mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
d09377bb1e
published
sources
talk
tech
translated
@ -7,25 +7,26 @@
|
||||
|
||||
### 它的时间是多少?
|
||||
|
||||
当让 Linux 来告诉你时间的时候,它是很奇怪的。你可能认为是使用 `time` 命令来告诉你时间,其实并不是,因为 `time` 只是一个测量一个进程运行了多少时间的计时器。为得到时间,你需要运行的是 `date` 命令,你想查看更多的日期,你可以运行 `cal` 命令。文件上的时间戳也是一个容易混淆的地方,因为根据你的发行版默认情况不同,它一般有两种不同的显示方法。下面是来自 Ubuntu 16.04 LTS 的示例:
|
||||
让 Linux 来告诉你时间的时候,它是很奇怪的。你可能认为是使用 `time` 命令来告诉你时间,其实并不是,因为 `time` 只是一个测量一个进程运行了多少时间的计时器。为得到时间,你需要运行的是 `date` 命令,你想查看更多的日期,你可以运行 `cal` 命令。文件上的时间戳也是一个容易混淆的地方,因为根据你的发行版默认情况不同,它一般有两种不同的显示方法。下面是来自 Ubuntu 16.04 LTS 的示例:
|
||||
|
||||
```
|
||||
$ ls -l
|
||||
drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
|
||||
drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
|
||||
-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
|
||||
-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
|
||||
|
||||
```
|
||||
|
||||
有些显示年,有些显示时间,这样的方式让你的文件更混乱。GNU 默认的情况是,如果你的文件在六个月以内,则显示时间而不是年。我想这样做可能是有原因的。如果你的 Linux 是这样的,尝试用 `ls -l --time-style=long-iso` 命令,让时间戳用同一种方式去显示,按字母顺序排序。查阅 [如何更改 Linux 的日期和时间:简单的命令][1] 去学习 Linux 上管理时间的各种方法。
|
||||
有些显示年,有些显示时间,这样的方式让你的文件更混乱。GNU 默认的情况是,如果你的文件在六个月以内,则显示时间而不是年。我想这样做可能是有原因的。如果你的 Linux 是这样的,尝试用 `ls -l --time-style=long-iso` 命令,让时间戳用同一种方式去显示,按字母顺序排序。请查阅 [如何更改 Linux 的日期和时间:简单的命令][1] 去学习 Linux 上管理时间的各种方法。
|
||||
|
||||
### 检查当前设置
|
||||
|
||||
NTP —— 网络时间协议,它是老式的保持计算机正确时间的方法。`ntpd` 是 NTP 守护程序,它通过周期性地查询公共时间服务器来按需调整你的计算机时间。它是一个简单的、轻量级的协议,使用它的基本功能时设置非常容易。Systemd 通过使用 `systemd-timesyncd.service` 已经越俎代庖 “干了 NTP 的活”,它可以用作 `ntpd` 的客户端。
|
||||
NTP —— 网络时间协议,它是保持计算机正确时间的老式方法。`ntpd` 是 NTP 守护程序,它通过周期性地查询公共时间服务器来按需调整你的计算机时间。它是一个简单的、轻量级的协议,使用它的基本功能时设置非常容易。systemd 通过使用 `systemd-timesyncd.service` 已经越俎代庖地 “干了 NTP 的活”,它可以用作 `ntpd` 的客户端。
|
||||
|
||||
在我们开始与 NTP “打交道” 之前,先花一些时间来了检查一下当前的时间设置是否正确。
|
||||
|
||||
你的系统上(至少)有两个时钟:系统时间 —— 它由 Linux 内核管理,第二个是你的主板上的硬件时钟,它也称为实时时钟(RTC)。当你进入系统的 BIOS 时,你可以看到你的硬件时钟的时间,你也可以去改变它的设置。当你安装一个新的 Linux 时,在一些图形化的时间管理器中,你会被询问是否设置你的 RTC 为 UTC(协调世界时间)时区,因为所有的时区和夏令时都是基于 UTC 的。你可以使用 `hwclock` 命令去检查:
|
||||
你的系统上(至少)有两个时钟:系统时间 —— 它由 Linux 内核管理,第二个是你的主板上的硬件时钟,它也称为实时时钟(RTC)。当你进入系统的 BIOS 时,你可以看到你的硬件时钟的时间,你也可以去改变它的设置。当你安装一个新的 Linux 时,在一些图形化的时间管理器中,你会被询问是否设置你的 RTC 为 UTC(<ruby>世界标准时间<rt>Coordinated Universal Time</rt></ruby>)时区,因为所有的时区和夏令时都是基于 UTC 的。你可以使用 `hwclock` 命令去检查:
|
||||
|
||||
```
|
||||
$ sudo hwclock --debug
|
||||
hwclock from util-linux 2.27.1
|
||||
@ -39,27 +40,27 @@ Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
|
||||
Time since last adjustment is 1516659271 seconds
|
||||
Calculated Hardware Clock drift is 0.000000 seconds
|
||||
Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
|
||||
|
||||
```
|
||||
|
||||
"硬件时钟用 UTC 时间维护" 确认了你的计算机的 RTC 是使用 UTC 时间,虽然你的本地时间是通过 UTC 转换来的。如果设置本地时间,它将报告 “硬件时钟用本地时间维护”。
|
||||
`Hardware clock is on UTC time` 表明了你的计算机的 RTC 是使用 UTC 时间的,虽然它把该时间转换为你的本地时间。如果它被设置为本地时间,它将显示 `Hardware clock is on local time`。
|
||||
|
||||
你应该有一个 `/etc/adjtime` 文件。如果没有的话,使用如下命令同步你的 RTC 为系统时间,
|
||||
|
||||
如果你不同步你的 RTC 到系统时间,你应该有一个 `/etc/adjtime` 文件。
|
||||
```
|
||||
$ sudo hwclock -w
|
||||
|
||||
```
|
||||
|
||||
这个命令将生成这个文件,它将包含如下示例中的内容:
|
||||
这个命令将生成该文件,内容看起来类似如下:
|
||||
|
||||
```
|
||||
$ cat /etc/adjtime
|
||||
0.000000 1516661953 0.000000
|
||||
1516661953
|
||||
UTC
|
||||
|
||||
```
|
||||
|
||||
新发明的 systemd 方式是去运行 `timedatectl` 命令,运行它不需要 root 权限:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
Local time: Mon 2018-01-22 14:17:51 PST
|
||||
@ -69,35 +70,36 @@ $ timedatectl
|
||||
Network time on: yes
|
||||
NTP synchronized: yes
|
||||
RTC in local TZ: no
|
||||
|
||||
```
|
||||
|
||||
"RTC in local TZ: no" 确认了它没有使用 UTC 时间。如果要改变它的本地时间,怎么办?这里有许多种方法可以做到。最简单的方法是使用一个图形配置工具,比如像 openSUSE 中的 YaST。你可使用 `timedatectl`:
|
||||
`RTC in local TZ: no` 表明它使用 UTC 时间。那么怎么改成使用本地时间?这里有许多种方法可以做到。最简单的方法是使用一个图形配置工具,比如像 openSUSE 中的 YaST。你也可使用 `timedatectl`:
|
||||
|
||||
```
|
||||
$ timedatectl set-local-rtc 0
|
||||
```
|
||||
|
||||
或者编辑 `/etc/adjtime`,将 UTC 替换为 LOCAL。
|
||||
或者编辑 `/etc/adjtime`,将 `UTC` 替换为 `LOCAL`。
|
||||
|
||||
### systemd-timesyncd 客户端
|
||||
|
||||
现在,我已经累了,但是我们刚到非常精彩的部分。谁能想到计时如此复杂?我们甚至还没有了解到它的皮毛;阅读 `man 8 hwclock` 去了解你的计算机如何保持时间的详细内容。
|
||||
|
||||
Systemd 提供了 `systemd-timesyncd.service` 客户端,它查询远程时间服务器并调整你的本地系统时间。在 `/etc/systemd/timesyncd.conf` 中配置你的服务器。大多数 Linux 发行版都提供一个默认配置,它指向他们维护的时间服务器上,比如,以下是 Fedora 的:
|
||||
systemd 提供了 `systemd-timesyncd.service` 客户端,它可以查询远程时间服务器并调整你的本地系统时间。在 `/etc/systemd/timesyncd.conf` 中配置你的(时间)服务器。大多数 Linux 发行版都提供了一个默认配置,它指向他们维护的时间服务器上,比如,以下是 Fedora 的:
|
||||
|
||||
```
|
||||
[Time]
|
||||
#NTP=
|
||||
#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
|
||||
|
||||
```
|
||||
|
||||
你可以输入你希望的其它时间服务器,比如你自己的本地 NTP 服务器,在 `NTP=` 行上输入一个以空格分隔的服务器列表。(别忘了取消这一行的注释)`NTP=` 行上的任何内容都将覆盖掉 fallback 行上的配置项。
|
||||
你可以输入你希望使用的其它时间服务器,比如你自己的本地 NTP 服务器,在 `NTP=` 行上输入一个以空格分隔的服务器列表。(别忘了取消这一行的注释)`NTP=` 行上的任何内容都将覆盖掉 `FallbackNTP` 行上的配置项。
|
||||
|
||||
如果你不想使用 systemd 呢?那么,你将需要一个 NTP。
|
||||
如果你不想使用 systemd 呢?那么,你将需要 NTP 就行。
|
||||
|
||||
### 配置 NTP 服务器和客户端
|
||||
|
||||
配置你自己的局域网 NTP 服务器是一个非常好的实践,这样你的网内计算机就不需要不停查询公共 NTP 服务器。在大多数 Linux 的 `ntp` 包中都带了 NTP,它们大多都提供 `/etc/ntp.conf` 文件去配置服务器。查阅 [NTP 时间服务器池][2] 去找到你所在的区域的合适的 NTP 服务器池。然后在你的 `/etc/ntp.conf` 中输入 4- 5 个服务器,每个服务器用单独的一行:
|
||||
配置你自己的局域网 NTP 服务器是一个非常好的实践,这样你的网内计算机就不需要不停查询公共 NTP 服务器。在大多数 Linux 上的 NTP 都来自 `ntp` 包,它们大多都提供 `/etc/ntp.conf` 文件去配置时间服务器。查阅 [NTP 时间服务器池][2] 去找到你所在的区域的合适的 NTP 服务器池。然后在你的 `/etc/ntp.conf` 中输入 4 - 5 个服务器,每个服务器用单独的一行:
|
||||
|
||||
```
|
||||
driftfile /var/ntp.drift
|
||||
logfile /var/log/ntp.log
|
||||
@ -105,12 +107,12 @@ server 0.europe.pool.ntp.org
|
||||
server 1.europe.pool.ntp.org
|
||||
server 2.europe.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
|
||||
```
|
||||
|
||||
`driftfile` 告诉 `ntpd` 在这里保存的信息是用于在启动时,使用时间服务器去快速同步你的系统时钟的。而日志将保存在他们自己指定的目录中,而不是转储到 syslog 中。如果你的 Linux 发行版默认提供了这些文件,请使用它们。
|
||||
`driftfile` 告诉 `ntpd` 它需要保存用于启动时使用时间服务器快速同步你的系统时钟的信息。而日志也将保存在他们自己指定的目录中,而不是转储到 syslog 中。如果你的 Linux 发行版默认提供了这些文件,请使用它们。
|
||||
|
||||
现在去启动守护程序;在大多数主流的 Linux 中它的命令是 `sudo systemctl start ntpd`。让它运行几分钟之后,我们再次去检查它的状态:
|
||||
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
@ -119,16 +121,15 @@ $ ntpq -p
|
||||
*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
|
||||
+four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
|
||||
-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
|
||||
|
||||
```
|
||||
|
||||
我不知道这些内容是什么意思,但重要的是,你的守护程序已经与时间服务器开始对话了,而这正是我们所需要的。你可以去运行 `sudo systemctl enable ntpd` 命令,永久启用它。如果你的 Linux 没有使用 systemd,那么,给你留下的家庭作业就是找出如何去运行 `ntpd`。
|
||||
|
||||
现在,你可以在你的局域网中的其它计算机上设置 `systemd-timesyncd`,这样它们就可以使用你的本地 NTP 服务器了,或者,在它们上面安装 NTP,然后在它们的 `/etc/ntp.conf` 上输入你的本地 NTP 服务器。
|
||||
|
||||
NTP 服务器持续地接受客户端查询,并且这种需求在不断增加。你可以通过运行你自己的公共 NTP 服务器来提供帮助。下周我们将学习如何运行你自己的公共服务器。
|
||||
NTP 服务器会受到攻击,而且需求在不断增加。你可以通过运行你自己的公共 NTP 服务器来提供帮助。下周我们将学习如何运行你自己的公共服务器。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][3] 来学习更多 Linux 的知识。
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][3] 来学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -136,7 +137,7 @@ via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,114 +0,0 @@
|
||||
lontow Translating
|
||||
|
||||
Evolutional Steps of Computer Systems
|
||||
======
|
||||
Throughout the history of the modern computer, there were several evolutional steps related to the way we interact with the system. I tend to categorize those steps as following:
|
||||
|
||||
1. Numeric Systems
|
||||
2. Application-Specific Systems
|
||||
3. Application-Centric Systems
|
||||
4. Information-Centric Systems
|
||||
5. Application-Less Systems
|
||||
|
||||
|
||||
|
||||
Following sections describe how I see those categories.
|
||||
|
||||
### Numeric Systems
|
||||
|
||||
[Early computers][1] were designed with numbers in mind. They could add, subtract, multiply, divide. Some of them were able to perform more complex mathematical operations such as differentiate or integrate.
|
||||
|
||||
If you map characters to numbers, they were able to «compute» [strings][2] as well but this is somewhat «creative use of numbers» instead of meaningful processing arbitrary information.
|
||||
|
||||
### Application-Specific Systems
|
||||
|
||||
For higher-level problems, pure numeric systems are not sufficient. Application-specific systems were developed to do one single task. They were very similar to numeric systems. However, with sufficiently complex number calculations, systems were able to accomplish very well-defined higher level tasks such as calculations related to scheduling problems or other optimization problems.
|
||||
|
||||
Systems of this category were built for one single purpose, one distinct problem they solved.
|
||||
|
||||
### Application-Centric Systems
|
||||
|
||||
Systems that are application-centric are the first real general purpose systems. Their main usage style is still mostly application-specific but with multiple applications working either time-sliced (one app after another) or in multi-tasking mode (multiple apps at the same time).
|
||||
|
||||
Early personal computers [from the 70s][3] of the previous century were the first application-centric systems that became popular for a wide group of people.
|
||||
|
||||
Yet modern operating systems - Windows, macOS, most GNU/Linux desktop environments - still follow the same principles.
|
||||
|
||||
Of course, there are sub-categories as well:
|
||||
|
||||
1. Strict Application-Centric Systems
|
||||
2. Loose Application-Centric Systems
|
||||
|
||||
|
||||
|
||||
Strict application-centric systems such as [Windows 3.1][4] (Program Manager and File Manager) or even the initial version of [Windows 95][5] had no pre-defined folder hierarchy. The user did start text processing software like [WinWord][6] and saved the files in the program folder of WinWord. When working with a spreadsheet program, its files were saved in the application folder of the spreadsheet tool. And so on. Users did not create their own hierarchy of folders mostly because of convenience, laziness, or because they did not saw any necessity. The number of files per user were sill within dozens up to a few hundreds.
|
||||
|
||||
For accessing information, the user typically opened an application and within the application, the files containing the generated data were retrieved using file/open.
|
||||
|
||||
It was [Windows 95][5] SP2 that introduced «[My Documents][7]» for the Windows platform. With this file hierarchy template, application designers began switching to «My Documents» as a default file save/open location instead of using the software product installation path. This made the users embrace this pattern and start to maintain folder hierarchies on their own.
|
||||
|
||||
This resulted in loose application-centric systems: typical file retrieval is done via a file manager. When a file is opened, the associated application is started by the operating system. It is a small or subtle but very important usage shift. Application-centric systems are still the dominant usage pattern for personal computers.
|
||||
|
||||
Nevertheless, this pattern comes with many disadvantages. For example in order to prevent data retrieval problems, there is the need to maintain a strict hierarchy of folders that contain all related files of a given project. Unfortunately, nature does not fit well in strict hierarchy of folders. Further more, [this does not scale well][8]. Desktop search engines and advanced data organizing tools like [tagstore][9] are able to smooth the edged a bit. As studies show, only a minority of users are using such advanced retrieval tools. Most users still navigate through the file system without using any alternative or supplemental retrieval techniques.
|
||||
|
||||
### Information-Centric Systems
|
||||
|
||||
One possible way of dealing with the issue that a certain topic needs to have a folder that holds all related files is to switch from an application-centric system to an information-centric systems.
|
||||
|
||||
Instead of opening a spreadsheet application to work with the project budget, opening a word processor application to write the project report, and opening another tool to work with image files, an information-centric system combines all the information on the project in one place, in one application.
|
||||
|
||||
The calculations for the previous month is right beneath notes from a client meeting which is right beneath a photography of the whiteboard notes which is right beneath some todo tasks. Without any application or file border in between.
|
||||
|
||||
Early attempts to create such an environment were IBM [OS/2][10], Microsoft [OLE][11] or [NeXT][12]. None of them were a major success for a variety of reasons. A very interesting information-centric environment is [Acme][13] from [Plan 9][14]. It combines [a wide variety of applications][15] within one application but it never reached a notable distribution even with its ports to Windows or GNU/Linux.
|
||||
|
||||
Modern approaches for an information-centric system are advanced [personal wikis][16] like [TheBrain][17] or [Microsoft OneNote][18].
|
||||
|
||||
My personal tool of choice is the [GNU/Emacs][19] platform with its [Org-mode][19] extension. I hardly leave Org-mode when I work with my computer. For accessing external data sources, I created [Memacs][20] which brings me a broad variety of data into Org-mode. I love to do spreadsheet calculations right beneath scheduled tasks, in-line images, internal and external links, and so forth. It is truly an information-centric system where the user doesn't have to deal with application borders or strictly hierarchical file-system folders. Multi-classifications is possible using simple or advanced tagging. All kinds of views can be derived with a single command. One of those views is my calendar, the agenda. Another derived view is the list of borrowed things. And so on. There are no limits for Org-mode users. If you can think of it, it is most likely possible within Org-mode.
|
||||
|
||||
Is this the end of the evolution? Certainly not.
|
||||
|
||||
### Application-Less Systems
|
||||
|
||||
I can think of a class of systems which I refer to as application-less systems. As the next logical step, there is no need to have single-domain applications even when they are as capable as Org-mode. The computer offers a nice to use interface to information and features, not files and applications. Even a classical operating system is not accessible.
|
||||
|
||||
Application-less systems might as well be combined with [artificial intelligence][21]. Think of it as some kind of [HAL 9000][22] from [A Space Odyssey][23]. Or [LCARS][24] from Star Trek.
|
||||
|
||||
It is hard to believe that there is a transition between our application-based, vendor-based software culture and application-less systems. Maybe the open source movement with its slow but constant development will be able to form a truly application-less environment where all kinds of organizations and people are contributing to.
|
||||
|
||||
Information and features to retrieve and manipulate information, this is all it takes. This is all we need. Everything else is just limiting distraction.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/2017/02/10/evolution-of-systems/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/History_of_computing_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/String_%2528computer_science%2529
|
||||
[3]:https://en.wikipedia.org/wiki/Xerox_Alto
|
||||
[4]:https://en.wikipedia.org/wiki/Windows_3.1x
|
||||
[5]:https://en.wikipedia.org/wiki/Windows_95
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Word
|
||||
[7]:https://en.wikipedia.org/wiki/My_Documents
|
||||
[8]:http://karl-voit.at/tagstore/downloads/Voit2012b.pdf
|
||||
[9]:http://karl-voit.at/tagstore/
|
||||
[10]:https://en.wikipedia.org/wiki/OS/2
|
||||
[11]:https://en.wikipedia.org/wiki/Object_Linking_and_Embedding
|
||||
[12]:https://en.wikipedia.org/wiki/NeXT
|
||||
[13]:https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529
|
||||
[14]:https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs
|
||||
[15]:https://en.wikipedia.org/wiki/List_of_Plan_9_applications
|
||||
[16]:https://en.wikipedia.org/wiki/Personal_wiki
|
||||
[17]:https://en.wikipedia.org/wiki/TheBrain
|
||||
[18]:https://en.wikipedia.org/wiki/Microsoft_OneNote
|
||||
[19]:../../../../tags/emacs
|
||||
[20]:https://github.com/novoid/Memacs
|
||||
[21]:https://en.wikipedia.org/wiki/Artificial_intelligence
|
||||
[22]:https://en.wikipedia.org/wiki/HAL_9000
|
||||
[23]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey
|
||||
[24]:https://en.wikipedia.org/wiki/LCARS
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by rockouc
|
||||
|
||||
Why pair writing helps improve documentation
|
||||
======
|
||||

|
||||
|
||||
@ -1,177 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Microservices vs. monolith: How to choose
|
||||
============================================================
|
||||
|
||||
### Both architectures have pros and cons, and the right decision depends on your organization's unique needs.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
Onasill ~ Bill Badzo on [Flickr][11]. [CC BY-NC-SA 2.0][12]. Modified by Opensource.com.
|
||||
|
||||
For many startups, conventional wisdom says to start with a monolith architecture over microservices. But are there exceptions to this?
|
||||
|
||||
The upcoming book, [_Microservices for Startups_][13] , explores the benefits and drawbacks of microservices, offering insights from dozens of CTOs.
|
||||
|
||||
While different CTOs take different approaches when starting new ventures, they agree that context and capability are key. If you're pondering whether your business would be best served by a monolith or microservices, consider the factors discussed below.
|
||||
|
||||
### Understanding the spectrum
|
||||
|
||||
More on Microservices
|
||||
|
||||
* [How to explain microservices to your CEO][1]
|
||||
|
||||
* [Free eBook: Microservices vs. service-oriented architecture][2]
|
||||
|
||||
* [Secured DevOps for microservices][3]
|
||||
|
||||
Let's first clarify what exactly we mean by “monolith” and “microservice.”
|
||||
|
||||
Microservices are an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery.
|
||||
|
||||
A monolithic application is built as a single, unified unit, and usually one massive code base. Often a monolith consists of three parts: a database, a client-side user interface (consisting of HTML pages and/or JavaScript running in a browser), and a server-side application.
|
||||
|
||||
“System architectures lie on a spectrum,” Zachary Crockett, CTO of [Particle][14], said in an interview. “When discussing microservices, people tend to focus on one end of that spectrum: many tiny applications passing too many messages to each other. At the other end of the spectrum, you have a giant monolith doing too many things. For any real system, there are many possible service-oriented architectures between those two extremes.”
|
||||
|
||||
Depending on your situation, there are good reasons to tend toward either a monolith or microservices.
|
||||
|
||||
"We want to use the best tool for each service." Julien Lemoine, CTO at Algolia
|
||||
|
||||
Contrary to what many people think, a monolith isn’t a dated architecture that's best left in the past. In certain circumstances, a monolith is ideal. I spoke to Steven Czerwinski, head of engineering at [Scaylr][15] and a former Google employee, to better understand this.
|
||||
|
||||
“Even though we had had positive experiences of using microservices at Google, we [at Scalyr] went [for a monolith] route because having one monolithic server means less work for us as two engineers,” he explained. (This was back in the early days of Scalyr.)
|
||||
|
||||
But if your team is experienced with microservices and you have a clear idea of the direction you’re going, microservices can be a great alternative.
|
||||
|
||||
Julien Lemoine, CTO at [Algolia][16], chimed in on this point: “We have always started with a microservices approach. The main goal was to be able to use different technology to build our service, for two big reasons:
|
||||
|
||||
* We want to use the best tool for each service. Our search API is highly optimized at the lowest level, and C++ is the perfect language for that. That said, using C++ for everything is a waste of productivity, especially to build a dashboard.
|
||||
|
||||
* We want the best talent, and using only one technology would limit our options. This is why we have different languages in the company.”
|
||||
|
||||
If your team is prepared, starting with microservices allows your organization to get used to the rhythm of developing in a microservice environment right from the start.
|
||||
|
||||
### Weighing the pros and cons
|
||||
|
||||
Before you decide which approach is best for your organization, it's important to consider the strengths and weaknesses of each.
|
||||
|
||||
### Monoliths
|
||||
|
||||
### Pros:
|
||||
|
||||
* **Fewer cross-cutting concerns:** Most apps have cross-cutting concerns, such as logging, rate limiting, and security features like audit trails and DOS protection. When everything is running through the same app, it’s easy to address those concerns by hooking up components.
|
||||
|
||||
* **Less operational overhead:** There’s only one application to set up for logging, monitoring, and testing. Also, it's generally less complex to deploy.
|
||||
|
||||
* **Performance:** A monolith architecture can offer performance advantages since shared-memory access is faster than inter-process communication (IPC).
|
||||
|
||||
### Cons:
|
||||
|
||||
* **Tightly coupled:** Monolithic app services tend to get tightly coupled and entangled as the application evolves, making it difficult to isolate services for purposes such as independent scaling or code maintainability.
|
||||
|
||||
* **Harder to understand:** Monolithic architectures are more difficult to understand because of dependencies, side effects, and other factors that are not obvious when you’re looking at a specific service or controller.
|
||||
|
||||
### Microservices
|
||||
|
||||
### Pros:
|
||||
|
||||
* **Better organization:** Microservice architectures are typically better organized, since each microservice has a specific job and is not concerned with the jobs of other components.
|
||||
|
||||
* **Decoupled:** Decoupled services are easier to recompose and reconfigure to serve different apps (for example, serving both web clients and the public API). They also allow fast, independent delivery of individual parts within a larger integrated system.
|
||||
|
||||
* **Performance:** Depending on how they're organized, microservices can offer performance advantages because you can isolate hot services and scale them independently of the rest of the app.
|
||||
|
||||
* **Fewer mistakes:** Microservices enable parallel development by establishing a strong boundary between different parts of your system. Doing this makes it more difficult to connect parts that shouldn’t be connected, for example, or couple too tightly those that need to be connected.
|
||||
|
||||
### Cons:
|
||||
|
||||
* **Cross-cutting concerns across each service:** As you build a new microservice architecture, you’re likely to discover cross-cutting concerns you may not have anticipated at design time. You’ll either need to incur the overhead of separate modules for each cross-cutting concern (i.e., testing), or encapsulate cross-cutting concerns in another service layer through which all traffic is routed. Eventually, even monolithic architectures tend to route traffic through an outer service layer for cross-cutting concerns, but with a monolithic architecture, it’s possible to delay the cost of that work until the project is more mature.
|
||||
|
||||
* **Higher operational overhead:** Microservices are frequently deployed on their own virtual machines or containers, causing a proliferation of VM wrangling. These tasks are frequently automated with container fleet management tools.
|
||||
|
||||
### Decision time
|
||||
|
||||
Once you understand the pros and cons of both approaches, how do you apply this information to your startup? Based on interviews with CTOs, here are three questions to guide your decision process:
|
||||
|
||||
**Are you in familiar territory?**
|
||||
|
||||
Diving directly into microservices is less risky if your team has previous domain experience (for example, in e-commerce) and knowledge concerning the needs of your customers. If you’re traveling down an unknown path, on the other hand, a monolith may be a safer option.
|
||||
|
||||
**Is your team prepared?**
|
||||
|
||||
Does your team have experience with microservices? If you quadruple the size of your team within the next year, will microservices offer the best environment? Evaluating the dimensions of your team is crucial to the success of your project.
|
||||
|
||||
**How’s your infrastructure?**
|
||||
|
||||
To make microservices work, you’ll need a cloud-based infrastructure.
|
||||
|
||||
David Strauss, CTO of [Pantheon][17], explained: “[Previously], you would want to start with a monolith because you wanted to deploy one database server. The idea of having to set up a database server for every single microservice and then scale out was a mammoth task. Only a huge, tech-savvy organization could do that. Today, with services like Google Cloud and Amazon AWS, you have many options for deploying tiny things without needing to own the persistence layer for each one.”
|
||||
|
||||
### Evaluate the business risk
|
||||
|
||||
As a tech-savvy startup with high ambitions, you might think microservices is the “right” way to go. But microservices can pose a business risk. Strauss explained, “A lot of teams overbuild their project initially. Everyone wants to think their startup will be the next unicorn, and they should therefore build everything with microservices or some other hyper-scalable infrastructure. But that's usually wrong.” In these cases, Strauss continued, the areas that they thought they needed to scale are often not the ones that actually should scale first, resulting in wasted time and effort.
|
||||
|
||||
### Situational awareness
|
||||
|
||||
Ultimately, context is key. Here are some tips from CTOs:
|
||||
|
||||
#### When to start with a monolith
|
||||
|
||||
* **Your team is at founding stage:** Your team is small—say, 2 to 5 members—and is unable to tackle a broader, high-overhead microservices architecture.
|
||||
|
||||
* **You’re building an unproven product or proof of concept:** If you're bringing a brand-new product to market, it will likely evolve over time, and a monolith is better-suited to allow for rapid product iteration. The same notion applies to a proof of concept, where your goal is to learn as much as possible as quickly as possible, even if you end up throwing it away.
|
||||
|
||||
* **You have no microservices experience:** Unless you can justify the risk of learning on the fly at an early stage, a monolith may be a safer approach for an inexperienced team.
|
||||
|
||||
#### When to start with microservices
|
||||
|
||||
* **You need quick, independent service delivery:** Microservices allow for fast, independent delivery of individual parts within a larger integrated system. Note that it can take some time to see service delivery gains with microservices compared to a monolith, depending on your team's size.
|
||||
|
||||
* **A piece of your platform needs to be extremely efficient:** If your business does intensive processing of petabytes of log volume, you’ll likely want to build that service out in an efficient language like C++, while your user dashboard may be built in [Ruby on Rails][5].
|
||||
|
||||
* **You plan to grow your team:** Starting with microservices gets your team used to developing in separate small services from the beginning, and teams that are separated by service boundaries are easier to scale as needed.
|
||||
|
||||
To decide whether a monolith or microservices is right for your organization, be honest and self-aware about your context and capabilities. This will help you find the best path to grow your business.
|
||||
|
||||
### Topics
|
||||
|
||||
[Microservices][21][DevOps][22]
|
||||
|
||||
### About the author
|
||||
|
||||
[][18] jakelumetta - Jake is the CEO of [ButterCMS, an API-first CMS][6]. He loves whipping up Butter puns and building tools that makes developers lives better. For more content like this, follow [@ButterCMS][7] on Twitter and [subscribe to our blog][8].[More about me][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-choose-between-monolith-microservices
|
||||
|
||||
作者:[jakelumetta ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://blog.openshift.com/microservices-how-to-explain-them-to-your-ceo/?intcmp=7016000000127cYAAQ&src=microservices_resource_menu1
|
||||
[2]:https://www.openshift.com/promotions/microservices.html?intcmp=7016000000127cYAAQ&src=microservices_resource_menu2
|
||||
[3]:https://opensource.com/business/16/11/secured-devops-microservices?src=microservices_resource_menu3
|
||||
[4]:https://opensource.com/article/18/1/how-choose-between-monolith-microservices?rate=tSotlNvwc-Itch5fhYiIn5h0L8PcUGm_qGvqSVzu9w8
|
||||
[5]:http://rubyonrails.org/
|
||||
[6]:https://buttercms.com/
|
||||
[7]:https://twitter.com/ButterCMS
|
||||
[8]:https://buttercms.com/blog/
|
||||
[9]:https://opensource.com/users/jakelumetta
|
||||
[10]:https://opensource.com/user/205531/feed
|
||||
[11]:https://www.flickr.com/photos/onasill/16452059791/in/photolist-r4P7ci-r3xUqZ-JkWzgN-dUr8Mo-biVsvF-kA2Vot-qSLczk-nLvGTX-biVxwe-nJJmzt-omA1vW-gFtM5-8rsk8r-dk9uPv-5kja88-cv8YTq-eQqNJu-7NJiqd-pBUkk-pBUmQ-6z4dAw-pBULZ-vyM3V3-JruMsr-pBUiJ-eDrP5-7KCWsm-nsetSn-81M3EC-pBURh-HsVXuv-qjgBy-biVtvx-5KJ5zK-81F8xo-nGFQo3-nJr89v-8Mmi8L-81C9A6-qjgAW-564xeQ-ihmDuk-biVBNz-7C5VBr-eChMAV-JruMBe-8o4iKu-qjgwW-JhhFXn-pBUjw
|
||||
[12]:https://creativecommons.org/licenses/by-nc-sa/2.0/
|
||||
[13]:https://buttercms.com/books/microservices-for-startups/
|
||||
[14]:https://www.particle.io/Particle
|
||||
[15]:https://www.scalyr.com/
|
||||
[16]:https://www.algolia.com/
|
||||
[17]:https://pantheon.io/
|
||||
[18]:https://opensource.com/users/jakelumetta
|
||||
[19]:https://opensource.com/users/jakelumetta
|
||||
[20]:https://opensource.com/users/jakelumetta
|
||||
[21]:https://opensource.com/tags/microservices
|
||||
[22]:https://opensource.com/tags/devops
|
||||
@ -1,205 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
How to clone, modify, add, and delete files in Git
|
||||
======
|
||||

|
||||
|
||||
In the [first article in this series][1] on getting started with Git, we created a simple Git repo and added a file to it by connecting it with our computer. In this article, we will learn a handful of other things about Git, namely how to clone (download), modify, add, and delete files in a Git repo.
|
||||
|
||||
### Let's make some clones
|
||||
|
||||
Say you already have a Git repo on GitHub and you want to get your files from it—maybe you lost the local copy on your computer or you're working on a different computer and want access to the files in your repository. What should you do? Download your files from GitHub? Exactly! We call this "cloning" in Git terminology. (You could also download the repo as a ZIP file, but we'll explore the clone method in this article.)
|
||||
|
||||
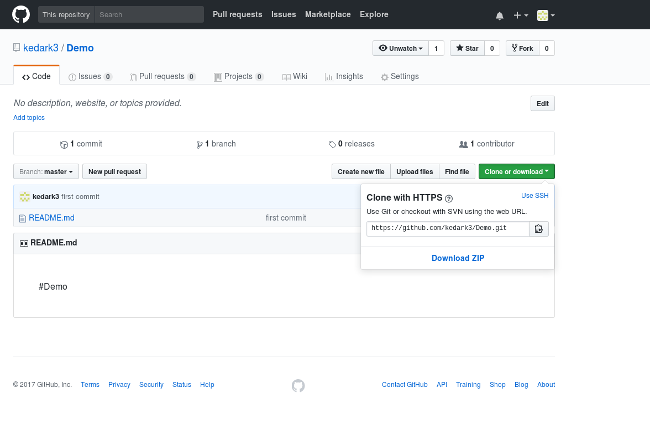
Let's clone the repo, called Demo, we created in the last article. (If you have not yet created a Demo repo, jump back to that article and do those steps before you proceed here.) To clone your file, just open your browser and navigate to `https://github.com/<your_username>/Demo` (where `<your_username>` is the name of your own repo. For example, my repo is `https://github.com/kedark3/Demo`). Once you navigate to that URL, click the "Clone or download" button, and your browser should look something like this:
|
||||
|
||||
|
||||
|
||||
As you can see above, the "Clone with HTTPS" option is open. Copy your repo's URL from that dropdown box (`https://github.com/<your_username>/Demo.git`). Open the terminal and type the following command to clone your GitHub repo to your computer:
|
||||
```
|
||||
git clone https://github.com/<your_username>/Demo.git
|
||||
|
||||
```
|
||||
|
||||
Then, to see the list of files in the `Demo` directory, enter the command:
|
||||
```
|
||||
ls Demo/
|
||||
|
||||
```
|
||||
|
||||
Your terminal should look like this:
|
||||
|
||||

|
||||
|
||||
### Modify files
|
||||
|
||||
Now that we have cloned the repo, let's modify the files and update them on GitHub. To begin, enter the commands below, one by one, to change the directory to `Demo/`, check the contents of `README.md`, echo new (additional) content to `README.md`, and check the status with `git status`:
|
||||
```
|
||||
cd Demo/
|
||||
|
||||
ls
|
||||
|
||||
cat README.md
|
||||
|
||||
echo "Added another line to REAMD.md" >> README.md
|
||||
|
||||
cat README.md
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
This is how it will look in the terminal if you run these commands one by one:
|
||||
|
||||

|
||||
|
||||
Let's look at the output of `git status` and walk through what it means. Don't worry about the part that says:
|
||||
```
|
||||
On branch master
|
||||
|
||||
Your branch is up-to-date with 'origin/master'.".
|
||||
|
||||
```
|
||||
|
||||
because we haven't learned it yet. The next line says: `Changes not staged for commit`; this is telling you that the files listed below it aren't marked ready ("staged") to be committed. If you run `git add`, Git takes those files and marks them as `Ready for commit`; in other (Git) words, `Changes staged for commit`. Before we do that, let's check what we are adding to Git with the `git diff` command, then run `git add`.
|
||||
|
||||
Here is your terminal output:
|
||||
|
||||

|
||||
|
||||
Let's break this down:
|
||||
|
||||
* `diff --git a/README.md b/README.md` is what Git is comparing (i.e., `README.md` in this example).
|
||||
* `--- a/README.md` would show anything removed from the file.
|
||||
* `+++ b/README.md` would show anything added to your file.
|
||||
* Anything added to the file is printed in green text with a + at the beginning of the line.
|
||||
* If we had removed anything, it would be printed in red text with a - sign at the beginning.
|
||||
* Git status now says `Changes to be committed:` and lists the filename (i.e., `README.md`) and what happened to that file (i.e., it has been `modified` and is ready to be committed).
|
||||
|
||||
|
||||
|
||||
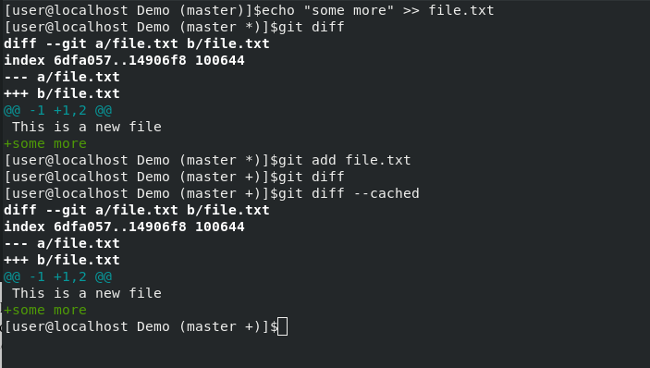
Tip: If you have already run `git add`, and now you want to see what's different, the usual `git diff` won't yield anything because you already added the file. Instead, you must use `git diff --cached`. It will show you the difference between the current version and previous version of files that Git was told to add. Your terminal output would look like this:
|
||||
|
||||
|
||||
|
||||
### Upload a file to your repo
|
||||
|
||||
We have modified the `README.md` file with some new content and it's time to upload it to GitHub.
|
||||
|
||||
Let's commit the changes and push those to GitHub. Run:
|
||||
```
|
||||
git commit -m "Updated Readme file"
|
||||
|
||||
```
|
||||
|
||||
This tells Git that you are "committing" to changes that you have "added" to it. You may recall from the first part of this series that it's important to add a message to explain what you did in your commit so you know its purpose when you look back at your Git log later. (We will look more at this topic in the next article.) `Updated Readme file` is the message for this commit—if you don't think this is the most logical way to explain what you did, feel free to write your commit message differently.
|
||||
|
||||
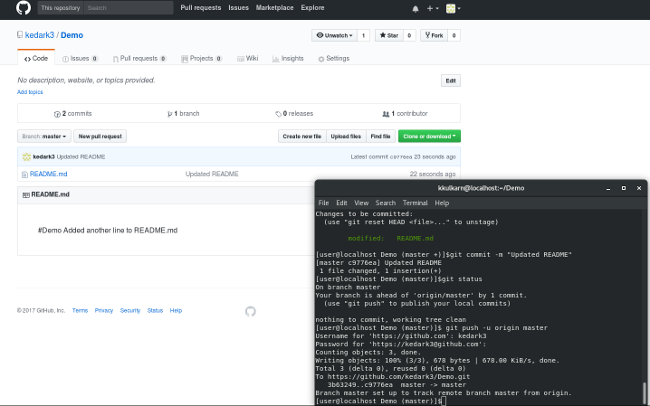
Run `git push -u origin master`. This will prompt you for your username and password, then upload the file to your GitHub repo. Refresh your GitHub page, and you should see the changes you just made to `README.md`.
|
||||
|
||||
|
||||
|
||||
The bottom-right corner of the terminal shows that I committed the changes, checked the Git status, and pushed the changes to GitHub. Git status says:
|
||||
```
|
||||
Your branch is ahead of 'origin/master' by 1 commit
|
||||
|
||||
(use "git push" to publish your local commits)
|
||||
|
||||
```
|
||||
|
||||
The first line indicates there is one commit in the local repo but not present in origin/master (i.e., on GitHub). The next line directs us to push those changes to origin/master, and that is what we did. (To refresh your memory on what "origin" means in this case, refer to the first article in this series. I will explain what "master" means in the next article, when we discuss branching.)
|
||||
|
||||
### Add a new file to Git
|
||||
|
||||
Now that we have modified a file and updated it on GitHub, let's create a new file, add it to Git, and upload it to GitHub. Run:
|
||||
```
|
||||
echo "This is a new file" >> file.txt
|
||||
|
||||
```
|
||||
|
||||
This will create a new file named `file.txt`.
|
||||
|
||||
If you `cat` it out:
|
||||
```
|
||||
cat file.txt
|
||||
|
||||
```
|
||||
|
||||
You should see the contents of the file. Now run:
|
||||
```
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
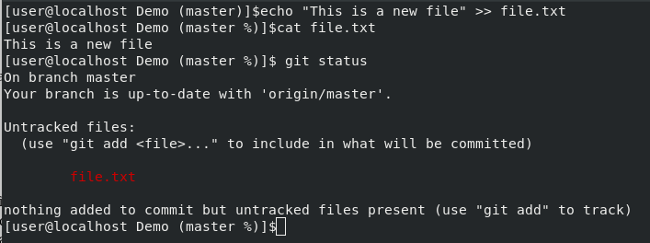
Git reports that you have an untracked file (named `file.txt`) in your repository. This is Git's way of telling you that there is a new file in the repo directory on your computer that you haven't told Git about, and Git is not tracking that file for any changes you make.
|
||||
|
||||
|
||||
|
||||
We need to tell Git to track this file so we can commit it and upload it to our repo. Here's the command to do that:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Your terminal output is:
|
||||
|
||||

|
||||
|
||||
Git status is telling you there are changes to `file.txt` to be committed, and that it is a `new file` to Git, which it was not aware of before this. Now that we have added `file.txt` to Git, we can commit the changes and push it to origin/master.
|
||||
|
||||

|
||||
|
||||
Git has now uploaded this new file to GitHub; if you refresh your GitHub page, you should see the new file, `file.txt`, in your Git repo on GitHub.
|
||||
|
||||
|
||||
|
||||
With these steps, you can create as many files as you like, add them to Git, and commit and push them up to GitHub.
|
||||
|
||||
### Delete a file from Git
|
||||
|
||||
What if we discovered we made an error and need to delete `file.txt` from our repo. One way is to remove the file from our local copy of the repo with this command:
|
||||
```
|
||||
rm file.txt
|
||||
|
||||
```
|
||||
|
||||
If you do `git status` now, Git says there is a file that is `not staged for commit` and it has been `deleted` from the local copy of the repo. If we now run:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
I know we are deleting the file, but we still run `git add` ** because we need to tell Git about the **change** we are making. `git add` ** can be used when we are adding a new file to Git, modifying contents of an existing file and adding it to Git, or deleting a file from a Git repo. Effectively, `git add` takes all the changes into account and stages those changes for commit. If in doubt, carefully look at output of each command in the terminal screenshot below.
|
||||
|
||||
Git will tell us the deleted file is staged for commit. As soon as you commit this change and push it to GitHub, the file will be removed from the repo on GitHub as well. Do this by running:
|
||||
```
|
||||
git commit -m "Delete file.txt"
|
||||
|
||||
git push -u origin master
|
||||
|
||||
```
|
||||
|
||||
Now your terminal looks like this:
|
||||
|
||||
|
||||
|
||||
And your GitHub looks like this:
|
||||
|
||||
|
||||
|
||||
Now you know how to clone, add, modify, and delete Git files from your repo. The next article in this series will examine Git branching.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by MjSeven
|
||||
|
||||
Test Your BASH Skills By Playing Command Line Games
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
计算机系统的进化论
|
||||
======
|
||||
纵观现代计算机的历史,从与系统的交互方式方面,可以划分为数个进化阶段。而我更倾向于将之归类为以下几个阶段:
|
||||
|
||||
1. 数字系统
|
||||
2. 专用应用系统
|
||||
3. 应用中心系统
|
||||
4. 信息中心系统
|
||||
5. 无应用系统
|
||||
|
||||
|
||||
|
||||
下面我们详细聊聊这几种分类。
|
||||
|
||||
### 数字系统
|
||||
|
||||
在我看来,[ 早期计算机 ][1],只被设计用来处理数字。它们能够加,减,乘,除。在它们中有一些能够运行像是微分和积分之类的更复杂的数学操作。
|
||||
|
||||
当然,如果你把字符映射成数字,它们也可以计算字符串。但这多少有点“数字的创造性使用”的意思,而不是直接处理各种信息。
|
||||
|
||||
### 专用应用系统
|
||||
|
||||
对于更高层级的问题,纯粹的数字系统是不够的。专用应用系统被开发用来处理单一任务。它们和数字系统十分相似,但是,它们拥有足够的复杂数字计算能力。这些系统能够完成十分明确的高层级任务,像调度问题的相关计算或者其他优化问题。
|
||||
|
||||
这类系统为单一目的而搭建,它们解决的是单一明确的问题。
|
||||
|
||||
### 应用中心系统
|
||||
|
||||
应用中心系统是第一个真正的通用系统。它们的主要使用风格很像专用应用系统,但是它们拥有以时间片模式(一个接一个)或以多任务模式(多应用同时)运行的多个应用程序。
|
||||
|
||||
上世纪 70 年代的[ 早期的个人电脑 ][3]是第一种受大量人们欢迎的应用中心系统。
|
||||
|
||||
如今的现在操作系统 —— Windows , macOS , 大多数 GNU/Linux 桌面环境 —— 一直遵循相同的法则。
|
||||
|
||||
当然,应用中心系统还可以再细分为两种子类:
|
||||
|
||||
1. 紧密型应用中心系统
|
||||
2. 松散型应用中心系统
|
||||
|
||||
|
||||
|
||||
精密型应用中心系统像是 [Windows 3.1][4] (拥有程序管理器和文件管理器)或者甚至 [ Windows 95 ][5] 的最初版本都没有预定义文件夹层次。用户启动文本处理程序(像 [ WinWord ][6])并且把文件保存在 WinWord 的程序文件夹中。在使用表格处理程序的时候,又把文件保存在表格处理工具的程序文件夹中。诸如此类。用户几乎不创建自己的文件层次结构,可能由于此举的不方便,用户单方面的懒惰,或者他们认为根本没有必要。那时,每个用户拥有几十个至多几百个文件。
|
||||
|
||||
为了访问文件中的信息,用户常常先打开一个应用程序,然后通过程序中的“文件/打开”功能来获取处理过的数据文件。
|
||||
|
||||
在 Windows 平台的[ Windows 95][5] SP2 中,«[ 我的文档 ][7]»首次被使用。有了这样一个文件层次结构的样板,应用设计者开始把 «[我的文档][7]» 作为程序的默认 保存 / 打开 目录,抛弃了原来将软件产品安装目录作为默认目录的做法。这样一来,用户渐渐适应了这种模式,并且开始自己维护文件夹层次。
|
||||
|
||||
松散型应用中心系统(通过文件管理器来提取文件)应用而生。在这种系统下,当打开一个文件的时候,操作系统会自动启动与之相关的应用程序。这是一次小而精妙的用法转变。这种应用中心系统的用法模式一直是个人电脑的主要用法模式。
|
||||
|
||||
然而,这种模式有很多的缺点。例如,对于一个给定的项目,为了防止数据提取出现问题,需要维护一个包含所有相关文件的严格文件夹层次结构。不幸的是,人们并不总能这样做。当然,也有可能因为[ 文件数量规模还不是很大 ][8]。 桌面搜索引擎和高级数据组织工具(像[ tagstore ][9])可以起到一点改善作用。正如研究显示的那样,只有一少部分人正在使用那些高级文件提取工具。大多数的用户不使用替代提取工具或者辅助提取技术在文件系统中寻找文件。
|
||||
|
||||
### 信息中心系统
|
||||
|
||||
解决上述问题的可行办法之一就是从应用中心系统转换到信息中心系统。
|
||||
|
||||
信息中心系统将项目的所有信息联合起来,放在一个地方,放在同一个应用程序里。
|
||||
因此,我们再也不需要计算项目预算时,打开表格处理程序;写工程报告时,打开文本处理程序;处理图片文件时,又打开另一个工具。
|
||||
|
||||
上个月的预算情况在客户会议笔记的右下方,客户会议笔记又在画板的右下方,而画板又在另一些要去完成的任务的右下方。在各个层之间没有文件或者应用程序来回切换的麻烦。
|
||||
|
||||
早期,IBM [ OS/2 ][10], Microsoft [ OLE ][11] 和 [NeXT][12] 都做过类似的尝试。但都由于各种原因没有取得重大成功。从 [ Plan 9][14] 发展而来的 [ACme][13] 是一个令人兴奋的信息中心环境。它在一个应用程序中包含了多种应用程序。但是相比 Windows 和 GNU/Linux 而言,它从不是一个值得注意的系统发行版(即使在系统接口级别)。
|
||||
|
||||
信息中心系统的现代形式是高级 [ 个人 wikis ][16](像 [ TheBrain ][17]和[ Microsoft OneNote ][18])。
|
||||
|
||||
我选择的个人工具是带 [Org-mode][19] 扩展的 [GNU/Emacs][20]。在用电脑的时候,我几乎不能没有 Org-mode 。为了访问外部数据资源,我创建了一个可以将多种数据导入 Org-mode 的插件 —— [Memacs][20] 。我喜欢将表格数据计算放到日程任务的右下方,然后是行内图片,内部和外部链接,等等。它是一个真正的用户不用必须切换程序或者切换严格层次文件系统文件夹的信息中心系统。同时,用简单的或高级的标签也可以进行多分类。一个命令可以派生多种视图。比如,一个视图有日历,待办事项。另一个视图是租借事宜。等等。它对 Org-mode 用户没有限制。只有你想不到,没有它做不到。
|
||||
|
||||
进化结束了吗? 当然没有。
|
||||
|
||||
### 无应用系统
|
||||
|
||||
我能想到这样一类操作系统,我称之为无应用系统。在下一步的发展中,系统将不需要单域应用程序,即使它们能和 Org-mode 一样出色。计算机直接提供一个处理信息和使用功能的友好用户接口,而不通过文件和程序。甚至连传统的操作系统也不需要。
|
||||
|
||||
无应用系统也可能和 [人工智能][21] 联系起来。把它想象成 [2001太空漫游][23] 中的 02[HAL 9000][22] 和星际迷航中的 [LCARS][24]一类的东西就可以了。
|
||||
|
||||
从基于应用的,基于供应商的软件文化到无应用系统的转化让人很难相信。 或许,缓慢但却不断发展的开源环境,可以使一个由各种各样组织和人们贡献的真正无应用环境成型。
|
||||
|
||||
信息和提取、操作信息的功能,这是系统应该有的,同时也是我们所需要的。其他的东西仅仅是为了使我们不至于分散注意力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/2017/02/10/evolution-of-systems/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[lontow](https://github.com/lontow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/History_of_computing_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/String_%2528computer_science%2529
|
||||
[3]:https://en.wikipedia.org/wiki/Xerox_Alto
|
||||
[4]:https://en.wikipedia.org/wiki/Windows_3.1x
|
||||
[5]:https://en.wikipedia.org/wiki/Windows_95
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Word
|
||||
[7]:https://en.wikipedia.org/wiki/My_Documents
|
||||
[8]:http://karl-voit.at/tagstore/downloads/Voit2012b.pdf
|
||||
[9]:http://karl-voit.at/tagstore/
|
||||
[10]:https://en.wikipedia.org/wiki/OS/2
|
||||
[11]:https://en.wikipedia.org/wiki/Object_Linking_and_Embedding
|
||||
[12]:https://en.wikipedia.org/wiki/NeXT
|
||||
[13]:https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529
|
||||
[14]:https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs
|
||||
[15]:https://en.wikipedia.org/wiki/List_of_Plan_9_applications
|
||||
[16]:https://en.wikipedia.org/wiki/Personal_wiki
|
||||
[17]:https://en.wikipedia.org/wiki/TheBrain
|
||||
[18]:https://en.wikipedia.org/wiki/Microsoft_OneNote
|
||||
[19]:../../../../tags/emacs
|
||||
[20]:https://github.com/novoid/Memacs
|
||||
[21]:https://en.wikipedia.org/wiki/Artificial_intelligence
|
||||
[22]:https://en.wikipedia.org/wiki/HAL_9000
|
||||
[23]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey
|
||||
[24]:https://en.wikipedia.org/wiki/LCARS
|
||||
@ -0,0 +1,176 @@
|
||||
微服务 vs. 整体服务:如何选择
|
||||
============================================================
|
||||
|
||||
### 任何一种架构都是有利有弊的,而能满足你组织的独特需要的决策才是正确的选择。
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
Onasill ~ Bill Badzo on [Flickr][11]. [CC BY-NC-SA 2.0][12]. Modified by Opensource.com.
|
||||
|
||||
对于许多初创公司来说,传统的知识认为,从单一整体架构开始,而不是使用微服务。但是,我们还有别的选择吗?
|
||||
|
||||
这本新书 —— [初创公司的微服务][13],从许多 CIO 们理解的微服务的角度,解释了微服务的优点与缺点。
|
||||
|
||||
对于初创公司,虽然不同的 CTO 对此给出的建议是不同的,但是他们都一致认为环境和性能很重要。如果你正考虑你的业务到底是采用微服务还是单一整体架构更好,下面讨论的这些因素正好可以为你提供一些参考。
|
||||
|
||||
### 理解范围
|
||||
|
||||
更多有关微服务的内容
|
||||
|
||||
* [如何向你的 CEO 解释微服务][1]
|
||||
|
||||
* [免费电子书:微服务 vs. 面向服务的架构][2]
|
||||
|
||||
* [DevOps 确保微服务安全][3]
|
||||
|
||||
首先,我们先来准确定义我们所谓的 “整体服务” 和 “微服务” 是什么。
|
||||
|
||||
微服务是一种方法,它开发一个单一的应用程序来作为构成整体服务的小服务,每个小服务都运行在它自己的进程中,并且使用一个轻量级的机制进行通讯,通常是一个 HTTP 资源 API。这些服务都围绕业务能力来构建,并且可依赖全自动部署机制来独立部署。
|
||||
|
||||
一个整体应用程序是按单个的、统一的单元来构建,并且,通常情况下它是基于一个大量的代码来实现的。一般来说,一个整体服务是由三部分组成的:一个数据库、一个客户端用户界面(由 HTML 页面和/或运行在浏览器中的 JavaScript 组成)、以及一个服务器端应用程序。
|
||||
|
||||
“系统架构处于一个范围之中”,Zachary Crockett,[Particle][14] 的 CTO,在一次访谈中,他说,”在讨论微服务时,人们倾向于关注这个范围的一端:许多极小的应用程序给其它应用程序传递了过多的信息。在另一端,有一个巨大的整体服务做了太多的事情。在任何现实中的系统上,在这两个极端之间有很多合适的面向服务的架构“。
|
||||
|
||||
根据你的情况不同,不论是使用整体服务还是微服务都有很多很好的理由。
|
||||
|
||||
"我们希望为每个服务使用最好的工具”,Julien Lemoine 说,他是 Algolia 的 CTO。
|
||||
|
||||
与很多人的想法正好相反,整体服务并不是过去遗留下来的过时的架构。在某些情况下,整体服务是非常理想的。我采访了 Steven Czerwinski 之后,更好地理解了这一点,他是 [Scaylr][15] 的工程主管,前谷歌员工。
|
||||
|
||||
“尽管我们在谷歌时有使用微服务的一些好的经验,我们现在 [在 Scalyr] 却使用的是整体服务的架构,因为一个整体服务架构意味着我们的工作量更少,我们只有两位工程师。“ 他解释说。(采访他时,Scaylr 正处于早期阶段)
|
||||
|
||||
但是,如果你的团队使用微服务的经验很丰富,并且你对你们的发展方向有明确的想法,微服务可能是一个很好的 替代者。
|
||||
|
||||
Julien Lemoine,[Algolia][16] 的 CTO,在这个问题上,他认为:”我们通常从使用微服务开始,主要目的是我们可以使用不同的技术来构建我们的服务,因为如下的两个主要原因:
|
||||
|
||||
* 我们想为每个服务使用最好的工具。我们的搜索 API 是在底层做过高度优化的,而 C++ 是非常适合这项工作的。他说,在任何地方都使用 C++ 是一种生产力的浪费,尤其是在构建仪表板方面。
|
||||
|
||||
* 我们希望使用最好的人才,而只使用一种技术将极大地限制我们的选择。这就是为什么在公司中有不同语言的原因。“
|
||||
|
||||
如果你的团队已经准备好从一开始就使用微服务,这样你的组织从一开始就可以适应微服务环境的开发节奏。
|
||||
|
||||
### 权衡利弊
|
||||
|
||||
在你决定那种方法更适合你的组织之前,考虑清楚每种方法的优缺点是非常重要的。
|
||||
|
||||
### 整体服务
|
||||
|
||||
### 优点:
|
||||
|
||||
* **很少担心横向联系:** 大多数应用程序开发者都担心横向联系,比如,日志、速度限制、以及像审计跟踪和 DoS 防护这样的安全特性。当所有的东西都运行在同一个应用程序中时,通过组件钩子来处理这些关注点就非常容易了。
|
||||
|
||||
* **运营开销很少:** 只需要为一个应用程序设置日志、监视、以及测试。一般情况下,部署也相对要简单。
|
||||
|
||||
* **性能:** 一个整体的架构可能会有更好的性能,因为共享内存的访问速度要比进程间通讯(IPC)更快。
|
||||
|
||||
### 缺点:
|
||||
|
||||
* **紧耦合:** 整体服务的应用程序倾向于紧耦合,并且应用程序是整体进化,分离特定用途的服务是非常困难的,比如,独立扩展或者代码维护。
|
||||
|
||||
* **理解起来很困难:** 当你想查看一个特定的服务或者控制器时,因为依赖、副作用、和其它的不可预见因素,整体架构理解起来更困难。
|
||||
|
||||
### 微服务
|
||||
|
||||
### 优点:
|
||||
|
||||
* **非常好组织:** 微服务架构一般很好组织它们,因为每个微服务都有一个特定的工作,并且还不用考虑其它组件的工作。
|
||||
|
||||
* **解耦合:** 解耦合的服务是能够非常容易地进行重组织和重配置,以服务于不同的应用程序(比如,同时向 Web 客户端和公共 API 提供服务)。它们在一个大的集成系统中,也允许快速、独立分发单个部分。
|
||||
|
||||
* **性能:** 根据组织的情况,微服务可以提供更好的性能,因为你可以分离热点服务,并根据其余应用程序的情况来扩展它们。
|
||||
|
||||
* **更少的错误:** 微服务允许系统中的不同部分,在维护良好边界的前提下进行并行开发。这样将使连接不该被连接的部分变得更困难,比如,需要连接的那些紧耦合部分。
|
||||
|
||||
### 缺点:
|
||||
|
||||
* **跨每个服务的横向联系点:** 由于你构建了一个新的微服务架构,你可能会发现在设计时没有预料到的很多横向联系的问题。这也将导致需要每个横向联系点的独立模块(比如,测试)的开销增加,或者在其它服务层面因封装横向联系点,所导致的所有流量都需要路由。最终,即便是整体服务架构也倾向于通过横向联系点的外部服务层来路由流量,但是,如果使用整体架构,在项目更加成熟之前,也不过只是推迟了工作成本。
|
||||
|
||||
* **更高的运营开销:** 微服务在它所属的虚拟机或容器上部署非常频繁,导致虚拟机争用激增。这些任务都是使用容器管理工具进行频繁的自动化部署的。
|
||||
|
||||
### 决策时刻
|
||||
|
||||
当你了解了每种方法的利弊之后,如何在你的初创公司使用这些信息?通过与这些 CTO 们的访谈,这里有三个问题可以指导你的决策过程:
|
||||
|
||||
**你是在熟悉的领域吗?**
|
||||
|
||||
如果你的团队有以前的一些领域的经验(比如,电子商务)和了解你的客户需求,那么分割成微服务是低风险的。如果你从未做过这些,从另一个角度说,整体服务或许是一个更安全的选择。
|
||||
|
||||
**你的团队做好准备了吗?**
|
||||
|
||||
你的团队有使用微服务的经验吗?如果明年,你的团队扩充到现在的四倍,将为微服务提供更好的环境?评估团队大小对项目的成功是非常重要的。
|
||||
|
||||
**你的基础设施怎么样?**
|
||||
|
||||
实施微服务,你需要基于云的基础设施。
|
||||
|
||||
David Strauss,[Pantheon][17] 的 CTO,他解释说:"[以前],你使用整体服务是因为,你希望部署在一个数据库上。每个单个的微服务都需要配置数据库服务器,然后,扩展它将是一个很重大的任务。只有大的、技术力量雄厚的组织才能做到。现在,使用像谷歌云和亚马逊 AWS 这样的云服务,为部署一个小的东西而不需要为它们中的每个都提供持久存储,对于这种需求你有很多的选择。“
|
||||
|
||||
### 评估业务风险
|
||||
|
||||
技术力量雄厚的初创公司为追求较高的目标,可以考虑使用微服务。但是微服务可能会带来业务风险。Strauss 解释说,”许多团队一开始就过度构建他们的项目。每个人都认为,他们的公司会成为下一个 “独角兽”,因此,他们使用微服务构建任何一个东西,或者一些其它的高扩展性的基础设施。但是这通常是一种错误的做法“。Strauss 说,在那种情况下,他们认为需要扩大规模的领域往往并不是一开始真正需要扩展的领域,最后的结果是浪费了时间和努力。
|
||||
|
||||
### 态势感知
|
||||
|
||||
最终,环境是关键。以下是一些来自 CTO 们的提示:
|
||||
|
||||
#### 什么时候使用整体服务
|
||||
|
||||
* **你的团队还在创建阶段:** 你的团队很小 —— 也就是说,有 2 到 5 位成员 —— 还无法应对大范围、高成本的微服务架构。
|
||||
|
||||
* **你正在构建的是一个未经证实的产品或者概念验证:** 如果你将一个全新的产品推向市场,随着时间的推移,它有可能会成功,而对于一个快速迭代的产品,整体架构是最合适的。这个提示也同样适用于概念验证,你的目标是尽可能快地学习,即便最终你可能会放弃它。
|
||||
|
||||
* **你没有使用微服务的经验:** 除非你有合理的理由证明早期学习阶段的风险可控,否则,一个整体的架构更适用于一个没有经验的团队。
|
||||
|
||||
#### 什么时候开始使用微服务
|
||||
|
||||
* **你需要快速、独立的分发服务:** 微服务允许在一个大的集成系统中快速、独立分发单个部分。请注意,根据你的团队规模,获取与整体服务的比较优势,可能需要一些时间。
|
||||
|
||||
* **你的平台中的某些部分需要更高效:** 如果你的业务要求集中处理 PB 级别的日志卷,你可能需要使用一个像 C++ 这样的更高效的语言来构建这个服务,尽管你的用户仪表板或许还是用 [Ruby on Rails][5] 构建的。
|
||||
|
||||
* **计划扩展你的团队:** 使用微服务,将让你的团队从一开始就开发独立的小服务,而服务边界独立的团队更易于按需扩展。
|
||||
|
||||
要决定整体服务还是微服务更适合你的组织,要坦诚并正确认识自己的环境和能力。这将有助于你找到业务成长的最佳路径。
|
||||
|
||||
### 主题
|
||||
|
||||
[微服务][21]、 [DevOps][22]
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][18] jakelumetta - Jake 是 ButterCMS 的 CEO,它是一个 [API-first CMS][6]。他喜欢搅动出黄油双峰,以及构建让开发者工作更舒适的工具,喜欢他的更多内容,请在 Twitter 上关注 [@ButterCMS][7],订阅 [他的博客][8]。[关于他的更多信息][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-choose-between-monolith-microservices
|
||||
|
||||
作者:[jakelumetta ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://blog.openshift.com/microservices-how-to-explain-them-to-your-ceo/?intcmp=7016000000127cYAAQ&src=microservices_resource_menu1
|
||||
[2]:https://www.openshift.com/promotions/microservices.html?intcmp=7016000000127cYAAQ&src=microservices_resource_menu2
|
||||
[3]:https://opensource.com/business/16/11/secured-devops-microservices?src=microservices_resource_menu3
|
||||
[4]:https://opensource.com/article/18/1/how-choose-between-monolith-microservices?rate=tSotlNvwc-Itch5fhYiIn5h0L8PcUGm_qGvqSVzu9w8
|
||||
[5]:http://rubyonrails.org/
|
||||
[6]:https://buttercms.com/
|
||||
[7]:https://twitter.com/ButterCMS
|
||||
[8]:https://buttercms.com/blog/
|
||||
[9]:https://opensource.com/users/jakelumetta
|
||||
[10]:https://opensource.com/user/205531/feed
|
||||
[11]:https://www.flickr.com/photos/onasill/16452059791/in/photolist-r4P7ci-r3xUqZ-JkWzgN-dUr8Mo-biVsvF-kA2Vot-qSLczk-nLvGTX-biVxwe-nJJmzt-omA1vW-gFtM5-8rsk8r-dk9uPv-5kja88-cv8YTq-eQqNJu-7NJiqd-pBUkk-pBUmQ-6z4dAw-pBULZ-vyM3V3-JruMsr-pBUiJ-eDrP5-7KCWsm-nsetSn-81M3EC-pBURh-HsVXuv-qjgBy-biVtvx-5KJ5zK-81F8xo-nGFQo3-nJr89v-8Mmi8L-81C9A6-qjgAW-564xeQ-ihmDuk-biVBNz-7C5VBr-eChMAV-JruMBe-8o4iKu-qjgwW-JhhFXn-pBUjw
|
||||
[12]:https://creativecommons.org/licenses/by-nc-sa/2.0/
|
||||
[13]:https://buttercms.com/books/microservices-for-startups/
|
||||
[14]:https://www.particle.io/Particle
|
||||
[15]:https://www.scalyr.com/
|
||||
[16]:https://www.algolia.com/
|
||||
[17]:https://pantheon.io/
|
||||
[18]:https://opensource.com/users/jakelumetta
|
||||
[19]:https://opensource.com/users/jakelumetta
|
||||
[20]:https://opensource.com/users/jakelumetta
|
||||
[21]:https://opensource.com/tags/microservices
|
||||
[22]:https://opensource.com/tags/devops
|
||||
@ -0,0 +1,202 @@
|
||||
在 Git 中怎样克隆,修改,添加和删除文件?
|
||||
=====
|
||||
|
||||

|
||||
|
||||
在 [本系列的第一篇文章][1] 开始使用 Git 时,我们创建了一个简单的 Git 仓库,并通过它连接到我们的计算机向其中添加一个文件。在本文中,我们将学习一些关于 Git 的其他内容,即如何克隆(下载),修改,添加和删除 Git 仓库中的文件。
|
||||
|
||||
|
||||
### 让我们来克隆一下
|
||||
|
||||
假设你在 GitHub 上已经有一个 Git 仓库,并且想从它那里获取你的文件-也许你在你的计算机上丢失了本地副本,或者你正在另一台计算机上工作,但是想访问仓库中的文件,你该怎么办?从 GitHub 下载你的文件?没错!我们称之为 Git 术语中的“克隆”。(你也可以将仓库作为 ZIP 文件下载,但我们将在本文中探讨克隆方法。)
|
||||
|
||||
让我们克隆在上一篇文章中创建的称为 Demo 的仓库。(如果你还没有创建 Demo 仓库,请跳回到那篇文章并在继续之前执行那些步骤。)要克隆文件,只需打开浏览器并导航到 `https://github.com/<your_username>/Demo` (其中 `<your_username>` 是你仓库的名称。例如,我的仓库是 `https://github.com/kedark3/Demo`)。一旦你导航到该 URL,点击“克隆或下载”按钮,你的浏览器看起来应该是这样的:
|
||||
|
||||

|
||||
|
||||
正如你在上面看到的,“使用 HTTPS 克隆”选项已打开。从该下拉框中复制你的仓库地址(`https://github.com/<your_username>/Demo.git`),打开终端并输入以下命令将 GitHub 仓库克隆到你的计算机:
|
||||
```
|
||||
git clone https://github.com/<your_username>/Demo.git
|
||||
|
||||
```
|
||||
|
||||
然后,要查看 `Demo` 目录中的文件列表,请输入以下命令:
|
||||
```
|
||||
ls Demo/
|
||||
|
||||
```
|
||||
|
||||
终端看起来应该是这样的:
|
||||
|
||||

|
||||
|
||||
### 修改文件
|
||||
|
||||
现在我们已经克隆了仓库,让我们修改文件并在 GitHub 上更新它们。首先,逐个输入下面的命令,将目录更改为 `Demo/`,检查 `README.md` 中的内容,添加新的(附加的)内容到 `README.md`,然后使用 `git status` 检查状态:
|
||||
```
|
||||
cd Demo/
|
||||
|
||||
ls
|
||||
|
||||
cat README.md
|
||||
|
||||
echo "Added another line to REAMD.md" >> README.md
|
||||
|
||||
cat README.md
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
如果你逐一运行这些命令,终端看起开将会是这样:
|
||||
|
||||

|
||||
|
||||
让我们看一下 `git status` 的输出,并了解它的意思。不要担心这样的语句:
|
||||
```
|
||||
On branch master
|
||||
|
||||
Your branch is up-to-date with 'origin/master'.".
|
||||
|
||||
```
|
||||
因为我们还没有学习这些。(译注:学了你就知道了)下一行说:`Changes not staged for commit`;这是告诉你,它下面列出的文件没有标记就绪(“分阶段”)提交。如果你运行 `git add`,Git 会把这些文件标记为 `Ready for commit`;换句话说就是 `Changes staged for commit`。在我们这样做之前,让我们用 `git diff` 命令来检查我们添加了什么到 Git 中,然后运行 `git add`。
|
||||
|
||||
这里是终端输出:
|
||||
|
||||

|
||||
|
||||
我们来分析一下:
|
||||
|
||||
* `diff --git a/README.md b/README.md` 是 Git 比较的内容(在这个例子中是 `README.md`)。
|
||||
* `--- a/README.md` 会显示从文件中删除的任何东西。
|
||||
* `+++ b/README.md` 会显示从文件中添加的任何东西。
|
||||
* 任何添加到文件中的内容都以绿色文本打印,并在该行的开头加上 + 号。
|
||||
* 如果我们删除了任何内容,它将以红色文本打印,并在该行的开头加上 - 号。
|
||||
* 现在 git status 显示“Changes to be committed:”,并列出文件名(即 `README.md`)以及该文件发生了什么(即它已经被 `modified` 并准备提交)。
|
||||
|
||||
|
||||
提示:如果你已经运行了 `git add`,现在你想看看文件有什么不同,通常 `git diff` 不会产生任何东西,因为你已经添加了文件。相反,你必须使用 `git diff --cached`。它会告诉你 Git 添加的当前版本和以前版本文件之间的差别。你的终端输出看起来会是这样:
|
||||
|
||||

|
||||
|
||||
### 上传文件到你的仓库
|
||||
|
||||
我们用一些新内容修改了 `README.md` 文件,现在是时候将它上传到 GitHub。
|
||||
|
||||
让我们提交更改并将其推送到 GitHub。运行:
|
||||
```
|
||||
git commit -m "更新文件的名字"
|
||||
|
||||
```
|
||||
|
||||
这告诉 Git 你正在“提交”已经“添加”的更改,你可能还记得,从本系列的第一部分中,添加一条消息来解释你在提交中所做的操作是非常重要的,以便你在稍后回顾 Git 日志时了解当时的目的。(我们将在下一篇文章中更多地关注这个话题。)`Updated Readme file` 是这个提交的消息--如果你认为这不是解释你所做的事情的最合理的方式,那么请随便写下你的提交消息。
|
||||
|
||||
运行 `git push -u origin master`,这会提示你输入用户名和密码,然后将文件上传到你的 GitHub 仓库。刷新你的 GitHub 页面,你应该会看到刚刚对 `README.md` 所做的更改。
|
||||
|
||||

|
||||
|
||||
终端的右下角显示我提交了更改,检查了 Git 状态,并将更改推送到了 GitHub。git status 显示:
|
||||
```
|
||||
Your branch is ahead of 'origin/master' by 1 commit
|
||||
|
||||
(use "git push" to publish your local commits)
|
||||
|
||||
```
|
||||
|
||||
第一行表示在本地仓库中有一个提交,但不在原始/主文件中(即在 GitHub 上)。下一行指示我们将这些更改推送到原始/主文件中,这就是我们所做的。(在本例中,请参阅本系列的第一篇文章,以唤醒你对“原始”含义的记忆。我将在下一篇文章中讨论分支的时候,解释“主文件”的含义。)
|
||||
|
||||
### 添加新文件到 Git
|
||||
|
||||
现在我们修改了一个文件并在 GitHub 上更新了它,让我们创建一个新文件,将它添加到 Git,然后将其上传到 GitHub。
|
||||
运行:
|
||||
```
|
||||
echo "This is a new file" >> file.txt
|
||||
|
||||
```
|
||||
|
||||
这将会创建一个名为 `file.txt` 的新文件。
|
||||
|
||||
如果使用 `cat` 查看它:
|
||||
```
|
||||
cat file.txt
|
||||
|
||||
```
|
||||
你将看到文件的内容。现在继续运行:
|
||||
```
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Git 报告说你的仓库中有一个未跟踪的文件(名为 `file.txt`)。这是 Git 告诉你说在你的计算机中的仓库目录下有一个新文件,然而你并没有告诉 Git,Git 也没有跟踪你所做的任何修改。
|
||||
|
||||

|
||||
|
||||
我们需要告诉 Git 跟踪这个文件,以便我们可以提交并上传文件到我们的仓库。以下是执行该操作的命令:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
终端输出如下:
|
||||

|
||||
|
||||
git status 告诉你有 `file.txt` 被修改,对于 Git 来说它是一个 `new file`,Git 在此之前并不知道。现在我们已经为 Git 添加了 `file.txt`,我们可以提交更改并将其推送到 原始/主文件。
|
||||
|
||||

|
||||
|
||||
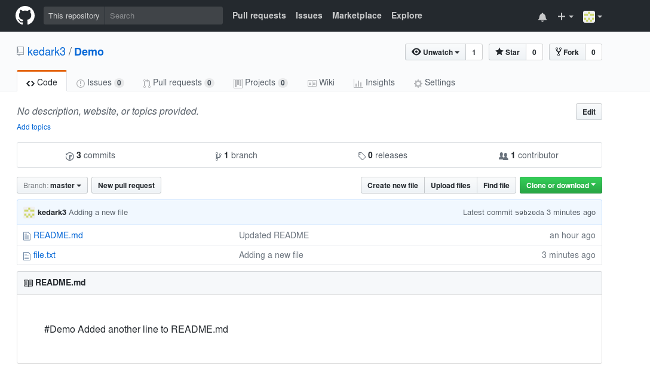
Git 现在已经将这个新文件上传到 GitHub;如果刷新 GitHub 页面,则应该在 GitHub 上的仓库中看到新文件 `file.txt`。
|
||||
|
||||

|
||||
|
||||
通过这些步骤,你可以创建尽可能多的文件,将它们添加到 Git 中,然后提交并将它们推送到 GitHub。
|
||||
|
||||
### 从 Git 中删除文件
|
||||
|
||||
如果我们发现我们犯了一个错误,并且需要从我们的仓库中删除 `file.txt`,该怎么办?一种方法是使用以下命令从本地副本中删除文件:
|
||||
```
|
||||
rm file.txt
|
||||
|
||||
```
|
||||
|
||||
如果你现在做 `git status`,Git 就会说有一个文件 `not staged for commit`,并且它已经从仓库的本地拷贝中删除了。如果我们现在运行:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
我知道我们正在删除这个文件,但是我们仍然运行 `git add`,因为我们需要告诉 Git 我们正在做的**更改**,`git add` 可以用在我们添加新文件,修改一个已存在文件的内容,或者从仓库中删除文件。实际上,`git add` 将所有更改考虑在内,并将这些更改分阶段进行提交。如果有疑问,请仔细查看下面终端屏幕截图中每个命令的输出。
|
||||
|
||||
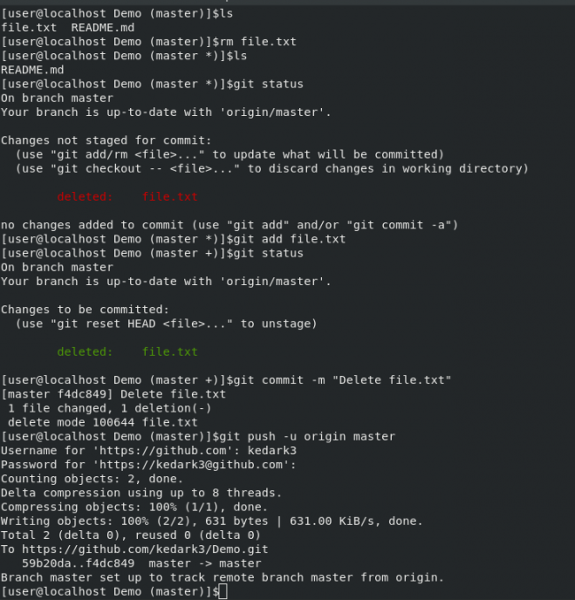
Git 会告诉我们已删除的文件正在进行提交。只要你提交此更改并将其推送到 GitHub,该文件也将从 GitHub 的仓库中删除。运行以下命令:
|
||||
```
|
||||
git commit -m "Delete file.txt"
|
||||
|
||||
git push -u origin master
|
||||
|
||||
```
|
||||
|
||||
现在你的终端看起来像这样:
|
||||
|
||||

|
||||
|
||||
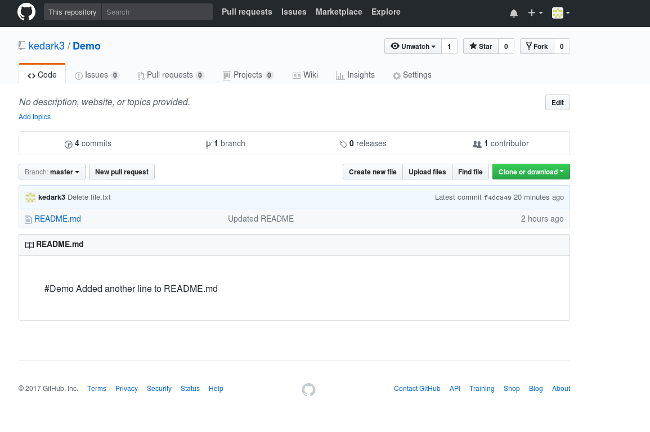
你的 GitHub 看起来像这样:
|
||||
|
||||

|
||||
|
||||
现在你知道如何从你的仓库克隆,添加,修改和删除 Git 文件。本系列的下一篇文章将检查 Git 分支。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
Loading…
Reference in New Issue
Block a user