mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
commit
d2505351fb
@ -64,6 +64,7 @@ LCTT 的组成
|
||||
* 2017/11/19 wxy 在上海交大举办的 2017 中国开源年会上做了演讲:《[如何以翻译贡献参与开源社区](https://linux.cn/article-9084-1.html)》。
|
||||
* 2018/01/11 提升 lujun9972 成为核心成员,并加入选题组。
|
||||
* 2018/02/20 遭遇 DMCA 仓库被封。
|
||||
* 2018/05/15 提升 MjSeven 为核心成员。
|
||||
|
||||
核心成员
|
||||
-------------------------------
|
||||
@ -92,6 +93,7 @@ LCTT 的组成
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @qhwdw,
|
||||
- 核心成员 @lujun9972
|
||||
- 核心成员 @MjSeven
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
|
||||
103
published/20140107 Caffeinated 6.828- Exercise- Shell.md
Normal file
103
published/20140107 Caffeinated 6.828- Exercise- Shell.md
Normal file
@ -0,0 +1,103 @@
|
||||
Caffeinated 6.828:练习 shell
|
||||
======
|
||||
|
||||
通过在 shell 中实现多项功能,该作业将使你更加熟悉 Unix 系统调用接口和 shell。你可以在支持 Unix API 的任何操作系统(一台 Linux Athena 机器、装有 Linux 或 Mac OS 的笔记本电脑等)上完成此作业。请在第一次上课前将你的 shell 提交到[网站][1]。
|
||||
|
||||
如果你在练习中遇到困难或不理解某些内容时,你不要羞于给[员工邮件列表][2]发送邮件,但我们确实希望全班的人能够自行处理这级别的 C 编程。如果你对 C 不是很熟悉,可以认为这个是你对 C 熟悉程度的检查。再说一次,如果你有任何问题,鼓励你向我们寻求帮助。
|
||||
|
||||
下载 xv6 shell 的[框架][3],然后查看它。框架 shell 包含两个主要部分:解析 shell 命令并实现它们。解析器只能识别简单的 shell 命令,如下所示:
|
||||
|
||||
```
|
||||
ls > y
|
||||
cat < y | sort | uniq | wc > y1
|
||||
cat y1
|
||||
rm y1
|
||||
ls | sort | uniq | wc
|
||||
rm y
|
||||
```
|
||||
|
||||
将这些命令剪切并粘贴到 `t.sh` 中。
|
||||
|
||||
你可以按如下方式编译框架 shell 的代码:
|
||||
|
||||
```
|
||||
$ gcc sh.c
|
||||
```
|
||||
|
||||
它会生成一个名为 `a.out` 的文件,你可以运行它:
|
||||
|
||||
```
|
||||
$ ./a.out < t.sh
|
||||
```
|
||||
|
||||
执行会崩溃,因为你还没有实现其中的几个功能。在本作业的其余部分中,你将实现这些功能。
|
||||
|
||||
### 执行简单的命令
|
||||
|
||||
实现简单的命令,例如:
|
||||
|
||||
```
|
||||
$ ls
|
||||
```
|
||||
|
||||
解析器已经为你构建了一个 `execcmd`,所以你唯一需要编写的代码是 `runcmd` 中的 case ' '。要测试你可以运行 “ls”。你可能会发现查看 `exec` 的手册页是很有用的。输入 `man 3 exec`。
|
||||
|
||||
你不必实现引用(即将双引号之间的文本视为单个参数)。
|
||||
|
||||
### I/O 重定向
|
||||
|
||||
实现 I/O 重定向命令,这样你可以运行:
|
||||
|
||||
```
|
||||
echo "6.828 is cool" > x.txt
|
||||
cat < x.txt
|
||||
```
|
||||
|
||||
解析器已经识别出 '>' 和 '<',并且为你构建了一个 `redircmd`,所以你的工作就是在 `runcmd` 中为这些符号填写缺少的代码。确保你的实现在上面的测试输入中正确运行。你可能会发现 `open`(`man 2 open`) 和 `close` 的 man 手册页很有用。
|
||||
|
||||
请注意,此 shell 不会像 `bash`、`tcsh`、`zsh` 或其他 UNIX shell 那样处理引号,并且你的示例文件 `x.txt` 预计包含引号。
|
||||
|
||||
### 实现管道
|
||||
|
||||
实现管道,这样你可以运行命令管道,例如:
|
||||
|
||||
```
|
||||
$ ls | sort | uniq | wc
|
||||
```
|
||||
|
||||
解析器已经识别出 “|”,并且为你构建了一个 `pipecmd`,所以你必须编写的唯一代码是 `runcmd` 中的 case '|'。测试你可以运行上面的管道。你可能会发现 `pipe`、`fork`、`close` 和 `dup` 的 man 手册页很有用。
|
||||
|
||||
现在你应该可以正确地使用以下命令:
|
||||
|
||||
```
|
||||
$ ./a.out < t.sh
|
||||
```
|
||||
|
||||
无论是否完成挑战任务,不要忘记将你的答案提交给[网站][1]。
|
||||
|
||||
### 挑战练习
|
||||
|
||||
如果你想进一步尝试,可以将所选的任何功能添加到你的 shell。你可以尝试以下建议之一:
|
||||
|
||||
* 实现由 `;` 分隔的命令列表
|
||||
* 通过实现 `(` 和 `)` 来实现子 shell
|
||||
* 通过支持 `&` 和 `wait` 在后台执行命令
|
||||
* 实现参数引用
|
||||
|
||||
|
||||
所有这些都需要改变解析器和 `runcmd` 函数。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sipb.mit.edu/iap/6.828/lab/shell/
|
||||
|
||||
作者:[mit][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sipb.mit.edu
|
||||
[1]:https://exokernel.scripts.mit.edu/submit/
|
||||
[2]:mailto:sipb-iap-6.828@mit.edu
|
||||
[3]:https://sipb.mit.edu/iap/6.828/files/sh.c
|
||||
@ -0,0 +1,101 @@
|
||||
在 Ubuntu 和 Linux Mint 中轻松安装 Android Studio
|
||||
======
|
||||
|
||||
[Android Studio][1] 是谷歌自己的 Android 开发 IDE,是带 ADT 插件的 Eclipse 的不错替代品。Android Studio 可以通过源代码安装,但在这篇文章中,我们将看到**如何在 Ubuntu 18.04、16.04 和相应的 Linux Mint 变体**中安装 Android Studio。
|
||||
|
||||
在继续安装 Android Studio 之前,请确保你已经[在 Ubuntu 中安装了 Java][2]。
|
||||
|
||||
![How to install Android Studio in Ubuntu][3]
|
||||
|
||||
### 使用 Snap 在 Ubuntu 和其他发行版中安装 Android Studio
|
||||
|
||||
自从 Ubuntu 开始专注于 Snap 软件包以来,越来越多的软件开始提供易于安装的 Snap 软件包。Android Studio 就是其中之一。Ubuntu 用户可以直接在软件中心找到 Android Studio 程序并从那里安装。
|
||||
|
||||
![Install Android Studio in Ubuntu from Software Center][4]
|
||||
|
||||
如果你在软件中心安装 Android Studio 时看到错误,则可以使用[ Snap 命令][5] 安装 Android Studio。
|
||||
|
||||
```
|
||||
sudo snap install android-studio --classic
|
||||
```
|
||||
|
||||
非常简单!
|
||||
|
||||
### 另一种方式 1:在 Ubuntu 中使用 umake 安装 Android Studio
|
||||
|
||||
你也可以使用 Ubuntu Developer Tools Center,现在称为 [Ubuntu Make][6],轻松安装 Android Studio。Ubuntu Make 提供了一个命令行工具来安装各种开发工具和 IDE 等。Ubuntu Make 在 Ubuntu 仓库中就有。
|
||||
|
||||
要安装 Ubuntu Make,请在终端中使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt-get install ubuntu-make
|
||||
```
|
||||
|
||||
安装 Ubuntu Make 后,请使用以下命令在 Ubuntu 中安装 Android Studio:
|
||||
|
||||
```
|
||||
umake android
|
||||
```
|
||||
|
||||
在安装过程中它会给你的几个选项。我认为你可以处理。如果你决定卸载 Android Studio,则可以按照以下方式使用相同的 umake 工具:
|
||||
|
||||
```
|
||||
umake android --remove
|
||||
|
||||
```
|
||||
|
||||
### 另一种方式 2:通过非官方的 PPA 在 Ubuntu 和 Linux Mint 中安装 Android Studio
|
||||
|
||||
感谢 [Paolo Ratolo][7],我们有一个 PPA,可用于 Ubuntu 16.04、14.04、Linux Mint 和其他基于 Ubuntu 的发行版中轻松安装 Android Studio。请注意,它将下载大约 650MB 的数据。请注意你的互联网连接以及数据费用(如果有的话)。
|
||||
|
||||
打开一个终端并使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:paolorotolo/android-studio
|
||||
sudo apt-get update
|
||||
sudo apt-get install android-studio
|
||||
```
|
||||
|
||||
这不容易吗?虽然从源代码安装程序很有趣,但拥有这样的 PPA 总是不错的。我们看到了如何安装 Android Studio,现在来看看如何卸载它。
|
||||
|
||||
### 卸载 Android Studio:
|
||||
|
||||
如果你还没有安装 PPA Purge:
|
||||
|
||||
```
|
||||
sudo apt-get install ppa-purge
|
||||
```
|
||||
|
||||
现在使用 PPA Purge 来清除已安装的 PPA:
|
||||
|
||||
```
|
||||
sudo apt-get remove android-studio
|
||||
sudo ppa-purge ppa:paolorotolo/android-studio
|
||||
```
|
||||
|
||||
就是这些了。我希望这能够帮助你**在 Ubuntu 和 Linux Mint 上安装 Android Studio**。在运行 Android Studio 之前,请确保[在 Ubuntu 中安装了Java][8]。在类似的文章中,我建议你阅读[如何安装和配置 Ubuntu SDK ][9]和[如何在 Ubuntu 中轻松安装 Microsoft Visual Studio][10]。
|
||||
|
||||
欢迎提出任何问题或建议。再见 :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-android-studio-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:http://developer.android.com/sdk/installing/studio.html
|
||||
[2]:https://itsfoss.com/install-java-ubuntu-1404/
|
||||
[3]:https://itsfoss.com/wp-content/uploads/2014/04/Android_Studio_Ubuntu.jpeg
|
||||
[4]:https://itsfoss.com/wp-content/uploads/2014/04/install-android-studio-snap-800x469.jpg
|
||||
[5]:https://itsfoss.com/install-snap-linux/
|
||||
[6]:https://wiki.ubuntu.com/ubuntu-make
|
||||
[7]:https://plus.google.com/+PaoloRotolo
|
||||
[8]:https://itsfoss.com/install-java-ubuntu-1404/ (How To Install Java On Ubuntu 14.04)
|
||||
[9]:https://itsfoss.com/install-configure-ubuntu-sdk/
|
||||
[10]:https://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
129
published/20140410 Recursion- dream within a dream.md
Normal file
129
published/20140410 Recursion- dream within a dream.md
Normal file
@ -0,0 +1,129 @@
|
||||
递归:梦中梦
|
||||
======
|
||||
|
||||
> “方其梦也,不知其梦也。梦之中又占其梦焉,觉而后知其梦也。” —— 《庄子·齐物论》
|
||||
|
||||
**递归**是很神奇的,但是在大多数的编程类书藉中对递归讲解的并不好。它们只是给你展示一个递归阶乘的实现,然后警告你递归运行的很慢,并且还有可能因为栈缓冲区溢出而崩溃。“你可以将头伸进微波炉中去烘干你的头发,但是需要警惕颅内高压并让你的头发生爆炸,或者你可以使用毛巾来擦干头发。”难怪人们不愿意使用递归。但这种建议是很糟糕的,因为在算法中,递归是一个非常强大的思想。
|
||||
|
||||
我们来看一下这个经典的递归阶乘:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
*递归阶乘 - factorial.c*
|
||||
|
||||
|
||||
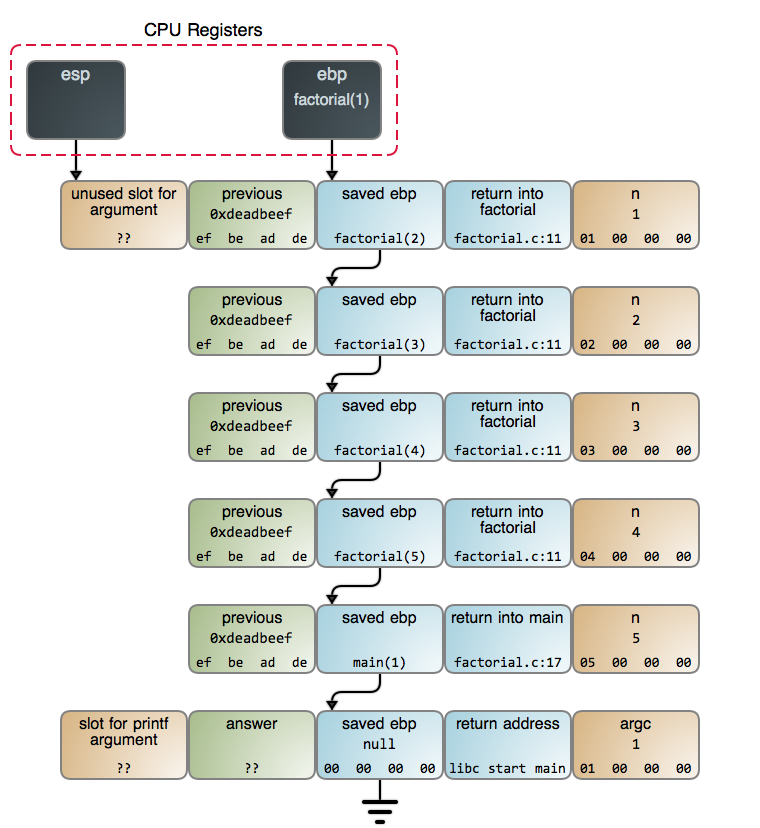
函数调用自身的这个观点在一开始是让人很难理解的。为了让这个过程更形象具体,下图展示的是当调用 `factorial(5)` 并且达到 `n == 1`这行代码 时,[栈上][3] 端点的情况:
|
||||
|
||||
|
||||
|
||||
每次调用 `factorial` 都生成一个新的 [栈帧][4]。这些栈帧的创建和 [销毁][5] 是使得递归版本的阶乘慢于其相应的迭代版本的原因。在调用返回之前,累积的这些栈帧可能会耗尽栈空间,进而使你的程序崩溃。
|
||||
|
||||
而这些担心经常是存在于理论上的。例如,对于每个 `factorial` 的栈帧占用 16 字节(这可能取决于栈排列以及其它因素)。如果在你的电脑上运行着现代的 x86 的 Linux 内核,一般情况下你拥有 8 GB 的栈空间,因此,`factorial` 程序中的 `n` 最多可以达到 512,000 左右。这是一个 [巨大无比的结果][6],它将花费 8,971,833 比特来表示这个结果,因此,栈空间根本就不是什么问题:一个极小的整数 —— 甚至是一个 64 位的整数 —— 在我们的栈空间被耗尽之前就早已经溢出了成千上万次了。
|
||||
|
||||
过一会儿我们再去看 CPU 的使用,现在,我们先从比特和字节回退一步,把递归看作一种通用技术。我们的阶乘算法可归结为:将整数 N、N-1、 … 1 推入到一个栈,然后将它们按相反的顺序相乘。实际上我们使用了程序调用栈来实现这一点,这是它的细节:我们在堆上分配一个栈并使用它。虽然调用栈具有特殊的特性,但是它也只是又一种数据结构而已,你可以随意使用。我希望这个示意图可以让你明白这一点。
|
||||
|
||||
当你将栈调用视为一种数据结构,有些事情将变得更加清晰明了:将那些整数堆积起来,然后再将它们相乘,这并不是一个好的想法。那是一种有缺陷的实现:就像你拿螺丝刀去钉钉子一样。相对更合理的是使用一个迭代过程去计算阶乘。
|
||||
|
||||
但是,螺丝钉太多了,我们只能挑一个。有一个经典的面试题,在迷宫里有一只老鼠,你必须帮助这只老鼠找到一个奶酪。假设老鼠能够在迷宫中向左或者向右转弯。你该怎么去建模来解决这个问题?
|
||||
|
||||
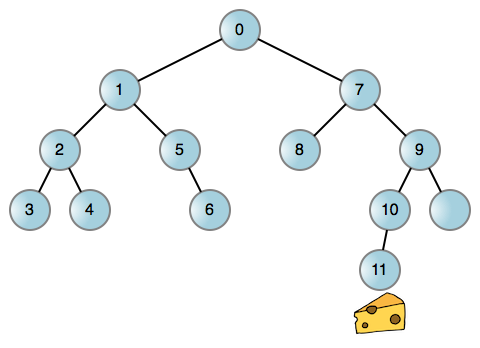
就像现实生活中的很多问题一样,你可以将这个老鼠找奶酪的问题简化为一个图,一个二叉树的每个结点代表在迷宫中的一个位置。然后你可以让老鼠在任何可能的地方都左转,而当它进入一个死胡同时,再回溯回去,再右转。这是一个老鼠行走的 [迷宫示例][7]:
|
||||
|
||||
|
||||
|
||||
每到边缘(线)都让老鼠左转或者右转来到达一个新的位置。如果向哪边转都被拦住,说明相关的边缘不存在。现在,我们来讨论一下!这个过程无论你是调用栈还是其它数据结构,它都离不开一个递归的过程。而使用调用栈是非常容易的:
|
||||
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include "maze.h"
|
||||
|
||||
int explore(maze_t *node)
|
||||
{
|
||||
int found = 0;
|
||||
|
||||
if (node == NULL)
|
||||
{
|
||||
return 0;
|
||||
}
|
||||
if (node->hasCheese){
|
||||
return 1;// found cheese
|
||||
}
|
||||
|
||||
found = explore(node->left) || explore(node->right);
|
||||
return found;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int found = explore(&maze);
|
||||
}
|
||||
```
|
||||
|
||||
*递归迷宫求解 [下载][2]*
|
||||
|
||||
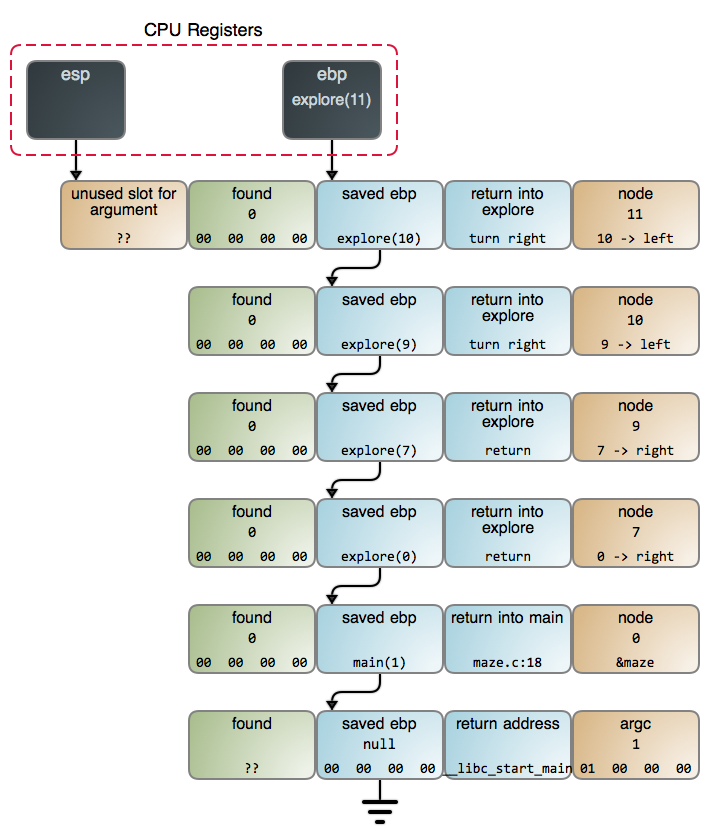
当我们在 `maze.c:13` 中找到奶酪时,栈的情况如下图所示。你也可以在 [GDB 输出][8] 中看到更详细的数据,它是使用 [命令][9] 采集的数据。
|
||||
|
||||
|
||||
|
||||
它展示了递归的良好表现,因为这是一个适合使用递归的问题。而且这并不奇怪:当涉及到算法时,*递归是规则,而不是例外*。它出现在如下情景中——进行搜索时、进行遍历树和其它数据结构时、进行解析时、需要排序时——它无处不在。正如众所周知的 pi 或者 e,它们在数学中像“神”一样的存在,因为它们是宇宙万物的基础,而递归也和它们一样:只是它存在于计算结构中。
|
||||
|
||||
Steven Skienna 的优秀著作 [算法设计指南][10] 的精彩之处在于,他通过 “战争故事” 作为手段来诠释工作,以此来展示解决现实世界中的问题背后的算法。这是我所知道的拓展你的算法知识的最佳资源。另一个读物是 McCarthy 的 [关于 LISP 实现的的原创论文][11]。递归在语言中既是它的名字也是它的基本原理。这篇论文既可读又有趣,在工作中能看到大师的作品是件让人兴奋的事情。
|
||||
|
||||
回到迷宫问题上。虽然它在这里很难离开递归,但是并不意味着必须通过调用栈的方式来实现。你可以使用像 `RRLL` 这样的字符串去跟踪转向,然后,依据这个字符串去决定老鼠下一步的动作。或者你可以分配一些其它的东西来记录追寻奶酪的整个状态。你仍然是实现了一个递归的过程,只是需要你实现一个自己的数据结构。
|
||||
|
||||
那样似乎更复杂一些,因为栈调用更合适。每个栈帧记录的不仅是当前节点,也记录那个节点上的计算状态(在这个案例中,我们是否只让它走左边,或者已经尝试向右)。因此,代码已经变得不重要了。然而,有时候我们因为害怕溢出和期望中的性能而放弃这种优秀的算法。那是很愚蠢的!
|
||||
|
||||
正如我们所见,栈空间是非常大的,在耗尽栈空间之前往往会遇到其它的限制。一方面可以通过检查问题大小来确保它能够被安全地处理。而对 CPU 的担心是由两个广为流传的有问题的示例所导致的:<ruby>哑阶乘<rt>dumb factorial</rt></ruby>和可怕的无记忆的 O( 2^n ) [Fibonacci 递归][12]。它们并不是栈递归算法的正确代表。
|
||||
|
||||
事实上栈操作是非常快的。通常,栈对数据的偏移是非常准确的,它在 [缓存][13] 中是热数据,并且是由专门的指令来操作它的。同时,使用你自己定义的在堆上分配的数据结构的相关开销是很大的。经常能看到人们写的一些比栈调用递归更复杂、性能更差的实现方法。最后,现代的 CPU 的性能都是 [非常好的][14] ,并且一般 CPU 不会是性能瓶颈所在。在考虑牺牲程序的简单性时要特别注意,就像经常考虑程序的性能及性能的[测量][15]那样。
|
||||
|
||||
下一篇文章将是探秘栈系列的最后一篇了,我们将了解尾调用、闭包、以及其它相关概念。然后,我们就该深入我们的老朋友—— Linux 内核了。感谢你的阅读!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/recursion/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[FSSlc](https://github.com/FSSlc)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/recursion/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/maze.c
|
||||
[3]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-gdb-output.txt
|
||||
[4]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[5]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[6]:https://gist.github.com/gduarte/9944878
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze.h
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-output.txt
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-commands.txt
|
||||
[10]:http://www.amazon.com/Algorithm-Design-Manual-Steven-Skiena/dp/1848000693/
|
||||
[11]:https://github.com/papers-we-love/papers-we-love/blob/master/comp_sci_fundamentals_and_history/recursive-functions-of-symbolic-expressions-and-their-computation-by-machine-parti.pdf
|
||||
[12]:http://stackoverflow.com/questions/360748/computational-complexity-of-fibonacci-sequence
|
||||
[13]:https://manybutfinite.com/post/intel-cpu-caches/
|
||||
[14]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait/
|
||||
[15]:https://manybutfinite.com/post/performance-is-a-science
|
||||
106
published/20140510 Journey to the Stack Part I.md
Normal file
106
published/20140510 Journey to the Stack Part I.md
Normal file
@ -0,0 +1,106 @@
|
||||
探秘“栈”之旅
|
||||
==============
|
||||
|
||||
早些时候,我们探索了 [“内存中的程序之秘”][2],我们欣赏了在一台电脑中是如何运行我们的程序的。今天,我们去探索*栈的调用*,它在大多数编程语言和虚拟机中都默默地存在。在此过程中,我们将接触到一些平时很难见到的东西,像<ruby>闭包<rt>closure</rt></ruby>、递归、以及缓冲溢出等等。但是,我们首先要作的事情是,描绘出栈是如何运作的。
|
||||
|
||||
栈非常重要,因为它追踪着一个程序中运行的*函数*,而函数又是一个软件的重要组成部分。事实上,程序的内部操作都是非常简单的。它大部分是由函数向栈中推入数据或者从栈中弹出数据的相互调用组成的,而在堆上为数据分配内存才能在跨函数的调用中保持数据。不论是低级的 C 软件还是像 JavaScript 和 C# 这样的基于虚拟机的语言,它们都是这样的。而对这些行为的深刻理解,对排错、性能调优以及大概了解究竟发生了什么是非常重要的。
|
||||
|
||||
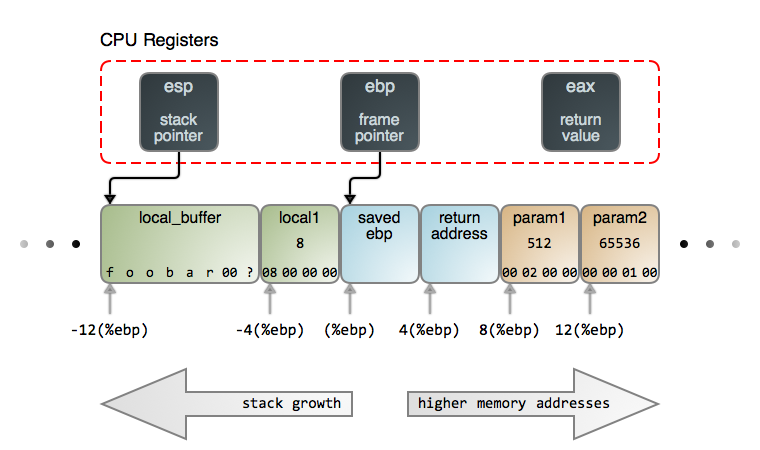
当一个函数被调用时,将会创建一个<ruby>栈帧<rt>stack frame</rt></ruby>去支持函数的运行。这个栈帧包含函数的*局部变量*和调用者传递给它的*参数*。这个栈帧也包含了允许被调用的函数(*callee*)安全返回给其调用者的内部事务信息。栈帧的精确内容和结构因处理器架构和函数调用规则而不同。在本文中我们以 Intel x86 架构和使用 C 风格的函数调用(`cdecl`)的栈为例。下图是一个处于栈顶部的一个单个栈帧:
|
||||
|
||||
|
||||
|
||||
在图上的场景中,有三个 CPU 寄存器进入栈。<ruby>栈指针<rt>stack pointer</rt></ruby> `esp`(LCTT 译注:扩展栈指针寄存器) 指向到栈的顶部。栈的顶部总是被最*后一个推入到栈且还没有弹出*的东西所占据,就像现实世界中堆在一起的一叠盘子或者 100 美元大钞一样。
|
||||
|
||||
保存在 `esp` 中的地址始终在变化着,因为栈中的东西不停被推入和弹出,而它总是指向栈中的最后一个推入的东西。许多 CPU 指令的一个副作用就是自动更新 `esp`,离开寄存器而使用栈是行不通的。
|
||||
|
||||
在 Intel 的架构中,绝大多数情况下,栈的增长是向着*低位内存地址*的方向。因此,这个“顶部” 在包含数据的栈中是处于低位的内存地址(在这种情况下,包含的数据是 `local_buffer`)。注意,关于从 `esp` 到 `local_buffer` 的箭头不是随意连接的。这个箭头代表着事务:它*专门*指向到由 `local_buffer` 所拥有的*第一个字节*,因为,那是一个保存在 `esp` 中的精确地址。
|
||||
|
||||
第二个寄存器跟踪的栈是 `ebp`(LCTT 译注:扩展基址指针寄存器),它包含一个<ruby>基指针<rt>base pointer</rt></ruby>或者称为<ruby>帧指针<rt>frame pointer</rt></ruby>。它指向到一个*当前运行*的函数的栈帧内的固定位置,并且它为参数和局部变量的访问提供一个稳定的参考点(基址)。仅当开始或者结束调用一个函数时,`ebp` 的内容才会发生变化。因此,我们可以很容易地处理在栈中的从 `ebp` 开始偏移后的每个东西。如图所示。
|
||||
|
||||
不像 `esp`, `ebp` 大多数情况下是在程序代码中通过花费很少的 CPU 来进行维护的。有时候,完成抛弃 `ebp` 有一些性能优势,可以通过 [编译标志][3] 来做到这一点。Linux 内核就是一个这样做的示例。
|
||||
|
||||
最后,`eax`(LCTT 译注:扩展的 32 位通用数据寄存器)寄存器惯例被用来转换大多数 C 数据类型返回值给调用者。
|
||||
|
||||
现在,我们来看一下在我们的栈帧中的数据。下图清晰地按字节展示了字节的内容,就像你在一个调试器中所看到的内容一样,内存是从左到右、从顶部至底部增长的,如下图所示:
|
||||
|
||||

|
||||
|
||||
局部变量 `local_buffer` 是一个字节数组,包含一个由 null 终止的 ASCII 字符串,这是 C 程序中的一个基本元素。这个字符串可以读取自任意地方,例如,从键盘输入或者来自一个文件,它只有 7 个字节的长度。因为,`local_buffer` 只能保存 8 字节,所以还剩下 1 个未使用的字节。*这个字节的内容是未知的*,因为栈不断地推入和弹出,*除了你写入的之外*,你根本不会知道内存中保存了什么。这是因为 C 编译器并不为栈帧初始化内存,所以它的内容是未知的并且是随机的 —— 除非是你自己写入。这使得一些人对此很困惑。
|
||||
|
||||
再往上走,`local1` 是一个 4 字节的整数,并且你可以看到每个字节的内容。它似乎是一个很大的数字,在8 后面跟着的都是零,在这里可能会误导你。
|
||||
|
||||
Intel 处理器是<ruby>小端<rt>little endian</rt></ruby>机器,这表示在内存中的数字也是首先从小的一端开始的。因此,在一个多字节数字中,较小的部分在内存中处于最低端的地址。因为一般情况下是从左边开始显示的,这背离了我们通常的数字表示方式。我们讨论的这种从小到大的机制,使我想起《格里佛游记》:就像小人国的人们吃鸡蛋是从小头开始的一样,Intel 处理器处理它们的数字也是从字节的小端开始的。
|
||||
|
||||
因此,`local1` 事实上只保存了一个数字 8,和章鱼的腿数量一样。然而,`param1` 在第二个字节的位置有一个值 2,因此,它的数学上的值是 `2 * 256 = 512`(我们与 256 相乘是因为,每个位置值的范围都是从 0 到 255)。同时,`param2` 承载的数量是 `1 * 256 * 256 = 65536`。
|
||||
|
||||
这个栈帧的内部数据是由两个重要的部分组成:*前一个*栈帧的地址(保存的 `ebp` 值)和函数退出才会运行的指令的地址(返回地址)。它们一起确保了函数能够正常返回,从而使程序可以继续正常运行。
|
||||
|
||||
现在,我们来看一下栈帧是如何产生的,以及去建立一个它们如何共同工作的内部蓝图。首先,栈的增长是非常令人困惑的,因为它与你你预期的方式相反。例如,在栈上分配一个 8 字节,就要从 `esp` 减去 8,去,而减法是与增长不同的奇怪方式。
|
||||
|
||||
我们来看一个简单的 C 程序:
|
||||
|
||||
```
|
||||
Simple Add Program - add.c
|
||||
|
||||
int add(int a, int b)
|
||||
{
|
||||
int result = a + b;
|
||||
return result;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer;
|
||||
answer = add(40, 2);
|
||||
}
|
||||
```
|
||||
|
||||
*简单的加法程序 - add.c*
|
||||
|
||||
假设我们在 Linux 中不使用命令行参数去运行它。当你运行一个 C 程序时,实际运行的第一行代码是在 C 运行时库里,由它来调用我们的 `main` 函数。下图展示了程序运行时每一步都发生了什么。每个图链接的 GDB 输出展示了内存和寄存器的状态。你也可以看到所使用的 [GDB 命令][4],以及整个 [GDB 输出][5]。如下:
|
||||
|
||||
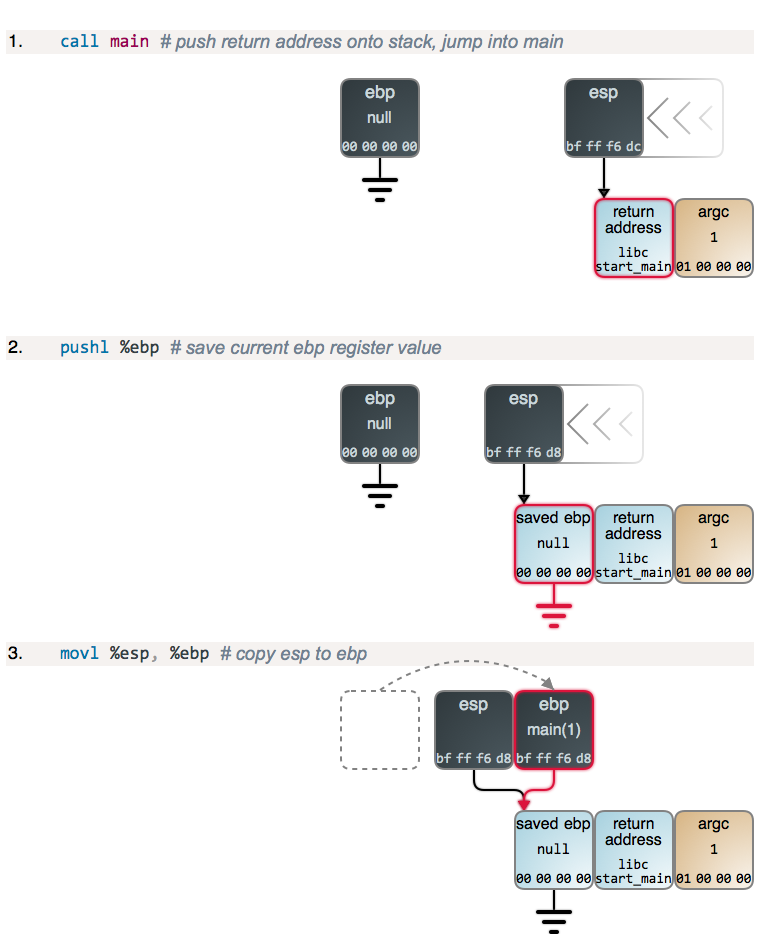
|
||||
|
||||
第 2 步和第 3 步,以及下面的第 4 步,都只是函数的<ruby>序言<rt>prologue</rt></ruby>,几乎所有的函数都是这样的:`ebp` 的当前值被保存到了栈的顶部,然后,将 `esp` 的内容拷贝到 `ebp`,以建立一个新的栈帧。`main` 的序言和其它函数一样,但是,不同之处在于,当程序启动时 `ebp` 被清零。
|
||||
|
||||
如果你去检查栈下方(右边)的整形变量(`argc`),你将找到更多的数据,包括指向到程序名和命令行参数(传统的 C 的 `argv`)、以及指向 Unix 环境变量以及它们真实的内容的指针。但是,在这里这些并不是重点,因此,继续向前调用 `add()`:
|
||||
|
||||
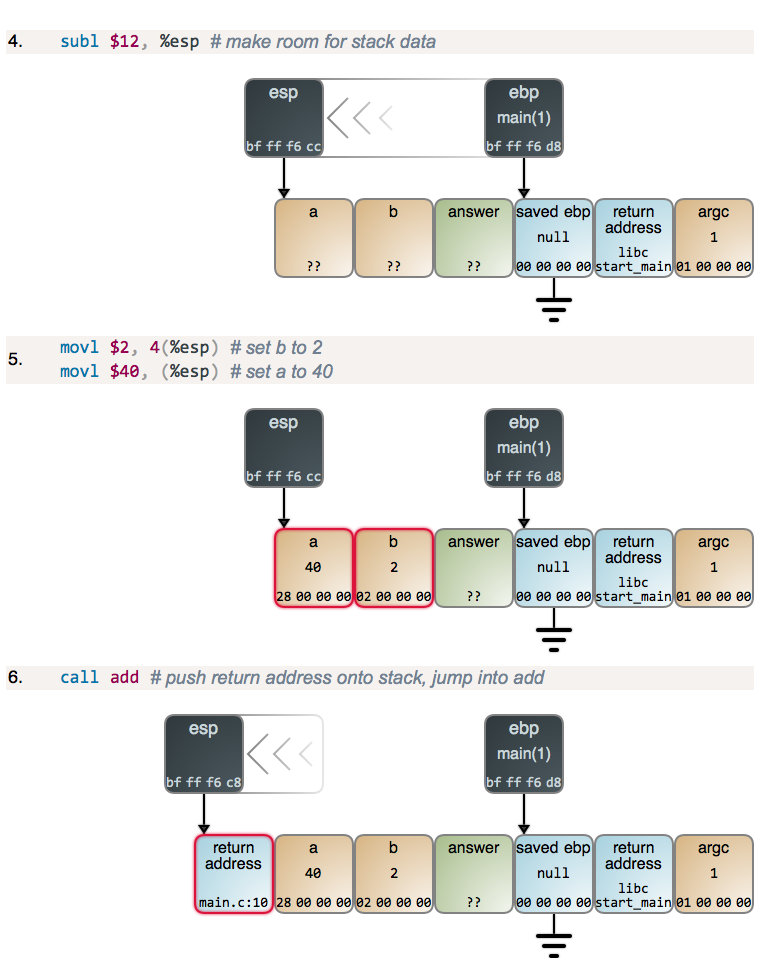
|
||||
|
||||
在 `main` 从 `esp` 减去 12 之后得到它所需的栈空间,它为 `a` 和 `b` 设置值。在内存中的值展示为十六进制,并且是小端格式,与你从调试器中看到的一样。一旦设置了参数值,`main` 将调用 `add`,并且开始运行:
|
||||
|
||||
|
||||
|
||||
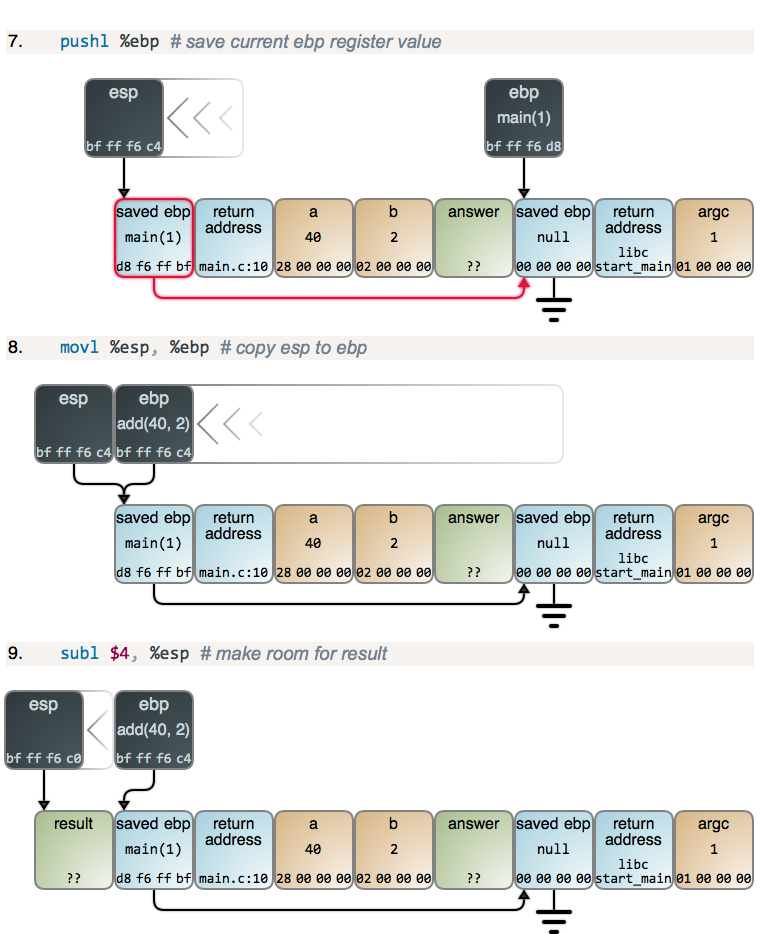
现在,有一点小激动!我们进入了另一个函数序言,但这次你可以明确看到栈帧是如何从 `ebp` 到栈建立一个链表。这就是调试器和高级语言中的 `Exception` 对象如何对它们的栈进行跟踪的。当一个新帧产生时,你也可以看到更多这种典型的从 `ebp` 到 `esp` 的捕获。我们再次从 `esp` 中做减法得到更多的栈空间。
|
||||
|
||||
当 `ebp` 寄存器的值拷贝到内存时,这里也有一个稍微有些怪异的字节逆转。在这里发生的奇怪事情是,寄存器其实并没有字节顺序:因为对于内存,没有像寄存器那样的“增长的地址”。因此,惯例上调试器以对人类来说最自然的格式展示了寄存器的值:数位从最重要的到最不重要。因此,这个在小端机器中的副本的结果,与内存中常用的从左到右的标记法正好相反。我想用图去展示你将会看到的东西,因此有了下面的图。
|
||||
|
||||
在比较难懂的部分,我们增加了注释:
|
||||
|
||||
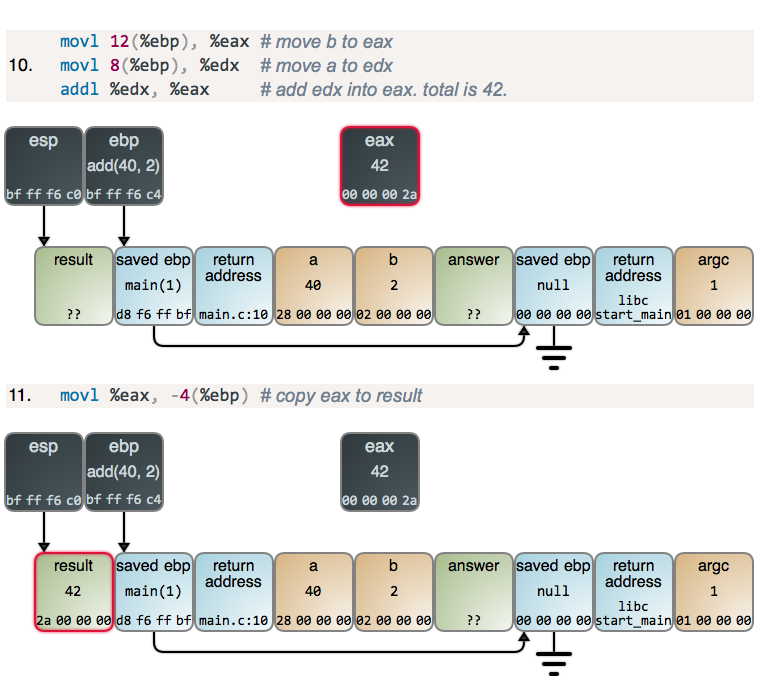
|
||||
|
||||
这是一个临时寄存器,用于帮你做加法,因此没有什么警报或者惊喜。对于加法这样的作业,栈的动作正好相反,我们留到下次再讲。
|
||||
|
||||
对于任何读到这里的人都应该有一个小礼物,因此,我做了一个大的图表展示了 [组合到一起的所有步骤][6]。
|
||||
|
||||
一旦把它们全部布置好了,看上起似乎很乏味。这些小方框给我们提供了很多帮助。事实上,在计算机科学中,这些小方框是主要的展示工具。我希望这些图片和寄存器的移动能够提供一种更直观的构想图,将栈的增长和内存的内容整合到一起。从软件的底层运作来看,我们的软件与一个简单的图灵机器差不多。
|
||||
|
||||
这就是我们栈探秘的第一部分,再讲一些内容之后,我们将看到构建在这个基础上的高级编程的概念。下周见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/journey-to-the-stack/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/journey-to-the-stack/
|
||||
[2]:https://linux.cn/article-9255-1.html
|
||||
[3]:http://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer
|
||||
[4]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-commands.txt
|
||||
[5]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-output.txt
|
||||
[6]:https://manybutfinite.com/img/stack/callSequence.png
|
||||
197
published/20141106 System Calls Make the World Go Round.md
Normal file
197
published/20141106 System Calls Make the World Go Round.md
Normal file
@ -0,0 +1,197 @@
|
||||
系统调用,让世界转起来!
|
||||
=====================
|
||||
|
||||
|
||||
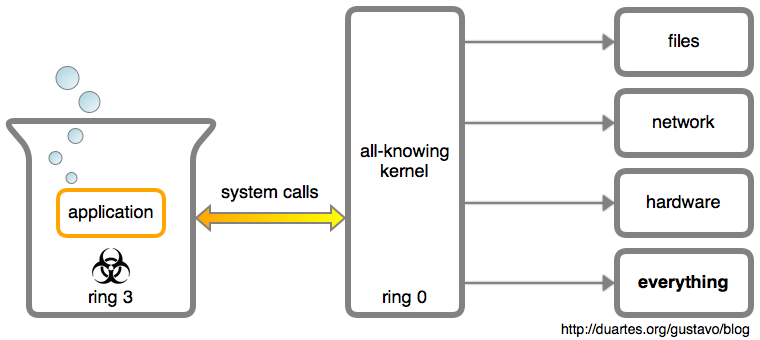
我其实不想将它分解开给你看,用户应用程序其实就是一个可怜的<ruby>瓮中大脑<rt>brain in a vat</rt></ruby>:
|
||||
|
||||
|
||||
|
||||
它与外部世界的*每个*交流都要在内核的帮助下通过**系统调用**才能完成。一个应用程序要想保存一个文件、写到终端、或者打开一个 TCP 连接,内核都要参与。应用程序是被内核高度怀疑的:认为它到处充斥着 bug,甚至是个充满邪恶想法的脑子。
|
||||
|
||||
这些系统调用是从一个应用程序到内核的函数调用。出于安全考虑,它们使用了特定的机制,实际上你只是调用了内核的 API。“<ruby>系统调用<rt>system call</rt></ruby>”这个术语指的是调用由内核提供的特定功能(比如,系统调用 `open()`)或者是调用途径。你也可以简称为:**syscall**。
|
||||
|
||||
这篇文章讲解系统调用,系统调用与调用一个库有何区别,以及在操作系统/应用程序接口上的刺探工具。如果彻底了解了应用程序借助操作系统发生的哪些事情,那么就可以将一个不可能解决的问题转变成一个快速而有趣的难题。
|
||||
|
||||
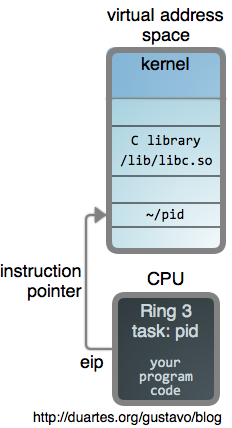
那么,下图是一个运行着的应用程序,一个用户进程:
|
||||
|
||||
|
||||
|
||||
它有一个私有的 [虚拟地址空间][2]—— 它自己的内存沙箱。整个系统都在它的地址空间中(即上面比喻的那个“瓮”),程序的二进制文件加上它所使用的库全部都 [被映射到内存中][3]。内核自身也映射为地址空间的一部分。
|
||||
|
||||
下面是我们程序 `pid` 的代码,它通过 [getpid(2)][4] 直接获取了其进程 id:
|
||||
|
||||
|
||||
```
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
pid_t p = getpid();
|
||||
printf("%d\n", p);
|
||||
}
|
||||
```
|
||||
|
||||
*pid.c [download][1]*
|
||||
|
||||
|
||||
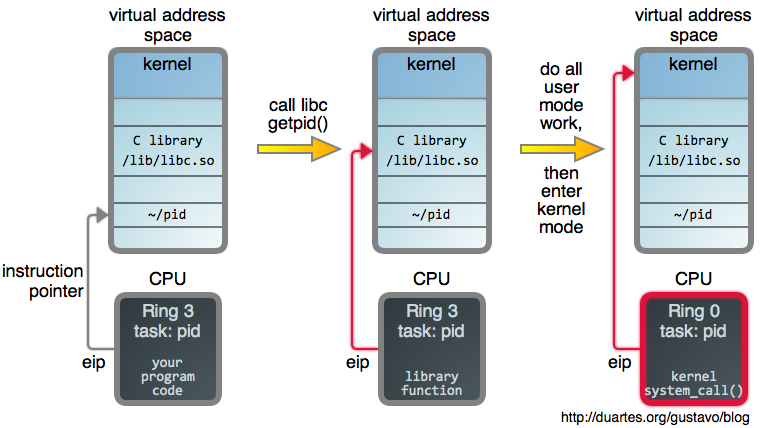
在 Linux 中,一个进程并不是一出生就知道它的 PID。要想知道它的 PID,它必须去询问内核,因此,这个询问请求也是一个系统调用:
|
||||
|
||||
|
||||
|
||||
它的第一步是开始于调用 C 库的 [getpid()][5],它是系统调用的一个*封装*。当你调用一些函数时,比如,`open(2)`、`read(2)` 之类,你是在调用这些封装。其实,对于大多数编程语言在这一块的原生方法,最终都是在 libc 中完成的。
|
||||
|
||||
封装为这些基本的操作系统 API 提供了方便,这样可以保持内核的简洁。*所有的内核代码*运行在特权模式下,有 bug 的内核代码行将会产生致命的后果。能在用户模式下做的任何事情都应该在用户模式中完成。由库来提供友好的方法和想要的参数处理,像 `printf(3)` 这样。
|
||||
|
||||
我们拿一个 web API 进行比较,内核的封装方式可以类比为构建一个尽可能简单的 HTTP 接口去提供服务,然后提供特定语言的库及辅助方法。或者也可能有一些缓存,这就是 libc 的 `getpid()` 所做的:首次调用时,它真实地去执行了一个系统调用,然后,它缓存了 PID,这样就可以避免后续调用时的系统调用开销。
|
||||
|
||||
一旦封装完成,它做的第一件事就是进入了<ruby>~~超空间~~<rt>hyperspace</rt></ruby>:内核。这种转换机制因处理器架构设计不同而不同。在 Intel 处理器中,参数和 [系统调用号][6] 是 [加载到寄存器中的][7],然后,运行一个 [指令][8] 将 CPU 置于 [特权模式][9] 中,并立即将控制权转移到内核中的全局系统调用 [入口][10]。如果你对这些细节感兴趣,David Drysdale 在 LWN 上有两篇非常好的文章([其一][11],[其二][12])。
|
||||
|
||||
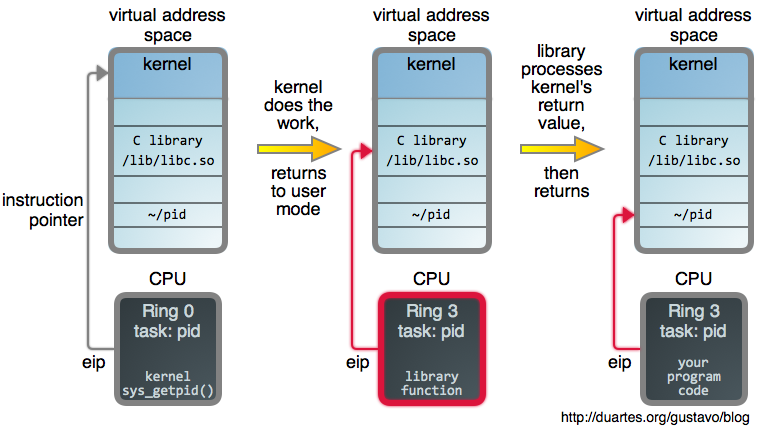
内核然后使用这个系统调用号作为进入 [`sys_call_table`][14] 的一个 [索引][13],它是一个函数指针到每个系统调用实现的数组。在这里,调用了 [`sys_getpid`][15]:
|
||||
|
||||
|
||||
|
||||
在 Linux 中,系统调用大多数都实现为架构无关的 C 函数,有时候这样做 [很琐碎][16],但是通过内核优秀的设计,系统调用机制被严格隔离。它们是工作在一般数据结构中的普通代码。嗯,除了*完全偏执*的参数校验以外。
|
||||
|
||||
一旦它们的工作完成,它们就会正常*返回*,然后,架构特定的代码会接手转回到用户模式,封装将在那里继续做一些后续处理工作。在我们的例子中,[getpid(2)][17] 现在缓存了由内核返回的 PID。如果内核返回了一个错误,另外的封装可以去设置全局 `errno` 变量。这些细节可以让你知道 GNU 是怎么处理的。
|
||||
|
||||
如果你想要原生的调用,glibc 提供了 [syscall(2)][18] 函数,它可以不通过封装来产生一个系统调用。你也可以通过它来做一个你自己的封装。这对一个 C 库来说,既不神奇,也不特殊。
|
||||
|
||||
这种系统调用的设计影响是很深远的。我们从一个非常有用的 [strace(1)][19] 开始,这个工具可以用来监视 Linux 进程的系统调用(在 Mac 上,参见 [dtruss(1m)][20] 和神奇的 [dtrace][21];在 Windows 中,参见 [sysinternals][22])。这是对 `pid` 程序的跟踪:
|
||||
|
||||
```
|
||||
~/code/x86-os$ strace ./pid
|
||||
|
||||
execve("./pid", ["./pid"], [/* 20 vars */]) = 0
|
||||
brk(0) = 0x9aa0000
|
||||
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
|
||||
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7767000
|
||||
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
|
||||
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
|
||||
fstat64(3, {st_mode=S_IFREG|0644, st_size=18056, ...}) = 0
|
||||
mmap2(NULL, 18056, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7762000
|
||||
close(3) = 0
|
||||
|
||||
[...snip...]
|
||||
|
||||
getpid() = 14678
|
||||
fstat64(1, {st_mode=S_IFCHR|0600, st_rdev=makedev(136, 1), ...}) = 0
|
||||
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7766000
|
||||
write(1, "14678\n", 614678
|
||||
) = 6
|
||||
exit_group(6) = ?
|
||||
```
|
||||
|
||||
输出的每一行都显示了一个系统调用、它的参数,以及返回值。如果你在一个循环中将 `getpid(2)` 运行 1000 次,你就会发现始终只有一个 `getpid()` 系统调用,因为,它的 PID 已经被缓存了。我们也可以看到在格式化输出字符串之后,`printf(3)` 调用了 `write(2)`。
|
||||
|
||||
`strace` 可以开始一个新进程,也可以附加到一个已经运行的进程上。你可以通过不同程序的系统调用学到很多的东西。例如,`sshd` 守护进程一天都在干什么?
|
||||
|
||||
```
|
||||
~/code/x86-os$ ps ax | grep sshd
|
||||
12218 ? Ss 0:00 /usr/sbin/sshd -D
|
||||
|
||||
~/code/x86-os$ sudo strace -p 12218
|
||||
Process 12218 attached - interrupt to quit
|
||||
select(7, [3 4], NULL, NULL, NULL
|
||||
|
||||
[
|
||||
... nothing happens ...
|
||||
No fun, it's just waiting for a connection using select(2)
|
||||
If we wait long enough, we might see new keys being generated and so on, but
|
||||
let's attach again, tell strace to follow forks (-f), and connect via SSH
|
||||
]
|
||||
|
||||
~/code/x86-os$ sudo strace -p 12218 -f
|
||||
|
||||
[lots of calls happen during an SSH login, only a few shown]
|
||||
|
||||
[pid 14692] read(3, "-----BEGIN RSA PRIVATE KEY-----\n"..., 1024) = 1024
|
||||
[pid 14692] open("/usr/share/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)
|
||||
[pid 14692] open("/etc/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)
|
||||
[pid 14692] open("/etc/ssh/ssh_host_dsa_key", O_RDONLY|O_LARGEFILE) = 3
|
||||
[pid 14692] open("/etc/protocols", O_RDONLY|O_CLOEXEC) = 4
|
||||
[pid 14692] read(4, "# Internet (IP) protocols\n#\n# Up"..., 4096) = 2933
|
||||
[pid 14692] open("/etc/hosts.allow", O_RDONLY) = 4
|
||||
[pid 14692] open("/lib/i386-linux-gnu/libnss_dns.so.2", O_RDONLY|O_CLOEXEC) = 4
|
||||
[pid 14692] stat64("/etc/pam.d", {st_mode=S_IFDIR|0755, st_size=4096, ...}) = 0
|
||||
[pid 14692] open("/etc/pam.d/common-password", O_RDONLY|O_LARGEFILE) = 8
|
||||
[pid 14692] open("/etc/pam.d/other", O_RDONLY|O_LARGEFILE) = 4
|
||||
```
|
||||
|
||||
看懂 SSH 的调用是块难啃的骨头,但是,如果搞懂它你就学会了跟踪。能够看到应用程序打开的是哪个文件是有用的(“这个配置是从哪里来的?”)。如果你有一个出现错误的进程,你可以 `strace` 它,然后去看它通过系统调用做了什么?当一些应用程序意外退出而没有提供适当的错误信息时,你可以去检查它是否有系统调用失败。你也可以使用过滤器,查看每个调用的次数,等等:
|
||||
|
||||
```
|
||||
~/code/x86-os$ strace -T -e trace=recv curl -silent www.google.com. > /dev/null
|
||||
|
||||
recv(3, "HTTP/1.1 200 OK\r\nDate: Wed, 05 N"..., 16384, 0) = 4164 <0.000007>
|
||||
recv(3, "fl a{color:#36c}a:visited{color:"..., 16384, 0) = 2776 <0.000005>
|
||||
recv(3, "adient(top,#4d90fe,#4787ed);filt"..., 16384, 0) = 4164 <0.000007>
|
||||
recv(3, "gbar.up.spd(b,d,1,!0);break;case"..., 16384, 0) = 2776 <0.000006>
|
||||
recv(3, "$),a.i.G(!0)),window.gbar.up.sl("..., 16384, 0) = 1388 <0.000004>
|
||||
recv(3, "margin:0;padding:5px 8px 0 6px;v"..., 16384, 0) = 1388 <0.000007>
|
||||
recv(3, "){window.setTimeout(function(){v"..., 16384, 0) = 1484 <0.000006>
|
||||
```
|
||||
|
||||
我鼓励你在你的操作系统中的试验这些工具。把它们用好会让你觉得自己有超能力。
|
||||
|
||||
但是,足够有用的东西,往往要让我们深入到它的设计中。我们可以看到那些用户空间中的应用程序是被严格限制在它自己的虚拟地址空间里,运行在 Ring 3(非特权模式)中。一般来说,只涉及到计算和内存访问的任务是不需要请求系统调用的。例如,像 [strlen(3)][23] 和 [memcpy(3)][24] 这样的 C 库函数并不需要内核去做什么。这些都是在应用程序内部发生的事。
|
||||
|
||||
C 库函数的 man 页面所在的节(即圆括号里的 `2` 和 `3`)也提供了线索。节 2 是用于系统调用封装,而节 3 包含了其它 C 库函数。但是,正如我们在 `printf(3)` 中所看到的,库函数最终可以产生一个或者多个系统调用。
|
||||
|
||||
如果你对此感到好奇,这里是 [Linux][25] (也有 [Filippo 的列表][26])和 [Windows][27] 的全部系统调用列表。它们各自有大约 310 和 460 个系统调用。看这些系统调用是非常有趣的,因为,它们代表了*软件*在现代的计算机上能够做什么。另外,你还可能在这里找到与进程间通讯和性能相关的“宝藏”。这是一个“不懂 Unix 的人注定最终还要重新发明一个蹩脚的 Unix ” 的地方。(LCTT 译注:原文 “Those who do not understand Unix are condemned to reinvent it,poorly。” 这句话是 [Henry Spencer][35] 的名言,反映了 Unix 的设计哲学,它的一些理念和文化是一种技术发展的必须结果,看似糟糕却无法超越。)
|
||||
|
||||
与 CPU 周期相比,许多系统调用花[很长的时间][28]去执行任务,例如,从一个硬盘驱动器中读取内容。在这种情况下,调用进程在底层的工作完成之前一直*处于休眠状态*。因为,CPU 运行的非常快,一般的程序都因为 **I/O 的限制**在它的生命周期的大部分时间处于休眠状态,等待系统调用返回。相反,如果你跟踪一个计算密集型任务,你经常会看到没有任何的系统调用参与其中。在这种情况下,[top(1)][29] 将显示大量的 CPU 使用。
|
||||
|
||||
在一个系统调用中的开销可能会是一个问题。例如,固态硬盘比普通硬盘要快很多,但是,操作系统的开销可能比 I/O 操作本身的开销 [更加昂贵][30]。执行大量读写操作的程序可能就是操作系统开销的瓶颈所在。[向量化 I/O][31] 对此有一些帮助。因此要做 [文件的内存映射][32],它允许一个程序仅访问内存就可以读或写磁盘文件。类似的映射也存在于像视频卡这样的地方。最终,云计算的经济性可能导致内核消除或最小化用户模式/内核模式的切换。
|
||||
|
||||
最终,系统调用还有益于系统安全。一是,无论如何来历不明的一个二进制程序,你都可以通过观察它的系统调用来检查它的行为。这种方式可能用于去检测恶意程序。例如,我们可以记录一个未知程序的系统调用的策略,并对它的异常行为进行报警,或者对程序调用指定一个白名单,这样就可以让漏洞利用变得更加困难。在这个领域,我们有大量的研究,和许多工具,但是没有“杀手级”的解决方案。
|
||||
|
||||
这就是系统调用。很抱歉这篇文章有点长,我希望它对你有用。接下来的时间,我将写更多(短的)文章,也可以在 [RSS][33] 和 [Twitter][34] 关注我。这篇文章献给 glorious Clube Atlético Mineiro。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/system-calls/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/code/x86-os/pid.c
|
||||
[2]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[3]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[4]:http://linux.die.net/man/2/getpid
|
||||
[5]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/getpid.c;h=937b1d4e113b1cff4a5c698f83d662e130d596af;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l49
|
||||
[6]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl#L48
|
||||
[7]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l139
|
||||
[8]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l179
|
||||
[9]:https://manybutfinite.com/post/cpu-rings-privilege-and-protection
|
||||
[10]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L354-L386
|
||||
[11]:http://lwn.net/Articles/604287/
|
||||
[12]:http://lwn.net/Articles/604515/
|
||||
[13]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L422
|
||||
[14]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/syscall_64.c#L25
|
||||
[15]:https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L809
|
||||
[16]:https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L859
|
||||
[17]:http://linux.die.net/man/2/getpid
|
||||
[18]:http://linux.die.net/man/2/syscall
|
||||
[19]:http://linux.die.net/man/1/strace
|
||||
[20]:https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/dtruss.1m.html
|
||||
[21]:http://dtrace.org/blogs/brendan/2011/10/10/top-10-dtrace-scripts-for-mac-os-x/
|
||||
[22]:http://technet.microsoft.com/en-us/sysinternals/bb842062.aspx
|
||||
[23]:http://linux.die.net/man/3/strlen
|
||||
[24]:http://linux.die.net/man/3/memcpy
|
||||
[25]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl
|
||||
[26]:https://filippo.io/linux-syscall-table/
|
||||
[27]:http://j00ru.vexillium.org/ntapi/
|
||||
[28]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait/
|
||||
[29]:http://linux.die.net/man/1/top
|
||||
[30]:http://danluu.com/clwb-pcommit/
|
||||
[31]:http://en.wikipedia.org/wiki/Vectored_I/O
|
||||
[32]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[33]:http://feeds.feedburner.com/GustavoDuarte
|
||||
[34]:http://twitter.com/food4hackers
|
||||
[35]:https://en.wikipedia.org/wiki/Henry_Spencer
|
||||
@ -1,31 +1,29 @@
|
||||
成为你所在社区的美好力量
|
||||
============================================================
|
||||
|
||||
>明白如何传递美好,了解积极意愿的力量,以及更多。
|
||||
> 明白如何传递美好,了解积极意愿的力量,以及更多。
|
||||
|
||||

|
||||
|
||||
|
||||
>图片来自:opensource.com
|
||||
|
||||
激烈的争论是开源社区和开放组织的标志特征之一。在我们最好的日子里,这些争论充满活力和建设性。他们面红耳赤的背后其实是幽默和善意。各方实事求是,共同解决问题,推动持续改进。对我们中的许多人来说,他们只是单纯的娱乐而已。
|
||||
激烈的争论是开源社区和开放组织的标志特征之一。在好的时候,这些争论充满活力和建设性。他们面红耳赤的背后其实是幽默和善意。各方实事求是,共同解决问题,推动持续改进。对我们中的许多人来说,他们只是单纯的喜欢而已。
|
||||
|
||||
然而在我们最糟糕的日子里,这些争论演变成了对旧话题的反复争吵。或者我们用各种方式来传递伤害和相互攻击,或是使用卑劣的手段,而这些侵蚀着我们社区的激情、信任和生产力。
|
||||
然而在那些不好的日子里,这些争论演变成了对旧话题的反复争吵。或者我们用各种方式来传递伤害和相互攻击,或是使用卑劣的手段,而这些侵蚀着我们社区的激情、信任和生产力。
|
||||
|
||||
我们茫然四顾,束手无策,因为社区的对话开始变得有毒。然而,正如 [DeLisa Alexander最近的分享][1],我们每个人都有很多方法可以成为我们社区的一种力量。
|
||||
我们茫然四顾,束手无策,因为社区的对话开始变得有毒。然而,正如 [DeLisa Alexander 最近的分享][1],我们每个人都有很多方法可以成为我们社区的一种力量。
|
||||
|
||||
在这个“开源文化”系列的第一篇文章中,我将分享一些策略,教你如何在这个关键时刻进行干预,引导每个人走向更积极、更有效率的方向。
|
||||
|
||||
### 不要将人推开,而是将人推向前方
|
||||
|
||||
最近,我和我的朋友和同事 [Mark Rumbles][2] 一起吃午饭。多年来,我们在许多支持开源文化和引领 Red Hat 的项目中合作。在这一天,马克问我是怎么坚持的,当我看到辩论变得越来越丑陋的时候,他看到我最近介入了一个邮件列表的对话。
|
||||
最近,我和我的朋友和同事 [Mark Rumbles][2] 一起吃午饭。多年来,我们在许多支持开源文化和引领 Red Hat 的项目中合作。在这一天,Mark 问我,他看到我最近介入了一个邮件列表的对话,当其中的辩论越来越过分时我是怎么坚持的。
|
||||
|
||||
幸运的是,这事早已尘埃落定,事实上我几乎忘记了谈话的内容。然而,它让我们开始讨论如何在一个拥有数千名成员的社区里,公开和坦率的辩论。
|
||||
|
||||
>在我们的社区里,我们成为一种美好力量的最好的方法之一就是:在回应冲突时,以一种迫使每个人提升他们的行为,而不是使冲突升级的方式。
|
||||
|
||||
Mark 说了一些让我印象深刻的话。他说:“你知道,作为一个社区,我们真的很擅长将人推开。但我想看到的是,我们更多的是互相扶持 _向前_ 。”
|
||||
|
||||
Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量的最好的方法之一就是:在回应冲突时,以一种迫使每个人提升他们的行为,而不是使冲突升级的方式。
|
||||
Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量的最好的方法之一就是:以一种迫使每个人提升他们的行为的方式回应冲突,而不是使冲突升级的方式。
|
||||
|
||||
### 积极意愿假想
|
||||
|
||||
@ -33,9 +31,9 @@ Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量
|
||||
|
||||
诚然,这不是一件容易的事情。当我看到一场辩论正在变得肮脏的迹象时,我停下来问自己,史蒂芬·科维(Steven Covey)所说的人性化问题是什么:
|
||||
|
||||
“为什么一个理性、正直的人会做这样的事情?”
|
||||
> “为什么一个理性、正直的人会做这样的事情?”
|
||||
|
||||
现在,如果他是你的一个“普通的观察对象”——一个有消极行为倾向的社区成员——也许你的第一个想法是,“嗯,也许这个人是个不靠谱,不理智的人”
|
||||
现在,如果他是你的一个“普通的观察对象”—— 一个有消极行为倾向的社区成员——也许你的第一个想法是,“嗯,也许这个人是个不靠谱,不理智的人”
|
||||
|
||||
回过头来说。我并不是说你让你自欺欺人。这其实就是人性化的问题,不仅是因为它让你理解别人的立场,它还让你变得人性化。
|
||||
|
||||
@ -51,7 +49,7 @@ Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量
|
||||
|
||||
一个简单的积极意愿假想,我们可以适用于几乎所有的不良行为,其实就是那个人想要被聆听,被尊重,或被理解。我想这是相当合理的。
|
||||
|
||||
通过站在这个更客观、更有同情心的角度,我们可以看到他们的行为几乎肯定 **_不_** 会帮助他们得到他们想要的东西,而社区也会因此而受到影响。如果没有我们的帮助的话。
|
||||
通过站在这个更客观、更有同情心的角度,我们可以看到他们的行为几乎肯定 **_不会_** 帮助他们得到他们想要的东西,而社区也会因此而受到影响。如果没有我们的帮助的话。
|
||||
|
||||
对我来说,这激发了一个愿望:帮助每个人从我们所处的这个丑陋的地方“摆脱困境”。
|
||||
|
||||
@ -60,7 +58,7 @@ Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量
|
||||
容易想到的例子包括:
|
||||
|
||||
* 他们担心我们错过了一些重要的东西,或者我们犯了一个错误,没有人能看到它。
|
||||
* 他们想为自己的贡献感到有价值。
|
||||
* 他们想感受到自己的贡献的价值。
|
||||
* 他们精疲力竭,因为在社区里工作过度或者在他们的个人生活中发生了一些事情。
|
||||
* 他们讨厌一些东西被破坏,并感到沮丧,因为没有人能看到造成的伤害或不便。
|
||||
* ……诸如此类。
|
||||
@ -69,11 +67,11 @@ Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量
|
||||
|
||||
### 传递美好,挣脱泥潭
|
||||
|
||||
什么是 an out?(类似与佛家“解脱法门”的意思)把它想象成一个逃跑的门。这是一种退出对话的方式,或者放弃不良的行为,恢复表现得像一个体面的人,而不是丢面子。是叫某人振作向上,而不是叫他走开。
|
||||
什么是 an out?(LCTT 译注:类似与佛家“解脱法门”的意思)把它想象成一个逃跑的门。这是一种退出对话的方式,或者放弃不良的行为,恢复表现得像一个体面的人,而不是丢面子。是叫某人振作向上,而不是叫他走开。
|
||||
|
||||
你可能经历过这样的事情,在你的生活中,当 _你_ 在一次谈话中表现不佳时,咆哮着,大喊大叫,对某事大惊小怪,而有人慷慨地给 _你_ 提供了一个台阶下。也许他们选择不去和你“抬杠”,相反,他们说了一些表明他们相信你是一个理性、正直的人,他们采用积极意愿假想,比如:
|
||||
|
||||
> _所以,嗯,我听到的是你真的很担心,你很沮丧,因为似乎没有人在听。或者你担心我们忽略了它的重要性。是这样对吧?_
|
||||
> 所以,嗯,我听到的是你真的很担心,你很沮丧,因为似乎没有人在听。或者你担心我们忽略了它的重要性。是这样对吧?
|
||||
|
||||
于是乎:即使这不是完全正确的(也许你的意图不那么高尚),在那一刻,你可能抓住了他们提供给你的台阶,并欣然接受了重新定义你的不良行为的机会。你几乎可以肯定地转向一个更富有成效的角度,甚至你自己可能都没有意识到。
|
||||
|
||||
@ -85,13 +83,13 @@ Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量
|
||||
|
||||
### 坏行为还是坏人?
|
||||
|
||||
如果这个人特别激动,他们可能不会听到或者接受你给出的第一台阶。没关系。最可能的是,他们迟钝的大脑已经被史前曾经对人类生存至关重要的杏仁核接管了,他们需要更多的时间来认识到你并不是一个威胁。只是需要你保持温和的态度,坚定地对待他们,就好像他们 _曾经是_ 一个理性、正直的人,看看会发生什么。
|
||||
如果这个人特别激动,他们可能不会听到或者接受你给出的第一个台阶。没关系。最可能的是,他们迟钝的大脑已经被史前曾经对人类生存至关重要的杏仁体接管了,他们需要更多的时间来认识到你并不是一个威胁。只是需要你保持温和的态度,坚定地对待他们,就好像他们 _曾经是_ 一个理性、正直的人,看看会发生什么。
|
||||
|
||||
根据我的经验,这些社区干预以三种方式结束:
|
||||
|
||||
大多数情况下,这个人实际上 _是_ 一个理性的人,很快,他们就感激地接受了这个事实。在这个过程中,每个人都跳出了“黑与白”,“赢或输”的心态。人们开始思考创造性的选择和“双赢”的结果,每个人都将受益。
|
||||
|
||||
> 为什么一个理性、正直的人会做这样的事呢?
|
||||
> 为什么一个理性、正直的人会做这样的事呢?
|
||||
|
||||
有时候,这个人天生不是特别理性或正直的,但当他被你以如此一致的、不知疲倦的、耐心的慷慨和善良的对待的时候,他们就会羞愧地从谈话中撤退。这听起来像是,“嗯,我想我已经说了所有要说的了。谢谢你听我的意见”。或者,对于不那么开明的人来说,“嗯,我厌倦了这种谈话。让我们结束吧。”(好的,谢谢)。
|
||||
|
||||
@ -99,7 +97,7 @@ Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量
|
||||
|
||||
这就是积极意愿假想的力量。通过对愤怒和充满敌意的言辞做出回应,优雅而有尊严地回应,你就能化解一场战争,理清混乱,解决棘手的问题,而且在这个过程中很有可能会交到一个新朋友。
|
||||
|
||||
我每次应用这个原则都成功吗?见鬼,不。但我从不后悔选择了积极意愿。但是我能生动的回想起,当我采用消极意愿假想时,将问题变得更糟糕的场景。
|
||||
我每次应用这个原则都成功吗?见鬼,不会。但我从不后悔选择了积极意愿。但是我能生动的回想起,当我采用消极意愿假想时,将问题变得更糟糕的场景。
|
||||
|
||||
现在轮到你了。我很乐意听到你提出的一些策略和原则,当你的社区里的对话变得激烈的时候,要成为一股好力量。在下面的评论中分享你的想法。
|
||||
|
||||
@ -111,7 +109,7 @@ Mark 是绝对正确的。在我们的社区里,我们成为一种美好力量
|
||||
|
||||

|
||||
|
||||
丽贝卡·费尔南德斯(Rebecca Fernandez)是红帽公司(Red Hat)的首席就业品牌 + 通讯专家,是《开源组织》书籍的贡献者,也是开源决策框架的维护者。她的兴趣是开源和业务管理模型的开源方式。Twitter:@ruhbehka
|
||||
丽贝卡·费尔南德斯(Rebecca Fernandez)是红帽公司(Red Hat)的首席就业品牌 + 通讯专家,是《开放组织》书籍的贡献者,也是开源决策框架的维护者。她的兴趣是开源和业务管理模型的开源方式。Twitter:@ruhbehka
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -119,7 +117,7 @@ via: https://opensource.com/open-organization/17/1/force-for-good-community
|
||||
|
||||
作者:[Rebecca Fernandez][a]
|
||||
译者:[chao-zhi](https://github.com/chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,64 +1,67 @@
|
||||
Getting Started with Taskwarrior
|
||||
======
|
||||
Taskwarrior is a flexible [command-line task management program][1]. In their [own words][2]:
|
||||
基于命令行的任务管理器 Taskwarrior
|
||||
=====
|
||||
|
||||
Taskwarrior manages your TODO list from your command line. It is flexible, fast, efficient, unobtrusive, does its job then gets out of your way.
|
||||
Taskwarrior 是一个灵活的[命令行任务管理程序][1],用他们[自己的话说][2]:
|
||||
|
||||
Taskwarrior is highly customizable, but can also be used "right out of the box." In this article, we'll show you the basic commands to add and complete tasks. Then we'll cover a couple more advanced commands. And finally, we'll show you some basic configuration settings to begin customizing your setup.
|
||||
> Taskwarrior 在命令行里管理你的 TODO 列表。它灵活,快速,高效,不显眼,它默默做自己的事情让你避免自己管理。
|
||||
|
||||
### Installing Taskwarrior
|
||||
Taskwarrior 是高度可定制的,但也可以“立即使用”。在本文中,我们将向你展示添加和完成任务的基本命令,然后我们将介绍几个更高级的命令。最后,我们将向你展示一些基本的配置设置,以开始自定义你的设置。
|
||||
|
||||
### 安装 Taskwarrior
|
||||
|
||||
Taskwarrior 在 Fedora 仓库中是可用的,所有安装它很容易:
|
||||
|
||||
Taskwarrior is available in the Fedora repositories, so installing it is simple:
|
||||
```
|
||||
sudo dnf install task
|
||||
|
||||
```
|
||||
|
||||
Once installed, run `task`. This first run will create a `~/.taskrc` file for you.
|
||||
一旦完成安装,运行 `task` 命令。第一次运行将会创建一个 `~/.taskrc` 文件。
|
||||
|
||||
```
|
||||
$ **task**
|
||||
$ task
|
||||
A configuration file could not be found in ~
|
||||
|
||||
Would you like a sample /home/link/.taskrc created, so Taskwarrior can proceed? (yes/no) yes
|
||||
[task next]
|
||||
No matches.
|
||||
|
||||
```
|
||||
|
||||
### Adding Tasks
|
||||
### 添加任务
|
||||
|
||||
添加任务快速而不显眼。
|
||||
|
||||
Adding tasks is fast and unobtrusive.
|
||||
```
|
||||
$ **task add Plant the wheat**
|
||||
$ task add Plant the wheat
|
||||
Created task 1.
|
||||
|
||||
```
|
||||
|
||||
Run `task` or `task list` to show upcoming tasks.
|
||||
运行 `task` 或者 `task list` 来显示即将来临的任务。
|
||||
|
||||
```
|
||||
$ **task list**
|
||||
$ task list
|
||||
|
||||
ID Age Description Urg
|
||||
1 8s Plant the wheat 0
|
||||
|
||||
1 task
|
||||
|
||||
```
|
||||
|
||||
Let's add a few more tasks to round out the example.
|
||||
让我们添加一些任务来完成这个示例。
|
||||
|
||||
```
|
||||
$ **task add Tend the wheat**
|
||||
$ task add Tend the wheat
|
||||
Created task 2.
|
||||
$ **task add Cut the wheat**
|
||||
$ task add Cut the wheat
|
||||
Created task 3.
|
||||
$ **task add Take the wheat to the mill to be ground into flour**
|
||||
$ task add Take the wheat to the mill to be ground into flour
|
||||
Created task 4.
|
||||
$ **task add Bake a cake**
|
||||
$ task add Bake a cake
|
||||
Created task 5.
|
||||
|
||||
```
|
||||
|
||||
Run `task` again to view the list.
|
||||
再次运行 `task` 来查看列表。
|
||||
|
||||
```
|
||||
[task next]
|
||||
|
||||
@ -70,83 +73,83 @@ ID Age Description Urg
|
||||
5 2s Bake a cake 0
|
||||
|
||||
5 tasks
|
||||
|
||||
```
|
||||
|
||||
### Completing Tasks
|
||||
### 完成任务
|
||||
|
||||
将一个任务标记为完成, 查找其 ID 并运行:
|
||||
|
||||
To mark a task as complete, look up its ID and run:
|
||||
```
|
||||
$ **task 1 done**
|
||||
$ task 1 done
|
||||
Completed task 1 'Plant the wheat'.
|
||||
Completed 1 task.
|
||||
|
||||
```
|
||||
|
||||
You can also mark a task done with its description.
|
||||
你也可以用它的描述来标记一个任务已完成。
|
||||
|
||||
```
|
||||
$ **task 'Tend the wheat' done**
|
||||
$ task 'Tend the wheat' done
|
||||
Completed task 1 'Tend the wheat'.
|
||||
Completed 1 task.
|
||||
|
||||
```
|
||||
|
||||
With `add`, `list` and `done`, you're all ready to get started with Taskwarrior.
|
||||
通过使用 `add`、`list` 和 `done`,你可以说已经入门了。
|
||||
|
||||
### Setting Due Dates
|
||||
### 设定截止日期
|
||||
|
||||
很多任务不需要一个截止日期:
|
||||
|
||||
Many tasks do not require a due date:
|
||||
```
|
||||
task add Finish the article on Taskwarrior
|
||||
|
||||
```
|
||||
|
||||
But sometimes, setting a due date is just the kind of motivation you need to get productive. Use the `due` modifier when adding a task to set a specific due date.
|
||||
但是有时候,设定一个截止日期正是你需要提高效率的动力。在添加任务时使用 `due` 修饰符来设置特定的截止日期。
|
||||
|
||||
```
|
||||
task add Finish the article on Taskwarrior due:tomorrow
|
||||
|
||||
```
|
||||
|
||||
`due` is highly flexible. It accepts specific dates ("2017-02-02"), or ISO-8601 ("2017-02-02T20:53:00Z"), or even relative time ("8hrs"). See the [Date & Time][3] documentation for all the examples.
|
||||
`due` 非常灵活。它接受特定日期 (`2017-02-02`) 或 ISO-8601 (`2017-02-02T20:53:00Z`),甚至相对时间 (`8hrs`)。可以查看所有示例的 [Date & Time][3] 文档。
|
||||
|
||||
日期也不只有截止日期,Taskwarrior 有 `scheduled`, `wait` 和 `until` 选项。
|
||||
|
||||
Dates go beyond due dates too. Taskwarrior has `scheduled`, `wait`, and `until`.
|
||||
```
|
||||
task add Proof the article on Taskwarrior scheduled:thurs
|
||||
|
||||
```
|
||||
|
||||
Once the date (Thursday in this example) passes, the task is tagged with the `READY` virtual tag. It will then show up in the `ready` report.
|
||||
一旦日期(本例中的星期四)通过,该任务就会被标记为 `READY` 虚拟标记。它会显示在 `ready` 报告中。
|
||||
|
||||
```
|
||||
$ **task ready**
|
||||
$ task ready
|
||||
|
||||
ID Age S Description Urg
|
||||
1 2s 1d Proof the article on Taskwarrior 5
|
||||
|
||||
```
|
||||
|
||||
To remove a date, `modify` the task with a blank value:
|
||||
要移除一个日期,使用空白值来 `modify` 任务:
|
||||
|
||||
```
|
||||
$ task 1 modify scheduled:
|
||||
|
||||
```
|
||||
|
||||
### Searching Tasks
|
||||
### 查找任务
|
||||
|
||||
如果没有使用正则表达式搜索的能力,任务列表是不完整的,对吧?
|
||||
|
||||
No task list is complete without the ability to search with regular expressions, right?
|
||||
```
|
||||
$ **task '/.* the wheat/' list**
|
||||
$ task '/.* the wheat/' list
|
||||
|
||||
ID Age Project Description Urg
|
||||
2 42min Take the wheat to the mill to be ground into flour 0
|
||||
1 42min Home Cut the wheat 1
|
||||
|
||||
2 tasks
|
||||
|
||||
```
|
||||
|
||||
### Customizing Taskwarrior
|
||||
### 自定义 Taskwarrior
|
||||
|
||||
记得我们在开头创建的文件 (`~/.taskrc`)吗?让我们来看看默认设置:
|
||||
|
||||
Remember that file we created back in the beginning (`~/.taskrc`). Let's take at the defaults:
|
||||
```
|
||||
# [Created by task 2.5.1 2/9/2017 16:39:14]
|
||||
# Taskwarrior program configuration file.
|
||||
@ -178,47 +181,46 @@ data.location=~/.task
|
||||
#include /usr//usr/share/task/solarized-dark-256.theme
|
||||
#include /usr//usr/share/task/solarized-light-256.theme
|
||||
#include /usr//usr/share/task/no-color.theme
|
||||
|
||||
|
||||
```
|
||||
|
||||
The only active option right now is `data.location=~/.task`. To view active configuration settings (including the built-in defaults), run `show`.
|
||||
现在唯一生效的选项是 `data.location=~/.task`。要查看活动配置设置(包括内置的默认设置),运行 `show`。
|
||||
|
||||
```
|
||||
task show
|
||||
|
||||
```
|
||||
|
||||
To change a setting, use `config`.
|
||||
要改变设置,使用 `config`。
|
||||
|
||||
```
|
||||
$ **task config displayweeknumber no**
|
||||
$ task config displayweeknumber no
|
||||
Are you sure you want to add 'displayweeknumber' with a value of 'no'? (yes/no) yes
|
||||
Config file /home/link/.taskrc modified.
|
||||
|
||||
```
|
||||
|
||||
### Examples
|
||||
### 示例
|
||||
|
||||
These are just some of the things you can do with Taskwarrior.
|
||||
这些只是你可以用 Taskwarrior 做的一部分事情。
|
||||
|
||||
将你的任务分配到一个项目:
|
||||
|
||||
Assign a project to your tasks:
|
||||
```
|
||||
task 'Fix leak in the roof' modify project:Home
|
||||
|
||||
```
|
||||
|
||||
Use `start` to mark what you were working on. This can help you remember what you were working on after the weekend:
|
||||
使用 `start` 来标记你正在做的事情,这可以帮助你回忆起你周末后在做什么:
|
||||
|
||||
```
|
||||
task 'Fix bug #141291' start
|
||||
|
||||
```
|
||||
|
||||
Use relevant tags:
|
||||
使用相关的标签:
|
||||
|
||||
```
|
||||
task add 'Clean gutters' +weekend +house
|
||||
|
||||
```
|
||||
|
||||
Be sure to read the [complete documentation][4] to learn all the ways you can catalog and organize your tasks.
|
||||
务必阅读[完整文档][4]以了解你可以编目和组织任务的所有方式。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -226,8 +228,8 @@ Be sure to read the [complete documentation][4] to learn all the ways you can ca
|
||||
via: https://fedoramagazine.org/getting-started-taskwarrior/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,122 +1,116 @@
|
||||
程序员的学习之路
|
||||
============================================================
|
||||
|
||||
*2016 年 10 月,当我从微软离职时,我已经在微软工作了近 21 年,在工业界也快 35 年了。我花了一些时间反思我这些年来学到的东西,这些文字是那篇帖子稍加修改后得到。请见谅,文章有一点长。*
|
||||
*2016 年 10 月,当我从微软离职时,我已经在微软工作了近 21 年,在业界也快 35 年了。我花了一些时间反思我这些年来学到的东西,这些文字是那篇帖子稍加修改后得到。请见谅,文章有一点长。*
|
||||
|
||||
要成为一名专业的程序员,你需要知道的事情多得令人吃惊:语言的细节,API,算法,数据结构,系统和工具。这些东西一直在随着时间变化——新的语言和编程环境不断出现,似乎总有热门的新工具或新语言是“每个人”都在使用的。紧跟潮流,保持专业,这很重要。木匠需要知道如何为工作选择合适的锤子和钉子,并且要有能力笔直精准地钉入钉子。
|
||||
要成为一名专业的程序员,你需要知道的事情多得令人吃惊:语言的细节、API、算法、数据结构、系统和工具。这些东西一直在随着时间变化——新的语言和编程环境不断出现,似乎总有一些“每个人”都在使用的热门的新工具或新语言。紧跟潮流,保持专业,这很重要。木匠需要知道如何为工作选择合适的锤子和钉子,并且要有能力笔直精准地钉入钉子。
|
||||
|
||||
与此同时,我也发现有一些理论和方法有着广泛的应用场景,它们能使用几十年。底层设备的性能和容量在这几十年来增长了几个数量级,但系统设计的思考方式还是互相有关联的,这些思考方式比具体的实现更根本。理解这些重复出现的主题对分析与设计我们所负责的系统大有帮助。
|
||||
|
||||
谦卑和自我
|
||||
### 谦卑和自我
|
||||
|
||||
这不仅仅局限于编程,但在编程这个持续发展的领域,一个人需要在谦卑和自我中保持平衡。总有新的东西需要学习,并且总有人能帮助你学习——如果你愿意学习的话。一个人即需要保持谦卑,认识到自己不懂并承认它,也要保持自我,相信自己能掌握一个新的领域,并且能运用你已经掌握的知识。我见过的最大的挑战就是一些人在某个领域深入专研了很长时间,“忘记”了自己擅长学习新的东西。最好的学习来自放手去做,建造一些东西,即便只是一个原型或者 hack。我知道的最好的程序员对技术有广泛的认识,但同时他们对某个技术深入研究,成为了专家。而深入的学习来自努力解决真正困难的问题。
|
||||
这不仅仅局限于编程,但在编程这个持续发展的领域,一个人需要在谦卑和自我中保持平衡。总有新的东西需要学习,并且总有人能帮助你学习——如果你愿意学习的话。一个人即需要保持谦卑,认识到自己不懂并承认它,也要保持自我,相信自己能掌握一个新的领域,并且能运用你已经掌握的知识。我见过的最大的挑战就是一些人在某个领域深入专研了很长时间,“忘记”了自己擅长学习新的东西。最好的学习来自放手去做,建造一些东西,即便只是一个原型或者 hack。我知道的最好的程序员对技术有广泛的认识,但同时他们对某个技术深入研究,成为了专家。而深入的学习来自努力解决真正困难的问题。
|
||||
|
||||
端到端观点
|
||||
### 端到端观点
|
||||
|
||||
1981 年,Jerry Saltzer, Dave Reed 和 Dave Clark 在做因特网和分布式系统的早期工作,他们提出了端到端观点,并作出了[经典的阐述][4]。网络上的文章有许多误传,所以更应该阅读论文本身。论文的作者很谦虚,没有声称这是他们自己的创造——从他们的角度看,这只是一个常见的工程策略,不只在通讯领域中,在其他领域中也有运用。他们只是将其写下来并收集了一些例子。下面是文章的一个小片段:
|
||||
1981 年,Jerry Saltzer、 Dave Reed 和 Dave Clark 在做因特网和分布式系统的早期工作,他们提出了<ruby>端到端<rt>end to end</rt></ruby>观点,并作出了[经典的阐述][4]。网络上的文章有许多误传,所以更应该阅读论文本身。论文的作者很谦虚,没有声称这是他们自己的创造——从他们的角度看,这只是一个常见的工程策略,不只在通讯领域中,在其他领域中也有运用。他们只是将其写下来并收集了一些例子。下面是文章的一个小片段:
|
||||
|
||||
> 当我们设计系统的一个功能时,仅依靠端点的知识和端点的参与,就能正确地完整地实现这个功能。在一些情况下,系统的内部模块局部实现这个功能,可能会对性能有重要的提升。
|
||||
|
||||
论文称这是一个“观点”,虽然在维基百科和其他地方它已经被上升成“原则”。实际上,还是把它看作一个观点比较好,正如作者们所说,系统设计者面临的最难的问题之一就是如何在系统组件之间划分责任,这会引发不断的讨论:怎样在划分功能时权衡利弊,怎样隔离复杂性,怎样设计一个灵活的高性能系统来满足不断变化的需求。没有简单的原则可以直接遵循。
|
||||
该论文称这是一个“观点”,虽然在维基百科和其他地方它已经被上升成“原则”。实际上,还是把它看作一个观点比较好,正如作者们所说,系统设计者面临的最难的问题之一就是如何在系统组件之间划分责任,这会引发不断的讨论:怎样在划分功能时权衡利弊,怎样隔离复杂性,怎样设计一个灵活的高性能系统来满足不断变化的需求。没有简单的原则可以直接遵循。
|
||||
|
||||
互联网上的大部分讨论集中在通信系统上,但端到端观点的适用范围其实更广泛。分布式系统中的“最终一致性”就是一个例子。一个满足“最终一致性”的系统,可以让系统中的元素暂时进入不一致的状态,从而简化系统,优化性能,因为有一个更大的端到端过程来解决不一致的状态。我喜欢横向拓展的订购系统的例子(例如亚马逊),它不要求每个请求都通过中央库存的控制点。缺少中央控制点可能允许两个终端出售相同的最后一本书,所以系统需要用某种方法来解决这个问题,如通知客户该书会延期交货。不论怎样设计,想购买的最后一本书在订单完成前都有可能被仓库中的叉车运出厍(译者注:比如被其他人下单购买)。一旦你意识到你需要一个端到端的解决方案,并实现了这个方案,那系统内部的设计就可以被优化,并利用这个解决方案。
|
||||
互联网上的大部分讨论集中在通信系统上,但端到端观点的适用范围其实更广泛。分布式系统中的“<ruby>最终一致性<rt>eventual consistency</rt></ruby>”就是一个例子。一个满足“最终一致性”的系统,可以让系统中的元素暂时进入不一致的状态,从而简化系统,优化性能,因为有一个更大的端到端过程来解决不一致的状态。我喜欢横向拓展的订购系统的例子(例如亚马逊),它不要求每个请求都通过中央库存的控制点。缺少中央控制点可能允许两个终端出售相同的最后一本书,所以系统需要用某种方法来解决这个问题,如通知客户该书会延期交货。不论怎样设计,想购买的最后一本书在订单完成前都有可能被仓库中的叉车运出厍(LCTT 译注:比如被其他人下单购买)。一旦你意识到你需要一个端到端的解决方案,并实现了这个方案,那系统内部的设计就可以被优化以利用这个解决方案。
|
||||
|
||||
事实上,这种设计上的灵活性可以优化系统的性能,或者提供其他的系统功能,从而使得端到端的方法变得如此强大。端到端的思考往往允许内部进行灵活的操作,使整个系统更加健壮,并且能适应每个组件特性的变化。这些都让端到端的方法变得健壮,并能适应变化。
|
||||
|
||||
端到端方法意味着,添加会牺牲整体性能灵活性的抽象层和功能时要非常小心(也可能是其他的灵活性,但性能,特别是延迟,往往是特殊的)。如果你展示出底层的原始性能(performance, 也可能指操作),端到端的方法可以根据这个性能(操作)来优化,实现特定的需求。如果你破坏了底层性能(操作),即使你实现了重要的有附加价值的功能,你也牺牲了设计灵活性。
|
||||
端到端方法意味着,添加会牺牲整体性能灵活性的抽象层和功能时要非常小心(也可能是其他的灵活性,但性能,特别是延迟,往往是特殊的)。如果你展示出底层的原始性能(LCTT 译注:performance,也可能指操作,下同),端到端的方法可以根据这个性能(操作)来优化,实现特定的需求。如果你破坏了底层性能(操作),即使你实现了重要的有附加价值的功能,你也牺牲了设计灵活性。
|
||||
|
||||
如果系统足够庞大而且足够复杂,需要把整个开发团队分配给系统内部的组件,那么端到端观点可以和团队组织相结合。这些团队自然要扩展这些组件的功能,他们通常从牺牲设计上的灵活性开始,尝试在组件上实现端到端的功能。
|
||||
|
||||
应用端到端方法面临的挑战之一是确定端点在哪里。 俗话说,“大跳蚤上有小跳蚤,小跳蚤上有更少的跳蚤……等等”。
|
||||
|
||||
关注复杂性
|
||||
### 关注复杂性
|
||||
|
||||
编程是一门精确的艺术,每一行代码都要确保程序的正确执行。但这是带有误导的。编程的复杂性不在于各个部分的整合,也不在于各个部分之间如何相互交互。最健壮的程序将复杂性隔离开,让最重要的部分变的简单直接,通过简单的方式与其他部分交互。虽然隐藏复杂性和信息隐藏、数据抽象等其他设计方法一样,但我仍然觉得,如果你真的要定位出系统的复杂所在,并将其隔离开,那你需要对设计特别敏锐。
|
||||
编程是一门精确的艺术,每一行代码都要确保程序的正确执行。但这是带有误导的。编程的复杂性不在于各个部分的整合,也不在于各个部分之间如何相互交互。最健壮的程序会将复杂性隔离开,让最重要的部分变的简单直接,通过简单的方式与其他部分交互。虽然隐藏复杂性和信息隐藏、数据抽象等其他设计方法一样,但我仍然觉得,如果你真的要定位出系统的复杂所在,并将其隔离开,那你需要对设计特别敏锐。
|
||||
|
||||
在我的[文章][5]中反复提到的例子是早期的终端编辑器 VI 和 Emacs 中使用的屏幕重绘算法。早期的视频终端实现了控制序列,来控制绘制字符核心操作,也实现了附加的显示功能,来优化重新绘制屏幕,如向上向下滚动当前行,或者插入新行,或在当前行中移动字符。这些命令都具有不同的开销,并且这些开销在不同制造商的设备中也是不同的。(参见[TERMCAP][6]以获取代码链接和更完整的历史记录。)像文本编辑器这样的全屏应用程序希望尽快更新屏幕,因此需要优化使用这些控制序列来转换屏幕从一个状态到另一个状态。
|
||||
在我的[文章][5]中反复提到的例子是早期的终端编辑器 VI 和 Emacs 中使用的屏幕重绘算法。早期的视频终端实现了控制序列,来控制绘制字符核心操作,也实现了附加的显示功能,来优化重新绘制屏幕,如向上向下滚动当前行,或者插入新行,或在当前行中移动字符。这些命令都具有不同的开销,并且这些开销在不同制造商的设备中也是不同的。(参见[TERMCAP][6] 以获取代码和更完整的历史记录的链接。)像文本编辑器这样的全屏应用程序希望尽快更新屏幕,因此需要优化使用这些控制序列来从一个状态到另一个状态屏幕转换。
|
||||
|
||||
这些程序在设计上隐藏了底层的复杂性。系统中修改文本缓冲区的部分(功能上大多数创新都在这里)完全忽略了这些改变如何被转换成屏幕更新命令。这是可以接受的,因为针对*任何*内容的改变计算最佳命令所消耗的性能代价,远不及被终端本身实际执行这些更新命令的性能代价。在确定如何隐藏复杂性,以及隐藏哪些复杂性时,性能分析扮演着重要的角色,这一点在系统设计中非常常见。屏幕的更新与底层文本缓冲区的更改是异步的,并且可以独立于缓冲区的实际历史变化顺序。缓冲区*怎样*改变的并不重要,重要的是改变了*什么*。异步耦合,在组件交互时消除组件对历史路径依赖的组合,以及用自然的交互方式以有效地将组件组合在一起是隐藏耦合复杂度的常见特征。
|
||||
这些程序在设计上隐藏了底层的复杂性。系统中修改文本缓冲区的部分(功能上大多数创新都在这里)完全忽略了这些改变如何被转换成屏幕更新命令。这是可以接受的,因为针对*任何*内容的改变计算最佳命令所消耗的性能代价,远不及被终端本身实际执行这些更新命令的性能代价。在确定如何隐藏复杂性,以及隐藏哪些复杂性时,性能分析扮演着重要的角色,这一点在系统设计中非常常见。屏幕的更新与底层文本缓冲区的更改是异步的,并且可以独立于缓冲区的实际历史变化顺序。缓冲区是*怎样*改变的并不重要,重要的是改变了*什么*。异步耦合,在组件交互时消除组件对历史路径依赖的组合,以及用自然的交互方式以有效地将组件组合在一起是隐藏耦合复杂度的常见特征。
|
||||
|
||||
隐藏复杂性的成功不是由隐藏复杂性的组件决定的,而是由使用该模块的使用者决定的。这就是为什么组件的提供者至少要为组件的某些端到端过程负责。他们需要清晰的知道系统的其他部分如何与组件相互作用,复杂性是如何泄漏出来的(以及是否泄漏出来)。这常常表现为“这个组件很难使用”这样的反馈——这通常意味着它不能有效地隐藏内部复杂性,或者没有选择一个隐藏复杂性的功能边界。
|
||||
|
||||
分层与组件化
|
||||
### 分层与组件化
|
||||
|
||||
系统设计人员的一个基本工作是确定如何将系统分解成组件和层;决定自己要开发什么,以及从别的地方获取什么。开源项目在决定自己开发组件还是购买服务时,大多会选择自己开发,但组件之间交互的过程是一样的。在大规模工程中,理解这些决策将如何随着时间的推移而发挥作用是非常重要的。从根本上说,变化是程序员所做的一切的基础,所以这些设计决定不仅在当下被评估,还要随着产品的不断发展而在未来几年得到评估。
|
||||
系统设计人员的一个基本工作是确定如何将系统分解成组件和层;决定自己要开发什么,以及从别的地方获取什么。开源项目在决定自己开发组件还是购买服务时,大多会选择自己开发,但组件之间交互的过程是一样的。在大规模工程中,理解这些决策将如何随着时间的推移而发挥作用是非常重要的。从根本上说,变化是程序员所做的一切的基础,所以这些设计决定不仅要在当下评估,还要随着产品的不断发展而在未来几年得到评估。
|
||||
|
||||
以下是关于系统分解的一些事情,它们最终会占用大量的时间,因此往往需要更长的时间来学习和欣赏。
|
||||
|
||||
* 层泄漏。层(或抽象)[基本上是泄漏的][1]。这些泄漏会立即产生后果,也会随着时间的推移而产生两方面的后果。其中一方面就是该抽象层的特性渗透到了系统的其他部分,渗透的程度比你意识到得更深入。这些渗透可能是关于具体的性能特征的假设,以及抽象层的文档中没有明确的指出的行为发生的顺序。这意味着假如内部组件的行为发生变化,你的系统会比想象中更加脆弱。第二方面是你比表面上看起来更依赖组件内部的行为,所以如果你考虑改变这个抽象层,后果和挑战可能超出你的想象。
|
||||
* **层泄漏。**层(或抽象)[基本上是泄漏的][1]。这些泄漏会立即产生后果,也会随着时间的推移而产生两方面的后果。其中一方面就是该抽象层的特性渗透到了系统的其他部分,渗透的程度比你意识到得更深入。这些渗透可能是关于具体的性能特征的假设,以及抽象层的文档中没有明确的指出的行为发生的顺序。这意味着假如内部组件的行为发生变化,你的系统会比想象中更加脆弱。第二方面是你比表面上看起来更依赖组件内部的行为,所以如果你考虑改变这个抽象层,后果和挑战可能超出你的想象。
|
||||
* **层具有太多功能。**您所采用的组件具有比实际需要更多的功能,这几乎是一个真理。在某些情况下,你决定采用这个组件是因为你想在将来使用那些尚未用到的功能。有时,你采用组件是想“上快车”,利用组件完成正在进行的工作。在功能强大的抽象层上开发会带来一些后果。
|
||||
1. 组件往往会根据你并不需要的功能作出取舍。
|
||||
2. 为了实现那些你并不没有用到的功能,组件引入了复杂性和约束,这些约束将阻碍该组件的未来的演变。
|
||||
3. 层泄漏的范围更大。一些泄漏是由于真正的“抽象泄漏”,另一些是由于明显的,逐渐增加的对组件全部功能的依赖(但这些依赖通常都没有处理好)。Office 软件太大了,我们发现,对于我们建立的任何抽象层,我们最终都在系统的某个部分完全运用了它的功能。虽然这看起来是积极的(我们完全地利用了这个组件),但并不是所用的使用都有同样的价值。所以,我们最终要付出巨大的代价才能从一个抽象层往另一个抽象层迁移,这种“长尾”没什么价值,并且对使用场景认识不足。
|
||||
4. 附加的功能会增加复杂性,并增加功能滥用的可能。如果将验证 XML 的 API 指定为 XML 树的一部分,那这个 API 可以选择动态下载 XML 的模式定义。这在我们的基本文件解析代码中被错误地执行,导致 w3c.org 服务器上的大量性能下降以及(无意)分布式拒绝服务攻击。(这些被通俗地称为“地雷”API)。
|
||||
* **抽象层被更换。**需求在进化,系统在进化,组件被放弃。您最终需要更换该抽象层或组件。不管是对外部组件的依赖还是对内部组件的依赖都是如此。这意味着上述问题将变得重要起来。
|
||||
* **自己构建还是购买的决定将会改变。**这是上面几方面的必然结果。这并不意味着自己构建还是购买的决定在当时是错误的。一开始时往往没有合适的组件,一段时间之后才有合适的组件出现。或者,也可能你使用了一个组件,但最终发现它不符合您不断变化的要求,而且你的要求非常窄、很好理解,或者对你的价值体系来说是非常重要的,以至于拥有自己的模块是有意义的。这意味着你像关心自己构造的模块一样,关心购买的模块,关心它们是怎样泄漏并深入你的系统中的。
|
||||
* **抽象层会变臃肿。**一旦你定义了一个抽象层,它就开始增加功能。层是对使用模式优化的自然分界点。臃肿的层的困难在于,它往往会降低您利用底层的不断创新的能力。从某种意义上说,这就是操作系统公司憎恨构建在其核心功能之上的臃肿的层的原因——采用创新的速度放缓了。避免这种情况的一种比较规矩的方法是禁止在适配器层中进行任何额外的状态存储。微软基础类在 Win32 上采用这个一般方法。在短期内,将功能集成到现有层(最终会导致上述所有问题)而不是重构和重新推导是不可避免的。理解这一点的系统设计人员寻找分解和简化组件的方法,而不是在其中增加越来越多的功能。
|
||||
|
||||
* 层具有太多功能了。您所采用的组件具有比实际需要更多的功能,这几乎是一个真理。在某些情况下,你决定采用这个组件是因为你想在将来使用那些尚未用到的功能。有时,你采用组件是想“上快车”,利用组件完成正在进行的工作。在功能强大的抽象层上开发会带来一些后果。1) 组件往往会根据你并不需要的功能作出取舍。 2) 为了实现那些你并不没有用到的功能,组件引入了复杂性和约束,这些约束将阻碍该组件的未来的演变。3) 层泄漏的范围更大。一些泄漏是由于真正的“抽象泄漏”,另一些是由于明显的,逐渐增加的对组件全部功能的依赖(但这些依赖通常都没有处理好)。Office 太大了,我们发现,对于我们建立的任何抽象层,我们最终都在系统的某个部分完全运用了它的功能。虽然这看起来是积极的(我们完全地利用了这个组件),但并不是所用的使用都有同样的价值。所以,我们最终要付出巨大的代价才能从一个抽象层往另一个抽象层迁移,这种“长尾巴”没什么价值,并且对使用场景认识不足。4) 附加的功能会增加复杂性,并增加功能滥用的可能。如果将验证 XML 的 API 指定为 XML 树的一部分,那这个 API 可以选择动态下载 XML 的模式定义。这在我们的基本文件解析代码中被错误地执行,导致 w3c.org 服务器上的大量性能下降以及(无意)分布式拒绝服务攻击。(这些被通俗地称为“地雷”API)。
|
||||
### 爱因斯坦宇宙
|
||||
|
||||
* 抽象层被更换。需求发展,系统发展,组件被放弃。您最终需要更换该抽象层或组件。不管是对外部组件的依赖还是对内部组件的依赖都是如此。这意味着上述问题将变得重要起来。
|
||||
|
||||
* 自己构建还是购买的决定将会改变。这是上面几方面的必然结果。这并不意味着自己构建还是购买的决定在当时是错误的。一开始时往往没有合适的组件,一段时间之后才有合适的组件出现。或者,也可能你使用了一个组件,但最终发现它不符合您不断变化的要求,而且你的要求非常窄,能被理解,或着对你的价值体系来说是非常重要的,以至于拥有自己的模块是有意义的。这意味着你像关心自己构造的模块一样,关心购买的模块,关心它们是怎样泄漏并深入你的系统中的。
|
||||
|
||||
* 抽象层会变臃肿。一旦你定义了一个抽象层,它就开始增加功能。层是对使用模式优化的自然分界点。臃肿的层的困难在于,它往往会降低您利用底层的不断创新的能力。从某种意义上说,这就是操作系统公司憎恨构建在其核心功能之上的臃肿的层的原因——采用创新的速度放缓了。避免这种情况的一种比较规矩的方法是禁止在适配器层中进行任何额外的状态存储。微软基础类在 Win32 上采用这个一般方法。在短期内,将功能集成到现有层(最终会导致上述所有问题)而不是重构和重新推导是不可避免的。理解这一点的系统设计人员寻找分解和简化组件的方法,而不是在其中增加越来越多的功能。
|
||||
|
||||
爱因斯坦宇宙
|
||||
|
||||
几十年来,我一直在设计异步分布式系统,但是在微软内部的一次演讲中,SQL 架构师 Pat Helland 的一句话震惊了我。 “我们生活在爱因斯坦的宇宙中,没有同时性。”在构建分布式系统时(基本上我们构建的都是分布式系统),你无法隐藏系统的分布式特性。这是物理的。我一直感到远程过程调用在根本上错误的,这是一个原因,尤其是那些“透明的”远程过程调用,它们就是想隐藏分布式的交互本质。你需要拥抱系统的分布式特性,因为这些意义几乎总是需要通过系统设计和用户体验来完成。
|
||||
几十年来,我一直在设计异步分布式系统,但是在微软内部的一次演讲中,SQL 架构师 Pat Helland 的一句话震惊了我。 “我们生活在爱因斯坦的宇宙中,没有同时性这种东西。”在构建分布式系统时(基本上我们构建的都是分布式系统),你无法隐藏系统的分布式特性。这是物理的。我一直感到远程过程调用在根本上错误的,这是一个原因,尤其是那些“透明的”远程过程调用,它们就是想隐藏分布式的交互本质。你需要拥抱系统的分布式特性,因为这些意义几乎总是需要通过系统设计和用户体验来完成。
|
||||
|
||||
拥抱分布式系统的本质则要遵循以下几个方面:
|
||||
|
||||
* 一开始就要思考设计对用户体验的影响,而不是试图在处理错误,取消请求和报告状态上打补丁。
|
||||
|
||||
* 使用异步技术来耦合组件。同步耦合是*不可能*的。如果某些行为看起来是同步的,是因为某些内部层尝试隐藏异步,这样做会遮蔽(但绝对不隐藏)系统运行时的基本行为特征。
|
||||
|
||||
* 认识到并且明确设计了交互状态机,这些状态表示长期的可靠的内部系统状态(而不是由深度调用堆栈中的变量值编码的临时,短暂和不可发现的状态)。
|
||||
|
||||
* 认识到失败是在所难免的。要保证能检测出分布式系统中的失败,唯一的办法就是直接看你的等待时间是否“太长”。这自然意味着[取消的等级最高][2]。系统的某一层(可能直接通向用户)需要决定等待时间是否过长,并取消操作。取消只是为了重建局部状态,回收局部的资源——没有办法在系统内广泛使用取消机制。有时用一种低成本,不可靠的方法广泛使用取消机制对优化性能可能有用。
|
||||
|
||||
* 认识到取消不是回滚,因为它只是回收本地资源和状态。如果回滚是必要的,它必须实现成一个端到端的功能。
|
||||
|
||||
* 承认永远不会真正知道分布式组件的状态。只要你发现一个状态,它可能就已经改变了。当你发送一个操作时,请求可能在传输过程中丢失,也可能被处理了但是返回的响应丢失了,或者请求需要一定的时间来处理,这样远程状态最终会在未来的某个任意的时间转换。这需要像幂等操作这样的方法,并且要能够稳健有效地重新发现远程状态,而不是期望可靠地跟踪分布式组件的状态。“[最终一致性][3]”的概念简洁地捕捉了这其中大多数想法。
|
||||
|
||||
我喜欢说你应该“陶醉在异步”。与其试图隐藏异步,不如接受异步,为异步而设计。当你看到像幂等性或不变性这样的技术时,你就认识到它们是拥抱宇宙本质的方法,而不仅仅是工具箱中的一个设计工具。
|
||||
|
||||
性能
|
||||
### 性能
|
||||
|
||||
我确信 Don Knuth 会对人们怎样误解他的名言“过早的优化是一切罪恶的根源”而感到震惊。事实上,性能,及性能持续超过60年的指数增长(或超过10年,取决于您是否愿意将晶体管,真空管和机电继电器的发展算入其中),为所有行业内的惊人创新和影响经济的“软件吃遍世界”的变化打下了基础。
|
||||
我确信 Don Knuth 会对人们怎样误解他的名言“过早的优化是一切罪恶的根源”而感到震惊。事实上,性能,及性能的持续超过 60 年的指数增长(或超过 10 年,取决于您是否愿意将晶体管,真空管和机电继电器的发展算入其中),为所有行业内的惊人创新和影响经济的“软件吃掉全世界”的变化打下了基础。
|
||||
|
||||
要认识到这种指数变化的一个关键是,虽然系统的所有组件正在经历指数变化,但这些指数是不同的。硬盘容量的增长速度与内存容量的增长速度不同,与 CPU 的增长速度不同,与内存 CPU 之间的延迟的性能改善速度也不用。即使性能发展的趋势是由相同的基础技术驱动的,增长的指数也会有分歧。[延迟的改进从根本上改善了带宽][7]。指数变化在近距离或者短期内看起来是线性的,但随着时间的推移可能是压倒性的。系统不同组件的性能的增长不同,会出现压倒性的变化,并迫使对设计决策定期进行重新评估。
|
||||
要认识到这种指数变化的一个关键是,虽然系统的所有组件正在经历指数级变化,但这些指数是不同的。硬盘容量的增长速度与内存容量的增长速度不同,与 CPU 的增长速度不同,与内存 CPU 之间的延迟的性能改善速度也不用。即使性能发展的趋势是由相同的基础技术驱动的,增长的指数也会有分歧。[延迟的改进从根本上改善了带宽][7]。指数变化在近距离或者短期内看起来是线性的,但随着时间的推移可能是压倒性的。系统不同组件的性能的增长不同,会出现压倒性的变化,并迫使对设计决策定期进行重新评估。
|
||||
|
||||
这样做的结果是,几年后,一度有意义的设计决定就不再有意义了。或者在某些情况下,二十年前有意义的方法又开始变成一个好的决定。现代内存映射的特点看起来更像是早期分时的进程切换,而不像分页那样。 (这样做有时会让我这样的老人说“这就是我们在 1975 年时用的方法”——忽略了这种方法在 40 年都没有意义,但现在又重新成为好的方法,因为两个组件之间的关系——可能是闪存和 NAND 而不是磁盘和核心内存——已经变得像以前一样了)。
|
||||
这样做的结果是,几年后,一度有意义的设计决策就不再有意义了。或者在某些情况下,二十年前有意义的方法又开始变成一个好的决策。现代内存映射的特点看起来更像是早期分时的进程切换,而不像分页那样。 (这样做有时会让我这样的老人说“这就是我们在 1975 年时用的方法”——忽略了这种方法在 40 年都没有意义,但现在又重新成为好的方法,因为两个组件之间的关系——可能是闪存和 NAND 而不是磁盘和核心内存——已经变得像以前一样了)。
|
||||
|
||||
当这些指数超越人自身的限制时,重要的转变就发生了。你能从 2 的 16 次方个字符(一个人可以在几个小时打这么多字)过渡到 2 的 3 次方个字符(远超出了一个人打字的范围)。你可以捕捉比人眼能感知的分辨率更高的数字图像。或者你可以将整个音乐专辑存在小巧的磁盘上,放在口袋里。或者你可以将数字化视频录制存储在硬盘上。再通过实时流式传输的能力,可以在一个地方集中存储一次,不需要在数千个本地硬盘上重复记录。
|
||||
当这些指数超越人自身的限制时,重要的转变就发生了。你能从 2 的 16 次方个字符(一个人可以在几个小时打这么多字)过渡到 2 的 32 次方个字符(远超出了一个人打字的范围)。你可以捕捉比人眼能感知的分辨率更高的数字图像。或者你可以将整个音乐专辑存在小巧的磁盘上,放在口袋里。或者你可以将数字化视频录制存储在硬盘上。再通过实时流式传输的能力,可以在一个地方集中存储一次,不需要在数千个本地硬盘上重复记录。
|
||||
|
||||
但有的东西仍然是根本的限制条件,那就是空间的三维和光速。我们又回到了爱因斯坦的宇宙。内存的分级结构将始终存在——它是物理定律的基础。稳定的存储和 IO,内存,计算和通信也都将一直存在。这些模块的相对容量,延迟和带宽将会改变,但是系统始终要考虑这些元素如何组合在一起,以及它们之间的平衡和折衷。Jim Gary 是这方面的大师。
|
||||
但有的东西仍然是根本的限制条件,那就是空间的三维和光速。我们又回到了爱因斯坦的宇宙。内存的分级结构将始终存在——它是物理定律的基础。稳定的存储和 IO、内存、计算和通信也都将一直存在。这些模块的相对容量,延迟和带宽将会改变,但是系统始终要考虑这些元素如何组合在一起,以及它们之间的平衡和折衷。Jim Gary 是这方面的大师。
|
||||
|
||||
空间和光速的根本限制造成的另一个后果是,性能分析主要是关于三件事:局部化 (locality),局部化,局部化。无论是将数据打包在磁盘上,管理处理器缓存的层次结构,还是将数据合并到通信数据包中,数据如何打包在一起,如何在一段时间内从局部获取数据,数据如何在组件之间传输数据是性能的基础。把重点放在减少管理数据的代码上,增加空间和时间上的局部性,是消除噪声的好办法。
|
||||
空间和光速的根本限制造成的另一个后果是,性能分析主要是关于三件事:<ruby>局部化<rt>locality</rt></ruby>、<ruby>局部化<rt>locality</rt></ruby>、<ruby>局部化<rt>locality</rt></ruby>。无论是将数据打包在磁盘上,管理处理器缓存的层次结构,还是将数据合并到通信数据包中,数据如何打包在一起,如何在一段时间内从局部获取数据,数据如何在组件之间传输数据是性能的基础。把重点放在减少管理数据的代码上,增加空间和时间上的局部性,是消除噪声的好办法。
|
||||
|
||||
Jon Devaan 曾经说过:“设计数据,而不是设计代码”。这也通常意味着当查看系统结构时,我不太关心代码如何交互——我想看看数据如何交互和流动。如果有人试图通过描述代码结构来解释一个系统,而不理解数据流的速率和数量,他们就不了解这个系统。
|
||||
|
||||
内存的层级结构也意味着我缓存将会一直存在——即使某些系统层正在试图隐藏它。缓存是根本的,但也是危险的。缓存试图利用代码的运行时行为,来改变系统中不同组件之间的交互模式。它们需要对运行时行为进行建模,即使模型填充缓存并使缓存失效,并测试缓存命中。如果模型由于行为改变而变差或变得不佳,缓存将无法按预期运行。一个简单的指导方针是,缓存必须被检测——由于应用程序行为的改变,事物不断变化的性质和组件之间性能的平衡,缓存的行为将随着时间的推移而退化。每一个老程序员都有缓存变糟的经历。
|
||||
内存的层级结构也意味着缓存将会一直存在——即使某些系统层正在试图隐藏它。缓存是根本的,但也是危险的。缓存试图利用代码的运行时行为,来改变系统中不同组件之间的交互模式。它们需要对运行时行为进行建模,即使模型填充缓存并使缓存失效,并测试缓存命中。如果模型由于行为改变而变差或变得不佳,缓存将无法按预期运行。一个简单的指导方针是,缓存必须被检测——由于应用程序行为的改变,事物不断变化的性质和组件之间性能的平衡,缓存的行为将随着时间的推移而退化。每一个老程序员都有缓存变糟的经历。
|
||||
|
||||
我很幸运,我的早期职业生涯是在互联网的发源地之一 BBN 度过的。 我们很自然地将将异步组件之间的通信视为系统连接的自然方式。流量控制和队列理论是通信系统的基础,更是任何异步系统运行的方式。流量控制本质上是资源管理(管理通道的容量),但资源管理是更根本的关注点。流量控制本质上也应该由端到端的应用负责,所以用端到端的方式思考异步系统是自然的。[缓冲区膨胀][8]的故事在这种情况下值得研究,因为它展示了当对端到端行为的动态性以及技术“改进”(路由器中更大的缓冲区)缺乏理解时,在整个网络基础设施中导致的长久的问题。
|
||||
|
||||
我发现“光速”的概念在分析任何系统时都非常有用。光速分析并不是从当前的性能开始分析,而是问“这个设计理论上能达到的最佳性能是多少?”真正传递的信息是什么,以什么样的速度变化?组件之间的底层延迟和带宽是多少?光速分析迫使设计师深入思考他们的方法能否达到性能目标,或者否需要重新考虑设计的基本方法。它也迫使人们更深入地了解性能在哪里损耗,以及损耗是由固有的,还是由于一些不当行为产生的。从构建的角度来看,它迫使系统设计人员了解其构建的模块的真实性能特征,而不是关注其他功能特性。
|
||||
我发现“<ruby>光速<rt>light speed</rt></ruby>”的概念在分析任何系统时都非常有用。光速分析并不是从当前的性能开始分析,而是问“这个设计理论上能达到的最佳性能是多少?”真正传递的信息是什么,以什么样的速度变化?组件之间的底层延迟和带宽是多少?光速分析迫使设计师深入思考他们的方法能否达到性能目标,或者否需要重新考虑设计的基本方法。它也迫使人们更深入地了解性能在哪里损耗,以及损耗是由固有的,还是由于一些不当行为产生的。从构建的角度来看,它迫使系统设计人员了解其构建的模块的真实性能特征,而不是关注其他功能特性。
|
||||
|
||||
我的职业生涯大多花费在构建图形应用程序上。用户坐在系统的一端,定义关键的常量和约束。人类的视觉和神经系统没有经历过指数性的变化。它们固有地受到限制,这意味着系统设计者可以利用(必须利用)这些限制,例如,通过虚拟化(限制底层数据模型需要映射到视图数据结构中的数量),或者通过将屏幕更新的速率限制到人类视觉系统的感知限制。
|
||||
|
||||
复杂性的本质
|
||||
### 复杂性的本质
|
||||
|
||||
我的整个职业生涯都在与复杂性做斗争。为什么系统和应用变得复杂呢?为什么在一个应用领域内进行开发并没有随着时间变得简单,而基础设施却没有变得更复杂,反而变得更强大了?事实上,管理复杂性的一个关键方法就是“走开”然后重新开始。通常新的工具或语言迫使我们从头开始,这意味着开发人员将工具的优点与从新开始的优点结合起来。从新开始是重要的。这并不是说新工具,新平台,或新语言可能不好,但我保证它们不能解决复杂性增长的问题。控制复杂性的最简单的方法就是用更少的程序员,建立一个更小的系统。
|
||||
|
||||
当然,很多情况下“走开”并不是一个选择——Office 建立在有巨大的价值的复杂的资源上。通过 OneNote, Office 从 Word 的复杂性上“走开”,从而在另一个维度上进行创新。Sway 是另一个例子, Office 决定从限制中跳出来,利用关键的环境变化,抓住机会从底层上采取全新的设计方案。我们有 Word,Excel,PowerPoint 这些应用,它们的数据结构非常有价值,我们并不能完全放弃这些数据结构,它们成为了开发中持续的显著的限制条件。
|
||||
当然,很多情况下“走开”并不是一个选择——Office 软件建立在有巨大的价值的复杂的资源上。通过 OneNote, Office 从 Word 的复杂性上“走开”,从而在另一个维度上进行创新。Sway 是另一个例子, Office 决定从限制中跳出来,利用关键的环境变化,抓住机会从底层上采取全新的设计方案。我们有 Word、Excel、PowerPoint 这些应用,它们的数据结构非常有价值,我们并不能完全放弃这些数据结构,它们成为了开发中持续的显著的限制条件。
|
||||
|
||||
我受到 Fred Brook 讨论软件开发中的意外和本质的文章[《没有银子弹》][9]的影响,他希望用两个趋势来尽可能地推动程序员的生产力:一是在选择自己开发还是购买时,更多地关注购买——这预示了开源社区和云架构的改变;二是从单纯的构建方法转型到更“有机”或者“生态”的增量开发方法。现代的读者可以认为是向敏捷开发和持续开发的转型。但那篇文章可是写于 1986 年!
|
||||
我受到 Fred Brook 讨论软件开发中的意外和本质的文章[《没有银弹》][9]的影响,他希望用两个趋势来尽可能地推动程序员的生产力:一是在选择自己开发还是购买时,更多地关注购买——这预示了开源社区和云架构的改变;二是从单纯的构建方法转型到更“有机”或者“生态”的增量开发方法。现代的读者可以认为是向敏捷开发和持续开发的转型。但那篇文章可是写于 1986 年!
|
||||
|
||||
我很欣赏 Stuart Kauffman 的在复杂性的基本性上的研究工作。Kauffman 从一个简单的布尔网络模型(“[NK 模型][10]”)开始建立起来,然后探索这个基本的数学结构在相互作用的分子,基因网络,生态系统,经济系统,计算机系统(以有限的方式)等系统中的应用,来理解紧急有序行为的数学基础及其与混沌行为的关系。在一个高度连接的系统中,你固有地有一个相互冲突的约束系统,使得它(在数学上)很难向前发展(这被看作是在崎岖景观上的优化问题)。控制这种复杂性的基本方法是将系统分成独立元素并限制元素之间的相互连接(实质上减少 NK 模型中的“N”和“K”)。当然对那些使用复杂隐藏,信息隐藏和数据抽象,并且使用松散异步耦合来限制组件之间的交互的技术的系统设计者来说,这是很自然的。
|
||||
|
||||
|
||||
我们一直面临的一个挑战是,我们想到的许多拓展系统的方法,都跨越了所有的方面。实时共同编辑是 Office 应用程序最近的一个非常具体的(也是最复杂的)例子。
|
||||
|
||||
我们的数据模型的复杂性往往等同于“能力”。设计用户体验的固有挑战是我们需要将有限的一组手势,映射到底层数据模型状态空间的转换。增加状态空间的维度不可避免地在用户手势中产生模糊性。这是“[纯数学][11]”,这意味着确保系统保持“易于使用”的最基本的方式常常是约束底层的数据模型。
|
||||
|
||||
管理
|
||||
### 管理
|
||||
|
||||
我从高中开始着手一些领导角色(学生会主席!),对承担更多的责任感到理所当然。同时,我一直为自己在每个管理阶段都坚持担任全职程序员而感到自豪。但 Office 的开发副总裁最终还是让我从事管理,离开了日常的编程工作。当我在去年离开那份工作时,我很享受重返编程——这是一个出奇地充满创造力的充实的活动(当修完“最后”的 bug 时,也许也会有一点令人沮丧)。
|
||||
我从高中开始担任一些领导角色(学生会主席!),对承担更多的责任感到理所当然。同时,我一直为自己在每个管理阶段都坚持担任全职程序员而感到自豪。但 Office 软件的开发副总裁最终还是让我从事管理,离开了日常的编程工作。当我在去年离开那份工作时,我很享受重返编程——这是一个出奇地充满创造力的充实的活动(当修完“最后”的 bug 时,也许也会有一点令人沮丧)。
|
||||
|
||||
尽管在我加入微软前已经做了十多年的“主管”,但是到了 1996 年我加入微软才真正了解到管理。微软强调“工程领导是技术领导”。这与我的观点一致,帮助我接受并承担更大的管理责任。
|
||||
|
||||
@ -124,21 +118,19 @@ Jon Devaan 曾经说过:“设计数据,而不是设计代码”。这也通
|
||||
|
||||
我过去说我的工作是设计反馈回路。独立工程师,经理,行政人员,每一个项目的参与者都能通过分析记录的项目数据,推进项目,产出结果,了解自己在整个项目中扮演的角色。最终,透明化最终成为增强能力的一个很好的工具——管理者可以将更多的局部控制权给予那些最接近问题的人,因为他们对所取得的进展有信心。这样的话,合作自然就会出现。
|
||||
|
||||
Key to this is that the goal has actually been properly framed (including key resource constraints like ship schedule). Decision-making that needs to constantly flow up and down the management chain usually reflects poor framing of goals and constraints by management.
|
||||
|
||||
关键需要确定目标框架(包括关键资源的约束,如发布的时间表)。如果决策需要在管理链上下不断流动,那说明管理层对目标和约束的框架不好。
|
||||
|
||||
当我在 Beyond Software 工作时,我真正理解了一个项目拥有一个唯一领导的重要性。原来的项目经理离职了(后来从 FrontPage 雇佣了我)。我们四个主管在是否接任这个岗位上都有所犹豫,这不仅仅由于我们都不知道要在这家公司坚持多久。我们都技术高超,并且相处融洽,所以我们决定以同级的身份一起来领导这个项目。然而这槽糕透了。有一个显而易见的问题,我们没有相应的战略用来在原有的组织之间分配资源——这应当是管理者的首要职责之一!当你知道你是唯一的负责人时,你会有很深的责任感,但在这个例子中,这种责任感缺失了。我们没有真正的领导来负责统一目标和界定约束。
|
||||
当我在 Beyond Software 工作时,我真正理解了一个项目拥有一个唯一领导的重要性。原来的项目经理离职了(后来从 FrontPage 团队雇佣了我)。我们四个主管在是否接任这个岗位上都有所犹豫,这不仅仅由于我们都不知道要在这家公司坚持多久。我们都技术高超,并且相处融洽,所以我们决定以同级的身份一起来领导这个项目。然而这槽糕透了。有一个显而易见的问题,我们没有相应的战略用来在原有的组织之间分配资源——这应当是管理者的首要职责之一!当你知道你是唯一的负责人时,你会有很深的责任感,但在这个例子中,这种责任感缺失了。我们没有真正的领导来负责统一目标和界定约束。
|
||||
|
||||
我有清晰地记得,我第一次充分认识到*倾听*对一个领导者的重要性。那时我刚刚担任了 Word,OneNote,Publisher 和 Text Services 团队的开发经理。关于我们如何组织文本服务团队,我们有一个很大的争议,我走到了每个关键参与者身边,听他们想说的话,然后整合起来,写下了我所听到的一切。当我向其中一位主要参与者展示我写下的东西时,他的反应是“哇,你真的听了我想说的话”!作为一名管理人员,我所经历的所有最大的问题(例如,跨平台和转型持续工程)涉及到仔细倾听所有的参与者。倾听是一个积极的过程,它包括:尝试以别人的角度去理解,然后写出我学到的东西,并对其进行测试,以验证我的理解。当一个关键的艰难决定需要发生的时候,在最终决定前,每个人都知道他们的想法都已经被听到并理解(不论他们是否同意最后的决定)。
|
||||
我有清晰地记得,我第一次充分认识到*倾听*对一个领导者的重要性。那时我刚刚担任了 Word、OneNote、Publisher 和 Text Services 团队的开发经理。关于我们如何组织文本服务团队,我们有一个很大的争议,我走到了每个关键参与者身边,听他们想说的话,然后整合起来,写下了我所听到的一切。当我向其中一位主要参与者展示我写下的东西时,他的反应是“哇,你真的听了我想说的话”!作为一名管理人员,我所经历的所有最大的问题(例如,跨平台和转型持续工程)涉及到仔细倾听所有的参与者。倾听是一个积极的过程,它包括:尝试以别人的角度去理解,然后写出我学到的东西,并对其进行测试,以验证我的理解。当一个关键的艰难决定需要发生的时候,在最终决定前,每个人都知道他们的想法都已经被听到并理解(不论他们是否同意最后的决定)。
|
||||
|
||||
在 FrontPage 担任开发经理的工作,让我理解了在只有部分信息的情况下做决定的“操作困境”。你等待的时间越长,你就会有更多的信息做出决定。但是等待的时间越长,实际执行的灵活性就越低。在某个时候,你仅需要做出决定。
|
||||
在 FrontPage 团队担任开发经理的工作,让我理解了在只有部分信息的情况下做决定的“操作困境”。你等待的时间越长,你就会有更多的信息做出决定。但是等待的时间越长,实际执行的灵活性就越低。在某个时候,你仅需要做出决定。
|
||||
|
||||
设计一个组织涉及类似的两难情形。您希望增加资源领域,以便可以在更大的一组资源上应用一致的优先级划分框架。但资源领域越大,越难获得作出决定所需要的所有信息。组织设计就是要平衡这两个因素。软件复杂化,因为软件的特点可以在任意维度切入设计。Office 已经使用[共享团队][12]来解决这两个问题(优先次序和资源),让跨领域的团队能与需要产品的团队分享工作(增加资源)。
|
||||
设计一个组织涉及类似的两难情形。您希望增加资源领域,以便可以在更大的一组资源上应用一致的优先级划分框架。但资源领域越大,越难获得作出决定所需要的所有信息。组织设计就是要平衡这两个因素。软件复杂化,因为软件的特点可以在任意维度切入设计。Office 软件部门已经使用[共享团队][12]来解决这两个问题(优先次序和资源),让跨领域的团队能与需要产品的团队分享工作(增加资源)。
|
||||
|
||||
随着管理阶梯的提升,你会懂一个小秘密:你和你的新同事不会因为你现在承担更多的责任,就突然变得更聪明。这强调了整个组织比顶层领导者更聪明。赋予每个级别在一致框架下拥有自己的决定是实现这一目标的关键方法。听取并使自己对组织负责,阐明和解释决策背后的原因是另一个关键策略。令人惊讶的是,害怕做出一个愚蠢的决定可能是一个有用的激励因素,以确保你清楚地阐明你的推理,并确保你听取所有的信息。
|
||||
|
||||
结语
|
||||
### 结语
|
||||
|
||||
我离开大学寻找第一份工作时,面试官在最后一轮面试时问我对做“系统”和做“应用”哪一个更感兴趣。我当时并没有真正理解这个问题。在软件技术栈的每一个层面都会有趣的难题,我很高兴深入研究这些问题。保持学习。
|
||||
|
||||
@ -146,9 +138,9 @@ Key to this is that the goal has actually been properly framed (including key re
|
||||
|
||||
via: https://hackernoon.com/education-of-a-programmer-aaecf2d35312
|
||||
|
||||
作者:[ Terry Crowley][a]
|
||||
作者:[Terry Crowley][a]
|
||||
译者:[explosic4](https://github.com/explosic4)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -7,17 +7,16 @@
|
||||
|
||||
我想在讨论的基础上去写一些笔记,因为,我觉得它超级棒!
|
||||
|
||||
这是 [幻灯片][9] 和一个 [pdf][10]。这个 pdf 非常好,结束的位置有一些链接,在 PDF 中你可以直接点击这个链接。
|
||||
开始前,这里有个 [幻灯片][9] 和一个 [pdf][10]。这个 pdf 非常好,结束的位置有一些链接,在 PDF 中你可以直接点击这个链接。
|
||||
|
||||
### 什么是 BPF?
|
||||
|
||||
在 BPF 出现之前,如果你想去做包过滤,你必须拷贝所有进入用户空间的包,然后才能去过滤它们(使用 “tap”)。
|
||||
在 BPF 出现之前,如果你想去做包过滤,你必须拷贝所有的包到用户空间,然后才能去过滤它们(使用 “tap”)。
|
||||
|
||||
这样做存在两个问题:
|
||||
|
||||
1. 如果你在用户空间中过滤,意味着你将拷贝所有进入用户空间的包,拷贝数据的代价是很昂贵的。
|
||||
|
||||
2. 使用的过滤算法很低效
|
||||
1. 如果你在用户空间中过滤,意味着你将拷贝所有的包到用户空间,拷贝数据的代价是很昂贵的。
|
||||
2. 使用的过滤算法很低效。
|
||||
|
||||
问题 #1 的解决方法似乎很明显,就是将过滤逻辑移到内核中。(虽然具体实现的细节并没有明确,我们将在稍后讨论)
|
||||
|
||||
@ -35,12 +34,11 @@
|
||||
|
||||
### 为什么 BPF 要工作在内核中
|
||||
|
||||
这里的关键点是,包仅仅是个字节的数组。BPF 程序是运行在这些字节的数组上。它们不允许有循环(loops),但是,它们 _可以_ 有聪明的办法知道 IP 包头(IPv6 和 IPv4 长度是不同的)以及基于它们的长度来找到 TCP 端口
|
||||
这里的关键点是,包仅仅是个字节的数组。BPF 程序是运行在这些字节的数组之上。它们不允许有循环(loop),但是,它们 _可以_ 有聪明的办法知道 IP 包头(IPv6 和 IPv4 长度是不同的)以及基于它们的长度来找到 TCP 端口:
|
||||
|
||||
```
|
||||
x = ip_header_length
|
||||
port = *(packet_start + x + port_offset)
|
||||
|
||||
```
|
||||
|
||||
(看起来不一样,其实它们基本上都相同)。在这个论文/幻灯片上有一个非常详细的虚拟机的描述,因此,我不打算解释它。
|
||||
@ -48,13 +46,9 @@ port = *(packet_start + x + port_offset)
|
||||
当你运行 `tcpdump host foo` 后,这时发生了什么?就我的理解,应该是如下的过程。
|
||||
|
||||
1. 转换 `host foo` 为一个高效的 DAG 规则
|
||||
|
||||
2. 转换那个 DAG 规则为 BPF 虚拟机的一个 BPF 程序(BPF 字节码)
|
||||
|
||||
3. 发送 BPF 字节码到 Linux 内核,由 Linux 内核验证它
|
||||
|
||||
4. 编译这个 BPF 字节码程序为一个原生(native)代码。例如, [在 ARM 上是 JIT 代码][1] 以及为 [x86][2] 的机器码
|
||||
|
||||
4. 编译这个 BPF 字节码程序为一个<ruby>原生<rt>native</rt></ruby>代码。例如,这是个[ARM 上的 JIT 代码][1] 以及 [x86][2] 的机器码
|
||||
5. 当包进入时,Linux 运行原生代码去决定是否过滤这个包。对于每个需要去处理的包,它通常仅需运行 100 - 200 个 CPU 指令就可以完成,这个速度是非常快的!
|
||||
|
||||
### 现状:eBPF
|
||||
@ -63,19 +57,15 @@ port = *(packet_start + x + port_offset)
|
||||
|
||||
关于 eBPF 的一些事实是:
|
||||
|
||||
* eBPF 程序有它们自己的字节码语言,并且从那个字节码语言编译成内核原生代码,就像 BPF 程序
|
||||
|
||||
* eBPF 程序有它们自己的字节码语言,并且从那个字节码语言编译成内核原生代码,就像 BPF 程序一样
|
||||
* eBPF 运行在内核中
|
||||
|
||||
* eBPF 程序不能随心所欲的访问内核内存。而是通过内核提供的函数去取得一些受严格限制的所需要的内容的子集。
|
||||
|
||||
* eBPF 程序不能随心所欲的访问内核内存。而是通过内核提供的函数去取得一些受严格限制的所需要的内容的子集
|
||||
* 它们 _可以_ 与用户空间的程序通过 BPF 映射进行通讯
|
||||
|
||||
* 这是 Linux 3.18 的 `bpf` 系统调用
|
||||
|
||||
### kprobes 和 eBPF
|
||||
|
||||
你可以在 Linux 内核中挑选一个函数(任意函数),然后运行一个你写的每次函数被调用时都运行的程序。这样看起来是不是很神奇。
|
||||
你可以在 Linux 内核中挑选一个函数(任意函数),然后运行一个你写的每次该函数被调用时都运行的程序。这样看起来是不是很神奇。
|
||||
|
||||
例如:这里有一个 [名为 disksnoop 的 BPF 程序][12],它的功能是当你开始/完成写入一个块到磁盘时,触发它执行跟踪。下图是它的代码片断:
|
||||
|
||||
@ -92,45 +82,37 @@ b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
|
||||
|
||||
```
|
||||
|
||||
从根本上来说,它声明一个 BPF 哈希(它的作用是当请求开始/完成时,这个程序去触发跟踪),一个名为 `trace_start` 的函数将被编译进 BPF 字节码,然后附加 `trace_start` 到内核函数 `blk_start_request` 上。
|
||||
本质上它声明一个 BPF 哈希(它的作用是当请求开始/完成时,这个程序去触发跟踪),一个名为 `trace_start` 的函数将被编译进 BPF 字节码,然后附加 `trace_start` 到内核函数 `blk_start_request` 上。
|
||||
|
||||
这里使用的是 `bcc` 框架,它可以使你写的 Python 化的程序去生成 BPF 代码。你可以在 [https://github.com/iovisor/bcc][13] 找到它(那里有非常多的示例程序)。
|
||||
这里使用的是 `bcc` 框架,它可以让你写 Python 式的程序去生成 BPF 代码。你可以在 [https://github.com/iovisor/bcc][13] 找到它(那里有非常多的示例程序)。
|
||||
|
||||
### uprobes 和 eBPF
|
||||
|
||||
因为我知道你可以附加 eBPF 程序到内核函数上,但是,我不知道你能否将 eBPF 程序附加到用户空间函数上!那会有更多令人激动的事情。这是 [在 Python 中使用一个 eBPF 程序去计数 malloc 调用的示例][14]。
|
||||
因为我知道可以附加 eBPF 程序到内核函数上,但是,我不知道能否将 eBPF 程序附加到用户空间函数上!那会有更多令人激动的事情。这是 [在 Python 中使用一个 eBPF 程序去计数 malloc 调用的示例][14]。
|
||||
|
||||
### 附加 eBPF 程序时应该考虑的事情
|
||||
|
||||
* 带 XDP 的网卡(我之前写过关于这方面的文章)
|
||||
|
||||
* tc egress/ingress (在网络栈上)
|
||||
|
||||
* kprobes(任意内核函数)
|
||||
|
||||
* uprobes(很明显,任意用户空间函数??像带符号的任意 C 程序)
|
||||
|
||||
* uprobes(很明显,任意用户空间函数??像带调试符号的任意 C 程序)
|
||||
* probes 是为 dtrace 构建的名为 “USDT probes” 的探针(像 [这些 mysql 探针][3])。这是一个 [使用 dtrace 探针的示例程序][4]
|
||||
|
||||
* [JVM][5]
|
||||
|
||||
* 跟踪点
|
||||
|
||||
* seccomp / landlock 安全相关的事情
|
||||
|
||||
* 更多的事情
|
||||
* 等等
|
||||
|
||||
### 这个讨论超级棒
|
||||
|
||||
在幻灯片里有很多非常好的链接,并且在 iovisor 仓库里有个 [LINKS.md][15]。现在已经很晚了,但是,很快我将写我的第一个 eBPF 程序了!
|
||||
在幻灯片里有很多非常好的链接,并且在 iovisor 仓库里有个 [LINKS.md][15]。虽然现在已经很晚了,但是我马上要去写我的第一个 eBPF 程序了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,122 @@
|
||||
ImageMagick 的一些高级图片查看技巧
|
||||
======
|
||||
|
||||
> 用这些 ImageMagick 命令行图像编辑应用的技巧更好的管理你的数码照片集。
|
||||
|
||||

|
||||
|
||||
图片源于 [Internet Archive Book Images](https://www.flickr.com/photos/internetarchivebookimages/14759826206/in/photolist-ougY7b-owgz5y-otZ9UN-waBxfL-oeEpEf-xgRirT-oeMHfj-wPAvMd-ovZgsb-xhpXhp-x3QSRZ-oeJmKC-ovWeKt-waaNUJ-oeHPN7-wwMsfP-oeJGTK-ovZPKv-waJnTV-xDkxoc-owjyCW-oeRqJh-oew25u-oeFTm4-wLchfu-xtjJFN-oxYznR-oewBRV-owdP7k-owhW3X-oxXxRg-oevDEY-oeFjP1-w7ZB6f-x5ytS8-ow9C7j-xc6zgV-oeCpG1-oewNzY-w896SB-wwE3yA-wGNvCL-owavts-oevodT-xu9Lcr-oxZqZg-x5y4XV-w89d3n-x8h6fi-owbfiq),Opensource.com 修改,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)协议
|
||||
|
||||
在我先前的[ImageMagick 入门:使用命令行来编辑图片][1] 文章中,我展示了如何使用 ImageMagick 的菜单栏进行图片的编辑和变换风格。在这篇续文里,我将向你展示使用这个开源的图像编辑器来查看图片的另外方法。
|
||||
|
||||
### 别样的风格
|
||||
|
||||
在深入 ImageMagick 的高级图片查看技巧之前,我想先分享另一个使用 `convert` 达到的有趣但简单的效果,在[上一篇文章][1]中我已经详细地介绍了 `convert` 命令,这个技巧涉及这个命令的 `edge` 和 `negate` 选项:
|
||||
|
||||
```
|
||||
convert DSC_0027.JPG -edge 3 -negate edge3+negate.jpg
|
||||
```
|
||||
|
||||
![在图片上使用 `edge` 和 `negate` 选项][3]
|
||||
|
||||
*使用`edge` 和 `negate` 选项前后的图片对比*
|
||||
|
||||
这些使我更喜爱编辑后的图片:海的外观,作为前景和背景的植被,特别是太阳及其在海上的反射,最后是天空。
|
||||
|
||||
### 使用 display 来查看一系列图片
|
||||
|
||||
假如你跟我一样是个命令行用户,你就知道 shell 为复杂任务提供了更多的灵活性和快捷方法。下面我将展示一个例子来佐证这个观点。ImageMagick 的 `display` 命令可以克服我在 GNOME 桌面上使用 [Shotwell][4] 图像管理器导入图片时遇到的问题。
|
||||
|
||||
Shotwell 会根据每张导入图片的 [Exif][5] 数据,创建以图片被生成或者拍摄时的日期为名称的目录结构。最终的效果是最上层的目录以年命名,接着的子目录是以月命名 (01、 02、 03 等等),然后是以每月的日期命名的子目录。我喜欢这种结构,因为当我想根据图片被创建或者拍摄时的日期来查找它们时将会非常方便。
|
||||
|
||||
但这种结构也并不是非常完美的,当我想查看最近几个月或者最近一年的所有图片时就会很麻烦。使用常规的图片查看器,我将不停地在不同层级的目录间跳转,但 ImageMagick 的 `display` 命令可以使得查看更加简单。例如,假如我想查看最近一年的图片,我便可以在命令行中键入下面的 `display` 命令:
|
||||
|
||||
```
|
||||
display -resize 35% 2017/*/*/*.JPG
|
||||
```
|
||||
|
||||
我可以一个月又一个月,一天又一天地遍历这一年。
|
||||
|
||||
现在假如我想查看某张图片,但我不确定我是在 2016 年的上半年还是在 2017 的上半年拍摄的,那么我便可以使用下面的命令来找到它:
|
||||
|
||||
```
|
||||
display -resize 35% 201[6-7]/0[1-6]/*/*.JPG
|
||||
```
|
||||
|
||||
这限制查看的图片拍摄于 2016 和 2017 年的一月到六月
|
||||
|
||||
### 使用 montage 来查看图片的缩略图
|
||||
|
||||
假如现在我要查找一张我想要编辑的图片,使用 `display` 的一个问题是它只会显示每张图片的文件名,而不显示其在目录结构中的位置,所以想要找到那张图片并不容易。另外,假如我很偶然地在从相机下载图片的过程中将这些图片从相机的内存里面清除了它们,结果使得下次拍摄照片的名称又从 `DSC_0001.jpg` 开始命名,那么当使用 `display` 来展示一整年的图片时,将会在这 12 个月的图片中花费很长的时间来查找它们。
|
||||
|
||||
这时 `montage` 命令便可以派上用场了。它可以将一系列的图片缩略图放在一张图片中,这样就会非常有用。例如可以使用下面的命令来完成上面的任务:
|
||||
|
||||
```
|
||||
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-4]/*/*.JPG 2017JanApr.jpg
|
||||
```
|
||||
|
||||
从左到右,这个命令以标签开头,标签的形式是包含文件名(`%f`)和以 `/` 分割的目录(`%d`)结构,接着这个命令以目录的名称(2017)来作为标题,然后将图片排成 5 列,每个图片缩放为 10% (这个参数可以很好地匹配我的屏幕)。`geometry` 的设定将在每张图片的四周留白,最后指定那些图片要包括到这张合成图片中,以及一个合适的文件名称(`2017JanApr.jpg`)。现在图片 `2017JanApr.jpg` 便可以成为一个索引,使得我可以不时地使用它来查看这个时期的所有图片。
|
||||
|
||||
### 注意内存消耗
|
||||
|
||||
你可能会好奇为什么我在上面的合成图中只特别指定了为期 4 个月(从一月到四月)的图片。因为 `montage` 将会消耗大量内存,所以你需要多加注意。我的相机产生的图片每张大约有 2.5MB,我发现我的系统可以很轻松地处理 60 张图片。但一旦图片增加到 80 张,如果此时还有另外的程序(例如 Firefox 、Thunderbird)在后台工作,那么我的电脑将会死机,这似乎和内存使用相关,`montage`可能会占用可用 RAM 的 80% 乃至更多(你可以在此期间运行 `top` 命令来查看内存占用)。假如我关掉其他的程序,我便可以在我的系统死机前处理 80 张图片。
|
||||
|
||||
下面的命令可以让你知晓在你运行 `montage` 命令前你需要处理图片张数:
|
||||
|
||||
```
|
||||
ls 2017/0[1-4/*/*.JPG > filelist; wc -l filelist
|
||||
```
|
||||
|
||||
`ls` 命令生成我们搜索的文件的列表,然后通过重定向将这个列表保存在任意以名为 `filelist` 的文件中。接着带有 `-l` 选项的 `wc` 命令输出该列表文件共有多少行,换句话说,展示出了需要处理的文件个数。下面是我运行命令后的输出:
|
||||
|
||||
```
|
||||
163 filelist
|
||||
```
|
||||
|
||||
啊呀!从一月到四月我居然有 163 张图片,使用这些图片来创建一张合成图一定会使得我的系统死机的。我需要将这个列表减少点,可能只处理到 3 月份或者更早的图片。但如果我在 4 月 20 号到 30 号期间拍摄了很多照片,我想这便是问题的所在。下面的命令便可以帮助指出这个问题:
|
||||
|
||||
```
|
||||
ls 2017/0[1-3]/*/*.JPG > filelist; ls 2017/04/0[1-9]/*.JPG >> filelist; ls 2017/04/1[0-9]/*.JPG >> filelist; wc -l filelist
|
||||
```
|
||||
|
||||
上面一行中共有 4 个命令,它们以分号分隔。第一个命令特别指定从一月到三月期间拍摄的照片;第二个命令使用 `>>` 将拍摄于 4 月 1 日至 9 日的照片追加到这个列表文件中;第三个命令将拍摄于 4 月 10 日到 19 日的照片追加到列表中。最终它的显示结果为:
|
||||
|
||||
```
|
||||
81 filelist
|
||||
```
|
||||
|
||||
我知道假如我关掉其他的程序,处理 81 张图片是可行的。
|
||||
|
||||
使用 `montage` 来处理它们是很简单的,因为我们只需要将上面所做的处理添加到 `montage` 命令的后面即可:
|
||||
|
||||
```
|
||||
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-3]/*/*.JPG 2017/04/0[1-9]/*.JPG 2017/04/1[0-9]/*.JPG 2017Jan01Apr19.jpg
|
||||
```
|
||||
|
||||
从左到右,`montage` 命令后面最后的那个文件名将会作为输出,在它之前的都是输入。这个命令将花费大约 3 分钟来运行,并生成一张大小约为 2.5MB 的图片,但我的系统只是有一点反应迟钝而已。
|
||||
|
||||
### 展示合成图片
|
||||
|
||||
当你第一次使用 `display` 查看一张巨大的合成图片时,你将看到合成图的宽度很合适,但图片的高度被压缩了,以便和屏幕相适应。不要慌,只需要左击图片,然后选择 `View > Original Size` 便会显示整个图片。再次点击图片便可以使菜单栏隐藏。
|
||||
|
||||
我希望这篇文章可以在你使用新方法查看图片时帮助你。在我的下一篇文章中,我将讨论更加复杂的图片操作技巧。
|
||||
|
||||
### 作者简介
|
||||
|
||||
Greg Pittman - Greg 肯塔基州路易斯维尔的一名退休的神经科医生,对计算机和程序设计有着长期的兴趣,最早可以追溯到 1960 年代的 Fortran IV 。当 Linux 和开源软件相继出现时,他开始学习更多的相关知识,并分享自己的心得。他是 Scribus 团队的成员。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/9/imagemagick-viewing-images
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://linux.cn/article-8851-1.html
|
||||
[3]:https://opensource.com/sites/default/files/u128651/edge3negate.jpg "Using the edge and negate options on an image."
|
||||
[4]:https://wiki.gnome.org/Apps/Shotwell
|
||||
[5]:https://en.wikipedia.org/wiki/Exif
|
||||
120
published/20171109 Testing IPv6 Networking in KVM- Part 2.md
Normal file
120
published/20171109 Testing IPv6 Networking in KVM- Part 2.md
Normal file
@ -0,0 +1,120 @@
|
||||
在 KVM 中测试 IPv6 网络:第 2 部分
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们又见面了,在上一篇 [在 KVM 中测试 IPv6 网络:第 1 部分][1] 中,我们学习了有关 IPv6 私有地址的内容。今天,我们将使用 KVM 创建一个网络,去测试上一星期学习的 IPv6 的内容。
|
||||
|
||||
如果你想重新温习如何使用 KVM,可以查看 [在 KVM 中创建虚拟机:第 1 部分][2] 和 [在 KVM 中创建虚拟机:第 2 部分— 网络][3]。
|
||||
|
||||
### 在 KVM 中创建网络
|
||||
|
||||
在 KVM 中你至少需要两个虚拟机。当然了,如果你愿意,也可以创建更多的虚拟机。在我的系统中有 Fedora、Ubuntu、以及 openSUSE。去创建一个新的 IPv6 网络,在主虚拟机管理窗口中打开 “Edit > Connection Details > Virtual Networks”。点击左下角的绿色十字按钮去创建一个新的网络(图 1)。
|
||||
|
||||

|
||||
|
||||
*图 1:创建一个网络*
|
||||
|
||||
给新网络输入一个名字,然后,点击 “Forward” 按钮。如果你愿意,也可以不创建 IPv4 网络。当你创建一个新的 IPv4 网络时,虚拟机管理器将不让你创建重复网络,或者是使用了一个无效地址。在我的宿主机 Ubuntu 系统上,有效的地址是以绿色高亮显示的,而无效地址是使用高亮的玫瑰红色调。在我的 openSUSE 机器上没有高亮颜色。启用或不启用 DHCP,以及创建或不创建一个静态路由,然后进入下一个窗口。
|
||||
|
||||
选中 “Enable IPv6 network address space definition”,然后输入你的私有地址范围。你可以使用任何你希望的 IPv6 地址类,但是要注意,不能将你的实验网络泄漏到公网上去。我们将使用非常好用的 IPv6 唯一本地地址(ULA),并且使用在 [Simple DNS Plus][4] 上的在线地址生成器,去创建我们的网络地址。拷贝 “Combined/CID” 地址到网络框中(图 2)。
|
||||
|
||||
![network address][6]
|
||||
|
||||
*图 2:拷贝 "Combined/CID" 地址到网络框中*
|
||||
|
||||
虚拟机认为我的地址是无效的,因为,它显示了高亮的玫瑰红色。它做的对吗?我们使用 `ipv6calc` 去验证一下:
|
||||
|
||||
```
|
||||
$ ipv6calc -qi fd7d:844d:3e17:f3ae::/64
|
||||
Address type: unicast, unique-local-unicast, iid, iid-local
|
||||
Registry for address: reserved(RFC4193#3.1)
|
||||
Address type has SLA: f3ae
|
||||
Interface identifier: 0000:0000:0000:0000
|
||||
Interface identifier is probably manual set
|
||||
```
|
||||
|
||||
`ipv6calc` 认为没有问题。如果感兴趣,你可以改变其中一个数字为无效的东西,比如字母 `g`,然后再试一次。(问 “如果…?”,试验和错误是最好的学习方法)。
|
||||
|
||||
我们继续进行,启用 DHCPv6(图 3)。你可以接受缺省值,或者输入一个你自己的设置值。
|
||||
|
||||

|
||||
|
||||
*图 3: 启用 DHCPv6*
|
||||
|
||||
我们将跳过缺省路由定义这一步,继续进入下一屏,在那里我们将启用 “Isolated Virtual Network” 和 “Enable IPv6 internal routing/networking”。
|
||||
|
||||
### 虚拟机网络选择
|
||||
|
||||
现在,你可以配置你的虚拟机去使用新的网络。打开你的虚拟机,然后点击顶部左侧的 “i” 按钮去打开 “Show virtual hardware details” 屏幕。在 “Add Hardware” 列点击 “NIC” 按钮去打开网络选择器,然后选择你喜欢的新的 IPv6 网络。点击 “Apply”,然后重新启动。(或者使用你喜欢的方法去重新启动网络,或者更新你的 DHCP 租期。)
|
||||
|
||||
### 测试
|
||||
|
||||
`ifconfig` 告诉我们它做了什么?
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
ens3: flags=4163 UP,BROADCAST,RUNNING,MULTICAST mtu 1500
|
||||
inet 192.168.30.207 netmask 255.255.255.0
|
||||
broadcast 192.168.30.255
|
||||
inet6 fd7d:844d:3e17:f3ae::6314
|
||||
prefixlen 128 scopeid 0x0
|
||||
inet6 fe80::4821:5ecb:e4b4:d5fc
|
||||
prefixlen 64 scopeid 0x20
|
||||
```
|
||||
|
||||
这是我们新的 ULA,`fd7d:844d:3e17:f3ae::6314`,它是自动生成的本地链路地址。如果你有兴趣,可以 ping 一下,ping 网络上的其它虚拟机:
|
||||
|
||||
```
|
||||
vm1 ~$ ping6 -c2 fd7d:844d:3e17:f3ae::2c9f
|
||||
PING fd7d:844d:3e17:f3ae::2c9f(fd7d:844d:3e17:f3ae::2c9f) 56 data bytes
|
||||
64 bytes from fd7d:844d:3e17:f3ae::2c9f: icmp_seq=1 ttl=64 time=0.635 ms
|
||||
64 bytes from fd7d:844d:3e17:f3ae::2c9f: icmp_seq=2 ttl=64 time=0.365 ms
|
||||
|
||||
vm2 ~$ ping6 -c2 fd7d:844d:3e17:f3ae:a:b:c:6314
|
||||
PING fd7d:844d:3e17:f3ae:a:b:c:6314(fd7d:844d:3e17:f3ae:a:b:c:6314) 56 data bytes
|
||||
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=1 ttl=64 time=0.744 ms
|
||||
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=2 ttl=64 time=0.364 ms
|
||||
```
|
||||
|
||||
当你努力去理解子网时,这是一个可以让你尝试不同地址是否可以正常工作的快速易用的方法。你可以给单个接口分配多个 IP 地址,然后 ping 它们去看一下会发生什么。在一个 ULA 中,接口,或者主机是 IP 地址的最后四部分,因此,你可以在那里做任何事情,只要它们在同一个子网中即可,在那个例子中是 `f3ae`。在我的其中一个虚拟机上,我只改变了这个示例的接口 ID,以展示使用这四个部分,你可以做任何你想做的事情:
|
||||
|
||||
```
|
||||
vm1 ~$ sudo /sbin/ip -6 addr add fd7d:844d:3e17:f3ae:a:b:c:6314 dev ens3
|
||||
|
||||
vm2 ~$ ping6 -c2 fd7d:844d:3e17:f3ae:a:b:c:6314
|
||||
PING fd7d:844d:3e17:f3ae:a:b:c:6314(fd7d:844d:3e17:f3ae:a:b:c:6314) 56 data bytes
|
||||
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=1 ttl=64 time=0.744 ms
|
||||
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=2 ttl=64 time=0.364 ms
|
||||
```
|
||||
|
||||
现在,尝试使用不同的子网,在下面的示例中使用了 `f4ae` 代替 `f3ae`:
|
||||
|
||||
```
|
||||
$ ping6 -c2 fd7d:844d:3e17:f4ae:a:b:c:6314
|
||||
PING fd7d:844d:3e17:f4ae:a:b:c:6314(fd7d:844d:3e17:f4ae:a:b:c:6314) 56 data bytes
|
||||
From fd7d:844d:3e17:f3ae::1 icmp_seq=1 Destination unreachable: No route
|
||||
From fd7d:844d:3e17:f3ae::1 icmp_seq=2 Destination unreachable: No route
|
||||
```
|
||||
|
||||
这也是练习路由的好机会,以后,我们将专门做一期,如何在不使用 DHCP 情况下实现自动寻址。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-2
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://linux.cn/article-9594-1.html
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1
|
||||
[3]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking
|
||||
[4]:http://simpledns.com/private-ipv6.aspx
|
||||
[5]:/files/images/kvm-fig-2png
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/kvm-fig-2.png?itok=gncdPGj- "network address"
|
||||
[7]:https://www.linux.com/licenses/category/used-permission
|
||||
@ -0,0 +1,74 @@
|
||||
从专有到开源的十个简单步骤
|
||||
======
|
||||
|
||||
> 这个共同福利并不适用于专有软件:保持隐藏的东西是不能照亮或丰富这个世界的。
|
||||
|
||||
|
||||
|
||||
“开源软件肯定不太安全,因为每个人都能看到它的源代码,而且他们能重新编译它,用他们自己写的不好的东西进行替换。”举手示意:谁之前听说过这个说法?^注1
|
||||
|
||||
当我和客户讨论的时候(是的,他们有时候会让我和客户交谈),对于这个领域^注2 的人来说种问题是很常见的。在前一篇文章中,“[许多只眼睛的审查并不一定能防止错误代码]”,我谈论的是开源软件(尤其是安全软件)并不能神奇地比专有软件更安全,但是和专有软件比起来,我每次还是比较青睐开源软件。但我听到“关于开源软件不是很安全”这种问题表明了有时候只是说“开源需要参与”是不够的,我们也需要积极的参与辩护^注3 。
|
||||
|
||||
我并不期望能够达到牛顿或者维特根斯坦的逻辑水平,但是我会尽我所能,而且我会在结尾做个总结,如果你感兴趣的话可以去快速的浏览一下。
|
||||
|
||||
### 关键因素
|
||||
|
||||
首先,我们必须明白没有任何软件是完美的^注6 。无论是专有软件还是开源软件。第二,我们应该承认确实还是存在一些很不错的专有软件的,以及第三,也存在一些糟糕的开源软件。第四,有很多非常聪明的,很有天赋的,专业的架构师、设计师和软件工程师设计开发了专有软件。
|
||||
|
||||
但也有些问题:第五,从事专有软件的人员是有限的,而且你不可能总是能够雇佣到最好的员工。即使在政府部门或者公共组织 —— 他们拥有丰富的人才资源池,但在安全应用这块,他们的人才也是有限的。第六,可以查看、测试、改进、拆解、再次改进和发布开源软件的人总是无限的,而且还包含最好的人才。第七(也是我最喜欢的一条),这群人也包含很多编写专有软件的人才。第八,许多政府或者公共组织开发的软件也都逐渐开源了。
|
||||
|
||||
第九,如果你在担心你在运行的软件的不被支持或者来源不明,好消息是:有一批组织^注7 会来检查软件代码的来源,提供支持、维护和补丁更新。他们会按照专利软件模式那样去运行开源软件,你也可以确保你从他们那里得到的软件是正确的软件:他们的技术标准就是对软件包进行签名,以便你可以验证你正在运行的开源软件不是来源不明或者是恶意的软件。
|
||||
|
||||
第十(也是这篇文章的重点),当你运行开源软件,测试它,对问题进行反馈,发现问题并且报告的时候,你就是在为<ruby>共同福利<rt>commonwealth</rt></ruby>贡献知识、专业技能以及经验,这就是开源,其因为你的所做的这些而变得更好。如果你是通过个人或者提供支持开源软件的商业组织之一^注8 参与的,你已经成为了这个共同福利的一部分了。开源让软件变得越来越好,你可以看到它们的变化。没有什么是隐藏封闭的,它是完全开放的。事情会变坏吗?是的,但是我们能够及时发现问题并且修复。
|
||||
|
||||
这个共同福利并不适用于专有软件:保持隐藏的东西是不能照亮或丰富这个世界的。
|
||||
|
||||
我知道作为一个英国人在使用<ruby>共同福利<rt>commonwealth</rt></ruby>这个词的时候要小心谨慎的;它和帝国连接着的,但我所表达的不是这个意思。它不是克伦威尔^注9 在对这个词所表述的意思,无论如何,他是一个有争议的历史人物。我所表达的意思是这个词有“共同”和“福利”连接,福利不是指钱而是全人类都能拥有的福利。
|
||||
|
||||
我真的很相信这点的。如果i想从这篇文章中得到一些虔诚信息的话,那应该是第十条^注10 :共同福利是我们的遗产,我们的经验,我们的知识,我们的责任。共同福利是全人类都能拥有的。我们共同拥有它而且它是一笔无法估量的财富。
|
||||
|
||||
### 便利贴
|
||||
|
||||
1. (几乎)没有一款软件是完美无缺的。
|
||||
2. 有很好的专有软件。
|
||||
3. 有不好的专有软件。
|
||||
4. 有聪明,有才能,专注的人开发专有软件。
|
||||
5. 从事开发完善专有软件的人是有限的,即使在政府或者公共组织也是如此。
|
||||
6. 相对来说从事开源软件的人是无限的。
|
||||
7. …而且包括很多从事专有软件的人才。
|
||||
8. 政府和公共组织的人经常开源它们的软件。
|
||||
9. 有商业组织会为你的开源软件提供支持。
|
||||
10. 贡献--即使是使用--为开源软件贡献。
|
||||
|
||||
|
||||
### 脚注
|
||||
|
||||
- 注1: 好的--你现在可以放下手了
|
||||
- 注2:这应该大写吗?有特定的领域吗?或者它是如何工作的?我不确定。
|
||||
- 注3:我有一个英国文学和神学的学位--这可能不会惊讶到我的文章的普通读者^注4 。
|
||||
- 注4: 我希望不是,因为我说的太多神学了^注5 。但是它经常充满了冗余的,无关紧要的人文科学引用。
|
||||
- 注5: Emacs,每一次。
|
||||
- 注6: 甚至是 Emacs。而且我知道有技术能够去证明一些软件的正确性。(我怀疑 Emacs 不能全部通过它们...)
|
||||
- 注7: 注意这里:我被他们其中之一 [Red Hat][3] 所雇佣,去查看一下--它是一个有趣的工作地方,而且[我们经常在招聘][4]。
|
||||
- 注8: 假设他们完全遵守他们正在使用的开源软件许可证。
|
||||
- 注9: 昔日的“英格兰、苏格兰、爱尔兰的上帝守护者”--比克伦威尔。
|
||||
- 注10: 很明显,我选择 Emacs 而不是 Vi 变体。
|
||||
|
||||
这篇文章原载于 [Alice, Eve, and Bob - a security blog] 而且已经被授权重新发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/commonwealth-open-source
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://opensource.com/article/17/10/many-eyes
|
||||
[2]:https://en.wikipedia.org/wiki/Apologetics
|
||||
[3]:https://www.redhat.com/
|
||||
[4]:https://www.redhat.com/en/jobs
|
||||
[5]:https://aliceevebob.com/2017/10/24/the-commonwealth-of-open-source/
|
||||
@ -1,55 +1,55 @@
|
||||
5 个最佳实践开始你的 DevOps 之旅
|
||||
============================================================
|
||||
|
||||
### 想要实现 DevOps 但是不知道如何开始吗?试试这 5 个最佳实践吧。
|
||||
|
||||
> 想要实现 DevOps 但是不知道如何开始吗?试试这 5 个最佳实践吧。
|
||||
|
||||

|
||||
|
||||
Image by : [Andrew Magill][8]. Modified by Opensource.com. [CC BY 4.0][9]
|
||||
|
||||
想要采用 DevOps 的人通常会过早的被它的歧义性给吓跑,更不要说更加深入的使用了。当一些人开始使用 DevOps 的时候都会问:“如何开始使用呢?”,”怎么才算使用了呢?“。这 5 个最佳实践是很好的路线图来指导你的 DevOps 之旅。
|
||||
想要采用 DevOps 的人通常会过早的被它的歧义性给吓跑,更不要说更加深入的使用了。当一些人开始使用 DevOps 的时候都会问:“如何开始使用呢?”,”怎么才算使用了呢?“。这 5 个最佳实践是指导你的 DevOps 之旅的很好的路线图。
|
||||
|
||||
### 1\. 衡量所有的事情
|
||||
### 1、 衡量所有的事情
|
||||
|
||||
除非你能量化输出结果,否则你并不能确认你的努力能否使事情变得更好。新功能能否快速的输出给客户?有更少的漏洞泄漏给他们吗?出错了能快速应对和恢复吗?
|
||||
除非你能够量化输出结果,否则你并不能确认你的努力能否使事情变得更好。新功能能否快速的输出给客户?带给他们的缺陷更少吗?出错了能快速应对和恢复吗?
|
||||
|
||||
在你开始做任何修改之前,思考一下你切换到 DevOps 之后想要一些什么样的输出。随着你的 DevOps 之旅,将享受到服务的所有内容的丰富的实时报告,从这两个指标考虑一下:
|
||||
|
||||
* **上架时间** 衡量端到端,通常是面向客户的业务经验。这通常从一个功能被正式提出而开始,客户在产品中开始使用这个功能而结束。上架时间不是团队的主要指标;更加重要的是,当开发出一个有价值的新功能时,它表明了你完成业务的效率,为系统改进提供了一个机会。
|
||||
* **上架时间** 衡量端到端,通常是面向客户的业务经验。这通常从一个功能被正式提出而开始,客户在产品中开始使用这个功能而结束。上架时间不是工程团队的主要指标;更加重要的是,当开发出一个有价值的新功能时,它表明了你完成业务的效率,为系统改进提供了一个机会。
|
||||
|
||||
* **时间周期** 衡量工程团队的进度。从开始开发一个新功能开始,到在产品中运行需要多久?这个指标对于你理解团队的效率是非常有用的,为团队等级的提升提供了一个机会。
|
||||
* **时间周期** 衡量工程团队的进度。从开始开发一个新功能开始,到在产品环境中运行需要多久?这个指标对于你了解团队的效率是非常有用的,为团队层面的提升提供了一个机会。
|
||||
|
||||
### 2\. 放飞你的流程
|
||||
### 2、 放飞你的流程
|
||||
|
||||
DevOps 的成功需要团队布置一个定期流程并且持续提升它。这不总是有效的,但是必须是一个定期(希望有效)的流程。通常它有一些敏捷开发的味道,就像 Scrum 或者 Scrumban 一样;一些时候它也像精益开发。不论你用的什么方法,挑选一个正式的流程,开始使用它,并且做好这些基础。
|
||||
DevOps 的成功需要团队布置一个定期(但愿有效)流程并且持续提升它。这不总是有效的,但是必须是一个定期的流程。通常它有一些敏捷开发的味道,就像 Scrum 或者 Scrumban 一样;一些时候它也像精益开发。不论你用的什么方法,挑选一个正式的流程,开始使用它,并且做好这些基础。
|
||||
|
||||
定期检查和调整流程是 DevOps 成功的关键,抓住相关演示,团队回顾,每日会议的机会来提升你的流程。
|
||||
定期检查和调整流程是 DevOps 成功的关键,抓住相关演示、团队回顾、每日会议的机会来提升你的流程。
|
||||
|
||||
DevOps 的成功取决于大家一起有效的工作。团队的成员需要在一个有权改进的公共流程中工作。他们也需要定期找机会分享从这个流程中上游或下游的其他人那里学到的东西。
|
||||
|
||||
随着你构建成功。好的流程规范能帮助你的团队以很快的速度体会到 DevOps 其他的好处
|
||||
随着你构建成功,好的流程规范能帮助你的团队以很快的速度体会到 DevOps 其他的好处
|
||||
|
||||
尽管更多面向开发的团队采用 Scrum 是常见的,但是以运营为中心的团队(或者其他中断驱动的团队)可能选用一个更短期的流程,例如 Kanban。
|
||||
|
||||
### 3\. 可视化工作流程
|
||||
### 3、 可视化工作流程
|
||||
|
||||
这是很强大的,能够看到哪个人在给定的时间做哪一部分工作,可视化你的工作流程能帮助大家知道接下来应该做什么,流程中有多少工作以及流程中的瓶颈在哪里。
|
||||
|
||||
在你看到和衡量之前你并不能有效的限制流程中的工作。同样的,你也不能有效的排除瓶颈直到你清楚的看到它。
|
||||
|
||||
全部工作可视化能帮助团队中的成员了解他们在整个工作中的贡献。这样可以促进跨组织边界的关系建设,帮助您的团队更有效地协作,实现共同的成就感。
|
||||
|
||||
### 4\. 持续化所有的事情
|
||||
### 4、 持续化所有的事情
|
||||
|
||||
DevOps 应该是强制自动化的。然而罗马不是一日建成的。你应该注意的第一个事情应该是努力的持续集成(CI),但是不要停留到这里;紧接着的是持续交付(CD)以及最终的持续部署。
|
||||
DevOps 应该是强制自动化的。然而罗马不是一日建成的。你应该注意的第一个事情应该是努力的[持续集成(CI)][10],但是不要停留到这里;紧接着的是[持续交付(CD)][11]以及最终的持续部署。
|
||||
|
||||
持续部署的过程中是个注入自动测试的好时机。这个时候新代码刚被提交,你的持续部署应该运行测试代码来测试你的代码和构建成功的加工品。这个加工品经受流程的考验被产出直到最终被客户看到。
|
||||
持续部署的过程中是个注入自动测试的好时机。这个时候新代码刚被提交,你的持续部署应该运行测试代码来测试你的代码和构建成功的加工品。这个加工品经受流程的考验被产出,直到最终被客户看到。
|
||||
|
||||
另一个“持续”是不太引人注意的持续改进。一个简单的场景是每天询问你旁边的同事:“今天做些什么能使工作变得更好?”,随着时间的推移,这些日常的小改进融合到一起会引起很大的结果,你将很惊喜!但是这也会让人一直思考着如何改进。
|
||||
另一个“持续”是不太引人注意的持续改进。一个简单的场景是每天询问你旁边的同事:“今天做些什么能使工作变得更好?”,随着时间的推移,这些日常的小改进融合到一起会带来很大的结果,你将很惊喜!但是这也会让人一直思考着如何改进。
|
||||
|
||||
### 5\. Gherkinize
|
||||
### 5、 Gherkinize
|
||||
|
||||
促进组织间更有效的沟通对于成功的 DevOps 的系统思想至关重要。在程序员和业务员之间直接使用共享语言来描述新功能的需求文档对于沟通是个好办法。一个好的产品经理能在一天内学会 [Gherkin][12] 然后使用它构造出明确的英语来描述需求文档,工程师会使用 Gherkin 描述的需求文档来写功能测试,之后开发功能代码直到代码通过测试。这是一个简化的 [验收测试驱动开发][13](ATDD),这样就开始了你的 DevOps 文化和开发实践。
|
||||
促进组织间更有效的沟通对于成功的 DevOps 的系统思想至关重要。在程序员和业务员之间直接使用共享语言来描述新功能的需求文档对于沟通是个好办法。一个好的产品经理能在一天内学会 [Gherkin][12] 然后使用它以平实的英语构造出明确的描述需求文档,工程师会使用 Gherkin 描述的需求文档来写功能测试,之后开发功能代码直到代码通过测试。这是一个简化的 [验收测试驱动开发][13](ATDD),能够帮助你开始你的 DevOps 文化和开发实践。
|
||||
|
||||
### 开始你旅程
|
||||
|
||||
@ -60,15 +60,15 @@ DevOps 应该是强制自动化的。然而罗马不是一日建成的。你应
|
||||
|
||||
[][14]
|
||||
|
||||
Magnus Hedemark - Magnus 在IT行业已有20多年,并且一直热衷于技术。他目前是 nitedHealth Group 的 DevOps 工程师。在业余时间,Magnus 喜欢摄影和划独木舟。
|
||||
Magnus Hedemark - Magnus 在 IT 行业已有 20 多年,并且一直热衷于技术。他目前是 nitedHealth Group 的 DevOps 工程师。在业余时间,Magnus 喜欢摄影和划独木舟。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/5-keys-get-started-devops
|
||||
|
||||
作者:[Magnus Hedemark ][a]
|
||||
作者:[Magnus Hedemark][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
DevOps 将让你失业?
|
||||
DevOps 会让你失业吗?
|
||||
======
|
||||
|
||||
>你是否担心工作中自动化将代替人?可能是对的,但是这并不是件坏事。
|
||||
@ -8,19 +8,19 @@ DevOps 将让你失业?
|
||||
|
||||
这是一个很正常的担心:DevOps 最终会让你失业?毕竟,DevOps 意味着开发人员做运营,对吗?DevOps 是自动化的。如果我的工作都自动化了,我去做什么?实行持续分发和容器化意味着运营已经过时了吗?对于 DevOps 来说,所有的东西都是代码:基础设施是代码、测试是代码、这个和那个都是代码。如果我没有这些技能怎么办?
|
||||
|
||||
[DevOps][1] 是一个即将到来的变化,将颠覆这一领域,狂热的拥挤者们正在谈论,如何使用 [三种方法][2] 去改变世界 —— 即 DevOps 的三大基础 —— 去推翻一个旧的世界。它是势不可档的。那么,问题来了 —— DevOps 将会让我失业吗?
|
||||
[DevOps][1] 是一个即将到来的变化,它将颠覆这一领域,狂热的拥挤者们正在谈论,如何使用 [三种方法][2] 去改变世界 —— 即 DevOps 的三大基础 —— 去推翻一个旧的世界。它是势不可档的。那么,问题来了 —— DevOps 将会让我失业吗?
|
||||
|
||||
### 第一个担心:再也不需要我了
|
||||
### 第一个担心:再也不需要我了
|
||||
|
||||
由于开发者来管理应用程序的整个生命周期,接受 DevOps 的理念很容易。容器化可能是影响这一想法的重要因素。当容器化在各种场景下铺开之后,它们被吹嘘成开发者构建、测试、和部署他们代码的一站式解决方案。DevOps 对于运营、测试、以及 QA 团队来说,有什么作用呢?
|
||||
由于开发者来管理应用程序的整个生命周期,接受 DevOps 的理念很容易。容器化可能是影响这一想法的重要因素。当容器化在各种场景下铺开之后,它们被吹嘘成开发者构建、测试和部署他们代码的一站式解决方案。DevOps 对于运营、测试、以及 QA 团队来说,有什么作用呢?
|
||||
|
||||
这源于对 DevOps 原则的误解。DevOps 的第一原则,或者第一方法是,_系统思考_ ,或者强调整体管理方法和了解应用程序或服务的整个生命周期。这并不意味着应用程序的开发者将学习和管理整个过程。相反,是拥有各个专业和技能的人共同合作,以确保成功。让开发者对这一过程完全负责的作法,几乎是将开发者置于使用者的对立面—— 本质上就是 “将鸡蛋放在了一个篮子里”。
|
||||
这源于对 DevOps 原则的误解。DevOps 的第一原则,或者第一方法是,<ruby>系统思考<rt>Systems Thinking</rt></ruby>,或者强调整体管理方法和了解应用程序或服务的整个生命周期。这并不意味着应用程序的开发者将学习和管理整个过程。相反,是拥有各个专业和技能的人共同合作,以确保成功。让开发者对这一过程完全负责的作法,几乎是将开发者置于使用者的对立面 —— 本质上就是 “将鸡蛋放在了一个篮子里”。
|
||||
|
||||
在 DevOps 中有一个为你保留的专门职位。就像将一个受过传统教育的、拥有线性回归和二分查找知识的软件工程师,被用去写一些 Ansible playbooks 和 Docker 文件,这是一种浪费。而对于那些拥有高级技能,知道如何保护一个系统和优化数据库执行的系统管理员,被浪费在写一些 CSS 和设计用户流这样的工作上。写代码、做测试、和维护应用程序的高效团队一般是跨学科、跨职能的、拥有不同专业技术和背景的人组成的混编团队。
|
||||
|
||||
### 第二个担心:我的工作将被自动化
|
||||
|
||||
或许是,或许不是,DevOps 可能在有时候是自动化的同义词。当自动化构建、测试、部署、监视、以及提醒等事项,已经占据了整个应用程序生命周期管理的时候,还会给我们剩下什么工作呢?这种对自动化的关注可能与第二个方法有关:_放大反馈循环_。DevOps 的第二个方法是在团队和部署的应用程序之间,采用相反的方向优先处理快速反馈 —— 从监视和维护部署、测试、开发、等等,通过强调,使反馈更加重要并且可操作。虽然这第二种方式与自动化并不是特别相关,许多自动化工具团队在它们的部署流水线中使用,以促进快速提醒和快速行动,或者基于对使用者的支持业务中产生的反馈来改进。传统的做法是靠人来完成的,这就可以理解为什么自动化可能会导致未来一些人失业的焦虑了。
|
||||
或许是,或许不是,DevOps 可能在有时候是自动化的同义词。当自动化构建、测试、部署、监视,以及提醒等事项,已经占据了整个应用程序生命周期管理的时候,还会给我们剩下什么工作呢?这种对自动化的关注可能与第二个方法有关:<ruby>放大反馈循环<rt>Amplify Feedback Loops</rt></ruby>。DevOps 的第二个方法是在团队和部署的应用程序之间,采用相反的方向优先处理快速反馈 —— 从监视和维护部署、测试、开发、等等,通过强调,使反馈更加重要并且可操作。虽然这第二种方式与自动化并不是特别相关,许多自动化工具团队在它们的部署流水线中使用,以促进快速提醒和快速行动,或者基于对使用者的支持业务中产生的反馈来改进。传统的做法是靠人来完成的,这就可以理解为什么自动化可能会导致未来一些人失业的焦虑了。
|
||||
|
||||
自动化只是一个工具,它并不能代替人。聪明的人使用它来做一些重复的工作,不去开发智力和创造性的财富,而是去按红色的 “George Jetson” 按钮是一种极大的浪费。让每天工作中的苦活自动化,意味着有更多的时间去解决真正的问题和即将到来的创新的解决方案。人类需要解决更多的 “怎么做和为什么” 问题,而计算机只能处理 “复制和粘贴”。
|
||||
|
||||
@ -28,17 +28,17 @@ DevOps 将让你失业?
|
||||
|
||||
### 第三个担心:我没有这些技能怎么办
|
||||
|
||||
"我怎么去继续做这些事情?我不懂如何自动化。现在所有的工作都是代码 —— 我不是开发人员,我不会做 DevOps 中写代码的工作“,第三个担心是一种不自信的担心。由于文化的改变,是的,团队将也会要求随之改变,一些人可能担心,他们缺乏继续做他们工作的技能。
|
||||
“我怎么去继续做这些事情?我不懂如何自动化。现在所有的工作都是代码 —— 我不是开发人员,我不会做 DevOps 中写代码的工作”,第三个担心是一种不自信的担心。由于文化的改变,是的,团队将也会要求随之改变,一些人可能担心,他们缺乏继续做他们工作的技能。
|
||||
|
||||
然而,大多数人或许已经比他们所想的更接近。Dockerfile 是什么,或者像 Puppet 或 Ansible 配置管理是什么,但是环境即代码,系统管理员已经写了 shell 脚本和 Python 程序去处理他们重复的任务。学习更多的知识并使用已有的工具处理他们的更多问题 —— 编排、部署、维护即代码 —— 尤其是当从繁重的手动任务中解放出来,专注于成长时。
|
||||
然而,大多数人或许已经比他们所想的更接近。Dockerfile 是什么,或者像 Puppet 或 Ansible 配置管理是什么,这就是环境即代码,系统管理员已经写了 shell 脚本和 Python 程序去处理他们重复的任务。学习更多的知识并使用已有的工具处理他们的更多问题 —— 编排、部署、维护即代码 —— 尤其是当从繁重的手动任务中解放出来,专注于成长时。
|
||||
|
||||
在 DevOps 的使用者中去回答这第三个担心,第三个方法是:_一种不断实验和学习的文化_。尝试、失败、并从错误中吸取教训而不是责怪它们的能力,是设计出更有创意的解决方案的重要因素。第三个方法是为前两个方法授权—— 允许快速检测和修复问题,并且开发人员可以自由地尝试和学习,其它的团队也是如此。从未使用过配置管理或者写过自动供给基础设施程序的运营团队也要自由尝试并学习。测试和 QA 团队也要自由实现新测试流水线,并且自动批准和发布新流程。在一个拥抱学习和成长的文化中,每个人都可以自由地获取他们需要的技术,去享受工作带来的成功和喜悦。
|
||||
在 DevOps 的使用者中去回答这第三个担心,第三个方法是:<ruby>一种不断实验和学习的文化<rt>A Culture of Continual Experimentation and Learning</ruby>。尝试、失败,并从错误中吸取教训而不是责怪它们的能力,是设计出更有创意的解决方案的重要因素。第三个方法是为前两个方法授权 —— 允许快速检测和修复问题,并且开发人员可以自由地尝试和学习,其它的团队也是如此。从未使用过配置管理或者写过自动供给基础设施程序的运营团队也要自由尝试并学习。测试和 QA 团队也要自由实现新测试流水线,并且自动批准和发布新流程。在一个拥抱学习和成长的文化中,每个人都可以自由地获取他们需要的技术,去享受工作带来的成功和喜悦。
|
||||
|
||||
### 结束语
|
||||
|
||||
在一个行业中,任何可能引起混乱的实践或变化都会产生担心和不确定,DevOps 也不例外。对自己工作的担心是对成百上千的文章和演讲的合理回应,其中列举了无数的实践和技术,而这些实践和技术正致力于授权开发者对行业的各个方面承担职责。
|
||||
|
||||
然而,事实上,DevOps 是 "[一个跨学科的沟通实践,致力于研究构建、进化、和运营快速变化的弹性系统][3]"。 DevOps 意味着终结 ”筒仓“,但并不专业化。它是受委托去做苦差事的自动化系统,解放你,让你去做人类更擅长做的事:思考和想像。并且,如果你愿意去学习和成长,它将不会终结你解决新的、挑战性的问题的机会。
|
||||
然而,事实上,DevOps 是 “[一个跨学科的沟通实践,致力于研究构建、进化、和运营快速变化的弹性系统][3]”。 DevOps 意味着终结 “筒仓”,但并不专业化。它是受委托去做苦差事的自动化系统,解放你,让你去做人类更擅长做的事:思考和想像。并且,如果你愿意去学习和成长,它将不会终结你解决新的、挑战性的问题的机会。
|
||||
|
||||
DevOps 会让你失业吗?会的,但它同时给你提供了更好的工作。
|
||||
|
||||
@ -48,7 +48,7 @@ via: https://opensource.com/article/17/12/will-devops-steal-my-job
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
117
published/20171220 Containers without Docker at Red Hat.md
Normal file
117
published/20171220 Containers without Docker at Red Hat.md
Normal file
@ -0,0 +1,117 @@
|
||||
Red Hat 的去 Docker 化容器实践
|
||||
======
|
||||
|
||||
最近几年,开源项目 Docker (已更名为[Moby][1]) 在容器普及化方面建树颇多。然而,它的功能特性不断集中到一个单一、庞大的系统,该系统由具有 root 权限运行的守护进程 `dockerd` 管控,这引发了人们的焦虑。对这些焦虑的阐述,具有代表性的是 Red Hat 公司的容器团队负责人 Dan Walsh 在 [KubeCon + CloudNativecon][3] 会议中的[演讲][2]。Walsh 讲述了他的容器团队目前的工作方向,即使用一系列更小、可协同工作的组件替代 Docker。他的战斗口号是“拒绝臃肿的守护进程”,理由是与公认的 Unix 哲学相违背。
|
||||
|
||||
### Docker 模块化实践
|
||||
|
||||
就像我们在[早期文献][4]中看到的那样,容器的基础操作不复杂:你首先拉取一个容器镜像,利用该镜像创建一个容器,最后启动这个容器。除此之外,你要懂得如何构建镜像并推送至镜像仓库。大多数人在上述这些步骤中使用 Docker,但其实 Docker 并不是唯一的选择,目前的可替换选择是 `rkt`。rkt 引发了一系列标准的创建,包括运行时标准 CRI,镜像标准 OCI 及网络标准 CNI 等。遵守这些标准的后端,如 [CRI-O][5] 和 Docker,可以与 [Kubernetes][6] 为代表的管理软件协同工作。
|
||||
|
||||
这些标准促使 Red Hat 公司开发了一系列实现了部分标准的“核心应用”供 Kubernetes 使用,例如 CRI-O 运行时。但 Kubernetes 提供的功能不足以满足 Red Hat 公司的 [OpenShift][7] 项目所需。开发者可能需要构建容器并推送至镜像仓库,实现这些操作需要额外的一整套方案。
|
||||
|
||||
事实上,目前市面上已有多种构建容器的工具。来自 Sysdig 公司的 Michael Ducy 在[分会场][8]中回顾了 Docker 本身之外的 8 种镜像构建工具,而这也很可能不是全部。Ducy 将理想的构建工具定义如下:可以用可重现的方式创建最小化镜像。最小化镜像并不包含操作系统,只包含应用本身及其依赖。Ducy 认为 [Distroless][9], [Smith][10] 及 [Source-to-Image][11] 都是很好的工具,可用于构建最小化镜像。Ducy 将最小化镜像称为“微容器”。
|
||||
|
||||
<ruby>可重现镜像<rt>reproducible container</rt></ruby>是指构建多次结果保持不变的镜像。为达到这个目标,Ducy 表示应该使用“宣告式”而不是“命令式”的方式。考虑到 Ducy 来自 Chef 配置管理工具领域,你应该能理解他的意思。Ducy 给出了符合标准的几个不错的实现,包括 [Ansible 容器][12]、 [Habitat][13]、 [nixos-容器][14]和 [Simth][10] 等,但你需要了解这些项目对应的编程语言。Ducy 额外指出 Habitat 构建的容器自带管理功能,如果你已经使用了 systemd、 Docker 或 Kubernetes 等外部管理工具,Habitat 的管理功能可能是冗余的。除此之外,我们还要提到从 Docker 和 [Buildah][16] 项目诞生的新项目 [BuildKit][15], 它是 Red Hat 公司 [Atomic 工程][17]的一个组件。
|
||||
|
||||
### 使用 Buildah 构建容器
|
||||
|
||||
![\[Buildah logo\]][18]
|
||||
|
||||
Buildah 名称显然来自于 Walsh 风趣的 [波士顿口音][19]; 该工具的品牌宣传中充满了波士顿风格,例如 logo 使用了波士顿梗犬(如图所示)。该项目的实现思路与 Ducy 不同:为了构建容器,与其被迫使用宣告式配置管理的方案,不如构建一些简单工具,结合你最喜欢的配置管理工具使用。这样你可以如愿的使用命令行,例如使用 `cp` 命令代替 Docker 的自定义指令 `COPY` 。除此之外,你可以使用如下工具为容器提供内容:1) 配置管理工具,例如Ansible 或 Puppet;2) 操作系统相关或编程语言相关的安装工具,例如 APT 和 pip; 3) 其它系统。下面展示了基于通用 shell 命令的容器构建场景,其中只需要使用 `make` 命令即可为容器安装可执行文件。
|
||||
|
||||
```
|
||||
# 拉取基础镜像, 类似 Dockerfile 中的 FROM 命令
|
||||
buildah from redhat
|
||||
|
||||
# 挂载基础镜像, 在其基础上工作
|
||||
crt=$(buildah mount)
|
||||
ap foo $crt
|
||||
make install DESTDIR=$crt
|
||||
|
||||
# 下一步,生成快照
|
||||
buildah commit
|
||||
```
|
||||
|
||||
有趣的是,基于这个思路,你可以复用主机环境中的构建工具,无需在镜像中安装这些依赖,故可以构建非常微小的镜像。通常情况下,构建容器镜像时需要在容器中安装目标应用的构建依赖。例如,从源码构建需要容器中有编译器工具链,这是因为构建并不在主机环境进行。大量的容器也包含了 `ps` 和 `bash` 这样的 Unix 命令,对微容器而言其实是多余的。开发者经常忘记或无法从构建好的容器中移除一些依赖,增加了不必要的开销和攻击面。
|
||||
|
||||
Buildah 的模块化方案能够以非 root 方式进行部分构建;但`mount` 命令仍然需要 `CAP_SYS_ADMIN`,有一个 [工单][20] 试图解决该问题。但 Buildah 与 Docker [都有][21]同样的[限制][22],即无法在容器内构建容器。对于 Docker,你需要使用“特权”模式运行容器,一些特殊的环境很难满足这个条件,例如 [GitLab 持续集成][23];即使满足该条件,配置也特别[繁琐][24]。
|
||||
|
||||
手动提交的步骤可以对创建容器快照的时间节点进行细粒度控制。Dockerfile 每一行都会创建一个新的快照;相比而言,Buildah 的提交检查点都是事先选择好的,这可以减少不必要的快照并节省磁盘空间。这也有利于隔离私钥或密码等敏感信息,避免其出现在公共镜像中。
|
||||
|
||||
Docker 构建的镜像是非标准的、仅供其自身使用;相比而言,Buildah 提供[多种输出格式][25],其中包括符合 OCI 标准的镜像。为向后兼容,Buildah 提供了一个“使用 Dockerfile 构建”的命令,即 [`buildah bud`][26], 它可以解析标准的 Dockerfile。Buildah 提供 `enter` 命令直接查看镜像内部信息,`run` 命令启动一个容器。实现这些功能仅使用了 `runc` 在内的标准工具,无需在后台运行一个“臃肿的守护进程”。
|
||||
|
||||
Ducy 对 Buildah 表示质疑,认为采用非宣告性不利于可重现性。如果允许使用 shell 命令,可能产生很多预想不到的情况;例如,一个 shell 脚本下载了任意的可执行程序,但后续无法追溯文件的来源。shell 命令的执行受环境变量影响,执行结果可能大相径庭。与基于 shell 的工具相比,Puppet 或 Chef 这样的配置管理系统在理论上更加可靠,因为它们的设计初衷就是收敛于最终配置;事实上,可以通过配置管理系统调用 shell 命令。但 Walsh 对此提出反驳,认为已有的配置管理工具可以在 Buildah 的基础上工作,用户可以选择是否使用配置管理;这样更加符合“机制与策略分离”的经典 Unix 哲学。
|
||||
|
||||
目前 Buildah 处于测试阶段,Red Hat 公司正努力将其集成到 OpenShift。我写这篇文章时已经测试过 Buildah,它缺少一些文档,但基本可以稳定运行。尽管在错误处理方面仍有待提高,但它确实是一款值得你关注的容器工具。
|
||||
|
||||
### 替换其它 Docker 命令行
|
||||
|
||||
Walsh 在其演讲中还简单介绍了 Red hat 公司 正在开发的另一个暂时叫做 [libpod][24] 的项目。项目名称来源于 Kubernetes 中的 “pod”, 在 Kubernetes 中 “pod” 用于分组主机内的容器,分享名字空间等。
|
||||
|
||||
Libpod 提供 `kpod` 命令,用于直接检查和操作容器存储。Walsh 分析了该命令发挥作用的场景,例如 `dockerd` 停止响应或 Kubernetes 集群崩溃。基本上,`kpod` 独立地再次实现了 `docker` 命令行工具。`kpod ps` 返回运行中的容器列表,`kpod images` 返回镜像列表。事实上,[命令转换速查手册][28] 中给出了每一条 Docker 命令对应的 `kpod` 命令。
|
||||
|
||||
这种模块化实现的一个好处是,当你使用 `kpod run` 运行容器时,容器直接作为当前 shell 而不是 `dockerd` 的子进程启动。理论上,可以直接使用 systemd 启动容器,这样可以消除 `dockerd` 引入的冗余。这让[由套接字激活的容器][29]成为可能,但暂时基于 Docker 实现该特性[并不容易][30],[即使借助 Kubernetes][31] 也是如此。但我在测试过程中发现,使用 `kpod` 启动的容器有一些基础功能性缺失,具体而言是网络功能(!),相关实现在[活跃开发][32]过程中。
|
||||
|
||||
我们最后提到的命令是 `push`。虽然上述命令已经足以满足本地使用容器的需求,但没有提到远程仓库,借助远程仓库开发者可以活跃地进行应用打包协作。仓库也是持续部署框架的核心组件。[skopeo][33] 项目用于填补这个空白,它是另一个 Atomic 成员项目,按其 `README` 文件描述,“包含容器镜像及镜像库的多种操作”。该项目的设计初衷是,在不用类似 `docker pull` 那样实际去下载可能体积庞大的镜像的前提下,检查容器镜像的内容。Docker [拒绝加入][34] 检查功能,建议通过一个额外的工具实现该功能,这促成了 Skopeo 项目。除了 `pull`、`push`,Skopeo 现在还可以完成很多其它操作,例如在,不产生本地副本的情况下将镜像在不同的仓库中复制和转换。由于部分功能比较基础,可供其它项目使用,目前很大一部分 Skopeo 代码位于一个叫做 [containers/image][35] 的基础库。[Pivotal][36]、 Google 的 [container-diff][37] 、`kpod push` 及 `buildah push` 都使用了该库。
|
||||
|
||||
`kpod` 与 Kubernetes 并没有紧密的联系,故未来可能会更换名称(事实上,在本文刊发过程中,已经更名为 [`podman`][38]),毕竟 Red Hat 法务部门还没有明确其名称。该团队希望实现更多 pod 级别的命令,这样可以对多个容器进行操作,有点类似于 [`docker compose`][39] 实现的功能。但在这方面,[Kompose][40] 是更好的工具,可以通过 [复合 YAML 文件][41] 在 Kubernetes 集群中运行容器。按计划,我们不会实现类似于 [`swarm`] 的 Docker 命令,这部分功能最好由 Kubernetes 本身完成。
|
||||
|
||||
目前看来,已经持续数年的 Docker 模块化努力终将硕果累累。但目前 `kpod` 处于快速迭代过程中,不太适合用于生产环境,不过那些工具的与众不同的设计理念让人很感兴趣,而且其中大部分的工具已经可以用于开发环境。目前只能通过编译源码的方式安装 libpod,但最终会提供各个发行版的二进制包。
|
||||
|
||||
> 本文[最初发表][43]于 [Linux Weekly News][44]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2017-12-20-docker-without-docker/
|
||||
|
||||
作者:[Anarcat][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://anarc.at
|
||||
[1]:https://mobyproject.org/
|
||||
[2]:https://kccncna17.sched.com/event/CU8j/cri-o-hosted-by-daniel-walsh-red-hat
|
||||
[3]:http://events.linuxfoundation.org/events/kubecon-and-cloudnativecon-north-america
|
||||
[4]:https://lwn.net/Articles/741897/
|
||||
[5]:http://cri-o.io/
|
||||
[6]:https://kubernetes.io/
|
||||
[7]:https://www.openshift.com/
|
||||
[8]:https://kccncna17.sched.com/event/CU6B/building-better-containers-a-survey-of-container-build-tools-i-michael-ducy-chef
|
||||
[9]:https://github.com/GoogleCloudPlatform/distroless
|
||||
[10]:https://github.com/oracle/smith
|
||||
[11]:https://github.com/openshift/source-to-image
|
||||
[12]:https://www.ansible.com/ansible-container
|
||||
[13]:https://www.habitat.sh/
|
||||
[14]:https://nixos.org/nixos/manual/#ch-containers
|
||||
[15]:https://github.com/moby/buildkit
|
||||
[16]:https://github.com/projectatomic/buildah
|
||||
[17]:https://www.projectatomic.io/
|
||||
[18]:https://raw.githubusercontent.com/projectatomic/buildah/master/logos/buildah-logomark_large.png (Buildah logo)
|
||||
[19]:https://en.wikipedia.org/wiki/Boston_accent
|
||||
[20]:https://github.com/projectatomic/buildah/issues/171
|
||||
[21]:https://github.com/projectatomic/buildah/issues/158
|
||||
[22]:https://github.com/moby/moby/issues/27886#issuecomment-281278525
|
||||
[23]:https://about.gitlab.com/features/gitlab-ci-cd/
|
||||
[24]:https://jpetazzo.github.io/2015/09/03/do-not-use-docker-in-docker-for-ci/
|
||||
[25]:https://github.com/projectatomic/buildah/blob/master/docs/buildah-push.md
|
||||
[26]:https://github.com/projectatomic/buildah/blob/master/docs/buildah-bud.md
|
||||
[27]:https://github.com/projectatomic/libpod
|
||||
[28]:https://github.com/projectatomic/libpod/blob/master/transfer.md#development-transfer
|
||||
[29]:http://0pointer.de/blog/projects/socket-activated-containers.html
|
||||
[30]:https://legacy-developer.atlassian.com/blog/2015/03/docker-systemd-socket-activation/
|
||||
[31]:https://github.com/kubernetes/kubernetes/issues/484
|
||||
[32]:https://github.com/projectatomic/libpod/issues/129
|
||||
[33]:https://github.com/projectatomic/skopeo
|
||||
[34]:https://github.com/moby/moby/pull/14258
|
||||
[35]:https://github.com/containers/image
|
||||
[36]:https://pivotal.io/
|
||||
[37]:https://github.com/GoogleCloudPlatform/container-diff
|
||||
[38]:https://github.com/projectatomic/libpod/blob/master/docs/podman.1.md
|
||||
[39]:https://docs.docker.com/compose/overview/#compose-documentation
|
||||
[40]:http://kompose.io/
|
||||
[41]:https://docs.docker.com/compose/compose-file/
|
||||
[42]:https://docs.docker.com/engine/swarm/
|
||||
[43]:https://lwn.net/Articles/741841/
|
||||
[44]:http://lwn.net/
|
||||
155
published/20171221 A Commandline Food Recipes Manager.md
Normal file
155
published/20171221 A Commandline Food Recipes Manager.md
Normal file
@ -0,0 +1,155 @@
|
||||
HeRM's :一个命令行食谱管理器
|
||||
======
|
||||
|
||||

|
||||
|
||||
烹饪让爱变得可见,不是吗?确实!烹饪也许是你的热情或爱好或职业,我相信你会维护一份烹饪日记。保持写烹饪日记是改善烹饪习惯的一种方法。有很多方法可以记录食谱。你可以维护一份小日记/笔记或将配方的笔记存储在智能手机中,或将它们保存在计算机中文档中。这有很多选择。今天,我介绍 **HeRM's**,这是一个基于 Haskell 的命令行食谱管理器,能为你的美食食谱做笔记。使用 Herm's,你可以添加、查看、编辑和删除食物配方,甚至可以制作购物清单。这些全部来自你的终端!它是免费的,是使用 Haskell 语言编写的开源程序。源代码在 GitHub 中免费提供,因此你可以复刻它,添加更多功能或改进它。
|
||||
|
||||
### HeRM's - 一个命令食谱管理器
|
||||
|
||||
#### 安装 HeRM's
|
||||
|
||||
由于它是使用 Haskell 编写的,因此我们需要首先安装 Cabal。 Cabal 是一个用于下载和编译用 Haskell 语言编写的软件的命令行程序。Cabal 存在于大多数 Linux 发行版的核心软件库中,因此你可以使用发行版的默认软件包管理器来安装它。
|
||||
|
||||
例如,你可以使用以下命令在 Arch Linux 及其变体(如 Antergos、Manjaro Linux)中安装 cabal:
|
||||
|
||||
```
|
||||
sudo pacman -S cabal-install
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu 上:
|
||||
|
||||
```
|
||||
sudo apt-get install cabal-install
|
||||
```
|
||||
|
||||
安装 Cabal 后,确保你已经添加了 `PATH`。为此,请编辑你的 `~/.bashrc`:
|
||||
|
||||
```
|
||||
vi ~/.bashrc
|
||||
```
|
||||
|
||||
添加下面这行:
|
||||
|
||||
```
|
||||
PATH=$PATH:~/.cabal/bin
|
||||
```
|
||||
|
||||
按 `:wq` 保存并退出文件。然后,运行以下命令更新所做的更改。
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
安装 cabal 后,运行以下命令安装 `herms`:
|
||||
|
||||
```
|
||||
cabal install herms
|
||||
```
|
||||
|
||||
喝一杯咖啡!这将需要一段时间。几分钟后,你会看到一个输出,如下所示。
|
||||
|
||||
```
|
||||
[...]
|
||||
Linking dist/build/herms/herms ...
|
||||
Installing executable(s) in /home/sk/.cabal/bin
|
||||
Installed herms-1.8.1.2
|
||||
```
|
||||
|
||||
恭喜! Herms 已经安装完成。
|
||||
|
||||
#### 添加食谱
|
||||
|
||||
让我们添加一个食谱,例如 Dosa。对于那些想知道的,Dosa 是一种受欢迎的南印度食物,配以 sambar(LCTT 译注:扁豆和酸豆炖菜,像咖喱汤) 和**酸辣酱**。这是一种健康的,可以说是最美味的食物。它不含添加的糖或饱和脂肪。制作一个也很容易。有几种不同的 Dosas,在我们家中最常见的是 Plain Dosa。
|
||||
|
||||
要添加食谱,请输入:
|
||||
|
||||
```
|
||||
herms add
|
||||
```
|
||||
|
||||
你会看到一个如下所示的屏幕。开始输入食谱的详细信息。
|
||||
|
||||
![][2]
|
||||
|
||||
要变换字段,请使用以下键盘快捷键:
|
||||
|
||||
* `Tab` / `Shift+Tab` - 下一个/前一个字段
|
||||
* `Ctrl + <箭头键>` - 导航字段
|
||||
* `[Meta 或者 Alt] + <h-j-k-l>` - 导航字段
|
||||
* `Esc` - 保存或取消。
|
||||
|
||||
|
||||
添加完配方的详细信息后,按下 `ESC` 键并点击 `Y` 保存。同样,你可以根据需要添加尽可能多的食谱。
|
||||
|
||||
要列出添加的食谱,输入:
|
||||
|
||||
```
|
||||
herms list
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
要查看上面列出的任何食谱的详细信息,请使用下面的相应编号。
|
||||
|
||||
```
|
||||
herms view 1
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
要编辑任何食谱,使用:
|
||||
|
||||
```
|
||||
herms edit 1
|
||||
```
|
||||
|
||||
完成更改后,按下 `ESC` 键。系统会询问你是否要保存。你只需选择适当的选项。
|
||||
|
||||
![][5]
|
||||
|
||||
要删除食谱,命令是:
|
||||
|
||||
```
|
||||
herms remove 1
|
||||
```
|
||||
|
||||
要为指定食谱生成购物清单,运行:
|
||||
|
||||
```
|
||||
herms shopping 1
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
要获得帮助,运行:
|
||||
|
||||
```
|
||||
herms -h
|
||||
```
|
||||
|
||||
当你下次听到你的同事、朋友或其他地方谈到好的食谱时,只需打开 Herm's,并快速记下,并将它们分享给你的配偶。她会很高兴!
|
||||
|
||||
今天就是这些。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/herms-commandline-food-recipes-manager/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/12/Make-Dosa-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/12/herms-1-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/12/herms-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/12/herms-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/12/herms-4.png
|
||||
@ -0,0 +1,84 @@
|
||||
如何创建适合移动设备的文档
|
||||
=====
|
||||
|
||||
> 帮助用户在智能手机或平板上快速轻松地找到他们所需的信息。
|
||||
|
||||

|
||||
|
||||
我并不是完全相信[移动为先][1]的理念,但是我确实发现更多的人使用智能手机和平板电脑等移动设备来获取信息。这包括在线的软件和硬件文档,但它们大部分都是冗长的,不适合小屏幕。通常情况下,它的伸缩性不太好,而且很难导航。
|
||||
|
||||
当用户使用移动设备访问文档时,他们通常需要迅速获取信息以了解如何执行任务或解决问题,他们不想通过看似无尽的页面来寻找他们需要的特定信息。幸运的是,解决这个问题并不难。以下是一些技巧,可以帮助你构建文档以满足移动阅读器的需求。
|
||||
|
||||
### 简短一点
|
||||
|
||||
这意味着简短的句子,简短的段落和简短的流程。你不是在写一部长篇小说或一段长新闻。使你的文档简洁。尽可能使用少量的语言来获得想法和信息。
|
||||
|
||||
以广播新闻报道为示范:关注关键要素,用简单直接的语言对其进行解释。不要让你的读者在屏幕上看到冗长的文字。
|
||||
|
||||
另外,直接切入重点。关注读者需要的信息。在线发布的文档不应该像以前厚厚的手册一样。不要把所有东西都放在一个页面上,把你的信息分成更小的块。接下来是怎样做到这一点:
|
||||
|
||||
### 主题
|
||||
|
||||
在技术写作的世界里,主题是独立的,独立的信息块。每个主题都由你网站上的单个页面组成。读者应该能从特定的主题中获取他们需要的信息 -- 并且只是那些信息。要做到这一点,选择哪些主题要包含在文档中并决定如何组织它们:
|
||||
|
||||
### DITA
|
||||
|
||||
<ruby>[达尔文信息类型化体系结构][2]<rt>Darwin Information Typing Architecture</rt></ruby> (DITA) 是用于编写和发布的一个 XML 模型。它[广泛采用][3]在技术写作中,特别是作为较长的文档集中。
|
||||
|
||||
我并不是建议你将文档转换为 XML(除非你真的想)。相反,考虑将 DITA 的不同类型主题的概念应用到你的文档中:
|
||||
|
||||
* 一般:概述信息
|
||||
* 任务:分步骤的流程
|
||||
* 概念:背景或概念信息
|
||||
* 参考:API 参考或数据字典等专用信息
|
||||
* 术语表:定义术语
|
||||
* 故障排除:有关用户可能遇到的问题以及如何解决问题的信息
|
||||
|
||||
你会得到很多单独的页面。要连接这些页面:
|
||||
|
||||
### 链接
|
||||
|
||||
许多内容管理系统、维基和发布框架都包含某种形式的导航 —— 通常是目录或[面包屑导航][4],这是一种在移动设备上逐渐消失的导航。
|
||||
|
||||
为了加强导航,在主题之间添加明确的链接。将这些链接放在每个主题末尾的标题**另请参阅**或**相关主题**。每个部分应包含两到五个链接,指向与当前主题相关的概述、概念和参考主题。
|
||||
|
||||
如果你需要指向文档集之外的信息,请确保链接在浏览器新的选项卡中打开。这将把读者送到另一个网站,同时也将读者继续留你的网站上。
|
||||
|
||||
这解决了文本问题,那么图片呢?
|
||||
|
||||
### 不使用图片
|
||||
|
||||
除少数情况之外,不应该加太多图片到文档中。仔细查看文档中的每个图片,然后问自己:
|
||||
|
||||
* 它有用吗?
|
||||
* 它是否增强了文档?
|
||||
* 如果删除它,读者会错过这张图片吗?
|
||||
|
||||
如果回答否,那么移除图片。
|
||||
|
||||
另一方面,如果你绝对不能没有图片,就让它变成[响应式的][5]。这样,图片就会自动调整以适应更小的屏幕。
|
||||
|
||||
如果你仍然不确定图片是否应该出现,Opensource.com 社区版主 Ben Cotton 提供了一个关于在文档中使用屏幕截图的[极好的解释][6]。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
通过少量努力,你就可以构建适合移动设备用户的文档。此外,这些更改也改进了桌面计算机和笔记本电脑用户的文档体验。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/think-mobile
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/chrisshort
|
||||
[1]:https://www.uxmatters.com/mt/archives/2012/03/mobile-first-what-does-it-mean.php
|
||||
[2]:https://en.wikipedia.org/wiki/Darwin_Information_Typing_Architecture
|
||||
[3]:http://dita.xml.org/book/list-of-organizations-using-dita
|
||||
[4]:https://en.wikipedia.org/wiki/Breadcrumb_(navigation)
|
||||
[5]:https://en.wikipedia.org/wiki/Responsive_web_design
|
||||
[6]:https://opensource.com/business/15/9/when-does-your-documentation-need-screenshots
|
||||
@ -0,0 +1,164 @@
|
||||
“Exit Trap” 让你的 Bash 脚本更稳固可靠
|
||||
============================================================
|
||||
|
||||
有个简单实用的技巧可以让你的 bash 脚本更稳健 -- 确保总是执行必要的收尾工作,哪怕是在发生异常的时候。要做到这一点,秘诀就是 bash 提供的一个叫做 EXIT 的伪信号,你可以 [trap][1] 它,当脚本因为任何原因退出时,相应的命令或函数就会执行。我们来看看它是如何工作的。
|
||||
|
||||
基本的代码结构看起来像这样:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
function finish {
|
||||
# 你的收尾代码
|
||||
}
|
||||
trap finish EXIT
|
||||
```
|
||||
|
||||
你可以把任何你觉得务必要运行的代码放在这个 `finish` 函数里。一个很好的例子是:创建一个临时目录,事后再删除它。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
function finish {
|
||||
rm -rf "$scratch"
|
||||
}
|
||||
trap finish EXIT
|
||||
```
|
||||
|
||||
这样,在你的核心代码中,你就可以在这个 `$scratch` 目录里下载、生成、操作中间或临时数据了。^[注1][2]
|
||||
|
||||
```
|
||||
# 下载所有版本的 linux 内核…… 为了科学研究!
|
||||
for major in {1..4}; do
|
||||
for minor in {0..99}; do
|
||||
for patchlevel in {0..99}; do
|
||||
tarball="linux-${major}-${minor}-${patchlevel}.tar.bz2"
|
||||
curl -q "http://kernel.org/path/to/$tarball" -o "$scratch/$tarball" || true
|
||||
if [ -f "$scratch/$tarball" ]; then
|
||||
tar jxf "$scratch/$tarball"
|
||||
fi
|
||||
done
|
||||
done
|
||||
done
|
||||
# 整合成单个文件
|
||||
# 复制到目标位置
|
||||
cp "$scratch/frankenstein-linux.tar.bz2" "$1"
|
||||
# 脚本结束, scratch 目录自动被删除
|
||||
```
|
||||
|
||||
比较一下如果不用 `trap` ,你是怎么删除 `scratch` 目录的:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# 别这样做!
|
||||
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
|
||||
# 在这里插入你的几十上百行代码
|
||||
|
||||
# 都搞定了,退出之前把目录删除
|
||||
rm -rf "$scratch"
|
||||
```
|
||||
|
||||
这有什么问题么?很多:
|
||||
|
||||
* 如果运行出错导致脚本提前退出, `scratch` 目录及里面的内容不会被删除。这会导致资料泄漏,可能引发安全问题。
|
||||
* 如果这个脚本的设计初衷就是在脚本末尾以前退出,那么你必须手动复制粘贴 `rm` 命令到每一个出口。
|
||||
|
||||
* 这也给维护带来了麻烦。如果今后在脚本某处添加了一个 `exit` ,你很可能就忘了加上删除操作 -- 从而制造潜在的安全漏洞。
|
||||
|
||||
### 无论如何,服务要在线
|
||||
|
||||
另外一个场景: 想象一下你正在运行一些自动化系统运维任务,要临时关闭一项服务,最后这项服务需要重启,而且要万无一失,即使脚本运行出错。那么你可以这样做:
|
||||
|
||||
```
|
||||
function finish {
|
||||
# 重启服务
|
||||
sudo /etc/init.d/something start
|
||||
}
|
||||
trap finish EXIT
|
||||
sudo /etc/init.d/something stop
|
||||
# 主要任务代码
|
||||
|
||||
# 脚本结束,执行 finish 函数重启服务
|
||||
```
|
||||
|
||||
一个具体的实例:比如 Ubuntu 服务器上运行着 MongoDB ,你要为 crond 写一个脚本来临时关闭服务并做一些日常维护工作。你应该这样写:
|
||||
|
||||
```
|
||||
function finish {
|
||||
# 重启服务
|
||||
sudo service mongdb start
|
||||
}
|
||||
trap finish EXIT
|
||||
# 关闭 mongod 服务
|
||||
sudo service mongdb stop
|
||||
# (如果 mongod 配置了 fork ,比如 replica set ,你可能需要执行 “sudo killall --wait /usr/bin/mongod”)
|
||||
```
|
||||
|
||||
### 控制开销
|
||||
|
||||
有一种情况特别能体现 EXIT `trap` 的价值:如果你的脚本运行过程中需要初始化一下成本高昂的资源,结束时要确保把它们释放掉。比如你在 AWS (Amazon Web Services) 上工作,要在脚本中创建一个镜像。
|
||||
|
||||
(名词解释: 在亚马逊云上的运行的服务器叫“[实例][3]”。实例从<ruby>亚马逊机器镜像<rt>Amazon Machine Image</rt></ruby>创建而来,通常被称为 “AMI” 或 “镜像” 。AMI 相当于某个特殊时间点的服务器快照。)
|
||||
|
||||
我们可以这样创建一个自定义的 AMI :
|
||||
|
||||
1. 基于一个基准 AMI 运行一个实例(例如,启动一个服务器)。
|
||||
2. 在实例中手动或运行脚本来做一些修改。
|
||||
3. 用修改后的实例创建一个镜像。
|
||||
4. 如果不再需要这个实例,可以将其删除。
|
||||
|
||||
最后一步**相当重要**。如果你的脚本没有把实例删除掉,它会一直运行并计费。(到月底你的账单让你大跌眼镜时,恐怕哭都来不及了!)
|
||||
|
||||
如果把 AMI 的创建封装在脚本里,我们就可以利用 `trap` EXIT 来删除实例了。我们还可以用上 EC2 的命令行工具:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# 定义基准 AMI 的 ID
|
||||
ami=$1
|
||||
# 保存临时实例的 ID
|
||||
instance=''
|
||||
# 作为 IT 人,让我们看看 scratch 目录的另类用法
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
function finish {
|
||||
if [ -n "$instance" ]; then
|
||||
ec2-terminate-instances "$instance"
|
||||
fi
|
||||
rm -rf "$scratch"
|
||||
}
|
||||
trap finish EXIT
|
||||
# 创建实例,将输出(包含实例 ID )保存到 scratch 目录下的文件里
|
||||
ec2-run-instances "$ami" > "$scratch/run-instance"
|
||||
# 提取实例 ID
|
||||
instance=$(grep '^INSTANCE' "$scratch/run-instance" | cut -f 2)
|
||||
```
|
||||
|
||||
脚本执行到这里,实例(EC2 服务器)已经开始运行 ^[注2][4]。接下来你可以做任何事情:在实例中安装软件,修改配置文件等,然后为最终版本创建一个镜像。实例会在脚本结束时被删除 -- 即使脚本因错误而提前退出。(请确保实例创建成功后再运行业务代码。)
|
||||
|
||||
### 更多应用
|
||||
|
||||
这篇文章只讲了些皮毛。我已经使用这个 bash 技巧很多年了,现在还能不时发现一些有趣的用法。你也可以把这个方法应用到你自己的场景中,从而提升你的 bash 脚本的可靠性。
|
||||
|
||||
### 尾注
|
||||
|
||||
- 注1. `mktemp` 的选项 `-t` 在 Linux 上是可选的,在 OS X 上是必需的。带上此选项可以让你的脚本有更好的可移植性。
|
||||
- 注2. 如果只是为了获取实例 ID ,我们不用创建文件,直接写成 `instance=$(ec2-run-instances "$ami" | grep '^INSTANCE' | cut -f 2)` 就可以。但把输出写入文件可以记录更多有用信息,便于调试 ,代码可读性也更强。
|
||||
|
||||
作者简介:美国加利福尼亚旧金山的作家,软件工程师,企业家。[Powerful Python][5] 的作者,他的 [blog][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: http://redsymbol.net/articles/bash-exit-traps/
|
||||
|
||||
作者:[aaron maxwell][a]
|
||||
译者:[Dotcra](https://github.com/Dotcra)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://redsymbol.net/
|
||||
[1]:http://www.gnu.org/software/bash/manual/bashref.html#index-trap
|
||||
[2]:http://redsymbol.net/articles/bash-exit-traps/#footnote-1
|
||||
[3]:http://aws.amazon.com/ec2/
|
||||
[4]:http://redsymbol.net/articles/bash-exit-traps/#footnote-2
|
||||
[5]:https://www.amazon.com/d/0692878971
|
||||
[6]:https://powerfulpython.com/blog/
|
||||
@ -0,0 +1,122 @@
|
||||
两款 Linux 桌面端可用的科学计算器
|
||||
======
|
||||
|
||||
> 如果你想找个高级的桌面计算器的话,你可以看看开源软件,以及一些其它有趣的工具。
|
||||
|
||||

|
||||
|
||||
每个 Linux 桌面环境都至少带有一个功能简单的桌面计算器,但大多数计算器只能进行一些简单的计算。
|
||||
|
||||
幸运的是,还是有例外的:不仅可以做得比开平方根和一些三角函数还多,而且还很简单。这里将介绍两款强大的计算器,外加一大堆额外的功能。
|
||||
|
||||
### SpeedCrunch
|
||||
|
||||
[SpeedCrunch][1] 是一款高精度科学计算器,有着简明的 Qt5 图像界面,并且强烈依赖键盘。
|
||||
|
||||
![SpeedCrunch graphical interface][3]
|
||||
|
||||
*SpeedCrunch 运行中*
|
||||
|
||||
它支持单位,并且可用在所有函数中。
|
||||
|
||||
例如,
|
||||
|
||||
```
|
||||
2 * 10^6 newton / (meter^2)
|
||||
```
|
||||
|
||||
你可以得到:
|
||||
|
||||
```
|
||||
= 2000000 pascal
|
||||
```
|
||||
|
||||
SpeedCrunch 会默认地将结果转化为国际标准单位,但还是可以用 `in` 命令转换:
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
3*10^8 meter / second in kilo meter / hour
|
||||
```
|
||||
|
||||
结果是:
|
||||
|
||||
```
|
||||
= 1080000000 kilo meter / hour
|
||||
```
|
||||
|
||||
`F5` 键可以将所有结果转为科学计数法(`1.08e9 kilo meter / hour`),`F2` 键可以只将那些很大的数或很小的数转为科学计数法。更多选项可以在配置页面找到。
|
||||
|
||||
可用的函数的列表看上去非常壮观。它可以用在 Linux 、 Windows、macOS。许可证是 GPLv2,你可以在 [Bitbucket][4] 上得到它的源码。
|
||||
|
||||
### Qalculate!
|
||||
|
||||
[Qalculate!][5](有感叹号)有一段长而复杂的历史。
|
||||
|
||||
这个项目给了我们一个强大的库,而这个库可以被其它程序使用(在 Plasma 桌面中,krunner 可以用它来计算),以及一个用 GTK3 搭建的图形界面。它允许你转换单位,处理物理常量,创建图像,使用复数,矩阵以及向量,选择任意精度,等等。
|
||||
|
||||
![Qalculate! Interface][7]
|
||||
|
||||
*在 Qalculate! 中查看物理常量*
|
||||
|
||||
在单位的使用方面,Qalculate! 会比 SppedCrunch 更加直观,而且可以识别一些常用前缀。你有听说过 exapascal 压力吗?反正我没有(太阳的中心大概在 `~26 PPa`),但 Qalculate! ,可以准确 `1 EPa` 的意思。同时,Qalculate! 可以更加灵活地处理语法错误,所以你不需要担心打括号:如果没有歧义,Qalculate! 会直接给出正确答案。
|
||||
|
||||
一段时间之后这个项目看上去被遗弃了。但在 2016 年,它又变得强大了,在一年里更新了 10 个版本。它的许可证是 GPLv2 (源码在 [GitHub][8] 上),提供Linux 、Windows 、macOS的版本。
|
||||
|
||||
### 更多计算器
|
||||
|
||||
#### ConvertAll
|
||||
|
||||
好吧,这不是“计算器”,但这个程序非常好用。
|
||||
|
||||
大部分单位转换器只是一个大的基本单位列表以及一大堆基本组合,但 [ConvertAll][9] 与它们不一样。有试过把天文单位每年转换为英寸每秒吗?不管它们说不说得通,只要你想转换任何种类的单位,ConvertAll 就是你要的工具。
|
||||
|
||||
只需要在相应的输入框内输入转换前和转换后的单位:如果单位相容,你会直接得到答案。
|
||||
|
||||
主程序是在 PyQt5 上搭建的,但也有 [JavaScript 的在线版本][10]。
|
||||
|
||||
#### 带有单位包的 (wx)Maxima
|
||||
|
||||
有时候(好吧,很多时候)一款桌面计算器时候不够你用的,然后你需要更多的原力。
|
||||
|
||||
[Maxima][11] 是一款计算机代数系统(LCTT 译注:进行符号运算的软件。这种系统的要件是数学表示式的符号运算),你可以用它计算导数、积分、方程、特征值和特征向量、泰勒级数、拉普拉斯变换与傅立叶变换,以及任意精度的数字计算、二维或三维图像··· ···列出这些都够我们写几页纸的了。
|
||||
|
||||
[wxMaxima][12] 是一个设计精湛的 Maxima 的图形前端,它简化了许多 Maxima 的选项,但并不会影响其它。在 Maxima 的基础上,wxMaxima 还允许你创建 “笔记本”,你可以在上面写一些笔记,保存你的图像等。其中一项 (wx)Maxima 最惊艳的功能是它可以处理尺寸单位。
|
||||
|
||||
在提示符只需要输入:
|
||||
|
||||
```
|
||||
load("unit")
|
||||
```
|
||||
|
||||
按 `Shift+Enter`,等几秒钟的时间,然后你就可以开始了。
|
||||
|
||||
默认地,单位包可以用基本的 MKS 单位,但如果你喜欢,例如,你可以用 `N` 为单位而不是 `kg*m/s2`,你只需要输入:`setunits(N)`。
|
||||
|
||||
Maxima 的帮助(也可以在 wxMaxima 的帮助菜单中找到)会给你更多信息。
|
||||
|
||||
你使用这些程序吗?你知道还有其它好的科学、工程用途的桌面计算器或者其它相关的计算器吗?在评论区里告诉我们吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/scientific-calculators-linux
|
||||
|
||||
作者:[Ricardo Berlasso][a]
|
||||
译者:[zyk2290](https://github.com/zyk2290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rgb-es
|
||||
[1]:http://speedcrunch.org/index.html
|
||||
[2]:/file/382511
|
||||
[3]:https://opensource.com/sites/default/files/u128651/speedcrunch.png "SpeedCrunch graphical interface"
|
||||
[4]:https://bitbucket.org/heldercorreia/speedcrunch
|
||||
[5]:https://qalculate.github.io/
|
||||
[6]:/file/382506
|
||||
[7]:https://opensource.com/sites/default/files/u128651/qalculate-600.png "Qalculate! Interface"
|
||||
[8]:https://github.com/Qalculate
|
||||
[9]:http://convertall.bellz.org/
|
||||
[10]:http://convertall.bellz.org/js/
|
||||
[11]:http://maxima.sourceforge.net/
|
||||
[12]:https://andrejv.github.io/wxmaxima/
|
||||
@ -0,0 +1,66 @@
|
||||
为什么建设一个社区值得额外的努力
|
||||
======
|
||||
|
||||
> 建立 NethServer 社区是有风险的。但是我们从这些激情的人们所带来的力量当中学习到了很多。
|
||||
|
||||

|
||||
|
||||
当我们在 2003 年推出 [Nethesis][1] 时,我们还只是系统集成商。我们只使用已有的开源项目。我们的业务模式非常明确:为这些项目增加多种形式的价值:实践知识、针对意大利市场的文档、额外模块、专业支持和培训课程。我们还通过向上游贡献代码并参与其社区来回馈上游项目。
|
||||
|
||||
那时时代不同。我们不能太张扬地使用“开源”这个词。人们将它与诸如“书呆子”,“没有价值”以及最糟糕的“免费”这些词联系起来。这些不太适合生意。
|
||||
|
||||
在 2010 年的一个星期六,Nethesis 的工作人员,他们手中拿着馅饼和浓咖啡,正在讨论如何推进事情发展(嘿,我们喜欢在创新的同时吃喝东西!)。尽管势头对我们不利,但我们决定不改变方向。事实上,我们决定加大力度 —— 去做开源和开放的工作方式,这是一个成功运营企业的模式。
|
||||
|
||||
多年来,我们已经证明了该模型的潜力。有一件事是我们成功的关键:社区。
|
||||
|
||||
在这个由三部分组成的系列文章中,我将解释社区在开放组织的存在中扮演的重要角色。我将探讨为什么一个组织希望建立一个社区,并讨论如何建立一个社区 —— 因为我确实认为这是如今产生新创新的最佳方式。
|
||||
|
||||
### 这个疯狂的想法
|
||||
|
||||
与 Nethesis 伙伴一起,我们决定构建自己的开源项目:我们自己的操作系统,它建立在 CentOS 之上(因为我们不想重新发明轮子)。我们假设我们拥有实现它的经验、实践知识和人力。我们感到很勇敢。
|
||||
|
||||
我们非常希望构建一个名为 [NethServer][2] 的操作系统,其使命是:通过开源使系统管理员的生活更轻松。我们知道我们可以为服务器创建一个 Linux 发行版,与当前已有的相比,它更容易使用、更易于部署,并且更易于理解。
|
||||
|
||||
不过,最重要的是,我们决定创建一个真正的,100% 开放的项目,其主要规则有三条:
|
||||
|
||||
* 完全免费下载
|
||||
* 开发公开
|
||||
* 社区驱动
|
||||
|
||||
最后一个很重要。我们是一家公司。我们能够自己开发它。如果我们在内部完成这项工作,我们将会更有效(并且做出更快的决定)。与其他任何意大利公司一样,这将非常简单。
|
||||
|
||||
但是我们已经如此深入到开源文化中,所以我们选择了不同的路径。
|
||||
|
||||
我们确实希望有尽可能多的人围绕着我们、围绕着产品、围绕着公司周围。我们希望对工作有尽可能多的视角。我们意识到:独自一人,你可以走得快 —— 但是如果你想走很远,你需要一起走。
|
||||
|
||||
所以我们决定建立一个社区。
|
||||
|
||||
### 下一步是什么?
|
||||
|
||||
我们意识到创建社区有很多好处。例如,如果使用产品的人真正参与到项目中,他们将提供反馈和测试用例、编写文档、发现 bug,与其他产品进行比较,建议功能并为开发做出贡献。所有这些都会产生创新,吸引贡献者和客户,并扩展你产品的用户群。
|
||||
|
||||
但是很快就出现了这样一个问题:我们如何建立一个社区?我们不知道如何实现这一点。我们参加了很多社区,但我们从未建立过一个社区。
|
||||
|
||||
我们擅长编码 —— 而不是人。我们是一家公司,是一个有非常具体优先事项的组织。那么我们如何建立一个社区,并在公司和社区之间建立良好的关系呢?
|
||||
|
||||
我们做了你必须做的第一件事:学习。我们从专家、博客和许多书中学到了知识。我们进行了实验。我们失败了多次,从结果中收集数据,并再次进行测试。
|
||||
|
||||
最终我们学到了社区管理的黄金法则:**没有社区管理的黄金法则。**
|
||||
|
||||
人们太复杂了,社区无法用一条规则来“统治他们”。
|
||||
|
||||
然而,我可以说的一件事是,社区和公司之间的健康关系总是一个给予和接受的过程。在我的下一篇文章中,我将讨论你的组织如果想要一个蓬勃发展和创新的社区,应该期望提供什么。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/1/why-build-community-1
|
||||
|
||||
作者:[Alessio Fattorini][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alefattorini
|
||||
[1]:http://www.nethesis.it/
|
||||
[2]:http://www.nethserver.org/
|
||||
345
published/20180122 A Simple Command-line Snippet Manager.md
Normal file
345
published/20180122 A Simple Command-line Snippet Manager.md
Normal file
@ -0,0 +1,345 @@
|
||||
Pet:一个简单的命令行片段管理器
|
||||
=====
|
||||
|
||||

|
||||
|
||||
我们不可能记住所有的命令,对吧?是的。除了经常使用的命令之外,我们几乎不可能记住一些很少使用的长命令。这就是为什么需要一些外部工具来帮助我们在需要时找到命令。在过去,我们已经点评了两个有用的工具,名为 “Bashpast” 和 “Keep”。使用 Bashpast,我们可以轻松地为 Linux 命令添加书签,以便更轻松地重复调用。而 Keep 实用程序可以用来在终端中保留一些重要且冗长的命令,以便你可以随时使用它们。今天,我们将看到该系列中的另一个工具,以帮助你记住命令。现在让我们认识一下 “Pet”,这是一个用 Go 语言编写的简单的命令行代码管理器。
|
||||
|
||||
使用 Pet,你可以:
|
||||
|
||||
* 注册/添加你重要的、冗长和复杂的命令片段。
|
||||
* 以交互方式来搜索保存的命令片段。
|
||||
* 直接运行代码片段而无须一遍又一遍地输入。
|
||||
* 轻松编辑保存的代码片段。
|
||||
* 通过 Gist 同步片段。
|
||||
* 在片段中使用变量
|
||||
* 还有很多特性即将来临。
|
||||
|
||||
### 安装 Pet 命令行接口代码管理器
|
||||
|
||||
由于它是用 Go 语言编写的,所以确保你在系统中已经安装了 Go。
|
||||
|
||||
安装 Go 后,从 [**Pet 发布页面**][3] 获取最新的二进制文件。
|
||||
|
||||
```
|
||||
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_amd64.zip
|
||||
```
|
||||
|
||||
对于 32 位计算机:
|
||||
|
||||
```
|
||||
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_386.zip
|
||||
```
|
||||
|
||||
解压下载的文件:
|
||||
|
||||
```
|
||||
unzip pet_0.2.4_linux_amd64.zip
|
||||
```
|
||||
|
||||
对于 32 位:
|
||||
|
||||
```
|
||||
unzip pet_0.2.4_linux_386.zip
|
||||
```
|
||||
|
||||
将 `pet` 二进制文件复制到 PATH(即 `/usr/local/bin` 之类的)。
|
||||
|
||||
```
|
||||
sudo cp pet /usr/local/bin/
|
||||
```
|
||||
|
||||
最后,让它可以执行:
|
||||
|
||||
```
|
||||
sudo chmod +x /usr/local/bin/pet
|
||||
```
|
||||
|
||||
如果你使用的是基于 Arch 的系统,那么你可以使用任何 AUR 帮助工具从 AUR 安装它。
|
||||
|
||||
使用 [Pacaur][4]:
|
||||
|
||||
```
|
||||
pacaur -S pet-git
|
||||
```
|
||||
|
||||
使用 [Packer][5]:
|
||||
|
||||
```
|
||||
packer -S pet-git
|
||||
```
|
||||
|
||||
使用 [Yaourt][6]:
|
||||
|
||||
```
|
||||
yaourt -S pet-git
|
||||
```
|
||||
|
||||
使用 [Yay][7]:
|
||||
|
||||
```
|
||||
yay -S pet-git
|
||||
```
|
||||
|
||||
此外,你需要安装 [fzf][8] 或 [peco][9] 工具以启用交互式搜索。请参阅官方 GitHub 链接了解如何安装这些工具。
|
||||
|
||||
### 用法
|
||||
|
||||
运行没有任何参数的 `pet` 来查看可用命令和常规选项的列表。
|
||||
|
||||
```
|
||||
$ pet
|
||||
pet - Simple command-line snippet manager.
|
||||
|
||||
Usage:
|
||||
pet [command]
|
||||
|
||||
Available Commands:
|
||||
configure Edit config file
|
||||
edit Edit snippet file
|
||||
exec Run the selected commands
|
||||
help Help about any command
|
||||
list Show all snippets
|
||||
new Create a new snippet
|
||||
search Search snippets
|
||||
sync Sync snippets
|
||||
version Print the version number
|
||||
|
||||
Flags:
|
||||
--config string config file (default is $HOME/.config/pet/config.toml)
|
||||
--debug debug mode
|
||||
-h, --help help for pet
|
||||
|
||||
Use "pet [command] --help" for more information about a command.
|
||||
```
|
||||
|
||||
要查看特定命令的帮助部分,运行:
|
||||
|
||||
```
|
||||
$ pet [command] --help
|
||||
```
|
||||
|
||||
#### 配置 Pet
|
||||
|
||||
默认配置其实工作的挺好。但是,你可以更改保存片段的默认目录,选择要使用的选择器(fzf 或 peco),编辑片段的默认文本编辑器,添加 GIST id 详细信息等。
|
||||
|
||||
要配置 Pet,运行:
|
||||
|
||||
```
|
||||
$ pet configure
|
||||
```
|
||||
|
||||
该命令将在默认的文本编辑器中打开默认配置(例如我是 vim),根据你的要求更改或编辑特定值。
|
||||
|
||||
```
|
||||
[General]
|
||||
snippetfile = "/home/sk/.config/pet/snippet.toml"
|
||||
editor = "vim"
|
||||
column = 40
|
||||
selectcmd = "fzf"
|
||||
|
||||
[Gist]
|
||||
file_name = "pet-snippet.toml"
|
||||
access_token = ""
|
||||
gist_id = ""
|
||||
public = false
|
||||
~
|
||||
```
|
||||
|
||||
#### 创建片段
|
||||
|
||||
为了创建一个新的片段,运行:
|
||||
|
||||
```
|
||||
$ pet new
|
||||
```
|
||||
|
||||
添加命令和描述,然后按下回车键保存它。
|
||||
|
||||
```
|
||||
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'
|
||||
Description> Remove numbers from output.
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
这是一个简单的命令,用于从 `echo` 命令输出中删除所有数字。你可以很轻松地记住它。但是,如果你很少使用它,几天后你可能会完全忘记它。当然,我们可以使用 `CTRL+R` 搜索历史记录,但 Pet 会更容易。另外,Pet 可以帮助你添加任意数量的条目。
|
||||
|
||||
另一个很酷的功能是我们可以轻松添加以前的命令。为此,在你的 `.bashrc` 或 `.zshrc` 文件中添加以下行。
|
||||
|
||||
```
|
||||
function prev() {
|
||||
PREV=$(fc -lrn | head -n 1)
|
||||
sh -c "pet new `printf %q "$PREV"`"
|
||||
}
|
||||
```
|
||||
|
||||
执行以下命令来使保存的更改生效。
|
||||
|
||||
```
|
||||
source .bashrc
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
source .zshrc
|
||||
```
|
||||
|
||||
现在,运行任何命令,例如:
|
||||
|
||||
```
|
||||
$ cat Documents/ostechnix.txt | tr '|' '\n' | sort | tr '\n' '|' | sed "s/.$/\\n/g"
|
||||
```
|
||||
|
||||
要添加上述命令,你不必使用 `pet new` 命令。只需要:
|
||||
|
||||
```
|
||||
$ prev
|
||||
```
|
||||
|
||||
将说明添加到该命令代码片段中,然后按下回车键保存。
|
||||
|
||||
![][12]
|
||||
|
||||
#### 片段列表
|
||||
|
||||
要查看保存的片段,运行:
|
||||
|
||||
```
|
||||
$ pet list
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
#### 编辑片段
|
||||
|
||||
如果你想编辑代码片段的描述或命令,运行:
|
||||
|
||||
```
|
||||
$ pet edit
|
||||
```
|
||||
|
||||
这将在你的默认文本编辑器中打开所有保存的代码片段,你可以根据需要编辑或更改片段。
|
||||
|
||||
```
|
||||
[[snippets]]
|
||||
description = "Remove numbers from output."
|
||||
command = "echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'"
|
||||
output = ""
|
||||
|
||||
[[snippets]]
|
||||
description = "Alphabetically sort one line of text"
|
||||
command = "\t prev"
|
||||
output = ""
|
||||
```
|
||||
|
||||
#### 在片段中使用标签
|
||||
|
||||
要将标签用于判断,使用下面的 `-t` 标志。
|
||||
|
||||
```
|
||||
$ pet new -t
|
||||
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9
|
||||
Description> Remove numbers from output.
|
||||
Tag> tr command examples
|
||||
```
|
||||
|
||||
#### 执行片段
|
||||
|
||||
要执行一个保存的片段,运行:
|
||||
|
||||
```
|
||||
$ pet exec
|
||||
```
|
||||
|
||||
从列表中选择你要运行的代码段,然后按回车键来运行它:
|
||||
|
||||
![][14]
|
||||
|
||||
记住你需要安装 fzf 或 peco 才能使用此功能。
|
||||
|
||||
#### 寻找片段
|
||||
|
||||
如果你有很多要保存的片段,你可以使用字符串或关键词如 below.qjz 轻松搜索它们。
|
||||
|
||||
```
|
||||
$ pet search
|
||||
```
|
||||
|
||||
输入搜索字词或关键字以缩小搜索结果范围。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 同步片段
|
||||
|
||||
首先,你需要获取访问令牌。转到此链接 <https://github.com/settings/tokens/new> 并创建访问令牌(只需要 “gist” 范围)。
|
||||
|
||||
使用以下命令来配置 Pet:
|
||||
|
||||
```
|
||||
$ pet configure
|
||||
```
|
||||
|
||||
将令牌设置到 `[Gist]` 字段中的 `access_token`。
|
||||
|
||||
设置完成后,你可以像下面一样将片段上传到 Gist。
|
||||
|
||||
```
|
||||
$ pet sync -u
|
||||
Gist ID: 2dfeeeg5f17e1170bf0c5612fb31a869
|
||||
Upload success
|
||||
```
|
||||
|
||||
你也可以在其他 PC 上下载片段。为此,编辑配置文件并在 `[Gist]` 中将 `gist_id` 设置为 GIST id。
|
||||
|
||||
之后,使用以下命令下载片段:
|
||||
|
||||
```
|
||||
$ pet sync
|
||||
Download success
|
||||
```
|
||||
|
||||
获取更多细节,参阅帮助选项:
|
||||
|
||||
```
|
||||
pet -h
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
pet [command] -h
|
||||
```
|
||||
|
||||
这就是全部了。希望这可以帮助到你。正如你所看到的,Pet 使用相当简单易用!如果你很难记住冗长的命令,Pet 实用程序肯定会有用。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/pet-simple-command-line-snippet-manager/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/bookmark-linux-commands-easier-repeated-invocation/
|
||||
[2]:https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
[3]:https://github.com/knqyf263/pet/releases
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://github.com/junegunn/fzf
|
||||
[9]:https://github.com/peco/peco
|
||||
[10]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-1.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-2.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-3.png
|
||||
[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-4.png
|
||||
[15]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-5.png
|
||||
401
published/20180126 How To Manage NodeJS Packages Using Npm.md
Normal file
401
published/20180126 How To Manage NodeJS Packages Using Npm.md
Normal file
@ -0,0 +1,401 @@
|
||||
如何使用 npm 管理 NodeJS 包
|
||||
=====
|
||||
|
||||

|
||||
|
||||
前一段时间,我们发布了一个[使用 pip 管理 Python 包][3]的指南。今天,我们将讨论如何使用 npm 管理 NodeJS 包。npm 是最大的软件注册中心,包含 600,000 多个包。每天,世界各地的开发人员通过 npm 共享和下载软件包。在本指南中,我将解释使用 npm 基础知识,例如安装包(本地和全局)、安装特定版本的包、更新、删除和管理 NodeJS 包等等。
|
||||
|
||||
### 安装 npm
|
||||
|
||||
用于 npm 是用 NodeJS 编写的,我们需要安装 NodeJS 才能使用 npm。要在不同的 Linux 发行版上安装 NodeJS,请参考下面的链接。
|
||||
|
||||
- [在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
|
||||
|
||||
检查 node 安装的位置:
|
||||
|
||||
```
|
||||
$ which node
|
||||
/home/sk/.nvm/versions/node/v9.4.0/bin/node
|
||||
```
|
||||
|
||||
检查它的版本:
|
||||
|
||||
```
|
||||
$ node -v
|
||||
v9.4.0
|
||||
```
|
||||
|
||||
进入 Node 交互式解释器:
|
||||
|
||||
```
|
||||
$ node
|
||||
> .help
|
||||
.break Sometimes you get stuck, this gets you out
|
||||
.clear Alias for .break
|
||||
.editor Enter editor mode
|
||||
.exit Exit the repl
|
||||
.help Print this help message
|
||||
.load Load JS from a file into the REPL session
|
||||
.save Save all evaluated commands in this REPL session to a file
|
||||
> .exit
|
||||
```
|
||||
|
||||
检查 npm 安装的位置:
|
||||
|
||||
```
|
||||
$ which npm
|
||||
/home/sk/.nvm/versions/node/v9.4.0/bin/npm
|
||||
```
|
||||
|
||||
还有版本:
|
||||
|
||||
```
|
||||
$ npm -v
|
||||
5.6.0
|
||||
```
|
||||
|
||||
棒极了!Node 和 npm 已安装好!正如你可能已经注意到,我已经在我的 `$HOME` 目录中安装了 NodeJS 和 NPM,这样是为了避免在全局模块时出现权限问题。这是 NodeJS 团队推荐的方法。
|
||||
|
||||
那么,让我们继续看看如何使用 npm 管理 NodeJS 模块(或包)。
|
||||
|
||||
### 安装 NodeJS 模块
|
||||
|
||||
NodeJS 模块可以安装在本地或全局(系统范围)。现在我将演示如何在本地安装包(LCTT 译注:即将包安装到一个 NodeJS 项目当中,所以下面会先创建一个空项目做演示)。
|
||||
|
||||
#### 在本地安装包
|
||||
|
||||
为了在本地管理包,我们通常使用 `package.json` 文件来管理。
|
||||
|
||||
首先,让我们创建我们的项目目录。
|
||||
|
||||
```
|
||||
$ mkdir demo
|
||||
$ cd demo
|
||||
```
|
||||
|
||||
在项目目录中创建一个 `package.json` 文件。为此,运行:
|
||||
|
||||
```
|
||||
$ npm init
|
||||
```
|
||||
|
||||
输入你的包的详细信息,例如名称、版本、作者、GitHub 页面等等,或者按下回车键接受默认值并键入 `yes` 确认。
|
||||
|
||||
```
|
||||
This utility will walk you through creating a package.json file.
|
||||
It only covers the most common items, and tries to guess sensible defaults.
|
||||
|
||||
See `npm help json` for definitive documentation on these fields
|
||||
and exactly what they do.
|
||||
|
||||
Use `npm install <pkg>` afterwards to install a package and
|
||||
save it as a dependency in the package.json file.
|
||||
|
||||
Press ^C at any time to quit.
|
||||
package name: (demo)
|
||||
version: (1.0.0)
|
||||
description: demo nodejs app
|
||||
entry point: (index.js)
|
||||
test command:
|
||||
git repository:
|
||||
keywords:
|
||||
author:
|
||||
license: (ISC)
|
||||
About to write to /home/sk/demo/package.json:
|
||||
|
||||
{
|
||||
"name": "demo",
|
||||
"version": "1.0.0",
|
||||
"description": "demo nodejs app",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC"
|
||||
}
|
||||
|
||||
Is this ok? (yes) yes
|
||||
```
|
||||
|
||||
上面的命令初始化你的项目并创建了 `package.json` 文件。
|
||||
|
||||
你也可以使用命令以非交互式方式执行此操作:
|
||||
|
||||
```
|
||||
npm init --y
|
||||
```
|
||||
|
||||
现在让我们安装名为 [commander][2] 的包。
|
||||
|
||||
```
|
||||
$ npm install commander
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
npm notice created a lockfile as package-lock.json. You should commit this file.
|
||||
npm WARN demo@1.0.0 No repository field.
|
||||
|
||||
+ commander@2.13.0
|
||||
added 1 package in 2.519s
|
||||
```
|
||||
|
||||
这将在项目的根目录中创建一个名为 `node_modules` 的目录(如果它不存在的话),并在其中下载包。
|
||||
|
||||
让我们检查 `pachage.json` 文件。
|
||||
|
||||
```
|
||||
$ cat package.json
|
||||
{
|
||||
"name": "demo",
|
||||
"version": "1.0.0",
|
||||
"description": "demo nodejs app",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC",
|
||||
"dependencies": {
|
||||
"commander": "^2.13.0"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
你会看到添加了依赖文件,版本号前面的插入符号 ( `^` ) 表示在安装时,npm 将取出它可以找到的最高版本的包。
|
||||
|
||||
```
|
||||
$ ls node_modules/
|
||||
commander
|
||||
```
|
||||
|
||||
`package.json` 文件的优点是,如果你的项目目录中有 `package.json` 文件,只需键入 `npm install`,那么 `npm` 将查看文件中列出的依赖关系并下载它们。你甚至可以与其他开发人员共享它或将其推送到你的 GitHub 仓库。因此,当他们键入 `npm install` 时,他们将获得你拥有的所有相同的包。
|
||||
|
||||
你也可能会注意到另一个名为 `package-lock.json` 的文件,该文件确保在项目安装的所有系统上都保持相同的依赖关系。
|
||||
|
||||
要在你的程序中使用已安装的包,使用实际代码在项目目录中创建一个 `index.js`(或者其他任何名称)文件,然后使用以下命令运行它:
|
||||
|
||||
```
|
||||
$ node index.js
|
||||
```
|
||||
|
||||
#### 在全局安装包
|
||||
|
||||
如果你想使用一个包作为命令行工具,那么最好在全局安装它。这样,无论你的当前目录是哪个目录,它都能正常工作。
|
||||
|
||||
```
|
||||
$ npm install async -g
|
||||
+ async@2.6.0
|
||||
added 2 packages in 4.695s
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ npm install async --global
|
||||
```
|
||||
|
||||
要安装特定版本的包,我们可以:
|
||||
|
||||
```
|
||||
$ npm install async@2.6.0 --global
|
||||
```
|
||||
|
||||
### 更新 NodeJS 模块
|
||||
|
||||
要更新本地包,转到 `package.json` 所在的项目目录并运行:
|
||||
|
||||
```
|
||||
$ npm update
|
||||
```
|
||||
|
||||
然后,运行以下命令确保所有包都更新了。
|
||||
|
||||
```
|
||||
$ npm outdated
|
||||
```
|
||||
|
||||
如果没有需要更新的,那么它返回空。
|
||||
|
||||
要找出哪一个全局包需要更新,运行:
|
||||
|
||||
```
|
||||
$ npm outdated -g --depth=0
|
||||
```
|
||||
|
||||
如果没有输出,意味着所有包都已更新。
|
||||
|
||||
更新单个全局包,运行:
|
||||
|
||||
```
|
||||
$ npm update -g <package-name>
|
||||
```
|
||||
|
||||
更新所有的全局包,运行:
|
||||
|
||||
```
|
||||
$ npm update -g
|
||||
```
|
||||
|
||||
### 列出 NodeJS 模块
|
||||
|
||||
列出本地包,转到项目目录并运行:
|
||||
|
||||
```
|
||||
$ npm list
|
||||
demo@1.0.0 /home/sk/demo
|
||||
└── commander@2.13.0
|
||||
```
|
||||
|
||||
如你所见,我在本地安装了 `commander` 这个包。
|
||||
|
||||
要列出全局包,从任何位置都可以运行以下命令:
|
||||
|
||||
```
|
||||
$ npm list -g
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
/home/sk/.nvm/versions/node/v9.4.0/lib
|
||||
├─┬ async@2.6.0
|
||||
│ └── lodash@4.17.4
|
||||
└─┬ npm@5.6.0
|
||||
├── abbrev@1.1.1
|
||||
├── ansi-regex@3.0.0
|
||||
├── ansicolors@0.3.2
|
||||
├── ansistyles@0.1.3
|
||||
├── aproba@1.2.0
|
||||
├── archy@1.0.0
|
||||
[...]
|
||||
```
|
||||
|
||||
该命令将列出所有模块及其依赖关系。
|
||||
|
||||
要仅仅列出顶级模块,使用 `-depth=0` 选项:
|
||||
|
||||
```
|
||||
$ npm list -g --depth=0
|
||||
/home/sk/.nvm/versions/node/v9.4.0/lib
|
||||
├── async@2.6.0
|
||||
└── npm@5.6.0
|
||||
```
|
||||
|
||||
#### 寻找 NodeJS 模块
|
||||
|
||||
要搜索一个模块,使用 `npm search` 命令:
|
||||
|
||||
```
|
||||
npm search <search-string>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
$ npm search request
|
||||
```
|
||||
|
||||
该命令将显示包含搜索字符串 `request` 的所有模块。
|
||||
|
||||
##### 移除 NodeJS 模块
|
||||
|
||||
要删除本地包,转到项目目录并运行以下命令,这会从 `node_modules` 目录中删除包:
|
||||
|
||||
```
|
||||
$ npm uninstall <package-name>
|
||||
```
|
||||
|
||||
要从 `package.json` 文件中的依赖关系中删除它,使用如下所示的 `save` 选项:
|
||||
|
||||
```
|
||||
$ npm uninstall --save <package-name>
|
||||
```
|
||||
|
||||
要删除已安装的全局包,运行:
|
||||
|
||||
```
|
||||
$ npm uninstall -g <package>
|
||||
```
|
||||
|
||||
### 清除 npm 缓存
|
||||
|
||||
默认情况下,npm 在安装包时,会将其副本保存在 `$HOME` 目录中名为 `.npm` 的缓存文件夹中。所以,你可以在下次安装时不必再次下载。
|
||||
|
||||
查看缓存模块:
|
||||
|
||||
```
|
||||
$ ls ~/.npm
|
||||
```
|
||||
|
||||
随着时间的推移,缓存文件夹会充斥着大量旧的包。所以不时清理缓存会好一些。
|
||||
|
||||
从 npm@5 开始,npm 缓存可以从 corruption 问题中自行修复,并且保证从缓存中提取的数据有效。如果你想确保一切都一致,运行:
|
||||
|
||||
```
|
||||
$ npm cache verify
|
||||
```
|
||||
|
||||
清除整个缓存,运行:
|
||||
|
||||
```
|
||||
$ npm cache clean --force
|
||||
```
|
||||
|
||||
### 查看 npm 配置
|
||||
|
||||
要查看 npm 配置,键入:
|
||||
|
||||
```
|
||||
$ npm config list
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
$ npm config ls
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
; cli configs
|
||||
metrics-registry = "https://registry.npmjs.org/"
|
||||
scope = ""
|
||||
user-agent = "npm/5.6.0 node/v9.4.0 linux x64"
|
||||
|
||||
; node bin location = /home/sk/.nvm/versions/node/v9.4.0/bin/node
|
||||
; cwd = /home/sk
|
||||
; HOME = /home/sk
|
||||
; "npm config ls -l" to show all defaults.
|
||||
```
|
||||
|
||||
要显示当前的全局位置:
|
||||
|
||||
```
|
||||
$ npm config get prefix
|
||||
/home/sk/.nvm/versions/node/v9.4.0
|
||||
```
|
||||
|
||||
好吧,这就是全部了。我们刚才介绍的只是基础知识,npm 是一个广泛话题。有关更多详细信息,参阅 [**NPM Getting Started**][3] 指南。
|
||||
|
||||
希望这对你有帮助。更多好东西即将来临,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.npmjs.com/package/commander
|
||||
[3]:https://docs.npmjs.com/getting-started/
|
||||
@ -0,0 +1,99 @@
|
||||
如何使用 rsync 通过 SSH 恢复部分传输的文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
由于诸如电源故障、网络故障或用户干预等各种原因,使用 `scp` 命令通过 SSH 复制的大型文件可能会中断、取消或损坏。有一天,我将 Ubuntu 16.04 ISO 文件复制到我的远程系统。不幸的是断电了,网络连接立即断了。结果么?复制过程终止!这只是一个简单的例子。Ubuntu ISO 并不是那么大,一旦电源恢复,我就可以重新启动复制过程。但在生产环境中,当你在传输大型文件时,你可能并不希望这样做。
|
||||
|
||||
而且,你不能继续使用 `scp` 命令恢复被中止的进度。因为,如果你这样做,它只会覆盖现有的文件。这时你会怎么做?别担心!这是 `rsync` 派上用场的地方!`rsync` 可以帮助你恢复中断的复制或下载过程。对于那些好奇的人,`rsync` 是一个快速、多功能的文件复制程序,可用于复制和传输远程和本地系统中的文件或文件夹。
|
||||
|
||||
它提供了大量控制其各种行为的选项,并允许非常灵活地指定要复制的一组文件。它以增量传输算法而闻名,它通过仅发送源文件和目标中现有文件之间的差异来减少通过网络发送的数据量。 `rsync` 广泛用于备份和镜像,以及日常使用中改进的复制命令。
|
||||
|
||||
就像 `scp` 一样,`rsync` 也会通过 SSH 复制文件。如果你想通过 SSH 下载或传输大文件和文件夹,我建议您使用 `rsync`。请注意,应该在两边(远程和本地系统)都安装 `rsync` 来恢复部分传输的文件。
|
||||
|
||||
### 使用 rsync 恢复部分传输的文件
|
||||
|
||||
好吧,让我给你看一个例子。我将使用命令将 Ubuntu 16.04 ISO 从本地系统复制到远程系统:
|
||||
|
||||
```
|
||||
$ scp Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.2:/home/sk/
|
||||
```
|
||||
|
||||
这里,
|
||||
|
||||
* `sk`是我的远程系统的用户名
|
||||
* `192.168.43.2` 是远程机器的 IP 地址。
|
||||
|
||||
现在,我按下 `CTRL+C` 结束它。
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
sk@192.168.43.2's password:
|
||||
ubuntu-16.04-desktop-amd64.iso 26% 372MB 26.2MB/s 00:39 ETA^c
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
正如你在上面的输出中看到的,当它达到 26% 时,我终止了复制过程。
|
||||
|
||||
如果我重新运行上面的命令,它只会覆盖现有的文件。换句话说,复制过程不会在我断开的地方恢复。
|
||||
|
||||
为了恢复复制过程,我们可以使用 `rsync` 命令,如下所示。
|
||||
|
||||
```
|
||||
$ rsync -P -rsh=ssh Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.2:/home/sk/
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
sk@192.168.1.103's password:
|
||||
sending incremental file list
|
||||
ubuntu-16.04-desktop-amd64.iso
|
||||
380.56M 26% 41.05MB/s 0:00:25
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
看见了吗?现在,复制过程在我们之前断开的地方恢复了。你也可以像下面那样使用 `-partial` 而不是 `-P` 参数。
|
||||
|
||||
```
|
||||
$ rsync --partial -rsh=ssh Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.2:/home/sk/
|
||||
```
|
||||
|
||||
这里,参数 `-partial` 或 `-P` 告诉 `rsync` 命令保留部分下载的文件并恢复进度。
|
||||
|
||||
或者,我们也可以使用以下命令通过 SSH 恢复部分传输的文件。
|
||||
|
||||
```
|
||||
$ rsync -avP Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.2:/home/sk/
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
rsync -av --partial Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.2:/home/sk/
|
||||
```
|
||||
|
||||
就是这样了。你现在知道如何使用 `rsync` 命令恢复取消、中断和部分下载的文件。正如你所看到的,它也不是那么难。如果两个系统都安装了 `rsync`,我们可以轻松地通过上面描述的那样恢复复制的进度。
|
||||
|
||||
如果你觉得本教程有帮助,请在你的社交、专业网络上分享,并支持我们。还有更多的好东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-resume-partially-downloaded-or-transferred-files-using-rsync/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/02/scp.png
|
||||
[3]:/cdn-cgi/l/email-protection
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/02/rsync.png
|
||||
@ -1,24 +1,26 @@
|
||||
How to Create, Revert and Delete KVM Virtual machine snapshot with virsh command
|
||||
如何使用 virsh 命令创建、还原和删除 KVM 虚拟机快照
|
||||
======
|
||||
[![KVM-VirtualMachine-Snapshot][1]![KVM-VirtualMachine-Snapshot][2]][2]
|
||||
|
||||
While working on the virtualization platform system administrators usually take the snapshot of virtual machine before doing any major activity like deploying the latest patch and code.
|
||||
![KVM-VirtualMachine-Snapshot][2]
|
||||
|
||||
Virtual machine **snapshot** is a copy of virtual machine’s disk at the specific point of time. In other words we can say snapshot keeps or preserve the state and data of a virtual machine at given point of time.
|
||||
在虚拟化平台上进行系统管理工作时,经常需要在开始重大操作比如部署补丁和代码前先设置一个虚拟机<ruby>快照<rt>snapshot</rt></ruby>。
|
||||
|
||||
### Where we can use VM snapshots ..?
|
||||
虚拟机**快照**是特定时间点的虚拟机磁盘的副本。换句话说,快照保存了给定的时间点虚拟机的状态和数据。
|
||||
|
||||
If you are working on **KVM** based **hypervisors** we can take virtual machines or domain snapshot using the virsh command. Snapshot becomes very helpful in a situation where you have installed or apply the latest patches on the VM but due to some reasons, application hosted in the VMs becomes unstable and application team wants to revert all the changes or patches. If you had taken the snapshot of the VM before applying patches then we can restore or revert the VM to its previous state using snapshot.
|
||||
### 我们可以在哪里使用虚拟机快照?
|
||||
|
||||
如果你在使用基于 **KVM** 的**虚拟机管理程序**,那么可以使用 `virsh` 命令获取虚拟机或域快照。快照在一种情况下变得非常有用,当你已经在虚拟机上安装或应用了最新的补丁,但是由于某些原因,虚拟机上的程序变得不稳定,开发团队想要还原所有的更改和补丁。如果你在应用补丁之前设置了虚拟机的快照,那么可以使用快照将虚拟机恢复到之前的状态。
|
||||
|
||||
**注意:**我们只能对磁盘格式为 **Qcow2** 的虚拟机的进行快照,并且 kvm 的 `virsh` 命令不支持 raw 磁盘格式,请使用以下命令将原始磁盘格式转换为 qcow2。
|
||||
|
||||
**Note:** We can only take the snapshot of the VMs whose disk format is **Qcow2** and raw disk format is not supported by kvm virsh command, Use below command to convert the raw disk format to qcow2
|
||||
```
|
||||
# qemu-img convert -f raw -O qcow2 image-name.img image-name.qcow2
|
||||
|
||||
```
|
||||
|
||||
### Create KVM Virtual Machine (domain) Snapshot
|
||||
### 创建 KVM 虚拟机(域)快照
|
||||
|
||||
我假设 KVM 管理程序已经在 CentOS 7 / RHEL 7 机器上配置好了,并且有虚拟机正在运行。我们可以使用下面的 `virsh` 命令列出虚拟机管理程序中的所有虚拟机,
|
||||
|
||||
I am assuming KVM hypervisor is already configured on CentOS 7 / RHEL 7 box and VMs are running on it. We can list the all the VMs on hypervisor using below virsh command,
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh list --all
|
||||
Id Name State
|
||||
@ -29,35 +31,33 @@ I am assuming KVM hypervisor is already configured on CentOS 7 / RHEL 7 box and
|
||||
103 overcloud-compute1 running
|
||||
114 webserver running
|
||||
115 Test-MTN running
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
Let’s suppose we want to create the snapshot of ‘ **webserver** ‘ VM, run the below command,
|
||||
假设我们想创建 webserver 虚拟机的快照,运行下面的命令,
|
||||
|
||||
**Syntax :**
|
||||
**语法:**
|
||||
|
||||
```
|
||||
# virsh snapshot-create-as –domain {vm_name} –name {snapshot_name} –description “enter description here”
|
||||
```
|
||||
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-create-as --domain webserver --name webserver_snap --description "snap before patch on 4Feb2018"
|
||||
Domain snapshot webserver_snap created
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
Once the snapshot is created then we can list snapshots related to the VM using below command,
|
||||
创建快照后,我们可以使用下面的命令列出与虚拟机相关的快照:
|
||||
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-list webserver
|
||||
Name Creation Time State
|
||||
------------------------------------------------------------
|
||||
webserver_snap 2018-02-04 15:05:05 +0530 running
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
To list the detailed info of VM’s snapshot, run the beneath virsh command,
|
||||
要列出虚拟机快照的详细信息,请运行下面的 `virsh` 命令:
|
||||
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-info --domain webserver --snapshotname webserver_snap
|
||||
Name: webserver_snap
|
||||
@ -69,58 +69,52 @@ Parent: -
|
||||
Children: 0
|
||||
Descendants: 0
|
||||
Metadata: yes
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
We can view the size of snapshot using below qemu-img command,
|
||||
我们可以使用下面的 `qemu-img` 命令查看快照的大小:
|
||||
|
||||
```
|
||||
[root@kvm-hypervisor ~]# qemu-img info /var/lib/libvirt/images/snaptestvm.img
|
||||
|
||||
```
|
||||
|
||||
[![qemu-img-command-output-kvm][1]![qemu-img-command-output-kvm][3]][3]
|
||||
![qemu-img-command-output-kvm][3]
|
||||
|
||||
### Revert / Restore KVM virtual Machine to Snapshot
|
||||
### 还原 KVM 虚拟机快照
|
||||
|
||||
Let’s assume we want to revert or restore webserver VM to the snapshot that we have created in above step. Use below virsh command to restore Webserver VM to its snapshot “ **webserver_snap** ”
|
||||
假设我们想要将 webserver 虚拟机还原到我们在上述步骤中创建的快照。使用下面的 `virsh` 命令将 Webserver 虚拟机恢复到其快照 webserver_snap 时。
|
||||
|
||||
**Syntax :**
|
||||
**语法:**
|
||||
|
||||
```
|
||||
# virsh snapshot-revert {vm_name} {snapshot_name}
|
||||
```
|
||||
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-revert webserver webserver_snap
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
### Delete KVM virtual Machine Snapshots
|
||||
### 删除 KVM 虚拟机快照
|
||||
|
||||
要删除 KVM 虚拟机快照,首先使用 `virsh snapshot-list` 命令获取虚拟机的快照详细信息,然后使用 `virsh snapshot-delete` 命令删除快照。如下示例所示:
|
||||
|
||||
To delete KVM virtual machine snapshots, first get the VM’s snapshot details using “ **virsh snapshot-list** ” command and then use “ **virsh snapshot-delete** ” command to delete the snapshot. Example is shown below:
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-list --domain webserver
|
||||
Name Creation Time State
|
||||
------------------------------------------------------------
|
||||
webserver_snap 2018-02-04 15:05:05 +0530 running
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-delete --domain webserver --snapshotname webserver_snap
|
||||
Domain snapshot webserver_snap deleted
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
That’s all from this article, I hope you guys get an idea on how to manage KVM virtual machine snapshots using virsh command. Please do share your feedback and don’t hesitate to share it among your technical friends 🙂
|
||||
这就是本文的全部内容,我希望你们能够了解如何使用 `virsh` 命令来管理 KVM 虚拟机快照。请分享你的反馈,并不要犹豫地分享给你的技术朋友🙂
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/create-revert-delete-kvm-virtual-machine-snapshot-virsh-command/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,198 @@
|
||||
初识 Python:全局、局部和非局部变量(带示例)
|
||||
======
|
||||
|
||||
### 全局变量
|
||||
|
||||
在 Python 中,在函数之外或在全局范围内声明的变量被称为全局变量。 这意味着,全局变量可以在函数内部或外部访问。
|
||||
|
||||
我们来看一个关于如何在 Python 中创建一个全局变量的示例。
|
||||
|
||||
#### 示例 1:创建全局变量
|
||||
|
||||
```python
|
||||
x = "global"
|
||||
|
||||
def foo():
|
||||
print("x inside :", x)
|
||||
|
||||
foo()
|
||||
print("x outside:", x)
|
||||
```
|
||||
|
||||
当我们运行代码时,将会输出:
|
||||
|
||||
```
|
||||
x inside : global
|
||||
x outside: global
|
||||
```
|
||||
|
||||
在上面的代码中,我们创建了 `x` 作为全局变量,并定义了一个 `foo()` 来打印全局变量 `x`。 最后,我们调用 `foo()` 来打印x的值。
|
||||
|
||||
倘若你想改变一个函数内的 `x` 的值该怎么办?
|
||||
|
||||
```python
|
||||
x = "global"
|
||||
|
||||
def foo():
|
||||
x = x * 2
|
||||
print(x)
|
||||
foo()
|
||||
```
|
||||
|
||||
当我们运行代码时,将会输出:
|
||||
|
||||
```
|
||||
UnboundLocalError: local variable 'x' referenced before assignment
|
||||
```
|
||||
|
||||
输出显示一个错误,因为 Python 将 `x` 视为局部变量,而 `x` 没有在 `foo()` 内部定义。
|
||||
|
||||
为了运行正常,我们使用 `global` 关键字,查看 [PythonGlobal 关键字][1]以便了解更多。
|
||||
|
||||
### 局部变量
|
||||
|
||||
在函数体内或局部作用域内声明的变量称为局部变量。
|
||||
|
||||
#### 示例 2:访问作用域外的局部变量
|
||||
|
||||
```python
|
||||
def foo():
|
||||
y = "local"
|
||||
|
||||
foo()
|
||||
print(y)
|
||||
```
|
||||
|
||||
当我们运行代码时,将会输出:
|
||||
|
||||
```
|
||||
NameError: name 'y' is not defined
|
||||
```
|
||||
|
||||
输出显示了一个错误,因为我们试图在全局范围内访问局部变量 `y`,而局部变量只能在 `foo()` 函数内部或局部作用域内有效。
|
||||
|
||||
我们来看一个关于如何在 Python 中创建一个局部变量的例子。
|
||||
|
||||
#### 示例 3:创建一个局部变量
|
||||
|
||||
通常,我们在函数内声明一个变量来创建一个局部变量。
|
||||
|
||||
```python
|
||||
def foo():
|
||||
y = "local"
|
||||
print(y)
|
||||
|
||||
foo()
|
||||
```
|
||||
|
||||
当我们运行代码时,将会输出:
|
||||
|
||||
```
|
||||
local
|
||||
```
|
||||
|
||||
让我们来看看前面的问题,其中x是一个全局变量,我们想修改 `foo()` 内部的 `x`。
|
||||
|
||||
### 全局变量和局部变量
|
||||
|
||||
在这里,我们将展示如何在同一份代码中使用全局变量和局部变量。
|
||||
|
||||
#### 示例 4:在同一份代码中使用全局变量和局部变量
|
||||
|
||||
```python
|
||||
x = "global"
|
||||
|
||||
def foo():
|
||||
global x
|
||||
y = "local"
|
||||
x = x * 2
|
||||
print(x)
|
||||
print(y)
|
||||
|
||||
foo()
|
||||
```
|
||||
|
||||
当我们运行代码时,将会输出(LCTT 译注:原文中输出结果的两个 `global` 有空格,正确的是没有空格):
|
||||
```
|
||||
globalglobal
|
||||
local
|
||||
```
|
||||
|
||||
在上面的代码中,我们将 `x` 声明为全局变量,将 `y` 声明为 `foo()` 中的局部变量。 然后,我们使用乘法运算符 `*` 来修改全局变量 `x`,并打印 `x` 和 `y`。
|
||||
|
||||
在调用 `foo()` 之后,`x` 的值变成 `globalglobal`了(LCTT 译注:原文同样有空格,正确的是没有空格),因为我们使用 `x * 2` 打印两次 `global`。 之后,我们打印局部变量y的值,即 `local` 。
|
||||
|
||||
#### 示例 5:具有相同名称的全局变量和局部变量
|
||||
|
||||
```python
|
||||
x = 5
|
||||
|
||||
def foo():
|
||||
x = 10
|
||||
print("local x:", x)
|
||||
|
||||
foo()
|
||||
print("global x:", x)
|
||||
```
|
||||
|
||||
当我们运行代码时,将会输出:
|
||||
|
||||
```
|
||||
local x: 10
|
||||
global x: 5
|
||||
```
|
||||
|
||||
在上面的代码中,我们对全局变量和局部变量使用了相同的名称 `x`。 当我们打印相同的变量时却得到了不同的结果,因为这两个作用域内都声明了变量,即 `foo()` 内部的局部作用域和 `foo()` 外面的全局作用域。
|
||||
|
||||
当我们在 `foo()` 内部打印变量时,它输出 `local x: 10`,这被称为变量的局部作用域。
|
||||
|
||||
同样,当我们在 `foo()` 外部打印变量时,它输出 `global x: 5`,这被称为变量的全局作用域。
|
||||
|
||||
### 非局部变量
|
||||
|
||||
非局部变量用于局部作用域未定义的嵌套函数。 这意味着,变量既不能在局部也不能在全局范围内。
|
||||
|
||||
我们来看一个关于如何在 Python 中创建一个非局部变量的例子。(LCTT 译者注:原文为创建全局变量,疑为笔误)
|
||||
|
||||
我们使用 `nonlocal` 关键字来创建非局部变量。
|
||||
|
||||
#### 例 6:创建一个非局部变量
|
||||
|
||||
```python
|
||||
def outer():
|
||||
x = "local"
|
||||
|
||||
def inner():
|
||||
nonlocal x
|
||||
x = "nonlocal"
|
||||
print("inner:", x)
|
||||
|
||||
inner()
|
||||
print("outer:", x)
|
||||
|
||||
outer()
|
||||
```
|
||||
|
||||
当我们运行代码时,将会输出:
|
||||
|
||||
```
|
||||
inner: nonlocal
|
||||
outer: nonlocal
|
||||
```
|
||||
|
||||
在上面的代码中有一个嵌套函数 `inner()`。 我们使用 `nonlocal` 关键字来创建非局部变量。`inner()` 函数是在另一个函数 `outer()` 的作用域中定义的。
|
||||
|
||||
注意:如果我们改变非局部变量的值,那么变化就会出现在局部变量中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.programiz.com/python-programming/global-local-nonlocal-variables
|
||||
|
||||
作者:[programiz][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.programiz.com/
|
||||
[1]:https://www.programiz.com/python-programming/global-keyword
|
||||
@ -1,6 +1,8 @@
|
||||
放慢速度是如何使我变得更好的领导者
|
||||
放慢速度如何使我变成更好的领导者
|
||||
======
|
||||
|
||||
> 开放式领导和耐心、倾听一样重要,它们都是关于执行的。
|
||||
|
||||

|
||||
|
||||
在我职业生涯的早期,我认为我能做的最重要的事情就是行动。如果我的老板说跳,我的回答是“跳多高?”
|
||||
@ -9,15 +11,15 @@
|
||||
|
||||
实行开放式领导需要培养耐心和倾听技能,我需要在[最佳行动计划上进行合作,而不仅仅是最快的计划][2]。它还为我提供了一些工具,以解释 [为什么我会对某人说“不”][3] (或者,也许是“不是现在”),这样我就能以透明和自信的方式领导。
|
||||
|
||||
如果你正在进行软件开发和实践 scrum 中,那么下面的观点可能会引起你的共鸣:在 sprint 计划和 sprint 演示中,耐心和倾听经理的表现和它的技能一样重要。(译注: scrum 是迭代式增量软件开发过程,通常用于敏捷软件开发。 sprint 计划和 sprint 演示是其中的两个术语。)忘掉它们,你会减少你能够产生的影响。
|
||||
如果你正在进行软件开发和实践 scrum 中,那么下面的观点可能会引起你的共鸣:在 sprint 计划和 sprint 演示中,耐心和倾听经理的表现和它的技能一样重要。(LCTT 译注: scrum 是迭代式增量软件开发过程,通常用于敏捷软件开发。 sprint 计划和 sprint 演示是其中的两个术语。)忘掉它们,你会减少你能够产生的影响。
|
||||
|
||||
### 专注于耐心
|
||||
|
||||
专注和耐心并不总是容易的。通常,我发现自己正坐在会议上,用行动项目填满我的笔记本时,我一般会思考:“我们可以简单地对 x 和 y 进行改进”。然后我记得事情不是那么线性的。(译者注:这句话感觉翻译得并不通顺)
|
||||
专注和耐心并不总是容易的。通常,我发现自己正坐在会议上,用行动项目填满我的笔记本时,我一般会思考:“我们只要做了某事,另外一件事就会得到改善”。然后我记得事物不是那么线性发展的。
|
||||
|
||||
我需要考虑可能影响情况的其他因素。暂停下来从多个人和资源中获取数据可以帮我充实策略,以确保出组织长期成功。它还帮助我确定那些短期的里程碑,这些里程碑应该会让我负责生产的业务完成交付。
|
||||
我需要考虑可能影响情况的其他因素。暂停下来从多个人和资源中获取数据可以帮我充实策略,以确保组织长期成功。它还帮助我确定那些短期的里程碑,这些里程碑应该可以让我负责生产的业务完成交付。
|
||||
|
||||
这里有一个很好的例子,以前耐心不是我认为应该拥有的东西,而这又是如何影响了我的表现。当我在北卡罗来纳州工作时,我与一个在亚利桑那州的人共事。我们没有使用视频会议技术,所以当我们交谈时我没有看到她的肢体语言。然而当我负责为我领导的项目交付结果时,她是确保我获得足够支持的两个人之一。
|
||||
这里有一个很好的例子,以前耐心不是我认为应该拥有、以及影响我的表现的东西。当我在北卡罗来纳州工作时,我与一个在亚利桑那州的人共事。我们没有使用视频会议技术,所以当我们交谈时我没有看到她的肢体语言。然而当我负责为我领导的项目交付结果时,她是确保我获得足够支持的两个人之一。
|
||||
|
||||
无论出于何种原因,当我与她交谈时,当她要求我做某件事时,我做了。她会为我的绩效评估提供意见,所以我想确保她高兴。那时,我还不够成熟不懂得其实没必要非要讨她开心;我的重点应该放在其他绩效指标上。我本应该花更多的时间倾听并与她合作,而不是在她还在说话的时候拿起第一个“行动项目”并开始工作。
|
||||
|
||||
@ -35,7 +37,7 @@
|
||||
|
||||
我最终对她有一些反馈。 下次我们一起工作时,我不想在六个月后听到反馈意见。 我想早些时候和更频繁地听到反馈意见,以便我能够尽早从错误中学习。 关于这项工作的持续讨论是任何团队都应该发生的事情。
|
||||
|
||||
当我成为一名管理者和领导者时,我坚持要求我的团队达到相同的标准:计划,制定计划并反思。 重复。 不要让外力造成的麻烦让你偏离你需要实施的计划。 将工作分成小的增量,以便反思和调整计划。 正如 Daniel Goleman 写道:“把注意力放在需要的地方是领导力的一个主要任务。” 不要害怕面对这个挑战。
|
||||
当我成为一名管理者和领导者时,我坚持要求我的团队达到相同的标准:计划,执行计划并反思。 重复。 不要让外力造成的麻烦让你偏离你需要实施的计划。 将工作分成小的增量,以便反思和调整计划。 正如 Daniel Goleman 写道:“把注意力放在需要的地方是领导力的一个主要任务。” 不要害怕面对这个挑战。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,7 +45,7 @@ via: [https://opensource.com/open-organization/18/2/open-leadership-patience-lis
|
||||
|
||||
作者:[Angela Robertson][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,64 +1,51 @@
|
||||
# 在 Linux 上使用 groff -me 格式化你的学术论文
|
||||
在 Linux 上使用 groff -me 格式化你的学术论文
|
||||
===========
|
||||
|
||||
> 学习用简单的宏为你的课程论文添加脚注、引用、子标题及其它格式。
|
||||
|
||||
|
||||
|
||||
当我在 1993 年发现 Linux 时,我还是一名本科生。我很兴奋在我的宿舍里拥有 Unix 系统的强大功能,但是尽管它有很多功能,Linux 却缺乏应用程序。像 LibreOffice 和 OpenOffice 这样的文字处理程序还需要几年的时间。如果你想使用文字处理器,你可能会将你的系统引导到 MS-DOS 中,并使用 WordPerfect、shareware GalaxyWrite 或类似的程序。
|
||||
当我在 1993 年发现 Linux 时,我还是一名本科生。我很兴奋在我的宿舍里拥有 Unix 系统的强大功能,但是尽管它有很多功能,但 Linux 却缺乏应用程序。像 LibreOffice 和 OpenOffice 这样的文字处理程序还需要几年的时间才出现。如果你想使用文字处理器,你可能会将你的系统引导到 MS-DOS 中,并使用 WordPerfect、共享软件 GalaxyWrite 或类似的程序。
|
||||
|
||||
`nroff` 和 `troff ` 。它们是同一系统的不同接口:`nroff` 生成纯文本输出,适用于屏幕或行式打印机,而 `troff` 产生非常优美的输出,通常用于在激光打印机上打印。
|
||||
|
||||
这就是我的方法,因为我需要为我的课程写论文,但我更喜欢呆在 Linux 中。我从我们的 “大 Unix ” 校园计算机实验室得知,Unix 系统提供了一组文本格式化的程序。它们是同一系统的不同接口:生成纯文本的输出,适合于屏幕或行打印机,或者生成非常优美的输出,通常用于在激光打印机上打印。
|
||||
这就是我的方法,因为我需要为我的课程写论文,但我更喜欢呆在 Linux 中。我从我们的 “大 Unix” 校园计算机实验室得知,Unix 系统提供了一组文本格式化的程序 `nroff` 和 `troff ` ,它们是同一系统的不同接口:`nroff` 生成纯文本输出,适用于屏幕或行式打印机,而 `troff` 产生非常优美的输出,通常用于在激光打印机上打印。
|
||||
|
||||
在 Linux 上,`nroff` 和 `troff` 被合并为 GNU troff,通常被称为 [groff][1]。 我很高兴看到早期的 Linux 发行版中包含了某个版本的 groff,因此我着手学习如何使用它来编写课程论文。 我学到的第一个宏集是 `-me` 宏包,一个简单易学的宏集。
|
||||
|
||||
关于 `groff` ,首先要了解的是它根据一组宏处理和格式化文本。一个宏通常是一个两个字符的命令,它自己设置在一行上,并带有一个引导点。宏可能包含一个或多个选项。当 groff 在处理文档时遇到这些宏中的一个时,它会自动对文本进行格式化。
|
||||
关于 `groff` ,首先要了解的是它根据一组宏来处理和格式化文本。宏通常是个两个字符的命令,它自己设置在一行上,并带有一个引导点。宏可能包含一个或多个选项。当 `groff` 在处理文档时遇到这些宏中的一个时,它会自动对文本进行格式化。
|
||||
|
||||
下面,我将分享使用 `groff -me` 编写课程论文等简单文档的基础知识。 我不会深入细节进行讨论,比如如何创建嵌套列表,保存和显示,以及使用表格和数字。
|
||||
|
||||
### 段落
|
||||
|
||||
让我们从一个简单的例子开始,在几乎所有类型的文档中都可以看到:段落。段落可以格式化第一行的缩进或不缩进(即,与左边齐平)。 包括学术论文,杂志,期刊和书籍在内的许多印刷文档都使用了这两种类型的组合,其中文档或章节中的第一个(主要)段落与左侧的所有段落以及所有其他(常规)段落缩进。 在 `groff -me`中,您可以使用两种段落类型:前导段落(`.lp`)和常规段落(`.pp`)。
|
||||
让我们从一个简单的例子开始,在几乎所有类型的文档中都可以看到:段落。段落可以格式化为首行缩进或不缩进(即,与左边齐平)。 包括学术论文,杂志,期刊和书籍在内的许多印刷文档都使用了这两种类型的组合,其中文档或章节中的第一个(主要)段落左侧对齐,而所有其他(常规)的段落缩进。 在 `groff -me`中,您可以使用两种段落类型:前导段落(`.lp`)和常规段落(`.pp`)。
|
||||
|
||||
```
|
||||
.lp
|
||||
|
||||
This is the first paragraph.
|
||||
|
||||
.pp
|
||||
|
||||
This is a standard paragraph.
|
||||
|
||||
```
|
||||
|
||||
### 文本格式
|
||||
|
||||
用粗体格式化文本的宏是 `.b`,斜体格式是 `.i` 。 如果您将 `.b` 或 `.i` 放在一行上,则后面的所有文本将以粗体或斜体显示。 但更有可能你只是想用粗体或斜体来表示一个或几个词。 要将一个词加粗或斜体,将该单词放在与 `.b` 或 `.i` 相同的行上作为选项。 要用**粗体**或斜体格式化多个单词,请将文字用引号引起来。
|
||||
用粗体格式化文本的宏是 `.b`,斜体格式是 `.i` 。 如果您将 `.b` 或 `.i` 放在一行上,则后面的所有文本将以粗体或斜体显示。 但更有可能你只是想用粗体或斜体来表示一个或几个词。 要将一个词加粗或斜体,将该单词放在与 `.b` 或 `.i` 相同的行上作为选项。 要用粗体或斜体格式化多个单词,请将文字用引号引起来。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
You can do basic formatting such as
|
||||
|
||||
.i italics
|
||||
|
||||
or
|
||||
|
||||
.b "bold text."
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中,粗体文本结尾的句点也是粗体。 在大多数情况下,这不是你想要的。 只要文字是粗体字,而不是后面的句点也是粗体字。 要获得您想要的效果,您可以向 `.b` 或 `.i` 添加第二个参数,以指示要以粗体或斜体显示的文本,但是正常类型的文本。 您可以这样做,以确保尾随句点不会以粗体显示。
|
||||
在上面的例子中,粗体文本结尾的句点也是粗体。 在大多数情况下,这不是你想要的。 只要文字是粗体字,而不是后面的句点也是粗体字。 要获得您想要的效果,您可以向 `.b` 或 `.i` 添加第二个参数,以指示以粗体或斜体显示的文本后面跟着的任意文本以正常类型显示。 您可以这样做,以确保尾随句点不会以粗体显示。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
You can do basic formatting such as
|
||||
|
||||
.i italics
|
||||
|
||||
or
|
||||
|
||||
.b "bold text" .
|
||||
|
||||
```
|
||||
|
||||
### 列表
|
||||
@ -67,64 +54,38 @@ or
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Bullet lists are easy to make:
|
||||
|
||||
.bu
|
||||
|
||||
Apple
|
||||
|
||||
.bu
|
||||
|
||||
Banana
|
||||
|
||||
.bu
|
||||
|
||||
Pineapple
|
||||
|
||||
.pp
|
||||
|
||||
Numbered lists are as easy as:
|
||||
|
||||
.np
|
||||
|
||||
One
|
||||
|
||||
.np
|
||||
|
||||
Two
|
||||
|
||||
.np
|
||||
|
||||
Three
|
||||
|
||||
.pp
|
||||
|
||||
Note that numbered lists will reset at the next pp or lp.
|
||||
|
||||
```
|
||||
|
||||
### 副标题
|
||||
|
||||
如果你正在写一篇长论文,你可能想把你的内容分成几部分。使用 `groff -me`,您可以创建编号的标题 (`.sh`) 和未编号的标题 (`.uh`)。在这两种方法中,将节标题作为参数括起来。对于编号的标题,您还需要提供标题级别 `:1` 将给出一个一级标题(例如,1)。同样,`2` 和 `3` 将给出第二和第三级标题,如 2.1 或 3.1.1。
|
||||
如果你正在写一篇长论文,你可能想把你的内容分成几部分。使用 `groff -me`,您可以创建编号的标题(`.sh`) 和未编号的标题 (`.uh`)。在这两种方法中,将节标题作为参数括起来。对于编号的标题,您还需要提供标题级别 `:1` 将给出一个一级标题(例如,`1`)。同样,`2` 和 `3` 将给出第二和第三级标题,如 `2.1` 或 `3.1.1`。
|
||||
|
||||
```
|
||||
.uh Introduction
|
||||
|
||||
.pp
|
||||
|
||||
Provide one or two paragraphs to describe the work
|
||||
|
||||
and why it is important.
|
||||
|
||||
.sh 1 "Method and Tools"
|
||||
|
||||
.pp
|
||||
|
||||
Provide a few paragraphs to describe how you
|
||||
|
||||
did the research, including what equipment you used
|
||||
|
||||
```
|
||||
|
||||
### 智能引号和块引号
|
||||
@ -133,135 +94,88 @@ did the research, including what equipment you used
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson coined the phrase \*(lqopen source.\*(rq
|
||||
|
||||
```
|
||||
|
||||
`groff -me` 中还有一个快捷方式来创建这些引号(`.q`),我发现它更易于使用。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson coined the phrase
|
||||
|
||||
.q "open source."
|
||||
|
||||
```
|
||||
|
||||
如果引用的是跨越几行的较长的引用,则需要使用一个块引用。为此,在引用的开头和结尾插入块引用宏(
|
||||
|
||||
`.(q`)。
|
||||
如果引用的是跨越几行的较长的引用,则需要使用一个块引用。为此,在引用的开头和结尾插入块引用宏(`.(q`)。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson recently wrote about open source:
|
||||
|
||||
.(q
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key
|
||||
|
||||
leaders in the field. Announced in advance as the first
|
||||
|
||||
.q "Freeware Summit,"
|
||||
|
||||
by April 14 it was referred to as the first
|
||||
|
||||
.q "Open Source Summit."
|
||||
|
||||
.)q
|
||||
|
||||
```
|
||||
|
||||
### 脚注
|
||||
|
||||
要插入脚注,请在脚注文本前后添加脚注宏(`.(f`),并使用内联宏(`\ **`)添加脚注标记。脚注标记应出现在文本中和脚注中。
|
||||
要插入脚注,请在脚注文本前后添加脚注宏(`.(f`),并使用内联宏(`\**`)添加脚注标记。脚注标记应出现在文本中和脚注中。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson recently wrote about open source:\**
|
||||
|
||||
.(f
|
||||
|
||||
\**Christine Peterson.
|
||||
|
||||
.q "How I coined the term open source."
|
||||
|
||||
.i "OpenSource.com."
|
||||
|
||||
1 Feb 2018.
|
||||
|
||||
.)f
|
||||
|
||||
.(q
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key
|
||||
|
||||
leaders in the field. Announced in advance as the first
|
||||
|
||||
.q "Freeware Summit,"
|
||||
|
||||
by April 14 it was referred to as the first
|
||||
|
||||
.q "Open Source Summit."
|
||||
|
||||
.)q
|
||||
|
||||
```
|
||||
|
||||
### 封面
|
||||
|
||||
大多数课程论文都需要一个包含论文标题,姓名和日期的封面。 在 `groff -me` 中创建封面需要一些组件。 我发现最简单的方法是使用居中的文本块并在标题,名称和日期之间添加额外的行。 (我倾向于在每一行之间使用两个空行)。在文章顶部,从标题页(`.tp`)宏开始,插入五个空白行(`.sp 5`),然后添加居中文本(`.(c`) 和额外的空白行(`.sp 2`)。
|
||||
大多数课程论文都需要一个包含论文标题,姓名和日期的封面。 在 `groff -me` 中创建封面需要一些组件。 我发现最简单的方法是使用居中的文本块并在标题、名字和日期之间添加额外的行。 (我倾向于在每一行之间使用两个空行)。在文章顶部,从标题页(`.tp`)宏开始,插入五个空白行(`.sp 5`),然后添加居中文本(`.(c`) 和额外的空白行(`.sp 2`)。
|
||||
|
||||
```
|
||||
.tp
|
||||
|
||||
.sp 5
|
||||
|
||||
.(c
|
||||
|
||||
.b "Writing Class Papers with groff -me"
|
||||
|
||||
.)c
|
||||
|
||||
.sp 2
|
||||
|
||||
.(c
|
||||
|
||||
Jim Hall
|
||||
|
||||
.)c
|
||||
|
||||
.sp 2
|
||||
|
||||
.(c
|
||||
|
||||
February XX, 2018
|
||||
|
||||
.)c
|
||||
|
||||
.bp
|
||||
|
||||
```
|
||||
|
||||
最后一个宏(`.bp`)告诉 groff 在标题页后添加一个分页符。
|
||||
|
||||
### 更多内容
|
||||
|
||||
这些是用 `groff-me` 写一份专业的论文非常基础的东西,包括前导和缩进段落,粗体和斜体,有序和无需列表,编号和不编号的章节标题,块引用以及脚注。
|
||||
这些是用 `groff-me` 写一份专业的论文非常基础的东西,包括前导和缩进段落,粗体和斜体,有序和无需列表,编号和不编号的章节标题,块引用以及脚注。
|
||||
|
||||
我已经包含一个示例 groff 文件来演示所有这些格式。 将 `lorem-ipsum.me` 文件保存到您的系统并通过 groff 运行。 `-Tps` 选项将输出类型设置为 `PostScript` ,以便您可以将文档发送到打印机或使用 `ps2pdf` 程序将其转换为 PDF 文件。
|
||||
我已经包含一个[示例 groff 文件](https://opensource.com/sites/default/files/lorem-ipsum.me_.txt)来演示所有这些格式。 将 `lorem-ipsum.me` 文件保存到您的系统并通过 groff 运行。 `-Tps` 选项将输出类型设置为 `PostScript` ,以便您可以将文档发送到打印机或使用 `ps2pdf` 程序将其转换为 [PDF 文件](https://opensource.com/sites/default/files/lorem-ipsum.me_.pdf)。
|
||||
|
||||
```
|
||||
groff -Tps -me lorem-ipsum.me > lorem-ipsum.me.ps
|
||||
|
||||
ps2pdf lorem-ipsum.me.ps lorem-ipsum.me.pdf
|
||||
|
||||
```
|
||||
|
||||
如果你想使用 groff-me 的更多高级功能,请参阅 Eric Allman 所著的 “使用 `Groff-me` 来写论文”,你可以在你系统的 groff 的 `doc` 目录下找到一个名叫 `meintro.me` 的文件。这份文档非常完美的说明了如何使用 `groff-me` 宏来格式化你的论文。
|
||||
如果你想使用 `groff -me` 的更多高级功能,请参阅 Eric Allman 所著的 “使用 Groff -me 来写论文”,你可以在你系统的 groff 的 `doc` 目录下找到一个名叫 `meintro.me` 的文件。这份文档非常完美的说明了如何使用 `groff-me` 宏来格式化你的论文。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -269,7 +183,7 @@ via: https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,13 +2,14 @@ Linux 局域网路由新手指南:第 1 部分
|
||||
======
|
||||
|
||||

|
||||
|
||||
前面我们学习了 [IPv6 路由][1]。现在我们继续深入学习 Linux 中的 IPv4 路由的基础知识。我们从硬件概述、操作系统和 IPv4 地址的基础知识开始,下周我们将继续学习它们如何配置,以及测试路由。
|
||||
|
||||
### 局域网路由器硬件
|
||||
|
||||
Linux 实际上是一个网络操作系统,一直都是,从一开始它就有内置的网络功能。为将你的局域网连入因特网,构建一个局域网路由器比起构建网关路由器要简单的多。你不要太过于执念安全或者防火墙规则,对于处理 NAT 它还是比较复杂的,网络地址转换是 IPv4 的一个痛点。我们为什么不放弃 IPv4 去转到 IPv6 呢?这样将使网络管理员的工作更加简单。
|
||||
Linux 实际上是一个网络操作系统,一直都是,从一开始它就有内置的网络功能。要将你的局域网连入因特网,构建一个局域网路由器比起构建网关路由器要简单的多。你不要太过于执念安全或者防火墙规则,对于处理网络地址转换(NAT)它还是比较复杂的,NAT是 IPv4 的一个痛点。我们为什么不放弃 IPv4 去转到 IPv6 呢?这样将使网络管理员的工作更加简单。
|
||||
|
||||
有点跑题了。从理论上讲,你的 Linux 路由器是一个至少有两个网络接口的小型机器。Linux Gizmos 是一个单片机的综合体:[98 个开放规格的目录,黑客友好的 SBCs][2]。你能够使用一个很老的笔记本电脑或者台式计算机。你也可以使用一个精简版计算机,像 ZaReason Zini 或者 System76 Meerkat 一样,虽然这些有点贵,差不多要 $600。但是它们又结实又可靠,并且你不用在 Windows 许可证上浪费钱。
|
||||
有点跑题了。从理论上讲,你的 Linux 路由器是一个至少有两个网络接口的小型机器。Linux Gizmos 有一个很大的单板机名单:[98 个开放规格、适于黑客的 SBC 的目录][2]。你能够使用一个很老的笔记本电脑或者台式计算机。你也可以使用一个紧凑型计算机,像 ZaReason Zini 或者 System76 Meerkat 一样,虽然这些有点贵,差不多要 $600。但是它们又结实又可靠,并且你不用在 Windows 许可证上浪费钱。
|
||||
|
||||
如果对路由器的要求不高,使用树莓派 3 Model B 作为路由器是一个非常好的选择。它有一个 10/100 以太网端口,板载 2.4GHz 的 802.11n 无线网卡,并且它还有四个 USB 端口,因此你可以插入多个 USB 网卡。USB 2.0 和低速板载网卡可能会让树莓派变成你的网络上的瓶颈,但是,你不能对它期望太高(毕竟它只有 $35,既没有存储也没有电源)。它支持很多种风格的 Linux,因此你可以选择使用你喜欢的版本。基于 Debian 的树莓派是我的最爱。
|
||||
|
||||
@ -16,63 +17,63 @@ Linux 实际上是一个网络操作系统,一直都是,从一开始它就
|
||||
|
||||
你可以在你选择的硬件上安装将你喜欢的 Linux 的简化版,因为定制的路由器操作系统,比如 OpenWRT、 Tomato、DD-WRT、Smoothwall、Pfsense 等等,都有它们自己的非标准界面。我的观点是,没有必要这么麻烦,它们对你并没有什么帮助。尽量使用标准的 Linux 工具,因为你只需要学习它们一次就够了。
|
||||
|
||||
Debian 的网络安装镜像大约有 300MB 大小,并且支持多种架构,包括 ARM、i386、amd64、和 armhf。Ubuntu 的服务器网络安装镜像也小于 50MB,这样你就可以控制你要安装哪些包。Fedora、Mageia、和 openSUSE 都提供精简的网络安装镜像。如果你需要创意,你可以浏览 [Distrowatch][3]。
|
||||
Debian 的网络安装镜像大约有 300MB 大小,并且支持多种架构,包括 ARM、i386、amd64 和 armhf。Ubuntu 的服务器网络安装镜像也小于 50MB,这样你就可以控制你要安装哪些包。Fedora、Mageia、和 openSUSE 都提供精简的网络安装镜像。如果你需要创意,你可以浏览 [Distrowatch][3]。
|
||||
|
||||
### 路由器能做什么
|
||||
|
||||
我们需要网络路由器做什么?一个路由器连接不同的网络。如果没有路由,那么每个网络都是相互隔离的,所有的悲伤和孤独都没有人与你分享,所有节点只能孤独终老。假设你有一个 192.168.1.0/24 和一个 192.168.2.0/24 网络。如果没有路由器,你的两个网络之间不能相互沟通。这些都是 C 类的私有地址,它们每个都有 254 个可用网络地址。使用 ipcalc 可以非常容易地得到它们的这些信息:
|
||||
我们需要网络路由器做什么?一个路由器连接不同的网络。如果没有路由,那么每个网络都是相互隔离的,所有的悲伤和孤独都没有人与你分享,所有节点只能孤独终老。假设你有一个 192.168.1.0/24 和一个 192.168.2.0/24 网络。如果没有路由器,你的两个网络之间不能相互沟通。这些都是 C 类的私有地址,它们每个都有 254 个可用网络地址。使用 `ipcalc` 可以非常容易地得到它们的这些信息:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.1.0/24
|
||||
Address: 192.168.1.0 11000000.10101000.00000001. 00000000
|
||||
Netmask: 255.255.255.0 = 24 11111111.11111111.11111111. 00000000
|
||||
Wildcard: 0.0.0.255 00000000.00000000.00000000. 11111111
|
||||
Address: 192.168.1.0 11000000.10101000.00000001. 00000000
|
||||
Netmask: 255.255.255.0 = 24 11111111.11111111.11111111. 00000000
|
||||
Wildcard: 0.0.0.255 00000000.00000000.00000000. 11111111
|
||||
=>
|
||||
Network: 192.168.1.0/24 11000000.10101000.00000001. 00000000
|
||||
HostMin: 192.168.1.1 11000000.10101000.00000001. 00000001
|
||||
HostMax: 192.168.1.254 11000000.10101000.00000001. 11111110
|
||||
Broadcast: 192.168.1.255 11000000.10101000.00000001. 11111111
|
||||
Hosts/Net: 254 Class C, Private Internet
|
||||
|
||||
Network: 192.168.1.0/24 11000000.10101000.00000001. 00000000
|
||||
HostMin: 192.168.1.1 11000000.10101000.00000001. 00000001
|
||||
HostMax: 192.168.1.254 11000000.10101000.00000001. 11111110
|
||||
Broadcast: 192.168.1.255 11000000.10101000.00000001. 11111111
|
||||
Hosts/Net: 254 Class C, Private Internet
|
||||
```
|
||||
|
||||
我喜欢 ipcalc 的二进制输出信息,它更加可视地表示了掩码是如何工作的。前三个八位组表示了网络地址,第四个八位组是主机地址,因此,当你分配主机地址时,你将 “掩盖” 掉网络地址部分,只使用剩余的主机部分。你的两个网络有不同的网络地址,而这就是如果两个网络之间没有路由器它们就不能互相通讯的原因。
|
||||
我喜欢 `ipcalc` 的二进制输出信息,它更加可视地表示了掩码是如何工作的。前三个八位组表示了网络地址,第四个八位组是主机地址,因此,当你分配主机地址时,你将 “掩盖” 掉网络地址部分,只使用剩余的主机部分。你的两个网络有不同的网络地址,而这就是如果两个网络之间没有路由器它们就不能互相通讯的原因。
|
||||
|
||||
每个八位组一共有 256 字节,但是它们并不能提供 256 个主机地址,因为第一个和最后一个值 ,也就是 0 和 255,是被保留的。0 是网络标识,而 255 是广播地址,因此,只有 254 个主机地址。ipcalc 可以帮助你很容易地计算出这些。
|
||||
每个八位组一共有 256 字节,但是它们并不能提供 256 个主机地址,因为第一个和最后一个值 ,也就是 0 和 255,是被保留的。0 是网络标识,而 255 是广播地址,因此,只有 254 个主机地址。`ipcalc` 可以帮助你很容易地计算出这些。
|
||||
|
||||
当然,这并不意味着你不能有一个结尾是 0 或者 255 的主机地址。假设你有一个 16 位的前缀:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.0.0/16
|
||||
Address: 192.168.0.0 11000000.10101000. 00000000.00000000
|
||||
Netmask: 255.255.0.0 = 16 11111111.11111111. 00000000.00000000
|
||||
Wildcard: 0.0.255.255 00000000.00000000. 11111111.11111111
|
||||
Address: 192.168.0.0 11000000.10101000. 00000000.00000000
|
||||
Netmask: 255.255.0.0 = 16 11111111.11111111. 00000000.00000000
|
||||
Wildcard: 0.0.255.255 00000000.00000000. 11111111.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/16 11000000.10101000. 00000000.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000. 00000000.00000001
|
||||
HostMax: 192.168.255.254 11000000.10101000. 11111111.11111110
|
||||
Broadcast: 192.168.255.255 11000000.10101000. 11111111.11111111
|
||||
Hosts/Net: 65534 Class C, Private Internet
|
||||
|
||||
Network: 192.168.0.0/16 11000000.10101000. 00000000.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000. 00000000.00000001
|
||||
HostMax: 192.168.255.254 11000000.10101000. 11111111.11111110
|
||||
Broadcast: 192.168.255.255 11000000.10101000. 11111111.11111111
|
||||
Hosts/Net: 65534 Class C, Private Internet
|
||||
```
|
||||
|
||||
ipcalc 列出了你的第一个和最后一个主机地址,它们是 192.168.0.1 和 192.168.255.254。你是可以有以 0 或者 255 结尾的主机地址的,例如,192.168.1.0 和 192.168.0.255,因为它们都在最小主机地址和最大主机地址之间。
|
||||
`ipcalc` 列出了你的第一个和最后一个主机地址,它们是 192.168.0.1 和 192.168.255.254。你是可以有以 0 或者 255 结尾的主机地址的,例如,192.168.1.0 和 192.168.0.255,因为它们都在最小主机地址和最大主机地址之间。
|
||||
|
||||
不论你的地址块是私有的还是公共的,这个原则同样都是适用的。不要羞于使用 ipcalc 来帮你计算地址。
|
||||
不论你的地址块是私有的还是公共的,这个原则同样都是适用的。不要羞于使用 `ipcalc` 来帮你计算地址。
|
||||
|
||||
### CIDR
|
||||
|
||||
CIDR(无类域间路由)就是通过可变长度的子网掩码来扩展 IPv4 的。CIDR 允许对网络空间进行更精细地分割。我们使用 ipcalc 来演示一下:
|
||||
CIDR(无类域间路由)就是通过可变长度的子网掩码来扩展 IPv4 的。CIDR 允许对网络空间进行更精细地分割。我们使用 `ipcalc` 来演示一下:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.1.0/22
|
||||
Address: 192.168.1.0 11000000.10101000.000000 01.00000000
|
||||
Netmask: 255.255.252.0 = 22 11111111.11111111.111111 00.00000000
|
||||
Wildcard: 0.0.3.255 00000000.00000000.000000 11.11111111
|
||||
Address: 192.168.1.0 11000000.10101000.000000 01.00000000
|
||||
Netmask: 255.255.252.0 = 22 11111111.11111111.111111 00.00000000
|
||||
Wildcard: 0.0.3.255 00000000.00000000.000000 11.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/22 11000000.10101000.000000 00.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000.000000 00.00000001
|
||||
HostMax: 192.168.3.254 11000000.10101000.000000 11.11111110
|
||||
Broadcast: 192.168.3.255 11000000.10101000.000000 11.11111111
|
||||
Hosts/Net: 1022 Class C, Private Internet
|
||||
|
||||
Network: 192.168.0.0/22 11000000.10101000.000000 00.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000.000000 00.00000001
|
||||
HostMax: 192.168.3.254 11000000.10101000.000000 11.11111110
|
||||
Broadcast: 192.168.3.255 11000000.10101000.000000 11.11111111
|
||||
Hosts/Net: 1022 Class C, Private Internet
|
||||
```
|
||||
|
||||
网络掩码并不局限于整个八位组,它可以跨越第三和第四个八位组,并且子网部分的范围可以是从 0 到 3,而不是非得从 0 到 255。可用主机地址的数量并不一定是 8 的倍数,因为它是由整个八位组定义的。
|
||||
@ -81,7 +82,7 @@ Hosts/Net: 1022 Class C, Private Internet
|
||||
|
||||
从 [理解 IP 地址和 CIDR 图表][4]、[IPv4 私有地址空间和过滤][5]、以及 [IANA IPv4 地址空间注册][6] 开始。接下来的我们将学习如何创建和管理路由器。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][7]学习更多 Linux 知识。
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][7]学习更多 Linux 知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -89,7 +90,7 @@ via: https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginne
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
如何使用 Linux 防火墙隔离本地欺骗地址
|
||||
======
|
||||
|
||||
> 如何使用 iptables 防火墙保护你的网络免遭黑客攻击。
|
||||
|
||||

|
||||
|
||||
即便是被入侵检测和隔离系统所保护的远程网络,黑客们也在寻找各种精巧的方法入侵。IDS/IPS 不能停止或者减少那些想要接管你的网络控制权的黑客攻击。不恰当的配置允许攻击者绕过所有部署的安全措施。
|
||||
|
||||
在这篇文章中,我将会解释安全工程师或者系统管理员该怎样避免这些攻击。
|
||||
|
||||
几乎所有的 Linux 发行版都带着一个内建的防火墙来保护运行在 Linux 主机上的进程和应用程序。大多数防火墙都按照 IDS/IPS 解决方案设计,这样的设计的主要目的是检测和避免恶意包获取网络的进入权。
|
||||
|
||||
Linux 防火墙通常有两种接口:iptables 和 ipchains 程序(LCTT 译注:在支持 systemd 的系统上,采用的是更新的接口 firewalld)。大多数人将这些接口称作 iptables 防火墙或者 ipchains 防火墙。这两个接口都被设计成包过滤器。iptables 是有状态防火墙,其基于先前的包做出决定。ipchains 不会基于先前的包做出决定,它被设计为无状态防火墙。
|
||||
|
||||
在这篇文章中,我们将会专注于内核 2.4 之后出现的 iptables 防火墙。
|
||||
|
||||
有了 iptables 防火墙,你可以创建策略或者有序的规则集,规则集可以告诉内核该如何对待特定的数据包。在内核中的是Netfilter 框架。Netfilter 既是框架也是 iptables 防火墙的项目名称。作为一个框架,Netfilter 允许 iptables 勾连被设计来操作数据包的功能。概括地说,iptables 依靠 Netfilter 框架构筑诸如过滤数据包数据的功能。
|
||||
|
||||
每个 iptables 规则都被应用到一个表中的链上。一个 iptables 链就是一个比较包中相似特征的规则集合。而表(例如 `nat` 或者 `mangle`)则描述不同的功能目录。例如, `mangle` 表用于修改包数据。因此,特定的修改包数据的规则被应用到这里;而过滤规则被应用到 `filter` 表,因为 `filter` 表过滤包数据。
|
||||
|
||||
iptables 规则有一个匹配集,以及一个诸如 `Drop` 或者 `Deny` 的目标,这可以告诉 iptables 对一个包做什么以符合规则。因此,没有目标和匹配集,iptables 就不能有效地处理包。如果一个包匹配了一条规则,目标会指向一个将要采取的特定措施。另一方面,为了让 iptables 处理,每个数据包必须匹配才能被处理。
|
||||
|
||||
现在我们已经知道 iptables 防火墙如何工作,让我们着眼于如何使用 iptables 防火墙检测并拒绝或丢弃欺骗地址吧。
|
||||
|
||||
### 打开源地址验证
|
||||
|
||||
作为一个安全工程师,在处理远程的欺骗地址的时候,我采取的第一步是在内核打开源地址验证。
|
||||
|
||||
源地址验证是一种内核层级的特性,这种特性丢弃那些伪装成来自你的网络的包。这种特性使用反向路径过滤器方法来检查收到的包的源地址是否可以通过包到达的接口可以到达。(LCTT 译注:到达的包的源地址应该可以从它到达的网络接口反向到达,只需反转源地址和目的地址就可以达到这样的效果)
|
||||
|
||||
利用下面简单的脚本可以打开源地址验证而不用手工操作:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
#作者: Michael K Aboagye
|
||||
#程序目标: 打开反向路径过滤
|
||||
#日期: 7/02/18
|
||||
#在屏幕上显示 “enabling source address verification”
|
||||
echo -n "Enabling source address verification…"
|
||||
#将值0覆盖为1来打开源地址验证
|
||||
echo 1 > /proc/sys/net/ipv4/conf/default/rp_filter
|
||||
echo "completed"
|
||||
```
|
||||
|
||||
上面的脚本在执行的时候只显示了 `Enabling source address verification` 这条信息而不会换行。默认的反向路径过滤的值是 `0`,`0` 表示没有源验证。因此,第二行简单地将默认值 `0` 覆盖为 `1`。`1` 表示内核将会通过确认反向路径来验证源地址。
|
||||
|
||||
最后,你可以使用下面的命令通过选择 `DROP` 或者 `REJECT` 目标之一来丢弃或者拒绝来自远端主机的欺骗地址。但是,处于安全原因的考虑,我建议使用 `DROP` 目标。
|
||||
|
||||
像下面这样,用你自己的 IP 地址代替 `IP-address` 占位符。另外,你必须选择使用 `REJECT` 或者 `DROP` 中的一个,这两个目标不能同时使用。
|
||||
|
||||
```
|
||||
iptables -A INPUT -i internal_interface -s IP_address -j REJECT / DROP
|
||||
iptables -A INPUT -i internal_interface -s 192.168.0.0/16 -j REJECT / DROP
|
||||
```
|
||||
|
||||
这篇文章只提供了如何使用 iptables 防火墙来避免远端欺骗攻击的基础知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/block-local-spoofed-addresses-using-linux-firewall
|
||||
|
||||
作者:[Michael Kwaku Aboagye][a]
|
||||
译者:[leemeans](https://github.com/leemeans)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/revoks
|
||||
@ -1,43 +1,43 @@
|
||||
使用 PGP 保护代码完整性 - 第 3 部分:生成 PGP 子密钥
|
||||
使用 PGP 保护代码完整性(三):生成 PGP 子密钥
|
||||
======
|
||||
|
||||
> 在第三篇文章中,我们将解释如何生成用于日常工作的 PGP 子密钥。
|
||||
|
||||

|
||||
|
||||
在本系列教程中,我们提供了使用 PGP 的实用指南。在此之前,我们介绍了[基本工具和概念][1],并介绍了如何[生成并保护您的主 PGP 密钥][2]。在第三篇文章中,我们将解释如何生成 PGP 子密钥,以及它们在日常工作中使用。
|
||||
在本系列教程中,我们提供了使用 PGP 的实用指南。在此之前,我们介绍了[基本工具和概念][1],并介绍了如何[生成并保护您的主 PGP 密钥][2]。在第三篇文章中,我们将解释如何生成用于日常工作的 PGP 子密钥。
|
||||
|
||||
### 清单
|
||||
|
||||
1. 生成 2048 位加密子密钥(必要)
|
||||
|
||||
2. 生成 2048 位签名子密钥(必要)
|
||||
|
||||
3. 生成一个 2048 位验证子密钥(可选)
|
||||
|
||||
3. 生成一个 2048 位验证子密钥(推荐)
|
||||
4. 将你的公钥上传到 PGP 密钥服务器(必要)
|
||||
|
||||
5. 设置一个刷新的定时任务(必要)
|
||||
|
||||
### 注意事项
|
||||
|
||||
现在我们已经创建了主密钥,让我们创建用于日常工作的密钥。我们创建 2048 位的密钥是因为很多专用硬件(我们稍后会讨论这个)不能处理更长的密钥,但同样也是出于实用的原因。如果我们发现自己处于一个 2048 位 RSA 密钥也不够好的世界,那将是由于计算或数学有了基本突破,因此更长的 4096 位密钥不会产生太大的差别。
|
||||
|
||||
#### 注意事项
|
||||
|
||||
现在我们已经创建了主密钥,让我们创建用于日常工作的密钥。我们创建了 2048 位密钥,因为很多专用硬件(我们稍后会讨论这个)不能处理更长的密钥,但同样也是出于实用的原因。如果我们发现自己处于一个 2048 位 RSA 密钥也不够好的世界,那将是由于计算或数学的基本突破,因此更长的 4096 位密钥不会产生太大的差别。
|
||||
|
||||
##### 创建子密钥
|
||||
### 创建子密钥
|
||||
|
||||
要创建子密钥,请运行:
|
||||
|
||||
```
|
||||
$ gpg --quick-add-key [fpr] rsa2048 encr
|
||||
$ gpg --quick-add-key [fpr] rsa2048 sign
|
||||
|
||||
```
|
||||
|
||||
你也可以创建验证密钥,这能让你使用你的 PGP 密钥来使用 ssh:
|
||||
用你密钥的完整指纹替换 `[fpr]`。
|
||||
|
||||
你也可以创建验证密钥,这能让你将你的 PGP 密钥用于 ssh:
|
||||
|
||||
```
|
||||
$ gpg --quick-add-key [fpr] rsa2048 auth
|
||||
|
||||
```
|
||||
|
||||
你可以使用 gpg --list-key [fpr] 来查看你的密钥信息:
|
||||
你可以使用 `gpg --list-key [fpr]` 来查看你的密钥信息:
|
||||
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
@ -45,55 +45,57 @@ uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
sub rsa2048 2017-12-06 [E]
|
||||
sub rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
##### 上传你的公钥到密钥服务器
|
||||
### 上传你的公钥到密钥服务器
|
||||
|
||||
你的密钥创建已完成,因此现在需要你将其上传到一个公共密钥服务器,使其他人能更容易找到密钥。 (如果你不打算实际使用你创建的密钥,请跳过这一步,因为这只会在密钥服务器上留下垃圾数据。)
|
||||
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
如果此命令不成功,你可以尝试指定一台密钥服务器以及端口,这很有可能成功:
|
||||
|
||||
```
|
||||
$ gpg --keyserver hkp://pgp.mit.edu:80 --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
大多数密钥服务器彼此进行通信,因此你的密钥信息最终将与所有其他密钥信息同步。
|
||||
|
||||
**关于隐私的注意事项:**密钥服务器是完全公开的,因此在设计上会泄露有关你的潜在敏感信息,例如你的全名、昵称以及个人或工作邮箱地址。如果你签名了其他人的钥匙或某人签名你的钥匙,那么密钥服务器还会成为你的社交网络的泄密者。一旦这些个人信息发送给密钥服务器,就不可能编辑或删除。即使你撤销签名或身份,它也不会将你的密钥记录删除,它只会将其标记为已撤消 - 这甚至会显得更突出。
|
||||
**关于隐私的注意事项:**密钥服务器是完全公开的,因此在设计上会泄露有关你的潜在敏感信息,例如你的全名、昵称以及个人或工作邮箱地址。如果你签名了其他人的钥匙或某人签名了你的钥匙,那么密钥服务器还会成为你的社交网络的泄密者。一旦这些个人信息发送给密钥服务器,就不可能被编辑或删除。即使你撤销签名或身份,它也不会将你的密钥记录删除,它只会将其标记为已撤消 —— 这甚至会显得更显眼。
|
||||
|
||||
也就是说,如果你参与公共项目的软件开发,以上所有信息都是公开记录,因此通过密钥服务器另外让这些信息可见,不会导致隐私的净损失。
|
||||
|
||||
###### 上传你的公钥到 GitHub
|
||||
### 上传你的公钥到 GitHub
|
||||
|
||||
如果你在开发中使用 GitHub(谁不是呢?),则应按照他们提供的说明上传密钥:
|
||||
|
||||
- [添加 PGP 密钥到你的 GitHub 账户](https://help.github.com/articles/adding-a-new-gpg-key-to-your-github-account/)
|
||||
|
||||
要生成适合粘贴的公钥输出,只需运行:
|
||||
|
||||
```
|
||||
$ gpg --export --armor [fpr]
|
||||
|
||||
```
|
||||
|
||||
##### 设置一个刷新定时任务
|
||||
### 设置一个刷新定时任务
|
||||
|
||||
你需要定期刷新你的钥匙环,以获取其他人公钥的最新更改。你可以设置一个定时任务来做到这一点:
|
||||
|
||||
你需要定期刷新你的 keyring,以获取其他人公钥的最新更改。你可以设置一个定时任务来做到这一点:
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
在新行中添加以下内容:
|
||||
|
||||
```
|
||||
@daily /usr/bin/gpg2 --refresh >/dev/null 2>&1
|
||||
|
||||
```
|
||||
|
||||
**注意:**检查你的 gpg 或 gpg2 命令的完整路径,如果你的 gpg 是旧式的 GnuPG v.1,请使用 gpg2。
|
||||
**注意:**检查你的 `gpg` 或 `gpg2` 命令的完整路径,如果你的 `gpg` 是旧式的 GnuPG v.1,请使用 gpg2。
|
||||
|
||||
通过 Linux 基金会和 edX 的免费“[Introduction to Linux](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)” 课程了解关于 Linux 的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -101,10 +103,10 @@ via: https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-p
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[1]:https://linux.cn/article-9524-1.html
|
||||
[2]:https://linux.cn/article-9529-1.html
|
||||
@ -0,0 +1,178 @@
|
||||
如何在 Web 服务器文档根目录上设置只读文件权限
|
||||
======
|
||||
|
||||
**Q:如何对我存放在 `/var/www/html/` 目录中的所有文件设置只读权限?**
|
||||
|
||||
你可以使用 `chmod` 命令对 Linux/Unix/macOS/OS X/*BSD 操作系统上的所有文件来设置只读权限。这篇文章介绍如何在 Linux/Unix 的 web 服务器(如 Nginx、 Lighttpd、 Apache 等)上来设置只读文件权限。
|
||||
|
||||
[![Proper read-only permissions for Linux/Unix Nginx/Apache web server's directory][1]][1]
|
||||
|
||||
### 如何设置文件为只读模式
|
||||
|
||||
语法为:
|
||||
|
||||
```
|
||||
### 仅针对文件 ###
|
||||
chmod 0444 /var/www/html/*
|
||||
chmod 0444 /var/www/html/*.php
|
||||
```
|
||||
|
||||
### 如何设置目录为只读模式
|
||||
|
||||
语法为:
|
||||
|
||||
```
|
||||
### 仅针对目录 ###
|
||||
chmod 0444 /var/www/html/
|
||||
chmod 0444 /path/to/your/dir/
|
||||
# ***************************************************************************
|
||||
# 假如 web 服务器的用户/用户组是 www-data,文件拥有者是 ftp-data 用户/用户组
|
||||
# ***************************************************************************
|
||||
# 设置目录所有文件为只读
|
||||
chmod -R 0444 /var/www/html/
|
||||
# 设置文件/目录拥有者为 ftp-data
|
||||
chown -R ftp-data:ftp-data /var/www/html/
|
||||
# 所有目录和子目录的权限为 0445 (这样 web 服务器的用户或用户组就可以读取我们的文件)
|
||||
find /var/www/html/ -type d -print0 | xargs -0 -I {} chmod 0445 "{}"
|
||||
```
|
||||
|
||||
找到所有 `/var/www/html` 下的所有文件(包括子目录),键入:
|
||||
|
||||
```
|
||||
### 仅对文件有效 ###
|
||||
find /var/www/html -type f -iname "*" -print0 | xargs -I {} -0 chmod 0444 {}
|
||||
```
|
||||
|
||||
然而,你需要在 `/var/www/html` 目录及其子目录上设置只读和执行权限,如此才能让 web 服务器能够访问根目录,键入:
|
||||
|
||||
```
|
||||
### 仅对目录有效 ###
|
||||
find /var/www/html -type d -iname "*" -print0 | xargs -I {} -0 chmod 0544 {}
|
||||
```
|
||||
|
||||
### 警惕写权限
|
||||
|
||||
请注意在 `/var/www/html/` 目录上的写权限会允许任何人删除文件或添加新文件。也就是说,你可能需要设置一个只读权限给 `/var/www/html/` 目录本身。
|
||||
|
||||
```
|
||||
### web根目录只读 ###
|
||||
chmod 0555 /var/www/html
|
||||
```
|
||||
|
||||
在某些情况下,根据你的设置要求,你可以改变文件的属主和属组来设置严格的权限。
|
||||
|
||||
```
|
||||
### 如果 /var/www/html 目录的拥有人是普通用户,你可以设置拥有人为:root:root 或 httpd:httpd (推荐) ###
|
||||
chown -R root:root /var/www/html/
|
||||
|
||||
### 确保 apache 拥有 /var/www/html/ ###
|
||||
chown -R apache:apache /var/www/html/
|
||||
```
|
||||
|
||||
### 关于 NFS 导出目录
|
||||
|
||||
你可以在 `/etc/exports` 文件中指定哪个目录应该拥有[只读或者读写权限 ][2]。这个文件定义各种各样的共享在 NFS 服务器和他们的权限。如:
|
||||
|
||||
|
||||
```
|
||||
# 对任何人只读权限
|
||||
/var/www/html *(ro,sync)
|
||||
|
||||
# 对192.168.1.10(upload.example.com)客户端读写权限访问
|
||||
/var/www/html 192.168.1.10(rw,sync)
|
||||
```
|
||||
|
||||
### 关于用于 MS-Windows客户端的 Samba(CIFS)只读共享
|
||||
|
||||
|
||||
要以只读共享 `sales`,更新 `smb.conf`,如下:
|
||||
|
||||
```
|
||||
[sales]
|
||||
comment = Sales Data
|
||||
path = /export/cifs/sales
|
||||
read only = Yes
|
||||
guest ok = Yes
|
||||
```
|
||||
|
||||
### 关于文件系统表(fstab)
|
||||
|
||||
你可以在 Unix/Linux 上的 `/etc/fstab` 文件中配置挂载某些文件为只读模式。
|
||||
|
||||
你需要有专用分区,不要设置其他系统分区为只读模式。
|
||||
|
||||
如下在 `/etc/fstab` 文件中设置 `/srv/html` 为只读模式。
|
||||
|
||||
```
|
||||
/dev/sda6 /srv/html ext4 ro 1 1
|
||||
```
|
||||
|
||||
你可以使用 `mount` 命令[重新挂载分区为只读模式][3](使用 root 用户)
|
||||
|
||||
```
|
||||
# mount -o remount,ro /dev/sda6 /srv/html
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
# mount -o remount,ro /srv/html
|
||||
```
|
||||
|
||||
上面的命令会尝试重新挂载已挂载的文件系统到 `/srv/html`上。这是改变文件系统挂载标志的常用方法,特别是让只读文件改为可写的。这种方式不会改变设备或者挂载点。让文件变得再次可写,键入:
|
||||
|
||||
```
|
||||
# mount -o remount,rw /dev/sda6 /srv/html
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
# mount -o remount,rw /srv/html
|
||||
```
|
||||
|
||||
### Linux:chattr 命令
|
||||
|
||||
|
||||
你可以在 Linux 文件系统上使用 `chattr` 命令[改变文件属性为只读][4],如:
|
||||
|
||||
```
|
||||
chattr +i /path/to/file.php
|
||||
chattr +i /var/www/html/
|
||||
|
||||
# 查找任何在/var/www/html下的文件并设置为只读#
|
||||
find /var/www/html -iname "*" -print0 | xargs -I {} -0 chattr +i {}
|
||||
```
|
||||
|
||||
通过提供 `-i` 选项可删除只读属性:
|
||||
|
||||
```
|
||||
chattr -i /path/to/file.php
|
||||
```
|
||||
|
||||
FreeBSD、Mac OS X 和其他 BSD Unix 用户可使用[`chflags`命令][5]:
|
||||
|
||||
```
|
||||
### 设置只读 ##
|
||||
chflags schg /path/to/file.php
|
||||
|
||||
### 删除只读 ##
|
||||
chflags noschg /path/to/file.php
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/howto-set-readonly-file-permission-in-linux-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2012/04/linux-unix-set-read-only-file-system-permission-for-apache-nginx.jpg
|
||||
[2]:https://www.cyberciti.biz//www.cyberciti.biz/faq/centos-fedora-rhel-nfs-v4-configuration/
|
||||
[3]:https://www.cyberciti.biz/faq/howto-freebsd-remount-partition/
|
||||
[4]:https://www.cyberciti.biz/tips/linux-password-trick.html
|
||||
[5]:https://www.cyberciti.biz/tips/howto-write-protect-file-with-immutable-bit.html
|
||||
@ -0,0 +1,92 @@
|
||||
如何安全地生成随机数
|
||||
======
|
||||
|
||||
### 使用 urandom
|
||||
|
||||
使用 [urandom][1]!使用 [urandom][2]!使用 [urandom][3]!
|
||||
|
||||
使用 [urandom][4]!使用 [urandom][5]!使用 [urandom][6]!
|
||||
|
||||
### 但对于密码学密钥呢?
|
||||
|
||||
仍然使用 [urandom][6]。
|
||||
|
||||
### 为什么不是 SecureRandom、OpenSSL、havaged 或者 c 语言实现呢?
|
||||
|
||||
这些是用户空间的 CSPRNG(伪随机数生成器)。你应该用内核的 CSPRNG,因为:
|
||||
|
||||
* 内核可以访问原始设备熵。
|
||||
* 它可以确保不在应用程序之间共享相同的状态。
|
||||
* 一个好的内核 CSPRNG,像 FreeBSD 中的,也可以保证它播种之前不给你随机数据。
|
||||
|
||||
研究过去十年中的随机失败案例,你会看到一连串的用户空间的随机失败案例。[Debian 的 OpenSSH 崩溃][7]?用户空间随机!安卓的比特币钱包[重复 ECDSA 随机 k 值][8]?用户空间随机!可预测洗牌的赌博网站?用户空间随机!
|
||||
|
||||
用户空间的生成器几乎总是依赖于内核的生成器。即使它们不这样做,整个系统的安全性也会确保如此。**但用户空间的 CSPRNG 不会增加防御深度;相反,它会产生两个单点故障。**
|
||||
|
||||
### 手册页不是说使用 /dev/random 嘛?
|
||||
|
||||
这个稍后详述,保留你的意见。你应该忽略掉手册页。不要使用 `/dev/random`。`/dev/random` 和 `/dev/urandom` 之间的区别是 Unix 设计缺陷。手册页不想承认这一点,因此它产生了一个并不存在的安全顾虑。把 `random(4)` 中的密码学上的建议当作传说,继续你的生活吧。
|
||||
|
||||
### 但是如果我需要的是真随机值,而非伪随机值呢?
|
||||
|
||||
urandom 和 `/dev/random` 提供的是同一类型的随机。与流行的观念相反,`/dev/random` 不提供“真正的随机”。从密码学上来说,你通常不需要“真正的随机”。
|
||||
|
||||
urandom 和 `/dev/random` 都基于一个简单的想法。它们的设计与流密码的设计密切相关:一个小秘密被延伸到不可预测值的不确定流中。 这里的秘密是“熵”,而流是“输出”。
|
||||
|
||||
只在 Linux 上 `/dev/random` 和 urandom 仍然有意义上的不同。Linux 内核的 CSPRNG 定期进行密钥更新(通过收集更多的熵)。但是 `/dev/random` 也试图跟踪内核池中剩余的熵,并且如果它没有足够的剩余熵时,偶尔也会罢工。这种设计和我所说的一样蠢;这与基于“密钥流”中剩下多少“密钥”的 AES-CTR 设计类似。
|
||||
|
||||
如果你使用 `/dev/random` 而非 urandom,那么当 Linux 对自己的 RNG(随机数生成器)如何工作感到困惑时,你的程序将不可预测地(或者如果你是攻击者,非常可预测地)挂起。使用 `/dev/random` 会使你的程序不太稳定,但这不会让你在密码学上更安全。
|
||||
|
||||
### 这是个缺陷,对吗?
|
||||
|
||||
不是,但存在一个你可能想要了解的 Linux 内核 bug,即使这并不能改变你应该使用哪一个 RNG。
|
||||
|
||||
在 Linux 上,如果你的软件在引导时立即运行,或者这个操作系统你刚刚安装好,那么你的代码可能会与 RNG 发生竞争。这很糟糕,因为如果你赢了竞争,那么你可能会在一段时间内从 urandom 获得可预测的输出。这是 Linux 中的一个 bug,如果你正在为 Linux 嵌入式设备构建平台级代码,那你需要了解它。
|
||||
|
||||
在 Linux 上,这确实是 urandom(而不是 `/dev/random`)的问题。这也是 [Linux 内核中的错误][9]。 但它也容易在用户空间中修复:在引导时,明确地为 urandom 提供种子。长期以来,大多数 Linux 发行版都是这么做的。但**不要**切换到不同的 CSPRNG。
|
||||
|
||||
### 在其它操作系统上呢?
|
||||
|
||||
FreeBSD 和 OS X 消除了 urandom 和 `/dev/random` 之间的区别;这两个设备的行为是相同的。不幸的是,手册页在解释为什么这样做上干的很糟糕,并延续了 Linux 上 urandom 可怕的神话。
|
||||
|
||||
无论你使用 `/dev/random` 还是 urandom,FreeBSD 的内核加密 RNG 都不会停摆。 除非它没有被提供种子,在这种情况下,这两者都会停摆。与 Linux 不同,这种行为是有道理的。Linux 应该采用它。但是,如果你是一名应用程序开发人员,这对你几乎没有什么影响:Linux、FreeBSD、iOS,无论什么:使用 urandom 吧。
|
||||
|
||||
### 太长了,懒得看
|
||||
|
||||
直接使用 urandom 吧。
|
||||
|
||||
### 结语
|
||||
|
||||
[ruby-trunk Feature #9569][10]
|
||||
|
||||
> 现在,在尝试检测 `/dev/urandom` 之前,SecureRandom.random_bytes 会尝试检测要使用的 OpenSSL。 我认为这应该反过来。在这两种情况下,你只需要将随机字节进行解压,所以 SecureRandom 可以跳过中间人(和第二个故障点),如果可用的话可以直接与 `/dev/urandom` 进行交互。
|
||||
|
||||
总结:
|
||||
|
||||
> `/dev/urandom` 不适合用来直接生成会话密钥和频繁生成其他应用程序级随机数据。
|
||||
>
|
||||
> GNU/Linux 上的 random(4) 手册所述......
|
||||
|
||||
感谢 Matthew Green、 Nate Lawson、 Sean Devlin、 Coda Hale 和 Alex Balducci 阅读了本文草稿。公正警告:Matthew 只是大多同意我的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
|
||||
|
||||
作者:[Thomas & Erin Ptacek][a]
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sockpuppet.org/blog
|
||||
[1]:http://blog.cr.yp.to/20140205-entropy.html
|
||||
[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
|
||||
[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
|
||||
[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
|
||||
[5]:http://stackoverflow.com/a/5639631
|
||||
[6]:https://twitter.com/bramcohen/status/206146075487240194
|
||||
[7]:http://research.swtch.com/openssl
|
||||
[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
|
||||
[9]:https://factorable.net/weakkeys12.extended.pdf
|
||||
[10]:https://bugs.ruby-lang.org/issues/9569
|
||||
@ -1,9 +1,9 @@
|
||||
gdb 如何工作?
|
||||
============================================================
|
||||
|
||||
大家好!今天,我开始进行我的 [ruby 堆栈跟踪项目][1],我意识到,我现在了解了一些关于 gdb 内部如何工作的内容。
|
||||
大家好!今天,我开始进行我的 [ruby 堆栈跟踪项目][1],我发觉我现在了解了一些关于 `gdb` 内部如何工作的内容。
|
||||
|
||||
最近,我使用 gdb 来查看我的 Ruby 程序,所以,我们将对一个 Ruby 程序运行 gdb 。它实际上就是一个 Ruby 解释器。首先,我们需要打印出一个全局变量的地址:`ruby_current_thread`。
|
||||
最近,我使用 `gdb` 来查看我的 Ruby 程序,所以,我们将对一个 Ruby 程序运行 `gdb` 。它实际上就是一个 Ruby 解释器。首先,我们需要打印出一个全局变量的地址:`ruby_current_thread`。
|
||||
|
||||
### 获取全局变量
|
||||
|
||||
@ -13,10 +13,9 @@ gdb 如何工作?
|
||||
$ sudo gdb -p 2983
|
||||
(gdb) p & ruby_current_thread
|
||||
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
|
||||
|
||||
```
|
||||
|
||||
变量能够位于的地方有堆、栈或者程序的文本段。全局变量也是程序的一部分。某种程度上,你可以把它们想象成是在编译的时候分配的。因此,我们可以很容易的找出全局变量的地址。让我们来看看,gdb 是如何找出 `0x5598a9a87f0` 这个地址的。
|
||||
变量能够位于的地方有<ruby>堆<rt>heap</rt></ruby>、<ruby>栈<rt>stack</rt></ruby>或者程序的<ruby>文本段<rt>text</rt></ruby>。全局变量是程序的一部分。某种程度上,你可以把它们想象成是在编译的时候分配的。因此,我们可以很容易的找出全局变量的地址。让我们来看看,`gdb` 是如何找出 `0x5598a9a87f0` 这个地址的。
|
||||
|
||||
我们可以通过查看位于 `/proc` 目录下一个叫做 `/proc/$pid/maps` 的文件,来找到这个变量所位于的大致区域。
|
||||
|
||||
@ -42,35 +41,33 @@ $4 = 0x48a7f0
|
||||
```
|
||||
sudo nm /proc/2983/exe | grep ruby_current_thread
|
||||
000000000048a7f0 b ruby_current_thread
|
||||
|
||||
```
|
||||
|
||||
我们看到了什么?能够看到 `0x48a7f0` 吗?是的,没错。所以,如果我们想找到程序中一个全局变量的地址,那么只需在符号表中查找变量的名字,然后再加上在 `/proc/whatever/maps` 中的起始地址,就得到了。
|
||||
|
||||
所以现在,我们知道 gdb 做了什么。但是,gdb 实际做的事情更多,让我们跳过直接转到…
|
||||
所以现在,我们知道 `gdb` 做了什么。但是,`gdb` 实际做的事情更多,让我们跳过直接转到…
|
||||
|
||||
### 解引用指针
|
||||
|
||||
```
|
||||
(gdb) p ruby_current_thread
|
||||
$1 = (rb_thread_t *) 0x5598ab3235b0
|
||||
|
||||
```
|
||||
|
||||
我们要做的下一件事就是解引用 `ruby_current_thread` 这一指针。我们想看一下它所指向的地址。为了完成这件事,gdb 会运行大量系统调用比如:
|
||||
我们要做的下一件事就是解引用 `ruby_current_thread` 这一指针。我们想看一下它所指向的地址。为了完成这件事,`gdb` 会运行大量系统调用比如:
|
||||
|
||||
```
|
||||
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
|
||||
```
|
||||
|
||||
你是否还记得 `0x5598a9a8f7f0` 这个地址?gdb 会问:“嘿,在这个地址中的实际内容是什么?”。`2983` 是我们运行 gdb 这个进程的 ID。gdb 使用 `ptrace` 这一系统调用来完成这一件事。
|
||||
你是否还记得 `0x5598a9a8f7f0` 这个地址?`gdb` 会问:“嘿,在这个地址中的实际内容是什么?”。`2983` 是我们运行 gdb 这个进程的 ID。gdb 使用 `ptrace` 这一系统调用来完成这一件事。
|
||||
|
||||
好极了!因此,我们可以解引用内存并找出内存地址中存储的内容。一些有用的 gdb 命令能够分别知道 `x/40w` 和 `x/40b` 这两个变量哪一个会在给定地址展示 40 个字/字节。
|
||||
好极了!因此,我们可以解引用内存并找出内存地址中存储的内容。有一些有用的 `gdb` 命令,比如 `x/40w 变量` 和 `x/40b 变量` 分别会显示给定地址的 40 个字/字节。
|
||||
|
||||
### 描述结构
|
||||
|
||||
一个内存地址中的内容可能看起来像下面这样。大量的字节!
|
||||
一个内存地址中的内容可能看起来像下面这样。可以看到很多字节!
|
||||
|
||||
```
|
||||
(gdb) x/40b ruby_current_thread
|
||||
@ -79,7 +76,6 @@ ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
|
||||
0x5598ab3235c8: 0 0 2 0 0 0 0 0
|
||||
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
|
||||
|
||||
```
|
||||
|
||||
这很有用,但也不是非常有用!如果你是一个像我一样的人类并且想知道它代表什么,那么你需要更多内容,比如像这样:
|
||||
@ -92,10 +88,9 @@ $8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
|
||||
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
|
||||
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
|
||||
140322820187904,
|
||||
|
||||
```
|
||||
|
||||
太好了。现在就更加有用了。gdb 是如何知道这些所有域的,比如 `stack_size` ?输入 `DWARF`。`DWARF` 是存储额外程序调试数据的一种方式,从而调试器比如 gdb 能够更好的工作。它通常存储为一部分二进制。如果我对我的 Ruby 二进制文件运行 `dwarfdump` 命令,那么我将会得到下面的输出:
|
||||
太好了。现在就更加有用了。`gdb` 是如何知道这些所有域的,比如 `stack_size` ?是从 `DWARF` 得知的。`DWARF` 是存储额外程序调试数据的一种方式,从而像 `gdb` 这样的调试器能够工作的更好。它通常存储为二进制的一部分。如果我对我的 Ruby 二进制文件运行 `dwarfdump` 命令,那么我将会得到下面的输出:
|
||||
|
||||
(我已经重新编排使得它更容易理解)
|
||||
|
||||
@ -128,7 +123,7 @@ DW_TAG_member
|
||||
|
||||
```
|
||||
|
||||
所以,`ruby_current_thread` 的类型名为 `rb_thread_struct`,它的大小为 0x3e8 (或 1000 字节),它有许多成员项,`stack_size` 是其中之一,在偏移为 24 的地方,它有类型 `31\` 。`31` 是什么?不用担心,我们也可以在 DWARF 信息中查看。
|
||||
所以,`ruby_current_thread` 的类型名为 `rb_thread_struct`,它的大小为 `0x3e8` (即 1000 字节),它有许多成员项,`stack_size` 是其中之一,在偏移为 `24` 的地方,它有类型 `31` 。`31` 是什么?不用担心,我们也可以在 DWARF 信息中查看。
|
||||
|
||||
```
|
||||
< 1><0x00000031> DW_TAG_typedef
|
||||
@ -141,67 +136,61 @@ DW_TAG_member
|
||||
|
||||
```
|
||||
|
||||
所以,`stack_size` 具有类型 `size_t`,即 `long unsigned int`,它是 8 字节的。这意味着我们可以查看栈大小。
|
||||
所以,`stack_size` 具有类型 `size_t`,即 `long unsigned int`,它是 8 字节的。这意味着我们可以查看该栈的大小。
|
||||
|
||||
如果我们有了 DWARF 调试数据,该如何分解:
|
||||
|
||||
1. 查看 `ruby_current_thread` 所指向的内存区域
|
||||
|
||||
2. 加上 24 字节来得到 `stack_size`
|
||||
|
||||
2. 加上 `24` 字节来得到 `stack_size`
|
||||
3. 读 8 字节(以小端的格式,因为是在 x86 上)
|
||||
|
||||
4. 得到答案!
|
||||
|
||||
在上面这个例子中是 131072 或 128 kb 。
|
||||
在上面这个例子中是 `131072`(即 128 kb)。
|
||||
|
||||
对我来说,这使得调试信息的用途更加明显。如果我们不知道这些所有变量所表示的额外元数据,那么我们无法知道在 `0x5598ab325b0` 这一地址的字节是什么。
|
||||
对我来说,这使得调试信息的用途更加明显。如果我们不知道这些所有变量所表示的额外的元数据,那么我们无法知道存储在 `0x5598ab325b0` 这一地址的字节是什么。
|
||||
|
||||
这就是为什么你可以从你的程序中单独安装一个程序的调试信息,因为 gdb 并不关心从何处获取额外的调试信息。
|
||||
这就是为什么你可以为你的程序单独安装程序的调试信息,因为 `gdb` 并不关心从何处获取这些额外的调试信息。
|
||||
|
||||
### DWARF 很迷惑
|
||||
### DWARF 令人迷惑
|
||||
|
||||
我最近阅读了大量的 DWARF 信息。现在,我使用 libdwarf,使用体验不是很好,这个 API 很令人迷惑,你将以一种奇怪的方式初始化所有东西,它真的很慢(需要花费 0.3 s 的时间来读取我的 Ruby 程序的所有调试信息,这真是可笑)。有人告诉我,libdw 比 elfutils 要好一些。
|
||||
我最近阅读了大量的 DWARF 知识。现在,我使用 libdwarf,使用体验不是很好,这个 API 令人迷惑,你将以一种奇怪的方式初始化所有东西,它真的很慢(需要花费 0.3 秒的时间来读取我的 Ruby 程序的所有调试信息,这真是可笑)。有人告诉我,来自 elfutils 的 libdw 要好一些。
|
||||
|
||||
同样,你可以查看 `DW_AT_data_member_location` 来查看结构成员的偏移。我在 Stack Overflow 上查找如何完成这件事,并且得到[这个答案][2]。基本上,以下面这样一个检查开始:
|
||||
同样,再提及一点,你可以查看 `DW_AT_data_member_location` 来查看结构成员的偏移。我在 Stack Overflow 上查找如何完成这件事,并且得到[这个答案][2]。基本上,以下面这样一个检查开始:
|
||||
|
||||
```
|
||||
dwarf_whatform(attrs[i], &form, &error);
|
||||
if (form == DW_FORM_data1 || form == DW_FORM_data2
|
||||
form == DW_FORM_data2 || form == DW_FORM_data4
|
||||
form == DW_FORM_data8 || form == DW_FORM_udata) {
|
||||
|
||||
```
|
||||
|
||||
继续往前。为什么会有 800 万种不同的 `DW_FORM_data` 需要检查?发生了什么?我没有头绪。
|
||||
|
||||
不管怎么说,我的印象是,DWARF 是一个庞大而复杂的标准(可能是人们用来生成 DWARF 的库不匹配),但是这是我们所拥有的,所以我们只能用它来工作。
|
||||
不管怎么说,我的印象是,DWARF 是一个庞大而复杂的标准(可能是人们用来生成 DWARF 的库稍微不兼容),但是我们有的就是这些,所以我们只能用它来工作。
|
||||
|
||||
我能够编写代码并查看 DWARF 并且我的代码实际上大多数能够工作,这就很酷了,除了程序崩溃的时候。我就是这样工作的。
|
||||
我能够编写代码并查看 DWARF ,这就很酷了,并且我的代码实际上大多数能够工作。除了程序崩溃的时候。我就是这样工作的。
|
||||
|
||||
### 展开栈路径
|
||||
|
||||
在这篇文章的早期版本中,我说过,gdb 使用 libunwind 来展开栈路径,这样说并不总是对的。
|
||||
在这篇文章的早期版本中,我说过,`gdb` 使用 libunwind 来展开栈路径,这样说并不总是对的。
|
||||
|
||||
有一位对 gdb 有深入研究的人发了大量邮件告诉我,他们花费了大量时间来尝试如何展开栈路径从而能够做得比 libunwind 更好。这意味着,如果你在程序的一个奇怪的中间位置停下来了,你所能够获取的调试信息又很少,那么你可以对栈做一些奇怪的事情,gdb 会尝试找出你位于何处。
|
||||
有一位对 `gdb` 有深入研究的人发了大量邮件告诉我,为了能够做得比 libunwind 更好,他们花费了大量时间来尝试如何展开栈路径。这意味着,如果你在程序的一个奇怪的中间位置停下来了,你所能够获取的调试信息又很少,那么你可以对栈做一些奇怪的事情,`gdb` 会尝试找出你位于何处。
|
||||
|
||||
### gdb 能做的其他事
|
||||
|
||||
我在这儿所描述的一些事请(查看内存,理解 DWARF 所展示的结构)并不是 gdb 能够做的全部事情。阅读 Brendan Gregg 的[昔日 gdb 例子][3],我们可以知道,gdb 也能够完成下面这些事情:
|
||||
我在这儿所描述的一些事请(查看内存,理解 DWARF 所展示的结构)并不是 `gdb` 能够做的全部事情。阅读 Brendan Gregg 的[昔日 gdb 例子][3],我们可以知道,`gdb` 也能够完成下面这些事情:
|
||||
|
||||
* 反汇编
|
||||
|
||||
* 查看寄存器内容
|
||||
|
||||
在操作程序方面,它可以:
|
||||
|
||||
* 设置断点,单步运行程序
|
||||
|
||||
* 修改内存(这是一个危险行为)
|
||||
|
||||
了解 gdb 如何工作使得当我使用它的时候更加自信。我过去经常感到迷惑,因为 gdb 有点像 C,当你输入 `ruby_current_thread->cfp->iseq`,就好像是在写 C 代码。但是你并不是在写 C 代码。我很容易遇到 gdb 的限制,不知道为什么。
|
||||
了解 `gdb` 如何工作使得当我使用它的时候更加自信。我过去经常感到迷惑,因为 `gdb` 有点像 C,当你输入 `ruby_current_thread->cfp->iseq`,就好像是在写 C 代码。但是你并不是在写 C 代码。我很容易遇到 `gdb` 的限制,不知道为什么。
|
||||
|
||||
知道使用 DWARF 来找出结构内容给了我一个更好的心理模型和更加正确的期望!这真是极好的!
|
||||
知道使用 DWARF 来找出结构内容给了我一个更好的心智模型和更加正确的期望!这真是极好的!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -209,7 +198,7 @@ via: https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
计算机系统进化论
|
||||
======
|
||||
|
||||
纵观现代计算机的历史,从与系统的交互方式方面,可以划分为数个进化阶段。而我更倾向于将之归类为以下几个阶段:
|
||||
|
||||
1. 数字系统
|
||||
2. 专用应用系统
|
||||
3. 应用中心系统
|
||||
4. 信息中心系统
|
||||
5. 无应用系统
|
||||
|
||||
下面我们详细聊聊这几种分类。
|
||||
|
||||
### 数字系统
|
||||
|
||||
在我看来,[早期计算机][1],只被设计用来处理数字。它们能够加、减、乘、除。在它们中有一些能够运行像是微分和积分之类的更复杂的数学操作。
|
||||
|
||||
当然,如果你把字符映射成数字,它们也可以计算字符串。但这多少有点“数字的创造性使用”的意思,而不是直接处理各种信息。
|
||||
|
||||
### 专用应用系统
|
||||
|
||||
对于更高层级的问题,纯粹的数字系统是不够的。专用应用系统被开发用来处理单一任务。它们和数字系统十分相似,但是,它们拥有足够的复杂数字计算能力。这些系统能够完成十分明确的高层级任务,像调度问题的相关计算或者其他优化问题。
|
||||
|
||||
这类系统为单一目的而搭建,它们解决的是单一明确的问题。
|
||||
|
||||
### 应用中心系统
|
||||
|
||||
应用中心系统是第一个真正的通用系统。它们的主要使用风格很像专用应用系统,但是它们拥有以时间片模式(一个接一个)或以多任务模式(多应用同时)运行的多个应用程序。
|
||||
|
||||
上世纪 70 年代的 [早期的个人电脑][3]是第一种受人们欢迎的应用中心系统。
|
||||
|
||||
如今的现在操作系统 —— Windows 、macOS 、大多数 GNU/Linux 桌面环境 —— 一直遵循相同的法则。
|
||||
|
||||
当然,应用中心系统还可以再细分为两种子类:
|
||||
|
||||
1. 紧密型应用中心系统
|
||||
2. 松散型应用中心系统
|
||||
|
||||
紧密型应用中心系统像是 [Windows 3.1][4] (拥有程序管理器和文件管理器)或者甚至 [Windows 95][5] 的最初版本都没有预定义的文件夹层次。用户启动文本处理程序(像 [ WinWord ][6])并且把文件保存在 WinWord 的程序文件夹中。在使用表格处理程序的时候,又把文件保存在表格处理工具的程序文件夹中。诸如此类。用户几乎不创建自己的文件层次结构,可能由于此举的不方便、用户单方面的懒惰,或者他们认为根本没有必要。那时,每个用户拥有几十个至多几百个文件。
|
||||
|
||||
为了访问文件中的信息,用户常常先打开一个应用程序,然后通过程序中的“文件/打开”功能来获取处理过的数据文件。
|
||||
|
||||
在 Windows 平台的 [Windows 95][5] SP2 中,“[我的文档][7]”首次被使用。有了这样一个文件层次结构的样板,应用设计者开始把 “[我的文档][7]” 作为程序的默认的保存 / 打开目录,抛弃了原来将软件产品安装目录作为默认目录的做法。这样一来,用户渐渐适应了这种模式,并且开始自己维护文件夹层次。
|
||||
|
||||
松散型应用中心系统(通过文件管理器来提取文件)应运而生。在这种系统下,当打开一个文件的时候,操作系统会自动启动与之相关的应用程序。这是一次小而精妙的用法转变。这种应用中心系统的用法模式一直是个人电脑的主要用法模式。
|
||||
|
||||
然而,这种模式有很多的缺点。例如,为了防止数据提取出现问题,需要维护一个包含给定项目的所有相关文件的严格文件夹层次结构。不幸的是,人们并不总能这样做。更进一步说,[这种模式不能很好的扩展][8]。 桌面搜索引擎和高级数据组织工具(像 [tagstore][9])可以起到一点改善作用。正如研究显示的那样,只有一少部分人正在使用那些高级文件提取工具。大多数的用户不使用替代提取工具或者辅助提取技术在文件系统中寻找文件。
|
||||
|
||||
### 信息中心系统
|
||||
|
||||
解决上述需要将所有文件都放到一个文件夹的问题的可行办法之一就是从应用中心系统转换到信息中心系统。
|
||||
|
||||
信息中心系统将项目的所有信息联合起来,放在一个地方,放在同一个应用程序里。因此,我们再也不需要计算项目预算时,打开表格处理程序;写工程报告时,打开文本处理程序;处理图片文件时,又打开另一个工具。
|
||||
|
||||
上个月的预算情况在客户会议笔记的右下方,客户会议笔记又在画板的右下方,而画板又在另一些要去完成的任务的右下方。在各个层之间没有文件或者应用程序来回切换的麻烦。
|
||||
|
||||
早期,IBM [OS/2][10]、 Microsoft [OLE][11] 和 [NeXT][12] 都做过类似的尝试。但都由于种种原因没有取得重大成功。从 [Plan 9][14] 发展而来的 [ACme][13] 是一个非常有趣的信息中心环境。它在一个应用程序中包含了[多种应用程序][15]。但是即时是它移植到了 Windows 和 GNU/Linux,也从来没有成为一个引起关注的软件。
|
||||
|
||||
信息中心系统的现代形式是高级 [个人维基][16](像 [TheBrain][17] 和 [Microsoft OneNote][18])。
|
||||
|
||||
我选择的个人工具是带 [Org 模式][19] 扩展的 [GNU/Emacs][20] 平台。在用电脑的时候,我几乎不能没有 Org 模式 。为了访问外部数据资源,我创建了一个可以将多种数据导入 Org 模式的插件 —— [Memacs][20] 。我喜欢将表格数据计算放到日程任务的右下方,然后是行内图片,内部和外部链接,等等。它是一个真正的用户不用必须操心程序或者严格的层次文件系统文件夹的信息中心系统。同时,用简单的或高级的标签也可以进行多分类。一个命令可以派生多种视图。比如,一个视图有日历,待办事项。另一个视图是租借事宜列表。等等。它对 Org 模式的用户没有限制。只有你想不到,没有它做不到。
|
||||
|
||||
进化结束了吗? 当然没有。
|
||||
|
||||
### 无应用系统
|
||||
|
||||
我能想到这样一类操作系统,我称之为无应用系统。在下一步的发展中,系统将不需要单一领域的应用程序,即使它们能和 Org 模式一样出色。计算机直接提供一个处理信息和使用功能的友好用户接口,而不通过文件和程序。甚至连传统的操作系统也不需要。
|
||||
|
||||
无应用系统也可能和 [人工智能][21] 联系起来。把它想象成 [2001 太空漫游][23] 中的 [HAL 9000][22] 和星际迷航中的 [LCARS][24] 一类的东西就可以了。
|
||||
|
||||
从基于应用的、基于供应商的软件文化到无应用系统的转化让人很难相信。 或许,缓慢但却不断发展的开源环境,可以使一个由各种各样组织和人们贡献的真正无应用环境成型。
|
||||
|
||||
信息和提取、操作信息的功能,这是系统应该具有的,同时也是我们所需要的。其他的东西仅仅是为了使我们不至于分散注意力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/2017/02/10/evolution-of-systems/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[lontow](https://github.com/lontow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/History_of_computing_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/String_%2528computer_science%2529
|
||||
[3]:https://en.wikipedia.org/wiki/Xerox_Alto
|
||||
[4]:https://en.wikipedia.org/wiki/Windows_3.1x
|
||||
[5]:https://en.wikipedia.org/wiki/Windows_95
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Word
|
||||
[7]:https://en.wikipedia.org/wiki/My_Documents
|
||||
[8]:http://karl-voit.at/tagstore/downloads/Voit2012b.pdf
|
||||
[9]:http://karl-voit.at/tagstore/
|
||||
[10]:https://en.wikipedia.org/wiki/OS/2
|
||||
[11]:https://en.wikipedia.org/wiki/Object_Linking_and_Embedding
|
||||
[12]:https://en.wikipedia.org/wiki/NeXT
|
||||
[13]:https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529
|
||||
[14]:https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs
|
||||
[15]:https://en.wikipedia.org/wiki/List_of_Plan_9_applications
|
||||
[16]:https://en.wikipedia.org/wiki/Personal_wiki
|
||||
[17]:https://en.wikipedia.org/wiki/TheBrain
|
||||
[18]:https://en.wikipedia.org/wiki/Microsoft_OneNote
|
||||
[19]:../../../../tags/emacs
|
||||
[20]:https://github.com/novoid/Memacs
|
||||
[21]:https://en.wikipedia.org/wiki/Artificial_intelligence
|
||||
[22]:https://en.wikipedia.org/wiki/HAL_9000
|
||||
[23]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey
|
||||
[24]:https://en.wikipedia.org/wiki/LCARS
|
||||
@ -0,0 +1,137 @@
|
||||
如何使用 GNU Stow 来管理从源代码安装的程序和点文件
|
||||
=====
|
||||
|
||||
### 目的
|
||||
|
||||
使用 GNU Stow 轻松管理从源代码安装的程序和点文件(LCTT 译注:<ruby>点文件<rt>dotfile</rt></ruby>,即以 `.` 开头的文件,在 *nix 下默认为隐藏文件,常用于存储程序的配置信息。)
|
||||
|
||||
### 要求
|
||||
|
||||
* root 权限
|
||||
|
||||
### 难度
|
||||
|
||||
简单
|
||||
|
||||
### 约定
|
||||
|
||||
* `#` - 给定的命令要求直接以 root 用户身份或使用 `sudo` 命令以 root 权限执行
|
||||
* `$` - 给定的命令将作为普通的非特权用户来执行
|
||||
|
||||
### 介绍
|
||||
|
||||
有时候我们必须从源代码安装程序,因为它们也许不能通过标准渠道获得,或者我们可能需要特定版本的软件。 GNU Stow 是一个非常不错的<ruby>符号链接工厂<rt>symlinks factory</rt></ruby>程序,它可以帮助我们保持文件的整洁,易于维护。
|
||||
|
||||
### 获得 stow
|
||||
|
||||
你的 Linux 发行版本很可能包含 `stow`,例如在 Fedora,你安装它只需要:
|
||||
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
在 Ubuntu/Debian 中,安装 `stow` 需要执行:
|
||||
|
||||
```
|
||||
# apt install stow
|
||||
```
|
||||
|
||||
在某些 Linux 发行版中,`stow` 在标准库中是不可用的,但是可以通过一些额外的软件源(例如 RHEL 和 CentOS7 中的EPEL )轻松获得,或者,作为最后的手段,你可以从源代码编译它。只需要很少的依赖关系。
|
||||
|
||||
### 从源代码编译
|
||||
|
||||
最新的可用 stow 版本是 `2.2.2`。源码包可以在这里下载:`https://ftp.gnu.org/gnu/stow/`。
|
||||
|
||||
一旦你下载了源码包,你就必须解压它。切换到你下载软件包的目录,然后运行:
|
||||
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
解压源文件后,切换到 `stow-2.2.2` 目录中,然后编译该程序,只需运行:
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
```
|
||||
|
||||
最后,安装软件包:
|
||||
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
默认情况下,软件包将安装在 `/usr/local/` 目录中,但是我们可以改变它,通过配置脚本的 `--prefix` 选项指定目录,或者在运行 `make install` 时添加 `prefix="/your/dir"`。
|
||||
|
||||
此时,如果所有工作都按预期工作,我们应该已经在系统上安装了 `stow`。
|
||||
|
||||
### stow 是如何工作的?
|
||||
|
||||
`stow` 背后主要的概念在程序手册中有很好的解释:
|
||||
|
||||
> Stow 使用的方法是将每个软件包安装到自己的目录树中,然后使用符号链接使它看起来像文件一样安装在公共的目录树中
|
||||
|
||||
为了更好地理解这个软件的运作,我们来分析一下它的关键概念:
|
||||
|
||||
#### stow 文件目录
|
||||
|
||||
stow 目录是包含所有 stow 软件包的根目录,每个包都有自己的子目录。典型的 stow 目录是 `/usr/local/stow`:在其中,每个子目录代表一个软件包。
|
||||
|
||||
#### stow 软件包
|
||||
|
||||
如上所述,stow 目录包含多个“软件包”,每个软件包都位于自己单独的子目录中,通常以程序本身命名。包就是与特定软件相关的文件和目录列表,作为一个实体进行管理。
|
||||
|
||||
#### stow 目标目录
|
||||
|
||||
stow 目标目录解释起来是一个非常简单的概念。它是包文件应该安装到的目录。默认情况下,stow 目标目录被视作是调用 stow 的目录。这种行为可以通过使用 `-t` 选项( `--target` 的简写)轻松改变,这使我们可以指定一个替代目录。
|
||||
|
||||
### 一个实际的例子
|
||||
|
||||
我相信一个好的例子胜过 1000 句话,所以让我来展示 `stow` 如何工作。假设我们想编译并安装 `libx264`,首先我们克隆包含其源代码的仓库:
|
||||
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
运行该命令几秒钟后,将创建 `x264` 目录,它将包含准备编译的源代码。我们切换到 `x264` 目录中并运行 `configure` 脚本,将 `--prefix` 指定为 `/usr/local/stow/libx264` 目录。
|
||||
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
然后我们构建该程序并安装它:
|
||||
|
||||
```
|
||||
$ make
|
||||
# make install
|
||||
```
|
||||
|
||||
`x264` 目录应该创建在 `stow` 目录内:它包含了所有通常直接安装在系统中的东西。 现在,我们所要做的就是调用 `stow`。 我们必须从 `stow` 目录内运行这个命令,通过使用 `-d` 选项来手动指定 `stow` 目录的路径(默认为当前目录),或者通过如前所述用 `-t` 指定目标。我们还应该提供要作为参数存储的软件包的名称。 在这里,我们从 `stow` 目录运行程序,所以我们需要输入的内容是:
|
||||
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
libx264 软件包中包含的所有文件和目录现在已经在调用 stow 的父目录 (/usr/local) 中进行了符号链接,因此,例如在 `/usr/local/ stow/x264/bin` 中包含的 libx264 二进制文件现在符号链接在 `/usr/local/bin` 之中,`/usr/local/stow/x264/etc` 中的文件现在符号链接在 `/usr/local/etc` 之中等等。通过这种方式,系统将显示文件已正常安装,并且我们可以容易地跟踪我们编译和安装的每个程序。要反转该操作,我们只需使用 `-D` 选项:
|
||||
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
完成了!符号链接不再存在:我们只是“卸载”了一个 stow 包,使我们的系统保持在一个干净且一致的状态。 在这一点上,我们应该清楚为什么 stow 还可以用于管理点文件。 通常的做法是在 git 仓库中包含用户特定的所有配置文件,以便轻松管理它们并使它们在任何地方都可用,然后使用 stow 将它们放在适当位置,如放在用户主目录中。
|
||||
|
||||
stow 还会阻止你错误地覆盖文件:如果目标文件已经存在,并且没有指向 stow 目录中的包时,它将拒绝创建符号链接。 这种情况在 stow 术语中称为冲突。
|
||||
|
||||
就是这样!有关选项的完整列表,请参阅 stow 帮助页,并且不要忘记在评论中告诉我们你对此的看法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -0,0 +1,101 @@
|
||||
你没听过的 10 个免费的 Linux 生产力应用程序
|
||||
=====
|
||||
|
||||

|
||||
|
||||
高效率的应用程序确实可以让你工作变得更轻松。如果你是一位 Linux 用户,这 10 个不太知名的 Linux 桌面应用程序可以帮助到你。事实上,Linux 用户可能已经听说过这个列表上的所有应用,但对于那些只用过主流应用的人来说,应该是不知道这些应用的。
|
||||
|
||||
### 1. Tomboy/Gnote
|
||||
|
||||
![linux-productivity-apps-01-tomboy][1]
|
||||
|
||||
[Tomboy][2] 是一个简单的便签应用。它不仅仅适用于 Linux,你也可以在 Unix、Windows 和 macOS 上获得它。Tomboy 很容易使用——你写一个便条,选择是否让它粘贴在你的桌面上,当你完成它时删除它。
|
||||
|
||||
### 2. MyNotex
|
||||
|
||||
![linux-productivity-apps-02-mynotex][3]
|
||||
|
||||
如果你想要一个更多功能的便签,但是仍喜欢一个小而简单的应用程序,而不是一个巨大的套件,请看看 [MyNotex][4]。除了简单的笔记和检索之外,它还带有一些不错的功能,例如格式化、键盘快捷键和附件等等。你也可以将其用作图片管理器。
|
||||
|
||||
### 3. Trojitá
|
||||
|
||||
![linux-productivity-apps-03-trojita][5]
|
||||
|
||||
尽管你可以没有桌面电子邮件客户端,但如果你想要一个的话,在几十个的桌面电子邮件客户端里,请尝试下 [Trojita][6]。这有利于生产力,因为它是一个快速而轻量级的电子邮件客户端,但它提供了一个好的电子邮件客户端所必须具备的所有功能(以及更多)。
|
||||
|
||||
### 4. Kontact
|
||||
|
||||
![linux-productivity-apps-04-kontact][7]
|
||||
|
||||
个人信息管理器(PIM)是一款出色的生产力工具。我的个人喜好是 [Kontact][8]。尽管它已经有几年没有更新,但它仍然是一个非常有用的 PIM 工具,用于管理电子邮件、地址簿、日历、任务、新闻源等。Kontact 是一个 KDE 原生程序,但你也可以在其他桌面上使用它。
|
||||
|
||||
### 5. Osmo
|
||||
|
||||
![linux-productivity-apps-05-osmo][9]
|
||||
|
||||
[Osmo][10] 是一款更先进的应用,包括日历、任务、联系人和便签功能。它还附带一些额外的功能,比如加密私有数据备份和地图上的地理位置,以及对便签、任务、联系人等的强大搜索功能。
|
||||
|
||||
### 6. Catfish
|
||||
|
||||
![linux-productivity-apps-06-catfish][11]
|
||||
|
||||
没有好的搜索工具就没有高生产力。[Catfish][12] 是一个必须尝试的搜索工具。它是一个 GTK+ 工具,非常快速,轻量级。Catfish 会利用 Zeitgeist 的自动完成功能,你还可以按日期和类型过滤搜索结果。
|
||||
|
||||
### 7. KOrganizer
|
||||
|
||||
![linux-productivity-apps-07-korganizer][13]
|
||||
|
||||
[KOrganizer][14] 是我上面提到的 Kontact 应用程序的日历和计划组件。如果你不需要完整的 PIM 应用程序,只需要日历和日程安排,则可以使用 KOrganizer。KOrganizer 提供快速的待办事项和快速事件条目,以及事件和待办事项的附件。
|
||||
|
||||
### 8. Evolution
|
||||
|
||||
![linux-productivity-apps-08-evolution][15]
|
||||
|
||||
如果你不是 KDE 应用程序的粉丝,但你仍然需要一个好的 PIM,那么试试 GNOME 的 [Evolution][16]。Evolution 并不是一个你从没听过的少见的应用程序,但因为它有用,所以它出现在这个列表中。也许你已经听说过 Evolution 是一个电子邮件客户端,但它远不止于此——你可以用它来管理日历、邮件、地址簿和任务。
|
||||
|
||||
### 9. Freeplane
|
||||
|
||||
![linux-productivity-apps-09-freeplane][17]
|
||||
|
||||
我不知道你们中的大多数是否每天都使用思维导图软件,但是如果你使用,请选择 [Freeplane][18]。这是一款免费的思维导图和知识管理软件,可用于商业或娱乐。你可以创建笔记,将其排列在云图或图表中,使用日历和提醒设置任务等。
|
||||
|
||||
### 10. Calligra Flow
|
||||
|
||||
![linux-productivity-apps-10-calligra-flow][19]
|
||||
|
||||
最后,如果你需要流程图和图表工具,请尝试 [Calligra Flow][20]。你可以将其视为开放源代码的 [Microsoft Visio][21] 替代品,但 Calligra Flow 不提供 Viso 提供的所有特性。不过,你可以使用它来创建网络图、组织结构图、流程图等等。
|
||||
|
||||
生产力工具不仅可以加快工作速度,还可以让你更有条理。我敢打赌,几乎没有人不使用某种形式的生产力工具。尝试这里列出的应用程序可以使你的工作效率更高,还能让你的生活至少轻松一些。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/free-linux-productivity-apps-you-havent-heard-of/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-01-Tomboy.png (linux-productivity-apps-01-tomboy)
|
||||
[2]:https://wiki.gnome.org/Apps/Tomboy
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-02-MyNotex.jpg (linux-productivity-apps-02-mynotex)
|
||||
[4]:https://sites.google.com/site/mynotex/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-03-Trojita.jpg (linux-productivity-apps-03-trojita)
|
||||
[6]:http://trojita.flaska.net/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-04-Kontact.jpg (linux-productivity-apps-04-kontact)
|
||||
[8]:https://userbase.kde.org/Kontact
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-05-Osmo.jpg (linux-productivity-apps-05-osmo)
|
||||
[10]:http://clayo.org/osmo/
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-06-Catfish.png (linux-productivity-apps-06-catfish)
|
||||
[12]:http://www.twotoasts.de/index.php/catfish/
|
||||
[13]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-07-KOrganizer.jpg (linux-productivity-apps-07-korganizer)
|
||||
[14]:https://userbase.kde.org/KOrganizer
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-08-Evolution.jpg (linux-productivity-apps-08-evolution)
|
||||
[16]:https://help.gnome.org/users/evolution/3.22/intro-main-window.html.en
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-09-Freeplane.jpg (linux-productivity-apps-09-freeplane)
|
||||
[18]:https://www.freeplane.org/wiki/index.php/Home
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-10-Calligra-Flow.jpg (linux-productivity-apps-10-calligra-flow)
|
||||
[20]:https://www.calligra.org/flow/
|
||||
[21]:https://www.maketecheasier.com/5-best-free-alternatives-to-microsoft-visio/
|
||||
@ -1,7 +1,7 @@
|
||||
如何使用 GNOME Shell 扩展[完整指南]
|
||||
如何使用 GNOME Shell 扩展
|
||||
=====
|
||||
|
||||
**简介:这是一份详细指南,我将会向你展示如何手动或通过浏览器轻松安装 GNOME Shell 扩展。**
|
||||
> 简介:这是一份详细指南,我将会向你展示如何手动或通过浏览器轻松安装 GNOME Shell <ruby>扩展<rt>Extension</rt></ruby>。
|
||||
|
||||
在讨论 [如何在 Ubuntu 17.10 上安装主题][1] 一文时,我简要地提到了 GNOME Shell 扩展,它用来安装用户主题。今天,我们将详细介绍 Ubuntu 17.10 中的 GNOME Shell 扩展。
|
||||
|
||||
@ -11,94 +11,103 @@
|
||||
|
||||
在此之前,如果你喜欢视频,我已经在 [FOSS 的 YouTube 频道][2] 上展示了所有的这些操作。我强烈建议你订阅它来获得更多有关 Linux 的视频。
|
||||
|
||||
## 什么是 GNOME Shell 扩展?
|
||||
### 什么是 GNOME Shell 扩展?
|
||||
|
||||
[GNOME Shell 扩展][3] 根本上来说是增强 GNOME 桌面功能的一小段代码。
|
||||
|
||||
把它看作是你浏览器的一个附加组件。例如,你可以在浏览器中安装附加组件来禁用广告。这个附加组件是由第三方开发者开发的。虽然你的 Web 浏览器默认不提供此项功能,但安装此附加组件可增强你 Web 浏览器的功能。
|
||||
把它看作是你的浏览器的一个附加组件。例如,你可以在浏览器中安装附加组件来禁用广告。这个附加组件是由第三方开发者开发的。虽然你的 Web 浏览器默认不提供此项功能,但安装此附加组件可增强你 Web 浏览器的功能。
|
||||
|
||||
同样, GNOME Shell 扩展就像那些可以安装在 GNOME 之上的第三方附加组件和插件。这些扩展程序是为执行特定任务而创建的,例如显示天气状况,网速等。大多数情况下,你可以在顶部面板中访问它们。
|
||||
同样, GNOME Shell 扩展就像那些可以安装在 GNOME 之上的第三方附加组件和插件。这些扩展程序是为执行特定任务而创建的,例如显示天气状况、网速等。大多数情况下,你可以在顶部面板中访问它们。
|
||||
|
||||
![GNOME Shell 扩展 in action][5]
|
||||
![GNOME Shell 扩展显示天气信息][5]
|
||||
|
||||
还有一些 GNOME 扩展在顶部面板上不可见,但它们仍然可以调整 GNOME 的行为。例如,鼠标中轴可以使用扩展来关闭一个应用程序。
|
||||
也有一些 GNOME 扩展在顶部面板上不可见,但它们仍然可以调整 GNOME 的行为。例如,有一个这样的扩展可以让鼠标中键来关闭应用程序。
|
||||
|
||||
## 安装 GNOME Shell 扩展
|
||||
### 安装 GNOME Shell 扩展
|
||||
|
||||
现在你知道了什么是 GNOME Shell 扩展,那么让我们来看看如何安装它吧。有三种方式可以使用 GNOME 扩展:
|
||||
|
||||
* 使用来自 Ubuntu 的最小扩展集(或你的 Linux 发行版)
|
||||
* 在 Web 浏览器种查找并安装扩展程序
|
||||
* 使用来自 Ubuntu (或你的 Linux 发行版)的最小扩展集
|
||||
* 在 Web 浏览器中查找并安装扩展程序
|
||||
* 下载并手动安装扩展
|
||||
|
||||
在你学习如何使用 GNOME Shell 扩展之前,你应该安装 GNOME Tweak Tool。你可以在软件中心找到它,或者你可以使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install gnome-tweak-tool
|
||||
```
|
||||
|
||||
有时候,你需要知道你正在使用的 GNOME Shell 的版本,这有助于你确定扩展是否与系统兼容。你可以使用下面的命令来找到它:
|
||||
|
||||
```
|
||||
gnome-shell --version
|
||||
```
|
||||
|
||||
### 1. 使用 gnome-shell-extensions 包 [最简单最安全的方式]
|
||||
#### 1. 使用 gnome-shell-extensions 包 [最简单最安全的方式]
|
||||
|
||||
Ubuntu (以及其他几个 Linux 发行版,如 Fedora )提供了一个包,这个包有最小的 GNOME 扩展。由于 Linux 发行版经过测试,所以你不必担心兼容性问题。
|
||||
Ubuntu(以及其他几个 Linux 发行版,如 Fedora )提供了一个包,这个包有最小集合的 GNOME 扩展。由于 Linux 发行版经过测试,所以你不必担心兼容性问题。
|
||||
|
||||
如果你不想费神,你只需获得这个包,你就可以安装 8-10 个 GNOME 扩展。
|
||||
|
||||
如果你想要一个简单易懂的程序,你只需获得这个包,你就可以安装 8-10 个 GNOME 扩展。
|
||||
```
|
||||
sudo apt install gnome-shell-extensions
|
||||
```
|
||||
|
||||
你将不得不重新启动系统(或者重新启动 GNOME Shell,我具体忘了是哪个)。之后,启动 GNOME Tweaks,你会发现一些扩展自动安装了,你只需切换按钮即可开始使用已安装的扩展程序。
|
||||
你将需要重新启动系统(或者重新启动 GNOME Shell,我具体忘了是哪个)。之后,启动 GNOME Tweaks,你会发现一些扩展自动安装了,你只需切换按钮即可开始使用已安装的扩展程序。
|
||||
|
||||
![Change GNOME Shell theme in Ubuntu 17.1][6]
|
||||
|
||||
### 2. 从 Web 浏览器安装 GNOME Shell 扩展
|
||||
#### 2. 从 Web 浏览器安装 GNOME Shell 扩展
|
||||
|
||||
GNOME 项目有一个专门用于扩展的网站。不是这个,你可以找到并安装它,从而管理你的扩展程序,甚至不需要 GNOME Tweaks Tool。
|
||||
GNOME 项目有一个专门用于扩展的网站,不干别的,你可以在这里找到并安装扩展,并管理它们,甚至不需要 GNOME Tweaks Tool。
|
||||
|
||||
[GNOME Shell Extensions Website][3]
|
||||
- [GNOME Shell Extensions Website][3]
|
||||
|
||||
但是为了安装 Web 浏览器扩展,你需要两件东西:浏览器附加组件和本地主机连接器。
|
||||
|
||||
#### 步骤 1: 安装 浏览器附加组件
|
||||
**步骤 1: 安装 浏览器附加组件**
|
||||
|
||||
当你访问 GNOME Shell 扩展网站时,你会看到如下消息:
|
||||
> "要使用此站点控制 GNOME Shell 扩展,你必须安装由两部分组成的 GNOME Shell 集成:浏览器扩展和本地主机消息应用。"
|
||||
|
||||
> “要使用此站点控制 GNOME Shell 扩展,你必须安装由两部分组成的 GNOME Shell 集成:浏览器扩展和本地主机消息应用。”
|
||||
|
||||
![Installing GNOME Shell Extensions][7]
|
||||
|
||||
你只需在你的 Web 浏览器上点击建议的附加组件即可。你也可以从下面的链接安装它们:
|
||||
你只需在你的 Web 浏览器上点击建议的附加组件链接即可。你也可以从下面的链接安装它们:
|
||||
|
||||
#### 步骤 2: 安装本地连接器
|
||||
- 对于 Google Chrome、Chromium 和 Vivaldi: [Chrome Web 商店][21]
|
||||
- 对于 Firefox: [Mozilla Addons][22]
|
||||
- 对于 Opera: [Opera Addons][23]
|
||||
|
||||
**步骤 2: 安装本地连接器**
|
||||
|
||||
仅仅安装浏览器附加组件并没有帮助。你仍然会看到如下错误:
|
||||
|
||||
> "尽管 GNOME Shell 集成扩展正在运行,但未检测到本地主机连接器。请参阅文档以获取有关安装连接器的信息。"
|
||||
> “尽管 GNOME Shell 集成扩展正在运行,但未检测到本地主机连接器。请参阅文档以获取有关安装连接器的信息。”
|
||||
|
||||
![How to install GNOME Shell Extensions][8]
|
||||
|
||||
这是因为你尚未安装主机连接器。要做到这一点,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install chrome-gnome-shell
|
||||
```
|
||||
|
||||
不要担心包名中的 'chrome' 前缀,它与 Chrome 无关,你无需再次安装 Firefox 或 Opera 的单独软件包。
|
||||
不要担心包名中的 “chrome” 前缀,它与 Chrome 无关,你无需再次安装 Firefox 或 Opera 的单独软件包。
|
||||
|
||||
#### 步骤 3: 在 Web 浏览器中安装 GNOME Shell 扩展
|
||||
**步骤 3: 在 Web 浏览器中安装 GNOME Shell 扩展**
|
||||
|
||||
一旦你完成了这两个要求,你就可以开始了。现在,你将看不到任何错误消息。
|
||||
|
||||
![GNOME Shell Extension][9]
|
||||
|
||||
一件好事情是它会按照 GNOME Shell 版本对扩展进行排序,但这不是强制性的。这里发生的事情是开发人员为当前的 GNOME 版本创建扩展。在一年之内,还会有两个 GNOME 发行版本。但开发人员没有时间测试或更新他/她的扩展。
|
||||
一件好的做法是按照 GNOME Shell 版本对扩展进行排序,但这不是强制性的。这是因为开发人员是为其当前的 GNOME 版本创建的扩展。而在一年之内,会发布两个或更多 GNOME 发行版本,但开发人员没有时间(在新的 GNOME 版本上)测试或更新他/她的扩展。
|
||||
|
||||
因此,你不知道该扩展是否与你的系统兼容。尽管扩展已经存在很长一段时间了,但是有可能在最新的 GNOME Shell 版本中,它也能正常工作。同样它也有可能不工作。
|
||||
|
||||
你也可以去搜索扩展程序。假设你想要安装有关天气的扩展,只要搜索它并选择一个搜索结果即可。
|
||||
|
||||
当你访问扩展页面是,你会看到一个切换按钮。
|
||||
当你访问扩展页面时,你会看到一个切换按钮。
|
||||
|
||||
![Installing GNOME Shell Extension ][10]
|
||||
|
||||
@ -106,21 +115,21 @@ sudo apt install chrome-gnome-shell
|
||||
|
||||
![Install GNOME Shell Extensions via web browser][11]
|
||||
|
||||
很明显,直接安装。安装完成后,你会看到切换按钮已打开,旁边有一个设置选项。你也可以使用设置选项配置扩展,也可以禁用扩展。
|
||||
显然,直接安装就好。安装完成后,你会看到切换按钮已打开,旁边有一个设置选项。你也可以使用设置选项配置扩展,也可以禁用扩展。
|
||||
|
||||
![Configuring installed GNOME Shell Extensions][12]
|
||||
|
||||
你还可以在 GNOME Tweaks Tool 中配置 Web 浏览器中安装的扩展:
|
||||
你也可以在 GNOME Tweaks Tool 中配置通过 Web 浏览器安装的扩展:
|
||||
|
||||
![GNOME Tweaks to handle GNOME Shell Extensions][13]
|
||||
|
||||
你可以在 GNOME 网站中 [安装的扩展部分][14] 下查看所有已安装的扩展。
|
||||
你可以在 GNOME 网站中 [已安装的扩展部分][14] 下查看所有已安装的扩展。
|
||||
|
||||
![Manage your installed GNOME Shell Extensions][15]
|
||||
|
||||
使用 GNOME 扩展网站的一个主要优点是你可以查看是否有可用于扩展的更新,你不会在 GNOME Tweaks 或系统更新中获得它。
|
||||
使用 GNOME 扩展网站的一个主要优点是你可以查看扩展是否有可用的更新,你不会在 GNOME Tweaks 或系统更新中得到更新(和提示)。
|
||||
|
||||
### 3. 手动安装 GNOME Shell 扩展
|
||||
#### 3. 手动安装 GNOME Shell 扩展
|
||||
|
||||
你不需要始终在线才能安装 GNOME Shell 扩展,你可以下载文件并稍后安装,这样就不必使用互联网了。
|
||||
|
||||
@ -128,41 +137,41 @@ sudo apt install chrome-gnome-shell
|
||||
|
||||
![Download GNOME Shell Extension][16]
|
||||
|
||||
解压下载的文件,将该文件夹复制到 **~/.local/share/gnome-shell/extensions** 目录。到主目录下并按 Crl+H 显示隐藏的文件夹,在这里找到 .local 文件夹,你可以找到你的路径,直至扩展目录。
|
||||
解压下载的文件,将该文件夹复制到 `~/.local/share/gnome-shell/extensions` 目录。到主目录下并按 `Ctrl+H` 显示隐藏的文件夹,在这里找到 `.local` 文件夹,你可以找到你的路径,直至 `extensions` 目录。
|
||||
|
||||
一旦你将文件复制到正确的目录后,进入它并打开 metadata.json 文件,寻找 uuid 的值。
|
||||
一旦你将文件复制到正确的目录后,进入它并打开 `metadata.json` 文件,寻找 `uuid` 的值。
|
||||
|
||||
确保扩展文件夹名称与 metadata.json 中的 uuid 值相同。如果不相同,请将目录重命名为 uuid 的值。
|
||||
确保该扩展的文件夹名称与 `metadata.json` 中的 `uuid` 值相同。如果不相同,请将目录重命名为 `uuid` 的值。
|
||||
|
||||
![Manually install GNOME Shell extension][17]
|
||||
|
||||
差不多了!现在重新启动 GNOME Shell。 按 Alt+F2 并输入 r 重新启动 GNOME Shell。
|
||||
差不多了!现在重新启动 GNOME Shell。 按 `Alt+F2` 并输入 `r` 重新启动 GNOME Shell。
|
||||
|
||||
![Restart GNOME Shell][18]
|
||||
|
||||
同样重新启动 GNOME Tweaks Tool。你现在应该可以在 Tweaks Tool 中看到手动安装 GNOME 扩展,你可以在此处配置或启用新安装的扩展。
|
||||
同样重新启动 GNOME Tweaks Tool。你现在应该可以在 Tweaks Tool 中看到手动安装的 GNOME 扩展,你可以在此处配置或启用新安装的扩展。
|
||||
|
||||
这就是安装 GNOME Shell 扩展你需要知道的所有内容。
|
||||
|
||||
## 移除 GNOME Shell 扩展
|
||||
### 移除 GNOME Shell 扩展
|
||||
|
||||
你可能想要删除一个已安装的 GNOME Shell 扩展,这是完全可以理解的。
|
||||
|
||||
如果你是通过 Web 浏览器安装的,你可以到 [GNOME 网站的以安装的扩展部分][14] 那移除它(如前面的图片所示)。
|
||||
|
||||
如果你是手动安装的,可以从 ~/.local/share/gnome-shell/extensions 目录中删除扩展文件来删除它。
|
||||
如果你是手动安装的,可以从 `~/.local/share/gnome-shell/extensions` 目录中删除扩展文件来删除它。
|
||||
|
||||
## 特别提示:获得 GNOME Shell 扩展更新的通知
|
||||
### 特别提示:获得 GNOME Shell 扩展更新的通知
|
||||
|
||||
到目前为止,你已经意识到除了访问 GNOME 扩展网站之外,无法知道更新是否可用于 GNOME Shell 扩展。
|
||||
|
||||
幸运的是,有一个 GNOME Shell 扩展可以通知你是否有可用于已安装扩展的更新。你可以从下面的链接中获得它:
|
||||
|
||||
[Extension Update Notifier][19]
|
||||
- [Extension Update Notifier][19]
|
||||
|
||||
### 你如何管理 GNOME Shell 扩展?
|
||||
|
||||
我觉得很奇怪你不能通过系统更新来更新扩展,就好像 GNOME Shell 扩展不是系统的一部分。
|
||||
我觉得很奇怪不能通过系统更新来更新扩展,就好像 GNOME Shell 扩展不是系统的一部分。
|
||||
|
||||
如果你正在寻找一些建议,请阅读这篇文章: [关于最佳 GNOME 扩展][20]。同时,你可以分享有关 GNOME Shell 扩展的经验。你经常使用它们吗?如果是,哪些是你最喜欢的?
|
||||
|
||||
@ -172,7 +181,7 @@ via: [https://itsfoss.com/gnome-shell-extensions/](https://itsfoss.com/gnome-she
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -196,3 +205,6 @@ via: [https://itsfoss.com/gnome-shell-extensions/](https://itsfoss.com/gnome-she
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/restart-gnome-shell-800x299.jpeg
|
||||
[19]:https://extensions.gnome.org/extension/1166/extension-update-notifier/
|
||||
[20]:https://itsfoss.com/best-gnome-extensions/
|
||||
[21]:https://chrome.google.com/webstore/detail/gnome-shell-integration/gphhapmejobijbbhgpjhcjognlahblep
|
||||
[22]:https://addons.mozilla.org/en/firefox/addon/gnome-shell-integration/
|
||||
[23]:https://addons.opera.com/en/extensions/details/gnome-shell-integration/
|
||||
@ -1,57 +1,75 @@
|
||||
命令行乐趣:恶搞输错 Bash 命令的用户
|
||||
命令行乐趣:嘲讽输错 Bash 命令的用户
|
||||
======
|
||||
你可以通过配置 sudo 命令去恶搞输入错误密码的用户。但是之后,shell 的恶搞提示语可能会滥用于输入错误命令的用户。
|
||||
|
||||
你可以通过配置 `sudo` 命令去嘲讽输入错误密码的用户。但是现在,当用户在 shell 输错命令时,就能嘲讽他了(滥用?)。
|
||||
|
||||
## 你好 bash-insulter
|
||||
### 你好 bash-insulter
|
||||
|
||||
来自 Github 页面:
|
||||
|
||||
> 当用户键入错误命令,随机嘲讽。它使用了一个 bash4.x. 版本的全新内置错误处理函数,叫 command_not_found_handle。
|
||||
> 当用户键入错误命令,随机嘲讽。它使用了一个 bash4.x. 版本的全新内置错误处理函数,叫 `command_not_found_handle`。
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
键入下列 git 命令克隆一个仓库:
|
||||
`git clone https://github.com/hkbakke/bash-insulter.git bash-insulter`
|
||||
|
||||
```
|
||||
git clone https://github.com/hkbakke/bash-insulter.git bash-insulter
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Cloning into 'bash-insulter'...
|
||||
remote: Counting objects: 52, done.
|
||||
remote: Compressing objects: 100% (49/49), done.
|
||||
remote: Total 52 (delta 12), reused 12 (delta 2), pack-reused 0
|
||||
Unpacking objects: 100% (52/52), done.
|
||||
|
||||
```
|
||||
|
||||
用文本编辑器,编辑你的 ~/.bashrc 或者 /etc/bash.bashrc 文件,比如说使用 vi:
|
||||
`$ vi ~/.bashrc`
|
||||
在其后追加这一行(具体了解请查看 [if..else..fi 声明][1] 和 [命令源码][2]):
|
||||
用文本编辑器,比如说使用 `vi`,编辑你的 `~/.bashrc` 或者 `/etc/bash.bashrc` 文件:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
在其后追加这一行(具体了解请查看 [if..else..fi 声明][1] 和 [source 命令][2]):
|
||||
|
||||
```
|
||||
if [ -f $HOME/bash-insulter/src/bash.command-not-found ]; then
|
||||
source $HOME/bash-insulter/src/bash.command-not-found
|
||||
fi
|
||||
```
|
||||
|
||||
保存并关闭文件。重新登陆,如果不想退出账号也可以手动运行它:
|
||||
保存并关闭文件。重新登录,如果不想退出账号也可以手动运行它:
|
||||
|
||||
```
|
||||
$ . $HOME/bash-insulter/src/bash.command-not-found
|
||||
```
|
||||
|
||||
## 如何使用它?
|
||||
### 如何使用它?
|
||||
|
||||
尝试键入一些无效命令:
|
||||
|
||||
```
|
||||
$ ifconfigs
|
||||
$ dates
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
[![一个有趣的 bash 钩子功能,嘲讽输入了错误命令的你。][3]][3]
|
||||
|
||||
## 自定义
|
||||
### 自定义
|
||||
|
||||
你需要编辑 `$HOME/bash-insulter/src/bash.command-not-found`:
|
||||
|
||||
```
|
||||
$ vi $HOME/bash-insulter/src/bash.command-not-found
|
||||
```
|
||||
|
||||
你需要编辑 $HOME/bash-insulter/src/bash.command-not-found:
|
||||
`$ vi $HOME/bash-insulter/src/bash.command-not-found`
|
||||
示例代码:
|
||||
|
||||
```
|
||||
command_not_found_handle () {
|
||||
local INSULTS=(
|
||||
@ -104,15 +122,28 @@ command_not_found_handle () {
|
||||
}
|
||||
```
|
||||
|
||||
## sudo 嘲讽
|
||||
### 赠品:sudo 嘲讽
|
||||
|
||||
编辑 `sudoers` 文件:
|
||||
|
||||
```
|
||||
$ sudo visudo
|
||||
```
|
||||
|
||||
编辑 sudoers 文件:
|
||||
`$ sudo visudo`
|
||||
追加下面这一行:
|
||||
`Defaults insults`
|
||||
|
||||
```
|
||||
Defaults insults
|
||||
```
|
||||
|
||||
或者像下面尾行增加一句嘲讽语:
|
||||
`Defaults !lecture,tty_tickets,!fqdn,insults`
|
||||
|
||||
```
|
||||
Defaults !lecture,tty_tickets,!fqdn,insults
|
||||
```
|
||||
|
||||
这是我的文件:
|
||||
|
||||
```
|
||||
Defaults env_reset
|
||||
Defaults mail_badpass
|
||||
@ -140,19 +171,26 @@ root ALL = (ALL:ALL) ALL
|
||||
#includedir /etc/sudoers.d
|
||||
```
|
||||
|
||||
Try it out:
|
||||
试一试:
|
||||
|
||||
```
|
||||
$ sudo -k # clear old stuff so that we get a fresh prompt
|
||||
$ sudo -k # 清除缓存,从头开始
|
||||
$ sudo ls /root/
|
||||
$ sudo -i
|
||||
```
|
||||
样例对话:
|
||||
|
||||
样例对话:
|
||||
|
||||
[![当输入错误密码时,你会被一个有趣的的 sudo 嘲讽语戏弄。][4]][4]
|
||||
|
||||
## 你好 sl
|
||||
### 赠品:你好 sl
|
||||
|
||||
[sl 或是 UNIX 经典捣蛋软件][5] 游戏。当你错误的把 `ls` 输入成 `sl`,将会有一辆蒸汽机车穿过你的屏幕。
|
||||
|
||||
```
|
||||
$ sl
|
||||
```
|
||||
|
||||
[sl 或是 UNIX 经典捣蛋软件][5] 游戏。当你错误的把 “ls” 输入成 “sl”,将会有一辆蒸汽机车穿过你的屏幕。
|
||||
`$ sl`
|
||||
[![Linux / UNIX 桌面乐趣: 蒸汽机车][6]][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -161,7 +199,7 @@ via: https://www.cyberciti.biz/howto/insult-linux-unix-bash-user-when-typing-wro
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +1,47 @@
|
||||
什么是容器?为什么我们关注它?
|
||||
======
|
||||
|
||||

|
||||
|
||||
什么是容器?你需要它们吗?为什么?在这篇文章中,我们会回答这些基本问题。
|
||||
|
||||
但是,为了回答这些问题,我们要提出更多的问题。当你开始考虑怎么用容器适配你的工作时,你需要弄清楚:你在哪开发应用?你在哪测试它?你在哪使用它?
|
||||
|
||||
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件,扩展包,开发工具,和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产。问题是这三种环境不一定都是一样的;他们没有同样的工具,框架,和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
|
||||
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件、扩展包、开发工具和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产环境。问题是这三种环境不一定都是一样的;它们没有同样的工具、框架和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
|
||||
|
||||
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的,独立的,可执行的包,包括了执行它所需要的所有东西:代码,运行环境,系统工具,系统库,设置。”
|
||||
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的、独立的、可执行的包,包括了执行它所需要的所有东西:代码、运行环境、系统工具、系统库、设置。”
|
||||
|
||||
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发者,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
|
||||
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发人员,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
|
||||
|
||||
### 容器对开发者的好处
|
||||
### 容器对开发人员的好处
|
||||
|
||||
现在开发者或执行者不再需要关注他们要使用什么平台来运行应用。开发者不会再说:“这在我的系统上运行得好好的。”
|
||||
现在开发人员或运维人员不再需要关注他们要使用什么平台来运行应用。开发人员不会再说:“这在我的系统上运行得好好的。”
|
||||
|
||||
容器的另一个重大优势时它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
|
||||
容器的另一个重大优势是它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
|
||||
|
||||
这不是虚拟机( VM )所提供的吗?是的,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
|
||||
这不是虚拟机( VM )所提供的吗?既是,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
|
||||
|
||||
### 容器对应用生态的好处
|
||||
|
||||
现在,一个庞大的,由供应商和解决方案组成的生态系统已经允许公司大规模地运用容器,不管是用于编排,监控,记录,或者生命周期管理。
|
||||
现在,一个庞大的,由供应商和解决方案组成的生态系统已经可以让公司大规模地运用容器,不管是用于编排、监控、记录或者生命周期管理。
|
||||
|
||||
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器空间中不会有任何碎片。
|
||||
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器领域中不会有任何不一致。
|
||||
|
||||
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux,Windows,Azure,AWS,Google 计算引擎,Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
|
||||
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux、Windows、Azure、AWS、Google 计算引擎、Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
|
||||
|
||||
### 容器对 CIO 的好处
|
||||
|
||||
容器在开发者中因为以上的原因而变得十分流行,同时他们也给CIO提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
|
||||
容器在开发人员中因为以上的原因而变得十分流行,同时他们也给 CIO 提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
|
||||
|
||||
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是独立于平台的,有时需要经过几年的努力才能看到生产效果。由于这个生命周期,开发者会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
|
||||
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是依赖于平台的,有时几年也不能到达产品阶段。由于这个生命周期,开发人员会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
|
||||
|
||||
这个过程影响了公司内部的创新文化。当人们几个月甚至几年都不能看到他们的创意被实现时,他们就不再有动力了。
|
||||
|
||||
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发,测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
|
||||
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发、测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
|
||||
|
||||
### 结论
|
||||
|
||||
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本属于,然后我们会解释如何开始构建容器。
|
||||
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本术语,然后我们会解释如何开始构建容器。
|
||||
|
||||
通过 Linux 基金会和 edX 提供的免费的 ["Introduction to Linux" ][4] 课程学习更多 Linux 知识。
|
||||
|
||||
@ -46,9 +49,9 @@
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-Linux/2017/12/what-are-containers-and-why-should-you-care
|
||||
|
||||
作者:[wapnil Bhartiya][a]
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[lonaparte](https://github.com/lonaparte)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
277
published/201803/20171221 Mail transfer agent (MTA) basics.md
Normal file
277
published/201803/20171221 Mail transfer agent (MTA) basics.md
Normal file
@ -0,0 +1,277 @@
|
||||
邮件传输代理(MTA)基础
|
||||
======
|
||||
|
||||
### 概述
|
||||
|
||||
本教程中,你将学习:
|
||||
|
||||
* 使用 `mail` 命令。
|
||||
* 创建邮件别名。
|
||||
* 配置电子邮件转发。
|
||||
* 了解常见邮件传输代理(MTA),比如,postfix、sendmail、qmail、以及 exim。
|
||||
|
||||
### 控制邮件去向
|
||||
|
||||
Linux 系统上的电子邮件是使用 MTA 投递的。你的 MTA 投递邮件到你的系统上的其他用户,并且 MTA 彼此通讯跨越系统投递到全世界。
|
||||
|
||||
Sendmail 是最古老的 Linux MTA。它最初起源于 1979 年用于阿帕网(ARPANET)的 delivermail 程序。如今它有几个替代品,在本教程中,我也会介绍它们。
|
||||
|
||||
#### 前提条件
|
||||
|
||||
为完成本系列教程的大部分内容,你需要具备 Linux 的基础知识,你需要拥有一个 Linux 系统来实践本教程中的命令。你应该熟悉 GNU 以及 UNIX 命令。有时候不同版本的程序的输出格式可能不同,因此,在你的系统中输出的结果可能与我在下面列出的稍有不同。
|
||||
|
||||
在本教程中,我使用的是 Ubuntu 14.04 LTS 和 sendmail 8.14.4 来做的演示。
|
||||
|
||||
### 邮件传输
|
||||
|
||||
邮件传输代理(比如 sendmail)在用户之间和系统之间投递邮件。大量的因特网邮件使用简单邮件传输协议(SMTP),但是本地邮件可能是通过文件或者套接字等其它可能的方式来传输的。邮件是一种存储和转发的操作,因此,在用户接收邮件或者接收系统和通讯联系可用之前,邮件一直是存储在某种文件或者数据库中。配置和确保 MTA 的安全是非常复杂的任务,它们中的大部分内容都已经超出了本教程的范围。
|
||||
|
||||
### mail 命令
|
||||
|
||||
如果你使用 SMTP 协议传输电子邮件,你或许知道你可以使用许多邮件客户端,包括 `mail`、`mutt`、`alpine`、`notmuch`、以及其它基于主机控制台或者图形界面的邮件客户端。`mail` 命令是最老的、可用于脚本中的、发送和接收以及管理收到的邮件的备用命令。
|
||||
|
||||
你可以使用 `mail` 命令交互式的向列表中的收件人发送信息,或者不使用参数去查看你收到的邮件。清单 1 展示了如何在你的系统上去发送信息到用户 steve 和 pat,同时抄送拷贝给用户 bob。当提示 `Cc:` 和 `subject:` 时,输入相应的抄送用户以及邮件主题,接着输入邮件正文,输入完成后按下 `Ctrl+D` (按下 `Ctrl` 键并保持再按下 `D` 之后全部松开)。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ mail steve,pat
|
||||
Cc: bob
|
||||
Subject: Test message 1
|
||||
This is a test message
|
||||
|
||||
Ian
|
||||
```
|
||||
|
||||
*清单 1. 使用 `mail` 交互式发送邮件*
|
||||
|
||||
如果一切顺利,你的邮件已经发出。如果在这里发生错误,你将看到错误信息。例如,如果你在接收者列表中输入一个无效的用户名,邮件将无法发送。注意在本示例中,所有的用户都在本地系统上存在,因此他们都是有效用户。
|
||||
|
||||
你也可以使用命令行以非交互式发送邮件。清单 2 展示了如何给用户 steve 和 pat 发送一封邮件。这种方式可以用在脚本中。在不同的软件包中 `mail` 命令的版本不同。对于抄送(`Cc:`)有些支持一个 `-c` 选项,但是我使用的这个版本不支持这个选项,因此,我仅将邮件发送到收件人。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t steve,pat -s "Test message 2" <<< "Another test.\n\nIan"
|
||||
```
|
||||
|
||||
*清单 2. 使用 `mail` 命令非交互式发送邮件*
|
||||
|
||||
如果你使用没有选项的 `mail` 命令,你将看到一个如清单 3 中所展示的那样一个收到信息的列表。你将看到用户 steve 有我上面发送的两个信息,再加上我以前发送的一个信息和后来用户 bob 发送的信息。所有的邮件都用 'N' 标记为新邮件。
|
||||
|
||||
```
|
||||
steve@attic4-u14:~$ mail
|
||||
"/var/mail/steve": 4 messages 4 new
|
||||
>N 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
N 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
N 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
*清单 3. 使用 `mail` 查看收到的邮件*
|
||||
|
||||
当前选中的信息使用一个 `>` 来标识,它是清单 3 中的第一封邮件。如果你按下回车键(`Enter`),将显示下一封未读邮件的第一页。按下空格楗将显示这个邮件的下一页。当你读完这个邮件并想返回到 `?` 提示符时,按下回车键再次查看下一封邮件,依次类推。在 `?` 提示符下,你可以输入 `h` 再次去查看邮件头。你看过的邮件前面将显示一个 `R` 状态,如清单 4 所示。
|
||||
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
*清单 4. 使用 `h` 去显示邮件头*
|
||||
|
||||
在这个图中,Steve 已经读了三个邮件,但是没有读来自 bob 的邮件。你可以通过数字来选择单个的信息,你也可以通过输入 `d` 删除你不想要的信息,或者输入 `3d` 去删除第三个信息。如果你输入 `q` 你将退出 `mail` 命令。已读的信息将被转移到你的家目录下的 `mbox` 文件中,而未读的信息仍然保留在你的收件箱中,默认在 `/var/mail/$(id -un)`。如清单 5 所示。
|
||||
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
? q
|
||||
Saved 3 messages in /home/steve/mbox
|
||||
Held 1 message in /var/mail/steve
|
||||
You have mail in /var/mail/steve
|
||||
```
|
||||
|
||||
*清单 5. 使用 `q` 退出 `mail`*
|
||||
|
||||
如果你输入 `x` 而不是使用 `q` 去退出,你的邮箱在退出后将不保留你做的改变。因为这在 `/var` 文件系统中,你的系统管理员可能仅允许邮件在一个有限的时间范围内保留。要重新读取或者以其它方式再次处理保存在你的本地邮箱中的邮件,你可以使用 `-f` 选项去指定想要去读的文件。比如,`mail -f mbox`。
|
||||
|
||||
### 邮件别名
|
||||
|
||||
在前面的节中,看了如何在系统上给许多用户发送邮件。你可以使用一个全限定名字(比如 ian@myexampledomain.com)给其它系统上的用户发送邮件。
|
||||
|
||||
有时候你可能希望用户的所有邮件都可以发送到其它地方。比如,你有一个服务器群,你希望所有的 root 用户的邮件都发给中心的系统管理员。或者你可能希望去创建一个邮件列表,将邮件发送给一些人。为实现上述目标,你可以使用别名,别名允许你为一个给定的用户名定义一个或者多个目的地。这个目的地或者是其它用户的邮箱、文件、管道、或者是某个进一步处理的命令。你可以在 `/etc/mail/aliases` 或者 `/etc/aliases` 中创建别名来实现上述目的。根据你的系统的不同,你可以找到上述其中一个,符号链接到它们、或者其中之一。改变别名文件你需要有 root 权限。
|
||||
|
||||
别名的格式一般是:
|
||||
|
||||
```
|
||||
name: addr_1, addr_2, addr_3, ...
|
||||
```
|
||||
|
||||
这里 `name` 是一个要别名的本地用户名字(即别名),而 `addr_1`,`addr_2`,... 可以是一个或多个别名。别名可以是一个本地用户、一个本地文件名、另一个别名、一个命令、一个包含文件,或者一个外部地址。
|
||||
|
||||
因此,发送邮件时如何区分别名呢(addr-N)?
|
||||
|
||||
* 本地用户名是你机器上系统中的一个用户名字。从技术角度来说,它可以通过调用 `getpwnam` 命令找到它。
|
||||
* 本地文件名是以 `/` 开始的完全路径和文件名。它必须是 `sendmail` 可写的。信息会追加到这个文件上。
|
||||
* 命令是以一个管道符号开始的(`|`)。信息是通过标准输入的方式发送到命令的。
|
||||
* 包含文件别名是以 `:include:` 和指定的路径和文件名开始的。在该文件中的别名被添加到该名字所代表的别名中。
|
||||
* 外部地址是一个电子邮件地址,比如 john@somewhere.com。
|
||||
|
||||
你可以在你的系统中找到一个示例文件,它是与你的 sendmail 包一起安装的,它的位置在 `/usr/share/sendmail/examples/db/aliases`。它包含一些给 `postmaster`、`MAILER-DAEMON`、`abuse` 和 `spam 的别名建议。在清单 6,我把我的 Ubuntu 14.04 LTS 系统上的一些示例文件,和人工修改的示例结合起来说明一些可能的情况。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/mail/aliases
|
||||
# First include some default system aliases from
|
||||
# /usr/share/sendmail/examples/db/aliases
|
||||
|
||||
#
|
||||
# Mail aliases for sendmail
|
||||
#
|
||||
# You must run newaliases(1) after making changes to this file.
|
||||
#
|
||||
|
||||
# Required aliases
|
||||
postmaster: root
|
||||
MAILER-DAEMON: postmaster
|
||||
|
||||
# Common aliases
|
||||
abuse: postmaster
|
||||
spam: postmaster
|
||||
|
||||
# Other aliases
|
||||
|
||||
# Send steve's mail to bob and pat instead
|
||||
steve: bob,pat
|
||||
|
||||
# Send pat's mail to a file in her home directory and also to her inbox.
|
||||
# Finally send it to a command that will make another copy.
|
||||
pat: /home/pat/accumulated-mail,
|
||||
\pat,
|
||||
|/home/pat/makemailcopy.sh
|
||||
|
||||
# Mailing list for system administrators
|
||||
sysadmins: :include: /etc/aliases-sysadmins
|
||||
```
|
||||
|
||||
*清单 6. 人工修改的 /etc/mail/aliases 示例*
|
||||
|
||||
注意那个 pat 既是一个别名也是一个系统中的用户。别名是以递归的方式展开的,因此,如果一个别名也是一个名字,那么它将被展开。Sendmail 并不会给同一个用户发送相同的邮件两遍,因此,如果你正好将 pat 作为 pat 的别名,那么 sendmail 在已经找到并处理完用户 pat 之后,将忽略别名 pat。为避免这种问题,你可以在别名前使用一个 `\` 做为前缀去指示它是一个不要进一步引起混淆的名字。在这种情况下,pat 的邮件除了文件和命令之外,其余的可能会被发送到他的正常的邮箱中。
|
||||
|
||||
在 `aliases` 文件中以 `#` 开始的行是注释,它会被忽略。以空白开始的行会以延续行来处理。
|
||||
|
||||
清单 7 展示了包含文件 `/etc/aliases-sysadmins`。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/aliases-sysadmins
|
||||
|
||||
# Mailing list for system administrators
|
||||
bob,pat
|
||||
```
|
||||
|
||||
*清单 7 包含文件 /etc/aliases-sysadmins*
|
||||
|
||||
### newaliases 命令
|
||||
|
||||
sendmail 使用的主要配置文件会被编译成数据库文件。邮件别名也是如此。你可以使用 `newaliases` 命令去编译你的 `/etc/mail/aliases` 和任何包含文件到 `/etc/mail/aliases.db` 中。注意,`newaliases` 命令等价于 `sendmail -bi`。清单 8 展示了一个示例。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ sudo newaliases
|
||||
/etc/mail/aliases: 7 aliases, longest 62 bytes, 184 bytes total
|
||||
ian@attic4-u14:~$ ls -l /etc/mail/aliases*
|
||||
lrwxrwxrwx 1 root smmsp 10 Dec 8 15:48 /etc/mail/aliases -> ../aliases
|
||||
-rw-r----- 1 smmta smmsp 12288 Dec 13 23:18 /etc/mail/aliases.db
|
||||
```
|
||||
|
||||
*清单 8. 为邮件别名重建数据库*
|
||||
|
||||
### 使用别名的示例
|
||||
|
||||
清单 9 展示了一个简单的 shell 脚本,它在我的别名示例中以一个命令的方式来使用。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat ~pat/makemailcopy.sh
|
||||
#!/bin/bash
|
||||
|
||||
# Note: Target file ~/mail-copy must be writeable by sendmail!
|
||||
cat >> ~pat/mail-copy
|
||||
```
|
||||
|
||||
*清单 9. makemailcopy.sh 脚本*
|
||||
|
||||
清单 10 展示了用于测试时更新的文件。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ date
|
||||
Wed Dec 13 22:54:22 EST 2017
|
||||
ian@attic4-u14:~$ mail -t sysadmins -s "sysadmin test 1" <<< "Testing mail"
|
||||
ian@attic4-u14:~$ ls -lrt $(find /var/mail ~pat -type f -mmin -3 2>/dev/null )
|
||||
-rw-rw---- 1 pat mail 2046 Dec 13 22:54 /home/pat/mail-copy
|
||||
-rw------- 1 pat mail 13240 Dec 13 22:54 /var/mail/pat
|
||||
-rw-rw---- 1 pat mail 9442 Dec 13 22:54 /home/pat/accumulated-mail
|
||||
-rw-rw---- 1 bob mail 12522 Dec 13 22:54 /var/mail/bob
|
||||
```
|
||||
|
||||
*清单 10. /etc/aliases-sysadmins 包含文件*
|
||||
|
||||
需要注意的几点:
|
||||
|
||||
* sendmail 使用的用户和组的名字是 mail。
|
||||
* sendmail 在 `/var/mail` 保存用户邮件,它也是用户 mail 的家目录。用户 ian 的默认收件箱在 `/var/mail/ian` 中。
|
||||
* 如果你希望 sendmail 在用户目录下写入文件,这个文件必须允许 sendmail 可写入。与其让任何人都可以写入,还不如定义一个组可写入,组名称为 mail。这需要系统管理员来帮你完成。
|
||||
|
||||
### 使用一个 `.forward` 文件去转发邮件
|
||||
|
||||
别名文件是由系统管理员来管理的。个人用户可以使用它们自己的家目录下的 `.forward` 文件去转发他们自己的邮件。你可以在你的 `.forward` 文件中放任何可以出现在别名文件的右侧的东西。这个文件的内容是明文的,不需要编译。当你收到邮件时,sendmail 将检查你的家目录中的 `.forward` 文件,然后就像处理别名一样处理它。
|
||||
|
||||
### 邮件队列和 mailq 命令
|
||||
|
||||
Linux 邮件使用存储-转发的处理模式。你已经看到的已接收邮件,在你读它之前一直保存在文件 `/var/mail` 中。你发出的邮件在接收服务器连接可用之前也会被保存。你可以使用 `mailq` 命令去查看邮件队列。清单 11 展示了一个发送给外部用户 ian@attic4-c6 的一个邮件示例,以及运行 `mailq` 命令的结果。在这个案例中,当前服务器没有连接到 attic4-c6,因此邮件在与对方服务器连接可用之前一直保存在队列中。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t ian@attic4-c6 -s "External mail" <<< "Testing external mail queues"
|
||||
ian@attic4-u14:~$ mailq
|
||||
MSP Queue status...
|
||||
/var/spool/mqueue-client is empty
|
||||
Total requests: 0
|
||||
MTA Queue status...
|
||||
/var/spool/mqueue (1 request)
|
||||
-----Q-ID----- --Size-- -----Q-Time----- ------------Sender/Recipient-----------
|
||||
vBE4mdE7025908* 29 Wed Dec 13 23:48 <ian@attic4-u14.hopto.org>
|
||||
<ian@attic4-c6.hopto.org>
|
||||
Total requests: 1
|
||||
```
|
||||
|
||||
*清单 11. 使用 `mailq` 命令*
|
||||
|
||||
### 其它邮件传输代理
|
||||
|
||||
为解决使用 sendmail 时安全方面的问题,在上世纪九十年代开发了几个其它的邮件传输代理。Postfix 或许是最流行的一个,但是 qmail 和 exim 也大量使用。
|
||||
|
||||
Postfix 是 IBM 为代替 sendmail 而研发的。它更快、也易于管理、安全性更好一些。从外表看它非常像 sendmail,但是它的内部完全与 sendmail 不同。
|
||||
|
||||
Qmail 是一个安全、可靠、高效、简单的邮件传输代理,它由 Dan Bernstein 开发。但是,最近几年以来,它的核心包已经不再更新了。Qmail 和几个其它的包已经被吸收到 IndiMail 中了。
|
||||
|
||||
Exim 是另外一个 MTA,它由 University of Cambridge 开发。最初,它的名字是 `EXperimental Internet Mailer`。
|
||||
|
||||
所有的这些 MTA 都是为代替 sendmail 而设计的,因此,它们它们都兼容 sendmail 的一些格式。它们都能够处理别名和 `.forward` 文件。有些封装了一个 `sendmail` 命令作为一个到特定的 MTA 自有命令的前端。尽管一些选项可能会被静默忽略,但是大多数都允许使用常见的 sendmail 选项。`mailq` 命令是被直接支持的,或者使用一个类似功能的命令来代替。比如,你可以使用 `mailq` 或者 `exim -bp` 去显示 exim 邮件队列。当然,输出可以看到与 sendmail 的 `mailq` 命令的不同之外。
|
||||
|
||||
查看相关的主题,你可以找到更多的关于这些 MTA 的更多信息。
|
||||
|
||||
对 Linux 上的邮件传输代理的介绍到此结束。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-3/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
@ -0,0 +1,177 @@
|
||||
如何在 Linux 中查找最大的 10 个文件
|
||||
======
|
||||
|
||||
当系统的磁盘空间不足时,您可能会使用 `df`、`du` 或 `ncdu` 命令进行检查,但这些命令只会显示当前目录的文件,并不会显示整个系统范围的文件。
|
||||
|
||||
您得花费大量的时间才能用上述命令获取系统中最大的文件,因为要进入到每个目录重复运行上述命令。
|
||||
|
||||
这种方法比较麻烦,也并不恰当。
|
||||
|
||||
如果是这样,那么该如何在 Linux 中找到最大的 10 个文件呢?
|
||||
|
||||
我在谷歌上搜索了很久,却没发现类似的文章,我反而看到了很多关于列出当前目录中最大的 10 个文件的文章。所以,我希望这篇文章对那些有类似需求的人有所帮助。
|
||||
|
||||
本教程中,我们将教您如何使用以下四种方法在 Linux 系统中查找最大的前 10 个文件。
|
||||
|
||||
### 方法 1
|
||||
|
||||
在 Linux 中没有特定的命令可以直接执行此操作,因此我们需要将多个命令结合使用。
|
||||
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
```
|
||||
|
||||
详解:
|
||||
|
||||
- `find`:在目录结构中搜索文件的命令
|
||||
- `/`:在整个系统(从根目录开始)中查找
|
||||
- `-type`:指定文件类型
|
||||
- `f`:普通文件
|
||||
- `-print0`:在标准输出显示完整的文件名,其后跟一个空字符(null)
|
||||
- `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
- `xargs`:将标准输入转换成命令行参数的命令
|
||||
- `-0`:以空字符(null)而不是空白字符(LCTT 译者注:即空格、制表符和换行)来分割记录
|
||||
- `du -h`:以可读格式计算磁盘空间使用情况的命令
|
||||
- `sort`:对文本文件进行排序的命令
|
||||
- `-r`:反转结果
|
||||
- `-h`:用可读格式打印输出
|
||||
- `head`:输出文件开头部分的命令
|
||||
- `n -10`:打印前 10 个文件
|
||||
|
||||
### 方法 2
|
||||
|
||||
这是查找 Linux 系统中最大的前 10 个文件的另一种方法。我们依然使用多个命令共同完成这个任务。
|
||||
|
||||
```
|
||||
# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
```
|
||||
|
||||
详解:
|
||||
|
||||
- `find`:在目录结构中搜索文件的命令
|
||||
- `/`:在整个系统(从根目录开始)中查找
|
||||
- `-type`:指定文件类型
|
||||
- `f`:普通文件
|
||||
- `-exec`:在所选文件上运行指定命令
|
||||
- `du`:计算文件占用的磁盘空间的命令
|
||||
- `-S`:不包含子目录的大小
|
||||
- `-h`:以可读格式打印
|
||||
- `{}`:递归地查找目录,统计每个文件占用的磁盘空间
|
||||
- `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
- `sort`:对文本文件进行按行排序的命令
|
||||
- `-r`:反转结果
|
||||
- `-h`:用可读格式打印输出
|
||||
- `head`:输出文件开头部分的命令
|
||||
- `n -10`:打印前 10 个文件
|
||||
|
||||
### 方法 3
|
||||
|
||||
这里介绍另一种在 Linux 系统中搜索最大的前 10 个文件的方法。
|
||||
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
|
||||
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
1.4G /swapfile
|
||||
```
|
||||
|
||||
详解:
|
||||
|
||||
- `find`:在目录结构中搜索文件的命令
|
||||
- `/`:在整个系统(从根目录开始)中查找
|
||||
- `-type`:指定文件类型
|
||||
- `f`:普通文件
|
||||
- `-print0`:输出完整的文件名,其后跟一个空字符(null)
|
||||
- `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
- `xargs`:将标准输入转换成命令行参数的命令
|
||||
- `-0`:以空字符(null)而不是空白字符来分割记录
|
||||
- `du`:计算文件占用的磁盘空间的命令
|
||||
- `sort`:对文本文件进行按行排序的命令
|
||||
- `-n`:根据数字大小进行比较
|
||||
- `tail -10`:输出文件结尾部分的命令(最后 10 个文件)
|
||||
- `cut`:从每行删除特定部分的命令
|
||||
- `-f2`:只选择特定字段值
|
||||
- `-I{}`:将初始参数中出现的每个替换字符串都替换为从标准输入读取的名称
|
||||
- `-s`:仅显示每个参数的总和
|
||||
- `-h`:用可读格式打印输出
|
||||
- `{}`:递归地查找目录,统计每个文件占用的磁盘空间
|
||||
|
||||
### 方法 4
|
||||
|
||||
还有一种在 Linux 系统中查找最大的前 10 个文件的方法。
|
||||
|
||||
```
|
||||
# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
|
||||
|
||||
1494845440 /swapfile
|
||||
1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
97356256 /usr/lib/firefox/libxul.so
|
||||
87896064 /var/lib/snapd/snaps/core_3604.snap
|
||||
87793664 /var/lib/snapd/snaps/core_3440.snap
|
||||
87089152 /var/lib/snapd/snaps/core_3247.snap
|
||||
```
|
||||
|
||||
详解:
|
||||
|
||||
- `find`:在目录结构中搜索文件的命令
|
||||
- `/`:在整个系统(从根目录开始)中查找
|
||||
- `-type`:指定文件类型
|
||||
- `f`:普通文件
|
||||
- `-ls`:在标准输出中以 `ls -dils` 的格式列出当前文件
|
||||
- `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
- `sort`:对文本文件进行按行排序的命令
|
||||
- `-k`:按指定列进行排序
|
||||
- `-r`:反转结果
|
||||
- `-n`:根据数字大小进行比较
|
||||
- `head`:输出文件开头部分的命令
|
||||
- `-10`:打印前 10 个文件
|
||||
- `column`:将其输入格式化为多列的命令
|
||||
- `-t`:确定输入包含的列数并创建一个表
|
||||
- `awk`:模式扫描和处理语言
|
||||
- `'{print $7,$11}'`:只打印指定的列
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
@ -0,0 +1,98 @@
|
||||
Tlog:录制/播放终端 IO 和会话的工具
|
||||
======
|
||||
|
||||
Tlog 是 Linux 中终端 I/O 录制和回放软件包。它用于实现一个集中式用户会话录制。它将所有经过的消息录制为 JSON 消息。录制为 JSON 格式的主要目的是将数据传送到 ElasticSearch 之类的存储服务,可以从中搜索和查询,以及回放。同时,它们保留所有通过的数据和时序。
|
||||
|
||||
Tlog 包含三个工具,分别是 `tlog-rec`、tlog-rec-session` 和 `tlog-play`。
|
||||
|
||||
* `tlog-rec` 工具一般用于录制终端、程序或 shell 的输入或输出。
|
||||
* `tlog-rec-session` 工具用于录制整个终端会话的 I/O,包括录制的用户。
|
||||
* `tlog-play` 工具用于回放录制。
|
||||
|
||||
在本文中,我将解释如何在 CentOS 7.4 服务器上安装 Tlog。
|
||||
|
||||
### 安装
|
||||
|
||||
在安装之前,我们需要确保我们的系统满足编译和安装程序的所有软件要求。在第一步中,使用以下命令更新系统仓库和软件包。
|
||||
|
||||
```
|
||||
# yum update
|
||||
```
|
||||
|
||||
我们需要安装此软件安装所需的依赖项。在安装之前,我已经使用这些命令安装了所有依赖包。
|
||||
|
||||
```
|
||||
# yum install wget gcc
|
||||
# yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
```
|
||||
|
||||
完成这些安装后,我们可以下载该工具的[源码包][1]并根据需要将其解压到服务器上:
|
||||
|
||||
```
|
||||
# wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
# tar -xvf tlog-3.tar.gz
|
||||
# cd tlog-3
|
||||
```
|
||||
|
||||
现在,你可以使用我们通常的配置和编译方法开始构建此工具。
|
||||
|
||||
```
|
||||
# ./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
# make install
|
||||
# ldconfig
|
||||
```
|
||||
|
||||
最后,你需要运行 `ldconfig`。它对命令行中指定目录、`/etc/ld.so.conf` 文件,以及信任的目录( `/lib` 和 `/usr/lib`)中最近的共享库创建必要的链接和缓存。
|
||||
|
||||
### Tlog 工作流程图
|
||||
|
||||
![Tlog working process][2]
|
||||
|
||||
首先,用户通过 PAM 进行身份验证登录。名称服务交换器(NSS)提供的 `tlog` 信息是用户的 shell。这初始化了 tlog 部分,并从环境变量/配置文件收集关于实际 shell 的信息,并在 PTY 中启动实际的 shell。然后通过 syslog 或 sd-journal 开始录制在终端和 PTY 之间传递的所有内容。
|
||||
|
||||
### 用法
|
||||
|
||||
你可以使用 `tlog-rec` 录制一个会话并使用 `tlog-play` 回放它,以测试新安装的 tlog 是否能够正常录制和回放会话。
|
||||
|
||||
#### 录制到文件中
|
||||
|
||||
要将会话录制到文件中,请在命令行中执行 `tlog-rec`,如下所示:
|
||||
|
||||
```
|
||||
tlog-rec --writer=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令会将我们的终端会话录制到名为 `tlog.log` 的文件中,并将其保存在命令中指定的路径中。
|
||||
|
||||
#### 从文件中回放
|
||||
|
||||
你可以在录制过程中或录制后使用 `tlog-play` 命令回放录制的会话。
|
||||
|
||||
```
|
||||
tlog-play --reader=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令从指定的路径读取先前录制的文件 `tlog.log`。
|
||||
|
||||
### 总结
|
||||
|
||||
Tlog 是一个开源软件包,可用于实现集中式用户会话录制。它主要是作为一个更大的用户会话录制解决方案的一部分使用,但它被设计为独立且可重用的。该工具可以帮助录制用户所做的一切,并将其存储在服务器的某个位置,以备将来参考。你可以从这个[文档][3]中获得关于这个软件包使用的更多细节。我希望这篇文章对你有用。请发表你的宝贵建议和意见。
|
||||
|
||||
**关于 Saheetha Shameer (作者)**
|
||||
|
||||
我正在担任高级系统管理员。我是一名快速学习者,有轻微的倾向跟随行业中目前和正在出现的趋势。我的爱好包括听音乐、玩策略游戏、阅读和园艺。我对尝试各种美食也有很高的热情 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
[2]:https://linoxide.com/wp-content/uploads/2018/01/Tlog-working-process.png
|
||||
[3]:https://github.com/Scribery/tlog/blob/master/README.md
|
||||
@ -0,0 +1,180 @@
|
||||
Ansible:像系统管理员一样思考的自动化框架
|
||||
======
|
||||
|
||||
这些年来,我已经写了许多关于 DevOps 工具的文章,也培训了这方面的人员。尽管这些工具很棒,但很明显,大多数都是按照开发人员的思路设计出来的。这也没有什么问题,因为以编程的方式接近配置管理是重点。不过,直到我开始接触 Ansible,我才觉得这才是系统管理员喜欢的东西。
|
||||
|
||||
喜欢的一部分原因是 Ansible 与客户端计算机通信的方式,是通过 SSH 的。作为系统管理员,你们都非常熟悉通过 SSH 连接到计算机,所以从单词“去”的角度来看,相对于其它选择,你更容易理解 Ansible。
|
||||
|
||||
考虑到这一点,我打算写一些文章,探讨如何使用 Ansible。这是一个很好的系统,但是当我第一次接触到这个系统的时候,不知道如何开始。这并不是学习曲线陡峭。事实上,问题是在开始使用 Ansible 之前,我并没有太多的东西要学,这才是让人感到困惑的。例如,如果您不必安装客户端程序(Ansible 没有在客户端计算机上安装任何软件),那么您将如何启动?
|
||||
|
||||
### 踏出第一步
|
||||
|
||||
起初 Ansible 对我来说非常困难的原因在于配置服务器/客户端的关系是非常灵活的,我不知道我该从何入手。事实是,Ansible 并不关心你如何设置 SSH 系统。它会利用你现有的任何配置。需要考虑以下几件事情:
|
||||
|
||||
1. Ansible 需要通过 SSH 连接到客户端计算机。
|
||||
2. 连接后,Ansible 需要提升权限才能配置系统,安装软件包等等。
|
||||
|
||||
不幸的是,这两个考虑真的带来了一堆蠕虫。连接到远程计算机并提升权限是一件可怕的事情。当您在远程计算机上安装代理并使用 Chef 或 Puppet 处理特权升级问题时,似乎感觉就没那么可怕了。 Ansible 并非不安全,而是安全的决定权在你手中。
|
||||
|
||||
接下来,我将列出一系列潜在的配置,以及每个配置的优缺点。这不是一个详尽的清单,但是你会受到正确的启发,去思考在你自己的环境中什么是理想的配置。也需要注意,我不会提到像 Vagrant 这样的系统,因为尽管 Vagrant 在构建测试和开发的敏捷架构时非常棒,但是和一堆服务器是非常不同的,因此考虑因素是极不相似的。
|
||||
|
||||
### 一些 SSH 场景
|
||||
|
||||
#### 1)在 Ansible 配置中,root 用户以密码进入远程计算机。
|
||||
|
||||
拥有这个想法是一个非常可怕的开始。这个设置的“优点”是它消除了对特权提升的需要,并且远程服务器上不需要其他用户帐户。 但是,这种便利的成本是不值得的。 首先,大多数系统不会让你在不改变默认配置的情况下以 root 身份进行 SSH 登录。默认的配置之所以如此,坦率地说,是因为允许 root 用户远程连接是一个不好的主意。 其次,将 root 密码放在 Ansible 机器上的纯文本配置文件中是不合适的。 真的,我提到了这种可能性,因为这是可以的,但这是应该避免的。 请记住,Ansible 允许你自己配置连接,它可以让你做真正愚蠢的事情。 但是请不要这么做。
|
||||
|
||||
#### 2)使用存储在 Ansible 配置中的密码,以普通用户的身份进入远程计算机。
|
||||
|
||||
这种情况的一个优点是它不需要太多的客户端配置。 大多数用户默认情况下都可以使用 SSH,因此 Ansible 应该能够使用用户凭据并且能够正常登录。 我个人不喜欢在配置文件中以纯文本形式存储密码,但至少它不是 root 密码。 如果您使用此方法,请务必考虑远程服务器上的权限提升方式。 我知道我还没有谈到权限提升,但是如果你在配置文件中配置了一个密码,这个密码可能会被用来获得 sudo 访问权限。 因此,一旦发生泄露,您不仅已经泄露了远程用户的帐户,还可能泄露整个系统。
|
||||
|
||||
#### 3)使用具有空密码的密钥对进行身份验证,以普通用户身份进入远程计算机。
|
||||
|
||||
这消除了将密码存储在配置文件中的弊端,至少在登录的过程中消除了。 没有密码的密钥对并不理想,但这是我经常做的事情。 在我的个人内部网络中,我通常使用没有密码的密钥对来自动执行许多事情,如需要身份验证的定时任务。 这不是最安全的选择,因为私钥泄露意味着可以无限制地访问远程用户的帐户,但是相对于在配置文件中存储密码我更喜欢这种方式。
|
||||
|
||||
#### 4)使用通过密码保护的密钥对进行身份验证,以普通用户的身份通过 SSH 连接到远程计算机。
|
||||
|
||||
这是处理远程访问的一种非常安全的方式,因为它需要两种不同的身份验证因素来解密:私钥和密码。 如果你只是以交互方式运行 Ansible,这可能是理想的设置。 当你运行命令时,Ansible 会提示你输入私钥的密码,然后使用密钥对登录到远程系统。 是的,只需使用标准密码登录并且不用在配置文件中指定密码即可完成,但是如果不管怎样都要在命令行上输入密码,那为什么不在保护层添加密钥对呢?
|
||||
|
||||
#### 5)使用密码保护密钥对进行 SSH 连接,但是使用 ssh-agent “解锁”私钥。
|
||||
|
||||
这并不能完美地解决无人值守、自动化的 Ansible 命令的问题,但是它确实也使安全设置变得相当方便。 ssh-agent 程序一次验证密码,然后使用该验证进行后续连接。当我使用 Ansible 时,这是我想要做的事情。如果我是完全值得信任的,我通常仍然使用没有密码的密钥对,但是这通常是因为我在我的家庭服务器上工作,是不是容易受到攻击的。
|
||||
|
||||
在配置 SSH 环境时还要记住一些其他注意事项。 也许你可以限制 Ansible 用户(通常是你的本地用户),以便它只能从一个特定的 IP 地址登录。 也许您的 Ansible 服务器可以位于不同的子网中,位于强大的防火墙之后,因此其私钥更难以远程访问。 也许 Ansible 服务器本身没有安装 SSH 服务器,所以根本没法访问。 同样,Ansible 的优势之一是它使用 SSH 协议进行通信,而且这是一个你用了多年的协议,你已经把你的系统调整到最适合你的环境了。 我不是宣传“最佳实践”的忠实粉丝,因为实际上最好的做法是考虑你的环境,并选择最适合你情况的设置。
|
||||
|
||||
### 权限提升
|
||||
|
||||
一旦您的 Ansible 服务器通过 SSH 连接到它的客户端,就需要能够提升特权。 如果你选择了上面的选项 1,那么你已经是 root 了,这是一个有争议的问题。 但是由于没有人选择选项 1(对吧?),您需要考虑客户端计算机上的普通用户如何获得访问权限。 Ansible 支持各种权限提升的系统,但在 Linux 中,最常用的选项是 `sudo` 和 `su`。 和 SSH 一样,有几种情况需要考虑,虽然肯定还有其他选择。
|
||||
|
||||
#### 1)使用 su 提升权限。
|
||||
|
||||
对于 RedHat/CentOS 用户来说,可能默认是使用 `su` 来获得系统访问权限。 默认情况下,这些系统在安装过程中配置了 root 密码,要想获得特殊访问权限,您需要输入该密码。使用 `su` 的问题在于,虽说它可以给了您完全访问远程系统,而您确实也可以完全访问远程系统。 (是的,这是讽刺。)另外,`su` 程序没有使用密钥对进行身份验证的能力,所以密码必须以交互方式输入或存储在配置文件中。 由于它实际上是 root 密码,因此将其存储在配置文件中听起来像、也确实是一个可怕的想法。
|
||||
|
||||
#### 2)使用 sudo 提升权限。
|
||||
|
||||
这就是 Debian/Ubuntu 系统的配置方式。 正常用户组中的用户可以使用 `sudo` 命令并使用 root 权限执行该命令。 随之而来的是,这仍然存在密码存储或交互式输入的问题。 由于在配置文件中存储用户的密码看起来不太可怕,我猜这是使用 `su` 的一个进步,但是如果密码被泄露,仍然可以完全访问系统。 (毕竟,输入 `sudo` 和 `su -` 都将允许用户成为 root 用户,就像拥有 root 密码一样。)
|
||||
|
||||
#### 3) 使用 sudo 提升权限,并在 sudoers 文件中配置 NOPASSWD。
|
||||
|
||||
再次,在我的本地环境中,我就是这么做的。 这并不完美,因为它给予用户帐户无限制的 root 权限,并且不需要任何密码。 但是,当我这样做并且使用没有密码短语的 SSH 密钥对时,我可以让 Ansible 命令更轻松的自动化。 再次提示,虽然这很方便,但这不是一个非常安全的想法。
|
||||
|
||||
#### 4)使用 sudo 提升权限,并在特定的可执行文件上配置 NOPASSWD。
|
||||
|
||||
这个想法可能是安全性和便利性的最佳折衷。 基本上,如果你知道你打算用 Ansible 做什么,那么你可以为远程用户使用的那些应用程序提供 NOPASSWD 权限。 这可能会让人有些困惑,因为 Ansible 使用 Python 来处理很多事情,但是经过足够的尝试和错误,你应该能够弄清原理。 这是额外的工作,但确实消除了一些明显的安全漏洞。
|
||||
|
||||
### 计划实施
|
||||
|
||||
一旦你决定如何处理 Ansible 认证和权限提升,就需要设置它。 在熟悉 Ansible 之后,您可能会使用该工具来帮助“引导”新客户端,但首先手动配置客户端非常重要,以便您知道发生了什么事情。 将你熟悉的事情变得自动化比从头开始自动化要好。
|
||||
|
||||
我已经写过关于 SSH 密钥对的文章,网上有无数的设置类的文章。 来自 Ansible 服务器的简短版本看起来像这样:
|
||||
|
||||
```
|
||||
# ssh-keygen
|
||||
# ssh-copy-id -i .ssh/id_dsa.pub remoteuser@remote.computer.ip
|
||||
# ssh remoteuser@remote.computer.ip
|
||||
```
|
||||
|
||||
如果您在创建密钥对时选择不使用密码,最后一步您应该可以直接进入远程计算机,而不用输入密码或密钥串。
|
||||
|
||||
为了在 `sudo` 中设置权限提升,您需要编辑 `sudoers` 文件。 你不应该直接编辑文件,而是使用:
|
||||
|
||||
```
|
||||
# sudo visudo
|
||||
```
|
||||
|
||||
这将打开 `sudoers` 文件并允许您安全地进行更改(保存时会进行错误检查,所以您不会意外地因为输入错误将自己锁住)。 这个文件中有一些例子,所以你应该能够弄清楚如何分配你想要的确切的权限。
|
||||
|
||||
一旦配置完成,您应该在使用 Ansible 之前进行手动测试。 尝试 SSH 到远程客户端,然后尝试使用您选择的任何方法提升权限。 一旦你确认配置的方式可以连接,就可以安装 Ansible 了。
|
||||
|
||||
### 安装 Ansible
|
||||
|
||||
由于 Ansible 程序仅安装在一台计算机上,因此开始并不是一件繁重的工作。 Red Hat/Ubuntu 系统的软件包安装有点不同,但都不是很困难。
|
||||
|
||||
在 Red Hat/CentOS 中,首先启用 EPEL 库:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
|
||||
然后安装 Ansible:
|
||||
|
||||
```
|
||||
sudo yum install ansible
|
||||
```
|
||||
|
||||
在 Ubuntu 中,首先启用 Ansible PPA:
|
||||
|
||||
```
|
||||
sudo apt-add-repository spa:ansible/ansible
|
||||
(press ENTER to access the key and add the repo)
|
||||
```
|
||||
|
||||
然后安装 Ansible:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get install ansible
|
||||
```
|
||||
|
||||
### Ansible 主机文件配置
|
||||
|
||||
Ansible 系统无法知道您希望它控制哪个客户端,除非您给它一个计算机列表。 该列表非常简单,看起来像这样:
|
||||
|
||||
```
|
||||
# file /etc/ansible/hosts
|
||||
|
||||
[webservers]
|
||||
blogserver ansible_host=192.168.1.5
|
||||
wikiserver ansible_host=192.168.1.10
|
||||
|
||||
[dbservers]
|
||||
mysql_1 ansible_host=192.168.1.22
|
||||
pgsql_1 ansible_host=192.168.1.23
|
||||
```
|
||||
|
||||
方括号内的部分是指定的组。 单个主机可以列在多个组中,而 Ansible 可以指向单个主机或组。 这也是配置文件,比如纯文本密码的东西将被存储,如果这是你计划的那种设置。 配置文件中的每一行配置一个主机地址,并且可以在 `ansible_host` 语句之后添加多个声明。 一些有用的选项是:
|
||||
|
||||
```
|
||||
ansible_ssh_pass
|
||||
ansible_become
|
||||
ansible_become_method
|
||||
ansible_become_user
|
||||
ansible_become_pass
|
||||
```
|
||||
|
||||
### Ansible <ruby>保险库<rt>Vault</rt></ruby>
|
||||
|
||||
(LCTT 译注:Vault 作为 ansible 的一项新功能可将例如密码、密钥等敏感数据文件进行加密,而非明文存放)
|
||||
|
||||
我也应该注意到,尽管安装程序比较复杂,而且这不是在您首次进入 Ansible 世界时可能会做的事情,但该程序确实提供了一种加密保险库中的密码的方法。 一旦您熟悉 Ansible,并且希望将其投入生产,将这些密码存储在加密的 Ansible 保险库中是非常理想的。 但是本着先学会爬再学会走的精神,我建议首先在非生产环境下使用无密码方法。
|
||||
|
||||
### 系统测试
|
||||
|
||||
最后,你应该测试你的系统,以确保客户端可以正常连接。 `ping` 测试将确保 Ansible 计算机可以 `ping` 每个主机:
|
||||
|
||||
```
|
||||
ansible -m ping all
|
||||
```
|
||||
|
||||
运行后,如果 `ping` 成功,您应该看到每个定义的主机显示 `ping` 的消息:`pong`。 这实际上并没有测试认证,只是测试网络连接。 试试这个来测试你的认证:
|
||||
|
||||
```
|
||||
ansible -m shell -a 'uptime' webservers
|
||||
```
|
||||
|
||||
您应该可以看到 webservers 组中每个主机的运行时间命令的结果。
|
||||
|
||||
在后续文章中,我计划开始深入 Ansible 管理远程计算机的功能。 我将介绍各种模块,以及如何使用 ad-hoc 模式来完成一些按键操作,这些操作在命令行上单独处理都需要很长时间。 如果您没有从上面的示例 Ansible 命令中获得预期的结果,请花些时间确保身份验证可以工作。 如果遇到困难,请查阅 [Ansible 文档][1]获取更多帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
|
||||
|
||||
作者:[Shawn Powers][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/shawn-powers
|
||||
[1]:http://docs.ansible.com
|
||||
@ -0,0 +1,232 @@
|
||||
如何在 Linux 上安装应用程序
|
||||
=====
|
||||
|
||||
> 学习在你的 Linux 计算机上摆弄那些软件。
|
||||
|
||||

|
||||
|
||||
图片提供:Internet Archive Book Images。由 Opensource.com 修改。CC BY-SA 4.0
|
||||
|
||||
如何在 Linux 上安装应用程序?因为有许多操作系统,这个问题不止有一个答案。应用程序可以可以来自许多来源 —— 几乎不可能数的清,并且每个开发团队都可以以他们认为最好的方式提供软件。知道如何安装你所得到的软件是成为操作系统高级用户的一部分。
|
||||
|
||||
### 仓库
|
||||
|
||||
十多年来,Linux 已经在使用软件库来分发软件。在这种情况下,“仓库”是一个托管可安装软件包的公共服务器。Linux 发行版提供了一条命令,以及该命令的图形界面,用于从服务器获取软件并将其安装到你的计算机。这是一个非常简单的概念,它已经成为所有主流手机操作系统的模式,最近,该模式也成为了两大闭源计算机操作系统的“应用商店”。
|
||||
|
||||
![Linux repository][2]
|
||||
|
||||
*不是应用程序商店*
|
||||
|
||||
从软件仓库安装是在 Linux 上安装应用程序的主要方法,它应该是你寻找想要安装的任何应用程序的首选地方。
|
||||
|
||||
从软件仓库安装,通常需要一个命令,如:
|
||||
|
||||
```
|
||||
$ sudo dnf install inkscape
|
||||
```
|
||||
|
||||
实际使用的命令取决于你所使用的 Linux 发行版。Fedora 使用 `dnf`,OpenSUSE 使用 `zypper`,Debian 和 Ubuntu 使用 `apt`,Slackware 使用 `sbopkg`,FreeBSD 使用 `pkg_add`,而基于 lllumos 的 Openlndiana 使用 `pkg`。无论你使用什么,该命令通常要搜索你想要安装应用程序的正确名称,因为有时候你认为的软件名称不是它官方或独有的名称:
|
||||
|
||||
```
|
||||
$ sudo dnf search pyqt
|
||||
PyQt.x86_64 : Python bindings for Qt3
|
||||
PyQt4.x86_64 : Python bindings for Qt4
|
||||
python-qt5.x86_64 : PyQt5 is Python bindings for Qt5
|
||||
```
|
||||
|
||||
一旦你找到要安装的软件包的名称后,使用 `install` 子命令执行实际的下载和自动安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install python-qt5
|
||||
```
|
||||
|
||||
有关从软件仓库安装的具体信息,请参阅你的 Linux 发行版的文档。
|
||||
|
||||
图形工具通常也是如此。搜索你认为你想要的,然后安装它。
|
||||
|
||||
|
||||
|
||||
与底层命令一样,图形安装程序的名称取决于你正在运行的 Linux 发行版。相关的应用程序通常使用“软件(software)”或“包(package)”等关键字进行标记,因此请在你的启动项或菜单中搜索这些词汇,然后你将找到所需的内容。 由于开源全由用户来选择,所以如果你不喜欢你的发行版提供的图形用户界面(GUI),那么你可以选择安装替代品。 你知道该如何做到这一点。
|
||||
|
||||
#### 额外仓库
|
||||
|
||||
你的 Linux 发行版为其打包的软件提供了标准仓库,通常也有额外的仓库。例如,[EPEL][3] 服务于 Red Hat Enterprise Linux 和 CentOS,[RPMFusion][4] 服务于 Fedora,Ubuntu 有各种级别的支持以及个人包存档(PPA),[Packman][5] 为 OpenSUSE 提供额外的软件以及 [SlackBuilds.org][6] 为 Slackware 提供社区构建脚本。
|
||||
|
||||
默认情况下,你的 Linux 操作系统设置为只查看其官方仓库,因此如果你想使用其他软件集合,则必须自己添加额外库。你通常可以像安装软件包一样安装仓库。实际上,当你安装例如 [GNU Ring][7] 视频聊天,[Vivaldi][8] web 浏览器,谷歌浏览器等许多软件时,你的实际安装是访问他们的私有仓库,从中将最新版本的应用程序安装到你的机器上。
|
||||
|
||||
![Installing a repo][10]
|
||||
|
||||
*安装仓库*
|
||||
|
||||
你还可以通过编辑文本文件将仓库手动添加到你的软件包管理器的配置目录,或者运行命令来添加添加仓库。像往常一样,你使用的确切命令取决于 Linux 发行版本。例如,这是一个 `dnf` 命令,它将一个仓库添加到系统中:
|
||||
|
||||
```
|
||||
$ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
|
||||
```
|
||||
|
||||
### 不使用仓库来安装应用程序
|
||||
|
||||
仓库模型非常流行,因为它提供了用户(你)和开发人员之间的链接。重要更新发布之后,系统会提示你接受更新,并且你可以从一个集中位置接受所有更新。
|
||||
|
||||
然而,有时候一个软件包还没有放到仓库中时。这些安装包有几种形式。
|
||||
|
||||
#### Linux 包
|
||||
|
||||
有时候,开发人员会以通用的 Linux 打包格式分发软件,例如 RPM、DEB 或较新但非常流行的 FlatPak 或 Snap 格式。你不是访问仓库下载的,你只是得到了这个包。
|
||||
|
||||
例如,视频编辑器 [Lightworks][11] 为 APT 用户提供了一个 `.deb` 文件,RPM 用户提供了 `.rpm` 文件。当你想要更新时,可以到网站下载最新的适合的文件。
|
||||
|
||||
这些一次性软件包可以使用从仓库进行安装时所用的一样的工具进行安装。如果双击下载的软件包,图形安装程序将启动并逐步完成安装过程。
|
||||
|
||||
或者,你可以从终端进行安装。这里的区别在于你从互联网下载的独立包文件不是来自仓库。这是一个“本地”安装,这意味着你的软件安装包不需要下载来安装。大多数软件包管理器都是透明处理的:
|
||||
|
||||
```
|
||||
$ sudo dnf install ~/Downloads/lwks-14.0.0-amd64.rpm
|
||||
```
|
||||
|
||||
在某些情况下,你需要采取额外的步骤才能使应用程序运行,因此请仔细阅读有关你正在安装软件的文档。
|
||||
|
||||
#### 通用安装脚本
|
||||
|
||||
一些开发人员以几种通用格式发布他们的包。常见的扩展名包括 `.run` 和 `.sh`。NVIDIA 显卡驱动程序、像 Nuke 和 Mari 这样的 Foundry visual FX 软件包以及来自 [GOG][12] 的许多非 DRM 游戏都是用这种安装程序。(LCTT 译注:DRM 是数字版权管理。)
|
||||
|
||||
这种安装模式依赖于开发人员提供安装“向导”。一些安装程序是图形化的,而另一些只是在终端中运行。
|
||||
|
||||
有两种方式来运行这些类型的安装程序。
|
||||
|
||||
1、 你可以直接从终端运行安装程序:
|
||||
|
||||
```
|
||||
$ sh ./game/gog_warsow_x.y.z.sh
|
||||
```
|
||||
|
||||
2、 另外,你可以通过标记其为可执行文件来运行它。要标记为安装程序可执行文件,右键单击它的图标并选择其属性。
|
||||
|
||||
![Giving an installer executable permission][14]
|
||||
|
||||
*给安装程序可执行权限。*
|
||||
|
||||
一旦你允许其运行,双击图标就可以安装了。
|
||||
|
||||
![GOG installer][16]
|
||||
|
||||
*GOG 安装程序*
|
||||
|
||||
对于其余的安装程序,只需要按照屏幕上的说明进行操作。
|
||||
|
||||
#### AppImage 便携式应用程序
|
||||
|
||||
AppImage 格式对于 Linux 相对来说比较新,尽管它的概念是基于 NeXT 和 Rox 的。这个想法很简单:运行应用程序所需的一切都应该放在一个目录中,然后该目录被视为一个“应用程序”。要运行该应用程序,只需双击该图标即可运行。不需要也要不应该把应用程序安装在传统意义的地方;它从你在硬盘上的任何地方运行都行。
|
||||
|
||||
尽管它可以作为独立应用运行,但 AppImage 通常提供一些系统集成。
|
||||
|
||||
![AppImage system integration][18]
|
||||
|
||||
*AppImage 系统集成*
|
||||
|
||||
如果你接受此条件,则将一个本地的 `.desktop` 文件安装到你的主目录。`.desktop` 文件是 Linux 桌面的应用程序菜单和 mimetype 系统使用的一个小配置文件。实质上,只是将桌面配置文件放置在主目录的应用程序列表中“安装”应用程序,而不实际安装它。你获得了安装某些东西的所有好处,以及能够在本地运行某些东西的好处,即“便携式应用程序”。
|
||||
|
||||
#### 应用程序目录
|
||||
|
||||
有时,开发人员只是编译一个应用程序,然后将结果发布到下载中,没有安装脚本,也没有打包。通常,这意味着你下载了一个 TAR 文件,然后 [解压缩][19],然后双击可执行文件(通常是你下载软件的名称)。
|
||||
|
||||
![Twine downloaded for Linux][21]
|
||||
|
||||
*下载 Twine*
|
||||
|
||||
当使用这种软件方式交付时,你可以将它放在你下载的地方,当你需要它时,你可以手动启动它,或者你可以自己进行快速但是麻烦的安装。这包括两个简单的步骤:
|
||||
|
||||
1. 将目录保存到一个标准位置,并在需要时手动启动它。
|
||||
2. 将目录保存到一个标准位置,并创建一个 `.desktop` 文件,将其集成到你的系统中。
|
||||
|
||||
如果你只是为自己安装应用程序,那么传统上会在你的主目录中放个 `bin` (“<ruby>二进制文件<rt>binary</rt></ruby>” 的简称)目录作为本地安装的应用程序和脚本的存储位置。如果你的系统上有其他用户需要访问这些应用程序,传统上将二进制文件放置在 `/opt` 中。最后,这取决于你存储应用程序的位置。
|
||||
|
||||
下载通常以带版本名称的目录进行,如 `twine_2.13` 或者 `pcgen-v6.07.04`。由于假设你将在某个时候更新应用程序,因此将版本号删除或创建目录的符号链接是个不错的主意。这样,即使你更新应用程序本身,为应用程序创建的启动程序也可以保持不变。
|
||||
|
||||
要创建一个 `.desktop` 启动文件,打开一个文本编辑器并创建一个名为 `twine.desktop` 的文件。[桌面条目规范][22] 由 [FreeDesktop.org][23] 定义。下面是一个简单的启动器,用于一个名为 Twine 的游戏开发 IDE,安装在系统范围的 `/opt` 目录中:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Name=Twine
|
||||
GenericName=Twine
|
||||
Comment=Twine
|
||||
Exec=/opt/twine/Twine
|
||||
Icon=/usr/share/icons/oxygen/64x64/categories/applications-games.png
|
||||
Terminal=false
|
||||
Type=Application
|
||||
Categories=Development;IDE;
|
||||
```
|
||||
|
||||
棘手的一行是 `Exec` 行。它必须包含一个有效的命令来启动应用程序。通常,它只是你下载的东西的完整路径,但在某些情况下,它更复杂一些。例如,Java 应用程序可能需要作为 Java 自身的参数启动。
|
||||
|
||||
```
|
||||
Exec=java -jar /path/to/foo.jar
|
||||
```
|
||||
|
||||
有时,一个项目包含一个可以运行的包装脚本,这样你就不必找出正确的命令:
|
||||
|
||||
```
|
||||
Exec=/opt/foo/foo-launcher.sh
|
||||
```
|
||||
|
||||
在这个 Twine 例子中,没有与该下载的软件捆绑的图标,因此示例 `.desktop` 文件指定了 KDE 桌面附带的通用游戏图标。你可以使用类似的解决方法,但如果你更具艺术性,可以创建自己的图标,或者可以在 Internet 上搜索一个好的图标。只要 `Icon` 行指向一个有效的 PNG 或 SVG 文件,你的应用程序就会以该图标为代表。
|
||||
|
||||
示例脚本还将应用程序类别主要设置为 Development,因此在 KDE、GNOME 和大多数其他应用程序菜单中,Twine 出现在开发类别下。
|
||||
|
||||
为了让这个例子出现在应用程序菜单中,把 `twine.desktop` 文件放这到两个地方之一:
|
||||
|
||||
* 如果你将应用程序存储在你自己的家目录下,那么请将其放在 `~/.local/share/applications`。
|
||||
* 如果你将应用程序存储在 `/opt` 目录或者其他系统范围的位置,并希望它出现在所有用户的应用程序菜单中,请将它放在 `/usr/share/applications` 目录中。
|
||||
|
||||
现在,该应用程序已安装,因为它需要与系统的其他部分集成。
|
||||
|
||||
### 从源代码编译
|
||||
|
||||
最后,还有真正的通用格式安装格式:源代码。从源代码编译应用程序是学习如何构建应用程序,如何与系统交互以及如何定制应用程序的好方法。尽管如此,它绝不是一个点击按钮式过程。它需要一个构建环境,通常需要安装依赖库和头文件,有时还要进行一些调试。
|
||||
|
||||
要了解更多关于从源代码编译的内容,请阅读[我这篇文章][24]。
|
||||
|
||||
### 现在你明白了
|
||||
|
||||
有些人认为安装软件是一个神奇的过程,只有开发人员理解,或者他们认为它“激活”了应用程序,就好像二进制可执行文件在“安装”之前无效。学习许多不同的安装方法会告诉你安装实际上只是“将文件从一个地方复制到系统中适当位置”的简写。 没有什么神秘的。只要你去了解每次安装,不是期望应该如何发生,并且寻找开发者为安装过程设置了什么,那么通常很容易,即使它与你的习惯不同。
|
||||
|
||||
重要的是安装器要诚实于你。 如果你遇到未经你的同意尝试安装其他软件的安装程序(或者它可能会以混淆或误导的方式请求同意),或者尝试在没有明显原因的情况下对系统执行检查,则不要继续安装。
|
||||
|
||||
好的软件是灵活的、诚实的、开放的。 现在你知道如何在你的计算机上获得好软件了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-install-apps-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:/file/382591
|
||||
[2]:https://opensource.com/sites/default/files/u128651/repo.png (Linux repository)
|
||||
[3]:https://fedoraproject.org/wiki/EPEL
|
||||
[4]:http://rpmfusion.org
|
||||
[5]:http://packman.links2linux.org/
|
||||
[6]:http://slackbuilds.org
|
||||
[7]:https://ring.cx/en/download/gnu-linux
|
||||
[8]:http://vivaldi.com
|
||||
[9]:/file/382566
|
||||
[10]:https://opensource.com/sites/default/files/u128651/access.png (Installing a repo)
|
||||
[11]:https://www.lwks.com/
|
||||
[12]:http://gog.com
|
||||
[13]:/file/382581
|
||||
[14]:https://opensource.com/sites/default/files/u128651/exec.jpg (Giving an installer executable permission)
|
||||
[15]:/file/382586
|
||||
[16]:https://opensource.com/sites/default/files/u128651/gog.jpg (GOG installer)
|
||||
[17]:/file/382576
|
||||
[18]:https://opensource.com/sites/default/files/u128651/appimage.png (AppImage system integration)
|
||||
[19]:https://opensource.com/article/17/7/how-unzip-targz-file
|
||||
[20]:/file/382596
|
||||
[21]:https://opensource.com/sites/default/files/u128651/twine.jpg (Twine downloaded for Linux)
|
||||
[22]:https://specifications.freedesktop.org/desktop-entry-spec/desktop-entry-spec-latest.html
|
||||
[23]:http://freedesktop.org
|
||||
[24]:https://opensource.com/article/17/10/open-source-cats
|
||||
@ -1,4 +1,4 @@
|
||||
构建你自己的 RSS 提示系统——让杂志文章一篇也不会错过
|
||||
用 Python 构建你自己的 RSS 提示系统
|
||||
======
|
||||
|
||||

|
||||
@ -7,9 +7,9 @@
|
||||
|
||||
### Fedora 和 Python —— 入门知识
|
||||
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [**sqlite3**][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是在标准库中没有的特定的问题,也有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [**feedparser**][3] 去解析 RSS 源。
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [sqlite3][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是这样的一个特定问题,在标准库中没有包含,而有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [feedparser][3] 去解析 RSS 源。
|
||||
|
||||
因为 **feedparser** 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 **feedparser**:
|
||||
因为 feedparser 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 feedparser:
|
||||
```
|
||||
$ sudo dnf install python3-feedparser
|
||||
```
|
||||
@ -18,11 +18,12 @@ $ sudo dnf install python3-feedparser
|
||||
|
||||
### 存储源数据
|
||||
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的**标题**和**发布日期**。
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的标题和发布日期。
|
||||
|
||||
因此,我们来使用 Python **sqlite3** 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(**feedparse**,**smtplib**,和 **email**)。
|
||||
因此,我们来使用 Python sqlite3 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(feedparse,smtplib,和 email)。
|
||||
|
||||
#### 创建数据库
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
import sqlite3
|
||||
@ -34,14 +35,14 @@ import feedparser
|
||||
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
|
||||
db = db_connection.cursor()
|
||||
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
|
||||
|
||||
```
|
||||
|
||||
这几行代码创建一个新的保存在一个名为 'magazine_rss.sqlite' 文件中的 sqlite 数据库,然后在数据库创建一个名为 'magazine' 的新表。这个表有两个列 —— 'title' 和 'date' —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
这几行代码创建一个名为 `magazine_rss.sqlite` 文件的新 sqlite 数据库,然后在数据库创建一个名为 `magazine` 的新表。这个表有两个列 —— `title` 和 `date` —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
|
||||
#### 检查数据库中的旧文章
|
||||
|
||||
由于我们仅希望增加新的文章到我们的数据库中,因此我们需要一个功能去检查 RSS 源中的文章在数据库中是否存在。我们将根据它来判断是否发送(有新文章的)邮件提示。Ok,现在我们来写这个功能的代码。
|
||||
|
||||
```
|
||||
def article_is_not_db(article_title, article_date):
|
||||
""" Check if a given pair of article title and date
|
||||
@ -60,13 +61,14 @@ def article_is_not_db(article_title, article_date):
|
||||
return False
|
||||
```
|
||||
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 SELECT 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(title 和 date)。然后,我们使用查询的 WHERE 条件 `article_title` and `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 `SELECT` 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(`title` 和 `date`)。然后,我们使用查询的 `WHERE` 条件 `article_title` 和 `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
|
||||
最后,我们使用一个简单的返回 `True` 或者 `False` 的逻辑来表示是否在数据库中找到匹配的文章。
|
||||
|
||||
#### 在数据库中添加新文章
|
||||
|
||||
现在我们可以写一些代码去添加新文章到数据库中。
|
||||
|
||||
```
|
||||
def add_article_to_db(article_title, article_date):
|
||||
""" Add a new article title and date to the database
|
||||
@ -78,13 +80,14 @@ def add_article_to_db(article_title, article_date):
|
||||
db_connection.commit()
|
||||
```
|
||||
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 'magazine' 表的 article_title 和 article_date 列中。然后提交它到数据库中永久保存。
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 `magazine` 表的 `article_title` 和 `article_date` 列中。然后提交它到数据库中永久保存。
|
||||
|
||||
这些就是在数据库中所需要的东西,接下来我们看一下,如何使用 Python 实现提示系统和发送电子邮件。
|
||||
|
||||
### 发送电子邮件提示
|
||||
|
||||
我们来使用 Python 标准库模块 **smtplib** 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 **email** 模块去格式化我们的电子邮件信息。
|
||||
我们使用 Python 标准库模块 smtplib 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 email 模块去格式化我们的电子邮件信息。
|
||||
|
||||
```
|
||||
def send_notification(article_title, article_url):
|
||||
""" Add a new article title and date to the database
|
||||
@ -113,6 +116,7 @@ def send_notification(article_title, article_url):
|
||||
### 读取 Fedora Magazine 的 RSS 源
|
||||
|
||||
我们已经有了在数据库中存储文章和发送提示电子邮件的功能,现在来创建一个解析 Fedora Magazine RSS 源并提取文章数据的功能。
|
||||
|
||||
```
|
||||
def read_article_feed():
|
||||
""" Get articles from RSS feed """
|
||||
@ -127,25 +131,26 @@ if __name__ == '__main__':
|
||||
db_connection.close()
|
||||
```
|
||||
|
||||
在这里我们将使用 **feedparser.parse** 功能。这个功能返回一个用字典表示的 RSS 源,对于 **feedparser** 的完整描述可以参考它的 [文档][5]。
|
||||
在这里我们将使用 `feedparser.parse` 功能。这个功能返回一个用字典表示的 RSS 源,对于 feedparser 的完整描述可以参考它的 [文档][5]。
|
||||
|
||||
RSS 源解析将返回最后的 10 篇文章作为 `entries`,然后我们提取以下信息:标题、链接、文章发布日期。因此,我们现在可以使用前面定义的检查文章是否在数据库中存在的功能,然后,发送提示电子邮件并将这个文章添加到数据库中。
|
||||
|
||||
当运行我们的脚本时,最后的 if 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
当运行我们的脚本时,最后的 `if` 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
|
||||
### 运行我们的脚本
|
||||
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 **cron** 实用程序去每小时自动运行一次我们的脚本。**cron** 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 cron 实用程序去每小时自动运行一次我们的脚本。cron 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
|
||||
```
|
||||
$ chmod a+x my_rss_notifier.py
|
||||
$ sudo cp my_rss_notifier.py /etc/cron.hourly
|
||||
```
|
||||
|
||||
**为了使该教程保持简单**,我们使用了 cron.hourly 目录每小时运行一次我们的脚本,如果你想学习关于 **cron** 的更多知识以及如何配置 **crontab**,请阅读 **cron** 的 wikipedia [页面][6]。
|
||||
为了使该教程保持简单,我们使用了 `cron.hourly` 目录每小时运行一次我们的脚本,如果你想学习关于 cron 的更多知识以及如何配置 crontab,请阅读 cron 的 wikipedia [页面][6]。
|
||||
|
||||
### 总结
|
||||
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,**使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事**。
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事。
|
||||
|
||||
这个脚本在 [GitHub][7] 上可以找到。
|
||||
|
||||
@ -155,7 +160,7 @@ via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notificat
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,22 @@
|
||||
一月 COPR 中 4 个新的很酷的项目
|
||||
COPR 仓库中 4 个很酷的新软件
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR 是一个个人软件仓库[集合][1],它们不存在于 Fedora 中。有些软件不符合标准而不容易打包。或者它可能不符合其他的 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 支持或者由项目自己签名。但是,它是尝试新的或实验性软件的一种很好的方法。
|
||||
COPR 是一个个人软件仓库[集合][1],它们不存在于 Fedora 中。有些软件不符合标准而不容易打包。或者它可能不符合其他的 Fedora 标准,尽管它是自由和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己签名的。但是,它是尝试新的或实验性软件的一种很好的方法。
|
||||
|
||||
这是 COPR 中一系列新的和有趣的项目。
|
||||
|
||||
### Elisa
|
||||
|
||||
[Elisa][2] 是一个最小的音乐播放器。它可以让你通过专辑、艺术家或曲目浏览音乐。它会自动检测你的 ~/Music 目录中的所有可播放音乐,因此它根本不需要设置 - 它也不提供任何音乐。目前,Elisa 专注于做一个简单的音乐播放器,所以它不提供管理音乐收藏的工具。
|
||||
[Elisa][2] 是一个极小的音乐播放器。它可以让你通过专辑、艺术家或曲目浏览音乐。它会自动检测你的 `~/Music` 目录中的所有可播放音乐,因此它根本不需要设置 - 它也不提供任何音乐。目前,Elisa 专注于做一个简单的音乐播放器,所以它不提供管理音乐收藏的工具。
|
||||
|
||||
![][3]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27 和 Rawhide 提供 Elisa。要安装 Elisa,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable eclipseo/elisa
|
||||
sudo dnf install elisa
|
||||
@ -28,6 +29,7 @@ sudo dnf install elisa
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 25、26、27 和 Rawhide 提供必应壁纸。要安装必应壁纸,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable julekgwa/Bingwallpapers
|
||||
sudo dnf install bingwallpapers
|
||||
@ -35,11 +37,12 @@ sudo dnf install bingwallpapers
|
||||
|
||||
### Polybar
|
||||
|
||||
[Polybar][5] 是一个创建状态栏的工具。它有很多自定义选项以及内置的功能来显示常用服务的信息,例如 [bspwm][6]、[i3][7] 的系统托盘图标、窗口标题、工作区和桌面面板等。你也可以为你的状态栏配置你自己的模块。有关使用和配置的更多信息,请参考[ Polybar 的 wiki][8]。
|
||||
[Polybar][5] 是一个创建状态栏的工具。它有很多自定义选项以及显示常用服务的信息的内置功能,例如 [bspwm][6]、[i3][7] 的系统托盘图标、窗口标题、工作区和桌面面板等。你也可以为你的状态栏配置你自己的模块。有关使用和配置的更多信息,请参考[ Polybar 的 wiki][8]。
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 27 提供 Polybar。要安装 Polybar,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable tomwishaupt/polybar
|
||||
sudo dnf install polybar
|
||||
@ -59,14 +62,13 @@ sudo dnf copr enable recteurlp/netdata
|
||||
sudo dnf install netdata
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-january/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,14 @@
|
||||
使用 Ansible 在树莓派上构建一个基于 Linux 的高性能计算系统
|
||||
============================================================
|
||||
|
||||
### 使用低成本的硬件和开源软件设计一个高性能计算集群。
|
||||
> 使用低成本的硬件和开源软件设计一个高性能计算集群。
|
||||
|
||||

|
||||
图片来源:opensource.com
|
||||
|
||||
在我的 [Opensource.com 上前面的文章中][14],我介绍了 [OpenHPC][15] 项目,它的目标是致力于加速高性能计算(HPC)的创新。这篇文章将更深入来介绍使用 OpenHPC 的特性来构建一个小型的 HPC 系统。将它称为 _HPC 系统_ 可能有点“扯虎皮拉大旗”的意思,因此,更确切的说法应该是,通过 OpenHPC 项目发布的 [方法构建集群][16] 系统。
|
||||
|
||||
这个集群由两台树莓派 3 系统作为活动计算节点,以及一台虚拟机作为主节点,结构示意如下:
|
||||
在我的 [之前发表在 Opensource.com 上的文章中][14],我介绍了 [OpenHPC][15] 项目,它的目标是致力于加速高性能计算(HPC)的创新。这篇文章将更深入来介绍使用 OpenHPC 的特性来构建一个小型的 HPC 系统。将它称为 _HPC 系统_ 可能有点“扯虎皮拉大旗”的意思,因此,更确切的说法应该是,它是一个基于 OpenHPC 项目发布的 [集群构建方法][16] 的系统。
|
||||
|
||||
这个集群由两台树莓派 3 系统作为计算节点,以及一台虚拟机作为主节点,结构示意如下:
|
||||
|
||||

|
||||
|
||||
@ -17,13 +16,12 @@
|
||||
|
||||
下图是真实的设备工作照:
|
||||
|
||||
|
||||

|
||||
|
||||
去配置一台像上图这样的 HPC 系统,我是按照 OpenHPC 集群构建方法 —— [CentOS 7.4/aarch64 + Warewulf + Slurm 安装指南][17] (PDF) 的一些步骤来做的。这个方法包括 [Warewulf][18] 提供的使用说明;因为我的那三个系统是手动安装的,我跳过了 Warewulf 部分以及创建 [Ansible playbook][19] 的一些步骤。
|
||||
要把我的系统配置成像上图这样的 HPC 系统,我是按照 OpenHPC 的集群构建方法的 [CentOS 7.4/aarch64 + Warewulf + Slurm 安装指南][17] (PDF)的一些步骤来做的。这个方法包括了使用 [Warewulf][18] 的配置说明;因为我的那三个系统是手动安装的,我跳过了 Warewulf 部分以及创建 [Ansible 剧本][19] 的一些步骤。
|
||||
|
||||
在 [Ansible][26] 剧本中设置完成我的集群之后,我就可以向资源管理器提交作业了。在我的这个案例中, [Slurm][27] 充当了资源管理器,它是集群中的一个实例,由它来决定我的作业什么时候在哪里运行。在集群上启动一个简单的作业的方式之一:
|
||||
|
||||
在 [Ansible][26] playbooks 中设置完成我的集群之后,我就可以向资源管理器提交作业了。在我的这个案例中, [Slurm][27] 充当了资源管理器,它是集群中的一个实例,由它来决定我的作业什么时候在哪里运行。其中一种可做的事情是,在集群上启动一个简单的作业:
|
||||
```
|
||||
[ohpc@centos01 ~]$ srun hostname
|
||||
calvin
|
||||
@ -66,9 +64,9 @@ calvin
|
||||
Mon 11 Dec 16:42:41 UTC 2017
|
||||
```
|
||||
|
||||
为示范资源管理器的基本功能、简单的和一系列的命令行工具,这个集群系统是挺合适的,但是,去配置一个类似HPC 系统去做各种工作就有点无聊了。
|
||||
为示范资源管理器的基本功能,简单的串行命令行工具就行,但是,做各种工作去配置一个类似 HPC 系统就有点无聊了。
|
||||
|
||||
一个更有趣的应用是在这个集群的所有可用 CPU 上运行一个 [Open MPI][20] 并行作业。我使用了一个基于 [Game of Life][21] 的应用,它被用于一个名为“使用 Red Hat 企业版 Linux 跨多种架构运行 `Game of Life`“的 [视频][22]。除了以前实现的基于 MPI 的 `Game of Life` 之外,在我的集群中现在运行的这个版本对每个涉及的主机的单元格颜色都是不同的。下面的脚本以图形输出的方式来交互式启动应用:
|
||||
一个更有趣的应用是在这个集群的所有可用 CPU 上运行一个 [Open MPI][20] 的并行作业。我使用了一个基于 [康威生命游戏][21] 的应用,它被用于一个名为“使用 Red Hat 企业版 Linux 跨多种架构运行康威生命游戏”的 [视频][22]。除了以前基于 MPI 的 `Game of Life` 版本之外,在我的集群中现在运行的这个版本对每个涉及的主机的单元格颜色都是不同的。下面的脚本以图形输出的方式来交互式启动应用:
|
||||
|
||||
```
|
||||
$ cat life.mpi
|
||||
@ -91,15 +89,13 @@ $ srun -n 8 --x11 life.mpi
|
||||
|
||||
为了演示,这个作业有一个图形界面,它展示了当前计算的结果:
|
||||
|
||||
|
||||

|
||||
|
||||
红色单元格是由其中一个计算节点来计算的,而绿色单元格是由另外一个计算节点来计算的。我也可以让 `Game of Life` 程序为使用的每个 CPU 核心(这里的每个计算节点有四个核心)去生成不同的颜色,这样它的输出如下:
|
||||
|
||||
红色单元格是由其中一个计算节点来计算的,而绿色单元格是由另外一个计算节点来计算的。我也可以让康威生命游戏程序为使用的每个 CPU 核心(这里的每个计算节点有四个核心)去生成不同的颜色,这样它的输出如下:
|
||||
|
||||

|
||||
|
||||
感谢 OpenHPC 提供的软件包和安装方法,因为它们我可以去配置一个由两个计算节点和一个主节点的 HPC 式的系统。我可以在资源管理器上提交作业,然后使用 OpenHPC 提供的软件在我的树莓派的 CPU 上去启动 MPI 应用程序。
|
||||
感谢 OpenHPC 提供的软件包和安装方法,因为它们让我可以去配置一个由两个计算节点和一个主节点的 HPC 式的系统。我可以在资源管理器上提交作业,然后使用 OpenHPC 提供的软件在我的树莓派的 CPU 上去启动 MPI 应用程序。
|
||||
|
||||
* * *
|
||||
|
||||
@ -107,15 +103,15 @@ $ srun -n 8 --x11 life.mpi
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][23] Adrian Reber —— Adrian 是 Red Hat 的高级软件工程师,他早在 2010 年就开始了迁移的过程,迁移到高性能计算环境中,从那个时候起迁移了许多的程序,并因此获得了博士学位,然后加入了 Red Hat 公司并开始去迁移到容器。偶尔他仍然去迁移单个进程,并且它至今仍然对高性能计算非常感兴趣。[关于我的更多信息点这里][12]
|
||||
[][23] Adrian Reber —— Adrian 是 Red Hat 的高级软件工程师,他早在 2010 年就开始了迁移处理过程到高性能计算环境,从那个时候起迁移了许多的处理过程,并因此获得了博士学位,然后加入了 Red Hat 公司并开始去迁移到容器。偶尔他仍然去迁移单个处理过程,并且它至今仍然对高性能计算非常感兴趣。[关于我的更多信息点这里][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-build-hpc-system-raspberry-pi-and-openhpc
|
||||
|
||||
作者:[Adrian Reber ][a]
|
||||
作者:[Adrian Reber][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,64 +1,53 @@
|
||||
如何搭建“我的世界”服务器
|
||||
======
|
||||
我们将通过一个一步步的、新手友好的教程来向你展示如何搭建一个“我的世界”服务器。这将会是一个长期的多人游戏服务器,你可以与来自世界各地的朋友们一起玩,而不用在同一个局域网下。
|
||||
|
||||

|
||||
|
||||
我们将通过一个一步步的、新手友好的教程来向你展示如何搭建一个“我的世界(Minecraft)”服务器。这将会是一个长期的多人游戏服务器,你可以与来自世界各地的朋友们一起玩,而不用在同一个局域网下。
|
||||
|
||||
### 如何搭建一个“我的世界”服务器 - 快速指南
|
||||
|
||||
如果你很急,想直达重点的话,这是我们的目录。我们推荐通读整篇文章。
|
||||
|
||||
* [学点东西][1] (可选)
|
||||
|
||||
* [再学点东西][2] (可选)
|
||||
|
||||
* [需求][3] (必读)
|
||||
|
||||
* [安装并运行“我的世界”服务器][4] (必读)
|
||||
|
||||
* [在你登出 VPS 后继续运行服务端][5] (可选)
|
||||
|
||||
* [让服务端随系统启动][6] (可选)
|
||||
|
||||
* [配置你的“我的世界”服务器][7] (必读)
|
||||
|
||||
* [常见问题][8] (可选)
|
||||
|
||||
在你开始行动之前,要先了解一些事情:
|
||||
|
||||
#### 为什么你不应该使用专门的“我的世界”服务器提供商
|
||||
#### 为什么你**不**应该使用专门的“我的世界”服务器提供商
|
||||
|
||||
既然你正在阅读这篇文章,你肯定对搭建自己的“我的世界”服务器感兴趣。不应该使用专门的“我的世界”服务器提供商的原因有很多,以下是其中一些:
|
||||
|
||||
* 它们通常很慢。这是因为你是在和很多用户一起共享资源。这有的时候会超负荷,他们中很多都会超售。
|
||||
|
||||
* 你并不能完全控制”我的世界“服务端,或是真正的服务器。你没法按照你的意愿进行自定义。
|
||||
|
||||
* 你并不能完全控制“我的世界”服务端或真正的服务器。你没法按照你的意愿进行自定义。
|
||||
* 你是受限制的。这种主机套餐或多或少都会有限制。
|
||||
|
||||
当然,使用现成的提供商也是有优点的。最好的就是你不用做下面这些操作。但是那还有什么意思呢?
|
||||
当然,使用现成的提供商也是有优点的。最好的就是你不用做下面这些操作。但是那还有什么意思呢?!
|
||||
|
||||
#### 为什么不应该用你的个人电脑作为”我的世界“服务器
|
||||
#### 为什么不应该用你的个人电脑作为“我的世界”服务器
|
||||
|
||||
我们注意到很多教程都展示的是如何在你自己的电脑上搭建服务器。这样做有一些弊端,比如:
|
||||
|
||||
* 你的家庭网络不够安全,无法抵挡 DDoS 攻击。游戏服务器通常容易被 DDoS 攻击,而你的家庭网络设置通常不够安全,来抵挡它们。很可能连小型攻击都无法阻挡。
|
||||
|
||||
* 你得处理端口转发。如果你试着在家庭网络中搭建”我的世界“服务器的话,你肯定会偶然发现端口转发的问题,并且处理时可能会有问题。
|
||||
|
||||
* 你得处理端口转发。如果你试着在家庭网络中搭建“我的世界”服务器的话,你肯定会偶然发现端口转发的问题,并且处理时可能会有问题。
|
||||
* 你得保持你的电脑一直开着。你的电费将会突破天际,并且你会增加不必要的硬件负载。大部分服务器硬件都是企业级的,提升了稳定性和持久性,专门设计用来处理负载。
|
||||
|
||||
* 你的家庭网络速度不够快。家庭网络并不是设计用来负载多人联机游戏的。即使你想搭建一个小型服务器,你也需要一个更好的网络套餐。幸运的是,数据中心有多个高速的、企业级的互联网连接,来保证他们达到(或尽量达到)100%在线。
|
||||
|
||||
* 你的硬件很可能不够好。再说一次,服务器使用的都是企业级硬件,最新最快的处理器、固态硬盘,等等。你的个人电脑很可能不是的。
|
||||
* 你的个人电脑很可能是 Windows/MacOS。尽管这有所争议,但我们相信 Linux 更适合搭建游戏服务器。不用担心,搭建“我的世界”服务器不需要完全了解 Linux(尽管推荐这样)。我们会向你展示你需要了解的。
|
||||
|
||||
* 你的个人电脑很可能是 Windows/MacOS。尽管这是有争议的,我们相信 Linux 更适合搭建游戏服务器。不用担心,搭建”我的世界“服务器不需要完全了解 Linux(尽管推荐这样)。我们会向你展示你需要了解的。
|
||||
我们的建议是不要使用个人电脑,即使从技术角度来说你能做到。买一个云服务器并不是很贵。下面我们会向你展示如何在云服务器上搭建“我的世界”服务端。小心地遵守以下步骤,就很简单。
|
||||
|
||||
我们的建议是不要使用个人电脑,即使从技术角度来说你能做到。买一个云服务器并不是很贵。下面我们会向你展示如何在云服务器上搭建”我的世界“服务端。小心地遵守以下步骤,就很简单。
|
||||
|
||||
### 搭建一个”我的世界“服务器 - 需求
|
||||
### 搭建一个“我的世界”服务器 - 需求
|
||||
|
||||
这是一些需求,你在教程开始之前需要拥有并了解它们:
|
||||
|
||||
* 你需要一个 [Linux 云服务器][9]。我们推荐 [Vultr][10]。这家价格便宜,服务质量高,客户支持很好,并且所有的服务器硬件都很高端。检查[“我的世界”服务器需求][11]来选择你需要哪种类型的服务器(像内存和硬盘之类的资源)。我们推荐每月 20 美元的套餐。他们也支持按小时收费,所以如果你只是临时需要服务器和朋友们联机的话,你的花费会更少。注册时选择 Ubuntu 16.04 发行版。在注册时选择离你的朋友们最近的地域。这样的话你就需要保护并管理服务器。如果你不想这样的话,你可以选择[托管的服务器][],这样的话服务器提供商可能会给你搭建好一个“我的世界”服务器。
|
||||
* 你需要一个 [Linux 云服务器][9]。我们推荐 [Vultr][10]。这家价格便宜,服务质量高,客户支持很好,并且所有的服务器硬件都很高端。检查[“我的世界”服务器需求][11]来选择你需要哪种类型的服务器(像内存和硬盘之类的资源)。我们推荐每月 20 美元的套餐。他们也支持按小时收费,所以如果你只是临时需要服务器和朋友们联机的话,你的花费会更少。注册时选择 Ubuntu 16.04 发行版。在注册时选择离你的朋友们最近的地域。这样的话你就需要保护并管理服务器。如果你不想这样的话,你可以选择[托管的服务器][12],这样的话服务器提供商可能会给你搭建好一个“我的世界”服务器。
|
||||
* 你需要一个 SSH 客户端来连接到你的 Linux 云服务器。新手通常建议使用 [PuTTy][13],但我们也推荐使用 [MobaXTerm][14]。也有很多 SSH 客户端,所以挑一个你喜欢的吧。
|
||||
* 你需要设置你的服务器(至少做好基本的安全设置)。谷歌一下你会发现很多教程。你也可以按照 [Linode 的 安全指南][15],然后在你的 [Vultr][16] 服务器上一步步操作。
|
||||
* 下面我们将会处理软件依赖,比如 Java。
|
||||
@ -67,17 +56,17 @@
|
||||
|
||||
### 如何在 Ubuntu(Linux)上搭建一个“我的世界”服务器
|
||||
|
||||
这篇教程是为 [Vultr][17] 上的 Ubuntu 16.04 撰写并测试可行的。但是这对 Ubuntu 14.04, [Ubuntu 18.04][18],以及其他基于 Ubuntu 的发行版,其他服务器提供商也是可行的。
|
||||
这篇教程是为 [Vultr][17] 上的 Ubuntu 16.04 撰写并测试可行的。但是这对 Ubuntu 14.04, [Ubuntu 18.04][18],以及其他基于 Ubuntu 的发行版、其他服务器提供商也是可行的。
|
||||
|
||||
我们使用默认的 Vanilla 服务端。你也可以使用像 CraftBukkit 或 Spigot 这样的服务端,来支持更多的自定义和插件。虽然如果你使用过多插件的话会毁了服务端。这各有优缺点。不管怎么说,下面的教程使用默认的 Vanilla 服务端,来使事情变得简单和更新手友好。如果有兴趣的话我们可能会发表一篇 CraftBukkit 的教程。
|
||||
我们使用默认的 Vanilla 服务端。你也可以使用像 CraftBukkit 或 Spigot 这样的服务端,来支持更多的自定义和插件。虽然如果你使用过多插件的话会影响服务端。这各有优缺点。不管怎么说,下面的教程使用默认的 Vanilla 服务端,来使事情变得简单和更新手友好。如果有兴趣的话我们可能会发表一篇 CraftBukkit 的教程。
|
||||
|
||||
#### 1. 登陆到你的服务器
|
||||
#### 1. 登录到你的服务器
|
||||
|
||||
我们将使用 root 账户。如果你使用受限的账户的话,大部分命令都需要 ‘sudo’。做你没有权限的事情时会出现警告。
|
||||
我们将使用 root 账户。如果你使用受限的账户的话,大部分命令都需要 `sudo`。做你没有权限的事情时会出现警告。
|
||||
|
||||
你可以通过 SSH 客户端来登陆你的服务器。使用你的 IP 和端口(大部分都是 22)。
|
||||
你可以通过 SSH 客户端来登录你的服务器。使用你的 IP 和端口(大部分都是 22)。
|
||||
|
||||
在你登陆之后,确保你的[服务器安全][19]。
|
||||
在你登录之后,确保你的[服务器安全][19]。
|
||||
|
||||
#### 2. 更新 Ubuntu
|
||||
|
||||
@ -87,7 +76,7 @@
|
||||
apt-get update && apt-get upgrade
|
||||
```
|
||||
|
||||
在提示时敲击“回车键” 和/或 “y”。
|
||||
在提示时敲击“回车键” 和/或 `y`。
|
||||
|
||||
#### 3. 安装必要的工具
|
||||
|
||||
@ -113,37 +102,37 @@ mkdir /opt/minecraft
|
||||
cd /opt/minecraft
|
||||
```
|
||||
|
||||
现在你可以下载“我的世界“服务端文件了。去往[下载页面][20]获取下载链接。使用wget下载文件:
|
||||
现在你可以下载“我的世界“服务端文件了。去往[下载页面][20]获取下载链接。使用 `wget` 下载文件:
|
||||
|
||||
```
|
||||
wget https://s3.amazonaws.com/Minecraft.Download/versions/1.12.2/minecraft_server.1.12.2.jar
|
||||
```
|
||||
|
||||
#### 5. 安装”我的世界“服务端
|
||||
#### 5. 安装“我的世界”服务端
|
||||
|
||||
下载好了服务端 .jar 文件之后,你就需要先运行一下,它会生成一些文件,包括一个 eula.txt 许可文件。第一次运行的时候,它会返回一个错误并退出。这是正常的。使用下面的命令运行它:
|
||||
下载好了服务端的 .jar 文件之后,你就需要先运行一下,它会生成一些文件,包括一个 `eula.txt` 许可文件。第一次运行的时候,它会返回一个错误并退出。这是正常的。使用下面的命令运行它:
|
||||
|
||||
```
|
||||
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
”-Xms2048M“是你的服务端能使用的最小的内存,”-Xmx3472M“是最大的。[调整][21]基于你服务器的硬件资源。如果你在 [Vultr][22] 服务器上有 4GB 内存,并且不用服务器来干其他事情的话可以就这样留着不动。
|
||||
`-Xms2048M` 是你的服务端能使用的最小的内存,`-Xmx3472M` 是最大的内存。[调整][21]基于你服务器的硬件资源。如果你在 [Vultr][22] 服务器上有 4GB 内存,并且不用服务器来干其他事情的话可以就这样留着不动。
|
||||
|
||||
在这条命令结束并返回一个错误之后,将会生成一个新的 eula.txt 文件。你需要同意那个文件里的协议。你可以通过下面这条命令将”eula=true“添加到文件中:
|
||||
在这条命令结束并返回一个错误之后,将会生成一个新的 `eula.txt` 文件。你需要同意那个文件里的协议。你可以通过下面这条命令将 `eula=true` 添加到文件中:
|
||||
|
||||
```
|
||||
sed -i.orig 's/eula=false/eula=true/g' eula.txt
|
||||
```
|
||||
|
||||
你现在可以通过和上面一样的命令来开启服务端并进入”我的世界“服务端控制台了:
|
||||
你现在可以通过和上面一样的命令来开启服务端并进入“我的世界”服务端控制台了:
|
||||
|
||||
```
|
||||
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
确保你在 /opt/minecraft 目录,或者其他你安装你的 MC 服务端的目录下。
|
||||
确保你在 `/opt/minecraft` 目录,或者其他你安装你的 MC 服务端的目录下。
|
||||
|
||||
如果你只是测试或暂时需要的话,到这里就可以停了。如果你在登陆服务器时有问题的话,你就需要[配置你的防火墙][23]。
|
||||
如果你只是测试或暂时需要的话,到这里就可以停了。如果你在登录服务器时有问题的话,你就需要[配置你的防火墙][23]。
|
||||
|
||||
第一次成功启动服务端时会花费一点时间来生成。
|
||||
|
||||
@ -166,7 +155,7 @@ nano /opt/minecraft/startminecraft.sh
|
||||
cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
如果你不熟悉 nano 的话 - 你可以使用“CTRL + X”,再敲击“Y”,然后回车。这个脚本将进入你先前创建的“我的世界”服务端并运行 Java 命令来开启服务端。你需要执行下面的命令来使脚本可执行:
|
||||
如果你不熟悉 nano 的话 - 你可以使用 `CTRL + X`,再敲击 `Y`,然后回车。这个脚本将进入你先前创建的“我的世界”服务端并运行 Java 命令来开启服务端。你需要执行下面的命令来使脚本可执行:
|
||||
|
||||
```
|
||||
chmod +x startminecraft.sh
|
||||
@ -178,7 +167,7 @@ chmod +x startminecraft.sh
|
||||
/opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
但是,如果/当你登出 SSH 会话的话,服务端就会关闭。要想让服务端不登陆也持续运行的话,你可以使用 screen 会话。一个 screen 会话会一直运行,直到实际的服务器被关闭或重启。
|
||||
但是,如果/当你登出 SSH 会话的话,服务端就会关闭。要想让服务端不登录也持续运行的话,你可以使用 `screen` 会话。`screen` 会话会一直运行,直到实际的服务器被关闭或重启。
|
||||
|
||||
使用下面的命令开启一个 screen 会话:
|
||||
|
||||
@ -186,23 +175,23 @@ chmod +x startminecraft.sh
|
||||
screen -S minecraft
|
||||
```
|
||||
|
||||
一旦你进入了 screen 会话(看起来就像是你新建了一个 SSH 会话),你就可以使用先前创建的 bash 脚本来启动服务端:
|
||||
一旦你进入了 `screen` 会话(看起来就像是你新建了一个 SSH 会话),你就可以使用先前创建的 bash 脚本来启动服务端:
|
||||
|
||||
```
|
||||
/opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
要退出 screen 会话的话,你应该按 CTRL +A-D。即使你离开 screen 会话(断开的),服务端也会继续运行。你现在可以安全的登出 Ubuntu 服务器了,你创建的“我的世界”服务端将会继续运行。
|
||||
要退出 `screen` 会话的话,你应该按 `CTRL+A-D`。即使你离开 `screen` 会话(断开的),服务端也会继续运行。你现在可以安全的登出 Ubuntu 服务器了,你创建的“我的世界”服务端将会继续运行。
|
||||
|
||||
但是,如果 Ubuntu 服务器重启或关闭了的话,screen 会话将不再起作用。所以**为了让我们之前做的这些在启动时自动运行**,做下面这些:
|
||||
但是,如果 Ubuntu 服务器重启或关闭了的话,`screen` 会话将不再起作用。所以**为了让我们之前做的这些在启动时自动运行**,做下面这些:
|
||||
|
||||
打开 /etc/rc.local 文件:
|
||||
打开 `/etc/rc.local` 文件:
|
||||
|
||||
```
|
||||
nano /etc/rc.local
|
||||
```
|
||||
|
||||
在“exit 0”语句前添加如下内容:
|
||||
在 `exit 0` 语句前添加如下内容:
|
||||
|
||||
```
|
||||
screen -dm -S minecraft /opt/minecraft/startminecraft.sh
|
||||
@ -211,7 +200,7 @@ exit 0
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
要访问“我的世界”服务端控制台,只需运行下面的命令来重新连接 screen 会话:
|
||||
要访问“我的世界”服务端控制台,只需运行下面的命令来重新连接 `screen` 会话:
|
||||
|
||||
```
|
||||
screen -r minecraft
|
||||
@ -247,7 +236,7 @@ ufw allow 25565/tcp
|
||||
nano /opt/minecraft/server.properties
|
||||
```
|
||||
|
||||
并将“white-list”行改为“true”:
|
||||
并将 `white-list` 行改为 `true`:
|
||||
|
||||
```
|
||||
white-list=true
|
||||
@ -279,7 +268,7 @@ whitelist add PlayerUsername
|
||||
whitelist remove PlayerUsername
|
||||
```
|
||||
|
||||
使用 CTRL + A-D 来退出 screen(服务器控制台)。值得注意的是,这会拒绝除白名单以外的所有人连接到服务端。
|
||||
使用 `CTRL+A-D` 来退出 `screen`(服务器控制台)。值得注意的是,这会拒绝除白名单以外的所有人连接到服务端。
|
||||
|
||||
[][26]
|
||||
|
||||
@ -305,7 +294,7 @@ whitelist remove PlayerUsername
|
||||
screen -r minecraft
|
||||
```
|
||||
|
||||
在这里执行[命令][28]。像下面这些命令:
|
||||
并执行[命令][28]。像下面这些命令:
|
||||
|
||||
```
|
||||
difficulty hard
|
||||
@ -321,7 +310,7 @@ gamemode survival @a
|
||||
|
||||
如果有新版本发布的话,你需要这样做:
|
||||
|
||||
进入”我的世界“目录:
|
||||
进入“我的世界”目录:
|
||||
|
||||
```
|
||||
cd /opt/minecraft
|
||||
@ -356,7 +345,7 @@ cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.3.jar
|
||||
|
||||
#### 为什么你们的教程这么长,而其他的只有 2 行那么长?!
|
||||
|
||||
我们想让这个教程对新手来说更友好,并且尽可能详细。我们还向你展示了了如何让服务端长期运行并跟随系统启动,我们向你展示了如何配置你的服务端以及所有的东西。我是说,你当然可以用几行来启动“我的世界”服务器,但那样的话绝对很烂,从不仅一方面说。
|
||||
我们想让这个教程对新手来说更友好,并且尽可能详细。我们还向你展示了如何让服务端长期运行并跟随系统启动,我们向你展示了如何配置你的服务端以及所有的东西。我是说,你当然可以用几行来启动“我的世界”服务器,但那样的话绝对很烂,从不仅一方面说。
|
||||
|
||||
#### 我不知道 Linux 或者这里说的什么东西,我该如何搭建一个“我的世界”服务器呢?
|
||||
|
||||
@ -372,7 +361,7 @@ via: https://thishosting.rocks/how-to-make-a-minecraft-server/
|
||||
|
||||
作者:[ThisHosting.Rocks][a]
|
||||
译者:[heart4lor](https://github.com/heart4lor)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
225
published/201803/20180129 Parsing HTML with Python.md
Normal file
225
published/201803/20180129 Parsing HTML with Python.md
Normal file
@ -0,0 +1,225 @@
|
||||
如何用 Python 解析 HTML
|
||||
======
|
||||
|
||||
用一些简单的脚本,可以很容易地清理文档和其它大量的 HTML 文件。但是首先你需要解析它们。
|
||||

|
||||
|
||||
图片由 Jason Baker 为 Opensource.com 所作。
|
||||
|
||||
作为 Scribus 文档团队的长期成员,我要随时了解最新的源代码更新,以便对文档进行更新和补充。 我最近在刚升级到 Fedora 27 系统的计算机上使用 Subversion 进行检出操作时,对于下载该文档所需要的时间我感到很惊讶,文档由 HTML 页面和相关图像组成。 我恐怕该项目的文档看起来比项目本身大得多,并且怀疑其中的一些内容是“僵尸”文档——不再使用的 HTML 文件以及 HTML 中无法访问到的图像。
|
||||
|
||||
我决定为自己创建一个项目来解决这个问题。 一种方法是搜索未使用的现有图像文件。 如果我可以扫描所有 HTML 文件中的图像引用,然后将该列表与实际图像文件进行比较,那么我可能会看到不匹配的文件。
|
||||
|
||||
这是一个典型的图像标签:
|
||||
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我对 `src=` 之后的第一组引号之间的部分很感兴趣。 在寻找了一些解决方案后,我找到一个名为 [BeautifulSoup][1] 的 Python 模块。 脚本的核心部分如下所示:
|
||||
|
||||
```
|
||||
soup = BeautifulSoup(all_text, 'html.parser')
|
||||
match = soup.findAll("img")
|
||||
if len(match) > 0:
|
||||
for m in match:
|
||||
imagelist.append(str(m))
|
||||
```
|
||||
|
||||
我们可以使用这个 `findAll` 方法来挖出图片标签。 这是一小部分输出:
|
||||
|
||||
```
|
||||
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
|
||||
```
|
||||
|
||||
到现在为止还挺好。我原以为下一步就可以搞定了,但是当我在脚本中尝试了一些字符串方法时,它返回了有关标记的错误而不是字符串的错误。 我将输出保存到一个文件中,并在 [KWrite][2] 中进行编辑。 KWrite 的一个好处是你可以使用正则表达式(regex)来做“查找和替换”操作,所以我可以用 `\n<img` 替换 `<img`,这样可以看得更清楚。 KWrite 的另一个好处是,如果你用正则表达式做了一个不明智的选择,你还可以撤消。
|
||||
|
||||
但我认为,肯定有比这更好的东西,所以我转而使用正则表达式,或者更具体地说 Python 的 `re` 模块。 这个新脚本的相关部分如下所示:
|
||||
|
||||
```
|
||||
match = re.findall(r'src="(.*)/>', all_text)
|
||||
if len(match)>0:
|
||||
for m in match:
|
||||
imagelist.append(m)
|
||||
```
|
||||
|
||||
它的一小部分输出如下所示:
|
||||
|
||||
```
|
||||
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
|
||||
```
|
||||
|
||||
乍一看,它看起来与上面的输出类似,并且附带有去除图像的标签部分的好处,但是有令人费解的是还夹杂着表格标签和其他内容。 我认为这涉及到这个正则表达式 `src="(.*)/>`,这被称为*贪婪*,意味着它不一定停止在遇到 `/>` 的第一个实例。我应该补充一点,我也尝试过 `src="(.*)"`,这真的没有什么更好的效果,我不是一个正则表达式专家(只是做了这个),找了各种方法来改进这一点但是并没什么用。
|
||||
|
||||
做了一系列的事情之后,甚至尝试了 Perl 的 `HTML::Parser` 模块,最终我试图将这与我为 Scribus 编写的一些脚本进行比较,这些脚本逐个字符的分析文本内容,然后采取一些行动。 为了最终目的,我终于想出了所有这些方法,并且完全不需要正则表达式或 HTML 解析器。 让我们回到展示的那个 `img` 标签的例子。
|
||||
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我决定回到 `src=` 这一块。 一种方法是等待 `s` 出现,然后看下一个字符是否是 `r`,下一个是 `c`,下一个是否 `=`。 如果是这样,那就匹配上了! 那么两个双引号之间的内容就是我所需要的。 这种方法的问题在于需要连续识别上面这样的结构。 一种查看代表一行 HTML 文本的字符串的方法是:
|
||||
|
||||
```
|
||||
for c in all_text:
|
||||
```
|
||||
|
||||
但是这个逻辑太乱了,以至于不能持续匹配到前面的 `c`,还有之前的字符,更之前的字符,更更之前的字符。
|
||||
|
||||
最后,我决定专注于 `=` 并使用索引方法,以便我可以轻松地引用字符串中的任何先前或将来的字符。 这里是搜索部分:
|
||||
|
||||
```
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
```
|
||||
|
||||
我用第四个字符开始搜索(索引从 0 开始),所以我在下面没有出现索引错误,并且实际上,在每一行的第四个字符之前不会有等号。 第一个测试是看字符串中是否出现了 `=`,如果没有,我们就会前进。 如果我们确实看到一个等号,那么我们会看前三个字符是否是 `s`、`r` 和 `c`。 如果全都匹配了,就调用函数 `imagefound`:
|
||||
|
||||
```
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
```
|
||||
|
||||
我们给函数发送当前索引,它代表着 `=`。 我们知道下一个字符将会是 `"`,所以我们跳过两个字符,并开始向名为 `newimage` 的控制字符串添加字符,直到我们发现下一个 `"`,此时我们完成了一次匹配。 我们将字符串加一个换行符(`\n`)添加到列表 `imagelist` 中并返回(`return`),请记住,在剩余的这个 HTML 字符串中可能会有更多图片标签,所以我们马上回到搜索循环中。
|
||||
|
||||
以下是我们的输出现在的样子:
|
||||
|
||||
```
|
||||
images/text-frame-link.png
|
||||
images/text-frame-unlink.png
|
||||
images/gimpoptions1.png
|
||||
images/gimpoptions3.png
|
||||
images/gimpoptions2.png
|
||||
images/fontpref3.png
|
||||
images/font-subst.png
|
||||
images/fontpref2.png
|
||||
images/fontpref1.png
|
||||
images/dtp-studio.png
|
||||
```
|
||||
|
||||
啊,干净多了,而这只花费几秒钟的时间。 我本可以将索引前移 7 步来剪切 `images/` 部分,但我更愿意把这个部分保存下来,以确保我没有剪切掉图像文件名的第一个字母,这很容易用 KWrite 编辑成功 —— 你甚至不需要正则表达式。 做完这些并保存文件后,下一步就是运行我编写的另一个脚本 `sortlist.py`:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# sortlist.py
|
||||
|
||||
import os
|
||||
|
||||
imagelist = []
|
||||
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
|
||||
imagelist.append(line)
|
||||
|
||||
imagelist.sort()
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
```
|
||||
|
||||
这会读取文件内容,并存储为列表,对其排序,然后另存为另一个文件。 之后,我可以做到以下几点:
|
||||
|
||||
```
|
||||
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
|
||||
```
|
||||
|
||||
然后我需要在该文件上运行 `sortlist.py`,因为 `ls` 方法的排序与 Python 不同。 我原本可以在这些文件上运行比较脚本,但我更愿意以可视方式进行操作。 最后,我成功找到了 42 个图像,这些图像没有来自文档的 HTML 引用。
|
||||
|
||||
这是我的完整解析脚本:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# parseimg4.py
|
||||
|
||||
import os
|
||||
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
|
||||
htmlnames = []
|
||||
imagelist = []
|
||||
tempstring = ''
|
||||
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
|
||||
for name in filenames:
|
||||
if name.endswith('.html'):
|
||||
htmlnames.append(name)
|
||||
#print htmlnames
|
||||
for htmlfile in htmlnames:
|
||||
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
|
||||
linelength = len(all_text)
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
|
||||
(all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
imageno = len(imagelist)
|
||||
print str(imageno) + " images were found and saved"
|
||||
```
|
||||
|
||||
脚本名称为 `parseimg4.py`,这并不能真实反映我陆续编写的脚本数量(包括微调的和大改的以及丢弃并重新开始写的)。 请注意,我已经对这些目录和文件名进行了硬编码,但是很容易变得通用化,让用户输入这些信息。 同样,因为它们是工作脚本,所以我将输出发送到 `/tmp` 目录,所以一旦重新启动系统,它们就会消失。
|
||||
|
||||
这不是故事的结尾,因为下一个问题是:僵尸 HTML 文件怎么办? 任何未使用的文件都可能会引用图像,不能被前面的方法所找出。 我们有一个 `menu.xml` 文件作为联机手册的目录,但我还需要考虑 TOC(LCTT 译注:TOC 是 table of contents 的缩写)中列出的某些文件可能引用了不在 TOC 中的文件,是的,我确实找到了一些这样的文件。
|
||||
|
||||
最后我可以说,这是一个比图像搜索更简单的任务,而且开发的过程对我有很大的帮助。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][7]
|
||||
|
||||
Greg Pittman 是 Kentucky 州 Louisville 市的一名退休的神经学家,从二十世纪六十年代的 Fortran IV 语言开始长期以来对计算机和编程有着浓厚的兴趣。 当 Linux 和开源软件出现的时候,Greg 深受启发,去学习更多知识,并实现最终贡献的承诺。 他是 Scribus 团队的成员。[更多关于我][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/parsing-html-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[2]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[7]:https://opensource.com/users/greg-p
|
||||
[8]:https://opensource.com/users/greg-p
|
||||
107
published/201803/20180201 How I coined the term open source.md
Normal file
107
published/201803/20180201 How I coined the term open source.md
Normal file
@ -0,0 +1,107 @@
|
||||
我是如何创造“开源”这个词的
|
||||
============================================================
|
||||
|
||||
|
||||
> Christine Peterson 最终公开讲述了二十年前那决定命运的一天。
|
||||
|
||||

|
||||
|
||||
图片来自: opensource.com
|
||||
|
||||
2 月 3 日是术语“<ruby>[开源软件][6]<rt>open source software</rt></ruby>”创立 20 周年的纪念日。由于开源软件渐受欢迎,并且为这个时代强有力的重要变革提供了动力,我们仔细反思了它的初生到崛起。
|
||||
|
||||
我是 “开源软件” 这个词的始作俑者,它是我在<ruby>前瞻协会<rt>Foresight Institute</rt></ruby>担任执行董事时提出的。我不像其它人是个软件开发者,所以感谢 Linux 程序员 Todd Anderson 对这个术语的支持并将它提交小组讨论。
|
||||
|
||||
这是我对于它如何想到的,如何提出的,以及后续影响的记叙。当然,还有一些有关该术语的其它记叙,例如 Eric Raymond 和 Richard Stallman 写的,而我的,则写于 2006 年 1 月 2 日。
|
||||
|
||||
但直到今天,我才公诸于世。
|
||||
|
||||
* * *
|
||||
|
||||
推行术语“开源软件”是特别为了让新手和商业人士更加理解这个领域,对它的推广被认为对于更广泛的用户社区很有必要。早期的称呼“<ruby>自由软件<rt>free software</rt></ruby>”不适用并非是因为含有政治意义,而是对于新手来说会误导关注于价格。所以需要一个关注于关键的源代码,而且不会让新用户混淆概念的术语。第一个在正确时间出现并且满足这些要求的术语被迅速接受了:<ruby>开源<rt>open source</rt></ruby>。
|
||||
|
||||
这个术语很长一段时间被用在“情报”(即间谍活动)活动中,但据我所知,确实在 1998 年以前软件领域从未使用过该术语。下面这个就是讲述了术语“开源软件”如何流行起来,并且变成了一项产业和一场运动名称的故事。
|
||||
|
||||
### 计算机安全会议
|
||||
|
||||
在 1997 年的晚些时候,<ruby>前瞻协会<rt>Foresight Institute</rt></ruby>开始举办周会讨论计算机安全问题。这个协会是一个非盈利性智库,它专注于纳米技术和人工智能,而二者的安全性及可靠性取决于软件安全。我们确定了自由软件是一个改进软件安全可靠性且具有发展前景的方法,并将寻找推动它的方式。 对自由软件的兴趣开始在编程社区外开始增长,而且越来越清晰,一个改变世界的机会正在来临。然而,该怎么做我们并不清楚,因为我们当时正在摸索中。
|
||||
|
||||
在这些会议中,由于“容易混淆”的因素,我们讨论了采用一个新术语的必要性。观点主要如下:对于那些新接触“自由软件”的人会把 “free” 当成了价格上的 “免费” 。老资格的成员们开始解释,通常像下面所说的:“我们指的是 ‘freedom’ 中的自由,而不是‘免费啤酒’的免费。”在这一点上,关于软件方面的讨论就会变成了关于酒精饮料价格的讨论。问题不在于解释不了它的含义 —— 问题在于重要概念的术语不应该使新手们感到困惑。所以需要一个更清晰的术语。自由软件一词并没有政治上的问题;问题在于这个术语不能对新人清晰表明其概念。
|
||||
|
||||
### 开放的网景
|
||||
|
||||
1998 年 2 月 2 日,Eric Raymond 访问网景公司,并与它一起计划采用自由软件风格的许可证发布其浏览器的源代码。我们那晚在前瞻协会位于<ruby>罗斯阿尔托斯<rt>Los Altos</rt></ruby>的办公室开会,商讨并完善了我们的计划。除了 Eric 和我,积极参与者还有 Brian Behlendorf、Michael Tiemann、Todd Anderson、Mark S. Miller 和 Ka-Ping Yee。但在那次会议上,这一领域仍然被描述成“自由软件”,或者用 Brian 的话说, 叫“可获得源代码的” 软件。
|
||||
|
||||
在这个镇上,Eric 把前瞻协会作为行动的大本营。他访问行程期间,他接到了网景的法律和市场部门人员的电话。当他聊完后,我要求和他们(一男一女,可能是 Mitchell Baker)通电话,以便我告诉他们一个新的术语的必要性。他们原则上立即同意了,但我们在具体术语上并未达成一致。
|
||||
|
||||
在那周的会议中,我始终专注于起一个更好的名字并提出了 “开源软件”一词。 虽然不太理想,但我觉得足够好了。我找到至少四个人征求意见:Eric Drexler、Mark Miller 以及 Todd Anderson 都喜欢它,而一个从事市场公关的朋友觉得术语 “open” 被滥用了,并且觉得我们能找到一个更好。理论上他是对的,可我想不出更好的了,所以我想试着先推广它。事后想起来,我应该直接向 Eric Raymond 提议,但在那时我并不是很了解他,所以我采取了间接的策略。
|
||||
|
||||
Todd 强烈同意需要一个新的术语,并提供协助推广它。这很有帮助,因为作为一个非编程人员,我在自由软件社区的影响力很弱。我从事的纳米技术教育是一个加分项,但不足以让我在自由软件问题上非常得到重视。而作为一个 Linux 程序员,Todd 的话更容易被倾听。
|
||||
|
||||
### 关键性会议
|
||||
|
||||
那周稍晚时候,1998 年的 2 月 5 日,一伙人在 VA Research 进行头脑风暴商量对策。与会者除了 Eric Raymond、Todd 和我之外,还有 Larry Augustin、Sam Ockman,和 Jon Hall (“maddog”)通过电话参与。
|
||||
|
||||
会议的主要议题是推广策略,特别是要联系的公司。 我几乎没说什么,但是一直在寻找机会介绍提议的术语。我觉得我直接说“你们这些技术人员应当开始使用我的新术语了。”没有什么用。大多数与会者不认识我,而且据我所知,他们可能甚至不同意现在就迫切需要一个新术语。
|
||||
|
||||
幸运的是,Todd 一直留心着。他没有主张社区应该用哪个特定的术语,而是面对社区这些固执的人间接地做了一些事。他仅仅是在其它话题中使用了那个术语 —— 把它放进对话里看看会发生什么。我很紧张,期待得到回应,但是起初什么也没有。讨论继续进行原来的话题。似乎只有他和我注意了这个术语的使用。
|
||||
|
||||
不仅如此——模因演化(LCTT 译注:人类学术语)在起作用。几分钟后,另一个人使用了这个术语,显然没有注意到,而在继续进行话题讨论。Todd 和我用眼角互觑了一下:是的,我们都注意到发生了什么。我很激动——它或许有用!但我保持了安静:我在小组中仍然地位不高。可能有些人都奇怪为什么 Eric 会邀请我。
|
||||
|
||||
临近会议尾声,可能是 Todd 或 Eric,明确提出了[术语问题][8]。Maddog 提及了一个早期的术语“可自由分发的”,和一个新的术语“合作开发的”。Eric 列出了“自由软件”、“开源软件”和“软件源”作为主要选项。Todd 提议使用“开源”,然后 Eric 支持了他。我没说太多,就让 Todd 和 Eric(轻松、非正式地)就“开源”这个名字达成了共识。显然对于大多数与会者,改名并不是在这讨论的最重要议题;那只是一个次要的相关议题。从我的会议记录中看只有大约 10% 的内容是术语的。
|
||||
|
||||
但是我很高兴。在那有许多社区的关键领导人,并且他们喜欢这新名字,或者至少没反对。这是一个好的信号。可能我帮不上什么忙; Eric Raymond 更适合宣传新的名称,而且他也这么做了。Bruce Perens 立即表示支持,帮助建立了 [Opensource.org][9] 并在新术语的宣传中发挥了重要作用。
|
||||
|
||||
为了让这个名字获得认同,Tim O'Reilly 同意在代表社区的多个项目中积极使用它,这是很必要,甚至是非常值得的。并且在官方即将发布的 Netscape Navigator(网景浏览器)代码中也使用了此术语。 到二月底, O'Reilly & Associates 还有网景公司(Netscape) 已经开始使用新术语。
|
||||
|
||||
### 名字的宣传
|
||||
|
||||
在那之后的一段时间,这条术语由 Eric Raymond 向媒体推广,由 Tim O'Reilly 向商业推广,并由二人向编程社区推广,它似乎传播的相当快。
|
||||
|
||||
1998 年 4 月 17 日,Tim O'Reilly 召集了该领域的一些重要领袖的峰会,宣布为第一次 “[自由软件峰会][10]” ,在 4 月14 日之后,它又被称作首届 “[开源峰会][11]”。
|
||||
|
||||
这几个月对于开源来说是相当激动人心的。似乎每周都有一个新公司宣布加入计划。读 Slashdot(LCTT 译注:科技资讯网站)已经成了一个必需操作,甚至对于那些像我一样只能外围地参与者亦是如此。我坚信新术语能对快速传播到商业很有帮助,能被公众广泛使用。
|
||||
|
||||
尽管在谷歌搜索一下表明“开源”比“自由软件”出现的更多,但后者仍然有大量的使用,在和偏爱它的人们沟通的时候我们应该包容。
|
||||
|
||||
### 快乐的感觉
|
||||
|
||||
当 Eric Raymond 写的有关术语更改的[早期声明][12]被发布在了<ruby>开源促进会<rt>Open Source Initiative</rt></ruby>的网站上时,我被列在 VA 头脑风暴会议的名单上,但并不是作为术语的创始人。这是我自己的失误,我没告诉 Eric 细节。我的想法就是让它过去吧,我呆在幕后就好,但是 Todd 不这样认为。他认为我总有一天会为被称作“开源软件”这个名词的创造者而高兴。他向 Eric 解释了这个情况,Eric 及时更新了网站。
|
||||
|
||||
想出这个短语只是一个小贡献,但是我很感激那些把它归功于我的人。每次我听到它(现在经常听到了),它都给我些许的感动。
|
||||
|
||||
说服社区的巨大功劳要归功于 Eric Raymond 和 Tim O'Reilly,是他们让这一切成为可能。感谢他们对我的归功,并感谢 Todd Anderson 所做的一切。以上内容并非完整的开源一词的历史,让我对很多没有提及的关键人士表示歉意。那些寻求更完整讲述的人应该参考本文和网上其他地方的链接。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13]
|
||||
|
||||
Christine Peterson 撰写、举办讲座,并向媒体介绍未来强大的技术,特别是在纳米技术,人工智能和长寿方面。她是纳米科技公益组织前瞻协会的共同创始人和前任主席。前瞻协会向公众、技术团体和政策制定者提供未来强大的技术的教育以及告诉它是如何引导他们的长期影响。她服务于[机器智能][2]咨询委员会……[更多关于 Christine Peterson][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
|
||||
作者:[Christine Peterson][a]
|
||||
译者:[fuzheng1998](https://github.com/fuzheng1998)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/christine-peterson
|
||||
[1]:https://opensource.com/article/18/2/coining-term-open-source-software?rate=HFz31Mwyy6f09l9uhm5T_OFJEmUuAwpI61FY-fSo3Gc
|
||||
[2]:http://intelligence.org/
|
||||
[3]:https://opensource.com/users/christine-peterson
|
||||
[4]:https://opensource.com/users/christine-peterson
|
||||
[5]:https://opensource.com/user/206091/feed
|
||||
[6]:https://opensource.com/resources/what-open-source
|
||||
[7]:https://opensource.org/osd
|
||||
[8]:https://wiki2.org/en/Alternative_terms_for_free_software
|
||||
[9]:https://opensource.org/
|
||||
[10]:http://www.oreilly.com/pub/pr/636
|
||||
[11]:http://www.oreilly.com/pub/pr/796
|
||||
[12]:https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html
|
||||
[13]:https://opensource.com/users/christine-peterson
|
||||
[14]:https://opensource.com/users/christine-peterson
|
||||
[15]:https://opensource.com/users/christine-peterson
|
||||
[16]:https://opensource.com/article/18/2/coining-term-open-source-software#comments
|
||||
@ -1,18 +1,18 @@
|
||||
如何检查你的 Linux PC 是否存在 Meltdown 或者 Spectre 漏洞
|
||||
如何检查你的 Linux 系统是否存在 Meltdown 或者 Spectre 漏洞
|
||||
======
|
||||
|
||||

|
||||
|
||||
Meltdown 和 Specter 漏洞的最恐怖的现实之一是它们涉及非常广泛。几乎每台现代计算机都会受到一些影响。真正的问题是_你_是否受到了影响?每个系统都处于不同的脆弱状态,具体取决于已经或者还没有打补丁的软件。
|
||||
|
||||
由于 Meltdown 和 Spectre 都是相当新的,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
由于 Meltdown 和 Spectre 都是相当新的漏洞,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
|
||||
### 简单测试
|
||||
|
||||
顶级的 Linux 内核开发人员之一提供了一种简单的方式来检查系统在 Meltdown 和 Specter 漏洞方面的状态。它是简单的,也是最简洁的,但它不适用于每个系统。有些发行版不支持它。即使如此,也值得一试。
|
||||
|
||||
```
|
||||
grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
|
||||
```
|
||||
|
||||
![Kernel Vulnerability Check][1]
|
||||
@ -24,24 +24,24 @@ grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
如果上面的方法不适合你,或者你希望看到更详细的系统报告,一位开发人员已创建了一个 shell 脚本,它将检查你的系统来查看系统收到什么漏洞影响,还有做了什么来减轻 Meltdown 和 Spectre 的影响。
|
||||
|
||||
要得到脚本,请确保你的系统上安装了 Git,然后将脚本仓库克隆到一个你不介意运行它的目录中。
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
git clone https://github.com/speed47/spectre-meltdown-checker.git
|
||||
|
||||
```
|
||||
|
||||
这不是一个大型仓库,所以它应该只需要几秒钟就克隆完成。完成后,输入新创建的目录并运行提供的脚本。
|
||||
|
||||
```
|
||||
cd spectre-meltdown-checker
|
||||
./spectre-meltdown-checker.sh
|
||||
|
||||
```
|
||||
|
||||
你会在中断看到很多输出。别担心,它不是太难查看。首先,脚本检查你的硬件,然后运行三个漏洞:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
你会在终端看到很多输出。别担心,它不是太难理解。首先,脚本检查你的硬件,然后运行三个漏洞检查:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
|
||||
![Meltdown Spectre Check Script Ubuntu][2]
|
||||
|
||||
每个部分为你提供潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
每个部分为你提供了潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
|
||||
### 这意味着什么
|
||||
|
||||
@ -53,7 +53,7 @@ via: https://www.maketecheasier.com/check-linux-meltdown-spectre-vulnerability/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,35 +3,36 @@
|
||||
|
||||

|
||||
|
||||
公共服务最重要的一点就是守时,但是很多人并没有意识到这一点。大多数公共时间服务器都是由志愿者管理,以满足不断增长的需求。学习如何运行你自己的时间服务器,为基本的公共利益做贡献。(查看 [在 Linux 上使用 NTP 保持精确时间][1] 去学习如何设置一台局域网时间服务器)
|
||||
最重要的公共服务之一就是<ruby>报时<rt>timekeeping</rt></ruby>,但是很多人并没有意识到这一点。大多数公共时间服务器都是由志愿者管理,以满足不断增长的需求。这里学习一下如何运行你自己的时间服务器,为基础公共利益做贡献。(查看 [在 Linux 上使用 NTP 保持精确时间][1] 去学习如何设置一台局域网时间服务器)
|
||||
|
||||
### 著名的时间服务器滥用事件
|
||||
|
||||
就像现实生活中任何一件事情一样,即便是像时间服务器这样的公益项目,也会遭受不称职的或者恶意的滥用。
|
||||
|
||||
消费类网络设备的供应商因制造了大混乱而臭名昭著。我回想起的第一件事发生在 2003 年,那时,Netgear 在它们的路由器中硬编码了 University of Wisconsin-Madison 的 NTP 时间服务器地址。使得时间服务器的查询请求突然增加,随着 NetGear 卖出越来越多的路由器,这种情况越发严重。更有意思的是,路由器的程序设置是每秒钟发送一次请求,这将使服务器难堪重负。后来 Netgear 发布了升级固件,但是,升级他们的设备的用户很少,并且他们的其中一些用户的设备,到今天为止,还在不停地每秒钟查询一次 University of Wisconsin-Madison 的 NTP 服务器。Netgear 给 University of Wisconsin-Madison 捐献了一些钱,以帮助弥补他们带来的成本增加,直到这些路由器全部淘汰。类似的事件还有 D-Link、Snapchat、TP-Link 等等。
|
||||
消费类网络设备的供应商因制造了大混乱而臭名昭著。我回想起的第一件事发生在 2003 年,那时,NetGear 在它们的路由器中硬编码了威斯康星大学的 NTP 时间服务器地址。使得时间服务器的查询请求突然增加,随着 NetGear 卖出越来越多的路由器,这种情况越发严重。更有意思的是,路由器的程序设置是每秒钟发送一次请求,这将使服务器难堪重负。后来 Netgear 发布了升级固件,但是,升级他们的设备的用户很少,并且他们的其中一些用户的设备,到今天为止,还在不停地每秒钟查询一次威斯康星大学的 NTP 服务器。Netgear 给威斯康星大学捐献了一些钱,以帮助弥补他们带来的成本增加,直到这些路由器全部淘汰。类似的事件还有 D-Link、Snapchat、TP-Link 等等。
|
||||
|
||||
对 NTP 协议进行反射和放大,已经成为发起 DDoS 攻击的一个选择。当攻击者使用一个伪造的源地址向目标受害者发送请求,称为反射;攻击者发送请求到多个服务器,这些服务器将回复请求,这样就使伪造的地址受到轰炸。放大是指一个很小的请求收到大量的回复信息。例如,在 Linux 上,`ntpq` 命令是一个查询你的 NTP 服务器并验证它们的系统时间是否正确的很有用的工具。一些回复,比如,对端列表,是非常大的。组合使用反射和放大,攻击者可以将 10 倍甚至更多带宽的数据量发送到被攻击者。
|
||||
对 NTP 协议进行反射和放大,已经成为发起 DDoS 攻击的一个选择。当攻击者使用一个伪造的目标受害者的源地址向时间服务器发送请求,称为反射攻击;攻击者发送请求到多个服务器,这些服务器将回复请求,这样就使伪造的源地址受到轰炸。放大攻击是指一个很小的请求收到大量的回复信息。例如,在 Linux 上,`ntpq` 命令是一个查询你的 NTP 服务器并验证它们的系统时间是否正确的很有用的工具。一些回复,比如,对端列表,是非常大的。组合使用反射和放大,攻击者可以将 10 倍甚至更多带宽的数据量发送到被攻击者。
|
||||
|
||||
那么,如何保护提供公益服务的公共 NTP 服务器呢?从使用 NTP 4.2.7p26 或者更新的版本开始,它们可以帮助你的 Linux 发行版不会发生前面所说的这种问题,因为它们都是在 2010 年以后发布的。这个发行版都默认禁用了最常见的滥用攻击。目前,[最新版本是 4.2.8p10][2],它发布于 2017 年。
|
||||
|
||||
你可以采用的另一个措施是,在你的网络上启用入站和出站过滤器。阻塞进入你的网络的数据包,以及拦截发送到伪造地址的出站数据包。入站过滤器帮助你,而出站过滤器则帮助你和其他人。阅读 [BCP38.info][3] 了解更多信息。
|
||||
你可以采用的另一个措施是,在你的网络上启用入站和出站过滤器。阻塞宣称来自你的网络的数据包进入你的网络,以及拦截发送到伪造返回地址的出站数据包。入站过滤器可以帮助你,而出站过滤器则帮助你和其他人。阅读 [BCP38.info][3] 了解更多信息。
|
||||
|
||||
### 层级为 0、1、2 的时间服务器
|
||||
|
||||
NTP 有超过 30 年的历史了,它是至今还在使用的最老的因特网协议之一。它的用途是保持计算机与协调世界时间(UTC)的同步。NTP 网络是分层组织的,并且同层的设备是对等的。层次 0 包含主守时设备,比如,原子钟。层级 1 的时间服务器与层级 0 的设备同步。层级 2 的设备与层级 1 的设备同步,层级 3 的设备与层级 2 的设备同步。NTP 协议支持 16 个层级,现实中并没有使用那么多的层级。同一个层级的服务器是相互对等的。
|
||||
NTP 有超过 30 年的历史了,它是至今还在使用的最老的因特网协议之一。它的用途是保持计算机与世界标准时间(UTC)的同步。NTP 网络是分层组织的,并且同层的设备是对等的。<ruby>层次<rt>Stratum</rt></ruby> 0 包含主报时设备,比如,原子钟。层级 1 的时间服务器与层级 0 的设备同步。层级 2 的设备与层级 1 的设备同步,层级 3 的设备与层级 2 的设备同步。NTP 协议支持 16 个层级,现实中并没有使用那么多的层级。同一个层级的服务器是相互对等的。
|
||||
|
||||
过去很长一段时间内,我们都为客户端选择配置单一的 NTP 服务器,而现在更好的做法是使用 [NTP 服务器地址池][4],它使用往返的 DNS 信息去共享负载。池地址只是为客户端服务的,比如单一的 PC 和你的本地局域网 NTP 服务器。当你运行一台自己的公共服务器时,你不能使用这些池中的地址。
|
||||
过去很长一段时间内,我们都为客户端选择配置单一的 NTP 服务器,而现在更好的做法是使用 [NTP 服务器地址池][4],它使用轮询的 DNS 信息去共享负载。池地址只是为客户端服务的,比如单一的 PC 和你的本地局域网 NTP 服务器。当你运行一台自己的公共服务器时,你不用使用这些池地址。
|
||||
|
||||
### 公共 NTP 服务器配置
|
||||
|
||||
运行一台公共 NTP 服务器只有两步:设置你的服务器,然后加入到 NTP 服务器池。运行一台公共的 NTP 服务器是一种很高尚的行为,但是你得先知道如何加入到 NTP 服务器池中。加入 NTP 服务器池是一种长期责任,因为即使你加入服务器池后,运行了很短的时间马上退出,然后接下来的很多年你仍然会接收到请求。
|
||||
运行一台公共 NTP 服务器只有两步:设置你的服务器,然后申请加入到 NTP 服务器池。运行一台公共的 NTP 服务器是一种很高尚的行为,但是你得先知道这意味着什么。加入 NTP 服务器池是一种长期责任,因为即使你加入服务器池后,运行了很短的时间马上退出,然后接下来的很多年你仍然会接收到请求。
|
||||
|
||||
你需要一个静态的公共 IP 地址,一个至少 512Kb/s 带宽的、可靠的、持久的因特网连接。NTP 使用的是 UDP 的 123 端口。它对机器本身要求并不高,很多管理员在其它的面向公共的服务器(比如,Web 服务器)上顺带架设了 NTP 服务。
|
||||
|
||||
配置一台公共的 NTP 服务器与配置一台用于局域网的 NTP 服务器是一样的,只需要几个配置。我们从阅读 [协议规则][5] 开始。遵守规则并注意你的行为;几乎每个时间服务器的维护者都是像你这样的志愿者。然后,从 [StratumTwoTimeServers][6] 中选择 2 台层级为 4-7 的上游服务器。选择的时候,选取地理位置上靠近(小于 300 英里的)你的因特网服务提供商的上游服务器,阅读他们的访问规则,然后,使用 `ping` 和 `mtr` 去找到延迟和跳数最小的服务器。
|
||||
配置一台公共的 NTP 服务器与配置一台用于局域网的 NTP 服务器是一样的,只需要几个配置。我们从阅读 [协议规则][5] 开始。遵守规则并注意你的行为;几乎每个时间服务器的维护者都是像你这样的志愿者。然后,从 [StratumTwoTimeServers][6] 中选择 4 到 7 个层级 2 的上游服务器。选择的时候,选取地理位置上靠近(小于 300 英里的)你的因特网服务提供商的上游服务器,阅读他们的访问规则,然后,使用 `ping` 和 `mtr` 去找到延迟和跳数最小的服务器。
|
||||
|
||||
以下的 `/etc/ntp.conf` 配置示例文件,包括了 IPv4 和 IPv6,以及基本的安全防护:
|
||||
|
||||
```
|
||||
# stratum 2 server list
|
||||
server servername_1 iburst
|
||||
@ -47,10 +48,10 @@ restrict -6 default kod noquery nomodify notrap nopeer limited
|
||||
# Allow ntpq and ntpdc queries only from localhost
|
||||
restrict 127.0.0.1
|
||||
restrict ::1
|
||||
|
||||
```
|
||||
|
||||
启动你的 NTP 服务器,让它运行几分钟,然后测试它对远程服务器的查询:
|
||||
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
@ -63,21 +64,21 @@ $ ntpq -p
|
||||
```
|
||||
|
||||
目前表现很好。现在从另一台 PC 上使用你的 NTP 服务器名字进行测试。以下的示例是一个正确的输出。如果有不正确的地方,你将看到一些错误信息。
|
||||
|
||||
```
|
||||
$ ntpdate -q _yourservername_
|
||||
$ ntpdate -q yourservername
|
||||
server 66.96.99.10, stratum 2, offset 0.017690, delay 0.12794
|
||||
server 98.191.213.2, stratum 1, offset 0.014798, delay 0.22887
|
||||
server 173.49.198.27, stratum 2, offset 0.020665, delay 0.15012
|
||||
server 129.6.15.28, stratum 1, offset -0.018846, delay 0.20966
|
||||
26 Jan 11:13:54 ntpdate[17293]: adjust time server 98.191.213.2 offset 0.014798 sec
|
||||
|
||||
```
|
||||
|
||||
一旦你的服务器运行的很好,你就可以向 [manage.ntppool.org][7] 申请加入池中。
|
||||
|
||||
查看官方的手册 [分布式网络时间服务器(NTP)][8] 学习所有的命令、配置选项、以及高级特性,比如,管理、查询、和验证。访问以下的站点学习关于运行一台时间服务器所需要的一切东西。
|
||||
查看官方的手册 [分布式网络时间服务器(NTP)][8] 学习所有的命令、配置选项、以及高级特性,比如,管理、查询、和验证。访问以下的站点学习关于运行一台时间服务器所需要的一切东西。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][9] 学习更多 Linux 的知识。
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][9] 学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -85,12 +86,12 @@ via: https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-t
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
|
||||
[1]:https://linux.cn/article-9462-1.html
|
||||
[2]:http://www.ntp.org/downloads.html
|
||||
[3]:http://www.bcp38.info/index.php/Main_Page
|
||||
[4]:http://www.pool.ntp.org/en/use.html
|
||||
@ -1,11 +1,11 @@
|
||||
如何在命令行上编辑文件?-- 三个命令行编辑器使用教程
|
||||
快捷教程:如何在命令行上编辑文件
|
||||
======
|
||||
|
||||
此次教程中,我们将向您展示三种命令行编辑文件的方式。本文一共覆盖了三种命令行编辑器,vi(或 vim)、nano 和 emacs。
|
||||
|
||||
#### 在命令行上使用 Vi 或 Vim 编辑文件
|
||||
### 在命令行上使用 Vi 或 Vim 编辑文件
|
||||
|
||||
您可以使用 vi 编辑文件。运行如下命令,打开文件:
|
||||
您可以使用 `vi` 编辑文件。运行如下命令,打开文件:
|
||||
|
||||
```
|
||||
vi /path/to/file
|
||||
@ -13,13 +13,13 @@ vi /path/to/file
|
||||
|
||||
现在,您可以看见文件中的内容了(如果文件存在。请注意,如果此文件不存在,该命令会创建文件)。
|
||||
|
||||
vi 最重要的命令莫过于此:
|
||||
`vi` 最重要的命令莫过于此:
|
||||
|
||||
键入 `i` 进入 `Insert`(编辑)模式。如此,您可以编辑文本。
|
||||
键入 `i` 进入<ruby>编辑<rt>Insert</rt></ruby>模式。如此,您可以编辑文本。
|
||||
|
||||
退出编辑模式请键入 `ESC`。
|
||||
|
||||
正处于光标之下的字符,使用 `x` 键删除(您千万不要在编辑模式这样做,如果您这样做了,将不会删除光标下的字符,而是会在光标下插入 `x` 字符)。因此,当您仅仅使用 vi 打开文本(此时默认进入指令模式),此时您可以使用 `x` 键立即删除字符。在编辑模式下,您需要键入 `ESC` 退出编辑模式。
|
||||
正处于光标之下的字符,使用 `x` 键删除(您千万不要在编辑模式这样做,如果您这样做了,将不会删除光标下的字符,而是会在光标下插入 `x` 字符)。因此,当您仅仅使用 `vi` 打开文本(LCTT 译注:此时默认进入指令模式),此时您可以使用 `x` 键立即删除字符。在编辑模式下,您需要键入 `ESC` 退出编辑模式。
|
||||
|
||||
如果您做了修改,想要保存文件,请键入 `:x`(同样,您不能在编辑模式执行此操作。请按 `ESC` 退出编辑模式,完成此操作)。
|
||||
|
||||
@ -29,19 +29,19 @@ vi 最重要的命令莫过于此:
|
||||
|
||||
请注意在上述所有操作中,您都可以使用方向键操控光标在文本中的位置。
|
||||
|
||||
以上所有都是 vi 编辑器的内容。请注意,vim 编辑器或多或少也会支持这些操作,如果您有深层次了解 vim 的需求,请看 [这里][1]。
|
||||
以上所有都是 `vi` 编辑器的内容。请注意,`vim` 编辑器或多或少也会支持这些操作,如果您想深层次了解 `vim`,请看 [这里][1]。
|
||||
|
||||
#### 使用 Nano 命令行编辑器编辑文件
|
||||
### 使用 Nano 命令行编辑器编辑文件
|
||||
|
||||
接下来是 Nano 编辑器。您可以执行 'nano' 命令调用它:
|
||||
接下来是 Nano 编辑器。您可以执行 `nano` 命令调用它:
|
||||
|
||||
```
|
||||
nano
|
||||
```
|
||||
|
||||
这里是 nano 的用户界面:
|
||||
这里是 `nano` 的用户界面:
|
||||
|
||||
[![Nano 命令行编辑器][2]][3]
|
||||
![Nano 命令行编辑器][3]
|
||||
|
||||
您同样可以使用它启动文件。
|
||||
|
||||
@ -55,105 +55,105 @@ nano [filename]
|
||||
nano test.txt
|
||||
```
|
||||
|
||||
[![在 nano 中打开文件][4]][5]
|
||||
![在 nano 中打开文件][5]
|
||||
|
||||
如您所见的用户界面,大致被分成四个部分。编辑器顶部显示编辑器版本、正在编辑的文件和编辑状态。然后是实际编辑区域,在这里,您能看见文件的内容。编辑器下方高亮区展示着重要的信息,最后两行显示能执行基础任务地快捷键,切实地帮助初学者。
|
||||
|
||||
这里是您前期应当了解的快捷键快表。
|
||||
|
||||
使用方向键浏览文本,退格键删除文本,**Ctrl+o** 保存文件修改。当您尝试保存时,nano 会征询您的确认(请参阅截图中主编辑器下方区域):
|
||||
使用方向键浏览文本,退格键删除文本,`Ctrl+O` 保存文件修改。当您尝试保存时,`nano` 会征询您的确认(请参阅截图中主编辑器下方区域):
|
||||
|
||||
[![在 nano 中保存文件][6]][7]
|
||||
![在 nano 中保存文件][7]
|
||||
|
||||
注意,在这个阶段,您有一个选项,可以保存不同的系统格式。键入 **Altd+d** 选择 DOS 格式,**Atl+m** 选择 Mac 格式。
|
||||
注意,在这个阶段,您有一个选项,可以保存不同的系统格式。键入 `Alt+D` 选择 DOS 格式,`Atl+M` 选择 Mac 格式。
|
||||
|
||||
[![以 DOS 格式保存文件][8]][9]
|
||||
![以 DOS 格式保存文件][9]
|
||||
|
||||
敲回车保存更改。
|
||||
|
||||
[![文件已经被保存][10]][11]
|
||||
![文件已经被保存][11]
|
||||
|
||||
继续,文本剪切使用 **Ctrl+K**,文本复制使用 **Ctrl+u**。这些快捷键同样可以用来粘贴剪切单个单词,但您需要先选择好单词,通常,您可以通过键入 **Alt+A**(光标在第一个单词下) 然后使用方向键选择完整的单词。
|
||||
继续,文本剪切使用 `Ctrl+K`,文本复制使用 `Ctrl+U`。这些快捷键同样可以用来粘贴剪切单个单词,但您需要先选择好单词,通常,您可以通过键入 `Alt+A`(光标在第一个单词下) 然后使用方向键选择完整的单词。
|
||||
|
||||
现在来进行搜索操作。使用 **Ctrl+w** 可以执行一个简单的搜索,同时搜索和替换您可以使用 **Ctrl+\\**。
|
||||
现在来进行搜索操作。使用 `Ctrl+W` 可以执行一个简单的搜索,同时搜索和替换您可以使用 `Ctrl+\\`。
|
||||
|
||||
[![使用 nano 在文件中搜索][12]][13]
|
||||
![使用 nano 在文件中搜索][13]
|
||||
|
||||
这些就是 nano 的一些基础功,它能给您带来一些不错的开始,如果您是初次使用 nano 编辑器。更多内容,请阅读我们的完整内容,点击 [这里][14]。
|
||||
这些就是 `nano` 的一些基础功,它能给您带来一些不错的开始,如果您是初次使用 `nano` 编辑器。更多内容,请阅读我们的完整内容,点击 [这里][14]。
|
||||
|
||||
#### 使用 Emacs 命令行编辑器编辑文件
|
||||
### 使用 Emacs 命令行编辑器编辑文件
|
||||
|
||||
接下来登场的是 **Emacs**。如果系统未安装此软件,您可以使用下面的命令在您的系统中安装它:
|
||||
接下来登场的是 Emacs。如果系统未安装此软件,您可以使用下面的命令在您的系统中安装它:
|
||||
|
||||
```
|
||||
sudo apt-get install emacs
|
||||
```
|
||||
|
||||
和 nano 一致,您可以使用下面的方式在 emacs 中直接打开文件:
|
||||
和 `nano` 一致,您可以使用下面的方式在 `emacs` 中直接打开文件:
|
||||
|
||||
```
|
||||
emacs -nw [filename]
|
||||
```
|
||||
|
||||
**注意**:**-nw** 选项确保 emacs 在本窗口启动,而不是打开一个新窗口,默认情况下,它会打开一个新窗口。
|
||||
注意:`-nw` 选项确保 `emacs` 在本窗口启动,而不是打开一个新窗口,默认情况下,它会打开一个新窗口。
|
||||
|
||||
一个实例:
|
||||
|
||||
```
|
||||
emacs -nw test.txt
|
||||
|
||||
```
|
||||
|
||||
下面是编辑器的用户界面:
|
||||
|
||||
[![在 emacs 中打开文件][15]][16]
|
||||
![在 emacs 中打开文件][16]
|
||||
|
||||
和 nano 一样,emacs 的界面同样被分割成了几个部分。第一部分是最上方的菜单区域,和您在图形界面下的应用程序一致。接下来是显示文本(您打开的文件文本)内容的主编辑区域。
|
||||
和 `nano` 一样,`emacs` 的界面同样被分割成了几个部分。第一部分是最上方的菜单区域,和您在图形界面下的应用程序一致。接下来是显示文本(您打开的文件文本)内容的主编辑区域。
|
||||
|
||||
编辑区域下方坐落着另一个高亮菜单条,显示了文件名,编辑模式(如截图内的‘Text’)和状态(** 已修改,- 未修改,%% 只读状态)。最后是提供输入指令的区域,同时也能查看输出。
|
||||
编辑区域下方坐落着另一个高亮菜单条,显示了文件名,编辑模式(如截图内的 ‘Text’)和状态(`**` 为已修改,`-` 为未修改,`%%` 为只读)。最后是提供输入指令的区域,同时也能查看输出。
|
||||
|
||||
现在开始基础操作,当您做了修改、想要保存时,在 **Ctrl+x** 之后键入 **Ctrl+s**。最后,在面板最后一行会向您显示一些信息:‘**Wrote ........’。这里有一个例子:
|
||||
现在开始基础操作,当您做了修改、想要保存时,在 `Ctrl+x` 之后键入 `Ctrl+s`。最后,在面板最后一行会向您显示一些信息:‘Wrote ........’。这里有一个例子:
|
||||
|
||||
[![emascs 中保存文件][17]][18]
|
||||
![emascs 中保存文件][18]
|
||||
|
||||
现在,如果您放弃修改并且退出时,在 **Ctrl+x** 之后键入**Ctrl+c**。编辑器将会立即询问,如下图:
|
||||
现在,如果您放弃修改并且退出时,在 `Ctrl+x` 之后键入`Ctrl+c`。编辑器将会立即询问,如下图:
|
||||
|
||||
[![emacs 中抛弃修改][19]][20]
|
||||
![emacs 中抛弃修改][20]
|
||||
|
||||
输入 ‘n’ 之后键入 ‘yes’,之后编辑器将会不保存而直接退出。
|
||||
输入 `n` 之后键入 `yes`,之后编辑器将会不保存而直接退出。
|
||||
|
||||
请注意,Emacs 中 ‘C’ 代表 ‘Ctrl’,‘M’ 代表 ‘Alt’。比如,当你看见 C-x,这意味着 Ctrl+x。
|
||||
请注意,Emacs 中 `C` 代表 `Ctrl`,`M` 代表 `Alt`。比如,当你看见 `C-x`,这意味着按下 `Ctrl+x`。
|
||||
|
||||
至于其他基本编辑器操作,以删除为例,大多数人都会,使用 Backspace/Delete 键。然而,这里的一些删除快捷键能够提高用户体验。比如,使用 **Ctrl+k** 删除一整行,**Alt+d** 删除一个单词,**Alt+k** 删除一个整句。
|
||||
至于其他基本编辑器操作,以删除为例,大多数人都会,使用 `Backspace`/`Delete` 键。然而,这里的一些删除快捷键能够提高用户体验。比如,使用 `Ctrl+k` 删除一整行,`Alt+d` 删除一个单词,`Alt+k` 删除一个整句。
|
||||
|
||||
在键入 ‘ **Ctrl+k** ’ 之后键入 ‘ **u** ’ 将不会生效,输入 **Ctrl+g** 之后输入 **Crel+_** 撤销操作。使用 **Crel+s** 向前搜索,**Ctrl+r** 反向搜索。
|
||||
在键入 `Ctrl+k` 之后键入 `u` 将撤销操作,输入 `Ctrl+g` 之后输入 `Ctrl+_` 恢复撤销的操作。使用 `Ctrl+s` 向前搜索,`Ctrl+r` 反向搜索。
|
||||
|
||||
[![使用 emacs 在文件中搜索][21]][22]
|
||||
![使用 emacs 在文件中搜索][22]
|
||||
|
||||
继续,使用 Alt+Shift+% 执行替换操作。您将被询问替换单词。回复并回车。之后编辑器将会询问您是否替换。例如,下方截图展示了 emacs 询问使用者关于单词 ‘This’ 的替换操作。
|
||||
继续,使用 `Alt+Shift+%` 执行替换操作。您将被询问要替换单词。回复并回车。之后编辑器将会询问您是否替换。例如,下方截图展示了 `emacs` 询问使用者关于单词 ‘This’ 的替换操作。
|
||||
|
||||
[![使用 emacs 替换单词][23]][24]
|
||||
![使用 emacs 替换单词][24]
|
||||
|
||||
输入替换文本并回车。每一个替换操作 emacs 都会等待询问,下面是首次询问:
|
||||
输入替换文本并回车。每一个替换操作 `emacs` 都会等待询问,下面是首次询问:
|
||||
|
||||
[![确定文本替换][25]][26]
|
||||
![确定文本替换][26]
|
||||
|
||||
键入 'y' 之后,单词将会被替换。
|
||||
键入 `y` 之后,单词将会被替换。
|
||||
|
||||
[![键入 y 确定操作][27]][28]
|
||||
![键入 y 确定操作][28]
|
||||
|
||||
这些就是几乎所有的基础操作,您在开始使用 emacs 时需要了解掌握的。对了,我们忘记讨论如何访问顶部菜单,其实这些可以通过使用 F10 访问它们。
|
||||
这些就是几乎所有的基础操作,您在开始使用 `emacs` 时需要了解掌握的。对了,我们忘记讨论如何访问顶部菜单,其实这些可以通过使用 `F10` 访问它们。
|
||||
|
||||
[![基础编辑器操作][29]][30]
|
||||
![基础编辑器操作][30]
|
||||
|
||||
按 Esc 键三次,退出这些菜单。
|
||||
按 `Esc` 键三次,退出这些菜单。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/faq/how-to-edit-files-on-the-command-line
|
||||
|
||||
作者:[falko][a]
|
||||
作者:[Falko Timme, Himanshu Arora][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user