mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
cc97a887b4
@ -1,3 +1,5 @@
|
||||
申请翻译 WangYueScream
|
||||
================================
|
||||
Best Websites to Download Linux Games
|
||||
======
|
||||
Brief: New to Linux gaming and wondering where to **download Linux games** from? We list the best resources from where you can **download free Linux games** as well as buy premium Linux games.
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
8 simple ways to promote team communication
|
||||
======
|
||||
|
||||
translating
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
73
sources/talk/20180122 How to price cryptocurrencies.md
Normal file
73
sources/talk/20180122 How to price cryptocurrencies.md
Normal file
@ -0,0 +1,73 @@
|
||||
How to price cryptocurrencies
|
||||
======
|
||||
|
||||

|
||||
|
||||
Predicting cryptocurrency prices is a fool's game, yet this fool is about to try. The drivers of a single cryptocurrency's value are currently too varied and vague to make assessments based on any one point. News is trending up on Bitcoin? Maybe there's a hack or an API failure that is driving it down at the same time. Ethereum looking sluggish? Who knows: Maybe someone will build a new smarter DAO tomorrow that will draw in the big spenders.
|
||||
|
||||
So how do you invest? Or, more correctly, on which currency should you bet?
|
||||
|
||||
The key to understanding what to buy or sell and when to hold is to use the tools associated with assessing the value of open-source projects. This has been said again and again, but to understand the current crypto boom you have to go back to the quiet rise of Linux.
|
||||
|
||||
Linux appeared on most radars during the dot-com bubble. At that time, if you wanted to set up a web server, you had to physically ship a Windows server or Sun Sparc Station to a server farm where it would do the hard work of delivering Pets.com HTML. At the same time, Linux, like a freight train running on a parallel path to Microsoft and Sun, would consistently allow developers to build one-off projects very quickly and easily using an OS and toolset that were improving daily. In comparison, then, the massive hardware and software expenditures associated with the status quo solution providers were deeply inefficient, and very quickly all of the tech giants that made their money on software now made their money on services or, like Sun, folded.
|
||||
|
||||
From the acorn of Linux an open-source forest bloomed. But there was one clear problem: You couldn't make money from open source. You could consult and you could sell products that used open-source components, but early builders built primarily for the betterment of humanity and not the betterment of their bank accounts.
|
||||
|
||||
Cryptocurrencies have followed the Linux model almost exactly, but cryptocurrencies have cash value. Therefore, when you're working on a crypto project you're not doing it for the common good or for the joy of writing free software. You're writing it with the expectation of a big payout. This, therefore, clouds the value judgements of many programmers. The same folks that brought you Python, PHP, Django and Node.js are back… and now they're programming money.
|
||||
|
||||
### Check the codebase
|
||||
|
||||
This year will be the year of great reckoning in the token sale and cryptocurrency space. While many companies have been able to get away with poor or unusable codebases, I doubt developers will let future companies get away with so much smoke and mirrors. It's safe to say we can [expect posts like this one detailing Storj's anemic codebase to become the norm][1] and, more importantly, that these commentaries will sink many so-called ICOs. Though massive, the money trough that is flowing from ICO to ICO is finite and at some point there will be greater scrutiny paid to incomplete work.
|
||||
|
||||
What does this mean? It means to understand cryptocurrency you have to treat it like a startup. Does it have a good team? Does it have a good product? Does the product work? Would someone want to use it? It's far too early to assess the value of cryptocurrency as a whole, but if we assume that tokens or coins will become the way computers pay each other in the future, this lets us hand wave away a lot of doubt. After all, not many people knew in 2000 that Apache was going to beat nearly every other web server in a crowded market or that Ubuntu instances would be so common that you'd spin them up and destroy them in an instant.
|
||||
|
||||
The key to understanding cryptocurrency pricing is to ignore the froth, hype and FUD and instead focus on true utility. Do you think that some day your phone will pay another phone for, say, an in-game perk? Do you expect the credit card system to fold in the face of an Internet of Value? Do you expect that one day you'll move through life splashing out small bits of value in order to make yourself more comfortable? Then by all means, buy and hold or speculate on things that you think will make your life better. If you don't expect the Internet of Value to improve your life the way the TCP/IP internet did (or you do not understand enough to hold an opinion), then you're probably not cut out for this. NASDAQ is always open, at least during banker's hours.
|
||||
|
||||
Still will us? Good, here are my predictions.
|
||||
|
||||
### The rundown
|
||||
|
||||
Here is my assessment of what you should look at when considering an "investment" in cryptocurrencies. There are a number of caveats we must address before we begin:
|
||||
|
||||
* Crypto is not a monetary investment in a real currency, but an investment in a pie-in-the-sky technofuture. That's right: When you buy crypto you're basically assuming that we'll all be on the deck of the Starship Enterprise exchanging them like Galactic Credits one day. This is the only inevitable future for crypto bulls. While you can force crypto into various economic models and hope for the best, the entire platform is techno-utopianist and assumes all sorts of exciting and unlikely things will come to pass in the next few years. If you have spare cash lying around and you like Star Wars, then you're golden. If you bought bitcoin on a credit card because your cousin told you to, then you're probably going to have a bad time.
|
||||
* Don't trust anyone. There is no guarantee and, in addition to offering the disclaimer that this is not investment advice and that this is in no way an endorsement of any particular cryptocurrency or even the concept in general, we must understand that everything I write here could be wrong. In fact, everything ever written about crypto could be wrong, and anyone who is trying to sell you a token with exciting upside is almost certainly wrong. In short, everyone is wrong and everyone is out to get you, so be very, very careful.
|
||||
* You might as well hold. If you bought when BTC was $18,000 you'd best just hold on. Right now you're in Pascal's Wager territory. Yes, maybe you're angry at crypto for screwing you, but maybe you were just stupid and you got in too high and now you might as well keep believing because nothing is certain, or you can admit that you were a bit overeager and now you're being punished for it but that there is some sort of bitcoin god out there watching over you. Ultimately you need to take a deep breath, agree that all of this is pretty freaking weird, and hold on.
|
||||
|
||||
|
||||
|
||||
Now on with the assessments.
|
||||
|
||||
**Bitcoin** - Expect a rise over the next year that will surpass the current low. Also expect [bumps as the SEC and other federal agencies][2] around the world begin regulating the buying and selling of cryptocurrencies in very real ways. Now that banks are in on the joke they're going to want to reduce risk. Therefore, the bitcoin will become digital gold, a staid, boring and volatility proof safe haven for speculators. Although all but unusable as a real currency, it's good enough for what we need it to do and we also can expect quantum computing hardware to change the face of the oldest and most familiar cryptocurrency.
|
||||
|
||||
**Ethereum** - Ethereum could sustain another few thousand dollars on its price as long as Vitalik Buterin, the creator, doesn't throw too much cold water on it. Like a remorseful Victor Frankenstein, Buterin tends to make amazing things and then denigrate them online, a sort of self-flagellation that is actually quite useful in a space full of froth and outright lies. Ethereum is the closest we've come to a useful cryptocurrency, but it is still the Raspberry Pi of distributed computing -- it's a useful and clever hack that makes it easy to experiment but no one has quite replaced the old systems with new distributed data stores or applications. In short, it's a really exciting technology, but nobody knows what to do with it.
|
||||
|
||||
![][3]
|
||||
|
||||
Where will the price go? It will hover around $1,000 and possibly go as high as $1,500 this year, but this is a principled tech project and not a store of value.
|
||||
|
||||
**Altcoins** - One of the signs of a bubble is when average people make statements like "I couldn't afford a Bitcoin so I bought a Litecoin." This is exactly what I've heard multiple times from multiple people and it's akin to saying "I couldn't buy hamburger so I bought a pound of sawdust instead. I think the kids will eat it, right?" Play at your own risk. Altcoins are a very useful low-risk play for many, and if you create an algorithm -- say to sell when the asset hits a certain level -- then you could make a nice profit. Further, most altcoins will not disappear overnight. I would honestly recommend playing with Ethereum instead of altcoins, but if you're dead set on it, then by all means, enjoy.
|
||||
|
||||
**Tokens** - This is where cryptocurrency gets interesting. Tokens require research, education and a deep understanding of technology to truly assess. Many of the tokens I've seen are true crapshoots and are used primarily as pump and dump vehicles. I won't name names, but the rule of thumb is that if you're buying a token on an open market then you've probably already missed out. The value of the token sale as of January 2018 is to allow crypto whales to turn a few cent per token investment into a 100X return. While many founders talk about the magic of their product and the power of their team, token sales are quite simply vehicles to turn 4 cents into 20 cents into a dollar. Multiply that by millions of tokens and you see the draw.
|
||||
|
||||
The answer is simple: find a few projects you like and lurk in their message boards. Assess if the team is competent and figure out how to get in very, very early. Also expect your money to disappear into a rat hole in a few months or years. There are no sure things, and tokens are far too bleeding-edge a technology to assess sanely.
|
||||
|
||||
You are reading this post because you are looking to maintain confirmation bias in a confusing space. That's fine. I've spoken to enough crypto-heads to know that nobody knows anything right now and that collusion and dirty dealings are the rule of the day. Therefore, it's up to folks like us to slowly buy surely begin to understand just what's going on and, perhaps, profit from it. At the very least we'll all get a new Linux of Value when we're all done.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2018/01/22/how-to-price-cryptocurrencies/
|
||||
|
||||
作者:[John Biggs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/john-biggs/
|
||||
[1]:https://shitcoin.com/storj-not-a-dropbox-killer-1a9f27983d70
|
||||
[2]:http://www.businessinsider.com/bitcoin-price-cryptocurrency-warning-from-sec-cftc-2018-1
|
||||
[3]:https://tctechcrunch2011.files.wordpress.com/2018/01/vitalik-twitter-1312.png?w=525&h=615
|
||||
[4]:https://unsplash.com/photos/pElSkGRA2NU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/cash?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,170 @@
|
||||
Linux / Unix Bash Shell List All Builtin Commands
|
||||
======
|
||||
|
||||
Builtin commands contained within the bash shell itself. How do I list all built-in bash commands on Linux / Apple OS X / *BSD / Unix like operating systems without reading large size bash man page?
|
||||
|
||||
A shell builtin is nothing but command or a function, called from a shell, that is executed directly in the shell itself. The bash shell executes the command directly, without invoking another program. You can view information for Bash built-ins with help command. There are different types of built-in commands.
|
||||
|
||||
|
||||
### built-in command types
|
||||
|
||||
1. Bourne Shell Builtins: Builtin commands inherited from the Bourne Shell.
|
||||
2. Bash Builtins: Table of builtins specific to Bash.
|
||||
3. Modifying Shell Behavior: Builtins to modify shell attributes and optional behavior.
|
||||
4. Special Builtins: Builtin commands classified specially by POSIX.
|
||||
|
||||
|
||||
|
||||
### How to see all bash builtins
|
||||
|
||||
Type the following command:
|
||||
```
|
||||
$ help
|
||||
$ help | less
|
||||
$ help | grep read
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
GNU bash, version 4.1.5(1)-release (x86_64-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
Type `help name' to find out more about the function `name'.
|
||||
Use `info bash' to find out more about the shell in general.
|
||||
Use `man -k' or `info' to find out more about commands not in this list.
|
||||
|
||||
A star (*) next to a name means that the command is disabled.
|
||||
|
||||
job_spec [&] history [-c] [-d offset] [n] or hist>
|
||||
(( expression )) if COMMANDS; then COMMANDS; [ elif C>
|
||||
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs >
|
||||
: kill [-s sigspec | -n signum | -sigs>
|
||||
[ arg... ] let arg [arg ...]
|
||||
[[ expression ]] local [option] name[=value] ...
|
||||
alias [-p] [name[=value] ... ] logout [n]
|
||||
bg [job_spec ...] mapfile [-n count] [-O origin] [-s c>
|
||||
bind [-lpvsPVS] [-m keymap] [-f filen> popd [-n] [+N | -N]
|
||||
break [n] printf [-v var] format [arguments]
|
||||
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
|
||||
caller [expr] pwd [-LP]
|
||||
case WORD in [PATTERN [| PATTERN]...)> read [-ers] [-a array] [-d delim] [->
|
||||
cd [-L|-P] [dir] readarray [-n count] [-O origin] [-s>
|
||||
command [-pVv] command [arg ...] readonly [-af] [name[=value] ...] or>
|
||||
compgen [-abcdefgjksuv] [-o option] > return [n]
|
||||
complete [-abcdefgjksuv] [-pr] [-DE] > select NAME [in WORDS ... ;] do COMM>
|
||||
compopt [-o|+o option] [-DE] [name ..> set [--abefhkmnptuvxBCHP] [-o option>
|
||||
continue [n] shift [n]
|
||||
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
|
||||
declare [-aAfFilrtux] [-p] [name[=val> source filename [arguments]
|
||||
dirs [-clpv] [+N] [-N] suspend [-f]
|
||||
disown [-h] [-ar] [jobspec ...] test [expr]
|
||||
echo [-neE] [arg ...] time [-p] pipeline
|
||||
enable [-a] [-dnps] [-f filename] [na> times
|
||||
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
|
||||
exec [-cl] [-a name] [command [argume> true
|
||||
exit [n] type [-afptP] name [name ...]
|
||||
export [-fn] [name[=value] ...] or ex> typeset [-aAfFilrtux] [-p] name[=val>
|
||||
false ulimit [-SHacdefilmnpqrstuvx] [limit>
|
||||
fc [-e ename] [-lnr] [first] [last] o> umask [-p] [-S] [mode]
|
||||
fg [job_spec] unalias [-a] name [name ...]
|
||||
for NAME [in WORDS ... ] ; do COMMAND> unset [-f] [-v] [name ...]
|
||||
for (( exp1; exp2; exp3 )); do COMMAN> until COMMANDS; do COMMANDS; done
|
||||
function name { COMMANDS ; } or name > variables - Names and meanings of so>
|
||||
getopts optstring name [arg] wait [id]
|
||||
hash [-lr] [-p pathname] [-dt] [name > while COMMANDS; do COMMANDS; done
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
### Viewing information for Bash built-ins
|
||||
|
||||
To get detailed info run:
|
||||
```
|
||||
help command
|
||||
help read
|
||||
```
|
||||
To just get a list of all built-ins with a short description, execute:
|
||||
|
||||
`$ help -d`
|
||||
|
||||
### Find syntax and other options for builtins
|
||||
|
||||
Use the following syntax ' to find out more about the builtins commands:
|
||||
```
|
||||
help name
|
||||
help cd
|
||||
help fg
|
||||
help for
|
||||
help read
|
||||
help :
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
:: :
|
||||
Null command.
|
||||
|
||||
No effect; the command does nothing.
|
||||
|
||||
Exit Status:
|
||||
Always succeeds
|
||||
```
|
||||
|
||||
### Find out if a command is internal (builtin) or external
|
||||
|
||||
Use the type command or command command:
|
||||
```
|
||||
type -a command-name-here
|
||||
type -a cd
|
||||
type -a uname
|
||||
type -a :
|
||||
type -a ls
|
||||
```
|
||||
|
||||
|
||||
OR
|
||||
```
|
||||
type -a cd uname : ls uname
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
cd is a shell builtin
|
||||
uname is /bin/uname
|
||||
: is a shell builtin
|
||||
ls is aliased to `ls --color=auto'
|
||||
ls is /bin/ls
|
||||
l is a function
|
||||
l ()
|
||||
{
|
||||
ls --color=auto
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
OR
|
||||
```
|
||||
command -V ls
|
||||
command -V cd
|
||||
command -V foo
|
||||
```
|
||||
|
||||
[![View list bash built-ins command info on Linux or Unix][1]][1]
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][2], [Facebook][3], [Google+][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/linux-unix-bash-shell-list-all-builtin-commands/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2013/03/View-list-bash-built-ins-command-info-on-Linux-or-Unix.jpg
|
||||
[2]:https://twitter.com/nixcraft
|
||||
[3]:https://facebook.com/nixcraft
|
||||
[4]:https://plus.google.com/+CybercitiBiz
|
||||
173
sources/tech/20140523 Tail Calls Optimization and ES6.md
Normal file
173
sources/tech/20140523 Tail Calls Optimization and ES6.md
Normal file
@ -0,0 +1,173 @@
|
||||
#Translating by qhwdw [Tail Calls, Optimization, and ES6][1]
|
||||
|
||||
|
||||
In this penultimate post about the stack, we take a quick look at tail calls, compiler optimizations, and the proper tail calls landing in the newest version of JavaScript.
|
||||
|
||||
A tail call happens when a function F makes a function call as its final action. At that point F will do absolutely no more work: it passes the ball to whatever function is being called and vanishes from the game. This is notable because it opens up the possibility of tail call optimization: instead of [creating a new stack frame][6] for the function call, we can simply reuse F's stack frame, thereby saving stack space and avoiding the work involved in setting up a new frame. Here are some examples in C and their results compiled with [mild optimization][7]:
|
||||
|
||||
Simple Tail Calls[download][2]
|
||||
|
||||
```
|
||||
int add5(int a)
|
||||
{
|
||||
return a + 5;
|
||||
}
|
||||
|
||||
int add10(int a)
|
||||
{
|
||||
int b = add5(a); // not tail
|
||||
return add5(b); // tail
|
||||
}
|
||||
|
||||
int add5AndTriple(int a){
|
||||
int b = add5(a); // not tail
|
||||
return 3 * add5(a); // not tail, doing work after the call
|
||||
}
|
||||
|
||||
int finicky(int a){
|
||||
if (a > 10){
|
||||
return add5AndTriple(a); // tail
|
||||
}
|
||||
|
||||
if (a > 5){
|
||||
int b = add5(a); // not tail
|
||||
return finicky(b); // tail
|
||||
}
|
||||
|
||||
return add10(a); // tail
|
||||
}
|
||||
```
|
||||
|
||||
You can normally spot tail call optimization (hereafter, TCO) in compiler output by seeing a [jump][8] instruction where a [call][9] would have been expected. At runtime TCO leads to a reduced call stack.
|
||||
|
||||
A common misconception is that tail calls are necessarily [recursive][10]. That's not the case: a tail call may be recursive, such as in finicky() above, but it need not be. As long as caller F is completely done at the call site, we've got ourselves a tail call. Whether it can be optimized is a different question whose answer depends on your programming environment.
|
||||
|
||||
"Yes, it can, always!" is the best answer we can hope for, which is famously the case for Scheme, as discussed in [SICP][11] (by the way, if when you program you don't feel like "a Sorcerer conjuring the spirits of the computer with your spells," I urge you to read that book). It's also the case for [Lua][12]. And most importantly, it is the case for the next version of JavaScript, ES6, whose spec does a good job defining [tail position][13] and clarifying the few conditions required for optimization, such as [strict mode][14]. When a language guarantees TCO, it supports proper tail calls.
|
||||
|
||||
Now some of us can't kick that C habit, heart bleed and all, and the answer there is a more complicated "sometimes" that takes us into compiler optimization territory. We've seen the [simple examples][15] above; now let's resurrect our factorial from [last post][16]:
|
||||
|
||||
Recursive Factorial[download][3]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
So, is line 11 a tail call? It's not, because of the multiplication by n afterwards. But if you're not used to optimizations, gcc's [result][17] with [O2 optimization][18] might shock you: not only it transforms factorial into a [recursion-free loop][19], but the factorial(5) call is eliminated entirely and replaced by a [compile-time constant][20] of 120 (5! == 120). This is why debugging optimized code can be hard sometimes. On the plus side, if you call this function it will use a single stack frame regardless of n's initial value. Compiler algorithms are pretty fun, and if you're interested I suggest you check out [Building an Optimizing Compiler][21] and [ACDI][22].
|
||||
|
||||
However, what happened here was not tail call optimization, since there was no tail call to begin with. gcc outsmarted us by analyzing what the function does and optimizing away the needless recursion. The task was made easier by the simple, deterministic nature of the operations being done. By adding a dash of chaos (e.g., getpid()) we can throw gcc off:
|
||||
|
||||
Recursive PID Factorial[download][4]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int pidFactorial(int n)
|
||||
{
|
||||
if (1 == n) {
|
||||
return getpid(); // tail
|
||||
}
|
||||
|
||||
return n * pidFactorial(n-1) * getpid(); // not tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = pidFactorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
Optimize that, unix fairies! So now we have a regular [recursive call][23] and this function allocates O(n) stack frames to do its work. Heroically, gcc still does [TCO for getpid][24] in the recursion base case. If we now wished to make this function tail recursive, we'd need a slight change:
|
||||
|
||||
tailPidFactorial.c[download][5]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int tailPidFactorial(int n, int acc)
|
||||
{
|
||||
if (1 == n) {
|
||||
return acc * getpid(); // not tail
|
||||
}
|
||||
|
||||
acc = (acc * getpid() * n);
|
||||
return tailPidFactorial(n-1, acc); // tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = tailPidFactorial(5, 1);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
The accumulation of the result is now [a loop][25] and we've achieved true TCO. But before you go out partying, what can we say about the general case in C? Sadly, while good C compilers do TCO in a number of cases, there are many situations where they cannot do it. For example, as we saw in our [function epilogues][26], the caller is responsible for cleaning up the stack after a function call using the standard C calling convention. So if function F takes two arguments, it can only make TCO calls to functions taking two or fewer arguments. This is one among many restrictions. Mark Probst wrote an excellent thesis discussing [Proper Tail Recursion in C][27] where he discusses these issues along with C stack behavior. He also does [insanely cool juggling][28].
|
||||
|
||||
"Sometimes" is a rocky foundation for any relationship, so you can't rely on TCO in C. It's a discrete optimization that may or may not take place, rather than a language feature like proper tail calls, though in practice the compiler will optimize the vast majority of cases. But if you must have it, say for transpiling Scheme into C, you will [suffer][29].
|
||||
|
||||
Since JavaScript is now the most popular transpilation target, proper tail calls become even more important there. So kudos to ES6 for delivering it along with many other significant improvements. It's like Christmas for JS programmers.
|
||||
|
||||
This concludes our brief tour of tail calls and compiler optimization. Thanks for reading and see you next time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/tail.c
|
||||
[3]:https://manybutfinite.com/code/x86-stack/factorial.c
|
||||
[4]:https://manybutfinite.com/code/x86-stack/pidFactorial.c
|
||||
[5]:https://manybutfinite.com/code/x86-stack/tailPidFactorial.c
|
||||
[6]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39
|
||||
[10]:https://manybutfinite.com/post/recursion/
|
||||
[11]:http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html
|
||||
[12]:http://www.lua.org/pil/6.3.html
|
||||
[13]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-tail-position-calls
|
||||
[14]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-strict-mode-code
|
||||
[15]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c
|
||||
[16]:https://manybutfinite.com/post/recursion/
|
||||
[17]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s
|
||||
[18]:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
|
||||
[19]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19
|
||||
[20]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38
|
||||
[21]:http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/
|
||||
[22]:http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/
|
||||
[23]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20
|
||||
[24]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43
|
||||
[25]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27
|
||||
[26]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[27]:http://www.complang.tuwien.ac.at/schani/diplarb.ps
|
||||
[28]:http://www.complang.tuwien.ac.at/schani/jugglevids/index.html
|
||||
[29]:http://en.wikipedia.org/wiki/Tail_call#Through_trampolining
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Ansible Tutorial: Intorduction to simple Ansible commands
|
||||
======
|
||||
In our earlier Ansible tutorial, we discussed [**the installation & configuration of Ansible**][1]. Now in this ansible tutorial, we will learn some basic examples of ansible commands that we will use to manage our infrastructure. So let us start by looking at the syntax of a complete ansible command,
|
||||
|
||||
@ -1,93 +0,0 @@
|
||||
Translated by name1e5s
|
||||
|
||||
The big break in computer languages
|
||||
============================================================
|
||||
|
||||
|
||||
My last post ([The long goodbye to C][3]) elicited a comment from a C++ expert I was friends with long ago, recommending C++ as the language to replace C. Which ain’t gonna happen; if that were a viable future, Go and Rust would never have been conceived.
|
||||
|
||||
But my readers deserve more than a bald assertion. So here, for the record, is the story of why I don’t touch C++ any more. This is a launch point for a disquisition on the economics of computer-language design, why some truly unfortunate choices got made and baked into our infrastructure, and how we’re probably going to fix them.
|
||||
|
||||
Along the way I will draw aside the veil from a rather basic mistake that people trying to see into the future of programming languages (including me) have been making since the 1980s. Only very recently do we have the field evidence to notice where we went wrong.
|
||||
|
||||
I think I first picked up C++ because I needed GNU eqn to be able to output MathXML, and eqn was written in C++. That project succeeded. Then I was a senior dev on Battle For Wesnoth for a number of years in the 2000s and got comfortable with the language.
|
||||
|
||||
Then came the day we discovered that a person we incautiously gave commit privileges to had fucked up the games’s AI core. It became apparent that I was the only dev on the team not too frightened of that code to go in. And I fixed it all right – took me two weeks of struggle. After which I swore a mighty oath never to go near C++ again.
|
||||
|
||||
My problem with the language, starkly revealed by that adventure, is that it piles complexity on complexity upon chrome upon gingerbread in an attempt to address problems that cannot actually be solved because the foundational abstractions are leaky. It’s all very well to say “well, don’t do that” about things like bare pointers, and for small-scale single-developer projects (like my eqn upgrade) it is realistic to expect the discipline can be enforced.
|
||||
|
||||
Not so on projects with larger scale or multiple devs at varying skill levels (the case I normally deal with). With probability asymptotically approaching one over time and increasing LOC, someone is inadvertently going to poke through one of the leaks. At which point you have a bug which, because of over-layers of gnarly complexity such as STL, is much more difficult to characterize and fix than the equivalent defect in C. My Battle For Wesnoth experience rubbed my nose in this problem pretty hard.
|
||||
|
||||
What works for a Steve Heller (my old friend and C++ advocate) doesn’t scale up when I’m dealing with multiple non-Steve-Hellers and might end up having to clean up their mess. So I just don’t go there any more. Not worth the aggravation. C is flawed, but it does have one immensely valuable property that C++ didn’t keep – if you can mentally model the hardware it’s running on, you can easily see all the way down. If C++ had actually eliminated C’s flaws (that it, been type-safe and memory-safe) giving away that transparency might be a trade worth making. As it is, nope.
|
||||
|
||||
One way we can tell that C++ is not sufficient is to imagine an alternate world in which it is. In that world, older C projects would routinely up-migrate to C++. Major OS kernels would be written in C++, and existing kernel implementations like Linux would be upgrading to it. In the real world, this ain’t happening. Not only has C++ failed to present enough of a value proposition to keep language designers uninterested in imagining languages like D, Go, and Rust, it has failed to displace its own ancestor. There’s no path forward from C++ without breaching its core assumptions; thus, the abstraction leaks won’t go away.
|
||||
|
||||
Since I’ve mentioned D, I suppose this is also the point at which I should explain why I don’t see it as a serious contender to replace C. Yes, it was spun up eight years before Rust and nine years before Go – props to Walter Bright for having the vision. But in 2001 the example of Perl and Python had already been set – the window when a proprietary language could compete seriously with open source was already closing. The wrestling match between the official D library/runtime and Tango hurt it, too. It has never recovered from those mistakes.
|
||||
|
||||
So now there’s Go (I’d say “…and Rust”, but for reasons I’ve discussed before I think it will be years before Rust is fully competitive). It _is_ type-safe and memory-safe (well, almost; you can partway escape using interfaces, but it’s not normal to have to go to the unsafe places). One of my regulars, Mark Atwood, has correctly pointed out that Go is a language made of grumpy-old-man rage, specifically rage by _one of the designers of C_ (Ken Thompson) at the bloated mess that C++ became.
|
||||
|
||||
I can relate to Ken’s grumpiness; I’ve been muttering for decades that C++ attacked the wrong problem. There were two directions a successor language to C might have gone. One was to do what C++ did – accept C’s leaky abstractions, bare pointers and all, for backward compatibility, than try to build a state-of-the-art language on top of them. The other would have been to attack C’s problems at their root – _fix_ the leaky abstractions. That would break backward compatibility, but it would foreclose the class of problems that dominate C/C++ defects.
|
||||
|
||||
The first serious attempt at the second path was Java in 1995\. It wasn’t a bad try, but the choice to build it over a j-code interpreter mode it unsuitable for systems programming. That left a huge hole in the options for systems programming that wouldn’t be properly addressed for another 15 years, until Rust and Go. In particular, it’s why software like my GPSD and NTPsec projects is still predominantly written in C in 2017 despite C’s manifest problems.
|
||||
|
||||
This is in many ways a bad situation. It was hard to really see this because of the lack of viable alternatives, but C/C++ has not scaled well. Most of us take for granted the escalating rate of defects and security compromises in infrastructure software without really thinking about how much of that is due to really fundamental language problems like buffer-overrun vulnerabilities.
|
||||
|
||||
So, why did it take so long to address that? It was 37 years from C (1972) to Go (2009); Rust only launched a year sooner. I think the underlying reasons are economic.
|
||||
|
||||
Ever since the very earliest computer languages it’s been understood that every language design embodies an assertion about the relative value of programmer time vs. machine resources. At one end of that spectrum you have languages like assembler and (later) C that are designed to extract maximum performance at the cost of also pessimizing developer time and costs; at the other, languages like Lisp and (later) Python that try to automate away as much housekeeping detail as possible, at the cost of pessimizing machine performance.
|
||||
|
||||
In broadest terms, the most important discriminator between the ends of this spectrum is the presence or absence of automatic memory management. This corresponds exactly to the empirical observation that memory-management bugs are by far the most common class of defects in machine-centric languages that require programmers to manage that resource by hand.
|
||||
|
||||
A language becomes economically viable where and when its relative-value assertion matches the actual cost drivers of some particular area of software development. Language designers respond to the conditions around them by inventing languages that are a better fit for present or near-future conditions than the languages they have available to use.
|
||||
|
||||
Over time, there’s been a gradual shift from languages that require manual memory management to languages with automatic memory management and garbage collection (GC). This shift corresponds to the Moore’s Law effect of decreasing hardware costs making programmer time relatively more expensive. But there are at least two other relevant dimensions.
|
||||
|
||||
One is distance from the bare metal. Inefficiency low in the software stack (kernels and service code) ripples multiplicatively up the stack. This, we see machine-centric languages down low and programmer-centric languages higher up, most often in user-facing software that only has to respond at human speed (time scale 0.1 sec).
|
||||
|
||||
Another is project scale. Every language also has an expected rate of induced defects per thousand lines of code due to programmers tripping over leaks and flaws in its abstractions. This rate runs higher in machine-centric languages, much lower in programmer-centric ones with GC. As project scale goes up, therefore, languages with GC become more and more important as a strategy against unacceptable defect rates.
|
||||
|
||||
When we view language deployments along these three dimensions, the observed pattern today – C down below, an increasing gallimaufry of languages with GC above – almost makes sense. Almost. But there is something else going on. C is stickier than it ought to be, and used way further up the stack than actually makes sense.
|
||||
|
||||
Why do I say this? Consider the classic Unix command-line utilities. These are generally pretty small programs that would run acceptably fast implemented in a scripting language with a full POSIX binding. Re-coded that way they would be vastly easier to debug, maintain and extend.
|
||||
|
||||
Why are these still in C (or, in unusual exceptions like eqn, in C++)? Transition costs. It’s difficult to translate even small, simple programs between languages and verify that you have faithfully preserved all non-error behaviors. More generally, any area of applications or systems programming can stay stuck to a language well after the tradeoff that language embodies is actually obsolete.
|
||||
|
||||
Here’s where I get to the big mistake I and other prognosticators made. We thought falling machine-resource costs – increasing the relative cost of programmer-hours – would be enough by themselves to displace C (and non-GC languages generally). In this we were not entirely or even mostly wrong – the rise of scripting languages, Java, and things like Node.js since the early 1990s was pretty obviously driven that way.
|
||||
|
||||
Not so the new wave of contending systems-programming languages, though. Rust and Go are both explicitly responses to _increasing project scale_ . Where scripting languages got started as an effective way to write small programs and gradually scaled up, Rust and Go were positioned from the start as ways to reduce defect rates in _really large_ projects. Like, Google’s search service and Facebook’s real-time-chat multiplexer.
|
||||
|
||||
I think this is the answer to the “why not sooner” question. Rust and Go aren’t actually late at all, they’re relatively prompt responses to a cost driver that was underweighted until recently.
|
||||
|
||||
OK, so much for theory. What predictions does this one generate? What does it tell us about what comes after C?
|
||||
|
||||
Here’s the big one. The largest trend driving development towards GC languages haven’t reversed, and there’s no reason to expect it will. Therefore: eventually we _will_ have GC techniques with low enough latency overhead to be usable in kernels and low-level firmware, and those will ship in language implementations. Those are the languages that will truly end C’s long reign.
|
||||
|
||||
There are broad hints in the working papers from the Go development group that they’re headed in this direction – references to academic work on concurrent garbage collectors that never have stop-the-world pauses. If Go itself doesn’t pick up this option, other language designers will. But I think they will – the business case for Google to push them there is obvious (can you say “Android development”?).
|
||||
|
||||
Well before we get to GC that good, I’m putting my bet on Go to replace C anywhere that the GC it has now is affordable – which means not just applications but most systems work outside of kernels and embedded. The reason is simple: there is no path out of C’s defect rates with lower transition costs.
|
||||
|
||||
I’ve been experimenting with moving C code to Go over the last week, and I’m noticing two things. One is that it’s easy to do – C’s idioms map over pretty well. The other is that the resulting code is much simpler. One would expect that, with GC in the language and maps as a first-class data type, but I’m seeing larger reductions in code volume than initially expected – about 2:1, similar to what I see when moving C code to Python.
|
||||
|
||||
Sorry, Rustaceans – you’ve got a plausible future in kernels and deep firmware, but too many strikes against you to beat Go over most of C’s range. No GC, plus Rust is a harder transition from C because of the borrow checker, plus the standardized part of the API is still seriously incomplete (where’s my select(2), again?).
|
||||
|
||||
The only consolation you get, if it is one, is that the C++ fans are screwed worse than you are. At least Rust has a real prospect of dramatically lowering downstream defect rates relative to C anywhere it’s not crowded out by Go; C++ doesn’t have that.
|
||||
|
||||
This entry was posted in [Software][4] by [Eric Raymond][5]. Bookmark the [permalink][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7724
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7724
|
||||
[3]:http://esr.ibiblio.org/?p=7711
|
||||
[4]:http://esr.ibiblio.org/?cat=13
|
||||
[5]:http://esr.ibiblio.org/?author=2
|
||||
[6]:http://esr.ibiblio.org/?p=7724
|
||||
319
sources/tech/20180122 A Simple Command-line Snippet Manager.md
Normal file
319
sources/tech/20180122 A Simple Command-line Snippet Manager.md
Normal file
@ -0,0 +1,319 @@
|
||||
A Simple Command-line Snippet Manager
|
||||
======
|
||||
|
||||

|
||||
|
||||
We can't remember all the commands, right? Yes. Except the frequently used commands, it is nearly impossible to remember some long commands that we rarely use. That's why we need to some external tools to help us to find the commands when we need them. In the past, we have reviewed two useful utilities named [**" Bashpast"**][1] and [**" Keep"**][2]. Using Bashpast, we can easily bookmark the Linux commands for easier repeated invocation. And, the Keep utility can be used to keep the some important and lengthy commands in your Terminal, so you can use them on demand. Today, we are going to see yet another tool in the series to help you remembering commands. Say hello to **" Pet"**, a simple command-line snippet manager written in **Go** language.
|
||||
|
||||
Using Pet, you can;
|
||||
|
||||
* Register/add your important, long and complex command snippets.
|
||||
* Search the saved command snippets interactively.
|
||||
* Run snippets directly without having to type over and over.
|
||||
* Edit the saved command snippets easily.
|
||||
* Sync the snippets via Gist.
|
||||
* Use variables in snippets.
|
||||
* And more yet to come.
|
||||
|
||||
|
||||
|
||||
#### Installing Pet CLI Snippet Manager
|
||||
|
||||
Since it is written in Go language, make sure you have installed Go in your system.
|
||||
|
||||
After Go language, grab the latest binaries from [**the releases page**][3].
|
||||
```
|
||||
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_amd64.zip
|
||||
```
|
||||
|
||||
For 32 bit:
|
||||
```
|
||||
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_386.zip
|
||||
```
|
||||
|
||||
Extract the downloaded archive:
|
||||
```
|
||||
unzip pet_0.2.4_linux_amd64.zip
|
||||
```
|
||||
|
||||
32 bit:
|
||||
```
|
||||
unzip pet_0.2.4_linux_386.zip
|
||||
```
|
||||
|
||||
Copy the pet binary file to your PATH (i.e **/usr/local/bin** or the like).
|
||||
```
|
||||
sudo cp pet /usr/local/bin/
|
||||
```
|
||||
|
||||
Finally, make it executable:
|
||||
```
|
||||
sudo chmod +x /usr/local/bin/pet
|
||||
```
|
||||
|
||||
If you're using Arch based systems, then you can install it from AUR using any AUR helper tools.
|
||||
|
||||
Using [**Pacaur**][4]:
|
||||
```
|
||||
pacaur -S pet-git
|
||||
```
|
||||
|
||||
Using [**Packer**][5]:
|
||||
```
|
||||
packer -S pet-git
|
||||
```
|
||||
|
||||
Using [**Yaourt**][6]:
|
||||
```
|
||||
yaourt -S pet-git
|
||||
```
|
||||
|
||||
Using [**Yay** :][7]
|
||||
```
|
||||
yay -S pet-git
|
||||
```
|
||||
|
||||
Also, you need to install **[fzf][8]** or [**peco**][9] tools to enable interactive search. Refer the official GitHub links to know how to install these tools.
|
||||
|
||||
#### Usage
|
||||
|
||||
Run 'pet' without any arguments to view the list of available commands and general options.
|
||||
```
|
||||
$ pet
|
||||
pet - Simple command-line snippet manager.
|
||||
|
||||
Usage:
|
||||
pet [command]
|
||||
|
||||
Available Commands:
|
||||
configure Edit config file
|
||||
edit Edit snippet file
|
||||
exec Run the selected commands
|
||||
help Help about any command
|
||||
list Show all snippets
|
||||
new Create a new snippet
|
||||
search Search snippets
|
||||
sync Sync snippets
|
||||
version Print the version number
|
||||
|
||||
Flags:
|
||||
--config string config file (default is $HOME/.config/pet/config.toml)
|
||||
--debug debug mode
|
||||
-h, --help help for pet
|
||||
|
||||
Use "pet [command] --help" for more information about a command.
|
||||
```
|
||||
|
||||
To view the help section of a specific command, run:
|
||||
```
|
||||
$ pet [command] --help
|
||||
```
|
||||
|
||||
**Configure Pet**
|
||||
|
||||
It just works fine with default values. However, you can change the default directory to save snippets, choose the selector (fzf or peco) to use, the default text editor to edit snippets, add GIST id details etc.
|
||||
|
||||
To configure Pet, run:
|
||||
```
|
||||
$ pet configure
|
||||
```
|
||||
|
||||
This command will open the default configuration in the default text editor (for example **vim** in my case). Change/edit the values as per your requirements.
|
||||
```
|
||||
[General]
|
||||
snippetfile = "/home/sk/.config/pet/snippet.toml"
|
||||
editor = "vim"
|
||||
column = 40
|
||||
selectcmd = "fzf"
|
||||
|
||||
[Gist]
|
||||
file_name = "pet-snippet.toml"
|
||||
access_token = ""
|
||||
gist_id = ""
|
||||
public = false
|
||||
~
|
||||
```
|
||||
|
||||
**Creating Snippets**
|
||||
|
||||
To create a new snippet, run:
|
||||
```
|
||||
$ pet new
|
||||
```
|
||||
|
||||
Add the command and the description and hit ENTER to save it.
|
||||
```
|
||||
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'
|
||||
Description> Remove numbers from output.
|
||||
```
|
||||
|
||||
[![][10]][11]
|
||||
|
||||
This is a simple command to remove all numbers from the echo command output. You can easily remember it. But, if you rarely use it, you may forgot it completely after few days. Of course we can search the history using "CTRL+r", but "Pet" is much easier. Also, Pet can help you to add any number of entries.
|
||||
|
||||
Another cool feature is we can easily add the previous command. To do so, add the following lines in your **.bashrc** or **.zshrc** file.
|
||||
```
|
||||
function prev() {
|
||||
PREV=$(fc -lrn | head -n 1)
|
||||
sh -c "pet new `printf %q "$PREV"`"
|
||||
}
|
||||
```
|
||||
|
||||
Do the following command to take effect the saved changes.
|
||||
```
|
||||
source .bashrc
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
source .zshrc
|
||||
```
|
||||
|
||||
Now, run any command, for example:
|
||||
```
|
||||
$ cat Documents/ostechnix.txt | tr '|' '\n' | sort | tr '\n' '|' | sed "s/.$/\\n/g"
|
||||
```
|
||||
|
||||
To add the above command, you don't have to use "pet new" command. just do:
|
||||
```
|
||||
$ prev
|
||||
```
|
||||
|
||||
Add the description to the command snippet and hit ENTER to save.
|
||||
|
||||
[![][10]][12]
|
||||
|
||||
**List snippets**
|
||||
|
||||
To view the saved snippets, run:
|
||||
```
|
||||
$ pet list
|
||||
```
|
||||
|
||||
[![][10]][13]
|
||||
|
||||
**Edit Snippets**
|
||||
|
||||
If you want to edit the description or the command of a snippet, run:
|
||||
```
|
||||
$ pet edit
|
||||
```
|
||||
|
||||
This will open all saved snippets in your default text editor. You can edit or change the snippets as you wish.
|
||||
```
|
||||
[[snippets]]
|
||||
description = "Remove numbers from output."
|
||||
command = "echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'"
|
||||
output = ""
|
||||
|
||||
[[snippets]]
|
||||
description = "Alphabetically sort one line of text"
|
||||
command = "\t prev"
|
||||
output = ""
|
||||
```
|
||||
|
||||
**Use Tags in snippets**
|
||||
|
||||
To use tags to a snippet, use **-t** flag like below.
|
||||
```
|
||||
$ pet new -t
|
||||
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9
|
||||
Description> Remove numbers from output.
|
||||
Tag> tr command examples
|
||||
|
||||
```
|
||||
|
||||
**Execute Snippets**
|
||||
|
||||
To execute a saved snippet, run:
|
||||
```
|
||||
$ pet exec
|
||||
```
|
||||
|
||||
Choose the snippet you want to run from the list and hit ENTER to run it.
|
||||
|
||||
[![][10]][14]
|
||||
|
||||
Remember you need to install fzf or peco to use this feature.
|
||||
|
||||
**Search Snippets**
|
||||
|
||||
If you have plenty of saved snippets, you can easily search them using a string or key word like below.
|
||||
```
|
||||
$ pet search
|
||||
```
|
||||
|
||||
Enter the search term or keyword to narrow down the search results.
|
||||
|
||||
[![][10]][15]
|
||||
|
||||
**Sync Snippets**
|
||||
|
||||
First, you need to obtain the access token. Go to this link <https://github.com/settings/tokens/new> and create access token (only need "gist" scope).
|
||||
|
||||
Configure Pet using command:
|
||||
```
|
||||
$ pet configure
|
||||
```
|
||||
|
||||
Set that token to **access_token** in **[Gist]** field.
|
||||
|
||||
After setting, you can upload snippets to Gist like below.
|
||||
```
|
||||
$ pet sync -u
|
||||
Gist ID: 2dfeeeg5f17e1170bf0c5612fb31a869
|
||||
Upload success
|
||||
|
||||
```
|
||||
|
||||
You can also download snippets on another PC. To do so, edit configuration file and set **Gist ID** to **gist_id** in **[Gist]**.
|
||||
|
||||
Then, download the snippets using command:
|
||||
```
|
||||
$ pet sync
|
||||
Download success
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section:
|
||||
```
|
||||
pet -h
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
pet [command] -h
|
||||
```
|
||||
|
||||
And, that's all. Hope this helps. As you can see, Pet usage is fairly simple and easy to use! If you're having hard time remembering lengthy commands, Pet utility can definitely be useful.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/pet-simple-command-line-snippet-manager/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/bookmark-linux-commands-easier-repeated-invocation/
|
||||
[2]:https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
[3]:https://github.com/knqyf263/pet/releases
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://github.com/junegunn/fzf
|
||||
[9]:https://github.com/peco/peco
|
||||
[10]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-1.png ()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-2.png ()
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-3.png ()
|
||||
[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-4.png ()
|
||||
[15]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-5.png ()
|
||||
@ -0,0 +1,95 @@
|
||||
Linux mkdir Command Explained for Beginners (with examples)
|
||||
======
|
||||
|
||||
At any given time on the command line, you are in a directory. So it speaks for itself how integral directories are to the command line. In Linux, while the rm command lets you delete directories, it's the **mkdir** command that allows you create them in the first place. In this tutorial, we will discuss the basics of this tool using some easy to understand examples.
|
||||
|
||||
But before we do that, it's worth mentioning that all examples in this tutorial have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
### Linux mkdir command
|
||||
|
||||
As already mentioned, the mkdir command allows the user to create directories. Following is its syntax:
|
||||
|
||||
```
|
||||
mkdir [OPTION]... DIRECTORY...
|
||||
```
|
||||
|
||||
And here's how the tool's man page describes it:
|
||||
```
|
||||
Create the DIRECTORY(ies), if they do not already exist.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples should give you a better idea on how mkdir works.
|
||||
|
||||
### Q1. How to create directories using mkdir?
|
||||
|
||||
Creating directories is pretty simple, all you need to do is to pass the name of the directory you want to create to the mkdir command.
|
||||
|
||||
```
|
||||
mkdir [dir-name]
|
||||
```
|
||||
|
||||
Following is an example:
|
||||
|
||||
```
|
||||
mkdir test-dir
|
||||
```
|
||||
|
||||
### Q2. How to make sure parent directories (if non-existent) are created in process?
|
||||
|
||||
Sometimes the requirement is to create a complete directory structure with a single mkdir command. This is possible, but you'll have to use the **-p** command line option.
|
||||
|
||||
For example, if you want to create dir1/dir2/dir2 when none of these directories are already existing, then you can do this in the following way:
|
||||
|
||||
```
|
||||
mkdir -p dir1/dir2/dir3
|
||||
```
|
||||
|
||||
[![How to make sure parent directories \(if non-existent\) are created][1]][2]
|
||||
|
||||
### Q3. How to set permissions for directory being created?
|
||||
|
||||
By default, the mkdir command sets rwx, rwx, and r-x permissions for the directories created through it.
|
||||
|
||||
[![How to set permissions for directory being created][3]][4]
|
||||
|
||||
However, if you want, you can set custom permissions using the **-m** command line option.
|
||||
|
||||
[![mkdir -m command option][5]][6]
|
||||
|
||||
### Q4. How to make mkdir emit details of operation?
|
||||
|
||||
In case you want mkdir to display complete details of the operation it's performing, then this can be done through the **-v** command line option.
|
||||
|
||||
```
|
||||
mkdir -v [dir]
|
||||
```
|
||||
|
||||
Here's an example:
|
||||
|
||||
[![How to make mkdir emit details of operation][7]][8]
|
||||
|
||||
### Conclusion
|
||||
|
||||
So you can see mkdir is a pretty simple command to understand and use. It doesn't have any learning curve associated with it. We have covered almost all of its command line options here. Just practice them and you can start using the command in your day-to-day work. In case you want to know more about the tool, head to its [man page][9].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-mkdir-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/mkdir-p.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-p.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/mkdir-def-perm.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-def-perm.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/mkdir-custom-perm.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-custom-perm.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/mkdir-verbose.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-verbose.png
|
||||
[9]:https://linux.die.net/man/1/mkdir
|
||||
@ -0,0 +1,170 @@
|
||||
Never miss a Magazine's article, build your own RSS notification system
|
||||
======
|
||||
|
||||

|
||||
|
||||
Python is a great programming language to quickly build applications that make our life easier. In this article we will learn how to use Python to build a RSS notification system, the goal being to have fun learning Python using Fedora. If you are looking for a complete RSS notifier application, there are a few already packaged in Fedora.
|
||||
|
||||
### Fedora and Python - getting started
|
||||
|
||||
Python 3.6 is available by default in Fedora, that includes Python's extensive standard library. The standard library provides a collection of modules which make some tasks simpler for us. For example, in our case we will use the [**sqlite3**][1] module to create, add and read data from a database. In the case where a particular problem we are trying to solve is not covered by the standard library, the chance is that someone has already developed a module for everyone to use. The best place to search for such modules is the Python Package Index known as [PyPI][2]. In our example we are going to use the [**feedparser**][3] to parse an RSS feed.
|
||||
|
||||
Since **feedparser** is not in the standard library, we have to install it in our system. Luckily for us there is an rpm package in Fedora, so the installation of **feedparser** is as simple as:
|
||||
```
|
||||
$ sudo dnf install python3-feedparser
|
||||
```
|
||||
|
||||
We now have everything we need to start coding our application.
|
||||
|
||||
### Storing the feed data
|
||||
|
||||
We need to store data from the articles that have already been published so that we send a notification only for new articles. The data we want to store will give us a unique way to identify an article. Therefore we will store the **title** and the **publication date** of the article.
|
||||
|
||||
So let's create our database using python **sqlite3** module and a simple SQL query. We are also adding the modules we are going to use later ( **feedparser** , **smtplib** and **email** ).
|
||||
|
||||
#### Creating the Database
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
import sqlite3
|
||||
import smtplib
|
||||
from email.mime.text import MIMEText
|
||||
|
||||
import feedparser
|
||||
|
||||
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
|
||||
db = db_connection.cursor()
|
||||
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
|
||||
|
||||
```
|
||||
|
||||
These few lines of code create a new sqlite database stored in a file called 'magazine_rss.sqlite', and then create a new table within the database called 'magazine'. This table has two columns - 'title' and 'date' - that can store data of the type TEXT, which means that the value of each column will be a text string.
|
||||
|
||||
#### Checking the Database for old articles
|
||||
|
||||
Since we only want to add new articles to our database we need a function that will check if the article we get from the RSS feed is already in our database or not. We will use it to decide if we should send an email notification (new article) or not (old article). Ok let's code this function.
|
||||
```
|
||||
def article_is_not_db(article_title, article_date):
|
||||
""" Check if a given pair of article title and date
|
||||
is in the database.
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_date (str): The publication date of an article
|
||||
Return:
|
||||
True if the article is not in the database
|
||||
False if the article is already present in the database
|
||||
"""
|
||||
db.execute("SELECT * from magazine WHERE title=? AND date=?", (article_title, article_date))
|
||||
if not db.fetchall():
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
```
|
||||
|
||||
The main part of this function is the SQL query we execute to search through the database. We are using a SELECT instruction to define which column of our magazine table we will run the query on. We are using the 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh symbol to select all columns ( title and date). Then we ask to select only the rows of the table WHERE the article_title and article_date string are equal to the value of the title and date column.
|
||||
|
||||
To finish, we have a simple logic that will return True if the query did not return any results and False if the query found an article in database matching our title, date pair.
|
||||
|
||||
#### Adding a new article to the Database
|
||||
|
||||
Now we can code the function to add a new article to the database.
|
||||
```
|
||||
def add_article_to_db(article_title, article_date):
|
||||
""" Add a new article title and date to the database
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_date (str): The publication date of an article
|
||||
"""
|
||||
db.execute("INSERT INTO magazine VALUES (?,?)", (article_title, article_date))
|
||||
db_connection.commit()
|
||||
```
|
||||
|
||||
This function is straight forward, we are using a SQL query to INSERT a new row INTO the magazine table with the VALUES of the article_title and article_date. Then we commit the change to make it persistent.
|
||||
|
||||
That's all we need from the database's point of view, let's look at the notification system and how we can use python to send emails.
|
||||
|
||||
### Sending an email notification
|
||||
|
||||
Let's create a function to send an email using the python standard library module **smtplib.** We are also using the **email** module from the standard library to format our email message.
|
||||
```
|
||||
def send_notification(article_title, article_url):
|
||||
""" Add a new article title and date to the database
|
||||
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_url (str): The url to access the article
|
||||
"""
|
||||
|
||||
smtp_server = smtplib.SMTP('smtp.gmail.com', 587)
|
||||
smtp_server.ehlo()
|
||||
smtp_server.starttls()
|
||||
smtp_server.login('your_email@gmail.com', '123your_password')
|
||||
msg = MIMEText(f'\nHi there is a new Fedora Magazine article : {article_title}. \nYou can read it here {article_url}')
|
||||
msg['Subject'] = 'New Fedora Magazine Article Available'
|
||||
msg['From'] = 'your_email@gmail.com'
|
||||
msg['To'] = 'destination_email@gmail.com'
|
||||
smtp_server.send_message(msg)
|
||||
smtp_server.quit()
|
||||
```
|
||||
|
||||
In this example I am using the Google mail smtp server to send an email, but this will work with any email services that provides you with a SMTP server. Most of this function is boilerplate needed to configure the access to the smtp server. You will need to update the code with your email address and credentials.
|
||||
|
||||
If you are using 2 Factor Authentication with your gmail account you can setup a password app that will give you a unique password to use for this application. Check out this help [page][4].
|
||||
|
||||
### Reading Fedora Magazine RSS feed
|
||||
|
||||
We now have functions to store an article in the database and send an email notification, let's create a function that parses the Fedora Magazine RSS feed and extract the articles' data.
|
||||
```
|
||||
def read_article_feed():
|
||||
""" Get articles from RSS feed """
|
||||
feed = feedparser.parse('https://fedoramagazine.org/feed/')
|
||||
for article in feed['entries']:
|
||||
if article_is_not_db(article['title'], article['published']):
|
||||
send_notification(article['title'], article['link'])
|
||||
add_article_to_db(article['title'], article['published'])
|
||||
|
||||
if __name__ == '__main__':
|
||||
read_article_feed()
|
||||
db_connection.close()
|
||||
```
|
||||
|
||||
Here we are making use of the **feedparser.parse** function. The function returns a dictionary representation of the RSS feed, for the full reference of the representation you can consult **feedparser** 's [documentation][5].
|
||||
|
||||
The RSS feed parser will return the last 10 articles as entries and then we extract the following information: the title, the link and the date the article was published. As a result, we can now use the functions we have previously defined to check if the article is not in the database, then send a notification email and finally, add the article to our database.
|
||||
|
||||
The last if statement is used to execute our read_article_feed function and then close the database connection when we execute our script.
|
||||
|
||||
### Running our script
|
||||
|
||||
Finally, to run our script we need to give the correct permission to the file. Next, we make use of the **cron** utility to automatically execute our script every hour (1 minute past the hour). **cron** is a job scheduler that we can use to run a task at a fixed time.
|
||||
```
|
||||
$ chmod a+x my_rss_notifier.py
|
||||
$ sudo cp my_rss_notifier.py /etc/cron.hourly
|
||||
```
|
||||
|
||||
To keep this tutorial simple, we are using the cron.hourly directory to execute the script every hours, I you wish to learn more about **cron** and how to configure the **crontab,** please read **cron 's** wikipedia [page][6].
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this tutorial we have learned how to use Python to create a simple sqlite database, parse an RSS feed and send emails. I hope that this showed you how you can easily build your own application using Python and Fedora.
|
||||
|
||||
The script is available on github [here][7].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notification-system/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://docs.python.org/3/library/sqlite3.html
|
||||
[2]:https://pypi.python.org/pypi
|
||||
[3]:https://pypi.python.org/pypi/feedparser/5.2.1
|
||||
[4]:https://support.google.com/accounts/answer/185833?hl=en
|
||||
[5]:https://pythonhosted.org/feedparser/reference.html
|
||||
[6]:https://en.wikipedia.org/wiki/Cron
|
||||
[7]:https://github.com/cverna/rss_feed_notifier
|
||||
@ -0,0 +1,61 @@
|
||||
Containers, the GPL, and copyleft: No reason for concern
|
||||
============================================================
|
||||
|
||||
### Wondering how open source licensing affects Linux containers? Here's what you need to know.
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Though open source is thoroughly mainstream, new software technologies and old technologies that get newly popularized sometimes inspire hand-wringing about open source licenses. Most often the concern is about the GNU General Public License (GPL), and specifically the scope of its copyleft requirement, which is often described (somewhat misleadingly) as the GPL’s derivative work issue.
|
||||
|
||||
One imperfect way of framing the question is whether GPL-licensed code, when combined in some sense with proprietary code, forms a single modified work such that the proprietary code could be interpreted as being subject to the terms of the GPL. While we haven’t yet seen much of that concern directed to Linux containers, we expect more questions to be raised as adoption of containers continues to grow. But it’s fairly straightforward to show that containers do _not_ raise new or concerning GPL scope issues.
|
||||
|
||||
Statutes and case law provide little help in interpreting a license like the GPL. On the other hand, many of us give significant weight to the interpretive views of the Free Software Foundation (FSF), the drafter and steward of the GPL, even in the typical case where the FSF is not a copyright holder of the software at issue. In addition to being the author of the license text, the FSF has been engaged for many years in providing commentary and guidance on its licenses to the community. Its views have special credibility and influence based on its public interest mission and leadership in free software policy.
|
||||
|
||||
The FSF’s existing guidance on GPL interpretation has relevance for understanding the effects of including GPL and non-GPL code in containers. The FSF has placed emphasis on the process boundary when considering copyleft scope, and on the mechanism and semantics of the communication between multiple software components to determine whether they are closely integrated enough to be considered a single program for GPL purposes. For example, the [GNU Licenses FAQ][4] takes the view that pipes, sockets, and command-line arguments are mechanisms that are normally suggestive of separateness (in the absence of sufficiently "intimate" communications).
|
||||
|
||||
Consider the case of a container in which both GPL code and proprietary code might coexist and execute. A container is, in essence, an isolated userspace stack. In the [OCI container image format][5], code is packaged as a set of filesystem changeset layers, with the base layer normally being a stripped-down conventional Linux distribution without a kernel. As with the userspace of non-containerized Linux distributions, these base layers invariably contain many GPL-licensed packages (both GPLv2 and GPLv3), as well as packages under licenses considered GPL-incompatible, and commonly function as a runtime for proprietary as well as open source applications. The ["mere aggregation" clause][6] in GPLv2 (as well as its counterpart GPLv3 provision on ["aggregates"][7]) shows that this type of combination is generally acceptable, is specifically contemplated under the GPL, and has no effect on the licensing of the two programs, assuming incompatibly licensed components are separate and independent.
|
||||
|
||||
Of course, in a given situation, the relationship between two components may not be "mere aggregation," but the same is true of software running in non-containerized userspace on a Linux system. There is nothing in the technical makeup of containers or container images that suggests a need to apply a special form of copyleft scope analysis.
|
||||
|
||||
It follows that when looking at the relationship between code running in a container and code running outside a container, the "separate and independent" criterion is almost certainly met. The code will run as separate processes, and the whole technical point of using containers is isolation from other software running on the system.
|
||||
|
||||
Now consider the case where two components, one GPL-licensed and one proprietary, are running in separate but potentially interacting containers, perhaps as part of an application designed with a [microservices][8] architecture. In the absence of very unusual facts, we should not expect to see copyleft scope extending across multiple containers. Separate containers involve separate processes. Communication between containers by way of network interfaces is analogous to such mechanisms as pipes and sockets, and a multi-container microservices scenario would seem to preclude what the FSF calls "[intimate][9]" communication by definition. The composition of an application using multiple containers may not be dispositive of the GPL scope issue, but it makes the technical boundaries between the components more apparent and provides a strong basis for arguing separateness. Here, too, there is no technical feature of containers that suggests application of a different and stricter approach to copyleft scope analysis.
|
||||
|
||||
A company that is overly concerned with the potential effects of distributing GPL-licensed code might attempt to prohibit its developers from adding any such code to a container image that it plans to distribute. Insofar as the aim is to avoid distributing code under the GPL, this is a dubious strategy. As noted above, the base layers of conventional container images will contain multiple GPL-licensed components. If the company pushes a container image to a registry, there is normally no way it can guarantee that this will not include the base layer, even if it is widely shared.
|
||||
|
||||
On the other hand, the company might decide to embrace containerization as a means of limiting copyleft scope issues by isolating GPL and proprietary code—though one would hope that technical benefits would drive the decision, rather than legal concerns likely based on unfounded anxiety about the GPL. While in a non-containerized setting the relationship between two interacting software components will often be mere aggregation, the evidence of separateness that containers provide may be comforting to those who worry about GPL scope.
|
||||
|
||||
Open source license compliance obligations may arise when sharing container images. But there’s nothing technically different or unique about containers that changes the nature of these obligations or makes them harder to satisfy. With respect to copyleft scope, containerization should, if anything, ease the concerns of the extra-cautious.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][10] Richard Fontana - Richard is Senior Commercial Counsel on the Products and Technologies team in Red Hat's legal department. Most of his work focuses on open source-related legal issues.[More about me][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/containers-gpl-and-copyleft
|
||||
|
||||
作者:[Richard Fontana ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/fontana
|
||||
[1]:https://opensource.com/article/18/1/containers-gpl-and-copyleft?rate=qTlANxnuA2tf0hcGE6Po06RGUzcbB-cBxbU3dCuCt9w
|
||||
[2]:https://opensource.com/users/fontana
|
||||
[3]:https://opensource.com/user/10544/feed
|
||||
[4]:https://www.gnu.org/licenses/gpl-faq.en.html#MereAggregation
|
||||
[5]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[6]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html#section2
|
||||
[7]:https://www.gnu.org/licenses/gpl.html#section5
|
||||
[8]:https://www.redhat.com/en/topics/microservices
|
||||
[9]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPlugins
|
||||
[10]:https://opensource.com/users/fontana
|
||||
[11]:https://opensource.com/users/fontana
|
||||
[12]:https://opensource.com/users/fontana
|
||||
[13]:https://opensource.com/tags/licensing
|
||||
[14]:https://opensource.com/tags/containers
|
||||
122
translated/tech/20140410 Recursion- dream within a dream.md
Normal file
122
translated/tech/20140410 Recursion- dream within a dream.md
Normal file
@ -0,0 +1,122 @@
|
||||
#[递归:梦中梦][1]
|
||||
递归是很神奇的,但是在大多数的编程类书藉中对递归讲解的并不好。它们只是给你展示一个递归阶乘的实现,然后警告你递归运行的很慢,并且还有可能因为栈缓冲区溢出而崩溃。“你可以将头伸进微波炉中去烘干你的头发,但是需要警惕颅内高压以及让你的头发生爆炸,或者你可以使用毛巾来擦干头发。”这就是人们不愿意使用递归的原因。这是很糟糕的,因为在算法中,递归是最强大的。
|
||||
|
||||
我们来看一下这个经典的递归阶乘:
|
||||
|
||||
递归阶乘 - factorial.c
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
函数的目的是调用它自己,这在一开始是让人很难理解的。为了解具体的内容,当调用 `factorial(5)` 并且达到 `n == 1` 时,[在栈上][3] 究竟发生了什么?
|
||||
|
||||
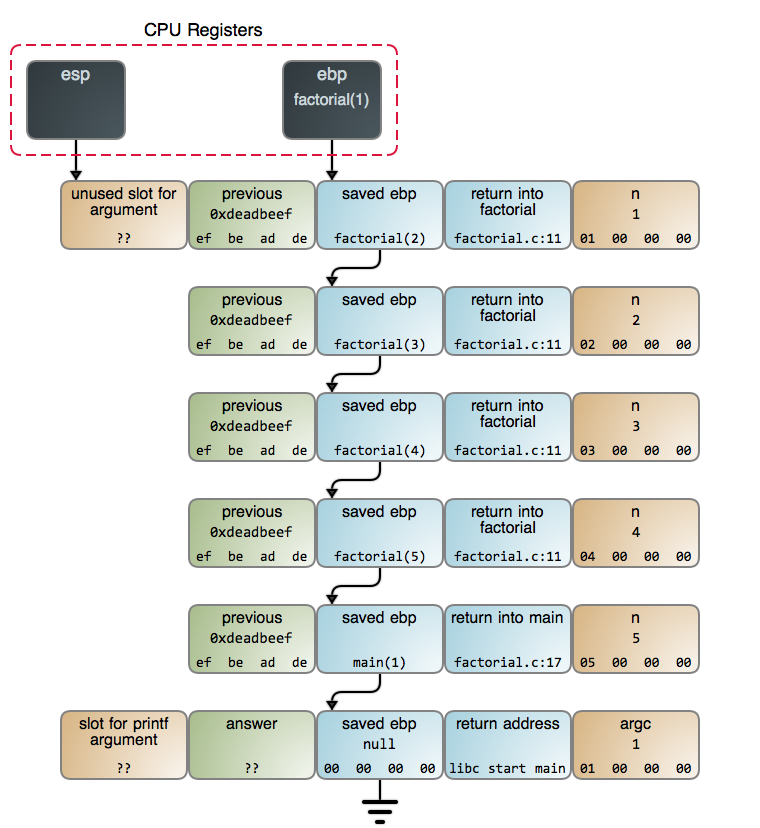
|
||||
|
||||
每次调用 `factorial` 都生成一个新的 [栈帧][4]。这些栈帧的创建和 [销毁][5] 是递归慢于迭代的原因。在调用返回之前,累积的这些栈帧可能会耗尽栈空间,进而使你的程序崩溃。
|
||||
|
||||
而这些担心经常是存在于理论上的。例如,对于每个 `factorial` 的栈帧取 16 字节(这可能取决于栈排列以及其它因素)。如果在你的电脑上运行着现代的 x86 的 Linux 内核,一般情况下你拥有 8 GB 的栈空间,因此,`factorial` 最多可以被运行 ~512,000 次。这是一个 [巨大无比的结果][6],它相当于 8,971,833 比特,因此,栈空间根本就不是什么问题:一个极小的整数 - 甚至是一个 64 位的整数 - 在我们的栈空间被耗尽之前就早已经溢出了成千上万次了。
|
||||
|
||||
过一会儿我们再去看 CPU 的使用,现在,我们先从比特和字节回退一步,把递归看作一种通用技术。我们的阶乘算法总结为将整数 N、N-1、 … 1 推入到一个栈,然后将它们按相反的顺序相乘。实际上我们使用了程序调用栈来实现这一点,这是它的细节:我们在堆上分配一个栈并使用它。虽然调用栈具有特殊的特性,但是,你只是把它用作一种另外的数据结构。我希望示意图可以让你明白这一点。
|
||||
|
||||
当你看到栈调用作为一种数据结构使用,有些事情将变得更加清晰明了:将那些整数堆积起来,然后再将它们相乘,这并不是一个好的想法。那是一种有缺陷的实现:就像你拿螺丝刀去钉钉子一样。相对更合理的是使用一个迭代过程去计算阶乘。
|
||||
|
||||
但是,螺丝钉太多了,我们只能挑一个。有一个经典的面试题,在迷宫里有一只老鼠,你必须帮助这只老鼠找到一个奶酪。假设老鼠能够在迷宫中向左或者向右转弯。你该怎么去建模来解决这个问题?
|
||||
|
||||
就像现实生活中的很多问题一样,你可以将这个老鼠找奶酪的问题简化为一个图,一个二叉树的每个结点代表在迷宫中的一个位置。然后你可以让老鼠在任何可能的地方都左转,而当它进入一个死胡同时,再返回来右转。这是一个老鼠行走的 [迷宫示例][7]:
|
||||
|
||||
|
||||
|
||||
每到边缘(线)都让老鼠左转或者右转来到达一个新的位置。如果向哪边转都被拦住,说明相关的边缘不存在。现在,我们来讨论一下!这个过程无论你是调用栈还是其它数据结构,它都离不开一个递归的过程。而使用调用栈是非常容易的:
|
||||
|
||||
递归迷宫求解 [下载][2]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include "maze.h"
|
||||
|
||||
int explore(maze_t *node)
|
||||
{
|
||||
int found = 0;
|
||||
|
||||
if (node == NULL)
|
||||
{
|
||||
return 0;
|
||||
}
|
||||
if (node->hasCheese){
|
||||
return 1;// found cheese
|
||||
}
|
||||
|
||||
found = explore(node->left) || explore(node->right);
|
||||
return found;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int found = explore(&maze);
|
||||
}
|
||||
```
|
||||
当我们在 `maze.c:13` 中找到奶酪时,栈的情况如下图所示。你也可以在 [GDB 输出][8] 中看到更详细的数据,它是使用 [命令][9] 采集的数据。
|
||||
|
||||
|
||||
|
||||
它展示了递归的良好表现,因为这是一个适合使用递归的问题。而且这并不奇怪:当涉及到算法时,递归是一种使用较多的算法,而不是被排除在外的。当进行搜索时、当进行遍历树和其它数据结构时、当进行解析时、当需要排序时:它的用途无处不在。正如众所周知的 pi 或者 e,它们在数学中像“神”一样的存在,因为它们是宇宙万物的基础,而递归也和它们一样:只是它在计算的结构中。
|
||||
|
||||
Steven Skienna 的优秀著作 [算法设计指南][10] 的精彩之处在于,他通过“战争故事” 作为手段来诠释工作,以此来展示解决现实世界中的问题背后的算法。这是我所知道的拓展你的算法知识的最佳资源。另一个较好的做法是,去读 McCarthy 的 [LISP 上的原创论文][11]。递归在语言中既是它的名字也是它的基本原理。这篇论文既可读又有趣,在工作中能看到大师的作品是件让人兴奋的事情。
|
||||
|
||||
回到迷宫问题上。虽然它在这里很难离开递归,但是并不意味着必须通过调用栈的方式来实现。你可以使用像 “RRLL” 这样的字符串去跟踪转向,然后,依据这个字符串去决定老鼠下一步的动作。或者你可以分配一些其它的东西来记录奶酪的状态。你仍然是去实现一个递归的过程,但是需要你实现一个自己的数据结构。
|
||||
|
||||
那样似乎更复杂一些,因为栈调用更合适。每个栈帧记录的不仅是当前节点,也记录那个节点上的计算状态(在这个案例中,我们是否只让它走左边,或者已经尝试向右)。因此,代码已经变得不重要了。然而,有时候我们因为害怕溢出和期望中的性能而放弃这种优秀的算法。那是很愚蠢的!
|
||||
|
||||
正如我们所见,栈空间是非常大的,在耗尽栈空间之前往往会遇到其它的限制。一方面可以通过检查问题大小来确保它能够被安全地处理。而对 CPU 的担心是由两个广为流传的有问题的示例所导致的:哑阶乘(dumb factorial)和可怕的无记忆的 O(2n) [Fibonacci 递归][12]。它们并不是栈递归算法的正确代表。
|
||||
|
||||
事实上栈操作是非常快的。通常,栈对数据的偏移是非常准确的,它在 [缓存][13] 中是热点,并且是由专门的指令来操作它。同时,使用你自己定义的堆上分配的数据结构的相关开销是很大的。经常能看到人们写的一些比栈调用递归更复杂、性能更差的实现方法。最后,现代的 CPU 的性能都是 [非常好的][14] ,并且一般 CPU 不会是性能瓶颈所在。要注意牺牲简单性与保持性能的关系。[测量][15]。
|
||||
|
||||
下一篇文章将是探秘栈系列的最后一篇了,我们将了解尾调用、闭包、以及其它相关概念。然后,我们就该深入我们的老朋友—— Linux 内核了。感谢你的阅读!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/recursion/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/recursion/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/maze.c
|
||||
[3]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-gdb-output.txt
|
||||
[4]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[5]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[6]:https://gist.github.com/gduarte/9944878
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze.h
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-output.txt
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-commands.txt
|
||||
[10]:http://www.amazon.com/Algorithm-Design-Manual-Steven-Skiena/dp/1848000693/
|
||||
[11]:https://github.com/papers-we-love/papers-we-love/blob/master/comp_sci_fundamentals_and_history/recursive-functions-of-symbolic-expressions-and-their-computation-by-machine-parti.pdf
|
||||
[12]:http://stackoverflow.com/questions/360748/computational-complexity-of-fibonacci-sequence
|
||||
[13]:https://manybutfinite.com/post/intel-cpu-caches/
|
||||
[14]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait/
|
||||
[15]:https://manybutfinite.com/post/performance-is-a-science
|
||||
@ -1,26 +1,23 @@
|
||||
translating---geekpi
|
||||
|
||||
Bash Bypass Alias Linux/Unix Command
|
||||
绕过 Linux/Unix 命令别名
|
||||
======
|
||||
I defined mount bash shell alias as follows on my Linux system:
|
||||
我在我的 Linux 系统上定义了如下 mount 别名:
|
||||
```
|
||||
alias mount='mount | column -t'
|
||||
```
|
||||
However, I need to bash bypass alias for mounting the file system and another usage. How can I disable or bypass my bash shell aliases temporarily on a Linux, *BSD, macOS or Unix-like system?
|
||||
但是我需要在挂载文件系统和其他用途时绕过 bash 别名。我如何在 Linux、\*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
|
||||
|
||||
|
||||
|
||||
You can define or display bash shell aliases with alias command. Once bash shell aliases created, they take precedence over external or internal commands. This page shows how to bypass bash aliases temporarily so that you can run actual internal or external command.
|
||||
你可以使用 alias 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
|
||||
[![Bash Bypass Alias Linux BSD macOS Unix Command][1]][1]
|
||||
|
||||
## Four ways to bash bypass alias
|
||||
## 4 种绕过 bash 别名的方法
|
||||
|
||||
|
||||
Try any one of the following ways to run a command that is shadowed by a bash shell alias. Let us [define an alias as follows][2]:
|
||||
尝试以下任意一种方法来运行被 bash shell 别名绕过的命令。让我们[如下定义一个别名][2]:
|
||||
`alias mount='mount | column -t'`
|
||||
Run it as follows:
|
||||
运行如下:
|
||||
`mount `
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
```
|
||||
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
|
||||
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
|
||||
@ -33,16 +30,16 @@ binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_m
|
||||
lxcfs on /var/lib/lxcfs type fuse.lxcfs (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other)
|
||||
```
|
||||
|
||||
### Method 1 - Use \command
|
||||
### 方法1 - 使用 \command
|
||||
|
||||
Type the following command to temporarily bypass a bash alias called mount:
|
||||
输入以下命令暂时绕过名为 mount 的 bash 别名:
|
||||
`\mount`
|
||||
|
||||
### Method 2 - Use "command" or 'command'
|
||||
### 方法2 - 使用 "command" 或 'command'
|
||||
|
||||
Quote the mount command as follows to call actual /bin/mount:
|
||||
如下引用 mount 命令调用实际的 /bin/mount:
|
||||
`"mount"`
|
||||
OR
|
||||
或者
|
||||
`'mount'`
|
||||
|
||||
### Method 3 - Use full command path
|
||||
@ -51,27 +48,27 @@ Use full binary path such as /bin/mount:
|
||||
`/bin/mount
|
||||
/bin/mount /dev/sda1 /mnt/sda`
|
||||
|
||||
### Method 4 - Use internal command
|
||||
### 方法3 - 使用完整的命令路径
|
||||
|
||||
The syntax is:
|
||||
语法是:
|
||||
`command cmd
|
||||
command cmd arg1 arg2`
|
||||
To override alias set in .bash_aliases such as mount:
|
||||
要覆盖 .bash_aliases 中设置的别名,例如 mount:
|
||||
`command mount
|
||||
command mount /dev/sdc /mnt/pendrive/`
|
||||
[The 'command' run a simple command or display][3] information about commands. It runs COMMAND with ARGS suppressing shell function lookup or aliases, or display information about the given COMMANDs.
|
||||
[”command“ 运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
|
||||
|
||||
## A note about unalias command
|
||||
## 关于 unalias 命令的说明
|
||||
|
||||
To remove each alias from the list of defined aliases from the current session use unalias command:
|
||||
要从当前会话的已定义别名列表中移除别名,请使用 unalias 命令:
|
||||
`unalias mount`
|
||||
To remove all alias definitions from the current bash session:
|
||||
要从当前 bash 会话中删除所有别名定义:
|
||||
`unalias -a`
|
||||
Make sure you update your ~/.bashrc or $HOME/.bash_aliases file. You must remove defined aliases if you want to remove them permanently:
|
||||
确保你更新你的 ~/.bashrc 或 $HOME/.bash_aliases。如果要永久删除定义的别名,则必须删除定义的别名:
|
||||
`vi ~/.bashrc`
|
||||
OR
|
||||
或者
|
||||
`joe $HOME/.bash_aliases`
|
||||
For more information see bash command man page online [here][4] or read it by typing the following command:
|
||||
想了解更多信息,参考[这里][4]的在线手册,或者输入下面的命令查看:
|
||||
```
|
||||
man bash
|
||||
help command
|
||||
@ -85,7 +82,7 @@ help alias
|
||||
via: https://www.cyberciti.biz/faq/bash-bypass-alias-command-on-linux-macos-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,91 @@
|
||||
计算机语言的巨变
|
||||
====================================================
|
||||
|
||||
|
||||
我的上一篇博文([与 C 的长久别离][3])引来了我的老朋友,一位 C++ 专家的评论。在评论里,他推荐把 C++ 作为 C 的替代品。这是不可能发生的,如果 C ++ 代替 C 是趋势的话,那么 Go 和 Rust 也就不会出现了。
|
||||
|
||||
但是我不能只给我的读者一个空洞的看法。所以,在这篇文章中,我来讲述一下为什么我不再碰 C++ 的故事。这是关于计算机语言设计经济学专题文章的起始点。这篇文章会讨论为什么一些真心不好的决策会被做出来,然后进入语言的基础设计之中,以及我们该如何修正这些问题。
|
||||
|
||||
在这篇文章中,我会一点一点的指出人们(当然也包括我)自从 20 世纪 80 年代以来就存在的关于未来的编程语言的预见失误。直到最近我们才找到了证明我们错了的证据。
|
||||
|
||||
我第一次学习 C++ 是因为我需要使用 GNU eqn 输出 MathXML,而 eqn 是使用 C++ 写的。那个项目不错。在那之后,21世纪初,我在韦诺之战那边当了多年的高级开发工程师,并且与 C++ 相处甚欢。
|
||||
|
||||
在那之后啊,有一天我们发现一个不小心被我们授予特权的人已经把游戏的 AI 核心搞崩掉了。显然,在团队中只有我是不那么害怕查看代码的。最终,我把一切都恢复正常了 —— 我折腾了整整两周。再那之后,我就发誓我再也不靠近 C++ 了。
|
||||
|
||||
在那次经历过后,我发现这个语言的问题就是它在尝试使得本来就复杂的东西更加复杂,来属兔补上因为基础概念的缺失造成的漏洞。对于裸指针,他说“别这样做”,这没有问题。对于小规模的个人项目(比如我的魔改版 eqn),遵守这些规定没有问题。
|
||||
|
||||
但是对于大型项目,或者开发者水平不同的多人项目(这是我经常要处理的情况)就不能这样。随着时间的推移以及代码行数的增加,有的人就会捅篓子。当别人指出有 BUG 时,因为诸如 STL 之类的东西给你增加了一层复杂度,你处理这种问题所需要的精力就比处理同等规模的 C 语言的问题就要难上很多。我在韦诺之战时,我就知道了,处理这种问题真的相当棘手。
|
||||
|
||||
我给 Stell Heller(我的老朋友 ,C++ 的支持者)写代码时不会发生的问题在我与非 Heller 们合作时就被放大了,我和他们合作的结局可能就是我得给他们擦屁股。所以我就不用 C++ ,我觉得不值得为了其花时间。 C 是有缺陷的,但是 C 有 C++ 没有的优点 —— 如果你能在脑内模拟出硬件,那么你就能很简单的看出程序是怎么运行的。如果 C++ 真的能解决 C 的问题(也就是说,C++ 是类型安全以及内存安全的),那么失去其透明性也是值得的。但是,C++ 并没有这样。
|
||||
|
||||
我们判断 C++ 做的还不够的方法之一是想象一个 C++ 已经搞得不错的世界。在那个世界里,老旧的 C 语言项目会被迁移到 C++ 上来。主流的操作系统内核会是 C++ 写就,而现存的内核实现,比如 Linux 会渐渐升级成那样。在现实世界,这些都没有发生。C++ 不仅没有打消语言设计者设想像 D,Go 以及 Rust 那样的新语言的想法,他甚至都没有取代他的前辈。不改变 C++ 的核心思想,他就没有未来,也因此,C++ 的抽象泄露也不会消失。
|
||||
|
||||
既然我刚刚提到了 D 语言,那我就说说为什么我不把 D 视为一个够格的 C 语言竞争者的原因吧.尽管他比 Rust 早出现了八年 -- 和 Rust 相比是九年 -- Walter Bright 早在那时就有了构建那样一个语言的想法.但是在 2001 年,以 Python 和 Perl 为首的语言的出现已经确定了,专有语言能和开源语言抗衡的时代已经过去.官方 D 语言库/运行时和 Tangle 的无谓纷争也打击了其发展.它从未修正这些错误。
|
||||
|
||||
然后就是 Go 语言(我本来想说“以及 Rust”。但是如前文所述,我认为 Rust 还需要几年时间才能有竞争力)。它 _的确是_ 类型安全以及内存安全的(好吧,是在大多数时候是这样,但是如果你要使用接口的话就不是如此了,但是自找麻烦可不是正常人的做法)。我的一位好友,Mark Atwood,曾指出过 Go 语言是脾气暴躁的老头子因为愤怒创造出的语言,主要是 _C 语言的作者之一_(Ken Thompson) 因为 C++ 的混乱臃肿造成的愤怒,我深以为然。
|
||||
|
||||
我能理解 Ken 恼火的原因。这几十年来我就一直认为 C++ 搞错了需要解决的问题。C 语言的后继者有两条路可走。其一就是 C++ 那样,接受 C 的抽象泄漏,裸指针等等,以保证兼容性。然后以此为基础,构建一个最先进的语言。还有一条道路,就是从根源上解决问题 —— _修正_ C语言的抽象泄露。这一来就会破环其兼容性,但是也会杜绝 C/C++ 现有的问题。
|
||||
|
||||
对于第二条道路,第一次严谨的尝试就是 1995 年出现的 Java。Java 搞得不错,但是在语言解释器上构建这门语言使其不适合系统编程。这就在系统编程那留下一个巨大的漏洞,在 Go 以及 Rust 出现之前的 15 年里,都没有语言来填补这个空白。这也就是我的GPSD和NTPsec等软件在2017年仍然主要用C写成的原因,尽管C的问题也很多。
|
||||
|
||||
程序员的现状很差。尽管由于缺少足够多样化的选择,我们很难认识到 C/C++ 做的不够好的地方。我们都认为在软件里面出现缺陷以及基于安全方面考虑的妥协是理所当然的,而不是想想这其中多少是真的由于语言的设计问题导致的,就像缓存区溢出漏洞一样。
|
||||
|
||||
所以,为什么我们花了这么长时间才开始解决这个问题?从 C(1972) 面世到 Go(2009) 出现,这其中隔了 37 年;Rust也是在其仅仅一年之前出现。我想根本原因还是经济。
|
||||
|
||||
从最早的计算机语言开始,人们就已经知道,每种语言的设计都体现了程序员时间与机器资源的相对价值。在机器这端,就是汇编语言,以及之后的 C 语言,这些语言以牺牲开发人员的时间为代价来提高性能。 另一方面,像 Lisp 和(之后的)Python 这样的语言则试图自动处理尽可能多的细节,但这是以牺牲机器性能为代价的。
|
||||
|
||||
广义地说,这两端的语言的最重要的区别就是有没有自动内存管理。这与经验一致,内存管理缺陷是以机器为中心的语言中最常见的一类缺陷,程序员需要手动管理资源。
|
||||
|
||||
当一个语言对于程序员和机器的价值的理念与软件开发的某些领域的理念一致时,这个语言就是在经济上可行的。语言设计者通过设计一个适合处理现在或者不远的将来出现的情况的语言,而不是使用现有的语言来解决他们遇到的问题。
|
||||
|
||||
今年来,时兴的编程语言已经渐渐从需要手动管理内存的语言变为带有自动内存管理以及垃圾回收(GC)机制的语言。这种变化对应了摩尔定律导致的计算机硬件成本的降低,使得程序员的时间与之前相比更加的宝贵。但是,除了程序员的时间以及机器效率的变化之外,至少还有两个维度与这种变化相关。
|
||||
|
||||
其一就是距离底层硬件的距离。底层软件(内核与服务代码)的低效率会被成倍地扩大。因此我们可以发现,以机器为中心的语言像底层推进而以程序员为中心的语言向着高级发展。因为大多数情况下面向用户的语言仅仅需要以人类的反应速度(0.1秒)做出回应即可。
|
||||
|
||||
另一个维度就是项目的规模。由于程序员抽象出的问题的漏洞以及自身的疏忽,任何语言都会有预期的每千行代码的出错率。这个比率在以机器为中心的语言上很高,而在程序员为中心的带有 GC 的语言里就大大降低。随着项目规模的增大,带有 GC 语言作为一个防止出错率不堪入目的策略就显得愈发重要起来。
|
||||
|
||||
当我们使用这三种维度来看当今的编程语言的形势 —— C 语言在底层,蓬勃发展的带有 GC 的语言在上层,我们会发现这基本上很合理。但是还有一些看似不合理的是 —— C 语言的应用不合理地广泛。
|
||||
|
||||
我为什么这么说?想想那些经典的 Unix 命令行工具吧。这些通常都是可以使用带有完整的POSIX绑定的脚本语言写出的小程序。那样重新编码的程序调试维护拓展起来都会更加简单。
|
||||
|
||||
但是为什么还是使用 C (或者某些像 eqn 的项目,使用 C++)?因为有转型成本。就算是把相当小相当简单的语言使用新的语言重写并且确认你已经忠实地保留了所有非错误行为都是相当困难的。笼统地说,在任何一个领域的应用编程或者系统编程在语言的权衡过去之后,都可以使用一种哪怕是过时的语言。
|
||||
|
||||
这就是我和其他预测者犯的大错。 我们认为,降低机器资源成本(增加程序员时间的相对成本)本身就足以取代C语言(以及没有 GC 的语言)。 在这个过程中,我们有一部分或者甚至一大部分都是错误的 - 自20世纪90年代初以来,脚本语言,Java 以及像 Node.js 这样的东西的兴起显然都是这样兴起的的。
|
||||
|
||||
但是,竞争系统编程语言的新浪潮并非如此。 Rust和Go都明确地回应了_增加项目规模_ 这一需求。 脚本语言是先是作为编写小程序的有效途径,并逐渐扩大规模,而Rust和Go从一开始就定位为减少_大型项目_中的缺陷率。 比如 Google 的搜索服务和 Facebook 的实时聊天多服务。
|
||||
|
||||
我认为这就是对 "为什么不再早点儿" 这个问题的回答。Rust 和 Go 实际上并不算晚,他们相对迅速地回应了一个直到最近才被发现低估的成本问题。
|
||||
|
||||
好,说了这么多理论上的问题。按照这些理论我们能预言什么?它高偶素我们在 C 之后会出现什么?
|
||||
|
||||
推动 GC 语言发展的趋势还没有扭转,也不要期待其扭转。这是大势所趋。因此:最终我们将拥有具有足够低延迟的 GC 技术,可用于内核和底层固件,这些技术将以语言实现方式被提供。 这些才是真正结束C长期统治的语言应有的特性。
|
||||
|
||||
我们能从 Go 语言开发团队的工作文件中发现端倪,他们正朝着这个方向前进 - 参考关于并发GC 的学术研究,从来没有停止研究。 如果 Go 语言自己没有选择这么做,其他的语言设计师也会这样。 但我认为他们会这么做 - 谷歌推动他们的项目的能力是显而易见的(我们从 “Android 的发展”就能看出来)。
|
||||
|
||||
在我们拥有那么理想的 GC 之前,我把能替换 C 语言的赌注押在 Go 语言上。因为其 GC 的开销是可以接受的 —— 也就是说不只是应用,甚至是大部分内核外的服务都可以使用。原因很简单: C 的出错率无药可医,转化成本还很高。
|
||||
|
||||
上周我尝试将 C 语言项目转化到 Go 语言上,我发现了两件事。其一就是这话很简单, C 的语言和 Go 对应的很好。还有就是写出的代码相当简单。因为 GC 的存在以及把集合视为首要的我数据结构,人人都要注意到这一点。但是我意识到我写的代码比我期望的多了不少,比例约为 2:1 —— 和 C 转 Python 类似。
|
||||
|
||||
抱歉呐,Rust 粉们。你们在内核以及底层固件上有着美好的未来。但是你们在别的领域被 Go 压的很惨。没有 GC ,再加上难以从 C 语言转化过来,还有就是有一部分 API 还是不够完善。(我的 select(2) 又哪去了啊?)。
|
||||
|
||||
对你们来说,唯一的安慰就是,C++ 粉比你们更糟糕 —— 如果这算是安慰的话。至少 Rust 还可以在 Go 顾及不到的 C 领域内大展宏图。C++ 可不能。
|
||||
|
||||
本文由 [Eric Raymond][5] 发布在 [Software][4] 栏。[收藏链接][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7724
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7724
|
||||
[3]:http://esr.ibiblio.org/?p=7711
|
||||
[4]:http://esr.ibiblio.org/?cat=13
|
||||
[5]:http://esr.ibiblio.org/?author=2
|
||||
[6]:http://esr.ibiblio.org/?p=7724
|
||||
Loading…
Reference in New Issue
Block a user