mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
d224f895ed
@ -0,0 +1,109 @@
|
||||
使用统一阻止列表和白名单来更新主机文件
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
网上有许多持续维护的含有不同垃圾域的有用列表。将这些列表复制到你的主机文件中可以轻松阻止大量的域,你的系统将根本不用去连接它们。此方法可以在不安装浏览器插件的情况下工作,并且将为系统上任何浏览器(和任何其他程序)提供阻止操作。
|
||||
|
||||
在本教程中,我将向你展示如何在 Linux 中启动并运行 Steven Black 的[统一主机脚本][1]。该脚本将使用来自多个来源的最新已知的广告服务器、网络钓鱼网站和其他网络垃圾的地址来更新你的计算机主机文件,同时提供一个漂亮、干净的方式来管理你自己的黑名单/白名单,其分别来自于该脚本管理的各个列表。
|
||||
|
||||
在将 30,000 个域放入主机文件之前,需要注意两点。首先,这些巨大的列表包含可能需要解除封锁的服务器,以便进行在线购买或其他一些临时情况。如果你弄乱了你的主机文件,你要知道网上的某些东西可能会出现问题。为了解决这个问题,我将向你展示如何使用方便的打开/关闭开关,以便你可以快速禁用你的阻止列表来购买喜马拉雅盐雾灯(它是等离子灯)。我仍然认为这些列表的目的之一是将所有的一切都封锁(有点烦人,直到我想到了做一个关闭开关)。如果你经常遇到你需要的服务器被阻止的问题,只需将其添加到白名单文件中即可。
|
||||
|
||||
第二个问题是性能受到了轻微的影响, 因为每次调用一个域时, 系统都必须检查整个列表。只是有一点点影响, 而没有大到让我因此而放弃黑名单,让每一个连接都通过。你具体要怎么选择自己看着办。
|
||||
|
||||
主机文件通过将请求定向到 127.0.0.1 或 0.0.0.0(换句话说定向到空地址)来阻止请求。有人说使用 0.0.0.0 是更快,问题更少的方法。你可以将脚本配置为使用 `-ip nnn.nnn.nnn.nnn` 这样的 ip 选项来作为阻止 ip,但默认值是 0.0.0.0,这是我使用的值。
|
||||
|
||||
我曾经将 Steven Black 的脚本做的事每隔一段时间就手动做一遍,进到每一个站点,将他们的列表拷贝/粘贴到我的主机文件中,做一个查找替换将其中的 127 变成 0 等等。我知道整件事情可以自动化,这样做有点傻,但我从来没有花时间解决这个问题。直到我找到这个脚本,现在这事已经是一个被遗忘的杂务。
|
||||
|
||||
让我们先下载一份最新的 Steven Black 的代码拷贝(大约 150MB),以便我们可以进行下一步。你需要安装 git,因此如果还没安装,进入到终端输入:
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
安装完之后,输入:
|
||||
|
||||
```
|
||||
mkdir unifiedhosts
|
||||
cd unifiedhosts
|
||||
git clone https://github.com/StevenBlack/hosts.git
|
||||
cd hosts
|
||||
```
|
||||
|
||||
当你打开了 Steven 的脚本时,让我们来看看有什么选项。该脚本有几个选项和扩展,但扩展我不会在这里提交,但如果你到了这一步并且你有兴趣,[readme.md][3] 可以告诉你所有你需要知道的。
|
||||
|
||||
你需要安装 python 来运行此脚本,并且与版本有关。要找到你安装的 Python 版本,请输入:
|
||||
|
||||
```
|
||||
python --version
|
||||
```
|
||||
|
||||
如果你还没安装 Python:
|
||||
|
||||
```
|
||||
sudo apt-get install python
|
||||
```
|
||||
|
||||
对于 Python 2.7,如下所示,输入 `python` 来执行脚本。对于 Python 3,在命令中的 `python` 替换成 `python3`。执行后,该脚本会确保它具有每个列表的最新版本,如果没有,它会抓取一个新的副本。然后,它会写入一个新的主机文件,包括了你的黑名单/白名单中的任何内容。让我们尝试使用 `-r` 选项来替换我们的当前的主机文件,而 `-a` 选项可以脚本不会问我们任何问题。回到终端:
|
||||
|
||||
```
|
||||
python updateHostsFile.py -r -a
|
||||
```
|
||||
|
||||
该命令将询问你的 root 密码,以便能够写入 `/etc/`。为了使新更新的列表处于激活状态,某些系统需要清除 DNS 缓存。在同一个硬件设备上,我观察到不同的操作系统表现出非常不同的行为,在没有刷新缓存的情况下不同的服务器变为可访问/不可访问所需的时间长度都不同。我已经看到了从即时更新(Slackware)到重启更新(Windows)的各种情况。有一些命令可以刷新 DNS 缓存,但是它们在每个操作系统甚至每个发行版上都不同,所以如果没有生效,只需要重新启动就行了。
|
||||
|
||||
现在,只要将你的个人例外添加到黑名单/白名单中,并且只要你想要更新主机文件,运行该脚本就好。该脚本将根据你的要求调整生成的主机文件,每次运行文件时会自动追加你额外的列表。
|
||||
|
||||
最后,我们来创建一个打开/关闭开关,对于打开和关闭功能每个都创建一个脚本,所以回到终端输入下面的内容创建关闭开关(用你自己的文本编辑器替换 leafpad):
|
||||
|
||||
```
|
||||
leafpad hosts-off.sh
|
||||
```
|
||||
|
||||
在新文件中输入下面的内容:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
sudo mv /etc/hosts /etc/hostsDISABLED
|
||||
```
|
||||
|
||||
接着让它可执行:
|
||||
|
||||
```
|
||||
chmod +x hosts-off.sh
|
||||
```
|
||||
|
||||
相似地,对于打开开关:
|
||||
|
||||
```
|
||||
leafpad hosts-on.sh
|
||||
```
|
||||
在新文件中输入下面的内容:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
sudo mv /etc/hostsDISABLED /etc/hosts
|
||||
```
|
||||
|
||||
最后让它可执行:
|
||||
|
||||
```
|
||||
chmod +x hosts-on.sh
|
||||
```
|
||||
|
||||
你所需要做的是为每个脚本创建一个快捷方式,标记为 HOSTS-ON 和 HOSTS-OFF,放在你能找到它们的地方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.darrentoback.com/this-script-updates-hosts-files-using-a-multi-source-unified-block-list-with-whitelisting
|
||||
|
||||
作者:[dmt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.darrentoback.com/about-me
|
||||
[1]:https://github.com/StevenBlack/hosts
|
||||
[2]:https://github.com/StevenBlack/hosts.git
|
||||
[3]:https://github.com/StevenBlack/hosts/blob/master/readme.md
|
||||
93
published/201707/20170213 The decline of GPL.md
Normal file
93
published/201707/20170213 The decline of GPL.md
Normal file
@ -0,0 +1,93 @@
|
||||
GPL 没落了吗?
|
||||
===================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
不久之前我看到了 RedMonk 的 Stephen O'Grady 发了一个[关于开源协议][2]的有趣的推特,那个推特里面有这张图。
|
||||
|
||||

|
||||
|
||||
这张图片显示了从 2010 到 2017 年间各种开源协议之间的使用率的变化。在这张图片里,显然 GPL 2.0 —— 最纯净的 copyleft 协议之一 —— 的使用率降低了一多半。该图表表明,开源项目中 [MIT][3] 协议和 [Apache][4] 协议开始受欢迎。[GPL 3.0][5] 的使用率也有所上涨。
|
||||
|
||||
这些意味着什么?
|
||||
|
||||
为什么 GPL 2.0 的使用率跌的这么多但是 GPL 3.0 仅仅是涨了一丁点?为什么 MIT 协议和 Apache 协议的使用率涨了那么多?
|
||||
|
||||
当然,有很多原因可以解释这件事情,但是我想这是因为商业开源项目的增多,以及商业社会对于 GPL 协议的担心导致的,我们细细掰扯。
|
||||
|
||||
### GPL 协议与商业社会
|
||||
|
||||
我知道我要说的可能会激怒一些 GPL 粉,所以在你们开始喷之前,我想说明的是:我支持 GPL,我也是 GPL 粉丝。
|
||||
|
||||
我写过的所有软件都使用的是 GPL 协议,我也是一直是积极出资支持 [自由软件基金会][6] 以及 [软件自由保护组织][7] 以及他们的工作的,我支持使用 GPL 协议。我在这说的无关 GPL 的合法性或者 GPL 的巨大价值 —— 毫无疑问这是一个好协议 —— 我在这要说的是业内对于这个协议的看法。
|
||||
|
||||
大概四年之前,我参加了一个叫做<ruby>开源智库<rt>Open Source Think Tank</rt></ruby>的峰会。这个峰会是一个私人小型峰会,每年都会把各大开源企业的管理人员请到加利福尼亚的酒庄。这个峰会聚焦于建立关系、构建联盟,找到并解决行业问题。
|
||||
|
||||
在这个峰会上,有一个分组研究,在其中,与会者被分成小组,被要求给一个真实存在的核心的开源技术推荐一个开源协议。每个小组都给出了回应。不到十分之一的小组推荐了宽容许可证,没有人推荐 GPL 许可证。
|
||||
|
||||
我看到了开源行业对于 Apache 协议以及 MIT 协议的逐步认可,但是他们却对花时间理解、接受和熟悉 GPL 这件事高高挂起。
|
||||
|
||||
在这几年里,这种趋势仍在蔓延。除了 Black Duck 的调查之外, 2015 年 [GitHub 上的开源协议调查][8] 也显示 MIT 是人们的首选。我还能看到,在我工作的 XPRIZE (我们为我们的 [Global Learning XPRIZE][9] 选择了开源协议),在我作为[社区领导顾问][10]的工作方面,我也能感觉到那种倾向,因为越来越多的客户觉得把他们的代码用 GPL 发布不舒服。
|
||||
|
||||
随着 [大约 65% 的公司对开源事业做贡献][11] ,自从 2010 年以后显然开源行业已经引来了不少商业兴趣和投资。我相信,我之前说的那些趋势,已经表明这行业不认为 GPL 适合搞开源生意。
|
||||
|
||||
### 连接社区和公司
|
||||
|
||||
说真的,GPL 的没落不太让人吃惊,因为有如下原因。
|
||||
|
||||
首先,开源行业已经转型升级,它要在社区发展以及……你懂的……真正能赚钱的商业模型中做出均衡,这是它们要做的最重要的决策。在开源思想发展之初,人们有种误解说,“如果你搞出来了,他们就会用”,他们确实会来使用你的软件,但是在很多情况下,都是“如果你搞出来了,他们不是一定要给你钱。”
|
||||
|
||||
随着历史的进程,我们看到了许多公司,比如 Red Hat、Automattic、Docker、Canonical、Digital Ocean 等等等等,探索着在开源领域中赚钱的法子。他们探索过分发模式、服务模式,核心开源模式等等。现在可以确定的是,传统的商业软件赚钱的方式已经不再适用开源软件;因此,你得选择一个能够支持你的公司的经营方式的开源协议。在赚钱和免费提供你的技术之间找到平衡在很多情况下是很困难的一件事。
|
||||
|
||||
这就是我们看到那些变化的原因。尽管 GPL 是一个开源协议,但是它根本上是个自由软件协议,作为自由软件协议,它的管理以及支持是由自由软件基金会提供的。
|
||||
|
||||
我喜欢自由软件基金会的作品,但是他们已经把观点局限于软件必须 100% 绝对自由。对于自由软件基金会没有多少可以妥协的余地,甚至很多出名的开源项目(比如很多 Linux 发行版)仅仅是因为一丁点二进制固件就被认为是 “非自由” 软件。
|
||||
|
||||
对于商业来说,最复杂的是它不是非黑即白的,更多的时候是两者混合的灰色,很少有公司有自由软件基金会(或者类似的组织,比如软件自由保护组织)的那种纯粹的理念,因此我想那些公司也不喜欢选择和那些理念相关的协议。
|
||||
|
||||
我需要说明,我不是在这是说自由软件基金会以及类似的组织(比如软件自由保护组织)的错。他们有着打造完全自由的软件的目标,对于他们来说,走它们选择的路十分合理。自由软件基金会以及软件自由保护组织做了_了不起_的工作,我将继续支持这些组织以及为他们工作的人们。我只是觉得这种对纯粹性的高要求的一个后果就是让那些公司认为自己难以达到要求,因此,他们使用了非 GPL 的其他协议。
|
||||
|
||||
我怀疑 GPL 的使用是随着开源软件增长而变化的。在以前,启动(开源)项目的根本原因之一是对开放性和软件自由的伦理因素的严格关注。GPL 无疑是项目的自然选择,Debian、Ubuntu、Fedora 和 Linux 内核以及很多都是例子。
|
||||
|
||||
近年来,尽管我们已经看到了不再那么挑剔的一代开发者的出现,但是如果我说的过激一些,他们缺少对于自由的关注。对于他们来说开源软件是构建软件的务实、实用的一部分,而无关伦理。我想,这就是为什么我们发现 MIT 和 Apache 协议的流行的原因。
|
||||
|
||||
### 未来 ?
|
||||
|
||||
这对于 GPL 意味着什么?
|
||||
|
||||
我的猜想是 GPL 依然将是一个主要选项,但是开发者将将之视为纯粹的自由软件协议。我想对于软件的纯粹性有高要求的项目会优先选择 GPL 协议。但是对于商业软件,为了保持我们之前讨论过的那种平衡,他们不会那么做。我猜测, MIT 以及 Apache 依然会继续流行下去。
|
||||
|
||||
不管怎样,好消息是开源/自由软件行业确实在增长。无论使用的协议会发生怎样的变化,技术确实变得更加开放,可以接触,人人都能使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jono Bacon - Jono Bacon 是一位领袖级的社区管理者、演讲者、作者和播客主。他是 Jono Bacon 咨询公司的创始人,提供社区战略和执行、开发者流程和其它的服务。他之前任职于 GitHub、Canonical 和 XPRIZE、OpenAdvantage 的社区总监,并为大量的组织提供咨询和顾问服务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/decline-gpl
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jonobacon
|
||||
[1]:https://opensource.com/article/17/2/decline-gpl?rate=WfBHpUyo5BSde1SNTJjuzZTJbjkZTES77tcHwpfTMdU
|
||||
[2]:https://twitter.com/sogrady/status/820001441733607424
|
||||
[3]:https://opensource.org/licenses/MIT
|
||||
[4]:http://apache.org/licenses/
|
||||
[5]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[6]:http://www.fsf.org/
|
||||
[7]:https://sfconservancy.org/
|
||||
[8]:https://github.com/blog/1964-open-source-license-usage-on-github-com
|
||||
[9]:http://learning.xprize.org/
|
||||
[10]:http://www.jonobacon.org/consulting
|
||||
[11]:https://opensource.com/business/16/5/2016-future-open-source-survey
|
||||
[12]:https://opensource.com/user/26312/feed
|
||||
[13]:https://opensource.com/article/17/2/decline-gpl#comments
|
||||
[14]:https://opensource.com/users/jonobacon
|
||||
@ -1,50 +1,47 @@
|
||||
Linux Kernel Utilities (LKU) – A Set Of Shell Scripts To Compile, Install & Update Latest Kernel In Ubuntu/LinuxMint
|
||||
LKU:一套在 Ubuntu/LinuxMint 上编译、安装和更新最新内核的 Shell 脚本
|
||||
============================================================
|
||||
|
||||
以手动方式安装和升级最新的 Linux 内核对于每个人来说都不是一件小事,甚至包括一些有经验的人也是如此。它需要对 Linux 内核有深入的了解。过去我们已经介绍了 UKUU(Ubuntu Kernel Upgrade Utility),它可以从 kernel.ubuntu.com 网站上自动检测最新的主线内核,并弹出一个不错的窗口界面进行安装。
|
||||
|
||||
Installing & Upgrading latest Linux kernel in the manual way is not a small task for everyone, including experience guys. It requires depth knowledge on Linux core. We have already covered in the past about UKUU (Ubuntu Kernel Upgrade Utility) which automatically detect the latest mainline kernel from kernel.ubuntu.com and popup the nice GUI for installation.
|
||||
[Linux Kernel Utilities][2] (LKU)提供一组 shell 脚本(三个 Shell 脚本),可以帮助用户从 kernel.org 获取并编译和安装最新的 Linux 内核,也可以从 kernel.ubuntu.com 获取安装最新的预编译的 Ubuntu 内核。甚至可以根据需要选择所需的内核(手动内核选择)。
|
||||
|
||||
[Linux Kernel Utilities][2] (LKU) offers set of shell scripts (Three Shell Scripts) which help users to compile & install latest Linux kernel from kernel.org, also install precompiled latest Ubuntu kernel from kernel.ubuntu.com. Even it has an option to choose required kernel (manual kernel selection) based on our requirement.
|
||||
该脚本还将根据 PGP 签名文件检查下载的归档文件,并且可以选择通用和低延迟版内核。
|
||||
|
||||
This script will also check the downloaded archive against the PGP signature file and possible to choose generic and lowlatency kernels.
|
||||
建议阅读:[ukuu:一种在基于 Ubuntu 的系统上轻松安装升级 Linux 内核的方式][3]
|
||||
|
||||
Suggested Read : [Ukuu – An Easy Way To Install/Upgrade Linux Kernel In Ubuntu based Systems][3]
|
||||
它可以删除或清除所有非活动的内核,并且不会为了安全目的留下备份的内核。强烈建议在执行此脚本之前重新启动一次。
|
||||
|
||||
It remove/purge all inactive kernels and won’t leave backup kernel for safety purpose. It is highly recommended that a reboot be performed before executing this script.
|
||||
* `compile_linux_kernel.sh` :用户可以从 kernel.org 编译和安装所需的或最新的内核
|
||||
* `update_ubuntu_kernel.sh` :用户可以从 kernel.ubuntu.com 安装并更新所需或最新的预编译 Ubuntu 内核
|
||||
* `remove_old_kernels.sh` :这将删除或清除所有非活动内核,并且只保留当前加载的版本
|
||||
|
||||
* compile_linux_kernel.sh : Users can able to compile & install required or latest kernel from kernel.org
|
||||
kernel.org 有固定的发布周期(每三个月一次),发布的内核包括了新的功能,改进了硬件和系统性能。由于它具有标准的发布周期,除了滚动发布的版本(如 Arch Linux,openSUSE Tumbleweed 等),大多数发行版都不提供最新的内核。
|
||||
|
||||
* update_ubuntu_kernel.sh : Users can able to install & update required or latest precompiled ubuntu kernel from kernel.ubuntu.com
|
||||
### 如何安装 Linux Kernel Utilities (LKU)
|
||||
|
||||
* remove_old_kernels.sh : This will remove/purge all inactive kernels and will keep only the currently loaded version
|
||||
|
||||
Kernel.org has regular release cycle (every three months once) which comes with new features, Improved Hardware & System Performance. Most of the distributions doesn’t offer/include the latest kernel except rolling release distributions such as Arch Linux, openSUSE Tumbleweed, etc., since it has a standard release cycle.
|
||||
|
||||
#### How to Install Linux Kernel Utilities (LKU)
|
||||
|
||||
As we told in the beginning of the article, its set of shell script so just clone the developer github repository and run the appropriate shell file to perform the activity.
|
||||
正如我们在文章的开头所说的,它的 shell 脚本集只是克隆开发人员的 github 仓库并运行相应的 shell 文件来执行这个过程。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/mtompkins/linux-kernel-utilities.git && cd linux-kernel-utilities
|
||||
```
|
||||
|
||||
#### Install Specific kernel
|
||||
### 安装指定版本内核
|
||||
|
||||
For testing purpose we are going to install `Linux v4.4.10-xenial` kernel. Before proceeding the new kernel installation we need to check current installed kernel version with help of `uanme -a` command so that we can check whether the new kernel get installed or not?
|
||||
为了测试的目的,我们将安装 Linux v4.4.10-xenial 内核。在安装新内核之前,我们需要通过 `uanme -a` 命令检查当前安装的内核版本,以便我们可以检查新内核是否可以安装。
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
Linux magi-VirtualBox 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
|
||||
```
|
||||
|
||||
As per the above output, our system has `4.4.0-21-generic` kernel.
|
||||
根据上面的输出,我们的系统使用的是 4.4.0-21 通用内核。
|
||||
|
||||
Just run `update_ubuntu_kernel.sh` shell file. In the very first time script will check whether all dependencies are met or not? and will install missing dependencies automatically. It detect which distribution it is and retrieve Precompiled kernels available from kernel.ubuntu.com. Now, choose your desired kernel from the list and input the value, and hit `Enter` then sit-back because it’s going to download the kernel images (linux-headers-4.4.10, linux-headers-4.4.10-xxx-generic & linux-image-4.4.10-xxx-generic).
|
||||
只需运行 `update_ubuntu_kernel.sh` shell 脚本。第一次运行脚本时会检查是否满足所有的依赖关系,然后自动安装缺少的依赖项。它会检测系统使用的发行版,并检索 kernel.ubuntu.com 中可用的预编译内核。现在,从列表中选择你需要的内核并输入序号,然后按回车键,它将下载内核映像(linux-headers-4.4.10,linux-headers-4.4.10-xxx-generic 和 linux-image-4.4.10-xxx-generic)。
|
||||
|
||||
Once the kernel images get downloaded, it will popup the `sudo` password to start the new kernel installation.
|
||||
一旦内核镜像被下载,它将要求输入 `sudo` 密码来启动新内核的安装。
|
||||
|
||||
```
|
||||
$ ./update_ubuntu_kernel.sh
|
||||
$ ./update_ubuntu_kernel.sh
|
||||
|
||||
[+] Checking Distro
|
||||
\_ Distro identified as LinuxMint.
|
||||
@ -168,7 +165,7 @@ Do you want the lowlatency kernel? (y/[n]):
|
||||
|
||||
[+] Checking AntiVirus flag and disabling if necessary
|
||||
[+] Installing kernel . . .
|
||||
[sudo] password for magi:
|
||||
[sudo] password for magi:
|
||||
Selecting previously unselected package linux-headers-4.4.10-040410.
|
||||
(Reading database ... 230647 files and directories currently installed.)
|
||||
Preparing to unpack linux-headers-4.4.10-040410_4.4.10-040410.201605110631_all.deb ...
|
||||
@ -210,22 +207,22 @@ done
|
||||
\_ Done
|
||||
```
|
||||
|
||||
Post installation do the reboot to use the newly installed kernel.
|
||||
安装后需要重新启动以使用新安装的内核。
|
||||
|
||||
```
|
||||
$ sudo reboot now
|
||||
```
|
||||
|
||||
yes, we are using newly installed kernel `4.4.10-040410-generic`
|
||||
现在,你正在使用的就是新安装的 4.4.10-040410-generic 版本内核。
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
Linux magi-VirtualBox 4.4.10-040410-generic #201605110631 SMP Wed May 11 10:33:23 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
|
||||
```
|
||||
|
||||
#### Install Latest Kernel
|
||||
### 安装最新版本内核
|
||||
|
||||
Its same as above but we don’t want to choose the descried one, its automatically install most recent latest kernel.
|
||||
过程与上述相同,它将自动安装最新版本的内核。
|
||||
|
||||
```
|
||||
$ ./update_ubuntu_kernel.sh --latest
|
||||
@ -269,28 +266,28 @@ done
|
||||
\_ Done
|
||||
```
|
||||
|
||||
Post installation do the reboot to use the newly installed kernel.
|
||||
安装后需要重新启动以使用新安装的内核。
|
||||
|
||||
```
|
||||
$ sudo reboot now
|
||||
```
|
||||
|
||||
yes, we are using newly installed kernel `4.11.3-041103-generic`.
|
||||
现在,你正在使用的就是最新版本 4.11.3-041103-generic 的内核。
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
Linux magi-VirtualBox 4.11.3-041103-generic #201705251233 SMP Thu May 25 16:34:52 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
|
||||
```
|
||||
|
||||
#### Remove/Purge Old Kernel
|
||||
### 删除或清除旧内核
|
||||
|
||||
Just run `remove_old_kernels.sh` shell file to remove/purge all inactive kernels.
|
||||
只需要运行 `remove_old_kernels.sh` shell 脚本即可删除或清除所有非活动状态的内核。
|
||||
|
||||
```
|
||||
$ ./remove_old_kernels.sh
|
||||
$ ./remove_old_kernels.sh
|
||||
|
||||
++++++++++++++++++++++++++++++++
|
||||
+++ W A R N I N G +++
|
||||
+++ W A R N I N G +++
|
||||
++++++++++++++++++++++++++++++++
|
||||
|
||||
A reboot is recommended before running this script to ensure the current kernel tagged
|
||||
@ -303,7 +300,7 @@ You have been warned.
|
||||
|
||||
[?]Continue to automagically remove ALL old kernels? (y/N)y
|
||||
\_ Removing ALL old kernels . . .
|
||||
[sudo] password for magi:
|
||||
[sudo] password for magi:
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
@ -337,9 +334,9 @@ run-parts: executing /etc/kernel/postrm.d/zz-update-grub 4.4.9-040409-lowlatency
|
||||
|
||||
via: http://www.2daygeek.com/lku-linux-kernel-utilities-compile-install-update-latest-kernel-in-linux-mint-ubuntu/
|
||||
|
||||
作者:[ 2DAYGEEK ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,267 @@
|
||||
使用 Kdump 检查 Linux 内核崩溃
|
||||
============================================================
|
||||
|
||||
> 让我们先看一下 kdump 的基本使用方法,和 kdump/kexec 在内核中是如何实现。
|
||||
|
||||

|
||||
|
||||
[kdump][16] 是获取崩溃的 Linux 内核转储的一种方法,但是想找到解释其使用和内部结构的文档可能有点困难。在本文中,我将研究 kdump 的基本使用方法,和 kdump/kexec 在内核中是如何实现。
|
||||
|
||||
[kexec][17] 是一个 Linux 内核到内核的引导加载程序,可以帮助从第一个内核的上下文引导到第二个内核。kexec 会关闭第一个内核,绕过 BIOS 或固件阶段,并跳转到第二个内核。因此,在没有 BIOS 阶段的情况下,重新启动变得更快。
|
||||
|
||||
kdump 可以与 kexec 应用程序一起使用 —— 例如,当第一个内核崩溃时第二个内核启动,第二个内核用于复制第一个内核的内存转储,可以使用 `gdb` 和 `crash` 等工具分析崩溃的原因。(在本文中,我将使用术语“第一内核”作为当前运行的内核,“第二内核” 作为使用 kexec 运行的内核,“捕获内核” 表示在当前内核崩溃时运行的内核。)
|
||||
|
||||
kexec 机制在内核以及用户空间中都有组件。内核提供了几个用于 kexec 重启功能的系统调用。名为 kexec-tools 的用户空间工具使用这些调用,并提供可执行文件来加载和引导“第二内核”。有的发行版还会在 kexec-tools 上添加封装器,这有助于捕获并保存各种转储目标配置的转储。在本文中,我将使用名为 distro-kexec-tools 的工具来避免上游 kexec 工具和特定于发行版的 kexec-tools 代码之间的混淆。我的例子将使用 Fedora Linux 发行版。
|
||||
|
||||
### Fedora kexec-tools 工具
|
||||
|
||||
使用 `dnf install kexec-tools` 命令在 Fedora 机器上安装 fedora-kexec-tools。在安装 fedora-kexec-tools 后可以执行 `systemctl start kdump` 命令来启动 kdump 服务。当此服务启动时,它将创建一个根文件系统(initramfs),其中包含了要挂载到目标位置的资源,以保存 vmcore,以及用来复制和转储 vmcore 到目标位置的命令。然后,该服务将内核和 initramfs 加载到崩溃内核区域内的合适位置,以便在内核崩溃时可以执行它们。
|
||||
|
||||
Fedora 封装器提供了两个用户配置文件:
|
||||
|
||||
1. `/etc/kdump.conf` 指定修改后需要重建 initramfs 的配置参数。例如,如果将转储目标从本地磁盘更改为 NFS 挂载的磁盘,则需要由“捕获内核”所加载的 NFS 相关的内核模块。
|
||||
2. `/etc/sysconfig/kdump` 指定修改后不需要重新构建 initramfs 的配置参数。例如,如果只需修改传递给“捕获内核”的命令行参数,则不需要重新构建 initramfs。
|
||||
|
||||
如果内核在 kdump 服务启动之后出现故障,那么“捕获内核”就会执行,其将进一步执行 initramfs 中的 vmcore 保存过程,然后重新启动到稳定的内核。
|
||||
|
||||
### kexec-tools 工具
|
||||
|
||||
编译 kexec-tools 的源代码得到了一个名为 `kexec` 的可执行文件。这个同名的可执行文件可用于加载和执行“第二内核”,或加载“捕获内核”,它可以在内核崩溃时执行。
|
||||
|
||||
加载“第二内核”的命令:
|
||||
|
||||
```
|
||||
# kexec -l kernel.img --initrd=initramfs-image.img –reuse-cmdline
|
||||
```
|
||||
|
||||
`--reuse-command` 参数表示使用与“第一内核”相同的命令行。使用 `--initrd` 传递 initramfs。 `-l` 表明你正在加载“第二内核”,其可以由 `kexec` 应用程序本身执行(`kexec -e`)。使用 `-l` 加载的内核不能在内核崩溃时执行。为了加载可以在内核崩溃时执行的“捕获内核”,必须传递参数 `-p` 取代 `-l`。
|
||||
|
||||
加载捕获内核的命令:
|
||||
|
||||
```
|
||||
# kexec -p kernel.img --initrd=initramfs-image.img –reuse-cmdline
|
||||
```
|
||||
|
||||
`echo c > /pros/sysrq-trigger` 可用于使内核崩溃以进行测试。有关 kexec-tools 提供的选项的详细信息,请参阅 `man kexec`。在转到下一个部分之前,请看这个 kexec_dump 的演示:
|
||||
|
||||
[kexec_dump_demo (YouTube)](https://www.youtube.com/embed/iOq_rJhrKhA?rel=0&origin=https://opensource.com&enablejsapi=1)
|
||||
|
||||
### kdump: 端到端流
|
||||
|
||||
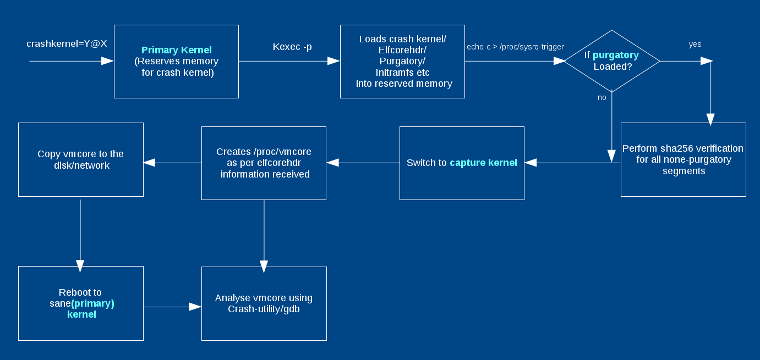
下图展示了流程图。必须在引导“第一内核”期间为捕获内核保留 crashkernel 的内存。您可以在内核命令行中传递 `crashkernel=Y@X`,其中 `@X` 是可选的。`crashkernel=256M` 适用于大多数 x86_64 系统;然而,为崩溃内核选择适当的内存取决于许多因素,如内核大小和 initramfs,以及 initramfs 中包含的模块和应用程序运行时的内存需求。有关传递崩溃内核参数的更多方法,请参阅 [kernel-parameters 文档][18]。
|
||||
|
||||
|
||||
|
||||
您可以将内核和 initramfs 镜像传递给 `kexec` 可执行文件,如(`kexec-tools`)部分的命令所示。“捕获内核”可以与“第一内核”相同,也可以不同。通常,一样即可。Initramfs 是可选的;例如,当内核使用 `CONFIG_INITRAMFS_SOURCE` 编译时,您不需要它。通常,从第一个 initramfs 中保存一个不一样的捕获 initramfs,因为在捕获 initramfs 中自动执行 vmcore 的副本能获得更好的效果。当执行 `kexec` 时,它还加载了 `elfcorehdr` 数据和 purgatory 可执行文件(LCTT 译注:purgatory 就是一个引导加载程序,是为 kdump 定作的。它被赋予了“炼狱”这样一个古怪的名字应该只是一种调侃)。 `elfcorehdr` 具有关于系统内存组织的信息,而 purgatory 可以在“捕获内核”执行之前执行并验证第二阶段的二进制或数据是否具有正确的 SHA。purgatory 也是可选的。
|
||||
|
||||
当“第一内核”崩溃时,它执行必要的退出过程并切换到 purgatory(如果存在)。purgatory 验证加载二进制文件的 SHA256,如果是正确的,则将控制权传递给“捕获内核”。“捕获内核”根据从 `elfcorehdr` 接收到的系统内存信息创建 vmcore。因此,“捕获内核”启动后,您将看到 `/proc/vmcore` 中“第一内核”的转储。根据您使用的 initramfs,您现在可以分析转储,将其复制到任何磁盘,也可以是自动复制的,然后重新启动到稳定的内核。
|
||||
|
||||
### 内核系统调用
|
||||
|
||||
内核提供了两个系统调用:`kexec_load()` 和 `kexec_file_load()`,可以用于在执行 `kexec -l` 时加载“第二内核”。它还为 `reboot()` 系统调用提供了一个额外的标志,可用于使用 `kexec -e` 引导到“第二内核”。
|
||||
|
||||
`kexec_load()`:`kexec_load()` 系统调用加载一个可以在之后通过 `reboot()` 执行的新的内核。其原型定义如下:
|
||||
|
||||
```
|
||||
long kexec_load(unsigned long entry, unsigned long nr_segments,
|
||||
struct kexec_segment *segments, unsigned long flags);
|
||||
```
|
||||
|
||||
用户空间需要为不同的组件传递不同的段,如内核,initramfs 等。因此,`kexec` 可执行文件有助于准备这些段。`kexec_segment` 的结构如下所示:
|
||||
|
||||
```
|
||||
struct kexec_segment {
|
||||
void *buf;
|
||||
/* 用户空间缓冲区 */
|
||||
size_t bufsz;
|
||||
/* 用户空间中的缓冲区长度 */
|
||||
void *mem;
|
||||
/* 内核的物理地址 */
|
||||
size_t memsz;
|
||||
/* 物理地址长度 */
|
||||
};
|
||||
```
|
||||
|
||||
当使用 `LINUX_REBOOT_CMD_KEXEC` 调用 `reboot()` 时,它会引导进入由 `kexec_load` 加载的内核。如果标志 `KEXEC_ON_CRASH` 被传递给 `kexec_load()`,则加载的内核将不会使用 `reboot(LINUX_REBOOT_CMD_KEXEC)` 来启动;相反,这将在内核崩溃中执行。必须定义 `CONFIG_KEXEC` 才能使用 `kexec`,并且为 `kdump` 定义 `CONFIG_CRASH_DUMP`。
|
||||
|
||||
`kexec_file_load()`:作为用户,你只需传递两个参数(即 `kernel` 和 `initramfs`)到 `kexec` 可执行文件。然后,`kexec` 从 sysfs 或其他内核信息源中读取数据,并创建所有段。所以使用 `kexec_file_load()` 可以简化用户空间,只传递内核和 initramfs 的文件描述符。其余部分由内核本身完成。使用此系统调用时应该启用 `CONFIG_KEXEC_FILE`。它的原型如下:
|
||||
|
||||
```
|
||||
long kexec_file_load(int kernel_fd, int initrd_fd, unsigned long
|
||||
cmdline_len, const char __user * cmdline_ptr, unsigned long
|
||||
flags);
|
||||
```
|
||||
|
||||
请注意,`kexec_file_load` 也可以接受命令行,而 `kexec_load()` 不行。内核根据不同的系统架构来接受和执行命令行。因此,在 `kexec_load()` 的情况下,`kexec-tools` 将通过其中一个段(如在 dtb 或 ELF 引导注释等)中传递命令行。
|
||||
|
||||
目前,`kexec_file_load()` 仅支持 x86 和 PowerPC。
|
||||
|
||||
#### 当内核崩溃时会发生什么
|
||||
|
||||
当第一个内核崩溃时,在控制权传递给 purgatory 或“捕获内核”之前,会执行以下操作:
|
||||
|
||||
* 准备 CPU 寄存器(参见内核代码中的 `crash_setup_regs()`);
|
||||
* 更新 vmcoreinfo 备注(请参阅 `crash_save_vmcoreinfo()`);
|
||||
* 关闭非崩溃的 CPU 并保存准备好的寄存器(请参阅 `machine_crash_shutdown()` 和 `crash_save_cpu()`);
|
||||
* 您可能需要在此处禁用中断控制器;
|
||||
* 最后,它执行 kexec 重新启动(请参阅 `machine_kexec()`),它将加载或刷新 kexec 段到内存,并将控制权传递给进入段的执行文件。输入段可以是下一个内核的 purgatory 或开始地址。
|
||||
|
||||
#### ELF 程序头
|
||||
|
||||
kdump 中涉及的大多数转储核心都是 ELF 格式。因此,理解 ELF 程序头部很重要,特别是当您想要找到 vmcore 准备的问题。每个 ELF 文件都有一个程序头:
|
||||
|
||||
* 由系统加载器读取,
|
||||
* 描述如何将程序加载到内存中,
|
||||
* 可以使用 `Objdump -p elf_file` 来查看程序头。
|
||||
|
||||
vmcore 的 ELF 程序头的示例如下:
|
||||
|
||||
```
|
||||
# objdump -p vmcore
|
||||
vmcore:
|
||||
file format elf64-littleaarch64
|
||||
Program Header:
|
||||
NOTE off 0x0000000000010000 vaddr 0x0000000000000000 paddr 0x0000000000000000 align 2**0 filesz
|
||||
0x00000000000013e8 memsz 0x00000000000013e8 flags ---
|
||||
LOAD off 0x0000000000020000 vaddr 0xffff000008080000 paddr 0x0000004000280000 align 2**0 filesz
|
||||
0x0000000001460000 memsz 0x0000000001460000 flags rwx
|
||||
LOAD off 0x0000000001480000 vaddr 0xffff800000200000 paddr 0x0000004000200000 align 2**0 filesz
|
||||
0x000000007fc00000 memsz 0x000000007fc00000 flags rwx
|
||||
LOAD off 0x0000000081080000 vaddr 0xffff8000ffe00000 paddr 0x00000040ffe00000 align 2**0 filesz
|
||||
0x00000002fa7a0000 memsz 0x00000002fa7a0000 flags rwx
|
||||
LOAD off 0x000000037b820000 vaddr 0xffff8003fa9e0000 paddr 0x00000043fa9e0000 align 2**0 filesz
|
||||
0x0000000004fc0000 memsz 0x0000000004fc0000 flags rwx
|
||||
LOAD off 0x00000003807e0000 vaddr 0xffff8003ff9b0000 paddr 0x00000043ff9b0000 align 2**0 filesz
|
||||
0x0000000000010000 memsz 0x0000000000010000 flags rwx
|
||||
LOAD off 0x00000003807f0000 vaddr 0xffff8003ff9f0000 paddr 0x00000043ff9f0000 align 2**0 filesz
|
||||
0x0000000000610000 memsz 0x0000000000610000 flags rwx
|
||||
```
|
||||
|
||||
在这个例子中,有一个 note 段,其余的是 load 段。note 段提供了有关 CPU 信息,load 段提供了关于复制的系统内存组件的信息。
|
||||
|
||||
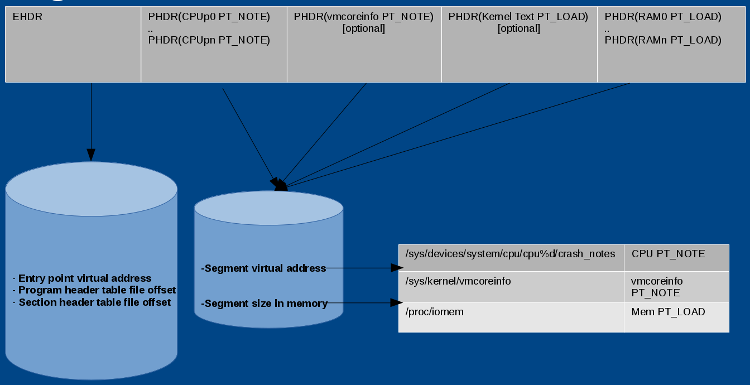
vmcore 从 `elfcorehdr` 开始,它具有与 ELF 程序头相同的结构。参见下图中 `elfcorehdr` 的表示:
|
||||
|
||||
|
||||
|
||||
`kexec-tools` 读取 `/sys/devices/system/cpu/cpu%d/crash_notes` 并准备 `CPU PT_NOTE` 的标头。同样,它读取 `/sys/kernel/vmcoreinfo` 并准备 `vmcoreinfo PT_NOTE` 的标头,从 `/proc/iomem` 读取系统内存并准备存储器 `PT_LOAD` 标头。当“捕获内核”接收到 `elfcorehdr` 时,它从标头中提到的地址中读取数据,并准备 vmcore。
|
||||
|
||||
#### Crash note
|
||||
|
||||
Crash notes 是每个 CPU 中用于在系统崩溃的情况下存储 CPU 状态的区域;它有关于当前 PID 和 CPU 寄存器的信息。
|
||||
|
||||
#### vmcoreinfo
|
||||
|
||||
该 note 段具有各种内核调试信息,如结构体大小、符号值、页面大小等。这些值由捕获内核解析并嵌入到 `/proc/vmcore` 中。 `vmcoreinfo` 主要由 `makedumpfile` 应用程序使用。在 Linux 内核,`include/linux/kexec.h` 宏定义了一个新的 `vmcoreinfo`。 一些示例宏如下所示:
|
||||
|
||||
* `VMCOREINFO_PAGESIZE()`
|
||||
* `VMCOREINFO_SYMBOL()`
|
||||
* `VMCOREINFO_SIZE()`
|
||||
* `VMCOREINFO_STRUCT_SIZE()`
|
||||
|
||||
#### makedumpfile
|
||||
|
||||
vmcore 中的许多信息(如可用页面)都没有用处。`makedumpfile` 是一个用于排除不必要的页面的应用程序,如:
|
||||
|
||||
* 填满零的页面;
|
||||
* 没有私有标志的缓存页面(非专用缓存);
|
||||
* 具有私有标志的缓存页面(专用缓存);
|
||||
* 用户进程数据页;
|
||||
* 可用页面。
|
||||
|
||||
此外,`makedumpfile` 在复制时压缩 `/proc/vmcore` 的数据。它也可以从转储中删除敏感的符号信息; 然而,为了做到这一点,它首先需要内核的调试信息。该调试信息来自 `VMLINUX` 或 `vmcoreinfo`,其输出可以是 ELF 格式或 kdump 压缩格式。
|
||||
|
||||
典型用法:
|
||||
|
||||
```
|
||||
# makedumpfile -l --message-level 1 -d 31 /proc/vmcore makedumpfilecore
|
||||
```
|
||||
|
||||
详细信息请参阅 `man makedumpfile`。
|
||||
|
||||
### kdump 调试
|
||||
|
||||
新手在使用 kdump 时可能会遇到的问题:
|
||||
|
||||
#### `Kexec -p kernel_image` 没有成功
|
||||
|
||||
* 检查是否分配了崩溃内存。
|
||||
* `cat /sys/kernel/kexec_crash_size` 不应该有零值。
|
||||
* `cat /proc/iomem | grep "Crash kernel"` 应该有一个分配的范围。
|
||||
* 如果未分配,则在命令行中传递正确的 `crashkernel=` 参数。
|
||||
* 如果没有显示,则在 `kexec` 命令中传递参数 `-d`,并将输出信息发送到 kexec-tools 邮件列表。
|
||||
|
||||
#### 在“第一内核”的最后一个消息之后,在控制台上看不到任何东西(比如“bye”)
|
||||
|
||||
* 检查 `kexec -e` 之后的 `kexec -l kernel_image` 命令是否工作。
|
||||
* 可能缺少支持的体系结构或特定机器的选项。
|
||||
* 可能是 purgatory 的 SHA 验证失败。如果您的体系结构不支持 purgatory 中的控制台,则很难进行调试。
|
||||
* 可能是“第二内核”早已崩溃。
|
||||
* 将您的系统的 `earlycon` 或 `earlyprintk` 选项传递给“第二内核”的命令行。
|
||||
* 使用 kexec-tools 邮件列表共享第一个内核和捕获内核的 `dmesg` 日志。
|
||||
|
||||
### 资源
|
||||
|
||||
#### fedora-kexec-tools
|
||||
|
||||
* GitHub 仓库:`git://pkgs.fedoraproject.org/kexec-tools`
|
||||
* 邮件列表:[kexec@lists.fedoraproject.org][7]
|
||||
* 说明:Specs 文件和脚本提供了用户友好的命令和服务,以便 `kexec-tools` 可以在不同的用户场景下实现自动化。
|
||||
|
||||
#### kexec-tools
|
||||
|
||||
* GitHub 仓库:git://git.kernel.org/pub/scm/utils/kernel/kexec/kexec-tools.git
|
||||
* 邮件列表:[kexec@lists.infradead.org][8]
|
||||
* 说明:使用内核系统调用并提供用户命令 `kexec`。
|
||||
|
||||
#### Linux kernel
|
||||
|
||||
* GitHub 仓库: `git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git`
|
||||
* 邮件列表:[kexec@lists.infradead.org][9]
|
||||
* 说明:实现了 `kexec_load()`、`kexec_file_load()`、`reboot()` 系统调用和特定体系结构的代码,例如 `machine_kexec()` 和 `machine_crash_shutdown()`。
|
||||
|
||||
#### Makedumpfile
|
||||
|
||||
* GitHub 仓库: `git://git.code.sf.net/p/makedumpfile/code`
|
||||
* 邮件列表:[kexec@lists.infradead.org][10]
|
||||
* 说明:从转储文件中压缩和过滤不必要的组件。
|
||||
|
||||
(题图:[Penguin][13]、 [Boot][14],修改:Opensource.com. [CC BY-SA 4.0][15])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Pratyush Anand - Pratyush 正在以以为 Linux 内核专家的身份与 Red Hat 合作。他主要负责 Red Hat 产品和上游所面临的几个 kexec/kdump 问题。他还处理 Red Hat 支持的 ARM64 平台周围的其他内核调试、跟踪和性能问题。除了 Linux 内核,他还在上游的 kexec-tools 和 makedumpfile 项目中做出了贡献。他是一名开源爱好者,并在教育机构举办志愿者讲座,促进了 FOSS。
|
||||
|
||||
-------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/6/kdump-usage-and-internals
|
||||
|
||||
作者:[Pratyush Anand][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pratyushanand
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/article/17/6/kdump-usage-and-internals?rate=7i_-TnAGi8Q9GR7fhULKlQUNJw8KWgzadgMY9TDuiAY
|
||||
[7]:mailto:kexec@lists.fedoraproject.org
|
||||
[8]:mailto:kexec@lists.infradead.org
|
||||
[9]:mailto:kexec@lists.infradead.org
|
||||
[10]:mailto:kexec@lists.infradead.org
|
||||
[11]:http://sched.co/AVB4
|
||||
[12]:https://opensource.com/user/143191/feed
|
||||
[13]:https://pixabay.com/en/penguins-emperor-antarctic-life-429136/
|
||||
[14]:https://pixabay.com/en/shoe-boots-home-boots-house-1519804/
|
||||
[15]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[16]:https://www.kernel.org/doc/Documentation/kdump/kdump.txt
|
||||
[17]:https://linux.die.net/man/8/kexec
|
||||
[18]:https://github.com/torvalds/linux/blob/master/Documentation/admin-guide/kernel-parameters.txt
|
||||
[19]:https://opensource.com/users/pratyushanand
|
||||
@ -0,0 +1,224 @@
|
||||
网络分析利器:在 Ubuntu 16.04 上安装 Bro
|
||||
============================================================
|
||||
|
||||
|
||||
[][4]
|
||||
|
||||
### 简介:Bro 网络分析框架
|
||||
|
||||
Bro 是一个开源的网络分析框架,侧重于网络安全监控。这是一项长达 15 年的研究成果,被各大学、研究实验室、超级计算机中心和许多开放科学界广泛使用。它主要由伯克利国际计算机科学研究所和伊利诺伊大学厄巴纳-香槟分校的国家超级计算机应用中心开发。
|
||||
|
||||
Bro 的功能包括:
|
||||
|
||||
* Bro 的脚本语言支持针对站点定制监控策略
|
||||
* 针对高性能网络
|
||||
* 分析器支持许多协议,可以在应用层面实现高级语义分析
|
||||
* 它保留了其所监控的网络的丰富的应用层统计信息
|
||||
* Bro 能够与其他应用程序接口实时地交换信息
|
||||
* 它的日志全面地记录了一切信息,并提供网络活动的高级存档
|
||||
|
||||
本教程将介绍如何从源代码构建,并在 Ubuntu 16.04 服务器上安装 Bro。
|
||||
|
||||
### 准备工作
|
||||
|
||||
Bro 有许多依赖文件:
|
||||
|
||||
* Libpcap ([http://www.tcpdump.org][2])
|
||||
* OpenSSL 库 ([http://www.openssl.org][3])
|
||||
* BIND8 库
|
||||
* Libz
|
||||
* Bash (BroControl 所需要)
|
||||
* Python 2.6+ (BroControl 所需要)
|
||||
|
||||
从源代码构建还需要:
|
||||
|
||||
* CMake 2.8+
|
||||
* Make
|
||||
* GCC 4.8+ or Clang 3.3+
|
||||
* SWIG
|
||||
* GNU Bison
|
||||
* Flex
|
||||
* Libpcap headers
|
||||
* OpenSSL headers
|
||||
* zlib headers
|
||||
|
||||
### 起步
|
||||
|
||||
首先,通过执行以下命令来安装所有必需的依赖项:
|
||||
|
||||
```
|
||||
# apt-get install cmake make gcc g++ flex bison libpcap-dev libssl-dev python-dev swig zlib1g-dev
|
||||
```
|
||||
|
||||
#### 安装定位 IP 地理位置的 GeoIP 数据库
|
||||
|
||||
Bro 使用 GeoIP 的定位地理位置。安装 IPv4 和 IPv6 版本:
|
||||
|
||||
```
|
||||
$ wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz
|
||||
$wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCityv6-beta/GeoLiteCityv6.dat.gz
|
||||
```
|
||||
|
||||
解压这两个压缩包:
|
||||
|
||||
```
|
||||
$ gzip -d GeoLiteCity.dat.gz
|
||||
$ gzip -d GeoLiteCityv6.dat.gz
|
||||
```
|
||||
|
||||
将解压后的文件移动到 `/usr/share/GeoIP` 目录下:
|
||||
|
||||
```
|
||||
# mvGeoLiteCity.dat /usr/share/GeoIP/GeoIPCity.dat
|
||||
# mv GeoLiteCityv6.dat /usr/share/GeoIP/GeoIPCityv6.dat
|
||||
```
|
||||
|
||||
现在,可以从源代码构建 Bro 了。
|
||||
|
||||
### 构建 Bro
|
||||
|
||||
最新的 Bro 开发版本可以通过 `git` 仓库获得。执行以下命令:
|
||||
|
||||
```
|
||||
$ git clone --recursive git://git.bro.org/bro
|
||||
```
|
||||
|
||||
转到克隆下来的目录,然后使用以下命令就可以简单地构建 Bro:
|
||||
|
||||
```
|
||||
$ cd bro
|
||||
$ ./configure
|
||||
$ make
|
||||
```
|
||||
|
||||
`make` 命令需要一些时间来构建一切。确切的时间取决于服务器的性能。
|
||||
|
||||
可以使用一些参数来执行 `configure` 脚本,以指定要构建的依赖关系,特别是 `--with-*` 选项。
|
||||
|
||||
### 安装 Bro
|
||||
|
||||
在克隆的 `bro` 目录中执行:
|
||||
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
默认安装路径为 `/usr/local/bro`。
|
||||
|
||||
### 配置 Bro
|
||||
|
||||
Bro 的配置文件位于 `/usr/local/bro/etc` 目录下。 这里有三个文件:
|
||||
|
||||
* `node.cfg`,用于配置要监视的单个节点(或多个节点)。
|
||||
* `broctl.cfg`,BroControl 的配置文件。
|
||||
* `networks.cgf`,包含一个使用 CIDR 标记法表示的网络列表。
|
||||
|
||||
#### 配置邮件设置
|
||||
|
||||
打开 `broctl.cfg` 配置文件:
|
||||
|
||||
```
|
||||
# $EDITOR /usr/local/bro/etc/broctl.cfg
|
||||
```
|
||||
|
||||
查看 `Mail Options` 选项,并编辑 `MailTo` 行如下:
|
||||
|
||||
```
|
||||
# Recipient address for emails sent out by Bro and BroControl
|
||||
MailTo = admin@example.com
|
||||
```
|
||||
|
||||
保存并关闭。还有许多其他选项,但在大多数情况下,默认值就足够好了。
|
||||
|
||||
#### 选择要监视的节点
|
||||
|
||||
开箱即用,Bro 被配置为以独立模式运行。在本教程中,我们就是做一个独立的安装,所以没有必要改变。但是,也请查看 `node.cfg` 配置文件:
|
||||
|
||||
```
|
||||
# $EDITOR /usr/local/bro/etc/node.cfg
|
||||
```
|
||||
|
||||
在 `[bro]` 部分,你应该看到这样的东西:
|
||||
|
||||
```
|
||||
[bro]
|
||||
type=standalone
|
||||
host=localhost
|
||||
interface=eth0
|
||||
```
|
||||
|
||||
请确保 `inferface` 与 Ubuntu 16.04 服务器的公网接口相匹配。
|
||||
|
||||
保存并退出。
|
||||
|
||||
#### 配置监视节点的网络
|
||||
|
||||
最后一个要编辑的文件是 `network.cfg`。使用文本编辑器打开它:
|
||||
|
||||
```
|
||||
# $EDITOR /usr/local/bro/etc/networks.cfg
|
||||
```
|
||||
|
||||
默认情况下,你应该看到以下内容:
|
||||
|
||||
```
|
||||
# List of local networks in CIDR notation, optionally followed by a
|
||||
# descriptive tag.
|
||||
# For example, "10.0.0.0/8" or "fe80::/64" are valid prefixes.
|
||||
|
||||
10.0.0.0/8 Private IP space
|
||||
172.16.0.0/12 Private IP space
|
||||
192.168.0.0/16 Private IP space
|
||||
```
|
||||
|
||||
删除这三个条目(这只是如何使用此文件的示例),并输入服务器的公用和专用 IP 空间,格式如下:
|
||||
|
||||
```
|
||||
X.X.X.X/X Public IP space
|
||||
X.X.X.X/X Private IP space
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
### 使用 BroControl 管理 Bro 的安装
|
||||
|
||||
管理 Bro 需要使用 BroControl,它支持交互式 shell 和命令行工具两种形式。启动该 shell:
|
||||
|
||||
```
|
||||
# /usr/local/bro/bin/broctl
|
||||
```
|
||||
|
||||
要想使用命令行工具,只需将参数传递给上一个命令,例如:
|
||||
|
||||
```
|
||||
# /usr/local/bro/bin/broctl status
|
||||
```
|
||||
|
||||
这将通过显示以下的输出来检查 Bro 的状态:
|
||||
|
||||
```
|
||||
Name Type Host Status Pid Started
|
||||
bro standalone localhost running 6807 20 Jul 12:30:50
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
这是一篇 Bro 的安装教程。我们使用基于源代码的安装,因为它是获得可用的最新版本的最有效的方法,但是该网络分析框架也可以下载预构建的二进制格式文件。
|
||||
|
||||
下次见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/how-to-install-bro-ubuntu-1604/
|
||||
|
||||
作者:[Giuseppe Molica][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/tutan/
|
||||
[1]:https://www.unixmen.com/author/tutan/
|
||||
[2]:http://www.tcpdump.org/
|
||||
[3]:http://www.openssl.org/
|
||||
[4]:https://www.unixmen.com/wp-content/uploads/2017/07/brologo.jpg
|
||||
@ -0,0 +1,231 @@
|
||||
NoSQL: 如何在 Ubuntu 16.04 上安装 OrientDB
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
### 说明 - 非关系型数据库(NoSQL)和 OrientDB
|
||||
|
||||
通常在我们提及数据库的时候,想到的是两个主要的分类:使用用于用户和应用程序之间进行对接的一种被称为结构化查询语言(**S**tructured **Q**uery **L**anguage ,缩写 SQL)的关系型数据库管理系统(**R**elational **D**ata **b**ase **M**anagement **S**ystem,缩写 RDBMS) 以及非关系型数据库管理系统(non-relational database management systems 或称 NoSQL 数据库)。
|
||||
|
||||
这两种模型在如何处理(存储)数据的方面存在着巨大的差异。
|
||||
|
||||
#### 关系数据库管理系统
|
||||
|
||||
在关系模型中(如 MySQL,或者其分支 MariaDB),一个数据库是一个表的集合,其中每个表包含一个或多个以列组织的数据分类。数据库的每行包含一个唯一的数据实例,其分类由列定义。
|
||||
|
||||
举个例子,想象一个包含客户的表。每一行相当于一个客户,而其中的每一列分别对应名字、地址以及其他所必须的信息。
|
||||
|
||||
而另一个表可能是包含订单、产品、客户、日期以及其它的种种。而这个数据库的使用者则可以获得一个满足其需要的视图,例如一个客户在一个特定的价格范围购买产品的报告。
|
||||
|
||||
#### 非关系型数据库管理系统
|
||||
|
||||
在非关系型数据库(或称为<ruby>不仅仅是数据库<rt>Not only SQL</rt></ruby>)管理系统中,数据库被设计为使用不同的方式存储数据,比如文档存储、键值对存储、图形关系存储以及其他方式存储。使用此种形式实现的数据库系统专门被用于大型数据库集群和大型 Web 应用。现今,非关系型数据库被用于某些大公司,如谷歌和亚马逊。
|
||||
|
||||
##### 文档存储数据库
|
||||
|
||||
文档存储数据库是将数据用文档的形式存储。这种类型的运用通常表现为 JavaScript 和 JSON,实际上,XML 和其他形式的存储也是可以被采用的。这里的一个例子就是 MongoDB。
|
||||
|
||||
##### 键值对存储数据库
|
||||
|
||||
这是一个由唯一的<ruby>键<rt>key</rt></ruby>配对一个<ruby>值<rt>value</rt></ruby>的简单模型。这个系统在高速缓存方面具有高性能和高度可扩展性。这里的例子包括 BerkeleyDB 和 MemacacheDB。
|
||||
|
||||
##### 图形关系数据库
|
||||
|
||||
正如其名,这种数据库通过使用<ruby>图<rt>graph</rt></ruby>模型存储数据,这意味着数据通过节点和节点之间的互连进行组织。这是一个可以随着时间的推移和使用而发展的灵活模型。这个系统应用于那些强调映射关系的地方。这里的例子有 IBM Graphs、Neo4j 以及 **OrientDB**。
|
||||
|
||||
### OrientDB
|
||||
|
||||
[OrientDB][3] 是一个多模式的非关系型数据库管理系统。正如开发它的公司所说的“_它是一个将图形关系与文档、键值对、反应性、面向对象和地理空间模型结合在一起的**可扩展的、高性能的数据库**_”。
|
||||
|
||||
OrientDB 还支持 SQL ,经过扩展可以用来操作树和图。
|
||||
|
||||
### 目标
|
||||
|
||||
这个教程旨在教会大家如何在运行 Ubuntu 16.04 的服务器上下载并配置 OrientDB 社区版。
|
||||
|
||||
### 下载 OrientDB
|
||||
|
||||
我们可以从最新的服务端上通过输入下面的指令来下载最新版本的 OrientDB。
|
||||
|
||||
```
|
||||
$ wget -O orientdb-community-2.2.22.tar.gz http://orientdb.com/download.php?file=orientdb-community-2.2.22.tar.gz&os=linux
|
||||
```
|
||||
|
||||
这里下载的是一个包含预编译二进制文件的压缩包,所以我们可以使用 `tar` 指令来操作解压它:
|
||||
|
||||
```
|
||||
$ tar -zxf orientdb-community-2.2.22.tar.gz
|
||||
```
|
||||
|
||||
将从中提取出来的文件夹整体移动到 `/opt`:
|
||||
|
||||
```
|
||||
# mv orientdb-community-2.2.22 /opt/orientdb
|
||||
```
|
||||
|
||||
### 启动 OrientDB 服务器
|
||||
|
||||
启动 OrientDB 服务器需要运行 `orientdb/bin/` 目录下的 shell 脚本:
|
||||
|
||||
```
|
||||
# /opt/orientdb/bin/server.sh
|
||||
```
|
||||
|
||||
如果你是第一次开启 OrientDB 服务器,安装程序还会显示一些提示信息,以及提醒你设置 OrientDB 的 root 用户密码:
|
||||
|
||||
```
|
||||
+---------------------------------------------------------------+
|
||||
| WARNING: FIRST RUN CONFIGURATION |
|
||||
+---------------------------------------------------------------+
|
||||
| This is the first time the server is running. Please type a |
|
||||
| password of your choice for the 'root' user or leave it blank |
|
||||
| to auto-generate it. |
|
||||
| |
|
||||
| To avoid this message set the environment variable or JVM |
|
||||
| setting ORIENTDB_ROOT_PASSWORD to the root password to use. |
|
||||
+---------------------------------------------------------------+
|
||||
|
||||
Root password [BLANK=auto generate it]: ********
|
||||
Please confirm the root password: ********
|
||||
```
|
||||
|
||||
在完成这些后,OrientDB 数据库服务器将成功启动:
|
||||
|
||||
```
|
||||
INFO OrientDB Server is active v2.2.22 (build fb2b7d321ea8a5a5b18a82237049804aace9e3de). [OServer]
|
||||
```
|
||||
|
||||
从现在开始,我们需要用第二个终端来与 OrientDB 服务器进行交互。
|
||||
|
||||
若要强制停止 OrientDB 执行 `Ctrl+C` 即可。
|
||||
|
||||
### 配置守护进程
|
||||
|
||||
此时,我们可以认为 OrientDB 仅仅是一串 shell 脚本,可以用编辑器打开 `/opt/orientdb/bin/orientdb.sh`:
|
||||
|
||||
```
|
||||
# $EDITOR /opt/orientdb/bin/orientdb.sh
|
||||
```
|
||||
|
||||
在它的首段,我们可以看到:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# OrientDB service script
|
||||
#
|
||||
# Copyright (c) OrientDB LTD (http://orientdb.com/)
|
||||
|
||||
# chkconfig: 2345 20 80
|
||||
# description: OrientDb init script
|
||||
# processname: orientdb.sh
|
||||
|
||||
# You have to SET the OrientDB installation directory here
|
||||
ORIENTDB_DIR="YOUR_ORIENTDB_INSTALLATION_PATH"
|
||||
ORIENTDB_USER="USER_YOU_WANT_ORIENTDB_RUN_WITH"
|
||||
```
|
||||
|
||||
我们需要配置`ORIENTDB_DIR` 以及 `ORIENTDB_USER`.
|
||||
|
||||
然后创建一个用户,例如我们创建一个名为 `orientdb` 的用户,我们需要输入下面的指令:
|
||||
|
||||
```
|
||||
# useradd -r orientdb -s /sbin/nologin
|
||||
```
|
||||
|
||||
`orientdb` 就是我们在 `ORIENTDB_USER` 处输入的用户。
|
||||
|
||||
再更改 `/opt/orientdb` 目录的所有权:
|
||||
|
||||
```
|
||||
# chown -R orientdb:orientdb /opt/orientdb
|
||||
```
|
||||
|
||||
改变服务器配置文件的权限:
|
||||
|
||||
```
|
||||
# chmod 640 /opt/orientdb/config/orientdb-server-config.xml
|
||||
```
|
||||
|
||||
#### 下载系统守护进程服务
|
||||
|
||||
OrientDB 的压缩包包含一个服务文件 `/opt/orientdb/bin/orientdb.service`。我们将其复制到 `/etc/systemd/system` 文件夹下:
|
||||
|
||||
```
|
||||
# cp /opt/orientdb/bin/orientdb.service /etc/systemd/system
|
||||
```
|
||||
|
||||
编辑该服务文件:
|
||||
|
||||
```
|
||||
# $EDITOR /etc/systemd/system/orientdb.service
|
||||
```
|
||||
|
||||
其中 `[service]` 内容块看起来应该是这样的:
|
||||
|
||||
```
|
||||
[Service]
|
||||
User=ORIENTDB_USER
|
||||
Group=ORIENTDB_GROUP
|
||||
ExecStart=$ORIENTDB_HOME/bin/server.sh
|
||||
```
|
||||
|
||||
将其改成如下样式:
|
||||
|
||||
```
|
||||
[Service]
|
||||
User=orientdb
|
||||
Group=orientdb
|
||||
ExecStart=/opt/orientdb/bin/server.sh
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
重新加载系统守护进程:
|
||||
|
||||
```
|
||||
# systemctl daemon-reload
|
||||
```
|
||||
|
||||
启动 OrientDB 并使其开机自启动:
|
||||
|
||||
```
|
||||
# systemctl start orientdb
|
||||
# systemctl enable orientdb
|
||||
```
|
||||
|
||||
确认 OrientDB 的状态:
|
||||
|
||||
```
|
||||
# systemctl status orientdb
|
||||
```
|
||||
|
||||
上述指令应该会输出:
|
||||
|
||||
```
|
||||
● orientdb.service - OrientDB Server
|
||||
Loaded: loaded (/etc/systemd/system/orientdb.service; disabled; vendor preset: enabled)
|
||||
Active: active (running) ...
|
||||
```
|
||||
|
||||
流程就是这样了!OrientDB 社区版成功安装并且正确运行在我们的服务器上了。
|
||||
|
||||
### 总结
|
||||
|
||||
在这个指导中,我们看到了一些关系型数据库管理系统(RDBMS)以及非关系型数据库管理系统(NoSQL DBMS)的简单对照。我们也安装 OrientDB 社区版的服务器端并完成了其基础的配置。
|
||||
|
||||
这是我们部署完全的 OrientDB 基础设施的第一步,也是我们用于管理大型系统数据的起步。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/nosql-install-orientdb-ubuntu-16-04/
|
||||
|
||||
作者:[Giuseppe Molica][a]
|
||||
译者:[a92667237](https://github.com/a972667237)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/tutan/
|
||||
[1]:https://www.unixmen.com/author/tutan/
|
||||
[2]:https://www.unixmen.com/wp-content/uploads/2017/07/orientdb.png
|
||||
[3]:https://orientdb.com/
|
||||
@ -0,0 +1,50 @@
|
||||
使用开源代码构建机器人时需要考虑的事项
|
||||
=============
|
||||
|
||||

|
||||
|
||||
或许你正在考虑(或正在进行)将机器人使用开源软件推向市场。这个机器人是基于 linux 构建的。也许你正在使用[机器人操作系统][1](ROS)或[任务导向操作套件][2](MOOS),或者是另外一个可以帮助你简化开发过程的开源中间件。当开发接近实用化,对回报的期望开始给你带来一些压力。你可能会被问到“我们的产品什么时候可以开始销售?”,这时你将面临重要的抉择。
|
||||
|
||||
你可以做下面两件事之一:
|
||||
|
||||
1. 对现有的产品开始出货
|
||||
|
||||
2. 回过头去,把产品化当做一个全新的问题来解决,并处理新的问题
|
||||
|
||||
不需要看很远,就可以找到采用方式(1)的例子。事实上,在物联网设备市场上,到处都是这样的设备。由于急于将设备推向市场,这些可以在设备中找到硬编码证书、开发密钥、各种安全漏洞和没有更新方式的产品并不少见。
|
||||
|
||||
想想 Mirai 僵尸网络,通过该僵尸网络发起的流量超过 1Tbps 的分布式拒绝服务攻击(DDos),导致一些互联网上最大的网站停止服务。这个僵尸网络主要由物联网设备组成。这种攻破设备的防御机制进而控制设备所开发的僵尸程序,是采用了超级酷的黑魔法在一个没有窗户的实验室(或地下基地)开发的吗?不是,默认(通常是硬编码)证书而已。这些设备的制造商是否快速反应并发布所有这些设备的更新,以确保设备的安全?不,很多制造商根本没有更新方法。[他们召回设备而不是发布更新][3]。
|
||||
|
||||
不要急于将产品推向市场,而是退后一步。只要多思考几点,就可以使你自己和你所在公司避免痛苦。
|
||||
|
||||
例如,**你的软件如何更新?**你*必须*能回答这个问题。你的软件不是完美的。只要几个星期你就会发现,当你在加利福尼亚使用自主的高机动性多用途轮式车辆(HMMWV)时,它把小灌木识别为一棵橡树。或者你不小心在软件中包含了你的 SSH 密钥。
|
||||
|
||||
**基础操作系统如何更新?**也许这仍然是你的产品的一部分,也是你回答上一个问题的答案。但也许你使用的操作系统来自于另外一个供应商。你如何从供应商那里得到更新并提供给客户?这就是安全漏洞真正让你头痛的地方:从来不更新的内核,或者严重过时的 openssl。
|
||||
|
||||
当你解决了更新问题,**在更新过程出现问题时,机器人怎么恢复?**我的示例是对前面问题的一个常见解决方案:自动安全更新。对于服务器和台式机以及显然是计算机的东西来说,这是一个很好的做法,因为大多数人意识到有一个可接受的方法来关闭它,而*不是*按住电源按钮 5 秒钟。机器人系统(以及大多数物联网系统)有一个问题,有时它们根本不被认为是计算机。如果您的机器人表现奇怪,有可能会被强制关闭。如果你的机器人行为奇怪是因为它正在快速安装一个内核更新,那么,现在你就有一个安装了半个内核的机器人镇纸了。你需要能够处理这种情况。
|
||||
|
||||
最后,**你的工厂流程是什么?**你如何安装 Linux,ROS(或者你使用的中间件),以及你要安装在设备上的你自己的东西?小的工厂可能会手工操作,但这种方法不成规模,也容易出错。其他厂商可能会制作一个定制化的初始发行版 ISO,但这是个不小的任务,在更新软件时也不容易维护。还有一些厂商会使用 Chef 或者有陡峭学习曲线的自动化工具,不久你就会意识到,你把大量的工程精力投入到了本来应该很简单的工作中。
|
||||
|
||||
所有这些问题都很重要。针对这些问题,如果你发现自己没有任何明确的答案,你应该加入我们的[网络研讨会][4],在研讨会上我们讨论如何使用开放源代码构建一个商业化机器人。我们会帮助你思考这些问题,并可以回答你更多问题。
|
||||
|
||||
----------
|
||||
|
||||
作者简介:
|
||||
|
||||
Kyle 是 Snapcraft 团队的一员,也是 Canonical 公司的常驻机器人专家,他专注于 snaps 和 snap 开发实践,以及 snaps 和 Ubuntu Core 的机器人技术实现。
|
||||
|
||||
----------
|
||||
|
||||
via: [https://insights.ubuntu.com/2017/07/18/things-to-consider-when-building-a-robot-with-open-source/](https://insights.ubuntu.com/2017/07/18/things-to-consider-when-building-a-robot-with-open-source/)
|
||||
|
||||
作者:[Kyle Fazzari][a]
|
||||
译者:[SunWave](https://github.com/SunWave)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 LCTT 原创编译,Linux中国 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/kyrofa/
|
||||
[1]:http://www.ros.org/
|
||||
[2]:http://www.robots.ox.ac.uk/~mobile/MOOS/wiki/pmwiki.php/Main/HomePage
|
||||
[3]:https://krebsonsecurity.com/2016/10/iot-device-maker-vows-product-recall-legal-action-against-western-accusers/
|
||||
[4]:https://www.brighttalk.com/webcast/6793/268763?utm_source=insights
|
||||
@ -0,0 +1,84 @@
|
||||
我选择 dwm 作为窗口管理器的 4 大理由
|
||||
============================================================
|
||||
|
||||
> <ruby>窗口管理器<rt>window manager</rt></ruby>负责管理打开窗口的大小、布置以及其它相关的方面。
|
||||
|
||||
|
||||

|
||||
|
||||
(图片来自:Internet Archive [Book][4] [Images][5] 由 Opensource.com 修改 CC BY-SA 4.0)
|
||||
|
||||
我喜欢极简。如果可能,我会尽量在一个终端下运行所有需要的程序。这避免了一些浮夸的特效占用我的资源或者分散我的注意力。而且,无论怎么调整窗口大小和位置却依旧无法使它们完美地对齐,这也让我感到厌烦。
|
||||
|
||||
出于对极简化的追求,我喜欢上了 [Xfce][6] 并且把它作为我主要的 Linux [桌面环境][7]好几年了。直到后来我看了 [Bryan Lunduke][8] 关于他所使用的名为 [Awesome][10] 的[窗口管理器][9]的视频。Awesome 为用户整齐地布置好他们的窗口,看起来就是我想要的效果。但在我尝试之后却发现我难以把它配置成我喜欢的样子。于是我继续搜寻,发现了 [xmonad][11],然而我遇到了同样的问题。[xmonad][11] 可以良好运作但为了把它配置成我理想中的样子我却不得不先通过 Haskell 语言这关。(LCTT 译注: AwesomeWM 使用 lua 语言作为配置语言,而 xmonad 使用 Haskell 语言)
|
||||
|
||||
几年后,我无意间发现了 [suckless.org][12] 和他们的窗口管理器 [dwm][13]。
|
||||
|
||||
简而言之,一个窗口管理器,例如 KDE,Gnome 或者 Xfce,包括了许多部件,其中除了窗口管理器还有其它应用程序。窗口管理器负责管理打开窗口的大小、布置(以及其它窗口相关的方面)。不同的桌面环境使用不同的窗口管理器,KDE 使用 KWin,Gnome 2 使用 Metacity, Gnome 3 使用 Mutter, 以及 Xfce 使用 Xfwm。当然,你可以方便地替换这些桌面环境的默认窗口管理器。我已经把我的窗口管理器替换成 dwm,下面我说说我喜欢 dwm 的理因。
|
||||
|
||||
### 动态窗口管理
|
||||
|
||||
与 Awesome 及 xmonad 一样,dwm 的杀手锏是它能利用屏幕的所有空间为你自动排布好窗口。当然,在现在的大多数桌面环境中,你也可以设置相应的快捷键把你的窗口放置在屏幕的上下左右或者是全屏,但是有了 dwm 我们就不需要考虑这么多了。
|
||||
|
||||
dwm 把屏幕分为主区域和栈区域。它包含三种布局:平铺,单片镜(monocle)和浮动。平铺模式是我最常使用的,它把一个主要的窗口放置在主区域来获取最大关注力,而将其余窗口平铺在栈区域中。在单片镜模式中,所有窗口都会被最大化,你可以在它们之间相互切换。浮动模式允许你自由调整窗口大小(就像在大多数窗口管理器下那样),这在你使用像 Gimp 这类需要自定义窗口大小的应用时更为方便。
|
||||
|
||||
一般情况下,在你的桌面环境下你可以使用不同的工作空间(workspace)来分类你的窗口,把相近的应用程序放置在计划好的工作空间中。在工作时,我会使用一个工作空间来进行工作,同时使用另一个工作空间来浏览网页。dwm 有一个相似的功能叫标签。你可以使用标签给窗口分组,当你选中一个标签时,就能显示具有相应标签的窗口。
|
||||
|
||||
### 高效
|
||||
|
||||
dwm 能让你的计算机尽量地节省电量。Xfce 和其它轻量桌面环境在较旧或者较低性能的机器上很受欢迎,但是相比于 Xfce,dwm 在登录后只使用了它们 1/3 的资源(在我的例子中)。当我在使用一台 1 GB 内存的 Eee PC (LCTT 译注:华硕生产的一款上网本,已停产)时,占用 660 MB 和 230MB 的差别就很大了。这让我有足够的内存空间运行我的编辑器和浏览器。
|
||||
|
||||
### 极简
|
||||
|
||||
通常,我让我的应用程序彼此相邻:作为主窗口的终端(通常运行着 Vim)、用来查阅邮件的浏览器,和另外一个用来查阅资料或者打开 [Trello][14] 的浏览器窗口。对于临时的网页浏览,我会在另一个工作空间或者说是另一个 _标签_ 中开启一个 Chromium 窗口。
|
||||
|
||||
|
||||
|
||||
*来自作者的屏幕截图。*
|
||||
|
||||
在标准的桌面环境下,通常会有一或两个面板占据着屏幕上下或者两侧的空间。我尝试过使用自动隐藏功能,但当光标太靠近边缘导致面板弹出造成的不便实在让我很厌烦。你也可以把它们设置得更小,但我还是更喜欢 dwm 的极简状态栏。
|
||||
|
||||
### 速度
|
||||
|
||||
评判速度时,我比较看重 dwm 在登录后的加载速度和启动程序的速度。如果使用更快、更新的计算机,你可能不会在意这些细节,但是对我来说,不同的桌面环境和窗口管理器会有明显的差距。我实在不想连这种简单的操作也要等待,它们应该一下子就完成。另外,使用键盘快捷键来启动程序比起用鼠标或者触控板要快一些,而且我不想让双手离开键盘。
|
||||
|
||||
### 小结
|
||||
|
||||
即便如此,我也不会向新手用户推荐 dwm。研究如何配置它需要耗费一些时间(除非你对你的发行版提供的默认配置感到满意)。我发现要让一些你想要的补丁正常工作可能会有点棘手,而且相应的社区也比较小(其 IRC 频道明确表示不提供补丁的手把手帮助)。所以,为了得到你想要的效果,你得有些付出才行。不过,这也是值得的。
|
||||
|
||||
而且你看,它就像 Awesome 一样 awesome。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jimmy Sjölund - 他是 Telia Company 的高级 IT 服务经理,关注团队开发、探索敏捷工作流和精益工作流的创新导师,以及可视化方向爱好者。他同时也是一名开源布道者,先前从事于 Ubuntu Studio 和 Plume Creator。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/7/top-4-reasons-i-use-dwm-linux-window-manager
|
||||
|
||||
作者:[Jimmy Sjölund][a]
|
||||
译者:[haoqixu](https://github.com/haoqixu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jimmysjolund
|
||||
[1]:https://opensource.com/file/363336
|
||||
[2]:https://opensource.com/article/17/7/top-4-reasons-i-use-dwm-linux-window-manager?rate=T8qhopZLfd1eum_NMLOSGckUh2nIjfeRpkERGjGhu7w
|
||||
[3]:https://opensource.com/user/56551/feed
|
||||
[4]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
||||
[5]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
||||
[6]:https://xfce.org/
|
||||
[7]:https://en.wikipedia.org/wiki/Desktop_environment
|
||||
[8]:http://lunduke.com/
|
||||
[9]:https://en.wikipedia.org/wiki/Window_manager
|
||||
[10]:https://awesomewm.org/
|
||||
[11]:http://xmonad.org/
|
||||
[12]:http://suckless.org/
|
||||
[13]:http://dwm.suckless.org/
|
||||
[14]:https://opensource.com/node/22546
|
||||
[15]:https://opensource.com/users/jimmysjolund
|
||||
[16]:https://opensource.com/users/jimmysjolund
|
||||
[17]:https://opensource.com/article/17/7/top-4-reasons-i-use-dwm-linux-window-manager#comments
|
||||
@ -1,3 +1,5 @@
|
||||
Translated by DPueng
|
||||
|
||||
Why we need open leaders more than ever
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Best Linux Adobe Alternatives You Need to Know
|
||||
Best Linux Adobe Alternatives You Need to Know ###translating by ninaiwohe109
|
||||
============================================================
|
||||

|
||||
|
||||
|
||||
@ -1,313 +0,0 @@
|
||||
Using Kdump for examining Linux Kernel crashes
|
||||
============================================================
|
||||
|
||||
### Let's examine the basics of kdump usage and look at the internals of kdump/kexec kernel implementation.
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Penguin][13], [Boot][14]. Modified by Opensource.com. [CC BY-SA 4.0][15].
|
||||
|
||||
[Kdump][16] is a way to acquire a crashed Linux kernel dump, but finding documents that explain its usage and internals can be challenging. In this article, I'll examine the basics of kdump usage and look at the internals of kdump/kexec kernel implementation.
|
||||
|
||||
[Kexec][17] is a Linux kernel-to-kernel boot loader that helps to boot the second kernel from the context of first kernel. Kexec shuts down the first kernel, bypasses the BIOS or firmware stage, and jumps to second kernel. Thus, reboots become faster in absence of the BIOS stage.
|
||||
|
||||
Kdump can be used with the kexec application—for example, when the second kernel is booted when the first kernel panics, the second kernel is used to copy the memory dump of first kernel, which can be analyzed with tools such as gdb and crash to determine the panic reasons. (In this article, I'll use the terms _first kernel_ for the currently running kernel, _second kernel_ for the kernel run using kexec, and _capture kernel_ for kernel run when current kernel panics.)
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
The kexec mechanism has components in the kernel as well as in user space. The kernel provides few system calls for kexec reboot functionality. A user space tool called kexec-tools uses those calls and provides an executable to load and boot the second kernel. Sometimes a distribution also adds wrappers on top of kexec-tools, which helps capture and save the dump for various dump target configurations. In this article, I will use the name _distro-kexec-tools_ to avoid confusion between upstream kexec-tools and distro-specific kexec-tools code. My example will use the Fedora Linux distribution.
|
||||
|
||||
### Fedora kexec-tools
|
||||
|
||||
**dnf install kexec-tools** installs fedora-kexec-tools on Fedora machines. The kdump service can be started by executing **systemctl start kdump** after installation of fedora-kexec-tools. When this service starts, it creates a root file system (initramfs) that contains resources to mount the target for saving vmcore, and a command to copy/dump vmcore to the target. This service then loads the kernel and initramfs at the suitable location within the crash kernel region so that they can be executed upon kernel panic.
|
||||
|
||||
Fedora wrapper provides two user configuration files:
|
||||
|
||||
1. **/etc/kdump.conf** specifies configuration parameters whose modification requires rebuild of the initramfs. For example, if you change the dump target from a local disk to an NFS-mounted disk, you will need NFS-related kernel modules to be loaded by the capture kernel.
|
||||
|
||||
2. **/etc/sysconfig/kdump** specifies configuration parameters whose modification do not require rebuild of the initramfs. For example, you do not need to rebuild the initramfs if you only need to modify command-line arguments passed to the capture kernel.
|
||||
|
||||
If the kernel panics after the kdump service starts, then the capture kernel is executed, which further executes the vmcore save process from initramfs and reboots to a stable kernel afterward.
|
||||
|
||||
### kexec-tools
|
||||
|
||||
Compilation of kexec-tools source code provides an executable called **kexec**. The same executable can be used to load and execute a second kernel or to load a capture kernel, which can be executed upon kernel panic.
|
||||
|
||||
A typical command to load a second kernel:
|
||||
|
||||
```
|
||||
# kexec -l kernel.img --initrd=initramfs-image.img –reuse-cmdline
|
||||
```
|
||||
|
||||
**--reuse-command** line says to use the same command line as that of first kernel. Pass initramfs using **--initrd**. **-l** says that you are loading the second kernel, which can be executed by the kexec application itself (**kexec -e**). A kernel loaded using **-l** cannot be executed at kernel panic. You must pass **-p**instead of **-l** to load the capture kernel that can be executed upon kernel panic.
|
||||
|
||||
A typical command to load a capture kernel:
|
||||
|
||||
```
|
||||
# kexec -p kernel.img --initrd=initramfs-image.img –reuse-cmdline
|
||||
```
|
||||
|
||||
**echo c > /pros/sysrq-trigger** can be used to crash the kernel for test purposes. See **man kexec** for detail about options provided by kexec-tools. Before moving to the next section, which focuses on internal implementation, watch this kexec_dump demo:
|
||||
|
||||
** 此处有iframe,请手动处理 **
|
||||
|
||||
### Kdump: End-to-end flow
|
||||
|
||||
Figure 1 shows a flow diagram. Crashkernel memory must be reserved for the capture kernel during booting of the first kernel. You can pass **crashkernel=Y@X** in the kernel command line, where **@X** is optional. **crashkernel=256M** works with most of the x86_64 systems; however, selecting a right amount of memory for the crash kernel is dependent on many factors, such as kernel size and initramfs, as well as runtime memory requirement of modules and applications included in initramfs. See the [kernel-parameters documentation][18] for more ways to pass crash kernel arguments.
|
||||
|
||||

|
||||
|
||||
You can pass kernel and initramfs images to a **kexec** executable as shown in the typical command of section (**kexec-tools**). The capture kernel can be the same as the first kernel or can be different. Typically, keep it the same. Initramfs can be optional; for example, when the kernel is compiled with **CONFIG_INITRAMFS_SOURCE**, you do not need it. Typically, you keep a different capture initramfs from the first initramfs, because automating a copy of vmcore in capture initramfs is better. When **kexec** is executed, it also loads **elfcorehdr** data and the purgatory executable. **elfcorehdr** has information about the system RAM memory organization, and purgatory is a binary that executes before the capture kernel executes and verifies that the second stage binary/data have the correct SHA. Purgatory can be made optional as well.
|
||||
|
||||
When the first kernel panics, it does a minimal necessary exit process and switches to purgatory if it exists. Purgatory verifies SHA256 of loaded binaries and, if those are correct, then it passes control to the capture kernel. The capture kernel creates vmcore per the system RAM information received from **elfcorehdr**. Thus, you will see a dump of the first kernel in /proc/vmcore after the capture kernel boots. Depending on the initramfs you have used, you can now analyze the dump, copy it to any disk, or there can be an automated copy followed by reboot to a stable kernel.
|
||||
|
||||
### Kernel system calls
|
||||
|
||||
The kernel provides two system calls—**kexec_load()** and **kexec_file_load()**, which can be used to load the second kernel when **kexec -l** is executed. It also provides an extra flag for the **reboot()** system call, which can be used to boot into second kernel using **kexec -e**.
|
||||
|
||||
**kexec_load()**: The **kexec_load()** system call loads a new kernel that can be executed later by **reboot()**. Its prototype is defined as follows:
|
||||
|
||||
```
|
||||
long kexec_load(unsigned long entry, unsigned long nr_segments,
|
||||
struct kexec_segment *segments, unsigned long flags);
|
||||
```
|
||||
|
||||
User space needs to pass segments for different components, such as kernel, initramfs, etc. Thus, the **kexec** executable helps in preparing these segments. The structure of **kexec_segment** looks like as follows:
|
||||
|
||||
```
|
||||
struct kexec_segment {
|
||||
void *buf;
|
||||
/* Buffer in user space */
|
||||
size_t bufsz;
|
||||
/* Buffer length in user space */
|
||||
void *mem;
|
||||
/* Physical address of kernel */
|
||||
size_t memsz;
|
||||
/* Physical address length */
|
||||
};
|
||||
```
|
||||
|
||||
When **reboot()** is called with **LINUX_REBOOT_CMD_KEXEC**, it boots into a kernel loaded by **kexec_load()**. If a flag **KEXEC_ON_CRASH** is passed to **kexec_load()**, then the loaded kernel will not be executed with **reboot(LINUX_REBOOT_CMD_KEXEC)**; rather, that will be executed on kernel panic. **CONFIG_KEXEC** must be defined to use kexec and **CONFIG_CRASH_DUMP** should be defined for kdump.
|
||||
|
||||
**kexec_file_load()**: As a user you pass only two arguments (i.e., kernel and initramfs) to the **kexec** executable. **kexec** then reads data from sysfs or other kernel information source and creates all segments. So, **kexec_file_load()**gives you simplification in user space, where you pass only file descriptors of kernel and initramfs. The rest of the all segment preparation is done by the kernel itself. **CONFIG_KEXEC_FILE** should be enabled to use this system call. Its prototype looks like:
|
||||
|
||||
```
|
||||
long kexec_file_load(int kernel_fd, int initrd_fd, unsigned long
|
||||
cmdline_len, const char __user * cmdline_ptr, unsigned long
|
||||
flags);
|
||||
```
|
||||
|
||||
Notice that **kexec_file_load()** also accepts the command line, whereas **kexec_load()** did not. The kernel has different architecture-specific ways to accept the command line. Therefore, **kexec-tools** passes the command-line through one of the segments (like in **dtb** or **ELF boot notes**, etc.) in case of **kexec_load()**.
|
||||
|
||||
Currently, **kexec_file_load()** is supported for x86 and PowerPC only.
|
||||
|
||||
### What happens when the kernel crashes
|
||||
|
||||
When the first kernel panics, before control is passed to the purgatory or capture kernel it does the following:
|
||||
|
||||
* prepares CPU registers (see **crash_setup_regs()** in kernel code);
|
||||
|
||||
* updates vmcoreinfo note (see **crash_save_vmcoreinfo()**);
|
||||
|
||||
* shuts down non-crashing CPUs and saves the prepared registers (see **machine_crash_shutdown()** and **crash_save_cpu()**);
|
||||
|
||||
* you also might need to disable the interrupt controller here;
|
||||
|
||||
* and at the end, it performs the kexec reboot (see **machine_kexec()**), which loads/flushes kexec segments to memory and passes control to the execution of entry segment. Entry segment could be purgatory or start address of next kernel.
|
||||
|
||||
### ELF program headers
|
||||
|
||||
Most of the dump cores involved in kdump are in ELF format. Thus, understanding ELF Program headers is important, especially if you want to find issues with vmcore preparation. Each ELF file has a program header that:
|
||||
|
||||
* is read by the system loader,
|
||||
|
||||
* describes how the program should be loaded into memory,
|
||||
|
||||
* and one can use **Objdump -p elf_file** to look into program headers.
|
||||
|
||||
An example of ELF program headers of a vmcore:
|
||||
|
||||
```
|
||||
# objdump -p vmcore
|
||||
vmcore:
|
||||
file format elf64-littleaarch64
|
||||
Program Header:
|
||||
NOTE off 0x0000000000010000 vaddr 0x0000000000000000 paddr 0x0000000000000000 align 2**0 filesz
|
||||
0x00000000000013e8 memsz 0x00000000000013e8 flags ---
|
||||
LOAD off 0x0000000000020000 vaddr 0xffff000008080000 paddr 0x0000004000280000 align 2**0 filesz
|
||||
0x0000000001460000 memsz 0x0000000001460000 flags rwx
|
||||
LOAD off 0x0000000001480000 vaddr 0xffff800000200000 paddr 0x0000004000200000 align 2**0 filesz
|
||||
0x000000007fc00000 memsz 0x000000007fc00000 flags rwx
|
||||
LOAD off 0x0000000081080000 vaddr 0xffff8000ffe00000 paddr 0x00000040ffe00000 align 2**0 filesz
|
||||
0x00000002fa7a0000 memsz 0x00000002fa7a0000 flags rwx
|
||||
LOAD off 0x000000037b820000 vaddr 0xffff8003fa9e0000 paddr 0x00000043fa9e0000 align 2**0 filesz
|
||||
0x0000000004fc0000 memsz 0x0000000004fc0000 flags rwx
|
||||
LOAD off 0x00000003807e0000 vaddr 0xffff8003ff9b0000 paddr 0x00000043ff9b0000 align 2**0 filesz
|
||||
0x0000000000010000 memsz 0x0000000000010000 flags rwx
|
||||
LOAD off 0x00000003807f0000 vaddr 0xffff8003ff9f0000 paddr 0x00000043ff9f0000 align 2**0 filesz
|
||||
0x0000000000610000 memsz 0x0000000000610000 flags rwx
|
||||
```
|
||||
|
||||
In this example, there is one note section and the rest are load sections. The note section has information about CPU notes and load sections have information about copied system RAM components.
|
||||
|
||||
Vmcore starts with **elfcorehdr**, which has the same structure as that of a an ELF program header. See the representation of **elfcorehdr** in Figure 2:
|
||||
|
||||

|
||||
|
||||
**kexec-tools** reads /sys/devices/system/cpu/cpu%d/crash_notes and prepares headers for **CPU PT_NOTE**. Similarly, it reads **/sys/kernel/vmcoreinfo** and prepares headers for **vmcoreinfo PT_NOTE**, and reads system RAM values from **/proc/iomem** and prepares memory **PT_LOAD** headers. When the capture kernel receives **elfcorehdr**, it appends data from addresses mentioned in the header and prepares vmcore.
|
||||
|
||||
### Crash notes
|
||||
|
||||
Crash notes is a per-CPU area for storing CPU states in case of a system crash; it has information about current PID and CPU registers.
|
||||
|
||||
### vmcoreinfo
|
||||
|
||||
This note section has various kernel debug information, such as struct size, symbol values, page size, etc. Values are parsed by capture kernel and embedded into **/proc/vmcore**. **vmcoreinfo** is used mainly by the **makedumpfile** application. **include/linux/kexec.h** in the Linux kernel has macros to define a new **vmcoreinfo**. Some of the example macros are like these:
|
||||
|
||||
* **VMCOREINFO_PAGESIZE()**
|
||||
|
||||
* **VMCOREINFO_SYMBOL()**
|
||||
|
||||
* **VMCOREINFO_SIZE()**
|
||||
|
||||
* **VMCOREINFO_STRUCT_SIZE()**
|
||||
|
||||
### makedumpfile
|
||||
|
||||
Much information (such as free pages) in a vmcore is not useful. Makedumpfile is an application that excludes unnecessary pages, such as:
|
||||
|
||||
* pages filled with zeroes,
|
||||
|
||||
* cache pages without private flag (non-private cache);
|
||||
|
||||
* cache pages with private flag (private cache);
|
||||
|
||||
* user process data pages;
|
||||
|
||||
* free pages.
|
||||
|
||||
Additionally, makedumpfile compresses **/proc/vmcore** data while copying. It can also erase sensitive symbol information from dump; however, it first needs kernel's debug information to do that. This debug information comes from either **VMLINUX** or **vmcoreinfo**, and its output either can be in ELF format or kdump-compressed format.
|
||||
|
||||
Typical usage:
|
||||
|
||||
```
|
||||
# makedumpfile -l --message-level 1 -d 31 /proc/vmcore makedumpfilecore
|
||||
```
|
||||
|
||||
See **man makedumpfile** for detail.
|
||||
|
||||
### Debugging kdump issues
|
||||
|
||||
Issues that new kdump users might have:
|
||||
|
||||
### _Kexec -p kernel_image_ did not succeed
|
||||
|
||||
* Check whether crash memory is allocated.
|
||||
|
||||
* **cat /sys/kernel/kexec_crash_size** should have no zero value.
|
||||
|
||||
* **cat /proc/iomem | grep "Crash kernel"** should have an allocated range.
|
||||
|
||||
* If not allocated, then pass the proper **crashkernel=** argument in the command line.
|
||||
|
||||
* If nothing shows up, then pass **-d** in the **kexec** command and share the debug output with the kexec-tools mailing list.
|
||||
|
||||
### Do not see anything on console after last message from first kernel (such as "bye")
|
||||
|
||||
* Check whether **kexec -l kernel_image** followed by **kexec -e** works.
|
||||
|
||||
* Might be missing architecture- or machine-specific options.
|
||||
|
||||
* Might have purgatory SHA verification failed. If your architecture does not support a console in purgatory, then it is difficult to debug.
|
||||
|
||||
* Might have second kernel crashed early.
|
||||
|
||||
* Pass **earlycon**/**earlyprintk** option for your system to the second kernel command line.
|
||||
|
||||
* Share **dmesg** log of both the first and capture kernel with kexec-tools mailing list.
|
||||
|
||||
### Resources
|
||||
|
||||
#### fedora-kexec-tools
|
||||
|
||||
* Repository: **git://pkgs.fedoraproject.org/kexec-tools**
|
||||
|
||||
* Mailing list: [kexec@lists.fedoraproject.org][7]
|
||||
|
||||
* Description: Specs file and scripts to provide user-friendly command/services so that **kexec-tools** can be automated in different user scenarios.
|
||||
|
||||
#### kexec-tools
|
||||
|
||||
* Repository: git://git.kernel.org/pub/scm/utils/kernel/kexec/kexec-tools.git
|
||||
|
||||
* Mailing list: [kexec@lists.infradead.org][8]
|
||||
|
||||
* Description: Uses kernel system calls and provides a user command **kexec**.
|
||||
|
||||
#### Linux kernel
|
||||
|
||||
* Repository: **git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git**
|
||||
|
||||
* Mailing list: [kexec@lists.infradead.org][9]
|
||||
|
||||
* Description: Implements **kexec_load()**, **kexec_file_load()**, and **reboot()**system call and architecture-specific code, such as **machine_kexec()** and **machine_crash_shutdown()**, etc.
|
||||
|
||||
#### Makedumpfile
|
||||
|
||||
* Repository: **git://git.code.sf.net/p/makedumpfile/code**
|
||||
|
||||
* Mailing list: [kexec@lists.infradead.org][10]
|
||||
|
||||
* Description: Compresses and filters unnecessary component from the dumpfile.
|
||||
|
||||
_Learn more in Pratyush Anand's [KDUMP: Usage and Internals][11] talk at LinuxCon ContainerCon CloudOpen China on June 20, 2017._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Pratyush Anand - Pratyush is working with Red Hat as a Linux Kernel Generalist. Primarily, he takes care of several kexec/kdump issues being faced by Red Hat product and upstream. He also handles other kernel debugging/tracing/performance issues around Red Hat supported ARM64 platforms. Apart from Linux Kernel, he has also contributed in upstream kexec-tools and makedumpfile project. He is an open source enthusiast and delivers volunteer lectures in educational institutes for the promotion of FOSS.
|
||||
|
||||
-------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/6/kdump-usage-and-internals
|
||||
|
||||
作者:[Pratyush Anand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pratyushanand
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/article/17/6/kdump-usage-and-internals?rate=7i_-TnAGi8Q9GR7fhULKlQUNJw8KWgzadgMY9TDuiAY
|
||||
[7]:mailto:kexec@lists.fedoraproject.org
|
||||
[8]:mailto:kexec@lists.infradead.org
|
||||
[9]:mailto:kexec@lists.infradead.org
|
||||
[10]:mailto:kexec@lists.infradead.org
|
||||
[11]:http://sched.co/AVB4
|
||||
[12]:https://opensource.com/user/143191/feed
|
||||
[13]:https://pixabay.com/en/penguins-emperor-antarctic-life-429136/
|
||||
[14]:https://pixabay.com/en/shoe-boots-home-boots-house-1519804/
|
||||
[15]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[16]:https://www.kernel.org/doc/Documentation/kdump/kdump.txt
|
||||
[17]:https://linux.die.net/man/8/kexec
|
||||
[18]:https://github.com/torvalds/linux/blob/master/Documentation/admin-guide/kernel-parameters.txt
|
||||
[19]:https://opensource.com/users/pratyushanand
|
||||
@ -1,5 +1,9 @@
|
||||
translating----geekpi
|
||||
|
||||
Encryption: How To Secure an NGINX web server on Ubuntu 16.04
|
||||
============================================================By [Giuseppe Molica][1]</header>
|
||||
============================================================
|
||||
|
||||
By [Giuseppe Molica][1]</header>
|
||||
|
||||
[][2]
|
||||
|
||||
|
||||
@ -1,244 +0,0 @@
|
||||
Network Analysis: How To Install Bro On Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
|
||||
[][4]
|
||||
|
||||
### Introduction: Bro Network Analysis Framework
|
||||
|
||||
Bro is an open source network analysis framework with a focus on network security monitoring. It is the result of 15 years of research, widely used by major universities, research labs, supercomputing centers and many open-science communities. It is developed mainly at the International Computer Science Institute, in Berkeley, and the National Center for Supercomputing Applications, in Urbana-Champaign.
|
||||
|
||||
Bro has various features, including the following:
|
||||
|
||||
* Bro’s scripting language enables site-specific monitoring policies
|
||||
|
||||
* Targeting of high-performance networks
|
||||
|
||||
* Analyzers for many protocols, enabling high-level semantic analysis at the application level
|
||||
|
||||
* It keeps extensive application-layer stats about the network it monitors.
|
||||
|
||||
* Bro interfaces with other applications for real-time exchange of information
|
||||
|
||||
* It comprehensively logs everything and provides a high-level archive of a network’s activity.
|
||||
|
||||
This tutorial explains how to build from source and install Bro on an Ubuntu 16.04 Server.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Bro has many dependencies:
|
||||
|
||||
* Libpcap ([http://www.tcpdump.org][2])
|
||||
|
||||
* OpenSSL libraries ([http://www.openssl.org][3])
|
||||
|
||||
* BIND8 library
|
||||
|
||||
* Libz
|
||||
|
||||
* Bash (required for BroControl)
|
||||
|
||||
* Python 2.6+ (required for BroControl)
|
||||
|
||||
Building from source requires also:
|
||||
|
||||
* CMake 2.8+
|
||||
|
||||
* Make
|
||||
|
||||
* GCC 4.8+ or Clang 3.3+
|
||||
|
||||
* SWIG
|
||||
|
||||
* GNU Bison
|
||||
|
||||
* Flex
|
||||
|
||||
* Libpcap headers
|
||||
|
||||
* OpenSSL headers
|
||||
|
||||
* zlib headers
|
||||
|
||||
### Getting Started
|
||||
|
||||
First of all, install all the required dependencies, by executing the following command:
|
||||
|
||||
```
|
||||
# apt-get install cmake make gcc g++ flex bison libpcap-dev libssl-dev python-dev swig zlib1g-dev
|
||||
```
|
||||
|
||||
#### Install GeoIP Database for IP Geolocation
|
||||
|
||||
Bro depends on GeoIP for address geolocation. Install both the IPv4 and IPv6 versions:
|
||||
|
||||
```
|
||||
$ wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz
|
||||
$wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCityv6-beta/GeoLiteCityv6.dat.gz
|
||||
```
|
||||
|
||||
Decompress both archives:
|
||||
|
||||
```
|
||||
$ gzip -d GeoLiteCity.dat.gz
|
||||
$ gzip -d GeoLiteCityv6.dat.gz
|
||||
```
|
||||
|
||||
Move the decompressed files to `/usr/share/GeoIP` directory:
|
||||
|
||||
```
|
||||
# mvGeoLiteCity.dat /usr/share/GeoIP/GeoIPCity.dat
|
||||
# mv GeoLiteCityv6.dat /usr/share/GeoIP/GeoIPCityv6.dat
|
||||
```
|
||||
|
||||
Now, it’s possible to build Bro from source.
|
||||
|
||||
### Build Bro
|
||||
|
||||
The latest Bro development version can be obtained through `git` repositories. Execute the following command:
|
||||
|
||||
```
|
||||
$ git clone --recursive git://git.bro.org/bro
|
||||
```
|
||||
|
||||
Go to the cloned directory and simply build Bro with the following commands:
|
||||
|
||||
```
|
||||
$ cd bro
|
||||
$ ./configure
|
||||
$ make
|
||||
```
|
||||
|
||||
The make command will require some time to build everything. The exact amount of time, of course, depends on the server performances.
|
||||
|
||||
The `configure` script can be executed with some argument to specify what dependencies you want build to, in particular the `--with-*` options.
|
||||
|
||||
### Install Bro
|
||||
|
||||
Inside the cloned `bro` directory, execute:
|
||||
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
The default installation path is `/usr/local/bro`.
|
||||
|
||||
### Configure Bro
|
||||
|
||||
Bro configuration files are located in the `/usr/local/bro/etc` directory. There are three files:
|
||||
|
||||
* `node.cfg`, used to configure which node (or nodes) to monitor.
|
||||
|
||||
* `broctl.cfg`, the BroControl configuration file.
|
||||
|
||||
* `networks.cgf`, containing a list of networks in CIDR notation.
|
||||
|
||||
#### Configure Mail Settings
|
||||
|
||||
Open the `broctl.cfg` configuration file:
|
||||
|
||||
```
|
||||
# $EDITOR /usr/local/bro/etc/broctl.cfg
|
||||
```
|
||||
|
||||
Look for the **Mail Options** section, and edit the `MailTo` line as follow:
|
||||
|
||||
```
|
||||
# Recipient address for emails sent out by Bro and BroControl
|
||||
MailTo = admin@example.com
|
||||
```
|
||||
|
||||
Save and close. There are many other options, but in most cases the defaults are good enough.
|
||||
|
||||
#### Choose Nodes To Monitor
|
||||
|
||||
Out of the box, Bro is configured to operate in the standalone mode. In this tutorial we are doing a standalone installation, so it’s not necessary to change very much. However, look at the `node.cfg` configuration file:
|
||||
|
||||
```
|
||||
# $EDITOR /usr/local/bro/etc/node.cfg
|
||||
```
|
||||
|
||||
In the `[bro]` section, you should see something like this:
|
||||
|
||||
```
|
||||
[bro]
|
||||
type=standalone
|
||||
host=localhost
|
||||
interface=eth0
|
||||
```
|
||||
|
||||
Make sure that the interface matches the public interface of the Ubuntu 16.04 server.
|
||||
|
||||
Save and exit.
|
||||
|
||||
### Configure Node’s Networks
|
||||
|
||||
The last file to edit is `network.cfg`. Open it with a text editor:
|
||||
|
||||
```
|
||||
# $EDITOR /usr/local/bro/etc/networks.cfg
|
||||
```
|
||||
|
||||
By default, you should see the following content:
|
||||
|
||||
```
|
||||
# List of local networks in CIDR notation, optionally followed by a
|
||||
# descriptive tag.
|
||||
# For example, "10.0.0.0/8" or "fe80::/64" are valid prefixes.
|
||||
|
||||
10.0.0.0/8 Private IP space
|
||||
172.16.0.0/12 Private IP space
|
||||
192.168.0.0/16 Private IP space
|
||||
```
|
||||
|
||||
Delete the three entries (which are just example for how to use this file), and enter the public and private IP space of your server, in the format:
|
||||
|
||||
```
|
||||
X.X.X.X/X Public IP space
|
||||
X.X.X.X/X Private IP space
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
### Manage Bro Installation with BroControl
|
||||
|
||||
Managing Bro requires using BroControl, which comes in form of an interactive shell and a command line tool. Start the shell with:
|
||||
|
||||
```
|
||||
# /usr/local/bro/bin/broctl
|
||||
```
|
||||
|
||||
To use as a command line tool, just pass an argument to the previous command, for example:
|
||||
|
||||
```
|
||||
# /usr/local/bro/bin/broctl status
|
||||
```
|
||||
|
||||
This will check Bro’s status, by showing output like:
|
||||
|
||||
```
|
||||
Name Type Host Status Pid Started
|
||||
bro standalone localhost running 6807 20 Jul 12:30:50
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
This concludes the Bro’s installation tutorial. We used the source based installation because it is the most efficient way to obtain the latest version available, however this network analysis framework can also be downloaded in pre-built binary format.
|
||||
|
||||
See you next time!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/how-to-install-bro-ubuntu-1604/
|
||||
|
||||
作者:[ Giuseppe Molica][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/tutan/
|
||||
[1]:https://www.unixmen.com/author/tutan/
|
||||
[2]:http://www.tcpdump.org/
|
||||
[3]:http://www.openssl.org/
|
||||
[4]:https://www.unixmen.com/wp-content/uploads/2017/07/brologo.jpg
|
||||
@ -1,233 +0,0 @@
|
||||
Translating by a972667237
|
||||
NoSQL: How To Install OrientDB on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
|
||||
[][2]
|
||||
|
||||
### Introduction – NoSQL and OrientDB
|
||||
|
||||
When talking about databases, in general, we refer to two major families: RDBMS (**R**elational **D**ata**b**ase **M**anagement **S**ystem), which use as user and application program interface a language named **S**tructured **Q**uery **L**anguage (or SQL) and non-relational database management systems, or **NoSQL** databases.
|
||||
|
||||
Between the two models there is a huge difference in the way they consider (and store) data.
|
||||
|
||||
#### Relational Database Management Systems
|
||||
|
||||
In the relational model (like MySQL, or its fork, MariaDB), a database is a set of tables, each containing one or more data categories organized in columns. Each row of the DB contains a unique instance of data for categories defined by columns.
|
||||
|
||||
Just as an example, consider a table containing customers. Each row correspond to a customer, with columns for name, address, and every required information.
|
||||
Another table could contain an order, with product, customer, date and everything else. A user of this DB can obtain a view that fits its needs, for example a report about customers that bought products in a specific range of prices.
|
||||
|
||||
#### NoSQL Database Management Systems
|
||||
|
||||
In the NoSQL (or Not only SQL) database management systems, databases are designed implementing different “formats” for data, like a document, key-value, graph and others. The database systems realized with this paradigm are built especially for large-scale database clusters, and huge web applications. Today, NoSQL databases are used by major companies like Google and Amazon.
|
||||
|
||||
##### Document databases
|
||||
|
||||
Document databases store data in document format. The usage of this kind of DBs is usually raised with JavaScript and JSON, however, XML and other formats are accepted. An example is MongoDB.
|
||||
|
||||
##### Key-value databases
|
||||
|
||||
This is a simple model pairing a unique key with a value. These systems are performant and highly scalable for caching. Examples include BerkeleyDB and MemcacheDB.
|
||||
|
||||
##### Graph databases
|
||||
|
||||
As the name predicts, these databases store data using graph models, meaning that data is organized as nodes and interconnections between them. This is a flexible model which can evolve over time and use. These systems are applied where there is the necessity of mapping relationships.
|
||||
Examples are IBM Graphs and Neo4j **and OrientDB**.
|
||||
|
||||
### OrientDB
|
||||
|
||||
[OrientDB][3], as stated by the company behind it, is a multi-model NoSQL Database Management System that “ _combines the power of graphs with documents, key/value, reactive, object-oriented and geospatial models into one **scalable, high-performance operational database**“._
|
||||
|
||||
OrientDB has also support for SQL, with extensions to manipulate trees and graphs.
|
||||
|
||||
### Goals
|
||||
|
||||
This tutorial explains how to install and configure OrientDB Community on a server running Ubuntu 16.04.
|
||||
|
||||
### Download OrientDB
|
||||
|
||||
On an up to date server, download the latest version of OrientDB by executing the following command:
|
||||
|
||||
```
|
||||
$ wget -O orientdb-community-2.2.22.tar.gz http://orientdb.com/download.php?file=orientdb-community-2.2.22.tar.gz&os=linux
|
||||
```
|
||||
|
||||
This is a tarball containing pre-compiled binaries, so extract the archive with `tar`:
|
||||
|
||||
```
|
||||
$ tar -zxf orientdb-community-2.2.22.tar.gz
|
||||
```
|
||||
|
||||
Move the extracted directory into `/opt`:
|
||||
|
||||
```
|
||||
# mv orientdb-community-2.2.22 /opt/orientdb
|
||||
```
|
||||
|
||||
### Start OrientDB Server
|
||||
|
||||
Starting the OrientDB server requires the execution of the shell script contained in `orientdb/bin/`:
|
||||
|
||||
```
|
||||
# /opt/orientdb/bin/server.sh
|
||||
```
|
||||
|
||||
During the first start, this installer will display some information and will ask for an OrientDB root password:
|
||||
|
||||
```
|
||||
+---------------------------------------------------------------+
|
||||
| WARNING: FIRST RUN CONFIGURATION |
|
||||
+---------------------------------------------------------------+
|
||||
| This is the first time the server is running. Please type a |
|
||||
| password of your choice for the 'root' user or leave it blank |
|
||||
| to auto-generate it. |
|
||||
| |
|
||||
| To avoid this message set the environment variable or JVM |
|
||||
| setting ORIENTDB_ROOT_PASSWORD to the root password to use. |
|
||||
+---------------------------------------------------------------+
|
||||
|
||||
Root password [BLANK=auto generate it]: ********
|
||||
Please confirm the root password: ********
|
||||
```
|
||||
|
||||
After that, the OrientDB server will start:
|
||||
|
||||
```
|
||||
INFO OrientDB Server is active v2.2.22 (build fb2b7d321ea8a5a5b18a82237049804aace9e3de). [OServer]
|
||||
```
|
||||
|
||||
From now on, we will need a second terminal to interact with the OrientDB server.
|
||||
|
||||
Stop OrientDB by hitting `Ctrl+C`.
|
||||
|
||||
### Configure a Daemon
|
||||
|
||||
At this point, OrientDB is just a bunch of shell scripts. With a text editor, open `/opt/orientdb/bin/orientdb.sh`:
|
||||
|
||||
```
|
||||
# $EDITOR /opt/orientdb/bin/orientdb.sh
|
||||
```
|
||||
|
||||
In the first lines, we will see:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# OrientDB service script
|
||||
#
|
||||
# Copyright (c) OrientDB LTD (http://orientdb.com/)
|
||||
|
||||
# chkconfig: 2345 20 80
|
||||
# description: OrientDb init script
|
||||
# processname: orientdb.sh
|
||||
|
||||
# You have to SET the OrientDB installation directory here
|
||||
ORIENTDB_DIR="YOUR_ORIENTDB_INSTALLATION_PATH"
|
||||
ORIENTDB_USER="USER_YOU_WANT_ORIENTDB_RUN_WITH"
|
||||
```
|
||||
|
||||
Configure `ORIENTDB_DIR` and `ORIENTDB_USER`.
|
||||
|
||||
Create a user, for example **orientdb**, by executing the following command:
|
||||
|
||||
```
|
||||
# useradd -r orientdb -s /sbin/nologin
|
||||
```
|
||||
|
||||
**orientdb** is the user we enter in the `ORIENTDB_USER` line.
|
||||
|
||||
Change the ownership of `/opt/orientdb`:
|
||||
|
||||
```
|
||||
# chown -R orientdb:orientdb /opt/orientdb
|
||||
```
|
||||
|
||||
Change the configuration server file’s permission:
|
||||
|
||||
```
|
||||
# chmod 640 /opt/orientdb/config/orientdb-server-config.xml
|
||||
```
|
||||
|
||||
#### Install the Systemd Service
|
||||
|
||||
OrientDB tarball contains a service file, `/opt/orientdb/bin/orientdb.service`. Copy it to the `/etc/systemd/system` directory:
|
||||
|
||||
```
|
||||
# cp /opt/orientdb/bin/orientdb.service /etc/systemd/system
|
||||
```
|
||||
|
||||
Edit the OrientDB service file:
|
||||
|
||||
```
|
||||
# $EDITOR /etc/systemd/system/orientdb.service
|
||||
```
|
||||
|
||||
There, the `[service]` block should look like this:
|
||||
|
||||
```
|
||||
[Service]
|
||||
User=ORIENTDB_USER
|
||||
Group=ORIENTDB_GROUP
|
||||
ExecStart=$ORIENTDB_HOME/bin/server.sh
|
||||
```
|
||||
|
||||
Edit as follow:
|
||||
|
||||
```
|
||||
[Service]
|
||||
User=orientdb
|
||||
Group=orientdb
|
||||
ExecStart=/opt/orientdb/bin/server.sh
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Reload systemd daemon service:
|
||||
|
||||
```
|
||||
# systemctl daemon-reload
|
||||
```
|
||||
|
||||
Start OrientDB and enable for starting at boot time:
|
||||
|
||||
```
|
||||
# systemctl start orientdb
|
||||
# systemctl enable orientdb
|
||||
```
|
||||
|
||||
Check OrientDB status:
|
||||
|
||||
```
|
||||
# systemctl status orientdb
|
||||
```
|
||||
|
||||
The command should output:
|
||||
|
||||
```
|
||||
● orientdb.service - OrientDB Server
|
||||
Loaded: loaded (/etc/systemd/system/orientdb.service; disabled; vendor preset: enabled)
|
||||
Active: active (running) ...
|
||||
```
|
||||
|
||||
And that’s all! OrientDB Community is installed and correctly running.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this tutorial we have seen a brief comparison between RDBMS and NoSQL DBMS. We have also installed and completed a basic configuration of OrientDB Community server-side.
|
||||
|
||||
This is the first step for deploying a full OrientDB infrastructure, ready for managing large-scale systems data.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/nosql-install-orientdb-ubuntu-16-04/
|
||||
|
||||
作者:[Giuseppe Molica ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/tutan/
|
||||
[1]:https://www.unixmen.com/author/tutan/
|
||||
[2]:https://www.unixmen.com/wp-content/uploads/2017/07/orientdb.png
|
||||
[3]:https://orientdb.com/
|
||||
@ -1,56 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Robot development made easy with Husarion CORE2-ROS running Ubuntu
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||
_This is the first in a series of two posts by guest blogger; Dominik Nowak, CEO at Husarion._
|
||||
|
||||
We’ve seen many breakthroughs happening in the IT industry over the last decade. Arguably the most meaningful one on the consumer side was the adoption of smartphones and mobile development. What’s the next big thing, now that the smartphones are so common and, let’s face it, slightly boring? We say: robotics.
|
||||
|
||||
Business knows that well with many manufacturing lines running solely by robots. The consumer and service side, though, have yet to see a massive breakthrough. We believe it’s all a matter of accessibility and lowering the barrier to entry for developers. There just have to be good, simple tools to quickly prototype and develop robots. To test new ideas and empower engineers, so they can solve many of the issues humanity still faces. Issues that are trickier to tackle than a tap in an app.
|
||||
|
||||
Building robots is a challenging task that the [Husarion][2] team is trying to make easier. Husarion is a robotic company working on rapid development platform for robots. The products of the company are CORE2 robotic controller and the cloud platform to manage all CORE2 based robots. CORE2 is the second generation of Husarion’s robotics controller and it’s now available [here][3].
|
||||
|
||||
CORE2 combines a real-time microcontroller board and a single board computer running Ubuntu. Ubuntu is the most popular Linux distribution not only for [desktops][4], but also for embedded hardware in IoT & [robotics][5] applications.
|
||||
|
||||

|
||||
|
||||
CORE2 controller comes in two configurations. The first one with ESP32 Wi-Fi module is dedicated for robotic applications that need low power consumption and real-time, secure remote control. The second one, called CORE2-ROS, basically integrates two boards in one:
|
||||
– A board with real-time microcontroller running firmware using the Real-Time Operating System (RTOS) and integrating interfaces for motors, encoders and sensors
|
||||
– A single board computer (SBC) running Linux with ROS packages ([Robot Operating System][6]) and other software tools.
|
||||
|
||||
The ‘real-time’ board does the low-level job. It contains the efficient STM32F4 series microcontroller which is great for driving motors, reading encoders, communicating with sensors and controlling the whole mechatronic or robotic system. In most applications, the CPU load does not exceed a few percents and the real-time operation is guaranteed by a dedicated programming framework based on RTOS. We also assured the compatibility with Arduino libraries. The majority of the tasks are processed in the microcontroller peripherals, such as timers, communication interfaces, ADCs etc. with the strong support of interrupts and DMA channels. In short, it is not a job for a single-board computer that has the other tasks.
|
||||
|
||||
On the other hand, it’s almost obvious that the modern and advanced robotic applications can no longer be based only on microcontrollers, for a few reasons:
|
||||
– Autonomous robots need a lot of processing power to perform navigation, image and sound recognition, moving in a swarm etc.,
|
||||
– Writing the advanced software requires standardisation to be efficient – SBCs become more and more popular in the industry and the same is observed for the software written for SBCs, which is very similar to PC computers
|
||||
– SBCs are getting less expensive every year
|
||||
– Husarion believes that combining these two worlds is very beneficial in robotics.
|
||||
|
||||
CORE2-ROS controller is available in two configurations with [Raspberry Pi 3 ][7]or [ASUS Tinker Board][8]. CORE-ROS is running Ubuntu, Husarion dev & management tools and ROS packets.
|
||||
|
||||
In the next post, find out why Husarion decided to use Ubuntu.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/12/robot-development-made-easy-with-husarion-core2-ros-running-ubuntu/
|
||||
|
||||
作者:[Guest ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/guest/
|
||||
[1]:https://insights.ubuntu.com/author/guest/
|
||||
[2]:https://husarion.com/
|
||||
[3]:https://www.crowdsupply.com/husarion/core2
|
||||
[4]:https://www.ubuntu.com/desktop
|
||||
[5]:https://www.ubuntu.com/internet-of-things/robotics
|
||||
[6]:http://www.ros.org/
|
||||
[7]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[8]:https://www.asus.com/uk/Single-Board-Computer/Tinker-Board/
|
||||
@ -1,83 +0,0 @@
|
||||
Storage management in LXD 2.15
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||
|
||||
|
||||
For a long time LXD has supported multiple storage drivers. Users could choose between zfs, btrfs, lvm, or plain directory storage pools but they could only ever use a single storage pool. A frequent feature request was to support not just a single storage pool but multiple storage pools. This way users would for example be able to maintain a zfs storage pool backed by an SSD to be used by very I/O intensive containers and another simple directory based storage pool for other containers. Luckily, this is now possible since LXD gained its own storage management API a few versions back.
|
||||
|
||||
### Creating storage pools
|
||||
|
||||
A new LXD installation comes without any storage pool defined. If you run `lxd init`LXD will offer to create a storage pool for you. The storage pool created by `lxd init`will be the default storage pool on which containers are created.
|
||||
|
||||
[][2]
|
||||
|
||||
### Creating further storage pools
|
||||
|
||||
Our client tool makes it really simple to create additional storage pools. In order to create and administer new storage pools you can use the `lxc storage` command. So if you wanted to create an additional btrfs storage pool on a block device `/dev/sdb`you would simply use `lxc storage create my-btrfs btrfs source=/dev/sdb`. But let’s take a look:
|
||||
|
||||
[][3]
|
||||
|
||||
### Creating containers on the default storage pool
|
||||
|
||||
If you started from a fresh install of LXD and created a storage pool via `lxd init` LXD will use this pool as the default storage pool. That means if you’re doing a `lxc launch images:ubuntu/xenial xen1` LXD will create a storage volume for the container’s root filesystem on this storage pool. In our examples we’ve been using `my-first-zfs-pool`as our default storage pool:
|
||||
|
||||
[][4]
|
||||
|
||||
### Creating containers on a specific storage pool
|
||||
|
||||
But you can also tell `lxc launch` and `lxc init` to create a container on a specific storage pool by simply passing the `-s` argument. For example, if you wanted to create a new container on the `my-btrfs` storage pool you would do `lxc launch images:ubuntu/xenial xen-on-my-btrfs -s my-btrfs`:
|
||||
|
||||
[][5]
|
||||
|
||||
### Creating custom storage volumes
|
||||
|
||||
If you need additional space for one of your containers to for example store additional data the new storage API will let you create storage volumes that can be attached to a container. This is as simple as doing `lxc storage volume create my-btrfs my-custom-volume`:
|
||||
|
||||
[][6]
|
||||
|
||||
### Attaching custom storage volumes to containers
|
||||
|
||||
Of course this feature is only helpful because the storage API let’s you attach those storage volume to containers. To attach a storage volume to a container you can use `lxc storage volume attach my-btrfs my-custom-volume xen1 data /opt/my/data`:
|
||||
|
||||
[][7]
|
||||
|
||||
### Sharing custom storage volumes between containers
|
||||
|
||||
By default LXD will make an attached storage volume writable by the container it is attached to. This means it will change the ownership of the storage volume to the container’s id mapping. But Storage volumes can also be attached to multiple containers at the same time. This is great for sharing data among multiple containers. However, this comes with a few restrictions. In order for a storage volume to be attached to multiple containers they must all share the same id mapping. Let’s create an additional container `xen-isolated` that has an isolated id mapping. This means its id mapping will be unique in this LXD instance such that no other container does have the same id mapping. Attaching the same storage volume `my-custom-volume` to this container will now fail:
|
||||
|
||||
[][8]
|
||||
|
||||
But let’s make `xen-isolated` have the same mapping as `xen1` and let’s also rename it to `xen2` to reflect that change. Now we can attach `my-custom-volume` to both `xen1` and `xen2` without a problem:
|
||||
|
||||
[][9]
|
||||
|
||||
### Summary
|
||||
|
||||
The storage API is a very powerful addition to LXD. It provides a set of essential features that are helpful in dealing with a variety of problems when using containers at scale. This short introducion hopefully gave you an impression on what you can do with it. There will be more to come in the future.
|
||||
|
||||
This blog was originally featured at [Brauner's Blog][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/12/storage-management-in-lxd-2-15/
|
||||
|
||||
作者:[Christian Brauner ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://cbrauner.wordpress.com/
|
||||
[1]:https://insights.ubuntu.com/author/christian-brauner/
|
||||
[2]:https://asciinema.org/a/126892
|
||||
[3]:https://asciinema.org/a/128580
|
||||
[4]:https://asciinema.org/a/128582
|
||||
[5]:https://asciinema.org/a/128583
|
||||
[6]:https://asciinema.org/a/128584
|
||||
[7]:https://asciinema.org/a/128585
|
||||
[8]:https://asciinema.org/a/128588
|
||||
[9]:https://asciinema.org/a/128593
|
||||
[10]:https://cbrauner.wordpress.com/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by firmianay
|
||||
|
||||
DYNAMIC PORT FORWARDING / MOUNT A SOCKS SERVER WITH SSH
|
||||
=================
|
||||
|
||||
|
||||
@ -1,55 +0,0 @@
|
||||
Things to consider when building a robot with open source
|
||||
==============================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
So you’re considering (or are in the process of) bringing a robot, using open source software, to market. It’s based on Linux. Maybe you’re using the [Robot Operating System][2] (ROS), or the [Mission Oriented Operating Suite][3] (MOOS), or yet another open-source middleware that’s helping you streamline development. As development nears something useful, you start receiving some pressure about desired returns on this thing. You might be asked ‘When can we start selling it?’ This is where you reach a crossroads.
|
||||
|
||||
You can do one of two things:
|
||||
|
||||
1. Start shipping essentially what you have now
|
||||
|
||||
2. Step back, and treat going to production as an entirely new problem to solve, with new questions to answer
|
||||
|
||||
You don’t need to look very far to see examples of people who settled on (1). In fact, the IoT market is flooded with them. With the rush to get devices to market, it’s not at all rare to find devices left with hard-coded credentials, development keys, various security vulnerabilities, and no update path.
|
||||
|
||||
Think of Mirai, the botnet that mounted a DDoS attack with traffic surpassing 1Tbps, bringing down some of the biggest websites on the Internet. It’s made up primarily of IoT devices. Does it use super cool black magic developed in a windowless lab (or basement) to overwhelm the devices’ defenses and become their master? Nope, default (and often hard-coded) credentials. Did the manufacturers of these devices react quickly and release updates to all these devices in order to secure them? No, many of them don’t have an update method at all. [They recalled them instead][4].
|
||||
|
||||
Rather than rushing to market, take a step back. You can save yourself and your company a lot of pain simply by thinking through a few points.
|
||||
|
||||
For example, **how is your software updated**? You _must_ be able to answer this question. Your software is not perfect. In a few weeks you’ll find out that, when your autonomous HMMWV is used in California, it thinks that little sagebrush is an oak. Or you accidentally included your SSH keys.
|
||||
|
||||
**How is the base OS updated**? Perhaps this is still part of your product, and answering the above question answers this one as well. But perhaps your OS comes from another vendor. How do you get updates from them to your customers? This is where security vulnerabilities can really bite you: a kernel that is never updated, or a severely out-of-date openssl.
|
||||
|
||||
Once you have updates figured out, **how is your robot recovered if an update goes sideways**? My go-to example for this is a common solution to the previous problem: automatic security updates. That’s a great practice for servers and desktops and things that are obviously computers, because most people realize that there’s an acceptable way to turn those off, and it’s _not_ to hold the power button for 5 seconds. Robotic systems (and IoT systems in general) have a bit of an issue in that sometimes they’re not viewed as computers at all. If your robot is behaving oddly, chances are it will be forcefully powered off. If it was behaving oddly because it was installing a kernel update real quick, well, now you have a robotic paperweight with a partially installed kernel. You need to be able to deal with this type of situation.
|
||||
|
||||
Finally, **what is your factory process**? How do you install Linux, ROS (or whatever middleware you’re using), and your own stuff on a device you’re about to ship? Small shops might do it by hand, but that doesn’t scale and is error-prone. Others might make a custom seeded distro ISO, but that’s no small task and it’s not easy to maintain as you update your software. Still others use Chef or some other automation tool with a serious learning curve, and before long you realize that you dumped a significant amount of engineering effort into something that should have been easy.
|
||||
|
||||
All of these questions are important. If you find yourself not having clear answers to any of them, you should join our webinar, where we discuss how to build a commercial robot with open source. We’ll help you think through these questions, and be available to answer any more you have!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Kyle is a member of the Snapcraft team, and is also Canonical's resident roboticist. He focuses on snaps and the snap developer experience, as well as robotics enablement for snaps and Ubuntu Core.
|
||||
|
||||
|
||||
|
||||
-----------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/18/things-to-consider-when-building-a-robot-with-open-source/
|
||||
|
||||
作者:[Kyle Fazzari ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/kyrofa/
|
||||
[1]:https://insights.ubuntu.com/author/kyrofa/
|
||||
[2]:http://www.ros.org/
|
||||
[3]:http://www.robots.ox.ac.uk/~mobile/MOOS/wiki/pmwiki.php/Main/HomePage
|
||||
[4]:https://krebsonsecurity.com/2016/10/iot-device-maker-vows-product-recall-legal-action-against-western-accusers/
|
||||
@ -1,87 +0,0 @@
|
||||
【haoqixu 翻译中】Top 4 reasons I use dwm for my Linux window manager
|
||||
============================================================
|
||||
|
||||
### A window manager handles the sizing and arrangement of the windows you open, among other things.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
Internet Archive [Book][4] [Images][5]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
I like minimalistic views. If I could run everything in a terminal I would. It's free from shiny stuff that hogs my resources and distracts my feeble mind. I also grow tired of resizing and moving windows, never getting them to align perfectly.
|
||||
|
||||
On my quest for minimalism, I grew fond of [Xfce][6] and used it as my main [desktop environment][7] for years on my Linux computers. Then, one day I came across a video of [Bryan Lunduke][8] talking about the awesome [window manager][9] he used called [Awesome][10]. It neatly arranges all of your windows for you, and so, sounded like just what I wanted. I tried it out but didn't get the hang of the configuration needed to tweak it into my liking. So, I moved on and discovered [xmonad][11], but I had a similar result. It worked fine but I couldn't get around the Haskell part to really turn it into my perfect desktop.
|
||||
|
||||
Years passed and by accident, I found my way to [suckless.org][12] and their version of a window manager called [dwm][13].
|
||||
|
||||
In short, a desktop environment such as KDE, Gnome, or Xfce includes many things, of which a window manager is one, but also with select applications. A window manager alone handles (among other window related things) the sizing and arrangement of the windows you open. Different desktop environments use different window managers. KDE has KWin, Gnome 2 has Metacity, Gnome 3 has Mutter, and Xfce has Xfwm. Conveniently, for all of these, you can change the default window manager to something else, which is what I've been doing for a while. I've been switching mine to dwm, and here's why I love it.
|
||||
|
||||
### Dynamic window management
|
||||
|
||||
The killer feature for dwm, as with Awesome and xmonad, is the part where the tool automatically arranges the windows for you, filling the entire space of your screen. Sure, for most desktop environments today it's possible to create keyboard shortcuts to arrange windows to the left, right, top, bottom or full screen, but with dwm it's just one less thing to think about.
|
||||
|
||||
Dwm divides the screen into a master and a stack area. There are three layouts to choose from: tile, monocle, and floating. When using tile mode, which is what I use the most, it puts the window which requires the most attention in the master area while the others are tiled in the stack area. In the monocle layout, all windows are maximized and you toggle between them. The floating layout allows you resize the windows as you want (as the most window managers do), which is handy if you're using Gimp or a similar application where custom size windows makes more sense.
|
||||
|
||||
Usually, in your desktop environment, you can use different workspaces to sort your windows and gather similar applications in designated workspaces. At work, I use one workspace for ongoing work and one for internet browsing. Dwm has a similar function called tags. You can group windows by tags and by selecting a tag, you display all the windows with that tag.
|
||||
|
||||
### Efficiency
|
||||
|
||||
Dwm is efficient if you want to save as much power as you can on your computer. Xfce and other lightweight environments are great on older or weaker machines, but dwm uses (in my case) about 1/3 of resources compared to Xfce after login. When I was using an eee pc with 1 GB RAM it made quite a difference if the memory was occupied to 660 MB or 230 MB. That left me with more room for the editors and browsers I wanted to use.
|
||||
|
||||
### Minimalistic
|
||||
|
||||
I typically set up my applications beside each other: the terminal as the master window (usually running Vim as an editor), a browser for email, and another browser window open for research or [Trello][14]. For casual internet browsing, I fire up a Chromium window in another workspace or a _tag_ as I mentioned earlier.
|
||||
|
||||
### [dwm.png][1]
|
||||
|
||||

|
||||
|
||||
Screenshot by author.
|
||||
|
||||
With standard desktop environments, you often have at least one or two panels, top and bottom or on the side, taking up space. I have tried out the autohide panel function that most of them have, but I was annoyed every time I accidently put the mouse pointer too close to the edge and the panel popped out at the most inconvenient time. You can make them smaller as well but I still enjoy the minimalistic status bar on top of the screen available in dwm.
|
||||
|
||||
### Speed
|
||||
|
||||
When evaluating speed, I count both how quickly dwm is loaded when I log in and how quickly the applications launch when I start them. When using newer, faster computers you might not care about this detail yet, but for me, there is a noticable difference between various desktop environments and window managers. I don't want to actually wait for my computer to perform such easy tasks, it should just pop up. Also, using keyboard shortcuts to launch everything is faster than using a mouse or a touchpad, and my hands don't have to leave the keyboard.
|
||||
|
||||
### Conclusion
|
||||
|
||||
That said, I would not recommend dwm to the novice user. It takes some time to read up on how to configure it to your liking (unless you are satisfied with the setup provided by your Linux distribution). I have found some of the patches you might want to include can be tricky to get working and the support community is small (the IRC channel states "No patch-handholding"). So, it might take a bit of effort to get exactly what you want. However, once you do, it's well worth that bit investment.
|
||||
|
||||
And hey, it looks as awesome as Awesome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jimmy Sjölund - Jimmy Sjölund is a senior IT service manager and innovation coach at Telia Company, focusing on organisation development, exploring agile and lean workflows and is a visualisation enthusiast. He's also an open source evangelist, previously engaged in Ubuntu Studio and Plume Creator.
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/7/top-4-reasons-i-use-dwm-linux-window-manager
|
||||
|
||||
作者:[ Jimmy Sjölund Feed ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jimmysjolund
|
||||
[1]:https://opensource.com/file/363336
|
||||
[2]:https://opensource.com/article/17/7/top-4-reasons-i-use-dwm-linux-window-manager?rate=T8qhopZLfd1eum_NMLOSGckUh2nIjfeRpkERGjGhu7w
|
||||
[3]:https://opensource.com/user/56551/feed
|
||||
[4]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
||||
[5]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
||||
[6]:https://xfce.org/
|
||||
[7]:https://en.wikipedia.org/wiki/Desktop_environment
|
||||
[8]:http://lunduke.com/
|
||||
[9]:https://en.wikipedia.org/wiki/Window_manager
|
||||
[10]:https://awesomewm.org/
|
||||
[11]:http://xmonad.org/
|
||||
[12]:http://suckless.org/
|
||||
[13]:http://dwm.suckless.org/
|
||||
[14]:https://opensource.com/node/22546
|
||||
[15]:https://opensource.com/users/jimmysjolund
|
||||
[16]:https://opensource.com/users/jimmysjolund
|
||||
[17]:https://opensource.com/article/17/7/top-4-reasons-i-use-dwm-linux-window-manager#comments
|
||||
@ -1,91 +0,0 @@
|
||||
GPL 没落了吗?
|
||||
===================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
不久之前我看到了 RedMonk 的 Stephen O'Grady 发了一个[关于开源协议的有趣的推特][2],那个推特里面有这张图。
|
||||
|
||||

|
||||
|
||||
这张图片显示了从 2010 到 2017 年间各种开源协议之间的使用率的变化。在这张图片里,显然 GPL 2.0,最纯净的 copyleft 协议之一,的使用率不只是折了个半。表格表明,开源项目中 [MIT][3] 协议和 [Apache][4] 协议开始受欢迎。[GPL 3.0][5] 的使用率也有所上涨。
|
||||
|
||||
这些意味着什么?
|
||||
|
||||
为什么 GPL 2.0 的使用率跌的这么多但是 GPL 3.0 仅仅是涨了一丁点?为什么 MIT 和 Apache 的使用率涨了那么多?
|
||||
|
||||
当然,有很多原因可以解释这件事情,但是我想这是因为商业开源项目的增多,以及商业社会对于 GPL 协议的担心导致的,我们细细掰扯。
|
||||
|
||||
### GPL 协议与商业社会
|
||||
|
||||
我知道我要说的可能会激怒一些 GPL粉,所以在你们开始喷之前,我想说明:我支持 GPL,也是 GPL 粉丝。
|
||||
|
||||
我写过的所有软件都使用的 GPL 协议,我也是一直是出资支持 [自由软件基金会][6] 以及 [软件自由保护组织][7] 以及他们的工作的,我支持使用 GPL 协议。我在这说的无关 GPL 的合法性或者 GPL 的巨大价值 —— 毫无疑问这是一个好协议 —— 我在这要说的是商业社会对于这个协议的看法。
|
||||
|
||||
大概四年之前,我参加了一个叫做 开源智库 的峰会。这个峰会是一个私人小型峰会,每年都会把各大开源企业的管理人员请到加利福尼亚的酒庄。这个峰会聚焦于网络,构建联盟,识别报告企业问题。
|
||||
|
||||
在这个峰会上,有一个小组研究,在这个小组研究中,与会者被分成小组,被要求给一个真实存在的核心开源技术推荐一个开源协议。每个小组都给出了回应。不到十分之一的小组推荐了公共许可证,没有热推荐 GPL 许可证。
|
||||
|
||||
我看到了开源行业对于 Apache 以及 MIT 协议的逐步认可,但是他们却对花时间理解,接受,熟悉 GPL 这件事高高挂起。
|
||||
|
||||
在这几年里,这种趋势仍在蔓延。除了 Black Duck 的调查之外, 2015 年 [GitHub 上的开源协议调查][8] 也显示 MIT 是人们的首选。我还能看到,在我工作的 XPRIZE (我们为我们的 [Global Learning XPRIZE][9] 选择了开源协议),在我的职位,[社区领导顾问][10],我也能感觉到那种倾向,因为越来越多的客户觉得把他们的代码用 GPL 发布不舒服。
|
||||
|
||||
随着 [大约 65% 的公司对开源事业做贡献][11] ,自从 2010 年以后显然开源行业已经有了不少商业资本和投资。我相信,我之前说的那些趋势,已经表明这行业不认为 GPL 适合搞开源生意。
|
||||
|
||||
### 连接社区和公司
|
||||
|
||||
说真的,GPL 的没落不太让人吃惊,因为有如下原因。
|
||||
|
||||
首先,开源行业已经转型升级,它要在社区发展以及...你懂的...真正能赚钱的商业模型中做出均衡,这是它们要做的最重要的决策。在开源思想发展之初,人们有种误解说,“如果你搞出来了,他们就会用”,他们确实会来使用你的软件,但是在很多情况下,都是“如果你搞出来了,他们不一定会给你钱。”
|
||||
|
||||
随着历史的进程,我们看到了许多公司,比如 Red Hat, Automattic, Docker, Canonical, Digital Ocean 等等等等,发展着在开源领域中赚钱的法子。他们发展过分发模型,服务模型,开源核心服务模型等等等等。现在可以确定的是,传统的商业软件赚钱的方式已经不在开源软件这适用;因此,你得选择一个能够支持你的公司的营业方式的开源协议。在赚钱和免费提供你的技术之间找到平衡在很多情况下是很困难的一件事。
|
||||
|
||||
这就是我们看到那些变化的原因。尽管 GPL 是一个开源协议,但是它还是自由软件协议,作为自由软件协议,它的管理以及支持是由自由软件基金会提供的。
|
||||
|
||||
我喜欢自由软件基金会的作品,但是他们已经把观点局限于软件必须 100 % 绝对免费。对于 FSF 没有多少可以妥协的,甚至很多出名的开源项目(比如很多 Linux 发行版)仅仅是因为一丁点二进制固件就被认为是 “非免费” 软件。
|
||||
|
||||
对于商业来说,最复杂的就是它不是非黑即白,更多的时候是两者混合的灰色,很少有公司有自由软件基金会(或者类似的组织,比如软件自由保护组织)的那种纯粹的理念,因此我想那些公司也不喜欢选择和那些理念相关的协议。
|
||||
|
||||
我需要说明,我不是在这是说 FSF 以及类似的组织(比如 SFC)的错。他们有着打造完全免费的软件的目标,对于他们来说,走它们选择的路十分合理。FSF 以及 SFC 做了_了不起_的工作,我将继续支持这些组织以及为他们工作的人们。我相信,这种纯粹性的高要求的一个后果就是让那些公司认为自己难以达到要求,因此,他们使用了非 GPL 的其他协议。
|
||||
|
||||
近年来,尽管我们已经看到了不再那么挑剔的一代开发者的出现,但是他们却缺少对于自由的关注。对于他们来说开源软件是务实实用的构建软件的一部分,而不是关乎伦理的问题。我想,这就是为什么我们发现 MIT 和 Apache 协议的流行的原因。
|
||||
|
||||
### 未来 ?
|
||||
|
||||
这对于 GPL 意味着什么?
|
||||
|
||||
我的猜想是 GPL 依然将是一个主要选项,但是开发者将将他视为纯粹的自由软件协议。我想对于软件的纯粹性有高要求的项目会优先选择 GPL 协议。但是对于商业软件,为了保持我们之前讨论的平衡,他们不会那么做。我猜测, MIT 以及 Apache 依然会继续流行下去。
|
||||
|
||||
不管怎样,好消息是开源/免费软件行业确实在增长。无论使用的协议会发生怎样的变化,技术确实变得更加开放,可以接触,人人都能使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jono Bacon - Jono Bacon is a leading community manager, speaker, author, and podcaster. He is the founder of Jono Bacon Consulting which provides community strategy/execution, developer workflow, and other services. He also previously served as director of community at GitHub, Canonical, XPRIZE, OpenAdvantage, and consulted and advised a range of organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/decline-gpl
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jonobacon
|
||||
[1]:https://opensource.com/article/17/2/decline-gpl?rate=WfBHpUyo5BSde1SNTJjuzZTJbjkZTES77tcHwpfTMdU
|
||||
[2]:https://twitter.com/sogrady/status/820001441733607424
|
||||
[3]:https://opensource.org/licenses/MIT
|
||||
[4]:http://apache.org/licenses/
|
||||
[5]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[6]:http://www.fsf.org/
|
||||
[7]:https://sfconservancy.org/
|
||||
[8]:https://github.com/blog/1964-open-source-license-usage-on-github-com
|
||||
[9]:http://learning.xprize.org/
|
||||
[10]:http://www.jonobacon.org/consulting
|
||||
[11]:https://opensource.com/business/16/5/2016-future-open-source-survey
|
||||
[12]:https://opensource.com/user/26312/feed
|
||||
[13]:https://opensource.com/article/17/2/decline-gpl#comments
|
||||
[14]:https://opensource.com/users/jonobacon
|
||||
@ -1,90 +0,0 @@
|
||||
此脚本使用含多来源统一阻止列表的白名单来更新主机文件
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
网上有许多持续维护的含有不同垃圾域的有用列表。将这些列表复制到你的主机文件中可以轻松阻止大量的域,你的系统则无法连接它们。此方法在不安装浏览器插件的情况下工作,并且将处理系统上任何浏览器(和任何其他程序)的阻止操作。
|
||||
|
||||
在本教程中,我将向你展示如何在 Linux 中启动并运行 Steven Black 的[统一主机脚本][1]。该脚本将使用最新的已知广告服务器、网络钓鱼网站和其他网络垃圾邮件更新(多个来源)的计算机主机文件,同时提供一个漂亮、干净的方式来管理自己的黑名单/白名单,与脚本管理的列表分开管理。
|
||||
|
||||
在将 30,000 个域放入主机文件之前,需要注意两点。首先,这些巨大的列表包含可能需要解除封锁的服务器,以便进行在线购买或其他一些临时情况。当网上的事情出现问题时,你会意识到你遇到一个麻烦了,因为你搞砸了你的主机文件。为了解决这个问题,我将向你展示如何使用方便的打开/关闭开关,以便你可以快速禁用阻止列表购买喜马拉雅盐雾灯(它是等离子灯)。我仍然认为这些列表的一个特点是将所有的一切都封锁(这只是烦人,直到我想到了关闭开关)。如果你经常遇到你需要的服务器被阻止的问题,只需将其添加到白名单文件中即可。
|
||||
|
||||
第二个问题是性能受到了轻微的影响, 因为每次调用一个域时, 系统都必须检查整个列表。也许会有一个小的命中, 但不够大, 因此我放弃名单, 让每一个连接都通过。但是, 请你自己考虑。
|
||||
|
||||
主机文件通过将请求定向到 127.0.0.1 或 0.0.0.0(换句话说定向到空地址)来阻止请求。有人说使用 0 是更快,问题更少的方法。你可以将脚本配置为使用 “-ip nnn.nnn.nnn.nnn” 这样的 ip
|
||||
选项来作为阻止 ip, 但默认值是 0.0.0.0, 这是我使用的值。
|
||||
|
||||
|
||||
我曾经将 Steven 脚本做的事每隔一段时间就手动做一遍,进到每一个站点,将他们的列表拷贝/粘贴到我的主机文件中,做一个查找替换将其中一些变成 0 等等。我知道整件事情可以自动化,这样做有点傻,但我从来没有花时间解决这个问题。直到我找到这个脚本, 现在这已经是一个被遗忘的杂务。
|
||||
|
||||
让我们先下载一份 Black 代码拷贝(大约 150MB),以便我们可以进行下一步。你需要安装 git,因此如果还没安装,进入到终端输入:
|
||||
|
||||
**sudo apt-get install git**
|
||||
|
||||
安装完之后,输入:
|
||||
|
||||
**mkdir unifiedhosts**
|
||||
**cd unifiedhosts**
|
||||
**git clone** [**https://github.com/StevenBlack/hosts.git** ][2]
|
||||
**cd hosts**
|
||||
|
||||
当您的光标在 Steven 的脚本中闪烁时,让我们来谈谈选择。该脚本有几个选项和扩展,但扩展我不会在这里覆盖,但如果你到了这一步并且你有兴趣,[readme.md][3] 可以告诉你所有你需要知道的。
|
||||
|
||||
你需要安装 python 来运行此脚本,并且与版本有关。要找到你安装的 Python 版本,请输入:
|
||||
|
||||
**python --version**
|
||||
|
||||
如果你还没安装 Python:
|
||||
|
||||
**sudo apt-get install python**
|
||||
|
||||
对于 Python 2.7,如下所示,输入 “python” 来执行脚本。对于 Python 3,在命令中的 “python” 替换成 “python3”。执行后,该脚本会确保它具有每个列表的最新版本,如果没有,它会抓取一个新的副本。然后,它会写入一个新的 hosts 文件,包括了黑名单/白名单中的任何内容。让我们尝试使用 -r 选项来替换我们的活动主机文件以及 -a 选项,以便脚本不会发生任何问题。回到终端:
|
||||
|
||||
**python updateHostsFile.py -r -a**
|
||||
|
||||
该命令将询问你的密码,以便能够写入 /etc/。为了使新更新的列表处于活动状态,某些系统需要清除 DNS 缓存。在同一个硬件上,我观察到不同的操作系统表现出非常不同的行为,在没有刷新缓存的情况下不同的服务器变为可访问/不可访问所需的时间长度都不同。我已经看到了从即时(Slackware)到重启更新(Windows)的所有情况。有一些命令可以刷新 DNS 缓存,但是它们在每个操作系统甚至每个发行版上都不同,所以如果没有生效,只需要重新启动就行了。
|
||||
|
||||
现在,只要将你的个人例外添加到黑名单/白名单中,并且只要你想要更新主机文件,运行该脚本就好。该脚本将根据你的要求调整生成的主机文件,每次运行文件时会自动追加你额外的列表。
|
||||
|
||||
最后,我们来创建一个打开/关闭开关。我们每个功能都需要一个脚本,所以回到终端输入下面的内容创建关闭开关(用你自己的文本编辑器替换 leafpad):
|
||||
|
||||
**leafpad hosts-off.sh**
|
||||
|
||||
在新文件中输入下面的内容:
|
||||
|
||||
**#!/bin/sh**
|
||||
**sudo mv /etc/hosts /etc/hostsDISABLED**
|
||||
|
||||
接着让它可执行:
|
||||
|
||||
**chmod +x hosts-off.sh**
|
||||
|
||||
相似地,对于打开开关:
|
||||
|
||||
**leafpad hosts-on.sh
|
||||
**
|
||||
在新文件中输入下面的内容:
|
||||
|
||||
**#!/bin/sh**
|
||||
**sudo mv /etc/hostsDISABLED /etc/hosts
|
||||
**
|
||||
最后让它可执行:
|
||||
|
||||
**chmod +x hosts-on.sh
|
||||
|
||||
**你所需要做的是为每个脚本创建一个快捷方式,标记它们的 HOSTS-ON 和 HOSTS-OFF,你就能找到它们了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.darrentoback.com/this-script-updates-hosts-files-using-a-multi-source-unified-block-list-with-whitelisting
|
||||
|
||||
作者:[dmt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.darrentoback.com/about-me
|
||||
[1]:https://github.com/StevenBlack/hosts
|
||||
[2]:https://github.com/StevenBlack/hosts.git
|
||||
[3]:https://github.com/StevenBlack/hosts/blob/master/readme.md
|
||||
@ -0,0 +1,54 @@
|
||||
运行 Ubuntu 的 Husarion CORE2-ROS 使得机器人开发变得容易
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
### 分享或保存
|
||||
|
||||
_这是游客投稿的本系列两篇中的第一篇;Dominik Nowak,Husarion 的 CEO _
|
||||
|
||||
过去十年,我们见证了 IT 行业的许多突破。可以说对消费者最有意义的一个方面是智能手机和移动开发的普及。接下来的大事件是什么,现在智能手机是如此常见,让我们面对它,有点无聊吗?我们猜是:机器人。
|
||||
|
||||
众所周知,许多生产线完全由机器人运行。但在消费者和服务方面,还没有看到巨大的突破。我们认为这是一个无障碍的问题,并降低开发人员进入的门槛。这只需要好的,简单的工具来快速做出原型和开发机器人。为了测试新的想法并赋予工程师权利,所以他们可以解决许多人类仍然面临的问题。比应用中的点按更棘手的问题。
|
||||
|
||||
构建机器人是一个具有挑战性的任务,[Husarion][2] 团队正在努力使其更容易。Husarion 是一家从事机器人快速开发平台的机器人公司。该公司的产品是 CORE2 机器人控制器和云平台,它用于管理所有基于 CORE2 的机器人。CORE2 是第二代 Husarion 机器人控制器,它可在[这里][3]看到。
|
||||
|
||||
CORE2 结合了实时微控制器板和运行 Ubuntu 的单板计算机。Ubuntu 是最受欢迎的 Linux 发行版,不仅适用于[桌面][4],还适用于物联网和 [机器人][5]程序中的嵌入式硬件。
|
||||
|
||||

|
||||
|
||||
CORE2 控制器有两种配置。第一款采用 ESP32 Wi-Fi 模块的专用于需要低功耗和实时、安全遥控的机器人应用。第二个,称为 CORE2-ROS,基本来讲集成了两块板:
|
||||
- 使用实时操作系统(RTOS)的实时微控制器并集成电机、编码器和传感器接口的电路板
|
||||
- 带有 ROS([Robot Operating System] [6])包的运行 Linux 的单板计算机(SBC)和其他软件工具。
|
||||
|
||||
“实时”电路板做底层工作。它包含高效的 STM32F4 系列微控制器,非常适用于驱动电机、读码器、与传感器通信,并控制整个机电或机器人系统。在大多数应用中,CPU 负载不超过几个百分点,实时操作由基于 RTOS 的专用编程框架保证。我们还保证与 Arduino 库的兼容性。大多数任务都在微控制器外设中处理,如定时器、通信接口、ADC 等,它具有中断和 DMA 通道的强大支持。简而言之,对于具有其他任务的单板计算机来说,这不是一项任务。
|
||||
|
||||
另一方面,很显然,现代和先进的机器人程序不能仅仅基于微控制器,原因如下:
|
||||
- 自动机器人需要大量的处理能力来执行导航、图像和声音识别、移动等等,
|
||||
- 编写先进的软件需要标准化才能有效 - SBC 在行业中越来越受欢迎,而对于为 SBC 编写的软件也是如此,这与 PC 电脑非常相似
|
||||
- SBC 每年都变得越来越便宜
|
||||
– Husarion 认为,结合这两个世界在机器人技术方面是非常有益的。
|
||||
|
||||
CORE2-ROS 控制器有两种配置:[Raspberry Pi 3][7] 或 [ASUS Tinker Board][8]。CORE-ROS 运行于 Ubuntu、Husarion 开发和管理工具以及 ROS 软件包上。
|
||||
|
||||
下篇文章将发现为何 Husarion 决定使用 Ubuntu
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/12/robot-development-made-easy-with-husarion-core2-ros-running-ubuntu/
|
||||
|
||||
作者:[Guest ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/guest/
|
||||
[1]:https://insights.ubuntu.com/author/guest/
|
||||
[2]:https://husarion.com/
|
||||
[3]:https://www.crowdsupply.com/husarion/core2
|
||||
[4]:https://www.ubuntu.com/desktop
|
||||
[5]:https://www.ubuntu.com/internet-of-things/robotics
|
||||
[6]:http://www.ros.org/
|
||||
[7]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[8]:https://www.asus.com/uk/Single-Board-Computer/Tinker-Board/
|
||||
85
translated/tech/20170712 Storage management in LXD 2.15.md
Normal file
85
translated/tech/20170712 Storage management in LXD 2.15.md
Normal file
@ -0,0 +1,85 @@
|
||||
LXD 2.15 中的存储管理
|
||||
============================================================
|
||||
|
||||
|
||||
### 分享或保存
|
||||
|
||||

|
||||
|
||||
长久以来 LXD 已经支持多种存储驱动。用户可以在 zfs、btrfs、lvm 或纯目录存储池之间进行选择,但它们只能使用单个存储池。一个被频繁被提到的需求是不仅支持单个存储池,还支持多个存储池。这样,用户可以维护一个由 SSD 支持的 zfs 存储池用于 I/O 密集型容器,另一个简单的基于目录的存储池用于其他容器。幸运的是,现在这是可能的,因为 LXD 在几个版本后有了自己的存储管理 API。
|
||||
|
||||
### 创建存储池
|
||||
|
||||
新安装 LXD 没有定义任何存储池。如果你运行 `lxd init` ,LXD 将提供为你创建一个存储池。由 `lxd init` 创建的存储池将是创建容器的默认存储池。
|
||||
|
||||
|
||||
[][2]
|
||||
|
||||
### 创建更多的存储池
|
||||
|
||||
我们的客户端工具使得创建额外的存储池变得非常简单。为了创建和管理新的存储池,你可以使用 `lxc storage` 命令。所以如果你想在块设备 `/dev/sdb` 上创建一个额外的 btrfs 存储池,你只需使用 `lxc storage create my-btrfs btrfs source=/dev/sdb`。让我们来看看:
|
||||
|
||||
[][3]
|
||||
|
||||
### 在默认存储池上创建容器
|
||||
|
||||
如果你从全新安装的 LXD 开始,并通过 `lxd init` 创建了一个存储池,LXD 将使用此池作为默认存储池。这意味着如果你执行 `lxc launch images:ubuntu/xenial xen1`,LXD 将为此存储池上的容器的根文件系统创建一个存储卷。在示例中,我们使用 `my-first-zfs-pool` 作为默认存储池
|
||||
|
||||
[][4]
|
||||
|
||||
### 在特定存储池上创建容器
|
||||
|
||||
但是你也可以通过传递 `-s` 参数来告诉 `lxc launch` 和 `lxc init` 在特定存储池上创建一个容器。例如,如果要在 `my-btrfs` 存储池上创建一个新的容器,你可以执行 `lxc launch images:ubuntu/xenial xen-on-my-btrfs -s my-btrfs`:
|
||||
|
||||
[][5]
|
||||
|
||||
### 创建自定义存储卷
|
||||
|
||||
如果你其中一个容器需要额外的空间存储额外的数据,那么新的存储 API 将允许你创建可以连接到容器的存储卷。只需要 `lxc storage volume create my-btrfs my-custom-volume`:
|
||||
|
||||
[][6]
|
||||
|
||||
### 连接自定义卷到容器中
|
||||
|
||||
Of course this feature is only helpful because the storage API let’s you attach those storage volume to containers. To attach a storage volume to a container you can use `lxc storage volume attach my-btrfs my-custom-volume xen1 data /opt/my/data`:
|
||||
当然,这个功能是有用的,因为存储 API 让你把这些存储卷连接到容器。要将存储卷连接到容器,可以使用 `lxc storage volume attach my-btrfs my-custom-volume xen1 data /opt/my/data`:
|
||||
|
||||
[][7]
|
||||
|
||||
### 在容器之间共享自定义存储卷
|
||||
|
||||
默认情况下,LXD 将使连接的存储卷由其所连接的容器写入。这意味着它会将存储卷的所有权更改为容器的 id 映射。但存储卷也可以同时连接到多个容器。这对于在多个容器之间共享数据是非常好的。但是,这有一些限制。为了将存储卷连接到多个容器,它们必须共享相同的 id 映射。让我们创建一个额外的具有一个隔离的 id 映射的容器 `xen-isolated`。这意味着它的 id 映射在这个 LXD 实例中将是唯一的,因此没有其他容器具有相同的id映射。将相同的存储卷 `my-custom-volume` 连接到此容器现在将会失败:
|
||||
|
||||
[][8]
|
||||
|
||||
但是我们让 `xen-isolated` 与 `xen1` 有相同的映射,并把它重命名为 `xen2` 来反映这个变化。现在我们可以将 `my-custom-volume` 连接到 `xen1` 和 `xen2` 而不会有问题:
|
||||
|
||||
[][9]
|
||||
|
||||
### 总结
|
||||
|
||||
存储 API 是 LXD 非常强大的补充。它提供了一组基本功能,有助于在大规模使用容器时处理各种问题。这个简短的介绍希望给你一个印象,你可以做什么。将来会有更多介绍。
|
||||
|
||||
本篇文章最初在[ Brauner 的博客][10]中发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/12/storage-management-in-lxd-2-15/
|
||||
|
||||
作者:[Christian Brauner ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://cbrauner.wordpress.com/
|
||||
[1]:https://insights.ubuntu.com/author/christian-brauner/
|
||||
[2]:https://asciinema.org/a/126892
|
||||
[3]:https://asciinema.org/a/128580
|
||||
[4]:https://asciinema.org/a/128582
|
||||
[5]:https://asciinema.org/a/128583
|
||||
[6]:https://asciinema.org/a/128584
|
||||
[7]:https://asciinema.org/a/128585
|
||||
[8]:https://asciinema.org/a/128588
|
||||
[9]:https://asciinema.org/a/128593
|
||||
[10]:https://cbrauner.wordpress.com/
|
||||
Loading…
Reference in New Issue
Block a user