+++ /dev/null
@@ -1,335 +0,0 @@
-How subroutine signatures work in Perl 6
-======
-In the fourth article in this series comparing Perl 5 to Perl 6, learn how signatures work in Perl 6.
-
-
-
-In the [first article][1] in this series comparing Perl 5 to Perl 6, we looked into some of the issues you might encounter when migrating code into Perl 6. In the [second article][2], we examined how garbage collection works in Perl 6, and in the [third article][3], we looked at how containers replaced references in Perl 6. Here in the fourth article, we will focus on (subroutine) signatures in Perl 6 and how they differ from those in Perl 5.
-
-### Experimental signatures in Perl 5
-
-If you're migrating from Perl 5 code to Perl 6, you're probably not using the [experimental signature feature][4] that became available in Perl 5.20 or any of the older CPAN modules like [signatures][5], [Function::Parameters][6], or any of the other Perl 5 modules on CPAN with ["signature" in their name][7].
-
-Also, in my experience, [prototypes][8] haven't been used very often in the Perl programs out in the world (e.g., the [DarkPAN][9] ).
-
-For these reasons, I will compare Perl 6 functionality only with the most common use of "classic" Perl 5 argument passing.
-
-### Argument passing in Perl 5
-
-All arguments you pass to a Perl 5 subroutine are flattened and put into the automatically defined `@_` array variable inside. That is basically all Perl 5 does with passing arguments to subroutines. Nothing more, nothing less. There are, however, several idioms in Perl 5 that take it from there. The most common (I would say "standard") idiom in my experience is:
-
-```
-# Perl 5
-sub do_something {
- my ($foo, $bar) = @_;
- # actually do something with $foo and $bar
-}
-```
-
-This idiom performs a list assignment (copy) to two (new) lexical variables. This way of accessing the arguments to a subroutine is also supported in Perl 6, but it's intended just as a way to make migrations easier.
-
-If you expect a fixed number of arguments followed by a variable number of arguments, the following idiom is typically used:
-
-```
-# Perl 5
-sub do_something {
- my $foo = shift;
- my $bar = shift;
- for (@_) {
- # do something for each element in @_
- }
-}do_something
-```
-
-This idiom depends on the magic behavior of [shift][10], which shifts from `@_` in this context. If the subroutine is intended to be called as a method, something like this is usually seen:
-
-```
-# Perl 5
-sub do_something {
- my $self = shift;
- # do something with $self
-}do_something
-```
-
-as the first argument passed is the [invocant][11] in Perl 5.
-
-By the way, this idiom can also be written in the first idiom:
-
-```
-# Perl 5
-sub do_something {
- my ($foo, $bar, @rest) = @_;
- for (@rest) {
- # do something for each element in @rest
- }
-}
-```
-
-But that would be less efficient, as it would involve copying a potentially long list of values.
-
-The third idiom revolves on directly accessing the `@_` array.
-
-```
-# Perl 5
-sub sum_two {
- return $_[0] + $_[1]; # return the sum of the two parameters
-}sum_two
-```
-
-This idiom is typically used for small, one-line subroutines, as it is one of the most efficient ways of handling arguments because no copying takes place.
-
-This idiom is also used if you want to change any variable that is passed as a parameter. Since the elements in `@_` are aliases to any variables specified (in Perl 6 you would say: "are bound to the variables"), it is possible to change the contents:
-
-```
-# Perl 5
-sub make42 {
- $_[0] = 42;
-}
-my $a = 666;
-make42($a);
-say $a; # 42
-```
-
-### Named arguments in Perl 5
-
-Named arguments (as such) don't exist in Perl 5. But there is an often-used idiom that effectively mimics named arguments:
-
-```
-# Perl 5
-sub do_something {
- my %named = @_;
- if (exists %named{bar}) {
- # do stuff if named variable "bar" exists
- }
-}do_somethingbar
-```
-
-This initializes the hash `%named` by alternately taking a key and a value from the `@_` array. If you call a subroutine with arguments using the fat-comma syntax:
-
-```
-# Perl 5
-frobnicate( bar => 42 );
-```
-
-it will pass two values, `"foo"` and `42`, which will be placed into the `%named` hash as the value `42` associated with key `"foo"`. But the same thing would have happened if you had specified:
-
-```
-# Perl 5
-frobnicate( "bar", 42 );
-```
-
-The `=>` is syntactic sugar for automatically quoting the left side. Otherwise, it functions just like a comma (hence the name "fat comma").
-
-If a subroutine is called as a method with named arguments, this idiom is combined with the standard idiom:
-
-```
-# Perl 5
-sub do_something {
- my ($self, %named) = @_;
- # do something with $self and %named
-}
-```
-
-alternatively:
-
-```
-# Perl 5
-sub do_something {
- my $self = shift;
- my %named = @_;
- # do something with $self and %named
-}do_something
-```
-
-### Argument passing in Perl 6
-
-In their simplest form, subroutine signatures in Perl 6 are very much like the "standard" idiom of Perl 5. But instead of being part of the code, they are part of the definition of the subroutine, and you don't need to do the assignment:
-
-```
-# Perl 6
-sub do-something($foo, $bar) {
- # actually do something with $foo and $bar
-}
-```
-
-versus:
-
-```
-# Perl 5
-sub do_something {
- my ($foo, $bar) = @_;
- # actually do something with $foo and $bar
-}
-```
-
-In Perl 6, the `($foo, $bar)` part is called the signature of the subroutine.
-
-Since Perl 6 has an actual `method` keyword, it is not necessary to take the invocant into account, as that is automatically available with the `self` term:
-
-```
-# Perl 6
-class Foo {
- method do-something-else($foo, $bar) {
- # do something else with self, $foo and $bar
- }
-}
-```
-
-Such parameters are called positional parameters in Perl 6. Unless indicated otherwise, positional parameters must be specified when calling the subroutine.
-
-If you need the aliasing behavior of using `$_[0]` directly in Perl 5, you can mark the parameter as writable by specifying the `is rw` trait:
-
-```
-# Perl 6
-sub make42($foo is rw) {
- $foo = 42;
-}
-my $a = 666;
-make42($a);
-say $a; # 42
-```
-
-When you pass an array as an argument to a subroutine, it doesn't get flattened in Perl 6. You only need to accept an array as an array in the signature:
-
-```
-# Perl 6
-sub handle-array(@a) {
- # do something with @a
-}
-my @foo = "a" .. "z";
-handle-array(@foo);
-```
-
-You can pass any number of arrays:
-
-```
-# Perl 6
-sub handle-two-arrays(@a, @b) {
- # do something with @a and @b
-}
-my @bar = 1..26;
-handle-two-arrays(@foo, @bar);
-```
-
-If you want the ([variadic][12]) flattening semantics of Perl 5, you can indicate this with a so-called "slurpy array" by prefixing the array with an asterisk in the signature:
-
-```
-# Perl 6
-sub slurp-an-array(*@values) {
- # do something with @values
-}
-slurp-an-array("foo", 42, "baz");slurpanarrayslurpanarray
-```
-
-A slurpy array can occur only as the last positional parameter in a signature.
-
-If you prefer to use the Perl 5 way of specifying parameters in Perl 6, you can do this by specifying a slurpy array `*@_` in the signature:
-
-```
-# Perl 6
-sub do-like-5(*@_) {
- my ($foo, $bar) = @_;
-}
-```
-
-### Named arguments in Perl 6
-
-On the calling side, named arguments in Perl 6 can be expressed very similarly to how they are expressed in Perl 5:
-
-```
-# Perl 5 and Perl 6
-frobnicate( bar => 42 );
-```
-
-However, on the definition side of the subroutine, things are very different:
-
-```
-# Perl 6
-sub frobnicate(:$bar) {
- # do something with $bar
-}
-```
-
-The difference between an ordinary (positional) parameter and a named parameter is the colon, which precedes the [sigil][13] and the variable name in the definition:
-
-```
-$foo # positional parameter, receives in $foo
-:$bar # named parameter "bar", receives in $bar
-```
-
-Unless otherwise specified, named parameters are optional. If a named argument is not specified, the associated variable will contain the default value, which usually is the type object `Any`.
-
-If you want to catch any (other) named arguments, you can use a so-called "slurpy hash." Just like the slurpy array, it is indicated with an asterisk before a hash:
-
-```
-# Perl 6
-sub slurp-nameds(*%nameds) {
- say "Received: " ~ join ", ", sort keys %nameds;
-}
-slurp-nameds(foo => 42, bar => 666); # Received: bar, fooslurpnamedssayslurpnamedsfoobar
-```
-
-As with the slurpy array, there can be only one slurpy hash in a signature, and it must be specified after any other named parameters.
-
-Often you want to pass a named argument to a subroutine from a variable with the same name. In Perl 5 this looks like: `do_something(bar => $bar)`. In Perl 6, you can specify this in the same way: `do-something(bar => $bar)`. But you can also use a shortcut: `do-something(:$bar)`. This means less typing–and less chance of typos.
-
-### Default values in Perl 6
-
-Perl 5 has the following idiom for making parameters optional with a default value:
-
-```
-# Perl 5
-sub dosomething_with_defaults {
- my $foo = @_ ? shift : 42;
- my $bar = @_ ? shift : 666;
- # actually do something with $foo and $bar
-}dosomething_with_defaults
-```
-
-In Perl 6, you can specify default values as part of the signature by specifying an equal sign and an expression:
-
-```
-# Perl 6
-sub dosomething-with-defaults($foo = 42, :$bar = 666) {
- # actually do something with $foo and $bar
-}
-```
-
-Positional parameters become optional if a default value is specified for them. Named parameters stay optional regardless of any default value.
-
-### Summary
-
-Perl 6 has a way of describing how arguments to a subroutine should be captured into parameters of that subroutine. Positional parameters are indicated by their name and the appropriate sigil (e.g., `$foo`). Named parameters are prefixed with a colon (e.g. `:$bar`). Positional parameters can be marked as `is rw` to allow changing variables in the caller's scope.
-
-Positional arguments can be flattened in a slurpy array, which is prefixed by an asterisk (e.g., `*@values`). Unexpected named arguments can be collected using a slurpy hash, which is also prefixed with an asterisk (e.g., `*%nameds`).
-
-Default values can be specified inside the signature by adding an expression after an equal sign (e.g., `$foo = 42`), which makes that parameter optional.
-
-Signatures in Perl 6 have many other interesting features, aside from the ones summarized here; if you want to know more about them, check out the Perl 6 [signature object documentation][14].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/signatures-perl-6
-
-作者:[Elizabeth Mattijsen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/lizmat
-[1]: https://opensource.com/article/18/7/migrating-perl-5-perl-6
-[2]: https://opensource.com/article/18/7/garbage-collection-perl-6
-[3]: https://opensource.com/article/18/7/containers-perl-6
-[4]: https://metacpan.org/pod/distribution/perl/pod/perlsub.pod#Signatures
-[5]: https://metacpan.org/pod/signatures
-[6]: https://metacpan.org/pod/Function::Parameters
-[7]: https://metacpan.org/search?q=signature
-[8]: https://metacpan.org/pod/perlsub#Prototypes
-[9]: http://modernperlbooks.com/mt/2009/02/the-darkpan-dependency-management-and-support-problem.html
-[10]: https://perldoc.perl.org/functions/shift.html
-[11]: https://docs.perl6.org/routine/invocant
-[12]: https://en.wikipedia.org/wiki/Variadic_function
-[13]: https://www.perl.com/article/on-sigils/
-[14]: https://docs.perl6.org/type/Signature
diff --git a/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md b/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
deleted file mode 100644
index baaf08e92d..0000000000
--- a/sources/tech/20180914 Freespire Linux- A Great Desktop for the Open Source Purist.md
+++ /dev/null
@@ -1,114 +0,0 @@
-Freespire Linux: A Great Desktop for the Open Source Purist
-======
-
-
-
-Quick. Click on your Linux desktop menu and scan through the list of installed software. How much of that software is strictly open sources To make matters a bit more complicated, have you installed closed source media codecs (to play the likes of MP3 files perhaps)? Is everything fully open, or do you have a mixture of open and closed source tools?
-
-If you’re a purist, you probably strive to only use open source tools on your desktop. But how do you know, for certain, that your distribution only includes open source software? Fortunately, a few distributions go out of their way to only include applications that are 100% open. One such distro is [Freespire][1].
-
-Does that name sound familiar? It should, as it is closely related to[Linspire][2]. Now we’re talking familiarity. Remember back in the early 2000s, when Walmart sold Linux desktop computers? Those computers were powered by the Linspire operating system. Linspire went above and beyond to create an experience that would be similar to that of Windows—even including the tools to install Windows apps on Linux. That experiment failed, mostly because consumers thought they were getting a Windows desktop machine for a dirt cheap price. After that debacle, Linspire went away for a while. It’s now back, thanks to [PC/OpenSystems LLC][3]. Their goal isn’t to recreate the past but to offer two different flavors of Linux:
-
- * Linspire—a commercial distribution of Linux that includes proprietary software and does have an associated cost ($39.99 USD for a single license).
-
- * Freespire—a non-commercial distribution of Linux that only includes open source software and is free to download.
-
-
-
-
-We’re here to discuss Freespire and why it is an outstanding addition to the Linux community, especially those who strive to use only free and open source software. This version of Freespire (4.0) was released on August 20, 2018, so it’s fresh and ready to go.
-
-Let’s dig into the operating system and see what makes this a viable candidate for open source fans.
-
-### Installation
-
-In keeping with my usual approach, there’s very little reason to even mention the installation of Freespire Linux. There is nothing out of the ordinary here. Download the ISO image, burn it to a USB Drive (or CD/DVD if you’re dealing with older hardware), boot the drive, click the Install icon, answer a few simple questions, and wait for the installation to prompt for a reboot. That’s how far we’ve come with Linux installations… they are simple, and rarely will you have a single issue with the process. In the end, you’ll be presented with a simple (modified) Mate desktop (Figure 1) that makes it easy for any user (of any skill level) to feel right at home.
-
-
-
-### Software Titles
-
-Once you’ve logged into the desktop, you’ll find a main menu where you can view all of the installed applications. That list of software includes:
-
- * Geary
-
- * Chromium Browser
-
- * Abiword
-
- * Gnumeric
-
- * Calendar
-
- * Audacious
-
- * Totem Video Player
-
- * Software Center
-
- * Synaptic
-
- * G-Debi
-
-
-
-
-Also rolled into the system is support for both Flatpak and Snap applications, so you shouldn’t miss out on any software you need, which brings me to the part when purists might want to look away.
-
-Just because Freespire is marketed as a purely open source distribution, it doesn’t mean users are locked down to only open source software. In fact, if you open the Software Center, you can do a quick search for Spotify (a closed source application with an available Linux desktop client) and there it is! (Figure 2).
-
-![Spotify][5]
-
-Figure 2: The closed source Spotify client available for installation.
-
-[Used with permission][6]
-
-Fortunately, for those productive-minded folks, the likes of LibreOffice (which is not installed by default) is open source and can be installed easily from the Software Center. That doesn’t mean you must install other software, but those who need to do serious business-centric work (such as collaborating on documents), will likely want/need to install a more powerful office suite (as Abiword won’t cut it as a business-level word processor).
-
-For those who tend to work long hours on the Linux desktop and want to protect their eyes from extended strain, Freespire does include a nightlight tool that can adjust the color temperature of the interface. To open this tool, click on the main desktop menu and type night in the Search bar (Figure 3).
-
-![Night Light][8]
-
-Figure 3: Opening the Night Light tool.
-
-[Used with permission][6]
-
-Once opened, Night Light will automatically adjust the color temperature, based on the time of day. From the notification tray, you can click the icon to suspend Night Light, set it to autostart, and close the service (Figure 4).
-
-![Night Light controls.][10]
-
-Figure 4: The Night Light controls.
-
-[Used with permission][6]
-
-### Beyond the Mate Desktop
-
-As is, Mate fans might not exactly recognize the Freespire desktop. The developers have clearly given Mate a significant set of tweaks to make it slightly resemble the Mac OS desktop. It’s not quite as elegant as, say, Elementary OS, but this is certainly an outstanding take on the Linux desktop. Whether you’re a fan of Mate or Mac OS, you should feel immediately at home on the desktop. On the top bar, the developers have included an appmenu that changes, based on what application you have open. Start any app and you’ll find that app’s menu appears in the top bar. This active menu makes the desktop quite efficient.
-
-### Are you ready for Freespire?
-
-Every piece of the Freespire puzzle is equally as user-friendly as it is intuitive. The developers of Freespire have gone to great lengths to make this pure open source distribution a treat to use. Even if a 100% open source desktop isn’t your thing, Freespire is still a worthy contender in the world of desktop Linux. It’s clean and stable (as it’s based on Ubuntu 18.04) and able to help you be efficient and productive on the desktop.
-
-Learn more about Linux through the free ["Introduction to Linux" ][11]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/9/freespire-linux-great-desktop-open-source-purist
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/jlwallen
-[1]: https://www.freespirelinux.com/
-[2]: https://www.linspirelinux.com/
-[3]: https://www.pc-opensystems.com
-[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_2.jpg?itok=zcr94Dk6 (Spotify)
-[6]: /licenses/category/used-permission
-[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_3.jpg?itok=aZYtBPgE (Night Light)
-[9]: /files/images/freespire4jpg
-[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/freespire_4.jpg?itok=JCcQwmJ5 (Night Light controls.)
-[11]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md b/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
deleted file mode 100644
index 8450d6fd11..0000000000
--- a/sources/tech/20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md
+++ /dev/null
@@ -1,72 +0,0 @@
-Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files
-======
-[Cozy][1] **is a free and open source audiobook player for the Linux desktop. The application lets you listen to DRM-free audiobooks (mp3, m4a, flac, ogg and wav) using a modern Gtk3 interface.**
-
-
-
-You could use any audio player to listen to audiobooks, but a specialized audiobook player like Cozy makes everything easier, by **remembering your playback position and continuing from where you left off for each audiobook** , or by letting you **set the playback speed of each book individually** , among others.
-
-The Cozy interface lets you browse books by author, reader or recency, while also providing search functionality. **Books front covers are supported by Cozy** \- either by using embedded images, or by adding a cover.jpg or cover.png image in the book folder, which is automatically picked up and displayed by Cozy.
-
-When you click on an audiobook, Cozy lists the book chapters on the right, while displaying the book cover (if available) on the left, along with the book name, author and the last played time, along with total and remaining time:
-
-
-
-From the application toolbar you can easily **go back 30 seconds** by clicking the rewind icon from its top left-hand side corner. Besides regular controls, cover and title, you'll also find a playback speed button on the toolbar, which lets you increase the playback speed up to 2X.
-
-**A sleep timer is also available**. It can be set to stop after the current chapter or after a given number of minutes.
-
-Other Cozy features worth mentioning:
-
- * **Mpris integration** (Media keys & playback info)
- * **Supports multiple storage locations**
- * **Drag'n'drop support for importing new audiobooks**
- * **Offline Mode**. If your audiobooks are on an external or network drive, you can switch the download button to keep a local cached copy of the book to listen to on the go. To enable this feature you have to set your storage location to external in the settings
- * **Prevents your system from suspend during playback**
- * **Dark mode**
-
-
-
-What I'd like to see in Cozy is a way to get audiobooks metadata, including the book cover, automatically. A feature to retrieve metadata from Audible.com was proposed on the Cozy GitHub project page and the developer seems interested in this, but it's not clear when or if this will be implemented.
-
-Like I was mentioning in the beginning of the article, Cozy only supports DRM-free audio files. Currently it supports mp3, m4a, flac, ogg and wav. Support for more formats will probably come in the future, with m4b being listed on the Cozy 0.7.0 todo list.
-
-Cozy cannot play Audible audiobooks due to DRM. But you'll find some solutions out there for converting Audible (.aa/.aax) audiobooks to mp3, like
-
-### Install Cozy
-
-**Any Linux distribution / Flatpak** : Cozy is available as a Flatpak on FlatHub. To install it, follow the quick Flatpak [setup][4], then go to the Cozy FlaHub [page][5] and click the install button, or use the install command at the bottom if its page.
-
-**elementary OS** : Cozy is available in the [AppCenter][6].
-
-**Ubuntu 18.04 / Linux Mint 19** : you can install Cozy from its repository:
-
-```
-wget -nv https://download.opensuse.org/repositories/home:geigi/Ubuntu_18.04/Release.key -O Release.key
-sudo apt-key add - < Release.key
-sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/geigi/Ubuntu_18.04/ /' > /etc/apt/sources.list.d/home:geigi.list"
-sudo apt update
-sudo apt install com.github.geigi.cozy
-```
-
-**For other ways of installing Cozy check out its[website][2].**
-
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxuprising.com/2018/09/cozy-is-nice-linux-audiobook-player-for.html
-
-作者:[Logix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://plus.google.com/118280394805678839070
-[1]: https://cozy.geigi.de/
-[2]: https://cozy.geigi.de/#how-can-i-get-it
-[3]: https://gitlab.com/ReverendJ1/audiblefreedom/blob/master/audiblefreedom
-[4]: https://flatpak.org/setup/
-[5]: https://flathub.org/apps/details/com.github.geigi.cozy
-[6]: https://appcenter.elementary.io/com.github.geigi.cozy/
diff --git a/sources/tech/20180919 Host your own cloud with Raspberry Pi NAS.md b/sources/tech/20180919 Host your own cloud with Raspberry Pi NAS.md
deleted file mode 100644
index 5d34623e8c..0000000000
--- a/sources/tech/20180919 Host your own cloud with Raspberry Pi NAS.md
+++ /dev/null
@@ -1,128 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Host your own cloud with Raspberry Pi NAS)
-[#]: via: (https://opensource.com/article/18/9/host-cloud-nas-raspberry-pi?extIdCarryOver=true)
-[#]: author: (Manuel Dewald https://opensource.com/users/ntlx)
-
-Host your own cloud with Raspberry Pi NAS
-======
-
-Protect and secure your data with a self-hosted cloud powered by your Raspberry Pi.
-
-![Tree clouds][1]
-
-In the first two parts of this series, we discussed the [hardware and software fundamentals][2] for building network-attached storage (NAS) on a Raspberry Pi. We also put a proper [backup strategy][3] in place to secure the data on the NAS. In this third part, we will talk about a convenient way to store, access, and share your data with [Nextcloud][4].
-
-![Raspberry Pi NAS infrastructure with Nextcloud][6]
-
-### Prerequisites
-
-To use Nextcloud conveniently, you have to meet a few prerequisites. First, you should have a domain you can use for the Nextcloud instance. For the sake of simplicity in this how-to, we'll use **nextcloud.pi-nas.com**. This domain should be directed to your Raspberry Pi. If you want to run it on your home network, you probably need to set up dynamic DNS for this domain and enable port forwarding of ports 80 and 443 (if you go for an SSL setup, which is highly recommended; otherwise port 80 should be sufficient) from your router to the Raspberry Pi.
-
-You can automate dynamic DNS updates from the Raspberry Pi using [ddclient][7].
-
-### Install Nextcloud
-
-To run Nextcloud on your Raspberry Pi (using the setup described in the [first part][2] of this series), install the following packages as dependencies to Nextcloud using **apt**.
-
-```
-sudo apt install unzip wget php apache2 mysql-server php-zip php-mysql php-dom php-mbstring php-gd php-curl
-```
-
-The next step is to download Nextcloud. [Get the latest release's URL][8] and copy it to download via **wget** on the Raspberry Pi. In the first article in this series, we attached two disk drives to the Raspberry Pi, one for current data and one for backups. Install Nextcloud on the data drive to make sure data is backed up automatically every night.
-```
-sudo mkdir -p /nas/data/nextcloud
-sudo chown pi /nas/data/nextcloud
-cd /nas/data/
-wget <https://download.nextcloud.com/server/releases/nextcloud-14.0.0.zip> -O /nas/data/nextcloud.zip
-unzip nextcloud.zip
-sudo ln -s /nas/data/nextcloud /var/www/nextcloud
-sudo chown -R www-data:www-data /nas/data/nextcloud
-```
-
-When I wrote this, the latest release (as you see in the code above) was 14. Nextcloud is under heavy development, so you may find a newer version when installing your copy of Nextcloud onto your Raspberry Pi.
-
-### Database setup
-
-When we installed Nextcloud above, we also installed MySQL as a dependency to use it for all the metadata Nextcloud generates (for example, the users you create to access Nextcloud). If you would rather use a Postgres database, you'll need to adjust some of the modules installed above.
-
-To access the MySQL database as root, start the MySQL client as root:
-
-```
-sudo mysql
-```
-
-This will open a SQL prompt where you can insert the following commands—substituting the placeholder with the password you want to use for the database connection—to create a database for Nextcloud.
-```
-CREATE USER nextcloud IDENTIFIED BY '<insert-password-here>';
-CREATE DATABASE nextcloud;
-GRANT ALL ON nextcloud.* TO nextcloud;
-```
-
-
-You can exit the SQL prompt by pressing **Ctrl+D** or entering **quit**.
-
-### Web server configuration
-
-Nextcloud can be configured to run using Nginx or other web servers, but for this how-to, I decided to go with the Apache web server on my Raspberry Pi NAS. (Feel free to try out another alternative and let me know if you think it performs better.)
-
-To set it up, configure a virtual host for the domain you created for your Nextcloud instance **nextcloud.pi-nas.com**. To create a virtual host, create the file **/etc/apache2/sites-available/001-nextcloud.conf** with content similar to the following. Make sure to adjust the ServerName to your domain and paths, if you didn't use the ones suggested earlier in this series.
-```
-<VirtualHost *:80>
-ServerName nextcloud.pi-nas.com
-ServerAdmin [admin@pi-nas.com][9]
-DocumentRoot /var/www/nextcloud/
-
-<Directory /var/www/nextcloud/>
-AllowOverride None
-</Directory>
-</VirtualHost>
-```
-
-
-To enable this virtual host, run the following two commands.
-```
-a2ensite 001-nextcloud
-sudo systemctl reload apache2
-```
-
-
-With this configuration, you should now be able to reach the web server with your domain via the web browser. To secure your data, I recommend using HTTPS instead of HTTP to access Nextcloud. A very easy (and free) way is to obtain a [Let's Encrypt][10] certificate with [Certbot][11] and have a cron job automatically refresh it. That way you don't have to mess around with self-signed or expiring certificates. Follow Certbot's simple how-to [instructions to install it on your Raspberry Pi][12]. During Certbot configuration, you can even decide to automatically forward HTTP to HTTPS, so visitors to **<http://nextcloud.pi-nas.com>** will be redirected to **<https://nextcloud.pi-nas.com>**. Please note, if your Raspberry Pi is running behind your home router, you must have port forwarding enabled for ports 443 and 80 to obtain Let's Encrypt certificates.
-
-### Configure Nextcloud
-
-The final step is to visit your fresh Nextcloud instance in a web browser to finish the configuration. To do so, open your domain in a browser and insert the database details from above. You can also set up your first Nextcloud user here, the one you can use for admin tasks. By default, the data directory should be inside the Nextcloud folder, so you don't need to change anything for the backup mechanisms from the [second part of this series][3] to pick up the data stored by users in Nextcloud.
-
-Afterward, you will be directed to your Nextcloud and can log in with the admin user you created previously. To see a list of recommended steps to ensure a performant and secure Nextcloud installation, visit the Basic Settings tab in the Settings page (in our example: <https://nextcloud.pi-nas.com/>settings/admin) and see the Security & Setup Warnings section.
-
-Congratulations! You've set up your own Nextcloud powered by a Raspberry Pi. Go ahead and [download a Nextcloud client][13] from the Nextcloud page to sync data with your client devices and access it offline. Mobile clients even provide features like instant upload of pictures you take, so they'll automatically sync to your desktop PC without wondering how to get them there.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/host-cloud-nas-raspberry-pi?extIdCarryOver=true
-
-作者:[Manuel Dewald][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ntlx
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life_tree_clouds.png?itok=b_ftihhP (Tree clouds)
-[2]: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
-[3]: https://opensource.com/article/18/8/automate-backups-raspberry-pi
-[4]: https://nextcloud.com/
-[5]: /file/409336
-[6]: https://opensource.com/sites/default/files/uploads/nas_part3.png (Raspberry Pi NAS infrastructure with Nextcloud)
-[7]: https://sourceforge.net/p/ddclient/wiki/Home/
-[8]: https://nextcloud.com/install/#instructions-server
-[9]: mailto:admin@pi-nas.com
-[10]: https://letsencrypt.org/
-[11]: https://certbot.eff.org/
-[12]: https://certbot.eff.org/lets-encrypt/debianother-apache
-[13]: https://nextcloud.com/install/#install-clients
diff --git a/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md b/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
deleted file mode 100644
index 521a8f5b95..0000000000
--- a/sources/tech/20180919 Streama - Setup Your Own Streaming Media Server In Minutes.md
+++ /dev/null
@@ -1,171 +0,0 @@
-Streama – Setup Your Own Streaming Media Server In Minutes
-======
-
-
-
-**Streama** is a free, open source application that helps to setup your own personal streaming media server in minutes in Unix-like operating systems. It’s like Netflix, but self-hostable. You can deploy it on your local system or VPS or dedicated server and stream the media files across multiple devices. The media files can be accessed from a web-browser from any system on your network. If you have deployed on your VPS, you can access it from anywhere. Streama works like your own personal Netflix system to stream your TV shows, videos, audios and movies. Streama is a web-based application written using Grails 3 (server-side) with SpringSecurity and all frond-end components are written in AngularJS. The built-in player is completely HTML5-based.
-
-### Prominent Features
-
-Streama ships with a lot features as listed below.
-
- * Easy to install configure. You can either download docker instance and fire up your media server in minutes or install vanilla version on your local or VPS or dedicated server.
- * Drag and drop support to upload media files.
- * Live sync watching support. You can watch videos with your friends, family remotely. It doesn’t matter where they are. You can all watch the same video at a time.
- * Built-in beautiful video player to watch/listen video and audio.
- * Built-in browser to access the media files in the server.
- * Multi-user support. You can create individual user accounts to your family members and access the media server simultaneously.
- * Streama supports pause-play option. Pause the playback at any time and Streama remembers where you left off last time.
- * Streama can be able to detect similar movies and videos and shows for you to add.
- * Self-hostable
- * It is completely free and open source.
-
-
-
-What do you need more? Streama has everything you to need to setup a full-fledged streaming media server in your Linux box.
-
-### Setup Your Own Streaming Media Server Using Streama
-
-Streama requires JAVA 8 or later, preferably **OpenJDK**. And, the recommended OS is **Ubuntu**. For the purpose of this guide, I will be using Ubuntu 18.04 LTS.
-
-By default, the latest Ubuntu 18.04 includes Open JDK 11. To install default openJDK in Ubuntu 18.04 or later, run:
-
-```
-$ sudo apt install default-jdk
-
-```
-
-Java 8 is the latest stable Long Time Support version. If you prefer to use Java LTS, run:
-
-```
-$ sudo apt install openjdk-8-jdk
-```
-
-I have installed openjdk-8-jdk. To check the installed Java version, run:
-
-```
-$ java -version
-openjdk version "1.8.0_181"
-OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-0ubuntu0.18.04.1-b13)
-OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
-```
-
-Once java installed, create a directory to save Streama executable and yml files.
-
-```
-$ sudo mkdir /data
-
-$ sudo mkdir /data/streama
-```
-
-I followed the official documentation, so I used this path – /data/streama. It is optional. You’re free to use any location of your choice.
-
-Switch to streama directory:
-
-```
-$ cd /data/streama
-```
-
-Download the latest Streama executable file from [**releases page**][1]. As of writing this guide, the latest version was **v1.6.0-RC8**.
-
-```
-$ sudo wget https://github.com/streamaserver/streama/releases/download/v1.6.0-RC8/streama-1.6.0-RC8.war
-```
-
-Make it executable:
-
-```
-$ sudo chmod +x streama-1.6.0-RC8.war
-```
-
-Now, run Streama application using command:
-
-```
-$ sudo ./streama-1.6.0-RC8.war
-```
-
-If you an output something like below, Streama is working!
-
-```
-INFO streama.Application - Starting Application on ubuntuserver with PID 26714 (/data/streama/streama-1.6.0-RC8.war started by root in /data/streama)
-DEBUG streama.Application - Running with Spring Boot v1.4.4.RELEASE, Spring v4.3.6.RELEASE
-INFO streama.Application - The following profiles are active: production
-
-Configuring Spring Security Core ...
-... finished configuring Spring Security Core
-
-INFO streama.Application - Started Application in 92.003 seconds (JVM running for 98.66)
-Grails application running at http://localhost:8080 in environment: production
-```
-
-Open your web browser and navigate to URL – **<http://ip-address:8080>**
-
-You should see Streama login screen. Login with default credentials – **admin/admin**
-
-
-
-Now, You need to fill out some required base-settings. Click OK button in the next screen and you will be redirected to the settings page. In the Settings page, you need to set some parameters such as the location of the Uploads directory, Streama logo, name of the media server, base URL, allow anonymous access, allow users to download videos. All fields marked with ***** is necessary to fill. Once you provided the details, click **Save settings** button.
-
-
-
-Congratulations! Your media server is ready to use!
-
-Here is how Stream dashboard looks like.
-
-
-
-And, this is the contents management page where you can upload movies, shows, access files via file manager, view the notifications and highlights.
-
-
-
-### Adding movies/shows
-
-Let me show you how to add a movie.
-
-Go to the **“Manage Content”** page from the dashboard and click **“Create New Movie”** link.
-
-Enter the movie details, such as name, release date, IMDB ID and movie description and click **Save**. These are all optional, you can simply ignore them if you don’t know about the details.
-
-
-
-We have added the movie details, but we haven’t added the actual movie yet. To do so, click on the red box in the bottom that says – **“No video file yet! Drop file or Click here to add”**.
-
-
-
-You could either drag and drop the movie file inside this dashboard or click on the red box to manually upload it.
-
-Choose the movie file to upload and click Upload.
-
-
-
-Once the upload is completed, you could see the uploaded movie details. Click on the three horizontal lines next to the movie if you want to edit/modify movie details.
-
-
-
-Similarly, you can create TV shows, videos and audios.
-
-
-
-And also the movies/shows are started to appear in the home screen of your dashboard. Simply click on it to play the video and enjoy Netflix experience right from your Linux desktop.
-
-For more details, refer the product’s official website.
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/streama-setup-your-own-streaming-media-server-in-minutes/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[1]: https://github.com/streamaserver/streama/releases
diff --git a/sources/tech/20180920 Distributed tracing in a microservices world.md b/sources/tech/20180920 Distributed tracing in a microservices world.md
deleted file mode 100644
index 1b39a5e30a..0000000000
--- a/sources/tech/20180920 Distributed tracing in a microservices world.md
+++ /dev/null
@@ -1,113 +0,0 @@
-Distributed tracing in a microservices world
-======
-What is distributed tracing and why is it so important in a microservices environment?
-
-
-
-[Microservices][1] have become the default choice for greenfield applications. After all, according to practitioners, microservices provide the type of decoupling required for a full digital transformation, allowing individual teams to innovate at a far greater speed than ever before.
-
-Microservices are nothing more than regular distributed systems, only at a larger scale. Therefore, they exacerbate the well-known problems that any distributed system faces, like lack of visibility into a business transaction across process boundaries.
-
-Given that it's extremely common to have multiple versions of a single service running in production at the same time—be it in a [A/B testing][2] scenario or as part of rolling out a new release following the [Canary release][3] technique—when we account for the fact that we are talking about hundreds of services, it's clear that what we have is chaos. It's almost impossible to map the interdependencies and understand the path of a business transaction across services and their versions.
-
-### Observability
-
-This chaos ends up being a good thing, as long as we can observe what's going on and diagnose the problems that will eventually occur.
-
-A system is said to be observable when we can understand its state based on the [metrics, logs, and traces][4] it emits. Given that we are talking about distributed systems, knowing the state of a single instance of a single service isn't enough; we need to be able to aggregate the metrics for all instances of a given service, perhaps grouped by version. Metrics solutions like [Prometheus][5] are very popular in tackling this aspect of the observability problem. Similarly, we need logs to be stored in a central location, as it's impossible to analyze the logs from the individual instances of each service. [Logstash][6] is usually applied here, in combination with a backing storage like [Elasticsearch][7]. And finally, we need to get end-to-end traces to understand the path a given transaction has taken. This is where distributed tracing solutions come into play.
-
-### Distributed tracing
-
-In monolithic web applications, logging frameworks provide enough capabilities to do a basic root-cause analysis when something fails. A developer just needs to place log statements in the code. Information like "context" (usually "thread") and "timestamp" are automatically added to the log entry, making it easier to understand the execution of a given request and correlate the entries.
-
-```
-Thread-1 2018-09-03T15:52:54+02:00 Request started
-Thread-2 2018-09-03T15:52:55+02:00 Charging credit card x321
-Thread-1 2018-09-03T15:52:55+02:00 Order submitted
-Thread-1 2018-09-03T15:52:56+02:00 Charging credit card x123
-Thread-1 2018-09-03T15:52:57+02:00 Changing order status
-Thread-1 2018-09-03T15:52:58+02:00 Dispatching event to inventory
-Thread-1 2018-09-03T15:52:59+02:00 Request finished
-```
-
-We can safely say that the second log entry above is not related to the other entries, as it's being executed in a different thread.
-
-In microservices architectures, logging alone fails to deliver the complete picture. Is this service the first one in the call chain? And what happened at the inventory service (where we apparently dispatched an event)?
-
-A common strategy to answer this question is creating an identifier at the very first building block of our transaction and propagating this identifier across all the calls, probably by sending it as an HTTP header whenever a remote call is made.
-
-In a central log collector, we could then see entries like the ones below. Note how we could log the correlation ID (the first column in our example), so we know that the second entry is not related to the other entries.
-
-```
-abc123 Order 2018-09-03T15:52:58+02:00 Dispatching event to inventory
-def456 Order 2018-09-03T15:52:58+02:00 Dispatching event to inventory
-abc123 Inventory 2018-09-03T15:52:59+02:00 Received `order-submitted` event
-abc123 Inventory 2018-09-03T15:53:00+02:00 Checking inventory status
-abc123 Inventory 2018-09-03T15:53:01+02:00 Updating inventory
-abc123 Inventory 2018-09-03T15:53:02+02:00 Preparing order manifest
-```
-
-This technique is one of the concepts at the core of any modern distributed tracing solution, but it's not really new; correlating log entries is decades old, probably as old as "distributed systems" itself.
-
-What sets distributed tracing apart from regular logging is that the data structure that holds tracing data is more specialized, so we can also identify causality. Looking at the log entries above, it's hard to tell if the last step was caused by the previous entry, if they were performed concurrently, or if they share the same caller. Having a dedicated data structure also allows distributed tracing to record not only a message in a single point in time but also the start and end time of a given procedure.
-
-![Trace showing spans][9]
-
-Trace showing spans similar to the logs described above
-
-[Click to enlarge][10]
-
-Most of the modern distributed tracing tools are inspired by a 2010 [paper about Dapper][11], the distributed tracing solution used at Google. In that paper, the data structure described above was called a span, and you can see nine of them in the image above. This particular "forest" of spans is called a trace and is equivalent to the correlated log entries we've seen before.
-
-The image above is a screenshot of a trace displayed in [Jaeger][12], an open source distributed tracing solution hosted by the [Cloud Native Computing Foundation (CNCF)][13]. It marks each service with a color to make it easier to see the process boundaries. Timing information can be easily visualized, both by looking at the macro timeline at the top of the screen or at the individual spans, giving a sense of how long each span takes and how impactful it is in this particular execution. It's also easy to observe when processes are asynchronous and therefore may outlive the initial request.
-
-Like with logging, we need to annotate or instrument our code with the data we want to record. Unlike logging, we record spans instead of messages and do some demarcation to know when the span starts and finishes so we can get accurate timing information. As we would probably like to have our business code independent from a specific distributed tracing implementation, we can use an API such as [OpenTracing][14], leaving the decision about the concrete implementation as a packaging or runtime concern. Following is pseudo-Java code showing such demarcation.
-
-```
-try (Scope scope = tracer.buildSpan("submitOrder").startActive(true)) {
- scope.span().setTag("order-id", "c85b7644b6b5");
- chargeCreditCard();
- changeOrderStatus();
- dispatchEventToInventory();
-}
-```
-
-Given the nature of the distributed tracing concept, it's clear the code executed "between" our business services can also be part of the trace. For instance, we could [turn on][15] the distributed tracing integration for [Istio][16], a service mesh solution that helps in the communication between microservices, and we'll suddenly have a better picture about the network latency and routing decisions made at this layer. Another example is the work done in the OpenTracing community to provide instrumentation for popular stacks, frameworks, and APIs, such as Java's [JAX-RS][17], [Spring Cloud][18], or [JDBC][19]. This enables us to see how our business code interacts with the rest of the middleware, understand where a potential problem might be happening, and identify the best areas to improve. In fact, today's middleware instrumentation is so rich that it's common to get started with distributed tracing by using only the so-called "framework instrumentation," leaving the business code free from any tracing-related code.
-
-While a microservices architecture is almost unavoidable nowadays for established companies to innovate faster and for ambitious startups to achieve web scale, it's easy to feel helpless while conducting a root cause analysis when something eventually fails and the right tools aren't available. The good news is tools like Prometheus, Logstash, OpenTracing, and Jaeger provide the pieces to bring observability to your application.
-
-Juraci Paixão Kröhling will present [What are My Microservices Doing?][20] at [Open Source Summit Europe][21], October 22-24 in Edinburgh, Scotland.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/distributed-tracing-microservices-world
-
-作者:[Juraci Paixão Kröhling][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/jpkroehling
-[1]: https://en.wikipedia.org/wiki/Microservices
-[2]: https://en.wikipedia.org/wiki/A/B_testing
-[3]: https://martinfowler.com/bliki/CanaryRelease.html
-[4]: https://blog.twitter.com/engineering/en_us/a/2016/observability-at-twitter-technical-overview-part-i.html
-[5]: https://prometheus.io/
-[6]: https://github.com/elastic/logstash
-[7]: https://github.com/elastic/elasticsearch
-[8]: /file/409621
-[9]: https://opensource.com/sites/default/files/uploads/distributed-trace.png (Trace showing spans)
-[10]: /sites/default/files/uploads/trace.png
-[11]: https://ai.google/research/pubs/pub36356
-[12]: https://www.jaegertracing.io/
-[13]: https://www.cncf.io/
-[14]: http://opentracing.io/
-[15]: https://istio.io/docs/tasks/telemetry/distributed-tracing/
-[16]: https://istio.io/
-[17]: https://github.com/opentracing-contrib/java-jaxrs
-[18]: https://github.com/opentracing-contrib/java-spring-cloud
-[19]: https://github.com/opentracing-contrib/java-jdbc
-[20]: https://osseu18.sched.com/event/FxW3/what-are-my-microservices-doing-juraci-paixao-krohling-red-hat#
-[21]: https://osseu18.sched.com/
diff --git a/sources/tech/20180920 Record Screen in Ubuntu Linux With Kazam -Beginner-s Guide.md b/sources/tech/20180920 Record Screen in Ubuntu Linux With Kazam -Beginner-s Guide.md
deleted file mode 100644
index a2f57f592a..0000000000
--- a/sources/tech/20180920 Record Screen in Ubuntu Linux With Kazam -Beginner-s Guide.md
+++ /dev/null
@@ -1,185 +0,0 @@
-Record Screen in Ubuntu Linux With Kazam [Beginner’s Guide]
-======
-**This tutorial shows you how to install Kazam screen recorder and explains how to record screen in Ubuntu. The guide also lists useful shortcuts and handy tips for using Kazam.**
-
-![How to record your screen in Ubuntu Linux with Kazam][1]
-
-[Kazam][2] is one of the [best screen recorders for Linux][3]. To me, it’s the best screen recording tool. I have been using it for years. All the video tutorials on YouTube have been recorded with Kazam.
-
-Some of the main features of Kazam are:
-
- * Record entire screen, part of screen, application window or all screens (for multi-monitor setup)
- * Take screenshots
- * Keyboard shortcut support for easily pausing and resuming while recording screen
- * Record in various file formats such as MP4, AVI and more.
- * Capture audio from speaker or microphone while recording the screen
- * Capture mouse clicks and key presses
- * Capture video from webcam
- * Insert a webcam window on the side
- * Broadcast to YouTube live video
-
-
-
-Like the screenshot tool [Shutter][4], Kazam is also not being actively developed for the last couple of years. And like Shutter, the present Kazam release works just fine.
-
-I am using Ubuntu in the tutorial. The installation instructions should work for other Ubuntu-based distributions such as Linux Mint, elementary OS etc. For all the other distributions, you can still read about using Kazam and its features.
-
-### Install Kazam in Ubuntu
-
-Kazam is available in the official repository in Ubuntu. However, the official repository consists Kazam version 1.4.5, the last stable version of Kazam.
-
-![Kazam Version 1.4.5][5]
-Kazam Version 1.4.5
-
-Kazam developer(s) also worked on a newer release, Kazam 1.5.3. The version was almost sable and ready to release, but for unknown reasons, the development stopped after this. There have been [no updates][6] since then.
-
-You can use either of Kazam 1.4.5 and 1.5.3 without hesitating. Kazam 1.5 provides additional features like recording mouse clicks and key presses, webcam support, live broadcast support, and a refreshed countdown timer.
-
-![Kazam Version 1.5.3][7]
-Kazam Version 1.5.3
-
-It’s up to you to decide which version you want to use. I would suggest go for version 1.5.3 because it has more features.
-
-You can install the older Kazam 1.4.5 from the Software Center. You can also use the command below:
-
-```
-sudo apt install kazam
-```
-
-If you want to install the newer Kazam 1.5.3, you can use this [unofficial PPA][8] that is available for Ubuntu 18.04 and 16.04:
-
-```
-sudo add-apt-repository ppa:sylvain-pineau/kazam
-sudo apt-get update
-sudo apt install kazam
-```
-
-You also need to install a few libraries in order to record the mouse clicks and keyboard presses.
-
-```
-sudo apt install python3-cairo python3-xlib
-```
-
-### Recording your screen with Kazam
-
-Once you have installed Kazam, search for it in the application menu and start it. You should see a screen like this with some options on it. You can check the options as per your need and click on capture to start recording screen with Kazam.
-
-![Screen recording with Kazam][9]
-Screen recording with Kazam
-
-It will show you a countdown before recording the screen. The default wait time is 5 seconds and you can change it from Kazam interface (see the previous image). It gives you a breathing time so that you can prepare for your recording.
-
-![Countdown before screen recording][10]
-Countdown before screen recording
-
-Once the recording starts,the main Kazam interface disappears and an indicator appears in the panel. If you want to pause the recording or finish the recording, you can do it from this indicator.
-
-![Pause or finish screen recording][11]
-Pause or finish screen recording
-
-If you choose to finish the recording, it will give you the option to “Save for later”. If you have a [video editor installed in Linux][12], you can also start editing the recording from this point.
-
-![Save screen recording in Kazam][13]
-Save recording
-
-By default it prompts you to install the recording in Videos folder but you can change the location and save it elsewhere as well.
-
-That’s the basic you need to know about screen recording in Linux with Kazam.
-
-Now let me give you a few tips on how to utilize more features in Kazam.
-
-### Getting more out of Kazam screen recorder
-
-Kazam is a featureful screen recorder for Linux. You can access its advanced or additional features from the preferences.
-
-![Accessing Kazam preferences][14]
-Accessing Kazam preferences
-
-#### Autosave screen recording in a specified location
-
-You can choose to automatically save the screen recordings in Kazam. The default location is Videos but you can change it to any other location.
-
-![Autosave screen recordings in a chosen location][15]
-Autosave in a chosen location
-
-#### Avoid screen recording in RAW mode
-
-You can save your screen recordings in file formats like WEBM, MP4, AVI etc. You are free to choose what you want. However, I would advise avoiding RAW (AVI) file format. If you use RAW file format, the recorded files will be in GBs even for a few minutes of recordings.
-
-It’s wise to verify that Kazam is not using the RAW file format for recording. If you ask my suggestion, prefer H264 with MP4 file format.
-
-![file format in Kazam][16]
-Don’t use RAW files
-
-#### Capture mouse clicks and key presses while screen recording
-
-If you want to highlight when a mouse was clicked, you can easily do that in the newer version of Kazam.
-
-![Record mouse clicks while screen recording with Kazam][17]
-Record mouse clicks
-
-All you have to do is to check the “Key presses and mouse clicks” option on the Kazam interface (the same screen where you press Capture).
-
-#### Use keyboard shortcuts for more efficient screen recordings
-
-Imagine you are recording screen in Linux and suddenly you realized that you have to pause the recording for some reasons. Now, you can pause the recording by going to the Kazam indicator and selecting the pause option. But this activity of selecting the pause option will also be recorded.
-
-You can edit out this part later but it unnecessarily adds to the already cumbersome editing task.
-
-A better option will be to use the [keyboard shortcuts in Ubuntu][18]. Screen recording becomes a lot better if you use the shortcuts.
-
-While Kazam is running, you can use the following hotkeys:
-
- * Super+Ctrl+R: Start recording
- * Super+Ctrl+P: Pause recording, press again for resuming the recording
- * Super+Ctrl+F: Finish recording
- * Super+Ctrl+Q: Quit recording
-
-
-
-Super key is the Windows key on your keyboard.
-
-The most important is Super+Ctrl+P for pausing and resuming the recording.
-
-You can further explore the Kazam preferences for webcam recording and YouTube live broadcasting options.
-
-### Do you like Kazam?
-
-I am repeating myself here. I love Kazam. I have used other screen recorders like [SimpleScreenRecorder][19] or [Green Recorder][20] but I feel a lot more comfortable with Kazam.
-
-I hope you like Kazam for screen recording in Ubuntu or any other Linux distribution. I have tried highlighting some of the additional features here to help you with a better screen recording.
-
-What features do you like about Kazam? Do you use some other screen recorder? Do they work better than Kazam? Please share your views in the comments section below.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/kazam-screen-recorder/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/screen-recording-kazam-ubuntu-linux.png
-[2]: https://launchpad.net/kazam
-[3]: https://itsfoss.com/best-linux-screen-recorders/
-[4]: http://shutter-project.org/
-[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-1-4-5.png
-[6]: https://launchpad.net/~kazam-team/+archive/ubuntu/unstable-series
-[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-1-5-3.png
-[8]: https://launchpad.net/~sylvain-pineau/+archive/ubuntu/kazam
-[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-start-recording.png
-[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-countdown.jpg
-[11]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-finish-recording.png
-[12]: https://itsfoss.com/best-video-editing-software-linux/
-[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-save-recording.jpg
-[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-preferences.png
-[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/kazam-auto-save.jpg
-[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/select-file-type-kazam.jpg
-[17]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/record-mouse-clicks-kazam.jpeg
-[18]: https://itsfoss.com/ubuntu-shortcuts/
-[19]: https://itsfoss.com/record-screen-ubuntu-simplescreenrecorder/
-[20]: https://itsfoss.com/green-recorder-3/
diff --git a/sources/tech/20180923 Gunpoint is a Delight for Stealth Game Fans.md b/sources/tech/20180923 Gunpoint is a Delight for Stealth Game Fans.md
deleted file mode 100644
index 3ff6857f78..0000000000
--- a/sources/tech/20180923 Gunpoint is a Delight for Stealth Game Fans.md
+++ /dev/null
@@ -1,104 +0,0 @@
-Gunpoint is a Delight for Stealth Game Fans
-======
-Gunpoint is a 2D stealth game in which you play as a spy stealing secrets and hacking networks like Ethan Hunt of Mission Impossible movie series.
-
-<https://youtu.be/QMS3s3xZFlY>
-
-Hi, Fellow Linux gamers. Let’s take a look at a fun stealth game. Let’s take a look at [Gunpoint][1].
-
-Gunpoint is neither free nor open source. It is an independent game you can purchase directly from the creator or from Steam.
-
-![][2]
-
-### The Interesting History of Gunpoint
-
-> The instant success of Gunpoint enabled its creator to become a full time game developer.
-
-Gunpoint is a stealth game created by [Tom Francis][3]. Francis was inspired to create the game after he heard about Spelunky, which was created by one person. Francis played games as part of his day job, as an editor for PC Gamer UK magazine. He had no previous programming experience but used the easy-to-use Game Maker. He planned to create a demo with the hopes of getting a job as a developer.
-
-He released his first prototype in May 2010 under the name Private Dick. Based on the response, Francis continued to work on the game. The final version was released in June of 2013 to high praise.
-
-In a [blog post][4] weeks after Gunpoint’s launch, Francis revealed that he made back all the money he spent on development ($30 for Game Maker 8) in 64 seconds. Francis didn’t reveal Gunpoint’s sales figures, but he did quit his job and today creates [games][5] full time.
-
-### Experiencing the Gunpoint Gameplay
-
-![Gunpoint Gameplay][6]
-
-Like I said earlier, Gunpoint is a stealth game. You play a freelance spy named Richard Conway. As Conway, you will use a pair of Bullfrog hypertrousers to infiltrate buildings for clients. The hypertrousers allow you to jump very high, even through windows. You can also cling to walls or ceilings like a ninja.
-
-Another tool you have is the Crosslink, which allows you to rewire circuits. Often you will need to use the Crosslink to reroute motion detections to unlock doors instead of setting off an alarm or rewire a light switch to turn off the light on another floor to distract a guard.
-
-When you sneak into a building, your biggest concern is the on-site security guards. If they see Conway, they will shoot and in this game, it’s one shot one kill. You can jump off a three-story building no problem, but bullets will take you down. Thankfully, if Conway is killed you can just jump back a few seconds and try again.
-
-Along the way, you will earn money to upgrade your tools and unlock new features. For example, I just unlocked the ability to rewire a guard’s gun. Don’t ask me how that works.
-
-### Minimum System Requirements
-
-Here are the minimum system requirements for Gunpoint:
-
-##### Linux
-
- * Processor: 2GHz
- * Memory: 1GB RAM
- * Video card: 512MB
- * Hard Drive: 700MB HD space
-
-
-
-##### Windows
-
- * OS: Windows XP, Visa, 7 or 8
- * Processor: 2GHz
- * Memory: 1GB RAM
- * Video card: 512MB
- * DirectX®: 9.0
- * Hard Drive: 700MB HD space
-
-
-
-##### macOS
-
- * OS: OS X 10.7 or later
- * Processor: 2GHz
- * Memory: 1GB RAM
- * Video card: 512MB
- * Hard Drive: 700MB HD space
-
-
-
-### Thoughts on Gunpoint
-
-![Gunpoint game on Linux][7]
-Image Courtesy: Steam Community
-
-Gunpoint is a very fun game. The early levels are easy to get through, but the later levels make you put your thinking cap on. The hypertrousers and Crosslink are fun to play with. There is nothing like turning the lights off on a guard and bouncing over his head to hack a terminal.
-
-Besides the fun mechanics, it also has an interesting [noir][8] murder mystery story. Several different (and conflicting) clients hire you to look into different aspects of the case. Some of them seem to have ulterior motives that are not in your best interest.
-
-I always enjoy good mysteries and this one is no different. If you like noir or platforming games, be sure to check out [Gunpoint][1].
-
-Have you every played Gunpoint? What other games should we review for your entertainment? Let us know in the comments below.
-
-If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][9].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/gunpoint-game-review/
-
-作者:[John Paul][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[1]: http://www.gunpointgame.com/
-[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint.jpg
-[3]: https://www.pentadact.com/
-[4]: https://www.pentadact.com/2013-06-18-gunpoint-recoups-development-costs-in-64-seconds/
-[5]: https://www.pentadact.com/2014-08-09-what-im-working-on-and-what-ive-done/
-[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint-gameplay-1.jpeg
-[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint-game-1.jpeg
-[8]: https://en.wikipedia.org/wiki/Noir_fiction
-[9]: http://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20180925 9 Easiest Ways To Find Out Process ID (PID) In Linux.md b/sources/tech/20180925 9 Easiest Ways To Find Out Process ID (PID) In Linux.md
deleted file mode 100644
index ae353bf11f..0000000000
--- a/sources/tech/20180925 9 Easiest Ways To Find Out Process ID (PID) In Linux.md
+++ /dev/null
@@ -1,208 +0,0 @@
-9 Easiest Ways To Find Out Process ID (PID) In Linux
-======
-Everybody knows about PID, Exactly what is PID? Why you want PID? What are you going to do using PID? Are you having the same questions on your mind? If so, you are in the right place to get all the details.
-
-Mainly, we are looking PID to kill an unresponsive program and it’s similar to Windows task manager. Linux GUI also offering the same feature but CLI is an efficient way to perform the kill operation.
-
-### What Is Process ID?
-
-PID stands for process identification number which is generally used by most operating system kernels such as Linux, Unix, macOS and Windows. It is a unique identification number that is automatically assigned to each process when it is created in an operating system. A process is a running instance of a program.
-
-**Suggested Read :**
-**(#)** [How To Find Out Which Port Number A Process Is Using In Linux][1]
-**(#)** [3 Easy Ways To Kill Or Terminate A Process In Linux][2]
-
-Each time process ID will be getting change to all the processes except init because init is always the first process on the system and is the ancestor of all other processes. It’s PID is 1.
-
-The default maximum value of PIDs is `32,768`. The same has been verified by running the following command on your system `cat /proc/sys/kernel/pid_max`. On 32-bit systems 32768 is the maximum value but we can set to any value up to 2^22 (approximately 4 million) on 64-bit systems.
-
-You may ask, why we need such amount of PIDs? because we can’t reused the PIDs immediately that’s why. Also in order to prevent possible errors.
-
-The PID for the running processes on the system can be found by using the below nine methods such as pidof command, pgrep command, ps command, pstree command, ss command, netstat command, lsof command, fuser command and systemctl command.
-
-This can be achieved using the below six methods.
-
- * `pidof:` pidof — find the process ID of a running program.
- * `pgrep:` pgre – look up or signal processes based on name and other attributes.
- * `ps:` ps – report a snapshot of the current processes.
- * `pstree:` pstree – display a tree of processes.
- * `ss:` ss is used to dump socket statistics.
- * `netstat:` netstat is displays a list of open sockets.
- * `lsof:` lsof – list open files.
- * `fuser:` fuser – list process IDs of all processes that have one or more files open
- * `systemctl:` systemctl – Control the systemd system and service manager
-
-
-
-In this tutorial we are going to find out the Apache process id to test this article. Make sure your need to input your process name instead of us.
-
-### Method-1 : Using pidof Command
-
-pidof used to find the process ID of a running program. It’s prints those id’s on the standard output. To demonstrate this, we are going to find out the Apache2 process id from Debian 9 (stretch) system.
-
-```
-# pidof apache2
-3754 2594 2365 2364 2363 2362 2361
-
-```
-
-From the above output you may face difficulties to identify the Process ID because it’s shows all the PIDs (included Parent and Childs) aginst the process name. Hence we need to find out the parent PID (PPID), which is the one we are looking. It could be the first number. In my case it’s `3754` and it’s shorted in descending order.
-
-### Method-2 : Using pgrep Command
-
-pgrep looks through the currently running processes and lists the process IDs which match the selection criteria to stdout.
-
-```
-# pgrep apache2
-2361
-2362
-2363
-2364
-2365
-2594
-3754
-
-```
-
-This also similar to the above output but it’s shorting the results in ascending order, which clearly says that the parent PID is the last one. In my case it’s `3754`.
-
-**Note :** If you have more than one process id of the process, you may face trouble to identify the parent process id when using pidof & pgrep command.
-
-### Method-3 : Using pstree Command
-
-pstree shows running processes as a tree. The tree is rooted at either pid or init if pid is omitted. If a user name is specified in the pstree command then it’s shows all the process owned by the corresponding user.
-
-pstree visually merges identical branches by putting them in square brackets and prefixing them with the repetition count.
-
-```
-# pstree -p | grep "apache2"
- |-apache2(3754)-|-apache2(2361)
- | |-apache2(2362)
- | |-apache2(2363)
- | |-apache2(2364)
- | |-apache2(2365)
- | `-apache2(2594)
-
-```
-
-To get parent process alone, use the following format.
-
-```
-# pstree -p | grep "apache2" | head -1
- |-apache2(3754)-|-apache2(2361)
-
-```
-
-pstree command is very simple because it’s segregating the Parent and Child processes separately but it’s not easy when using pidof & pgrep command.
-
-### Method-4 : Using ps Command
-
-ps displays information about a selection of the active processes. It displays the process ID (pid=PID), the terminal associated with the process (tname=TTY), the cumulated CPU time in [DD-]hh:mm:ss format (time=TIME), and the executable name (ucmd=CMD). Output is unsorted by default.
-
-```
-# ps aux | grep "apache2"
-www-data 2361 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
-www-data 2362 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
-www-data 2363 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
-www-data 2364 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
-www-data 2365 0.0 0.4 302652 8400 ? S 06:25 0:00 /usr/sbin/apache2 -k start
-www-data 2594 0.0 0.4 302652 8400 ? S 06:55 0:00 /usr/sbin/apache2 -k start
-root 3754 0.0 1.4 302580 29324 ? Ss Dec11 0:23 /usr/sbin/apache2 -k start
-root 5648 0.0 0.0 12784 940 pts/0 S+ 21:32 0:00 grep apache2
-
-```
-
-From the above output we can easily identify the parent process id (PPID) based on the process start date. In my case apache2 process was started @ `Dec11` which is the parent and others are child’s. PID of apache2 is `3754`.
-
-### Method-5: Using ss Command
-
-ss is used to dump socket statistics. It allows showing information similar to netstat. It can display more TCP and state informations than other tools.
-
-It can display stats for all kind of sockets such as PACKET, TCP, UDP, DCCP, RAW, Unix domain, etc.
-
-```
-# ss -tnlp | grep apache2
-LISTEN 0 128 :::80 :::* users:(("apache2",pid=3319,fd=4),("apache2",pid=3318,fd=4),("apache2",pid=3317,fd=4))
-
-```
-
-### Method-6: Using netstat Command
-
-netstat – Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships.
-By default, netstat displays a list of open sockets.
-
-If you don’t specify any address families, then the active sockets of all configured address families will be printed. This program is obsolete. Replacement for netstat is ss.
-
-```
-# netstat -tnlp | grep apache2
-tcp6 0 0 :::80 :::* LISTEN 3317/apache2
-
-```
-
-### Method-7: Using lsof Command
-
-lsof – list open files. The Linux lsof command lists information about files that are open by processes running on the system.
-
-```
-# lsof -i -P | grep apache2
-apache2 3317 root 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
-apache2 3318 www-data 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
-apache2 3319 www-data 4u IPv6 40518 0t0 TCP *:80 (LISTEN)
-
-```
-
-### Method-8: Using fuser Command
-
-The fuser utility shall write to standard output the process IDs of processes running on the local system that have one or more named files open.
-
-```
-# fuser -v 80/tcp
- USER PID ACCESS COMMAND
-80/tcp: root 3317 F.... apache2
- www-data 3318 F.... apache2
- www-data 3319 F.... apache2
-
-```
-
-### Method-9: Using systemctl Command
-
-systemctl – Control the systemd system and service manager. This is the replacement of old SysV init system management and
-most of the modern Linux operating systems were adapted systemd.
-
-```
-# systemctl status apache2
-● apache2.service - The Apache HTTP Server
- Loaded: loaded (/lib/systemd/system/apache2.service; disabled; vendor preset: enabled)
- Drop-In: /lib/systemd/system/apache2.service.d
- └─apache2-systemd.conf
- Active: active (running) since Tue 2018-09-25 10:03:28 IST; 3s ago
- Process: 3294 ExecStart=/usr/sbin/apachectl start (code=exited, status=0/SUCCESS)
- Main PID: 3317 (apache2)
- Tasks: 55 (limit: 4915)
- Memory: 7.9M
- CPU: 71ms
- CGroup: /system.slice/apache2.service
- ├─3317 /usr/sbin/apache2 -k start
- ├─3318 /usr/sbin/apache2 -k start
- └─3319 /usr/sbin/apache2 -k start
-
-Sep 25 10:03:28 ubuntu systemd[1]: Starting The Apache HTTP Server...
-Sep 25 10:03:28 ubuntu systemd[1]: Started The Apache HTTP Server.
-
-```
-
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/9-methods-to-check-find-the-process-id-pid-ppid-of-a-running-program-in-linux/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[1]: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-using-in-linux/
-[2]: https://www.2daygeek.com/kill-terminate-a-process-in-linux-using-kill-pkill-killall-command/
diff --git a/sources/tech/20180925 Taking the Audiophile Linux distro for a spin.md b/sources/tech/20180925 Taking the Audiophile Linux distro for a spin.md
deleted file mode 100644
index 1c813cb30a..0000000000
--- a/sources/tech/20180925 Taking the Audiophile Linux distro for a spin.md
+++ /dev/null
@@ -1,161 +0,0 @@
-Taking the Audiophile Linux distro for a spin
-======
-
-This lightweight open source audio OS offers a rich feature set and high-quality digital sound.
-
-
-
-I recently stumbled on the [Audiophile Linux project][1], one of a number of special-purpose music-oriented Linux distributions. Audiophile Linux:
-
- 1. is based on [ArchLinux][2]
-
- 2. provides a real-time Linux kernel customized for playing music
-
- 3. uses the lightweight [Fluxbox][3] window manager
-
- 4. avoids unnecessary daemons and services
-
- 5. allows playback of DSF and supports the usual PCM formats
-
- 6. supports various music players, including one of my favorite combos: MPD + Cantata
-
-
-
-
-The Audiophile Linux site hasn’t shown a lot of activity since April 2017, but it does contain some updates and commentary from this year. Given its orientation and feature set, I decided to take it for a spin on my old Toshiba laptop.
-
-### Installing Audiophile Linux
-
-The site provides [a clear set of install instructions][4] that require the use of the terminal. The first step after downloading the .iso is burning it to a USB stick. I used the GNOME Disks utility’s Restore Disk Image for this purpose. Once I had the USB set up and ready to go, I plugged it into the Toshiba and booted it. When the splash screen came up, I set the boot device to the USB stick and a minute or so later, the Arch Grub menu was displayed. I booted Linux from that menu, which put me in a root shell session, where I could carry out the install to the hard drive:
-
-
-
-I was willing to sacrifice the 320-GB hard drive in the Toshiba for this test, so I was able to use the previous Linux partitioning (from the last experiment). I then proceeded as follows:
-
-```
-fdisk -l # find the disk / partition, in my case /dev/sda and /dev/sda1
-mkfs.ext4 /dev/sda1 # build the ext4 filesystem in the root partition
-mount /dev/sda1 /mnt # mount the new file system
-time cp -ax / /mnt # copy over the OS
- # reported back cp -ax / /mnt 1.36s user 136.54s system 88% cpu 2:36.37 total
-arch-chroot /mnt /bin/bash # run in the new system root
-cd /etc/apl-files
-./runme.sh # do the rest of the install
-grub-install --target=i386-pc /dev/sda # make the new OS bootable part 1
-grub-mkconfig -o /boot/grub/grub.cfg # part 2
-passwd root # set root’s password
-ln -s /usr/share/zoneinfo/America/Vancouver /etc/localtime # set my time zone
-hwclock --systohc --utc # update the hardware clock
-./autologin.sh # set the system up so that it automatically logs in
-exit # done with the chroot session
-genfstab -U /mnt >> /mnt/etc/fstab # create the fstab for the new system
-```
-
-At that point, I was ready to boot the new operating system, so I did—and voilà, up came the system!
-
-
-
-### Finishing the configuration
-
-Once Audiophile Linux was up and running, I needed to [finish the configuration][4] and load some music. Grabbing the application menu by right-clicking on the screen background, I started **X-terminal** and entered the remaining configuration commands:
-
-```
-ping 8.8.8.8 # check connectivity (works fine)
-su # become root
-pacman-key –init # create pacman’s encryption data part 1
-pacman-key --populate archlinux # part 2
-pacman -Sy # part 3
-pacman -S archlinux-keyring # part 4
-```
-
-At this point, the install instructions note that there is a problem with updating software with the `pacman -Suy` command, and that first the **libxfont** package must be removed using `pacman -Rc libxfont`. I followed this instruction, but the second run of `pacman -Suy` led to another dependency error, this time with the **x265** package. I looked further down the page in the install instructions and saw this recommendation:
-
-_Again there is an error in upstream repo of Arch packages. Try to remove conflicting packages with “pacman -R ffmpeg2.8” and then do pacman -Suy later._
-
-I chose to use `pacman -Rc ffmpeg2.8`, and then reran `pacman -Suy`. (As an aside, typing all these **pacman** commands made me realize how familiar I am with **apt** , and how much this whole process made me feel like I was trying to write an email in some language I don’t know using an online translator.)
-
-To be clear, here was my sequence of operations:
-
-```
-pacman -Suy # failed
-pacman -Rc libxfont
-pacman -Suy # failed, again
-pacman -Rc ffmpeg2.8 # uninstalled Cantata, have to fix that later!
-pacman -Suy # worked!
-```
-
-Now back to the rest of the instructions:
-
-```
-pacman -S terminus-font
-pacman -S xorg-server
-pacman -S firefox # the docs suggested installing chromium but I prefer FF
-reboot
-```
-
-And the last little bit, fiddling `/etc/fstab` to avoid access time modifications. I also thought I’d try installing [Cantata][5] once more using `pacman -S cantata`, and it worked just fine (no `ffmpeg2.8` problems).
-
-I found the `DAC Setup > List cards` on the application menu, which showed the built-in Intel sound hardware plus my USB DAC that I had plugged in earlier. Then I selected `DAC Setup > Edit mpd.conf` and adjusted the output stanza of `mpd.conf`. I used `scp` to copy an album over from my main music server into **~/Music**. And finally, I used the application menu `DAC Setup > Restart mpd`. And… nothing… the **conky** info on the screen indicated “MPD not responding”. So I scanned again through the comments at the bottom of the installation instructions and spotted this:
-
-_After every update of mpd, you have to do:
-1. Become root
-```
-$su
-```
-2. run this commands
-```
-# cat /etc/apl-files/mpd.service > /usr/lib/systemd/system/mpd.service
-# systemctl daemon-reload
-# systemctl restart mpd.service_
-```
-_And this will be fixed._
-
-
-
-And it works! Right now I’m enjoying [Nils Frahm’s "All Melody"][6] from the album of the same name, playing over my [Schiit Fulla 2][7] in glorious high-resolution sound. Time to copy in some more music so I can give it a better listen.
-
-So… does it sound better than the same DAC connected to my regular work laptop and playing back through [Guayadeque][8] or [GogglesMM][9]? I’m going to see if I can detect a difference at some point, but right now all I can say is it sounds just wonderful; plus [I like the Cantata / mpd combo a lot][10], and I really enjoy having the heads-up display in the upper right of the screen.
-
-### As for the music...
-
-The other day I was reorganizing my work hard drive a bit and I decided to check to make sure that 1) all the music on it was also on the house music servers and 2) _vice versa_ (gotta set up `rsync` for that purpose one day soon). In doing so, I found some music I hadn’t enjoyed for a while, which is kind of like buying a brand-new album, except it costs much less.
-
-[Six Degrees Records][11] has long been one of my favorite purveyors of unusual music. A great example is the group [Zuco 103][12]'s album [Whaa!][13], whose CD version I purchased from Six Degrees’ online store some years ago. Check out [this fun documentary about the group][14].
-
-<https://youtu.be/ncaqD92cjQ8>
-
-For a completely different experience, take a look at the [Ragazze Quartet’s performance of Terry Riley’s "Four Four Three."][15] I picked up ahigh-resolutionn version of this fascinating music from [Channel Classics][16], which operates a Linux-friendly download store (no bloatware to install on your computer).
-
-And finally, I was saddened to hear of the recent passing of [Rachid Taha][17], whose wonderful blend of North African and French musical traditions, along with his frank confrontation of the challenges of being North African and living in Europe, has made some powerful—and fun—music. Check out [Taha’s version of "Rock the Casbah."][18] I have a few of his songs scattered around various compilation albums, and some time ago bought the CD version of [Rachid Taha: The Definitive Collection][19], which I’ve been enjoying again recently.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/audiophile-linux-distro
-
-作者:[Chris Hermansen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/clhermansen
-[1]: https://www.ap-linux.com/
-[2]: https://www.archlinux.org/
-[3]: http://fluxbox.org/
-[4]: https://www.ap-linux.com/documentation/ap-linux-v4-install-instructions/
-[5]: https://github.com/CDrummond/cantata
-[6]: https://www.youtube.com/watch?v=1PTj1qIqcWM
-[7]: https://www.audiostream.com/content/listening-session-history-lesson-bw-schiit-and-shinola-together-last
-[8]: http://www.guayadeque.org/
-[9]: https://gogglesmm.github.io/
-[10]: https://opensource.com/article/17/8/cantata-music-linux
-[11]: https://www.sixdegreesrecords.com/
-[12]: https://www.sixdegreesrecords.com/?s=zuco+103
-[13]: https://www.musicomh.com/reviews/albums/zuco-103-whaa
-[14]: https://www.youtube.com/watch?v=ncaqD92cjQ8
-[15]: https://www.youtube.com/watch?v=DwMaO7bMVD4
-[16]: https://www.channelclassics.com/catalogue/37816-Riley-Four-Four-Three/
-[17]: https://en.wikipedia.org/wiki/Rachid_Taha
-[18]: https://www.youtube.com/watch?v=n1p_dkJo6Y8
-[19]: http://www.bbc.co.uk/music/reviews/26rg/
diff --git a/sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md b/sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md
deleted file mode 100644
index 8e6583f046..0000000000
--- a/sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md
+++ /dev/null
@@ -1,138 +0,0 @@
-Use Cozy to Play Audiobooks in Linux
-======
-**We review Cozy, an audiobook player for Linux. Read to find out if it’s worth to install Cozy on your Linux system or not.**
-
-![Audiobook player for Linux][1]
-
-Audiobooks are a great way to consume literature. Many people who don’t have time to read, choose to listen. Most people, myself included, just use a regular media player like VLC or [MPV][2] for listening to audiobooks on Linux.
-
-Today, we will look at a Linux application built solely for listening to audiobooks.
-
-![][3]Cozy Audiobook Player
-
-### Cozy Audiobook Player for Linux
-
-The [Cozy Audiobook Player][4] is created by [Julian Geywitz][5] from Germany. It is built using both Python and GTK+ 3. According to the site, Julian wrote Cozy on Fedora and optimized it for [elementary OS][6].
-
-The player borrows its layout from iTunes. The player controls are placed along the top of the application The library takes up the rest. You can sort all of your audiobooks based on the title, author and reader, and search very quickly.
-
-![][7]Initial setup
-
-When you first launch [Cozy][8], you are given the option to choose where you will store your audiobook files. Cozy will keep an eye on that folder and update your library as you add new audiobooks. You can also set it up to use an external or network drive.
-
-#### Features of Cozy
-
-Here is a full list of the features that [Cozy][9] has to offer.
-
- * Import all your audiobooks into Cozy to browse them comfortably
- * Sort your audiobooks by author, reader & title
- * Remembers your playback position
- * Sleep timer
- * Playback speed control
- * Search your audiobook library
- * Add multiple storage locations
- * Drag & Drop to import new audio books
- * Support for DRM free mp3, m4a (aac, ALAC, …), flac, ogg, wav files
- * Mpris integration (Media keys & playback info for the desktop environment)
- * Developed on Fedora and tested under elementaryOS
-
-
-
-#### Experiencing Cozy
-
-![][10]Audiobook library
-
-At first, I was excited to try our Cozy because I like to listen to audiobooks. However, I ran into a couple of issues. There is no way to edit the information of an audiobook. For example, I downloaded a couple audiobooks from [LibriVox][11] to test it. All three audiobooks were listed under “Unknown” for the reader. There was nothing to edit or change the audiobook info. I guess you could edit all of the files, but that would take quite a bit of time.
-
-When I listen to an audiobook, I like to know what track is currently playing. Cozy only has a single progress bar for the whole audiobook. I know that Cozy is designed to remember where you left off in an audiobook, but if I was going to continue to listen to the audiobook on my phone, I would like to know what track I am on.
-
-![][12]Settings
-
-There was also an option in the setting menu to turn on a dark theme. As you can see in the screenshots, the application has a black theme, to begin with. I turned the option on, but nothing happened. There isn’t even an option to add a theme or change any of the colors. Overall, the application had a feeling of not being finished.
-
-#### Installing Cozy on Linux
-
-If you would like to install Cozy, you have several options for different distros.
-
-##### Ubuntu, Debian, openSUSE, Fedora
-
-Julian used the [openSUSE Build Service][13] to create custom repos for Ubuntu, Debian, openSUSE and Fedora. Each one only takes a couple terminal commands to install.
-
-##### Install Cozy using Flatpak on any Linux distribution (including Ubuntu)
-
-If your [distro supports Flatpak][14], you can install Cozy using the following commands:
-
-```
-flatpak remote-add --user --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
-flatpak install --user flathub com.github.geigi.cozy
-```
-
-##### Install Cozy on elementary OS
-
-If you have elementary OS installed, you can install Cozy from the [built-in App Store][15].
-
-##### Install Cozy on Arch Linux
-
-Cozy is available in the [Arch User Repository][16]. All you have to do is search for `cozy-audiobooks`.
-
-### Where to find free Audiobooks?
-
-In order to try out this application, you will need to find some audiobooks to listen to. My favorite site for audiobooks is [LibriVox][11]. Since [LibriVox][17] depends on volunteers to record audiobooks, the quality can vary. However, there are a number of very talented readers.
-
-Here is a list of free audiobook sources:
-
-+ [Open Culture][20]
-+ [Project Gutenberg][21]
-+ [Digitalbook.io][22]
-+ [FreeClassicAudioBooks.com][23]
-+ [MindWebs][24]
-+ [Scribl][25]
-
-
-### Final Thoughts on Cozy
-
-For now, I think I’ll stick with my preferred audiobook software (VLC) for now. Cozy just doesn’t add anything. I won’t call it a [must-have application for Linux][18] just yet. There is no compelling reason for me to switch. Maybe, I’ll revisit it again in the future, maybe when it hits 1.0.
-
-Take Cozy for a spin. You might come to a different conclusion.
-
-Have you ever used Cozy? If not, what is your favorite audiobook player? What is your favorite source for free audiobooks? Let us know in the comments below.
-
-If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][19].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/cozy-audiobook-player/
-
-作者:[John Paul][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/audiobook-player-linux.png
-[2]: https://itsfoss.com/mpv-video-player/
-[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy3.jpg
-[4]: https://cozy.geigi.de/
-[5]: https://github.com/geigi
-[6]: https://elementary.io/
-[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy1.jpg
-[8]: https://github.com/geigi/cozy
-[9]: https://www.patreon.com/geigi
-[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy2.jpg
-[11]: https://librivox.org/
-[12]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy4.jpg
-[13]: https://software.opensuse.org//download.html?project=home%3Ageigi&package=com.github.geigi.cozy
-[14]: https://itsfoss.com/flatpak-guide/
-[15]: https://elementary.io/store/
-[16]: https://aur.archlinux.org/
-[17]: https://archive.org/details/librivoxaudio
-[18]: https://itsfoss.com/essential-linux-applications/
-[19]: http://reddit.com/r/linuxusersgroup
-[20]: http://www.openculture.com/freeaudiobooks
-[21]: http://www.gutenberg.org/browse/categories/1
-[22]: https://www.digitalbook.io/
-[23]: http://freeclassicaudiobooks.com/
-[24]: https://archive.org/details/MindWebs_201410
-[25]: https://scribl.com/
diff --git a/sources/tech/20181003 Manage NTP with Chrony.md b/sources/tech/20181003 Manage NTP with Chrony.md
deleted file mode 100644
index aaec88da26..0000000000
--- a/sources/tech/20181003 Manage NTP with Chrony.md
+++ /dev/null
@@ -1,291 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Manage NTP with Chrony)
-[#]: via: (https://opensource.com/article/18/12/manage-ntp-chrony)
-[#]: author: (David Both https://opensource.com/users/dboth)
-
-Manage NTP with Chrony
-======
-Chronyd is a better choice for most networks than ntpd for keeping computers synchronized with the Network Time Protocol.
-
-
-> "Does anybody really know what time it is? Does anybody really care?"
-> – [Chicago][1], 1969
-
-Perhaps that rock group didn't care what time it was, but our computers do need to know the exact time. Timekeeping is very important to computer networks. In banking, stock markets, and other financial businesses, transactions must be maintained in the proper order, and exact time sequences are critical for that. For sysadmins and DevOps professionals, it's easier to follow the trail of email through a series of servers or to determine the exact sequence of events using log files on geographically dispersed hosts when exact times are kept on the computers in question.
-
-I used to work at an organization that received over 20 million emails per day and had four servers just to accept and do a basic filter on the incoming flood of email. From there, emails were sent to one of four other servers to perform more complex anti-spam assessments, then they were delivered to one of several additional servers where the emails were placed in the correct inboxes. At each layer, the emails would be sent to one of the next-level servers, selected only by the randomness of round-robin DNS. Sometimes we had to trace a new message through the system until we could determine where it "got lost," according to the pointy-haired bosses. We had to do this with frightening regularity.
-
-Most of that email turned out to be spam. Some people actually complained that their [joke, cat pic, recipe, inspirational saying, or other-strange-email]-of-the-day was missing and asked us to find it. We did reject those opportunities.
-
-Our email and other transactional searches were aided by log entries with timestamps that—today—can resolve down to the nanosecond in even the slowest of modern Linux computers. In very high-volume transaction environments, even a few microseconds of difference in the system clocks can mean sorting thousands of transactions to find the correct one(s).
-
-### The NTP server hierarchy
-
-Computers worldwide use the [Network Time Protocol][2] (NTP) to synchronize their times with internet standard reference clocks via a hierarchy of NTP servers. The primary servers are at stratum 1, and they are connected directly to various national time services at stratum 0 via satellite, radio, or even modems over phone lines. The time service at stratum 0 may be an atomic clock, a radio receiver tuned to the signals broadcast by an atomic clock, or a GPS receiver using the highly accurate clock signals broadcast by GPS satellites.
-
-To prevent time requests from time servers lower in the hierarchy (i.e., with a higher stratum number) from overwhelming the primary reference servers, there are several thousand public NTP stratum 2 servers that are open and available for anyone to use. Many organizations with large numbers of hosts that need an NTP server will set up their own time servers so that only one local host accesses the stratum 2 time servers, then they configure the remaining network hosts to use the local time server which, in my case, is a stratum 3 server.
-
-### NTP choices
-
-The original NTP daemon, **ntpd** , has been joined by a newer one, **chronyd**. Both keep the local host's time synchronized with the time server. Both services are available, and I have seen nothing to indicate that this will change anytime soon.
-
-Chrony has features that make it the better choice for most environments for the following reasons:
-
- * Chrony can synchronize to the time server much faster than NTP. This is good for laptops or desktops that don't run constantly.
-
- * It can compensate for fluctuating clock frequencies, such as when a host hibernates or enters sleep mode, or when the clock speed varies due to frequency stepping that slows clock speeds when loads are low.
-
- * It handles intermittent network connections and bandwidth saturation.
-
- * It adjusts for network delays and latency.
-
- * After the initial time sync, Chrony never steps the clock. This ensures stable and consistent time intervals for system services and applications.
-
- * Chrony can work even without a network connection. In this case, the local host or server can be updated manually.
-
-
-
-
-The NTP and Chrony RPM packages are available from standard Fedora repositories. You can install both and switch between them, but modern Fedora, CentOS, and RHEL releases have moved from NTP to Chrony as their default time-keeping implementation. I have found that Chrony works well, provides a better interface for the sysadmin, presents much more information, and increases control.
-
-Just to make it clear, NTP is a protocol that is implemented with either NTP or Chrony. If you'd like to know more, read this [comparison between NTP and Chrony][3] as implementations of the NTP protocol.
-
-This article explains how to configure Chrony clients and servers on a Fedora host, but the configuration for CentOS and RHEL current releases works the same.
-
-### Chrony structure
-
-The Chrony daemon, **chronyd** , runs in the background and monitors the time and status of the time server specified in the **chrony.conf** file. If the local time needs to be adjusted, **chronyd** does it smoothly without the programmatic trauma that would occur if the clock were instantly reset to a new time.
-
-Chrony's **chronyc** tool allows someone to monitor the current status of Chrony and make changes if necessary. The **chronyc** utility can be used as a command that accepts subcommands, or it can be used as an interactive text-mode program. This article will explain both uses.
-
-### Client configuration
-
-The NTP client configuration is simple and requires little or no intervention. The NTP server can be defined during the Linux installation or provided by the DHCP server at boot time. The default **/etc/chrony.conf** file (shown below in its entirety) requires no intervention to work properly as a client. For Fedora, Chrony uses the Fedora NTP pool, and CentOS and RHEL have their own NTP server pools. Like many Red Hat-based distributions, the configuration file is well commented.
-
-```
-# Use public servers from the pool.ntp.org project.
-# Please consider joining the pool (http://www.pool.ntp.org/join.html).
-pool 2.fedora.pool.ntp.org iburst
-
-# Record the rate at which the system clock gains/losses time.
-driftfile /var/lib/chrony/drift
-
-# Allow the system clock to be stepped in the first three updates
-# if its offset is larger than 1 second.
-makestep 1.0 3
-
-# Enable kernel synchronization of the real-time clock (RTC).
-
-
-# Enable hardware timestamping on all interfaces that support it.
-#hwtimestamp *
-
-# Increase the minimum number of selectable sources required to adjust
-# the system clock.
-#minsources 2
-
-# Allow NTP client access from local network.
-#allow 192.168.0.0/16
-
-# Serve time even if not synchronized to a time source.
-#local stratum 10
-
-# Specify file containing keys for NTP authentication.
-keyfile /etc/chrony.keys
-
-# Get TAI-UTC offset and leap seconds from the system tz database.
-leapsectz right/UTC
-
-# Specify directory for log files.
-logdir /var/log/chrony
-
-# Select which information is logged.
-#log measurements statistics tracking
-```
-
-Let's look at the current status of NTP on a virtual machine I use for testing. The **chronyc** command, when used with the **tracking** subcommand, provides statistics that report how far off the local system is from the reference server.
-
-```
-[root@studentvm1 ~]# chronyc tracking
-Reference ID : 23ABED4D (ec2-35-171-237-77.compute-1.amazonaws.com)
-Stratum : 3
-Ref time (UTC) : Fri Nov 16 16:21:30 2018
-System time : 0.000645622 seconds slow of NTP time
-Last offset : -0.000308577 seconds
-RMS offset : 0.000786140 seconds
-Frequency : 0.147 ppm slow
-Residual freq : -0.073 ppm
-Skew : 0.062 ppm
-Root delay : 0.041452706 seconds
-Root dispersion : 0.022665167 seconds
-Update interval : 1044.2 seconds
-Leap status : Normal
-[root@studentvm1 ~]#
-```
-
-The Reference ID in the first line of the result is the server the host is synchronized to—in this case, a stratum 3 reference server that was last contacted by the host at 16:21:30 2018. The other lines are described in the [chronyc(1) man page][4].
-
-The **sources** subcommand is also useful because it provides information about the time source configured in **chrony.conf**.
-
-```
-[root@studentvm1 ~]# chronyc sources
-210 Number of sources = 5
-MS Name/IP address Stratum Poll Reach LastRx Last sample
-===============================================================================
-^+ 192.168.0.51 3 6 377 0 -2613us[-2613us] +/- 63ms
-^+ dev.smatwebdesign.com 3 10 377 28m -2961us[-3534us] +/- 113ms
-^+ propjet.latt.net 2 10 377 465 -1097us[-1085us] +/- 77ms
-^* ec2-35-171-237-77.comput> 2 10 377 83 +2388us[+2395us] +/- 95ms
-^+ PBX.cytranet.net 3 10 377 507 -1602us[-1589us] +/- 96ms
-[root@studentvm1 ~]#
-```
-
-The first source in the list is the time server I set up for my personal network. The others were provided by the pool. Even though my NTP server doesn't appear in the Chrony configuration file above, my DHCP server provides its IP address for the NTP server. The "S" column—Source State—indicates with an asterisk ( ***** ) the server our host is synced to. This is consistent with the data from the **tracking** subcommand.
-
-The **-v** option provides a nice description of the fields in this output.
-
-```
-[root@studentvm1 ~]# chronyc sources -v
-210 Number of sources = 5
-
- .-- Source mode '^' = server, '=' = peer, '#' = local clock.
- / .- Source state '*' = current synced, '+' = combined , '-' = not combined,
-| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
-|| .- xxxx [ yyyy ] +/- zzzz
-|| Reachability register (octal) -. | xxxx = adjusted offset,
-|| Log2(Polling interval) --. | | yyyy = measured offset,
-|| \ | | zzzz = estimated error.
-|| | | \
-MS Name/IP address Stratum Poll Reach LastRx Last sample
-===============================================================================
-^+ 192.168.0.51 3 7 377 28 -2156us[-2156us] +/- 63ms
-^+ triton.ellipse.net 2 10 377 24 +5716us[+5716us] +/- 62ms
-^+ lithium.constant.com 2 10 377 351 -820us[ -820us] +/- 64ms
-^* t2.time.bf1.yahoo.com 2 10 377 453 -992us[ -965us] +/- 46ms
-^- ntp.idealab.com 2 10 377 799 +3653us[+3674us] +/- 87ms
-[root@studentvm1 ~]#
-```
-
-If I wanted my server to be the preferred reference time source for this host, I would add the line below to the **/etc/chrony.conf** file.
-
-```
-server 192.168.0.51 iburst prefer
-```
-
-I usually place this line just above the first pool server statement near the top of the file. There is no special reason for this, except I like to keep the server statements together. It would work just as well at the bottom of the file, and I have done that on several hosts. This configuration file is not sequence-sensitive.
-
-The **prefer** option marks this as the preferred reference source. As such, this host will always be synchronized with this reference source (as long as it is available). We can also use the fully qualified hostname for a remote reference server or the hostname only (without the domain name) for a local reference time source as long as the search statement is set in the **/etc/resolv.conf** file. I prefer the IP address to ensure that the time source is accessible even if DNS is not working. In most environments, the server name is probably the better option, because NTP will continue to work even if the server's IP address changes.
-
-If you don't have a specific reference source you want to synchronize to, it is fine to use the defaults.
-
-### Configuring an NTP server with Chrony
-
-The nice thing about the Chrony configuration file is that this single file configures the host as both a client and a server. To add a server function to our host—it will always be a client, obtaining its time from a reference server—we just need to make a couple of changes to the Chrony configuration, then configure the host's firewall to accept NTP requests.
-
-Open the **/etc/ ** **chrony****.conf** file in your favorite text editor and uncomment the **local stratum 10** line. This enables the Chrony NTP server to continue to act as if it were connected to a remote reference server if the internet connection fails; this enables the host to continue to be an NTP server to other hosts on the local network.
-
-Let's restart **chronyd** and track how the service is working for a few minutes. Before we enable our host as an NTP server, we want to test a bit.
-
-```
-[root@studentvm1 ~]# systemctl restart chronyd ; watch chronyc tracking
-```
-
-The results should look like this. The **watch** command runs the **chronyc tracking** command every two seconds so we can watch changes occur over time.
-
-```
-Every 2.0s: chronyc tracking studentvm1: Fri Nov 16 20:59:31 2018
-
-Reference ID : C0A80033 (192.168.0.51)
-Stratum : 4
-Ref time (UTC) : Sat Nov 17 01:58:51 2018
-System time : 0.001598277 seconds fast of NTP time
-Last offset : +0.001791533 seconds
-RMS offset : 0.001791533 seconds
-Frequency : 0.546 ppm slow
-Residual freq : -0.175 ppm
-Skew : 0.168 ppm
-Root delay : 0.094823152 seconds
-Root dispersion : 0.021242738 seconds
-Update interval : 65.0 seconds
-Leap status : Normal
-```
-
-Notice that my NTP server, the **studentvm1** host, synchronizes to the host at 192.168.0.51, which is my internal network NTP server, at stratum 4. Synchronizing directly to the Fedora pool machines would result in synchronization at stratum 3. Notice also that the amount of error decreases over time. Eventually, it should stabilize with a tiny variation around a fairly small range of error. The size of the error depends upon the stratum and other network factors. After a few minutes, use Ctrl+C to break out of the watch loop.
-
-To turn our host into an NTP server, we need to allow it to listen on the local network. Uncomment the following line to allow hosts on the local network to access our NTP server.
-
-```
-# Allow NTP client access from local network.
-allow 192.168.0.0/16
-```
-
-Note that the server can listen for requests on any local network it's attached to. The IP address in the "allow" line is just intended for illustrative purposes. Be sure to change the IP network and subnet mask in that line to match your local network's.
-
-Restart **chronyd**.
-
-```
-[root@studentvm1 ~]# systemctl restart chronyd
-```
-
-To allow other hosts on your network to access this server, configure the firewall to allow inbound UDP packets on port 123. Check your firewall's documentation to find out how to do that.
-
-### Testing
-
-Your host is now an NTP server. You can test it with another host or a VM that has access to the network on which the NTP server is listening. Configure the client to use the new NTP server as the preferred server in the **/etc/chrony.conf** file, then monitor that client using the **chronyc** tools we used above.
-
-### Chronyc as an interactive tool
-
-As I mentioned earlier, **chronyc** can be used as an interactive command tool. Simply run the command without a subcommand and you get a **chronyc** command prompt.
-
-```
-[root@studentvm1 ~]# chronyc
-chrony version 3.4
-Copyright (C) 1997-2003, 2007, 2009-2018 Richard P. Curnow and others
-chrony comes with ABSOLUTELY NO WARRANTY. This is free software, and
-you are welcome to redistribute it under certain conditions. See the
-GNU General Public License version 2 for details.
-
-chronyc>
-```
-
-You can enter just the subcommands at this prompt. Try using the **tracking** , **ntpdata** , and **sources** commands. The **chronyc** command line allows command recall and editing for **chronyc** subcommands. You can use the **help** subcommand to get a list of possible commands and their syntax.
-
-### Conclusion
-
-Chrony is a powerful tool for synchronizing the times of client hosts, whether they are all on the local network or scattered around the globe. It's easy to configure because, despite the large number of options available, only a few configurations are required for most circumstances.
-
-After my client computers have synchronized with the NTP server, I like to set the system hardware clock from the system (OS) time by using the following command:
-
-```
-/sbin/hwclock --systohc
-```
-
-This command can be added as a cron job or a script in **cron.daily** to keep the hardware clock synced with the system time.
-
-Chrony and NTP (the service) both use the same configuration, and the files' contents are interchangeable. The man pages for [chronyd][5], [chronyc][4], and [chrony.conf][6] contain an amazing amount of information that can help you get started or learn about esoteric configuration options.
-
-Do you run your own NTP server? Let us know in the comments and be sure to tell us which implementation you are using, NTP or Chrony.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/manage-ntp-chrony
-
-作者:[David Both][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/dboth
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Does_Anybody_Really_Know_What_Time_It_Is%3F
-[2]: https://en.wikipedia.org/wiki/Network_Time_Protocol
-[3]: https://chrony.tuxfamily.org/comparison.html
-[4]: https://linux.die.net/man/1/chronyc
-[5]: https://linux.die.net/man/8/chronyd
-[6]: https://linux.die.net/man/5/chrony.conf
diff --git a/sources/tech/20181004 4 Must-Have Tools for Monitoring Linux.md b/sources/tech/20181004 4 Must-Have Tools for Monitoring Linux.md
deleted file mode 100644
index beb3bab797..0000000000
--- a/sources/tech/20181004 4 Must-Have Tools for Monitoring Linux.md
+++ /dev/null
@@ -1,102 +0,0 @@
-4 Must-Have Tools for Monitoring Linux
-======
-
-
-
-Linux. It’s powerful, flexible, stable, secure, user-friendly… the list goes on and on. There are so many reasons why people have adopted the open source operating system. One of those reasons which particularly stands out is its flexibility. Linux can be and do almost anything. In fact, it will (in most cases) go well above what most platforms can. Just ask any enterprise business why they use Linux and open source.
-
-But once you’ve deployed those servers and desktops, you need to be able to keep track of them. What’s going on? How are they performing? Is something afoot? In other words, you need to be able to monitor your Linux machines. “How?” you ask. That’s a great question, and one with many answers. I want to introduce you to a few such tools—from command line, to GUI, to full-blown web interfaces (with plenty of bells and whistles). From this collection of tools, you can gather just about any kind of information you need. I will stick only with tools that are open source, which will exempt some high-quality, proprietary solutions. But it’s always best to start with open source, and, chances are, you’ll find everything you need to monitor your desktops and servers. So, let’s take a look at four such tools.
-
-### Top
-
-We’ll first start with the obvious. The top command is a great place to start, when you need to monitor what processes are consuming resources. The top command has been around for a very long time and has, for years, been the first tool I turn to when something is amiss. What top does is provide a real-time view of all running systems on a Linux machine. The top command not only displays dynamic information about each running process (as well as the necessary information to manage those processes), but also gives you an overview of the machine (such as, how many CPUs are found, and how much RAM and swap space is available). When I feel something is going wrong with a machine, I immediately turn to top to see what processes are gobbling up the most CPU and MEM (Figure 1). From there, I can act accordingly.
-
-![top][2]
-
-Figure 1: Top running on Elementary OS.
-
-[Used with permission][3]
-
-There is no need to install anything to use the top command, because it is installed on almost every Linux distribution by default. For more information on top, issue the command man top.
-
-### Glances
-
-If you thought the top command offered up plenty of information, you’ve yet to experience Glances. Glances is another text-based monitoring tool. In similar fashion to top, glances offers a real-time listing of more information about your system than nearly any other monitor of its kind. You’ll see disk/network I/O, thermal readouts, fan speeds, disk usage by hardware device and logical volume, processes, warnings, alerts, and much more. Glances also includes a handy sidebar that displays information about disk, filesystem, network, sensors, and even Docker stats. To enable the sidebar, hit the 2 key (while glances is running). You’ll then see the added information (Figure 2).
-
-![glances][5]
-
-Figure 2: The glances monitor displaying docker stats along with all the other information it offers.
-
-[Used with permission][3]
-
-You won’t find glances installed by default. However, the tool is available in most standard repositories, so it can be installed from the command line or your distribution’s app store, without having to add a third-party repository.
-
-### GNOME System Monitor
-
-If you're not a fan of the command line, there are plenty of tools to make your monitoring life a bit easier. One such tool is GNOME System Monitor, which is a front-end for the top tool. But if you prefer a GUI, you can’t beat this app.
-
-With GNOME System Monitor, you can scroll through the listing of running apps (Figure 3), select an app, and then either end the process (by clicking End Process) or view more details about said process (by clicking the gear icon).
-
-![GNOME System Monitor][7]
-
-Figure 3: GNOME System Monitor in action.
-
-[Used with permission][3]
-
-You can also click any one of the tabs at the top of the window to get even more information about your system. The Resources tab is a very handy way to get real-time data on CPU, Memory, Swap, and Network (Figure 4).
-
-![GNOME System Monitor][9]
-
-Figure 4: The GNOME System Monitor Resources tab in action.
-
-[Used with permission][3]
-
-If you don’t find GNOME System Monitor installed by default, it can be found in the standard repositories, so it’s very simple to add to your system.
-
-### Nagios
-
-If you’re looking for an enterprise-grade networking monitoring system, look no further than [Nagios][10]. But don’t think Nagios is limited to only monitoring network traffic. This system has over 5,000 different add-ons that can be added to expand the system to perfectly meet (and exceed your needs). The Nagios monitor doesn’t come pre-installed on your Linux distribution and although the install isn’t quite as difficult as some similar tools, it does have some complications. And, because the Nagios version found in many of the default repositories is out of date, you’ll definitely want to install from source. Once installed, you can log into the Nagios web GUI and start monitoring (Figure 5).
-
-![Nagios ][12]
-
-Figure 5: With Nagios you can even start and stop services.
-
-[Used with permission][3]
-
-Of course, at this point, you’ve only installed the core and will also need to walk through the process of installing the plugins. Trust me when I say it’s worth the extra time.
-The one caveat with Nagios is that you must manually install any remote hosts to be monitored (outside of the host the system is installed on) via text files. Fortunately, the installation will include sample configuration files (found in /usr/local/nagios/etc/objects) which you can use to create configuration files for remote servers (which are placed in /usr/local/nagios/etc/servers).
-
-Although Nagios can be a challenge to install, it is very much worth the time, as you will wind up with an enterprise-ready monitoring system capable of handling nearly anything you throw at it.
-
-### There’s More Where That Came From
-
-We’ve barely scratched the surface in terms of monitoring tools that are available for the Linux platform. No matter whether you’re looking for a general system monitor or something very specific, a command line or GUI application, you’ll find what you need. These four tools offer an outstanding starting point for any Linux administrator. Give them a try and see if you don’t find exactly the information you need.
-
-Learn more about Linux through the free ["Introduction to Linux" ][13] course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/10/4-must-have-tools-monitoring-linux
-
-作者:[Jack Wallen][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/jlwallen
-[b]: https://github.com/lujun9972
-[1]: /files/images/monitoring1jpg
-[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/monitoring_1.jpg?itok=UiyNGji0 (top)
-[3]: /licenses/category/used-permission
-[4]: /files/images/monitoring2jpg
-[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/monitoring_2.jpg?itok=K3OxLcvE (glances)
-[6]: /files/images/monitoring3jpg
-[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/monitoring_3.jpg?itok=UKcyEDcT (GNOME System Monitor)
-[8]: /files/images/monitoring4jpg
-[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/monitoring_4.jpg?itok=orLRH3m0 (GNOME System Monitor)
-[10]: https://www.nagios.org/
-[11]: /files/images/monitoring5jpg
-[12]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/monitoring_5.jpg?itok=RGcLLWL7 (Nagios )
-[13]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20181005 How to use Kolibri to access educational material offline.md b/sources/tech/20181005 How to use Kolibri to access educational material offline.md
deleted file mode 100644
index f856a497cd..0000000000
--- a/sources/tech/20181005 How to use Kolibri to access educational material offline.md
+++ /dev/null
@@ -1,107 +0,0 @@
-How to use Kolibri to access educational material offline
-======
-Kolibri makes digital educational materials available to students without internet access.
-
-
-
-While the internet has thoroughly transformed the availability of educational content for much of the world, many people still live in places where online access is poor or even nonexistent. [Kolibri][1] is a great solution for these communities. It's an app that creates an offline server to deliver high-quality educational resources to learners. You can set up Kolibri on a wide range of [hardware][2], including low-cost Windows, MacOS, and Linux (including Raspberry Pi) computers. A version for Android tablets is in the works.
-
-Because it's open source, free to use, works without broadband access (after initial setup), and includes a wide range of educational content, it gives students in rural schools, refugee camps, orphanages, informal schools, prisons, and other places without reliable internet service access to many of the same resources used by students all over the world.
-
-In addition to being simple to install, it's easy to customize Kolibri for various educational missions and needs, including literacy building, general reference materials, and life skills training. Kolibri includes content from sources including [OpenStax,][3] [CK-12][4], [Khan Academy][5], and [EngageNY][6]; once these packages are "seeded" by connecting the Kolibri serving device to a robust internet connection, they are immediately available for offline access on client devices through a compatible browser.
-
-### Installation and setup
-
-I installed Kolibri on an Intel i3-based laptop running Fedora 28. I chose the **pip install** method, which is very easy. Here's how to do it.
-
-Open a terminal and enter:
-
-```
-$ sudo pip install kolibri
-
-```
-
-Start Kolibri by entering **$** **kolibri** **start** in the terminal.
-
-Find your Kolibri installation's URL in the terminal.
-
-
-
-Open your browser and point it to that URL, being sure to append port **8080**.
-
-Select the default language—options include English, Spanish, French, Arabic, Portuguese, Hindi, Farsi, Burmese, and Bengali. (I chose English.)
-
-Name your facility, i.e., your classroom, library, or home. (I named mine Test.)
-
-
-
-Tell Kolibri what type of facility you're setting up—self-managed, admin-managed, or informal. (I chose self-managed.)
-
-
-
-Create an admin account.
-
-
-
-### Add content
-
-You can add Kolibri-curated content channels while you are connected to broadband service. Explore and add content from the menu at the top-left of the browser.
-
-
-
-Choose Device and Import.
-
-
-
-Selecting English as the default language provides access to 29 content channels including Touchable Earth, Global Digital Library, Khan Academy, OpenStax, CK-12, EngageNY, Blockly games, and more.
-
-Select a channel you're interested in. You have the option to download the entire channel (which might take a long time) or to select the specific content you want to download.
-
-
-
-To access your content, return to the top-left menu and select Learn.
-
-
-
-### Add users
-
-User accounts can be set up as learners, coaches, or admins. Users can access the Kolibri server from most web browsers on any Linux, MacOS, Windows, Android, or iOS device on the same network, even if the network isn't connected to the internet. Admins can set up classes on the device, assign coaches and learners to classes, and see every user's interaction and how much time they spend with the content.
-
-If your Kolibri server is set up as self-managed, users can create their own accounts by entering the Kolibri URL in their browser and following the prompts. For information on setting up users on an admin-managed server, check out Kolibri's [documentation][7].
-
-
-
-After logging in, the user can access content right away to begin learning.
-
-### Learn more
-
-Kolibri is a very powerful learning resource, especially for people who don't have a robust connection to the internet. Its [documentation][8] is very complete, and a [demo][9] site maintained by the project allows you to try it out.
-
-Kolibri is open source under the [MIT License][10]. The project, which is managed by the nonprofit organization Learning Equality, is looking for developers—if you would like to get involved, be sure to check out them on [GitHub][11]. To learn more, follow Learning Equality and Kolibri on its [blog][12], [Twitter][13], and [Facebook][14] pages.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/getting-started-kolibri
-
-作者:[Don Watkins][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/don-watkins
-[1]: https://learningequality.org/kolibri/
-[2]: https://drive.google.com/file/d/0B9ZzDms8cSNgVWRKdUlPc2lkTkk/view
-[3]: https://openstax.org/
-[4]: https://www.ck12.org/
-[5]: https://www.khanacademy.org/
-[6]: https://www.engageny.org/
-[7]: https://kolibri.readthedocs.io/en/latest/manage.html#create-a-new-user-account
-[8]: https://learningequality.org/documentation/
-[9]: http://kolibridemo.learningequality.org/learn/#/topics
-[10]: https://github.com/learningequality/kolibri/blob/develop/LICENSE
-[11]: https://github.com/learningequality/
-[12]: https://blog.learningequality.org/
-[13]: https://twitter.com/LearnEQ/
-[14]: https://www.facebook.com/learningequality
diff --git a/sources/tech/20181008 Taking notes with Laverna, a web-based information organizer.md b/sources/tech/20181008 Taking notes with Laverna, a web-based information organizer.md
deleted file mode 100644
index 27616a9f6e..0000000000
--- a/sources/tech/20181008 Taking notes with Laverna, a web-based information organizer.md
+++ /dev/null
@@ -1,128 +0,0 @@
-Taking notes with Laverna, a web-based information organizer
-======
-
-
-
-I don’t know anyone who doesn’t take notes. Most of the people I know use an online note-taking application like Evernote, Simplenote, or Google Keep.
-
-All of those are good tools, but they’re proprietary. And you have to wonder about the privacy of your information—especially in light of [Evernote’s great privacy flip-flop of 2016][1]. If you want more control over your notes and your data, you need to turn to an open source tool—preferably one that you can host yourself.
-
-And there are a number of good [open source alternatives to Evernote][2]. One of these is Laverna. Let’s take a look at it.
-
-### Getting Laverna
-
-You can [host Laverna yourself][3] or use the [web version][4]
-
-Since I have nowhere to host the application, I’ll focus here on using the web version of Laverna. Aside from the installation and setting up storage (more on that below), I’m told that the experience with a self-hosted version of Laverna is the same.
-
-### Setting up Laverna
-
-To start using Laverna right away, click the **Start using now** button on the front page of [Laverna.cc][5].
-
-On the welcome screen, click **Next**. You’ll be asked to enter an encryption password to secure your notes and get to them when you need to. You’ll also be asked to choose a way to synchronize your notes. I’ll discuss synchronization in a moment, so just enter a password and click **Next**.
-
-
-
-When you log in, you'll see a blank canvas:
-
-
-
-### Storing your notes
-
-Before diving into how to use Laverna, let’s walk through how to store your notes.
-
-Out of the box, Laverna stores your notes in your browser’s cache. The problem with that is when you clear the cache, you lose your notes. You can also store your notes using:
-
- * Dropbox, a popular and proprietary web-based file syncing and storing service
- * [remoteStorage][6], which offers a way for web applications to store information in the cloud.
-
-
-
-Using Dropbox is convenient, but it’s proprietary. There are also concerns about [privacy and surveillance][7]. Laverna encrypts your notes before saving them, but not all encryption is foolproof. Even if you don’t have anything illegal or sensitive in your notes, they’re no one’s business but your own.
-
-remoteStorage, on the other hand, is kind of techie to set up. There are few hosted storage services out there. I use [5apps][8].
-
-To change how Laverna stores your notes, click the hamburger menu in the top-left corner. Click **Settings** and then **Sync**.
-
-
-
-Select the service you want to use, then click **Save**. After that, click the left arrow in the top-left corner. You’ll be asked to authorize Laverna with the service you chose.
-
-### Using Laverna
-
-With that out of the way, let’s get down to using Laverna. Create a new note by clicking the **New Note** icon, which opens the note editor:
-
-
-
-Type a title for your note, then start typing the note in the left pane of the editor. The right pane displays a preview of your note:
-
-
-
-You can format your notes using Markdown; add formatting using your keyboard or the toolbar at the top of the window.
-
-You can also embed an image or file from your computer into a note, or link to one on the web. When you embed an image, it’s stored with your note.
-
-When you’re done, click **Save**.
-
-### Organizing your notes
-
-Like some other note-taking tools, Laverna lists the last note that you created or edited at the top. If you have a lot of notes, it can take a bit of work to find the one you're looking for.
-
-To better organize your notes, you can group them into notebooks, where you can quickly filter them based on a topic or a grouping.
-
-When you’re creating or editing a note, you can select a notebook from the **Select notebook** list in the top-left corner of the window. If you don’t have any notebooks, select **Add a new notebook** from the list and type the notebook’s name.
-
-You can also make that notebook a child of another notebook. Let’s say, for example, you maintain three blogs. You can create a notebook called **Blog Post Notes** and name children for each blog.
-
-To filter your notes by notebook, click the hamburger menu, followed by the name of a notebook. Only the notes in the notebook you choose will appear in the list.
-
-
-
-### Using Laverna across devices
-
-I use Laverna on my laptop and on an eight-inch tablet running [LineageOS][9]. Getting the two devices to use the same storage and display the same notes takes a little work.
-
-First, you’ll need to export your settings. Log into wherever you’re using Laverna and click the hamburger menu. Click **Settings** , then **Import & Export**. Under **Settings** , click **Export settings**. Laverna saves a file named laverna-settings.json to your device.
-
-Copy that file to the other device or devices on which you want to use Laverna. You can do that by emailing it to yourself or by syncing the file across devices using an application like [ownCloud][10] or [Nextcloud][11].
-
-On the other device, click **Import** on the splash screen. Otherwise, click the hamburger menu and then **Settings > Import & Export**. Click **Import settings**. Find the JSON file with your settings, click **Open** and then **Save**.
-
-Laverna will ask you to:
-
- * Log back in using your password.
- * Register with the storage service you’re using.
-
-
-
-Repeat this process for each device that you want to use. It’s cumbersome, I know. I’ve done it. You should need to do it only once per device, though.
-
-### Final thoughts
-
-Once you set up Laverna, it’s easy to use and has just the right features for what I need to do. I’m hoping that the developers can expand the storage and syncing options to include open source applications like Nextcloud and ownCloud.
-
-While Laverna doesn’t have all the bells and whistles of a note-taking application like Evernote, it does a great job of letting you take and organize your notes. The fact that Laverna is open source and supports Markdown are two additional great reasons to use it.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/taking-notes-laverna
-
-作者:[Scott Nesbitt][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/scottnesbitt
-[1]: https://blog.evernote.com/blog/2016/12/15/evernote-revisits-privacy-policy/
-[2]: https://opensource.com/life/16/8/open-source-alternatives-evernote
-[3]: https://github.com/Laverna/laverna
-[4]: https://laverna.cc/
-[5]: http://laverna.cc/
-[6]: https://remotestorage.io/
-[7]: https://www.zdnet.com/article/dropbox-faces-questions-over-claims-of-improper-data-sharing/
-[8]: https://5apps.com/storage/beta
-[9]: https://lineageos.org/
-[10]: https://owncloud.com/
-[11]: https://nextcloud.com/
diff --git a/sources/tech/20181015 An introduction to Ansible Operators in Kubernetes.md b/sources/tech/20181015 An introduction to Ansible Operators in Kubernetes.md
deleted file mode 100644
index a7d8fd86e7..0000000000
--- a/sources/tech/20181015 An introduction to Ansible Operators in Kubernetes.md
+++ /dev/null
@@ -1,81 +0,0 @@
-An introduction to Ansible Operators in Kubernetes
-======
-The new Operator SDK makes it easy to create a Kubernetes controller to deploy and manage a service or application in a cluster.
-
-
-For years, Ansible has been a go-to choice for infrastructure automation. As Kubernetes adoption has skyrocketed, Ansible has continued to shine in the emerging container orchestration ecosystem.
-
-Ansible fits naturally into a Kubernetes workflow, using YAML to describe the desired state of the world. Multiple projects, including the [Automation Broker][1], are adapting Ansible for use behind specific APIs. This article will focus on a new technique, created through a joint effort by the Ansible core team and the developers of Automation Broker, that uses Ansible to create Operators with minimal effort.
-
-### What is an Operator?
-
-An [Operator][2] is a Kubernetes controller that deploys and manages a service or application in a cluster. It automates human operation knowledge and best practices to keep services running and healthy. Input is received in the form of a custom resource. Let's walk through that using a Memcached Operator as an example.
-
-The [Memcached Operator][3] can be deployed as a service running in a cluster, and it includes a custom resource definition (CRD) for a resource called Memcached. The end user creates an instance of that custom resource to describe how the Memcached Deployment should look. The following example requests a Deployment with three Pods.
-
-```
-apiVersion: "cache.example.com/v1alpha1"
-kind: "Memcached"
-metadata:
- name: "example-memcached"
-spec:
- size: 3
-```
-
-The Operator's job is called reconciliation—continuously ensuring that what is specified in the "spec" matches the real state of the world. This sample Operator delegates Pod management to a Deployment controller. So while it does not directly create or delete Pods, if you change the size, the Operator's reconciliation loop ensures that the new value is applied to the Deployment resource it created.
-
-A mature Operator can deploy, upgrade, back up, repair, scale, and reconfigure an application that it manages. As you can see, not only does an Operator provide a simple way to deploy arbitrary services using only native Kubernetes APIs; it enables full day-two (post-deployment, such as updates, backups, etc.) management, limited only by what you can code.
-
-### Creating an Operator
-
-The [Operator SDK][4] makes it easy to get started. It lays down the skeleton of a new Operator with many of the complex pieces already handled. You can focus on defining your custom resources and coding the reconciliation logic in Go. The SDK saves you a lot of time and ongoing maintenance burden, but you will still end up owning a substantial software project.
-
-Ansible was recently introduced to the Operator SDK as an even simpler way to make an Operator, with no coding required. To create an Operator, you merely:
-
- * Create a CRD in the form of YAML
- * Define what reconciliation should do by creating an Ansible role or playbook
-
-
-
-It's YAML all the way down—a familiar experience for Kubernetes users.
-
-### How does it work?
-
-There is a preexisting Ansible Operator base container image that includes Ansible, [ansible-runner][5], and the Operator's executable service. The SDK helps to build a layer on top that adds one or more CRDs and associates each with an Ansible role or playbook.
-
-When it's running, the Operator uses a Kubernetes feature to "watch" for changes to any resource of the type defined. Upon receiving such a notification, it reconciles the resource that changed. The Operator runs the corresponding role or playbook, and information about the resource is passed to Ansible as [extra-vars][6].
-
-### Using Ansible with Kubernetes
-
-Following several iterations, the Ansible community has produced a remarkably easy-to-use module for working with Kubernetes. Especially if you have any experience with a Kubernetes module prior to Ansible 2.6, you owe it to yourself to have a look at the [k8s module][7]. Creating, retrieving, and updating resources is a natural experience that will feel familiar to any Kubernetes user. It makes creating an Operator that much easier.
-
-### Give it a try
-
-If you need to build a Kubernetes Operator, doing so with Ansible could save time and complexity. To learn more, head over to the Operator SDK documentation and work through the [Getting Started Guide][8] for Ansible-based Operators. Then join us on the [Operator Framework mailing list][9] and let us know what you think.
-
-Michael Hrivnak will present [Automating Multi-Service Deployments on Kubernetes][10] at [LISA18][11], October 29-31 in Nashville, Tennessee, USA.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/ansible-operators-kubernetes
-
-作者:[Michael Hrivnak][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mhrivnak
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/article/18/2/automated-provisioning-kubernetes
-[2]: https://coreos.com/operators/
-[3]: https://github.com/operator-framework/operator-sdk-samples/tree/master/memcached-operator
-[4]: https://github.com/operator-framework/operator-sdk/
-[5]: https://github.com/ansible/ansible-runner
-[6]: https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#passing-variables-on-the-command-line
-[7]: https://docs.ansible.com/ansible/2.6/modules/k8s_module.html
-[8]: https://github.com/operator-framework/operator-sdk/blob/master/doc/ansible/user-guide.md
-[9]: https://groups.google.com/forum/#!forum/operator-framework
-[10]: https://www.usenix.org/conference/lisa18/presentation/hrivnak
-[11]: https://www.usenix.org/conference/lisa18
diff --git a/sources/tech/20181016 piwheels- Speedy Python package installation for the Raspberry Pi.md b/sources/tech/20181016 piwheels- Speedy Python package installation for the Raspberry Pi.md
deleted file mode 100644
index a50f5d71d7..0000000000
--- a/sources/tech/20181016 piwheels- Speedy Python package installation for the Raspberry Pi.md
+++ /dev/null
@@ -1,87 +0,0 @@
-piwheels: Speedy Python package installation for the Raspberry Pi
-======
-https://opensource.com/article/18/10/piwheels-python-raspberrypi
-
-
-
-One of the great things about the Python programming language is [PyPI][1], the Python Package Index, where third-party libraries are hosted, available for anyone to install and gain access to pre-existing functionality without starting from scratch. These libraries are handy utilities, written by members of the community, that aren't found within the Python standard library. But they work in much the same way—you import them into your code and have access to functions and classes you didn't write yourself.
-
-### The cross-platform problem
-
-Many of the 150,000+ libraries hosted on PyPI are written in Python, but that's not the only option—you can write Python libraries in C, C++, or anything with Python bindings. The usual benefit of writing a library in C or C++ is speed. The NumPy project is a good example: NumPy provides highly powerful mathematical functionality for dealing with matrix operations. It is highly optimized code that allows users to write in Python but have access to speedy mathematics operations.
-
-The problem comes when trying to distribute libraries for others to use cross-platform. The standard is to create built distributions called Python wheels. While pure Python libraries are automatically compatible cross-platform, those implemented in C/C++ must be built separately for each operating system, Python version, and system architecture. So, if a library wanted to support Windows, MacOS, and Linux, for both 32-bit and 64-bit computers, and for Python 2.7, 3.4, 3.5, and 3.6, that would require 24 different versions! Some packages do this, but others rely on users building the package from the source code, which can take a long time and can often be complex.
-
-### Raspberry Pi and Arm
-
-While the Raspberry Pi runs Linux, it's not the same architecture as your regular PC—it's Arm, rather than Intel. That means the Linux wheels don't work, and Raspberry Pi users had to build from source—until the piwheels project came to fruition last year. [Piwheels][2] is an open source project that aims to build Raspberry Pi platform wheels for every package on PyPI.
-
-
-
-Packages are natively compiled on Raspberry Pi 3 hardware and hosted in a data center provided by UK-based [Mythic Beasts][3], which provides cloud Pis as part of its hosting service. The piwheels website hosts the wheels in a [pip][4]-compatible web server configuration so Raspberry Pi users can use them easily. Raspbian Stretch even comes preconfigured to use piwheels.org as an additional index to PyPI by default.
-
-### The piwheels stack
-
-The piwheels project runs (almost) entirely on Raspberry Pi hardware:
-
- * **Master**
- * A Raspberry Pi web server hosts the wheel files and distributes jobs to the builder Pis.
- * **Database server**
- * All package information is stored in a [Postgres database][5].
- * The master logs build attempts and downloads.
- * **Builders**
- * Builder Pis are given build jobs to attempt, and they communicate with the database.
- * The backlog of packages on PyPI was completed using around 20 Raspberry Pis.
- * A smaller number of Pis is required to keep up with new releases. Currently, there are three with Raspbian Jessie (Python 3.4) and two with Raspbian Stretch (Python 3.5).
-
-
-
-The database server was originally a Raspberry Pi but was moved to another server when the database got too large.
-
-
-
-### Time saved
-
-Around 500,000 packages are downloaded from piwheels.org every month.
-
-Every time a package is built by piwheels or downloaded by a user, its status information (including build duration) is recorded in a database. Therefore, it's possible to calculate how much time has been saved with pre-compiled packages.
-
-In the 10 months that the service has been running, over 25 years of build time has been saved.
-
-### Great for projects
-
-Raspberry Pi project tutorials requiring Python libraries often include warnings like "this step takes a few hours"—but that's no longer true, thanks to piwheels. Piwheels makes it easy for makers and developers to dive straight into their project and not get bogged down waiting for software to install. Amazing libraries are just a **pip install** away; no need to wait for compilation.
-
-Piwheels has wheels for NumPy, SciPy, OpenCV, Keras, and even [Tensorflow][6], Google's machine learning framework. These libraries are great for [home projects][7], including image and facial recognition with the [camera module][8]. For inspiration, take a look at the Raspberry Pi category on [PyImageSearch][9] (which is one of my [favorite Raspberry Pi blogs][10]) to follow.
-
-
-
-Read more about piwheels on the project's [blog][11] and the [Raspberry Pi blog][12], see the [source code on GitHub][13], and check out the [piwheels website][2]. If you want to contribute to the project, check the [missing packages tag][14] and see if you can successfully build one of them.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/piwheels-python-raspberrypi
-
-作者:[Ben Nuttall][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/bennuttall
-[b]: https://github.com/lujun9972
-[1]: https://pypi.org/
-[2]: https://www.piwheels.org/
-[3]: https://www.mythic-beasts.com/order/rpi
-[4]: https://en.wikipedia.org/wiki/Pip_(package_manager)
-[5]: https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
-[6]: https://www.tensorflow.org/
-[7]: https://opensource.com/article/17/4/5-projects-raspberry-pi-home
-[8]: https://opensource.com/life/15/6/raspberry-pi-camera-projects
-[9]: https://www.pyimagesearch.com/category/raspberry-pi/
-[10]: https://opensource.com/article/18/8/top-10-raspberry-pi-blogs-follow
-[11]: https://blog.piwheels.org/
-[12]: https://www.raspberrypi.org/blog/piwheels/
-[13]: https://github.com/bennuttall/piwheels
-[14]: https://github.com/bennuttall/piwheels/issues?q=is%3Aissue+is%3Aopen+label%3A%22missing+package%22
diff --git a/sources/tech/20181017 Automating upstream releases with release-bot.md b/sources/tech/20181017 Automating upstream releases with release-bot.md
deleted file mode 100644
index 7543af8981..0000000000
--- a/sources/tech/20181017 Automating upstream releases with release-bot.md
+++ /dev/null
@@ -1,327 +0,0 @@
-Automating upstream releases with release-bot
-======
-All you need to do is file an issue into your upstream repository and release-bot takes care of the rest.
-
-
-If you own or maintain a GitHub repo and have ever pushed a package from it into [PyPI][1] and/or [Fedora][2], you know it requires some additional work using the Fedora infrastructure.
-
-Good news: We have developed a tool called [release-bot][3] that automates the process. All you need to do is file an issue into your upstream repository and release-bot takes care of the rest. But let’s not get ahead of ourselves. First, let’s look at what needs to be set up for this automation to happen. I’ve chosen the **meta-test-family** upstream repository as an example.
-
-### Configuration files for release-bot
-
-There are two configuration files for release-bot: **conf.yaml** and **release-conf.yaml**.
-
-#### conf.yaml
-
-**conf.yaml** must be accessible during bot initialization; it specifies how to access the GitHub repository. To show that, I have created a new git repository named **mtf-release-bot** , which contains **conf.yaml** and the other secret files.
-
-```
-repository_name: name
-repository_owner: owner
-# https://help.github.com/articles/creating-a-personal-access-token-for-the-command-line/
-github_token: xxxxxxxxxxxxxxxxxxxxxxxxx
-# time in seconds during checks for new releases
-refresh_interval: 180
-```
-
-For the meta-test-family case, the configuration file looks like this:
-
-```
-repository_name: meta-test-family
-repository_owner: fedora-modularity
-github_token: xxxxxxxxxxxxxxxxxxxxx
-refresh_interval: 180
-```
-
-#### release-conf.yaml
-
-**release-conf.yaml** must be stored [in the repository itself][4]; it specifies how to do GitHub/PyPI/Fedora releases.
-
-```
-# list of major python versions that bot will build separate wheels for
-python_versions:
- - 2
- - 3
-# optional:
-changelog:
- - Example changelog entry
- - Another changelog entry
-# this is info for the authorship of the changelog
-# if this is not set, person who merged the release PR will be used as an author
-author_name: John Doe
-author_email: johndoe@example.com
-# whether to release on fedora. False by default
-fedora: false
-# list of fedora branches bot should release on. Master is always implied
-fedora_branches:
- - f27
-```
-
-For the meta-test-family case, the configuration file looks like this:
-
-```
-python_versions:
-- 2
-fedora: true
-fedora_branches:
-- f29
-- f28
-trigger_on_issue: true
-```
-
-#### PyPI configuration file
-
-The file **.pypirc** , stored in your **mtf-release-bot** private repository, is needed for uploading the new package version into PyPI:
-
-```
-[pypi]
-username = phracek
-password = xxxxxxxx
-```
-
-Private SSH key, **id_rsa** , that you configured in [FAS][5].
-
-The final structure of the git repository, with **conf.yaml** and the others, looks like this:
-
-```
-$ ls -la
-total 24
-drwxrwxr-x 3 phracek phracek 4096 Sep 24 12:38 .
-drwxrwxr-x. 20 phracek phracek 4096 Sep 24 12:37 ..
--rw-rw-r-- 1 phracek phracek 199 Sep 24 12:26 conf.yaml
-drwxrwxr-x 8 phracek phracek 4096 Sep 24 12:38 .git
--rw-rw-r-- 1 phracek phracek 3243 Sep 24 12:38 id_rsa
--rw------- 1 phracek phracek 78 Sep 24 12:28 .pypirc
-```
-
-### Requirements
-
-**requirements.txt** with both versions of pip. You must also set up your PyPI login details in **$HOME/.pypirc** , as described in the `-k/–keytab`. Also, **fedpkg** requires that you have an SSH key in your keyring that you uploaded to FAS.
-
-### How to deploy release-bot
-
-Releasing to PyPI requires the [wheel package][6] for both Python 2 and Python 3, so installwith both versions of pip. You must also set up your PyPI login details in, as described in the [PyPI documentation][7] . If you are releasing to Fedora, you must have an active [Kerberos][8] ticket while the bot runs, or specify the path to the Kerberos keytab file with. Also,requires that you have an SSH key in your keyring that you uploaded to FAS.
-
-There are two ways to use release-bot: as a Docker image or as an OpenShift template.
-
-#### Docker image
-
-Let’s build the image using the `s2i` command:
-
-```
-$ s2i build $CONFIGURATION_REPOSITORY_URL usercont/release-bot app-name
-```
-
-where `$CONFIGURATION_REPOSITORY_URL` is a reference to the GitHub repository, like _https:// <GIT_LAB_PATH>/mtf-release-conf._
-
-Let’s look at Docker images:
-
-```
-$ docker images
-REPOSITORY TAG IMAGE ID CREATED SIZE
-mtf-release-bot latest 08897871e65e 6 minutes ago 705 MB
-docker.io/usercont/release-bot latest 5b34aa670639 9 days ago 705 MB
-```
-
-Now let’s try to run the **mtf-release-bot** image with this command:
-
-```
-$ docker run mtf-release-bot
----> Setting up ssh key...
-Agent pid 12
-Identity added: ./.ssh/id_rsa (./.ssh/id_rsa)
-12:21:18.982 configuration.py DEBUG Loaded configuration for fedora-modularity/meta-test-family
-12:21:18.982 releasebot.py INFO release-bot v0.4.1 reporting for duty!
-12:21:18.982 github.py DEBUG Fetching release-conf.yaml
-12:21:37.611 releasebot.py DEBUG No merged release PR found
-12:21:38.282 releasebot.py INFO Found new release issue with version: 0.8.5
-12:21:42.565 releasebot.py DEBUG No more open issues found
-12:21:43.190 releasebot.py INFO Making a new PR for release of version 0.8.5 based on an issue.
-12:21:46.709 utils.py DEBUG ['git', 'clone', 'https://github.com/fedora-modularity/meta-test-family.git', '.']
-
-12:21:47.401 github.py DEBUG {"message":"Branch not found","documentation_url":"https://developer.github.com/v3/repos/branches/#get-branch"}
-12:21:47.994 utils.py DEBUG ['git', 'config', 'user.email', 'the.conu.bot@gmail.com']
-
-12:21:47.996 utils.py DEBUG ['git', 'config', 'user.name', 'Release bot']
-
-12:21:48.009 utils.py DEBUG ['git', 'checkout', '-b', '0.8.5-release']
-
-12:21:48.014 utils.py ERROR No version files found. Aborting version update.
-12:21:48.014 utils.py WARNING No CHANGELOG.md present in repository
-[Errno 2] No such file or directory: '/tmp/tmpmbvb05jq/CHANGELOG.md'
-12:21:48.020 utils.py DEBUG ['git', 'commit', '--allow-empty', '-m', '0.8.5 release']
-[0.8.5-release 7ee62c6] 0.8.5 release
-
-12:21:51.342 utils.py DEBUG ['git', 'push', 'origin', '0.8.5-release']
-
-12:21:51.905 github.py DEBUG No open PR's found
-12:21:51.905 github.py DEBUG Attempting a PR for 0.8.5-release branch
-12:21:53.215 github.py INFO Created PR: https://github.com/fedora-modularity/meta-test-family/pull/243
-12:21:53.216 releasebot.py INFO I just made a PR request for a release version 0.8.5
-12:21:54.154 github.py DEBUG Comment added to PR: I just made a PR request for a release version 0.8.5
- Here's a [link to the PR](https://github.com/fedora-modularity/meta-test-family/pull/243)
-12:21:54.154 github.py DEBUG Attempting to close issue #242
-12:21:54.992 github.py DEBUG Closed issue #242
-```
-
-As you can see, release-bot automatically closed the following issue, requesting a new upstream release of the meta-test-family: [https://github.com/fedora-modularity/meta-test-family/issues/243][9].
-
-In addition, release-bot created a new PR with changelog. You can update the PR—for example, squash changelog—and once you merge it, it will automatically release to GitHub, and PyPI and Fedora will start.
-
-You now have a working solution to easily release upstream versions of your package into PyPi and Fedora.
-
-#### OpenShift template
-
-Another option to deliver automated releases using release-bot is to deploy it in OpenShift.
-
-The OpenShift template looks as follows:
-
-```
-kind: Template
-apiVersion: v1
-metadata:
- name: release-bot
- annotations:
- description: S2I Relase-bot image builder
- tags: release-bot s2i
- iconClass: icon-python
-labels:
- template: release-bot
- role: releasebot_application_builder
-objects:
- - kind : ImageStream
- apiVersion : v1
- metadata :
- name : ${APP_NAME}
- labels :
- appid : release-bot-${APP_NAME}
- - kind : ImageStream
- apiVersion : v1
- metadata :
- name : ${APP_NAME}-s2i
- labels :
- appid : release-bot-${APP_NAME}
- spec :
- tags :
- - name : latest
- from :
- kind : DockerImage
- name : usercont/release-bot:latest
- #importPolicy:
- # scheduled: true
- - kind : BuildConfig
- apiVersion : v1
- metadata :
- name : ${APP_NAME}
- labels :
- appid : release-bot-${APP_NAME}
- spec :
- triggers :
- - type : ConfigChange
- - type : ImageChange
- source :
- type : Git
- git :
- uri : ${CONFIGURATION_REPOSITORY}
- contextDir : ${CONFIGURATION_REPOSITORY}
- sourceSecret :
- name : release-bot-secret
- strategy :
- type : Source
- sourceStrategy :
- from :
- kind : ImageStreamTag
- name : ${APP_NAME}-s2i:latest
- output :
- to :
- kind : ImageStreamTag
- name : ${APP_NAME}:latest
- - kind : DeploymentConfig
- apiVersion : v1
- metadata :
- name: ${APP_NAME}
- labels :
- appid : release-bot-${APP_NAME}
- spec :
- strategy :
- type : Rolling
- triggers :
- - type : ConfigChange
- - type : ImageChange
- imageChangeParams :
- automatic : true
- containerNames :
- - ${APP_NAME}
- from :
- kind : ImageStreamTag
- name : ${APP_NAME}:latest
- replicas : 1
- selector :
- deploymentconfig : ${APP_NAME}
- template :
- metadata :
- labels :
- appid: release-bot-${APP_NAME}
- deploymentconfig : ${APP_NAME}
- spec :
- containers :
- - name : ${APP_NAME}
- image : ${APP_NAME}:latest
- resources:
- requests:
- memory: "64Mi"
- cpu: "50m"
- limits:
- memory: "128Mi"
- cpu: "100m"
-
-parameters :
- - name : APP_NAME
- description : Name of application
- value :
- required : true
- - name : CONFIGURATION_REPOSITORY
- description : Git repository with configuration
- value :
- required : true
-```
-
-The easiest way to deploy the **mtf-release-bot** repository with secret files into OpenShift is to use the following two commands:
-
-```
-$ curl -sLO https://github.com/user-cont/release-bot/raw/master/openshift-template.yml
-```
-
-In your OpenShift instance, deploy the template by running the following command:
-
-```
-oc process -p APP_NAME="mtf-release-bot" -p CONFIGURATION_REPOSITORY="git@<git_lab_path>/mtf-release-conf.git" -f openshift-template.yml | oc apply
-```
-
-### Summary
-
-See the [example pull request][10] in the meta-test-family upstream repository, where you'll find information about what release-bot released. Once you get to this point, you can see that release-bot is able to push new upstream versions into GitHub, PyPI, and Fedora without heavy user intervention. It automates all the steps so you don’t need to manually upload and build new upstream versions of your package.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/upstream-releases-pypi-fedora-release-bot
-
-作者:[Petr Stone Hracek][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/phracek
-[b]: https://github.com/lujun9972
-[1]: https://pypi.org/
-[2]: https://getfedora.org/
-[3]: https://github.com/user-cont/release-bot
-[4]: https://github.com/fedora-modularity/meta-test-family
-[5]: https://admin.fedoraproject.org/accounts/
-[6]: https://pypi.org/project/wheel/
-[7]: https://packaging.python.org/tutorials/distributing-packages/#create-an-account
-[8]: https://web.mit.edu/kerberos/
-[9]: https://github.com/fedora-modularity/meta-test-family/issues/238
-[10]: https://github.com/fedora-modularity/meta-test-family/pull/243
diff --git a/sources/tech/20181018 4 open source alternatives to Microsoft Access.md b/sources/tech/20181018 4 open source alternatives to Microsoft Access.md
deleted file mode 100644
index 19f78e81d6..0000000000
--- a/sources/tech/20181018 4 open source alternatives to Microsoft Access.md
+++ /dev/null
@@ -1,94 +0,0 @@
-4 open source alternatives to Microsoft Access
-======
-Build simple business applications and keep track of your data with these worthy open source alternatives.
-
-
-When small businesses, community organizations, and similar-sized groups realize they need software to manage their data, they think first of Microsoft Access. That may be the right choice if you're already paying for a Microsoft Office subscription or don't care that it's proprietary. But it's far from your only option—whether you prefer to use open source alternatives from a philosophical standpoint or you don't have the big budget for a Microsoft Office subscription—there are several open source database applications that are worthy alternatives to proprietary software like Microsoft Access or Apple FileMaker.
-
-If that sounds like you, here are four open source database tools for your consideration.
-
-### LibreOffice Base
-
-
-In case it's not obvious from its name, [Base][1] is part of the [LibreOffice][2] productivity suite, which includes Writer (word processing), Calc (spreadsheet), Impress (presentations), Draw (graphics), Charts (chart creation), and Math (formulas). As such, Base integrates with the other LibreOffice applications, much like Access does with the Microsoft Office suite. This means you can import and export data from Base into the suite's other applications to create financial reports, mail merges, charts, and more.
-
-Base includes drivers that natively support multi-user database engines, including the open source MySQL, MariaDB, and PostgreSQL; Access; and other JDBC and ODBC-compliant databases. Built-in wizards and table definitions make it easy for new users to quickly get started building tables, writing queries, and creating forms and reports (such as invoices, sales reports, and customer lists). To learn more, consult the comprehensive [user manual][3] and dive into the [user forums][4]. If you're still stuck, you can find a [certified][5] support professional to help you out.
-
-Installers are available for Linux, MacOS, Windows, and Android. LibreOffice is available under the [Mozilla Public License v2][6]; if you'd like to join the large contributor community and help improve the software, visit the [Get Involved][7] section of LibreOffice's website.
-
-### DB Browser for SQLite
-
-
-
-[DB Browser for SQLite][8] enables users to create and use SQLite database files without having to know complex SQL commands. This, plus its spreadsheet-like interface and pre-built wizards, make it a great option for new database users to get going without much background knowledge.
-
-Although the application has gone through several name changes—from the original Arca Database Browser to the SQLite Database Browser and finally to the current name (in 2014, to avoid confusion with SQLite), it's stayed true to its goal of being easy for users to operate.
-
-Its wizards enable users to easily create and modify database files, tables, indexes, records, etc.; import and export data to common file formats; create and issue queries and searches; and more. Installers are available for Windows, MacOS, and a variety of Linux versions, and its [wiki on GitHub][9] offers a wealth of information for users and developers.
-
-DB Browser for SQLite is [bi-licensed][10] under the Mozilla Public License Version 2 and the GNU General Public License Version 3 or later, and you can download the source code from the project's website.
-
-### Kexi
-
-
-As the database application in the [Calligra Suite][11] productivity software for the KDE desktop, [Kexi][12] integrates with the other applications in the suite, including Words (word processing), Sheets (spreadsheet), Stage (presentations), and Plan (project management).
-
-As a full member of the [KDE][13] project, Kexi is purpose-built for KDE Plasma, but it's not limited to KDE users: Linux, BSD, and Unix users running GNOME can run the database, as can MacOS and Windows users.
-
-Kexi's website says its development was "motivated by the lack of rapid application development ([RAD][14]) tools for database systems that are sufficiently powerful, inexpensive, open standards driven, and portable across many operating systems and hardware platforms." It has all the standard features you'd expect: designing databases, storing data, doing queries, processing data, and so forth.
-
-Kexi is available under the [LGPL][15] open source license and you can download its [source code][16] from its development wiki. If you'd like to learn more, take a look at its [user handbook][17], [forums][18], and [userbase wiki][17].
-
-### nuBuilder Forte
-
-
-[NuBuilder Forte][19] is designed to be as easy as possible for people to use. It's a browser-based tool for developing web-based database applications.
-
-Its clean interface and low-code tools (including support for drag-and-drop) allow users to create and use a database quickly. As a fully web-based application, data is accessible anywhere from a browser. Everything is stored in MySQL and can be backed up in one database file.
-
-It uses industry-standard coding languages—HTML, PHP, JavaScript, and SQL—making it easy for developers to get started also.
-
-Help is available in [videos][20] and other [documentation][21] for topics including creating forms, doing searches, building reports, and more.
-
-nuBuilder Forte is licensed under [GPLv3.0][22] and you can download it on [GitHub][23]. You can learn more by consulting the [nuBuilder Forum][24] or watching its [demo][25] video.
-
-Do you have a favorite open source database tool for building simple projects with little or no coding skill required? If so, please share in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/alternatives/access
-
-作者:[Opensource.com][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com
-[b]: https://github.com/lujun9972
-[1]: https://www.libreoffice.org/discover/base/
-[2]: https://www.libreoffice.org/
-[3]: https://documentation.libreoffice.org/en/english-documentation/base/
-[4]: http://document-foundation-mail-archive.969070.n3.nabble.com/Users-f1639498.html
-[5]: https://www.libreoffice.org/get-help/professional-support/
-[6]: https://www.libreoffice.org/download/license/
-[7]: https://www.libreoffice.org/community/get-involved/
-[8]: http://sqlitebrowser.org/
-[9]: https://github.com/sqlitebrowser/sqlitebrowser/wiki
-[10]: https://github.com/sqlitebrowser/sqlitebrowser/blob/master/LICENSE
-[11]: https://www.calligra.org/
-[12]: https://www.calligra.org/kexi/
-[13]: https://www.kde.org/
-[14]: http://en.wikipedia.org/wiki/Rapid_application_development
-[15]: http://kexi-project.org/wiki/wikiview/index.php@KexiLicense.html
-[16]: http://kexi-project.org/wiki/wikiview/index.php@Download.html
-[17]: https://userbase.kde.org/Kexi/Handbook
-[18]: http://forum.kde.org/kexi
-[19]: https://www.nubuilder.com/
-[20]: https://www.nubuilder.com/videos
-[21]: https://www.nubuilder.com/wiki
-[22]: https://github.com/nuSoftware/nuBuilder4/blob/master/LICENSE.txt
-[23]: https://github.com/nuSoftware/nuBuilder4
-[24]: https://forums.nubuilder.com/viewforum.php?f=18&sid=7036bccdc08ba0da73181bc72cd63c62
-[25]: https://www.youtube.com/watch?v=tdh9ILCUAco&feature=youtu.be
diff --git a/sources/tech/20181018 TimelineJS- An interactive, JavaScript timeline building tool.md b/sources/tech/20181018 TimelineJS- An interactive, JavaScript timeline building tool.md
deleted file mode 100644
index 1f45811416..0000000000
--- a/sources/tech/20181018 TimelineJS- An interactive, JavaScript timeline building tool.md
+++ /dev/null
@@ -1,82 +0,0 @@
-TimelineJS: An interactive, JavaScript timeline building tool
-======
-Learn how to tell a story with TimelineJS.
-
-
-[TimelineJS 3][1] is an open source storytelling tool that anyone can use to create visually rich, interactive timelines to post on their websites. To get started, simply click “Make a Timeline” on the homepage and follow the easy [step-by-step instructions][1].
-
-TimelineJS was developed at Northwestern University’s KnightLab in Evanston, Illinois. KnightLab is a community of designers, developers, students, and educators who work on experiments designed to push journalism into new spaces. TimelineJS has been used by more than 250,000 people, according to its website, to tell stories viewed millions of times. And TimelineJS3 is available in more than 60 languages.
-
-Joe Germuska, the “chief nerd” who runs KnightLab’s technology, professional staff, and student fellows, explains, "TimelineJS was originally developed by Northwestern professor Zach Wise. He assigned his students a task to tell stories in a timeline format, only to find that none of the free available tools were as good as he thought they could be. KnightLab funded some of his time to develop the tool in 2012. Near the end of that year, I joined the lab, and among my early tasks was to bring TimelineJS in as a fully supported project of the lab. The next year, I helped Zach with a rewrite to address some issues. Along the way, many students have contributed. Interestingly, a group of students from Victoria University in Wellington, New Zealand, worked on TimelineJS (and some of our other tools) as part of a class project in 2016."
-
-"In general, we designed TimelineJS to make it easy for non-technical people to tell rich, dynamic stories on the web in the context of events in time.”
-
-Users create timelines by adding content into a Google spreadsheet. KnightLab provides a downloadable template that can be edited to create custom timelines. Experts can use their JSON skills to [create custom installations][2] while keeping TimelineJS’s core functionality.
-
-This easy-to-follow [Vimeo video][3] shows how to get started with TimelineJS, and I used it myself to create my first timeline.
-
-### Open sourcing the Adirondacks
-
-Reid Larson, research and scholarly communication librarian at Hamilton College in Clinton, New York, began searching for ways to combine open data and visualization to chronicle the history of Essex County (a county in northern New York that makes up part of the Adirondacks), in the 1990s, when he was the director of the Essex County Historical Society/Adirondack History Center Museum.
-
-"I wanted to take all the open data available on the history of Essex County and be able to present it to people visually. Most importantly, I wanted to make sure that the data would be available for use even if the applications used to present it are no longer available or supported," Larson explains.
-
-Now at Hamilton College, Larson has found TimelineJS to be the ideal open source program to do just what he wanted: Chronicle and present a visually appealing timeline of selected places.
-
-"It was a professor who was working on a project that required a solution such as Timeline, and after researching the possibilities, I started using Timeline for that project and subsequent projects," Larson adds.
-
-TimelineJS can be used via a web browser, or the source code can be downloaded from [GitHub][4] for local use.
-
-"I’ve been using the browser version, but I push it to the limits to see how far I can go with it, such as adding my own HTML tags. I want to fully understand it so that I can educate the students and faculty at Hamilton College on its uses," Larson says.
-
-### An open source Eagle Scout project
-
-Not only has Larson used TimelineJS for collegiate purposes, but his son, Erik, created an [interactive historical website][5] for his Eagle Scout project in 2017 using WordPress. The project is a chronicle of places in Waterville, New York, just south of Clinton, in Oneida County. Erik explains that he wants what he started to expand beyond the 36 places in Waterville. "The site is an experiment in online community building," Erik’s website reads.
-
-Larson says he did a lot of the “tech work” on the project so that Erik could concentrate on content. The site was created with [Omeka][6], an open source web publishing platform for sharing digital collections and creating media-rich online exhibits, and [Curatescape][7], a framework for the open source Omeka CMS.
-
-Larson explains that a key feature of TimelineJS is that it uses Google Sheets to store and organize the data used in the timeline. "Google Sheets is a good structure for organizing data simply, and that data will be available even if TimelineJS becomes unavailable in the future."
-
-Larson says that he prefers using [ArcGIS][8] over KnightLab’s StoryMap because it uses spreadsheets to store content, whereas [StoryMap][9] does not. Larson is looking forward to integrating augmented reality into his projects in the future.
-
-### Create your own open source timeline
-
-I plan on using TimelineJS to create interactive content for the Development and Alumni Relations department at Clarkson University, where I am the development communications specialist. To practice with working with it, I created [a simple timeline][10] of the articles I’ve written for [Opensource.com][11]:
-
-
-
-
-
-
-As Reid Larson stated, it is very easy to use and the results are quite satisfactory. I was able to get a working timeline created and posted to my WordPress site in a matter of minutes. I used media that I had already uploaded to my Media Library in WordPress and simply copied the image address. I typed in the dates, locations, and information in the other cells and used “publish to web” under “file” in the Google spreadsheet. That produced a link and embed code. I created a new post in my WordPress site and pasted in the embed code, and the timeline was live and working.
-
-Of course, there is more customization I need to do, but I was able to get it working quickly and easily, much as Reid said it would.
-
-I will continue experimenting with TimelineJS on my own site, and when I get more comfortable with it, I’ll use it for my professional projects and try out the other apps that KnightLab has created for interactive, visually appealing storytelling.
-
-What might you use TimelineJS for?
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/create-interactive-timelines-open-source-tool
-
-作者:[Jeff Macharyas][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/rikki-endsley
-[b]: https://github.com/lujun9972
-[1]: https://timeline.knightlab.com/
-[2]: https://timeline.knightlab.com/docs/json-format.html
-[3]: https://vimeo.com/knightlab/timelinejs
-[4]: https://github.com/NUKnightLab/TimelineJS3
-[5]: http://nysplaces.com/
-[6]: https://github.com/omeka
-[7]: https://github.com/CPHDH/Curatescape
-[8]: https://www.arcgis.com/index.html
-[9]: https://storymap.knightlab.com/
-[10]: https://macharyas.com/index.php/2018/10/06/timeline/
-[11]: http://opensource.com/
diff --git a/sources/tech/20181023 How to Check HP iLO Firmware Version from Linux Command Line.md b/sources/tech/20181023 How to Check HP iLO Firmware Version from Linux Command Line.md
deleted file mode 100644
index 5dc19ed73c..0000000000
--- a/sources/tech/20181023 How to Check HP iLO Firmware Version from Linux Command Line.md
+++ /dev/null
@@ -1,131 +0,0 @@
-How to Check HP iLO Firmware Version from Linux Command Line
-======
-There are many utilities are available in Linux to get a [hardware information][1].
-
-Each tool has their own unique feature which help us to gather the required information.
-
-We have already wrote many articles about this, the hardware tools are Dmidecode, hwinfo, lshw, inxi, lspci, lssci, lsusb, lsblk, neofetch, screenfetch, etc.,
-
-Today we are going to discuss about the same topic. I will tell you, how to check HP iLO firmware version through Linux command line.
-
-Also read a following articles which is related to Linux hardware.
-
-**Suggested Read :**
-**(#)** [LSHW (Hardware Lister) – A Nifty Tool To Get A Hardware Information On Linux][2]
-**(#)** [inxi – A Great Tool to Check Hardware Information on Linux][3]
-**(#)** [Dmidecode – Easy Way To Get Linux System Hardware Information][4]
-**(#)** [Neofetch – Shows Linux System Information With ASCII Distribution Logo][5]
-**(#)** [ScreenFetch – Fetch Linux System Information on Terminal with Distribution ASCII art logo][6]
-**(#)** [16 Methods To Check If A Linux System Is Physical or Virtual Machine][7]
-**(#)** [hwinfo (Hardware Info) – A Nifty Tool To Detect System Hardware Information On Linux][8]
-**(#)** [How To Find WWN, WWNN and WWPN Number Of HBA Card In Linux][9]
-**(#)** [How To Check System Hardware Manufacturer, Model And Serial Number In Linux][1]
-**(#)** [How To Use lspci, lsscsi, lsusb, And lsblk To Get Linux System Devices Information][10]
-
-### What is iLO?
-
-iLO stands for Integrated Lights-Out is a proprietary embedded server management technology by Hewlett-Packard which provides out-of-band management facilities.
-
-I can say this in simple term, it’s a dedicated device management channel which allow users to manage and monitor the device remotely regardless of whether the machine is powered on, or whether an operating system is installed or functional.
-
-It allows a system administrator to monitor all devices such as CPU, RAM, Hardware RAID, fan speed, power voltages, chassis intrusion, firmware (BIOS or UEFI), also manage remote terminals (KVM over IP), remote reboot, shutdown, powering on, etc.
-
-The below list of lights out management (LOM) technology offered by other vendors.
-
- * **`iLO:`** Integrated Lights-Out by HP
- * **`IMM:`** Integrated Management Module by IBM
- * **`iDRAC:`** Integrated Dell Remote Access Controllers by Dell
- * **`IPMI:`** Intelligent Platform Management Interface – General Standard, it’s used on Supermicro hardware
- * **`AMT:`** Intel Active Management Technology by Intel
- * **`CIMC:`** Cisco Integrated Management Controller by Cisco
-
-
-
-The below table will give the details about iLO version and supported hardware’s.
-
- * **`iLO:`** ProLiant G2, G3, G4, and G6 servers, model numbers under 300
- * **`iLO 2:`** ProLiant G5 and G6 servers, model numbers 300 and higher
- * **`iLO 3:`** ProLiant G7 servers
- * **`iLO 4:`** ProLiant Gen8 and Gen9 servers
- * **`iLO 5:`** ProLiant Gen10 servers
-
-
-
-There are three easy ways to check HP iLO firmware version in Linux, Here we are going to show you one by one.
-
-### Method-1: Using Dmidcode Command
-
-[Dmidecode][4] is a tool which reads a computer’s DMI (stands for Desktop Management Interface) (some say SMBIOS – stands for System Management BIOS) table contents and display system hardware information in a human-readable format.
-
-This table contains a description of the system’s hardware components, as well as other useful information such as serial number, Manufacturer information, Release Date, and BIOS revision, etc,.,
-
-The DMI table doesn’t only describe what the system is currently made of, it also can report the possible evolution’s (such as the fastest supported CPU or the maximal amount of memory supported). This will help you to analyze your hardware capability like whether it’s support latest application version or not?
-
-As you run it, dmidecode will try to locate the DMI table. If it succeeds, it will then parse this table and display a list of records which you expect.
-
-First, learn about DMI Types and its keywords, so that we can play nicely without any trouble otherwise we can’t.
-
-```
-# dmidecode | grep "Firmware Revision"
- Firmware Revision: 2.40
-```
-
-### Method-2: Using HPONCFG Utility
-
-HPONCFG is an online configuration tool used to set up and reconfigure iLO without requiring a reboot of the server operating system. The utility runs in a command-line mode and must be executed from an operating system command line on the local server. HPONCFG enables you to initially configure features exposed through the RBSU or iLO.
-
-Before using HPONCFG, the iLO Management Interface Driver must be loaded on the server. HPONCFG displays a warning if the driver is not installed.
-
-To install this, visit the [HP website][11] and get the latest hponcfg package by searching the following keyword (sample search key word for iLO 4 “HPE Integrated Lights-Out 4 (iLO 4)”). In that you need to click “HP Lights-Out Online Configuration Utility for Linux (AMD64/EM64T)” and download the package.
-
-```
-# rpm -ivh /tmp/hponcfg-5.3.0-0.x86_64.rpm
-```
-
-Use hponcfg command to get the information.
-
-```
-# hponcfg | grep Firmware
-Firmware Revision = 2.40 Device type = iLO 4 Driver name = hpilo
-```
-
-### Method-3: Using CURL Command
-
-We can use cURL command to get some of the information in XML format, for HP iLO, iLO 2, iLO 3, iLO 4 and iLO 5.
-
-Using cURL command we can get the iLO firmware version without to login to the server or console.
-
-Make sure you have to use right iLO management IP instead of us to get the details. I have removed all the unnecessary details from the below output for better clarification.
-
-```
-# curl -k https://10.2.0.101/xmldata?item=All
-
-ProLiant DL380p G8
-Integrated Lights-Out 4 (iLO 4)
-2.40
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-check-hp-ilo-firmware-version-from-linux-command-line/
-
-作者:[Prakash Subramanian][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/prakash/
-[b]: https://github.com/lujun9972
-[1]: https://www.2daygeek.com/how-to-check-system-hardware-manufacturer-model-and-serial-number-in-linux/
-[2]: https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
-[3]: https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
-[4]: https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
-[5]: https://www.2daygeek.com/neofetch-display-linux-systems-information-ascii-distribution-logo-terminal/
-[6]: https://www.2daygeek.com/install-screenfetch-to-fetch-linux-system-information-on-terminal-with-distribution-ascii-art-logo/
-[7]: https://www.2daygeek.com/check-linux-system-physical-virtual-machine-virtualization-technology/
-[8]: https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
-[9]: https://www.2daygeek.com/how-to-find-wwn-wwnn-and-wwpn-number-of-hba-card-in-linux/
-[10]: https://www.2daygeek.com/check-system-hardware-devices-bus-information-lspci-lsscsi-lsusb-lsblk-linux/
-[11]: https://support.hpe.com/hpesc/public/home
diff --git a/sources/tech/20181031 Working with data streams on the Linux command line.md b/sources/tech/20181031 Working with data streams on the Linux command line.md
deleted file mode 100644
index 87403558d7..0000000000
--- a/sources/tech/20181031 Working with data streams on the Linux command line.md
+++ /dev/null
@@ -1,302 +0,0 @@
-Working with data streams on the Linux command line
-======
-Learn to connect data streams from one utility to another using STDIO.
-
-
-**Author’s note:** Much of the content in this article is excerpted, with some significant edits to fit the Opensource.com article format, from Chapter 3: Data Streams, of my new book, [The Linux Philosophy for SysAdmins][1].
-
-Everything in Linux revolves around streams of data—particularly text streams. Data streams are the raw materials upon which the [GNU Utilities][2], the Linux core utilities, and many other command-line tools perform their work.
-
-As its name implies, a data stream is a stream of data—especially text data—being passed from one file, device, or program to another using STDIO. This chapter introduces the use of pipes to connect streams of data from one utility program to another using STDIO. You will learn that the function of these programs is to transform the data in some manner. You will also learn about the use of redirection to redirect the data to a file.
-
-I use the term “transform” in conjunction with these programs because the primary task of each is to transform the incoming data from STDIO in a specific way as intended by the sysadmin and to send the transformed data to STDOUT for possible use by another transformer program or redirection to a file.
-
-The standard term, “filters,” implies something with which I don’t agree. By definition, a filter is a device or a tool that removes something, such as an air filter removes airborne contaminants so that the internal combustion engine of your automobile does not grind itself to death on those particulates. In my high school and college chemistry classes, filter paper was used to remove particulates from a liquid. The air filter in my home HVAC system removes particulates that I don’t want to breathe.
-
-Although they do sometimes filter out unwanted data from a stream, I much prefer the term “transformers” because these utilities do so much more. They can add data to a stream, modify the data in some amazing ways, sort it, rearrange the data in each line, perform operations based on the contents of the data stream, and so much more. Feel free to use whichever term you prefer, but I prefer transformers. I expect that I am alone in this.
-
-Data streams can be manipulated by inserting transformers into the stream using pipes. Each transformer program is used by the sysadmin to perform some operation on the data in the stream, thus changing its contents in some manner. Redirection can then be used at the end of the pipeline to direct the data stream to a file. As mentioned, that file could be an actual data file on the hard drive, or a device file such as a drive partition, a printer, a terminal, a pseudo-terminal, or any other device connected to a computer.
-
-The ability to manipulate these data streams using these small yet powerful transformer programs is central to the power of the Linux command-line interface. Many of the core utilities are transformer programs and use STDIO.
-
-In the Unix and Linux worlds, a stream is a flow of text data that originates at some source; the stream may flow to one or more programs that transform it in some way, and then it may be stored in a file or displayed in a terminal session. As a sysadmin, your job is intimately associated with manipulating the creation and flow of these data streams. In this post, we will explore data streams—what they are, how to create them, and a little bit about how to use them.
-
-### Text streams—a universal interface
-
-The use of Standard Input/Output (STDIO) for program input and output is a key foundation of the Linux way of doing things. STDIO was first developed for Unix and has found its way into most other operating systems since then, including DOS, Windows, and Linux.
-
-> “This is the Unix philosophy: Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.”
->
-> — Doug McIlroy, Basics of the Unix Philosophy
-
-### STDIO
-
-STDIO was developed by Ken Thompson as a part of the infrastructure required to implement pipes on early versions of Unix. Programs that implement STDIO use standardized file handles for input and output rather than files that are stored on a disk or other recording media. STDIO is best described as a buffered data stream, and its primary function is to stream data from the output of one program, file, or device to the input of another program, file, or device.
-
-There are three STDIO data streams, each of which is automatically opened as a file at the startup of a program—well, those programs that use STDIO. Each STDIO data stream is associated with a file handle, which is just a set of metadata that describes the attributes of the file. File handles 0, 1, and 2 are explicitly defined by convention and long practice as STDIN, STDOUT, and STDERR, respectively.
-
-**STDIN, File handle 0** , is standard input which is usually input from the keyboard. STDIN can be redirected from any file, including device files, instead of the keyboard. It is not common to need to redirect STDIN, but it can be done.
-
-**STDOUT, File handle 1** , is standard output which sends the data stream to the display by default. It is common to redirect STDOUT to a file or to pipe it to another program for further processing.
-
-**STDERR, File handle 2**. The data stream for STDERR is also usually sent to the display.
-
-If STDOUT is redirected to a file, STDERR continues to be displayed on the screen. This ensures that when the data stream itself is not displayed on the terminal, that STDERR is, thus ensuring that the user will see any errors resulting from execution of the program. STDERR can also be redirected to the same or passed on to the next transformer program in a pipeline.
-
-STDIO is implemented as a C library, **stdio.h** , which can be included in the source code of programs so that it can be compiled into the resulting executable.
-
-### Simple streams
-
-You can perform the following experiments safely in the **/tmp** directory of your Linux host. As the root user, make **/tmp** the PWD, create a test directory, and then make the new directory the PWD.
-
-```
-# cd /tmp ; mkdir test ; cd test
-```
-
-Enter and run the following command line program to create some files with content on the drive. We use the `dmesg` command simply to provide data for the files to contain. The contents don’t matter as much as just the fact that each file has some content.
-
-```
-# for I in 0 1 2 3 4 5 6 7 8 9 ; do dmesg > file$I.txt ; done
-```
-
-Verify that there are now at least 10 files in **/tmp/** with the names **file0.txt** through **file9.txt**.
-
-```
-# ll
-total 1320
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file0.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file1.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file2.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file3.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file4.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file5.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file6.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file7.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file8.txt
--rw-r--r-- 1 root root 131402 Oct 17 15:50 file9.txt
-```
-
-We have generated data streams using the `dmesg` command, which was redirected to a series of files. Most of the core utilities use STDIO as their output stream and those that generate data streams, rather than acting to transform the data stream in some way, can be used to create the data streams that we will use for our experiments. Data streams can be as short as one line or even a single character, and as long as needed.
-
-### Exploring the hard drive
-
-It is now time to do a little exploring. In this experiment, we will look at some of the filesystem structures.
-
-Let’s start with something simple. You should be at least somewhat familiar with the `dd` command. Officially known as “disk dump,” many sysadmins call it “disk destroyer” for good reason. Many of us have inadvertently destroyed the contents of an entire hard drive or partition using the `dd` command. That is why we will hang out in the **/tmp/test** directory to perform some of these experiments.
-
-Despite its reputation, `dd` can be quite useful in exploring various types of storage media, hard drives, and partitions. We will also use it as a tool to explore other aspects of Linux.
-
-Log into a terminal session as root if you are not already. We first need to determine the device special file for your hard drive using the `lsblk` command.
-
-```
-[root@studentvm1 test]# lsblk -i
-NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
-sda 8:0 0 60G 0 disk
-|-sda1 8:1 0 1G 0 part /boot
-`-sda2 8:2 0 59G 0 part
- |-fedora_studentvm1-pool00_tmeta 253:0 0 4M 0 lvm
- | `-fedora_studentvm1-pool00-tpool 253:2 0 2G 0 lvm
- | |-fedora_studentvm1-root 253:3 0 2G 0 lvm /
- | `-fedora_studentvm1-pool00 253:6 0 2G 0 lvm
- |-fedora_studentvm1-pool00_tdata 253:1 0 2G 0 lvm
- | `-fedora_studentvm1-pool00-tpool 253:2 0 2G 0 lvm
- | |-fedora_studentvm1-root 253:3 0 2G 0 lvm /
- | `-fedora_studentvm1-pool00 253:6 0 2G 0 lvm
- |-fedora_studentvm1-swap 253:4 0 10G 0 lvm [SWAP]
- |-fedora_studentvm1-usr 253:5 0 15G 0 lvm /usr
- |-fedora_studentvm1-home 253:7 0 2G 0 lvm /home
- |-fedora_studentvm1-var 253:8 0 10G 0 lvm /var
- `-fedora_studentvm1-tmp 253:9 0 5G 0 lvm /tmp
-sr0 11:0 1 1024M 0 rom
-```
-
-We can see from this that there is only one hard drive on this host, that the device special file associated with it is **/dev/sda** , and that it has two partitions. The **/dev/sda1** partition is the boot partition, and the **/dev/sda2** partition contains a volume group on which the rest of the host’s logical volumes have been created.
-
-As root in the terminal session, use the `dd` command to view the boot record of the hard drive, assuming it is assigned to the **/dev/sda** device. The `bs=` argument is not what you might think; it simply specifies the block size, and the `count=` argument specifies the number of blocks to dump to STDIO. The `if=` argument specifies the source of the data stream, in this case, the **/dev/sda** device. Notice that we are not looking at the first block of the partition, we are looking at the very first block of the hard drive.
-
-```
-[root@studentvm1 test]# dd if=/dev/sda bs=512 count=1
-�c�#�м���؎���|�#�#���!#��8#u
- ��#���u��#�#�#�|���t#�L#�#�|���#�����t��pt#���y|1��؎м ��d|<�t#��R�|1��D#@�D��D#�##f�#\|f�f�#`|f�\
- �D#p�B�#r�p�#�K`#�#��1��������#a`���#f��u#����f1�f�TCPAf�#f�#a�&Z|�#}�#�.}�4�3}�.�#��GRUB GeomHard DiskRead Error
-�#��#�<u��ܻޮ�###��� ������ �_U�1+0 records in
-1+0 records out
-512 bytes copied, 4.3856e-05 s, 11.7 MB/s
-```
-
-This prints the text of the boot record, which is the first block on the disk—any disk. In this case, there is information about the filesystem and, although it is unreadable because it is stored in binary format, the partition table. If this were a bootable device, stage 1 of GRUB or some other boot loader would be located in this sector. The last three lines contain data about the number of records and bytes processed.
-
-Starting with the beginning of **/dev/sda1** , let’s look at a few blocks of data at a time to find what we want. The command is similar to the previous one, except that we have specified a few more blocks of data to view. You may have to specify fewer blocks if your terminal is not large enough to display all of the data at one time, or you can pipe the data through the less utility and use that to page through the data—either way works. Remember, we are doing all of this as root user because non-root users do not have the required permissions.
-
-Enter the same command as you did in the previous experiment, but increase the block count to be displayed to 100, as shown below, in order to show more data.
-
-```
-[root@studentvm1 test]# dd if=/dev/sda1 bs=512 count=100
-##33��#:�##�� :o�[:o�[#��S�###�q[#
- #<�#{5OZh�GJ͞#t�Ұ##boot/bootysimage/booC�dp��G'�*)�#A�##@
- #�q[
-�## ## ###�#���To=###<#8���#'#�###�#�����#�' �����#Xi �#��` qT���
- <���
- � r���� ]�#�#�##�##�##�#�##�##�##�#�##�##�#��#�#�##�#�##�##�#��#�#����# � �# �# �#
-�
-�#
-�#
-�#
- �
- �#
- �#
- �#
- �
- �#
- �#
- �#100+0 records in
-100+0 records out
-51200 bytes (51 kB, 50 KiB) copied, 0.00117615 s, 43.5 MB/s
-```
-
-Now try this command. I won’t reproduce the entire data stream here because it would take up huge amounts of space. Use **Ctrl-C** to break out and stop the stream of data.
-
-```
-[root@studentvm1 test]# dd if=/dev/sda
-```
-
-This command produces a stream of data that is the complete content of the hard drive, **/dev/sda** , including the boot record, the partition table, and all of the partitions and their content. This data could be redirected to a file for use as a complete backup from which a bare metal recovery can be performed. It could also be sent directly to another hard drive to clone the first. But do not perform this particular experiment.
-
-```
-[root@studentvm1 test]# dd if=/dev/sda of=/dev/sdx
-```
-
-You can see that the `dd` command can be very useful for exploring the structures of various types of filesystems, locating data on a defective storage device, and much more. It also produces a stream of data on which we can use the transformer utilities in order to modify or view.
-
-The real point here is that `dd`, like so many Linux commands, produces a stream of data as its output. That data stream can be searched and manipulated in many ways using other tools. It can even be used for ghost-like backups or disk duplication.
-
-### Randomness
-
-It turns out that randomness is a desirable thing in computers—who knew? There are a number of reasons that sysadmins might want to generate a stream of random data. A stream of random data is sometimes useful to overwrite the contents of a complete partition, such as **/dev/sda1** , or even the entire hard drive, as in **/dev/sda**.
-
-Perform this experiment as a non-root user. Enter this command to print an unending stream of random data to STDIO.
-
-```
-[student@studentvm1 ~]$ cat /dev/urandom
-```
-
-Use **Ctrl-C** to break out and stop the stream of data. You may need to use **Ctrl-C** multiple times.
-
-Random data is also used as the input seed to programs that generate random passwords and random data and numbers for use in scientific and statistical calculations. I will cover randomness and other interesting data sources in a bit more detail in Chapter 24: Everything is a file.
-
-### Pipe dreams
-
-Pipes are critical to our ability to do the amazing things on the command line, so much so that I think it is important to recognize that they were invented by Douglas McIlroy during the early days of Unix (thanks, Doug!). The Princeton University website has a fragment of an [interview][3] with McIlroy in which he discusses the creation of the pipe and the beginnings of the Unix philosophy.
-
-Notice the use of pipes in the simple command-line program shown next, which lists each logged-in user a single time, no matter how many logins they have active. Perform this experiment as the student user. Enter the command shown below:
-
-```
-[student@studentvm1 ~]$ w | tail -n +3 | awk '{print $1}' | sort | uniq
-root
-student
-[student@studentvm1 ~]$
-```
-
-The results from this command produce two lines of data that show that the user's root and student are both logged in. It does not show how many times each user is logged in. Your results will almost certainly differ from mine.
-
-Pipes—represented by the vertical bar ( | )—are the syntactical glue, the operator, that connects these command-line utilities together. Pipes allow the Standard Output from one command to be “piped,” i.e., streamed from Standard Output of one command to the Standard Input of the next command.
-
-The |& operator can be used to pipe the STDERR along with STDOUT to STDIN of the next command. This is not always desirable, but it does offer flexibility in the ability to record the STDERR data stream for the purposes of problem determination.
-
-A string of programs connected with pipes is called a pipeline, and the programs that use STDIO are referred to officially as filters, but I prefer the term “transformers.”
-
-Think about how this program would have to work if we could not pipe the data stream from one command to the next. The first command would perform its task on the data and then the output from that command would need to be saved in a file. The next command would have to read the stream of data from the intermediate file and perform its modification of the data stream, sending its own output to a new, temporary data file. The third command would have to take its data from the second temporary data file and perform its own manipulation of the data stream and then store the resulting data stream in yet another temporary file. At each step, the data file names would have to be transferred from one command to the next in some way.
-
-I cannot even stand to think about that because it is so complex. Remember: Simplicity rocks!
-
-### Building pipelines
-
-When I am doing something new, solving a new problem, I usually do not just type in a complete Bash command pipeline from scratch off the top of my head. I usually start with just one or two commands in the pipeline and build from there by adding more commands to further process the data stream. This allows me to view the state of the data stream after each of the commands in the pipeline and make corrections as they are needed.
-
-It is possible to build up very complex pipelines that can transform the data stream using many different utilities that work with STDIO.
-
-### Redirection
-
-Redirection is the capability to redirect the STDOUT data stream of a program to a file instead of to the default target of the display. The “greater than” ( > ) character, aka “gt”, is the syntactical symbol for redirection of STDOUT.
-
-Redirecting the STDOUT of a command can be used to create a file containing the results from that command.
-
-```
-[student@studentvm1 ~]$ df -h > diskusage.txt
-```
-
-There is no output to the terminal from this command unless there is an error. This is because the STDOUT data stream is redirected to the file and STDERR is still directed to the STDOUT device, which is the display. You can view the contents of the file you just created using this next command:
-
-```
-[student@studentvm1 test]# cat diskusage.txt
-Filesystem Size Used Avail Use% Mounted on
-devtmpfs 2.0G 0 2.0G 0% /dev
-tmpfs 2.0G 0 2.0G 0% /dev/shm
-tmpfs 2.0G 1.2M 2.0G 1% /run
-tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
-/dev/mapper/fedora_studentvm1-root 2.0G 50M 1.8G 3% /
-/dev/mapper/fedora_studentvm1-usr 15G 4.5G 9.5G 33% /usr
-/dev/mapper/fedora_studentvm1-var 9.8G 1.1G 8.2G 12% /var
-/dev/mapper/fedora_studentvm1-tmp 4.9G 21M 4.6G 1% /tmp
-/dev/mapper/fedora_studentvm1-home 2.0G 7.2M 1.8G 1% /home
-/dev/sda1 976M 221M 689M 25% /boot
-tmpfs 395M 0 395M 0% /run/user/0
-tmpfs 395M 12K 395M 1% /run/user/1000
-```
-
-When using the > symbol to redirect the data stream, the specified file is created if it does not already exist. If it does exist, the contents are overwritten by the data stream from the command. You can use double greater-than symbols, >>, to append the new data stream to any existing content in the file.
-
-```
-[student@studentvm1 ~]$ df -h >> diskusage.txt
-```
-
-You can use `cat` and/or `less` to view the **diskusage.txt** file in order to verify that the new data was appended to the end of the file.
-
-The < (less than) symbol redirects data to the STDIN of the program. You might want to use this method to input data from a file to STDIN of a command that does not take a filename as an argument but that does use STDIN. Although input sources can be redirected to STDIN, such as a file that is used as input to grep, it is generally not necessary as grep also takes a filename as an argument to specify the input source. Most other commands also take a filename as an argument for their input source.
-
-### Just grep’ing around
-
-The `grep` command is used to select lines that match a specified pattern from a stream of data. `grep` is one of the most commonly used transformer utilities and can be used in some very creative and interesting ways. The `grep` command is one of the few that can correctly be called a filter because it does filter out all the lines of the data stream that you do not want; it leaves only the lines that you do want in the remaining data stream.
-
-If the PWD is not the **/tmp/test** directory, make it so. Let’s first create a stream of random data to store in a file. In this case, we want somewhat less random data that would be limited to printable characters. A good password generator program can do this. The following program (you may have to install `pwgen` if it is not already) creates a file that contains 50,000 passwords that are 80 characters long using every printable character. Try it without redirecting to the **random.txt** file first to see what that looks like, and then do it once redirecting the output data stream to the file.
-
-```
-$ pwgen -sy 80 50000 > random.txt
-```
-
-Considering that there are so many passwords, it is very likely that some character strings in them are the same. First, `cat` the **random.txt** file, then use the `grep` command to locate some short, randomly selected strings from the last ten passwords on the screen. I saw the word “see” in one of those ten passwords, so my command looked like this: `grep see random.txt`, and you can try that, but you should also pick some strings of your own to check. Short strings of two to four characters work best.
-
-```
-$ grep see random.txt
- R=p)'s/~0}wr~2(OqaL.S7DNyxlmO69`"12u]h@rp[D2%3}1b87+>Vk,;4a0hX]d7see;1%9|wMp6Yl.
- bSM_mt_hPy|YZ1<TY/Hu5{g#mQ<u_(@8B5Vt?w%i-&C>NU@[;zV2-see)>(BSK~n5mmb9~h)yx{a&$_e
- cjR1QWZwEgl48[3i-(^x9D=v)seeYT2R#M:>wDh?Tn$]HZU7}j!7bIiIr^cI.DI)W0D"'vZU@.Kxd1E1
- z=tXcjVv^G\nW`,y=bED]d|7%s6iYT^a^Bvsee:v\UmWT02|P|nq%A*;+Ng[$S%*s)-ls"dUfo|0P5+n
-```
-
-### Summary
-
-It is the use of pipes and redirection that allows many of the amazing and powerful tasks that can be performed with data streams on the Linux command line. It is pipes that transport STDIO data streams from one program or file to another. The ability to pipe streams of data through one or more transformer programs supports powerful and flexible manipulation of data in those streams.
-
-Each of the programs in the pipelines demonstrated in the experiments is small, and each does one thing well. They are also transformers; that is, they take Standard Input, process it in some way, and then send the result to Standard Output. Implementation of these programs as transformers to send processed data streams from their own Standard Output to the Standard Input of the other programs is complementary to, and necessary for, the implementation of pipes as a Linux tool.
-
-STDIO is nothing more than streams of data. This data can be almost anything from the output of a command to list the files in a directory, or an unending stream of data from a special device like **/dev/urandom** , or even a stream that contains all of the raw data from a hard drive or a partition.
-
-Any device on a Linux computer can be treated like a data stream. You can use ordinary tools like `dd` and `cat` to dump data from a device into a STDIO data stream that can be processed using other ordinary Linux tools.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/10/linux-data-streams
-
-作者:[David Both][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/dboth
-[b]: https://github.com/lujun9972
-[1]: https://www.apress.com/us/book/9781484237298
-[2]: https://www.gnu.org/software/coreutils/coreutils.html
-[3]: https://www.princeton.edu/~hos/mike/transcripts/mcilroy.htm
diff --git a/sources/tech/20181101 Getting started with OKD on your Linux desktop.md b/sources/tech/20181101 Getting started with OKD on your Linux desktop.md
deleted file mode 100644
index 7825a47553..0000000000
--- a/sources/tech/20181101 Getting started with OKD on your Linux desktop.md
+++ /dev/null
@@ -1,407 +0,0 @@
-Getting started with a local OKD cluster on Linux
-======
-Try out OKD, the community edition of the OpenShift container platform, with this tutorial.
-
-
-OKD is the open source upstream community edition of Red Hat's OpenShift container platform. OKD is a container management and orchestration platform based on [Docker][1] and [Kubernetes][2].
-
-OKD is a complete solution to manage, deploy, and operate containerized applications that (in addition to the features provided by Kubernetes) includes an easy-to-use web interface, automated build tools, routing capabilities, and monitoring and logging aggregation features.
-
-OKD provides several deployment options aimed at different requirements with single or multiple master nodes, high-availability capabilities, logging, monitoring, and more. You can create OKD clusters as small or as large as you need.
-
-In addition to these deployment options, OKD provides a way to create a local, all-in-one cluster on your own machine using the oc command-line tool. This is a great option if you want to try OKD locally without committing the resources to create a larger multi-node cluster, or if you want to have a local cluster on your machine as part of your workflow or development process. In this case, you can create and deploy the applications locally using the same APIs and interfaces required to deploy the application on a larger scale. This process ensures a seamless integration that prevents issues with applications that work in the developer's environment but not in production.
-
-This tutorial will show you how to create an OKD cluster using **oc cluster up** in a Linux box.
-
-### 1\. Install Docker
-
-The **oc cluster up** command creates a local OKD cluster on your machine using Docker containers. In order to use this command, you need Docker installed on your machine. For OKD version 3.9 and later, Docker 1.13 is the minimum recommended version. If Docker is not installed on your system, install it by using your distribution package manager. For example, on CentOS or RHEL, install Docker with this command:
-
-```
-$ sudo yum install -y docker
-```
-
-On Fedora, use dnf:
-
-```
-$ sudo dnf install -y docker
-```
-
-This installs Docker and all required dependencies.
-
-### 2\. Configure Docker insecure registry
-
-Once you have Docker installed, you need to configure it to allow the communication with an insecure registry on address 172.30.0.0/16. This insecure registry will be deployed with your local OKD cluster later.
-
-On CentOS or RHEL, edit the file **/etc/docker/daemon.json** by adding these lines:
-
-```
-{
- "insecure-registries": ["172.30.0.0/16"]
-}
-```
-
-On Fedora, edit the file **/etc/containers/registries.conf** by adding these lines:
-
-```
-[registries.insecure]
-registries = ['172.30.0.0/16']
-```
-
-### 3\. Start Docker
-
-Before starting Docker, create a system group named **docker** and assign this group to your user so you can run Docker commands with your own user, without requiring root or sudo access. This allows you to create your OKD cluster using your own user.
-
-For example, these are the commands to create the group and assign it to my local user, **ricardo** :
-
-```
-$ sudo groupadd docker
-$ sudo usermod -a -G docker ricardo
-```
-
-You need to log out and log back in to see the new group association. After logging back in, run the **id** command and ensure you're a member of the **docker** group:
-
-```
-$ id
-uid=1000(ricardo) gid=1000(ricardo) groups=1000(ricardo),10(wheel),1001(docker)
-context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
-```
-
-Now, start and enable the Docker daemon like this:
-
-```
-$ sudo systemctl start docker
-$ sudo systemctl enable docker
-Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
-```
-
-Verify that Docker is running:
-
-```
-$ docker version
-Client:
- Version: 1.13.1
- API version: 1.26
- Package version: docker-1.13.1-75.git8633870.el7.centos.x86_64
- Go version: go1.9.4
- Git commit: 8633870/1.13.1
- Built: Fri Sep 28 19:45:08 2018
- OS/Arch: linux/amd64
-
-Server:
- Version: 1.13.1
- API version: 1.26 (minimum version 1.12)
- Package version: docker-1.13.1-75.git8633870.el7.centos.x86_64
- Go version: go1.9.4
- Git commit: 8633870/1.13.1
- Built: Fri Sep 28 19:45:08 2018
- OS/Arch: linux/amd64
- Experimental: false
-```
-
-Ensure that the insecure registry option has been enabled by running **docker info** and looking for these lines:
-
-```
-$ docker info
-... Skipping long output ...
-Insecure Registries:
- 172.30.0.0/16
- 127.0.0.0/8
-```
-
-### 4\. Open firewall ports
-
-Next, open firewall ports to ensure your OKD containers can communicate with the master API. By default, some distributions have the firewall enabled, which blocks required connectivity from the OKD containers to the master API. If your system has the firewall enabled, you need to add rules to allow communication on ports **8443/tcp** for the master API and **53/udp** for DNS resolution on the Docker bridge subnet.
-
-For CentOS, RHEL, and Fedora, you can use the **firewall-cmd** command-line tool to add the rules. For other distributions, you can use the provided firewall manager, such as [UFW][3] or [iptables][4].
-
-Before adding the firewall rules, obtain the Docker bridge network subnet's address, like this:
-
-```
-$ docker network inspect bridge | grep Subnet
- "Subnet": "172.17.0.0/16",
-```
-
-Enable the firewall rules using this subnet. For CentOS, RHEL, and Fedora, use **firewall-cmd** to add a new zone:
-
-```
-$ sudo firewall-cmd --permanent --new-zone okdlocal
-success
-```
-
-Include the subnet address you obtained before as a source to the new zone:
-
-```
-$ sudo firewall-cmd --permanent --zone okdlocal --add-source 172.17.0.0/16
-success
-```
-
-Next, add the required rules to the **okdlocal** zone:
-
-```
-$ sudo firewall-cmd --permanent --zone okdlocal --add-port 8443/tcp
-success
-$ sudo firewall-cmd --permanent --zone okdlocal --add-port 53/udp
-success
-$ sudo firewall-cmd --permanent --zone okdlocal --add-port 8053/udp
-success
-```
-
-Finally, reload the firewall to enable the new rules:
-
-```
-$ sudo firewall-cmd --reload
-success
-```
-
-Ensure that the new zone and rules are in place:
-
-```
-$ sudo firewall-cmd --zone okdlocal --list-sources
-172.17.0.0/16
-$ sudo firewall-cmd --zone okdlocal --list-ports
-8443/tcp 53/udp 8053/udp
-```
-
-Your system is ready to start the cluster. It's time to download the OKD client tools.
-
-To deploy a local OKD cluster using **oc** , you need to download the OKD client tools package. For some distributions, like CentOS and Fedora, this package can be downloaded as an RPM from the official repositories. Please note that these packages may follow the distribution update cycle and usually are not the most recent version available.
-
-For this tutorial, download the OKD client package directly from the official GitHub repository so you can get the most recent version available. At the time of writing, this was OKD v3.11.
-
-Go to the [OKD downloads page][5] to get the link to the OKD tools for Linux, then download it with **wget** :
-
-```
-$ cd ~/Downloads/
-$ wget https://github.com/openshift/origin/releases/download/v3.11.0/openshift-origin-client-tools-v3.11.0-0cbc58b-linux-64bit.tar.gz
-```
-
-Uncompress the downloaded package:
-
-```
-$ tar -xzvf openshift-origin-client-tools-v3.11.0-0cbc58b-linux-64bit.tar.gz
-```
-
-Finally, to make it easier to use the **oc** command systemwide, move it to a directory included in your **$PATH** variable. A good location is **/usr/local/bin** :
-
-```
-$ sudo cp openshift-origin-client-tools-v3.11.0-0cbc58b-linux-64bit/oc /usr/local/bin/
-```
-
-One of the nicest features of the **oc** command is that it's a static single binary. You don't need to install it to use it.
-
-Check that the **oc** command is working:
-
-```
-$ oc version
-oc v3.11.0+0cbc58b
-kubernetes v1.11.0+d4cacc0
-features: Basic-Auth GSSAPI Kerberos SPNEGO
-```
-
-### 6\. Start your OKD cluster
-
-Once you have all the prerequisites in place, start your local OKD cluster by running this command:
-
-```
-$ oc cluster up
-```
-
-This command connects to your local Docker daemon, downloads all required images from Docker Hub, and starts the containers. The first time you run it, it takes a few minutes to complete. When it's finished, you will see this message:
-
-```
-... Skipping long output ...
-
-OpenShift server started.
-
-The server is accessible via web console at:
- https://127.0.0.1:8443
-
-You are logged in as:
- User: developer
- Password: <any value>
-
-To login as administrator:
- oc login -u system:admin
-```
-
-Access the OKD web console by using the browser and navigating to <https://127.0.0.1:8443:>
-
-
-
-From the command line, you can check if the cluster is running by entering this command:
-
-```
-$ oc cluster status
-Web console URL: https://127.0.0.1:8443/console/
-
-Config is at host directory
-Volumes are at host directory
-Persistent volumes are at host directory /home/ricardo/openshift.local.clusterup/openshift.local.pv
-Data will be discarded when cluster is destroyed
-```
-
-You can also verify your cluster is working by logging in as the **system:admin** user and checking available nodes using the **oc** command-line tool:
-
-```
-$ oc login -u system:admin
-Logged into "https://127.0.0.1:8443" as "system:admin" using existing credentials.
-
-You have access to the following projects and can switch between them with 'oc project <projectname>':
-
- default
- kube-dns
- kube-proxy
- kube-public
- kube-system
- * myproject
- openshift
- openshift-apiserver
- openshift-controller-manager
- openshift-core-operators
- openshift-infra
- openshift-node
- openshift-service-cert-signer
- openshift-web-console
-
-Using project "myproject".
-
-$ oc get nodes
-NAME STATUS ROLES AGE VERSION
-localhost Ready <none> 52m v1.11.0+d4cacc0
-```
-
-Since this is a local, all-in-one cluster, you see only **localhost** in the nodes list.
-
-### 7\. Smoke-test your cluster
-
-Now that your local OKD cluster is running, create a test app to smoke-test it. Use OKD to build and start the sample application so you can ensure the different components are working.
-
-Start by logging in as the **developer** user:
-
-```
-$ oc login -u developer
-Logged into "https://127.0.0.1:8443" as "developer" using existing credentials.
-
-You have one project on this server: "myproject"
-
-Using project "myproject".
-```
-
-You're automatically assigned to a new, empty project named **myproject**. Create a sample PHP application based on an existing GitHub repository, like this:
-
-```
-$ oc new-app php:5.6~https://github.com/rgerardi/ocp-smoke-test.git
---> Found image 92ed8b3 (5 months old) in image stream "openshift/php" under tag "5.6" for "php:5.6"
-
- Apache 2.4 with PHP 5.6
- -----------------------
- PHP 5.6 available as container is a base platform for building and running various PHP 5.6 applications and frameworks. PHP is an HTML-embedded scripting language. PHP attempts to make it easy for developers to write dynamically generated web pages. PHP also offers built-in database integration for several commercial and non-commercial database management systems, so writing a database-enabled webpage with PHP is fairly simple. The most common use of PHP coding is probably as a replacement for CGI scripts.
-
- Tags: builder, php, php56, rh-php56
-
- * A source build using source code from https://github.com/rgerardi/ocp-smoke-test.git will be created
- * The resulting image will be pushed to image stream tag "ocp-smoke-test:latest"
- * Use 'start-build' to trigger a new build
- * This image will be deployed in deployment config "ocp-smoke-test"
- * Ports 8080/tcp, 8443/tcp will be load balanced by service "ocp-smoke-test"
- * Other containers can access this service through the hostname "ocp-smoke-test"
-
---> Creating resources ...
- imagestream.image.openshift.io "ocp-smoke-test" created
- buildconfig.build.openshift.io "ocp-smoke-test" created
- deploymentconfig.apps.openshift.io "ocp-smoke-test" created
- service "ocp-smoke-test" created
---> Success
- Build scheduled, use 'oc logs -f bc/ocp-smoke-test' to track its progress.
- Application is not exposed. You can expose services to the outside world by executing one or more of the commands below:
- 'oc expose svc/ocp-smoke-test'
- Run 'oc status' to view your app.
-```
-
-OKD starts the build process, which clones the provided GitHub repository, compiles the application (if required), and creates the necessary images. You can follow the build process by tailing its log with this command:
-
-```
-$ oc logs -f bc/ocp-smoke-test
-Cloning "https://github.com/rgerardi/ocp-smoke-test.git" ...
- Commit: 391a475713d01ab0afab700bab8a3d7549c5cc27 (Create index.php)
- Author: Ricardo Gerardi <ricardo.gerardi@gmail.com>
- Date: Tue Oct 2 13:47:25 2018 -0400
-Using 172.30.1.1:5000/openshift/php@sha256:f3c95020fa870fcefa7d1440d07a2b947834b87bdaf000588e84ef4a599c7546 as the s2i builder image
----> Installing application source...
-=> sourcing 20-copy-config.sh ...
----> 04:53:28 Processing additional arbitrary httpd configuration provided by s2i ...
-=> sourcing 00-documentroot.conf ...
-=> sourcing 50-mpm-tuning.conf ...
-=> sourcing 40-ssl-certs.sh ...
-Pushing image 172.30.1.1:5000/myproject/ocp-smoke-test:latest ...
-Pushed 1/10 layers, 10% complete
-Push successful
-```
-
-After the build process completes, OKD starts the application automatically by running a new pod based on the created image. You can see this new pod with this command:
-
-```
-$ oc get pods
-NAME READY STATUS RESTARTS AGE
-ocp-smoke-test-1-build 0/1 Completed 0 1m
-ocp-smoke-test-1-d8h76 1/1 Running 0 7s
-```
-
-You can see two pods are created; the first one (with the status Completed) is the pod used to build the application. The second one (with the status Running) is the application itself.
-
-In addition, OKD creates a service for this application. Verify it by using this command:
-
-```
-$ oc get service
-NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
-ocp-smoke-test ClusterIP 172.30.232.241 <none> 8080/TCP,8443/TCP 1m
-```
-
-Finally, expose this service externally using OKD routes so you can access the application from a local browser:
-
-```
-$ oc expose svc ocp-smoke-test
-route.route.openshift.io/ocp-smoke-test exposed
-
-$ oc get route
-NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
-ocp-smoke-test ocp-smoke-test-myproject.127.0.0.1.nip.io ocp-smoke-test 8080-tcp None
-```
-
-Verify that your new application is running by navigating to <http://ocp-smoke-test-myproject.127.0.0.1.nip.io> in a web browser:
-
-
-
-You can also see the status of your application by logging into the OKD web console:
-
-
-
-### Learn more
-
-You can find more information about OKD on the [official site][6], which includes a link to the OKD [documentation][7].
-
-If this is your first time working with OKD/OpenShift, you can learn the basics of the platform, including how to build and deploy containerized applications, through the [Interactive Learning Portal][8]. Another good resource is the official [OpenShift YouTube channel][9].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/local-okd-cluster-linux
-
-作者:[Ricardo Gerardi][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/rgerardi
-[b]: https://github.com/lujun9972
-[1]: https://www.docker.com/
-[2]: https://kubernetes.io/
-[3]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
-[4]: https://en.wikipedia.org/wiki/Iptables
-[5]: https://www.okd.io/download.html#oc-platforms
-[6]: https://www.okd.io/
-[7]: https://docs.okd.io/
-[8]: https://learn.openshift.com/
-[9]: https://www.youtube.com/openshift
diff --git a/sources/tech/20181105 How to manage storage on Linux with LVM.md b/sources/tech/20181105 How to manage storage on Linux with LVM.md
deleted file mode 100644
index 36cc8d47a0..0000000000
--- a/sources/tech/20181105 How to manage storage on Linux with LVM.md
+++ /dev/null
@@ -1,237 +0,0 @@
-How to manage storage on Linux with LVM
-======
-Create, expand, and encrypt storage pools as needed with the Linux LVM utilities.
-
-
-Logical Volume Manager ([LVM][1]) is a software-based RAID-like system that lets you create "pools" of storage and add hard drive space to those pools as needed. There are lots of reasons to use it, especially in a data center or any place where storage requirements change over time. Many Linux distributions use it by default for desktop installations, though, because users find the flexibility convenient and there are some built-in encryption features that the LVM structure simplifies.
-
-However, if you aren't used to seeing an LVM volume when booting off of a Live CD for data rescue or migration purposes, LVM can be confusing because the **mount** command can't mount LVM volumes. For that, you need LVM tools installed. The chances are great that your distribution has LVM utils available—if they aren't already installed.
-
-This tutorial explains how to create and deal with LVM volumes.
-
-### Create an LVM pool
-
-This article assumes you have a working knowledge of how to interact with hard drives on Linux. If you need more information on the basics before continuing, read my [introduction to hard drives on Linux][2]
-
-Usually, you don't have to set up LVM at all. When you install Linux, it often defaults to creating a virtual "pool" of storage and adding your machine's hard drive(s) to that pool. However, manually creating an LVM storage pool is a great way to learn what happens behind the scenes.
-
-You can practice with two spare thumb drives of any size, or two hard drives, or a virtual machine with two imaginary drives defined.
-
-First, format the imaginary drive **/dev/sdx** so that you have a fresh drive ready to use for this demo.
-
-```
-# echo "warning, this ERASES everything on this drive."
-warning, this ERASES everything on this drive.
-# dd if=/dev/zero of=/dev/sdx count=8196
-# parted /dev/sdx print | grep Disk
-Disk /dev/sdx: 100GB
-# parted /dev/sdx mklabel gpt
-# parted /dev/sdx mkpart primary 1s 100%
-```
-
-This LVM command creates a storage pool. A pool can consist of one or more drives, and right now it consists of one. This example storage pool is named **billiards** , but you can call it anything.
-
-```
-# vgcreate billiards /dev/sdx1
-```
-
-Now you have a big, nebulous pool of storage space. Time to hand it out. To create two logical volumes (you can think of them as virtual drives), one called **vol0** and the other called **vol1** , enter the following:
-
-```
-# lvcreate billiards 49G --name vol0
-# lvcreate billiards 49G --name vol1
-```
-
-Now you have two volumes carved out of one storage pool, but neither of them has a filesystem yet. To create a filesystem on each volume, you must bring the **billiards** volume group online.
-
-```
-# vgchange --activate y billiards
-```
-
-Now make the file systems. The **-L** option provides a label for the drive, which is displayed when the drive is mounted on your desktop. The path to the volume is a little different than the usual device paths you're used to because these are virtual devices in an LVM storage pool.
-
-```
-# mkfs.ext4 -L finance /dev/billiards/vol0
-# mkfs.ext4 -L production /dev/billiards/vol1
-```
-
-You can mount these new volumes on your desktop or from a terminal.
-
-```
-# mkdir -p /mnt/vol0 /mnt/vol1
-# mount /dev/billiards/vol0 /mnt/vol0
-# mount /dev/billiards/vol1 /mnt/vol1
-```
-
-### Add space to your pool
-
-So far, LVM has provided nothing more than partitioning a drive normally provides: two distinct sections of drive space on a single physical drive (in this example, 49GB and 49GB on a 100GB drive). Imagine now that the finance department needs more space. Traditionally, you'd have to restructure. Maybe you'd move the finance department data to a new, dedicated physical drive, or maybe you'd add a drive and then use an ugly symlink hack to provide users easy access to their additional storage space. With LVM, however, all you have to do is expand the storage pool.
-
-You can add space to your pool by formatting another drive and using it to create more additional space.
-
-First, create a partition on the new drive you're adding to the pool.
-
-```
-# part /dev/sdy mkpart primary 1s 100%
-```
-
-Then use the **vgextend** command to mark the new drive as part of the pool.
-
-```
-# vgextend billiards /dev/sdy1
-```
-
-Finally, dedicate some portion of the newly available storage pool to the appropriate logical volume.
-
-```
-# lvextend -L +49G /dev/billiards/vol0
-```
-
-Of course, the expansion doesn't have to be so linear. Imagine that the production department suddenly needs 100TB of additional space. With LVM, you can add as many physical drives as needed, adding each one and using **vgextend** to create a 100TB storage pool, then using **lvextend** to "stretch" the production department's storage space across 100TB of available space.
-
-### Use utils to understand your storage structure
-
-Once you start using LVM in earnest, the landscape of storage can get overwhelming. There are two commands to gather information about the structure of your storage infrastructure.
-
-First, there is **vgdisplay** , which displays information about your volume groups (you can think of these as LVM's big, high-level virtual drives).
-
-```
-# vgdisplay
- --- Volume group ---
- VG Name billiards
- System ID
- Format lvm2
- Metadata Areas 1
- Metadata Sequence No 4
- VG Access read/write
- VG Status resizable
- MAX LV 0
- Cur LV 3
- Open LV 3
- Max PV 0
- Cur PV 1
- Act PV 1
- VG Size <237.47 GiB
- PE Size 4.00 MiB
- Total PE 60792
- Alloc PE / Size 60792 / <237.47 GiB
- Free PE / Size 0 / 0
- VG UUID j5RlhN-Co4Q-7d99-eM3K-G77R-eDJO-nMR9Yg
-```
-
-The second is **lvdisplay** , which displays information about your logical volumes (you can think of these as user-facing drives).
-
-```
-# lvdisplay
- --- Logical volume ---
- LV Path /dev/billiards/finance
- LV Name finance
- VG Name billiards
- LV UUID qPgRhr-s0rS-YJHK-0Cl3-5MME-87OJ-vjjYRT
- LV Write Access read/write
- LV Creation host, time localhost, 2018-12-16 07:31:01 +1300
- LV Status available
- # open 1
- LV Size 149.68 GiB
- Current LE 46511
- Segments 1
- Allocation inherit
- Read ahead sectors auto
- - currently set to 256
- Block device 253:3
-
-[...]
-```
-
-### Use LVM in a rescue environment
-
-The "problem" with LVM is that it wraps partitions in a way that is unfamiliar to many administrative users who are used to traditional drive partitioning. Under normal circumstances, LVM drives are activated and mounted fairly invisibly during the boot process or desktop LVM integration. It's not something you typically have to think about. It only becomes problematic when you find yourself in recovery mode after something goes wrong with your system.
-
-If you need to mount a volume that's "hidden" within the structure of LVM, you must make sure that the LVM toolchain is installed. If you have access to your **/usr/sbin** directory, you probably have access to all of your usual LVM commands. But if you've booted into a minimal shell or a rescue environment, you may not have those tools. A good rescue environment has LVM installed, so if you're in a minimal shell, find a rescue system that does. If you're using a rescue disc and it doesn't have LVM installed, either install it manually or find a rescue disc that already has it.
-
-For the sake of repetition and clarity, here's how to mount an LVM volume.
-
-```
-# vgchange --activate y
-2 logical volume(s) in volume group "billiards" now active
-# mkdir /mnt/finance
-# mount /dev/billiards/finance /mnt/finance
-```
-
-### Integrate LVM with LUKS encryption
-
-Many Linux distributions use LVM by default when installing the operating system. This permits storage extension later, but it also integrates nicely with disk encryption provided by the Linux Unified Key Setup ([LUKS][3]) encryption toolchain.
-
-Encryption is pretty important, and there are two ways to encrypt things: you can encrypt on a per-file basis with a tool like GnuPG, or you can encrypt an entire partition. On Linux, encrypting a partition is easy with LUKS, which, being completely integrated into Linux by way of kernel modules, permits drives to be mounted for seamless reading and writing.
-
-Encrypting your entire main drive usually happens as an option during installation. You select to encrypt your entire drive or just your home partition when prompted, and from that point on you're using LUKS. It's mostly invisible to you, aside from a password prompt during boot.
-
-If your distribution doesn't offer this option during installation, or if you just want to encrypt a drive or partition manually, you can do that.
-
-You can follow this example by using a spare drive; I used a small 4GB thumb drive.
-
-First, plug the drive into your computer. Make sure it's safe to erase the drive and [use lsblk][2] to locate the drive on your system.
-
-If the drive isn't already partitioned, partition it now. If you don't know how to partition a drive, check out the link above for instructions.
-
-Now you can set up the encryption. First, format the partition with the **cryptsetup** command.
-
-```
-# cryptsetup luksFormat /dev/sdx1
-```
-
-Note that you're encrypting the partition, not the physical drive itself. You'll see a warning that LUKS is going to erase your drive; you must accept it to continue. You'll be prompted to create a passphrase, so do that. Don't forget that passphrase. Without it, you will never be able to get into that drive again!
-
-You've encrypted the thumb drive's partition, but there's no filesystem on the drive yet. Of course, you can't write a filesystem to the drive while you're locked out of it, so open the drive with LUKS first. You can provide a human-friendly name for your drive; for this example, I used **mySafeDrive**.
-
-```
-# cryptsetup luksOpen /dev/sdx1 mySafeDrive
-```
-
-Enter your passphrase to open the drive.
-
-Look in **/dev/mapper** and you'll see that you've mounted the volume along with any other LVM volumes you might have, meaning you now have access to that drive. The custom name (e.g., mySafeDrive) is a symlink to an auto-generated designator in **/dev/mapper**. You can use either path when operating on this drive.
-
-```
-# ls -l /dev/mapper/mySafeDrive
-lrwxrwxrwx. 1 root root 7 Oct 24 03:58 /dev/mapper/mySafeDrive -> ../dm-4
-```
-
-Create your filesystem.
-
-```
-# mkfs.ext4 -o Linux -L mySafeExt4Drive /dev/mapper/mySafeDrive
-```
-
-Now do an **ls -lh** on **/dev/mapper** and you'll see that mySafeDrive is actually a symlink to some other dev; probably **/dev/dm0** or similar. That's the filesystem you can mount:
-
-```
-# mount /dev/mapper/mySafeExt4Drive /mnt/hd
-```
-
-Now the filesystem on the encrypted drive is mounted. You can read and write files as you'd expect with any drive.
-
-### Use encrypted drives with the desktop
-
-LUKS is built into the kernel, so your Linux system is fully aware of how to handle it. Detach the drive, plug it back in, and mount it from your desktop. In KDE's Dolphin file manager, you'll be prompted for a password before the drive is decrypted and mounted.
-
-
-
-Using LVM and LUKS is easy, and it provides flexibility for you as a user and an admin. Being tightly integrated into Linux itself, it's well-supported and a great way to add a layer of security to your data. Try it today!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/manage-storage-lvm
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)
-[2]: https://opensource.com/article/18/10/partition-and-format-drive-linux
-[3]: https://en.wikipedia.org/wiki/Linux_Unified_Key_Setup
diff --git a/sources/tech/20181106 How To Check The List Of Packages Installed From Particular Repository.md b/sources/tech/20181106 How To Check The List Of Packages Installed From Particular Repository.md
deleted file mode 100644
index 81111b465c..0000000000
--- a/sources/tech/20181106 How To Check The List Of Packages Installed From Particular Repository.md
+++ /dev/null
@@ -1,342 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (How To Check The List Of Packages Installed From Particular Repository?)
-[#]: via: (https://www.2daygeek.com/how-to-check-the-list-of-packages-installed-from-particular-repository/)
-[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
-[#]: url: ( )
-
-How To Check The List Of Packages Installed From Particular Repository?
-======
-
-If you would like to check the list of package installed from particular repository then you are in the right place to get it done.
-
-Why we need this detail? It may helps you to isolate the installed packages list based on the repository.
-
-Like, it’s coming from distribution official repository or these are coming from PPA or these are coming from other resources, etc.,
-
-You may want to know what are the packages came from third party repositories to keep eye on those to avoid any damages on your system.
-
-So many third party repositories and PPAs are available for Linux. These repositories are included set of packages which is not available in distribution repository due to some limitation.
-
-It helps administrator to easily install some of the important packages which is not available in the distribution official repository. Installing third party repository on production system is not advisable as this may not properly maintained by the repository maintainer due to many reasons.
-
-So, you have to decide whether you want to install or not. I can say, we can believe some of the third party repositories which is well maintained and suggested by Linux distributions like [EPEL repository][1], Copr (Cool Other Package Repo), etc,.
-
-If you would like to see the list of package was installed from the corresponding repo, use the following commands based on your distributions.
-
-[List of Major repositories][2] and it’s details are below.
-
- * **`CentOS:`** [EPEL][1], [ELRepo][3], etc is [CentOS Community Approved Repositories][4].
- * **`Fedora:`** [RPMfusion repo][5] is commonly used by most of the [Fedora][6] users.
- * **`ArchLinux:`** ArchLinux community repository contains packages that have been adopted by Trusted Users from the Arch User Repository.
- * **`openSUSE:`** [Packman repo][7] offers various additional packages for openSUSE, especially but not limited to multimedia related applications and libraries that are on the openSUSE Build Service application blacklist. It’s the largest external repository of openSUSE packages.
- * **`Ubuntu:`** Personal Package Archives (PPAs) are a kind of repository. Developers create them in order to distribute their software. You can find this information on the PPA’s Launchpad page. Also, you can enable Cananical partners repositories.
-
-
-
-### What Is Repository?
-
-A software repository is a central place which stores the software packages for the particular application.
-
-All the Linux distributions are maintaining their own repositories and they allow users to retrieve and install packages on their machine.
-
-Each vendor offered a unique package management tool to manage their repositories such as search, install, update, upgrade, remove, etc.
-
-Most of the Linux distributions comes as freeware except RHEL and SUSE. To access their repositories you need to buy a subscriptions.
-
-### How To Check The List Of Packages Installed From Particular Repository on RHEL/CentOS Systems?
-
-This can be done in multiple ways. Here we will be giving you all the possible options and you can choose which one is best for you.
-
-### Method-1: Using Yum Command
-
-RHEL & CentOS systems are using RPM packages hence we can use the [Yum Package Manager][8] to get this information.
-
-YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
-
-Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
-
-```
-[[email protected] ~]# yum list installed | grep @epel
-apachetop.x86_64 0.15.6-1.el7 @epel
-aria2.x86_64 1.18.10-2.el7.1 @epel
-atop.x86_64 2.3.0-8.el7 @epel
-axel.x86_64 2.4-9.el7 @epel
-epel-release.noarch 7-11 @epel
-lighttpd.x86_64 1.4.50-1.el7 @epel
-```
-
-Alternatively, you can use the yum command with other option to get the same details like above.
-
-```
-# yum repo-pkgs epel list installed
-Loaded plugins: fastestmirror
-Loading mirror speeds from cached hostfile
- * epel: epel.mirror.constant.com
-Installed Packages
-apachetop.x86_64 0.15.6-1.el7 @epel
-aria2.x86_64 1.18.10-2.el7.1 @epel
-atop.x86_64 2.3.0-8.el7 @epel
-axel.x86_64 2.4-9.el7 @epel
-epel-release.noarch 7-11 @epel
-lighttpd.x86_64 1.4.50-1.el7 @epel
-```
-
-### Method-2: Using Yumdb Command
-
-Yumdb info provides information similar to yum info but additionally it provides package checksum data, type, user info (who installed the package). Since yum 3.2.26 yum has started storing additional information outside of the rpmdatabase (where user indicates it was installed by the user, and dep means it was brought in as a dependency).
-
-```
-# yumdb search from_repo epel* |egrep -v '(from_repo|^$)'
-Loaded plugins: fastestmirror
-apachetop-0.15.6-1.el7.x86_64
-aria2-1.18.10-2.el7.1.x86_64
-atop-2.3.0-8.el7.x86_64
-axel-2.4-9.el7.x86_64
-epel-release-7-11.noarch
-lighttpd-1.4.50-1.el7.x86_64
-```
-
-### Method-3: Using Repoquery Command
-
-repoquery is a program for querying information from YUM repositories similarly to rpm queries.
-
-```
-# repoquery -a --installed --qf "%{ui_from_repo} %{name}" | grep '^@epel'
-@epel apachetop
-@epel aria2
-@epel atop
-@epel axel
-@epel epel-release
-@epel lighttpd
-```
-
-### How To Check The List Of Packages Installed From Particular Repository on Fedora System?
-
-DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for back-end. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
-
-[Dnf command][9] is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
-
-```
-# dnf list installed | grep @updates
-NetworkManager.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-adsl.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-bluetooth.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-libnm.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-libreswan.x86_64 1.2.10-1.fc29 @updates
-NetworkManager-libreswan-gnome.x86_64 1.2.10-1.fc29 @updates
-NetworkManager-openvpn.x86_64 1:1.8.8-1.fc29 @updates
-NetworkManager-openvpn-gnome.x86_64 1:1.8.8-1.fc29 @updates
-NetworkManager-ovs.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-ppp.x86_64 1:1.12.4-2.fc29 @updates
-.
-.
-```
-
-Alternatively, you can use the dnf command with other option to get the same details like above.
-
-```
-# dnf repo-pkgs updates list installed
-Installed Packages
-NetworkManager.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-adsl.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-bluetooth.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-libnm.x86_64 1:1.12.4-2.fc29 @updates
-NetworkManager-libreswan.x86_64 1.2.10-1.fc29 @updates
-NetworkManager-libreswan-gnome.x86_64 1.2.10-1.fc29 @updates
-NetworkManager-openvpn.x86_64 1:1.8.8-1.fc29 @updates
-NetworkManager-openvpn-gnome.x86_64 1:1.8.8-1.fc29 @updates
-NetworkManager-ovs.x86_64 1:1.12.4-2.fc29 @updates
-.
-.
-```
-
-### How To Check The List Of Packages Installed From Particular Repository on openSUSE System?
-
-Zypper is a command line package manager which makes use of libzypp. [Zypper command][10] provides functions like repository access, dependency solving, package installation, etc.
-
-```
-zypper search -ir "Update Repository (Non-Oss)"
-Loading repository data...
-Reading installed packages...
-
-S | Name | Summary | Type
----+----------------------------+---------------------------------------------------+--------
-i | gstreamer-0_10-fluendo-mp3 | GStreamer plug-in from Fluendo for MP3 support | package
-i+ | openSUSE-2016-615 | Test-update for openSUSE Leap 42.2 Non Free | patch
-i+ | openSUSE-2017-724 | Security update for unrar | patch
-i | unrar | A program to extract, test, and view RAR archives | package
-```
-
-Alternatively, we can use repo id instead of repo name.
-
-```
-zypper search -ir 2
-Loading repository data...
-Reading installed packages...
-
-S | Name | Summary | Type
----+----------------------------+---------------------------------------------------+--------
-i | gstreamer-0_10-fluendo-mp3 | GStreamer plug-in from Fluendo for MP3 support | package
-i+ | openSUSE-2016-615 | Test-update for openSUSE Leap 42.2 Non Free | patch
-i+ | openSUSE-2017-724 | Security update for unrar | patch
-i | unrar | A program to extract, test, and view RAR archives | package
-```
-
-### How To Check The List Of Packages Installed From Particular Repository on ArchLinux System?
-
-[Pacman command][11] stands for package manager utility. pacman is a simple command-line utility to install, build, remove and manage Arch Linux packages. Pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
-
-```
-$ paclist community
-acpi 1.7-2
-acpid 2.0.30-1
-adapta-maia-theme 3.94.0.149-1
-android-tools 9.0.0_r3-1
-blueman 2.0.6-1
-brotli 1.0.7-1
-.
-.
-ufw 0.35-5
-unace 2.5-10
-usb_modeswitch 2.5.2-1
-viewnior 1.7-1
-wallpapers-2018 1.0-1
-xcursor-breeze 5.11.5-1
-xcursor-simpleandsoft 0.2-8
-xcursor-vanilla-dmz-aa 0.4.5-1
-xfce4-whiskermenu-plugin-gtk3 2.3.0-1
-zeromq 4.2.5-1
-```
-
-### How To Check The List Of Packages Installed From Particular Repository on Debian Based Systems?
-
-For Debian based systems, it can be done using grep command.
-
-If you want to know the list of installed repositories on your system, use the following command.
-
-```
-$ ls -lh /var/lib/apt/lists/ | uniq
-total 370M
--rw-r--r-- 1 root root 10K Oct 26 10:53 archive.canonical.com_ubuntu_dists_bionic_InRelease
--rw-r--r-- 1 root root 6.4K Oct 26 10:53 archive.canonical.com_ubuntu_dists_bionic_partner_binary-amd64_Packages
--rw-r--r-- 1 root root 6.4K Oct 26 10:53 archive.canonical.com_ubuntu_dists_bionic_partner_binary-i386_Packages
--rw-r--r-- 1 root root 3.2K Jun 12 21:19 archive.canonical.com_ubuntu_dists_bionic_partner_i18n_Translation-en
-drwxr-xr-x 2 _apt root 4.0K Jul 25 08:44 auxfiles
--rw-r--r-- 1 root root 3.7K Oct 16 15:13 download.virtualbox.org_virtualbox_debian_dists_bionic_contrib_binary-amd64_Packages
--rw-r--r-- 1 root root 7.2K Oct 16 15:13 download.virtualbox.org_virtualbox_debian_dists_bionic_contrib_Contents-amd64.lz4
--rw-r--r-- 1 root root 4.4K Oct 16 15:13 download.virtualbox.org_virtualbox_debian_dists_bionic_InRelease
--rw-r--r-- 1 root root 34 Mar 19 2018 download.virtualbox.org_virtualbox_debian_dists_bionic_non-free_Contents-amd64.lz4
--rw-r--r-- 1 root root 6.4K Sep 21 09:42 in.archive.ubuntu.com_ubuntu_dists_bionic-backports_Contents-amd64.lz4
--rw-r--r-- 1 root root 6.4K Sep 21 09:42 in.archive.ubuntu.com_ubuntu_dists_bionic-backports_Contents-i386.lz4
--rw-r--r-- 1 root root 73K Nov 6 11:16 in.archive.ubuntu.com_ubuntu_dists_bionic-backports_InRelease
-.
-.
--rw-r--r-- 1 root root 29 May 11 06:39 security.ubuntu.com_ubuntu_dists_bionic-security_main_dep11_icons-64x64.tar.gz
--rw-r--r-- 1 root root 747K Nov 5 23:57 security.ubuntu.com_ubuntu_dists_bionic-security_main_i18n_Translation-en
--rw-r--r-- 1 root root 2.8K Oct 9 22:37 security.ubuntu.com_ubuntu_dists_bionic-security_multiverse_binary-amd64_Packages
--rw-r--r-- 1 root root 3.7K Oct 9 22:37 security.ubuntu.com_ubuntu_dists_bionic-security_multiverse_binary-i386_Packages
--rw-r--r-- 1 root root 1.8K Jul 24 23:06 security.ubuntu.com_ubuntu_dists_bionic-security_multiverse_i18n_Translation-en
--rw-r--r-- 1 root root 519K Nov 5 20:12 security.ubuntu.com_ubuntu_dists_bionic-security_universe_binary-amd64_Packages
--rw-r--r-- 1 root root 517K Nov 5 20:12 security.ubuntu.com_ubuntu_dists_bionic-security_universe_binary-i386_Packages
--rw-r--r-- 1 root root 11K Nov 6 05:36 security.ubuntu.com_ubuntu_dists_bionic-security_universe_dep11_Components-amd64.yml.gz
--rw-r--r-- 1 root root 8.9K Nov 6 05:36 security.ubuntu.com_ubuntu_dists_bionic-security_universe_dep11_icons-48x48.tar.gz
--rw-r--r-- 1 root root 16K Nov 6 05:36 security.ubuntu.com_ubuntu_dists_bionic-security_universe_dep11_icons-64x64.tar.gz
--rw-r--r-- 1 root root 315K Nov 5 20:12 security.ubuntu.com_ubuntu_dists_bionic-security_universe_i18n_Translation-en
-```
-
-To get the list of installed packages from the `security.ubuntu.com` repository.
-
-```
-$ grep Package /var/lib/apt/lists/security.ubuntu.com_*_Packages | awk '{print $2;}'
-amd64-microcode
-apache2
-apache2-bin
-apache2-data
-apache2-dbg
-apache2-dev
-.
-.
-znc
-znc-dev
-znc-perl
-znc-python
-znc-tcl
-zsh-static
-zziplib-bin
-```
-
-The security repository containing multiple branches (main, multiverse and universe) and if you would like to list out the installed packages from the particular repository `universe` then use the following format.
-
-```
-$ grep Package /var/lib/apt/lists/security.ubuntu.com_ubuntu_dists_bionic-security_universe*_Packages | awk '{print $2;}'
-ant
-ant-doc
-ant-optional
-apache2-suexec-custom
-apache2-suexec-pristine
-apparmor-easyprof
-apport-kde
-apport-noui
-apport-valgrind
-apt-transport-https
-.
-.
-xul-ext-gdata-provider
-xul-ext-lightning
-xvfb
-znc
-znc-dev
-znc-perl
-znc-python
-znc-tcl
-zsh-static
-zziplib-bin
-```
-
-one more example for `ppa.launchpad.net` repository.
-
-```
-$ grep Package /var/lib/apt/lists/ppa.launchpad.net_*_Packages | awk '{print $2;}'
-notepadqq
-notepadqq-gtk
-notepadqq-common
-notepadqq
-notepadqq-gtk
-notepadqq-common
-numix-gtk-theme
-numix-icon-theme
-numix-icon-theme-circle
-numix-icon-theme-square
-numix-gtk-theme
-numix-icon-theme
-numix-icon-theme-circle
-numix-icon-theme-square
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-check-the-list-of-packages-installed-from-particular-repository/
-
-作者:[Prakash Subramanian][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/prakash/
-[b]: https://github.com/lujun9972
-[1]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
-[2]: https://www.2daygeek.com/category/repository/
-[3]: https://www.2daygeek.com/install-enable-elrepo-on-rhel-centos-scientific-linux/
-[4]: https://www.2daygeek.com/additional-yum-repositories-for-centos-rhel-fedora-systems/
-[5]: https://www.2daygeek.com/install-enable-rpm-fusion-repository-on-centos-fedora-rhel/
-[6]: https://fedoraproject.org/wiki/Third_party_repositories
-[7]: https://www.2daygeek.com/install-enable-packman-repository-on-opensuse-leap/
-[8]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
-[9]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
-[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
-[11]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
diff --git a/sources/tech/20181111 Some notes on running new software in production.md b/sources/tech/20181111 Some notes on running new software in production.md
deleted file mode 100644
index bfdfb66a44..0000000000
--- a/sources/tech/20181111 Some notes on running new software in production.md
+++ /dev/null
@@ -1,151 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Some notes on running new software in production)
-[#]: via: (https://jvns.ca/blog/2018/11/11/understand-the-software-you-use-in-production/)
-[#]: author: (Julia Evans https://jvns.ca/)
-
-Some notes on running new software in production
-======
-
-I’m working on a talk for kubecon in December! One of the points I want to get across is the amount of time/investment it takes to use new software in production without causing really serious incidents, and what that’s looked like for us in our use of Kubernetes.
-
-To start out, this post isn’t blanket advice. There are lots of times when it’s totally fine to just use software and not worry about **how** it works exactly. So let’s start by talking about when it’s important to invest.
-
-### when it matters: 99.99%
-
-If you’re running a service with a low SLO like 99% I don’t think it matters that much to understand the software you run in production. You can be down for like 2 hours a month! If something goes wrong, just fix it and it’s fine.
-
-At 99.99%, it’s different. That’s 45 minutes / year of downtime, and if you find out about a serious issue for the first time in production it could easily take you 20 minutes or to revert the change. That’s half your uptime budget for the year!
-
-### when it matters: software that you’re using heavily
-
-Also, even if you’re running a service with a 99.99% SLO, it’s impossible to develop a super deep understanding of every single piece of software you’re using. For example, a web service might use:
-
- * 100 library dependencies
- * the filesystem (so there’s linux filesystem code!)
- * the network (linux networking code!)
- * a database (like postgres)
- * a proxy (like nginx/haproxy)
-
-
-
-If you’re only reading like 2 files from disk, you don’t need to do a super deep dive into Linux filesystems internals, you can just read the file from disk.
-
-What I try to do in practice is identify the components which we rely on the (or have the most unusual use cases for!), and invest time into understanding those. These are usually pretty easy to identify because they’re the ones which will cause the most problems :)
-
-### when it matters: new software
-
-Understanding your software especially matters for newer/less mature software projects, because it’s morely likely to have bugs & or just not have matured enough to be used by most people without having to worry. I’ve spent a bunch of time recently with Kubernetes/Envoy which are both relatively new projects, and neither of those are remotely in the category of “oh, it’ll just work, don’t worry about it”. I’ve spent many hours debugging weird surprising edge cases with both of them and learning how to configure them in the right way.
-
-### a playbook for understanding your software
-
-The playbook for understanding the software you run in production is pretty simple. Here it is:
-
- 1. Start using it in production in a non-critical capacity (by sending a small percentage of traffic to it, on a less critical service, etc)
- 2. Let that bake for a few weeks.
- 3. Run into problems.
- 4. Fix the problems. Go to step 3.
-
-
-
-Repeat until you feel like you have a good handle on this software’s failure modes and are comfortable running it in a more critical capacity. Let’s talk about that in a little more detail, though:
-
-### what running into bugs looks like
-
-For example, I’ve been spending a lot of time with Envoy in the last year. Some of the issues we’ve seen along the way are: (in no particular order)
-
- * One of the default settings resulted in retry & timeout headers not being respected
- * Envoy (as a client) doesn’t support TLS session resumption, so servers with a large amount of Envoy clients get DDOSed by TLS handshakes
- * Envoy’s active healthchecking means that you services get healthchecked by every client. This is mostly okay but (again) services with many clients can get overwhelmed by it.
- * Having every client independently healthcheck every server interacts somewhat poorly with services which are under heavy load, and can exacerbate performance issues by removing up-but-slow clients from the load balancer rotation.
- * Envoy doesn’t retry failed connections by default
- * it frequently segfaults when given incorrect configuration
- * various issues with it segfaulting because of resource leaks / memory safety issues
- * hosts running out of disk space between we didn’t rotate Envoy log files often enough
-
-
-
-A lot of these aren’t bugs – they’re just cases where what we expected the default configuration to do one thing, and it did another thing. This happens all the time, and it can result in really serious incidents. Figuring out how to configure a complicated piece of software appropriately takes a lot of time, and you just have to account for that.
-
-And Envoy is great software! The maintainers are incredibly responsive, they fix bugs quickly and its performance is good. It’s overall been quite stable and it’s done well in production. But just because something is great software doesn’t mean you won’t also run into 10 or 20 relatively serious issues along the way that need to be addressed in one way or another. And it’s helpful to understand those issues **before** putting the software in a really critical place.
-
-### try to have each incident only once
-
-My view is that running new software in production inevitably results in incidents. The trick:
-
- 1. Make sure the incidents aren’t too serious (by making ‘production’ a less critical system first)
- 2. Whenever there’s an incident (even if it’s not that serious!!!), spend the time necessary to understand exactly why it happened and how to make sure it doesn’t happen again
-
-
-
-My experience so far has been that it’s actually relatively possible to pull off “have every incident only once”. When we investigate issues and implement remediations, usually that issue **never comes back**. The remediation can either be:
-
- * a configuration change
- * reporting a bug upstream and either fixing it ourselves or waiting for a fix
- * a workaround (“this software doesn’t work with 10,000 clients? ok, we just won’t use it with in cases where there are that many clients for now!“, “oh, a memory leak? let’s just restart it every hour”)
-
-
-
-Knowledge-sharing is really important here too – it’s always unfortunate when one person finds an incident in production, fixes it, but doesn’t explain the issue to the rest of the team so somebody else ends up causing the same incident again later because they didn’t hear about the original incident.
-
-### Understand what is ok to break and isn’t
-
-Another huge part of understanding the software I run in production is understanding which parts are OK to break (aka “if this breaks, it won’t result in a production incident”) and which aren’t. This lets me **focus**: I can put big boxes around some components and decide “ok, if this breaks it doesn’t matter, so I won’t pay super close attention to it”.
-
-For example, with Kubernetes:
-
-ok to break:
-
- * any stateless control plane component can crash or be cycled out or go down for 5 minutes at any time. If we had 95% uptime for the kubernetes control plane that would probably be fine, it just needs to be working most of the time.
- * kubernetes networking (the system where you give every pod an IP addresses) can break as much as it wants because we decided not to use it to start
-
-
-
-not ok:
-
- * for us, if etcd goes down for 10 minutes, that’s ok. If it goes down for 2 hours, it’s not
- * containers not starting or crashing on startup (iam issues, docker not starting containers, bugs in the scheduler, bugs in other controllers) is serious and needs to be looked at immediately
- * containers not having access to the resources they need (because of permissions issues, etc)
- * pods being terminated unexpectedly by Kubernetes (if you configure kubernetes wrong it can terminate your pods!)
-
-
-
-with Envoy, the breakdown is pretty different:
-
-ok to break:
-
- * if the envoy control plane goes down for 5 minutes, that’s fine (it’ll keep working with stale data)
- * segfaults on startup due to configuration errors are sort of okay because they manifest so early and they’re unlikely to surprise us (if the segfault doesn’t happen the 1st time, it shouldn’t happen the 200th time)
-
-
-
-not ok:
-
- * Envoy crashes / segfaults are not good – if it crashes, network connections don’t happen
- * if the control server serves incorrect or incomplete data that’s extremely dangerous and can result in serious production incidents. (so downtime is fine, but serving incorrect data is not!)
-
-
-
-Neither of these lists are complete at all, but they’re examples of what I mean by “understand your sofware”.
-
-### sharing ok to break / not ok lists is useful
-
-I think these “ok to break” / “not ok” lists are really useful to share, because even if they’re not 100% the same for every user, the lessons are pretty hard won. I’d be curious to hear about your breakdown of what kinds of failures are ok / not ok for software you’re using!
-
-Figuring out all the failure modes of a new piece of software and how they apply to your situation can take months. (this is is why when you ask your database team “hey can we just use NEW DATABASE” they look at you in such a pained way). So anything we can do to help other people learn faster is amazing
---------------------------------------------------------------------------------
-
-via: https://jvns.ca/blog/2018/11/11/understand-the-software-you-use-in-production/
-
-作者:[Julia Evans][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://jvns.ca/
-[b]: https://github.com/lujun9972
diff --git a/sources/tech/20181112 Behind the scenes with Linux containers.md b/sources/tech/20181112 Behind the scenes with Linux containers.md
deleted file mode 100644
index 0f813ac517..0000000000
--- a/sources/tech/20181112 Behind the scenes with Linux containers.md
+++ /dev/null
@@ -1,205 +0,0 @@
-Behind the scenes with Linux containers
-======
-Become a better container troubleshooter by using LXC to understand how they work.
-
-
-Can you have Linux containers without [Docker][1]? Without [OpenShift][2]? Without [Kubernetes][3]?
-
-Yes, you can. Years before Docker made containers a household term (if you live in a data center, that is), the [LXC][4] project developed the concept of running a kind of virtual operating system, sharing the same kernel, but contained within defined groups of processes.
-
-Docker built on LXC, and today there are plenty of platforms that leverage the work of LXC both directly and indirectly. Most of these platforms make creating and maintaining containers sublimely simple, and for large deployments, it makes sense to use such specialized services. However, not everyone's managing a large deployment or has access to big services to learn about containerization. The good news is that you can create, use, and learn containers with nothing more than a PC running Linux and this article. This article will help you understand containers by looking at LXC, how it works, why it works, and how to troubleshoot when something goes wrong.
-
-### Sidestepping the simplicity
-
-If you're looking for a quick-start guide to LXC, refer to the excellent [Linux Containers][5] website.
-
-### Installing LXC
-
-If it's not already installed, you can install [LXC][6] with your package manager.
-
-On Fedora or similar, enter:
-
-```
-$ sudo dnf install lxc lxc-templates lxc-doc
-```
-
-On Debian, Ubuntu, and similar, enter:
-
-```
-$ sudo apt install lxc
-```
-
-### Creating a network bridge
-
-Most containers assume a network will be available, and most container tools expect the user to be able to create virtual network devices. The most basic unit required for containers is the network bridge, which is more or less the software equivalent of a network switch. A network switch is a little like a smart Y-adapter used to split a headphone jack so two people can hear the same thing with separate headsets, except instead of an audio signal, a network switch bridges network data.
-
-You can create your own software network bridge so your host computer and your container OS can both send and receive different network data over a single network device (either your Ethernet port or your wireless card). This is an important concept that often gets lost once you graduate from manually generating containers, because no matter the size of your deployment, it's highly unlikely you have a dedicated physical network card for each container you run. It's vital to understand that containers talk to virtual network devices, so you know where to start troubleshooting if a container loses its network connection.
-
-To create a network bridge on your machine, you must have the appropriate permissions. For this article, use the **sudo** command to operate with root privileges. (However, LXC docs provide a configuration to grant users permission to do this without using **sudo**.)
-
-```
-$ sudo ip link add br0 type bridge
-```
-
-Verify that the imaginary network interface has been created:
-
-```
-$ sudo ip addr show br0
-7: br0: <BROADCAST,MULTICAST> mtu 1500 qdisc
- noop state DOWN group default qlen 1000
- link/ether 26:fa:21:5f:cf:99 brd ff:ff:ff:ff:ff:ff
-```
-
-Since **br0** is seen as a network interface, it requires its own IP address. Choose a valid local IP address that doesn't conflict with any existing IP address on your network and assign it to the **br0** device:
-
-```
-$ sudo ip addr add 192.168.168.168 dev br0
-```
-
-And finally, ensure that **br0** is up and running:
-
-```
-$ sudo ip link set br0 up
-```
-
-### Setting the container config
-
-The config file for an LXC container can be as complex as it needs to be to define a container's place in your network and the host system, but for this example the config is simple. Create a file in your favorite text editor and define a name for the container and the network's required settings:
-
-```
-lxc.utsname = opensourcedotcom
-lxc.network.type = veth
-lxc.network.flags = up
-lxc.network.link = br0
-lxc.network.hwaddr = 4a:49:43:49:79:bd
-lxc.network.ipv4 = 192.168.168.1/24
-lxc.network.ipv6 = 2003:db8:1:0:214:1234:fe0b:3596
-```
-
-Save this file in your home directory as **mycontainer.conf**.
-
-The **lxc.utsname** is arbitrary. You can call your container whatever you like; it's the name you'll use when starting and stopping it.
-
-The network type is set to **veth** , which is a kind of virtual Ethernet patch cable. The idea is that the **veth** connection goes from the container to the bridge device, which is defined by the **lxc.network.link** property, set to **br0**. The IP address for the container is in the same network as the bridge device but unique to avoid collisions.
-
-With the exception of the **veth** network type and the **up** network flag, you invent all the values in the config file. The list of properties is available from **man lxc.container.conf**. (If it's missing on your system, check your package manager for separate LXC documentation packages.) There are several example config files in **/usr/share/doc/lxc/examples** , which you should review later.
-
-### Launching a container shell
-
-At this point, you're two-thirds of the way to an operable container: you have the network infrastructure, and you've installed the imaginary network cards in an imaginary PC. All you need now is to install an operating system.
-
-However, even at this stage, you can see LXC at work by launching a shell within a container space.
-
-```
-$ sudo lxc-execute --name basic \
---rcfile ~/mycontainer.conf /bin/bash \
---logfile mycontainer.log
-#
-```
-
-In this very bare container, look at your network configuration. It should look familiar, yet unique, to you.
-
-```
-# /usr/sbin/ip addr show
-1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state [...]
-link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
-inet 127.0.0.1/8 scope host lo
-[...]
-22: eth0@if23: <BROADCAST,MULTICAST,UP,LOWER_UP> [...] qlen 1000
-link/ether 4a:49:43:49:79:bd brd ff:ff:ff:ff:ff:ff link-netnsid 0
-inet 192.168.168.167/24 brd 192.168.168.255 scope global eth0
- valid_lft forever preferred_lft forever
-inet6 2003:db8:1:0:214:1234:fe0b:3596/64 scope global
- valid_lft forever preferred_lft forever
-[...]
-```
-
-Your container is aware of its fake network infrastructure and of a familiar-yet-unique kernel.
-
-```
-# uname -av
-Linux opensourcedotcom 4.18.13-100.fc27.x86_64 #1 SMP Wed Oct 10 18:34:01 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
-```
-
-Use the **exit** command to leave the container:
-
-```
-# exit
-```
-
-### Installing the container operating system
-
-Building out a fully containerized environment is a lot more complex than the networking and config steps, so you can borrow a container template from LXC. If you don't have any templates, look for a separate LXC template package in your software repository.
-
-The default LXC templates are available in **/usr/share/lxc/templates**.
-
-```
-$ ls -m /usr/share/lxc/templates/
-lxc-alpine, lxc-altlinux, lxc-archlinux, lxc-busybox, lxc-centos, lxc-cirros, lxc-debian, lxc-download, lxc-fedora, lxc-gentoo, lxc-openmandriva, lxc-opensuse, lxc-oracle, lxc-plamo, lxc-slackware, lxc-sparclinux, lxc-sshd, lxc-ubuntu, lxc-ubuntu-cloud
-```
-
-Pick your favorite, then create the container. This example uses Slackware.
-
-```
-$ sudo lxc-create --name slackware --template slackware
-```
-
-Watching a template being executed is almost as educational as building one from scratch; it's very verbose, and you can see that **lxc-create** sets the "root" of the container to **/var/lib/lxc/slackware/rootfs** and several packages are being downloaded and installed to that directory.
-
-Reading through the template files gives you an even better idea of what's involved: LXC sets up a minimal device tree, common spool files, a file systems table (fstab), init files, and so on. It also prevents some services that make no sense in a container (like udev for hardware detection) from starting. Since the templates cover a wide spectrum of typical Linux configurations, if you intend to design your own, it's wise to base your work on a template closest to what you want to set up; otherwise, you're sure to make errors of omission (if nothing else) that the LXC project has already stumbled over and accounted for.
-
-Once you've installed the minimal operating system environment, you can start your container.
-
-```
-$ sudo lxc-start --name slackware \
---rcfile ~/mycontainer.conf
-```
-
-You have started the container, but you have not attached to it. (Unlike the previous basic example, you're not just running a shell this time, but a containerized operating system.) Attach to it by name.
-
-```
-$ sudo lxc-attach --name slackware
-#
-```
-
-Check that the IP address of your environment matches the one in your config file.
-
-```
-# /usr/sbin/ip addr SHOW | grep eth
-34: eth0@if35: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 [...] 1000
-link/ether 4a:49:43:49:79:bd brd ff:ff:ff:ff:ff:ff link-netnsid 0
-inet 192.168.168.167/24 brd 192.168.168.255 scope global eth0
-```
-
-Exit the container, and shut it down.
-
-```
-# exit
-$ sudo lxc-stop slackware
-```
-
-### Running real-world containers with LXC
-
-In real life, LXC makes it easy to create and run safe and secure containers. Containers have come a long way since the introduction of LXC in 2008, so use its developers' expertise to your advantage.
-
-While the LXC instructions on [linuxcontainers.org][5] make the process simple, this tour of the manual side of things should help you understand what's going on behind the scenes.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/behind-scenes-linux-containers
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/resources/what-docker
-[2]: https://opensource.com/sitewide-search?search_api_views_fulltext=openshift
-[3]: https://opensource.com/resources/what-is-kubernetes
-[4]: https://linuxcontainers.org
-[5]: https://linuxcontainers.org/lxc/getting-started
-[6]: https://github.com/lxc/lxc
diff --git a/sources/tech/20181115 11 Things To Do After Installing elementary OS 5 Juno.md b/sources/tech/20181115 11 Things To Do After Installing elementary OS 5 Juno.md
deleted file mode 100644
index 5e23c6e5c4..0000000000
--- a/sources/tech/20181115 11 Things To Do After Installing elementary OS 5 Juno.md
+++ /dev/null
@@ -1,260 +0,0 @@
-11 Things To Do After Installing elementary OS 5 Juno
-======
-I’ve been using [elementary OS 5 Juno][1] for over a month and it has been an amazing experience. It is easily the [best Mac OS inspired Linux distribution][2] and one of the [best Linux distribution for beginners][3].
-
-However, you will need to take care of a couple of things after installing it.
-In this article, we will discuss the most important things that you need to do after installing [elementary OS][4] 5 Juno.
-
-### Things to do after installing elementary OS 5 Juno
-
-![Things to do after installing elementary OS Juno][5]
-
-Things I mentioned in this list are from my personal experience and preference. Of course, you are not restricted to these few things. You can explore and tweak the system as much as you like. However, if you follow (some of) these recommendations, things might be smoother for you.
-
-#### 1.Run a System Update
-
-![terminal showing system updates in elementary os 5 Juno][6]
-
-Even when you download the latest version of a distribution – it is always recommended to check for the latest System updates. You might have a quick fix for an annoying bug, or, maybe there’s an important security patch that you shouldn’t ignore. So, no matter what – you should always ensure that you have everything up-to-date.
-
-To do that, you need to type in the following command in the terminal:
-
-```
-sudo apt-get update
-```
-
-#### 2\. Set Window Hotcorner
-
-![][7]
-
-You wouldn’t notice the minimize button for a window. So, how do you do it?
-
-Well, you can just bring up the dock and click the app icon again to minimize it or press **Windows key + H** as a shortcut to minimize the active window.
-
-But, I’ll recommend something way more easy and intuitive. Maybe you already knew it, but for the users who were unaware of the “ **hotcorners** ” feature, here’s what it does:
-
-Whenever you hover the cursor to any of the 4 corners of the window, you can set a preset action to happen when you do that. For example, when you move your cursor to the **left corner** of the screen you get the **multi-tasking view** to switch between apps – which acts like a “gesture“.
-
-In order to utilize the functionality, you can follow the steps below:
-
- 1. Head to the System Settings.
- 2. Click on the “ **Desktop** ” option (as shown in the image above).
- 3. Next, select the “ **Hot Corner** ” section (as shown in the image below).
- 4. Depending on what corner you prefer, choose an appropriate action (refer to the image below – that’s what I personally prefer as my settings)
-
-
-
-#### 3\. Install Multimedia codecs
-
-I’ve tried playing MP3/MP4 files – it just works fine. However, there are a lot of file formats when it comes to multimedia.
-
-So, just to be able to play almost every format of multimedia, you should install the codecs. Here’s what you need to enter in the terminal:
-
-To get certain proprietary codecs:
-
-```
-sudo apt install ubuntu-restricted-extras
-```
-
-To specifically install [Libav][8]:
-
-```
-sudo apt install libavcodec-extra
-```
-
-To install a codec in order to facilitate playing video DVDs:
-
-```
-sudo apt install libdvd-pkg
-```
-
-#### 4\. Install GDebi
-
-You don’t get to install .deb files by just double-clicking it on elementary OS 5 Juno. It just does not let you do that.
-
-So, you need an additional tool to help you install .deb files.
-
-We’ll recommend you to use **GDebi**. I prefer it because it lets you know about the dependencies even before trying to install it – that way – you can be sure about what you need in order to correctly install an application.
-
-Simply install GDebi and open any .deb files by performing a right-click on them **open in GDebi Package Installer.**
-
-To install it, type in the following command:
-
-```
-sudo apt install gdebi
-```
-
-#### 5\. Add a PPA for your Favorite App
-
-Yes, elementary OS 5 Juno now supports PPA (unlike its previous version). So, you no longer need to enable the support for PPAs explicitly.
-
-Just grab a PPA and add it via terminal to install something you like.
-
-#### 6\. Install Essential Applications
-
-If you’re a Linux power user, you already know what you want and where to get it, but if you’re new to this Linux distro and looking out for some applications to have installed, I have a few recommendations:
-
-**Steam app** : If you’re a gamer, this is a must-have app. You just need to type in a single command to install it:
-
-```
-sudo apt install steam
-```
-
-**GIMP** : It is the best photoshop alternative across every platform. Get it installed for every type of image manipulation:
-
-```
-sudo apt install gimp
-```
-
-**Wine** : If you want to install an application that only runs on Windows, you can try using Wine to run such Windows apps here on Linux. To install, follow the command:
-
-```
-sudo apt install wine-stable
-```
-
-**qBittorrent** : If you prefer downloading Torrent files, you should have this installed as your Torrent client. To install it, enter the following command:
-
-```
-sudo apt install qbittorrent
-```
-
-**Flameshot** : You can obviously utilize the default screenshot tool to take screenshots. But, if you want to instantly share your screenshots and the ability to annotate – install flameshot. Here’s how you can do that:
-
-```
-sudo apt install flameshot
-```
-
-**Chrome/Firefox: **The default browser isn’t much useful. So, you should install Chrome/Firefox – as per your choice.
-
-To install chrome, enter the command:
-
-```
-sudo apt install chromium-browser
-```
-
-To install Firefox, enter:
-
-```
-sudo apt install firefox
-```
-
-These are some of the most common applications you should definitely have installed. For the rest, you should browse through the App Center or the Flathub to install your favorite applications.
-
-#### 7\. Install Flatpak (Optional)
-
-It’s just my personal recommendation – I find flatpak to be the preferred way to install apps on any Linux distro I use.
-
-You can try it and learn more about it at its [official website][9].
-
-To install flatpak, type in:
-
-```
-sudo apt install flatpak
-```
-
-After you are done installing flatpak, you can directly head to [Flathub][10] to install some of your favorite apps and you will also find the command/instruction to install it via the terminal.
-
-In case you do not want to launch the browser, you can search for your app by typing in (example – finding Discord and installing it):
-
-```
-flatpak search discord flathub
-```
-
-After gettting the application ID, you can proceed installing it by typing in:
-
-```
-flatpak install flathub com.discordapp.Discord
-```
-
-#### 8\. Enable the Night Light
-
-![Night Light in elementary OS Juno][11]
-
-You might have installed Redshift as per our recommendation for [elemantary OS 0.4 Loki][12] to filter the blue light to avoid straining our eyes- but you do not need any 3rd party tool anymore.
-
-It comes baked in as the “ **Night Light** ” feature.
-
-You just head to System Settings and click on “ **Displays** ” (as shown in the image above).
-
-Select the **Night Light** section and activate it with your preferred settings.
-
-#### 9\. Install NVIDIA driver metapackage (for NVIDIA GPUs)
-
-![Nvidia drivers in elementary OS juno][13]
-
-The NVIDIA driver metapackage should be listed right at the App Center – so you can easily the NVIDIA driver.
-
-However, it’s not the latest driver version – I have version **390.77** installed and it’s performing just fine.
-
-If you want the latest version for Linux, you should check out NVIDIA’s [official download page][14].
-
-Also, if you’re curious about the version installed, just type in the following command:
-
-```
-nvidia-smi
-```
-
-#### 10\. Install TLP for Advanced Power Management
-
-We’ve said it before. And, we’ll still recommend it.
-
-If you want to manage your background tasks/activity and prevent overheating of your system – you should install TLP.
-
-It does not offer a GUI, but you don’t have to bother. You just install it and let it manage whatever it takes to prevent overheating.
-
-It’s very helpful for laptop users.
-
-To install, type in:
-
-```
-supo apt install tlp tlp-rdw
-```
-
-#### 11\. Perform visual customizations
-
-![][15]
-
-If you need to change the look of your Linux distro, you can install GNOME tweaks tool to get the options. In order to install the tweak tool, type in:
-
-```
-sudo apt install gnome-tweaks
-```
-
-Once you install it, head to the application launcher and search for “Tweaks”, you’ll find something like this:
-
-Here, you can select the icon, theme, wallpaper, and you’ll also be able to tweak a couple more options that’s not limited to the visual elements.
-
-### Wrapping Up
-
-It’s the least you should do after installing elementary OS 5 Juno. However, considering that elementary OS 5 Juno comes with numerous new features – you can explore a lot more new things as well.
-
-Let us know what you did first after installing elementary OS 5 Juno and how’s your experience with it so far?
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/things-to-do-after-installing-elementary-os-5-juno/
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: https://itsfoss.com/elementary-os-juno-features/
-[2]: https://itsfoss.com/macos-like-linux-distros/
-[3]: https://itsfoss.com/best-linux-beginners/
-[4]: https://elementary.io/
-[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/things-to-do-after-installing-elementary-os-juno.jpeg?ssl=1
-[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-system-update.jpg?ssl=1
-[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-hotcorners.jpg?ssl=1
-[8]: https://libav.org/
-[9]: https://flatpak.org/
-[10]: https://flathub.org/home
-[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-night-light.jpg?ssl=1
-[12]: https://itsfoss.com/things-to-do-after-installing-elementary-os-loki/
-[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-nvidia-metapackage.jpg?ssl=1
-[14]: https://www.nvidia.com/Download/index.aspx
-[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-gnome-tweaks.jpg?ssl=1
diff --git a/sources/tech/20181118 An example of how C-- destructors are useful in Envoy.md b/sources/tech/20181118 An example of how C-- destructors are useful in Envoy.md
deleted file mode 100644
index f95f17db01..0000000000
--- a/sources/tech/20181118 An example of how C-- destructors are useful in Envoy.md
+++ /dev/null
@@ -1,130 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (An example of how C++ destructors are useful in Envoy)
-[#]: via: (https://jvns.ca/blog/2018/11/18/c---destructors---really-useful/)
-[#]: author: (Julia Evans https://jvns.ca/)
-
-An example of how C++ destructors are useful in Envoy
-======
-
-For a while now I’ve been working with a C++ project (Envoy), and sometimes I need to contribute to it, so my C++ skills have gone from “nonexistent” to “really minimal”. I’ve learned what an initializer list is and that a method starting with `~` is a destructor. I almost know what an lvalue and an rvalue are but not quite.
-
-But the other day when writing some C++ code I figured out something exciting about how to use destructors that I hadn’t realized! (the tl;dr of this post for people who know C++ is “julia finally understands what RAII is and that it is useful” :))
-
-### what’s a destructor?
-
-C++ has objects. When an C++ object goes out of scope, the compiler inserts a call to its destructor. So if you have some code like
-
-```
-function do_thing() {
- Thing x{}; // this calls the Thing constructor
- return 2;
-}
-```
-
-there will be a call to x’s destructor at the end of the `do_thing` function. so the code c++ generates looks something like:
-
- * make new thing
- * call the new thing’s destructor
- * return 2
-
-
-
-Obviously destructors are way more complicated like this. They need to get called when there are exceptions! And sometimes they get called manually. And for lots of other reasons too. But there are 10 million things to know about C++ and that is not what we’re doing today, we are just talking about one thing.
-
-### what happens in a destructor?
-
-A lot of the time memory gets freed, which is how you avoid having memory leaks. But that’s not what we’re talking about in this post! We are talking about something more interesting.
-
-### the thing we’re interested in: Envoy circuit breakers
-
-So I’ve been working with Envoy a lot. 3 second Envoy refresher: it’s a HTTP proxy, your application makes requests to Envoy, which then proxies the request to the servers the application wants to talk to.
-
-One very useful feature Envoy has is this thing called “circuit breakers”. Basically the idea with is that if your application makes 50 billion connections to a service, that will probably overwhelm the service. So Envoy keeps track how many TCP connections you’ve made to a service, and will stop you from making new requests if you hit the limit. The default `max_connection` limit
-
-### how do you track connection count?
-
-To maintain a circuit breaker on the number of TCP connections, that means you need to keep an accurate count of how many TCP connections are currently open! How do you do that? Well, the way it works is to maintain a `connections` counter and:
-
- * every time a connection is opened, increment the counter
- * every time a connection is destroyed (because of a reset / timeout / whatever), decrement the counter
- * when creating a new connection, check that the `connections` counter is not over the limit
-
-
-
-that’s all! And incrementing the counter when creating a new connection is pretty easy. But how do you make sure that the counter gets _decremented_ wheh the connection is destroyed? Connections can be destroyed in a lot of ways (they can time out! they can be closed by Envoy! they can be closed by the server! maybe something else I haven’t thought of could happen!) and it seems very easy to accidentally miss a way of closing them.
-
-### destructors to the rescue
-
-The way Envoy solves this problem is to create a connection object (called `ActiveClient` in the HTTP connection pool) for every connection.
-
-Then it:
-
- * increments the counter in the constructor ([code][1])
- * decrements the counter in the destructor ([code][2])
- * checks the counter when a new connection is created ([code][3])
-
-
-
-The beauty of this is that now you don’t need to make sure that the counter gets decremented in all the right places, you now just need to organize your code so that the `ActiveClient` object’s destructor gets called when the connection has closed.
-
-Where does the `ActiveClient` destructor get called in Envoy? Well, Envoy maintains 2 lists of clients (`ready_clients` and `busy_clients`), and when a connection gets closed, Envoy removes the client from those lists. And when it does that, it doesn’t need to do any extra cleanup!! In C++, anytime a object is removed from a list, its destructor is called. So `client.removeFromList(ready_clients_);` takes care of all the cleanup. And there’s no chance of forgetting to decrement the counter!! It will definitely always happen unless you accidentally leave the object on one of these lists, which would be a bug anyway because the connection is closed :)
-
-### RAII
-
-This pattern Envoy is using here is an extremely common C++ programming pattern called “resource acquisition is initialization”. I find that name very confusing but that’s what it’s called. basically the way it works is:
-
- * identify a resource (like “connection”) where a lot of things need to happen when the connection is initialized / finished
- * make a class for that connection
- * put all the initialization / finishing code in the constructor / destructor
- * make sure the object’s destructor method gets called when appropriate! (by removing it from a vector / having it go out of scope)
-
-
-
-Previously I knew about using this pattern for kind of obvious things (make sure all the memory gets freed in the destructor, or make sure file descriptors get closed). But I didn’t realize it was also useful for cases that are slightly less obviously a resource like “decrement a counter”.
-
-The reason this pattern works is because the C++ compiler/standard library does a bunch of work to make sure that destructors get called when you’re done with an object – the compiler inserts destructor calls at the end of each block of code, after exceptions, and many standard library collections make sure destructors are called when you remove an object from a collection.
-
-### RAII gives you prompt, deterministic, and hard-to-screw-up cleanup of resources
-
-The exciting thing here is that this programming pattern gives you a way to schedule cleaning up resources that’s:
-
- * easy to ensure always happens (when the object goes away, it always happens, even if there was an exception!)
- * prompt & determinstic (it happens right away and it’s guaranteed to happen!)
-
-
-
-### what languages have RAII?
-
-C++ and Rust have RAII. Probably other languages too. Java, Python, Go, and garbage collected languages in general do not. In a garbage collected language you can often set up destructors to be run when the object is GC’d. But often (like in this case, which the connection count) you want things to be cleaned up **right away** when the object is no longer in use, not some indeterminate period later whenever GC happens to run.
-
-Python context managers are a related idea, you could do something like:
-
-```
-with conn_pool.connection() as conn:
- do stuff
-```
-
-### that’s all for now!
-
-Hopefully this explanation of RAII is interesting and mostly correct. Thanks to Kamal for clarifying some RAII things for me!
-
---------------------------------------------------------------------------------
-
-via: https://jvns.ca/blog/2018/11/18/c---destructors---really-useful/
-
-作者:[Julia Evans][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://jvns.ca/
-[b]: https://github.com/lujun9972
-[1]: https://github.com/envoyproxy/envoy/blob/200b0e41641be46471c2ce3d230aae395fda7ded/source/common/http/http1/conn_pool.cc#L301
-[2]: https://github.com/envoyproxy/envoy/blob/200b0e41641be46471c2ce3d230aae395fda7ded/source/common/http/http1/conn_pool.cc#L315
-[3]: https://github.com/envoyproxy/envoy/blob/200b0e41641be46471c2ce3d230aae395fda7ded/source/common/http/http1/conn_pool.cc#L97
diff --git a/sources/tech/20181122 Getting started with Jenkins X.md b/sources/tech/20181122 Getting started with Jenkins X.md
deleted file mode 100644
index 1c2aab6903..0000000000
--- a/sources/tech/20181122 Getting started with Jenkins X.md
+++ /dev/null
@@ -1,148 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (Getting started with Jenkins X)
-[#]: via: (https://opensource.com/article/18/11/getting-started-jenkins-x)
-[#]: author: (Dave Johnson https://opensource.com/users/snoopdave)
-[#]: url: ( )
-
-Getting started with Jenkins X
-======
-Jenkins X provides continuous integration, automated testing, and continuous delivery to Kubernetes.
-
-
-[Jenkins X][1] is an open source system that offers software developers continuous integration, automated testing, and continuous delivery, known as CI/CD, in Kubernetes. Jenkins X-managed projects get a complete CI/CD process with a Jenkins pipeline that builds and packages project code for deployment to Kubernetes and access to pipelines for promoting projects to staging and production environments.
-
-Developers are already benefiting from running "classic" open source Jenkins and CloudBees Jenkins on Kubernetes, thanks in part to the Jenkins Kubernetes plugin, which allows you to dynamically spin-up Kubernetes pods to run Jenkins build agents. Jenkins X adds what's missing from Jenkins: comprehensive support for continuous delivery and managing the promotion of projects to preview, staging, and production environments running in Kubernetes.
-
-This article is a high-level explanation of how Jenkins X works; it assumes you have some knowledge of Kubernetes and classic Jenkins.
-
-### What you get with Jenkins X
-
-If you're running on one of the major cloud providers (Amazon Elastic Container Service for Kubernetes, Google Kubernetes Engine, or Microsoft Azure Kubernetes Service), installing and deploying Jenkins X is easy. Download the Jenkins X command-line interface and run the **jx create cluster** command. You'll be prompted for the necessary information and, if you take the defaults, Jenkins X will create a starter-size Kubernetes cluster and install Jenkins X.
-
-When you deploy Jenkins X, a number of services are put in motion to watch your Git repositories and respond by building, testing, and promoting your applications to staging, production, and other environments you define. Jenkins X also deploys a set of supporting services, including [Jenkins][2], [Docker Registry][3], [Chart Museum][4], and [Monocular][5] to manage [Helm][6] charts, and [Nexus][7], which serves as a Maven and npm repository.
-
-The Jenkins X deployment also creates two Git repositories, one for your staging environment and one for production. These are in addition to the Git repositories you use to manage your project source code. Jenkins X uses these repositories to manage what is deployed to each environment, and promotions are done via Git pull requests (PRs)—this approach is known as [GitOps][8]. Each repository contains a Helm chart that specifies the applications to be deployed to the corresponding environment. Each repository also has a Jenkins pipeline to handle promotions.
-
-### Creating a new project with Jenkins X
-
-To create a new project with Jenkins X, use the **jx create quickstart** command. If you don't specify any options, jx will prompt you to select a project name and a platform—which can be just about anything. SpringBoot, Go, Python, Node, ASP.NET, Rust, Angular, and React are all supported, and the list keeps growing. Once you have chosen your project name and platform, Jenkins X will:
-
- * Create a new project that includes a "hello-world"-style web project
- * Add the appropriate type of makefile or build script for the chosen platform
- * Add a Jenkinsfile to manage promotions to staging and production environments
- * Add a Dockerfile and Helm charts, created via [Draft][9]
- * Add a [Skaffold][10] configuration for deploying the application to Kubernetes
- * Create a Git repository and push the new project code there
-
-
-
-Next, a webhook from Git will notify Jenkins X that a project changed, and it will run your project's Jenkins pipeline to build and push your Docker image and Helm charts.
-
-Finally, the pipeline will submit a PR to the staging environment's Git repository with the changes needed to promote the application.
-
-Once the PR is merged, the staging pipeline will run to apply those changes and do the promotion. A couple of minutes after creating your project, you'll have end-to-end CI/CD, and your project will be running in staging and available for use.
-
-![Developer commits changes, project deployed to staging][12]
-
-Developer commits changes, project deployed to the staging environment.
-
-The figure above illustrates the repositories, registries, and pipelines and how they interact in a Jenkins X promotion to staging. Here are the steps:
-
- 1. The developer commits and pushes the change to the project's Git repository
- 2. Jenkins X is notified and runs the project's Jenkins pipeline in a Docker image that includes the project's language and supporting frameworks
- 3. The project pipeline builds, tests, and pushes the project's Helm chart to Chart Museum and its Docker image to the registry
- 4. The project pipeline creates a PR with changes needed to add the project to the staging environment
- 5. Jenkins X automatically merges the PR to Master
- 6. Jenkins X is notified and runs the staging pipeline
- 7. The staging pipeline runs Helm, which deploys the environment, pulling Helm charts from Chart Museum and Docker images from the Docker registry. Kubernetes creates the project's resources, typically a pod, service, and ingress.
-
-
-
-### Importing your existing projects into Jenkins X
-
-**jx import** , Jenkins X adds the things needed for your project to be deployed to Kubernetes and participate in CI/CD. It will add a Jenkins pipeline, Helm charts, and a Skaffold configuration for deploying the application to Kubernetes. Jenkins X will create a Git repository and push the changes there. Next, a webhook from Git will notify Jenkins X that a project changed, and promotion to staging will happen as described above for new projects.
-
-### Promoting your project to production
-
-When you import a project via, Jenkins X adds the things needed for your project to be deployed to Kubernetes and participate in CI/CD. It will add a Jenkins pipeline, Helm charts, and a Skaffold configuration for deploying the application to Kubernetes. Jenkins X will create a Git repository and push the changes there. Next, a webhook from Git will notify Jenkins X that a project changed, and promotion to staging will happen as described above for new projects.
-
-To promote a version of your project to the production environment, use the **jx promote** command. This command will prepare a Git PR that contains the Helm chart changes needed to deploy into the production environment and submit this request to the production environment's Git repository. Once the request is manually approved, Jenkins X will run the production pipeline to deploy your project via Helm.
-
-![Promoting project to production][14]
-
-Developer promotes the project to production.
-
-This figure illustrates the repositories, registries, and pipelines and how they interact in a Jenkins X promotion to production. Here are the steps:
-
- 1. The developer runs the **jx promote** command to promote a project to production
- 2. Jenkins X creates a PR with changes needed to add the project to the production environment
- 3. The developer manually approves the PR, and it is merged to Master
- 4. Jenkins X is notified and runs the production pipeline
- 5. The production pipeline runs Helm, which deploys the environment, pulling Helm charts from Chart Museum and Docker images from the Docker registry. Kubernetes creates the project's resources, typically a pod, service, and ingress.
-
-
-
-### Other features of Jenkins X
-
-Other interesting and appealing features of Jenkins X include:
-
-#### Preview environments
-
-When you create a PR to add a new feature to your project, you can ask Jenkins X to create a preview environment so you can make your new feature available for preview and testing before the PR is merged.
-
-#### Extensions
-
-It is possible to create extensions to Jenkins X. An extension is code that runs at specific times in the CI/CD process. An extension can provide code that runs when the extension is installed, uninstalled, as well as before and after each pipeline.
-
-#### Serverless Jenkins
-
-Instead of running the Jenkins web application, which continually consumes CPU and memory resources, you can run Jenkins only when you need it. During the past year, the Jenkins community created a version of Jenkins that can run classic Jenkins pipelines via the command line with the configuration defined by code instead of HTML forms.
-
-This capability is now available in Jenkins X. When you create a Jenkins X cluster, you can choose to use Serverless Jenkins. If you do, Jenkins X will deploy [Prow][15] to handle webhooks from GitHub and [Knative][16] to run Jenkins pipelines.
-
-### Jenkins X limitations
-
-Jenkins X also has some limitations that should be considered:
-
- * **Jenkins X is currently limited to projects that use Git:** Jenkins X is opinionated about CI/CD and assumes everybody wants to run and deploy software to Kubernetes and everybody is happy to use Git for source code and defining environments. Also, the Serverless Jenkins feature currently works only with GitHub.
- * **Jenkins X is limited to Kubernetes:** It is true that Jenkins X can run automated builds, testing, and continuous integration for any type of software, but the continuous delivery part targets a Kubernetes namespace managed by Jenkins X.
- * **Jenkins X requires cluster-admin level Kubernetes access:** Jenkins X needs cluster-admin access so it can define and manage a Kubernetes custom resource definition. Hopefully, this is a temporary limitation, because it could be a show-stopper for some.
-
-
-
-### Conclusions
-
-Jenkins X looks to be a good way to implement CI/CD for Kubernetes, and I'm looking forward to putting it to the test in production. Using Jenkins X is also a good way to learn about some useful open source tools for deploying to Kubernetes, including Helm, Draft, Skaffold, Prow, and more. These are things you might want to use even if you decide Jenkins X is not for you. If you're deploying to Kubernetes, take Jenkins X for a spin.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/getting-started-jenkins-x
-
-作者:[Dave Johnson][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/snoopdave
-[b]: https://github.com/lujun9972
-[1]: https://jenkins-x.io/
-[2]: https://jenkins.io/
-[3]: https://docs.docker.com/registry/
-[4]: https://github.com/helm/chartmuseum
-[5]: https://github.com/helm/monocular
-[6]: https://helm.sh
-[7]: https://www.sonatype.com/nexus-repository-oss
-[8]: https://www.weave.works/blog/gitops-operations-by-pull-request
-[9]: https://draft.sh/
-[10]: https://github.com/GoogleContainerTools/skaffold
-[11]: /file/414941
-[12]: https://opensource.com/sites/default/files/uploads/jenkinsx_fig1.png (Developer commits changes, project deployed to staging)
-[13]: /file/414946
-[14]: https://opensource.com/sites/default/files/uploads/jenkinsx_fig2.png (Promoting project to production)
-[15]: https://github.com/kubernetes/test-infra/tree/master/prow
-[16]: https://cloud.google.com/knative/
diff --git a/sources/tech/20181127 Bio-Linux- A stable, portable scientific research Linux distribution.md b/sources/tech/20181127 Bio-Linux- A stable, portable scientific research Linux distribution.md
deleted file mode 100644
index a38acec9da..0000000000
--- a/sources/tech/20181127 Bio-Linux- A stable, portable scientific research Linux distribution.md
+++ /dev/null
@@ -1,79 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (Bio-Linux: A stable, portable scientific research Linux distribution)
-[#]: via: (https://opensource.com/article/18/11/bio-linux)
-[#]: author: (Matt Calverley https://opensource.com/users/mattcalverley)
-[#]: url: ( )
-
-Bio-Linux: A stable, portable scientific research Linux distribution
-======
-Linux distro's integrated software approach offers powerful bioinformatic data analysis with a familiar look and feel.
-
-
-Bio-Linux was introduced and detailed in a [Nature Biotechnology paper in July 2006][1]. The distribution was a group effort by the Natural Environment Research Council in the UK. As the creators and authors point out, the analysis demands of high-throughput “-omic” (genomic, proteomic, metabolomic) science has necessitated the development of integrated computing solutions to analyze the resultant mountains of experimental data.
-
-From this need, Bio-Linux was born. The distribution, [according to its creators][2], serves as a “free bioinformatics workstation platform that can be installed on anything from a laptop to a large server.” The current distro version, Bio-Linux 8, is built on an Ubuntu 14.04 LTS base. Thus, the general look and feel of Bio-Linux is similar to that of Ubuntu.
-
-In my own work as a research immunologist, I can attest to both the need for and success of the integrated software approach in Bio-Linux's design and development. Bio-Linux functions as a true turnkey solution to data pipeline requirements of modern science. As the website mentions, Bio-Linux includes [more than 250 pre-installed software packages][3], many of which are specific to the requirements of bioinformatic data analysis.
-
-The power of this approach becomes immediately evident when you try to duplicate the software installation process under another operating system. Integrating all software components and installing all required dependencies is immensely time-consuming, and in some instances is not even possible outside of the Linux operating system. The Bio-Linux distro provides a portable, stable, integrated environment with pre-installed software sufficient to begin a vast array of bioinformatic analysis tasks.
-
-By now you’re probably saying, “I’m sold—how do I get this amazing distro?”
-
-I’m glad you asked. I'll start by saying that there is excellent documentation on the Bio-Linux website. This [documentation][4] covers both installation instructions and a very thorough overview of using the distro.
-
-The distro can be installed and run locally, run off a CD/DVD or USB, installed on a server, or run out of a virtual machine environment. To begin the installation process for local installation, [download the disk image or ISO][5] for the Bio-Linux distro. The disk image is a 3.3GB file, and depending on your internet download speed, this may be a good time to get a cup of coffee or take a nice nap.
-
-Once the ISO has been downloaded, the Bio-Linux developers recommend using [UNetBootin][6], a freely available cross-platform software package used to make bootable USBs. There is a link provided for UNetBootin on the Bio-Linux website. I can attest to the effectiveness of UNetBootin in both Mac and Linux operating systems.
-
-On Unix family operating systems (Mac OS and Linux), it is also possible to make a bootable USB from the command line using the `dd `command:
-
-```
-sudo umount “USB location”
-
-sudo dd bs=4M if=”ISO location” of =”USB location” conv=fdatasync
-```
-Regardless of the method you use, this might be another good time for a coffee break.
-
-At this point in my installation, UNetBootin appeared to freeze at the `squashfs` file transfer during bootable USB creation. However, a quick check of the Ubuntu disks application confirmed that the file was still being written to the USB. In other words, be patient—it takes quite some time to make the bootable USB.
-
-Once you’ve had your coffee and you have a finished USB in hand, you are ready to use Bio-Linux. As the Bio-Linux website points out, if you are trying to use a bootable USB with a Mac computer (particularly newer hardware versions), you may not be able to boot from the USB. There are workarounds, but they involve configuring the system for dual boot. Likewise, on Windows-based machines, it may be necessary to make changes to the boot order and possibly the secure boot settings for the machine from within BIOS.
-
-From this point, how you use the distro is up to you. You can run the distro from the USB to test it. You can install the distro to your computer. You can even follow the instructions on the Bio-Linux website to make a VM instance of the distro or run it on a server. Regardless of how you use it, you have a high-powered bioinformatic data analysis workstation at your disposal.
-
-Maybe you have a professional need for such a workstation, but even if you never use Bio-Linux as a professional researcher, it could provide a great resource for biology teaching professionals at all levels to introduce students to modern bioinformatics principles. For the price of a laptop and a USB, every school can have an in silico teaching resource to complement classroom lessons in the “-omics” age. Your only limitations are your creativity and the performance of your hardware.
-
-### More on Linux
-
-As an open source operating system with strong community support, the Linux kernel shares many of the strengths common to other successful open source software endeavors. Linux tends to be both stable and amenable to customization. It is also fairly hardware-agnostic, capable of running alongside other operating systems on a wide array of hardware configurations. In fact, installing Linux is a common method of regaining usability from dated hardware that is incapable of running other modern operating systems. Linux is also highly portable and can be run from any bootable external storage device, such as a USB drive, without the need to permanently install the operating system.
-
-It is this combination of stability, customizability, and portability that initially drew me to Linux. Each Linux operating system variant is referred to as a distribution (or distro), and it seems as though there is a Linux distribution for every imaginable computing scenario or desire. The options can actually be rather intimidating, and I suspect they may often discourage people from trying Linux.
-
-“How many different distributions can there possibly be?” you might wonder. If you have a few minutes, or even a few hours, have a look at [DistroWatch.com][7]. As its name implies, this site is devoted to the cataloging of all things Linux distribution-related. For visual learners, there is an amazing [Linux family tree][8] that really puts it into perspective.
-
-While [entire books][9] are devoted to the topic of Linux distributions, the differences often depend on what software is included in the base installation, how the software is managed, and graphical differences affecting the “look and feel” of the distribution. Certainly, there are also subtleties of hardware compatibility, speed, and stability.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/bio-linux
-
-作者:[Matt Calverley][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mattcalverley
-[b]: https://github.com/lujun9972
-[1]: https://www.nature.com/articles/nbt0706-801
-[2]: http://environmentalomics.org/bio-linux/
-[3]: http://environmentalomics.org/bio-linux-software-list/
-[4]: http://nebc.nerc.ac.uk/downloads/courses/Bio-Linux/bl8_latest.pdf
-[5]: http://environmentalomics.org/bio-linux-download/
-[6]: https://unetbootin.github.io/
-[7]: https://distrowatch.com/
-[8]: https://distrowatch.com/images/other/distro-family-tree.png
-[9]: https://www.amazon.com/Introducing-Linux-Distros-Dieguez-Castro/dp/1484213939
diff --git a/sources/tech/20181128 Building custom documentation workflows with Sphinx.md b/sources/tech/20181128 Building custom documentation workflows with Sphinx.md
deleted file mode 100644
index 7d9137fa40..0000000000
--- a/sources/tech/20181128 Building custom documentation workflows with Sphinx.md
+++ /dev/null
@@ -1,126 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (Building custom documentation workflows with Sphinx)
-[#]: via: (https://opensource.com/article/18/11/building-custom-workflows-sphinx)
-[#]: author: ([Mark Meyer](https://opensource.com/users/ofosos))
-[#]: url: ( )
-
-Building custom documentation workflows with Sphinx
-======
-Create documentation the way that works best for you.
-
-
-[Sphinx][1] is a popular application for creating documentation, similar to JavaDoc or Jekyll. However, Sphinx's reStructured Text input allows for a higher degree of customization than those other tools.
-
-This tutorial will explain how to customize Sphinx to suit your workflow. You can follow along using sample code on [GitHub][2].
-
-### Some definitions
-
-Sphinx goes far beyond just enabling you to style text with predefined tags. It allows you to shape and automate your documentation by defining new roles and directives. A role is a single word element that usually is rendered inline in your documentation, while a directive can contain more complex content. These can be contained in a domain.
-
-A Sphinx domain is a collection of directives and roles as well as a few other things, such as an index definition. Your next Sphinx domain could be a specific programming language (Sphinx was developed to create Python's documentation). Or you might have a command line tool that implements the same command pattern (e.g., **tool <command> \--args**) over and over. You can document it with a custom domain, adding directives and indexes along the way.
-
-Here's an example from our **recipe** domain:
-
-```
-The recipe contains `tomato` and `cilantro`.
-
-.. rcp:recipe:: TomatoSoup
- :contains: tomato cilantro salt pepper
-
- This recipe is a tasty tomato soup, combine all ingredients
- and cook.
-```
-
-Now that we've defined the recipe **TomatoSoup** , we can reference it anywhere in our documentation using the custom role **refef**. For example:
-
-```
-You can use the :rcp:reref:`TomatoSoup` recipe to feed your family.
-```
-
-This enables our recipes to show up in two indices: the first lists all recipes, and the second lists all recipes by ingredient.
-
-### What's in a domain?
-
-A Sphinx domain is a specialized container that ties together roles, directives, and indices, among other things. The domain has a name ( **rcp** ) to address its components in the documentation source. It announces its existence to Sphinx in the **setup()** method of the package. From there, Sphinx can find roles and directives, since these are part of the domain.
-
-This domain also serves as the central catalog of objects in this sample. Using initial data, it defines two variables, **objects** and **obj2ingredient**. These contain a list of all objects defined (all recipes) and a hash that maps a canonical ingredient name to the list of objects.
-
-```
-initial_data = {
- 'objects': [], # object list
- 'obj2ingredient': {}, # ingredient -> [objects]
-}
-```
-
-The way we name objects is common across our extension. For each object created, the canonical name is **rcp. <typename>.<objectname>**, where **< typename>** is the Python type of the object, and **< objectname>** is the name the documentation writer gives the object. This enables the extension to use different object types that share the same name.
-
-Having a canonical name and central place for our objects is a huge advantage. Both our indices and our cross-referencing code use this feature.
-
-### Custom roles and directives
-
-In our example, **.. rcp:recipe::** indicates a custom directive. You might think it's overly specific to create custom syntax for these items, but it illustrates the degree of customization you can get in Sphinx. This provides rich markup that structures documents and leads to better docs. Specialization allows us to extract information from our docs.
-
-Our definition for this directive will provide minimal formatting, but it will be functional.
-
-```
-class RecipeNode(ObjectDescription):
- """A custom node that describes a recipe."""
-
- required_arguments = 1
-
- option_spec = {
- 'contains': rst.directives.unchanged_required
- }
-```
-
-For this directive, **required_arguments** tells Sphinx to expect one parameter, the recipe name. **option_spec** lists the optional arguments, including their names. Finally, **has_content** specifies that there will be more reStructured Text as a child to this node.
-
-We also implement multiple methods:
-
- * **handle_signature()** implements parsing the signature of the directive and passes on the object's name and type to its superclass
- * **add_taget_and_index()** adds a target (to link to) and an entry to the index for this node
-
-
-
-### Creating indices
-
-Both **IngredientIndex** and **RecipeIndex** are derived from Sphinx's **Index** class. They implement custom logic to generate a tuple of values that define the index. Note that **RecipeIndex** is a degenerate index that has only one entry. Extending it to cover more object types—and moving from a **RecipeDomain** to a **CookbookDomain** —is not yet part of the code.
-
-Both indices use the method **generate()** to do their work. This method combines the information from our domain, sorts it, and returns it in a list structure that will be accepted by Sphinx. See the [Sphinx Domain API][3] page for more information.
-
-The first time you visit the Domain API page, you may be a little overwhelmed by the structure. But our ingredient index is just a list of tuples, like **('tomato', 'TomatoSoup', 'test', 'rec-TomatoSoup',...)**.
-
-### Referencing recipes
-
-Adding cross-references is not difficult (but it's also not a given). Add an **XRefRole** to the domain and implement the method **resolve_xref()**. Having a custom role to reference a type allows us to unambiguously reference any object, even if two objects have the same name. If you look at the parameters of **resolve_xref()** in **Domain** , you'll see **typ** and **target**. These define the cross-reference type and its target name. We'll use **target** to resolve our destination from our domain's **objects** because we currently have only one type of node.
-
-We can add the cross-reference role to **RecipeDomain** in the following way:
-
-```
-roles = {
- 'reref': XRefRole()
-}
-```
-
-There's nothing for us to implement. Defining a working **resolve_xref()** and attaching an **XRefRole** to the domain is all you need to do.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/building-custom-workflows-sphinx
-
-作者:[Mark Meyer][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ofosos
-[b]: https://github.com/lujun9972
-[1]: http://www.sphinx-doc.org/en/master/
-[2]: https://github.com/ofosos/sphinxrecipes
-[3]: https://www.sphinx-doc.org/en/master/extdev/domainapi.html#sphinx.domains.Index.generate
diff --git a/sources/tech/20181128 How to test your network with PerfSONAR.md b/sources/tech/20181128 How to test your network with PerfSONAR.md
deleted file mode 100644
index 9e9e66ef62..0000000000
--- a/sources/tech/20181128 How to test your network with PerfSONAR.md
+++ /dev/null
@@ -1,148 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (How to test your network with PerfSONAR)
-[#]: via: (https://opensource.com/article/18/11/how-test-your-network-perfsonar)
-[#]: author: (Jessica Repka https://opensource.com/users/jrepka)
-[#]: url: ( )
-
-How to test your network with PerfSONAR
-======
-Set up a single-node configuration to measure your network performance.
-
-
-[PerfSONAR][1] is a network measurement toolkit collection for testing and sharing data on end-to-end network perfomance.
-
-The overall benefit of using network measurement tools like PerfSONAR is they can find issues before they become a large elephant in the room that nobody wants to talk about. Specifically, with the right answers from the right tools, patching can become more stringent, network traffic can be shaped to speed connections across the board, and the network infrastructure design can be improved.
-
-PerfSONAR is licensed under the open source Apache 2.0 license, which makes it more affordable than most tools that do this type of analysis, a key advantage given constrained network infrastructure budgets.
-
-### PerfSONAR versions
-
-Several versions of PerfSONAR are available:
-
- * **Perfsonar-tools:** The command line client version meant for on-demand testing.
- * **Perfsonar-testpoint:** Adds automated testing and central management testing to PerfSONAR-tools. It has an archiving feature, but the archive must be set to an external node.
- * **Perfsonar-core:** Includes everything in the testpoint software, but with local rather than external archiving.
- * **Perfsonar-toolkit:** The core software; it includes a web UI with systemwide security settings.
- * **Perfsonar-centralmanagement:** A completely separate version of PerfSONAR that uses mass grids of nodes to display results. It also has a feature to push out task templates to every node that is sending measurements back to the central host.
-
-
-
-This tutorial will use **PerfSonar-toolkit** ; the tools used in this software include [iPerf, iPerf3][2], and [OWAMP][3].
-
-### Requirements
-
- * **Recommended operating system:** CentOS/RHEL7
- * **ISO:** [Downloading][4] the full installation ISO is the fastest way to get the software up and running. While there is a [Debian version][5], it is much harder and more complicated to use.
- * **Minimum hardware requirements:** 2 cores and 4GB RAM
- * **Recommended hardware:** 200GB HDD, 4 cores, 6GB of RAM
-
-
-
-### Installing and configuring PerfSONAR
-
-The installation is a quick CentOS install where you pick your timezone and configuration for the hard drive and user. I suggest using hard drive autoconfiguration, as you only need to choose "Install Toolkit" and follow the prompts from there.
-
-Select your language.
-
-Select a destination.
-
-After base installation, you see the Linux login screen.
-
-After you log in, you are prompted to create a user ID and password to log into PerfSONAR's web frontend—make sure to remember your login information.
-
-You're also asked to disable SSH access for root and create a new user for sudo; just follow the steps to create the new user.
-
-You can use a provisioning service to automatically provide an IP address and hostname. Otherwise, you will have to set the hostname (optional) and configure the IP address.
-
-### Log into the web frontend
-
-Once the base configuration is complete, you can log into the web frontend via **<http://ipaddress/toolkit>** or **<http://hostname/toolkit>**. The web frontend will appear with the name or IP address of the device you just set up, the list of tools used, a test result area, host information, global node directory, and on-demand testing.
-
-These options appear on the right-hand side of the web page.
-
-
-
-For a single configuration mode, you will need another node to test with. To get one, click on the global node [Lookup Service Directory][6] link, which will bring you to a list of available nodes.
-
-
-Pick an external node from the pScheduler Server list on the left. (I picked ESnet's Atlanta testing server.)
-
-
-Configure the node by clicking the Log In button and entering the user ID and password you created during base configuration.
-
-
-Next, choose Configuration.
-
-
-This takes you to the configuration page, where you can add tests to other nodes by clicking Test, then clicking +Test.
-
-
-After you click +Test, you'll see a pop-up window with some drop-down options. For this tutorial, I used One-Way Active Measurement Protocol (OWAMP) testing for one-way latency against the ESnet Atlanta node that is IPv4.
-
-#### Side bar
-
- * The OWAMP measures unidirectional characteristics such as one-way delay and one-way loss. High-precision measurement of these one-way IP performance metrics became possible with wider availability of good time sources (such as GPS and CDMA). OWAMP enables the interoperability of these measurements.
- * IPv4 is a fourth version of the Internet Protocol, which today is the main protocol to most of the internet. IPv4 protocol defines the rules for the operation of computer networks on the packet-exchange principle. This is a low-level protocol that is responsible for the connection between the nodes of the network on the basis of IP Addresses.
- * The IPv4 node is a perfsonar testing node that only does network testing using the IPv4 protocols. The perfsonar testing node you connect to is the same application that is built in this documentation.
-
-
-
-The drop-down should use the server's main interface. Confirm that the test is enabled (the Test Status switch will be green) and click the OK button at the bottom of the window.
-
-
-Once you have added the test information, click the Save button at the bottom of the page.
-
-
-You will see information about all of the scheduled tests and the hosts they are testing. You can add more hosts to the test by clicking the Settings icon in the Actions column.
-
-
-The testing intervals are automatically set according to the recommended settings. If the test frequency increases, the tests will still run OK, but your hard drive may fill up with data more quickly.
-
-Once the test finishes, click View Public Dashboard to see the data that's returned. Note that it may take anywhere from five minutes to several hours to access the first sets of data.
-
-
-The public dashboard shows a high-level summary dataset. If you want more information, click Details.
-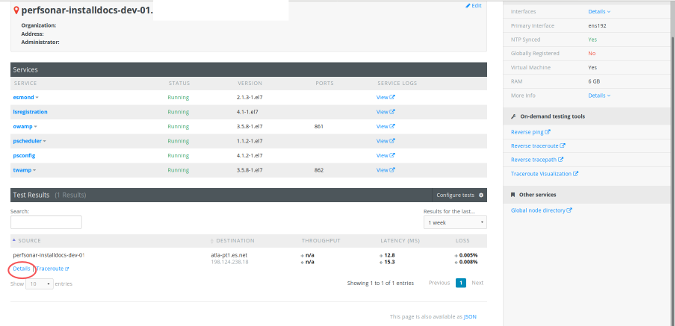
-
-You'll see a larger graph and have the option to expand the graph over a year as data is collected.
-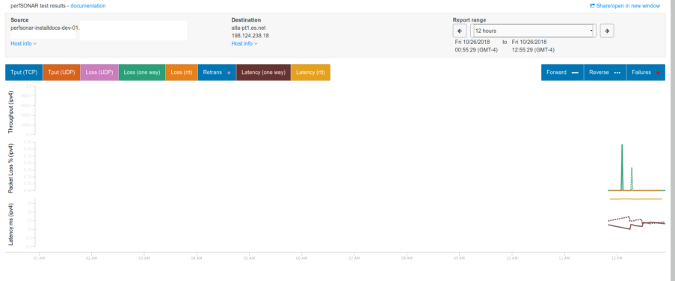
-
-PerfSONAR is now up, running, and testing the network. You can also test with two nodes inside your network (or one internal network node and one external node).
-
-### What can you learn about your network?
-
-In the time I've been using PerfSONAR, I've already uncovered the following issues:
-
- * Asymmetrical throughput
- * Fiber outages
- * Speed on circuit not meeting contractual agreement
- * Internal network slowdowns due to misconfigurations
- * Incorrect routes
-
-
-
-Have you used PerfSONAR or a similar tool? What benefits have you seen?
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/11/how-test-your-network-perfsonar
-
-作者:[Jessica Repka][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/jrepka
-[b]: https://github.com/lujun9972
-[1]: https://www.perfsonar.net/
-[2]: https://iperf.fr/
-[3]: http://software.internet2.edu/owamp/
-[4]: http://downloads.perfsonar.net/toolkit/pS-Toolkit-4.1.3-CentOS7-FullInstall-x86_64-2018Oct24.iso
-[5]: http://docs.perfsonar.net/install_options.html#
-[6]: http://stats.es.net/ServicesDirectory/
diff --git a/sources/tech/20181129 The Top Command Tutorial With Examples For Beginners.md b/sources/tech/20181129 The Top Command Tutorial With Examples For Beginners.md
deleted file mode 100644
index df932ebb83..0000000000
--- a/sources/tech/20181129 The Top Command Tutorial With Examples For Beginners.md
+++ /dev/null
@@ -1,192 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (The Top Command Tutorial With Examples For Beginners)
-[#]: via: (https://www.ostechnix.com/the-top-command-tutorial-with-examples-for-beginners/)
-[#]: author: ([SK](https://www.ostechnix.com/author/sk/))
-[#]: url: ( )
-
-The Top Command Tutorial With Examples For Beginners
-======
-
-
-
-As a Linux administrator, you may need to need to know some basic details of your Linux system, such as the currently running processes, average system load, cpu and memory usage etc., at some point. Thankfully, we have a command line utility called **“top”** to get such details. The top command is a well-known and most widely used utility to display dynamic real-time information about running processes in Unix-like operating systems. In this brief tutorial, we are going to see some common use cases of top command.
-
-### Top Command Examples
-
-**Monitor all processes**
-
-To start monitoring the running processes, simply run the top command without any options:
-
-```
-$ top
-```
-
-Sample output:
-
-
-
-As you see in the above screenshot, top command displays the list of processes in multiple columns. Each column displays details such as pid, user, cpu usage, memory usage. Apart from the list of processes, you will also see the brief stats about average system load, number of tasks, cpu usage, memory usage and swap usage on the top.
-
-Here is the explanation of the parameters mentioned above.
-
- * **PID** – Process id of the task.
- * **USER** – Username of the the task’s owner.
- * **PR** – Priority of the task.
- * **NI** – Nice value of the task. If the nice value is negative, the process gets higher priority. If the nice value is positive, the priority is low. Refer [**this guide**][1] to know more about nice.
- * **VIRT** – Total amount of virtual memory used by the task.
- * **RES** – Resident Memory Size, the non-swapped physical memory a task is currently using.
- * **SHR** – Shared Memory Size. The amount of shared memory used by a task.
- * **S** – The status of the process (S=sleep R=running Z=zombie).
- * **%CPU** – CPU usage. The task’s share of the elapsed CPU time since the last screen update, expressed as a percentage of total CPU time.
- * **%MEM** – Memory Usage. A task’s currently resident share of available physical memory.
- * **TIME+** – Total CPU time used by the task since it has started, precise to the hundredths of a second.
- * **COMMAND** – Name of the running program.
-
-
-
-**Display path of processes**
-
-If you want to see the absolute path of the running processes, just press **‘c’**. Now you will see the actual path of the programs under the COMMAND column in the below screenshot.
-
-![][3]
-
-**Monitor processes owned by a specific user**
-
-If you run top command without any options, it will list all running processes owned by all users. How about displaying processes owned by a specific user? It is easy! To show the processes owned by a given user, for example **sk** , simply run:
-
-```
-$ top -u sk
-```
-
-
-
-**Do not show idle/zombie processes**
-
-Instead of viewing all processes, you can simply ignore the idle or zombie processes. The following command will not show any idle or zombie processes:
-
-```
-$ top -i
-```
-
-**Monitor processes with PID**
-
-If you know the PID of any processes, for example 21180, you can monitor that process using **-p** flag.
-
-```
-$ top -p 21180
-```
-
-You can specify multiple PIDs with comma-separated values.
-
-**Monitor processes with process name**
-
-I don’t know PID, but know only the process name. How to monitor it? Simple!
-
-```
-$ top -p $(pgrep -d ',' firefox)
-```
-
-Here, **firefox** is the process name and **‘pgrep -d’** picks the respective PID from the process name.
-
-**Display processes by CPU usage**
-
-Sometimes, you might want to display processes sorted by CPU usage. If so, use the following command:
-
-```
-$ top -o %CPU
-```
-
-![][4]
-
-The processes with higher CPU usage will be displayed on the top. Alternatively, you sort the processes by CPU usage by pressing **SHIFT+p**.
-
-**Display processes by Memory usage**
-
-Similarly, to order processes by memory usage, the command would be:
-
-```
-$ top -o %MEM
-```
-
-**Renice processes**
-
-You can change the priority of a process at any time using the option **‘r’**. Run the top command and press **r** and type the PID of a process to change its priority.
-
-![][5]
-
-Here, **‘r’** refers renice.
-
-**Set update interval**
-
-Top program has an option to specify the delay between screen updates. If want to change the delay-time, say 5 seconds, run:
-
-```
-$ top -d 5
-```
-
-The default value is **3.0** seconds.
-
-If you already started the top command, just press **‘d’** and type delay-time and hit ENTER key.
-
-![][6]
-
-**Set number of iterations (repetition)**
-
-By default, top command will keep running until you press **q** to exit. However, you can set the number of iterations after which top will end. For instance, to exit top command automatically after 5 iterations, run:
-
-```
-$ top -n 5
-```
-
-**Kill running processes**
-
-To kill a running process, simply press **‘k’** and type its PID and hit ENTER key.
-
-![][7]
-
-Top command supports few other options as well. For example, press **‘z’** to switch between mono and color output. It will help you to easily highlight running processes.
-
-![][8]
-
-Press **‘h’** to view all available keyboard shortcuts and help section.
-
-To quit top, just press **q**.
-
-At this stage, you will have a basic understanding of top command. For more details, refer man pages.
-
-```
-$ man top
-```
-
-As you can see, using Top command to monitor the running processes isn’t that hard. Top command is easy to learn and use!
-
-And, that’s all for now. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/the-top-command-tutorial-with-examples-for-beginners/
-
-作者:[SK][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[b]: https://github.com/lujun9972
-[1]: https://www.ostechnix.com/change-priority-process-linux/
-[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]: http://www.ostechnix.com/wp-content/uploads/2018/11/top-command-2.png
-[4]: http://www.ostechnix.com/wp-content/uploads/2018/11/top-command-4.png
-[5]: http://www.ostechnix.com/wp-content/uploads/2018/11/top-command-8.png
-[6]: http://www.ostechnix.com/wp-content/uploads/2018/11/top-command-7.png
-[7]: http://www.ostechnix.com/wp-content/uploads/2018/11/top-command-5.png
-[8]: http://www.ostechnix.com/wp-content/uploads/2018/11/top-command-6.png
diff --git a/sources/tech/20181203 ANGRYsearch - Quick Search GUI Tool for Linux.md b/sources/tech/20181203 ANGRYsearch - Quick Search GUI Tool for Linux.md
deleted file mode 100644
index 7c8952549f..0000000000
--- a/sources/tech/20181203 ANGRYsearch - Quick Search GUI Tool for Linux.md
+++ /dev/null
@@ -1,108 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: subject: (ANGRYsearch – Quick Search GUI Tool for Linux)
-[#]: via: (https://itsfoss.com/angrysearch/)
-[#]: author: (John Paul https://itsfoss.com/author/john/)
-[#]: url: ( )
-
-ANGRYsearch – Quick Search GUI Tool for Linux
-======
-
-A search application is one of the most important tools you can have on your computer. Most are slow to indexes your system and find results. However, today we will be looking at an application that can display results as you type. Today, we will be looking at ANGRYsearch.
-
-### What is ANGRYsearch?
-
-![][1]
-Newly installed ANGRYsearch
-
-[ANGRYsearch][2] is a Python-based application that delivers results as you type your search query. The overall idea and design of the application are both inspired by [Everything][3] a search tool for Windows. (I discovered Everything ad couple of years ago and install it wherever I use Windows.)
-
-ANGRYsearch is able to display the search results so quickly because it only indexes filenames. After you install ANGRYsearch, you create a database of filenames by indexing your system. ANGRYsearch then quickly filters filenames as you type your query.
-
-Even though there is not much to ANGRYsearch, there are several things you can do to customize the experience. First, ANGRYsearch has two different display modes: lite and full. Lite mode only shows the filename and path. Full mode displays filename, path, size, and date of the last modification. Full mode, obviously, takes longer to display. The default is lite mode. In order to switch to full mode, you need to edit the config file at `~/.config/angrysearch/angrysearch.conf`. In that file change the `angrysearch_lite` value to false.
-
-ANGRYsearch also has three different search modes: fast, slow, and regex. Fast mode displays filenames that start with your search term. For example, if you had a folder full of the latest releases of a bunch of Linux distros and you searched “Ubuntu”, ANGRYsearch would display Ubuntu, Ubuntu Mate, Ubuntu Budgie, but not Kubuntu, Xubuntu, or Lubuntu. Fast mode is on by default and can be turned off by unchecking the checkbox next to the “update” button. Slow mode is slightly slower (obviously), but it will display files that have your search term anywhere in their name. In the previous example, ANGRYsearch would show all Ubuntu distros. Regex mode is the slowest and most precise. It uses [regular expressions][4] and is case insensitive. Regex mode is activated by pressing F8.
-
-You can also tell ANGRYsearch to ignore certain folders when it indexes your system. Just click the “update” button and enter the names of the folders you want to be ignored in the space provided. You can also choose from several icon themes, though it doesn’t make that much difference.
-
-![][5]Fast mode results
-
-### Installing ANGRYsearch on Linux
-
-ANGRYsearch is available in the [Arch User Repository][6]. It has also been packaged for [Fedora and openSUSE][7].
-
-To install on other distros, follow these instructions. Instructions are written for a Debian or Ubuntu based system.
-
-ANGRYsearch depends on `python3-pyqt5` and`xdg-utils` so you will need to install them first. Most distros have `xdg-utils`already installed.
-
-`sudo apt install python3-pyqt5`
-
-Next. download the latest version (1.0.1).
-
-`wget https://github.com/DoTheEvo/ANGRYsearch/archive/v1.0.1.zip`
-
-Now, unzip the archive file.
-
-`unzip v1.0.1.zip`
-
-Next, we will navigate to the new folder (ANGRYsearch-1.0.1) and run the installer.
-
-`cd ANGRYsearch-1.0.1`
-
-`chmod +x install.sh`
-
-`sudo ./install.sh`
-
-The installation process is very quick, so don’t be surprised when a new command line is displayed as soon as you hit `Enter`.
-
-The first time that you start ANGRYsearch, you will need to index your system. ANGRYsearch does not automatically keep its database updated. You can use `crontab` to schedule a system scan.
-
-To open a text editor to create a new cronjob, use `crontab -e`. To make sure that the ANGRYsearch database is updated every 6 hours, use this command `0 */6 选题模板.txt 中文排版指北.md core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE published README.md scripts sources translated 选题模板.txt 中文排版指北.md core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE published README.md scripts sources translated 选题模板.txt 中文排版指北.md core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE published README.md scripts sources translated /usr/share/angrysearch/angrysearch_update_database.py`. `crontab` does not run the job if it is powered off when the timer does off. In some case, you may need to manually update the database, but it should not take long.
-
-![][8]ANGRYsearch update/options menu
-
-### Experience
-
-In the past, I was always frustrated by how painfully slow it was to search my computer. I knew that Windows had the Everything app, but I thought Linux out of luck. It didn’t even occur to me to look for something similar on Linux. I’m glad I accidentally stumbled upon ANGRYsearch.
-
-I know there will be quite a few people complaining that ANGRYsearch only searches filenames, but most of the time that is all I need. Thankfully, most of the time I only need to remember part of the name to find what I am looking for.
-
-The only thing that annoys me about ANGRYsearch is that fact that it does not automatically update its database. You’d think there would be a way for the installer to create a cron job when you install it.
-
-![][9]Slow mode results
-
-### Final Thoughts
-
-Since ANGRYsearch is basically a Linux port of one of my favorite Windows apps, I’m pretty happy with it. I plan to install it on all my systems going forward.
-
-I know that I have ragged on other Linux apps for not being packaged for easy install, but I can’t do the same for ANGRYsearch. The installation process is pretty easy. I would definitely recommend it for Linux noobs.
-
-Have you ever used [ANGRYsearch][2]? If not, what is your favorite Linux search application? Let us know in the comments below.
-
-If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][10].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/angrysearch/
-
-作者:[John Paul][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[b]: https://github.com/lujun9972
-[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/angrysearch3.jpg?resize=800%2C627&ssl=1
-[2]: https://github.com/dotheevo/angrysearch/
-[3]: https://www.voidtools.com/
-[4]: http://www.aivosto.com/articles/regex.html
-[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/angrysearch1.jpg?resize=800%2C627&ssl=1
-[6]: https://aur.archlinux.org/packages/angrysearch/
-[7]: https://software.opensuse.org/package/angrysearch
-[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/angrysearch2.jpg?resize=800%2C626&ssl=1
-[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/angrysearch4.jpg?resize=800%2C627&ssl=1
-[10]: http://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20181206 How to view XML files in a web browser.md b/sources/tech/20181206 How to view XML files in a web browser.md
deleted file mode 100644
index 6060c792e2..0000000000
--- a/sources/tech/20181206 How to view XML files in a web browser.md
+++ /dev/null
@@ -1,109 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to view XML files in a web browser)
-[#]: via: (https://opensource.com/article/18/12/xml-browser)
-[#]: author: (Greg Pittman https://opensource.com/users/greg-p)
-
-How to view XML files in a web browser
-======
-Turn XML files into something more useful.
-
-
-Once you learn that HTML is a form of XML, you might wonder what would happen if you tried to view an XML file in a browser. The results are quite disappointing—Firefox shows you a banner at the top of the page that says, "This XML file does not appear to have any style information associated with it. The document tree is shown below." The document tree looks like the file would look in an editor:
-
-This is the beginning of the **menu.xml** file for the online manual that comes with [Scribus][1], to which I'm a contributor. Although you see blue text, they are not clickable links. I wanted to be able to view this in a regular browser, since sometimes I need to go back and forth from the canvas in Scribus to the manual to figure out how to do something (maybe to see if I need to edit the manual to straighten out some misinformation or to add some missing information).
-
-The way to help a browser know what to do with these XML tags is by using XSLT—Extensible Stylesheet Language Transformations. In a broad sense, you could use XSLT to transform XML to a variety of outputs, or even HTML to XML. Here I want to use it to present the XML tags to a browser as suitable HTML.
-
-One slight modification needs to happen to the XML file:
-
-
-
-Adding this second line to the file tells the browser to look for a file named **scribus-manual.xsl** for the style information. The more important part is to create this XSL file. Here is the complete listing of **scribus-manual.xsl** for the Scribus manual:
-
-```
-<?xml version="1.0" encoding="utf-8"?>
-
-<xsl:stylesheet version="1.0"
- xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
- <xsl:template match="/">
- <html>
- <title>Scribus Online Manual</title>
-<style type="text/css">
-h2,h3,h4 { text-indent: 50px;}
-ul { margin-left: 100px;}
-</style>
-<table border="0" cellspacing="0" cellpadding="0" width="100%"
-bgcolor="#183867" >
- <tr>
- <td align="left"><img src="images/docheader1.png" width="222"
-height="87"/></td>
- <td align="right"><img src="images/docheader2.png" width="318"
-height="87"/></td>
- </tr>
-</table>
-
- <body bgcolor="#ffffff">
-
- <xsl:for-each select="menu">
- <xsl:for-each select="area">
- <h3><a href="{@file}" ><xsl:value-of select = "@text" /></a></h3>
- <xsl:for-each select="submenuitem">
- <h4><a href="{@file}" ><xsl:value-of select = "@text" /></a></h4>
- <xsl:for-each select="submenuitem">
- <p><ul>
- <li><a href="{@file}" ><xsl:value-of select = "@text" /></a></li>
- </ul></p>
- </xsl:for-each>
- </xsl:for-each>
- <xsl:for-each select="area">
- <h3><a href="{@file}" ><xsl:value-of select = "@text" /></a></h3>
- </xsl:for-each>
- </xsl:for-each>
- </xsl:for-each>
- </body>
- </html>
- </xsl:template>
-</xsl:stylesheet>
-```
-
-This looks a lot more like HTML, and you can see it contains a number of HTML tags. After some preliminary tags and some particulars about displaying H2, H3, and H4 tags, you see a Table tag. This adds a graphical heading at the top of the page and uses some images already in the documentation files.
-
-After this, you get into the process of dissecting the various **submenuitem** tags, trying to create the nested listing structure as it appears in Scribus when you view the manual. One feature I did not try to duplicate is the ability to collapse and expand **submenuitem** areas. As you can imagine, it takes some time to sort through the number of nested lists you need to create, but when I finished, here is how it looked:
-
-
-
-This minimal editing to **menu.xml** does not interfere with Scribus' ability to show the manual in its own browser. I put this modified **menu.xml** file and the **scribus-manual.xsl** in the English documentation folder for 1.5.x versions of Scribus, so anyone using these versions can simply point their browser to the **menu.xml** file and it should show up just like you see above.
-
-A much bigger chore I took on a few years ago was to create a version of the ICD10 (International Classification of Diseases, version 10) when it came out. Many changes were made from the previous version (ICD9) to 10. These are important since these codes must be used for diagnostic purposes in medical practice. You can easily download XML files from the US [Centers for Medicare and Medicaid][2] website since it is public information, but—just as with the Scribus manual—these files are hard to use.
-
-Here is the beginning of the tabular listing of diseases:
-
-
-
-One of the features I created was the color coding used in the listing shown here:
-
-
-
-As with **menu.xml** , the only editing I did in this **Tabular.xml** file was to add **<?xml-stylesheet type="text/xsl" href="tabular.xsl"? >** as the second line of the file. I started this project with the 2014 version, and I was quite pleased to find that the original **tabular.xsl** stylesheet worked perfectly when the 2016 version came out, which is the last one I worked on. The** Tabular.xml** file is 8.4MB, quite large for a plaintext file. It takes a few seconds to load into a browser, but once it's loaded, navigation is fast.
-
-While you may not often have to deal with an XML file in this way, if you do, I hope this article shows that your file can easily be turned into something much more usable.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/xml-browser
-
-作者:[Greg Pittman][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/greg-p
-[b]: https://github.com/lujun9972
-[1]: https://www.scribus.net/
-[2]: https://www.cms.gov/
diff --git a/sources/tech/20181207 5 Screen Recorders for the Linux Desktop.md b/sources/tech/20181207 5 Screen Recorders for the Linux Desktop.md
deleted file mode 100644
index 4dd47e948a..0000000000
--- a/sources/tech/20181207 5 Screen Recorders for the Linux Desktop.md
+++ /dev/null
@@ -1,177 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (5 Screen Recorders for the Linux Desktop)
-[#]: via: (https://www.linux.com/blog/intro-to-linux/2018/12/5-screen-recorders-linux-desktop)
-[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
-
-5 Screen Recorders for the Linux Desktop
-======
-
-
-
-There are so many reasons why you might need to record your Linux desktop. The two most important are for training and for support. If you are training users, a video recording of the desktop can go a long way to help them understand what you are trying to impart. Conversely, if you’re having trouble with one aspect of your Linux desktop, recording a video of the shenanigans could mean the difference between solving the problem and not. But what tools are available for the task? Fortunately, for every Linux user (regardless of desktop), there are options available. I want to highlight five of my favorite screen recorders for the Linux desktop. Among these five, you are certain to find one that perfectly meets your needs. I will only be focusing on those screen recorders that save as video. What video format you prefer may or may not dictate which tool you select.
-
-And, without further ado, let’s get on with the list.
-
-### Simple Screen Recorder
-
-I’m starting out with my go-to screen recorder. I use [Simple Screen Recorder][1] on a daily basis, and it never lets me down. This particular take on the screen recorder is available for nearly every flavor of Linux and is, as the name implies, very simple to use. With Simple Screen Recorder you can select a single window, a portion of the screen, or the entire screen to record. One of the best features of Simple Screen Recorder is the ability to save profiles (Figure 1), which allows you to configure the input for a recording (including scaling, frame rate, width, height, left edge and top edge spacing, and more). By saving profiles, you can easily use a specific profile to meet a unique need, without having to go through the customization every time. This is handy for those who do a lot of screen recording, with different input variables for specific jobs.
-
-![Simple Screen Recorder ][3]
-
-Figure 1: Simple Screen Recorder input profile window.
-
-[Used with permission][4]
-
-Simple screen recorder also:
-
- * Records audio input
-
- * Allows you to pause and resume recording
-
- * Offers a preview during recording
-
- * Allows for the selection of video containers and codecs
-
- * Adds timestamp to file name (optional)
-
- * Includes hotkey recording and sound notifications
-
- * Works well on slower machines
-
- * And much more
-
-
-
-
-Simple Screen Recorder is one of the most reliable screen recording tools I have found for the Linux desktop. Simple Screen Recorder can be installed from the standard repositories on many desktops, or via easy to follow instructions on the [application download page][5].
-
-### Gtk-recordmydesktop
-
-The next entry, [gtk-recordmydesktop][6], doesn’t give you nearly the options found in Simple Screen Recorder, but it does offer a command line component (for those who prefer not working with a GUI). The simplicity that comes along with this tool also means you are limited to a specific video output format (.ogv). That doesn’t mean gtk-recordmydesktop isn’t without appeal. In fact, there are a few features that make this option in the genre fairly appealing. First and foremost, it’s very simple to use. Second, the record window automatically gets out of your way while you record (as opposed to Simple Screen Recorder, where you need to minimize the recording window when recording full screen). Another feature found in gtk-recordmydesktop is the ability to have the recording follow the mouse (Figure 2).
-
-![gtk-recordmydesktop][8]
-
-Figure 2: Some of the options for gtk-recordmydesktop.
-
-[Used with permission][4]
-
-Unfortunately, the follow the mouse feature doesn’t always work as expected, so chances are you’ll be using the tool without this interesting option. In fact, if you opt to go the gtk-recordmydesktop route, you should understand the GUI frontend isn’t nearly as reliable as is the command line version of the tool. From the command line, you could record a specific position of the screen like so:
-
-```
-recordmydesktop -x X_POS -y Y_POS --width WIDTH --height HEIGHT -o FILENAME.ogv
-```
-
-where:
-
- * X_POS is the offset on the X axis
-
- * Y_POS is the offset on the Y axis
-
- * WIDTH is the width of the screen to be recorded
-
- * HEIGHT is the height of the screen to be recorded
-
- * FILENAME is the name of the file to be saved
-
-
-
-
-To find out more about the command line options, issue the command man recordmydesktop and read through the manual page.
-
-### Kazam
-
-If you’re looking for a bit more than just a recorded screencast, you might want to give Kazam a go. Not only can you record a standard screen video (with the usual—albeit limited amount of—bells and whistles), you can also take screenshots and even broadcast video to YouTube Live (Figure 3).
-
-![Kazam][10]
-
-Figure 3: Setting up YouTube Live broadcasting in Kazam.
-
-[Used with permission][4]
-
-Kazam falls in line with gtk-recordmydesktop, when it comes to features. In other words, it’s slightly limited in what it can do. However, that doesn’t mean you shouldn’t give Kazam a go. In fact, Kazam might be one of the best screen recorders out there for new Linux users, as this app is pretty much point and click all the way. But if you’re looking for serious bells and whistles, look away.
-
-The version of Kazam, with broadcast goodness, can be found in the following repository:
-
-```
-ppa:sylvain-pineau/kazam
-```
-
-For Ubuntu (and Ubuntu-based distributions), install with the following commands:
-
-```
-sudo apt-add-repository ppa:sylvain-pineau/kazam
-
-sudo apt-get update
-
-sudo apt-get install kazam -y
-```
-
-### Vokoscreen
-
-The [Vokoscreen][11] recording app is for new-ish users who need more options. Not only can you configure the output format and the video/audio codecs, you can also configure it to work with a webcam (Figure 4).
-
-![Vokoscreen][13]
-
-Figure 4: Configuring a web cam for a Vokoscreen screen recording.
-
-[Used with permission][4]
-
-As with most every screen recording tool, Vokoscreen allows you to specify what on your screen to record. You can record the full screen (even selecting which display on multi-display setups), window, or area. Vokoscreen also allows you to select a magnification level (200x200, 400x200, or 600x200). The magnification level makes for a great tool to highlight a specific section of the screen (the magnification window follows your mouse).
-
-Like all the other tools, Vokoscreen can be installed from the standard repositories or cloned from its [GitHub repository][14].
-
-### OBS Studio
-
-For many, [OBS Studio][15] will be considered the mack daddy of all screen recording tools. Why? Because OBS Studio is as much a broadcasting tool as it is a desktop recording tool. With OBS Studio, you can broadcast to YouTube, Smashcast, Mixer.com, DailyMotion, Facebook Live, Restream.io, LiveEdu.tv, Twitter, and more. In fact, OBS Studio should seriously be considered the de facto standard for live broadcasting the Linux desktop.
-
-Upon installation (the software is only officially supported for Ubuntu Linux 14.04 and newer), you will be asked to walk through an auto-configuration wizard, where you setup your streaming service (Figure 5). This is, of course, optional; however, if you’re using OBS Studio, chances are this is exactly why, so you won’t want to skip out on configuring your default stream.
-
-![OBS Studio][17]
-
-Figure 5: Configuring your streaming service for OBS Studio.
-
-[Used with permission][4]
-
-I will warn you: OBS Studio isn’t exactly for the faint of heart. Plan on spending a good amount of time getting the streaming service up and running and getting up to speed with the tool. But for anyone needing such a solution for the Linux desktop, OBS Studio is what you want. Oh … it can also record your desktop screencast and save it locally.
-
-### There’s More Where That Came From
-
-This is a short list of screen recording solutions for Linux. Although there are plenty more where this came from, you should be able to fill all your desktop recording needs with one of these five apps.
-
-Learn more about Linux through the free ["Introduction to Linux" ][18]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/intro-to-linux/2018/12/5-screen-recorders-linux-desktop
-
-作者:[Jack Wallen][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/jlwallen
-[b]: https://github.com/lujun9972
-[1]: http://www.maartenbaert.be/simplescreenrecorder/
-[2]: /files/images/screenrecorder1jpg
-[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/screenrecorder_1.jpg?itok=hZJ5xugI (Simple Screen Recorder )
-[4]: /licenses/category/used-permission
-[5]: http://www.maartenbaert.be/simplescreenrecorder/#download
-[6]: http://recordmydesktop.sourceforge.net/about.php
-[7]: /files/images/screenrecorder2jpg
-[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/screenrecorder_2.jpg?itok=TEGXaVYI (gtk-recordmydesktop)
-[9]: /files/images/screenrecorder3jpg
-[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/screenrecorder_3.jpg?itok=cvtFjxen (Kazam)
-[11]: https://github.com/vkohaupt/vokoscreen
-[12]: /files/images/screenrecorder4jpg
-[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/screenrecorder_4.jpg?itok=c3KVS954 (Vokoscreen)
-[14]: https://github.com/vkohaupt/vokoscreen.git
-[15]: https://obsproject.com/
-[16]: /files/images/desktoprecorder5jpg
-[17]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/desktoprecorder_5.jpg?itok=xyM-dCa7 (OBS Studio)
-[18]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20181207 Automatic continuous development and delivery of a hybrid mobile app.md b/sources/tech/20181207 Automatic continuous development and delivery of a hybrid mobile app.md
deleted file mode 100644
index c513f36017..0000000000
--- a/sources/tech/20181207 Automatic continuous development and delivery of a hybrid mobile app.md
+++ /dev/null
@@ -1,102 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Automatic continuous development and delivery of a hybrid mobile app)
-[#]: via: (https://opensource.com/article/18/12/hybrid-mobile-app-development)
-[#]: author: (Angelo Manganiello https://opensource.com/users/amanganiello90)
-
-Automatic continuous development and delivery of a hybrid mobile app
-======
-Hybrid apps are a good middle ground between native and web apps.
-
-
-Offering a mobile app is essentially a business requirement for organizations today. One of the first steps in developing an app is to understand the different types—native, hybrid (or cross-platform), and web—so you can decide which one will best meet your needs.
-
-### Native is better, right?
-
-**Native apps** represent the vast majority of applications that people download every day. Native applications are developed specifically for an operating system. Thus, a native iOS application will not work on an Android system and vice versa. To develop a native app, you need to know two things:
-
- 1. How to develop in a specific programming language (e.g., Swift for Apple devices; Java for Android)
- 2. The app will not work for other platforms
-
-
-
-Even though native apps will work only on the platform they're developed for, they have several notable advantages over hybrid and web apps:
-
- * Increased speed, reliability, and responsiveness and higher resolution, all of which provide a better user experience
- * May work offline/without internet service
- * Easier access to all phone features (e.g., accelerometer, camera, microphone)
-
-
-
-### But my business is still linked to the web…
-
-Most companies have focused their resources on web development and now want to enter the mobile market. But many don't have the right technical resources to develop a native app for each platform. For these companies, **hybrid** development is the right choice. In this model, developers can use their existing frontend skills to develop a single, cross-platform mobile app.
-
-![Hybrid mobile apps][2]
-
-Hybrid apps are a good middle ground: they're faster and less expensive to develop than native apps, and they offer more possibilities than web apps. The tradeoffs are they don't perform as well as native apps and developers can't maintain their existing tight focus on web development (as they could with web apps).
-
-If you already are a fan of the [Angular][3] cross-platform development framework, I recommend trying the [Ionic][4] framework, which "lets web developers build, test, and deploy cross-platform hybrid mobile apps." I see Ionic as an extension of the [Apache Cordova][5] framework, which enables a normal web app (JS, HTML, or CSS) to run as a mobile app in a container. Ionic uses the base Cordova features that support the Angular development for its user interface.
-
-The advantage of this approach is simple: the Angular paradigm is maintained, so developers can continue writing [TypeScript][6] files but target a build for Android, iOS, and Windows by properly configuring the development environment. It also provides two important tools:
-
- * An appealing design and widget that are very similar to a native app's, so your hybrid app will look less "web"
- * Cordova Plugins allow the app to communicate with all phone features
-
-
-
-### What about the Node.js backend?
-
-The programming world likes to standardize, which is why hybrid apps are so popular. Frontend developers' common skills are useful in the mobile world. But if we have a technology stack for the user interface, why not focus on a single backend with the same programming paradigm?
-
-This makes [Node.js][7] an appealing option. Node.js is a JavaScript runtime built on the Chrome V8 JavaScript engine. It can make the API development backend very fast and easy, and it integrates fully with web technologies. You can develop a Cordova plugin, using your Node.js backend, internally in your hybrid app, as I did with the [nodejs-cordova-plugin][8]. This plugin, following the Cordova guidelines, integrates a mobile-compatible version of the Node.js platform to provide a full-stack mobile app.
-
-If you need a simple CRUD Node.js backend, you can use my [API][9] [node generator][9] that generates an app using a [MongoDB][10] embedded database.
-
-![Cordova Full Stack application][12]
-
-### Deploying your app
-
-Open source offers everything you need to deploy your app in the best way. You just need a GitHub repository and a good continuous integration tool. I recommend [Travis-ci][13], an excellent tool that allows you to build and deploy your product for every commit.
-
-Travis-ci is a fork of the better known [Jenkins][14]. Like with Jenkins, you have to configure your pipeline through a configuration file (in this case a **.travis.yml** file) in your GitHub repo. See the [.travis.yml file][15] in my repository as an example.
-
-
-
-In addition, this pipeline automatically delivers and installs your app on [Appetize.io][16], a web-based iOS simulator and Android emulator, for testing.
-
-You can learn more in the [Cordova Android][17] section of my GitHub repository.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/hybrid-mobile-app-development
-
-作者:[Angelo Manganiello][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/amanganiello90
-[b]: https://github.com/lujun9972
-[1]: /file/416441
-[2]: https://opensource.com/sites/default/files/uploads/1-title.png (Hybrid mobile apps)
-[3]: https://angular.io/
-[4]: https://ionicframework.com/
-[5]: https://cordova.apache.org/
-[6]: https://www.typescriptlang.org/
-[7]: https://nodejs.org/
-[8]: https://github.com/fullStackApp/nodejs-cordova-plugin
-[9]: https://github.com/fullStackApp/generator-full-stack-api
-[10]: https://www.mongodb.com/
-[11]: /file/416351
-[12]: https://opensource.com/sites/default/files/uploads/2-cordova-full-stack-app.png (Cordova Full Stack application)
-[13]: https://travis-ci.org/
-[14]: https://jenkins.io/
-[15]: https://github.com/amanganiello90/java-angular-web-app/blob/master/.travis.yml
-[16]: https://appetize.io/
-[17]: https://github.com/amanganiello90/java-angular-web-app#cordova-android
diff --git a/sources/tech/20181209 How do you document a tech project with comics.md b/sources/tech/20181209 How do you document a tech project with comics.md
deleted file mode 100644
index 02d4981875..0000000000
--- a/sources/tech/20181209 How do you document a tech project with comics.md
+++ /dev/null
@@ -1,100 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How do you document a tech project with comics?)
-[#]: via: (https://jvns.ca/blog/2018/12/09/how-do-you-document-a-tech-project-with-comics/)
-[#]: author: (Julia Evans https://jvns.ca/)
-
-How do you document a tech project with comics?
-======
-
-Every so often I get email from people saying basically “hey julia! we have an open source project! we’d like to use comics / zines / art to document our project! Can we hire you?“.
-
-spoiler: the answer is “no, you can’t hire me” – I don’t do commissions. But I do think this is a cool idea and I’ve often wished I had something more useful to say to people than “no”, so if you’re interested in this, here are some ideas about how to accomplish it!
-
-### zine != drawing
-
-First, a terminology distinction. One weird thing I’ve noticed is that people frequently refer to individual tech drawings as “zines”. I think this is due to me communicating poorly somehow, but – drawings are not zines! A zine is a **printed booklet**, like a small maga**zine**. You wouldn’t call a photo of a model in Vogue a magazine! The magazine has like a million pages! An individual drawing is a drawing/comic/graphic/whatever. Just clarifying this because I think it causes a bit of unnecessary confusion.
-
-### comics without good information are useless
-
-Usually when folks ask me “hey, could we make a comic explaining X”, it doesn’t seem like they have a clear idea of what information exactly they want to get across, they just have a vague idea that maybe it would be cool to draw some comics. This makes sense – figuring out what information would be useful to tell people is very hard!! It’s 80% of what I spend my time on when making comics.
-
-You should think about comics the same way as any kind of documentation – start with the information you want to convey, who your target audience is, and how you want to distribute it (twitter? on your website? in person?), and figure out how to illustrate it after :). The information is the main thing, not the art!
-
-Once you have a clear story about what you want to get across, you can start trying to think about how to represent it using illustrations!
-
-### focus on concepts that don’t change
-
-Drawing comics is a much bigger investment than writing documentation (it takes me like 5x longer to convey the same information in a comic than in writing). So use it wisely! Because it’s not that easy to edit, if you’re going to make something a comic you want to focus on concepts that are very unlikely to change. So talk about the core ideas in your project instead of the exact command line arguments it takes!
-
-Here are a couple of options for how you could use comics/illustrations to document your project!
-
-### option 1: a single graphic
-
-One format you might want to try is a single, small graphic explaining what your project is about and why folks might be interested in it. For example: [this zulip comic][1]
-
-This is a short thing, you could post it on Twitter or print it as a pamphlet to give out. The information content here would probably be basically what’s on your project homepage, but presented in a more fun/exciting way :)
-
-You can put a pretty small amount of information in a single comic. With that Zulip comic, the things I picked out were:
-
- * zulip is sort of like slack, but it has threads
- * it’s easy to keep track of threads even if the conversation takes place over several days
- * you can much more easily selectively catch up with Zulip
- * zulip is open source
- * there’s an open zulip server you can try out
-
-
-
-That’s not a lot of information! It’s 50 words :). So to do this effectively you need to distill your project down to 50 words in a way that’s still useful. It’s not easy!
-
-### option 2: many comics
-
-Another approach you can take is to make a more in depth comic / illustration, like [google’s guide to kubernetes][2] or [the children’s illustrated guide to kubernetes][3].
-
-To do this, you need a much stronger concept than “uh, I want to explain our project” – you want to have a clear target audience in mind! For example, if I were drawing a set of Docker comics, I’d probably focus on folks who want to use Docker in production. so I’d want to discuss:
-
- * publishing your containers to a public/private registry
- * some best practices for tagging your containers
- * how to make sure your hosts don’t run out of disk space from downloading too many containers
- * how to use layers to save on disk space / download less stuff
- * whether it’s reasonable to run the same containers in production & in dev
-
-
-
-That’s totally different from the set of comics I’d write for folks who just want to use Docker to develop locally!
-
-### option 3: a printed zine
-
-The main thing that differentiates this from “many comics” is that zines are printed! Because of that, for this to make sense you need to have a place to give out the printed copies! Maybe you’re going present your project at a major conference? Maybe you give workshops about your project and want to give our the zine to folks in the workshop as notes? Maybe you want to mail it to people?
-
-### how to hire someone to help you
-
-There are basically 3 ways to hire someone:
-
- 1. Hire someone who both understands (or can quickly learn) the technology you want to document and can illustrate well. These folks are tricky to find and probably expensive (I certainly wouldn’t do a project like this for less than $10,000 even if I did do commissions), just because programmers can usually charge a pretty high consulting rate. I’d guess that the main failure mode here is that it might be impossible/very hard to find someone, and it might be expensive.
- 2. Collaborate with an illustrator to draw it for you. The main failure mode here is that if you don’t give the illustrator clear explanations of your tech to work with, you.. won’t end up with a clear and useful explanation. From what I’ve seen, **most folks underinvest in writing clear explanations for their illustrators** – I’ve seen a few really adorable tech comics that I don’t find useful or clear at all. I’d love to see more people do a better job of this. What’s the point of having an adorable illustration if it doesn’t teach anyone anything? :)
- 3. Draw it yourself :). This is what I do, obviously. stick figures are okay!
-
-
-
-Most people seem to use method #2 – I’m not actually aware of any tech folks who have done commissioned comics (though I’m sure it’s happened!). I think method #2 is a great option and I’d love to see more folks do it. Paying illustrators is really fun!
-
---------------------------------------------------------------------------------
-
-via: https://jvns.ca/blog/2018/12/09/how-do-you-document-a-tech-project-with-comics/
-
-作者:[Julia Evans][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://jvns.ca/
-[b]: https://github.com/lujun9972
-[1]: https://twitter.com/b0rk/status/986444234365521920
-[2]: https://cloud.google.com/kubernetes-engine/kubernetes-comic/
-[3]: https://thenewstack.io/kubernetes-gets-childrens-book/
diff --git a/sources/tech/20181211 How To Benchmark Linux Commands And Programs From Commandline.md b/sources/tech/20181211 How To Benchmark Linux Commands And Programs From Commandline.md
deleted file mode 100644
index 3962e361f3..0000000000
--- a/sources/tech/20181211 How To Benchmark Linux Commands And Programs From Commandline.md
+++ /dev/null
@@ -1,265 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How To Benchmark Linux Commands And Programs From Commandline)
-[#]: via: (https://www.ostechnix.com/how-to-benchmark-linux-commands-and-programs-from-commandline/)
-[#]: author: (SK https://www.ostechnix.com/author/sk/)
-
-How To Benchmark Linux Commands And Programs From Commandline
-======
-
-
-
-A while ago, I have written a guide about the [**alternatives to ‘top’, the command line utility**][1]. Some of the users asked me which one among those tools is best and on what basis (like features, contributors, years active, page requests etc.) I compared those tools. They also asked me to share the bench-marking results If I have any. Unfortunately, I didn’t even know how to benchmark programs at that time. While searching for some simple and easy to use bench-marking tools to compare the Linux programs, I stumbled upon two utilities named **‘Bench’** and **‘Hyperfine’**. These are simple and easy-to-use command line tools to benchmark Linux commands and programs on Unix-like systems.
-
-### 1\. Bench Tool
-
-The **‘Bench’** utility benchmarks one or more given commands/programs using **Haskell’s criterion** library and displays the output statistics in an easy-to-understandable format. This tool can be helpful where you need to compare similar programs based on the bench-marking result. We can also export the results to HTML format or CSV or templated output.
-
-#### Installing Bench Utility
-
-The bench utility can be installed in three methods.
-
-**1\. Using Linuxbrew**
-
-We can install Bench utility using Linuxbrew package manager. If you haven’t installed Linuxbrew yet, refer the following link.
-
-After installing Linuxbrew, run the following command to install Bench:
-
-```
-$ brew install bench
-```
-
-**2\. Using Haskell’s stack tool**
-
-First, install Haskell as described in the following link.
-
-And then, run the following commands to install Bench.
-
-```
-$ stack setup
-
-$ stack install bench
-```
-
-The ‘stack’ will install bench to **~/.local/bin** or something similar. Make sure that the installation directory is on your executable search path before using bench tool. You will be reminded to do this even if you forgot.
-
-**3\. Using Nix package manager**
-
-Another way to install Bench is using **Nix** package manager. Install Nix as shown in the below link.
-
-After installing Nix, install Bench tool using command:
-
-```
-$ nix-env -i bench
-```
-
-#### Benchmark Linux Commands And Programs Using Bench
-
-It is time to start benchmarking the programs.
-
-For instance, let me show you the benchmark result of ‘ls -al’ command.
-
-```
-$ bench 'ls -al'
-```
-
-**Sample output:**
-
-
-
-You must quote the commands when you use flags/options with them.
-
-Similarly, you can benchmark any programs installed in your system. The following commands shows the benchmarking result of ‘htop’ and ‘ptop’ programs.
-
-```
-$ bench htop
-
-$ bench ptop
-```
-
-Bench tool can benchmark multiple programs at once as well. Here is the benchmarking result of ls, htop, ptop programs.
-
-```
-$ bench ls htop ptop
-```
-
-Sample output:
-
-
-We can also export the benchmark result to a HTML like below.
-
-```
-$ bench htop --output example.html
-```
-
-To export the result to CSV, just run:
-
-```
-$ bench htop --csv FILE
-```
-
-View help section:
-
-```
-$ bench --help
-```
-
-### **2. Hyperfine Benchmark Tool
-
-**
-
-**Hyperfine** is yet another command line benchmarking tool inspired by the ‘Bench’ tool which we just discussed above. It is free, open source, cross-platform benchmarking program and written in **Rust** programming language. It has few additional features compared to the Bench tool as listed below.
-
- * Statistical analysis across multiple runs.
- * Support for arbitrary shell commands.
- * Constant feedback about the benchmark progress and current estimates.
- * Perform warmup runs before the actual benchmark.
- * Cache-clearing commands can be set up before each timing run.
- * Statistical outlier detection.
- * Export benchmark results to various formats, such as CSV, JSON, Markdown.
- * Parameterized benchmarks.
-
-
-
-#### Installing Hyperfine
-
-We can install Hyperfine using any one of the following methods.
-
-**1\. Using Linuxbrew**
-
-```
-$ brew install hyperfine
-```
-
-**2\. Using Cargo**
-
-Make sure you have installed Rust as described in the following link.
-
-After installing Rust, run the following command to install Hyperfine via Cargo:
-
-```
-$ cargo install hyperfine
-```
-
-**3\. Using AUR helper programs**
-
-Hyperfine is available in [**AUR**][2]. So, you can install it on Arch-based systems using any helper programs, such as [**YaY**][3], like below.
-
-```
-$ yay -S hyperfine
-```
-
-**4\. Download and install the binaries**
-
-Hyperfine is available in binaries for Debian-based systems. Download the latest .deb binary file from the [**releases page**][4] and install it using ‘dpkg’ package manager. As of writing this guide, the latest version was **1.4.0**.
-
-```
-$ wget https://github.com/sharkdp/hyperfine/releases/download/v1.4.0/hyperfine_1.4.0_amd64.deb
-
-$ sudo dpkg -i hyperfine_1.4.0_amd64.deb
-
-$ sudo apt install -f
-```
-
-#### Benchmark Linux Commands And Programs Using Hyperfine
-
-To run a benchmark using Hyperfine, simply run it along with the program/command as shown below.
-
-```
-$ hyperfine 'ls -al'
-```
-
-
-
-Benchmark multiple commands/programs:
-
-```
-$ hyperfine htop ptop
-```
-
-Sample output:
-
-
-
-As you can see at the end of the output, Hyperfine mentiones – **‘htop ran 1.96 times faster than ptop’** , so we can immediately conclude htop performs better than Ptop. This will help you to quickly find which program performs better when benchmarking multiple programs. We don’t get this detailed output in Bench utility though.
-
-Hyperfine will automatically determine the number of runs to perform for each command. By default, it will perform at least **10 benchmarking runs**. If you want to set the **minimum number of runs** (E.g 5 runs), use the `-m` **/`--min-runs`** option like below:
-
-```
-$ hyperfine --min-runs 5 htop ptop
-```
-
-Or,
-
-```
-$ hyperfine -m 5 htop ptop
-```
-
-Similarly, to perform **maximum number of runs** for each command, the command would be:
-
-```
-$ hyperfine --max-runs 5 htop ptop
-```
-
-Or,
-
-```
-$ hyperfine -M 5 htop ptop
-```
-
-We can even perform **exact number of runs** for each command using the following command:
-
-```
-$ hyperfine -r 5 htop ptop
-```
-
-As you may know, if the program execution time is limited by disk I/O, the benchmarking results can be heavily influenced by disk caches and whether they are cold or warm. Luckily, Hyperfine has the options to perform a certain number of program executions before performing the actual benchmark.
-
-To perform NUM warmup runs (E.g 3) before the actual benchmark, use the **`-w`/**`--warmup` option like below:
-
-```
-$ hyperfine --warmup 3 htop
-```
-
-Just like Bench utility, Hyperfine also allows us to export the benchmark results to a given file. We can export the results to CSV, JSON, and Markdown formats.
-
-For instance, to export the results in Markdown format, use the following command:
-
-```
-$ hyperfine htop ptop --export-markdown <FILE-NAME>
-```
-
-For more options and usage details, refer the help secion:
-
-```
-$ hyperfine --help
-```
-
-And, that’s all for now. If you ever be in a situation where you need to benchmark similar and alternative programs, these tools might help to compare how they performs and share the details with your peers and colleagues.
-
-More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-benchmark-linux-commands-and-programs-from-commandline/
-
-作者:[SK][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[b]: https://github.com/lujun9972
-[1]: https://www.ostechnix.com/some-alternatives-to-top-command-line-utility-you-might-want-to-know/
-[2]: https://aur.archlinux.org/packages/hyperfine
-[3]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
-[4]: https://github.com/sharkdp/hyperfine/releases
diff --git a/sources/tech/20181214 Tips for using Flood Element for performance testing.md b/sources/tech/20181214 Tips for using Flood Element for performance testing.md
deleted file mode 100644
index 90994b0724..0000000000
--- a/sources/tech/20181214 Tips for using Flood Element for performance testing.md
+++ /dev/null
@@ -1,180 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Tips for using Flood Element for performance testing)
-[#]: via: (https://opensource.com/article/18/12/tips-flood-element-testing)
-[#]: author: (Nicole van der Hoeven https://opensource.com/users/nicolevanderhoeven)
-
-Tips for using Flood Element for performance testing
-======
-Get started with this powerful, intuitive load testing tool.
-
-
-In case you missed it, there’s a new performance test tool on the block: [Flood Element][1]. It’s a scalable, browser-based tool that allows you to write scripts in JavaScript that interact with web pages like a real user would.
-
-Browser Level Users is a [newer approach to load testing][2] that overcomes many of the common challenges we hear about traditional methods of testing. It offers:
-
- * Scripting that is akin to common functional tools like Selenium and easier to learn
- * More realistic results that are based on true browser performance rather than API response
- * The ability to test against all components of your web app, including things like JavaScript that are rendered via the browser
-
-
-
-Given the above benefits, it’s a no-brainer to check out Flood Element for your web load testing, especially if you have struggled with existing tools like JMeter or HP LoadRunner.
-
-Pairing Element with [Flood][3] turns it into a pretty powerful load test tool. We have a [great guide here][4] that you can follow if you’d like to get started. I’ve been using and testing Element for several months now, and I’d like to share some tips I’ve learned along the way.
-
-### Initializing your script
-
-You can always start from scratch, but the quickest way to get started is to type `element init myfirstelementtest` from your terminal, filling in your preferred project name.
-
-You’ll then be asked to type the title of your test as well as the URL you’d like to script against. After a minute, you’ll see that a new directory has been created:
-
-
-
-Element will automatically create a file called **test.ts**. This file contains the skeleton of a script, along with some sample code to help you find a button and then click on it. But before you open it, let’s move on to…
-
-### Choosing the right text editor
-
-Scripting in Element is already pretty simple, but two things that help are syntax highlighting and code completion. Syntax highlighting will greatly improve the experience of learning a new test tool like Element, and code completion will make your scripting lightning-fast as you become more experienced. My text editor of choice is [Visual Studio Code][5], which has both of those features. It’s slick and clean, and it does the job.
-
-Syntax highlighting is when the text editor intelligently changes the font color of your code according to its role in the programming language you’re using. Here’s a screenshot of the **test.ts** file we generated earlier in VS Code to show you what I mean:
-
-
-
-This makes it easier to make sense of the code at a glance: Comments are in green, values and labels are in orange, etc.
-
-Code completion is when you start to type something, and VS Code helpfully opens a context menu with suggestions for methods you can use.
-
-![][6]
-
-I love this because it means I don’t need to remember the exact name of the method. It also suggests names of variables you’ve already defined and highlights code that doesn’t make sense. This will help to make your tests more maintainable and readable for others, which is a great benefit as you look to scale your testing out in the future.
-
-
-
-### Taking screenshots
-
-One of the most powerful features of Element is its ability to take screenshots. I find it immensely useful when debugging because sometimes it’s just easier to see what’s going on visually. With protocol-based tools, debugging can be a much more involved and technical process.
-
-There are two ways to take screenshots in Element:
-
- 1. Add a setting to automatically take a screenshot when an error is encountered. You can do this by setting `screenshotOnFailure` to "true" in `TestSettings`:
-
-
-
-```
-export const settings: TestSettings = {
- device: Device.iPadLandscape,
- userAgent: 'flood-chrome-test',
- clearCache: true,
- disableCache: true,
- screenshotOnFailure: true,
-}
-```
-
- 2. Explicitly take a screenshot at a particular point in the script. You can do this by adding
-
-
-
-```
-await browser.takeScreenshot()
-```
-
-to your code.
-
-### Viewing screenshots
-
-Once you’ve taken screenshots within your tests, you will probably want to view them and know that they will be stored for future safekeeping. Whether you are running your test locally on have uploaded it to Flood to run with increased concurrency, Flood Element has you covered.
-
-**Locally run tests**
-
-Screenshots will be saved as .jpg files in a timestamped folder corresponding to your run. It should look something like this: **…myfirstelementtest/tmp/element-results/test/2018-11-20T135700.595Z/flood/screenshots/**. The screenshots will be uniquely named so that new screenshots, even for the same step, don’t overwrite older ones.
-
-However, I rarely need to look up the screenshots in that folder because I prefer to see them in iTerm2 for MacOS. iTerm is an alternative to the terminal that works particularly well with Element. When you take a screenshot, iTerm actually shows it in-line:
-
-
-
-**Tests run in Flood**
-
-Running an Element script on Flood is ideal when you need larger concurrency. Rather than accessing your screenshot locally, Flood will centralize the images into your account, so the images remain even after the cloud load injectors are destroyed. You can get to the screenshot files by downloading Archived Results:
-
-
-
-You can also click on a step on the dashboard to see a filmstrip of your test:
-
-
-
-### Using logs
-
-You may need to check out the logs for more technical debugging, especially when the screenshots don’t tell the whole story. Again, whether you are running your test locally or have uploaded it to Flood to run with increased concurrency, Flood Element has you covered.
-
-**Locally run tests**
-
-You can print to the console by typing, for example: `console.log('orderValues = ’ + orderValues)`
-
-This will print the value of the variable `orderValues` at that point in the script. You would see this in your terminal if you’re running Element locally.
-
-**Tests run in Flood**
-
-If you’re running the script on Flood, you can either download the log (in the same Archived Results zipped file mentioned earlier) or click on the Logs tab:
-
-
-
-### Fun with flags
-
-Element comes with a few flags that give you more control over how the script is run locally. Here are a few of my favorites:
-
-**Headless flag**
-
-When in doubt, run Element in non-headless mode to see the script actually opening the web app on Chrome and interacting with the page. This is only possible locally, but there’s nothing like actually seeing for yourself what’s happening in real time instead of relying on screenshots and logs after the fact. To enable this mode, add the flag when running your test:
-
-```
-element run myfirstelementtest.ts --no-headless
-```
-
-**Watch flag**
-
-Element will automatically close the browser window when it encounters an error or finishes the iteration. Adding `--watch` will leave the browser window open and then monitor the script. As soon as the script is saved, it will automatically run it in the same window from the beginning. Simply add this flag like the above example:
-
-```
---watch
-```
-
-**Dev tools flag**
-
-This opens a browser instance and runs the script with the Chrome Dev Tools open, allowing you to find locators for the next action you want to script. Simply add this flag as in the first example:
-
-```
---dev-tools
-```
-
-For more flags, use `element run --help`.
-
-### Try Element
-
-You’ve just gotten a crash course on Flood Element and are ready to get started. [Download Element][1] to start writing functional test scripts and reusing them as load test scripts on Flood. If you don’t have a Flood account, you can easily sign up for a free trial [on the Flood website][7].
-
-We’re proud to contribute to the open source community and can’t wait to have you try this new addition to the Flood line.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/tips-flood-element-testing
-
-作者:[Nicole van der Hoeven][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/nicolevanderhoeven
-[b]: https://github.com/lujun9972
-[1]: https://element.flood.io/
-[2]: https://flood.io/blog/why-you-should-load-test-with-browsers/
-[3]: https://flood.io/
-[4]: https://help.flood.io/getting-started-with-load-testing/step-by-step-guide-flood-element
-[5]: https://code.visualstudio.com/
-[6]: https://flood.io/wp-content/uploads/2018/11/vscode-codecompletion2.gif
-[7]: https://flood.io/load-performance-testing-tool/free-load-testing-trial/
diff --git a/sources/tech/20181215 New talk- High Reliability Infrastructure Migrations.md b/sources/tech/20181215 New talk- High Reliability Infrastructure Migrations.md
deleted file mode 100644
index 93755329c7..0000000000
--- a/sources/tech/20181215 New talk- High Reliability Infrastructure Migrations.md
+++ /dev/null
@@ -1,78 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (New talk: High Reliability Infrastructure Migrations)
-[#]: via: (https://jvns.ca/blog/2018/12/15/new-talk--high-reliability-infrastructure-migrations/)
-[#]: author: (Julia Evans https://jvns.ca/)
-
-New talk: High Reliability Infrastructure Migrations
-======
-
-On Tuesday I gave a talk at KubeCon called [High Reliability Infrastructure Migrations][1]. The abstract was:
-
-> For companies with high availability requirements (99.99% uptime or higher), running new software in production comes with a lot of risks. But it’s possible to make significant infrastructure changes while maintaining the availability your customers expect! I’ll give you a toolbox for derisking migrations and making infrastructure changes with confidence, with examples from our Kubernetes & Envoy experience at Stripe.
-
-### video
-
-#### slides
-
-Here are the slides:
-
-since everyone always asks, I drew them in the Notability app on an iPad. I do this because it’s faster than trying to use regular slides software and I can make better slides.
-
-### a few notes
-
-Here are a few links & notes about things I mentioned in the talk
-
-#### skycfg: write functions, not YAML
-
-I talked about how my team is working on non-YAML interfaces for configuring Kubernetes. The demo is at [skycfg.fun][2], and it’s [on GitHub here][3]. It’s based on [Starlark][4], a configuration language that’s a subset of Python.
-
-My coworker [John][5] has promised that he’ll write a blog post about it at some point, and I’m hoping that’s coming soon :)
-
-#### no haunted forests
-
-I mentioned a deploy system rewrite we did. John has a great blog post about when rewrites are a good idea and how he approached that rewrite called [no haunted forests][6].
-
-#### ignore most kubernetes ecosystem software
-
-One small point that I made in the talk was that on my team we ignore almost all software in the Kubernetes ecosystem so that we can focus on a few core pieces (Kubernetes & Envoy, plus some small things like kiam). I wanted to mention this because I think often in Kubernetes land it can seem like everyone is using Cool New Things (helm! istio! knative! eep!). I’m sure those projects are great but I find it much simpler to stay focused on the basics and I wanted people to know that it’s okay to do that if that’s what works for your company.
-
-I think the reality is that actually a lot of folks are still trying to work out how to use this new software in a reliable and secure way.
-
-#### other talks
-
-I haven’t watched other Kubecon talks yet, but here are 2 links:
-
-I heard good things about [this keynote from melanie cebula about kubernetes at airbnb][7], and I’m excited to see [this talk about kubernetes security][8]. The [slides from that security talk look useful][9]
-
-Also I’m very excited to see Kelsey Hightower’s keynote as always, but that recording isn’t up yet. If you have other Kubecon talks to recommend I’d love to know what they are.
-
-#### my first work talk I’m happy with
-
-I usually give talks about debugging tools, or side projects, or how I approach my job at a high level – not on the actual work that I do at my job. What I talked about in this talk is basically what I’ve been learning how to do at work for the last ~2 years. Figuring out how to make big infrastructure changes safely took me a long time (and I’m not done!), and so I hope this talk helps other folks do the same thing.
-
---------------------------------------------------------------------------------
-
-via: https://jvns.ca/blog/2018/12/15/new-talk--high-reliability-infrastructure-migrations/
-
-作者:[Julia Evans][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://jvns.ca/
-[b]: https://github.com/lujun9972
-[1]: https://www.youtube.com/watch?v=obB2IvCv-K0
-[2]: http://skycfg.fun
-[3]: https://github.com/stripe/skycfg
-[4]: https://github.com/bazelbuild/starlark
-[5]: https://john-millikin.com/
-[6]: https://john-millikin.com/sre-school/no-haunted-forests
-[7]: https://www.youtube.com/watch?v=ytu3aUCwlSg&index=127&t=0s&list=PLj6h78yzYM2PZf9eA7bhWnIh_mK1vyOfU
-[8]: https://www.youtube.com/watch?v=a03te8xEjUg&index=65&list=PLj6h78yzYM2PZf9eA7bhWnIh_mK1vyOfU&t=0s
-[9]: https://schd.ws/hosted_files/kccna18/1c/KubeCon%20NA%20-%20This%20year%2C%20it%27s%20about%20security%20-%2020181211.pdf
diff --git a/sources/tech/20181217 6 tips and tricks for using KeePassX to secure your passwords.md b/sources/tech/20181217 6 tips and tricks for using KeePassX to secure your passwords.md
deleted file mode 100644
index ad688a7820..0000000000
--- a/sources/tech/20181217 6 tips and tricks for using KeePassX to secure your passwords.md
+++ /dev/null
@@ -1,78 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (6 tips and tricks for using KeePassX to secure your passwords)
-[#]: via: (https://opensource.com/article/18/12/keepassx-security-best-practices)
-[#]: author: (Michael McCune https://opensource.com/users/elmiko)
-
-6 tips and tricks for using KeePassX to secure your passwords
-======
-Get more out of your password manager by following these best practices.
-
-
-Our increasingly interconnected digital world makes security an essential and common discussion topic. We hear about [data breaches][1] with alarming regularity and are often on our own to make informed decisions about how to use technology securely. Although security is a deep and nuanced topic, there are some easy daily habits you can keep to reduce your attack surface.
-
-Securing passwords and account information is something that affects anyone today. Technologies like [OAuth][2] help make our lives simpler by reducing the number of accounts we need to create, but we are still left with a staggering number of places where we need new, unique information to keep our records secure. An easy way to deal with the increased mental load of organizing all this sensitive information is to use a password manager like [KeePassX][3].
-
-In this article, I will explain the importance of keeping your password information secure and offer suggestions for getting the most out of KeePassX. For an introduction to KeePassX and its features, I highly recommend Ricardo Frydman's article "[Managing passwords in Linux with KeePassX][4]."
-
-### Why are unique passwords important?
-
-Using a different password for each account is the first step in ensuring that your accounts are not vulnerable to shared information leaks. Generating new credentials for every account is time-consuming, and it is extremely common for people to fall into the trap of using the same password on several accounts. The main problem with reusing passwords is that you increase the number of accounts an attacker could access if one of them experiences a credential breach.
-
-It may seem like a burden to create new credentials for each account, but the few minutes you spend creating and recording this information will pay for itself many times over in the event of a data breach. This is where password management tools like KeePassX are invaluable for providing convenience and reliability in securing your logins.
-
-### 3 tips for getting the most out of KeePassX
-
-I have been using KeePassX to manage my password information for many years, and it has become a primary resource in my digital toolbox. Overall, it's fairly simple to use, but there are a few best practices I've learned that I think are worth highlighting.
-
- 1. Add the direct login URL for each account entry. KeePassX has a very convenient shortcut to open the URL listed with an entry. (It's Control+Shift+U on Linux.) When creating a new account entry for a website, I spend some time to locate the site's direct login URL. Although most websites have a login widget in their navigation toolbars, they also usually have direct pages for login forms. By putting this URL into the URL field on the account entry setup form, I can use the shortcut to directly open the login page in my browser.
-
-
-
- 2. Use the Notes field to record extra security information. In addition to passwords, most websites will ask several questions to create additional authentication factors for an account. I use the Notes sections in my account entries to record these additional factors.
-
-
-
- 3. Turn on automatic database locking. In the **Application Settings** under the **Tools** menu, there is an option to lock the database after a period of inactivity. Enabling this option is a good common-sense measure, similar to enabling a password-protected screen lock, that will help ensure your password database is not left open and unprotected if someone else gains access to your computer.
-
-
-
-### Food for thought
-
-Protecting your accounts with better password practices and daily habits is just the beginning. Once you start using a password manager, you need to consider issues like protecting the password database file and ensuring you don't forget or lose the master credentials.
-
-The cloud-native world of disconnected devices and edge computing makes having a central password store essential. The practices and methodologies you adopt will help minimize your risk while you explore and work in the digital world.
-
- 1. Be aware of retention policies when storing your database in the cloud. KeePassX's database has an open format used by several tools on multiple platforms. Sooner or later, you will want to transfer your database to another device. As you do this, consider the medium you will use to transfer the file. The best option is to use some sort of direct transfer between devices, but this is not always convenient. Always think about where the database file might be stored as it winds its way through the information superhighway; an email may get cached on a server, an object store may move old files to a trash folder. Learn about these interactions for the platforms you are using before deciding where and how you will share your database file.
-
- 2. Consider the source of truth for your database while you're making edits. After you share your database file between devices, you might need to create accounts for new services or change information for existing services while using a device. To ensure your information is always correct across all your devices, you need to make sure any edits you make on one device end up in all copies of the database file. There is no easy solution to this problem, but you might think about making all edits from a single device or storing the master copy in a location where all your devices can make edits.
-
- 3. Do you really need to know your passwords? This is more of a philosophical question that touches on the nature of memorable passwords, convenience, and secrecy. I hardly look at passwords as I create them for new accounts; in most cases, I don't even click the "Show Password" checkbox. There is an idea that you can be more secure by not knowing your passwords, as it would be impossible to compel you to provide them. This may seem like a worrisome idea at first, but consider that you can recover or reset passwords for most accounts through alternate verification methods. When you consider that you might want to change your passwords on a semi-regular basis, it almost makes more sense to treat them as ephemeral information that can be regenerated or replaced.
-
-
-
-
-Here are a few more ideas to consider as you develop your best practices.
-
-I hope these tips and tricks have helped expand your knowledge of password management and KeePassX. You can find tools that support the KeePass database format on nearly every platform. If you are not currently using a password manager or have never tried KeePassX, I highly recommend doing so now!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/12/keepassx-security-best-practices
-
-作者:[Michael McCune][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/elmiko
-[b]: https://github.com/lujun9972
-[1]: https://vigilante.pw/
-[2]: https://en.wikipedia.org/wiki/OAuth
-[3]: https://www.keepassx.org/
-[4]: https://opensource.com/business/16/5/keepassx
diff --git a/sources/tech/20181218 Insync- The Hassleless Way of Using Google Drive on Linux.md b/sources/tech/20181218 Insync- The Hassleless Way of Using Google Drive on Linux.md
deleted file mode 100644
index c10e7ae4ed..0000000000
--- a/sources/tech/20181218 Insync- The Hassleless Way of Using Google Drive on Linux.md
+++ /dev/null
@@ -1,137 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Insync: The Hassleless Way of Using Google Drive on Linux)
-[#]: via: (https://itsfoss.com/insync-linux-review/)
-[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-
-Insync: The Hassleless Way of Using Google Drive on Linux
-======
-
-Using Google Drive on Linux is a pain and you probably already know that. There is no official desktop client of Google Drive for Linux. It’s been [more than six years since Google promised Google Drive on Linux][1] but it doesn’t seem to be happening.
-
-In the absence of the official Google Drive client on Linux, you have no option other than trying the alternatives. I have already discussed a number of [tools that allow you to use Google Drive on Linux][2]. One of those to[ols is][3] Insync, and in my opinion, this is your best bet for a native Google Drive experience on desktop Linux.
-
-Note that Insync is not an open source software. Heck, it is not even free to use.
-
-But it has so many features that it becomes an essential tool for those Linux users who rely heavily on Google Drive.
-
-I briefly discussed Insync in the old article about [Google Drive and Linux][2]. In this article, I’ll discuss Insync features in detail.
-
-### Insync brings native Google Drive experience to Linux desktop
-
-![Use insync to access Google Drive in Linux][4]
-
-The core competency of Insync is syncing your Google Drive, but the app is much more than that. It has features to help you maximize and control your productivity, your Google Drive and your files such as:
-
- * Cross-platform access (supports Linux, Windows and macOS)
- * Easy multiple Google Drive accounts access
- * Choose your syncing location. Sync files to your hard drive, external drives and NAS!
- * Support for features like file matching, symlink and ignore list
-
-
-
-Let me show you some of the main features in action:
-
-#### Cross-platform in true sense
-
-Insync claims to run the same app across all operating systems i.e., Linux, Windows, and macOS. That means that you can access the same UI across different OSes, making it easy for you to manage your files across multiple machines.
-
-![The UI of Insync and the default location of the Insync folder.][5]The UI of Insync and the default location of the Insync folder.
-
-#### Multiple Google account management
-
-Insync interface allows you to manage multiple Google Drive accounts seamlessly. You can easily switch between several accounts just by clicking your Google account.
-
-![Switching between multiple Google accounts in Insync][6]Switching between multiple Google accounts
-
-#### Custom sync folders
-
-Customize the way you sync your files and folders. You can easily set your syncing destination anywhere on your machine including external drive and network drives.
-
-![Customize sync location in Insync][7]Customize sync location
-
-The selective syncing mode also allows you to easily select a number of files and folders you’d want to sync (or unsync) in your local machine. This includes selectively syncing files within folders.
-
-![Selective synchronization in Insync][8]Selective synchronization
-
-It has features like file matching and ‘ignore list’ to help you filter files you don’t want to sync or files that you already have on your machine.
-
-![File matching feature in Insync][9]Avoids duplication of files
-
-The ‘ignore list’ allows you to set rules to exclude certain type of files from synchronization.
-
-![Selective syncing based on rules in Insync][10]Selective syncing based on rules
-
-If you prefer to work out of the desktop, you have an “Add to Insync” feature that will allow you to add any local file to your Drive.
-
-![Sync files right from your desktop][11]Sync files right from your desktop
-
-Insync also supports symlinks for those with workflows that use symbolic links. To learn more about Insync and symlinks, you can refer to [this article.][12]
-
-#### Exclusive features for Linux
-
-Insync supports the most commonly used 64-bit Linux distributions like **Ubuntu, Debian and Fedora**. You can check out the full list of distribution support [here][13].
-
-Insync also has [headless][14] support for those looking to sync through the command line interface. This is perfect if you use a distro that is not fully supported by the GUI app or if you are working with servers or if you simply prefer the CLI.
-
-![Insync CLI][15]Command Line Interface
-
-You can learn more about installing and running Insync headless [here][16].
-
-### Insync pricing and special discount
-
-Insync is a premium tool and it comes with a [price tag][17]. You have 2 licenses to choose from:
-
- * **Prime** is priced at $29.99 per Google account. You’ll get access to: cross-platform syncing, multiple accounts access and **support**.
- * **Teams** is priced at $49.99 per Google account. You’ll be able to access all the Prime features + Team Drives syncing
-
-
-
-It’s a one-time fee which means once you buy it, you don’t have to pay it again. In a world where everything is paid monthly, it’s refreshing to pay for software that is still one-time!
-
-Each Google account has a 15-day free trial that will allow you to test the full suite of features, including [Team Drives][18] syncing.
-
-If you think it’s a bit expensive for your budget, I have good news for you. As an It’s FOSS reader, you get Insync at 25% discount.
-
-Just use the code ITSFOSS25 at checkout time and you will get 25% immediate discount on any license. Isn’t it cool?
-
-If you are not certain yet, you can try Insync free for 15 days. And if you think it’s worth the money, purchase the license with **ITSFOSS25** coupon code.
-
-You can download Insync from their website.
-
-I have used Insync from the time when it was available for free and I have always liked it. They have added more features over the time and improved its UI and performance. Overall, it’s a nice-to-have application if you use Google Drive a lot and do not mind paying for the efforts of the developers.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/insync-linux-review/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[b]: https://github.com/lujun9972
-[1]: https://abevoelker.github.io/how-long-since-google-said-a-google-drive-linux-client-is-coming/
-[2]: https://itsfoss.com/use-google-drive-linux/
-[3]: https://www.insynchq.com
-[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/12/google-drive-linux-insync.jpeg?resize=800%2C450&ssl=1
-[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_interface.jpeg?fit=800%2C501&ssl=1
-[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_multiple_google_account.jpeg?ssl=1
-[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_folder_settings.png?ssl=1
-[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_selective_sync.png?ssl=1
-[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_file_matching.jpeg?ssl=1
-[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_ignore_list_1.png?ssl=1
-[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/add-to-insync-shortcut.jpeg?ssl=1
-[12]: https://help.insynchq.com/key-features-and-syncing-explained/syncing-superpowers/using-symlinks-on-google-drive-with-insync
-[13]: https://www.insynchq.com/downloads
-[14]: https://en.wikipedia.org/wiki/Headless_software
-[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_cli.jpeg?fit=800%2C478&ssl=1
-[16]: https://help.insynchq.com/installation-on-windows-linux-and-macos/advanced/linux-controlling-insync-via-command-line-cli
-[17]: https://www.insynchq.com/pricing
-[18]: https://gsuite.google.com/learning-center/products/drive/get-started-team-drive/#!/
diff --git a/sources/tech/20181221 Large files with Git- LFS and git-annex.md b/sources/tech/20181221 Large files with Git- LFS and git-annex.md
deleted file mode 100644
index 29a76f810f..0000000000
--- a/sources/tech/20181221 Large files with Git- LFS and git-annex.md
+++ /dev/null
@@ -1,145 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Large files with Git: LFS and git-annex)
-[#]: via: (https://anarc.at/blog/2018-12-21-large-files-with-git/)
-[#]: author: (Anarc.at https://anarc.at/)
-
-Large files with Git: LFS and git-annex
-======
-
-Git does not handle large files very well. While there is work underway to handle large repositories through the [commit graph work][2], Git's internal design has remained surprisingly constant throughout its history, which means that storing large files into Git comes with a significant and, ultimately, prohibitive performance cost. Thankfully, other projects are helping Git address this challenge. This article compares how Git LFS and git-annex address this problem and should help readers pick the right solution for their needs.
-
-### The problem with large files
-
-As readers probably know, Linus Torvalds wrote Git to manage the history of the kernel source code, which is a large collection of small files. Every file is a "blob" in Git's object store, addressed by its cryptographic hash. A new version of that file will store a new blob in Git's history, with no deduplication between the two versions. The pack file format can store binary deltas between similar objects, but if many objects of similar size change in a repository, that algorithm might fail to properly deduplicate. In practice, large binary files (say JPEG images) have an irritating tendency of changing completely when even the smallest change is made, which makes delta compression useless.
-
-There have been different attempts at fixing this in the past. In 2006, Torvalds worked on [improving the pack-file format][3] to reduce object duplication between the index and the pack files. Those changes were eventually reverted because, as Nicolas Pitre [put it][4]: "that extra loose object format doesn't appear to be worth it anymore".
-
-Then in 2009, [Caca Labs][5] worked on improving the `fast-import` and `pack-objects` Git commands to do special handling for big files, in an effort called [git-bigfiles][6]. Some of those changes eventually made it into Git: for example, since [1.7.6][7], Git will stream large files directly to a pack file instead of holding them all in memory. But files are still kept forever in the history.
-
-An example of trouble I had to deal with is for the Debian security tracker, which follows all security issues in the entire Debian history in a single file. That file is around 360,000 lines for a whopping 18MB. The resulting repository takes 1.6GB of disk space and a local clone takes 21 minutes to perform, mostly taken up by Git resolving deltas. Commit, push, and pull are noticeably slower than a regular repository, taking anywhere from a few seconds to a minute depending one how old the local copy is. And running annotate on that large file can take up to ten minutes. So even though that is a simple text file, it's grown large enough to cause significant problems for Git, which is otherwise known for stellar performance.
-
-Intuitively, the problem is that Git needs to copy files into its object store to track them. Third-party projects therefore typically solve the large-files problem by taking files out of Git. In 2009, Git evangelist Scott Chacon released [GitMedia][8], which is a Git filter that simply takes large files out of Git. Unfortunately, there hasn't been an official release since then and it's [unclear][9] if the project is still maintained. The next effort to come up was [git-fat][10], first released in 2012 and still maintained. But neither tool has seen massive adoption yet. If I would have to venture a guess, it might be because both require manual configuration. Both also require a custom server (rsync for git-fat; S3, SCP, Atmos, or WebDAV for GitMedia) which limits collaboration since users need access to another service.
-
-### Git LFS
-
-That was before GitHub [released][11] Git Large File Storage (LFS) in August 2015. Like all software taking files out of Git, LFS tracks file hashes instead of file contents. So instead of adding large files into Git directly, LFS adds a pointer file to the Git repository, which looks like this:
-
-```
-version https://git-lfs.github.com/spec/v1
-oid sha256:4d7a214614ab2935c943f9e0ff69d22eadbb8f32b1258daaa5e2ca24d17e2393
-size 12345
-```
-
-LFS then uses Git's smudge and clean filters to show the real file on checkout. Git only stores that small text file and does so efficiently. The downside, of course, is that large files are not version controlled: only the latest version of a file is kept in the repository.
-
-Git LFS can be used in any repository by installing the right hooks with `git lfs install` then asking LFS to track any given file with `git lfs track`. This will add the file to the `.gitattributes` file which will make Git run the proper LFS filters. It's also possible to add patterns to the `.gitattributes` file, of course. For example, this will make sure Git LFS will track MP3 and ZIP files:
-
-```
-$ cat .gitattributes
-*.mp3 filter=lfs -text
-*.zip filter=lfs -text
-```
-
-After this configuration, we use Git normally: `git add`, `git commit`, and so on will talk to Git LFS transparently.
-
-The actual files tracked by LFS are copied to a path like `.git/lfs/objects/{OID-PATH}`, where `{OID-PATH}` is a sharded file path of the form `OID[0:2]/OID[2:4]/OID` and where `OID` is the content's hash (currently SHA-256) of the file. This brings the extra feature that multiple copies of the same file in the same repository are automatically deduplicated, although in practice this rarely occurs.
-
-Git LFS will copy large files to that internal storage on `git add`. When a file is modified in the repository, Git notices, the new version is copied to the internal storage, and the pointer file is updated. The old version is left dangling until the repository is pruned.
-
-This process only works for new files you are importing into Git, however. If a Git repository already has large files in its history, LFS can fortunately "fix" repositories by retroactively rewriting history with [git lfs migrate][12]. This has all the normal downsides of rewriting history, however --- existing clones will have to be reset to benefit from the cleanup.
-
-LFS also supports [file locking][13], which allows users to claim a lock on a file, making it read-only everywhere except in the locking repository. This allows users to signal others that they are working on an LFS file. Those locks are purely advisory, however, as users can remove other user's locks by using the `--force` flag. LFS can also [prune][14] old or unreferenced files.
-
-The main [limitation][15] of LFS is that it's bound to a single upstream: large files are usually stored in the same location as the central Git repository. If it is hosted on GitHub, this means a default quota of 1GB storage and bandwidth, but you can purchase additional "packs" to expand both of those quotas. GitHub also limits the size of individual files to 2GB. This [upset][16] some users surprised by the bandwidth fees, which were previously hidden in GitHub's cost structure.
-
-While the actual server-side implementation used by GitHub is closed source, there is a [test server][17] provided as an example implementation. Other Git hosting platforms have also [implemented][18] support for the LFS [API][19], including GitLab, Gitea, and BitBucket; that level of adoption is something that git-fat and GitMedia never achieved. LFS does support hosting large files on a server other than the central one --- a project could run its own LFS server, for example --- but this will involve a different set of credentials, bringing back the difficult user onboarding that affected git-fat and GitMedia.
-
-Another limitation is that LFS only supports pushing and pulling files over HTTP(S) --- no SSH transfers. LFS uses some [tricks][20] to bypass HTTP basic authentication, fortunately. This also might change in the future as there are proposals to add [SSH support][21], resumable uploads through the [tus.io protocol][22], and other [custom transfer protocols][23].
-
-Finally, LFS can be slow. Every file added to LFS takes up double the space on the local filesystem as it is copied to the `.git/lfs/objects` storage. The smudge/clean interface is also slow: it works as a pipe, but buffers the file contents in memory each time, which can be prohibitive with files larger than available memory.
-
-### git-annex
-
-The other main player in large file support for Git is git-annex. We [covered the project][24] back in 2010, shortly after its first release, but it's certainly worth discussing what has changed in the eight years since Joey Hess launched the project.
-
-Like Git LFS, git-annex takes large files out of Git's history. The way it handles this is by storing a symbolic link to the file in `.git/annex`. We should probably credit Hess for this innovation, since the Git LFS storage layout is obviously inspired by git-annex. The original design of git-annex introduced all sorts of problems however, especially on filesystems lacking symbolic-link support. So Hess has implemented different solutions to this problem. Originally, when git-annex detected such a "crippled" filesystem, it switched to [direct mode][25], which kept files directly in the work tree, while internally committing the symbolic links into the Git repository. This design turned out to be a little confusing to users, including myself; I have managed to shoot myself in the foot more than once using this system.
-
-Since then, git-annex has adopted a different v7 mode that is also based on smudge/clean filters, which it called "[unlocked files][26]". Like Git LFS, unlocked files will double disk space usage by default. However it is possible to reduce disk space usage by using "thin mode" which uses hard links between the internal git-annex disk storage and the work tree. The downside is, of course, that changes are immediately performed on files, which means previous file versions are automatically discarded. This can lead to data loss if users are not careful.
-
-Furthermore, git-annex in v7 mode suffers from some of the performance problems affecting Git LFS, because both use the smudge/clean filters. Hess actually has [ideas][27] on how the smudge/clean interface could be improved. He proposes changing Git so that it stops buffering entire files into memory, allows filters to access the work tree directly, and adds the hooks he found missing (for `stash`, `reset`, and `cherry-pick`). Git-annex already implements some tricks to work around those problems itself but it would be better for those to be implemented in Git natively.
-
-Being more distributed by design, git-annex does not have the same "locking" semantics as LFS. Locking a file in git-annex means protecting it from changes, so files need to actually be in the "unlocked" state to be editable, which might be counter-intuitive to new users. In general, git-annex has some of those unusual quirks and interfaces that often come with more powerful software.
-
-And git-annex is much more powerful: it not only addresses the "large-files problem" but goes much further. For example, it supports "partial checkouts" --- downloading only some of the large files. I find that especially useful to manage my video, music, and photo collections, as those are too large to fit on my mobile devices. Git-annex also has support for location tracking, where it knows how many copies of a file exist and where, which is useful for archival purposes. And while Git LFS is only starting to look at transfer protocols other than HTTP, git-annex already supports a [large number][28] through a [special remote protocol][29] that is fairly easy to implement.
-
-"Large files" is therefore only scratching the surface of what git-annex can do: I have used it to build an [archival system for remote native communities in northern Québec][30], while others have built a [similar system in Brazil][31]. It's also used by the scientific community in projects like [GIN][32] and [DataLad][33], which manage terabytes of data. Another example is the [Japanese American Legacy Project][34] which manages "upwards of 100 terabytes of collections, transporting them from small cultural heritage sites on USB drives".
-
-Unfortunately, git-annex is not well supported by hosting providers. GitLab [used to support it][35], but since it implemented Git LFS, it [dropped support for git-annex][36], saying it was a "burden to support". Fortunately, thanks to git-annex's flexibility, it may eventually be possible to treat [LFS servers as just another remote][37] which would make git-annex capable of storing files on those servers again.
-
-### Conclusion
-
-Git LFS and git-annex are both mature and well maintained programs that deal efficiently with large files in Git. LFS is easier to use and is well supported by major Git hosting providers, but it's less flexible than git-annex.
-
-Git-annex, in comparison, allows you to store your content anywhere and espouses Git's distributed nature more faithfully. It also uses all sorts of tricks to save disk space and improve performance, so it should generally be faster than Git LFS. Learning git-annex, however, feels like learning Git: you always feel you are not quite there and you can always learn more. It's a double-edged sword and can feel empowering for some users and terrifyingly hard for others. Where you stand on the "power-user" scale, along with project-specific requirements will ultimately determine which solution is the right one for you.
-
-Ironically, after thorough evaluation of large-file solutions for the Debian security tracker, I ended up proposing to rewrite history and [split the file by year][38] which improved all performance markers by at least an order of magnitude. As it turns out, keeping history is critical for the security team so any solution that moves large files outside of the Git repository is not acceptable to them. Therefore, before adding large files into Git, you might want to think about organizing your content correctly first. But if large files are unavoidable, the Git LFS and git-annex projects allow users to keep using most of their current workflow.
-
-> This article [first appeared][39] in the [Linux Weekly News][40].
-
---------------------------------------------------------------------------------
-
-via: https://anarc.at/blog/2018-12-21-large-files-with-git/
-
-作者:[Anarc.at][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://anarc.at/
-[b]: https://github.com/lujun9972
-[1]: https://anarc.at/blog/
-[2]: https://github.com/git/git/blob/master/Documentation/technical/commit-graph.txt
-[3]: https://public-inbox.org/git/Pine.LNX.4.64.0607111010320.5623@g5.osdl.org/
-[4]: https://public-inbox.org/git/alpine.LFD.0.99.0705091422130.24220@xanadu.home/
-[5]: http://caca.zoy.org/
-[6]: http://caca.zoy.org/wiki/git-bigfiles
-[7]: https://public-inbox.org/git/7v8vsnz2nc.fsf@alter.siamese.dyndns.org/
-[8]: https://github.com/alebedev/git-media
-[9]: https://github.com/alebedev/git-media/issues/15
-[10]: https://github.com/jedbrown/git-fat
-[11]: https://blog.github.com/2015-04-08-announcing-git-large-file-storage-lfs/
-[12]: https://github.com/git-lfs/git-lfs/blob/master/docs/man/git-lfs-migrate.1.ronn
-[13]: https://github.com/git-lfs/git-lfs/wiki/File-Locking
-[14]: https://github.com/git-lfs/git-lfs/blob/master/docs/man/git-lfs-prune.1.ronn
-[15]: https://github.com/git-lfs/git-lfs/wiki/Limitations
-[16]: https://medium.com/@megastep/github-s-large-file-storage-is-no-panacea-for-open-source-quite-the-opposite-12c0e16a9a91
-[17]: https://github.com/git-lfs/lfs-test-server
-[18]: https://github.com/git-lfs/git-lfs/wiki/Implementations%0A
-[19]: https://github.com/git-lfs/git-lfs/tree/master/docs/api
-[20]: https://github.com/git-lfs/git-lfs/blob/master/docs/api/authentication.md
-[21]: https://github.com/git-lfs/git-lfs/blob/master/docs/proposals/ssh_adapter.md
-[22]: https://tus.io/
-[23]: https://github.com/git-lfs/git-lfs/blob/master/docs/custom-transfers.md
-[24]: https://lwn.net/Articles/419241/
-[25]: http://git-annex.branchable.com/direct_mode/
-[26]: https://git-annex.branchable.com/tips/unlocked_files/
-[27]: http://git-annex.branchable.com/todo/git_smudge_clean_interface_suboptiomal/
-[28]: http://git-annex.branchable.com/special_remotes/
-[29]: http://git-annex.branchable.com/special_remotes/external/
-[30]: http://isuma-media-players.readthedocs.org/en/latest/index.html
-[31]: https://github.com/RedeMocambos/baobaxia
-[32]: https://web.gin.g-node.org/
-[33]: https://www.datalad.org/
-[34]: http://www.densho.org/
-[35]: https://docs.gitlab.com/ee/workflow/git_annex.html
-[36]: https://gitlab.com/gitlab-org/gitlab-ee/issues/1648
-[37]: https://git-annex.branchable.com/todo/LFS_API_support/
-[38]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=908678#52
-[39]: https://lwn.net/Articles/774125/
-[40]: http://lwn.net/
diff --git a/sources/tech/20181224 Turn GNOME to Heaven With These 23 GNOME Extensions.md b/sources/tech/20181224 Turn GNOME to Heaven With These 23 GNOME Extensions.md
deleted file mode 100644
index e49778eab7..0000000000
--- a/sources/tech/20181224 Turn GNOME to Heaven With These 23 GNOME Extensions.md
+++ /dev/null
@@ -1,288 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Turn GNOME to Heaven With These 23 GNOME Extensions)
-[#]: via: (https://fosspost.org/tutorials/turn-gnome-to-heaven-with-these-23-gnome-extensions)
-[#]: author: (M.Hanny Sabbagh https://fosspost.org/author/mhsabbagh)
-
-Turn GNOME to Heaven With These 23 GNOME Extensions
-======
-
-GNOME Shell is one of the most used desktop interfaces on the Linux desktop. It’s part of the GNOME project and is considered to be the next generation of the old classic GNOME 2.x interface. GNOME Shell was first released in 2011 carrying a lot of features, including GNOME Shell extensions feature.
-
-GNOME Extensions are simply extra functionality that you can add to your interface, they can be panel extensions, performance extensions, quick access extensions, productivity extensions or for any other type of usage. They are all free and open source of course; you can install them with a single click **from your web browser** actually.
-
-### How To Install GNOME Extensions?
-
-You main way to install GNOME extensions will be via the extensions.gnome.org website. It’s an official platform belonging to GNOME where developers publish their extensions easily so that users can install them in a single click.
-
-In order to for this to work, you’ll need two things:
-
- 1. Browser Add-on: You’ll need to install a browser add-on that allows the website to communicate with your local GNOME desktop. You install it from [here for Firefox][1], or [here for Chrome][2] or [here for Opera][3].
-
- 2. Native Connector: You still need another part to allow your system to accept installing files locally from your web browser. To install this component, you must install the `chrome-gnome-shell` package. Do not be deceived! Although the package name is containing “chrome”, it also works on Firefox too. To install it on Debian/Ubuntu/Mint run the following command in terminal:
-
-```
-sudo apt install chrome-gnome-shell
-```
-
-For Fedora:
-
-```
-sudo dnf install chrome-gnome-shell
-```
-
-For Arch:
-
-```
-sudo pacman -S chrome-gnome-shell
-```
-
-After you have installed the two components above, you can easily install extensions from the GNOME extensions website.
-
-### How to Configure GNOME Extensions Settings?
-
-Many of these extensions do have a settings window that you can access to adjust the preferences of that extension. You must make sure that you have seen its options at least once so that you know what you can possibly do using that extension.
-
-To do this, you can head to the [installed extensions page on the GNOME website][4], and you’ll see a small options button near every extension that offers one:
-
-![Screenshot 2018 12 24 20 50 55 41][5]
-
-Clicking it will display a window for you, from which you can see the possible settings:
-
-![Screenshot 2018 12 24 20 51 29 43][6]
-
-Read our article below for our list of recommended extension!
-
-### General Extensions
-
-#### 1\. User Themes
-
-![Screenshot from 2018 12 23 12 30 20 45][7]
-
-This is the first must-install extension on the GNOME Shell interface, it simply allows you to change the desktop theme to another one using the tweak tool. After installation run gnome-tweak-tool, and you’ll be able to change your desktop theme.
-
-Installation link: <https://extensions.gnome.org/extension/19/user-themes/>
-
-#### 2\. Dash to Panel
-
-![Screenshot from 2018 12 24 21 16 11 47][8]
-
-Converts the GNOME top bar into a taskbar with many added features, such as favorite icons, moving the clock to right, adding currently opened windows to the panel and many other features. (Make sure not to install this one with some other extensions below which do provide the same functionality).
-
-Installation link: <https://extensions.gnome.org/extension/1160/dash-to-panel/>
-
-#### 3\. Desktop Icons
-
-![gnome shell screenshot SSP3UZ 49][9]
-
-Restores desktop icons back again to GNOME. Still in continues development.
-
-Installation link: <https://extensions.gnome.org/extension/1465/desktop-icons/>
-
-#### 4\. Dash to Dock
-
-![Screenshot from 2018 12 24 21 50 07 51][10]
-
-If you are a fan of the Unity interface, then this extension may help you. It simply adds a dock to the left/right side of the screen, which is very similar to Unity. You can customize that dock however you like.
-
-Installation link: <https://extensions.gnome.org/extension/307/dash-to-dock/>
-
-### Productivity Extensions
-
-#### 5\. Todo.txt
-
-![screenshot_570_5X5YkZb][11]
-
-For users who like to maintain productivity, you can use this extension to add a simple To-Do list functionality to your desktop, it will use the [syntax][12] from todotxt.com, you can add unlimited to-dos, mark them as complete or remove them, change their position beside modifying or taking a backup of the todo.txt file manually.
-
-Installation link: <https://extensions.gnome.org/extension/570/todotxt/>
-
-#### 6\. Screenshot Tool
-
-![Screenshot from 2018 12 24 21 04 14 54][13]
-
-Easily take a screenshot of your desktop or a specific area, with the possibility of also auto-uploading it to imgur.com and auto-saving the link into the clipboard! Very useful extension.
-
-Installation link: <https://extensions.gnome.org/extension/1112/screenshot-tool/>
-
-#### 7\. OpenWeather
-
-![screenshot_750][14]
-
-If you would like to know the weather forecast everyday then this extension will be the right one for you, this extension will simply add an applet to the top panel allowing you to fetch the weather data from openweathermap.org or forecast.io, it supports all the countries and cities around the world. It also shows the wind and humidity.
-
-Installation link: <https://extensions.gnome.org/extension/750/openweather/>
-
-#### 8 & 9\. Search Providers Extensions
-
-![Screenshot from 2018 12 24 21 29 41 57][15]
-
-In GNOME, you can add what’s known as “search providers” to the shell, meaning that when you type something in the search box, you’ll be able to automatically search these websites (search providers) using the same text you entered, and see the results directly from your shell!
-
-YouTube Search Provider: <https://extensions.gnome.org/extension/1457/youtube-search-provider/>
-
-Wikipedia Search Provider: <https://extensions.gnome.org/extension/512/wikipedia-search-provider/>
-
-### Workflow Extensions
-
-#### 10\. No Title Bar
-
-![Screenshot 20181224210737 59][16]
-
-This extension simply removes the title bar from all the maximized windows, and moves it into the top GNOME Panel. In this way, you’ll be able to save a complete horizontal line on your screen, more space for your work!
-
-Installation Link: <https://extensions.gnome.org/extension/1267/no-title-bar/>
-
-#### 11\. Applications Menu
-
-![Screenshot 2018 12 23 13 58 07 61][17]
-
-This extension simply adds a classic menu to the “activities” menu on the corner. By using it, you will be able to browse the installed applications and categories without the need to use the dash or the search feature, which saves you time. (Check the “No hot corner” extension below to get a better usage).
-
-Installation link: <https://extensions.gnome.org/extension/6/applications-menu/>
-
-#### 12\. Places Status Indicator
-
-![screenshot_8_1][18]
-
-This indicator will put itself near the left corner of the activities button, it allows you to access your home folder and sub-folders easily using a menu, you can also browse the available devices and networks using it.
-
-Installation link: <https://extensions.gnome.org/extension/8/places-status-indicator/>
-
-#### 13\. Window List
-
-![Screenshot from 2016-08-12 08-05-48][19]
-
-Officially supported by GNOME team, this extension adds a bottom panel to the desktop which allows you to navigate between the open windows easily, it also include a workspace indicator to switch between them.
-
-Installation link: <https://extensions.gnome.org/extension/602/window-list/>
-
-#### 14\. Frippery Panel Favorites
-
-![screenshot_4][20]
-
-This extensions adds your favorite applications and programs to the panel near the activities button, allowing you to access to it more quickly with just 1 click, you can add or remove applications from it just by modifying your applications in your favorites (the same applications in the left panel when you click the activities button will appear here).
-
-Installation link: <https://extensions.gnome.org/extension/4/panel-favorites/>
-
-#### 15\. TopIcons
-
-![Screenshot 20181224211009 66][21]
-
-Those extensions restore the system tray back into the top GNOME panel. Very needed in cases of where applications are very much dependent on the tray icon.
-
-For GNOME 3.28, installation link: <https://extensions.gnome.org/extension/1031/topicons/>
-
-For GNOME 3.30, installation link: <https://extensions.gnome.org/extension/1497/topicons-redux/>
-
-#### 16\. Clipboard Indicator
-
-![Screenshot 20181224214626 68][22]
-
-A clipboard manager is simply an applications that manages all the copy & paste operations you do on your system and saves them into a history, so that you can access them later whenever you want.
-
-This extension does exactly this, plus many other cool features that you can check.
-
-Installation link: <https://extensions.gnome.org/extension/779/clipboard-indicator/>
-
-### Other Extensions
-
-#### 17\. Frippery Move Clock
-
-![screenshot_2][23]
-
-If you are from those people who like alignment a lot, and dividing the panels into 2 parts only, then you may like this extension, what it simply does is moving the clock from the middle of the GNOME Shell panel to the right near the other applets on the panel, which makes it more organized.
-
-Installation link: <https://extensions.gnome.org/extension/2/move-clock/>
-
-#### 18\. No Topleft Hot Corner
-
-If you don’t like opening the dash whenever you move the mouse to the left corner, you can disable it easily using this extension. You can for sure click the activities button if you want to open the dash view (or via the Super key on the keyboard), but the hot corner will be disabled only.
-
-Installation link: <https://extensions.gnome.org/extension/118/no-topleft-hot-corner/>
-
-#### 19\. No Annoyance
-
-Simply removes the “window is ready” notification each time a new window a opened.
-
-Installation link: <https://extensions.gnome.org/extension/1236/noannoyance/>
-
-#### 20\. EasyScreenCast
-
-![Screenshot 20181224214219 71][24]
-
-If you would like to quickly take a screencast for your desktop, then this extension may help you. By simply just choosing the type of recording you want, you’ll be able to take screencasts any time. You can also configure advanced options for the extension, such as the pipeline and many other things.
-
-Installation link: <https://extensions.gnome.org/extension/690/easyscreencast/>
-
-#### 21\. Removable drive Menu
-
-![Screenshot 20181224214131 73][25]
-
-Adds an icon to the top bar which shows you a list of your currently removable drives.
-
-Installation link: <https://extensions.gnome.org/extension/7/removable-drive-menu/>
-
-#### 22\. BottomPanel
-
-![Screenshot 20181224214419 75][26]
-
-As its title says.. It simply moves the top GNOME bar into the bottom of the screen.
-
-Installation link: <https://extensions.gnome.org/extension/949/bottompanel/>
-
-#### 23\. Unite
-
-If you would like one extension only to do most of the above tasks, then Unite extension can help you. It adds panel favorites, removes title bar, moves the clock, allows you to change the location of the panel.. And many other features. All using this extension alone!
-
-Installation link: <https://extensions.gnome.org/extension/1287/unite/>
-
-### Conclusion
-
-This was our list for some great GNOME Shell extensions to try out. Of course, you don’t (and shouldn’t!) install all of these, but just what you need for your own usage. As you can see, you can convert GNOME into any form you would like, but be careful for RAM usage (because if you use more extensions, the shell will consume very much resources).
-
-What other GNOME Shell extensions do you use? What do you think of this list?
-
-
---------------------------------------------------------------------------------
-
-via: https://fosspost.org/tutorials/turn-gnome-to-heaven-with-these-23-gnome-extensions
-
-作者:[M.Hanny Sabbagh][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fosspost.org/author/mhsabbagh
-[b]: https://github.com/lujun9972
-[1]: https://addons.mozilla.org/en/firefox/addon/gnome-shell-integration/
-[2]: https://chrome.google.com/webstore/detail/gnome-shell-integration/gphhapmejobijbbhgpjhcjognlahblep
-[3]: https://addons.opera.com/en/extensions/details/gnome-shell-integration/
-[4]: https://extensions.gnome.org/local/
-[5]: https://i1.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot_2018-12-24_20-50-55.png?resize=850%2C359&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 42)
-[6]: https://i1.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot_2018-12-24_20-51-29.png?resize=850%2C462&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 44)
-[7]: https://i2.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-from-2018-12-23-12-30-20.png?resize=850%2C478&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 46)
-[8]: https://i0.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-from-2018-12-24-21-16-11.png?resize=850%2C478&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 48)
-[9]: https://i2.wp.com/fosspost.org/wp-content/uploads/2018/12/gnome-shell-screenshot-SSP3UZ.png?resize=850%2C492&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 50)
-[10]: https://i1.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-from-2018-12-24-21-50-07.png?resize=850%2C478&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 52)
-[11]: https://i0.wp.com/fosspost.org/wp-content/uploads/2016/08/screenshot_570_5X5YkZb.png?resize=478%2C474&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 53)
-[12]: https://github.com/ginatrapani/todo.txt-cli/wiki/The-Todo.txt-Format
-[13]: https://i1.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-from-2018-12-24-21-04-14.png?resize=715%2C245&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 55)
-[14]: https://i2.wp.com/fosspost.org/wp-content/uploads/2016/08/screenshot_750.jpg?resize=648%2C276&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 56)
-[15]: https://i2.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-from-2018-12-24-21-29-41.png?resize=850%2C478&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 58)
-[16]: https://i0.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-20181224210737-380x95.png?resize=380%2C95&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 60)
-[17]: https://i0.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot_2018-12-23_13-58-07.png?resize=524%2C443&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 62)
-[18]: https://i0.wp.com/fosspost.org/wp-content/uploads/2016/08/screenshot_8_1.png?resize=247%2C620&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 63)
-[19]: https://i1.wp.com/fosspost.org/wp-content/uploads/2016/08/Screenshot-from-2016-08-12-08-05-48.png?resize=850%2C478&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 64)
-[20]: https://i0.wp.com/fosspost.org/wp-content/uploads/2016/08/screenshot_4.png?resize=414%2C39&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 65)
-[21]: https://i0.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-20181224211009-631x133.png?resize=631%2C133&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 67)
-[22]: https://i1.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-20181224214626-520x443.png?resize=520%2C443&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 69)
-[23]: https://i0.wp.com/fosspost.org/wp-content/uploads/2016/08/screenshot_2.png?resize=388%2C26&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 70)
-[24]: https://i2.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-20181224214219-327x328.png?resize=327%2C328&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 72)
-[25]: https://i1.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-20181224214131-366x199.png?resize=366%2C199&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 74)
-[26]: https://i2.wp.com/fosspost.org/wp-content/uploads/2018/12/Screenshot-20181224214419-830x143.png?resize=830%2C143&ssl=1 (Turn GNOME to Heaven With These 23 GNOME Extensions 76)
diff --git a/sources/tech/20181226 -Review- Polo File Manager in Linux.md b/sources/tech/20181226 -Review- Polo File Manager in Linux.md
deleted file mode 100644
index cf763850cf..0000000000
--- a/sources/tech/20181226 -Review- Polo File Manager in Linux.md
+++ /dev/null
@@ -1,139 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: ([Review] Polo File Manager in Linux)
-[#]: via: (https://itsfoss.com/polo-file-manager/)
-[#]: author: (John Paul https://itsfoss.com/author/john/)
-
-[Review] Polo File Manager in Linux
-======
-
-We are all familiar with file managers. It’s that piece of software that allows you to access your directories, files in a GUI.
-
-Most of us use the default file manager included with our desktop of choice. The creator of [Polo][1] hopes to get you to use his file manager by adding extra features but hides the good ones behind a paywall.
-
-![][2]Polo file manager
-
-### What is Polo file manager?
-
-According to its [website][1], Polo is an “advanced file manager for Linux written in [Vala][3])”. Further down the page, Polo is referred to as a “modern, light-weight file manager for Linux with support for multiple panes and tabs; support for archives, and much more.”
-
-It is from the same developer (Tony George) that has given us some of the most popular applications for desktop Linux. [Timeshift backup][4] tool, [Conky Manager][5], [Aptik backup tool][6]s for applications etc. Polo is the latest offering from Tony.
-
-Note that Polo is still in the beta stage of development which means the first stable version of the software is not out yet.
-
-### Features of Polo file manager
-
-![Polo File Manager in Ubuntu Linux][7]Polo File Manager in Ubuntu Linux
-
-It’s true that Polo has a bunch of neat features that most file managers don’t have. However, the really neat features are only available if you donate more than $10 to the project or sign up for the creator’s Patreon. I will be separating the free features from the features that require the “donation plugin”.
-
-![Cloud storage support in Polo file manager][8]Support cloud storage
-
-#### Free Features
-
- * Multiple Panes – Single-pane, dual-pane (vertical or horizontal split) and quad-pane layouts.
- * Multiple Views – List view, Icon view, Tiled view, and Media view
- * Device Manager – Devices popup displays the list of connected devices with options to mount and unmount
- * Archive Support – Support for browsing archives as normal folders. Supports creation of archives in multiple formats with advanced compression settings.
- * Checksum & Hashing – Generate and compare MD5, SHA1, SHA2-256 ad SHA2-512 checksums
- * Built-in [Fish shell][9]
- * Support for [cloud storage][10], such as Dropbox, Google Drive, Amazon Drive, Amazon S3, Backblaze B2, Hubi, Microsoft OneDrive, OpenStack Swift, and Yandex Disk
- * Compare files
- * Analyses disk usage
- * KVM support
- * Connect to FTP, SFTP, SSH and Samba servers
-
-
-
-![Dual pane view of Polo file manager][11]Polo in dual pane view
-
-#### Donation/Paywall Features
-
- * Write ISO to USB Device
- * Image optimization and adjustment tools
- * Optimize PNG
- * Reduce JPEG Quality
- * Remove Color
- * Reduce Color
- * Boost Color
- * Set as Wallpaper
- * Rotate
- * Resize
- * Convert to PNG, JPEG, TIFF, BMP, ICO and more
- * PDF tools
- * Split
- * Merge
- * Add and Remove Password
- * Reduce File Size
- * Uncompress
- * Remove Colors
- * Rotate
- * Optimize
- * Video Download via [youtube-dl][12]
-
-
-
-### Installing Polo
-
-Let’s see how to install Polo file manager on various Linux distributions.
-
-#### 1\. Ubuntu based distributions
-
-For all Ubuntu based systems (Ubuntu, Linux Mint, Elementary OS, etc), you can install Polo via the [official PPA][13]. Not sure what a PPA is? [Read about PPA here][14].
-
-`sudo apt-add-repository -y ppa:teejee2008/ppa`
-`sudo apt-get update`
-`sudo apt-get install polo-file-manager`
-
-#### 2\. Arch based distributions
-
-For all Arch-based systems (Arch, Manjaro, ArchLabs, etc), you can install Polo from the [Arch User Repository][15].
-
-#### 3\. Other Distros
-
-For all other distros, you can download and use the [.RUN installer][16] to setup Polo.
-
-### Thoughts on Polo
-
-I’ve installed tons of different distros and never had a problem with the default file manager. (I’ve probably used Thunar and Caja the most.) The free version of Polo doesn’t contain any features that would make me switch. As for the paid features, I already use a number of applications that accomplish the same things.
-
-One final note: the paid version of Polo is supposed to help fund development of the project. However, [according to GitHub][17], the last commit on Polo was three months ago. That’s quite a big interval of inactivity for a software that is still in the beta stages of development.
-
-Have you ever used [Polo][1]? If not, what is your favorite Linux file manager? Let us know in the comments below.
-
-If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][18].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/polo-file-manager/
-
-作者:[John Paul][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[b]: https://github.com/lujun9972
-[1]: https://teejee2008.github.io/polo/
-[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/12/polo.jpg?fit=800%2C500&ssl=1
-[3]: https://en.wikipedia.org/wiki/Vala_(programming_language
-[4]: https://itsfoss.com/backup-restore-linux-timeshift/
-[5]: https://itsfoss.com/conky-gui-ubuntu-1304/
-[6]: https://github.com/teejee2008/aptik
-[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/12/polo-file-manager-in-ubuntu.jpeg?resize=800%2C450&ssl=1
-[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/polo-coud-options.jpg?fit=800%2C795&ssl=1
-[9]: https://fishshell.com/
-[10]: https://itsfoss.com/cloud-services-linux/
-[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/polo-dual-pane.jpg?fit=800%2C520&ssl=1
-[12]: https://itsfoss.com/download-youtube-linux/
-[13]: https://launchpad.net/~teejee2008/+archive/ubuntu/ppa
-[14]: https://itsfoss.com/ppa-guide/
-[15]: https://aur.archlinux.org/packages/polo
-[16]: https://github.com/teejee2008/polo/releases
-[17]: https://github.com/teejee2008/polo
-[18]: http://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20181228 The office coffee model of concurrent garbage collection.md b/sources/tech/20181228 The office coffee model of concurrent garbage collection.md
deleted file mode 100644
index 825eb4b536..0000000000
--- a/sources/tech/20181228 The office coffee model of concurrent garbage collection.md
+++ /dev/null
@@ -1,62 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (The office coffee model of concurrent garbage collection)
-[#]: via: (https://dave.cheney.net/2018/12/28/the-office-coffee-model-of-concurrent-garbage-collection)
-[#]: author: (Dave Cheney https://dave.cheney.net/author/davecheney)
-
-The office coffee model of concurrent garbage collection
-======
-
-Garbage collection is a field with its own terminology. Concepts like like _mutator_ s, _card marking_ , and _write barriers_ create a hurdle to understanding how garbage collectors work. Here’s an analogy to explain the operations of a concurrent garbage collector using everyday items found in the workplace.
-
-Before we discuss the operation of _concurrent_ garbage collection, let’s introduce the dramatis personae. In offices around the world you’ll find one of these:
-
-![][1]
-
-In the workplace coffee is a natural resource. Employees visit the break room and fill their cups as required. That is, until the point someone goes to fill their cup only to discover the pot is _empty_!
-
-Immediately the office is thrown into chaos. Meeting are called. Investigations are held. The perpetrator who took the last cup without refilling the machine is found and [reprimanded][2]. Despite many passive aggressive notes the situation keeps happening, thus a committee is formed to decide if a larger coffee pot should be requisitioned. Once the coffee maker is again full office productivity slowly returns to normal.
-
-This is the model of _stop the world_ garbage collection. The various parts of your program proceed through their day consuming memory, or in our analogy coffee, without a care about the next allocation that needs to be made. Eventually one unlucky attempt to allocate memory is made only to find the heap, or the coffee pot, exhausted, triggering a stop the world garbage collection.
-
-* * *
-
-Down the road at a more enlightened workplace, management have adopted a different strategy for mitigating their break room’s coffee problems. Their policy is simple: if the pot is more than half full, fill your cup and be on your way. However, if the pot is less than half full, _before_ filling your cup, you must add a little coffee and a little water to the top of the machine. In this way, by the time the next person arrives for their re-up, the level in the pot will hopefully have risen higher than when the first person found it.
-
-This policy does come at a cost to office productivity. Rather than filling their cup and hoping for the best, each worker may, depending on the aggregate level of consumption in the office, have to spend a little time refilling the percolator and topping up the water. However, this is time spent by a person who was already heading to the break room. It costs a few extra minutes to maintain the coffee machine, but does not impact their officemates who aren’t in need of caffeination. If several people take a break at the same time, they will all find the level in the pot below the half way mark and all proceed to top up the coffee maker–the more consumption, the greater the rate the machine will be refilled, although this takes a little longer as the break room becomes congested.
-
-This is the model of _concurrent garbage collection_ as practiced by the Go runtime (and probably other language runtimes with concurrent collectors). Rather than each heap allocation proceeding blindly until the heap is exhausted, leading to a long stop the world pause, concurrent collection algorithms spread the work of walking the heap to find memory which is no longer reachable over the parts of the program allocating memory. In this way the parts of the program which allocate memory each pay a small cost–in terms of latency–for those allocations rather than the whole program being forced to halt when the heap is exhausted.
-
-Lastly, in keeping with the office coffee model, if the rate of coffee consumption in the office is so high that management discovers that their staff are always in the break room trying desperately to refill the coffee machine, it’s time to invest in a machine with a bigger pot–or in garbage collection terms, grow the heap.
-
-### Related posts:
-
- 1. [Visualising the Go garbage collector][3]
- 2. [A whirlwind tour of Go’s runtime environment variables][4]
- 3. [Why is a Goroutine’s stack infinite ?][5]
- 4. [Introducing Go 2.0][6]
-
-
-
---------------------------------------------------------------------------------
-
-via: https://dave.cheney.net/2018/12/28/the-office-coffee-model-of-concurrent-garbage-collection
-
-作者:[Dave Cheney][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://dave.cheney.net/author/davecheney
-[b]: https://github.com/lujun9972
-[1]: https://dave.cheney.net/wp-content/uploads/2018/12/20181204175004_79256.jpg
-[2]: https://www.youtube.com/watch?v=ww86iaucd2A
-[3]: https://dave.cheney.net/2014/07/11/visualising-the-go-garbage-collector (Visualising the Go garbage collector)
-[4]: https://dave.cheney.net/2015/11/29/a-whirlwind-tour-of-gos-runtime-environment-variables (A whirlwind tour of Go’s runtime environment variables)
-[5]: https://dave.cheney.net/2013/06/02/why-is-a-goroutines-stack-infinite (Why is a Goroutine’s stack infinite ?)
-[6]: https://dave.cheney.net/2016/10/25/introducing-go-2-0 (Introducing Go 2.0)
diff --git a/sources/tech/20181229 Some nonparametric statistics math.md b/sources/tech/20181229 Some nonparametric statistics math.md
deleted file mode 100644
index 452c295781..0000000000
--- a/sources/tech/20181229 Some nonparametric statistics math.md
+++ /dev/null
@@ -1,178 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Some nonparametric statistics math)
-[#]: via: (https://jvns.ca/blog/2018/12/29/some-initial-nonparametric-statistics-notes/)
-[#]: author: (Julia Evans https://jvns.ca/)
-
-Some nonparametric statistics math
-======
-
-I’m trying to understand nonparametric statistics a little more formally. This post may not be that intelligible because I’m still pretty confused about nonparametric statistics, there is a lot of math, and I make no attempt to explain any of the math notation. I’m working towards being able to explain this stuff in a much more accessible way but first I would like to understand some of the math!
-
-There’s some MathJax in this post so the math may or may not render in an RSS reader.
-
-Some questions I’m interested in:
-
- * what is nonparametric statistics exactly?
- * what guarantees can we make? are there formulas we can use?
- * why do methods like the bootstrap method work?
-
-
-
-since these notes are from reading a math book and math books are extremely dense this is basically going to be “I read 7 pages of this math book and here are some points I’m confused about”
-
-### what’s nonparametric statistics?
-
-Today I’m looking at “all of nonparametric statistics” by Larry Wasserman. He defines nonparametric inference as:
-
-> a set of modern statistical methods that aim to keep the number of underlying assumptions as weak as possible
-
-Basically my interpretation of this is that – instead of assuming that your data comes from a specific family of distributions (like the normal distribution) and then trying to estimate the paramters of that distribution, you don’t make many assumptions about the distribution (“this is just some data!!“). Not having to make assumptions is nice!
-
-There aren’t **no** assumptions though – he says
-
-> we assume that the distribution $F$ lies in some set $\mathfrak{F}$ called a **statistical model**. For example, when estimating a density $f$, we might assume that $$ f \in \mathfrak{F} = \left\\{ g : \int(g^{\prime\prime}(x))^2dx \leq c^2 \right\\}$$ which is the set of densities that are not “too wiggly”.
-
-I have not too much intuition for the condition $\int(g^{\prime\prime}(x))^2dx \leq c^2$. I calculated that integral for [the normal distribution on wolfram alpha][1] and got 4, which is a good start. (4 is not infinity!)
-
-some questions I still have about this definition:
-
- * what’s an example of a probability density function that _doesn’t_ satisfy that $\int(g^{\prime\prime}(x))^2dx \leq c^2$ condition? (probably something with an infinite number of tiny wiggles, and I don’t think any distribution i’m interested in in practice would have an infinite number of tiny wiggles?)
- * why does the density function being “too wiggly” cause problems for nonparametric inference? very unclear as yet.
-
-
-
-### we still have to assume independence
-
-One assumption we **won’t** get away from is that the samples in the data we’re dealing with are independent. Often data in the real world actually isn’t really independent, but I think the what people do a lot of the time is to make a good effort at something approaching independence and then close your eyes and pretend it is?
-
-### estimating the density function
-
-Okay! Here’s a useful section! Let’s say that I have 100,000 data points from a distribution. I can draw a histogram like this of those data points:
-
-![][2]
-
-If I have 100,000 data points, it’s pretty likely that that histogram is pretty close to the actual distribution. But this is math, so we should be able to make that statement precise, right?
-
-For example suppose that 5% of the points in my sample are more than 100. Is the probability that a point is greater than 100 **actually** 0.05? The book gives a nice formula for this:
-
-$$ \mathbb{P}(|\widehat{P}_n(A) - P(A)| > \epsilon ) \leq 2e^{-2n\epsilon^2} $$
-
-(by [“Hoeffding’s inequality”][3] which I’ve never heard of before). Fun aside about that inequality: here’s a nice jupyter notebook by henry wallace using it to [identify the most common Boggle words][4].
-
-here, in our example:
-
- * n is 1000 (the number of data points we have)
- * $A$ is the set of points more than 100
- * $\widehat{P}_n(A)$ is the empirical probability that a point is more than 100 (0.05)
- * $P(A)$ is the actual probability
- * $\epsilon$ is how certain we want to be that we’re right
-
-
-
-So, what’s the probability that the **real** probability is between 0.04 and 0.06? $\epsilon = 0.01$, so it’s $2e^{-2 \times 100,000 \times (0.01)^2} = 4e^{-9} $ ish (according to wolfram alpha)
-
-here is a table of how sure we can be:
-
- * 100,000 data points: 4e-9 (TOTALLY CERTAIN that 4% - 6% of points are more than 100)
- * 10,000 data points: 0.27 (27% probability that we’re wrong! that’s… not bad?)
- * 1,000 data points: 1.6 (we know the probability we’re wrong is less than.. 160%? that’s not good!)
- * 100 data points: lol
-
-
-
-so basically, in this case, using this formula: 100,000 data points is AMAZING, 10,000 data points is pretty good, and 1,000 is much less useful. If we have 1000 data points and we see that 5% of them are more than 100, we DEFINITELY CANNOT CONCLUDE that 4% to 6% of points are more than 100. But (using the same formula) we can use $\epsilon = 0.04$ and conclude that with 92% probability 1% to 9% of points are more than 100. So we can still learn some stuff from 1000 data points!
-
-This intuitively feels pretty reasonable to me – like it makes sense to me that if you have NO IDEA what your distribution that with 100,000 points you’d be able to make quite strong inferences, and that with 1000 you can do a lot less!
-
-### more data points are exponentially better?
-
-One thing that I think is really cool about this estimating the density function formula is that how sure you can be of your inferences scales **exponentially** with the size of your dataset (this is the $e^{-n\epsilon^2}$). And also exponentially with the square of how sure you want to be (so wanting to be sure within 0.01 is VERY DIFFERENT than within 0.04). So 100,000 data points isn’t 10x better than 10,000 data points, it’s actually like 10000000000000x better.
-
-Is that true in other places? If so that seems like a super useful intuition! I still feel pretty uncertain about this, but having some basic intuition about “how much more useful is 10,000 data points than 1,000 data points?“) feels like a really good thing.
-
-### some math about the bootstrap
-
-The next chapter is about the bootstrap! Basically the way the bootstrap works is:
-
- 1. you want to estimate some statistic (like the median) of your distribution
- 2. the bootstrap lets you get an estimate and also the variance of that estimate
- 3. you do this by repeatedly sampling with replacement from your data and then calculating the statistic you want (like the median) on your samples
-
-
-
-I’m not going to go too much into how to implement the bootstrap method because it’s explained in a lot of place on the internet. Let’s talk about the math!
-
-I think in order to say anything meaningful about bootstrap estimates I need to learn a new term: a **consistent estimator**.
-
-### What’s a consistent estimator?
-
-Wikipedia says:
-
-> In statistics, a **consistent estimator** or **asymptotically consistent estimator** is an estimator — a rule for computing estimates of a parameter $\theta_0$ — having the property that as the number of data points used increases indefinitely, the resulting sequence of estimates converges in probability to $\theta_0$.
-
-This includes some terms where I forget what they mean (what’s “converges in probability” again?). But this seems like a very good thing! If I’m estimating some parameter (like the median), I would DEFINITELY LIKE IT TO BE TRUE that if I do it with an infinite amount of data then my estimate works. An estimator that is not consistent does not sound very useful!
-
-### why/when are bootstrap estimators consistent?
-
-spoiler: I have no idea. The book says the following:
-
-> Consistency of the boostrap can now be expressed as follows.
->
-> **3.19 Theorem**. Suppose that $\mathbb{E}(X_1^2) < \infty$. Let $T_n = g(\overline{X}_n)$ where $g$ is continuously differentiable at $\mu = \mathbb{E}(X_1)$ and that $g\prime(\mu) \neq 0$. Then,
->
-> $$ \sup_u | \mathbb{P}_{\widehat{F}_n} \left( \sqrt{n} (T( \widehat{F}_n*) - T( \widehat{F}_n) \leq u \right) - \mathbb{P}_{\widehat{F}} \left( \sqrt{n} (T( \widehat{F}_n) - T( \widehat{F}) \leq u \right) | \rightarrow^\text{a.s.} 0 $$
->
-> **3.21 Theorem**. Suppose that $T(F)$ is Hadamard differentiable with respect to $d(F,G)= sup_x|F(x)-G(x)|$ and that $0 < \int L^2_F(x) dF(x) < \infty$. Then,
->
-> $$ \sup_u | \mathbb{P}_{\widehat{F}_n} \left( \sqrt{n} (T( \widehat{F}_n*) - T( \widehat{F}_n) \leq u \right) - \mathbb{P}_{\widehat{F}} \left( \sqrt{n} (T( \widehat{F}_n) - T( \widehat{F}) \leq u \right) | \rightarrow^\text{P} 0 $$
-
-things I understand about these theorems:
-
- * the two formulas they’re concluding are the same, except I think one is about convergence “almost surely” and one about “convergence in probability”. I don’t remember what either of those mean.
- * I think for our purposes of doing Regular Boring Things we can replace “Hadamard differentiable” with “differentiable”
- * I think they don’t actually show the consistency of the bootstrap, they’re actually about consistency of the bootstrap confidence interval estimate (which is a different thing)
-
-
-
-I don’t really understand how they’re related to consistency, and in particular the $\sup_u$ thing is weird, like if you’re looking at $\mathbb{P}(something < u)$, wouldn’t you want to minimize $u$ and not maximize it? Maybe it’s a typo and it should be $\inf_u$?
-
-it concludes:
-
-> there is a tendency to treat the bootstrap as a panacea for all problems. But the bootstrap requires regularity conditions to yield valid answers. It should not be applied blindly.
-
-### this book does not seem to explain why the bootstrap is consistent
-
-In the appendix (3.7) it gives a sketch of a proof for showing that estimating the **median** using the bootstrap is consistent. I don’t think this book actually gives a proof anywhere that bootstrap estimates in general are consistent, which was pretty surprising to me. It gives a bunch of references to papers. Though I guess bootstrap confidence intervals are the most important thing?
-
-### that’s all for now
-
-This is all extremely stream of consciousness and I only spent 2 hours trying to work through this, but some things I think I learned in the last couple hours are:
-
- 1. maybe having more data is exponentially better? (is this true??)
- 2. “consistency” of an estimator is a thing, not all estimators are consistent
- 3. understanding when/why nonparametric bootstrap estimators are consistent in general might be very hard (the proof that the bootstrap median estimator is consistent already seems very complicated!)
- 4. boostrap confidence intervals are not the same thing as bootstrap estimators. Maybe I’ll learn the difference next!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://jvns.ca/blog/2018/12/29/some-initial-nonparametric-statistics-notes/
-
-作者:[Julia Evans][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://jvns.ca/
-[b]: https://github.com/lujun9972
-[1]: https://www.wolframalpha.com/input/?i=integrate+(d%2Fdx(d%2Fdx(exp(-x%5E2))))%5E2++dx+from+x%3D-infinity+to+infinity
-[2]: https://jvns.ca/images/nonpar-histogram.png
-[3]: https://en.wikipedia.org/wiki/Hoeffding%27s_inequality
-[4]: https://nbviewer.jupyter.org/github/henrywallace/games/blob/master/boggle/boggle.ipynb#Estimating-Word-Probabilities
From 5e8b351f6e00be26190fc816aeb560ff39961152 Mon Sep 17 00:00:00 2001
From: Xingyu Wang <xingyu.wang@gmail.com>
Date: Sat, 1 Feb 2020 12:18:49 +0800
Subject: [PATCH 11/11] =?UTF-8?q?=E8=A1=A5=E5=85=85=E9=81=97=E5=A4=B1?=
=?UTF-8?q?=E7=9A=84=E8=AF=B4=E6=98=8E=E6=96=87=E4=BB=B6?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
sources/README.md | 1 +
sources/news/README.md | 1 +
translated/{translated.md => README.md} | 0
translated/news/README.md | 1 +
4 files changed, 3 insertions(+)
create mode 100644 sources/README.md
create mode 100644 sources/news/README.md
rename translated/{translated.md => README.md} (100%)
create mode 100644 translated/news/README.md
diff --git a/sources/README.md b/sources/README.md
new file mode 100644
index 0000000000..5615087474
--- /dev/null
+++ b/sources/README.md
@@ -0,0 +1 @@
+这里放待翻译的文件。
diff --git a/sources/news/README.md b/sources/news/README.md
new file mode 100644
index 0000000000..98d53847b1
--- /dev/null
+++ b/sources/news/README.md
@@ -0,0 +1 @@
+这里放新闻类文章,要求时效性
diff --git a/translated/translated.md b/translated/README.md
similarity index 100%
rename from translated/translated.md
rename to translated/README.md
diff --git a/translated/news/README.md b/translated/news/README.md
new file mode 100644
index 0000000000..98d53847b1
--- /dev/null
+++ b/translated/news/README.md
@@ -0,0 +1 @@
+这里放新闻类文章,要求时效性