mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-04-14 03:30:29 +08:00
commit
cc3e99df41
published
20140510 Managing Digital Files (e.g., Photographs) in Files and Folders.md20180906 What a shell dotfile can do for you.md20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md20190301 Guide to Install VMware Tools on Linux.md20190320 Move your dotfiles to version control.md20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md20190627 RPM packages explained.md20190701 Learn how to Record and Replay Linux Terminal Sessions Activity.md20190719 Buying a Linux-ready laptop.md20190809 Mutation testing is the evolution of TDD.md20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md20190823 The lifecycle of Linux kernel testing.md20190824 How to compile a Linux kernel in the 21st century.md20190826 Introduction to the Linux chown command.md
201909
20180116 Command Line Heroes- Season 1- OS Wars_2.md20180117 How technology changes the rules for doing agile.md20180330 Go on very small hardware Part 1.md20180704 BASHing data- Truncated data items.md20180705 Building a Messenger App- Schema.md20180802 Top 5 CAD Software Available for Linux in 2018.md20180904 How blockchain can complement open source.md20181113 Eldoc Goes Global.md20181227 Linux commands for measuring disk activity.md20190129 Create an online store with this Java-based framework.md20190401 Build and host a website with Git.md20190402 Manage your daily schedule with Git.md20190403 Use Git as the backend for chat.md20190408 A beginner-s guide to building DevOps pipelines with open source tools.md20190409 Working with variables on Linux.md20190505 Blockchain 2.0 - What Is Ethereum -Part 9.md20190524 Spell Checking Comments.md20190528 A Quick Look at Elvish Shell.md20190603 How many browser tabs do you usually have open.md20190603 How to stream music with GNOME Internet Radio.md20190628 How to Install and Use R on Ubuntu.md20190701 Get modular with Python functions.md20190705 Learn object-oriented programming with Python.md20190730 How to manage logs in Linux.md20190805 Is your enterprise software committing security malpractice.md20190810 How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).md20190812 Cloud-native Java, open source security, and more industry trends.md20190812 Why const Doesn-t Make C Code Faster.md20190819 Moving files on Linux without mv.md20190821 Getting Started with Go on Fedora.md20190822 How to move a file in Linux.md20190823 How To Check Your IP Address in Ubuntu -Beginner-s Tip.md20190823 The Linux kernel- Top 5 innovations.md20190825 Top 5 IoT networking security mistakes.md20190826 5 ops tasks to do with Ansible.md20190826 How to rename a group of files on Linux.md20190828 Managing Ansible environments on MacOS with Conda.md20190829 Getting started with HTTPie for API testing.md20190829 Three Ways to Exclude Specific-Certain Packages from Yum Update.md20190830 Change your Linux terminal color theme.md20190830 How to Create and Use Swap File on Linux.md20190830 git exercises- navigate a repository.md20190831 Google opens Android speech transcription and gesture tracking, Twitter-s telemetry tooling, Blender-s growing adoption, and more news.md20190901 Best Linux Distributions For Everyone in 2019.md20190901 Different Ways to Configure Static IP Address in RHEL 8.md20190902 Why I use Java.md20190903 5 open source speed-reading applications.md20190903 An introduction to Hyperledger Fabric.md20190903 The birth of the Bash shell.md20190904 How to build Fedora container images.md20190905 How to Change Themes in Linux Mint.md20190905 How to Get Average CPU and Memory Usage from SAR Reports Using the Bash Script.md20190905 USB4 gets final approval, offers Ethernet-like speed.md20190906 Great News- Firefox 69 Blocks Third-Party Cookies, Autoplay Videos - Cryptominers by Default.md20190906 How to change the color of your Linux terminal.md20190906 How to put an HTML page on the internet.md20190909 Firefox 69 available in Fedora.md20190909 How to Install Shutter Screenshot Tool in Ubuntu 19.04.md20190909 How to Setup Multi Node Elastic Stack Cluster on RHEL 8 - CentOS 8.md20190909 How to use Terminator on Linux to run multiple terminals in one window.md20190911 How to set up a TFTP server on Fedora.md20190912 An introduction to Markdown.md20190912 Bash Script to Send a Mail About New User Account Creation.md20190913 An introduction to Virtual Machine Manager.md20190913 How to Find and Replace a String in File Using the sed Command in Linux.md20190914 GNOME 3.34 Released With New Features - Performance Improvements.md20190914 Manjaro Linux Graduates From A Hobby Project To A Professional Project.md20190915 Sandboxie-s path to-open source, update on the Pentagon-s open source initiative, open source in Hollywood,-and more.md20190916 How to freeze and lock your Linux system (and why you would want to).md20190916 How to start developing with .NET.md20190916 Linux Plumbers, Appwrite, and more industry trends.md20190917 Getting started with Zsh.md20190917 How to Check Linux Mint Version Number - Codename.md20190918 Amid Epstein Controversy, Richard Stallman is Forced to Resign as FSF President.md20190918 How to remove carriage returns from text files on Linux.md20190918 Microsoft brings IBM iron to Azure for on-premises migrations.md20190918 Oracle Unleashes World-s Fastest Database Machine ‘Exadata X8M.md20190921 How to Remove (Delete) Symbolic Links in Linux.md20190921 Oracle Autonomous Linux- A Self Updating, Self Patching Linux Distribution for Cloud Computing.md20190923 Getting started with data science using Python.md20190923 Introduction to the Linux chgrp and newgrp commands.md20190927 IBM brings blockchain to Red Hat OpenShift- adds Apache CouchDB for hybrid cloud customers.md
20190901 Best Linux Distributions For Everyone in 2019.md20190911 4 open source cloud security tools.md20190916 Copying large files with Rsync, and some misconceptions.md20190916 Linux commands to display your hardware information.md@ -0,0 +1,619 @@
|
||||
数码文件与文件夹收纳术(以照片为例)
|
||||
======
|
||||
|
||||

|
||||
|
||||
- 更新 2014-05-14:增加了一些具体实例
|
||||
- 更新 2015-03-16:根据照片的 GPS 坐标过滤图片
|
||||
- 更新 2016-08-29:以新的 `filetags --filter` 替换已经过时的 `show-sel.sh` 脚本
|
||||
- 更新 2017-08-28: geeqier 视频缩略图的邮件评论
|
||||
- 更新 2018-03-06:增加了 Julian Kahnert 的链接
|
||||
- 更新 2018-05-06:增加了作者在 2018 Linuxtage Graz 大会上 45 分钟演讲的视频
|
||||
- 更新 2018-06-05:关于 metadata 的邮件回复
|
||||
- 更新 2018-07-22:移动文件夹结构的解释到一篇它自己的文章中
|
||||
- 更新 2019-07-09:关于在文件名中避免使用系谱和字符的邮件回复
|
||||
|
||||
每当度假或去哪游玩时我就会化身为一个富有激情的摄影师。所以,过去的几年中我积累了许多的 [JPEG][1] 文件。这篇文章中我会介绍我是如何避免 [供应商锁定][2](LCTT 译注:<ruby>供应商锁定<rt>vendor lock-in</rt></ruby>,原为经济学术语,这里引申为避免过于依赖某一服务平台)造成受限于那些临时性的解决方案及数据丢失。相反,我更倾向于使用那些可以让我**投入时间和精力打理,并能长久使用**的解决方案。
|
||||
|
||||
这一(相当长的)攻略 **并不仅仅适用于图像文件**:我将进一步阐述像是文件夹结构、文件的命名规则等等许多领域的事情。因此,这些规范适用于我所能接触到的所有类型的文件。
|
||||
|
||||
在我开始传授我的方法之前,我们应该先就我将要介绍方法的达成一个共识,那就是我们是否有相同的需求。如果你对 [raw 图像格式][3]十分推崇,将照片存储在云端或其他你信赖的地方(对我而言可能不会),那么你可能不会认同这篇文章将要描述的方式了。请根据你的情况来灵活做出选择。
|
||||
|
||||
### 我的需求
|
||||
|
||||
对于 **将照片(或视频)从我的数码相机中导出到电脑里**,我只需要将 SD 卡插到我的电脑里并调用 `fetch-workflow` 软件。这一步也完成了**图像软件的预处理**以适用于我的文件命名规范(下文会具体论述),同时也可以将图片旋转至正常的方向(而不是横着)。
|
||||
|
||||
这些文件将会被存入到我的摄影收藏文件夹 `$HOME/tmp/digicam/`。在这一文件夹中我希望能**遍历我的图像和视频文件**,以便于**整理/删除、重命名、添加/移除标签,以及将一系列相关的文件移动到相应的文件夹中**。
|
||||
|
||||
在完成这些以后,我将会**浏览包含图像/电影文件集的文件夹**。在极少数情况下,我希望**在独立的图像处理工具**(比如 [GIMP][4])中打开一个图像文件。如果仅是为了**旋转 JPEG 文件**,我想找到一个快速的方法,不需要图像处理工具,并且是[以无损的方式][5]旋转 JPEG 图像。
|
||||
|
||||
我的数码相机支持用 [GPS][6] 坐标标记图像。因此,我需要一个方法来**对单个文件或一组文件可视化 GPS 坐标**来显示我走过的路径。
|
||||
|
||||
我想拥有的另一个好功能是:假设你在威尼斯度假时拍了几百张照片。每一个都很漂亮,所以你每张都舍不得删除。另一方面,你可能想把一组更少的照片送给家里的朋友。而且,在他们嫉妒的爆炸之前,他们可能只希望看到 20 多张照片。因此,我希望能够**定义并显示一组特定的照片子集**。
|
||||
|
||||
就独立性和**避免锁定效应**而言,我不想使用那种一旦公司停止产品或服务就无法使用的工具。出于同样的原因,由于我是一个注重隐私的人,**我不想使用任何基于云的服务**。为了让自己对新的可能性保持开放的心态,我不希望只在一个特定的操作系统平台才可行的方案上倾注全部的精力。**基本的东西必须在任何平台上可用**(查看、导航、……),而**全套需求必须可以在 GNU/Linux 上运行**,对我而言,我选择 Debian GNU/Linux。
|
||||
|
||||
在我传授当前针对上述大量需求的解决方案之前,我必须解释一下我的一般文件夹结构和文件命名约定,我也使用它来命名数码照片。但首先,你必须认清一个重要的事实:
|
||||
|
||||
#### iPhoto、Picasa,诸如此类应被认为是有害的
|
||||
|
||||
管理照片集的软件工具确实提供了相当酷的功能。它们提供了一个良好的用户界面,并试图为你提供满足各种需求的舒适的工作流程。
|
||||
|
||||
对它们我确实遇到了很多大问题。它们几乎对所有东西都使用专有的存储格式:图像文件、元数据等等。当你打算在几年内换一个不同的软件,这是一个大问题。相信我:总有一天你会因为多种原因而**更换软件**。
|
||||
|
||||
如果你现在正打算更换相应的工具,你会意识到 iPhoto 或 Picasa 是分别存储原始图像文件和你对它们所做的所有操作的(旋转图像、向图像文件添加描述/标签、裁剪等等)。如果你不能导出并重新导入到新工具,那么**所有的东西都将永远丢失**。而无损的进行转换和迁移几乎是不可能的。
|
||||
|
||||
我不想在一个会锁住我工作的工具上投入任何精力。**我也拒绝把自己绑定在任何专有工具上**。我是一个过来人,希望你们吸取我的经验。
|
||||
|
||||
这就是我在文件名中保留时间戳、图像描述或标记的原因。文件名是永久性的,除非我手动更改它们。当我把照片备份或复制到 U 盘或其他操作系统时,它们不会丢失。每个人都能读懂。任何未来的系统都能够处理它们。
|
||||
|
||||
### 我的文件命名规范
|
||||
|
||||
这里有一个我在 [2018 Linuxtage Graz 大会][44]上做的[演讲][45],其中详细阐述了我的在本文中提到的想法和工作流程。
|
||||
|
||||
- [Grazer Linuxtage 2018 - The Advantages of File Name Conventions and Tagging](https://youtu.be/rckSVmYCH90)
|
||||
- [备份视频托管在 media.CCC.de](https://media.ccc.de/v/GLT18_-_321_-_en_-_g_ap147_004_-_201804281550_-_the_advantages_of_file_name_conventions_and_tagging_-_karl_voit)
|
||||
|
||||
我所有的文件都与一个特定的日期或时间有关,根据所采用的 [ISO 8601][7] 规范,我采用的是**日期戳**或**时间戳**
|
||||
|
||||
带有日期戳和两个标签的示例文件名:`2014-05-09 Budget export for project 42 -- finance company.csv`。
|
||||
|
||||
带有时间戳(甚至包括可选秒)和两个标签的示例文件名:`2014-05-09T22.19.58 Susan presenting her new shoes -- family clothing.jpg`。
|
||||
|
||||
由于我使用的 ISO 时间戳冒号不适用于 Windows [NTFS 文件系统][8],因此,我用点代替冒号,以便将小时与分钟(以及可选的秒)区别开来。
|
||||
|
||||
如果是**持续的一段日期或时间**,我会将两个日期戳或时间戳用两个减号分开:`2014-05-09--2014-05-13 Jazz festival Graz -- folder tourism music.pdf`。
|
||||
|
||||
文件名中的时间/日期戳的优点是,除非我手动更改它们,否则它们保持不变。当通过某些不处理这些元数据的软件进行处理时,包含在文件内容本身中的元数据(如 [Exif][9])往往会丢失。此外,使用这样的日期/时间戳开始的文件名可以确保文件按时间顺序显示,而不是按字母顺序显示。字母表是一种[完全人工的排序顺序][10],对于用户定位文件通常不太实用。
|
||||
|
||||
当我想将**标签**关联到文件名时,我将它们放在原始文件名和[文件名扩展名][11]之间,中间用空格、两个减号和两端额外的空格分隔 ` -- `。我的标签是小写的英文单词,不包含空格或特殊字符。有时,我可能会使用 `quantifiedself` 或 `usergenerated` 这样的连接词。我[倾向于选择一般类别][12],而不是太过具体的描述标签。我在 Twitter [hashtags][13]、文件名、文件夹名、书签、诸如此类的博文等诸如此类地地方重用这些标签。
|
||||
|
||||
标签作为文件名的一部分有几个优点。通过使用常用的桌面搜索引擎,你可以在标签的帮助下定位文件。文件名称中的标签不会因为复制到不同的存储介质上而丢失。当系统使用与文件名之外的存储位置(如:元数据数据库、[点文件][14]、[备用数据流][15]等)存储元信息通常会发生丢失。
|
||||
|
||||
当然,通常在文件和文件夹名称中,**请避免使用特殊字符**、变音符、冒号等。尤其是在不同操作系统平台之间同步文件时。
|
||||
|
||||
我的**文件夹名命名约定**与文件的相应规范相同。
|
||||
|
||||
注意:由于 [Memacs][17] 的 [filenametimestamp][16] 模块的聪明之处,所有带有日期/时间戳的文件和文件夹都出现在我的 Org 模式的日历(日程)上的同一天/同一时间。这样,我就能很好地了解当天发生了什么,包括我拍的所有照片。
|
||||
|
||||
### 我的一般文件夹结构
|
||||
|
||||
在本节中,我将描述我的主文件夹中最重要的文件夹。注意:这可能在将来的被移动到一个独立的页面。或许不是。让我们等着瞧 :-) (LCTT 译注:后来这一节已被作者扩展并移动到另外一篇[文章](https://karl-voit.at/folder-hierarchy/)。)
|
||||
|
||||
很多东西只有在一定的时间内才会引起人们的兴趣。这些内容包括快速浏览其内容的下载、解压缩文件以检查包含的文件、一些有趣的小内容等等。对于**临时的东西**,我有 `$HOME/tmp/` 子层次结构。新照片放在 `$HOME/tmp/digicam/` 中。我从 CD、DVD 或 USB 记忆棒临时复制的东西放在 `$HOME/tmp/fromcd/` 中。每当软件工具需要用户文件夹层次结构中的临时数据时,我就使用 `$HOME/tmp/Tools/`作为起点。我经常使用的文件夹是 `$HOME/tmp/2del/`:`2del` 的意思是“随时可以删除”。例如,我所有的浏览器都使用这个文件夹作为默认的下载文件夹。如果我需要在机器上腾出空间,我首先查看这个 `2del` 文件夹,用于删除内容。
|
||||
|
||||
与上面描述的临时文件相比,我当然也想将文件**保存更长的时间**。这些文件被移动到我的 `$HOME/archive/` 子层次结构中。它有几个子文件夹用于备份、我想保留的 web 下载类、我要存档的二进制文件、可移动媒体(CD、DVD、记忆棒、外部硬盘驱动器)的索引文件,和一个稍后(寻找一个合适的的目标文件夹)存档的文件夹。有时,我太忙或没有耐心的时候将文件妥善整理。是的,那就是我,我甚至有一个名为“现在不要烦我”的文件夹。这对你而言是否很怪?:-)
|
||||
|
||||
我的归档中最重要的子层次结构是 `$HOME/archive/events_memories/` 及其子文件夹 `2014/`、`2013/`、`2012/` 等等。正如你可能已经猜到的,每个年份有一个**子文件夹**。其中每个文件中都有单个文件和文件夹。这些文件是根据我在前一节中描述的文件名约定命名的。文件夹名称以 [ISO 8601][7] 日期标签 “YYYY-MM-DD” 开头,后面跟着一个具有描述性的名称,如 `$HOME/archive/events_memories/2014/2014-05-08 Business marathon with/`。在这些与日期相关的文件夹中,我保存着各种与特定事件相关的文件:照片、(扫描的)pdf 文件、文本文件等等。
|
||||
|
||||
对于**共享数据**,我设置一个 `$HOME/share/` 子层次结构。这是我的 Dropbox 文件夹,我用各种各样的方法(比如 [unison][18])来分享数据。我也在我的设备之间共享数据:家里的 Mac Mini、家里的 GNU/Linux 笔记本、Android 手机,root-server(我的个人云),工作用的 Windows 笔记本。我不想在这里详细说明我的同步设置。如果你想了解相关的设置,可以参考另一篇相关的文章。:-)
|
||||
|
||||
在我的 `$HOME/templates_tags/` 子层次结构中,我保存了各种**模板文件**([LaTeX][19]、脚本、…),插图和**徽标**,等等。
|
||||
|
||||
我的 **Org 模式** 文件,主要是保存在 `$HOME/org/`。我练习记忆力,不会解释我有多喜欢 [Emacs/Org 模式][20] 以及我从中获益多少。你可能读过或听过我详细描述我用它做的很棒的事情。具体可以在我的博客上查找 [我的 Emacs 标签][21],在 Twitter 上查找 [hashtag #orgmode][22]。
|
||||
|
||||
以上就是我最重要的文件夹子层次结构设置方式。
|
||||
|
||||
### 我的工作流程
|
||||
|
||||
哒哒哒,在你了解了我的文件夹结构和文件名约定之后,下面是我当前的工作流程和工具,我使用它们来满足我前面描述的需求。
|
||||
|
||||
请注意,**你必须知道你在做什么**。我这里的示例及文件夹路径和更多**只适用我的机器或我的环境**。**你必须采用相应的**路径、文件名等来满足你的需求!
|
||||
|
||||
#### 工作流程:将文件从 SD 卡移动到笔记本电脑、旋转人像图像,并重命名文件
|
||||
|
||||
当我想把数据从我的数码相机移到我的 GNU/Linux 笔记本上时,我拿出它的 mini SD 存储卡,把它放在我的笔记本上。然后它会自动挂载在 `/media/digicam` 上。
|
||||
|
||||
然后,调用 [getdigicamdata][23]。它做了如下几件事:它将文件从 SD 卡移动到一个临时文件夹中进行处理。原始文件名会转换为小写字符。所有的人像照片会使用 [jhead][24] 旋转。同样使用 jhead,我从 Exif 头的时间戳中生成文件名称中的时间戳。使用 [date2name][25],我也将时间戳添加到电影文件中。处理完所有这些文件后,它们将被移动到新的数码相机文件的目标文件夹: `$HOME/tmp/digicam/tmp/`。
|
||||
|
||||
#### 工作流程:文件夹索引、查看、重命名、删除图像文件
|
||||
|
||||
为了快速浏览我的图像和电影文件,我喜欢使用 GNU/Linux 上的 [geeqie][26]。这是一个相当轻量级的图像浏览器,它具有其他文件浏览器所缺少的一大优势:我可以添加通过键盘快捷方式调用的外部脚本/工具。通过这种方式,我可以通过任意外部命令扩展这个图像浏览器的特性。
|
||||
|
||||
基本的图像管理功能是内置在 geeqie:浏览我的文件夹层次结构、以窗口模式或全屏查看图像(快捷键 `f`)、重命名文件名、删除文件、显示 Exif 元数据(快捷键 `Ctrl-e`)。
|
||||
|
||||
在 OS X 上,我使用 [Xee][27]。与 geeqie 不同,它不能通过外部命令进行扩展。不过,基本的浏览、查看和重命名功能也是可用的。
|
||||
|
||||
#### 工作流程:添加和删除标签
|
||||
|
||||
我创建了一个名为 [filetags][28] 的 Python 脚本,用于向单个文件以及一组文件添加和删除标记。
|
||||
|
||||
对于数码照片,我使用标签,例如,`specialL` 用于我认为适合桌面背景的风景图片,`specialP` 用于我想展示给其他人的人像照片,`sel` 用于筛选,等等。
|
||||
|
||||
##### 使用 geeqie 初始设置 filetags
|
||||
|
||||
向 geeqie 添加 `filetags` 是一个手动步骤:“Edit > Preferences > Configure Editors ...”,然后创建一个附加条目 `New`。在这里,你可以定义一个新的桌面文件,如下所示:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=filetags
|
||||
GenericName=filetags
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vk-filetags-interactive-adding-wrapper-with-gnome-terminal.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*add-tags.desktop*
|
||||
|
||||
封装脚本 `vk-filetags-interactive-adding-wrapper-with-gnome-terminal.sh` 是必须的,因为我想要弹出一个新的终端,以便添加标签到我的文件:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=85x15+330+5 \
|
||||
--tab-with-profile=big \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/filetags/filetags.py --interactive "${@}"
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-filetags-interactive-adding-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
在 geeqie 中,你可以在 “Edit > Preferences > Preferences ... > Keyboard”。我将 `t` 与 `filetags` 命令相关联。
|
||||
|
||||
这个 `filetags` 脚本还能够从单个文件或一组文件中删除标记。它基本上使用与上面相同的方法。唯一的区别是 `filetags` 脚本额外的 `--remove` 参数:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=filetags-remove
|
||||
GenericName=filetags-remove
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vk-filetags-interactive-removing-wrapper-with-gnome-terminal.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*remove-tags.desktop*
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=85x15+330+5 \
|
||||
--tab-with-profile=big \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/filetags/filetags.py --interactive --remove "${@}"
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-filetags-interactive-removing-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
为了删除标签,我创建了一个键盘快捷方式 `T`。
|
||||
|
||||
##### 在 geeqie 中使用 filetags
|
||||
|
||||
当我在 geeqie 文件浏览器中浏览图像文件时,我选择要标记的文件(一到多个)并按 `t`。然后,一个小窗口弹出,要求我提供一个或多个标签。用回车确认后,这些标签被添加到文件名中。
|
||||
|
||||
删除标签也是一样:选择多个文件,按下 `T`,输入要删除的标签,然后按回车确认。就是这样。几乎没有[给文件添加或删除标签的更简单的方法了][29]。
|
||||
|
||||
#### 工作流程:改进的使用 appendfilename 重命名文件
|
||||
|
||||
##### 不使用 appendfilename
|
||||
|
||||
重命名一组大型文件可能是一个冗长乏味的过程。对于 `2014-04-20T17.09.11_p1100386.jpg` 这样的原始文件名,在文件名中添加描述的过程相当烦人。你将按 `Ctrl-r` (重命名)在 geeqie 中打开文件重命名对话框。默认情况下,原始名称(没有文件扩展名的文件名称)被标记。因此,如果不希望删除/覆盖文件名(但要追加),则必须按下光标键 `→`。然后,光标放在基本名称和扩展名之间。输入你的描述(不要忘记以空格字符开始),并用回车进行确认。
|
||||
|
||||
##### 在 geeqie 使中用 appendfilename
|
||||
|
||||
使用 [appendfilename][30],我的过程得到了简化,可以获得将文本附加到文件名的最佳用户体验:当我在 geeqie 中按下 `a`(附加)时,会弹出一个对话框窗口,询问文本。在回车确认后,输入的文本将放置在时间戳和可选标记之间。
|
||||
|
||||
例如,当我在 `2014-04-20T17.09.11_p1100386.jpg` 上按下 `a`,然后键入`Pick-nick in Graz` 时,文件名变为 `2014-04-20T17.09.11_p1100386 Pick-nick in Graz.jpg`。当我再次按下 `a` 并输入 `with Susan` 时,文件名变为 `2014-04-20T17.09.11_p1100386 Pick-nick in Graz with Susan.jpg`。当文件名添加标记时,附加的文本前将附加标记分隔符。
|
||||
|
||||
这样,我就不必担心覆盖时间戳或标记。重命名的过程对我来说变得更加有趣!
|
||||
|
||||
最好的部分是:当我想要将相同的文本添加到多个选定的文件中时,也可以使用 `appendfilename`。
|
||||
|
||||
##### 在 geeqie 中初始设置 appendfilename
|
||||
|
||||
添加一个额外的编辑器到 geeqie: “Edit > Preferences > Configure Editors ... > New”。然后输入桌面文件定义:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=appendfilename
|
||||
GenericName=appendfilename
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vk-appendfilename-interactive-wrapper-with-gnome-terminal.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*appendfilename.desktop*
|
||||
|
||||
同样,我也使用了一个封装脚本,它将为我打开一个新的终端:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=90x5+330+5 \
|
||||
--tab-with-profile=big \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/appendfilename/appendfilename.py "${@}"
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-appendfilename-interactive-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
#### 工作流程:播放电影文件
|
||||
|
||||
在 GNU/Linux 上,我使用 [mplayer][31] 回放视频文件。由于 geeqie 本身不播放电影文件,所以我必须创建一个设置,以便在 mplayer 中打开电影文件。
|
||||
|
||||
##### 在 geeqie 中初始设置 mplayer
|
||||
|
||||
我已经使用 [xdg-open][32] 将电影文件扩展名关联到 mplayer。因此,我只需要为 geeqie 创建一个通用的“open”命令,让它使用 `xdg-open` 打开任何文件及其关联的应用程序。
|
||||
|
||||
在 geeqie 中,再次访问 “Edit > Preferences > Configure Editors ...” 添加“open”的条目:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=open
|
||||
GenericName=open
|
||||
Comment=
|
||||
Exec=/usr/bin/xdg-open %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
hidden=false
|
||||
NOMimeType=*;
|
||||
MimeType=image/*;video/*
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*open.desktop*
|
||||
|
||||
当你也将快捷方式 `o` (见上文)与 geeqie 关联时,你就能够打开与其关联的应用程序的视频文件(和其他文件)。
|
||||
|
||||
##### 使用 xdg-open 打开电影文件(和其他文件)
|
||||
|
||||
在上面的设置过程之后,当你的 geeqie 光标位于文件上方时,你只需按下 `o` 即可。就是如此简洁。
|
||||
|
||||
#### 工作流程:在外部图像编辑器中打开
|
||||
|
||||
我不太希望能够在 GIMP 中快速编辑图像文件。因此,我添加了一个快捷方式 `g`,并将其与外部编辑器 “"GNU Image Manipulation Program" (GIMP)” 关联起来,geeqie 已经默认创建了该外部编辑器。
|
||||
|
||||
这样,只需按下 `g` 就可以在 GIMP 中打开当前图像。
|
||||
|
||||
#### 工作流程:移动到存档文件夹
|
||||
|
||||
现在我已经在我的文件名中添加了注释,我想将单个文件移动到 `$HOME/archive/events_memories/2014/`,或者将一组文件移动到这个文件夹中的新文件夹中,如 `$HOME/archive/events_memories/2014/2014-05-08 business marathon after show - party`。
|
||||
|
||||
通常的方法是选择一个或多个文件,并用快捷方式 `Ctrl-m` 将它们移动到文件夹中。
|
||||
|
||||
何等繁复无趣之至!
|
||||
|
||||
因此,我(再次)编写了一个 Python 脚本,它为我完成了这项工作:[move2archive][33](简写为:` m2a `),需要一个或多个文件作为命令行参数。然后,出现一个对话框,我可以在其中输入一个可选文件夹名。当我不输入任何东西而是按回车,文件被移动到相应年份的文件夹。当我输入一个类似 `Business-Marathon After-Show-Party` 的文件夹名称时,第一个图像文件的日期戳被附加到该文件夹(`$HOME/archive/events_memories/2014/2014-05-08 Business-Marathon After-Show-Party`),然后创建该文件夹,并移动文件。
|
||||
|
||||
再一次,我在 geeqie 中选择一个或多个文件,按 `m`(移动),或者只按回车(没有特殊的子文件夹),或者输入一个描述性文本,这是要创建的子文件夹的名称(可选不带日期戳)。
|
||||
|
||||
**没有一个图像管理工具像我的带有 appendfilename 和 move2archive 的 geeqie 一样可以通过快捷键快速且有趣的完成工作。**
|
||||
|
||||
##### 在 geeqie 里初始化 m2a 的相关设置
|
||||
|
||||
同样,向 geeqie 添加 `m2a` 是一个手动步骤:“Edit > Preferences > Configure Editors ...”,然后创建一个附加条目“New”。在这里,你可以定义一个新的桌面文件,如下所示:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=move2archive
|
||||
GenericName=move2archive
|
||||
Comment=Moving one or more files to my archive folder
|
||||
Exec=/home/vk/src/misc/vk-m2a-interactive-wrapper-with-gnome-terminal.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*m2a.desktop*
|
||||
|
||||
封装脚本 `vk-m2a-interactive-wrapper-with-gnome-terminal.sh` 是必要的,因为我想要弹出一个新的终端窗口,以便我的文件进入我指定的目标文件夹:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=157x56+330+5 \
|
||||
--tab-with-profile=big \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/m2a/m2a.py --pauseonexit "${@}"
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-m2a-interactive-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
在 geeqie 中,你可以在 “Edit > Preferences > Preferences ... > Keyboard” 将 `m` 与 `m2a` 命令相关联。
|
||||
|
||||
#### 工作流程:旋转图像(无损)
|
||||
|
||||
通常,我的数码相机会自动将人像照片标记为人像照片。然而,在某些特定的情况下(比如从装饰图案上方拍照),我的相机会出错。在那些**罕见的情况下**,我必须手动修正方向。
|
||||
|
||||
你必须知道,JPEG 文件格式是一种有损格式,应该只用于照片,而不是计算机生成的东西,如屏幕截图或图表。以傻瓜方式旋转 JPEG 图像文件通常会解压/可视化图像文件、旋转生成新的图像,然后重新编码结果。这将导致生成的图像[比原始图像质量差得多][5]。
|
||||
|
||||
因此,你应该使用无损方法来旋转 JPEG 图像文件。
|
||||
|
||||
再一次,我添加了一个“外部编辑器”到 geeqie:“Edit > Preferences > Configure Editors ... > New”。在这里,我添加了两个条目:使用 [exiftran][34],一个用于旋转 270 度(即逆时针旋转 90 度),另一个用于旋转 90 度(顺时针旋转 90 度):
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Version=1.0
|
||||
Type=Application
|
||||
Name=Losslessly rotate JPEG image counterclockwise
|
||||
|
||||
# call the helper script
|
||||
TryExec=exiftran
|
||||
Exec=exiftran -p -2 -i -g %f
|
||||
|
||||
# Desktop files that are usable only in Geeqie should be marked like this:
|
||||
Categories=X-Geeqie;
|
||||
OnlyShowIn=X-Geeqie;
|
||||
|
||||
# Show in menu "Edit/Orientation"
|
||||
X-Geeqie-Menu-Path=EditMenu/OrientationMenu
|
||||
|
||||
MimeType=image/jpeg;
|
||||
```
|
||||
|
||||
*rotate-270.desktop*
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Version=1.0
|
||||
Type=Application
|
||||
Name=Losslessly rotate JPEG image clockwise
|
||||
|
||||
# call the helper script
|
||||
TryExec=exiftran
|
||||
Exec=exiftran -p -9 -i -g %f
|
||||
|
||||
# Desktop files that are usable only in Geeqie should be marked like this:
|
||||
Categories=X-Geeqie;
|
||||
OnlyShowIn=X-Geeqie;
|
||||
|
||||
# Show in menu "Edit/Orientation"
|
||||
X-Geeqie-Menu-Path=EditMenu/OrientationMenu
|
||||
|
||||
# It can be made verbose
|
||||
# X-Geeqie-Verbose=true
|
||||
|
||||
MimeType=image/jpeg;
|
||||
```
|
||||
|
||||
*rotate-90.desktop*
|
||||
|
||||
我创建了 geeqie 快捷键 `[`(逆时针方向)和 `]`(顺时针方向)。
|
||||
|
||||
#### 工作流程:可视化 GPS 坐标
|
||||
|
||||
我的数码相机有一个 GPS 传感器,它在 JPEG 文件的 Exif 元数据中存储当前的地理位置。位置数据以 [WGS 84][35] 格式存储,如 `47, 58, 26.73; 16, 23, 55.51`(纬度;经度)。这一方式可读性较差,我期望:要么是地图,要么是位置名称。因此,我向 geeqie 添加了一些功能,这样我就可以在 [OpenStreetMap][36] 上看到单个图像文件的位置: `Edit > Preferences > Configure Editors ... > New`。
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=vkphotolocation
|
||||
GenericName=vkphotolocation
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vkphotolocation.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/bmp;image/gif;image/jpeg;image/jpg;image/pjpeg;image/png;image/tiff;image/x-bmp;image/x-gray;image/x-icb;image/x-ico;image/x-png;image/x-portable-anymap;image/x-portable-bitmap;image/x-portable-graymap;image/x-portable-pixmap;image/x-xbitmap;image/x-xpixmap;image/x-pcx;image/svg+xml;image/svg+xml-compressed;image/vnd.wap.wbmp;
|
||||
```
|
||||
|
||||
*photolocation.desktop*
|
||||
|
||||
这调用了我的名为 `vkphotolocation.sh` 的封装脚本,它使用 [ExifTool][37] 以 [Marble][38] 能够读取和可视化的适当格式提取该坐标:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
IMAGEFILE="${1}"
|
||||
IMAGEFILEBASENAME=`basename ${IMAGEFILE}`
|
||||
|
||||
COORDINATES=`exiftool -c %.6f "${IMAGEFILE}" | awk '/GPS Position/ { print $4 " " $6 }'`
|
||||
|
||||
if [ "x${COORDINATES}" = "x" ]; then
|
||||
zenity --info --title="${IMAGEFILEBASENAME}" --text="No GPS-location found in the image file."
|
||||
else
|
||||
/usr/bin/marble --latlon "${COORDINATES}" --distance 0.5
|
||||
fi
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vkphotolocation.sh*
|
||||
|
||||
映射到键盘快捷键 `G`,我可以快速地得到**单个图像文件的位置的地图定位**。
|
||||
|
||||
当我想将多个 JPEG 图像文件的**位置可视化为路径**时,我使用 [GpsPrune][39]。我无法挖掘出 GpsPrune 将一组文件作为命令行参数的方法。正因为如此,我必须手动启动 GpsPrune,用 “File > Add photos”选择一组文件或一个文件夹。
|
||||
|
||||
通过这种方式,我可以为每个 JPEG 位置在 OpenStreetMap 地图上获得一个点(如果配置为这样)。通过单击这样一个点,我可以得到相应图像的详细信息。
|
||||
|
||||
如果你恰好在国外拍摄照片,可视化 GPS 位置对**在文件名中添加描述**大有帮助!
|
||||
|
||||
#### 工作流程:根据 GPS 坐标过滤照片
|
||||
|
||||
这并非我的工作流程。为了完整起见,我列出该工作流对应工具的特性。我想做的就是从一大堆图片中寻找那些在一定区域内(范围或点 + 距离)的照片。
|
||||
|
||||
到目前为止,我只找到了 [DigiKam][40],它能够[根据矩形区域进行过滤][41]。如果你知道其他工具,请将其添加到下面的评论或给我写一封电子邮件。
|
||||
|
||||
#### 工作流程:显示给定集合的子集
|
||||
|
||||
如上面的需求所述,我希望能够对一个文件夹中的文件定义一个子集,以便将这个小集合呈现给其他人。
|
||||
|
||||
工作流程非常简单:我向选择的文件添加一个标记(通过 `t`/`filetags`)。为此,我使用标记 `sel`,它是 “selection” 的缩写。在标记了一组文件之后,我可以按下 `s`,它与一个脚本相关联,该脚本只显示标记为 `sel` 的文件。
|
||||
|
||||
当然,这也适用于任何标签或标签组合。因此,用同样的方法,你可以得到一个适当的概述,你的婚礼上的所有照片都标记着“教堂”和“戒指”。
|
||||
|
||||
很棒的功能,不是吗?:-)
|
||||
|
||||
##### 初始设置 filetags 以根据标签和 geeqie 过滤
|
||||
|
||||
你必须定义一个额外的“外部编辑器”,“ Edit > Preferences > Configure Editors ... > New”:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=filetag-filter
|
||||
GenericName=filetag-filter
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vk-filetag-filter-wrapper-with-gnome-terminal.sh
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*filter-tags.desktop*
|
||||
|
||||
再次调用我编写的封装脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=85x15+330+5 \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/filetags/filetags.py --filter
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-filetag-filter-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
带有参数 `--filter` 的 `filetags` 基本上完成的是:用户被要求输入一个或多个标签。然后,当前文件夹中所有匹配的文件都使用[符号链接][42]链接到 `$HOME/.filetags_tagfilter/`。然后,启动了一个新的 geeqie 实例,显示链接的文件。
|
||||
|
||||
在退出这个新的 geeqie 实例之后,你会看到进行选择的旧的 geeqie 实例。
|
||||
|
||||
#### 用一个真实的案例来总结
|
||||
|
||||
哇哦, 这是一篇很长的博客文章。你可能已经忘了之前的概述。总结一下我在(扩展了标准功能集的) geeqie 中可以做的事情,我有一个很酷的总结:
|
||||
|
||||
快捷键 | 功能
|
||||
--- | ---
|
||||
`m` | 移到归档(m2a)
|
||||
`o` | 打开(针对非图像文件)
|
||||
`a` | 在文件名里添加字段
|
||||
`t` | 文件标签(添加)
|
||||
`T` | 文件标签(删除)
|
||||
`s` | 文件标签(排序)
|
||||
`g` | gimp
|
||||
`G` | 显示 GPS 信息
|
||||
`[` | 无损的逆时针旋转
|
||||
`]` | 无损的顺时针旋转
|
||||
`Ctrl-e` | EXIF 图像信息
|
||||
`f` | 全屏显示
|
||||
|
||||
文件名(包括它的路径)的部分及我用来操作该部分的相应工具:
|
||||
|
||||
```
|
||||
/this/is/a/folder/2014-04-20T17.09 Picknick in Graz -- food graz.jpg
|
||||
[ move2archive ] [ date2name ] [appendfilename] [ filetags ]
|
||||
```
|
||||
|
||||
在实践中,我按照以下步骤将照片从相机保存到存档:我将 SD 存储卡放入计算机的 SD 读卡器中。然后我运行 [getdigicamdata.sh][23]。完成之后,我在 geeqie 中打开 `$HOME/tmp/digicam/tmp/`。我浏览了一下照片,把那些不成功的删除了。如果有一个图像的方向错误,我用 `[` 或 `]` 纠正它。
|
||||
|
||||
在第二步中,我向我认为值得评论的文件添加描述 (`a`)。每当我想添加标签时,我也这样做:我快速地标记所有应该共享相同标签的文件(`Ctrl + 鼠标点击`),并使用 [filetags][28](`t`)进行标记。
|
||||
|
||||
要合并来自给定事件的文件,我选中相应的文件,将它们移动到年度归档文件夹中的 `event-folder`,并通过在 [move2archive][33](`m`)中键入事件描述,其余的(非特殊的文件夹)无需声明事件描述由 `move2archive` (`m`)直接移动到年度归档中。
|
||||
|
||||
结束我的工作流程,我删除了 SD 卡上的所有文件,把它从操作系统上弹出,然后把它放回我的数码相机里。
|
||||
|
||||
以上。
|
||||
|
||||
因为这种工作流程几乎不需要任何开销,所以评论、标记和归档照片不再是一项乏味的工作。
|
||||
|
||||
### 最后
|
||||
|
||||
所以,这是一个详细描述我关于照片和电影的工作流程的叙述。你可能已经发现了我可能感兴趣的其他东西。所以请不要犹豫,请使用下面的链接留下评论或电子邮件。
|
||||
|
||||
我也希望得到反馈,如果我的工作流程适用于你。并且,如果你已经发布了你的工作流程或者找到了其他人工作流程的描述,也请留下评论!
|
||||
|
||||
及时行乐,莫让错误的工具或低效的方法浪费了我们的人生!
|
||||
|
||||
### 其他工具
|
||||
|
||||
阅读关于[本文中关于 gThumb 的部分][43]。
|
||||
|
||||
当你觉得你以上文中所叙述的符合你的需求时,请根据相关的建议来选择对应的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/managing-digital-photographs/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/Jpeg
|
||||
[2]:http://en.wikipedia.org/wiki/Vendor_lock-in
|
||||
[3]:https://en.wikipedia.org/wiki/Raw_image_format
|
||||
[4]:http://www.gimp.org/
|
||||
[5]:http://petapixel.com/2012/08/14/why-you-should-always-rotate-original-jpeg-photos-losslessly/
|
||||
[6]:https://en.wikipedia.org/wiki/Gps
|
||||
[7]:https://en.wikipedia.org/wiki/Iso_date
|
||||
[8]:https://en.wikipedia.org/wiki/Ntfs
|
||||
[9]:https://en.wikipedia.org/wiki/Exif
|
||||
[10]:http://www.isisinform.com/reinventing-knowledge-the-medieval-controversy-of-alphabetical-order/
|
||||
[11]:https://en.wikipedia.org/wiki/File_name_extension
|
||||
[12]:http://karl-voit.at/tagstore/en/papers.shtml
|
||||
[13]:https://en.wikipedia.org/wiki/Hashtag
|
||||
[14]:https://en.wikipedia.org/wiki/Dot-file
|
||||
[15]:https://en.wikipedia.org/wiki/NTFS#Alternate_data_streams_.28ADS.29
|
||||
[16]:https://github.com/novoid/Memacs/blob/master/docs/memacs_filenametimestamps.org
|
||||
[17]:https://github.com/novoid/Memacs
|
||||
[18]:http://www.cis.upenn.edu/~bcpierce/unison/
|
||||
[19]:https://github.com/novoid/LaTeX-KOMA-template
|
||||
[20]:http://orgmode.org/
|
||||
[21]:http://karl-voit.at/tags/emacs
|
||||
[22]:https://twitter.com/search?q%3D%2523orgmode&src%3Dtypd
|
||||
[23]:https://github.com/novoid/getdigicamdata.sh
|
||||
[24]:http://www.sentex.net/%3Ccode%3Emwandel/jhead/
|
||||
[25]:https://github.com/novoid/date2name
|
||||
[26]:http://geeqie.sourceforge.net/
|
||||
[27]:http://xee.c3.cx/
|
||||
[28]:https://github.com/novoid/filetag
|
||||
[29]:http://karl-voit.at/tagstore/
|
||||
[30]:https://github.com/novoid/appendfilename
|
||||
[31]:http://www.mplayerhq.hu
|
||||
[32]:https://wiki.archlinux.org/index.php/xdg-open
|
||||
[33]:https://github.com/novoid/move2archive
|
||||
[34]:http://manpages.ubuntu.com/manpages/raring/man1/exiftran.1.html
|
||||
[35]:https://en.wikipedia.org/wiki/WGS84#A_new_World_Geodetic_System:_WGS_84
|
||||
[36]:http://www.openstreetmap.org/
|
||||
[37]:http://www.sno.phy.queensu.ca/~phil/exiftool/
|
||||
[38]:http://userbase.kde.org/Marble/Tracking
|
||||
[39]:http://activityworkshop.net/software/gpsprune/
|
||||
[40]:https://en.wikipedia.org/wiki/DigiKam
|
||||
[41]:https://docs.kde.org/development/en/extragear-graphics/digikam/using-kapp.html#idp7659904
|
||||
[42]:https://en.wikipedia.org/wiki/Symbolic_link
|
||||
[43]:http://karl-voit.at/2017/02/19/gthumb
|
||||
[44]:https://glt18.linuxtage.at
|
||||
[45]:https://glt18-programm.linuxtage.at/events/321.html
|
||||
277
published/20180906 What a shell dotfile can do for you.md
Normal file
277
published/20180906 What a shell dotfile can do for you.md
Normal file
@ -0,0 +1,277 @@
|
||||
Shell 点文件可以为你做点什么
|
||||
======
|
||||
|
||||
> 了解如何使用配置文件来改善你的工作环境。
|
||||
|
||||

|
||||
|
||||
不要问你可以为你的 shell <ruby>点文件<rt>dotfile</rt></ruby>做什么,而是要问一个 shell 点文件可以为你做什么!
|
||||
|
||||
我一直在操作系统领域里面打转,但是在过去的几年中,我的日常使用的一直是 Mac。很长一段时间,我都在使用 Bash,但是当几个朋友开始把 [zsh][1] 当成宗教信仰时,我也试试了它。我没用太长时间就喜欢上了它,几年后,我越发喜欢它做的许多小事情。
|
||||
|
||||
我一直在使用 zsh(通过 [Homebrew][2] 提供,而不是由操作系统安装的)和 [Oh My Zsh 增强功能][3]。
|
||||
|
||||
本文中的示例是我的个人 `.zshrc`。大多数都可以直接用在 Bash 中,我觉得不是每个人都依赖于 Oh My Zsh,但是如果不用的话你的工作量可能会有所不同。曾经有一段时间,我同时为 zsh 和 Bash 维护一个 shell 点文件,但是最终我还是放弃了我的 `.bashrc`。
|
||||
|
||||
### 不偏执不行
|
||||
|
||||
如果你希望在各个操作系统上使用相同的点文件,则需要让你的点文件聪明点。
|
||||
|
||||
```
|
||||
### Mac 专用
|
||||
if [[ "$OSTYPE" == "darwin"* ]]; then
|
||||
# Mac 专用内容在此
|
||||
```
|
||||
|
||||
例如,我希望 `Alt + 箭头键` 将光标按单词移动而不是单个空格。为了在 [iTerm2][4](我的首选终端)中实现这一目标,我将此代码段添加到了 `.zshrc` 的 Mac 专用部分:
|
||||
|
||||
```
|
||||
### Mac 专用
|
||||
if [[ "$OSTYPE" == "darwin"* ]]; then
|
||||
### Mac 用于 iTerm2 的光标命令;映射 ctrl+arrows 或 alt+arrows 来快速移动
|
||||
bindkey -e
|
||||
bindkey '^[[1;9C' forward-word
|
||||
bindkey '^[[1;9D' backward-word
|
||||
bindkey '\e\e[D' backward-word
|
||||
bindkey '\e\e[C' forward-word
|
||||
fi
|
||||
```
|
||||
|
||||
(LCTT 译注:标题 “We're all mad here” 是电影《爱丽丝梦游仙境》中,微笑猫对爱丽丝讲的一句话:“我们这儿全都是疯的”。)
|
||||
|
||||
### 在家不工作
|
||||
|
||||
虽然我开始喜欢我的 Shell 点文件了,但我并不总是想要家用计算机上的东西与工作的计算机上的东西一样。解决此问题的一种方法是让补充的点文件在家中使用,而不是在工作中使用。以下是我的实现方式:
|
||||
|
||||
```
|
||||
if [[ `egrep 'dnssuffix1|dnssuffix2' /etc/resolv.conf` ]]; then
|
||||
if [ -e $HOME/.work ]
|
||||
source $HOME/.work
|
||||
else
|
||||
echo "This looks like a work machine, but I can't find the ~/.work file"
|
||||
fi
|
||||
fi
|
||||
```
|
||||
|
||||
在这种情况下,我根据我的工作 dns 后缀(或多个后缀,具体取决于你的情况)来提供(`source`)一个可以使我的工作环境更好的单独文件。
|
||||
|
||||
(LCTT 译注:标题 “What about Bob?” 是 1991 年的美国电影《天才也疯狂》。)
|
||||
|
||||
### 你该这么做
|
||||
|
||||
现在可能是放弃使用波浪号(`~`)表示编写脚本时的主目录的好时机。你会发现在某些上下文中无法识别它。养成使用环境变量 `$HOME` 的习惯,这将为你节省大量的故障排除时间和以后的工作。
|
||||
|
||||
如果你愿意,合乎逻辑的扩展是应该包括特定于操作系统的点文件。
|
||||
|
||||
(LCTT 译注:标题 “That thing you do” 是 1996 年由汤姆·汉克斯执导的喜剧片《挡不住的奇迹》。)
|
||||
|
||||
### 别指望记忆
|
||||
|
||||
我写了那么多 shell 脚本,我真的再也不想写脚本了。并不是说 shell 脚本不能满足我大部分时间的需求,而是我发现写 shell 脚本,可能只是拼凑了一个胶带式解决方案,而不是永久地解决问题。
|
||||
|
||||
同样,我讨厌记住事情,在我的整个职业生涯中,我经常不得不在一天之中就彻彻底底地改换环境。实际的结果是这些年来,我不得不一再重新学习很多东西。(“等等……这种语言使用哪种 for 循环结构?”)
|
||||
|
||||
因此,每隔一段时间我就会觉得自己厌倦了再次寻找做某事的方法。我改善生活的一种方法是添加别名。
|
||||
|
||||
对于任何一个使用操作系统的人来说,一个常见的情况是找出占用了所有磁盘的内容。不幸的是,我从来没有记住过这个咒语,所以我做了一个 shell 别名,创造性地叫做 `bigdirs`:
|
||||
|
||||
```
|
||||
alias bigdirs='du --max-depth=1 2> /dev/null | sort -n -r | head -n20'
|
||||
```
|
||||
|
||||
虽然我可能不那么懒惰,并实际记住了它,但是,那不太 Unix ……
|
||||
|
||||
(LCTT 译注:标题 “Memory, all alone in the moonlight” 是一手英文老歌。)
|
||||
|
||||
### 输错的人们
|
||||
|
||||
使用 shell 别名改善我的生活的另一种方法是使我免于输入错误。我不知道为什么,但是我已经养成了这种讨厌的习惯,在序列 `ea` 之后输入 `w`,所以如果我想清除终端,我经常会输入 `cleawr`。不幸的是,这对我的 shell 没有任何意义。直到我添加了这个小东西:
|
||||
|
||||
```
|
||||
alias cleawr='clear'
|
||||
```
|
||||
|
||||
在 Windows 中有一个等效但更好的命令 `cls`,但我发现自己会在 Shell 也输入它。看到你的 shell 表示抗议真令人沮丧,因此我添加:
|
||||
|
||||
```
|
||||
alias cls='clear'
|
||||
```
|
||||
|
||||
是的,我知道 `ctrl + l`,但是我从不使用它。
|
||||
|
||||
(LCTT 译注:标题 “Typos, and the people who love them” 可能来自某部电影。)
|
||||
|
||||
### 要自娱自乐
|
||||
|
||||
工作压力很大。有时你需要找点乐子。如果你的 shell 不知道它显然应该执行的命令,则可能你想直接让它耸耸肩!你可以使用以下功能执行此操作:
|
||||
|
||||
```
|
||||
shrug() { echo "¯\_(ツ)_/¯"; }
|
||||
```
|
||||
|
||||
如果还不行,也许你需要掀桌不干了:
|
||||
|
||||
```
|
||||
fliptable() { echo "(╯°□°)╯ ┻━┻"; } # 掀桌,用法示例: fsck -y /dev/sdb1 || fliptable
|
||||
```
|
||||
|
||||
想想看,当我想掀桌子时而我不记得我给它起了个什么名字,我会有多沮丧和失望,所以我添加了更多的 shell 别名:
|
||||
|
||||
```
|
||||
alias flipdesk='fliptable'
|
||||
alias deskflip='fliptable'
|
||||
alias tableflip='fliptable'
|
||||
```
|
||||
|
||||
而有时你需要庆祝一下:
|
||||
|
||||
```
|
||||
disco() {
|
||||
echo "(•_•)"
|
||||
echo "<) )╯"
|
||||
echo " / \ "
|
||||
echo ""
|
||||
echo "\(•_•)"
|
||||
echo " ( (>"
|
||||
echo " / \ "
|
||||
echo ""
|
||||
echo " (•_•)"
|
||||
echo "<) )>"
|
||||
echo " / \ "
|
||||
}
|
||||
```
|
||||
|
||||
通常,我会将这些命令的输出通过管道传递到 `pbcopy`,并将其粘贴到我正在使用的相关聊天工具中。
|
||||
|
||||
我从一个我关注的一个叫 “Command Line Magic” [@ climagic][5] 的 Twitter 帐户得到了下面这个有趣的函数。自从我现在住在佛罗里达州以来,我很高兴看到我这一生中唯一的一次下雪:
|
||||
|
||||
```
|
||||
snow() {
|
||||
clear;while :;do echo $LINES $COLUMNS $(($RANDOM%$COLUMNS));sleep 0.1;done|gawk '{a[$3]=0;for(x in a) {o=a[x];a[x]=a[x]+1;printf "\033[%s;%sH ",o,x;printf "\033[%s;%sH*\033[0;0H",a[x],x;}}'
|
||||
}
|
||||
```
|
||||
|
||||
(LCTT 译注:标题 “Amuse yourself” 是 1936 年的美国电影《自娱自乐》)
|
||||
|
||||
### 函数的乐趣
|
||||
|
||||
我们已经看到了一些我使用的函数示例。由于这些示例中几乎不需要参数,因此可以将它们作为别名来完成。 当比一个短句更长时,我出于个人喜好使用函数。
|
||||
|
||||
在我职业生涯的很多时期我都运行过 [Graphite][6],这是一个开源、可扩展的时间序列指标解决方案。 在很多的情况下,我需要将度量路径(用句点表示)转换到文件系统路径(用斜杠表示),反之亦然,拥有专用于这些任务的函数就变得很有用:
|
||||
|
||||
```
|
||||
# 在 Graphite 指标和文件路径之间转换很有用
|
||||
function dottoslash() {
|
||||
echo $1 | sed 's/\./\//g'
|
||||
}
|
||||
function slashtodot() {
|
||||
echo $1 | sed 's/\//\./g'
|
||||
}
|
||||
```
|
||||
|
||||
在我的另外一段职业生涯里,我运行了很多 Kubernetes。如果你对运行 Kubernetes 不熟悉,你需要编写很多 YAML。不幸的是,一不小心就会编写了无效的 YAML。更糟糕的是,Kubernetes 不会在尝试应用 YAML 之前对其进行验证,因此,除非你应用它,否则你不会发现它是无效的。除非你先进行验证:
|
||||
|
||||
```
|
||||
function yamllint() {
|
||||
for i in $(find . -name '*.yml' -o -name '*.yaml'); do echo $i; ruby -e "require 'yaml';YAML.load_file(\"$i\")"; done
|
||||
}
|
||||
```
|
||||
|
||||
因为我厌倦了偶尔破坏客户的设置而让自己感到尴尬,所以我写了这个小片段并将其作为提交前挂钩添加到我所有相关的存储库中。在持续集成过程中,类似的内容将非常有帮助,尤其是在你作为团队成员的情况下。
|
||||
|
||||
(LCTT 译注:哦抱歉,我不知道这个标题的出处。)
|
||||
|
||||
### 手指不听话
|
||||
|
||||
我曾经是一位出色的盲打打字员。但那些日子已经一去不回。我的打字错误超出了我的想象。
|
||||
|
||||
在各种时期,我多次用过 Chef 或 Kubernetes。对我来说幸运的是,我从未同时使用过这两者。
|
||||
|
||||
Chef 生态系统的一部分是 Test Kitchen,它是加快测试的一组工具,可通过命令 `kitchen test` 来调用。Kubernetes 使用 CLI 工具 `kubectl` 进行管理。这两个命令都需要几个子命令,并且这两者都不会特别顺畅地移动手指。
|
||||
|
||||
我没有创建一堆“输错别名”,而是将这两个命令别名为 `k`:
|
||||
|
||||
```
|
||||
alias k='kitchen test $@'
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
alias k='kubectl $@'
|
||||
```
|
||||
|
||||
(LCTT 译注:标题 “Oh, fingers, where art thou?” 演绎自《O Brother, Where Art Thou?》,这是 2000 年美国的一部电影《逃狱三王》。)
|
||||
|
||||
### 分裂与合并
|
||||
|
||||
我职业生涯的后半截涉及与其他人一起编写更多代码。我曾在许多环境中工作过,在这些环境中,我们在帐户中复刻了存储库副本,并将拉取请求用作审核过程的一部分。当我想确保给定存储库的复刻与父版本保持最新时,我使用 `fetchupstream`:
|
||||
|
||||
```
|
||||
alias fetchupstream='git fetch upstream && git checkout master && git merge upstream/master && git push'
|
||||
```
|
||||
|
||||
(LCTT 译注:标题 “Timesplitters” 是一款视频游戏《时空分裂者》。)
|
||||
|
||||
### 颜色之荣耀
|
||||
|
||||
我喜欢颜色。它可以使 `diff` 之类的东西更易于使用。
|
||||
|
||||
```
|
||||
alias diff='colordiff'
|
||||
```
|
||||
|
||||
我觉得彩色的手册页是个巧妙的技巧,因此我合并了以下函数:
|
||||
|
||||
```
|
||||
# 彩色化手册页,来自:
|
||||
# http://boredzo.org/blog/archives/2016-08-15/colorized-man-pages-understood-and-customized
|
||||
man() {
|
||||
env \
|
||||
LESS_TERMCAP_md=$(printf "\e[1;36m") \
|
||||
LESS_TERMCAP_me=$(printf "\e[0m") \
|
||||
LESS_TERMCAP_se=$(printf "\e[0m") \
|
||||
LESS_TERMCAP_so=$(printf "\e[1;44;33m") \
|
||||
LESS_TERMCAP_ue=$(printf "\e[0m") \
|
||||
LESS_TERMCAP_us=$(printf "\e[1;32m") \
|
||||
man "$@"
|
||||
}
|
||||
```
|
||||
|
||||
我喜欢命令 `which`,但它只是告诉你正在运行的命令在文件系统中的位置,除非它是 Shell 函数才能告诉你更多。在多个级联的点文件之后,有时会不清楚函数的定义位置或作用。事实证明,`whence` 和 `type` 命令可以帮助解决这一问题。
|
||||
|
||||
```
|
||||
# 函数定义在哪里?
|
||||
whichfunc() {
|
||||
whence -v $1
|
||||
type -a $1
|
||||
}
|
||||
```
|
||||
|
||||
(LCTT 译注:标题“Mine eyes have seen the glory of the coming of color” 演绎自歌曲 《Mine Eyes Have Seen The Glory Of The Coming Of The Lord》)
|
||||
|
||||
### 总结
|
||||
|
||||
希望本文对你有所帮助,并能激发你找到改善日常使用 Shell 的方法。这些方法不必庞大、新颖或复杂。它们可能会解决一些微小但频繁的摩擦、创建捷径,甚至提供减少常见输入错误的解决方案。
|
||||
|
||||
欢迎你浏览我的 [dotfiles 存储库][7],但我要警示你,这样做可能会花费很多时间。请随意使用你认为有帮助的任何东西,并互相取长补短。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/shell-dotfile
|
||||
|
||||
作者:[H.Waldo Grunenwald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gwaldo
|
||||
[1]: http://www.zsh.org/
|
||||
[2]: https://brew.sh/
|
||||
[3]: https://github.com/robbyrussell/oh-my-zsh
|
||||
[4]: https://www.iterm2.com/
|
||||
[5]: https://twitter.com/climagic
|
||||
[6]: https://github.com/graphite-project/
|
||||
[7]: https://github.com/gwaldo/dotfiles
|
||||
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11420-1.html)
|
||||
[#]: subject: (The Earliest Linux Distros: Before Mainstream Distros Became So Popular)
|
||||
[#]: via: (https://itsfoss.com/earliest-linux-distros/)
|
||||
[#]: author: (Avimanyu Bandyopadhyay https://itsfoss.com/author/avimanyu/)
|
||||
|
||||
主流发行版之前的那些最早的 Linux 发行版
|
||||
======
|
||||
|
||||
> 在这篇回溯历史的文章中,我们尝试回顾一些最早的 Linux 发行版是如何演变的,并形成我们今天所知道的发行版的。
|
||||
|
||||
![][1]
|
||||
|
||||
在这里,我们尝试探讨了第一个 Linux 内核问世后,诸如 Red Hat、Debian、Slackware、SUSE、Ubuntu 等诸多流行的发行版的想法是如何产生的。
|
||||
|
||||
随着 1991 年 Linux 最初以内核的形式发布,今天我们所知道的发行版在世界各地众多合作者的帮助下得以创建 shell、库、编译器和相关软件包,从而使其成为一个完整的操作系统。
|
||||
|
||||
### 1、第一个已知的“发行版”是由 HJ Lu 创建的
|
||||
|
||||
Linux 发行版这种方式可以追溯到 1992 年,当时可以用来访问 Linux 的第一个已知的类似发行版的工具是由 HJ Lu 发布的。它由两个 5.25 英寸软盘组成:
|
||||
|
||||
![Linux 0.12 Boot and Root Disks | Photo Credit][2]
|
||||
|
||||
* LINUX 0.12 BOOT DISK:“启动”磁盘用来先启动系统。
|
||||
* LINUX 0.12 ROOT DISK:第二个“根”磁盘,用于在启动后获取命令提示符以访问 Linux 文件系统。
|
||||
|
||||
要在硬盘上安装 LINUX 0.12,必须使用十六进制编辑器来编辑其主启动记录(MBR),这是一个非常复杂的过程,尤其是在那个时代。
|
||||
|
||||
> 感觉太怀旧了?
|
||||
>
|
||||
> 你可以[安装 cool-retro-term 应用程序][3],它可以为你提供 90 年代计算机的复古外观的 Linux 终端。
|
||||
|
||||
### 2、MCC Interim Linux
|
||||
|
||||
![MCC Linux 0.99.14, 1993 | Image Credit][4]
|
||||
|
||||
MCC Interim Linux 最初由英格兰曼彻斯特计算中心的 Owen Le Blanc 与 “LINUX 0.12” 同年发布,它是针对普通用户的第一个 Linux 发行版,它具有菜单驱动的安装程序和最终用户/编程工具。它也是以软盘集的形式,可以将其安装在系统上以提供基于文本的基本环境。
|
||||
|
||||
MCC Interim Linux 比 0.12 更加易于使用,并且在硬盘驱动器上的安装过程更加轻松和类似于现代方式。它不需要使用十六进制编辑器来编辑 MBR。
|
||||
|
||||
尽管它于 1992 年 2 月首次发布,但自当年 11 月以来也可以通过 FTP 下载。
|
||||
|
||||
### 3、TAMU Linux
|
||||
|
||||
![TAMU Linux | Image Credit][5]
|
||||
|
||||
TAMU Linux 由 Texas A&M 的 Aggies 与 Texas A&M Unix & Linux 用户组于 1992 年 5 月开发,被称为 TAMU 1.0A。它是第一个提供 X Window System 的 Linux 发行版,而不仅仅是基于文本的操作系统。
|
||||
|
||||
### 4、Softlanding Linux System (SLS)
|
||||
|
||||
![SLS Linux 1.05, 1994 | Image Credit][6]
|
||||
|
||||
他们的口号是“DOS 伞降的温柔救援”!SLS 由 Peter McDonald 于 1992 年 5 月发布。SLS 在其时代得到了广泛的使用和流行,并极大地推广了 Linux 的思想。但是由于开发人员决定更改发行版中的可执行格式,因此用户停止使用它。
|
||||
|
||||
当今社区最熟悉的许多流行发行版是通过 SLS 演变而成的。其中两个是:
|
||||
|
||||
* Slackware:它是最早的 Linux 发行版之一,由 Patrick Volkerding 于 1993 年创建。Slackware 基于 SLS,是最早的 Linux 发行版之一。
|
||||
* Debian:由 Ian Murdock 发起,Debian 在从 SLS 模型继续发展之后于 1993 年发布。我们今天知道的非常流行的 Ubuntu 发行版基于 Debian。
|
||||
|
||||
### 5、Yggdrasil
|
||||
|
||||
![LGX Yggdrasil Fall 1993 | Image Credit][7]
|
||||
|
||||
Yggdrasil 于 1992 年 12 月发行,是第一个产生 Live Linux CD 想法的发行版。它是由 Yggdrasil 计算公司开发的,该公司由位于加利福尼亚州伯克利的 Adam J. Richter 创立。它可以在系统硬件上自动配置自身,即“即插即用”功能,这是当今非常普遍且众所周知的功能。Yggdrasil 后来的版本包括一个用于在 Linux 中运行任何专有 MS-DOS CD-ROM 驱动程序的黑科技。
|
||||
|
||||
![Yggdrasil’s Plug-and-Play Promo | Image Credit][8]
|
||||
|
||||
他们的座右铭是“我们其余人的免费软件”。
|
||||
|
||||
### 6、Mandriva
|
||||
|
||||
在 90 年代后期,有一个非常受欢迎的发行版 [Mandriva][9],该发行版于 1998 年首次发行,是通过将法国的 Mandrake Linux 发行版与巴西的 Conectiva Linux 发行版统一起来形成的。它的发布寿命为 18 个月,会对 Linux 和系统软件进行更新,并且每年都会发布基于桌面的更新。它还有带有 5 年支持的服务器版本。现在是 [Open Mandriva][10]。
|
||||
|
||||
如果你在 Linux 发行之初就用过更多的怀旧发行版,请在下面的评论中与我们分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/earliest-linux-distros/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/avimanyu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/earliest-linux-distros.png?resize=800%2C450&ssl=1
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-0.12-Floppies.jpg?ssl=1
|
||||
[3]: https://itsfoss.com/cool-retro-term/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/MCC-Interim-Linux-0.99.14-1993.jpg?fit=800%2C600&ssl=1
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/TAMU-Linux.jpg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/SLS-1.05-1994.jpg?ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/LGX_Yggdrasil_CD_Fall_1993.jpg?fit=781%2C800&ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Yggdrasil-Linux-Summer-1994.jpg?ssl=1
|
||||
[9]: https://en.wikipedia.org/wiki/Mandriva_Linux
|
||||
[10]: https://www.openmandriva.org/
|
||||
134
published/20190301 Guide to Install VMware Tools on Linux.md
Normal file
134
published/20190301 Guide to Install VMware Tools on Linux.md
Normal file
@ -0,0 +1,134 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11467-1.html)
|
||||
[#]: subject: (Guide to Install VMware Tools on Linux)
|
||||
[#]: via: (https://itsfoss.com/install-vmware-tools-linux)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
在 Linux 上安装 VMware 工具
|
||||
======
|
||||
|
||||
> VMware 工具通过允许你共享剪贴板和文件夹以及其他东西来提升你的虚拟机体验。了解如何在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具。
|
||||
|
||||
![如何在 Linux 上安装 VMware 工具][4]
|
||||
|
||||
在先前的教程中,你学习了[在 Ubuntu 上安装 VMware 工作站][1]。你还可以通过安装 VMware 工具进一步提升你的虚拟机功能。
|
||||
|
||||
如果你已经在 VMware 上安装了一个访客机系统,你必须要注意 [VMware 工具][2]的要求 —— 尽管并不完全清楚到底有什么要求。
|
||||
|
||||
在本文中,我们将要强调 VMware 工具的重要性、所提供的特性,以及在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具的方法。
|
||||
|
||||
### VMware 工具:概览及特性
|
||||
|
||||
![在 Ubuntu 上安装 VMware 工具][3]
|
||||
|
||||
出于显而易见的理由,虚拟机(你的访客机系统)并不能做到与宿主机上的表现完全一致。在其性能和操作上会有特定的限制。那就是为什么引入 VMware 工具的原因。
|
||||
|
||||
VMware 工具以一种高效的形式在提升了其性能的同时,也可以帮助管理访客机系统。
|
||||
|
||||
#### VMware 工具到底负责什么?
|
||||
|
||||
你大致知道它可以做什么,但让我们探讨一下细节:
|
||||
|
||||
* 同步访客机系统与宿主机系统间的时间以简化操作
|
||||
* 提供从宿主机系统向访客机系统传递消息的能力。比如说,你可以复制文字到剪贴板,并将它轻松粘贴到你的访客机系统
|
||||
* 在访客机系统上启用声音
|
||||
* 提升访客机视频分辨率
|
||||
* 修正错误的网络速度数据
|
||||
* 减少不合适的色深
|
||||
|
||||
在访客机系统上安装了 VMware 工具会给它带来显著改变,但是它到底包含了什么特性才解锁或提升这些功能的呢?让我们来看看……
|
||||
|
||||
#### VMware 工具:核心特性细节
|
||||
|
||||
![用 VMware 工具在宿主机系统与访客机系统间共享剪切板][5]
|
||||
|
||||
如果你不想知道它包含什么来启用这些功能的话,你可以跳过这部分。但是为了好奇的读者,让我们简短地讨论它一下:
|
||||
|
||||
**VMware 设备驱动:** 它具体取决于操作系统。大多数主流操作系统都默认包含了设备驱动,因此你不必另外安装它。这主要涉及到内存控制驱动、鼠标驱动、音频驱动、网卡驱动、VGA 驱动以及其它。
|
||||
|
||||
**VMware 用户进程:** 这是这里真正有意思的地方。通过它你获得了在访客机和宿主机间复制粘贴和拖拽的能力。基本上,你可以从宿主机复制粘贴文本到虚拟机,反之亦然。
|
||||
|
||||
你同样也可以拖拽文件。此外,在你未安装 SVGA 驱动时它会启用鼠标指针的释放/锁定。
|
||||
|
||||
**VMware 工具生命周期管理:** 嗯,我们会在下面看看如何安装 VMware 工具,但是这个特性帮你在虚拟机中轻松安装/升级 VMware 工具。
|
||||
|
||||
**共享文件夹**:除了这些。VMware 工具同样允许你在访客机与宿主机系统间共享文件夹。
|
||||
|
||||
![使用 VMware 工具在访客机与宿机系统间共享文件][6]
|
||||
|
||||
当然,它的效果同样取决于访客机系统。例如在 Windows 上你通过 Unity 模式运行虚拟机上的程序并从宿主机系统上操作它。
|
||||
|
||||
### 如何在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具
|
||||
|
||||
**注意:** 对于 Linux 操作系统,你应该已经安装好了“Open VM 工具”,大多数情况下免除了额外安装 VMware 工具的需要。
|
||||
|
||||
大部分时候,当你安装了访客机系统时,如果操作系统支持 [Easy Install][7] 的话你会收到软件更新或弹窗告诉你要安装 VMware 工具。
|
||||
|
||||
Windows 和 Ubuntu 都支持 Easy Install。因此如果你使用 Windows 作为你的宿主机或尝试在 Ubuntu 上安装 VMware 工具,你应该会看到一个和弹窗消息差不多的选项来轻松安装 VMware 工具。这是它应该看起来的样子:
|
||||
|
||||
![安装 VMware 工具的弹窗][8]
|
||||
|
||||
这是搞定它最简便的办法。因此当你配置虚拟机时确保你有一个通畅的网络连接。
|
||||
|
||||
如果你没收到任何弹窗或者选项来轻松安装 VMware 工具。你需要手动安装它。以下是如何去做:
|
||||
|
||||
1. 运行 VMware Workstation Player。
|
||||
2. 从菜单导航至 “Virtual Machine -> Install VMware tools”。如果你已经安装了它并想修复安装,你会看到 “Re-install VMware tools” 这一选项出现。
|
||||
3. 一旦你点击了,你就会看到一个虚拟 CD/DVD 挂载在访客机系统上。
|
||||
4. 打开该 CD/DVD,并复制粘贴那个 tar.gz 文件到任何你选择的区域并解压,这里我们选择“桌面”作为解压目的地。
|
||||
|
||||
![][9]
|
||||
5. 在解压后,运行终端并通过输入以下命令导航至里面的文件夹:
|
||||
|
||||
```
|
||||
cd Desktop/VMwareTools-10.3.2-9925305/vmware-tools-distrib
|
||||
```
|
||||
|
||||
你需要检查文件夹与路径名,这取决于版本与解压目的地,名字可能会改变。
|
||||
|
||||
![][10]
|
||||
|
||||
用你的存储位置(如“下载”)替换“桌面”,如果你安装的也是 10.3.2 版本,其它的保持一样即可。
|
||||
6. 现在仅需输入以下命令开始安装:
|
||||
|
||||
```
|
||||
sudo ./vmware-install.pl -d
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
你会被询问密码以获得安装权限,输入密码然后应当一切都搞定了。
|
||||
|
||||
到此为止了,你搞定了。这系列步骤应当适用于几乎大部分基于 Ubuntu 的访客机系统。如果你想要在 Ubuntu 服务器上或其它系统安装 VMware 工具,步骤应该类似。
|
||||
|
||||
### 总结
|
||||
|
||||
在 Ubuntu Linux 上安装 VMware 工具应该挺简单。除了简单办法,我们也详述了手动安装的方法。如果你仍需帮助或者对安装有任何建议,在评论区评论让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-vmware-tools-linux
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
|
||||
[2]: https://kb.vmware.com/s/article/340
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-downloading.jpg?fit=800%2C531&ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/install-vmware-tools-linux.png?resize=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-features.gif?resize=800%2C500&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-shared-folder.jpg?fit=800%2C660&ssl=1
|
||||
[7]: https://docs.vmware.com/en/VMware-Workstation-Player-for-Linux/15.0/com.vmware.player.linux.using.doc/GUID-3F6B9D0E-6CFC-4627-B80B-9A68A5960F60.html
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools.jpg?fit=800%2C481&ssl=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-extraction.jpg?fit=800%2C564&ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-folder.jpg?fit=800%2C487&ssl=1
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-installation-ubuntu.jpg?fit=800%2C492&ssl=1
|
||||
125
published/20190320 Move your dotfiles to version control.md
Normal file
125
published/20190320 Move your dotfiles to version control.md
Normal file
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11419-1.html)
|
||||
[#]: subject: (Move your dotfiles to version control)
|
||||
[#]: via: (https://opensource.com/article/19/3/move-your-dotfiles-version-control)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
|
||||
|
||||
把“点文件”放到版本控制中
|
||||
======
|
||||
|
||||
> 通过在 GitLab 或 GitHub 上分享你的点文件,可以在整个系统上备份或同步你的自定义配置。
|
||||
|
||||

|
||||
|
||||
通过隐藏文件集(称为<ruby>点文件<rt>dotfile</rt></ruby>)来定制操作系统是个非常棒的想法。在这篇 [Shell 点文件可以为你做点什么][1]中,H. "Waldo" Grunenwald 详细介绍了为什么以及如何设置点文件的细节。现在让我们深入探讨分享它们的原因和方式。
|
||||
|
||||
### 什么是点文件?
|
||||
|
||||
“<ruby>点文件<rt>dotfile</rt></ruby>”是指我们计算机中四处漂泊的配置文件。这些文件通常在文件名的开头以 `.` 开头,例如 `.gitconfig`,并且操作系统通常在默认情况下将其隐藏。例如,当我在 MacOS 上使用 `ls -a` 时,它才会显示所有可爱的点文件,否则就不会显示这些点文件。
|
||||
|
||||
```
|
||||
dotfiles on master
|
||||
➜ ls
|
||||
README.md Rakefile bin misc profiles zsh-custom
|
||||
|
||||
dotfiles on master
|
||||
➜ ls -a
|
||||
. .gitignore .oh-my-zsh README.md zsh-custom
|
||||
.. .gitmodules .tmux Rakefile
|
||||
.gemrc .global_ignore .vimrc bin
|
||||
.git .gvimrc .zlogin misc
|
||||
.gitconfig .maid .zshrc profiles
|
||||
```
|
||||
|
||||
如果看一下用于 Git 配置的 `.gitconfig`,我能看到大量的自定义配置。我设置了帐户信息、终端颜色首选项和大量别名,这些别名可以使我的命令行界面看起来就像我的一样。这是 `[alias]` 块的摘录:
|
||||
|
||||
```
|
||||
87 # Show the diff between the latest commit and the current state
|
||||
88 d = !"git diff-index --quiet HEAD -- || clear; git --no-pager diff --patch-with-stat"
|
||||
89
|
||||
90 # `git di $number` shows the diff between the state `$number` revisions ago and the current state
|
||||
91 di = !"d() { git diff --patch-with-stat HEAD~$1; }; git diff-index --quiet HEAD -- || clear; d"
|
||||
92
|
||||
93 # Pull in remote changes for the current repository and all its submodules
|
||||
94 p = !"git pull; git submodule foreach git pull origin master"
|
||||
95
|
||||
96 # Checkout a pull request from origin (of a github repository)
|
||||
97 pr = !"pr() { git fetch origin pull/$1/head:pr-$1; git checkout pr-$1; }; pr"
|
||||
```
|
||||
|
||||
由于我的 `.gitconfig` 有 200 多行的自定义设置,我无意于在我使用的每一台新计算机或系统上重写它,其他人肯定也不想这样。这是分享点文件变得越来越流行的原因之一,尤其是随着社交编码网站 GitHub 的兴起。正式提倡分享点文件的文章是 Zach Holman 在 2008 年发表的《[点文件意味着被复刻][2]》。其前提到今天依然如此:我想与我自己、与点文件新手,以及那些分享了他们的自定义配置从而教会了我很多知识的人分享它们。
|
||||
|
||||
### 分享点文件
|
||||
|
||||
我们中的许多人拥有多个系统,或者知道硬盘变化无常,因此我们希望备份我们精心策划的自定义设置。那么我们如何在环境之间同步这些精彩的文件?
|
||||
|
||||
我最喜欢的答案是分布式版本控制,最好是可以为我处理繁重任务的服务。我经常使用 GitHub,随着我对 GitLab 的使用经验越来越丰富,我肯定会一如既往地继续喜欢它。任何一个这样的服务都是共享你的信息的理想场所。要自己设置的话可以这样做:
|
||||
|
||||
1. 登录到你首选的基于 Git 的服务。
|
||||
2. 创建一个名为 `dotfiles` 的存储库。(将其设置为公开!分享即关爱。)
|
||||
3. 将其克隆到你的本地环境。(你可能需要设置 Git 配置命令来克隆存储库。GitHub 和 GitLab 都会提示你需要运行的命令。)
|
||||
4. 将你的点文件复制到该文件夹中。
|
||||
5. 将它们符号链接回到其目标文件夹(最常见的是 `$HOME`)。
|
||||
6. 将它们推送到远程存储库。
|
||||
|
||||
|
||||
|
||||
上面的步骤 4 是这项工作的关键,可能有些棘手。无论是使用脚本还是手动执行,工作流程都是从 `dotfiles` 文件夹符号链接到点文件的目标位置,以便对点文件的任何更新都可以轻松地推送到远程存储库。要对我的 `.gitconfig` 文件执行此操作,我要输入:
|
||||
|
||||
```
|
||||
$ cd dotfiles/
|
||||
$ ln -nfs .gitconfig $HOME/.gitconfig
|
||||
```
|
||||
|
||||
添加到符号链接命令的标志还具有其他一些用处:
|
||||
|
||||
* `-s` 创建符号链接而不是硬链接。
|
||||
* `-f` 在发生错误时继续做其他符号链接(此处不需要,但在循环中很有用)
|
||||
* `-n` 避免符号链接到一个符号链接文件(等同于其他版本的 `ln` 的 `-h` 标志)
|
||||
|
||||
如果要更深入地研究可用参数,可以查看 IEEE 和开放小组的 [ln 规范][3]以及 [MacOS 10.14.3] [4] 上的版本。自从其他人的点文件中拉取出这些标志以来,我才发现了这些标志。
|
||||
|
||||
你还可以使用一些其他代码来简化更新,例如我从 [Brad Parbs][6] 复刻的 [Rakefile][5]。另外,你也可以像 Jeff Geerling [在其点文件中][7]那样,使它保持极其简单的状态。他使用[此 Ansible 剧本][8]对文件进行符号链接。这样使所有内容保持同步很容易:你可以从点文件的文件夹中进行 cron 作业或偶尔进行 `git push`。
|
||||
|
||||
### 简单旁注:什么不能分享
|
||||
|
||||
在继续之前,值得注意的是你不应该添加到共享的点文件存储库中的内容 —— 即使它以点开头。任何有安全风险的东西,例如 `.ssh/` 文件夹中的文件,都不是使用此方法分享的好选择。确保在在线发布配置文件之前仔细检查配置文件,并再三检查文件中没有 API 令牌。
|
||||
|
||||
### 我应该从哪里开始?
|
||||
|
||||
如果你不熟悉 Git,那么我[有关 Git 术语的文章][9]和常用命令[备忘清单][10]将会帮助你继续前进。
|
||||
|
||||
还有其他超棒的资源可帮助你开始使用点文件。多年前,我就发现了 [dotfiles.github.io][11],并继续使用它来更广泛地了解人们在做什么。在其他人的点文件中隐藏了许多秘传知识。花时间浏览一些,大胆地将它们添加到自己的内容中。
|
||||
|
||||
我希望这是让你在计算机上拥有一致的点文件的快乐开端。
|
||||
|
||||
你最喜欢的点文件技巧是什么?添加评论或在 Twitter 上找我 [@mbbroberg][12]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/move-your-dotfiles-version-control
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberg
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-11417-1.html
|
||||
[2]: https://zachholman.com/2010/08/dotfiles-are-meant-to-be-forked/
|
||||
[3]: http://pubs.opengroup.org/onlinepubs/9699919799/utilities/ln.html
|
||||
[4]: https://www.unix.com/man-page/FreeBSD/1/ln/
|
||||
[5]: https://github.com/mbbroberg/dotfiles/blob/master/Rakefile
|
||||
[6]: https://github.com/bradp/dotfiles
|
||||
[7]: https://github.com/geerlingguy/dotfiles
|
||||
[8]: https://github.com/geerlingguy/mac-dev-playbook
|
||||
[9]: https://opensource.com/article/19/2/git-terminology
|
||||
[10]: https://opensource.com/downloads/cheat-sheet-git
|
||||
[11]: http://dotfiles.github.io/
|
||||
[12]: https://twitter.com/mbbroberg?lang=en
|
||||
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11461-1.html)
|
||||
[#]: subject: (Blockchain 2.0 – Introduction To Hyperledger Fabric [Part 10])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
区块链 2.0:Hyperledger Fabric 介绍(十)
|
||||
======
|
||||
|
||||
![Hyperledger Fabric][1]
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
[Hyperledger 项目][2] 是一个伞形组织,包括许多正在开发的不同模块和系统。在这些子项目中,最受欢迎的是 “Hyperledger Fabric”。这篇博文将探讨一旦区块链系统开始大量使用到主流,将使 Fabric 在不久的将来成为几乎不可或缺的功能。最后,我们还将快速了解开发人员和爱好者们需要了解的有关 Hyperledger Fabric 技术的知识。
|
||||
|
||||
### 起源
|
||||
|
||||
按照 Hyperledger 项目的常规方式,Fabric 由其核心成员之一 IBM “捐赠”给该组织,而 IBM 以前是该组织的主要开发者。由 IBM 共享的这个技术平台在 Hyperledger 项目中进行了联合开发,来自 100 多个成员公司和机构为之做出了贡献。
|
||||
|
||||
目前,Fabric 正处于 LTS 版本的 v1.4,该版本已经发展很长一段时间,并且被视为企业管理业务数据的解决方案。Hyperledger 项目的核心愿景也必然会渗透到 Fabric 中。Hyperledger Fabric 系统继承了所有企业级的可扩展功能,这些功能已深深地刻入到 Hyperledger 组织旗下所有的项目当中。
|
||||
|
||||
### Hyperledger Fabric 的亮点
|
||||
|
||||
Hyperledger Fabric 提供了多种功能和标准,这些功能和标准围绕着支持快速开发和模块化体系结构的使命而构建。此外,与竞争对手(主要是瑞波和[以太坊][3])相比,Fabric 明确用于封闭和[许可区块链][4]。它们的核心目标是开发一套工具,这些工具将帮助区块链开发人员创建定制的解决方案,而不是创建独立的生态系统或产品。
|
||||
|
||||
Hyperledger Fabric 的一些亮点如下:
|
||||
|
||||
#### 许可区块链系统
|
||||
|
||||
这是一个 Hyperledger Fabric 与其他平台(如以太坊和瑞波)差异很大的地方。默认情况下,Fabric 是一种旨在实现私有许可的区块链的工具。此类区块链不能被所有人访问,并且其中致力于达成共识或验证交易的节点将由中央机构进行选择。这对于某些应用(例如银行和保险)可能很重要,在这些应用中,交易必须由中央机构而不是参与者来验证。
|
||||
|
||||
#### 机密和受控的信息流
|
||||
|
||||
Fabric 内置了权限系统,该权限系统将视情况限制特定组或某些个人中的信息流。与公有区块链不同,在公有区块链中,任何运行节点的人都可以对存储在区块链中的数据进行复制和选择性访问,而 Fabric 系统的管理员可以选择谁能访问共享的信息,以及访问的方式。与现有竞争产品相比,它还有以更好的安全性标准对存储的数据进行加密的子系统。
|
||||
|
||||
#### 即插即用架构
|
||||
|
||||
Hyperledger Fabric 具有即插即用类型的体系结构。可以选择实施系统的各个组件,而开发人员看不到用处的系统组件可能会被废弃。Fabric 采取高度模块化和可定制的方式进行开发,而不是一种与其竞争对手采用的“一种方法适应所有需求”的方式。对于希望快速构建精益系统的公司和公司而言,这尤其有吸引力。这与 Fabric 和其它 Hyperledger 组件的互操作性相结合,意味着开发人员和设计人员现在可以使用各种标准化工具,而不必从其他来源提取代码并随后进行集成。它还提供了一种相当可靠的方式来构建健壮的模块化系统。
|
||||
|
||||
#### 智能合约和链码
|
||||
|
||||
运行在区块链上的分布式应用程序称为[智能合约][5]。虽然智能合约这个术语或多或少与以太坊平台相关联,但<ruby>链码<rt>chaincode</rt></ruby>是 Hyperledger 阵营中为其赋予的名称。链码应用程序除了拥有 DApp 中有的所有优点之外,使 Hyperledger 与众不同的是,该应用程序的代码可以用多种高级编程语言编写。它本身支持 [Go][6] 和 JavaScript,并且在与适当的编译器模块集成后还支持许多其它编程语言。尽管这一事实在此时可能并不代表什么,但这意味着,如果可以将现有人才用于正在进行的涉及区块链的项目,从长远来看,这有可能为公司节省数十亿美元的人员培训和管理费用。开发人员可以使用自己喜欢的语言进行编码,从而在 Hyperledger Fabric 上开始构建应用程序,而无需学习或培训平台特定的语言和语法。这提供了 Hyperledger Fabric 当前竞争对手无法提供的灵活性。
|
||||
|
||||
### 总结
|
||||
|
||||
* Hyperledger Fabric 是一个后端驱动程序平台,是一个主要针对需要区块链或其它分布式账本技术的集成项目。因此,除了次要的脚本功能外,它不提供任何面向用户的服务。(认可以为它更像是一种脚本语言。)
|
||||
* Hyperledger Fabric 支持针对特定用例构建侧链。如果开发人员希望将一组用户或参与者隔离到应用程序的特定部分或功能,则可以通过侧链来实现。侧链是衍生自主要父代的区块链,但在其初始块之后形成不同的链。产生新链的块将不受新链进一步变化的影响,即使将新信息添加到原始链中,新链也将保持不变。此功能将有助于扩展正在开发的平台,并引入用户特定的和案例特定的处理功能。
|
||||
* 前面的功能还意味着并非所有用户都会像通常对公有链所期望的那样拥有区块链中所有数据的“精确”副本。参与节点将具有仅与之相关的数据副本。例如,假设有一个类似于印度的 PayTM 的应用程序,该应用程序具有钱包功能以及电子商务功能。但是,并非所有的钱包用户都使用 PayTM 在线购物。在这种情况下,只有活跃的购物者将在 PayTM 电子商务网站上拥有相应的交易链,而钱包用户将仅拥有存储钱包交易的链的副本。这种灵活的数据存储和检索体系结构在扩展时非常重要,因为大量的单链区块链已经显示出会增加处理交易的前置时间。这样可以保持链的精简和分类。
|
||||
|
||||
我们将在以后的文章中详细介绍 Hyperledger Project 下的其他模块。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/05/Hyperledger-Fabric-720x340.png
|
||||
[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||
[3]: https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/
|
||||
[4]: https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/
|
||||
[5]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
|
||||
[6]: https://www.ostechnix.com/install-go-language-linux/
|
||||
313
published/20190627 RPM packages explained.md
Normal file
313
published/20190627 RPM packages explained.md
Normal file
@ -0,0 +1,313 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11452-1.html)
|
||||
[#]: subject: (RPM packages explained)
|
||||
[#]: via: (https://fedoramagazine.org/rpm-packages-explained/)
|
||||
[#]: author: (Ankur Sinha "FranciscoD" https://fedoramagazine.org/author/ankursinha/)
|
||||
|
||||
RPM 包初窥
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
也许,Fedora 社区追求其[促进自由和开源的软件及内容的使命][2]的最著名的方式就是开发 [Fedora 软件发行版][3]了。因此,我们将很大一部分的社区资源用于此任务也就不足为奇了。这篇文章总结了这些软件是如何“打包”的,以及使之成为可能的基础工具,如 `rpm` 之类。
|
||||
|
||||
### RPM:最小的软件单元
|
||||
|
||||
可供用户选择的“版本”和“风味版”([spins][4] / [labs][5] / [silverblue][6])其实非常相似。它们都是由各种软件组成的,这些软件经过混合和搭配,可以很好地协同工作。它们之间的不同之处在于放入其中的具体工具不同。这种选择取决于它们所针对的用例。所有这些的“版本”和“风味版”基本组成单位都是 RPM 软件包文件。
|
||||
|
||||
RPM 文件是类似于 ZIP 文件或 tarball 的存档文件。实际上,它们使用了压缩来减小存档文件的大小。但是,除了文件之外,RPM 存档中还包含有关软件包的元数据。可以使用 `rpm` 工具查询:
|
||||
|
||||
```
|
||||
$ rpm -q fpaste
|
||||
fpaste-0.3.9.2-2.fc30.noarch
|
||||
|
||||
$ rpm -qi fpaste
|
||||
Name : fpaste
|
||||
Version : 0.3.9.2
|
||||
Release : 2.fc30
|
||||
Architecture: noarch
|
||||
Install Date: Tue 26 Mar 2019 08:49:10 GMT
|
||||
Group : Unspecified
|
||||
Size : 64144
|
||||
License : GPLv3+
|
||||
Signature : RSA/SHA256, Thu 07 Feb 2019 15:46:11 GMT, Key ID ef3c111fcfc659b9
|
||||
Source RPM : fpaste-0.3.9.2-2.fc30.src.rpm
|
||||
Build Date : Thu 31 Jan 2019 20:06:01 GMT
|
||||
Build Host : buildhw-07.phx2.fedoraproject.org
|
||||
Relocations : (not relocatable)
|
||||
Packager : Fedora Project
|
||||
Vendor : Fedora Project
|
||||
URL : https://pagure.io/fpaste
|
||||
Bug URL : https://bugz.fedoraproject.org/fpaste
|
||||
Summary : A simple tool for pasting info onto sticky notes instances
|
||||
Description :
|
||||
It is often useful to be able to easily paste text to the Fedora
|
||||
Pastebin at http://paste.fedoraproject.org and this simple script
|
||||
will do that and return the resulting URL so that people may
|
||||
examine the output. This can hopefully help folks who are for
|
||||
some reason stuck without X, working remotely, or any other
|
||||
reason they may be unable to paste something into the pastebin
|
||||
|
||||
$ rpm -ql fpaste
|
||||
/usr/bin/fpaste
|
||||
/usr/share/doc/fpaste
|
||||
/usr/share/doc/fpaste/README.rst
|
||||
/usr/share/doc/fpaste/TODO
|
||||
/usr/share/licenses/fpaste
|
||||
/usr/share/licenses/fpaste/COPYING
|
||||
/usr/share/man/man1/fpaste.1.gz
|
||||
```
|
||||
|
||||
安装 RPM 软件包后,`rpm` 工具可以知道具体哪些文件被添加到了系统中。因此,删除该软件包也会删除这些文件,并使系统保持一致状态。这就是为什么要尽可能地使用 `rpm` 安装软件,而不是从源代码安装软件的原因。
|
||||
|
||||
### 依赖关系
|
||||
|
||||
如今,完全独立的软件已经非常罕见。甚至 [fpaste][7],连这样一个简单的单个文件的 Python 脚本,都需要安装 Python 解释器。因此,如果系统未安装 Python(几乎不可能,但有可能),则无法使用 `fpaste`。用打包者的术语来说,“Python 是 `fpaste` 的**运行时依赖项**。”
|
||||
|
||||
构建 RPM 软件包时(本文不讨论构建 RPM 的过程),生成的归档文件中包括了所有这些元数据。这样,与 RPM 软件包归档文件交互的工具就知道必须要安装其它的什么东西,以便 `fpaste` 可以正常工作:
|
||||
|
||||
```
|
||||
$ rpm -q --requires fpaste
|
||||
/usr/bin/python3
|
||||
python3
|
||||
rpmlib(CompressedFileNames) <= 3.0.4-1
|
||||
rpmlib(FileDigests) <= 4.6.0-1
|
||||
rpmlib(PayloadFilesHavePrefix) <= 4.0-1
|
||||
rpmlib(PayloadIsXz) <= 5.2-1
|
||||
|
||||
$ rpm -q --provides fpaste
|
||||
fpaste = 0.3.9.2-2.fc30
|
||||
|
||||
$ rpm -qi python3
|
||||
Name : python3
|
||||
Version : 3.7.3
|
||||
Release : 3.fc30
|
||||
Architecture: x86_64
|
||||
Install Date: Thu 16 May 2019 18:51:41 BST
|
||||
Group : Unspecified
|
||||
Size : 46139
|
||||
License : Python
|
||||
Signature : RSA/SHA256, Sat 11 May 2019 17:02:44 BST, Key ID ef3c111fcfc659b9
|
||||
Source RPM : python3-3.7.3-3.fc30.src.rpm
|
||||
Build Date : Sat 11 May 2019 01:47:35 BST
|
||||
Build Host : buildhw-05.phx2.fedoraproject.org
|
||||
Relocations : (not relocatable)
|
||||
Packager : Fedora Project
|
||||
Vendor : Fedora Project
|
||||
URL : https://www.python.org/
|
||||
Bug URL : https://bugz.fedoraproject.org/python3
|
||||
Summary : Interpreter of the Python programming language
|
||||
Description :
|
||||
Python is an accessible, high-level, dynamically typed, interpreted programming
|
||||
language, designed with an emphasis on code readability.
|
||||
It includes an extensive standard library, and has a vast ecosystem of
|
||||
third-party libraries.
|
||||
|
||||
The python3 package provides the "python3" executable: the reference
|
||||
interpreter for the Python language, version 3.
|
||||
The majority of its standard library is provided in the python3-libs package,
|
||||
which should be installed automatically along with python3.
|
||||
The remaining parts of the Python standard library are broken out into the
|
||||
python3-tkinter and python3-test packages, which may need to be installed
|
||||
separately.
|
||||
|
||||
Documentation for Python is provided in the python3-docs package.
|
||||
|
||||
Packages containing additional libraries for Python are generally named with
|
||||
the "python3-" prefix.
|
||||
|
||||
$ rpm -q --provides python3
|
||||
python(abi) = 3.7
|
||||
python3 = 3.7.3-3.fc30
|
||||
python3(x86-64) = 3.7.3-3.fc30
|
||||
python3.7 = 3.7.3-3.fc30
|
||||
python37 = 3.7.3-3.fc30
|
||||
```
|
||||
|
||||
### 解决 RPM 依赖关系
|
||||
|
||||
虽然 `rpm` 知道每个归档文件所需的依赖关系,但不知道在哪里找到它们。这是设计使然:`rpm` 仅适用于本地文件,必须具体告知它们的位置。因此,如果你尝试安装单个 RPM 软件包,则 `rpm` 找不到该软件包的运行时依赖项时就会出错。本示例尝试安装从 Fedora 软件包集中下载的软件包:
|
||||
|
||||
```
|
||||
$ ls
|
||||
python3-elephant-0.6.2-3.fc30.noarch.rpm
|
||||
|
||||
$ rpm -qpi python3-elephant-0.6.2-3.fc30.noarch.rpm
|
||||
Name : python3-elephant
|
||||
Version : 0.6.2
|
||||
Release : 3.fc30
|
||||
Architecture: noarch
|
||||
Install Date: (not installed)
|
||||
Group : Unspecified
|
||||
Size : 2574456
|
||||
License : BSD
|
||||
Signature : (none)
|
||||
Source RPM : python-elephant-0.6.2-3.fc30.src.rpm
|
||||
Build Date : Fri 14 Jun 2019 17:23:48 BST
|
||||
Build Host : buildhw-02.phx2.fedoraproject.org
|
||||
Relocations : (not relocatable)
|
||||
Packager : Fedora Project
|
||||
Vendor : Fedora Project
|
||||
URL : http://neuralensemble.org/elephant
|
||||
Bug URL : https://bugz.fedoraproject.org/python-elephant
|
||||
Summary : Elephant is a package for analysis of electrophysiology data in Python
|
||||
Description :
|
||||
Elephant - Electrophysiology Analysis Toolkit Elephant is a package for the
|
||||
analysis of neurophysiology data, based on Neo.
|
||||
|
||||
$ rpm -qp --requires python3-elephant-0.6.2-3.fc30.noarch.rpm
|
||||
python(abi) = 3.7
|
||||
python3.7dist(neo) >= 0.7.1
|
||||
python3.7dist(numpy) >= 1.8.2
|
||||
python3.7dist(quantities) >= 0.10.1
|
||||
python3.7dist(scipy) >= 0.14.0
|
||||
python3.7dist(six) >= 1.10.0
|
||||
rpmlib(CompressedFileNames) <= 3.0.4-1
|
||||
rpmlib(FileDigests) <= 4.6.0-1
|
||||
rpmlib(PartialHardlinkSets) <= 4.0.4-1
|
||||
rpmlib(PayloadFilesHavePrefix) <= 4.0-1
|
||||
rpmlib(PayloadIsXz) <= 5.2-1
|
||||
|
||||
$ sudo rpm -i ./python3-elephant-0.6.2-3.fc30.noarch.rpm
|
||||
error: Failed dependencies:
|
||||
python3.7dist(neo) >= 0.7.1 is needed by python3-elephant-0.6.2-3.fc30.noarch
|
||||
python3.7dist(quantities) >= 0.10.1 is needed by python3-elephant-0.6.2-3.fc30.noarch
|
||||
```
|
||||
|
||||
理论上,你可以下载 `python3-elephant` 所需的所有软件包,并告诉 `rpm` 它们都在哪里,但这并不方便。如果 `python3-neo` 和 `python3-quantities` 还有其它的运行时要求怎么办?很快,这种“依赖链”就会变得相当复杂。
|
||||
|
||||
#### 存储库
|
||||
|
||||
幸运的是,有了 `dnf` 和它的朋友们,可以帮助解决此问题。与 `rpm` 不同,`dnf` 能感知到**存储库**。存储库是程序包的集合,带有告诉 `dnf` 这些存储库包含什么内容的元数据。所有 Fedora 系统都带有默认启用的默认 Fedora 存储库:
|
||||
|
||||
```
|
||||
$ sudo dnf repolist
|
||||
repo id repo name status
|
||||
fedora Fedora 30 - x86_64 56,582
|
||||
fedora-modular Fedora Modular 30 - x86_64 135
|
||||
updates Fedora 30 - x86_64 - Updates 8,573
|
||||
updates-modular Fedora Modular 30 - x86_64 - Updates 138
|
||||
updates-testing Fedora 30 - x86_64 - Test Updates 8,458
|
||||
```
|
||||
|
||||
在 Fedora 快速文档中有[这些存储库][8]以及[如何管理][9]它们的更多信息。
|
||||
|
||||
`dnf` 可用于查询存储库以获取有关它们包含的软件包信息。它还可以在这些存储库中搜索软件,或从中安装/卸载/升级软件包:
|
||||
|
||||
```
|
||||
$ sudo dnf search elephant
|
||||
Last metadata expiration check: 0:05:21 ago on Sun 23 Jun 2019 14:33:38 BST.
|
||||
============================================================================== Name & Summary Matched: elephant ==============================================================================
|
||||
python3-elephant.noarch : Elephant is a package for analysis of electrophysiology data in Python
|
||||
python3-elephant.noarch : Elephant is a package for analysis of electrophysiology data in Python
|
||||
|
||||
$ sudo dnf list \*elephant\*
|
||||
Last metadata expiration check: 0:05:26 ago on Sun 23 Jun 2019 14:33:38 BST.
|
||||
Available Packages
|
||||
python3-elephant.noarch 0.6.2-3.fc30 updates-testing
|
||||
python3-elephant.noarch 0.6.2-3.fc30 updates
|
||||
```
|
||||
|
||||
#### 安装依赖项
|
||||
|
||||
现在使用 `dnf` 安装软件包时,它将*解决*所有必需的依赖项,然后调用 `rpm` 执行该事务操作:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-elephant
|
||||
Last metadata expiration check: 0:06:17 ago on Sun 23 Jun 2019 14:33:38 BST.
|
||||
Dependencies resolved.
|
||||
==============================================================================================================================================================================================
|
||||
Package Architecture Version Repository Size
|
||||
==============================================================================================================================================================================================
|
||||
Installing:
|
||||
python3-elephant noarch 0.6.2-3.fc30 updates-testing 456 k
|
||||
Installing dependencies:
|
||||
python3-neo noarch 0.8.0-0.1.20190215git49b6041.fc30 fedora 753 k
|
||||
python3-quantities noarch 0.12.2-4.fc30 fedora 163 k
|
||||
Installing weak dependencies:
|
||||
python3-igor noarch 0.3-5.20150408git2c2a79d.fc30 fedora 63 k
|
||||
|
||||
Transaction Summary
|
||||
==============================================================================================================================================================================================
|
||||
Install 4 Packages
|
||||
|
||||
Total download size: 1.4 M
|
||||
Installed size: 7.0 M
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
(1/4): python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch.rpm 222 kB/s | 63 kB 00:00
|
||||
(2/4): python3-elephant-0.6.2-3.fc30.noarch.rpm 681 kB/s | 456 kB 00:00
|
||||
(3/4): python3-quantities-0.12.2-4.fc30.noarch.rpm 421 kB/s | 163 kB 00:00
|
||||
(4/4): python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch.rpm 840 kB/s | 753 kB 00:00
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Total 884 kB/s | 1.4 MB 00:01
|
||||
Running transaction check
|
||||
Transaction check succeeded.
|
||||
Running transaction test
|
||||
Transaction test succeeded.
|
||||
Running transaction
|
||||
Preparing : 1/1
|
||||
Installing : python3-quantities-0.12.2-4.fc30.noarch 1/4
|
||||
Installing : python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch 2/4
|
||||
Installing : python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch 3/4
|
||||
Installing : python3-elephant-0.6.2-3.fc30.noarch 4/4
|
||||
Running scriptlet: python3-elephant-0.6.2-3.fc30.noarch 4/4
|
||||
Verifying : python3-elephant-0.6.2-3.fc30.noarch 1/4
|
||||
Verifying : python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch 2/4
|
||||
Verifying : python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch 3/4
|
||||
Verifying : python3-quantities-0.12.2-4.fc30.noarch 4/4
|
||||
|
||||
Installed:
|
||||
python3-elephant-0.6.2-3.fc30.noarch python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch python3-quantities-0.12.2-4.fc30.noarch
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
请注意,`dnf` 甚至还安装了`python3-igor`,而它不是 `python3-elephant` 的直接依赖项。
|
||||
|
||||
### DnfDragora:DNF 的一个图形界面
|
||||
|
||||
尽管技术用户可能会发现 `dnf` 易于使用,但并非所有人都这样认为。[Dnfdragora][10] 通过为 `dnf` 提供图形化前端来解决此问题。
|
||||
|
||||
![dnfdragora (version 1.1.1-2 on Fedora 30) listing all the packages installed on a system.][11]
|
||||
|
||||
从上面可以看到,dnfdragora 似乎提供了 `dnf` 的所有主要功能。
|
||||
|
||||
Fedora 中还有其他工具也可以管理软件包,GNOME 的“<ruby>软件<rt>Software</rt></ruby>”和“<ruby>发现<rt>Discover</rt></ruby>”就是其中两个。GNOME “软件”仅专注于图形应用程序。你无法使用这个图形化前端来安装命令行或终端工具,例如 `htop` 或 `weechat`。但是,GNOME “软件”支持安装 `dnf` 所不支持的 [Flatpak][12] 和 Snap 应用程序。它们是针对不同目标受众的不同工具,因此提供了不同的功能。
|
||||
|
||||
这篇文章仅触及到了 Fedora 软件的生命周期的冰山一角。本文介绍了什么是 RPM 软件包,以及使用 `rpm` 和 `dnf` 的主要区别。
|
||||
|
||||
在以后的文章中,我们将详细介绍:
|
||||
|
||||
* 创建这些程序包所需的过程
|
||||
* 社区如何测试它们以确保它们正确构建
|
||||
* 社区用来将其给到社区用户的基础设施
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/rpm-packages-explained/
|
||||
|
||||
作者:[Ankur Sinha "FranciscoD"][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/ankursinha/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/rpm.png-816x345.jpg
|
||||
[2]: https://docs.fedoraproject.org/en-US/project/#_what_is_fedora_all_about
|
||||
[3]: https://getfedora.org
|
||||
[4]: https://spins.fedoraproject.org/
|
||||
[5]: https://labs.fedoraproject.org/
|
||||
[6]: https://silverblue.fedoraproject.org/
|
||||
[7]: https://src.fedoraproject.org/rpms/fpaste
|
||||
[8]: https://docs.fedoraproject.org/en-US/quick-docs/repositories/
|
||||
[9]: https://docs.fedoraproject.org/en-US/quick-docs/adding-or-removing-software-repositories-in-fedora/
|
||||
[10]: https://src.fedoraproject.org/rpms/dnfdragora
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/06/dnfdragora-1024x558.png
|
||||
[12]: https://fedoramagazine.org/getting-started-flatpak/
|
||||
@ -1,48 +1,50 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11429-1.html)
|
||||
[#]: subject: (Learn how to Record and Replay Linux Terminal Sessions Activity)
|
||||
[#]: via: (https://www.linuxtechi.com/record-replay-linux-terminal-sessions-activity/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
Learn how to Record and Replay Linux Terminal Sessions Activity
|
||||
在 Linux 上记录和重放终端会话活动
|
||||
======
|
||||
|
||||
Generally, all Linux administrators use **history** command to track which commands were executed in previous sessions, but there is one limitation of history command is that it doesn’t store the command’s output. There can be some scenarios where we want to check commands output of previous session and want to compare it with current session. Apart from this, there are some situations where we are troubleshooting the issues on Linux production boxes and want to save all terminal session activities for future reference, so in such cases script command become handy.
|
||||
通常,Linux 管理员们都使用 `history` 命令来跟踪在先前的会话中执行过哪些命令,但是 `history` 命令的局限性在于它不存储命令的输出。在某些情况下,我们要检查上一个会话的命令输出,并希望将其与当前会话进行比较。除此之外,在某些情况下,我们正在对 Linux 生产环境中的问题进行故障排除,并希望保存所有终端会话活动以供将来参考,因此在这种情况下,`script` 命令就变得很方便。
|
||||
|
||||
<https://www.linuxtechi.com/wp-content/uploads/2019/06/Record-linux-terminal-session-activity.jpg>
|
||||

|
||||
|
||||
Script is a command line tool which is used to capture or record your Linux server terminal sessions activity and later the recorded session can be replayed using scriptreplay command. In this article we will demonstrate how to install script command line tool and how to record Linux server terminal session activity and then later we will see how the recorded session can be replayed using **scriptreplay** command.
|
||||
`script` 是一个命令行工具,用于捕获/记录你的 Linux 服务器终端会话活动,以后可以使用 `scriptreplay` 命令重放记录的会话。在本文中,我们将演示如何安装 `script` 命令行工具以及如何记录 Linux 服务器终端会话活动,然后,我们将看到如何使用 `scriptreplay` 命令来重放记录的会话。
|
||||
|
||||
### Installation of Script tool on RHEL 7/ CentOS 7
|
||||
### 安装 script 工具
|
||||
|
||||
Script command is provided by the rpm package “**util-linux**”, in case it is not installed on your CentOS 7 / RHEL 7 system , run the following yum command,
|
||||
#### 在 RHEL 7/ CentOS 7 上安装 script 工具
|
||||
|
||||
`script` 命令由 RPM 包 `util-linux` 提供,如果你没有在你的 CentOS 7 / RHEL 7 系统上安装它,运行下面的 `yum` 安装它:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# yum install util-linux -y
|
||||
```
|
||||
|
||||
**On RHEL 8 / CentOS 8**
|
||||
#### 在 RHEL 8 / CentOS 8 上安装 script 工具
|
||||
|
||||
Run the following dnf command to install script utility on RHEL 8 and CentOS 8 system,
|
||||
运行下面的 `dnf` 命令来在 RHEL 8 / CentOS 8 上安装 `script` 工具:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# dnf install util-linux -y
|
||||
```
|
||||
|
||||
**Installation of Script tool on Debian based systems (Ubuntu / Linux Mint)**
|
||||
#### 在基于 Debian 的系统(Ubuntu / Linux Mint)上安装 script 工具
|
||||
|
||||
Execute the beneath apt-get command to install script utility
|
||||
运行下面的 `apt-get` 命令来安装 `script` 工具:
|
||||
|
||||
```
|
||||
root@linuxtechi ~]# apt-get install util-linux -y
|
||||
```
|
||||
|
||||
### How to Use script utility
|
||||
### 如何使用 script 工具
|
||||
|
||||
Use of script command is straight forward, type script command on terminal then hit enter, it will start capturing your current terminal session activities inside a file called “**typescript**”
|
||||
直接使用 `script` 命令,在终端上键入 `script` 命令,然后按回车,它将开始在名为 `typescript` 的文件中捕获当前的终端会话活动。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script
|
||||
@ -50,7 +52,7 @@ Script started, file is typescript
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
To stop recording the session activities, type exit command and hit enter.
|
||||
要停止记录会话活动,请键入 `exit` 命令,然后按回车:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# exit
|
||||
@ -59,23 +61,23 @@ Script done, file is typescript
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Syntax of Script command:
|
||||
`script` 命令的语法格式:
|
||||
|
||||
```
|
||||
~ ] # script {options} {file_name}
|
||||
~] # script {options} {file_name}
|
||||
```
|
||||
|
||||
Different options used in script command,
|
||||
能在 `script` 命令中使用的不同选项:
|
||||
|
||||
![options-script-command][1]
|
||||
|
||||
Let’s start recording of your Linux terminal session by executing script command and then execute couple of command like ‘**w**’, ‘**route -n**’ , ‘[**df -h**][2]’ and ‘**free-h**’, example is shown below
|
||||
让我们开始通过执行 `script` 命令来记录 Linux 终端会话,然后执行诸如 `w`,`route -n`,`df -h` 和 `free -h`,示例如下所示:
|
||||
|
||||
![script-examples-linux-server][3]
|
||||
|
||||
As we can see above, terminal session logs are saved in the file “typescript”
|
||||
正如我们在上面看到的,终端会话日志保存在文件 `typescript` 中:
|
||||
|
||||
Now view the contents of typescript file using [cat][4] / vi command,
|
||||
现在使用 `cat` / `vi` 命令查看 `typescript` 文件的内容,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ls -l typescript
|
||||
@ -85,11 +87,11 @@ Now view the contents of typescript file using [cat][4] / vi command,
|
||||
|
||||
![typescript-file-content-linux][5]
|
||||
|
||||
Above confirms that whatever commands we execute on terminal that have been saved inside the file “typescript”
|
||||
以上内容确认了我们在终端上执行的所有命令都已保存在 `typescript` 文件中。
|
||||
|
||||
### Use Custom File name in script command
|
||||
### 在 script 命令中使用定制文件名
|
||||
|
||||
Let’s assume we want to use our customize file name to script command, so specify the file name after script command, in the below example we are using a file name “session-log-(current-date-time).txt”
|
||||
假设我们要使用自定义文件名来执行 `script` 命令,可以在 `script` 命令后指定文件名。在下面的示例中,我们使用的文件名为 `session-log-(当前日期时间).txt`。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script sessions-log-$(date +%d-%m-%Y-%T).txt
|
||||
@ -97,7 +99,7 @@ Script started, file is sessions-log-21-06-2019-01:37:39.txt
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Now run the commands and then type exit,
|
||||
现在运行该命令并输入 `exit`:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# exit
|
||||
@ -106,9 +108,9 @@ Script done, file is sessions-log-21-06-2019-01:37:39.txt
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Append the commands output to script file
|
||||
### 附加命令输出到 script 记录文件
|
||||
|
||||
Let assume script command had already recorded the commands output to a file called session-log.txt file and now we want to append output of new sessions commands output to this file, then use “**-a**” command in script command
|
||||
假设 `script` 命令已经将命令输出记录到名为 `session-log.txt` 的文件中,现在我们想将新会话命令的输出附加到该文件中,那么可以在 `script` 命令中使用 `-a` 选项。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script -a sessions-log.txt
|
||||
@ -129,11 +131,11 @@ Script done, file is sessions-log.txt
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
To view updated session’s logs, use “cat session-log.txt ”
|
||||
要查看更新的会话记录,使用 `cat session-log.txt` 命令。
|
||||
|
||||
### Capture commands output to script file without interactive shell
|
||||
### 无需 shell 交互而捕获命令输出到 script 记录文件
|
||||
|
||||
Let’s assume we want to capture commands output to a script file, then use **-c** option, example is shown below,
|
||||
假设我们要捕获命令的输出到会话记录文件,那么使用 `-c` 选项,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script -c "uptime && hostname && date" root-session.txt
|
||||
@ -145,9 +147,9 @@ Script done, file is root-session.txt
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Run script command in quiet mode
|
||||
### 以静默模式运行 script 命令
|
||||
|
||||
To run script command in quiet mode use **-q** option, this option will suppress the script started and script done message, example is shown below,
|
||||
要以静默模式运行 `script` 命令,请使用 `-q` 选项,该选项将禁止 `script` 的启动和完成消息,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script -c "uptime && date" -q root-session.txt
|
||||
@ -156,11 +158,13 @@ Fri Jun 21 02:01:10 EDT 2019
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Record Timing information to a file and capture commands output to a separate file, this can be achieved in script command by passing timing file (**–timing**) , example is shown below,
|
||||
要将时序信息记录到文件中并捕获命令输出到单独的文件中,这可以通过在 `script` 命令中传递时序文件(`-timing`)实现,示例如下所示:
|
||||
|
||||
Syntax:
|
||||
语法格式:
|
||||
|
||||
~ ]# script -t <timing-file-name> {file_name}
|
||||
```
|
||||
~ ]# script -t <timing-file-name> {file_name}
|
||||
```
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script --timing=timing.txt session.log
|
||||
@ -185,23 +189,23 @@ Script done, file is session.log
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Replay recorded Linux terminal session activity
|
||||
### 重放记录的 Linux 终端会话活动
|
||||
|
||||
Now replay the recorded terminal session activities using scriptreplay command,
|
||||
现在,使用 `scriptreplay` 命令重放录制的终端会话活动。
|
||||
|
||||
**Note:** Scriptreplay is also provided by rpm package “**util-linux**”. Scriptreplay command requires timing file to work.
|
||||
注意:`scriptreplay` 也由 RPM 包 `util-linux` 提供。`scriptreplay` 命令需要时序文件才能工作。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# scriptreplay --timing=timing.txt session.log
|
||||
```
|
||||
|
||||
Output of above command would be something like below,
|
||||
上面命令的输出将如下所示,
|
||||
|
||||
<https://www.linuxtechi.com/wp-content/uploads/2019/06/scriptreplay-linux.gif>
|
||||
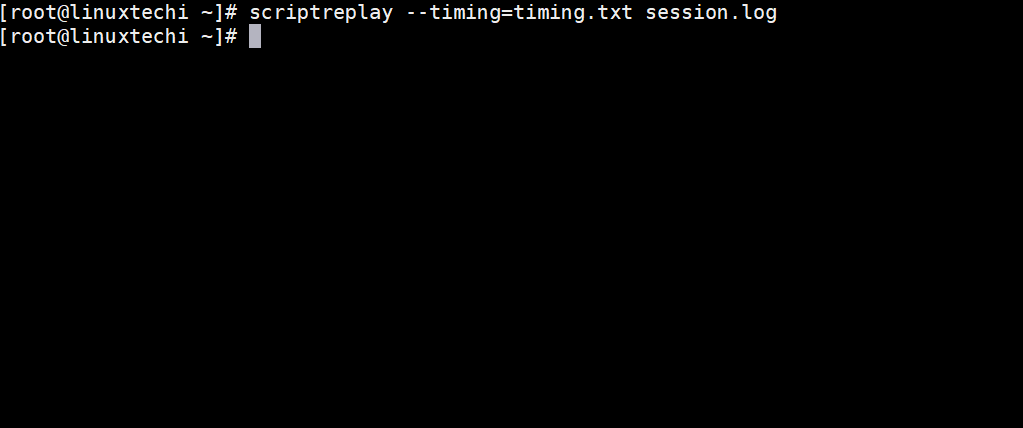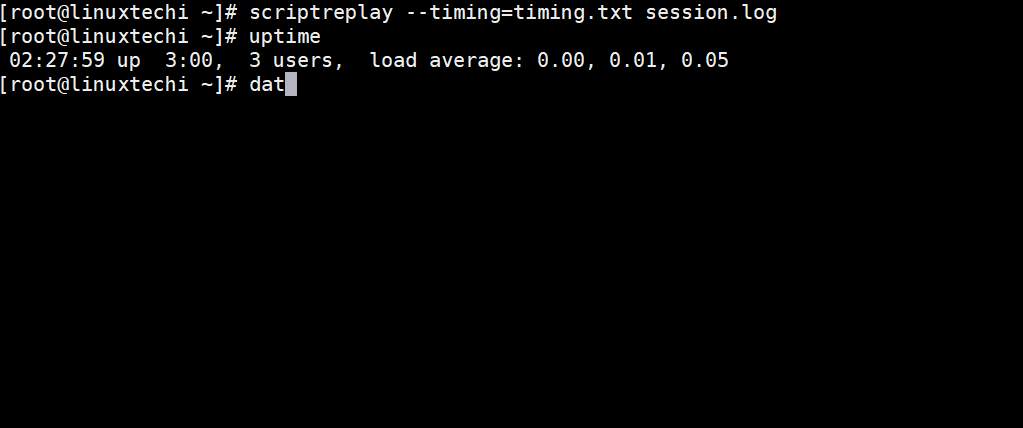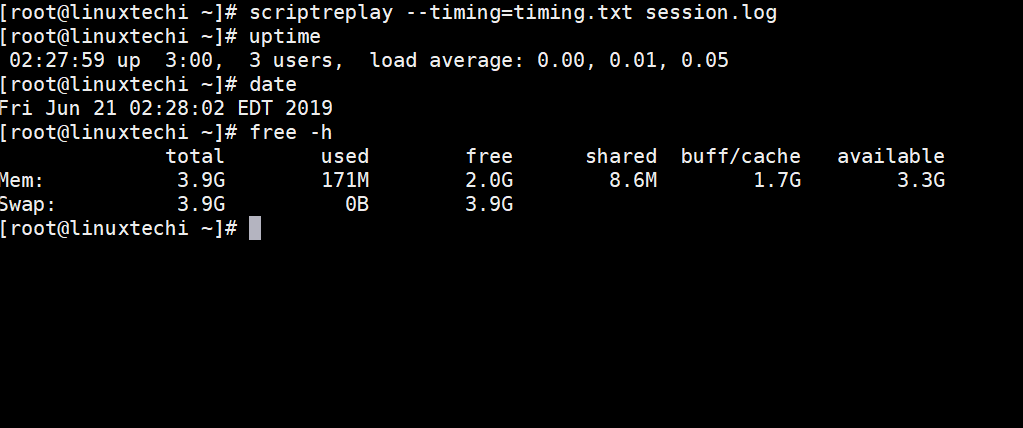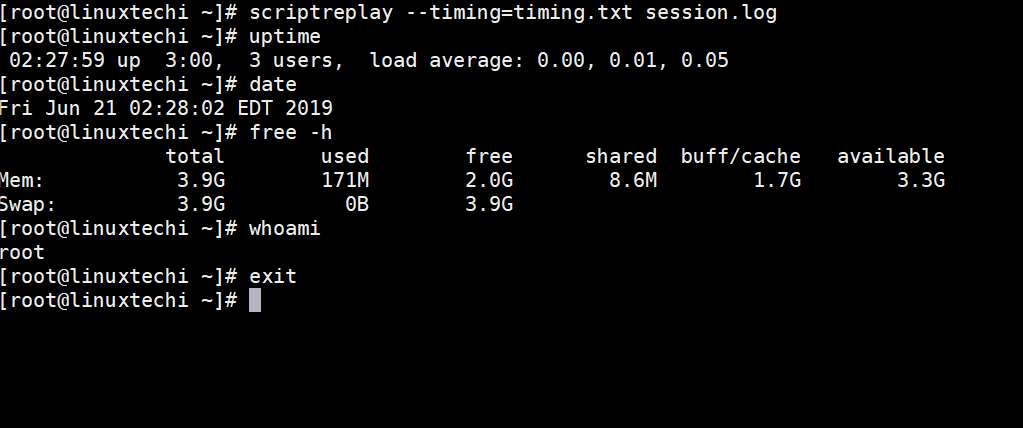
|
||||
|
||||
### Record all User’s Linux terminal session activities
|
||||
### 记录所有用户的 Linux 终端会话活动
|
||||
|
||||
There are some business critical Linux servers where we want keep track on all users activity, so this can be accomplished using script command, place the following content in /etc/profile file ,
|
||||
在某些关键业务的 Linux 服务器上,我们希望跟踪所有用户的活动,这可以使用 `script` 命令来完成,将以下内容放在 `/etc/profile` 文件中,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/profile
|
||||
@ -218,22 +222,22 @@ fi
|
||||
……………………………………………………
|
||||
```
|
||||
|
||||
Save & exit the file.
|
||||
保存文件并退出。
|
||||
|
||||
Create the session directory under /var/log folder,
|
||||
在 `/var/log` 文件夹下创建 `session` 目录:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# mkdir /var/log/session
|
||||
```
|
||||
|
||||
Assign the permissions to session folder,
|
||||
给该文件夹指定权限:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# chmod 777 /var/log/session/
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Now verify whether above code is working or not. Login to ordinary user to linux server, in my I am using pkumar user,
|
||||
现在,验证以上代码是否有效。在我正在使用 `pkumar` 用户的情况下,登录普通用户到 Linux 服务器:
|
||||
|
||||
```
|
||||
~ ] # ssh root@linuxtechi
|
||||
@ -263,13 +267,13 @@ Login as root and view user’s linux terminal session activity
|
||||
|
||||
![Session-output-file-linux][6]
|
||||
|
||||
We can also use scriptreplay command to replay user’s terminal session activities,
|
||||
我们还可以使用 `scriptreplay` 命令来重放用户的终端会话活动:
|
||||
|
||||
```
|
||||
[root@linuxtechi session]# scriptreplay --timing session.pkumar.19785.21-06-2019-04\:34\:05.timing session.pkumar.19785.21-06-2019-04\:34\:05
|
||||
```
|
||||
|
||||
That’s all from this tutorial, please do share your feedback and comments in the comments section below.
|
||||
以上就是本教程的全部内容,请在下面的评论部分中分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -277,8 +281,8 @@ via: https://www.linuxtechi.com/record-replay-linux-terminal-sessions-activity/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
82
published/20190719 Buying a Linux-ready laptop.md
Normal file
82
published/20190719 Buying a Linux-ready laptop.md
Normal file
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11436-1.html)
|
||||
[#]: subject: (Buying a Linux-ready laptop)
|
||||
[#]: via: (https://opensource.com/article/19/7/linux-laptop)
|
||||
[#]: author: (Ricardo Berlasso https://opensource.com/users/rgb-es)
|
||||
|
||||
我买了一台 Linux 笔记本
|
||||
======
|
||||
|
||||
> Tuxedo 让买一台开箱即用的 Linux 笔记本变得容易。
|
||||
|
||||

|
||||
|
||||
最近,我开始使用我买的 Linux 笔记本计算机 Tuxedo Book BC1507。十年前,如果有人告诉我,十年后我可以从 [System76][2]、[Slimbook][3] 和 [Tuxedo][4] 等公司购买到高质量的“企鹅就绪”的笔记本电脑。我可能会发笑。好吧,现在我也在笑,但是很开心!
|
||||
|
||||
除了为免费/自由开源软件(FLOSS)设计计算机之外,这三家公司最近[宣布][5]都试图通过切换到[Coreboot][6]来消除专有的 BIOS 软件。
|
||||
|
||||
### 买一台
|
||||
|
||||
Tuxedo Computers 是一家德国公司,生产支持 Linux 的笔记本电脑。实际上,如果你要使用其他的操作系统,则它的价格会更高。
|
||||
|
||||
购买他们的计算机非常容易。Tuxedo 提供了许多付款方式:不仅包括信用卡,而且还包括 PayPal 甚至银行转帐(LCTT 译注:我们需要支付宝和微信支付……此外,要国际配送,还需要支付运输费和清关费用等)。只需在 Tuxedo 的网页上填写银行转帐表格,公司就会给你发送银行信息。
|
||||
|
||||
Tuxedo 可以按需构建每台计算机,只需选择基本模型并浏览下拉菜单以选择不同的组件,即可轻松准确地选择所需内容。页面上有很多信息可以指导你进行购买。
|
||||
|
||||
如果你选择的 Linux 发行版与推荐的发行版不同,则 Tuxedo 会进行“网络安装”,因此请准备好网络电缆以完成安装,也可以将你首选的镜像文件刻录到 USB 盘上。我通过外部 DVD 阅读器来安装刻录了 openSUSE Leap 15.1 安装程序的 DVD,但是你可用你自己的方式。
|
||||
|
||||
我选择的型号最多可以容纳两个磁盘:一个 SSD,另一个可以是 SSD 或常规硬盘。由于已经超出了我的预算,因此我决定选择传统的 1TB 磁盘并将 RAM 增加到 16GB。该处理器是具有四个内核的第八代 i5。我选择了背光西班牙语键盘、1920×1080/96dpi 屏幕和 SD 卡读卡器。总而言之,这是一个很棒的系统。
|
||||
|
||||
如果你对默认的英语或德语键盘感觉满意,甚至可以要求在 Meta 键上印上一个企鹅图标!我需要的西班牙语键盘则不提供此选项。
|
||||
|
||||
### 收货并开箱使用
|
||||
|
||||
付款完成后仅六个工作日,完好包装的计算机就十分安全地到达了我家。打开计算机包装并解锁电池后,我准备好开始浪了。
|
||||
|
||||
![Tuxedo Book BC1507][7]
|
||||
|
||||
*我的(物理)桌面上的新玩具。*
|
||||
|
||||
该电脑的设计确实很棒,而且感觉扎实。即使此型号的外壳不是铝制的(LCTT 译注:他们有更好看的铝制外壳的型号),也可以保持凉爽。风扇真的很安静,气流像许多其他笔记本电脑一样导向后边缘,而不是流向侧面。电池可提供数小时的续航时间。BIOS 中的一个名为 FlexiCharger 的选项会在达到一定百分比后停止为电池充电,因此在插入电源长时间工作时,无需卸下电池。
|
||||
|
||||
键盘真的很舒适,而且非常安静。甚至触摸板按键也很安静!另外,你可以轻松调整背光键盘上的光强度。
|
||||
|
||||
最后,很容易访问笔记本电脑中的每个组件,因此可以毫无问题地对计算机进行更新或维修。Tuxedo 甚至送了几个备用螺丝!
|
||||
|
||||
### 结语
|
||||
|
||||
经过一个月的频繁使用,我对该系统感到非常满意。它完全满足了我的要求,并且一切都很完美。
|
||||
|
||||
因为它们通常是高端系统,所以包含 Linux 的计算机往往比较昂贵。如果你将 Tuxedo 或 Slimbook 电脑的价格与更知名品牌的类似规格的价格进行比较,价格相差无几。如果你想要一台使用自由软件的强大系统,请毫不犹豫地支持这些公司:他们所提供的物有所值。
|
||||
|
||||
请在评论中让我们知道你在 Tuxedo 和其他“企鹅友好”公司的经历。
|
||||
|
||||
* * *
|
||||
|
||||
本文基于 Ricardo 的博客 [From Mind to Type][9] 上发表的“ [我的新企鹅笔记本电脑:Tuxedo-Book-BC1507][8]”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/linux-laptop
|
||||
|
||||
作者:[Ricardo Berlasso][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgb-es
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
|
||||
[2]: https://system76.com/
|
||||
[3]: https://slimbook.es/en/
|
||||
[4]: https://www.tuxedocomputers.com/
|
||||
[5]: https://www.tuxedocomputers.com/en/Infos/News/Tuxedo-Computers-stands-for-Free-Software-and-Security-.tuxedo
|
||||
[6]: https://coreboot.org/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/tuxedo-600_0.jpg (Tuxedo Book BC1507)
|
||||
[8]: https://frommindtotype.wordpress.com/2019/06/17/my-new-penguin-ready-laptop-tuxedo-book-bc1507/
|
||||
[9]: https://frommindtotype.wordpress.com/
|
||||
273
published/20190809 Mutation testing is the evolution of TDD.md
Normal file
273
published/20190809 Mutation testing is the evolution of TDD.md
Normal file
@ -0,0 +1,273 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11468-1.html)
|
||||
[#]: subject: (Mutation testing is the evolution of TDD)
|
||||
[#]: via: (https://opensource.com/article/19/8/mutation-testing-evolution-tdd)
|
||||
[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzic)
|
||||
|
||||
变异测试是测试驱动开发(TDD)的演变
|
||||
======
|
||||
|
||||
> 测试驱动开发技术是根据大自然的运作规律创建的,变异测试自然成为 DevOps 演变的下一步。
|
||||
|
||||
![Ants and a leaf making the word "open"][1]
|
||||
|
||||
在 “[故障是无懈可击的开发运维中的一个特点][2]”,我讨论了故障在通过征求反馈来交付优质产品的过程中所起到的重要作用。敏捷 DevOps 团队就是用故障来指导他们并推动开发进程的。<ruby>[测试驱动开发][3]<rt>Test-driven development</rt></ruby>(TDD)是任何敏捷 DevOps 团队评估产品交付的[必要条件][4]。以故障为中心的 TDD 方法仅在与可量化的测试配合使用时才有效。
|
||||
|
||||
TDD 方法仿照大自然是如何运作的以及自然界在进化博弈中是如何产生赢家和输家为模型而建立的。
|
||||
|
||||
### 自然选择
|
||||
|
||||
![查尔斯·达尔文][5]
|
||||
|
||||
1859 年,<ruby>[查尔斯·达尔文][6]<rt>Charles Darwin</rt></ruby>在他的《<ruby>[物种起源][7]<rt>On the Origin of Species</rt></ruby>》一书中提出了进化论学说。达尔文的论点是,自然变异是由生物个体的自发突变和环境压力共同造成的。环境压力淘汰了适应性较差的生物体,而有利于其他适应性强的生物的发展。每个生物体的染色体都会发生变异,而这些自发的变异会携带给下一代(后代)。然后在自然选择下测试新出现的变异性 —— 当下存在的环境压力是由变异性的环境条件所导致的。
|
||||
|
||||
这张简图说明了调整适应环境条件的过程。
|
||||
|
||||
![环境压力对鱼类的影响][8]
|
||||
|
||||
*图1. 不同的环境压力导致自然选择下的不同结果。图片截图来源于[理查德·道金斯的一个视频][9]。*
|
||||
|
||||
该图显示了一群生活在自己栖息地的鱼。栖息地各不相同(海底或河床底部的砾石颜色有深有浅),每条鱼长的也各不相同(鱼身图案和颜色也有深有浅)。
|
||||
|
||||
这张图还显示了两种情况(即环境压力的两种变化):
|
||||
|
||||
1. 捕食者在场
|
||||
2. 捕食者不在场
|
||||
|
||||
在第一种情况下,在砾石颜色衬托下容易凸显出来的鱼被捕食者捕获的风险更高。当砾石颜色较深时,浅色鱼的数量会更少一些。反之亦然,当砾石颜色较浅时,深色鱼的数量会更少。
|
||||
|
||||
在第二种情况下,鱼完全放松下来进行交配。在没有捕食者和没有交配仪式的情况下,可以预料到相反的结果:在砾石背景下显眼的鱼会有更大的机会被选来交配并将其特性传递给后代。
|
||||
|
||||
### 选择标准
|
||||
|
||||
变异性在进行选择时,绝不是任意的、反复无常的、异想天开的或随机的。选择过程中的决定性因素通常是可以度量的。该决定性因素通常称为测试或目标。
|
||||
|
||||
一个简单的数学例子可以说明这一决策过程。(在该示例中,这种选择不是由自然选择决定的,而是由人为选择决定。)假设有人要求你构建一个小函数,该函数将接受一个正数,然后计算该数的平方根。你将怎么做?
|
||||
|
||||
敏捷 DevOps 团队的方法是快速验证失败。谦虚一点,先承认自己并不真的知道如何开发该函数。这时,你所知道的就是如何描述你想做的事情。从技术上讲,你已准备好进行单元测试。
|
||||
|
||||
“<ruby>单元测试<rt>unit test</rt></ruby>”描述了你的具体期望结果是什么。它可以简单地表述为“给定数字 16,我希望平方根函数返回数字 4”。你可能知道 16 的平方根是 4。但是,你不知道一些较大数字(例如 533)的平方根。
|
||||
|
||||
但至少,你已经制定了选择标准,即你的测试或你的期望值。
|
||||
|
||||
### 进行故障测试
|
||||
|
||||
[.NET Core][10] 平台可以演示该测试。.NET 通常使用 xUnit.net 作为单元测试框架。(要跟随进行这个代码示例,请安装 .NET Core 和 xUnit.net。)
|
||||
|
||||
打开命令行并创建一个文件夹,在该文件夹实现平方根解决方案。例如,输入:
|
||||
|
||||
```
|
||||
mkdir square_root
|
||||
```
|
||||
|
||||
再输入:
|
||||
|
||||
```
|
||||
cd square_root
|
||||
```
|
||||
|
||||
为单元测试创建一个单独的文件夹:
|
||||
|
||||
```
|
||||
mkdir unit_tests
|
||||
```
|
||||
|
||||
进入 `unit_tests` 文件夹下(`cd unit_tests`),初始化 xUnit 框架:
|
||||
|
||||
```
|
||||
dotnet new xunit
|
||||
```
|
||||
|
||||
现在,转到 `square_root` 下, 创建 `app` 文件夹:
|
||||
|
||||
```
|
||||
mkdir app
|
||||
cd app
|
||||
```
|
||||
|
||||
如果有必要的话,为你的代码创建一个脚手架:
|
||||
|
||||
```
|
||||
dotnet new classlib
|
||||
```
|
||||
|
||||
现在打开你最喜欢的编辑器开始编码!
|
||||
|
||||
在你的代码编辑器中,导航到 `unit_tests` 文件夹,打开 `UnitTest1.cs`。
|
||||
|
||||
将 `UnitTest1.cs` 中自动生成的代码替换为:
|
||||
|
||||
```
|
||||
using System;
|
||||
using Xunit;
|
||||
using app;
|
||||
|
||||
namespace unit_tests{
|
||||
|
||||
public class UnitTest1{
|
||||
Calculator calculator = new Calculator();
|
||||
|
||||
[Fact]
|
||||
public void GivenPositiveNumberCalculateSquareRoot(){
|
||||
var expected = 4;
|
||||
var actual = calculator.CalculateSquareRoot(16);
|
||||
Assert.Equal(expected, actual);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
该单元测试描述了变量的**期望值**应该为 4。下一行描述了**实际值**。建议通过将输入值发送到称为`calculator` 的组件来计算**实际值**。对该组件的描述是通过接收数值来处理`CalculateSquareRoot` 信息。该组件尚未开发。但这并不重要,我们在此只是描述期望值。
|
||||
|
||||
最后,描述了触发消息发送时发生的情况。此时,判断**期望值**是否等于**实际值**。如果是,则测试通过,目标达成。如果**期望值**不等于**实际值**,则测试失败。
|
||||
|
||||
接下来,要实现称为 `calculator` 的组件,在 `app` 文件夹中创建一个新文件,并将其命名为`Calculator.cs`。要实现计算平方根的函数,请在此新文件中添加以下代码:
|
||||
|
||||
```
|
||||
namespace app {
|
||||
public class Calculator {
|
||||
public double CalculateSquareRoot(double number) {
|
||||
double bestGuess = number;
|
||||
return bestGuess;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
在测试之前,你需要通知单元测试如何找到该新组件(`Calculator`)。导航至 `unit_tests` 文件夹,打开 `unit_tests.csproj` 文件。在 `<ItemGroup>` 代码块中添加以下代码:
|
||||
|
||||
```
|
||||
<ProjectReference Include="../app/app.csproj" />
|
||||
```
|
||||
|
||||
保存 `unit_test.csproj` 文件。现在,你可以运行第一个测试了。
|
||||
|
||||
切换到命令行,进入 `unit_tests` 文件夹。运行以下命令:
|
||||
|
||||
```
|
||||
dotnet test
|
||||
```
|
||||
|
||||
运行单元测试,会输出以下内容:
|
||||
|
||||
![单元测试失败后xUnit的输出结果][12]
|
||||
|
||||
*图2. 单元测试失败后 xUnit 的输出结果*
|
||||
|
||||
正如你所看到的,单元测试失败了。期望将数字 16 发送到 `calculator` 组件后会输出数字 4,但是输出(`Actual`)的是 16。
|
||||
|
||||
恭喜你!创建了第一个故障。单元测试为你提供了强有力的反馈机制,敦促你修复故障。
|
||||
|
||||
### 修复故障
|
||||
|
||||
要修复故障,你必须要改进 `bestGuess`。当下,`bestGuess` 仅获取函数接收的数字并返回。这不够好。
|
||||
|
||||
但是,如何找到一种计算平方根值的方法呢? 我有一个主意 —— 看一下大自然母亲是如何解决问题的。
|
||||
|
||||
### 效仿大自然的迭代
|
||||
|
||||
在第一次(也是唯一的)尝试中要得出正确值是非常难的(几乎不可能)。你必须允许自己进行多次尝试猜测,以增加解决问题的机会。允许多次尝试的一种方法是进行迭代。
|
||||
|
||||
要迭代,就要将 `bestGuess` 值存储在 `previousGuess` 变量中,转换 `bestGuess` 的值,然后比较两个值之间的差。如果差为 0,则说明问题已解决。否则,继续迭代。
|
||||
|
||||
这是生成任何正数的平方根的函数体:
|
||||
|
||||
```
|
||||
double bestGuess = number;
|
||||
double previousGuess;
|
||||
|
||||
do {
|
||||
previousGuess = bestGuess;
|
||||
bestGuess = (previousGuess + (number/previousGuess))/2;
|
||||
} while((bestGuess - previousGuess) != 0);
|
||||
|
||||
return bestGuess;
|
||||
```
|
||||
|
||||
该循环(迭代)将 `bestGuess` 值集中到设想的解决方案。现在,你精心设计的单元测试通过了!
|
||||
|
||||
![单元测试通过了][13]
|
||||
|
||||
*图 3. 单元测试通过了。*
|
||||
|
||||
### 迭代解决了问题
|
||||
|
||||
正如大自然母亲解决问题的方法,在本练习中,迭代解决了问题。增量方法与逐步改进相结合是获得满意解决方案的有效方法。该示例中的决定性因素是具有可衡量的目标和测试。一旦有了这些,就可以继续迭代直到达到目标。
|
||||
|
||||
### 关键点!
|
||||
|
||||
好的,这是一个有趣的试验,但是更有趣的发现来自于使用这种新创建的解决方案。到目前为止,`bestGuess` 从开始一直把函数接收到的数字作为输入参数。如果更改 `bestGuess` 的初始值会怎样?
|
||||
|
||||
为了测试这一点,你可以测试几种情况。 首先,在迭代多次尝试计算 25 的平方根时,要逐步细化观察结果:
|
||||
|
||||
![25 平方根的迭代编码][14]
|
||||
|
||||
*图 4. 通过迭代来计算 25 的平方根。*
|
||||
|
||||
以 25 作为 `bestGuess` 的初始值,该函数需要八次迭代才能计算出 25 的平方根。但是,如果在设计 `bestGuess` 初始值上犯下荒谬的错误,那将怎么办? 尝试第二次,那 100 万可能是 25 的平方根吗? 在这种明显错误的情况下会发生什么?你写的函数是否能够处理这种低级错误。
|
||||
|
||||
直接来吧。回到测试中来,这次以一百万开始:
|
||||
|
||||
![逐步求精法][15]
|
||||
|
||||
*图 5. 在计算 25 的平方根时,运用逐步求精法,以 100 万作为 bestGuess 的初始值。*
|
||||
|
||||
哇! 以一个荒谬的数字开始,迭代次数仅增加了两倍(从八次迭代到 23 次)。增长幅度没有你直觉中预期的那么大。
|
||||
|
||||
### 故事的寓意
|
||||
|
||||
啊哈! 当你意识到,迭代不仅能够保证解决问题,而且与你的解决方案的初始猜测值是好是坏也没有关系。 不论你最初理解得多么不正确,迭代过程以及可衡量的测试/目标,都可以使你走上正确的道路并得到解决方案。
|
||||
|
||||
图 4 和 5 显示了陡峭而戏剧性的燃尽图。一个非常错误的开始,迭代很快就产生了一个绝对正确的解决方案。
|
||||
|
||||
简而言之,这种神奇的方法就是敏捷 DevOps 的本质。
|
||||
|
||||
### 回到一些更深层次的观察
|
||||
|
||||
敏捷 DevOps 的实践源于人们对所生活的世界的认知。我们生活的世界存在不确定性、不完整性以及充满太多的困惑。从科学/哲学的角度来看,这些特征得到了<ruby>[海森堡的不确定性原理][16]<rt>Heisenberg's Uncertainty Principle</rt></ruby>(涵盖不确定性部分),<ruby>[维特根斯坦的逻辑论哲学][17]<rt>Wittgenstein's Tractatus Logico-Philosophicus</rt></ruby>(歧义性部分),<ruby>[哥德尔的不完全性定理][18]<rt>Gödel's incompleteness theorems</rt></ruby>(不完全性方面)以及<ruby>[热力学第二定律][19]<rt>Second Law of Thermodynamics</rt></ruby>(无情的熵引起的混乱)的充分证明和支持。
|
||||
|
||||
简而言之,无论你多么努力,在尝试解决任何问题时都无法获得完整的信息。因此,放下傲慢的姿态,采取更为谦虚的方法来解决问题对我们会更有帮助。谦卑会给为你带来巨大的回报,这个回报不仅是你期望的一个解决方案,还会有它的副产品。
|
||||
|
||||
### 总结
|
||||
|
||||
大自然在不停地运作,这是一个持续不断的过程。大自然没有总体规划。一切都是对先前发生的事情的回应。 反馈循环是非常紧密的,明显的进步/倒退都是逐步实现的。大自然中随处可见,任何事物的都在以一种或多种形式逐步完善。
|
||||
|
||||
敏捷 DevOps 是工程模型逐渐成熟的一个非常有趣的结果。DevOps 基于这样的认识,即你所拥有的信息总是不完整的,因此你最好谨慎进行。获得可衡量的测试(例如,假设、可测量的期望结果),进行简单的尝试,大多数情况下可能失败,然后收集反馈,修复故障并继续测试。除了同意每个步骤都必须要有可衡量的假设/测试之外,没有其他方法。
|
||||
|
||||
在本系列的下一篇文章中,我将仔细研究变异测试是如何提供及时反馈来推动实现结果的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/mutation-testing-evolution-tdd
|
||||
|
||||
作者:[Alex Bunardzic][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/Morisun029)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alex-bunardzic
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_520X292_openanttrail-2.png?itok=xhD3WmUd (Ants and a leaf making the word "open")
|
||||
[2]: https://opensource.com/article/19/7/failure-feature-blameless-devops
|
||||
[3]: https://en.wikipedia.org/wiki/Test-driven_development
|
||||
[4]: https://www.merriam-webster.com/dictionary/conditio%20sine%20qua%20non
|
||||
[5]: https://opensource.com/sites/default/files/uploads/darwin.png (Charles Darwin)
|
||||
[6]: https://en.wikipedia.org/wiki/Charles_Darwin
|
||||
[7]: https://en.wikipedia.org/wiki/On_the_Origin_of_Species
|
||||
[8]: https://opensource.com/sites/default/files/uploads/environmentalconditions2.png (Environmental pressures on fish)
|
||||
[9]: https://www.youtube.com/watch?v=MgK5Rf7qFaU
|
||||
[10]: https://dotnet.microsoft.com/
|
||||
[11]: https://xunit.net/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/xunit-output.png (xUnit output after the unit test run fails)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/unit-test-success.png (Unit test successful)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/iterating-square-root.png (Code iterating for the square root of 25)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/bestguess.png (Stepwise refinement)
|
||||
[16]: https://en.wikipedia.org/wiki/Uncertainty_principle
|
||||
[17]: https://en.wikipedia.org/wiki/Tractatus_Logico-Philosophicus
|
||||
[18]: https://en.wikipedia.org/wiki/G%C3%B6del%27s_incompleteness_theorems
|
||||
[19]: https://en.wikipedia.org/wiki/Second_law_of_thermodynamics
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11414-1.html)
|
||||
[#]: subject: (A Raspberry Pi Based Open Source Tablet is in Making and it’s Called CutiePi)
|
||||
[#]: via: (https://itsfoss.com/cutiepi-open-source-tab/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
CutiePi:正在开发中的基于树莓派的开源平板
|
||||
======
|
||||
|
||||
|
||||
|
||||
CutiePi 是一款 8 英寸的构建在树莓派上的开源平板。他们在[树莓派论坛][1]上宣布:现在,它只是一台原型机。
|
||||
|
||||
在本文中,你将了解有关 CutiePi 的规格、价格和可用性的更多详细信息。
|
||||
|
||||
它们使用一款定制的计算模块载版(CM3)来制造平板。[官网][2]提到使用定制 CM3 载板的目的是:
|
||||
|
||||
> 定制 CM3/CM3+ 载板是专为便携使用而设计,拥有增强的电源管理和锂聚合物电池电量监控功能。还可与指定的 HDMI 或 MIPI DSI 显示器配合使用。
|
||||
|
||||
因此,这使得该平板足够薄而且便携。
|
||||
|
||||
### CutiePi 规格
|
||||
|
||||
![CutiePi Board][3]
|
||||
|
||||
我惊讶地了解到它有 8 英寸的 IPS LCD 显示屏,这对新手而言是个好事。然而,你不会有一个真正高清的屏幕,因为官方宣称它的分辨率是 1280×800。
|
||||
|
||||
它还计划配备 4800 mAh 锂电池(原型机的电池为 5000 mAh)。嗯,对于平板来说,这不算坏。
|
||||
|
||||
连接性上包括支持 Wi-Fi 和蓝牙 4.0。此外,还有一个 USB Type-A 插口、6 个 GPIO 引脚和 microSD 卡插槽。
|
||||
|
||||
![CutiePi Specifications][4]
|
||||
|
||||
硬件与 [Raspbian OS][5] 官方兼容,用户界面采用 [Qt][6] 构建,以获得快速直观的用户体验。此外,除了内置应用外,它还将通过 XWayland 支持 Raspbian PIXEL 应用。
|
||||
|
||||
### CutiePi 源码
|
||||
|
||||
你可以通过分析所用材料的清单来猜测此平板的定价。CutiePi 遵循 100% 的开源硬件设计。因此,如果你觉得好奇,可以查看它的 [GitHub 页面][7],了解有关硬件设计和内容的详细信息。
|
||||
|
||||
### CutiePi 价格、发布日期和可用性
|
||||
|
||||
CutiePi 计划在 8 月进行[设计验证测试][8]批量 PCB。他们的目标是在 2019 年底推出最终产品。
|
||||
|
||||
官方预计,发售价大约在 $150-$250 左右。这只是一个近似的范围,还应该保有怀疑。
|
||||
|
||||
显然,即使产品听上去挺有希望,但价格将是它成功的一个主要因素。
|
||||
|
||||
### 总结
|
||||
|
||||
CutiePi 并不是第一个使用[像树莓派这样的单板计算机][9]来制作平板的项目。我们有即将推出的 [PineTab][10],它基于 Pine64 单板电脑。Pine 还有一种笔记本电脑,名为 [Pinebook][11]。
|
||||
|
||||
从原型来看,它确实是一个我们可以期望使用的产品。但是,预安装的应用和它将支持的应用可能会扭转局面。此外,考虑到价格估计,这听起来很有希望。
|
||||
|
||||
你觉得怎么样?让我们在下面的评论中知道你的想法,或者投个票。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cutiepi-open-source-tab/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/forums/viewtopic.php?t=247380
|
||||
[2]: https://cutiepi.io/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/cutiepi-board.png?ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/cutiepi-specifications.jpg?ssl=1
|
||||
[5]: https://itsfoss.com/raspberry-pi-os-desktop/
|
||||
[6]: https://en.wikipedia.org/wiki/Qt_%28software%29
|
||||
[7]: https://github.com/cutiepi-io/cutiepi-board
|
||||
[8]: https://en.wikipedia.org/wiki/Engineering_validation_test#Design_verification_test
|
||||
[9]: https://itsfoss.com/raspberry-pi-alternatives/
|
||||
[10]: https://www.pine64.org/pinetab/
|
||||
[11]: https://itsfoss.com/pinebook-pro/
|
||||
75
published/20190823 The lifecycle of Linux kernel testing.md
Normal file
75
published/20190823 The lifecycle of Linux kernel testing.md
Normal file
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11464-1.html)
|
||||
[#]: subject: (The lifecycle of Linux kernel testing)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-kernel-testing)
|
||||
[#]: author: (Major Hayden https://opensource.com/users/mhaydenhttps://opensource.com/users/mhaydenhttps://opensource.com/users/marcobravohttps://opensource.com/users/mhayden)
|
||||
|
||||
Linux 内核测试的生命周期
|
||||
======
|
||||
|
||||
> 内核持续集成(CKI)项目旨在防止错误进入 Linux 内核。
|
||||
|
||||

|
||||
|
||||
在 [Linux 内核的持续集成测试][2] 一文中,我介绍了 <ruby>[内核持续集成][3]<rt>Continuous Kernel Integration</rt></ruby>(CKI)项目及其使命:改变内核开发人员和维护人员的工作方式。本文深入探讨了该项目的某些技术方面,以及这所有的部分是如何组合在一起的。
|
||||
|
||||
### 从一次更改开始
|
||||
|
||||
内核中每一项令人兴奋的功能、改进和错误都始于开发人员提出的更改。这些更改出现在各个内核存储库的大量邮件列表中。一些存储库关注内核中的某些子系统,例如存储或网络,而其它存储库关注内核的更多方面。 当开发人员向内核提出更改或补丁集时,或者维护者在存储库本身中进行更改时,CKI 项目就会付诸行动。
|
||||
|
||||
CKI 项目维护的触发器用于监视这些补丁集并采取措施。诸如 [Patchwork][4] 之类的软件项目通过将多个补丁贡献整合为单个补丁系列,使此过程变得更加容易。补丁系列作为一个整体历经 CKI 系统,并可以针对该系列发布单个报告。
|
||||
|
||||
其他触发器可以监视存储库中的更改。当内核维护人员合并补丁集、还原补丁或创建新标签时,就会触发。测试这些关键的更改可确保开发人员始终具有坚实的基线,可以用作编写新补丁的基础。
|
||||
|
||||
所有这些更改都会进入 GitLab CI 管道,并历经多个阶段和多个系统。
|
||||
|
||||
### 准备构建
|
||||
|
||||
首先要准备好要编译的源代码。这需要克隆存储库、打上开发人员建议的补丁集,并生成内核配置文件。这些配置文件具有成千上万个用于打开或关闭功能的选项,并且配置文件在不同的系统体系结构之间差异非常大。 例如,一个相当标准的 x86\_64 系统在其配置文件中可能有很多可用选项,但是 s390x 系统(IBM zSeries 大型机)的选项可能要少得多。在该大型机上,某些选项可能有意义,但在消费类笔记本电脑上没有任何作用。
|
||||
|
||||
内核进一步转换为源代码工件。该工件包含整个存储库(已打上补丁)以及编译所需的所有内核配置文件。 上游内核会打包成压缩包,而 Red Hat 的内核会生成下一步所用的源代码 RPM 包。
|
||||
|
||||
### 成堆的编译
|
||||
|
||||
编译内核会将源代码转换为计算机可以启动和使用的代码。配置文件描述了要构建的内容,内核中的脚本描述了如何构建它,系统上的工具(例如 GCC 和 glibc)完成构建。此过程需要一段时间才能完成,但是 CKI 项目需要针对四种体系结构快速完成:aarch64(64 位 ARM)、ppc64le(POWER)、s390x(IBM zSeries)和 x86\_64。重要的是,我们必须快速编译内核,以便使工作任务不会积压,而开发人员可以及时收到反馈。
|
||||
|
||||
添加更多的 CPU 可以大大提高速度,但是每个系统都有其局限性。CKI 项目在 OpenShift 的部署环境中的容器内编译内核;尽管 OpenShift 可以实现高伸缩性,但在部署环境中的可用 CPU 仍然是数量有限的。CKI 团队分配了 20 个虚拟 CPU 来编译每个内核。涉及到四个体系结构,这就涨到了 80 个 CPU!
|
||||
|
||||
另一个速度的提高来自 [ccache][5] 工具。内核开发进展迅速,但是即使在多个发布版本之间,内核的大部分仍保持不变。ccache 工具进行编译期间会在磁盘上缓存已构建的对象(整个内核的一小部分)。稍后再进行另一个内核编译时,ccache 会查找以前看到的内核的未更改部分。ccache 会从磁盘中提取缓存的对象并重新使用它。这样可以加快编译速度并降低总体 CPU 使用率。现在,耗时 20 分钟编译的内核在不到几分钟的时间内就完成了。
|
||||
|
||||
### 测试时间
|
||||
|
||||
内核进入最后一步:在真实硬件上进行测试。每个内核都使用 Beaker 在其原生体系结构上启动,并且开始无数次的测试以发现问题。一些测试会寻找简单的问题,例如容器问题或启动时的错误消息。其他测试则深入到各种内核子系统中,以查找系统调用、内存分配和线程中的回归问题。
|
||||
|
||||
大型测试框架,例如 [Linux Test Project][6](LTP),包含了大量测试,这些测试在内核中寻找麻烦的回归问题。其中一些回归问题可能会回滚关键的安全修复程序,并且进行测试以确保这些改进仍保留在内核中。
|
||||
|
||||
测试完成后,关键的一步仍然是:报告。内核开发人员和维护人员需要一份简明的报告,准确地告诉他们哪些有效、哪些无效以及如何获取更多信息。每个 CKI 报告都包含所用源代码、编译参数和测试输出的详细信息。该信息可帮助开发人员知道从哪里开始寻找解决问题的方法。此外,它还可以帮助维护人员在漏洞进入内核存储库之前知道何时需要保留补丁集以进行其他查看。
|
||||
|
||||
### 总结
|
||||
|
||||
CKI 项目团队通过向内核开发人员和维护人员提供及时、自动的反馈,努力防止错误进入 Linux 内核。这项工作通过发现导致内核错误、安全性问题和性能问题等易于找到的问题,使他们的工作更加轻松。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-kernel-testing
|
||||
|
||||
作者:[Major Hayden][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhaydenhttps://opensource.com/users/mhaydenhttps://opensource.com/users/marcobravohttps://opensource.com/users/mhayden
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
|
||||
[2]: https://opensource.com/article/19/6/continuous-kernel-integration-linux
|
||||
[3]: https://cki-project.org/
|
||||
[4]: https://github.com/getpatchwork/patchwork
|
||||
[5]: https://ccache.dev/
|
||||
[6]: https://linux-test-project.github.io
|
||||
[7]: https://cki-project.org/posts/hackfest-agenda/
|
||||
[8]: https://www.linuxplumbersconf.org/
|
||||
@ -0,0 +1,212 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11427-1.html)
|
||||
[#]: subject: (How to compile a Linux kernel in the 21st century)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-kernel-21st-century)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 21 世纪该怎样编译 Linux 内核
|
||||
======
|
||||
|
||||
> 也许你并不需要编译 Linux 内核,但你能通过这篇教程快速上手。
|
||||
|
||||

|
||||
|
||||
在计算机世界里,<ruby>内核<rt>kernel</rt></ruby>是处理硬件与一般系统之间通信的<ruby>低阶软件<rt>low-level software</rt></ruby>。除过一些烧录进计算机主板的初始固件,当你启动计算机时,内核让系统意识到它有一个硬盘驱动器、屏幕、键盘以及网卡。分配给每个部件相等时间(或多或少)使得图像、音频、文件系统和网络可以流畅甚至并行地运行。
|
||||
|
||||
然而,对于硬件的需求是源源不断的,随着发布的硬件越多,内核就必须纳入更多代码来保证那些硬件正常工作。得到具体的数字很困难,但是 Linux 内核无疑是硬件兼容性方面的顶级内核之一。Linux 操作着无数的计算机和移动电话、工业用途和爱好者使用的板级嵌入式系统(SoC)、RAID 卡、缝纫机等等。
|
||||
|
||||
回到 20 世纪(甚至是 21 世纪初期),对于 Linux 用户来说,在刚买到新的硬件后就需要下载最新的内核代码并编译安装才能使用这是不可理喻的。而现在你也很难见到 Linux 用户为了好玩而编译内核或通过高度专业化定制的硬件的方式赚钱。现在,通常已经不需要再编译 Linux 内核了。
|
||||
|
||||
这里列出了一些原因以及快速编译内核的教程。
|
||||
|
||||
### 更新当前的内核
|
||||
|
||||
无论你买了配备新显卡或 Wifi 芯片集的新品牌电脑还是给家里配备一个新的打印机,你的操作系统(称为 GNU+Linux 或 Linux,它也是该内核的名字)需要一个驱动程序来打开新部件(显卡、芯片集、打印机和其他任何东西)的信道。有时候当你插入某些新的设备时而你的电脑表示发现了它,这具有一定的欺骗性。别被骗到了,有时候那就够了,但更多的情况是你的操作系统仅仅是使用了通用的协议检测到安装了新的设备。
|
||||
|
||||
例如,你的计算机也许能够鉴别出新的网络打印机,但有时候那仅仅是因为打印机的网卡被设计成为了获得 DHCP 地址而在网络上标识自己。它并不意味着你的计算机知道如何发送文档给打印机进行打印。事实上,你可以认为计算机甚至不“知道”那台设备是一个打印机。它也许仅仅是显示网络有个设备在一个特定的地址上,并且该设备以一系列字符 “p-r-i-n-t-e-r” 标识自己而已。人类语言的便利性对于计算机毫无意义。计算机需要的是一个驱动程序。
|
||||
|
||||
内核开发者、硬件制造商、技术支持和爱好者都知道新的硬件会不断地发布。它们大多数都会贡献驱动程序,直接提交给内核开发团队以包含在 Linux 中。例如,英伟达显卡驱动程序通常都会写入 [Nouveau][2] 内核模块中,并且因为英伟达显卡很常用,它的代码都包含在任一个日常使用的发行版内核中(例如当下载 [Fedora][3] 或 [Ubuntu][4] 得到的内核)。英伟达也有不常用的地方,例如嵌入式系统中 Nouveau 模块通常被移除。对其他设备来说也有类似的模块:打印机得益于 [Foomatic][5] 和 [CUPS][6],无线网卡有 [b43、ath9k、wl][7] 模块等等。
|
||||
|
||||
发行版往往会在它们 Linux 内核的构建中包含尽可能多合理的驱动程序,因为他们想让你在接入新设备时不用安装驱动程序能够立即使用。对于大多数情况来说就是这样的,尤其是现在很多设备厂商都在资助自己售卖硬件的 Linux 驱动程序开发,并且直接将这些驱动程序提交给内核团队以用在通常的发行版上。
|
||||
|
||||
有时候,或许你正在运行六个月之前安装的内核,并配备了上周刚刚上市令人兴奋的新设备。在这种情况下,你的内核也许没有那款设备的驱动程序。好消息是经常会出现那款设备的驱动程序已经存在于最近版本的内核中,意味着你只要更新运行的内核就可以了。
|
||||
|
||||
通常,这些都是通过安装包管理软件完成的。例如在 RHEL、CentOS 和 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf update kernel
|
||||
```
|
||||
|
||||
在 Debian 和 Ubuntu 上,首先获取你当前内核的版本:
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
4.4.186
|
||||
```
|
||||
|
||||
搜索新的版本:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt search linux-image
|
||||
```
|
||||
|
||||
安装找到的最新版本。在这个例子中,最新的版本是 5.2.4:
|
||||
|
||||
```
|
||||
$ sudo apt install linux-image-5.2.4
|
||||
```
|
||||
|
||||
内核更新后,你必须 [reboot][8] (除非你使用 kpatch 或 kgraft)。这时,如果你需要的设备驱动程序包含在最新的内核中,你的硬件就会正常工作。
|
||||
|
||||
### 安装内核模块
|
||||
|
||||
有时候一个发行版没有预计到用户会使用某个设备(或者该设备的驱动程序至少不足以包含在 Linux 内核中)。Linux 对于驱动程序采用模块化方式,因此尽管驱动程序没有编译进内核,但发行版可以推送单独的驱动程序包让内核去加载。尽管有些复杂但是非常有用,尤其是当驱动程序没有包含进内核中而是在引导过程中加载,或是内核中的驱动程序相比模块化的驱动程序过期时。第一个问题可以用 “initrd” 解决(初始化 RAM 磁盘),这一点超出了本文的讨论范围,第二点通过 “kmod” 系统解决。
|
||||
|
||||
kmod 系统保证了当内核更新后,所有与之安装的模块化驱动程序也得到更新。如果你手动安装一个驱动程序,你就体验不到 kmod 提供的自动化,因此只要能用 kmod 安装包,就应该选择它。例如,尽管英伟达驱动程序以 Nouveau 模块构建在内核中,但官方的驱动程序仅由英伟达发布。你可以去网站上手动安装英伟达旗下的驱动程序,下载 “.run” 文件,并运行提供的 shell 脚本,但在安装了新的内核之后你必须重复相同的过程,因为没有任何东西告诉包管理软件你手动安装了一个内核驱动程序。英伟达驱动着你的显卡,手动更新英伟达驱动程序通常意味着你需要通过终端来执行更新,因为没有显卡驱动程序将无法显示。
|
||||
|
||||
![Nvidia configuration application][9]
|
||||
|
||||
然而,如果你通过 kmod 包安装英伟达驱动程序,更新你的内核也会更新你的英伟达驱动程序。在 Fedora 和相关的发行版中:
|
||||
|
||||
```
|
||||
$ sudo dnf install kmod-nvidia
|
||||
```
|
||||
|
||||
在 Debian 和相关发行版上:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install nvidia-kernel-common nvidia-kernel-dkms nvidia-glx nvidia-xconfig nvidia-settings nvidia-vdpau-driver vdpau-va-driver
|
||||
```
|
||||
|
||||
这仅仅是一个例子,但是如果你真的要安装英伟达驱动程序,你也必须屏蔽掉 Nouveau 驱动程序。参考你使用发行版的文档获取最佳的步骤吧。
|
||||
|
||||
### 下载并安装驱动程序
|
||||
|
||||
不是所有的东西都包含在内核中,也不是所有的东西都可以作为内核模块使用。在某些情况下,你需要下载一个由供应商编写并绑定好的特殊驱动程序,还有一些情况,你有驱动程序,但是没有配置驱动程序的前端界面。
|
||||
|
||||
有两个常见的例子是 HP 打印机和 [Wacom][10] 数位板。如果你有一台 HP 打印机,你可能有能够和打印机通信的通用的驱动程序,甚至能够打印出东西。但是通用的驱动程序却不能为特定型号的打印机提供定制化的选项,例如双面打印、校对、纸盒选择等等。[HPLIP][11](HP Linux 成像和打印系统)提供了选项来进行任务管理、调整打印设置、选择可用的纸盒等等。
|
||||
|
||||
HPLIP 通常包含在包管理软件中;只要搜索“hplip”就行了。
|
||||
|
||||
![HPLIP in action][12]
|
||||
|
||||
同样的,电子艺术家主要使用的数位板 Wacom 的驱动程序通常也包含在内核中,但是例如调整压感和按键功能等设置只能通过默认包含在 GNOME 的图形控制面板访问。但也可以作为 KDE 上额外的程序包“kde-config-tablet”来访问。
|
||||
|
||||
这里也有几个类似的个别例子,例如内核中没有驱动程序,但是以 RPM 或 DEB 文件提供了可供下载并且通过包管理软件安装的 kmod 版本的驱动程序。
|
||||
|
||||
### 打上补丁并编译你的内核
|
||||
|
||||
即使在 21 世纪的未来主义乌托邦里,仍有厂商不够了解开源,没有提供可安装的驱动程序。有时候,一些公司为驱动程序提供开源代码,而需要你下载代码、修补内核、编译并手动安装。
|
||||
|
||||
这种发布方式和在 kmod 系统之外安装打包的驱动程序拥有同样的缺点:对内核的更新会破坏驱动程序,因为每次更换新的内核时都必须手动将其重新集成到内核中。
|
||||
|
||||
令人高兴的是,这种事情变得少见了,因为 Linux 内核团队在呼吁公司们与他们交流方面做得很好,并且公司们最终接受了开源不会很快消失的事实。但仍有新奇的或高度专业的设备仅提供了内核补丁。
|
||||
|
||||
官方上,对于你如何编译内核以使包管理器参与到升级系统如此重要的部分中,发行版有特定的习惯。这里有太多的包管理器,所以无法一一涵盖。举一个例子,当你使用 Fedora 上的工具例如 `rpmdev` 或 `build-essential`,Debian 上的 `devscripts`。
|
||||
|
||||
首先,像通常那样,找到你正在运行内核的版本:
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
```
|
||||
|
||||
在大多数情况下,如果你还没有升级过内核那么可以试试升级一下内核。搞定之后,也许你的问题就会在最新发布的内核中解决。如果你尝试后发现不起作用,那么你应该下载正在运行内核的源码。大多数发行版提供了特定的命令来完成这件事,但是手动操作的话,可以在 [kernel.org][13] 上找到它的源代码。
|
||||
|
||||
你必须下载内核所需的任何补丁。有时候,这些补丁对应具体的内核版本,因此请谨慎选择。
|
||||
|
||||
通常,或至少在人们习惯于编译内核的那时,都是拿到源代码并对 `/usr/src/linux` 打上补丁。
|
||||
|
||||
解压内核源码并打上需要的补丁:
|
||||
|
||||
```
|
||||
$ cd /usr/src/linux
|
||||
$ bzip2 --decompress linux-5.2.4.tar.bz2
|
||||
$ cd linux-5.2.4
|
||||
$ bzip2 -d ../patch*bz2
|
||||
```
|
||||
|
||||
补丁文件也许包含如何使用的教程,但通常它们都设计成在内核源码树的顶层可用来执行。
|
||||
|
||||
```
|
||||
$ patch -p1 < patch*example.patch
|
||||
```
|
||||
|
||||
当内核代码打上补丁后,你可以继续使用旧的配置来对打了补丁的内核进行配置。
|
||||
|
||||
```
|
||||
$ make oldconfig
|
||||
```
|
||||
|
||||
`make oldconfig` 命令有两个作用:它继承了当前的内核配置,并且允许你配置补丁带来的新的选项。
|
||||
|
||||
你或许需要运行 `make menuconfig` 命令,它启动了一个基于 ncurses 的菜单界面,列出了新的内核所有可能的选项。整个菜单可能看不过来,但是它是以旧的内核配置为基础的,你可以遍历菜单并且禁用掉你没有或不需要的硬件模块。另外,如果你知道自己有一些硬件没有包含在当前的配置中,你可以选择构建它,当作模块或者直接嵌入内核中。理论上,这些并不是必要的,因为你可以猜想,当前的内核运行良好只是缺少了补丁,当使用补丁的时候可能已经激活了所有设备所必要的选项。
|
||||
|
||||
下一步,编译内核和它的模块:
|
||||
|
||||
```
|
||||
$ make bzImage
|
||||
$ make modules
|
||||
```
|
||||
|
||||
这会产生一个叫作 `vmlinuz` 的文件,它是你的可引导内核的压缩版本。保存旧的版本并在 `/boot` 文件夹下替换为新的。
|
||||
|
||||
```
|
||||
$ sudo mv /boot/vmlinuz /boot/vmlinuz.nopatch
|
||||
$ sudo cat arch/x86_64/boot/bzImage > /boot/vmlinuz
|
||||
$ sudo mv /boot/System.map /boot/System.map.stock
|
||||
$ sudo cp System.map /boot/System.map
|
||||
```
|
||||
|
||||
到目前为止,你已经打上了补丁并且编译了内核和它的模块,你安装了内核,但你并没有安装任何模块。那就是最后的步骤:
|
||||
|
||||
```
|
||||
$ sudo make modules_install
|
||||
```
|
||||
|
||||
新的内核已经就位,并且它的模块也已经安装。
|
||||
|
||||
最后一步是更新你的引导程序,为了让你的计算机在加载 Linux 内核之前知道它的位置。GRUB 引导程序使这一过程变得相当简单:
|
||||
|
||||
```
|
||||
$ sudo grub2-mkconfig
|
||||
```
|
||||
|
||||
### 现实生活中的编译
|
||||
|
||||
当然,现在没有人手动执行这些命令。相反的,参考你的发行版,寻找发行版维护人员使用的开发者工具集修改内核的说明。这些工具集可能会创建一个集成所有补丁的可安装软件包,告诉你的包管理器来升级并更新你的引导程序。
|
||||
|
||||
### 内核
|
||||
|
||||
操作系统和内核都是玄学,但要理解构成它们的组件并不难。下一次你看到某个技术无法应用在 Linux 上时,深呼吸,调查可用的驱动程序,寻找一条捷径。Linux 比以前简单多了——包括内核。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-kernel-21st-century
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/migration_innovation_computer_software.png?itok=VCFLtd0q (and old computer and a new computer, representing migration to new software or hardware)
|
||||
[2]: https://nouveau.freedesktop.org/wiki/
|
||||
[3]: http://fedoraproject.org
|
||||
[4]: http://ubuntu.com
|
||||
[5]: https://wiki.linuxfoundation.org/openprinting/database/foomatic
|
||||
[6]: https://www.cups.org/
|
||||
[7]: https://wireless.wiki.kernel.org/en/users/drivers
|
||||
[8]: https://opensource.com/article/19/7/reboot-linux
|
||||
[9]: https://opensource.com/sites/default/files/uploads/nvidia.jpg (Nvidia configuration application)
|
||||
[10]: https://linuxwacom.github.io
|
||||
[11]: https://developers.hp.com/hp-linux-imaging-and-printing
|
||||
[12]: https://opensource.com/sites/default/files/uploads/hplip.jpg (HPLIP in action)
|
||||
[13]: https://www.kernel.org/
|
||||
131
published/20190826 Introduction to the Linux chown command.md
Normal file
131
published/20190826 Introduction to the Linux chown command.md
Normal file
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11416-1.html)
|
||||
[#]: subject: (Introduction to the Linux chown command)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-chown-command)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
chown 命令简介
|
||||
======
|
||||
|
||||
> 学习如何使用 chown 命令更改文件或目录的所有权。
|
||||
|
||||

|
||||
|
||||
Linux 系统上的每个文件和目录均由某个人拥有,拥有者可以完全控制更改或删除他们拥有的文件。除了有一个*拥有用户*外,文件还有一个*拥有组*。
|
||||
|
||||
你可以使用 `ls -l` 命令查看文件的所有权:
|
||||
|
||||
```
|
||||
[pablo@workstation Downloads]$ ls -l
|
||||
total 2454732
|
||||
-rw-r--r--. 1 pablo pablo 1934753792 Jul 25 18:49 Fedora-Workstation-Live-x86_64-30-1.2.iso
|
||||
```
|
||||
|
||||
该输出的第三和第四列是拥有用户和组,它们一起称为*所有权*。上面的那个 ISO 文件这两者都是 `pablo`。
|
||||
|
||||
所有权设置由 [chmod 命令][2]进行设置,控制允许谁可以执行读取、写入或运行的操作。你可以使用 `chown` 命令更改所有权(一个或两者)。
|
||||
|
||||
所有权经常需要更改。文件和目录一直存在在系统中,但用户不断变来变去。当文件和目录在系统中移动时,或从一个系统移动到另一个系统时,所有权也可能需要更改。
|
||||
|
||||
我的主目录中的文件和目录的所有权是我的用户和我的主要组,以 `user:group` 的形式表示。假设 Susan 正在管理 Delta 组,该组需要编辑一个名为 `mynotes` 的文件。你可以使用 `chown` 命令将该文件的用户更改为 `susan`,组更改为 `delta`:
|
||||
|
||||
```
|
||||
$ chown susan:delta mynotes
|
||||
ls -l
|
||||
-rw-rw-r--. 1 susan delta 0 Aug 1 12:04 mynotes
|
||||
```
|
||||
|
||||
当给该文件设置好了 Delta 组时,它可以分配回给我:
|
||||
|
||||
```
|
||||
$ chown alan mynotes
|
||||
$ ls -l mynotes
|
||||
-rw-rw-r--. 1 alan delta 0 Aug 1 12:04 mynotes
|
||||
```
|
||||
|
||||
给用户后添加冒号(`:`),可以将用户和组都分配回给我:
|
||||
|
||||
```
|
||||
$ chown alan: mynotes
|
||||
$ ls -l mynotes
|
||||
-rw-rw-r--. 1 alan alan 0 Aug 1 12:04 mynotes
|
||||
```
|
||||
|
||||
通过在组前面加一个冒号,可以只更改组。现在,`gamma` 组的成员可以编辑该文件:
|
||||
|
||||
```
|
||||
$ chown :gamma mynotes
|
||||
$ ls -l
|
||||
-rw-rw-r--. 1 alan gamma 0 Aug 1 12:04 mynotes
|
||||
```
|
||||
|
||||
`chown` 的一些附加参数都能用在命令行和脚本中。就像许多其他 Linux 命令一样,`chown` 有一个递归参数(`-R`),它告诉该命令进入目录以对其中的所有文件进行操作。没有 `-R` 标志,你就只能更改文件夹的权限,而不会更改其中的文件。在此示例中,假定目的是更改目录及其所有内容的权限。这里我添加了 `-v`(详细)参数,以便 `chown` 报告其工作情况:
|
||||
|
||||
```
|
||||
$ ls -l . conf
|
||||
.:
|
||||
drwxrwxr-x 2 alan alan 4096 Aug 5 15:33 conf
|
||||
|
||||
conf:
|
||||
-rw-rw-r-- 1 alan alan 0 Aug 5 15:33 conf.xml
|
||||
|
||||
$ chown -vR susan:delta conf
|
||||
changed ownership of 'conf/conf.xml' from alan:alan to susan:delta
|
||||
changed ownership of 'conf' from alan:alan to susan:delta
|
||||
```
|
||||
|
||||
根据你的角色,你可能需要使用 `sudo` 来更改文件的所有权。
|
||||
|
||||
在更改文件的所有权以匹配特定配置时,或者在你不知道所有权时(例如运行脚本时),可以使用参考文件(`--reference=RFILE`)。例如,你可以复制另一个文件(`RFILE`,称为参考文件)的用户和组,以撤消上面所做的更改。回想一下,点(`.`)表示当前的工作目录。
|
||||
|
||||
```
|
||||
$ chown -vR --reference=. conf
|
||||
```
|
||||
|
||||
### 报告更改
|
||||
|
||||
大多数命令都有用于控制其输出的参数。最常见的是 `-v`(`--verbose`)以启用详细信息,但是 `chown` 还具有 `-c`(`--changes`)参数来指示 `chown` 仅在进行更改时报告。`chown` 还会报告其他情况,例如不允许进行的操作。
|
||||
|
||||
参数 `-f`(`--silent`、`--quiet`)用于禁止显示大多数错误消息。在下一节中,我将使用 `-f` 和 `-c`,以便仅显示实际更改。
|
||||
|
||||
### 保持根目录
|
||||
|
||||
Linux 文件系统的根目录(`/`)应该受到高度重视。如果命令在此层级上犯了一个错误,则后果可能会使系统完全无用。尤其是在运行一个会递归修改甚至删除的命令时。`chown` 命令具有一个可用于保护和保持根目录的参数,它是 `--preserve-root`。如果在根目录中将此参数和递归一起使用,那么什么也不会发生,而是会出现一条消息:
|
||||
|
||||
```
|
||||
$ chown -cfR --preserve-root alan /
|
||||
chown: it is dangerous to operate recursively on '/'
|
||||
chown: use --no-preserve-root to override this failsafe
|
||||
```
|
||||
|
||||
如果不与 `--recursive` 结合使用,则该选项无效。但是,如果该命令由 `root` 用户运行,则 `/` 本身的权限将被更改,但其下的其他文件或目录的权限则不会更改:
|
||||
|
||||
```
|
||||
$ chown -c --preserve-root alan /
|
||||
chown: changing ownership of '/': Operation not permitted
|
||||
[root@localhost /]# chown -c --preserve-root alan /
|
||||
changed ownership of '/' from root to alan
|
||||
```
|
||||
|
||||
### 所有权即安全
|
||||
|
||||
文件和目录所有权是良好的信息安全性的一部分,因此,偶尔检查和维护文件所有权以防止不必要的访问非常重要。`chown` 命令是 Linux 安全命令集中最常见和最重要的命令之一。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-chown-command
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
|
||||
[2]: https://opensource.com/article/19/8/introduction-linux-chmod-command
|
||||
@ -0,0 +1,93 @@
|
||||
技术如何改变敏捷的规则
|
||||
======
|
||||
|
||||
> 当我们开始推行敏捷时,还没有容器和 Kubernetes。但是它们改变了过去最困难的部分:将敏捷性从小团队应用到整个组织。
|
||||
|
||||

|
||||
|
||||
越来越多的企业正因为一个非常明显的原因开始尝试敏捷和 [DevOps][1]: 企业需要通过更快的速度和更多的实验为创新和竞争性提供优势。而 DevOps 将帮助我们得到所需的创新速度。但是,在小团队或初创企业中实践 DevOps 与进行大规模实践完全是两码事。我们都明白这样的一个事实,那就是在十个人的跨职能团队中能够很好地解决问题的方案,当将相同的模式应用到一百个人的团队中时就可能无法奏效。这条道路是如此艰难,以至于 IT 领导者最简单的应对就是将敏捷方法的推行再推迟一年。
|
||||
|
||||
但那样的时代已经结束了。如果你已经尝试过,但是没有成功,那么现在是时候重新开始了。
|
||||
|
||||
到目前为止,DevOps 需要为许多组织提供个性化的解决方案,因此往往需要进行大量的调整以及付出额外的工作。但在今天,[Linux 容器][2]和 Kubernetes 正在推动 DevOps 工具和过程的标准化。而这样的标准化将会加速整个软件开发过程。因此,我们用来实践 DevOps 工作方式的技术最终能够满足我们加快软件开发速度的愿望。
|
||||
|
||||
Linux 容器和 [Kubernetes][3] 正在改变团队交互的方式。此外,你可以在 Kubernetes 平台上运行任何能够在 Linux 运行的应用程序。这意味着什么呢?你可以运行大量的企业及应用程序(甚至可以解决以前令人烦恼的 Windows 和 Linux 之间的协调问题)。最后,容器和 Kubernetes 能够满足你未来将要运行的几乎所有工作。它们正在经受着未来的考验,以应对机器学习、人工智能和分析工作等下一代解决问题工具。
|
||||
|
||||
让我们以机器学习为例来思考一下。今天,人们可以在大量的企业数据中找到一些模式。当机器发现这些模式时(想想机器学习),你的员工就能更快地采取行动。随着人工智能的加入,机器不仅可以发现模式,还可以对模式进行操作。如今,一个积极的软件开发冲刺周期也就是三个星期而已。有了人工智能,机器每秒可以多次修改代码。创业公司会利用这种能力来“打扰你”。
|
||||
|
||||
考虑一下你需要多快才能参与到竞争当中。如果你对于无法对于 DevOps 和每周一个迭代周期充满信心,那么考虑一下当那个创业公司将 AI 驱动的过程指向你时会发生什么?现在是时候转向 DevOps 的工作方式了,否则就会像你的竞争对手一样被甩在后面。
|
||||
|
||||
### 容器技术如何改变团队的工作?
|
||||
|
||||
DevOps 使得许多试图将这种工作方式扩展到更大范围的团队感到沮丧。即使许多 IT(和业务)人员之前都听说过敏捷相关的语言、框架、模型(如 DevOps),而这些都有望彻底应用程序开发和 IT 流程,但他们还是对此持怀疑态度。
|
||||
|
||||
向你的受众“推销”快速开发冲刺也不是一件容易的事情。想象一下,如果你以这种方式买了一栋房子 —— 你将不再需要向开发商支付固定的金额,而是会得到这样的信息:“我们将在 4 周内浇筑完地基,其成本是 X,之后再搭建房屋框架和铺设电路,但是我们现在只能够知道地基完成的时间表。”人们已经习惯了买房子的时候有一个预先的价格和交付时间表。
|
||||
|
||||
挑战在于构建软件与构建房屋不同。同一个建筑商往往建造了成千上万个完全相同的房子,而软件项目从来都各不相同。这是你要克服的第一个障碍。
|
||||
|
||||
开发和运维团队的工作方式确实不同,我之所以知道这一点是因为我曾经从事过这两方面的工作。企业往往会用不同的方式来激励他们,开发人员会因为更改和创建而获得奖励,而运维专家则会因降低成本和确保安全性而获得奖励。我们会把他们分成不同的小组,并且尽量减少互动。而这些角色通常会吸引那些思维方式完全不同的技术人员。但是这样的解决方案注定会失败,你必须打破横亘在开发和运维之间的藩篱。
|
||||
|
||||
想想传统情况下会发生什么。业务会把需求扔过墙,这是因为他们在“买房”模式下运作,并且说上一句“我们 9 个月后见。”开发人员根据这些需求进行开发,并根据技术约束的需要进行更改。然后,他们把它扔过墙传递给运维人员,并说一句“搞清楚如何运行这个软件”。然后,运维人员勤就会勤奋地进行大量更改,使软件与基础设施保持一致。然而,最终的结果是什么呢?
|
||||
|
||||
通常情况下,当业务人员看到需求实现的最终结果时甚至根本辨认不出。在过去 20 年的大部分时间里,我们一次又一次地目睹了这种模式在软件行业中上演。而现在,是时候改变了。
|
||||
|
||||
Linux 容器能够真正地解决这样的问题,这是因为容器弥合开发和运维之间的鸿沟。容器技术允许两个团队共同理解和设计所有的关键需求,但仍然独立地履行各自团队的职责。基本上,我们去掉了开发人员和运维人员之间的电话游戏。
|
||||
|
||||
有了容器技术,我们可以使得运维团队的规模更小,但依旧能够承担起数百万应用程序的运维工作,并且能够使得开发团队可以更加快速地根据需要更改软件。(在较大的组织中,所需的速度可能比运维人员的响应速度更快。)
|
||||
|
||||
有了容器技术,你可以将所需要交付的内容与它运行的位置分开。你的运维团队只需要负责运行容器的主机和安全的内存占用,仅此而已。这意味着什么呢?
|
||||
|
||||
首先,这意味着你现在可以和团队一起实践 DevOps 了。没错,只需要让团队专注于他们已经拥有的专业知识,而对于容器,只需让团队了解所需集成依赖关系的必要知识即可。
|
||||
|
||||
如果你想要重新训练每个人,没有人会精通所有事情。容器技术允许团队之间进行交互,但同时也会为每个团队提供一个围绕该团队优势而构建的强大边界。开发人员会知道需要消耗什么资源,但不需要知道如何使其大规模运行。运维团队了解核心基础设施,但不需要了解应用程序的细节。此外,运维团队也可以通过更新应用程序来解决新的安全问题,以免你成为下一个数据泄露的热门话题。
|
||||
|
||||
想要为一个大型 IT 组织,比如 30000 人的团队教授运维和开发技能?那或许需要花费你十年的时间,而你可能并没有那么多时间。
|
||||
|
||||
当人们谈论“构建新的云原生应用程序将帮助我们摆脱这个问题”时,请批判性地进行思考。你可以在 10 个人的团队中构建云原生应用程序,但这对《财富》杂志前 1000 强的企业而言或许并不适用。除非你不再需要依赖现有的团队,否则你无法一个接一个地构建新的微服务:你最终将成为一个孤立的组织。这是一个诱人的想法,但你不能指望这些应用程序来重新定义你的业务。我还没见过哪家公司能在如此大规模的并行开发中获得成功。IT 预算已经受到限制;在很长时间内,将预算翻倍甚至三倍是不现实的。
|
||||
|
||||
### 当奇迹发生时:你好,速度
|
||||
|
||||
Linux 容器就是为扩容而生的。一旦你开始这样做,[Kubernetes 之类的编制工具就会发挥作用][6],这是因为你将需要运行数千个容器。应用程序将不仅仅由一个容器组成,它们将依赖于许多不同的部分,所有的部分都会作为一个单元运行在容器上。如果不这样做,你的应用程序将无法在生产环境中很好地运行。
|
||||
|
||||
思考一下有多少小滑轮和杠杆组合在一起来支撑你的业务,对于任何应用程序都是如此。开发人员负责应用程序中的所有滑轮和杠杆。(如果开发人员没有这些组件,你可能会在集成时做噩梦。)与此同时,无论是在线下还是在云上,运维团队都会负责构成基础设施的所有滑轮和杠杆。做一个较为抽象的比喻,使用Kubernetes,你的运维团队就可以为应用程序提供运行所需的燃料,但又不必成为所有方面的专家。
|
||||
|
||||
开发人员进行实验,运维团队则保持基础设施的安全和可靠。这样的组合使得企业敢于承担小风险,从而实现创新。不同于打几个孤注一掷的赌,公司中真正的实验往往是循序渐进的和快速的。
|
||||
|
||||
从个人经验来看,这就是组织内部发生的显著变化:因为人们说:“我们如何通过改变计划来真正地利用这种实验能力?”它会强制执行敏捷计划。
|
||||
|
||||
举个例子,使用 DevOps 模型、容器和 Kubernetes 的 KeyBank 如今每天都会部署代码。(观看[视频][7],其中主导了 KeyBank 持续交付和反馈的 John Rzeszotarski 将解释这一变化。)类似地,Macquarie 银行也借助 DevOps 和容器技术每天将一些东西投入生产环境。
|
||||
|
||||
一旦你每天都推出软件,它就会改变你计划的每一个方面,并且会[加速业务的变化速度][8]。Macquarie 银行和金融服务集团的 CDO,Luis Uguina 表示:“创意可以在一天内触达客户。”(参见对 Red Hat 与 Macquarie 银行合作的[案例研究][9])。
|
||||
|
||||
### 是时候去创造一些伟大的东西了
|
||||
|
||||
Macquarie 的例子说明了速度的力量。这将如何改变你的经营方式?记住,Macquarie 不是一家初创企业。这是 CIO 们所面临的颠覆性力量,它不仅来自新的市场进入者,也来自老牌同行。
|
||||
|
||||
开发人员的自由还改变了运营敏捷商店的 CIO 们的人才方程式。突然之间,大公司里的个体(即使不是在最热门的行业或地区)也可以产生巨大的影响。Macquarie 利用这一变动作为招聘工具,并向开发人员承诺,所有新招聘的员工将会在第一周内推出新产品。
|
||||
|
||||
与此同时,在这个基于云的计算和存储能力的时代,我们比以往任何时候都拥有更多可用的基础设施。考虑到[机器学习和人工智能工具将很快实现的飞跃][10],这是幸运的。
|
||||
|
||||
所有这些都说明现在正是打造伟大事业的好时机。考虑到市场创新的速度,你需要不断地创造伟大的东西来保持客户的忠诚度。因此,如果你一直在等待将赌注押在 DevOps 上,那么现在就是正确的时机。容器技术和 Kubernetes 改变了规则,并且对你有利。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/how-technology-changes-rules-doing-agile
|
||||
|
||||
作者:[Matt Hicks][a]
|
||||
译者:[JayFrank](https://github.com/JayFrank)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/matt-hicks
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/topics/containers?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=701f2000000tjyaAAA
|
||||
[4]:https://enterprisersproject.com/article/2017/8/4-container-adoption-patterns-what-you-need-know?sc_cid=70160000000h0aXAAQ
|
||||
[5]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/11/how-enterprise-it-uses-kubernetes-tame-container-complexity
|
||||
[7]:https://www.redhat.com/en/about/videos/john-rzeszotarski-keybank-red-hat-summit-2017?intcmp=701f2000000tjyaAAA
|
||||
[8]:https://enterprisersproject.com/article/2017/11/dear-cios-stop-beating-yourselves-being-behind-transformation
|
||||
[9]:https://www.redhat.com/en/resources/macquarie-bank-case-study?intcmp=701f2000000tjyaAAA
|
||||
[10]:https://enterprisersproject.com/article/2018/1/4-ai-trends-watch
|
||||
[11]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
480
published/201909/20180330 Go on very small hardware Part 1.md
Normal file
480
published/201909/20180330 Go on very small hardware Part 1.md
Normal file
@ -0,0 +1,480 @@
|
||||
Go 语言在极小硬件上的运用(一)
|
||||
=========
|
||||
|
||||
Go 语言,能在多低下的配置上运行并发挥作用呢?
|
||||
|
||||
我最近购买了一个特别便宜的开发板:
|
||||
|
||||

|
||||
|
||||
我购买它的理由有三个。首先,我(作为程序员)从未接触过 STM320 系列的开发板。其次,STM32F10x 系列使用也有点少了。STM320 系列的 MCU 很便宜,有更新一些的外设,对系列产品进行了改进,问题修复也做得更好了。最后,为了这篇文章,我选用了这一系列中最低配置的开发板,整件事情就变得有趣起来了。
|
||||
|
||||
### 硬件部分
|
||||
|
||||
[STM32F030F4P6][3] 给人留下了很深的印象:
|
||||
|
||||
* CPU: [Cortex M0][1] 48 MHz(最低配置,只有 12000 个逻辑门电路)
|
||||
* RAM: 4 KB,
|
||||
* Flash: 16 KB,
|
||||
* ADC、SPI、I2C、USART 和几个定时器
|
||||
|
||||
以上这些采用了 TSSOP20 封装。正如你所见,这是一个很小的 32 位系统。
|
||||
|
||||
### 软件部分
|
||||
|
||||
如果你想知道如何在这块开发板上使用 [Go][4] 编程,你需要反复阅读硬件规范手册。你必须面对这样的真实情况:在 Go 编译器中给 Cortex-M0 提供支持的可能性很小。而且,这还仅仅只是第一个要解决的问题。
|
||||
|
||||
我会使用 [Emgo][5],但别担心,之后你会看到,它如何让 Go 在如此小的系统上尽可能发挥作用。
|
||||
|
||||
在我拿到这块开发板之前,对 [stm32/hal][6] 系列下的 F0 MCU 没有任何支持。在简单研究[参考手册][7]后,我发现 STM32F0 系列是 STM32F3 削减版,这让在新端口上开发的工作变得容易了一些。
|
||||
|
||||
如果你想接着本文的步骤做下去,需要先安装 Emgo
|
||||
|
||||
```
|
||||
cd $HOME
|
||||
git clone https://github.com/ziutek/emgo/
|
||||
cd emgo/egc
|
||||
go install
|
||||
```
|
||||
|
||||
然后设置一下环境变量
|
||||
|
||||
```
|
||||
export EGCC=path_to_arm_gcc # eg. /usr/local/arm/bin/arm-none-eabi-gcc
|
||||
export EGLD=path_to_arm_linker # eg. /usr/local/arm/bin/arm-none-eabi-ld
|
||||
export EGAR=path_to_arm_archiver # eg. /usr/local/arm/bin/arm-none-eabi-ar
|
||||
|
||||
export EGROOT=$HOME/emgo/egroot
|
||||
export EGPATH=$HOME/emgo/egpath
|
||||
|
||||
export EGARCH=cortexm0
|
||||
export EGOS=noos
|
||||
export EGTARGET=f030x6
|
||||
```
|
||||
|
||||
更详细的说明可以在 [Emgo][8] 官网上找到。
|
||||
|
||||
要确保 `egc` 在你的 `PATH` 中。 你可以使用 `go build` 来代替 `go install`,然后把 `egc` 复制到你的 `$HOME/bin` 或 `/usr/local/bin` 中。
|
||||
|
||||
现在,为你的第一个 Emgo 程序创建一个新文件夹,随后把示例中链接器脚本复制过来:
|
||||
|
||||
```
|
||||
mkdir $HOME/firstemgo
|
||||
cd $HOME/firstemgo
|
||||
cp $EGPATH/src/stm32/examples/f030-demo-board/blinky/script.ld .
|
||||
```
|
||||
|
||||
### 最基本程序
|
||||
|
||||
在 `main.go` 文件中创建一个最基本的程序:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
func main() {
|
||||
}
|
||||
```
|
||||
|
||||
文件编译没有出现任何问题:
|
||||
|
||||
```
|
||||
$ egc
|
||||
$ arm-none-eabi-size cortexm0.elf
|
||||
text data bss dec hex filename
|
||||
7452 172 104 7728 1e30 cortexm0.elf
|
||||
```
|
||||
|
||||
第一次编译可能会花点时间。编译后产生的二进制占用了 7624 个字节的 Flash 空间(文本 + 数据)。对于一个什么都没做的程序来说,占用的空间有些大。还剩下 8760 字节,可以用来做些有用的事。
|
||||
|
||||
不妨试试传统的 “Hello, World!” 程序:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
fmt.Println("Hello, World!")
|
||||
}
|
||||
```
|
||||
|
||||
不幸的是,这次结果有些糟糕:
|
||||
|
||||
```
|
||||
$ egc
|
||||
/usr/local/arm/bin/arm-none-eabi-ld: /home/michal/P/go/src/github.com/ziutek/emgo/egpath/src/stm32/examples/f030-demo-board/blog/cortexm0.elf section `.text' will not fit in region `Flash'
|
||||
/usr/local/arm/bin/arm-none-eabi-ld: region `Flash' overflowed by 10880 bytes
|
||||
exit status 1
|
||||
```
|
||||
|
||||
“Hello, World!” 需要 STM32F030x6 上至少 32KB 的 Flash 空间。
|
||||
|
||||
`fmt` 包强制包含整个 `strconv` 和 `reflect` 包。这三个包,即使在精简版本中的 Emgo 中,占用空间也很大。我们不能使用这个例子了。有很多的应用不需要好看的文本输出。通常,一个或多个 LED,或者七段数码管显示就足够了。不过,在第二部分,我会尝试使用 `strconv` 包来格式化,并在 UART 上显示一些数字和文本。
|
||||
|
||||
### 闪烁
|
||||
|
||||
我们的开发板上有一个与 PA4 引脚和 VCC 相连的 LED。这次我们的代码稍稍长了一些:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"delay"
|
||||
|
||||
"stm32/hal/gpio"
|
||||
"stm32/hal/system"
|
||||
"stm32/hal/system/timer/systick"
|
||||
)
|
||||
|
||||
var led gpio.Pin
|
||||
|
||||
func init() {
|
||||
system.SetupPLL(8, 1, 48/8)
|
||||
systick.Setup(2e6)
|
||||
|
||||
gpio.A.EnableClock(false)
|
||||
led = gpio.A.Pin(4)
|
||||
|
||||
cfg := &gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain}
|
||||
led.Setup(cfg)
|
||||
}
|
||||
|
||||
func main() {
|
||||
for {
|
||||
led.Clear()
|
||||
delay.Millisec(100)
|
||||
led.Set()
|
||||
delay.Millisec(900)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
按照惯例,`init` 函数用来初始化和配置外设。
|
||||
|
||||
`system.SetupPLL(8, 1, 48/8)` 用来配置 RCC,将外部的 8 MHz 振荡器的 PLL 作为系统时钟源。PLL 分频器设置为 1,倍频数设置为 48/8 =6,这样系统时钟频率为 48MHz。
|
||||
|
||||
`systick.Setup(2e6)` 将 Cortex-M SYSTICK 时钟作为系统时钟,每隔 2e6 次纳秒运行一次(每秒钟 500 次)。
|
||||
|
||||
`gpio.A.EnableClock(false)` 开启了 GPIO A 口的时钟。`False` 意味着这一时钟在低功耗模式下会被禁用,但在 STM32F0 系列中并未实现这一功能。
|
||||
|
||||
`led.Setup(cfg)` 设置 PA4 引脚为开漏输出。
|
||||
|
||||
`led.Clear()` 将 PA4 引脚设为低,在开漏设置中,打开 LED。
|
||||
|
||||
`led.Set()` 将 PA4 设为高电平状态,关掉LED。
|
||||
|
||||
编译这个代码:
|
||||
|
||||
```
|
||||
$ egc
|
||||
$ arm-none-eabi-size cortexm0.elf
|
||||
text data bss dec hex filename
|
||||
9772 172 168 10112 2780 cortexm0.elf
|
||||
```
|
||||
|
||||
正如你所看到的,这个闪烁程序占用了 2320 字节,比最基本程序占用空间要大。还有 6440 字节的剩余空间。
|
||||
|
||||
看看代码是否能运行:
|
||||
|
||||
```
|
||||
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; reset run; exit'
|
||||
Open On-Chip Debugger 0.10.0+dev-00319-g8f1f912a (2018-03-07-19:20)
|
||||
Licensed under GNU GPL v2
|
||||
For bug reports, read
|
||||
http://openocd.org/doc/doxygen/bugs.html
|
||||
debug_level: 0
|
||||
adapter speed: 1000 kHz
|
||||
adapter_nsrst_delay: 100
|
||||
none separate
|
||||
adapter speed: 950 kHz
|
||||
target halted due to debug-request, current mode: Thread
|
||||
xPSR: 0xc1000000 pc: 0x0800119c msp: 0x20000da0
|
||||
adapter speed: 4000 kHz
|
||||
** Programming Started **
|
||||
auto erase enabled
|
||||
target halted due to breakpoint, current mode: Thread
|
||||
xPSR: 0x61000000 pc: 0x2000003a msp: 0x20000da0
|
||||
wrote 10240 bytes from file cortexm0.elf in 0.817425s (12.234 KiB/s)
|
||||
** Programming Finished **
|
||||
adapter speed: 950 kHz
|
||||
```
|
||||
|
||||
在这篇文章中,这是我第一次,将一个短视频转换成[动画 PNG][9]。我对此印象很深,再见了 YouTube。 对于 IE 用户,我很抱歉,更多信息请看 [apngasm][10]。我本应该学习 HTML5,但现在,APNG 是我最喜欢的,用来播放循环短视频的方法了。
|
||||
|
||||

|
||||
|
||||
### 更多的 Go 语言编程
|
||||
|
||||
如果你不是一个 Go 程序员,但你已经听说过一些关于 Go 语言的事情,你可能会说:“Go 语法很好,但跟 C 比起来,并没有明显的提升。让我看看 Go 语言的通道和协程!”
|
||||
|
||||
接下来我会一一展示:
|
||||
|
||||
```
|
||||
import (
|
||||
"delay"
|
||||
|
||||
"stm32/hal/gpio"
|
||||
"stm32/hal/system"
|
||||
"stm32/hal/system/timer/systick"
|
||||
)
|
||||
|
||||
var led1, led2 gpio.Pin
|
||||
|
||||
func init() {
|
||||
system.SetupPLL(8, 1, 48/8)
|
||||
systick.Setup(2e6)
|
||||
|
||||
gpio.A.EnableClock(false)
|
||||
led1 = gpio.A.Pin(4)
|
||||
led2 = gpio.A.Pin(5)
|
||||
|
||||
cfg := &gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain}
|
||||
led1.Setup(cfg)
|
||||
led2.Setup(cfg)
|
||||
}
|
||||
|
||||
func blinky(led gpio.Pin, period int) {
|
||||
for {
|
||||
led.Clear()
|
||||
delay.Millisec(100)
|
||||
led.Set()
|
||||
delay.Millisec(period - 100)
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
go blinky(led1, 500)
|
||||
blinky(led2, 1000)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
代码改动很小: 添加了第二个 LED,上一个例子中的 `main` 函数被重命名为 `blinky` 并且需要提供两个参数。 `main` 在新的协程中先调用 `blinky`,所以两个 LED 灯在并行使用。值得一提的是,`gpio.Pin` 可以同时访问同一 GPIO 口的不同引脚。
|
||||
|
||||
Emgo 还有很多不足。其中之一就是你需要提前规定 `goroutines(tasks)` 的最大执行数量。是时候修改 `script.ld` 了:
|
||||
|
||||
```
|
||||
ISRStack = 1024;
|
||||
MainStack = 1024;
|
||||
TaskStack = 1024;
|
||||
MaxTasks = 2;
|
||||
|
||||
INCLUDE stm32/f030x4
|
||||
INCLUDE stm32/loadflash
|
||||
INCLUDE noos-cortexm
|
||||
```
|
||||
|
||||
栈的大小需要靠猜,现在还不用关心这一点。
|
||||
|
||||
```
|
||||
$ egc
|
||||
$ arm-none-eabi-size cortexm0.elf
|
||||
text data bss dec hex filename
|
||||
10020 172 172 10364 287c cortexm0.elf
|
||||
```
|
||||
|
||||
另一个 LED 和协程一共占用了 248 字节的 Flash 空间。
|
||||
|
||||

|
||||
|
||||
### 通道
|
||||
|
||||
通道是 Go 语言中协程之间相互通信的一种[推荐方式][11]。Emgo 甚至能允许通过*中断处理*来使用缓冲通道。下一个例子就展示了这种情况。
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"delay"
|
||||
"rtos"
|
||||
|
||||
"stm32/hal/gpio"
|
||||
"stm32/hal/irq"
|
||||
"stm32/hal/system"
|
||||
"stm32/hal/system/timer/systick"
|
||||
"stm32/hal/tim"
|
||||
)
|
||||
|
||||
var (
|
||||
leds [3]gpio.Pin
|
||||
timer *tim.Periph
|
||||
ch = make(chan int, 1)
|
||||
)
|
||||
|
||||
func init() {
|
||||
system.SetupPLL(8, 1, 48/8)
|
||||
systick.Setup(2e6)
|
||||
|
||||
gpio.A.EnableClock(false)
|
||||
leds[0] = gpio.A.Pin(4)
|
||||
leds[1] = gpio.A.Pin(5)
|
||||
leds[2] = gpio.A.Pin(9)
|
||||
|
||||
cfg := &gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain}
|
||||
for _, led := range leds {
|
||||
led.Set()
|
||||
led.Setup(cfg)
|
||||
}
|
||||
|
||||
timer = tim.TIM3
|
||||
pclk := timer.Bus().Clock()
|
||||
if pclk < system.AHB.Clock() {
|
||||
pclk *= 2
|
||||
}
|
||||
freq := uint(1e3) // Hz
|
||||
timer.EnableClock(true)
|
||||
timer.PSC.Store(tim.PSC(pclk/freq - 1))
|
||||
timer.ARR.Store(700) // ms
|
||||
timer.DIER.Store(tim.UIE)
|
||||
timer.CR1.Store(tim.CEN)
|
||||
|
||||
rtos.IRQ(irq.TIM3).Enable()
|
||||
}
|
||||
|
||||
func blinky(led gpio.Pin, period int) {
|
||||
for range ch {
|
||||
led.Clear()
|
||||
delay.Millisec(100)
|
||||
led.Set()
|
||||
delay.Millisec(period - 100)
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
go blinky(leds[1], 500)
|
||||
blinky(leds[2], 500)
|
||||
}
|
||||
|
||||
func timerISR() {
|
||||
timer.SR.Store(0)
|
||||
leds[0].Set()
|
||||
select {
|
||||
case ch <- 0:
|
||||
// Success
|
||||
default:
|
||||
leds[0].Clear()
|
||||
}
|
||||
}
|
||||
|
||||
//c:__attribute__((section(".ISRs")))
|
||||
var ISRs = [...]func(){
|
||||
irq.TIM3: timerISR,
|
||||
}
|
||||
```
|
||||
|
||||
与之前例子相比较下的不同:
|
||||
|
||||
1. 添加了第三个 LED,并连接到 PA9 引脚(UART 头的 TXD 引脚)。
|
||||
2. 时钟(`TIM3`)作为中断源。
|
||||
3. 新函数 `timerISR` 用来处理 `irq.TIM3` 的中断。
|
||||
4. 新增容量为 1 的缓冲通道是为了 `timerISR` 和 `blinky` 协程之间的通信。
|
||||
5. `ISRs` 数组作为*中断向量表*,是更大的*异常向量表*的一部分。
|
||||
6. `blinky` 中的 `for` 语句被替换成 `range` 语句。
|
||||
|
||||
为了方便起见,所有的 LED,或者说它们的引脚,都被放在 `leds` 这个数组里。另外,所有引脚在被配置为输出之前,都设置为一种已知的初始状态(高电平状态)。
|
||||
|
||||
在这个例子里,我们想让时钟以 1 kHz 的频率运行。为了配置 TIM3 预分频器,我们需要知道它的输入时钟频率。通过参考手册我们知道,输入时钟频率在 `APBCLK = AHBCLK` 时,与 `APBCLK` 相同,反之等于 2 倍的 `APBCLK`。
|
||||
|
||||
如果 CNT 寄存器增加 1 kHz,那么 ARR 寄存器的值等于*更新事件*(重载事件)在毫秒中的计数周期。 为了让更新事件产生中断,必须要设置 DIER 寄存器中的 UIE 位。CEN 位能启动时钟。
|
||||
|
||||
时钟外设在低功耗模式下必须启用,为了自身能在 CPU 处于休眠时保持运行: `timer.EnableClock(true)`。这在 STM32F0 中无关紧要,但对代码可移植性却十分重要。
|
||||
|
||||
`timerISR` 函数处理 `irq.TIM3` 的中断请求。`timer.SR.Store(0)` 会清除 SR 寄存器里的所有事件标志,无效化向 [NVIC][12] 发出的所有中断请求。凭借经验,由于中断请求无效的延时性,需要在程序一开始马上清除所有的中断标志。这避免了无意间再次调用处理。为了确保万无一失,需要先清除标志,再读取,但是在我们的例子中,清除标志就已经足够了。
|
||||
|
||||
下面的这几行代码:
|
||||
|
||||
```
|
||||
select {
|
||||
case ch <- 0:
|
||||
// Success
|
||||
default:
|
||||
leds[0].Clear()
|
||||
}
|
||||
```
|
||||
|
||||
是 Go 语言中,如何在通道上非阻塞地发送消息的方法。中断处理程序无法一直等待通道中的空余空间。如果通道已满,则执行 `default`,开发板上的LED就会开启,直到下一次中断。
|
||||
|
||||
`ISRs` 数组包含了中断向量表。`//c:__attribute__((section(".ISRs")))` 会导致链接器将数组插入到 `.ISRs` 节中。
|
||||
|
||||
`blinky` 的 `for` 循环的新写法:
|
||||
|
||||
```
|
||||
for range ch {
|
||||
led.Clear()
|
||||
delay.Millisec(100)
|
||||
led.Set()
|
||||
delay.Millisec(period - 100)
|
||||
}
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```
|
||||
for {
|
||||
_, ok := <-ch
|
||||
if !ok {
|
||||
break // Channel closed.
|
||||
}
|
||||
led.Clear()
|
||||
delay.Millisec(100)
|
||||
led.Set()
|
||||
delay.Millisec(period - 100)
|
||||
}
|
||||
```
|
||||
|
||||
注意,在这个例子中,我们不在意通道中收到的值,我们只对其接受到的消息感兴趣。我们可以在声明时,将通道元素类型中的 `int` 用空结构体 `struct{}` 来代替,发送消息时,用 `struct{}{}` 结构体的值代替 0,但这部分对新手来说可能会有些陌生。
|
||||
|
||||
让我们来编译一下代码:
|
||||
|
||||
```
|
||||
$ egc
|
||||
$ arm-none-eabi-size cortexm0.elf
|
||||
text data bss dec hex filename
|
||||
11096 228 188 11512 2cf8 cortexm0.elf
|
||||
```
|
||||
|
||||
新的例子占用了 11324 字节的 Flash 空间,比上一个例子多占用了 1132 字节。
|
||||
|
||||
采用现在的时序,两个闪烁协程从通道中获取数据的速度,比 `timerISR` 发送数据的速度要快。所以它们在同时等待新数据,你还能观察到 `select` 的随机性,这也是 [Go 规范][13]所要求的。
|
||||
|
||||

|
||||
|
||||
开发板上的 LED 一直没有亮起,说明通道从未出现过溢出。
|
||||
|
||||
我们可以加快消息发送的速度,将 `timer.ARR.Store(700)` 改为 `timer.ARR.Store(200)`。 现在 `timerISR` 每秒钟发送 5 条消息,但是两个接收者加起来,每秒也只能接受 4 条消息。
|
||||
|
||||

|
||||
|
||||
正如你所看到的,`timerISR` 开启黄色 LED 灯,意味着通道上已经没有剩余空间了。
|
||||
|
||||
第一部分到这里就结束了。你应该知道,这一部分并未展示 Go 中最重要的部分,接口。
|
||||
|
||||
协程和通道只是一些方便好用的语法。你可以用自己的代码来替换它们,这并不容易,但也可以实现。接口是Go 语言的基础。这是文章中 [第二部分][14]所要提到的.
|
||||
|
||||
在 Flash 上我们还有些剩余空间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ziutek.github.io/2018/03/30/go_on_very_small_hardware.html
|
||||
|
||||
作者:[Michał Derkacz][a]
|
||||
译者:[wenwensnow](https://github.com/wenwensnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ziutek.github.io/
|
||||
[1]:https://en.wikipedia.org/wiki/ARM_Cortex-M#Cortex-M0
|
||||
[2]:https://ziutek.github.io/2018/03/30/go_on_very_small_hardware.html
|
||||
[3]:http://www.st.com/content/st_com/en/products/microcontrollers/stm32-32-bit-arm-cortex-mcus/stm32-mainstream-mcus/stm32f0-series/stm32f0x0-value-line/stm32f030f4.html
|
||||
[4]:https://golang.org/
|
||||
[5]:https://github.com/ziutek/emgo
|
||||
[6]:https://github.com/ziutek/emgo/tree/master/egpath/src/stm32/hal
|
||||
[7]:http://www.st.com/resource/en/reference_manual/dm00091010.pdf
|
||||
[8]:https://github.com/ziutek/emgo
|
||||
[9]:https://en.wikipedia.org/wiki/APNG
|
||||
[10]:http://apngasm.sourceforge.net/
|
||||
[11]:https://blog.golang.org/share-memory-by-communicating
|
||||
[12]:http://infocenter.arm.com/help/topic/com.arm.doc.ddi0432c/Cihbecee.html
|
||||
[13]:https://golang.org/ref/spec#Select_statements
|
||||
[14]:https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html
|
||||
116
published/201909/20180705 Building a Messenger App- Schema.md
Normal file
116
published/201909/20180705 Building a Messenger App- Schema.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "PsiACE"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-11396-1.html"
|
||||
[#]: subject: "Building a Messenger App: Schema"
|
||||
[#]: via: "https://nicolasparada.netlify.com/posts/go-messenger-schema/"
|
||||
[#]: author: "Nicolás Parada https://nicolasparada.netlify.com/"
|
||||
|
||||
构建一个即时消息应用(一):模式
|
||||
========
|
||||
|
||||

|
||||
|
||||
这是一系列关于构建“即时消息”应用的新帖子。你应该对这类应用并不陌生。有了它们的帮助,我们才可以与朋友畅聊无忌。[Facebook Messenger][1]、[WhatsApp][2] 和 [Skype][3] 就是其中的几个例子。正如你所看到的那样,这些应用允许我们发送图片、传输视频、录制音频、以及和一大帮子人聊天等等。当然,我们的教程应用将会尽量保持简单,只在两个用户之间发送文本消息。
|
||||
|
||||
我们将会用 [CockroachDB][4] 作为 SQL 数据库,用 [Go][5] 作为后端语言,并且用 JavaScript 来制作 web 应用。
|
||||
|
||||
这是第一篇帖子,我们将会讲述数据库的设计。
|
||||
|
||||
```
|
||||
CREATE TABLE users (
|
||||
id SERIAL NOT NULL PRIMARY KEY,
|
||||
username STRING NOT NULL UNIQUE,
|
||||
avatar_url STRING,
|
||||
github_id INT NOT NULL UNIQUE
|
||||
);
|
||||
```
|
||||
|
||||
显然,这个应用需要一些用户。我们这里采用社交登录的形式。由于我选用了 [GitHub][6],所以这里需要保存一个对 GitHub 用户 ID 的引用。
|
||||
|
||||
```
|
||||
CREATE TABLE conversations (
|
||||
id SERIAL NOT NULL PRIMARY KEY,
|
||||
last_message_id INT,
|
||||
INDEX (last_message_id DESC)
|
||||
);
|
||||
```
|
||||
|
||||
每个对话都会引用最近一条消息。每当我们输入一条新消息时,我们都会更新这个字段。我会在后面添加外键约束。
|
||||
|
||||
… 你可能会想,我们可以先对对话进行分组,然后再通过这样的方式获取最近一条消息。但这样做会使查询变得更加复杂。
|
||||
|
||||
```
|
||||
CREATE TABLE participants (
|
||||
user_id INT NOT NULL REFERENCES users ON DELETE CASCADE,
|
||||
conversation_id INT NOT NULL REFERENCES conversations ON DELETE CASCADE,
|
||||
messages_read_at TIMESTAMPTZ NOT NULL DEFAULT now(),
|
||||
PRIMARY KEY (user_id, conversation_id)
|
||||
);
|
||||
```
|
||||
|
||||
尽管之前我提到过对话只会在两个用户之间进行,但我们还是采用了允许向对话中添加多个参与者的设计。因此,在对话和用户之间有一个参与者表。
|
||||
|
||||
为了知道用户是否有未读消息,我们在消息表中添加了“读取时间”(`messages_read_at`)字段。每当用户在对话中读取消息时,我们都会更新它的值,这样一来,我们就可以将它与对话中最后一条消息的“创建时间”(`created_at`)字段进行比较。
|
||||
|
||||
```
|
||||
CREATE TABLE messages (
|
||||
id SERIAL NOT NULL PRIMARY KEY,
|
||||
content STRING NOT NULL,
|
||||
user_id INT NOT NULL REFERENCES users ON DELETE CASCADE,
|
||||
conversation_id INT NOT NULL REFERENCES conversations ON DELETE CASCADE,
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
|
||||
INDEX(created_at DESC)
|
||||
);
|
||||
```
|
||||
|
||||
尽管我们将消息表放在最后,但它在应用中相当重要。我们用它来保存对创建它的用户以及它所出现的对话的引用。而且还可以根据“创建时间”(`created_at`)来创建索引以完成对消息的排序。
|
||||
|
||||
```
|
||||
ALTER TABLE conversations
|
||||
ADD CONSTRAINT fk_last_message_id_ref_messages
|
||||
FOREIGN KEY (last_message_id) REFERENCES messages ON DELETE SET NULL;
|
||||
```
|
||||
|
||||
我在前面已经提到过这个外键约束了,不是吗:D
|
||||
|
||||
有这四张表就足够了。你也可以将这些查询保存到一个文件中,并将其通过管道传送到 Cockroach CLI。
|
||||
|
||||
首先,我们需要启动一个新节点:
|
||||
|
||||
```
|
||||
cockroach start --insecure --host 127.0.0.1
|
||||
```
|
||||
|
||||
然后创建数据库和这些表:
|
||||
|
||||
```
|
||||
cockroach sql --insecure -e "CREATE DATABASE messenger"
|
||||
cat schema.sql | cockroach sql --insecure -d messenger
|
||||
```
|
||||
|
||||
这篇帖子就到这里。在接下来的部分中,我们将会介绍「登录」,敬请期待。
|
||||
|
||||
- [源代码][7]
|
||||
|
||||
---
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/go-messenger-schema/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[PsiACE](https://github.com/PsiACE)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nicolasparada.netlify.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.messenger.com/
|
||||
[2]: https://www.whatsapp.com/
|
||||
[3]: https://www.skype.com/
|
||||
[4]: https://www.cockroachlabs.com/
|
||||
[5]: https://golang.org/
|
||||
[6]: https://github.com/
|
||||
[7]: https://github.com/nicolasparada/go-messenger-demo
|
||||
@ -0,0 +1,252 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (laingke)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11387-1.html)
|
||||
[#]: subject: (Linux commands for measuring disk activity)
|
||||
[#]: via: (https://www.networkworld.com/article/3330497/linux/linux-commands-for-measuring-disk-activity.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
用于测量磁盘活动的 Linux 命令
|
||||
======
|
||||
> Linux 发行版提供了几个度量磁盘活动的有用命令。让我们了解一下其中的几个。
|
||||
|
||||

|
||||
|
||||
Linux 系统提供了一套方便的命令,帮助你查看磁盘有多忙,而不仅仅是磁盘有多满。在本文中,我们将研究五个非常有用的命令,用于查看磁盘活动。其中两个命令(`iostat` 和 `ioping`)可能必须添加到你的系统中,这两个命令一样要求你使用 sudo 特权,所有这五个命令都提供了查看磁盘活动的有用方法。
|
||||
|
||||
这些命令中最简单、最直观的一个可能是 `dstat` 了。
|
||||
|
||||
### dtstat
|
||||
|
||||
尽管 `dstat` 命令以字母 “d” 开头,但它提供的统计信息远远不止磁盘活动。如果你只想查看磁盘活动,可以使用 `-d` 选项。如下所示,你将得到一个磁盘读/写测量值的连续列表,直到使用 `CTRL-c` 停止显示为止。注意,在第一个报告信息之后,显示中的每个后续行将在接下来的时间间隔内报告磁盘活动,缺省值仅为一秒。
|
||||
|
||||
```
|
||||
$ dstat -d
|
||||
-dsk/total-
|
||||
read writ
|
||||
949B 73k
|
||||
65k 0 <== first second
|
||||
0 24k <== second second
|
||||
0 16k
|
||||
0 0 ^C
|
||||
```
|
||||
|
||||
在 `-d` 选项后面包含一个数字将把间隔设置为该秒数。
|
||||
|
||||
```
|
||||
$ dstat -d 10
|
||||
-dsk/total-
|
||||
read writ
|
||||
949B 73k
|
||||
65k 81M <== first five seconds
|
||||
0 21k <== second five second
|
||||
0 9011B ^C
|
||||
```
|
||||
|
||||
请注意,报告的数据可能以许多不同的单位显示——例如,M(Mb)、K(Kb)和 B(字节)。
|
||||
|
||||
如果没有选项,`dstat` 命令还将显示许多其他信息——指示 CPU 如何使用时间、显示网络和分页活动、报告中断和上下文切换。
|
||||
|
||||
```
|
||||
$ dstat
|
||||
You did not select any stats, using -cdngy by default.
|
||||
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
|
||||
usr sys idl wai stl| read writ| recv send| in out | int csw
|
||||
0 0 100 0 0| 949B 73k| 0 0 | 0 3B| 38 65
|
||||
0 0 100 0 0| 0 0 | 218B 932B| 0 0 | 53 68
|
||||
0 1 99 0 0| 0 16k| 64B 468B| 0 0 | 64 81 ^C
|
||||
```
|
||||
|
||||
`dstat` 命令提供了关于整个 Linux 系统性能的有价值的见解,几乎可以用它灵活而功能强大的命令来代替 `vmstat`、`netstat`、`iostat` 和 `ifstat` 等较旧的工具集合,该命令结合了这些旧工具的功能。要深入了解 `dstat` 命令可以提供的其它信息,请参阅这篇关于 [dstat][1] 命令的文章。
|
||||
|
||||
### iostat
|
||||
|
||||
`iostat` 命令通过观察设备活动的时间与其平均传输速率之间的关系,帮助监视系统输入/输出设备的加载情况。它有时用于评估磁盘之间的活动平衡。
|
||||
|
||||
```
|
||||
$ iostat
|
||||
Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
0.07 0.01 0.03 0.05 0.00 99.85
|
||||
|
||||
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
loop0 0.00 0.00 0.00 1048 0
|
||||
loop1 0.00 0.00 0.00 365 0
|
||||
loop2 0.00 0.00 0.00 1056 0
|
||||
loop3 0.00 0.01 0.00 16169 0
|
||||
loop4 0.00 0.00 0.00 413 0
|
||||
loop5 0.00 0.00 0.00 1184 0
|
||||
loop6 0.00 0.00 0.00 1062 0
|
||||
loop7 0.00 0.00 0.00 5261 0
|
||||
sda 1.06 0.89 72.66 2837453 232735080
|
||||
sdb 0.00 0.02 0.00 48669 40
|
||||
loop8 0.00 0.00 0.00 1053 0
|
||||
loop9 0.01 0.01 0.00 18949 0
|
||||
loop10 0.00 0.00 0.00 56 0
|
||||
loop11 0.00 0.00 0.00 7090 0
|
||||
loop12 0.00 0.00 0.00 1160 0
|
||||
loop13 0.00 0.00 0.00 108 0
|
||||
loop14 0.00 0.00 0.00 3572 0
|
||||
loop15 0.01 0.01 0.00 20026 0
|
||||
loop16 0.00 0.00 0.00 24 0
|
||||
```
|
||||
|
||||
当然,当你只想关注磁盘时,Linux 回环设备上提供的所有统计信息都会使结果显得杂乱无章。不过,该命令也确实提供了 `-p` 选项,该选项使你可以仅查看磁盘——如以下命令所示。
|
||||
|
||||
```
|
||||
$ iostat -p sda
|
||||
Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
0.07 0.01 0.03 0.05 0.00 99.85
|
||||
|
||||
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 1.06 0.89 72.54 2843737 232815784
|
||||
sda1 1.04 0.88 72.54 2821733 232815784
|
||||
```
|
||||
|
||||
请注意 `tps` 是指每秒的传输量。
|
||||
|
||||
你还可以让 `iostat` 提供重复的报告。在下面的示例中,我们使用 `-d` 选项每五秒钟进行一次测量。
|
||||
|
||||
```
|
||||
$ iostat -p sda -d 5
|
||||
Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
|
||||
|
||||
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 1.06 0.89 72.51 2843749 232834048
|
||||
sda1 1.04 0.88 72.51 2821745 232834048
|
||||
|
||||
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 0.80 0.00 11.20 0 56
|
||||
sda1 0.80 0.00 11.20 0 56
|
||||
```
|
||||
|
||||
如果你希望省略第一个(自启动以来的统计信息)报告,请在命令中添加 `-y`。
|
||||
|
||||
```
|
||||
$ iostat -p sda -d 5 -y
|
||||
Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
|
||||
|
||||
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 0.80 0.00 11.20 0 56
|
||||
sda1 0.80 0.00 11.20 0 56
|
||||
```
|
||||
|
||||
接下来,我们看第二个磁盘驱动器。
|
||||
|
||||
```
|
||||
$ iostat -p sdb
|
||||
Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
0.07 0.01 0.03 0.05 0.00 99.85
|
||||
|
||||
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sdb 0.00 0.02 0.00 48669 40
|
||||
sdb2 0.00 0.00 0.00 4861 40
|
||||
sdb1 0.00 0.01 0.00 35344 0
|
||||
```
|
||||
|
||||
### iotop
|
||||
|
||||
`iotop` 命令是类似 `top` 的实用程序,用于查看磁盘 I/O。它收集 Linux 内核提供的 I/O 使用信息,以便你了解哪些进程在磁盘 I/O 方面的要求最高。在下面的示例中,循环时间被设置为 5 秒。显示将自动更新,覆盖前面的输出。
|
||||
|
||||
```
|
||||
$ sudo iotop -d 5
|
||||
Total DISK READ: 0.00 B/s | Total DISK WRITE: 1585.31 B/s
|
||||
Current DISK READ: 0.00 B/s | Current DISK WRITE: 12.39 K/s
|
||||
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
|
||||
32492 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.12 % [kworker/u8:1-ev~_power_efficient]
|
||||
208 be/3 root 0.00 B/s 1585.31 B/s 0.00 % 0.11 % [jbd2/sda1-8]
|
||||
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % init splash
|
||||
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
|
||||
3 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_gp]
|
||||
4 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_par_gp]
|
||||
8 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [mm_percpu_wq]
|
||||
```
|
||||
|
||||
### ioping
|
||||
|
||||
`ioping` 命令是一种完全不同的工具,但是它可以报告磁盘延迟——也就是磁盘响应请求需要多长时间,而这有助于诊断磁盘问题。
|
||||
|
||||
```
|
||||
$ sudo ioping /dev/sda1
|
||||
4 KiB <<< /dev/sda1 (block device 111.8 GiB): request=1 time=960.2 us (warmup)
|
||||
4 KiB <<< /dev/sda1 (block device 111.8 GiB): request=2 time=841.5 us
|
||||
4 KiB <<< /dev/sda1 (block device 111.8 GiB): request=3 time=831.0 us
|
||||
4 KiB <<< /dev/sda1 (block device 111.8 GiB): request=4 time=1.17 ms
|
||||
^C
|
||||
--- /dev/sda1 (block device 111.8 GiB) ioping statistics ---
|
||||
3 requests completed in 2.84 ms, 12 KiB read, 1.05 k iops, 4.12 MiB/s
|
||||
generated 4 requests in 3.37 s, 16 KiB, 1 iops, 4.75 KiB/s
|
||||
min/avg/max/mdev = 831.0 us / 947.9 us / 1.17 ms / 158.0 us
|
||||
```
|
||||
|
||||
### atop
|
||||
|
||||
`atop` 命令,像 `top` 一样提供了大量有关系统性能的信息,包括有关磁盘活动的一些统计信息。
|
||||
|
||||
```
|
||||
ATOP - butterfly 2018/12/26 17:24:19 37d3h13m------ 10ed
|
||||
PRC | sys 0.03s | user 0.01s | #proc 179 | #zombie 0 | #exit 6 |
|
||||
CPU | sys 1% | user 0% | irq 0% | idle 199% | wait 0% |
|
||||
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
|
||||
CPL | avg1 0.00 | avg5 0.00 | avg15 0.00 | csw 677 | intr 470 |
|
||||
MEM | tot 5.8G | free 223.4M | cache 4.6G | buff 253.2M | slab 394.4M |
|
||||
SWP | tot 2.0G | free 2.0G | | vmcom 1.9G | vmlim 4.9G |
|
||||
DSK | sda | busy 0% | read 0 | write 7 | avio 1.14 ms |
|
||||
NET | transport | tcpi 4 | tcpo stall 8 | udpi 1 | udpo 0swout 2255 |
|
||||
NET | network | ipi 10 | ipo 7 | ipfrw 0 | deliv 60.67 ms |
|
||||
NET | enp0s25 0% | pcki 10 | pcko 8 | si 1 Kbps | so 3 Kbp0.73 ms |
|
||||
|
||||
PID SYSCPU USRCPU VGROW RGROW ST EXC THR S CPUNR CPU CMD 1/1673e4 |
|
||||
3357 0.01s 0.00s 672K 824K -- - 1 R 0 0% atop
|
||||
3359 0.01s 0.00s 0K 0K NE 0 0 E - 0% <ps>
|
||||
3361 0.00s 0.01s 0K 0K NE 0 0 E - 0% <ps>
|
||||
3363 0.01s 0.00s 0K 0K NE 0 0 E - 0% <ps>
|
||||
31357 0.00s 0.00s 0K 0K -- - 1 S 1 0% bash
|
||||
3364 0.00s 0.00s 8032K 756K N- - 1 S 1 0% sleep
|
||||
2931 0.00s 0.00s 0K 0K -- - 1 I 1 0% kworker/u8:2-e
|
||||
3356 0.00s 0.00s 0K 0K -E 0 0 E - 0% <sleep>
|
||||
3360 0.00s 0.00s 0K 0K NE 0 0 E - 0% <sleep>
|
||||
3362 0.00s 0.00s 0K 0K NE 0 0 E - 0% <sleep>
|
||||
```
|
||||
|
||||
如果你*只*想查看磁盘统计信息,则可以使用以下命令轻松进行管理:
|
||||
|
||||
```
|
||||
$ atop | grep DSK
|
||||
DSK | sda | busy 0% | read 122901 | write 3318e3 | avio 0.67 ms |
|
||||
DSK | sdb | busy 0% | read 1168 | write 103 | avio 0.73 ms |
|
||||
DSK | sda | busy 2% | read 0 | write 92 | avio 2.39 ms |
|
||||
DSK | sda | busy 2% | read 0 | write 94 | avio 2.47 ms |
|
||||
DSK | sda | busy 2% | read 0 | write 99 | avio 2.26 ms |
|
||||
DSK | sda | busy 2% | read 0 | write 94 | avio 2.43 ms |
|
||||
DSK | sda | busy 2% | read 0 | write 94 | avio 2.43 ms |
|
||||
DSK | sda | busy 2% | read 0 | write 92 | avio 2.43 ms |
|
||||
^C
|
||||
```
|
||||
|
||||
### 了解磁盘 I/O
|
||||
|
||||
Linux 提供了足够的命令,可以让你很好地了解磁盘的工作强度,并帮助你关注潜在的问题或减缓。希望这些命令中的一个可以告诉你何时需要质疑磁盘性能。偶尔使用这些命令将有助于确保当你需要检查磁盘,特别是忙碌或缓慢的磁盘时可以显而易见地发现它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3330497/linux/linux-commands-for-measuring-disk-activity.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[laingke](https://github.com/laingke)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3291616/linux/examining-linux-system-performance-with-dstat.html
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11404-1.html)
|
||||
[#]: subject: (Blockchain 2.0 – What Is Ethereum [Part 9])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/)
|
||||
[#]: author: (editor https://www.ostechnix.com/author/editor/)
|
||||
@ -12,29 +12,29 @@
|
||||
|
||||
![Ethereum][1]
|
||||
|
||||
在本系列的上一指南中,我们讨论了 [Hyperledger 项目(HLP)][2],这是一个由 Linux 基金会开发的增长最快的产品。在本指南中,我们将详细讨论什么是“<ruby>以太坊<rt>Ethereum</rt></ruby>”及其功能。许多研究人员认为,互联网的未来将基于<ruby>去中心化计算<rt>decentralized computing</rt></ruby>的原理。实际上,去中心化计算是互联网放在首位的更广泛目标之一。但是,由于可用的计算能力不同,互联网发生了另一次变化。尽管现代服务器功能使服务器端处理和执行成为可能,但在世界上大部分地区缺乏像样的移动网络使客户端也是如此。现在,现代智能手机具有 SoC(片上系统),在客户端本身上也能够处理许多此类操作,但是,由于安全地检索和存储数据而受到的限制仍然迫使开发人员进行服务器端计算和数据管理。因此,当前可以观察到数据传输能力的瓶颈。
|
||||
在本系列的上一指南中,我们讨论了 [Hyperledger 项目(HLP)][2],这是一个由 Linux 基金会开发的增长最快的产品。在本指南中,我们将详细讨论什么是“<ruby>以太坊<rt>Ethereum</rt></ruby>”及其功能。许多研究人员认为,互联网的未来将基于<ruby>去中心化计算<rt>decentralized computing</rt></ruby>的原理。实际上,去中心化计算是互联网放在首位的更广泛目标之一。但是,由于可用的计算能力不同,互联网发生了转折。尽管现代服务器功能使得服务器端处理和执行成为可能,但在世界上大部分地区缺乏像样的移动网络使得客户端也是如此。现在,现代智能手机具有 SoC(片上系统),在客户端本身上也能够处理许多此类操作,但是,由于安全地检索和存储数据而受到的限制仍然迫使开发人员需要在服务器端进行计算和数据管理。因此,当前可以观察到数据传输能力方面存在瓶颈。
|
||||
|
||||
由于分布式数据存储和程序执行平台的进步,所有这些可能很快就会改变。[区块链][3]允许在分布式用户网络(而不是中央服务器)上进行安全的数据管理和程序执行,这在互联网历史上基本上是第一次。
|
||||
|
||||
以太坊就是一个这样的区块链平台,使开发人员可以访问用于在这样的去中心化网络上构建和运行应用程序的框架和工具。尽管它以其加密货币而广为人知,以太坊不只是<ruby>以太币<rt>ether</rt></ruby>(加密货币)。这是一种完整的<ruby>图灵完备<rt>Turing complete</rt></ruby>编程语言,旨在开发和部署 DApp(即<ruby>分布式应用<rt>Distributed APPlication</rt></ruby>) [^1]。我们会在接下来的一篇文章中详细介绍 DApp。
|
||||
|
||||
以太坊是开源的,默认情况下是一个公共(非许可)区块链,并具有一个大范围的智能合约平台底层(Solidity)。以太坊提供了一个称为“以太坊虚拟机(EVM)”的虚拟计算环境,以运行应用程序和[智能合约][4] [^2]。 以太坊虚拟机在世界各地成千上万个参与节点上运行,这意味着应用程序数据在保证安全的同时,几乎不可能被篡改或丢失。
|
||||
以太坊是开源的,默认情况下是一个公共(非许可)区块链,并具有一个大范围的智能合约平台底层(Solidity)。以太坊提供了一个称为“<ruby>以太坊虚拟机<rt>Ethereum virtual machine</rt></ruby>(EVM)”的虚拟计算环境,以运行应用程序和[智能合约][4] [^2]。以太坊虚拟机运行在世界各地的成千上万个参与节点上,这意味着应用程序数据在保证安全的同时,几乎不可能被篡改或丢失。
|
||||
|
||||
### 以太坊的背后:什么使之不同
|
||||
|
||||
在 2017 年,为了推广以太坊区块链的功能的利用,30 多个技术和金融领域的名人聚集在一起。因此,“<ruby>以太坊企业联盟<rt>Ethereum Enterprise Alliance</rt></ruby>”(EEA)由众多支持成员组成,包括微软、摩根大通、思科、德勤和埃森哲。摩根大通已经拥有 Quorum,这是一个基于以太坊的去中心化金融服务计算平台,目前正在运营中;而微软拥有通过其 Azure 云业务销售的基于以太坊的云服务[^3]。
|
||||
在 2017 年,为了推广对以太坊区块链的功能的利用,技术和金融领域的 30 多个团队汇聚一堂。因此,“<ruby>以太坊企业联盟<rt>Ethereum Enterprise Alliance</rt></ruby>”(EEA)由众多支持成员组成,包括微软、摩根大通、思科、德勤和埃森哲。摩根大通已经拥有 Quorum,这是一个基于以太坊的去中心化金融服务计算平台,目前已经投入运行;而微软拥有基于以太坊的云服务,通过其 Azure 云业务销售 [^3]。
|
||||
|
||||
### 什么是以太币,它和以太坊有什么关系
|
||||
|
||||
以太坊的创建者<ruby>维塔利克·布特林<rt>Vitalik Buterin</rt></ruby>深谙去中心化处理平台的真正价值以及为比特币提供动力的底层区块链技术。他提议比特币应该开发以支持运行分布式应用程序(DApp)和程序(现在称为智能合约)的想法,未能获得多数同意。
|
||||
|
||||
因此,他在 2013 年发表的白皮书中提出了以太坊的想法。原始白皮书仍在维护中,读者可从[此处][5]获得。这个想法是开发一个基于区块链的平台来运行智能合约和应用程序,这些合约和应用程序设计为在节点和用户设备而非服务器上运行。
|
||||
因此,他在 2013 年发表的白皮书中提出了以太坊的想法。原始白皮书仍然保留,[可供][5]读者阅读。其理念是开发一个基于区块链的平台来运行智能合约和应用程序,这些合约和应用程序设计为在节点和用户设备上运行,而非服务器上运行。
|
||||
|
||||
以太坊系统经常被误认为就是加密货币以太币,但是,必须重申,以太坊是一个用于开发和执行应用程序的全栈平台,自成立以来一直如此,而比特币并非如此。**以太网目前是按市值计算的第二大加密货币**,在撰写本文时,其平均交易价格为每个以太币 170 美元 [^4]。
|
||||
以太坊系统经常被误认为就是加密货币以太币,但是,必须重申,以太坊是一个用于开发和执行应用程序的全栈平台,自成立以来一直如此,而比特币则不是。**以太网目前是按市值计算的第二大加密货币**,在撰写本文时,其平均交易价格为每个以太币 170 美元 [^4]。
|
||||
|
||||
### 该平台的功能和技术特性 [^5]
|
||||
|
||||
* 正如我们已经提到的,称为以太币的加密货币只是该平台功能之一。该系统的目的不仅仅是处理金融交易。 实际上,以太坊平台和比特币之间的主要区别在于它们的脚本功能。以太坊是以图灵完备的编程语言开发的,这意味着它具有类似于其他主要编程语言的脚本和应用程序功能。开发人员需要此功能才能在平台上创建 DApp 和复杂的智能合约,而该功能是比特币缺失的。
|
||||
* 正如我们已经提到的,称为以太币的加密货币只是该平台功能之一。该系统的目的不仅仅是处理金融交易。 实际上,以太坊平台和比特币之间的主要区别在于它们的脚本能力。以太坊是以图灵完备的编程语言开发的,这意味着它具有类似于其他主要编程语言的脚本编程和应用程序功能。开发人员需要此功能才能在平台上创建 DApp 和复杂的智能合约,而该功能是比特币缺失的。
|
||||
* 以太币的“挖矿”过程更加严格和复杂。尽管可以使用专用的 ASIC 来开采比特币,但以太坊使用的基本哈希算法(EThash)降低了 ASIC 在这方面的优势。
|
||||
* 为激励矿工和节点运营者运行网络而支付的交易费用本身是使用称为 “<ruby>燃料<rt>Gas</rt></ruby>”的计算令牌来计算的。通过要求交易的发起者支付与执行交易所需的计算资源数量成比例的以太币,燃料提高了系统的弹性以及对外部黑客和攻击的抵抗力。这与其他平台(例如比特币)相反,在该平台上,交易费用与交易规模一并衡量。因此,以太坊的平均交易成本从根本上低于比特币。这也意味着在以太坊虚拟机上运行的应用程序需要付费,具体取决于应用程序要解决的计算问题。基本上,执行越复杂,费用就越高。
|
||||
* 以太坊的出块时间估计约为 10 - 15 秒。出块时间是在区块链网络上打时间戳和创建区块所需的平均时间。与将在比特币网络上进行同样的交易要花费 10 分钟以上的时间相比,很明显,就交易和区块验证而言,以太坊要快得多。
|
||||
@ -44,7 +44,7 @@
|
||||
|
||||
尽管与以太坊相比,它远远超过了类似的平台,但在以太坊企业联盟开始推动之前,该平台本身尚缺乏明确的发展道路。虽然以太坊平台确实推动了企业发展,但必须注意,以太坊还可以满足小型开发商和个人的需求。 这样一来,为最终用户和企业开发的平台就为以太坊遗漏了许多特定功能。另外,以太坊基金会提出和开发的区块链模型是一种公共模型,而 Hyperledger 项目等项目提出的模型是私有的和需要许可的。
|
||||
|
||||
虽然只有时间才能证明以太坊、Hyperledger 和 R3 Corda 等平台中,哪一个平台会在现实场景中找到最多粉丝,但此类系统确实证明了以区块链为动力的未来主张的正确性。
|
||||
虽然只有时间才能证明以太坊、Hyperledger 和 R3 Corda 等平台中,哪一个平台会在现实场景中找到最多粉丝,但此类系统确实证明了以区块链为动力的未来主张背后的有效性。
|
||||
|
||||
[^1]: [Gabriel Nicholas, “Ethereum Is Coding’s New Wild West | WIRED,” Wired , 2017][6].
|
||||
[^2]: [What is Ethereum? — Ethereum Homestead 0.1 documentation][7].
|
||||
@ -52,25 +52,23 @@
|
||||
[^4]: [Cryptocurrency Market Capitalizations | CoinMarketCap][9].
|
||||
[^5]: [Introduction — Ethereum Homestead 0.1 documentation][10].
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/
|
||||
|
||||
作者:[editor][a]
|
||||
作者:[ostechnix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Ethereum-720x340.png
|
||||
[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||
[3]: https://www.ostechnix.com/blockchain-2-0-an-introduction/
|
||||
[4]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
|
||||
[2]: https://linux.cn/article-11275-1.html
|
||||
[3]: https://linux.cn/article-10650-1.html
|
||||
[4]: https://linux.cn/article-10956-1.html
|
||||
[5]: https://github.com/ethereum/wiki/wiki/White-Paper
|
||||
[6]: https://www.wired.com/story/ethereum-is-codings-new-wild-west/
|
||||
[7]: http://www.ethdocs.org/en/latest/introduction/what-is-ethereum.html#ethereum-virtual-machine
|
||||
104
published/201909/20190528 A Quick Look at Elvish Shell.md
Normal file
104
published/201909/20190528 A Quick Look at Elvish Shell.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11393-1.html)
|
||||
[#]: subject: (A Quick Look at Elvish Shell)
|
||||
[#]: via: (https://itsfoss.com/elvish-shell/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
Elvish Shell 速览
|
||||
======
|
||||
|
||||
每个来到这里的人都会对许多系统中默认 Bash shell 有所了解(无论多少)。过去这些年已经有一些新的 shell 出现来解决 Bash 中的一些缺点。Elvish 就是其中之一,我们将在今天讨论它。
|
||||
|
||||
### 什么是 Elvish Shell?
|
||||
|
||||
![Pipelines In Elvish][1]
|
||||
|
||||
[Elvish][2] 不仅仅是一个 shell。它[也是][3]“一种表达性编程语言”。它有许多有趣的特性,包括:
|
||||
|
||||
* 它是由 Go 语言编写的
|
||||
* 内置文件管理器,灵感来自 [Ranger 文件管理器][4](`Ctrl + N`)
|
||||
* 可搜索的命令历史记录(`Ctrl + R`)
|
||||
* 访问的目录的历史记录(`Ctrl + L`)
|
||||
* 支持结构化数据,例如列表、字典和函数的强大的管道
|
||||
* 包含“一组标准的控制结构:有 `if` 条件控制、`for` 和 `while` 循环,还有 `try` 的异常处理”
|
||||
* 通过包管理器支持[第三方模块扩展 Elvish][5]
|
||||
* BSD 两句版许可证
|
||||
|
||||
你肯定在喊,“为什么叫 Elvish?”。好吧,根据[他们的网站][6],他们之所以选择当前的名字,是因为:
|
||||
|
||||
> 在 Roguelike 游戏中,精灵制造的物品质量很高。它们通常被称为“精灵物品”。但是之所以选择 “elvish” 是因为它以 “sh” 结尾,这是 Unix shell 的久远传统。这个与 fish 押韵,它是影响 Elvish 哲学的 shell 之一。
|
||||
|
||||
### 如何安装 Elvish Shell
|
||||
|
||||
Elvish 在几种主流发行版中都有。
|
||||
|
||||
请注意,该软件还很年轻。最新版本是 0.12。根据该项目的 [GitHub 页面][3]:“尽管还处在 1.0 之前,但它已经适合大多数日常交互使用。”
|
||||
|
||||
![Elvish Control Structures][7]
|
||||
|
||||
#### Debian 和 Ubuntu
|
||||
|
||||
Elvish 包已引入 Debian Buster 和 Ubuntu 17.10。不幸的是,这些包已经过时,你需要使用 [PPA][8] 安装最新版本。你需要使用以下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:zhsj/elvish
|
||||
sudo apt update
|
||||
sudo apt install elvish
|
||||
```
|
||||
|
||||
#### Fedora
|
||||
|
||||
Elvish 在 Fedora 的主仓库中没有。你需要添加 [FZUG 仓库][9]安装 Evlish。为此,你需要使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf config-manager --add-repo=http://repo.fdzh.org/FZUG/FZUG.repol
|
||||
sudo dnf install elvish
|
||||
```
|
||||
|
||||
#### Arch
|
||||
|
||||
Elvish 在 [Arch 用户仓库][10]中可用。
|
||||
|
||||
我相信你知道该[如何在 Linux 中更改 Shell][11],因此安装后可以切换到 Elvish 来使用它。
|
||||
|
||||
### 对 Elvish Shell 的想法
|
||||
|
||||
就个人而言,我没有理由在任何系统上安装 Elvish。我可以通过安装几个小的命令行程序或使用已经安装的程序来获得它的大多数功能。
|
||||
|
||||
例如,Bash 中已经存在“搜索历史命令”功能,并且效果很好。如果要提高历史命令的能力,我建议安装 [fzf][12]。`fzf` 使用模糊搜索,因此你无需记住要查找的确切命令。`fzf` 还允许你预览和打开文件。
|
||||
|
||||
我认为 Elvish 作为一种编程语言是不错的,但是我会坚持使用 Bash shell 脚本,直到 Elvish 变得更成熟。
|
||||
|
||||
你们都有用过 Elvish 么?你认为安装 Elvish 是否值得?你最喜欢的 Bash 替代品是什么?请在下面的评论中告诉我们。
|
||||
|
||||
如果你发现这篇文章有趣,请花一点时间在社交媒体、Hacker News 或 Reddit 上分享它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/elvish-shell/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/pipelines-in-elvish.png?fit=800%2C421&ssl=1
|
||||
[2]: https://elv.sh/
|
||||
[3]: https://github.com/elves/elvish
|
||||
[4]: https://ranger.github.io/
|
||||
[5]: https://github.com/elves/awesome-elvish
|
||||
[6]: https://elv.sh/ref/name.html
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/Elvish-control-structures.png?fit=800%2C425&ssl=1
|
||||
[8]: https://launchpad.net/%7Ezhsj/+archive/ubuntu/elvish
|
||||
[9]: https://github.com/FZUG/repo/wiki/Add-FZUG-Repository
|
||||
[10]: https://aur.archlinux.org/packages/elvish/
|
||||
[11]: https://linuxhandbook.com/change-shell-linux/
|
||||
[12]: https://github.com/junegunn/fzf
|
||||
[13]: http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (laingke)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11400-1.html)
|
||||
[#]: subject: (Cloud-native Java, open source security, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/8/cloud-native-java-and-more)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
每周开源点评:云原生 Java、开源安全以及更多行业趋势
|
||||
======
|
||||
|
||||
> 开源社区和行业趋势的每周总览。
|
||||
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
作为我在具有开源开发模型的企业软件公司担任高级产品营销经理的角色的一部分,我为产品营销人员、经理和其他影响者定期发布有关开源社区,市场和行业趋势的定期更新。 以下是该更新中我和他们最喜欢的五篇文章。
|
||||
|
||||
### 《为什么现代 web 开发如此复杂?》
|
||||
|
||||
- [文章地址][2]
|
||||
|
||||
> 现代前端 web 开发带来了一种两极分化的体验:许多人喜欢它,而其他人则鄙视它。
|
||||
>
|
||||
> 我是现代Web开发的忠实拥护者,尽管我将其描述为“魔法”——而魔法也有其优点和缺点……。最近,我一直在向那些只具有粗略的原始 web 开发工作流程的人们讲解“现代 web 开发工作流程”……,但我发现需要解释的内容实在是太多了!甚至笼统的解释最终都会变得冗长。因此,在我努力写下更多解释的过程中,这里是对 web 开发演变的一个长期而笼统的解释的开始……
|
||||
|
||||
**影响**:足够具体,对前端开发人员非常有用(特别是对新开发人员),且足够简单,解释得足够好,可以帮助非开发人员更好地理解前端开发人员的一些问题。到最后,你将(有点)了解 Javascript 和 WebAPI 之间的区别,以及 2019 年的 Javascript 与 2006 年的 Javascript 有何不同。
|
||||
|
||||
### 开源 Kubernetes 安全审计
|
||||
|
||||
- [文章链接][3]
|
||||
|
||||
> 去年,云原生计算基金会(CNCF)开始为其项目执行并开源第三方安全审计,以提高我们生态系统的整体安全性。这个想法是从一些项目开始,并从 CNCF 社区收集了关于这个试点项目是否有用的反馈。第一批经历这个过程的项目是 [CoreDNS][4]、[Envoy][5] 和 [Prometheus][6]。这些首次公开审计发现了从一般漏洞到严重漏洞的安全问题。有了这些结果,CoreDNS、Envoy 和 Prometheus 的项目维护者就能够解决已发现的漏洞,并添加文档来帮助用户。
|
||||
>
|
||||
> 从这些初始审计中得出的主要结论是,公开安全审计是测试开源项目的质量及其漏洞管理过程的一个很好的方法,更重要的是,测试开源项目的安全实践有多大的弹性。特别是 CNCF 的[毕业项目][7],它们被世界上一些最大的公司广泛应用于生产中,它们必须坚持最高级别的安全最佳实践。
|
||||
|
||||
**影响**:就像 Linux 之于数据中心一样,很多公司都把云计算押宝在 Kubernetes 上。从安全的角度来看,看到其中 4 家公司以确保项目正在做应该做的事情,这激发了人们的信心。共享这项研究表明,开源远远不止是仓库中的代码;它是以一种有益于整个社区而不是少数人利益的方式获取和分享专家意见。
|
||||
|
||||
### Quarkus——这个轻量级 Java 框架的下一步是什么?
|
||||
|
||||
- [文章链接][8]
|
||||
|
||||
> “容器优先”是什么意思?Quarkus 有哪些优势?0.20.0 版本有什么新功能?未来我们可以期待哪些功能?1.0.0 版什么时候发布?我们对 Quarkus 有很多问题,而 Alex Soto 也很耐心地回答了所有问题。 随着 Quarkus 0.20.0 的发布,我们和 [JAX 伦敦演讲者][9],Java 拥护者和红帽的开发人员体验总监 Alex Soto 进行了接触。他很好地回答了我们关于 Quarkus 的过去、现在和未来的所有问题。看起来我们对这个令人兴奋的轻量级框架有很多期待!
|
||||
|
||||
**影响**:最近有个聪明的人告诉我,Quarkus 有潜力使 Java “可能成为容器和无服务器环境的最佳语言之一”。不禁使我多看了一眼。尽管 Java 是最流行的编程语言之一([如果不是最流行的][10]),但当你听到“云原生”一词时,它可能并不是第一个想到的语言。Quarkus 可以通过让开发人员将他们的经验应用到新的挑战中,从而扩展和提高他们所拥有的技能的价值。
|
||||
|
||||
### Julia 编程语言:用户批露他们最喜欢和最讨厌它的地方
|
||||
|
||||
- [文章链接][11]
|
||||
|
||||
> Julia 最受欢迎的技术特性是速度和性能,其次是易用性,而最受欢迎的非技术特性是使用者无需付费即可使用它。
|
||||
>
|
||||
> 用户还报告了他们对该语言最大的不满。排在首位的是附加功能的包不够成熟,或者维护得不够好,无法满足他们的需求。
|
||||
|
||||
**影响**:Julia 1.0 版本已经发布了一年,并且在一系列相关指标(下载、GitHub 星级等)中取得了令人瞩目的增长。它是一种直接针对我们当前和未来最大挑战(“科学计算、机器学习、数据挖掘、大规模线性代数、分布式和并行计算”)的语言,因此,了解用户对它的感受,就可以间接看到有关这些挑战的应对情况。
|
||||
|
||||
### 多云数据解读:11 个有趣的统计数据
|
||||
|
||||
- [文章链接][12]
|
||||
|
||||
> 如果你把我们最近对 [Kubernetes 的有趣数据][13]的深入研究归结最基本的一条,它看起来是这样的:[Kubernetes][14] 的受欢迎程度在可预见的未来将持续下去。
|
||||
>
|
||||
> 剧透警报:当你挖掘有关[多云][15]使用情况的最新数据时,他们告诉你一个类似的描述:使用率正在飙升。
|
||||
>
|
||||
> 这种一致性是有道理的。也许不是每个组织都将使用 Kubernetes 来管理其多云和/或[混合云][16]基础架构,但是两者越来越紧密地联系在一起。即使不这样做,它们都反映了向更分散和异构 IT 环境的普遍转变,以及[云原生开发][17]和其他重叠趋势。
|
||||
|
||||
**影响**:越来越多地采用“多云战略”的另一种解释是,它们将组织中单独部分未经协商而作出的决策追溯为“战略”,从而使决策合法化。“等等,所以你从谁那里买了几个小时?又从另一个人那里买了几个小时?为什么在会议纪要中没有呢?我想我们现在是一家多云公司!”。当然,我在开玩笑,我敢肯定大多数大公司的协调能力远胜于此,对吗?
|
||||
|
||||
*我希望你喜欢这张上周让我印象深刻的列表,并在下周一回来了解更多的开放源码社区、市场和行业趋势。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/cloud-native-java-and-more
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[laingke](https://github.com/laingke)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://www.vrk.dev/2019/07/11/why-is-modern-web-development-so-complicated-a-long-yet-hasty-explanation-part-1/
|
||||
[3]: https://www.cncf.io/blog/2019/08/06/open-sourcing-the-kubernetes-security-audit/
|
||||
[4]: https://coredns.io/2018/03/15/cure53-security-assessment/
|
||||
[5]: https://github.com/envoyproxy/envoy/blob/master/docs/SECURITY_AUDIT.pdf
|
||||
[6]: https://cure53.de/pentest-report_prometheus.pdf
|
||||
[7]: https://www.cncf.io/projects/
|
||||
[8]: https://jaxenter.com/quarkus-whats-next-for-the-lightweight-java-framework-160793.html
|
||||
[9]: https://jaxlondon.com/cloud-kubernetes-serverless/java-particle-acceleration-using-quarkus/
|
||||
[10]: https://opensource.com/article/19/8/possibly%20one%20of%20the%20best%20languages%20for%20containers%20and%20serverless%20environments.
|
||||
[11]: https://www.zdnet.com/article/julia-programming-language-users-reveal-what-they-love-and-hate-the-most-about-it/#ftag=RSSbaffb68
|
||||
[12]: https://enterprisersproject.com/article/2019/8/multi-cloud-statistics
|
||||
[13]: https://enterprisersproject.com/article/2019/7/kubernetes-statistics-13-compelling
|
||||
[14]: https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=701f2000000tjyaAAA
|
||||
[15]: https://www.redhat.com/en/topics/cloud-computing/what-is-multicloud?intcmp=701f2000000tjyaAAA
|
||||
[16]: https://enterprisersproject.com/hybrid-cloud
|
||||
[17]: https://enterprisersproject.com/article/2018/10/how-explain-cloud-native-apps-plain-english
|
||||
269
published/201909/20190822 How to move a file in Linux.md
Normal file
269
published/201909/20190822 How to move a file in Linux.md
Normal file
@ -0,0 +1,269 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11380-1.html)
|
||||
[#]: subject: (How to move a file in Linux)
|
||||
[#]: via: (https://opensource.com/article/19/8/moving-files-linux-depth)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/doni08521059)
|
||||
|
||||
在 Linux 中如何移动文件
|
||||
======
|
||||
|
||||
> 无论你是刚接触 Linux 的文件移动的新手还是已有丰富的经验,你都可以通过此深入的文章中学到一些东西。
|
||||
|
||||

|
||||
|
||||
在 Linux 中移动文件看似比较简单,但是可用的选项却比大多数人想象的要多。本文介绍了初学者如何在 GUI 和命令行中移动文件,还介绍了底层实际上发生了什么,并介绍了许多有一定经验的用户也很少使用的命令行选项。
|
||||
|
||||
### 移动什么?
|
||||
|
||||
在研究移动文件之前,有必要仔细研究*移动*文件系统对象时实际发生的情况。当文件创建后,会将其分配给一个<ruby>索引节点<rt>inode</rt></ruby>,这是文件系统中用于数据存储的固定点。你可以使用 [ls][2] 命令看到文件对应的索引节点:
|
||||
|
||||
```
|
||||
$ ls --inode example.txt
|
||||
7344977 example.txt
|
||||
```
|
||||
|
||||
移动文件时,实际上并没有将数据从一个索引节点移动到另一个索引节点,只是给文件对象分配了新的名称或文件路径而已。实际上,文件在移动时会保留其权限,因为移动文件不会更改或重新创建文件。(LCTT 译注:在不跨卷、分区和存储器时,移动文件是不会重新创建文件的;反之亦然)
|
||||
|
||||
文件和目录的索引节点并没有暗示这种继承关系,而是由文件系统本身决定的。索引节点的分配是基于文件创建时的顺序分配的,并且完全独立于你组织计算机文件的方式。一个目录“内”的文件的索引节点号可能比其父目录的索引节点号更低或更高。例如:
|
||||
|
||||
```
|
||||
$ mkdir foo
|
||||
$ mv example.txt foo
|
||||
$ ls --inode
|
||||
7476865 foo
|
||||
$ ls --inode foo
|
||||
7344977 example.txt
|
||||
```
|
||||
|
||||
但是,将文件从一个硬盘驱动器移动到另一个硬盘驱动器时,索引节点基本上会更改。发生这种情况是因为必须将新数据写入新文件系统。因此,在 Linux 中,移动和重命名文件的操作实际上是相同的操作。无论你将文件移动到另一个目录还是在同一目录使用新名称,这两个操作均由同一个底层程序执行。
|
||||
|
||||
本文重点介绍将文件从一个目录移动到另一个目录。
|
||||
|
||||
### 用鼠标移动文件
|
||||
|
||||
图形用户界面是大多数人都熟悉的友好的抽象层,位于复杂的二进制数据集合之上。这也是在 Linux 桌面上移动文件的首选方法,也是最直观的方法。从一般意义上来说,如果你习惯使用台式机,那么你可能已经知道如何在硬盘驱动器上移动文件。例如,在 GNOME 桌面上,将文件从一个窗口拖放到另一个窗口时的默认操作是移动文件而不是复制文件,因此这可能是该桌面上最直观的操作之一:
|
||||
|
||||
![Moving a file in GNOME.][3]
|
||||
|
||||
而 KDE Plasma 桌面中的 Dolphin 文件管理器默认情况下会提示用户以执行不同的操作。拖动文件时按住 `Shift` 键可强制执行移动操作:
|
||||
|
||||
![Moving a file in KDE.][4]
|
||||
|
||||
### 在命令行移动文件
|
||||
|
||||
用于在 Linux、BSD、Illumos、Solaris 和 MacOS 上移动文件的 shell 命令是 `mv`。不言自明,简单的命令 `mv <source> <destination>` 会将源文件移动到指定的目标,源和目标都由[绝对][5]或[相对][6]文件路径定义。如前所述,`mv` 是 [POSIX][7] 用户的常用命令,其有很多不为人知的附加选项,因此,无论你是新手还是有经验的人,本文都会为你带来一些有用的选项。
|
||||
|
||||
但是,不是所有 `mv` 命令都是由同一个人编写的,因此取决于你的操作系统,你可能拥有 GNU `mv`、BSD `mv` 或 Sun `mv`。命令的选项因其实现而异(BSD `mv` 根本没有长选项),因此请参阅你的 `mv` 手册页以查看支持的内容,或安装你的首选版本(这是开源的奢侈之处)。
|
||||
|
||||
#### 移动文件
|
||||
|
||||
要使用 `mv` 将文件从一个文件夹移动到另一个文件夹,请记住语法 `mv <source> <destination>`。 例如,要将文件 `example.txt` 移到你的 `Documents` 目录中:
|
||||
|
||||
```
|
||||
$ touch example.txt
|
||||
$ mv example.txt ~/Documents
|
||||
$ ls ~/Documents
|
||||
example.txt
|
||||
```
|
||||
|
||||
就像你通过将文件拖放到文件夹图标上来移动文件一样,此命令不会将 `Documents` 替换为 `example.txt`。相反,`mv` 会检测到 `Documents` 是一个文件夹,并将 `example.txt` 文件放入其中。
|
||||
|
||||
你还可以方便地在移动文件时重命名该文件:
|
||||
|
||||
```
|
||||
$ touch example.txt
|
||||
$ mv example.txt ~/Documents/foo.txt
|
||||
$ ls ~/Documents
|
||||
foo.txt
|
||||
```
|
||||
|
||||
这很重要,这使你不用将文件移动到另一个位置,也可以重命名文件,例如:
|
||||
|
||||
```
|
||||
$ touch example.txt
|
||||
$ mv example.txt foo2.txt
|
||||
$ ls foo2.txt`
|
||||
```
|
||||
|
||||
#### 移动目录
|
||||
|
||||
不像 [cp][8] 命令,`mv` 命令处理文件和目录没有什么不同,你可以用同样的格式移动目录或文件:
|
||||
|
||||
```
|
||||
$ touch file.txt
|
||||
$ mkdir foo_directory
|
||||
$ mv file.txt foo_directory
|
||||
$ mv foo_directory ~/Documents
|
||||
```
|
||||
|
||||
#### 安全地移动文件
|
||||
|
||||
如果你移动一个文件到一个已有同名文件的地方,默认情况下,`mv` 会用你移动的文件替换目标文件。这种行为被称为<ruby>清除<rt>clobbering</rt></ruby>,有时候这就是你想要的结果,而有时则不是。
|
||||
|
||||
一些发行版将 `mv` 别名定义为 `mv --interactive`(你也可以[自己写一个][9]),这会提醒你确认是否覆盖。而另外一些发行版没有这样做,那么你可以使用 `--interactive` 或 `-i` 选项来确保当两个文件有一样的名字而发生冲突时让 `mv` 请你来确认。
|
||||
|
||||
```
|
||||
$ mv --interactive example.txt ~/Documents
|
||||
mv: overwrite '~/Documents/example.txt'?
|
||||
```
|
||||
|
||||
如果你不想手动干预,那么可以使用 `--no-clobber` 或 `-n`。该选项会在发生冲突时静默拒绝移动操作。在这个例子当中,一个名为 `example.txt` 的文件以及存在于 `~/Documents`,所以它不会如命令要求从当前目录移走。
|
||||
|
||||
```
|
||||
$ mv --no-clobber example.txt ~/Documents
|
||||
$ ls
|
||||
example.txt
|
||||
```
|
||||
|
||||
#### 带备份的移动
|
||||
|
||||
如果你使用 GNU `mv`,有一个备份选项提供了另外一种安全移动的方式。要为任何冲突的目标文件创建备份文件,可以使用 `-b` 选项。
|
||||
|
||||
```
|
||||
$ mv -b example.txt ~/Documents
|
||||
$ ls ~/Documents
|
||||
example.txt example.txt~
|
||||
```
|
||||
|
||||
这个选项可以确保 `mv` 完成移动操作,但是也会保护目录位置的已有文件。
|
||||
|
||||
另外的 GNU 备份选项是 `--backup`,它带有一个定义了备份文件如何命名的参数。
|
||||
|
||||
* `existing`:如果在目标位置已经存在了编号备份文件,那么会创建编号备份。否则,会使用 `simple` 方式。
|
||||
* `none`:即使设置了 `--backup`,也不会创建备份。当 `mv` 被别名定义为带有备份选项时,这个选项可以覆盖这种行为。
|
||||
* `numbered`:给目标文件名附加一个编号。
|
||||
* `simple`:给目标文件附加一个 `~`,当你日常使用带有 `--ignore-backups` 选项的 [ls][2] 时,这些文件可以很方便地隐藏起来。
|
||||
|
||||
简单来说:
|
||||
|
||||
```
|
||||
$ mv --backup=numbered example.txt ~/Documents
|
||||
$ ls ~/Documents
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:23 example.txt
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:20 example.txt.~1~
|
||||
```
|
||||
|
||||
可以使用环境变量 `VERSION_CONTROL` 设置默认的备份方案。你可以在 `~/.bashrc` 文件中设置该环境变量,也可以在命令前动态设置:
|
||||
|
||||
```
|
||||
$ VERSION_CONTROL=numbered mv --backup example.txt ~/Documents
|
||||
$ ls ~/Documents
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:23 example.txt
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:20 example.txt.~1~
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:22 example.txt.~2~
|
||||
```
|
||||
|
||||
`--backup` 选项仍然遵循 `--interactive` 或 `-i` 选项,因此即使它在执行备份之前创建了备份,它仍会提示你覆盖目标文件:
|
||||
|
||||
```
|
||||
$ mv --backup=numbered example.txt ~/Documents
|
||||
mv: overwrite '~/Documents/example.txt'? y
|
||||
$ ls ~/Documents
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:24 example.txt
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:20 example.txt.~1~
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:22 example.txt.~2~
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:23 example.txt.~3~
|
||||
```
|
||||
|
||||
你可以使用 `--force` 或 `-f` 选项覆盖 `-i`。
|
||||
|
||||
```
|
||||
$ mv --backup=numbered --force example.txt ~/Documents
|
||||
$ ls ~/Documents
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:26 example.txt
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:20 example.txt.~1~
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:22 example.txt.~2~
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:24 example.txt.~3~
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:25 example.txt.~4~
|
||||
```
|
||||
|
||||
`--backup` 选项在 BSD `mv` 中不可用。
|
||||
|
||||
#### 一次性移动多个文件
|
||||
|
||||
移动多个文件时,`mv` 会将最终目录视为目标:
|
||||
|
||||
```
|
||||
$ mv foo bar baz ~/Documents
|
||||
$ ls ~/Documents
|
||||
foo bar baz
|
||||
```
|
||||
|
||||
如果最后一个项目不是目录,则 `mv` 返回错误:
|
||||
|
||||
```
|
||||
$ mv foo bar baz
|
||||
mv: target 'baz' is not a directory
|
||||
```
|
||||
|
||||
GNU `mv` 的语法相当灵活。如果无法把目标目录作为提供给 `mv` 命令的最终参数,请使用 `--target-directory` 或 `-t` 选项:
|
||||
|
||||
```
|
||||
$ mv --target-directory=~/Documents foo bar baz
|
||||
$ ls ~/Documents
|
||||
foo bar baz
|
||||
```
|
||||
|
||||
当从某些其他命令的输出构造 `mv` 命令时(例如 `find` 命令、`xargs` 或 [GNU Parallel][10]),这特别有用。
|
||||
|
||||
#### 基于修改时间移动
|
||||
|
||||
使用 GNU `mv`,你可以根据要移动的文件是否比要替换的目标文件新来定义移动动作。该方式可以通过 `--update` 或 `-u` 选项使用,在BSD `mv` 中不可用:
|
||||
|
||||
```
|
||||
$ ls -l ~/Documents
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:32 example.txt
|
||||
$ ls -l
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:42 example.txt
|
||||
$ mv --update example.txt ~/Documents
|
||||
$ ls -l ~/Documents
|
||||
-rw-rw-r--. 1 seth users 128 Aug 1 17:42 example.txt
|
||||
$ ls -l
|
||||
```
|
||||
|
||||
此结果仅基于文件的修改时间,而不是两个文件的差异,因此请谨慎使用。只需使用 `touch` 命令即可愚弄 `mv`:
|
||||
|
||||
```
|
||||
$ cat example.txt
|
||||
one
|
||||
$ cat ~/Documents/example.txt
|
||||
one
|
||||
two
|
||||
$ touch example.txt
|
||||
$ mv --update example.txt ~/Documents
|
||||
$ cat ~/Documents/example.txt
|
||||
one
|
||||
```
|
||||
|
||||
显然,这不是最智能的更新功能,但是它提供了防止覆盖最新数据的基本保护。
|
||||
|
||||
### 移动
|
||||
|
||||
除了 `mv` 命令以外,还有更多的移动数据的方法,但是作为这项任务的默认程序,`mv` 是一个很好的通用选择。现在你知道了有哪些可以使用的选项,可以比以前更智能地使用 `mv` 了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/moving-files-linux-depth
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/doni08521059
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_paper_folder.png?itok=eIJWac15 (Files in a folder)
|
||||
[2]: https://opensource.com/article/19/7/master-ls-command
|
||||
[3]: https://opensource.com/sites/default/files/uploads/gnome-mv.jpg (Moving a file in GNOME.)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/kde-mv.jpg (Moving a file in KDE.)
|
||||
[5]: https://opensource.com/article/19/7/understanding-file-paths-and-how-use-them
|
||||
[6]: https://opensource.com/article/19/7/navigating-filesystem-relative-paths
|
||||
[7]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[8]: https://opensource.com/article/19/7/copying-files-linux
|
||||
[9]: https://opensource.com/article/19/7/bash-aliases
|
||||
[10]: https://opensource.com/article/18/5/gnu-parallel
|
||||
@ -0,0 +1,386 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11411-1.html)
|
||||
[#]: subject: (Best Linux Distributions For Everyone in 2019)
|
||||
[#]: via: (https://itsfoss.com/best-linux-distributions/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
2019 年最好的 Linux 发行版
|
||||
======
|
||||
|
||||
> 哪个是最好的 Linux 发行版呢?这个问题是没有明确的答案的。这就是为什么我们按各种分类汇编了这个最佳 Linux 列表的原因。
|
||||
|
||||
有许多 Linux 发行版,我甚至想不出一个确切的数量,因为你会发现很多不同的 Linux 发行版。
|
||||
|
||||
其中有些只是另外一个的复制品,而有些往往是独一无二的。这虽然有点混乱——但这也是 Linux 的优点。
|
||||
|
||||
不用担心,尽管有成千上万的发行版,在这篇文章中,我已经列出了目前最好的 Linux 发行版。当然,这个列表是主观的。但是,在这里,我们试图对发行版进行分类——每个发行版本都有自己的特点的。
|
||||
|
||||
* 面向初学者的 Linux 用户的最佳发行版
|
||||
* 最佳 Linux 服务器发行版
|
||||
* 可以在旧计算机上运行的最佳 Linux 发行版
|
||||
* 面向高级 Linux 用户的最佳发行版
|
||||
* 最佳常青树 Linux 发行版
|
||||
|
||||
**注:** 该列表没有特定的排名顺序。
|
||||
|
||||
### 面向初学者的最佳 Linux 发行版
|
||||
|
||||
在这个分类中,我们的目标是列出开箱即用的易用发行版。你不需要深度学习,你可以在安装后马上开始使用,不需要知道任何命令或技巧。
|
||||
|
||||
#### Ubuntu
|
||||
|
||||
![][6]
|
||||
|
||||
Ubuntu 无疑是最流行的 Linux 发行版之一。你甚至可以发现它已经预装在很多笔记本电脑上了。
|
||||
|
||||
用户界面很容易适应。如果你愿意,你可以根据自己的要求轻松定制它的外观。无论哪种情况,你都可以选择安装一个主题。你可以从了解更多关于[如何在 Ubuntu 安装主题的][7]的信息来起步。
|
||||
|
||||
除了它本身提供的功能外,你会发现一个巨大的 Ubuntu 用户在线社区。因此,如果你有问题——可以去任何论坛(或版块)寻求帮助。如果你想直接寻找解决方案,你应该看看我们对 [Ubuntu][8] 的报道(我们有很多关于 Ubuntu 的教程和建议)。
|
||||
|
||||
- [Ubuntu][9]
|
||||
|
||||
#### Linux Mint
|
||||
|
||||
![][10]
|
||||
|
||||
Linux Mint Cinnamon 是另一个受初学者欢迎的 Linux 发行版。默认的 Cinnamon 桌面类似于 Windows XP,这就是为什么当 Windows XP 停止维护时许多用户选择它的原因。
|
||||
|
||||
Linux Mint 基于 Ubuntu,因此它具有适用于 Ubuntu 的所有应用程序。简单易用是它成为 Linux 新用户首选的原因。
|
||||
|
||||
- [Linux Mint][11]
|
||||
|
||||
#### elementary OS
|
||||
|
||||
![][12]
|
||||
|
||||
elementary OS 是我用过的最漂亮的 Linux 发行版之一。用户界面类似于苹果操作系统——所以如果你已经使用了苹果系统,则很容易适应。
|
||||
|
||||
该发行版基于 Ubuntu,致力于提供一个用户友好的 Linux 环境,该环境在考虑性能的同时尽可能美观。如果你选择安装 elementary OS,这份[在安装 elementary OS 后要做的 11 件事的清单][13]会派上用场。
|
||||
|
||||
- [elementary OS][14]
|
||||
|
||||
#### MX Linux
|
||||
|
||||
![][15]
|
||||
|
||||
大约一年前,MX Linux 成为众人瞩目的焦点。现在(在发表这篇文章的时候),它是 [DistroWatch.com][16] 上最受欢迎的 Linux 发行版。如果你还没有使用过它,那么当你开始使用它时,你会感到惊讶。
|
||||
|
||||
与 Ubuntu 不同,MX Linux 是一个基于 Debian 的日益流行的发行版,采用 Xfce 作为其桌面环境。除了无与伦比的稳定性之外,它还配备了许多图形用户界面工具,这使得任何习惯了 Windows/Mac 的用户易于使用它。
|
||||
|
||||
此外,软件包管理器还专门针对一键安装进行了量身定制。你甚至可以搜索 [Flatpak][18] 软件包并立即安装它(默认情况下,Flathub 在软件包管理器中是可用的来源之一)。
|
||||
|
||||
- [MX Linux][19]
|
||||
|
||||
#### Zorin OS
|
||||
|
||||
![][20]
|
||||
|
||||
Zorin OS 是又一个基于 Ubuntu 的发行版,它又是桌面上最漂亮、最直观的操作系统之一。尤其是在[Zorin OS 15 发布][21]之后——我绝对会向没有任何 Linux 经验的用户推荐它。它也引入了许多基于图形用户界面的应用程序。
|
||||
|
||||
你也可以将其安装在旧电脑上,但是,请确保选择“Lite”版本。此外,你还有“Core”、“Education”和 “Ultimate”版本可以选择。你可以选择免费安装 Core 版,但是如果你想支持开发人员并帮助改进 Zorin,请考虑获得 Ultimate 版。
|
||||
|
||||
Zorin OS 是由两名爱尔兰的青少年创建的。你可以[在这里阅读他们的故事][22]。
|
||||
|
||||
- [Zorin OS][23]
|
||||
|
||||
#### Pop!_OS
|
||||
|
||||

|
||||
|
||||
Sytem76 的 Pop!_OS 是开发人员或计算机科学专业人员的理想选择。当然,不仅限于编码人员,如果你刚开始使用 Linux,这也是一个很好的选择。它基于 Ubuntu,但是其 UI 感觉更加直观和流畅。除了 UI 外,它还强制执行全盘加密。
|
||||
|
||||
你可以通过文章下面的评论看到,我们的许多读者似乎都喜欢(并坚持使用)它。如果你对此感到好奇,也应该查看一下我们关于 Phillip Prado 的 [Pop!_OS 的动手实践](https://itsfoss.com/pop-os-linux-review/)的文章。
|
||||
|
||||
(LCTT 译注:这段推荐是原文后来补充的,因为原文下面很多人在评论推荐。)
|
||||
|
||||
- [Pop!_OS](https://system76.com/pop)
|
||||
|
||||
#### 其他选择
|
||||
|
||||
[深度操作系统][24] 和其他的 Ubuntu 变种(如 Kubuntu、Xubuntu)也是初学者的首选。如果你想寻求更多的选择,你可以看看。(LCTT 译注:我知道你们肯定对将深度操作系统列入其它不满意——这个锅归原作者。)
|
||||
|
||||
如果你想要挑战自己,你可以试试 Ubuntu 之外的 Fedora —— 但是一定要看看我们关于 [Ubuntu 和 Fedora 对比][25]的文章,从桌面的角度做出更好的选择。
|
||||
|
||||
### 最好的服务器发行版
|
||||
|
||||
对于服务器来说,选择 Linux 发行版取决于稳定性、性能和企业级支持。如果你只是尝试,则可以尝试任何你想要的发行版。
|
||||
|
||||
但是,如果你要为 Web 服务器或任何重要的组件安装它,你应该看看我们的一些建议。
|
||||
|
||||
#### Ubuntu 服务器
|
||||
|
||||
根据你的需要,Ubuntu 为你的服务器提供了不同的选项。如果你正在寻找运行在 AWS、Azure、谷歌云平台等平台上的优化解决方案,[Ubuntu Cloud][26] 是一个很好的选择。
|
||||
|
||||
无论是哪种情况,你都可以选择 Ubuntu 服务器包,并将其安装在你的服务器上。然而,Ubuntu 在云上部署时也是最受欢迎的 Linux 发行版(根据数字判断——[来源1][27]、[来源2][28])。
|
||||
|
||||
请注意,除非你有特殊要求,我们建议你选择 LTS 版。
|
||||
|
||||
- [Ubuntu Server][29]
|
||||
|
||||
#### 红帽企业版 Linux(RHEL)
|
||||
|
||||
红帽企业版 Linux(RHEL)是面向企业和组织的顶级 Linux 平台。如果我们按数字来看,红帽可能不是服务器领域最受欢迎的。但是,有相当一部分企业用户依赖于 RHEL (比如联想)。
|
||||
|
||||
从技术上讲,Fedora 和红帽企业版是相关联的。无论红帽要支持什么——在出现在 RHEL 之前,都要在 Fedora 上进行测试。我不是定制需求的服务器发行版专家,所以你一定要查看他们的[官方文档][30]以了解它是否适合你。
|
||||
|
||||
- [RHEL][31]
|
||||
|
||||
#### SUSE Linux 企业服务器(SLES)
|
||||
|
||||
![][32]
|
||||
|
||||
别担心,不要把这和 OpenSUSE 混淆。一切都以一个共同的品牌 “SUSE” 命名 —— 但是 OpenSUSE 是一个开源发行版,目标是社区,并且由社区维护。
|
||||
|
||||
SUSE Linux 企业服务器(SLES)是基于云的服务器最受欢迎的解决方案之一。为了获得管理开源解决方案的优先支持和帮助,你必须选择订阅。
|
||||
|
||||
- [SLES][33]
|
||||
|
||||
#### CentOS
|
||||
|
||||
![][34]
|
||||
|
||||
正如我提到的,对于 RHEL 你需要订阅。而 CentOS 更像是 RHEL 的社区版,因为它是从 RHEL 的源代码中派生出来的。而且,它是开源的,也是免费的。尽管与过去几年相比,使用 CentOS 的托管提供商数量明显减少,但这仍然是一个很好的选择。
|
||||
|
||||
CentOS 可能没有加载最新的软件包,但它被认为是最稳定的发行版之一,你可以在各种云平台上找到 CentOS 镜像。如果没有,你可以选择 CentOS 提供的自托管镜像。
|
||||
|
||||
- [CentOS][35]
|
||||
|
||||
#### 其他选择
|
||||
|
||||
你也可以尝试 [Fedora Server][36]或[Debian][37]作为上述发行版的替代品。
|
||||
|
||||
### 旧电脑的最佳 Linux 发行版
|
||||
|
||||
如果你有一台旧电脑,或者你真的不需要升级你的系统,你仍然可以尝试一些最好的 Linux 发行版。
|
||||
|
||||
我们已经详细讨论了一些[最好的轻量级 Linux 发行版][42]。在这里,我们将只提到那些真正突出的东西(以及一些新的补充)。
|
||||
|
||||
#### Puppy Linux
|
||||
|
||||
![][43]
|
||||
|
||||
Puppy Linux 实际上是最小的发行版本之一。刚开始使用 Linux 时,我的朋友建议我尝试一下 Puppy Linux,因为它可以轻松地在较旧的硬件配置上运行。
|
||||
|
||||
如果你想在你的旧电脑上享受一次爽快的体验,那就值得去看看。多年来,随着一些新的有用特性的增加,用户体验得到了改善。
|
||||
|
||||
- [Puppy Linux][44]
|
||||
|
||||
#### Solus Budgie
|
||||
|
||||
![][45]
|
||||
|
||||
在最近的一个主要版本——[Solus 4 Fortitude][46] 之后,它是一个令人印象深刻的轻量级桌面操作系统。你可以选择像 GNOME 或 MATE 这样的桌面环境。然而,Solus Budgie 恰好是我的最爱之一,它是一款适合初学者的功能齐全的 Linux发行版,同时对系统资源要求很少。
|
||||
|
||||
- [Solus][47]
|
||||
|
||||
#### Bodhi
|
||||
|
||||
![][48]
|
||||
|
||||
Bodhi Linux 构建于 Ubuntu 之上。然而,与Ubuntu不同,它在较旧的配置上运行良好。
|
||||
|
||||
这个发行版的主要亮点是它的 [Moksha 桌面][49](这是 Enlightenment 17 桌面的延续)。用户体验直观且反应极快。即使我个人不用它,你也应该在你的旧系统上试一试。
|
||||
|
||||
- [Bodhi Linux][50]
|
||||
|
||||
#### antiX
|
||||
|
||||
![][51]
|
||||
|
||||
antiX 部分担起了 MX Linux 的责任,它是一个轻量级的 Linux 发行版,为新的或旧的计算机量身定制。其用户界面并不令人印象深刻——但它可以像预期的那样工作。
|
||||
|
||||
它基于 Debian,可以作为一个现场版 CD 发行版使用,而不需要安装它。antiX 还提供现场版引导加载程序。与其他发行版相比,你可以保存设置,这样就不会在每次重新启动时丢失设置。不仅如此,你还可以通过其“持久保留”功能将更改保存到根目录中。
|
||||
|
||||
因此,如果你正在寻找一个可以在旧硬件上提供快速用户体验的现场版 USB 发行版,antiX 是一个不错的选择。
|
||||
|
||||
- [antiX][52]
|
||||
|
||||
#### Sparky Linux
|
||||
|
||||
![][53]
|
||||
|
||||
Sparky Linux 基于 Debian,它是理想的低端系统 Linux 发行版。伴随着超快的用户体验,Sparky Linux 为不同的用户提供了几个特殊版本(或变种)。
|
||||
|
||||
例如,它提供了针对一组用户的稳定版本(和变种)和滚动版本。Sparky Linux GameOver 版非常受游戏玩家欢迎,因为它包含了一堆预装的游戏。你可以查看我们的[最佳 Linux 游戏发行版][54] —— 如果你也想在你的系统上玩游戏。
|
||||
|
||||
#### 其他选择
|
||||
|
||||
你也可以尝试 [Linux Lite][55]、[Lubuntu][56]、[Peppermint][57] 等轻量级 Linux 发行版。
|
||||
|
||||
### 面向高级用户的最佳 Linux 发行版
|
||||
|
||||
一旦你习惯了各种软件包管理器和命令来帮助你解决任何问题,你就可以开始找寻只为高级用户量身定制的 Linux 发行版。
|
||||
|
||||
当然,如果你是专业人士,你会有一套具体的要求。然而,如果你已经作为普通用户使用了一段时间——以下发行版值得一试。
|
||||
|
||||
#### Arch Linux
|
||||
|
||||
![][58]
|
||||
|
||||
Arch Linux 本身是一个简单而强大的发行版,具有陡峭的学习曲线。不像其系统,你不会一次就把所有东西都预先安装好。你必须配置系统并根据需要添加软件包。
|
||||
|
||||
此外,在安装 Arch Linux 时,必须按照一组命令来进行(没有图形用户界面)。要了解更多信息,你可以按照我们关于[如何安装 Arch Linux][59] 的指南进行操作。如果你要安装它,你还应该知道在[安装 Arch Linux 后需要做的一些基本事情][60]。这会帮助你快速入门。
|
||||
|
||||
除了多才多艺和简便性之外,值得一提的是 Arch Linux 背后的社区非常活跃。所以,如果你遇到问题,你不用担心。
|
||||
|
||||
- [Arch Linux][61]
|
||||
|
||||
#### Gentoo
|
||||
|
||||
![][62]
|
||||
|
||||
如果你知道如何编译源代码,Gentoo Linux 是你必须尝试的版本。这也是一个轻量级的发行版,但是,你需要具备必要的技术知识才能使它发挥作用。
|
||||
|
||||
当然,[官方手册][63]提供了许多你需要知道的信息。但是,如果你不确定自己在做什么——你需要花很多时间去想如何充分利用它。
|
||||
|
||||
- [Gentoo Linux][64]
|
||||
|
||||
#### Slackware
|
||||
|
||||
![][65]
|
||||
|
||||
Slackware 是仍然重要的最古老的 Linux 发行版之一。如果你愿意编译或开发软件来为自己建立一个完美的环境 —— Slackware 是一个不错的选择。
|
||||
|
||||
如果你对一些最古老的 Linux 发行版感到好奇,我们有一篇关于[最早的 Linux 发行版][66]可以去看看。
|
||||
|
||||
尽管使用它的用户/开发人员的数量已经显著减少,但对于高级用户来说,它仍然是一个极好的选择。此外,最近有个新闻是 [Slackware 有了一个 Patreon 捐赠页面][67],我们希望 Slackware 继续作为最好的 Linux 发行版之一存在。
|
||||
|
||||
- [Slackware][68]
|
||||
|
||||
### 最佳多用途 Linux 发行版
|
||||
|
||||
有些 Linux 发行版既可以作为初学者友好的桌面又可以作为高级操作系统的服务器。因此,我们考虑为这样的发行版编辑一个单独的部分。
|
||||
|
||||
如果你不同意我们的观点(或者有建议要补充),请在评论中告诉我们。我们认为,这对于每个用户都可以派上用场:
|
||||
|
||||
#### Fedora
|
||||
|
||||
![][69]
|
||||
|
||||
Fedora 提供两个独立的版本:一个用于台式机/笔记本电脑(Fedora 工作站),另一个用于服务器(Fedora 服务器)。
|
||||
|
||||
因此,如果你正在寻找一款时髦的桌面操作系统,有点学习曲线,又对用户友好,那么 Fedora 是一个选择。无论是哪种情况,如果你正在为你的服务器寻找一个 Linux 操作系统,这也是一个不错的选择。
|
||||
|
||||
- [Fedora][70]
|
||||
|
||||
#### Manjaro
|
||||
|
||||
![][71]
|
||||
|
||||
Manjaro 基于 [Arch Linux][72]。不用担心,虽然 Arch Linux 是为高级用户量身定制的,但Manjaro 让新手更容易上手。这是一个简单且对初学者友好的 Linux 发行版。用户界面足够好,并且内置了一系列有用的图形用户界面应用程序。
|
||||
|
||||
下载时,你可以为 Manjaro 选择[桌面环境][73]。就个人而言,我喜欢 Manjaro 的 KDE 桌面。
|
||||
|
||||
- [Manjaro Linux][74]
|
||||
|
||||
#### Debian
|
||||
|
||||
![][75]
|
||||
|
||||
嗯,Ubuntu 是基于 Debian 的——所以它本身是一个非常好的发行版本。Debian 是台式机和服务器的理想选择。
|
||||
|
||||
这可能不是对初学者最友好的操作系统——但你可以通过阅读[官方文档][76]轻松开始。[Debian 10 Buster][77] 的最新版本引入了许多变化和必要的改进。所以,你必须试一试!
|
||||
|
||||
### 总结
|
||||
|
||||
总的来说,这些是我们推荐你去尝试的最好的 Linux 发行版。是的,还有许多其他的 Linux 发行版值得一提,但是根据个人喜好,对每个发行版来说,取决于个人喜好,这种选择是主观的。
|
||||
|
||||
但是,我们也为 [Windows 用户][78]、[黑客和脆弱性测试人员][41]、[游戏玩家][54]、[程序员][39]和[偏重隐私者][79]提供了单独的发行版列表所以,如果你感兴趣的话请仔细阅读。
|
||||
|
||||
如果你认为我们遗漏了你最喜欢的 Linux 发行版,请在下面的评论中告诉我们你的想法,我们将更新这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-linux-distributions/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: tmp.NoRXbIWHkg#for-beginners
|
||||
[2]: tmp.NoRXbIWHkg#for-servers
|
||||
[3]: tmp.NoRXbIWHkg#for-old-computers
|
||||
[4]: tmp.NoRXbIWHkg#for-advanced-users
|
||||
[5]: tmp.NoRXbIWHkg#general-purpose
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/install-google-chrome-ubuntu-10.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/install-themes-ubuntu/
|
||||
[8]: https://itsfoss.com/tag/ubuntu/
|
||||
[9]: https://ubuntu.com/download/desktop
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-Mint-19-desktop.jpg?ssl=1
|
||||
[11]: https://www.linuxmint.com/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/elementary-os-juno-feat.jpg?ssl=1
|
||||
[13]: https://itsfoss.com/things-to-do-after-installing-elementary-os-5-juno/
|
||||
[14]: https://elementary.io/
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/mx-linux.jpg?ssl=1
|
||||
[16]: https://distrowatch.com/
|
||||
[17]: https://en.wikipedia.org/wiki/Linux_distribution#Rolling_distributions
|
||||
[18]: https://flatpak.org/
|
||||
[19]: https://mxlinux.org/
|
||||
[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/zorin-os-15.png?ssl=1
|
||||
[21]: https://itsfoss.com/zorin-os-15-release/
|
||||
[22]: https://itsfoss.com/zorin-os-interview/
|
||||
[23]: https://zorinos.com/
|
||||
[24]: https://www.deepin.org/en/
|
||||
[25]: https://itsfoss.com/ubuntu-vs-fedora/
|
||||
[26]: https://ubuntu.com/download/cloud
|
||||
[27]: https://w3techs.com/technologies/details/os-linux/all/all
|
||||
[28]: https://thecloudmarket.com/stats
|
||||
[29]: https://ubuntu.com/download/server
|
||||
[30]: https://developers.redhat.com/products/rhel/docs-and-apis
|
||||
[31]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[32]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/SUSE-Linux-Enterprise.jpg?ssl=1
|
||||
[33]: https://www.suse.com/products/server/
|
||||
[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/centos.png?ssl=1
|
||||
[35]: https://www.centos.org/
|
||||
[36]: https://getfedora.org/en/server/
|
||||
[37]: https://www.debian.org/distrib/
|
||||
[38]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/coding.jpg?ssl=1
|
||||
[39]: https://itsfoss.com/best-linux-distributions-progammers/
|
||||
[40]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/hacking.jpg?ssl=1
|
||||
[41]: https://itsfoss.com/linux-hacking-penetration-testing/
|
||||
[42]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[43]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/puppy-linux-bionic.jpg?ssl=1
|
||||
[44]: http://puppylinux.com/
|
||||
[45]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/solus-4-featured.jpg?resize=800%2C450&ssl=1
|
||||
[46]: https://itsfoss.com/solus-4-release/
|
||||
[47]: https://getsol.us/home/
|
||||
[48]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/bodhi-linux.png?fit=800%2C436&ssl=1
|
||||
[49]: http://www.bodhilinux.com/moksha-desktop/
|
||||
[50]: http://www.bodhilinux.com/
|
||||
[51]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/10/antix-linux-screenshot.jpg?ssl=1
|
||||
[52]: https://antixlinux.com/
|
||||
[53]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/sparky-linux.jpg?ssl=1
|
||||
[54]: https://itsfoss.com/linux-gaming-distributions/
|
||||
[55]: https://www.linuxliteos.com/
|
||||
[56]: https://lubuntu.me/
|
||||
[57]: https://peppermintos.com/
|
||||
[58]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/arch_linux_screenshot.jpg?ssl=1
|
||||
[59]: https://itsfoss.com/install-arch-linux/
|
||||
[60]: https://itsfoss.com/things-to-do-after-installing-arch-linux/
|
||||
[61]: https://www.archlinux.org
|
||||
[62]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/gentoo-linux.png?ssl=1
|
||||
[63]: https://wiki.gentoo.org/wiki/Handbook:Main_Page
|
||||
[64]: https://www.gentoo.org
|
||||
[65]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/slackware-screenshot.jpg?ssl=1
|
||||
[66]: https://itsfoss.com/earliest-linux-distros/
|
||||
[67]: https://distrowatch.com/dwres.php?resource=showheadline&story=8743
|
||||
[68]: http://www.slackware.com/
|
||||
[69]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/fedora-overview.png?ssl=1
|
||||
[70]: https://getfedora.org/
|
||||
[71]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/manjaro-gnome.jpg?ssl=1
|
||||
[72]: https://www.archlinux.org/
|
||||
[73]: https://itsfoss.com/glossary/desktop-environment/
|
||||
[74]: https://manjaro.org/
|
||||
[75]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/debian-screenshot.png?ssl=1
|
||||
[76]: https://www.debian.org/releases/stable/installmanual
|
||||
[77]: https://itsfoss.com/debian-10-buster/
|
||||
[78]: https://itsfoss.com/windows-like-linux-distributions/
|
||||
[79]: https://itsfoss.com/privacy-focused-linux-distributions/
|
||||
@ -0,0 +1,237 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11390-1.html)
|
||||
[#]: subject: (Different Ways to Configure Static IP Address in RHEL 8)
|
||||
[#]: via: (https://www.linuxtechi.com/configure-static-ip-address-rhel8/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
在 RHEL8 配置静态 IP 地址的不同方法
|
||||
======
|
||||
|
||||
在 Linux 服务器上工作时,在网卡/以太网卡上分配静态 IP 地址是每个 Linux 工程师的常见任务之一。如果一个人在 Linux 服务器上正确配置了静态地址,那么他/她就可以通过网络远程访问它。在本文中,我们将演示在 RHEL 8 服务器网卡上配置静态 IP 地址的不同方法。
|
||||
|
||||

|
||||
|
||||
以下是在网卡上配置静态IP的方法:
|
||||
|
||||
* `nmcli`(命令行工具)
|
||||
* 网络脚本文件(`ifcfg-*`)
|
||||
* `nmtui`(基于文本的用户界面)
|
||||
|
||||
### 使用 nmcli 命令行工具配置静态 IP 地址
|
||||
|
||||
每当我们安装 RHEL 8 服务器时,就会自动安装命令行工具 `nmcli`,它是由网络管理器使用的,可以让我们在以太网卡上配置静态 IP 地址。
|
||||
|
||||
运行下面的 `ip addr` 命令,列出 RHEL 8 服务器上的以太网卡
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ip addr
|
||||
```
|
||||
|
||||
正如我们在上面的命令输出中看到的,我们有两个网卡 `enp0s3` 和 `enp0s8`。当前分配给网卡的 IP 地址是通过 DHCP 服务器获得的。
|
||||
|
||||
假设我们希望在第一个网卡 (`enp0s3`) 上分配静态 IP 地址,具体内容如下:
|
||||
|
||||
* IP 地址 = 192.168.1.4
|
||||
* 网络掩码 = 255.255.255.0
|
||||
* 网关 = 192.168.1.1
|
||||
* DNS = 8.8.8.8
|
||||
|
||||
依次运行以下 `nmcli` 命令来配置静态 IP,
|
||||
|
||||
使用 `nmcli connection` 命令列出当前活动的以太网卡,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# nmcli connection
|
||||
NAME UUID TYPE DEVICE
|
||||
enp0s3 7c1b8444-cb65-440d-9bf6-ea0ad5e60bae ethernet enp0s3
|
||||
virbr0 3020c41f-6b21-4d80-a1a6-7c1bd5867e6c bridge virbr0
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
使用下面的 `nmcli` 给 `enp0s3` 分配静态 IP。
|
||||
|
||||
**命令语法:**
|
||||
|
||||
```
|
||||
# nmcli connection modify <interface_name> ipv4.address <ip/prefix>
|
||||
```
|
||||
|
||||
**注意:** 为了简化语句,在 `nmcli` 命令中,我们通常用 `con` 关键字替换 `connection`,并用 `mod` 关键字替换 `modify`。
|
||||
|
||||
将 IPv4 地址 (192.168.1.4) 分配给 `enp0s3` 网卡上,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.addresses 192.168.1.4/24
|
||||
```
|
||||
|
||||
使用下面的 `nmcli` 命令设置网关,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.gateway 192.168.1.1
|
||||
```
|
||||
|
||||
设置手动配置(从 dhcp 到 static),
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.method manual
|
||||
```
|
||||
|
||||
设置 DNS 值为 “8.8.8.8”,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.dns "8.8.8.8"
|
||||
```
|
||||
|
||||
要保存上述更改并重新加载,请执行如下 `nmcli` 命令,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# nmcli con up enp0s3
|
||||
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
|
||||
```
|
||||
|
||||
以上命令显示网卡 `enp0s3` 已成功配置。我们使用 `nmcli` 命令做的那些更改都将永久保存在文件 `etc/sysconfig/network-scripts/ifcfg-enp0s3` 里。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# cat /etc/sysconfig/network-scripts/ifcfg-enp0s3
|
||||
```
|
||||
|
||||
![ifcfg-enp0s3-file-rhel8][2]
|
||||
|
||||
要确认 IP 地址是否分配给了 `enp0s3` 网卡了,请使用以下 IP 命令查看,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]#ip addr show enp0s3
|
||||
```
|
||||
|
||||
### 使用网络脚本文件(ifcfg-*)手动配置静态 IP 地址
|
||||
|
||||
我们可以使用配置以太网卡的网络脚本或 `ifcfg-*` 文件来配置以太网卡的静态 IP 地址。假设我们想在第二个以太网卡 `enp0s8` 上分配静态 IP 地址:
|
||||
|
||||
* IP 地址 = 192.168.1.91
|
||||
* 前缀 = 24
|
||||
* 网关 =192.168.1.1
|
||||
* DNS1 =4.2.2.2
|
||||
|
||||
|
||||
转到目录 `/etc/sysconfig/network-scripts`,查找文件 `ifcfg-enp0s8`,如果它不存在,则使用以下内容创建它,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# cd /etc/sysconfig/network-scripts/
|
||||
[root@linuxtechi network-scripts]# vi ifcfg-enp0s8
|
||||
TYPE="Ethernet"
|
||||
DEVICE="enp0s8"
|
||||
BOOTPROTO="static"
|
||||
ONBOOT="yes"
|
||||
NAME="enp0s8"
|
||||
IPADDR="192.168.1.91"
|
||||
PREFIX="24"
|
||||
GATEWAY="192.168.1.1"
|
||||
DNS1="4.2.2.2"
|
||||
```
|
||||
|
||||
保存并退出文件,然后重新启动网络管理器服务以使上述更改生效,
|
||||
|
||||
```
|
||||
[root@linuxtechi network-scripts]# systemctl restart NetworkManager
|
||||
```
|
||||
|
||||
现在使用下面的 `ip` 命令来验证 IP 地址是否分配给网卡,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ip add show enp0s8
|
||||
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
|
||||
link/ether 08:00:27:7c:bb:cb brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.1.91/24 brd 192.168.1.255 scope global noprefixroute enp0s8
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe7c:bbcb/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
以上输出内容确认静态 IP 地址已在网卡 `enp0s8` 上成功配置了。
|
||||
|
||||
### 使用 nmtui 实用程序配置静态 IP 地址
|
||||
|
||||
`nmtui` 是一个基于文本用户界面的,用于控制网络的管理器,当我们执行 `nmtui` 时,它将打开一个基于文本的用户界面,通过它我们可以添加、修改和删除连接。除此之外,`nmtui` 还可以用来设置系统的主机名。
|
||||
|
||||
假设我们希望通过以下细节将静态 IP 地址分配给网卡 `enp0s3` ,
|
||||
|
||||
* IP 地址 = 10.20.0.72
|
||||
* 前缀 = 24
|
||||
* 网关 = 10.20.0.1
|
||||
* DNS1 = 4.2.2.2
|
||||
|
||||
运行 `nmtui` 并按照屏幕说明操作,示例如下所示,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# nmtui
|
||||
```
|
||||
|
||||
![nmtui-rhel8][3]
|
||||
|
||||
选择第一个选项 “Edit a connection”,然后选择接口为 “enp0s3”,
|
||||
|
||||
![Choose-interface-nmtui-rhel8][4]
|
||||
|
||||
选择 “Edit”,然后指定 IP 地址、前缀、网关和域名系统服务器 IP,
|
||||
|
||||
![set-ip-nmtui-rhel8][5]
|
||||
|
||||
选择确定,然后点击回车。在下一个窗口中,选择 “Activate a connection”,
|
||||
|
||||
![Activate-option-nmtui-rhel8][6]
|
||||
|
||||
选择 “enp0s3”,选择 “Deactivate” 并点击回车,
|
||||
|
||||
![Deactivate-interface-nmtui-rhel8][7]
|
||||
|
||||
现在选择 “Activate” 并点击回车,
|
||||
|
||||
![Activate-interface-nmtui-rhel8][8]
|
||||
|
||||
选择 “Back”,然后选择 “Quit”,
|
||||
|
||||
![Quit-Option-nmtui-rhel8][9]
|
||||
|
||||
使用下面的 `ip` 命令验证 IP 地址是否已分配给接口 `enp0s3`,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ip add show enp0s3
|
||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
|
||||
link/ether 08:00:27:53:39:4d brd ff:ff:ff:ff:ff:ff
|
||||
inet 10.20.0.72/24 brd 10.20.0.255 scope global noprefixroute enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::421d:5abf:58bd:c47e/64 scope link noprefixroute
|
||||
valid_lft forever preferred_lft forever
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
以上输出内容显示我们已经使用 `nmtui` 实用程序成功地将静态 IP 地址分配给接口 `enp0s3`。
|
||||
|
||||
以上就是本教程的全部内容,我们已经介绍了在 RHEL 8 系统上为以太网卡配置 IPv4 地址的三种不同方法。请在下面的评论部分分享反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/configure-static-ip-address-rhel8/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Configure-Static-IP-RHEL8.jpg
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/ifcfg-enp0s3-file-rhel8.jpg
|
||||
[3]: https://www.linuxtechi.com/wp-content/uploads/2019/09/nmtui-rhel8.jpg
|
||||
[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Choose-interface-nmtui-rhel8.jpg
|
||||
[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/set-ip-nmtui-rhel8.jpg
|
||||
[6]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Activate-option-nmtui-rhel8.jpg
|
||||
[7]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Deactivate-interface-nmtui-rhel8.jpg
|
||||
[8]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Activate-interface-nmtui-rhel8.jpg
|
||||
[9]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Quit-Option-nmtui-rhel8.jpg
|
||||
@ -0,0 +1,462 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11394-1.html)
|
||||
[#]: subject: (How to Setup Multi Node Elastic Stack Cluster on RHEL 8 / CentOS 8)
|
||||
[#]: via: (https://www.linuxtechi.com/setup-multinode-elastic-stack-cluster-rhel8-centos8/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
如何在 RHEL8 /CentOS8 上建立多节点 Elastic stack 集群
|
||||
======
|
||||
|
||||
|
||||
Elastic stack 俗称 ELK stack,是一组包括 Elasticsearch、Logstash 和 Kibana 在内的开源产品。Elastic Stack 由 Elastic 公司开发和维护。使用 Elastic stack,可以将系统日志发送到 Logstash,它是一个数据收集引擎,接受来自可能任何来源的日志或数据,并对日志进行归一化,然后将日志转发到 Elasticsearch,用于分析、索引、搜索和存储,最后使用 Kibana 表示为可视化数据,使用 Kibana,我们还可以基于用户的查询创建交互式图表。
|
||||
|
||||
![Elastic-Stack-Cluster-RHEL8-CentOS8][2]
|
||||
|
||||
在本文中,我们将演示如何在 RHEL 8 / CentOS 8 服务器上设置多节点 elastic stack 集群。以下是我的 Elastic Stack 集群的详细信息:
|
||||
|
||||
**Elasticsearch:**
|
||||
|
||||
* 三台服务器,最小化安装 RHEL 8 / CentOS 8
|
||||
* IP & 主机名 – 192.168.56.40(`elasticsearch1.linuxtechi.local`)、192.168.56.50 (`elasticsearch2.linuxtechi.local`)、192.168.56.60(elasticsearch3.linuxtechi.local`)
|
||||
|
||||
Logstash:**
|
||||
|
||||
* 两台服务器,最小化安装 RHEL 8 / CentOS 8
|
||||
* IP & 主机 – 192.168.56.20(`logstash1.linuxtechi.local`)、192.168.56.30(`logstash2.linuxtechi.local`)
|
||||
|
||||
**Kibana:**
|
||||
|
||||
* 一台服务器,最小化安装 RHEL 8 / CentOS 8
|
||||
* IP & 主机名 – 192.168.56.10(`kibana.linuxtechi.local`)
|
||||
|
||||
**Filebeat:**
|
||||
|
||||
* 一台服务器,最小化安装 CentOS 7
|
||||
* IP & 主机名 – 192.168.56.70(`web-server`)
|
||||
|
||||
让我们从设置 Elasticsearch 集群开始,
|
||||
|
||||
### 设置3个节点 Elasticsearch 集群
|
||||
|
||||
正如我已经说过的,设置 Elasticsearch 集群的节点,登录到每个节点,设置主机名并配置 yum/dnf 库。
|
||||
|
||||
使用命令 `hostnamectl` 设置各个节点上的主机名:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# hostnamectl set-hostname "elasticsearch1.linuxtechi. local"
|
||||
[root@linuxtechi ~]# exec bash
|
||||
[root@linuxtechi ~]#
|
||||
[root@linuxtechi ~]# hostnamectl set-hostname "elasticsearch2.linuxtechi. local"
|
||||
[root@linuxtechi ~]# exec bash
|
||||
[root@linuxtechi ~]#
|
||||
[root@linuxtechi ~]# hostnamectl set-hostname "elasticsearch3.linuxtechi. local"
|
||||
[root@linuxtechi ~]# exec bash
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
对于 CentOS 8 系统,我们不需要配置任何操作系统包库,对于 RHEL 8 服务器,如果你有有效订阅,那么用红帽订阅以获得包存储库就可以了。如果你想为操作系统包配置本地 yum/dnf 存储库,请参考以下网址:
|
||||
|
||||
- [如何使用 DVD 或 ISO 文件在 RHEL 8 服务器上设置本地 Yum / DNF 存储库][3]
|
||||
|
||||
在所有节点上配置 Elasticsearch 包存储库,在 `/etc/yum.repo.d/` 文件夹下创建一个包含以下内容的 `elastic.repo` 文件:
|
||||
|
||||
```
|
||||
~]# vi /etc/yum.repos.d/elastic.repo
|
||||
|
||||
[elasticsearch-7.x]
|
||||
name=Elasticsearch repository for 7.x packages
|
||||
baseurl=https://artifacts.elastic.co/packages/7.x/yum
|
||||
gpgcheck=1
|
||||
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
enabled=1
|
||||
autorefresh=1
|
||||
type=rpm-md
|
||||
```
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
在所有三个节点上使用 `rpm` 命令导入 Elastic 公共签名密钥。
|
||||
|
||||
```
|
||||
~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
```
|
||||
|
||||
在所有三个节点的 `/etc/hosts` 文件中添加以下行:
|
||||
|
||||
```
|
||||
192.168.56.40 elasticsearch1.linuxtechi.local
|
||||
192.168.56.50 elasticsearch2.linuxtechi.local
|
||||
192.168.56.60 elasticsearch3.linuxtechi.local
|
||||
```
|
||||
|
||||
使用 `yum`/`dnf` 命令在所有三个节点上安装 Java:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# dnf install java-openjdk -y
|
||||
[root@linuxtechi ~]# dnf install java-openjdk -y
|
||||
[root@linuxtechi ~]# dnf install java-openjdk -y
|
||||
```
|
||||
|
||||
使用 `yum`/`dnf` 命令在所有三个节点上安装 Elasticsearch:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# dnf install elasticsearch -y
|
||||
[root@linuxtechi ~]# dnf install elasticsearch -y
|
||||
[root@linuxtechi ~]# dnf install elasticsearch -y
|
||||
```
|
||||
|
||||
**注意:** 如果操作系统防火墙已启用并在每个 Elasticsearch 节点中运行,则使用 `firewall-cmd` 命令允许以下端口开放:
|
||||
|
||||
```
|
||||
~]# firewall-cmd --permanent --add-port=9300/tcp
|
||||
~]# firewall-cmd --permanent --add-port=9200/tcp
|
||||
~]# firewall-cmd --reload
|
||||
```
|
||||
|
||||
配置 Elasticsearch, 在所有节点上编辑文件 `/etc/elasticsearch/elasticsearch.yml` 并加入以下内容:
|
||||
|
||||
```
|
||||
~]# vim /etc/elasticsearch/elasticsearch.yml
|
||||
|
||||
cluster.name: opn-cluster
|
||||
node.name: elasticsearch1.linuxtechi.local
|
||||
network.host: 192.168.56.40
|
||||
http.port: 9200
|
||||
discovery.seed_hosts: ["elasticsearch1.linuxtechi.local", "elasticsearch2.linuxtechi.local", "elasticsearch3.linuxtechi.local"]
|
||||
cluster.initial_master_nodes: ["elasticsearch1.linuxtechi.local", "elasticsearch2.linuxtechi.local", "elasticsearch3.linuxtechi.local"]
|
||||
```
|
||||
|
||||
**注意:** 在每个节点上,在 `node.name` 中填写正确的主机名,在 `network.host` 中填写正确的 IP 地址,其他参数保持不变。
|
||||
|
||||
现在使用 `systemctl` 命令在所有三个节点上启动并启用 Elasticsearch 服务:
|
||||
|
||||
```
|
||||
~]# systemctl daemon-reload
|
||||
~]# systemctl enable elasticsearch.service
|
||||
~]# systemctl start elasticsearch.service
|
||||
```
|
||||
|
||||
使用下面 `ss` 命令验证 elasticsearch 节点是否开始监听 9200 端口:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ss -tunlp | grep 9200
|
||||
tcp LISTEN 0 128 [::ffff:192.168.56.40]:9200 *:* users:(("java",pid=2734,fd=256))
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
使用以下 `curl` 命令验证 Elasticsearch 群集状态:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# curl http://elasticsearch1.linuxtechi.local:9200
|
||||
[root@linuxtechi ~]# curl -X GET http://elasticsearch2.linuxtechi.local:9200/_cluster/health?pretty
|
||||
```
|
||||
|
||||
命令的输出如下所示:
|
||||
|
||||
![Elasticsearch-cluster-status-rhel8][3]
|
||||
|
||||
以上输出表明我们已经成功创建了 3 节点的 Elasticsearch 集群,集群的状态也是绿色的。
|
||||
|
||||
**注意:** 如果你想修改 JVM 堆大小,那么你可以编辑了文件 `/etc/elasticsearch/jvm.options`,并根据你的环境更改以下参数:
|
||||
|
||||
* `-Xms1g`
|
||||
* `-Xmx1g`
|
||||
|
||||
现在让我们转到 Logstash 节点。
|
||||
|
||||
### 安装和配置 Logstash
|
||||
|
||||
在两个 Logstash 节点上执行以下步骤。
|
||||
|
||||
登录到两个节点使用 `hostnamectl` 命令设置主机名:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# hostnamectl set-hostname "logstash1.linuxtechi.local"
|
||||
[root@linuxtechi ~]# exec bash
|
||||
[root@linuxtechi ~]#
|
||||
[root@linuxtechi ~]# hostnamectl set-hostname "logstash2.linuxtechi.local"
|
||||
[root@linuxtechi ~]# exec bash
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
在两个 logstash 节点的 `/etc/hosts` 文件中添加以下条目:
|
||||
|
||||
```
|
||||
~]# vi /etc/hosts
|
||||
192.168.56.40 elasticsearch1.linuxtechi.local
|
||||
192.168.56.50 elasticsearch2.linuxtechi.local
|
||||
192.168.56.60 elasticsearch3.linuxtechi.local
|
||||
```
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
在两个节点上配置 Logstash 存储库,在文件夹 `/ete/yum.repo.d/` 下创建一个包含以下内容的文件 `logstash.repo`:
|
||||
|
||||
```
|
||||
~]# vi /etc/yum.repos.d/logstash.repo
|
||||
|
||||
[elasticsearch-7.x]
|
||||
name=Elasticsearch repository for 7.x packages
|
||||
baseurl=https://artifacts.elastic.co/packages/7.x/yum
|
||||
gpgcheck=1
|
||||
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
enabled=1
|
||||
autorefresh=1
|
||||
type=rpm-md
|
||||
```
|
||||
|
||||
保存并退出文件,运行 `rpm` 命令导入签名密钥:
|
||||
|
||||
```
|
||||
~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
```
|
||||
|
||||
使用 `yum`/`dnf` 命令在两个节点上安装 Java OpenJDK:
|
||||
|
||||
```
|
||||
~]# dnf install java-openjdk -y
|
||||
```
|
||||
|
||||
从两个节点运行 `yum`/`dnf` 命令来安装 logstash:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# dnf install logstash -y
|
||||
[root@linuxtechi ~]# dnf install logstash -y
|
||||
```
|
||||
|
||||
现在配置 logstash,在两个 logstash 节点上执行以下步骤,创建一个 logstash 配置文件,首先我们在 `/etc/logstash/conf.d/` 下复制 logstash 示例文件:
|
||||
|
||||
```
|
||||
# cd /etc/logstash/
|
||||
# cp logstash-sample.conf conf.d/logstash.conf
|
||||
```
|
||||
|
||||
编辑配置文件并更新以下内容:
|
||||
|
||||
```
|
||||
# vi conf.d/logstash.conf
|
||||
|
||||
input {
|
||||
beats {
|
||||
port => 5044
|
||||
}
|
||||
}
|
||||
|
||||
output {
|
||||
elasticsearch {
|
||||
hosts => ["http://elasticsearch1.linuxtechi.local:9200", "http://elasticsearch2.linuxtechi.local:9200", "http://elasticsearch3.linuxtechi.local:9200"]
|
||||
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
|
||||
#user => "elastic"
|
||||
#password => "changeme"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
在 `output` 部分之下,在 `hosts` 参数中指定所有三个 Elasticsearch 节点的 FQDN,其他参数保持不变。
|
||||
|
||||
使用 `firewall-cmd` 命令在操作系统防火墙中允许 logstash 端口 “5044”:
|
||||
|
||||
```
|
||||
~ # firewall-cmd --permanent --add-port=5044/tcp
|
||||
~ # firewall-cmd –reload
|
||||
```
|
||||
|
||||
现在,在每个节点上运行以下 `systemctl` 命令,启动并启用 Logstash 服务:
|
||||
|
||||
```
|
||||
~]# systemctl start logstash
|
||||
~]# systemctl eanble logstash
|
||||
```
|
||||
|
||||
使用 `ss` 命令验证 logstash 服务是否开始监听 5044 端口:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ss -tunlp | grep 5044
|
||||
tcp LISTEN 0 128 *:5044 *:* users:(("java",pid=2416,fd=96))
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
以上输出表明 logstash 已成功安装和配置。让我们转到 Kibana 安装。
|
||||
|
||||
### 安装和配置 Kibana
|
||||
|
||||
登录 Kibana 节点,使用 `hostnamectl` 命令设置主机名:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# hostnamectl set-hostname "kibana.linuxtechi.local"
|
||||
[root@linuxtechi ~]# exec bash
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
编辑 `/etc/hosts` 文件并添加以下行:
|
||||
|
||||
```
|
||||
192.168.56.40 elasticsearch1.linuxtechi.local
|
||||
192.168.56.50 elasticsearch2.linuxtechi.local
|
||||
192.168.56.60 elasticsearch3.linuxtechi.local
|
||||
```
|
||||
|
||||
使用以下命令设置 Kibana 存储库:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/yum.repos.d/kibana.repo
|
||||
[elasticsearch-7.x]
|
||||
name=Elasticsearch repository for 7.x packages
|
||||
baseurl=https://artifacts.elastic.co/packages/7.x/yum
|
||||
gpgcheck=1
|
||||
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
enabled=1
|
||||
autorefresh=1
|
||||
type=rpm-md
|
||||
|
||||
[root@linuxtechi ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
```
|
||||
|
||||
执行 `yum`/`dnf` 命令安装 kibana:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# yum install kibana -y
|
||||
```
|
||||
|
||||
通过编辑 `/etc/kibana/kibana.yml` 文件,配置 Kibana:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vim /etc/kibana/kibana.yml
|
||||
…………
|
||||
server.host: "kibana.linuxtechi.local"
|
||||
server.name: "kibana.linuxtechi.local"
|
||||
elasticsearch.hosts: ["http://elasticsearch1.linuxtechi.local:9200", "http://elasticsearch2.linuxtechi.local:9200", "http://elasticsearch3.linuxtechi.local:9200"]
|
||||
…………
|
||||
```
|
||||
|
||||
启用并启动 kibana 服务:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# systemctl start kibana
|
||||
[root@linuxtechi ~]# systemctl enable kibana
|
||||
```
|
||||
|
||||
在系统防火墙上允许 Kibana 端口 “5601”:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# firewall-cmd --permanent --add-port=5601/tcp
|
||||
success
|
||||
[root@linuxtechi ~]# firewall-cmd --reload
|
||||
success
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
使用以下 URL 访问 Kibana 界面:<http://kibana.linuxtechi.local:5601>
|
||||
|
||||
![Kibana-Dashboard-rhel8][4]
|
||||
|
||||
从面板上,我们可以检查 Elastic Stack 集群的状态。
|
||||
|
||||
![Stack-Monitoring-Overview-RHEL8][5]
|
||||
|
||||
这证明我们已经在 RHEL 8 /CentOS 8 上成功地安装并设置了多节点 Elastic Stack 集群。
|
||||
|
||||
现在让我们通过 `filebeat` 从其他 Linux 服务器发送一些日志到 logstash 节点中,在我的例子中,我有一个 CentOS 7服务器,我将通过 `filebeat` 将该服务器的所有重要日志推送到 logstash。
|
||||
|
||||
登录到 CentOS 7 服务器使用 yum/rpm 命令安装 filebeat 包:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# rpm -ivh https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-x86_64.rpm
|
||||
Retrieving https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-x86_64.rpm
|
||||
Preparing... ################################# [100%]
|
||||
Updating / installing...
|
||||
1:filebeat-7.3.1-1 ################################# [100%]
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
编辑 `/etc/hosts` 文件并添加以下内容:
|
||||
|
||||
```
|
||||
192.168.56.20 logstash1.linuxtechi.local
|
||||
192.168.56.30 logstash2.linuxtechi.local
|
||||
```
|
||||
|
||||
现在配置 `filebeat`,以便它可以使用负载平衡技术向 logstash 节点发送日志,编辑文件 `/etc/filebeat/filebeat.yml`,并添加以下参数:
|
||||
|
||||
在 `filebeat.inputs:` 部分将 `enabled: false` 更改为 `enabled: true`,并在 `paths` 参数下指定我们可以发送到 logstash 的日志文件的位置;注释掉 `output.elasticsearch` 和 `host` 参数;删除 `output.logstash:` 和 `hosts:` 的注释,并在 `hosts` 参数添加两个 logstash 节点,以及设置 `loadbalance: true`。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/filebeat/filebeat.yml
|
||||
|
||||
filebeat.inputs:
|
||||
- type: log
|
||||
enabled: true
|
||||
paths:
|
||||
- /var/log/messages
|
||||
- /var/log/dmesg
|
||||
- /var/log/maillog
|
||||
- /var/log/boot.log
|
||||
#output.elasticsearch:
|
||||
# hosts: ["localhost:9200"]
|
||||
|
||||
output.logstash:
|
||||
hosts: ["logstash1.linuxtechi.local:5044", "logstash2.linuxtechi.local:5044"]
|
||||
loadbalance: true
|
||||
```
|
||||
|
||||
使用下面的 2 个 `systemctl` 命令 启动并启用 `filebeat` 服务:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# systemctl start filebeat
|
||||
[root@linuxtechi ~]# systemctl enable filebeat
|
||||
```
|
||||
|
||||
现在转到 Kibana 用户界面,验证新索引是否可见。
|
||||
|
||||
从左侧栏中选择管理选项,然后单击 Elasticsearch 下的索引管理:
|
||||
|
||||
![Elasticsearch-index-management-Kibana][6]
|
||||
|
||||
正如我们上面看到的,索引现在是可见的,让我们现在创建索引模型。
|
||||
|
||||
点击 Kibana 部分的 “Index Patterns”,它将提示我们创建一个新模型,点击 “Create Index Pattern” ,并将模式名称指定为 “filebeat”:
|
||||
|
||||
![Define-Index-Pattern-Kibana-RHEL8][7]
|
||||
|
||||
点击下一步。
|
||||
|
||||
选择 “Timestamp” 作为索引模型的时间过滤器,然后单击 “Create index pattern”:
|
||||
|
||||
![Time-Filter-Index-Pattern-Kibana-RHEL8][8]
|
||||
|
||||
![filebeat-index-pattern-overview-Kibana][9]
|
||||
|
||||
现在单击查看实时 filebeat 索引模型:
|
||||
|
||||
![Discover-Kibana-REHL8][10]
|
||||
|
||||
这表明 Filebeat 代理已配置成功,我们能够在 Kibana 仪表盘上看到实时日志。
|
||||
|
||||
以上就是本文的全部内容,对这些帮助你在 RHEL 8 / CentOS 8 系统上设置 Elastic Stack 集群的步骤,请不要犹豫分享你的反馈和意见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/setup-multinode-elastic-stack-cluster-rhel8-centos8/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Elastic-Stack-Cluster-RHEL8-CentOS8.jpg
|
||||
[3]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Elasticsearch-cluster-status-rhel8.jpg
|
||||
[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Kibana-Dashboard-rhel8.jpg
|
||||
[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Stack-Monitoring-Overview-RHEL8.jpg
|
||||
[6]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Elasticsearch-index-management-Kibana.jpg
|
||||
[7]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Define-Index-Pattern-Kibana-RHEL8.jpg
|
||||
[8]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Time-Filter-Index-Pattern-Kibana-RHEL8.jpg
|
||||
[9]: https://www.linuxtechi.com/wp-content/uploads/2019/09/filebeat-index-pattern-overview-Kibana.jpg
|
||||
[10]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Discover-Kibana-REHL8.jpg
|
||||
@ -0,0 +1,117 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11409-1.html)
|
||||
[#]: subject: (How to use Terminator on Linux to run multiple terminals in one window)
|
||||
[#]: via: (https://www.networkworld.com/article/3436784/how-to-use-terminator-on-linux-to-run-multiple-terminals-in-one-window.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
使用 Terminator 在一个窗口中运行多个终端
|
||||
======
|
||||
|
||||

|
||||
|
||||
> Terminator 为在单窗口中运行多个 GNOME 终端提供了一个选择,让你可以灵活地调整工作空间来适应你的需求。
|
||||
|
||||
|
||||
|
||||
如果你曾经希望可以排列多个终端并将它们组织在一个窗口中,那么我们可能会给你带来一个好消息。 Linux 的 Terminator 可以为你做到这一点。没有问题!
|
||||
|
||||
### 分割窗口
|
||||
|
||||
Terminator 最初打开像是一个单一窗口的终端窗口一样。但是,一旦在该窗口中单击鼠标,它将弹出一个选项,让你可以灵活地进行更改。你可以选择“水平分割”或“垂直分割”,将你当前所在的窗口分为两个较小的窗口。实际上,菜单旁会有小的分割结果图示(类似于 `=` and `||`),你可以根据需要重复拆分窗口。当然,你如果将整个窗口分为六个或九个以上,那么你可能会发现它们太小而无法有效使用。
|
||||
|
||||
使用 ASCII 艺术来说明分割窗口的过程,你可能会看到类似以下的样子:
|
||||
|
||||
```
|
||||
+-------------------+ +-------------------+ +-------------------+
|
||||
| | | | | |
|
||||
| | | | | |
|
||||
| | ==> |-------------------| ==> |-------------------|
|
||||
| | | | | | |
|
||||
| | | | | | |
|
||||
+-------------------+ +-------------------+ +-------------------+
|
||||
原始终端 水平分割 垂直分割
|
||||
```
|
||||
|
||||
另一种拆分窗口的方法是使用控制键组合,例如,使用 `Ctrl+Shift+e` 垂直分割窗口,使用 `Ctrl+Shift+o`(“o” 表示“打开”)水平分割窗口。
|
||||
|
||||
在 Terminator 分割完成后,你可以点击任意窗口使用,并根据工作需求在窗口间移动。
|
||||
|
||||
### 最大化窗口
|
||||
|
||||
如果你想暂时忽略除了一个窗口外的其他窗口而只关注一个,你可以单击该窗口,然后从菜单中选择“最大化”选项。接着该窗口会撑满所有空间。再次单击并选择“还原所有终端”可以返回到多窗口显示。使用 `Ctrl+Shift+x` 将在正常和最大化设置之间切换。
|
||||
|
||||
窗口标签上的窗口大小指示(例如 80x15)显示了每行的字符数以及每个窗口的行数。
|
||||
|
||||
### 关闭窗口
|
||||
|
||||
要关闭任何窗口,请打开 Terminator 菜单,然后选择“关闭”。其他窗口将自行调整占用空间,直到你关闭最后一个窗口。
|
||||
|
||||
### 保存你的自定义设置
|
||||
|
||||
将窗口分为多个部分后,将自定义的 Terminator 设置设置为默认非常容易。从弹出菜单中选择“首选项”,然后从打开的窗口顶部的选项卡中选择“布局”。接着你应该看到列出了“新布局”。只需单击底部的“保存”,然后单击右下角的“关闭”。Terminator 会将你的设置保存在 `~/.config/terminator/config` 中,然后每次使用到时都会使用该文件。
|
||||
|
||||
你也可以通过使用鼠标拉伸来扩大整个窗口。再说一次,如果要保留更改,请从菜单中选择“首选项”,“布局”,接着选择“保存”和“关闭”。
|
||||
|
||||
### 在保存的配置之间进行选择
|
||||
|
||||
如果愿意,你可以通过维护多个配置文件来设置多种 Terminator 窗口布局,重命名每个配置文件(如 `config-1`、`config-2`),接着在你想使用它时将它移动到 `~/.config/terminator/config`。这有一个类似执行此任务的脚本。它让你在 3 个预配置的窗口布局之间进行选择。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
PS3='Terminator options: '
|
||||
options=("Split 1" "Split 2" "Split 3" "Quit")
|
||||
select opt in "${options[@]}"
|
||||
do
|
||||
case $opt in
|
||||
"Split 1")
|
||||
config=config-1
|
||||
break
|
||||
;;
|
||||
"Split 2")
|
||||
config=config-2
|
||||
break
|
||||
;;
|
||||
"Split 3")
|
||||
config=config-3
|
||||
break
|
||||
;;
|
||||
*)
|
||||
exit
|
||||
;;
|
||||
esac
|
||||
done
|
||||
|
||||
cd ~/.config/terminator
|
||||
cp config config-
|
||||
cp $config config
|
||||
cd
|
||||
terminator &
|
||||
```
|
||||
|
||||
如果有用的话,你可以给选项一个比 `config-1` 更有意义的名称。
|
||||
|
||||
### 总结
|
||||
|
||||
Terminator 是设置多窗口处理相关任务的不错选择。如果你从未使用过它,那么可能需要先使用 `sudo apt install terminator` 或 `sudo yum install -y terminator` 之类的命令进行安装。
|
||||
|
||||
希望你喜欢使用 Terminator。还有,如另一个同名角色所说,“我会回来的!”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3436784/how-to-use-terminator-on-linux-to-run-multiple-terminals-in-one-window.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
153
published/201909/20190912 An introduction to Markdown.md
Normal file
153
published/201909/20190912 An introduction to Markdown.md
Normal file
@ -0,0 +1,153 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11402-1.html)
|
||||
[#]: subject: (An introduction to Markdown)
|
||||
[#]: via: (https://opensource.com/article/19/9/introduction-markdown)
|
||||
[#]: author: (Juan Islas https://opensource.com/users/xislas)
|
||||
|
||||
一份 Markdown 简介
|
||||
======
|
||||
|
||||
> 一次编辑便可将文本转换为多种格式。下面是如何开始使用 Markdown。
|
||||
|
||||

|
||||
|
||||
在很长一段时间里,我发现我在 GitLab 和 GitHub 上看到的所有文件都带有 **.md** 扩展名,这是专门为开发人员编写的文件类型。几周前,当我开始使用 Markdown 时,我的观念发生了变化。它很快成为我日常工作中最重要的工具。
|
||||
|
||||
Markdown 使我的生活更简易。我只需要在已经编写的代码中添加一些符号,并且在浏览器扩展或开源程序的帮助下,即可将文本转换为各种常用格式,如 ODT、电子邮件(稍后将详细介绍)、PDF 和 EPUB。
|
||||
|
||||
### 什么是 Markdown?
|
||||
|
||||
来自 [维基百科][2]的友情提示:
|
||||
|
||||
> Markdown 是一种轻量级标记语言,具有纯文本格式语法。
|
||||
|
||||
这意味着通过在文本中使用一些额外的符号,Markdown 可以帮助你创建具有特定结构和格式的文档。当你以纯文本(例如,在记事本应用程序中)做笔记时,没有任何东西表明哪个文本应该是粗体或斜体。在普通文本中,你在写链接时需要将一个链接写为 “http://example.com”,或者写为 “example.com”,又或“访问网站(example.com)”。这样没有内在的一致性。
|
||||
|
||||
但是如果你按照 Markdown 的方式编写,你的文本就有了内在的一致性。计算机喜欢一致性,因为这使得它们能够遵循严格的指令而不用担心异常。
|
||||
|
||||
相信我;一旦你学会使用 Markdown,每一项写作任务在某种程度上都会比以前更容易、更好。让我们开始吧。
|
||||
|
||||
### Markdown 基础
|
||||
|
||||
以下是使用 Markdown 的基础语法。
|
||||
|
||||
1、创建一个以 **.md** 扩展名结尾的文本文件(例如,`example.md`)。你可以使用任何文本编辑器(甚至像 LibreOffice 或 Microsoft word 这样的文字处理程序亦可),只要记住将其保存为*文本*文件。
|
||||
|
||||
![Names of Markdown files][3]
|
||||
|
||||
2、想写什么就写什么,就像往常一样:
|
||||
|
||||
```
|
||||
Lorem ipsum
|
||||
|
||||
Consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
|
||||
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
|
||||
Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
|
||||
|
||||
De Finibus Bonorum et Malorum
|
||||
|
||||
Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo.
|
||||
Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt.
|
||||
|
||||
Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem.
|
||||
```
|
||||
|
||||
(LCTT 译注:上述这段“Lorem ipsum”,中文又称“乱数假文”,是一篇常用于排版设计领域的拉丁文文章,主要目的为测试文章或文字在不同字型、版型下看起来的效果。)
|
||||
|
||||
3、确保在段落之间留有空行。如果你习惯写商务信函或传统散文,这可能会觉得不自然,因为那里段落只有一行,甚至在第一个单词前还有一个缩进。对于 Markdown,空行(一些文字处理程序使用 `¶`,称为Pilcrow 符号)保证在创建一个新段落应用另一种格式(如 HTML)。
|
||||
|
||||
4、指定标题和副标题。对于文档的标题,在文本前面添加一个井号或散列符号(`#`)和一个空格(例如 `# Lorem ipsum`)。第一个副标题级别使用两个(`## De Finibus Bonorum et Malorum`),下一个级别使用三个(`### 第三个副标题`),以此类推。注意,在井号和第一个单词之间有一个空格。
|
||||
|
||||
```
|
||||
# Lorem ipsum
|
||||
|
||||
Consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
|
||||
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
|
||||
Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
|
||||
|
||||
## De Finibus Bonorum et Malorum
|
||||
|
||||
Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo.
|
||||
Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt.
|
||||
|
||||
Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem.
|
||||
```
|
||||
|
||||
5、如果你想使用**粗体**字符,只需将字母放在两个星号之间,没有空格:`**对应的文本将以粗体显示**`。
|
||||
|
||||
![Bold text in Markdown][4]
|
||||
|
||||
6、对于**斜体**,将文本放在没有空格的下划线符号之间:`_我希望这个本文以斜体显示_`。(LCTT 译注:有的 Markdown 流派会将用下划线引起来的字符串视作下划线文本,而单个星号 `*` 引用起来的才视作斜体。从兼容性的角度看,使用星号比较兼容。)
|
||||
|
||||
![Italics text in Markdown][5]
|
||||
|
||||
7、要插入一个链接(像 [Markdown Tutorial][6]),把你想链接的文本放在括号里,URL 放在括号里,中间没有空格:`[Markdown Tutorial](<https://www.markdowntutorial.com/>)`。
|
||||
|
||||
![Hyperlinks in Markdown][7]
|
||||
|
||||
8、块引用是用大于号编写的(`>`)在你要引用的文本前加上大于符号和空格: `> 名言引用`。
|
||||
|
||||
![Blockquote text in Markdown][8]
|
||||
|
||||
### Markdown 教程和技巧
|
||||
|
||||
这些技巧可以帮助你上手 Markdown ,但它涵盖了很多功能,不仅仅是粗体、斜体和链接。学习 Markdown 的最好方法是使用它,但是我建议你花 15 分钟来学习这篇简单的 [Markdown 教程][6],学以致用,勤加练习。
|
||||
|
||||
由于现代 Markdown 是对结构化文本概念的许多不同解释的融合,[CommonMark][9] 项目定义了一个规范,其中包含一组严格的规则,以使 Markdown 更加清晰。在编辑时手边准备一份[符合 CommonMark 的快捷键列表][10]可能会有帮助。
|
||||
|
||||
### 你能用 Markdown 做什么
|
||||
|
||||
Markdown 可以让你写任何你想写的东西,仅需一次编辑,就可以把它转换成几乎任何你想使用的格式。下面的示例演示如何将用 MD 编写简单的文本并转换为不同的格式。你不需要多种格式的文档-你可以仅仅编辑一次…然后拥有无限可能。
|
||||
|
||||
1、**简单的笔记**:你可以用 Markdown 编写你的笔记,并且在保存笔记时,开源笔记应用程序 [Turtl][11] 将解释你的文本文件并显示为对应的格式。你可以把笔记存储在任何地方!
|
||||
|
||||
![Turtl application][12]
|
||||
|
||||
2、**PDF 文件**:使用 [Pandoc][13] 应用程序,你可以使用一个简单的命令将 Markdown 文件转换为 PDF:
|
||||
|
||||
```
|
||||
pandoc <file.md> -o <file.pdf>
|
||||
```
|
||||
|
||||
![Markdown text converted to PDF with Pandoc][14]
|
||||
|
||||
3、**Email**:你还可以通过安装浏览器扩展 [Markdown Here][15] 将 Markdown 文本转换为 html 格式的电子邮件。要使用它,只需选择你的 Markdown 文本,在这里使用 Markdown 将其转换为 HTML,并使用你喜欢的电子邮件客户端发送消息。
|
||||
|
||||
![Markdown text converted to email with Markdown Here][16]
|
||||
|
||||
### 现在就开始上手吧
|
||||
|
||||
你不需要一个特殊的应用程序来使用 Markdown,你只需要一个文本编辑器和上面的技巧。它与你已有的写作方式兼容;你所需要做的就是使用它,所以试试吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/9/introduction-markdown
|
||||
|
||||
作者:[Juan Islas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/xislas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop-music-headphones.png?itok=EQZ2WKzy (Woman programming)
|
||||
[2]: https://en.wikipedia.org/wiki/Markdown
|
||||
[3]: https://opensource.com/sites/default/files/uploads/markdown_names_md-1.png (Names of Markdown files)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/markdown_bold.png (Bold text in Markdown)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/markdown_italic.png (Italics text in Markdown)
|
||||
[6]: https://www.markdowntutorial.com/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/markdown_link.png (Hyperlinks in Markdown)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/markdown_blockquote.png (Blockquote text in Markdown)
|
||||
[9]: https://commonmark.org/help/
|
||||
[10]: https://opensource.com/downloads/cheat-sheet-markdown
|
||||
[11]: https://turtlapp.com/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/markdown_turtl_02.png (Turtl application)
|
||||
[13]: https://opensource.com/article/19/5/convert-markdown-to-word-pandoc
|
||||
[14]: https://opensource.com/sites/default/files/uploads/markdown_pdf.png (Markdown text converted to PDF with Pandoc)
|
||||
[15]: https://markdown-here.com/
|
||||
[16]: https://opensource.com/sites/default/files/uploads/markdown_mail_02.png (Markdown text converted to email with Markdown Here)
|
||||
@ -1,15 +1,18 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11384-1.html)
|
||||
[#]: subject: (How to freeze and lock your Linux system (and why you would want to))
|
||||
[#]: via: (https://www.networkworld.com/article/3438818/how-to-freeze-and-lock-your-linux-system-and-why-you-would-want-to.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何冻结和锁定你的 Linux 系统(以及为何你会希望做)
|
||||
如何冻结和锁定你的 Linux 系统
|
||||
======
|
||||
冻结终端窗口并锁定屏幕意味着什么 - 以及如何在 Linux 系统上管理这些活动。
|
||||
|
||||
> 冻结终端窗口并锁定屏幕意味着什么 - 以及如何在 Linux 系统上管理这些活动。
|
||||
|
||||

|
||||
|
||||
如何在 Linux 系统上冻结和“解冻”屏幕,很大程度上取决于这些术语的含义。有时“冻结屏幕”可能意味着冻结终端窗口,以便该窗口内的活动停止。有时它意味着锁定屏幕,这样就没人可以在你去拿一杯咖啡时,走到你的系统旁边代替你输入命令了。
|
||||
|
||||
@ -17,9 +20,9 @@
|
||||
|
||||
### 如何在 Linux 上冻结终端窗口
|
||||
|
||||
你可以输入 **Ctrl+S**(按住 Ctrl 键和 “s” 键)冻结 Linux 系统上的终端窗口。把 “s” 想象成“开始冻结” (start the freeze)。如果在此操作后继续输入命令,那么你不会看到输入的命令或你希望看到的输出。实际上,命令将堆积在一个队列中,并且只有在通过输入 **Ctrl+Q** 解冻时才会运行。把它想象成“退出冻结” (quit the freeze)。
|
||||
你可以输入 `Ctrl+S`(按住 `Ctrl` 键和 `s` 键)冻结 Linux 系统上的终端窗口。把 `s` 想象成“<ruby>开始冻结<rt>start the freeze</rt></ruby>”。如果在此操作后继续输入命令,那么你不会看到输入的命令或你希望看到的输出。实际上,命令将堆积在一个队列中,并且只有在通过输入 `Ctrl+Q` 解冻时才会运行。把它想象成“<ruby>退出冻结<rt>quit the freeze</rt></ruby>”。
|
||||
|
||||
查看其工作的一种简单方式是使用 date 命令,然后输入 **Ctrl+S**。接着再次输入 date 命令并等待几分钟后再次输入 **Ctrl+Q**。你会看到这样的情景:
|
||||
查看其工作的一种简单方式是使用 `date` 命令,然后输入 `Ctrl+S`。接着再次输入 `date` 命令并等待几分钟后再次输入 `Ctrl+Q`。你会看到这样的情景:
|
||||
|
||||
```
|
||||
$ date
|
||||
@ -28,25 +31,25 @@ $ date
|
||||
Mon 16 Sep 2019 06:49:49 PM EDT
|
||||
```
|
||||
|
||||
这两次时间显示的差距表示第二次的 date 命令直到你解冻窗口时才运行。
|
||||
这两次时间显示的差距表示第二次的 `date` 命令直到你解冻窗口时才运行。
|
||||
|
||||
无论你是坐在计算机屏幕前还是使用 PuTTY 等工具远程运行,终端窗口都可以冻结和解冻。
|
||||
|
||||
这有一个可以派上用场的小技巧。如果你发现终端窗口似乎处于非活动状态,那么可能是你或其他人无意中输入了 **Ctrl+S**。无论如何,输入 **Ctrl+Q** 来尝试解决不妨是个不错的办法。
|
||||
这有一个可以派上用场的小技巧。如果你发现终端窗口似乎处于非活动状态,那么可能是你或其他人无意中输入了 `Ctrl+S`。那么,输入 `Ctrl+Q` 来尝试解决不妨是个不错的办法。
|
||||
|
||||
### 如何锁定屏幕
|
||||
|
||||
要在离开办公桌前锁定屏幕,请按住 **Ctrl+Alt+L** 或 **Super+L**(即按住 Windows 键和 L 键)。屏幕锁定后,你必须输入密码才能重新登录。
|
||||
要在离开办公桌前锁定屏幕,请按住 `Ctrl+Alt+L` 或 `Super+L`(即按住 `Windows` 键和 `L` 键)。屏幕锁定后,你必须输入密码才能重新登录。
|
||||
|
||||
### Linux 系统上的自动屏幕锁定
|
||||
|
||||
虽然最佳做法建议你在即将离开办公桌时锁定屏幕,但 Linux 系统通常会在一段时间没有活动后自动锁定。 “消隐”屏幕(使其变暗)并实际锁定屏幕(需要登录才能再次使用)的时间取决于你个人首选项中的设置。
|
||||
|
||||
要更改使用 GNOME 屏幕保护程序时屏幕变暗所需的时间,请打开设置窗口并选择 **Power** 然后 **Blank screen**。你可以选择 1 到 15 分钟或从不变暗。要选择屏幕变暗后锁定所需时间,请进入设置,选择 **Privacy**,然后选择**Blank screen**。设置应包括 1、2、3、5 和 30 分钟或一小时。
|
||||
要更改使用 GNOME 屏幕保护程序时屏幕变暗所需的时间,请打开设置窗口并选择 “Power” 然后 “Blank screen”。你可以选择 1 到 15 分钟或从不变暗。要选择屏幕变暗后锁定所需时间,请进入设置,选择 “Privacy”,然后选择 “Blank screen”。设置应包括 1、2、3、5 和 30 分钟或一小时。
|
||||
|
||||
### 如何在命令行锁定屏幕
|
||||
|
||||
如果你使用的是 Gnome 屏幕保护程序,你还可以使用以下命令从命令行锁定屏幕:
|
||||
如果你使用的是 GNOME 屏幕保护程序,你还可以使用以下命令从命令行锁定屏幕:
|
||||
|
||||
```
|
||||
gnome-screensaver-command -l
|
||||
@ -56,7 +59,7 @@ gnome-screensaver-command -l
|
||||
|
||||
### 如何检查锁屏状态
|
||||
|
||||
你还可以使用 gnome-screensaver 命令检查屏幕是否已锁定。使用 **\--query** 选项,该命令会告诉你屏幕当前是否已锁定(即处于活动状态)。使用 --time 选项,它会告诉你锁定生效的时间。这是一个示例脚本:
|
||||
你还可以使用 `gnome-screensaver` 命令检查屏幕是否已锁定。使用 `--query` 选项,该命令会告诉你屏幕当前是否已锁定(即处于活动状态)。使用 `--time` 选项,它会告诉你锁定生效的时间。这是一个示例脚本:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
@ -77,8 +80,6 @@ The screensaver has been active for 1013 seconds.
|
||||
|
||||
如果你记住了正确的控制方式,那么锁定终端窗口是很简单的。对于屏幕锁定,它的效果取决于你自己的设置,或者你是否习惯使用默认设置。
|
||||
|
||||
在 [Facebook][3] 和 [LinkedIn][4] 上加入 Network World 社区,来评论最新主题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3438818/how-to-freeze-and-lock-your-linux-system-and-why-you-would-want-to.html
|
||||
@ -86,7 +87,7 @@ via: https://www.networkworld.com/article/3438818/how-to-freeze-and-lock-your-li
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
160
published/201909/20190916 How to start developing with .NET.md
Normal file
160
published/201909/20190916 How to start developing with .NET.md
Normal file
@ -0,0 +1,160 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11397-1.html)
|
||||
[#]: subject: (How to start developing with .NET)
|
||||
[#]: via: (https://opensource.com/article/19/9/getting-started-net)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在 Linux/Windows/MacOS 上使用 .NET 进行开发
|
||||
======
|
||||
|
||||
> 了解 .NET 开发平台启动和运行的基础知识。
|
||||
|
||||

|
||||
|
||||
.NET 框架由 Microsoft 于 2000 年发布。该平台的开源实现 [Mono][2] 在 21 世纪初成为了争议的焦点,因为微软拥有 .NET 技术的多项专利,并且可能使用这些专利来终止 Mono 项目。幸运的是,在 2014 年,微软宣布 .NET 开发平台从此成为 MIT 许可下的开源平台,并在 2016 年收购了开发 Mono 的 Xamarin 公司。
|
||||
|
||||
.NET 和 Mono 已经同时可用于 C#、F#、GTK+、Visual Basic、Vala 等的跨平台编程环境。使用 .NET 和 Mono 创建的程序已经应用于 Linux、BSD、Windows、MacOS、Android,甚至一些游戏机。你可以使用 .NET 或 Mono 来开发 .NET 应用。这两个都是开源的,并且都有活跃和充满活力的社区。本文重点介绍微软的 .NET 环境。
|
||||
|
||||
### 如何安装 .NET
|
||||
|
||||
.NET 下载被分为多个包:一个仅包含 .NET 运行时,另一个 .NET SDK 包含了 .NET Core 和运行时。根据架构和操作系统版本,这些包可能有多个版本。要开始使用 .NET 进行开发,你必须[安装该 SDK][3]。它为你提供了 [dotnet][4] 终端或 PowerShell 命令,你可以使用它们来创建和生成项目。
|
||||
|
||||
#### Linux
|
||||
|
||||
要在 Linux 上安装 .NET,首先将微软 Linux 软件仓库添加到你的计算机。
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
|
||||
$ sudo wget -q -O /etc/yum.repos.d/microsoft-prod.repo https://packages.microsoft.com/config/fedora/27/prod.repo
|
||||
```
|
||||
|
||||
在 Ubuntu 上:
|
||||
|
||||
```
|
||||
$ wget -q https://packages.microsoft.com/config/ubuntu/19.04/packages-microsoft-prod.deb -O packages-microsoft-prod.deb
|
||||
$ sudo dpkg -i packages-microsoft-prod.deb
|
||||
```
|
||||
|
||||
接下来,使用包管理器安装 SDK,将 `<X.Y>` 替换为当前版本的 .NET 版本:
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install dotnet-sdk-<X.Y>
|
||||
```
|
||||
|
||||
在 Ubuntu 上:
|
||||
|
||||
```
|
||||
$ sudo apt install apt-transport-https
|
||||
$ sudo apt update
|
||||
$ sudo apt install dotnet-sdk-<X.Y>
|
||||
```
|
||||
|
||||
下载并安装所有包后,打开终端并输入下面命令确认安装:
|
||||
|
||||
```
|
||||
$ dotnet --version
|
||||
X.Y.Z
|
||||
```
|
||||
|
||||
#### Windows
|
||||
|
||||
如果你使用的是微软 Windows,那么你可能已经安装了 .NET 运行时。但是,要开发 .NET 应用,你还必须安装 .NET Core SDK。
|
||||
|
||||
首先,[下载安装程序][3]。请认准下载 .NET Core 进行跨平台开发(.NET Framework 仅适用于 Windows)。下载 .exe 文件后,双击该文件启动安装向导,然后单击两下进行安装:接受许可证并允许安装继续。
|
||||
|
||||
![Installing dotnet on Windows][5]
|
||||
|
||||
然后,从左下角的“应用程序”菜单中打开 PowerShell。在 PowerShell 中,输入测试命令:
|
||||
|
||||
```
|
||||
PS C:\Users\osdc> dotnet
|
||||
```
|
||||
|
||||
如果你看到有关 dotnet 安装的信息,那么说明 .NET 已正确安装。
|
||||
|
||||
#### MacOS
|
||||
|
||||
如果你使用的是 Apple Mac,请下载 .pkg 形式的 [Mac 安装程序][3]。下载并双击该 .pkg 文件,然后单击安装程序。你可能需要授予安装程序权限,因为该软件包并非来自 App Store。
|
||||
|
||||
下载并安装所有软件包后,请打开终端并输入以下命令来确认安装:
|
||||
|
||||
```
|
||||
$ dotnet --version
|
||||
X.Y.Z
|
||||
```
|
||||
|
||||
### Hello .NET
|
||||
|
||||
`dotnet` 命令提供了一个用 .NET 编写的 “hello world” 示例程序。或者,更准确地说,该命令提供了示例应用。
|
||||
|
||||
首先,使用 `dotnet` 命令以及 `new` 和 `console` 参数创建一个控制台应用的项目目录及所需的代码基础结构。使用 `-o` 选项指定项目名称:
|
||||
|
||||
```
|
||||
$ dotnet new console -o hellodotnet
|
||||
```
|
||||
|
||||
这将在当前目录中创建一个名为 `hellodotnet` 的目录。进入你的项目目录并看一下:
|
||||
|
||||
```
|
||||
$ cd hellodotnet
|
||||
$ dir
|
||||
hellodotnet.csproj obj Program.cs
|
||||
```
|
||||
|
||||
`Program.cs` 是一个空的 C# 文件,它包含了一个简单的 Hello World 程序。在文本编辑器中打开查看它。微软的 Visual Studio Code 是一个使用 dotnet 编写的跨平台的开源应用,虽然它不是一个糟糕的文本编辑器,但它会收集用户的大量数据(在它的二进制发行版的许可证中授予了自己权限)。如果要尝试使用 Visual Studio Code,请考虑使用 [VSCodium][6],它是使用 Visual Studio Code 的 MIT 许可的源码构建的版本,而*没有*远程收集(请阅读[此文档][7]来禁止此构建中的其他形式追踪)。或者,只需使用现有的你最喜欢的文本编辑器或 IDE。
|
||||
|
||||
新控制台应用中的样板代码为:
|
||||
|
||||
```
|
||||
using System;
|
||||
|
||||
namespace hellodotnet
|
||||
{
|
||||
class Program
|
||||
{
|
||||
static void Main(string[] args)
|
||||
{
|
||||
Console.WriteLine("Hello World!");
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
要运行该程序,请使用 `dotnet run` 命令:
|
||||
|
||||
```
|
||||
$ dotnet run
|
||||
Hello World!
|
||||
```
|
||||
|
||||
这是 .NET 和 `dotnet` 命令的基本工作流程。这里有完整的 [.NET C# 指南][8],并且都是与 .NET 相关的内容。关于 .NET 实战示例,请关注 [Alex Bunardzic][9] 在 opensource.com 中的变异测试文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/9/getting-started-net
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: https://www.monodevelop.com/
|
||||
[3]: https://dotnet.microsoft.com/download
|
||||
[4]: https://docs.microsoft.com/en-us/dotnet/core/tools/dotnet?tabs=netcore21
|
||||
[5]: https://opensource.com/sites/default/files/uploads/dotnet-windows-install.jpg (Installing dotnet on Windows)
|
||||
[6]: https://vscodium.com/
|
||||
[7]: https://github.com/VSCodium/vscodium/blob/master/DOCS.md
|
||||
[8]: https://docs.microsoft.com/en-us/dotnet/csharp/tutorials/intro-to-csharp/
|
||||
[9]: https://opensource.com/users/alex-bunardzic (View user profile.)
|
||||
@ -0,0 +1,111 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11389-1.html)
|
||||
[#]: subject: (How to remove carriage returns from text files on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3438857/how-to-remove-carriage-returns-from-text-files-on-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何在 Linux 中删除文本中的回车字符
|
||||
======
|
||||
|
||||
> 当回车字符(`Ctrl+M`)让你紧张时,别担心。有几种简单的方法消除它们。
|
||||
|
||||

|
||||
|
||||
“回车”字符可以往回追溯很长一段时间 —— 早在打字机上就有一个机械装置或杠杆将承载纸滚筒的机架移到右边,以便可以重新在左侧输入字母。他们在 Windows 上的文本文件上保留了它,但从未在 Linux 系统上使用过。当你尝试在 Linux 上处理在 Windows 上创建的文件时,这种不兼容性有时会导致问题,但这是一个非常容易解决的问题。
|
||||
|
||||
如果你使用 `od`(<ruby>八进制转储<rt>octal dump</rt></ruby>)命令查看文件,那么回车(也用 `Ctrl+M` 代表)字符将显示为八进制的 15。字符 `CRLF` 通常用于表示 Windows 文本文件中的一行结束的回车符和换行符序列。那些注意看八进制转储的会看到 `\r\n`。相比之下,Linux 文本仅以换行符结束。
|
||||
|
||||
这有一个 `od` 输出的示例,高亮显示了行中的 `CRLF` 字符,以及它的八进制。
|
||||
|
||||
```
|
||||
$ od -bc testfile.txt
|
||||
0000000 124 150 151 163 040 151 163 040 141 040 164 145 163 164 040 146
|
||||
T h i s i s a t e s t f
|
||||
0000020 151 154 145 040 146 162 157 155 040 127 151 156 144 157 167 163
|
||||
i l e f r o m W i n d o w s
|
||||
0000040 056 015 012 111 164 047 163 040 144 151 146 146 145 162 145 156 <==
|
||||
. \r \n I t ' s d i f f e r e n <==
|
||||
0000060 164 040 164 150 141 156 040 141 040 125 156 151 170 040 164 145
|
||||
t t h a n a U n i x t e
|
||||
0000100 170 164 040 146 151 154 145 015 012 167 157 165 154 144 040 142 <==
|
||||
x t f i l e \r \n w o u l d b <==
|
||||
```
|
||||
|
||||
虽然这些字符不是大问题,但是当你想要以某种方式解析文本,并且不希望就它们是否存在进行编码时,这有时候会产生干扰。
|
||||
|
||||
### 3 种从文本中删除回车符的方法
|
||||
|
||||
幸运的是,有几种方法可以轻松删除回车符。这有三个选择:
|
||||
|
||||
#### dos2unix
|
||||
|
||||
你可能会在安装时遇到麻烦,但 `dos2unix` 可能是将 Windows 文本转换为 Unix/Linux 文本的最简单方法。一个命令带上一个参数就行了。不需要第二个文件名。该文件会被直接更改。
|
||||
|
||||
```
|
||||
$ dos2unix testfile.txt
|
||||
dos2unix: converting file testfile.txt to Unix format...
|
||||
```
|
||||
|
||||
你应该会发现文件长度减少,具体取决于它包含的行数。包含 100 行的文件可能会缩小 99 个字符,因为只有最后一行不会以 `CRLF` 字符结尾。
|
||||
|
||||
之前:
|
||||
|
||||
```
|
||||
-rw-rw-r-- 1 shs shs 121 Sep 14 19:11 testfile.txt
|
||||
```
|
||||
|
||||
之后:
|
||||
|
||||
```
|
||||
-rw-rw-r-- 1 shs shs 118 Sep 14 19:12 testfile.txt
|
||||
```
|
||||
|
||||
如果你需要转换大量文件,不用每次修复一个。相反,将它们全部放在一个目录中并运行如下命令:
|
||||
|
||||
```
|
||||
$ find . -type f -exec dos2unix {} \;
|
||||
```
|
||||
|
||||
在此命令中,我们使用 `find` 查找常规文件,然后运行 `dos2unix` 命令一次转换一个。命令中的 `{}` 将被替换为文件名。运行时,你应该处于包含文件的目录中。此命令可能会损坏其他类型的文件,例如除了文本文件外在上下文中包含八进制 15 的文件(如,镜像文件中的字节)。
|
||||
|
||||
#### sed
|
||||
|
||||
你还可以使用流编辑器 `sed` 来删除回车符。但是,你必须提供第二个文件名。以下是例子:
|
||||
|
||||
```
|
||||
$ sed -e “s/^M//” before.txt > after.txt
|
||||
```
|
||||
|
||||
一件需要注意的重要的事情是,请不要输入你看到的字符。你必须按下 `Ctrl+V` 后跟 `Ctrl+M` 来输入 `^M`。`s` 是替换命令。斜杠将我们要查找的文本(`Ctrl + M`)和要替换的文本(这里为空)分开。
|
||||
|
||||
#### vi
|
||||
|
||||
你甚至可以使用 `vi` 删除回车符(`Ctrl+M`),但这里假设你没有打开数百个文件,或许也在做一些其他的修改。你可以键入 `:` 进入命令行,然后输入下面的字符串。与 `sed` 一样,命令中 `^M` 需要通过 `Ctrl+V` 输入 `^`,然后 `Ctrl+M` 插入 `M`。`%s` 是替换操作,斜杠再次将我们要删除的字符和我们想要替换它的文本(空)分开。 `g`(全局)意味在所有行上执行。
|
||||
|
||||
```
|
||||
:%s/^M//g
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
`dos2unix` 命令可能是最容易记住的,也是从文本中删除回车的最可靠的方法。其他选择使用起来有点困难,但它们提供相同的基本功能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3438857/how-to-remove-carriage-returns-from-text-files-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.flickr.com/photos/kmsiever/5895380540/in/photolist-9YXnf5-cNmpxq-2KEvib-rfecPZ-9snnkJ-2KAcDR-dTxzKW-6WdgaG-6H5i46-2KzTZX-7cnSw7-e3bUdi-a9meh9-Zm3pD-xiFhs-9Hz6YM-ar4DEx-4PXAhw-9wR4jC-cihLcs-asRFJc-9ueXvG-aoWwHq-atwL3T-ai89xS-dgnntH-5en8Te-dMUDd9-aSQVn-dyZqij-cg4SeS-abygkg-f2umXt-Xk129E-4YAeNn-abB6Hb-9313Wk-f9Tot-92Yfva-2KA7Sv-awSCtG-2KDPzb-eoPN6w-FE9oi-5VhaNf-eoQgx7-eoQogA-9ZWoYU-7dTGdG-5B1aSS
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11382-1.html)
|
||||
[#]: subject: (How to Remove (Delete) Symbolic Links in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/remove-delete-symbolic-link-softlink-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,50 +10,40 @@
|
||||
在 Linux 中怎样移除(删除)符号链接
|
||||
======
|
||||
|
||||
你可能有时需要在 Linux 上创建或者删除符号链接。
|
||||
你可能有时需要在 Linux 上创建或者删除符号链接。如果有,你知道该怎样做吗?之前你做过吗?你踩坑没有?如果你踩过坑,那没什么问题。如果还没有,别担心,我们将在这里帮助你。
|
||||
|
||||
如果有,你知道该怎样做吗?
|
||||
|
||||
之前你做过吗?你踩坑没有?
|
||||
|
||||
如果你踩过坑,那没什么问题。如果还没有,别担心,我们将在这里帮助你。
|
||||
|
||||
使用 rm 和 unlink 命令就能完成移除(删除)符号链接的操作。
|
||||
使用 `rm` 和 `unlink` 命令就能完成移除(删除)符号链接的操作。
|
||||
|
||||
### 什么是符号链接?
|
||||
|
||||
符号链接又称 symlink 或者 软链接,它是一种特殊的文件类型,在 Linux 中该文件指向另一个文件或者目录。
|
||||
符号链接(symlink)又称软链接,它是一种特殊的文件类型,在 Linux 中该文件指向另一个文件或者目录。它类似于 Windows 中的快捷方式。它能在相同或者不同的文件系统或分区中指向一个文件或着目录。
|
||||
|
||||
它类似于 Windows 中的快捷方式。
|
||||
|
||||
它能在相同或者不同的文件系统或分区中指向一个文件或着目录。
|
||||
|
||||
符号链接通常用来链接库文件。它也可用于链接日志文件和在 NFS (网络文件系统)上的文件夹。
|
||||
符号链接通常用来链接库文件。它也可用于链接日志文件和挂载的 NFS(网络文件系统)上的文件夹。
|
||||
|
||||
### 什么是 rm 命令?
|
||||
|
||||
这个 **[rm command][1]** 被用来移除文件和目录。它非常危险,你每次使用 rm 命令的时候要非常小心。
|
||||
[rm 命令][1] 被用来移除文件和目录。它非常危险,你每次使用 `rm` 命令的时候要非常小心。
|
||||
|
||||
### 什么是 unlink 命令?
|
||||
|
||||
unlink 命令被用来移除特殊的文件。它被作为 GNU Gorutils 的一部分安装了。
|
||||
`unlink` 命令被用来移除特殊的文件。它被作为 GNU Gorutils 的一部分安装了。
|
||||
|
||||
### 1) 使用 rm 命令怎样移除符号链接文件
|
||||
|
||||
rm 命令是在 Linux 中使用最频繁的命令,它允许我们像下列描述那样去移除符号链接。
|
||||
`rm` 命令是在 Linux 中使用最频繁的命令,它允许我们像下列描述那样去移除符号链接。
|
||||
|
||||
```
|
||||
# rm symlinkfile
|
||||
```
|
||||
|
||||
始终将 rm 命令与 “-i” 一起使用以了解正在执行的操作。
|
||||
始终将 `rm` 命令与 `-i` 一起使用以了解正在执行的操作。
|
||||
|
||||
```
|
||||
# rm -i symlinkfile1
|
||||
rm: remove symbolic link ‘symlinkfile1’? y
|
||||
```
|
||||
|
||||
它允许我们一次移除多个符号链接
|
||||
它允许我们一次移除多个符号链接:
|
||||
|
||||
```
|
||||
# rm -i symlinkfile2 symlinkfile3
|
||||
@ -62,11 +52,9 @@ rm: remove symbolic link ‘symlinkfile2’? y
|
||||
rm: remove symbolic link ‘symlinkfile3’? y
|
||||
```
|
||||
|
||||
### 1a) 使用 rm 命令怎样移除符号链接目录
|
||||
#### 1a) 使用 rm 命令怎样移除符号链接目录
|
||||
|
||||
这像移除符号链接文件那样。
|
||||
|
||||
使用下列命令移除符号链接目录。
|
||||
这像移除符号链接文件那样。使用下列命令移除符号链接目录。
|
||||
|
||||
```
|
||||
# rm -i symlinkdir
|
||||
@ -83,7 +71,7 @@ rm: remove symbolic link ‘symlinkdir1’? y
|
||||
rm: remove symbolic link ‘symlinkdir2’? y
|
||||
```
|
||||
|
||||
如果你增加 _**“/”**_ 在结尾,这个符号链接目录将不会被删除。如果你加了,你将得到一个错误。
|
||||
如果你在结尾增加 `/`,这个符号链接目录将不会被删除。如果你加了,你将得到一个错误。
|
||||
|
||||
```
|
||||
# rm -i symlinkdir/
|
||||
@ -91,7 +79,7 @@ rm: remove symbolic link ‘symlinkdir2’? y
|
||||
rm: cannot remove ‘symlinkdir/’: Is a directory
|
||||
```
|
||||
|
||||
你可以增加 **“-r”** 去处理上述问题。如果你增加这个参数,它将会删除目标目录下的内容,并且它不会删除这个符号链接文件。
|
||||
你可以增加 `-r` 去处理上述问题。**但如果你增加这个参数,它将会删除目标目录下的内容,并且它不会删除这个符号链接文件。**(LCTT 译注:这可能不是你的原意。)
|
||||
|
||||
```
|
||||
# rm -ri symlinkdir/
|
||||
@ -104,21 +92,21 @@ rm: cannot remove ‘symlinkdir/’: Not a directory
|
||||
|
||||
### 2) 使用 unlink 命令怎样移除符号链接
|
||||
|
||||
unlink 命令删除指定文件。它一次仅接受一个文件。
|
||||
`unlink` 命令删除指定文件。它一次仅接受一个文件。
|
||||
|
||||
删除符号链接文件
|
||||
删除符号链接文件:
|
||||
|
||||
```
|
||||
# unlink symlinkfile
|
||||
```
|
||||
|
||||
删除符号链接目录
|
||||
删除符号链接目录:
|
||||
|
||||
```
|
||||
# unlink symlinkdir2
|
||||
```
|
||||
|
||||
如果你增加 _**“/”**_ 在结尾,你不能使用 unlink 命令删除符号链接目录
|
||||
如果你在结尾增加 `/`,你不能使用 `unlink` 命令删除符号链接目录。
|
||||
|
||||
```
|
||||
# unlink symlinkdir3/
|
||||
@ -133,7 +121,7 @@ via: https://www.2daygeek.com/remove-delete-symbolic-link-softlink-linux/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,312 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (GraveAccent)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11406-1.html)
|
||||
[#]: subject: (Getting started with data science using Python)
|
||||
[#]: via: (https://opensource.com/article/19/9/get-started-data-science-python)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Python 入门数据科学
|
||||
======
|
||||
|
||||
> 使用 Python 开展数据科学为你提供了无限的潜力,使你能够以有意义和启发性的方式解析、解释和组织数据。
|
||||
|
||||

|
||||
|
||||
数据科学是计算领域一个令人兴奋的新领域,它围绕分析、可视化和关联以解释我们的计算机收集的有关世界的无限信息而建立。当然,称其为“新”领域有点不诚实,因为该学科是统计学、数据分析和普通而古老的科学观察派生而来的。
|
||||
|
||||
但是数据科学是这些学科的形式化分支,拥有自己的流程和工具,并且可以广泛应用于以前从未产生过大量不可管理数据的学科(例如视觉效果)。数据科学是一个新的机会,可以重新审视海洋学、气象学、地理学、制图学、生物学、医学和健康以及娱乐行业的数据,并更好地了解其中的模式、影响和因果关系。
|
||||
|
||||
像其他看似包罗万象的大型领域一样,知道从哪里开始探索数据科学可能会令人生畏。有很多资源可以帮助数据科学家使用自己喜欢的编程语言来实现其目标,其中包括最流行的编程语言之一:Python。使用 [Pandas][2]、[Matplotlib][3] 和 [Seaborn][4] 这些库,你可以学习数据科学的基本工具集。
|
||||
|
||||
如果你对 Python 的基本用法不是很熟悉,请在继续之前先阅读我的 [Python 介绍][5]。
|
||||
|
||||
### 创建 Python 虚拟环境
|
||||
|
||||
程序员有时会忘记在开发计算机上安装了哪些库,这可能导致他们提供了在自己计算机上可以运行,但由于缺少库而无法在所有其它电脑上运行的代码。Python 有一个系统旨在避免这种令人不快的意外:虚拟环境。虚拟环境会故意忽略你已安装的所有 Python 库,从而有效地迫使你一开始使用通常的 Python 进行开发。
|
||||
|
||||
为了用 `venv` 激活虚拟环境, 为你的环境取个名字 (我会用 `example`) 并且用下面的指令创建它:
|
||||
|
||||
```
|
||||
$ python3 -m venv example
|
||||
```
|
||||
|
||||
<ruby>导入<rt>source</rt></ruby>该环境的 `bin` 目录里的 `activate` 文件以激活它:
|
||||
|
||||
```
|
||||
$ source ./example/bin/activate
|
||||
(example) $
|
||||
```
|
||||
|
||||
你现在“位于”你的虚拟环境中。这是一个干净的状态,你可以在其中构建针对该问题的自定义解决方案,但是额外增加了需要有意识地安装依赖库的负担。
|
||||
|
||||
### 安装 Pandas 和 NumPy
|
||||
|
||||
你必须在新环境中首先安装的库是 Pandas 和 NumPy。这些库在数据科学中很常见,因此你肯定要时不时安装它们。它们也不是你在数据科学中唯一需要的库,但是它们是一个好的开始。
|
||||
|
||||
Pandas 是使用 BSD 许可证的开源库,可轻松处理数据结构以进行分析。它依赖于 NumPy,这是一个提供多维数组、线性代数和傅立叶变换等等的科学库。使用 `pip3` 安装两者:
|
||||
|
||||
```
|
||||
(example) $ pip3 install pandas
|
||||
```
|
||||
|
||||
安装 Pandas 还会安装 NumPy,因此你无需同时指定两者。一旦将它们安装到虚拟环境中,安装包就会被缓存,这样,当你再次安装它们时,就不必从互联网上下载它们。
|
||||
|
||||
这些是你现在仅需的库。接下来,你需要一些样本数据。
|
||||
|
||||
### 生成样本数据集
|
||||
|
||||
数据科学都是关于数据的,幸运的是,科学、计算和政府组织可以提供许多免费和开放的数据集。虽然这些数据集是用于教育的重要资源,但它们具有比这个简单示例所需的数据更多的数据。你可以使用 Python 快速创建示例和可管理的数据集:
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
def rgb():
|
||||
NUMBER=random.randint(0,255)/255
|
||||
return NUMBER
|
||||
|
||||
FILE = open('sample.csv','w')
|
||||
FILE.write('"red","green","blue"')
|
||||
for COUNT in range(10):
|
||||
FILE.write('\n{:0.2f},{:0.2f},{:0.2f}'.format(rgb(),rgb(),rgb()))
|
||||
```
|
||||
|
||||
这将生成一个名为 `sample.csv` 的文件,该文件由随机生成的浮点数组成,这些浮点数在本示例中表示 RGB 值(在视觉效果中通常是数百个跟踪值)。你可以将 CSV 文件用作 Pandas 的数据源。
|
||||
|
||||
### 使用 Pandas 提取数据
|
||||
|
||||
Pandas 的基本功能之一是可以提取数据和处理数据,而无需程序员编写仅用于解析输入的新函数。如果你习惯于自动执行此操作的应用程序,那么这似乎不是很特别,但请想象一下在 [LibreOffice][6] 中打开 CSV 并且必须编写公式以在每个逗号处拆分值。Pandas 可以让你免受此类低级操作的影响。以下是一些简单的代码,可用于提取和打印以逗号分隔的值的文件:
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from pandas import read_csv, DataFrame
|
||||
import pandas as pd
|
||||
|
||||
FILE = open('sample.csv','r')
|
||||
DATAFRAME = pd.read_csv(FILE)
|
||||
print(DATAFRAME)
|
||||
```
|
||||
|
||||
一开始的几行导入 Pandas 库的组件。Pandas 库功能丰富,因此在寻找除本文中基本功能以外的功能时,你会经常参考它的文档。
|
||||
|
||||
接下来,通过打开你创建的 `sample.csv` 文件创建变量 `FILE`。Pandas 模块 `read_csv`(在第二行中导入)使用该变量来创建<ruby>数据帧<rt>dataframe</rt></ruby>。在 Pandas 中,数据帧是二维数组,通常可以认为是表格。数据放入数据帧中后,你可以按列和行进行操作,查询其范围,然后执行更多操作。目前,示例代码仅将该数据帧输出到终端。
|
||||
|
||||
运行代码。你的输出会和下面的输出有些许不同,因为这些数字都是随机生成的,但是格式都是一样的。
|
||||
|
||||
```
|
||||
(example) $ python3 ./parse.py
|
||||
red green blue
|
||||
0 0.31 0.96 0.47
|
||||
1 0.95 0.17 0.64
|
||||
2 0.00 0.23 0.59
|
||||
3 0.22 0.16 0.42
|
||||
4 0.53 0.52 0.18
|
||||
5 0.76 0.80 0.28
|
||||
6 0.68 0.69 0.46
|
||||
7 0.75 0.52 0.27
|
||||
8 0.53 0.76 0.96
|
||||
9 0.01 0.81 0.79
|
||||
```
|
||||
|
||||
假设你只需要数据集中的红色值(`red`),你可以通过声明数据帧的列名称并有选择地仅打印你感兴趣的列来做到这一点:
|
||||
|
||||
```python
|
||||
from pandas import read_csv, DataFrame
|
||||
import pandas as pd
|
||||
|
||||
FILE = open('sample.csv','r')
|
||||
DATAFRAME = pd.read_csv(FILE)
|
||||
|
||||
# define columns
|
||||
DATAFRAME.columns = [ 'red','green','blue' ]
|
||||
|
||||
print(DATAFRAME['red'])
|
||||
```
|
||||
|
||||
现在运行代码,你只会得到红色列:
|
||||
|
||||
```
|
||||
(example) $ python3 ./parse.py
|
||||
0 0.31
|
||||
1 0.95
|
||||
2 0.00
|
||||
3 0.22
|
||||
4 0.53
|
||||
5 0.76
|
||||
6 0.68
|
||||
7 0.75
|
||||
8 0.53
|
||||
9 0.01
|
||||
Name: red, dtype: float64
|
||||
```
|
||||
|
||||
处理数据表是经常使用 Pandas 解析数据的好方法。从数据帧中选择数据的方法有很多,你尝试的次数越多就越习惯。
|
||||
|
||||
### 可视化你的数据
|
||||
|
||||
很多人偏爱可视化信息已不是什么秘密,这是图表和图形成为与高层管理人员开会的主要内容的原因,也是“信息图”在新闻界如此流行的原因。数据科学家的工作之一是帮助其他人理解大量数据样本,并且有一些库可以帮助你完成这项任务。将 Pandas 与可视化库结合使用可以对数据进行可视化解释。一个流行的可视化开源库是 [Seaborn][7],它基于开源的 [Matplotlib][3]。
|
||||
|
||||
#### 安装 Seaborn 和 Matplotlib
|
||||
|
||||
你的 Python 虚拟环境还没有 Seaborn 和 Matplotlib,所以用 `pip3` 安装它们。安装 Seaborn 的时候,也会安装 Matplotlib 和很多其它的库。
|
||||
|
||||
```
|
||||
(example) $ pip3 install seaborn
|
||||
```
|
||||
|
||||
为了使 Matplotlib 显示图形,你还必须安装 [PyGObject][8] 和 [Pycairo][9]。这涉及到编译代码,只要你安装了必需的头文件和库,`pip3` 便可以为你执行此操作。你的 Python 虚拟环境不了解这些依赖库,因此你可以在环境内部或外部执行安装命令。
|
||||
|
||||
在 Fedora 和 CentOS 上:
|
||||
|
||||
```
|
||||
(example) $ sudo dnf install -y gcc zlib-devel bzip2 bzip2-devel readline-devel \
|
||||
sqlite sqlite-devel openssl-devel tk-devel git python3-cairo-devel \
|
||||
cairo-gobject-devel gobject-introspection-devel
|
||||
```
|
||||
|
||||
在 Ubuntu 和 Debian 上:
|
||||
|
||||
```
|
||||
(example) $ sudo apt install -y libgirepository1.0-dev build-essential \
|
||||
libbz2-dev libreadline-dev libssl-dev zlib1g-dev libsqlite3-dev wget \
|
||||
curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev libcairo2-dev
|
||||
```
|
||||
|
||||
一旦它们安装好了,你可以安装 Matplotlib 需要的 GUI 组件。
|
||||
|
||||
```
|
||||
(example) $ pip3 install PyGObject pycairo
|
||||
```
|
||||
|
||||
### 用 Seaborn 和 Matplotlib 显示图形
|
||||
|
||||
在你最喜欢的文本编辑器新建一个叫 `vizualize.py` 的文件。要创建数据的线形图可视化,首先,你必须导入必要的 Python 模块 —— 先前代码示例中使用的 Pandas 模块:
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from pandas import read_csv, DataFrame
|
||||
import pandas as pd
|
||||
```
|
||||
|
||||
接下来,导入 Seaborn、Matplotlib 和 Matplotlib 的几个组件,以便你可以配置生成的图形:
|
||||
|
||||
```python
|
||||
import seaborn as sns
|
||||
import matplotlib
|
||||
import matplotlib.pyplot as plt
|
||||
from matplotlib import rcParams
|
||||
```
|
||||
|
||||
Matplotlib 可以将其输出导出为多种格式,包括 PDF、SVG 和桌面上的 GUI 窗口。对于此示例,将输出发送到桌面很有意义,因此必须将 Matplotlib 后端设置为 `GTK3Agg`。如果你不使用 Linux,则可能需要使用 `TkAgg` 后端。
|
||||
|
||||
设置完 GUI 窗口以后,设置窗口大小和 Seaborn 预设样式:
|
||||
|
||||
```python
|
||||
matplotlib.use('GTK3Agg')
|
||||
rcParams['figure.figsize'] = 11,8
|
||||
sns.set_style('darkgrid')
|
||||
```
|
||||
|
||||
现在,你的显示已配置完毕,代码已经很熟悉了。使用 Pandas 导入 `sample.csv` 文件,并定义数据帧的列:
|
||||
|
||||
```python
|
||||
FILE = open('sample.csv','r')
|
||||
DATAFRAME = pd.read_csv(FILE)
|
||||
DATAFRAME.columns = [ 'red','green','blue' ]
|
||||
```
|
||||
|
||||
有了适当格式的数据,你可以将其绘制在图形中。将每一列用作绘图的输入,然后使用 `plt.show()` 在 GUI 窗口中绘制图形。`plt.legend()` 参数将列标题与图形上的每一行关联(`loc` 参数将图例放置在图表之外而不是在图表上方):
|
||||
|
||||
|
||||
```python
|
||||
for i in DATAFRAME.columns:
|
||||
DATAFRAME[i].plot()
|
||||
|
||||
plt.legend(bbox_to_anchor=(1, 1), loc=2, borderaxespad=1)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
运行代码以获得结果。
|
||||
|
||||
![第一个数据可视化][10]
|
||||
|
||||
你的图形可以准确显示 CSV 文件中包含的所有信息:值在 Y 轴上,索引号在 X 轴上,并且图形中的线也被标识出来了,以便你知道它们代表什么。然而,由于此代码正在跟踪颜色值(至少是假装),所以线条的颜色不仅不直观,而且违反直觉。如果你永远不需要分析颜色数据,则可能永远不会遇到此问题,但是你一定会遇到类似的问题。在可视化数据时,你必须考虑呈现数据的最佳方法,以防止观看者从你呈现的内容中推断出虚假信息。
|
||||
|
||||
为了解决此问题(并展示一些可用的自定义设置),以下代码为每条绘制的线分配了特定的颜色:
|
||||
|
||||
```python
|
||||
import matplotlib
|
||||
from pandas import read_csv, DataFrame
|
||||
import pandas as pd
|
||||
import seaborn as sns
|
||||
import matplotlib.pyplot as plt
|
||||
from matplotlib import rcParams
|
||||
|
||||
matplotlib.use('GTK3Agg')
|
||||
rcParams['figure.figsize'] = 11,8
|
||||
sns.set_style('whitegrid')
|
||||
|
||||
FILE = open('sample.csv','r')
|
||||
DATAFRAME = pd.read_csv(FILE)
|
||||
DATAFRAME.columns = [ 'red','green','blue' ]
|
||||
|
||||
plt.plot(DATAFRAME['red'],'r-')
|
||||
plt.plot(DATAFRAME['green'],'g-')
|
||||
plt.plot(DATAFRAME['blue'],'b-')
|
||||
plt.plot(DATAFRAME['red'],'ro')
|
||||
plt.plot(DATAFRAME['green'],'go')
|
||||
plt.plot(DATAFRAME['blue'],'bo')
|
||||
|
||||
plt.show()
|
||||
```
|
||||
|
||||
这使用特殊的 Matplotlib 表示法为每列创建两个图。每列的初始图分配有一种颜色(红色为 `r`,绿色为 `g`,蓝色为 `b`)。这些是内置的 Matplotlib 设置。 `-` 表示实线(双破折号,例如 `r--`,将创建虚线)。为每个具有相同颜色的列创建第二个图,但是使用 `o` 表示点或节点。为了演示内置的 Seaborn 主题,请将 `sns.set_style` 的值更改为 `whitegrid`。
|
||||
|
||||
![改进的数据可视化][11]
|
||||
|
||||
### 停用你的虚拟环境
|
||||
|
||||
探索完 Pandas 和绘图后,可以使用 `deactivate` 命令停用 Python 虚拟环境:
|
||||
|
||||
```
|
||||
(example) $ deactivate
|
||||
$
|
||||
```
|
||||
|
||||
当你想重新使用它时,只需像在本文开始时一样重新激活它即可。重新激活虚拟环境时,你必须重新安装模块,但是它们是从缓存安装的,而不是从互联网下载的,因此你不必联网。
|
||||
|
||||
### 无尽的可能性
|
||||
|
||||
Pandas、Matplotlib、Seaborn 和数据科学的真正力量是无穷的潜力,使你能够以有意义和启发性的方式解析、解释和组织数据。下一步是使用你在本文中学到的新工具探索简单的数据集。Matplotlib 和 Seaborn 不仅有折线图,还有很多其他功能,因此,请尝试创建条形图或饼图或完全不一样的东西。
|
||||
|
||||
一旦你了解了你的工具集并对如何关联数据有了一些想法,则可能性是无限的。数据科学是寻找隐藏在数据中的故事的新方法。让开源成为你的媒介。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/9/get-started-data-science-python
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_graph_stats_blue.png?itok=OKCc_60D (Metrics and a graph illustration)
|
||||
[2]: https://pandas.pydata.org/
|
||||
[3]: https://matplotlib.org/
|
||||
[4]: https://seaborn.pydata.org/index.html
|
||||
[5]: https://opensource.com/article/17/10/python-101
|
||||
[6]: http://libreoffice.org
|
||||
[7]: https://seaborn.pydata.org/
|
||||
[8]: https://pygobject.readthedocs.io/en/latest/getting_started.html
|
||||
[9]: https://pycairo.readthedocs.io/en/latest/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/seaborn-matplotlib-graph_0.png (First data visualization)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/seaborn-matplotlib-graph_1.png (Improved data visualization)
|
||||
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11399-1.html)
|
||||
[#]: subject: (Introduction to the Linux chgrp and newgrp commands)
|
||||
[#]: via: (https://opensource.com/article/19/9/linux-chgrp-and-newgrp-commands)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
chgrp 和 newgrp 命令简介
|
||||
======
|
||||
|
||||
> chgrp 和 newgrp 命令可帮助你管理需要维护组所有权的文件。
|
||||
|
||||

|
||||
|
||||
在最近的一篇文章中,我介绍了 [chown][2] 命令,它用于修改系统上的文件所有权。回想一下,所有权是分配给一个对象的用户和组的组合。`chgrp` 和 `newgrp` 命令为管理需要维护组所有权的文件提供了帮助。
|
||||
|
||||
### 使用 chgrp
|
||||
|
||||
`chgrp` 只是更改文件的组所有权。这与 `chown :<group>` 命令相同。你可以使用:
|
||||
|
||||
```
|
||||
$chown :alan mynotes
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
$chgrp alan mynotes
|
||||
```
|
||||
|
||||
#### 递归
|
||||
|
||||
`chgrp` 和它的一些参数可以用在命令行和脚本中。就像许多其他 Linux 命令一样,`chgrp` 有一个递归参数 `-R`。如下所示,你需要它来对文件夹及其内容进行递归操作。我加了 `-v`(详细)参数,因此 `chgrp` 会告诉我它在做什么:
|
||||
|
||||
|
||||
```
|
||||
$ ls -l . conf
|
||||
.:
|
||||
drwxrwxr-x 2 alan alan 4096 Aug 5 15:33 conf
|
||||
|
||||
conf:
|
||||
-rw-rw-r-- 1 alan alan 0 Aug 5 15:33 conf.xml
|
||||
# chgrp -vR delta conf
|
||||
changed group of 'conf/conf.xml' from alan to delta
|
||||
changed group of 'conf' from alan to delta
|
||||
```
|
||||
|
||||
#### 参考
|
||||
|
||||
当你要更改文件的组以匹配特定的配置,或者当你不知道具体的组时(比如你运行一个脚本时),可使用参考文件 (`--reference=RFILE`)。你可以复制另外一个作为参考的文件(RFILE)的组。比如,为了撤销上面的更改 (请注意,点 `.` 代表当前工作目录):
|
||||
|
||||
```
|
||||
$ chgrp -vR --reference=. conf
|
||||
```
|
||||
|
||||
#### 报告更改
|
||||
|
||||
大多数命令都有用于控制其输出的参数。最常见的是 `-v` 来启用详细信息,而且 `chgrp` 命令也拥有详细模式。它还具有 `-c`(`--changes`)参数,指示 `chgrp` 仅在进行了更改时报告。`chgrp` 还会报告其他内容,例如是操作不被允许时。
|
||||
|
||||
参数 `-f`(`--silent`、`--quiet`)用于禁止显示大部分错误消息。我将在下一节中使用此参数和 `-c` 来显示实际更改。
|
||||
|
||||
#### 保持根目录
|
||||
|
||||
Linux 文件系统的根目录(`/`)应该受到高度重视。如果命令在此层级犯了一个错误,那么后果可能是可怕的,并会让系统无法使用。尤其是在运行一个会递归修改甚至删除的命令时。`chgrp` 命令有一个可用于保护和保持根目录的参数。它是 `--preserve-root`。如果在根目录中将此参数和递归一起使用,那么什么也不会发生,而是会出现一条消息:
|
||||
|
||||
```
|
||||
[root@localhost /]# chgrp -cfR --preserve-root a+w /
|
||||
chgrp: it is dangerous to operate recursively on '/'
|
||||
chgrp: use --no-preserve-root to override this failsafe
|
||||
```
|
||||
|
||||
不与递归(-R)结合使用时,该选项无效。但是,如果该命令由 `root` 用户运行,那么 `/` 的权限将会更改,但其下的其他文件或目录的权限则不会被更改:
|
||||
|
||||
```
|
||||
[alan@localhost /]$ chgrp -c --preserve-root alan /
|
||||
chgrp: changing group of '/': Operation not permitted
|
||||
[root@localhost /]# chgrp -c --preserve-root alan /
|
||||
changed group of '/' from root to alan
|
||||
```
|
||||
|
||||
令人惊讶的是,它似乎不是默认参数。而选项 `--no-preserve-root` 是默认的。如果你在不带“保持”选项的情况下运行上述命令,那么它将默认为“无保持”模式,并可能会更改不应更改的文件的权限:
|
||||
|
||||
```
|
||||
[alan@localhost /]$ chgrp -cfR alan /
|
||||
changed group of '/dev/pts/0' from tty to alan
|
||||
changed group of '/dev/tty2' from tty to alan
|
||||
changed group of '/var/spool/mail/alan' from mail to alan
|
||||
```
|
||||
|
||||
### 关于 newgrp
|
||||
|
||||
`newgrp` 命令允许用户覆盖当前的主要组。当你在所有文件必须有相同的组所有权的目录中操作时,`newgrp` 会很方便。假设你的内网服务器上有一个名为 `share` 的目录,不同的团队在其中存储市场活动照片。组名为 `share`。当不同的用户将文件放入目录时,文件的主要组可能会变得混乱。每当添加新文件时,你都可以运行 `chgrp` 将错乱的组纠正为 `share`:
|
||||
|
||||
```
|
||||
$ cd share
|
||||
ls -l
|
||||
-rw-r--r--. 1 alan share 0 Aug 7 15:35 pic13
|
||||
-rw-r--r--. 1 alan alan 0 Aug 7 15:35 pic1
|
||||
-rw-r--r--. 1 susan delta 0 Aug 7 15:35 pic2
|
||||
-rw-r--r--. 1 james gamma 0 Aug 7 15:35 pic3
|
||||
-rw-rw-r--. 1 bill contract 0 Aug 7 15:36 pic4
|
||||
```
|
||||
|
||||
我在 [chmod 命令][3]的文章中介绍了 `setgid` 模式。它是解决此问题的一种方法。但是,假设由于某种原因未设置 `setgid` 位。`newgrp` 命令在此时很有用。在任何用户将文件放入 `share` 目录之前,他们可以运行命令 `newgrp share`。这会将其主要组切换为 `share`,因此他们放入目录中的所有文件都将有 `share` 组,而不是用户自己的主要组。完成后,用户可以使用以下命令切换回常规主要组(举例):
|
||||
|
||||
```
|
||||
newgrp alan
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
了解如何管理用户、组和权限非常重要。最好知道一些替代方法来解决可能遇到的问题,因为并非所有环境都以相同的方式设置。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/9/linux-chgrp-and-newgrp-commands
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdosshttps://opensource.com/users/sethhttps://opensource.com/users/alanfdosshttps://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/community-penguins-osdc-lead.png?itok=BmqsAF4A (Penguins walking on the beach )
|
||||
[2]: https://opensource.com/article/19/8/linux-chown-command
|
||||
[3]: https://opensource.com/article/19/8/linux-chmod-command
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11405-1.html)
|
||||
[#]: subject: (IBM brings blockchain to Red Hat OpenShift; adds Apache CouchDB for hybrid cloud customers)
|
||||
[#]: via: (https://www.networkworld.com/article/3441362/ibm-brings-blockchain-to-red-hat-openshift-adds-apache-couchdb-for-hybrid-cloud-customers.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
IBM 将区块链引入红帽 OpenShift;为混合云客户添加了Apache CouchDB
|
||||
======
|
||||
|
||||
> IBM 在其区块链平台上增加了红帽 OpenShift 支持,并将用于 Apache CouchDB 的 Kubernetes Operator 引入其混合云服务中。
|
||||
|
||||

|
||||
|
||||
IBM 本周继续推进其红帽和开源集成工作,在其[区块链][1]平台上添加了红帽 OpenShift 支持,并在其[混合云][2]服务产品之外为 Apache CouchDB 引入了 Kubernetes Operator。
|
||||
|
||||
在该公司的旗舰级企业 Kubernetes 平台 [红帽 OpenShift 上部署 IBM 区块链][3] 的能力,意味着 IBM 区块链的开发人员将能够在本地、公共云或混合云架构中部署安全软件。
|
||||
|
||||
区块链是一个分布式数据库,维护着一个不断增长的记录列表,可以使用哈希技术对其进行验证,并且 IBM 区块链平台包括用于构建、操作、治理和发展受保护的区块链网络的工具。
|
||||
|
||||
IBM 表示,其区块链 / OpenShift 组合的目标客户面对的公司客户是:希望保留区块链分类帐副本并在自己的基础设施上运行工作负载以实现安全性,降低风险或合规性;需要将数据存储在特定位置以满足数据驻留要求;需要在多个云或混合云架构中部署区块链组件。
|
||||
|
||||
自 7 月份完成对红帽的收购以来,IBM 一直在围绕红帽基于 Kubernetes 的 OpenShift 容器平台构建云开发生态系统。最近,这位蓝色巨人将其[新 z15 大型机与 IBM 的红帽][4]技术融合在一起,称它将为红帽 OpenShift 容器平台提供 IBM z/OS 云代理。该产品将通过连接到 Kubernetes 容器为用户提供 z/OS 计算资源的直接自助访问。
|
||||
|
||||
IBM 表示,打算在 IBM z 系列和 LinuxONE 产品上向 Linux 提供 IBM [Cloud Pak 产品][5]。Cloud Paks 是由 OpenShift 与 100 多种其他 IBM 软件产品组成的捆绑包。LinuxONE 是 IBM 专为支持 Linux 环境而设计的非常成功的大型机系统。
|
||||
|
||||
IBM 表示,愿景是使支持 OpenShift 的 IBM 软件成为客户用来转变其组织的基础构建组件。
|
||||
|
||||
IBM 表示:“我们的大多数客户都需要支持混合云工作负载以及可在任何地方运行这些工作负载的灵活性的解决方案,而用于红帽的 z/OS 云代理将成为我们在平台上启用云原生的关键。”
|
||||
|
||||
在相关新闻中,IBM 宣布支持开源 Apache CouchDB,这是 [Apache CouchDB][7] 的 Kubernetes Operator,并且该 Operator 已通过认证可与红帽 OpenShift 一起使用。Operator 可以自动部署、管理和维护 Apache CouchDB 部署。Apache CouchDB 是非关系型开源 NoSQL 数据库。
|
||||
|
||||
在最近的 [Forrester Wave 报告][8]中,研究人员说:“企业喜欢 NoSQL 这样的能力,可以使用低成本服务器和可以存储、处理和访问任何类型的业务数据的灵活的无模式模型进行横向扩展。NoSQL 平台为企业基础设施专业人士提供了对数据存储和处理的更好控制,并提供了可加速应用程序部署的配置。当许多组织使用 NoSQL 来补充其关系数据库时,一些组织已开始替换它们以支持更好的性能、扩展规模并降低其数据库成本。”
|
||||
|
||||
当前,IBM 云使用 Cloudant Db 服务作为其针对新的云原生应用程序的标准数据库。IBM 表示,对 CouchDB 的强大支持为用户提供了替代方案和后备选项。IBM 表示,能够将它们全部绑定到红帽 OpenShift Kubernetes 部署中,可以使客户在部署应用程序并在多个云环境中移动数据时使用数据库本地复制功能来维持对数据的低延迟访问。
|
||||
|
||||
“我们的客户正在转向基于容器化和[微服务][9]的架构,以提高速度、敏捷性和运营能力。在云原生应用程序开发中,应用程序需要具有支持可伸缩性、可移植性和弹性的数据层。”IBM 院士兼云数据库副总裁 Adam Kocoloski 写道,“我们相信数据可移植性和 CouchDB 可以大大改善多云架构的功能,使客户能够构建真正可在私有云、公共云和边缘位置之间移植的解决方案。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3441362/ibm-brings-blockchain-to-red-hat-openshift-adds-apache-couchdb-for-hybrid-cloud-customers.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3330937/how-blockchain-will-transform-the-iot.html
|
||||
[2]: https://www.networkworld.com/article/3268448/what-is-hybrid-cloud-really-and-whats-the-best-strategy.html
|
||||
[3]: https://www.ibm.com/blogs/blockchain/2019/09/ibm-blockchain-platform-meets-red-hat-openshift/
|
||||
[4]: https://www.networkworld.com/article/3438542/ibm-z15-mainframe-amps-up-cloud-security-features.html
|
||||
[5]: https://www.networkworld.com/article/3429596/ibm-fuses-its-software-with-red-hats-to-launch-hybrid-cloud-juggernaut.html
|
||||
[6]: https://www.networkworld.com/article/3400740/achieve-compliant-cost-effective-hybrid-cloud-operations.html
|
||||
[7]: https://www.ibm.com/cloud/learn/couchdb
|
||||
[8]: https://reprints.forrester.com/#/assets/2/363/RES136481/reports
|
||||
[9]: https://www.networkworld.com/article/3137250/what-you-need-to-know-about-microservices.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,386 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11411-1.html)
|
||||
[#]: subject: (Best Linux Distributions For Everyone in 2019)
|
||||
[#]: via: (https://itsfoss.com/best-linux-distributions/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
2019 年最好的 Linux 发行版
|
||||
======
|
||||
|
||||
> 哪个是最好的 Linux 发行版呢?这个问题是没有明确的答案的。这就是为什么我们按各种分类汇编了这个最佳 Linux 列表的原因。
|
||||
|
||||
有许多 Linux 发行版,我甚至想不出一个确切的数量,因为你会发现很多不同的 Linux 发行版。
|
||||
|
||||
其中有些只是另外一个的复制品,而有些往往是独一无二的。这虽然有点混乱——但这也是 Linux 的优点。
|
||||
|
||||
不用担心,尽管有成千上万的发行版,在这篇文章中,我已经列出了目前最好的 Linux 发行版。当然,这个列表是主观的。但是,在这里,我们试图对发行版进行分类——每个发行版本都有自己的特点的。
|
||||
|
||||
* 面向初学者的 Linux 用户的最佳发行版
|
||||
* 最佳 Linux 服务器发行版
|
||||
* 可以在旧计算机上运行的最佳 Linux 发行版
|
||||
* 面向高级 Linux 用户的最佳发行版
|
||||
* 最佳常青树 Linux 发行版
|
||||
|
||||
**注:** 该列表没有特定的排名顺序。
|
||||
|
||||
### 面向初学者的最佳 Linux 发行版
|
||||
|
||||
在这个分类中,我们的目标是列出开箱即用的易用发行版。你不需要深度学习,你可以在安装后马上开始使用,不需要知道任何命令或技巧。
|
||||
|
||||
#### Ubuntu
|
||||
|
||||
![][6]
|
||||
|
||||
Ubuntu 无疑是最流行的 Linux 发行版之一。你甚至可以发现它已经预装在很多笔记本电脑上了。
|
||||
|
||||
用户界面很容易适应。如果你愿意,你可以根据自己的要求轻松定制它的外观。无论哪种情况,你都可以选择安装一个主题。你可以从了解更多关于[如何在 Ubuntu 安装主题的][7]的信息来起步。
|
||||
|
||||
除了它本身提供的功能外,你会发现一个巨大的 Ubuntu 用户在线社区。因此,如果你有问题——可以去任何论坛(或版块)寻求帮助。如果你想直接寻找解决方案,你应该看看我们对 [Ubuntu][8] 的报道(我们有很多关于 Ubuntu 的教程和建议)。
|
||||
|
||||
- [Ubuntu][9]
|
||||
|
||||
#### Linux Mint
|
||||
|
||||
![][10]
|
||||
|
||||
Linux Mint Cinnamon 是另一个受初学者欢迎的 Linux 发行版。默认的 Cinnamon 桌面类似于 Windows XP,这就是为什么当 Windows XP 停止维护时许多用户选择它的原因。
|
||||
|
||||
Linux Mint 基于 Ubuntu,因此它具有适用于 Ubuntu 的所有应用程序。简单易用是它成为 Linux 新用户首选的原因。
|
||||
|
||||
- [Linux Mint][11]
|
||||
|
||||
#### elementary OS
|
||||
|
||||
![][12]
|
||||
|
||||
elementary OS 是我用过的最漂亮的 Linux 发行版之一。用户界面类似于苹果操作系统——所以如果你已经使用了苹果系统,则很容易适应。
|
||||
|
||||
该发行版基于 Ubuntu,致力于提供一个用户友好的 Linux 环境,该环境在考虑性能的同时尽可能美观。如果你选择安装 elementary OS,这份[在安装 elementary OS 后要做的 11 件事的清单][13]会派上用场。
|
||||
|
||||
- [elementary OS][14]
|
||||
|
||||
#### MX Linux
|
||||
|
||||
![][15]
|
||||
|
||||
大约一年前,MX Linux 成为众人瞩目的焦点。现在(在发表这篇文章的时候),它是 [DistroWatch.com][16] 上最受欢迎的 Linux 发行版。如果你还没有使用过它,那么当你开始使用它时,你会感到惊讶。
|
||||
|
||||
与 Ubuntu 不同,MX Linux 是一个基于 Debian 的日益流行的发行版,采用 Xfce 作为其桌面环境。除了无与伦比的稳定性之外,它还配备了许多图形用户界面工具,这使得任何习惯了 Windows/Mac 的用户易于使用它。
|
||||
|
||||
此外,软件包管理器还专门针对一键安装进行了量身定制。你甚至可以搜索 [Flatpak][18] 软件包并立即安装它(默认情况下,Flathub 在软件包管理器中是可用的来源之一)。
|
||||
|
||||
- [MX Linux][19]
|
||||
|
||||
#### Zorin OS
|
||||
|
||||
![][20]
|
||||
|
||||
Zorin OS 是又一个基于 Ubuntu 的发行版,它又是桌面上最漂亮、最直观的操作系统之一。尤其是在[Zorin OS 15 发布][21]之后——我绝对会向没有任何 Linux 经验的用户推荐它。它也引入了许多基于图形用户界面的应用程序。
|
||||
|
||||
你也可以将其安装在旧电脑上,但是,请确保选择“Lite”版本。此外,你还有“Core”、“Education”和 “Ultimate”版本可以选择。你可以选择免费安装 Core 版,但是如果你想支持开发人员并帮助改进 Zorin,请考虑获得 Ultimate 版。
|
||||
|
||||
Zorin OS 是由两名爱尔兰的青少年创建的。你可以[在这里阅读他们的故事][22]。
|
||||
|
||||
- [Zorin OS][23]
|
||||
|
||||
#### Pop!_OS
|
||||
|
||||

|
||||
|
||||
Sytem76 的 Pop!_OS 是开发人员或计算机科学专业人员的理想选择。当然,不仅限于编码人员,如果你刚开始使用 Linux,这也是一个很好的选择。它基于 Ubuntu,但是其 UI 感觉更加直观和流畅。除了 UI 外,它还强制执行全盘加密。
|
||||
|
||||
你可以通过文章下面的评论看到,我们的许多读者似乎都喜欢(并坚持使用)它。如果你对此感到好奇,也应该查看一下我们关于 Phillip Prado 的 [Pop!_OS 的动手实践](https://itsfoss.com/pop-os-linux-review/)的文章。
|
||||
|
||||
(LCTT 译注:这段推荐是原文后来补充的,因为原文下面很多人在评论推荐。)
|
||||
|
||||
- [Pop!_OS](https://system76.com/pop)
|
||||
|
||||
#### 其他选择
|
||||
|
||||
[深度操作系统][24] 和其他的 Ubuntu 变种(如 Kubuntu、Xubuntu)也是初学者的首选。如果你想寻求更多的选择,你可以看看。(LCTT 译注:我知道你们肯定对将深度操作系统列入其它不满意——这个锅归原作者。)
|
||||
|
||||
如果你想要挑战自己,你可以试试 Ubuntu 之外的 Fedora —— 但是一定要看看我们关于 [Ubuntu 和 Fedora 对比][25]的文章,从桌面的角度做出更好的选择。
|
||||
|
||||
### 最好的服务器发行版
|
||||
|
||||
对于服务器来说,选择 Linux 发行版取决于稳定性、性能和企业级支持。如果你只是尝试,则可以尝试任何你想要的发行版。
|
||||
|
||||
但是,如果你要为 Web 服务器或任何重要的组件安装它,你应该看看我们的一些建议。
|
||||
|
||||
#### Ubuntu 服务器
|
||||
|
||||
根据你的需要,Ubuntu 为你的服务器提供了不同的选项。如果你正在寻找运行在 AWS、Azure、谷歌云平台等平台上的优化解决方案,[Ubuntu Cloud][26] 是一个很好的选择。
|
||||
|
||||
无论是哪种情况,你都可以选择 Ubuntu 服务器包,并将其安装在你的服务器上。然而,Ubuntu 在云上部署时也是最受欢迎的 Linux 发行版(根据数字判断——[来源1][27]、[来源2][28])。
|
||||
|
||||
请注意,除非你有特殊要求,我们建议你选择 LTS 版。
|
||||
|
||||
- [Ubuntu Server][29]
|
||||
|
||||
#### 红帽企业版 Linux(RHEL)
|
||||
|
||||
红帽企业版 Linux(RHEL)是面向企业和组织的顶级 Linux 平台。如果我们按数字来看,红帽可能不是服务器领域最受欢迎的。但是,有相当一部分企业用户依赖于 RHEL (比如联想)。
|
||||
|
||||
从技术上讲,Fedora 和红帽企业版是相关联的。无论红帽要支持什么——在出现在 RHEL 之前,都要在 Fedora 上进行测试。我不是定制需求的服务器发行版专家,所以你一定要查看他们的[官方文档][30]以了解它是否适合你。
|
||||
|
||||
- [RHEL][31]
|
||||
|
||||
#### SUSE Linux 企业服务器(SLES)
|
||||
|
||||
![][32]
|
||||
|
||||
别担心,不要把这和 OpenSUSE 混淆。一切都以一个共同的品牌 “SUSE” 命名 —— 但是 OpenSUSE 是一个开源发行版,目标是社区,并且由社区维护。
|
||||
|
||||
SUSE Linux 企业服务器(SLES)是基于云的服务器最受欢迎的解决方案之一。为了获得管理开源解决方案的优先支持和帮助,你必须选择订阅。
|
||||
|
||||
- [SLES][33]
|
||||
|
||||
#### CentOS
|
||||
|
||||
![][34]
|
||||
|
||||
正如我提到的,对于 RHEL 你需要订阅。而 CentOS 更像是 RHEL 的社区版,因为它是从 RHEL 的源代码中派生出来的。而且,它是开源的,也是免费的。尽管与过去几年相比,使用 CentOS 的托管提供商数量明显减少,但这仍然是一个很好的选择。
|
||||
|
||||
CentOS 可能没有加载最新的软件包,但它被认为是最稳定的发行版之一,你可以在各种云平台上找到 CentOS 镜像。如果没有,你可以选择 CentOS 提供的自托管镜像。
|
||||
|
||||
- [CentOS][35]
|
||||
|
||||
#### 其他选择
|
||||
|
||||
你也可以尝试 [Fedora Server][36]或[Debian][37]作为上述发行版的替代品。
|
||||
|
||||
### 旧电脑的最佳 Linux 发行版
|
||||
|
||||
如果你有一台旧电脑,或者你真的不需要升级你的系统,你仍然可以尝试一些最好的 Linux 发行版。
|
||||
|
||||
我们已经详细讨论了一些[最好的轻量级 Linux 发行版][42]。在这里,我们将只提到那些真正突出的东西(以及一些新的补充)。
|
||||
|
||||
#### Puppy Linux
|
||||
|
||||
![][43]
|
||||
|
||||
Puppy Linux 实际上是最小的发行版本之一。刚开始使用 Linux 时,我的朋友建议我尝试一下 Puppy Linux,因为它可以轻松地在较旧的硬件配置上运行。
|
||||
|
||||
如果你想在你的旧电脑上享受一次爽快的体验,那就值得去看看。多年来,随着一些新的有用特性的增加,用户体验得到了改善。
|
||||
|
||||
- [Puppy Linux][44]
|
||||
|
||||
#### Solus Budgie
|
||||
|
||||
![][45]
|
||||
|
||||
在最近的一个主要版本——[Solus 4 Fortitude][46] 之后,它是一个令人印象深刻的轻量级桌面操作系统。你可以选择像 GNOME 或 MATE 这样的桌面环境。然而,Solus Budgie 恰好是我的最爱之一,它是一款适合初学者的功能齐全的 Linux发行版,同时对系统资源要求很少。
|
||||
|
||||
- [Solus][47]
|
||||
|
||||
#### Bodhi
|
||||
|
||||
![][48]
|
||||
|
||||
Bodhi Linux 构建于 Ubuntu 之上。然而,与Ubuntu不同,它在较旧的配置上运行良好。
|
||||
|
||||
这个发行版的主要亮点是它的 [Moksha 桌面][49](这是 Enlightenment 17 桌面的延续)。用户体验直观且反应极快。即使我个人不用它,你也应该在你的旧系统上试一试。
|
||||
|
||||
- [Bodhi Linux][50]
|
||||
|
||||
#### antiX
|
||||
|
||||
![][51]
|
||||
|
||||
antiX 部分担起了 MX Linux 的责任,它是一个轻量级的 Linux 发行版,为新的或旧的计算机量身定制。其用户界面并不令人印象深刻——但它可以像预期的那样工作。
|
||||
|
||||
它基于 Debian,可以作为一个现场版 CD 发行版使用,而不需要安装它。antiX 还提供现场版引导加载程序。与其他发行版相比,你可以保存设置,这样就不会在每次重新启动时丢失设置。不仅如此,你还可以通过其“持久保留”功能将更改保存到根目录中。
|
||||
|
||||
因此,如果你正在寻找一个可以在旧硬件上提供快速用户体验的现场版 USB 发行版,antiX 是一个不错的选择。
|
||||
|
||||
- [antiX][52]
|
||||
|
||||
#### Sparky Linux
|
||||
|
||||
![][53]
|
||||
|
||||
Sparky Linux 基于 Debian,它是理想的低端系统 Linux 发行版。伴随着超快的用户体验,Sparky Linux 为不同的用户提供了几个特殊版本(或变种)。
|
||||
|
||||
例如,它提供了针对一组用户的稳定版本(和变种)和滚动版本。Sparky Linux GameOver 版非常受游戏玩家欢迎,因为它包含了一堆预装的游戏。你可以查看我们的[最佳 Linux 游戏发行版][54] —— 如果你也想在你的系统上玩游戏。
|
||||
|
||||
#### 其他选择
|
||||
|
||||
你也可以尝试 [Linux Lite][55]、[Lubuntu][56]、[Peppermint][57] 等轻量级 Linux 发行版。
|
||||
|
||||
### 面向高级用户的最佳 Linux 发行版
|
||||
|
||||
一旦你习惯了各种软件包管理器和命令来帮助你解决任何问题,你就可以开始找寻只为高级用户量身定制的 Linux 发行版。
|
||||
|
||||
当然,如果你是专业人士,你会有一套具体的要求。然而,如果你已经作为普通用户使用了一段时间——以下发行版值得一试。
|
||||
|
||||
#### Arch Linux
|
||||
|
||||
![][58]
|
||||
|
||||
Arch Linux 本身是一个简单而强大的发行版,具有陡峭的学习曲线。不像其系统,你不会一次就把所有东西都预先安装好。你必须配置系统并根据需要添加软件包。
|
||||
|
||||
此外,在安装 Arch Linux 时,必须按照一组命令来进行(没有图形用户界面)。要了解更多信息,你可以按照我们关于[如何安装 Arch Linux][59] 的指南进行操作。如果你要安装它,你还应该知道在[安装 Arch Linux 后需要做的一些基本事情][60]。这会帮助你快速入门。
|
||||
|
||||
除了多才多艺和简便性之外,值得一提的是 Arch Linux 背后的社区非常活跃。所以,如果你遇到问题,你不用担心。
|
||||
|
||||
- [Arch Linux][61]
|
||||
|
||||
#### Gentoo
|
||||
|
||||
![][62]
|
||||
|
||||
如果你知道如何编译源代码,Gentoo Linux 是你必须尝试的版本。这也是一个轻量级的发行版,但是,你需要具备必要的技术知识才能使它发挥作用。
|
||||
|
||||
当然,[官方手册][63]提供了许多你需要知道的信息。但是,如果你不确定自己在做什么——你需要花很多时间去想如何充分利用它。
|
||||
|
||||
- [Gentoo Linux][64]
|
||||
|
||||
#### Slackware
|
||||
|
||||
![][65]
|
||||
|
||||
Slackware 是仍然重要的最古老的 Linux 发行版之一。如果你愿意编译或开发软件来为自己建立一个完美的环境 —— Slackware 是一个不错的选择。
|
||||
|
||||
如果你对一些最古老的 Linux 发行版感到好奇,我们有一篇关于[最早的 Linux 发行版][66]可以去看看。
|
||||
|
||||
尽管使用它的用户/开发人员的数量已经显著减少,但对于高级用户来说,它仍然是一个极好的选择。此外,最近有个新闻是 [Slackware 有了一个 Patreon 捐赠页面][67],我们希望 Slackware 继续作为最好的 Linux 发行版之一存在。
|
||||
|
||||
- [Slackware][68]
|
||||
|
||||
### 最佳多用途 Linux 发行版
|
||||
|
||||
有些 Linux 发行版既可以作为初学者友好的桌面又可以作为高级操作系统的服务器。因此,我们考虑为这样的发行版编辑一个单独的部分。
|
||||
|
||||
如果你不同意我们的观点(或者有建议要补充),请在评论中告诉我们。我们认为,这对于每个用户都可以派上用场:
|
||||
|
||||
#### Fedora
|
||||
|
||||
![][69]
|
||||
|
||||
Fedora 提供两个独立的版本:一个用于台式机/笔记本电脑(Fedora 工作站),另一个用于服务器(Fedora 服务器)。
|
||||
|
||||
因此,如果你正在寻找一款时髦的桌面操作系统,有点学习曲线,又对用户友好,那么 Fedora 是一个选择。无论是哪种情况,如果你正在为你的服务器寻找一个 Linux 操作系统,这也是一个不错的选择。
|
||||
|
||||
- [Fedora][70]
|
||||
|
||||
#### Manjaro
|
||||
|
||||
![][71]
|
||||
|
||||
Manjaro 基于 [Arch Linux][72]。不用担心,虽然 Arch Linux 是为高级用户量身定制的,但Manjaro 让新手更容易上手。这是一个简单且对初学者友好的 Linux 发行版。用户界面足够好,并且内置了一系列有用的图形用户界面应用程序。
|
||||
|
||||
下载时,你可以为 Manjaro 选择[桌面环境][73]。就个人而言,我喜欢 Manjaro 的 KDE 桌面。
|
||||
|
||||
- [Manjaro Linux][74]
|
||||
|
||||
#### Debian
|
||||
|
||||
![][75]
|
||||
|
||||
嗯,Ubuntu 是基于 Debian 的——所以它本身是一个非常好的发行版本。Debian 是台式机和服务器的理想选择。
|
||||
|
||||
这可能不是对初学者最友好的操作系统——但你可以通过阅读[官方文档][76]轻松开始。[Debian 10 Buster][77] 的最新版本引入了许多变化和必要的改进。所以,你必须试一试!
|
||||
|
||||
### 总结
|
||||
|
||||
总的来说,这些是我们推荐你去尝试的最好的 Linux 发行版。是的,还有许多其他的 Linux 发行版值得一提,但是根据个人喜好,对每个发行版来说,取决于个人喜好,这种选择是主观的。
|
||||
|
||||
但是,我们也为 [Windows 用户][78]、[黑客和脆弱性测试人员][41]、[游戏玩家][54]、[程序员][39]和[偏重隐私者][79]提供了单独的发行版列表所以,如果你感兴趣的话请仔细阅读。
|
||||
|
||||
如果你认为我们遗漏了你最喜欢的 Linux 发行版,请在下面的评论中告诉我们你的想法,我们将更新这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-linux-distributions/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: tmp.NoRXbIWHkg#for-beginners
|
||||
[2]: tmp.NoRXbIWHkg#for-servers
|
||||
[3]: tmp.NoRXbIWHkg#for-old-computers
|
||||
[4]: tmp.NoRXbIWHkg#for-advanced-users
|
||||
[5]: tmp.NoRXbIWHkg#general-purpose
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/install-google-chrome-ubuntu-10.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/install-themes-ubuntu/
|
||||
[8]: https://itsfoss.com/tag/ubuntu/
|
||||
[9]: https://ubuntu.com/download/desktop
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-Mint-19-desktop.jpg?ssl=1
|
||||
[11]: https://www.linuxmint.com/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/elementary-os-juno-feat.jpg?ssl=1
|
||||
[13]: https://itsfoss.com/things-to-do-after-installing-elementary-os-5-juno/
|
||||
[14]: https://elementary.io/
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/mx-linux.jpg?ssl=1
|
||||
[16]: https://distrowatch.com/
|
||||
[17]: https://en.wikipedia.org/wiki/Linux_distribution#Rolling_distributions
|
||||
[18]: https://flatpak.org/
|
||||
[19]: https://mxlinux.org/
|
||||
[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/zorin-os-15.png?ssl=1
|
||||
[21]: https://itsfoss.com/zorin-os-15-release/
|
||||
[22]: https://itsfoss.com/zorin-os-interview/
|
||||
[23]: https://zorinos.com/
|
||||
[24]: https://www.deepin.org/en/
|
||||
[25]: https://itsfoss.com/ubuntu-vs-fedora/
|
||||
[26]: https://ubuntu.com/download/cloud
|
||||
[27]: https://w3techs.com/technologies/details/os-linux/all/all
|
||||
[28]: https://thecloudmarket.com/stats
|
||||
[29]: https://ubuntu.com/download/server
|
||||
[30]: https://developers.redhat.com/products/rhel/docs-and-apis
|
||||
[31]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[32]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/SUSE-Linux-Enterprise.jpg?ssl=1
|
||||
[33]: https://www.suse.com/products/server/
|
||||
[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/centos.png?ssl=1
|
||||
[35]: https://www.centos.org/
|
||||
[36]: https://getfedora.org/en/server/
|
||||
[37]: https://www.debian.org/distrib/
|
||||
[38]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/coding.jpg?ssl=1
|
||||
[39]: https://itsfoss.com/best-linux-distributions-progammers/
|
||||
[40]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/hacking.jpg?ssl=1
|
||||
[41]: https://itsfoss.com/linux-hacking-penetration-testing/
|
||||
[42]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[43]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/puppy-linux-bionic.jpg?ssl=1
|
||||
[44]: http://puppylinux.com/
|
||||
[45]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/solus-4-featured.jpg?resize=800%2C450&ssl=1
|
||||
[46]: https://itsfoss.com/solus-4-release/
|
||||
[47]: https://getsol.us/home/
|
||||
[48]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/bodhi-linux.png?fit=800%2C436&ssl=1
|
||||
[49]: http://www.bodhilinux.com/moksha-desktop/
|
||||
[50]: http://www.bodhilinux.com/
|
||||
[51]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/10/antix-linux-screenshot.jpg?ssl=1
|
||||
[52]: https://antixlinux.com/
|
||||
[53]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/sparky-linux.jpg?ssl=1
|
||||
[54]: https://itsfoss.com/linux-gaming-distributions/
|
||||
[55]: https://www.linuxliteos.com/
|
||||
[56]: https://lubuntu.me/
|
||||
[57]: https://peppermintos.com/
|
||||
[58]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/arch_linux_screenshot.jpg?ssl=1
|
||||
[59]: https://itsfoss.com/install-arch-linux/
|
||||
[60]: https://itsfoss.com/things-to-do-after-installing-arch-linux/
|
||||
[61]: https://www.archlinux.org
|
||||
[62]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/gentoo-linux.png?ssl=1
|
||||
[63]: https://wiki.gentoo.org/wiki/Handbook:Main_Page
|
||||
[64]: https://www.gentoo.org
|
||||
[65]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/slackware-screenshot.jpg?ssl=1
|
||||
[66]: https://itsfoss.com/earliest-linux-distros/
|
||||
[67]: https://distrowatch.com/dwres.php?resource=showheadline&story=8743
|
||||
[68]: http://www.slackware.com/
|
||||
[69]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/fedora-overview.png?ssl=1
|
||||
[70]: https://getfedora.org/
|
||||
[71]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/manjaro-gnome.jpg?ssl=1
|
||||
[72]: https://www.archlinux.org/
|
||||
[73]: https://itsfoss.com/glossary/desktop-environment/
|
||||
[74]: https://manjaro.org/
|
||||
[75]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/debian-screenshot.png?ssl=1
|
||||
[76]: https://www.debian.org/releases/stable/installmanual
|
||||
[77]: https://itsfoss.com/debian-10-buster/
|
||||
[78]: https://itsfoss.com/windows-like-linux-distributions/
|
||||
[79]: https://itsfoss.com/privacy-focused-linux-distributions/
|
||||
88
published/20190911 4 open source cloud security tools.md
Normal file
88
published/20190911 4 open source cloud security tools.md
Normal file
@ -0,0 +1,88 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11432-1.html)
|
||||
[#]: subject: (4 open source cloud security tools)
|
||||
[#]: via: (https://opensource.com/article/19/9/open-source-cloud-security)
|
||||
[#]: author: (Alison Naylor https://opensource.com/users/asnaylor,Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
4 种开源云安全工具
|
||||
======
|
||||
|
||||
> 查找并排除你存储在 AWS 和 GitHub 中的数据里的漏洞。
|
||||
|
||||
![Tools in a cloud][1]
|
||||
|
||||
如果你的日常工作是开发者、系统管理员、全栈工程师或者是网站可靠性工程师(SRE),工作内容包括使用 Git 从 GitHub 上推送、提交和拉取,并部署到亚马逊 Web 服务上(AWS),安全性就是一个需要持续考虑的一个点。幸运的是,开源工具能帮助你的团队避免犯常见错误,这些常见错误会导致你的组织损失数千美元。
|
||||
|
||||
本文介绍了四种开源工具,当你在 GitHub 和 AWS 上进行开发时,这些工具能帮助你提升项目的安全性。同样的,本着开源的精神,我会与三位安全专家——[Travis McPeak][2],奈飞高级云安全工程师;[Rich Monk][3],红帽首席高级信息安全分析师;以及 [Alison Naylor][4],红帽首席信息安全分析师——共同为本文做出贡献。
|
||||
|
||||
我们已经按场景对每个工具都做了区分,但是它们并不是相互排斥的。
|
||||
|
||||
### 1、使用 gitrob 发现敏感数据
|
||||
|
||||
你需要发现任何出现于你们团队的 Git 仓库中的敏感信息,以便你能将其删除。借助专注于攻击应用程序或者操作系统的工具以使用红/蓝队模型,这样可能会更有意义,在这个模型中,一个信息安全团队会划分为两块,一个是攻击团队(又名红队),以及一个防守团队(又名蓝队)。有一个红队来尝试渗透你的系统和应用要远远好于等待一个攻击者来实际攻击你。你的红队可能会尝试使用 [Gitrob][5],该工具可以克隆和爬取你的 Git 仓库,以此来寻找凭证和敏感信息。
|
||||
|
||||
即使像 Gitrob 这样的工具可以被用来造成破坏,但这里的目的是让你的信息安全团队使用它来发现无意间泄露的属于你的组织的敏感信息(比如 AWS 的密钥对或者是其他被失误提交上去的凭证)。这样,你可以修整你的仓库并清除敏感数据——希望能赶在攻击者发现它们之前。记住不光要修改受影响的文件,还要[删除它们的历史记录][6]。
|
||||
|
||||
### 2、使用 git-secrets 来避免合并敏感数据
|
||||
|
||||
虽然在你的 Git 仓库里发现并移除敏感信息很重要,但在一开始就避免合并这些敏感信息岂不是更好?即使错误地提交了敏感信息,使用 [git-secrets][7] 可以避免你陷入公开的困境。这款工具可以帮助你设置钩子,以此来扫描你的提交、提交信息和合并信息,寻找常见的敏感信息模式。注意你选择的模式要匹配你的团队使用的凭证,比如 AWS 访问密钥和秘密密钥。如果发现了一个匹配项,你的提交就会被拒绝,一个潜在的危机就此得到避免。
|
||||
|
||||
为你已有的仓库设置 git-secrets 是很简单的,而且你可以使用一个全局设置来保护所有你以后要创建或克隆的仓库。你同样可以在公开你的仓库之前,使用 git-secrets 来扫描它们(包括之前所有的历史版本)。
|
||||
|
||||
### 3、使用 Key Conjurer 创建临时凭证
|
||||
|
||||
有一点额外的保险来防止无意间公开了存储的敏感信息,这是很好的事,但我们还可以做得更好,就完全不存储任何凭证。追踪凭证,谁访问了它,存储到了哪里,上次更新是什么时候——太麻烦了。然而,以编程的方式生成的临时凭证就可以避免大量的此类问题,从而巧妙地避开了在 Git 仓库里存储敏感信息这一问题。使用 [Key Conjurer][8],它就是为解决这一需求而被创建出来的。有关更多 Riot Games 为什么创建 Key Conjurer,以及 Riot Games 如何开发的 Key Conjurer,请阅读 [Key Conjurer:我们最低权限的策略][9]。
|
||||
|
||||
### 4、使用 Repokid 自动化地提供最小权限
|
||||
|
||||
任何一个参加过基本安全课程的人都知道,设置最小权限是基于角色的访问控制的最佳实现。难过的是,离开校门,会发现手动运用最低权限策略会变得如此艰难。一个应用的访问需求会随着时间的流逝而变化,开发人员又太忙了没时间去手动削减他们的权限。[Repokid][10] 使用 AWS 提供提供的有关身份和访问管理(IAM)的数据来自动化地调整访问策略。Repokid 甚至可以在 AWS 中为超大型组织提供自动化地最小权限设置。
|
||||
|
||||
### 工具而已,又不是大招
|
||||
|
||||
这些工具并不是什么灵丹妙药,它们只是工具!所以,在尝试使用这些工具或其他的控件之前,请和你的组织里一起工作的其他人确保你们已经理解了你的云服务的使用情况和用法模式。
|
||||
|
||||
应该严肃对待你的云服务和代码仓库服务,并熟悉最佳实现的做法。下面的文章将帮助你做到这一点。
|
||||
|
||||
**对于 AWS:**
|
||||
|
||||
* [管理 AWS 访问密钥的最佳实现][11]
|
||||
* [AWS 安全审计指南][12]
|
||||
|
||||
**对于 GitHub:**
|
||||
|
||||
* [介绍一种新方法来让你的代码保持安全][13]
|
||||
* [GitHub 企业版最佳安全实现][14]
|
||||
|
||||
同样重要的一点是,和你的安全团队保持联系;他们应该可以为你团队的成功提供想法、建议和指南。永远记住:安全是每个人的责任,而不仅仅是他们的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/9/open-source-cloud-security
|
||||
|
||||
作者:[Alison Naylor][a1],[Anderson Silva][a2]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]: https://opensource.com/users/asnaylor
|
||||
[a2]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cloud_tools_hardware.png?itok=PGjJenqT (Tools in a cloud)
|
||||
[2]: https://twitter.com/travismcpeak?lang=en
|
||||
[3]: https://github.com/rmonk
|
||||
[4]: https://www.linkedin.com/in/alperkins/
|
||||
[5]: https://github.com/michenriksen/gitrob
|
||||
[6]: https://help.github.com/en/articles/removing-sensitive-data-from-a-repository
|
||||
[7]: https://github.com/awslabs/git-secrets
|
||||
[8]: https://github.com/RiotGames/key-conjurer
|
||||
[9]: https://technology.riotgames.com/news/key-conjurer-our-policy-least-privilege
|
||||
[10]: https://github.com/Netflix/repokid
|
||||
[11]: https://docs.aws.amazon.com/general/latest/gr/aws-access-keys-best-practices.html
|
||||
[12]: https://docs.aws.amazon.com/general/latest/gr/aws-security-audit-guide.html
|
||||
[13]: https://github.blog/2019-05-23-introducing-new-ways-to-keep-your-code-secure/
|
||||
[14]: https://github.blog/2015-10-09-github-enterprise-security-best-practices/
|
||||
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11415-1.html)
|
||||
[#]: subject: (Copying large files with Rsync, and some misconceptions)
|
||||
[#]: via: (https://fedoramagazine.org/copying-large-files-with-rsync-and-some-misconceptions/)
|
||||
[#]: author: (Daniel Leite de Abreu https://fedoramagazine.org/author/dabreu/)
|
||||
|
||||
使用 rsync 复制大文件的一些误解
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
有一种观点认为,在 IT 行业工作的许多人经常从网络帖子里复制和粘贴。我们都干过,复制粘贴本身不是问题。问题是当我们在不理解它们的情况下这样干。
|
||||
|
||||
几年前,一个曾经在我团队中工作的朋友需要将虚拟机模板从站点 A 复制到站点 B。他们无法理解为什么复制的文件在站点 A 上为 10GB,但是在站点 B 上却变为 100GB。
|
||||
|
||||
这位朋友认为 `rsync` 是一个神奇的工具,应该仅“同步”文件本身。但是,我们大多数人所忘记的是了解 `rsync` 的真正含义、用法,以及我认为最重要的是它原本是用来做什么的。本文提供了有关 `rsync` 的更多信息,并解释了那件事中发生了什么。
|
||||
|
||||
### 关于 rsync
|
||||
|
||||
`rsync` 是由 Andrew Tridgell 和 Paul Mackerras 创建的工具,其动机是以下问题:
|
||||
|
||||
假设你有两个文件,`file_A` 和 `file_B`。你希望将 `file_B` 更新为与 `file_A` 相同。显而易见的方法是将 `file_A` 复制到 `file_B`。
|
||||
|
||||
现在,假设这两个文件位于通过慢速通信链接(例如,拨号 IP 链接)连接的两个不同的服务器上。如果`file_A` 大,将其复制到 `file_B` 将会很慢,有时甚至是不可能完成的。为了提高效率,你可以在发送前压缩 `file_A`,但这通常只会获得 2 到 4 倍的效率提升。
|
||||
|
||||
现在假设 `file_A` 和 `file_B` 非常相似,并且为了加快处理速度,你可以利用这种相似性。一种常见的方法是仅通过链接发送 `file_A` 和 `file_B` 之间的差异,然后使用这个差异列表在远程端重建文件。
|
||||
|
||||
问题在于,用于在两个文件之间创建一组差异的常规方法依赖于能够读取两个文件。因此,它们要求链接的一端预先提供两个文件。如果它们在同一台计算机上不是同时可用的,则无法使用这些算法。(一旦将文件复制过来,就不需要做对比差异了)。而这是 `rsync` 解决的问题。
|
||||
|
||||
`rsync` 算法有效地计算源文件的哪些部分与现有目标文件的部分匹配。这样,匹配的部分就不需要通过链接发送了;所需要的只是对目标文件部分的引用。只有源文件中不匹配的部分才需要发送。
|
||||
|
||||
然后,接收者可以使用对现有目标文件各个部分的引用和原始素材来构造源文件的副本。
|
||||
|
||||
另外,可以使用一系列常用压缩算法中的任何一种来压缩发送到接收器的数据,以进一步提高速度。
|
||||
|
||||
我们都知道,`rsync` 算法以一种漂亮的方式解决了这个问题。
|
||||
|
||||
在 `rsync` 的介绍之后,回到那件事!
|
||||
|
||||
### 问题 1:自动精简配置
|
||||
|
||||
有两件事可以帮助那个朋友了解正在发生的事情。
|
||||
|
||||
该文件在其他地方的大小变得越来越大的问题是由源系统上启用了<ruby>自动精简配置<rt>Thin Provisioning</rt></ruby>(TP)引起的,这是一种优化存储区域网络(SAN)或网络连接存储(NAS)中可用空间效率的方法。
|
||||
|
||||
由于启用了 TP,源文件只有 10GB,并且在不使用任何其他配置的情况下使用 `rsync` 进行传输时,目标位置将接收到全部 100GB 的大小。`rsync` 无法自动完成该(TP)操作,必须对其进行配置。
|
||||
|
||||
进行此工作的选项是 `-S`(或 `–sparse`),它告诉 `rsync` 有效地处理稀疏文件。它会按照它说的做!它只会发送该稀疏数据,因此源和目标将有一个 10GB 的文件。
|
||||
|
||||
### 问题 2:更新文件
|
||||
|
||||
当发送一个更新的文件时会出现第二个问题。现在目标仅接收 10GB 了,但始终传输的是整个文件(包含虚拟磁盘),即使只是在该虚拟磁盘上更改了一个配置文件。换句话说,只是该文件的一小部分发生了更改。
|
||||
|
||||
用于此传输的命令是:
|
||||
|
||||
```
|
||||
rsync -avS vmdk_file syncuser@host1:/destination
|
||||
```
|
||||
|
||||
同样,了解 `rsync` 的工作方式也将有助于解决此问题。
|
||||
|
||||
上面是关于 `rsync` 的最大误解。我们许多人认为 `rsync` 只会发送文件的增量更新,并且只会自动更新需要更新的内容。**但这不是 `rsync` 的默认行为**。
|
||||
|
||||
如手册页所述,`rsync` 的默认行为是在目标位置创建文件的新副本,并在传输完成后将其移动到正确的位置。
|
||||
|
||||
要更改 `rsync` 的默认行为,你必须设置以下标志,然后 `rsync` 将仅发送增量:
|
||||
|
||||
```
|
||||
--inplace 原地更新目标文件
|
||||
--partial 保留部分传输的文件
|
||||
--append 附加数据到更短的文件
|
||||
--progress 在传输时显示进度条
|
||||
```
|
||||
|
||||
因此,可以确切地执行我那个朋友想要的功能的完整命令是:
|
||||
|
||||
```
|
||||
rsync -av --partial --inplace --append --progress vmdk_file syncuser@host1:/destination
|
||||
```
|
||||
|
||||
注意,出于两个原因,这里必须删除稀疏选项 `-S`。首先是通过网络发送文件时,不能同时使用 `–sparse` 和 `–inplace`。其次,当你以前使用过 `–sparse` 发送文件时,就无法再使用 `–inplace` 进行更新。请注意,低于 3.1.3 的 `rsync` 版本将拒绝 `–sparse` 和 `–inplace` 的组合。
|
||||
|
||||
因此,即使那个朋友最终通过网络复制了 100GB,那也只需发生一次。以下所有更新仅复制差异,从而使复制非常高效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/copying-large-files-with-rsync-and-some-misconceptions/
|
||||
|
||||
作者:[Daniel Leite de Abreu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/dabreu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/rsync-816x345.jpg
|
||||
@ -0,0 +1,363 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (way-ww)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11422-1.html)
|
||||
[#]: subject: (Linux commands to display your hardware information)
|
||||
[#]: via: (https://opensource.com/article/19/9/linux-commands-hardware-information)
|
||||
[#]: author: (Howard Fosdick https://opensource.com/users/howtechhttps://opensource.com/users/sethhttps://opensource.com/users/sethhttps://opensource.com/users/seth)
|
||||
|
||||
用 Linux 命令显示硬件信息
|
||||
======
|
||||
|
||||
> 通过命令行获取计算机硬件详细信息。
|
||||
|
||||

|
||||
|
||||
你可能会有很多的原因需要查清计算机硬件的详细信息。例如,你需要修复某些问题并在论坛上发出请求,人们可能会立即询问你的计算机具体的信息。或者当你想要升级计算机配置时,你需要知道现有的硬件型号和能够升级的型号。这些都需要查询你的计算机具体规格信息。
|
||||
|
||||
最简单的方法是使用标准的 Linux GUI 程序之一:
|
||||
|
||||
* [i-nex][2] 收集硬件信息,并且类似于 Windows 下流行的 [CPU-Z][3] 的显示。
|
||||
* [HardInfo][4] 显示硬件具体信息,甚至包括一组八个的流行的性能基准程序,你可以用它们评估你的系统性能。
|
||||
* [KInfoCenter][5] 和 [Lshw][6] 也能够显示硬件的详细信息,并且可以从许多软件仓库中获取。
|
||||
|
||||
或者,你也可以拆开计算机机箱去查看硬盘、内存和其他设备上的标签信息。或者你可以在系统启动时,按下[相应的按键][7]进入 UEFI 和 BIOS 界面获得信息。这两种方式都会向你显示硬件信息但省略软件信息。
|
||||
|
||||
你也可以使用命令行获取硬件信息。等一下… 这听起来有些困难。为什么你会要这样做?
|
||||
|
||||
有时候通过使用一条针对性强的命令可以很轻松的找到特定信息。也可能你没有可用的 GUI 程序或者只是不想安装这样的程序。
|
||||
|
||||
使用命令行的主要原因可能是编写脚本。无论你是使用 Linux shell 还是其他编程语言来编写脚本通常都需要使用命令行。
|
||||
|
||||
很多检测硬件信息的命令行都需要使用 root 权限。所以要么切换到 root 用户,要么使用 `sudo` 在普通用户状态下发出命令:
|
||||
|
||||
```
|
||||
sudo <the_line_command>
|
||||
```
|
||||
|
||||
并按提示输入你的密码。
|
||||
|
||||
这篇文章介绍了很多用于发现系统信息的有用命令。文章最后的快速查询表对它们作出了总结。
|
||||
|
||||
### 硬件概述
|
||||
|
||||
下面几条命令可以全面概述计算机硬件信息。
|
||||
|
||||
`inxi` 命令能够列出包括 CPU、图形、音频、网络、驱动、分区、传感器等详细信息。当论坛里的人尝试帮助其他人解决问题的时候,他们常常询问此命令的输出。这是解决问题的标准诊断程序:
|
||||
|
||||
```
|
||||
inxi -Fxz
|
||||
```
|
||||
|
||||
`-F` 参数意味着你将得到完整的输出,`x` 增加细节信息,`z` 参数隐藏像 MAC 和 IP 等私人身份信息。
|
||||
|
||||
`hwinfo` 和 `lshw` 命令以不同的格式显示大量相同的信息:
|
||||
|
||||
```
|
||||
hwinfo --short
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
lshw -short
|
||||
```
|
||||
|
||||
这两条命令的长格式输出非常详细,但也有点难以阅读:
|
||||
|
||||
```
|
||||
hwinfo
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
lshw
|
||||
```
|
||||
|
||||
### CPU 详细信息
|
||||
|
||||
通过命令你可以了解关于你的 CPU 的任何信息。使用 `lscpu` 命令或与它相近的 `lshw` 命令查看 CPU 的详细信息:
|
||||
|
||||
```
|
||||
lscpu
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
lshw -C cpu
|
||||
```
|
||||
|
||||
在这两个例子中,输出的最后几行都列出了所有 CPU 的功能。你可以查看你的处理器是否支持特定的功能。
|
||||
|
||||
使用这些命令的时候,你可以通过使用 `grep` 命令过滤复杂的信息,并缩小所需信息范围。例如,只查看 CPU 品牌和型号:
|
||||
|
||||
```
|
||||
lshw -C cpu | grep -i product
|
||||
```
|
||||
|
||||
仅查看 CPU 的速度(兆赫兹):
|
||||
|
||||
```
|
||||
lscpu | grep -i mhz
|
||||
```
|
||||
|
||||
或其 [BogoMips][8] 额定功率:
|
||||
|
||||
```
|
||||
lscpu | grep -i bogo
|
||||
```
|
||||
|
||||
`grep` 命令的 `-i` 参数代表搜索结果忽略大小写。
|
||||
|
||||
### 内存
|
||||
|
||||
Linux 命令行使你能够收集关于你的计算机内存的所有可能的详细信息。你甚至可以不拆开计算机机箱就能确定是否可以为计算机添加额外的内存条。
|
||||
|
||||
使用 `dmidecode` 命令列出每根内存条和其容量:
|
||||
|
||||
```
|
||||
dmidecode -t memory | grep -i size
|
||||
```
|
||||
|
||||
使用以下命令获取系统内存更多的信息,包括类型、容量、速度和电压:
|
||||
|
||||
```
|
||||
lshw -short -C memory
|
||||
```
|
||||
|
||||
你肯定想知道的一件事是你的计算机可以安装的最大内存:
|
||||
|
||||
```
|
||||
dmidecode -t memory | grep -i max
|
||||
```
|
||||
|
||||
现在检查一下计算机是否有空闲的插槽可以插入额外的内存条。你可以通过使用命令在不打开计算机机箱的情况下就做到:
|
||||
|
||||
```
|
||||
lshw -short -C memory | grep -i empty
|
||||
```
|
||||
|
||||
输出为空则意味着所有的插槽都在使用中。
|
||||
|
||||
确定你的计算机拥有多少显卡内存需要下面的命令。首先使用 `lspci` 列出所有设备信息然后过滤出你想要的显卡设备信息:
|
||||
|
||||
```
|
||||
lspci | grep -i vga
|
||||
```
|
||||
|
||||
视频控制器的设备号输出信息通常如下:
|
||||
|
||||
```
|
||||
00:02.0 VGA compatible controller: Intel Corporation 82Q35 Express Integrated Graphics Controller (rev 02)
|
||||
```
|
||||
|
||||
现在再加上视频设备号重新运行 `lspci` 命令:
|
||||
|
||||
```
|
||||
lspci -v -s 00:02.0
|
||||
```
|
||||
|
||||
输出信息中 `prefetchable` 那一行显示了系统中的显卡内存大小:
|
||||
|
||||
```
|
||||
...
|
||||
Memory at f0100000 (32-bit, non-prefetchable) [size=512K]
|
||||
I/O ports at 1230 [size=8]
|
||||
Memory at e0000000 (32-bit, prefetchable) [size=256M]
|
||||
Memory at f0000000 (32-bit, non-prefetchable) [size=1M]
|
||||
...
|
||||
```
|
||||
|
||||
最后使用下面的命令展示当前内存使用量(兆字节):
|
||||
|
||||
```
|
||||
free -m
|
||||
```
|
||||
|
||||
这条命令告诉你多少内存是空闲的,多少命令正在使用中以及交换内存的大小和是否正在使用。例如,输出信息如下:
|
||||
|
||||
```
|
||||
total used free shared buff/cache available
|
||||
Mem: 11891 1326 8877 212 1687 10077
|
||||
Swap: 1999 0 1999
|
||||
```
|
||||
|
||||
`top` 命令为你提供内存使用更加详细的信息。它显示了当前全部内存和 CPU 使用情况并按照进程 ID、用户 ID 及正在运行的命令细分。同时这条命令也是全屏输出:
|
||||
|
||||
```
|
||||
top
|
||||
```
|
||||
|
||||
### 磁盘文件系统和设备
|
||||
|
||||
你可以轻松确定有关磁盘、分区、文件系统和其他设备信息。
|
||||
|
||||
显示每个磁盘设备的描述信息:
|
||||
|
||||
```
|
||||
lshw -short -C disk
|
||||
```
|
||||
|
||||
通过以下命令获取任何指定的 SATA 磁盘详细信息,例如其型号、序列号以及支持的模式和扇区数量等:
|
||||
|
||||
```
|
||||
hdparm -i /dev/sda
|
||||
```
|
||||
|
||||
当然,如果需要的话你应该将 `sda` 替换成 `sdb` 或者其他设备号。
|
||||
|
||||
要列出所有磁盘及其分区和大小,请使用以下命令:
|
||||
|
||||
```
|
||||
lsblk
|
||||
```
|
||||
|
||||
使用以下命令获取更多有关扇区数量、大小、文件系统 ID 和 类型以及分区开始和结束扇区:
|
||||
|
||||
```
|
||||
fdisk -l
|
||||
```
|
||||
|
||||
要启动 Linux,你需要确定 [GRUB][9] 引导程序的可挂载分区。你可以使用 `blkid` 命令找到此信息。它列出了每个分区的唯一标识符(UUID)及其文件系统类型(例如 ext3 或 ext4):
|
||||
|
||||
```
|
||||
blkid
|
||||
```
|
||||
|
||||
使用以下命令列出已挂载的文件系统和它们的挂载点,以及已用的空间和可用的空间(兆字节为单位):
|
||||
|
||||
```
|
||||
df -m
|
||||
```
|
||||
|
||||
最后,你可以列出所有的 USB 和 PCI 总线以及其他设备的详细信息:
|
||||
|
||||
```
|
||||
lsusb
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
lspci
|
||||
```
|
||||
|
||||
### 网络
|
||||
|
||||
Linux 提供大量的网络相关命令,下面只是几个例子。
|
||||
|
||||
查看你的网卡硬件详细信息:
|
||||
|
||||
```
|
||||
lshw -C network
|
||||
```
|
||||
|
||||
`ifconfig` 是显示网络接口的传统命令:
|
||||
|
||||
```
|
||||
ifconfig -a
|
||||
```
|
||||
|
||||
但是现在很多人们使用:
|
||||
|
||||
```
|
||||
ip link show
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
netstat -i
|
||||
```
|
||||
|
||||
在阅读输出时,了解常见的网络缩写十分有用:
|
||||
|
||||
缩写 | 含义
|
||||
---|---
|
||||
`lo` | 回环接口
|
||||
`eth0` 或 `enp*` | 以太网接口
|
||||
`wlan0` | 无线网接口
|
||||
`ppp0` | 点对点协议接口(由拨号调制解调器、PPTP VPN 连接或者 USB 调制解调器使用)
|
||||
`vboxnet0` 或 `vmnet*` | 虚拟机网络接口
|
||||
|
||||
表中的星号是通配符,代表不同系统的任意字符。
|
||||
|
||||
使用以下命令显示默认网关和路由表:
|
||||
|
||||
```
|
||||
ip route | column -t
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
netstat -r
|
||||
```
|
||||
|
||||
### 软件
|
||||
|
||||
让我们以显示最底层软件详细信息的两条命令来结束。例如,如果你想知道是否安装了最新的固件该怎么办?这条命令显示了 UEFI 或 BIOS 的日期和版本:
|
||||
|
||||
```
|
||||
dmidecode -t bios
|
||||
```
|
||||
|
||||
内核版本是多少,以及它是 64 位的吗?网络主机名是什么?使用下面的命令查出结果:
|
||||
|
||||
```
|
||||
uname -a
|
||||
```
|
||||
|
||||
### 快速查询表
|
||||
|
||||
用途 | 命令
|
||||
--- | ---
|
||||
显示所有硬件信息 | `inxi -Fxz` 或 `hwinfo --short` 或 `lshw -short`
|
||||
CPU 信息 | `lscpu` 或 `lshw -C cpu`
|
||||
显示 CPU 功能(例如 PAE、SSE2) | `lshw -C cpu | grep -i capabilities`
|
||||
报告 CPU 位数 | `lshw -C cpu | grep -i width`
|
||||
显示当前内存大小和配置 | `dmidecode -t memory | grep -i size` 或 `lshw -short -C memory`
|
||||
显示硬件支持的最大内存 | `dmidecode -t memory | grep -i max`
|
||||
确定是否有空闲内存插槽 | `lshw -short -C memory | grep -i empty`(输出为空表示没有可用插槽)
|
||||
确定显卡内存数量 | `lspci | grep -i vga` 然后指定设备号再次使用;例如:`lspci -v -s 00:02.0` 显卡内存数量就是 `prefetchable` 的值
|
||||
显示当前内存使用情况 | `free -m` 或 `top`
|
||||
列出磁盘驱动器 | `lshw -short -C disk`
|
||||
显示指定磁盘驱动器的详细信息 | `hdparm -i /dev/sda`(需要的话替换掉 `sda`)
|
||||
列出磁盘和分区信息 | `lsblk`(简单) 或 `fdisk -l`(详细)
|
||||
列出分区 ID(UUID)| `blkid`
|
||||
列出已挂载文件系统挂载点以及已用和可用空间 | `df -m`
|
||||
列出 USB 设备 | `lsusb`
|
||||
列出 PCI 设备 | `lspci`
|
||||
显示网卡详细信息 | `lshw -C network`
|
||||
显示网络接口 | `ifconfig -a` 或 `ip link show` 或 `netstat -i`
|
||||
显示路由表 | `ip route | column -t` 或 `netstat -r`
|
||||
显示 UEFI/BIOS 信息 | `dmidecode -t bios`
|
||||
显示内核版本网络主机名等 | `uname -a`
|
||||
|
||||
你有喜欢的命令被我忽略掉的吗?请添加评论分享给大家。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/9/linux-commands-hardware-information
|
||||
|
||||
作者:[Howard Fosdick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/howtechhttps://opensource.com/users/sethhttps://opensource.com/users/sethhttps://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/features_solutions_command_data.png?itok=4_VQN3RK (computer screen )
|
||||
[2]: http://sourceforge.net/projects/i-nex/
|
||||
[3]: https://www.cpuid.com/softwares/cpu-z.html
|
||||
[4]: http://sourceforge.net/projects/hardinfo.berlios/
|
||||
[5]: https://userbase.kde.org/KInfoCenter
|
||||
[6]: http://www.binarytides.com/linux-lshw-command/
|
||||
[7]: http://www.disk-image.com/faq-bootmenu.htm
|
||||
[8]: https://en.wikipedia.org/wiki/BogoMips
|
||||
[9]: https://www.dedoimedo.com/computers/grub.html
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user