mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
d0af6dec34
146
published/20141211 Open source all over the world.md
Normal file
146
published/20141211 Open source all over the world.md
Normal file
@ -0,0 +1,146 @@
|
||||
一个开源的世界
|
||||
================================================================================
|
||||

|
||||
|
||||
经过了一整天的Opensource.com[社区版主][1]年会,最后一项日程提了上来,内容只有“特邀嘉宾:待定”几个字。作为[Opensource.com][3]的项目负责人和社区管理员,[Jason Hibbets][2]起身解释道,“因为这个嘉宾有可能无法到场,因此我不想提前说是谁。在几个月前我问他何时有空过来,他给了我两个时间点,我选了其中一个。今天是这三周中Jim唯一能来的一天”。(译者注:Jim是指下文中提到的Jim Whitehurst,即红帽公司总裁兼首席执行官)
|
||||
|
||||
这句话在版主们(Moderators)中引起一阵轰动,他们从世界各地赶来参加此次的[拥抱开源大会(All Things Open Conference)][4]。版主们纷纷往前挪动椅子,仔细聆听。
|
||||
|
||||
“他会首先作半个小时的演讲,然后会回答几个提问。”,Jason说道。
|
||||
|
||||
会场的门开着,似乎一直在等着这位大人物的出现。这时,会场前唯一一个空位上来了一位高个子。
|
||||
|
||||
“大家好!”,这个家伙开口了。他没穿正装,只是衬衫和休闲裤。
|
||||
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版主今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
|
||||
“我叫[Jen Wike Huger][6],负责Opensource.com的内容管理,很高兴见到大家。”
|
||||
|
||||
“我叫[Nicole][7]。是[ByWater Solutions][8]的副总裁,我们在做免费的开源库。我到各地旅行并教会人们如何使用软件。”
|
||||
|
||||
“我叫[Robin][9],从2013年开始参与版主项目。我在OSDC做了一些事情,工作是在[City of the Hague][10]维护[网站][11]。”
|
||||
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS science software的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能参与到FOSS和开源科学。”
|
||||
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆的28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
|
||||
“我叫[Joshua Holm][19]。我大多数时间都在关注系统更新,以及帮助人们在网上找工作。”
|
||||
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets][22]和[Mark Bohannon][23]一起主要关注[政府][21]渠道方面。”
|
||||
|
||||
“我叫[Scott Nesbitt][24],写过很多东西,使用FOSS很久了。我是个普通人,不是系统管理员,也不是程序员,只希望能更加高效工作。我帮助人们在商业和生活中使用FOSS。”
|
||||
|
||||
“我叫[Luis Ibanez][25],刚加入[Google][26]。我对DIY和FOSS感兴趣。”
|
||||
|
||||
“我叫[Remy DeCausemaker][27],在[RIT MAGIC Center][28]的黑客学院(Resident Hackademic),也是[交互式游戏和媒体系][29]的一个兼职教授。现在为Opensource.com写作将近四年。”
|
||||
|
||||
“你在[新FOSS Minor][30]教书?!”,Jim说道,“很酷!”
|
||||
|
||||
“我叫[Jason Baker][31]。我是红帽的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
|
||||
“我叫[Mark Bohannan][33],是红帽全球开放协议的一员,在华盛顿外工作。和Mel一样,我花了相当多时间写作,也从法律和政府部门中找合作者。我做了一个很好的小册子来讨论正在发生在政府中的积极变化。”
|
||||
|
||||
“我叫[Jason Hibbets][34],我组织了这次讨论。”
|
||||
|
||||
会场中一片笑声。
|
||||
|
||||
“我也组织了这个讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
|
||||
我当时在他左边,时不时从记录的间隙中抬头看一眼,我注意到淡淡微笑背后的那个令人瞩目的人,是自2008年1月起开始领导红帽公司的CEO [Jim Whitehurst][35]。
|
||||
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的最美好的事情是开源已经脱离了条条框框。我现在认为,信息技术正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代品走向创新驱动力。我们的用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能带来可控和创新的解决方案。这也是个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的可控。”
|
||||
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这种事情在证券交易领域就没有听说过。那时FOSS正在重复发明轮子。今天看来,实际上大数据的每件事情都出现在FOSS领域。几乎所有的新框架,语言和方法论,包括移动通讯(尽管不包括设备),都首先发生在开源世界。”
|
||||
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉许可协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop是在厂商们意识到规模带来的问题时的一个解决方案。他们实际上有足够的资金和资源来解决自己的问题。开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的实体产品。”
|
||||
|
||||
“源代码的开源确实很酷,但开源不应当仅限于此。在各行各业不同领域开源仍有可以用武之地。我们要问下自己:‘开源能够为教育,政府,法律带来什么?其它的呢?其它的领域如何能学习我们?’”
|
||||
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新更好,那么我们需要更多的商业模式。”
|
||||
|
||||
“教育让我担心,其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学的校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
|
||||
“改变世界的潜力是无穷无尽的,我们已经取得了很棒的进步。”六年前我们痴迷于制定宣言,我们说‘我们是领导者’。我们用错词了,因为那潜在意味着控制。积极的参与者们同样也不能很好理解……[Máirín Duffy][43]提出了[催化剂][44]这个词。然后我们组成了红帽,不断地促进行动,指引方向。”
|
||||
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们付出的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
|
||||
我瞥了一下桌子,发现几个人眼中带泪。
|
||||
|
||||
然后Whitehurst又回顾了大会的开放教育议题。“极端一点看,如果你有一门[Ulysses][45]的公开课。在这里你能和一群人一起合作体验课堂。这样就和代码块一样的:大家一起努力,代码随着时间不断改进。”
|
||||
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,像“基础”和“可能不调和”这些词语都跳了出来。
|
||||
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中犯了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS让你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
|
||||
**Nicole**: “学术界有太多自我的家伙,你们需要一个发布经理。”
|
||||
|
||||
**Marcus**: “为了合作,你必须展示自己不懂的地方,这些发生在幕后。奖励模型是所有你信任的东西,我们需要改变它。尽可能多地发表,我们最后会发布,但希望能尽早地释放努力。”
|
||||
|
||||
**Luis**: “团队和分享应该优先考虑,红帽可以多向它们强调这一点。”
|
||||
|
||||
**Jim**: “还有公司在其中扮演积极角色了吗?”
|
||||
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。Fed没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均花费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作有更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着出了门……留给我们更多的激励。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/14/12/jim-whitehurst-inspiration-open-source
|
||||
|
||||
作者:[Remy][a]
|
||||
译者:[fyh](https://github.com/fyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:http://opensource.com/community-moderator-program
|
||||
[2]:https://twitter.com/jhibbets
|
||||
[3]:http://opensource.com/
|
||||
[4]:http://allthingsopen.org/
|
||||
[5]:http://opensource.com/users/mackanic
|
||||
[6]:https://twitter.com/JenWike
|
||||
[7]:http://opensource.com/users/nengard
|
||||
[8]:http://bywatersolutions.com/
|
||||
[9]:http://opensource.com/life/13/7/community-spotlight-robin-muilwijk
|
||||
[10]:https://en.wikipedia.org/wiki/The_Hague
|
||||
[11]:http://www.denhaag.nl/en.htm
|
||||
[12]:https://twitter.com/mhanwell
|
||||
[13]:http://www.kitware.com/
|
||||
[14]:http://www.nvidia.com/gtx-700-graphics-cards/gtx-titan-z/
|
||||
[15]:https://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units
|
||||
[16]:https://www.gentoo.org/
|
||||
[17]:http://kde.org/
|
||||
[18]:https://twitter.com/philshapiro
|
||||
[19]:http://opensource.com/community/13/9/contributor-spotlight-joshua-holm
|
||||
[20]:http://opensource.com/users/melanie
|
||||
[21]:http://opensource.com/government
|
||||
[22]:https://twitter.com/jhibbets
|
||||
[23]:https://twitter.com/markbotech
|
||||
[24]:http://scottnesbitt.me/
|
||||
[25]:http://opensource.com/users/luis-ibanez
|
||||
[26]:http://google.com/
|
||||
[27]:http://twitter.com/remy_d
|
||||
[28]:http://foss.rit.edu/
|
||||
[29]:http://igm.rit.edu/
|
||||
[30]:http://www.rit.edu/news/story.php?id=50590
|
||||
[31]:https://twitter.com/jehb
|
||||
[32]:http://openstack.org/
|
||||
[33]:https://twitter.com/markbotech
|
||||
[34]:https://twitter.com/jhibbets
|
||||
[35]:http://www.redhat.com/en/about/company/management/james-whitehurst
|
||||
[36]:http://www.bseindia.com/
|
||||
[37]:http://google.com/
|
||||
[38]:https://mail.corp.redhat.com/service/home/%7E/Amazon
|
||||
[39]:https://mail.corp.redhat.com/service/home/%7E/Facebook
|
||||
[40]:https://hadoop.apache.org/
|
||||
[41]:https://cassandra.apache.org/
|
||||
[42]:https://en.wikipedia.org/wiki/3D_printing
|
||||
[43]:https://twitter.com/mairin
|
||||
[44]:http://jobs.redhat.com/life-at-red-hat/our-culture/
|
||||
[45]:http://www.gutenberg.org/ebooks/4300
|
||||
[46]:https://twitter.com/philshapiro
|
||||
[47]:http://libreoffice.org/
|
||||
@ -0,0 +1,86 @@
|
||||
7 个驱动开源发展的社区
|
||||
================================================================================
|
||||
不久前,开源模式还被成熟的工业级厂商以怀疑的态度认作是叛逆小孩的玩物。如今,开源的促进会和基金会在一长列的供应商提供者的支持下正蓬勃发展,而他们将开源模式视作创新的关键。
|
||||
|
||||

|
||||
|
||||
### 技术的开放发展驱动着创新 ###
|
||||
|
||||
在过去的 20 几年间,技术的开源推进已被视作驱动创新的关键因素。即使那些以前将开源视作威胁的公司也开始接受这个观点 — 例如微软,如今它在一系列的开源的促进会中表现活跃。到目前为止,大多数的开源推进都集中在软件方面,但甚至这个也正在改变,因为社区已经开始向开源硬件倡议方面聚拢。这里介绍 7 个成功地在硬件和软件方面同时促进和发展开源技术的组织。
|
||||
|
||||
### OpenPOWER 基金会 ###
|
||||
|
||||

|
||||
|
||||
[OpenPOWER 基金会][2] 由 IBM, Google, Mellanox, Tyan 和 NVIDIA 于 2013 年共同创建,在与开源软件发展相同的精神下,旨在驱动开放协作硬件的发展,在过去的 20 几年间,开源软件发展已经找到了肥沃的土壤。
|
||||
|
||||
IBM 通过开放其基于 Power 架构的硬件和软件技术,向使用 Power IP 的独立硬件产品提供许可证等方式为基金会的建立播下种子。如今超过 70 个成员共同协作来为基于 Linux 的数据中心提供自定义的开放服务器,组件和硬件。
|
||||
|
||||
去年四月,在比最新基于 x86 系统快 50 倍的数据分析能力的新的 POWER8 处理器的服务器的基础上, OpenPOWER 推出了一个技术路线图。七月, IBM 和 Google 发布了一个固件堆栈。去年十月见证了 NVIDIA GPU 带来加速 POWER8 系统的能力和来自 Tyan 的第一个 OpenPOWER 参考服务器。
|
||||
|
||||
### Linux 基金会 ###
|
||||
|
||||

|
||||
|
||||
于 2000 年建立的 [Linux 基金会][2] 如今成为掌控着历史上最大的开源协同开发成果,它有着超过 180 个合作成员和许多独立成员及学生成员。它赞助 Linux 核心开发者的工作并促进、保护和推进 Linux 操作系统,并协调软件的协作开发。
|
||||
|
||||
它最为成功的协作项目包括 Code Aurora Forum (一个拥有为移动无线产业服务的企业财团),MeeGo (一个为移动设备和 IVI [注:指的是车载消息娱乐设备,为 In-Vehicle Infotainment 的简称] 构建一个基于 Linux 内核的操作系统的项目) 和 Open Virtualization Alliance (开放虚拟化联盟,它促进自由和开源软件虚拟化解决方案的采用)。
|
||||
|
||||
### 开放虚拟化联盟 ###
|
||||
|
||||

|
||||
|
||||
[开放虚拟化联盟(OVA)][3] 的存在目的为:通过提供使用案例和对具有互操作性的通用接口和 API 的发展提供支持,来促进自由、开源软件的虚拟化解决方案,例如 KVM 的采用。KVM 将 Linux 内核转变为一个虚拟机管理程序。
|
||||
|
||||
如今, KVM 已成为和 OpenStack 共同使用的最为常见的虚拟机管理程序。
|
||||
|
||||
### OpenStack 基金会 ###
|
||||
|
||||

|
||||
|
||||
原本作为一个 IaaS(基础设施即服务) 产品由 NASA 和 Rackspace 于 2010 年启动,[OpenStack 基金会][4] 已成为最大的开源项目聚居地之一。它拥有超过 200 家公司成员,其中包括 AT&T, AMD, Avaya, Canonical, Cisco, Dell 和 HP。
|
||||
|
||||
大约以 6 个月为一个发行周期,基金会的 OpenStack 项目开发用于通过一个基于 Web 的仪表盘,命令行工具或一个 RESTful 风格的 API 来控制或调配流经一个数据中心的处理存储池和网络资源。至今为止,基金会支持的协同开发已经孕育出了一系列 OpenStack 组件,其中包括 OpenStack Compute(一个云计算网络控制器,它是一个 IaaS 系统的主要部分),OpenStack Networking(一个用以管理网络和 IP 地址的系统) 和 OpenStack Object Storage(一个可扩展的冗余存储系统)。
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||

|
||||
|
||||
作为来自 Linux 基金会的另一个协作项目, [OpenDaylight][5] 是一个由诸如 Dell, HP, Oracle 和 Avaya 等行业厂商于 2013 年 4 月建立的联合倡议。它的任务是建立一个由社区主导、开源、有工业支持的针对软件定义网络( SDN: Software-Defined Networking)的包含代码和蓝图的框架。其思路是提供一个可直接部署的全功能 SDN 平台,而不需要其他组件,供应商可提供附件组件和增强组件。
|
||||
|
||||
### Apache 软件基金会 ###
|
||||
|
||||

|
||||
|
||||
[Apache 软件基金会 (ASF)][7] 是将近 150 个顶级项目的聚居地,这些项目涵盖从开源的企业级自动化软件到与 Apache Hadoop 相关的分布式计算的整个生态系统。这些项目分发企业级、可免费获取的软件产品,而 Apache 协议则是为了让无论是商业用户还是个人用户更方便地部署 Apache 的产品。
|
||||
|
||||
ASF 是 1999 年成立的一个会员制,非盈利公司,以精英为其核心 — 要成为它的成员,你必须首先在基金会的一个或多个协作项目中做出积极贡献。
|
||||
|
||||
### 开放计算项目 ###
|
||||
|
||||

|
||||
|
||||
作为 Facebook 重新设计其 Oregon 数据中心的副产物, [开放计算项目][7] 旨在发展针对数据中心的开源硬件解决方案。 OCP 是一个由廉价无浪费的服务器、针对 Open Rack(为数据中心设计的机架标准,来让机架集成到数据中心的基础设施中) 的模块化 I/O 存储和一个相对 "绿色" 的数据中心设计方案等构成。
|
||||
|
||||
OCP 董事会成员包括来自 Facebook,Intel,Goldman Sachs,Rackspace 和 Microsoft 的代表。
|
||||
|
||||
OCP 最近宣布了有两种可选的许可证: 一个类似 Apache 2.0 的允许衍生工作的许可证,和一个更规范的鼓励将更改回馈到原有软件的许可证。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities-driving-open-source-development.html
|
||||
|
||||
作者:[Thor Olavsrud][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Thor-Olavsrud/
|
||||
[1]:http://openpowerfoundation.org/
|
||||
[2]:http://www.linuxfoundation.org/
|
||||
[3]:https://openvirtualizationalliance.org/
|
||||
[4]:http://www.openstack.org/foundation/
|
||||
[5]:http://www.opendaylight.org/
|
||||
[6]:http://www.apache.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
@ -1,20 +1,20 @@
|
||||
如何在 Ubuntu 中管理和使用 LVM(Logical Volume Management,逻辑卷管理)
|
||||
如何在 Ubuntu 中管理和使用 逻辑卷管理 LVM
|
||||
================================================================================
|
||||

|
||||
|
||||
在我们之前的文章中,我们介绍了[什么是 LVM 以及能用 LVM 做什么][1],今天我们会给你介绍一些 LVM 的主要管理工具,使得你在设置和扩展安装时更游刃有余。
|
||||
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是,你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘驱动汇集而成或是一个软件磁盘阵列。
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘汇集而成的或是一个软件磁盘阵列。
|
||||
|
||||
要管理 LVM,这里有很多可用的 GUI 工具,但要真正理解 LVM 配置发生的事情,最好要知道一些命令行工具。这当你在一个服务器或不提供 GUI 工具的发行版上管理 LVM 时尤为有用。
|
||||
|
||||
LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以下其中之一开头:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
- Physical Volume (物理卷) = pv
|
||||
- Volume Group (卷组)= vg
|
||||
- Logical Volume (逻辑卷)= lv
|
||||
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组使得你的操作系统能使用指定的空间。
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组,使得你的操作系统能使用指定的空间。
|
||||
|
||||
### 可下载的 LVM 备忘单 ###
|
||||
|
||||
@ -26,7 +26,7 @@ LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以
|
||||
|
||||
### 如何查看当前 LVM 信息 ###
|
||||
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置好的开始点。
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令可以和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置的好起点。
|
||||
|
||||
display 命令会格式化输出信息,因此比 s 命令更易于理解。对每个命令你会看到名称和 pv/vg 的路径,它还会给出空闲和已使用空间的信息。
|
||||
|
||||
@ -40,17 +40,17 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||
#### 创建物理卷 ####
|
||||
|
||||
我们会从一个完全新的没有任何分区和信息的硬盘驱动开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
我们会从一个全新的没有任何分区和信息的硬盘开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
|
||||
> 注意:记住所有的命令都要以 root 身份运行或者在命令前面添加 'sudo' 。
|
||||
|
||||
fdisk -l
|
||||
|
||||
如果之前你的硬盘驱动从没有格式化或分区,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
如果之前你的硬盘从未格式化或分区过,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
|
||||

|
||||
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在驱动上创建一个新的分区。
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在磁盘上创建一个新的分区。
|
||||
|
||||
这里有大量能创建新分区的 GUI 工具,包括 [Gparted][2],但由于我们已经打开了终端,我们将使用 fdisk 命令创建需要的分区。
|
||||
|
||||
@ -62,9 +62,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
以指定的顺序输入命令创建一个使用新硬盘驱动 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或相应多个分区,我建议使用 GParted 或自己了解关于 fdisk 命令的使用。
|
||||
以指定的顺序输入命令创建一个使用新硬盘 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或想要多个分区,我建议使用 GParted 或自己了解一下关于 fdisk 命令的使用。
|
||||
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何信息。**
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何有用的信息。**
|
||||
|
||||
- n = 创建新分区
|
||||
- p = 创建主分区
|
||||
@ -79,9 +79,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
- t = 更改分区类型
|
||||
- 8e = 更改为 LVM 分区类型
|
||||
|
||||
核实并将信息写入硬盘驱动器。
|
||||
核实并将信息写入硬盘。
|
||||
|
||||
- p = 查看分区设置使得写入更改到磁盘之前可以回看
|
||||
- p = 查看分区设置使得在写入更改到磁盘之前可以回看
|
||||
- w = 写入更改到磁盘
|
||||
|
||||

|
||||
@ -102,7 +102,7 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
|
||||
#### 创建逻辑卷 ####
|
||||
|
||||
@ -112,7 +112,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 所以 lvcreate 命令知道从什么卷获取空间。
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 以便 lvcreate 命令知道从什么卷获取空间。
|
||||
|
||||
#### 格式化并挂载逻辑卷 ####
|
||||
|
||||
@ -131,7 +131,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
#### 重新设置逻辑卷大小 ####
|
||||
|
||||
逻辑卷的一个好处是你能使你的共享物理变大或变小而不需要移动所有东西到一个更大的硬盘驱动。另外,你可以添加新的硬盘驱动并同时扩展你的卷组。或者如果你有一个不使用的硬盘驱动,你可以从卷组中移除它使得逻辑卷变小。
|
||||
逻辑卷的一个好处是你能使你的存储物理地变大或变小,而不需要移动所有东西到一个更大的硬盘。另外,你可以添加新的硬盘并同时扩展你的卷组。或者如果你有一个不使用的硬盘,你可以从卷组中移除它使得逻辑卷变小。
|
||||
|
||||
这里有三个用于使物理卷、卷组和逻辑卷变大或变小的基础工具。
|
||||
|
||||
@ -147,9 +147,9 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
按照上面创建新分区并更改分区类型为 LVM(8e) 的步骤安装一个新硬盘驱动。然后用 pvcreate 命令创建一个 LVM 能识别的物理卷。
|
||||
|
||||
#### 添加新硬盘驱动到卷组 ####
|
||||
#### 添加新硬盘到卷组 ####
|
||||
|
||||
要添加新的硬盘驱动到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
要添加新的硬盘到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
|
||||
这会添加新物理卷到已存在的卷组中。
|
||||
|
||||
@ -189,7 +189,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
1. 调整文件系统大小 (调整之前确保已经移动文件到硬盘驱动安全的地方)
|
||||
1. 减小逻辑卷 (除了 + 可以扩展大小,你也可以用 - 压缩大小)
|
||||
1. 用 vgreduce 从卷组中移除硬盘驱动
|
||||
1. 用 vgreduce 从卷组中移除硬盘
|
||||
|
||||
#### 备份逻辑卷 ####
|
||||
|
||||
@ -197,7 +197,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该照片可以用于在不同的硬盘驱动上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的“照片”,该“照片”可以用于在不同的硬盘上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
|
||||
要创建一个快照,我们需要创建拥有足够空闲空间的逻辑卷,用于保存我们备份的时候会写入该逻辑卷的任何新信息。如果驱动并不是经常写入,你可以使用很小的一个存储空间。备份完成的时候我们只需要移除临时逻辑卷,原始逻辑卷会和往常一样。
|
||||
|
||||
@ -209,7 +209,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为驱动实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为该硬盘实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
|
||||
#### 挂载新快照 ####
|
||||
|
||||
@ -222,7 +222,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||
#### 复制快照和删除逻辑卷 ####
|
||||
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘驱动或者打包所有文件到一个文件。
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘或者打包所有文件到一个文件。
|
||||
|
||||
**注意:tar -c 会创建一个归档文件,-f 要指出归档文件的名称和路径。要获取 tar 命令的帮助信息,可以在终端中输入 man tar。**
|
||||
|
||||
@ -230,7 +230,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
记住备份发生的时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
记住备份时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
|
||||
备份完成后,卸载卷并移除临时快照。
|
||||
|
||||
@ -259,10 +259,10 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[1]:https://linux.cn/article-5953-1.html
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -0,0 +1,131 @@
|
||||
如何通过反向 SSH 隧道访问 NAT 后面的 Linux 服务器
|
||||
================================================================================
|
||||
你在家里运行着一台 Linux 服务器,它放在一个 NAT 路由器或者限制性防火墙后面。现在你想在外出时用 SSH 登录到这台服务器。你如何才能做到呢?SSH 端口转发当然是一种选择。但是,如果你需要处理多级嵌套的 NAT 环境,端口转发可能会变得非常棘手。另外,在多种 ISP 特定条件下可能会受到干扰,例如阻塞转发端口的限制性 ISP 防火墙、或者在用户间共享 IPv4 地址的运营商级 NAT。
|
||||
|
||||
### 什么是反向 SSH 隧道? ###
|
||||
|
||||
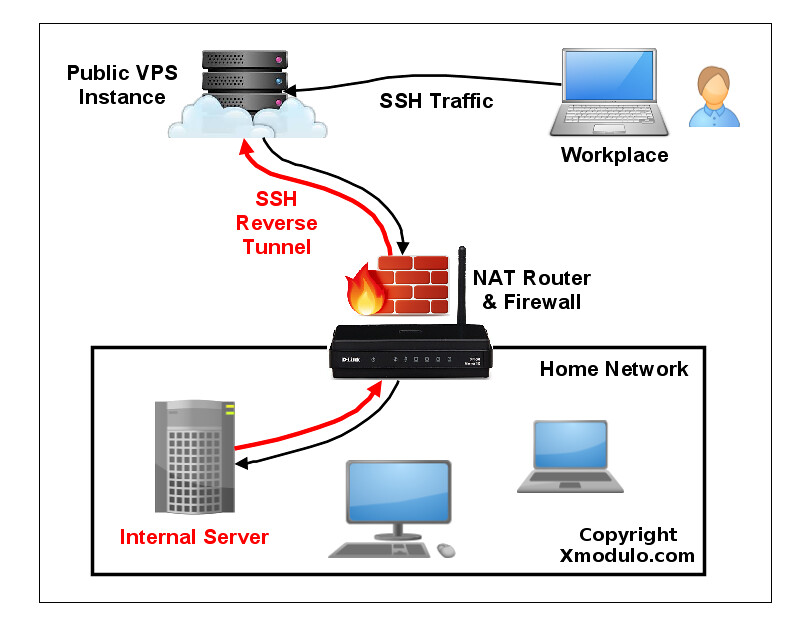
SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧道的概念非常简单。使用这种方案,在你的受限的家庭网络之外你需要另一台主机(所谓的“中继主机”),你能从当前所在地通过 SSH 登录到它。你可以用有公网 IP 地址的 [VPS 实例][1] 配置一个中继主机。然后要做的就是从你的家庭网络服务器中建立一个到公网中继主机的永久 SSH 隧道。有了这个隧道,你就可以从中继主机中连接“回”家庭服务器(这就是为什么称之为 “反向” 隧道)。不管你在哪里、你的家庭网络中的 NAT 或 防火墙限制多么严格,只要你可以访问中继主机,你就可以连接到家庭服务器。
|
||||
|
||||
|
||||
|
||||
### 在 Linux 上设置反向 SSH 隧道 ###
|
||||
|
||||
让我们来看看怎样创建和使用反向 SSH 隧道。我们做如下假设:我们会设置一个从家庭服务器(homeserver)到中继服务器(relayserver)的反向 SSH 隧道,然后我们可以通过中继服务器从客户端计算机(clientcomputer) SSH 登录到家庭服务器。本例中的**中继服务器** 的公网 IP 地址是 1.1.1.1。
|
||||
|
||||
在家庭服务器上,按照以下方式打开一个到中继服务器的 SSH 连接。
|
||||
|
||||
homeserver~$ ssh -fN -R 10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
这里端口 10022 是任何你可以使用的端口数字。只需要确保中继服务器上不会有其它程序使用这个端口。
|
||||
|
||||
“-R 10022:localhost:22” 选项定义了一个反向隧道。它转发中继服务器 10022 端口的流量到家庭服务器的 22 号端口。
|
||||
|
||||
用 “-fN” 选项,当你成功通过 SSH 服务器验证时 SSH 会进入后台运行。当你不想在远程 SSH 服务器执行任何命令,就像我们的例子中只想转发端口的时候非常有用。
|
||||
|
||||
运行上面的命令之后,你就会回到家庭主机的命令行提示框中。
|
||||
|
||||
登录到中继服务器,确认其 127.0.0.1:10022 绑定到了 sshd。如果是的话就表示已经正确设置了反向隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 127.0.0.1:10022 0.0.0.0:* LISTEN 8493/sshd
|
||||
|
||||
现在就可以从任何其它计算机(客户端计算机)登录到中继服务器,然后按照下面的方法访问家庭服务器。
|
||||
|
||||
relayserver~$ ssh -p 10022 homeserver_user@localhost
|
||||
|
||||
需要注意的一点是你在上面为localhost输入的 SSH 登录/密码应该是家庭服务器的,而不是中继服务器的,因为你是通过隧道的本地端点登录到家庭服务器,因此不要错误输入中继服务器的登录/密码。成功登录后,你就在家庭服务器上了。
|
||||
|
||||
### 通过反向 SSH 隧道直接连接到网络地址变换后的服务器 ###
|
||||
|
||||
上面的方法允许你访问 NAT 后面的 **家庭服务器**,但你需要登录两次:首先登录到 **中继服务器**,然后再登录到**家庭服务器**。这是因为中继服务器上 SSH 隧道的端点绑定到了回环地址(127.0.0.1)。
|
||||
|
||||
事实上,有一种方法可以只需要登录到中继服务器就能直接访问NAT之后的家庭服务器。要做到这点,你需要让中继服务器上的 sshd 不仅转发回环地址上的端口,还要转发外部主机的端口。这通过指定中继服务器上运行的 sshd 的 **GatewayPorts** 实现。
|
||||
|
||||
打开**中继服务器**的 /etc/ssh/sshd_conf 并添加下面的行。
|
||||
|
||||
relayserver~$ vi /etc/ssh/sshd_conf
|
||||
|
||||
----------
|
||||
|
||||
GatewayPorts clientspecified
|
||||
|
||||
重启 sshd。
|
||||
|
||||
基于 Debian 的系统:
|
||||
|
||||
relayserver~$ sudo /etc/init.d/ssh restart
|
||||
|
||||
基于红帽的系统:
|
||||
|
||||
relayserver~$ sudo systemctl restart sshd
|
||||
|
||||
现在在家庭服务器中按照下面方式初始化一个反向 SSH 隧道。
|
||||
|
||||
homeserver~$ ssh -fN -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
登录到中继服务器然后用 netstat 命令确认成功建立的一个反向 SSH 隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 1.1.1.1:10022 0.0.0.0:* LISTEN 1538/sshd: dev
|
||||
|
||||
不像之前的情况,现在隧道的端点是 1.1.1.1:10022(中继服务器的公网 IP 地址),而不是 127.0.0.1:10022。这就意味着从外部主机可以访问隧道的另一端。
|
||||
|
||||
现在在任何其它计算机(客户端计算机),输入以下命令访问网络地址变换之后的家庭服务器。
|
||||
|
||||
clientcomputer~$ ssh -p 10022 homeserver_user@1.1.1.1
|
||||
|
||||
在上面的命令中,1.1.1.1 是中继服务器的公共 IP 地址,homeserver_user必须是家庭服务器上的用户账户。这是因为你真正登录到的主机是家庭服务器,而不是中继服务器。后者只是中继你的 SSH 流量到家庭服务器。
|
||||
|
||||
### 在 Linux 上设置一个永久反向 SSH 隧道 ###
|
||||
|
||||
现在你已经明白了怎样创建一个反向 SSH 隧道,然后把隧道设置为 “永久”,这样隧道启动后就会一直运行(不管临时的网络拥塞、SSH 超时、中继主机重启,等等)。毕竟,如果隧道不是一直有效,你就不能可靠的登录到你的家庭服务器。
|
||||
|
||||
对于永久隧道,我打算使用一个叫 autossh 的工具。正如名字暗示的,这个程序可以让你的 SSH 会话无论因为什么原因中断都会自动重连。因此对于保持一个反向 SSH 隧道非常有用。
|
||||
|
||||
第一步,我们要设置从家庭服务器到中继服务器的[无密码 SSH 登录][2]。这样的话,autossh 可以不需要用户干预就能重启一个损坏的反向 SSH 隧道。
|
||||
|
||||
下一步,在建立隧道的家庭服务器上[安装 autossh][3]。
|
||||
|
||||
在家庭服务器上,用下面的参数运行 autossh 来创建一个连接到中继服务器的永久 SSH 隧道。
|
||||
|
||||
homeserver~$ autossh -M 10900 -fN -o "PubkeyAuthentication=yes" -o "StrictHostKeyChecking=false" -o "PasswordAuthentication=no" -o "ServerAliveInterval 60" -o "ServerAliveCountMax 3" -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
“-M 10900” 选项指定中继服务器上的监视端口,用于交换监视 SSH 会话的测试数据。中继服务器上的其它程序不能使用这个端口。
|
||||
|
||||
“-fN” 选项传递给 ssh 命令,让 SSH 隧道在后台运行。
|
||||
|
||||
“-o XXXX” 选项让 ssh:
|
||||
|
||||
- 使用密钥验证,而不是密码验证。
|
||||
- 自动接受(未知)SSH 主机密钥。
|
||||
- 每 60 秒交换 keep-alive 消息。
|
||||
- 没有收到任何响应时最多发送 3 条 keep-alive 消息。
|
||||
|
||||
其余 SSH 隧道相关的选项和之前介绍的一样。
|
||||
|
||||
如果你想系统启动时自动运行 SSH 隧道,你可以将上面的 autossh 命令添加到 /etc/rc.local。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇博文中,我介绍了你如何能从外部通过反向 SSH 隧道访问限制性防火墙或 NAT 网关之后的 Linux 服务器。这里我介绍了家庭网络中的一个使用事例,但在企业网络中使用时你尤其要小心。这样的一个隧道可能被视为违反公司政策,因为它绕过了企业的防火墙并把企业网络暴露给外部攻击。这很可能被误用或者滥用。因此在使用之前一定要记住它的作用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:https://linux.cn/article-5444-1.html
|
||||
[3]:https://linux.cn/article-5459-1.html
|
||||
183
published/20150522 Analyzing Linux Logs.md
Normal file
183
published/20150522 Analyzing Linux Logs.md
Normal file
@ -0,0 +1,183 @@
|
||||
如何分析 Linux 日志
|
||||
==============================================================================
|
||||

|
||||
|
||||
日志中有大量的信息需要你处理,尽管有时候想要提取并非想象中的容易。在这篇文章中我们会介绍一些你现在就能做的基本日志分析例子(只需要搜索即可)。我们还将涉及一些更高级的分析,但这些需要你前期努力做出适当的设置,后期就能节省很多时间。对数据进行高级分析的例子包括生成汇总计数、对有效值进行过滤,等等。
|
||||
|
||||
我们首先会向你展示如何在命令行中使用多个不同的工具,然后展示了一个日志管理工具如何能自动完成大部分繁重工作从而使得日志分析变得简单。
|
||||
|
||||
### 用 Grep 搜索 ###
|
||||
|
||||
搜索文本是查找信息最基本的方式。搜索文本最常用的工具是 [grep][1]。这个命令行工具在大部分 Linux 发行版中都有,它允许你用正则表达式搜索日志。正则表达式是一种用特殊的语言写的、能识别匹配文本的模式。最简单的模式就是用引号把你想要查找的字符串括起来。
|
||||
|
||||
#### 正则表达式 ####
|
||||
|
||||
这是一个在 Ubuntu 系统的认证日志中查找 “user hoover” 的例子:
|
||||
|
||||
$ grep "user hoover" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
pam_unix(sshd:session): session opened for user hoover by (uid=0)
|
||||
pam_unix(sshd:session): session closed for user hoover
|
||||
|
||||
构建精确的正则表达式可能很难。例如,如果我们想要搜索一个类似端口 “4792” 的数字,它可能也会匹配时间戳、URL 以及其它不需要的数据。Ubuntu 中下面的例子,它匹配了一个我们不想要的 Apache 日志。
|
||||
|
||||
$ grep "4792" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972 HTTP/1.0" 404 545 "-" "-”
|
||||
|
||||
#### 环绕搜索 ####
|
||||
|
||||
另一个有用的小技巧是你可以用 grep 做环绕搜索。这会向你展示一个匹配前面或后面几行是什么。它能帮助你调试导致错误或问题的东西。`B` 选项展示前面几行,`A` 选项展示后面几行。举个例子,我们知道当一个人以管理员员身份登录失败时,同时他们的 IP 也没有反向解析,也就意味着他们可能没有有效的域名。这非常可疑!
|
||||
|
||||
$ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
|
||||
#### Tail ####
|
||||
|
||||
你也可以把 grep 和 [tail][2] 结合使用来获取一个文件的最后几行,或者跟踪日志并实时打印。这在你做交互式更改的时候非常有用,例如启动服务器或者测试代码更改。
|
||||
|
||||
$ tail -f /var/log/auth.log | grep 'Invalid user'
|
||||
Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
|
||||
Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
|
||||
|
||||
关于 grep 和正则表达式的详细介绍并不在本指南的范围,但 [Ryan’s Tutorials][3] 有更深入的介绍。
|
||||
|
||||
日志管理系统有更高的性能和更强大的搜索能力。它们通常会索引数据并进行并行查询,因此你可以很快的在几秒内就能搜索 GB 或 TB 的日志。相比之下,grep 就需要几分钟,在极端情况下可能甚至几小时。日志管理系统也使用类似 [Lucene][4] 的查询语言,它提供更简单的语法来检索数字、域以及其它。
|
||||
|
||||
### 用 Cut、 AWK、 和 Grok 解析 ###
|
||||
|
||||
#### 命令行工具 ####
|
||||
|
||||
Linux 提供了多个命令行工具用于文本解析和分析。当你想要快速解析少量数据时非常有用,但处理大量数据时可能需要很长时间。
|
||||
|
||||
#### Cut ####
|
||||
|
||||
[cut][5] 命令允许你从有分隔符的日志解析字段。分隔符是指能分开字段或键值对的等号或逗号等。
|
||||
|
||||
假设我们想从下面的日志中解析出用户:
|
||||
|
||||
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
|
||||
|
||||
我们可以像下面这样用 cut 命令获取用等号分割后的第八个字段的文本。这是一个 Ubuntu 系统上的例子:
|
||||
|
||||
$ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
|
||||
root
|
||||
hoover
|
||||
root
|
||||
nagios
|
||||
nagios
|
||||
|
||||
#### AWK ####
|
||||
|
||||
另外,你也可以使用 [awk][6],它能提供更强大的解析字段功能。它提供了一个脚本语言,你可以过滤出几乎任何不相干的东西。
|
||||
|
||||
例如,假设在 Ubuntu 系统中我们有下面的一行日志,我们想要提取登录失败的用户名称:
|
||||
|
||||
Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
|
||||
|
||||
你可以像下面这样使用 awk 命令。首先,用一个正则表达式 /sshd.*invalid user/ 来匹配 sshd invalid user 行。然后用 { print $9 } 根据默认的分隔符空格打印第九个字段。这样就输出了用户名。
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
你可以在 [Awk 用户指南][7] 中阅读更多关于如何使用正则表达式和输出字段的信息。
|
||||
|
||||
#### 日志管理系统 ####
|
||||
|
||||
日志管理系统使得解析变得更加简单,使用户能快速的分析很多的日志文件。他们能自动解析标准的日志格式,比如常见的 Linux 日志和 Web 服务器日志。这能节省很多时间,因为当处理系统问题的时候你不需要考虑自己写解析逻辑。
|
||||
|
||||
下面是一个 sshd 日志消息的例子,解析出了每个 remoteHost 和 user。这是 Loggly 中的一张截图,它是一个基于云的日志管理服务。
|
||||
|
||||

|
||||
|
||||
你也可以对非标准格式自定义解析。一个常用的工具是 [Grok][8],它用一个常见正则表达式库,可以解析原始文本为结构化 JSON。下面是一个 Grok 在 Logstash 中解析内核日志文件的事例配置:
|
||||
|
||||
filter{
|
||||
grok {
|
||||
match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
|
||||
}
|
||||
}
|
||||
|
||||
下图是 Grok 解析后输出的结果:
|
||||
|
||||

|
||||
|
||||
### 用 Rsyslog 和 AWK 过滤 ###
|
||||
|
||||
过滤使得你能检索一个特定的字段值而不是进行全文检索。这使你的日志分析更加准确,因为它会忽略来自其它部分日志信息不需要的匹配。为了对一个字段值进行搜索,你首先需要解析日志或者至少有对事件结构进行检索的方式。
|
||||
|
||||
#### 如何对应用进行过滤 ####
|
||||
|
||||
通常,你可能只想看一个应用的日志。如果你的应用把记录都保存到一个文件中就会很容易。如果你需要在一个聚集或集中式日志中过滤一个应用就会比较复杂。下面有几种方法来实现:
|
||||
|
||||
1. 用 rsyslog 守护进程解析和过滤日志。下面的例子将 sshd 应用的日志写入一个名为 sshd-message 的文件,然后丢弃事件以便它不会在其它地方重复出现。你可以将它添加到你的 rsyslog.conf 文件中测试这个例子。
|
||||
|
||||
:programname, isequal, “sshd” /var/log/sshd-messages
|
||||
&~
|
||||
|
||||
2. 用类似 awk 的命令行工具提取特定字段的值,例如 sshd 用户名。下面是 Ubuntu 系统中的一个例子。
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
3. 用日志管理系统自动解析日志,然后在需要的应用名称上点击过滤。下面是在 Loggly 日志管理服务中提取 syslog 域的截图。我们对应用名称 “sshd” 进行过滤,如维恩图图标所示。
|
||||
|
||||

|
||||
|
||||
#### 如何过滤错误 ####
|
||||
|
||||
一个人最希望看到日志中的错误。不幸的是,默认的 syslog 配置不直接输出错误的严重性,也就使得难以过滤它们。
|
||||
|
||||
这里有两个解决该问题的方法。首先,你可以修改你的 rsyslog 配置,在日志文件中输出错误的严重性,使得便于查看和检索。在你的 rsyslog 配置中你可以用 pri-text 添加一个 [模板][9],像下面这样:
|
||||
|
||||
"<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
|
||||
|
||||
这个例子会按照下面的格式输出。你可以看到该信息中指示错误的 err。
|
||||
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
你可以用 awk 或者 grep 检索错误信息。在 Ubuntu 中,对这个例子,我们可以用一些语法特征,例如 . 和 >,它们只会匹配这个域。
|
||||
|
||||
$ grep '.err>' /var/log/auth.log
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
你的第二个选择是使用日志管理系统。好的日志管理系统能自动解析 syslog 消息并抽取错误域。它们也允许你用简单的点击过滤日志消息中的特定错误。
|
||||
|
||||
下面是 Loggly 中一个截图,显示了高亮错误严重性的 syslog 域,表示我们正在过滤错误:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/analyzing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a],[Amy Echeverri][b],[ Sadequl Hussain][c]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jasonskowronski
|
||||
[b]:https://www.linkedin.com/in/amyecheverri
|
||||
[c]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:http://linux.die.net/man/1/grep
|
||||
[2]:http://linux.die.net/man/1/tail
|
||||
[3]:http://ryanstutorials.net/linuxtutorial/grep.php
|
||||
[4]:https://lucene.apache.org/core/2_9_4/queryparsersyntax.html
|
||||
[5]:http://linux.die.net/man/1/cut
|
||||
[6]:http://linux.die.net/man/1/awk
|
||||
[7]:http://www.delorie.com/gnu/docs/gawk/gawk_26.html#IDX155
|
||||
[8]:http://logstash.net/docs/1.4.2/filters/grok
|
||||
[9]:http://www.rsyslog.com/doc/v8-stable/configuration/templates.html
|
||||
@ -0,0 +1,70 @@
|
||||
在 Ubuntu 中给你的照片加上 Instagram 风格的滤镜程序
|
||||
================================================================================
|
||||
拿起你的自拍杆跟我来。
|
||||
|
||||
### XnRetro 照片编辑器 ###
|
||||
|
||||
**XnRetro** 是一个可以让你快速给你照片添加“类 Instagram”效果的程序。
|
||||
|
||||
你肯定知道我说的这些效果:划痕、噪点、相框、过度处理、复古和怀旧色调(因为在这个数字过客的时代,我们一定知道无穷无尽的自拍永远也找不回怀旧的自己。)
|
||||
|
||||
无论你认为这些效果是愚蠢的艺术还是创作的捷径,这些滤镜非常流行,可以帮助那些平实无奇的照片添加个性。
|
||||
|
||||

|
||||
|
||||
*XnRetro是一个照片编辑应用*
|
||||
|
||||
#### XnRetro的功能 ####
|
||||
|
||||
**XnRetro 有下面那些功能**
|
||||
|
||||
- 20 种色彩滤镜
|
||||
- 15 种光影效果(虚化、泄露等等)
|
||||
- 28 种画框和边线
|
||||
- 5 种插图 (带力度控制)
|
||||
- 对比度、伽马校正、饱和度等图像调整
|
||||
- 矩形修剪选项
|
||||
|
||||

|
||||
|
||||
*灯光效果调整*
|
||||
|
||||
(理论上)你可以保存编辑过的 .jpg 或者 .png 文件,并且直接在 app 中分享到社交媒体上。
|
||||
|
||||
我说“理论上”的意思是保存.jpg图像无法正常在 linux 版的程序上工作(你可以保存 .png 的图像)。相似问题还有,大多数内置的社交链接失效或者无法导出。
|
||||
|
||||
要使用**15 种光影效果**,你需要在 XnRetro 的‘light’文件夹下将 .jpg 文件重新保存成 .png 文件。编辑‘light.xml’来匹配新的文件名,点击保存那么灯光效果就可以没有问题的加载进 XnRetro 了。
|
||||
|
||||
|
||||
**XnRetro 值得安装么?**
|
||||
|
||||
XnRetro 并不是完美的。它看上去很老土、很难正确的安装,**并且已经几年没有更新了**。
|
||||
|
||||
但它还可以使用,除了保存 .jpg 文件外。同时也是那些像 Gimp 或者 Shotwell 的那些‘正规’的图片调整工具的一个灵活替代品。
|
||||
|
||||
虽然像 [Pixlr Touch Up][1] 和 [Polarr][2] 这样的 web 应用和 Chrome Apps 也提供相似的功能,但你也许正在寻找真正原生的解决方案。
|
||||
|
||||
习惯了 XnRetro 就很难离开它。
|
||||
|
||||
### 下载 Ubuntu 下的 XnRetro ###
|
||||
|
||||
XnRetro 没有可用的 .deb 安装包。它以二进制文件的形式发行,这意味着你需要每次双击程序来运行。它也只有32位的版本。
|
||||
|
||||
你可以使用下面的 XnRetro下载链接。下载完成后你需要解压压缩包并进入。双击里面的‘xnretro’程序。
|
||||
|
||||
- [下载 Linux 版 XnRetro (32位, tar.gz)][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/05/instagram-photo-filters-ubuntu-desktop-app
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgchrome.com/?s=pixlr
|
||||
[2]:http://www.omgchrome.com/the-best-chrome-apps-of-2014/
|
||||
[3]:http://www.xnview.com/en/xnretro/#downloads
|
||||
@ -0,0 +1,172 @@
|
||||
12 个全球认可的 Linux 认证
|
||||
================================================================================
|
||||
大家好,今天我们将会认识一些非常有价值的全球认可的Linux认证。Linux认证是不同的Linux专业机构在全球范围内进行的认证程序。Linux认证可以让Linux专业人才可以在服务器领域或者相关公司等等这些地方更容易获得Linux相关的工作。Linux认证评估一个人在Linux的各个领域里的专业程度。有很多不错的Linux专业机构提供不同的Linux认证。但是,在公司谋取一份工作时全球仅有少数被非常认可的Linux认证含金量很高,这些工作包括管理服务器,虚拟化,安装系统与软件,配置程序,应用支持和其他Linux操作系统相关的东西。随着全球使用Linux操作系统的服务器的增长,拉动了对于Linux专业人才的需求。为了更好的证明Linux专业技术水平,在全球看来,更好的、著名的认证总是有着更高的优先级。
|
||||
|
||||
这里是一些全球认可的Linux认证,我们接下来将会一一谈到。
|
||||
|
||||
### 1. CompTIA Linxu+ ###
|
||||
|
||||
CompTIA Linux+ 是LPI(Linux Professional Institute,Linux专业委员会)主办的一个Linux认证,在全世界范围内提供培训。其提供的Linux相关知识,可以用于从事一大批Linux相关专业的工作,如Linux管理员、高级网络管理员、系统管理员、Linux数据库管理员和Web管理员。如果任何人想从事安装和维护Linux操作系统,该课程会帮助他达到认证要求,并且通过提供对Linux系统更宽阔的认识,能够为通过考试做好准备。LPI的CompTIA Linux+认证的主要目的就是,提供给证书持有者足够扎实的,关于安装软件、操作、管理和设备排障的知识。我们可以付出一定的费用、时间和努力,完成CompTIA Linux+,同时获得三个业内认可的证书:**LPI LPIC-1**和**SUSE Certified Linux Administrator (CLA)**证书。
|
||||
|
||||
- **认证代码** : LX0-103,LX0-104(2015年3月30日启动)或者LX0-101,LX0-102
|
||||
- 题目数量:每次考试60道题
|
||||
- 题目类型:多选
|
||||
- 考试时长:90分钟
|
||||
- 要求:A+,Network+,并且有至少12个月的Linux管理经验
|
||||
- 分数线:500 (对于200-800的范围来说)
|
||||
- 语言:英语,将来会有德语,葡萄牙语,繁体中文,西班牙。
|
||||
- 有效期:认证后三年有效
|
||||
|
||||
**注意**:不同系列的考试不能合并。如果你考的是LX0-101,那么你必须考LX0-102完成认证。同样的,LX0-103和LX0-104又是一个系列。LX0-103和LX0-104系列是LX0-101和LX0-102系列的升级版。
|
||||
|
||||
### 2. LPIC ###
|
||||
|
||||
LPIC,全称Linux专业委员会认证( Linux Professional Institute Certification),是Linux专业委员会的一个Linux认证程序。这是一个多级别的认证程序,要求在每个级别通过一系列(通常是两个)的认证考试。该认证有三个级别,包括初级水平认证 **LPIC-1** ,高级水平认证 **LPIC-2**和最高水平认证 **LPIC-3**。前两个认证侧重于 **Linux系统管理**,而最后一个认证侧重一些专业技能,包括虚拟化和安全。为了得到 **LPIC-3** 认证,一个持有有效的 **LPIC-1** 与**LPIC-2** 认证的考生必须通过300复杂环境测试、303安全测试、304虚拟化测试和高可用性测试中的一个。**LPIC-1**认证按照证书持有者可以通过运行Linux,使用命令行界面和基本的网络知识安装,维护,配置等任务而设计,LPIC-2测试考生是否作为管理中小型混合网络的候选人。LPIC-3认证是为企业级Linux专业技能设计所设计,代表了最高的专业水平和不针对特定 Linux 发行版的行业认证。
|
||||
|
||||
- **认证代码**:LPIC-1(101和102),LPIC-2(201和202)和LPIC-3(300,303或者304)
|
||||
- 题目类型:60个多项选择
|
||||
- 考试时长:90分钟
|
||||
- 要求:无,建议有 Linux Essentials 认证
|
||||
- 分数线:500(在200-800的范围内)
|
||||
- 语言:LPIC-1:英语,德语,意大利语,葡萄牙语,西班牙语(现代),汉语(简体),汉语(繁体),日语
|
||||
- LPIC-2:英语,德语,葡萄牙语,日语
|
||||
- LPIC-3:英语,日语
|
||||
- 有效期:退休之后五年内仍然有效
|
||||
|
||||
### 3.Oracle Linux OCA ###
|
||||
|
||||
Oracle联合认证(OCA)为个人而定制,适用于那些想证明其部署和管理Oracle Linux操作系统的知识牢固的人。该认证专业知识仅仅针对Oracle Linux发行版,这个系统完全是为Oracle产品特别剪裁的,可以运行Oracle设计的系统,包括Oracle Exadata数据库服务器,Oracle Exalytics In-Memory 服务器,Oracle Exalogic 均衡云,和Oracle数据库应用等。Oracle Linux的“坚不可摧企业内核”为企业应用带来了高性能、高扩展性和稳定性。OCA认证覆盖了如管理本地磁盘设备、管理文件系统、安装和移除Solaris包与补丁,优化系统启动过程和系统进程。这是拿到OCP证书系列的第一步。OCA认证以其前身为Sun Certified Solaris Associate(SCSAS)而为人所知。
|
||||
|
||||
- **认证代码**:OCA
|
||||
- 题目类型:75道多项选择
|
||||
- 考试时长:120分钟
|
||||
- 要求:无
|
||||
- 分数线:64%
|
||||
- 有效期:永远有效
|
||||
|
||||
### 4. Oracle Linux OCP ###
|
||||
|
||||
Oracle专业认证(OCP)是Oracle公司为Oracle Linux提供的一个认证,覆盖更多的进阶知识和技能,对于一个Oracle Linux管理员来说。它囊括的知识有配置网络接口、管理交换分区配置、崩溃转储、管理软件、数据库和重要文件。OCP认证是技术性专业知识和专业技能的基准测试,这些知识与技能需要在公司里广泛用于开发、部署和管理应用、中间件和数据库。Oracle Linux OCP的工作机会在增长,这得益于工作市场和经济发展。根据考试纲领,证书持有者有能力胜任安全管理、为Oracle 数据库准备Oracle Linux系统、排除故障和进行恢复操作、安装软件包、安装和配置内核模块、维护交换空间、完成用户和组管理、创建文件系统、配置逻辑卷管理(LVM)、文件分享服务等等。
|
||||
|
||||
- **认证代码**:OCP
|
||||
- 题目类型:60至80道多项选择题
|
||||
- 考试时长:120分钟
|
||||
- 要求:Oracle Linux OCA
|
||||
- 分数线:64%
|
||||
- 有效期:永远有效
|
||||
|
||||
### 5. RHCSA ###
|
||||
|
||||
RHCSA是红帽公司作为红帽认证系统工程师推出的一个认证程序。RHCSA们是指一些拥有在著名的红帽Linux环境下完成核心系统管理技能和能力的人。这是一个入门级的认证程序,关注在系统管理上的实际胜任能力,包括安装、配置一个红帽Linux系统,接入一个可用的网络提供网络服务。一个红帽认证的系统管理员可以理解和使用基本的工具,用以处理文件、目录、命令行环境和文档;操作运行中的系统,包括以不同的启动级别启动、识别进程、开启和停止虚拟机和控制服务;使用分区和逻辑卷配置本地存储;创建和配置文件系统和文件系统属性,包括权限、加密、访问控制列表和网络文件系统;部署配置和维护系统,包括软件安装、更新和核心服务;管理用户和组,包括使用一个中心的目录用于验证;安全性的工作,包括基本的基本防火墙和SELinux配置。要获得RHCE和其他认证,首先得认证过RHCSA。
|
||||
|
||||
- **认证代码**:RHCSA
|
||||
- 课程代码:RH124,RH134和RH199
|
||||
- 考试代码:EX200
|
||||
- 考试时长:21-22小时,取决于选择的课程
|
||||
- 要求:无。有一些Linux基础知识更好
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 6. RHCE ###
|
||||
|
||||
RHCE,也叫做红帽认证工程师,是一个中到高级水平的认证程序,为一些想要学习更多技能和知识,成为一个负责红帽企业Linux的高级系统管理员的RHCSA开设的,RHCE应该有能力、知识和技能来配置静态路由、包过滤、NAT、设定内核运行参数、配置一个ISCSI初始化程序,生成并发送系统用量报告、使用shell脚本自动完成系统维护任务、配置系统日志,包括远程日志、提供网络服务如HTTP/HTTPS、FTP、NFS、SMB、SMTP、SSH和NTP等等。推荐希望获得更多高级水平的认证的RHCSA们、已经完成系统管理员I,II和III、或者已经完成RHCE 快速跟进培训的人们参加认证。
|
||||
|
||||
- **认证代码**:RHCE
|
||||
- 课程代码:RH124,RH134,RH254和RH199
|
||||
- 考试代码:EX200和EX300
|
||||
- 考试时长:21-22个小时,取决于所选课程
|
||||
- 要求:一个RHCSA证书
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 7. RHCA ###
|
||||
|
||||
RHCA即红帽认证架构师,是红帽公司的一个认证程序。它的关注点在系统管理的实际能力,包括安装和配置一个红帽Linux系统,并加入到一个可用网络中运行网络服务。RHCA是所有红帽认证中最高水平的认证。考生需要选择他们希望针对的领域,或者选择合格的红帽认证的任意组合来创建一个他们自己的领域。这里有三个主要的领域:数据中心、云和应用平台。精通数据中心领域的RHCA能够运行、管理数据中心;而熟悉云的可以创建、配置和管理私有云和混合云、云应用平台以及使用红帽企业Linux平台的灵活存储方案;精通应用平台集合的RHCA拥有技能如安装、配置和管理红帽JBoss企业应用平台和应用,云应用平台和混合云环境,借助红帽的OpenShift企业版,使用红帽JBoss数据虚拟化技术从多个资源里组合数据。
|
||||
|
||||
- **认证代码**:RHCA
|
||||
- 课程代码:CL210,CL220.CL280,RH236,RH318,RH413,RH436,RH442,JB248和JB450
|
||||
- 考试代码:EX333,EX401,EX423或者EX318,EX436和EX442
|
||||
- 考试时长:21-22个小时,取决于所选课程
|
||||
- 要求:未过期的RHCE证书
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 8. SUSE CLA ###
|
||||
|
||||
SUSE认证Linux管理员(SUSE CLA)是SUSE推出的一个初级认证,关注点在SUSE Linux企业服务器环境下的日常任务管理。为了获得SUSE CLA认证,不用必须完成课程任务,只需要通过考试就能获得认证。SUSE CLA们能够、也有技术去使用Linux桌面、定位并利用帮助资源、管理Linux文件系统、用Linux Shell和命令行工作、安装SLE 11 SP22、管理系统安装、硬件、备份和恢复、用YaST管理Linux、Linux进程和服务、存储、配置网络、远程接入、SLE 11 SP2监控,任务自动化和管理用户访问和安全工作。我们可以同时获得SUSE CLA,LPIC-1和CompTIA Linux认证,因为SUSE,Linux Professional Institute和CompATI合作提供了这个同时获得三个Linux认证的机会。
|
||||
|
||||
- **认证代码**:SUSE CLA
|
||||
- 课程代码:3115,3116
|
||||
- 考试代码:050-720,050-710
|
||||
- 问题类型:多项选择
|
||||
- 考试时长:90分钟
|
||||
- 要求:无
|
||||
- 分数线:512
|
||||
|
||||
### 9. SUSE CLP ###
|
||||
|
||||
SUSE认证Linux专业人员(CLP)是一个认证程序,为那些希望获得关于SUSE Linux企业服务器更多高级且专业的知识的人而服务。SUSE CLP是通过SUSE CLA认证后的下一步。应该通过CLA的考试并拥有证书,然后通过完成CLP的考试才能获得CLP的认证。通过SUSE CLP认证的人员有能力完成安装和配置SLES 11系统、维护文件系统、管理软件包、进程、打印、配置基础网络服务、samba、Web服务器、使用IPv6、创建和运行bash shell脚本。
|
||||
|
||||
- **认证代码**:SUSE CLP
|
||||
- 课程代码:3115,3116和3117
|
||||
- 考试代码:050-721,050-697
|
||||
- 考试类型:手写
|
||||
- 考试时长:180分钟
|
||||
- 要求:SUSE CLA 认证
|
||||
|
||||
### 10. SUSE CLE ###
|
||||
|
||||
SUSE认证Linux工程师(CLE)是一个工程师级别的高级认证,为那些已经通过CLE考试的人准备。为了获得CLE认证,人们需要已经获得SUSE CLA和CLP的认证。获得CLE认证的人员拥有架设复杂SUSE Linux企业服务器环境的技能。CLE认证过的人可以配置基本的网络服务、管理打印、配置和使用Open LDAP、samba、IPv6、完成服务器健康检测和性能调优、创建和执行shell脚本、部署SUSE Linux企业板、通过Xen实现虚拟化等等。
|
||||
|
||||
- **认证代码**:SUSE CLE
|
||||
- 课程代码:3107
|
||||
- 考试代码:050-723
|
||||
- 考试类型:手写
|
||||
- 考试时长:120分钟
|
||||
- 要求:SUSE CLP 10或者11证书
|
||||
|
||||
### 11. LFCS ###
|
||||
|
||||
Linux基金会认证系统管理员(LFCS)认证考生使用Linux和通过终端环境使用Linux的知识。LFCS是Linux基金会的一个认证程序,为使用Linux操作系统工作的系统管理员和工程师准备。Linux基金会联合业内专家、Linux内核社区,测试考生的核心领域、关键技能、知识和应用能力。通过LFCS认证的人员拥有一些技能、知识和能力,包括在命令行下编辑和操作文件、管理和处理文件系统与存储的错误、聚合分区作为LVM设备、配置交换分区、管理网络文件系统、管理用户帐号/权限和属组、创建并执行bash shell脚本、安装/升级/移除软件包等等。
|
||||
|
||||
- **认证代码**:LFCS
|
||||
- 课程代码:LFCS201,LFCS220(可选)
|
||||
- 考试代码:LFCS 考试
|
||||
- 考试时长:2小时
|
||||
- 要求:无
|
||||
- 分数线:74%
|
||||
- 语言:英语
|
||||
- 有效期:两年
|
||||
|
||||
### 12. LFCE ###
|
||||
|
||||
Linux基金会认证工程师(LFCE),是Linux基金会为Linux工程师推出的认证。相比于LFCS,通过LFCE认证的人员在Linux方面拥有更大范围的技能。这是一个工程师级别的高级认证程序。LFCE认证的人具备一些网络管理方面的技能和能力,如配置网络服务、配置包过滤、监控网络性能、IP流量、配置文件系统和文件服务、网络文件系统、从仓库安装/升级软件包、管理网络安全、配置iptables、http服务、代理服务、邮件服务等等。由于其为高级工程级别的认证程序,所以普遍认为相比LFCS,学习和通过的难度更大些。
|
||||
|
||||
- **认证代码**:LFCE
|
||||
- 课程代码:LFS230
|
||||
- 考试代码:LFCE 考试
|
||||
- 考试时长:2小时
|
||||
- 要求:认证过LFCS
|
||||
- 分数线:72%
|
||||
- 语言:英语
|
||||
- 有效期:2年
|
||||
|
||||
### 我们发现的情况(这仅仅是我们的观点)###
|
||||
|
||||
最近的调查表明,在不同的高端招聘代理中,称80%的Linux工作描述更倾向于红帽的认证。如果你是一个学生/新手,并且想学习Linux,那么我们建议选择越来越流行的Linux基金会认证,或者CompTIA Linux也可以是一个选择。如果你已经了解了oracle或suse,或者在他们的产品上工作,那oracle/suse的认证会更好些,如果你在公司里工作了,这些认证会对你的职业生涯成长有帮助:-)
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这个世界上,成千上万的大公司正在运行跑着Linux操作系统的服务器和主框架机,为了在这些服务器上管理、配置和工作,总是存在着对Linux技术/专业知识高度认证的需求。这些国际上承认的认证对某些人在Linux的职业生涯扮演很重要的角色。这些遍布全球的公司运行着Linux,需要Linux工程师、系统管理员和已经获得认证且在Linux相关领域干得不错的人员。全球认可的Linux认证,对于专业知识和职业生涯的辉煌都是重中之重,所以好好准备考试并获得认证,对于在Linux建立职业生涯是一个很好的选择。如果你有任何问题,想法,反馈,请写在下方的评论框里,让我们好知道哪些东西需要添加或者改进。谢谢!:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/12-globally-recognized-linux-certifications/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,77 @@
|
||||
在Ubuntu中安装Unity 8桌面预览版
|
||||
================================================================================
|
||||

|
||||
|
||||
如果你一直关注新闻,那么就知道Ubuntu将会切换到带有[Unity 8][2]桌面的[Mir显示服务器][1]。然而,在尚未确定运行在 Mir 上的Unity 8是否会出现在[Ubuntu 15.10 Willy Werewolf][3]之前,有了一个Unity 8的预览版本可供你体验和测试。通过官方PPA,可以很容易地**安装Unity 8到Ubuntu 14.04,14.10和15.04中**。
|
||||
|
||||
到目前为止,开发者已经可以通过[ISO][4](主要途径)获得该Unity 8预览来进行测试。不过Canonical也通过[LXC容器][5]发布了它。通过该方法,你可以使用Unity 8桌面会话,让它像其它桌面环境一样运行在Mir显示服务器上。就像你[在Ubuntu中安装Mate桌面][6],然后从LightDm登录屏幕选择桌面会话一样。
|
||||
|
||||
想要试试Unity 8?让我们来看怎样安装它吧。
|
||||
|
||||
**注意: 它是一个实验性预览,可能不是所有人都可以让它正确工作的。**
|
||||
|
||||
### 安装Unity 8桌面到Ubuntu ###
|
||||
|
||||
下面是安装并使用Unity 8的步骤:
|
||||
|
||||
#### 步骤 1: 安装Unity 8到Ubuntu 12.04和14.04 ####
|
||||
|
||||
如果你正运行着Ubuntu 12.04和14.04,那么你必须使用官方PPA来安装Unity 8。使用以下命令进行安装:
|
||||
|
||||
sudo apt-add-repository ppa:unity8-desktop-session-team/unity8-preview-lxc
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install unity8-lxc
|
||||
|
||||
#### 步骤 1: 安装Unity 8到Ubuntu 14.10和15.04 ####
|
||||
|
||||
如果你正运行着Ubuntu 14.10或15.04,那么Unity 8 LXC已经在源中准备好。你只需要运行以下命令:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install unity8-lxc
|
||||
|
||||
#### 步骤 2: 设置Unity 8桌面预览LXC ####
|
||||
|
||||
安装Unity 8 LXC后,该对它进行设置,下面的命令就可达到目的:
|
||||
|
||||
sudo unity8-lxc-setup
|
||||
|
||||
它将花费一些时间来设置,所以,耐心点。它会下载ISO,然后解压缩,接着完成最后一些必要的设置来让它工作。它也会安装一个LightDM的轻度修改版本。这一切都搞定后,需要重启。
|
||||
|
||||
#### 步骤 3: 选择Unity 8 ####
|
||||
|
||||
重启后,在登录屏幕,点击你的登录旁边的Ubuntu图标:
|
||||
|
||||

|
||||
|
||||
你应该可以在这看到Unity 8的选项,选择它:
|
||||
|
||||

|
||||
|
||||
### 卸载Unity 8 LXC ###
|
||||
|
||||
如果你发现Unity 8毛病太多,或者你不喜欢它,那么你可以以相同的方式切换回默认Unity版本。此外,你也可以通过下面的命令移除Unity 8:
|
||||
|
||||
sudo apt-get remove unity8-lxc
|
||||
|
||||
该命令会将Unity 8选项从LightDM屏幕移除,但是配置仍然保留着。
|
||||
|
||||
以上就是你在Ubuntu中安装带有Mir的Unity 8的全部过程,试玩后请分享你关于Unity 8的想法哦!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-unity-8-desktop-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://en.wikipedia.org/wiki/Mir_%28software%29
|
||||
[2]:https://wiki.ubuntu.com/Unity8Desktop
|
||||
[3]:http://itsfoss.com/ubuntu-15-10-codename/
|
||||
[4]:https://wiki.ubuntu.com/Unity8DesktopIso
|
||||
[5]:https://wiki.ubuntu.com/Unity8inLXC
|
||||
[6]:http://itsfoss.com/install-mate-desktop-ubuntu-14-04/
|
||||
@ -0,0 +1,285 @@
|
||||
15 个有用的 MySQL/MariaDB 性能调整和优化技巧
|
||||
================================================================================
|
||||
MySQL 是一个强大的开源关系数据库管理系统(简称 RDBMS)。它发布于 1995 年(20年前)。它采用结构化查询语言(SQL),这可能是数据库内容管理中最流行的选择。最新的 MySQL 版本是 5.6.25,于 2015 年 5 月 29 日发布。
|
||||
|
||||
关于 MySQL 一个有趣的事实是它的名字来自于 Michael Widenius(MySQL 的创始人)的女儿“ My”。尽管有许多关于 MySQL 有趣的传闻,不过本文主要是向你展示一些有用的实践,以帮助你管理你的 MySQL 服务器。
|
||||
|
||||

|
||||
|
||||
*MySQL 性能优化*
|
||||
|
||||
2009 年 4 月,MySQL 被 Oracle 收购。其结果是MySQL 社区分裂,创建了一个叫 MariaDB 的分支 。创建该分支的主要原因是为了保持这个项目可以在 GPL 下的自由。
|
||||
|
||||
今天,MySQL 和 MariaDB 是用于类似 WordPress、Joomla、Magento 和其他 web 应用程序的最流行的 RDMS 之一(如果不是最多的)。
|
||||
|
||||
这篇文章将告诉你一些基本的,但非常有用的关于如何优化 MySQL/MariaDB 性能的技巧。注意,本文假定您已经安装了 MySQL 或 MariaDB。如果你仍然不知道如何在系统上安装它们,你可以按照以下说明去安装:
|
||||
|
||||
- [在 RHEL/CentOS 7 上安装 LAMP][1]
|
||||
- [在 Fedora 22 上安装 LAMP][2]
|
||||
- [在 Ubuntu 15.04 安装 LAMP][3]
|
||||
- [在 Debian 8 上安装 MariaDB][4]
|
||||
- [在 Gentoo Linux 上安装 MariaDB][5]
|
||||
- [在 Arch Linux 上安装 MariaDB][6]
|
||||
|
||||
**重要提示**: 在开始之前,不要盲目的接受这些建议。每个 MySQL 设置都是不同的,在进行任何更改之前需要慎重考虑。
|
||||
|
||||
你需要明白这些:
|
||||
|
||||
- MySQL/MariaDB 配置文件位于 `/etc/my.cnf`。 每次更改此文件后你需要重启 MySQL 服务,以使更改生效。
|
||||
- 这篇文章使用 MySQL 5.6 版本。
|
||||
|
||||
### 1. 启用 InnoDB 的每张表一个数据文件设置 ###
|
||||
|
||||
首先,有一个重要的解释, InnoDB 是一个存储引擎。MySQL 和 MariaDB 使用 InnoDB 作为默认存储引擎。以前,MySQL 使用系统表空间来保存数据库中的表和索引。这意味着服务器唯一的目的就是数据库处理,它们的存储盘不用于其它目的。
|
||||
|
||||
InnoDB 提供了更灵活的方式,它把每个数据库的信息保存在一个 `.ibd` 数据文件中。每个 .idb 文件代表它自己的表空间。通过这样的方式可以更快地完成类似 “TRUNCATE” 的数据库操作,当删除或截断一个数据库表时,你也可以回收未使用的空间。
|
||||
|
||||
这样配置的另一个好处是你可以将某些数据库表放在一个单独的存储设备。这可以大大提升你磁盘的 I/O 负载。
|
||||
|
||||
MySQL 5.6及以上的版本默认启用 `innodb_file_per_table`。你可以在 /etc/my.cnf 文件中看到。该指令看起来是这样的:
|
||||
|
||||
innodb_file_per_table=1
|
||||
|
||||
### 2. 将 MySQL 数据库数据存储到独立分区上 ###
|
||||
|
||||
**注意**:此设置只在 MySQL 上有效, 在 MariaDB 上无效。
|
||||
|
||||
有时候操作系统的读/写会降低你 MySQL 服务器的性能,尤其是如果操作系统和数据库的数据位于同一块磁盘上。因此,我建议你使用单独的磁盘(最好是 SSD)用于 MySQL 服务。
|
||||
|
||||
要完成这步,你需要将新的磁盘连接到你的计算机/服务器上。对于这篇文章,我假定磁盘挂在到 /dev/sdb。
|
||||
|
||||
####下一步是准备新的分区:
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
现在按 “N” 来创建新的分区。接着按 “P”,使其创建为主分区。在此之后,从 1-4 设置分区号。之后,你可以选择分区大小。这里按 enter。在下一步,你需要配置分区的大小。
|
||||
|
||||
如果你希望使用全部的磁盘,再按一次 enter。否则,你可以手动设置新分区的大小。准备就绪后按 “w” 保存更改。现在,我们需要为我们的新分区创建一个文件系统。这可以用下面命令轻松地完成:
|
||||
|
||||
# mkfs.ext4 /dev/sdb1
|
||||
|
||||
现在我们会挂载新分区到一个目录。我在根目录下创建了一个名为 “ssd” 的目录:
|
||||
|
||||
# mkdir /ssd/
|
||||
|
||||
挂载新分区到刚才创建的目录下:
|
||||
|
||||
# mount /dev/sdb1 /ssd/
|
||||
|
||||
你可以在 /etc/fstab 文件中添加如下行设置为开机自动挂载:
|
||||
|
||||
/dev/sdb1 /ssd ext3 defaults 0 0
|
||||
|
||||
####现在我们将 MySQL 移动到新磁盘中
|
||||
|
||||
首先停止 MySQL 服务:
|
||||
|
||||
# service mysqld stop
|
||||
|
||||
我建议你同时停止 Apache/nginx,以防止任何试图写入数据库的操作:
|
||||
|
||||
# service httpd stop
|
||||
# service nginx stop
|
||||
|
||||
现在复制整个 MySQL 目录到新分区中:
|
||||
|
||||
# cp /var/lib/mysql /ssd/ -Rp
|
||||
|
||||
这可能需要一段时间,具体取决于你的 MySQL 数据库的大小。一旦这个过程完成后重命名 MySQL 目录:
|
||||
|
||||
# mv /var/lib/mysql /var/lib/mysql-backup
|
||||
|
||||
然后创建一个符号链接:
|
||||
|
||||
# ln -s /ssd/mysql /var/lib/mysql
|
||||
|
||||
现在启动你的 MySQL 和 web 服务:
|
||||
|
||||
# service mysqld start
|
||||
# service httpd start
|
||||
# service nginx start
|
||||
|
||||
以后你的数据库将使用新的磁盘访问。
|
||||
|
||||
### 3. 优化使用 InnoDB 的缓冲池 ###
|
||||
|
||||
InnoDB 引擎在内存中有一个缓冲池用于缓存数据和索引。这当然有助于你更快地执行 MySQL/MariaDB 查询语句。选择合适的内存大小需要一些重要的决策并对系统的内存消耗有较多的认识。
|
||||
|
||||
下面是你需要考虑的:
|
||||
|
||||
- 其它的进程需要消耗多少内存。这包括你的系统进程,页表,套接字缓冲。
|
||||
- 你的服务器是否专门用于 MySQL 还是你运行着其它非常消耗内存的服务。
|
||||
|
||||
在一个专用的机器上,你可能会把 60-70% 的内存分配给 `innodb_buffer_pool_size`。如果你打算在一个机器上运行更多的服务,你应该重新考虑专门用于 `innodb_buffer_pool_size` 的内存大小。
|
||||
|
||||
你需要设置 my.cnf 中的此项:
|
||||
|
||||
innodb_buffer_pool_size
|
||||
|
||||
### 4. 在 MySQL 中避免使用 Swappiness ###
|
||||
|
||||
“交换”是一个当系统移动部分内存到一个称为 “交换空间” 的特殊磁盘空间时的过程。通常当你的系统用完物理内存后就会出现这种情况,系统将信息写入磁盘而不是释放一些内存。正如你猜测的磁盘比你的内存要慢得多。
|
||||
|
||||
该选项默认情况下是启用的:
|
||||
|
||||
# sysctl vm.swappiness
|
||||
|
||||
vm.swappiness = 60
|
||||
|
||||
运行以下命令关闭 swappiness:
|
||||
|
||||
# sysctl -w vm.swappiness=0
|
||||
|
||||
### 5. 设置 MySQL 的最大连接数 ###
|
||||
|
||||
`max_connections` 指令告诉你当前你的服务器允许多少并发连接。MySQL/MariaDB 服务器允许有 SUPER 权限的用户在最大连接之外再建立一个连接。只有当执行 MySQL 请求的时候才会建立连接,执行完成后会关闭连接并被新的连接取代。
|
||||
|
||||
请记住,太多的连接会导致内存的使用量过高并且会锁住你的 MySQL 服务器。一般小网站需要 100-200 的连接数,而较大可能需要 500-800 甚至更多。这里的值很大程度上取决于你 MySQL/MariaDB 的使用情况。
|
||||
|
||||
你可以动态地改变 `max_connections` 的值而无需重启MySQL服务器:
|
||||
|
||||
# mysql -u root -p
|
||||
mysql> set global max_connections = 300;
|
||||
|
||||
### 6. 配置 MySQL 的线程缓存数量 ###
|
||||
|
||||
`thread_cache_size` 指令用来设置你服务器缓存的线程数量。当客户端断开连接时,如果当前线程数小于 `thread_cache_size`,它的线程将被放入缓存中。下一个请求通过使用缓存池中的线程来完成。
|
||||
|
||||
要提高服务器的性能,你可以设置 `thread_cache_size` 的值相对高一些。你可以通过以下方法来查看线程缓存命中率:
|
||||
|
||||
mysql> show status like 'Threads_created';
|
||||
mysql> show status like 'Connections';
|
||||
|
||||
你可以用以下公式来计算线程池的命中率:
|
||||
|
||||
100 - ((Threads_created / Connections) * 100)
|
||||
|
||||
如果你得到一个较低的数字,这意味着大多数 mysql 连接使用新的线程,而不是从缓存加载。在这种情况下,你需要增加 `thread_cache_size`。
|
||||
|
||||
这里有一个好处是可以动态地改变 `thread_cache_size` 而无需重启 MySQL 服务。你可以通过以下方式来实现:
|
||||
|
||||
mysql> set global thread_cache_size = 16;
|
||||
|
||||
### 7. 禁用 MySQL 的 DNS 反向查询 ###
|
||||
|
||||
默认情况下当新的连接出现时,MySQL/MariaDB 会进行 DNS 查询解析用户的 IP 地址/主机名。对于每个客户端连接,它的 IP 都会被解析为主机名。然后,主机名又被反解析为 IP 来验证两者是否一致。
|
||||
|
||||
当 DNS 配置错误或服务器出现问题时,这很可能会导致延迟。这就是为什么要关闭 DNS 的反向查询的原因,你可以在你的配置文件中添加以下选项去设定:
|
||||
|
||||
[mysqld]
|
||||
# Skip reverse DNS lookup of clients
|
||||
skip-name-resolve
|
||||
|
||||
更改后你需要重启 MySQL 服务。
|
||||
|
||||
### 8. 配置 MySQL 的查询缓存容量 ###
|
||||
|
||||
如果你有很多重复的查询并且数据不经常改变 – 请使用缓存查询。 人们常常不理解 `query_cache_size` 的实际含义而将此值设置为 GB 级,这实际上会降低服务器的性能。
|
||||
|
||||
背后的原因是,在更新过程中线程需要锁定缓存。通常设置为 200-300 MB应该足够了。如果你的网站比较小的,你可以尝试给 64M 并在以后及时去增加。
|
||||
|
||||
在你的 MySQL 配置文件中添加以下设置:
|
||||
|
||||
query_cache_type = 1
|
||||
query_cache_limit = 256K
|
||||
query_cache_min_res_unit = 2k
|
||||
query_cache_size = 80M
|
||||
|
||||
### 9. 配置临时表容量和内存表最大容量 ###
|
||||
|
||||
`tmp_table_size` 和 `max_heap_table_size` 这两个变量的大小应该相同,它们可以让你避免磁盘写入。`tmp_table_size` 是内置内存表的最大空间。如果表的大小超出限值将会被转换为磁盘上的 MyISAM 表。
|
||||
|
||||
这会影响数据库的性能。管理员通常建议在服务器上设置这两个值为每 GB 内存给 64M。
|
||||
|
||||
[mysqld]
|
||||
tmp_table_size= 64M
|
||||
max_heap_table_size= 64M
|
||||
|
||||
### 10. 启用 MySQL 慢查询日志 ###
|
||||
|
||||
记录慢查询可以帮助你定位数据库中的问题并帮助你调试。这可以通过在你的 MySQL 配置文件中添加以下值来启用:
|
||||
|
||||
slow-query-log = 1
|
||||
slow-query-log-file = /var/lib/mysql/mysql-slow.log
|
||||
long_query_time = 1
|
||||
|
||||
第一个变量启用慢查询日志,第二个告诉 MySQL 实际的日志文件存储位置。使用 `long_query_time` 来定义完成 MySQL 查询多少用时算长。
|
||||
|
||||
### 11. 检查 MySQL 的空闲连接 ###
|
||||
|
||||
空闲连接会消耗资源,可以的话应该被终止或者刷新。空闲连接是指处于 “sleep” 状态并且保持了很长一段时间的连接。你可以通过运行以下命令查看空闲连接:
|
||||
|
||||
# mysqladmin processlist -u root -p | grep “Sleep”
|
||||
|
||||
这会显示处于睡眠状态的进程列表。当代码使用持久连接到数据库时会出现这种情况。使用 PHP 调用 mysql_pconnect 可以打开这个连接,执行完查询之后,删除认证信息并保持连接为打开状态。这会导致每个线程的缓冲都被保存在内存中,直到该线程结束。
|
||||
|
||||
首先你要做的就是检查代码问题并修复它。如果你不能访问正在运行的代码,你可以修改 `wait_timeout` 变量。默认值是 28800 秒,而你可以安全地将其降低到 60 :
|
||||
|
||||
wait_timeout=60
|
||||
|
||||
### 12. 为 MySQL 选择正确的文件系统 ###
|
||||
|
||||
选择正确的文件系统对数据库至关重要。在这里你需要考虑的最重要的事情是 - 数据的完整性,性能和易管理性。
|
||||
|
||||
按照 MariaDB 的建议,最好的文件系统是XFS、ext4 和 Btrfs。它们都是可以使用超大文件和大容量存储卷的企业级日志型文件系统。
|
||||
|
||||
下面你可以找到一些关于这三个文件系统的有用信息:
|
||||
|
||||
| 文件系统 | XFS | Ext4 | Btrfs |
|
||||
|---------------|-----|------|-------|
|
||||
| 文件系统最大容量 | 8EB | 1EB | 16EB |
|
||||
| 最大文件大小 | 8EB | 16TB | 16EB |
|
||||
|
||||
|
||||
我们的这篇文章详细介绍了 Linux 文件系统的利与弊: [Linux 文件系统解析][7]。
|
||||
|
||||
### 13. 设置 MySQL 允许的最大数据包 ###
|
||||
|
||||
MySQL 把数据拆分成包。通常一个包就是发送到客户端的一行数据。`max_allowed_packet` 变量定义了可以被发送的最大的包。
|
||||
|
||||
此值设置得过低可能会导致查询速度变得非常慢,然后你会在 MySQL 的错误日志看到一个错误。建议将该值设置为最大包的大小。
|
||||
|
||||
### 14. 测试 MySQL 的性能优化 ###
|
||||
|
||||
你应该定期检查 MySQL/MariaDB 的性能。这将帮助你了解资源的使用情况是否发生了改变或需要进行改进。
|
||||
|
||||
有大量的测试工具可用,但我推荐你一个简单易用的。该工具被称为 mysqltuner。
|
||||
|
||||
使用下面的命令下载并运行它:
|
||||
|
||||
# wget https://github.com/major/MySQLTuner-perl/tarball/master
|
||||
# tar xf master
|
||||
# cd major-MySQLTuner-perl-993bc18/
|
||||
# ./mysqltuner.pl
|
||||
|
||||
你将收到有关 MySQL 使用的详细报告和推荐提示。下面是默认 MariaDB 安装的输出样例:
|
||||
|
||||

|
||||
|
||||
### 15. 优化和修复 MySQL 数据库 ###
|
||||
|
||||
有时候 MySQL/MariaDB 数据库中的表很容易崩溃,尤其是服务器意外关机、文件系统突然崩溃或复制过程中仍然访问数据库。幸运的是,有一个称为 'mysqlcheck' 的免费开源工具,它会自动检查、修复和优化 Linux 中数据库的所有表。
|
||||
|
||||
# mysqlcheck -u root -p --auto-repair --check --optimize --all-databases
|
||||
# mysqlcheck -u root -p --auto-repair --check --optimize databasename
|
||||
|
||||
就是这些!我希望上述文章对你有用,并帮助你优化你的 MySQL 服务器。一如往常,如果你有任何疑问或评论,请在下面的评论部分提交。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mysql-mariadb-performance-tuning-and-optimization/
|
||||
|
||||
作者:[Marin Todorov][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[ictlyh](https://github.com/ictlyh)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/marintodorov89/
|
||||
[1]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[2]:http://www.tecmint.com/install-lamp-linux-apache-mysql-php-on-fedora-22/
|
||||
[3]:http://www.tecmint.com/install-lamp-on-ubuntu-15-04/
|
||||
[4]:http://www.tecmint.com/install-mariadb-in-debian/
|
||||
[5]:http://www.tecmint.com/install-lemp-in-gentoo-linux/
|
||||
[6]:http://www.tecmint.com/install-lamp-in-arch-linux/
|
||||
[7]:http://www.tecmint.com/linux-file-system-explained/
|
||||
@ -1,18 +1,18 @@
|
||||
Ubuntu 15.04上配置OpenVPN服务器-客户端
|
||||
在 Ubuntu 15.04 上配置 OpenVPN 服务器和客户端
|
||||
================================================================================
|
||||
虚拟专用网(VPN)是几种用于建立与其它网络连接的网络技术中常见的一个名称。它被称为虚拟网,因为各个节点的连接不是通过物理线路实现的。而由于没有网络所有者的正确授权是不能通过公共线路访问到网络,所以它是专用的。
|
||||
虚拟专用网(VPN)常指几种通过其它网络建立连接技术。它之所以被称为“虚拟”,是因为各个节点间的连接不是通过物理线路实现的,而“专用”是指如果没有网络所有者的正确授权是不能被公开访问到。
|
||||
|
||||

|
||||
|
||||
[OpenVPN][1]软件通过TUN/TAP驱动的帮助,使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提额外提供了灵活的配置,可以帮助你避免防火墙限制。
|
||||
[OpenVPN][1]软件借助TUN/TAP驱动使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提供了更多的灵活配置,可以帮助你避免防火墙限制。
|
||||
|
||||
OpenVPN中,由OpenSSL库和传输层安全协议(TLS)提供了安全和加密。TLS是SSL协议的一个改进版本。
|
||||
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何预备使用带有公共密钥非对称加密和TLS协议基础结构(PKI)。
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何配置使用带有公共密钥基础结构(PKI)的非对称加密和TLS协议。
|
||||
|
||||
### 服务器端配置 ###
|
||||
|
||||
首先,我们必须安装OpenVPN。在Ubuntu 15.04和其它带有‘apt’报管理器的Unix系统中,可以通过如下命令安装:
|
||||
首先,我们必须安装OpenVPN软件。在Ubuntu 15.04和其它带有‘apt’包管理器的Unix系统中,可以通过如下命令安装:
|
||||
|
||||
sudo apt-get install openvpn
|
||||
|
||||
@ -20,7 +20,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
sudo apt-get unstall easy-rsa
|
||||
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在“sudo -i”命令后;此外,你可以使用“sudo -E”作为接下来所有命令的前缀。
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在使用`sudo -i`命令后执行,或者你可以使用`sudo -E`作为接下来所有命令的前缀。
|
||||
|
||||
开始之前,我们需要拷贝“easy-rsa”到openvpn文件夹。
|
||||
|
||||
@ -32,15 +32,15 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
这里,我们开启了一个密钥生成进程。
|
||||
这里,我们开始密钥生成进程。
|
||||
|
||||
首先,我们编辑一个“var”文件。为了简化生成过程,我们需要在里面指定数据。这里是“var”文件的一个样例:
|
||||
首先,我们编辑一个“vars”文件。为了简化生成过程,我们需要在里面指定数据。这里是“vars”文件的一个样例:
|
||||
|
||||
export KEY_COUNTRY="US"
|
||||
export KEY_PROVINCE="CA"
|
||||
export KEY_CITY="SanFrancisco"
|
||||
export KEY_ORG="Fort-Funston"
|
||||
export KEY_EMAIL="my@myhost.mydomain"
|
||||
export KEY_COUNTRY="CN"
|
||||
export KEY_PROVINCE="BJ"
|
||||
export KEY_CITY="Beijing"
|
||||
export KEY_ORG="Linux.CN"
|
||||
export KEY_EMAIL="open@vpn.linux.cn"
|
||||
export KEY_OU=server
|
||||
|
||||
希望这些字段名称对你而言已经很清楚,不需要进一步说明了。
|
||||
@ -61,7 +61,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
./build-ca
|
||||
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查以下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查一下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
.............................................+++
|
||||
@ -75,14 +75,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [Fort-Funston CA]:
|
||||
Country Name (2 letter code) [CN]:
|
||||
State or Province Name (full name) [BJ]:
|
||||
Locality Name (eg, city) [Beijing]:
|
||||
Organization Name (eg, company) [Linux.CN]:
|
||||
Organizational Unit Name (eg, section) [Tech]:
|
||||
Common Name (eg, your name or your server's hostname) [Linux.CN CA]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
Email Address [open@vpn.linux.cn]:
|
||||
|
||||
接下来,我们需要生成一个服务器密钥
|
||||
|
||||
@ -102,14 +102,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [server]:
|
||||
Country Name (2 letter code) [CN]:
|
||||
State or Province Name (full name) [BJ]:
|
||||
Locality Name (eg, city) [Beijing]:
|
||||
Organization Name (eg, company) [Linux.CN]:
|
||||
Organizational Unit Name (eg, section) [Tech]:
|
||||
Common Name (eg, your name or your server's hostname) [Linux.CN server]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
Email Address [open@vpn.linux.cn]:
|
||||
|
||||
Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
@ -119,14 +119,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
countryName :PRINTABLE:'US'
|
||||
stateOrProvinceName :PRINTABLE:'CA'
|
||||
localityName :PRINTABLE:'SanFrancisco'
|
||||
organizationName :PRINTABLE:'Fort-Funston'
|
||||
organizationalUnitName:PRINTABLE:'MyOrganizationalUnit'
|
||||
commonName :PRINTABLE:'server'
|
||||
countryName :PRINTABLE:'CN'
|
||||
stateOrProvinceName :PRINTABLE:'BJ'
|
||||
localityName :PRINTABLE:'Beijing'
|
||||
organizationName :PRINTABLE:'Linux.CN'
|
||||
organizationalUnitName:PRINTABLE:'Tech'
|
||||
commonName :PRINTABLE:'Linux.CN server'
|
||||
name :PRINTABLE:'EasyRSA'
|
||||
emailAddress :IA5STRING:'me@myhost.mydomain'
|
||||
emailAddress :IA5STRING:'open@vpn.linux.cn'
|
||||
Certificate is to be certified until May 22 19:00:25 2025 GMT (3650 days)
|
||||
Sign the certificate? [y/n]:y
|
||||
1 out of 1 certificate requests certified, commit? [y/n]y
|
||||
@ -143,7 +143,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
Generating DH parameters, 2048 bit long safe prime, generator 2
|
||||
This is going to take a long time
|
||||
................................+................<and many many dots>
|
||||
................................+................<许多的点>
|
||||
|
||||
在漫长的等待之后,我们可以继续生成最后的密钥了,该密钥用于TLS验证。命令如下:
|
||||
|
||||
@ -176,7 +176,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
### Unix的客户端配置 ###
|
||||
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要从先前的部分连接到OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的目录中:
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要连接到前面建立的OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的对应目录中:
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
@ -211,7 +211,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
# 远程 OpenVPN 服务器的 IP 和 端口号
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
@ -243,7 +243,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
安卓设备上的OpenVPN配置和Unix系统上的十分类似,我们需要一个含有配置文件、密钥和证书的包。文件列表如下:
|
||||
|
||||
- configuration file (.ovpn),
|
||||
- 配置文件 (扩展名 .ovpn),
|
||||
- ca.crt,
|
||||
- dh2048.pem,
|
||||
- client.crt,
|
||||
@ -257,7 +257,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
# 远程 OpenVPN 服务器的 IP 和 端口号
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
@ -274,21 +274,21 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
所有这些文件我们必须移动我们设备的SD卡上。
|
||||
|
||||
然后,我们需要安装[OpenVPN连接][2]。
|
||||
然后,我们需要安装一个[OpenVPN Connect][2] 应用。
|
||||
|
||||
接下来,配置过程很是简单:
|
||||
|
||||
open setting of OpenVPN and select Import options
|
||||
select Import Profile from SD card option
|
||||
in opened window go to folder with prepared files and select .ovpn file
|
||||
application offered us to create a new profile
|
||||
tap on the Connect button and wait a second
|
||||
- 打开 OpenVPN 并选择“Import”选项
|
||||
- 选择“Import Profile from SD card”
|
||||
- 在打开的窗口中导航到我们放置好文件的目录,并选择那个 .ovpn 文件
|
||||
- 应用会要求我们创建一个新的配置文件
|
||||
- 点击“Connect”按钮并稍等一下
|
||||
|
||||
搞定。现在,我们的安卓设备已经通过安全的VPN连接连接到我们的专用网。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和在企业中使用。
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易的客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和企业中使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -296,7 +296,7 @@ via: http://linoxide.com/ubuntu-how-to/configure-openvpn-server-client-ubuntu-15
|
||||
|
||||
作者:[Ivan Zabrovskiy][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,205 @@
|
||||
关于Linux防火墙'iptables'的面试问答
|
||||
================================================================================
|
||||
Nishita Agarwal是Tecmint的用户,她将分享关于她刚刚经历的一家公司(印度的一家私人公司Pune)的面试经验。在面试中她被问及许多不同的问题,但她是iptables方面的专家,因此她想分享这些关于iptables的问题和相应的答案给那些以后可能会进行相关面试的人。
|
||||
|
||||

|
||||
|
||||
所有的问题和相应的答案都基于Nishita Agarwal的记忆并经过了重写。
|
||||
|
||||
> “嗨,朋友!我叫**Nishita Agarwal**。我已经取得了理学学士学位,我的专业集中在UNIX和它的变种(BSD,Linux)。它们一直深深的吸引着我。我在存储方面有1年多的经验。我正在寻求职业上的变化,并将供职于印度的Pune公司。”
|
||||
|
||||
下面是我在面试中被问到的问题的集合。我已经把我记忆中有关iptables的问题和它们的答案记录了下来。希望这会对您未来的面试有所帮助。
|
||||
|
||||
### 1. 你听说过Linux下面的iptables和Firewalld么?知不知道它们是什么,是用来干什么的? ###
|
||||
|
||||
**答案** : iptables和Firewalld我都知道,并且我已经使用iptables好一段时间了。iptables主要由C语言写成,并且以GNU GPL许可证发布。它是从系统管理员的角度写的,最新的稳定版是iptables 1.4.21。iptables通常被用作类UNIX系统中的防火墙,更准确的说,可以称为iptables/netfilter。管理员通过终端/GUI工具与iptables打交道,来添加和定义防火墙规则到预定义的表中。Netfilter是内核中的一个模块,它执行包过滤的任务。
|
||||
|
||||
Firewalld是RHEL/CentOS 7(也许还有其他发行版,但我不太清楚)中最新的过滤规则的实现。它已经取代了iptables接口,并与netfilter相连接。
|
||||
|
||||
### 2. 你用过一些iptables的GUI或命令行工具么? ###
|
||||
|
||||
**答案** : 虽然我既用过GUI工具,比如与[Webmin][1]结合的Shorewall;以及直接通过终端访问iptables,但我必须承认通过Linux终端直接访问iptables能给予用户更高级的灵活性、以及对其背后工作更好的理解的能力。GUI适合初级管理员,而终端适合有经验的管理员。
|
||||
|
||||
### 3. 那么iptables和firewalld的基本区别是什么呢? ###
|
||||
|
||||
**答案** : iptables和firewalld都有着同样的目的(包过滤),但它们使用不同的方式。iptables与firewalld不同,在每次发生更改时都刷新整个规则集。通常iptables配置文件位于‘/etc/sysconfig/iptables‘,而firewalld的配置文件位于‘/etc/firewalld/‘。firewalld的配置文件是一组XML文件。以XML为基础进行配置的firewalld比iptables的配置更加容易,但是两者都可以完成同样的任务。例如,firewalld可以在自己的命令行界面以及基于XML的配置文件下使用iptables。
|
||||
|
||||
### 4. 如果有机会的话,你会在你所有的服务器上用firewalld替换iptables么? ###
|
||||
|
||||
**答案** : 我对iptables很熟悉,它也工作的很好。如果没有任何需求需要firewalld的动态特性,那么没有理由把所有的配置都从iptables移动到firewalld。通常情况下,目前为止,我还没有看到iptables造成什么麻烦。IT技术的通用准则也说道“为什么要修一件没有坏的东西呢?”。上面是我自己的想法,但如果组织愿意用firewalld替换iptables的话,我不介意。
|
||||
|
||||
### 5. 你看上去对iptables很有信心,巧的是,我们的服务器也在使用iptables。 ###
|
||||
|
||||
iptables使用的表有哪些?请简要的描述iptables使用的表以及它们所支持的链。
|
||||
|
||||
**答案** : 谢谢您的赞赏。至于您问的问题,iptables使用的表有四个,它们是:
|
||||
|
||||
- Nat 表
|
||||
- Mangle 表
|
||||
- Filter 表
|
||||
- Raw 表
|
||||
|
||||
Nat表 : Nat表主要用于网络地址转换。根据表中的每一条规则修改网络包的IP地址。流中的包仅遍历一遍Nat表。例如,如果一个通过某个接口的包被修饰(修改了IP地址),该流中其余的包将不再遍历这个表。通常不建议在这个表中进行过滤,由NAT表支持的链称为PREROUTING 链,POSTROUTING 链和OUTPUT 链。
|
||||
|
||||
Mangle表 : 正如它的名字一样,这个表用于校正网络包。它用来对特殊的包进行修改。它能够修改不同包的头部和内容。Mangle表不能用于地址伪装。支持的链包括PREROUTING 链,OUTPUT 链,Forward 链,Input 链和POSTROUTING 链。
|
||||
|
||||
Filter表 : Filter表是iptables中使用的默认表,它用来过滤网络包。如果没有定义任何规则,Filter表则被当作默认的表,并且基于它来过滤。支持的链有INPUT 链,OUTPUT 链,FORWARD 链。
|
||||
|
||||
Raw表 : Raw表在我们想要配置之前被豁免的包时被使用。它支持PREROUTING 链和OUTPUT 链。
|
||||
|
||||
### 6. 简要谈谈什么是iptables中的目标值(能被指定为目标),他们有什么用 ###
|
||||
|
||||
**答案** : 下面是在iptables中可以指定为目标的值:
|
||||
|
||||
- ACCEPT : 接受包
|
||||
- QUEUE : 将包传递到用户空间 (应用程序和驱动所在的地方)
|
||||
- DROP : 丢弃包
|
||||
- RETURN : 将控制权交回调用的链并且为当前链中的包停止执行下一调用规则
|
||||
|
||||
### 7. 让我们来谈谈iptables技术方面的东西,我的意思是说实际使用方面 ###
|
||||
|
||||
你怎么检测在CentOS中安装iptables时需要的iptables的rpm?
|
||||
|
||||
**答案** : iptables已经被默认安装在CentOS中,我们不需要单独安装它。但可以这样检测rpm:
|
||||
|
||||
# rpm -qa iptables
|
||||
|
||||
iptables-1.4.21-13.el7.x86_64
|
||||
|
||||
如果您需要安装它,您可以用yum来安装。
|
||||
|
||||
# yum install iptables-services
|
||||
|
||||
### 8. 怎样检测并且确保iptables服务正在运行? ###
|
||||
|
||||
**答案** : 您可以在终端中运行下面的命令来检测iptables的状态。
|
||||
|
||||
# service status iptables [On CentOS 6/5]
|
||||
# systemctl status iptables [On CentOS 7]
|
||||
|
||||
如果iptables没有在运行,可以使用下面的语句
|
||||
|
||||
---------------- 在CentOS 6/5下 ----------------
|
||||
# chkconfig --level 35 iptables on
|
||||
# service iptables start
|
||||
|
||||
---------------- 在CentOS 7下 ----------------
|
||||
# systemctl enable iptables
|
||||
# systemctl start iptables
|
||||
|
||||
我们还可以检测iptables的模块是否被加载:
|
||||
|
||||
# lsmod | grep ip_tables
|
||||
|
||||
### 9. 你怎么检查iptables中当前定义的规则呢? ###
|
||||
|
||||
**答案** : 当前的规则可以简单的用下面的命令查看:
|
||||
|
||||
# iptables -L
|
||||
|
||||
示例输出
|
||||
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
ACCEPT icmp -- anywhere anywhere
|
||||
ACCEPT all -- anywhere anywhere
|
||||
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
### 10. 你怎样刷新所有的iptables规则或者特定的链呢? ###
|
||||
|
||||
**答案** : 您可以使用下面的命令来刷新一个特定的链。
|
||||
|
||||
# iptables --flush OUTPUT
|
||||
|
||||
要刷新所有的规则,可以用:
|
||||
|
||||
# iptables --flush
|
||||
|
||||
### 11. 请在iptables中添加一条规则,接受所有从一个信任的IP地址(例如,192.168.0.7)过来的包。 ###
|
||||
|
||||
**答案** : 上面的场景可以通过运行下面的命令来完成。
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
|
||||
我们还可以在源IP中使用标准的斜线和子网掩码:
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
# iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
### 12. 怎样在iptables中添加规则以ACCEPT,REJECT,DENY和DROP ssh的服务? ###
|
||||
|
||||
**答案** : 但愿ssh运行在22端口,那也是ssh的默认端口,我们可以在iptables中添加规则来ACCEPT ssh的tcp包(在22号端口上)。
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
REJECT ssh服务(22号端口)的tcp包。
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j REJECT
|
||||
|
||||
DENY ssh服务(22号端口)的tcp包。
|
||||
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j DENY
|
||||
|
||||
DROP ssh服务(22号端口)的tcp包。
|
||||
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j DROP
|
||||
|
||||
### 13. 让我给你另一个场景,假如有一台电脑的本地IP地址是192.168.0.6。你需要封锁在21、22、23和80号端口上的连接,你会怎么做? ###
|
||||
|
||||
**答案** : 这时,我所需要的就是在iptables中使用‘multiport‘选项,并将要封锁的端口号跟在它后面。上面的场景可以用下面的一条语句搞定:
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
||||
|
||||
可以用下面的语句查看写入的规则。
|
||||
|
||||
# iptables -L
|
||||
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
ACCEPT icmp -- anywhere anywhere
|
||||
ACCEPT all -- anywhere anywhere
|
||||
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
**面试官** : 好了,我问的就是这些。你是一个很有价值的雇员,我们不会错过你的。我将会向HR推荐你的名字。如果你有什么问题,请问我。
|
||||
|
||||
作为一个候选人我不愿不断的问将来要做的项目的事以及公司里其他的事,这样会打断愉快的对话。更不用说HR轮会不会比较难,总之,我获得了机会。
|
||||
|
||||
同时我要感谢Avishek和Ravi(我的朋友)花时间帮我整理我的面试。
|
||||
|
||||
朋友!如果您有过类似的面试,并且愿意与数百万Tecmint读者一起分享您的面试经历,请将您的问题和答案发送到admin@tecmint.com。
|
||||
|
||||
谢谢!保持联系。如果我能更好的回答我上面的问题的话,请记得告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
@ -0,0 +1,126 @@
|
||||
如何使用Docker Machine部署Swarm集群
|
||||
================================================================================
|
||||
|
||||
大家好,今天我们来研究一下如何使用Docker Machine部署Swarm集群。Docker Machine提供了标准的Docker API 支持,所以任何可以与Docker守护进程进行交互的工具都可以使用Swarm来(透明地)扩增到多台主机上。Docker Machine可以用来在个人电脑、云端以及的数据中心里创建Docker主机。它为创建服务器,安装Docker以及根据用户设定来配置Docker客户端提供了便捷化的解决方案。我们可以使用任何驱动来部署swarm集群,并且swarm集群将由于使用了TLS加密具有极好的安全性。
|
||||
|
||||
下面是我提供的简便方法。
|
||||
|
||||
### 1. 安装Docker Machine ###
|
||||
|
||||
Docker Machine 在各种Linux系统上都支持的很好。首先,我们需要从Github上下载最新版本的Docker Machine。我们使用curl命令来下载最先版本Docker Machine ie 0.2.0。
|
||||
|
||||
64位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
32位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
下载了最先版本的Docker Machine之后,我们需要对 /usr/local/bin/ 目录下的docker-machine文件的权限进行修改。命令如下:
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
在做完上面的事情以后,我们要确保docker-machine已经安装正确。怎么检查呢?运行`docker-machine -v`指令,该指令将会给出我们系统上所安装的docker-machine版本。
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
为了让Docker命令能够在我们的机器上运行,必须还要在机器上安装Docker客户端。命令如下。
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建Machine ###
|
||||
|
||||
在将Docker Machine安装到我们的设备上之后,我们需要使用Docker Machine创建一个machine。在这篇文章中,我们会将其部署在Digital Ocean Platform上。所以我们将使用“digitalocean”作为它的Driver API,然后将docker swarm运行在其中。这个Droplet会被设置为Swarm主控节点,我们还要创建另外一个Droplet,并将其设定为Swarm节点代理。
|
||||
|
||||
创建machine的命令如下:
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**备注**: 假设我们要创建一个名为“linux-dev”的machine。<API-Token>是用户在Digital Ocean Cloud Platform的Digital Ocean控制面板中生成的密钥。为了获取这个密钥,我们需要登录我们的Digital Ocean控制面板,然后点击API选项,之后点击Generate New Token,起个名字,然后在Read和Write两个选项上打钩。之后我们将得到一个很长的十六进制密钥,这个就是<API-Token>了。用其替换上面那条命令中的API-Token字段。
|
||||
|
||||
现在,运行下面的指令,将Machine 的配置变量加载进shell里。
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||

|
||||
|
||||
然后,我们使用如下命令将我们的machine标记为ACTIVE状态。
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
现在,我们检查它(指machine)是否被标记为了 ACTIVE "*"。
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
### 3. 运行Swarm Docker镜像 ###
|
||||
|
||||
现在,在我们创建完成了machine之后。我们需要将swarm docker镜像部署上去。这个machine将会运行这个docker镜像,并且控制Swarm主控节点和从节点。使用下面的指令运行镜像:
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
如果你想要在**32位操作系统**上运行swarm docker镜像。你需要SSH登录到Droplet当中。
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. 创建Swarm主控节点 ###
|
||||
|
||||
在我们的swarm image已经运行在machine当中之后,我们将要创建一个Swarm主控节点。使用下面的语句,添加一个主控节点。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-master \
|
||||
--swarm-discovery token://<CLUSTER-ID> \
|
||||
swarm-master
|
||||
|
||||

|
||||
|
||||
### 5. 创建Swarm从节点 ###
|
||||
|
||||
现在,我们将要创建一个swarm从节点,此节点将与Swarm主控节点相连接。下面的指令将创建一个新的名为swarm-node的droplet,其与Swarm主控节点相连。到此,我们就拥有了一个两节点的swarm集群了。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-discovery token://<TOKEN-FROM-ABOVE> \
|
||||
swarm-node
|
||||
|
||||

|
||||
|
||||
### 6. 与Swarm主控节点连接 ###
|
||||
|
||||
现在,我们连接Swarm主控节点以便我们可以依照需求和配置文件在节点间部署Docker容器。运行下列命令将Swarm主控节点的Machine配置文件加载到环境当中。
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
然后,我们就可以跨节点地运行我们所需的容器了。在这里,我们还要检查一下是否一切正常。所以,运行**docker info**命令来检查Swarm集群的信息。
|
||||
|
||||
# docker info
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们可以用Docker Machine轻而易举地创建Swarm集群。这种方法有非常高的效率,因为它极大地减少了系统管理员和用户的时间消耗。在这篇文章中,我们以Digital Ocean作为驱动,通过创建一个主控节点和一个从节点成功地部署了集群。其他类似的驱动还有VirtualBox,Google Cloud Computing,Amazon Web Service,Microsoft Azure等等。这些连接都是通过TLS进行加密的,具有很高的安全性。如果你有任何的疑问,建议,反馈,欢迎在下面的评论框中注明以便我们可以更好地提高文章的质量!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,223 @@
|
||||
Autojump:一个可以在 Linux 文件系统快速导航的高级 cd 命令
|
||||
================================================================================
|
||||
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行导航有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
现在,有一个用 Python 写的名为 `autojump` 的 Linux 命令行实用程序,它是 Linux ‘[cd][1]’命令的高级版本。
|
||||
|
||||

|
||||
|
||||
*Autojump – Linux 文件系统导航的最快方式*
|
||||
|
||||
这个应用原本由 Joël Schaerer 编写,现在由 +William Ting 维护。
|
||||
|
||||
Autojump 应用可以从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录导航。与传统的 `cd` 命令相比,autojump 能够更加快速地导航至目的目录。
|
||||
|
||||
#### autojump 的特色 ####
|
||||
|
||||
- 自由开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的导航习惯中学习。
|
||||
- 更快速地导航。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat 和 Fedora。
|
||||
- 也能在其他平台中使用,例如 OS X(使用 Homebrew) 和 Windows (通过 Clink 来实现)
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以用文件管理器打开某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
|
||||
#### 前提 ####
|
||||
|
||||
- 版本号不低于 2.6 的 Python
|
||||
|
||||
### 第 1 步: 做一次完整的系统升级 ###
|
||||
|
||||
1、 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [基于 APT 的系统]
|
||||
# yum update && yum upgrade [基于 YUM 的系统]
|
||||
# dnf update && dnf upgrade [基于 DNF 的系统]
|
||||
|
||||
**注** : 这里特别提醒,在基于 YUM 或 DNF 的系统中,更新和升级执行相同的行动,大多数时间里它们是通用的,这点与基于 APT 的系统不同。
|
||||
|
||||
### 第 2 步: 下载和安装 Autojump ###
|
||||
|
||||
2、 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
|
||||
#### 从源代码安装 ####
|
||||
|
||||
若没有安装 git,请安装它。我们需要使用它来克隆 git 仓库。
|
||||
|
||||
# apt-get install git [基于 APT 的系统]
|
||||
# yum install git [基于 YUM 的系统]
|
||||
# dnf install git [基于 DNF 的系统]
|
||||
|
||||
一旦安装完 git,以普通用户身份登录,然后像下面那样来克隆 autojump:
|
||||
|
||||
$ git clone git://github.com/joelthelion/autojump.git
|
||||
|
||||
接着,使用 `cd` 命令切换到下载目录。
|
||||
|
||||
$ cd autojump
|
||||
|
||||
下载,赋予安装脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
|
||||
# chmod 755 install.py
|
||||
# ./install.py
|
||||
|
||||
#### 从软件仓库中安装 ####
|
||||
|
||||
3、 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
|
||||
在 Debian, Ubuntu, Mint 及类似系统中安装 autojump :
|
||||
|
||||
# apt-get install autojump
|
||||
|
||||
为了在 Fedora, CentOS, RedHat 及类似系统中安装 autojump, 你需要启用 [EPEL 软件仓库][2]。
|
||||
|
||||
# yum install epel-release
|
||||
# yum install autojump
|
||||
或
|
||||
# dnf install autojump
|
||||
|
||||
### 第 3 步: 安装后的配置 ###
|
||||
|
||||
4、 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
|
||||
为了暂时激活 autojump 应用,即直到你关闭当前会话或打开一个新的会话之前让 autojump 均有效,你需要以常规用户身份运行下面的命令:
|
||||
|
||||
$ source /usr/share/autojump/autojump.sh on startup
|
||||
|
||||
为了使得 autojump 在 BASH shell 中永久有效,你需要运行下面的命令。
|
||||
|
||||
$ echo '. /usr/share/autojump/autojump.sh' >> ~/.bashrc
|
||||
|
||||
### 第 4 步: Autojump 的预测试和使用 ###
|
||||
|
||||
5、 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
|
||||
$ cd
|
||||
$ cd
|
||||
$ cd Desktop/
|
||||
$ cd
|
||||
$ cd Documents/
|
||||
$ cd
|
||||
$ cd Downloads/
|
||||
$ cd
|
||||
$ cd Music/
|
||||
$ cd
|
||||
$ cd Pictures/
|
||||
$ cd
|
||||
$ cd Public/
|
||||
$ cd
|
||||
$ cd Templates
|
||||
$ cd
|
||||
$ cd /var/www/
|
||||
$ cd
|
||||
$ mkdir autojump-test/
|
||||
$ cd
|
||||
$ mkdir autojump-test/a/ && cd autojump-test/a/
|
||||
$ cd
|
||||
$ mkdir autojump-test/b/ && cd autojump-test/b/
|
||||
$ cd
|
||||
$ mkdir autojump-test/c/ && cd autojump-test/c/
|
||||
$ cd
|
||||
|
||||
现在,我们已经切换到过上面所列的目录,并为了测试创建了一些目录,一切准备就绪,让我们开始吧。
|
||||
|
||||
**需要记住的一点** : `j` 是 autojump 的一个封装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
|
||||
6、 使用 -v 选项查看安装的 autojump 的版本。
|
||||
|
||||
$ j -v
|
||||
或
|
||||
$ autojump -v
|
||||
|
||||

|
||||
|
||||
*查看 Autojump 的版本*
|
||||
|
||||
7、 跳到先前到过的目录 ‘/var/www‘。
|
||||
|
||||
$ j www
|
||||
|
||||
|
||||
|
||||
*跳到目录*
|
||||
|
||||
8、 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
|
||||
$ jc b
|
||||
|
||||

|
||||
|
||||
*跳到子目录*
|
||||
|
||||
9、 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
|
||||
$ jo www
|
||||
|
||||
|
||||
|
||||
*打开目录*
|
||||
|
||||

|
||||
|
||||
*在文件管理器中打开目录*
|
||||
|
||||
你也可以在一个文件管理器中打开一个子目录。
|
||||
|
||||
$ jco c
|
||||
|
||||

|
||||
|
||||
*打开子目录*
|
||||
|
||||

|
||||
|
||||
*在文件管理器中打开子目录*
|
||||
|
||||
10、 查看每个文件夹的权重和全部文件夹计算得出的总权重的统计数据。文件夹的权重代表在这个文件夹中所花的总时间。 文件夹权重是该列表中目录的数字。(LCTT 译注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
|
||||
$ j --stat
|
||||
|
||||

|
||||
|
||||
*查看文件夹统计数据*
|
||||
|
||||
**提醒** : autojump 存储其运行日志和错误日志的地方是文件夹 `~/.local/share/autojump/`。千万不要重写这些文件,否则你将失去你所有的统计状态结果。
|
||||
|
||||
$ ls -l ~/.local/share/autojump/
|
||||
|
||||
|
||||
|
||||
*Autojump 的日志*
|
||||
|
||||
11、 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
|
||||
$ j --help
|
||||
|
||||

|
||||
|
||||
*Autojump 的帮助和选项*
|
||||
|
||||
### 功能需求和已知的冲突 ###
|
||||
|
||||
- autojump 只能让你跳到那些你已经用 `cd` 到过的目录。一旦你用 `cd` 切换到一个特定的目录,这个行为就会被记录到 autojump 的数据库中,这样 autojump 才能工作。不管怎样,在你设定了 autojump 后,你不能跳到那些你没有用 `cd` 到过的目录。
|
||||
- 你不能跳到名称以破折号 (-) 开头的目录。或许你可以考虑阅读我的有关[操作文件或目录][3] 的文章,尤其是有关操作那些以‘-‘ 或其他特殊字符开头的文件和目录的内容。
|
||||
- 在 BASH shell 中,autojump 通过修改 `$PROMPT_COMMAND` 环境变量来跟踪目录的行为,所以强烈建议不要去重写 `$PROMPT_COMMAND` 这个环境变量。若你需要添加其他的命令到现存的 `$PROMPT_COMMAND` 环境变量中,请添加到`$PROMPT_COMMAND` 环境变量的最后。
|
||||
|
||||
### 结论: ###
|
||||
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中导航 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
[3]:http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
@ -0,0 +1,207 @@
|
||||
Syncthing: 一个在计算机之间同步文件/文件夹的私密安全同步工具
|
||||
================================================================================
|
||||
### 简介 ###
|
||||
|
||||
**Syncthing**是一个免费开源的工具,它能在你的各个网络计算机间同步文件/文件夹。它不像其它的同步工具,如**BitTorrent Sync**和**Dropbox**那样,它的同步数据是直接从一个系统中直接传输到另一个系统的,并且它是完全开源的,安全且私密的。你所有的珍贵数据都会被存储在你的系统中,这样你就能对你的文件和文件夹拥有全面的控制权,没有任何的文件或文件夹会被存储在第三方系统中。此外,你有权决定这些数据该存于何处,是否要分享到第三方,或这些数据在互联网上的传输方式。
|
||||
|
||||
所有的信息通讯都使用TLS进行加密,这样你的数据便能十分安全地逃离窥探。Syncthing有一个强大的响应式的网页管理界面(WebGUI,下同),它能够帮助用户简便地添加、删除和管理那些通过网络进行同步的文件夹。通过使用Syncthing,你可以在多个系统上一次同步多个文件夹。在安装和使用上,Syncthing是一个可移植的、简单而强大的工具。即然文件或文件夹是从一部计算机中直接传输到另一计算机中的,那么你就无需考虑向云服务供应商支付金钱来获取额外的云空间。你所需要的仅仅是非常稳定的LAN/WAN连接以及在你的系统中有足够的硬盘空间。它支持所有的现代操作系统,包括GNU/Linux, Windows, Mac OS X, 当然还有Android。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
基于本文的目的,我们将使用两个系统,一个是Ubuntu 14.04 LTS, 一个是Ubuntu 14.10 server。为了简单辨别这两个系统,我们将分别称其为**系统1**和**系统2**。
|
||||
|
||||
### 系统1细节: ###
|
||||
|
||||
- **操作系统**: Ubuntu 14.04 LTS server;
|
||||
- **主机名**: **server1**.unixmen.local;
|
||||
- **IP地址**: 192.168.1.150.
|
||||
- **系统用户**: sk (你可以使用你自己的系统用户)
|
||||
- **同步文件夹**: /home/Sync/ (Syncthing会默认创建)
|
||||
|
||||
### 系统2细节 ###
|
||||
|
||||
- **操作系统**: Ubuntu 14.10 server;
|
||||
- **主机名**: **server**.unixmen.local;
|
||||
- **IP地址**: 192.168.1.151.
|
||||
- **系统用户**: sk (你可以使用你自己的系统用户)
|
||||
- **同步文件夹**: /home/Sync/ (Syncthing会默认创建)
|
||||
|
||||
### 在系统1和系统2上为Syncthing创建用户 ###
|
||||
|
||||
在两个系统上运行下面的命令来为Syncthing创建用户以及两系统间的同步文件夹。
|
||||
|
||||
sudo useradd sk
|
||||
sudo passwd sk
|
||||
|
||||
### 为系统1和系统2安装Syncthing ###
|
||||
|
||||
在系统1和系统2上遵循以下步骤进行操作。
|
||||
|
||||
从[官方下载页][1]上下载最新版本。我使用的是64位版本,因此下载64位版的软件包。
|
||||
|
||||
wget https://github.com/syncthing/syncthing/releases/download/v0.10.20/syncthing-linux-amd64-v0.10.20.tar.gz
|
||||
|
||||
解压缩下载的文件:
|
||||
|
||||
tar xzvf syncthing-linux-amd64-v0.10.20.tar.gz
|
||||
|
||||
切换到解压缩出来的文件夹:
|
||||
|
||||
cd syncthing-linux-amd64-v0.10.20/
|
||||
|
||||
复制可执行文件"syncthing"到**$PATH**:
|
||||
|
||||
sudo cp syncthing /usr/local/bin/
|
||||
|
||||
现在,执行下列命令来首次运行Syncthing:
|
||||
|
||||
syncthing
|
||||
|
||||
当你执行上述命令后,syncthing会生成一个配置以及一些配置键值,并且在你的浏览器上打开一个管理界面。
|
||||
|
||||
输入示例:
|
||||
|
||||
[monitor] 15:40:27 INFO: Starting syncthing
|
||||
15:40:27 INFO: Generating RSA key and certificate for syncthing...
|
||||
[BQXVO] 15:40:34 INFO: syncthing v0.10.20 (go1.4 linux-386 default) unknown-user@syncthing-builder 2015-01-13 16:27:47 UTC
|
||||
[BQXVO] 15:40:34 INFO: My ID: BQXVO3D-VEBIDRE-MVMMGJI-ECD2PC3-T5LT3JB-OK4Z45E-MPIDWHI-IRW3NAZ
|
||||
[BQXVO] 15:40:34 INFO: No config file; starting with empty defaults
|
||||
[BQXVO] 15:40:34 INFO: Edit /home/sk/.config/syncthing/config.xml to taste or use the GUI
|
||||
[BQXVO] 15:40:34 INFO: Starting web GUI on http://127.0.0.1:8080/
|
||||
[BQXVO] 15:40:34 INFO: Loading HTTPS certificate: open /home/sk/.config/syncthing/https-cert.pem: no such file or directory
|
||||
[BQXVO] 15:40:34 INFO: Creating new HTTPS certificate
|
||||
[BQXVO] 15:40:34 INFO: Generating RSA key and certificate for server1...
|
||||
[BQXVO] 15:41:01 INFO: Starting UPnP discovery...
|
||||
[BQXVO] 15:41:07 INFO: Starting local discovery announcements
|
||||
[BQXVO] 15:41:07 INFO: Starting global discovery announcements
|
||||
[BQXVO] 15:41:07 OK: Ready to synchronize default (read-write)
|
||||
[BQXVO] 15:41:07 INFO: Device BQXVO3D-VEBIDRE-MVMMGJI-ECD2PC3-T5LT3JB-OK4Z45E-MPIDWHI-IRW3NAZ is "server1" at [dynamic]
|
||||
[BQXVO] 15:41:07 INFO: Completed initial scan (rw) of folder default
|
||||
|
||||
Syncthing已经被成功地初始化了,网页管理接口也可以通过浏览器访问URL: **http://localhost:8080**。如上面输入所看到的,Syncthing在你的**home**目录中的Sync目录**下自动为你创建了一个名为**default**的文件夹。
|
||||
|
||||
默认情况下,Syncthing的网页管理界面只能在本地端口(localhost)中进行访问,要从远程进行访问,你需要在两个系统中进行以下操作:
|
||||
|
||||
首先,按下CTRL+C键来终止Syncthing初始化进程。现在你回到了终端界面。
|
||||
|
||||
编辑**config.xml**文件,
|
||||
|
||||
sudo nano ~/.config/syncthing/config.xml
|
||||
|
||||
找到下面的指令:
|
||||
|
||||
[...]
|
||||
<gui enabled="true" tls="false">
|
||||
<address>127.0.0.1:8080</address>
|
||||
<apikey>-Su9v0lW80JWybGjK9vNK00YDraxXHGP</apikey>
|
||||
</gui>
|
||||
[...]
|
||||
|
||||
在**<address>**区域中,把**127.0.0.1:8080**改为**0.0.0.0:8080**。结果,你的config.xml看起来会是这样的:
|
||||
|
||||
<gui enabled="true" tls="false">
|
||||
<address>0.0.0.0:8080</address>
|
||||
<apikey>-Su9v0lW80JWybGjK9vNK00YDraxXHGP</apikey>
|
||||
</gui>
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
在两个系统上再次执行下述命令:
|
||||
|
||||
syncthing
|
||||
|
||||
### 访问网页管理界面 ###
|
||||
|
||||
现在,在你的浏览器上打开**http://ip-address:8080/**。你会看到下面的界面:
|
||||
|
||||

|
||||
|
||||
网页管理界面分为两个窗格,在左窗格中,你应该可以看到同步的文件夹列表。如前所述,文件夹**default**在你初始化Syncthing时被自动创建。如果你想同步更多文件夹,点击**Add Folder**按钮。
|
||||
|
||||
在右窗格中,你可以看到已连接的设备数。现在这里只有一个,就是你现在正在操作的计算机。
|
||||
|
||||
### 网页管理界面上设置Syncthing ###
|
||||
|
||||
为了提高安全性,让我们启用TLS,并且设置访问网页管理界面的管理员用户和密码。要做到这点,点击右上角的齿轮按钮,然后选择**Settings**
|
||||
|
||||

|
||||
|
||||
输入管理员的帐户名/密码。我设置的是admin/Ubuntu。你应该使用一些更复杂的密码。
|
||||
|
||||

|
||||
|
||||
点击Save按钮,现在,你会被要求重启Syncthing使更改生效。点击Restart。
|
||||
|
||||

|
||||
|
||||
刷新你的网页浏览器。你可以看到一个像下面一样的SSL警告。点击显示**我了解风险(I understand the Risks)**的按钮。接着,点击“添加例外(Add Exception)“按钮把当前页面添加进浏览器的信任列表中。
|
||||
|
||||

|
||||
|
||||
输入前面几步设置的管理员用户和密码。我设置的是**admin/ubuntu**。
|
||||
|
||||

|
||||
|
||||
现在,我们提高了网页管理界面的安全性。别忘了两个系统都要执行上面同样的步骤。
|
||||
|
||||
### 连接到其它服务器 ###
|
||||
|
||||
要在各个系统之间同步文件,你必须各自告诉它们其它服务器的信息。这是通过交换设备IDs(device IDs)来实现的。你可以通过选择“齿轮菜单(gear menu)”(在右上角)中的”Show ID(显示ID)“来找到它。
|
||||
|
||||
例如,下面是我系统1的ID.
|
||||
|
||||

|
||||
|
||||
复制这个ID,然后到另外一个系统(系统2)的网页管理界面,在右边窗格点击Add Device按钮。
|
||||
|
||||

|
||||
|
||||
接着会出现下面的界面。在Device区域粘贴**系统1 ID **。输入设备名称(可选)。在地址区域,你可以输入其它系统( LCTT 译注:即粘贴的ID所属的系统,此应为系统1)的IP地址,或者使用默认值。默认值为**dynamic**。最后,选择要同步的文件夹。在我们的例子中,同步文件夹为**default**。
|
||||
|
||||

|
||||
|
||||
一旦完成了,点击save按钮。你会被要求重启Syncthing。点击Restart按钮重启使更改生效。
|
||||
|
||||
现在,我们到**系统1**的网页管理界面,你会看到来自系统2的连接和同步请求。点击**Add**按钮。现在,系统2会要求系统1分享和同步名为default的文件夹。
|
||||
|
||||

|
||||
|
||||
接着重启系统1的Syncthing服务使更改生效。
|
||||
|
||||

|
||||
|
||||
等待大概60秒,接着你会看到两个系统之间已成功连接并同步。
|
||||
|
||||
你可以在网页管理界面中的Add Device区域核实该情况。
|
||||
|
||||
添加系统2后,系统1网页管理界面中的控制窗口如下:
|
||||
|
||||

|
||||
|
||||
添加系统1后,系统2网页管理界面中的控制窗口如下:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
现在,在任一个系统中的“**default**”文件夹中放进任意文件或文件夹。你应该可以看到这些文件/文件夹被自动同步到其它系统。
|
||||
|
||||
本文完!祝同步愉快!
|
||||
|
||||
噢耶!!!
|
||||
|
||||
- [Syncthing网站][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/syncthing-private-secure-tool-sync-filesfolders-computers/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://github.com/syncthing/syncthing/releases/tag/v0.10.20
|
||||
[2]:http://syncthing.net/
|
||||
@ -1,43 +1,44 @@
|
||||
用于提高网站安全性和自定义网站的 25 个有用 Apache ‘.htaccess’ 小技巧
|
||||
25 个有用 Apache ‘.htaccess’ 技巧
|
||||
================================================================================
|
||||
网站是我们生活中重要的一部分。它们是实现扩大业务、分享知识以及其它更多功能的方式。之前受制于只能提供静态内容,随着动态客户端和服务器端脚本语言的引入和现有静态语言的持续改进,例如从 html 到 html5,动态网站成为可能,剩下的也许在不久的将来也会实现。
|
||||
网站是我们生活中重要的一部分。它们是实现扩大业务、分享知识以及其它更多功能的方式。早期受制于只能提供静态内容,随着动态客户端和服务器端脚本语言的引入和现有静态语言的持续改进,例如从 html 到 html5,动态网站成为可能,剩下的也许在不久的将来也会实现。
|
||||
|
||||
有了网站,随之而来的是对能向全球大规模用户显示站点的单元的需求。这个需求通过托管网站的服务器实现。这包括一系列的服务器,例如:Apache HTTP Server、Joomla 以及 允许个人拥有自己网站的 WordPress。
|
||||
对于网站,随之而来的是需要一个能向全球大规模用户显示站点的某个东西。这个需求可以通过托管网站的服务器实现。这包括一系列的服务器,例如:Apache HTTP Server、Joomla 以及 允许个人拥有自己网站的 WordPress。
|
||||
|
||||

|
||||
25 个 htaccess 小技巧
|
||||
|
||||
*25 个 htaccess 小技巧*
|
||||
|
||||
想要拥有一个网站,可以创建一个自己的本地服务器,或者联系任何上面提到的或其它服务器管理员来托管他的网站。但实际问题也从这点开始。网站的性能主要取决于以下因素:
|
||||
|
||||
- 网站消耗的带宽。
|
||||
- 针对黑客网站有多安全。
|
||||
- 面对黑客,网站有多安全。
|
||||
- 对数据库进行数据检索时的优化。
|
||||
- 显示导航菜单和提供更多 UI 功能时的用户友好性。
|
||||
|
||||
除此之外,保证托管网站服务器成功的多种因素还包括:
|
||||
|
||||
- 对于一个流行站点的数据压缩量。
|
||||
- 同时为多个请求同一或不同站点的用户服务的能力。
|
||||
- 同时为多个对请求同一或不同站点的用户服务的能力。
|
||||
- 保证网站上输入的机密数据安全,例如:Email、信用卡信息等等。
|
||||
- 允许更多的选项用于增强站点的动态性。
|
||||
|
||||
这篇文章讨论一个服务器提供的用于增强网站性能和提高针对坏机器人、热链接等的安全性的功能。例如 ‘.htaccess’ 文件。
|
||||
这篇文章讨论一个服务器提供的用于增强网站性能和提高针对坏机器人、热链等的安全性的功能:‘.htaccess’ 文件。
|
||||
|
||||
### .htaccess 是什么? ###
|
||||
|
||||
htaccess (hypertext access,超文本访问) 是为网站所有者提供用于控制服务器环境变量以及其它参数的选项,从而增强他们网站的功能的文件。这些文件可以在网站目录树的任何一个目录中,并向该目录以及目录中的文件和子目录提供功能。
|
||||
|
||||
这些功能是什么呢?其实这些是服务器的指令,例如命令服务器执行特定任务的行,这些命令只对该文件所在目录中的文件和子目录有效。这些文件默认是隐藏的,因为所有操作系统和网站服务器默认配置为忽略。但让隐藏文件可见可以让你看到这些特殊文件。后续章节的话题将讨论能控制什么类型的参数。
|
||||
这些功能是什么呢?其实这些是服务器的指令,例如命令服务器执行特定任务的行,这些命令只对该文件所在目录中的文件和子目录有效。这些文件默认是隐藏的,因为所有操作系统和网站服务器默认配置为忽略它们,但如果查看隐藏文件的话,你就可以看到这些特殊文件。后续章节的话题将讨论能控制什么类型的参数。
|
||||
|
||||
注意:如果 .htaccess 文件保存在 /apache/home/www/Gunjit/ 目录,那么它会向该目录中的所有文件和子目录提供命令,但如果该目录包含一个名为 /Gunjit/images/ 子目录,且该子目录中也有一个 .htaccess 文件,那么这个子目录中的命令会覆盖父目录中 .htaccess 文件(或者层次结构中更上层文件)提供的命令。
|
||||
注意:如果 .htaccess 文件保存在 /apache/home/www/Gunjit/ 目录,那么它会向该目录中的所有文件和子目录提供命令,但如果该目录包含一个名为 /Gunjit/images/ 子目录,且该子目录中也有一个 .htaccess 文件,那么这个子目录中的命令会覆盖父目录中 .htaccess 文件(或者目录层次结构中更上层的文件)提供的命令。
|
||||
|
||||
### Apache Server 和 .htaccess 文件 ###
|
||||
|
||||
Apache HTTP Server 俗称为 Apache,是为了表示对一个有卓越战争策略技能的美洲土著部落的尊敬而命名。它是用 C/C++ 和 XML 建立的基于 [NCSA HTTPd 服务器][1] 的跨平台 Web 服务器,它在万维网的成长和发展中起到了关键作用。
|
||||
Apache HTTP Server 俗称为 Apache,是为了表示对一个有卓越战争策略技能的美洲土著部落的尊敬而命名。它基于 [NCSA HTTPd 服务器][1] ,是用 C/C++ 和 XML 建立的跨平台 Web 服务器,它在万维网的成长和发展中起到了关键作用。
|
||||
|
||||
最常用于 UNIX,Apache 也能用于多种平台,包括 FreeBSD、Linux、Windows、Mac OS、Novel Netware 等。在 2009 年,Apache 成为第一个为超过一亿站点提供服务的服务器。
|
||||
它最常用于 UNIX,但 Apache 也能用于多种平台,包括 FreeBSD、Linux、Windows、Mac OS、Novel Netware 等。在 2009 年,Apache 成为第一个为超过一亿站点提供服务的服务器。
|
||||
|
||||
Apache 服务器对于 www/ 目录中的每个用户有一个单独的 .htaccess 文件。尽管这些文件是隐藏的,但如果需要的话可以使它们可见。在 www/ 目录中有很多子目录,每个子目录通过用户名或所有者名称命名,包含了一个站点。除此之外你可以在每个子目录中有一个 .htaccess 文件,像之前所述用于配置子目录中的文件。
|
||||
Apache 服务器可以让 www/ 目录中的每个用户有一个单独的 .htaccess 文件。尽管这些文件是隐藏的,但如果需要的话可以使它们可见。在 www/ 目录中可以有很多子目录,每个子目录通过用户名或所有者名称命名,包含了一个站点。除此之外你可以在每个子目录中有一个 .htaccess 文件,像之前所述用于配置子目录中的文件。
|
||||
|
||||
下面介绍如果配置 Apache 服务器上的 htaccess 文件。
|
||||
|
||||
@ -65,19 +66,19 @@ Apache 服务器对于 www/ 目录中的每个用户有一个单独的 .htaccess
|
||||
|
||||
在这种情况下最好咨询托管管理员,如果他们允许访问 .htaccess 文件的话。
|
||||
|
||||
### 用于站点的 25 个 Apache Web 服务器 ‘.htaccess’ 小技巧 ###
|
||||
### 用于网站的 25 个 Apache Web 服务器 ‘.htaccess’ 小技巧 ###
|
||||
|
||||
#### 1. 如何在 .htaccess 文件中启用 mod_rewrite ####
|
||||
|
||||
mod_rewrite 选项允许你使用重定向并通过重定向到其它 URL 隐藏你真实的 URL。这个选项非常有用,允许你用短的容易记忆的 URL 替换长 URL。
|
||||
mod_rewrite 选项允许你使用重定向并通过重定向到其它 URL 来隐藏你真实的 URL。这个选项非常有用,允许你用短的容易记忆的 URL 替换长 URL。
|
||||
|
||||
要允许 mod_rewrite,只需要在你的 .htaccess 文件的第一行添加如下一行。
|
||||
|
||||
Options +FollowSymLinks
|
||||
|
||||
该选项允许你跟踪符号链接从而在站点中启用 mod_rewrite。后面会介绍用短 URL 替换。
|
||||
该选项允许你跟踪符号链接从而在站点中启用 mod_rewrite。后面会介绍用短 URL 替换。(LCTT 译注:+FollowSymLinks 只是启用 mod_rewrite 的前提之一,还需要在全局和虚拟机中设置 `RewriteEngine on` 才能启用重写模块。)
|
||||
|
||||
#### 2. 如果允许或禁止对站点的访问 ####
|
||||
#### 2. 如何允许或禁止对站点的访问 ####
|
||||
|
||||
通过使用 order、allow 和 deny 关键字,htaccess 文件可以允许或者禁止对站点或目录中子目录或文件的访问。
|
||||
|
||||
@ -109,13 +110,13 @@ mod_rewrite 选项允许你使用重定向并通过重定向到其它 URL 隐藏
|
||||
|
||||
#### 3. 为不同错误码生成 Apache 错误文档 ####
|
||||
|
||||
用一些简单行,我们可以解决当用户/客户端请求一个站点上不可用的网页时服务器产生的错误码的错误文档,例如我们大部分人见过的浏览器中显示的 ‘404 Page not found’。‘.htaccess’ 文件指定了发生这些错误情况时采取何种操作。
|
||||
用简单几行,我们可以解决当用户/客户端请求一个站点上不可用的网页时服务器产生的错误码的错误文档,例如我们大部分人见过的浏览器中显示的 ‘404 Page not found’。‘.htaccess’ 文件指定了发生这些错误情况时采取何种操作。
|
||||
|
||||
要做到这点,需要添加下面的行到 ‘.htaccess’ 文件:
|
||||
|
||||
ErrorDocument <error-code> <path-of-document/string-representing-html-file-content>
|
||||
|
||||
‘ErrorDocument’ 是一个关键字,error-code 可以是 401、403、404、500 或任何有效的表示错误的代码,最后 ‘path-of-document’ 表示本地机器上的路径(如果你使用的是你自己的本地服务器) 或 服务器上的路径(如果你使用任何其它服务器来托管网站)。
|
||||
‘ErrorDocument’ 是一个关键字,error-code 可以是 401、403、404、500 或任何有效的表示错误的代码,最后 ‘path-of-document’ 表示本地机器上的路径(如果你使用的是你自己的本地服务器) 或服务器上的路径(如果你使用任何其它服务器来托管网站)。
|
||||
|
||||
**例子:**
|
||||
|
||||
@ -123,13 +124,13 @@ mod_rewrite 选项允许你使用重定向并通过重定向到其它 URL 隐藏
|
||||
|
||||
上面一行设置客户请求任何无效页面,服务器报告 404 错误时显示 error-docs 目录下的 ‘error-404.html’ 文档。
|
||||
|
||||
ErrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>The page you request is not present. Check the URL you have typed</p></body></html>"
|
||||
ErrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>The page you request is not present. Check the URL you have typed</p></body></html>"
|
||||
|
||||
上面的表示也正确,其中字符串表示一个普通的 html 文件。
|
||||
上面的表示也正确,其中字符串相当于一个普通的 html 文件。
|
||||
|
||||
#### 4. 设置/取消 Apache 服务器环境变量 ####
|
||||
|
||||
在 .htaccess 文件中你可以设置或者取消站点所有者用来更改服务器设置的全局环境变量。要设置或取消环境变量,你需要在你的 .htaccess 文件中添加下面的行。
|
||||
在 .htaccess 文件中你可以设置或者取消站点所有者可以更改的全局环境变量。要设置或取消环境变量,你需要在你的 .htaccess 文件中添加下面的行。
|
||||
|
||||
**设置环境变量**
|
||||
|
||||
@ -141,29 +142,29 @@ ErrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>
|
||||
|
||||
#### 5. 为文件定义不同 MIME 类型 ####
|
||||
|
||||
MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体扩展) 是浏览器运行任何页面默认能识别的类型。你可以在 .htaccess 文件中为你的站点定义 MIME 类型,然后服务器就可以识别你定义的类型的文件并运行。
|
||||
MIME(多用途 Internet 多媒体扩展)是浏览器运行任何页面所默认识别的类型。你可以在 .htaccess 文件中为你的站点定义 MIME 类型,然后服务器就可以识别你定义类型的文件并运行。
|
||||
|
||||
<IfModule mod_mime.c>
|
||||
AddType application/javascript js
|
||||
AddType application/x-font-ttf ttf ttc
|
||||
</IfModule>
|
||||
|
||||
这里,mod_mime.c 是用于控制定义不同 MIME 类型的模块,如果在你的系统中已经安装了这个模块,那么你就可以用该模块去为你站点中不同的扩展定义不同的 MIME 类型,从而服务器可以理解这些文件。
|
||||
这里,mod_mime.c 是用于控制定义不同 MIME 类型的模块,如果在你的系统中已经安装了这个模块,那么你就可以用该模块去为你站点中不同的扩展名定义不同的 MIME 类型,从而让服务器可以理解这些文件。
|
||||
|
||||
#### 6. 如何在 Apache 中限制上传和下载的大小 ####
|
||||
|
||||
.htaccess 文件允许你拥有控制一个特定用户从你的站点上传或下载数据量大小的功能。要做到这点你只需要添加下面的行到你的 .htaccess 文件:
|
||||
.htaccess 文件允许你能够控制某个用户从你的站点(通过 PHP)单次上传数据量的大小(LCTT 译注:原文有误,修改)。要做到这点你只需要添加下面的行到你的 .htaccess 文件:
|
||||
|
||||
php_value upload_max_filesize 20M
|
||||
php_value post_max_size 20M
|
||||
php_value max_execution_time 200
|
||||
php_value max_input_time 200
|
||||
|
||||
上面的行设置最大上传大小、最大推送数据大小、最大执行时间,例如允许用户在本地机器运行站点的最大时间、限制的最大输入时间。
|
||||
上面的行设置最大上传大小、最大POST 提交数据大小、最长执行时间(例如,允许用户在他的本地机器上单次执行一个请求的最大时间)、限制的最大输入时间。
|
||||
|
||||
#### 7. 让用户在站点上播放 .mp3 和其它文件之前预先下载 ####
|
||||
#### 7. 让用户不能在你的站点上在线播放 .mp3 和其它文件 ####
|
||||
|
||||
大部分情况下,人们在下载检查音乐质量之前会在网站上播放等等。作为一个聪明的销售者,你可以添加一个简单的功能,不允许任何用户在线播放音乐或视频,而是必须下载后才能播放。这非常有用,因为在线播放音乐和视频会消耗很多带宽。
|
||||
大部分情况下,人们在下载检查音乐质量之前会在网站上播放等等。作为一个聪明的销售者,你可以添加一个简单的功能,不允许任何用户在线播放音乐或视频,而是必须下载完成后才能播放。这非常有用,因为(无缓冲的)在线播放音乐和视频会消耗很多带宽。
|
||||
|
||||
要添加下面的行到你的 .htaccess 文件:
|
||||
|
||||
@ -171,23 +172,23 @@ MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体
|
||||
|
||||
#### 8. 为站点设置目录索引 ####
|
||||
|
||||
大部分网站开发者都知道第一个显示的页面,例如一个站点的主页面,被命名为 ‘index.html’。我们大部分也见过这个。但是如何设置呢?
|
||||
大部分网站开发者都知道第一个显示的页面是哪个,例如一个站点的首页,被命名为 ‘index.html’。我们大部分也见过这个。但是如何设置呢?
|
||||
|
||||
.htaccess 文件提供了一种方式用于列出一个客户端请求访问网站的主页面时会顺序扫描的一些网页集,相应地如果找到了列出的页面中的任何一个就会作为站点的主页面并显示给用户。
|
||||
.htaccess 文件提供了一种方式用于列出一个客户端请求访问网站的主页面时会顺序扫描的一些网页集合,相应地如果找到了列出的页面中的任何一个就会作为站点的主页面并显示给用户。
|
||||
|
||||
需要添加下面的行产生所需的效果。
|
||||
|
||||
DirectoryIndex index.html index.php yourpage.php
|
||||
|
||||
上面一行指定如果有任何访问主页面的请求到来,首先会在目录中顺序搜索上面列出的网页:如果发现了 index.html 则显示为主页面,否则会处理下一个页面,例如 index.php,如此直到你在列表中输入的最后一个页面。
|
||||
上面一行指定如果有任何访问首页的请求到来,首先会在目录中顺序搜索上面列出的网页:如果发现了 index.html 则显示为主页面,否则会找下一个页面,例如 index.php,如此直到你在列表中输入的最后一个页面。
|
||||
|
||||
#### 9. 如何为文件启用 GZip 压缩以节省网站带宽 ####
|
||||
|
||||
繁重站点通常比只占少量空间的轻量级站点运行更慢是常见的现象。这是因为对于繁重站点需要时间加载大量的脚本文件和图片用于在客户端的 Web 浏览器上显示。
|
||||
繁忙的站点通常比只占少量空间的轻量级站点运行更慢,这是常见的现象。因为对于繁忙的站点需要时间加载巨大的脚本文件和图片以在客户端的 Web 浏览器上显示。
|
||||
|
||||
当浏览器请求一个 web 页面时,服务器提供给浏览器该页面并局部显示该 web 页面,浏览器需要下载该页面然后在页面内部运行脚本,这是一种常见机制。
|
||||
通常的机制是这样的,当浏览器请求一个 web 页面时,服务器提供给浏览器该页面,并在浏览器端显示该 web 页面,浏览器需要下载该页面并运行页面内的脚本。
|
||||
|
||||
这里 GZip 压缩所做的就是节省单个用户的服务时间从而提高带宽。服务器上站点的源文件以压缩形式保存,当用户请求到来的时候,这些文件以压缩形式传送,然后在服务器上解压并执行。这改进了带宽限制。
|
||||
这里 GZip 压缩所做的就是节省单个用户的服务时间而不用增加带宽。服务器上站点的源文件以压缩形式保存,当用户请求到来的时候,这些文件以压缩形式传送,然后在客户端上解压(LCTT 译注:原文此处有误)。这改善了带宽限制。
|
||||
|
||||
下面的行允许你压缩站点的源文件,但要求在你的服务器上安装 mod_deflate.c 模块。
|
||||
|
||||
@ -202,7 +203,7 @@ MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体
|
||||
|
||||
#### 10. 处理文件类型 ####
|
||||
|
||||
服务器默认的有一些特定情况。例如:在服务器上运行 .php 文件,显示 .txt 文件。像这些我们可以以源代码形式只显示一些可执行 cgi 脚本或文件而不是执行它们。
|
||||
服务器默认的有一些特定情况。例如:在服务器上运行 .php 文件,显示 .txt 文件。像这些我们可以以源代码形式只显示一些可执行 cgi 脚本或文件而不是执行它们(LCTT 译注:这是为了避免攻击者通过上传恶意脚本,进而在服务器上执行恶意脚本进行破坏和窃取)。
|
||||
|
||||
要做到这点在 .htaccess 文件中有如下行。
|
||||
|
||||
@ -213,7 +214,7 @@ MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体
|
||||
|
||||
#### 11. 为 Apache 服务器设置时区 ####
|
||||
|
||||
.htaccess 文件可用于为服务器设置时区可以看出它的能力和重要性。这可以通过设置一个服务器为每个托管站点提供的一系列全局环境变量中的 ‘TZ’ 完成。
|
||||
从 .htaccess 文件可用于为服务器设置时区可以看出它的能力和重要性。这可以通过设置一个服务器为每个托管站点提供的一系列全局环境变量中的 ‘TZ’ 完成。
|
||||
|
||||
由于这个原因,我们可以在网站上看到根据我们的时区显示的时间。也许服务器上其他拥有网站的人会根据他居住地点的位置设置时区。
|
||||
|
||||
@ -223,9 +224,9 @@ MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体
|
||||
|
||||
#### 12. 如果在站点上启用缓存控制 ####
|
||||
|
||||
浏览器很有趣的一个功能是,已经观察到多次同时打开一个网站,和第一次打开相比之后会更快。但为什么会这样呢?事实上,浏览器在它的缓存中保存了一些通常访问的页面用于加快后面的访问。
|
||||
浏览器很有趣的一个功能是,很多时间你可以看到,当多次同时打开一个网站和第一次打开相比前者会更快。但为什么会这样呢?事实上,浏览器在它的缓存中保存了一些通常访问的页面用于加快后面的访问。
|
||||
|
||||
但保存多长时间呢?这取决于你自己。例如,你的 .htaccess 文件中设置的缓存控制时间。.htaccess 文件指定了站点的网页可以在浏览器缓存中保存的时间,时间到期后需要重新验证,例如页面会从缓存中删除然后在下次用户访问站点的时候重建。
|
||||
但保存多长时间呢?这取决于你自己。例如,你的 .htaccess 文件中设置的缓存控制时间。.htaccess 文件指定了站点的网页可以在浏览器缓存中保存的时间,时间到期后需要重新验证缓存,页面可能会从缓存中删除然后在下次用户访问站点的时候重建。
|
||||
|
||||
下面的行为你的站点实现缓存控制。
|
||||
|
||||
@ -243,7 +244,7 @@ MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体
|
||||
|
||||
通常 .htaccess 文件中的内容会对该文件所在目录中的所有文件和子目录起作用,但是你也可以对特殊文件设置一些特殊权限,例如只禁止对某个文件的访问等等。
|
||||
|
||||
要做到这点,你需要在文件中以类似方式添加 <File> 标记:
|
||||
要做到这点,你需要在文件中以类似方式添加 \<Files> 标记:
|
||||
|
||||
<files conf.html="">
|
||||
Order allow, deny
|
||||
@ -256,26 +257,26 @@ MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体
|
||||
|
||||
#### 14. 启用在 cgi-bin 目录以外运行 CGI 脚本 ####
|
||||
|
||||
通常服务器运行的 CGI 脚本都保存在 cgi-bin 目录中,但是你可以启用在你需要的目录运行 CGI 脚本,只需要在所需的目录中添加下面的行到 .htaccess 文件,如果没有改文件就创建一个,并添加下面的行:
|
||||
通常服务器运行的 CGI 脚本都保存在 cgi-bin 目录中,但是你可以在你需要的目录运行 CGI 脚本,只需要在所需的目录中的 .htaccess 文件添加下面的行,如果没有该文件就创建一个,并添加下面的行:
|
||||
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
|
||||
#### 15.如何用 .htaccess 在站点上启用 SSI ####
|
||||
|
||||
服务器端包括顾名思义的和服务器部分相关的东西。但是什么呢?通常当我们在站点上有很多页面的时候,我们在主页面上会有一个显示到其它页面链接的导航菜单,我们可以启用 SSI(Server Size Includes) 选项允许导航菜单中显示的所有页面完全包含在主页面中。
|
||||
服务器端包括(SSI)顾名思义是和服务器部分相关的东西。这是什么呢?通常当我们在站点上有很多页面的时候,我们在主页上会有一个显示到其它页面链接的导航菜单,我们可以启用 SSI 选项允许导航菜单中显示的所有页面完全包含在主页面中。
|
||||
|
||||
SSI 允许包含多个页面,好像他们包含的内容就是一个单一页面的一部分,因此任何需要的编辑都只有一个文件,从而可以节省很多磁盘空间。除了 .shtml 文件,服务器默认启用了该选项。
|
||||
SSI 允许多个页面包含同样的内容,因此只需要编辑一个文件就行,从而可以节省很多磁盘空间。对于 .shtml 文件,服务器默认启用了该选项。
|
||||
|
||||
如果你想要对 .html 启用该选项,你需要添加下面的行:
|
||||
|
||||
AddHandler server-parsed .html
|
||||
|
||||
这之后 html 文件会导向 SSI。
|
||||
这样 html 文件中如下部分会被替换为 SSI。
|
||||
|
||||
<!--#inlcude virtual= “gk/document.html”-->
|
||||
<!--#inlcude virtual="gk/document.html"-->
|
||||
|
||||
#### 16. 如何防止网站目录列表 ####
|
||||
#### 16. 如何防止网站列出目录列表 ####
|
||||
|
||||
为防止任何客户端在本地机器罗列服务器上的网站目录列表,添加下面的行到你不想列出的目录的文件中。
|
||||
|
||||
@ -290,16 +291,28 @@ SSI 允许包含多个页面,好像他们包含的内容就是一个单一页
|
||||
AddDefaultCharset UTF-8
|
||||
DefaultLanguage en-US
|
||||
|
||||
#### 18. 重定向一个非 www URL 到 www URL ####
|
||||
|
||||
在开始解释之前,首先看看如何启用该功能,添加下列行到 .htaccess 文件。
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_HOST} ^abc\.net$
|
||||
RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
|
||||
|
||||
上面的行启用重写引擎,然后在第二行检查所有涉及到主机 abc.net 或 环境变量 HTTP_HOST 为 “abc.net” 的 URL。
|
||||
|
||||
对于所有这样的 URL,代码永久重定向它们(如果启用了 R=301 规则)到新 URL http://www.abc.net/$1,其中 $1 是主机为 abc.net 的非 www URL。非 www URL 是大括号内的内容,并通过 $1 引用。
|
||||
|
||||
**重写 URL 的重定向规则**
|
||||
|
||||
重写功能仅意味着用短而易记的 URL 替换长而难以记忆的 URL。但是,在开始这个话题之前,这里有一些本文后面会使用的特殊字符的规则和约定。
|
||||
重写功能简单的说,就是用短而易记的 URL 替换长而难以记忆的 URL。但是,在开始这个话题之前,这里有一些本文后面会使用的特殊字符的规则和约定。
|
||||
|
||||
**特殊符号:**
|
||||
|
||||
符号 含义
|
||||
^ - 字符串开头
|
||||
$ - 字符串结尾
|
||||
| - 或 [a|b] – a 或 b
|
||||
| - 或 [a|b] : a 或 b
|
||||
[a-z] - a 到 z 的任意字母
|
||||
+ - 之前字母的一次或多次出现
|
||||
* - 之前字母的零次或多次出现
|
||||
@ -309,30 +322,19 @@ SSI 允许包含多个页面,好像他们包含的内容就是一个单一页
|
||||
|
||||
常量 含义
|
||||
NC - 区分大小写
|
||||
L - 最后的规则 – 停止处理更多规则
|
||||
L - 最后的规则 – 停止处理后面规则
|
||||
R - 临时重定向到新 URL
|
||||
R=301 - 永久重定向到新 URL
|
||||
F - 禁止发送 403 头给用户
|
||||
P - 代理 – 获取远程内容代替部分并返回
|
||||
G - Gone, 不再存在
|
||||
P - 代理 - 获取远程内容代替部分并返回
|
||||
G - Gone, 不再存在
|
||||
S=x - 跳过后面的 x 条规则
|
||||
T=mime-type - 强制指定 MIME 类型
|
||||
E=var:value - 设置环境变量 var 的值为 value
|
||||
H=handler - 设置处理器
|
||||
PT - Pass through – 如果 URL 有额外的头
|
||||
QSA - 从到替换 URL 的请求追加查询字符串
|
||||
PT - Pass through - 用于 URL 还有额外的头
|
||||
QSA - 将查询字符串追加到替换 URL
|
||||
|
||||
#### 18. 重定向一个非 www URL 到 www URL ####
|
||||
|
||||
在开始解释之前,首先看看启用该功能需要添加到 .htaccess 文件的行。
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_HOST} ^abc\.net$
|
||||
RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
|
||||
|
||||
上面的行启用 Rewrite Engine 然后在第二行检查所有涉及到主机 abc.net 或 环境变量 HTTP_HOST 为 “abc.net” 的 URL。
|
||||
|
||||
对于所有这样的 URL,代码永久重定向它们(如果启用了 R=301 规则)到新 URL http://www.abc.net/$1,其中 $1 是主机为 abc.net 的非 www URL。非 www URL 是大括号内的内容,并通过 $1 引用。
|
||||
|
||||
#### 19. 重定向整个站点到 https ####
|
||||
|
||||
@ -342,7 +344,7 @@ SSI 允许包含多个页面,好像他们包含的内容就是一个单一页
|
||||
RewriteCond %{HTTPS} !on
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
上面的行启用 re-write engine 然后检查环境变量 HTTPS 的值。如果设置了那么重写所有网站页面到 https。
|
||||
上面的行启用重写引擎,然后检查环境变量 HTTPS 的值。如果设置了那么重写所有网站页面到 https。
|
||||
|
||||
#### 20.一个自定义重写例子 ####
|
||||
|
||||
@ -359,11 +361,11 @@ SSI 允许包含多个页面,好像他们包含的内容就是一个单一页
|
||||
|
||||
AccessFileName htac.cess
|
||||
|
||||
#### 22. 如何为你的网站禁用图片链接 ####
|
||||
#### 22. 如何为你的网站禁用图片盗链 ####
|
||||
|
||||
网站大的带宽消耗的另外一个重要问题是热链接问题,这是其它站点用于显示你网站的图片而链接到你的网站的链接,这会消耗你的带宽。这问题也被成为 ‘带宽盗窃’。
|
||||
网站带宽消耗比较大的另外一个重要问题是盗链问题,这是其它站点用于显示你网站的图片而链接到你的网站的链接,这会消耗你的带宽。这问题也被成为 ‘带宽盗窃’。
|
||||
|
||||
一个常见现象是当一个网站要显示其它网站所包含的图片时,由于该链接你的网站需要被加载,消耗你站点的带宽而显示其它站点的图片。为了防止出现这种情况,例如 .gif、.jpeg 图片等,下面的代码行会有所帮助:
|
||||
一个常见现象是当一个网站要显示其它网站所包含的图片时,由于该链接需要从你的网站加载内容,消耗你站点的带宽而为其它站点显示图片。为了防止出现这种情况,比如对于 .gif、.jpeg 图片等,下面的代码行会有所帮助:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_REFERER} !^$
|
||||
@ -374,20 +376,19 @@ SSI 允许包含多个页面,好像他们包含的内容就是一个单一页
|
||||
|
||||
#### 23. 如何将用户重定向到维护页面 ####
|
||||
|
||||
如果你的网站需要进行维护并且你想向所有需要访问该网站的你的所有客户通知这个消息,对于这种情况,你可以添加下面的行到你的 .htaccess 文件,从而只允许管理员访问并替换所有有 .jpg、.css、.gif、.js 等的页面。
|
||||
如果你的网站需要进行维护并且你想向所有需要访问该网站的你的所有客户通知这个消息,对于这种情况,你可以添加下面的行到你的 .htaccess 文件,从而只允许管理员访问并替换所有访问 .jpg、.css、.gif、.js 等的页面内容。
|
||||
|
||||
RewriteCond %{REQUEST_URI} !^/admin/ [NC]
|
||||
RewriteCond %{REQUEST_URI} !^((.*).css|(.*).js|(.*).png|(.*).jpg) [NC]
|
||||
RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html
|
||||
[NC,L,U,QSA]
|
||||
RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html [NC,L,U,QSA]
|
||||
|
||||
这些行检查请求 URL 是否包含任何例如以 ‘/admin/’ 开头的管理页面的请求,或任何到 ‘.png, .jpg, .js, .css’ 页面的请求,对于任何这样的请求,用 ‘ErrorDocs/Maintainence_Page.html’ 替换那个页面。
|
||||
|
||||
#### 24. 映射 IP 地址到域名 ####
|
||||
|
||||
名称服务器是将特定 IP 地址转换为域名的服务器。该映射也可以在 .htaccess 文件中用以下形式指定。
|
||||
名称服务器是将特定 IP 地址转换为域名的服务器。这种映射也可以在 .htaccess 文件中用以下形式指定。
|
||||
|
||||
为了将地址 L.M.N.O 映射到域名 www.hellovisit.com
|
||||
# 为了将IP地址 L.M.N.O 映射到域名 www.hellovisit.com
|
||||
RewriteCond %{HTTP_HOST} ^L\.M\.N\.O$ [NC]
|
||||
RewriteRule ^(.*)$ http://www.hellovisit.com/$1 [L,R=301]
|
||||
|
||||
@ -414,7 +415,7 @@ via: http://www.tecmint.com/apache-htaccess-tricks/
|
||||
|
||||
作者:[Gunjit Khera][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
修复Linux中的“提供类似行编辑的袖珍BASH...”的GRUB错误
|
||||
================================================================================
|
||||
|
||||
这两天我[安装了Elementary OS和Windows双系统][1],在启动的时候遇到了一个Grub错误。命令行中呈现如下信息:
|
||||
|
||||
**Minimal BASH like line editing is supported. For the first word, TAB lists possible command completions. anywhere else TAB lists possible device or file completions.**
|
||||
|
||||
**提供类似行编辑的袖珍 BASH。TAB键补全第一个词,列出可以使用的命令。除此之外,TAB键补全可以列出可用的设备或文件。**
|
||||
|
||||

|
||||
|
||||
事实上这并不是Elementary OS独有的错误。这是常见的[Grub][2]错误,会在Ubuntu,Fedora,Linux Mint等Linux操作系统上发生。
|
||||
|
||||
通过这篇文章里我们可以学到基于Linux系统**如何修复Ubuntu中出现的“minimal BASH like line editing is supported” Grub错误**。
|
||||
|
||||
> 你可以参阅这篇教程来修复类似的常见问题,[错误:分区未找到Linux grub救援模式][3]。
|
||||
|
||||
### 先决条件 ###
|
||||
|
||||
要修复这个问题,你需要达成以下的条件:
|
||||
|
||||
- 一个包含相同版本、相同OS的LiveUSB或磁盘
|
||||
- 当前会话的Internet连接正常工作
|
||||
|
||||
在确认了你拥有先决条件了之后,让我们看看如何修复Linux的死亡黑屏(如果我可以这样的称呼它的话 ;) )。
|
||||
|
||||
### 如何在基于Ubuntu的Linux中修复“minimal BASH like line editing is supported” Grub错误 ###
|
||||
|
||||
我知道你一定疑问这种Grub错误并不局限于在基于Ubuntu的Linux发行版上发生,那为什么我要强调在基于Ubuntu的发行版上呢?原因是,在这里我们将采用一个简单的方法,用个叫做**Boot Repair**的工具来修复我们的问题。我并不确定在其他的诸如Fedora的发行版中是否有这个工具可用。不再浪费时间,我们来看如何修复“minimal BASH like line editing is supported” Grub错误。
|
||||
|
||||
### 步骤 1: 引导进入lives会话 ###
|
||||
|
||||
插入live USB,引导进入live会话。
|
||||
|
||||
### 步骤 2: 安装 Boot Repair ###
|
||||
|
||||
等你进入了lives会话后,打开终端使用以下命令来安装Boot Repair:
|
||||
|
||||
sudo add-apt-repository ppa:yannubuntu/boot-repair
|
||||
sudo apt-get update
|
||||
sudo apt-get install boot-repair
|
||||
|
||||
注意:推荐这篇教程[如何修复 apt-get update 无法添加新的 CD-ROM 的错误][4],如果你在运行以上命令是遭遇同样的问题。
|
||||
|
||||
### 步骤 3: 使用Boot Repair修复引导 ###
|
||||
|
||||
装完Boot Repair后,在命令行运行如下命令启动:
|
||||
|
||||
boot-repair &
|
||||
|
||||
其实操作非常简单直接,你仅需按照Boot Repair工具提供的说明操作即可。首先,点击Boot Repair中的**Recommended repair**选项。
|
||||
|
||||

|
||||
|
||||
Boot Repair需要花费一些时间来分析引导和Grub中存在的问题。然后,它会提供一些可在命令行中直接运行的命令。将这些命令一个个在终端中执行。我这边屏幕上显示的是:
|
||||
|
||||

|
||||
|
||||
在输入了这些命令之后,它会执行执行一段时间:
|
||||
|
||||

|
||||
|
||||
在这一过程结束后,它会提供一个由boot repair的日志组成的网页网址。如果你的引导问题这样都没有修复,你就可以去社区或是发邮件给开发团队并提交该网址作为参考。很酷!不是吗?
|
||||
|
||||

|
||||
|
||||
在boot repair成功完成后,关闭你的电脑,移除USB并再次引导。我这就能成功的引导了,但是在Grub画面上会多出额外的两行。相比于看到系统能够再次正常引导的喜悦这些对我来说并不重要。
|
||||
|
||||

|
||||
|
||||
### 对你有效吗? ###
|
||||
|
||||
这就是我修复**Elementary OS Freya中的minimal BASH like line editing is supported Grub 错误**的方法。怎么样?是否对你也有效呢?请自由的在下方的评论区提出你的问题和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/guide-install-elementary-os-luna/
|
||||
[2]:http://www.gnu.org/software/grub/
|
||||
[3]:http://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
|
||||
[4]:http://itsfoss.com/fix-failed-fetch-cdrom-aptget-update-add-cdroms/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user