mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge branch 'master' into dev-20151015-new-rtl
This commit is contained in:
commit
d2bd973365
@ -0,0 +1,28 @@
|
||||
Linux 4.3 内核增加了 MOST 驱动子系统
|
||||
================================================================================
|
||||
当 4.2 内核还没有正式发布的时候,Greg Kroah-Hartman 就为他维护的各种子系统模块打开了4.3 的合并窗口。
|
||||
|
||||
之前 Greg KH 发起的拉取请求(pull request)里包含了 linux 4.3 的合并窗口更新,内容涉及驱动核心、TTY/串口、USB 驱动、字符/杂项以及暂存区内容。这些拉取申请没有提供任何震撼性的改变,大部分都是改进/附加/修改bug。暂存区内容又是大量的修正和清理,但是还是有一个新的驱动子系统。
|
||||
|
||||
Greg 提到了[4.3 的暂存区改变][2],“这里的很多东西,几乎全部都是细小的修改和改变。通常的 IIO 更新和新驱动,以及我们已经添加了的 MOST 驱动子系统,已经在源码树里整理了。ozwpan 驱动最终还是被删掉,因为它很明显被废弃了而且也没有人关心它。”
|
||||
|
||||
MOST 驱动子系统是面向媒体的系统传输(Media Oriented Systems Transport)的简称。在 linux 4.3 新增的文档里面解释道,“MOST 驱动支持 LInux 应用程序访问 MOST 网络:汽车信息骨干网(Automotive Information Backbone),高速汽车多媒体网络的事实上的标准。MOST 定义了必要的协议、硬件和软件层,提供高效且低消耗的传输控制,实时的数据包传输,而只需要使用一个媒介(物理层)。目前使用的媒介是光线、非屏蔽双绞线(UTP)和同轴电缆。MOST 也支持多种传输速度,最高支持150Mbps。”如文档解释的,MOST 主要是关于 Linux 在汽车上的应用。
|
||||
|
||||
当 Greg KH 发出了他为 Linux 4.3 多个子系统做出的更新,但是他还没有打算提交 [KDBUS][5] 的内核代码。他之前已经放出了 [linux 4.3 的 KDBUS] 的开发计划,所以我们将需要等待官方的4.3 合并窗口,看看会发生什么。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.3-Staging-Pull
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/scan.php?page=search&q=Linux+4.2
|
||||
[2]:http://lkml.iu.edu/hypermail/linux/kernel/1508.2/02604.html
|
||||
[3]:http://www.phoronix.com/scan.php?page=news_item&px=KDBUS-Not-In-Linux-4.2
|
||||
[4]:http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.2-rc7-Released
|
||||
[5]:http://www.phoronix.com/scan.php?page=search&q=KDBUS
|
||||
@ -1,10 +1,12 @@
|
||||
如何使用 GRUB 2 直接从硬盘运行 ISO 文件
|
||||
================================================================================
|
||||

|
||||
|
||||
大多数 Linux 发行版都会提供一个可以从 USB 启动的 live 环境,以便用户无需安装即可测试系统。我们可以用它来评测这个发行版或仅仅是当成一个一次性系统,并且很容易将这些文件复制到一个 U 盘上,在某些情况下,我们可能需要经常运行同一个或不同的 ISO 镜像。GRUB 2 可以配置成直接从启动菜单运行一个 live 环境,而不需要烧录这些 ISO 到硬盘或 USB 设备。
|
||||
|
||||
### 获取和检查可启动的 ISO 镜像 ###
|
||||
为了获取 ISO 镜像,我们通常应该访问所需要的发行版的网站下载与我们架构兼容的镜像文件。如果这个镜像可以从 U 盘启动,那它也应该可以从 GRUB 菜单启动。
|
||||
|
||||
为了获取 ISO 镜像,我们通常应该访问所需的发行版的网站下载与我们架构兼容的镜像文件。如果这个镜像可以从 U 盘启动,那它也应该可以从 GRUB 菜单启动。
|
||||
|
||||
当镜像下载完后,我们应该通过 MD5 校验检查它的完整性。这会输出一大串数字与字母合成的序列。
|
||||
|
||||
@ -13,13 +15,12 @@
|
||||
将这个序列与下载页提供的 MD5 校验码进行比较,两者应该完全相同。
|
||||
|
||||
### 配置 GRUB 2 ###
|
||||
|
||||
ISO 镜像文件包含了整个系统。我们要做的仅仅是告诉 GRUB 2 哪里可以找到 kernel 和 initramdisk 或 initram 文件系统(这取决于我们所使用的发行版)。
|
||||
|
||||
在下面的例子中,一个 Kubuntu 15.04 live 环境将被配置到 Ubuntu 14.04 盒子的 Grub 启动菜单项。这应该能在大多数新的以 Ubuntu 为基础的系统上运行。如果你是其他系统并且想实现一些其它的东西,你可以从[这些文件][1]获取灵感,但这会要求你拥有一点 GRUB 使用经验。
|
||||
在下面的例子中,一个 Kubuntu 15.04 live 环境将被配置到 Ubuntu 14.04 机器的 Grub 启动菜单项。这应该能在大多数新的以 Ubuntu 为基础的系统上运行。如果你是其它系统并且想实现一些其它的东西,你可以从[这些文件][1]了解更多细节,但这会要求你拥有一点 GRUB 使用经验。
|
||||
|
||||
这个例子的文件 `kubuntu-15.04-desktop-amd64.iso`
|
||||
|
||||
放在位于 `/dev/sda1` 的 `/home/maketecheasier/TempISOs/` 上.
|
||||
这个例子的文件 `kubuntu-15.04-desktop-amd64.iso` 放在位于 `/dev/sda1` 的 `/home/maketecheasier/TempISOs/` 上。
|
||||
|
||||
为了使 GRUB 2 能正确找到它,我们应该编辑
|
||||
|
||||
@ -39,7 +40,7 @@ ISO 镜像文件包含了整个系统。我们要做的仅仅是告诉 GRUB 2
|
||||
|
||||
### 分析上述代码 ###
|
||||
|
||||
首先设置了一个变量名 `$menuentry` ,这是 ISO 文件的所在位置 。如果你想改变一个 ISO ,你应该修改 `isofile="/path/to/file/name-of-iso-file-.iso"`.
|
||||
首先设置了一个变量名 `$menuentry` ,这是 ISO 文件的所在位置 。如果你想换一个 ISO ,你应该修改 `isofile="/path/to/file/name-of-iso-file-.iso"`.
|
||||
|
||||
下一行是指定回环设备,且必须给出正确的分区号码。
|
||||
|
||||
@ -51,11 +52,11 @@ GRUB 的命名在这里稍微有点困惑,对于硬盘来说,它从 “0”
|
||||
|
||||
在 Linux 中第一块硬盘,第一个分区是 `/dev/sda1` ,但在 GRUB2 中则是 `hd0,1` 。第二块硬盘,第三个分区则是 `hd1,3`, 依此类推.
|
||||
|
||||
下一个重要的行是
|
||||
下一个重要的行是:
|
||||
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
|
||||
这会载入内核镜像,在新的 Ubuntu Live CD 中,内核被存放在 `/casper` 目录,并且命名为 `vmlinuz.efi` 。如果你使用的是其它系统,可能会没有 `.efi` 扩展名或内核被存放在其它地方 (可以使用归档管理器打开 ISO 文件在 `/casper` 中查找确认)。最后一个选项, `quiet splash`, 是一个常规的 GRUB 选项无论你是否在意改动它们。
|
||||
这会载入内核镜像,在新的 Ubuntu Live CD 中,内核被存放在 `/casper` 目录,并且命名为 `vmlinuz.efi` 。如果你使用的是其它系统,可能会没有 `.efi` 扩展名或内核被存放在其它地方 (可以使用归档管理器打开 ISO 文件在 `/casper` 中查找确认)。最后一个选项, `quiet splash` ,是一个常规的 GRUB 选项,改不改无所谓。
|
||||
|
||||
最后
|
||||
|
||||
@ -65,13 +66,13 @@ GRUB 的命名在这里稍微有点困惑,对于硬盘来说,它从 “0”
|
||||
|
||||
### 启动 live 系统 ###
|
||||
|
||||
做完上面所有的步骤后,需要更新 GRUB2
|
||||
做完上面所有的步骤后,需要更新 GRUB2:
|
||||
|
||||
sudo update-grub
|
||||
|
||||

|
||||
|
||||
当重启系统后,应该可以看见一个新的,并且允许我们启动刚刚配置的 ISO 镜像的 GRUB 条目
|
||||
当重启系统后,应该可以看见一个新的、并且允许我们启动刚刚配置的 ISO 镜像的 GRUB 条目:
|
||||
|
||||

|
||||
|
||||
@ -83,7 +84,7 @@ via: https://www.maketecheasier.com/run-iso-files-hdd-grub2/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,72 @@
|
||||
Linux 有问必答:如何在 Linux 命令行下浏览天气预报
|
||||
================================================================================
|
||||
> **Q**: 我经常在 Linux 桌面查看天气预报。然而,是否有一种在终端环境下,不通过桌面小插件或者浏览器查询天气预报的方法?
|
||||
|
||||
对于 Linux 桌面用户来说,有很多办法获取天气预报,比如使用专门的天气应用、桌面小插件,或者面板小程序。但是如果你的工作环境是基于终端的,这里也有一些在命令行下获取天气的手段。
|
||||
|
||||
其中有一个就是 [wego][1],**一个终端下的小巧程序**。使用基于 ncurses 的接口,这个命令行程序允许你查看当前的天气情况和之后的预报。它也会通过一个天气预报的 API 收集接下来 5 天的天气预报。
|
||||
|
||||
### 在 Linux 下安装 wego ###
|
||||
|
||||
安装 wego 相当简单。wego 是用 Go 编写的,引起第一个步骤就是安装 [Go 语言][2]。然后再安装 wego。
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
wego 会被安装到 $GOPATH/bin,所以要将 $GOPATH/bin 添加到 $PATH 环境变量。
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
现在就可与直接从命令行启动 wego 了。
|
||||
|
||||
$ wego
|
||||
|
||||
第一次运行 weg 会生成一个配置文件(`~/.wegorc`),你需要指定一个天气 API key。
|
||||
你可以从 [worldweatheronline.com][3] 获取一个免费的 API key。免费注册和使用。你只需要提供一个有效的邮箱地址。
|
||||
|
||||

|
||||
|
||||
你的 .wegorc 配置文件看起来会这样:
|
||||
|
||||

|
||||
|
||||
除了 API key,你还可以把你想要查询天气的地方、使用的城市/国家名称、语言配置在 `~/.wegorc` 中。
|
||||
注意,这个天气 API 的使用有限制:每秒最多 5 次查询,每天最多 250 次查询。
|
||||
当你重新执行 wego 命令,你将会看到最新的天气预报(当然是你的指定地方),如下显示。
|
||||
|
||||

|
||||
|
||||
显示出来的天气信息包括:(1)温度,(2)风速和风向,(3)可视距离,(4)降水量和降水概率
|
||||
默认情况下会显示3 天的天气预报。如果要进行修改,可以通过参数改变天气范围(最多5天),比如要查看 5 天的天气预报:
|
||||
|
||||
$ wego 5
|
||||
|
||||
如果你想检查另一个地方的天气,只需要提供城市名即可:
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### 问题解决 ###
|
||||
|
||||
1. 可能会遇到下面的错误:
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
当你在一个不支持原生 Go 编译器的环境下运行 wego 时就会出现这个错误。在这种情况下你只需要使用 gccgo ——一个 Go 的编译器前端来编译程序即可。这一步可以通过下面的命令完成。
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
在 [MPlayer][1] 1.1 发布将近3年后,新版 MPlayer 终于在上周发布了。在新版本 MPlayer 1.2 中带来了对许多新编码的解码支持。
|
||||
|
||||
MPlayer 是一款跨平台的开源媒体播放器。它的名字是“Movie Player”的缩写。MPlayer 已经成为 Linux 上最老牌的媒体播放器之一,在过去的15年里,它还启发了许多其他媒体播放器。著名的基于 MPlayer 的媒体播放器有:
|
||||
MPlayer 是一款跨平台的开源媒体播放器。它的名字是“Movie Player”的缩写。MPlayer 是 Linux 上最老牌的媒体播放器之一,在过去的15年里,它还带动出现了许多其他媒体播放器。著名的基于 MPlayer 的媒体播放器有:
|
||||
|
||||
- [MPV][2]
|
||||
- SMPlayer
|
||||
@ -30,19 +30,14 @@ MPlayer 是一款跨平台的开源媒体播放器。它的名字是“Movie Pla
|
||||
打开一个终端,运行下列命令:
|
||||
|
||||
wget http://www.mplayerhq.hu/MPlayer/releases/MPlayer-1.2.tar.xz
|
||||
|
||||
tar xvf MPlayer-1.1.1.tar.xz
|
||||
|
||||
cd MPlayer-1.2
|
||||
|
||||
sudo apt-get install yasm
|
||||
|
||||
./configure
|
||||
|
||||
在你运行 make 的时候,在你的终端屏幕上会显示一些东西,并且你需要一些时间来编译它。保持耐心。
|
||||
|
||||
make
|
||||
|
||||
sudo make install
|
||||
|
||||
如果你觉得从源码编译不大习惯的话,我建议你等待 MPlayer 1.2 提交到你的 Linux 发行版仓库中,或者用其它的播放器替代,比如 MPV。
|
||||
@ -53,7 +48,7 @@ via: http://itsfoss.com/mplayer-1-2-released/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux产能工具及其使用技巧
|
||||
Linux 产能工具及其使用技巧
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -6,7 +6,7 @@ Linux产能工具及其使用技巧
|
||||
|
||||
### Linux产能工具及其使用技巧 ###
|
||||
|
||||
再次说明,我在写下本文时正在使用的是Ubuntu。但是,我将要在这里展示给大家产能工具及其使用技巧却适用于外面的大多数Linux发行版。
|
||||
再次说明,我在写下本文时正在使用的是Ubuntu。但是,我将要在这里展示给大家产能工具及其使用技巧却适用于市面上的大多数Linux发行版。
|
||||
|
||||
#### 外界的音乐 ####
|
||||
|
||||
@ -36,14 +36,14 @@ Ctrl+ C和Ctrl+V是我们日常计算机生活中不可缺少的一部分,它
|
||||
|
||||
如果你正忙着处理其它事情,而此时一个桌面通知闪了出来又逐渐消失了,你会怎么做?你会想要看看通知都说了什么,不是吗?最近通知指示器就是用于处理此项工作,它会保留一个最近所有通知的历史记录。这样,你就永远不会错过桌面通知了。
|
||||
|
||||
你可以阅读[最近通知指示器这里][13]。
|
||||
你可以在此阅读[最近通知指示器][13]。
|
||||
|
||||
#### 终端技巧 ####
|
||||
|
||||
不,我不打算给你们展示所有那些Linux命令技巧和快捷方法,那会写满整个博客了。我打算给你们展示一些终端黑技巧,你可以用它们来提高你的生产力。
|
||||
|
||||
- **修改**sudo**密码超时**:默认情况下,sudo命令要求你在15分钟后再次输入密码,这真是让人讨厌。实际上,你可以修改默认的sudo密码超时。[此教程][14]会给你展示如何来实现。
|
||||
- **获取命令完成的桌面通知**:这是IT朋友们之间的一个常见的玩笑,开发者们花费大量时间来等待程序编译完成,而这不完全是正确的。但是,它确实影响到了生产力,因为在你等待程序编译完成时,你可以做其它事情,并忘了你在终端中运行的命令。一个更好的途径,就是在一个命令完成时,让它显示桌面通知。这样,你就不会长时间被打断,并且可以回到之前想要做的事情上。请阅读[如何获取命令完成的桌面通知][15]。
|
||||
- **获取命令完成的桌面通知**:这是IT朋友们之间的一个常见的玩笑——开发者们花费大量时间来等待程序编译完成——然而这不完全是正确的。但是,它确实影响到了生产力,因为在你等待程序编译完成时,你可以做其它事情,并忘了你在终端中运行的命令。一个更好的途径,就是在一个命令完成时,让它显示桌面通知。这样,你就不会长时间被打断,并且可以回到之前想要做的事情上。请阅读[如何获取命令完成的桌面通知][15]。
|
||||
|
||||
我知道,这不是一篇全面涵盖了**提升生产力**的文章。但是,这些小应用和小技巧可以在实际生活中帮助你在你宝贵的时间中做得更多。
|
||||
|
||||
@ -55,20 +55,20 @@ via: http://itsfoss.com/productivity-tips-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://www.helpscout.net/blog/music-productivity/
|
||||
[2]:http://itsfoss.com/ambient-noise-music-player-ubuntu/
|
||||
[2]:https://linux.cn/article-5233-1.html
|
||||
[3]:http://www.noisli.com/
|
||||
[4]:https://en.wikipedia.org/wiki/Pomodoro_Technique
|
||||
[5]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[6]:http://todotxt.com/
|
||||
[7]:http://itsfoss.com/go-for-it-to-do-app-in-linux/
|
||||
[7]:https://linux.cn/article-5337-1.html
|
||||
[8]:http://itsfoss.com/indicator-stickynotes-windows-like-sticky-note-app-for-ubuntu/
|
||||
[9]:http://itsfoss.com/install-google-keep-ubuntu-1310/
|
||||
[9]:https://linux.cn/article-2634-1.html
|
||||
[10]:https://evernote.com/
|
||||
[11]:http://itsfoss.com/5-evernote-alternatives-linux/
|
||||
[12]:https://esite.ch/tag/diodon/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
What is a good IDE for R on Linux
|
||||
================================================================================
|
||||
Some time ago, I covered some of the [best IDEs for C/C++][1] on Linux. Obviously C and C++ are not the only programming languages out there, and it is time to turn to something a bit more specific.
|
||||
|
||||
@ -1,127 +0,0 @@
|
||||
translating...
|
||||
|
||||
Interview: Larry Wall
|
||||
================================================================================
|
||||
> Perl 6 has been 15 years in the making, and is now due to be released at the end of this year. We speak to its creator to find out what’s going on.
|
||||
|
||||
Larry Wall is a fascinating man. He’s the creator of Perl, a programming language that’s widely regarded as the glue holding the internet together, and mocked by some as being a “write-only” language due to its density and liberal use of non-alphanumeric characters. Larry also has a background in linguistics, and is well known for delivering entertaining “State of the Onion” presentations about the future of Perl.
|
||||
|
||||
At FOSDEM 2015 in Brussels, we caught up with Larry to ask him why Perl 6 has taken so long (Perl 5 was released in 1994), how difficult it is to manage a project when everyone has strong opinions and pulling in different directions, and how his background in linguistics influenced the design of Perl from the start. Get ready for some intriguing diversions…
|
||||
|
||||

|
||||
|
||||
**Linux Voice: You once had a plan to go and find an undocumented language somewhere in the world and create a written script for it, but you never had the opportunity to fulfil this plan. Is that something you’d like to go back and do now?**
|
||||
|
||||
Larry Wall: You have to be kind of young to be able to carry that off! It’s actually a lot of hard work, and organisations that do these things don’t tend to take people in when they’re over a certain age. Partly this is down to health and vigour, but also because people are much better at picking up new languages when they’re younger, and you have to learn the language before making a script for it.
|
||||
|
||||
I started trying to teach myself Japanese about 10 years ago, and I could speak it quite well, because of my phonology and phonetics training – but it’s very hard for me to understand what anybody says. So I can go to Japan and ask for directions, but I can’t really understand the answers!
|
||||
|
||||
> “With Perl 6, we found some ways to make the computer more sure about what the user is talking about.”
|
||||
|
||||
So usually learning a language well enough to develop a writing system, and to at least be conversational in the language, takes some period of years before you can get to the point where you can actually do literacy and start educating people on their own culture, as it were. And then you teach them to write about their own culture as well.
|
||||
|
||||
Of course, if you have language helpers – and we were told not to call them “language informants”, or everyone would think we were working for the CIA! – if you have these people, you can get them to come in and help you learn the foreign language. They are not teachers but there are ways of eliciting things from someone who’s not a language teacher – they can still teach you how to speak. They can take a stick and point to it and say “that’s a stick”, and drop it and say “the stick falls”. Then you start writing things down and systematising things.
|
||||
|
||||
The motivation that most people have, going out to these groups, is to translate the Bible into their languages. But that’s only one part of it; the other is also culture preservation. Missionaries get kind of a bad rep on that, because anthropologists think they should be left to sit their in their own culture. But somebody is probably going to change their culture anyway – it’s usually the army, or businesses coming in, like Coca Cola or the sewing machine people, or missionaries. And of those three, the missionaries are the least damaging, if they’re doing their job right.
|
||||
|
||||
**LV: Many writing systems are based on existing scripts, and then you have invented ones like Greenlandic…**
|
||||
|
||||
LW: The Cherokee invented their own just by copying letters, and they have no mapping much to what we think of letters, and it’s fairly arbitrary in that sense. It just has to represent how the people themselves think of the language, and sufficiently well to communicate. Often there will be variations on Western orthography, using characters from Latin where possible. Tonal languages have to mark the tones somehow, by accents or by numbers.
|
||||
|
||||
As soon as you start leaning towards a phoenetic or phonological representation, then you also start to lose dialectical differences – or you have to write the dialectal differences. Or you have conventional spelling like we have in English, but pronunciation that doesn’t really match it.
|
||||
|
||||
**LV: When you started working on Perl, what did you take from your background in linguistics that made you think: “this is really important in a programming language”?**
|
||||
|
||||
LW: I thought a lot about how people use languages. In real languages, you have a system of nouns and verbs and adjectives, and you kind of know which words are which type. And in real natural languages, you have a lot of instances of shoving one word into a different slot. The linguistic theory I studied was called tagmemics, and it accounts for how this works in a natural language – that you could have something that you think of as a noun, but you can verb it, and people do that all time.
|
||||
|
||||
You can pretty much shove anything in any slot, and you can communicate. One of my favourite examples is shoving an entire sentence in as an adjective. The sentence goes like this: “I don’t like your I-can-use-anything-as-an-adjective attitude”!
|
||||
|
||||
So natural language is very flexible this way because you have a very intelligent listener – or at least, compared with a computer – who you can rely on to figure out what you must have meant, in case of ambiguity. Of course, in a computer language you have to manage the ambiguity much more closely.
|
||||
|
||||
Arguably in Perl 1 through to 5 we didn’t manage it quite adequately enough. Sometimes the computer was confused when it really shouldn’t be. With Perl 6, we discovered some ways to make the computer more sure about what the user is talking about, even if the user is confused about whether something is really a string or a number. The computer knows the exact type of it. We figured out ways of having stronger typing internally but still have the allomorphic “you can use this as that” idea.
|
||||
|
||||

|
||||
|
||||
**LV: For a long time Perl was seen as the “glue” language of the internet, for fitting bits and pieces together. Do you see Perl 6 as a release to satisfy the needs of existing users, or as a way to bring in new people, and bring about a resurgence in the language?**
|
||||
|
||||
LW: The initial intent was to make a better Perl for Perl programmers. But as we looked at the some of the inadequacies of Perl 5, it became apparent that if we fixed these inadequacies, Perl 6 would be more applicable, as I mentioned in my talk – like how J. R. R. Tolkien talked about applicability [see http://tinyurl.com/nhpr8g2].
|
||||
|
||||
The idea that “easy things should be easy and hard things should be possible” goes way back, to the boundary between Perl 2 and Perl 3. In Perl 2, we couldn’t handle binary data or embedded nulls – it was just C-style strings. I said then that “Perl is just a text processing language – you don’t need those things in a text processing language”.
|
||||
|
||||
But it occurred to me at the time that there were a large number of problems that were mostly text, and had a little bit of binary data in them – network addresses and things like that. You use binary data to open the socket but then text to process it. So the applicability of the language more than doubled by making it possible to handle binary data.
|
||||
|
||||
That began a trade-off about what things should be easy in a language. Nowadays we have a principle in Perl, and we stole the phrase Huffman coding for it, from the bit encoding system where you have different sizes for characters. Common characters are encoded in a fewer number of bits, and rarer characters are encoded in more bits.
|
||||
|
||||
> “There had to be a very careful balancing act. There were just so many good ideas at the beginning.”
|
||||
|
||||
We stole that idea as a general principle for Perl, for things that are commonly used, or when you have to type them very often – the common things need to be shorter or more succinct. Another bit of that, however, is that they’re allowed to be more irregular. In natural language, it’s actually the most commonly used verbs that tend to be the most irregular.
|
||||
|
||||
And there’s a reason for that, because you need more differentiation of them. One of my favourite books is called The Search for the Perfect Language by Umberto Eco, and it’s not about computer languages; it’s about philosophical languages, and the whole idea that maybe some ancient language was the perfect language and we should get back to it.
|
||||
|
||||
All of those languages make the mistake of thinking that similar things should always be encoded similarly. But that’s not how you communicate. If you have a bunch of barnyard animals, and they all have related names, and you say “Go out and kill the Blerfoo”, but you really wanted them to kill the Blerfee, you might get a cow killed when you want a chicken killed.
|
||||
|
||||
So in realms like that it’s actually better to differentiate the words, for more redundancy in the communication channel. The common words need to have more of that differentiation. It’s all about communicating efficiently, and then there’s also this idea of self-clocking codes. If you look at a UPC label on a product – a barcode – that’s actually a self-clocking code where each pair of bars and spaces is always in a unit of seven columns wide. You rely on that – you know the width of the bars will always add up to that. So it’s self-clocking.
|
||||
|
||||
There are other self-clocking codes used in electronics. In the old transmission serial protocols there were stop and start bits so you could keep things synced up. Natural languages also do this. For instance, in the writing of Japanese, they don’t use spaces. Because the way they write it, they will have a Kanji character from Chinese at the head of each phrase, and then the endings are written in the a syllabary.
|
||||
|
||||
**LV: Hiragana, right?**
|
||||
|
||||
LW: Yes, Hiragana. So naturally the head of each phrase really stands out with this system. Similarly, in ancient Greek, most of the verbs were declined or conjugated. So they had standard endings were sort-of a clocking mechanism. Spaces were optional in their writing system as well – it was a more modern invention to put the spaces in.
|
||||
|
||||
So similarly in computer languages, there’s value in having a self-clocking code. We rely on this heavily in Perl, and even more heavily in Perl 6 than in previous releases. The idea that when you’re parsing an expression, you’re either expecting a term or an infix operator. When you’re expecting a term you might also get a prefix operator – that’s kind-of in the same expectation slot – and when you’re expecting an infix you might also get a postfix for the previous term.
|
||||
|
||||
But it flips back and forth. And if the compiler actually knows which it is expecting, you can overload those a little bit, and Perl does this. So a slash when it’s expecting a term will introduce a regular expression, whereas a slash when you’re expecting an infix will be division. On the other hand, we don’t want to overload everything, because then you lose the self-clocking redundancy.
|
||||
|
||||
Most of our best error messages, for syntax errors, actually come out of noticing that you have two terms in a row. And then we try to figure out why there are two terms in a row – “oh, you must have left a semicolon out on the previous line”. So we can produce much better error messages than the more ad-hoc parsers.
|
||||
|
||||

|
||||
|
||||
**LV: Why has Perl 6 taken fifteen years? It must be hard overseeing a language when everyone has different opinions about things, and there’s not always the right way to do things, and the wrong way.**
|
||||
|
||||
LW: There had to be a very careful balancing act. There were just so many good ideas at the beginning – well, I don’t want to say they were all good ideas. There were so many pain points, like there were 361 RFCs [feature proposal documents] when I expected maybe 20. We had to sit back and actually look at them all, and ignore the proposed solutions, because they were all over the map and all had tunnel vision. Each one many have just changed one thing, but if we had done them all, it would’ve been a complete mess.
|
||||
|
||||
So we had to re-rationalise based on how people were actually hurting when they tried to use Perl 5. We started to look at the unifying, underlying ideas. Many of these RFCs were based on the fact that we had an inadequate type system. By introducing a more coherent type system we could fix many problems in a sane fashion and a cohesive fashion.
|
||||
|
||||
And we started noticing other ways how we could unify the featuresets and start reusing ideas in different areas. Not necessarily that they were the same thing underneath. We have a standard way of writing pairs – well, two ways in Perl! But the way of writing pairs with a colon could also be reused for radix notation, or for literal numbers in any base. It could also be used for various alternative forms of quoting. We say in Perl that it’s “strangely consistent”.
|
||||
|
||||
> “People who made early implementations of Perl 6 came back to me, cap in hand, and said “We really need a language designer.””
|
||||
|
||||
Similar ideas pop up, and you say “I’m already familiar with how that syntax works, but I see it’s being used for something else”. So it took some unity of vision to find these unifications. People who had the various ideas and made early implementations of Perl 6 came back to me, cap-in-hand, and said “We really need a language designer. Could you be our benevolent dictator?”
|
||||
|
||||
So I was the language designer, but I was almost explicitly told: “Stay out of the implementation! We saw what you did made out of Perl 5, and we don’t like it!” It was really funny because the innards of the new implementation started looking a whole lot like Perl 5 inside, and maybe that’s why some of the early implementations didn’t work well.
|
||||
|
||||
Because we were still feeling our way into the whole design, the implementations made a lot of assumptions about what VM should do and shouldn’t do, so we ended up with something like an object oriented assembly language. That sort of problem was fairly pervasive at the beginning. Then the Pugs guys came along and said “Let’s use Haskell, because it makes you think very clearly about what you’re doing. Let’s use it to clarify our semantic model underneath.”
|
||||
|
||||
So we nailed down some of those semantic models, but more importantly, we started building the test suite at that point, to be consistent with those semantic models. Then after that, the Parrot VM continued developing, and then another implementation, Niecza, came along and it was based on .NET. It was by a young fellow who was very smart and implemented a large subset of Perl 6, but he was kind of a loner, didn’t really figure out a way to get other people involved in his project.
|
||||
|
||||
At the same time the Parrot project was getting too big for anyone to really manage it inside, and very difficult to refactor. At that point the fellows working on Rakudo decided that we probably needed to be on more platforms than just the Parrot VM. So they invented a portability layer called NQP which stands for “Not Quite Perl”. They ported it to first of all run on the JVM (Java Virtual Machine), and while they were doing that they were also secretly working on a new VM called MoarVM. That became public a little over a year ago.
|
||||
|
||||
Both MoarVM and JVM run a pretty much equivalent set of regression tests – Parrot is kind-of trailing back in some areas. So that has been very good to flush out VM-specific assumptions, and we’re starting to think about NQP targeting other things. There was a Google Summer of Code project year to target NQP to JavaScript, and that might fit right in, because MoarVM also uses Node.js for much of its more mundane processing.
|
||||
|
||||
We probably need to concentrate on MoarVM for the rest of this year, until we actually define 6.0, and then the rest will catch up.
|
||||
|
||||
**LV: Last year in the UK, the government kicked off the Year of Code, an attempt to get young people interested in programming. There are lots of opinions about how this should be done – like whether you should teach low-level languages at the start, so that people really understand memory usage, or a high-level language. What’s your take on that?**
|
||||
|
||||
LW: Up until now, the Python community has done a much better job of getting into the lower levels of education than we have. We’d like to do something in that space too, and that’s partly why we have the butterfly logo, because it’s going to be appealing to seven year old girls!
|
||||
|
||||
But we do think that Perl 6 will be learnable as a first language. A number of people have surprised us by learning Perl 5 as their first language. And you know, there are a number of fairly powerful concepts even in Perl 5, like closures, lexical scoping, and features you generally get from functional programming. Even more so in Perl 6.
|
||||
|
||||
> “Until now, the Python community has done a much better job of getting into the lower levels of education.”
|
||||
|
||||
Part of the reason the Perl 6 has taken so long is that we have around 50 different principles we try to stick to, and in language design you’re end up juggling everything and saying “what’s really the most important principle here”? There has been a lot of discussion about a lot of different things. Sometimes we commit to a decision, work with it for a while, and then realise it wasn’t quite the right decision.
|
||||
|
||||
We didn’t design or specify pretty much anything about concurrent programming until someone came along who was smart enough about it and knew what the different trade-offs were, and that’s Jonathan Worthington. He has blended together ideas from other languages like Go and C#, with concurrent primitives that compose well. Composability is important in the rest of the language.
|
||||
|
||||
There are an awful lot of concurrent and parallel programming systems that don’t compose well – like threads and locks, and there have been lots of ways to do it poorly. So in one sense, it’s been worth waiting this extra time to see some of these languages like Go and C# develop really good high-level primitives – that’s sort of a contradiction in terms – that compose well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/interview-larry-wall/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
203
sources/talk/20151019 Gaming On Linux--All You Need To Know.md
Normal file
203
sources/talk/20151019 Gaming On Linux--All You Need To Know.md
Normal file
@ -0,0 +1,203 @@
|
||||
Gaming On Linux: All You Need To Know
|
||||
================================================================================
|
||||

|
||||
|
||||
**Can I play games on Linux?**
|
||||
|
||||
This is one of the most frequently asked questions by people who are thinking about [switching to Linux][1]. After all, gaming on Linux often termed as a distant possibility. In fact, some people even wonder if they can listen to music or watch movies on Linux. Considering that, question about native Linux games seem genuine.
|
||||
|
||||
In this article, I am going to answer most of the Linux gaming questions a Linux beginner may have. For example, if it is possible to play games on Linux, if yes, what are the Linux games available, where can you **download Linux games** from or how do you get more information of gaming on Linux.
|
||||
|
||||
But before I do that, let me make a confession. I am not a PC gamer or rather I should say, I am not desktop Linux gamer. I prefer to play games on my PS4 and I don’t care about PC games or even mobile games (no candy crush request sent to anyone in my friend list). This is the reason you see only a few articles in [Linux games][2] section of It’s FOSS.
|
||||
|
||||
So why am I covering this topic then?
|
||||
|
||||
Because I have been asked questions about playing games on Linux several times and I wanted to come up with a Linux gaming guide that could answer all those question. And remember, it’s not just gaming on Ubuntu I am talking about here. I am talking about Linux in general.
|
||||
|
||||
### Can you play games on Linux? ###
|
||||
|
||||
Yes and no!
|
||||
|
||||
Yes, you can play games on Linux and no, you cannot play ‘all the games’ in Linux.
|
||||
|
||||
Confused? Don’t be. What I meant here is that you can get plenty of popular games on Linux such as [Counter Strike, Metro Last Night][3] etc. But you might not get all the latest and popular Windows games on Linux, for e.g., [PES 2015][4].
|
||||
|
||||
The reason, in my opinion, is that Linux has less than 2% of desktop market share and these numbers are demotivating enough for most game developers to avoid working on the Linux version of their games.
|
||||
|
||||
Which means that there is huge possibility that the most talked about games of the year may not be playable in Linux. Don’t despair, there are ‘other means’ to get these games on Linux and we shall see it in coming sections, but before that let’s talk about what kind of games are available for Linux.
|
||||
|
||||
If I have to categorize, I’ll divide them in four categories:
|
||||
|
||||
1. Native Linux Games
|
||||
1. Windows games in Linux
|
||||
1. Browser Games
|
||||
1. Terminal Games
|
||||
|
||||
Let’s start with the most important one, native Linux games, first.
|
||||
|
||||
----------
|
||||
|
||||
### 1. Where to find native Linux games? ###
|
||||
|
||||
Native Linux games mean those games which are officially supported in Linux. These games have native Linux client and can be installed like most other applications in Linux without requiring any additional effort (we’ll see about these in next section).
|
||||
|
||||
So, as you see, there are games developed for Linux. Next question that arises is where can you find these Linux games and how can you play them. I am going to list some of the resources where you can get Linux games.
|
||||
|
||||
#### Steam ####
|
||||
|
||||

|
||||
|
||||
“[Steam][5] is a digital distribution platform for video games. As Amazon Kindle is digital distribution platform for e-Books, iTunes for music, similarly Steam is for games. It provides you the option to buy and install games, play multiplayer and stay in touch with other games via social networking on its platform. The games are protected with [DRM][6].”
|
||||
|
||||
A couple of years ago, when gaming platform Steam announced support for Linux, it was a big news. It was an indication that gaming on Linux is being taken seriously. Though Steam’s decision was more influenced with its own Linux-based gaming console and a separate [Linux distribution called Steam OS][7], it still was a reassuring move that has brought a number of games on Linux.
|
||||
|
||||
I have written a detailed article about installing and using Steam. If you are getting started with Steam, do read it.
|
||||
|
||||
- [Install and use Steam for gaming on Linux][8]
|
||||
|
||||
#### GOG.com ####
|
||||
|
||||
[GOG.com][9] is another platform similar to Steam. Like Steam, you can browse and find hundreds of native Linux games on GOG.com, purchase the games and install them. If the games support several platforms, you can download and use them across various operating systems. Your purchased games are available for you all the time in your account. You can download them anytime you wish.
|
||||
|
||||
One main difference between the two is that GOG.com offers only DRM free games and movies. Also, GOG.com is entirely web based. So you don’t need to install a client like Steam. You can simply download the games from browser and install them in your system.
|
||||
|
||||
#### Portable Linux Games ####
|
||||
|
||||
[Portable Linux Games][10] is a website that has a collection of a number of Linux games. The unique and best thing about Portable Linux Games is that you can download and store the games for offline installation.
|
||||
|
||||
The downloaded files have all the dependencies (at times Wine and Perl installation) and these are also platform independent. All you need to do is to download the files and double click to install them. Store the downloadable file on external hard disk and use them in future. Highly recommend if you don’t have continuous access to high speed internet.
|
||||
|
||||
#### Game Drift Game Store ####
|
||||
|
||||
[Game Drift][11] is actually a Linux distribution based on Ubuntu with sole focus on gaming. While you might not want to start using this Linux distribution for the sole purpose of gaming, you can always visit its game store online and see what games are available for Linux and install them.
|
||||
|
||||
#### Linux Game Database ####
|
||||
|
||||
As the name suggests, [Linux Game Database][12] is a website with a huge collection of Linux games. You can browse through various category of games and download/install them from the game developer’s website. As a member of Linux Game Database, you can even rate the games. LGDB, kind of, aims to be the IGN or IMDB for Linux games.
|
||||
|
||||
#### Penguspy ####
|
||||
|
||||
Created by a gamer who refused to use Windows for playing games, [Penguspy][13] showcases a collection of some of the best Linux games. You can browse games based on category and if you like the game, you’ll have to go to the respective game developer’s website.
|
||||
|
||||
#### Software Repositories ####
|
||||
|
||||
Look into the software repositories of your own Linux distribution. There always will be some games in it. If you are using Ubuntu, Ubuntu Software Center itself has an entire section for games. Same is true for other Linux distributions such as Linux Mint etc.
|
||||
|
||||
----------
|
||||
|
||||
### 2. How to play Windows games in Linux? ###
|
||||
|
||||

|
||||
|
||||
So far we talked about native Linux games. But there are not many Linux games, or to be more precise, most popular Linux games are not available for Linux but they are available for Windows PC. So the questions arises, how to play Windows games in Linux?
|
||||
|
||||
Good thing is that with the help of tools like Wine, PlayOnLinux and CrossOver, you can play a number of popular Windows games in Linux.
|
||||
|
||||
#### Wine ####
|
||||
|
||||
Wine is a compatibility layer which is capable of running Windows applications in systems like Linux, BSD and OS X. With the help of Wine, you can install and use a number of Windows applications in Linux.
|
||||
|
||||
[Installing Wine in Ubuntu][14] or any other Linux is easy as it is available in most Linux distributions’ repository. There is a huge [database of applications and games supported by Wine][15] that you can browse.
|
||||
|
||||
#### CrossOver ####
|
||||
|
||||
[CrossOver][16] is an improved version of Wine that brings professional and technical support to Wine. But unlike Wine, CrossOver is not free. You’ll have to purchase the yearly license for it. Good thing about CrossOver is that every purchase contributes to Wine developers and that in fact boosts the development of Wine to support more Windows games and applications. If you can afford $48 a year, you should buy CrossOver for the support they provide.
|
||||
|
||||
### PlayOnLinux ###
|
||||
|
||||
PlayOnLinux too is based on Wine but implemented differently. It has different interface and slightly easier to use than Wine. Like Wine, PlayOnLinux too is free to use. You can browse the [applications and games supported by PlayOnLinux on its database][17].
|
||||
|
||||
----------
|
||||
|
||||
### 3. Browser Games ###
|
||||
|
||||

|
||||
|
||||
Needless to say that there are tons of browser based games that are available to play in any operating system, be it Windows or Linux or Mac OS X. Most of the addictive mobile games, such as [GoodGame Empire][18], also have their web browser counterparts.
|
||||
|
||||
Apart from that, thanks to [Google Chrome Web Store][19], you can play some more games in Linux. These Chrome games are installed like a standalone app and they can be accessed from the application menu of your Linux OS. Some of these Chrome games are playable offline as well.
|
||||
|
||||
----------
|
||||
|
||||
### 4. Terminal Games ###
|
||||
|
||||

|
||||
|
||||
Added advantage of using Linux is that you can use the command line terminal to play games. I know that it’s not the best way to play games but at times, it’s fun to play games like [Snake][20] or [2048][21] in terminal. There is a good collection of Linux terminal games at [this blog][22]. You can browse through it and play the ones you want.
|
||||
|
||||
----------
|
||||
|
||||
### How to stay updated about Linux games? ###
|
||||
|
||||
When you have learned a lot about what kind of games are available on Linux and how could you use them, next question is how to stay updated about new games on Linux? And for that, I advise you to follow these blogs that provide you with the latest happenings of the Linux gaming world:
|
||||
|
||||
- [Gaming on Linux][23]: I won’t be wrong if I call it the nest Linux gaming news portal. You get all the latest rumblings and news about Linux games. Frequently updated, Gaming on Linux has dedicated fan following which makes it a nice community of Linux game lovers.
|
||||
- [Free Gamer][24]: A blog focusing on free and open source games.
|
||||
- [Linux Game News][25]: A Tumbler blog that updates on various Linux games.
|
||||
|
||||
#### What else? ####
|
||||
|
||||
I think that’s pretty much what you need to know to get started with gaming on Linux. If you are still not convinced, I would advise you to [dual boot Linux with Windows][26]. Use Linux as your main desktop and if you want to play games, boot into Windows. This could be a compromised solution.
|
||||
|
||||
I think that’s pretty much what you need to know to get started with gaming on Linux. If you are still not convinced, I would advise you to [dual boot Linux with Windows][27]. Use Linux as your main desktop and if you want to play games, boot into Windows. This could be a compromised solution.
|
||||
|
||||
It’s time for you to add your inputs. Do you play games on your Linux desktop? What are your favorites? What blogs you follow to stay updated on latest Linux games?
|
||||
|
||||
|
||||
投票项目:
|
||||
How do you play games on Linux?
|
||||
|
||||
- I use Wine and PlayOnLinux along with native Linux Games
|
||||
- I am happy with Browser Games
|
||||
- I prefer the Terminal Games
|
||||
- I use native Linux games only
|
||||
- I play it on Steam
|
||||
- I dual boot and go in to Windows to play games
|
||||
- I don't play games at all
|
||||
|
||||
注:投票代码
|
||||
<div class="PDS_Poll" id="PDI_container9132962" style="display:inline-block;"></div>
|
||||
<div id="PD_superContainer"></div>
|
||||
<script type="text/javascript" charset="UTF-8" src="http://static.polldaddy.com/p/9132962.js"></script>
|
||||
<noscript><a href="http://polldaddy.com/poll/9132962">Take Our Poll</a></noscript>
|
||||
|
||||
注,发布时根据情况看怎么处理
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/linux-gaming-guide/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[2]:http://itsfoss.com/category/games/
|
||||
[3]:http://blog.counter-strike.net/
|
||||
[4]:https://pes.konami.com/tag/pes-2015/
|
||||
[5]:http://store.steampowered.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Digital_rights_management
|
||||
[7]:http://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[8]:http://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[9]:http://www.gog.com/
|
||||
[10]:http://www.portablelinuxgames.org/
|
||||
[11]:http://gamedrift.org/GameStore.html
|
||||
[12]:http://www.lgdb.org/
|
||||
[13]:http://www.penguspy.com/
|
||||
[14]:http://itsfoss.com/wine-1-5-11-released-ppa-available-to-download/
|
||||
[15]:https://appdb.winehq.org/
|
||||
[16]:https://www.codeweavers.com/products/
|
||||
[17]:https://www.playonlinux.com/en/supported_apps.html
|
||||
[18]:http://empire.goodgamestudios.com/
|
||||
[19]:https://chrome.google.com/webstore/category/apps
|
||||
[20]:http://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[21]:http://itsfoss.com/play-2048-linux-terminal/
|
||||
[22]:https://ttygames.wordpress.com/
|
||||
[23]:https://www.gamingonlinux.com/
|
||||
[24]:http://freegamer.blogspot.fr/
|
||||
[25]:http://linuxgamenews.com/
|
||||
[26]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[27]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
@ -0,0 +1,38 @@
|
||||
Nautilus File Search Is About To Get A Big Power Up
|
||||
================================================================================
|
||||

|
||||
|
||||
**Finding stray files and folders in Nautilus is about to get a whole lot easier. **
|
||||
|
||||
A new **search filter** for the default [GNOME file manager][1] is in development. It makes heavy use of GNOME’s spiffy pop-over menus in an effort to offer a simpler way to narrow in on search results and find exactly what you’re after.
|
||||
|
||||
Developer Georges Stavracas is working on the new UI and [describes][2] the new editor as “cleaner, saner and more intuitive”.
|
||||
|
||||
Based on a video he’s [uploaded to YouTube][3] demoing the new approach – which he hasn’t made available for embedding – he’s not wrong.
|
||||
|
||||
> “Nautilus has very complex but powerful internals, which allows us to do many things. And indeed, there is code for the many options in there. So, why did it used to look so poorly implemented/broken?”, he writes on his blog.
|
||||
|
||||
The question is part rhetorical; the new search filter interface surfaces many of these ‘powerful internals’ to yhe user. Searches can be filtered ad **hoc** based on content type, name or by date range.
|
||||
|
||||
Changing anything in an app like Nautilus is likely to upset some users, so as helpful and straightforward as the new UI seems it could come in for some heat.
|
||||
|
||||
Not that worry of discontent seems to hamper progress (though the outcry at the [removal of ‘type ahead’ search][4] in 2014 still rings loud in many ears, no doubt). GNOME 3.18, [released last month][5], introduced a new file progress dialog to Nautilus and better integration for remote shares, including Google Drive.
|
||||
|
||||
Stavracas’ search filter are not yet merged in to Files’ trunk, but the reworked search UI is tentatively targeted for inclusion in GNOME 3.20, due spring next year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/10/new-nautilus-search-filter-ui
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://wiki.gnome.org/Apps/Nautilus
|
||||
[2]:http://feaneron.com/2015/10/12/the-new-search-for-gnome-files-aka-nautilus/
|
||||
[3]:https://www.youtube.com/watch?v=X2sPRXDzmUw
|
||||
[4]:http://www.omgubuntu.co.uk/2014/01/ubuntu-14-04-nautilus-type-ahead-patch
|
||||
[5]:http://www.omgubuntu.co.uk/2015/09/gnome-3-18-release-new-features
|
||||
@ -1,251 +0,0 @@
|
||||
ictlyh Translating
|
||||
How to Setup Red Hat Ceph Storage on CentOS 7.0
|
||||
================================================================================
|
||||
Ceph is an open source software platform that stores data on a single distributed computer cluster. When you are planning to build a cloud, then on top of the requirements you have to decide on how to implement your storage. Open Source CEPH is one of RED HAT mature technology based on object-store system, called RADOS, with a set of gateway APIs that present the data in block, file, and object modes. As a result of its open source nature, this portable storage platform may be installed and used in public or private clouds. The topology of a Ceph cluster is designed around replication and information distribution, which are intrinsic and provide data integrity. It is designed to be fault-tolerant, and can run on commodity hardware, but can also be run on a number of more advanced systems with the right setup.
|
||||
|
||||
Ceph can be installed on any Linux distribution but it requires the recent kernel and other up-to-date libraries in order to be properly executed. But, here in this tutorial we will be using CentOS-7.0 with minimal installation packages on it.
|
||||
|
||||
### System Resources ###
|
||||
|
||||
**CEPH-STORAGE**
|
||||
OS: CentOS Linux 7 (Core)
|
||||
RAM:1 GB
|
||||
CPU:1 CPU
|
||||
DISK: 20
|
||||
Network: 45.79.136.163
|
||||
FQDN: ceph-storage.linoxide.com
|
||||
|
||||
**CEPH-NODE**
|
||||
OS: CentOS Linux 7 (Core)
|
||||
RAM:1 GB
|
||||
CPU:1 CPU
|
||||
DISK: 20
|
||||
Network: 45.79.171.138
|
||||
FQDN: ceph-node.linoxide.com
|
||||
|
||||
### Pre-Installation Setup ###
|
||||
|
||||
There are few steps that we need to perform on each of our node before the CEPH storage setup. So first thing is to make sure that each node is configured with its networking setup with FQDN that is reachable to other nodes.
|
||||
|
||||
**Configure Hosts**
|
||||
|
||||
To setup the hosts entry on each node let's open the default hosts configuration file as shown below.
|
||||
|
||||
# vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
45.79.136.163 ceph-storage ceph-storage.linoxide.com
|
||||
45.79.171.138 ceph-node ceph-node.linoxide.com
|
||||
|
||||
**Install VMware Tools**
|
||||
|
||||
While working on the VMware virtual environment, its recommended that you have installed its open VM tools. You can install using below command.
|
||||
|
||||
#yum install -y open-vm-tools
|
||||
|
||||
**Firewall Setup**
|
||||
|
||||
If you are working on a restrictive environment where your local firewall in enabled then make sure that the number of following ports are allowed from in your CEPH storge admin node and client nodes.
|
||||
|
||||
You must open ports 80, 2003, and 4505-4506 on your Admin Calamari node and port 80 to CEPH admin or Calamari node for inbound so that clients in your network can access the Calamari web user interface.
|
||||
|
||||
You can start and enable firewall in centos 7 with given below command.
|
||||
|
||||
#systemctl start firewalld
|
||||
#systemctl enable firewalld
|
||||
|
||||
To allow the mentioned ports in the Admin Calamari node run the following commands.
|
||||
|
||||
#firewall-cmd --zone=public --add-port=80/tcp --permanent
|
||||
#firewall-cmd --zone=public --add-port=2003/tcp --permanent
|
||||
#firewall-cmd --zone=public --add-port=4505-4506/tcp --permanent
|
||||
#firewall-cmd --reload
|
||||
|
||||
On the CEPH Monitor nodes you have to allow the following ports in the firewall.
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6789/tcp --permanent
|
||||
|
||||
Then allow the following list of default ports for talking to clients and monitors and for sending data to other OSDs.
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
|
||||
|
||||
It quite fair that you should disable firewall and SELinux settings if you are working in a non-production environment , so we are going to disable the firewall and SELinux in our test environment.
|
||||
|
||||
#systemctl stop firewalld
|
||||
#systemctl disable firewalld
|
||||
|
||||
**System Update**
|
||||
|
||||
Now update your system and then give it a reboot to implement the required changes.
|
||||
|
||||
#yum update
|
||||
#shutdown -r 0
|
||||
|
||||
### Setup CEPH User ###
|
||||
|
||||
Now we will create a separate sudo user that will be used for installing the ceph-deploy utility on each node and allow that user to have password less access on each node because it needs to install software and configuration files without prompting for passwords on CEPH nodes.
|
||||
|
||||
To create new user with its separate home directory run the below command on the ceph-storage host.
|
||||
|
||||
[root@ceph-storage ~]# useradd -d /home/ceph -m ceph
|
||||
[root@ceph-storage ~]# passwd ceph
|
||||
|
||||
Each user created on the nodes must have sudo rights, you can assign the sudo rights to the user using running the following command as shown.
|
||||
|
||||
[root@ceph-storage ~]# echo "ceph ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph
|
||||
ceph ALL = (root) NOPASSWD:ALL
|
||||
|
||||
[root@ceph-storage ~]# sudo chmod 0440 /etc/sudoers.d/ceph
|
||||
|
||||
### Setup SSH-Key ###
|
||||
|
||||
Now we will generate SSH keys on the admin ceph node and then copy that key to each Ceph cluster nodes.
|
||||
|
||||
Let's run the following command on the ceph-node to copy its ssh key on the ceph-storage.
|
||||
|
||||
[root@ceph-node ~]# ssh-keygen
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/root/.ssh/id_rsa):
|
||||
Created directory '/root/.ssh'.
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /root/.ssh/id_rsa.
|
||||
Your public key has been saved in /root/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
5b:*:*:*:*:*:*:*:*:*:c9 root@ceph-node
|
||||
The key's randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
|
||||
----------
|
||||
|
||||
[root@ceph-node ~]# ssh-copy-id ceph@ceph-storage
|
||||
|
||||

|
||||
|
||||
### Configure PID Count ###
|
||||
|
||||
To configure the PID count value, we will make use of the following commands to check the default kernel value. By default its a small maximum number of threads that is '32768'.
|
||||
So will configure this value to a higher number of threads by editing the system conf file as shown in the image.
|
||||
|
||||

|
||||
|
||||
### Setup Your Administration Node Server ###
|
||||
|
||||
With all the networking setup and verified, now we will install ceph-deploy using the user ceph. So, check the hosts entry by opening its file.
|
||||
|
||||
#vim /etc/hosts
|
||||
ceph-storage 45.79.136.163
|
||||
ceph-node 45.79.171.138
|
||||
|
||||
Now to add its repository run the below command.
|
||||
|
||||
#rpm -Uhv http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm
|
||||
|
||||

|
||||
|
||||
OR create a new file and update the CEPH repository parameters but do not forget to mention your current release and distribution.
|
||||
|
||||
[root@ceph-storage ~]# vi /etc/yum.repos.d/ceph.repo
|
||||
|
||||
----------
|
||||
|
||||
[ceph-noarch]
|
||||
name=Ceph noarch packages
|
||||
baseurl=http://ceph.com/rpm-{ceph-release}/{distro}/noarch
|
||||
enabled=1
|
||||
gpgcheck=1
|
||||
type=rpm-md
|
||||
gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc
|
||||
|
||||
After this update your system and install the ceph deploy package.
|
||||
|
||||
### Installing CEPH-Deploy Package ###
|
||||
|
||||
To upate the system with latest ceph repository and other packages, we will run the following command along with ceph-deploy installation command.
|
||||
|
||||
#yum update -y && yum install ceph-deploy -y
|
||||
|
||||
Image-
|
||||
|
||||
### Setup the cluster ###
|
||||
|
||||
Create a new directory and move into it on the admin ceph-node to collect all output files and logs by using the following commands.
|
||||
|
||||
#mkdir ~/ceph-cluster
|
||||
#cd ~/ceph-cluster
|
||||
|
||||
----------
|
||||
|
||||
#ceph-deploy new storage
|
||||
|
||||

|
||||
|
||||
Upon successful execution of above command you can see it creating its configuration files.
|
||||
Now to configure the default configuration file of CEPH, open it using any editor and place the following two lines under its global parameters that reflects your public network.
|
||||
|
||||
#vim ceph.conf
|
||||
osd pool default size = 1
|
||||
public network = 45.79.0.0/16
|
||||
|
||||
### Installing CEPH ###
|
||||
|
||||
We are now going to install CEPH on each of the node associated with our CEPH cluster. To do so we make use of the following command to install CEPH on our both nodes that is ceph-storage and ceph-node as shown below.
|
||||
|
||||
#ceph-deploy install ceph-node ceph-storage
|
||||
|
||||

|
||||
|
||||
This will takes some time while processing all its required repositories and installing the required packages.
|
||||
|
||||
Once the ceph installation process is complete on both nodes we will proceed to create monitor and gather keys by running the following command on the same node.
|
||||
|
||||
#ceph-deploy mon create-initial
|
||||
|
||||

|
||||
|
||||
### Setup OSDs and OSD Daemons ###
|
||||
|
||||
Now we will setup disk storages, to do so first run the below command to List all of your usable disks by using the below command.
|
||||
|
||||
#ceph-deploy disk list ceph-storage
|
||||
|
||||
In results will get the list of your disks used on your storage nodes that you will use for creating the OSD. Let's run the following command that consists of your disks names as shown below.
|
||||
|
||||
#ceph-deploy disk zap storage:sda
|
||||
#ceph-deploy disk zap storage:sdb
|
||||
|
||||
Now to finalize the OSD setup let's run the below commands to setup the journaling disk along with data disk.
|
||||
|
||||
#ceph-deploy osd prepare storage:sdb:/dev/sda
|
||||
#ceph-deploy osd activate storage:/dev/sdb1:/dev/sda1
|
||||
|
||||
You will have to repeat the same command on all the nodes while it will clean everything present on the disk. Afterwards to have a functioning cluster, we need to copy the different keys and configuration files from the admin ceph-node to all the associated nodes by using the following command.
|
||||
|
||||
#ceph-deploy admin ceph-node ceph-storage
|
||||
|
||||
### Testing CEPH ###
|
||||
|
||||
We have almost completed the CEPH cluster setup, let's run the below command to check the status of the running ceph by using the below command on the admin ceph-node.
|
||||
|
||||
#ceph status
|
||||
#ceph health
|
||||
HEALTH_OK
|
||||
|
||||
So, if you did not get any error message at ceph status , that means you have successfully setup your ceph storage cluster on CentOS 7.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this detailed article we learned about the CEPH storage clustering setup using the two virtual Machines with CentOS 7 OS installed on them that can be used as a backup or as your local storage that can be used to precess other virtual machines by creating its pools. We hope you have got this article helpful. Do share your experiences when you try this at your end.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/setup-red-hat-ceph-storage-centos-7-0/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
147
sources/tech/20151019 10 passwd command examples in Linux.md
Normal file
147
sources/tech/20151019 10 passwd command examples in Linux.md
Normal file
@ -0,0 +1,147 @@
|
||||
translation by strugglingyouth
|
||||
10 passwd command examples in Linux
|
||||
================================================================================
|
||||
As the name suggest **passwd** command is used to change the password of system users. If the passwd command is executed by non-root user then it will ask for the current password and then set the new password of a user who invoked the command. When this command is executed by super user or root then it can reset the password for any user including root without knowing the current password.
|
||||
|
||||
In this post we will discuss passwd command with practical examples.
|
||||
|
||||
#### Syntax : ####
|
||||
|
||||
# passwd {options} {user_name}
|
||||
|
||||
Different options that can be used in passwd command are listed below :
|
||||
|
||||
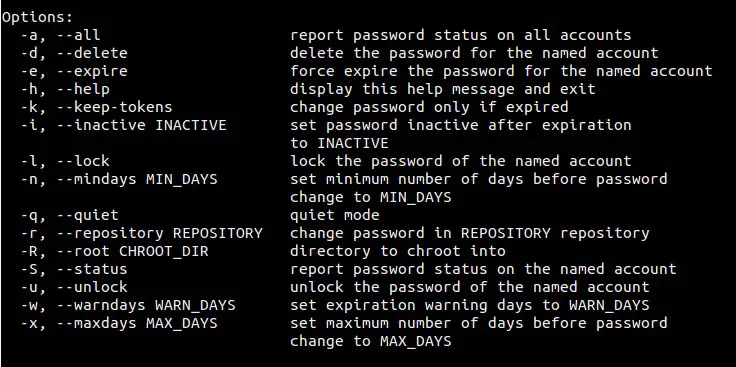
|
||||
|
||||
### Example:1 Change Password of System Users ###
|
||||
|
||||
When you logged in as non-root user like ‘linuxtechi’ in my case and run passwd command then it will reset password of logged in user.
|
||||
|
||||
[linuxtechi@linuxworld ~]$ passwd
|
||||
Changing password for user linuxtechi.
|
||||
Changing password for linuxtechi.
|
||||
(current) UNIX password:
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
[linuxtechi@linuxworld ~]$
|
||||
|
||||
When you logged in as root user and run **passwd** command then it will reset the root password by default and if you specify the user-name after passwd command then it will change the password of that user.
|
||||
|
||||
[root@linuxworld ~]# passwd
|
||||
[root@linuxworld ~]# passwd linuxtechi
|
||||
|
||||
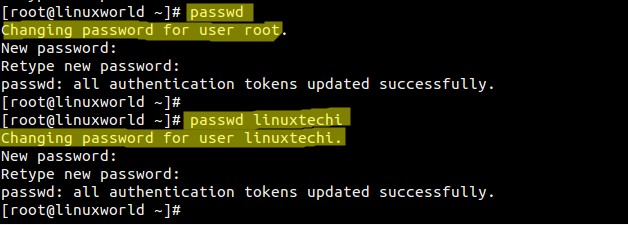
|
||||
|
||||
**Note** : System user’s password is stored in an encrypted form in /etc/shadow file.
|
||||
|
||||
### Example:2 Display Password Status Information. ###
|
||||
|
||||
To display password status information of a user , use **-S** option in passwd command.
|
||||
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 2015-09-20 0 99999 7 -1 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
In the above output first field shows the user name and second field shows Password status ( **PS = Password Set , LK = Password locked , NP = No Password** ), third field shows when the password was changed and last & fourth field shows minimum age, maximum age, warning period, and inactivity period for the password
|
||||
|
||||
### Example:3 Display Password Status info for all the accounts ###
|
||||
|
||||
To display password status info for all the accounts use “**-aS**” option in passwd command, example is shown below :
|
||||
|
||||
root@localhost:~# passwd -Sa
|
||||
|
||||
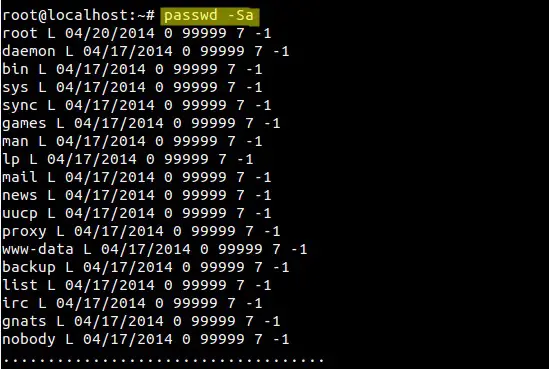
|
||||
|
||||
### Example:4 Removing Password of a User using -d option ###
|
||||
|
||||
In my case i am removing/ deleting the password of ‘**linuxtechi**‘ user.
|
||||
|
||||
[root@linuxworld ~]# passwd -d linuxtechi
|
||||
Removing password for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]#
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi NP 2015-09-20 0 99999 7 -1 (Empty password.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
“**-d**” option will make user’s password empty and will disable user’s account.
|
||||
|
||||
### Example:5 Set Password Expiry Immediately ###
|
||||
|
||||
Use ‘-e’ option in passwd command to expire user’s password immediately , this will force the user to change the password in the next login.
|
||||
|
||||
[root@linuxworld ~]# passwd -e linuxtechi
|
||||
Expiring password for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 1970-01-01 0 99999 7 -1 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
Now Try to ssh machine using linuxtechi user.
|
||||
|
||||
|
||||
|
||||
### Example:6 Lock the password of System User ###
|
||||
|
||||
Use ‘**-l**‘ option in passwd command to lock a user’s password, it will add “!” at starting of user’s password. A User can’t Change it’s password when his/her password is locked.
|
||||
|
||||
[root@linuxworld ~]# passwd -l linuxtechi
|
||||
Locking password for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi LK 2015-09-20 0 99999 7 -1 (Password locked.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
### Example:7 Unlock User’s Password using -u option ###
|
||||
|
||||
[root@linuxworld ~]# passwd -u linuxtechi
|
||||
Unlocking password for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]#
|
||||
|
||||
### Example:8 Setting inactive days using -i option ###
|
||||
|
||||
-i option in passwd command is used to set inactive days for a system user. This will come into the picture when password of user ( in my case linuxtechi) expired and user didn’t change its password in ‘**n**‘ number of days ( i.e 10 days in my case) then after that user will not able to login.
|
||||
|
||||
[root@linuxworld ~]# passwd -i 10 linuxtechi
|
||||
Adjusting aging data for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]#
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 2015-09-20 0 99999 7 10 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
### Example:9 Set Minimum Days to Change Password using -n option. ###
|
||||
|
||||
In the below example linuxtechi user has to change the password in 90 days. A value of zero shows that user can change it’s password in any time.
|
||||
|
||||
[root@linuxworld ~]# passwd -n 90 linuxtechi
|
||||
Adjusting aging data for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 2015-09-20 90 99999 7 10 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
### Example:10 Set Warning days before password expire using -w option ###
|
||||
|
||||
‘**-w**’ option in passwd command is used to set warning days for a user. It means a user will be warned for n number of days that his/her password is going to expire.
|
||||
|
||||
[root@linuxworld ~]# passwd -w 12 linuxtechi
|
||||
Adjusting aging data for user linuxtechi.
|
||||
passwd: Success
|
||||
[root@linuxworld ~]# passwd -S linuxtechi
|
||||
linuxtechi PS 2015-09-20 90 99999 12 10 (Password set, SHA512 crypt.)
|
||||
[root@linuxworld ~]#
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/10-passwd-command-examples-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
258
sources/tech/20151019 11 df command examples in Linux.md
Normal file
258
sources/tech/20151019 11 df command examples in Linux.md
Normal file
@ -0,0 +1,258 @@
|
||||
11 df command examples in Linux
|
||||
================================================================================
|
||||
df (disk free) command is used to display disk usage of the file system. By default df command shows the file system usage in 1K blocks for all the current mounted file system, if you want to display the output of df command in human readable format , use -h option like “df -h”.
|
||||
|
||||
In this post we will discuss 11 different examples of ‘**df**‘ command in Linux
|
||||
|
||||
Basic Format of df command in Linux
|
||||
|
||||
# df {options} {mount_point_of_filesystem}
|
||||
|
||||
Options used in df command :
|
||||
|
||||
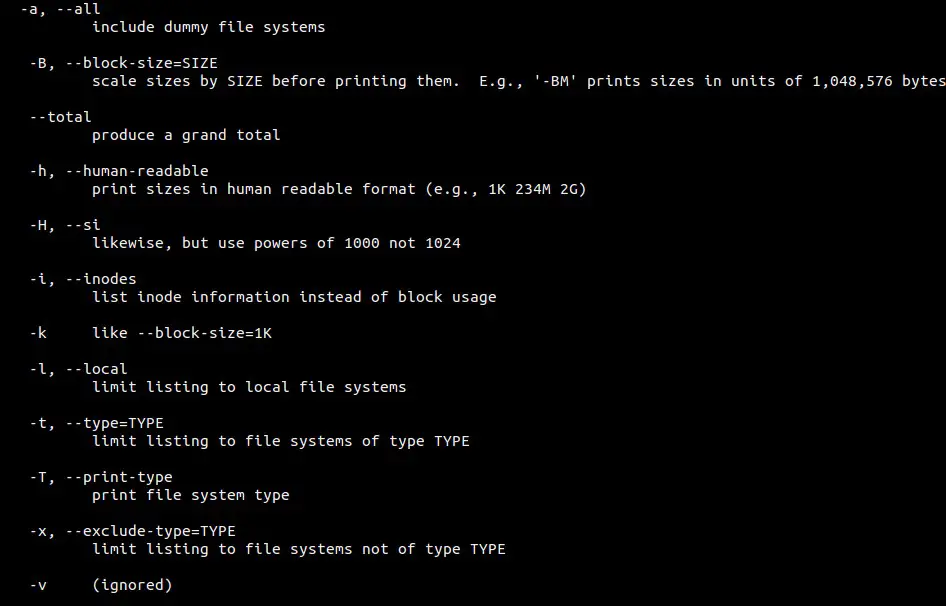
|
||||
|
||||
Sample Output of df :
|
||||
|
||||
[root@linux-world ~]# df
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root 17003304 804668 15311852 5% /
|
||||
devtmpfs 771876 0 771876 0% /dev
|
||||
tmpfs 777928 0 777928 0% /dev/shm
|
||||
tmpfs 777928 8532 769396 2% /run
|
||||
tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
/dev/sda1 487652 62593 395363 14% /boot
|
||||
/dev/mapper/vg00-var 9948012 48692 9370936 1% /var
|
||||
/dev/mapper/vg00-sap 14987656 37636 14165636 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:1 List disk usage of all the file system using ‘-a’ ###
|
||||
|
||||
when we use ‘-a’ option in df command , it will display disk usage of all the file systems.
|
||||
|
||||
[root@linux-world ~]# df -a
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
rootfs 17003304 804668 15311852 5% /
|
||||
proc 0 0 0 - /proc
|
||||
sysfs 0 0 0 - /sys
|
||||
devtmpfs 771876 0 771876 0% /dev
|
||||
securityfs 0 0 0 - /sys/kernel/security
|
||||
tmpfs 777928 0 777928 0% /dev/shm
|
||||
devpts 0 0 0 - /dev/pts
|
||||
tmpfs 777928 8532 769396 2% /run
|
||||
tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/systemd
|
||||
pstore 0 0 0 - /sys/fs/pstore
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/cpuset
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/cpu,cpuacct
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/memory
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/devices
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/freezer
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/net_cls
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/blkio
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/perf_event
|
||||
cgroup 0 0 0 - /sys/fs/cgroup/hugetlb
|
||||
configfs 0 0 0 - /sys/kernel/config
|
||||
/dev/mapper/vg00-root 17003304 804668 15311852 5% /
|
||||
selinuxfs 0 0 0 - /sys/fs/selinux
|
||||
systemd-1 0 0 0 - /proc/sys/fs/binfmt_misc
|
||||
debugfs 0 0 0 - /sys/kernel/debug
|
||||
hugetlbfs 0 0 0 - /dev/hugepages
|
||||
mqueue 0 0 0 - /dev/mqueue
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
/dev/sda1 487652 62593 395363 14% /boot
|
||||
/dev/mapper/vg00-var 9948012 48692 9370936 1% /var
|
||||
/dev/mapper/vg00-sap 14987656 37636 14165636 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:2 Display the output of df command in human readable format. ###
|
||||
|
||||
Using ‘-h’ option in df command , output can be displayed in human readable format ( e.g 5K , 500M & 5G )
|
||||
|
||||
[root@linux-world ~]# df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg00-root 17G 786M 15G 5% /
|
||||
devtmpfs 754M 0 754M 0% /dev
|
||||
tmpfs 760M 0 760M 0% /dev/shm
|
||||
tmpfs 760M 8.4M 752M 2% /run
|
||||
tmpfs 760M 0 760M 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 15G 41M 14G 1% /home
|
||||
/dev/sda1 477M 62M 387M 14% /boot
|
||||
/dev/mapper/vg00-var 9.5G 48M 9.0G 1% /var
|
||||
/dev/mapper/vg00-sap 15G 37M 14G 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:3 Display Space usage of particular file system ###
|
||||
|
||||
Suppose we want to print space usage of /sap file system,
|
||||
|
||||
[root@linux-world ~]# df -h /sap/
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg00-sap 15G 37M 14G 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:4 Print file system type of all mounted file systems ###
|
||||
|
||||
‘**-T**’ is used in df command to display the file system type in the output.
|
||||
|
||||
[root@linux-world ~]# df -T
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root ext4 17003304 804668 15311852 5% /
|
||||
devtmpfs devtmpfs 771876 0 771876 0% /dev
|
||||
tmpfs tmpfs 777928 0 777928 0% /dev/shm
|
||||
tmpfs tmpfs 777928 8532 769396 2% /run
|
||||
tmpfs tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home ext4 14987616 41000 14162232 1% /home
|
||||
/dev/sda1 ext3 487652 62593 395363 14% /boot
|
||||
/dev/mapper/vg00-var ext3 9948012 48696 9370932 1% /var
|
||||
/dev/mapper/vg00-sap ext3 14987656 37636 14165636 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:5 Print disk usage of file systems in block-size. ###
|
||||
|
||||
[root@linux-world ~]# df -k
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root 17003304 804668 15311852 5% /
|
||||
devtmpfs 771876 0 771876 0% /dev
|
||||
tmpfs 777928 0 777928 0% /dev/shm
|
||||
tmpfs 777928 8532 769396 2% /run
|
||||
tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
/dev/sda1 487652 62593 395363 14% /boot
|
||||
/dev/mapper/vg00-var 9948012 48696 9370932 1% /var
|
||||
/dev/mapper/vg00-sap 14987656 37636 14165636 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:6 Display inodes information of file system. ###
|
||||
|
||||
‘**-i**’ option in df command is used to display inode information of the file system
|
||||
|
||||
inodes info of all the file system :
|
||||
|
||||
[root@linux-world ~]# df -i
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
/dev/mapper/vg00-root 1089536 22031 1067505 3% /
|
||||
devtmpfs 192969 357 192612 1% /dev
|
||||
tmpfs 194482 1 194481 1% /dev/shm
|
||||
tmpfs 194482 420 194062 1% /run
|
||||
tmpfs 194482 13 194469 1% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 960992 15 960977 1% /home
|
||||
/dev/sda1 128016 337 127679 1% /boot
|
||||
/dev/mapper/vg00-var 640848 1235 639613 1% /var
|
||||
/dev/mapper/vg00-sap 960992 11 960981 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
inodes info of particular file system :
|
||||
|
||||
[root@linux-world ~]# df -i /sap/
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
/dev/mapper/vg00-sap 960992 11 960981 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:7 Print grant total space usage of all file system. ###
|
||||
|
||||
‘–total‘ option in df command is used to display the grant total of disk usage of all the file system.
|
||||
|
||||
[root@linux-world ~]# df -h --total
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg00-root 17G 786M 15G 5% /
|
||||
devtmpfs 754M 0 754M 0% /dev
|
||||
tmpfs 760M 0 760M 0% /dev/shm
|
||||
tmpfs 760M 8.4M 752M 2% /run
|
||||
tmpfs 760M 0 760M 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 15G 41M 14G 1% /home
|
||||
/dev/sda1 477M 62M 387M 14% /boot
|
||||
/dev/mapper/vg00-var 9.5G 48M 9.0G 1% /var
|
||||
/dev/mapper/vg00-sap 15G 37M 14G 1% /sap
|
||||
total 58G 980M 54G 2% -
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:8 Print only Local file system space usage info. ###
|
||||
|
||||
Suppose network file system also mounted on linux box and but we want to display local file system information only, this can be achieved by using ‘-l‘ option in df command.
|
||||
|
||||
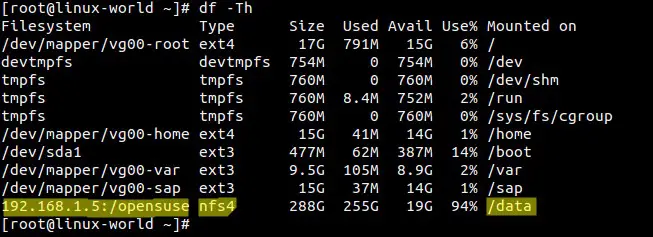
|
||||
|
||||
Limiting to local file system :
|
||||
|
||||
[root@linux-world ~]# df -Thl
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg00-root ext4 17G 791M 15G 6% /
|
||||
devtmpfs devtmpfs 754M 0 754M 0% /dev
|
||||
tmpfs tmpfs 760M 0 760M 0% /dev/shm
|
||||
tmpfs tmpfs 760M 8.4M 752M 2% /run
|
||||
tmpfs tmpfs 760M 0 760M 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home ext4 15G 41M 14G 1% /home
|
||||
/dev/sda1 ext3 477M 62M 387M 14% /boot
|
||||
/dev/mapper/vg00-var ext3 9.5G 105M 8.9G 2% /var
|
||||
/dev/mapper/vg00-sap ext3 15G 37M 14G 1% /sap
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:9 Print Disk Space information of particular file system type. ###
|
||||
|
||||
‘**-t**’ option in df command is used to print information of particular file system type, after ‘-t’ specify the file system type, example is shown below :
|
||||
|
||||
for ext4 :
|
||||
|
||||
[root@linux-world ~]# df -t ext4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root 17003304 809492 15307028 6% /
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
[root@linux-world ~]#
|
||||
|
||||
for nfs4 :
|
||||
|
||||
[root@linux-world ~]# df -t nfs4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
192.168.1.5:/opensuse 301545472 266833920 19371008 94% /data
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:10 Exclude Particular file system type using ‘-x’ option ###
|
||||
|
||||
“**-x** or **–exclude-type**” is used to exclude the certain file system type in the output of df command.
|
||||
|
||||
Let suppose we want to print all the file systems excluding ext3 file system.
|
||||
|
||||
[root@linux-world ~]# df -x ext3
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/vg00-root 17003304 809492 15307028 6% /
|
||||
devtmpfs 771876 0 771876 0% /dev
|
||||
tmpfs 777928 0 777928 0% /dev/shm
|
||||
tmpfs 777928 8540 769388 2% /run
|
||||
tmpfs 777928 0 777928 0% /sys/fs/cgroup
|
||||
/dev/mapper/vg00-home 14987616 41000 14162232 1% /home
|
||||
192.168.1.5:/opensuse 301545472 266834944 19369984 94% /data
|
||||
[root@linux-world ~]#
|
||||
|
||||
### Example:11 Print only certain fields in output of df command. ###
|
||||
|
||||
‘**–output={field_name1,field_name2….}**‘ option is used to display the certain fields in df command output.
|
||||
|
||||
Valid field names are: ‘source’, ‘fstype’, ‘itotal’, ‘iused’, ‘iavail’, ‘ipcent’, ‘size’, ‘used’, ‘avail’, ‘pcent’ and ‘target’
|
||||
|
||||
[root@linux-world ~]# df --output=fstype,size,iused
|
||||
Type 1K-blocks IUsed
|
||||
ext4 17003304 22275
|
||||
devtmpfs 771876 357
|
||||
tmpfs 777928 1
|
||||
tmpfs 777928 423
|
||||
tmpfs 777928 13
|
||||
ext4 14987616 15
|
||||
ext3 487652 337
|
||||
ext3 9948012 1373
|
||||
ext3 14987656 11
|
||||
nfs4 301545472 451099
|
||||
[root@linux-world ~]#
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/11-df-command-examples-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,61 @@
|
||||
Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy
|
||||
================================================================================
|
||||
> **Question:** My computer is connected to a corporate network sitting behind an HTTP proxy. When I try to install Ubuntu desktop on the computer from a CD-ROM drive, the installation hangs and never finishes while trying to retrieve files, which is presumably due to the proxy. However, the problem is that Ubuntu installer never asks me to configure proxy during installation procedure. Then how can I install Ubuntu desktop behind a proxy?
|
||||
|
||||
Unlike Ubuntu server, installation of Ubuntu desktop is pretty much auto-pilot, not leaving much room for customization, such as custom disk partitioning, manual network settings, package selection, etc. While such simple, one-shot installation is considered user-friendly, it leaves much to be desired for those users looking for "advanced installation mode" to customize their Ubuntu desktop installation.
|
||||
|
||||
In addition, one big problem of the default Ubuntu desktop installer is the absense of proxy settings. If your computer is connected behind a proxy, you will notice that Ubuntu installation gets stuck while preparing to download files.
|
||||
|
||||

|
||||
|
||||
This post describes how to get around the limitation of Ubuntu installer and **install Ubuntu desktop when you are behind a proxy**.
|
||||
|
||||
The basic idea is as follows. Instead of starting with Ubuntu installer directly, boot into live Ubuntu desktop first, configure proxy settings, and finally launch Ubuntu installer manually from live desktop. The following is the step by step procedure.
|
||||
|
||||
After booting from Ubuntu desktop CD/DVD or USB, click on "Try Ubuntu" on the first welcome screen.
|
||||
|
||||

|
||||
|
||||
Once you boot into live Ubuntu desktop, click on Settings icon in the left.
|
||||
|
||||

|
||||
|
||||
Go to Network menu.
|
||||
|
||||

|
||||
|
||||
Configure proxy settings manually.
|
||||
|
||||

|
||||
|
||||
Next, open a terminal.
|
||||
|
||||

|
||||
|
||||
Enter a root session by typing the following:
|
||||
|
||||
$ sudo su
|
||||
|
||||
Finally, type the following command as the root.
|
||||
|
||||
# ubiquity gtk_ui
|
||||
|
||||
This will launch GUI-based Ubuntu installer as follows.
|
||||
|
||||

|
||||
|
||||
Proceed with the rest of installation.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-ubuntu-desktop-behind-proxy.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -1,168 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
How to Recover Data and Rebuild Failed Software RAID’s – Part 8
|
||||
================================================================================
|
||||
In the previous articles of this [RAID series][1] you went from zero to RAID hero. We reviewed several software RAID configurations and explained the essentials of each one, along with the reasons why you would lean towards one or the other depending on your specific scenario.
|
||||
|
||||

|
||||
|
||||
Recover Rebuild Failed Software RAID’s – Part 8
|
||||
|
||||
In this guide we will discuss how to rebuild a software RAID array without data loss when in the event of a disk failure. For brevity, we will only consider a RAID 1 setup – but the concepts and commands apply to all cases alike.
|
||||
|
||||
#### RAID Testing Scenario ####
|
||||
|
||||
Before proceeding further, please make sure you have set up a RAID 1 array following the instructions provided in Part 3 of this series: [How to set up RAID 1 (Mirror) in Linux][2].
|
||||
|
||||
The only variations in our present case will be:
|
||||
|
||||
1) a different version of CentOS (v7) than the one used in that article (v6.5), and
|
||||
|
||||
2) different disk sizes for /dev/sdb and /dev/sdc (8 GB each).
|
||||
|
||||
In addition, if SELinux is enabled in enforcing mode, you will need to add the corresponding labels to the directory where you’ll mount the RAID device. Otherwise, you’ll run into this warning message while attempting to mount it:
|
||||
|
||||
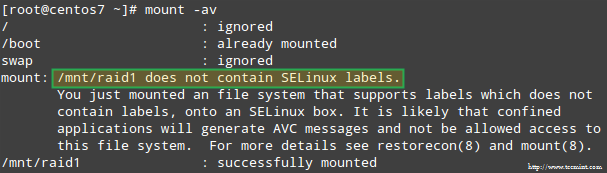
|
||||
|
||||
SELinux RAID Mount Error
|
||||
|
||||
You can fix this by running:
|
||||
|
||||
# restorecon -R /mnt/raid1
|
||||
|
||||
### Setting up RAID Monitoring ###
|
||||
|
||||
There is a variety of reasons why a storage device can fail (SSDs have greatly reduced the chances of this happening, though), but regardless of the cause you can be sure that issues can occur anytime and you need to be prepared to replace the failed part and to ensure the availability and integrity of your data.
|
||||
|
||||
A word of advice first. Even when you can inspect /proc/mdstat in order to check the status of your RAIDs, there’s a better and time-saving method that consists of running mdadm in monitor + scan mode, which will send alerts via email to a predefined recipient.
|
||||
|
||||
To set this up, add the following line in /etc/mdadm.conf:
|
||||
|
||||
MAILADDR user@<domain or localhost>
|
||||
|
||||
In my case:
|
||||
|
||||
MAILADDR gacanepa@localhost
|
||||
|
||||

|
||||
|
||||
RAID Monitoring Email Alerts
|
||||
|
||||
To run mdadm in monitor + scan mode, add the following crontab entry as root:
|
||||
|
||||
@reboot /sbin/mdadm --monitor --scan --oneshot
|
||||
|
||||
By default, mdadm will check the RAID arrays every 60 seconds and send an alert if it finds an issue. You can modify this behavior by adding the `--delay` option to the crontab entry above along with the amount of seconds (for example, `--delay` 1800 means 30 minutes).
|
||||
|
||||
Finally, make sure you have a Mail User Agent (MUA) installed, such as [mutt or mailx][3]. Otherwise, you will not receive any alerts.
|
||||
|
||||
In a minute we will see what an alert sent by mdadm looks like.
|
||||
|
||||
### Simulating and Replacing a failed RAID Storage Device ###
|
||||
|
||||
To simulate an issue with one of the storage devices in the RAID array, we will use the `--manage` and `--set-faulty` options as follows:
|
||||
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
|
||||
|
||||
This will result in /dev/sdc1 being marked as faulty, as we can see in /proc/mdstat:
|
||||
|
||||
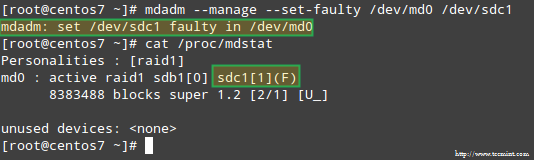
|
||||
|
||||
Stimulate Issue with RAID Storage
|
||||
|
||||
More importantly, let’s see if we received an email alert with the same warning:
|
||||
|
||||

|
||||
|
||||
Email Alert on Failed RAID Device
|
||||
|
||||
In this case, you will need to remove the device from the software RAID array:
|
||||
|
||||
# mdadm /dev/md0 --remove /dev/sdc1
|
||||
|
||||
Then you can physically remove it from the machine and replace it with a spare part (/dev/sdd, where a partition of type fd has been previously created):
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
Luckily for us, the system will automatically start rebuilding the array with the part that we just added. We can test this by marking /dev/sdb1 as faulty, removing it from the array, and making sure that the file tecmint.txt is still accessible at /mnt/raid1:
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
# mount | grep raid1
|
||||
# ls -l /mnt/raid1 | grep tecmint
|
||||
# cat /mnt/raid1/tecmint.txt
|
||||
|
||||

|
||||
|
||||
Confirm Rebuilding RAID Array
|
||||
|
||||
The image above clearly shows that after adding /dev/sdd1 to the array as a replacement for /dev/sdc1, the rebuilding of data was automatically performed by the system without intervention on our part.
|
||||
|
||||
Though not strictly required, it’s a great idea to have a spare device in handy so that the process of replacing the faulty device with a good drive can be done in a snap. To do that, let’s re-add /dev/sdb1 and /dev/sdc1:
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdb1
|
||||
# mdadm --manage /dev/md0 --add /dev/sdc1
|
||||
|
||||

|
||||
|
||||
Replace Failed Raid Device
|
||||
|
||||
### Recovering from a Redundancy Loss ###
|
||||
|
||||
As explained earlier, mdadm will automatically rebuild the data when one disk fails. But what happens if 2 disks in the array fail? Let’s simulate such scenario by marking /dev/sdb1 and /dev/sdd1 as faulty:
|
||||
|
||||
# umount /mnt/raid1
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdb1
|
||||
# mdadm --stop /dev/md0
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdd1
|
||||
|
||||
Attempts to re-create the array the same way it was created at this time (or using the `--assume-clean` option) may result in data loss, so it should be left as a last resort.
|
||||
|
||||
Let’s try to recover the data from /dev/sdb1, for example, into a similar disk partition (/dev/sde1 – note that this requires that you create a partition of type fd in /dev/sde before proceeding) using ddrescue:
|
||||
|
||||
# ddrescue -r 2 /dev/sdb1 /dev/sde1
|
||||
|
||||
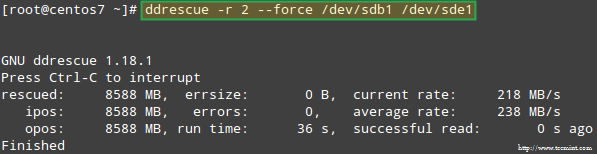
|
||||
|
||||
Recovering Raid Array
|
||||
|
||||
Please note that up to this point, we haven’t touched /dev/sdb or /dev/sdd, the partitions that were part of the RAID array.
|
||||
|
||||
Now let’s rebuild the array using /dev/sde1 and /dev/sdf1:
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
|
||||
|
||||
Please note that in a real situation, you will typically use the same device names as with the original array, that is, /dev/sdb1 and /dev/sdc1 after the failed disks have been replaced with new ones.
|
||||
|
||||
In this article I have chosen to use extra devices to re-create the array with brand new disks and to avoid confusion with the original failed drives.
|
||||
|
||||
When asked whether to continue writing array, type Y and press Enter. The array should be started and you should be able to watch its progress with:
|
||||
|
||||
# watch -n 1 cat /proc/mdstat
|
||||
|
||||
When the process completes, you should be able to access the content of your RAID:
|
||||
|
||||
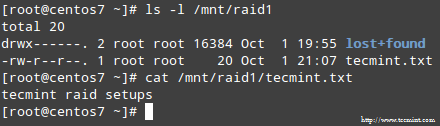
|
||||
|
||||
Confirm Raid Content
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have reviewed how to recover from RAID failures and redundancy losses. However, you need to remember that this technology is a storage solution and DOES NOT replace backups.
|
||||
|
||||
The principles explained in this guide apply to all RAID setups alike, as well as the concepts that we will cover in the next and final guide of this series (RAID management).
|
||||
|
||||
If you have any questions about this article, feel free to drop us a note using the comment form below. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/recover-data-and-rebuild-failed-software-raid/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[3]:http://www.tecmint.com/send-mail-from-command-line-using-mutt-command/
|
||||
125
translated/talk/20150716 Interview--Larry Wall.md
Normal file
125
translated/talk/20150716 Interview--Larry Wall.md
Normal file
@ -0,0 +1,125 @@
|
||||
专访: Larry Wall
|
||||
================================================================================
|
||||
> 经历了15年的打造,Perl 6终将在年底与大家见面。我们预先采访了她的作者了解一下新特性。
|
||||
|
||||
Larry Wall是个相当有趣的人。他即编程语言Perl的创造者,这种语言被广泛的誉为将互联网粘在一起的胶水,也因为对非字母使用的密度和宽容度被嘲笑是‘只写’语言。Larry本人具有语言学背景,曾风趣的使用“洋葱的状态”来介绍Perl特性,为人津道。
|
||||
|
||||
在2015年布鲁塞尔的FOSDEM上,我们赶上Larry,问了问他为什么Perl 6花了如此长的时间(Perl 5的发布时间是1994年),了解当项目中的每个人都各执己见时是多么的难以管理,以及他的语言学背景自始至终究竟给Perl带来了怎样的影响。做好准备,让我们来领略其中的奥妙……
|
||||
|
||||

|
||||
|
||||
**Linux Voice:你有计划寻找世界某处某种不知名的语言来写脚本,但你还未曾有机会去实现它。现在呢?**
|
||||
|
||||
Larry Wall:那需要多么青春,才能承担得起呀!做这些事需要投入很大的努力和人力,以至于已经不适合那些上了年纪的人了。健康、活力是其中的一部分,同样也因为人们在年轻的时候更容易学习一门新的语言,只有在你学会了语言之后你才能写脚本呀。
|
||||
|
||||
我自学了日语十年,由于语音和发声联系我能说的比流利——但要理解别人的意思对我来说还十分困难。所以到了日本我会问路,但我听不懂他们的回答!
|
||||
|
||||
> “在Perl 6中,我们试图让电脑更准确的了解我们。”
|
||||
|
||||
通常需要学习一门语言直到能开发一个书写系统,并且可以使用这种语言进行少量的交流,经过日积月累直到,你能用它学习研究、教书育人,最后达到可以教授本土人如何以他们的文明书写。
|
||||
|
||||
当然如果在语言方面你有帮手 —— 经过别人的提醒我们不再使用“语言线人”来称呼他们了,那样显得我们像是在CIA工作的一样!—— 你可以通过他们的帮助来学习外语。他们不是老师,但他们会以另一种方式来激发你学习 —— 当然他们也能叫你如何说。他们会拿着一根棍子,指着它说“这是一根棍子”,然后丢掉同时说“棒子掉下去了”。你开始记下一些东西并将其系统化。
|
||||
|
||||
大多数迫使人们站出来的原因是翻译圣经。但是这只是其中的一方面;另一方面也是为了保护自己的文明。传教士在这方面臭名昭著,应为人类学家认为人们应该基于自己的文明来做这件事。但注定有些有些人会改变他们的文明——他们可能是军队、或是商人,如可口可乐或者缝纫机器,或传教士。在这三者之间,传教士式相对来讲伤害最小的了,如果他们恪守本职的话。
|
||||
|
||||
**LV:许多文字系统有本可依,相较而言你的发明就像是格林兰语…**
|
||||
|
||||
切诺基人照搬字母就发明了他们自己的语言,并没有在这些字母上施加任何他们的想法,这种做法相当任性。它们必须要能够表达出人们所想,才能使交流更顺畅。经常是有些声调语言使用的是西方文字拼写,并尽可能的使用拉丁文的字符变化。然后用重音符或数字标注出音调。
|
||||
|
||||
在你开始学习如何使用语音和语调表示之后,你也开始变得迷糊——或者你书写就不如从前准确。或者你对话的时候像在讲英文,但发音开始无法匹配拼写。
|
||||
|
||||
**LV:当你在维护Perl的时候,你的语言学背景会不会使你认为:“这对程序设计语言真的非常重要”?**
|
||||
|
||||
LW:我在人们是如何使用语言上想了很多。在现实的语言中,你有一套名词、动词和形容词的体系,并且你知道这些单词的词性。在现实的自然语言中,你时常将一个单词放到不同的位置。我所学的语言学理论也被称为法位学,他会解释这些在自然语言中工作的原理 —— 也就是有些东西你考虑的时候是名词,但你可以将它用作动词,并且人们总是这样做。
|
||||
|
||||
你能很好的将任何单词放在任何位置,然后你就能沟通了。我比较喜欢的例子是将一整句话用作为一个形容词。这句话会是这样的:“我不喜欢你[我可以用任何东西来取代这个形容词的]态度”!
|
||||
|
||||
所以自然语言非常灵活,因为聆听者非常聪明 —— 至少,相对于电脑而言 —— 你相信他们会理解你最想表达的意思,即使存在歧义。当然对电脑而言,你必须保证歧义不大。
|
||||
|
||||
可以说在Perl 1到5上,我们针对这方面的管理做得还不够。有时电脑会在不应该的时候抽风。在Perl 6上,我们找了许多方法,使得电脑对你所说的话能更准确的理解,就算用户并不清楚这底是字符串还是数字。电脑准确的知道它的类型。
|
||||
|
||||

|
||||
|
||||
**LV:Perl被视作互联网上的“胶水”语言已久,能将点点滴滴组合在一起。在你看来Perl 6的发布是否符合当前用户的需要,或者旨在招揽更多新用户,能使她重获新生吗?**
|
||||
|
||||
LW:最初的设想是为Perl程序员带来更好的Perl。但在看到了Perl 5上的不足后,很明显改掉这些不足会使Perl 6更易用,就像我在讨论中提到过 —— 类似于在J. R. R. Tolkien上对易用性的讨论一样[see http://tinyurl.com/nhpr8g2]。
|
||||
|
||||
重点是“简单的东西应该简单,而难得东西应该可以实现”。让我们回顾一下,在Perl 2和3之间的那段时间。在Perl 2上我们不能处理二进制数据或嵌入的空值 —— 只有C语言风格的字符串。我曾说过“Perl只是文本执行语言 —— 你并不需要有这些功能的文本执行语言”。
|
||||
|
||||
但当时发生了一大对的问题,因为大多数的文本中会包含少量的二进制数据 —— 类似的例如网址。你使用二进制数据打开套接字,然后文本处理它。所以语言的可用性两倍于处理二进制的可能性。
|
||||
|
||||
那我们开始探讨在语言中什么应该简单。现在的Perl中有一条原则,我们偷师了哈夫曼编码,在位编码系统中为字符采取了不同的尺寸。常用的字符占用的位数较少,不常用的字符占用的位数更多。
|
||||
|
||||
> “掌握平衡时需要格外小心。毕竟在刚开始的时候总会有许多的好主意。”
|
||||
|
||||
我们偷师了这种想法并将它作为Perl的原则,针对常用的或者说常输入的 —— 这些常用的东西必须简单或简洁。另一方面,也显得更加的不规则。在自然语言中也是这样的,由诸多的常用的动词趋于诸多的不规律。
|
||||
|
||||
所以在这样的情况下需要更多的差异存在。我很喜欢一本书是Umberto Eco写的的《探寻完美的语言》,说的并不是计算机语言;而是哲学语言,大体的意思是古代的语言也许是完美的,我们应该将她们带回来。
|
||||
|
||||
所有的这类语言错误的认为同样的事物,其编码也应该一直是相同的。但这并不是我们沟通的方式。如果你的农场中有许多动物,他们都有对应的名字,当你想杀一只鸡的时候说“走,去把Blerfoo宰了”,你的真实想法是宰了Blerfee,但有可能最后死的是一头牛。
|
||||
|
||||
所以在这种时候我们其实更需要好好的将单词区分开,使沟通的信道的冗余增加。
|
||||
|
||||
在电子学中还有另一种自时钟码。在从前的串行传输协议中有停止和启动位,来保持同步。自然语言中也会包含这些。比如说,在写日语时,你不用空格。由于书写方式的原因,他们会在每个词组的开头使用中文中的汉字字符,然后用音节表中的字符来结尾。
|
||||
|
||||
**LV:平假名,对吗?**
|
||||
|
||||
LW: 是的,平假名。所以使用这一系统,每个词组的开头就自然而然的脱颖而出了。同样的,在古老的希腊,大多数的动词都是搭配好的。所以它们拥有时钟排序机制的标准结尾。在他们的书写体系中空格也是可有可无的 —— 引入空格是更现代的一大发明。
|
||||
|
||||
所以在计算机语言上也要如此,将值包含于自时钟码中。在Perl上我们重度依赖此道,而且在Perl 6上相较于前几代这种依赖更重。当你使用表达式时,你要么想得到一个词,要么想到得到插入操作符。当你想要得到一个词,你有可能同时得到一个前缀操作符,同样当你想要得到一个插入符,你也可能同时得到前一个词的后缀。
|
||||
|
||||
但是反过来。如果编译器准确的知道它想要什么,你只用多写那么一丢丢,其他的让Perl来完成。所以在切断的时候,它会根据需要推荐常规表达式,分割处也会如你所愿。而我们并不需要操心任何事,因为那只会使你失去自时钟冗余。
|
||||
|
||||
大多数我们最好的语法错误消息,源于对一行中出现两个词的观察。然后我们尝试找出原因 —— “哦,你一定漏掉了上一行的分号”。所以我们相较于很多其他特殊解析器可以生成更加好的错误消息。
|
||||
|
||||

|
||||
|
||||
**LV:为什么Perl 6花了15年?当每个人对她有不同看法时一定十分难管理,而且正确和错误并不是绝对的。**
|
||||
|
||||
LW:这其中必定会有非常微妙的平衡。刚开始会有许多的想法 —— 当然,我并不是想说那些是好想法。也有很多令人烦恼的地方,就像有361条RFC[功能建议文件],而我想要实现的可能只有其中的20条。我们需要坐下来,将它们全部看完,并忽略其中的解决方案,因为它们通常流于表象、视野狭隘。几乎每一条只针对一样事物,如若我们将它们全部拼凑起来,那简直是一堆垃圾。
|
||||
|
||||
所以我们必须基于人们在使用Perl 5时的真实感受重新整理。寻找统一、深层的解决方案。许多的RFC文档都提到了一个事实,就是类型系统的不足。通过引入更条理分明的类型系统,我们可以解决很多问题并且即聪明又紧凑。
|
||||
|
||||
同时我们开始关注其他面:如何统一特征集并开始重用不同领域的想法。并不需要他们在下层相同。我们有一种标准的书写配对方式——好的吧,Perl的话有两种!但使用冒号书写配对的方法同样可以被基数计数法或是任何文字编号所重用。同样也可以用于其他形式的引用。在Perl里我们称它为“奇妙的一致”。
|
||||
|
||||
> “早先组建Perl 6实施小组的朋友,挽着我的手说:“我们真的很需要一位语言的设计者。””
|
||||
|
||||
同样的想法涌现出来,你说“我已经熟悉了语法如何运作,但是我实在别处看到的”。所以说视角相同才能找出这种一致。那些早期将Perl 6呈现在我面前的人们,握着我的手说:“我们真的需要一位语言的设计者。您能作为我们的精神领袖吗?”
|
||||
|
||||
所以我是语言的设计者,但总是听到:“离实施小组远点!我们目睹了你对Perl 5做的那些,我们不想历史重演!”真是让我忍俊不禁因为他们作为起步的核心和原先Perl 5的内部结构上几乎别无二致,也许就只因为这个原因实施小组早期的工作并不顺利。
|
||||
|
||||
因为我们始终坚持我们的整体设计方法,所以在是否应该使用VM上讨论良久,最后解决的方式很像面向对象的汇编语言。类似的问题在伊始阶段无处不在。然后Pugs这家伙走过来说:“用用看Haskell吧,它能让你们清醒的认识自己正在干什么。让我们用它来弄清自己的言下之意。”
|
||||
|
||||
因此,我们明确了其中的一些语义模型的,但更重要的是,我们开始建立符合哪些语义模型的测试套件。在这时候,持续的对Parrot VM进行开发,以及另一个实施项目Niecza的到来,它基于.Net,是由一个年轻的家伙搞出来的。他很聪明且实施了一大部分的Perl 6。不过他还是一个人干,并没有找到什么好方法让别人介入他的项目。
|
||||
|
||||
同时Parrot项目变得过于庞大,以至于任何人都不能真正的由内而外的管理它,并且很难重构。负责这方面工作的Rakudo觉得我们可能需要在更多平台上运行不止Parrot VM。于是他们发明了所谓的可移植层,“Not Quite Perl”简写成NQP。他们一开始将它移植到JVM(Java虚拟机)上运行,与此同时,他们还秘密的在一个新的VM上工作。这个叫做MoarVM的VM这去年刚刚为人知晓。
|
||||
|
||||
无论MoarVM还是JVM在回归测试中表现得十分接近 —— 在许多方面Parrot算是紧随其后。这样不挑剔VM真的很棒,我们也能开始考虑将NQP发扬光大。谷歌夏季编码大赛的目标就是针对JavaScript的NQP,这应该靠谱,因为MoarVM平时处理也同样使用Node.js。
|
||||
|
||||
我们可能要将今年余下的时光投在MoarVM上,直到6.0发布,方可休息片刻。
|
||||
|
||||
**LV:去年英国,政府开展编程年,来激发年轻人对编程的兴趣。针对活动的建议五花八门——类似为了让人们准确的认识到内存的使用你是否应该从低阶语言开授,或是一门高阶语言。你对此作和看法?**
|
||||
|
||||
LW:到现在为止,Python社区在低阶方面的教学工作做得比我们要好。我们也很想在这一方面做点什么,这也是我们有蝴蝶logo的部分原因,以此来吸引七岁大小的女孩子!
|
||||
|
||||
我们认为将Perl 6作为第一门语言来学习是可行的。一大堆的将Perl 5作为第一门语言学习的人让我们吃惊。你知道,在Perl 5中有许多相当大的概念,如闭包,范围操作符,和一些你通常在函数式编程中学到的特性。这才Perl 6中同样有很多。
|
||||
|
||||
> “到现在为止,Python社区在低阶方面的教学工作做得比我们要好。”
|
||||
|
||||
Perl 6花了这么长时间的部分原因是我们尝试去坚持将近50种互不相同的原则,在设计语言的最后对于“哪点是最重要的规则”这个问题还是悬而未决。有太多的问题需要讨论。优势我们做出了决定,并已经工作了一段时间,才发现这个决定并不正确。
|
||||
|
||||
之前我们并未针对并发程序设计设计或指定些什么,直到Jonathan Worthington的出现,他非常巧妙的权衡了各个方面。他结合了一些其他语言诸如Go和C#的想法,将并发原语写的非常好。可组合性是一个语言至关重要的一部分。
|
||||
|
||||
很滑稽的是很多程序设计系统的并发和并行写的并不好 —— 就像线程和锁,不良的操作方式有很多。所以在我看来,额外花点时间看一下Go或者C#这种高阶原语的开发是很值得的 —— 他们在条目中列出了矛盾 —— 写的相当棒。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/interview-larry-wall/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
@ -1,30 +0,0 @@
|
||||
为Linux 4.3 内核添加MOST 驱动子系统
|
||||
================================================================================
|
||||
当4.2 内核还没有正式发布的时候,Greg Kroah-Hartman 就为他维护的各种子系统模块打开了4.3 的合并窗口。
|
||||
|
||||
周二Greg KH 发起的拉取请求(pull request)里包含了linux 4.3 的合并窗口更新,内容涉及驱动核心、TTY/串口、USB驱动、字符/杂项以及暂存区内容。这些拉取申请没有提供任何震撼性的改变,大部分都是改进/附加/修改bug。暂存区内容又是大量的修正和清理,但是还是有一个新的驱动子系统。
|
||||
|
||||
|
||||
Greg 提到了[4.3 的暂存区改变][2],“这里的很多东西,几乎全部都是细小的修改和改变。通常的IIO 更新和新驱动,以及我们已经添加了的MOST 驱动子系统,已经在源码树里整理了。ozwpan 驱动最终还是被删掉,引文它很明显被废弃了而且也没有人关心它。”
|
||||
|
||||
MOST 驱动子系统是面向媒体的系统传输的简称。在linux 4.3 新增的文档里面解释道,“MOST 驱动支持LInux 应用程序访问MOST 网络:汽车信息骨干网和高速汽车多媒体网络的事实上的标准。MOST 定义了必要的协议、硬件和软件层,提供高效且低消耗的传输控制,实时的数据包传输,只需要使用一个媒介(物理层)。目前使用的媒介是光线、非屏蔽双绞线(UTP)和同轴电缆。MOST 也支持多种传输速度,最高支持150Mbps。”如文档解释的,MOST 主要是关于Linux 在汽车上的应用。
|
||||
|
||||
当Greg KH 发出了他为Linux 4.3 多个子系统做出的更新,但是他还没有打算提交[KDBUS][5]的内核代码。他之前已经放出了[linux 4.3 的KDBUS] 的开发计划,所以我们将需要等待官方的4.3 合并窗口,看看会发生什么。关注Phoronix 下周关于linux 4.3 内核的新闻报道,此时合并窗口将会开始,假如Linus 在本周[发布linux 4.2][4]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.3-Staging-Pull
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/scan.php?page=search&q=Linux+4.2
|
||||
[2]:http://lkml.iu.edu/hypermail/linux/kernel/1508.2/02604.html
|
||||
[3]:http://www.phoronix.com/scan.php?page=news_item&px=KDBUS-Not-In-Linux-4.2
|
||||
[4]:http://www.phoronix.com/scan.php?page=news_item&px=Linux-4.2-rc7-Released
|
||||
[5]:http://www.phoronix.com/scan.php?page=search&q=KDBUS
|
||||
@ -1,70 +0,0 @@
|
||||
Linux 问与答:如何在Linux 命令行下浏览天气预报
|
||||
================================================================================
|
||||
> **Q**: 我经常在Linux 桌面查看天气预报。然而,是否有一种在终端环境下,不通过桌面小插件或者网络查询天气预报的方法?
|
||||
|
||||
对于Linux 桌面用户来说,有很多办法获取天气预报,比如使用专门的天气应用,桌面小插件,或者面板小程序。但是如果你的工作环境实际与终端的,这里也有一些在命令行下获取天气的手段。
|
||||
|
||||
其中有一个就是 [wego][1],**一个终端下的小巧程序**。使用基于ncurses 的接口,这个命令行程序允许你查看当前的天气情况和之后的预报。它也会通过一个天气预报的API 收集接下来5 天的天气预报。
|
||||
|
||||
### 在Linux 下安装Wego ###
|
||||
安装wego 相当简单。wego 是用Go 编写的,引起第一个步骤就是安装[Go 语言][2]。然后再安装wego。
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
wego 会被安装到$GOPATH/bin,所以要将$GOPATH/bin 添加到$PATH 环境变量。
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
现在就可与直接从命令行启动wego 了。
|
||||
|
||||
$ wego
|
||||
|
||||
第一次运行weg 会生成一个配置文件(~/.wegorc),你需要指定一个天气API key。
|
||||
你可以从[worldweatheronline.com][3] 获取一个免费的API key。免费注册和使用。你只需要提供一个有效的邮箱地址。
|
||||
|
||||

|
||||
|
||||
你的 .wegorc 配置文件看起来会这样:
|
||||
|
||||

|
||||
|
||||
除了API key,你还可以把你想要查询天气的地方、使用的城市/国家名称、语言配置在~/.wegorc 中。
|
||||
注意,这个天气API 的使用有限制:每秒最多5 次查询,每天最多250 次查询。
|
||||
当你重新执行wego 命令,你将会看到最新的天气预报(当然是你的指定地方),如下显示。
|
||||
|
||||

|
||||
|
||||
显示出来的天气信息包括:(1)温度,(2)风速和风向,(3)可视距离,(4)降水量和降水概率
|
||||
默认情况下会显示3 天的天气预报。如果要进行修改,可以通过参数改变天气范围(最多5天),比如要查看5 天的天气预报:
|
||||
|
||||
$ wego 5
|
||||
|
||||
如果你想检查另一个地方的天气,只需要提供城市名即可:
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### 问题解决 ###
|
||||
1. 可能会遇到下面的错误:
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
当你在一个不支持原生Go 编译器的环境下运行wego 时就会出现这个错误。在这种情况下你只需要使用gccgo ——一个Go 的编译器前端来编译程序即可。这一步可以通过下面的命令完成。
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -0,0 +1,250 @@
|
||||
如何在 CentOS 7.0 上配置 Ceph 存储
|
||||
How to Setup Red Hat Ceph Storage on CentOS 7.0
|
||||
================================================================================
|
||||
Ceph 是一个将数据存储在单一分布式计算机集群上的开源软件平台。当你计划构建一个云时,你首先需要决定如何实现你的存储。开源的 CEPH 是红帽原生技术之一,它基于称为 RADOS 的对象存储系统,用一组网关 API 表示块、文件、和对象模式中的数据。由于它自身开源的特性,这种便携存储平台能在公有和私有云上安装和使用。Ceph 集群的拓扑结构是按照备份和信息分布设计的,这内在设计能提供数据完整性。它的设计目标就是容错、通过正确配置能运行于商业硬件和一些更高级的系统。
|
||||
|
||||
Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要求最近的内核以及其它最新的库。在这篇指南中,我们会使用最小化安装的 CentOS-7.0。
|
||||
|
||||
### 系统资源 ###
|
||||
|
||||
**CEPH-STORAGE**
|
||||
OS: CentOS Linux 7 (Core)
|
||||
RAM:1 GB
|
||||
CPU:1 CPU
|
||||
DISK: 20
|
||||
Network: 45.79.136.163
|
||||
FQDN: ceph-storage.linoxide.com
|
||||
|
||||
**CEPH-NODE**
|
||||
OS: CentOS Linux 7 (Core)
|
||||
RAM:1 GB
|
||||
CPU:1 CPU
|
||||
DISK: 20
|
||||
Network: 45.79.171.138
|
||||
FQDN: ceph-node.linoxide.com
|
||||
|
||||
### 安装前的配置 ###
|
||||
|
||||
在安装 CEPH 存储之前,我们要在每个节点上完成一些步骤。第一件事情就是确保每个节点的网络已经配置好并且能相互访问。
|
||||
|
||||
**配置 Hosts**
|
||||
|
||||
要在每个节点上配置 hosts 条目,要像下面这样打开默认的 hosts 配置文件。
|
||||
|
||||
# vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
45.79.136.163 ceph-storage ceph-storage.linoxide.com
|
||||
45.79.171.138 ceph-node ceph-node.linoxide.com
|
||||
|
||||
**安装 VMware 工具**
|
||||
|
||||
工作环境是 VMWare 虚拟环境时,推荐你安装它的 open VM 工具。你可以使用下面的命令安装。
|
||||
|
||||
#yum install -y open-vm-tools
|
||||
|
||||
**配置防火墙**
|
||||
|
||||
如果你正在使用启用了防火墙的限制性环境,确保在你的 CEPH 存储管理节点和客户端节点中开放了以下的端口。
|
||||
|
||||
你必须在你的 Admin Calamari 节点开放 80、2003、以及4505-4506 端口,并且允许通过 80 号端口到 CEPH 或 Calamari 管理节点,以便你网络中的客户端能访问 Calamari web 用户界面。
|
||||
|
||||
你可以使用下面的命令在 CentOS 7 中启动并启用防火墙。
|
||||
|
||||
#systemctl start firewalld
|
||||
#systemctl enable firewalld
|
||||
|
||||
运行以下命令使 Admin Calamari 节点开放上面提到的端口。
|
||||
|
||||
#firewall-cmd --zone=public --add-port=80/tcp --permanent
|
||||
#firewall-cmd --zone=public --add-port=2003/tcp --permanent
|
||||
#firewall-cmd --zone=public --add-port=4505-4506/tcp --permanent
|
||||
#firewall-cmd --reload
|
||||
|
||||
在 CEPH Monitor 节点,你要在防火墙中允许通过以下端口。
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6789/tcp --permanent
|
||||
|
||||
然后允许以下默认端口列表,以便能和客户端以及监控节点交互,并发送数据到其它 OSD。
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
|
||||
|
||||
如果你工作在非生产环境,建议你停用防火墙以及 SELinux 设置,在我们的测试环境中我们会停用防火墙以及 SELinux。
|
||||
|
||||
#systemctl stop firewalld
|
||||
#systemctl disable firewalld
|
||||
|
||||
**系统升级**
|
||||
|
||||
现在升级你的系统并重启使所需更改生效。
|
||||
|
||||
#yum update
|
||||
#shutdown -r 0
|
||||
|
||||
### 设置 CEPH 用户 ###
|
||||
|
||||
现在我们会新建一个单独的 sudo 用户用于在每个节点安装 ceph-deploy工具,并允许该用户无密码访问每个节点,因为它需要在 CEPH 节点上安装软件和配置文件而不会有输入密码提示。
|
||||
|
||||
运行下面的命令在 ceph-storage 主机上新建有独立 home 目录的新用户。
|
||||
|
||||
[root@ceph-storage ~]# useradd -d /home/ceph -m ceph
|
||||
[root@ceph-storage ~]# passwd ceph
|
||||
|
||||
节点中新建的每个用户都要有 sudo 权限,你可以使用下面展示的命令赋予 sudo 权限。
|
||||
|
||||
[root@ceph-storage ~]# echo "ceph ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph
|
||||
ceph ALL = (root) NOPASSWD:ALL
|
||||
|
||||
[root@ceph-storage ~]# sudo chmod 0440 /etc/sudoers.d/ceph
|
||||
|
||||
### 设置 SSH 密钥 ###
|
||||
|
||||
现在我们会在 ceph 管理节点生成 SSH 密钥并把密钥复制到每个 Ceph 集群节点。
|
||||
|
||||
在 ceph-node 运行下面的命令复制它的 ssh 密钥到 ceph-storage。
|
||||
|
||||
[root@ceph-node ~]# ssh-keygen
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/root/.ssh/id_rsa):
|
||||
Created directory '/root/.ssh'.
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /root/.ssh/id_rsa.
|
||||
Your public key has been saved in /root/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
5b:*:*:*:*:*:*:*:*:*:c9 root@ceph-node
|
||||
The key's randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
|
||||
----------
|
||||
|
||||
[root@ceph-node ~]# ssh-copy-id ceph@ceph-storage
|
||||
|
||||

|
||||
|
||||
### 配置 PID 数目 ###
|
||||
|
||||
要配置 PID 数目的值,我们会使用下面的命令检查默认的内核值。默认情况下,是一个小的最大线程数 32768.
|
||||
如下图所示通过编辑系统配置文件配置该值为一个更大的数。
|
||||
|
||||

|
||||
|
||||
### 配置管理节点服务器 ###
|
||||
|
||||
配置并验证了所有网络后,我们现在使用 ceph 用户安装 ceph-deploy。通过打开文件检查 hosts 条目。
|
||||
|
||||
#vim /etc/hosts
|
||||
ceph-storage 45.79.136.163
|
||||
ceph-node 45.79.171.138
|
||||
|
||||
运行下面的命令添加它的库。
|
||||
|
||||
#rpm -Uhv http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm
|
||||
|
||||

|
||||
|
||||
或者创建一个新文件并更新 CEPH 库参数,别忘了替换你当前的 Release 和版本号。
|
||||
|
||||
[root@ceph-storage ~]# vi /etc/yum.repos.d/ceph.repo
|
||||
|
||||
----------
|
||||
|
||||
[ceph-noarch]
|
||||
name=Ceph noarch packages
|
||||
baseurl=http://ceph.com/rpm-{ceph-release}/{distro}/noarch
|
||||
enabled=1
|
||||
gpgcheck=1
|
||||
type=rpm-md
|
||||
gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc
|
||||
|
||||
之后更新你的系统并安装 ceph-deploy 软件包。
|
||||
|
||||
### 安装 CEPH-Deploy 软件包 ###
|
||||
|
||||
我们运行下面的命令以及 ceph-deploy 安装命令来更新系统以及最新的 ceph 库和其它软件包。
|
||||
|
||||
#yum update -y && yum install ceph-deploy -y
|
||||
|
||||
|
||||
### 配置集群 ###
|
||||
|
||||
使用下面的命令在 ceph 管理节点新建一个目录并进入新目录,用于收集所有输出文件和日志。
|
||||
|
||||
#mkdir ~/ceph-cluster
|
||||
#cd ~/ceph-cluster
|
||||
|
||||
----------
|
||||
|
||||
#ceph-deploy new storage
|
||||
|
||||

|
||||
|
||||
如果成功执行了上面的命令,你会看到它新建了配置文件。
|
||||
现在配置 CEPH 默认的配置文件,用任意编辑器打开它并在会影响你公共网络的 global 参数下面添加以下两行。
|
||||
|
||||
#vim ceph.conf
|
||||
osd pool default size = 1
|
||||
public network = 45.79.0.0/16
|
||||
|
||||
### 安装 CEPH ###
|
||||
|
||||
现在我们准备在和 CEPH 集群相关的每个节点上安装 CEPH。我们使用下面的命令在 ceph-storage 和 ceph-node 上安装 CEPH。
|
||||
|
||||
#ceph-deploy install ceph-node ceph-storage
|
||||
|
||||

|
||||
|
||||
处理所有所需仓库和安装所需软件包会需要一些时间。
|
||||
|
||||
当两个节点上的 ceph 安装过程都完成后,我们下一步会通过在相同节点上运行以下命令创建监视器并收集密钥。
|
||||
|
||||
#ceph-deploy mon create-initial
|
||||
|
||||

|
||||
|
||||
### 设置 OSDs 和 OSD 守护进程 ###
|
||||
|
||||
现在我们会设置磁盘存储,首先运行下面的命令列出你所有可用的磁盘。
|
||||
|
||||
#ceph-deploy disk list ceph-storage
|
||||
|
||||
结果中会列出你存储节点中使用的磁盘,你会用它们来创建 OSD。让我们运行以下包括你磁盘名称的命令。
|
||||
|
||||
#ceph-deploy disk zap storage:sda
|
||||
#ceph-deploy disk zap storage:sdb
|
||||
|
||||
为了最后完成 OSD 配置,运行下面的命令配置日志磁盘以及数据磁盘。
|
||||
|
||||
#ceph-deploy osd prepare storage:sdb:/dev/sda
|
||||
#ceph-deploy osd activate storage:/dev/sdb1:/dev/sda1
|
||||
|
||||
你需要在所有节点上运行相同的命令,它会清除你磁盘上的所有东西。之后为了集群能运转起来,我们需要使用以下命令从 ceph 管理节点复制不同的密钥和配置文件到所有相关节点。
|
||||
|
||||
#ceph-deploy admin ceph-node ceph-storage
|
||||
|
||||
### 测试 CEPH ###
|
||||
|
||||
我们几乎完成了 CEPH 集群设置,让我们在 ceph 管理节点上运行下面的命令检查正在运行的 ceph 状态。
|
||||
|
||||
#ceph status
|
||||
#ceph health
|
||||
HEALTH_OK
|
||||
|
||||
如果你在 ceph status 中没有看到任何错误信息,就意味着你成功地在 CentOS 7 上安装了 ceph 存储集群。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇详细的文章中我们学习了如何使用两台安装了 CentOS 7 的虚拟机设置 CEPH 存储集群,这能用于备份或者作为用于处理其它虚拟机的本地存储。我们希望这篇文章能对你有所帮助。当你试着安装的时候记得分享你的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/setup-red-hat-ceph-storage-centos-7-0/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,39 @@
|
||||
如何在64位Ubuntu 15.10中编译最新版32位Wine
|
||||
================================================================================
|
||||
Wine发布了最新的1.7.53版本。此版本带来的大量性能提升,包括**XAudio**,**Direct3D**代码清理,改善**OLE对象嵌入**技术,更好的**Web服务dll**的实现,还有其他大量更新。
|
||||
|
||||
|
||||
|
||||
虽然官方PPA支持[Wine][1],但目前只提供1.7.44版本,所以安装最新版本可以从源码编译安装。
|
||||
|
||||
[下载源码包][2]([直接下载][3])并解压(**tar -xf wine-1.7.53**).然后,安装依赖。
|
||||
|
||||
sudo apt-get install build-essential gcc-multilib libx11-dev:i386 libfreetype6-dev:i386 libxcursor-dev:i386 libxi-dev:i386 libxshmfence-dev:i386 libxxf86vm-dev:i386 libxrandr-dev:i386 libxinerama-dev:i386 libxcomposite-dev:i386 libglu1-mesa-dev:i386 libosmesa6-dev:i386 libpcap0.8-dev:i386 libdbus-1-dev:i386 libncurses5-dev:i386 libsane-dev:i386 libv4l-dev:i386 libgphoto2-dev:i386 liblcms2-dev:i386 gstreamer0.10-plugins-base:i386 libcapi20-dev:i386 libcups2-dev:i386 libfontconfig1-dev:i386 libgsm1-dev:i386 libtiff5-dev:i386 libmpg123-dev:i386 libopenal-dev:i386 libldap2-dev:i386 libgnutls-dev:i386 libjpeg-dev:i386
|
||||
|
||||
现在切换到wine-1.7.53解压后的文件夹,并输入:
|
||||
|
||||
./configure
|
||||
make
|
||||
sudo make install
|
||||
|
||||
同样地,你也可以指定prefix配置脚本,以当前用户安装wine:
|
||||
|
||||
./configure --prefix=$HOME/usr/bin
|
||||
make
|
||||
make install
|
||||
|
||||
这种情况下,Wine将会安装在**$HOME/usr/bin/wine**,所以请检查$HOME/usr/bin在你的PATH变量中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tuxarena.com/2015/10/how-to-compile-latest-wine-32-bit-on-64-bit-ubuntu-15-10/
|
||||
|
||||
作者:Craciun Dan
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://launchpad.net/~ubuntu-wine/+archive/ubuntu/ppa
|
||||
[2]:https://www.winehq.org/announce/1.7.53
|
||||
[3]:http://prdownloads.sourceforge.net/wine/wine-1.7.53.tar.bz2
|
||||
@ -0,0 +1,169 @@
|
||||
|
||||
当软件 RAID 故障时如何恢复和重建数据 – 第 8 部分
|
||||
================================================================================
|
||||
|
||||
在阅读过 [RAID 系列][1] 前面的文章后你已经对 RAID 略微熟悉了。回顾前面几个软件 RAID 的配置,我们对每一个做了详细的解释,使用哪一个取决与你的具体情况。
|
||||
|
||||

|
||||
|
||||
恢复并重建故障的软件 RAID - 第8部分
|
||||
|
||||
在本文中,我们将讨论当一个磁盘发生故障时如何重建软件 RAID 阵列并且不会丢失数据。为方便起见,我们仅考虑RAID 1 的配置 - 但其方法和概念适用于所有情况。
|
||||
|
||||
#### RAID 测试方案 ####
|
||||
|
||||
在进一步讨论之前,请确保你已经配置了 RAID 1 阵列,可以按照本系列第3部分提供的方法:[在 Linux 中如何组建 RAID 1(镜像)][2]。
|
||||
|
||||
在目前的情况下,仅有的变化是:
|
||||
|
||||
1)使用不同版本 CentOS(v7),而不是前面文章中的(v6.5)。
|
||||
|
||||
2) 磁盘容量发生改变, /dev/sdb 和 /dev/sdc(各8GB)。
|
||||
|
||||
此外,如果 SELinux 是 enforcing 模式,你需要将相应的标签添加到挂载 RAID 设备的目录中。否则,当你试图挂载时,你会碰到这样的警告信息:
|
||||
|
||||

|
||||
|
||||
启用 SELinux 时 RAID 挂载错误
|
||||
|
||||
通过以下命令来解决:
|
||||
|
||||
# restorecon -R /mnt/raid1
|
||||
|
||||
### 配置 RAID 监控 ###
|
||||
|
||||
存储设备损坏的原因很多(尽管固态硬盘大大减少了这种情况发生的可能性),但不管是什么原因,可以肯定问题随时可能发生,你需要准备好替换发生故障的部分,并确保数据的可用性和完整性。
|
||||
|
||||
首先建议是。虽然你可以查看 /proc/mdstat 来检查 RAID 的状态,但有一个更好的和节省时间的方法,使用监控 + 扫描模式运行 mdadm,它将警报通过电子邮件发送到一个预定义的收件人。
|
||||
|
||||
要这样设置,在 /etc/mdadm.conf 添加以下行:
|
||||
|
||||
MAILADDR user@<domain or localhost>
|
||||
|
||||
我自己的设置:
|
||||
|
||||
MAILADDR gacanepa@localhost
|
||||
|
||||

|
||||
|
||||
监控 RAID 并使用电子邮件进行报警
|
||||
|
||||
要运行 mdadm 在监控 + 扫描模式中,以 root 用户添加以下 crontab 条目:
|
||||
|
||||
@reboot /sbin/mdadm --monitor --scan --oneshot
|
||||
|
||||
默认情况下,mdadm 每隔60秒会检查 RAID 阵列,如果发现问题将发出警报。你可以通过添加 `--delay` 选项到crontab 条目上面,后面跟上秒数,来修改默认行为(例如,`--delay` 1800意味着30分钟)。
|
||||
|
||||
最后,确保你已经安装了一个邮件用户代理(MUA),如[mutt or mailx][3]。否则,你将不会收到任何警报。
|
||||
|
||||
在一分钟内,我们就会看到 mdadm 发送的警报。
|
||||
|
||||
### 模拟和更换发生故障的 RAID 存储设备 ###
|
||||
|
||||
为了给 RAID 阵列中的存储设备模拟一个故障,我们将使用 `--manage` 和 `--set-faulty` 选项,如下所示:
|
||||
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
|
||||
|
||||
这将导致的 /dev/sdc1 被标记为 faulty,我们可以在 /proc/mdstat 看到:
|
||||
|
||||

|
||||
|
||||
在 RAID 存储设备上模拟问题
|
||||
|
||||
更重要的是,如果我们收到了同样的警报邮件:
|
||||
|
||||

|
||||
|
||||
RAID 设备故障时发送邮件警报
|
||||
|
||||
在这种情况下,你需要从软件 RAID 阵列中删除该设备:
|
||||
|
||||
# mdadm /dev/md0 --remove /dev/sdc1
|
||||
|
||||
然后,你可以直接从机器中取出,并将其使用备用设备来取代(/dev/sdd 中类型为 fd 的分区以前已被创建):
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
幸运的是,该系统会使用我们刚才添加的磁盘自动重建阵列。我们可以通过标记 dev/sdb1 为 faulty 来进行测试,从阵列中取出后,并确保 tecmint.txt 文件仍然在/mnt/raid1 是可访问的:
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
# mount | grep raid1
|
||||
# ls -l /mnt/raid1 | grep tecmint
|
||||
# cat /mnt/raid1/tecmint.txt
|
||||
|
||||

|
||||
|
||||
确认 RAID 重建
|
||||
|
||||
上面图片清楚的显示,添加 /dev/sdd1 到阵列中来替代 /dev/sdc1,数据的重建是系统自动完成的,不需要干预。
|
||||
|
||||
虽然要求不是很严格,有一个备用设备是个好主意,这样更换故障的设备就可以在瞬间完成了。要做到这一点,先让我们重新添加 /dev/sdb1 和 /dev/sdc1:
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdb1
|
||||
# mdadm --manage /dev/md0 --add /dev/sdc1
|
||||
|
||||

|
||||
|
||||
取代故障的 Raid 设备
|
||||
|
||||
### 从冗余丢失中恢复数据 ###
|
||||
|
||||
如前所述,当一个磁盘发生故障 mdadm 将自动重建数据。但是,如果阵列中的2个磁盘都故障时会发生什么?让我们来模拟这种情况,通过标记 /dev/sdb1 和 /dev/sdd1 为 faulty:
|
||||
|
||||
# umount /mnt/raid1
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdb1
|
||||
# mdadm --stop /dev/md0
|
||||
# mdadm --manage --set-faulty /dev/md0 /dev/sdd1
|
||||
|
||||
此时尝试以同样的方式重新创建阵列就(或使用 `--assume-clean` 选项)可能会导致数据丢失,因此不到万不得已不要使用。
|
||||
|
||||
|
||||
让我们试着从 /dev/sdb1 恢复数据,例如,在一个类似的磁盘分区(/dev/sde1 - 注意,这需要你执行前在/dev/sde 上创建一个 fd 类型的分区)上使用 ddrescue:
|
||||
|
||||
# ddrescue -r 2 /dev/sdb1 /dev/sde1
|
||||
|
||||

|
||||
|
||||
恢复 Raid 阵列
|
||||
|
||||
请注意,到现在为止,我们还没有触及 /dev/sdb 和 /dev/sdd,这是 RAID 阵列的一部分分区。
|
||||
|
||||
现在,让我们使用 /dev/sde1 和 /dev/sdf1 来重建阵列:
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
|
||||
|
||||
请注意,在真实的情况下,你需要使用与原来的阵列中相同的设备名称,即把 /dev/sdb1 和 /dev/sdc1 替换了的磁盘。
|
||||
|
||||
在本文中,我选择了使用额外的设备来重新创建全新的磁盘阵列,为了避免与原来的故障磁盘混淆。
|
||||
|
||||
当被问及是否继续写入阵列时,键入 Y,然后按 Enter。阵列被启动,你也可以查看它的进展:
|
||||
|
||||
# watch -n 1 cat /proc/mdstat
|
||||
|
||||
当这个过程完成后,你应该能够访问 RAID 的数据:
|
||||
|
||||

|
||||
|
||||
确认 Raid 数据
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本文中,我们回顾了从 RAID 故障和冗余丢失中恢复数据。但是,你要记住,这种技术是一种存储解决方案,不能取代备份。
|
||||
|
||||
本文中介绍的方法适用于所有 RAID 中,还有其中的理念,我将在本系列的最后一篇(RAID 管理)中涵盖它。
|
||||
|
||||
如果你对本文有任何疑问,随时给我们以评论的形式说明。我们期待倾听阁下的心声!
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/recover-data-and-rebuild-failed-software-raid/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[3]:http://www.tecmint.com/send-mail-from-command-line-using-mutt-command/
|
||||
Loading…
Reference in New Issue
Block a user