mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
d099251ca2
@ -0,0 +1,129 @@
|
||||
如何在 Linux 中使用屏幕键盘
|
||||
================================================================================
|
||||
|
||||
屏幕键盘可以作为实体键盘输入的替代方案。在某些时候,屏幕键盘显得非常需要。 比如, 你的键盘刚好坏了;你的机器太多,没有足够的键盘;你的机器没有多余的接口来连接键盘;你是个残疾人,打字有困难;或者你正在组建基于触摸屏的信息服务站。
|
||||
|
||||
屏幕键盘也可以作为一种防范实体键盘记录器的保护手段,键盘记录器会悄悄记录按键来获取密码等敏感信息。一些网上银行页面实际上会强制你使用屏幕键盘来增强交易的安全性。
|
||||
|
||||
在 linux 中有几个可用的开源键盘软件, 比如 [GOK (Gnome 的屏幕键盘)][1],[kvkbd][2],[onboard][3],[Florence][4]。
|
||||
|
||||
我会在这个教程中集中讲解 Florence, 告诉你**如何用 Florence 设置一个屏幕键盘**。 Florence 有着布局方案灵活、输入法多样、自动隐藏等特性。作为教程的一部分,我也将会示范**如何只使用鼠标来操作 Ubuntu 桌面**。
|
||||
|
||||
### 在 Linux 中安装 Florence 屏幕键盘 ###
|
||||
|
||||
幸运的是,Florence 存在于大多数 Linux 发行版的基础仓库中。
|
||||
|
||||
在 Debian,Ubuntu 或者 Linux Mint 中:
|
||||
|
||||
$ sudo apt-get install florence
|
||||
|
||||
在 Fedora,CentOS 或者 RHEL (CentOS/RHEL 需要[EPEL 仓库][5]) 中:
|
||||
|
||||
$ sudo yum install florence
|
||||
|
||||
在 Mandriva 或者 Mageia 中:
|
||||
|
||||
$ sudo urpmi florence
|
||||
|
||||
对于 Archlinux 用户,Florence 存在于 [AUR][6] 中。
|
||||
|
||||
### 配置和加载屏幕键盘 ###
|
||||
|
||||
当你安装好 Florence 之后,你只需要简单的输入以下命令就能加载屏幕键盘:
|
||||
|
||||
$ florence
|
||||
|
||||
默认情况下,屏幕键盘总是在其他窗口的顶部,让你能够在任意活动的窗口上进行输入。
|
||||
|
||||
在键盘的左侧点击工具按键来改变 Florence 的默认配置。
|
||||
|
||||
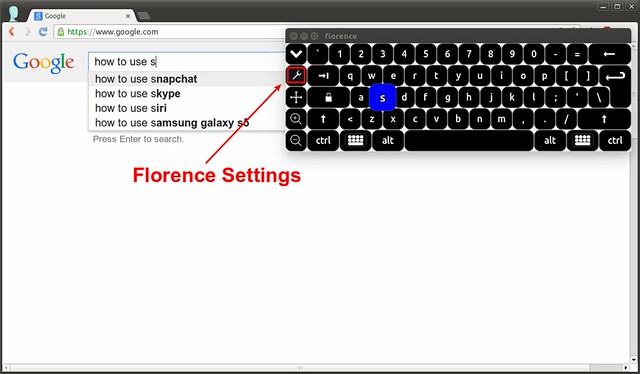
|
||||
|
||||
在 Florence 的 "样式 (style)" 菜单中,你能够自定义键盘样式,启用/取消声音效果。
|
||||
|
||||

|
||||
|
||||
在“窗口 (window)”菜单中,你能够调整键盘背景透明度、按键不透明度,以及控制键盘比例、工具栏、尺寸和总是置顶等特性。如果你的桌面分辨率不是非常高,透明度调整就显得非常有用,因为屏幕键盘会挡住其他窗口。在这个例子中,我切换到透明键盘,并且设置不透明度为 50%。
|
||||
|
||||

|
||||
|
||||
在“行为 (behaviour)”菜单中,你能够改变输入方法。Florence 支持几种不同的输入法: 鼠标 (mouse)、触摸屏 (touch screen)、计时器 (timer) 和漫步 (ramble)。鼠标输入是默认输入法。最后的两种输入法不需要按鼠标键。 计时器输入通过将指针滞留在按键上一定时间来触发按键。漫步输入的原理跟**计时器**输入差不多,但是经过训练和灵巧使用,能够比**计时器**输入更加迅速。
|
||||
|
||||

|
||||
|
||||
在“布局 (layout)”菜单中,你能够改变键盘布局。比如,你能够扩展键盘布局来增加导航键,数字键和功能键。
|
||||
|
||||

|
||||
|
||||
### 只使用鼠标来操作 Ubuntu 桌面
|
||||
|
||||
我将示范如何将 Florence 集成到 Ubuntu 桌面中,然后我们不需要实体键盘就能够进入桌面。这个教程使用 LightDM (Ubuntu 的默认显示管理器) 来进入 Ubuntu,其他桌面环境也能设置类似的环境。
|
||||
|
||||
初始设置时需要实体键盘,但是一旦设置完成,你只需要一个鼠标,而不是键盘。
|
||||
|
||||
当你启动 Ubuntu 桌面时,启动程序最后会停在显示管理器 (或者登录管理器) 的欢迎界面。在这个界面上你需要输入你的登录信息。默认的情况下,Ubuntu 桌面会使用 LightDM 显示管理器和 Unity 欢迎界面。如果没有实体键盘, 你就不能在登录界面输入用户名和密码。
|
||||
|
||||
为了能够在登录界面加载屏幕键盘,安装配备了屏幕键盘支持的 GTK+ 欢迎界面。
|
||||
|
||||
$ sudo apt-get install lightdm-gtk-greeter
|
||||
|
||||
然后用编辑器打开欢迎界面配置文件 (/etc/lightdm/lightdm-gtk-greeter.conf),指定 Florence 作为屏幕键盘来使用。如果你愿意,你也能够使用 Ubuntu 的默认屏幕键盘 onboard 来代替 Florence。
|
||||
|
||||
$ sudo vi /etc/lightdm/lightdm-gtk-greeter.conf
|
||||
|
||||
----------
|
||||
|
||||
[greeter]
|
||||
keyboard=florence --no-gnome --focus &
|
||||
|
||||

|
||||
|
||||
重启 Ubuntu 桌面,然后看看你是否能够在登录界面使用屏幕键盘。
|
||||
|
||||
启动之后当你看到 GTK+ 欢迎界面时, 点击右上角的人形符号。你会看到“使用屏幕键盘 (On Screen Keyboard)”菜单选项,如下:
|
||||
|
||||

|
||||
|
||||
点击这个选项,屏幕键盘就会在登录界面弹出。现在你应该能够用屏幕键盘来登录了。
|
||||
|
||||
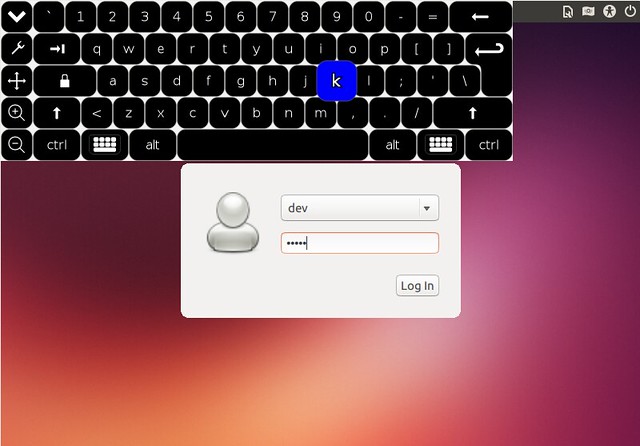
|
||||
|
||||
对于 GDM2/GDM3 用户怎么在 GDM2/GDM3 界面上使用屏幕键盘,Florence 官方网页提供了 [文档 (documentation)][7]。
|
||||
|
||||
Ubuntu 桌面完全无键盘化的最后一步是让屏幕键盘在登录后自动启动,这样我们在登录后能够不使用实体键盘就操作桌面,为了做到这一点,创建以下桌面文件:
|
||||
|
||||
$ mkdir -p ~/.config/autostart
|
||||
$ vi ~/.config/autostart/florence.desktop
|
||||
|
||||
----------
|
||||
|
||||
[Desktop Entry]
|
||||
Type=Application
|
||||
Name=Virtual Keyboard
|
||||
Comment=Auto-start virtual keyboard
|
||||
Exec=florence --no-gnome
|
||||
|
||||
这样可以让你在登录到桌面的时候就看到屏幕键盘。
|
||||
|
||||

|
||||
|
||||
希望这个教程对你有用。与你所看到的一样,Florence 是非常强大的屏幕键盘,可以用于不同目的。请和我分享你使用屏幕键盘的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/onscreen-virtual-keyboard-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[forsil](https://github.com/forsil)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://developer.gnome.org/gok/
|
||||
[2]:http://homepage3.nifty.com/tsato/xvkbd/
|
||||
[3]:https://launchpad.net/onboard
|
||||
[4]:http://florence.sourceforge.net/
|
||||
[5]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
[6]:https://aur.archlinux.org/packages/florence/
|
||||
[7]:http://florence.sourceforge.net/english/how-to.html
|
||||
@ -1,61 +1,64 @@
|
||||
# Peer Code Review的实战经验 #
|
||||
|
||||
(译者:Code Review中文可以翻译成代码复查,一般由开发待review的代码的成员以外的团队成员来进行这样的工作。由于是专业术语,没有将Code review用中文代替。)
|
||||
# 同等代码审查(Peer Code Review)实战经验 #
|
||||
|
||||
我有时候会听到我们的团队成员这样议论:
|
||||
|
||||
"项目的Code review 只是浪费时间。"
|
||||
|
||||
"我没有时间做Code review。"
|
||||
"我的发布时间延迟了,因为我的同时还没有完成我代码的Code review。"
|
||||
"你相信我的同事居然要求我对我的代码做修改吗?请跟他们说代码中的一些联系会被打断如果在我原来代码的基础之上做修改的话。"
|
||||
|
||||
"我的发布时间延迟了,因为我的同事还没有完成我代码的Code review。"
|
||||
|
||||
"你相信我的同事居然要求我对我的代码做修改吗?请跟他们说代码中的一些联系会被打断——如果在我原来代码的基础之上做修改的话。"
|
||||
|
||||
(LCTT 译注:Code Review中文可以翻译成代码复查,一般由开发待review的代码的成员以外的团队成员来进行这样的工作。由于是专业术语,没有将Code review用中文代替。)
|
||||
|
||||
### 为什么要做Code review? ###
|
||||
|
||||
每个专业软件开发者都有一个重要的目标:持续的提高它们的工作质量。即使你团队中都是一些优秀的程序员,你依然不能将你自己与一个有能力的自由职业者区分开来,除非你从团队的角度来工作。Code review是团队工作的一个重要的方面。尤其是:
|
||||
每个专业软件开发者都有一个重要的目标:持续的提高他们的工作质量。即使你团队中都是一些优秀的程序员,但是你依然不能将你自己与一个有能力的自由职业者区分开来,除非你从团队的角度来工作。Code review是团队工作的一个重要的方面。尤其是:
|
||||
|
||||
代码复查者(reviewer)能从他们的角度来发现问题并且提出更好的解决方案。
|
||||
|
||||
确保至少你团队的另一个其他成员熟悉你的代码,通过给新员工看有经验的开发者的代码能够某种程度上提高他们的水平。
|
||||
|
||||
公开code reviewer和reviewee的想法和经验能够促进团队间的知识的分享。
|
||||
公开reviewer和被复查者的想法和经验能够促进团队间的知识的分享。
|
||||
|
||||
能够鼓励开发者将他们的工作进行的更彻底,因为他们知道他们的代码将被其他的人阅读。
|
||||
|
||||
### 在review的过程中的注意点 ###
|
||||
|
||||
但是,由于Code review的时间有限,上面所说的目标未必能全部达到。就算只是想要打一个补丁,都要确保意图是正确的。如果只是将变量名改成骆驼拼写法(camelCase),不算是code review。在开发过程中进行结对编程是有益处的,它能够使两个人得到公平的锻炼。你能够在code review上花许多时间,并且仍然能够比在结对编程中使用更少的时间。
|
||||
但是,由于Code review的时间有限,上面所说的目标未必能全部达到。就算只是想要打一个补丁,都要确保意图是正确的。如果只是将变量名改成骆驼拼写法(camelCase),那不算是code review。在开发过程中进行结对编程是有益处的,它能够使两个人得到公平的锻炼。你能够在code review上花许多时间,并且仍然能够比在结对编程中使用更少的时间。
|
||||
|
||||
我的感受是,在项目开发的过程中,25%的时间应该花费在code review上。也就是说,如果开发者用两天的时间来开发一个东西,那么复查者应该使用至少四个小时来审查。
|
||||
|
||||
当然,只要你的review结果准确的话,具体花了多少时间就显得不是那么的重要。重要的是,你能够理解你看的那些代码。这里的理解并不是指你看懂了这些代码书写的语法,而是你要知道这段代码在整个庞大的应用程序,组件或者库中起着什么样的作用。如果你不理解每一行代码的作用,那么换句话说,你的code review就是没有价值的。这就是为什么好的code review不能很快完成的原因。需要时间来探讨各种各样的代码路径,让它们触发一个特定的函数,来确保第三方的API得到了正确的使用(包括一些边缘测试)。
|
||||
当然,只要你的review结果准确的话,具体花了多少时间就显得不是那么的重要。重要的是,你能够理解你看的那些代码。这里的理解并不是指你看懂了这些代码书写的语法,而是你要知道这段代码在整个庞大的应用程序、组件或者库中起着什么样的作用。如果你不理解每一行代码的作用,那么换句话说,你的code review就是没有价值的。这就是为什么好的code review不能很快完成的原因。需要时间来探讨各种各样的代码路径,让它们触发一个特定的函数,来确保第三方的API得到了正确的使用(包括一些边缘测试)。
|
||||
|
||||
为了查阅你所审查的代码的缺陷或者是其他问题,你应该确保:
|
||||
|
||||
所有有必要的测试都已经被包含进去。
|
||||
- 所有必要的测试都已经被包含进去。
|
||||
|
||||
合理的设计文档已经被编写。
|
||||
- 合理的设计文档已经被编写。
|
||||
|
||||
再熟练的开发者也不是每次都会记得在他们对代码改动的时候把测试程序和文档更新上去。来自reviewer的一个提醒能够使得测试用例和开发文档不会一直忘了更新。
|
||||
|
||||
### 避免code review负担太大 ###
|
||||
|
||||
如果你的团队没有强制性的code review,当你的code review记录停留在无法管理的节点上时会很危险。如果你已经两周没有进行code review了,你可以花几天的时间来跟上项目的进度。这意味着你自己的开发工作会被阻断,当你想要处理之前遗留下来的code review的时候。这也会使得你很难再确保code review的质量,因为合理的code review需要长期认真的努力。最终会很难持续几天都保持这样的状态。
|
||||
如果你的团队没有强制性的code review,当你的code review记录停留在无法管理的节点上时会很危险。如果你已经两周没有进行code review了,你可以花几天的时间来跟上项目的进度。这意味着你自己的开发工作会被阻断,当你想要处理之前遗留下来的code review的时候。这也会使得你很难再确保code review的质量,因为合理的code review需要长期认真的努力,最终会很难持续几天都保持这样的状态。
|
||||
|
||||
由于这个原因,开发者应当每天都完成他们的review任务。一种好办法就是将code review作为你每天的第一件事。在你开始自己的开发工作之前完成所有的code review工作,能够使你从头到尾都集中注意力。有些人可能更喜欢在午休前或午休后或者在傍晚下班前做review。无论你在哪个时间做,都要将code review看作你的工作之一并且不能分心,你要避免:
|
||||
|
||||
没有足够的时间来处理你的review任务。
|
||||
- 没有足够的时间来处理你的review任务。
|
||||
|
||||
由于你的code review工作没有做完导致版本的推迟发布。
|
||||
- 由于你的code review工作没有做完导致版本的推迟发布。
|
||||
|
||||
提交不在相关的review由于代码在你review期间已经改动太大。
|
||||
- 提交不再相关的review,由于代码在你review期间已经改动太大。
|
||||
|
||||
因为你要在最后一分钟完成他们一直于review质量太差。
|
||||
- 因为你要在最后一分钟完成他们,以至于review质量太差。
|
||||
|
||||
### 书写易于review的代码 ###
|
||||
|
||||
有时候review没有按时完成并不都是因为代码审查者(reviewer)。如果我的同事使用一周时间在一个大工程中添加了一些乱七八糟的代码,且他们提交的补丁实在是太难以阅读。在一段中有太多的东西要浏览。这样会让人难以理解它的作用,自然会拖慢review的进度。
|
||||
有时候review没有按时完成并不都是因为reviewer。如果我的同事使用一周时间在一个大工程中添加了一些乱七八糟的代码,且他们提交的补丁实在是太难以阅读。在一段代码中有太多的东西要浏览。这样会让人难以理解它的作用,自然会拖慢review的进度。
|
||||
|
||||
为什么将你的工作划分成一些易于管理的片段很重要有很多原因。我们使用scrum方法论(一种软件开发过程方法),因此对我们来说一个合理的单元就是一个story。通过努力将我们的工作使用story组织起来并且只是将review提交到我们正在工作的story上,这样,我们写的代码就会更加易于review。你们的可以使用其他的软件开发方法,但是目的是一样的。
|
||||
为什么将你的工作划分成一些易于管理的片段很重要有很多原因。我们使用scrum方法论(一种软件开发过程方法),因此对我们来说一个合理的单元就是一个story。通过努力将我们的工作使用story组织起来,并且只是将review提交到我们正在工作的story上,这样,我们写的代码就会更加易于review。你们也可以使用其他的软件开发方法,但是目的是一样的。
|
||||
|
||||
书写易于review的代码还有其他先决条件。如果要做一些复杂的架构决策,应该让reviewer事先知道并参与讨论。这会让他们之后review你们的代码更加容易,因为他们知道你们正在试图实现什么功能并且知道你们打算如何来实现。这也避免了开发者需要在reviewer提了一个不同的或者更好的解决方案后大片的重写代码。
|
||||
|
||||
@ -63,7 +66,7 @@
|
||||
|
||||
如果你在你的补丁中包含的第三方的代码,记得单独的提交它。当jQuery的9000行代码被插入到了项目代码的中间,毫无疑问会造成难以阅读。
|
||||
|
||||
创建易读的review代码的另一个非常重要的措施是添加相应的注释代码。这就要求你事先自己做一下review并且在一些你认为会帮助reviewer进行review的地方加上相应的注释。我发现加上注释相对与你来说往往只需要很短的时间(通常是几分钟),但是对于review来说会节约很多的时间。当然,代码注释还有其他相似的好处,应该在合理的地方使用,但往往对code review来说更重要。事实上,有研究表明,开发者在重读并注释他们代码的过程中,通常会发现很多问题。
|
||||
创建易读的review代码的另一个非常重要的措施是添加相应的注释代码。这就要求你事先自己做一下review并且在一些你认为会帮助reviewer进行review的地方加上相应的注释。我发现加上注释相对于你来说往往只需要很短的时间(通常是几分钟),但是对于review来说会节约很多的时间。当然,代码注释还有其他相似的好处,应该在合理的地方使用,但往往对code review来说更重要。事实上,有研究表明,开发者在重读并注释他们代码的过程中,通常会发现很多问题。
|
||||
|
||||
### 代码大范围重构的情况 ###
|
||||
|
||||
@ -77,16 +80,17 @@
|
||||
|
||||
你的团队中都是一些有能力的专家,在一些案例中,完全有可能因为对一个具体编码问题的意见的不同而产生争论。作为一个开发者,应该保持一个开发的头脑并且时刻准备着妥协,当你的reviewer更想要另一种解决方法时。不要对你的代码持有专有的态度,也不要自己持有审查的意见。因为有人会觉得你应该将一些重复的代码写入一个能够复用的函数中去,这并不意味着这是你的问题。
|
||||
|
||||
作为一个reviewer,要灵活。在提出修改建议之前,考虑你的建议是否真的更好或者只是无关紧要。如果你把力气和注意力花在那些原来的代码会明确需要改进的地方会更加成功。你应该说"它或许者的考虑..."或者"一些人建议..."而不是”我的宠物都能写一个比这个更加有效的排序方法"。
|
||||
作为一个reviewer,要灵活。在提出修改建议之前,考虑你的建议是否真的更好或者只是无关紧要。如果你把力气和注意力花在那些原来的代码会明确需要改进的地方会更加成功。你应该说"它或许值得考虑..."或者"一些人建议..."而不是”我的宠物都能写一个比这个更加有效的排序方法"。
|
||||
|
||||
如果你真的决定不了,那就询问另一个你和你的reviewee都尊敬的开发者来听一下你意见并给出建议。
|
||||
如果你真的决定不了,那就询问另一个你及你所审查的人都尊敬的开发者来听一下你意见并给出建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.salsitasoft.com/practical-lessons-in-peer-code-review/
|
||||
作者:[Matt][a]
|
||||
|
||||
作者:Matt
|
||||
译者:[john](https://github.com/johnhoow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,32 +1,32 @@
|
||||
如何在 Linux 上针对 Apache 日志文件运行 SQL 查询语句
|
||||
如何在 Linux 上用 SQL 语句来查询 Apache 日志
|
||||
================================================
|
||||
|
||||
Linux 有一个显著的特点,在正常情况下,你可以通过分析系统日志来了解你的系统中发生了什么,或正在发生什么。的确,系统日志是系统管理员在解决系统和应用问题时最需要的第一手资源。我们将在这篇文章中着重讲解 Apache HTTP web server 生成的 Apache access 日志。
|
||||
Linux 有一个显著的特点,在正常情况下,你可以通过日志分析系统日志来了解你的系统中发生了什么,或正在发生什么。的确,系统日志是系统管理员在解决系统和应用问题时最需要的第一手资源。我们将在这篇文章中着重讲解 Apache HTTP web server 生成的 Apache access 日志。
|
||||
|
||||
我们会通过另类的途径分析 Apache access 日志,我们使用的工具是 [asql][1]。asql 是一个开源的工具,它能够允许使用者针对日志运行 SQL 查询,从而通过更加友好的格式展现相同的信息。
|
||||
这次,我们会通过另类的途径来分析 Apache access 日志,我们使用的工具是 [asql][1]。asql 是一个开源的工具,它能够允许使用者使用 SQL 语句来查询日志,从而通过更加友好的格式展现相同的信息。
|
||||
|
||||
### Apache 日志背景知识 ###
|
||||
|
||||
Apache 有两种日志:
|
||||
|
||||
- **Access log**:存放在路径 /var/log/apache2/access.log (Debian) 或者 /var/log/httpd/access_log (Red Hat)。Access Log 记录所有 Apache web server 执行的请求。
|
||||
- **Error log**:存放在路径 /var/log/apache2/error.log (Debian) 或者 /var/log/httpd/error_log (Red Hat)。Error log 记录所有 Apache web server 报告的错误以及错误的情况。Error 情况包括(不限于)403(Forbidden,通常在有效请求丢失访问许可时被报告),404(Not found,在请求资源不存在时被报告)。
|
||||
- **Error log**:存放在路径 /var/log/apache2/error.log (Debian) 或者 /var/log/httpd/error_log (Red Hat)。Error log 记录所有 Apache web server 报告的错误以及错误的情况。Error 情况包括(不限于)403(Forbidden,通常在请求被拒绝访问时被报告),404(Not found,在请求资源不存在时被报告)。
|
||||
|
||||
虽然管理员可以通过配置 Apache 的配置文件来自定义 Apache access log 的罗嗦程度,在这篇文章中,我们会使用默认的配置,如下:
|
||||
虽然管理员可以通过配置 Apache 的配置文件来自定义 Apache access log 的详细程度,不过在这篇文章中,我们会使用默认的配置,如下:
|
||||
|
||||
Remote IP - Request date - Request type - Response code - Requested resource - Remote browser (may also include operating system)
|
||||
远程 IP - 请求时间 - 请求类型 - 响应代码 - 请求的 URL - 远程的浏览器信息 (也许包含操作系统信息)
|
||||
|
||||
因此一个典型的 Apache 日志条目就是下面这个样子:
|
||||
|
||||
192.168.0.101 - - [22/Aug/2014:12:03:36 -0300] "GET /icons/unknown.gif HTTP/1.1" 200 519 "http://192.168.0.10/test/projects/read_json/" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:30.0) Gecko/20100101 Firefox/30.0"
|
||||
|
||||
但是 Apache error log 又是怎么样的呢?因为 error log 条目主要记录 access log 中特殊的请求(你可以自定义),你可以通过 access log 来获得关于错误情况的更多信息(example 5 有更多细节)。
|
||||
但是 Apache error log 又是怎么样的呢?因为 error log 条目主要记录 access log 中特殊的请求(你可以自定义),所以你可以通过 access log 来获得关于错误情况的更多信息(example 5 有更多细节)。
|
||||
|
||||
话在前头, access log 是系统级别的日志文件。要分析 virtual hosts 的日志文件,你需要检查它们相应的配置文件(e.g. 在 /etc/apache2/sites-available/[virtual host name] 里(Debian))。
|
||||
此外要提前说明的, access log 是系统级别的日志文件。要分析虚拟主机的日志文件,你需要检查它们相应的配置文件(例如: 在 /etc/apache2/sites-available/[virtual host name] 里(Debian))。
|
||||
|
||||
### 在 Linux 上安装 asql ###
|
||||
|
||||
asql 由 Perl 编写,而且需求以下两个 Perl module:SQLite 的 DBI 驱动以及 GNU readline.
|
||||
asql 由 Perl 编写,而且需求以下两个 Perl 模块:SQLite 的 DBI 驱动以及 GNU readline。
|
||||
|
||||
### 在 Debian, Ubuntu 以及其衍生发行版上安装 asql ###
|
||||
|
||||
@ -46,7 +46,7 @@ asql 由 Perl 编写,而且需求以下两个 Perl module:SQLite 的 DBI 驱
|
||||
|
||||
### asql 是如何工作的? ###
|
||||
|
||||
从上面代码中的依赖中你就可以看出来,asql 转换未结构化的明文 Apache 日志成结构化的 SQLite 数据库信息。生成的 SQLite 数据库接受正常的 SQL 查询语句。数据库可以通过当前以及曾经的日志文件生成,其中包括压缩转换过的日志文件,类似 access.log.X.gz 或者 access_log.old。
|
||||
从上面代码中的依赖中你就可以看出来,asql 转换未结构化的明文 Apache 日志为结构化的 SQLite 数据库信息。生成的 SQLite 数据库可以接受正常的 SQL 查询语句。数据库可以通过当前以及之前的日志文件生成,其中也包括压缩转换过的日志文件,类似 access.log.X.gz 或者 access_log.old。
|
||||
|
||||
首先,从命令行启动 asql:
|
||||
|
||||
@ -62,7 +62,7 @@ asql 由 Perl 编写,而且需求以下两个 Perl module:SQLite 的 DBI 驱
|
||||
|
||||
首先在 asql 中加载所有的 access 日志:
|
||||
|
||||
asql > load <path/to/apache-access-logs>
|
||||
asql > load <apache-access-logs 的路径>
|
||||
|
||||
比如在 Debian 下:
|
||||
|
||||
@ -72,7 +72,7 @@ asql 由 Perl 编写,而且需求以下两个 Perl module:SQLite 的 DBI 驱
|
||||
|
||||
asql > load /var/log/httpd/access_log*
|
||||
|
||||
当 asql 完成对 access 日志的加载后,我们就可以开始数据库查询了。注意一下,加载后生成的数据库是 "temporary" 的,意思就是数据库会在你退出 asql 的时候被清除。如果你想要保留数据库,你必须先将其保存为一个文件。我们会在后面介绍如何这么做(参考 example 3 和 4)。
|
||||
当 asql 完成对 access 日志的加载后,我们就可以开始数据库查询了。注意一下,加载后生成的数据库是 "temporary" (临时)的,意思就是数据库会在你退出 asql 的时候被清除。如果你想要保留数据库,你必须先将其保存为一个文件。我们会在后面介绍如何这么做(参考 example 3 和 4)。
|
||||
|
||||
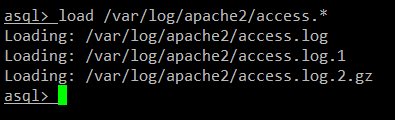
|
||||
|
||||
@ -80,7 +80,7 @@ asql 由 Perl 编写,而且需求以下两个 Perl module:SQLite 的 DBI 驱
|
||||
|
||||
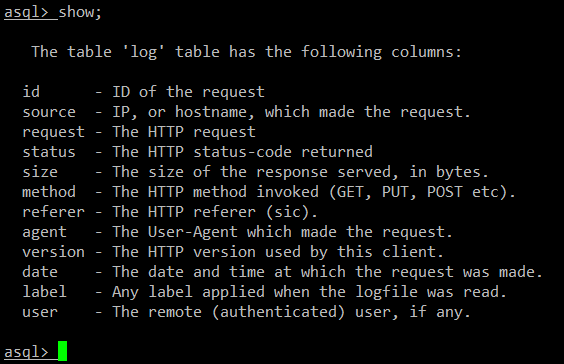
|
||||
|
||||
名为 .asql 的隐藏文件,保存于用户的 home 目录下,记录用户在 asql shell 中输入的命令历史。因此你可以使用方向键浏览历史命令,按下 ENTER 来重复执行之前的命令。
|
||||
一个名为 .asql 的隐藏文件,保存于用户的 home 目录下,记录用户在 asql shell 中输入的命令历史。因此你可以使用方向键浏览命令历史,按下 ENTER 来重复执行之前的命令。
|
||||
|
||||
### asql 上的示例 SQL 查询 ###
|
||||
|
||||
@ -106,7 +106,7 @@ asql 由 Perl 编写,而且需求以下两个 Perl module:SQLite 的 DBI 驱
|
||||
|
||||
这样做可以避免使用 load 命令对日志的语法分析所占用的处理时间。
|
||||
|
||||
**Example 4**:在重新启动 asql 后载入数据库。
|
||||
**Example 4**:在重新进入 asql 后载入数据库。
|
||||
|
||||
restore [filename]
|
||||
|
||||
@ -135,7 +135,7 @@ via: http://xmodulo.com/sql-queries-apache-log-files-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ThomazL](https://github.com/ThomazL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
Linux有问必答——如何修复“ImportError: No module named scapy.all”
|
||||
Linux有问必答:如何修复“ImportError: No module named scapy.all”
|
||||
================================================================================
|
||||
> **问题**:当我运行一个Python应用程序时,出现了这个提示消息“ImportError: No module named scapy.all”。我怎样才能修复这个导入错误呢?
|
||||
|
||||
[Scapy][1]是一个用Python写的灵活包生成和嗅探程序。使用Scapy,你可以完成创建专有包,发送上线,从线上或转储文件中读取包,转换包等工作。使用Scapy的通用包处理能力,你可以很容易地完成像SYN扫描、TCP路由跟踪以及OS指纹打印之类的工作。你也可以通过导入,将Scapy整合到其它工具中。
|
||||
[Scapy][1]是一个用Python写的灵活的数据包生成及嗅探程序。使用Scapy,你可以完成创建任意数据包并发送到网络上、从网络上或转储文件中读取数据包、转换数据包等工作。使用Scapy的通用包处理能力,你可以很容易地完成像SYN扫描、TCP路由跟踪以及OS指纹检测之类的工作。你也可以通过导入,将Scapy整合到其它工具中。
|
||||
|
||||
该导入错误表明:你还没有在你的Linux系统上安装Scapy。下面介绍安装方法。
|
||||
|
||||
### 安装Scapy到Debian, Ubuntu或Linux Mint ###
|
||||
|
||||
$ sudo apt-get install python-scapy
|
||||
@ -30,7 +31,7 @@ Linux有问必答——如何修复“ImportError: No module named scapy.all”
|
||||
via: http://ask.xmodulo.com/importerror-no-module-named-scapy-all.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,34 @@
|
||||
Ubuntu 14.10 ‘乌托邦的独角兽’官方 T 恤开始发售
|
||||
================================================================================
|
||||

|
||||
|
||||
**Ubuntu 14.10 发布以来,很少能见到随同发布的带有官方吉祥物的 T 恤。不过今天 Canonical 商店终于上架了这件粉丝喜欢的商品。**
|
||||
|
||||
现在有两种T恤,一种是‘dusk blue’(男士版本)或者‘hot pink’(女士版本),但是审美与设计的形式是相同的。每种T恤印有由Canonical定制设计的折纸型的‘乌托邦的独角兽’。每件衬衫的背面是Ubuntu的标识以及含有“Utopic Unicorn 14.10”文字,从前到后帮你推广系统-我喜欢!
|
||||
|
||||

|
||||
|
||||
男士的尺寸有从S到XXL, 女士的尺寸有8-10与14-16,每件T恤在英国的价格是£11,美国的价格是$17.45,欧洲的价格是$17.45。这个价格较往年高一点,与以往一样这是减去了运费和包装的费用。
|
||||
|
||||
- [购买男士的 Ubuntu 14.10 T恤][1]
|
||||
|
||||
- [购买女士的 Ubuntu 14.10 T恤][2]
|
||||
|
||||
吉祥物 T 恤已经成为自Ubuntu 8.04 Hardy Heron后每个Ubuntu版本发布的传统,虽然它一般在系统发布前发布。
|
||||
|
||||
如果你不是特定版本的粉丝,你会发现可以购买的老版本吉祥物商品的数量有限且降价出售。如果你想在你的衬衫上印一条蝾螈,推广穿山甲或者塔尔羊,可以在[出售页面][3]看看。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/12/last-ubuntu-14-10-unicorn-t-shirts-now-available
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://shop.canonical.com/product_info.php?products_id=1153
|
||||
[2]:http://shop.canonical.com/product_info.php?products_id=1159
|
||||
[3]:http://shop.canonical.com/index.php?cPath=29
|
||||
@ -1,34 +0,0 @@
|
||||
Official Ubuntu 14.10 ‘Utopic Unicorn’ T-Shirts Now Available to Buy
|
||||
================================================================================
|
||||

|
||||
|
||||
**For a while it looked like an official mascot t-shirt to accompany the release of Ubuntu 14.10 would be as rare as the Unicorn fronting it. But, today, the Canonical Store was finally furnished with the fan-favourite merch item.**
|
||||
|
||||
The shirt is available to buy in either ‘dusk blue’ (men’s fit) or ‘hot pink’ (women’s fit), but aesthetic and form aside the design is the same. Each shirt is emblazoned with the custom origami ‘Utopic Unicorn’ emblem designed by Canonical. On the reverse of each shirt is the Ubuntu logotype and the words “Utopic Unicorn 14.10“, helping you promote the OS from the back as well as the front — I like it!
|
||||
|
||||

|
||||
|
||||
Available in small to XX-Large for men’s, and women’s sizes spanning 8-10 through 14-16, each t-shirt is priced at £11 in the UK, $17.45 in the US and €13.42 in Europe. A little higher than previous years and, as ever, minus postage/shipping and packaging.
|
||||
|
||||
- [Buy Men’s Ubuntu 14.10 T-Shirt][1]
|
||||
|
||||
- [Buy Women’s Ubuntu 14.10 T-Shirt][2]
|
||||
|
||||
Mascot t-shirts have been a staple of each Ubuntu release since as far back as version 8.04 Hardy Heron though they typically see release prior to the OS itself.
|
||||
|
||||
If you’re not a fan of this particular release you’ll find a limited number of older mascot-matched merchandise still available to buy and at a reduced price. So if you’d rather strut your stuff with a Salamander, promote a Pangolin or look tahr-iffic in a Trusty design, be sure to check out [the Sale section][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/12/last-ubuntu-14-10-unicorn-t-shirts-now-available
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://shop.canonical.com/product_info.php?products_id=1153
|
||||
[2]:http://shop.canonical.com/product_info.php?products_id=1159
|
||||
[3]:http://shop.canonical.com/index.php?cPath=29
|
||||
@ -0,0 +1,38 @@
|
||||
Linus Torvalds Thanks Microsoft for a Great Black Friday Monitor Deal
|
||||
================================================================================
|
||||

|
||||
|
||||
> The creator of the Linux kernel now has a UHD display
|
||||
|
||||
**Linus Torvalds is the creator of the Linux Kernel, he advocated for years against Microsoft's practices and he often talked about Windows. These are just some of the reasons why it's funny to see him thank Microsoft, even if it's probably done sarcastically.**
|
||||
|
||||
The rhetoric regarding the Linux vs. Windows subject has subsided a great deal in the last few years. There have been some issues with UEFI and other similar problems, but for the most part things have quieted down.
|
||||
|
||||
There is no one left at the Redmond campus to call Linux a cancer and no one is making fun of Windows for crashing all the time. In fact, there has been some sort of reconciliation between the two sides, which seems to benefit everyone.
|
||||
|
||||
It's not like Microsoft is ready to adopt the Linux kernel for their operating system, but the new management of the company talks about Linux as a friend, especially in the cloud.
|
||||
|
||||
They can no longer ignore it, even if they want to. The same happened with Linus Torvalds who hasn't said anything bad about Microsoft and Windows for a long time, and that is a good thing.
|
||||
|
||||
### Linus Torvalds saying "thanks" to Microsoft is not something you see every day ###
|
||||
|
||||
The creator of the Linux kernel talked about a great Black Friday deal he got from the Microsoft store, for a UHD monitor. He shared this piece of info on Google+ and some of the users also found it amusing to read that he's giving sincere thanks to Microsoft for their great deal.
|
||||
|
||||
"Whee. Just installed a new monitor. 3840x2160 resolution - it's the Dell 28" UHD panel - for $299 (€241) thanks to Microsoft's black Friday deal. Thanks MS! Ok, I have to admit that it's not actually a great panel: very clear color shifts off-center, 30Hz refresh etc. But still - I'm a nut for resolution, and at $299 (€241) I decided that this will carry me over until better panels start showing up at good prices," wrote Linus on [Google+][1].
|
||||
|
||||
In the meantime, he is also working on the latest kernel branch, 3.18, which will probably be released sometime at the end of this week. It's not clear how things will evolve after that, especially given the fact that the holidays are approaching fast, and devs might be a little sluggish when it comes to pushing patches and new features for the next 3.19 branch.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Thanks-Microsoft-for-a-Great-Black-Friday-Monitor-Deal-466599.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://plus.google.com/+LinusTorvalds/posts/4MwQKZhGkEr
|
||||
@ -0,0 +1,47 @@
|
||||
U.S. Marine Corps Wants to Change OS for Radar System from Windows XP to Linux
|
||||
================================================================================
|
||||
**A new radar system has been sent back for upgrade**
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
> When it comes to stability and performance, nothing can really beat Linux. This is why the U.S. Marine Corps leaders have decided to ask Northrop Grumman Corp. Electronic Systems to change the operating system of the newly delivered Ground/Air Task-Oriented Radar (G/ATOR) from Windows XP to Linux.
|
||||
|
||||
The Ground/Air Task-Oriented Radar (G/ATOR) system has been in the works for many years and it's very likely that when the project was started, Windows XP could have been considered the logical choice. In the mean time, things changed. Microsoft has pulled the support for Windows XP and very few entities still use it. The operating system is either upgraded or replaced. In this case, Linux is the logical choice, especially since the replacement cost are probably much smaller than an eventual upgrade.
|
||||
|
||||
It's interesting to note that the Ground/Air Task-Oriented Radar (G/ATOR) was just delivered to the U.S. Marine Corps, but the company that built it chose to keep that aging operating system. Someone must have noticed the fact that it was a poor decision and the chain of command was informed of the problems that might have appeared.
|
||||
|
||||
### G/ATOR radar software will be Linux-based ###
|
||||
|
||||
Unix systems, like BSD-based or Linux-based OSes, are usually found in critical areas and technologies that can't fail, under any circumstances. That's why most of the servers out there are running Linux servers, for example. Having a radar system with an operating systems that is very unlikely to crash seems to fit the bill perfectly.
|
||||
|
||||
"Officials of the Marine Corps Systems Command at Quantico Marine Base, Va., announced a $10.2 million contract modification Wednesday to the Northrop Grumman Corp. Electronic Systems segment in Linthicum Heights, Md., to convert the Ground/Air Task-Oriented Radar (G/ATOR) operator command and control computer from Windows XP to Linux. The contract modification will incorporate a change order to switch the G/ATOR control computer from the Microsoft Windows XP operating system to a Defense Information Systems Agency (DISA)-compliant Linux operating system."
|
||||
|
||||
'G/ATOR is an expeditionary, three-dimensional, short-to-medium-range multi-role radar system designed to detect low-observable targets with low radar cross sections such as rockets, artillery, mortars, cruise missiles, and UAVs," reads the entry on [militaryaerospace.com][1].
|
||||
|
||||
This piece of military technology, the Ground/Air Task-Oriented Radar (G/ATOR) was first contracted from the Northrop Grumman Corp. back in 2005, so it's easy to understand why the US Marines might want to hurry this up. No time frame has been proposed for the switch.
|
||||
|
||||
视频链接:[http://youtu.be/H2ppl4x-eu8][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/U-S-Marine-Corps-Want-to-Change-OS-for-Radar-System-from-Windows-XP-to-Linux-466756.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://www.militaryaerospace.com/articles/2014/12/gator-linux-software.html
|
||||
[2]:http://youtu.be/H2ppl4x-eu8
|
||||
@ -0,0 +1,22 @@
|
||||
Getting Started With Ubuntu 14.04 (PDF Guide)
|
||||
================================================================================
|
||||
Become familiar with everyday tasks such as surfing the web, listening to music and scanning documents.
|
||||
|
||||
Enjoy this comprehensive beginners guide for the Ubuntu operating system. With easy-to-follow instructions, this guide is suitable for all levels of experience. Discover the potential of your Ubuntu system without getting bogged down with technical details.
|
||||
|
||||
- [**Getting Started With Ubuntu 14.04 (PDF Guide)**][1]
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/getting-started-with-ubuntu-14-04-pdf-guide.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://ubuntugeek.tradepub.com/free/w_ubun06/
|
||||
@ -0,0 +1,32 @@
|
||||
Nathive – A libre software image editor
|
||||
================================================================================
|
||||
Nathive is a libre software image editor, similar to Adobe Photoshop, Corel Photo-Paint or GIMP, but focused on usability, logic and providing a smooth learning curve for everyone. The project runs in the GNOME desktop environment and anyone is welcome to collaborate on it with code, translations or ideas.
|
||||
|
||||
This project is in beta phase, so it is an incomplete work, unfit for the end user yet. Until now the development was focused in laying down the application core and create easy dev tools, so for now we will focus on create new plugins, because there are obvious lacks yet.
|
||||
|
||||
The intention is to achieve a professional image editor progressively without giving up initial usability. Nathive is written from scratch in Python using GTK+, and is designed to be simple, lightweight, and easy to install and use.
|
||||
|
||||
### Install Nathive on ubuntu ###
|
||||
|
||||
You need to download .deb package from [here][1] .Once you have deb package you can double click to install
|
||||
|
||||
### Screenshots ###
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/nathive-a-libre-software-image-editor.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.nathive.org/download
|
||||
@ -1,56 +0,0 @@
|
||||
翻译中 by coloka
|
||||
Four ways Linux is headed for no-downtime kernel patching
|
||||
================================================================================
|
||||

|
||||
Credit: Shutterstock
|
||||
|
||||
These technologies are competing to provide the best way to patch the Linux kernel without reboots or downtime
|
||||
|
||||
Nobody loves a reboot, especially not if it involves a late-breaking patch for a kernel-level issue that has to be applied stat.
|
||||
|
||||
To that end, three projects are in the works to provide a mechanism for upgrading the kernel in a running Linux instance without having to reboot anything.
|
||||
|
||||
### Ksplice ###
|
||||
|
||||
The first and original contender is Ksplice, courtesy of a company of the same name founded in 2008. The kernel being replaced does not have to be pre-modified; all it needs is a diff file listing the changes to be made to the kernel source. Ksplice, Inc. offered support for the (free) software as a paid service and supported most common Linux distributions used in production.
|
||||
|
||||
All that changed in 2011, when [Oracle purchased the company][1], rolled the feature into its own Linux distribution, and kept updates for the technology to itself. As a result, other intrepid kernel hackers have been looking for ways to pick up where Ksplice left off, without having to pay the associated Oracle tax.
|
||||
|
||||
### Kgraft ###
|
||||
|
||||
In February 2014, Suse provided the exact solution needed: [Kgraft][2], its kernel-update technology released under a mixed GPLv2/GPLv3 license and not kept close as a proprietary creation. It's since been [submitted][3] as a possible inclusion to the mainline Linux kernel, although Suse has rolled a version of the technology into [Suse Linux Enterprise Server 12][4].
|
||||
|
||||
Kgraft works roughly like Ksplice by using a set of diffs to figure out what parts of the kernel to replace. But unlike Ksplice, Kgraft doesn't need to stop the kernel entirely to replace it. Any running functions can be directed to their old or new kernel-level counterparts until the patching process is finished.
|
||||
|
||||
### Kpatch ###
|
||||
|
||||
Red Hat came up with its own no-reboot kernel-patch mechanism, too. Also introduced earlier this year -- right after Suse's work in that vein, no less -- [Kpatch][5] works in roughly the same manner as Kgraft.
|
||||
|
||||
The main difference, [as outlined][6] by Josh Poimboeuf of Red Hat, is that Kpatch doesn't redirect calls to old kernel functions. Rather, it waits until all function calls have stopped, then swaps in the new kernel. Red Hat's engineers consider this approach safer, with less code to maintain, albeit at the cost of more latency during the patch process.
|
||||
|
||||
Like Kgraft, Kpatch has been submitted for consideration as a possible kernel inclusion and can be used with Linux kernels other than Red Hat's. The bad news is that Kpatch isn't yet considered production-ready by Red Hat. It's included as part of Red Hat Enterprise Linux 7, but only in the form of a technology preview.
|
||||
|
||||
### ...or Kgraft + Kpatch? ###
|
||||
|
||||
A fourth solution [proposed by Red Hat developer Seth Jennings][7] early in November 2014 is a mix of both the Kgraft and Kpatch approaches, using patches built for either one of those solutions. This new approach, Jennings explained, "consists of a live patching 'core' that provides an interface for other 'patch' kernel modules to register patches with the core." This way, the patching process -- specifically, how to deal with any running kernel functions -- can be handled in a more orderly fashion.
|
||||
|
||||
The sheer newness of these proposals means it'll be a while before any of them are officially part of the Linux kernel, although Suse's chosen to move fast and made it a part of its latest enterprise offering. Let's see if Red Hat and Canonical choose to follow suit in the short run as well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-for-no-downtime-kernel-patching.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]:http://www.infoworld.com/article/2622437/open-source-software/oracle-buys-ksplice-for-linux--zero-downtime--tech.html
|
||||
[2]:http://www.infoworld.com/article/2610749/linux/suse-open-sources-live-updater-for-linux-kernel.html
|
||||
[3]:https://lwn.net/Articles/596854/
|
||||
[4]:http://www.infoworld.com/article/2838421/linux/suse-linux-enterprise-12-goes-light-on-docker-heavy-on-reliability.html
|
||||
[5]:https://github.com/dynup/kpatch
|
||||
[6]:https://lwn.net/Articles/597123/
|
||||
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||
@ -1,3 +1,4 @@
|
||||
disylee占个坑~
|
||||
Docker: Present and Future
|
||||
================================================================================
|
||||
### Docker - the story so far ###
|
||||
@ -153,4 +154,4 @@ via: http://www.infoq.com/articles/docker-future
|
||||
[38]:https://coreos.com/
|
||||
[39]:http://www.projectatomic.io/
|
||||
[40]:https://github.com/coreos/fleet
|
||||
[41]:https://github.com/coreos/etcd
|
||||
[41]:https://github.com/coreos/etcd
|
||||
|
||||
@ -0,0 +1,49 @@
|
||||
CoreOS Team Develops Rocket, Breaks with Docker
|
||||
================================================================================
|
||||

|
||||
|
||||
[Docker][1] has easily emerged as one of the top open source stories of the year, and has helped many organizations [benefit from container technology][2]. As we’ve reported, even Google is [working closely][3] with it, and Microsoft is as well.
|
||||
|
||||
However, the folks behind CoreOS, a very popular Linux flavor for use in cloud deployments, are developing their own container technology, [dubbed Rocket][4], which will actually compete with Docker. Here are the details.
|
||||
|
||||
Rocket is a new container runtime, designed for composability, security, and speed, according to the CoreOS team. The group has released a [prototype version on GitHub][5] to begin getting community feedback.
|
||||
|
||||
“When Docker was first introduced to us in early 2013, the idea of a “standard container” was striking and immediately attractive: a simple component, a composable unit, that could be used in a variety of systems. The Docker repository [included a manifesto][6] of what a standard container should be. This was a rally cry to the industry, and we quickly followed. We thought Docker would become a simple unit that we can all agree on.”
|
||||
|
||||
“Unfortunately, a simple re-usable component is not how things are playing out. Docker now is building tools for launching cloud servers, systems for clustering, and a wide range of functions: building images, running images, uploading, downloading, and eventually even overlay networking, all compiled into one monolithic binary running primarily as root on your server. The standard container manifesto [was removed][7]. We should stop talking about Docker containers, and start talking about the Docker Platform.”
|
||||
|
||||
“We still believe in the original premise of containers that Docker introduced, so we are doing something about it. Rocket is a command line tool, rkt, for running App Containers. An ‘App Container’ is the specification of an image format, container runtime, and a discovery mechanism.”
|
||||
|
||||
There is a specification coming for App Container Images (ACI). Anyone can [Read about and contribute to the ACI draft][8].
|
||||
|
||||
The Register also [notes this interesting aspect][9] of Rocket:
|
||||
|
||||
“Significantly, all of CoreOS's tools for working with App Container will be integrated, yet independent from one another. Rocket can run as a standalone tool on any flavor of Linux, not just CoreOS.”
|
||||
|
||||
In a [blog post][10], Docker CEO Ben Golub voiced disagreement with CoreOS's move, and he writes:
|
||||
|
||||
“There are technical or philosophical differences, which appears to be the case with the recent announcement regarding Rocket. We hope to address some of the technical arguments posed by the Rocket project in a subsequent post.”
|
||||
|
||||
It sounds like a standards skirmish is going to come of all this, but, as is often the case with standards confrontations, users may benefit from the competition.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/coreos-team-develops-rocket-breaks-with-docker
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/samdean
|
||||
[1]:https://www.docker.com/
|
||||
[2]:http://ostatic.com/blog/linux-containers-with-docker
|
||||
[3]:http://ostatic.com/blog/google-sets-sights-squarely-on-docker-with-new-container-engine
|
||||
[4]:https://coreos.com/blog/rocket/
|
||||
[5]:https://github.com/coreos/rocket
|
||||
[6]:https://github.com/docker/docker/commit/0db56e6c519b19ec16c6fbd12e3cee7dfa6018c5
|
||||
[7]:https://github.com/docker/docker/commit/eed00a4afd1e8e8e35f8ca640c94d9c9e9babaf7
|
||||
[8]:https://github.com/coreos/rocket/blob/master/app-container/SPEC.md#app-container-image
|
||||
[9]:http://www.theregister.co.uk/2014/12/01/coreos_rocket_announcement/
|
||||
[10]:http://blog.docker.com/2014/12/initial-thoughts-on-the-rocket-announcement/
|
||||
@ -0,0 +1,57 @@
|
||||
Interview: Apache Software Foundation Elevates Drill to Top-Level Project
|
||||
================================================================================
|
||||

|
||||
|
||||
The Apache Software Foundation (ASF) has [announced][1] that [Apache Drill][2] has graduated from the Apache Incubator to become a Top-Level Project (TLP).
|
||||
|
||||
Apache Drill is billed as the world's first schema-free SQL query engine that delivers real-time insights by removing the constraint of building and maintaining schemas before data can be analyzed.
|
||||
|
||||
Drill enables rapid application development on Apache Hadoop and also allows enterprise BI analysts to access Hadoop in a self-service fashion. OStatic caught up with Tomer Shiran (shown here), a member of the Drill Project Management Committee, to get his thoughts. Here they are in an interview.
|
||||
|
||||
**Can you provide a brief overview of what Drill is and what kinds of users it can make a difference for?**
|
||||
|
||||
Drill is the world's first distributed, schema-free SQL engine. Analysts and developers can use Drill to interactively explore data in Hadoop and other NoSQL databases, such as HBase and MongoDB. There's no need to explicitly define and maintain schemas, as Drill can automatically leverage the structure that's embedded in the data.
|
||||
|
||||
This enables self-service data exploration, which is not possible with traditional data warehouses or SQL-on-Hadoop solutions like Hive and Impala, in which DBAs must manage schemas and transform the data before it can be analyzed.
|
||||
|
||||
**What level of community involvement with Drill already exists?**
|
||||
|
||||
Drill is an Apache project, so it's not owned by any vendor. Developers in the community can contribute to Drill. MapR currently employs the largest number of contributors, but we're seeing an increasing number of contributions from other companies, and that trend has been accelerating in recent months.
|
||||
|
||||
For example, the MongoDB storage plugin (enabling queries on MongoDB) was contributed by developers at Intuit.
|
||||
|
||||
**Hadoop has a lot of momentum on the Big Data front. How can Drill help organizations leveraging Hadoop?**
|
||||
|
||||
Drill is the ideal interactive SQL engine for Hadoop. One of the main reasons organizations choose Hadoop is due to its flexibility and agility. Unlike traditional databases, getting data into Hadoop is easy, and users can load data in any shape or size on their own. Early attempts at SQL on Hadoop (eg, Hive, Impala) force schemas to be created and maintained even for self-describing data like JSON, Parquet and HBase tables.
|
||||
|
||||
These systems also require data to be transformed before it can be queried. Drill is the only SQL engine for Hadoop that doesn't force schemas to be defined before data can be queried, and doesn't require any data transformations. In other words, Drill maintains the flexibility and agility paradigms that made Hadoop popular, thus making it the natural technology for data exploration and BI on Hadoop.
|
||||
|
||||
**What does Drill's status as a top-level project at Apache mean for its development and future?**
|
||||
|
||||
Drill's graduation to a top-level project is an indication that Drill has established a strong community of users and developers. Graduation is a decision made by the Apache Software Foundation (ASF) board, and it provides confidence to Drill's potential users and contributors that the project has a strong foundation. From a governance standpoint, a top-level project has its own board (also known as PMC). The PMC Chair (Jacques Nadeau) is a VP at Apache.
|
||||
|
||||
**How do you think Drill will evolve over the next several years?**
|
||||
|
||||
Drill has a large and growing community of contributors. Drill 1.0 will be out in Q1'15. We'll see many new features over the next several years. Here are a just a few examples of initiatives that are currently under way:
|
||||
|
||||
Drill currently supports HDFS, HBase and MongoDB. Additional data sources are being added, including Cassandra and RDBMS (all JDBC-enabled databases, including Oracle and MySQL). A single query can incorporate/join data from different sources. In the next year, Drill will become the standard SQL engine for modern datastores (which are all schema-free in nature): Hadoop, NoSQL databases - HBase/MongoDB/Cassandra, and search - Elasticsearch/Solr.
|
||||
|
||||
A single enterprise or cloud provider will be able to serve multiple groups/departments/organizations, each having its own workloads and SLA requirements. For example, in Drill 1.0 will support user impersonation, meaning that a query can only access the data that the user is authorized to access, and this will work with all supported data sources (Hadoop, HBase, MongoDB, etc.)
|
||||
|
||||
Drill will support not only SELECT and CREATE TABLE ... AS SELECT (CTAS) queries, but also INSERT/UPDATE/DELETE, enabling Drill to be used for operational applications (in addition to data exploration and analytics). Drill will also support the ultra-low latency and high concurrency required for such use cases.
|
||||
|
||||
Full TPC-DS support. Unlike other SQL-on-Hadoop technologies, Drill is designed to support the ANSI SQL standard as opposed to a SQL-like language. This provides better support for BI and other tools. Drill will be able to run TPC-DS, unmodified, in 2015.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/interview-apache-software-foundation-elevates-drill-to-top-level-project
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/samdean
|
||||
[1]:https://blogs.apache.org/foundation/entry/the_apache_software_foundation_announces66
|
||||
[2]:http://drill.apache.org/
|
||||
@ -1,76 +0,0 @@
|
||||
Translating by JonathanKang
|
||||
How to Install and Setup ‘My Weather Indicator’ in Ubuntu 14.10
|
||||
================================================================================
|
||||

|
||||
|
||||
**There’s no drought of ways to be kept abreast of the weather on the Ubuntu desktop, with the Unity Dash and desktop apps like [Typhoon][1] all offering to help.**
|
||||
|
||||
But panel applets that offer quick glance condition and temperature stats, with a ream of detailed meteorological data never more than a quick click away, are by far the most popular weather utilities on Linux.
|
||||
|
||||
[My Weather Indicator][2] by Atareao is one of this breed, and arguably the best.
|
||||
|
||||
It displays current temperature and conditions on the Unity panel, and has a menu stuffed full of stats, including ‘feels like’, cloudiness and sunrise/set times. In addition, there’s a desktop widget, multiple location support, a choice of backend data providers, and plenty of configuration options.
|
||||
|
||||
Sounds pretty comprehensive, right? Let’s walk through how to install and set it up on Ubuntu.
|
||||
|
||||
### Install My Weather Indicator in Ubuntu ###
|
||||
|
||||
My Weather Indicator is not available to install from the Ubuntu Software Center directly, but both a .deb installer and an officially maintained PPA (providing packages for both Ubuntu 14.04 LTS and 14.10) are provided by the developers.
|
||||
|
||||
- Download My Weather Indicator (.deb)
|
||||
|
||||
To ensure you’re always kept up-to-date with the latest release I recommend adding the [Atareao PPA][3] to your Software Sources and installing from there.
|
||||
|
||||
How? **Open a new Terminal** window (Unity Dash > Terminal, or press Ctrl+Alt+T) and **enter the following two commands carefully**, entering your system password when prompted:
|
||||
|
||||
sudo add-apt-repository ppa:atareao/atareao
|
||||
|
||||
sudo apt-get update && sudo apt-get install my-weather-indicator
|
||||
|
||||
#### Setting Up My Weather Indicator ####
|
||||
|
||||
Regardless of how you install the tool, once you have you can launch it from the Unity Dash by searching for “weather”.
|
||||
|
||||

|
||||
|
||||
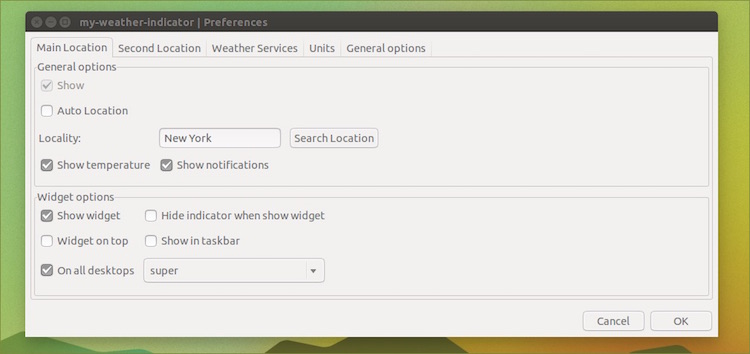
The first time you open the app the following Preferences window will open. From here you can search for a location manually or set it to auto-detect using geo-ip — the latter of which can sometimes be a little imprecise, but saves the need to faff.
|
||||
|
||||
|
||||
|
||||
If you’re travelling (or in need of some small talk fodder) **you can monitor a second locale**, too. This is set up in the same way as the first but in the ‘Second Location’ tab.
|
||||
|
||||
Checking the ‘**Show Widget**’ box in the “**Widget Options**” section adds a small forecast desklet to your desktop. There are a number of different skins included, so be sure to play around to find the one you like the most (note: widget changes are applied on clicking ‘Ok’).
|
||||
|
||||
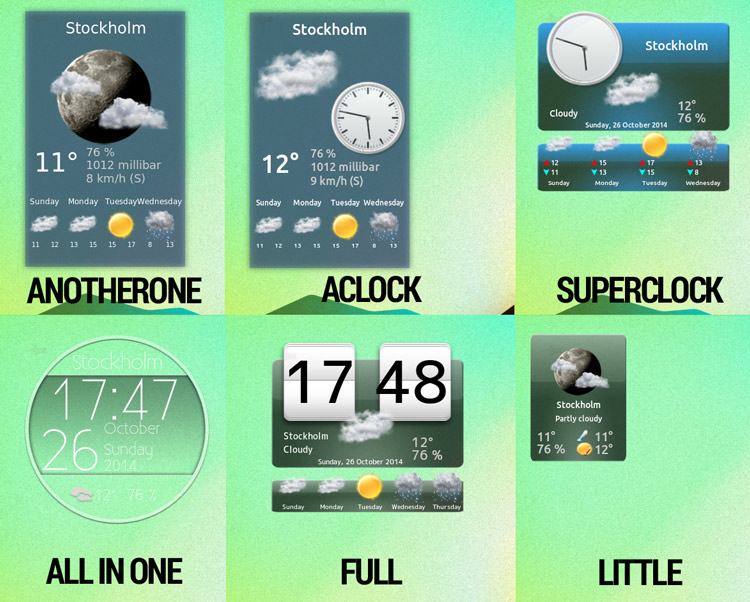
|
||||
|
||||
My Weather Indicator uses [Open Weather Map][4] as its forecast backend by default, but other options can be selected from the ‘**Weather Services**’ pane (*require an API key to function):
|
||||
|
||||
- Open Weather Map
|
||||
- Yahoo! Weather
|
||||
- Weather Underground*
|
||||
- World Weather Online*
|
||||
|
||||
The ‘**Units**’ tab is where you can configure measurements for temperature, pressure, wind speed, etc. These are applied globally to all configured locations; you can’t have one location in Celsius and the other in Fahrenheit.
|
||||
|
||||

|
||||
|
||||
Finally, in the ‘General Options‘ section you can set the refresh interval, set autostart preference, and choose from one of two panel icons.
|
||||
|
||||
MWI not your thing? Why not try [the nerdy way to view weather forecasts on Linux][5]?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/install-weather-indicator-ubuntu-14-10
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://launchpad.net/typhoon
|
||||
[2]:https://launchpad.net/my-weather-indicator
|
||||
[3]:https://launchpad.net/~atareao/+archive/ubuntu/atareao
|
||||
[4]:http://openweathermap.org/
|
||||
[5]:http://www.omgubuntu.co.uk/2014/02/get-weather-forecast-terminal-linux
|
||||
@ -1,86 +0,0 @@
|
||||
How To Run Linux Programs From The Terminal In Background Mode
|
||||
================================================================================
|
||||

|
||||
|
||||
Linux Terminal Window.
|
||||
|
||||
This is a short but useful guide to show how to run Linux applications from the terminal whilst allowing the terminal to retain control.
|
||||
|
||||
There are various ways of opening a terminal window in Linux and it largely depends on your choice of distribution and the desktop environment.
|
||||
|
||||
Using Ubuntu you can open a terminal by using the CTRL + ALT + T key combination. You can also open a terminal window by pressing the super key (Windows Key), on the keyboard, to [bring up the Dash][1] and search for "TERM". Clicking on the "Term" icon will open a terminal window.
|
||||
|
||||
For other desktop environments such as XFCE, KDE, LXDE, Cinnamon and MATE you will find the terminal within the menu. Some distributions will have a terminal icon in a dock or as a launcher on a panel.
|
||||
|
||||
You can generally start an application from the terminal by simply entering the name of the program. For instance you can start Firefox by typing "firefox".
|
||||
|
||||
The benefit of running an application from the terminal is that you can include additional options.
|
||||
|
||||
For instance if you type the following a new Firefox browser window will open and the default search engine will be used to search for the term between quotes:
|
||||
|
||||
firefox -search "Linux.About.Com"
|
||||
|
||||
You will notice that if you run Firefox, the application will open and the control will be returned to the terminal which means you can continue working within the terminal.
|
||||
|
||||
Generally if you run an application from within the terminal, the application will open and you won't regain control of the terminal until the application is closed. This is because you opened the program in the foreground.
|
||||
|
||||
To be able to open a program in the Linux terminal and return control to the terminal you need to open the application as a background process,
|
||||
|
||||
In order to open a program as a background process simply add the ampersand (&) symbol to the command as shown below:
|
||||
|
||||
libreoffice &
|
||||
|
||||
An application might not run just by providing the program's name in the terminal. If the program doesn't reside in one of the folders set within the PATH variable then you will need to specify the whole path name in order to run the program.
|
||||
|
||||
/path/to/yourprogram &
|
||||
|
||||
If you aren't sure where a program resides within the Linux folder structure use the find or [locate][2] command to find the application.
|
||||
|
||||
The syntax for finding a file is as follows:
|
||||
|
||||
find /path/to/start/from -name programname
|
||||
|
||||
For instance if you wanted to find the location of Firefox use the following command:
|
||||
|
||||
find / -name firefox
|
||||
|
||||
The output will whizz past quite quickly and so you will want to pipe the output to either [less][3] or [more][4] as follows:
|
||||
|
||||
find / -name firefox | more
|
||||
|
||||
find / -name firefox | less
|
||||
|
||||
The find command will return a number of permission denied errors for folders that you don't have permissions to search.
|
||||
|
||||
You can alway provide the [sudo command to elevate your permissions][5]. If sudo isn't installed you will need to switch to a user that has permissions.
|
||||
|
||||
sudo find / -name firefox | more
|
||||
|
||||
If you know that the file you are looking for is within the folder structure in which you are currently located then you can replace the forward slash with a period as follows:
|
||||
|
||||
sudo find . -name firefox | more
|
||||
|
||||
You may or may not need the elevated permissions provided by sudo. If you are looking for something within your home folder structure then it won't be required.
|
||||
|
||||
Some applications require elevated permissions to run and you may get a lack of permissions error unless you use either a user with adequate permissions or elevate those permissions using sudo.
|
||||
|
||||
Here is a neat trick. If you run an application and it requires elevated permissions to run, type the following:
|
||||
|
||||
sudo !!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-The-Terminal-In-Background-Mode.htm
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linux.about.com/bio/Gary-Newell-132058.htm
|
||||
[1]:http://linux.about.com/od/howtos/fl/Learn-Ubuntu-The-Unity-Dash.htm
|
||||
[2]:http://linux.about.com/od/commands/l/blcmdl1_locate.htm
|
||||
[3]:http://linux.about.com/library/cmd/blcmdl1_less.htm
|
||||
[4]:http://linux.about.com/library/cmd/blcmdl1_more.htm
|
||||
[5]:http://linux.about.com/od/commands/l/blcmdl8_sudo.htm
|
||||
@ -0,0 +1,131 @@
|
||||
[su-kaiyao]translating
|
||||
|
||||
10 ‘free’ Commands to Check Memory Usage in Linux
|
||||
================================================================================
|
||||
**Linux** is one of the most popular open source operating system and comes with huge set of commands. The most important and single way of determining the total available space of the **physical memory** and **swap memory** is by using “**free**” command.
|
||||
|
||||
The Linux “**free**” command gives information about total used and available space of **physical memory** and **swap memory** with **buffers** used by kernel in **Linux/Unix** like operating systems.
|
||||
|
||||

|
||||
|
||||
This article provides some useful examples of “**free**” commands with options, that might be useful for you to better utilize memory that you have.
|
||||
|
||||
### 1. Display System Memory ###
|
||||
|
||||
Free command used to check the used and available space of **physical memory** and **swap memory** in **KB**. See the command in action below.
|
||||
|
||||
# free
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912548 109080 0 120368 655548
|
||||
-/+ buffers/cache: 136632 884996
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
### 2. Display Memory in Bytes ###
|
||||
|
||||
Free command with option **-b**, display the size of memory in **Bytes**.
|
||||
|
||||
# free -b
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 1046147072 934420480 111726592 0 123256832 671281152
|
||||
-/+ buffers/cache: 139882496 906264576
|
||||
Swap: 4294959104 0 4294959104
|
||||
|
||||
### 3. Display Memory in Kilo Bytes ###
|
||||
|
||||
Free command with option **-k**, display the size of memory in (KB) **Kilobytes**.
|
||||
|
||||
# free -k
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
-/+ buffers/cache: 136604 885024
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
### 4. Display Memory in Megabytes ###
|
||||
|
||||
To see the size of the memory in **(MB) Megabytes** use option as **-m**.
|
||||
|
||||
# free -m
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 997 891 106 0 117 640
|
||||
-/+ buffers/cache: 133 864
|
||||
Swap: 4095 0 4095
|
||||
|
||||
### 5. Display Memory in Gigabytes ###
|
||||
|
||||
Using **-g** option with free command, would display the size of the memory in **GB(Gigabytes)**.
|
||||
|
||||
# free -g
|
||||
total used free shared buffers cached
|
||||
Mem: 0 0 0 0 0 0
|
||||
-/+ buffers/cache: 0 0
|
||||
Swap: 3 0 3
|
||||
|
||||
### 6. Display Total Line ###
|
||||
|
||||
Free command with -t option, will list the total line at the end.
|
||||
|
||||
# free -t
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
-/+ buffers/cache: 136604 885024
|
||||
Swap: 4194296 0 4194296
|
||||
Total: 5215924 912520 4303404
|
||||
|
||||
### 7. Disable Display of Buffer Adjusted Line ###
|
||||
|
||||
By default the free command display “**buffer adjusted**” line, to disable this line use option as -o.
|
||||
|
||||
# free -o
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
### 8. Dispaly Memory Status for Regular Intervals ###
|
||||
|
||||
The -s option with number, used to update free command at regular intervals. For example, the below command will update free command every 5 seconds.
|
||||
|
||||
# free -s 5
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912368 109260 0 120368 655548
|
||||
-/+ buffers/cache: 136452 885176
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
### 9. Show Low and High Memory Statistics ###
|
||||
|
||||
The -l switch displays detailed high and low memory size statistics.
|
||||
|
||||
# free -l
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912368 109260 0 120368 655548
|
||||
Low: 890036 789064 100972
|
||||
High: 131592 123304 8288
|
||||
-/+ buffers/cache: 136452 885176
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
### 10. Check Free Version ###
|
||||
|
||||
The -V option, display free command version information.
|
||||
|
||||
# free -V
|
||||
|
||||
procps version 3.2.8
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/check-memory-usage-in-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
@ -0,0 +1,145 @@
|
||||
How To Create A Bootable Ubuntu USB Drive For Mac In OS X
|
||||
================================================================================
|
||||

|
||||
|
||||
I bought a Macbook Air yesterday after Dell lost my laptop from their service centre last month. And among the first few things I did was to dual boot Mac OS X with Ubuntu Linux. I’ll cover up Linux installation on Macbook in later articles as first we need to learn **how to create a bootable Ubuntu USB drive for Mac in OS X**.
|
||||
|
||||
While it is fairly easy to create a bootable USB in Ubuntu or in Windows, it is not the same story in Mac OS X. This is why the official Ubuntu guide suggest to use a disk rather than USB for live Ubuntu in Mac. Considering my Macbook Air neither has a CD drive nor do I possess a DVD, I preferred to create a live USB in Mac OS X.
|
||||
|
||||
### Create a Bootable Ubuntu USB Drive in Mac OS X ###
|
||||
|
||||
As I said earlier, creating a bootable USB in Mac OS X is a tricky procedure, be it for Ubuntu or any other bootable OS. But don’t worry, following all the steps carefully will have you going. Let’s see what you need to for a bootable USB:
|
||||
|
||||
#### Step 1: Format the USB drive ####
|
||||
|
||||
Apple is known for defining its own standards and no surprises that Mac OS X has its own file system type known as Mac OS Extended or [HFS Plus][1]. So the first thing you would need to do is to format your USB drive in Mac OS Extended format.
|
||||
|
||||
To format the USB drive, plug in the USB key. Go to **Disk Utility** program from Launchpad (A rocket symboled icon in the bottom plank).
|
||||
|
||||

|
||||
|
||||
- In Disk Utility, from the left hand pane, select the USB drive to format.
|
||||
- Click the **Partition** tab in the right side pane.
|
||||
- From the drop-down menu, select **1 Partition**.
|
||||
- Name this drive anything you desire.
|
||||
- Next, change the **Format to Mac OS Extended (Journaled)**
|
||||
|
||||
The screenshot below should help you.
|
||||
|
||||

|
||||
|
||||
There is one last thing to do before we go with formatting the USB. Click the Options button in the right side pane and make sure that the partition scheme is **GUID Partition Table**.
|
||||
|
||||

|
||||
|
||||
When all is set to go, just hit the **Apply** button. It will give you a warning message about formatting the USB drive. Of course hit the Partition button to format the USB drive.
|
||||
|
||||
#### Step 2: Download Ubuntu ####
|
||||
|
||||
Of course, you need to download ISO image of Ubuntu desktop. Jump to [Ubuntu website to download your favorite Ubuntu desktop OS][2]. Since you are using a Macbook Air, I suggest you to download the 64 Bit version of whichever version you want. Ubuntu 14.04 is the latest LTS version, and this is what I would recommend to you.
|
||||
|
||||
#### Step 3: Convert ISO to IMG ####
|
||||
|
||||
The file you downloaded is in ISO format but we need it to be in IMG format. This can be easily done using [hdiutil][3] command tool. Open a terminal, either from Launchpad or from the Spotlight, and then use the following command to convert the ISO to IMG format:
|
||||
|
||||
hdiutil convert -format UDRW -o ~/Path-to-IMG-file ~/Path-to-ISO-file
|
||||
|
||||
Normally the downloaded file should be in ~/Downloads directory. So for me, the command is like this:
|
||||
|
||||
hdiutil convert -format UDRW -o ~/Downloads/ubuntu-14.10-desktop-amd64 ~/Downloads/ubuntu-14.10-desktop-amd64.iso
|
||||
|
||||

|
||||
|
||||
You might notice that I did not put a IMG extension to the newly converted file. It is fine as the extension is symbolic and it is the file type that matters not the file name extension. Also, the converted file may have an additional .dmg extension added to it by Mac OS X. Don’t worry, it’s normal.
|
||||
|
||||
#### Step 4: Get the device number for USB drive ####
|
||||
|
||||
The next thing is to get the device number for the USB drive. Run the following command in terminal:
|
||||
|
||||
diskutil list
|
||||
|
||||
It will list all the ‘disks’ currently available in the system. You should be able to identify the USB disk by its size. To avoid confusion, I would suggest that you should have just one USB drive plugged in. In my case, the device number is 2 (for a USB of size 8 GB): /dev/disk2
|
||||
|
||||

|
||||
|
||||
When you got the disk number, run the following command:
|
||||
|
||||
diskutil unmountDisk /dev/diskN
|
||||
|
||||
Where N is the device number for the USB you got previously. So, in my case, the above command becomes:
|
||||
|
||||
diskutil unmountDisk /dev/disk2
|
||||
|
||||
The result should be: **Unmount of all volumes on disk2 was successful**.
|
||||
|
||||
#### Step 5: Creating the bootable USB drive of Ubuntu in Mac OS X ####
|
||||
|
||||
And finally we come to the final step of creating the bootable USB drive. We shall be using [dd command][4] which is a very powerful and must be used with caution. Therefore, do remember the correct device number of your USB drive or else you might end up corrupting Mac OS X. Use the following command in terminal:
|
||||
|
||||
sudo dd if=/Path-to-IMG-DMG-file of=/dev/rdiskN bs=1m
|
||||
|
||||
Here, we are using dd (copy and convert) to copy and convert input file (if) IMG to diskN. I hope you remember where you put the converted IMG file, in step 3. For me the command was like this:
|
||||
|
||||
sudo dd if=~/Downloads/ubuntu-14.10-desktop-amd64.dmg of=/dev/rdisk2 bs=1m
|
||||
|
||||
As we are running the above command with super user privileges (sudo), it will require you to enter the password. Similar to Linux, you won’t see any asterisks or something to indicate that you have entered some keyboard input, but that’s the way Unix terminal behaves.
|
||||
|
||||
Even after you enter the password, **you won’t see any immediate output and that’s norma**l. It will take a few minutes for the process to complete.
|
||||
|
||||
#### Step 6: Complete the bootable USB drive process ####
|
||||
|
||||
Once the dd command finishes its process, you may see a dialogue box saying: **The disk you inserted was not readable by this computer**.
|
||||
|
||||

|
||||
|
||||
Don’t panic. Everything is just fine. Just **don’t click either of Initialize, Ignore or Eject just now**. Go back to the terminal. You’ll see some information about the last completed process. For me it was:
|
||||
|
||||
> 1109+1 records in
|
||||
> 1109+1 records out
|
||||
> 1162936320 bytes transferred in 77.611025 secs (14984164 bytes/sec)
|
||||
|
||||

|
||||
|
||||
Now, in the terminal use the following command to eject our USB disk:
|
||||
|
||||
diskutil eject /dev/diskN
|
||||
|
||||
N is of course the device number we have used previously which is 2 in my case:
|
||||
|
||||
diskutil eject /dev/disk2
|
||||
|
||||
Once ejected, click on **Ignore** in the dialogue box that appeared previously. Now your bootable USB disk is ready. Remove it from the system.
|
||||
|
||||
#### Step 7: Checking your newly created bootable USB disk ####
|
||||
|
||||
Once you have completed the mammoth task of creating a live USB of USB in Mac OS X, it is time to test your efforts.
|
||||
|
||||
- Plugin the bootable USB and reboot the system.
|
||||
- At start up when the Apple tune starts up, press and hold option (or alt) key.
|
||||
- This should present you with the available disks to boot in to. I presume you know what to do next.
|
||||
|
||||
For me it showed tow EFI boot:
|
||||
|
||||

|
||||
|
||||
I selected the first one and it took me straight to Grub screen:
|
||||
|
||||

|
||||
|
||||
I hope this guide helped you to create a bootable USB disk of Ubuntu for Mac in OS X. We’ll see how to dual boot Ubuntu with OS X in next article. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/create-bootable-ubuntu-usb-drive-mac-os/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://en.wikipedia.org/wiki/HFS_Plus
|
||||
[2]:http://www.ubuntu.com/download/desktop
|
||||
[3]:https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/hdiutil.1.html
|
||||
[4]:http://en.wikipedia.org/wiki/Dd_%28Unix%29
|
||||
@ -0,0 +1,156 @@
|
||||
translating by coloka...
|
||||
|
||||
How to configure a syslog server with rsyslog on Linux
|
||||
================================================================================
|
||||
A syslog server represents a central log monitoring point on a network, to which all kinds of devices including Linux or Windows servers, routers, switches or any other hosts can send their logs over network. By setting up a syslog server, you can filter and consolidate logs from different hosts and devices into a single location, so that you can view and archive important log messages more easily.
|
||||
|
||||
On most Linux distributions, **rsyslog** is the standard syslog daemon that comes pre-installed. Configured in a client/server architecture, **rsyslog** can play both roles; as a syslog server **rsyslog** can gather logs from other devices, and as a syslog client, **rsyslog** can transmit its internal logs to a remote syslog server.
|
||||
|
||||
In this tutorial, we cover how to configure a centralized syslog server using **rsyslog** on Linux. Before we go into the details, it is instructive to go over syslog standard first.
|
||||
|
||||
### Basic of Syslog Standard ###
|
||||
|
||||
When logs are collected with syslog mechanism, three important things must be taken into consideration:
|
||||
|
||||
- **Facility level**: what type of processes to monitor
|
||||
- **Severity (priority) level**: what type of log messages to collect
|
||||
- **Destination**: where to send or record log messages
|
||||
|
||||
Let's take a look at how the configuration is defined in more detail.
|
||||
|
||||
The facility levels define a way to categorize internal system processes. Some of the common standard facilities in Linux are:
|
||||
|
||||
- **auth**: messages related to authentication (login)
|
||||
- **cron**: messages related to scheduled processes or applications
|
||||
- **daemon**: messages related to daemons (internal servers)
|
||||
- **kernel**: messages related to the kernel
|
||||
- **mail**: messages related to internal mail servers
|
||||
- **syslog**: messages related to the syslog daemon itself
|
||||
- **lpr**: messages related to print servers
|
||||
- **local0 - local7**: messages defined by user (local7 is usually used by Cisco and Windows servers)
|
||||
|
||||
The severity (priority) levels are standardized, and defined by using standard abbreviation and an assigned number with number 7 being the highest level of all. These levels are:
|
||||
|
||||
- emerg: Emergency - 0
|
||||
- alert: Alerts - 1
|
||||
- crit: Critical - 2
|
||||
- err: Errors - 3
|
||||
- warn: Warnings - 4
|
||||
- notice: Notification - 5
|
||||
- info: Information - 6
|
||||
- debug: Debugging - 7
|
||||
|
||||
Finally, the destination statement enforces a syslog client to perform one of three following tasks: (1) save log messages on a local file, (2) route them to a remote syslog server over TCP/UDP, or (3) send them to stdout such as a console.
|
||||
|
||||
In rsyslog, syslog configuration is structured based on the following schema.
|
||||
|
||||
[facility-level].[severity-level] [destination]
|
||||
|
||||
### Configure Rsyslog on Linux ###
|
||||
|
||||
Now that we understand syslog, it's time to configure a Linux server as a central syslog server using rsyslog. We will also see how to configure a Windows based system as a syslog client to send internal logs to the syslog server.
|
||||
|
||||
#### Step One: Initial System Requirements ####
|
||||
|
||||
To set up a Linux host as a central log server, we need to create a separate /var partition, and allocate a large enough disk size or create a LVM special volume group. That way, the syslog server will be able to sustain the exponential growth of collected logs over time.
|
||||
|
||||
#### Step Two: Enable Rsyslog Daemon ####
|
||||
|
||||
rsyslog daemon comes pre-installed on modern Linux distributions, but is not enabled by default. To enable rsyslog daemon to receive external messages, edit its configuration file located in /etc/rsyslog.conf.
|
||||
|
||||
Once the file is opened for editing, search and uncomment the below two lines by removing the # sign from the beginning of lines.
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
|
||||
This will enable rsyslog daemon to receive log messages on UDP port 514. UDP is way faster than TCP, but does not provide reliability on data flow the same way as TCP does. If you need to reliable delivery, you can enable TCP by uncommenting the following lines.
|
||||
|
||||
$ModLoad imtcp
|
||||
$InputTCPServerRun 514
|
||||
|
||||
Note that both TCP and UDP can be set on the server simultaneously to listen on TCP/UDP connections.
|
||||
|
||||
#### Step Three: Create a Template for Log Receipt ####
|
||||
|
||||
In the next step we need to create a template for remote messages, and tell rsyslog daemon how to record messages received from other client machines.
|
||||
|
||||
Open /etc/rsyslog.conf with a text editor, and append the following template before the GLOBAL DIRECTIVES block:
|
||||
|
||||
$template RemoteLogs,"/var/log/%HOSTNAME%/%PROGRAMNAME%.log" *
|
||||
*.* ?RemoteLogs
|
||||
& ~
|
||||
|
||||
This template needs a little explanation. The $template RemoteLogs directive ("RemoteLogs" string can be changed to any other descriptive name) forces rsyslog daemon to write log messages to separate local log files in /var/log/, where log file names are defined based on the hostname of the remote sending machine as well as the remote application that generated the logs. The second line ("*.* ?RemoteLogs") implies that we apply RemoteLogs template to all received logs.
|
||||
|
||||
The "& ~" sign represents a redirect rule, and is used to tell rsyslog daemon to stop processing log messages further, and not write them locally. If this redirection is not used, all the remote messages would be also written on local log files besides the log files described above, which means they would practically be written twice. Another consequence of using this rule is that the syslog server's own log messages would only be written to dedicated files named after machine's hostname.
|
||||
|
||||
If you want, you can direct log messages with a specific facility or severity level to this new template using the following schema.
|
||||
|
||||
[facility-level].[severity-level] ?RemoteLogs
|
||||
|
||||
For example:
|
||||
|
||||
Direct all internal authentication messages of all priority levels to RemoteLogs template:
|
||||
|
||||
authpriv.* ?RemoteLogs
|
||||
|
||||
Direct informational messages generated by all system processes, except mail, authentication and cron messages to RemoteLogs template:
|
||||
|
||||
*.info,mail.none,authpriv.none,cron.none ?RemoteLogs
|
||||
|
||||
If we want all received messages from remote clients written to a single file named after their IP address, you can use the following template. We assign a new name "IpTemplate" to this template.
|
||||
|
||||
$template IpTemplate,"/var/log/%FROMHOST-IP%.log"
|
||||
*.* ?IpTemplate
|
||||
& ~
|
||||
|
||||
After we have enabled rsyslog daemon and edited its configuration file, we need to restart the daemon.
|
||||
|
||||
On Debian, Ubuntu or CentOS/RHEL 6:
|
||||
|
||||
$ sudo service rsyslog restart
|
||||
|
||||
On Fedora or CentOS/RHEL 7:
|
||||
|
||||
$ sudo systemctl restart rsyslog
|
||||
|
||||
We can verify that rsyslog daemon is functional by using netstat command.
|
||||
|
||||
$ sudo netstat -tulpn | grep rsyslog
|
||||
|
||||
The output should look like the following in case rsyslog daemon listens on UDP port.
|
||||
|
||||
udp 0 0 0.0.0.0:514 0.0.0.0:* 551/rsyslogd
|
||||
udp6 0 0 :::514 :::* 551/rsyslogd
|
||||
|
||||
If rsyslog daemon is set up to listen on TCP connections, the output should look like this.
|
||||
|
||||
tcp 0 0 0.0.0.0:514 0.0.0.0:* LISTEN 1891/rsyslogd
|
||||
tcp6 0 0 :::514 :::* LISTEN 1891/rsyslogd
|
||||
|
||||
#### Send Windows Logs to a Remote Rsyslog Server ####
|
||||
|
||||
To forward a Windows based client's log messages to our rsyslog server, we need a Windows syslog agent. While there are a multitude of syslog agents that can run on Windows, we can use [Datagram SyslogAgent][1], which is a freeware program.
|
||||
|
||||
After downloading and installing the syslog agent, we need to configure it to run as a service. Specify the protocol though which it will send data, the IP address and port of a remote rsyslog server, and what type of event logs should be transmitted as follows.
|
||||
|
||||
|
||||
|
||||
After we have set up all the configurations, we can start the service and watch the log files on the central rsyslog server using tailf command line utility.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
By creating a central rsyslog server that can collect log files of local or remote hosts, we can get a better idea on what is going on internally in their systems, and can debug their problems more easily should any of them become unresponsive or crash.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-syslog-server-linux.html
|
||||
|
||||
作者:[Caezsar M][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/caezsar
|
||||
[1]:http://www.syslogserver.com/download.html
|
||||
@ -0,0 +1,248 @@
|
||||
SPccman translating
|
||||
How to create a custom backup plan for Debian with backupninja
|
||||
================================================================================
|
||||
Backupninja is a powerful and highly-configurable backup tool for Debian based distributions. In the [previous tutorial][1], we explored how to install backupninja and how to set up two backup actions for the program to perform. However, we should note that those examples were only "the tip of the iceberg," so to speak. In this post we will discuss how to leverage custom handlers and helpers that allow this program to be customized in order to accomplish almost any backup need that you can think of.
|
||||
|
||||
And believe me - that is not an overstatement, so let's begin.
|
||||
|
||||
### A Quick Review of Backupninja ###
|
||||
|
||||
One of backupninja's distinguishing features is the fact that you can just drop plain text configuration or action files in /etc/backup.d, and the program will take care of the rest. In addition, we can write custom scripts (aka "handlers") and place them in /usr/share/backupninja to handle each type of backup action. Furthermore, we can have these scripts be executed via ninjahelper's ncurses-based interactive menus (aka "helpers") to guide us to create the configuration files we mentioned earlier, minimizing the chances of human error.
|
||||
|
||||
### Creating a Custom Handler and Helper ###
|
||||
|
||||
Our goal in this case is to create a script to handle the backup of chosen home directories into a tarball with either **gzip** or **bzip2** compression, excluding music and video files. We will simply name this script home, and place it under /usr/backup/ninja.
|
||||
|
||||
Although you could achieve the same objective with the default tar handler (refer to /usr/share/backupninja/tar and /usr/share/backupninja/tar.helper), we will use this approach to show how to create a useful handler script and ncurses-based helper from scratch. You can then decide how to apply the same principles depending on your specific needs.
|
||||
|
||||
Note that since handlers are sourced from the main script, there is no need to start with #!/bin/bash at the top.
|
||||
|
||||
Our proposed handler (/usr/share/backupninja/home) is as follows. It is heavily commented for clarification. The getconf function is used to read the backup action's configuration file. If you specify a value for a variable here, it will override the corresponding value present in the configuration file:
|
||||
|
||||
# home handler script for backupninja
|
||||
|
||||
# Every backup file will identify the host by its FQDN
|
||||
getconf backupname
|
||||
|
||||
# Directory to store backups
|
||||
getconf backupdir
|
||||
|
||||
# Default compression
|
||||
getconf compress
|
||||
|
||||
# Include /home directory
|
||||
getconf includes
|
||||
|
||||
# Exclude files with *.mp3 and *.mp4 extensions
|
||||
getconf excludes
|
||||
|
||||
# Default extension for the packaged backup file
|
||||
getconf EXTENSION
|
||||
|
||||
# Absolute path to date binary
|
||||
getconf TAR `which tar`
|
||||
|
||||
# Absolute path to date binary
|
||||
getconf DATE `which date`
|
||||
|
||||
# Chosen date format
|
||||
DATEFORMAT="%Y-%m-%d"
|
||||
|
||||
# If backupdir does not exist, exit with fatal error
|
||||
if [ ! -d "$backupdir" ]
|
||||
then
|
||||
mkdir -p "$backupdir" || fatal "Can not make directory $backupdir"
|
||||
fi
|
||||
|
||||
# If backupdir is not writeable, exit with fatal error as well
|
||||
if [ ! -w "$backupdir" ]
|
||||
then
|
||||
fatal "Directory $backupdir is not writable"
|
||||
fi
|
||||
|
||||
# Set the right tar option as per the chosen compression format
|
||||
case $compress in
|
||||
"gzip")
|
||||
compress_option="-z"
|
||||
EXTENSION="tar.gz"
|
||||
;;
|
||||
"bzip")
|
||||
compress_option="-j"
|
||||
EXTENSION="tar.bz2"
|
||||
;;
|
||||
"none")
|
||||
compress_option=""
|
||||
;;
|
||||
*)
|
||||
warning "Unknown compress filter ($tar_compress)"
|
||||
compress_option=""
|
||||
EXTENSION="tar.gz"
|
||||
;;
|
||||
esac
|
||||
|
||||
# Exclude the following file types / directories
|
||||
exclude_options=""
|
||||
for i in $excludes
|
||||
do
|
||||
exclude_options="$exclude_options --exclude $i"
|
||||
done
|
||||
|
||||
# Debugging messages, performing backup
|
||||
debug "Running backup: " $TAR -c -p -v $compress_option $exclude_options \
|
||||
-f "$backupdir/$backupname-"`$DATE "+$DATEFORMAT"`".$EXTENSION" \
|
||||
$includes
|
||||
|
||||
# Redirect standard output to a file with .list extension
|
||||
# and standard error to a file with .err extension
|
||||
$TAR -c -p -v $compress_option $exclude_options \
|
||||
-f "$backupdir/$backupname-"`$DATE "+$DATEFORMAT"`".$EXTENSION" \
|
||||
$includes \
|
||||
> "$backupdir/$backupname-"`$DATE "+$DATEFORMAT"`.list \
|
||||
2> "$backupdir/$backupname-"`$DATE "+$DATEFORMAT"`.err
|
||||
|
||||
[ $? -ne 0 ] && fatal "Tar backup failed"
|
||||
|
||||
Next, we will create our helper file (/usr/share/backupninja/home.helper) so that our handlers shows up as a menu in **ninjahelper**:
|
||||
|
||||
# Backup action's description. Separate words with underscores.
|
||||
HELPERS="$HELPERS home:backup_of_home_directories"
|
||||
|
||||
home_wizard() {
|
||||
home_title="Home action wizard"
|
||||
|
||||
backupname=`hostname --fqdn`
|
||||
|
||||
# Specify default value for the time when this backup actions is supposed to run
|
||||
inputBox "$home_title" "When to run this action?" "everyday at 01"
|
||||
[ $? = 1 ] && return
|
||||
home_when_run="when = $REPLY"
|
||||
|
||||
# Specify default value for backup file name
|
||||
inputBox "$home_title" "\"Name\" of backups" "$backupname"
|
||||
[ $? = 1 ] && return
|
||||
home_backupname="backupname = $REPLY"
|
||||
backupname="$REPLY"
|
||||
|
||||
# Specify default directory to store the backups
|
||||
inputBox "$home_title" "Directory where to store the backups" "/var/backups/home"
|
||||
[ $? = 1 ] && return
|
||||
home_backupdir="backupdir = $REPLY"
|
||||
|
||||
# Specify default values for the radiobox
|
||||
radioBox "$home_title" "Compression" \
|
||||
"none" "No compression" off \
|
||||
"gzip" "Compress with gzip" on \
|
||||
"bzip" "Compress with bzip" off
|
||||
[ $? = 1 ] && return;
|
||||
result="$REPLY"
|
||||
home_compress="compress = $REPLY "
|
||||
|
||||
REPLY=
|
||||
while [ -z "$REPLY" ]; do
|
||||
formBegin "$home_title: Includes"
|
||||
formItem "Include:" /home/gacanepa
|
||||
formDisplay
|
||||
[ $? = 0 ] || return 1
|
||||
home_includes="includes = "
|
||||
for i in $REPLY; do
|
||||
[ -n "$i" ] && home_includes="$home_includes $i"
|
||||
done
|
||||
done
|
||||
|
||||
REPLY=
|
||||
while [ -z "$REPLY" ]; do
|
||||
formBegin "$home_title: Excludes"
|
||||
formItem "Exclude:" *.mp3
|
||||
formItem "Exclude:" *.mp4
|
||||
# Add as many “Exclude” text boxes as needed to specify other exclude options
|
||||
formItem "Exclude:"
|
||||
formItem "Exclude:"
|
||||
formDisplay
|
||||
[ $? = 0 ] || return 1
|
||||
home_excludes="excludes = "
|
||||
for i in $REPLY; do
|
||||
[ -n "$i" ] && home_excludes="$home_excludes $i"
|
||||
done
|
||||
done
|
||||
|
||||
# Save the config
|
||||
get_next_filename $configdirectory/10.home
|
||||
cat > $next_filename <<EOF
|
||||
$home_when_run
|
||||
$home_backupname
|
||||
$home_backupdir
|
||||
$home_compress
|
||||
$home_includes
|
||||
$home_excludes
|
||||
|
||||
# tar binary - have to be GNU tar
|
||||
TAR `which tar`
|
||||
DATE `which date`
|
||||
DATEFORMAT "%Y-%m-%d"
|
||||
EXTENSION tar
|
||||
|
||||
EOF
|
||||
# Backupninja requires that configuration files be chmoded to 600
|
||||
chmod 600 $next_filename
|
||||
}
|
||||
|
||||
### Running Ninjahelper ###
|
||||
|
||||
Once we have created our handler script named home and the corresponding helper named home.helper, let's run ninjahelper command to create a new backup action:
|
||||
|
||||
# ninjahelper
|
||||
|
||||
And choose create a new backup action.
|
||||
|
||||

|
||||
|
||||
We will now be presented with the available action types. Let's select "backup of home directories":
|
||||
|
||||

|
||||
|
||||
The next screens will display the default values as set in the helper (only 3 of them are shown here). Feel free to edit the values in the text box. Particularly, refer to the scheduling section of the documentation for the right syntax for the when variable.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
When you are done creating the backup action, it will show in ninjahelper's initial menu:
|
||||
|
||||

|
||||
|
||||
Then you can press ENTER to show the options available for this action. Feel free to experiment with them, as their description is quite straightforward.
|
||||
|
||||
Particularly, "run this action now" will execute the backup action in debug mode immediately regardless of the scheduled time:
|
||||
|
||||

|
||||
|
||||
Should the backup action fail for some reason, the debug will display an informative message to help you locate the error and correct it. Consider, for example, the following error messages that were displayed after running a backup action with bugs that have not been corrected yet:
|
||||
|
||||

|
||||
|
||||
The image above tells you that the connection needed to complete the backup action could not be completed because the remote host seems to be down. In addition, the destination directory specified in the helper file does not exist. Once you correct the problems, re-run the backup action.
|
||||
|
||||
A few things to remember:
|
||||
|
||||
- If you create a custom script in /usr/share/backupninja (e.g., foobar) to handle a specific backup action, you also need to write a corresponding helper (e.g., foobar.helper) in order to create, through ninjahelper, a file named 10.foobar (11 and onward for further actions as well) in /etc/backup.d, which is the actual configuration file for the backup action.
|
||||
- You can execute your backups at any given time via ninjahelper as explained earlier, or have them run as per the specified frequency in the when variable.
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this post we have discussed how to create our own backup actions from scratch and how to add a related menu in ninjahelper to facilitate the creation of configuration files. With the previous [backupninja article][2] and the present one I hope I've given you enough good reasons to go ahead and at least try it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/create-custom-backup-plan-debian.html
|
||||
|
||||
作者:[ Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/backup-debian-system-backupninja.html
|
||||
[2]:http://xmodulo.com/backup-debian-system-backupninja.html
|
||||
@ -0,0 +1,152 @@
|
||||
How to use matplotlib for scientific plotting on Linux
|
||||
================================================================================
|
||||
If you want an efficient, automatable solution for producing high-quality scientific plots in Linux, then consider using matplotlib. Matplotlib is a Python-based open-source scientific plotting package with a license based on the Python Software Foundation license. The extensive documentation and examples, integration with Python and the NumPy scientific computing package, and automation capability are just a few reasons why this package is a solid choice for scientific plotting in a Linux environment. This tutorial will provide several example plots created with matplotlib.
|
||||
|
||||
### Features ###
|
||||
|
||||
- Numerous plot types (bar, box, contour, histogram, scatter, line plots...)
|
||||
- Python-based syntax
|
||||
- Integration with the NumPy scientific computing package
|
||||
- Source data can be Python lists, Python tuples, or NumPy arrays
|
||||
- Customizable plot format (axes scales, tick positions, tick labels...)
|
||||
- Customizable text (font, size, position...)
|
||||
- TeX formatting (equations, symbols, Greek characters...)
|
||||
- Compatible with IPython (allows interactive plotting from a Python shell)
|
||||
- Automation use Python loops to iteratively create plots
|
||||
- Save plots to image files (png, pdf, ps, eps, and svg format)
|
||||
|
||||
The Python-based syntax of matplotlib serves as the foundation for many of its features and enables an efficient workflow. There are many scientific plotting packages that can produce quality plots, but do they allow you to do it directly from within your Python code? On top of that, do they allow you to create automated routines for iterative creation of plots that can be saved as image files? Matplotlib allows you to accomplish all of these tasks. You can now look forward to saving time that would have otherwise been spent manually creating multiple plots.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Installation of Python and the NumPy package is a prerequisite for use of matplotlib. Instructions for installing NumPy can be found [here][1].
|
||||
|
||||
To install matplotlib in Debian or Ubuntu, run the following command:
|
||||
|
||||
$ sudo apt-get install python-matplotlib
|
||||
|
||||
To install matplotlib in Fedora or CentOS/RHEL, run the following command:
|
||||
|
||||
$ sudo yum install python-matplotlib
|
||||
|
||||
### Matplotlib Examples ###
|
||||
|
||||
This tutorial will provide several plotting examples that demonstrate how to use matplotlib:
|
||||
|
||||
- Scatter and line plot
|
||||
- Histogram plot
|
||||
- Pie chart
|
||||
|
||||
In these examples we will use Python scripts to execute matplotlib commands. Note that the numpy and matplotlib modules must be imported from within the scripts via the import command. np is specified as a reference to the numpy module and plt is specified as a reference to the matplotlib.pyplot namespace:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
### Example 1: Scatter and Line Plot ###
|
||||
|
||||
The first script, **script1.py** completes the following tasks:
|
||||
|
||||
- Creates three data sets (xData, yData1, and yData2)
|
||||
- Creates a new figure (assigned number 1) with a width and height of 8 inches and 6 inches, respectively
|
||||
- Sets the plot title, x-axis label, and y-axis label (all with font size of 14)
|
||||
- Plots the first data set, yData1, as a function of the xData dataset as a dotted blue line with circular markers and a label of "y1 data"
|
||||
- Plots the second data set, yData2, as a function of the xData dataset as a solid red line with no markers and a label of "y2 data".
|
||||
- Positions the legend in the upper left-hand corner of the plot
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of **script1.py**:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
xData = np.arange(0, 10, 1)
|
||||
yData1 = xData.__pow__(2.0)
|
||||
yData2 = np.arange(15, 61, 5)
|
||||
plt.figure(num=1, figsize=(8, 6))
|
||||
plt.title('Plot 1', size=14)
|
||||
plt.xlabel('x-axis', size=14)
|
||||
plt.ylabel('y-axis', size=14)
|
||||
plt.plot(xData, yData1, color='b', linestyle='--', marker='o', label='y1 data')
|
||||
plt.plot(xData, yData2, color='r', linestyle='-', label='y2 data')
|
||||
plt.legend(loc='upper left')
|
||||
plt.savefig('images/plot1.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Example 2: Histogram Plot ###
|
||||
|
||||
The second script, **script2.py** completes the following tasks:
|
||||
|
||||
- Creates a data set containing 1000 random samples from a Normal distribution
|
||||
- Creates a new figure (assigned number 1) with a width and height of 8 inches and 6 inches, respectively
|
||||
- Sets the plot title, x-axis label, and y-axis label (all with font size of 14)
|
||||
- Plots the data set, samples, as a histogram with 40 bins and an upper and lower bound of -10 and 10, respectively
|
||||
- Adds text to the plot and uses TeX formatting to display the Greek letters mu and sigma (font size of 16)
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of **script2.py**:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
mu = 0.0
|
||||
sigma = 2.0
|
||||
samples = np.random.normal(loc=mu, scale=sigma, size=1000)
|
||||
plt.figure(num=1, figsize=(8, 6))
|
||||
plt.title('Plot 2', size=14)
|
||||
plt.xlabel('value', size=14)
|
||||
plt.ylabel('counts', size=14)
|
||||
plt.hist(samples, bins=40, range=(-10, 10))
|
||||
plt.text(-9, 100, r'$\mu$ = 0.0, $\sigma$ = 2.0', size=16)
|
||||
plt.savefig('images/plot2.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Example 3: Pie Chart ###
|
||||
|
||||
The third script, **script3.py** completes the following tasks:
|
||||
|
||||
- Creates data set containing five integers
|
||||
- Creates a new figure (assigned number 1) with a width and height of 6 inches and 6 inches, respectively
|
||||
- Adds an axes to the figure with an aspect ratio of 1
|
||||
- Sets the plot title (font size of 14)
|
||||
- Plots the data set, data, as a pie chart with labels included
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of **script3.py**:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
data = [33, 25, 20, 12, 10]
|
||||
plt.figure(num=1, figsize=(6, 6))
|
||||
plt.axes(aspect=1)
|
||||
plt.title('Plot 3', size=14)
|
||||
plt.pie(data, labels=('Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5'))
|
||||
plt.savefig('images/plot3.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Summary ###
|
||||
|
||||
This tutorial provides several examples of plots that can be created with the matplotlib scientific plotting package. Matplotlib is a great solution for scientific plotting in a Linux environment given its natural integration with Python and NumPy, its ability to be automated, and its production of a wide variety of customizable high quality plots. Documentation and examples for the matplotlib package can be found [here][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/matplotlib-scientific-plotting-linux.html
|
||||
|
||||
作者:[Joshua Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/joshua
|
||||
[1]:http://xmodulo.com/numpy-scientific-computing-linux.html
|
||||
[2]:http://matplotlib.org/
|
||||
@ -0,0 +1,155 @@
|
||||
What is a good free control panel for VPS
|
||||
================================================================================
|
||||
Anyone with a reasonable level of Linux skills knows that no control panel can beat the plain-old command line interface for managing a [virtual private server][1] (VPS). One can still argue that there is a place for a good server control panel though, due to the streamlined interface for getting routine administration tasks done easily with a few mouse clicks.
|
||||
|
||||
As far as control panels are concerned, even with the feature-rich commercial control panels with all the bells and whistles, there are viable free open-source alternatives which can be as powerful and versatile. Standing out among them is [Ajenti][2] server administration panel.
|
||||
|
||||
Ajenti allows you to easily configure a variety of common server programs such as Apache/nginx, Samba, BIND, Squid, MySQL, cron, firewall, and so on, making it a great time saver for administering common VPS instances. For production environments, Ajenti also offers add-ons and platform support for virtual web hosting management and custom web UI development.
|
||||
|
||||
Ajenti comes with a [dual license][3]; It is free to use (AGPLv3) for your personal servers, a company's internal hardware boxes, or educational institutions. However, if you are a hosting company or a hardware vendor, you need to purchase a commercial license to use Ajenti as part of commercial offerings.
|
||||
|
||||
### Install Ajenti on Linux ###
|
||||
|
||||
For easy of installation, Ajenti offers its own repository for major Linux distros. All it takes to install Ajenti on Linux is to configure a target repository and install it with a default package manager.
|
||||
|
||||
Upon installation, a RSA private key and certificate will be automatically generated for SSL, and Ajenti will listen on HTTPS port 8000 for secure web access. If you are using firewall, you need to allow TCP/8000 port in the firewall. For security, it is a good idea to block access to port 8000 by default, and add only selected few IP addresses to the white list.
|
||||
|
||||
#### Install Ajenti on Debian ####
|
||||
|
||||
$ wget http://repo.ajenti.org/debian/key -O- | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://repo.ajenti.org/debian main main debian" >> /etc/apt/sources.list'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install ajenti
|
||||
|
||||
#### Install Ajenti on Ubuntu ####
|
||||
|
||||
$ wget http://repo.ajenti.org/debian/key -O- | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://repo.ajenti.org/ng/debian main main ubuntu" >> /etc/apt/sources.list'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install ajenti
|
||||
|
||||
#### Install Ajenti on CentOS/RHEL or Fedora ####
|
||||
|
||||
On CentOS/RHEL, [configure][4] EPEL repository first, and then run the following. On Fedora, use the following commands directly.
|
||||
|
||||
$ wget http://repo.ajenti.org/ajenti-repo-1.0-1.noarch.rpm
|
||||
$ sudo rpm -ivh ajenti-repo-1.0-1.noarch.rpm
|
||||
$ sudo yum install ajenti
|
||||
|
||||
Next, configure the firewall.
|
||||
|
||||
On Fedora or CentOS/RHEL 7:
|
||||
|
||||
$ sudo firewall-cmd --zone=public --add-port=8000/tcp --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
$ sudo iptables -I INPUT -p tcp -m tcp --dport 8000 -j ACCEPT
|
||||
$ sudo service iptables save
|
||||
|
||||
### Access Ajenti Web Interface ###
|
||||
|
||||
Before accessing Ajenti's web interface, make sure to start ajenti service.
|
||||
|
||||
$ sudo service ajenti restart
|
||||
|
||||
Direct your web browser to https://<server-ip-address>:8000, and you will see the following Ajenti login interface.
|
||||
|
||||

|
||||
|
||||
The default login credential is "root" for username and "admin" for password. Once you log in, you will see the initial Ajengi menu.
|
||||
|
||||
|
||||
|
||||
Under "SOFTWARE" section in the left panel, you will see a list of installed services. When you install any new server software supported by Ajenti, the software will be automatically added to the list once you restart ajenti service.
|
||||
|
||||
$ sudo service ajenti restart
|
||||
|
||||
### VPS Management via Ajenti Web Interface ###
|
||||
|
||||
Ajenti's web interface is extremely intuitive and easy to use. Here are a few examples of Ajenti functionality.
|
||||
|
||||
#### Pluggable Architecture ####
|
||||
|
||||
Ajenti comes with a number of application-specific plugins, which makes Ajenti highly extensible. When you install a new software on your VPS, a corresponding Ajenti plugin (if any) will be automatically enabled to manage the software. The "Plugins" menu will show what plugins are available/enabled, and which plugin is associated with what software.
|
||||
|
||||
|
||||
|
||||
#### Package Management ####
|
||||
|
||||
Ajenti offers a web interface for installing and upgrading packages on VPS.
|
||||
|
||||
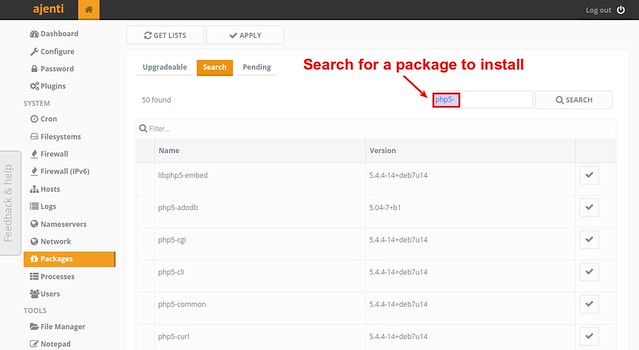
|
||||
|
||||
#### Firewall Configuration ####
|
||||
|
||||
Ajenti allows you to manage firewall rules (iptables or CSF) in two ways. One is to use a user-friendly web panel interface, and the other is to edit raw firewall rules directly.
|
||||
|
||||
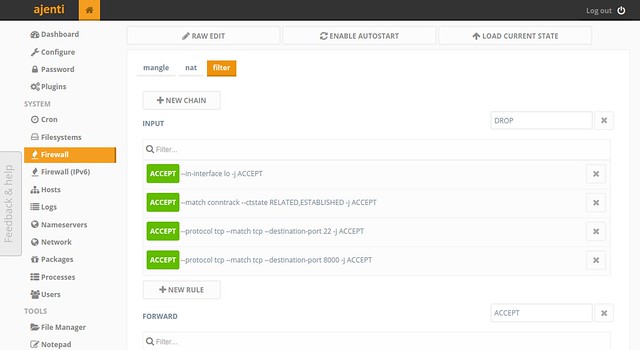
|
||||
|
||||
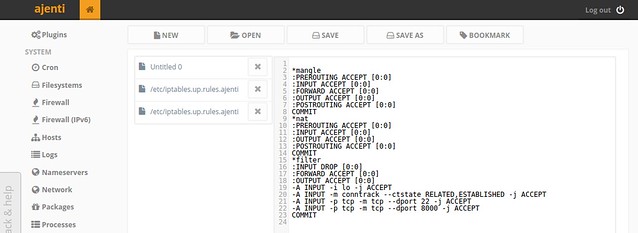
|
||||
|
||||
#### Log Inspection ####
|
||||
|
||||
You can browse system logs in /var/log via Ajenti's web interface.
|
||||
|
||||
|
||||
|
||||
#### Process Monitoring ####
|
||||
|
||||
You can see a list of processes sorted by CPU or RAM usage, and can kill them as needed.
|
||||
|
||||
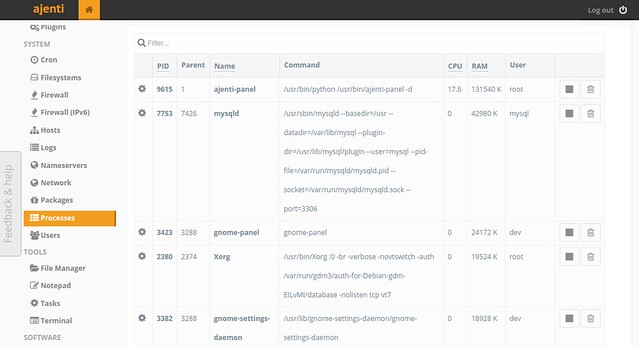
|
||||
|
||||
#### Terminal Access ####
|
||||
|
||||
For low-level VPS access, Ajenti offers a web-based terminal interface where you can type Linux commands. You can open multiple terminal tabs within a web panel as shown below.
|
||||
|
||||
|
||||
|
||||
#### Apache Web Server Administration ####
|
||||
|
||||
You can edit Apache configuration file, and manage apache2 service.
|
||||
|
||||
|
||||
|
||||
#### MySQL/MariaDB Management ####
|
||||
|
||||
You can access MySQL/MariaDB server and execute raw SQL commands on it.
|
||||
|
||||
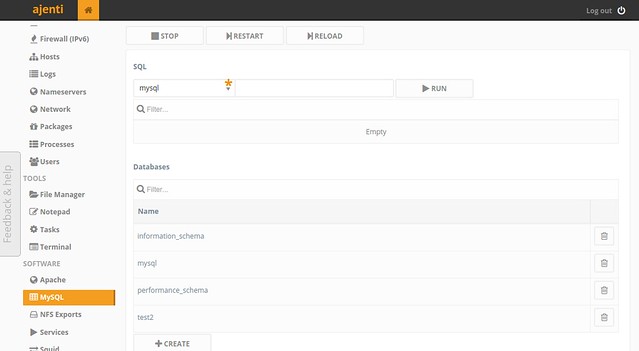
|
||||
|
||||
#### Squid Configuration ####
|
||||
|
||||
You can configure ACL, HTTP access rules, filtering ports for Squid proxy server.
|
||||
|
||||
|
||||
|
||||
#### Startup Service Management ####
|
||||
|
||||
You can view, start, stop and restart installed services.
|
||||
|
||||
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Ajenti is a convenient and easy-to-use web control panel for common server administration, with the possibility to add [custom plugins][5] that you can develop. However, remember that any good control panel does not obviate the need for you to learn what's happening behind the scene on your [VPS][6]. A control panel will become a real time saver only when you fully understand what you are doing, and be able to handle the consequence of your action without relying on the control panel.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/free-control-panel-for-vps.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://ajenti.org/
|
||||
[3]:http://ajenti.org/licensing
|
||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://docs.ajenti.org/en/latest/dev/intro.html
|
||||
[6]:http://xmodulo.com/go/digitalocean
|
||||
@ -0,0 +1,106 @@
|
||||
Install Jetty 9 (Java servlet engine and webserver) on Ubuntu 14.10 Server
|
||||
================================================================================
|
||||
Jetty provides a Web server and javax.servlet container, plus support for SPDY, WebSocket, OSGi, JMX, JNDI, JAAS and many other integrations. These components are open source and available for commercial use and distribution.
|
||||
|
||||
Jetty is used in a wide variety of projects and products, both in development and production. Jetty can be easily embedded in devices, tools, frameworks, application servers, and clusters. See the Jetty Powered page for more uses of Jetty.
|
||||
|
||||
### Jetty Features ###
|
||||
|
||||
- Full-featured and standards-based
|
||||
- Open source and commercially usable
|
||||
- Flexible and extensible
|
||||
- Small footprint
|
||||
- Embeddable
|
||||
- Asynchronous
|
||||
- Enterprise scalable
|
||||
- Dual licensed under Apache and Eclipse
|
||||
|
||||
### Install Jetty9 on ubuntu 14.10 server ###
|
||||
|
||||
#### Prerequisites ####
|
||||
|
||||
You need to install Java before installing jetty server using the following command
|
||||
|
||||
sudo apt-get install openjdk-8-jdk
|
||||
|
||||
This will install it to /usr/lib/jvm/java-8-openjdk-i386. A symlink java-1.8.0-openjdk-i386 is created in the directory /usr/lib/jvm/. A symlink is also created at /usr/bin/java
|
||||
|
||||
Now you need to download Jetty9 from [here][1] after downloading you need to extract using the following command
|
||||
|
||||
$tar -xvf jetty-distribution-9.2.5.v20141112.tar.gz
|
||||
|
||||
This unpacks the jetty-distribution-9.2.5.v20141112 and you need to Move the archive to /opt/jetty using the following command
|
||||
|
||||
$mv jetty-distribution-9.2.5.v20141112 /opt/jetty
|
||||
|
||||
You need to Create jetty user and make it the owner of /opt/jetty directory
|
||||
|
||||
sudo useradd jetty -U -s /bin/false
|
||||
|
||||
sudo chown -R jetty:jetty /opt/jetty
|
||||
|
||||
#### Jetty Startup Script ####
|
||||
|
||||
Copy the Jetty script to run as a service using the following command
|
||||
|
||||
$ cp /opt/jetty/bin/jetty.sh /etc/init.d/jetty
|
||||
|
||||
Now you need to create jetty settings file with the following content
|
||||
|
||||
sudo vi /etc/default/jetty
|
||||
|
||||
Add the following lines
|
||||
|
||||
JAVA_HOME=/usr/bin/java
|
||||
JETTY_HOME=/opt/jetty
|
||||
NO_START=0
|
||||
JETTY_ARGS=jetty.port=8085
|
||||
JETTY_HOST=0.0.0.0
|
||||
JETTY_USER=jetty
|
||||
|
||||
Save and exit the file
|
||||
|
||||
You need to start jetty service using the following command
|
||||
|
||||
sudo service jetty start
|
||||
|
||||
You should see output similar to the following
|
||||
|
||||
Starting Jetty: OK Mon Nov 24 11:55:48 GMT 2014
|
||||
|
||||
If you see the following error
|
||||
|
||||
#### ** ERROR: JETTY_HOME not set, you need to set it or install in a standard location ####
|
||||
|
||||
You need to make sure you have correct jetty home path in /etc/default/jetty file i.e JETTY_HOME=/opt/jetty
|
||||
|
||||
You can test the jetty using the following URL
|
||||
|
||||
It should now be running on port 8085! Visit in your browser http://serverip:8085 and you should see a Jetty screen.
|
||||
|
||||
#### Jetty Service checking ####
|
||||
|
||||
Verify and check your configuration with the following command
|
||||
|
||||
sudo service jetty check
|
||||
|
||||
Jetty automatically start on reboot using the following command
|
||||
|
||||
sudo update-rc.d jetty defaults
|
||||
|
||||
Reboot the server and test if Jetty starts automatically.
|
||||
|
||||
To check which port Jetty is running or whether there are any conflicts with other programs for that port, run netstat -tln
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-jetty-9-java-servlet-engine-and-webserver-on-ubuntu-14-10-server.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://download.eclipse.org/jetty/stable-9/dist/
|
||||
@ -0,0 +1,44 @@
|
||||
Linux FAQs with Answers--How to crop an image from the command line on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to get rid of white margins of an image file. Is there an easy way to crop an image file from the command line on Linux?
|
||||
|
||||
When it comes to converting or editing images files on Linux, ImageMagick is undoubtedly one of the best known all-in-one image software. It boasts of a suite of command-line tools to display, convert, or manipulate more than 200 types of raster or vector image files, all from the command line. ImageMagick can be used for a variety of image editing tasks, such as converting file format, adding special effects, adding text, and transforming (resize, rotate, flip, crop) images.
|
||||
|
||||
If you want to crop an image to trim its margins, you can use two command-line utilities that come with ImageMagick. If you haven't installed ImageMagick, follow [this guideline][1] to install it.
|
||||
|
||||
In this tutorial, let's crop the following PNG image. We want to get rid of the right and bottom margins of the image, so that the chart will be centered.
|
||||
|
||||
|
||||
|
||||
First, identify the dimension (width and height) of the image file. You can use identify command for that.
|
||||
|
||||
$ identify chart.png
|
||||
|
||||
----------
|
||||
|
||||
chart.png PNG 1500x1000 1500x1000+0+0 8-bit DirectClass 31.7KB 0.000u 0:00.000
|
||||
|
||||
As shown above, the input image is 1500x1000px.
|
||||
|
||||
Next, determine two things for image cropping: (1) the position at which the cropped image will start, and (2) the size of the cropped rectangle.
|
||||
|
||||
In this example, let's assume that the cropped image starts at top left corner, more specifically at x=20px and y=10px, and that the size of a cropped image will be 1200x700px.
|
||||
|
||||
The utility used to crop an image is convert. With "-crop" option, the convert command cuts out a rectangular region of an input image.
|
||||
|
||||
$ convert chart.png -crop 1200x700+20+10 chart-cropped.png
|
||||
|
||||
Given the input image chart.png, the convert command will store the cropped image as chart-cropped.png.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/crop-image-command-line-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://ask.xmodulo.com/install-imagemagick-linux.html
|
||||
@ -0,0 +1,44 @@
|
||||
Vic020
|
||||
|
||||
Linux FAQs with Answers--How to disable Apport internal error reporting on Ubuntu
|
||||
================================================================================
|
||||
> **Question**: On Ubuntu desktop, I often encounter a popup window, alerting that Ubuntu has experienced an internal error, and asking me to send an error report. This is bothering me as it keeps popping up for every application crash. How can I turn off the error reporting feature?
|
||||
|
||||
Ubuntu desktop comes with Apport pre-installed, which is a system that catches applications crashes, unhandled exceptions or any non-crash application bugs, and automatically generates a crash report for debugging purposes. When an application crash or bug is detected, Apport alerts user of the event by showing a popup window and asking the user to submit a crash report. You will see messages like the following.
|
||||
|
||||
- "Sorry, the application XXXX has closed unexpectedly."
|
||||
- "Sorry, Ubuntu XX.XX has experienced an internal error."
|
||||
- "System program problem detected."
|
||||
|
||||
|
||||
|
||||
If application crashes are recurring, frequent error reporting alerts can be disturbing. Or you may be worried that Apport can collect and upload any sensitive information of your Ubuntu system. Whatever the reason is, you may want to disable Apport's error reporting feature.
|
||||
|
||||
### Disable Apport Error Reporting Temporarily ###
|
||||
|
||||
If you want to disable Apport temporarily, use this command:
|
||||
|
||||
$ sudo service apport stop
|
||||
|
||||
Note that Apport will be enabled back after you boot your Ubuntu system.
|
||||
|
||||
### Disable Apport Error Reporting Permanently ###
|
||||
|
||||
To turn off Apport permanently, edit /etc/default/apport with a text editor, and change the content to the following.
|
||||
|
||||
enabled=0
|
||||
|
||||
Now if you reboot your Ubuntu system, Apport will automatically be disabled.
|
||||
|
||||
If you think you will never use Apport, another method is to simply remove it altogether.
|
||||
|
||||
$ sudo apt-get purge apport
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/disable-apport-internal-error-reporting-ubuntu.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,54 @@
|
||||
四招搞定Linux内核热补丁
|
||||
================================================================================
|
||||

|
||||
Credit: Shutterstock
|
||||
|
||||
多种技术在竞争成为实现inux内核热补丁的最优方案。
|
||||
没人喜欢重启机器,尤其是涉及到一个内核问题的最新补丁程序。
|
||||
为达到不重启的目的,目前有3个项目在朝这方面努力,将为大家提供对内核进行运行时打热补丁的机制,这样就可以做到完全不重启机器。
|
||||
|
||||
### Ksplice项目 ###
|
||||
|
||||
首先要介绍的项目是Ksplice,它是热补丁技术的创始者,并于2008年建立了与项目同名的公司。Ksplice在替换新内核时,不需要预先修改;只需要一个diff文件,将内核的修改点列全即可。Ksplice公司免费提供软件,但技术支持是需要收费的,目前能够支持大部分常用的Linux发行版本。
|
||||
|
||||
但在2011年[Oracle收购了这家公司][1]后,情况发生了变化。 这项功能被合入到Oracle的Linux发行版本中,且只对Oralcle的版本提供技术更新。 这就导致,其他内核hacker们开始寻找替代Ksplice的方法,以避免缴纳Oracle税。
|
||||
|
||||
### Kgraft项目 ###
|
||||
|
||||
2014年2月,Suse提供了一个很好的解决方案:[Kgraft][2],该技术以GPLv2/GPLv3混合许可证发布,且Suse不会将其作为一个专有的实现。Kgraft被[提交][3]到Linux内核主线,很有可能被内核主线采用。目前Suse已经把此技术集成到[Suse Linux Enterprise Server 12][4]。
|
||||
|
||||
Kgraft和Ksplice在工作原理上很相似,都是使用一组diff文件来计算内核中需要修改的部分。但与Ksplice不同的是,Kgraft在做替换时,不需要完全停止内核。 在打补丁时,正在运行的函数可以先使用老版本中对应的部分,当补丁打完后就可以切换新的版本。
|
||||
|
||||
### Kpatch项目 ###
|
||||
|
||||
Red Hat也提出了他们的内核热补丁技术。同样是在今年年初 -- 与Suse在这方面的工作差不多 -- [Kpatch][5]的工作原理也和Kgraft相似。
|
||||
|
||||
主要的区别点在于,正如Red Hat的Josh Poimboeuf[总结][6]的那样,Kpatch不能将内核调用重定向到老版本。相反,它会等待所有函数调用都停止时,再切换到新内核。Red Hat的工程师认为这种方法更为安全,且更容易维护,缺点就是在打补丁的过程中会带来更大的延迟。
|
||||
|
||||
和Kgraft一样,Kpatch不仅仅能在Red Hat的发行版本上可以使用,同时也被提交到了内核主线,作为一个可能的候选。 坏消息是Red Hat还未将此技术集成到产品中。 它只是被合入到了Red Hat Enterprise Linux 7的技术预览版中。
|
||||
|
||||
### ...也许 Kgraft + Kpatch更合适? ###
|
||||
|
||||
Red Hat的工程师Seth Jennings在2014年11月初,提出了[第四种解决方案][7]。将Kgraft和Kpatch结合起来, 补丁包用这两种方式都可以。在新的方法中,Jennings提出,“热补丁核心为其他内核模块提供了热补丁的注册机制”, 通过这种方法,打补丁的过程 -- 更准确的说,如何处理运行时内核调用 --可以被更加有序的进行。
|
||||
|
||||
这项新建议也意味着两个方案都还需要更长的时间,才能被linux内核正式采纳。尽管Suse步子迈得更快,并把Kgraft应用到了最新的enterprise版本中。让我们也关注一下Red Hat和Linux官方近期的动态。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-for-no-downtime-kernel-patching.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]:http://www.infoworld.com/article/2622437/open-source-software/oracle-buys-ksplice-for-linux--zero-downtime--tech.html
|
||||
[2]:http://www.infoworld.com/article/2610749/linux/suse-open-sources-live-updater-for-linux-kernel.html
|
||||
[3]:https://lwn.net/Articles/596854/
|
||||
[4]:http://www.infoworld.com/article/2838421/linux/suse-linux-enterprise-12-goes-light-on-docker-heavy-on-reliability.html
|
||||
[5]:https://github.com/dynup/kpatch
|
||||
[6]:https://lwn.net/Articles/597123/
|
||||
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||
@ -1,130 +0,0 @@
|
||||
|
||||
如何在 Linux 中使用屏幕键盘
|
||||
================================================================================
|
||||
|
||||
屏幕键盘可以作为实体键盘输入的替代方案. 在某些时候,屏幕键盘显得非常需要. 比如, 你的键盘刚好坏了; 你的机器太多, 没有足够的键盘; 你的机器没有多余的接口来连接键盘; 你是个残疾人, 打字有困难; 或者你正在组建基于触摸屏的信息服务站.
|
||||
|
||||
屏幕键盘也可以作为一种针对实体键盘背后记录按键来获取密码等敏感信息的情况的保护手段. 一些网上银行页面实际上会强制你使用屏幕键盘来增强交易的安全性.
|
||||
|
||||
在linux 中有几个可用的开源键盘软件, 比如 [GOK (Gnome 的屏幕键盘)][1], [kvkbd][2], [onboard][3], [Florence][4].
|
||||
|
||||
我会在这个教程中集中讲解 Florence, 告诉你 ** 如何用 Florence 配置屏幕键盘 **. Florence 有着布局方案灵活, 输入法多样, 自动隐藏等特性. 作为教程的一部分, 我也将会示范 ** 如何只使用鼠标来操作 Ubuntu 桌面 **.
|
||||
|
||||
### 在 Linux 中安装 Florence 屏幕键盘 ###
|
||||
|
||||
幸运的是, Florence 存在于大多数 Linux 发行版的基础仓库中.
|
||||
|
||||
在 Debian, Ubuntu 或者 Linux Mint 中:
|
||||
|
||||
$ sudo apt-get install florence
|
||||
|
||||
在 Fedora, CentOS 或者 RHEL (CentOS/RHEL 需要 [EPEL 仓库][5]) 中:
|
||||
|
||||
$ sudo yum install florence
|
||||
|
||||
在 Mandriva 或者 Mageia 中:
|
||||
|
||||
$ sudo urpmi florence
|
||||
|
||||
对于 Archlinux 用户, Florence 存在于 [AUR][6] 中.
|
||||
|
||||
### 配置和加载屏幕键盘 ###
|
||||
|
||||
当你安装好 Florence 之后, 你只需要简单的输入以下命令就能加载屏幕键盘:
|
||||
|
||||
$ florence
|
||||
|
||||
默认情况下, 屏幕键盘总是在其他窗口的顶部, 让你能够在任意活动窗口上进行输入.
|
||||
|
||||
在键盘的左侧点击工具按键来改变 Florence 的默认配置.
|
||||
|
||||

|
||||
|
||||
在 Florence 的 "样式 (style)" 菜单中, 你能够自定义键盘样式, 启用/取消声音效果.
|
||||
|
||||

|
||||
|
||||
在 "窗口 (window)" 菜单中, 你能够调整键盘背景透明度, 按键不透明度, 以及控制键盘比例, 工具栏, 大小和总是置顶等特性. 如果你的分辨率不是非常高, 透明度调整就显得非常有用. 因为屏幕键盘会挡住其他窗口. 在这个例子中, 我切换到透明键盘, 并且设置不透明度为 50%.
|
||||
|
||||

|
||||
|
||||
在 "行为 (behaviour)" 菜单中, 你能够改变输入方法. Florence 支持几种不同的输入法: 鼠标 (mouse), 触摸屏 (touch screen), 计时器 (timer) 和漫步 (ramble). 鼠标输入是默认输入法. 最后的两种输入法不需要按键. 计时器输入通过将指针滞留在按键上一定时间来触发按键. 漫步输入的原理跟 ** 计时器 ** 输入差不多, 但是经过训练和灵巧使用, 能够比 ** 计时器 ** 输入更加迅速.
|
||||
|
||||

|
||||
|
||||
在 "布局 (layout)" 菜单中, 你能够改变键盘布局. 比如, 你能够扩展键盘布局来增加导航键, 数字键和功能键.
|
||||
|
||||

|
||||
|
||||
### 只使用鼠标来操作 Ubuntu 桌面
|
||||
|
||||
我将示范如何将 Florence 集成到 Ubuntu 桌面中, 然后我们不需要实体键盘就能够进入桌面. 这个教程使用 LightDM (Ubuntu 的默认显示管理器) 来进入 Ubuntu, 而类似的环境也能够设置为其他桌面环境.
|
||||
|
||||
初始设置需要实体键盘, 但是一旦设置完成, 你只需要一个鼠标, 而不是键盘.
|
||||
|
||||
当你启动 Ubuntu 桌面时, 启动程序最后会停在显示管理器 (或者登录管理器) 的问候界面. 在这个界面上你需要输入你的登录信息. 默认的情况下, Ubuntu 桌面会使用 LightDM 显示管理器和 Unity 问候界面. 如果没有实体键盘, 你就不能在登录界面输入用户名和密码.
|
||||
|
||||
为了能够在登录界面加载屏幕键盘, 安装配备了屏幕键盘支持的 GTK+ 问候界面.
|
||||
|
||||
$ sudo apt-get install lightdm-gtk-greeter
|
||||
|
||||
然后用编辑器打开问候界面配置文件 (/etc/lightdm/lightdm-gtk-greeter.conf), 指定 Florence 作为屏幕键盘来使用. 你也能够使用 Ubuntu 的默认屏幕键盘 onboard 来代替 Florence.
|
||||
|
||||
$ sudo vi /etc/lightdm/lightdm-gtk-greeter.conf
|
||||
|
||||
----------
|
||||
|
||||
[greeter]
|
||||
keyboard=florence --no-gnome --focus &
|
||||
|
||||

|
||||
|
||||
重启 Ubuntu 桌面, 然后检查你是否能够在登录界面使用屏幕键盘.
|
||||
|
||||
启动之后当你看到 GTK+ 问候登录界面时, 点击右上角的人形符号. 你会看到 "使用屏幕键盘 (On Screen Keyboard)" 菜单选项, 如下
|
||||
|
||||

|
||||
|
||||
点击这个选项, 屏幕键盘就会在登录界面弹出. 现在你应该能够用屏幕键盘来登录了.
|
||||
|
||||

|
||||
|
||||
对于 GDM2/GDM3 用户怎么在 GDM2/GDM3 界面上使用屏幕键盘, Florence 官方网页提供了 [文档 (documentation)][7].
|
||||
|
||||
Ubuntu 桌面完全少键盘化的最后一步是让屏幕键盘在登录后自动启动, 然后我们在登录后能够不使用实体键盘就操作桌面. 为了做到这一点, 创建以下桌面文件.
|
||||
|
||||
$ mkdir -p ~/.config/autostart
|
||||
$ vi ~/.config/autostart/florence.desktop
|
||||
|
||||
----------
|
||||
|
||||
[Desktop Entry]
|
||||
Type=Application
|
||||
Name=Virtual Keyboard
|
||||
Comment=Auto-start virtual keyboard
|
||||
Exec=florence --no-gnome
|
||||
|
||||
这样可以让你在登录到桌面的时候就看到屏幕键盘.
|
||||
|
||||

|
||||
|
||||
希望这个教程对你有用. 与你所看到的一样, Florence 是非常强大的屏幕键盘, 可以用于不同目的. 让我知道你是否在任何情况下使用屏幕键盘.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/onscreen-virtual-keyboard-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://developer.gnome.org/gok/
|
||||
[2]:http://homepage3.nifty.com/tsato/xvkbd/
|
||||
[3]:https://launchpad.net/onboard
|
||||
[4]:http://florence.sourceforge.net/
|
||||
[5]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
[6]:https://aur.archlinux.org/packages/florence/
|
||||
[7]:http://florence.sourceforge.net/english/how-to.html
|
||||
@ -0,0 +1,75 @@
|
||||
在Ubuntu 14.10中如何安装和配置‘My Weather Indicator’
|
||||
================================================================================
|
||||

|
||||
|
||||
**在Ubuntu桌面中不缺乏若干应用同时提供天气信息的方法,你可以使用Unity Dash和桌面应用,比如[Typhoon][1],来获得天气信息。**
|
||||
|
||||
但是可以提供快速查询天气状况和温度数据,并且只需要一次鼠标点击而获得大量气象数据的面板插件,是到目前为止Linux平台下最受欢迎的天气应用。
|
||||
|
||||
Atareao开发的[My Weather Indicator][2]就是这类应用中的一个,也可以说是最好的一个。
|
||||
|
||||
它在Unity面板上显示实时温度和天气状况,并且有一个包括体感温度、云量和日升日落时间等天气数据的菜单。除此之外,该应用还支持桌面小部件、多地区支持、天气数据提供方选择以及其他很多的配置选项。
|
||||
|
||||
听起来很不错,是吧?那我们下面就来看看如何在Ubuntu上安装和配置它吧。
|
||||
|
||||
### 在Ubuntu上安装My Weather Indicator ###
|
||||
|
||||
My Weather Indicator无法从Ubuntu软件商店中直接获取。不过开发者为我们提供了.deb安装包和官方维护的PPA(为Ubuntu 14.04 LTS和14.10提供安装包)。
|
||||
|
||||
- 下载My Weather Indicator (.deb安装包)
|
||||
|
||||
为了确保你的应用最是最新版本,我建议将[Atareao PPA][3]添加到你的软件镜像源然后通过PPA来安装。
|
||||
|
||||
怎么做?**打开一个新的终端**窗口(Unity Dash > 终端,或者按Ctrl+Alt+T快捷键),然后**输入下面的两行命令**,期间你需要在提示处输入你的系统密码:
|
||||
|
||||
sudo add-apt-repository ppa:atareao/atareao
|
||||
|
||||
sudo apt-get update && sudo apt-get install my-weather-indicator
|
||||
|
||||
#### 配置My Weather Indicator ####
|
||||
|
||||
无论你是通过什么方法安装该应用,你都可以在Unity Dash中搜索“weather”并且点击该应用来打开它。
|
||||
|
||||

|
||||
|
||||
首次打开应用时会出现下面的配置窗口。在这里你可以手动设置地区或者使用geo-ip来自动获取。或者有时可能会不够精确,不过它可以省去手动设置过程。
|
||||
|
||||

|
||||
|
||||
如果你正在旅行(或者是出于聊天需要),**你可以添加一个第二地区**。这个设置和第一地区的设置相同,只不过是在“第二地区”的标签栏罢了。
|
||||
|
||||
在“**小部件设置**”区域勾选“**显示桌面小部件**”选项就会在你的桌面上添加一个小的天气小部件。小部件提供许多不同的皮肤,所以你一定要精心挑选你最喜欢的一个(注释:点击“确定”后对小部件的更改才会保存)。
|
||||
|
||||

|
||||
|
||||
My Weather Indicator使用[Open Weather Map][4]作为默认的天气数据提供方。不过你可以在‘**Weather Services**’面板中选择其他的数据提供方(有*标记的需要提供相关API key):
|
||||
|
||||
- Open Weather Map
|
||||
- Yahoo! Weather
|
||||
- Weather Underground*
|
||||
- World Weather Online*
|
||||
|
||||
在‘**Units**’标签页中,你可以设置温度、压力、风速等数据的单位。这些设置适用于所有添加的地区,也就是说你不能在一个地区使用摄氏度,另一个地区使用华氏度。
|
||||
|
||||

|
||||
|
||||
最后,在‘General Options‘标签页,你可以设置数据更新间隔、设置开机自动运行选项以及从两个图标中选择一个作为面板图标。
|
||||
|
||||
如果你不喜欢该应用,你可以尝试[Linux下查看天气数据的方法][5]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/install-weather-indicator-ubuntu-14-10
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[JonathanKang](https://github.com/JonathanKang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://launchpad.net/typhoon
|
||||
[2]:https://launchpad.net/my-weather-indicator
|
||||
[3]:https://launchpad.net/~atareao/+archive/ubuntu/atareao
|
||||
[4]:http://openweathermap.org/
|
||||
[5]:http://www.omgubuntu.co.uk/2014/02/get-weather-forecast-terminal-linux
|
||||
@ -1,17 +1,18 @@
|
||||
Vic020
|
||||
|
||||
How To Drop Database In Oracle 11 Without Using DBCA
|
||||
如何不使用DBCA在Oracle 11中删除数据库
|
||||
================================================================================
|
||||
In this small tutorial, I want to show you how to drop the database without using the GUI tool DBCA
|
||||
本文简短的教程,将会向你展示如何不使用DBCA(数据库配置助手)在Oracle 11中删除数据
|
||||
|
||||
#### 1- Export database SID if not yet Already defined ####
|
||||
#### 1- 导入数据库的SID,如果没有定义的话 ####
|
||||
|
||||
命令:
|
||||
export ORACLE_SID=database
|
||||
|
||||
#### 2- Connect as sysdba ####
|
||||
#### 2- 以操作系统认证连接数据库 ####
|
||||
|
||||
命令:
|
||||
[oracle@Oracle11 ~]$ sqlplus / as sysdba
|
||||
|
||||
提示:
|
||||
----------
|
||||
|
||||
SQL*Plus: Release 11.2.0.1.0 Production on Mon Dec 1 17:38:02 2014
|
||||
@ -24,9 +25,11 @@ In this small tutorial, I want to show you how to drop the database without usin
|
||||
|
||||
Connected to an idle instance.
|
||||
|
||||
#### 3- Start The database ####
|
||||
#### 3- 启动数据库实例 ####
|
||||
|
||||
命令:
|
||||
SQL> startup
|
||||
提示:
|
||||
ORACLE instance started.
|
||||
Total System Global Area 3340451840 bytes
|
||||
Fixed Size 2217952 bytes
|
||||
@ -36,16 +39,20 @@ In this small tutorial, I want to show you how to drop the database without usin
|
||||
Database mounted.
|
||||
Database opened.
|
||||
|
||||
#### 4- Shutdown the database ####
|
||||
#### 4- 关闭数据库 ####
|
||||
|
||||
命令:
|
||||
SQL> shutdown immediate;
|
||||
提示:
|
||||
Database closed.
|
||||
Database dismounted.
|
||||
ORACLE instance shut down.
|
||||
|
||||
#### 5- Start in Exclusive mode ####
|
||||
#### 5- 启动独占模式 ####
|
||||
|
||||
命令:
|
||||
SQL> startup mount exclusive restrict
|
||||
提示:
|
||||
ORACLE instance started.
|
||||
|
||||
----------
|
||||
@ -57,10 +64,12 @@ In this small tutorial, I want to show you how to drop the database without usin
|
||||
Redo Buffers 16343040 bytes
|
||||
Database mounted.
|
||||
|
||||
#### 6- Drop the database ####
|
||||
#### 6- 删除数据库 ####
|
||||
|
||||
命令:
|
||||
SQL> drop database;
|
||||
|
||||
提示:
|
||||
----------
|
||||
|
||||
Database dropped.
|
||||
@ -71,14 +80,14 @@ In this small tutorial, I want to show you how to drop the database without usin
|
||||
With the Partitioning, OLAP, Data Mining and Real Application Testing options
|
||||
SQL>
|
||||
|
||||
Cheers!
|
||||
完成!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/drop-database-oracle-11-without-using-dcba/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[VicYu/Vic020](http://vicyu.net/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,89 @@
|
||||
如何从终端以后台模式运行Linux程序
|
||||
===
|
||||
|
||||

|
||||
|
||||
Linux终端窗口。
|
||||
|
||||
这是一个简短但是非常有用的教程:它向你展示从终端运行Linux应用程序的同时,如何保证终端仍然在控制之中。
|
||||
|
||||
在Linux中有许多方式可以打开一个终端,这主要取决于你分类的选择和桌面环境。
|
||||
|
||||
使用Ubuntu,你可以使用CTRL + ALT + T组合键打开一个终端。你也可以点击超级键(Windows键)打开一个终端窗口。在键盘上,[打开Ubuntu Dash][1],然后搜索"TERM"。点击"Term"图标将会打开一个终端窗口。
|
||||
|
||||
其他诸如XFCE, KDE, LXDE, Cinnamon和MATE的桌面环境,你将会在菜单中发现终端。还有一些分类会把终端图标放在入口处,或者在面板上放置终端启动器。
|
||||
|
||||
你可以在终端输入一个程序的名字来启动一个应用。举例,你可以通过输入"firefox"启动火狐浏览器。
|
||||
|
||||
从终端运行程序的好处是一可以包含额外的选项。
|
||||
|
||||
举个例子,如果你输入下面的命令,一个新的火狐浏览器将会打开,而且默认的搜索引擎将会搜索引用之间的术语:
|
||||
|
||||
firefox -search "Linux.About.Com"
|
||||
|
||||
你会发现,如果你运行火狐浏览器,应用程序将被打开,并且控制将会回到终端,这将意味着你可以继续在终端工作。
|
||||
|
||||
通常情况下,如果你通过终端运行一个程序,程序将被打开,并且直到那个程序关闭结束,你将不会重新获得终端的控制权。这是因为你是在前台打开程序的。
|
||||
|
||||
想要从终端运行一个程序,并且立即将终端的控制权返回给你,你需要以后台进程的方式打开程序。
|
||||
|
||||
为了以后台进程的方式打开一个程序,只需要添加符号(&)到命令中,如下面所示:
|
||||
|
||||
libreoffice &
|
||||
|
||||
在终端中仅仅提供程序的名字,应用程序可能运行不了。如果程序不存在于一个设置了路径变量的文件夹中,你需要指定完成的路径名来运行程序。
|
||||
|
||||
/path/to/yourprogram &
|
||||
|
||||
如果你并不确定一个程序是否存在于Linux文件结构,使用find或者locate命令来查询应用程序。
|
||||
|
||||
找一个文件的语法如下:
|
||||
|
||||
find /path/to/start/from -name programname
|
||||
|
||||
举个例子,可以使用下面的命令寻找Firefox的位置:
|
||||
|
||||
find / -name firefox
|
||||
|
||||
输出会很快掠过,所以你可以以管道的方式控制输出的多少:
|
||||
|
||||
find / -name firefox | more
|
||||
|
||||
find / -name firefox | less
|
||||
|
||||
find命令将会返回因权限拒绝而发生错误的文件夹数量,这些文件夹你没有权限去搜索。
|
||||
|
||||
你可以使用sudo命令提升你的权限。如果sudo没有安装,你需要切换到拥有权限的用户:
|
||||
|
||||
sudo find / -name firefox | more
|
||||
|
||||
如果你知道你想寻找的文件在你的当前文件夹结构中,你可以一个点代替先前的斜线,如下:
|
||||
|
||||
sudo find . -name firefox | more
|
||||
|
||||
你可能不需要sudo来提升权限。如果你在home文件夹结构中寻找文件,sudo就不需要。
|
||||
|
||||
一些应用程序需要提升用户权限来运行,你可能得到一个缺少权限的错误,除非你使用一个具有足够权限的用户,或者使用sudo提升你的权限。
|
||||
|
||||
下面是一个小花招。如果你运行一个程序,而且它需要提升权限来运行,输入下面命令:
|
||||
|
||||
sudo !!
|
||||
|
||||
---
|
||||
|
||||
via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-T
|
||||
he-Terminal-In-Background-Mode.htm
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中>
|
||||
国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linux.about.com/bio/Gary-Newell-132058.htm
|
||||
[1]:http://linux.about.com/od/howtos/fl/Learn-Ubuntu-The-Unity-Dash.htm
|
||||
[2]:http://linux.about.com/od/commands/l/blcmdl1_locate.htm
|
||||
[3]:http://linux.about.com/library/cmd/blcmdl1_less.htm
|
||||
[4]:http://linux.about.com/library/cmd/blcmdl1_more.htm
|
||||
[5]:http://linux.about.com/od/commands/l/blcmdl8_sudo.htm
|
||||
@ -0,0 +1,100 @@
|
||||
在Ubuntu上找出可用的网络适配器
|
||||
================================================================================
|
||||
想知道**在Linux中你正在使用的网卡是什么吗?** 在Linux中很容易就找出网卡的生产商。打开一个终端并输入下面的额命令:
|
||||
|
||||
sudo lshw -C network
|
||||
|
||||
如果上面的命令不能在sudo下使用,那就移除sudo。它的输出看上去有点奇怪但是很有用。
|
||||
|
||||

|
||||
|
||||
> *-network
|
||||
>
|
||||
> description: Wireless interface
|
||||
>
|
||||
> product: BCM4360 802.11ac Wireless Network Adapter
|
||||
>
|
||||
> vendor: Broadcom Corporation
|
||||
>
|
||||
> physical id: 0
|
||||
>
|
||||
> bus info: pci@0000:03:00.0
|
||||
>
|
||||
> logical name: wlan0
|
||||
>
|
||||
> version: 03
|
||||
>
|
||||
> serial: 9c:f3:87:c1:5d:6a
|
||||
>
|
||||
> width: 64 bits
|
||||
>
|
||||
> clock: 33MHz
|
||||
>
|
||||
> capabilities: bus_master cap_list ethernet physical wireless
|
||||
>
|
||||
> configuration: broadcast=yes driver=wl0 driverversion=6.30.223.248 (r487574) ip=192.168.1.23 latency=0 multicast=yes wireless=IEEE 802.11abg
|
||||
>
|
||||
> resources: irq:18 memory:b0600000-b0607fff memory:b0400000-b05fffff
|
||||
|
||||
如你所见,我Macbook Air上的无线网卡是BCM4360,这是一款在Ubuntu下面经常无法检测无线网络的很容易出问题的网卡。
|
||||
|
||||
[lshw][1] 命令实际上死用来列出硬件的,因此命令的名字是lshw。带上网络的选项后,就会只过滤出网络硬件了。
|
||||
|
||||
### 了解网卡的其他方法 ###
|
||||
|
||||
另外你还可以使用lspci命令来显示PCI总线上的信息。你不应该用特权模式来运行这个命令。只需要在命令行下输入:
|
||||
|
||||
lspci
|
||||
|
||||
命令的输出看上去想这样:
|
||||
|
||||

|
||||
|
||||
> 00:00.0 Host bridge: Intel Corporation Haswell-ULT DRAM Controller (rev 09)
|
||||
>
|
||||
> 00:02.0 VGA compatible controller: Intel Corporation Haswell-ULT Integrated Graphics Controller (rev 09)
|
||||
>
|
||||
> 00:03.0 Audio device: Intel Corporation Haswell-ULT HD Audio Controller (rev 09)
|
||||
>
|
||||
> 00:14.0 USB controller: Intel Corporation 8 Series USB xHCI HC (rev 04)
|
||||
>
|
||||
> 00:16.0 Communication controller: Intel Corporation 8 Series HECI #0 (rev 04)
|
||||
>
|
||||
> 00:1b.0 Audio device: Intel Corporation 8 Series HD Audio Controller (rev 04)
|
||||
>
|
||||
> 00:1c.0 PCI bridge: Intel Corporation 8 Series PCI Express Root Port 1 (rev e4)
|
||||
>
|
||||
> 00:1c.1 PCI bridge: Intel Corporation 8 Series PCI Express Root Port 2 (rev e4)
|
||||
>
|
||||
> 00:1c.2 PCI bridge: Intel Corporation 8 Series PCI Express Root Port 3 (rev e4)
|
||||
>
|
||||
> 00:1c.4 PCI bridge: Intel Corporation 8 Series PCI Express Root Port 5 (rev e4)
|
||||
>
|
||||
> 00:1c.5 PCI bridge: Intel Corporation 8 Series PCI Express Root Port 6 (rev e4)
|
||||
>
|
||||
> 00:1f.0 ISA bridge: Intel Corporation 8 Series LPC Controller (rev 04)
|
||||
>
|
||||
> 00:1f.3 SMBus: Intel Corporation 8 Series SMBus Controller (rev 04)
|
||||
>
|
||||
> 02:00.0 Multimedia controller: Broadcom Corporation Device 1570
|
||||
>
|
||||
> 03:00.0 Network controller: Broadcom Corporation BCM4360 802.11ac Wireless Network Adapter (rev 03)
|
||||
>
|
||||
> 04:00.0 SATA controller: Marvell Technology Group Ltd. 88SS9183 PCIe SSD Controller (rev 14)
|
||||
|
||||
这些命令会同时列出有线和无线的网卡。你应该注意到上面的输出中显示我的系统中没有有线网卡。因为我使用的是Macbook Air,他没有以太网端口
|
||||
|
||||
我希望这边文章可以帮助你找到你系统中的网卡。欢迎提出问题和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/find-network-adapter-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://linux.die.net/man/1/lshw
|
||||
Loading…
Reference in New Issue
Block a user