mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
cef0cf4b25
@ -0,0 +1,129 @@
|
||||
马克·沙特尔沃思 – Ubuntu 背后的那个男人
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
**马克·理查德·沙特尔沃思(Mark Richard Shuttleworth)** 是 Ubuntu 的创始人,也被称作 [Debian 背后的人][1]([之一][2])。他于 1973 年出生在南非的韦尔科姆(Welkom)。他不仅是个企业家,还是个太空游客——他是第一个前往太空旅行的非洲独立国家的公民。
|
||||
|
||||
马克曾在 1996 年成立了一家名为 **Thawte** 的互联网商务安全公司,那时他还在开普敦大学( University of Cape Town)的学习金融和信息技术。
|
||||
|
||||
2000 年,马克创立了 HBD(Here be Dragons (此处有龙/危险)的缩写,所以其吉祥物是一只龙),这是一家投资公司,同时他还创立了沙特尔沃思基金会(Shuttleworth Foundation),致力于以奖金和投资等形式给社会中有创新性的领袖提供资助。
|
||||
|
||||
> “移动设备对于个人电脑行业的未来而言至关重要。比如就在这个月,相对于平板电脑的发展而言,传统 PC 行业很明显正在萎缩。所以如果我们想要涉足个人电脑产业,我们必须首先涉足移动行业。移动产业之所以有趣,是因为在这里没有盗版 Windows 操作系统的市场。所以如果你为你的操作系统赢得了一台设备的市场份额,这台设备会一直使用你的操作系统。在传统 PC 行业,我们时不时得和“免费”的 Windows 产生竞争,这是一种非常微妙的挑战。所以我们现在的重心是围绕 Ubuntu 和移动设备——手机和平板——以图与普通用户建立更深层次的联系。”
|
||||
>
|
||||
> — 马克·沙特尔沃思
|
||||
|
||||
2002 年,他在俄罗斯的星城(Star City)接受了为期一年的训练,随后作为联盟号 TM-34 任务组的一员飞往了国际空间站。再后来,在面向有志于航空航天或者其相关学科的南非学生群体发起了推广科学、编程及数学的运动后,马克 创立了 **Canonical Ltd**。此后直至2013年,他一直在领导 Ubuntu 操作系统的开发。
|
||||
|
||||
现今,沙特尔沃思拥有英国与南非双重国籍并和 18 只可爱的鸭子住在英国的 Isle of Man 小岛上的一处花园,一同的还有他可爱的女友 Claire,两条黑色母狗以及时不时经过的羊群。
|
||||
|
||||
> “电脑不仅仅是一台电子设备了。它现在是你思维的延续,以及通向他人的大门。”
|
||||
>
|
||||
> — 马克·沙特尔沃思
|
||||
|
||||
### 马克·沙特尔沃思的早年生活###
|
||||
|
||||
正如我们之前提到的,马克出生在南非的奥兰治自由邦(Orange Free State)的韦尔科姆(Welkom)。他是一名外科医生和护士学校教师的孩子。他在西部省预科学校就读并在 1986 年成为了学生会主席,一个学期后就读于 Rondebosch 男子高中,再之后入学 Bishops Diocesan 学院并在 1991 年再次成为那里的学生会主席。
|
||||
|
||||
马克在开普敦大学( University of Cape Town)拿到了金融和信息系统的商业科学双学士学位,他在学校就读时住在 Smuts Hall。作为学生,他也在那里帮助安装了学校的第一条宿舍互联网接入。
|
||||
|
||||
>“无数的企业和国家已经证明,引入开源政策能提高竞争力和效率。在不同层面上创造生产力对于公司和国家而言都是至关重要的。”
|
||||
>
|
||||
> — 马克·沙特尔沃思
|
||||
|
||||
### 马克·沙特尔沃思的职业生涯 ###
|
||||
|
||||
马克在 1995 年创立了 Thawte,公司专注于数字证书和互联网安全,然后在 1999 年把公司卖给了 VeriSign,赚取了大约 5.75 亿美元。
|
||||
|
||||
2000 年,马克创立了 HBD 风险资本公司,成为了商业投资人和项目孵化器。2004 年,他创立了 Canonical Ltd. 以支持和鼓励自由软件开发项目的商业化,特别是 Ubuntu 操作系统的项目。直到 2009 年,马克才从 Canonical CEO 的位置上退下。
|
||||
|
||||
> “在 [DDC](https://en.wikipedia.org/wiki/DCC_Alliance) (LCTT 译注:一个 Debian GNU/Linux 开发者联盟) 的早期,我更倾向于让拥护者们放手去做,看看能发展出什么。”
|
||||
>
|
||||
> — 马克·沙特尔沃思
|
||||
|
||||
### Linux、自由开源软件与马克·沙特尔沃思 ###
|
||||
|
||||
在 90 年代后期,马克曾作为一名开发者参与 Debian 操作系统项目。
|
||||
|
||||
2001 年,马克创立了沙特尔沃思基金会,这是个扎根南非的、非赢利性的基金会,专注于赞助社会创新、免费/教育用途开源软件,曾赞助过[自由烤面包机][3](Freedom Toaster)(LCTT 译注:自由烤面包机是一个可以给用户带来的 CD/DVD 上刻录自由软件的公共信息亭)。
|
||||
|
||||
2004 年,马克通过出资开发基于 Debian 的 Ubuntu 操作系统返回了自由软件界,这一切也经由他的 Canonical 公司完成。
|
||||
|
||||
2005 年,马克出资建立了 Ubuntu 基金会并投入了一千万美元作为启动资金。在 Ubuntu 项目内,人们经常用一个朗朗上口的名字称呼他——“**SABDFL :自封的生命之仁慈独裁者(Self-Appointed Benevolent Dictator for Life)**”。为了能够找到足够多的高手开发这个巨大的项目,马克花费了 6 个月的时间从 Debian 邮件列表里寻找,这一切都是在他乘坐在南极洲的一艘破冰船——赫列布尼科夫船长号(Kapitan Khlebnikov)——上完成的。同年,马克买下了 Impi Linux 65% 的股份。
|
||||
|
||||
|
||||
> “我呼吁电信公司的掌权者们尽快开发出跨洲际的高效信息传输服务。”
|
||||
>
|
||||
> — 马克·沙特尔沃思
|
||||
|
||||
2006 年,KDE 宣布沙特尔沃思成为 KDE 的**第一赞助人(first patron)**——彼时 KDE 最高级别的赞助。这一赞助协议在 2012 年终止,取而代之的是对 Kubuntu 的资金支持,这是一个使用 KDE 作为默认桌面环境的 Ubuntu 变种。
|
||||
|
||||

|
||||
|
||||
2009 年,Shuttleworth 宣布他会从 Canonical 的 CEO 上退位以更好地关注合作关系、产品设计和客户。从 2004 年起担任公司 COO 的珍妮·希比尔(Jane Silber)晋升为 CEO。
|
||||
|
||||
2010 年,马克由于其贡献而被开放大学(Open University)授予了荣誉学位。
|
||||
|
||||
2012 年,马克和肯尼斯·罗格夫(Kenneth Rogoff)一同在牛津大学与彼得·蒂尔(Peter Thiel)和加里·卡斯帕罗夫(Garry Kasparov)就**创新悖论**(The Innovation Enigma)展开辩论。
|
||||
|
||||
2013 年,马克和 Ubuntu 一同被授予**澳大利亚反个人隐私大哥奖**(Austrian anti-privacy Big Brother Award),理由是默认情况下, Ubuntu 会把 Unity 桌面的搜索框的搜索结果发往 Canonical 服务器(LCTT 译注:因此侵犯了个人隐私)。而一年前,马克曾经申明过这一过程进行了匿名化处理。
|
||||
|
||||
> “所有主流 PC 厂家现在都提供 Ubuntu 预安装选项,所以我们和业界的合作已经相当紧密了。但那些 PC 厂家对于给买家推广新东西这件事都很紧张。如果我们可以让 PC 买家习惯 Ubuntu 的平板/手机操作系统的体验,那他们也应该更愿意买预装 Ubuntu 的 PC。没有哪个操作系统是通过抄袭模仿获得成功的,Android 很棒,但如果我们想成功的话我们必须给市场带去更新更好的东西(LCTT 译注:而不是改进或者模仿 Android)。如果我们中没有人追寻未来的话,我们将陷入停滞不前的危险。但如果你尝试去追寻未来了,那你必须接受不是所有人对未来的预见都和你一样这一事实。”
|
||||
>
|
||||
> — 马克·沙特尔沃思
|
||||
|
||||
### 马克·沙特尔沃思的太空之旅 ###
|
||||
|
||||
马克在 2002 年作为世界第二名自费太空游客而闻名世界,同时他也是南非第一个旅行太空的人。这趟旅行中,马克作为俄罗斯联盟号 TM-34 任务的一名乘员加入,并为此支付了约两千万美元。2 天后,联盟号宇宙飞船抵达了国际空间站,在那里马克呆了 8 天并参与了艾滋病和基因组研究的相关实验。同年晚些时候,马克随联盟号 TM-33 任务返回了地球。为了参与这趟旅行,马克花了一年时间准备与训练,其中有 7 个月居住在俄罗斯的星城。
|
||||
|
||||

|
||||
|
||||
在太空中,马克与纳尔逊·曼德拉(Nelson Mandela)和另一个 14 岁的南非女孩米歇尔·福斯特(Michelle Foster) (她问马克要不要娶她)通过无线电进行了交谈。马克礼貌地回避了这个结婚问题,但在巧妙地改换话题之前他说他感到很荣幸。身患绝症的女孩福斯特通过梦想基金会( Dream foundation)的赞助获得了与马克和纳尔逊·曼德拉交谈的机会。
|
||||
|
||||
归来后,马克在世界各地做了旅行,并和各地的学生就太空之旅发表了感言。
|
||||
|
||||
>“粗略的统计数据表明 Ubuntu 的实际用户依然在增长。而我们的合作方——戴尔、惠普、联想和其他硬件生产商,以及游戏厂商 EA、Valve 都在加入我们——这让我觉得我们在关键的领域继续领先。”
|
||||
>
|
||||
> — 马克·沙特尔沃思
|
||||
|
||||
### 马克·沙特尔沃思的交通工具 ###
|
||||
|
||||
马克有他自己的私人客机庞巴迪全球特快(Bombardier Global Express),虽然它经常被称为 Canonical 一号,但事实上此飞机是通过 HBD 风险投资公司注册拥有的。涂画在飞机侧面的龙图案是 HBD 风投公司的吉祥物 ,名叫 Norman。
|
||||
|
||||

|
||||
|
||||
### 与南非储备银行的法律冲突 ###
|
||||
|
||||
在从南非转移 25 亿南非兰特去往 Isle of Man 的过程中,南非储备银行征收了 2.5 亿南非兰特的税金。马克上诉了,经过冗长的法庭唇枪舌战,南非储备银行被勒令返还 2.5 亿征税,以及其利息。马克宣布他会把这 2.5 亿存入信托基金,以用于帮助那些上诉到宪法法院的案子。
|
||||
|
||||
|
||||
> “离境征税倒也不和宪法冲突。但离境征税的主要目的不是提高税收,而是通过监管资金流出来保护本国经济。”
|
||||
>
|
||||
> — Dikgang Moseneke 法官
|
||||
|
||||
2015 年,南非宪法法院修正了低级法院的判决结果,并宣布了上述对于离岸征税的理解。
|
||||
|
||||
### 马克·沙特尔沃思喜欢的东西 ###
|
||||
|
||||
Cesária Évora、mp3、春天、切尔西(Chelsea)、“恍然大悟”(finally seeing something obvious for first time)、回家、辛纳屈(Sinatra)、白日梦、暮后小酌、挑逗、苔丝(d’Urberville)、弦理论、Linux、粒子物理、Python、转世、米格-29、雪、旅行、Mozilla、酸橙果酱、激情代价(body shots)、非洲丛林、豹、拉贾斯坦邦、俄罗斯桑拿、单板滑雪、失重、Iain m 银行、宽度、阿拉斯泰尔·雷诺兹(Alastair Reynolds)、化装舞会服装、裸泳、灵机一动、肾上腺素激情消退、莫名(the inexplicable)、活动顶篷式汽车、Clifton、国家公路、国际空间站、机器学习、人工智能、维基百科、Slashdot、风筝冲浪(kitesurfing)和 Manx lanes。
|
||||
|
||||
|
||||
|
||||
### 马克·沙特尔沃思不喜欢的东西 ###
|
||||
|
||||
行政、涨工资、法律术语和公众演讲。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/mark-shuttleworth-man-behind-ubuntu-operating-system/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
[1]:https://wiki.debian.org/PeopleBehindDebian
|
||||
[2]:https://raphaelhertzog.com/2011/11/17/people-behind-debian-mark-shuttleworth-ubuntus-founder/
|
||||
[3]:https://en.wikipedia.org/wiki/Freedom_Toaster
|
||||
@ -3,11 +3,11 @@
|
||||
|
||||

|
||||
|
||||
今年 Black Duck 和 North Bridge 发布了第十届年度开源软件前景调查,来检验开源软件的发展趋势。今年这份调查的亮点在于,当前主流社会对开源软件的接受程度以及过去的十年中人们对开源软件态度的变化。
|
||||
今年 Black Duck 和 North Bridge 发布了第十届年度开源软件前景调查,来调查开源软件的发展趋势。今年这份调查的亮点在于,当前主流社会对开源软件的接受程度以及过去的十年中人们对开源软件态度的变化。
|
||||
|
||||
[2016 年的开源软件前景调查][1],分析了来自约3400位专家的反馈。今年的调查中,开发者发表了他们的看法,包括了大约 70% 的参与者。数据显示,安全专家的参与人数呈指数级增长,增长超过 450% 。他们的参与表明,开源社区开始逐渐关注开源软件中存在的安全问题,以及当新的技术出现时确保它们的安全性。
|
||||
[2016 年的开源软件前景调查][1],分析了来自约3400位专家的反馈。今年的调查中,开发者发表了他们的看法,大约 70% 的参与者是开发者。数据显示,安全专家的参与人数呈指数级增长,增长超过 450% 。他们的参与表明,开源社区开始逐渐关注开源软件中存在的安全问题,以及当新的技术出现时确保它们的安全性。
|
||||
|
||||
Black Duck 的年度 [开源新秀奖][2] 涉及到一些新出现的技术,如 Docker 和 Kontena 容器。容器技术这一年有了巨大的发展 ———— 76% 的受访者表示,他们的企业有一些使用容器技术的规划。而 59% 的受访者正准备使用容器技术完成大量的部署,从开发与测试,到内部与外部的生产环境部署。开发者社区已经把容器技术作为一种简单快速开发的方法。
|
||||
Black Duck 的[年度开源新秀奖][2] 涉及到一些新出现的技术,如容器方面的 Docker 和 Kontena。容器技术这一年有了巨大的发展 ———— 76% 的受访者表示,他们的企业有一些使用容器技术的规划。而 59% 的受访者正准备使用容器技术完成大量的部署,从开发与测试,到内部与外部的生产环境部署。开发者社区已经把容器技术作为一种简单快速开发的方法。
|
||||
|
||||
调查显示,几乎每个组织都有开发者致力于开源软件,这一点毫不惊讶。当像微软和苹果这样的大公司将它们的一些解决方案开源时,开发者就获得了更多的机会来参与开源项目。我非常希望这样的趋势会延续下去,让更多的软件开发者无论在工作中,还是工作之余都可以致力于开源项目。
|
||||
|
||||
@ -30,11 +30,11 @@ Black Duck 的年度 [开源新秀奖][2] 涉及到一些新出现的技术,
|
||||
|
||||
#### 安全和管理
|
||||
|
||||
一流的开源安全与管理实践的发展,并没有跟上人们使用开源不断增长的步伐。尽管备受关注的开源项目近年来爆炸式地增长,调查结果却指出:
|
||||
一流的开源安全与管理实践的发展,也没有跟上人们使用开源不断增长的步伐。尽管备受关注的开源项目近年来爆炸式地增长,调查结果却指出:
|
||||
|
||||
* 50% 的企业在选择和批准开源代码这方面没有出台正式的政策。
|
||||
* 47% 的企业没有正式的流程来跟踪开源代码,这就限制了它们对开源代码的了解,以及控制开源代码的能力。
|
||||
* 超过三分之一的企业没有用于识别,跟踪,和修复重大开源安全漏洞的流程。
|
||||
* 超过三分之一的企业没有用于识别、跟踪和修复重大开源安全漏洞的流程。
|
||||
|
||||
#### 不断增长的开源参与者
|
||||
|
||||
@ -45,16 +45,17 @@ Black Duck 的年度 [开源新秀奖][2] 涉及到一些新出现的技术,
|
||||
* 约三分之一的企业有专门为开源项目设置的全职岗位。
|
||||
* 59% 的受访者参与开源项目以获得竞争优势。
|
||||
|
||||
Black Duck 和 North Bridge 从今年的调查中了解了很多,如安全,政策,商业模式等。我们很兴奋能够分享这些新发现。感谢我们的合作者,以及所有参与我们调查的受访者。这是一个伟大的十年,我很高兴我们可以肯定地说,开源的未来充满了无限可能。
|
||||
Black Duck 和 North Bridge 从今年的调查中了解到了很多,如安全,政策,商业模式等。我们很兴奋能够分享这些新发现。感谢我们的合作者,以及所有参与我们调查的受访者。这是一个伟大的十年,我很高兴我们可以肯定地说,开源的未来充满了无限可能。
|
||||
|
||||
想要了解更多内容,可以查看完整的[调查结果][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/2016-future-open-source-survey
|
||||
|
||||
作者:[Haidee LeClair][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
[a]: https://opensource.com/users/blackduck2016
|
||||
[1]: http://www.slideshare.net/blackducksoftware/2016-future-of-open-source-survey-results
|
||||
@ -3,23 +3,23 @@
|
||||
|
||||
谷歌安卓的一项新创新将可以让你无需安装即可在你的设备上使用应用程序。现在已经初具雏形。
|
||||
|
||||
还记得那时候吗,某人发给你了一个链接,要求你通过安装来查看应用。
|
||||
还记得那时候吗,某人发给你了一个链接,要求你通过安装一个应用才能查看。
|
||||
|
||||
是否要安装这个应用来查看一个一次性的链接,这种进退两难的选择一定让你感到很沮丧。而且,应用安装本身也会消耗你不少宝贵的时间。
|
||||
是否要安装这个应用就为了看一下链接,这种进退两难的选择一定让你感到很沮丧。而且,安装应用这个事也会消耗你不少宝贵的时间。
|
||||
|
||||
上述场景可能大多数人都经历过,或者说大多数现代科技用户都经历过。尽管如此,我们都接受这是正确且合理的过程。
|
||||
上述场景可能大多数人都经历过,或者说大多数现代科技用户都经历过。尽管如此,我们都接受,认为这是天经地义的事情。
|
||||
|
||||
事实真的如此吗?
|
||||
|
||||
针对这个问题谷歌的安卓部门给出了一个全新的,开箱即用的答案:
|
||||
针对这个问题谷歌的安卓部门给出了一个全新的、开箱即用的答案:
|
||||
|
||||
### Android Instant Apps
|
||||
### Android Instant Apps (AIA)
|
||||
|
||||
Android Instant Apps 声称第一时间帮你摆脱这样的两难境地,让你简单地点击链接(见打开链接的示例)然后直接开始使用这个应用。
|
||||
Android Instant Apps 声称可以从一开始就帮你摆脱这样的两难境地,让你简单地点击链接(见打开链接的示例)然后直接开始使用这个应用。
|
||||
|
||||
另一个真实生活场景的例子,如果你想停车但是没有停车码表的配对应用,有了 Instant Apps 在这种情况下就方便多了。
|
||||
另一个真实生活场景的例子,如果你想停车但是没有停车码表的相应应用,有了 Instant Apps 在这种情况下就方便多了。
|
||||
|
||||
根据谷歌的信息,你可以简单地将你的手机和码表触碰,停车应用就会直接显示在你的屏幕上,并且准备就绪可以使用。
|
||||
根据谷歌提供的信息,你可以简单地将你的手机和码表触碰,停车应用就会直接显示在你的屏幕上,并且准备就绪可以使用。
|
||||
|
||||
#### 它是怎么工作的?
|
||||
|
||||
@ -30,21 +30,25 @@ Instant Apps 和你已经熟悉的应用基本相同,只有一个不同——
|
||||
这样应用就可以快速打开,让你可以完成你的目标任务。
|
||||
|
||||

|
||||
>AIA 示例
|
||||
|
||||
*AIA 示例*
|
||||
|
||||
|
||||
>B&H 图片(通过谷歌搜索)
|
||||
|
||||
*B&H 图片(通过谷歌搜索)*
|
||||
|
||||
|
||||
>BuzzFeedVideo(通过一个共享链接)
|
||||
|
||||
*BuzzFeedVideo(通过一个共享链接)*
|
||||
|
||||

|
||||
>停车与支付(例)(通过 NFC)
|
||||
|
||||
*停车与支付(例)(通过 NFC)*
|
||||
|
||||
|
||||
听起来很棒,不是吗?但是其中还有很多技术方面的问题需要解决。
|
||||
|
||||
比如,从安全的观点来说:如果任何应用从理论上来说都能在你的设备上运行,甚至你都不用安装它——你要怎么保证设备远离恶意软件攻击?
|
||||
比如,从安全的观点来说:从理论上来说,如果任何应用都能在你的设备上运行,甚至你都不用安装它——你要怎么保证设备远离恶意软件攻击?
|
||||
|
||||
因此,为了消除这类威胁,谷歌还在这个项目上努力,目前只有少数合作伙伴,未来将逐步扩展。
|
||||
|
||||
@ -5,19 +5,19 @@ ORB:新一代 Linux 应用
|
||||
|
||||
我们之前讨论过[在 Ubuntu 上离线安装应用][1]。我们现在要再次讨论它。
|
||||
|
||||
[Orbital Apps][2] 给我们带来了新的软件包类型,**ORB**,它带有便携软件,交互式安装向导支持,以及离线使用的能力。
|
||||
[Orbital Apps][2] 给我们带来了一种新的软件包类型 **ORB**,它具有便携软件、交互式安装向导支持,以及离线使用的能力。
|
||||
|
||||
便携软件很方便。主要是因为它们能够无需任何管理员权限直接运行,也能够带着所有的设置和数据随U盘存储。而交互式的安装向导也能让我们轻松地安装应用。
|
||||
便携软件很方便。主要是因为它们能够无需任何管理员权限直接运行,也能够带着所有的设置和数据随 U 盘存储。而交互式的安装向导也能让我们轻松地安装应用。
|
||||
|
||||
### 开放可运行包 OPEN RUNNABLE BUNDLE (ORB)
|
||||
### 开放式可运行的打包(OPEN RUNNABLE BUNDLE) (ORB)
|
||||
|
||||
ORB 是一个免费和开源的包格式,它和其它包格式在很多方面有所不同。ORB 的一些特性:
|
||||
ORB 是一个自由开源的包格式,它和其它包格式在很多方面有所不同。ORB 的一些特性:
|
||||
|
||||
- **压缩**:所有的包经过压缩,使用 squashfs,体积最多减少 60%。
|
||||
- **便携模式**:如果一个便携 ORB 应用是从可移动设备运行的,它会把所有设置和数据存储在那之上。
|
||||
- **压缩**:所有的包都经过 squashfs 压缩,体积最多可减少 60%。
|
||||
- **便携模式**:如果一个便携 ORB 应用是在可移动设备上运行的,它会把所有设置和数据存储在那之上。
|
||||
- **安全**:所有的 ORB 包使用 PGP/RSA 签名,通过 TLS 1.2 分发。
|
||||
- **离线**:所有的依赖都打包进软件包,所以不再需要下载依赖。
|
||||
- **开放包**:ORB 包可以作为 ISO 镜像挂载。
|
||||
- **开放式软件包**:ORB 软件包可以作为 ISO 镜像挂载。
|
||||
|
||||
### 种类
|
||||
|
||||
@ -26,77 +26,69 @@ ORB 应用现在有两种类别:
|
||||
- 便携软件
|
||||
- SuperDEB
|
||||
|
||||
#### 1. 便携 ORB 软件
|
||||
### 1. 便携 ORB 软件
|
||||
|
||||
便携 ORB 软件可以立即运行而不需要任何的事先安装。那意味着它不需要管理员权限和依赖!你可以直接从 Orbital Apps 网站下载下来就能使用。
|
||||
便携 ORB 软件可以立即运行而不需要任何的事先安装。这意味着它不需要管理员权限,也没有依赖!你可以直接从 Orbital Apps 网站下载下来就能使用。
|
||||
|
||||
并且由于它支持便携模式,你可以将它拷贝到U盘携带。它所有的设置和数据会和它一起存储在U盘。只需将U盘连接到任何运行 Ubuntu 16.04 的机器上就行了。
|
||||
并且由于它支持便携模式,你可以将它拷贝到 U 盘携带。它所有的设置和数据会和它一起存储在 U 盘。只需将 U 盘连接到任何运行 Ubuntu 16.04 的机器上就行了。
|
||||
|
||||
##### 可用便携软件
|
||||
#### 可用便携软件
|
||||
|
||||
目前有超过 35 个软件以便携包的形式提供,包括一些十分流行的软件,比如:[Deluge][3],[Firefox][4],[GIMP][5],[Libreoffice][6],[uGet][7] 以及 [VLC][8]。
|
||||
|
||||
完整的可用包列表可以查阅 [便携 ORB 软件列表][9]。
|
||||
|
||||
##### 使用便携软件
|
||||
#### 使用便携软件
|
||||
|
||||
按照以下步骤使用便携 ORB 软件:
|
||||
|
||||
- 从 Orbital Apps 网站下载想要的软件包。
|
||||
- 将其移动到想要的位置(本地磁盘/U盘)。
|
||||
- 将其移动到想要的位置(本地磁盘/U 盘)。
|
||||
- 打开存储 ORB 包的目录。
|
||||
|
||||

|
||||
|
||||

|
||||
- 打开 ORB 包的属性。
|
||||
|
||||

|
||||
>给 ORB 包添加运行权限
|
||||

|
||||
|
||||
- 在权限标签页添加运行权限。
|
||||
- 双击打开它。
|
||||
|
||||
等待几秒,让它准备好运行。大功告成。
|
||||
|
||||
#### 2. SuperDEB
|
||||
### 2. SuperDEB
|
||||
|
||||
另一种类型的 ORB 软件是 SuperDEB。SuperDEB 很简单,交互式安装向导能够让软件安装过程顺利得多。如果你不喜欢从终端或软件中心安装软件,superDEB 就是你的菜。
|
||||
|
||||
最有趣的部分是你安装时不需要一个互联网连接,因为所有的依赖都由安装向导打包了。
|
||||
|
||||
##### 可用的 SuperDEB
|
||||
#### 可用的 SuperDEB
|
||||
|
||||
超过 60 款软件以 SuperDEB 的形式提供。其中一些流行的有:[Chromium][10],[Deluge][3],[Firefox][4],[GIMP][5],[Libreoffice][6],[uGet][7] 以及 [VLC][8]。
|
||||
|
||||
完整的可用 SuperDEB 列表,参阅 [SuperDEB 列表][11]。
|
||||
|
||||
##### 使用 SuperDEB 安装向导
|
||||
#### 使用 SuperDEB 安装向导
|
||||
|
||||
- 从 Orbital Apps 网站下载需要的 SuperDEB。
|
||||
- 像前面一样给它添加**运行权限**(属性 > 权限)。
|
||||
- 双击 SuperDEB 安装向导并按下列说明操作:
|
||||
|
||||

|
||||
>点击 OK
|
||||

|
||||
|
||||

|
||||
>输入你的密码并继续
|
||||

|
||||
|
||||

|
||||
>它会开始安装…
|
||||

|
||||
|
||||

|
||||
>一会儿他就完成了…
|
||||

|
||||
|
||||
- 完成安装之后,你就可以正常使用了。
|
||||
|
||||
### ORB 软件兼容性
|
||||
|
||||
从 Orbital Apps 可知,它们完全适配 Ubuntu 16.04 [64 bit]。
|
||||
从 Orbital Apps 可知,它们完全适配 Ubuntu 16.04 [64 位]。
|
||||
|
||||
>阅读建议:[如何在 Ubuntu 获知你的是电脑 32 位还是 64 位的][12]。
|
||||
|
||||
至于其它发行版兼容性不受保证。但我们可以说,它在所有 Ubuntu 16.04 衍生版(UbuntuMATE,UbuntuGNOME,Lubuntu,Xubuntu 等)以及基于 Ubuntu 16.04 的发行版(比如即将到来的 Linux Mint 18)上都适用。我们现在还不清楚 Orbital Apps 是否有计划拓展它的支持到其它版本 Ubuntu 或 Linux 发行版上。
|
||||
至于其它发行版兼容性则不受保证。但我们可以说,它在所有 Ubuntu 16.04 衍生版(UbuntuMATE,UbuntuGNOME,Lubuntu,Xubuntu 等)以及基于 Ubuntu 16.04 的发行版(比如即将到来的 Linux Mint 18)上都适用。我们现在还不清楚 Orbital Apps 是否有计划拓展它的支持到其它版本 Ubuntu 或 Linux 发行版上。
|
||||
|
||||
如果你在你的系统上经常使用便携 ORB 软件,你可以考虑安装 ORB 启动器。它不是必需的,但是推荐安装它以获取更佳的体验。最简短的 ORB 启动器安装流程是打开终端输入以下命令:
|
||||
|
||||
@ -116,11 +108,11 @@ wget -O - https://www.orbital-apps.com/orb.sh | bash
|
||||
|
||||
|
||||
----------------------------------
|
||||
via: http://itsfoss.com/orb-linux-apps/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
via: http://itsfoss.com/orb-linux-apps/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,106 @@
|
||||
与 Linux 一同驾车奔向未来
|
||||
===========================================
|
||||
|
||||

|
||||
|
||||
当我驾车的时候并没有这么想过,但是我肯定喜欢一个配有这样系统的车子,它可以让我按下几个按钮就能与我的妻子、母亲以及孩子们语音通话。这样的系统也可以让我选择是否从云端、卫星广播、以及更传统的 AM/FM 收音机收听音乐流媒体。我也会得到最新的天气情况,以及它可以引导我的车载 GPS 找到抵达下一个目的地的最快路线。[车载娱乐系统(In-vehicle infotainment)][1],业界常称作 IVI,它已经普及出现在最新的汽车上了。
|
||||
|
||||
前段时间,我乘坐飞机跨越了数百英里,然后租了一辆汽车。令人愉快的是,我发现我租赁的汽车上配置了类似我自己车上同样的 IVI 技术。毫不犹豫地,我就通过蓝牙连接把我的联系人上传到了系统当中,然后打电话回家给我的家人,让他们知道我已经安全抵达了,然后我的主机会让他们知道我正在去往他们家的路上。
|
||||
|
||||
在最近的[新闻综述][2]中,Scott Nesbitt 引述了一篇文章,说福特汽车公司因其开源的[智能设备连接(Smart Device Link)][3](SDL)从竞争对手汽车制造商中得到了足够多的回报,这个中间件框架可以用于支持移动电话。 SDL 是 [GENIVI 联盟][4]的一个项目,这个联盟是一个非营利性组织,致力于建设支持开源车载娱乐系统的中间件。据 GENIVI 的执行董事 [Steven Crumb][5] 称,他们的[成员][6]有很多,包括戴姆勒集团、现代、沃尔沃、日产、本田等等 170 个企业。
|
||||
|
||||
为了在同行业间保持竞争力,汽车生产企业需要一个中间设备系统,以支持现代消费者所使用的各种人机界面技术。无论您使用的是 Android、iOS 还是其他设备,汽车 OEM 厂商都希望自己的产品能够支持这些。此外,这些的 IVI 系统必须有足够适应能力以支持日益变化的移动技术。OEM 厂商希望提供有价值的服务,并可以在他们的 IVI 之上增加服务,以满足他们客户的各种需求。
|
||||
|
||||
### 步入 Linux 和开源软件
|
||||
|
||||
除了 GENIVI 在努力之外,[Linux 基金会][7]也赞助支持了[车载 Linux(Automotive Grade Linux)][8](AGL)工作组,这是一个致力于为汽车应用寻求开源解决方案的软件基金会。虽然 AGL 初期将侧重于 IVI 系统,但是未来他们希望发展到不同的方向,包括[远程信息处理(telematics)][9]、抬头显示器(HUD)及其他控制系统等等。 现在 AGL 已经有超过 50 名成员,包括捷豹、丰田、日产,并在其[最近发布的一篇公告][10]中宣称福特、马自达、三菱、和斯巴鲁也加入了。
|
||||
|
||||
为了了解更多信息,我们采访了这一新兴领域的两位领导人。具体来说,我们想知道 Linux 和开源软件是如何被使用的,并且它们是如何事实上改变了汽车行业的面貌。首先,我们将与 [Alison Chaiken][11] 谈谈,她是一位任职于 Peloton Technology 的软件工程师,也是一位在车载 Linux 、网络安全和信息透明化方面的专家。她曾任职于 [Alison Chaiken][11] 公司、诺基亚和斯坦福直线性加速器。然后我们和 [Steven Crumb][12] 进行了交谈,他是 GENIVI 执行董事,他之前从事于高性能计算环境(超级计算机和早期的云计算)的开源工作。他说,虽然他再不是一个程序员了,但是他乐于帮助企业解决在使用开源软件时的实际业务问题。
|
||||
|
||||
### 采访 Alison Chaiken (by [Deb Nicholson][13])
|
||||
|
||||
#### 你是如何开始对汽车软件领域感兴趣的?
|
||||
|
||||
我曾在诺基亚从事于手机上的 [MeeGo][14] 产品,2009 年该项目被取消了。我想,我下一步怎么办?其时,我的一位同事正在从事于 [MeeGo-IVI][15],这是一个早期的车载 Linux 发行版。 “Linux 在汽车方面将有很大发展,” 我想,所以我就朝着这个方向努力。
|
||||
|
||||
#### 你能告诉我们你在这些日子里工作在哪些方面吗?
|
||||
|
||||
我目前正在启动一个高级巡航控制系统的项目,它用在大型卡车上,使用实时 Linux 以提升安全性和燃油经济性。我喜欢在这方面的工作,因为没有人会反对提升货运的能力。
|
||||
|
||||
#### 近几年有几则汽车被黑的消息。开源代码方案可以帮助解决这个问题吗?
|
||||
|
||||
我恰好针对这一话题准备了一次讲演,我会在南加州 Linux 2016 博览会上就 Linux 能否解决汽车上的安全问题做个讲演 ([讲演稿在此][16])。值得注意的是,GENIVI 和车载 Linux 项目已经公开了他们的代码,这两个项目可以通过 Git 提交补丁。(如果你有补丁的话),请给上游发送您的补丁!许多眼睛都盯着,bug 将无从遁形。
|
||||
|
||||
#### 执法机构和保险公司可以找到很多汽车上的数据的用途。他们获取这些信息很容易吗?
|
||||
|
||||
好问题。IEEE-1609 专用短程通信标准(Dedicated Short Range Communication Standard)就是为了让汽车的 WiFi 消息可以安全、匿名地传递。不过,如果你从你的车上发推,那可能就有人能够跟踪到你。
|
||||
|
||||
#### 开发人员和公民个人可以做些什么,以在汽车技术进步的同时确保公民自由得到保护?
|
||||
|
||||
电子前沿基金会( Electronic Frontier Foundation)(EFF)在关注汽车问题方面做了出色的工作,包括对哪些数据可以存储在汽车 “黑盒子”里通过官方渠道发表了看法,以及 DMCA 规定 1201 如何应用于汽车上。
|
||||
|
||||
#### 在未来几年,你觉得在汽车方面会发生哪些令人激动的发展?
|
||||
|
||||
可以拯救生命的自适应巡航控制系统和防撞系统将取得长足发展。当它们大量进入汽车里面时,我相信这会使得(因车祸而导致的)死亡人数下降。如果这都不令人激动,我不知道还有什么会更令人激动。此外,像自动化停车辅助功能,将会使汽车更容易驾驶,减少汽车磕碰事故。
|
||||
|
||||
#### 我们需要做什么?人们怎样才能参与?
|
||||
|
||||
车载 Linux 开发是以开源的方式开发,它运行在每个人都能买得起的廉价硬件上(如树莓派 2 和中等价位的 Renesas Porter 主板)。 GENIVI 汽车 Linux 中间件联盟通过 Git 开源了很多软件。此外,还有很酷的 [OSVehicle 开源硬件][17]汽车平台。
|
||||
|
||||
只需要不太多的预算,人们就可以参与到 Linux 软件和开放硬件中。如果您感兴趣,请加入我们在 Freenode 上的IRC #automotive 吧。
|
||||
|
||||
### 采访 Steven Crumb (by Don Watkins)
|
||||
|
||||
#### GENIVI 在 IVI 方面做了哪些巨大贡献?
|
||||
|
||||
GENIVI 率先通过使用自由开源软件填补了汽车行业的巨大空白,这包括 Linux、非安全关键性汽车软件(如车载娱乐系统(IVI))等。作为消费者,他们很期望在车辆上有和智能手机一样的功能,对这种支持 IVI 功能的软件的需求量成倍地增长。不过不断提升的软件数量也增加了建设 IVI 系统的成本,从而延缓了其上市时间。
|
||||
|
||||
GENIVI 使用开源软件和社区开发的模式为汽车制造商及其软件提供商节省了大量资金,从而显著地缩短了产品面市时间。我为 GENIVI 而感到激动,我们有幸引导了一场革命,在缓慢进步的汽车行业中,从高度结构化和专有的解决方案转换为以社区为基础的开发方式。我们还没有完全达成目标,但是我们很荣幸在这个可以带来实实在在好处的转型中成为其中的一份子。
|
||||
|
||||
#### 你们的主要成员怎样推动了 GENIVI 的发展方向?
|
||||
|
||||
GENIVI 有很多成员和非成员致力于我们的工作。在许多开源项目中,任何公司都可以通过通过技术输出而发挥影响,包括简单地贡献代码、补丁、花点时间测试。前面说过,宝马、奔驰、现代汽车、捷豹路虎、标致雪铁龙、雷诺/日产和沃尔沃都是 GENIVI 积极的参与者和贡献者,其他的许多 OEM 厂商也在他们的汽车中采用了 IVI 解决方案,广泛地使用了 GENIVI 的软件。
|
||||
|
||||
#### 这些贡献的代码使用了什么许可证?
|
||||
|
||||
GENIVI 采用了一些许可证,包括从(L)GPLv2 到 MPLv2 和 Apache2.0。我们的一些工具使用的是 Eclipse 许可证。我们有一个[公开许可策略][18],详细地说明了我们的许可证偏好。
|
||||
|
||||
#### 个人或团体如何参与其中?社区的参与对于这个项目迈向成功有多重要?
|
||||
|
||||
GENIVI 的开发完全是开放的([projects.genivi.org][19]),因此,欢迎任何有兴趣在汽车中使用开源软件的人参加。也就是说,公司可以通过成员的方式[加入该联盟][20],联盟以开放的方式资助其不断进行开发。GENIVI 的成员可以享受各种各样的便利,在过去六年中,已经有多达 140 家公司参与到这个全球性的社区当中。
|
||||
|
||||
社区对于 GENIVI 是非常重要的,没有一个活跃的贡献者社区,我们不可能在这些年开发和维护了这么多有价值的软件。我们努力让参与到 GENIVI 更加简单,现在只要加入一个[邮件列表][21]就可以接触到各种软件项目中的人们。我们使用了许多开源项目采用的标准做法,并提供了高品质的工具和基础设施,以帮助开发人员宾至如归而富有成效。
|
||||
|
||||
无论你是否熟悉汽车软件,都欢迎你加入我们的社区。人们已经对汽车改装了许多年,所以对于许多人来说,在汽车上修修改改是自热而然的做法。对于汽车来说,软件是一个新的领域,GENIVI 希望能为对汽车和开源软件有兴趣的人打开这扇门。
|
||||
|
||||
-------------------------------
|
||||
via: https://opensource.com/business/16/5/interview-alison-chaiken-steven-crumb
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[erlinux](https://github.com/erlinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[1]: https://en.wikipedia.org/wiki/In_car_entertainment
|
||||
[2]: https://opensource.com/life/16/1/weekly-news-jan-9
|
||||
[3]: http://projects.genivi.org/smartdevicelink/home
|
||||
[4]: http://www.genivi.org/
|
||||
[5]: https://www.linkedin.com/in/stevecrumb
|
||||
[6]: http://www.genivi.org/genivi-members
|
||||
[7]: http://www.linuxfoundation.org/
|
||||
[8]: https://www.automotivelinux.org/
|
||||
[9]: https://en.wikipedia.org/wiki/Telematics
|
||||
[10]: https://www.automotivelinux.org/news/announcement/2016/01/ford-mazda-mitsubishi-motors-and-subaru-join-linux-foundation-and
|
||||
[11]: https://www.linkedin.com/in/alison-chaiken-3ba456b3
|
||||
[12]: https://www.linkedin.com/in/stevecrumb
|
||||
[13]: https://opensource.com/users/eximious
|
||||
[14]: https://en.wikipedia.org/wiki/MeeGo
|
||||
[15]: http://webinos.org/deliverable-d026-target-platform-requirements-and-ipr/automotive/
|
||||
[16]: http://she-devel.com/Chaiken_automotive_cybersecurity.pdf
|
||||
[17]: https://www.osvehicle.com/
|
||||
[18]: http://projects.genivi.org/how
|
||||
[19]: http://projects.genivi.org/
|
||||
[20]: http://genivi.org/join
|
||||
[21]: http://lists.genivi.org/mailman/listinfo/genivi-projects
|
||||
@ -0,0 +1,212 @@
|
||||
如何在 Linux 及 Unix 系统中添加定时任务
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
### 导言
|
||||
|
||||

|
||||
|
||||
定时任务 (cron job) 被用于安排那些需要被周期性执行的命令。利用它,你可以配置某些命令或者脚本,让它们在某个设定的时间周期性地运行。`cron` 是 Linux 或者类 Unix 系统中最为实用的工具之一。cron 服务(守护进程)在系统后台运行,并且会持续地检查 `/etc/crontab` 文件和 `/etc/cron.*/ `目录。它同样也会检查 `/var/spool/cron/` 目录。
|
||||
|
||||
### crontab 命令
|
||||
|
||||
`crontab` 是用来安装、卸载或者列出定时任务列表的命令。cron 配置文件则用于驱动 `Vixie Cron` 的 [cron(8)][1] 守护进程。每个用户都可以拥有自己的 crontab 文件,虽然这些文件都位于 `/var/spool/cron/crontabs` 目录中,但并不意味着你可以直接编辑它们。你需要通过 `crontab` 命令来编辑或者配置你自己的定时任务。
|
||||
|
||||
### 定时配置文件的类型
|
||||
|
||||
配置文件分为以下不同的类型:
|
||||
|
||||
- **UNIX 或 Linux 系统的 crontab** : 此类型通常由那些需要 root 或类似权限的系统服务和重要任务使用。第六个字段(见下方的字段介绍)为用户名,用来指定此命令以哪个用户身份来执行。如此一来,系统的 `crontab` 就能够以任意用户的身份来执行操作。
|
||||
|
||||
- **用户的 crontab**: 用户可以使用 `crontab` 命令来安装属于他们自己的定时任务。 第六个字段为需要运行的命令, 所有的命令都会以创建该 crontab 任务的用户的身份运行。
|
||||
|
||||
**注意**: 这种问答形式的 `Cron` 实现由 Paul Vixie 所编写,并且被包含在许多 [Linux][2] 发行版本和类 Unix 系统(如广受欢迎的第四版 BSD)中。它的语法被各种 crond 的实现所[兼容][3]。
|
||||
|
||||
那么我该如何安装、创建或者编辑我自己的定时任务呢?
|
||||
|
||||
要编辑你的 crontab 文件,需要在 Linux 或 Unix 的 shell 提示符后键入以下命令:
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
`crontab` 语法(字段介绍)
|
||||
|
||||
语法为:
|
||||
|
||||
```
|
||||
1 2 3 4 5 /path/to/command arg1 arg2
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
1 2 3 4 5 /root/ntp_sync.sh
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
- 第1个字段:分钟 (0-59)
|
||||
- 第2个字段:小时 (0-23)
|
||||
- 第3个字段:日期 (0-31)
|
||||
- 第4个字段:月份 (0-12 [12 代表 December])
|
||||
- 第5个字段:一周当中的某天 (0-7 [7 或 0 代表星期天])
|
||||
- /path/to/command - 计划执行的脚本或命令的名称
|
||||
|
||||
便于记忆的格式:
|
||||
|
||||
```
|
||||
* * * * * 要执行的命令
|
||||
----------------
|
||||
| | | | |
|
||||
| | | | ---- 周当中的某天 (0 - 7) (周日为 0 或 7)
|
||||
| | | ------ 月份 (1 - 12)
|
||||
| | -------- 一月当中的某天 (1 - 31)
|
||||
| ---------- 小时 (0 - 23)
|
||||
------------ 分钟 (0 - 59)
|
||||
```
|
||||
|
||||
简单的 `crontab` 示例:
|
||||
|
||||
````
|
||||
## 每隔 5 分钟运行一次 backupscript 脚本 ##
|
||||
*/5 * * * * /root/backupscript.sh
|
||||
|
||||
## 每天的凌晨 1 点运行 backupscript 脚本 ##
|
||||
|
||||
0 1 * * * /root/backupscript.sh
|
||||
|
||||
## 每月的第一个凌晨 3:15 运行 backupscript 脚本 ##
|
||||
|
||||
15 3 1 * * /root/backupscript.sh
|
||||
```
|
||||
|
||||
### 如何使用操作符
|
||||
|
||||
操作符允许你为一个字段指定多个值,这里有三个操作符可供使用:
|
||||
|
||||
- **星号 (*)** : 此操作符为字段指定所有可用的值。举个例子,在小时字段中,一个星号等同于每个小时;在月份字段中,一个星号则等同于每月。
|
||||
|
||||
- **逗号 (,)** : 这个操作符指定了一个包含多个值的列表,例如:`1,5,10,15,20,25`.
|
||||
|
||||
- **横杠 (-)** : 此操作符指定了一个值的范围,例如:`5-15` ,等同于使用逗号操作符键入的 `5,6,7,8,9,...,13,14,15`。
|
||||
|
||||
- **分隔符 (/)** : 此操作符指定了一个步进值,例如: `0-23/` 可以用于小时字段来指定某个命令每小时被执行一次。步进值也可以跟在星号操作符后边,如果你希望命令行每 2 小时执行一次,则可以使用 `*/2`。
|
||||
|
||||
### 如何禁用邮件输出
|
||||
|
||||
默认情况下,某个命令或者脚本的输出内容(如果有的话)会发送到你的本地邮箱账户中。若想停止收到 `crontab` 发送的邮件,需要添加 `>/dev/null 2>&1` 这段内容到执行的命令的后面,例如:
|
||||
|
||||
```
|
||||
0 3 * * * /root/backup.sh >/dev/null 2>&1
|
||||
```
|
||||
|
||||
如果想将输出内容发送到特定的邮件账户中,比如说 vivek@nixcraft.in 这个邮箱, 则你需要像下面这样定义一个 MAILTO 变量:
|
||||
|
||||
```
|
||||
MAILTO="vivek@nixcraft.in"
|
||||
0 3 * * * /root/backup.sh >/dev/null 2>&1
|
||||
```
|
||||
|
||||
访问 “[禁用 Crontab 命令的邮件提示](http://www.cyberciti.biz/faq/disable-the-mail-alert-by-crontab-command/)” 查看更多信息。
|
||||
|
||||
|
||||
### 任务:列出你所有的定时任务
|
||||
|
||||
键入以下命令:
|
||||
|
||||
```
|
||||
# crontab -l
|
||||
# crontab -u username -l
|
||||
```
|
||||
|
||||
要删除所有的定时任务,可以使用如下命令:
|
||||
|
||||
```
|
||||
# 删除当前定时任务 #
|
||||
crontab -r
|
||||
```
|
||||
|
||||
```
|
||||
## 删除某用户名下的定时任务,此命令需以 root 用户身份执行 ##
|
||||
crontab -r -u username
|
||||
```
|
||||
|
||||
### 使用特殊字符串来节省时间
|
||||
|
||||
你可以使用以下 8 个特殊字符串中的其中一个替代头五个字段,这样不但可以节省你的时间,还可以提高可读性。
|
||||
|
||||
特殊字符 |含义
|
||||
|:-- |:--
|
||||
@reboot | 在每次启动时运行一次
|
||||
@yearly | 每年运行一次,等同于 “0 0 1 1 *”.
|
||||
@annually | (同 @yearly)
|
||||
@monthly | 每月运行一次, 等同于 “0 0 1 * *”.
|
||||
@weekly | 每周运行一次, 等同于 “0 0 * * 0”.
|
||||
@daily | 每天运行一次, 等同于 “0 0 * * *”.
|
||||
@midnight | (同 @daily)
|
||||
@hourly | 每小时运行一次, 等同于 “0 * * * *”.
|
||||
|
||||
示例:
|
||||
|
||||
#### 每小时运行一次 ntpdate 命令 ####
|
||||
|
||||
```
|
||||
@hourly /path/to/ntpdate
|
||||
```
|
||||
|
||||
### 关于 `/etc/crontab` 文件和 `/etc/cron.d/*` 目录的更多内容
|
||||
|
||||
** /etc/crontab ** 是系统的 crontab 文件。通常只被 root 用户或守护进程用于配置系统级别的任务。每个独立的用户必须像上面介绍的那样使用 `crontab` 命令来安装和编辑自己的任务。`/var/spool/cron/` 或者 `/var/cron/tabs/` 目录存放了个人用户的 crontab 文件,它必定会备份在用户的家目录当中。
|
||||
|
||||
###理解默认的 `/etc/crontab` 文件
|
||||
|
||||
典型的 `/etc/crontab` 文件内容是这样的:
|
||||
|
||||
```
|
||||
SHELL=/bin/bash
|
||||
PATH=/sbin:/bin:/usr/sbin:/usr/bin
|
||||
MAILTO=root
|
||||
HOME=/
|
||||
# run-parts
|
||||
01 * * * * root run-parts /etc/cron.hourly
|
||||
02 4 * * * root run-parts /etc/cron.daily
|
||||
22 4 * * 0 root run-parts /etc/cron.weekly
|
||||
42 4 1 * * root run-parts /etc/cron.monthly
|
||||
```
|
||||
|
||||
首先,环境变量必须被定义。如果 SHELL 行被忽略,cron 会使用默认的 sh shell。如果 PATH 变量被忽略,就没有默认的搜索路径,所有的文件都需要使用绝对路径来定位。如果 HOME 变量被忽略,cron 会使用调用者(用户)的家目录替代。
|
||||
|
||||
另外,cron 会读取 `/etc/cron.d/`目录中的文件。通常情况下,像 sa-update 或者 sysstat 这样的系统守护进程会将他们的定时任务存放在此处。作为 root 用户或者超级用户,你可以使用以下目录来配置你的定时任务。你可以直接将脚本放到这里。`run-parts`命令会通过 `/etc/crontab` 文件来运行位于某个目录中的脚本或者程序。
|
||||
|
||||
目录 |描述
|
||||
|:-- |:--
|
||||
/etc/cron.d/ | 将所有的脚本文件放在此处,并从 /etc/crontab 文件中调用它们。
|
||||
/etc/cron.daily/ | 运行需要 每天 运行一次的脚本
|
||||
/etc/cron.hourly/ | 运行需要 每小时 运行一次的脚本
|
||||
/etc/cron.monthly/ | 运行需要 每月 运行一次的脚本
|
||||
/etc/cron.weekly/ | 运行需要 每周 运行一次的脚本
|
||||
|
||||
### 备份定时任务
|
||||
|
||||
```
|
||||
# crontab -l > /path/to/file
|
||||
|
||||
# crontab -u user -l > /path/to/file
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/add-cron-jobs-linux-unix/
|
||||
|
||||
作者:[Duy NguyenViet][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[FSSlc](https://github.com/FSSlc)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.unixmen.com/author/duynv/
|
||||
[1]: http://www.manpager.com/linux/man8/cron.8.html
|
||||
[2]: http://www.linuxsecrets.com/
|
||||
[3]: http://www.linuxsecrets.com/linux-hardware/
|
||||
@ -14,7 +14,8 @@
|
||||
基于这个信任分,一个需要登录认证的应用可以验证你确实可以授权登录,从而不会提示需要密码。
|
||||
|
||||

|
||||
>Abacus 到 Trust API
|
||||
|
||||
*Abacus 到 Trust API*
|
||||
|
||||
### 需要思考的地方
|
||||
|
||||
@ -31,7 +32,7 @@ via: http://www.iwillfolo.com/will-google-replace-passwords-with-a-new-trust-bas
|
||||
|
||||
作者:[iWillFolo][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,102 @@
|
||||
vlock – 一个锁定 Linux 用户虚拟控制台或终端的好方法
|
||||
=======================================================================
|
||||
|
||||
虚拟控制台是 Linux 上非常重要的功能,它们给系统用户提供了 shell 提示符,以保证用户在登录和远程登录一个未安装图形界面的系统时仍能使用。
|
||||
|
||||
一个用户可以同时操作多个虚拟控制台会话,只需在虚拟控制台间来回切换即可。
|
||||
|
||||

|
||||
|
||||
*用 vlock 锁定 Linux 用户控制台或终端*
|
||||
|
||||
这篇使用指导旨在教会大家如何使用 vlock 来锁定用户虚拟控制台和终端。
|
||||
|
||||
### vlock 是什么?
|
||||
|
||||
vlock 是一个用于锁定一个或多个用户虚拟控制台用户会话的工具。在多用户系统中 vlock 扮演着重要的角色,它让用户可以在锁住自己会话的同时不影响其他用户通过其他虚拟控制台操作同一个系统。必要时,还可以锁定所有的控制台,同时禁止在虚拟控制台间切换。
|
||||
|
||||
vlock 的主要功能面向控制台会话方面,同时也支持非控制台会话的锁定,但该功能的测试还不完全。
|
||||
|
||||
### 在 Linux 上安装 vlock
|
||||
|
||||
根据你的 Linux 系统选择 vlock 安装指令:
|
||||
|
||||
```
|
||||
# yum install vlock [On RHEL / CentOS / Fedora]
|
||||
$ sudo apt-get install vlock [On Ubuntu / Debian / Mint]
|
||||
```
|
||||
|
||||
### 在 Linux 上使用 vlock
|
||||
|
||||
vlock 操作选项的常规语法:
|
||||
|
||||
```
|
||||
# vlock option
|
||||
# vlock option plugin
|
||||
# vlock option -t <timeout> plugin
|
||||
```
|
||||
|
||||
#### vlock 常用选项及用法:
|
||||
|
||||
1、 锁定用户的当前虚拟控制台或终端会话,如下:
|
||||
|
||||
```
|
||||
# vlock --current
|
||||
```
|
||||
|
||||
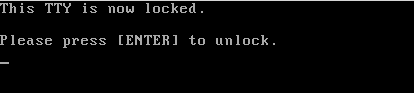
|
||||
|
||||
*锁定 Linux 用户终端会话*
|
||||
|
||||
选项 -c 或 --current,用于锁定当前的会话,该参数为运行 vlock 时的默认行为。
|
||||
|
||||
2、 锁定所有你的虚拟控制台会话,并禁用虚拟控制台间切换,命令如下:
|
||||
|
||||
```
|
||||
# vlock --all
|
||||
```
|
||||
|
||||

|
||||
|
||||
*锁定所有 Linux 终端会话*
|
||||
|
||||
选项 -a 或 --all,用于锁定所有用户的控制台会话,并禁用虚拟控制台间切换。
|
||||
|
||||
其他的选项只有在编译 vlock 时编入了相关插件支持和引用后,才能发挥作用:
|
||||
|
||||
3、 选项 -n 或 --new,调用时后,会在锁定用户的控制台会话前切换到一个新的虚拟控制台。
|
||||
|
||||
```
|
||||
# vlock --new
|
||||
```
|
||||
|
||||
4、 选项 -s 或 --disable-sysrq,在禁用虚拟控制台的同时禁用 SysRq 功能,只有在与 -a 或 --all 同时使用时才起作用。
|
||||
|
||||
```
|
||||
# vlock -sa
|
||||
```
|
||||
|
||||
5、 选项 -t 或 --timeout <time_in_seconds>,用以设定屏幕保护插件的 timeout 值。
|
||||
|
||||
```
|
||||
# vlock --timeout 5
|
||||
```
|
||||
|
||||
你可以使用 `-h` 或 `--help` 和 `-v` 或 `--version` 分别查看帮助消息和版本信息。
|
||||
|
||||
我们的介绍就到这了,提示一点,你可以将 vlock 的 `~/.vlockrc` 文件包含到系统启动中,并参考入门手册[添加环境变量][1],特别是 Debian 系的用户。
|
||||
|
||||
想要找到更多或是补充一些这里没有提及的信息,可以直接在写在下方评论区。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/vlock-lock-user-virtual-console-terminal-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/set-path-variable-linux-permanently/
|
||||
@ -0,0 +1,98 @@
|
||||
用 Docker 创建 serverless 应用
|
||||
======================================
|
||||
|
||||
当今世界会时不时地出现一波波科技浪潮,将以前的技术拍死在海滩上。针对 serverless 应用的概念我们已经谈了很多,它是指将你的应用程序按功能来部署,这些功能在被用到时才会启动。你不用费心去管理服务器和程序规模,因为它们会在需要的时候在一个集群中启动并运行。
|
||||
|
||||
但是 serverless 并不意味着没有 Docker 什么事儿,事实上 Docker 就是 serverless 的。你可以使用 Docker 来容器化这些功能,然后在 Swarm 中按需求来运行它们。serverless 是一项构建分布式应用的技术,而 Docker 是它们完美的构建平台。
|
||||
|
||||
### 从 servers 到 serverless
|
||||
|
||||
那如何才能写一个 serverless 应用呢?来看一下我们的例子,[5个服务组成的投票系统][1]:
|
||||
|
||||

|
||||
|
||||
投票系统由下面5个服务组成:
|
||||
|
||||
- 两个 web 前端
|
||||
- 一个后台处理投票的进程
|
||||
- 一个计票的消息队列
|
||||
- 一个数据库
|
||||
|
||||
后台处理投票的进程很容易转换成 serverless 构架,我们可以使用以下代码来实现:
|
||||
|
||||
```
|
||||
import dockerrun
|
||||
client = dockerrun.from_env()
|
||||
client.run("bfirsh/serverless-record-vote-task", [voter_id, vote], detach=True)
|
||||
```
|
||||
|
||||
这个投票处理进程和消息队列可以用运行在 Swarm 上的 Docker 容器来代替,并实现按需自动部署。
|
||||
|
||||
我们也可以用容器替换 web 前端,使用一个轻量级 HTTP 服务器来触发容器响应一个 HTTP 请求。Docker 容器代替长期运行的 HTTP 服务器来挑起响应请求的重担,这些容器可以自动扩容来支撑更大访问量。
|
||||
|
||||
新的架构就像这样:
|
||||
|
||||

|
||||
|
||||
红色框内是持续运行的服务,绿色框内是按需启动的容器。这个架构里需要你来管理的长期运行服务更少,并且可以自动扩容(最大容量由你的 Swarm 决定)。
|
||||
|
||||
### 我们可以做点什么?
|
||||
|
||||
你可以在你的应用中使用3种技术:
|
||||
|
||||
1. 在 Docker 容器中按需运行代码。
|
||||
2. 使用 Swarm 来部署集群。
|
||||
3. 通过使用 Docker API 套接字在容器中运行容器。
|
||||
|
||||
结合这3种技术,你可以有很多方法搭建你的应用架构。用这种方法来部署后台环境真是非常有效,而在另一些场景,也可以这么玩,比如说:
|
||||
|
||||
- 由于存在延时,使用容器实现面向用户的 HTTP 请求可能不是很合适,但你可以写一个负载均衡器,使用 Swarm 来对自己的 web 前端进行自动扩容。
|
||||
- 实现一个 MongoDB 容器,可以自检 Swarm 并且启动正确的分片和副本(LCTT 译注:分片技术为大规模并行检索提供支持,副本技术则是为数据提供冗余)。
|
||||
|
||||
### 下一步怎么做
|
||||
|
||||
我们提供了这些前卫的工具和概念来构建应用,并没有深入发掘它们的功能。我们的架构里还是存在长期运行的服务,将来我们需要使用 Swarm 来把所有服务都用按需扩容的方式实现。
|
||||
|
||||
希望本文能在你搭建架构时给你一些启发,但我们还是需要你的帮助。我们提供了所有的基本工具,但它们还不是很完善,我们需要更多更好的工具、库、应用案例、文档以及其他资料。
|
||||
|
||||
[我们在这里发布了工具、库和文档][3]。如果想了解更多,请贡献给我们一些你知道的资源,以便我们能够完善这篇文章。
|
||||
|
||||
玩得愉快。
|
||||
|
||||
### 更多关于 Docker 的资料
|
||||
|
||||
- New to Docker? Try our 10 min [online tutorial][4]
|
||||
- Share images, automate builds, and more with [a free Docker Hub account][5]
|
||||
- Read the Docker [1.12 Release Notes][6]
|
||||
- Subscribe to [Docker Weekly][7]
|
||||
- Sign up for upcoming [Docker Online Meetups][8]
|
||||
- Attend upcoming [Docker Meetups][9]
|
||||
- Watch [DockerCon EU 2015 videos][10]
|
||||
- Start [contributing to Docker][11]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2016/06/building-serverless-apps-with-docker/
|
||||
|
||||
作者:[Ben Firshman][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.docker.com/author/bfirshman/
|
||||
|
||||
[1]: https://github.com/docker/example-voting-app
|
||||
[3]: https://github.com/bfirsh/serverless-docker
|
||||
[4]: https://docs.docker.com/engine/understanding-docker/
|
||||
[5]: https://hub.docker.com/
|
||||
[6]: https://docs.docker.com/release-notes/
|
||||
[7]: https://www.docker.com/subscribe_newsletter/
|
||||
[8]: http://www.meetup.com/Docker-Online-Meetup/
|
||||
[9]: https://www.docker.com/community/meetup-groups
|
||||
[10]: https://www.youtube.com/playlist?list=PLkA60AVN3hh87OoVra6MHf2L4UR9xwJkv
|
||||
[11]: https://docs.docker.com/contributing/contributing/
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,392 @@
|
||||
如何用 Python 和 Flask 建立部署一个 Facebook Messenger 机器人
|
||||
==========================================================================
|
||||
|
||||
这是我建立一个简单的 Facebook Messenger 机器人的记录。功能很简单,它是一个回显机器人,只是打印回用户写了什么。
|
||||
|
||||
回显服务器类似于服务器的“Hello World”例子。
|
||||
|
||||
这个项目的目的不是建立最好的 Messenger 机器人,而是让你了解如何建立一个小型机器人和每个事物是如何整合起来的。
|
||||
|
||||
- [技术栈][1]
|
||||
- [机器人架构][2]
|
||||
- [机器人服务器][3]
|
||||
- [部署到 Heroku][4]
|
||||
- [创建 Facebook 应用][5]
|
||||
- [结论][6]
|
||||
|
||||
### 技术栈
|
||||
|
||||
使用到的技术栈:
|
||||
|
||||
- [Heroku][7] 做后端主机。免费级足够这个等级的教程。回显机器人不需要任何种类的数据持久,所以不需要数据库。
|
||||
- [Python][8] 是我们选择的语言。版本选择 2.7,虽然它移植到 Pyhton 3 很容易,只需要很少的改动。
|
||||
- [Flask][9] 作为网站开发框架。它是非常轻量的框架,用在小型工程或微服务是非常完美的。
|
||||
- 最后 [Git][10] 版本控制系统用来维护代码和部署到 Heroku。
|
||||
- 值得一提:[Virtualenv][11]。这个 python 工具是用来创建清洁的 python 库“环境”的,这样你可以只安装必要的需求和最小化应用的大小。
|
||||
|
||||
### 机器人架构
|
||||
|
||||
Messenger 机器人是由一个响应两种请求的服务器组成的:
|
||||
|
||||
- GET 请求被用来认证。他们与你注册的 FaceBook 认证码一同被 Messenger 发出。
|
||||
- POST 请求被用来实际的通信。典型的工作流是,机器人将通过用户发送带有消息数据的 POST 请求而建立通信,然后我们将处理这些数据,并发回我们的 POST 请求。如果这个请求完全成功(返回一个 200 OK 状态码),我们也将响应一个 200 OK 状态码给初始的 Messenger请求。
|
||||
|
||||
这个教程应用将托管到 Heroku,它提供了一个优雅而简单的部署应用的接口。如前所述,免费级可以满足这个教程。
|
||||
|
||||
在应用已经部署并且运行后,我们将创建一个 Facebook 应用然后连接它到我们的应用,以便 Messenger 知道发送请求到哪,这就是我们的机器人。
|
||||
|
||||
### 机器人服务器
|
||||
|
||||
基本的服务器代码可以在 Github 用户 [hult(Magnus Hult)][13] 的 [Chatbot][12] 项目上获取,做了一些只回显消息的代码修改和修正了一些我遇到的错误。最终版本的服务器代码如下:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
### 这需要填写被授予的页面通行令牌(PAT)
|
||||
### 它由将要创建的 Facebook 应用提供。
|
||||
PAT = ''
|
||||
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
|
||||
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run()
|
||||
```
|
||||
|
||||
让我们分解代码。第一部分是引入所需的依赖:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
```
|
||||
|
||||
接下来我们定义两个函数(使用 Flask 特定的 app.route 装饰器),用来处理到我们的机器人的 GET 和 POST 请求。
|
||||
|
||||
```
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
```
|
||||
|
||||
当我们创建 Facebook 应用时,verify_token 对象将由我们声明的 Messenger 发送。我们必须自己来校验它。最后我们返回“hub.challenge”给 Messenger。
|
||||
|
||||
处理 POST 请求的函数更有意思一些:
|
||||
|
||||
```
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
```
|
||||
|
||||
当被调用时,我们抓取消息载荷,使用函数 messaging_events 来拆解它,并且提取发件人身份和实际发送的消息,生成一个可以循环处理的 python 迭代器。请注意 Messenger 发送的每个请求有可能多于一个消息。
|
||||
|
||||
```
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
```
|
||||
|
||||
对每个消息迭代时,我们会调用 send_message 函数,然后我们使用 Facebook Graph messages API 对 Messenger 发回 POST 请求。在这期间我们一直没有回应我们阻塞的原始 Messenger请求。这会导致超时和 5XX 错误。
|
||||
|
||||
上述情况是我在解决遇到错误时发现的,当用户发送表情时实际上是发送的 unicode 标识符,但是被 Python 错误的编码了,最终我们发回了一些乱码。
|
||||
|
||||
这个发回 Messenger 的 POST 请求将永远不会完成,这会导致给初始请求返回 5xx 状态码,显示服务不可用。
|
||||
|
||||
通过使用 `encode('unicode_escape')` 封装消息,然后在我们发送回消息前用 `decode('unicode_escape')` 解码消息就可以解决。
|
||||
|
||||
```
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
```
|
||||
|
||||
### 部署到 Heroku
|
||||
|
||||
一旦代码已经建立成我想要的样子时就可以进行下一步。部署应用。
|
||||
|
||||
那么,该怎么做?
|
||||
|
||||
我之前在 Heroku 上部署过应用(主要是 Rails),然而我总是遵循某种教程做的,所用的配置是创建好了的。而在本文的情况下,我就需要从头开始。
|
||||
|
||||
幸运的是有官方 [Heroku 文档][14]来帮忙。这篇文档很好地说明了运行应用程序所需的最低限度。
|
||||
|
||||
长话短说,我们需要的除了我们的代码还有两个文件。第一个文件是“requirements.txt”,它列出了运行应用所依赖的库。
|
||||
|
||||
需要的第二个文件是“Procfile”。这个文件通知 Heroku 如何运行我们的服务。此外这个文件只需要一点点内容:
|
||||
|
||||
```
|
||||
web: gunicorn echoserver:app
|
||||
```
|
||||
|
||||
Heroku 对它的解读是,我们的应用通过运行 echoserver.py 启动,并且应用将使用 gunicorn 作为 Web 服务器。我们使用一个额外的网站服务器是因为与性能相关,在上面的 Heroku 文档里对此解释了:
|
||||
|
||||
> Web 应用程序并发处理传入的 HTTP 请求比一次只处理一个请求的 Web 应用程序会更有效利地用测试机的资源。由于这个原因,我们建议使用支持并发请求的 Web 服务器来部署和运行产品级服务。
|
||||
|
||||
> Django 和 Flask web 框架提供了一个方便的内建 Web 服务器,但是这些阻塞式服务器一个时刻只能处理一个请求。如果你部署这种服务到 Heroku 上,你的测试机就会资源利用率低下,应用会感觉反应迟钝。
|
||||
|
||||
> Gunicorn 是一个纯 Python 的 HTTP 服务器,用于 WSGI 应用。允许你在单独一个测试机内通过运行多 Python 进程的方式来并发的运行各种 Python 应用。它在性能、灵活性和配置简易性方面取得了完美的平衡。
|
||||
|
||||
回到我们之前提到过的“requirements.txt”文件,让我们看看它如何结合 Virtualenv 工具。
|
||||
|
||||
很多情况下,你的开发机器也许已经安装了很多 python 库。当部署应用时你不想全部加载那些库,但是辨认出你实际使用哪些库很困难。
|
||||
|
||||
Virtualenv 可以创建一个新的空白虚拟环境,以便你可以只安装你应用所需要的库。
|
||||
|
||||
你可以运行如下命令来检查当前安装了哪些库:
|
||||
|
||||
```
|
||||
kostis@KostisMBP ~ $ pip freeze
|
||||
cycler==0.10.0
|
||||
Flask==0.10.1
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
matplotlib==1.5.1
|
||||
numpy==1.10.4
|
||||
pyparsing==2.1.0
|
||||
python-dateutil==2.5.0
|
||||
pytz==2015.7
|
||||
requests==2.10.0
|
||||
scipy==0.17.0
|
||||
six==1.10.0
|
||||
virtualenv==15.0.1
|
||||
Werkzeug==0.11.10
|
||||
```
|
||||
|
||||
注意:pip 工具应该已经与 Python 一起安装在你的机器上。如果没有,查看[官方网站][15]如何安装它。
|
||||
|
||||
现在让我们使用 Virtualenv 来创建一个新的空白环境。首先我们给我们的项目创建一个新文件夹,然后进到目录下:
|
||||
|
||||
```
|
||||
kostis@KostisMBP projects $ mkdir echoserver
|
||||
kostis@KostisMBP projects $ cd echoserver/
|
||||
kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
现在来创建一个叫做 echobot 的新环境。运行下面的 source 命令激活它,然后使用 pip freeze 检查,我们能看到现在是空的。
|
||||
|
||||
```
|
||||
kostis@KostisMBP echoserver $ virtualenv echobot
|
||||
kostis@KostisMBP echoserver $ source echobot/bin/activate
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
(echobot) kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
我们可以安装需要的库。我们需要是 flask、gunicorn 和 requests,它们被安装后我们就创建 requirements.txt 文件:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install flask
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install gunicorn
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install requests
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
click==6.6
|
||||
Flask==0.11
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
requests==2.10.0
|
||||
Werkzeug==0.11.10
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze > requirements.txt
|
||||
```
|
||||
|
||||
上述完成之后,我们用 python 代码创建 echoserver.py 文件,然后用之前提到的命令创建 Procfile,我们最终的文件/文件夹如下:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ ls
|
||||
Procfile echobot echoserver.py requirements.txt
|
||||
```
|
||||
|
||||
我们现在准备上传到 Heroku。我们需要做两件事。第一是如果还没有安装 Heroku toolbet,就安装它(详见 [Heroku][16])。第二是通过 Heroku [网页界面][17]创建一个新的 Heroku 应用。
|
||||
|
||||
点击右上的大加号然后选择“Create new app”。
|
||||
|
||||

|
||||
|
||||
为你的应用选择一个名字,然后点击“Create App”。
|
||||
|
||||

|
||||
|
||||
你将会重定向到你的应用的控制面板,在那里你可以找到如何部署你的应用到 Heroku 的细节说明。
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ heroku login
|
||||
(echobot) kostis@KostisMBP echoserver $ git init
|
||||
(echobot) kostis@KostisMBP echoserver $ heroku git:remote -a <myappname>
|
||||
(echobot) kostis@KostisMBP echoserver $ git add .
|
||||
(echobot) kostis@KostisMBP echoserver $ git commit -m "Initial commit"
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ git push heroku master
|
||||
...
|
||||
remote: https://<myappname>.herokuapp.com/ deployed to Heroku
|
||||
...
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ heroku config:set WEB_CONCURRENCY=3
|
||||
```
|
||||
|
||||
如上,当你推送你的修改到 Heroku 之后,你会得到一个用于公开访问你新创建的应用的 URL。保存该 URL,下一步需要它。
|
||||
|
||||
### 创建这个 Facebook 应用
|
||||
|
||||
让我们的机器人可以工作的最后一步是创建这个我们将连接到其上的 Facebook 应用。Facebook 通常要求每个应用都有一个相关页面,所以我们来[创建一个][18]。
|
||||
|
||||
接下来我们去 [Facebook 开发者专页][19],点击右上角的“My Apps”按钮并选择“Add a New App”。不要选择建议的那个,而是点击“basic setup”。填入需要的信息并点击“Create App Id”,然后你会重定向到新的应用页面。
|
||||
|
||||

|
||||
|
||||
|
||||
在 “Products” 菜单之下,点击“+ Add Product” ,然后在“Messenger”下点击“Get Started”。跟随这些步骤设置 Messenger,当完成后你就可以设置你的 webhooks 了。Webhooks 简单的来说是你的服务所用的 URL 的名称。点击 “Setup Webhooks” 按钮,并添加该 Heroku 应用的 URL (你之前保存的那个)。在校验元组中写入 ‘my_voice_is_my_password_verify_me’。你可以写入任何你要的内容,但是不管你在这里写入的是什么内容,要确保同时修改代码中 handle_verification 函数。然后勾选 “messages” 选项。
|
||||
|
||||

|
||||
|
||||
点击“Verify and Save” 就完成了。Facebook 将访问该 Heroku 应用并校验它。如果不工作,可以试试运行:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP heroku logs -t
|
||||
```
|
||||
|
||||
然后看看日志中是否有错误。如果发现错误, Google 搜索一下可能是最快的解决方法。
|
||||
|
||||
最后一步是取得页面访问元组(PAT),它可以将该 Facebook 应用于你创建好的页面连接起来。
|
||||
|
||||

|
||||
|
||||
从下拉列表中选择你创建好的页面。这会在“Page Access Token”(PAT)下面生成一个字符串。点击复制它,然后编辑 echoserver.py 文件,将其贴入 PAT 变量中。然后在 Git 中添加、提交并推送该修改。
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ git add .
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ git commit -m "Initial commit"
|
||||
(echobot) kostis@KostisMBP echoserver (master) $ git push heroku master
|
||||
```
|
||||
|
||||
最后,在 Webhooks 菜单下再次选择你的页面并点击“Subscribe”。
|
||||
|
||||

|
||||
|
||||
现在去访问你的页面并建立会话:
|
||||
|
||||

|
||||
|
||||
成功了,机器人回显了!
|
||||
|
||||
注意:除非你要将这个机器人用在 Messenger 上测试,否则你就是机器人唯一响应的那个人。如果你想让其他人也试试它,到 [Facebook 开发者专页][19]中,选择你的应用、角色,然后添加你要添加的测试者。
|
||||
|
||||
###总结
|
||||
|
||||
这对于我来说是一个非常有用的项目,希望它可以指引你找到开始的正确方向。[官方的 Facebook 指南][20]有更多的资料可以帮你学到更多。
|
||||
|
||||
你可以在 [Github][21] 上找到该项目的代码。
|
||||
|
||||
如果你有任何评论、勘误和建议,请随时联系我。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/
|
||||
|
||||
作者:[Konstantinos Tsaprailis][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/kostistsaprailis
|
||||
[1]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#tech-stack
|
||||
[2]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#bot-architecture
|
||||
[3]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#the-bot-server
|
||||
[4]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#deploying-to-heroku
|
||||
[5]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#creating-the-facebook-app
|
||||
[6]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#conclusion
|
||||
[7]: https://www.heroku.com
|
||||
[8]: https://www.python.org
|
||||
[9]: http://flask.pocoo.org
|
||||
[10]: https://git-scm.com
|
||||
[11]: https://virtualenv.pypa.io/en/stable
|
||||
[12]: https://github.com/hult/facebook-chatbot-python
|
||||
[13]: https://github.com/hult
|
||||
[14]: https://devcenter.heroku.com/articles/python-gunicorn
|
||||
[15]: https://pip.pypa.io/en/stable/installing
|
||||
[16]: https://toolbelt.heroku.com
|
||||
[17]: https://dashboard.heroku.com/apps
|
||||
[18]: https://www.facebook.com/pages/create
|
||||
[19]: https://developers.facebook.com/
|
||||
[20]: https://developers.facebook.com/docs/messenger-platform/implementation
|
||||
[21]: https://github.com/kostistsaprailis/messenger-bot-tutorial
|
||||
@ -0,0 +1,80 @@
|
||||
Linus Torvalds 是一个糟糕的老板吗?
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
*1999 年 8 月 10 日,加利福尼亚州圣何塞市,在 LinuxWorld Show 上 Linus Torvalds 在一个坐满 Linux 爱好者的礼堂中发表了一篇演讲。图片来自:James Niccolai*
|
||||
|
||||
**这取决于所处的领域。在软件开发的世界中,他也是个普通人。问题是,这种情况是否应该继续下去?**
|
||||
|
||||
Linus Torvalds 是 Linux 的发明者,我认识他超过 20 年了。我们不是密友,但是我们欣赏彼此。
|
||||
|
||||
最近,因为 Linus Torvalds 的管理风格,他正遭到严厉的炮轰。Linus 无法忍受胡来的人。“代码的质量有多好?”是他在 Linux 内核的开发过程中评判人的一种方式。
|
||||
|
||||
没有什么比这个更重要了。正如 Linus 今年(2015年)早些时候在 Linux.conf.au 会议上说的那样,“我不是一个友好的人,我也不在意你。对我重要的是『[我所关心的技术和内核][1]』。”
|
||||
|
||||
现在我也可以和这种只关心技术的人打交道了。如果你不能,你应当避免参加 Linux 内核会议,因为在那里你会遇到许多有这种精英思想的人。这不代表我认为在 Linux 领域所有东西都是极好的,并且不应该受到其他影响而带来改变。我能够和一个精英待在一起;而在一个男性做主导的大城堡中遇到的问题是,女性经常受到蔑视和无礼的对待。
|
||||
|
||||
这就是我看到的最近关于 Linus 管理风格所引发争论的原因 -- 或者更准确的说,他对于个人管理方面是完全冷漠的 -- 就像是在软件开发世界的标准操作流程一样。与此同时,我看到了揭示了这个事情需要改变的另外一个证据。
|
||||
|
||||
第一次是在 [Linux 4.3 发布][2]的时候出现的这个情况,Linus 使用 Linux 内核邮件列表来狠狠的数落了一个插入了一些网络方面的代码的开发者——这些代码很“烂”,“[生成了如此烂的代码][3]。这看起来太糟糕了,并且完全没有理由这样做。”他继续咆哮了半天。这里使用“烂”这个词,相对他早期使用的“愚蠢的”这个同义词来说还算好的。
|
||||
|
||||
但是,事情就是这样。Linus 是对的。我读了代码后,发现代码确实很烂,并且开发者只是为了用新的“overflow_usub()” 函数而用的。
|
||||
|
||||
现在,一些人把 Linus 的这种谩骂的行为看作他脾气不好而且恃强凌弱的证据。我见过一个完美主义者,在他的领域中,他无法忍受这种糟糕。
|
||||
|
||||
许多人告诉我,这不是一个专业的程序员应当有的行为。群众们,你曾经和最优秀的开发者一起工作过吗?据我所知道的,在 Apple,Microsoft,Oracle 这就是他们的行为。
|
||||
|
||||
我曾经听过 Steve Jobs 攻击一个开发者,就像要把他撕成碎片那样。我也被一个 Oracle 的高级开发者攻击一屋子的新开发者吓到过,就像食人鱼穿过一群金鱼那样。
|
||||
|
||||
在 Robert X. Cringely 关于 PC 崛起的经典书籍《[意外帝国(Accidental Empires)][5]》,中,他这样描述了微软的软件管理风格,比尔·盖茨像计算机系统一样管理他们,“比尔·盖茨的是最高等级,从他开始每一个等级依次递减,上级会向下级叫嚷,刺激他们,甚至羞辱他们。”
|
||||
|
||||
Linus 和所有大型的商业软件公司的领导人不同的是,Linus 说在这里所有的东西是向全世界公开的。而其他人是在自己的会议室中做东西的。我听有人说 Linus 在那种公司中可能会被开除。这是不可能的。他会处于他现在所处的地位,他在编程世界的最顶端。
|
||||
|
||||
但是,这里有另外一个不同。如果 Larry Ellison (Oracle 的首席执行官)向你发火,你就别想在这里干了。如果 Linus 向你发火,你会在邮件中收到他的责骂。这就是差别。
|
||||
|
||||
你知道的,Linus 不是任何人的老板。他完全没有雇佣和解聘的权利,他只是负责着有 10000 个贡献者的一个项目而已。他仅仅能做的就是从心理上伤害你。
|
||||
|
||||
这说明,在开源软件开发圈和商业软件开发圈中同时存在一个非常严重的问题。不管你是一个多么好的编程者,如果你是一个女性,你的这个身份就是对你不利的。
|
||||
|
||||
这种情况并没有在 Sarah Sharp 的身上有任何好转,她现在是一个 Intel 的开发者,以前是一个顶尖的 Linux 程序员。[在她博客上10月份的一个帖子中][4],她解释道:“我最终发现,我不能够再为 Linux 社区做出贡献了。因为在那里,我虽然能够得到技术上的尊重,却得不到个人的尊重……我不想专职于同那些有着轻微的性别歧视或开同性恋玩笑的人一起工作。”
|
||||
|
||||
谁会责怪她呢?我不会。很抱歉,我必须说,Linus 就像所有我见过的软件经理一样,是他造成了这种不利的工作环境。
|
||||
|
||||
他可能会说,确保 Linux 的贡献者都表现出专业精神和相互尊重不应该是他的工作。除了代码以外,他不关心任何其他事情。
|
||||
|
||||
就像 Sarah Sharp 写的那样:
|
||||
|
||||
|
||||
> 我对于 Linux 内核社区做出的技术努力表示最大尊重。他们在那维护一些最高标准的代码,以此来平衡并且发展一个项目。他们专注于优秀的技术,以及超过负荷的维护人员,他们有不同的文化背景和社会规范,这些意味着这些 Linux 内核维护者说话非常直率、粗鲁,或者为了完成他们的任务而不讲道理。顶尖的 Linux 内核开发者经常为了使别人改正行为而向他们大喊大叫。
|
||||
>
|
||||
> 这种事情发生在我身上,但它不是一种有效的沟通方式。
|
||||
>
|
||||
> 许多高级的 Linux 内核开发者支持那些技术上和人性上不讲道理的维护者的权利。即使他们自己是非常友好的人,他们不想看到 Linux 内核交流方式改变。
|
||||
|
||||
她是对的。
|
||||
|
||||
我和其他观察者不同的是,我不认为这个问题对于 Linux 或开源社区在任何方面有特殊之处。作为一个从事技术商业工作超过五年和有着 25 年技术工作经历的记者,我见多了这种不成熟的小孩子行为。
|
||||
|
||||
这不是 Linus 的错误。他不是一个经理,他是一个有想象力的技术领导者。看起来真正的问题是,在软件开发领域没有人能够用一种支持的语气来对待团队和社区。
|
||||
|
||||
展望未来,我希望像 Linux 基金会这样的公司和组织,能够找到一种方式去授权社区经理或其他经理来鼓励并且强制实施民主的行为。
|
||||
|
||||
非常遗憾的是,我们不能够在我们这种纯技术或纯商业的领导人中找到这种管理策略。它不存在于这些人的基因中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[FrankXinqi](https://github.com/FrankXinqi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
[5]:https://www.amazon.cn/Accidental-Empires-Cringely-Robert-X/dp/0887308554/479-5308016-9671450?ie=UTF8&qid=1447101469&ref_=sr_1_1&tag=geo-23
|
||||
@ -1,25 +1,27 @@
|
||||
Securi-Pi: 使用树莓派作为安全跳板
|
||||
Securi-Pi:使用树莓派作为安全跳板
|
||||
================================================================================
|
||||
|
||||
像很多 LinuxJournal 的读者一样,我也过上了当今非常普遍的“科技游牧”生活,在网络到网络间,从一个接入点到另一个接入点,我们身处现实世界的不同地方却始终保持统一的互联网接入端。近来我发现越来越多的网络环境开始屏蔽对外的常用端口比如 SMTP(端口25),SSH(端口22)之类的。当你走进一家咖啡馆然后想 SSH 到你的一台服务器上做点事情的时候发现端口22被屏蔽了是一件很烦的事情。
|
||||
像很多 LinuxJournal 的读者一样,我也过上了当今非常普遍的“科技游牧”生活,在网络之间,从一个接入点到另一个接入点,我们身处现实世界的不同地方却始终保持连接到互联网和日常使用的其它网络上。近来我发现越来越多的网络环境开始屏蔽对外的常用端口比如 SMTP(端口25),SSH(端口22)之类的。当你走进一家咖啡馆然后想 SSH 到你的一台服务器上做点事情的时候发现端口 22 被屏蔽了是一件很烦的事情。
|
||||
|
||||
不过,我到目前为止还没发现有什么网络环境会把 HTTPS 给墙了(端口443)。在稍微配置了一下家中的树莓派 2之后,我成功地让自己能通过接入树莓派的443接口充当跳板从而让我在各种网络环境下连上想要的目标端口。简而言之,我把家中的树莓派设置成了一个 OpenVPN 的端点,SSH 端点同时也是一个 Apache 服务器——用于监听443端口上的我的接入活动并执行我预先设置好的网络策略。
|
||||
不过,我到目前为止还没发现有什么网络环境会把 HTTPS 给墙了(端口443)。在稍微配置了一下家中的树莓派 2 之后,我成功地让自己通过接入树莓派的 443 端口充当跳板,从而让我在各种网络环境下都能连上想要的目标端口。简而言之,我把家中的树莓派设置成了一个 OpenVPN 的端点和 SSH 端点,同时也是一个 Apache 服务器,所有这些服务都监听在 443 端口上,以便可以限制我不想暴露的网络服务。
|
||||
|
||||
|
||||
### 笔记
|
||||
此解决方案能搞定大多数有限制的网络环境,但有些防火墙会对外部流量调用深度包检查(Deep packet inspection),它们时常能屏蔽掉用本篇文章里的方式传输的信息。不过我到目前为止还没在这样的防火墙后测试过。同时,尽管我使用了很多基于密码学的工具(OpenVPN,HTTPS,SSH),我并没有非常严格地审计过这套配置方案(译者注:作者的意思是指这套方案能帮你绕过端口限制,但不代表你就是完全安全地连接上了树莓派)。有时候甚至 DNS 服务都会泄露你的信息,很可能在我没有考虑周到的角落里会有遗漏。我强烈不推荐把此跳板配置方案当作是万无一失的隐藏网络流量的办法,此配置只是希望能绕过一些端口限制连上网络,而不是做一些危险的事情。
|
||||
### 备注
|
||||
|
||||
此解决方案能搞定大多数有限制的网络环境,但有些防火墙会对外部流量调用深度包检查(Deep packet inspection),它们时常能屏蔽掉用本篇文章里的方式传输的信息。不过我到目前为止还没在这样的防火墙后测试过。同时,尽管我使用了很多基于密码学的工具(OpenVPN,HTTPS,SSH),我并没有非常严格地审计过这套配置方案(LCTT 译注:作者的意思是指这套方案能帮你绕过端口限制,但不代表你的活动就是完全安全的)。有时候甚至 DNS 服务都会泄露你的信息,很可能在我没有考虑周到的角落里会有遗漏。我强烈不推荐把此跳板配置方案当作是万无一失的隐藏网络流量的办法,此配置只是希望能绕过一些端口限制连上网络,而不是做一些危险的事情。
|
||||
|
||||
### 起步
|
||||
|
||||
让我们先从你需要什么说起,我用的是树莓派 2,装载了最新版本的 Raspbian,不过这个配置也应该能在树莓派 Model B 上运行;512MB 的内存对我们来说绰绰有余了,虽然性能可能没有树莓派 2这么好,毕竟Model B只有一颗单核心 CPU 相比于四核心的树莓派 2。我的树莓派在家里的防火墙和路由器之后,所以我还能用这个树莓派作为跳板访问家里的其他电子设备。同时这也意味着我的流量在互联网上看起来仿佛来自我家的ip地址,所以这也算某种意义上保护了我的匿名性。如果你没有树莓派,或者不想从家里运行这个服务,那你完全可以把这个配置放在一台小型云服务器上(译者:比如 IPS )。你只要确保服务器运行着基于 Debian 的 Linux 发行版即可,这份指南依然可用。
|
||||
让我们先从你需要什么说起,我用的是树莓派 2,装载了最新版本的 Raspbian,不过这个配置也应该能在树莓派 Model B 上运行;512MB 的内存对我们来说绰绰有余了,虽然性能可能没有树莓派 2这么好,毕竟相比于四核心的树莓派 2, Model B 只有一颗单核心 CPU。我的树莓派放置在家里的防火墙和路由器的后面,所以我还能用这个树莓派作为跳板访问家里的其他电子设备。同时这也意味着我的流量在互联网上看起来仿佛来自我家的 ip 地址,所以这也算某种意义上保护了我的匿名性。如果你没有树莓派,或者不想从家里运行这个服务,那你完全可以把这个配置放在一台小型云服务器上(LCTT 译注:比如 IPS )。你只要确保服务器运行着基于 Debian 的 Linux 发行版即可,这份指南依然可用。
|
||||
|
||||

|
||||
|
||||
图 1 树莓派,即将成为我们的加密网络端点
|
||||
*图 1 树莓派,即将成为我们的加密网络端点*
|
||||
|
||||
|
||||
### 安装并配置 BIND
|
||||
无论你是用树莓派还是一台服务器,当你成功启动之后你就可以安装 BIND 了,驱动了互联网相当一部分的域名服务软件。你将会把 BIND 仅仅作为缓存域名服务使用,而不用把它配置为用来处理来自互联网的域名请求。安装 BIND 会让你拥有一个可以被 OpenVPN 使用的 DNS 服务器。安装 BIND 十分简单,`apt-get` 就可以直接搞定:
|
||||
|
||||
无论你是用树莓派还是一台服务器,当你成功启动之后你就可以安装 BIND 了,这是一个驱动了互联网相当一部分的域名服务软件。你将会把 BIND 仅仅作为缓存域名服务使用,而不用把它配置为用来处理来自互联网的域名请求。安装 BIND 会让你拥有一个可以被 OpenVPN 使用的 DNS 服务器。安装 BIND 十分简单,`apt-get` 就可以直接搞定:
|
||||
|
||||
```
|
||||
root@test:~# apt-get install bind9
|
||||
@ -32,15 +34,13 @@ Suggested packages:
|
||||
bind9-doc resolvconf ufw
|
||||
The following NEW packages will be installed:
|
||||
bind9 bind9utils
|
||||
0 upgraded, 2 newly installed, 0 to remove and
|
||||
↪0 not upgraded.
|
||||
0 upgraded, 2 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 490 kB of archives.
|
||||
After this operation, 1,128 kB of additional disk
|
||||
↪space will be used.
|
||||
After this operation, 1,128 kB of additional disk space will be used.
|
||||
Do you want to continue [Y/n]? y
|
||||
```
|
||||
|
||||
在我们能把 BIND 当做缓存域名服务器之前,还有一些小细节需要配置。两个修改都在`/etc/bind/named.conf.options`里完成。首先你要反注释掉 forwarders 这一节内容,同时你还要增加一个可以转发域名请求的目标服务器。作为例子我会用 Google 的 DNS 服务器(8.8.8.8)(译者:国内的话需要找一个替代品);文件的 forwarders 节看上去大致是这样的:
|
||||
在我们把 BIND 作为缓存域名服务器之前,还有一些小细节需要配置。两个修改都在`/etc/bind/named.conf.options`里完成。首先你要取消注释掉 forwarders 这一节内容,同时你还要增加一个可以转发域名请求的目标服务器。作为例子我会用 Google 的 DNS 服务器(8.8.8.8)(LCTT 译注:国内的话需要找一个替代品);文件的 forwarders 节看上去大致是这样的:
|
||||
|
||||
|
||||
```
|
||||
@ -49,19 +49,18 @@ forwarders {
|
||||
};
|
||||
```
|
||||
|
||||
第二点你需要做的更改是允许来自互联网和本地局域网的 query,直接把这一行加入配置文件的低端,最后一个`}`之前就可以了:
|
||||
第二点你需要做的更改是允许来自内网和本机的查询请求,直接把这一行加入配置文件的后面,记得放在最后一个`};`之前就可以了:
|
||||
|
||||
|
||||
```
|
||||
allow-query { 192.168.1.0/24; 127.0.0.0/16; };
|
||||
```
|
||||
|
||||
上面那行配置会允许此 DNS 服务器接收来自网络和局域网的请求。下一步,你需要重启一下 BIND 的服务:
|
||||
上面那行配置会允许此 DNS 服务器接收来自其所在的网络(在本例中,我的网络就在我的防火墙之后)和本机的请求。下一步,你需要重启一下 BIND 的服务:
|
||||
|
||||
```
|
||||
root@test:~# /etc/init.d/bind9 restart
|
||||
[....] Stopping domain name service...: bind9waiting
|
||||
↪for pid 13209 to die
|
||||
[....] Stopping domain name service...: bind9waiting for pid 13209 to die
|
||||
. ok
|
||||
[ ok ] Starting domain name service...: bind9.
|
||||
```
|
||||
@ -91,12 +90,12 @@ Name: www.google.com
|
||||
Address: 173.194.33.180
|
||||
```
|
||||
|
||||
完美!现在你的系统里已经有一个正常的域名服务在允许了,下一步我们来配置一下OpenVPN。
|
||||
完美!现在你的系统里已经有一个正常的域名服务在工作了,下一步我们来配置一下OpenVPN。
|
||||
|
||||
|
||||
### 安装并配置 OpenVPN
|
||||
|
||||
OpenVPN 是一个运用 SSL/TLS 作为密钥交换的开源 VPN 解决方案。同时它也非常便于在 Linux 环境下部署。配置 OpenVPN 可能有一点艰巨,不过在此其实你也不需要在默认的配置文件里做太多修改。首先你会需要运行一下 `apt-get` 来安装 OpenVPN:
|
||||
OpenVPN 是一个运用 SSL/TLS 作为密钥交换的开源 VPN 解决方案。同时它也非常便于在 Linux 环境下部署。配置 OpenVPN 可能有一点点难,不过其实你也不需要在默认的配置文件里做太多修改。首先你需要运行一下 `apt-get` 来安装 OpenVPN:
|
||||
|
||||
|
||||
```
|
||||
@ -110,22 +109,18 @@ Suggested packages:
|
||||
resolvconf
|
||||
The following NEW packages will be installed:
|
||||
liblzo2-2 libpkcs11-helper1 openvpn
|
||||
0 upgraded, 3 newly installed, 0 to remove and
|
||||
↪0 not upgraded.
|
||||
0 upgraded, 3 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 621 kB of archives.
|
||||
After this operation, 1,489 kB of additional disk
|
||||
↪space will be used.
|
||||
After this operation, 1,489 kB of additional disk space will be used.
|
||||
Do you want to continue [Y/n]? y
|
||||
```
|
||||
|
||||
现在 OpenVPN 已经安装好了,你需要去配置它了。OpenVPN 是基于 SSL 的,并且它同时依赖于服务端和客户端两方的证书来工作。为了生成这些证书,你需要配置机器上的证书签发(CA)。幸运地,OpenVPN 在安装中自带了一些用于生成证书的脚本比如 “easy-rsa” 来帮助你加快这个过程。你将要创建一个文件目录用于放置 easy-rsa 脚本的模板:
|
||||
现在 OpenVPN 已经安装好了,你需要去配置它了。OpenVPN 是基于 SSL 的,并且它同时依赖于服务端和客户端两方的证书来工作。为了生成这些证书,你需要在机器上配置一个证书签发(CA)。幸运地,OpenVPN 在安装中自带了一些用于生成证书的脚本比如 “easy-rsa” 来帮助你加快这个过程。你将要创建一个文件目录用于放置 easy-rsa 脚本,从模板目录复制过来:
|
||||
|
||||
|
||||
```
|
||||
root@test:~# mkdir /etc/openvpn/easy-rsa
|
||||
root@test:~# cp -rpv
|
||||
↪/usr/share/doc/openvpn/examples/easy-rsa/2.0/*
|
||||
↪/etc/openvpn/easy-rsa/
|
||||
root@test:~# cp -rpv /usr/share/doc/openvpn/examples/easy-rsa/2.0/* /etc/openvpn/easy-rsa/
|
||||
```
|
||||
|
||||
下一步,把 vars 文件复制一个备份:
|
||||
@ -137,7 +132,6 @@ root@test:/etc/openvpn/easy-rsa# cp vars vars.bak
|
||||
|
||||
接下来,编辑一下 vars 以让其中的信息符合你的状态。我将以我需要编辑的信息作为例子:
|
||||
|
||||
|
||||
```
|
||||
KEY_SIZE=4096
|
||||
KEY_COUNTRY="US"
|
||||
@ -147,19 +141,17 @@ KEY_ORG="Linux Journal"
|
||||
KEY_EMAIL="bill.childers@linuxjournal.com"
|
||||
```
|
||||
|
||||
下一步是 source 一下 vars ,这样系统就能把其中的信息当作环境变量处理了:
|
||||
下一步是导入(source)一下 vars 中的环境变量,这样系统就能把其中的信息当作环境变量处理了:
|
||||
|
||||
|
||||
```
|
||||
root@test:/etc/openvpn/easy-rsa# source ./vars
|
||||
NOTE: If you run ./clean-all, I will be doing a
|
||||
↪rm -rf on /etc/openvpn/easy-rsa/keys
|
||||
NOTE: If you run ./clean-all, I will be doing a rm -rf on /etc/openvpn/easy-rsa/keys
|
||||
```
|
||||
|
||||
### 搭建CA(证书签发)
|
||||
### 搭建 CA(证书签发)
|
||||
|
||||
|
||||
接下来你要允许一下 `clean-all` 来确保有一个清理干净的系统工作环境,紧接着你也就要做证书签发了。注意一下我修改了一些 changeme 的跳出的交互提示内容以符合我需要的安装情况:
|
||||
接下来你要运行一下 `clean-all` 来确保有一个清理干净的系统工作环境,紧接着你就要做证书签发了。注意一下我修改了一些 changeme 的所提示修改的内容以符合我需要的安装情况:
|
||||
|
||||
|
||||
```
|
||||
@ -182,10 +174,8 @@ Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [Silicon Valley]:
|
||||
Organization Name (eg, company) [Linux Journal]:
|
||||
Organizational Unit Name (eg, section)
|
||||
↪[changeme]:SecTeam
|
||||
Common Name (eg, your name or your server's hostname)
|
||||
↪[changeme]:test.linuxjournal.com
|
||||
Organizational Unit Name (eg, section) [changeme]:SecTeam
|
||||
Common Name (eg, your name or your server's hostname) [changeme]:test.linuxjournal.com
|
||||
Name [changeme]:test.linuxjournal.com
|
||||
Email Address [bill.childers@linuxjournal.com]:
|
||||
```
|
||||
@ -193,12 +183,11 @@ Email Address [bill.childers@linuxjournal.com]:
|
||||
|
||||
### 生成服务端证书
|
||||
|
||||
一旦CA创建好了,你接着就可以生成客户端的 OpenVPN 证书了:
|
||||
一旦 CA 创建好了,你接着就可以生成客户端的 OpenVPN 证书了:
|
||||
|
||||
|
||||
```
|
||||
root@test:/etc/openvpn/easy-rsa#
|
||||
↪./build-key-server test.linuxjournal.com
|
||||
root@test:/etc/openvpn/easy-rsa# ./build-key-server test.linuxjournal.com
|
||||
Generating a 4096 bit RSA private key
|
||||
...................................................++
|
||||
writing new private key to 'test.linuxjournal.com.key'
|
||||
@ -215,10 +204,8 @@ Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [Silicon Valley]:
|
||||
Organization Name (eg, company) [Linux Journal]:
|
||||
Organizational Unit Name (eg, section)
|
||||
↪[changeme]:SecTeam
|
||||
Common Name (eg, your name or your server's hostname)
|
||||
↪[test.linuxjournal.com]:
|
||||
Organizational Unit Name (eg, section) [changeme]:SecTeam
|
||||
Common Name (eg, your name or your server's hostname) [test.linuxjournal.com]:
|
||||
Name [changeme]:test.linuxjournal.com
|
||||
Email Address [bill.childers@linuxjournal.com]:
|
||||
|
||||
@ -226,8 +213,7 @@ Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
A challenge password []:
|
||||
An optional company name []:
|
||||
Using configuration from
|
||||
↪/etc/openvpn/easy-rsa/openssl-1.0.0.cnf
|
||||
Using configuration from /etc/openvpn/easy-rsa/openssl-1.0.0.cnf
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
@ -238,10 +224,8 @@ organizationName :PRINTABLE:'Linux Journal'
|
||||
organizationalUnitName:PRINTABLE:'SecTeam'
|
||||
commonName :PRINTABLE:'test.linuxjournal.com'
|
||||
name :PRINTABLE:'test.linuxjournal.com'
|
||||
emailAddress
|
||||
↪:IA5STRING:'bill.childers@linuxjournal.com'
|
||||
Certificate is to be certified until Sep 1
|
||||
↪06:23:59 2025 GMT (3650 days)
|
||||
emailAddress :IA5STRING:'bill.childers@linuxjournal.com'
|
||||
Certificate is to be certified until Sep 1 06:23:59 2025 GMT (3650 days)
|
||||
Sign the certificate? [y/n]:y
|
||||
|
||||
1 out of 1 certificate requests certified, commit? [y/n]y
|
||||
@ -249,13 +233,12 @@ Write out database with 1 new entries
|
||||
Data Base Updated
|
||||
```
|
||||
|
||||
下一步需要用掉一些时间来生成 OpenVPN 服务器需要的 Diffie-Hellman 密钥。这个步骤在一般的桌面级 CPU 上会需要几分钟的时间,但在 ARM 构架的树莓派上,会用掉超级超级长的时间。耐心点,只要终端上的点还在跳,那么一切就在按部就班运行:
|
||||
下一步需要用掉一些时间来生成 OpenVPN 服务器需要的 Diffie-Hellman 密钥。这个步骤在一般的桌面级 CPU 上会需要几分钟的时间,但在 ARM 构架的树莓派上,会用掉超级超级长的时间。耐心点,只要终端上的点还在跳,那么一切就在按部就班运行(下面的示例省略了不少的点):
|
||||
|
||||
|
||||
```
|
||||
root@test:/etc/openvpn/easy-rsa# ./build-dh
|
||||
Generating DH parameters, 4096 bit long safe prime,
|
||||
↪generator 2
|
||||
Generating DH parameters, 4096 bit long safe prime, generator 2
|
||||
This is going to take a long time
|
||||
....................................................+
|
||||
<snipped out many more dots>
|
||||
@ -263,11 +246,10 @@ This is going to take a long time
|
||||
|
||||
### 生成客户端证书
|
||||
|
||||
现在你要生成一下客户端用于登陆 OpenVPN 的密钥。通常来说 OpenVPN 都会被配置成使用证书验证的加密方式,在这个配置下客户端需要持有由服务端签发的一份证书:
|
||||
现在你要生成一下客户端用于登录 OpenVPN 的密钥。通常来说 OpenVPN 都会被配置成使用证书验证的加密方式,在这个配置下客户端需要持有由服务端签发的一份证书:
|
||||
|
||||
```
|
||||
root@test:/etc/openvpn/easy-rsa# ./build-key
|
||||
↪bills-computer
|
||||
root@test:/etc/openvpn/easy-rsa# ./build-key bills-computer
|
||||
Generating a 4096 bit RSA private key
|
||||
...................................................++
|
||||
...................................................++
|
||||
@ -285,10 +267,8 @@ Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [Silicon Valley]:
|
||||
Organization Name (eg, company) [Linux Journal]:
|
||||
Organizational Unit Name (eg, section)
|
||||
↪[changeme]:SecTeam
|
||||
Common Name (eg, your name or your server's hostname)
|
||||
↪[bills-computer]:
|
||||
Organizational Unit Name (eg, section) [changeme]:SecTeam
|
||||
Common Name (eg, your name or your server's hostname) [bills-computer]:
|
||||
Name [changeme]:bills-computer
|
||||
Email Address [bill.childers@linuxjournal.com]:
|
||||
|
||||
@ -296,8 +276,7 @@ Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
A challenge password []:
|
||||
An optional company name []:
|
||||
Using configuration from
|
||||
↪/etc/openvpn/easy-rsa/openssl-1.0.0.cnf
|
||||
Using configuration from /etc/openvpn/easy-rsa/openssl-1.0.0.cnf
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
@ -308,30 +287,26 @@ organizationName :PRINTABLE:'Linux Journal'
|
||||
organizationalUnitName:PRINTABLE:'SecTeam'
|
||||
commonName :PRINTABLE:'bills-computer'
|
||||
name :PRINTABLE:'bills-computer'
|
||||
emailAddress
|
||||
↪:IA5STRING:'bill.childers@linuxjournal.com'
|
||||
Certificate is to be certified until
|
||||
↪Sep 1 07:35:07 2025 GMT (3650 days)
|
||||
emailAddress :IA5STRING:'bill.childers@linuxjournal.com'
|
||||
Certificate is to be certified until Sep 1 07:35:07 2025 GMT (3650 days)
|
||||
Sign the certificate? [y/n]:y
|
||||
|
||||
1 out of 1 certificate requests certified,
|
||||
↪commit? [y/n]y
|
||||
1 out of 1 certificate requests certified, commit? [y/n]y
|
||||
Write out database with 1 new entries
|
||||
Data Base Updated
|
||||
root@test:/etc/openvpn/easy-rsa#
|
||||
```
|
||||
|
||||
现在你需要再生成一个 HMAC 代码作为共享密钥来进一步增加整个加密提供的安全性:
|
||||
现在你需要再生成一个 HMAC 码作为共享密钥来进一步增加整个加密提供的安全性:
|
||||
|
||||
|
||||
```
|
||||
root@test:~# openvpn --genkey --secret
|
||||
↪/etc/openvpn/easy-rsa/keys/ta.key
|
||||
root@test:~# openvpn --genkey --secret /etc/openvpn/easy-rsa/keys/ta.key
|
||||
```
|
||||
|
||||
### 配置服务器
|
||||
|
||||
最后,你来到了需要配置 OpenVPN 服务的时候了。你需要创建一个 `/etc/openvpn/server.conf` 文件;这个配置文件的大多数地方都可以套用模板解决。设置 OpenVPN 服务的主要修改在于让它只用 TCP 而不是 UDP 链接。这是下一步所必需的---如果不是 TCP 链接那么你的服务将不能通过 端口443 运作。创建 `/etc/openvpn/server.conf` 然后把下述配置丢进去:
|
||||
最后,我们到了配置 OpenVPN 服务的时候了。你需要创建一个 `/etc/openvpn/server.conf` 文件;这个配置文件的大多数地方都可以套用模板解决。设置 OpenVPN 服务的主要修改在于让它只用 TCP 而不是 UDP 链接。这是下一步所必需的---如果不是 TCP 连接那么你的服务将不能工作在端口 443 上。创建 `/etc/openvpn/server.conf` 然后把下述配置丢进去:
|
||||
|
||||
|
||||
```
|
||||
@ -339,23 +314,15 @@ port 1194
|
||||
proto tcp
|
||||
dev tun
|
||||
ca easy-rsa/keys/ca.crt
|
||||
cert easy-rsa/keys/test.linuxjournal.com.crt ## or whatever
|
||||
↪your hostname was
|
||||
key easy-rsa/keys/test.linuxjournal.com.key ## Hostname key
|
||||
↪- This file should be kept secret
|
||||
cert easy-rsa/keys/test.linuxjournal.com.crt ## or whatever your hostname was
|
||||
key easy-rsa/keys/test.linuxjournal.com.key ## Hostname key - This file should be kept secret
|
||||
management localhost 7505
|
||||
dh easy-rsa/keys/dh4096.pem
|
||||
tls-auth /etc/openvpn/certs/ta.key 0
|
||||
server 10.8.0.0 255.255.255.0 # The server will use this
|
||||
↪subnet for clients connecting to it
|
||||
server 10.8.0.0 255.255.255.0 # The server will use this subnet for clients connecting to it
|
||||
ifconfig-pool-persist ipp.txt
|
||||
push "redirect-gateway def1 bypass-dhcp" # Forces clients
|
||||
↪to redirect all traffic through the VPN
|
||||
push "dhcp-option DNS 192.168.1.1" # Tells the client to
|
||||
↪use the DNS server at 192.168.1.1 for DNS -
|
||||
↪replace with the IP address of the OpenVPN
|
||||
↪machine and clients will use the BIND
|
||||
↪server setup earlier
|
||||
push "redirect-gateway def1 bypass-dhcp" # Forces clients to redirect all traffic through the VPN
|
||||
push "dhcp-option DNS 192.168.1.1" # Tells the client to use the DNS server at 192.168.1.1 for DNS - replace with the IP address of the OpenVPN machine and clients will use the BIND server setup earlier
|
||||
keepalive 30 240
|
||||
comp-lzo # Enable compression
|
||||
persist-key
|
||||
@ -364,14 +331,12 @@ status openvpn-status.log
|
||||
verb 3
|
||||
```
|
||||
|
||||
最后,你将需要在服务器上启用 IP 转发,配置 OpenVPN 为开机启动并立刻启动 OpenVPN 服务:
|
||||
最后,你将需要在服务器上启用 IP 转发,配置 OpenVPN 为开机启动,并立刻启动 OpenVPN 服务:
|
||||
|
||||
|
||||
```
|
||||
root@test:/etc/openvpn/easy-rsa/keys# echo
|
||||
↪"net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
|
||||
root@test:/etc/openvpn/easy-rsa/keys# sysctl -p
|
||||
↪/etc/sysctl.conf
|
||||
root@test:/etc/openvpn/easy-rsa/keys# echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
|
||||
root@test:/etc/openvpn/easy-rsa/keys# sysctl -p /etc/sysctl.conf
|
||||
net.core.wmem_max = 12582912
|
||||
net.core.rmem_max = 12582912
|
||||
net.ipv4.tcp_rmem = 10240 87380 12582912
|
||||
@ -387,61 +352,48 @@ net.ipv4.tcp_wmem = 10240 87380 12582912
|
||||
net.ipv4.ip_forward = 0
|
||||
net.ipv4.ip_forward = 1
|
||||
|
||||
root@test:/etc/openvpn/easy-rsa/keys# update-rc.d
|
||||
↪openvpn defaults
|
||||
root@test:/etc/openvpn/easy-rsa/keys# update-rc.d openvpn defaults
|
||||
update-rc.d: using dependency based boot sequencing
|
||||
|
||||
root@test:/etc/openvpn/easy-rsa/keys#
|
||||
↪/etc/init.d/openvpn start
|
||||
root@test:/etc/openvpn/easy-rsa/keys# /etc/init.d/openvpn start
|
||||
[ ok ] Starting virtual private network daemon:.
|
||||
```
|
||||
|
||||
### 配置 OpenVPN 客户端
|
||||
|
||||
客户端的安装取决于客户端的操作系统,但你需要将之前生成的证书和密钥复制到你的客户端上,并导入你的 OpenVPN 客户端并新建一个配置文件。每种操作系统下的 OpenVPN 客户端在操作上会有些稍许不同,这也不在这篇文章的覆盖范围内,所以你最好去看看特定操作系统下的 OpenVPN 文档来获取更多信息。请参考本文档里的资源那一节。
|
||||
|
||||
客户端的安装取决于客户端的操作系统,但你总会需要之前生成的证书和密钥,并导入你的 OpenVPN 客户端并新建一个配置文件。每种操作系统下的 OpenVPN 客户端在操作上会有些稍许不同,这也不在这篇文章的覆盖范围内,所以你最好去看看特定操作系统下的 OpenVPN 文档来获取更多信息。参考文档里的 Resources 章节。
|
||||
### 安装 SSLH —— "魔法"多协议切换工具
|
||||
|
||||
### 安装 SSLH —— "魔法"多协议工具
|
||||
|
||||
本文章介绍的解决方案最有趣的部分就是运用 SSLH 了。SSLH 是一个多重协议工具——它可以监听443端口的流量,然后分析他们是以SSH,HTTPS 还是 OpenVPN 的通讯包,并把他们分别转发给正确的系统服务。这就是为何本解决方案可以让你绕过大多数端口封杀——你可以一直使用HTTPS通讯,介于它几乎从来不会被封杀。
|
||||
本文章介绍的解决方案最有趣的部分就是运用 SSLH 了。SSLH 是一个多重协议工具——它可以监听 443 端口的流量,然后分析他们是 SSH,HTTPS 还是 OpenVPN 的通讯包,并把它们分别转发给正确的系统服务。这就是为何本解决方案可以让你绕过大多数端口封杀——你可以一直使用 HTTPS 通讯,因为它几乎从来不会被封杀。
|
||||
|
||||
同样,直接 `apt-get` 安装:
|
||||
|
||||
|
||||
```
|
||||
root@test:/etc/openvpn/easy-rsa/keys# apt-get
|
||||
↪install sslh
|
||||
root@test:/etc/openvpn/easy-rsa/keys# apt-get install sslh
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following extra packages will be installed:
|
||||
apache2 apache2-mpm-worker apache2-utils
|
||||
↪apache2.2-bin apache2.2-common
|
||||
libapr1 libaprutil1 libaprutil1-dbd-sqlite3
|
||||
↪libaprutil1-ldap libconfig9
|
||||
apache2 apache2-mpm-worker apache2-utils apache2.2-bin apache2.2-common
|
||||
libapr1 libaprutil1 libaprutil1-dbd-sqlite3 libaprutil1-ldap libconfig9
|
||||
Suggested packages:
|
||||
apache2-doc apache2-suexec apache2-suexec-custom
|
||||
↪openbsd-inetd inet-superserver
|
||||
apache2-doc apache2-suexec apache2-suexec-custom openbsd-inetd inet-superserver
|
||||
The following NEW packages will be installed:
|
||||
apache2 apache2-mpm-worker apache2-utils
|
||||
↪apache2.2-bin apache2.2-common
|
||||
libapr1 libaprutil1 libaprutil1-dbd-sqlite3
|
||||
↪libaprutil1-ldap libconfig9 sslh
|
||||
0 upgraded, 11 newly installed, 0 to remove
|
||||
↪and 0 not upgraded.
|
||||
apache2 apache2-mpm-worker apache2-utils apache2.2-bin apache2.2-common
|
||||
libapr1 libaprutil1 libaprutil1-dbd-sqlite3 libaprutil1-ldap libconfig9 sslh
|
||||
0 upgraded, 11 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 1,568 kB of archives.
|
||||
After this operation, 5,822 kB of additional
|
||||
↪disk space will be used.
|
||||
After this operation, 5,822 kB of additional disk space will be used.
|
||||
Do you want to continue [Y/n]? y
|
||||
```
|
||||
|
||||
在 SSLH 被安装之后,包管理器会询问要在 inetd 还是 standalone 模式下允许。选择 standalone 模式,因为你希望 SSLH 在它自己的进程里运行。如果你没有安装 Apache,apt包管理器会自动帮你下载并安装的,尽管它也不是完全不可或缺。如果你已经有 Apache 了,那你需要确保它只监听 localhost 端口而不是所有的端口(不然的话 SSLH 会无法运行因为 443 端口已经被 Apache 监听占用)。安装后,你会看到一个如下所示的错误信息:
|
||||
在 SSLH 被安装之后,包管理器会询问要在 inetd 还是 standalone 模式下允许。选择 standalone 模式,因为你希望 SSLH 在它自己的进程里运行。如果你没有安装 Apache,apt 包管理器会自动帮你下载并安装的,尽管它也不是完全不可或缺。如果你已经有 Apache 了,那你需要确保它只监听 localhost 端口而不是所有的端口(不然的话 SSLH 会无法运行,因为 443 端口已经被 Apache 监听占用)。安装后,你会看到一个如下所示的错误信息:
|
||||
|
||||
```
|
||||
[....] Starting ssl/ssh multiplexer: sslhsslh disabled,
|
||||
↪please adjust the configuration to your needs
|
||||
[FAIL] and then set RUN to 'yes' in /etc/default/sslh
|
||||
↪to enable it. ... failed!
|
||||
[....] Starting ssl/ssh multiplexer: sslhsslh disabled, please adjust the configuration to your needs
|
||||
[FAIL] and then set RUN to 'yes' in /etc/default/sslh to enable it. ... failed!
|
||||
failed!
|
||||
```
|
||||
|
||||
@ -461,20 +413,16 @@ failed!
|
||||
|
||||
RUN=yes
|
||||
|
||||
# binary to use: forked (sslh) or single-thread
|
||||
↪(sslh-select) version
|
||||
# binary to use: forked (sslh) or single-thread (sslh-select) version
|
||||
DAEMON=/usr/sbin/sslh
|
||||
|
||||
DAEMON_OPTS="--user sslh --listen 0.0.0.0:443 --ssh
|
||||
↪127.0.0.1:22 --ssl 127.0.0.1:443 --openvpn
|
||||
↪127.0.0.1:1194 --pidfile /var/run/sslh/sslh.pid"
|
||||
DAEMON_OPTS="--user sslh --listen 0.0.0.0:443 --ssh 127.0.0.1:22 --ssl 127.0.0.1:443 --openvpn 127.0.0.1:1194 --pidfile /var/run/sslh/sslh.pid"
|
||||
```
|
||||
|
||||
保存编辑并启动 SSLH:
|
||||
|
||||
```
|
||||
root@test:/etc/openvpn/easy-rsa/keys#
|
||||
↪/etc/init.d/sslh start
|
||||
root@test:/etc/openvpn/easy-rsa/keys# /etc/init.d/sslh start
|
||||
[ ok ] Starting ssl/ssh multiplexer: sslh.
|
||||
```
|
||||
|
||||
@ -485,26 +433,21 @@ $ ssh -p 443 root@test.linuxjournal.com
|
||||
root@test:~#
|
||||
```
|
||||
|
||||
SSLH 现在开始监听端口443 并且可以转发流量信息到 SSH,Apache 或者 OpenVPN 取决于抵达流量包的类型。这套系统现已整装待发了!
|
||||
SSLH 现在开始监听端口 443 并且可以转发流量信息到 SSH、Apache 或者 OpenVPN ,这取决于抵达流量包的类型。这套系统现已整装待发了!
|
||||
|
||||
### 结论
|
||||
|
||||
现在你可以启动 OpenVPN 并且配置你的客户端连接到服务器的 443 端口了,然后 SSLH 会从那里把流量转发到服务器的 1194 端口。但介于你正在和服务器的 443 端口通信,你的 VPN 流量不会被封锁。现在你可以舒服地坐在陌生小镇的咖啡店里,畅通无阻地通过树莓派上的 OpenVPN 浏览互联网。你顺便还给你的链接增加了一些安全性,这个额外作用也会让你的链接更安全和私密一些。享受通过安全跳板浏览互联网把!
|
||||
现在你可以启动 OpenVPN 并且配置你的客户端连接到服务器的 443 端口了,然后 SSLH 会从那里把流量转发到服务器的 1194 端口。但鉴于你正在和服务器的 443 端口通信,你的 VPN 流量不会被封锁。现在你可以舒服地坐在陌生小镇的咖啡店里,畅通无阻地通过你的树莓派上的 OpenVPN 浏览互联网。你顺便还给你的链接增加了一些安全性,这个额外作用也会让你的链接更安全和私密一些。享受通过安全跳板浏览互联网把!
|
||||
|
||||
|
||||
资源:
|
||||
### 参考资源
|
||||
|
||||
安装与配置 OpenVPN: [https://wiki.debian.org/OpenVPN](https://wiki.debian.org/OpenVPN) and [http://cryptotap.com/articles/openvpn](http://cryptotap.com/articles/openvpn)
|
||||
|
||||
OpenVPN 客户端下载: [https://openvpn.net/index.php/open-source/downloads.html](https://openvpn.net/index.php/open-source/downloads.html)
|
||||
|
||||
OpenVPN Client for iOS: [https://itunes.apple.com/us/app/openvpn-connect/id590379981?mt=8](https://itunes.apple.com/us/app/openvpn-connect/id590379981?mt=8)
|
||||
|
||||
OpenVPN Client for Android: [https://play.google.com/store/apps/details?id=net.openvpn.openvpn&hl=en](https://play.google.com/store/apps/details?id=net.openvpn.openvpn&hl=en)
|
||||
|
||||
Tunnelblick for Mac OS X (OpenVPN client): [https://tunnelblick.net](https://tunnelblick.net)
|
||||
|
||||
SSLH 介绍: [http://www.rutschle.net/tech/sslh.shtml](http://www.rutschle.net/tech/sslh.shtml) 和 [https://github.com/yrutschle/sslh](https://github.com/yrutschle/sslh)
|
||||
- 安装与配置 OpenVPN: [https://wiki.debian.org/OpenVPN](https://wiki.debian.org/OpenVPN) 和 [http://cryptotap.com/articles/openvpn](http://cryptotap.com/articles/openvpn)
|
||||
- OpenVPN 客户端下载: [https://openvpn.net/index.php/open-source/downloads.html](https://openvpn.net/index.php/open-source/downloads.html)
|
||||
- OpenVPN iOS 客户端: [https://itunes.apple.com/us/app/openvpn-connect/id590379981?mt=8](https://itunes.apple.com/us/app/openvpn-connect/id590379981?mt=8)
|
||||
- OpenVPN Android 客户端: [https://play.google.com/store/apps/details?id=net.openvpn.openvpn&hl=en](https://play.google.com/store/apps/details?id=net.openvpn.openvpn&hl=en)
|
||||
- Tunnelblick for Mac OS X (OpenVPN 客户端): [https://tunnelblick.net](https://tunnelblick.net)
|
||||
- SSLH 介绍: [http://www.rutschle.net/tech/sslh.shtml](http://www.rutschle.net/tech/sslh.shtml) 和 [https://github.com/yrutschle/sslh](https://github.com/yrutschle/sslh)
|
||||
|
||||
|
||||
----------
|
||||
@ -512,7 +455,7 @@ via: http://www.linuxjournal.com/content/securi-pi-using-raspberry-pi-secure-lan
|
||||
|
||||
作者:[Bill Childers][a]
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,111 @@
|
||||
JStock:Linux 上不错的股票投资组合管理软件
|
||||
================================================================================
|
||||
|
||||
如果你在股票市场做投资,那么你可能非常清楚投资组合管理计划有多重要。管理投资组合的目标是依据你能承受的风险,时间层面的长短和资金盈利的目标去为你量身打造的一种投资计划。鉴于这类软件的重要性,因此从来不会缺乏商业性的 app 和股票行情检测软件,每一个都可以兜售复杂的投资组合以及跟踪报告功能。
|
||||
|
||||
对于我们这些 Linux 爱好者们,我也找到了一些**好用的开源投资组合管理工具**,用来在 Linux 上管理和跟踪股票的投资组合,这里高度推荐一个基于 java 编写的管理软件 [JStock][1]。如果你不是一个 java 粉,也许你会放弃它,JStock 需要运行在沉重的 JVM 环境上。但同时,在每一个安装了 JRE 的环境中它都可以马上运行起来,在你的 Linux 环境中它会运行的很顺畅。
|
||||
|
||||
“开源”就意味着免费或标准低下的时代已经过去了。鉴于 JStock 只是一个个人完成的产物,作为一个投资组合管理软件它最令人印象深刻的是包含了非常多实用的功能,以上所有的荣誉属于它的作者 Yan Cheng Cheok!例如,JStock 支持通过监视列表去监控价格,多种投资组合,自选/内置的股票指标与相关监测,支持27个不同的股票市场和跨平台的云端备份/还原。JStock 支持多平台部署(Linux, OS X, Android 和 Windows),你可以通过云端保存你的 JStock 投资组合,并通过云平台无缝的备份/还原到其他的不同平台上面。
|
||||
|
||||
现在我将向你展示如何安装以及使用过程的一些具体细节。
|
||||
|
||||
### 在 Linux 上安装 JStock ###
|
||||
|
||||
因为 JStock 使用Java编写,所以必须[安装 JRE][2]才能让它运行起来。小提示,JStock 需要 JRE1.7 或更高版本。如你的 JRE 版本不能满足这个需求,JStock 将会运行失败然后出现下面的报错。
|
||||
|
||||
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/yccheok/jstock/gui/JStock : Unsupported major.minor version 51.0
|
||||
|
||||
|
||||
在你的 Linux 上安装好了 JRE 之后,从其官网下载最新的发布的 JStock,然后加载启动它。
|
||||
|
||||
$ wget https://github.com/yccheok/jstock/releases/download/release_1-0-7-13/jstock-1.0.7.13-bin.zip
|
||||
$ unzip jstock-1.0.7.13-bin.zip
|
||||
$ cd jstock
|
||||
$ chmod +x jstock.sh
|
||||
$ ./jstock.sh
|
||||
|
||||
教程的其他部分,让我来给大家展示一些 JStock 的实用功能
|
||||
|
||||
### 监视监控列表中股票价格的波动 ###
|
||||
|
||||
使用 JStock 你可以创建一个或多个监视列表,它可以自动的监视股票价格的波动并给你提供相应的通知。在每一个监视列表里面你可以添加多个感兴趣的股票进去。之后在“Fall Below”和“Rise Above”的表格里添加你的警戒值,分别设定该股票的最低价格和最高价格。
|
||||
|
||||
|
||||
|
||||
例如你设置了 AAPL 股票的最低/最高价格分别是 $102 和 $115.50,只要在价格低于 $102 或高于 $115.50 时你就得到桌面通知。
|
||||
|
||||
你也可以设置邮件通知,这样你将收到一些价格信息的邮件通知。设置邮件通知在“Options”菜单里,在“Alert”标签中国,打开“Send message to email(s)”,填入你的 Gmail 账户。一旦完成 Gmail 认证步骤,JStock 就会开始发送邮件通知到你的 Gmail 账户(也可以设置其他的第三方邮件地址)。
|
||||
|
||||
|
||||
|
||||
### 管理多个投资组合 ###
|
||||
|
||||
JStock 允许你管理多个投资组合。这个功能对于你使用多个股票经纪人时是非常实用的。你可以为每个经纪人创建一个投资组合去管理你的“买入/卖出/红利”用来了解每一个经纪人的业务情况。你也可以在“Portfolio”菜单里面选择特定的投资组合来切换不同的组合项目。下面是一张截图用来展示一个假设的投资组合。
|
||||
|
||||
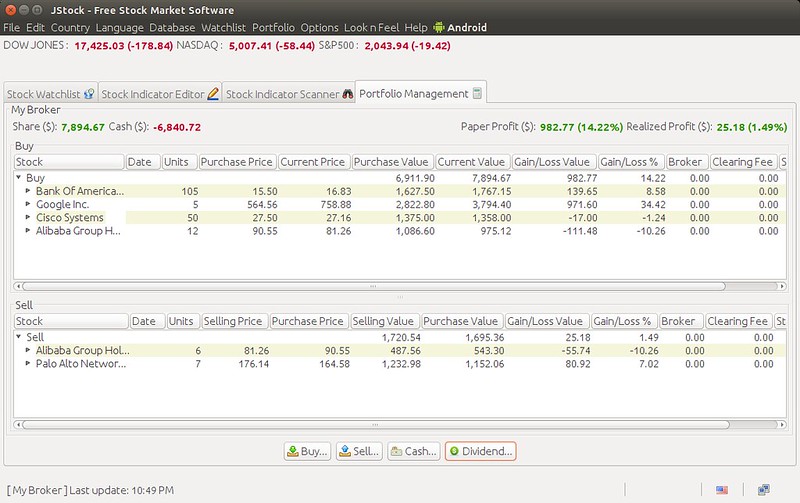
|
||||
|
||||
你也可以设置付给中介费,你可以为每个买卖交易设置中介费、印花税以及结算费。如果你比较懒,你也可以在选项菜单里面启用自动费用计算,并提前为每一家经济事务所设置费用方案。当你为你的投资组合增加交易之后,JStock 将自动的计算并计入费用。
|
||||
|
||||
|
||||
|
||||
### 使用内置/自选股票指标来监控 ###
|
||||
|
||||
如果你要做一些股票的技术分析,你可能需要基于各种不同的标准来监控股票(这里叫做“股票指标”)。对于股票的跟踪,JStock提供多个[预设的技术指示器][3] 去获得股票上涨/下跌/逆转指数的趋势。下面的列表里面是一些可用的指标。
|
||||
|
||||
- 平滑异同移动平均线(MACD)
|
||||
- 相对强弱指标 (RSI)
|
||||
- 资金流向指标 (MFI)
|
||||
- 顺势指标 (CCI)
|
||||
- 十字线
|
||||
- 黄金交叉线,死亡交叉线
|
||||
- 涨幅/跌幅
|
||||
|
||||
开启预设指示器能需要在 JStock 中点击“Stock Indicator Editor”标签。之后点击右侧面板中的安装按钮。选择“Install from JStock server”选项,之后安装你想要的指示器。
|
||||
|
||||

|
||||
|
||||
一旦安装了一个或多个指示器,你可以用他们来扫描股票。选择“Stock Indicator Scanner”标签,点击底部的“Scan”按钮,选择需要的指示器。
|
||||
|
||||

|
||||
|
||||
当你选择完需要扫描的股票(例如, NYSE, NASDAQ)以后,JStock 将执行该扫描,并将该指示器捕获的结果通过列表展现。
|
||||
|
||||

|
||||
|
||||
除了预设指示器以外,你也可以使用一个图形化的工具来定义自己的指示器。下面这张图例用于监控当前价格小于或等于60天平均价格的股票。
|
||||
|
||||

|
||||
|
||||
### 通过云在 Linux 和 Android JStock 之间备份/恢复###
|
||||
|
||||
另一个非常棒的功能是 JStock 支持云备份恢复。Jstock 可以通过 Google Drive 把你的投资组合/监视列表在云上备份和恢复,这个功能可以实现在不同平台上无缝穿梭。如果你在两个不同的平台之间来回切换使用 Jstock,这种跨平台备份和还原非常有用。我在 Linux 桌面和 Android 手机上测试过我的 Jstock 投资组合,工作的非常漂亮。我在 Android 上将 Jstock 投资组合信息保存到 Google Drive 上,然后我可以在我的 Linux 版的 Jstock 上恢复它。如果能够自动同步到云上,而不用我手动地触发云备份/恢复就更好了,十分期望这个功能出现。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
如果你在从 Google Drive 还原之后不能看到你的投资信息以及监视列表,请确认你的国家信息与“Country”菜单里面设置的保持一致。
|
||||
|
||||
JStock 的安卓免费版可以从 [Google Play Store][4] 获取到。如果你需要完整的功能(比如云备份,通知,图表等),你需要一次性支付费用升级到高级版。我认为高级版物有所值。
|
||||
|
||||
|
||||
|
||||
写在最后,我应该说一下它的作者,Yan Cheng Cheok,他是一个十分活跃的开发者,有bug及时反馈给他。这一切都要感谢他!!!
|
||||
|
||||
关于 JStock 这个投资组合跟踪软件你有什么想法呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/stock-portfolio-management-software-Linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ivo-wang](https://github.com/ivo-wang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://Linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://jstock.org/
|
||||
[2]:http://ask.xmodulo.com/install-java-runtime-Linux.html
|
||||
[3]:http://jstock.org/ma_indicator.html
|
||||
[4]:https://play.google.com/store/apps/details?id=org.yccheok.jstock.gui
|
||||
@ -0,0 +1,104 @@
|
||||
在 Linux 上管理加密密钥的最佳体验
|
||||
=============================================
|
||||
|
||||
存储 SSH 的加密秘钥和记住密码一直是一个让人头疼的问题。但是不幸的是,在当前这个充满了恶意黑客和攻击的世界中,基本的安全预防是必不可少的。对于许多普通用户来说,大多数人只能是记住密码,也可能寻找到一个好程序去存储密码,正如我们提醒这些用户不要在每个网站采用相同的密码。但是对于在各个 IT 领域的人们,我们需要将这个事情提高一个层面。我们需要使用像 SSH 密钥这样的加密秘钥,而不只是密码。
|
||||
|
||||
设想一个场景:我有一个运行在云上的服务器,用作我的主 git 库。我有很多台工作电脑,所有这些电脑都需要登录到这个中央服务器去做 push 与 pull 操作。这里我设置 git 使用 SSH。当 git 使用 SSH 时,git 实际上是以 SSH 的方式登录到服务器,就好像你通过 SSH 命令打开一个服务器的命令行一样。为了把这些配置好,我在我的 .ssh 目录下创建一个配置文件,其中包含一个有服务器名字、主机名、登录用户、密钥文件路径等信息的主机项。之后我可以通过输入如下命令来测试这个配置是否正确。
|
||||
|
||||
ssh gitserver
|
||||
|
||||
很快我就可以访问到服务器的 bash shell。现在我可以配置 git 使用相同配置项以及存储的密钥来登录服务器。这很简单,只是有一个问题:对于每一个我要用它登录服务器的电脑,我都需要有一个密钥文件,那意味着需要密钥文件会放在很多地方。我会在当前这台电脑上存储这些密钥文件,我的其他电脑也都需要存储这些。就像那些有特别多的密码的用户一样,我们这些 IT 人员也被这些特别多的密钥文件淹没。怎么办呢?
|
||||
|
||||
### 清理
|
||||
|
||||
在我们开始帮助你管理密钥之前,你需要有一些密钥应该怎么使用的基础知识,以及明白我们下面的提问的意义所在。同时,有个前提,也是最重要的,你应该知道你的公钥和私钥该放在哪里。然后假设你应该知道:
|
||||
|
||||
1. 公钥和私钥之间的差异;
|
||||
2. 为什么你不可以从公钥生成私钥,但是反之则可以?
|
||||
3. `authorized_keys` 文件的目的以及里面包含什么内容;
|
||||
4. 如何使用私钥去登录一个你的对应公钥存储在其上的 `authorized_keys` 文件中的服务器。
|
||||
|
||||

|
||||
|
||||
这里有一个例子。当你在亚马逊的网络服务上创建一个云服务器,你必须提供一个用于连接你的服务器的 SSH 密钥。每个密钥都有一个公开的部分(公钥)和私密的部分(私钥)。你要想让你的服务器安全,乍看之下你可能应该将你的私钥放到服务器上,同时你自己带着公钥。毕竟,你不想你的服务器被公开访问,对吗?但是实际上的做法正好是相反的。
|
||||
|
||||
你应该把自己的公钥放到 AWS 服务器,同时你持有用于登录服务器的私钥。你需要保护好私钥,并让它处于你的控制之中,而不是放在一些远程服务器上,正如上图中所示。
|
||||
|
||||
原因如下:如果公钥被其他人知道了,它们不能用于登录服务器,因为他们没有私钥。进一步说,如果有人成功攻入你的服务器,他们所能找到的只是公钥,他们不可以从公钥生成私钥。同时,如果你在其他的服务器上使用了相同的公钥,他们不可以使用它去登录别的电脑。
|
||||
|
||||
这就是为什么你要把你自己的公钥放到你的服务器上以便通过 SSH 登录这些服务器。你持有这些私钥,不要让这些私钥脱离你的控制。
|
||||
|
||||
但是还有一点麻烦。试想一下我 git 服务器的例子。我需要做一些抉择。有时我登录架设在别的地方的开发服务器,而在开发服务器上,我需要连接我的 git 服务器。如何使我的开发服务器连接 git 服务器?显然是通过使用私钥,但这样就会有问题。在该场景中,需要我把私钥放置到一个架设在别的地方的服务器上,这相当危险。
|
||||
|
||||
一个进一步的场景:如果我要使用一个密钥去登录许多的服务器,怎么办?如果一个入侵者得到这个私钥,这个人就能用这个私钥得到整个服务器网络的权限,这可能带来一些严重的破坏,这非常糟糕。
|
||||
|
||||
同时,这也带来了另外一个问题,我真的应该在这些其他服务器上使用相同的密钥吗?因为我刚才描述的,那会非常危险的。
|
||||
|
||||
最后,这听起来有些混乱,但是确实有一些简单的解决方案。让我们有条理地组织一下。
|
||||
|
||||
(注意,除了登录服务器,还有很多地方需要私钥密钥,但是我提出的这个场景可以向你展示当你使用密钥时你所面对的问题。)
|
||||
|
||||
### 常规口令
|
||||
|
||||
当你创建你的密钥时,你可以选择是否包含一个密钥使用时的口令。有了这个口令,私钥文件本身就会被口令所加密。例如,如果你有一个公钥存储在服务器上,同时你使用私钥去登录服务器的时候,你会被提示输入该口令。没有口令,这个密钥是无法使用的。或者你也可以配置你的密钥不需要口令,然后只需要密钥文件就可以登录服务器了。
|
||||
|
||||
一般来说,不使用口令对于用户来说是更方便的,但是在很多情况下我强烈建议使用口令,原因是,如果私钥文件被偷了,偷密钥的人仍然不可以使用它,除非他或者她可以找到口令。在理论上,这个将节省你很多时间,因为你可以在攻击者发现口令之前,从服务器上删除公钥文件,从而保护你的系统。当然还有一些使用口令的其它原因,但是在很多场合这个原因对我来说更有价值。(举一个例子,我的 Android 平板上有 VNC 软件。平板上有我的密钥。如果我的平板被偷了之后,我会马上从服务器上删除公钥,使得它的私钥没有作用,无论有没有口令。)但是在一些情况下我不使用口令,是因为我正在登录的服务器上没有什么有价值的数据,这取决于情境。
|
||||
|
||||
### 服务器基础设施
|
||||
|
||||
你如何设计自己服务器的基础设施将会影响到你如何管理你的密钥。例如,如果你有很多用户登录,你将需要决定每个用户是否需要一个单独的密钥。(一般来说,应该如此;你不会想在用户之间共享私钥。那样当一个用户离开组织或者失去信任时,你可以删除那个用户的公钥,而不需要必须给其他人生成新的密钥。相似地,通过共享密钥,他们能以其他人的身份登录,这就更糟糕了。)但是另外一个问题是你如何配置你的服务器。举例来说,你是否使用像 Puppet 这样工具配置大量的服务器?你是否基于你自己的镜像创建大量的服务器?当你复制你的服务器,是否每一个的密钥都一样?不同的云服务器软件允许你配置如何选择;你可以让这些服务器使用相同的密钥,也可以给每一个服务器生成一个新的密钥。
|
||||
|
||||
如果你在操作这些复制的服务器,如果用户需要使用不同的密钥登录两个不同但是大部分都一样的系统,它可能导致混淆。但是另一方面,服务器共享相同的密钥会有安全风险。或者,第三,如果你的密钥有除了登录之外的需要(比如挂载加密的驱动),那么你会在很多地方需要相同的密钥。正如你所看到的,你是否需要在不同的服务器上使用相同的密钥不是我能为你做的决定;这其中有权衡,你需要自己去决定什么是最好的。
|
||||
|
||||
最终,你可能会有:
|
||||
|
||||
- 需要登录的多个服务器
|
||||
- 多个用户登录到不同的服务器,每个都有自己的密钥
|
||||
- 每个用户使用多个密钥登录到不同的服务器
|
||||
|
||||
(如果你正在别的情况下使用密钥,这个同样的普适理论也能应用于如何使用密钥,需要多少密钥,它们是否共享,你如何处理公私钥等方面。)
|
||||
|
||||
### 安全方法
|
||||
|
||||
了解你的基础设施和特有的情况,你需要组合一个密钥管理方案,它会指导你如何去分发和存储你的密钥。比如,正如我之前提到的,如果我的平板被偷了,我会从我服务器上删除公钥,我希望这在平板在用于访问服务器之前完成。同样的,我会在我的整体计划中考虑以下内容:
|
||||
|
||||
1. 私钥可以放在移动设备上,但是必须包含口令;
|
||||
2. 必须有一个可以快速地从服务器上删除公钥的方法。
|
||||
|
||||
在你的情况中,你可能决定你不想在自己经常登录的系统上使用口令;比如,这个系统可能是一个开发者一天登录多次的测试机器。这没有问题,但是你需要调整一点你的规则。你可以添加一条规则:不可以通过移动设备登录该机器。换句话说,你需要根据自己的状况构建你的准则,不要假设某个方案放之四海而皆准。
|
||||
|
||||
### 软件
|
||||
|
||||
至于软件,令人吃惊的是,现实世界中并没有很多好的、可靠的存储和管理私钥的软件解决方案。但是应该有吗?考虑下这个,如果你有一个程序存储你所有服务器的全部密钥,并且这个程序被一个快捷的密钥锁住,那么你的密钥就真的安全了吗?或者类似的,如果你的密钥被放置在你的硬盘上,用于 SSH 程序快速访问,密钥管理软件是否真正提供了任何保护吗?
|
||||
|
||||
但是对于整体基础设施和创建/管理公钥来说,有许多的解决方案。我已经提到了 Puppet,在 Puppet 的世界中,你可以创建模块以不同的方式管理你的服务器。这个想法是服务器是动态的,而且不需要精确地复制彼此。[这里有一个聪明的方法](http://manuel.kiessling.net/2014/03/26/building-manageable-server-infrastructures-with-puppet-part-4/),在不同的服务器上使用相同的密钥,但是对于每一个用户使用不同的 Puppet 模块。这个方案可能适合你,也可能不适合你。
|
||||
|
||||
或者,另一个选择就是完全换个不同的档位。在 Docker 的世界中,你可以采取一个不同的方式,正如[关于 SSH 和 Docker 博客](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/)所描述的那样。
|
||||
|
||||
但是怎么样管理私钥?如果你搜索过的话,你无法找到很多可以选择的软件,原因我之前提到过;私钥存放在你的硬盘上,一个管理软件可能无法提到更多额外的安全。但是我使用这种方法来管理我的密钥:
|
||||
|
||||
首先,我的 `.ssh/config` 文件中有很多的主机项。我要登录的都有一个主机项,但是有时我对于一个单独的主机有不止一项。如果我有很多登录方式,就会出现这种情况。对于放置我的 git 库的服务器来说,我有两个不同的登录项;一个限制于 git,另一个用于一般用途的 bash 访问。这个为 git 设置的登录选项在机器上有极大的限制。还记得我之前说的我存储在远程开发机器上的 git 密钥吗?好了。虽然这些密钥可以登录到我其中一个服务器,但是使用的账号是被严格限制的。
|
||||
|
||||
其次,大部分的私钥都包含口令。(对于需要多次输入口令的情况,考虑使用 [ssh-agent](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/)。)
|
||||
|
||||
再次,我有一些我想要更加小心地保护的服务器,我不会把这些主机项放在我的 host 文件中。这更加接近于社会工程方面,密钥文件还在,但是可能需要攻击者花费更长的时间去找到这个密钥文件,分析出来它们对应的机器。在这种情况下,我就需要手动打出来一条长长的 SSH 命令。(没那么可怕。)
|
||||
|
||||
同时你可以看出来我没有使用任何特别的软件去管理这些私钥。
|
||||
|
||||
## 无放之四海而皆准的方案
|
||||
|
||||
我们偶尔会在 linux.com 收到一些问题,询问管理密钥的好软件的建议。但是退一步看,这个问题事实上需要重新思考,因为没有一个普适的解决方案。你问的问题应该基于你自己的状况。你是否简单地尝试找到一个位置去存储你的密钥文件?你是否寻找一个方法去管理多用户问题,其中每个人都需要将他们自己的公钥插入到 `authorized_keys` 文件中?
|
||||
|
||||
通过这篇文章,我已经囊括了这方面的基础知识,希望到此你明白如何管理你的密钥,并且,只有当你问出了正确的问题,无论你寻找任何软件(甚至你需要另外的软件),它都会出现。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/838235-how-to-best-manage-encryption-keys-on-linux
|
||||
|
||||
作者:[Jeff Cogswell][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/62256
|
||||
@ -0,0 +1,110 @@
|
||||
Linux 开发者如何看待 Git 和 Github?
|
||||
=====================================================
|
||||
|
||||
### Linux 开发者如何看待 Git 和 Github?
|
||||
|
||||
Git 和 Github 在 Linux 开发者中有很高的知名度。但是开发者如何看待它们呢?另外,Github 是不是真的和 Git 是一个意思?一个 Linux reddit 用户最近问到了这个问题,并且得到了很有意思的答案。
|
||||
|
||||
Dontwakemeup46 提问:
|
||||
|
||||
> 我正在学习 Git 和 Github。我感兴趣社区如何看待两者?据我所知,Git 和 Github 应用十分广泛。但是 Git 或 Github 有没有严重的不足?社区喜欢去改变些什么呢?
|
||||
|
||||
[更多见 Reddit](https://www.reddit.com/r/linux/comments/45jy59/the_popularity_of_git_and_github/)
|
||||
|
||||
与他志同道合的 Linux reddit 用户回答了他们对于 Git 和 Github的观点:
|
||||
|
||||
>**Derenir**: “Github 并不附属于 Git。
|
||||
|
||||
> Git 是由 Linus Torvalds 开发的。
|
||||
|
||||
> Github 几乎不支持 Linux。
|
||||
|
||||
> Github 是一家企图借助 Git 赚钱的公司。
|
||||
|
||||
> https://desktop.github.com/ 并没有支持 Linux。”
|
||||
|
||||
---
|
||||
>**Bilog78**: “一个小的补充: Linus Torvalds 已经不再维护 Git了。维护者是 Junio C Hamano,以及 在他之后的主要贡献者是 Jeff King 和 Shawn O. Pearce。”
|
||||
|
||||
---
|
||||
|
||||
>**Fearthefuture**: “我喜欢 Git,但是不明白人们为什么还要使用 Github。从我的角度,Github 比 Bitbucket 好的一点是用户统计和更大的用户基础。Bitbucket 有无限的免费私有库,更好的 UI,以及更好地集成了其他服务,比如说 Jenkins。”
|
||||
|
||||
---
|
||||
|
||||
>**Thunger**: “Gitlab.com 也很不错,特别是你可以在自己的服务器上架设自己的实例。”
|
||||
|
||||
---
|
||||
|
||||
>**Takluyver**: “很多人熟悉 Github 的 UI 以及相关联的服务,比如说 Travis 。并且很多人都有 Github 账号,所以它是存储项目的一个很好的地方。人们也使用他们的 Github 个人信息页作为一种求职用的作品选辑,所以他们很积极地将更多的项目放在这里。Github 是一个存放开源项目的事实标准。”
|
||||
|
||||
---
|
||||
|
||||
>**Tdammers**: “Git 严重问题在于 UI,它有些违反直觉,以至于很多用户只能达到使用一些容易记住的咒语的程度。”
|
||||
|
||||
> Github:最严重的问题在于它是商业托管的解决方案;你买了方便,但是代价是你的代码在别人的服务器上面,已经不在你的掌控范围之内了。另一个对于 Github 的普遍批判是它的工作流和 Git 本身的精神不符,特别是 pull requests 工作的方式。最后, Github 垄断了代码的托管环境,同时对于多样性是很不好的,这反过来对于旺盛的免费软件社区很重要。”
|
||||
|
||||
---
|
||||
|
||||
>**Dies**: “更重要的是,如果一旦是这样,按照现状来说,我猜我们会被 Github 所困,因为它们控制如此多的项目。”
|
||||
|
||||
---
|
||||
|
||||
>**Tdammers**: “代码托管在别人的服务器上,这里"别人"指的是 Github。这对于开源项目来说,并不是什么太大的问题,但是尽管如此,你无法控制它。如果你在 Github 上有私有项目,“它将保持私有”的唯一的保险只是 Github 的承诺而已。如果你决定删除东西,你不能确定东西是否被删除了,或者只是隐藏了。
|
||||
|
||||
Github 并不自己控制这些项目(你总是可以拿走你的代码,然后托管到别的地方,声明新位置是“官方”的),它只是有比开发者本身有更深的使用权。”
|
||||
|
||||
---
|
||||
|
||||
>**Drelos**: “我已经读了大量的关于 Github 的赞美与批评。(这里有一个[例子](http://www.wired.com/2015/06/problem-putting-worlds-code-github/)),但是我的幼稚问题是为什么不向一个免费开源的版本努力呢?”
|
||||
|
||||
---
|
||||
|
||||
>**Twizmwazin**: “Gitlab 的源码就存在这里”
|
||||
|
||||
---
|
||||
|
||||
[更多见 Reddit](https://www.reddit.com/r/linux/comments/45jy59/the_popularity_of_git_and_github/)
|
||||
|
||||
### DistroWatch 评估 XStream 桌面 153 版本
|
||||
|
||||
XStreamOS 是一个由 Sonicle 创建的 Solaris 的一个版本。XStream 桌面将 Solaris 的强大带给了桌面用户,同时新手用户很可能有兴趣体验一下。DistroWatch 对于 XStream 桌面 153 版本做了一个很全面的评估,并且发现它运行相当好。
|
||||
|
||||
Jesse Smith 为 DistroWatch 报道:
|
||||
|
||||
> 我认为 XStream 桌面做好了很多事情。诚然,当操作系统无法在我的硬件上启动,同时当运行在 VirtualBox 中时我无法使得桌面使用我显示器的完整分辨率,我的开端并不很成功。不过,除此之外,XStream 表现的很好。安装器工作的很好,该系统自动设置和使用了引导环境(boot environments),这让我们可以在发生错误时恢复该系统。包管理器有工作的不错, XStream 带了一套有用的软件。
|
||||
|
||||
> 我确实在播放多媒体文件时遇见一些问题,特别是使声卡工作。我不确定这是不是又一个硬件兼容问题,或者是该操作系统自带的多媒体软件的问题。另一方面,像 Web 浏览器,电子邮件,生产工具套件以及配置工具这样的工作的很好。
|
||||
|
||||
> 我最欣赏 XStream 的地方是这个操作系统是 OpenSolaris 家族的一个使用保持最新的分支。OpenSolaris 的其他衍生系统有落后的倾向,但是至少在桌面软件上,XStream 搭载最新版本的火狐和 LibreOffice。
|
||||
|
||||
> 对我个人来说,XStream 缺少一些组件,比如打印机管理器,多媒体支持和我的特定硬件的驱动。这个操作系统的其他方面也是相当吸引人的。我喜欢开发者搭配了 LXDE,也喜欢它的默认软件集,以及我最喜欢文件系统快照和启动环境开箱即用的方式。大多数的 Linux 发行版,openSUSE 除外,并没有利用好引导环境(boot environments)的用途。我希望它是一个被更多项目采用的技术。
|
||||
|
||||
[更多见 DistroWatch](http://distrowatch.com/weekly.php?issue=20160215#xstreamos)
|
||||
|
||||
### 街头霸王 V 和 SteamOS
|
||||
|
||||
街头霸王是最出名的游戏之一,并且 [Capcom 已经宣布](http://steamcommunity.com/games/310950/announcements/detail/857177755595160250) 街头霸王 V 将会在这个春天进入 Linux 和 StreamOS。这对于 Linux 游戏者是非常好的消息。
|
||||
|
||||
Joe Parlock 为 Destructoid 报道:
|
||||
|
||||
> 你是不足 1% 的那些在 Linux 系统上玩游戏的 Stream 用户吗?你是更少数的那些在 Linux 平台上玩游戏,同时也很喜欢街头霸王 V 的人之一吗?是的话,我有一些好消息要告诉你。
|
||||
|
||||
> Capcom 已经宣布,这个春天街头霸王 V 通过 Stream 进入 StreamOS 以及其他 Linux 发行版。它无需任何额外的花费,所以那些已经在自己的个人电脑上安装了该游戏的人可以很容易在 Linux 上安装它并玩了。
|
||||
|
||||
[更多 Destructoid](https://www.destructoid.com/street-fighter-v-is-coming-to-linux-and-steamos-this-spring-341531.phtml)
|
||||
|
||||
你是否错过了摘要?检查 [开源之眼的主页](http://www.infoworld.com/blog/eye-on-open/) 来获得关于 Linux 和开源的最新的新闻。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3033059/linux/what-do-linux-developers-think-of-git-and-github.html
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Jim-Lynch/
|
||||
|
||||
@ -0,0 +1,213 @@
|
||||
如何在 Ubuntu 15.04/CentOS 7 中安装 Lighttpd Web 服务器
|
||||
=================================================================================
|
||||
|
||||
Lighttpd 是一款开源 Web 服务器软件。Lighttpd 安全快速,符合行业标准,适配性强并且针对高配置环境进行了优化。相对于其它的 Web 服务器而言,Lighttpd 占用内存更少;因其对 CPU 占用小和对处理速度的优化而在效率和速度方面从众多 Web 服务器中脱颖而出。而 Lighttpd 诸如 FastCGI、CGI、认证、输出压缩、URL 重写等高级功能更是那些面临性能压力的服务器的福音。
|
||||
|
||||
以下便是我们在运行 Ubuntu 15.04 或 CentOS 7 Linux 发行版的机器上安装 Lighttpd Web 服务器的简要流程。
|
||||
|
||||
### 安装Lighttpd
|
||||
|
||||
#### 使用包管理器安装
|
||||
|
||||
这里我们通过使用包管理器这种最简单的方法来安装 Lighttpd。只需以 sudo 模式在终端或控制台中输入下面的指令即可。
|
||||
|
||||
**CentOS 7**
|
||||
|
||||
由于 CentOS 7.0 官方仓库中并没有提供 Lighttpd,所以我们需要在系统中安装额外的软件源 epel 仓库。使用下面的 yum 指令来安装 epel。
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
然后,我们需要更新系统及为 Lighttpd 的安装做前置准备。
|
||||
|
||||
# yum update
|
||||
# yum install lighttpd
|
||||
|
||||

|
||||
|
||||
**Ubuntu 15.04**
|
||||
|
||||
Ubuntu 15.04 官方仓库中包含了 Lighttpd,所以只需更新本地仓库索引并使用 apt-get 指令即可安装 Lighttpd。
|
||||
|
||||
# apt-get update
|
||||
# apt-get install lighttpd
|
||||
|
||||

|
||||
|
||||
#### 从源代码安装 Lighttpd
|
||||
|
||||
如果想从 Lighttpd 源码安装最新版本(例如 1.4.39),我们需要在本地编译源码并进行安装。首先我们要安装编译源码所需的依赖包。
|
||||
|
||||
# cd /tmp/
|
||||
# wget http://download.lighttpd.net/lighttpd/releases-1.4.x/lighttpd-1.4.39.tar.gz
|
||||
|
||||
下载完成后,执行下面的指令解压缩。
|
||||
|
||||
# tar -zxvf lighttpd-1.4.39.tar.gz
|
||||
|
||||
然后使用下面的指令进行编译。
|
||||
|
||||
# cd lighttpd-1.4.39
|
||||
# ./configure
|
||||
# make
|
||||
|
||||
**注:**在这份教程中,我们安装的是默认配置的 Lighttpd。其他拓展功能,如对 SSL 的支持,mod_rewrite,mod_redirect 等,需自行配置。
|
||||
|
||||
当编译完成后,我们就可以把它安装到系统中了。
|
||||
|
||||
# make install
|
||||
|
||||
### 设置 Lighttpd
|
||||
|
||||
如果有更高的需求,我们可以通过修改默认设置文件,如`/etc/lighttpd/lighttpd.conf`,来对 Lighttpd 进行进一步设置。 而在这份教程中我们将使用默认设置,不对设置文件进行修改。如果你曾做过修改并想检查设置文件是否出错,可以执行下面的指令。
|
||||
|
||||
# lighttpd -t -f /etc/lighttpd/lighttpd.conf
|
||||
|
||||
#### 使用 CentOS 7
|
||||
|
||||
在 CentOS 7 中,我们需创建一个在 Lighttpd 默认配置文件中设置的 webroot 文件夹,例如`/src/www/htdocs`。
|
||||
|
||||
# mkdir -p /srv/www/htdocs/
|
||||
|
||||
而后将默认欢迎页面从`/var/www/lighttpd`复制至刚刚新建的目录中:
|
||||
|
||||
# cp -r /var/www/lighttpd/* /srv/www/htdocs/
|
||||
|
||||
### 开启服务
|
||||
|
||||
现在,通过执行 systemctl 指令来重启 Web 服务。
|
||||
|
||||
# systemctl start lighttpd
|
||||
|
||||
然后我们将它设置为伴随系统启动自动运行。
|
||||
|
||||
# systemctl enable lighttpd
|
||||
|
||||
### 设置防火墙
|
||||
|
||||
如要让我们运行在 Lighttpd 上的网页或网站能在 Internet 或同一个网络内被访问,我们需要在防火墙程序中设置打开 80 端口。由于 CentOS 7 和 Ubuntu15.04 都附带 Systemd 作为默认初始化系统,所以我们默认用的都是 firewalld。如果要打开 80 端口或 http 服务,我们只需执行下面的命令:
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
success
|
||||
# firewall-cmd --reload
|
||||
success
|
||||
|
||||
### 连接至 Web 服务器
|
||||
|
||||
在将 80 端口设置为默认端口后,我们就可以直接访问 Lighttpd 的默认欢迎页了。我们需要根据运行 Lighttpd 的设备来设置浏览器的 IP 地址和域名。在本教程中,我们令浏览器访问 [http://lighttpd.linoxide.com/](http://lighttpd.linoxide.com/) ,同时将该子域名指向上述 IP 地址。如此一来,我们就可以在浏览器中看到如下的欢迎页面了。
|
||||
|
||||

|
||||
|
||||
此外,我们可以将网站的文件添加到 webroot 目录下,并删除 Lighttpd 的默认索引文件,使我们的静态网站可以在互联网上访问。
|
||||
|
||||
如果想在 Lighttpd Web 服务器中运行 PHP 应用,请参考下面的步骤:
|
||||
|
||||
### 安装 PHP5 模块
|
||||
|
||||
在 Lighttpd 成功安装后,我们需要安装 PHP 及相关模块,以在 Lighttpd 中运行 PHP5 脚本。
|
||||
|
||||
#### 使用 Ubuntu 15.04
|
||||
|
||||
# apt-get install php5 php5-cgi php5-fpm php5-mysql php5-curl php5-gd php5-intl php5-imagick php5-mcrypt php5-memcache php-pear
|
||||
|
||||
#### 使用 CentOS 7
|
||||
|
||||
# yum install php php-cgi php-fpm php-mysql php-curl php-gd php-intl php-pecl-imagick php-mcrypt php-memcache php-pear lighttpd-fastcgi
|
||||
|
||||
### 设置 Lighttpd 的 PHP 服务
|
||||
|
||||
如要让 PHP 与 Lighttpd 协同工作,我们只要根据所使用的发行版执行如下对应的指令即可。
|
||||
|
||||
#### 使用 CentOS 7
|
||||
|
||||
首先要做的便是使用文件编辑器编辑 php 设置文件(例如`/etc/php.ini`)并取消掉对**cgi.fix_pathinfo=1**这一行的注释。
|
||||
|
||||
# nano /etc/php.ini
|
||||
|
||||
完成上面的步骤之后,我们需要把 PHP-FPM 进程的所有权从 Apache 转移至 Lighttpd。要完成这些,首先用文件编辑器打开`/etc/php-fpm.d/www.conf`文件。
|
||||
|
||||
# nano /etc/php-fpm.d/www.conf
|
||||
|
||||
然后在文件中增加下面的语句:
|
||||
|
||||
user = lighttpd
|
||||
group = lighttpd
|
||||
|
||||
做完这些,我们保存并退出文本编辑器。然后从`/etc/lighttpd/modules.conf`设置文件中添加 FastCGI 模块。
|
||||
|
||||
# nano /etc/lighttpd/modules.conf
|
||||
|
||||
然后,去掉下面语句前面的`#`来取消对它的注释。
|
||||
|
||||
include "conf.d/fastcgi.conf"
|
||||
|
||||
最后我们还需在文本编辑器设置 FastCGI 的设置文件。
|
||||
|
||||
# nano /etc/lighttpd/conf.d/fastcgi.conf
|
||||
|
||||
在文件尾部添加以下代码:
|
||||
|
||||
fastcgi.server += ( ".php" =>
|
||||
((
|
||||
"host" => "127.0.0.1",
|
||||
"port" => "9000",
|
||||
"broken-scriptfilename" => "enable"
|
||||
))
|
||||
)
|
||||
|
||||
在编辑完成后保存并退出文本编辑器即可。
|
||||
|
||||
#### 使用 Ubuntu 15.04
|
||||
|
||||
如需启用 Lighttpd 的 FastCGI,只需执行下列代码:
|
||||
|
||||
# lighttpd-enable-mod fastcgi
|
||||
|
||||
Enabling fastcgi: ok
|
||||
Run /etc/init.d/lighttpd force-reload to enable changes
|
||||
|
||||
# lighttpd-enable-mod fastcgi-php
|
||||
|
||||
Enabling fastcgi-php: ok
|
||||
Run `/etc/init.d/lighttpd` force-reload to enable changes
|
||||
|
||||
然后,执行下列命令来重启 Lighttpd。
|
||||
|
||||
# systemctl force-reload lighttpd
|
||||
|
||||
### 检测 PHP 工作状态
|
||||
|
||||
如需检测 PHP 是否按预期工作,我们需在 Lighttpd 的 webroot 目录下新建一个 php 文件。本教程中,在 Ubuntu 下 /var/www/html 目录,CentOS 下 /src/www/htdocs 目录下使用文本编辑器创建并打开 info.php。
|
||||
|
||||
**使用 CentOS 7**
|
||||
|
||||
# nano /var/www/info.php
|
||||
|
||||
**使用 Ubuntu 15.04**
|
||||
|
||||
# nano /srv/www/htdocs/info.php
|
||||
|
||||
然后只需将下面的语句添加到文件里即可。
|
||||
|
||||
<?php phpinfo(); ?>
|
||||
|
||||
在编辑完成后保存并推出文本编辑器即可。
|
||||
|
||||
现在,我们需根据路径 [http://lighttpd.linoxide.com/info.php](http://lighttpd.linoxide.com/info.php) 下的 info.php 文件的 IP 地址或域名,来让我们的网页浏览器指向系统上运行的 Lighttpd。如果一切都按照以上说明进行,我们将看到如下图所示的 PHP 页面信息。
|
||||
|
||||

|
||||
|
||||
### 总结
|
||||
|
||||
至此,我们已经在 CentOS 7 和 Ubuntu 15.04 Linux 发行版上成功安装了轻巧快捷并且安全的 Lighttpd Web 服务器。现在,我们已经可以上传网站文件到网站根目录、配置虚拟主机、启用 SSL、连接数据库,在我们的 Lighttpd Web 服务器上运行 Web 应用等功能了。 如果你有任何疑问,建议或反馈请在下面的评论区中写下来以让我们更好的改良 Lighttpd。谢谢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-lighttpd-web-server-ubuntu-15-04-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[HaohongWANG](https://github.com/HaohongWANG)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -3,9 +3,9 @@
|
||||
|
||||

|
||||
|
||||
云存储服务 Copy 即将关闭,我们 Linux 用户是时候该寻找其他优秀的** Copy 之外的 Linux 云存储服务**。
|
||||
云存储服务 Copy 已经关闭,我们 Linux 用户是时候该寻找其他优秀的** Copy 之外的 Linux 云存储服务**。
|
||||
|
||||
全部文件将会在 2016年5月1号 被删除。如果你是 Copy 的用户,你应该保存你的文件并将它们移至其他地方。
|
||||
全部文件会在 2016年5月1号 被删除。如果你是 Copy 的用户,你应该保存你的文件并将它们移至其他地方。
|
||||
|
||||
在过去的两年里,Copy 已经成为了我最喜爱的云存储。它为我提供了大量的免费空间并且带有桌面平台的原生应用程序,包括 Linux 和移动平台如 iOS 和 Android。
|
||||
|
||||
@ -13,16 +13,16 @@
|
||||
|
||||
当我从 Copy.com 看到它即将关闭的消息,我的担忧成真了。事实上,Copy 并不孤独。它的母公司 [Barracuda Networks](https://www.barracuda.com/)正经历一段困难时期并且已经[雇佣 Morgan Stanely 寻找 合适的卖家](http://www.bloomberg.com/news/articles/2016-02-01/barracuda-networks-said-to-work-with-morgan-stanley-to-seek-sale)(s)
|
||||
|
||||
无论什么理由,我们所知道的是 Copy 将会成为历史,我们需要寻找相似的**优秀的 Linux 云服务**。我之所以强调 Linux 是因为其他流行的云存储服务,如[微软的OneDrive](https://onedrive.live.com/about/en-us/) 和 [Google Drive](https://www.google.com/drive/) 都没有提供本地 Linux 客户端。这是微软预计的事情,但是谷歌对 Linux 的冷漠令人震惊。
|
||||
无论什么理由,我们所知道的是 Copy 将会成为历史,我们需要寻找相似的**优秀的 Linux 云服务**。我之所以强调 Linux 是因为其他流行的云存储服务,如[微软的 OneDrive](https://onedrive.live.com/about/en-us/) 和 [Google Drive](https://www.google.com/drive/) 都没有提供本地 Linux 客户端。微软并没有出乎我们的预料,但是[谷歌对 Linux 的冷漠][1]令人震惊。
|
||||
|
||||
## Linux 下 Copy 的最佳替代者
|
||||
|
||||
现在,作为一个 Linux 存储,在云存储中你需要什么?让我们猜猜:
|
||||
什么样的云服务才适合作为 Linux 下的存储服务?让我们猜猜:
|
||||
|
||||
- 大量的免费空间。毕竟,个人用户无法每月支付巨额款项。
|
||||
- 原生的 Linux 客户端。因此你能够使用提供的服务,方便地同步文件,而不用做一些特殊的调整或者定时执行脚本。
|
||||
- 其他桌面系统的客户端,比如 Windows 和 OS X。便携性是必要的,并且同步设备间的文件是一种很好的缓解。
|
||||
- Android 和 iOS 的移动应用程序。在今天的现代世界里,你需要连接所有设备。
|
||||
- 大量的免费空间。毕竟,个人用户无法支付每月的巨额款项。
|
||||
- 原生的 Linux 客户端。以便你能够方便的在服务器之间同步文件,而不用做一些特殊的调整或者定时执行脚本。
|
||||
- 其他桌面系统的客户端,比如 Windows 和 OS X。移动性是必要的,并且同步设备间的文件也很有必要。
|
||||
- 基于 Android 和 iOS 的移动应用程序。在今天的现代世界里,你需要连接所有设备。
|
||||
|
||||
我不将自托管的云服务计算在内,比如 OwnCloud 或 [Seafile](https://www.seafile.com/en/home/) ,因为它们需要自己建立和运行一个服务器。这不适合所有想要类似 Copy 的云服务的家庭用户。
|
||||
|
||||
@ -32,7 +32,7 @@
|
||||
|
||||

|
||||
|
||||
如果你是一个 It’s FOSS 的普通读者,你可能已经看过我之前的一篇有关[Mega on Linux](http://itsfoss.com/install-mega-cloud-storage-linux/)的文章。这种云服务由[Megaupload scandal](https://en.wikipedia.org/wiki/Megaupload) 公司下臭名昭著的[Kim Dotcom](https://en.wikipedia.org/wiki/Kim_Dotcom)提供。这也使一些用户怀疑它,因为 Kim Dotcom 已经很长一段时间成为美国当局的目标。
|
||||
如果你是一个 It’s FOSS 的普通读者,你可能已经看过我之前的一篇有关 [Mega on Linux](http://itsfoss.com/install-mega-cloud-storage-linux/)的文章。这种云服务由 [Megaupload scandal](https://en.wikipedia.org/wiki/Megaupload) 公司下臭名昭著的 [Kim Dotcom](https://en.wikipedia.org/wiki/Kim_Dotcom) 提供。这也使一些用户怀疑它,因为 Kim Dotcom 已经很长一段时间成为美国当局的目标。
|
||||
|
||||
Mega 拥有方便免费云服务下你所期望的一切。它给每个个人用户提供 50 GB 的免费存储空间。提供Linux 和其他平台下的原生客户端,并带有端到端的加密。原生的 Linux 客户端运行良好,可以无缝地跨平台同步。你也能在浏览器上查看操作你的文件。
|
||||
|
||||
@ -74,7 +74,7 @@ Hubic 拥有一些不错的功能。除了简单的用户界面、文件共享
|
||||
|
||||

|
||||
|
||||
pCloud 是另一款欧洲的发行软件,但这一次从瑞士横跨法国边境。专注于加密和安全,pCloud 为每一个注册者提供 10 GB 的免费存储空间。你可以通过邀请好友、在社交媒体上分享链接等方式将空间增加至 20 GB。
|
||||
pCloud 是另一款欧洲的发行软件,但这一次跨过了法国边境,它来自瑞士。专注于加密和安全,pCloud 为每一个注册者提供 10 GB 的免费存储空间。你可以通过邀请好友、在社交媒体上分享链接等方式将空间增加至 20 GB。
|
||||
|
||||
它拥有云服务的所有标准特性,例如文件共享、同步、选择性同步等等。pCloud 也有跨平台原生客户端,当然包括 Linux。
|
||||
|
||||
@ -128,8 +128,9 @@ via: http://itsfoss.com/cloud-services-linux/
|
||||
|
||||
作者:[ABHISHEK][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/google-hates-desktop-linux/
|
||||
@ -0,0 +1,37 @@
|
||||
构建在开源之上的商业软件市场持续成长
|
||||
=====================================================================
|
||||
|
||||

|
||||
|
||||
*与会者在 Structure 上听取演讲,Structure Data 2016 也将在 UCSF Mission Bay 会议中心举办。图片来源:Structure Events。*
|
||||
|
||||
如今真的很难低估开源项目对于企业软件市场的影响;开源软件的集成如此快速地形成了业界常态,我们没能捕捉到转折点也情有可原。
|
||||
|
||||
举个例子,Hadoop,改变的不止是数据分析界,它引领了新一代数据公司,它们围绕开源项目创造自己的软件,按需调整和支持那些代码,更像红帽在上世纪 90 年代和本世纪早期拥抱 Linux 那样。软件越来越多地通过公有云交付,而不是运行在购买者自己的服务器,拥有了令人惊奇的操作灵活性,但同时也带来了一些关于授权、支持以及价格之类的新问题。
|
||||
|
||||
我们多年来持续追踪这个趋势,这些话题充斥了我们的 Structure Data 会议,而今年的 Structure Data 2016 也不例外。三家围绕 Hadoop 最重要的大数据公司——Hortonworks、Cloudera 和 MapR ——的 CEO 们将会共同讨论它们是如何销售他们围绕开源项目的企业软件和服务,获利的同时回报社区项目。
|
||||
|
||||
以前在企业软件上获利是很容易的事情。一个客户购买了之后,企业供应商的一系列软件就变成了收银机,从维护合同和阶段性升级中获得近乎终生的收入,软件也越来越难以被替代,因为它已经成为了客户的业务核心。客户抱怨这种绑定,但如果它们想提高工作队伍的生产力也确实没有多少选择。
|
||||
|
||||
而现在的情况不再是这样了。尽管无数的公司还陷于在他们的基础设施上运行至关重要的巨型软件包,新的项目被部署到使用开源技术的云服务器上。这让升级功能不再需要去掉大量软件包再重新安装别的,同时也让公司按需付费,而不是为一堆永远用不到的特性买单。
|
||||
|
||||
有很多客户想要利用开源项目的优势,而又不想建立和支持一支工程师队伍来调整那些开源项目以满足自己的需求。这些客户愿意为开源项目和在这之上的专有特性之间的差异付费。
|
||||
|
||||
这对于基础设施相关的软件来说格外正确。当然,你的客户们可以自己对项目进行调整,比如 Hadoop,Spark 或 Node.js,但付费可以帮助他们自定义地打包部署如今这些重要的开源技术,而不用自己干这些活儿。只需看看 Structure Data 2016 的发言者就明白了,比如 Confluent(Kafka),Databricks(Spark),以及 Cloudera-Hortonworks-MapR(Hadoop)三人组。
|
||||
|
||||
当然还有一个值得提到的是在出错的时候有个供应商给你背锅。如果你的工程师弄糟了开源项目的实现,那你只能怪你自己了。但是如果你和一个愿意提供服务级品质、能确保性能和正常运行时间指标的公司签订了合同,你实际上就是为得到支持、指导,以及有人背锅而买单。
|
||||
|
||||
构建在开源之上的商业软件市场的持续成长是我们在 Structure Data 上追踪多年的内容,如果这个话题正合你意,我们鼓励你加入我们,在旧金山,3 月 9 日和 10 日。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/enterprise/cloud-computing/889564-the-evolving-market-for-commercial-software-built-on-open-source-
|
||||
|
||||
作者:[Tom Krazit][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/community/forums/person/70513
|
||||
@ -0,0 +1,86 @@
|
||||
Linux 下五个顶级的开源命令行 Shell
|
||||
===============================================
|
||||
|
||||

|
||||
|
||||
这个世界上有两种 Linux 用户:敢于冒险的和态度谨慎的。
|
||||
|
||||
其中一类用户总是本能的去尝试任何能够戳中其痛点的新选择。他们尝试过不计其数的窗口管理器、系统发行版和几乎所有能找到的桌面插件。
|
||||
|
||||
另一类用户找到他们喜欢的东西后,会一直使用下去。他们往往喜欢所使用的系统发行版的默认配置。最先熟练掌握的文本编辑器会成为他们最钟爱的那一个。
|
||||
|
||||
作为一个使用桌面版和服务器版十五年之久的 Linux 用户,比起第一类来,我无疑属于第二类用户。我更倾向于使用现成的东西,如此一来,很多时候我就可以通过文档和示例方便地找到我所需要的使用案例。如果我决定选择使用非费标准的东西,这个切换过程一定会基于细致的研究,并且前提是来自好基友的大力推荐。
|
||||
|
||||
但这并不意味着我不喜欢尝试新事物并且查漏补失。所以最近一段时间,在我不假思索的使用了 bash shell 多年之后,决定尝试一下另外四个 shell 工具:ksh、tcsh、zsh 和 fish。这四个 shell 都可以通过我所用的 Fedora 系统的默认库轻松安装,并且他们可能已经内置在你所使用的系统发行版当中了。
|
||||
|
||||
这里对它们每个选择都稍作介绍,并且阐述下它适合做为你的下一个 Linux 命令行解释器的原因所在。
|
||||
|
||||
### bash
|
||||
|
||||
首先,我们回顾一下最为熟悉的一个。 [GNU Bash][1],又名 Bourne Again Shell,它是我这些年使用过的众多 Linux 发行版的默认选择。它最初发布于 1989 年,并且轻松成长为 Linux 世界中使用最广泛的 shell,甚至常见于其他一些类 Unix 系统当中。
|
||||
|
||||
Bash 是一个广受赞誉的 shell,当你通过互联网寻找各种事情解决方法所需的文档时,总能够无一例外的发现这些文档都默认你使用的是 bash shell。但 bash 也有一些缺点存在,如果你写过 Bash 脚本就会发现我们写的代码总是得比真正所需要的多那么几行。这并不是说有什么事情是它做不到的,而是说它读写起来并不总是那么直观,至少是不够优雅。
|
||||
|
||||
如上所述,基于其巨大的安装量,并且考虑到各类专业和非专业系统管理员已经适应了它的使用方式和独特之处,至少在将来一段时间内,bash 或许会一直存在。
|
||||
|
||||
### ksh
|
||||
|
||||
[KornShell][4],或许你对这个名字并不熟悉,但是你一定知道它的调用命令 ksh。这个替代性的 shell 于 80 年代起源于贝尔实验室,由 David Korn 所写。虽然最初是一个专有软件,但是后期版本是在 [Eclipse Public 许可][5]下发布的。
|
||||
|
||||
ksh 的拥趸们列出了他们觉得其优越的诸多理由,包括更好的循环语法,清晰的管道退出代码,处理重复命令和关联数组的更简单的方式。它能够模拟 vi 和 emacs 的许多行为,所以如果你是一个重度文本编辑器患者,它值得你一试。最后,我发现它虽然在高级脚本方面拥有不同的体验,但在基本输入方面与 bash 如出一辙。
|
||||
|
||||
### tcsh
|
||||
|
||||
[tcsh][6] 衍生于 csh(Berkely Unix C shell),并且可以追溯到早期的 Unix 和计算机时代开始。
|
||||
|
||||
tcsh 最大的卖点在于它的脚本语言,对于熟悉 C 语言编程的人来说,看起来会非常亲切。tcsh 的脚本编写有人喜欢,有人憎恶。但是它也有其他的技术特色,包括可以为 aliases 添加参数,各种可能迎合你偏好的默认行为,包括 tab 自动完成和将 tab 完成的工作记录下来以备后查。
|
||||
|
||||
tcsh 以 [BSD 许可][7]发布。
|
||||
|
||||
### zsh
|
||||
|
||||
[zsh][8] 是另外一个与 bash 和 ksh 有着相似之处的 shell。诞生于 90 年代初,zsh 支持众多有用的新技术,包括拼写纠正、主题化、可命名的目录快捷键,在多个终端中共享同一个命令历史信息和各种相对于原来的 bash 的轻微调整。
|
||||
|
||||
虽然部分需要遵照 GPL 许可,但 zsh 的代码和二进制文件可以在一个类似 MIT 许可证的许可下进行分发; 你可以在 [actual license][9] 中查看细节。
|
||||
|
||||
### fish
|
||||
|
||||
之前我访问了 [fish][10] 的主页,当看到 “好了,这是一个为 90 后而生的命令行 shell” 这条略带调侃的介绍时(fish 完成于 2005 年),我就意识到我会爱上这个交互友好的 shell 的。
|
||||
|
||||
fish 的作者提供了若干切换过来的理由,这些理由有点小幽默并且能戳中笑点,不过还真是那么回事。这些特性包括自动建议(“注意, Netscape Navigator 4.0 来了”,LCTT 译注:NN4 是一个重要版本。),支持“惊人”的 256 色 VGA 调色,不过也有真正有用的特性,包括根据你机器上的 man 页面自动补全命令,清除脚本和基于 web 界面的配置方式。
|
||||
|
||||
fish 的许可主要基于 GPLv2,但有些部分是在其他许可下的。你可以查看资源库来了解[完整信息][11]。
|
||||
|
||||
***
|
||||
|
||||
如果你想要寻找关于每个选择确切不同之处的详尽纲要,[这个网站][12]应该可以帮到你。
|
||||
|
||||
我的立场到底是怎样的呢?好吧,最终我应该还是会重新投入 bash 的怀抱,因为对于大多数时间都在使用命令行交互的人来说,切换过程对于编写高级的脚本能带来的好处微乎其微,并且我已经习惯于使用 bash 了。
|
||||
|
||||
但是我很庆幸做出了敞开大门并且尝试新选择的决定。我知道门外还有许许多多其他的东西。你尝试过哪些 shell,更中意哪一个?请在评论里告诉我们。
|
||||
|
||||
---
|
||||
|
||||
via: https://opensource.com/business/16/3/top-linux-shells
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
|
||||
[1]: https://www.gnu.org/software/bash/
|
||||
[2]: http://mywiki.wooledge.org/BashPitfalls
|
||||
[3]: http://www.gnu.org/licenses/gpl.html
|
||||
[4]: http://www.kornshell.org/
|
||||
[5]: https://www.eclipse.org/legal/epl-v10.html
|
||||
[6]: http://www.tcsh.org/Welcome
|
||||
[7]: https://en.wikipedia.org/wiki/BSD_licenses
|
||||
[8]: http://www.zsh.org/
|
||||
[9]: https://sourceforge.net/p/zsh/code/ci/master/tree/LICENCE
|
||||
[10]: https://fishshell.com/
|
||||
[11]: https://github.com/fish-shell/fish-shell/blob/master/COPYING
|
||||
[12]: http://hyperpolyglot.org/unix-shells
|
||||
|
||||
@ -0,0 +1,284 @@
|
||||
用 Python、 RabbitMQ 和 Nameko 实现微服务
|
||||
==============================================
|
||||
|
||||
>"微服务是一股新浪潮" - 现如今,将项目拆分成多个独立的、可扩展的服务是保障代码演变的最好选择。在 Python 的世界里,有个叫做 “Nameko” 的框架,它将微服务的实现变得简单并且强大。
|
||||
|
||||
|
||||
### 微服务
|
||||
|
||||
> 在最近的几年里,“微服务架构”如雨后春笋般涌现。它用于描述一种特定的软件应用设计方式,这种方式使得应用可以由多个独立部署的服务以服务套件的形式组成。 - M. Fowler
|
||||
|
||||
推荐各位读一下 [Fowler 的文章][1] 以理解它背后的原理。
|
||||
|
||||
#### 好吧,那它究竟意味着什么呢?
|
||||
|
||||
简单来说,**微服务架构**可以将你的系统拆分成多个负责不同任务的小的(单一上下文内)功能块(responsibilities blocks),它们彼此互无感知,各自只提供用于通讯的通用指向(common point)。这个指向通常是已经将通讯协议和接口定义好的消息队列。
|
||||
|
||||
#### 这里给大家提供一个真实案例
|
||||
|
||||
> 案例的代码可以通过 github: <http://github.com/rochacbruno/nameko-example> 访问,查看 service 和 api 文件夹可以获取更多信息。
|
||||
|
||||
想象一下,你有一个 REST API ,这个 API 有一个端点(LCTT 译注:REST 风格的 API 可以有多个端点用于处理对同一资源的不同类型的请求)用来接受数据,并且你需要将接收到的数据进行一些运算工作。那么相比阻塞接口调用者的请求来说,异步实现此接口是一个更好的选择。你可以先给用户返回一个 "OK - 你的请求稍后会处理" 的状态,然后在后台任务中完成运算。
|
||||
|
||||
同样,如果你想要在不阻塞主进程的前提下,在计算完成后发送一封提醒邮件,那么将“邮件发送”委托给其他服务去做会更好一些。
|
||||
|
||||
|
||||
#### 场景描述
|
||||
|
||||

|
||||
|
||||
|
||||
### 用代码说话
|
||||
|
||||
让我们将系统创建起来,在实践中理解它:
|
||||
|
||||
#### 环境
|
||||
|
||||
我们需要的环境:
|
||||
|
||||
- 运行良好的 RabbitMQ(LCTT 译注:[RabbitMQ][2] 是一个流行的消息队列实现)
|
||||
- 由 VirtualEnv 提供的 Services 虚拟环境
|
||||
- 由 VirtualEnv 提供的 API 虚拟环境
|
||||
|
||||
#### Rabbit
|
||||
|
||||
在开发环境中使用 RabbitMQ 最简单的方式就是运行其官方的 docker 容器。在你已经拥有 Docker 的情况下,运行:
|
||||
|
||||
```
|
||||
docker run -d --hostname my-rabbit --name some-rabbit -p 15672:15672 -p 5672:5672 rabbitmq:3-management
|
||||
```
|
||||
|
||||
在浏览器中访问 <http://localhost:15672> ,如果能够使用 guest:guest 验证信息登录 RabbitMQ 的控制面板,说明它已经在你的开发环境中运行起来了。
|
||||
|
||||

|
||||
|
||||
#### 服务环境
|
||||
|
||||
现在让我们创建微服务来满足我们的任务需要。其中一个服务用来执行计算任务,另一个用来发送邮件。按以下步骤执行:
|
||||
|
||||
在 Shell 中创建项目的根目录
|
||||
|
||||
```
|
||||
$ mkdir myproject
|
||||
$ cd myproject
|
||||
```
|
||||
|
||||
用 virtualenv 工具创建并且激活一个虚拟环境(你也可以使用virtualenv-wrapper)
|
||||
|
||||
```
|
||||
$ virtualenv service_env
|
||||
$ source service_env/bin/activate
|
||||
```
|
||||
|
||||
安装 nameko 框架和 yagmail
|
||||
|
||||
```
|
||||
(service_env)$ pip install nameko
|
||||
(service_env)$ pip install yagmail
|
||||
```
|
||||
|
||||
#### 服务的代码
|
||||
|
||||
现在我们已经准备好了 virtualenv 所提供的虚拟环境(可以想象成我们的服务是运行在一个独立服务器上的,而我们的 API 运行在另一个服务器上),接下来让我们编码,实现 nameko 的 RPC 服务。
|
||||
|
||||
我们会将这两个服务放在同一个 python 模块中,当然如果你乐意,也可以把它们放在单独的模块里并且当成不同的服务运行:
|
||||
|
||||
在名为 `service.py` 的文件中
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
from nameko.rpc import rpc, RpcProxy
|
||||
|
||||
|
||||
class Mail(object):
|
||||
name = "mail"
|
||||
|
||||
@rpc
|
||||
def send(self, to, subject, contents):
|
||||
yag = yagmail.SMTP('myname@gmail.com', 'mypassword')
|
||||
# 以上的验证信息请从安全的地方进行读取
|
||||
# 贴士: 可以去看看 Dynaconf 设置模块
|
||||
yag.send(to=to.encode('utf-8),
|
||||
subject=subject.encode('utf-8),
|
||||
contents=[contents.encode('utf-8)])
|
||||
|
||||
|
||||
class Compute(object):
|
||||
name = "compute"
|
||||
mail = RpcProxy('mail')
|
||||
|
||||
@rpc
|
||||
def compute(self, operation, value, other, email):
|
||||
operations = {'sum': lambda x, y: int(x) + int(y),
|
||||
'mul': lambda x, y: int(x) * int(y),
|
||||
'div': lambda x, y: int(x) / int(y),
|
||||
'sub': lambda x, y: int(x) - int(y)}
|
||||
try:
|
||||
result = operations[operation](value, other)
|
||||
except Exception as e:
|
||||
self.mail.send.async(email, "An error occurred", str(e))
|
||||
raise
|
||||
else:
|
||||
self.mail.send.async(
|
||||
email,
|
||||
"Your operation is complete!",
|
||||
"The result is: %s" % result
|
||||
)
|
||||
return result
|
||||
```
|
||||
|
||||
现在我们已经用以上代码定义好了两个服务,下面让我们将 Nameko RPC service 运行起来。
|
||||
|
||||
> 注意:我们会在控制台中启动并运行它。但在生产环境中,建议大家使用 supervisord 替代控制台命令。
|
||||
|
||||
在 Shell 中启动并运行服务
|
||||
|
||||
```
|
||||
(service_env)$ nameko run service --broker amqp://guest:guest@localhost
|
||||
starting services: mail, compute
|
||||
Connected to amqp://guest:**@127.0.0.1:5672//
|
||||
Connected to amqp://guest:**@127.0.0.1:5672//
|
||||
```
|
||||
|
||||
|
||||
#### 测试
|
||||
|
||||
在另外一个 Shell 中(使用相同的虚拟环境),用 nameko shell 进行测试:
|
||||
|
||||
```
|
||||
(service_env)$ nameko shell --broker amqp://guest:guest@localhost
|
||||
Nameko Python 2.7.9 (default, Apr 2 2015, 15:33:21)
|
||||
[GCC 4.9.2] shell on linux2
|
||||
Broker: amqp://guest:guest@localhost
|
||||
>>>
|
||||
```
|
||||
|
||||
现在你已经处在 RPC 客户端中了,Shell 的测试工作是通过 n.rpc 对象来进行的,它的使用方法如下:
|
||||
|
||||
```
|
||||
>>> n.rpc.mail.send("name@email.com", "testing", "Just testing")
|
||||
```
|
||||
|
||||
上边的代码会发送一封邮件,我们同样可以调用计算服务对其进行测试。需要注意的是,此测试还会附带进行异步的邮件发送。
|
||||
|
||||
```
|
||||
>>> n.rpc.compute.compute('sum', 30, 10, "name@email.com")
|
||||
40
|
||||
>>> n.rpc.compute.compute('sub', 30, 10, "name@email.com")
|
||||
20
|
||||
>>> n.rpc.compute.compute('mul', 30, 10, "name@email.com")
|
||||
300
|
||||
>>> n.rpc.compute.compute('div', 30, 10, "name@email.com")
|
||||
3
|
||||
```
|
||||
|
||||
### 在 API 中调用微服务
|
||||
|
||||
在另外一个 Shell 中(甚至可以是另外一台服务器上),准备好 API 环境。
|
||||
|
||||
用 virtualenv 工具创建并且激活一个虚拟环境(你也可以使用 virtualenv-wrapper)
|
||||
|
||||
```
|
||||
$ virtualenv api_env
|
||||
$ source api_env/bin/activate
|
||||
```
|
||||
|
||||
安装 Nameko、 Flask 和 Flasgger
|
||||
|
||||
```
|
||||
(api_env)$ pip install nameko
|
||||
(api_env)$ pip install flask
|
||||
(api_env)$ pip install flasgger
|
||||
```
|
||||
|
||||
>注意: 在 API 中并不需要 yagmail ,因为在这里,处理邮件是服务的职责
|
||||
|
||||
创建含有以下内容的 `api.py` 文件:
|
||||
|
||||
```python
|
||||
from flask import Flask, request
|
||||
from flasgger import Swagger
|
||||
from nameko.standalone.rpc import ClusterRpcProxy
|
||||
|
||||
app = Flask(__name__)
|
||||
Swagger(app)
|
||||
CONFIG = {'AMQP_URI': "amqp://guest:guest@localhost"}
|
||||
|
||||
|
||||
@app.route('/compute', methods=['POST'])
|
||||
def compute():
|
||||
"""
|
||||
Micro Service Based Compute and Mail API
|
||||
This API is made with Flask, Flasgger and Nameko
|
||||
---
|
||||
parameters:
|
||||
- name: body
|
||||
in: body
|
||||
required: true
|
||||
schema:
|
||||
id: data
|
||||
properties:
|
||||
operation:
|
||||
type: string
|
||||
enum:
|
||||
- sum
|
||||
- mul
|
||||
- sub
|
||||
- div
|
||||
email:
|
||||
type: string
|
||||
value:
|
||||
type: integer
|
||||
other:
|
||||
type: integer
|
||||
responses:
|
||||
200:
|
||||
description: Please wait the calculation, you'll receive an email with results
|
||||
"""
|
||||
operation = request.json.get('operation')
|
||||
value = request.json.get('value')
|
||||
other = request.json.get('other')
|
||||
email = request.json.get('email')
|
||||
msg = "Please wait the calculation, you'll receive an email with results"
|
||||
subject = "API Notification"
|
||||
with ClusterRpcProxy(CONFIG) as rpc:
|
||||
# asynchronously spawning and email notification
|
||||
rpc.mail.send.async(email, subject, msg)
|
||||
# asynchronously spawning the compute task
|
||||
result = rpc.compute.compute.async(operation, value, other, email)
|
||||
return msg, 200
|
||||
|
||||
app.run(debug=True)
|
||||
```
|
||||
|
||||
在其他的 shell 或者服务器上运行此文件
|
||||
|
||||
```
|
||||
(api_env) $ python api.py
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
然后访问 <http://localhost:5000/apidocs/index.html> 这个 url,就可以看到 Flasgger 的界面了,利用它可以进行 API 的交互并可以发布任务到队列以供服务进行消费。
|
||||
|
||||

|
||||
|
||||
> 注意: 你可以在 shell 中查看到服务的运行日志,打印信息和错误信息。也可以访问 RabbitMQ 控制面板来查看消息在队列中的处理情况。
|
||||
|
||||
Nameko 框架还为我们提供了很多高级特性,你可以从 <https://nameko.readthedocs.org/en/stable/> 获取更多的信息。
|
||||
|
||||
别光看了,撸起袖子来,实现微服务!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://brunorocha.org/python/microservices-with-python-rabbitmq-and-nameko.html
|
||||
|
||||
作者: [Bruno Rocha][a]
|
||||
译者: [mr-ping](http://www.mr-ping.com)
|
||||
校对: [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://facebook.com/rochacbruno
|
||||
[1]:http://martinfowler.com/articles/microservices.html
|
||||
[2]:http://rabbitmq.mr-ping.com/description.html
|
||||
@ -0,0 +1,107 @@
|
||||
如何使用 Awk 打印文件中的字段和列
|
||||
===================================================
|
||||
|
||||
在 [Linux Awk 命令系列介绍][1] 的这部分,我们来看一下 awk 最重要的功能之一,字段编辑。
|
||||
|
||||
首先我们要知道 Awk 会自动把输入的行切分为字段,字段可以定义为是一些字符集,这些字符集和其它字段被内部字段分隔符分离。
|
||||
|
||||

|
||||
>Awk 输出字段和列
|
||||
|
||||
如果你熟悉 Unix/Linux 或者懂得 [bash shell 编程][2],那么你也应该知道内部字段分隔符(IFS)变量。Awk 默认的 IFS 是 tab 和空格。
|
||||
|
||||
Awk 字段切分的工作原理如下:当获得一行输入时,根据定义的 IFS,第一个字符集是字段一,用 $1 表示,第二个字符集是字段二,用 $2 表示,第三个字符集是字段三,用 $3 表示,以此类推直到最后一个字符集。
|
||||
|
||||
为了更好的理解 Awk 的字段编辑,让我们来看看下面的例子:
|
||||
|
||||
**事例 1:**: 我创建了一个名为 tecmintinfo.txt 的文件。
|
||||
|
||||
```
|
||||
# vi tecmintinfo.txt
|
||||
# cat tecmintinfo.txt
|
||||
```
|
||||
|
||||

|
||||
>在 Linux 中创建文件
|
||||
|
||||
然后在命令行中使用以下命令打印 tecmintinfo.txt 文件中的第一、第二和第三个字段。
|
||||
|
||||
```
|
||||
$ awk '//{print $1 $2 $3 }' tecmintinfo.txt
|
||||
TecMint.comisthe
|
||||
```
|
||||
从上面的输出中你可以看到,三个字段中的第一个是按照定义的 IFS,也就是空格,打印的。
|
||||
|
||||
- 字段一 “TecMint.com” 使用 $1 访问。
|
||||
- 字段二 “is” 通过 $2 访问。
|
||||
- 字段三 “the” 通过 $3 访问。
|
||||
|
||||
如果你注意打印的输出,可以看到字段值之间并没有分隔开,这是 print 默认的方式。
|
||||
|
||||
为了在字段值之间加入空格,你需要像下面这样添加(,)分隔符:
|
||||
|
||||
```
|
||||
$ awk '//{print $1, $2, $3; }' tecmintinfo.txt
|
||||
|
||||
TecMint.com is the
|
||||
```
|
||||
|
||||
很重要而且必须牢记的一点是,Awk 中 ($) 的使用和在 shell 脚本中不一样。
|
||||
|
||||
在 shell 脚本中 ($) 用于获取变量的值,而在 Awk 中 ($) 只用于获取一个字段的内容,而不能用于获取变量的值。
|
||||
|
||||
**事例2**: 让我们再看一个使用多行文件 my_shoping.list 的例子。
|
||||
|
||||
```
|
||||
No Item_Name Unit_Price Quantity Price
|
||||
1 Mouse #20,000 1 #20,000
|
||||
2 Monitor #500,000 1 #500,000
|
||||
3 RAM_Chips #150,000 2 #300,000
|
||||
4 Ethernet_Cables #30,000 4 #120,000
|
||||
```
|
||||
|
||||
假设你只想打印购物清单中每个物品的 Unit_Price,你需要允许下面的命令:
|
||||
|
||||
```
|
||||
$ awk '//{print $2, $3 }' my_shopping.txt
|
||||
|
||||
Item_Name Unit_Price
|
||||
Mouse #20,000
|
||||
Monitor #500,000
|
||||
RAM_Chips #150,000
|
||||
Ethernet_Cables #30,000
|
||||
```
|
||||
|
||||
Awk 也有一个 printf 命令,它能帮助你用更好的方式格式化输出,正如你可以看到上面的输出并不清晰。
|
||||
|
||||
使用 printf 格式化输出 Item_Name 和 Unit_Price:
|
||||
|
||||
```
|
||||
$ awk '//{printf "%-10s %s\n",$2, $3 }' my_shopping.txt
|
||||
|
||||
Item_Name Unit_Price
|
||||
Mouse #20,000
|
||||
Monitor #500,000
|
||||
RAM_Chips #150,000
|
||||
Ethernet_Cables #30,000
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
使用 Awk 进行文本和字符串过滤时字段编辑功能非常重要,它能帮助你从列表中获取列的特定数据。同时需要记住 Awk 中 ($) 操作符和 shell 脚本中不一样。
|
||||
|
||||
我希望这篇文章能对你有所帮助,如果你需要获取其它信息或者有任何疑问,都可以在下面的评论框中告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/awk-print-fields-columns-with-space-separator/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/tag/awk-command/
|
||||
[2]: http://www.tecmint.com/category/bash-shell/
|
||||
@ -0,0 +1,45 @@
|
||||
Cassandra 和 Spark 数据处理一窥
|
||||
==============================================================
|
||||
|
||||

|
||||
|
||||
Apache Cassandra 数据库近来引起了很多的兴趣,这主要源于现代云端软件对于可用性及性能方面的要求。
|
||||
|
||||
那么,Apache Cassandra 是什么?它是一种为高可用性及线性可扩展性优化的分布式的联机交易处理 (OLTP) 数据库。具体说到 Cassandra 的用途时,可以想想你希望贴近用户的系统,比如说让我们的用户进行交互的系统、需要保证实时可用的程序等等,如:产品目录,物联网,医疗系统,以及移动应用。对这些程序而言,下线时间意味着利润降低甚至导致其他更坏的结果。Netfilix 是这个在 2008 年开源的项目的早期使用者,他们对此项目的贡献以及带来的成功让这个项目名声大噪。
|
||||
|
||||
Cassandra 于2010年成为了 Apache 软件基金会的顶级项目,并从此之后就流行起来。现在,只要你有 Cassadra 的相关知识,找工作时就能轻松不少。想想看,NoSQL 语言和开源技术能达到企业级 SQL 技术的高度,真让人觉得十分疯狂而又不可思议的。这引出了一个问题。是什么让它如此的流行?
|
||||
|
||||
因为采用了[亚马逊发表的 Dynamo 论文][1]中率先提出的设计,Cassandra 有能力在大规模的硬件及网络故障时保持实时在线。由于采用了点对点模式,在没有单点故障的情况下,我们能幸免于机架故障甚至全网中断。我们能在不影响用户体验的前提下处理数据中心故障。一个能考虑到故障的分布式系统才是一个没有后顾之忧的分布式系统,因为老实说,故障是迟早会发生的。有了 Cassandra, 我们可以直面残酷的生活并将之融入数据库的结构和功能中。
|
||||
|
||||
我们能猜到你现在在想什么,“但我只有关系数据库相关背景,难道这样的转变不会很困难吗?”这问题的答案介于是和不是之间。使用 Cassandra 建立数据模型对有关系数据库背景的开发者而言是轻车熟路。我们使用表格来建立数据模型,并使用 CQL ( Cassandra 查询语言)来查询数据库。然而,与 SQL 不同的是,Cassandra 支持更加复杂的数据结构,例如嵌套和用户自定义类型。举个例子,当要储存对一个小猫照片的点赞数目时,我们可以将整个数据储存在一个包含照片本身的集合之中从而获得更快的顺序查找而不是建立一个独立的表。这样的表述在 CQL 中十分的自然。在我们照片表中,我们需要记录名字,URL以及给此照片点赞过的人。
|
||||
|
||||

|
||||
|
||||
在一个高性能系统中,毫秒级处理都能对用户体验和客户维系产生影响。昂贵的 JOIN 操作制约了我们通过增加不可预见的网络调用而扩容的能力。当我们将数据反范式化使其能通过尽可能少的请求就可获取时,我们即可从磁盘空间成本的降低中获益并获得可预期的、高性能应用。我们将反范式化同 Cassandra 一同介绍是因为它提供了很有吸引力的的折衷方案。
|
||||
|
||||
很明显,我们不会局限于对于小猫照片的点赞数量。Canssandra 是一款为高并发写入优化的方案。这使其成为需要时常吞吐数据的大数据应用的理想解决方案。实时应用和物联网方面的应用正在稳步增长,无论是需求还是市场表现,我们也会不断的利用我们收集到的数据来寻求改进技术应用的方式。
|
||||
|
||||
这就引出了我们的下一步,我们已经提到了如何以一种现代的、性价比高的方式储存数据,但我们应该如何获得更多的动力呢?具体而言,当我们收集到了所需的数据,我们应该怎样处理呢?如何才能有效的分析几百 TB 的数据呢?如何才能实时的对我们所收集到的信息进行反馈,并在几秒而不是几小时的时间利作出决策呢?Apache Spark 将给我们答案。
|
||||
|
||||
Spark 是大数据变革中的下一步。 Hadoop 和 MapReduce 都是革命性的产品,它们让大数据界获得了分析所有我们所取得的数据的机会。Spark 对性能的大幅提升及对代码复杂度的大幅降低则将大数据分析提升到了另一个高度。通过 Spark,我们能大批量的处理计算,对流处理进行快速反应,通过机器学习作出决策,并通过图遍历来理解复杂的递归关系。这并非只是为你的客户提供与快捷可靠的应用程序连接(Cassandra 已经提供了这样的功能),这更是能洞悉 Canssandra 所储存的数据,作出更加合理的商业决策并同时更好地满足客户需求。
|
||||
|
||||
你可以看看 [Spark-Cassandra Connector][2] (开源) 并动手试试。若想了解更多关于这两种技术的信息,我们强烈推荐名为 [DataStax Academy][3] 的自学课程
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/basics-cassandra-and-spark-data-processing
|
||||
|
||||
作者:[Jon Haddad][a],[Dani Traphagen][b]
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/rustyrazorblade
|
||||
[b]: https://opensource.com/users/dtrapezoid
|
||||
[1]: http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
|
||||
[2]: https://github.com/datastax/spark-cassandra-connector
|
||||
[3]: https://academy.datastax.com/
|
||||
[4]: http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/49162
|
||||
[5]: https://twitter.com/dtrapezoid
|
||||
[6]: https://twitter.com/rustyrazorblade
|
||||
@ -0,0 +1,65 @@
|
||||
共享的未来:Pydio 与 ownCloud 的联合
|
||||
=========================================================
|
||||
|
||||

|
||||
|
||||
*图片来源 : opensource.com*
|
||||
|
||||
开源共享生态圈内容纳了许多各异的项目,它们每一个都给出了自己的解决方案,且每一个都不按套路来。有很多原因导致你选择开源的解决方案,而非 Dropbox、Google Drive、iCloud 或 OneDrive 这些商业的解决方案。这些商业的解决方案虽然能让你不必为如何管理数据担心,但也理所应当的带着种种限制,其中就包括对于原有基础结构的控制和整合不足。
|
||||
|
||||
对于用户而言仍有相当一部分可供选择的文件分享和同步的替代品,其中就包括了 Pydio 和 ownCloud。
|
||||
|
||||
### Pydio
|
||||
|
||||
Pydio (Put your data in orbit 把你的数据放上轨道) 项目由一位作曲家 Charles du Jeu 发起,起初他只是需要一种与乐队成员分享大型音频文件的方法。[Pydio][1] 是一种文件分享与同步的解决方案,综合了多存储后端,设计时还同时考虑了开发者和系统管理员两方面。在世界各地有逾百万的下载量,已被翻译成 27 种语言。
|
||||
|
||||
项目在刚开始的时候便开源了,先是在 [SourceForge][2] 上茁壮的成长,现在已在 [GitHub][3] 上安了家。
|
||||
|
||||
用户界面基于 Google 的 [Material 设计风格][4]。用户可以使用现有的传统文件基础结构或是根据预估的需求部署 Pydio,并通过 web、桌面和移动端应用随时随地地管理自己的东西。对于管理员来说,细粒度的访问权限绝对是配置访问时的利器。
|
||||
|
||||
在 [Pydio 社区][5],你可以找到许多让你增速的资源。Pydio 网站 [对于如何为 Pydio GitHub 仓库贡献][6] 给出了明确的指导方案。[论坛][7]中也包含了开发者板块和社区。
|
||||
|
||||
### ownCloud
|
||||
|
||||
[ownCloud][8] 在世界各地拥有逾 8 百万的用户,它是一个开源、自行管理的文件同步共享技术。同步客户端支持所有主流平台并支持 WebDAV 通过 web 界面实现。ownCloud 拥有简单的使用界面,强大的管理工具,和大规模的共享及协作功能——以满足用户管理数据时的需求。
|
||||
|
||||
ownCloud 的开放式架构是通过 API 和为应用提供平台来实现可扩展性的。迄今已有逾 300 款应用,功能包括处理像日历、联系人、邮件、音乐、密码、笔记等诸多数据类型。ownCloud 由一个数百位贡献者的国际化的社区开发,安全,并且能做到为小到一个树莓派大到好几百万用户的 PB 级存储集群量身定制。
|
||||
|
||||
### 联合共享 (Federated sharing)
|
||||
|
||||
文件共享开始转向团队合作时代,而标准化为合作提供了坚实的土壤。
|
||||
|
||||
联合共享(Federated sharing)——一个由 [OpenCloudMesh][9] 项目提供的新的开放标准,就是在这个方向迈出的一步。先不说别的,在支持该标准的服务器之间分享文件和文件夹,比如说 Pydio 和 ownCloud。
|
||||
|
||||
ownCloud 7 率先引入该标准,这种服务器到服务器的分享方式可以让你挂载远程服务器上共享的文件,实际上就是创建你自己的云上之云。你可以直接为其它支持联合共享的服务器上的用户创建共享链接。
|
||||
|
||||
实现这个新的 API 允许存储解决方案之间更深层次的集成,同时保留了原有平台的安全,控制和特性。
|
||||
|
||||
“交换和共享文件是当下和未来不可或缺的东西。”ownCloud 的创始人 Frank Karlitschek 说道:“正因如此,采用联合和分布的方式而非集中的数据孤岛就显得至关重要。联合共享的设计初衷便是在保证安全和用户隐私的同时追求分享的无缝、至简之道。”
|
||||
|
||||
### 下一步是什么呢?
|
||||
|
||||
正如 OpenCloudMesh 做的那样,将会通过像 Pydio 和 ownCloud 这样的机构和公司,合作推广这一文件共享的新开放标准。ownCloud 9 已经引入联合的服务器之间交换用户列表的功能,让你的用户们在你的服务器上享有和你同样的无缝体验。将来,一个中央地址簿服务(联合的)集合,用以检索其他联合云 ID 的构想可能会把云间合作推向一个新的高度。
|
||||
|
||||
这一举措无疑有助于日益开放的技术社区中的那些成员方便地讨论,开发,并推动“OCM 分享 API”作为一个厂商中立协议。所有领导 OCM 项目的合作伙伴都全心致力于开放 API 的设计原则,并欢迎其他开源的文件分享和同步社区参与并加入其中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/sharing-files-pydio-owncloud
|
||||
|
||||
作者:[ben van 't ende][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/benvantende
|
||||
[1]: https://pydio.com/
|
||||
[2]: https://sourceforge.net/projects/ajaxplorer/
|
||||
[3]: https://github.com/pydio/
|
||||
[4]: https://www.google.com/design/spec/material-design/introduction.html
|
||||
[5]: https://pydio.com/en/community
|
||||
[6]: https://pydio.com/en/community/contribute
|
||||
[7]: https://pydio.com/forum/f
|
||||
[8]: https://owncloud.org/
|
||||
[9]: https://wiki.geant.org/display/OCM/Open+Cloud+Mesh
|
||||
@ -2,7 +2,8 @@
|
||||
========================================
|
||||
|
||||

|
||||
>学习如何用 CloudReady 在你的旧电脑上安装 Chrome OS
|
||||
|
||||
*学习如何用 CloudReady 在你的旧电脑上安装 Chrome OS*
|
||||
|
||||
Linux 之年就在眼前。根据[报道][1],Google 在 2016 年第一季度卖出了比苹果卖出的 Macbook 更多的 Chromebook。并且,Chromebook 即将变得更加激动人心。在 Google I/O 大会上,Google 宣布安卓 Google Play 商店将在 6 月中旬来到 Chromebook,这让用户能够在他们的 Chrome OS 设备上运行安卓应用。
|
||||
|
||||
@ -16,33 +17,35 @@ Linux 之年就在眼前。根据[报道][1],Google 在 2016 年第一季度
|
||||
|
||||
在你开始在笔记本上安装 CloudReady 之前,你需要一些准备:
|
||||
|
||||
- 一个容量大于等于 4GB 的 USB 存储设备
|
||||
|
||||
- 一个容量不小于 4GB 的 USB 存储设备
|
||||
- 打开 Chrome 浏览器,到 Google Chrome Store 去安装 [Chromebook Recovery Utility(Chrome 恢复工具)][3]
|
||||
|
||||
- 更改目标机器的 BIOS 设置以便能从 USB 启动
|
||||
|
||||
### 开始
|
||||
|
||||
Neverware 提供两个版本的 CloudReady 镜像:32 位和 64 位。从下载页面[下载][4]合适你硬件的系统版本。
|
||||
|
||||
解压下载的 zip 文件,你会得到一个 chromiumos_image.bin 文件。现在插入 U 盘并打开 Chromebook recovery utility。点击工具右上角的齿轮,选择 erase recovery media(擦除恢复媒介,如图 1)。
|
||||
解压下载的 zip 文件,你会得到一个 chromiumos_image.bin 文件。现在插入 U 盘并打开 Chromebook Recovery Utility。点击工具右上角的齿轮,选择 erase recovery media(擦除恢复媒介,如图 1)。
|
||||
|
||||

|
||||
>图 1:选择 erase recovery media。[image:cloudready-erase]
|
||||
|
||||
*图 1:选择 erase recovery media。[image:cloudready-erase]*
|
||||
|
||||
接下来,选择目标 USB 驱动器并把它格式化。格式化完成后,再次打开右上齿轮,这次选择 use local image(使用本地镜像)。浏览解压的 bin 文件并选中,选好 USB 驱动器,点击继续,然后点击创建按钮(图 2)。它会开始将镜像写入驱动器。
|
||||
|
||||

|
||||
>图 2:创建 CloudReady 镜像。[Image:cloudready-create]
|
||||
|
||||
*图 2:创建 CloudReady 镜像。[Image:cloudready-create]*
|
||||
|
||||
驱动器写好可启动的 CloudReady 之后,插到目标 PC 上并启动。系统启动进 Chromium OS 需要一小段时间。启动之后,你会看到图 3 中的界面。
|
||||
|
||||

|
||||
>图 3:准备好安装 CloudReady。
|
||||
|
||||
*图 3:准备好安装 CloudReady。*
|
||||
|
||||

|
||||
>图 4:单系统选项。
|
||||
|
||||
*图 4:单系统选项。*
|
||||
|
||||
到任务栏选择 Install CloudReady(安装 CloudReady)。
|
||||
|
||||
@ -53,7 +56,8 @@ Neverware 提供两个版本的 CloudReady 镜像:32 位和 64 位。从下载
|
||||
按照下一步按钮说明选择安装。
|
||||
|
||||

|
||||
>图 5:双系统选项。
|
||||
|
||||
*图 5:双系统选项。*
|
||||
|
||||
整个过程最多 20 分钟左右,这取决于存储媒介和处理能力。安装完成后,电脑会关闭并重启。
|
||||
|
||||
@ -62,17 +66,20 @@ Neverware 提供两个版本的 CloudReady 镜像:32 位和 64 位。从下载
|
||||
你连上无线网络之后,系统会自动查找更新并提供 Adobe Flash 安装。安装完成后,你会看到 Chromium OS 登录界面。现在你只需登录你的 Gmail 账户,开始使用你的“Chromebook”即可。
|
||||
|
||||

|
||||
>图 6:网络设置。
|
||||
|
||||
*图 6:网络设置。*
|
||||
|
||||
### 让 Netflix 正常工作
|
||||
|
||||
如果你想要播放 Netflix 或其它 DRM 保护流媒体站点,你需要做一些额外的工作。转到设置并点击安装 Widevine 插件(图 7)。
|
||||
|
||||

|
||||
>图 7:安装 Widevine。
|
||||
|
||||
*图 7:安装 Widevine。*
|
||||
|
||||

|
||||
>图 8:安装 User Agent Switcher.
|
||||
|
||||
*图 8:安装 User Agent Switcher。*
|
||||
|
||||
现在你需要使用 user agent switcher 这个伎俩(图 8)。
|
||||
|
||||
@ -96,20 +103,20 @@ Indicator Flag: "IE"
|
||||
点击“添加(Add)”。
|
||||
|
||||

|
||||
>图 9:为 CloudReady 创建条目。
|
||||
|
||||
*图 9:为 CloudReady 创建条目。*
|
||||
|
||||
然后,到“permanent spoof list(永久欺骗列表)”选项中将 CloudReady Widevine 添加为 [www.netflix.com](http://www.netflix.com) 的永久 UA 串。
|
||||
|
||||
现在,重启机器,你就可以观看 Netflix 和其它一些服务了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/turn-your-old-laptop-chromebook
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,322 @@
|
||||
在 Ubuntu 16.04 为 Nginx 服务器安装 LEMP 环境(MariaDB,PHP 7 并支持 HTTP 2.0)
|
||||
=====================
|
||||
|
||||
LEMP 是个缩写,代表一组软件包(L:Linux OS,E:Nginx 网络服务器,M:MySQL/MariaDB 数据库和 P:PHP 服务端动态编程语言),它被用来搭建动态的网络应用和网页。
|
||||
|
||||

|
||||
|
||||
*在 Ubuntu 16.04 安装 Nginx 以及 MariaDB,PHP7 并且支持 HTTP 2.0*
|
||||
|
||||
这篇教程会教你怎么在 Ubuntu 16.04 的服务器上安装 LEMP (Nginx 和 MariaDB 以及 PHP7)。
|
||||
|
||||
**前置准备**
|
||||
|
||||
- [安装 Ubuntu 16.04 服务器版本][1]
|
||||
|
||||
### 步骤 1:安装 Nginx 服务器
|
||||
|
||||
1、Nginx 是一个先进的、资源优化的 Web 服务器程序,用来向因特网上的访客展示网页。我们从 Nginx 服务器的安装开始介绍,使用 [apt 命令][2] 从 Ubuntu 的官方软件仓库中获取 Nginx 程序。
|
||||
|
||||
```
|
||||
$ sudo apt-get install nginx
|
||||
```
|
||||
|
||||
|
||||
|
||||
*在 Ubuntu 16.04 安装 Nginx*
|
||||
|
||||
2、 然后输入 [netstat][3] 和 [systemctl][4] 命令,确认 Nginx 进程已经启动并且绑定在 80 端口。
|
||||
|
||||
```
|
||||
$ netstat -tlpn
|
||||
```
|
||||
|
||||
|
||||
|
||||
*检查 Nginx 网络端口连接*
|
||||
|
||||
```
|
||||
$ sudo systemctl status nginx.service
|
||||
```
|
||||
|
||||
|
||||
|
||||
*检查 Nginx 服务状态*
|
||||
|
||||
当你确认服务进程已经启动了,你可以打开一个浏览器,使用 HTTP 协议访问你的服务器 IP 地址或者域名,浏览 Nginx 的默认网页。
|
||||
|
||||
```
|
||||
http://IP-Address
|
||||
```
|
||||
|
||||
|
||||
|
||||
*验证 Nginx 网页*
|
||||
|
||||
### 步骤 2:启用 Nginx HTTP/2.0 协议
|
||||
|
||||
3、 对 HTTP/2.0 协议的支持默认包含在 Ubuntu 16.04 最新发行版的 Nginx 二进制文件中了,它只能通过 SSL 连接并且保证加载网页的速度有巨大提升。
|
||||
|
||||
要启用Nginx 的这个协议,首先找到 Nginx 提供的网站配置文件,输入下面这个命令备份配置文件。
|
||||
|
||||
```
|
||||
$ cd /etc/nginx/sites-available/
|
||||
$ sudo mv default default.backup
|
||||
```
|
||||
|
||||

|
||||
|
||||
*备份 Nginx 的网站配置文件*
|
||||
|
||||
4、然后,用文本编辑器新建一个默认文件,输入以下内容:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 443 ssl http2 default_server;
|
||||
listen [::]:443 ssl http2 default_server;
|
||||
|
||||
root /var/www/html;
|
||||
|
||||
index index.html index.htm index.php;
|
||||
|
||||
server_name 192.168.1.13;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ =404;
|
||||
}
|
||||
|
||||
ssl_certificate /etc/nginx/ssl/nginx.crt;
|
||||
ssl_certificate_key /etc/nginx/ssl/nginx.key;
|
||||
|
||||
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
|
||||
ssl_prefer_server_ciphers on;
|
||||
ssl_ciphers EECDH+CHACHA20:EECDH+AES128:RSA+AES128:EECDH+AES256:RSA+AES256:EECDH+3DES:RSA+3DES:!MD5;
|
||||
ssl_dhparam /etc/nginx/ssl/dhparam.pem;
|
||||
ssl_session_cache shared:SSL:20m;
|
||||
ssl_session_timeout 180m;
|
||||
resolver 8.8.8.8 8.8.4.4;
|
||||
add_header Strict-Transport-Security "max-age=31536000;
|
||||
#includeSubDomains" always;
|
||||
|
||||
|
||||
location ~ \.php$ {
|
||||
include snippets/fastcgi-php.conf;
|
||||
fastcgi_pass unix:/run/php/php7.0-fpm.sock;
|
||||
}
|
||||
|
||||
location ~ /\.ht {
|
||||
deny all;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
server {
|
||||
listen 80;
|
||||
listen [::]:80;
|
||||
server_name 192.168.1.13;
|
||||
return 301 https://$server_name$request_uri;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
*启用 Nginx HTTP 2 协议*
|
||||
|
||||
上面的配置片段向所有的 SSL 监听指令中添加 http2 参数来启用 `HTTP/2.0`。
|
||||
|
||||
上述添加到服务器配置的最后一段,是用来将所有非 SSL 的流量重定向到 SSL/TLS 默认主机。然后用你主机的 IP 地址或者 DNS 记录(最好用 FQDN 名称)替换掉 `server_name` 选项的参数。
|
||||
|
||||
5、 当你按照以上步骤编辑完 Nginx 的默认配置文件之后,用下面这些命令来生成、查看 SSL 证书和密钥。
|
||||
|
||||
用你自定义的设置完成证书的制作,注意 Common Name 设置成和你的 DNS FQDN 记录或者服务器 IP 地址相匹配。
|
||||
|
||||
```
|
||||
$ sudo mkdir /etc/nginx/ssl
|
||||
$ sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/nginx/ssl/nginx.key -out /etc/nginx/ssl/nginx.crt
|
||||
$ ls /etc/nginx/ssl/
|
||||
```
|
||||
|
||||
|
||||
|
||||
*生成 Nginx 的 SSL 证书和密钥*
|
||||
|
||||
6、 通过输入以下命令使用一个强 DH 加密算法,这会修改之前的配置文件 `ssl_dhparam` 所配置的文件。
|
||||
|
||||
```
|
||||
$ sudo openssl dhparam -out /etc/nginx/ssl/dhparam.pem 2048
|
||||
```
|
||||
|
||||
|
||||
|
||||
*创建 Diffie-Hellman 密钥*
|
||||
|
||||
7、 当 `Diffie-Hellman` 密钥生成之后,验证 Nginx 的配置文件是否正确、能否被 Nginx 网络服务程序应用。然后运行以下命令重启守护进程来观察有什么变化。
|
||||
|
||||
```
|
||||
$ sudo nginx -t
|
||||
$ sudo systemctl restart nginx.service
|
||||
```
|
||||
|
||||
|
||||
|
||||
*检查 Nginx 的配置*
|
||||
|
||||
8、 键入下面的命令来测试 Nginx 使用的是 HTTP/2.0 协议。看到协议中有 `h2` 的话,表明 Nginx 已经成功配置使用 HTTP/2.0 协议。所有最新的浏览器默认都能够支持这个协议。
|
||||
|
||||
```
|
||||
$ openssl s_client -connect localhost:443 -nextprotoneg ''
|
||||
```
|
||||
|
||||
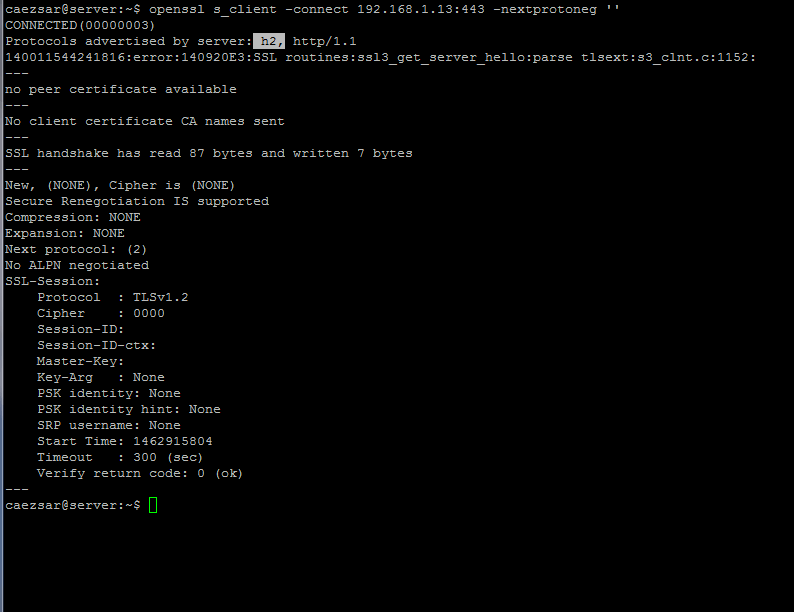
|
||||
|
||||
*测试 Nginx HTTP 2.0 协议*
|
||||
|
||||
### 第 3 步:安装 PHP 7 解释器
|
||||
|
||||
通过 FastCGI 进程管理程序的协助,Nginx 能够使用 PHP 动态语言解释器生成动态网络内容。FastCGI 能够从 Ubuntu 官方仓库中安装 php-fpm 二进制包来获取。
|
||||
|
||||
9、 在你的服务器控制台里输入下面的命令来获取 PHP7.0 和扩展包,这能够让 PHP 与 Nginx 网络服务进程通信。
|
||||
|
||||
```
|
||||
$ sudo apt install php7.0 php7.0-fpm
|
||||
```
|
||||
|
||||
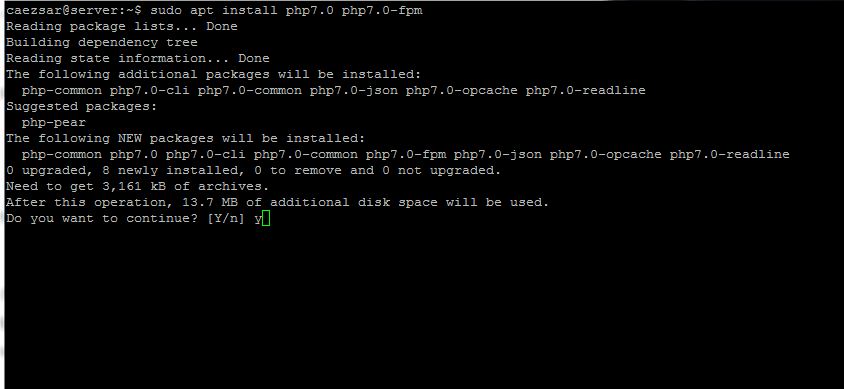
|
||||
|
||||
*安装 PHP 7 以及 PHP-FPM*
|
||||
|
||||
10、 当 PHP7.0 解释器安装成功后,输入以下命令启动或者检查 php7.0-fpm 守护进程:
|
||||
|
||||
```
|
||||
$ sudo systemctl start php7.0-fpm
|
||||
$ sudo systemctl status php7.0-fpm
|
||||
```
|
||||
|
||||
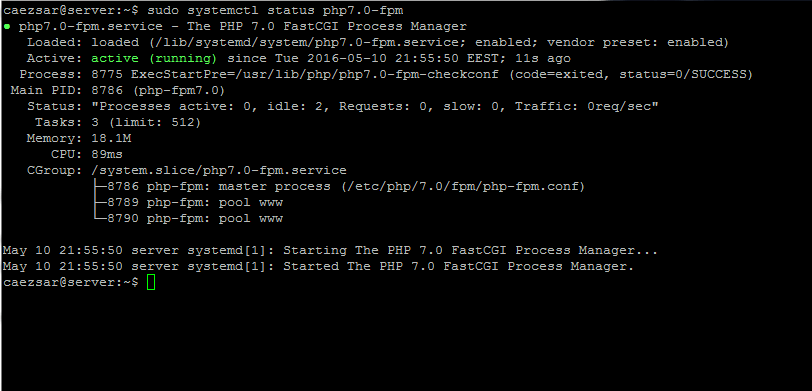
|
||||
|
||||
*开启、验证 php-fpm 服务*
|
||||
|
||||
11、 当前的 Nginx 配置文件已经配置了使用 PHP FPM 来提供动态内容。
|
||||
|
||||
下面给出的这部分服务器配置让 Nginx 能够使用 PHP 解释器,所以不需要对 Nginx 配置文件作别的修改。
|
||||
|
||||
```
|
||||
location ~ \.php$ {
|
||||
include snippets/fastcgi-php.conf;
|
||||
fastcgi_pass unix:/run/php/php7.0-fpm.sock;
|
||||
}
|
||||
```
|
||||
|
||||
下面是的截图是 Nginx 默认配置文件的内容。你可能需要对其中的代码进行修改或者取消注释。
|
||||
|
||||
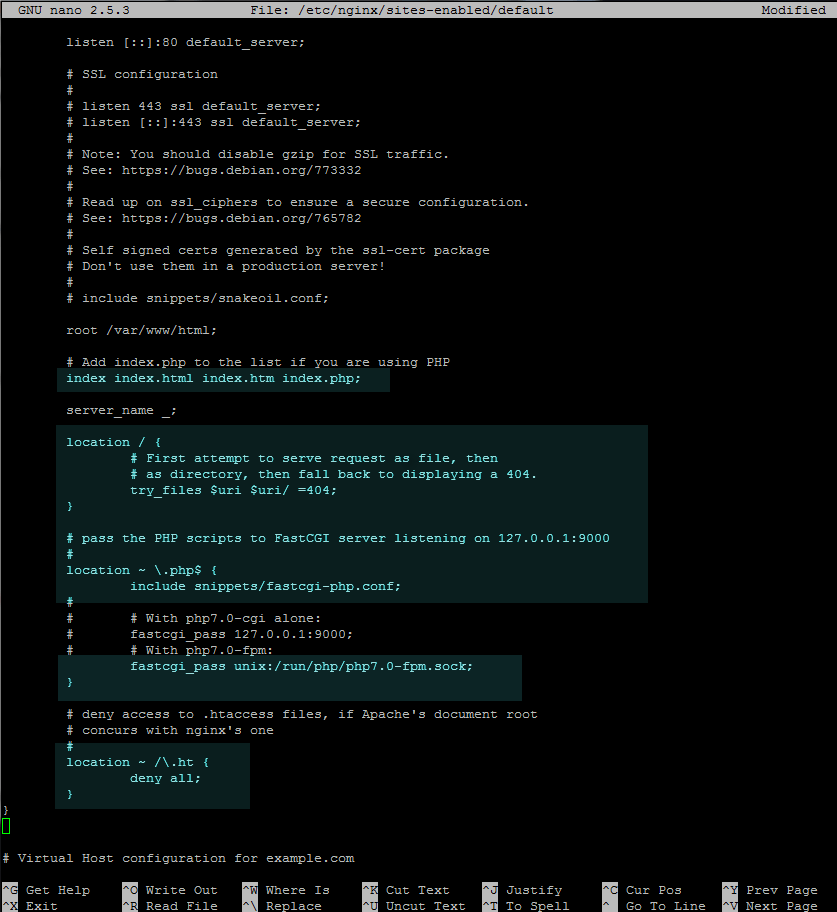
|
||||
|
||||
*启用 PHP FastCGI*
|
||||
|
||||
12、 要测试启用了 PHP-FPM 的 Nginx 服务器,用下面的命令创建一个 PHP 测试配置文件 `info.php`。接着用 `http://IP_or domain/info.php` 这个网址来查看配置。
|
||||
|
||||
```
|
||||
$ sudo su -c 'echo "<?php phpinfo(); ?>" |tee /var/www/html/info.php'
|
||||
```
|
||||
|
||||

|
||||
|
||||
*创建 PHP Info 文件*
|
||||
|
||||

|
||||
|
||||
*检查 PHP FastCGI 的信息*
|
||||
|
||||
检查服务器是否宣告支持 HTTP/2.0 协议,定位到 PHP 变量区域中的 `$_SERVER[‘SERVER_PROTOCOL’]` 就像下面这张截图一样。
|
||||
|
||||
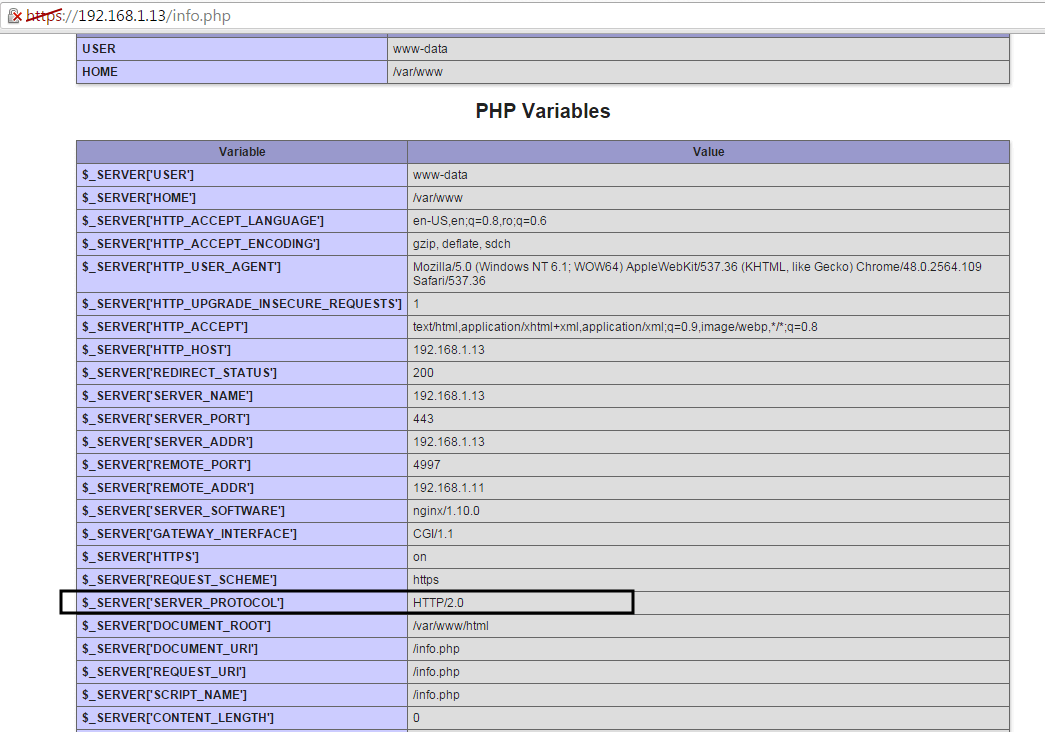
|
||||
|
||||
*检查 HTTP2.0 协议信息*
|
||||
|
||||
13、 为了安装其它的 PHP7.0 模块,使用 `apt search php7.0` 命令查找 php 的模块然后安装。
|
||||
|
||||
如果你想要 [安装 WordPress][5] 或者别的 CMS,需要安装以下的 PHP 模块,这些模块迟早有用。
|
||||
|
||||
```
|
||||
$ sudo apt install php7.0-mcrypt php7.0-mbstring
|
||||
```
|
||||
|
||||
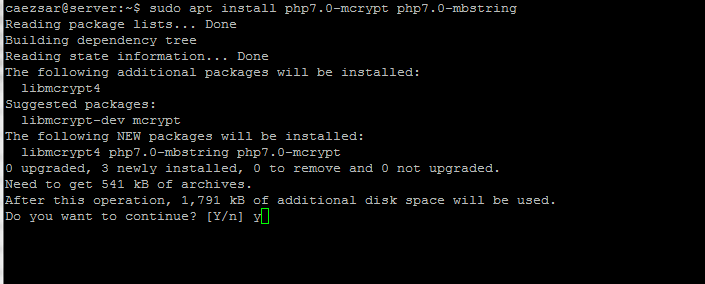
|
||||
|
||||
*安装 PHP 7 模块*
|
||||
|
||||
14、 要注册这些额外的 PHP 模块,输入下面的命令重启 PHP-FPM 守护进程。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart php7.0-fpm.service
|
||||
```
|
||||
|
||||
### 第 4 步:安装 MariaDB 数据库
|
||||
|
||||
15、 最后,我们需要 MariaDB 数据库来存储、管理网站数据,才算完成 LEMP 的搭建。
|
||||
|
||||
运行下面的命令安装 MariaDB 数据库管理系统,重启 PHP-FPM 服务以便使用 MySQL 模块与数据库通信。
|
||||
|
||||
```
|
||||
$ sudo apt install mariadb-server mariadb-client php7.0-mysql
|
||||
$ sudo systemctl restart php7.0-fpm.service
|
||||
```
|
||||
|
||||
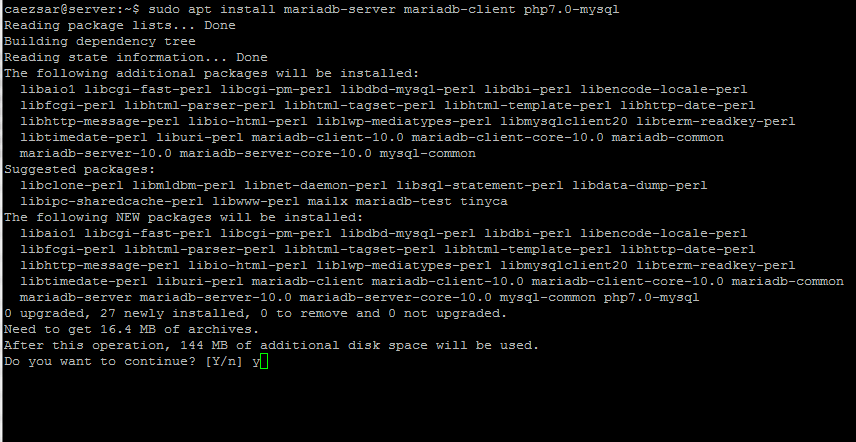
|
||||
|
||||
*安装 MariaDB*
|
||||
|
||||
16、 为了安全加固 MariaDB,运行来自 Ubuntu 软件仓库中的二进制包提供的安全脚本,这会询问你设置一个 root 密码,移除匿名用户,禁用 root 用户远程登录,移除测试数据库。
|
||||
|
||||
输入下面的命令运行脚本,并且确认所有的选择。参照下面的截图。
|
||||
|
||||
```
|
||||
$ sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
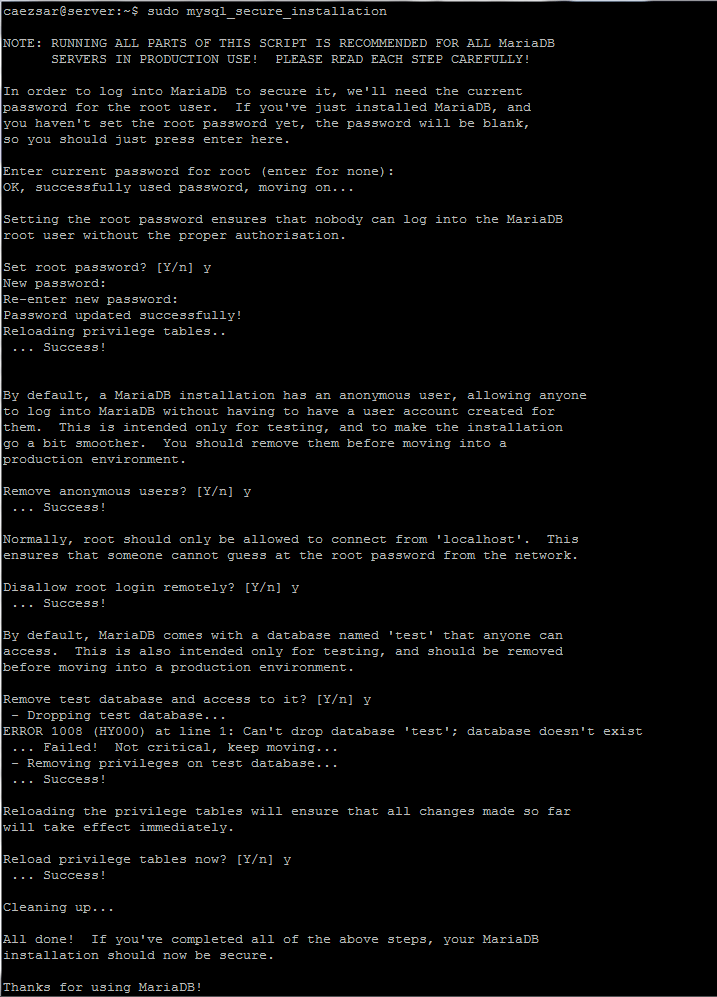
|
||||
|
||||
*MariaDB 的安全安装*
|
||||
|
||||
17、 配置 MariaDB 以便普通用户能够不使用系统的 sudo 权限来访问数据库。用 root 用户权限打开 MySQL 命令行界面,运行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo mysql
|
||||
MariaDB> use mysql;
|
||||
MariaDB> update user set plugin=’‘ where User=’root’;
|
||||
MariaDB> flush privileges;
|
||||
MariaDB> exit
|
||||
```
|
||||
|
||||
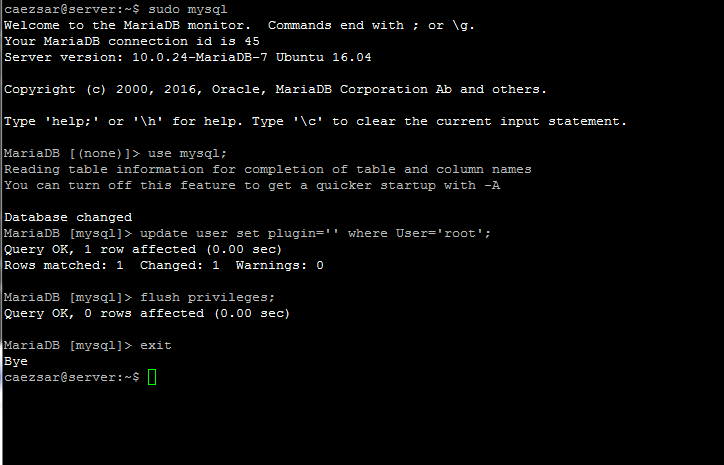
|
||||
|
||||
*MariaDB 的用户权限*
|
||||
|
||||
最后通过执行以下命令登录到 MariaDB 数据库,就可以不需要 root 权限而执行任意数据库内的命令:
|
||||
|
||||
```
|
||||
$ mysql -u root -p -e 'show databases'
|
||||
```
|
||||
|
||||
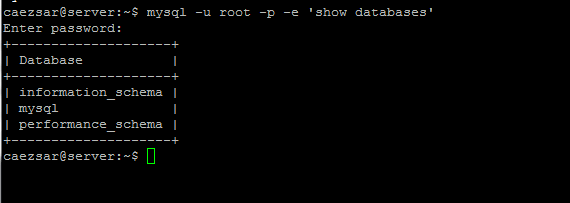
|
||||
|
||||
*查看 MariaDB 数据库*
|
||||
|
||||
好了!现在你拥有了配置在 **Ubuntu 16.04** 服务器上的 **LEMP** 环境,你能够部署能够与数据库交互的复杂动态网络应用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-nginx-mariadb-php7-http2-on-ubuntu-16-04/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/cezarmatei/
|
||||
[1]: http://www.tecmint.com/installation-of-ubuntu-16-04-server-edition/
|
||||
[2]: http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[3]: http://www.tecmint.com/20-netstat-commands-for-linux-network-management/
|
||||
[4]: http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux/
|
||||
[5]: http://www.tecmint.com/install-wordpress-using-lamp-or-lemp-on-rhel-centos-fedora/
|
||||
@ -1,14 +1,15 @@
|
||||
在 Ubuntu Linux 中使用 WEBP 图片
|
||||
在 Ubuntu Linux 中使用 WebP 图片
|
||||
=========================================
|
||||
|
||||

|
||||
>简介:这篇指南会向你展示如何在 Linux 下查看 WebP 图片以及将 WebP 图片转换为 JPEG 或 PNG 格式。
|
||||
|
||||
### 什么是 WEBP?
|
||||
> 简介:这篇指南会向你展示如何在 Linux 下查看 WebP 图片以及将 WebP 图片转换为 JPEG 或 PNG 格式。
|
||||
|
||||
Google 为图片推出 [WebP 文件格式][0]已经超过五年了。Google 说,WebP 提供有损和无损压缩,相比 JPEG 压缩,WebP 压缩文件大小能更小约 25%。
|
||||
### 什么是 WebP?
|
||||
|
||||
Google 的目标是让 WebP 成为 web 图片的新标准,但是我没能看到这一切发生。已经五年过去了,除了谷歌的生态系统以外它仍未被接受成为一个标准。但正如我们所知的,Google 对它的技术很有进取心。几个月前 Google 将 Google Plus 的所有图片改为了 WebP 格式。
|
||||
自从 Google 推出 [WebP 图片格式][0],已经过去五年了。Google 说,WebP 提供有损和无损压缩,相比 JPEG 压缩,WebP 压缩文件大小,能更小约 25%。
|
||||
|
||||
Google 的目标是让 WebP 成为 web 图片的新标准,但是并没有成为现实。已经五年过去了,除了谷歌的生态系统以外它仍未被接受成为一个标准。但正如我们所知的,Google 对它的技术很有进取心。几个月前 Google 将 Google Plus 的所有图片改为了 WebP 格式。
|
||||
|
||||
如果你用 Google Chrome 从 Google Plus 上下载那些图片,你会得到 WebP 图片,不论你之前上传的是 PNG 还是 JPEG。这都不是重点。真正的问题在于当你尝试着在 Ubuntu 中使用默认的 GNOME 图片查看器打开它时你会看到如下错误:
|
||||
|
||||
@ -17,7 +18,8 @@ Google 的目标是让 WebP 成为 web 图片的新标准,但是我没能看
|
||||
> **Unrecognized image file format(未识别文件格式)**
|
||||
|
||||

|
||||
>GNOME 图片查看器不支持 WebP 图片
|
||||
|
||||
*GNOME 图片查看器不支持 WebP 图片*
|
||||
|
||||
在这个教程里,我们会看到
|
||||
|
||||
@ -41,7 +43,8 @@ sudo apt-get install gthumb
|
||||
一旦安装完成,你就可以简单地右键点击 WebP 图片,选择 gThumb 来打开它。你现在应该可以看到如下画面:
|
||||
|
||||

|
||||
>gThumb 中显示的 WebP 图片
|
||||
|
||||
*gThumb 中显示的 WebP 图片*
|
||||
|
||||
### 让 gThumb 成为 Ubuntu 中 WebP 图片的默认应用
|
||||
|
||||
@ -50,28 +53,30 @@ sudo apt-get install gthumb
|
||||
#### 步骤 1:右键点击 WebP 文件选择属性。
|
||||
|
||||

|
||||
>从右键菜单中选择属性
|
||||
|
||||
*从右键菜单中选择属性*
|
||||
|
||||
#### 步骤 2:转到打开方式标签,选择 gThumb 并点击设置为默认。
|
||||
|
||||

|
||||
>让 gThumb 成为 Ubuntu 中 WebP 图片的默认应用
|
||||
|
||||
*让 gThumb 成为 Ubuntu 中 WebP 图片的默认应用*
|
||||
|
||||
### 让 gThumb 成为所有图片的默认应用
|
||||
|
||||
gThumb 的功能比图片查看器更多。举个例子,你可以做一些简单的编辑,给图片添加滤镜等。添加滤镜的效率没有 XnRetro(在[ Linux 下添加类似 Instagram 滤镜效果][5]的专用工具)那么高,但它还是有一些基础的滤镜可以用。
|
||||
gThumb 的功能比图片查看器更多。举个例子,你可以做一些简单的图片编辑,给图片添加滤镜等。添加滤镜的效率没有 XnRetro(在[ Linux 下添加类似 Instagram 滤镜效果][5]的专用工具)那么高,但它还是有一些基础的滤镜可以用。
|
||||
|
||||
我非常喜欢 gThumb 并且决定让它成为默认的图片查看器。如果你也想在 Ubuntu 中让 gThumb 成为所有图片的默认默认应用,遵照以下步骤操作:
|
||||
我非常喜欢 gThumb 并且决定让它成为默认的图片查看器。如果你也想在 Ubuntu 中让 gThumb 成为所有图片的默认应用,遵照以下步骤操作:
|
||||
|
||||
#### 步骤1:打开系统设置
|
||||
步骤1:打开系统设置
|
||||
|
||||

|
||||
|
||||
#### 步骤2:转到详情(Details)
|
||||
步骤2:转到详情(Details)
|
||||
|
||||

|
||||
|
||||
#### 步骤3:在这里将 gThumb 设置为图片的默认应用
|
||||
步骤3:在这里将 gThumb 设置为图片的默认应用
|
||||
|
||||

|
||||
|
||||
@ -100,7 +105,7 @@ sudo apt-get install webp
|
||||
|
||||
##### 将 JPEG/PNG 转换为 WebP
|
||||
|
||||
我们将使用 cwebp 命令(它代表压缩为 WebP 吗?)来将 JPEG 或 PNG 文件转换为 WebP。命令格式是这样的:
|
||||
我们将使用 cwebp 命令(它代表转换为 WebP 的意思吗?)来将 JPEG 或 PNG 文件转换为 WebP。命令格式是这样的:
|
||||
|
||||
```
|
||||
cwebp -q [图片质量] [JPEG/PNG_文件名] -o [WebP_文件名]
|
||||
@ -132,7 +137,7 @@ dwebp example.webp -o example.png
|
||||
|
||||
[下载 XnConvert][1]
|
||||
|
||||
XnConvert 是个强大的工具,你可以用它来批量修改图片尺寸。但在这个教程里,我们只能看到如何将单个 WebP 图片转换为 PNG/JPEG。
|
||||
XnConvert 是个强大的工具,你可以用它来批量修改图片尺寸。但在这个教程里,我们只介绍如何将单个 WebP 图片转换为 PNG/JPEG。
|
||||
|
||||
打开 XnConvert 并选择输入文件:
|
||||
|
||||
@ -148,24 +153,24 @@ XnConvert 是个强大的工具,你可以用它来批量修改图片尺寸。
|
||||
|
||||
也许你一点都不喜欢 WebP 图片格式,也不想在 Linux 仅仅为了查看 WebP 图片而安装一个新软件。如果你不得不将 WebP 文件转换以备将来使用,这会是件更痛苦的事情。
|
||||
|
||||
一个解决这个问题更简单,不那么痛苦的途径是安装一个 Chrome 扩展 Save Image as PNG。有了这个插件,你可以右键点击 WebP 图片并直接存储为 PNG 格式。
|
||||
解决这个问题的一个更简单、不那么痛苦的途径是安装一个 Chrome 扩展 Save Image as PNG。有了这个插件,你可以右键点击 WebP 图片并直接存储为 PNG 格式。
|
||||
|
||||

|
||||
>在 Google Chrome 中将 WebP 图片保存为 PNG 格式
|
||||
|
||||
[获取 Save Image as PNG 扩展][2]
|
||||
*在 Google Chrome 中将 WebP 图片保存为 PNG 格式*
|
||||
|
||||
- [获取 Save Image as PNG 扩展][2]
|
||||
|
||||
### 你的选择是?
|
||||
|
||||
我希望这个详细的教程能够帮你在 Linux 上获取 WebP 支持并帮你转换 WebP 图片。你在 Linux 怎么处理 WebP 图片?你使用哪个工具?以上描述的方法中,你最喜欢哪一个?
|
||||
|
||||
我希望这个详细的教程能够帮你在 Linux 上支持 WebP 并帮你转换 WebP 图片。你在 Linux 怎么处理 WebP 图片?你使用哪个工具?以上描述的方法中,你最喜欢哪一个?
|
||||
|
||||
----------------------
|
||||
via: http://itsfoss.com/webp-ubuntu-linux/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
via: http://itsfoss.com/webp-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,63 @@
|
||||
为什么 Ubuntu 家族会占据 Linux 发行版的主导地位?
|
||||
=========================================
|
||||
|
||||
在过去的数年中,我体验了一些优秀的 Linux 发行版。给我印象最深刻的是那些由强大的社区维护的发行版,而流行的发行版比强大的社区给我的印象更深。流行的 Linux 发行版往往能吸引新用户,这通常是由于其流行而使得使用该发行版会更加容易。并非绝对如此,但一般来说是这样的。
|
||||
|
||||
说到这里,首先映入我脑海的一个发行版是 [Ubuntu][1]。其基于健壮的 [Debian][2] 发行版构建,它不仅成为了一个非常受欢迎的 Linux 发行版,而且它也衍生出了不可计数的其他分支,比如 Linux Mint 就是一个例子。在本文中,我会探讨为何我认为 Ubuntu 会赢得 Linux 发行版之战的原因,以及它是怎样影响到了整个 Linux 桌面领域。
|
||||
|
||||
### Ubuntu 易于使用
|
||||
|
||||
在我几年前首次尝试使用 Ubuntu 前,我更喜欢使用 KED 桌面。在那个时期,我接触的大多是这种 KDE 桌面环境。主要原因还是 KDE 是大多数新手容易入手的 Linux 发行版中最受欢迎的。这些新手友好的发行版有 Knoppix、Simply Mepis、Xandros、Linspire 以及其它的发行版等等,这些发行版都推荐他们的用户去使用广受欢迎的 KDE。
|
||||
|
||||
现在 KDE 能满足我的需求,我也没有什么理由去折腾其他的桌面环境。有一天我的 Debian 安装失败了(由于我个人的操作不当),我决定尝试开发代号为 Dapper Drake 的 Ubuntu 版本(LCTT 译注:Ubuntu 6.06 - Dapper Drake,发布日期:2006 年 6 月 1 日),每个人都对它赞不绝口。那个时候,我对于它的印象仅限于屏幕截图,但是我想试试也挺有趣的。
|
||||
|
||||
Ubuntu Dapper Drake 给我的最大的印象是它让我很清楚地知道每个东西都在哪儿。记住,我是来自于 KDE 世界的用户,在 KDE 上要想改变菜单的设置就有 15 种方法 !而 Ubuntu 上的 GNOME 实现极具极简主义的。
|
||||
|
||||
时间来到 2016 年,最新的版本号是 16.04:我们有了好几种 Ubuntu 特色版本,也有一大堆基于 Ubuntu 的发行版。所有的 Ubuntu 特色版和衍生发行版的共同具有的核心都是为易用而设计。发行版想要增大用户基数时,这就是最重要的原因。
|
||||
|
||||
### Ubuntu LTS
|
||||
|
||||
过去,我几乎一直坚持使用 LTS(Long Term Support)发行版作为我的主要桌面系统。10月份的发行版很适合我测试硬盘驱动器,甚至把它用在一个老旧的手提电脑上。我这样做的原因很简单——我没有兴趣在一个正式使用的电脑上折腾短期发行版。我是个很忙的家伙,我觉得这样会浪费我的时间。
|
||||
|
||||
对于我来说,我认为 Ubuntu 提供 LTS 发行版是 Ubuntu 能够变得流行的最大的原因。这样说吧———给普罗大众提供一个桌面 Linux 发行版,这个发行版能够得到长期的有效支持就是它的优势。事实上,不只 Ubuntu 是这样,其他的分支在这一点上也做的很好。长期支持策略以及对新手的友好环境,我认为这就为 Ubuntu 的普及带来了莫大的好处。
|
||||
|
||||
### Ubuntu Snap 软件包
|
||||
|
||||
以前,用户会夸赞可以在他们的系统上使用 PPA(personal package archive 个人软件包档案)获得新的软件。不好的是,这种技术也有缺点。当它用在各种软件名称时, PPA 经常会找不到,这种情况很常见。
|
||||
|
||||
现在有了 [Snap 软件包][3] 。当然这不是一个全新的概念,过去已经进行了类似的尝试。用户可以在一个长期支持版本上运行最新的软件,而不必去使用最新的 Ubuntu 发行版。虽然我认为目前还处于 Snap 软件包的早期,但是我很期待可以在一个稳定的发行版上运行的崭新的软件。
|
||||
|
||||
最明显的问题是,如果你要运行很多软件,那么 Snap 包实际会占用很多硬盘空间。不仅如此,大多数 Ubuntu 软件仍然需要由官方从 deb 包进行转换。第一个问题可以通过使用更大的硬盘空间得到解决,而后一个问题的解决则需要等待。
|
||||
|
||||
### Ubuntu 社区
|
||||
|
||||
首先,我承认大多数主要的 Linux 发行版都有强大的社区。然而,我坚信 Ubuntu 社区的成员是最多样化的,他们来自各行各业。例如,我们的论坛包括从苹果硬件支持到游戏等不同分类。特别是这些专业的讨论话题还非常广泛。
|
||||
|
||||
除过论坛,Ubuntu 也提供了一个很正式的社区组织。这个组织包括一个理事会、技术委员会、[本地社区团队][4]和开发者成员委员会。还有很多,但是这些都是我知道的社区组织部分。
|
||||
|
||||
我们还有一个 [Ubuntu 问答][5]版块。我认为,这种功能可以代替人们从论坛寻求帮助的方式,我发现在这个网站你得到有用信息的可能性更大。不仅如此,那些提供的解决方案中被选出的最精准的答案也会被写入到官方文档中。
|
||||
|
||||
### Ubuntu 的未来
|
||||
|
||||
我认为 Ubuntu 的 Unity 界面(LCTT 译注:Unity 是 Canonical 公司为 Ubuntu 操作系统的 GNOME 桌面环境开发的图形化界面)在提升桌面占有率上少有作为。我能理解其中的缘由,现在它主要做一些诸如可以使开发团队的工作更轻松的事情。但是最终,我还是认为 Unity 为 Ubuntu MATE 和 Linux Mint 的普及铺平道路。
|
||||
|
||||
我最好奇的一点是 Ubuntu's IRC 和邮件列表的发展(LCTT 译注:可以在 Ubuntu LoCo Teams 的 IRC Chat 上提问关于地方团队和计划的事件的问题,也可以和一些不同团队的成员进行交流)。事实是,他们都不能像 Ubuntu 问答板块那样文档化。至于邮件列表,我一直认为这对于合作是一种很痛苦的过时方法,但这仅仅是我的个人看法——其他人可能有不同的看法,也可能会认为它很好。
|
||||
|
||||
你怎么看?你认为 Ubuntu 将来会占据主要的份额吗?也许你会认为 Arch 和 Linux Mint 或者其他的发行版会在普及度上打败 Ubuntu? 既然这样,那请大声说出你最喜爱的发行版。如果这个发行版是 Ubuntu 衍生版 ,说说你为什么更喜欢它而不是 Ubuntu 本身。如果不出意外,Ubuntu 会成为构建其他发行版的基础,我想很多人都是这样认为的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/why-ubuntu-based-distros-are-leaders.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]: http://www.ubuntu.com/
|
||||
[2]: https://www.debian.org/
|
||||
[3]: http://www.datamation.com/open-source/ubuntu-snap-packages-the-good-the-bad-the-ugly.html
|
||||
[4]: http://loco.ubuntu.com/
|
||||
[5]: http://askubuntu.com/
|
||||
@ -0,0 +1,64 @@
|
||||
教你用 google-drive-ocamlfuse 在 Linux 上挂载 Google Drive
|
||||
=====================
|
||||
|
||||
> 如果你在找一个方便的方式在 Linux 机器上挂载你的 Google Drive 文件夹, Jack Wallen 将教你怎么使用 google-drive-ocamlfuse 来挂载 Google Drive。
|
||||
|
||||

|
||||
|
||||
*图片来源: Jack Wallen*
|
||||
|
||||
Google 还没有发行 Linux 版本的 Google Drive 应用,尽管现在有很多方法从 Linux 中访问你的 Drive 文件。
|
||||
|
||||
如果你喜欢界面化的工具,你可以选择 Insync。如果你喜欢用命令行,有很多像 Grive2 这样的工具,和更容易使用的以 Ocaml 语言编写的基于 FUSE 的文件系统。我将会用后面这种方式演示如何在 Linux 桌面上挂载你的 Google Drive。尽管这是通过命令行完成的,但是它的用法会简单到让你吃惊。它太简单了以至于谁都能做到。
|
||||
|
||||
这个系统的特点:
|
||||
|
||||
- 对普通文件/文件夹有完全的读写权限
|
||||
- 对于 Google Docs,sheets,slides 这三个应用只读
|
||||
- 能够访问 Drive 回收站(.trash)
|
||||
- 处理重复文件功能
|
||||
- 支持多个帐号
|
||||
|
||||
让我们接下来完成 google-drive-ocamlfuse 在 Ubuntu 16.04 桌面的安装,然后你就能够访问云盘上的文件了。
|
||||
|
||||
### 安装
|
||||
|
||||
1. 打开终端。
|
||||
2. 用 `sudo add-apt-repository ppa:alessandro-strada/ppa` 命令添加必要的 PPA
|
||||
3. 出现提示的时候,输入你的 root 密码并按下回车。
|
||||
4. 用 `sudo apt-get update` 命令更新应用。
|
||||
5. 输入 `sudo apt-get install google-drive-ocamlfuse` 命令安装软件。
|
||||
|
||||
### 授权
|
||||
|
||||
接下来就是授权 google-drive-ocamlfuse,让它有权限访问你的 Google 账户。先回到终端窗口敲下命令 `google-drive-ocamlfuse`,这个命令将会打开一个浏览器窗口,它会提示你登陆你的 Google 帐号或者如果你已经登陆了 Google 帐号,它会询问是否允许 google-drive-ocamlfuse 访问 Google 账户。如果你还没有登录,先登录然后点击“允许”。接下来的窗口(在 Ubuntu 16.04 桌面上会出现,但不会出现在 Elementary OS Freya 桌面上)将会询问你是否授给 gdfuse 和 OAuth2 Endpoint 访问你的 Google 账户的权限,再次点击“允许”。然后出现的窗口就会告诉你等待授权令牌下载完成,这个时候就能最小化浏览器了。当你的终端提示如下图一样的内容,你就能知道令牌下载完了,并且你已经可以挂载 Google Drive 了。
|
||||
|
||||

|
||||
|
||||
*应用已经得到授权,你可以进行后面的工作。*
|
||||
|
||||
### 挂载 Google Drive
|
||||
|
||||
在挂载 Google Drive 之前,你得先创建一个文件夹,作为挂载点。在终端里,敲下`mkdir ~/google-drive`命令在你的家目录下创建一个新的文件夹。最后敲下命令`google-drive-ocamlfuse ~/google-drive`将你的 Google Drive 挂载到 google-drive 文件夹中。
|
||||
|
||||
这时你可以查看本地 google-drive 文件夹中包含的 Google Drive 文件/文件夹。你可以把 Google Drive 当作本地文件系统来进行工作。
|
||||
|
||||
当你想卸载 google-drive 文件夹,输入命令 `fusermount -u ~/google-drive`。
|
||||
|
||||
### 没有 GUI,但它特别好用
|
||||
|
||||
我发现这个特别的系统非常容易使用,在同步 Google Drive 时它出奇的快,并且这可以作为一种本地备份你的 Google Drive 账户的巧妙方式。(LCTT 译注:然而首先你得能使用……)
|
||||
|
||||
试试 google-drive-ocamlfuse,看看你能用它做出什么有趣的事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/how-to-mount-your-google-drive-on-linux-with-google-drive-ocamlfuse/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.techrepublic.com/search/?a=jack+wallen
|
||||
@ -1,17 +1,17 @@
|
||||
在 Ubuntu 16.04 上安装使用 VBoxManage 以及 VBoxManage 命令行选项的用法
|
||||
在 Linux 上安装使用 VirtualBox 的命令行管理界面 VBoxManage
|
||||
=================
|
||||
|
||||
VirtualBox 拥有一套命令行工具,然后你可以使用 VirtualBox 的命令行界面 (CLI) 对远端无界面的服务器上的虚拟机进行管理操作。在这篇教程中,你将会学到如何在没有 GUI 的情况下使用 VBoxManage 创建、启动一个虚拟机。VBoxManage 是 VirtualBox 的命令行界面,你可以在你的主机操作系统的命令行中来用它实现对 VirtualBox 的所有操作。VBoxManage 拥有图形化用户界面所支持的全部功能,而且它支持的功能远不止这些。它提供虚拟引擎的所有功能,甚至包含 GUI 还不能实现的那些功能。如果你想尝试不同的用户界面而不仅仅是 GUI,或者更改虚拟机更多高级和实验性的配置,那么你就需要用到命令行。
|
||||
VirtualBox 拥有一套命令行工具,你可以使用 VirtualBox 的命令行界面 (CLI) 对远程无界面的服务器上的虚拟机进行管理操作。在这篇教程中,你将会学到如何在没有 GUI 的情况下使用 VBoxManage 创建、启动一个虚拟机。VBoxManage 是 VirtualBox 的命令行界面,你可以在你的主机操作系统的命令行中用它来实现对 VirtualBox 的所有操作。VBoxManage 拥有图形化用户界面所支持的全部功能,而且它支持的功能远不止这些。它提供虚拟引擎的所有功能,甚至包含 GUI 还不能实现的那些功能。如果你想尝试下不同的用户界面而不仅仅是 GUI,或者更改虚拟机更多高级和实验性的配置,那么你就需要用到命令行。
|
||||
|
||||
当你想要在 VirtualBox 上创建或运行虚拟机时,你会发现 VBoxManage 非常有用,你只需要使用远程主机的终端就够了。这对于服务器来说是一种常见的情形,因为在服务器上需要进行虚拟机的远程操作。
|
||||
当你想要在 VirtualBox 上创建或运行虚拟机时,你会发现 VBoxManage 非常有用,你只需要使用远程主机的终端就够了。这对于需要远程管理虚拟机的服务器来说是一种常见的情形。
|
||||
|
||||
### 准备工作
|
||||
|
||||
在开始使用 VBoxManage 的命令行工具前,确保在运行着 Ubuntu 16.04 的服务器上,你拥有超级用户的权限或者你能够使用 sudo 命令,而且你已经在服务器上安装了 Oracle Virtual Box。 然后你需要安装 VirtualBox 扩展包,这是运行远程桌面环境,访问无界面启动虚拟机所必须的。(headless的翻译拿不准,翻译为无界面启动)
|
||||
在开始使用 VBoxManage 的命令行工具前,确保在运行着 Ubuntu 16.04 的服务器上,你拥有超级用户的权限或者你能够使用 sudo 命令,而且你已经在服务器上安装了 Oracle Virtual Box。 然后你需要安装 VirtualBox 扩展包,这是运行 VRDE 远程桌面环境,访问无界面虚拟机所必须的。
|
||||
|
||||
### 安装 VBoxManage
|
||||
|
||||
通过 [Virtual Box Download Page][1] 这个链接,你能够获取你所需要的软件扩展包的最新版本,扩展包的版本和你安装的 VirtualBox 版本需要一致!
|
||||
通过 [Virtual Box 下载页][1] 这个链接,你能够获取你所需要的软件扩展包的最新版本,扩展包的版本和你安装的 VirtualBox 版本需要一致!
|
||||
|
||||

|
||||
|
||||
@ -71,11 +71,11 @@ $ VBoxManage modifyvm Ubuntu10.10 --memory 512
|
||||
$ VBoxManage storagectl Ubuntu16.04 --name IDE --add ide --controller PIIX4 --bootable on
|
||||
```
|
||||
|
||||
这里的 “storagect1” 是给虚拟机创建存储控制器的,“--name” 指定了虚拟机里需要创建、更改或者移除的存储控制器的名称。“--add” 选项指明系统总线类型,可选的选项有 ide / sata / scsi / floppy,存储控制器必须要连接到系统总线。“--controller” 选择主板的类型,主板需要根据需要的存储控制器选择,可选的选项有 LsiLogic / LSILogicSAS / BusLogic / IntelAhci / PIIX3 / PIIX4 / ICH6 / I82078。最后的 “--bootable” 表示控制器是否可以引导。
|
||||
这里的 “storagect1” 是给虚拟机创建存储控制器的,“--name” 指定了虚拟机里需要创建、更改或者移除的存储控制器的名称。“--add” 选项指明存储控制器所需要连接到的系统总线类型,可选的选项有 ide / sata / scsi / floppy。“--controller” 选择主板的类型,主板需要根据需要的存储控制器选择,可选的选项有 LsiLogic / LSILogicSAS / BusLogic / IntelAhci / PIIX3 / PIIX4 / ICH6 / I82078。最后的 “--bootable” 表示控制器是否可以引导系统。
|
||||
|
||||
上面的命令创建了叫做 IDE 的存储控制器。然后虚拟设备就能通过 “storageattach” 命令连接到控制器。
|
||||
上面的命令创建了叫做 IDE 的存储控制器。之后虚拟介质就能通过 “storageattach” 命令连接到该控制器。
|
||||
|
||||
然后运行下面这个命令来创建一个叫做 SATA 的存储控制器,它将会连接到硬盘镜像上。
|
||||
然后运行下面这个命令来创建一个叫做 SATA 的存储控制器,它将会连接到之后的硬盘镜像上。
|
||||
|
||||
```
|
||||
$ VBoxManage storagectl Ubuntu16.04 --name SATA --add sata --controller IntelAhci --bootable on
|
||||
@ -87,7 +87,7 @@ $ VBoxManage storagectl Ubuntu16.04 --name SATA --add sata --controller IntelAhc
|
||||
$ VBoxManage storageattach Ubuntu16.04 --storagectl SATA --port 0 --device 0 --type hdd --medium "your_iso_filepath"
|
||||
```
|
||||
|
||||
用媒体把 SATA 存储控制器连接到 Ubuntu16.04 虚拟机中,也就是之前创建的虚拟硬盘镜像里。
|
||||
这将把 SATA 存储控制器及介质(比如之前创建的虚拟磁盘镜像)连接到 Ubuntu16.04 虚拟机中。
|
||||
|
||||
运行下面的命令添加像网络连接,音频之类的功能。
|
||||
|
||||
@ -120,9 +120,9 @@ $VBoxManage controlvm
|
||||
|
||||

|
||||
|
||||
完结!
|
||||
###完结
|
||||
|
||||
从这篇文章中,我们了解了 Oracle Virtual Box 中一个十分实用的工具,就是 VBoxManage,包含了 VBoxManage 的安装和在 Ubuntu 16.04 系统上的使用。文章包含详细的教程, 通过 VBoxManage 中实用的命令来创建和管理虚拟机。希望这篇文章对你有帮助,另外别忘了分享你的评论或者建议。
|
||||
从这篇文章中,我们了解了 Oracle Virtual Box 中一个十分实用的工具 VBoxManage,文章包含了 VBoxManage 的安装和在 Ubuntu 16.04 系统上的使用,包括通过 VBoxManage 中实用的命令来创建和管理虚拟机。希望这篇文章对你有帮助,另外别忘了分享你的评论或者建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -130,7 +130,7 @@ via: http://linuxpitstop.com/install-and-use-command-line-tool-vboxmanage-on-ubu
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -5,15 +5,15 @@
|
||||
|
||||
*简介:这个快速指南将向你展示所有的基础 Git 命令以及用法。你可以下载这些命令作为快速参考。*
|
||||
|
||||
我们在早先一篇文章中已经见过快速指南和 [Vi cheat sheet 下载][1]了。在这篇文章里,我们将会看到开始使用 Git 所需要的基础命令。
|
||||
我们在早先一篇文章中已经快速介绍过 [Vi 速查表][1]了。在这篇文章里,我们将会介绍开始使用 Git 时所需要的基础命令。
|
||||
|
||||
### GIT
|
||||
### Git
|
||||
|
||||
[Git][2] 是一个分布式版本控制系统,它被用在大量开源项目中。它是在 2005 年由 Linux 创始人 [Linus Torvalds][3] 写就的。这个程序允许非线性的项目开发,并且能够通过存储在本地服务器高效处理大量数据。在这个教程里,我们将要和 Git 愉快玩耍并学习如何开始使用它。
|
||||
|
||||
我在这个教程里使用 Ubuntu,但你可以使用你选择的任何发行版。除了安装以外,剩下的所有命令在任何 Linux 发行版上都是一样的。
|
||||
|
||||
### 安装 GIT
|
||||
### 安装 Git
|
||||
|
||||
要安装 git 执行以下命令:
|
||||
|
||||
@ -23,11 +23,11 @@ sudo apt-get install git-core
|
||||
|
||||
在它完成下载之后,你就安装好了 Git 并且可以使用了。
|
||||
|
||||
### 设置 GIT:
|
||||
### 设置 Git
|
||||
|
||||
在 Git 安装之后,不论是从 apt-get 还是从源码安装,你需要将你的用户名和邮箱地址复制到 gitconfig 文件。你可以访问 ~/.gitconfig 这个文件。
|
||||
|
||||
全新安装 Git 之后打开它会是完全空白的页面:
|
||||
全新安装 Git 之后打开它会是完全空白的:
|
||||
|
||||
```
|
||||
sudo vim ~/.gitconfig
|
||||
@ -42,7 +42,7 @@ git config --global user.email user@example.com
|
||||
|
||||
然后你就完成设置了。现在让我们开始 Git。
|
||||
|
||||
### 仓库:
|
||||
### 仓库
|
||||
|
||||
创建一个新目录,打开它并运行以下命令:
|
||||
|
||||
@ -52,13 +52,11 @@ git init
|
||||
|
||||

|
||||
|
||||
这个命令会创建一个新的 git 仓库。你的本地仓库由三个 git 维护的“树”组成。
|
||||
这个命令会创建一个新的 Git 仓库(repository)。你的本地仓库由三个 Git 维护的“树”组成。
|
||||
|
||||
第一个是你的**工作目录**,保存实际的文件。第二个是索引,实际上扮演的是暂存区,最后一个是 HEAD,它指向你最后一个 commit 提交。
|
||||
第一个是你的工作目录(Working Directory),保存实际的文件。第二个是索引,实际上扮演的是暂存区(staging area),最后一个是 HEAD,它指向你最后一个 commit 提交。使用 git clone /path/to/repository 签出你的仓库(从你刚创建的仓库或服务器上已存在的仓库)。
|
||||
|
||||
使用 git clone /path/to/repository 签出你的仓库(从你刚创建的仓库或服务器上已存在的仓库)。
|
||||
|
||||
### 添加文件并提交:
|
||||
### 添加文件并提交
|
||||
|
||||
你可以用以下命令添加改动:
|
||||
|
||||
@ -98,7 +96,7 @@ git commit -a
|
||||
|
||||
### 推送你的改动
|
||||
|
||||
你的改动在你本地工作副本的 HEAD 中。如果你还没有从一个已存在的仓库克隆或想将你的仓库连接到远程服务器,你需要先添加它:
|
||||
你的改动在你本地工作副本的 HEAD 中。如果你还没有从一个已存在的仓库克隆,或想将你的仓库连接到远程服务器,你需要先添加它:
|
||||
|
||||
```
|
||||
git remote add origin <服务器地址>
|
||||
@ -110,9 +108,9 @@ git remote add origin <服务器地址>
|
||||
git push -u origin master
|
||||
```
|
||||
|
||||
### 分支:
|
||||
### 分支
|
||||
|
||||
分支用于开发特性,它们之间是互相独立的。主分支 master 是你创建一个仓库时的“默认”分支。使用其它分支用于开发,在完成时将它合并回主分支。
|
||||
分支用于开发特性,分支之间是互相独立的。主分支 master 是你创建一个仓库时的“默认”分支。使用其它分支用于开发,在完成时将它合并回主分支。
|
||||
|
||||
创建一个名为“mybranch”的分支并切换到它之上:
|
||||
|
||||
@ -144,19 +142,19 @@ git push origin <分支名>
|
||||
|
||||
### 更新和合并
|
||||
|
||||
要将你本地仓库更新到最新提交,运行:
|
||||
要将你本地仓库更新到最新的提交上,运行:
|
||||
|
||||
```
|
||||
git pull
|
||||
```
|
||||
|
||||
在你的工作目录获取和合并远程变动。要合并其它分支到你的活动分支(如 master),使用:
|
||||
在你的工作目录获取并合并远程变动。要合并其它分支到你的活动分支(如 master),使用:
|
||||
|
||||
```
|
||||
git merge <分支>
|
||||
```
|
||||
|
||||
在这两种情况下,git 会尝试自动合并(auto-merge)改动。不幸的是,这不总是可能的,可能会导致冲突。你需要负责通过编辑 git 显示的文件,手动合并那些冲突。改动之后,你需要用以下命令将它们标记为已合并:
|
||||
在这两种情况下,git 会尝试自动合并(auto-merge)改动。不幸的是,这不总是可能的,可能会导致冲突。你需要通过编辑 git 所显示的文件,手动合并那些冲突。改动之后,你需要用以下命令将它们标记为已合并:
|
||||
|
||||
```
|
||||
git add <文件名>
|
||||
@ -168,7 +166,7 @@ git add <文件名>
|
||||
git diff <源分支> <目标分支>
|
||||
```
|
||||
|
||||
### GIT 日志:
|
||||
### Git 日志
|
||||
|
||||
你可以这么查看仓库历史:
|
||||
|
||||
@ -176,7 +174,7 @@ git diff <源分支> <目标分支>
|
||||
git log
|
||||
```
|
||||
|
||||
要查看每个提交一行样式的日志你可以用:
|
||||
要以每个提交一行的样式查看日志,你可以用:
|
||||
|
||||
```
|
||||
git log --pretty=oneline
|
||||
@ -196,9 +194,9 @@ git log --name-status
|
||||
|
||||
在这整个过程中如果你需要任何帮助,你可以用 git --help。
|
||||
|
||||
Git 棒不棒!!!祝贺你你已经会 git 基础了。如果你愿意的话,你可以从下面这个链接下载这些基础 Git 命令作为快速参考:
|
||||
Git 棒不棒?!祝贺你你已经会 Git 基础了。如果你愿意的话,你可以从下面这个链接下载这些基础 Git 命令作为快速参考:
|
||||
|
||||
[下载 Git Cheat Sheet][4]
|
||||
- [下载 Git 速查表][4]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -207,7 +205,7 @@ via: http://itsfoss.com/basic-git-commands-cheat-sheet/
|
||||
|
||||
作者:[Rakhi Sharma][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
如何在 Linux 上录制你的终端操作
|
||||
=================================================
|
||||
|
||||
录制一个终端操作可能是一个帮助他人学习 Linux 、展示一系列正确命令行操作的和分享知识的通俗易懂方法。不管是出于什么目的,从终端复制粘贴文本需要重复很多次,而录制视频的过程也是相当麻烦,有时候还不能录制。在这次的文章中,我们将简单的了解一下以 gif 格式记录和分享终端会话的方法。
|
||||
|
||||
### 预先要求
|
||||
|
||||
如果你只是希望能记录你的终端会话,并且能在终端进行回放或者和他人分享,那么你只需要一个叫做:ttyrec 的软件。Ubuntu 用户可以通过运行这行代码进行安装:
|
||||
|
||||
```
|
||||
sudo apt-get install ttyrec
|
||||
```
|
||||
|
||||
如果你想将生成的视频转换成一个 gif 文件,这样能够和那些不使用终端的人分享,就可以发布到网站上去,或者你只是想做一个 gif 方便使用而不想写命令。那么你需要安装额外的两个软件包。第一个就是 imagemagick , 你可以通过以下的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
第二个软件包就是:tty2gif.py,访问其[项目网站][1]下载。这个软件包需要安装如下依赖:
|
||||
|
||||
```
|
||||
sudo apt-get install python-opster
|
||||
```
|
||||
|
||||
### 录制
|
||||
|
||||
开始录制终端操作,你需要的仅仅是键入 `ttyprec` ,然后回车。这个命令将会在后台运行一个实时的记录工具。我们可以通过键入`exit`或者`ctrl+d`来停止。ttyrec 默认会在主目录下创建一个`ttyrecord`的文件。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 回放
|
||||
|
||||
回放这个文件非常简单。你只需要打开终端并且使用 `ttyplay` 命令打开 `ttyrecord` 文件即可。(在这个例子里,我们使用 ttyrecord 作为文件名,当然,你也可以改成你用的文件名)
|
||||
|
||||
|
||||
|
||||
然后就可以开始播放这个文件。这个视频记录了所有的操作,包括你的删除,修改。这看起来像一个拥有自我意识的终端,但是这个命令执行的过程并不是只是为了给系统看,而是为了更好的展现给人。
|
||||
|
||||
注意一点,播放这个记录是完全可控的,你可以通过点击 `+` 或者 `-` 进行加速减速,或者 `0`和 `1` 暂停和恢复播放。
|
||||
|
||||
### 导出成 GIF
|
||||
|
||||
为了方便,我们通常会将视频记录转换为 gif 格式,并且,这个非常容易做到。以下是方法:
|
||||
|
||||
将之前下载的 tty2gif.py 这个文件拷贝到 ttyprecord 文件(或者你命名的那个视频文件)相同的目录,然后在这个目录下打开终端,输入命令:
|
||||
|
||||
```
|
||||
python tty2gif.py typing ttyrecord
|
||||
```
|
||||
|
||||
如果出现了错误,检查一下你是否有安装 python-opster 包。如果还是有错误,使用如下命令进行排除。
|
||||
|
||||
```
|
||||
sudo apt-get install xdotool
|
||||
export WINDOWID=$(xdotool getwindowfocus)
|
||||
```
|
||||
|
||||
然后重复这个命令 `python tty2gif.py` 并且你将会看到在 ttyrecord 目录下多了一些 gif 文件。
|
||||
|
||||
|
||||
|
||||
接下来的一步就是整合所有的 gif 文件,将他打包成一个 gif 文件。我们通过使用 imagemagick 工具。输入下列命令:
|
||||
|
||||
```
|
||||
convert -delay 25 -loop 0 *.gif example.gif
|
||||
```
|
||||
|
||||
|
||||
|
||||
你可以使用任意的文件名,我用的是 example.gif。 并且,你可以改变这个延时和循环时间。 Enjoy。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-record-your-terminal-session-on-linux/
|
||||
|
||||
作者:[Bill Toulas][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/howtoforgecom
|
||||
[1]: https://bitbucket.org/antocuni/tty2gif/raw/61d5596c916512ce5f60fcc34f02c686981e6ac6/tty2gif.py
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
在 Ubuntu Mate 16.04 上通过 PPA 升级 Mate 1.14
|
||||
=================================================================
|
||||
|
||||
Mate 桌面环境 1.14 现在可以在 Ubuntu Mate 16.04 ("Xenial Xerus") 上使用了。根据这个[发布版本][1]的描述,为了全面测试 Mate 1.14,所以 Mate 桌面环境 1.14 已经在 PPA 上发布 2 个月了。因此,你不太可能遇到安装的问题。
|
||||
|
||||

|
||||
|
||||
**现在 PPA 提供 Mate 1.14.1 包含如下改变(Ubuntu Mate 16.04 默认安装的是 Mate 1.12.x):**
|
||||
|
||||
- 客户端的装饰应用现在可以正确的在所有主题中渲染;
|
||||
- 触摸板配置现在支持边缘操作和双指滚动;
|
||||
- 在 Caja 中的 Python 扩展可以被单独管理;
|
||||
- 所有三个窗口焦点模式都是可选的;
|
||||
- Mate Panel 中的所有菜单栏图标和菜单图标可以改变大小;
|
||||
- 音量和亮度 OSD 目前可以启用和禁用;
|
||||
- 更多的改进和 bug 修改;
|
||||
|
||||
Mate 1.14 同时改进了整个桌面环境中对 GTK+ 3 的支持,包括各种 GTK+3 小应用。但是,Ubuntu MATE 的博客中提到:PPA 的发行包使用 GTK+ 2 编译是“为了确保对 Ubuntu MATE 16.04 还有各种各样的第三方 MATE 应用、插件、扩展的支持"。
|
||||
|
||||
MATE 1.14 的完整修改列表[点击此处][2]阅读。
|
||||
|
||||
### 在 Ubuntu MATE 16.04 中升级 MATE 1.14.x
|
||||
|
||||
在 Ubuntu MATE 16.04 中打开终端,并且输入如下命令,来从官方的 Xenial MATE PPA 中升级最新的 MATE 桌面环境:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:ubuntu-mate-dev/xenial-mate
|
||||
sudo apt update
|
||||
sudo apt dist-upgrade
|
||||
```
|
||||
|
||||
**注意**: mate-netspeed 应用将会在升级中删除。因为该应用现在已经是 mate-applets 应用报的一部分,所以它依旧是可以使用的。
|
||||
|
||||
一旦升级完成,请重启你的系统,享受全新的 MATE!
|
||||
|
||||
### 如何回滚这次升级
|
||||
|
||||
如果你并不满意 MATE 1.14, 比如你遭遇了一些 bug 。或者你想回到 MATE 的官方源版本,你可以使用如下的命令清除 PPA,并且下载降级包。
|
||||
|
||||
```
|
||||
sudo apt install ppa-purge
|
||||
sudo ppa-purge ppa:ubuntu-mate-dev/xenial-mate
|
||||
```
|
||||
|
||||
在所有的 MATE 包降级之后,重启系统。
|
||||
|
||||
via [Ubuntu MATE blog][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2016/06/install-mate-114-in-ubuntu-mate-1604.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.webupd8.org/p/about.html
|
||||
[1]: https://ubuntu-mate.org/blog/mate-desktop-114-for-xenial-xerus/
|
||||
[2]: http://mate-desktop.com/blog/2016-04-08-mate-1-14-released/
|
||||
[3]: https://ubuntu-mate.org/blog/mate-desktop-114-for-xenial-xerus/
|
||||
@ -1,9 +1,7 @@
|
||||
ReactOS 新手指南
|
||||
====================================
|
||||
|
||||
|
||||
ReactOS 是一个比较年轻的开源操作系统,它提供了一个和 Windows NT 类似的图形界面,并且它的目标也是提供一个与 NT 功能和应用程序兼容性差不多的系统。这个项目在没有使用任何 Unix 的情况下实现了一个类似 Wine 的用户模式。它的开发者们从头实现了 NT 的架构以及对于 FAT32 的兼容,因此它也不需要负任何法律责任。这也就是说,它不是又双叒叕一个 Linux 发行版,而是一个独特的类 Windows 系统,并且是开源世界的一部分。这份快速指南是给那些想要一个易于使用的 Windows 的开源替代品的人准备的。
|
||||
|
||||
ReactOS 是一个比较年轻的开源操作系统,它提供了一个和 Windows NT 类似的图形界面,并且它的目标也是提供一个与 NT 功能和应用程序兼容性差不多的系统。这个项目在没有使用任何 Unix 架构的情况下实现了一个类似 Wine 的用户模式。它的开发者们从头实现了 NT 的架构以及对于 FAT32 的兼容,因此它也不需要负任何法律责任。这也就是说,它不是又双叒叕一个 Linux 发行版,而是一个独特的类 Windows 系统,并且是开源世界的一部分。这份快速指南是给那些想要一个易于使用的 Windows 的开源替代品的人准备的。
|
||||
|
||||
### 安装系统
|
||||
|
||||
@ -31,7 +29,6 @@ ReactOS 是一个比较年轻的开源操作系统,它提供了一个和 Windo
|
||||
|
||||
下一步是选择分区的格式,不过现在我们只能选择 FAT32。
|
||||
|
||||
|
||||
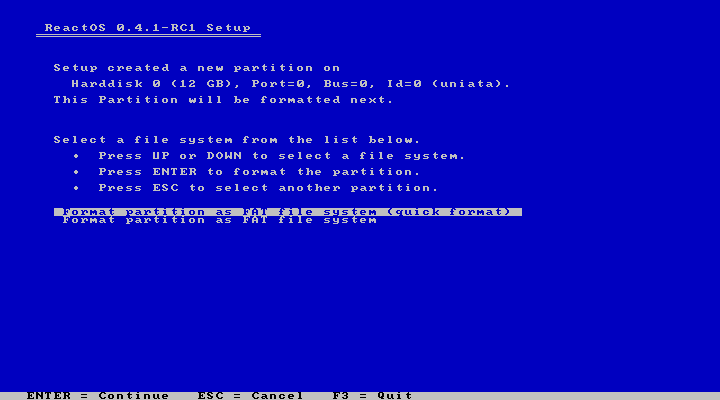
|
||||
|
||||
再下一步是选择安装文件夹。我就使用默认的“/ReactOS”了,应该没有问题。
|
||||
@ -96,7 +93,7 @@ ReactOS 是一个比较年轻的开源操作系统,它提供了一个和 Windo
|
||||
|
||||
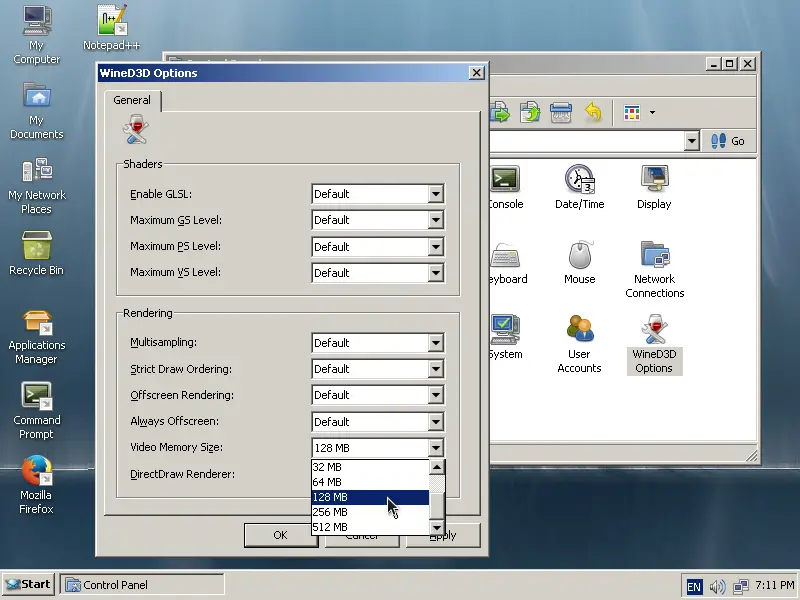
|
||||
|
||||
ReactOS 还有一个好啊,就是我们可以通过“我的电脑”来操作注册表。
|
||||
ReactOS 还有一个好的地方,就是我们可以通过“我的电脑”来操作注册表。
|
||||
|
||||
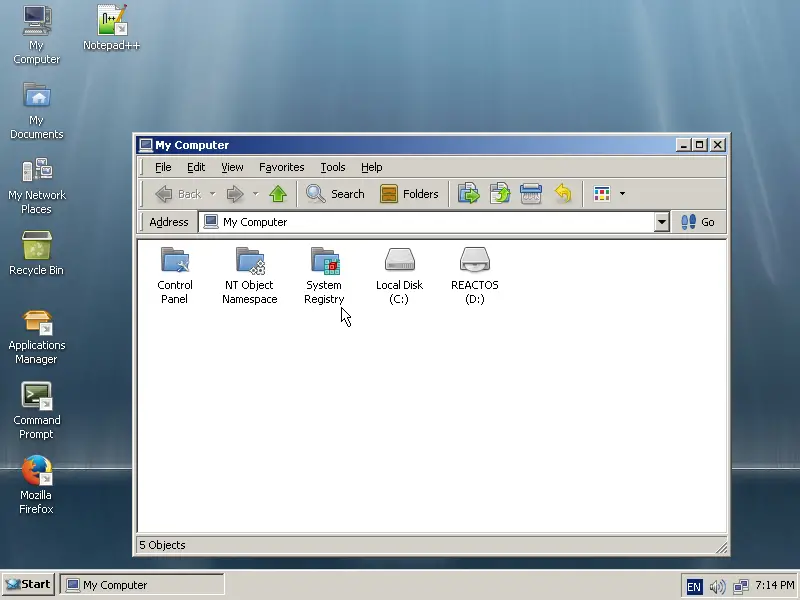
|
||||
|
||||
@ -0,0 +1,141 @@
|
||||
Linux 新手必知必会的 10 条 Linux 基本命令
|
||||
=====================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
Linux 对我们的生活产生了巨大的冲击。至少你的安卓手机使用的就是 Linux 核心。尽管如此,在第一次开始使用 Linux 时你还是会感到难以下手。因为在 Linux 中,通常需要使用终端命令来取代 Windows 系统中的点击启动图标操作。但是不必担心,这里我们会介绍 10 个 Linux 基本命令来帮助你开启 Linux 神秘之旅。
|
||||
|
||||
|
||||
### 帮助新手走出第一步的 10 个 Linux 基本命令
|
||||
|
||||
当我们谈论 Linux 命令时,实质上是在谈论 Linux 系统本身。这短短的 10 个 Linux 基本命令不会让你变成天才或者 Linux 专家,但是能帮助你轻松开始 Linux 之旅。使用这些基本命令会帮助新手们完成 Linux 的日常任务,由于它们的使用频率如此至高,所以我更乐意称他们为 Linux 命令之王!
|
||||
|
||||
让我们开始学习这 10 条 Linux 基本命令吧。
|
||||
|
||||
|
||||
#### 1. sudo
|
||||
|
||||
这条命令的意思是“以超级用户的身份执行”,是 SuperUserDo 的简写,它是新手将要用到的最重要的一条 Linux 命令。当一条单行命令需要 root 权限的时候,`sudo`命令就派上用场了。你可以在每一条需要 root 权限的命令前都加上`sudo`。
|
||||
|
||||
```
|
||||
$ sudo su
|
||||
```
|
||||
|
||||
|
||||
#### 2. ls (list)
|
||||
|
||||
|
||||
跟其他人一样,你肯定也经常想看看目录下都有些什么东西。使用列表命令,终端会把当前工作目录下所有的文件以及文件夹展示给你。比如说,我当前处在 /home 文件夹中,我想看看 /home 文件夹中都有哪些文件和目录。
|
||||
|
||||
```
|
||||
/home$ ls
|
||||
```
|
||||
|
||||
|
||||
在 /home 中执行`ls`命令将会返回类似下面的内容:
|
||||
|
||||
```
|
||||
imad lost+found
|
||||
```
|
||||
|
||||
|
||||
#### 3. cd
|
||||
|
||||
变更目录命令(cd)是终端中总会被用到的主要命令。它是最常用到的 Linux 基本命令之一。此命令使用非常简单,当你打算从当前目录跳转至某个文件夹时,只需要将文件夹键入此命令之后即可。如果你想跳转至上层目录,只需要在此命令之后键入两个点 (..) 就可以了。
|
||||
|
||||
举个例子,我现在处在 /home 目录中,我想移动到 /home 目录中的 usr 文件夹下,可以通过以下命令来完成操作。
|
||||
|
||||
```
|
||||
/home $ cd usr
|
||||
|
||||
/home/usr $
|
||||
```
|
||||
|
||||
|
||||
#### 4. mkdir
|
||||
|
||||
只是可以切换目录还是不够完美。有时候你会想要新建一个文件夹或子文件夹。此时可以使用 mkdir 命令来完成操作。使用方法很简单,只需要把新的文件夹名跟在 mkdir 命令之后就好了。
|
||||
|
||||
```
|
||||
~$ mkdir folderName
|
||||
```
|
||||
|
||||
|
||||
#### 5. cp
|
||||
|
||||
拷贝-粘贴(copy-and-paste)是我们组织文件需要用到的重要命令。使用 `cp` 命令可以帮助你在终端当中完成拷贝-粘贴操作。首先确定你想要拷贝的文件,然后键入打算粘贴此文件的目标位置。
|
||||
|
||||
```
|
||||
$ cp src des
|
||||
```
|
||||
|
||||
注意:如果目标目录对新建文件需要 root 权限时,你可以使用 `sudo` 命令来完成文件拷贝操作。
|
||||
|
||||
|
||||
#### 6. rm
|
||||
|
||||
rm 命令可以帮助你移除文件甚至目录。如果不希望每删除一个文件都提示确认一次,可以用`-f`参数来强制执行。也可以使用 `-r` 参数来递归的移除文件夹。
|
||||
|
||||
```
|
||||
$ rm myfile.txt
|
||||
```
|
||||
|
||||
|
||||
#### 7. apt-get
|
||||
|
||||
这个命令会依据发行版的不同而有所区别。在基于 Debian 的发行版中,我们拥有 Advanced Packaging Tool(APT)包管理工具来安装、移除和升级包。apt-get 命令会帮助你安装需要在 Linux 系统中运行的软件。它是一个功能强大的命令行,可以用来帮助你对软件执行安装、升级和移除操作。
|
||||
|
||||
在其他发行版中,例如 Fedora、Centos,都各自不同的包管理工具。Fedora 之前使用的是 yum,不过现在 dnf 成了它默认的包管理工具。
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo dnf update
|
||||
```
|
||||
|
||||
|
||||
#### 8. grep
|
||||
|
||||
当你需要查找一个文件,但是又忘记了它具体的位置和路径时,`grep` 命令会帮助你解决这个难题。你可以提供文件的关键字,使用`grep`命令来查找到它。
|
||||
|
||||
```
|
||||
$ grep user /etc/passwd
|
||||
```
|
||||
|
||||
|
||||
#### 9. cat
|
||||
|
||||
作为一个用户,你应该会经常需要浏览脚本内的文本或者代码。`cat`命令是 Linux 系统的基本命令之一,它的用途就是将文件的内容展示给你。
|
||||
|
||||
```
|
||||
$ cat CMakeLists.txt
|
||||
```
|
||||
|
||||
|
||||
#### 10. poweroff
|
||||
|
||||
最后一个命令是 `poweroff`。有时你需要直接在终端中执行关机操作。此命令可以完成这个任务。由于关机操作需要 root 权限,所以别忘了在此命令之前添加`sudo`。
|
||||
|
||||
```
|
||||
$ sudo poweroff
|
||||
```
|
||||
|
||||
|
||||
### 总结
|
||||
|
||||
如我在文章开始所言,这 10 条命令并不会让你立即成为一个 Linux 大拿,但它们会让你在初期快速上手 Linux。以这些命令为基础,给自己设置一个目标,每天学习一到三条命令,这就是此文的目的所在。在下方评论区分享有趣并且有用的命令。别忘了跟你的朋友分享此文。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/10-basic-linux-commands-that-every-linux-newbies-should-remember
|
||||
|
||||
作者:[Commenti][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxandubuntu.com/home/10-basic-linux-commands-that-every-linux-newbies-should-remember#comments
|
||||
[1]: http://linuxandubuntu.com/home/category/linux
|
||||
@ -0,0 +1,113 @@
|
||||
惊艳!6款面向儿童的 Linux 发行版
|
||||
======================================
|
||||
|
||||
毫无疑问未来是属于 Linux 和开源的。为了实现这样的未来、使 Linux 占据一席之地,人们已经着手开发尽可能简单的、面向儿童的 Linux 发行版,并尝试教导他们如何使用 Linux 操作系统。
|
||||
|
||||

|
||||
>面向儿童的 Linux 发行版
|
||||
|
||||
Linux 是一款非常强大的操作系统,原因之一便是它支撑了互联网上绝大多数的服务器。但出于对其用户友好性的担忧,坊间时常展开有关于 Linux 应如何取代 Mac OS X 或 Windows 的争论。而我认为用户应该接受 Linux 来见识它真正的威力。
|
||||
|
||||
如今,Linux 运行在绝大多数设备上,从智能手机到平板电脑,笔记本电脑,工作站,服务器,超级计算机,再到汽车,航空管制系统,电冰箱,到处都有 Linux 的身影。正如我在开篇所说,有了这一切, Linux 是未来的操作系统。
|
||||
|
||||
>参考阅读: [30 Big Companies and Devices Running on Linux][1]
|
||||
|
||||
未来是属于孩子们的,教育要从娃娃抓起。所以,要让小孩子尽早地学习计算机,而 Linux 就是其中一个重要的部分。
|
||||
|
||||
对小孩来说,一个常见的现象是,当他们在一个适合他的环境中学习时,好奇心和早期学习的能力会使他自己养成喜好探索的性格。
|
||||
|
||||
说了这么多儿童应该学习 Linux 的原因,接下来我就列出这些令人激动的发行版。你可以把它们推荐给小孩子来帮助他们开始学习使用 Linux 。
|
||||
|
||||
### Sugar on a Stick
|
||||
|
||||
Sugar on a Stick (译注:“糖棒”)是 Sugar 实验室旗下的工程,Sugar 实验室是一个由志愿者领导的非盈利组织。这一发行版旨在设计大量的免费工具来促进儿童在探索中学会技能,发现、创造,并将这些反映到自己的思想上。
|
||||
|
||||

|
||||
>Sugar Neighborhood 界面
|
||||
|
||||

|
||||
>Sugar 应用程序
|
||||
|
||||
你既可以将 Sugar 看作是普通的桌面环境,也可以把它当做是帮助鼓励孩子学习、提高参与活动的积极性的一款应用合集。
|
||||
|
||||
访问主页: <https://www.sugarlabs.org/>
|
||||
|
||||
### Edubuntu
|
||||
|
||||
Edubuntu 是基于当下最流行的发行版 Ubuntu 而开发的一款非官方发行版。主要致力于降低学校、家庭和社区安装、使用 Ubuntu 自由软件的难度。
|
||||
|
||||

|
||||
>Edubuntu 桌面应用
|
||||
|
||||
它是由来自不同组织的学生、教师、家长、一些利益相关者甚至黑客支持的,这些人都坚信自由的学习和共享知识能够提高自己和社区的发展。
|
||||
|
||||
该项目的主要目标是通过组建一款能够降低安装、管理软件难度的操作系统来增强学习和教育水平。
|
||||
|
||||
访问主页: <http://www.edubuntu.org/>
|
||||
|
||||
### Doudou Linux
|
||||
|
||||
Doudou Linux 是专为方便孩子们在建设创新思维时使用计算机而设计的发行版。它提供了简单但是颇具教育意义的应用来使儿童在应用过程中学习发现新的知识。
|
||||
|
||||

|
||||
>Doudou Linux
|
||||
|
||||
其最引人注目的一点便是内容过滤功能,顾名思义,它能够阻止孩童访问网络上的限制性内容。如果想要更进一步的儿童保护功能,Doudou Linux 还提供了互联网用户隐私功能,能够去除网页中的特定加载内容。
|
||||
|
||||
访问主页: <http://www.doudoulinux.org/>
|
||||
|
||||
### LinuxKidX
|
||||
|
||||
这是一款整合了许多专为儿童设计的教育软件的基于 Slackware Linux 发行版的 LiveCD。它使用 KDE 作为默认桌面环境并配置了诸如 Ktouch 打字指导,Kstars 虚拟天文台,Kalzium 元素周期表和 KwordQuiz 单词测试等应用。
|
||||
|
||||

|
||||
>LinuxKidX
|
||||
|
||||
访问主页: <http://linuxkidx.blogspot.in/>
|
||||
|
||||
### Ubermix
|
||||
|
||||
Ubermix 基于 Ubuntu 构建,同样以教学为目的。默认配备了超过60款应用,帮助学生更好地学习,同时给教师教学提供便利。
|
||||
|
||||

|
||||
>Ubermix Linux
|
||||
|
||||
Ubermix 还具有5分钟快速安装和快速恢复等功能,可以给小孩子更好的帮助。
|
||||
|
||||
访问主页: <http://www.ubermix.org/>
|
||||
|
||||
### Qimo
|
||||
|
||||
因为很多读者曾向我询问过 Qimo 发行版的情况,所以我把它写进这篇文章。但是截止发稿时,Qimo 儿童版的开发已经终止,不再提供更新。
|
||||
|
||||

|
||||
>Qimo Linux
|
||||
|
||||
你仍然可以在 Ubuntu 或者其他的 Linux 发行版中找到大多数儿童游戏。正如这些开发商所说,他们并不是要终止为孩子们开发教育软件,而是在开发能够提高儿童读写能力的 android 应用。
|
||||
|
||||
如果你想进一步了解,可以移步他们的官方网站。
|
||||
|
||||
访问主页: <http://www.qimo4kids.com/>
|
||||
|
||||
以上这些便是我所知道的面向儿童的Linux发行版,或有缺漏,欢迎评论补充。
|
||||
|
||||
如果你想让我们知道你对如何想儿童介绍 Linux 或者你对未来的 Linux ,特别是桌面计算机上的 Linux,欢迎与我联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-linux-distributions-for-kids/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[HaohongWANG](https://github.com/HaohongWANG)
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/big-companies-and-devices-running-on-gnulinux/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,227 @@
|
||||
使用 OpenCV 识别图片中的猫咪
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
你知道 OpenCV 可以识别在图片中小猫的脸吗?而且是拿来就能用,不需要其它的库之类的。
|
||||
|
||||
之前我也不知道。
|
||||
|
||||
但是在 [Kendrick Tan 曝出这个功能][1]后,我需要亲自体验一下……去看看到 OpenCV 是如何在我没有察觉到的情况下,将这一个功能添加进了他的软件库(就像一只悄悄溜进空盒子的猫咪一样,等待别人发觉)。
|
||||
|
||||
下面,我将会展示如何使用 OpenCV 的猫咪检测器在图片中识别小猫的脸。同样的,该技术也可以用在视频流中。
|
||||
|
||||
### 使用 OpenCV 在图片中检测猫咪
|
||||
|
||||
如果你查找过 [OpenCV 的代码仓库][3],尤其是在 [haarcascades 目录][4]里(OpenCV 在这里保存处理它预先训练好的 Haar 分类器,以检测各种物体、身体部位等), 你会看到这两个文件:
|
||||
|
||||
- haarcascade_frontalcatface.xml
|
||||
- haarcascade\_frontalcatface\_extended.xml
|
||||
|
||||
这两个 Haar Cascade 文件都将被用来在图片中检测小猫的脸。实际上,我使用了相同的 cascades 分类器来生成这篇博文顶端的图片。
|
||||
|
||||
在做了一些调查工作之后,我发现这些 cascades 分类器是由鼎鼎大名的 [Joseph Howse][5]训练和贡献给 OpenCV 仓库的,他写了很多很棒的教程和书籍,在计算机视觉领域有着很高的声望。
|
||||
|
||||
下面,我将会展示给你如何使用 Howse 的 Haar cascades 分类器来检测图片中的小猫。
|
||||
|
||||
### 猫咪检测代码
|
||||
|
||||
让我们开始使用 OpenCV 来检测图片中的猫咪。新建一个叫 cat_detector.py 的文件,并且输入如下的代码:
|
||||
|
||||
```
|
||||
# import the necessary packages
|
||||
import argparse
|
||||
import cv2
|
||||
|
||||
# construct the argument parse and parse the arguments
|
||||
ap = argparse.ArgumentParser()
|
||||
ap.add_argument("-i", "--image", required=True,
|
||||
help="path to the input image")
|
||||
ap.add_argument("-c", "--cascade",
|
||||
default="haarcascade_frontalcatface.xml",
|
||||
help="path to cat detector haar cascade")
|
||||
args = vars(ap.parse_args())
|
||||
```
|
||||
|
||||
第 2 和第 3 行主要是导入了必要的 python 包。6-12 行用于解析我们的命令行参数。我们仅要求一个必需的参数 `--image` ,它是我们要使用 OpenCV 检测猫咪的图片。
|
||||
|
||||
我们也可以(可选的)通过 `--cascade` 参数指定我们的 Haar cascade 分类器的路径。默认使用 `haarcascades_frontalcatface.xml`,假定这个文件和你的 `cat_detector.py` 在同一目录下。
|
||||
|
||||
注意:我已经打包了猫咪的检测代码,还有在这个教程里的样本图片。你可以在博文原文的 “下载” 部分下载到。如果你是刚刚接触 Python+OpenCV(或者 Haar cascade),我建议你下载这个 zip 压缩包,这个会方便你跟着教程学习。
|
||||
|
||||
接下来,就是检测猫的时刻了:
|
||||
|
||||
```
|
||||
# load the input image and convert it to grayscale
|
||||
image = cv2.imread(args["image"])
|
||||
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
|
||||
|
||||
# load the cat detector Haar cascade, then detect cat faces
|
||||
# in the input image
|
||||
detector = cv2.CascadeClassifier(args["cascade"])
|
||||
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
|
||||
minNeighbors=10, minSize=(75, 75))
|
||||
```
|
||||
|
||||
在 15、16 行,我们从硬盘上读取了图片,并且进行灰度化(这是一个在将图片传给 Haar cascade 分类器之前的常用的图片预处理步骤,尽管不是必须的)
|
||||
|
||||
20 行,从硬盘加载 Haar casacade 分类器,即猫咪检测器,并且实例化 `cv2.CascadeClassifier` 对象。
|
||||
|
||||
在 21、22 行通过调用 `detector` 的 `detectMultiScale` 方法使用 OpenCV 完成猫脸检测。我们给 `detectMultiScale` 方法传递了四个参数。包括:
|
||||
|
||||
1. 图片 `gray`,我们要在该图片中检测猫脸。
|
||||
2. 检测猫脸时的[图片金字塔][6] 的检测粒度 `scaleFactor` 。更大的粒度将会加快检测的速度,但是会对检测准确性( true-positive)产生影响。相反的,一个更小的粒度将会影响检测的时间,但是会增加准确性( true-positive)。但是,细粒度也会增加误报率(false-positive)。你可以看这篇博文的“ Haar cascades 注意事项”部分来获得更多的信息。
|
||||
3. `minNeighbors` 参数控制了检定框的最少数量,即在给定区域内被判断为猫脸的最少数量。这个参数可以很好的排除误报(false-positive)结果。
|
||||
4. 最后,`minSize` 参数不言自明。这个值描述每个检定框的最小宽高尺寸(单位是像素),这个例子中就是 75\*75
|
||||
|
||||
`detectMultiScale` 函数会返回 `rects`,这是一个 4 元组列表。这些元组包含了每个检测到的猫脸的 (x,y) 坐标值,还有宽度、高度。
|
||||
|
||||
最后,让我们在图片上画下这些矩形来标识猫脸:
|
||||
|
||||
```
|
||||
# loop over the cat faces and draw a rectangle surrounding each
|
||||
for (i, (x, y, w, h)) in enumerate(rects):
|
||||
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
|
||||
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
|
||||
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
|
||||
|
||||
# show the detected cat faces
|
||||
cv2.imshow("Cat Faces", image)
|
||||
cv2.waitKey(0)
|
||||
```
|
||||
|
||||
给我们这些框(比如,rects)的数据,我们在 25 行依次遍历它。
|
||||
|
||||
在 26 行,我们在每张猫脸的周围画上一个矩形。27、28 行展示了一个整数,即图片中猫咪的数量。
|
||||
|
||||
最后,31,32 行在屏幕上展示了输出的图片。
|
||||
|
||||
### 猫咪检测结果
|
||||
|
||||
为了测试我们的 OpenCV 猫咪检测器,可以在原文的最后,下载教程的源码。
|
||||
|
||||
然后,在你解压缩之后,你将会得到如下的三个文件/目录:
|
||||
|
||||
1. cat_detector.py:我们的主程序
|
||||
2. haarcascade_frontalcatface.xml: 猫咪检测器 Haar cascade
|
||||
3. images:我们将会使用的检测图片目录。
|
||||
|
||||
到这一步,执行以下的命令:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_01.jpg
|
||||
```
|
||||
|
||||
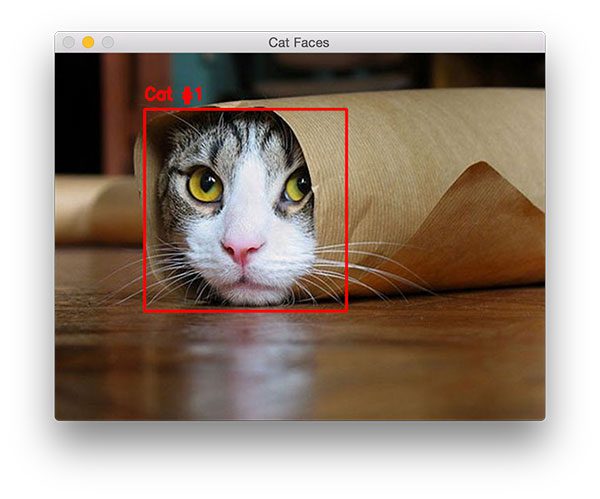
|
||||
|
||||
*图 1. 在图片中检测猫脸,甚至是猫咪部分被遮挡了。*
|
||||
|
||||
注意,我们已经可以检测猫脸了,即使它的其余部分是被遮挡的。
|
||||
|
||||
试下另外的一张图片:
|
||||
|
||||
```
|
||||
python cat_detector.py --image images/cat_02.jpg
|
||||
```
|
||||
|
||||

|
||||
|
||||
*图 2. 使用 OpenCV 检测猫脸的第二个例子,这次猫脸稍有不同。*
|
||||
|
||||
这次的猫脸和第一次的明显不同,因为它正在发出“喵呜”叫声的当中。这种情况下,我们依旧能检测到正确的猫脸。
|
||||
|
||||
在下面这张图片的结果也是正确的:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_03.jpg
|
||||
```
|
||||
|
||||
|
||||
|
||||
*图 3. 使用 OpenCV 和 python 检测猫脸*
|
||||
|
||||
我们最后的一个样例就是在一张图中检测多张猫脸:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_04.jpg
|
||||
```
|
||||
|
||||

|
||||
|
||||
*图 4. 在同一张图片中使用 OpenCV 检测多只猫*
|
||||
|
||||
注意,Haar cascade 返回的检定框不一定是以你预期的顺序。这种情况下,中间的那只猫会被标记成第三只。你可以通过判断他们的 (x, y) 坐标来自己排序这些检定框。
|
||||
|
||||
#### 关于精度的说明
|
||||
|
||||
在这个 xml 文件中的注释非常重要,Joseph Hower 提到了这个猫脸检测器有可能会将人脸识别成猫脸。
|
||||
|
||||
这种情况下,他推荐使用两种检测器(人脸 & 猫脸),然后将出现在人脸识别结果中的结果剔除掉。
|
||||
|
||||
#### Haar cascades 注意事项
|
||||
|
||||
这个方法首先出现在 Paul Viola 和 Michael Jones 2001 年出版的 [Rapid Object Detection using a Boosted Cascade of Simple Features][7] 论文中。现在它已经成为了计算机识别领域引用最多的论文之一。
|
||||
|
||||
这个算法能够识别图片中的对象,无论它们的位置和比例。而且最令人感兴趣的或许是它能在现有的硬件条件下实现实时检测。
|
||||
|
||||
在他们的论文中,Viola 和 Jones 关注在训练人脸检测器;但是,这个框架也能用来检测各类事物,如汽车、香蕉、路标等等。
|
||||
|
||||
#### 问题是?
|
||||
|
||||
Haar cascades 最大的问题就是如何确定 `detectMultiScale` 方法的参数正确。特别是 `scaleFactor` 和 `minNeighbors` 参数。你很容易陷入一张一张图片调参数的坑,这个就是该对象检测器很难被实用化的原因。
|
||||
|
||||
这个 `scaleFactor` 变量控制了用来检测对象的图片的各种比例的[图像金字塔][8]。如果 `scaleFactor` 参数过大,你就只需要检测图像金字塔中较少的层,这可能会导致你丢失一些在图像金字塔层之间缩放时少了的对象。
|
||||
|
||||
换句话说,如果 `scaleFactor` 参数过低,你会检测过多的金字塔图层。这虽然可以能帮助你检测到更多的对象。但是他会造成计算速度的降低,还会**明显**提高误报率。Haar cascades 分类器就是这样。
|
||||
|
||||
为了避免这个,我们通常使用 [Histogram of Oriented Gradients + 线性 SVM 检测][9] 替代。
|
||||
|
||||
上述的 HOG + 线性 SVM 框架的参数更容易调优。而且更好的误报率也更低,但是唯一不好的地方是无法实时运算。
|
||||
|
||||
### 对对象识别感兴趣?并且希望了解更多?
|
||||
|
||||

|
||||
|
||||
*图 5. 在 PyImageSearch Gurus 课程中学习如何构建自定义的对象识别器。*
|
||||
|
||||
如果你对学习如何训练自己的自定义对象识别器感兴趣,请务必要去了解下 PyImageSearch Gurus 课程。
|
||||
|
||||
在这个课程中,我提供了 15 节课,覆盖了超过 168 页的教程,来教你如何从 0 开始构建自定义的对象识别器。你会掌握如何应用 HOG + 线性 SVM 框架来构建自己的对象识别器来识别路标、面孔、汽车(以及附近的其它东西)。
|
||||
|
||||
要学习 PyImageSearch Gurus 课程(有 10 节示例免费课程),点此:https://www.pyimagesearch.com/pyimagesearch-gurus/?src=post-cat-detection
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇博文里,我们学习了如何使用 OpenCV 默认就有的 Haar cascades 分类器来识别图片中的猫脸。这些 Haar casacades 是由 [Joseph Howse][9] 训练兵贡献给 OpenCV 项目的。我是在 Kendrick Tan 的[这篇文章][10]中开始注意到这个。
|
||||
|
||||
尽管 Haar cascades 相当有用,但是我们也经常用 HOG + 线性 SVM 替代。因为后者相对而言更容易使用,并且可以有效地降低误报率。
|
||||
|
||||
我也会[在 PyImageSearch Gurus 课程中][11]详细的讲述如何构建定制的 HOG + 线性 SVM 对象识别器,来识别包括汽车、路标在内的各种事物。
|
||||
|
||||
不管怎样,我希望你喜欢这篇博文。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/
|
||||
|
||||
作者:[Adrian Rosebrock][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.pyimagesearch.com/author/adrian/
|
||||
[1]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[2]: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/#
|
||||
[3]: https://github.com/Itseez/opencv
|
||||
[4]: https://github.com/Itseez/opencv/tree/master/data/haarcascades
|
||||
[5]: http://nummist.com/
|
||||
[6]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[7]: https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
|
||||
[8]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[9]: http://www.pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/
|
||||
[10]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[11]: https://www.pyimagesearch.com/pyimagesearch-gurus/
|
||||
|
||||
|
||||
|
||||
118
published/201607/20160620 Monitor Linux With Netdata.md
Normal file
118
published/201607/20160620 Monitor Linux With Netdata.md
Normal file
@ -0,0 +1,118 @@
|
||||
用 Netdata 监控 Linux
|
||||
=======
|
||||
|
||||

|
||||
|
||||
Netdata 是一个实时的资源监控工具,它拥有基于 web 的友好界面,由 [FireHQL][1] 开发和维护。通过这个工具,你可以通过图表来了解 CPU,RAM,硬盘,网络,Apache, Postfix 等软硬件的资源使用情况。它很像 Nagios 等别的监控软件;但是,Netdata 仅仅支持通过 Web 界面进行实时监控。
|
||||
|
||||
### 了解 Netdata
|
||||
|
||||
目前 Netdata 还没有验证机制,如果你担心别人能从你的电脑上获取相关信息的话,你应该设置防火墙规则来限制访问。UI 很简单,所以任何人看懂图形并理解他们看到的结果,至少你会对它的快速安装印象深刻。
|
||||
|
||||
它的 web 前端响应很快,而且不需要 Flash 插件。 UI 很整洁,保持着 Netdata 应有的特性。第一眼看上去,你能够看到很多图表,幸运的是绝大多数常用的图表数据(像 CPU,RAM,网络和硬盘)都在顶部。如果你想深入了解图形化数据,你只需要下滑滚动条,或者点击在右边菜单的项目。通过每个图表的右下方的按钮, Netdata 还能让你控制图表的显示,重置,缩放。
|
||||
|
||||
|
||||
|
||||
*Netdata 图表控制*
|
||||
|
||||
Netdata 并不会占用多少系统资源,它占用的内存不会超过 40MB。因为这个软件是作者用 C 语言写的。
|
||||
|
||||
|
||||
|
||||
*Netdata 显示的内存使用情况*
|
||||
|
||||
### 下载 Netdata
|
||||
|
||||
要下载这个软件,你可以访问 [Netdata 的 GitHub 页面][2],然后点击页面左边绿色的 "Clone or download" 按钮 。你应该能看到以下两个选项:
|
||||
|
||||
#### 通过 ZIP 文件下载
|
||||
|
||||
一种方法是下载 ZIP 文件。它包含仓库里的所有东西。但是如果仓库更新了,你需要重新下载 ZIP 文件。下载完 ZIP 文件后,你要用 `unzip` 命令行工具来解压文件。运行下面的命令能把 ZIP 文件的内容解压到 `netdata` 文件夹。
|
||||
|
||||
```
|
||||
$ cd ~/Downloads
|
||||
$ unzip netdata-master.zip
|
||||
```
|
||||
|
||||
|
||||
|
||||
*解压 Netdata*
|
||||
|
||||
没必要在 unzip 命令后加上 `-d` 选项,因为文件都是是放在 ZIP 文件的根文件夹里面。如果没有那个文件夹, unzip 会把所有东西都解压到当前目录下面(这会让文件非常混乱)。
|
||||
|
||||
#### 通过 Git 下载
|
||||
|
||||
还有一种方式是通过 git 下载整个仓库。当然,你的系统需要安装 git。Git 在 Fedora 系统是默认安装的。如果没有安装,你可以用下面的命令在命令行里安装 git。
|
||||
|
||||
```
|
||||
$ sudo dnf install git
|
||||
```
|
||||
|
||||
安装好 git 后,你要把仓库 “clone” 到你的系统里。运行下面的命令。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/firehol/netdata.git
|
||||
```
|
||||
|
||||
这个命令会在当前工作目录克隆(或者说复制一份)仓库。
|
||||
|
||||
### 安装 Netdata
|
||||
|
||||
有些软件包是你成功构造 Netdata 时候需要的。 还好,一行命令就可以安装你所需要的东西([这写在它的安装文档中][3])。在命令行运行下面的命令就能满足安装 Netdata 需要的所有依赖关系。
|
||||
|
||||
```
|
||||
$ dnf install zlib-devel libuuid-devel libmnl-devel gcc make git autoconf autogen automake pkgconfig
|
||||
```
|
||||
|
||||
当所有需要的软件包都安装好了,你就 cd 到 netdata/ 目录,运行 netdata-installer.sh 脚本。
|
||||
|
||||
```
|
||||
$ sudo ./netdata-installer.sh
|
||||
```
|
||||
|
||||
然后就会提示你按回车键,开始安装程序。如果要继续的话,就按下回车吧。
|
||||
|
||||
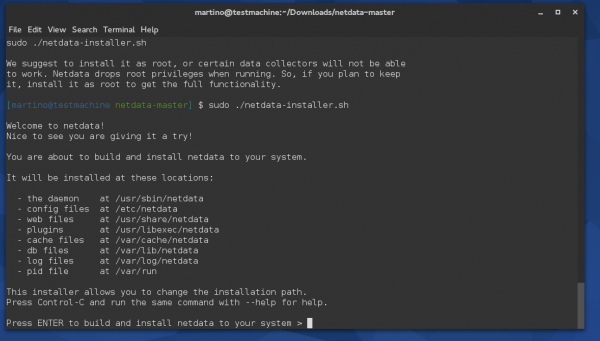
|
||||
|
||||
*Netdata 的安装*
|
||||
|
||||
如果一切顺利,你的系统上就已经安装并且运行了 Netdata。安装脚本还会在相应的文件夹里添加一个卸载脚本,叫做 `netdata-uninstaller.sh`。如果你以后不想使用 Netdata,运行这个脚本可以从你的系统里面卸载掉 Netdata。
|
||||
|
||||
你可以通过 systemctl 查看它的运行状态。
|
||||
|
||||
```
|
||||
$ sudo systemctl status netdata
|
||||
```
|
||||
|
||||
### 使用 Netdata
|
||||
|
||||
既然我们已经安装并且运行了 Netdata,你就能够通过 19999 端口来访问 web 界面。下面的截图是我在一个测试机器上运行的 Netdata。
|
||||
|
||||
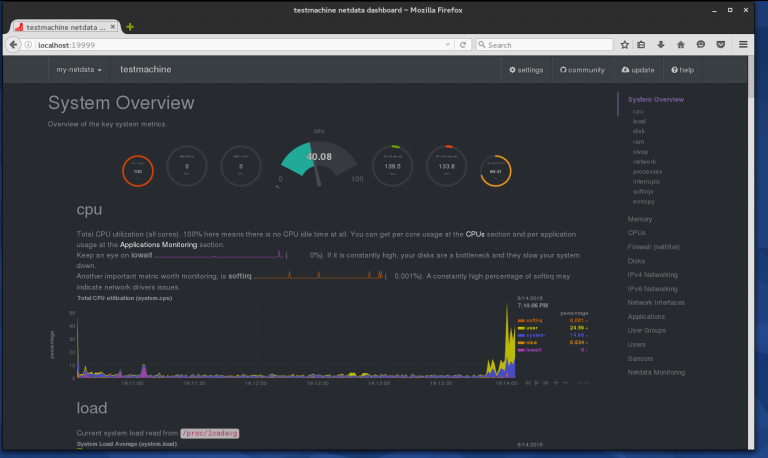
|
||||
|
||||
*关于 Netdata 运行时的概览*
|
||||
|
||||
恭喜!你已经成功安装并且能够看到漂亮的外观和图形,以及你的机器性能的高级统计数据。无论是否是你个人的机器,你都可以向你的朋友们炫耀,因为你能够深入的了解你的服务器性能,Netdata 在任何机器上的性能报告都非常出色。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/monitor-linux-netdata/
|
||||
|
||||
作者:[Martino Jones][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/monitor-linux-netdata/
|
||||
[1]: https://firehol.org/
|
||||
[2]: https://github.com/firehol/netdata
|
||||
[3]: https://github.com/firehol/netdata/wiki/Installation
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,106 @@
|
||||
Android 4.4 移植到了 PowerPC 架构,支持大端架构
|
||||
===========================================================
|
||||
|
||||
eInfochips(一家软件厂商) 已将将 Android 4.4 系统移植到 PowerPC 架构,它将用于一家航空电子客户用来监视引擎的健康状况的人机界面(HMI:Human Machine Interface)。
|
||||
|
||||
eInfochips 已经开发了第一个面向 PowerPC 架构的 CPU 的 Android 移植版本,并支持大端(Big Endian)架构。此移植基于 Android 开源项目 [Android Open Source Project (AOSP)] 中 Android 4.4 (KitKat) 的代码,其功能内核的版本号为 3.12.19。
|
||||
|
||||
Android 开始兴起的时候,PowerPC 正在快速丢失和 ARM 架构共同角逐的市场。高端的网络客户和其它的企业级的嵌入式工具大多运行在诸如飞思卡尔(Freescale)的 PowerQUICC 和 QorIQ 这样的 PowerPC 处理器上,但是并不是 Linux 系统。不过,有几个 Android 的移植计划。在 2009 年,飞思卡尔和 Embedded Alley(一家软件厂商,当前是 Mentor Graphics 的 Linux 团队的一部分)[宣布了针对 PowerQUICC 和 QorIQ 芯片的移植版本][15],当前由 NXP 公司构建。另一个名为 [Android-PowerPC][16] 的项目也作出了相似的工作。
|
||||
|
||||
这些努力来的都并不容易,然而,当航空公司找到 eInfochips,希望能够为他们那些基于 PowerPC 的引擎监控系统添加 Android 应用程序以改善人机界面。该公司找出了这些早期的移植版本,然而,它们都相距甚远。所以,他们不得不从头开始新的移植。
|
||||
|
||||
最主要的问题是这些移植的 Android 版本实在是太老了,和现在的 Android 差别太大了。Embedded Alley 移植的版本为 Android 1.5 (Cupcake),它于 2009 年发布,Linux 内核版本为 2.6.28。而 Android-PowerPC 项目最后一版的移植是 Android 2.2 (Froyo),它于 2010 年发布,内核版本为 2.6.32。此外,航空公司还有一些额外的技术诉求,例如对大端架构(Big Endian)的支持,这种老式的内存访问方式仍旧应用于网络通信和电信行业。然而那些早期的移植版本仅能够支持小端(Little Endian)的内存访问。
|
||||
|
||||
### 来自 eInfochips 的全新 PowerPC 架构移植
|
||||
|
||||
eInfochips, 它最为出名的应该是那些基于 ARM/骁龙处理器的模块计算机板卡,例如 [Eragon 600][17]。 它已经完成了基于 QorIQ 的 Android 4.4 系统移植,且发布了白皮书介绍了该项目。采用该项目的航空电子设备客户仍旧不愿透露名称,目前仍旧不清楚什么时候会公开此该移植版本。
|
||||
|
||||

|
||||
|
||||
*图片来自 eInfochips 的博客日志*
|
||||
|
||||
全新的 PowerPC Android 项目包括:
|
||||
|
||||
- 基于 PowerPC [e5500][1] 仿生定制
|
||||
- 基于 Android KitKat 的大端支持
|
||||
- 使用 GCC 5.2 工具链开发
|
||||
- Android 4.4 框架的 PowerPC 支持
|
||||
- PowerPC e5500 的 Android 内核版本为 3.12.19
|
||||
|
||||
根据 eInfochips 的销售经理 Sooryanarayanan Balasubramanian 描述,该航空电子客户想要使用 Android 主要是因为熟悉的界面能够缩减培训的时间,并且让程序更新和增加新程序变得更加容易。他继续解释说:“这次成功的移植了 Android,使得今后的工作仅仅需要在应用层作出修修改改,而不再向以前一样需要在所有层面之间作相互的校验。”,“这是第一次在航空航天工业作出这些尝试,这需要在设计时尽量认真。”
|
||||
|
||||
通过白皮书,可以知道将 Android 移植到 PowerPC 上需要对框架、核心库、开发工具链、运行时链接器、对象链接器和开源编译工具作出大量的修改。在字节码生成阶段,移植团队决定使用便携模式(portable mode)而不是快速解释模式(fast interpreter mode)。这是因为还没有 PowerPC 可用的快速解释模式,而使用开源的 [libffi][18] 的便携模式能够支持 PowerPC。
|
||||
|
||||
同时,团队还面临着在 Android 运行时 (ART) 环境和 Dalvik 虚拟机 (DVM) 环境之间的选择。他们发现,ART 环境下的便携模式还未经测试且缺乏良好的文档支持,所以最终选择了 DVM 环境下的便携模式。
|
||||
|
||||
白皮书中还提及了其它的一些在移植过程中遇到的困难,包括重新开发工具链,重写脚本以解决 AOSP 对编译器标志“非标准”使用的问题。最终完成的移植版本提供了 37 个服务,以及提供了无界面的 Android 部署,在前端使用用户空间的模拟 UI。
|
||||
|
||||
|
||||
### 目标硬件
|
||||
|
||||
感谢来自 [eInfochips 博客日志][2] 的图片(如下图所示),让我们能够确认此 PowerPC 的 Android 移植项目的硬件平台。这个板卡为 [X-ES Xpedite 6101][3],它是一个加固级 XMC/PrPMC 夹层模组。
|
||||
|
||||

|
||||
|
||||
*X-ES Xpedite 6101 照片和框图*
|
||||
|
||||
X-ES Xpedite 6101 板卡拥有一个可选的 NXP 公司基于 QorIQ T 系列通信处理器(T2081、T1042 和 T1022),它们分别集成了 8 个、4 个和 2 个 e6500 核心,稍有不同的是,T2081 的处理器主频为 1.8GHz,T1042/22 的处理器主频为 1.4GHz。所有的核心都集成了 AltiVec SIMD 引擎,这也就意味着它能够提供 DSP 级别的浮点运算性能。所有以上 3 款 X-ES 板卡都能够支持最高 8GB 的 DDR3-1600 ECC SDRAM 内存。外加 512MB NOR 和 32GB 的 NAND 闪存。
|
||||
|
||||

|
||||
|
||||
*NXP T2081 框图*
|
||||
|
||||
板卡的 I/O 包括一个 x4 PCI Express Gen2 通道,以及双工的千兆级网卡、 RS232/422/485 串口和 SATA 3.0 接口。此外,它可选 3 款 QorIQ 处理器,Xpedite 6101 提供了三种 [X-ES 加固等级][19],分别是额定工作温度 0 ~ 55°C, -40 ~ 70°C, 或者是 -40 ~ 85°C,且包含 3 类冲击和抗振类别。
|
||||
|
||||
此外,我们已经介绍过的基于 X-ES QorIQ 的 XMC/PrPMC 板卡包括 [XPedite6401 和 XPedite6370][20],它们支持已有的板卡级 Linux 、风河的 VxWorks(一种实时操作系统) 和 Green Hills 的 Integrity(也是一种操作系统)。
|
||||
|
||||
|
||||
### 更多信息
|
||||
|
||||
eInfochips Android PowerPC 移植白皮书可以[在此][4]下载(需要先免费注册)。
|
||||
|
||||
### 相关资料
|
||||
|
||||
- [Commercial embedded Linux distro boosts virtualization][5]
|
||||
- [Freescale unveils first ARM-based QorIQ SoCs][6]
|
||||
- [High-end boards run Linux on 64-bit ARM QorIQ SoCs][7]
|
||||
- [Free, Open Enea Linux taps Yocto Project and Linaro code][8]
|
||||
- [LynuxWorks reverts to its LynxOS roots, changes name][9]
|
||||
- [First quad- and octa-core QorIQ SoCs unveiled][10]
|
||||
- [Free white paper shows how Linux won embedded][11]
|
||||
- [Quad-core Snapdragon COM offers three dev kit options][12]
|
||||
- [Tiny COM runs Linux on quad-core 64-bit Snapdragon 410][13]
|
||||
- [PowerPC based IoT gateway COM ships with Linux BSP][14]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/powerpc-gains-android-4-4-port-with-big-endian-support/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[dongfengweixiao](https://github.com/dongfengweixiao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://hackerboards.com/powerpc-gains-android-4-4-port-with-big-endian-support/
|
||||
[1]: http://linuxdevices.linuxgizmos.com/low-cost-powerquicc-chips-offer-flexible-interconnect-options/
|
||||
[2]: https://www.einfochips.com/blog/k2-categories/aerospace/presenting-a-case-for-porting-android-on-powerpc-architecture.html
|
||||
[3]: http://www.xes-inc.com/products/processor-mezzanines/xpedite6101/
|
||||
[4]: http://biz.einfochips.com/portingandroidonpowerpc
|
||||
[5]: http://hackerboards.com/commercial-embedded-linux-distro-boosts-virtualization/
|
||||
[6]: http://hackerboards.com/freescale-unveils-first-arm-based-qoriq-socs/
|
||||
[7]: http://hackerboards.com/high-end-boards-run-linux-on-64-bit-arm-qoriq-socs/
|
||||
[8]: http://hackerboards.com/free-open-enea-linux-taps-yocto-and-linaro-code/
|
||||
[9]: http://hackerboards.com/lynuxworks-reverts-to-its-lynxos-roots-changes-name/
|
||||
[10]: http://hackerboards.com/first-quad-and-octa-core-qoriq-socs-unveiled/
|
||||
[11]: http://hackerboards.com/free-white-paper-shows-how-linux-won-embedded/
|
||||
[12]: http://hackerboards.com/quad-core-snapdragon-com-offers-three-dev-kit-options/
|
||||
[13]: http://hackerboards.com/tiny-com-runs-linux-and-android-on-quad-core-64-bit-snapdragon-410/
|
||||
[14]: http://hackerboards.com/powerpc-based-iot-gateway-com-ships-with-linux-bsp/
|
||||
[15]: http://linuxdevices.linuxgizmos.com/android-ported-to-powerpc/
|
||||
[16]: http://www.androidppc.com/
|
||||
[17]: http://hackerboards.com/quad-core-snapdragon-com-offers-three-dev-kit-options/
|
||||
[18]: https://sourceware.org/libffi/
|
||||
[19]: http://www.xes-inc.com/capabilities/ruggedization/
|
||||
[20]: http://hackerboards.com/high-end-boards-run-linux-on-64-bit-arm-qoriq-socs/
|
||||
@ -0,0 +1,105 @@
|
||||
Fedora 中的容器技术:systemd-nspawn
|
||||
===
|
||||
|
||||
欢迎来到“Fedora 中的容器技术”系列!本文是该系列文章中的第一篇,它将说明你可以怎样使用 Fedora 中各种可用的容器技术。本文将学习 `systemd-nspawn` 的相关知识。
|
||||
|
||||
### 容器是什么?
|
||||
|
||||
一个容器就是一个用户空间实例,它能够在与托管容器的系统(叫做宿主系统)相隔离的环境中运行一个程序或者一个操作系统。这和 `chroot` 或 [虚拟机][1] 的思想非常类似。运行在容器中的进程是由与宿主操作系统相同的内核来管理的,但它们是与宿主文件系统以及其它进程隔离开的。
|
||||
|
||||
### 什么是 systemd-nspawn?
|
||||
|
||||
systemd 项目认为应当将容器技术变成桌面的基础部分,并且应当和用户的其余系统集成在一起。为此,systemd 提供了 `systemd-nspawn`,这款工具能够使用多种 Linux 技术创建容器。它也提供了一些容器管理工具。
|
||||
|
||||
`systemd-nspawn` 和 `chroot` 在许多方面都是类似的,但是前者更加强大。它虚拟化了文件系统、进程树以及客户系统中的进程间通信。它的吸引力在于它提供了很多用于管理容器的工具,例如用来管理容器的 `machinectl`。由 `systemd-nspawn` 运行的容器将会与 systemd 组件一同运行在宿主系统上。举例来说,一个容器的日志可以输出到宿主系统的日志中。
|
||||
|
||||
在 Fedora 24 上,`systemd-nspawn` 已经从 systemd 软件包分离出来了,所以你需要安装 `systemd-container` 软件包。一如往常,你可以使用 `dnf install systemd-container` 进行安装。
|
||||
|
||||
### 创建容器
|
||||
|
||||
使用 `systemd-nspawn` 创建一个容器是很容易的。假设你有一个专门为 Debian 创造的应用,并且无法在其它发行版中正常运行。那并不是一个问题,我们可以创造一个容器!为了设置容器使用最新版本的 Debian(现在是 Jessie),你需要挑选一个目录来放置你的系统。我暂时将使用目录 `~/DebianJessie`。
|
||||
|
||||
一旦你创建完目录,你需要运行 `debootstrap`,你可以从 Fedora 仓库中安装它。对于 Debian Jessie,你运行下面的命令来初始化一个 Debian 文件系统。
|
||||
|
||||
```
|
||||
$ debootstrap --arch=amd64 stable ~/DebianJessie
|
||||
```
|
||||
|
||||
以上默认你的架构是 x86_64。如果不是的话,你必须将架构的名称改为 `amd64`。你可以使用 `uname -m` 得知你的机器架构。
|
||||
|
||||
一旦设置好你的根目录,你就可以使用下面的命令来启动你的容器。
|
||||
|
||||
```
|
||||
$ systemd-nspawn -bD ~/DebianJessie
|
||||
```
|
||||
|
||||
容器将会在数秒后准备好并运行,当你试图登录时就会注意到:你无法使用你的系统上任何账户。这是因为 `systemd-nspawn` 虚拟化了用户。修复的方法很简单:将之前的命令中的 `-b` 移除即可。你将直接进入容器的 root 用户的 shell。此时,你只能使用 `passwd` 命令为 root 设置密码,或者使用 `adduser` 命令添加一个新用户。一旦设置好密码或添加好用户,你就可以把 `-b` 标志添加回去然后继续了。你会进入到熟悉的登录控制台,然后你使用设置好的认证信息登录进去。
|
||||
|
||||
以上对于任意你想在容器中运行的发行版都适用,但前提是你需要使用正确的包管理器创建系统。对于 Fedora,你应使用 DNF 而非 `debootstrap`。想要设置一个最小化的 Fedora 系统,你可以运行下面的命令,要将“/absolute/path/”替换成任何你希望容器存放的位置。
|
||||
|
||||
```
|
||||
$ sudo dnf --releasever=24 --installroot=/absolute/path/ install systemd passwd dnf fedora-release
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 设置网络
|
||||
|
||||
如果你尝试启动一个服务,但它绑定了你宿主机正在使用的端口,你将会注意到这个问题:你的容器正在使用和宿主机相同的网络接口。幸运的是,`systemd-nspawn` 提供了几种可以将网络从宿主机分开的方法。
|
||||
|
||||
#### 本地网络
|
||||
|
||||
第一种方法是使用 `--private-network` 标志,它默认仅创建一个回环设备。这对于你不需要使用网络的环境是非常理想的,例如构建系统和其它持续集成系统。
|
||||
|
||||
#### 多个网络接口
|
||||
|
||||
如果你有多个网络接口设备,你可以使用 `--network-interface` 标志给容器分配一个接口。想要给我的容器分配 `eno1`,我会添加选项 `--network-interface=eno1`。当某个接口分配给一个容器后,宿主机就不能同时使用那个接口了。只有当容器彻底关闭后,宿主机才可以使用那个接口。
|
||||
|
||||
#### 共享网络接口
|
||||
|
||||
对于我们中那些并没有额外的网络设备的人来说,还有其它方法可以访问容器。一种就是使用 `--port` 选项。这会将容器中的一个端口定向到宿主机。使用格式是 `协议:宿主机端口:容器端口`,这里的协议可以是 `tcp` 或者 `udp`,`宿主机端口` 是宿主机的一个合法端口,`容器端口` 则是容器中的一个合法端口。你可以省略协议,只指定 `宿主机端口:容器端口`。我通常的用法类似 `--port=2222:22`。
|
||||
|
||||
你可以使用 `--network-veth` 启用完全的、仅宿主机模式的网络,这会在宿主机和容器之间创建一个虚拟的网络接口。你也可以使用 `--network-bridge` 桥接二者的连接。
|
||||
|
||||
### 使用 systemd 组件
|
||||
|
||||
如果你容器中的系统含有 D-Bus,你可以使用 systemd 提供的实用工具来控制并监视你的容器。基础安装的 Debian 并不包含 `dbus`。如果你想在 Debian Jessie 中使用 `dbus`,你需要运行命令 `apt install dbus`。
|
||||
|
||||
#### machinectl
|
||||
|
||||
为了能够轻松地管理容器,systemd 提供了 `machinectl` 实用工具。使用 `machinectl`,你可以使用 `machinectl login name` 登录到一个容器中、使用 `machinectl status name`检查状态、使用 `machinectl reboot name` 启动容器或者使用 `machinectl poweroff name` 关闭容器。
|
||||
|
||||
### 其它 systemd 命令
|
||||
|
||||
多数 systemd 命令,例如 `journalctl`, `systemd-analyze` 和 `systemctl`,都支持使用 `--machine` 选项来指定容器。例如,如果你想查看一个名为 “foobar” 的容器的日志,你可以使用 `journalctl --machine=foobar`。你也可以使用 `systemctl --machine=foobar status service` 来查看运行在这个容器中的服务状态。
|
||||
|
||||
|
||||
|
||||
### 和 SELinux 一起工作
|
||||
|
||||
如果你要使用 SELinux 强制模式(Fedora 默认模式),你需要为你的容器设置 SELinux 环境。想要那样的话,你需要在宿主系统上运行下面两行命令。
|
||||
|
||||
```
|
||||
$ semanage fcontext -a -t svirt_sandbox_file_t "/path/to/container(/.*)?"
|
||||
$ restorecon -R /path/to/container/
|
||||
```
|
||||
|
||||
确保使用你的容器路径替换 “/path/to/container”。对于我的容器 "DebianJessie",我会运行下面的命令:
|
||||
|
||||
```
|
||||
$ semanage fcontext -a -t svirt_sandbox_file_t "/home/johnmh/DebianJessie(/.*)?"
|
||||
$ restorecon -R /home/johnmh/DebianJessie/
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/
|
||||
|
||||
作者:[John M. Harris, Jr.][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/
|
||||
[1]: https://en.wikipedia.org/wiki/Virtual_machine
|
||||
@ -0,0 +1,123 @@
|
||||
如何在 Linux 上永久挂载一个 Windows 共享
|
||||
==================================================
|
||||
|
||||
> 如果你已经厌倦了每次重启 Linux 就得重新挂载 Windows 共享,读读这个让共享永久挂载的简单方法。
|
||||
|
||||

|
||||
|
||||
*图片: Jack Wallen*
|
||||
|
||||
在 Linux 上和一个 Windows 网络进行交互从来就不是件轻松的事情。想想多少企业正在采用 Linux,需要在这两个平台上彼此协作。幸运的是,有了一些工具的帮助,你可以轻松地将 Windows 网络驱动器映射到一台 Linux 机器上,甚至可以确保在重启 Linux 机器之后共享还在。
|
||||
|
||||
### 在我们开始之前
|
||||
|
||||
要实现这个,你需要用到命令行。过程十分简单,但你需要编辑 /etc/fstab 文件,所以小心操作。还有,我假设你已经让 Samba 正常工作了,可以手动从 Windows 网络挂载共享到你的 Linux 机器,还知道这个共享的主机 IP 地址。
|
||||
|
||||
准备好了吗?那就开始吧。
|
||||
|
||||
### 创建你的挂载点
|
||||
|
||||
我们要做的第一件事是创建一个文件夹,他将作为共享的挂载点。为了简单起见,我们将这个文件夹命名为 share,放在 /media 之下。打开你的终端执行以下命令:
|
||||
|
||||
```
|
||||
sudo mkdir /media/share
|
||||
```
|
||||
|
||||
### 安装一些软件
|
||||
|
||||
现在我们得安装允许跨平台文件共享的系统;这个系统是 cifs-utils。在终端窗口输入:
|
||||
|
||||
```
|
||||
sudo apt-get install cifs-utils
|
||||
```
|
||||
|
||||
这个命令同时还会安装 cifs-utils 所有的依赖。
|
||||
|
||||
安装完成之后,打开文件 /etc/nsswitch.conf 并找到这一行:
|
||||
|
||||
```
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] dns
|
||||
```
|
||||
|
||||
编辑这一行,让它看起来像这样:
|
||||
|
||||
```
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] wins dns
|
||||
```
|
||||
|
||||
现在你需要安装 windbind 让你的 Linux 机器可以在 DHCP 网络中解析 Windows 机器名。在终端里执行:
|
||||
|
||||
```
|
||||
sudo apt-get install libnss-windbind windbind
|
||||
```
|
||||
|
||||
用这个命令重启网络服务:
|
||||
|
||||
```
|
||||
sudo service networking restart
|
||||
```
|
||||
|
||||
### 挂载网络驱动器
|
||||
|
||||
现在我们要映射网络驱动器。这里我们必须编辑 /etc/fstab 文件。在你做第一次编辑之前,用这个命令备份以下这个文件:
|
||||
|
||||
```
|
||||
sudo cp /etc/fstab /etc/fstab.old
|
||||
```
|
||||
|
||||
如果你需要恢复这个文件,执行以下命令:
|
||||
|
||||
```
|
||||
sudo mv /etc/fstab.old /etc/fstab
|
||||
```
|
||||
|
||||
在你的主目录创建一个认证信息文件 .smbcredentials。在这个文件里添加你的用户名和密码,就像这样(USER 和 PASSWORD 替换为实际的用户名和密码):
|
||||
|
||||
```
|
||||
username=USER
|
||||
|
||||
password=PASSWORD
|
||||
```
|
||||
|
||||
你需要知道挂载这个驱动器的用户的组 ID(GID)和用户 ID(UID)。执行命令:
|
||||
|
||||
```
|
||||
id USER
|
||||
```
|
||||
|
||||
USER 是你的实际用户名,你应该会看到类似这样的信息:
|
||||
|
||||
```
|
||||
uid=1000(USER) gid=1000(GROUP)
|
||||
```
|
||||
|
||||
USER 是实际的用户名,GROUP 是组名。在(USER)和(GROUP)之前的数字将会被用在 /etc/fstab 文件之中。
|
||||
|
||||
是时候编辑 /etc/fstab 文件了。在你的编辑器中打开那个文件并添加下面这行到文件末尾(替换以下全大写字段以及远程机器的 IP 地址):
|
||||
|
||||
```
|
||||
//192.168.1.10/SHARE /media/share cifs credentials=/home/USER/.smbcredentials,iocharset=uft8,gid=GID,udi=UID,file_mode=0777,dir_mode=0777 0 0
|
||||
```
|
||||
|
||||
**注意**:上面这些内容应该在同一行上。
|
||||
|
||||
保存并关闭那个文件。执行 sudo mount -a 命令,共享将被挂载。检查一下 /media/share,你应该能看到那个网络共享上的文件和文件夹了。
|
||||
|
||||
### 共享很简单
|
||||
|
||||
有了 cifs-utils 和 Samba,映射网络共享在一台 Linux 机器上简单得让人难以置信。现在,你再也不用在每次机器启动的时候手动重新挂载那些共享了。
|
||||
|
||||
更多网络提示和技巧,订阅我们的 Data Center 消息吧。
|
||||
[订阅](https://secure.techrepublic.com/user/login/?regSource=newsletter-button&position=newsletter-button&appId=true&redirectUrl=http%3A%2F%2Fwww.techrepublic.com%2Farticle%2Fhow-to-permanently-mount-a-windows-share-on-linux%2F&)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/how-to-permanently-mount-a-windows-share-on-linux/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.techrepublic.com/search/?a=jack+wallen
|
||||
@ -0,0 +1,63 @@
|
||||
IT 运行在云端,而云运行在 Linux 上。你怎么看?
|
||||
===================================================================
|
||||
|
||||
> IT 正在逐渐迁移到云端。那又是什么驱动了云呢?答案是 Linux。 当连微软的 Azure 都开始拥抱 Linux 时,你就应该知道这一切都已经改变了。
|
||||
|
||||

|
||||
|
||||
*图片: ZDNet*
|
||||
|
||||
不管你接不接受, 云正在接管 IT 已经成为现实。 我们这几年见证了 [ 云在内部 IT 的崛起 ][1] 。 那又是什么驱动了云呢? 答案是 Linux 。
|
||||
|
||||
[Uptime Institute][2] 最近对 1000 个 IT 决策者进行了调查,发现约 50% 左右的资深企业 IT 决策者认为在将来[大部分的 IT 工作应该放在云上 ][3] 或托管网站上。在这个调查中,23% 的人认为这种改变即将发生在明年,有 70% 的人则认为这种情况会在四年内出现。
|
||||
|
||||
这一点都不奇怪。 我们中的许多人仍热衷于我们的物理服务器和机架, 但一般运营一个自己的数据中心并不会产生任何的经济效益。
|
||||
|
||||
很简单, 只需要对比你[运行在你自己的硬件上的资本费用(CAPEX)和使用云的业务费用(OPEX)][4]即可。 但这并不是说你应该把所有的东西都一股脑外包出去,而是说在大多数情况下你应该把许多工作都迁移到云端。
|
||||
|
||||
相应地,如果你想充分地利用云,你就得了解 Linux 。
|
||||
|
||||
[亚马逊的 AWS][5]、 [Apache CloudStack][6]、 [Rackspace][7]、[谷歌的 GCP][8] 以及 [ OpenStack ][9] 的核心都是运行在 Linux 上的。那么结果如何?截至到 2014 年, [在 Linux 服务器上部署的应用达到所有企业的 79% ][10],而 在 Windows 服务器上部署的则跌到 36%。从那时起, Linux 就获得了更多的发展动力。
|
||||
|
||||
即便是微软自身也明白这一点。
|
||||
|
||||
Azure 的技术主管 Mark Russinovich 曾说,仅仅在过去的几年内微软就从[四分之一的 Azure 虚拟机运行在 Linux 上][11] 变为[将近三分之一的 Azure 虚拟机运行在 Linux 上][12]。
|
||||
|
||||
试想一下。微软,一家正逐渐将[云变为自身财政收入的主要来源][13] 的公司,其三分之一的云产业依靠于 Linux 。
|
||||
|
||||
即使是到目前为止, 这些不论喜欢或者不喜欢微软的人都很难想象得到[微软会从一家以商业软件为基础的软件公司转变为一家开源的、基于云服务的企业][14] 。
|
||||
|
||||
Linux 对于这些专用服务器机房的渗透甚至比它刚开始的时候更深了。 举个例子, [Docker 最近发行了其在 Windows 10 和 Mac OS X 上的公测版本 ][15] 。 这难道是意味着 [Docker][16] 将会把其同名的容器服务移植到 Windows 10 和 Mac 上吗? 并不是的。
|
||||
|
||||
在这两个平台上, Docker 只是运行在一个 Linux 虚拟机内部。 在 Mac OS 上是 HyperKit ,在 Windows 上则是 Hyper-V 。 在图形界面上可能看起来就像另一个 Mac 或 Windows 上的应用, 但在其内部的容器仍然是运行在 Linux 上的。
|
||||
|
||||
所以,就像大量的安卓手机和 Chromebook 的用户压根就不知道他们所运行的是 Linux 系统一样。这些 IT 用户也会随之悄然地迁移到 Linux 和云上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/it-runs-on-the-cloud-and-the-cloud-runs-on-linux-any-questions/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[chenxinlong](https://github.com/chenxinlong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]: http://www.zdnet.com/article/2014-the-year-the-cloud-killed-the-datacenter/
|
||||
[2]: https://uptimeinstitute.com/
|
||||
[3]: http://www.zdnet.com/article/move-to-cloud-accelerating-faster-than-thought-survey-finds/
|
||||
[4]: http://www.zdnet.com/article/rethinking-capex-and-opex-in-a-cloud-centric-world/
|
||||
[5]: https://aws.amazon.com/
|
||||
[6]: https://cloudstack.apache.org/
|
||||
[7]: https://www.rackspace.com/en-us
|
||||
[8]: https://cloud.google.com/
|
||||
[9]: http://www.openstack.org/
|
||||
[10]: http://www.zdnet.com/article/linux-foundation-finds-enterprise-linux-growing-at-windows-expense/
|
||||
[11]: http://news.microsoft.com/bythenumbers/azure-virtual
|
||||
[12]: http://www.zdnet.com/article/microsoft-nearly-one-in-three-azure-virtual-machines-now-are-running-linux/
|
||||
[13]: http://www.zdnet.com/article/microsofts-q3-azure-commercial-cloud-strong-but-earnings-revenue-light/
|
||||
[14]: http://www.zdnet.com/article/why-microsoft-is-turning-into-an-open-source-company/
|
||||
[15]: http://www.zdnet.com/article/new-docker-betas-for-azure-windows-10-now-available/
|
||||
[16]: http://www.docker.com/
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
用树莓派计算模块搭建的工业单板计算机
|
||||
=====================================================
|
||||
|
||||

|
||||
|
||||
在 Kickstarter 众筹网站上,一个叫 “MyPi” 的项目用树莓派计算模块制作了一款 SBC(LCTT 译注: Single Board Computer 单板计算机),提供一个 mini-PCIe 插槽,串口,宽范围输入电源,以及模块扩展等功能。
|
||||
|
||||
你也许觉得奇怪,都 2016 年了,为什么还会有人发布这样一款长得有点像三明治,用过时的 ARM11 构建的 COM (LCTT 译注: Compuer on Module,模块化计算机)版本的树莓派单板计算机:[树莓派计算模块][1]。原因是这样的,首先,目前仍然有大量工业应用不需要太多 CPU 处理能力,第二,树莓派计算模块仍是目前仅有的基于树莓派硬件的 COM,虽然更便宜、有点像 COM 并采用同样的 700MHz 处理器的 [零号树莓派][2] 也很类似。
|
||||
|
||||

|
||||
|
||||
*安装了 COM 和 I/O 组件的 MyPi*
|
||||
|
||||

|
||||
|
||||
*装入了可选的工业外壳中*
|
||||
|
||||
另外,Embedded Micro Technology 还表示它的 SBC 还设计成可升级替换为支持的树莓派计算模块 —— 采用了树莓派 3 的四核、Cortex-A53 博通 BCM2837处理器的 SoC。因为这个产品最近很快就会到货,不确定他们怎么能及时为 Kickstarter 赞助者处理好这一切。不过,以后能支持也挺不错,就算要为这个升级付费也可以接受。
|
||||
|
||||
MyPi 并不是唯一一款新的基于树莓派计算模块的商业嵌入式设备。Pigeon Computers 在五月份启动了 [Pigeon RB100][3] 的项目,是一个基于 COM 的工业自动化控制器。不过,包括 [Techbase Modberry][4] 在内的这一类设备大都出现在 2014 年 COM 发布之后的一小段时间内。
|
||||
|
||||
MyPi 的目标是 30 天内筹集 $21,696,目前已经实现了三分之一。早期参与包的价格 $119 起,九月份发货。其他选项有 $187 版本,里面包含了价值 $30 的树莓派计算模块,以及各种线缆。套件里还有各种插件板以及工业外壳可选。
|
||||
|
||||

|
||||
|
||||
*不带 COM 和插件板的 MyPi 主板*
|
||||
|
||||

|
||||
|
||||
*以及它的接口定义*
|
||||
|
||||
树莓派计算模块能给 MyPi 带来博通 BCM2835 Soc,512MB 内存,以及 4GB eMMC 存储空间。MyPi 主板扩展了一个 microSD 卡槽,一个 HDMI 接口,两个 USB 2.0 接口,一个 10/100M 以太网口,还有一个像网口的 RS232 端口(通过 USB 连接)。
|
||||
|
||||

|
||||
|
||||
*插上树莓派计算模块和 mini-PCIe 模块的 MyPi 的两个视角*
|
||||
|
||||

|
||||
|
||||
*插上树莓派计算模块和 mini-PCIe 模块的 MyPi 的两个视角*
|
||||
|
||||
MyPi 还将配备一个 mini-PCIe 插槽,据说“只支持 USB,以及只适用 mPCIe 形式的调制解调器”。还带有一个 SIM 卡插槽。板上还有双标准的树莓派摄像头接口,一个音频输出接口,自带备用电池的 RTC,LED 灯。还支持宽范围的 9-23V 直流输入。
|
||||
|
||||
Embedded Micro 表示,MyPi 是为那些树莓派爱好者们设计的,他们拼接了太多 HAT 外接板,已经不能有效地工作了,或者不能很好地装入工业外壳里。MyPi 支持 HAT,另外还提供了公司自己定义的 “ASIO” (特定应用接口)插件模块,它会将自己的 I/O 扩展到载板上,载板再将它们连到载板边上的 8针的绿色凤凰式工业 I/O 连接器(标记了“ASIO Out”)上,在下面图片里有描述。
|
||||
|
||||

|
||||
|
||||
*MyPi 的模块扩展接口*
|
||||
|
||||
就像 Kickstarter 页面里描述的:“比起在板边插满带 IO 信号接头的 HAT 板,我们更愿意把同样的 IO 信号接到另一个接头,它直接接到绿色的工业接头上。” 另外,“通过简单地延长卡上的插脚长度(抬高),你将来可以直接扩展 IO 集 - 这些都不需要任何排线!”Embedded Micro 表示。
|
||||
|
||||

|
||||
|
||||
*MyPi 和它的可选 I/O 插件板卡*
|
||||
|
||||
像上面展示的,这家公司为 MyPi 提供了一系列可靠的 ASIO 插卡,。一开始这些会包括 CAN 总线,4-20mA 传感器信号,RS485,窄带 RF,等等。
|
||||
|
||||
### 更多信息
|
||||
|
||||
MyPi 在 Kickstarter 上提供了 7 月 23 日到期的 79 英镑($119)早期参与包(不包括树莓派计算模块),预计九月份发货。更多信息请查看 [Kickstarter 上 MyPi 的页面][5] 以及 [Embedded Micro Technology 官网][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/industrial-sbc-builds-on-rpi-compute-module/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://hackerboards.com/industrial-sbc-builds-on-rpi-compute-module/
|
||||
[1]: http://hackerboards.com/raspberry-pi-morphs-into-30-dollar-com/
|
||||
[2]: http://hackerboards.com/pi-zero-tweak-adds-camera-connector-keeps-5-price/
|
||||
[3]: http://hackerboards.com/automation-controller-runs-linux-on-raspberry-pi-com/
|
||||
[4]: http://hackerboards.com/automation-controller-taps-raspberry-pi-compute-module/
|
||||
[5]: https://www.kickstarter.com/projects/410598173/mypi-industrial-strength-raspberry-pi-for-iot-proj
|
||||
[6]: http://www.embeddedpi.com/
|
||||
@ -0,0 +1,126 @@
|
||||
如何隐藏你的 Linux 的命令行历史
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
如果你是 Linux 命令行的用户,有的时候你可能不希望某些命令记录在你的命令行历史中。原因可能很多,例如,你在公司担任某个职位,你有一些不希望被其它人滥用的特权。亦或者有些特别重要的命令,你不希望在你浏览历史列表时误执行。
|
||||
|
||||
然而,有方法可以控制哪些命令进入历史列表,哪些不进入吗?或者换句话说,我们在 Linux 终端中可以开启像浏览器一样的无痕模式吗?答案是肯定的,而且根据你想要的具体目标,有很多实现方法。在这篇文章中,我们将讨论一些行之有效的方法。
|
||||
|
||||
注意:文中出现的所有命令都在 Ubuntu 下测试过。
|
||||
|
||||
### 不同的可行方法
|
||||
|
||||
前面两种方法已经在之前[一篇文章][1]中描述了。如果你已经了解,这部分可以略过。然而,如果你不了解,建议仔细阅读。
|
||||
|
||||
#### 1. 在命令前插入空格
|
||||
|
||||
是的,没看错。在命令前面插入空格,这条命令会被 shell 忽略,也就意味着它不会出现在历史记录中。但是这种方法有个前提,只有在你的环境变量 `HISTCONTROL` 设置为 "ignorespace" 或者 "ignoreboth" 才会起作用。在大多数情况下,这个是默认值。
|
||||
|
||||
所以,像下面的命令(LCTT 译注:这里`[space]`表示输入一个空格):
|
||||
|
||||
```
|
||||
[space]echo "this is a top secret"
|
||||
```
|
||||
|
||||
如果你之前执行过如下设置环境变量的命令,那么上述命令不会出现在历史记录中。
|
||||
|
||||
```
|
||||
export HISTCONTROL = ignorespace
|
||||
```
|
||||
|
||||
下面的截图是这种方式的一个例子。
|
||||
|
||||

|
||||
|
||||
第四个 "echo" 命令因为前面有空格,它没有被记录到历史中。
|
||||
|
||||
#### 2. 禁用当前会话的所有历史记录
|
||||
|
||||
如果你想禁用某个会话所有历史,你可以在开始命令行工作前简单地清除环境变量 HISTFILESIZE 的值即可。执行下面的命令来清除其值:
|
||||
|
||||
```
|
||||
export HISTFILESIZE=0
|
||||
```
|
||||
|
||||
HISTFILESIZE 表示对于 bash 会话其历史文件中可以保存命令的个数(行数)。默认情况,它设置了一个非零值,例如在我的电脑上,它的值为 1000。
|
||||
|
||||
所以上面所提到的命令将其值设置为 0,结果就是直到你关闭终端,没有东西会存储在历史记录中。记住同样你也不能通过按向上的箭头按键或运行 history 命令来看到之前执行的命令。
|
||||
|
||||
#### 3. 工作结束后清除整个历史
|
||||
|
||||
这可以看作是前一部分所提方案的另外一种实现。唯一的区别是在你完成所有工作之后执行这个命令。下面是刚说到的命令:
|
||||
|
||||
```
|
||||
history -cw
|
||||
```
|
||||
|
||||
刚才已经提到,这个和 HISTFILESIZE 方法有相同效果。
|
||||
|
||||
#### 4. 只针对你的工作关闭历史记录
|
||||
|
||||
虽然前面描述的方法(2 和 3)可以实现目的,它们可以清除整个历史,在很多情况下,有些可能不是我们所期望的。有时候你可能想保存直到你开始命令行工作之间的历史记录。对于这样的需求,你开始在工作前执行下述命令:
|
||||
|
||||
```
|
||||
[space]set +o history
|
||||
```
|
||||
|
||||
备注:[space] 表示空格。并且由于空格的缘故,该命令本身也不会被记录。
|
||||
|
||||
上面的命令会临时禁用历史功能,这意味着在这命令之后你执行的所有操作都不会记录到历史中,然而这个命令之前的所有东西都会原样记录在历史列表中。
|
||||
|
||||
要重新开启历史功能,执行下面的命令:
|
||||
|
||||
```
|
||||
[Space]set -o history
|
||||
```
|
||||
|
||||
它将环境恢复原状,也就是你完成了你的工作,执行上述命令之后的命令都会出现在历史中。
|
||||
|
||||
#### 5. 从历史记录中删除指定的命令
|
||||
|
||||
现在假设历史记录中已经包含了一些你不希望记录的命令。这种情况下我们怎么办?很简单。直接动手删除它们。通过下面的命令来删除:
|
||||
|
||||
```
|
||||
history | grep "part of command you want to remove"
|
||||
```
|
||||
|
||||
上面的命令会输出历史记录中匹配的命令,每一条前面会有个数字。
|
||||
|
||||
一旦你找到你想删除的命令,执行下面的命令,从历史记录中删除那个指定的项:
|
||||
|
||||
```
|
||||
history -d [num]
|
||||
```
|
||||
|
||||
下面是这个例子的截图。
|
||||
|
||||

|
||||
|
||||
第二个 ‘echo’命令被成功的删除了。
|
||||
|
||||
(LCTT 译注:如果你不希望上述命令本身也被记录进历史中,你可以在上述命令前加个空格)
|
||||
|
||||
同样的,你可以使用向上的箭头一直往回翻看历史记录。当你发现你感兴趣的命令出现在终端上时,按下 “Ctrl + U”清除整行,也会从历史记录中删除它。
|
||||
|
||||
### 总结
|
||||
|
||||
有多种不同的方法可以操作 Linux 命令行历史来满足你的需求。然而请记住,从历史中隐藏或者删除命令通常不是一个好习惯,尽管本质上这并没有错。但是你必须知道你在做什么,以及可能产生的后果。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-command-line-history-incognito/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/himanshu/
|
||||
[1]: https://www.maketecheasier.com/command-line-history-linux/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
如何在 Ubuntu Linux 16.04上安装开源的 Discourse 论坛
|
||||
===============================================================================
|
||||
|
||||
Discourse 是一个开源的论坛,它可以以邮件列表、聊天室或者论坛等多种形式工作。它是一个广受欢迎的现代的论坛工具。在服务端,它使用 Ruby on Rails 和 Postgres 搭建, 并且使用 Redis 缓存来减少读取时间 , 在客户端,它使用支持 Java Script 的浏览器。它非常容易定制,结构良好,并且它提供了转换插件,可以对你现存的论坛、公告板进行转换,例如: vBulletin、phpBB、Drupal、SMF 等等。在这篇文章中,我们将学习在 Ubuntu 操作系统下安装 Discourse。
|
||||
|
||||
它以安全作为设计思想,所以发垃圾信息的人和黑客们不能轻易的实现其企图。它能很好的支持各种现代设备,并可以相应的调整以手机和平板的显示。
|
||||
|
||||
### 在 Ubuntu 16.04 上安装 Discourse
|
||||
|
||||
让我们开始吧 ! 最少需要 1G 的内存,并且官方支持的安装过程需要已经安装了 docker。 说到 docker,它还需要安装Git。要满足以上的两点要求我们只需要运行下面的命令:
|
||||
|
||||
```
|
||||
wget -qO- https://get.docker.com/ | sh
|
||||
```
|
||||
|
||||

|
||||
|
||||
用不了多久就安装好了 docker 和 Git,安装结束以后,在你的系统上的 /var 分区创建一个 Discourse 文件夹(当然你也可以选择其他的分区)。
|
||||
|
||||
```
|
||||
mkdir /var/discourse
|
||||
```
|
||||
|
||||
现在我们来克隆 Discourse 的 Github 仓库到这个新建的文件夹。
|
||||
|
||||
```
|
||||
git clone https://github.com/discourse/discourse_docker.git /var/discourse
|
||||
```
|
||||
|
||||
进入这个克隆的文件夹。
|
||||
|
||||
```
|
||||
cd /var/discourse
|
||||
```
|
||||
|
||||

|
||||
|
||||
你将看到“discourse-setup” 脚本文件,运行这个脚本文件进行 Discourse 的初始化。
|
||||
|
||||
```
|
||||
./discourse-setup
|
||||
```
|
||||
|
||||
**备注: 在安装 discourse 之前请确保你已经安装好了邮件服务器。**
|
||||
|
||||
安装向导将会问你以下六个问题:
|
||||
|
||||
```
|
||||
Hostname for your Discourse?
|
||||
Email address for admin account?
|
||||
SMTP server address?
|
||||
SMTP user name?
|
||||
SMTP port [587]:
|
||||
SMTP password? []:
|
||||
```
|
||||
|
||||

|
||||
|
||||
当你提交了以上信息以后, 它会让你提交确认, 如果一切都很正常,点击回车以后安装开始。
|
||||
|
||||

|
||||
|
||||
现在“坐等放宽”,需要花费一些时间来完成安装,倒杯咖啡,看看有什么错误信息没有。
|
||||
|
||||

|
||||
|
||||
安装成功以后看起来应该像这样。
|
||||
|
||||

|
||||
|
||||
现在打开浏览器,如果已经做了域名解析,你可以使用你的域名来连接 Discourse 页面 ,否则你只能使用IP地址了。你将看到如下信息:
|
||||
|
||||

|
||||
|
||||
就是这个,点击 “Sign Up” 选项创建一个新的账户,然后进行你的 Discourse 设置。
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
它安装简便,运行完美。 它拥有现代论坛所有必备功能。它以 GPL 发布,是完全开源的产品。简单、易用、以及特性丰富是它的最大特点。希望你喜欢这篇文章,如果有问题,你可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/aun/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,51 @@
|
||||
在 Linux 下使用任务管理器
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
有很多 Linux 初学者经常问起的问题,“**Linux 有任务管理器吗?**”,“**怎样在 Linux 上打开任务管理器呢?**”
|
||||
|
||||
来自 Windows 的用户都知道任务管理器非常有用。你可以在 Windows 中按下 `Ctrl+Alt+Del` 打开任务管理器。这个任务管理器向你展示了所有的正在运行的进程和它们消耗的内存,你可以从任务管理器程序中选择并杀死一个进程。
|
||||
|
||||
当你刚使用 Linux 的时候,你也会寻找一个**在 Linux 相当于任务管理器**的一个东西。一个 Linux 使用专家更喜欢使用命令行的方式查找进程和消耗的内存等等,但是你不用必须使用这种方式,至少在你初学 Linux 的时候。
|
||||
|
||||
所有主流的 Linux 发行版都有一个类似于任务管理器的东西。大部分情况下,它叫系统监视器(System Monitor),不过实际上它依赖于你的 Linux 的发行版及其使用的[桌面环境][1]。
|
||||
|
||||
在这篇文章中,我们将会看到如何在以 GNOME 为[桌面环境][2]的 Linux 上找到并使用任务管理器。
|
||||
|
||||
### 在使用 GNOME 桌面环境的 Linux 上的任务管理器等价物
|
||||
|
||||
使用 GNOME 时,按下 super 键(Windows 键)来查找任务管理器:
|
||||
|
||||

|
||||
|
||||
当你启动系统监视器的时候,它会向你展示所有正在运行的进程及其消耗的内存。
|
||||
|
||||

|
||||
|
||||
你可以选择一个进程并且点击“终止进程(End Process)”来杀掉它。
|
||||
|
||||

|
||||
|
||||
你也可以在资源(Resources)标签里面看到关于一些统计数据,例如 CPU 的每个核心的占用,内存用量、网络用量等。
|
||||
|
||||

|
||||
|
||||
这是图形化的方式。如果你想使用命令行,在终端里运行“top”命令然后你就可以看到所有运行的进程及其消耗的内存。你也可以很容易地使用命令行[杀死进程][3]。
|
||||
|
||||
这就是关于在 Fedora Linux 上任务管理器的知识。我希望这个教程帮你学到了知识,如果你有什么问题,请尽管问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/task-manager-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[xinglianfly](https://github.com/xinglianfly)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject)原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://wiki.archlinux.org/index.php/desktop_environment
|
||||
[2]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[3]: https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/
|
||||
31
published/201607/20160630 What makes up the Fedora kernel.md
Normal file
31
published/201607/20160630 What makes up the Fedora kernel.md
Normal file
@ -0,0 +1,31 @@
|
||||
Fedora 内核是由什么构成的?
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
每个 Fedora 系统都运行着一个内核。许多代码片段组合在一起使之成为现实。
|
||||
|
||||
每个 Fedora 内核都起始于一个来自于[上游社区][1]的基线版本——通常称之为 vanilla 内核。上游内核就是标准。(Fedora 的)目标是包含尽可能多的上游代码,这样使得 bug 修复和 API 更新更加容易,同时也会有更多的人审查代码。理想情况下,Fedora 能够直接获取 kernel.org 的内核,然后发送给所有用户。
|
||||
|
||||
现实情况是,使用 vanilla 内核并不能完全满足 Fedora。Vanilla 内核可能并不支持一些 Fedora 用户希望拥有的功能。用户接收的 [Fedora 内核] 是在 vanilla 内核之上打了很多补丁的内核。这些补丁被认为“不在树上(out of tree)”。许多这些位于补丁树之外的补丁都不会存在太久。如果某补丁能够修复一个问题,那么该补丁可能会被合并到 Fedora 树,以便用户能够更快地收到修复。当内核变基到一个新版本时,在新版本中的补丁都将被清除。
|
||||
|
||||
一些补丁会在 Fedora 内核树上存在很长时间。一个很好的例子是,安全启动补丁就是这类补丁。这些补丁提供了 Fedora 希望支持的功能,即使上游社区还没有接受它们。保持这些补丁更新是需要付出很多努力的,所以 Fedora 尝试减少不被上游内核维护者接受的补丁数量。
|
||||
|
||||
通常来说,想要在 Fedora 内核中获得一个补丁的最佳方法是先给 [Linux 内核邮件列表(LKML)][3] 发送补丁,然后请求将该补丁包含到 Fedora 中。如果某个维护者接受了补丁,就意味着 Fedora 内核树中将来很有可能会包含该补丁。一些来自于 GitHub 等地方的还没有提交给 LKML 的补丁是不可能进入内核树的。首先向 LKML 发送补丁是非常重要的,它能确保 Fedora 内核树中携带的补丁是功能正常的。如果没有社区审查,Fedora 最终携带的补丁将会充满 bug 并会导致问题。
|
||||
|
||||
Fedora 内核中包含的代码来自许多地方。一切都需要提供最佳的体验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
|
||||
作者:[Laura Abbott][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
[1]: http://www.kernel.org/
|
||||
[2]: http://pkgs.fedoraproject.org/cgit/rpms/kernel.git/
|
||||
[3]: http://www.labbott.name/blog/2015/10/02/the-art-of-communicating-with-lkml/
|
||||
@ -0,0 +1,144 @@
|
||||
如何在 Ubuntu 上建立网桥
|
||||
=======================================================================
|
||||
|
||||
> 作为一个 Ubuntu 16.04 LTS 的初学者。如何在 Ubuntu 14.04 和 16.04 的主机上建立网桥呢?
|
||||
|
||||
顾名思义,网桥的作用是通过物理接口连接内部和外部网络。对于虚拟端口或者 LXC/KVM/Xen/容器来说,这非常有用。网桥虚拟端口看起来是网络上的一个常规设备。在这个教程中,我将会介绍如何在 Ubuntu 服务器上通过 bridge-utils (brctl) 命令行来配置 Linux 网桥。
|
||||
|
||||
### 网桥化的网络示例
|
||||
|
||||
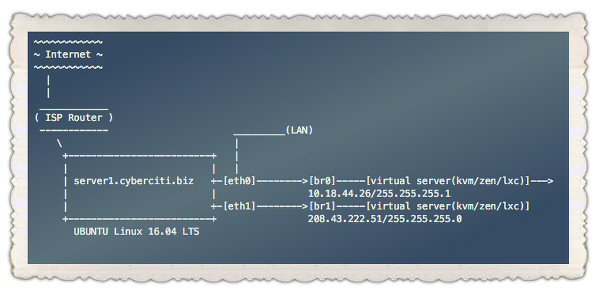
|
||||
|
||||
*图 01: Kvm/Xen/LXC 容器网桥示例 (br0)*
|
||||
|
||||
在这个例子中,eth0 和 eth1 是物理网络接口。eth0 连接着局域网,eth1 连接着上游路由器和互联网。
|
||||
|
||||
### 安装 bridge-utils
|
||||
|
||||
使用 [apt-get 命令][1] 安装 bridge-utils:
|
||||
|
||||
```
|
||||
$ sudo apt-get install bridge-utils
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
````
|
||||
$ sudo apt install bridge-utils
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
|
||||
|
||||
*图 02: Ubuntu 安装 bridge-utils 包*
|
||||
|
||||
### 在 Ubuntu 服务器上创建网桥
|
||||
|
||||
使用你熟悉的文本编辑器修改 `/etc/network/interfaces` ,例如 vi 或者 nano :
|
||||
|
||||
```
|
||||
$ sudo cp /etc/network/interfaces /etc/network/interfaces.bakup-1-july-2016
|
||||
$ sudo vi /etc/network/interfaces
|
||||
```
|
||||
|
||||
接下来设置 eth1 并且将它映射到 br1 ,输入如下(删除或者注释所有 eth1 相关配置):
|
||||
|
||||
```
|
||||
# br1 使用静态公网 IP 地址,并以 ISP 的路由器作为网关
|
||||
auto br1
|
||||
iface br1 inet static
|
||||
address 208.43.222.51
|
||||
network 255.255.255.248
|
||||
netmask 255.255.255.0
|
||||
broadcast 208.43.222.55
|
||||
gateway 208.43.222.49
|
||||
bridge_ports eth1
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
接下来设置 eth0 并将它映射到 br0,输入如下(删除或者注释所有 eth0 相关配置):
|
||||
|
||||
```
|
||||
auto br0
|
||||
iface br0 inet static
|
||||
address 10.18.44.26
|
||||
netmask 255.255.255.192
|
||||
broadcast 10.18.44.63
|
||||
dns-nameservers 10.0.80.11 10.0.80.12
|
||||
# set static route for LAN
|
||||
post-up route add -net 10.0.0.0 netmask 255.0.0.0 gw 10.18.44.1
|
||||
post-up route add -net 161.26.0.0 netmask 255.255.0.0 gw 10.18.44.1
|
||||
bridge_ports eth0
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
### 关于 br0 和 DHCP 的一点说明
|
||||
|
||||
如果使用 DHCP ,配置选项是这样的:
|
||||
|
||||
```
|
||||
auto br0
|
||||
iface br0 inet dhcp
|
||||
bridge_ports eth0
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
保存并且关闭文件。
|
||||
|
||||
### 重启服务器或者网络服务
|
||||
|
||||
你需要重启服务器或者输入下列命令来重启网络服务(在 SSH 登录的会话中这可能不管用):
|
||||
|
||||
```
|
||||
$ sudo systemctl restart networking
|
||||
```
|
||||
|
||||
如果你证使用 Ubuntu 14.04 LTS 或者更老的没有 systemd 的系统,输入:
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/restart networking
|
||||
```
|
||||
|
||||
### 验证网络配置成功
|
||||
|
||||
使用 ping/ip 命令来验证 LAN 和 WAN 网络接口运行正常:
|
||||
```
|
||||
# 查看 br0 和 br1
|
||||
ip a show
|
||||
# 查看路由信息
|
||||
ip r
|
||||
# ping 外部站点
|
||||
ping -c 2 cyberciti.biz
|
||||
# ping 局域网服务器
|
||||
ping -c 2 10.0.80.12
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
|
||||
|
||||
*图 03: 验证网桥的以太网连接*
|
||||
|
||||
现在,你就可以配置 br0 和 br1 来让 XEN/KVM/LXC 容器访问因特网或者私有局域网了。再也没有必要去设置特定路由或者 iptables 的 SNAT 规则了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/how-to-create-bridge-interface-ubuntu-linux/
|
||||
|
||||
作者:[VIVEK GITE][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/nixcraft
|
||||
[1]: http://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
|
||||
@ -0,0 +1,228 @@
|
||||
使用 Python 创建你自己的 Shell (一)
|
||||
==========================================
|
||||
|
||||
我很想知道一个 shell (像 bash,csh 等)内部是如何工作的。于是为了满足自己的好奇心,我使用 Python 实现了一个名为 **yosh** (Your Own Shell)的 Shell。本文章所介绍的概念也可以应用于其他编程语言。
|
||||
|
||||
(提示:你可以在[这里](https://github.com/supasate/yosh)查找本博文使用的源代码,代码以 MIT 许可证发布。在 Mac OS X 10.11.5 上,我使用 Python 2.7.10 和 3.4.3 进行了测试。它应该可以运行在其他类 Unix 环境,比如 Linux 和 Windows 上的 Cygwin。)
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
### 步骤 0:项目结构
|
||||
|
||||
对于此项目,我使用了以下的项目结构。
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- __init__.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
`yosh_project` 为项目根目录(你也可以把它简单命名为 `yosh`)。
|
||||
|
||||
`yosh` 为包目录,且 `__init__.py` 可以使它成为与包的目录名字相同的包(如果你不用 Python 编写的话,可以忽略它。)
|
||||
|
||||
`shell.py` 是我们主要的脚本文件。
|
||||
|
||||
### 步骤 1:Shell 循环
|
||||
|
||||
当启动一个 shell,它会显示一个命令提示符并等待你的命令输入。在接收了输入的命令并执行它之后(稍后文章会进行详细解释),你的 shell 会重新回到这里,并循环等待下一条指令。
|
||||
|
||||
在 `shell.py` 中,我们会以一个简单的 main 函数开始,该函数调用了 shell_loop() 函数,如下:
|
||||
|
||||
```
|
||||
def shell_loop():
|
||||
# Start the loop here
|
||||
|
||||
|
||||
def main():
|
||||
shell_loop()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
接着,在 `shell_loop()` 中,为了指示循环是否继续或停止,我们使用了一个状态标志。在循环的开始,我们的 shell 将显示一个命令提示符,并等待读取命令输入。
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
SHELL_STATUS_RUN = 1
|
||||
SHELL_STATUS_STOP = 0
|
||||
|
||||
|
||||
def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
### 显示命令提示符
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
### 读取命令输入
|
||||
cmd = sys.stdin.readline()
|
||||
```
|
||||
|
||||
之后,我们切分命令(tokenize)输入并进行执行(execute)(我们即将实现 `tokenize` 和 `execute` 函数)。
|
||||
|
||||
因此,我们的 shell_loop() 会是如下这样:
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
SHELL_STATUS_RUN = 1
|
||||
SHELL_STATUS_STOP = 0
|
||||
|
||||
|
||||
def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
### 显示命令提示符
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
### 读取命令输入
|
||||
cmd = sys.stdin.readline()
|
||||
|
||||
### 切分命令输入
|
||||
cmd_tokens = tokenize(cmd)
|
||||
|
||||
### 执行该命令并获取新的状态
|
||||
status = execute(cmd_tokens)
|
||||
```
|
||||
|
||||
这就是我们整个 shell 循环。如果我们使用 `python shell.py` 启动我们的 shell,它会显示命令提示符。然而如果我们输入命令并按回车,它会抛出错误,因为我们还没定义 `tokenize` 函数。
|
||||
|
||||
为了退出 shell,可以尝试输入 ctrl-c。稍后我将解释如何以优雅的形式退出 shell。
|
||||
|
||||
### 步骤 2:命令切分(tokenize)
|
||||
|
||||
当用户在我们的 shell 中输入命令并按下回车键,该命令将会是一个包含命令名称及其参数的长字符串。因此,我们必须切分该字符串(分割一个字符串为多个元组)。
|
||||
|
||||
咋一看似乎很简单。我们或许可以使用 `cmd.split()`,以空格分割输入。它对类似 `ls -a my_folder` 的命令起作用,因为它能够将命令分割为一个列表 `['ls', '-a', 'my_folder']`,这样我们便能轻易处理它们了。
|
||||
|
||||
然而,也有一些类似 `echo "Hello World"` 或 `echo 'Hello World'` 以单引号或双引号引用参数的情况。如果我们使用 cmd.spilt,我们将会得到一个存有 3 个标记的列表 `['echo', '"Hello', 'World"']` 而不是 2 个标记的列表 `['echo', 'Hello World']`。
|
||||
|
||||
幸运的是,Python 提供了一个名为 `shlex` 的库,它能够帮助我们如魔法般地分割命令。(提示:我们也可以使用正则表达式,但它不是本文的重点。)
|
||||
|
||||
|
||||
```
|
||||
import sys
|
||||
import shlex
|
||||
|
||||
...
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
然后我们将这些元组发送到执行进程。
|
||||
|
||||
### 步骤 3:执行
|
||||
|
||||
这是 shell 中核心而有趣的一部分。当 shell 执行 `mkdir test_dir` 时,到底发生了什么?(提示: `mkdir` 是一个带有 `test_dir` 参数的执行程序,用于创建一个名为 `test_dir` 的目录。)
|
||||
|
||||
`execvp` 是这一步的首先需要的函数。在我们解释 `execvp` 所做的事之前,让我们看看它的实际效果。
|
||||
|
||||
```
|
||||
import os
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
### 执行命令
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
|
||||
### 返回状态以告知在 shell_loop 中等待下一个命令
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
再次尝试运行我们的 shell,并输入 `mkdir test_dir` 命令,接着按下回车键。
|
||||
|
||||
在我们敲下回车键之后,问题是我们的 shell 会直接退出而不是等待下一个命令。然而,目录正确地创建了。
|
||||
|
||||
因此,`execvp` 实际上做了什么?
|
||||
|
||||
`execvp` 是系统调用 `exec` 的一个变体。第一个参数是程序名字。`v` 表示第二个参数是一个程序参数列表(参数数量可变)。`p` 表示将会使用环境变量 `PATH` 搜索给定的程序名字。在我们上一次的尝试中,它将会基于我们的 `PATH` 环境变量查找`mkdir` 程序。
|
||||
|
||||
(还有其他 `exec` 变体,比如 execv、execvpe、execl、execlp、execlpe;你可以 google 它们获取更多的信息。)
|
||||
|
||||
`exec` 会用即将运行的新进程替换调用进程的当前内存。在我们的例子中,我们的 shell 进程内存会被替换为 `mkdir` 程序。接着,`mkdir` 成为主进程并创建 `test_dir` 目录。最后该进程退出。
|
||||
|
||||
这里的重点在于**我们的 shell 进程已经被 `mkdir` 进程所替换**。这就是我们的 shell 消失且不会等待下一条命令的原因。
|
||||
|
||||
因此,我们需要其他的系统调用来解决问题:`fork`。
|
||||
|
||||
`fork` 会分配新的内存并拷贝当前进程到一个新的进程。我们称这个新的进程为**子进程**,调用者进程为**父进程**。然后,子进程内存会被替换为被执行的程序。因此,我们的 shell,也就是父进程,可以免受内存替换的危险。
|
||||
|
||||
让我们看看修改的代码。
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
### 分叉一个子 shell 进程
|
||||
### 如果当前进程是子进程,其 `pid` 被设置为 `0`
|
||||
### 否则当前进程是父进程的话,`pid` 的值
|
||||
### 是其子进程的进程 ID。
|
||||
pid = os.fork()
|
||||
|
||||
if pid == 0:
|
||||
### 子进程
|
||||
### 用被 exec 调用的程序替换该子进程
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
elif pid > 0:
|
||||
### 父进程
|
||||
while True:
|
||||
### 等待其子进程的响应状态(以进程 ID 来查找)
|
||||
wpid, status = os.waitpid(pid, 0)
|
||||
|
||||
### 当其子进程正常退出时
|
||||
### 或者其被信号中断时,结束等待状态
|
||||
if os.WIFEXITED(status) or os.WIFSIGNALED(status):
|
||||
break
|
||||
|
||||
### 返回状态以告知在 shell_loop 中等待下一个命令
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
当我们的父进程调用 `os.fork()` 时,你可以想象所有的源代码被拷贝到了新的子进程。此时此刻,父进程和子进程看到的是相同的代码,且并行运行着。
|
||||
|
||||
如果运行的代码属于子进程,`pid` 将为 `0`。否则,如果运行的代码属于父进程,`pid` 将会是子进程的进程 id。
|
||||
|
||||
当 `os.execvp` 在子进程中被调用时,你可以想象子进程的所有源代码被替换为正被调用程序的代码。然而父进程的代码不会被改变。
|
||||
|
||||
当父进程完成等待子进程退出或终止时,它会返回一个状态,指示继续 shell 循环。
|
||||
|
||||
### 运行
|
||||
|
||||
现在,你可以尝试运行我们的 shell 并输入 `mkdir test_dir2`。它应该可以正确执行。我们的主 shell 进程仍然存在并等待下一条命令。尝试执行 `ls`,你可以看到已创建的目录。
|
||||
|
||||
但是,这里仍有一些问题。
|
||||
|
||||
第一,尝试执行 `cd test_dir2`,接着执行 `ls`。它应该会进入到一个空的 `test_dir2` 目录。然而,你将会看到目录并没有变为 `test_dir2`。
|
||||
|
||||
第二,我们仍然没有办法优雅地退出我们的 shell。
|
||||
|
||||
我们将会在 [第二部分][1] 解决诸如此类的问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/
|
||||
@ -0,0 +1,211 @@
|
||||
使用 Python 创建你自己的 Shell(下)
|
||||
===========================================
|
||||
|
||||
在[上篇][1]中,我们已经创建了一个 shell 主循环、切分了命令输入,以及通过 `fork` 和 `exec` 执行命令。在这部分,我们将会解决剩下的问题。首先,`cd test_dir2` 命令无法修改我们的当前目录。其次,我们仍无法优雅地从 shell 中退出。
|
||||
|
||||
### 步骤 4:内置命令
|
||||
|
||||
“`cd test_dir2` 无法修改我们的当前目录” 这句话是对的,但在某种意义上也是错的。在执行完该命令之后,我们仍然处在同一目录,从这个意义上讲,它是对的。然而,目录实际上已经被修改,只不过它是在子进程中被修改。
|
||||
|
||||
还记得我们分叉(fork)了一个子进程,然后执行命令,执行命令的过程没有发生在父进程上。结果是我们只是改变了子进程的当前目录,而不是父进程的目录。
|
||||
|
||||
然后子进程退出,而父进程在原封不动的目录下继续运行。
|
||||
|
||||
因此,这类与 shell 自己相关的命令必须是内置命令。它必须在 shell 进程中执行而不是在分叉中(forking)。
|
||||
|
||||
#### cd
|
||||
|
||||
让我们从 `cd` 命令开始。
|
||||
|
||||
我们首先创建一个 `builtins` 目录。每一个内置命令都会被放进这个目录中。
|
||||
|
||||
```shell
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
|-- __init__.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
在 `cd.py` 中,我们通过使用系统调用 `os.chdir` 实现自己的 `cd` 命令。
|
||||
|
||||
```python
|
||||
import os
|
||||
from yosh.constants import *
|
||||
|
||||
def cd(args):
|
||||
os.chdir(args[0])
|
||||
|
||||
return SHELL_STATUS_RUN
|
||||
```
|
||||
|
||||
注意,我们会从内置函数返回 shell 的运行状态。所以,为了能够在项目中继续使用常量,我们将它们移至 `yosh/constants.py`。
|
||||
|
||||
```shell
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
|-- __init__.py
|
||||
|-- constants.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
在 `constants.py` 中,我们将状态常量都放在这里。
|
||||
|
||||
```python
|
||||
SHELL_STATUS_STOP = 0
|
||||
SHELL_STATUS_RUN = 1
|
||||
```
|
||||
|
||||
现在,我们的内置 `cd` 已经准备好了。让我们修改 `shell.py` 来处理这些内置函数。
|
||||
|
||||
```python
|
||||
...
|
||||
### 导入常量
|
||||
from yosh.constants import *
|
||||
|
||||
### 使用哈希映射来存储内建的函数名及其引用
|
||||
built_in_cmds = {}
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
def execute(cmd_tokens):
|
||||
### 从元组中分拆命令名称与参数
|
||||
cmd_name = cmd_tokens[0]
|
||||
cmd_args = cmd_tokens[1:]
|
||||
|
||||
### 如果该命令是一个内建命令,使用参数调用该函数
|
||||
if cmd_name in built_in_cmds:
|
||||
return built_in_cmds[cmd_name](cmd_args)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
我们使用一个 python 字典变量 `built_in_cmds` 作为哈希映射(hash map),以存储我们的内置函数。我们在 `execute` 函数中提取命令的名字和参数。如果该命令在我们的哈希映射中,则调用对应的内置函数。
|
||||
|
||||
(提示:`built_in_cmds[cmd_name]` 返回能直接使用参数调用的函数引用。)
|
||||
|
||||
我们差不多准备好使用内置的 `cd` 函数了。最后一步是将 `cd` 函数添加到 `built_in_cmds` 映射中。
|
||||
|
||||
```
|
||||
...
|
||||
### 导入所有内建函数引用
|
||||
from yosh.builtins import *
|
||||
|
||||
...
|
||||
|
||||
### 注册内建函数到内建命令的哈希映射中
|
||||
def register_command(name, func):
|
||||
built_in_cmds[name] = func
|
||||
|
||||
|
||||
### 在此注册所有的内建命令
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
|
||||
|
||||
def main():
|
||||
###在开始主循环之前初始化 shell
|
||||
init()
|
||||
shell_loop()
|
||||
```
|
||||
|
||||
我们定义了 `register_command` 函数,以添加一个内置函数到我们内置的命令哈希映射。接着,我们定义 `init` 函数并且在这里注册内置的 `cd` 函数。
|
||||
|
||||
注意这行 `register_command("cd", cd)` 。第一个参数为命令的名字。第二个参数为一个函数引用。为了能够让第二个参数 `cd` 引用到 `yosh/builtins/cd.py` 中的 `cd` 函数引用,我们必须将以下这行代码放在 `yosh/builtins/__init__.py` 文件中。
|
||||
|
||||
```
|
||||
from yosh.builtins.cd import *
|
||||
```
|
||||
|
||||
因此,在 `yosh/shell.py` 中,当我们从 `yosh.builtins` 导入 `*` 时,我们可以得到已经通过 `yosh.builtins` 导入的 `cd` 函数引用。
|
||||
|
||||
我们已经准备好了代码。让我们尝试在 `yosh` 同级目录下以模块形式运行我们的 shell,`python -m yosh.shell`。
|
||||
|
||||
现在,`cd` 命令可以正确修改我们的 shell 目录了,同时非内置命令仍然可以工作。非常好!
|
||||
|
||||
#### exit
|
||||
|
||||
最后一块终于来了:优雅地退出。
|
||||
|
||||
我们需要一个可以修改 shell 状态为 `SHELL_STATUS_STOP` 的函数。这样,shell 循环可以自然地结束,shell 将到达终点而退出。
|
||||
|
||||
和 `cd` 一样,如果我们在子进程中分叉并执行 `exit` 函数,其对父进程是不起作用的。因此,`exit` 函数需要成为一个 shell 内置函数。
|
||||
|
||||
让我们从这开始:在 `builtins` 目录下创建一个名为 `exit.py` 的新文件。
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
| |-- exit.py
|
||||
|-- __init__.py
|
||||
|-- constants.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
`exit.py` 定义了一个 `exit` 函数,该函数仅仅返回一个可以退出主循环的状态。
|
||||
|
||||
```
|
||||
from yosh.constants import *
|
||||
|
||||
def exit(args):
|
||||
return SHELL_STATUS_STOP
|
||||
```
|
||||
|
||||
然后,我们导入位于 `yosh/builtins/__init__.py` 文件的 `exit` 函数引用。
|
||||
|
||||
```
|
||||
from yosh.builtins.cd import *
|
||||
from yosh.builtins.exit import *
|
||||
```
|
||||
|
||||
最后,我们在 `shell.py` 中的 `init()` 函数注册 `exit` 命令。
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
### 在此注册所有的内建命令
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
register_command("exit", exit)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
到此为止!
|
||||
|
||||
尝试执行 `python -m yosh.shell`。现在你可以输入 `exit` 优雅地退出程序了。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
我希望你能像我一样享受创建 `yosh` (**y**our **o**wn **sh**ell)的过程。但我的 `yosh` 版本仍处于早期阶段。我没有处理一些会使 shell 崩溃的极端状况。还有很多我没有覆盖的内置命令。为了提高性能,一些非内置命令也可以实现为内置命令(避免新进程创建时间)。同时,大量的功能还没有实现(请看 [公共特性](http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html) 和 [不同特性](http://www.tldp.org/LDP/intro-linux/html/x12249.html))
|
||||
|
||||
我已经在 https://github.com/supasate/yosh 中提供了源代码。请随意 fork 和尝试。
|
||||
|
||||
现在该是创建你真正自己拥有的 Shell 的时候了。
|
||||
|
||||
Happy Coding!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://linux.cn/article-7624-1.html
|
||||
[2]: http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html
|
||||
[3]: http://www.tldp.org/LDP/intro-linux/html/x12249.html
|
||||
[4]: https://github.com/supasate/yosh
|
||||
@ -0,0 +1,67 @@
|
||||
使用 Vagrant 控制你的 DigitalOcean 云主机
|
||||
=========================================================
|
||||
|
||||

|
||||
|
||||
[Vagrant][1] 是一个使用虚拟机创建和支持虚拟开发环境的应用。Fedora 官方已经在本地系统上通过库 `libvirt` [支持 Vagrant][2]。[DigitalOcean][3] 是一个提供一键部署 Fedora 云服务实例到全 SSD 服务器的云计算服务提供商。在[最近的 Raleigh 举办的 FAD 大会][4]中,Fedora 云计算队伍为 Vagrant 打包了一个新的插件,它能够帮助 Fedora 用户通过使用本地的 Vagrantfile 文件来管理 DigitalOcean 上的云服务实例。
|
||||
|
||||
### 如何使用这个插件
|
||||
|
||||
第一步在命令行下是安装软件。
|
||||
|
||||
```
|
||||
$ sudo dnf install -y vagrant-digitalocean
|
||||
```
|
||||
|
||||
安装 结束之后,下一步是创建本地的 Vagrantfile 文件。下面是一个例子。
|
||||
|
||||
```
|
||||
$ mkdir digitalocean
|
||||
$ cd digitalocean
|
||||
$ cat Vagrantfile
|
||||
Vagrant.configure('2') do |config|
|
||||
config.vm.hostname = 'dropletname.kushaldas.in'
|
||||
# Alternatively, use provider.name below to set the Droplet name. config.vm.hostname takes precedence.
|
||||
|
||||
config.vm.provider :digital_ocean do |provider, override|
|
||||
override.ssh.private_key_path = '/home/kdas/.ssh/id_rsa'
|
||||
override.vm.box = 'digital_ocean'
|
||||
override.vm.box_url = "https://github.com/devopsgroup-io/vagrant- digitalocean/raw/master/box/digital_ocean.box"
|
||||
|
||||
provider.token = 'Your AUTH Token'
|
||||
provider.image = 'fedora-23-x64'
|
||||
provider.region = 'nyc2'
|
||||
provider.size = '512mb'
|
||||
provider.ssh_key_name = 'Kushal'
|
||||
end
|
||||
end
|
||||
```
|
||||
|
||||
### Vagrant DigitalOcean 插件的注意事项
|
||||
|
||||
一定要记住的几个关于 SSH 的关键命名规范 : 如果你已经在 DigitalOcean 上传了秘钥,请确保 `provider.ssh_key_name` 和已经在服务器中的名字吻合。 `provider.image` 具体的文档可以在[DigitalOcean documentation][5]找到。在控制面板上的 `App & API` 部分可以创建 AUTH 令牌。
|
||||
|
||||
你可以使用下面的命令启动一个实例。
|
||||
|
||||
```
|
||||
$ vagrant up --provider=digital_ocean
|
||||
```
|
||||
|
||||
这个命令会在 DigitalOcean 的启动一个服务器实例。然后你就可以使用 `vagrant ssh` 命令来 `ssh` 登录进入这个实例。可以执行 `vagrant destroy` 来删除这个实例。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-vagrant-digitalocean-cloud/
|
||||
|
||||
作者:[Kushal Das][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://kushal.id.fedoraproject.org/
|
||||
[1]: https://www.vagrantup.com/
|
||||
[2]: https://fedoramagazine.org/running-vagrant-fedora-22/
|
||||
[3]: https://www.digitalocean.com/
|
||||
[4]: https://communityblog.fedoraproject.org/fedora-cloud-fad-2016/
|
||||
[5]: https://developers.digitalocean.com/documentation/v2/#create-a-new-droplet
|
||||
80
published/201607/20160718 OPEN SOURCE ACCOUNTING SOFTWARE.md
Normal file
80
published/201607/20160718 OPEN SOURCE ACCOUNTING SOFTWARE.md
Normal file
@ -0,0 +1,80 @@
|
||||
GNU KHATA:开源的会计管理软件
|
||||
============================================
|
||||
|
||||
作为一个活跃的 Linux 爱好者,我经常向我的朋友们介绍 Linux,帮助他们选择最适合他们的发行版本,同时也会帮助他们安装一些适用于他们工作的开源软件。
|
||||
|
||||
但是在这一次,我就变得很无奈。我的叔叔,他是一个自由职业的会计师。他会有一系列的为了会计工作的漂亮而成熟的付费软件。我不那么确定我能在在开源软件中找到这么一款可以替代的软件——直到昨天。
|
||||
|
||||
Abhishek 给我推荐了一些[很酷的软件][1],而其中 GNU Khata 脱颖而出。
|
||||
|
||||
[GNU Khata][2] 是一个会计工具。 或者,我应该说成是一系列的会计工具集合?它就像经济管理方面的 [Evernote][3] 一样。它的应用是如此之广,以至于它不但可以用于个人的财务管理,也可以用于大型公司的管理,从店铺存货管理到税率计算,都可以有效处理。
|
||||
|
||||
有个有趣的地方,Khata 这个词在印度或者是其他的印度语国家中意味着账户,所以这个会计软件叫做 GNU Khata。
|
||||
|
||||
### 安装
|
||||
|
||||
互联网上有很多关于旧的 Web 版本的 Khata 安装介绍。现在,GNU Khata 只能用在 Debian/Ubuntu 和它们的衍生版本中。我建议你按照 GNU Khata 官网给出的如下步骤来安装。我们来快速过一下。
|
||||
|
||||
- 从[这里][4]下载安装器。
|
||||
- 在下载目录打开终端。
|
||||
- 粘贴复制以下的代码到终端,并且执行。
|
||||
|
||||
```
|
||||
sudo chmod 755 GNUKhatasetup.run
|
||||
sudo ./GNUKhatasetup.run
|
||||
```
|
||||
|
||||
这就结束了,从你的 Dash 或者是应用菜单中启动 GNU Khata 吧。
|
||||
|
||||
### 第一次启动
|
||||
|
||||
GNU Khata 在浏览器中打开,并且展现以下的画面。
|
||||
|
||||

|
||||
|
||||
填写组织的名字、组织形式,财务年度并且点击 proceed 按钮进入管理设置页面。
|
||||
|
||||

|
||||
|
||||
仔细填写你的用户名、密码、安全问题及其答案,并且点击“create and login”。
|
||||
|
||||

|
||||
|
||||
你已经全部设置完成了。使用菜单栏来开始使用 GNU Khata 来管理你的财务吧。这很容易。
|
||||
|
||||
### 移除 GNU KHATA
|
||||
|
||||
如果你不想使用 GNU Khata 了,你可以执行如下命令移除:
|
||||
|
||||
```
|
||||
sudo apt-get remove --auto-remove gnukhata-core-engine
|
||||
```
|
||||
|
||||
你也可以通过新立得软件管理来删除它。
|
||||
|
||||
### GNU KHATA 真的是市面上付费会计应用的竞争对手吗?
|
||||
|
||||
首先,GNU Khata 以简化为设计原则。顶部的菜单栏组织的很方便,可以帮助你有效的进行工作。你可以选择管理不同的账户和项目,并且切换非常容易。[它们的官网][5]表明,GNU Khata 可以“像说印度语一样方便”(LCTT 译注:原谅我,这个软件作者和本文作者是印度人……)。同时,你知道 GNU Khata 也可以在云端使用吗?
|
||||
|
||||
所有的主流的账户管理工具,比如分类账簿、项目报表、财务报表等等都用专业的方式整理,并且支持自定义格式和即时展示。这让会计和仓储管理看起来如此的简单。
|
||||
|
||||
这个项目正在积极的发展,正在寻求实操中的反馈以帮助这个软件更加进步。考虑到软件的成熟性、使用的便利性还有免费的情况,GNU Khata 可能会成为你最好的账簿助手。
|
||||
|
||||
请在评论框里留言吧,让我们知道你是如何看待 GNU Khata 的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/using-gnu-khata/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/aquil/
|
||||
[1]: https://itsfoss.com/category/apps/
|
||||
[2]: http://www.gnukhata.in/
|
||||
[3]: https://evernote.com/
|
||||
[4]: https://cloud.openmailbox.org/index.php/s/L8ppsxtsFq1345E/download
|
||||
[5]: http://www.gnukhata.in/
|
||||
@ -0,0 +1,36 @@
|
||||
在浏览器中体验 Ubuntu
|
||||
=====================================================
|
||||
|
||||
[Ubuntu][2] 的背后的公司 [Canonical][1] 为 Linux 推广做了很多努力。无论你有多么不喜欢 Ubuntu,你必须承认它对 “Linux 易用性”的影响。Ubuntu 以及其衍生是使用最多的 Linux 版本。
|
||||
|
||||
为了进一步推广 Ubuntu Linux,Canonical 把它放到了浏览器里,你可以在任何地方使用这个 [Ubuntu 演示版][0]。 它将帮你更好的体验 Ubuntu,以便让新人更容易决定是否使用它。
|
||||
|
||||
你可能争辩说 USB 版的 Linux 更好。我同意,但是你要知道你要下载 ISO,创建 USB 启动盘,修改配置文件,然后才能使用这个 USB 启动盘来体验。这么乏味并不是每个人都乐意这么干的。 在线体验是一个更好的选择。
|
||||
|
||||
那么,你能在 Ubuntu 在线看到什么。实际上并不多。
|
||||
|
||||
你可以浏览文件,你可以使用 Unity Dash,浏览 Ubuntu 软件中心,甚至装几个应用(当然它们不会真的安装),看一看文件浏览器和其它一些东西。以上就是全部了。但是在我看来,这已经做的很好了,让你知道它是个什么,对这个流行的操作系统有个直接感受。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
如果你的朋友或者家人对试试 Linux 抱有兴趣,但是想在安装前想体验一下 Linux 。你可以给他们以下链接:[Ubuntu 在线导览][0] 。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-online-demo/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[0]: http://tour.ubuntu.com/en/
|
||||
[1]: http://www.canonical.com/
|
||||
[2]: http://www.ubuntu.com/
|
||||
200
published/201607/20160722 7 Best Markdown Editors for Linux.md
Normal file
200
published/201607/20160722 7 Best Markdown Editors for Linux.md
Normal file
@ -0,0 +1,200 @@
|
||||
Linux 上 10 个最好的 Markdown 编辑器
|
||||
======================================
|
||||
|
||||
在这篇文章中,我们会点评一些可以在 Linux 上安装使用的最好的 Markdown 编辑器。 你可以找到非常多的 Linux 平台上的 Markdown 编辑器,但是在这里我们将尽可能地为您推荐那些最好的。
|
||||
|
||||
|
||||
|
||||
*Best Linux Markdown Editors*
|
||||
|
||||
对于不了解 Markdown 的人做个简单介绍,Markdown 是由著名的 Aaron Swartz 和 John Gruber 发明的标记语言,其最初的解析器是一个用 Perl 写的简单、轻量的[同名工具][1]。它可以将用户写的纯文本转为可用的 HTML(或 XHTML)。它实际上是一门易读,易写的纯文本语言,以及一个用于将文本转为 HTML 的转换工具。
|
||||
|
||||
希望你先对 Markdown 有一个稍微的了解,接下来让我们逐一列出这些编辑器。
|
||||
|
||||
### 1. Atom
|
||||
|
||||
Atom 是一个现代的、跨平台、开源且强大的文本编辑器,它可以运行在 Linux、Windows 和 MAC OS X 等操作系统上。用户可以在它的基础上进行定制,删减修改任何配置文件。
|
||||
|
||||
它包含了一些非常杰出的特性:
|
||||
|
||||
- 内置软件包管理器
|
||||
- 智能自动补全功能
|
||||
- 提供多窗口操作
|
||||
- 支持查找替换功能
|
||||
- 包含一个文件系统浏览器
|
||||
- 轻松自定义主题
|
||||
- 开源、高度扩展性的软件包等
|
||||
|
||||
|
||||
|
||||
*Atom Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://atom.io/>
|
||||
|
||||
### 2. GNU Emacs
|
||||
|
||||
Emacs 是 Linux 平台上一款的流行文本编辑器。它是一个非常棒的、具备高扩展性和定制性的 Markdown 语言编辑器。
|
||||
|
||||
它综合了以下这些神奇的特性:
|
||||
|
||||
- 带有丰富的内置文档,包括适合初学者的教程
|
||||
- 有完整的 Unicode 支持,可显示所有的人类符号
|
||||
- 支持内容识别的文本编辑模式
|
||||
- 包括多种文件类型的语法高亮
|
||||
- 可用 Emacs Lisp 或 GUI 对其进行高度定制
|
||||
- 提供了一个包系统可用来下载安装各种扩展等
|
||||
|
||||

|
||||
|
||||
*Emacs Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://www.gnu.org/software/emacs/>
|
||||
|
||||
### 3. Remarkable
|
||||
|
||||
Remarkable 可能是 Linux 上最好的 Markdown 编辑器了,它也适用于 Windows 操作系统。它的确是是一个卓越且功能齐全的 Markdown 编辑器,为用户提供了一些令人激动的特性。
|
||||
|
||||
一些卓越的特性:
|
||||
|
||||
- 支持实时预览
|
||||
- 支持导出 PDF 和 HTML
|
||||
- 支持 Github Markdown 语法
|
||||
- 支持定制 CSS
|
||||
- 支持语法高亮
|
||||
- 提供键盘快捷键
|
||||
- 高可定制性和其他
|
||||
|
||||
|
||||
|
||||
*Remarkable Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://remarkableapp.github.io>
|
||||
|
||||
### 4. Haroopad
|
||||
|
||||
Haroopad 是为 Linux,Windows 和 Mac OS X 构建的跨平台 Markdown 文档处理程序。用户可以用它来书写许多专家级格式的文档,包括电子邮件、报告、博客、演示文稿和博客文章等等。
|
||||
|
||||
功能齐全且具备以下的亮点:
|
||||
|
||||
- 轻松导入内容
|
||||
- 支持导出多种格式
|
||||
- 广泛支持博客和邮件
|
||||
- 支持许多数学表达式
|
||||
- 支持 Github Markdown 扩展
|
||||
- 为用户提供了一些令人兴奋的主题、皮肤和 UI 组件等等
|
||||
|
||||

|
||||
|
||||
*Haroopad Markdown Editor for Linux*
|
||||
|
||||
访问主页: <http://pad.haroopress.com/>
|
||||
|
||||
### 5. ReText
|
||||
|
||||
ReText 是为 Linux 和其它几个 POSIX 兼容操作系统提供的简单、轻量、强大的 Markdown 编辑器。它还可以作为一个 reStructuredText 编辑器,并且具有以下的特性:
|
||||
|
||||
- 简单直观的 GUI
|
||||
- 具备高定制性,用户可以自定义语法文件和配置选项
|
||||
- 支持多种配色方案
|
||||
- 支持使用多种数学公式
|
||||
- 启用导出扩展等等
|
||||
|
||||
|
||||
|
||||
*ReText Markdown Editor for Linux*
|
||||
|
||||
访问主页: <https://github.com/retext-project/retext>
|
||||
|
||||
### 6. UberWriter
|
||||
|
||||
UberWriter 是一个简单、易用的 Linux Markdown 编辑器。它的开发受 Mac OS X 上的 iA writer 影响很大,同样它也具备这些卓越的特性:
|
||||
|
||||
- 使用 pandoc 进行所有的文本到 HTML 的转换
|
||||
- 提供了一个简洁的 UI 界面
|
||||
- 提供了一种专心(distraction free)模式,高亮用户最后的句子
|
||||
- 支持拼写检查
|
||||
- 支持全屏模式
|
||||
- 支持用 pandoc 导出 PDF、HTML 和 RTF
|
||||
- 启用语法高亮和数学函数等等
|
||||
|
||||
|
||||
|
||||
*UberWriter Markdown Editor for Linux*
|
||||
|
||||
访问主页: <http://uberwriter.wolfvollprecht.de/>
|
||||
|
||||
### 7. Mark My Words
|
||||
|
||||
Mark My Words 同样也是一个轻量、强大的 Markdown 编辑器。它是一个相对比较新的编辑器,因此提供了包含语法高亮在内的大量的功能,简单和直观的 UI。
|
||||
|
||||
下面是一些棒极了,但还未捆绑到应用中的功能:
|
||||
|
||||
- 实时预览
|
||||
- Markdown 解析和文件 IO
|
||||
- 状态管理
|
||||
- 支持导出 PDF 和 HTML
|
||||
- 监测文件的修改
|
||||
- 支持首选项设置
|
||||
|
||||
|
||||
|
||||
*MarkMyWords Markdown Editor for-Linux*
|
||||
|
||||
访问主页: <https://github.com/voldyman/MarkMyWords>
|
||||
|
||||
### 8. Vim-Instant-Markdown 插件
|
||||
|
||||
Vim 是 Linux 上的一个久经考验的强大、流行而开源的文本编辑器。它用于编程极棒。它也高度支持插件功能,可以让用户为其增加一些其它功能,包括 Markdown 预览。
|
||||
|
||||
有好几种 Vim 的 Markdown 预览插件,但是 [Vim-Instant-Markdown][2] 的表现最佳。
|
||||
|
||||
###9. Bracket-MarkdownPreview 插件
|
||||
|
||||
Brackets 是一个现代、轻量、开源且跨平台的文本编辑器。它特别为 Web 设计和开发而构建。它的一些重要功能包括:支持内联编辑器、实时预览、预处理支持及更多。
|
||||
|
||||
它也是通过插件高度可扩展的,你可以使用 [Bracket-MarkdownPreview][3] 插件来编写和预览 Markdown 文档。
|
||||
|
||||

|
||||
|
||||
*Brackets Markdown Plugin Preview*
|
||||
|
||||
### 10. SublimeText-Markdown 插件
|
||||
|
||||
Sublime Text 是一个精心打造的、流行的、跨平台文本编辑器,用于代码、markdown 和普通文本。它的表现极佳,包括如下令人兴奋的功能:
|
||||
|
||||
- 简洁而美观的 GUI
|
||||
- 支持多重选择
|
||||
- 提供专心模式
|
||||
- 支持窗体分割编辑
|
||||
- 通过 Python 插件 API 支持高度插件化
|
||||
- 完全可定制化,提供命令查找模式
|
||||
|
||||
[SublimeText-Markdown][4] 插件是一个支持格式高亮的软件包,带有一些漂亮的颜色方案。
|
||||
|
||||
|
||||
|
||||
*SublimeText Markdown Plugin Preview*
|
||||
|
||||
### 结论
|
||||
|
||||
通过上面的列表,你大概已经知道要为你的 Linux 桌面下载、安装什么样的 Markdown 编辑器和文档处理程序了。
|
||||
|
||||
请注意,这里提到的最好的 Markdown 编辑器可能对你来说并不是最好的选择。因此你可以通过下面的反馈部分,为我们展示你认为列表中未提及的,并且具备足够的资格的,令人兴奋的 Markdown 编辑器。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-markdown-editors-for-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://daringfireball.net/projects/markdown/
|
||||
[2]: https://github.com/suan/vim-instant-markdown
|
||||
[3]: https://github.com/gruehle/MarkdownPreview
|
||||
[4]: https://github.com/SublimeText-Markdown/MarkdownEditing
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
怎样在 Ubuntu 中修改默认程序
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
> 简介: 这个新手指南会向你展示如何在 Ubuntu Linux 中修改默认程序
|
||||
|
||||
对于我来说,安装 [VLC 多媒体播放器][1]是[安装完 Ubuntu 16.04 该做的事][2]中最先做的几件事之一。为了能够使我双击一个视频就用 VLC 打开,在我安装完 VLC 之后我会设置它为默认程序。
|
||||
|
||||
作为一个新手,你需要知道如何在 Ubuntu 中修改任何默认程序,这也是我今天在这篇指南中所要讲的。
|
||||
|
||||
### 在 UBUNTU 中修改默认程序
|
||||
|
||||
这里提及的方法适用于所有的 Ubuntu 12.04,Ubuntu 14.04 和Ubuntu 16.04。在 Ubuntu 中,这里有两种基本的方法可以修改默认程序:
|
||||
|
||||
- 通过系统设置
|
||||
- 通过右键菜单
|
||||
|
||||
#### 1.通过系统设置修改 Ubuntu 的默认程序
|
||||
|
||||
进入 Unity 面板并且搜索系统设置(System Settings):
|
||||
|
||||

|
||||
|
||||
在系统设置(System Settings)中,选择详细选项(Details):
|
||||
|
||||

|
||||
|
||||
在左边的面板中选择默认程序(Default Applications),你会发现在右边的面板中可以修改默认程序。
|
||||
|
||||

|
||||
|
||||
正如看到的那样,这里只有少数几类的默认程序可以被改变。你可以在这里改变浏览器、邮箱客户端、日历、音乐、视频和相册的默认程序。那其他类型的默认程序怎么修改?
|
||||
|
||||
不要担心,为了修改其他类型的默认程序,我们会用到右键菜单。
|
||||
|
||||
#### 2.通过右键菜单修改默认程序
|
||||
|
||||
如果你使用过 Windows 系统,你应该看见过右键菜单的“打开方式”,可以通过这个来修改默认程序。我们在 Ubuntu 中也有相似的方法。
|
||||
|
||||
右键一个还没有设置默认打开程序的文件,选择“属性(properties)”
|
||||
|
||||

|
||||
|
||||
*从右键菜单中选择属性*
|
||||
|
||||
在这里,你可以选择使用什么程序打开,并且设置为默认程序。
|
||||
|
||||

|
||||
|
||||
*在 Ubuntu 中设置打开 WebP 图片的默认程序为 gThumb*
|
||||
|
||||
小菜一碟不是么?一旦你做完这些,所有同样类型的文件都会用你选择的默认程序打开。
|
||||
|
||||
我很希望这个新手指南对你在修改 Ubuntu 的默认程序时有帮助。如果你有任何的疑问或者建议,可以随时在下面评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/change-default-applications-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: http://www.videolan.org/vlc/index.html
|
||||
[2]: https://linux.cn/article-7453-1.html
|
||||
@ -0,0 +1,136 @@
|
||||
Terminix:一个很赞的基于 GTK3 的平铺式 Linux 终端模拟器
|
||||
============================================================
|
||||
|
||||
现在,你可以很容易的找到[大量的 Linux 终端模拟器][1],每一个都可以给用户留下深刻的印象。
|
||||
|
||||
但是,很多时候,我们会很难根据我们的喜好来找到一款心仪的日常使用的终端模拟器。这篇文章中,我们将会推荐一款叫做 Terminix 的令人激动的终端模拟机。
|
||||
|
||||
|
||||
|
||||
*Terminix Linux 终端模拟器*
|
||||
|
||||
Terminix 是一个使用 VTE GTK+ 3 组件的平铺式终端模拟器。使用 GTK 3 开发的原因主要是为了符合 GNOME HIG(人机接口 Human Interface Guidelines) 标准。另外,Terminix 已经在 GNOME 和 Unity 桌面环境下测试过了,也有用户在其他的 Linux 桌面环境下测试成功。
|
||||
|
||||
和其他的终端模拟器一样,Terminix 有着很多知名的特征,列表如下:
|
||||
|
||||
- 允许用户进行任意的垂直或者水平分屏
|
||||
- 支持拖拽功能来进行重新排布终端
|
||||
- 支持使用拖拽的方式终端从窗口中将脱离出来
|
||||
- 支持终端之间的输入同步,因此,可以在一个终端输入命令,而在另一个终端同步复现
|
||||
- 终端的分组配置可以保存在硬盘,并再次加载
|
||||
- 支持透明背景
|
||||
- 允许使用背景图片
|
||||
- 基于主机和目录来自动切换配置
|
||||
- 支持进程完成的通知信息
|
||||
- 配色方案采用文件存储,同时支持自定义配色方案
|
||||
|
||||
### 如何在 Linux 系统上安装 Terminix
|
||||
|
||||
现在来详细说明一下在不同的 Linux 发行版本上安装 Terminix 的步骤。首先,在此列出 Terminix 在 Linux 所需要的环境需求。
|
||||
|
||||
#### 依赖组件
|
||||
|
||||
为了正常运行,该应用需要使用如下库:
|
||||
|
||||
- GTK 3.14 或者以上版本
|
||||
- GTK VTE 0.42 或者以上版本
|
||||
- Dconf
|
||||
- GSettings
|
||||
- Nautilus 的 iNautilus-Python 插件
|
||||
|
||||
如果你已经满足了如上的系统要求,接下来就是安装 Terminix 的步骤。
|
||||
|
||||
#### 在 RHEL/CentOS 7 或者 Fedora 22-24 上
|
||||
|
||||
首先,你需要通过新建文件 `/etc/yum.repos.d/terminix.repo` 来增加软件仓库,使用你最喜欢的文本编辑器来进行编辑:
|
||||
|
||||
```
|
||||
# vi /etc/yum.repos.d/terminix.repo
|
||||
```
|
||||
|
||||
然后拷贝如下的文字到我们刚新建的文件中:
|
||||
|
||||
```
|
||||
[heikoada-terminix]
|
||||
name=Copr repo for terminix owned by heikoada
|
||||
baseurl=https://copr-be.cloud.fedoraproject.org/results/heikoada/terminix/fedora-$releasever-$basearch/
|
||||
skip_if_unavailable=True
|
||||
gpgcheck=1
|
||||
gpgkey=https://copr-be.cloud.fedoraproject.org/results/heikoada/terminix/pubkey.gpg
|
||||
enabled=1
|
||||
enabled_metadata=1
|
||||
```
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
然后更新你的系统,并且安装 Terminix,步骤如下:
|
||||
|
||||
```
|
||||
---------------- On RHEL/CentOS 7 ----------------
|
||||
# yum update
|
||||
# yum install terminix
|
||||
|
||||
---------------- On Fedora 22-24 ----------------
|
||||
# dnf update
|
||||
# dnf install terminix
|
||||
```
|
||||
|
||||
#### 在 Ubuntu 16.04-14.04 和 Linux Mint 18-17
|
||||
|
||||
虽然没有基于 Debian/Ubuntu 发行版本的官方的软件包,但是你依旧可以通过如下的命令手动安装。
|
||||
|
||||
```
|
||||
$ wget -c https://github.com/gnunn1/terminix/releases/download/1.1.1/terminix.zip
|
||||
$ sudo unzip terminix.zip -d /
|
||||
$ sudo glib-compile-schemas /usr/share/glib-2.0/schemas/
|
||||
```
|
||||
|
||||
#### 其它 Linux 发行版
|
||||
|
||||
OpenSUSE 用户可以从默认仓库中安装 Terminix,Arch Linux 用户也可以安装 [AUR Terminix 软件包][2]。
|
||||
|
||||
### Terminix 截图教程
|
||||
|
||||

|
||||
|
||||
*Terminix 终端*
|
||||
|
||||

|
||||
|
||||
*Terminix 终端设置*
|
||||
|
||||

|
||||
|
||||
*Terminix 多终端界面*
|
||||
|
||||
### 如何卸载删除 Terminix
|
||||
|
||||
|
||||
如果你是手动安装的 Terminix 并且想要删除它,那么你可以参照如下的步骤来卸载它。从 [Github 仓库][3]上下载 uninstall.sh,并且给它可执行权限并且执行它:
|
||||
|
||||
```
|
||||
$ wget -c https://github.com/gnunn1/terminix/blob/master/uninstall.sh
|
||||
$ chmod +x uninstall.sh
|
||||
$ sudo sh uninstall.sh
|
||||
```
|
||||
|
||||
但是如果你是通过包管理器安装的 Terminix,你可以使用包管理器来卸载它。
|
||||
|
||||
在这篇介绍中,我们在众多优秀的终端模拟器中发现了一个重要的 Linux 终端模拟器。你可以尝试着去体验下它的新特性,并且可以将它和你现在使用的终端进行比较。
|
||||
|
||||
重要的一点,如果你想得到更多信息或者有疑问,请使用评论区,而且不要忘了,给我一个关于你使用体验的反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/terminix-tiling-terminal-emulator-for-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/linux-terminal-emulators/
|
||||
[2]: https://aur.archlinux.org/packages/terminix
|
||||
[3]: https://github.com/gnunn1/terminix
|
||||
@ -0,0 +1,90 @@
|
||||
为你的 Linux 桌面设置一张实时的地球照片
|
||||
=================================================================
|
||||
|
||||
|
||||
|
||||
厌倦了看同样的桌面背景了么?这里有一个(可能是)世界上最棒的东西。
|
||||
|
||||
‘[Himawaripy][1]’ 是一个 Python 3 小脚本,它会抓取由[日本 Himawari 8 气象卫星][2]拍摄的接近实时的地球照片,并将它设置成你的桌面背景。
|
||||
|
||||
安装完成后,你可以将它设置成每 10 分钟运行的定时任务(自然,它要在后台运行),这样它就可以实时地取回地球的照片并设置成背景了。
|
||||
|
||||
因为 Himawari-8 是一颗同步轨道卫星,你只能看到澳大利亚上空的地球的图片——但是它实时的天气形态、云团和光线仍使它很壮丽,对我而言要是看到英国上方的就更好了!
|
||||
|
||||
高级设置允许你配置从卫星取回的图片质量,但是要记住增加图片质量会增加文件大小及更长的下载等待!
|
||||
|
||||
最后,虽然这个脚本与其他我们提到过的其他脚本类似,它还仍保持更新及可用。
|
||||
|
||||
###获取 Himawaripy
|
||||
|
||||
Himawaripy 已经在一系列的桌面环境中都测试过了,包括 Unity、LXDE、i3、MATE 和其他桌面环境。它是自由开源软件,但是整体来说安装及配置不太简单。
|
||||
|
||||
在该项目的 [Github 主页][0]上可以找到安装和设置该应用程序的所有指导(提示:没有一键安装功能)。
|
||||
|
||||
- [实时地球壁纸脚本的 GitHub 主页][0]
|
||||
|
||||
### 安装及使用
|
||||
|
||||

|
||||
|
||||
一些读者请我在本文中补充一下一步步安装该应用的步骤。以下所有步骤都在其 GitHub 主页上,这里再贴一遍。
|
||||
|
||||
1、下载及解压 Himawaripy
|
||||
|
||||
这是最容易的步骤。点击下面的下载链接,然后下载最新版本,并解压到你的下载目录里面。
|
||||
|
||||
- [下载 Himawaripy 主干文件(.zip 格式)][3]
|
||||
|
||||
2、安装 python3-setuptools
|
||||
|
||||
你需要手工来安装主干软件包,Ubuntu 里面默认没有安装它:
|
||||
|
||||
```
|
||||
sudo apt install python3-setuptools
|
||||
```
|
||||
|
||||
3、安装 Himawaripy
|
||||
|
||||
在终端中,你需要切换到之前解压的目录中,并运行如下安装命令:
|
||||
|
||||
```
|
||||
cd ~/Downloads/himawaripy-master
|
||||
sudo python3 setup.py install
|
||||
```
|
||||
|
||||
4、 看看它是否可以运行并下载最新的实时图片:
|
||||
```
|
||||
himawaripy
|
||||
```
|
||||
5、 设置定时任务
|
||||
|
||||
如果你希望该脚本可以在后台自动运行并更新(如果你需要手动更新,只需要运行 ‘himarwaripy’ 即可)
|
||||
|
||||
在终端中运行:
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
在其中新加一行(默认每10分钟运行一次)
|
||||
```
|
||||
*/10 * * * * /usr/local/bin/himawaripy
|
||||
```
|
||||
关于[配置定时任务][4]可以在 Ubuntu Wiki 上找到更多信息。
|
||||
|
||||
该脚本安装后你不需要不断运行它,它会自动的每十分钟在后台运行一次。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2016/07/set-real-time-earth-wallpaper-ubuntu-desktop
|
||||
|
||||
作者:[JOEY-ELIJAH SNEDDON][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]: https://github.com/boramalper/himawaripy
|
||||
[2]: https://en.wikipedia.org/wiki/Himawari_8
|
||||
[0]: https://github.com/boramalper/himawaripy
|
||||
[3]: https://github.com/boramalper/himawaripy/archive/master.zip
|
||||
[4]: https://help.ubuntu.com/community/CronHowto
|
||||
@ -0,0 +1,100 @@
|
||||
用 VeraCrypt 加密闪存盘
|
||||
============================================
|
||||
|
||||
很多安全专家偏好像 VeraCrypt 这类能够用来加密闪存盘的开源软件,是因为可以获取到它的源代码。
|
||||
|
||||
保护 USB 闪存盘里的数据,加密是一个聪明的方法,正如我们在使用 Microsoft 的 BitLocker [加密闪存盘][1] 一文中提到的。
|
||||
|
||||
但是如果你不想用 BitLocker 呢?
|
||||
|
||||
你可能有顾虑,因为你不能够查看 Microsoft 的程序源码,那么它容易被植入用于政府或其它用途的“后门”。而由于开源软件的源码是公开的,很多安全专家认为开源软件很少藏有后门。
|
||||
|
||||
还好,有几个开源加密软件能作为 BitLocker 的替代。
|
||||
|
||||
要是你需要在 Windows 系统,苹果的 OS X 系统或者 Linux 系统上加密以及访问文件,开源软件 [VeraCrypt][2] 提供绝佳的选择。
|
||||
|
||||
VeraCrypt 源于 TrueCrypt。TrueCrypt 是一个备受好评的开源加密软件,尽管它现在已经停止维护了。但是 TrueCrypt 的代码通过了审核,没有发现什么重要的安全漏洞。另外,在 VeraCrypt 中对它进行了改善。
|
||||
|
||||
Windows,OS X 和 Linux 系统的版本都有。
|
||||
|
||||
用 VeraCrypt 加密 USB 闪存盘不像用 BitLocker 那么简单,但是它也只要几分钟就好了。
|
||||
|
||||
### 用 VeraCrypt 加密闪存盘的 8 个步骤
|
||||
|
||||
对应你的操作系统 [下载 VeraCrypt][3] 之后:
|
||||
|
||||
打开 VeraCrypt,点击 Create Volume,进入 VeraCrypt 的创建卷的向导程序(VeraCrypt Volume Creation Wizard)。
|
||||
|
||||

|
||||
|
||||
VeraCrypt 创建卷向导(VeraCrypt Volume Creation Wizard)允许你在闪存盘里新建一个加密文件容器,这与其它未加密文件是独立的。或者你也可以选择加密整个闪存盘。这个时候你就选加密整个闪存盘就行。
|
||||
|
||||

|
||||
|
||||
然后选择标准模式(Standard VeraCrypt Volume)。
|
||||
|
||||

|
||||
|
||||
选择你想加密的闪存盘的驱动器卷标(这里是 O:)。
|
||||
|
||||

|
||||
|
||||
选择创建卷模式(Volume Creation Mode)。如果你的闪存盘是空的,或者你想要删除它里面的所有东西,选第一个。要么你想保持所有现存的文件,选第二个就好了。
|
||||
|
||||

|
||||
|
||||
这一步允许你选择加密选项。要是你不确定选哪个,就用默认的 AES 和 SHA-512 设置。
|
||||
|
||||

|
||||
|
||||
确定了卷容量后,输入并确认你想要用来加密数据密码。
|
||||
|
||||

|
||||
|
||||
要有效工作,VeraCrypt 要从一个熵或者“随机数”池中取出一个随机数。要初始化这个池,你将被要求随机地移动鼠标一分钟。一旦进度条变绿了,或者更方便的是等到进度条到了屏幕右边足够远的时候,点击 “Format” 来结束创建加密盘。
|
||||
|
||||

|
||||
|
||||
### 用 VeraCrypt 使用加密过的闪存盘
|
||||
|
||||
当你想要使用一个加密了的闪存盘,先插入闪存盘到电脑上,启动 VeraCrypt。
|
||||
|
||||
然后选择一个没有用过的卷标(比如 z:),点击自动挂载设备(Auto-Mount Devices)。
|
||||
|
||||

|
||||
|
||||
输入密码,点击确定。
|
||||
|
||||

|
||||
|
||||
挂载过程需要几分钟,这之后你的解密盘就能通过你先前选择的盘符进行访问了。
|
||||
|
||||
### VeraCrypt 移动硬盘安装步骤
|
||||
|
||||
如果你设置闪存盘的时候,选择的是加密过的容器而不是加密整个盘,你可以选择创建 VeraCrypt 称为移动盘(Traveler Disk)的设备。这会复制安装一个 VeraCrypt 到 USB 闪存盘。当你在别的 Windows 电脑上插入 U 盘时,就能从 U 盘自动运行 VeraCrypt;也就是说没必要在新电脑上安装 VeraCrypt。
|
||||
|
||||
你可以设置闪存盘作为一个移动硬盘(Traveler Disk),在 VeraCrypt 的工具栏(Tools)菜单里选择 Traveler Disk SetUp 就行了。
|
||||
|
||||

|
||||
|
||||
要从移动盘(Traveler Disk)上运行 VeraCrypt,你必须要有那台电脑的管理员权限,这不足为奇。尽管这看起来是个限制,机密文件无法在不受控制的电脑上安全打开,比如在一个商务中心的电脑上。
|
||||
|
||||
> 本文作者 Paul Rubens 从事技术行业已经超过 20 年。这期间他为英国和国际主要的出版社,包括 《The Economist》《The Times》《Financial Times》《The BBC》《Computing》和《ServerWatch》等出版社写过文章,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.esecurityplanet.com/open-source-security/how-to-encrypt-flash-drive-using-veracrypt.html
|
||||
|
||||
作者:[Paul Rubens][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.esecurityplanet.com/author/3700/Paul-Rubens
|
||||
[1]: http://www.esecurityplanet.com/views/article.php/3880616/How-to-Encrypt-a-USB-Flash-Drive.htm
|
||||
[2]: http://www.esecurityplanet.com/open-source-security/veracrypt-a-worthy-truecrypt-alternative.html
|
||||
[3]: https://veracrypt.codeplex.com/releases/view/619351
|
||||
|
||||
|
||||
|
||||
118
published/20160706 What is Git.md
Normal file
118
published/20160706 What is Git.md
Normal file
@ -0,0 +1,118 @@
|
||||
Git 系列(一):什么是 Git
|
||||
===========
|
||||
|
||||
欢迎阅读本系列关于如何使用 Git 版本控制系统的教程!通过本文的介绍,你将会了解到 Git 的用途及谁该使用 Git。
|
||||
|
||||
如果你刚步入开源的世界,你很有可能会遇到一些在 Git 上托管代码或者发布使用版本的开源软件。事实上,不管你知道与否,你都在使用基于 Git 进行版本管理的软件:Linux 内核(就算你没有在手机或者电脑上使用 Linux,你正在访问的网站也是运行在 Linux 系统上的),Firefox、Chrome 等其他很多项目都通过 Git 代码库和世界各地开发者共享他们的代码。
|
||||
|
||||
换个角度来说,你是否仅仅通过 Git 就可以和其他人共享你的代码?你是否可以在家里或者企业里私有化的使用 Git?你必须要通过一个 GitHub 账号来使用 Git 吗?为什么要使用 Git 呢?Git 的优势又是什么?Git 是我唯一的选择吗?这对 Git 所有的疑问都会把我们搞的一脑浆糊。
|
||||
|
||||
因此,忘记你以前所知的 Git,让我们重新走进 Git 世界的大门。
|
||||
|
||||
### 什么是版本控制系统?
|
||||
|
||||
Git 首先是一个版本控制系统。现在市面上有很多不同的版本控制系统:CVS、SVN、Mercurial、Fossil 当然还有 Git。
|
||||
|
||||
很多像 GitHub 和 GitLab 这样的服务是以 Git 为基础的,但是你也可以只使用 Git 而无需使用其他额外的服务。这意味着你可以以私有或者公有的方式来使用 Git。
|
||||
|
||||
如果你曾经和其他人有过任何电子文件方面的合作,你就会知道传统版本管理的工作流程。开始是很简单的:你有一个原始的版本,你把这个版本发送给你的同事,他们在接收到的版本上做了些修改,现在你们有两个版本了,然后他们把他们手上修改过的版本发回来给你。你把他们的修改合并到你手上的版本中,现在两个版本又合并成一个最新的版本了。
|
||||
|
||||
然后,你修改了你手上最新的版本,同时,你的同事也修改了他们手上合并前的版本。现在你们有 3 个不同的版本了,分别是合并后最新的版本,你修改后的版本,你同事手上继续修改过的版本。至此,你们的版本管理工作开始变得越来越混乱了。
|
||||
|
||||
正如 Jason van Gumster 在他的文章中指出 [即使是艺术家也需要版本控制][1],而且已经在个别人那里发现了这种趋势变化。无论是艺术家还是科学家,开发一个某种实验版本是并不鲜见的;在你的项目中,可能有某个版本大获成功,把项目推向一个新的高度,也可能有某个版本惨遭失败。因此,最终你不可避免的会创建出一堆名为project\_justTesting.kdenlive、project\_betterVersion.kdenlive、project\_best\_FINAL.kdenlive、project\_FINAL-alternateVersion.kdenlive 等类似名称的文件。
|
||||
|
||||
不管你是修改一个 for 循环,还是一些简单的文本编辑,一个好的版本控制系统都会让我们的生活更加的轻松。
|
||||
|
||||
### Git 快照
|
||||
|
||||
Git 可以为项目创建快照,并且存储这些快照为唯一的版本。
|
||||
|
||||
如果你将项目带领到了一个错误的方向上,你可以回退到上一个正确的版本,并且开始尝试另一个可行的方向。
|
||||
|
||||
如果你是和别人合作开发,当有人向你发送他们的修改时,你可以将这些修改合并到你的工作分支中,然后你的同事就可以获取到合并后的最新版本,并在此基础上继续工作。
|
||||
|
||||
Git 并不是魔法,因此冲突还是会发生的(“你修改了某文件的最后一行,但是我把这行整行都删除了;我们怎样处理这些冲突呢?”),但是总体而言,Git 会为你保留了所有更改的历史版本,甚至允许并行版本。这为你保留了以任何方式处理冲突的能力。
|
||||
|
||||
### 分布式 Git
|
||||
|
||||
在不同的机器上为同一个项目工作是一件复杂的事情。因为在你开始工作时,你想要获得项目的最新版本,然后此基础上进行修改,最后向你的同事共享这些改动。传统的方法是通过笨重的在线文件共享服务或者老旧的电邮附件,但是这两种方式都是效率低下且容易出错。
|
||||
|
||||
Git 天生是为分布式工作设计的。如果你要参与到某个项目中,你可以克隆(clone)该项目的 Git 仓库,然后就像这个项目只有你本地一个版本一样对项目进行修改。最后使用一些简单的命令你就可以拉取(pull)其他开发者的修改,或者你可以把你的修改推送(push)给别人。现在不用担心谁手上的是最新的版本,或者谁的版本又存放在哪里等这些问题了。全部人都是在本地进行开发,然后向共同的目标推送或者拉取更新。(或者不是共同的目标,这取决于项目的开发方式)。
|
||||
|
||||
### Git 界面
|
||||
|
||||
最原始的 Git 是运行在 Linux 终端上的应用软件。然而,得益于 Git 是开源的,并且拥有良好的设计,世界各地的开发者都可以为 Git 设计不同的访问界面。
|
||||
|
||||
Git 完全是免费的,并且已经打包在 Linux,BSD,Illumos 和其他类 Unix 系统中,Git 命令看起来像这样:
|
||||
|
||||
```
|
||||
$ git --version
|
||||
git version 2.5.3
|
||||
```
|
||||
|
||||
可能最著名的 Git 访问界面是基于网页的,像 GitHub、开源的 GitLab、Savannah、BitBucket 和 SourceForge 这些网站都是基于网页端的 Git 界面。这些站点为面向公众和面向社会的开源软件提供了最大限度的代码托管服务。在一定程度上,基于浏览器的图形界面(GUI)可以尽量的减缓 Git 的学习曲线。下面的 GitLab 界面的截图:
|
||||
|
||||
|
||||
|
||||
再者,第三方 Git 服务提供商或者独立开发者甚至可以在 Git 的基础上开发出不是基于 HTML 的定制化前端界面。此类界面让你可以不用打开浏览器就可以方便的使用 Git 进行版本管理。其中对用户最透明的方式是直接集成到文件管理器中。KDE 文件管理器 Dolphin 可以直接在目录中显示 Git 状态,甚至支持提交,推送和拉取更新操作。
|
||||
|
||||
|
||||
|
||||
[Sparkleshare][2] 使用 Git 作为其 Dropbox 式的文件共享界面的基础。
|
||||
|
||||
|
||||
|
||||
想了解更多的内容,可以查看 [Git wiki][3],这个(长长的)页面中展示了很多 Git 的图形界面项目。
|
||||
|
||||
### 谁应该使用 Git?
|
||||
|
||||
就是你!我们更应该关心的问题是什么时候使用 Git?和用 Git 来干嘛?
|
||||
|
||||
### 我应该在什么时候使用 Git 呢?我要用 Git 来干嘛呢?
|
||||
|
||||
想更深入的学习 Git,我们必须比平常考虑更多关于文件格式的问题。
|
||||
|
||||
Git 是为了管理源代码而设计的,在大多数编程语言中,源代码就意味者一行行的文本。当然,Git 并不知道你把这些文本当成是源代码还是下一部伟大的美式小说。因此,只要文件内容是以文本构成的,使用 Git 来跟踪和管理其版本就是一个很好的选择了。
|
||||
|
||||
但是什么是文本呢?如果你在像 Libre Office 这类办公软件中编辑一些内容,通常并不会产生纯文本内容。因为通常复杂的应用软件都会对原始的文本内容进行一层封装,就如把原始文本内容用 XML 标记语言包装起来,然后封装在 Zip 包中。这种对原始文本内容进行一层封装的做法可以保证当你把文件发送给其他人时,他们可以看到你在办公软件中编辑的内容及特定的文本效果。奇怪的是,虽然,通常你的需求可能会很复杂,就像保存 [Kdenlive][4] 项目文件,或者保存从 [Inkscape][5] 导出的SVG文件,但是,事实上使用 Git 管理像 XML 文本这样的纯文本类容是最简单的。
|
||||
|
||||
如果你在使用 Unix 系统,你可以使用 `file` 命令来查看文件内容构成:
|
||||
|
||||
```
|
||||
$ file ~/path/to/my-file.blah
|
||||
my-file.blah: ASCII text
|
||||
$ file ~/path/to/different-file.kra: Zip data (MIME type "application/x-krita")
|
||||
```
|
||||
|
||||
如果还是不确定,你可以使用 `head` 命令来查看文件内容:
|
||||
|
||||
```
|
||||
$ head ~/path/to/my-file.blah
|
||||
```
|
||||
|
||||
如果输出的文本你基本能看懂,这个文件就很有可能是文本文件。如果你仅仅在一堆乱码中偶尔看到几个熟悉的字符,那么这个文件就可能不是文本文件了。
|
||||
|
||||
准确的说:Git 可以管理其他格式的文件,但是它会把这些文件当成二进制大对象(blob)。两者的区别是,在文本文件中,Git 可以明确的告诉你在这两个快照(或者说提交)间有 3 行是修改过的。但是如果你在两个提交(commit)之间对一张图片进行的编辑操作,Git 会怎么指出这种修改呢?实际上,因为图片并不是以某种可以增加或删除的有意义的文本构成,因此 Git 并不能明确的描述这种变化。当然我个人是非常希望图片的编辑可以像把文本“\<sky>丑陋的蓝绿色\</sky>”修改成“\<sky>漂浮着蓬松白云的天蓝色\</sky>”一样的简单,但是事实上图片的编辑并没有这么简单。
|
||||
|
||||
经常有人在 Git 上放入 png 图标、电子表格或者流程图这类二进制大型对象(blob)。尽管,我们知道在 Git 上管理此类大型文件并不直观,但是,如果你需要使用 Git 来管理此类文件,你也并不需要过多的担心。如果你参与的项目同时生成文本文件和二进制大文件对象(如视频游戏中常见的场景,这些和源代码同样重要的图像和音频材料),那么你有两条路可以走:要么开发出你自己的解决方案,就如使用指向共享网络驱动器的引用;要么使用 Git 插件,如 Joey Hess 开发的 [git annex][6],以及 [Git-Media][7] 项目。
|
||||
|
||||
你看,Git 真的是一个任何人都可以使用的工具。它是你进行文件版本管理的一个强大而且好用工具,同时它并没有你开始认为的那么可怕。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/resources/what-is-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://opensource.com/life/16/2/version-control-isnt-just-programmers
|
||||
[2]: http://sparkleshare.org/
|
||||
[3]: https://git.wiki.kernel.org/index.php/InterfacesFrontendsAndTools#Graphical_Interfaces
|
||||
[4]: https://opensource.com/life/11/11/introduction-kdenlive
|
||||
[5]: http://inkscape.org/
|
||||
[6]: https://git-annex.branchable.com/
|
||||
[7]: https://github.com/alebedev/git-media
|
||||
141
published/20160711 Getting started with Git.md
Normal file
141
published/20160711 Getting started with Git.md
Normal file
@ -0,0 +1,141 @@
|
||||
初步了解 Git
|
||||
=========================
|
||||
|
||||

|
||||
|
||||
*图片来源:opensource.com*
|
||||
|
||||
在这个系列的[介绍篇][4]中,我们学习到了谁应该使用 Git,以及 Git 是用来做什么的。今天,我们将学习如何克隆公共 Git 仓库,以及如何提取出独立的文件而不用克隆整个仓库。
|
||||
|
||||
由于 Git 如此流行,因而如果你能够至少熟悉一些基础的 Git 知识也能为你的生活带来很多便捷。如果你可以掌握 Git 基础(你可以的,我发誓!),那么你将能够下载任何你需要的东西,甚至还可能做一些贡献作为回馈。毕竟,那就是开源的精髓所在:你拥有获取你使用的软件代码的权利,拥有和他人分享的自由,以及只要你愿意就可以修改它的权利。只要你熟悉了 Git,它就可以让这一切都变得很容易。
|
||||
|
||||
那么,让我们一起来熟悉 Git 吧。
|
||||
|
||||
### 读和写
|
||||
|
||||
一般来说,有两种方法可以和 Git 仓库交互:你可以从仓库中读取,或者你也能够向仓库中写入。它就像一个文件:有时候你打开一个文档只是为了阅读它,而其它时候你打开文档是因为你需要做些改动。
|
||||
|
||||
本文仅讲解如何从 Git 仓库读取。我们将会在后面的一篇文章中讲解如何向 Git 仓库写回的主题。
|
||||
|
||||
### Git 还是 GitHub?
|
||||
|
||||
一句话澄清:Git 不同于 GitHub(或 GitLab,或 Bitbucket)。Git 是一个命令行程序,所以它就像下面这样:
|
||||
|
||||
```
|
||||
$ git
|
||||
usage: Git [--version] [--help] [-C <path>]
|
||||
[-p | --paginate | --no-pager] [--bare]
|
||||
[--Git-dir=<path>] <command> [<args>]
|
||||
|
||||
```
|
||||
|
||||
由于 Git 是开源的,所以就有许多聪明人围绕它构建了基础软件;这些基础软件,包括在他们自己身边,都已经变得非常流行了。
|
||||
|
||||
我的文章系列将首先教你纯粹的 Git 知识,因为一旦你理解了 Git 在做什么,那么你就无需关心正在使用的前端工具是什么了。然而,我的文章系列也将涵盖通过流行的 Git 服务完成每项任务的常用方法,因为那些将可能是你首先会遇到的。
|
||||
|
||||
### 安装 Git
|
||||
|
||||
在 Linux 系统上,你可以从所使用的发行版软件仓库中获取并安装 Git。BSD 用户应当在 Ports 树的 devel 部分查找 Git。
|
||||
|
||||
对于闭源的操作系统,请前往其[项目官网][1],并根据说明安装。一旦安装后,在 Linux、BSD 和 Mac OS X 上的命令应当没有任何差别。Windows 用户需要调整 Git 命令,从而和 Windows 文件系统相匹配,或者安装 Cygwin 以原生的方式运行 Git,而不受 Windows 文件系统转换问题的羁绊。
|
||||
|
||||
### Git 下午茶
|
||||
|
||||
并非每个人都需要立刻将 Git 加入到我们的日常生活中。有些时候,你和 Git 最多的交互就是访问一个代码库,下载一两个文件,然后就不用它了。以这样的方式看待 Git,它更像是下午茶而非一次正式的宴会。你进行一些礼节性的交谈,获得了需要的信息,然后你就会离开,至少接下来的三个月你不再想这样说话。
|
||||
|
||||
当然,那是可以的。
|
||||
|
||||
一般来说,有两种方法访问 Git:使用命令行,或者使用一种神奇的因特网技术通过 web 浏览器快速轻松地访问。
|
||||
|
||||
假设你想要给终端安装一个回收站,因为你已经被 rm 命令毁掉太多次了。你可能听说过 Trashy ,它称自己为「理智的 rm 命令中间人」,也许你想在安装它之前阅读它的文档。幸运的是,[Trashy 公开地托管在 GitLab.com][2]。
|
||||
|
||||
### Landgrab
|
||||
|
||||
我们工作的第一步是对这个 Git 仓库使用 landgrab 排序方法:我们会克隆这个完整的仓库,然后会根据内容排序。由于该仓库是托管在公共的 Git 服务平台上,所以有两种方式来完成工作:使用命令行,或者使用 web 界面。
|
||||
|
||||
要想使用 Git 获取整个仓库,就要使用 git clone 命令和 Git 仓库的 URL 作为参数。如果你不清楚正确的 URL 是什么,仓库应该会告诉你的。GitLab 为你提供了 [Trashy][3] 仓库的用于拷贝粘贴的 URL。
|
||||
|
||||
|
||||
|
||||
你也许注意到了,在某些服务平台上,会同时提供 SSH 和 HTTPS 链接。只有当你拥有仓库的写权限时,你才可以使用 SSH。否则的话,你必须使用 HTTPS URL。
|
||||
|
||||
一旦你获得了正确的 URL,克隆仓库是非常容易的。就是 git clone 该 URL 即可,以及一个可选的指定要克隆到的目录。默认情况下会将 git 目录克隆到你当前所在的目录;例如,'trashy.git' 将会克隆到你当前位置的 'trashy' 目录。我使用 .clone 扩展名标记那些只读的仓库,而使用 .git 扩展名标记那些我可以读写的仓库,不过这并不是官方要求的。
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/trashy/trashy.git trashy.clone
|
||||
Cloning into 'trashy.clone'...
|
||||
remote: Counting objects: 142, done.
|
||||
remote: Compressing objects: 100% (91/91), done.
|
||||
remote: Total 142 (delta 70), reused 103 (delta 47)
|
||||
Receiving objects: 100% (142/142), 25.99 KiB | 0 bytes/s, done.
|
||||
Resolving deltas: 100% (70/70), done.
|
||||
Checking connectivity... done.
|
||||
```
|
||||
|
||||
一旦成功地克隆了仓库,你就可以像对待你电脑上任何其它目录那样浏览仓库中的文件。
|
||||
|
||||
另外一种获得仓库拷贝的方式是使用 web 界面。GitLab 和 GitHub 都会提供一个 .zip 格式的仓库快照文件。GitHub 有一个大大的绿色下载按钮,但是在 GitLab 中,可以在浏览器的右侧找到并不显眼的下载按钮。
|
||||
|
||||
|
||||
|
||||
### 仔细挑选
|
||||
|
||||
另外一种从 Git 仓库中获取文件的方法是找到你想要的文件,然后把它从仓库中拽出来。只有 web 界面才提供这种方法,本质上来说,你看到的是别人的仓库克隆;你可以把它想象成一个 HTTP 共享目录。
|
||||
|
||||
使用这种方法的问题是,你也许会发现某些文件并不存在于原始仓库中,因为完整形式的文件可能只有在执行 make 命令后才能构建,那只有你下载了完整的仓库,阅读了 README 或者 INSTALL 文件,然后运行相关命令之后才会产生。不过,假如你确信文件存在,而你只想进入仓库,获取那个文件,然后离开的话,你就可以那样做。
|
||||
|
||||
在 GitLab 和 GitHub 中,单击文件链接,并在 Raw 模式下查看,然后使用你的 web 浏览器的保存功能,例如:在 Firefox 中,“文件” \> “保存页面为”。在一个 GitWeb 仓库中(这是一个某些更喜欢自己托管 git 的人使用的私有 git 仓库 web 查看器),Raw 查看链接在文件列表视图中。
|
||||
|
||||
|
||||
|
||||
### 最佳实践
|
||||
|
||||
通常认为,和 Git 交互的正确方式是克隆完整的 Git 仓库。这样认为是有几个原因的。首先,可以使用 git pull 命令轻松地使克隆仓库保持更新,这样你就不必在每次文件改变时就重回 web 站点获得一份全新的拷贝。第二,你碰巧需要做些改进,只要保持仓库整洁,那么你可以非常轻松地向原来的作者提交所做的变更。
|
||||
|
||||
现在,可能是时候练习查找感兴趣的 Git 仓库,然后将它们克隆到你的硬盘中了。只要你了解使用终端的基础知识,那就不会太难做到。还不知道基本的终端使用方式吗?那再给多我 5 分钟时间吧。
|
||||
|
||||
### 终端使用基础
|
||||
|
||||
首先要知道的是,所有的文件都有一个路径。这是有道理的;如果我让你在常规的非终端环境下为我打开一个文件,你就要导航到文件在你硬盘的位置,并且直到你找到那个文件,你要浏览一大堆窗口。例如,你也许要点击你的家目录 > 图片 > InktoberSketches > monkey.kra。
|
||||
|
||||
在那样的场景下,文件 monkeysketch.kra 的路径是:$HOME/图片/InktoberSketches/monkey.kra。
|
||||
|
||||
在终端中,除非你正在处理一些特殊的系统管理员任务,你的文件路径通常是以 $HOME 开头的(或者,如果你很懒,就使用 ~ 字符),后面紧跟着一些列的文件夹直到文件名自身。
|
||||
|
||||
这就和你在 GUI 中点击各种图标直到找到相关的文件或文件夹类似。
|
||||
|
||||
如果你想把 Git 仓库克隆到你的文档目录,那么你可以打开一个终端然后运行下面的命令:
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/foo/bar.git
|
||||
$HOME/文档/bar.clone
|
||||
```
|
||||
|
||||
一旦克隆完成,你可以打开一个文件管理器窗口,导航到你的文档文件夹,然后你就会发现 bar.clone 目录正在等待着你访问。
|
||||
|
||||
如果你想要更高级点,你或许会在以后再次访问那个仓库,可以尝试使用 git pull 命令来查看项目有没有更新:
|
||||
|
||||
```
|
||||
$ cd $HOME/文档/bar.clone
|
||||
$ pwd
|
||||
bar.clone
|
||||
$ git pull
|
||||
```
|
||||
|
||||
到目前为止,你需要初步了解的所有终端命令就是那些了,那就去探索吧。你实践得越多,Git 掌握得就越好(熟能生巧),这是重点,也是事情的本质。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/stumbling-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://git-scm.com/download
|
||||
[2]: https://gitlab.com/trashy/trashy
|
||||
[3]: https://gitlab.com/trashy/trashy.git
|
||||
[4]: https://linux.cn/article-7639-1.html
|
||||
176
published/20160718 Creating your first Git repository.md
Normal file
176
published/20160718 Creating your first Git repository.md
Normal file
@ -0,0 +1,176 @@
|
||||
Git 系列(三):建立你的第一个 Git 仓库
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
现在是时候学习怎样创建你自己的 Git 仓库了,还有怎样增加文件和完成提交。
|
||||
|
||||
在本系列[前面的文章][4]中,你已经学习了怎样作为一个最终用户与 Git 进行交互;你就像一个漫无目的的流浪者一样偶然发现了一个开源项目网站,克隆了仓库,然后你就可以继续钻研它了。你知道了和 Git 进行交互并不像你想的那样困难,或许你只是需要被说服现在去使用 Git 完成你的工作罢了。
|
||||
|
||||
虽然 Git 确实是被许多重要软件选作版本控制工具,但是并不是仅能用于这些重要软件;它也能管理你购物清单(如果它们对你来说很重要的话,当然可以了!)、你的配置文件、周报或日记、项目进展日志、甚至源代码!
|
||||
|
||||
使用 Git 是很有必要的,毕竟,你肯定有过因为一个备份文件不能够辨认出版本信息而抓狂的时候。
|
||||
|
||||
Git 无法帮助你,除非你开始使用它,而现在就是开始学习和使用它的最好时机。或者,用 Git 的话来说,“没有其他的 `push` 能像 `origin HEAD` 一样有帮助了”(千里之行始于足下的意思)。我保证,你很快就会理解这一点的。
|
||||
|
||||
### 类比于录音
|
||||
|
||||
我们经常用名词“快照”来指代计算机上的镜像,因为很多人都能够对插满了不同时光的照片的相册充满了感受。这很有用,不过,我认为 Git 更像是进行一场录音。
|
||||
|
||||
也许你不太熟悉传统的录音棚卡座式录音机,它包括几个部件:一个可以正转或反转的转轴、保存声音波形的磁带,可以通过拾音头在磁带上记录声音波形,或者检测到磁带上的声音波形并播放给听众。
|
||||
|
||||
除了往前播放磁带,你也可以把磁带倒回到之前的部分,或快进跳过后面的部分。
|
||||
|
||||
想象一下上世纪 70 年代乐队录制磁带的情形。你可以想象到他们一遍遍地练习歌曲,直到所有部分都非常完美,然后记录到音轨上。起初,你会录下鼓声,然后是低音,再然后是吉他声,最后是主唱。每次你录音时,录音棚工作人员都会把磁带倒带,然后进入循环模式,这样它就会播放你之前录制的部分。比如说如果你正在录制低音,你就会在背景音乐里听到鼓声,就像你自己在击鼓一样,然后吉他手在录制时会听到鼓声、低音(和牛铃声)等等。在每个循环中,你都会录制一部分,在接下来的循环中,工作人员就会按下录音按钮将其合并记录到磁带中。
|
||||
|
||||
你也可以拷贝或换下整个磁带,如果你要对你的作品重新混音的话。
|
||||
|
||||
现在我希望对于上述的上世纪 70 年代的录音工作的描述足够生动,这样我们就可以把 Git 的工作想象成一个录音工作了。
|
||||
|
||||
### 新建一个 Git 仓库
|
||||
|
||||
首先得为我们的虚拟的录音机买一些磁带。用 Git 的话说,这些磁带就是*仓库*;它是完成所有工作的基础,也就是说这里是存放 Git 文件的地方(即 Git 工作区)。
|
||||
|
||||
任何目录都可以成为一个 Git 仓库,但是让我们从一个新目录开始。这需要下面三个命令:
|
||||
|
||||
- 创建目录(如果你喜欢的话,你可以在你的图形化的文件管理器里面完成。)
|
||||
- 在终端里切换到目录。
|
||||
- 将其初始化成一个 Git 管理的目录。
|
||||
|
||||
也就是运行如下代码:
|
||||
|
||||
```
|
||||
$ mkdir ~/jupiter # 创建目录
|
||||
$ cd ~/jupiter # 进入目录
|
||||
$ git init . # 初始化你的新 Git 工作区
|
||||
```
|
||||
|
||||
在这个例子中,文件夹 jupiter 是一个空的但是合法的 Git 仓库。
|
||||
|
||||
有了仓库接下来的事情就可以按部就班进行了。你可以克隆该仓库,你可以在一个历史点前后来回穿梭(前提是你有一个历史点),创建交替的时间线,以及做 Git 能做的其它任何事情。
|
||||
|
||||
在 Git 仓库里面工作和在任何目录里面工作都是一样的,可以在仓库中新建文件、复制文件、保存文件。你可以像平常一样做各种事情;Git 并不复杂,除非你把它想复杂了。
|
||||
|
||||
在本地的 Git 仓库中,一个文件可以有以下这三种状态:
|
||||
|
||||
- 未跟踪文件(Untracked):你在仓库里新建了一个文件,但是你没有把文件加入到 Git 的管理之中。
|
||||
- 已跟踪文件(Tracked):已经加入到 Git 管理的文件。
|
||||
- 暂存区文件(Staged):被修改了的已跟踪文件,并加入到 Git 的提交队列中。
|
||||
|
||||
任何你新加入到 Git 仓库中的文件都是未跟踪文件。这些文件保存在你的电脑硬盘上,但是你没有告诉 Git 这是需要管理的文件,用我们的录音机来类比,就是录音机还没打开;乐队就开始在录音棚里忙碌了,但是录音机并没有准备录音。
|
||||
|
||||
不用担心,Git 会在出现这种情况时告诉你:
|
||||
|
||||
```
|
||||
$ echo "hello world" > foo
|
||||
$ git status
|
||||
On branch master
|
||||
Untracked files:
|
||||
(use "git add <file>..." to include in what will be committed)
|
||||
foo
|
||||
nothing added but untracked files present (use "git add" to track)
|
||||
```
|
||||
|
||||
你看到了,Git 会提醒你怎样把文件加入到提交任务中。
|
||||
|
||||
### 不使用 Git 命令进行 Git 操作
|
||||
|
||||
在 GitHub 或 GitLab 上创建一个仓库只需要用鼠标点几下即可。这并不难,你单击“New Repository”这个按钮然后跟着提示做就可以了。
|
||||
|
||||
在仓库中包括一个“README”文件是一个好习惯,这样人们在浏览你的仓库的时候就可以知道你的仓库是干什么的,更有用的是可以让你在克隆一个有东西的仓库前知道它有些什么。
|
||||
|
||||
克隆仓库通常很简单,但是在 GitHub 上获取仓库改动权限就稍微复杂一些,为了通过 GitHub 验证你必须有一个 SSH 密钥。如果你使用 Linux 系统,可以通过下面的命令生成:
|
||||
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
然后复制你的新密钥的内容,它是纯文本文件,你可以使用一个文本编辑器打开它,也可以使用如下 cat 命令查看:
|
||||
|
||||
```
|
||||
$ cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
|
||||
现在把你的密钥粘贴到 [GitHub SSH 配置文件][1] 中,或者 [GitLab 配置文件][2]。
|
||||
|
||||
如果你通过使用 SSH 模式克隆了你的项目,你就可以将修改写回到你的仓库了。
|
||||
|
||||
另外,如果你的系统上没有安装 Git 的话也可以使用 GitHub 的文件上传接口来添加文件。
|
||||
|
||||
|
||||
|
||||
### 跟踪文件
|
||||
|
||||
正如命令 `git status` 的输出告诉你的那样,如果你想让 git 跟踪一个文件,你必须使用命令 `git add` 把它加入到提交任务中。这个命令把文件存在了暂存区,这里存放的都是等待提交的文件,或者也可以用在快照中。在将文件包括到快照中,和添加要 Git 管理的新的或临时文件时,`git add` 命令的目的是不同的,不过至少现在,你不用为它们之间的不同之处而费神。
|
||||
|
||||
类比录音机,这个动作就像打开录音机开始准备录音一样。你可以想象为对已经在录音的录音机按下暂停按钮,或者倒回开头等着记录下个音轨。
|
||||
|
||||
当你把文件添加到 Git 管理中,它会标识其为已跟踪文件:
|
||||
|
||||
```
|
||||
$ git add foo
|
||||
$ git status
|
||||
On branch master
|
||||
Changes to be committed:
|
||||
(use "git reset HEAD <file>..." to unstage)
|
||||
new file: foo
|
||||
```
|
||||
|
||||
加入文件到提交任务中并不是“准备录音”。这仅仅是将该文件置于准备录音的状态。在你添加文件后,你仍然可以修改该文件;它只是被标记为**已跟踪**和**处于暂存区**,所以在它被写到“磁带”前你可以将它撤出或修改它(当然你也可以再次将它加入来做些修改)。但是请注意:你还没有在磁带中记录该文件,所以如果弄坏了一个之前还是好的文件,你是没有办法恢复的,因为你没有在“磁带”中记下那个文件还是好着的时刻。
|
||||
|
||||
如果你最后决定不把文件记录到 Git 历史列表中,那么你可以撤销提交任务,在 Git 中是这样做的:
|
||||
|
||||
```
|
||||
$ git reset HEAD foo
|
||||
```
|
||||
|
||||
这实际上就是解除了录音机的准备录音状态,你只是在录音棚中转了一圈而已。
|
||||
|
||||
### 大型提交
|
||||
|
||||
有时候,你想要提交一些内容到仓库;我们以录音机类比,这就好比按下录音键然后记录到磁带中一样。
|
||||
|
||||
在一个项目所经历的不同阶段中,你会按下这个“记录键”无数次。比如,如果你尝试了一个新的 Python 工具包并且最终实现了窗口呈现功能,然后你肯定要进行提交,以便你在实验新的显示选项时搞砸了可以回退到这个阶段。但是如果你在 Inkscape 中画了一些图形草样,在提交前你可能需要等到已经有了一些要开发的内容。尽管你可能提交了很多次,但是 Git 并不会浪费很多,也不会占用太多磁盘空间,所以在我看来,提交的越多越好。
|
||||
|
||||
`commit` 命令会“记录”仓库中所有的暂存区文件。Git 只“记录”已跟踪的文件,即,在过去某个时间点你使用 `git add` 命令加入到暂存区的所有文件,以及从上次提交后被改动的文件。如果之前没有过提交,那么所有跟踪的文件都包含在这次提交中,以 Git 的角度来看,这是一次非常重要的修改,因为它们从没放到仓库中变成了放进去。
|
||||
|
||||
完成一次提交需要运行下面的命令:
|
||||
|
||||
```
|
||||
$ git commit -m 'My great project, first commit.'
|
||||
```
|
||||
|
||||
这就保存了所有提交的文件,之后可以用于其它操作(或者,用英国电视剧《神秘博士》中时间领主所讲的 Gallifreyan 语说,它们成为了“固定的时间点” )。这不仅是一个提交事件,也是一个你在 Git 日志中找到该提交的引用指针:
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
55df4c2 My great project, first commit.
|
||||
```
|
||||
|
||||
如果想浏览更多信息,只需要使用不带 `--oneline` 选项的 `git log` 命令。
|
||||
|
||||
在这个例子中提交时的引用号码是 55df4c2。它被叫做“提交哈希(commit hash)”(LCTT 译注:这是一个 SHA-1 算法生成的哈希码,用于表示一个 git 提交对象),它代表着刚才你的提交所包含的所有新改动,覆盖到了先前的记录上。如果你想要“倒回”到你的提交历史点上,就可以用这个哈希作为依据。
|
||||
|
||||
你可以把这个哈希想象成一个声音磁带上的 [SMPTE 时间码][3],或者再形象一点,这就是好比一个黑胶唱片上两首不同的歌之间的空隙,或是一个 CD 上的音轨编号。
|
||||
|
||||
当你改动了文件之后并且把它们加入到提交任务中,最终完成提交,这就会生成新的提交哈希,它们每一个所标示的历史点都代表着你的产品不同的版本。
|
||||
|
||||
这就是 Charlie Brown 这样的音乐家们为什么用 Git 作为版本控制系统的原因。
|
||||
|
||||
在接下来的文章中,我们将会讨论关于 Git HEAD 的各个方面,我们会真正地向你揭示时间旅行的秘密。不用担心,你只需要继续读下去就行了(或许你已经在读了?)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/creating-your-first-git-repository
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://github.com/settings/keys
|
||||
[2]: https://gitlab.com/profile/keys
|
||||
[3]: http://slackermedia.ml/handbook/doku.php?id=timecode
|
||||
[4]: https://linux.cn/article-7641-1.html
|
||||
60
published/20160721 5 tricks for getting started with Vim.md
Normal file
60
published/20160721 5 tricks for getting started with Vim.md
Normal file
@ -0,0 +1,60 @@
|
||||
Vim 起步的五个技巧
|
||||
=====================================
|
||||
|
||||

|
||||
|
||||
多年来,我一直想学 Vim。如今 Vim 是我最喜欢的 Linux 文本编辑器,也是开发者和系统管理者最喜爱的开源工具。我说的学习,指的是真正意义上的学习。想要精通确实很难,所以我只想要达到熟练的水平。我使用了这么多年的 Linux ,我会的也仅仅只是打开一个文件,使用上下左右箭头按键来移动光标,切换到插入模式,更改一些文本,保存,然后退出。
|
||||
|
||||
但那只是 Vim 的最最基本的操作。我的技能水平只能让我在终端使用 Vim 修改文本,但是它并没有任何一个我想象中强大的文本处理功能。这样我完全无法用 Vim 发挥出胜出 Pico 和 Nano 的能力。
|
||||
|
||||
所以到底为什么要学习 Vim?因为我花费了相当多的时间用于编辑文本,而且我知道还有很大的效率提升空间。为什么不选择 Emacs,或者是更为现代化的编辑器例如 Atom?因为 Vim 适合我,至少我有一丁点的使用经验。而且,很重要的一点就是,在我需要处理的系统上很少碰见没有装 Vim 或者它的弱化版(Vi)。如果你有强烈的欲望想学习对你来说更给力的 Emacs,我希望这些对于 Emacs 同类编辑器的建议能对你有所帮助。
|
||||
|
||||
花了几周的时间专注提高我的 Vim 使用技巧之后,我想分享的第一个建议就是必须使用它。虽然这看起来就是明知故问的回答,但事实上它比我所预想的计划要困难一些。我的大多数工作是在网页浏览器上进行的,而且每次我需要在浏览器之外打开并编辑一段文本时,就需要避免下意识地打开 Gedit。Gedit 已经放在了我的快速启动栏中,所以第一步就是移除这个快捷方式,然后替换成 Vim 的。
|
||||
|
||||
为了更好的学习 Vim,我尝试了很多。如果你也正想学习,以下列举了一些作为推荐。
|
||||
|
||||
### Vimtutor
|
||||
|
||||
通常如何开始学习最好就是使用应用本身。我找到一个小的应用叫 Vimtutor,当你在学习编辑一个文本时它能辅导你一些基础知识,它向我展示了很多我这些年都忽视的基础命令。Vimtutor 一般在有 Vim 的地方都能找到它,如果你的系统上没有 Vimtutor,Vimtutor 可以很容易从你的包管理器上安装。
|
||||
|
||||
### GVim
|
||||
|
||||
我知道并不是每个人都认同这个,但就是它让我从使用终端中的 Vim 转战到使用 GVim 来满足我基本编辑需求。反对者表示 GVim 鼓励使用鼠标,而 Vim 主要是为键盘党设计的。但是我能通过 GVim 的下拉菜单快速找到想找的指令,并且 GVim 可以提醒我正确的指令然后通过敲键盘执行它。努力学习一个新的编辑器然后陷入无法解决的困境,这种感觉并不好受。每隔几分钟读一下 man 出来的文字或者使用搜索引擎来提醒你该用的按键序列也并不是最好的学习新事物的方法。
|
||||
|
||||
### 键盘表
|
||||
|
||||
当我转战 GVim,我发现有一个键盘的“速查表”来提醒我最基础的按键很是便利。网上有很多这种可用的表,你可以下载、打印,然后贴在你身边的某一处地方。但是为了我的笔记本键盘,我选择买一沓便签纸。这些便签纸在美国不到 10 美元,当我使用键盘编辑文本,尝试新的命令的时候,可以随时提醒我。
|
||||
|
||||
### Vimium
|
||||
|
||||
上文提到,我工作都在浏览器上进行。其中一条我觉得很有帮助的建议就是,使用 [Vimium][1] 来用增强使用 Vim 的体验。Vimium 是 Chrome 浏览器上的一个开源插件,能用 Vim 的指令快捷操作 Chrome。我发现我只用了几次使用快捷键切换上下文,就好像比之前更熟悉这些快捷键了。同样的扩展 Firefox 上也有,例如 [Vimerator][2]。
|
||||
|
||||
### 其它人
|
||||
|
||||
毫无疑问,最好的学习方法就是求助于在你之前探索过的人,让他给你建议、反馈和解决方法。
|
||||
|
||||
如果你住在一个大城市,那么附近可能会有一个 Vim meetup 小组,或者还有 Freenode IRC 上的 #vim 频道。#vim 频道是 Freenode 上最活跃的频道之一,那上面可以针对你个人的问题来提供帮助。听上面的人发发牢骚或者看看别人尝试解决自己没有遇到过的问题,仅仅是这样我都觉得很有趣。
|
||||
|
||||
------
|
||||
|
||||
那么,现在怎么样了?到现在为止还不错。为它所花的时间是否值得就在于之后它为你节省了多少时间。但是当我发现一个新的按键序列可以来跳过词,或者一些相似的小技巧,我经常会收获意外的惊喜与快乐。每天我至少可以看见,一点点的回报,正在逐渐配得上当初的付出。
|
||||
|
||||
学习 Vim 并不仅仅只有这些建议,还有很多。我很喜欢指引别人去 [Vim Advantures][3],它是一种使用 Vim 按键方式进行移动的在线游戏。而在另外一天我在 [Vimgifts.com][4] 发现了一个非常神奇的虚拟学习工具,那可能就是你真正想要的:用一个小小的 gif 动图来描述 Vim 操作。
|
||||
|
||||
你有花时间学习 Vim 吗?或者是任何需要大量键盘操作的程序?那些经过你努力后掌握的工具,你认为这些努力值得吗?效率的提高有没有达到你的预期?分享你们的故事在下面的评论区吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/tips-getting-started-vim
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[maywanting](https://github.com/maywanting)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[1]: https://github.com/philc/vimium
|
||||
[2]: http://www.vimperator.org/
|
||||
[3]: http://vim-adventures.com/
|
||||
[4]: http://vimgifs.com/
|
||||
@ -1,10 +1,10 @@
|
||||
LFCS 第十讲:学习简单的 Shell 脚本编程和文件系统故障排除
|
||||
LFCS 系列第十讲:学习简单的 Shell 脚本编程和文件系统故障排除
|
||||
================================================================================
|
||||
Linux 基金会发起了 LFCS 认证 (Linux Foundation Certified Sysadmin, Linux 基金会认证系统管理员),这是一个全新的认证体系,主要目标是让全世界任何人都有机会考取认证。认证内容为 Linux 中间系统的管理,主要包括:系统运行和服务的维护、全面监控和分析的能力以及问题来临时何时想上游团队请求帮助的决策能力
|
||||
Linux 基金会发起了 LFCS 认证 (Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员),这是一个全新的认证体系,旨在让世界各地的人能够参与到中等水平的 Linux 系统的基本管理操作的认证考试中去,这项认证包括:维护正在运行的系统和服务的能力、全面监控和分析的能力以及何时向上游团队请求支持的决策能力。
|
||||
|
||||

|
||||
|
||||
LFCS 系列第十讲
|
||||
*LFCS 系列第十讲*
|
||||
|
||||
请看以下视频,这里边介绍了 Linux 基金会认证程序。
|
||||
|
||||
@ -18,54 +18,53 @@ LFCS 系列第十讲
|
||||
首先要声明一些概念。
|
||||
|
||||
- Shell 是一个程序,它将命令传递给操作系统来执行。
|
||||
- Terminal 也是一个程序,作为最终用户,我们需要使用它与 Shell 来交互。比如,下边的图片是 GNOME Terminal。
|
||||
- Terminal 也是一个程序,允许最终用户使用它与 Shell 来交互。比如,下边的图片是 GNOME Terminal。
|
||||
|
||||

|
||||
|
||||
Gnome Terminal
|
||||
*Gnome Terminal*
|
||||
|
||||
启动 Shell 之后,会呈现一个命令提示符 (也称为命令行) 提示我们 Shell 已经做好了准备,接受标准输入设备输入的命令,这个标准输入设备通常是键盘。
|
||||
|
||||
你可以参考该系列文章的 [第一讲 使用命令创建、编辑和操作文件][1] 来温习一些常用的命令。
|
||||
你可以参考该系列文章的 [第一讲 如何在 Linux 上使用 GNU sed 等命令来创建、编辑和操作文件][1] 来温习一些常用的命令。
|
||||
|
||||
Linux 为提供了许多可以选用的 Shell,下面列出一些常用的:
|
||||
|
||||
**bash Shell**
|
||||
|
||||
Bash 代表 Bourne Again Shell,它是 GNU 项目默认的 Shell。它借鉴了 Korn shell (ksh) 和 C shell (csh) 中有用的特性,并同时对性能进行了提升。它同时也是 LFCS 认证中所涵盖的风发行版中默认 Shell,也是本系列教程将使用的 Shell。
|
||||
Bash 代表 Bourne Again Shell,它是 GNU 项目默认的 Shell。它借鉴了 Korn shell (ksh) 和 C shell (csh) 中有用的特性,并同时对性能进行了提升。它同时也是 LFCS 认证中所涵盖的各发行版中默认 Shell,也是本系列教程将使用的 Shell。
|
||||
|
||||
**sh Shell**
|
||||
|
||||
Bash Shell 是一个比较古老的 shell,一次多年来都是多数类 Unix 系统的默认 shell。
|
||||
Bourne SHell 是一个比较古老的 shell,多年来一直都是很多类 Unix 系统的默认 shell。
|
||||
|
||||
**ksh Shell**
|
||||
|
||||
Korn SHell (ksh shell) 也是一个 Unix shell,是贝尔实验室 (Bell Labs) 的 David Korn 在 19 世纪 80 年代初的时候开发的。它兼容 Bourne shell ,并同时包含了 C shell 中的多数特性。
|
||||
|
||||
|
||||
一个 shell 脚本仅仅只是一个可执行的文本文件,里边包含一条条可执行命令。
|
||||
|
||||
### 简单的 Shell 脚本编程 ###
|
||||
|
||||
如前所述,一个 shell 脚本就是一个纯文本文件,因此,可以使用自己喜欢的文本编辑器来创建和编辑。你可以考虑使用 vi/vim (参考本系列 [第二部分 - vi/vim 编辑器的使用][2]),它的语法高亮让我的编辑工作非常方便。
|
||||
如前所述,一个 shell 脚本就是一个纯文本文件,因此,可以使用自己喜欢的文本编辑器来创建和编辑。你可以考虑使用 vi/vim (参考本系列 [第二讲 如何安装和使用纯文本编辑器 vi/vim][2]),它的语法高亮让我的编辑工作非常方便。
|
||||
|
||||
输入如下命令来创建一个名为 myscript.sh 的脚本文件:
|
||||
|
||||
# vim myscript.sh
|
||||
|
||||
shell 脚本的第一行 (著名的 [shebang 符](http://smilejay.com/2012/03/linux_shebang/)) 必须如下:
|
||||
shell 脚本的第一行 (著名的 [释伴(shebang)行](https://linux.cn/article-3664-1.html)) 必须如下:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
这条语句“告诉”操作系统需要用那个解释器来运行这个脚本文件之后命令。
|
||||
这条语句“告诉”操作系统需要用哪个解释器来运行这个脚本文件之后命令。
|
||||
|
||||
现在可以添加需要执行的命令了。通过注释,我们可以声明每一条命令或者整个脚本的具体含义。注意,shell 会忽略掉以井号 (#) 开始的语句。
|
||||
现在可以添加需要执行的命令了。通过注释,我们可以声明每一条命令或者整个脚本的具体含义。注意,shell 会忽略掉以井号 (#) 开始的注释语句。
|
||||
|
||||
#!/bin/bash
|
||||
echo 这是关于 LFCS 认证系列的第十部分
|
||||
echo 今天是 $(date +%Y-%m-%d)
|
||||
|
||||
编写并保存脚本之后,通过以下命令来是脚本文件称为可执行文件:
|
||||
编写并保存脚本之后,通过以下命令来使脚本文件成为可执行文件:
|
||||
|
||||
# chmod 755 myscript.sh
|
||||
|
||||
@ -73,17 +72,17 @@ shell 脚本的第一行 (著名的 [shebang 符](http://smilejay.com/2012/03/li
|
||||
|
||||
echo $PATH
|
||||
|
||||
我们就会看到环境变量 ($PATH) 的具体内容:当输入命令是系统搜索可执行程序的目录,每一项之间使用冒号 (:) 隔开。称它为环境变量,是因为他本是就是 shell 环境的一部分 —— 当 shell 第每次启动时 shell 及其子进程可以获取的一系列信息。
|
||||
我们就会看到环境变量 ($PATH) 的具体内容:这是当输入命令时系统所搜索可执行程序的目录,每一项之间使用冒号 (:) 隔开。称它为环境变量,是因为它本是就是 shell 环境的一部分 —— 这是当 shell 每次启动时 shell 及其子进程可以获取的一系列信息。
|
||||
|
||||
当我们输入一个命令并按下回车时,shell 会搜索 $PATH 变量中列出的目录并执行第一个知道的实例。请看如下例子:
|
||||
|
||||

|
||||
|
||||
环境变量
|
||||
*环境变量*
|
||||
|
||||
假如存在两个同名的可执行程序,一个在 /usr/local/bin,另一个在 /usr/bin,则会执行环境变量中最先列出的那个,并忽略另外一个。
|
||||
|
||||
如果我们自己编写的脚本没有在 $PATH 变量列出目录的其中一个,则需要输入 ./filename 来执行它。而如果存储在 $PATH 变量中的任意一个目录,我们就可以像运行其他命令一样来运行之前编写的脚本了。
|
||||
如果我们自己编写的脚本没有放在 $PATH 变量列出目录中的任何一个,则需要输入 ./filename 来执行它。而如果存储在 $PATH 变量中的任意一个目录,我们就可以像运行其他命令一样来运行之前编写的脚本了。
|
||||
|
||||
# pwd
|
||||
# ./myscript.sh
|
||||
@ -94,7 +93,7 @@ shell 脚本的第一行 (著名的 [shebang 符](http://smilejay.com/2012/03/li
|
||||
|
||||

|
||||
|
||||
执行脚本
|
||||
*执行脚本*
|
||||
|
||||
#### if 条件语句 ####
|
||||
|
||||
@ -106,22 +105,22 @@ shell 脚本的第一行 (著名的 [shebang 符](http://smilejay.com/2012/03/li
|
||||
OTHER-COMMANDS
|
||||
fi
|
||||
|
||||
其中,CONDITION 为如下情形的任意一项 (仅列出常用的),并且达到以下条件时返回 true:
|
||||
其中,CONDITION 可以是如下情形的任意一项 (仅列出常用的),并且达到以下条件时返回 true:
|
||||
|
||||
- [ -a file ] → 指定文件存在。
|
||||
- [ -d file ] → 指定文件存在,并且是一个目录。
|
||||
- [ -f file ] → 指定文件存在,并且是一个普通文件。
|
||||
- [ -u file ] → 指定文件存在,并设置了 SUID。
|
||||
- [ -g file ] → 指定文件存在,并设置了 SGID。
|
||||
- [ -u file ] → 指定文件存在,并设置了 SUID 权限位。
|
||||
- [ -g file ] → 指定文件存在,并设置了 SGID 权限位。
|
||||
- [ -k file ] → 指定文件存在,并设置了“黏连 (Sticky)”位。
|
||||
- [ -r file ] → 指定文件存在,并且文件可读。
|
||||
- [ -s file ] → 指定文件存在,并且文件为空。
|
||||
- [ -w file ] → 指定文件存在,并且文件可写入·
|
||||
- [ -s file ] → 指定文件存在,并且文件不为空。
|
||||
- [ -w file ] → 指定文件存在,并且文件可写入。
|
||||
- [ -x file ] → 指定文件存在,并且可执行。
|
||||
- [ string1 = string2 ] → 字符串相同。
|
||||
- [ string1 != string2 ] → 字符串不相同。
|
||||
|
||||
[ int1 op int2 ] 为前述列表中的一部分,紧跟着的项 (例如: -eq –> int1 与 int2 相同时返回 true) 则是 [ int1 op int2 ] 的一个子项, 其中 op 为以下比较操作符。
|
||||
[ int1 op int2 ] 为前述列表中的一部分 (例如: -eq –> int1 与 int2 相同时返回 true) ,其中比较项也可以是一个列表子项, 其中 op 为以下比较操作符。
|
||||
|
||||
- -eq –> int1 等于 int2 时返回 true。
|
||||
- -ne –> int1 不等于 int2 时返回 true。
|
||||
@ -142,13 +141,13 @@ shell 脚本的第一行 (著名的 [shebang 符](http://smilejay.com/2012/03/li
|
||||
|
||||
#### While 循环语句 ####
|
||||
|
||||
该循环结构会一直执行重复的命令,直到控制命令执行的退出状态值等于 0 时 (即执行成功) 停止。基本语法如下:
|
||||
该循环结构会一直执行重复的命令,直到控制命令(EVALUATION_COMMAND)执行的退出状态值等于 0 时 (即执行成功) 停止。基本语法如下:
|
||||
|
||||
while EVALUATION_COMMAND; do
|
||||
EXECUTE_COMMANDS;
|
||||
done
|
||||
|
||||
其中,EVALUATION_COMMAND 可以是任何能够返回成功 (0) 或失败 (0 以外的值) 的退出状态值的命令,EXECUTE_COMMANDS 则可以是任何的程序、脚本或者 shell 结构体,包括其他的嵌套循环。
|
||||
其中,EVALUATION\_COMMAND 可以是任何能够返回成功 (0) 或失败 (0 以外的值) 的退出状态值的命令,EXECUTE\_COMMANDS 则可以是任何的程序、脚本或者 shell 结构体,包括其他的嵌套循环。
|
||||
|
||||
#### 综合使用 ####
|
||||
|
||||
@ -168,7 +167,7 @@ shell 脚本的第一行 (著名的 [shebang 符](http://smilejay.com/2012/03/li
|
||||
|
||||
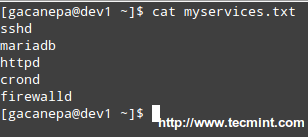
|
||||
|
||||
使用脚本监控 Linux 服务
|
||||
*使用脚本监控 Linux 服务*
|
||||
|
||||
我们编写的脚本看起来应该是这样的:
|
||||
|
||||
@ -188,7 +187,7 @@ shell 脚本的第一行 (著名的 [shebang 符](http://smilejay.com/2012/03/li
|
||||
|
||||
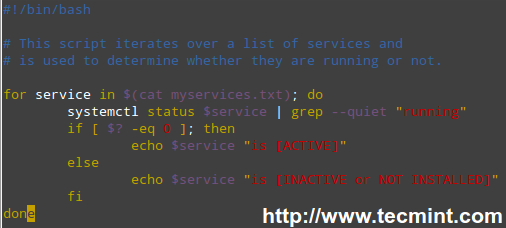
|
||||
|
||||
Linux 服务监控脚本
|
||||
*Linux 服务监控脚本*
|
||||
|
||||
**我们来解释一下这个脚本的工作流程**
|
||||
|
||||
@ -196,21 +195,21 @@ Linux 服务监控脚本
|
||||
|
||||
# cat myservices.txt
|
||||
|
||||
2). 以上命令由圆括号括着,并在前面添加美元符,表示它需要从 myservices.txt 的记录列表中取值作为变量传递给 for 循环。
|
||||
2). 以上命令由圆括号括着,并在前面添加美元符,表示它需要从 myservices.txt 的记录列表中取值并作为变量传递给 for 循环。
|
||||
|
||||
3). 对于记录列表中的每一项纪录 (即每一项纪录的服务变量),都会这行以下动作:
|
||||
3). 对于记录列表中的每一项纪录 (即每一项纪录的服务变量),都会执行以下动作:
|
||||
|
||||
# systemctl status $service | grep --quiet "running"
|
||||
|
||||
此时,需要在每个通用变量名 (即每一项纪录的服务变量) 的前面添加美元符,以表明它是作为变量来传递的。其输出则通过管道符传给 grep。
|
||||
|
||||
其中,-quiet 选项用于阻止 grep 命令将出现 "running" 的行回显到屏幕。当 grep 捕获到 "running" 时,则会返回一个退出状态码 "0" (在 if 结构体表示为 $?),由此确认某个服务正在运行中。
|
||||
其中,-quiet 选项用于阻止 grep 命令将发现的 “running” 的行回显到屏幕。当 grep 捕获到 “running” 时,则会返回一个退出状态码 “0” (在 if 结构体表示为 $?),由此确认某个服务正在运行中。
|
||||
|
||||
如果退出状态码是非零值 (即 systemctl status $service 命令中的回显中没有出现 "running"),则表明某个服务为运行。
|
||||
如果退出状态码是非零值 (即 systemctl status $service 命令中的回显中没有出现 “running”),则表明某个服务为运行。
|
||||
|
||||

|
||||
|
||||
服务监控脚本
|
||||
*服务监控脚本*
|
||||
|
||||
我们可以增加一步,在开始循环之前,先确认 myservices.txt 是否存在。
|
||||
|
||||
@ -236,7 +235,7 @@ Linux 服务监控脚本
|
||||
|
||||
你可能想把自己维护的主机写入一个文本文件,并使用脚本探测它们是否能够 ping 得通 (脚本中的 myhosts 可以随意替换为你想要的名称)。
|
||||
|
||||
内置的 read shell 命令将告诉 while 循环一行行的读取 myhosts,并将读取的每行内容传给 host 变量,随后 host 变量传递给 ping 命令。
|
||||
shell 的内置 read 命令将告诉 while 循环一行行的读取 myhosts,并将读取的每行内容传给 host 变量,随后 host 变量传递给 ping 命令。
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
@ -248,18 +247,18 @@ Linux 服务监控脚本
|
||||
|
||||
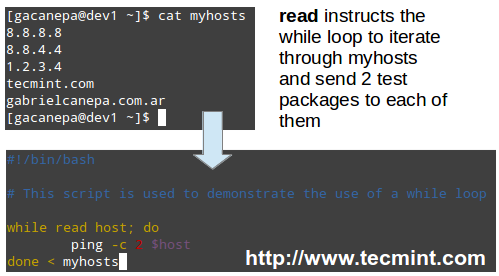
|
||||
|
||||
使用脚本 Ping 服务器
|
||||
*使用脚本 Ping 服务器*
|
||||
|
||||
扩展阅读:
|
||||
|
||||
- [Learn Shell Scripting: A Guide from Newbies to System Administrator][3]
|
||||
- [5 Shell Scripts to Learn Shell Programming][4]
|
||||
|
||||
### 文件系统排除 ###
|
||||
### 文件系统排错 ###
|
||||
|
||||
尽管 Linux 是一个很稳定的操作系统,但仍然会因为某些原因出现崩溃 (比如以外断电等),正好你有一个 (或者更多个) 文件系统未能正确卸载,Linux 重启的时候就会自动检测其中可能发生的错误。
|
||||
尽管 Linux 是一个很稳定的操作系统,但仍然会因为某些原因出现崩溃时 (比如因为断电等),正好你有一个 (或者更多个) 文件系统未能正确卸载,Linux 重启的时候就会自动检测其中可能发生的错误。
|
||||
|
||||
此外,每次系统正常启动的时候,都会在文件系统挂载之前校验它们的完整度。而这些全部都依赖于 fsck 工具 ("文件系统校验")。
|
||||
此外,每次系统正常启动的时候,都会在文件系统挂载之前校验它们的完整度。而这些全部都依赖于 fsck 工具 (“file system check,文件系统校验”)。
|
||||
|
||||
如果对 fsck 进行设定,它除了校验文件系统的完整性之外,还可以尝试修复错误。fsck 能否成功修复错误,取决于文件系统的损伤程度;如果可以修复,被损坏部分的文件会恢复到位于每个文件系统根目录的 lost+found。
|
||||
|
||||
@ -279,13 +278,13 @@ fsck 的基本用如下:
|
||||
|
||||

|
||||
|
||||
检查文件系统错误
|
||||
*检查文件系统错误*
|
||||
|
||||
除了 -y 选项,我们也可以使用 -a 选项来自动修复文件系统错误,而不必做出交互式应答,并在文件系统看起来 "干净" 的情况下强制校验。
|
||||
除了 -y 选项,我们也可以使用 -a 选项来自动修复文件系统错误,而不必做出交互式应答,并在文件系统看起来 “干净” 卸载的情况下强制校验。
|
||||
|
||||
# fsck -af /dev/sdg1
|
||||
|
||||
如果只是要找出什么地方发生了错误 (不用再检测到错误的时候修复),我们开使用 -n 选项,这样只会讲文集系统错误输出到标准输出设备。
|
||||
如果只是要找出什么地方发生了错误 (不用在检测到错误的时候修复),我们可以使用 -n 选项,这样只会将文件系统错误输出到标准输出设备上。
|
||||
|
||||
# fsck -n /dev/sdg1
|
||||
|
||||
@ -293,11 +292,11 @@ fsck 的基本用如下:
|
||||
|
||||
### 总结 ###
|
||||
|
||||
至此,系列教程的十讲就全部结束了,全系列教程涵盖了通过 LFCS 测试所需的基础内容。
|
||||
至此,系列教程的第十讲就全部结束了,全系列教程涵盖了通过 LFCS 测试所需的基础内容。
|
||||
|
||||
但显而易见的,本系列的十讲并不足以在单个主题方面做到全面描述,我们希望这一系列教程可以成为你学习的基础素材,并一直保持学习的热情。
|
||||
但显而易见的,本系列的十讲并不足以在单个主题方面做到全面描述,我们希望这一系列教程可以成为你学习的基础素材,并一直保持学习的热情(LCTT 译注:还有后继补充的几篇)。
|
||||
|
||||
我们欢迎你提出任何问题或者建议,所以你可以毫不犹豫的通过以下链接联系我们。
|
||||
我们欢迎你提出任何问题或者建议,所以你可以毫不犹豫的通过以下链接联系到我们: 成为一个 [Linux 认证系统工程师][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -305,12 +304,13 @@ via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-tro
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[1]:https://linux.cn/article-7161-1.html
|
||||
[2]:https://linux.cn/article-7165-1.html
|
||||
[3]:http://www.tecmint.com/learning-shell-scripting-language-a-guide-from-newbies-to-system-administrator/
|
||||
[4]:http://www.tecmint.com/basic-shell-programming-part-ii/
|
||||
[5]:http://www.shareasale.com/r.cfm?b=768106&u=1260899&m=59485&urllink=&afftrack=
|
||||
@ -0,0 +1,213 @@
|
||||
LFCS 系列第十一讲:如何使用命令 vgcreate、lvcreate 和 lvextend 管理和创建 LVM
|
||||
========================================================================================
|
||||
|
||||
由于 LFCS 考试中的一些改变已在 2016 年 2 月 2 日生效,我们添加了一些必要的专题到 [LFCS 系列][1]。我们也非常推荐备考的同学,同时阅读 [LFCE 系列][2]。
|
||||
|
||||

|
||||
|
||||
*LFCS:管理 LVM 和创建 LVM 分区*
|
||||
|
||||
在安装 Linux 系统的时候要做的最重要的决定之一便是给系统文件、home 目录等分配空间。在这个地方犯了错,再要扩大空间不足的分区,那样既麻烦又有风险。
|
||||
|
||||
**逻辑卷管理** (**LVM**)相较于传统的分区管理有许多优点,已经成为大多数(如果不能说全部的话) Linux 发行版安装时的默认选择。LVM 最大的优点应该是能方便的按照你的意愿调整(减小或增大)逻辑分区的大小。
|
||||
|
||||
LVM 的组成结构:
|
||||
|
||||
* 把一块或多块硬盘或者一个或多个分区配置成物理卷(PV)。
|
||||
* 一个用一个或多个物理卷创建出的卷组(**VG**)。可以把一个卷组想象成一个单独的存储单元。
|
||||
* 在一个卷组上可以创建多个逻辑卷。每个逻辑卷相当于一个传统意义上的分区 —— 优点是它的大小可以根据需求重新调整大小,正如之前提到的那样。
|
||||
|
||||
本文,我们将使用三块 **8 GB** 的磁盘(**/dev/sdb**、**/dev/sdc** 和 **/dev/sdd**)分别创建三个物理卷。你既可以直接在整个设备上创建 PV,也可以先分区在创建。
|
||||
|
||||
在这里我们选择第一种方式,如果你决定使用第二种(可以参考本系列[第四讲:创建分区和文件系统][3])确保每个分区的类型都是 `8e`。
|
||||
|
||||
### 创建物理卷,卷组和逻辑卷
|
||||
|
||||
要在 **/dev/sdb**、**/dev/sdc** 和 **/dev/sdd**上创建物理卷,运行:
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdb /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
你可以列出新创建的 PV ,通过:
|
||||
|
||||
```
|
||||
# pvs
|
||||
```
|
||||
|
||||
并得到每个 PV 的详细信息,通过:
|
||||
|
||||
```
|
||||
# pvdisplay /dev/sdX
|
||||
```
|
||||
|
||||
(**X** 即 b、c 或 d)
|
||||
|
||||
如果没有输入 `/dev/sdX` ,那么你将得到所有 PV 的信息。
|
||||
|
||||
使用 /dev/sdb` 和 `/dev/sdc` 创建卷组 ,命名为 `vg00` (在需要时是可以通过添加其他设备来扩展空间的,我们等到说明这点的时候再用,所以暂时先保留 `/dev/sdd`):
|
||||
|
||||
```
|
||||
# vgcreate vg00 /dev/sdb /dev/sdc
|
||||
```
|
||||
|
||||
就像物理卷那样,你也可以查看卷组的信息,通过:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
由于 `vg00` 是由两个 **8 GB** 的磁盘组成的,所以它将会显示成一个 **16 GB** 的硬盘:
|
||||
|
||||

|
||||
|
||||
*LVM 卷组列表*
|
||||
|
||||
当谈到创建逻辑卷,空间的分配必须考虑到当下和以后的需求。根据每个逻辑卷的用途来命名是一个好的做法。
|
||||
|
||||
举个例子,让我们创建两个 LV,命名为 `vol_projects` (**10 GB**) 和 `vol_backups` (剩下的空间), 在日后分别用于部署项目文件和系统备份。
|
||||
|
||||
参数 `-n` 用于为 LV 指定名称,而 `-L` 用于设定固定的大小,还有 `-l` (小写的 L)在 VG 的预留空间中用于指定百分比大小的空间。
|
||||
|
||||
```
|
||||
# lvcreate -n vol_projects -L 10G vg00
|
||||
# lvcreate -n vol_backups -l 100%FREE vg00
|
||||
```
|
||||
|
||||
和之前一样,你可以查看 LV 的列表和基础信息,通过:
|
||||
|
||||
```
|
||||
# lvs
|
||||
```
|
||||
|
||||
或是查看详细信息,通过:
|
||||
|
||||
```
|
||||
# lvdisplay
|
||||
```
|
||||
|
||||
若要查看单个 **LV** 的信息,使用 **lvdisplay** 加上 **VG** 和 **LV** 作为参数,如下:
|
||||
|
||||
```
|
||||
# lvdisplay vg00/vol_projects
|
||||
```
|
||||
|
||||

|
||||
|
||||
*逻辑卷列表*
|
||||
|
||||
如上图,我们看到 LV 已经被创建成存储设备了(参考 LV Path 那一行)。在使用每个逻辑卷之前,需要先在上面创建文件系统。
|
||||
|
||||
这里我们拿 ext4 来做举例,因为对于每个 LV 的大小, ext4 既可以增大又可以减小(相对的 xfs 就只允许增大):
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/vg00/vol_projects
|
||||
# mkfs.ext4 /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||
我们将在下一节向大家说明,如何调整逻辑卷的大小并在需要的时候添加额外的外部存储空间。
|
||||
|
||||
### 调整逻辑卷大小和扩充卷组
|
||||
|
||||
现在设想以下场景。`vol_backups` 中的空间即将用完,而 `vol_projects` 中还有富余的空间。由于 LVM 的特性,我们可以轻易的减小后者的大小(比方说 **2.5 GB**),并将其分配给前者,与此同时调整每个文件系统的大小。
|
||||
|
||||
幸运的是这很简单,只需:
|
||||
|
||||
```
|
||||
# lvreduce -L -2.5G -r /dev/vg00/vol_projects
|
||||
# lvextend -l +100%FREE -r /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
|
||||
*减小逻辑卷和卷组*
|
||||
|
||||
在调整逻辑卷的时候,其中包含的减号 `(-)` 或加号 `(+)` 是十分重要的。否则 LV 将会被设置成指定的大小,而非调整指定大小。
|
||||
|
||||
有些时候,你可能会遭遇那种无法仅靠调整逻辑卷的大小就可以解决的问题,那时你就需要购置额外的存储设备了,你可能需要再加一块硬盘。这里我们将通过添加之前配置时预留的 PV (`/dev/sdd`),用以模拟这种情况。
|
||||
|
||||
想把 `/dev/sdd` 加到 `vg00`,执行:
|
||||
|
||||
```
|
||||
# vgextend vg00 /dev/sdd
|
||||
```
|
||||
|
||||
如果你在运行上条命令的前后执行 vgdisplay `vg00` ,你就会看出 VG 的大小增加了。
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
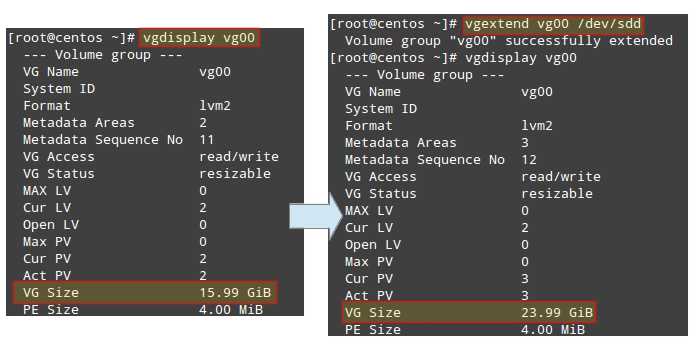
|
||||
|
||||
*查看卷组磁盘大小*
|
||||
|
||||
现在,你可以使用新加的空间,按照你的需求调整现有 LV 的大小,或者创建一个新的 LV。
|
||||
|
||||
### 在启动和需求时挂载逻辑卷
|
||||
|
||||
当然,如果我们不打算实际的使用逻辑卷,那么创建它们就变得毫无意义了。为了更好的识别逻辑卷,我们需要找出它的 `UUID` (用于识别一个格式化存储设备的唯一且不变的属性)。
|
||||
|
||||
要做到这点,可使用 blkid 加每个设备的路径来实现:
|
||||
|
||||
```
|
||||
# blkid /dev/vg00/vol_projects
|
||||
# blkid /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
|
||||
*寻找逻辑卷的 UUID*
|
||||
|
||||
为每个 LV 创建挂载点:
|
||||
|
||||
```
|
||||
# mkdir /home/projects
|
||||
# mkdir /home/backups
|
||||
```
|
||||
|
||||
并在 `/etc/fstab` 插入相应的条目(确保使用之前获得的UUID):
|
||||
|
||||
```
|
||||
UUID=b85df913-580f-461c-844f-546d8cde4646 /home/projects ext4 defaults 0 0
|
||||
UUID=e1929239-5087-44b1-9396-53e09db6eb9e /home/backups ext4 defaults 0 0
|
||||
```
|
||||
|
||||
保存并挂载 LV:
|
||||
|
||||
```
|
||||
# mount -a
|
||||
# mount | grep home
|
||||
```
|
||||
|
||||

|
||||
|
||||
*挂载逻辑卷*
|
||||
|
||||
在涉及到 LV 的实际使用时,你还需要按照曾在本系列[第八讲:管理用户和用户组][4]中讲解的那样,为其设置合适的 `ugo+rwx`。
|
||||
|
||||
### 总结
|
||||
|
||||
本文介绍了 [逻辑卷管理][5],一个用于管理可扩展存储设备的多功能工具。与 RAID(曾在本系列讲解过的 [第六讲:组装分区为RAID设备——创建和管理系统备份][6])结合使用,你将同时体验到(LVM 带来的)可扩展性和(RAID 提供的)冗余。
|
||||
|
||||
在这类的部署中,你通常会在 `RAID` 上发现 `LVM`,这就是说,要先配置好 RAID 然后它在上面配置 LVM。
|
||||
|
||||
如果你对本问有任何的疑问和建议,可以直接在下方的评论区告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-and-create-lvm-parition-using-vgcreate-lvcreate-and-lvextend/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: https://linux.cn/article-7161-1.html
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: https://linux.cn/article-7187-1.html
|
||||
[4]: https://linux.cn/article-7418-1.html
|
||||
[5]: https://linux.cn/article-3965-1.html
|
||||
[6]: https://linux.cn/article-7229-1.html
|
||||
@ -0,0 +1,184 @@
|
||||
LFCS 系列第十二讲:如何使用 Linux 的帮助文档和工具
|
||||
==================================================================================
|
||||
|
||||
由于 2016 年 2 月 2 号开始启用了新的 LFCS 考试要求, 我们在 [LFCS 系列][1]系列添加了一些必要的内容。为了考试的需要,我们强烈建议你看一下[LFCE 系列][2]。
|
||||
|
||||

|
||||
|
||||
*LFCS: 了解 Linux 的帮助文档和工具*
|
||||
|
||||
当你习惯了在命令行下进行工作,你会发现 Linux 已经有了许多使用和配置 Linux 系统所需要的文档。
|
||||
|
||||
另一个你必须熟悉命令行帮助工具的理由是,在[LFCS][3] 和 [LFCE][4] 考试中,它们是你唯一能够使用的信息来源,没有互联网也没有百度。你只能依靠你自己和命令行。
|
||||
|
||||
基于上面的理由,在这一章里我们将给你一些建议来可以让你有效的使用这些安装的文档和工具,以帮助你通过**Linux 基金会认证**考试。
|
||||
|
||||
### Linux 帮助手册(man)
|
||||
|
||||
man 手册是 manual 手册的缩写,就是其名字所揭示的那样:一个给定工具的帮助手册。它包含了命令所支持的选项列表(以及解释),有些工具甚至还提供一些使用范例。
|
||||
|
||||
我们用 **man 命令** 跟上你想要了解的工具名称来打开一个帮助手册。例如:
|
||||
|
||||
```
|
||||
# man diff
|
||||
```
|
||||
|
||||
这将打开`diff`的手册页,这个工具将逐行对比文本文件(如你想退出只需要轻轻的点一下 q 键)。
|
||||
|
||||
下面我来比较两个文本文件 `file1` 和 `file2`。这两个文本文件包含了使用同一个 Linux 发行版相同版本安装的两台机器上的的安装包列表。
|
||||
|
||||
输入`diff` 命令它将告诉我们 `file1` 和`file2` 有什么不同:
|
||||
|
||||
```
|
||||
# diff file1 file2
|
||||
```
|
||||
|
||||
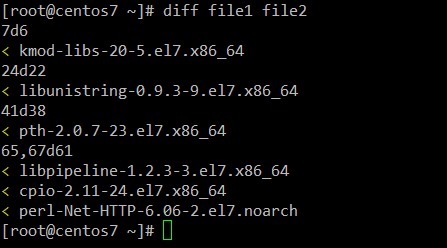
|
||||
|
||||
*在Linux中比较两个文本文件*
|
||||
|
||||
`<` 这个符号是说`file2`缺失的行。如果是 `file1`缺失,我们将用 `>` 符号来替代指示。
|
||||
|
||||
另外,**7d6** 意思是说`file1`的第**7**行要删除了才能和`file2`一致(**24d22** 和 **41d38** 也是同样的意思) **65,67d61** 告诉需要删除从第 **65** 行到 **67** 行。我们完成了以上步骤,那么这两个文件将完全一致。
|
||||
|
||||
此外,根据 man 手册说明,你还可以通过 `-y` 选项来以两路的方式显示文件。你可以发现这对于你找到两个文件间的不同根据方便容易。
|
||||
|
||||
```
|
||||
# diff -y file1 file2
|
||||
```
|
||||
|
||||

|
||||
|
||||
*比较并列出两个文件的不同*
|
||||
|
||||
此外,你也可以用`diff`来比较两个二进制文件。如果它们完全一样,`diff` 将什么也不会输出。否则,它将会返回如下信息:“**Binary files X and Y differ**”。
|
||||
|
||||
### –help 选项
|
||||
|
||||
`--help`选项,大多数命令都支持它(并不是所有), 它可以理解为一个命令的简短帮助手册。尽管它没有提供工具的详细介绍,但是确实是一个能够快速列出程序的所支持的选项的不错的方法。
|
||||
|
||||
例如,
|
||||
|
||||
```
|
||||
# sed --help
|
||||
```
|
||||
|
||||
将显示 sed (流编辑器)的每个支持的选项。
|
||||
|
||||
`sed`命令的一个典型用法是替换文件中的字符。用 `-i` 选项(意思是 “**原地编辑编辑文件**”),你可以编辑一个文件而且并不需要打开它。 如果你想要同时备份一个原始文件,用 `-i` 选项加后缀来创建一个原始文件的副本。
|
||||
|
||||
例如,替换 `lorem.txt` 中的`Lorem` 为 `Tecmint`(忽略大小写),并且创建一个原文件的备份副本,命令如下:
|
||||
|
||||
```
|
||||
# less lorem.txt | grep -i lorem
|
||||
# sed -i.orig 's/Lorem/Tecmint/gI' lorem.txt
|
||||
# less lorem.txt | grep -i lorem
|
||||
# less lorem.txt.orig | grep -i lorem
|
||||
```
|
||||
|
||||
请注意`lorem.txt`文件中`Lorem` 都已经替换为 `Tecmint`,并且原文件 `lorem.txt` 被保存为`lorem.txt.orig`。
|
||||
|
||||

|
||||
|
||||
*替换文件中的文本*
|
||||
|
||||
### /usr/share/doc 内的文档
|
||||
|
||||
这可能是我最喜欢的方法。如果你进入 `/usr/share/doc` 目录,并列出该目录,你可以看到许多以安装在你的 Linux 上的工具为名称的文件夹。
|
||||
|
||||
根据 [文件系统层级标准][5],这些文件夹包含了许多帮助手册没有的信息,还有一些可以使配置更方便的模板和配置文件。
|
||||
|
||||
例如,让我们来看一下 `squid-3.3.8` (不同发行版的版本可能会不同),这还是一个非常受欢迎的 HTTP 代理和 [squid 缓存服务器][6]。
|
||||
|
||||
让我们用`cd`命令进入目录:
|
||||
|
||||
```
|
||||
# cd /usr/share/doc/squid-3.3.8
|
||||
```
|
||||
|
||||
列出当前文件夹列表:
|
||||
|
||||
```
|
||||
# ls
|
||||
```
|
||||
|
||||

|
||||
|
||||
*使用 ls 列出目录*
|
||||
|
||||
你应该特别注意 `QUICKSTART` 和 `squid.conf.documented`。这些文件分别包含了 Squid 详细文档及其经过详细备注的配置文件。对于别的安装包来说,具体的名字可能不同(有可能是 **QuickRef** 或者**00QUICKSTART**),但意思是一样的。
|
||||
|
||||
对于另外一些安装包,比如 Apache web 服务器,在`/usr/share/doc`目录提供了配置模板,当你配置独立服务器或者虚拟主机的时候会非常有用。
|
||||
|
||||
### GNU 信息文档
|
||||
|
||||
你可以把它看做帮助手册的“开挂版”。它不仅仅提供工具的帮助信息,而且还是超级链接的形式(没错,在命令行中的超级链接),你可以通过箭头按钮从一个章节导航到另外章节,并按下回车按钮来确认。
|
||||
|
||||
一个典型的例子是:
|
||||
|
||||
```
|
||||
# info coreutils
|
||||
```
|
||||
|
||||
因为 coreutils 包含了每个系统中都有的基本文件、shell 和文本处理工具,你自然可以从 coreutils 的 info 文档中得到它们的详细介绍。
|
||||
|
||||
|
||||
|
||||
*Info Coreutils*
|
||||
|
||||
和帮助手册一样,你可以按 q 键退出。
|
||||
|
||||
此外,GNU info 还可以显示标准的帮助手册。 例如:
|
||||
|
||||
```
|
||||
# info tune2fs
|
||||
```
|
||||
|
||||
它将显示 **tune2fs**的帮助手册, 这是一个 ext2/3/4 文件系统管理工具。
|
||||
|
||||
我们现在看到了,让我们来试试怎么用**tune2fs**:
|
||||
|
||||
显示 **/dev/mapper/vg00-vol_backups** 文件系统信息:
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/mapper/vg00-vol_backups
|
||||
```
|
||||
|
||||
修改文件系统标签(修改为 Backups):
|
||||
|
||||
```
|
||||
# tune2fs -L Backups /dev/mapper/vg00-vol_backups
|
||||
```
|
||||
|
||||
设置文件系统的自检间隔及挂载计数(用`-c` 选项设置挂载计数间隔, 用 `-i` 选项设置自检时间间隔,这里 **d 表示天,w 表示周,m 表示月**)。
|
||||
|
||||
```
|
||||
# tune2fs -c 150 /dev/mapper/vg00-vol_backups # 每 150 次挂载检查一次
|
||||
# tune2fs -i 6w /dev/mapper/vg00-vol_backups # 每 6 周检查一次
|
||||
```
|
||||
|
||||
以上这些内容也可以通过 `--help` 选项找到,或者查看帮助手册。
|
||||
|
||||
### 摘要
|
||||
|
||||
不管你选择哪种方法,知道并且会使用它们在考试中对你是非常有用的。你知道其它的一些方法吗? 欢迎给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explore-linux-installed-help-documentation-and-tools/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]: https://linux.cn/article-7161-1.html
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: https://linux.cn/article-7161-1.html
|
||||
[4]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[5]: https://linux.cn/article-6132-1.html
|
||||
[6]: http://www.tecmint.com/configure-squid-server-in-linux/
|
||||
[7]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Part 1 - LXD 2.0: LXD 入门
|
||||
LXD 2.0 系列(一):LXD 入门
|
||||
======================================
|
||||
|
||||
这是 [LXD 2.0 系列介绍文章][1]的第一篇。
|
||||
@ -20,12 +20,11 @@ LXD 最主要的目标就是使用 Linux 容器而不是硬件虚拟化向用户
|
||||
|
||||
LXD 聚焦于系统容器,通常也被称为架构容器。这就是说 LXD 容器实际上如在裸机或虚拟机上运行一般运行了一个完整的 Linux 操作系统。
|
||||
|
||||
这些容器一般基于一个干净的发布镜像并会长时间运行。传统的配置管理工具和部署工具可以如在虚拟机、云和物理机器上一样与 LXD 一起使用。
|
||||
这些容器一般基于一个干净的发布镜像并会长时间运行。传统的配置管理工具和部署工具可以如在虚拟机、云实例和物理机器上一样与 LXD 一起使用。
|
||||
|
||||
相对的, Docker 关注于短期的、无状态的最小容器,这些容器通常并不会升级或者重新配置,而是作为一个整体被替换掉。这就使得 Docker 及类似项目更像是一种软件发布机制,而不是一个机器管理工具。
|
||||
|
||||
这两种模型并不是完全互斥的。你完全可以使用 LXD 为你的用户提供一个完整的 Linux 系统,而他们可以在 LXD 内安装 Docker 来运行他们想要的软件。
|
||||
相对的, Docker 关注于短期的、无状态的、最小化的容器,这些容器通常并不会升级或者重新配置,而是作为一个整体被替换掉。这就使得 Docker 及类似项目更像是一种软件发布机制,而不是一个机器管理工具。
|
||||
|
||||
这两种模型并不是完全互斥的。你完全可以使用 LXD 为你的用户提供一个完整的 Linux 系统,然后他们可以在 LXD 内安装 Docker 来运行他们想要的软件。
|
||||
|
||||
#### 为什么要用 LXD?
|
||||
|
||||
@ -35,56 +34,55 @@ LXD 聚焦于系统容器,通常也被称为架构容器。这就是说 LXD
|
||||
|
||||
我们把 LXD 作为解决这些缺陷的一个很好的机会。作为一个长时间运行的守护进程, LXD 可以绕开 LXC 的许多限制,比如动态资源限制、无法进行容器迁移和高效的在线迁移;同时,它也为创造新的默认体验提供了机会:默认开启安全特性,对用户更加友好。
|
||||
|
||||
|
||||
### LXD 的主要组件
|
||||
|
||||
LXD 是由几个主要组件构成的,这些组件都是 LXD 目录结构、命令行客户端和 API 结构体里下可见的。
|
||||
LXD 是由几个主要组件构成的,这些组件都出现在 LXD 目录结构、命令行客户端和 API 结构体里。
|
||||
|
||||
#### 容器
|
||||
|
||||
LXD 中的容器包括以下及部分:
|
||||
|
||||
- 根文件系统
|
||||
- 根文件系统(rootfs)
|
||||
- 配置选项列表,包括资源限制、环境、安全选项等等
|
||||
- 设备:包括磁盘、unix 字符/块设备、网络接口
|
||||
- 一组继承而来的容器配置文件
|
||||
- 属性(容器架构,暂时的或持久的,容器名)
|
||||
- 运行时状态(当时为了记录检查点、恢复时用到了 CRIU时)
|
||||
- 属性(容器架构、暂时的还是持久的、容器名)
|
||||
- 运行时状态(当用 CRIU 来中断/恢复时)
|
||||
|
||||
#### 快照
|
||||
|
||||
容器快照和容器是一回事,只不过快照是不可修改的,只能被重命名,销毁或者用来恢复系统,但是无论如何都不能被修改。
|
||||
|
||||
值得注意的是,因为我们允许用户保存容器的运行时状态,这就有效的为我们提供了“有状态”的快照的功能。这就是说我们可以使用快照回滚容器的 CPU 和内存。
|
||||
值得注意的是,因为我们允许用户保存容器的运行时状态,这就有效的为我们提供了“有状态”的快照的功能。这就是说我们可以使用快照回滚容器的状态,包括快照当时的 CPU 和内存状态。
|
||||
|
||||
#### 镜像
|
||||
|
||||
LXD 是基于镜像实现的,所有的 LXD 容器都是来自于镜像。容器镜像通常是一些纯净的 Linux 发行版的镜像,类似于你们在虚拟机和云实例上使用的镜像。
|
||||
|
||||
所以就可以「发布」容器:使用容器制作一个镜像并在本地或者远程 LXD 主机上使用。
|
||||
所以可以「发布」一个容器:使用容器制作一个镜像并在本地或者远程 LXD 主机上使用。
|
||||
|
||||
镜像通常使用全部或部分 sha256 哈希码来区分。因为输入长长的哈希码对用户来说不好,所以镜像可以使用几个自身的属性来区分,这就使得用户在镜像商店里方便搜索镜像。别名也可以用来 1 对 1 地把对用户友好的名字映射到某个镜像的哈希码。
|
||||
镜像通常使用全部或部分 sha256 哈希码来区分。因为输入长长的哈希码对用户来说不方便,所以镜像可以使用几个自身的属性来区分,这就使得用户在镜像商店里方便搜索镜像。也可以使用别名来一对一地将一个用户好记的名字映射到某个镜像的哈希码上。
|
||||
|
||||
LXD 安装时已经配置好了三个远程镜像服务器(参见下面的远程一节):
|
||||
|
||||
- “ubuntu:” 提供稳定版的 Ubuntu 镜像
|
||||
- “ubuntu-daily:” 提供每天构建出来的 Ubuntu
|
||||
- “images:” 社区维护的镜像服务器,提供一系列的 Linux 发布版,使用的是上游 LXC 的模板
|
||||
- “ubuntu”:提供稳定版的 Ubuntu 镜像
|
||||
- “ubuntu-daily”:提供 Ubuntu 的每日构建镜像
|
||||
- “images”: 社区维护的镜像服务器,提供一系列的其它 Linux 发布版,使用的是上游 LXC 的模板
|
||||
|
||||
LXD 守护进程会从镜像上次被使用开始自动缓存远程镜像一段时间(默认是 10 天),超过时限后这些镜像才会失效。
|
||||
|
||||
此外, LXD 还会自动更新远程镜像(除非指明不更新),所以本地的镜像会一直是最新版的。
|
||||
|
||||
|
||||
#### 配置
|
||||
|
||||
配置文件是一种在一处定义容器配置和容器设备,然后应用到一系列容器的方法。
|
||||
配置文件是一种在一个地方定义容器配置和容器设备,然后将其应用到一系列容器的方法。
|
||||
|
||||
一个容器可以被应用多个配置文件。当构建最终容器配置时(即通常的扩展配置),这些配置文件都会按照他们定义顺序被应用到容器上,当有重名的配置时,新的会覆盖掉旧的。然后本地容器设置会在这些基础上应用,覆盖所有来自配置文件的选项。
|
||||
一个容器可以被应用多个配置文件。当构建最终容器配置时(即通常的扩展配置),这些配置文件都会按照他们定义顺序被应用到容器上,当有重名的配置键或设备时,新的会覆盖掉旧的。然后本地容器设置会在这些基础上应用,覆盖所有来自配置文件的选项。
|
||||
|
||||
LXD 自带两种预配置的配置文件:
|
||||
|
||||
- 「 default 」配置是自动应用在所有容器之上,除非用户提供了一系列替代的配置文件。目前这个配置文件只做一件事,为容器定义 eth0 网络设备。
|
||||
- 「 docker” 」配置是一个允许你在容器里运行 Docker 容器的配置文件。它会要求 LXD 加载一些需要的内核模块以支持容器嵌套并创建一些设备入口。
|
||||
- “default”配置是自动应用在所有容器之上,除非用户提供了一系列替代的配置文件。目前这个配置文件只做一件事,为容器定义 eth0 网络设备。
|
||||
- “docker”配置是一个允许你在容器里运行 Docker 容器的配置文件。它会要求 LXD 加载一些需要的内核模块以支持容器嵌套并创建一些设备。
|
||||
|
||||
#### 远程
|
||||
|
||||
@ -92,14 +90,14 @@ LXD 自带两种预配置的配置文件:
|
||||
|
||||
默认情况下,我们的命令行客户端会与下面几个预定义的远程服务器通信:
|
||||
|
||||
- local:(默认的远程服务器,使用 UNIX socket 和本地的 LXD 守护进程通信)
|
||||
- ubuntu:( Ubuntu 镜像服务器,提供稳定版的 Ubuntu 镜像)
|
||||
- ubuntu-daily:( Ubuntu 镜像服务器,提供每天构建出来的 Ubuntu )
|
||||
- images:( images.linuxcontainers.org 镜像服务器)
|
||||
- local:默认的远程服务器,使用 UNIX socket 和本地的 LXD 守护进程通信
|
||||
- ubuntu:Ubuntu 镜像服务器,提供稳定版的 Ubuntu 镜像
|
||||
- ubuntu-daily:Ubuntu 镜像服务器,提供 Ubuntu 的每日构建版
|
||||
- images:images.linuxcontainers.org 的镜像服务器
|
||||
|
||||
所有这些远程服务器的组合都可以在命令行客户端里使用。
|
||||
|
||||
你也可以添加任意数量的远程 LXD 主机来监听网络。匿名的开放镜像服务器,或者通过认证可以管理远程容器的镜像服务器,都可以添加进来。
|
||||
你也可以添加任意数量的远程 LXD 主机,并配置它们监听网络。匿名的开放镜像服务器,或者通过认证可以管理远程容器的镜像服务器,都可以添加进来。
|
||||
|
||||
正是这种远程机制使得与远程镜像服务器交互及在主机间复制、移动容器成为可能。
|
||||
|
||||
@ -107,30 +105,29 @@ LXD 自带两种预配置的配置文件:
|
||||
|
||||
我们设计 LXD 时的一个核心要求,就是在不修改现代 Linux 发行版的前提下,使容器尽可能的安全。
|
||||
|
||||
LXD 使用的、通过使用 LXC 库实现的主要安全特性有:
|
||||
LXD 通过使用 LXC 库实现的主要安全特性有:
|
||||
|
||||
- 内核名字空间。尤其是用户名字空间,它让容器和系统剩余部分完全分离。LXD 默认使用用户名字空间(和 LXC 相反),并允许用户在需要的时候以容器为单位打开或关闭。
|
||||
- 内核名字空间。尤其是用户名字空间,它让容器和系统剩余部分完全分离。LXD 默认使用用户名字空间(和 LXC 相反),并允许用户在需要的时候以容器为单位关闭(将容器标为“特权的”)。
|
||||
- Seccomp 系统调用。用来隔离潜在危险的系统调用。
|
||||
- AppArmor:对 mount、socket、ptrace 和文件访问提供额外的限制。特别是限制跨容器通信。
|
||||
- AppArmor。对 mount、socket、ptrace 和文件访问提供额外的限制。特别是限制跨容器通信。
|
||||
- Capabilities。阻止容器加载内核模块,修改主机系统时间,等等。
|
||||
- CGroups。限制资源使用,防止对主机的 DoS 攻击。
|
||||
- CGroups。限制资源使用,防止针对主机的 DoS 攻击。
|
||||
|
||||
为了对用户友好,LXD 构建了一个新的配置语言把大部分的这些特性都抽象封装起来,而不是如 LXC 一般直接将这些特性暴露出来。举了例子,一个用户可以告诉 LXD 把主机设备放进容器而不需要手动检查他们的主/次设备号来手动更新 CGroup 策略。
|
||||
|
||||
为了对用户友好 , LXD 构建了一个新的配置语言把大部分的这些特性都抽象封装起来,而不是如 LXC 一般直接将这些特性暴露出来。举了例子,一个用户可以告诉 LXD 把主机设备放进容器而不需要手动检查他们的主/次设备号来更新 CGroup 策略。
|
||||
|
||||
和 LXD 本身通信是基于使用 TLS 1.2 保护的链路,这些链路只允许使用有限的几个被允许的密钥。当和那些经过系统证书认证之外的主机通信时, LXD 会提示用户验证主机的远程足迹(SSH 方式),然后把足迹缓存起来以供以后使用。
|
||||
和 LXD 本身通信是基于使用 TLS 1.2 保护的链路,只允许使用有限的几个被允许的密钥算法。当和那些经过系统证书认证之外的主机通信时, LXD 会提示用户验证主机的远程指纹(SSH 方式),然后把指纹缓存起来以供以后使用。
|
||||
|
||||
### REST 接口
|
||||
|
||||
LXD 的工作都是通过 REST 接口实现的。在客户端和守护进程之间并没有其他的通讯手段。
|
||||
LXD 的工作都是通过 REST 接口实现的。在客户端和守护进程之间并没有其他的通讯渠道。
|
||||
|
||||
REST 接口可以通过本地的 unix socket 访问,这只需要经过组认证,或者经过 HTTP 套接字使用客户端认证进行通信。
|
||||
REST 接口可以通过本地的 unix socket 访问,这只需要经过用户组认证,或者经过 HTTP 套接字使用客户端认证进行通信。
|
||||
|
||||
REST 接口的结构能够和上文所说的不同的组件匹配,是一种简单、直观的使用方法。
|
||||
|
||||
当需要一种复杂的通信机制时, LXD 将会进行 websocket 协商完成剩余的通信工作。这主要用于交互式终端会话、容器迁移和事件通知。
|
||||
|
||||
LXD 2.0 附带了 1.0 版的稳定 API。虽然我们在 1.0 版 API 添加了额外的特性,但是这不会在 1.0 版 API 的端点里破坏向后兼容性,因为我们会声明额外的 API 扩展使得客户端可以找到新的接口。
|
||||
LXD 2.0 附带了 1.0 版的稳定 API。虽然我们在 1.0 版 API 添加了额外的特性,但是这不会在 1.0 版 API 端点里破坏向后兼容性,因为我们会声明额外的 API 扩展使得客户端可以找到新的接口。
|
||||
|
||||
### 容器规模化
|
||||
|
||||
@ -0,0 +1,222 @@
|
||||
awk 系列:如何使用 awk 和正则表达式过滤文本或文件中的字符串
|
||||
=============================================================================
|
||||
|
||||

|
||||
|
||||
当我们在 Unix/Linux 下使用特定的命令从字符串或文件中读取或编辑文本时,我们经常需要过滤输出以得到感兴趣的部分。这时正则表达式就派上用场了。
|
||||
|
||||
### 什么是正则表达式?
|
||||
|
||||
正则表达式可以定义为代表若干个字符序列的字符串。它最重要的功能之一就是它允许你过滤一条命令或一个文件的输出、编辑文本或配置文件的一部分等等。
|
||||
|
||||
### 正则表达式的特点
|
||||
|
||||
正则表达式由以下内容组合而成:
|
||||
|
||||
- **普通字符**,例如空格、下划线、A-Z、a-z、0-9。
|
||||
- 可以扩展为普通字符的**元字符**,它们包括:
|
||||
- `(.)` 它匹配除了换行符外的任何单个字符。
|
||||
- `(*)` 它匹配零个或多个在其之前紧挨着的字符。
|
||||
- `[ character(s) ]` 它匹配任何由其中的字符/字符集指定的字符,你可以使用连字符(-)代表字符区间,例如 [a-f]、[1-5]等。
|
||||
- `^` 它匹配文件中一行的开头。
|
||||
- `$` 它匹配文件中一行的结尾。
|
||||
- `\` 这是一个转义字符。
|
||||
|
||||
你必须使用类似 awk 这样的文本过滤工具来过滤文本。你还可以把 awk 自身当作一个编程语言。但由于这个指南的适用范围是关于使用 awk 的,我会按照一个简单的命令行过滤工具来介绍它。
|
||||
|
||||
awk 的一般语法如下:
|
||||
|
||||
```
|
||||
# awk 'script' filename
|
||||
```
|
||||
|
||||
此处 `'script'` 是一个由 awk 可以理解并应用于 filename 的命令集合。
|
||||
|
||||
它通过读取文件中的给定行,复制该行的内容并在该行上执行脚本的方式工作。这个过程会在该文件中的所有行上重复。
|
||||
|
||||
该脚本 `'script'` 中内容的格式是 `'/pattern/ action'`,其中 `pattern` 是一个正则表达式,而 `action` 是当 awk 在该行中找到此模式时应当执行的动作。
|
||||
|
||||
### 如何在 Linux 中使用 awk 过滤工具
|
||||
|
||||
在下面的例子中,我们将聚焦于之前讨论过的元字符。
|
||||
|
||||
#### 一个使用 awk 的简单示例:
|
||||
|
||||
下面的例子打印文件 /etc/hosts 中的所有行,因为没有指定任何的模式。
|
||||
|
||||
```
|
||||
# awk '//{print}' /etc/hosts
|
||||
```
|
||||
|
||||
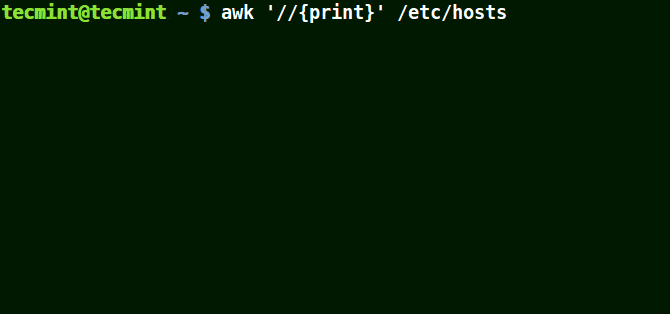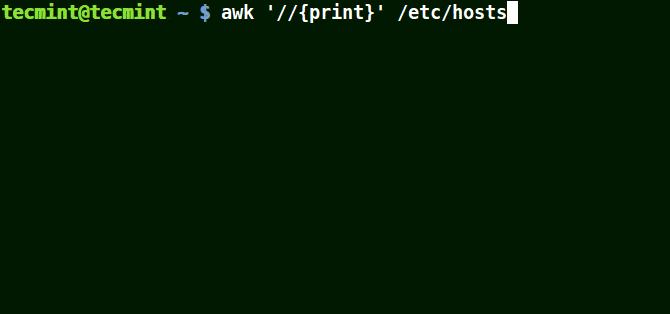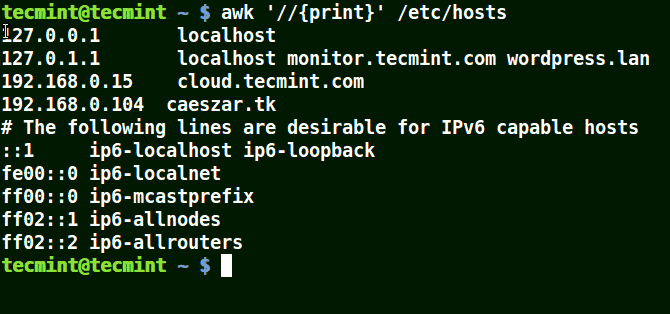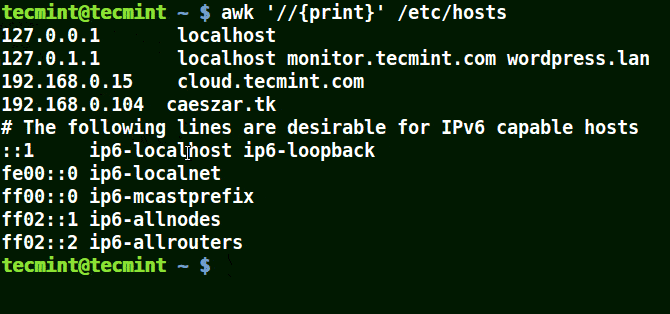
|
||||
|
||||
*awk 打印文件中的所有行*
|
||||
|
||||
#### 结合模式使用 awk
|
||||
|
||||
在下面的示例中,指定了模式 `localhost`,因此 awk 将匹配文件 `/etc/hosts` 中有 `localhost` 的那些行。
|
||||
|
||||
```
|
||||
# awk '/localhost/{print}' /etc/hosts
|
||||
```
|
||||
|
||||

|
||||
|
||||
*awk 打印文件中匹配模式的行*
|
||||
|
||||
#### 在 awk 模式中使用通配符 (.)
|
||||
|
||||
在下面的例子中,符号 `(.)` 将匹配包含 loc、localhost、localnet 的字符串。
|
||||
|
||||
这里的正则表达式的意思是匹配 **l一个字符c**。
|
||||
|
||||
```
|
||||
# awk '/l.c/{print}' /etc/hosts
|
||||
```
|
||||
|
||||
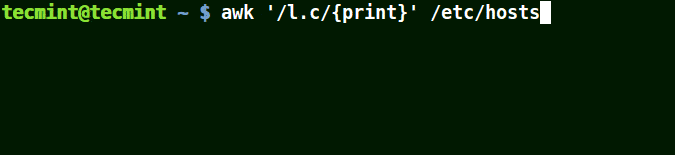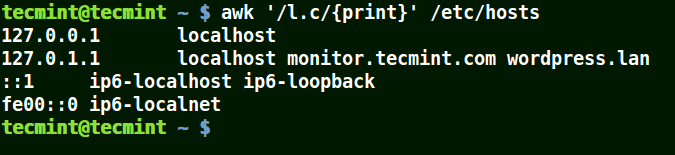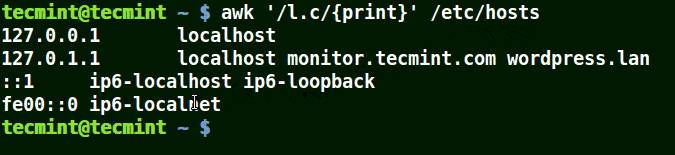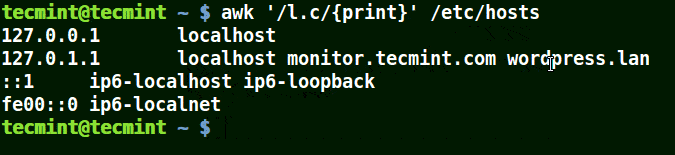
|
||||
|
||||
*使用 awk 打印文件中匹配模式的字符串*
|
||||
|
||||
#### 在 awk 模式中使用字符 (*)
|
||||
|
||||
在下面的例子中,将匹配包含 localhost、localnet、lines, capable 的字符串。
|
||||
|
||||
```
|
||||
# awk '/l*c/{print}' /etc/localhost
|
||||
```
|
||||
|
||||
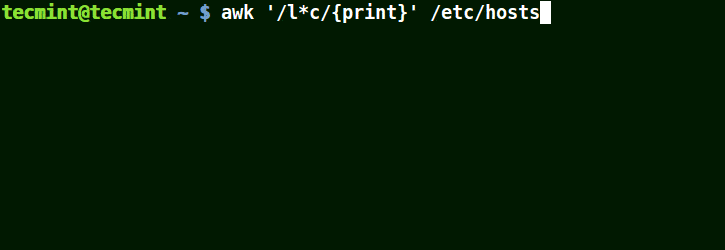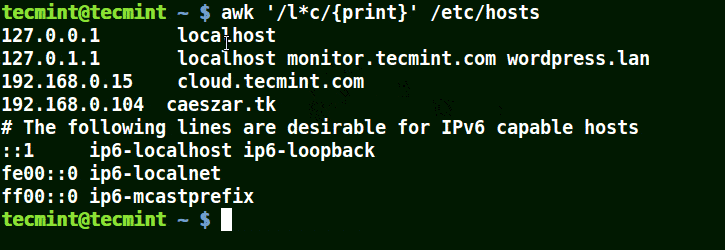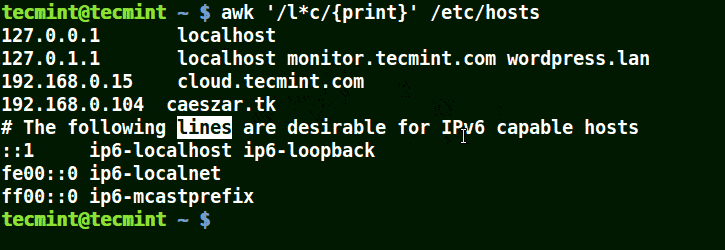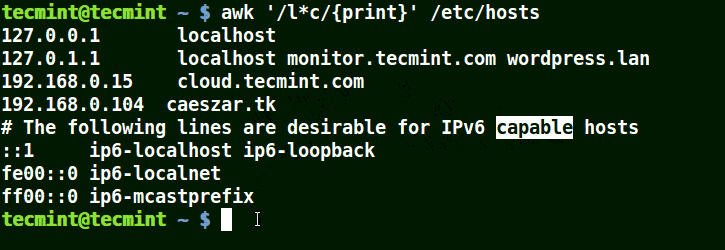
|
||||
|
||||
*使用 awk 匹配文件中的字符串*
|
||||
|
||||
你可能也意识到 `(*)` 将会尝试匹配它可能检测到的最长的匹配。
|
||||
|
||||
让我们看一看可以证明这一点的例子,正则表达式 `t*t` 的意思是在下面的行中匹配以 `t` 开始和 `t` 结束的字符串:
|
||||
|
||||
```
|
||||
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
|
||||
```
|
||||
|
||||
当你使用模式 `/t*t/` 时,会得到如下可能的结果:
|
||||
|
||||
```
|
||||
this is t
|
||||
this is tecmint
|
||||
this is tecmint, where you get t
|
||||
this is tecmint, where you get the best good t
|
||||
this is tecmint, where you get the best good tutorials, how t
|
||||
this is tecmint, where you get the best good tutorials, how tos, guides, t
|
||||
this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
|
||||
```
|
||||
|
||||
在 `/t*t/` 中的通配符 `(*)` 将使得 awk 选择匹配的最后一项:
|
||||
|
||||
```
|
||||
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
|
||||
```
|
||||
|
||||
#### 结合集合 [ character(s) ] 使用 awk
|
||||
|
||||
以集合 [al1] 为例,awk 将匹配文件 /etc/hosts 中所有包含字符 a 或 l 或 1 的字符串。
|
||||
|
||||
```
|
||||
# awk '/[al1]/{print}' /etc/hosts
|
||||
```
|
||||
|
||||
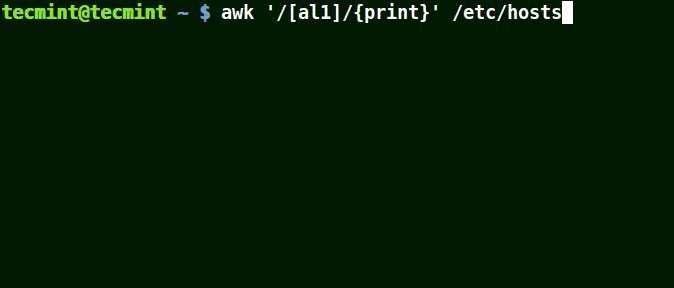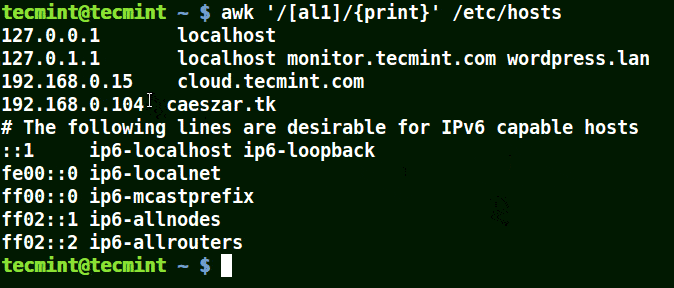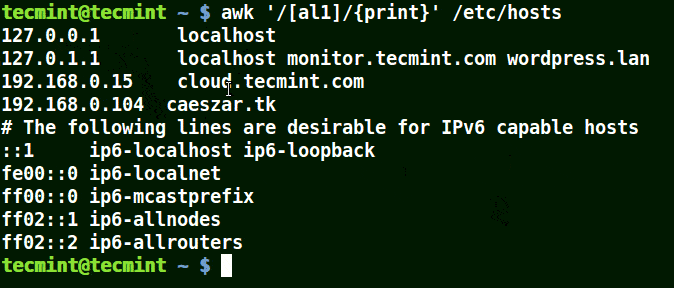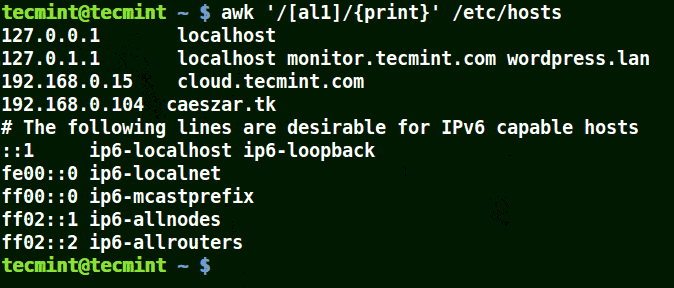
|
||||
|
||||
*使用 awk 打印文件中匹配的字符*
|
||||
|
||||
下一个例子匹配以 `K` 或 `k` 开始头,后面跟着一个 `T` 的字符串:
|
||||
|
||||
```
|
||||
# awk '/[Kk]T/{print}' /etc/hosts
|
||||
```
|
||||
|
||||

|
||||
|
||||
*使用 awk 打印文件中匹配的字符*
|
||||
|
||||
#### 以范围的方式指定字符
|
||||
|
||||
awk 所能理解的字符:
|
||||
|
||||
- `[0-9]` 代表一个单独的数字
|
||||
- `[a-z]` 代表一个单独的小写字母
|
||||
- `[A-Z]` 代表一个单独的大写字母
|
||||
- `[a-zA-Z]` 代表一个单独的字母
|
||||
- `[a-zA-Z 0-9]` 代表一个单独的字母或数字
|
||||
|
||||
让我们看看下面的例子:
|
||||
|
||||
```
|
||||
# awk '/[0-9]/{print}' /etc/hosts
|
||||
```
|
||||
|
||||
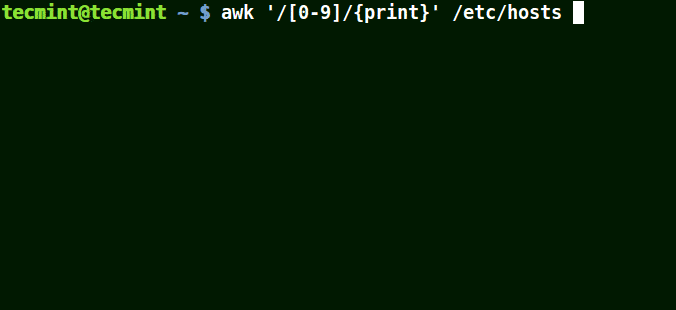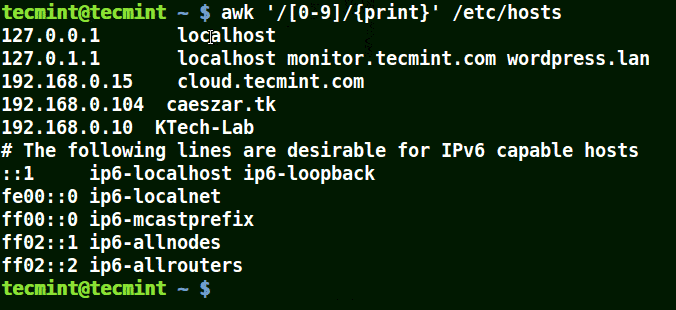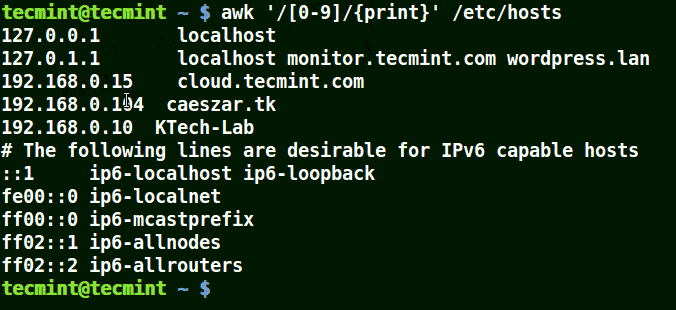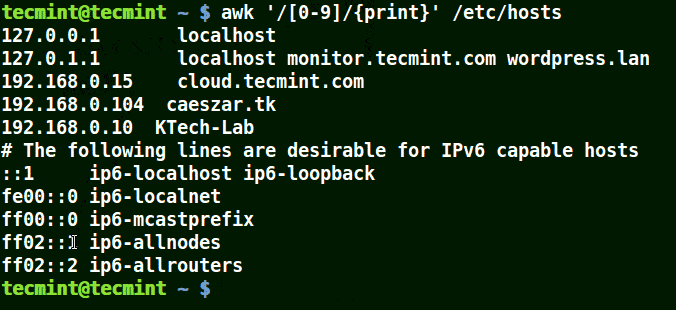
|
||||
|
||||
*使用 awk 打印文件中匹配的数字*
|
||||
|
||||
在上面的例子中,文件 /etc/hosts 中的所有行都至少包含一个单独的数字 [0-9]。
|
||||
|
||||
#### 结合元字符 (\^) 使用 awk
|
||||
|
||||
在下面的例子中,它匹配所有以给定模式开头的行:
|
||||
|
||||
```
|
||||
# awk '/^fe/{print}' /etc/hosts
|
||||
# awk '/^ff/{print}' /etc/hosts
|
||||
```
|
||||
|
||||
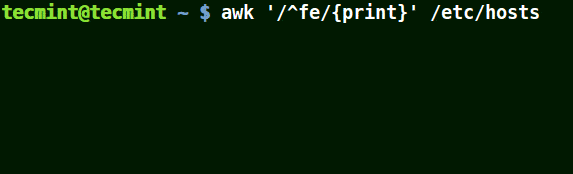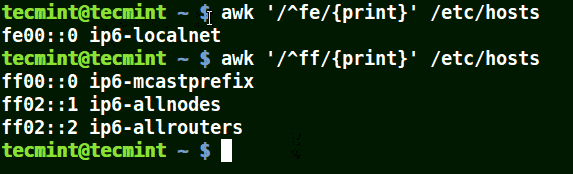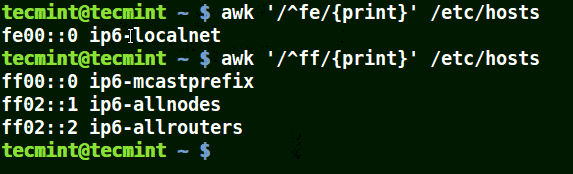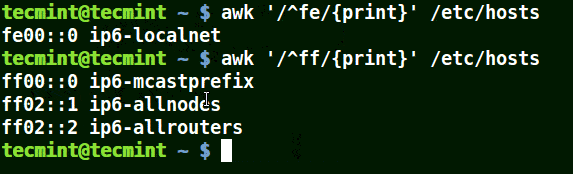
|
||||
|
||||
*使用 awk 打印与模式匹配的行*
|
||||
|
||||
#### 结合元字符 ($) 使用 awk
|
||||
|
||||
它将匹配所有以给定模式结尾的行:
|
||||
|
||||
```
|
||||
# awk '/ab$/{print}' /etc/hosts
|
||||
# awk '/ost$/{print}' /etc/hosts
|
||||
# awk '/rs$/{print}' /etc/hosts
|
||||
```
|
||||
|
||||
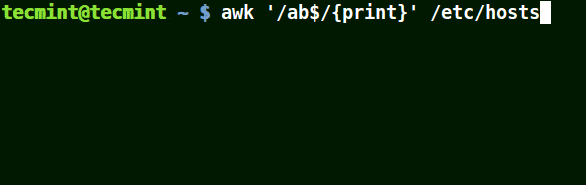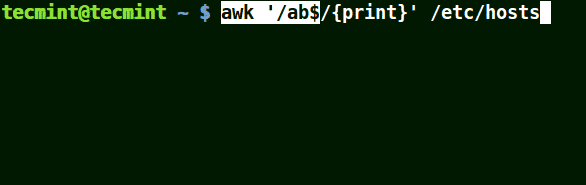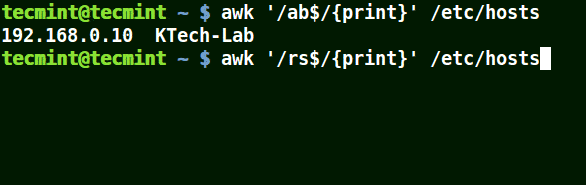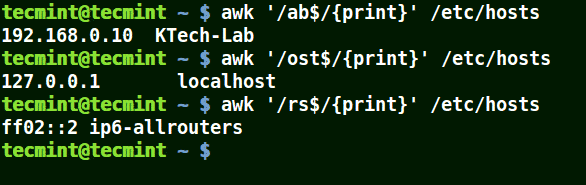
|
||||
|
||||
*使用 awk 打印与模式匹配的字符串*
|
||||
|
||||
#### 结合转义字符 (\\) 使用 awk
|
||||
|
||||
它允许你将该转义字符后面的字符作为文字,即理解为其字面的意思。
|
||||
|
||||
在下面的例子中,第一个命令打印出文件中的所有行,第二个命令中我想匹配具有 $25.00 的一行,但我并未使用转义字符,因而没有打印出任何内容。
|
||||
|
||||
第三个命令是正确的,因为一个这里使用了一个转义字符以转义 $,以将其识别为 '$'(而非元字符)。
|
||||
|
||||
```
|
||||
# awk '//{print}' deals.txt
|
||||
# awk '/$25.00/{print}' deals.txt
|
||||
# awk '/\$25.00/{print}' deals.txt
|
||||
```
|
||||
|
||||
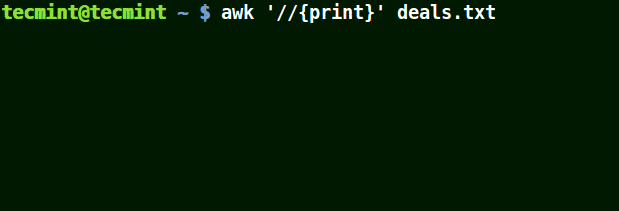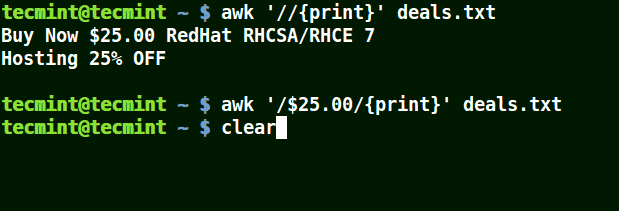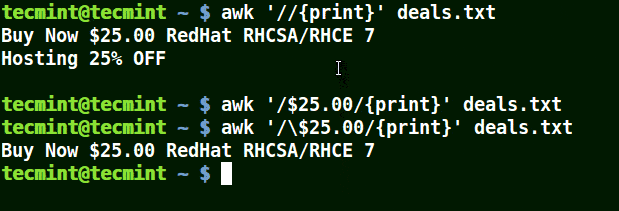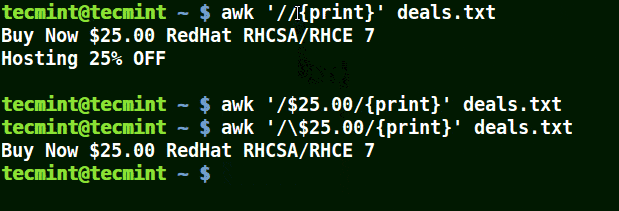
|
||||
|
||||
*结合转义字符使用 awk*
|
||||
|
||||
### 总结
|
||||
|
||||
以上内容并不是 awk 命令用做过滤工具的全部,上述的示例均是 awk 的基础操作。在下面的章节中,我将进一步介绍如何使用 awk 的高级功能。感谢您的阅读,请在评论区贴出您的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -0,0 +1,109 @@
|
||||
awk 系列:如何使用 awk 输出文本中的字段和列
|
||||
======================================================
|
||||
|
||||
在 Awk 系列的这一节中,我们将看到 awk 最重要的特性之一,字段编辑。
|
||||
|
||||
首先我们要知道,Awk 能够自动将输入的行,分隔为若干字段。每一个字段就是一组字符,它们和其他的字段由一个内部字段分隔符分隔开来。
|
||||
|
||||

|
||||
|
||||
*Awk 输出字段和列*
|
||||
|
||||
如果你熟悉 Unix/Linux 或者懂得 [bash shell 编程][1],那么你应该知道什么是内部字段分隔符(IFS)变量。awk 中默认的 IFS 是制表符和空格。
|
||||
|
||||
awk 中的字段分隔符的工作原理如下:当读到一行输入时,将它按照指定的 IFS 分割为不同字段,第一组字符就是字段一,可以通过 $1 来访问,第二组字符就是字段二,可以通过 $2 来访问,第三组字符就是字段三,可以通过 $3 来访问,以此类推,直到最后一组字符。
|
||||
|
||||
为了更好地理解 awk 的字段编辑,让我们看一个下面的例子:
|
||||
|
||||
**例 1**:我创建了一个名为 tecmintinfo.txt 的文本文件。
|
||||
|
||||
```
|
||||
# vi tecmintinfo.txt
|
||||
# cat tecmintinfo.txt
|
||||
```
|
||||
|
||||

|
||||
|
||||
*在 Linux 上创建一个文件*
|
||||
|
||||
然后在命令行中,我试着使用下面的命令从文本 tecmintinfo.txt 中输出第一个,第二个,以及第三个字段。
|
||||
|
||||
```
|
||||
$ awk '//{print $1 $2 $3 }' tecmintinfo.txt
|
||||
TecMint.comisthe
|
||||
```
|
||||
|
||||
从上面的输出中你可以看到,前三个字段的字符是以空格为分隔符输出的:
|
||||
|
||||
- 字段一是 “TecMint.com”,可以通过 `$1` 来访问。
|
||||
- 字段二是 “is”,可以通过 `$2` 来访问。
|
||||
- 字段三是 “the”,可以通过 `$3` 来访问。
|
||||
|
||||
如果你注意观察输出的话可以发现,输出的字段值并没有被分隔开,这是 print 函数默认的行为。
|
||||
|
||||
为了使输出看得更清楚,输出的字段值之间使用空格分开,你需要添加 (,) 操作符。
|
||||
|
||||
```
|
||||
$ awk '//{print $1, $2, $3; }' tecmintinfo.txt
|
||||
|
||||
TecMint.com is the
|
||||
```
|
||||
|
||||
需要记住而且非常重要的是,`($)` 在 awk 和在 shell 脚本中的使用是截然不同的!
|
||||
|
||||
在 shell 脚本中,`($)` 被用来获取变量的值。而在 awk 中,`($)` 只有在获取字段的值时才会用到,不能用于获取变量的值。
|
||||
|
||||
**例 2**:让我们再看一个例子,用到了一个名为 my_shoping.list 的包含多行的文件。
|
||||
|
||||
```
|
||||
No Item_Name Unit_Price Quantity Price
|
||||
1 Mouse #20,000 1 #20,000
|
||||
2 Monitor #500,000 1 #500,000
|
||||
3 RAM_Chips #150,000 2 #300,000
|
||||
4 Ethernet_Cables #30,000 4 #120,000
|
||||
```
|
||||
|
||||
如果你只想输出购物清单上每一个物品的`单价`,你只需运行下面的命令:
|
||||
|
||||
```
|
||||
$ awk '//{print $2, $3 }' my_shopping.txt
|
||||
|
||||
Item_Name Unit_Price
|
||||
Mouse #20,000
|
||||
Monitor #500,000
|
||||
RAM_Chips #150,000
|
||||
Ethernet_Cables #30,000
|
||||
```
|
||||
|
||||
可以看到上面的输出不够清晰,awk 还有一个 `printf` 的命令,可以帮助你将输出格式化。
|
||||
|
||||
使用 `printf` 来格式化 Item_Name 和 Unit_Price 的输出:
|
||||
|
||||
```
|
||||
$ awk '//{printf "%-10s %s\n",$2, $3 }' my_shopping.txt
|
||||
|
||||
Item_Name Unit_Price
|
||||
Mouse #20,000
|
||||
Monitor #500,000
|
||||
RAM_Chips #150,000
|
||||
Ethernet_Cables #30,000
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
使用 awk 过滤文本或字符串时,字段编辑的功能是非常重要的。它能够帮助你从一个表的数据中得到特定的列。一定要记住的是,awk 中 `($)` 操作符的用法与其在 shell 脚本中的用法是不同的!
|
||||
|
||||
希望这篇文章对您有所帮助。如有任何疑问,可以在评论区域发表评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/awk-print-fields-columns-with-space-separator/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[Cathon](https://github.com/Cathon),[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/category/bash-shell/
|
||||
@ -0,0 +1,85 @@
|
||||
awk 系列:如何使用 awk 按模式筛选文本或字符串
|
||||
=========================================================================
|
||||
|
||||

|
||||
|
||||
作为 awk 命令系列的第三部分,这次我们将看一看如何基于用户定义的特定模式来筛选文本或字符串。
|
||||
|
||||
在筛选文本时,有时你可能想根据某个给定的条件或使用一个可被匹配的特定模式,去标记某个文件或数行字符串中的某几行。使用 awk 来完成这个任务是非常容易的,这也正是 awk 中可能对你有所帮助的几个功能之一。
|
||||
|
||||
让我们看一看下面这个例子,比方说你有一个写有你想要购买的食物的购物清单,其名称为 food_prices.list,它所含有的食物名称及相应的价格如下所示:
|
||||
|
||||
```
|
||||
$ cat food_prices.list
|
||||
No Item_Name Quantity Price
|
||||
1 Mangoes 10 $2.45
|
||||
2 Apples 20 $1.50
|
||||
3 Bananas 5 $0.90
|
||||
4 Pineapples 10 $3.46
|
||||
5 Oranges 10 $0.78
|
||||
6 Tomatoes 5 $0.55
|
||||
7 Onions 5 $0.45
|
||||
```
|
||||
|
||||
然后,你想使用一个 `(*)` 符号去标记那些单价大于 $2 的食物,那么你可以通过运行下面的命令来达到此目的:
|
||||
|
||||
```
|
||||
$ awk '/ *\$[2-9]\.[0-9][0-9] */ { print $1, $2, $3, $4, "*" ; } / *\$[0-1]\.[0-9][0-9] */ { print ; }' food_prices.list
|
||||
```
|
||||
|
||||
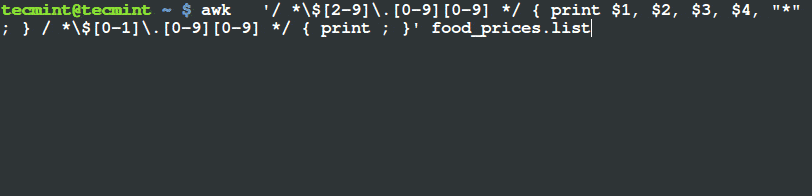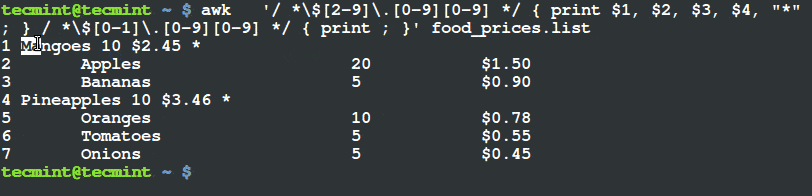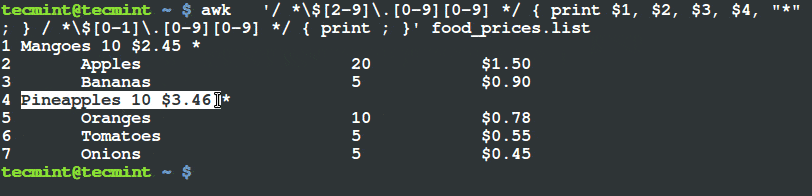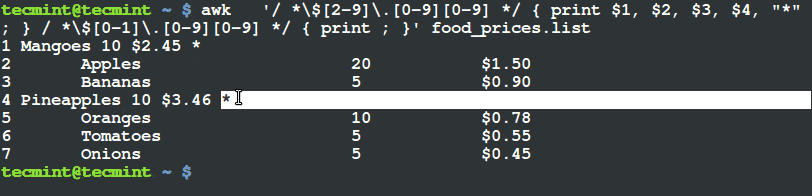
|
||||
|
||||
*打印出单价大于 $2 的项目*
|
||||
|
||||
从上面的输出你可以看到在含有 芒果(mangoes) 和菠萝(pineapples)的那行末尾都已经有了一个 `(*)` 标记。假如你检查它们的单价,你可以看到它们的单价的确超过了 $2 。
|
||||
|
||||
在这个例子中,我们已经使用了两个模式:
|
||||
|
||||
- 第一个模式: `/ *\$[2-9]\.[0-9][0-9] */` 将会得到那些含有食物单价大于 $2 的行,
|
||||
- 第二个模式: `/*\$[0-1]\.[0-9][0-9] */` 将查找那些食物单价小于 $2 的那些行。
|
||||
|
||||
上面的命令具体做了什么呢?这个文件有四个字段,当模式一匹配到含有食物单价大于 $2 的行时,它便会输出所有的四个字段并在该行末尾加上一个 `(*)` 符号来作为标记。
|
||||
|
||||
第二个模式只是简单地输出其他含有食物单价小于 $2 的行,按照它们出现在输入文件 food_prices.list 中的样子。
|
||||
|
||||
这样你就可以使用模式来筛选出那些价格超过 $2 的食物项目,尽管上面的输出还有些问题,带有 `(*)` 符号的那些行并没有像其他行那样被格式化输出,这使得输出显得不够清晰。
|
||||
|
||||
我们在 awk 系列的第二部分中也看到了同样的问题,但我们可以使用下面的两种方式来解决:
|
||||
|
||||
1、可以像下面这样使用 printf 命令,但这样使用又长又无聊:
|
||||
|
||||
```
|
||||
$ awk '/ *\$[2-9]\.[0-9][0-9] */ { printf "%-10s %-10s %-10s %-10s\n", $1, $2, $3, $4 "*" ; } / *\$[0-1]\.[0-9][0-9] */ { printf "%-10s %-10s %-10s %-10s\n", $1, $2, $3, $4; }' food_prices.list
|
||||
```
|
||||
|
||||
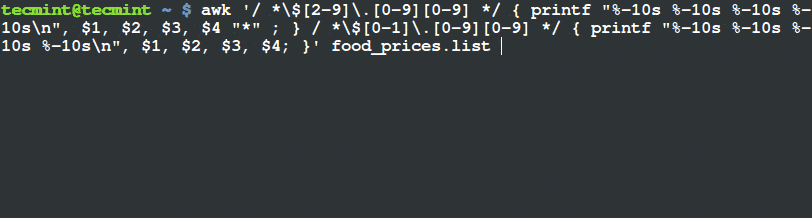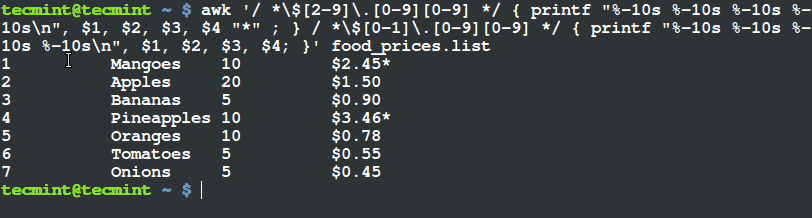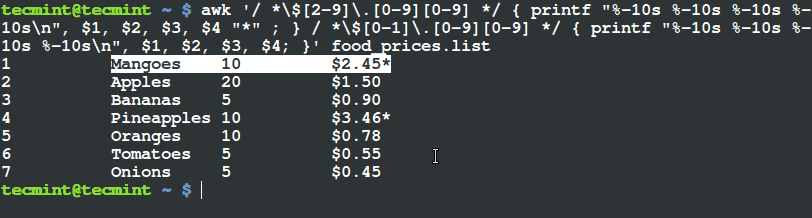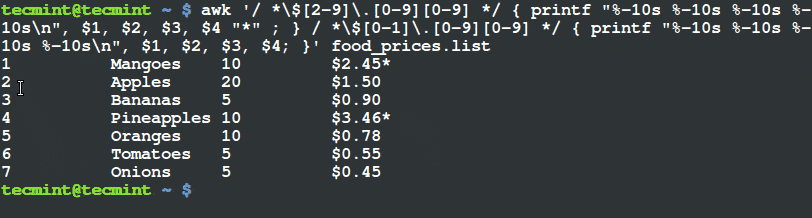
|
||||
|
||||
*使用 Awk 和 Printf 来筛选和输出项目*
|
||||
|
||||
2、 使用 `$0` 字段。Awk 使用变量 **0** 来存储整个输入行。对于上面的问题,这种方式非常方便,并且它还简单、快速:
|
||||
|
||||
```
|
||||
$ awk '/ *\$[2-9]\.[0-9][0-9] */ { print $0 "*" ; } / *\$[0-1]\.[0-9][0-9] */ { print ; }' food_prices.list
|
||||
```
|
||||
|
||||
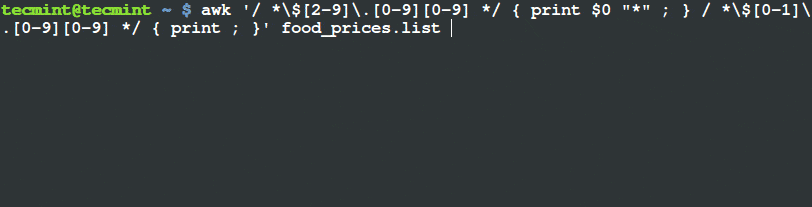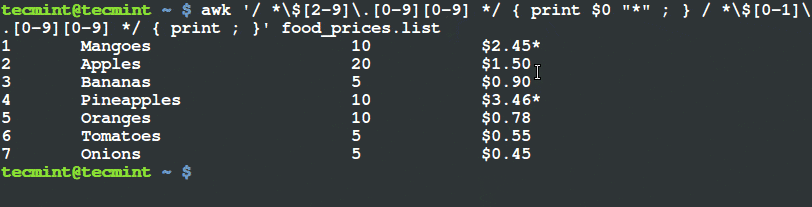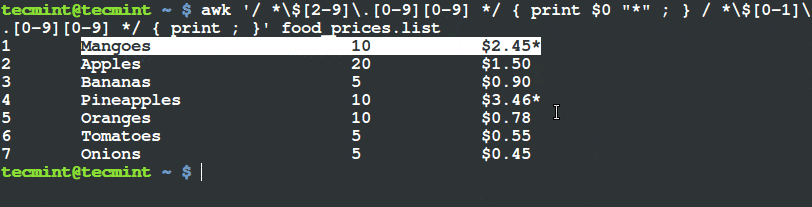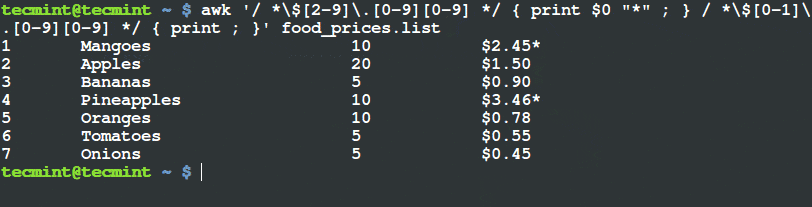
|
||||
|
||||
*使用 Awk 和变量来筛选和输出项目*
|
||||
|
||||
### 结论
|
||||
|
||||
这就是全部内容了,使用 awk 命令你便可以通过几种简单的方法去利用模式匹配来筛选文本,帮助你在一个文件中对文本或字符串的某些行做标记。
|
||||
|
||||
希望这篇文章对你有所帮助。记得阅读这个系列的下一部分,我们将关注在 awk 工具中使用比较运算符。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/awk-filter-text-or-string-using-patterns/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -0,0 +1,95 @@
|
||||
awk 系列:如何使用 awk 比较操作符
|
||||
===================================================
|
||||
|
||||

|
||||
|
||||
对于 使用 awk 命令的用户来说,处理一行文本中的数字或者字符串时,使用比较运算符来过滤文本和字符串是十分方便的。
|
||||
|
||||
在 awk 系列的此部分中,我们将探讨一下如何使用比较运算符来过滤文本或者字符串。如果你是程序员,那么你应该已经熟悉了比较运算符;对于其它人,下面的部分将介绍比较运算符。
|
||||
|
||||
### awk 中的比较运算符是什么?
|
||||
|
||||
awk 中的比较运算符用于比较字符串和或者数值,包括以下类型:
|
||||
|
||||
- `>` – 大于
|
||||
- `<` – 小于
|
||||
- `>=` – 大于等于
|
||||
- `<=` – 小于等于
|
||||
- `==` – 等于
|
||||
- `!=` – 不等于
|
||||
- `some_value ~ / pattern/` – 如果 some_value 匹配模式 pattern,则返回 true
|
||||
- `some_value !~ / pattern/` – 如果 some_value 不匹配模式 pattern,则返回 true
|
||||
|
||||
现在我们通过例子来熟悉 awk 中各种不同的比较运算符。
|
||||
|
||||
在这个例子中,我们有一个文件名为 food_list.txt 的文件,里面包括不同食物的购买列表。我想给食物数量小于或等于 30 的物品所在行的后面加上`(**)`
|
||||
|
||||
```
|
||||
File – food_list.txt
|
||||
No Item_Name Quantity Price
|
||||
1 Mangoes 45 $3.45
|
||||
2 Apples 25 $2.45
|
||||
3 Pineapples 5 $4.45
|
||||
4 Tomatoes 25 $3.45
|
||||
5 Onions 15 $1.45
|
||||
6 Bananas 30 $3.45
|
||||
```
|
||||
|
||||
Awk 中使用比较运算符的通用语法如下:
|
||||
|
||||
```
|
||||
# 表达式 { 动作; }
|
||||
```
|
||||
|
||||
为了实现刚才的目的,执行下面的命令:
|
||||
|
||||
```
|
||||
# awk '$3 <= 30 { printf "%s\t%s\n", $0,"**" ; } $3 > 30 { print $0 ;}' food_list.txt
|
||||
|
||||
No Item_Name` Quantity Price
|
||||
1 Mangoes 45 $3.45
|
||||
2 Apples 25 $2.45 **
|
||||
3 Pineapples 5 $4.45 **
|
||||
4 Tomatoes 25 $3.45 **
|
||||
5 Onions 15 $1.45 **
|
||||
6 Bananas 30 $3.45 **
|
||||
```
|
||||
|
||||
在刚才的例子中,发生如下两件重要的事情:
|
||||
|
||||
- 第一个“表达式 {动作;}”组合中, `$3 <= 30 { printf “%s\t%s\n”, $0,”**” ; }` 打印出数量小于等于30的行,并且在后面增加`(**)`。物品的数量是通过 `$3` 这个域变量获得的。
|
||||
- 第二个“表达式 {动作;}”组合中, `$3 > 30 { print $0 ;}` 原样输出数量小于等于 `30` 的行。
|
||||
|
||||
再举一个例子:
|
||||
|
||||
```
|
||||
# awk '$3 <= 20 { printf "%s\t%s\n", $0,"TRUE" ; } $3 > 20 { print $0 ;} ' food_list.txt
|
||||
|
||||
No Item_Name Quantity Price
|
||||
1 Mangoes 45 $3.45
|
||||
2 Apples 25 $2.45
|
||||
3 Pineapples 5 $4.45 TRUE
|
||||
4 Tomatoes 25 $3.45
|
||||
5 Onions 15 $1.45 TRUE
|
||||
6 Bananas 30 $3.45
|
||||
```
|
||||
|
||||
在这个例子中,我们想通过在行的末尾增加 (TRUE) 来标记数量小于等于20的行。
|
||||
|
||||
### 总结
|
||||
|
||||
这是一篇对 awk 中的比较运算符介绍性的指引,因此你需要尝试其他选项,发现更多使用方法。
|
||||
|
||||
如果你遇到或者想到任何问题,请在下面评论区留下评论。请记得阅读 awk 系列下一部分的文章,那里我将介绍组合表达式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/comparison-operators-in-awk/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -0,0 +1,80 @@
|
||||
awk 系列:如何使用 awk 复合表达式
|
||||
====================================================
|
||||
|
||||

|
||||
|
||||
一直以来在查对条件是否匹配时,我们使用的都是简单的表达式。那如果你想用超过一个表达式来查对特定的条件呢?
|
||||
|
||||
本文,我们将看看如何在过滤文本和字符串时,结合多个表达式,即复合表达式,用以查对条件。
|
||||
|
||||
awk 的复合表达式可由表示“与”的组合操作符 `&&` 和表示“或”的 `||` 构成。
|
||||
|
||||
复合表达式的常规写法如下:
|
||||
|
||||
```
|
||||
( 第一个表达式 ) && ( 第二个表达式 )
|
||||
```
|
||||
|
||||
这里只有当“第一个表达式” 和“第二个表达式”都是真值时整个表达式才为真。
|
||||
|
||||
```
|
||||
( 第一个表达式 ) || ( 第二个表达式)
|
||||
```
|
||||
|
||||
这里只要“第一个表达式” 为真或“第二个表达式”为真,整个表达式就为真。
|
||||
|
||||
**注意**:切记要加括号。
|
||||
|
||||
表达式可以由比较操作符构成,具体可查看[ awk 系列的第四节][1]。
|
||||
|
||||
现在让我们通过一个例子来加深理解:
|
||||
|
||||
此例中,有一个文本文件 `tecmint_deals.txt`,文本中包含着一张随机的 Tecmint 交易清单,其中包含了名称、价格和种类。
|
||||
|
||||
```
|
||||
TecMint Deal List
|
||||
No Name Price Type
|
||||
1 Mac_OS_X_Cleanup_Suite $9.99 Software
|
||||
2 Basics_Notebook $14.99 Lifestyle
|
||||
3 Tactical_Pen $25.99 Lifestyle
|
||||
4 Scapple $19.00 Unknown
|
||||
5 Nano_Tool_Pack $11.99 Unknown
|
||||
6 Ditto_Bluetooth_Altering_Device $33.00 Tech
|
||||
7 Nano_Prowler_Mini_Drone $36.99 Tech
|
||||
```
|
||||
|
||||
我们只想打印出价格超过 $20 且其种类为 “Tech” 的物品,在其行末用 (*) 打上标记。
|
||||
|
||||
我们将要执行以下命令。
|
||||
|
||||
```
|
||||
# awk '($3 ~ /^\$[2-9][0-9]*\.[0-9][0-9]$/) && ($4=="Tech") { printf "%s\t%s\n",$0,"*"; } ' tecmint_deals.txt
|
||||
|
||||
6 Ditto_Bluetooth_Altering_Device $33.00 Tech *
|
||||
7 Nano_Prowler_Mini_Drone $36.99 Tech *
|
||||
```
|
||||
|
||||
此例,在复合表达式中我们使用了两个表达式:
|
||||
|
||||
- 表达式 1:`($3 ~ /^\$[2-9][0-9]*\.[0-9][0-9]$/)` ;查找交易价格超过 `$20` 的行,即只有当 `$3` 也就是价格满足 `/^\$[2-9][0-9]*\.[0-9][0-9]$/` 时值才为真值。
|
||||
- 表达式 2:`($4 == “Tech”)` ;查找是否有种类为 “`Tech`”的交易,即只有当 `$4` 等于 “`Tech`” 时值才为真值。
|
||||
切记,只有当 `&&` 操作符的两端状态,也就是两个表达式都是真值的情况下,这一行才会被打上 `(*)` 标志。
|
||||
|
||||
### 总结
|
||||
|
||||
有些时候为了真正符合你的需求,就不得不用到复合表达式。当你掌握了比较和复合表达式操作符的用法之后,复杂的文本或字符串过滤条件也能轻松解决。
|
||||
|
||||
希望本向导对你有所帮助,如果你有任何问题或者补充,可以在下方发表评论,你的问题将会得到相应的解释。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/combine-multiple-expressions-in-awk/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://linux.cn/article-7602-1.html
|
||||
@ -0,0 +1,76 @@
|
||||
awk 系列:如何使用 awk 的 ‘next’ 命令
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
在 awk 系列的第六节,我们来看一下`next`命令 ,它告诉 awk 跳过你所提供的所有剩下的模式和表达式,直接处理下一个输入行。
|
||||
|
||||
`next` 命令帮助你阻止运行命令执行过程中多余的步骤。
|
||||
|
||||
要明白它是如何工作的, 让我们来分析一下 food_list.txt 它看起来像这样:
|
||||
|
||||
```
|
||||
Food List Items
|
||||
No Item_Name Price Quantity
|
||||
1 Mangoes $3.45 5
|
||||
2 Apples $2.45 25
|
||||
3 Pineapples $4.45 55
|
||||
4 Tomatoes $3.45 25
|
||||
5 Onions $1.45 15
|
||||
6 Bananas $3.45 30
|
||||
```
|
||||
|
||||
运行下面的命令,它将在每个食物数量小于或者等于 20 的行后面标一个星号:
|
||||
|
||||
```
|
||||
# awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; } $4 > 20 { print $0 ;} ' food_list.txt
|
||||
|
||||
No Item_Name Price Quantity
|
||||
1 Mangoes $3.45 5 *
|
||||
2 Apples $2.45 25
|
||||
3 Pineapples $4.45 55
|
||||
4 Tomatoes $3.45 25
|
||||
5 Onions $1.45 15 *
|
||||
6 Bananas $3.45 30
|
||||
```
|
||||
|
||||
上面的命令实际运行如下:
|
||||
|
||||
- 首先,它用`$4 <= 20`表达式检查每个输入行的第四列(数量(Quantity))是否小于或者等于 20,如果满足条件,它将在末尾打一个星号 `(*)`。
|
||||
- 接着,它用`$4 > 20`表达式检查每个输入行的第四列是否大于20,如果满足条件,显示出来。
|
||||
|
||||
但是这里有一个问题, 当第一个表达式用`{ printf "%s\t%s\n", $0,"**" ; }`命令进行标注的时候在同样的步骤第二个表达式也进行了判断这样就浪费了时间.
|
||||
|
||||
因此当我们已经用第一个表达式打印标志行的时候就不再需要用第二个表达式`$4 > 20`再次打印。
|
||||
|
||||
要处理这个问题, 我们需要用到`next` 命令:
|
||||
|
||||
```
|
||||
# awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; next; } $4 > 20 { print $0 ;} ' food_list.txt
|
||||
|
||||
No Item_Name Price Quantity
|
||||
1 Mangoes $3.45 5 *
|
||||
2 Apples $2.45 25
|
||||
3 Pineapples $4.45 55
|
||||
4 Tomatoes $3.45 25
|
||||
5 Onions $1.45 15 *
|
||||
6 Bananas $3.45 30
|
||||
```
|
||||
|
||||
当输入行用`$4 <= 20` `{ printf "%s\t%s\n", $0,"*" ; next ; }`命令打印以后,`next`命令将跳过第二个`$4 > 20` `{ print $0 ;}`表达式,继续判断下一个输入行,而不是浪费时间继续判断一下是不是当前输入行还大于 20。
|
||||
|
||||
`next`命令在编写高效的命令脚本时候是非常重要的,它可以提高脚本速度。本系列的下一部分我们将来学习如何使用 awk 来处理标准输入(STDIN)。
|
||||
|
||||
希望这篇文章对你有帮助,你可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-next-command-with-awk-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -0,0 +1,75 @@
|
||||
awk 系列:awk 怎么从标准输入(STDIN)读取输入
|
||||
============================================
|
||||
|
||||

|
||||
|
||||
在 awk 系列的前几节,我们看到大多数操作都是从一个文件或多个文件读取输入,或者你想要把标准输入作为 awk 的输入。
|
||||
|
||||
在 awk 系列的第七节中,我们将会看到几个例子,你可以筛选其他命令的输出代替从一个文件读取输入作为 awk 的输入。
|
||||
|
||||
我们首先从使用 [dir 命令][1]开始,它类似于 [ls 命令][2],在第一个例子下面,我们使用 `dir -l` 命令的输出作为 awk 命令的输入,这样就可以打印出文件拥有者的用户名,所属组组名以及在当前路径下他/她拥有的文件。
|
||||
|
||||
```
|
||||
# dir -l | awk '{print $3, $4, $9;}'
|
||||
```
|
||||
|
||||
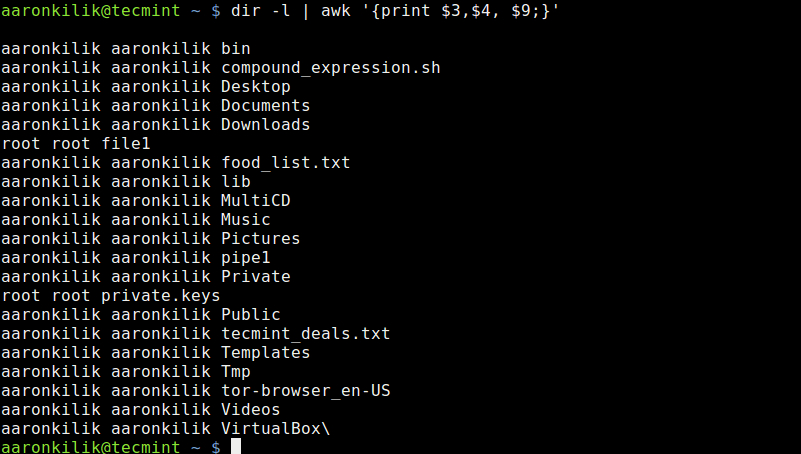
|
||||
|
||||
*列出当前路径下的用户文件*
|
||||
|
||||
|
||||
再来看另一个例子,我们[使用 awk 表达式][3] ,在这里,我们想要在 awk 命令里使用一个表达式筛选出字符串来打印出属于 root 用户的文件。命令如下:
|
||||
|
||||
```
|
||||
# dir -l | awk '$3=="root" {print $1,$3,$4, $9;} '
|
||||
```
|
||||
|
||||
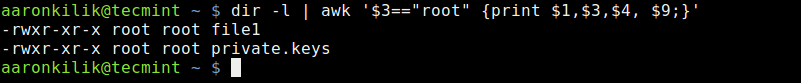
|
||||
|
||||
*列出 root 用户的文件*
|
||||
|
||||
上面的命令包含了 `(==)` 来进行比较操作,这帮助我们在当前路径下筛选出 root 用户的文件。这是通过使用 `$3=="root"` 表达式实现的。
|
||||
|
||||
让我们再看另一个例子,我们使用一个 [awk 比较运算符][4] 来匹配一个确定的字符串。
|
||||
|
||||
这里,我们使用了 [cat 命令][5] 来浏览文件名为 tecmint_deals.txt 的文件内容,并且我们想要仅仅查看有字符串 Tech 的部分,所以我们会运行下列命令:
|
||||
|
||||
```
|
||||
# cat tecmint_deals.txt
|
||||
# cat tecmint_deals.txt | awk '$4 ~ /tech/{print}'
|
||||
# cat tecmint_deals.txt | awk '$4 ~ /Tech/{print}'
|
||||
```
|
||||
|
||||
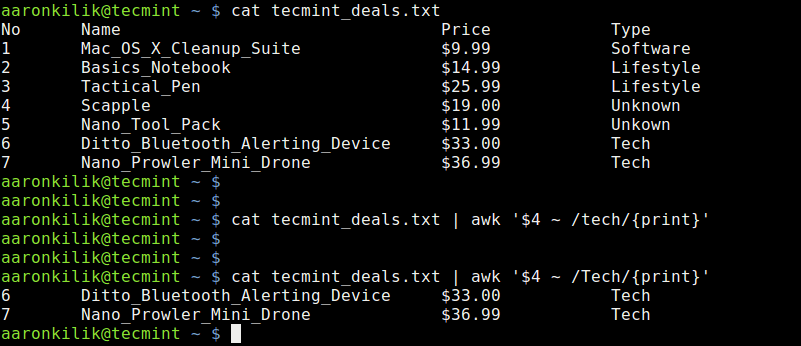
|
||||
|
||||
*用 Awk 比较运算符匹配字符串*
|
||||
|
||||
在上面的例子中,我们已经用了参数为 `~ /匹配字符/` 的比较操作,但是上面的两个命令给我们展示了一些很重要的问题。
|
||||
|
||||
当你运行带有 tech 字符串的命令时终端没有输出,因为在文件中没有 tech 这种字符串,但是运行带有 Tech 字符串的命令,你却会得到包含 Tech 的输出。
|
||||
|
||||
所以你应该在进行这种比较操作的时候时刻注意这种问题,正如我们在上面看到的那样,awk 对大小写很敏感。
|
||||
|
||||
你总是可以使用另一个命令的输出作为 awk 命令的输入来代替从一个文件中读取输入,这就像我们在上面看到的那样简单。
|
||||
|
||||
希望这些例子足够简单到可以使你理解 awk 的用法,如果你有任何问题,你可以在下面的评论区提问,记得查看 awk 系列接下来的章节内容,我们将关注 awk 的一些功能,比如变量,数字表达式以及赋值运算符。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/read-awk-input-from-stdin-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/linux-dir-command-usage-with-examples/
|
||||
[2]: http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[3]: https://linux.cn/article-7599-1.html
|
||||
[4]: https://linux.cn/article-7602-1.html
|
||||
[5]: http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
|
||||
|
||||
|
||||
@ -1 +0,0 @@
|
||||
这里放新闻类文章,要求时效性
|
||||
@ -1 +0,0 @@
|
||||
这里放分享类文章,包括各种软件的简单介绍、有用的书籍和网站等。
|
||||
@ -1,5 +1,6 @@
|
||||
Torvalds 2.0: Patricia Torvalds on computing, college, feminism, and increasing diversity in tech
|
||||
================================================================================
|
||||
|
||||

|
||||
Image by : Photo by Becky Svartström. Modified by Opensource.com. [CC BY-SA 4.0][1]
|
||||
|
||||
|
||||
@ -1,78 +0,0 @@
|
||||
sonofelice translating
|
||||
How bad a boss is Linus Torvalds?
|
||||
================================================================================
|
||||

|
||||
|
||||
*Linus Torvalds addressed a packed auditorium of Linux enthusiasts during his speech at the LinuxWorld show in San Jose, California, on August 10, 1999. Credit: James Niccolai*
|
||||
|
||||
**It depends on context. In the world of software development, he’s what passes for normal. The question is whether that situation should be allowed to continue.**
|
||||
|
||||
I've known Linus Torvalds, Linux's inventor, for over 20 years. We're not chums, but we like each other.
|
||||
|
||||
Lately, Torvalds has been getting a lot of flack for his management style. Linus doesn't suffer fools gladly. He has one way of judging people in his business of developing the Linux kernel: How good is your code?
|
||||
|
||||
Nothing else matters. As Torvalds said earlier this year at the Linux.conf.au Conference, "I'm not a nice person, and I don't care about you. [I care about the technology and the kernel][1] -- that's what's important to me."
|
||||
|
||||
Now, I can deal with that kind of person. If you can't, you should avoid the Linux kernel community, where you'll find a lot of this kind of meritocratic thinking. Which is not to say that I think everything in Linuxland is hunky-dory and should be impervious to calls for change. A meritocracy I can live with; a bastion of male dominance where women are subjected to scorn and disrespect is a problem.
|
||||
|
||||
That's why I see the recent brouhaha about Torvalds' management style -- or more accurately, his total indifference to the personal side of management -- as nothing more than standard operating procedure in the world of software development. And at the same time, I see another instance that has come to light as evidence of a need for things to really change.
|
||||
|
||||
The first situation arose with the [release of Linux 4.3][2], when Torvalds used the Linux Kernel Mailing List to tear into a developer who had inserted some networking code that Torvalds thought was -- well, let's say "crappy." "[[A]nd it generates [crappy] code.][3] It looks bad, and there's no reason for it." He goes on in this vein for quite a while. Besides the word "crap" and its earthier synonym, he uses the word "idiotic" pretty often.
|
||||
|
||||
Here's the thing, though. He's right. I read the code. It's badly written and it does indeed seem to have been designed to use the new "overflow_usub()" function just for the sake of using it.
|
||||
|
||||
Now, some people see this diatribe as evidence that Torvalds is a bad-tempered bully. I see a perfectionist who, within his field, doesn't put up with crap.
|
||||
|
||||
Many people have told me that this is not how professional programmers should act. People, have you ever worked with top developers? That's exactly how they act, at Apple, Microsoft, Oracle and everywhere else I've known them.
|
||||
|
||||
I've heard Steve Jobs rip a developer to pieces. I've cringed while a senior Oracle developer lead tore into a room of new programmers like a piranha through goldfish.
|
||||
|
||||
In Accidental Empires, his classic book on the rise of PCs, Robert X. Cringely described Microsoft's software management style when Bill Gates was in charge as a system where "Each level, from Gates on down, screams at the next, goading and humiliating them." Ah, yes, that's the Microsoft I knew and hated.
|
||||
|
||||
The difference between the leaders at big proprietary software companies and Torvalds is that he says everything in the open for the whole world to see. The others do it in private conference rooms. I've heard people claim that Torvalds would be fired in their company. Nope. He'd be right where he is now: on top of his programming world.
|
||||
|
||||
Oh, and there's another difference. If you get, say, Larry Ellison mad at you, you can kiss your job goodbye. When you get Torvalds angry at your work, you'll get yelled at in an email. That's it.
|
||||
|
||||
You see, Torvalds isn't anyone's boss. He's the guy in charge of a project with about 10,000 contributors, but he has zero hiring and firing authority. He can hurt your feelings, but that's about it.
|
||||
|
||||
That said, there is a serious problem within both open-source and proprietary software development circles. No matter how good a programmer you are, if you're a woman, the cards are stacked against you.
|
||||
|
||||
No case shows this better than that of Sarah Sharp, an Intel developer and formerly a top Linux programmer. [In a post on her blog in October][4], she explained why she had stopped contributing to the Linux kernel more than a year earlier: "I finally realized that I could no longer contribute to a community where I was technically respected, but I could not ask for personal respect.... I did not want to work professionally with people who were allowed to get away with subtle sexist or homophobic jokes."
|
||||
|
||||
Who can blame her? I can't. Torvalds, like almost every software manager I've ever known, I'm sorry to say, has permitted a hostile work environment.
|
||||
|
||||
He would probably say that it's not his job to ensure that Linux contributors behave with professionalism and mutual respect. He's concerned with the code and nothing but the code.
|
||||
|
||||
As Sharp wrote:
|
||||
|
||||
> I have the utmost respect for the technical efforts of the Linux kernel community. They have scaled and grown a project that is focused on maintaining some of the highest coding standards out there. The focus on technical excellence, in combination with overloaded maintainers, and people with different cultural and social norms, means that Linux kernel maintainers are often blunt, rude, or brutal to get their job done. Top Linux kernel developers often yell at each other in order to correct each other's behavior.
|
||||
>
|
||||
> That's not a communication style that works for me. …
|
||||
>
|
||||
> Many senior Linux kernel developers stand by the right of maintainers to be technically and personally brutal. Even if they are very nice people in person, they do not want to see the Linux kernel communication style change.
|
||||
|
||||
She's right.
|
||||
|
||||
Where I differ from other observers is that I don't think that this problem is in any way unique to Linux or open-source communities. With five years of work in the technology business and 25 years as a technology journalist, I've seen this kind of immature boy behavior everywhere.
|
||||
|
||||
It's not Torvalds' fault. He's a technical leader with a vision, not a manager. The real problem is that there seems to be no one in the software development universe who can set a supportive tone for teams and communities.
|
||||
|
||||
Looking ahead, I hope that companies and organizations, such as the Linux Foundation, can find a way to empower community managers or other managers to encourage and enforce civil behavior.
|
||||
|
||||
We won't, unfortunately, find that kind of managerial finesse in our pure technical or business leaders. It's not in their DNA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
@ -1,46 +0,0 @@
|
||||
Linus Torvalds Talks IoT, Smart Devices, Security Concerns, and More[video]
|
||||
===========================================================================
|
||||
|
||||

|
||||
>Dirk Hohndel interviews Linus Torvalds at ELC.
|
||||
|
||||
For the first time in the 11-year history of the [Embedded Linux Conference (ELC)][0], held in San Diego, April 4-6, the keynotes included a discussion with Linus Torvalds. The creator and lead overseer of the Linux kernel, and “the reason we are all here,” in the words of his interviewer, Intel Chief Linux and Open Source Technologist Dirk Hohndel, seemed upbeat about the state of Linux in embedded and Internet of Things applications. Torvalds very presence signaled that embedded Linux, which has often been overshadowed by Linux desktop, server, and cloud technologies, had come of age.
|
||||
|
||||

|
||||
>Linus Torvalds speaking at Embedded Linux Conference.
|
||||
|
||||
IoT was the main topic at ELC, which included an OpenIoT Summit track, and the chief topic in the Torvalds interview.
|
||||
|
||||
“Maybe you won’t see Linux at the IoT leaf nodes, but anytime you have a hub, you will need it,” Torvalds told Hohndel. “You need smart devices especially if you have 23 [IoT standards]. If you have all these stupid devices that don’t necessarily run Linux, and they all talk with slightly different standards, you will need a lot of smart devices. We will never have one completely open standard, one ring to rule them all, but you will have three of four major protocols, and then all these smart hubs that translate.”
|
||||
|
||||
Torvalds remained customarily philosophical when Hohndel asked about the gaping security holes in IoT. “I don’t worry about security because there’s not a lot we can do,” he said. “IoT is unpatchable -- it’s a fact of life.”
|
||||
|
||||
The Linux creator seemed more concerned about the lack of timely upstream contributions from one-off embedded projects, although he noted there have been significant improvements in recent years, partially due to consolidation on hardware.
|
||||
|
||||
“The embedded world has traditionally been hard to interact with as an open source developer, but I think that’s improving,” Torvalds said. “The ARM community has become so much better. Kernel people can now actually keep up with some of the hardware improvements. It’s improving, but we’re not nearly there yet.”
|
||||
|
||||
Torvalds admitted to being more at home on the desktop than in embedded and to having “two left hands” when it comes to hardware.
|
||||
|
||||
“I’ve destroyed things with a soldering iron many times,” he said. “I’m not really set up to do hardware.” On the other hand, Torvalds guessed that if he were a teenager today, he would be fiddling around with a Raspberry Pi or BeagleBone. “The great part is if you’re not great at soldering, you can just buy a new one.”
|
||||
|
||||
Meanwhile, Torvalds vowed to continue fighting for desktop Linux for another 25 years. “I’ll wear them down,” he said with a smile.
|
||||
|
||||
Watch the full video, below.
|
||||
|
||||
Get the Latest on Embedded Linux and IoT. Access 150+ recorded sessions from Embedded Linux Conference 2016. [Watch Now][1].
|
||||
|
||||
[video](https://youtu.be/tQKUWkR-wtM)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[0]: http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[1]: http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom
|
||||
87
sources/talk/20160509 Android vs. iPhone Pros and Cons.md
Normal file
87
sources/talk/20160509 Android vs. iPhone Pros and Cons.md
Normal file
@ -0,0 +1,87 @@
|
||||
Android vs. iPhone: Pros and Cons
|
||||
===================================
|
||||
|
||||
正在翻译 by jovov
|
||||
>When comparing Android vs. iPhone, clearly Android has certain advantages even as the iPhone is superior in some key ways. But ultimately, which is better?
|
||||
|
||||
The question of Android vs. iPhone is a personal one.
|
||||
|
||||
Take myself, for example. I'm someone who has used both Android and the iPhone iOS. I'm well aware of the strengths of both platforms along with their weaknesses. Because of this, I decided to share my perspective regarding these two mobile platforms. Additionally, we'll take a look at my impressions of the new Ubuntu mobile platform and where it stacks up.
|
||||
|
||||
### What iPhone gets right
|
||||
|
||||
Even though I'm a full time Android user these days, I do recognize the areas where the iPhone got it right. First, Apple has a better record in updating their devices. This is especially true for older devices running iOS. With Android, if it's not a “Google blessed” Nexus...it better be a higher end carrier supported phone. Otherwise, you're going to find updates are either sparse or non-existent.
|
||||
|
||||
Another area where the iPhone does well is apps availability. Expanding on that: iPhone apps almost always have a cleaner look to them. This isn't to say that Android apps are ugly, rather, they may not have an expected flow and consistency found with iOS. Two examples of exclusivity and great iOS-only layout would have to be [Dark Sky][1] (weather) and [Facebook Paper][2].
|
||||
|
||||
Then there is the backup process. Android can, by default, back stuff up to Google. But that doesn't help much with application data! By contrast, iCloud can essentially make a full backup of your iOS device.
|
||||
|
||||
### Where iPhone loses me
|
||||
|
||||
The biggest indisputable issue I have with the iPhone is more of a hardware limitation than a software one. That issue is storage.
|
||||
|
||||
Look, with most Android phones, I can buy a smaller capacity phone and then add an SD card later. This does two things: First, I can use the SD card to store a lot of media files. Second, I can even use the SD card to store "some" of my apps. Apple has nothing that will touch this.
|
||||
|
||||
Another area where the iPhone loses me is in the lack of choice it provides. Backing up your device? Hope you like iTunes or iCloud. For someone like myself who uses Linux, this means my ONLY option would be to use iCloud.
|
||||
|
||||
To be ultimately fair, there are additional solutions for your iPhone if you're willing to jailbreak it. But that's not what this article is about. Same goes for rooting Android. This article is addressing a vanilla setup for both platforms.
|
||||
|
||||
Finally, let us not forget this little treat – [iTunes decides to delete a user's music][3] because it was seen as a duplication of Apple Music contents...or something along those lines. Not iPhone specific? I disagree, as that music would have very well ended up onto the iPhone at some point. I can say with great certainty that in no universe would I ever put up with this kind of nonsense!
|
||||
|
||||

|
||||
>The Android vs. iPhone debate depends on what features matter the most to you.
|
||||
|
||||
### What Android gets right
|
||||
|
||||
The biggest thing Android gives me that the iPhone doesn't: choice. Choices in applications, devices and overall layout of how my phone works.
|
||||
|
||||
I love desktop widgets! To iPhone users, they may seem really silly. But I can tell you that they save me from opening up applications as I can see the desired data without the extra hassle. Another similar feature I love is being able to install custom launchers instead of my phone's default!
|
||||
|
||||
Finally, I can utilize tools like [Airdroid][4] and [Tasker][5] to add full computer-like functionality to my smart phone. Airdroid allows me treat my Android phone like a computer with file management and SMS with anyone – this becomes a breeze to use with my mouse and keyboard. Tasker is awesome in that I can setup "recipes" to connect/disconnect, put my phone into meeting mode or even put itself into power saving mode when I set the parameters to do so. I can even set it to launch applications when I arrive at specific destinations.
|
||||
|
||||
### Where Android loses me
|
||||
|
||||
Backup options are limited to specific user data, not a full clone of your phone. Without rooting, you're either left out in the wind or you must look to the Android SDK for solutions. Expecting casual users to either root their phone or run the SDK for a complete (I mean everything) Android backup is a joke.
|
||||
|
||||
Yes, Google's backup service will backup Google app data, along with other related customizations. But it's nowhere near as complete as what we see with the iPhone. To accomplish something similar to what the iPhone enjoys, I've found you're going to either be rooting your Android phone or connecting it to a Windows PC to utilize some random program.
|
||||
|
||||
To be fair, however, I believe Nexus owners benefit from a [full backup service][6] that is device specific. Sorry, but Google's default backup is not cutting it. Same applies for adb backups via your PC – they don't always restore things as expected.
|
||||
|
||||
Wait, it gets better. Now after a lot of failed let downs and frustration, I found that there was one app that looked like it "might" offer a glimmer of hope, it's called Helium. Unlike other applications I found to be misleading and frustrating with their limitations, [Helium][7] initially looked like it was the backup application Google should have been offering all along -- emphasis on "looked like." Sadly, it was a huge let down. Not only did I need to connect it to my computer for a first run, it didn't even work using their provided Linux script. After removing their script, I settling for a good old fashioned adb backup...to my Linux PC. Fun facts: You will need to turn on a laundry list of stuff in developer tools, plus if you run the Twilight app, that needs to be turned off. It took me a bit to put this together when the backup option for adb on my phone wasn't responding.
|
||||
|
||||
At the end of the day, Android has ample options for non-rooted users to backup superficial stuff like contacts, SMS and other data easily. But a deep down phone backup is best left to a wired connection and adb from my experience.
|
||||
|
||||
### Ubuntu will save us?
|
||||
|
||||
With the good and the bad examined between the two major players in the mobile space, there's a lot of hope that we're going to see good things from Ubuntu on the mobile front. Well, thus far, it's been pretty lackluster.
|
||||
|
||||
I like what the developers are doing with the OS and I certainly love the idea of a third option for mobile besides iPhone and Android. Unfortunately, though, it's not that popular on the phone and the tablet received a lot of bad press due to subpar hardware and a lousy demonstration that made its way onto YouTube.
|
||||
|
||||
To be fair, I've had subpar experiences with iPhone and Android, too, in the past. So this isn't a dig on Ubuntu. But until it starts showing up with a ready to go ecosystem of functionality that matches what Android and iOS offer, it's not something I'm terribly interested in yet. At a later date, perhaps, I'll feel like the Ubuntu phones are ready to meet my needs.
|
||||
|
||||
### Android vs. iPhone bottom line: Why Android wins long term
|
||||
|
||||
Despite its painful shortcomings, Android treats me like an adult. It doesn't lock me into only two methods for backing up my data. Yes, some of Android's limitations are due to the fact that it's focused on letting me choose how to handle my data. But, I also get to choose my own device, add storage on a whim. Android enables me to do a lot of cool stuff that the iPhone simply isn't capable of doing.
|
||||
|
||||
At its core, Android gives non-root users greater access to the phone's functionality. For better or worse, it's a level of freedom that I think people are gravitating towards. Now there are going to be many of you who swear by the iPhone thanks to efforts like the [libimobiledevice][8] project. But take a long hard look at all the stuff Apple blocks Linux users from doing...then ask yourself – is it really worth it as a Linux user? Hit the Comments, share your thoughts on Android, iPhone or Ubuntu.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/mobile-wireless/android-vs.-iphone-pros-and-cons.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]: http://darkskyapp.com/
|
||||
[2]: https://www.facebook.com/paper/
|
||||
[3]: https://blog.vellumatlanta.com/2016/05/04/apple-stole-my-music-no-seriously/
|
||||
[4]: https://www.airdroid.com/
|
||||
[5]: http://tasker.dinglisch.net/
|
||||
[6]: https://support.google.com/nexus/answer/2819582?hl=en
|
||||
[7]: https://play.google.com/store/apps/details?id=com.koushikdutta.backup&hl=en
|
||||
[8]: http://www.libimobiledevice.org/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
KevinSJ Translating
|
||||
Linux will be the major operating system of 21st century cars
|
||||
===============================================================
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user