mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
commit
cb20d2bf9a
published
20150616 Computer Laboratory - Raspberry Pi- Lesson 8 Screen03.md20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md20170223 Use Emacs to create OAuth 2.0 UML sequence diagrams.md20170519 zsh shell inside Emacs on Windows.md20170721 Firefox and org-protocol URL Capture.md20180122 Ick- a continuous integration system.md20180202 Tips for success when getting started with Ansible.md20180307 3 open source tools for scientific publishing.md20181216 Schedule a visit with the Emacs psychiatrist.md20181220 7 CI-CD tools for sysadmins.md20190104 Midori- A Lightweight Open Source Web Browser.md20190108 How ASLR protects Linux systems from buffer overflow attacks.md20190109 Configure Anaconda on Emacs - iD.md20190121 Akira- The Linux Design Tool We-ve Always Wanted.md20190121 Booting Linux faster.md20190123 Mind map yourself using FreeMind and Fedora.md
201902
20091104 Linux-Unix App For Prevention Of RSI (Repetitive Strain Injury).md20120203 Computer Laboratory - Raspberry Pi- Lesson 3 OK03.md20120204 Computer Laboratory - Raspberry Pi- Lesson 4 OK04.md20120205 Computer Laboratory - Raspberry Pi- Lesson 5 OK05.md20150513 XML vs JSON.md20150616 Computer Laboratory - Raspberry Pi- Lesson 6 Screen01.md20150616 Computer Laboratory - Raspberry Pi- Lesson 7 Screen02.md20160922 Annoying Experiences Every Linux Gamer Never Wanted.md20171215 Top 5 Linux Music Players.md20180112 8 KDE Plasma Tips and Tricks to Improve Your Productivity.md20180128 Get started with Org mode without Emacs.md20180206 Building Slack for the Linux community and adopting snaps.md20180530 Introduction to the Pony programming language.md20180531 Qalculate- - The Best Calculator Application in The Entire Universe.md20180614 An introduction to the Tornado Python web app framework.md20180621 How to connect to a remote desktop from Linux.md20180626 How To Search If A Package Is Available On Your Linux Distribution Or Not.md20180724 How To Mount Google Drive Locally As Virtual File System In Linux.md20180809 Two Years With Emacs as a CEO (and now CTO).md20181123 Three SSH GUI Tools for Linux.md20181124 14 Best ASCII Games for Linux That are Insanely Good.md20181204 4 Unique Terminal Emulators for Linux.md20181212 Top 5 configuration management tools.md20181219 PowerTOP - Monitors Power Usage and Improve Laptop Battery Life in Linux.md20181224 An Introduction to Go.md20181224 Go on an adventure in your Linux terminal.md20181227 Asciinema - Record And Share Your Terminal Sessions On The Fly.md20190102 How To Display Thumbnail Images In Terminal.md20190103 How to use Magit to manage Git projects.md20190108 Hacking math education with Python.md20190110 5 useful Vim plugins for developers.md20190110 Toyota Motors and its Linux Journey.md20190114 Hegemon - A Modular System And Hardware Monitoring Tool For Linux.md20190114 Remote Working Survival Guide.md20190115 Comparing 3 open source databases- PostgreSQL, MariaDB, and SQLite.md20190115 Getting started with Sandstorm, an open source web app platform.md20190116 The Evil-Twin Framework- A tool for improving WiFi security.md20190117 How to Update-Change Users Password in Linux Using Different Ways.md20190119 Get started with Roland, a random selection tool for the command line.md20190120 Get started with HomeBank, an open source personal finance app.md20190121 Get started with TaskBoard, a lightweight kanban board.md20190122 Dcp (Dat Copy) - Easy And Secure Way To Transfer Files Between Linux Systems.md20190122 Get started with Go For It, a flexible to-do list application.md20190122 How To Copy A File-Folder From A Local System To Remote System In Linux.md20190123 Book Review- Fundamentals of Linux.md20190123 Commands to help you monitor activity on your Linux server.md20190124 Get started with LogicalDOC, an open source document management system.md20190124 Understanding Angle Brackets in Bash.md20190125 PyGame Zero- Games without boilerplate.md20190125 Top 5 Linux Distributions for Development in 2019.md20190126 Get started with Tint2, an open source taskbar for Linux.md20190127 Get started with eDEX-UI, a Tron-influenced terminal program for tablets and desktops.md20190128 3 simple and useful GNOME Shell extensions.md20190128 Using more to view text files at the Linux command line.md20190128 fdisk - Easy Way To Manage Disk Partitions In Linux.md20190129 Get started with gPodder, an open source podcast client.md20190129 More About Angle Brackets in Bash.md20190130 Get started with Budgie Desktop, a Linux environment.md20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md20190131 Will quantum computing break security.md20190201 Top 5 Linux Distributions for New Users.md20190205 DNS and Root Certificates.md20190205 Installing Kali Linux on VirtualBox- Quickest - Safest Way.md20190206 4 cool new projects to try in COPR for February 2019.md20190207 10 Methods To Create A File In Linux.md20190207 How to determine how much memory is installed, used on Linux systems.md20190208 How To Install And Use PuTTY On Linux.md20190214 Drinking coffee with AWK.md20190216 How To Grant And Remove Sudo Privileges To Users On Ubuntu.md20190219 3 tools for viewing files at the command line.md20190219 How to List Installed Packages on Ubuntu and Debian -Quick Tip.md
20190206 And, Ampersand, and - in Linux.md20190206 Getting started with Vim visual mode.md20190208 7 steps for hunting down Python code bugs.md20190212 Ampersands and File Descriptors in Bash.md20190212 How To Check CPU, Memory And Swap Utilization Percentage In Linux.md20190212 Two graphical tools for manipulating PDFs on the Linux desktop.md20190213 How to use Linux Cockpit to manage system performance.md20190216 FinalCrypt - An Open Source File Encryption Application.md20190217 How to Change User Password in Ubuntu -Beginner-s Tutorial.md20190219 Logical - in Bash.md20190220 An Automated Way To Install Essential Applications On Ubuntu.md20190221 Bash-Insulter - A Script That Insults An User When Typing A Wrong Command.md20190223 Regex groups and numerals.md@ -1,34 +1,30 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10585-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 8 Screen03)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室 – 树莓派:课程 8 屏幕03
|
||||
计算机实验室之树莓派:课程 8 屏幕03
|
||||
======
|
||||
|
||||
屏幕03 课程基于屏幕02 课程来构建,它教你如何绘制文本,和一个操作系统命令行参数上的一个小特性。假设你已经有了[课程 7:屏幕02][1] 的操作系统代码,我们将以它为基础来构建。
|
||||
|
||||
### 1、字符串的理论知识
|
||||
|
||||
是的,我们的任务是为这个操作系统绘制文本。我们有几个问题需要去处理,最紧急的那个可能是如何去保存文本。令人难以置信的是,文本是迄今为止在计算机上最大的缺陷之一。原本应该是简单的数据类型却导致了操作系统的崩溃,破坏了完美的加密,并给使用不同字母表的用户带来了许多问题。尽管如此,它仍然是极其重要的数据类型,因为它将计算机和用户很好地连接起来。文本是计算机能够理解的非常好的结构,同时人类使用它时也有足够的可读性。
|
||||
是的,我们的任务是为这个操作系统绘制文本。我们有几个问题需要去处理,最紧急的那个可能是如何去保存文本。令人难以置信的是,文本是迄今为止在计算机上最大的缺陷之一。原本应该是简单的数据类型却导致了操作系统的崩溃,从而削弱其他方面的加密效果,并给使用其它字母表的用户带来了许多问题。尽管如此,它仍然是极其重要的数据类型,因为它将计算机和用户很好地连接起来。文本是计算机能够理解的非常好的结构,同时人类使用它时也有足够的可读性。
|
||||
|
||||
```
|
||||
可变数据类型,比如文本要求能够进行很复杂的处理。
|
||||
```
|
||||
那么,文本是如何保存的呢?非常简单,我们使用一种方法,给每个字母分配一个唯一的编号,然后我们保存一系列的这种编号。看起来很容易吧。问题是,那个编号的数量是不固定的。一些文本段可能比其它的长。保存普通数字,我们有一些固有的限制,即:32 位,我们不能超过这个限制,我们要添加方法去使用该长度的数字等等。“文本”这个术语,我们经常也叫它“字符串”,我们希望能够写一个可用于可变长度字符串的函数,否则就需要写很多函数!对于一般的数字来说,这不是个问题,因为只有几种通用的数字格式(字节、字、半字节、双字节)。
|
||||
|
||||
那么,文本是如何保存的呢?非常简单,我们使用一种方法,给每个字母分配一个唯一的编号,然后我们保存一系列的这种编号。看起来很容易吧。问题是,那个编号的数字是不固定的。一些文本片断可能比其它的长。与保存普通数字一样,我们有一些固有的限制,即:3 位,我们不能超过这个限制,我们添加方法去使用那种长数字等等。“文本”这个术语,我们经常也叫它“字符串”,我们希望能够写一个可用于变长字符串的函数,否则就需要写很多函数!对于一般的数字来说,这不是个问题,因为只有几种通用的数字格式(字节、字、半字节、双字节)。
|
||||
> 可变数据类型(比如文本)要求能够进行很复杂的处理。
|
||||
|
||||
```
|
||||
缓冲区溢出攻击祸害计算机由来已久。最近,Wii、Xbox 和 Playstation 2、以及大型系统如 Microsoft 的 Web 和数据库服务器,都遭受到缓冲区溢出攻击。
|
||||
```
|
||||
因此,如何判断字符串长度?我想显而易见的答案是存储字符串的长度,然后去存储组成字符串的字符。这称为长度前缀,因为长度位于字符串的前面。不幸的是,计算机科学家的先驱们不同意这么做。他们认为使用一个称为空终止符(`NULL`)的特殊字符(用 `\0` 表示)来表示字符串结束更有意义。这样确定简化了许多字符串算法,因为你只需要持续操作直到遇到空终止符为止。不幸的是,这成为了许多安全问题的根源。如果一个恶意用户给你一个特别长的字符串会发生什么状况?如果没有足够的空间去保存这个特别长的字符串会发生什么状况?你可以使用一个字符串复制函数来做复制,直到遇到空终止符为止,但是因为字符串特别长,而覆写了你的程序,怎么办?这看上去似乎有些较真,但是,缓冲区溢出攻击还是经常发生。长度前缀可以很容易地缓解这种问题,因为它可以很容易地推算出保存这个字符串所需要的缓冲区的长度。作为一个操作系统开发者,我留下这个问题,由你去决定如何才能更好地存储文本。
|
||||
|
||||
因此,如何判断字符串长度?我想显而易见的答案是存储多长的字符串,然后去存储组成字符串的字符。这称为长度前缀,因为长度位于字符串的前面。不幸的是,计算机科学家的先驱们不同意这么做。他们认为使用一个称为空终止符(NULL)的特殊字符(用 \0表示)来表示字符串结束更有意义。这样确定简化了许多字符串算法,因为你只需要持续操作直到遇到空终止符为止。不幸的是,这成为了许多安全问题的根源。如果一个恶意用户给你一个特别长的字符串会发生什么状况?如果没有足够的空间去保存这个特别长的字符串会发生什么状况?你可以使用一个字符串复制函数来做复制,直到遇到空终止符为止,但是因为字符串特别长,而覆写了你的程序,怎么办?这看上去似乎有些较真,但尽管如此,缓冲区溢出攻击还是经常发生。长度前缀可以很容易地缓解这种问题,因为它可以很容易地推算出保存这个字符串所需要的缓冲区的长度。作为一个操作系统开发者,我留下这个问题,由你去决定如何才能更好地存储文本。
|
||||
> 缓冲区溢出攻击祸害计算机由来已久。最近,Wii、Xbox 和 Playstation 2、以及大型系统如 Microsoft 的 Web 和数据库服务器,都遭受到缓冲区溢出攻击。
|
||||
|
||||
接下来的事情是,我们需要去维护一个很好的从字符到数字的映射。幸运的是,这是高度标准化的,我们有两个主要的选择,Unicode 和 ASCII。Unicode 几乎将每个单个的有用的符号都映射为数字,作为交换,我们得到的是很多很多的数字,和一个更复杂的编码方法。ASCII 为每个字符使用一个字节,因此它仅保存拉丁字母、数字、少数符号和少数特殊字符。因此,ASCII 是非常易于实现的,与 Unicode 相比,它的每个字符占用的空间并不相同,这使得字符串算法更棘手。一般操作系统上字符使用 ASCII,并不是为了显示给最终用户的(开发者和专家用户除外),给终端用户显示信息使用 Unicode,因为 Unicode 能够支持像日语字符这样的东西,并且因此可以实现本地化。
|
||||
接下来的事情是,我们需要确定的是如何最好地将字符映射到数字。幸运的是,这是高度标准化的,我们有两个主要的选择,Unicode 和 ASCII。Unicode 几乎将每个有用的符号都映射为数字,作为代价,我们需要有很多很多的数字,和一个更复杂的编码方法。ASCII 为每个字符使用一个字节,因此它仅保存拉丁字母、数字、少数符号和少数特殊字符。因此,ASCII 是非常易于实现的,与之相比,Unicode 的每个字符占用的空间并不相同,这使得字符串算法更棘手。通常,操作系统上字符使用 ASCII,并不是为了显示给最终用户的(开发者和专家用户除外),给终端用户显示信息使用 Unicode,因为 Unicode 能够支持像日语字符这样的东西,并且因此可以实现本地化。
|
||||
|
||||
幸运的是,在这里我们不需要去做选择,因为它们的前 128 个字符是完全相同的,并且编码也是完全一样的。
|
||||
|
||||
@ -45,27 +41,27 @@
|
||||
| 60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
|
||||
| 70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
|
||||
|
||||
这个表显示了前 128 个符号。一个符号的十六进制表示是行的值加上列的值,比如 A 是 41~16~。你可以惊奇地发现前两行和最后的值。这 33 个特殊字符是不可打印字符。事实上,许多人都忽略了它们。它们之所以存在是因为 ASCII 最初设计是基于计算机网络来传输数据的一种方法。因此它要发送的信息不仅仅是符号。你应该学习的重要的特殊字符是 `NUL`,它就是我们前面提到的空终止符。`HT` 水平制表符就是我们经常说的 `tab`,而 `LF` 换行符用于生成一个新行。你可能想研究和使用其它特殊字符在你的操行系统中的意义。
|
||||
这个表显示了前 128 个符号。一个符号的十六进制表示是行的值加上列的值,比如 A 是 41<sub>16</sub>。你可以惊奇地发现前两行和最后的值。这 33 个特殊字符是不可打印字符。事实上,许多人都忽略了它们。它们之所以存在是因为 ASCII 最初设计是基于计算机网络来传输数据的一种方法。因此它要发送的信息不仅仅是符号。你应该学习的重要的特殊字符是 `NUL`,它就是我们前面提到的空终止符。`HT` 水平制表符就是我们经常说的 `tab`,而 `LF` 换行符用于生成一个新行。你可能想研究和使用其它特殊字符在你的操行系统中的意义。
|
||||
|
||||
### 2、字符
|
||||
|
||||
到目前为止,我们已经知道了一些关于字符串的知识,我们可以开始想想它们是如何显示的。为了显示一个字符串,我们需要做的最基础的事情是能够显示一个字符。我们的第一个任务是编写一个 `DrawCharacter` 函数,给它一个要绘制的字符和一个位置,然后它将这个字符绘制出来。
|
||||
|
||||
```markdown
|
||||
在许多操作系统中使用的 `truetype` 字体格式是很强大的,它内置有它自己的汇编语言,以确保在任何分辨率下字母看起来都是正确的。
|
||||
```
|
||||
这就很自然地引出关于字体的讨论。我们已经知道有许多方式去按照选定的字体去显示任何给定的字母。那么字体又是如何工作的呢?在计算机科学的早期阶段,字体就是所有字母的一系列小图片而已,这种字体称为位图字体,而所有的字符绘制方法就是将图片复制到屏幕上。当人们想去调整字体大小时就出问题了。有时我们需要大的字母,而有时我们需要的是小的字母。尽管我们可以为每个字体、每种大小、每个字符都绘制新图片,但这种作法过于单调乏味。所以,发明了矢量字体。矢量字体不包含字体的图像,它包含的是如何去绘制字符的描述,即:一个 `o` 可能是最大字母高度的一半为半径绘制的圆。现代操作系统都几乎仅使用这种字体,因为这种字体在任何分辨率下都很完美。
|
||||
|
||||
这就很自然地引出关于字体的讨论。我们已经知道有许多方式去按照选定的字体去显示任何给定的字母。那么字体又是如何工作的呢?在计算机科学的早期阶段,一种字体就是所有字母的一系列小图片而已,这种字体称为位图字体,而所有的字符绘制方法就是将图片复制到屏幕上。当人们想去调整字体大小时就出问题了。有时我们需要大的字母,而有时我们需要的是小的字母。尽管我们可以为每个字体、每种大小、每个字符都绘制新图片,但这种作法过于单调乏味。所以,发明了矢量字体。矢量字体不包含字体的图像,它包含的是如何去绘制字符的描述,即:一个 `o` 可能是最大字母高度的一半为半径绘制的圆。现代操作系统都几乎仅使用这种字体,因为这种字体在任何分辨率下都很完美。
|
||||
> 在许多操作系统中使用的 TrueType 字体格式是很强大的,它内置有它自己的汇编语言,以确保在任何分辨率下字母看起来都是正确的。
|
||||
|
||||
不幸的是,虽然我很想包含一个矢量字体的格式的实现,但它的内容太多了,将占用这个站点的剩余部分。所以,我们将去实现一个位图字体,可是,如果你想去做一个正宗的图形化的操作系统,那么矢量字体将是很有用的。
|
||||
不幸的是,虽然我很想包含一个矢量字体的格式的实现,但它的内容太多了,将占用这个网站的剩余部分。所以,我们将去实现一个位图字体,可是,如果你想去做一个像样的图形操作系统,那么矢量字体将是很有用的。
|
||||
|
||||
在下载页面上的字体节中,我们提供了几个 `.bin` 文件。这些只是字体的原始二进制数据文件。为完成本教程,从等宽、单色、8x16 节中挑选你喜欢的字体。然后下载它并保存到 `source` 目录中并命名为 `font.bin` 文件。这些文件只是每个字母的单色图片,它们每个字母刚好是 8 x 16 个像素。所以,每个字母占用 16 字节,第一个字节是第一行,第二个字节是第二行,依此类推。
|
||||
|
||||

|
||||
|
||||
这个示意图展示了等宽、单色、8x16 的字符 A 的 `Bitstream Vera Sans Mono`。在这个文件中,我们可以找到,它从第 41~16~ × 10~16~ = 410~16~ 字节开始的十六进制序列:
|
||||
这个示意图展示了等宽、单色、8x16 的字符 A 的 “Bitstream Vera Sans Mono” 字体。在这个文件中,我们可以找到,它从第 41<sub>16</sub> × 10<sub>16</sub> = 410<sub>16</sub> 字节开始的十六进制序列:
|
||||
|
||||
```
|
||||
00, 00, 00, 10, 28, 28, 28, 44, 44, 7C, C6, 82, 00, 00, 00, 00
|
||||
```
|
||||
|
||||
在这里我们将使用等宽字体,因为等宽字体的每个字符大小是相同的。不幸的是,大多数字体的复杂之处就是因为它的宽度不同,从而导致它的显示代码更复杂。在下载页面上还包含有几个其它的字体,并包含了这种字体的存储格式介绍。
|
||||
|
||||
@ -77,9 +73,7 @@ font:
|
||||
.incbin "font.bin"
|
||||
```
|
||||
|
||||
```assembly
|
||||
.incbin "file" 插入来自文件 “file” 中的二进制数据。
|
||||
```
|
||||
> `.incbin "file"` 插入来自文件 “file” 中的二进制数据。
|
||||
|
||||
这段代码复制文件中的字体数据到标签为 `font` 的地址。我们在这里使用了一个 `.align 4` 去确保每个字符都是从 16 字节的倍数开始,这是一个以后经常用到的用于加快访问速度的技巧。
|
||||
|
||||
@ -98,8 +92,8 @@ function drawCharacter(r0 is character, r1 is x, r2 is y)
|
||||
next
|
||||
return r0 = 8, r1 = 16
|
||||
end function
|
||||
|
||||
```
|
||||
|
||||
如果直接去实现它,这显然不是个高效率的做法。像绘制字符这样的事情,效率是最重要的。因为我们要频繁使用它。我们来探索一些改善的方法,使其成为最优化的汇编代码。首先,因为我们有一个 `× 16`,你应该会马上想到它等价于逻辑左移 4 位。紧接着我们有一个变量 `row`,它只与 `charAddress` 和 `y` 相加。所以,我们可以通过增加替代变量来消除它。现在唯一的问题是如何判断我们何时完成。这时,一个很好用的 `.align 4` 上场了。我们知道,`charAddress` 将从包含 0 的低位半字节开始。这意味着我们可以通过检查低位半字节来看到进入字符数据的程度。
|
||||
|
||||
虽然我们可以消除对 `bit` 的需求,但我们必须要引入新的变量才能实现,因此最好还是保留它。剩下唯一的改进就是去除嵌套的 `bits >> bit`。
|
||||
@ -189,7 +183,7 @@ pop {r4,r5,r6,r7,r8,pc}
|
||||
|
||||
### 3、字符串
|
||||
|
||||
现在,我们可以绘制字符了,我们可以绘制文本了。我们需要去写一个方法,给它一个字符串为输入,它通过递增位置来绘制出每个字符。为了做的更好,我们应该去实现新的行和制表符。是时候决定关于空终止符的问题了,如果你想让你的操作系统使用它们,可以按需来修改下面的代码。为避免这个问题,我将给 `DrawString` 函数传递一个字符串长度,以及字符串的地址,和 x 和 y 的坐标作为参数。
|
||||
现在,我们可以绘制字符了,我们可以绘制文本了。我们需要去写一个方法,给它一个字符串为输入,它通过递增位置来绘制出每个字符。为了做的更好,我们应该去实现新的行和制表符。是时候决定关于空终止符的问题了,如果你想让你的操作系统使用它们,可以按需来修改下面的代码。为避免这个问题,我将给 `DrawString` 函数传递一个字符串长度,以及字符串的地址,和 `x` 和 `y` 的坐标作为参数。
|
||||
|
||||
```c
|
||||
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
|
||||
@ -215,7 +209,7 @@ end function
|
||||
|
||||
同样,这个函数与汇编代码还有很大的差距。你可以随意去尝试实现它,即可以直接实现它,也可以简化它。我在下面给出了简化后的函数和汇编代码。
|
||||
|
||||
很明显,写这个函数的人并不很有效率(感到奇怪吗?它就是我写的)。再说一次,我们有一个 `pos` 变量,它用于递增和与其它东西相加,这是完全没有必要的。我们可以去掉它,而同时进行长度递减,直到减到 0 为止,这样就少用了一个寄存器。除了那个烦人的乘以 5 以外,函数的其余部分还不错。在这里要做的一个重要事情是,将乘法移到循环外面;即便使用位移运算,乘法仍然是很慢的,由于我们总是加一个乘以 5 的相同的常数,因此没有必要重新计算它。实际上,在汇编代码中它可以在一个操作数中通过参数移位来实现,因此我将代码改变为下面这样。
|
||||
很明显,写这个函数的人并不很有效率(感到奇怪吗?它就是我写的)。再说一次,我们有一个 `pos` 变量,它用于递增及与其它东西相加,这是完全没有必要的。我们可以去掉它,而同时进行长度递减,直到减到 0 为止,这样就少用了一个寄存器。除了那个烦人的乘以 5 以外,函数的其余部分还不错。在这里要做的一个重要事情是,将乘法移到循环外面;即便使用位移运算,乘法仍然是很慢的,由于我们总是加一个乘以 5 的相同的常数,因此没有必要重新计算它。实际上,在汇编代码中它可以在一个操作数中通过参数移位来实现,因此我将代码改变为下面这样。
|
||||
|
||||
```c
|
||||
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
|
||||
@ -307,22 +301,20 @@ pop {r4,r5,r6,r7,r8,r9,pc}
|
||||
.unreq length
|
||||
```
|
||||
|
||||
```assembly
|
||||
subs reg,#val 从寄存器 reg 中减去 val,然后将结果与 0 进行比较。
|
||||
```
|
||||
|
||||
这个代码中非常聪明地使用了一个新运算,`subs` 是从一个操作数中减去另一个数,保存结果,然后将结果与 0 进行比较。实现上,所有的比较都可以实现为减法后的结果与 0 进行比较,但是结果通常会丢弃。这意味着这个操作与 `cmp` 一样快。
|
||||
|
||||
### 4、你的愿意是我的命令行
|
||||
> `subs reg,#val` 从寄存器 `reg` 中减去 `val`,然后将结果与 `0` 进行比较。
|
||||
|
||||
### 4、你的意愿是我的命令行
|
||||
|
||||
现在,我们可以输出字符串了,而挑战是找到一个有意思的字符串去绘制。一般在这样的教程中,人们都希望去绘制 “Hello World!”,但是到目前为止,虽然我们已经能做到了,我觉得这有点“君临天下”的感觉(如果喜欢这种感觉,请随意!)。因此,作为替代,我们去继续绘制我们的命令行。
|
||||
|
||||
有一个限制是我们所做的操作系统是用在 ARM 架构的计算机上。最关键的是,在它们引导时,给它一些信息告诉它有哪些可用资源。几乎所有的处理器都有某些方式来确定这些信息,而在 ARM 上,它是通过位于地址 100<sub>16</sub> 处的数据来确定的,这个数据的格式如下:
|
||||
|
||||
1. 数据是可分解的一系列的标签。
|
||||
2. 这里有九种类型的标签:`core`,`mem`,`videotext`,`ramdisk`,`initrd2`,`serial`,`revision`,`videolfb`,`cmdline`。
|
||||
3. 每个标签只能出现一次,除了 'core’ 标签是必不可少的之外,其它的都是可有可无的。
|
||||
4. 所有标签都依次放置在地址 0x100 处。
|
||||
2. 这里有九种类型的标签:`core`、`mem`、`videotext`、`ramdisk`、`initrd2`、`serial`、`revision`、`videolfb`、`cmdline`。
|
||||
3. 每个标签只能出现一次,除了 `core` 标签是必不可少的之外,其它的都是可有可无的。
|
||||
4. 所有标签都依次放置在地址 `0x100` 处。
|
||||
5. 标签列表的结束处总是有两个<ruby>字<rt>word</rt></ruby>,它们全为 0。
|
||||
6. 每个标签的字节数都是 4 的倍数。
|
||||
7. 每个标签都是以标签中(以字为单位)的标签大小开始(标签包含这个数字)。
|
||||
@ -334,11 +326,9 @@ subs reg,#val 从寄存器 reg 中减去 val,然后将结果与 0 进行比较
|
||||
13. 一个 `cmdline` 标签包含一个 `null` 终止符字符串,它是个内核参数。
|
||||
|
||||
|
||||
```markdown
|
||||
几乎所有的操作系统都支持一个`命令行`的程序。它的想法是为选择一个程序所期望的行为而提供一个通用的机制。
|
||||
```
|
||||
在目前的树莓派版本中,只提供了 `core`、`mem` 和 `cmdline` 标签。你可以在后面找到它们的用法,更全面的参考资料在树莓派的参考页面上。现在,我们感兴趣的是 `cmdline` 标签,因为它包含一个字符串。我们继续写一些搜索这个命令行(`cmdline`)标签的代码,如果找到了,以每个条目一个新行的形式输出它。命令行只是图形处理器或用户认为操作系统应该知道的东西的一个列表。在树莓派上,这包含了 MAC 地址、序列号和屏幕分辨率。字符串本身也是一个由空格隔开的表达式(像 `key.subkey=value` 这样的)的列表。
|
||||
|
||||
在目前的树莓派版本中,只提供了 `core`、`mem` 和 `cmdline` 标签。你可以在后面找到它们的用法,更全面的参考资料在树莓派的参考页面上。现在,我们感兴趣的是 `cmdline` 标签,因为它包含一个字符串。我们继续写一些搜索命令行标签的代码,如果找到了,以每个条目一个新行的形式输出它。命令行只是为了让操作系统理解图形处理器或用户认为的很好的事情的一个列表。在树莓派上,这包含了 MAC 地址,序列号和屏幕分辨率。字符串本身也是一个像 `key.subkey=value` 这样的由空格隔开的表达式列表。
|
||||
> 几乎所有的操作系统都支持一个“命令行”的程序。它的想法是为选择一个程序所期望的行为而提供一个通用的机制。
|
||||
|
||||
我们从查找 `cmdline` 标签开始。将下列的代码复制到一个名为 `tags.s` 的新文件中。
|
||||
|
||||
@ -355,7 +345,7 @@ tag_videolfb: .int 0
|
||||
tag_cmdline: .int 0
|
||||
```
|
||||
|
||||
通过标签列表来查找是一个很慢的操作,因为这涉及到许多内存访问。因此,我们只是想实现它一次。代码创建一些数据,用于保存每个类型的第一个标签的内存地址。接下来,用下面的伪代码就可以找到一个标签了。
|
||||
通过标签列表来查找是一个很慢的操作,因为这涉及到许多内存访问。因此,我们只想做一次。代码创建一些数据,用于保存每个类型的第一个标签的内存地址。接下来,用下面的伪代码就可以找到一个标签了。
|
||||
|
||||
```c
|
||||
function FindTag(r0 is tag)
|
||||
@ -373,7 +363,8 @@ function FindTag(r0 is tag)
|
||||
end loop
|
||||
end function
|
||||
```
|
||||
这段代码已经是优化过的,并且很接近汇编了。它尝试直接加载标签,第一次这样做是有些乐观的,但是除了第一次之外 的其它所有情况都是可以这样做的。如果失败了,它将去检查 `core` 标签是否有地址。因为 `core` 标签是必不可少的,如果它没有地址,唯一可能的原因就是它不存在。如果它有地址,那就是我们没有找到我们要找的标签。如果没有找到,那我们就需要查找所有标签的地址。这是通过读取标签编号来做的。如果标签编号为 0,意味着已经到了标签列表的结束位置。这意味着我们已经查找了目录中所有的标签。所以,如果我们再次运行我们的函数,现在它应该能够给出一个答案。如果标签编号不为 0,我们检查这个标签类型是否已经有一个地址。如果没有,我们在目录中保存这个标签的地址。然后增加这个标签的长度(以字节为单位)到标签地址中,然后去查找下一个标签。
|
||||
|
||||
这段代码已经是优化过的,并且很接近汇编了。它尝试直接加载标签,第一次这样做是有些乐观的,但是除了第一次之外的其它所有情况都是可以这样做的。如果失败了,它将去检查 `core` 标签是否有地址。因为 `core` 标签是必不可少的,如果它没有地址,唯一可能的原因就是它不存在。如果它有地址,那就是我们没有找到我们要找的标签。如果没有找到,那我们就需要查找所有标签的地址。这是通过读取标签编号来做的。如果标签编号为 0,意味着已经到了标签列表的结束位置。这意味着我们已经查找了目录中所有的标签。所以,如果我们再次运行我们的函数,现在它应该能够给出一个答案。如果标签编号不为 0,我们检查这个标签类型是否已经有一个地址。如果没有,我们在目录中保存这个标签的地址。然后增加这个标签的长度(以字节为单位)到标签地址中,然后去查找下一个标签。
|
||||
|
||||
尝试去用汇编实现这段代码。你将需要简化它。如果被卡住了,下面是我的答案。不要忘了 `.section .text`!
|
||||
|
||||
@ -459,11 +450,11 @@ via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
[1]: https://linux.cn/article-10551-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
|
||||
@ -1,73 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10605-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 9 Screen04)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室 – 树莓派:课程 9 屏幕04
|
||||
计算机实验室之树莓派:课程 9 屏幕04
|
||||
======
|
||||
|
||||
屏幕04 课程基于屏幕03 课程来构建,它教你如何操作文本。假设你已经有了[课程 8:屏幕03][1] 的操作系统代码,我们将以它为基础。
|
||||
|
||||
### 1、操作字符串
|
||||
|
||||
```
|
||||
变长函数在汇编代码中看起来似乎不好理解,然而 ,它却是非常有用和很强大的概念。
|
||||
```
|
||||
|
||||
能够绘制文本是极好的,但不幸的是,现在你只能绘制预先准备好的字符串。如果能够像命令行那样显示任何东西才是完美的,而理想情况下应该是,我们能够显示任何我们期望的东西。一如既往地,如果我们付出努力而写出一个非常好的函数,它能够操作我们所希望的所有字符串,而作为回报,这将使我们以后写代码更容易。曾经如此复杂的函数,在 C 语言编程中只不过是一个 `sprintf` 而已。这个函数基于给定的另一个字符串和作为描述的额外的一个参数而生成一个字符串。我们对这个函数感兴趣的地方是,这个函数是个变长函数。这意味着它可以带可变数量的参数。参数的数量取决于具体的格式字符串,因此它的参数的数量不能预先确定。
|
||||
|
||||
完整的函数有许多选项,而我们在这里只列出了几个。在本教程中将要实现的选项我做了高亮处理,当然,你可以尝试去实现更多的选项。
|
||||
> 变长函数在汇编代码中看起来似乎不好理解,然而 ,它却是非常有用和很强大的概念。
|
||||
|
||||
函数通过读取格式字符串来工作,然后使用下表的意思去解释它。一旦一个参数已经使用了,就不会再次考虑它了。函数 的返回值是写入的字符数。如果方法失败,将返回一个负数。
|
||||
这个完整的函数有许多选项,而我们在这里只列出了几个。在本教程中将要实现的选项我做了高亮处理,当然,你可以尝试去实现更多的选项。
|
||||
|
||||
函数通过读取格式化字符串来工作,然后使用下表的意思去解释它。一旦一个参数已经使用了,就不会再次考虑它了。函数的返回值是写入的字符数。如果方法失败,将返回一个负数。
|
||||
|
||||
表 1.1 sprintf 格式化规则
|
||||
|
||||
| 选项 | 含义 |
|
||||
| -------------------------- | ------------------------------------------------------------ |
|
||||
| ==Any character except %== | 复制字符到输出。 |
|
||||
| ==%%== | 写一个 % 字符到输出。 |
|
||||
| ==%c== | 将下一个参数写成字符格式。 |
|
||||
| ==%d or %i== | 将下一个参数写成十进制的有符号整数。 |
|
||||
| %e | 将下一个参数写成科学记数法,使用 eN 意思是 ×10N。 |
|
||||
| %E | 将下一个参数写成科学记数法,使用 EN 意思是 ×10N。 |
|
||||
| %f | 将下一个参数写成十进制的 IEEE 754 浮点数。 |
|
||||
| %g | 与 %e 和 %f 的指数表示形式相同。 |
|
||||
| %G | 与 %E 和 %f 的指数表示形式相同。 |
|
||||
| ==%o== | 将下一个参数写成八进制的无符号整数。 |
|
||||
| ==%s== | 下一个参数如果是一个指针,将它写成空终止符字符串。 |
|
||||
| ==%u== | 将下一个参数写成十进制无符号整数。 |
|
||||
| ==%x== | 将下一个参数写成十六进制无符号整数(使用小写的 a、b、c、d、e 和 f)。 |
|
||||
| %X | 将下一个参数写成十六进制的无符号整数(使用大写的 A、B、C、D、E 和 F)。 |
|
||||
| %p | 将下一个参数写成指针地址。 |
|
||||
| ==%n== | 什么也不输出。而是复制到目前为止被下一个参数在本地处理的字符个数。 |
|
||||
| ==除了 `%` 之外的任何支付== | 复制字符到输出。 |
|
||||
| ==`%%`== | 写一个 % 字符到输出。 |
|
||||
| ==`%c`== | 将下一个参数写成字符格式。 |
|
||||
| ==`%d` 或 `%i`== | 将下一个参数写成十进制的有符号整数。 |
|
||||
| `%e` | 将下一个参数写成科学记数法,使用 eN,意思是 ×10<sup>N</sup>。 |
|
||||
| `%E` | 将下一个参数写成科学记数法,使用 EN,意思是 ×10<sup>N</sup>。 |
|
||||
| `%f` | 将下一个参数写成十进制的 IEEE 754 浮点数。 |
|
||||
| `%g` | 与 `%e` 和 `%f` 的指数表示形式相同。 |
|
||||
| `%G` | 与 `%E` 和 `%f` 的指数表示形式相同。 |
|
||||
| ==`%o`== | 将下一个参数写成八进制的无符号整数。 |
|
||||
| ==`%s`== | 下一个参数如果是一个指针,将它写成空终止符字符串。 |
|
||||
| ==`%u`== | 将下一个参数写成十进制无符号整数。 |
|
||||
| ==`%x`== | 将下一个参数写成十六进制无符号整数(使用小写的 a、b、c、d、e 和 f)。 |
|
||||
| `%X` | 将下一个参数写成十六进制的无符号整数(使用大写的 A、B、C、D、E 和 F)。 |
|
||||
| `%p` | 将下一个参数写成指针地址。 |
|
||||
| ==`%n`== | 什么也不输出。而是复制到目前为止被下一个参数在本地处理的字符个数。 |
|
||||
|
||||
除此之外,对序列还有许多额外的处理,比如指定最小长度,符号等等。更多信息可以在 [sprintf - C++ 参考][2] 上找到。
|
||||
|
||||
下面是调用方法和返回的结果的示例。
|
||||
|
||||
表 1.2 sprintf 调用示例
|
||||
|
||||
| 格式化字符串 | 参数 | 结果 |
|
||||
| "%d" | 13 | "13" |
|
||||
| "+%d degrees" | 12 | "+12 degrees" |
|
||||
| "+%x degrees" | 24 | "+1c degrees" |
|
||||
| "'%c' = 0%o" | 65, 65 | "'A' = 0101" |
|
||||
| "%d * %d%% = %d" | 200, 40, 80 | "200 * 40% = 80" |
|
||||
| "+%d degrees" | -5 | "+-5 degrees" |
|
||||
| "+%u degrees" | -5 | "+4294967291 degrees" |
|
||||
|---------------|-------|---------------------|
|
||||
| `"%d"` | 13 | "13" |
|
||||
| `"+%d degrees"` | 12 | "+12 degrees" |
|
||||
| `"+%x degrees"` | 24 | "+1c degrees" |
|
||||
| `"'%c' = 0%o"` | 65, 65 | "'A' = 0101" |
|
||||
| `"%d * %d%% = %d"` | 200, 40, 80 | "200 * 40% = 80" |
|
||||
| `"+%d degrees"` | -5 | "+-5 degrees" |
|
||||
| `"+%u degrees"` | -5 | "+4294967291 degrees" |
|
||||
|
||||
希望你已经看到了这个函数是多么有用。实现它需要大量的编程工作,但给我们的回报却是一个非常有用的函数,可以用于各种用途。
|
||||
|
||||
### 2、除法
|
||||
|
||||
```
|
||||
除法是非常慢的,也是非常复杂的基础数学运算。它在 ARM 汇编代码中不能直接实现,因为如果直接实现的话,它得出答案需要花费很长的时间,因此它不是个“简单的”运算。
|
||||
```
|
||||
|
||||
虽然这个函数看起来很强大、也很复杂。但是,处理它的许多情况的最容易的方式可能是,编写一个函数去处理一些非常常见的任务。它是个非常有用的函数,可以为任何底的一个有符号或无符号的数字生成一个字符串。那么,我们如何去实现呢?在继续阅读之前,尝试快速地设计一个算法。
|
||||
|
||||
> 除法是非常慢的,也是非常复杂的基础数学运算。它在 ARM 汇编代码中不能直接实现,因为如果直接实现的话,它得出答案需要花费很长的时间,因此它不是个“简单的”运算。
|
||||
|
||||
最简单的方法或许就是我在 [课程 1:OK01][3] 中提到的“除法余数法”。它的思路如下:
|
||||
|
||||
1. 用当前值除以你使用的底。
|
||||
@ -75,11 +74,10 @@
|
||||
3. 如果得到的新值不为 0,转到第 1 步。
|
||||
4. 将余数反序连起来就是答案。
|
||||
|
||||
|
||||
|
||||
例如:
|
||||
|
||||
表 2.1 以 2 为底的例子
|
||||
|
||||
转换
|
||||
|
||||
| 值 | 新值 | 余数 |
|
||||
@ -100,7 +98,8 @@
|
||||
我们复习一下长除法
|
||||
|
||||
> 假如我们想把 4135 除以 17。
|
||||
>
|
||||
>
|
||||
> ```
|
||||
> 0243 r 4
|
||||
> 17)4135
|
||||
> 0 0 × 17 = 0000
|
||||
@ -111,9 +110,10 @@
|
||||
> 55 735 - 680 = 55
|
||||
> 51 3 × 17 = 51
|
||||
> 4 55 - 51 = 4
|
||||
> ```
|
||||
> 答案:243 余 4
|
||||
>
|
||||
> 首先我们来看被除数的最高位。 我们看到它是小于或等于除数的最小倍数,因此它是 0。我们在结果中写一个 0。
|
||||
> 首先我们来看被除数的最高位。我们看到它是小于或等于除数的最小倍数,因此它是 0。我们在结果中写一个 0。
|
||||
>
|
||||
> 接下来我们看被除数倒数第二位和所有的高位。我们看到小于或等于那个数的除数的最小倍数是 34。我们在结果中写一个 2,和减去 3400。
|
||||
>
|
||||
@ -124,16 +124,18 @@
|
||||
|
||||
在汇编代码中做除法,我们将实现二进制的长除法。我们之所以实现它是因为,数字都是以二进制方式保存的,这让我们很容易地访问所有重要位的移位操作,并且因为在二进制中做除法比在其它高进制中做除法都要简单,因为它的数更少。
|
||||
|
||||
> 1011 r 1
|
||||
>1010)1101111
|
||||
> 1010
|
||||
> 11111
|
||||
> 1010
|
||||
> 1011
|
||||
> 1010
|
||||
> 1
|
||||
这个示例展示了如何做二进制的长除法。简单来说就是,在不超出被除数的情况下,尽可能将除数右移,根据位置输出一个 1,和减去这个数。剩下的就是余数。在这个例子中,我们展示了 1101111<sub>2</sub> ÷ 1010<sub>2</sub> = 1011<sub>2</sub> 余数为 1<sub>2</sub>。用十进制表示就是,111 ÷ 10 = 11 余 1。
|
||||
```
|
||||
1011 r 1
|
||||
1010)1101111
|
||||
1010
|
||||
11111
|
||||
1010
|
||||
1011
|
||||
1010
|
||||
1
|
||||
```
|
||||
|
||||
这个示例展示了如何做二进制的长除法。简单来说就是,在不超出被除数的情况下,尽可能将除数右移,根据位置输出一个 1,和减去这个数。剩下的就是余数。在这个例子中,我们展示了 1101111<sub>2</sub> ÷ 1010<sub>2</sub> = 1011<sub>2</sub> 余数为 1<sub>2</sub>。用十进制表示就是,111 ÷ 10 = 11 余 1。
|
||||
|
||||
你自己尝试去实现这个长除法。你应该去写一个函数 `DivideU32` ,其中 `r0` 是被除数,而 `r1` 是除数,在 `r0` 中返回结果,在 `r1` 中返回余数。下面,我们将完成一个有效的实现。
|
||||
|
||||
@ -155,7 +157,7 @@ end function
|
||||
|
||||
这段代码实现了我们的目标,但却不能用于汇编代码。我们出现的问题是,我们的寄存器只能保存 32 位,而 `divisor << shift` 的结果可能在一个寄存器中装不下(我们称之为溢出)。这确实是个问题。你的解决方案是否有溢出的问题呢?
|
||||
|
||||
幸运的是,有一个称为 `clz` 或 `计数前导零(count leading zeros)` 的指令,它能计算一个二进制表示的数字的前导零的个数。这样我们就可以在溢出发生之前,可以将寄存器中的值进行相应位数的左移。你可以找出的另一个优化就是,每个循环我们计算 `divisor << shift` 了两遍。我们可以通过将除数移到开始位置来改进它,然后在每个循环结束的时候将它移下去,这样可以避免将它移到别处。
|
||||
幸运的是,有一个称为 `clz`(<ruby>计数前导零<rt>count leading zeros</rt></ruby>)的指令,它能计算一个二进制表示的数字的前导零的个数。这样我们就可以在溢出发生之前,可以将寄存器中的值进行相应位数的左移。你可以找出的另一个优化就是,每个循环我们计算 `divisor << shift` 了两遍。我们可以通过将除数移到开始位置来改进它,然后在每个循环结束的时候将它移下去,这样可以避免将它移到别处。
|
||||
|
||||
我们来看一下进一步优化之后的汇编代码。
|
||||
|
||||
@ -192,11 +194,10 @@ mov pc,lr
|
||||
.unreq shift
|
||||
```
|
||||
|
||||
```assembly
|
||||
clz dest,src 将第一个寄存器 dest 中二进制表示的值的前导零的数量,保存到第二个寄存器 src 中。
|
||||
```
|
||||
你可能毫无疑问的认为这是个非常高效的作法。它是很好,但是除法是个代价非常高的操作,并且我们的其中一个愿望就是不要经常做除法,因为如果能以任何方式提升速度就是件非常好的事情。当我们查看有循环的优化代码时,我们总是重点考虑一个问题,这个循环会运行多少次。在本案例中,在输入为 1 的情况下,这个循环最多运行 31 次。在不考虑特殊情况的时候,这很容易改进。例如,当 1 除以 1 时,不需要移位,我们将把除数移到它上面的每个位置。这可以通过简单地在被除数上使用新的 `clz` 命令并从中减去它来改进。在 `1 ÷ 1` 的案例中,这意味着移位将设置为 0,明确地表示它不需要移位。如果它设置移位为负数,表示除数大于被除数,因此我们就可以知道结果是 0,而余数是被除数。我们可以做的另一个快速检查就是,如果当前值为 0,那么它是一个整除的除法,我们就可以停止循环了。
|
||||
|
||||
> `clz dest,src` 将第一个寄存器 `dest` 中二进制表示的值的前导零的数量,保存到第二个寄存器 `src` 中。
|
||||
|
||||
你可能毫无疑问的认为这是个非常高效的作法。它是很好,但是除法是个代价非常高的操作,并且我们的其中一个愿望就是不要经常做除法,因为如果能以任何方式提升速度就是件非常好的事情。当我们查看有循环的优化代码时,我们总是重点考虑一个问题,这个循环会运行多少次。在本案例中,在输入为 1 的情况下,这个循环最多运行 31 次。在不考虑特殊情况的时候,这很容易改进。例如,当 1 除以 1 时,不需要移位,我们将把除数移到它上面的每个位置。这可以通过简单地在被除数上使用新的 clz 命令并从中减去它来改进。在 `1 ÷ 1` 的案例中,这意味着移位将设置为 0,明确地表示它不需要移位。如果它设置移位为负数,表示除数大于被除数,因此我们就可以知道结果是 0,而余数是被除数。我们可以做的另一个快速检查就是,如果当前值为 0,那么它是一个整除的除法,我们就可以停止循环了。
|
||||
|
||||
```assembly
|
||||
.globl DivideU32
|
||||
@ -291,17 +292,15 @@ end function
|
||||
|
||||
### 4、格式化字符串
|
||||
|
||||
我们继续回到我们的字符串格式化方法。因为我们正在编写我们自己的操作系统,我们根据我们自己的意愿来添加或修改格式化规则。我们可以发现,添加一个 `a %b` 操作去输出一个二进制的数字比较有用,而如果你不使用空终止符字符串,那么你应该去修改 `%s` 的行为,让它从另一个参数中得到字符串的长度,或者如果你愿意,可以从长度前缀中获取。我在下面的示例中使用了一个空终止符。
|
||||
我们继续回到我们的字符串格式化方法。因为我们正在编写我们自己的操作系统,我们根据我们自己的意愿来添加或修改格式化规则。我们可以发现,添加一个 `a % b` 操作去输出一个二进制的数字比较有用,而如果你不使用空终止符字符串,那么你应该去修改 `%s` 的行为,让它从另一个参数中得到字符串的长度,或者如果你愿意,可以从长度前缀中获取。我在下面的示例中使用了一个空终止符。
|
||||
|
||||
实现这个函数的一个主要的障碍是它的参数个数是可变的。根据 ABI 规定,额外的参数在调用方法之前以相反的顺序先推送到栈上。比如,我们使用 8 个参数 1、2、3、4、5、6、7 和 8 来调用我们的方法,我们将按下面的顺序来处理:
|
||||
|
||||
1. Set r0 = 5、r1 = 6、r2 = 7、r3 = 8
|
||||
2. Push {r0,r1,r2,r3}
|
||||
3. Set r0 = 1、r1 = 2、r2 = 3、r3 = 4
|
||||
4. 调用函数
|
||||
5. Add sp,#4*4
|
||||
|
||||
|
||||
1. 设置 r0 = 5、r1 = 6、r2 = 7、r3 = 8
|
||||
2. 推入 {r0,r1,r2,r3}
|
||||
3. 设置 r0 = 1、r1 = 2、r2 = 3、r3 = 4
|
||||
4. 调用函数
|
||||
5. 将 sp 和 #4*4 加起来
|
||||
|
||||
现在,我们必须确定我们的函数确切需要的参数。在我的案例中,我将寄存器 `r0` 用来保存格式化字符串地址,格式化字符串长度则放在寄存器 `r1` 中,目标字符串地址放在寄存器 `r2` 中,紧接着是要求的参数列表,从寄存器 `r3` 开始和像上面描述的那样在栈上继续。如果你想去使用一个空终止符格式化字符串,在寄存器 r1 中的参数将被移除。如果你想有一个最大缓冲区长度,你可以将它保存在寄存器 `r3` 中。由于有额外的修改,我认为这样修改函数是很有用的,如果目标字符串地址为 0,意味着没有字符串被输出,但如果仍然返回一个精确的长度,意味着能够精确的判断格式化字符串的长度。
|
||||
|
||||
@ -526,13 +525,13 @@ via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
[1]: https://linux.cn/article-10585-1.html
|
||||
[2]: http://www.cplusplus.com/reference/clibrary/cstdio/sprintf/
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html
|
||||
[3]: https://linux.cn/article-10458-1.html
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
@ -0,0 +1,149 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10582-1.html)
|
||||
[#]: subject: (Use Emacs to create OAuth 2.0 UML sequence diagrams)
|
||||
[#]: via: (https://www.onwebsecurity.com/configuration/use-emacs-to-create-oauth-2-0-uml-sequence-diagrams.html)
|
||||
[#]: author: (Peter Mosmans https://www.onwebsecurity.com)
|
||||
|
||||
使用 Emacs 创建 OAuth 2.0 的 UML 序列图
|
||||
======
|
||||
|
||||
![OAuth 2.0 abstract protocol flow][6]
|
||||
|
||||
看起来 [OAuth 2.0 框架][7] 已经越来越广泛地应用于 web (和 移动) 应用。太棒了!
|
||||
|
||||
虽然协议本身并不复杂,但有很多的使用场景、流程和实现可供选择。正如生活中的大多数事物一样,魔鬼在于细节之中。
|
||||
|
||||
在审查 OAuth 2.0 实现或编写渗透测试报告时我习惯画出 UML 图。这方便让人理解发生了什么事情,并发现潜在的问题。毕竟,一图抵千言。
|
||||
|
||||
使用基于 GPL 开源协议 [Emacs][8] 编辑器来实现,再加上基于 GPL 开源协议的工具 [PlantUML][9] (也可以选择基于 Eclipse Public 协议的 [Graphviz][10]) 很容易做到这一点。
|
||||
|
||||
Emacs 是世界上最万能的编辑器。在这种场景中,我们用它来编辑文本,并自动将文本转换成图片。PlantUML 是一个允许你用人类可读的文本来写 UML 并完成该转换的工具。Graphviz 是一个可视化的软件,这里我们可以用它来显示图片。
|
||||
|
||||
下载 [预先编译好了的 PlantUML jar 文件 ][11],[Emacs][12] 还可以选择下载并安装 [Graphviz][13]。
|
||||
|
||||
安装并启动 Emacs,然后将下面 Lisp 代码(实际上是配置)写入你的启动文件中(`~/.emacs.d/init.d`),这段代码将会:
|
||||
|
||||
* 配置 org 模式(一种用来组织并编辑文本文件的模式)来使用 PlantUML
|
||||
* 将 `plantuml` 添加到可识别的 “org-babel” 语言中(这让你可以在文本文件中执行源代码)
|
||||
* 将 PlantUML 代码标注为安全的,从而允许执行
|
||||
* 自动显示生成的结果图片
|
||||
|
||||
```elisp
|
||||
;; tell org-mode where to find the plantuml JAR file (specify the JAR file)
|
||||
(setq org-plantuml-jar-path (expand-file-name "~/plantuml.jar"))
|
||||
|
||||
;; use plantuml as org-babel language
|
||||
(org-babel-do-load-languages 'org-babel-load-languages '((plantuml . t)))
|
||||
|
||||
;; helper function
|
||||
(defun my-org-confirm-babel-evaluate (lang body)
|
||||
"Do not ask for confirmation to evaluate code for specified languages."
|
||||
(member lang '("plantuml")))
|
||||
|
||||
;; trust certain code as being safe
|
||||
(setq org-confirm-babel-evaluate 'my-org-confirm-babel-evaluate)
|
||||
|
||||
;; automatically show the resulting image
|
||||
(add-hook 'org-babel-after-execute-hook 'org-display-inline-images)
|
||||
```
|
||||
|
||||
如果你还没有启动文件,那么将该代码加入到 `~/.emacs.d/init.el` 文件中然后重启 Emacs。
|
||||
|
||||
提示:`Control-c Control-f` 可以让你创建/打开(新)文件。`Control-x Control-s` 保存文件,而 `Control-x Control-c` 退出 Emacs。
|
||||
|
||||
这就结了!
|
||||
|
||||
要测试该配置,可以创建/打开(`Control-c Control-f`)后缀为 `.org` 的文件,例如 `test.org`。这会让 Emacs 切换到 org 模式并识别 “org-babel” 语法。
|
||||
|
||||
输入下面代码,然后在代码中输入 `Control-c Control-c` 来测试是否安装正常:
|
||||
|
||||
```
|
||||
#+BEGIN_SRC plantuml :file test.png
|
||||
@startuml
|
||||
version
|
||||
@enduml
|
||||
#+END_SRC
|
||||
```
|
||||
|
||||
一切顺利的话,你会在 Emacs 中看到文本下面显示了一张图片。
|
||||
|
||||
> **注意:**
|
||||
|
||||
> 要快速插入类似 `#+BEGIN_SRC` 和 `#+END_SRC` 这样的代码片段,你可以使用内置的 Easy Templates 系统:输入 `<s` 然后按下 `TAB`,它就会自动为你插入模板。
|
||||
|
||||
还有更复杂的例子,下面是生成上面图片的 UML 源代码:
|
||||
|
||||
```
|
||||
#+BEGIN_SRC plantuml :file t:/oauth2-abstract-protocol-flow.png
|
||||
@startuml
|
||||
hide footbox
|
||||
title Oauth 2.0 Abstract protocol flow
|
||||
autonumber
|
||||
actor user as "resource owner (user)"
|
||||
box "token stays secure" #FAFAFA
|
||||
participant client as "client (application)"
|
||||
participant authorization as "authorization server"
|
||||
database resource as "resource server"
|
||||
end box
|
||||
|
||||
group user authorizes client
|
||||
client -> user : request authorization
|
||||
note left
|
||||
**grant types**:
|
||||
# authorization code
|
||||
# implicit
|
||||
# password
|
||||
# client_credentials
|
||||
end note
|
||||
user --> client : authorization grant
|
||||
end
|
||||
|
||||
group token is generated
|
||||
client -> authorization : request token\npresent authorization grant
|
||||
authorization --> client :var: access token
|
||||
note left
|
||||
**response types**:
|
||||
# code
|
||||
# token
|
||||
end note
|
||||
end group
|
||||
|
||||
group resource can be accessed
|
||||
client -> resource : request resource\npresent token
|
||||
resource --> client : resource
|
||||
end group
|
||||
@enduml
|
||||
#+END_SRC
|
||||
```
|
||||
|
||||
你难道会不喜欢 Emacs 和开源工具的多功能性吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.onwebsecurity.com/configuration/use-emacs-to-create-oauth-2-0-uml-sequence-diagrams.html
|
||||
|
||||
作者:[Peter Mosmans][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.onwebsecurity.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.onwebsecurity.com/category/configuration.html
|
||||
[2]: https://www.onwebsecurity.com/tag/emacs.html
|
||||
[3]: https://www.onwebsecurity.com/tag/oauth2.html
|
||||
[4]: https://www.onwebsecurity.com/tag/pentesting.html
|
||||
[5]: https://www.onwebsecurity.com/tag/security.html
|
||||
[6]: https://www.onwebsecurity.com/images/oauth2-abstract-protocol-flow.png
|
||||
[7]: https://tools.ietf.org/html/rfc6749
|
||||
[8]: https://www.gnu.org/software/emacs/
|
||||
[9]: https://plantuml.com
|
||||
[10]: http://www.graphviz.org/
|
||||
[11]: http://plantuml.com/download
|
||||
[12]: https://www.gnu.org/software/emacs/download.html
|
||||
[13]: http://www.graphviz.org/Download.php
|
||||
103
published/20170519 zsh shell inside Emacs on Windows.md
Normal file
103
published/20170519 zsh shell inside Emacs on Windows.md
Normal file
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10610-1.html)
|
||||
[#]: subject: (zsh shell inside Emacs on Windows)
|
||||
[#]: via: (https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html)
|
||||
[#]: author: (Peter Mosmans https://www.onwebsecurity.com/)
|
||||
|
||||
Windows 下 Emacs 中的 zsh shell
|
||||
======
|
||||
|
||||
![zsh shell inside Emacs on Windows][5]
|
||||
|
||||
运行跨平台 shell(例如 Bash 或 zsh)的最大优势在于你能在多平台上使用同样的语法和脚本。在 Windows 上设置(替换)shell 挺麻烦的,但所获得的回报远远超出这小小的付出。
|
||||
|
||||
MSYS2 子系统允许你在 Windows 上运行 Bash 或 zsh 之类的 shell。使用 MSYS2 很重要的一点在于确保搜索路径都指向 MSYS2 子系统本身:存在太多依赖关系了。
|
||||
|
||||
MSYS2 安装后默认的 shell 就是 Bash;zsh 则可以通过包管理器进行安装:
|
||||
|
||||
```
|
||||
pacman -Sy zsh
|
||||
```
|
||||
|
||||
通过修改 `etc/passwd` 文件可以设置 zsh 作为默认 shell,例如:
|
||||
|
||||
```
|
||||
mkpasswd -c | sed -e 's/bash/zsh/' | tee -a /etc/passwd
|
||||
```
|
||||
|
||||
这会将默认 shell 从 bash 改成 zsh。
|
||||
|
||||
要在 Windows 上的 Emacs 中运行 zsh ,需要修改 `shell-file-name` 变量,将它指向 MSYS2 子系统中的 zsh 二进制文件。该二进制 shell 文件在 Emacs `exec-path` 变量中的某个地方。
|
||||
|
||||
```
|
||||
(setq shell-file-name (executable-find "zsh.exe"))
|
||||
```
|
||||
|
||||
不要忘了修改 Emacs 的 `PATH` 环境变量,因为 MSYS2 路径应该先于 Windows 路径。接上一个例子,假设 MSYS2 安装在 `c:\programs\msys2` 中,那么执行:
|
||||
|
||||
```
|
||||
(setenv "PATH" "C:\\programs\\msys2\\mingw64\\bin;C:\\programs\\msys2\\usr\\local\\bin;C:\\programs\\msys2\\usr\\bin;C:\\Windows\\System32;C:\\Windows")
|
||||
```
|
||||
|
||||
在 Emacs 配置文件中设置好这两个变量后,在 Emacs 中运行:
|
||||
|
||||
```
|
||||
M-x shell
|
||||
```
|
||||
|
||||
应该就能看到熟悉的 zsh 提示符了。
|
||||
|
||||
Emacs 的终端设置(eterm)与 MSYS2 的标准终端设置(xterm-256color)不一样。这意味着某些插件和主题(提示符)可能不能正常工作 - 尤其在使用 oh-my-zsh 时。
|
||||
|
||||
检测 zsh 否则在 Emacs 中运行很简单,使用变量 `$INSIDE_EMACS`。
|
||||
|
||||
下面这段代码片段取自 `.zshrc`(当以交互式 shell 模式启动时会被加载),它会在 zsh 在 Emacs 中运行时启动 git 插件并更改主题:
|
||||
|
||||
```
|
||||
# Disable some plugins while running in Emacs
|
||||
if [[ -n "$INSIDE_EMACS" ]]; then
|
||||
plugins=(git)
|
||||
ZSH_THEME="simple"
|
||||
else
|
||||
ZSH_THEME="compact-grey"
|
||||
fi
|
||||
```
|
||||
|
||||
通过在本地 `~/.ssh/config` 文件中将 `INSIDE_EMACS` 变量设置为 `SendEnv` 变量……
|
||||
|
||||
```
|
||||
Host myhost
|
||||
SendEnv INSIDE_EMACS
|
||||
```
|
||||
|
||||
……同时在 ssh 服务器的 `/etc/ssh/sshd_config` 中设置为 `AcceptEnv` 变量……
|
||||
|
||||
```
|
||||
AcceptEnv LANG LC_* INSIDE_EMACS
|
||||
```
|
||||
|
||||
……这使得在 Emacs shell 会话中通过 ssh 登录另一个运行着 zsh 的 ssh 服务器也能工作的很好。当在 Windows 下的 Emacs 中的 zsh 上通过 ssh 远程登录时,记得使用参数 `-t`,`-t` 参数会强制分配伪终端(之所以需要这样,时因为 Windows 下的 Emacs 并没有真正的 tty)。
|
||||
|
||||
跨平台,开源真是个好东西……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html
|
||||
|
||||
作者:[Peter Mosmans][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.onwebsecurity.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.onwebsecurity.com/category/configuration.html
|
||||
[2]: https://www.onwebsecurity.com/tag/emacs.html
|
||||
[3]: https://www.onwebsecurity.com/tag/msys2.html
|
||||
[4]: https://www.onwebsecurity.com/tag/zsh.html
|
||||
[5]: https://www.onwebsecurity.com//images/zsh-shell-inside-emacs-on-windows.png
|
||||
121
published/20170721 Firefox and org-protocol URL Capture.md
Normal file
121
published/20170721 Firefox and org-protocol URL Capture.md
Normal file
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10586-1.html)
|
||||
[#]: subject: (Firefox and org-protocol URL Capture)
|
||||
[#]: via: (http://www.mediaonfire.com/blog/2017_07_21_org_protocol_firefox.html)
|
||||
[#]: author: (Andreas Viklund http://andreasviklund.com/)
|
||||
|
||||
在 Firefox 上使用 Org 协议捕获 URL
|
||||
======
|
||||
|
||||
### 介绍
|
||||
|
||||
作为一名 Emacs 人,我尽可能让所有的工作流都在 <ruby>[Org 模式][1]<rt>Org-mode</rt></ruby> 上进行 —— 我比较喜欢文本。
|
||||
|
||||
我倾向于将书签记录在 [Org 模式][1] 代办列表中,而 <ruby>[Org 协议][2]<rt>Org-protocol</rt></ruby> 则允许外部进程利用 [Org 模式][1] 的某些功能。然而,要做到这一点配置起来很麻烦。([搜索引擎上][3])有很多教程,Firefox 也有这类 [扩展][4],然而我对它们都不太满意。
|
||||
|
||||
因此我决定将我现在的配置记录在这篇博客中,方便其他有需要的人使用。
|
||||
|
||||
### 配置 Emacs Org 模式
|
||||
|
||||
启用 Org 协议:
|
||||
|
||||
```
|
||||
(require 'org-protocol)
|
||||
```
|
||||
|
||||
添加一个<ruby>捕获模板<rt>capture template</rt></ruby> —— 我的配置是这样的:
|
||||
|
||||
```
|
||||
(setq org-capture-templates
|
||||
(quote (...
|
||||
("w" "org-protocol" entry (file "~/org/refile.org")
|
||||
"* TODO Review %a\n%U\n%:initial\n" :immediate-finish)
|
||||
...)))
|
||||
```
|
||||
|
||||
你可以从 [Org 模式][1] 手册中 [捕获模板][5] 章节中获取帮助。
|
||||
|
||||
设置默认使用的模板:
|
||||
|
||||
```
|
||||
(setq org-protocol-default-template-key "w")
|
||||
```
|
||||
|
||||
执行这些新增配置让它们在当前 Emacs 会话中生效。
|
||||
|
||||
### 快速测试
|
||||
|
||||
在下一步开始前,最好测试一下配置:
|
||||
|
||||
```
|
||||
emacsclient -n "org-protocol:///capture?url=http%3a%2f%2fduckduckgo%2ecom&title=DuckDuckGo"
|
||||
```
|
||||
|
||||
基于的配置的模板,可能会弹出一个捕获窗口。请确保正常工作,否则后面的操作没有任何意义。如果工作不正常,检查刚才的配置并且确保你执行了这些代码块。
|
||||
|
||||
如果你的 [Org 模式][1] 版本比较老(老于 7 版本),测试的格式会有点不同:这种 URL 编码后的格式需要改成用斜杠来分割 url 和标题。在网上搜一下很容易找出这两者的不同。
|
||||
|
||||
### Firefox 协议
|
||||
|
||||
现在开始设置 Firefox。浏览 `about:config`。右击配置项列表,选择 “New -> Boolean”,然后输入 `network.protocol-handler.expose.org-protocol` 作为名字并且将值设置为 `true`。
|
||||
|
||||
有些教程说这一步是可以省略的 —— 配不配因人而异。
|
||||
|
||||
### 添加 Desktop 文件
|
||||
|
||||
大多数的教程都有这一步:
|
||||
|
||||
增加一个文件 `~/.local/share/applications/org-protocol.desktop`:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=org-protocol
|
||||
Exec=/path/to/emacsclient -n %u
|
||||
Type=Application
|
||||
Terminal=false
|
||||
Categories=System;
|
||||
MimeType=x-scheme-handler/org-protocol;
|
||||
```
|
||||
|
||||
然后运行更新器。对于 i3 窗口管理器我使用下面命令(跟 gnome 一样):
|
||||
|
||||
```
|
||||
update-desktop-database ~/.local/share/applications/
|
||||
```
|
||||
|
||||
KDE 的方法不太一样……你可以查询其他相关教程。
|
||||
|
||||
### 在 FireFox 中设置捕获按钮
|
||||
|
||||
创建一个书签(我是在工具栏上创建这个书签的),地址栏输入下面内容:
|
||||
|
||||
```
|
||||
javascript:location.href="org-protocol:///capture?url="+encodeURIComponent(location.href)+"&title="+encodeURIComponent(document.title||"[untitled page]")
|
||||
```
|
||||
|
||||
保存该书签后,再次编辑该书签,你应该会看到其中的所有空格都被替换成了 `%20` —— 也就是空格的 URL 编码形式。
|
||||
|
||||
现在当你点击该书签,你就会在某个 Emacs 框架中,可能是一个任意的框架中,打开一个窗口,显示你预定的模板。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.mediaonfire.com/blog/2017_07_21_org_protocol_firefox.html
|
||||
|
||||
作者:[Andreas Viklund][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://andreasviklund.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://orgmode.org/
|
||||
[2]: http://orgmode.org/worg/org-contrib/org-protocol.html
|
||||
[3]: https://duckduckgo.com/?q=org-protocol+firefox&t=ffab&ia=qa
|
||||
[4]: https://addons.mozilla.org/en-US/firefox/search/?q=org-protocol&cat=1,0&appver=53.0&platform=linux
|
||||
[5]: http://orgmode.org/manual/Capture-templates.html
|
||||
67
published/20180122 Ick- a continuous integration system.md
Normal file
67
published/20180122 Ick- a continuous integration system.md
Normal file
@ -0,0 +1,67 @@
|
||||
ick:一个持续集成系统
|
||||
======
|
||||
|
||||
> ick 是一个持续集成(CI)系统。访问 <http://ick.liw.fi/> 获取更多信息。
|
||||
|
||||
更加详细的内容如下:
|
||||
|
||||
### 首个公开版本发行
|
||||
|
||||
这个世界可能并不需要又一个持续集成系统(CI),但是我需要。我对我尝试过或者看过的持续集成系统感到不满意。更重要的是,有几样我感兴趣的东西比我所听说过的持续集成系统要强大得多。因此我开始编写我自己的 CI 系统。
|
||||
|
||||
我的新个人业余项目叫做 ick。它是一个 CI 系统,这意味着它可以运行自动化的步骤来构建、测试软件。它的主页是 <http://ick.liw.fi/>,[下载][1]页面有指向源代码、.deb 包和用来安装的 Ansible 脚本的链接。
|
||||
|
||||
我现已发布了首个公开版本,绰号 ALPHA-1,版本号 0.23。(LCTT 译注:截止至本译文发布,已经更新到 ALPHA-6)它现在是 alpha 品质,这意味着它并没拥有期望的全部特性,如果任何一个它已有的特性工作的话,那真是运气好。
|
||||
|
||||
### 诚邀贡献
|
||||
|
||||
ick 目前是我的个人项目。我希望能让它不仅限于此,同时我也诚邀更多贡献。访问[治理][2]页面查看章程,[入门][3]页面查看如何开始贡献的的小建议,[联系][4]页面查看如何联络。
|
||||
|
||||
### 架构
|
||||
|
||||
ick 拥有一个由几个通过 HTTPS 协议通信使用 RESTful API 和 JSON 处理结构化数据的部分组成的架构。访问[架构][5]页面了解细节。
|
||||
|
||||
### 宣告
|
||||
|
||||
持续集成(CI)是用于软件开发的强大工具。它不应枯燥、易溃或恼人。它构建起来应简单快速,除非正在测试、构建的代码中有问题,不然它应在后台安静地工作。
|
||||
|
||||
一个持续集成系统应该简单、易用、清楚、干净、可扩展、快速、综合、透明、可靠,并推动你的生产力。构建它不应花大力气、不应需要专门为 CI 而造的硬件、不应需要频繁留意以使其保持工作、开发者永远不必思考为什么某样东西不工作。
|
||||
|
||||
一个持续集成系统应该足够灵活以适应你的构建、测试需求。只要 CPU 架构和操作系统版本没问题,它应该支持各种操作者。
|
||||
|
||||
同时像所有软件一样,CI 应该彻彻底底的免费,你的 CI 应由你做主。
|
||||
|
||||
(目前的 ick 仅稍具雏形,但是它会尝试着有朝一日变得完美 —— 在最理想的情况下。)
|
||||
|
||||
### 未来的梦想
|
||||
|
||||
长远来看,我希望 ick 拥有像下面所描述的特性。落实全部特性可能需要一些时间。
|
||||
|
||||
* 各种事件都可以触发构建。时间是一个明显的事件,因为项目的源代码仓库改变了。更强大的是任何依赖的改变,不管依赖是来自于 ick 构建的另一个项目,或者是包(比如说来自 Debian):ick 应当跟踪所有安装进一个项目构建环境中的包,如果任何一个包的版本改变,都应再次触发项目构建和测试。
|
||||
* ick 应该支持构建于(或针对)任何合理的目标平台,包括任何 Linux 发行版,任何自由的操作系统,以及任何一息尚存的不自由的操作系统。
|
||||
* ick 应该自己管理构建环境,并且能够执行与构建主机或网络隔离的构建。这部分工作:可以要求 ick 构建容器并在容器中运行构建。容器使用 systemd-nspawn 实现。 然而,这可以改进。(如果您认为 Docker 是唯一的出路,请为此提供支持。)
|
||||
* ick 应当不需要安装任何专门的代理,就能支持各种它能够通过 ssh 或者串口或者其它这种中性的交流管道控制的<ruby>操作者<rt>worker</rt></ruby>。ick 不应默认它可以有比如说一个完整的 Java Runtime,如此一来,操作者就可以是一个微控制器了。
|
||||
* ick 应当能轻松掌控一大批项目。我觉得不管一个新的 Debian 源包何时上传,ick 都应该要能够跟得上在 Debian 中构建所有东西的进度。(明显这可行与否取决于是否有足够的资源确实用在构建上,但是 ick 自己不应有瓶颈。)
|
||||
* 如果有需要的话 ick 应当有选择性地补给操作者。如果所有特定种类的操作者处于忙碌中,且 ick 被设置成允许使用更多资源的话,它就应该这么做。这看起来用虚拟机、容器、云提供商等做可能会简单一些。
|
||||
* ick 应当灵活提醒感兴趣的团体,特别是关于其失败的方面。它应允许感兴趣的团体通过 IRC、Matrix、Mastodon、Twitter、email、SMS 甚至电话和语音合成来接受通知。例如“您好,感兴趣的团体。现在是四点钟您想被通知 hello 包什么时候为 RISC-V 构建好。”
|
||||
|
||||
### 请提供反馈
|
||||
|
||||
如果你尝试过 ick 或者甚至你仅仅是读到这,请在上面分享你的想法。在[联系][4]页面查看如何发送反馈。相比私下反馈我更偏爱公开反馈。但如果你偏爱私下反馈,那也行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.liw.fi/posts/2018/01/22/ick_a_continuous_integration_system/
|
||||
|
||||
作者:[Lars Wirzenius][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.liw.fi/
|
||||
[1]:http://ick.liw.fi/download/
|
||||
[2]:http://ick.liw.fi/governance/
|
||||
[3]:http://ick.liw.fi/getting-started/
|
||||
[4]:http://ick.liw.fi/contact/
|
||||
[5]:http://ick.liw.fi/architecture/
|
||||
@ -0,0 +1,70 @@
|
||||
Ansible 入门秘诀
|
||||
======
|
||||
|
||||
> 用 Ansible 自动化你的数据中心的关键点。
|
||||
|
||||

|
||||
|
||||
Ansible 是一个开源自动化工具,可以从中央控制节点统一配置服务器、安装软件或执行各种 IT 任务。它采用一对多、<ruby>无客户端<rt>agentless</rt></ruby>的机制,从控制节点上通过 SSH 发送指令给远端的客户机来完成任务(当然除了 SSH 外也可以用别的协议)。
|
||||
|
||||
Ansible 的主要使用群体是系统管理员,他们经常会周期性地执行一些安装、配置应用的工作。尽管如此,一些非特权用户也可以使用 Ansible,例如数据库管理员就可以通过 Ansible 用 `mysql` 这个用户来创建数据库、添加数据库用户、定义访问权限等。
|
||||
|
||||
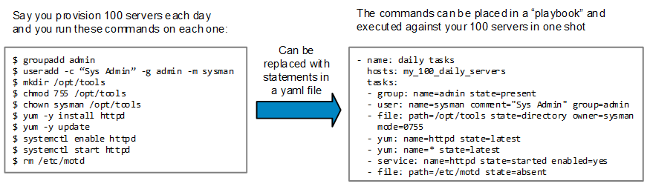
让我们来看一个简单的使用场景,一位系统管理员每天要配置 100 台服务器,并且必须在每台机器上执行一系列 Bash 命令,然后交付给用户。
|
||||
|
||||
|
||||
|
||||
这是个简单的例子,但应该能够证明:在 yaml 文件里写好命令然后在远程服务器上运行,是一件非常轻松的事。而且如果运行环境不同,就可以加入判断条件,指明某些命令只能在特定的服务器上运行(如:只在那些不是 Ubuntu 或 Debian 的系统上运行 `yum` 命令)。
|
||||
|
||||
Ansible 的一个重要特性是用<ruby>剧本<rt>playbook</rt></ruby>来描述一个计算机系统的最终状态,所以一个剧本可以在服务器上反复执行而不影响其最终状态(LCTT 译注:即是幂等的)。如果某个任务已经被实施过了(如,“用户 `sysman` 已经存在”),那么 Ansible 就会忽略它继续执行后续的任务。
|
||||
|
||||
### 定义
|
||||
|
||||
* <ruby>任务<rt>task</rt></ruby>:是工作的最小单位,它可以是个动作,比如“安装一个数据库服务”、“安装一个 web 服务器”、“创建一条防火墙规则”或者“把这个配置文件拷贝到那个服务器上去”。
|
||||
* <ruby>动作<rt>play</rt></ruby>: 由任务组成,例如,一个动作的内容是要“设置一个数据库,给 web 服务用”,这就包含了如下任务:1)安装数据库包;2)设置数据库管理员密码;3)创建数据库实例;4)为该实例分配权限。
|
||||
* <ruby>剧本<rt>playbook</rt></ruby>:(LCTT 译注:playbook 原指美式橄榄球队的[战术手册][5],也常指“剧本”,此处惯例采用“剧本”译名)由动作组成,一个剧本可能像这样:“设置我的网站,包含后端数据库”,其中的动作包括:1)设置数据库服务器;2)设置 web 服务器。
|
||||
* <ruby>角色<rt>role</rt></ruby>:用来保存和组织剧本,以便分享和再次使用它们。还拿上个例子来说,如果你需要一个全新的 web 服务器,就可以用别人已经写好并分享出来的角色来设置。因为角色是高度可配置的(如果编写正确的话),可以根据部署需求轻松地复用它们。
|
||||
* <ruby>[Ansible 星系][1]<rt>Ansible Galaxy</rt></ruby>:是一个在线仓库,里面保存的是由社区成员上传的角色,方便彼此分享。它与 GitHub 紧密集成,因此这些角色可以先在 Git 仓库里组织好,然后通过 Ansible 星系分享出来。
|
||||
|
||||
这些定义以及它们之间的关系可以用下图来描述:
|
||||
|
||||
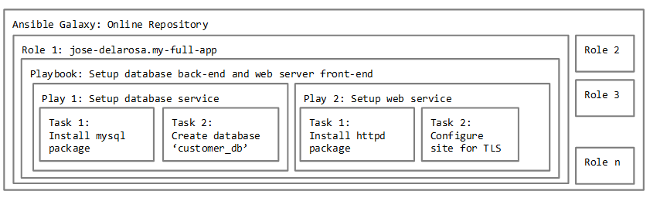
|
||||
|
||||
请注意上面的例子只是组织任务的方式之一,我们当然也可以把安装数据库和安装 web 服务器的剧本拆开,放到不同的角色里。Ansible 星系上最常见的角色是独立安装、配置每个应用服务,你可以参考这些安装 [mysql][2] 和 [httpd][3] 的例子。
|
||||
|
||||
### 编写剧本的小技巧
|
||||
|
||||
学习 Ansible 最好的资源是其[官方文档][4]。另外,像学习其他东西一样,搜索引擎是你的好朋友。我推荐你从一些简单的任务开始,比如安装应用或创建用户。下面是一些有用的指南:
|
||||
|
||||
* 在测试的时候少选几台服务器,这样你的动作可以执行的更快一些。如果它们在一台机器上执行成功,在其他机器上也没问题。
|
||||
* 总是在真正运行前做一次<ruby>测试<rt>dry run</rt></ruby>,以确保所有的命令都能正确执行(要运行测试,加上 `--check-mode` 参数 )。
|
||||
* 尽可能多做测试,别担心搞砸。任务里描述的是所需的状态,如果系统已经达到预期状态,任务会被简单地忽略掉。
|
||||
* 确保在 `/etc/ansible/hosts` 里定义的主机名都可以被正确解析。
|
||||
* 因为是用 SSH 与远程主机通信,主控节点必须要能接受密钥,所以你面临如下选择:1)要么在正式使用之前就做好与远程主机的密钥交换工作;2)要么在开始管理某台新的远程主机时做好准备输入 “Yes”,因为你要接受对方的 SSH 密钥交换请求(LCTT 译注:还有另一个不那么安全的选择,修改主控节点的 ssh 配置文件,将 `StrictHostKeyChecking` 设置成 “no”)。
|
||||
* 尽管你可以在同一个剧本内把不同 Linux 发行版的任务整合到一起,但为每个发行版单独编写剧本会更明晰一些。
|
||||
|
||||
### 总结一下
|
||||
|
||||
Ansible 是你在数据中心里实施运维自动化的好选择,因为它:
|
||||
|
||||
* 无需客户端,所以比其他自动化工具更易安装。
|
||||
* 将指令保存在 YAML 文件中(虽然也支持 JSON),比写 shell 脚本更简单。
|
||||
* 开源,因此你也可以做出自己的贡献,让它更加强大!
|
||||
|
||||
你是怎样使用 Ansible 让数据中心更加自动化的呢?请在评论中分享您的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/tips-success-when-getting-started-ansible
|
||||
|
||||
作者:[Jose Delarosa][a]
|
||||
译者:[jdh8383](https://github.com/jdh8383)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jdelaros1
|
||||
[1]:https://galaxy.ansible.com/
|
||||
[2]:https://galaxy.ansible.com/bennojoy/mysql/
|
||||
[3]:https://galaxy.ansible.com/xcezx/httpd/
|
||||
[4]:http://docs.ansible.com/
|
||||
[5]:https://usafootball.com/football-playbook/
|
||||
@ -0,0 +1,80 @@
|
||||
3 款用于学术出版的开源工具
|
||||
======
|
||||
> 学术出版业每年的价值超过 260 亿美元。
|
||||
|
||||
|
||||
|
||||
有一个行业在采用数字化或开源工具方面已落后其它行业,那就是竞争与利润并存的学术出版业。根据 Stephen Buranyi 去年在 [卫报][1] 上发表的一份图表,这个估值超过 190 亿英镑(260 亿美元)的行业,即使是最重要的科学研究方面,至今其系统在选题、出版甚至分享方面仍受限于印刷媒介的诸多限制。全新的数字时代科技展现了一个巨大机遇,可以加速探索、推动科学协作而非竞争,以及将投入从基础建设导向有益于社会的研究。
|
||||
|
||||
非盈利性的 [eLife 倡议][2] 是由研究资金赞助方建立,旨在通过使用数字或者开源技术来走出上述僵局。除了为生命科学和生物医疗方面的重大成就出版开放式获取的期刊,eLife 已将自己变成了一个在研究交流方面的实验和展示创新的平台 —— 而大部分的实验都是基于开源精神的。
|
||||
|
||||
致力于开放出版基础设施项目给予我们加速接触、采用科学技术、提升用户体验的机会。我们认为这种机会对于推动学术出版行业是重要的。大而化之地说,开源产品的用户体验经常是有待开发的,而有时候这种情况会阻止其他人去使用它。作为我们在 OSS(开源软件)开发中投入的一部分,为了鼓励更多用户使用这些产品,我们十分注重用户体验。
|
||||
|
||||
我们所有的代码都是开源的,并且我们也积极鼓励社区参与进我们的项目中。这对我们来说意味着更快的迭代、更多的实验、更大的透明度,同时也拓宽了我们工作的外延。
|
||||
|
||||
我们现在参与的项目,例如 Libero (之前称作 [eLife Continuum][3])和 <ruby>[可重现文档栈][4]<rt>Reproducible Document Stack</rt></ruby> 的开发,以及我们最近和 [Hypothesis][5] 的合作,展示了 OSS 是如何在评估、出版以及新发现的沟通方面带来正面影响的。
|
||||
|
||||
### Libero
|
||||
|
||||
Libero 是面向出版商的服务及应用套餐,它包括一个后期制作出版系统、整套前端用户界面样式套件、Libero 的镜头阅读器、一个 Open API 以及一个搜索及推荐引擎。
|
||||
|
||||
去年我们采取了用户驱动的方式重新设计了 Libero 的前端,可以使用户较少地分心于网站的“陈设”,而是更多地集中关注于研究文章上。我们和 eLife 社区成员测试并迭代了该站点所有的核心功能,以确保给所有人最好的阅读体验。该网站的新 API 也为机器阅读能力提供了更简单的访问途径,其中包括文本挖掘、机器学习以及在线应用开发。
|
||||
|
||||
我们网站上的内容以及引领新设计的样式都是开源的,以鼓励 eLife 和其它想要使用它的出版商后续的产品开发。
|
||||
|
||||
### 可重现文档栈
|
||||
|
||||
在与 [Substance][6] 和 [Stencila][7] 的合作下,eLife 也参与了一个项目来创建可重现文档栈(RDS)—— 一个开放式的创作、编纂以及在线出版可重现的计算型手稿的工具栈。
|
||||
|
||||
今天越来越多的研究人员能够通过 [R Markdown][8] 和 [Python][9] 等语言记录他们的计算实验。这些可以作为实验记录的重要部分,但是尽管它们可以独立于最终的研究文章或与之一同分享,但传统出版流程经常将它们视为次级内容。为了发表论文,使用这些语言的研究人员除了将他们的计算结果用图片的形式“扁平化”提交外别无他法。但是这导致了许多实验价值和代码和计算数据可重复利用性的流失。诸如 [Jupyter][10] 这样的电子笔记本解决方案确实可以使研究员以一种可重复利用、可执行的简单形式发布,但是这种方案仍然是出版的手稿的补充,而不是不可或缺的一部分。
|
||||
|
||||
[可重现文档栈][11] 项目旨在通过开发、发布一个可重现原稿的产品原型来解决这些挑战,该原型将代码和数据视为文档的组成部分,并展示了从创作到出版的完整端对端技术栈。它将最终允许用户以一种包含嵌入代码块和计算结果(统计结果、图表或图形)的形式提交他们的手稿,并在出版过程中保留这些可视、可执行的部分。那时出版商就可以将这些做为出版的在线文章的组成部分而保存。
|
||||
|
||||
### 用 Hypothesis 进行开放式注解
|
||||
|
||||
最近,我们与 [Hypothesis][12] 合作引进了开放式注解,使得我们网站的用户们可以写评语、高亮文章重要部分以及与在线阅读的群体互动。
|
||||
|
||||
通过这样的合作,开源的 Hypothesis 软件被定制得更具有现代化的特性,如单次登录验证、用户界面定制,给予了出版商在他们自己网站上实现更多的控制。这些提升正引导着关于出版学术内容的高质量讨论。
|
||||
|
||||
这个工具可以无缝集成到出版商的网站,学术出版平台 [PubFactory][13] 和内容解决方案供应商 [Ingenta][14] 已经利用了它优化后的特性集。[HighWire][15] 和 [Silverchair][16] 也为他们的出版商提供了实施这套方案的机会。
|
||||
|
||||
### 其它产业和开源软件
|
||||
|
||||
随着时间的推移,我们希望看到更多的出版商采用 Hypothesis、Libero 以及其它开源项目去帮助他们促进重要科学研究的发现以及循环利用。但是 eLife 的创新机遇也能被其它行业所利用,因为这些软件和其它 OSS 技术在其他行业也很普遍。
|
||||
|
||||
数据科学的世界离不开高质量、良好支持的开源软件和围绕它们形成的社区;[TensorFlow][17] 就是这样一个好例子。感谢 OSS 以及其社区,AI 和机器学习的所有领域相比于计算机的其它领域的提升和发展更加迅猛。与之类似的是以 Linux 作为云端 Web 主机的爆炸性增长、接着是 Docker 容器、以及现在 GitHub 上最流行的开源项目之一的 Kubernetes 的增长。
|
||||
|
||||
所有的这些技术使得机构们能够用更少的资源做更多的事情,并专注于创新而不是重新发明轮子上。最后,这就是 OSS 真正的好处:它使得我们从互相的失败中学习,在互相的成功中成长。
|
||||
|
||||
我们总是在寻找与研究和科技界面方面最好的人才和想法交流的机会。你可以在 [eLife Labs][18] 上或者联系 [innovation@elifesciences.org][19] 找到更多这种交流的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/scientific-publishing-software
|
||||
|
||||
作者:[Paul Shanno][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pshannon
|
||||
[1]:https://www.theguardian.com/science/2017/jun/27/profitable-business-scientific-publishing-bad-for-science
|
||||
[2]:https://elifesciences.org/about
|
||||
[3]:https://elifesciences.org/inside-elife/33e4127f/elife-introduces-continuum-a-new-open-source-tool-for-publishing
|
||||
[4]:https://elifesciences.org/for-the-press/e6038800/elife-supports-development-of-open-technology-stack-for-publishing-reproducible-manuscripts-online
|
||||
[5]:https://elifesciences.org/for-the-press/81d42f7d/elife-enhances-open-annotation-with-hypothesis-to-promote-scientific-discussion-online
|
||||
[6]:https://github.com/substance
|
||||
[7]:https://github.com/stencila/stencila
|
||||
[8]:https://rmarkdown.rstudio.com/
|
||||
[9]:https://www.python.org/
|
||||
[10]:http://jupyter.org/
|
||||
[11]:https://elifesciences.org/labs/7dbeb390/reproducible-document-stack-supporting-the-next-generation-research-article
|
||||
[12]:https://github.com/hypothesis
|
||||
[13]:http://www.pubfactory.com/
|
||||
[14]:http://www.ingenta.com/
|
||||
[15]:https://github.com/highwire
|
||||
[16]:https://www.silverchair.com/community/silverchair-universe/hypothesis/
|
||||
[17]:https://www.tensorflow.org/
|
||||
[18]:https://elifesciences.org/labs
|
||||
[19]:mailto:innovation@elifesciences.org
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10601-1.html)
|
||||
[#]: subject: (Schedule a visit with the Emacs psychiatrist)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-eliza)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
预约 Emacs 心理医生
|
||||
======
|
||||
|
||||
> Eliza 是一个隐藏于某个 Linux 最流行文本编辑器中的自然语言处理聊天机器人。
|
||||
|
||||
|
||||
|
||||
欢迎你,今天时期 24 天的 Linux 命令行玩具的又一天。如果你是第一次访问本系列,你可能会问什么是命令行玩具呢。我们将会逐步确定这个概念,但一般来说,它可能是一个游戏,或任何能让你在终端玩的开心的其他东西。
|
||||
|
||||
可能你们已经见过了很多我们之前挑选的那些玩具,但我们依然希望对所有人来说都至少有一件新鲜事物。
|
||||
|
||||
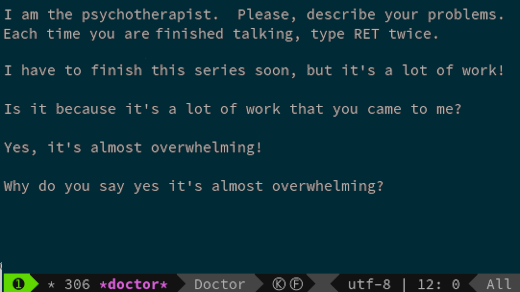
今天的选择是 Emacs 中的一个彩蛋:Eliza,Rogerian 心理医生,一个准备好倾听你述说一切的终端玩具。
|
||||
|
||||
旁白:虽然这个玩具很好玩,但你的健康不是用来开玩笑的。请在假期期间照顾好你自己,无论时身体上还是精神上,若假期中的压力和焦虑对你的健康产生负面影响,请考虑找专业人士进行指导。真的有用。
|
||||
|
||||
要启动 [Eliza][1],首先,你需要启动 Emacs。很有可能 Emacs 已经安装在你的系统中了,但若没有,它基本上也肯定在你默认的软件仓库中。
|
||||
|
||||
由于我要求本系列的工具一定要时运行在终端内,因此使用 `-nw` 标志来启动 Emacs 让它在你的终端模拟器中运行。
|
||||
|
||||
```
|
||||
$ emacs -nw
|
||||
```
|
||||
|
||||
在 Emacs 中,输入 `M-x doctor` 来启动 Eliza。对于像我这样有 Vim 背景的人可能不知道这是什么意思,只需要按下 `escape`,输入 `x` 然后输入 `doctor`。然后,向它倾述所有假日的烦恼吧。
|
||||
|
||||
Eliza 历史悠久,最早可以追溯到 1960 年代中期的 MIT 人工智能实验室。[维基百科][2] 上有它历史的详细说明。
|
||||
|
||||
Eliza 并不是 Emacs 中唯一的娱乐工具。查看 [手册][3] 可以看到一整列好玩的玩具。
|
||||
|
||||
![Linux toy:eliza animated][5]
|
||||
|
||||
你有什么喜欢的命令行玩具值得推荐吗?我们时间不多了,但我还是想听听你的建议。请在下面评论中告诉我,我会查看的。另外也欢迎告诉我你们对本次玩具的想法。
|
||||
|
||||
请一定要看看昨天的玩具,[带着这个复刻版吃豆人来到 Linux 终端游乐中心][6],然后明天再来看另一个玩具!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-eliza
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.emacswiki.org/emacs/EmacsDoctor
|
||||
[2]: https://en.wikipedia.org/wiki/ELIZA
|
||||
[3]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Amusements.html
|
||||
[4]: /file/417326
|
||||
[5]: https://opensource.com/sites/default/files/uploads/linux-toy-eliza-animated.gif (Linux toy: eliza animated)
|
||||
[6]: https://opensource.com/article/18/12/linux-toy-myman
|
||||
@ -1,36 +1,38 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (jdh8383)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10578-1.html)
|
||||
[#]: subject: (7 CI/CD tools for sysadmins)
|
||||
[#]: via: (https://opensource.com/article/18/12/cicd-tools-sysadmins)
|
||||
[#]: author: (Dan Barker https://opensource.com/users/barkerd427)
|
||||
|
||||
系统管理员的 7 个 CI/CD 工具
|
||||
======
|
||||
本文是一篇简单指南:介绍一些常见的开源 CI/CD 工具。
|
||||
|
||||
> 本文是一篇简单指南:介绍一些顶级的开源的持续集成、持续交付和持续部署(CI/CD)工具。
|
||||
|
||||

|
||||
|
||||
虽然持续集成、持续交付和持续部署(CI/CD)在开发者社区里已经存在很多年,一些机构在运维部门也有实施经验,但大多数公司并没有做这样的尝试。对于很多机构来说,让运维团队能够像他们的开发同行一样熟练操作 CI/CD 工具,已经变得十分必要了。
|
||||
虽然持续集成、持续交付和持续部署(CI/CD)在开发者社区里已经存在很多年,一些机构在其运维部门也有实施经验,但大多数公司并没有做这样的尝试。对于很多机构来说,让运维团队能够像他们的开发同行一样熟练操作 CI/CD 工具,已经变得十分必要了。
|
||||
|
||||
无论是基础设施、第三方应用还是内部开发的应用,都可以开展 CI/CD 实践。尽管你会发现有很多不同的工具,但它们都有着相似的设计模型。而且可能最重要的一点是:通过带领你的公司进行这些实践,会让你在公司内部变得举足轻重,成为他人学习的榜样。
|
||||
|
||||
一些机构在自己的基础设施上已有多年的 CI/CD 实践经验,常用的工具包括 [Ansible][1]、[Chef][2] 或者 [Puppet][3]。另一些工具,比如 [Test Kitchen][4],允许在最终要部署应用的基础设施上运行测试。事实上,如果使用更高级的配置方法,你甚至可以将应用部署到有真实负载的仿真“生产环境”上,来运行应用级别的测试。然而,单单是能够测试基础设施就是一项了不起的成就了。配置管理工具 Terraform 可以通过 Test Kitchen 来快速创建[可复用][6]的基础设施配置,这比它的前辈要强不少。再加上 Linux 容器和 Kubernetes,在数小时内,你就可以创建一套类似于生产环境的配置参数和系统资源,来测试整个基础设施和其上部署的应用,这在以前可能需要花费几个月的时间。而且,删除和再次创建整个测试环境也非常容易。
|
||||
一些机构在自己的基础设施上已有多年的 CI/CD 实践经验,常用的工具包括 [Ansible][1]、[Chef][2] 或者 [Puppet][3]。另一些工具,比如 [Test Kitchen][4],允许在最终要部署应用的基础设施上运行测试。事实上,如果使用更高级的配置方法,你甚至可以将应用部署到有真实负载的仿真“生产环境”上,来运行应用级别的测试。然而,单单是能够测试基础设施就是一项了不起的成就了。配置管理工具 Terraform 可以通过 Test Kitchen 来快速创建更[短暂][5]和[冥等的][6]的基础设施配置,这比它的前辈要强不少。再加上 Linux 容器和 Kubernetes,在数小时内,你就可以创建一套类似于生产环境的配置参数和系统资源,来测试整个基础设施和其上部署的应用,这在以前可能需要花费几个月的时间。而且,删除和再次创建整个测试环境也非常容易。
|
||||
|
||||
当然,作为初学者,你也可以把网络配置和 DDL(数据定义语言)文件加入版本控制,然后开始尝试一些简单的 CI/CD 流程。虽然只能帮你检查一下语义语法,但实际上大多数用于开发的管道(pipeline)都是这样起步的。只要你把脚手架搭起来,建造就容易得多了。而一旦起步,你就会发现各种真实的使用场景。
|
||||
当然,作为初学者,你也可以把网络配置和 DDL(<ruby>数据定义语言<rt>data definition language</rt></ruby>)文件加入版本控制,然后开始尝试一些简单的 CI/CD 流程。虽然只能帮你检查一下语义语法或某些最佳实践,但实际上大多数开发的管道都是这样起步的。只要你把脚手架搭起来,建造就容易得多了。而一旦起步,你就会发现各种管道的使用场景。
|
||||
|
||||
举个例子,我经常会在公司内部写新闻简报,我使用 [MJML][7] 制作邮件模板,然后把它加入版本控制。我一般会维护一个 web 版本,但是一些同事喜欢 PDF 版,于是我创建了一个[管道][8]。每当我写好一篇新闻稿,就在 Gitlab 上提交一个合并请求。这样做会自动创建一个 index.html 文件,生成这篇新闻稿的 HTML 和 PDF 版链接。HTML 和 PDF 文件也会在管道里同时生成。除非有人来检查确认,这些文件不会被直接发布出去。使用 GitLab Pages 发布这个网站后,我就可以下载一份 HTML 版,用来发送新闻简报。未来,我会修改这个流程,当合并请求成功或者在某个审核步骤后,自动发出对应的新闻稿。这些处理逻辑并不复杂,但的确为我节省了不少时间。实际上这些工具最核心的用途就是替你节省时间。
|
||||
举个例子,我经常会在公司内部写新闻简报,我使用 [MJML][7] 制作邮件模板,然后把它加入版本控制。我一般会维护一个 web 版本,但是一些同事喜欢 PDF 版,于是我创建了一个[管道][8]。每当我写好一篇新闻稿,就在 Gitlab 上提交一个合并请求。这样做会自动创建一个 index.html 文件,生成这篇新闻稿的 HTML 和 PDF 版链接。HTML 和 PDF 文件也会在该管道里同时生成。除非有人来检查确认,这些文件不会被直接发布出去。使用 GitLab Pages 发布这个网站后,我就可以下载一份 HTML 版,用来发送新闻简报。未来,我会修改这个流程,当合并请求成功或者在某个审核步骤后,自动发出对应的新闻稿。这些处理逻辑并不复杂,但的确为我节省了不少时间。实际上这些工具最核心的用途就是替你节省时间。
|
||||
|
||||
关键是要在抽象层创建出工具,这样稍加修改就可以处理不同的问题。值得留意的是,我创建的这套流程几乎不需要任何代码,除了一些[轻量级的 HTML 模板][9],一些[把 HTML 文件转换成 PDF 的 nodejs 代码][10],还有一些[生成 index 页面的 nodejs 代码][11]。
|
||||
关键是要在抽象层创建出工具,这样稍加修改就可以处理不同的问题。值得留意的是,我创建的这套流程几乎不需要任何代码,除了一些[轻量级的 HTML 模板][9],一些[把 HTML 文件转换成 PDF 的 nodejs 代码][10],还有一些[生成索引页面的 nodejs 代码][11]。
|
||||
|
||||
这其中一些东西可能看起来有点复杂,但其中大部分都源自我使用的不同工具的教学文档。而且很多开发人员也会乐意跟你合作,因为他们在完工时会发现这些东西也挺有用。上面我提供的那些代码链接是给 [DevOps KC][12](一个地方性DevOps组织) 发送新闻简报用的,其中大部分用来创建网站的代码来自我在内部新闻简报项目上所作的工作。
|
||||
这其中一些东西可能看起来有点复杂,但其中大部分都源自我使用的不同工具的教学文档。而且很多开发人员也会乐意跟你合作,因为他们在完工时会发现这些东西也挺有用。上面我提供的那些代码链接是给 [DevOps KC][12](LCTT 译注:一个地方性 DevOps 组织) 发送新闻简报用的,其中大部分用来创建网站的代码来自我在内部新闻简报项目上所作的工作。
|
||||
|
||||
下面列出的大多数工具都可以提供这种类型的交互,但是有些工具提供的模型略有不同。这一领域新兴的模型是用声明式的方法例如 YAML 来描述一个管道,其中的每个阶段都是短暂而幂等的。许多系统还会创建[有向无环图(DAG)][13],来确保管道上不同的阶段排序的正确性。
|
||||
|
||||
这些阶段一般运行在 Linux 容器里,和普通的容器并没有区别。有一些工具,比如 [Spinnaker][14],只关注部署组件,而且提供一些其他工具没有的操作特性。[Jenkins][15] 则通常把管道配置存成 XML 格式,大部分交互都可以在图形界面里完成,但最新的方案是使用[领域专用语言(DSL)][16]如[Groovy][17]。并且,Jenkins 的任务(job)通常运行在各个节点里,这些节点上会装一个专门的 Java 程序还有一堆混杂的插件和预装组件。
|
||||
这些阶段一般运行在 Linux 容器里,和普通的容器并没有区别。有一些工具,比如 [Spinnaker][14],只关注部署组件,而且提供一些其他工具没有的操作特性。[Jenkins][15] 则通常把管道配置存成 XML 格式,大部分交互都可以在图形界面里完成,但最新的方案是使用[领域专用语言(DSL)][16](如 [Groovy][17])。并且,Jenkins 的任务(job)通常运行在各个节点里,这些节点上会装一个专门的 Java 代理,还有一堆混杂的插件和预装组件。
|
||||
|
||||
Jenkins 在自己的工具里引入了管道的概念,但使用起来却并不轻松,甚至包含一些禁区。最近,Jenkins 的创始人决定带领社区向新的方向前进,希望能为这个项目注入新的活力,把 CI/CD 真正推广开(译者注:详见后面的 Jenkins 章节)。我认为其中最有意思的想法是构建一个云原生 Jenkins,能把 Kubernetes 集群转变成 Jenkins CI/CD 平台。
|
||||
Jenkins 在自己的工具里引入了管道的概念,但使用起来却并不轻松,甚至包含一些禁区。最近,Jenkins 的创始人决定带领社区向新的方向前进,希望能为这个项目注入新的活力,把 CI/CD 真正推广开(LCTT 译注:详见后面的 Jenkins 章节)。我认为其中最有意思的想法是构建一个云原生 Jenkins,能把 Kubernetes 集群转变成 Jenkins CI/CD 平台。
|
||||
|
||||
当你更多地了解这些工具并把实践带入你的公司和运维部门,你很快就会有追随者,因为你有办法提升自己和别人的工作效率。我们都有多年积累下来的技术债要解决,如果你能给同事们提供足够的时间来处理这些积压的工作,他们该会有多感激呢?不止如此,你的客户也会开始看到应用变得越来越稳定,管理层会把你看作得力干将,你也会在下次谈薪资待遇或参加面试时更有底气。
|
||||
|
||||
@ -38,49 +40,79 @@ Jenkins 在自己的工具里引入了管道的概念,但使用起来却并不
|
||||
|
||||
### GitLab CI
|
||||
|
||||
GitLab 可以说是 CI/CD 领域里新登场的玩家,但它却在 [Forrester(一个权威调研机构) 的调查报告][20]中位列第一。在一个高水平、竞争充分的领域里,这是个了不起的成就。是什么让 GitLab CI 这么成功呢?它使用 YAML 文件来描述整个管道。另有一个功能叫做 Auto DevOps,可以为较简单的项目自动生成管道,并且包含多种内置的测试单元。这套系统使用 [Herokuish buildpacks][21]来判断语言的种类以及如何构建应用。它和 Kubernetes 紧密整合,可以根据不同的方案将你的应用自动部署到 Kubernetes 集群,比如灰度发布、蓝绿部署等。
|
||||
- [项目主页](https://about.gitlab.com/product/continuous-integration/)
|
||||
- [源代码](https://gitlab.com/gitlab-org/gitlab-ce/)
|
||||
- 许可证:MIT
|
||||
|
||||
除了它的持续集成功能,GitLab 还提供了许多补充特性,比如:将 Prometheus 和你的应用一同部署,以提供监控功能;通过 GitLab 提供的 Issues、Epics 和 Milestones 功能来实现项目评估和管理;管道中集成了安全检测功能,多个项目的检测结果会聚合显示;你可以通过 GitLab 提供的网页版 IDE 在线编辑代码,还可以快速查看管道的预览或执行状态。
|
||||
GitLab 可以说是 CI/CD 领域里新登场的玩家,但它却在权威调研机构 [Forrester 的 CI 集成工具的调查报告][20]中位列第一。在一个高水平、竞争充分的领域里,这是个了不起的成就。是什么让 GitLab CI 这么成功呢?它使用 YAML 文件来描述整个管道。另有一个功能叫做 Auto DevOps,可以为较简单的项目用多种内置的测试单元自动生成管道。这套系统使用 [Herokuish buildpacks][21] 来判断语言的种类以及如何构建应用。有些语言也可以管理数据库,它真正改变了构建新应用程序和从开发的开始将它们部署到生产环境的过程。它原生集成于 Kubernetes,可以根据不同的方案将你的应用自动部署到 Kubernetes 集群,比如灰度发布、蓝绿部署等。
|
||||
|
||||
除了它的持续集成功能,GitLab 还提供了许多补充特性,比如:将 Prometheus 和你的应用一同部署,以提供操作监控功能;通过 GitLab 提供的 Issues、Epics 和 Milestones 功能来实现项目评估和管理;管道中集成了安全检测功能,多个项目的检测结果会聚合显示;你可以通过 GitLab 提供的网页版 IDE 在线编辑代码,还可以快速查看管道的预览或执行状态。
|
||||
|
||||
### GoCD
|
||||
|
||||
- [项目主页](https://www.gocd.org/)
|
||||
- [源代码](https://github.com/gocd/gocd)
|
||||
- 许可证:Apache 2.0
|
||||
|
||||
GoCD 是由老牌软件公司 Thoughtworks 出品,这已经足够证明它的能力和效率。对我而言,GoCD 最具亮点的特性是它的[价值流视图(VSM)][22]。实际上,一个管道的输出可以变成下一个管道的输入,从而把管道串联起来。这样做有助于提高不同开发团队在整个开发流程中的独立性。比如在引入 CI/CD 系统时,有些成立较久的机构希望保持他们各个团队相互隔离,这时候 VSM 就很有用了:让每个人都使用相同的工具就很容易在 VSM 中发现工作流程上的瓶颈,然后可以按图索骥调整团队或者想办法提高工作效率。
|
||||
|
||||
为公司的每个产品配置 VSM 是非常有价值的;GoCD 可以使用 [JSON 或 YAML 格式存储配置][23],还能以可视化的方式展示等待时间,这让一个机构能有效减少学习它的成本。刚开始使用 GoCD 创建你自己的流程时,建议使用人工审核的方式。让每个团队也采用人工审核,这样你就可以开始收集数据并且找到可能的瓶颈点。
|
||||
为公司的每个产品配置 VSM 是非常有价值的;GoCD 可以使用 [JSON 或 YAML 格式存储配置][23],还能以可视化的方式展示数据等待时间,这让一个机构能有效减少学习它的成本。刚开始使用 GoCD 创建你自己的流程时,建议使用人工审核的方式。让每个团队也采用人工审核,这样你就可以开始收集数据并且找到可能的瓶颈点。
|
||||
|
||||
### Travis CI
|
||||
|
||||
- [项目主页](https://docs.travis-ci.com/)
|
||||
- [源代码](https://github.com/travis-ci/travis-ci)
|
||||
- 许可证:MIT
|
||||
|
||||
我使用的第一个软件既服务(SaaS)类型的 CI 系统就是 Travis CI,体验很不错。管道配置以源码形式用 YAML 保存,它与 GitHub 等工具无缝整合。我印象中管道从来没有失效过,因为 Travis CI 的在线率很高。除了 SaaS 版之外,你也可以使用自行部署的版本。我还没有自行部署过,它的组件非常多,要全部安装的话,工作量就有点吓人了。我猜更简单的办法是把它部署到 Kubernetes 上,[Travis CI 提供了 Helm charts][26],这些 charts 目前不包含所有要部署的组件,但我相信以后会越来越丰富的。如果你不想处理这些细枝末节的问题,还有一个企业版可以试试。
|
||||
|
||||
假如你在开发一个开源项目,你就能免费使用 SaaS 版的 Travis CI,享受顶尖团队提供的优质服务!这样能省去很多麻烦,你可以在一个相对通用的平台上(如 GitHub)研发开源项目,而不用找服务器来运行任何东西。
|
||||
|
||||
### Jenkins
|
||||
|
||||
Jenkins在 CI/CD 界绝对是元老级的存在,也是事实上的标准。我强烈建议你读一读这篇文章:"[Jenkins: Shifting Gears][27]",作者 Kohsuke 是 Jenkins 的创始人兼 CloudBees 公司 CTO。这篇文章契合了我在过去十年里对 Jenkins 及其社区的感受。他在文中阐述了一些这几年呼声很高的需求,我很乐意看到 CloudBees 引领这场变革。长期以来,Jenkins 对于非开发人员来说有点难以接受,并且一直是其管理员的重担。还好,这些问题正是他们想要着手解决的。
|
||||
- [项目主页](https://jenkins.io/)
|
||||
- [源代码](https://github.com/jenkinsci/jenkins)
|
||||
- 许可证:MIT
|
||||
|
||||
Jenkins 在 CI/CD 界绝对是元老级的存在,也是事实上的标准。我强烈建议你读一读这篇文章:“[Jenkins: Shifting Gears][27]”,作者 Kohsuke 是 Jenkins 的创始人兼 CloudBees 公司 CTO。这篇文章契合了我在过去十年里对 Jenkins 及其社区的感受。他在文中阐述了一些这几年呼声很高的需求,我很乐意看到 CloudBees 引领这场变革。长期以来,Jenkins 对于非开发人员来说有点难以接受,并且一直是其管理员的重担。还好,这些问题正是他们想要着手解决的。
|
||||
|
||||
[Jenkins 配置既代码][28](JCasC)应该可以帮助管理员解决困扰了他们多年的配置复杂性问题。与其他 CI/CD 系统类似,只需要修改一个简单的 YAML 文件就可以完成 Jenkins 主节点的配置工作。[Jenkins Evergreen][29] 的出现让配置工作变得更加轻松,它提供了很多预设的使用场景,你只管套用就可以了。这些发行版会比官方的标准版本 Jenkins 更容易维护和升级。
|
||||
|
||||
Jenkins 2 引入了两种原生的管道(pipeline)功能,我在 LISA(一个系统架构和运维大会) 2017 年的研讨会上已经[讨论过了][30]。这两种功能都没有 YAML 简便,但在处理复杂任务时它们很好用。
|
||||
Jenkins 2 引入了两种原生的管道功能,我在 LISA(LCTT 译注:一个系统架构和运维大会) 2017 年的研讨会上已经[讨论过了][30]。这两种功能都没有 YAML 简便,但在处理复杂任务时它们很好用。
|
||||
|
||||
[Jenkins X][31] 是 Jenkins 的一个全新变种,用来实现云端原生 Jenkins(至少在用户看来是这样)。它会使用 JCasC 及 Evergreen,并且和 Kubernetes 整合的更加紧密。对于 Jenkins 来说这是个令人激动的时刻,我很乐意看到它在这一领域的创新,并且继续发挥领袖作用。
|
||||
|
||||
### Concourse CI
|
||||
|
||||
- [项目主页](https://concourse-ci.org/)
|
||||
- [源代码](https://github.com/concourse/concourse)
|
||||
- 许可证:Apache 2.0
|
||||
|
||||
我第一次知道 Concourse 是通过 Pivotal Labs 的伙计们介绍的,当时它处于早期 beta 版本,而且那时候也很少有类似的工具。这套系统是基于微服务构建的,每个任务运行在一个容器里。它独有的一个优良特性是能够在你本地系统上运行任务,体现你本地的改动。这意味着你完全可以在本地开发(假设你已经连接到了 Concourse 的服务器),像在真实的管道构建流程一样从你本地构建项目。而且,你可以在修改过代码后从本地直接重新运行构建,来检验你的改动结果。
|
||||
|
||||
Concourse 还有一个简单的扩展系统,它依赖于资源这一基础概念。基本上,你想给管道添加的每个新功能都可以用一个 Docker 镜像实现,并作为一个新的资源类型包含在你的配置中。这样可以保证每个功能都被封装在一个不易改变的独立工件中,方便对其单独修改和升级,改变其中一个时不会影响其他构建。
|
||||
Concourse 还有一个简单的扩展系统,它依赖于“资源”这一基础概念。基本上,你想给管道添加的每个新功能都可以用一个 Docker 镜像实现,并作为一个新的资源类型包含在你的配置中。这样可以保证每个功能都被封装在一个不可变的独立工件中,方便对其单独修改和升级,改变其中一个时不会影响其他构建。
|
||||
|
||||
### Spinnaker
|
||||
|
||||
Spinnaker 出自 Netflix,它更关注持续部署而非持续集成。它可以与其他工具整合,比如Travis 和 Jenkins,来启动测试和部署流程。它也能与 Prometheus、Datadog 这样的监控工具集成,参考它们提供的指标来决定如何部署。例如,在一次金丝雀发布(canary deployment)里,我们可以根据收集到的相关监控指标来做出判断:最近的这次发布是否导致了服务降级,应该立刻回滚;还是说看起来一切OK,应该继续执行部署。
|
||||
- [项目主页](https://www.spinnaker.io/)
|
||||
- [源代码](https://github.com/spinnaker/spinnaker)
|
||||
- 许可证:Apache 2.0
|
||||
|
||||
Spinnaker 出自 Netflix,它更关注持续部署而非持续集成。它可以与其他工具整合,比如 Travis 和 Jenkins,来启动测试和部署流程。它也能与 Prometheus、Datadog 这样的监控工具集成,参考它们提供的指标来决定如何部署。例如,在<ruby>金丝雀发布<rt>canary deployment</rt></ruby>里,我们可以根据收集到的相关监控指标来做出判断:最近的这次发布是否导致了服务降级,应该立刻回滚;还是说看起来一切 OK,应该继续执行部署。
|
||||
|
||||
谈到持续部署,一些另类但却至关重要的问题往往被忽略掉了,说出来可能有点让人困惑:Spinnaker 可以帮助持续部署不那么“持续”。在整个应用部署流程期间,如果发生了重大问题,它可以让流程停止执行,以阻止可能发生的部署错误。但它也可以在最关键的时刻让人工审核强制通过,发布新版本上线,使整体收益最大化。实际上,CI/CD 的主要目的就是在商业模式需要调整时,能够让待更新的代码立即得到部署。
|
||||
|
||||
### Screwdriver
|
||||
|
||||
Screwdriver 是个简单而又强大的软件。它采用微服务架构,依赖像 Nomad、Kubernetes 和 Docker 这样的工具作为执行引擎。官方有一篇很不错的[部署教学文档][34],介绍了如何将它部署到 AWS 和 Kubernetes 上,但如果相应的 [Helm chart][35] 也完成的话,就更完美了。
|
||||
- [项目主页](http://screwdriver.cd/)
|
||||
- [源代码](https://github.com/screwdriver-cd/screwdriver)
|
||||
- 许可证:BSD
|
||||
|
||||
Screwdriver 也使用 YAML 来描述它的管道,并且有很多合理的默认值,这样可以有效减少各个管道重复的配置项。用配置文件可以组织起高级的工作流,来描述各个 job 间复杂的依赖关系。例如,一项任务可以在另一个任务开始前或结束后运行;各个任务可以并行也可以串行执行;更赞的是你可以预先定义一项任务,只在特定的 pull request 请求时被触发,而且与之有依赖关系的任务并不会被执行,这能让你的管道具有一定的隔离性:什么时候被构造的工件应该被部署到生产环境,什么时候应该被审核。
|
||||
Screwdriver 是个简单而又强大的软件。它采用微服务架构,依赖像 Nomad、Kubernetes 和 Docker 这样的工具作为执行引擎。官方有一篇很不错的[部署教学文档][34],介绍了如何将它部署到 AWS 和 Kubernetes 上,但如果正在开发中的 [Helm chart][35] 也完成的话,就更完美了。
|
||||
|
||||
Screwdriver 也使用 YAML 来描述它的管道,并且有很多合理的默认值,这样可以有效减少各个管道重复的配置项。用配置文件可以组织起高级的工作流,来描述各个任务间复杂的依赖关系。例如,一项任务可以在另一个任务开始前或结束后运行;各个任务可以并行也可以串行执行;更赞的是你可以预先定义一项任务,只在特定的拉取请求时被触发,而且与之有依赖关系的任务并不会被执行,这能让你的管道具有一定的隔离性:什么时候被构造的工件应该被部署到生产环境,什么时候应该被审核。
|
||||
|
||||
---
|
||||
|
||||
以上只是我对这些 CI/CD 工具的简单介绍,它们还有许多很酷的特性等待你深入探索。而且它们都是开源软件,可以自由使用,去部署一下看看吧,究竟哪个才是最适合你的那个。
|
||||
|
||||
@ -91,7 +123,7 @@ via: https://opensource.com/article/18/12/cicd-tools-sysadmins
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[jdh8383](https://github.com/jdh8383)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,110 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10602-1.html)
|
||||
[#]: subject: (Midori: A Lightweight Open Source Web Browser)
|
||||
[#]: via: (https://itsfoss.com/midori-browser)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Midori:轻量级开源 Web 浏览器
|
||||
======
|
||||
|
||||
> 这是一个对再次回归的轻量级、快速、开源的 Web 浏览器 Midori 的快速回顾。
|
||||
|
||||
如果你正在寻找一款轻量级[网络浏览器替代品][1],请试试 Midori。
|
||||
|
||||
[Midori][2]是一款开源的网络浏览器,它更注重轻量级而不是提供大量功能。
|
||||
|
||||
如果你从未听说过 Midori,你可能会认为它是一个新的应用程序,但实际上 Midori 首次发布于 2007 年。
|
||||
|
||||
因为它专注于速度,所以 Midori 很快就聚集了一群爱好者,并成为了 Bodhi Linux、SilTaz 等轻量级 Linux 发行版的默认浏览器。
|
||||
|
||||
其他发行版如 [elementary OS][3] 也使用了 Midori 作为其默认浏览器。但 Midori 的开发在 2016 年左右停滞了,它的粉丝开始怀疑 Midori 已经死了。由于这个原因,elementary OS 从最新版本中删除了它。
|
||||
|
||||
好消息是 Midori 还没有死。经过近两年的不活跃,开发工作在 2018 年的最后一个季度恢复了。在后来的版本中添加了一些包括广告拦截器的扩展。
|
||||
|
||||
### Midori 网络浏览器的功能
|
||||
|
||||
![Midori web browser][4]
|
||||
|
||||
以下是 Midori 浏览器的一些主要功能
|
||||
|
||||
* 使用 Vala 编写,使用 GTK+3 和 WebKit 渲染引擎。
|
||||
* 标签、窗口和会话管理。
|
||||
* 快速拨号。
|
||||
* 默认保存下一个会话的选项卡。
|
||||
* 使用 DuckDuckGo 作为默认搜索引擎。可以更改为 Google 或 Yahoo。
|
||||
* 书签管理。
|
||||
* 可定制和可扩展的界面。
|
||||
* 扩展模块可以用 C 和 Vala 编写。
|
||||
* 支持 HTML5。
|
||||
* 少量的扩展程序包括广告拦截器、彩色标签等。没有第三方扩展程序。
|
||||
* 表单历史。
|
||||
* 隐私浏览。
|
||||
* 可用于 Linux 和 Windows。
|
||||
|
||||
小知识:Midori 是日语单词,意思是绿色。如果你因此而猜想的话,但 Midori 的开发者实际不是日本人。
|
||||
|
||||
### 体验 Midori
|
||||
|
||||
![Midori web browser in Ubuntu 18.04][5]
|
||||
|
||||
这几天我一直在使用 Midori。体验基本很好。它支持 HTML5 并能快速渲染网站。广告拦截器也没问题。正如你对任何标准 Web 浏览器所期望的那样,浏览体验挺顺滑。
|
||||
|
||||
缺少扩展一直是 Midori 的弱点,所以我不打算谈论这个。
|
||||
|
||||
我注意到的是它不支持国际语言。我找不到添加新语言支持的方法。它根本无法渲染印地语字体,我猜对其他非[罗曼语言][6]也是一样。
|
||||
|
||||
我也在 YouTube 中也遇到了麻烦。有些视频会抛出播放错误而其他视频没问题。
|
||||
|
||||
Midori 没有像 Chrome 那样吃我的内存,所以这是一个很大的优势。
|
||||
|
||||
如果你想尝试 Midori,让我们看下你该如何安装。
|
||||
|
||||
### 在 Linux 上安装 Midori
|
||||
|
||||
在 Ubuntu 18.04 仓库中不再提供 Midori。但是,可以使用 [Snap 包][7]轻松安装较新版本的 Midori。
|
||||
|
||||
如果你使用的是 Ubuntu,你可以在软件中心找到 Midori(Snap 版)并从那里安装。
|
||||
|
||||
![Midori browser is available in Ubuntu Software Center][8]
|
||||
|
||||
对于其他 Linux 发行版,请确保你[已启用 Snap 支持][9],然后你可以使用以下命令安装 Midori:
|
||||
|
||||
```
|
||||
sudo snap install midori
|
||||
```
|
||||
|
||||
你可以选择从源代码编译。你可以从 Midori 的网站下载它的代码。
|
||||
|
||||
- [下载 Midori](https://www.midori-browser.org/download/)
|
||||
|
||||
如果你喜欢 Midori 并希望帮助这个开源项目,请向他们捐赠或[从他们的商店购买 Midori 商品][10]。
|
||||
|
||||
你在使用 Midori 还是曾经用过么?你的体验如何?你更喜欢使用哪种其他网络浏览器?请在下面的评论栏分享你的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/midori-browser
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/open-source-browsers-linux/
|
||||
[2]: https://www.midori-browser.org/
|
||||
[3]: https://itsfoss.com/elementary-os-juno-features/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Midori-web-browser.jpeg?resize=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/midori-browser-linux.jpeg?resize=800%2C491&ssl=1
|
||||
[6]: https://en.wikipedia.org/wiki/Romance_languages
|
||||
[7]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/midori-ubuntu-software-center.jpeg?ssl=1
|
||||
[9]: https://itsfoss.com/install-snap-linux/
|
||||
[10]: https://www.midori-browser.org/shop
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Midori-web-browser.jpeg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (leommxj)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10592-1.html)
|
||||
[#]: subject: (How ASLR protects Linux systems from buffer overflow attacks)
|
||||
[#]: via: (https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
ASLR 是如何保护 Linux 系统免受缓冲区溢出攻击的
|
||||
======
|
||||
|
||||
> 地址空间随机化(ASLR)是一种内存攻击缓解技术,可以用于 Linux 和 Windows 系统。了解一下如何运行它、启用/禁用它,以及它是如何工作的。
|
||||
|
||||

|
||||
|
||||
<ruby>地址空间随机化<rt>Address Space Layout Randomization</rt></ruby>(ASLR)是一种操作系统用来抵御缓冲区溢出攻击的内存保护机制。这种技术使得系统上运行的进程的内存地址无法被预测,使得与这些进程有关的漏洞变得更加难以利用。
|
||||
|
||||
ASLR 目前在 Linux、Windows 以及 MacOS 系统上都有使用。其最早出现在 2005 的 Linux 系统上。2007 年,这项技术被 Windows 和 MacOS 部署使用。尽管 ASLR 在各个系统上都提供相同的功能,却有着不同的实现。
|
||||
|
||||
ASLR 的有效性依赖于整个地址空间布局是否对于攻击者保持未知。此外,只有编译时作为<ruby>位置无关可执行文件<rt>Position Independent Executable</rt></ruby>(PIE)的可执行程序才能得到 ASLR 技术的最大保护,因为只有这样,可执行文件的所有代码节区才会被加载在随机地址。PIE 机器码不管绝对地址是多少都可以正确执行。
|
||||
|
||||
### ASLR 的局限性
|
||||
|
||||
尽管 ASLR 使得对系统漏洞的利用更加困难了,但其保护系统的能力是有限的。理解关于 ASLR 的以下几点是很重要的:
|
||||
|
||||
* 它不能*解决*漏洞,而是增加利用漏洞的难度
|
||||
* 并不追踪或报告漏洞
|
||||
* 不能对编译时没有开启 ASLR 支持的二进制文件提供保护
|
||||
* 不能避免被绕过
|
||||
|
||||
### ASLR 是如何工作的
|
||||
|
||||
通过对攻击者在进行缓冲区溢出攻击时所要用到的内存布局中的偏移做了随机化,ASLR 加大了攻击成功的难度,从而增强了系统的控制流完整性。
|
||||
|
||||
通常认为 ASLR 在 64 位系统上效果更好,因为 64 位系统提供了更大的熵(可随机的地址范围)。
|
||||
|
||||
### ASLR 是否正在你的 Linux 系统上运行?
|
||||
|
||||
下面展示的两条命令都可以告诉你的系统是否启用了 ASLR 功能:
|
||||
|
||||
```
|
||||
$ cat /proc/sys/kernel/randomize_va_space
|
||||
2
|
||||
$ sysctl -a --pattern randomize
|
||||
kernel.randomize_va_space = 2
|
||||
```
|
||||
|
||||
上方指令结果中的数值(`2`)表示 ASLR 工作在全随机化模式。其可能为下面的几个数值之一:
|
||||
|
||||
```
|
||||
0 = Disabled
|
||||
1 = Conservative Randomization
|
||||
2 = Full Randomization
|
||||
```
|
||||
|
||||
如果你关闭了 ASLR 并且执行下面的指令,你将会注意到前后两条 `ldd` 的输出是完全一样的。`ldd` 命令会加载共享对象并显示它们在内存中的地址。
|
||||
|
||||
```
|
||||
$ sudo sysctl -w kernel.randomize_va_space=0 <== disable
|
||||
[sudo] password for shs:
|
||||
kernel.randomize_va_space = 0
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
|
||||
```
|
||||
|
||||
如果将其重新设置为 `2` 来启用 ASLR,你将会看到每次运行 `ldd`,得到的内存地址都不相同。
|
||||
|
||||
```
|
||||
$ sudo sysctl -w kernel.randomize_va_space=2 <== enable
|
||||
[sudo] password for shs:
|
||||
kernel.randomize_va_space = 2
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007fff47d0e000) <== first set of addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007f1cb7ce0000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f1cb7cda000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1cb7af0000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007f1cb8045000)
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffe1cbd7000) <== second set of addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007fed59742000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fed5973c000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fed59552000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007fed59aa7000)
|
||||
```
|
||||
|
||||
### 尝试绕过 ASLR
|
||||
|
||||
尽管这项技术有很多优点,但绕过 ASLR 的攻击并不罕见,主要有以下几类:
|
||||
|
||||
* 利用地址泄露
|
||||
* 访问与特定地址关联的数据
|
||||
* 针对 ASLR 实现的缺陷来猜测地址,常见于系统熵过低或 ASLR 实现不完善。
|
||||
* 利用侧信道攻击
|
||||
|
||||
### 总结
|
||||
|
||||
ASLR 有很大的价值,尤其是在 64 位系统上运行并被正确实现时。虽然不能避免被绕过,但这项技术的确使得利用系统漏洞变得更加困难了。这份参考资料可以提供 [在 64 位 Linux 系统上的完全 ASLR 的有效性][2] 的更多有关细节,这篇论文介绍了一种利用分支预测 [绕过 ASLR][3] 的技术。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[leommxj](https://github.com/leommxj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[2]: https://cybersecurity.upv.es/attacks/offset2lib/offset2lib-paper.pdf
|
||||
[3]: http://www.cs.ucr.edu/~nael/pubs/micro16.pdf
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -1,25 +1,23 @@
|
||||
[#]:collector:(lujun9972)
|
||||
[#]:translator:(lujun9972)
|
||||
[#]:reviewer:( )
|
||||
[#]:publisher:( )
|
||||
[#]:url:( )
|
||||
[#]:subject:(Configure Anaconda on Emacs – iD)
|
||||
[#]:via:(https://idevji.com/configure-anaconda-on-emacs/)
|
||||
[#]:author:(Devji Chhanga https://idevji.com/author/admin/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10604-1.html)
|
||||
[#]: subject: (Configure Anaconda on Emacs – iD)
|
||||
[#]: via: (https://idevji.com/configure-anaconda-on-emacs/)
|
||||
[#]: author: (Devji Chhanga https://idevji.com/author/admin/)
|
||||
|
||||
在 Emacs 上配置 Anaconda
|
||||
======
|
||||
|
||||
也许我所最求的究极 IDE 就是 [Emacs][1] 了。我的目标是使 Emacs 成为一款全能的 Python IDE。本文描述了如何在 Emacs 上配置 Anaconda。
|
||||
也许我所追求的究极 IDE 就是 [Emacs][1] 了。我的目标是使 Emacs 成为一款全能的 Python IDE。本文描述了如何在 Emacs 上配置 Anaconda。(LCTT 译注:Anaconda 自称“世界上最流行的 Python/R 的数据分析平台”)
|
||||
|
||||
我的配置信息:
|
||||
|
||||
```
|
||||
OS: Trisquel 8.0
|
||||
Emacs: GNU Emacs 25.3.2
|
||||
```
|
||||
- OS:Trisquel 8.0
|
||||
- Emacs:GNU Emacs 25.3.2
|
||||
|
||||
快捷键说明 [(参见完全指南 )][2]:
|
||||
快捷键说明([参见完全指南][2]):
|
||||
|
||||
```
|
||||
C-x = Ctrl + x
|
||||
@ -27,25 +25,26 @@ M-x = Alt + x
|
||||
RET = ENTER
|
||||
```
|
||||
|
||||
### 1。下载并安装 Anaconda
|
||||
### 1、下载并安装 Anaconda
|
||||
|
||||
#### 1.1 下载:
|
||||
[从这儿 ][3] 下载 Anaconda。你应该下载 Python 3.x 版本因为 Python 2 在 2020 年就不再支持了。你无需预先安装 Python 3.x。安装脚本会自动进行安装。
|
||||
#### 1.1 下载
|
||||
|
||||
#### 1.2 安装:
|
||||
[从这儿][3] 下载 Anaconda。你应该下载 Python 3.x 的版本,因为 Python 2 在 2020 年就不再支持了。你无需预先安装 Python 3.x。这个安装脚本会自动安装它。
|
||||
|
||||
#### 1.2 安装
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
cd ~/Downloads
|
||||
bash Anaconda3-2018.12-Linux-x86.sh
|
||||
```
|
||||
|
||||
|
||||
### 2。将 Anaconda 添加到 Emacs
|
||||
### 2、将 Anaconda 添加到 Emacs
|
||||
|
||||
#### 2.1 将 MELPA 添加到 Emacs
|
||||
我们需要用到 _anaconda-mode_ 这个 Emacs 包。该包位于 MELPA 仓库中。Emacs25 需要手工添加该仓库。
|
||||
|
||||
[注意:点击本文查看如何将 MELPA 添加到 Emacs。][4]
|
||||
我们需要用到 `anaconda-mode` 这个 Emacs 包。该包位于 MELPA 仓库中。Emacs25 需要手工添加该仓库。
|
||||
|
||||
- [注意:点击本文查看如何将 MELPA 添加到 Emacs][4]
|
||||
|
||||
#### 2.2 为 Emacs 安装 anaconda-mode 包
|
||||
|
||||
@ -60,8 +59,7 @@ anaconda-mode RET
|
||||
echo "(add-hook 'python-mode-hook 'anaconda-mode)" > ~/.emacs.d/init.el
|
||||
```
|
||||
|
||||
|
||||
### 3。在 Emacs 上通过 Anaconda 运行你第一个脚本
|
||||
### 3、在 Emacs 上通过 Anaconda 运行你第一个脚本
|
||||
|
||||
#### 3.1 创建新 .py 文件
|
||||
|
||||
@ -83,7 +81,7 @@ C-c C-p
|
||||
C-c C-c
|
||||
```
|
||||
|
||||
输出为
|
||||
输出为:
|
||||
|
||||
```
|
||||
Python 3.7.1 (default, Dec 14 2018, 19:46:24)
|
||||
@ -94,8 +92,9 @@ Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>>
|
||||
```
|
||||
|
||||
我是受到 [Codingquark;][5] 的影响才开始使用 Emacs 的。
|
||||
有任何错误和遗漏请在评论中之处。干杯!
|
||||
我是受到 [Codingquark][5] 的影响才开始使用 Emacs 的。
|
||||
|
||||
有任何错误和遗漏请在评论中写下。干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -104,7 +103,7 @@ via: https://idevji.com/configure-anaconda-on-emacs/
|
||||
作者:[Devji Chhanga][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,92 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10608-1.html)
|
||||
[#]: subject: (Akira: The Linux Design Tool We’ve Always Wanted?)
|
||||
[#]: via: (https://itsfoss.com/akira-design-tool)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Akira 是我们一直想要的 Linux 设计工具吗?
|
||||
======
|
||||
|
||||
先说一下,我不是一个专业的设计师,但我在 Windows 上使用过某些工具(如 Photoshop、Illustrator 等)和 [Figma] [1](这是一个基于浏览器的界面设计工具)。我相信 Mac 和 Windows 上还有更多的设计工具。
|
||||
|
||||
即使在 Linux 上,也有数量有限的专用[图形设计工具][2]。其中一些工具如 [GIMP][3] 和 [Inkscape][4] 也被专业人士使用。但不幸的是,它们中的大多数都不被视为专业级。
|
||||
|
||||
即使有更多解决方案,我也从未遇到过可以取代 [Sketch][5]、Figma 或 Adobe XD 的原生 Linux 应用。任何专业设计师都同意这点,不是吗?
|
||||
|
||||
### Akira 是否会在 Linux 上取代 Sketch、Figma 和 Adobe XD?
|
||||
|
||||
所以,为了开发一些能够取代那些专有工具的应用,[Alessandro Castellani][6] 发起了一个 [Kickstarter 活动][7],并与几位经验丰富的开发人员 [Alberto Fanjul][8]、[Bilal Elmoussaoui][9] 和 [Felipe Escoto][10] 组队合作。
|
||||
|
||||
是的,Akira 仍然只是一个想法,只有一个界面原型(正如我最近在 Kickstarter 的[直播流][11]中看到的那样)。
|
||||
|
||||
### 如果它还不存在,为什么会发起 Kickstarter 活动?
|
||||
|
||||
![][12]
|
||||
|
||||
Kickstarter 活动的目的是收集资金,以便雇用开发人员,并花几个月的时间开发,以使 Akira 成为可能。
|
||||
|
||||
尽管如此,如果你想支持这个项目,你应该知道一些细节,对吧?
|
||||
|
||||
不用担心,我们在他们的直播中问了几个问题 - 让我们看下:
|
||||
|
||||
### Akira:更多细节
|
||||
|
||||
![Akira prototype interface][13]
|
||||
|
||||
*图片来源:Kickstarter*
|
||||
|
||||
如 Kickstarter 活动描述的那样:
|
||||
|
||||
> Akira 的主要目的是提供一个快速而直观的工具来**创建 Web 和移动端界面**,更像是 **Sketch**、**Figma** 或 **Adobe XD**,并且是 Linux 原生体验。
|
||||
|
||||
他们还详细描述了该工具与 Inkscape、Glade 或 QML Editor 的不同之处。当然,如果你想要了解所有的技术细节,请查看 [Kickstarter][7]。但是,在此之前,让我们看一看当我询问有关 Akira 的一些问题时他们说了些什么。
|
||||
|
||||
**问:**如果你认为你的项目类似于 Figma,人们为什么要考虑安装 Akira 而不是使用基于网络的工具?它是否只是这些工具的克隆 —— 提供原生 Linux 体验,还是有一些非常有趣的东西可以鼓励用户切换(除了是开源解决方案之外)?
|
||||
|
||||
**Akira:** 与基于网络的 electron 应用相比,Linux 原生体验总是更好、更快。此外,如果你选择使用 Figma,硬件配置也很重要,但 Akira 将会占用很少的系统资源,并且你可以在不需要上网的情况下完成类似工作。
|
||||
|
||||
**问:**假设它成为了 Linux 用户一直在等待的开源方案(拥有专有工具的类似功能)。你有什么维护计划?你是否计划引入定价方案,或依赖捐赠?
|
||||
|
||||
**Akira:**该项目主要依靠捐赠(类似于 [Krita 基金会][14] 这样的想法)。但是,不会有“专业版”计划,它将免费提供,它将是一个开源项目。
|
||||
|
||||
根据我得到的回答,它看起来似乎很有希望,我们应该支持。
|
||||
|
||||
- [查看该 Kickstarter 活动](https://www.kickstarter.com/projects/alecaddd/akira-the-linux-design-tool/description)
|
||||
|
||||
### 总结
|
||||
|
||||
你怎么看 Akira?它只是一个概念吗?或者你希望看到进展?
|
||||
|
||||
请在下面的评论中告诉我们你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/akira-design-tool
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.figma.com/
|
||||
[2]: https://itsfoss.com/best-linux-graphic-design-software/
|
||||
[3]: https://itsfoss.com/gimp-2-10-release/
|
||||
[4]: https://inkscape.org/
|
||||
[5]: https://www.sketchapp.com/
|
||||
[6]: https://github.com/Alecaddd
|
||||
[7]: https://www.kickstarter.com/projects/alecaddd/akira-the-linux-design-tool/description
|
||||
[8]: https://github.com/albfan
|
||||
[9]: https://github.com/bilelmoussaoui
|
||||
[10]: https://github.com/Philip-Scott
|
||||
[11]: https://live.kickstarter.com/alessandro-castellani/live-stream/the-current-state-of-akira
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/akira-design-tool-kickstarter.jpg?resize=800%2C451&ssl=1
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/akira-mockup.png?ssl=1
|
||||
[14]: https://krita.org/en/about/krita-foundation/
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/akira-design-tool-kickstarter.jpg?fit=812%2C458&ssl=1
|
||||
57
published/20190121 Booting Linux faster.md
Normal file
57
published/20190121 Booting Linux faster.md
Normal file
@ -0,0 +1,57 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (alim0x)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10607-1.html)
|
||||
[#]: subject: (Booting Linux faster)
|
||||
[#]: via: (https://opensource.com/article/19/1/booting-linux-faster)
|
||||
[#]: author: (Stewart Smith https://opensource.com/users/stewart-ibm)
|
||||
|
||||
让 Linux 启动更快
|
||||
======
|
||||
|
||||
> 进行 Linux 内核与固件开发的时候,往往需要多次的重启,会浪费大把的时间。
|
||||
|
||||

|
||||
|
||||
在所有我拥有或使用过的电脑中,启动最快的那台是 20 世纪 80 年代的电脑。在你把手从电源键移到键盘上的时候,BASIC 解释器已经在等待你输入命令了。对于现代的电脑,启动时间从笔记本电脑的 15 秒到小型家庭服务器的数分钟不等。为什么它们的启动时间有差别?
|
||||
|
||||
那台直接启动到 BASIC 命令行提示符的 20 世纪 80 年代微电脑,有着一颗非常简单的 CPU,它在通电的时候就立即开始从一个内存地址中获取和执行指令。因为这些系统的 BASIC 在 ROM 里面,基本不需要载入的时间——你很快就进到 BASIC 命令提示符中了。同时代更加复杂的系统,比如 IBM PC 或 Macintosh,需要一段可观的时间来启动(大约 30 秒),尽管这主要是因为需要从软盘上读取操作系统的缘故。在可以加载操作系统之前,只有很小一部分时间是花费在固件上的。
|
||||
|
||||
现代服务器往往在从磁盘上读取操作系统之前,在固件上花费了数分钟而不是数秒。这主要是因为现代系统日益增加的复杂性。CPU 不再能够只是运行起来就开始全速执行指令,我们已经习惯于 CPU 频率变化、节省能源的待机状态以及 CPU 多核。实际上,在现代 CPU 内部有数量惊人的更简单的处理器,它们协助主 CPU 核心启动并提供运行时服务,比如在过热的时候压制频率。在绝大多数 CPU 架构中,在你的 CPU 内的这些核心上运行的代码都以不透明的二进制 blob 形式提供。
|
||||
|
||||
在 OpenPOWER 系统上,所有运行在 CPU 内部每个核心的指令都是开源的。在有 [OpenBMC][1](比如 IBM 的 AC922 系统和 Raptor 的 TALOS II 以及 Blackbird 系统)的机器上,这还延伸到了运行在<ruby>基板管理控制器<rt>Baseboard Management Controller</rt></ruby>上的代码。这就意味着我们可以一探究竟,到底为什么从接入电源线到显示出熟悉的登录界面花了这么长时间。
|
||||
|
||||
如果你是内核相关团队的一员,你可能启动过许多内核。如果你是固件相关团队的一员,你可能要启动许多不同的固件映像,接着是一个操作系统,来确保你的固件仍能工作。如果我们可以减少硬件的启动时间,这些团队可以更有生产力,并且终端用户在搭建系统或重启安装固件或系统更新的时候会对此表示感激。
|
||||
|
||||
过去的几年,Linux 发行版的启动时间已经做了很多改善。现代的初始化系统在处理并行和按需任务上做得很好。在一个现代系统上,一旦内核开始执行,它可以在短短数秒内进入登录提示符界面。这里短短的数秒不是优化启动时间的下手之处,我们要到更早的地方:在我们到达操作系统之前。
|
||||
|
||||
在 OpenPOWER 系统上,固件通过启动一个存储在固件闪存芯片上的 Linux 内核来加载操作系统,它运行一个叫做 [Petitboot][2] 的用户态程序去寻找用户想要启动的系统所在磁盘,并通过 [kexec][3] 启动它。有了这些优化,启动 Petitboot 环境只占了启动时间的百分之几,所以我们还得从其他地方寻找优化项。
|
||||
|
||||
在 Petitboot 环境启动前,有一个先导固件,叫做 [Skiboot][4],在它之前有个 [Hostboot][5]。在 Hostboot 之前是 [Self-Boot Engine][6],一个晶圆切片(die)上的单独核心,它启动单个 CPU 核心并执行来自 Level 3 缓存的指令。这些组件是我们可以在减少启动时间上取得进展的主要部分,因为它们花费了启动的绝大部分时间。或许这些组件中的一部分没有进行足够的优化或尽可能做到并行?
|
||||
|
||||
另一个研究路径是重启时间而不是启动时间。在重启的时候,我们真的需要对所有硬件重新初始化吗?
|
||||
|
||||
正如任何现代系统那样,改善启动(或重启)时间的方案已经变成了更多的并行执行、解决遗留问题、(可以认为)作弊的结合体。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/booting-linux-faster
|
||||
|
||||
作者:[Stewart Smith][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stewart-ibm
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/OpenBMC
|
||||
[2]: https://github.com/open-power/petitboot
|
||||
[3]: https://en.wikipedia.org/wiki/Kexec
|
||||
[4]: https://github.com/open-power/skiboot
|
||||
[5]: https://github.com/open-power/hostboot
|
||||
[6]: https://github.com/open-power/sbe
|
||||
[7]: https://linux.conf.au/schedule/presentation/105/
|
||||
[8]: https://linux.conf.au/
|
||||
@ -1,21 +1,22 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10579-1.html)
|
||||
[#]: subject: (Mind map yourself using FreeMind and Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
在 Fedora 中使用 FreeMind 制作自己的思维导图
|
||||
在 Fedora 中使用 FreeMind 介绍你自己
|
||||
======
|
||||
|
||||

|
||||
|
||||
你自己的思维导图一开始听起来有些牵强。它是关于神经通路么?还是心灵感应?完全不是。相反,自己的思维导图是一种在视觉上向他人描述自己的方式。它还展示了你拿来描述的特征之间的联系。这是一种以聪明的同时可控的与他人分享信息的有用方式。你可以使用任何思维导图应用来做到。本文向你展示如何使用 Fedora 中提供的 [FreeMind][1]。
|
||||
介绍你自己的思维导图,一开始听起来有些牵强。它是关于神经通路么?还是心灵感应?完全不是。相反,自己的思维导图是一种在视觉上向他人描述自己的方式。它还展示了你拿来描述自己的特征之间的联系。这是一种以聪明又同时可控的与他人分享信息的有用方式。你可以使用任何思维导图应用来做到。本文向你展示如何使用 Fedora 中提供的 [FreeMind][1]。
|
||||
|
||||
### 获取应用
|
||||
|
||||
FreeMind 已经出现有一段时间了。虽然 UI 有点过时,你也可以使用新的,但它是一个功能强大的应用,提供了许多构建思维导图的选项。当然,它是 100% 开源的。还有其他思维导图应用可供 Fedora 和 Linux 用户使用。查看[此前一篇涵盖多个思维导图选择的文章][2]。
|
||||
FreeMind 已经出现有一段时间了。虽然 UI 有点过时,应该做一些更新了,但它是一个功能强大的应用,提供了许多构建思维导图的选项。当然,它是 100% 开源的。还有其他思维导图应用可供 Fedora 和 Linux 用户使用。查看[此前一篇涵盖多个思维导图选择的文章][2]。
|
||||
|
||||
如果你运行的是 Fedora Workstation,请使用“软件”应用从 Fedora 仓库安装 FreeMind。或者在终端中使用这个 [sudo][3] 命令:
|
||||
|
||||
@ -26,31 +27,34 @@ $ sudo dnf install freemind
|
||||
你可以从 Fedora Workstation 中的 GNOME Shell Overview 启动应用。或者使用桌面环境提供的应用启动服务。默认情况下,FreeMind 会显示一个新的空白脑图:
|
||||
|
||||
![][4]
|
||||
FreeMind 初始(空白)思维导图
|
||||
|
||||
*FreeMind 初始(空白)思维导图*
|
||||
|
||||
脑图由链接的项目或描述(节点)组成。当你想到与节点相关的内容时,只需创建一个与其连接的新节点即可。
|
||||
|
||||
###
|
||||
### 做你自己的脑图
|
||||
|
||||
单击初始节点。编辑文本并点击**回车**将其替换为你的姓名。你就能开始你的思维导图。
|
||||
单击初始节点。编辑文本并按回车将其替换为你的姓名。你就能开始你的思维导图。
|
||||
|
||||
如果你必须向某人充分描述自己,你会怎么想?可能会有很多东西。你平时做什么?你喜欢什么?你不喜欢什么?你有什么价值?你有家庭吗?所有这些都可以在节点中体现。
|
||||
|
||||
要添加节点连接,请选择现有节点,然后单击**插入**,或使用“灯泡”图标作为新的子节点。要在与新子级相同的层级添加另一个节点,请使用**回车**。
|
||||
要添加节点连接,请选择现有节点,然后单击“Insert”,或使用“灯泡”图标作为新的子节点。要在与新子级相同的层级添加另一个节点,请使用回车。
|
||||
|
||||
如果你弄错了,别担心。你可以使用 **Delete** 键删除不需要的节点。内容上没有规则。但是最好是短节点。它们能让你在创建导图时思维更快。简洁的节点还能让其他浏览者更轻松地查看和理解。
|
||||
如果你弄错了,别担心。你可以使用 `Delete` 键删除不需要的节点。内容上没有规则。但是最好是短节点。它们能让你在创建导图时思维更快。简洁的节点还能让其他浏览者更轻松地查看和理解。
|
||||
|
||||
该示例使用节点规划了每个主要类别:
|
||||
|
||||
![][5]
|
||||
个人思维导图,第一级
|
||||
|
||||
*个人思维导图,第一级*
|
||||
|
||||
你可以为这些区域中的每个区域另外迭代一次。让你的思想自由地连接想法以生成导图。不要担心“做得正确“。最好将所有内容从头脑中移到显示屏上。这是下一级导图的样子。
|
||||
|
||||
![][6]
|
||||
个人思维导图,第二级
|
||||
|
||||
你可以以相同的方式扩展任何这些节点。请注意你在示例中可以了解多少有关 John Q. Public 的信息。
|
||||
*个人思维导图,第二级*
|
||||
|
||||
你可以以相同的方式扩展任何这些节点。请注意你在示例中可以了解多少有关 “John Q. Public” 的信息。
|
||||
|
||||
### 如何使用你的个人思维导图
|
||||
|
||||
@ -59,7 +63,6 @@ FreeMind 初始(空白)思维导图
|
||||
祝你在探索个人思维导图上玩得开心!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/
|
||||
@ -67,7 +70,7 @@ via: https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,6 +3,8 @@
|
||||
|
||||
[][10]
|
||||
|
||||
(LCTT 译注:本文原文发表于 2016 年,可能有些信息已经过时。)
|
||||
|
||||
[在 Linux 平台上玩游戏][12] 并不是什么新鲜事,现在甚至有专门的 [Linux 游戏发行版][13],但是这不意味着在 Linux 上打游戏的体验和在 Windows 上一样顺畅。
|
||||
|
||||
为了确保我们和 Windows 用户同样地享受游戏乐趣,哪些问题是我们应该考虑的呢?
|
||||
@ -13,79 +15,81 @@
|
||||
|
||||
正如 [StemOS 主页][16]所说, 即便 SteamOS 是一个开源平台,但 Steam for Linux 仍然是专有的软件。如果 Steam for Linux 也开源,那么它从开源社区得到的支持将会是巨大的。既然它不是,那么 [Ascension 计划的诞生自然是不可避免的][17]:
|
||||
|
||||
[video](https://youtu.be/07UiS5iAknA)
|
||||
- [Destination: Project Ascension • UI Design Mockups Reveal](https://youtu.be/07UiS5iAknA)
|
||||
|
||||
Ascension 开源的游戏启动器,旨在能够启动从任何平台购买、下载的游戏。这些游戏可以是 Steam 平台的、[Origin 游戏][18]平台的、Uplay 平台的,以及直接从游戏开发者主页或者从 DVD、CD-ROM 下载下来的。
|
||||
Ascension 是一个开源的游戏启动器,旨在能够启动从任何平台购买、下载的游戏。这些游戏可以是 Steam 平台的、[Origin 游戏][18]平台的、Uplay 平台的,以及直接从游戏开发者主页下载的,或者来自 DVD、CD-ROM 的。
|
||||
|
||||
这是 Ascension 计划如何开始的:[头脑风暴][19]激发了一场与游戏社区读者之间有趣的讨论,在这场讨论中读者们纷纷发表了自己的观点并给出建议。
|
||||
Ascension 计划的开端是这样:[某个观点的分享][19]激发了一场与游戏社区读者之间有趣的讨论,在这场讨论中读者们纷纷发表了自己的观点并给出建议。
|
||||
|
||||
### #2 与 Windows 平台的性能比较
|
||||
|
||||
在 Linux 平台上运行 Windows 游戏并不总是一件轻松的任务。但是感谢一个叫做 [CSMT][20](多线程命令流)的特性,尽管离 Windows 级别的性能还有相当长的路要走,PlayOnLinux 现在依旧可以更好地解决这些性能方面的问题。
|
||||
在 Linux 平台上运行 Windows 游戏并不总是一件轻松的任务。但是得益于一个叫做 [CSMT][20](多线程命令流)的特性,尽管离 Windows 级别的性能还有相当长的路要走,PlayOnLinux 现在依旧可以更好地解决这些性能方面的问题。
|
||||
|
||||
Linux 对游戏的原生支持在过去发行的游戏中从未如人意。
|
||||
Linux 对游戏的原生支持在过去发行的游戏中从未尽如人意。
|
||||
|
||||
去年,有报道说 SteamOS 比 Windows 在游戏方面的表现要[差得多][21]。古墓丽影去年在 SteamOS 及 Steam for Linux 上发行,然而基准测试的结果与 Windows 上的性能无法抗衡。
|
||||
去年,有报道说 SteamOS 比 Windows 在游戏方面的表现要[差得多][21]。古墓丽影去年在 SteamOS 及 Steam for Linux 上发行,然而其基准测试的结果与 Windows 上的性能无法抗衡。
|
||||
|
||||
[视频](https://youtu.be/nkWUBRacBNE)
|
||||
- [Destination: Tomb Raider benchmark video comparison, Linux vs Windows 10](https://youtu.be/nkWUBRacBNE)
|
||||
|
||||
这明显是因为游戏是基于 [DirectX][23] 而不是 [OpenGL][24] 开发的缘故。
|
||||
|
||||
古墓丽影是[第一个使用 TressFX 的游戏][25]。这个视频包涵了 TressFX 的比较:
|
||||
古墓丽影是[第一个使用 TressFX 的游戏][25]。下面这个视频包涵了 TressFX 的比较:
|
||||
|
||||
[视频](https://youtu.be/-IeY5ZS-LlA)
|
||||
- [Destination: Tomb Raider Benchmark - Ubuntu 15.10 vs Windows 8.1 + Ubuntu 16.04 vs Windows 10](https://youtu.be/-IeY5ZS-LlA)
|
||||
|
||||
下面是另一个有趣的比较,它显示出使用 Wine + CSMT 带来的游戏性能比 Steam 上原生的 Linux 版游戏带来的游戏性能要好得多!这就是开源的力量!
|
||||
|
||||
[视频](https://youtu.be/sCJkC6oJ08A)
|
||||
- [Destination: [LinuxBenchmark] Tomb Raider Linux vs Wine comparison](https://youtu.be/sCJkC6oJ08A)
|
||||
|
||||
以防 FPS 损失,TressFX 已经被关闭。
|
||||
|
||||
以下是另一个有关在 Linux 上最新发布的 “[Life is Strange][27]” 在 Linux 与 Windows 上的比较:
|
||||
|
||||
[视频](https://youtu.be/Vlflu-pIgIY)
|
||||
- [Destination: Life is Strange on radeonsi (Linux nine_csmt vs Windows 10)](https://youtu.be/Vlflu-pIgIY)
|
||||
|
||||
[Steam for Linux][28] 开始在这个新游戏上展示出比 Windows 更好的游戏性能,这是一件好事。
|
||||
|
||||
在发布任何 Linux 版的游戏前,开发者应该考虑优化游戏,特别是基于 DirectX 并需要 OpenGL 转换的游戏。我们十分希望 Linux 上的<ruby>[杀出重围:人类分裂][29]<rt>Deus Ex: Mankind Divided on Linux</rt></ruby> 在正式发行时能有一个好的基准测试结果。由于它是基于 DirectX 的游戏,我们希望它能良好地移植到 Linux 上。以下是该[游戏执行总监不得不说的话][30]。
|
||||
在发布任何 Linux 版的游戏前,开发者都应该考虑优化游戏,特别是基于 DirectX 并需要进行 OpenGL 转制的游戏。我们十分希望 Linux 上的<ruby>[杀出重围:人类分裂][29]<rt>Deus Ex: Mankind Divided</rt></ruby> 在正式发行时能有一个好的基准测试结果。由于它是基于 DirectX 的游戏,我们希望它能良好地移植到 Linux 上。[该游戏执行总监说过这样的话][30]。
|
||||
|
||||
### #3 专有的 NVIDIA 驱动
|
||||
|
||||
相比于 [NVIDIA][32],[AMD 对于开源的支持][31]绝对是值得称赞的。尽管 [AMD][33] 因其更好的开源驱动在 Linux 上的驱动支持挺不错,而 NVIDIA 显卡用户由于开源版本的 NVIDIA 显卡驱动 “Nouveau” 有限的能力,仍不得不用专有的 NVIDIA 驱动。
|
||||
|
||||
在过去,传奇般的 Linus Torvalds 同样分享了他关于“来自 NVIDIA 的 Linux 支持完全不可接受”的想法。
|
||||
曾经,Linus Torvalds 大神也分享过他关于“来自 NVIDIA 的 Linux 支持完全不可接受”的想法。
|
||||
|
||||
[视频](https://youtu.be/O0r6Pr_mdio)
|
||||
- [Destination: Linus Torvalds Publicly Attacks NVidia for lack of Linux & Android Support](https://youtu.be/O0r6Pr_mdio)
|
||||
|
||||
你可以在这里观看完整的[谈话][35],尽管 NVIDIA 用 [承诺更好的 Linux 平台支持][36]作为回复,但其开源显卡驱动仍如之前一样毫无起色。
|
||||
你可以在这里观看完整的[谈话][35],尽管 NVIDIA 回应 [承诺更好的 Linux 平台支持][36],但其开源显卡驱动仍如之前一样毫无起色。
|
||||
|
||||
### #4 需要Linux 平台上的 Uplay 和 Origin 的 DRM 支持
|
||||
### #4 需要 Linux 平台上的 Uplay 和 Origin 的 DRM 支持
|
||||
|
||||
[视频](https://youtu.be/rc96NFwyxWU)
|
||||
- [Destination: Uplay #1 Rayman Origins em Linux - como instalar - ago 2016](https://youtu.be/rc96NFwyxWU)
|
||||
|
||||
以上的视频描述了如何在 Linux 上安装 [Uplay][37] DRM。视频上传者还建议说并不推荐使用 Wine 作为 Linux 上的主要的应用和游戏支持软件。相反,使用原生的应用更值得鼓励。
|
||||
以上的视频描述了如何在 Linux 上安装 [Uplay][37] DRM。视频上传者还建议说并不推荐使用 Wine 作为 Linux 上的主要的应用和游戏支持软件。相反,更鼓励使用原生的应用。
|
||||
|
||||
以下视频是一个关于如何在 Linux 上安装 [Origin][38] DRM 的教程。
|
||||
|
||||
[视频](https://youtu.be/ga2lNM72-Kw)
|
||||
- [Destination: Install EA Origin in Ubuntu with PlayOnLinux (Updated)](https://youtu.be/ga2lNM72-Kw)
|
||||
|
||||
数字版权管理(DRM)软件给游戏运行又加了一层阻碍,使得在 Linux 上良好运行 Windows 游戏这一本就充满挑战性的任务更有难度。因此除了使游戏能够运行之外,W.I.N.E 不得不同时负责运行像 Uplay 或 Origin 之类的 DRM 软件。如果能像 Steam 一样,Linux 也能够有自己原生版本的 Uplay 和 Origin 那就好了。
|
||||
|
||||
### #5 DirectX 11 对于 Linux 的支持
|
||||
|
||||
尽管我们在 Linux 平台上有可以运行 Windows 应用的工具,每个游戏为了能在 Linux 上运行都带有自己的配套调整需求。尽管去年通过 Code Weavers 有一篇关于 [DirectX 11 对于 Linux 的支持][40] 的公告,在 Linux 上畅玩新发大作仍是长路漫漫。现在你可以[从 Codweavers 购买 Crossover][41] 以获得可得到的最佳 DirectX 11 支持。这个在 Arch Linux 论坛上的[频道][42]清楚展现了将这个梦想成真需要多少的努力。以下是一个 [Reddit 频道][44] 上的有趣 [发现][43]。这个发现提到了[来自 Codeweavers 的 DirectX 11 补丁][45],现在看来这无疑是好消息。
|
||||
尽管我们在 Linux 平台上有可以运行 Windows 应用的工具,每个游戏为了能在 Linux 上运行都带有自己的配套调整需求。尽管去年在 Code Weavers 有一篇关于 [DirectX 11 对于 Linux 的支持][40] 的公告,在 Linux 上畅玩新发大作仍是长路漫漫。
|
||||
|
||||
### #6 100% 的 Steam 游戏不适用于 Linux
|
||||
现在你可以[从 Codweavers 购买 Crossover][41] 以获得可得到的最佳 DirectX 11 支持。这个在 Arch Linux 论坛上的[频道][42]清楚展现了将这个梦想成真需要多少的努力。以下是一个 [Reddit 频道][44] 上的有趣 [发现][43]。这个发现提到了[来自 Codeweavers 的 DirectX 11 补丁][45],现在看来这无疑是好消息。
|
||||
|
||||
随着 Linux 游戏玩家持续错过每一款主要游戏的发行,这是需要考虑的一个重点,因为大部分主要游戏都在 Windows 上发行。以下是[如何在 Linux 上安装 Windows 版的 Steam 的教程][46]。
|
||||
### #6 不是全部的 Steam 游戏都可跑在 Linux 上
|
||||
|
||||
随着 Linux 游戏玩家一次次错过主要游戏的发行,这是需要考虑的一个重点,因为大部分主要游戏都在 Windows 上发行。这是[如何在 Linux 上安装 Windows 版的 Steam 的教程][46]。
|
||||
|
||||
### #7 游戏发行商对 OpenGL 更好的支持
|
||||
|
||||
目前开发者和发行商主要着眼于 DirectX 而不是 OpenGL 来开发游戏。现在随着 Steam 正式登录 Linux,开发者应该同样考虑在 OpenGL 下开发。
|
||||
目前开发者和发行商主要着眼于用 DirectX 而不是 OpenGL 来开发游戏。现在随着 Steam 正式登录 Linux,开发者应该同样考虑在 OpenGL 下开发。
|
||||
|
||||
[Direct3D][47] 仅仅是为了 Windows 平台打造。而 OpenGL API 拥有开放性标准,并且它不仅能在 Windows 上同样也能在其它各种各样的平台上实现。
|
||||
[Direct3D][47] 仅仅是为 Windows 平台而打造。而 OpenGL API 拥有开放性标准,并且它不仅能在 Windows 上同样也能在其它各种各样的平台上实现。
|
||||
|
||||
尽管是一篇很老的文章,[这个很有价值的资源][48]分享了许多有关 OpenGL 和 DirectX 现状的很有想法的信息。其所提出的观点确实十分明智,基于按时间排序的事件也能给予读者启迪。
|
||||
尽管是一篇很老的文章,但[这个很有价值的资源][48]分享了许多有关 OpenGL 和 DirectX 现状的很有想法的信息。其所提出的观点确实十分明智,基于按时间排序的事件也能给予读者启迪。
|
||||
|
||||
在 Linux 平台上发布大作的发行商绝不应该忽视一个事实:在 OpenGL 下直接开发游戏要比从 DirectX 移植到 OpenGL 合算得多。如果必须进行平台转制,移植必须被仔细优化并谨慎研究。发布游戏可能会有延迟,但这绝对值得。
|
||||
|
||||
@ -95,7 +99,7 @@ Linux 对游戏的原生支持在过去发行的游戏中从未如人意。
|
||||
|
||||
via: https://itsfoss.com/linux-gaming-problems/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay ][a]
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10574-1.html)
|
||||
[#]: subject: (Get started with Org mode without Emacs)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-org-mode)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 Org 模式吧,在没有 Emacs 的情况下
|
||||
======
|
||||
|
||||
> 不,你不需要 Emacs 也能用 Org,这是我开源工具系列的第 16 集,将会让你在 2019 年变得更加有生产率。
|
||||
|
||||

|
||||
|
||||
每到年初似乎总有这么一个疯狂的冲动来寻找提高生产率的方法。新年决心,正确地开始一年的冲动,以及“向前看”的态度都是这种冲动的表现。软件推荐通常都会选择闭源和专利软件。但这不是必须的。
|
||||
|
||||
这是我 2019 年改进生产率的 19 个新工具中的第 16 个。
|
||||
|
||||
### Org (非 Emacs)
|
||||
|
||||
[Org 模式][1] (或者就称为 Org) 并不是新鲜货,但依然有许多人没有用过。他们很乐意试用一下以体验 Org 是如何改善生产率的。但最大的障碍来自于 Org 是与 Emacs 相关联的,而且很多人都认为两者缺一不可。并不是这样的!一旦你理解了其基础,Org 就可以与各种其他工具和编辑器一起使用。
|
||||
|
||||
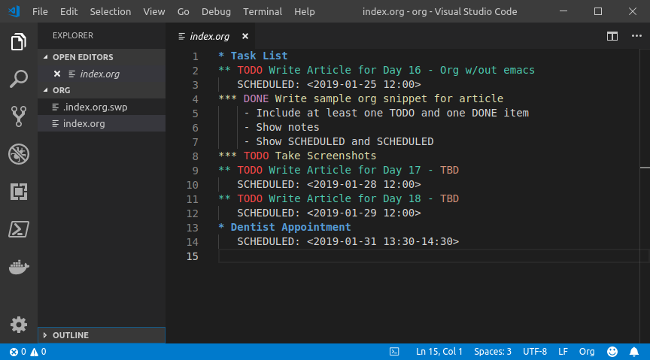
|
||||
|
||||
Org,本质上,是一个结构化的文本文件。它有标题、子标题,以及各种关键字,其他工具可以根据这些关键字将文件解析成日程表和代办列表。Org 文件可以被任何纯文本编辑器编辑(例如,[Vim][2]、[Atom][3] 或 [Visual Studio Code][4]),而且很多编辑器都有插件可以帮你创建和管理 Org 文件。
|
||||
|
||||
一个基础的 Org 文件看起来是这样的:
|
||||
|
||||
```
|
||||
* Task List
|
||||
** TODO Write Article for Day 16 - Org w/out emacs
|
||||
DEADLINE: <2019-01-25 12:00>
|
||||
*** DONE Write sample org snippet for article
|
||||
- Include at least one TODO and one DONE item
|
||||
- Show notes
|
||||
- Show SCHEDULED and DEADLINE
|
||||
*** TODO Take Screenshots
|
||||
** Dentist Appointment
|
||||
SCHEDULED: <2019-01-31 13:30-14:30>
|
||||
```
|
||||
|
||||
Org 是一种大纲格式,它使用 `*` 作为标识指明事项的级别。任何以 `TODO`(是的,全大些)开头的事项都是代办事项。标注为 `DONE` 的工作表示该工作已经完成。`SCHEDULED` 和 `DEADLINE` 标识与该事务相关的日期和时间。如何任何地方都没有时间,则该事务被视为全天活动。
|
||||
|
||||
使用正确的插件,你喜欢的文本编辑器可以成为一个充满生产率和组织能力的强大工具。例如,[vim-orgmode][5] 插件包括创建 Org 文件、语法高亮的功能,以及各种用来生成跨文件的日程和综合代办事项列表的关键命令。
|
||||
|
||||
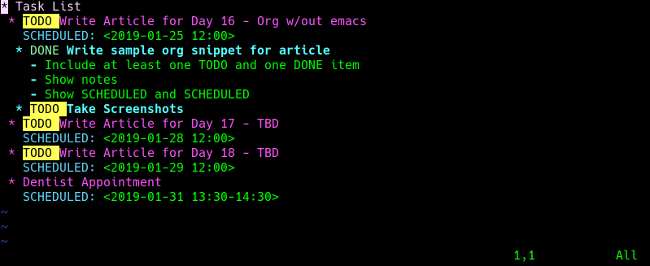
|
||||
|
||||
Atom 的 [Organized][6] 插件可以在屏幕右边添加一个侧边栏,用来显示 Org 文件中的日程和代办事项。默认情况下它从配置项中设置的路径中读取多个 Org 文件。Todo 侧边栏允许你通过点击未完事项来将其标记为已完成,它会自动更新源 Org 文件。
|
||||
|
||||
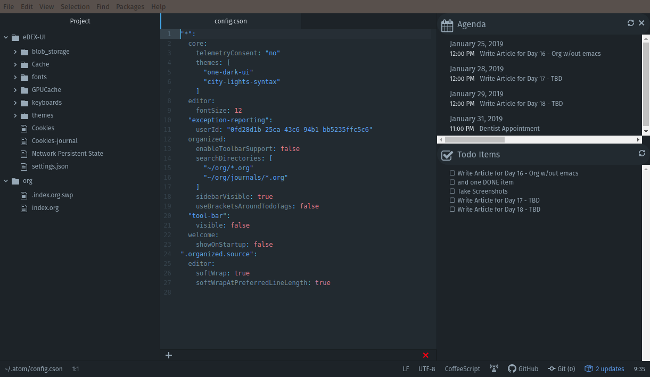
|
||||
|
||||
还有一大堆 Org 工具可以帮助你保持生产率。使用 Python、Perl、PHP、NodeJS 等库,你可以开发自己的脚本和工具。当然,少不了 [Emacs][7],它的核心功能就包括支持 Org。
|
||||
|
||||
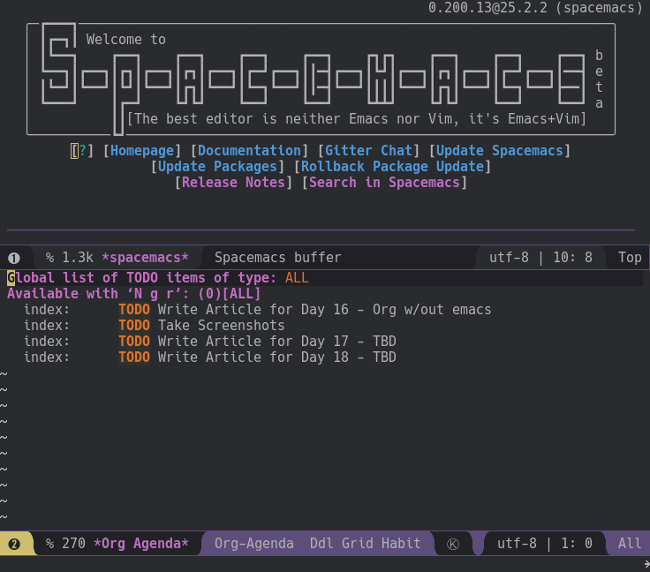
|
||||
|
||||
Org 模式是跟踪需要完成的工作和时间的最好工具之一。而且,与传闻相反,它无需 Emacs,任何一个文本编辑器都行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://orgmode.org/
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://atom.io/
|
||||
[4]: https://code.visualstudio.com/
|
||||
[5]: https://github.com/jceb/vim-orgmode
|
||||
[6]: https://atom.io/packages/organized
|
||||
[7]: https://www.gnu.org/software/emacs/
|
||||
@ -1,30 +1,32 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10577-1.html)
|
||||
[#]: subject: (Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro)
|
||||
[#]: via: (https://itsfoss.com/olive-video-editor)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Olive 是一个新的开源视频编辑器,一款类似 Final Cut Pro 的工具
|
||||
Olive:一款以 Final Cut Pro 为目标的开源视频编辑器
|
||||
======
|
||||
|
||||
[Olive][1] 是一个正在开发的新开源视频编辑器。这个非线性视频编辑器旨在提供高端专业视频编辑软件的免费替代品。目标高么?我认为是的。
|
||||
[Olive][1] 是一个正在开发的新的开源视频编辑器。这个非线性视频编辑器旨在提供高端专业视频编辑软件的免费替代品。目标高么?我认为是的。
|
||||
|
||||
如果你读过我们的 [Linux 中的最佳视频编辑器][2]这篇文章,你可能已经注意到大多数“专业级”视频编辑器(如 [Lightworks][3] 或 DaVinciResolve)既不免费也不开源。
|
||||
|
||||
[Kdenlive][4] 和 Shotcut 也出现在了文章中,但它通常无法达到专业视频编辑的标准(这是许多 Linux 用户说的)。
|
||||
[Kdenlive][4] 和 Shotcut 也是此类,但它通常无法达到专业视频编辑的标准(这是许多 Linux 用户说的)。
|
||||
|
||||
爱好者和专业视频编辑之间的这种差距促使 Olive 的开发人员启动了这个项目。
|
||||
爱好者级和专业级的视频编辑之间的这种差距促使 Olive 的开发人员启动了这个项目。
|
||||
|
||||
![Olive Video Editor][5]Olive Video Editor Interface
|
||||
![Olive Video Editor][5]
|
||||
|
||||
Libre Graphics World 中有一篇详细的[关于 Olive 的评论][6]。实际上,这是我第一次知道 Olive 的地方。如果你有兴趣了解更多信息,请阅读该文章。
|
||||
*Olive 视频编辑器界面*
|
||||
|
||||
Libre Graphics World 中有一篇详细的[关于 Olive 的点评][6]。实际上,这是我第一次知道 Olive 的地方。如果你有兴趣了解更多信息,请阅读该文章。
|
||||
|
||||
### 在 Linux 中安装 Olive 视频编辑器
|
||||
|
||||
提醒你一下。Olive 正处于发展的早期阶段。你会发现很多 bug 和缺失/不完整的功能。你不应该把它当作你的主要视频编辑器。
|
||||
> 提醒你一下。Olive 正处于发展的早期阶段。你会发现很多 bug 和缺失/不完整的功能。你不应该把它当作你的主要视频编辑器。
|
||||
|
||||
如果你想测试 Olive,有几种方法可以在 Linux 上安装它。
|
||||
|
||||
@ -50,11 +52,13 @@ sudo snap install --edge olive-editor
|
||||
|
||||
如果你的 [Linux 发行版支持 Flatpak][7],你可以通过 Flatpak 安装 Olive 视频编辑器。
|
||||
|
||||
- [Flatpak 地址](https://flathub.org/apps/details/org.olivevideoeditor.Olive)
|
||||
|
||||
#### 通过 AppImage 使用 Olive
|
||||
|
||||
不想安装吗?下载 [AppImage][8] 文件,将其设置为可执行文件并运行它。
|
||||
不想安装吗?下载 [AppImage][8] 文件,将其设置为可执行文件并运行它。32 位和 64 位 AppImage 文件都有。你应该下载相应的文件。
|
||||
|
||||
32 位和 64 位 AppImage 文件都有。你应该下载相应的文件。
|
||||
- [下载 Olive 的 AppImage](https://github.com/olive-editor/olive/releases/tag/continuous)
|
||||
|
||||
Olive 也可用于 Windows 和 macOS。你可以从它的[下载页面][9]获得它。
|
||||
|
||||
@ -64,10 +68,16 @@ Olive 也可用于 Windows 和 macOS。你可以从它的[下载页面][9]获得
|
||||
|
||||
如果你在测试 Olive 时发现一些 bug,请到它们的 GitHub 仓库中报告。
|
||||
|
||||
- [提交 bug 报告以帮助 Olive](https://github.com/olive-editor/olive/issues)
|
||||
|
||||
如果你是程序员,请浏览 Olive 的源代码,看看你是否可以通过编码技巧帮助项目。
|
||||
|
||||
- [Olive 的 GitHub 仓库](https://github.com/olive-editor/olive)
|
||||
|
||||
在经济上为项目做贡献是另一种可以帮助开发开源软件的方法。你可以通过成为赞助人来支持 Olive。
|
||||
|
||||
- [赞助 Olive](https://www.patreon.com/olivevideoeditor)
|
||||
|
||||
如果你没有支持 Olive 的金钱或编码技能,你仍然可以帮助它。在社交媒体或你经常访问的 Linux/软件相关论坛和群组中分享这篇文章或 Olive 的网站。一点微小的口碑都能间接地帮助它。
|
||||
|
||||
### 你如何看待 Olive?
|
||||
@ -83,7 +93,7 @@ via: https://itsfoss.com/olive-video-editor
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10576-1.html)
|
||||
[#]: subject: (How To Grant And Remove Sudo Privileges To Users On Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
如何在 Ubuntu 上为用户授予和移除 sudo 权限
|
||||
======
|
||||
|
||||

|
||||
|
||||
如你所知,用户可以在 Ubuntu 系统上使用 sudo 权限执行任何管理任务。在 Linux 机器上创建新用户时,他们无法执行任何管理任务,直到你将其加入 `sudo` 组的成员。在这个简短的教程中,我们将介绍如何将普通用户添加到 `sudo` 组以及移除给定的权限,使其成为普通用户。
|
||||
|
||||
### 在 Linux 上向普通用户授予 sudo 权限
|
||||
|
||||
通常,我们使用 `adduser` 命令创建新用户,如下所示。
|
||||
|
||||
```
|
||||
$ sudo adduser ostechnix
|
||||
```
|
||||
|
||||
如果你希望新创建的用户使用 `sudo` 执行管理任务,只需使用以下命令将它添加到 `sudo` 组:
|
||||
|
||||
```
|
||||
$ sudo usermod -a -G sudo hduser
|
||||
```
|
||||
|
||||
上面的命令将使名为 `ostechnix` 的用户成为 `sudo` 组的成员。
|
||||
|
||||
你也可以使用此命令将用户添加到 `sudo` 组。
|
||||
|
||||
```
|
||||
$ sudo adduser ostechnix sudo
|
||||
```
|
||||
|
||||
现在,注销并以新用户身份登录,以使此更改生效。此时用户已成为管理用户。
|
||||
|
||||
要验证它,只需在任何命令中使用 `sudo` 作为前缀。
|
||||
|
||||
```
|
||||
$ sudo mkdir /test
|
||||
[sudo] password for ostechnix:
|
||||
```
|
||||
|
||||
### 移除用户的 sudo 权限
|
||||
|
||||
有时,你可能希望移除特定用户的 `sudo` 权限,而不用在 Linux 中删除它。要将任何用户设为普通用户,只需将其从 `sudo` 组中删除即可。
|
||||
|
||||
比如说如果要从 `sudo` 组中删除名为 `ostechnix` 的用户,只需运行:
|
||||
|
||||
```
|
||||
$ sudo deluser ostechnix sudo
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Removing user `ostechnix' from group `sudo' ...
|
||||
Done.
|
||||
```
|
||||
|
||||
此命令仅从 `sudo` 组中删除用户 `ostechnix`,但不会永久地从系统中删除用户。现在,它成为了普通用户,无法像 `sudo` 用户那样执行任何管理任务。
|
||||
|
||||
此外,你可以使用以下命令撤消用户的 `sudo` 访问权限:
|
||||
|
||||
```
|
||||
$ sudo gpasswd -d ostechnix sudo
|
||||
```
|
||||
|
||||
从 `sudo` 组中删除用户时请小心。不要从 `sudo` 组中删除真正的管理员。
|
||||
|
||||
使用命令验证用户 `ostechnix` 是否已从 `sudo` 组中删除:
|
||||
|
||||
```
|
||||
$ sudo -l -U ostechnix
|
||||
User ostechnix is not allowed to run sudo on ubuntuserver.
|
||||
```
|
||||
|
||||
是的,用户 `ostechnix` 已从 `sudo` 组中删除,他无法执行任何管理任务。
|
||||
|
||||
从 `sudo` 组中删除用户时请小心。如果你的系统上只有一个 `sudo` 用户,并且你将他从 `sudo` 组中删除了,那么就无法执行任何管理操作,例如在系统上安装、删除和更新程序。所以,请小心。在我们的下一篇教程中,我们将解释如何恢复用户的 `sudo` 权限。
|
||||
|
||||
就是这些了。希望这篇文章有用。还有更多好东西。敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
196
published/20190206 And, Ampersand, and - in Linux.md
Normal file
196
published/20190206 And, Ampersand, and - in Linux.md
Normal file
@ -0,0 +1,196 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10587-1.html)
|
||||
[#]: subject: (And, Ampersand, and & in Linux)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Linux 中的 &
|
||||
======
|
||||
|
||||
> 这篇文章将了解一下 & 符号及它在 Linux 命令行中的各种用法。
|
||||
|
||||

|
||||
|
||||
如果阅读过我之前的三篇文章([1][1]、[2][2]、[3][3]),你会觉得掌握连接各个命令之间的连接符号用法也是很重要的。实际上,命令的用法并不难,例如 `mkdir`、`touch` 和 `find` 也分别可以简单概括为“建立新目录”、“更新文件”和“在目录树中查找文件”而已。
|
||||
|
||||
但如果要理解
|
||||
|
||||
```
|
||||
mkdir test_dir 2>/dev/null || touch images.txt && find . -iname "*jpg" > backup/dir/images.txt &
|
||||
```
|
||||
|
||||
这一串命令的目的,以及为什么要这样写,就没有这么简单了。
|
||||
|
||||
关键之处就在于命令之间的连接符号。掌握了这些符号的用法,不仅可以让你更好理解整体的工作原理,还可以让你知道如何将不同的命令有效地结合起来,提高工作效率。
|
||||
|
||||
在这一篇文章和接下来的文章中,我会介绍如何使用 `&` 号和管道符号(`|`)在不同场景下的使用方法。
|
||||
|
||||
### 幕后工作
|
||||
|
||||
我来举一个简单的例子,看看如何使用 `&` 号将下面这个命令放到后台运行:
|
||||
|
||||
```
|
||||
cp -R original/dir/ backup/dir/
|
||||
```
|
||||
|
||||
这个命令的目的是将 `original/dir/` 的内容递归地复制到 `backup/dir/` 中。虽然看起来很简单,但是如果原目录里面的文件太大,在执行过程中终端就会一直被卡住。
|
||||
|
||||
所以,可以在命令的末尾加上一个 `&` 号,将这个任务放到后台去执行:
|
||||
|
||||
```
|
||||
cp -R original/dir/ backup/dir/ &
|
||||
```
|
||||
|
||||
任务被放到后台执行之后,就可以立即继续在同一个终端上工作了,甚至关闭终端也不影响这个任务的正常执行。需要注意的是,如果要求这个任务输出内容到标准输出中(例如 `echo` 或 `ls`),即使使用了 `&`,也会等待这些输出任务在前台运行完毕。
|
||||
|
||||
当使用 `&` 将一个进程放置到后台运行的时候,Bash 会提示这个进程的进程 ID。在 Linux 系统中运行的每一个进程都有一个唯一的进程 ID,你可以使用进程 ID 来暂停、恢复或者终止对应的进程,因此进程 ID 是非常重要的。
|
||||
|
||||
这个时候,只要你还停留在启动进程的终端当中,就可以使用以下几个命令来对管理后台进程:
|
||||
|
||||
* `jobs` 命令可以显示当前终端正在运行的进程,包括前台运行和后台运行的进程。它对每个正在执行中的进程任务分配了一个序号(这个序号不是进程 ID),可以使用这些序号来引用各个进程任务。
|
||||
|
||||
```
|
||||
$ jobs
|
||||
[1]- Running cp -i -R original/dir/* backup/dir/ &
|
||||
[2]+ Running find . -iname "*jpg" > backup/dir/images.txt &
|
||||
```
|
||||
* `fg` 命令可以将后台运行的进程任务放到前台运行,这样可以比较方便地进行交互。根据 `jobs` 命令提供的进程任务序号,再在前面加上 `%` 符号,就可以把相应的进程任务放到前台运行。
|
||||
|
||||
```
|
||||
$ fg %1 # 将上面序号为 1 的 cp 任务放到前台运行
|
||||
cp -i -R original/dir/* backup/dir/
|
||||
```
|
||||
如果这个进程任务是暂停状态,`fg` 命令会将它启动起来。
|
||||
* 使用 `ctrl+z` 组合键可以将前台运行的任务暂停,仅仅是暂停,而不是将任务终止。当使用 `fg` 或者 `bg` 命令将任务重新启动起来的时候,任务会从被暂停的位置开始执行。但 [sleep][4] 命令是一个特例,`sleep` 任务被暂停的时间会计算在 `sleep` 时间之内。因为 `sleep` 命令依据的是系统时钟的时间,而不是实际运行的时间。也就是说,如果运行了 `sleep 30`,然后将任务暂停 30 秒以上,那么任务恢复执行的时候会立即终止并退出。
|
||||
* `bg` 命令会将任务放置到后台执行,如果任务是暂停状态,也会被启动起来。
|
||||
|
||||
```
|
||||
$ bg %1
|
||||
[1]+ cp -i -R original/dir/* backup/dir/ &
|
||||
```
|
||||
|
||||
如上所述,以上几个命令只能在同一个终端里才能使用。如果启动进程任务的终端被关闭了,或者切换到了另一个终端,以上几个命令就无法使用了。
|
||||
|
||||
如果要在另一个终端管理后台进程,就需要其它工具了。例如可以使用 [kill][5] 命令从另一个终端终止某个进程:
|
||||
|
||||
```
|
||||
kill -s STOP <PID>
|
||||
```
|
||||
|
||||
这里的 PID 就是使用 `&` 将进程放到后台时 Bash 显示的那个进程 ID。如果你当时没有把进程 ID 记录下来,也可以使用 `ps` 命令(代表 process)来获取所有正在运行的进程的进程 ID,就像这样:
|
||||
|
||||
```
|
||||
ps | grep cp
|
||||
```
|
||||
|
||||
执行以后会显示出包含 `cp` 字符串的所有进程,例如上面例子中的 `cp` 进程。同时还会显示出对应的进程 ID:
|
||||
|
||||
```
|
||||
$ ps | grep cp
|
||||
14444 pts/3 00:00:13 cp
|
||||
```
|
||||
|
||||
在这个例子中,进程 ID 是 14444,因此可以使用以下命令来暂停这个后台进程:
|
||||
|
||||
```
|
||||
kill -s STOP 14444
|
||||
```
|
||||
|
||||
注意,这里的 `STOP` 等同于前面提到的 `ctrl+z` 组合键的效果,也就是仅仅把进程暂停掉。
|
||||
|
||||
如果想要把暂停了的进程启动起来,可以对进程发出 `CONT` 信号:
|
||||
|
||||
```
|
||||
kill -s CONT 14444
|
||||
```
|
||||
|
||||
这个给出一个[可以向进程发出的常用信号][6]列表。如果想要终止一个进程,可以发送 `TERM` 信号:
|
||||
|
||||
```
|
||||
kill -s TERM 14444
|
||||
```
|
||||
|
||||
如果进程不响应 `TERM` 信号并拒绝退出,还可以发送 `KILL` 信号强制终止进程:
|
||||
|
||||
```
|
||||
kill -s KILL 14444
|
||||
```
|
||||
|
||||
强制终止进程可能会有一定的风险,但如果遇到进程无节制消耗资源的情况,这样的信号还是能够派上用场的。
|
||||
|
||||
另外,如果你不确定进程 ID 是否正确,可以在 `ps` 命令中加上 `x` 参数:
|
||||
|
||||
```
|
||||
$ ps x| grep cp
|
||||
14444 pts/3 D 0:14 cp -i -R original/dir/Hols_2014.mp4
|
||||
original/dir/Hols_2015.mp4 original/dir/Hols_2016.mp4
|
||||
original/dir/Hols_2017.mp4 original/dir/Hols_2018.mp4 backup/dir/
|
||||
```
|
||||
|
||||
这样就可以看到是不是你需要的进程 ID 了。
|
||||
|
||||
最后介绍一个将 `ps` 和 `grep` 结合到一起的命令:
|
||||
|
||||
```
|
||||
$ pgrep cp
|
||||
8
|
||||
18
|
||||
19
|
||||
26
|
||||
33
|
||||
40
|
||||
47
|
||||
54
|
||||
61
|
||||
72
|
||||
88
|
||||
96
|
||||
136
|
||||
339
|
||||
6680
|
||||
13735
|
||||
14444
|
||||
```
|
||||
|
||||
`pgrep` 可以直接将带有字符串 `cp` 的进程的进程 ID 显示出来。
|
||||
|
||||
可以加上一些参数让它的输出更清晰:
|
||||
|
||||
```
|
||||
$ pgrep -lx cp
|
||||
14444 cp
|
||||
```
|
||||
|
||||
在这里,`-l` 参数会让 `pgrep` 将进程的名称显示出来,`-x` 参数则是让 `pgrep` 完全匹配 `cp` 这个命令。如果还想了解这个命令的更多细节,可以尝试运行 `pgrep -ax`。
|
||||
|
||||
### 总结
|
||||
|
||||
在命令的末尾加上 `&` 可以让我们理解前台进程和后台进程的概念,以及如何管理这些进程。
|
||||
|
||||
在 UNIX/Linux 术语中,在后台运行的进程被称为<ruby>守护进程<rt>daemon</rt></ruby>。如果你曾经听说过这个词,那你现在应该知道它的意义了。
|
||||
|
||||
和其它符号一样,`&` 在命令行中还有很多别的用法。在下一篇文章中,我会更详细地介绍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10465-1.html
|
||||
[2]: https://linux.cn/article-10502-1.html
|
||||
[3]: https://linux.cn/article-10529-1.html
|
||||
[4]: https://ss64.com/bash/sleep.html
|
||||
[5]: https://bash.cyberciti.biz/guide/Sending_signal_to_Processes
|
||||
[6]: https://www.computerhope.com/unix/signals.htm
|
||||
|
||||
120
published/20190206 Getting started with Vim visual mode.md
Normal file
120
published/20190206 Getting started with Vim visual mode.md
Normal file
@ -0,0 +1,120 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10589-1.html)
|
||||
[#]: subject: (Getting started with Vim visual mode)
|
||||
[#]: via: (https://opensource.com/article/19/2/getting-started-vim-visual-mode)
|
||||
[#]: author: (Susan Lauber https://opensource.com/users/susanlauber)
|
||||
|
||||
Vim 可视化模式入门
|
||||
======
|
||||
|
||||
> 可视化模式使得在 Vim 中高亮显示和操作文本变得更加容易。
|
||||
|
||||

|
||||
|
||||
Ansible 剧本文件是 YAML 格式的文本文件,经常与它们打交道的人通过他们偏爱的编辑器和扩展插件以使格式化更容易。
|
||||
|
||||
当我使用大多数 Linux 发行版中提供的默认编辑器来教学 Ansible 时,我经常使用 Vim 的可视化模式。它可以让我在屏幕上高亮显示我的操作 —— 我要编辑什么以及我正在做的文本处理任务,以便使我的学生更容易学习。
|
||||
|
||||
### Vim 的可视化模式
|
||||
|
||||
使用 Vim 编辑文本时,可视化模式对于识别要操作的文本块非常有用。
|
||||
|
||||
Vim 的可视模式有三个模式:字符、行和块。进入每种模式的按键是:
|
||||
|
||||
* 字符模式: `v` (小写)
|
||||
* 行模式: `V` (大写)
|
||||
* 块模式: `Ctrl+v`
|
||||
|
||||
下面是使用每种模式简化工作的一些方法。
|
||||
|
||||
### 字符模式
|
||||
|
||||
字符模式可以高亮显示段落中的一个句子或句子中的一个短语,然后,可以使用任何 Vim 编辑命令删除、复制、更改/修改可视化模式识别的文本。
|
||||
|
||||
#### 移动一个句子
|
||||
|
||||
要将句子从一个地方移动到另一个地方,首先打开文件并将光标移动到要移动的句子的第一个字符。
|
||||
|
||||
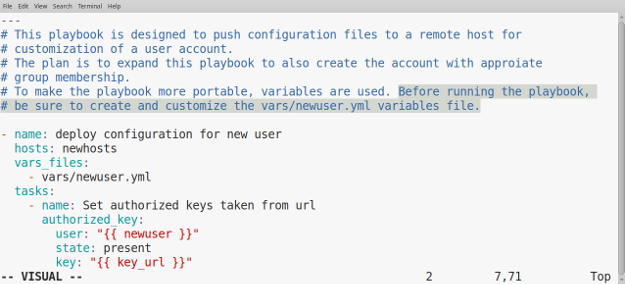
|
||||
|
||||
* 按下 `v` 键进入可视化字符模式。单词 `VISUAL` 将出现在屏幕底部。
|
||||
* 使用箭头来高亮显示所需的文本。你可以使用其他导航命令,例如 `w` 高亮显示至下一个单词的开头,`$` 来包含该行的其余部分。
|
||||
* 在文本高亮显示后,按下 `d` 删除文本。
|
||||
* 如果你删除得太多或不够,按下 `u` 撤销并重新开始。
|
||||
* 将光标移动到新位置,然后按 `p` 粘贴文本。
|
||||
|
||||
#### 改变一个短语
|
||||
|
||||
你还可以高亮显示要替换的一段文本。
|
||||
|
||||
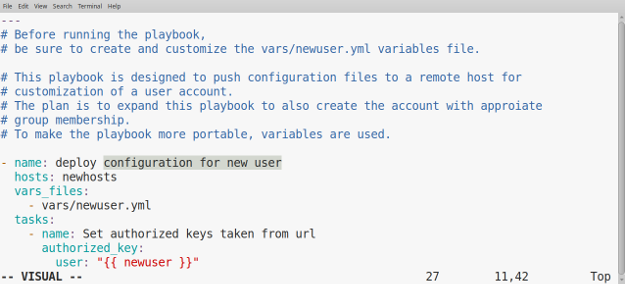
|
||||
|
||||
* 将光标放在要更改的第一个字符处。
|
||||
* 按下 `v` 进入可视化字符模式。
|
||||
* 使用导航命令(如箭头键)高亮显示该部分。
|
||||
* 按下 `c` 可更改高亮显示的文本。
|
||||
* 高亮显示的文本将消失,你将处于插入模式,你可以在其中添加新文本。
|
||||
* 输入新文本后,按下 `Esc` 返回命令模式并保存你的工作。
|
||||
|
||||
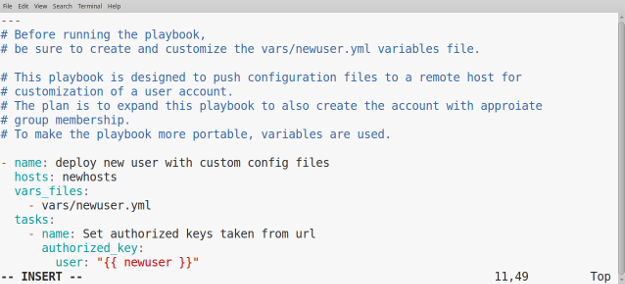
|
||||
|
||||
### 行模式
|
||||
|
||||
使用 Ansible 剧本时,任务的顺序很重要。使用可视化行模式将 Ansible 任务移动到该剧本文件中的其他位置。
|
||||
|
||||
#### 操纵多行文本
|
||||
|
||||
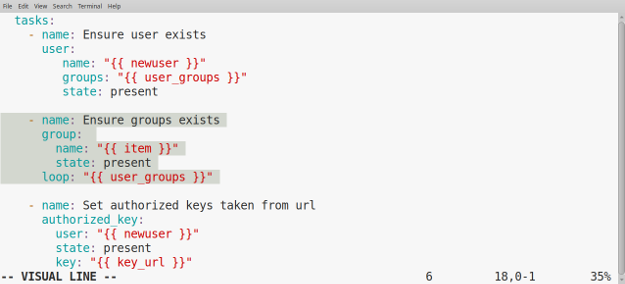
|
||||
|
||||
* 将光标放在要操作的文本的第一行或最后一行的任何位置。
|
||||
* 按下 `Shift+V` 进入行模式。单词 `VISUAL LINE` 将出现在屏幕底部。
|
||||
* 使用导航命令(如箭头键)高亮显示多行文本。
|
||||
* 高亮显示所需文本后,使用命令来操作它。按下 `d` 删除,然后将光标移动到新位置,按下 `p` 粘贴文本。
|
||||
* 如果要复制该 Ansible 任务,可以使用 `y`(yank)来代替 `d`(delete)。
|
||||
|
||||
#### 缩进一组行
|
||||
|
||||
使用 Ansible 剧本或 YAML 文件时,缩进很重要。高亮显示的块可以使用 `>` 和 `<` 键向右或向左移动。
|
||||
|
||||
|
||||
|
||||
* 按下 `>` 增加所有行的缩进。
|
||||
* 按下 `<` 减少所有行的缩进。
|
||||
|
||||
尝试其他 Vim 命令将它们应用于高亮显示的文本。
|
||||
|
||||
### 块模式
|
||||
|
||||
可视化块模式对于操作特定的表格数据文件非常有用,但它作为验证 Ansible 剧本文件缩进的工具也很有帮助。
|
||||
|
||||
Ansible 任务是个项目列表,在 YAML 中,每个列表项都以一个破折号跟上一个空格开头。破折号必须在同一列中对齐,以达到相同的缩进级别。仅凭肉眼很难看出这一点。缩进 Ansible 任务中的其他行也很重要。
|
||||
|
||||
#### 验证任务列表缩进相同
|
||||
|
||||
|
||||
|
||||
* 将光标放在列表项的第一个字符上。
|
||||
* 按下 `Ctrl+v` 进入可视化块模式。单词 `VISUAL BLOCK` 将出现在屏幕底部。
|
||||
* 使用箭头键高亮显示单个字符列。你可以验证每个任务的缩进量是否相同。
|
||||
* 使用箭头键向右或向左展开块,以检查其它缩进是否正确。
|
||||
|
||||
|
||||
|
||||
尽管我对其它 Vim 编辑快捷方式很熟悉,但我仍然喜欢使用可视化模式来整理我想要出来处理的文本。当我在讲演过程中演示其它概念时,我的学生将会在这个“对他们而言很新”的文本编辑器中看到一个可以高亮文本并可以点击删除的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/getting-started-vim-visual-mode
|
||||
|
||||
作者:[Susan Lauber][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/susanlauber
|
||||
[b]: https://github.com/lujun9972
|
||||
116
published/20190208 7 steps for hunting down Python code bugs.md
Normal file
116
published/20190208 7 steps for hunting down Python code bugs.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LazyWolfLin)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10603-1.html)
|
||||
[#]: subject: (7 steps for hunting down Python code bugs)
|
||||
[#]: via: (https://opensource.com/article/19/2/steps-hunting-code-python-bugs)
|
||||
[#]: author: (Maria Mckinley https://opensource.com/users/parody)
|
||||
|
||||
Python 七步捉虫法
|
||||
======
|
||||
|
||||
> 了解一些技巧助你减少代码查错时间。
|
||||
|
||||

|
||||
|
||||
在周五的下午三点钟(为什么是这个时间?因为事情总会在周五下午三点钟发生),你收到一条通知,客户发现你的软件出现一个错误。在有了初步的怀疑后,你联系运维,查看你的软件日志以了解发生了什么,因为你记得收到过日志已经搬家了的通知。
|
||||
|
||||
结果这些日志被转移到了你获取不到的地方,但它们正在导入到一个网页应用中——所以到时候你可以用这个漂亮的应用来检索日志,但是,这个应用现在还没完成。这个应用预计会在几天内完成。我知道,你觉得这完全不切实际。然而并不是,日志或者日志消息似乎经常在错误的时间消失不见。在我们开始查错前,一个忠告:经常检查你的日志以确保它们还在你认为它们应该在的地方,并记录你认为它们应该记的东西。当你不注意的时候,这些东西往往会发生令人惊讶的变化。
|
||||
|
||||
好的,你找到了日志或者尝试了呼叫运维人员,而客户确实发现了一个错误。甚至你可能认为你已经知道错误在哪儿。
|
||||
|
||||
你立即打开你认为可能有问题的文件并开始查错。
|
||||
|
||||
### 1、先不要碰你的代码
|
||||
|
||||
阅读代码,你甚至可能会想到该阅读哪些部分。但是在开始搞乱你的代码前,请重现导致错误的调用并把它变成一个测试。这将是一个集成测试,因为你可能还有其他疑问,目前你还不能准确地知道问题在哪儿。
|
||||
|
||||
确保这个测试结果是失败的。这很重要,因为有时你的测试不能重现失败的调用,尤其是你使用了可以混淆测试的 web 或者其他框架。很多东西可能被存储在变量中,但遗憾的是,只通过观察测试,你在测试里调用的东西并不总是明显可见的。当我尝试着重现这个失败的调用时,我并不是说我要创建一个可以通过的测试,但是,好吧,我确实是创建了一个测试,但我不认为这特别不寻常。
|
||||
|
||||
> 从自己的错误中吸取教训。
|
||||
|
||||
### 2、编写错误的测试
|
||||
|
||||
现在,你有了一个失败的测试,或者可能是一个带有错误的测试,那么是时候解决问题了。但是在你开干之前,让我们先检查下调用栈,因为这样可以更轻松地解决问题。
|
||||
|
||||
调用栈包括你已经启动但尚未完成地所有任务。因此,比如你正在烤蛋糕并准备往面糊里加面粉,那你的调用栈将是:
|
||||
|
||||
* 做蛋糕
|
||||
* 打面糊
|
||||
* 加面粉
|
||||
|
||||
你已经开始做蛋糕,开始打面糊,而你现在正在加面粉。往锅底抹油不在这个列表中,因为你已经完成了,而做糖霜不在这个列表上因为你还没开始做。
|
||||
|
||||
如果你对调用栈不清楚,我强烈建议你使用 [Python Tutor][1],它能帮你在执行代码时观察调用栈。
|
||||
|
||||
现在,如果你的 Python 程序出现了错误, Python 解释器会帮你打印出当前调用栈。这意味着无论那一时刻程序在做什么,很明显错误发生在调用栈的底部。
|
||||
|
||||
### 3、始终先检查调用栈底部
|
||||
|
||||
在栈底你不仅能看到发生了哪个错误,而且通常可以在调用栈的最后一行发现问题。如果栈底对你没有帮助,而你的代码还没有经过代码分析,那么使用代码分析是非常有用的。我推荐 pylint 或者 flake8。通常情况下,它会指出我一直忽略的错误的地方。
|
||||
|
||||
如果错误看起来很迷惑,你下一步行动可能是用 Google 搜索它。如果你搜索的内容不包含你的代码的相关信息,如变量名、文件等,那你将获得更好的搜索结果。如果你使用的是 Python 3(你应该使用它),那么搜索内容包含 Python 3 是有帮助的,否则 Python 2 的解决方案往往会占据大多数。
|
||||
|
||||
很久以前,开发者需要在没有搜索引擎的帮助下解决问题。那是一段黑暗时光。充分利用你可以使用的所有工具。
|
||||
|
||||
不幸的是,有时候问题发生在更早阶段,但只有在调用栈底部执行的地方才显现出来。就像当蛋糕没有膨胀时,忘记加发酵粉的事才被发现。
|
||||
|
||||
那就该检查整个调用栈。问题更可能在你的代码而不是 Python 标准库或者第三方包,所以先检查调用栈内你的代码。另外,在你的代码中放置断点通常会更容易检查代码。在调用栈的代码中放置断点,然后看看周围是否如你预期。
|
||||
|
||||
“但是,玛丽,”我听到你说,“如果我有一个调用栈,那这些都是有帮助的,但我只有一个失败的测试。我该从哪里开始?”
|
||||
|
||||
pdb,一个 Python 调试器。
|
||||
|
||||
找到你代码里会被这个调用命中的地方。你应该能够找到至少一个这样的地方。在那里打上一个 pdb 的断点。
|
||||
|
||||
#### 一句题外话
|
||||
|
||||
为什么不使用 `print` 语句呢?我曾经依赖于 `print` 语句。有时候,它们仍然很方便。但当我开始处理复杂的代码库,尤其是有网络调用的代码库,`print` 语句就变得太慢了。我最终在各种地方都加上了 `print` 语句,但我没法追踪它们的位置和原因,而且变得更复杂了。但是主要使用 pdb 还有一个更重要的原因。假设你添加一条 `print` 语句去发现错误问题,而且 `print` 语句必须早于错误出现的地方。但是,看看你放 `print` 语句的函数,你不知道你的代码是怎么执行到那个位置的。查看代码是寻找调用路径的好方法,但看你以前写的代码是恐怖的。是的,我会用 `grep` 处理我的代码库以寻找调用函数的地方,但这会变得乏味,而且搜索一个通用函数时并不能缩小搜索范围。pdb 就变得非常有用。
|
||||
|
||||
你遵循我的建议,打上 pdb 断点并运行你的测试。然而测试再次失败,但是没有任何一个断点被命中。留着你的断点,并运行测试套件中一个同这个失败的测试非常相似的测试。如果你有个不错的测试套件,你应该能够找到一个这样的测试。它会命中了你认为你的失败测试应该命中的代码。运行这个测试,然后当它运行到你的断点,按下 `w` 并检查调用栈。如果你不知道如何查看因为其他调用而变得混乱的调用栈,那么在调用栈的中间找到属于你的代码,并在堆栈中该代码的上一行放置一个断点。再试一次新的测试。如果仍然没命中断点,那么继续,向上追踪调用栈并找出你的调用在哪里脱轨了。如果你一直没有命中断点,最后到了追踪的顶部,那么恭喜你,你发现了问题:你的应用程序名称拼写错了。
|
||||
|
||||
> 没有经验,小白,一点都没有经验。
|
||||
|
||||
### 4、修改代码
|
||||
|
||||
如果你仍觉得迷惑,在你稍微改变了一些的地方尝试新的测试。你能让新的测试跑起来么?有什么是不同的呢?有什么是相同的呢?尝试改变一下别的东西。当你有了你的测试,以及可能也还有其它的测试,那就可以开始安全地修改代码了,确定是否可以缩小问题范围。记得从一个新提交开始解决问题,以便于可以轻松地撤销无效地更改。(这就是版本控制,如果你没有使用过版本控制,这将会改变你的生活。好吧,可能它只是让编码更容易。查阅“[版本控制可视指南][2]”,以了解更多。)
|
||||
|
||||
### 5、休息一下
|
||||
|
||||
尽管如此,当它不再感觉起来像一个有趣的挑战或者游戏而开始变得令人沮丧时,你最好的举措是脱离这个问题。休息一下。我强烈建议你去散步并尝试考虑别的事情。
|
||||
|
||||
### 6、把一切写下来
|
||||
|
||||
当你回来了,如果你没有突然受到启发,那就把你关于这个问题所知的每一个点信息写下来。这应该包括:
|
||||
|
||||
* 真正造成问题的调用
|
||||
* 真正发生了什么,包括任何错误信息或者相关的日志信息
|
||||
* 你真正期望发生什么
|
||||
* 到目前为止,为了找出问题,你做了什么工作;以及解决问题中你发现的任何线索。
|
||||
|
||||
有时这里有很多信息,但相信我,从零碎中挖掘信息是很烦人。所以尽量简洁,但是要完整。
|
||||
|
||||
### 7、寻求帮助
|
||||
|
||||
我经常发现写下所有信息能够启迪我想到还没尝试过的东西。当然,有时候我在点击求助邮件(或表单)的提交按钮后立刻意识到问题是是什么。无论如何,当你在写下所有东西仍一无所获时,那就试试向他人发邮件求助。首先是你的同事或者其他参与你的项目的人,然后是该项目的邮件列表。不要害怕向人求助。大多数人都是友善和乐于助人的,我发现在 Python 社区里尤其如此。
|
||||
|
||||
Maria McKinley 已在 [PyCascades 2019][4] 演讲 [代码查错][3],2 月 23-24,于西雅图。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/steps-hunting-code-python-bugs
|
||||
|
||||
作者:[Maria Mckinley][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LazyWolfLin](https://github.com/LazyWolfLin)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/parody
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.pythontutor.com/
|
||||
[2]: https://betterexplained.com/articles/a-visual-guide-to-version-control/
|
||||
[3]: https://2019.pycascades.com/talks/hunting-the-bugs
|
||||
[4]: https://2019.pycascades.com/
|
||||
164
published/20190212 Ampersands and File Descriptors in Bash.md
Normal file
164
published/20190212 Ampersands and File Descriptors in Bash.md
Normal file
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zero-mk)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10591-1.html)
|
||||
[#]: subject: (Ampersands and File Descriptors in Bash)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/2/ampersands-and-file-descriptors-bash)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Bash 中的 & 符号和文件描述符
|
||||
======
|
||||
|
||||
> 了解如何将 “&” 与尖括号结合使用,并从命令行中获得更多信息。
|
||||
|
||||

|
||||
|
||||
在我们探究大多数链式 Bash 命令中出现的所有的杂项符号(`&`、`|`、`;`、`>`、`<`、`{`、`[`、`(`、`)`、`]`、`}` 等等)的任务中,[我们一直在仔细研究 & 符号][1]。
|
||||
|
||||
[上次,我们看到了如何使用 & 把可能需要很长时间运行的进程放到后台运行][1]。但是,`&` 与尖括号 `<` 结合使用,也可用于将输出或输出通过管道导向其他地方。
|
||||
|
||||
在 [前面的][2] [尖括号教程中][3],你看到了如何使用 `>`,如下:
|
||||
|
||||
```
|
||||
ls > list.txt
|
||||
```
|
||||
|
||||
将 `ls` 输出传递给 `list.txt` 文件。
|
||||
|
||||
现在我们看到的是简写:
|
||||
|
||||
```
|
||||
ls 1> list.txt
|
||||
```
|
||||
|
||||
在这种情况下,`1` 是一个文件描述符,指向标准输出(`stdout`)。
|
||||
|
||||
以类似的方式,`2` 指向标准错误输出(`stderr`):
|
||||
|
||||
```
|
||||
ls 2> error.log
|
||||
```
|
||||
|
||||
所有错误消息都通过管道传递给 `error.log` 文件。
|
||||
|
||||
回顾一下:`1>` 是标准输出(`stdout`),`2>` 是标准错误输出(`stderr`)。
|
||||
|
||||
第三个标准文件描述符,`0<` 是标准输入(`stdin`)。你可以看到它是一个输入,因为箭头(`<`)指向`0`,而对于 `1` 和 `2`,箭头(`>`)是指向外部的。
|
||||
|
||||
### 标准文件描述符有什么用?
|
||||
|
||||
如果你在阅读本系列以后,你已经多次使用标准输出(`1>`)的简写形式:`>`。
|
||||
|
||||
例如,当(假如)你知道你的命令会抛出一个错误时,像 `stderr`(`2`)这样的东西也很方便,但是 Bash 告诉你的东西是没有用的,你不需要看到它。如果要在 `home/` 目录中创建目录,例如:
|
||||
|
||||
```
|
||||
mkdir newdir
|
||||
```
|
||||
|
||||
如果 `newdir/` 已经存在,`mkdir` 将显示错误。但你为什么要关心这些呢?(好吧,在某些情况下你可能会关心,但并非总是如此。)在一天结束时,`newdir` 会以某种方式让你填入一些东西。你可以通过将错误消息推入虚空(即 ``/dev/null`)来抑制错误消息:
|
||||
|
||||
```
|
||||
mkdir newdir 2> /dev/null
|
||||
```
|
||||
|
||||
这不仅仅是 “让我们不要看到丑陋和无关的错误消息,因为它们很烦人”,因为在某些情况下,错误消息可能会在其他地方引起一连串错误。比如说,你想找到 `/etc` 下所有的 `.service` 文件。你可以这样做:
|
||||
|
||||
```
|
||||
find /etc -iname "*.service"
|
||||
```
|
||||
|
||||
但事实证明,在大多数系统中,`find` 显示的错误会有许多行,因为普通用户对 `/etc` 下的某些文件夹没有读取访问权限。它使读取正确的输出变得很麻烦,如果 `find` 是更大的脚本的一部分,它可能会导致行中的下一个命令排队。
|
||||
|
||||
相反,你可以这样做:
|
||||
|
||||
```
|
||||
find /etc -iname "*.service" 2> /dev/null
|
||||
```
|
||||
|
||||
而且你只得到你想要的结果。
|
||||
|
||||
### 文件描述符入门
|
||||
|
||||
单独的文件描述符 `stdout` 和 `stderr` 还有一些注意事项。如果要将输出存储在文件中,请执行以下操作:
|
||||
|
||||
```
|
||||
find /etc -iname "*.service" 1> services.txt
|
||||
```
|
||||
|
||||
工作正常,因为 `1>` 意味着 “发送标准输出且自身标准输出(非标准错误)到某个地方”。
|
||||
|
||||
但这里存在一个问题:如果你想把命令抛出的错误信息记录到文件,而结果中没有错误信息你该怎么**做**?上面的命令并不会这样做,因为它只写入 `find` 正确的结果,而:
|
||||
|
||||
```
|
||||
find /etc -iname "*.service" 2> services.txt
|
||||
```
|
||||
|
||||
只会写入命令抛出的错误信息。
|
||||
|
||||
我们如何得到两者?请尝试以下命令:
|
||||
|
||||
```
|
||||
find /etc -iname "*.service" &> services.txt
|
||||
```
|
||||
|
||||
…… 再次和 `&` 打个招呼!
|
||||
|
||||
我们一直在说 `stdin`(`0`)、`stdout`(`1`)和 `stderr`(`2`)是“文件描述符”。文件描述符是一种特殊构造,是指向文件的通道,用于读取或写入,或两者兼而有之。这来自于将所有内容都视为文件的旧 UNIX 理念。想写一个设备?将其视为文件。想写入套接字并通过网络发送数据?将其视为文件。想要读取和写入文件?嗯,显然,将其视为文件。
|
||||
|
||||
因此,在管理命令的输出和错误的位置时,将目标视为文件。因此,当你打开它们来读取和写入它们时,它们都会获得文件描述符。
|
||||
|
||||
这是一个有趣的效果。例如,你可以将内容从一个文件描述符传递到另一个文件描述符:
|
||||
|
||||
```
|
||||
find /etc -iname "*.service" 1> services.txt 2>&1
|
||||
```
|
||||
|
||||
这会将 `stderr` 导向到 `stdout`,而 `stdout` 通过管道被导向到一个文件中 `services.txt` 中。
|
||||
|
||||
它再次出现:`&` 发信号通知 Bash `1` 是目标文件描述符。
|
||||
|
||||
标准文件描述符的另一个问题是,当你从一个管道传输到另一个时,你执行此操作的顺序有点违反直觉。例如,按照上面的命令。它看起来像是错误的方式。你应该像这样阅读它:“将输出导向到文件,然后将错误导向到标准输出。” 看起来错误输出会在后面,并且在输出到标准输出(`1`)已经完成时才发送。
|
||||
|
||||
但这不是文件描述符的工作方式。文件描述符不是文件的占位符,而是文件的输入和(或)输出通道。在这种情况下,当你做 `1> services.txt` 时,你的意思是 “打开一个写管道到 `services.txt` 并保持打开状态”。`1` 是你要使用的管道的名称,它将保持打开状态直到该行的结尾。
|
||||
|
||||
如果你仍然认为这是错误的方法,试试这个:
|
||||
|
||||
```
|
||||
find /etc -iname "*.service" 2>&1 1>services.txt
|
||||
```
|
||||
|
||||
并注意它是如何不工作的;注意错误是如何被导向到终端的,而只有非错误的输出(即 `stdout`)被推送到 `services.txt`。
|
||||
|
||||
这是因为 Bash 从左到右处理 `find` 的每个结果。这样想:当 Bash 到达 `2>&1` 时,`stdout` (`1`)仍然是指向终端的通道。如果 `find` 给 Bash 的结果包含一个错误,它将被弹出到 `2`,转移到 `1`,然后留在终端!
|
||||
|
||||
然后在命令结束时,Bash 看到你要打开 `stdout`(`1`) 作为到 `services.txt` 文件的通道。如果没有发生错误,结果将通过通道 `1` 进入文件。
|
||||
|
||||
相比之下,在:
|
||||
|
||||
```
|
||||
find /etc -iname "*.service" 1>services.txt 2>&1
|
||||
```
|
||||
|
||||
`1` 从一开始就指向 `services.txt`,因此任何弹出到 `2` 的内容都会导向到 `1` ,而 `1` 已经指向最终去的位置 `services.txt`,这就是它工作的原因。
|
||||
|
||||
在任何情况下,如上所述 `&>` 都是“标准输出和标准错误”的缩写,即 `2>&1`。
|
||||
|
||||
这可能有点多,但不用担心。重新导向文件描述符在 Bash 命令行和脚本中是司空见惯的事。随着本系列的深入,你将了解更多关于文件描述符的知识。下周见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/2/ampersands-and-file-descriptors-bash
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zero-mk](https://github.com/zero-mk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10587-1.html
|
||||
[2]: https://linux.cn/article-10502-1.html
|
||||
[3]: https://linux.cn/article-10529-1.html
|
||||
@ -0,0 +1,218 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (An-DJ)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10595-1.html)
|
||||
[#]: subject: (How To Check CPU, Memory And Swap Utilization Percentage In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/linux-check-cpu-memory-swap-utilization-percentage/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
如何查看 Linux 下 CPU、内存和交换分区的占用率?
|
||||
======
|
||||
|
||||
在 Linux 下有很多可以用来查看内存占用情况的命令和选项,但是我并没有看见关于内存占用率的更多的信息。
|
||||
|
||||
在大多数情况下我们只想查看内存使用情况,并没有考虑占用的百分比究竟是多少。如果你想要了解这些信息,那你看这篇文章就对了。我们将会详细地在这里帮助你解决这个问题。
|
||||
|
||||
这篇教程将会帮助你在面对 Linux 服务器下频繁的内存高占用情况时,确定内存使用情况。
|
||||
|
||||
而在同时,如果你使用的是 `free -m` 或者 `free -g`,占用情况描述地也并不是十分清楚。
|
||||
|
||||
这些格式化命令属于 Linux 高级命令。它将会对 Linux 专家和中等水平 Linux 使用者非常有用。
|
||||
|
||||
### 方法-1:如何查看 Linux 下内存占用率?
|
||||
|
||||
我们可以使用下面命令的组合来达到此目的。在该方法中,我们使用的是 `free` 和 `awk` 命令的组合来获取内存占用率。
|
||||
|
||||
如果你正在寻找其他有关于内存的文章,你可以导航到如下链接。这些文章有 [free 命令][1]、[smem 命令][2]、[ps_mem 命令][3]、[vmstat 命令][4] 及 [查看物理内存大小的多种方式][5]。
|
||||
|
||||
要获取不包含百分比符号的内存占用率:
|
||||
|
||||
```
|
||||
$ free -t | awk 'NR == 2 {print "Current Memory Utilization is : " $3/$2*100}'
|
||||
或
|
||||
$ free -t | awk 'FNR == 2 {print "Current Memory Utilization is : " $3/$2*100}'
|
||||
|
||||
Current Memory Utilization is : 20.4194
|
||||
```
|
||||
|
||||
要获取不包含百分比符号的交换分区占用率:
|
||||
|
||||
```
|
||||
$ free -t | awk 'NR == 3 {print "Current Swap Utilization is : " $3/$2*100}'
|
||||
或
|
||||
$ free -t | awk 'FNR == 3 {print "Current Swap Utilization is : " $3/$2*100}'
|
||||
|
||||
Current Swap Utilization is : 0
|
||||
```
|
||||
|
||||
要获取包含百分比符号及保留两位小数的内存占用率:
|
||||
|
||||
```
|
||||
$ free -t | awk 'NR == 2 {printf("Current Memory Utilization is : %.2f%"), $3/$2*100}'
|
||||
或
|
||||
$ free -t | awk 'FNR == 2 {printf("Current Memory Utilization is : %.2f%"), $3/$2*100}'
|
||||
|
||||
Current Memory Utilization is : 20.42%
|
||||
```
|
||||
|
||||
要获取包含百分比符号及保留两位小数的交换分区占用率:
|
||||
|
||||
```
|
||||
$ free -t | awk 'NR == 3 {printf("Current Swap Utilization is : %.2f%"), $3/$2*100}'
|
||||
或
|
||||
$ free -t | awk 'FNR == 3 {printf("Current Swap Utilization is : %.2f%"), $3/$2*100}'
|
||||
|
||||
Current Swap Utilization is : 0.00%
|
||||
```
|
||||
|
||||
如果你正在寻找有关于交换分区的其他文章,你可以导航至如下链接。这些链接有 [使用 LVM(逻辑盘卷管理)创建和扩展交换分区][6],[创建或扩展交换分区的多种方式][7] 和 [创建/删除和挂载交换分区文件的多种方式][8]。
|
||||
|
||||
键入 `free` 命令会更好地作出阐释:
|
||||
|
||||
```
|
||||
$ free
|
||||
total used free shared buff/cache available
|
||||
Mem: 15867 3730 9868 1189 2269 10640
|
||||
Swap: 17454 0 17454
|
||||
Total: 33322 3730 27322
|
||||
```
|
||||
|
||||
细节如下:
|
||||
|
||||
* `free`:是一个标准命令,用于在 Linux 下查看内存使用情况。
|
||||
* `awk`:是一个专门用来做文本数据处理的强大命令。
|
||||
* `FNR == 2`:该命令给出了每一个输入文件的行数。其基本上用于挑选出给定的行(针对于这里,它选择的是行号为 2 的行)
|
||||
* `NR == 2`:该命令给出了处理的行总数。其基本上用于过滤给出的行(针对于这里,它选择的是行号为 2 的行)
|
||||
* `$3/$2*100`:该命令将列 3 除以列 2 并将结果乘以 100。
|
||||
* `printf`:该命令用于格式化和打印数据。
|
||||
* `%.2f%`:默认情况下,其打印小数点后保留 6 位的浮点数。使用后跟的格式来约束小数位。
|
||||
|
||||
### 方法-2:如何查看 Linux 下内存占用率?
|
||||
|
||||
我们可以使用下面命令的组合来达到此目的。在这种方法中,我们使用 `free`、`grep` 和 `awk` 命令的组合来获取内存占用率。
|
||||
|
||||
要获取不包含百分比符号的内存占用率:
|
||||
|
||||
```
|
||||
$ free -t | grep Mem | awk '{print "Current Memory Utilization is : " $3/$2*100}'
|
||||
Current Memory Utilization is : 20.4228
|
||||
```
|
||||
|
||||
要获取不包含百分比符号的交换分区占用率:
|
||||
|
||||
```
|
||||
$ free -t | grep Swap | awk '{print "Current Swap Utilization is : " $3/$2*100}'
|
||||
Current Swap Utilization is : 0
|
||||
```
|
||||
|
||||
要获取包含百分比符号及保留两位小数的内存占用率:
|
||||
|
||||
```
|
||||
$ free -t | grep Mem | awk '{printf("Current Memory Utilization is : %.2f%"), $3/$2*100}'
|
||||
Current Memory Utilization is : 20.43%
|
||||
```
|
||||
|
||||
要获取包含百分比符号及保留两位小数的交换空间占用率:
|
||||
|
||||
```
|
||||
$ free -t | grep Swap | awk '{printf("Current Swap Utilization is : %.2f%"), $3/$2*100}'
|
||||
Current Swap Utilization is : 0.00%
|
||||
```
|
||||
|
||||
### 方法-1:如何查看 Linux 下 CPU 的占用率?
|
||||
|
||||
我们可以使用如下命令的组合来达到此目的。在这种方法中,我们使用 `top`、`print` 和 `awk` 命令的组合来获取 CPU 的占用率。
|
||||
|
||||
如果你正在寻找其他有关于 CPU(LCTT 译注:原文误为 memory)的文章,你可以导航至如下链接。这些文章有 [top 命令][9]、[htop 命令][10]、[atop 命令][11] 及 [Glances 命令][12]。
|
||||
|
||||
如果在输出中展示的是多个 CPU 的情况,那么你需要使用下面的方法。
|
||||
|
||||
```
|
||||
$ top -b -n1 | grep ^%Cpu
|
||||
%Cpu0 : 5.3 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 5.3 si, 0.0 st
|
||||
%Cpu3 : 5.3 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
%Cpu4 : 10.5 us, 15.8 sy, 0.0 ni, 73.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
%Cpu5 : 0.0 us, 5.0 sy, 0.0 ni, 95.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
%Cpu6 : 5.3 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
%Cpu7 : 5.3 us, 0.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
```
|
||||
|
||||
要获取不包含百分比符号的 CPU 占用率:
|
||||
|
||||
```
|
||||
$ top -b -n1 | grep ^%Cpu | awk '{cpu+=$9}END{print "Current CPU Utilization is : " 100-cpu/NR}'
|
||||
Current CPU Utilization is : 21.05
|
||||
```
|
||||
|
||||
要获取包含百分比符号及保留两位小数的 CPU 占用率:
|
||||
|
||||
```
|
||||
$ top -b -n1 | grep ^%Cpu | awk '{cpu+=$9}END{printf("Current CPU Utilization is : %.2f%"), 100-cpu/NR}'
|
||||
Current CPU Utilization is : 14.81%
|
||||
```
|
||||
|
||||
### 方法-2:如何查看 Linux 下 CPU 的占用率?
|
||||
|
||||
我们可以使用如下命令的组合来达到此目的。在这种方法中,我们使用的是 `top`、`print`/`printf` 和 `awk` 命令的组合来获取 CPU 的占用率。
|
||||
|
||||
如果在单个输出中一起展示了所有的 CPU 的情况,那么你需要使用下面的方法。
|
||||
|
||||
```
|
||||
$ top -b -n1 | grep ^%Cpu
|
||||
%Cpu(s): 15.3 us, 7.2 sy, 0.8 ni, 69.0 id, 6.7 wa, 0.0 hi, 1.0 si, 0.0 st
|
||||
```
|
||||
|
||||
要获取不包含百分比符号的 CPU 占用率:
|
||||
|
||||
```
|
||||
$ top -b -n1 | grep ^%Cpu | awk '{print "Current CPU Utilization is : " 100-$8}'
|
||||
Current CPU Utilization is : 5.6
|
||||
```
|
||||
|
||||
要获取包含百分比符号及保留两位小数的 CPU 占用率:
|
||||
|
||||
```
|
||||
$ top -b -n1 | grep ^%Cpu | awk '{printf("Current CPU Utilization is : %.2f%"), 100-$8}'
|
||||
Current CPU Utilization is : 5.40%
|
||||
```
|
||||
|
||||
如下是一些细节:
|
||||
|
||||
* `top`:是一种用于查看当前 Linux 系统下正在运行的进程的非常好的命令。
|
||||
* `-b`:选项允许 `top` 命令切换至批处理的模式。当你从本地系统运行 `top` 命令至远程系统时,它将会非常有用。
|
||||
* `-n1`:迭代次数。
|
||||
* `^%Cpu`:过滤以 `%CPU` 开头的行。
|
||||
* `awk`:是一种专门用来做文本数据处理的强大命令。
|
||||
* `cpu+=$9`:对于每一行,将第 9 列添加至变量 `cpu`。
|
||||
* `printf`:该命令用于格式化和打印数据。
|
||||
* `%.2f%`:默认情况下,它打印小数点后保留 6 位的浮点数。使用后跟的格式来限制小数位数。
|
||||
* `100-cpu/NR`:最终打印出 CPU 平均占用率,即用 100 减去其并除以行数。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-check-cpu-memory-swap-utilization-percentage/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[An-DJ](https://github.com/An-DJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
||||
[2]: https://www.2daygeek.com/smem-linux-memory-usage-statistics-reporting-tool/
|
||||
[3]: https://www.2daygeek.com/ps_mem-report-core-memory-usage-accurately-in-linux/
|
||||
[4]: https://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
||||
[5]: https://www.2daygeek.com/easy-ways-to-check-size-of-physical-memory-ram-in-linux/
|
||||
[6]: https://www.2daygeek.com/how-to-create-extend-swap-partition-in-linux-using-lvm/
|
||||
[7]: https://www.2daygeek.com/add-extend-increase-swap-space-memory-file-partition-linux/
|
||||
[8]: https://www.2daygeek.com/shell-script-create-add-extend-swap-space-linux/
|
||||
[9]: https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/
|
||||
[10]: https://www.2daygeek.com/linux-htop-command-linux-system-performance-resource-monitoring-tool/
|
||||
[11]: https://www.2daygeek.com/atop-system-process-performance-monitoring-tool/
|
||||
[12]: https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/
|
||||
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10584-1.html)
|
||||
[#]: subject: (Two graphical tools for manipulating PDFs on the Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/2/manipulating-pdfs-linux)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
两款 Linux 桌面中的图形化操作 PDF 的工具
|
||||
======
|
||||
|
||||
> PDF-Shuffler 和 PDF Chain 是在 Linux 中修改 PDF 的绝佳工具。
|
||||
|
||||

|
||||
|
||||
由于我谈论和写作了些 PDF 及使用它们的工具的文章,有些人认为我喜欢这种格式。其实我并不是,由于各种原因,我不会深入它。
|
||||
|
||||
我不会说 PDF 是我个人和职业生活中的一个躲不开的坏事 - 而实际上它们不是那么好。通常即使有更好的替代方案来交付文档,通常我也必须使用 PDF。
|
||||
|
||||
当我使用 PDF 时,通常是在白天工作时在其他的操作系统上使用,我使用 Adobe Acrobat 进行操作。但是当我必须在 Linux 桌面上使用 PDF 时呢?我们来看看我用来操作 PDF 的两个图形工具。
|
||||
|
||||
### PDF-Shuffler
|
||||
|
||||
顾名思义,你可以使用 [PDF-Shuffler][1] 在 PDF 文件中移动页面。它可以做得更多,但该软件的功能是有限的。这并不意味着 PDF-Shuffler 没用。它有用,很有用。
|
||||
|
||||
你可以将 PDF-Shuffler 用来:
|
||||
|
||||
* 从 PDF 文件中提取页面
|
||||
* 将页面添加到文件中
|
||||
* 重新排列文件中的页面
|
||||
|
||||
请注意,PDF-Shuffler 有一些依赖项,如 pyPDF 和 python-gtk。通常,通过包管理器安装它是最快且最不令人沮丧的途径。
|
||||
|
||||
假设你想从 PDF 中提取页面,也许是作为你书中的样本章节。选择 “File > Add”打开 PDF 文件。
|
||||
|
||||
|
||||
|
||||
要提取第 7 页到第 9 页,请按住 `Ctrl` 并单击选择页面。然后,右键单击并选择 “Export selection”。
|
||||
|
||||
|
||||
|
||||
选择要保存文件的目录,为其命名,然后单击 “Save”。
|
||||
|
||||
要添加文件 —— 例如,要添加封面或重新插入已扫描的且已签名的合同或者应用 - 打开 PDF 文件,然后选择 “File > Add” 并找到要添加的 PDF 文件。单击 “Open”。
|
||||
|
||||
PDF-Shuffler 有个不好的地方就是添加页面到你正在处理的 PDF 文件末尾。单击并将添加的页面拖动到文件中的所需位置。你一次只能在文件中单击并拖动一个页面。
|
||||
|
||||
|
||||
|
||||
### PDF Chain
|
||||
|
||||
我是 [PDFtk][2] 的忠实粉丝,它是一个可以对 PDF 做一些有趣操作的命令行工具。由于我不经常使用它,我不记得所有 PDFtk 的命令和选项。
|
||||
|
||||
[PDF Chain][3] 是 PDFtk 命令行的一个很好的替代品。它可以让你一键使用 PDFtk 最常用的命令。无需使用菜单,你可以:
|
||||
|
||||
* 合并 PDF(包括旋转一个或多个文件的页面)
|
||||
* 从 PDF 中提取页面并将其保存到单个文件中
|
||||
* 为 PDF 添加背景或水印
|
||||
* 将附件添加到文件
|
||||
|
||||
|
||||
|
||||
你也可以做得更多。点击 “Tools” 菜单,你可以:
|
||||
|
||||
* 从 PDF 中提取附件
|
||||
* 压缩或解压缩文件
|
||||
* 从文件中提取元数据
|
||||
* 用外部[数据][4]填充 PDF 表格
|
||||
* [扁平化][5] PDF
|
||||
* 从 PDF 表单中删除 [XML 表格结构][6](XFA)数据
|
||||
|
||||
老实说,我只使用 PDF Chain 或 PDFtk 提取附件、压缩或解压缩 PDF。其余的对我来说基本没听说。
|
||||
|
||||
### 总结
|
||||
|
||||
Linux 上用于处理 PDF 的工具数量一直让我感到吃惊。它们的特性和功能的广度和深度也是如此。无论是命令行还是图形,我总能找到一个能做我需要的。在大多数情况下,PDF Mod 和 PDF Chain 对我来说效果很好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/manipulating-pdfs-linux
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://savannah.nongnu.org/projects/pdfshuffler/
|
||||
[2]: https://en.wikipedia.org/wiki/PDFtk
|
||||
[3]: http://pdfchain.sourceforge.net/
|
||||
[4]: http://www.verypdf.com/pdfform/fdf.htm
|
||||
[5]: http://pdf-tips-tricks.blogspot.com/2009/03/flattening-pdf-layers.html
|
||||
[6]: http://en.wikipedia.org/wiki/XFA
|
||||
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10583-1.html)
|
||||
[#]: subject: (How to use Linux Cockpit to manage system performance)
|
||||
[#]: via: (https://www.networkworld.com/article/3340038/linux/sitting-in-the-linux-cockpit.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何使用 Linux Cockpit 来管理系统性能
|
||||
======
|
||||
|
||||
> Linux Cockpit 是一个基于 Web 界面的应用,它提供了对系统的图形化管理。看下它能够控制哪些。
|
||||
|
||||

|
||||
|
||||
如果你还没有尝试过相对较新的 Linux Cockpit,你可能会对它所能做的一切感到惊讶。它是一个用户友好的基于 web 的控制台,提供了一些非常简单的方法来管理 Linux 系统 —— 通过 web。你可以通过一个非常简单的 web 来监控系统资源、添加或删除帐户、监控系统使用情况、关闭系统以及执行其他一些其他任务。它的设置和使用也非常简单。
|
||||
|
||||
虽然许多 Linux 系统管理员将大部分时间花在命令行上,但使用 PuTTY 等工具访问远程系统并不总能提供最有用的命令输出。Linux Cockpit 提供了图形和易于使用的表单,来查看性能情况并对系统进行更改。
|
||||
|
||||
Linux Cockpit 能让你查看系统性能的许多方面并进行配置更改,但任务列表可能取决于你使用的特定 Linux。任务分类包括以下内容:
|
||||
|
||||
* 监控系统活动(CPU、内存、磁盘 IO 和网络流量) —— **系统**
|
||||
* 查看系统日志条目 —— **日志**
|
||||
* 查看磁盘分区的容量 —— **存储**
|
||||
* 查看网络活动(发送和接收) —— **网络**
|
||||
* 查看用户帐户 —— **帐户**
|
||||
* 检查系统服务的状态 —— **服务**
|
||||
* 提取已安装应用的信息 —— **应用**
|
||||
* 查看和安装可用更新(如果以 root 身份登录)并在需要时重新启动系统 —— **软件更新**
|
||||
* 打开并使用终端窗口 —— **终端**
|
||||
|
||||
某些 Linux Cockpit 安装还允许你运行诊断报告、转储内核、检查 SELinux(安全)设置和列出订阅。
|
||||
|
||||
以下是 Linux Cockpit 显示的系统活动示例:
|
||||
|
||||
![cockpit activity][1]
|
||||
|
||||
*Linux Cockpit 显示系统活动*
|
||||
|
||||
### 如何设置 Linux Cockpit
|
||||
|
||||
在某些 Linux 发行版(例如,最新的 RHEL)中,Linux Cockpit 可能已经安装并可以使用。在其他情况下,你可能需要采取一些简单的步骤来安装它并使其可使用。
|
||||
|
||||
例如,在 Ubuntu 上,这些命令应该可用:
|
||||
|
||||
```
|
||||
$ sudo apt-get install cockpit
|
||||
$ man cockpit <== just checking
|
||||
$ sudo systemctl enable --now cockpit.socket
|
||||
$ netstat -a | grep 9090
|
||||
tcp6 0 0 [::]:9090 [::]:* LISTEN
|
||||
$ sudo systemctl enable --now cockpit.socket
|
||||
$ sudo ufw allow 9090
|
||||
```
|
||||
|
||||
启用 Linux Cockpit 后,在浏览器中打开 `https://<system-name-or-IP>:9090`
|
||||
|
||||
可以在 [Cockpit 项目][2] 中找到可以使用 Cockpit 的发行版列表以及安装说明。
|
||||
|
||||
没有额外的配置,Linux Cockpit 将无法识别 `sudo` 权限。如果你被禁止使用 Cockpit 进行更改,你将会在你点击的按钮上看到一个红色的通用禁止标志。
|
||||
|
||||
要使 `sudo` 权限有效,你需要确保用户位于 `/etc/group` 文件中的 `wheel`(RHEL)或 `adm` (Debian)组中,即服务器当以 root 用户身份登录 Cockpit 并且用户在登录 Cockpit 时选择“重用我的密码”时,已勾选了 “Server Administrator”。
|
||||
|
||||
在你管理的系统位在千里之外或者没有控制台时,能使用图形界面控制也不错。虽然我喜欢在控制台上工作,但我偶然也乐于见到图形或者按钮。Linux Cockpit 为日常管理任务提供了非常有用的界面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3340038/linux/sitting-in-the-linux-cockpit.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/cockpit-activity-100787994-large.jpg
|
||||
[2]: https://cockpit-project.org/running.html
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,119 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10588-1.html)
|
||||
[#]: subject: (FinalCrypt – An Open Source File Encryption Application)
|
||||
[#]: via: (https://itsfoss.com/finalcrypt/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
FinalCrypt:一个开源文件加密应用
|
||||
======
|
||||
|
||||
我通常不会加密文件,但如果我打算整理我的重要文件或凭证,加密程序就会派上用场。
|
||||
|
||||
你可能已经在使用像 [GnuPG][1] 这样的程序来帮助你加密/解密 Linux 上的文件。还有 [EncryptPad][2] 也可以加密你的笔记。
|
||||
|
||||
但是,我看到了一个名为 FinalCrypt 的新的免费开源加密工具。你可以在 [GitHub 页面][3]上查看其最新的版本和源码。
|
||||
|
||||
在本文中,我将分享使用此工具的经验。请注意,我不会将它与其他程序进行比较 —— 因此,如果你想要多个程序之间的详细比较,请在评论中告诉我们。
|
||||
|
||||
![FinalCrypt][4]
|
||||
|
||||
### 使用 FinalCrypt 加密文件
|
||||
|
||||
FinalCrypt 使用[一次性密码本][5]密钥生成密码来加密文件。换句话说,它会生成一个 OTP 密钥,你将使用该密钥加密或解密你的文件。
|
||||
|
||||
根据你指定的密钥大小,密钥是完全随机的。因此,没有密钥文件就无法解密文件。
|
||||
|
||||
虽然 OTP 密钥用于加密/解密简单而有效,但管理或保护密钥文件对某些人来说可能是不方便的。
|
||||
|
||||
如果要使用 FinalCrypt,可以从它的网站下载 DEB/RPM 文件。FinalCrypt 也可用于 Windows 和 macOS。
|
||||
|
||||
- [下载 FinalCrypt](https://sites.google.com/site/ronuitholland/home/finalcrypt)
|
||||
|
||||
下载后,只需双击该 [deb][6] 或 rpm 文件就能安装。如果需要,你还可以从源码编译。
|
||||
|
||||
### 使用 FileCrypt
|
||||
|
||||
该视频演示了如何使用FinalCrypt:
|
||||
|
||||
<https://youtu.be/6Ir8VcZ26E4>
|
||||
|
||||
如果你喜欢 Linux 相关的视频,请[订阅我们的 YouTube 频道][7]。
|
||||
|
||||
安装 FinalCrypt 后,你将在已安装的应用列表中找到它。从这里启动它。
|
||||
|
||||
启动后,你将看到(分割的)两栏,一个进行加密/解密,另一个选择 OTP 文件。
|
||||
|
||||
![Using FinalCrypt for encrypting files in Linux][8]
|
||||
|
||||
首先,你必须生成 OTP 密钥。下面是做法:
|
||||
|
||||
![finalcrypt otp][9]
|
||||
|
||||
请注意你的文件名可以是任何内容 —— 但你需要确保密钥文件的大小大于或等于要加密的文件。我觉得这很荒谬,但事实就是如此。
|
||||
|
||||
![][10]
|
||||
|
||||
生成文件后,选择窗口右侧的密钥,然后选择要在窗口左侧加密的文件。
|
||||
|
||||
生成 OTP 后,你会看到高亮显示的校验和、密钥文件大小和有效状态:
|
||||
|
||||
![][11]
|
||||
|
||||
选择之后,你只需要点击 “Encrypt” 来加密这些文件,如果已经加密,那么点击 “Decrypt” 来解密这些文件。
|
||||
|
||||
![][12]
|
||||
|
||||
你还可以在命令行中使用 FinalCrypt 来自动执行加密作业。
|
||||
|
||||
#### 如何保护你的 OTP 密钥?
|
||||
|
||||
加密/解密你想要保护的文件很容易。但是,你应该在哪里保存你的 OTP 密钥?
|
||||
|
||||
如果你未能将 OTP 密钥保存在安全的地方,那么它几乎没用。
|
||||
|
||||
嗯,最好的方法之一是使用专门的 USB 盘保存你的密钥。只需要在解密文件时将它插入即可。
|
||||
|
||||
除此之外,如果你认为足够安全,你可以将密钥保存在[云服务][13]中。
|
||||
|
||||
有关 FinalCrypt 的更多信息,请访问它的网站。
|
||||
|
||||
[FinalCrypt](https://sites.google.com/site/ronuitholland/home/finalcrypt)
|
||||
|
||||
### 总结
|
||||
|
||||
它开始时看上去有点复杂,但它实际上是 Linux 中一个简单且用户友好的加密程序。如果你想看看其他的,还有一些其他的[加密保护文件夹][14]的程序。
|
||||
|
||||
你如何看待 FinalCrypt?你还知道其他类似可能更好的程序么?请在评论区告诉我们,我们将会查看的!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/finalcrypt/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gnupg.org/
|
||||
[2]: https://itsfoss.com/encryptpad-encrypted-text-editor-linux/
|
||||
[3]: https://github.com/ron-from-nl/FinalCrypt
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/finalcrypt.png?resize=800%2C450&ssl=1
|
||||
[5]: https://en.wikipedia.org/wiki/One-time_pad
|
||||
[6]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[7]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/finalcrypt.jpg?fit=800%2C439&ssl=1
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/finalcrypt-otp-key.jpg?resize=800%2C443&ssl=1
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/finalcrypt-otp-generate.jpg?ssl=1
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/finalcrypt-key.jpg?fit=800%2C420&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/finalcrypt-encrypt.jpg?ssl=1
|
||||
[13]: https://itsfoss.com/cloud-services-linux/
|
||||
[14]: https://itsfoss.com/password-protect-folder-linux/
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/finalcrypt.png?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,124 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (An-DJ)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10580-1.html)
|
||||
[#]: subject: (How to Change User Password in Ubuntu [Beginner’s Tutorial])
|
||||
[#]: via: (https://itsfoss.com/change-password-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
新手教程:Ubuntu 下如何修改用户密码
|
||||
======
|
||||
|
||||
> 想要在 Ubuntu 下修改 root 用户的密码?那我们来学习下如何在 Ubuntu Linux 下修改任意用户的密码。我们会讨论在终端下修改和在图形界面(GUI)修改两种做法。
|
||||
|
||||
那么,在 Ubuntu 下什么时候会需要修改密码呢?这里我给出如下两种场景。
|
||||
|
||||
- 当你刚安装 [Ubuntu][1] 系统时,你会创建一个用户并且为之设置一个密码。这个初始密码可能安全性较弱或者太过于复杂,你会想要对它做出修改。
|
||||
- 如果你是系统管理员,你可能需要去修改在你管理的系统内其他用户的密码。
|
||||
|
||||
当然,你可能会有其他的一些原因做这样的一件事。不过现在问题来了,我们到底如何在 Ubuntu 或其它 Linux 系统下修改单个用户的密码呢?
|
||||
|
||||
在这个快速教程中,我将会展示给你在 Ubuntu 中如何使用命令行和图形界面(GUI)两种方式修改密码。
|
||||
|
||||
### 在 Ubuntu 中修改用户密码 —— 通过命令行
|
||||
|
||||
![如何在 Ubuntu Linux 下修改用户密码][2]
|
||||
|
||||
在 Ubuntu 下修改用户密码其实非常简单。事实上,在任何 Linux 发行版上修改的方式都是一样的,因为你要使用的是叫做 `passwd` 的普通 Linux 命令来达到此目的。
|
||||
|
||||
如果你想要修改你的当前密码,只需要简单地在终端执行此命令:
|
||||
|
||||
```
|
||||
passwd
|
||||
```
|
||||
|
||||
系统会要求你输入当前密码和两次新的密码。
|
||||
|
||||
在键入密码时,你不会从屏幕上看到任何东西。这在 UNIX 和 Linux 系统中是非常正常的表现。
|
||||
|
||||
```
|
||||
passwd
|
||||
Changing password for abhishek.
|
||||
(current) UNIX password:
|
||||
Enter new UNIX password:
|
||||
Retype new UNIX password:
|
||||
passwd: password updated successfully
|
||||
```
|
||||
|
||||
由于这是你的管理员账户,你刚刚修改了 Ubuntu 下 sudo 密码,但你甚至没有意识到这个操作。(LCTT 译注:执行 sudo 操作时,输入的是的用户自身的密码,此处修改的就是自身的密码。而所说的“管理员账户”指的是该用户处于可以执行 `sudo` 命令的用户组中。本文此处描述易引起误会,特注明。)
|
||||
|
||||
![在 Linux 命令行中修改用户密码][3]
|
||||
|
||||
如果你想要修改其他用户的密码,你也可以使用 `passwd` 命令来做。但是在这种情况下,你将不得不使用`sudo`。(LCTT 译注:此处执行 `sudo`,要先输入你的 sudo 密码 —— 如上提示已经修改,再输入给其它用户设置的新密码 —— 两次。)
|
||||
|
||||
```
|
||||
sudo passwd <user_name>
|
||||
```
|
||||
|
||||
如果你对密码已经做出了修改,不过之后忘记了,不要担心。你可以[很容易地在Ubuntu下重置密码][4].
|
||||
|
||||
### 修改 Ubuntu 下 root 用户密码
|
||||
|
||||
默认情况下,Ubuntu 中 root 用户是没有密码的。不必惊讶,你并不是在 Ubuntu 下一直使用 root 用户。不太懂?让我快速地给你解释下。
|
||||
|
||||
当[安装 Ubuntu][5] 时,你会被强制创建一个用户。这个用户拥有管理员访问权限。这个管理员用户可以通过 `sudo` 命令获得 root 访问权限。但是,该用户使用的是自身的密码,而不是 root 账户的密码(因为就没有)。
|
||||
|
||||
你可以使用 `passwd` 命令来设置或修改 root 用户的密码。然而,在大多数情况下,你并不需要它,而且你不应该去做这样的事。
|
||||
|
||||
你将必须使用 `sudo` 命令(对于拥有管理员权限的账户)。~~如果 root 用户的密码之前没有被设置,它会要求你设置。另外,你可以使用已有的 root 密码对它进行修改。~~(LCTT 译注:此处描述有误,使用 `sudo` 或直接以 root 用户执行 `passwd` 命令时,不需要输入该被改变密码的用户的当前密码。)
|
||||
|
||||
```
|
||||
sudo password root
|
||||
```
|
||||
|
||||
### 在 Ubuntu 下使用图形界面(GUI)修改密码
|
||||
|
||||
我这里使用的是 GNOME 桌面环境,Ubuntu 版本为 18.04。这些步骤对于其他的桌面环境和 Ubuntu 版本应该差别不大。
|
||||
|
||||
打开菜单(按下 `Windows`/`Super` 键)并搜索 “Settings”(设置)。
|
||||
|
||||
在 “Settings” 中,向下滚动一段距离打开进入 “Details”。
|
||||
|
||||
![在 Ubuntu GNOME Settings 中进入 Details][6]
|
||||
|
||||
在这里,点击 “Users” 获取系统下可见的所有用户。
|
||||
|
||||
![Ubuntu 下用户设置][7]
|
||||
|
||||
你可以选择任一你想要的用户,包括你的主要管理员账户。你需要先解锁用户并点击 “Password” 区域。
|
||||
|
||||
![Ubuntu 下修改用户密码][8]
|
||||
|
||||
你会被要求设置密码。如果你正在修改的是你自己的密码,你将必须也输入当前使用的密码。
|
||||
|
||||
![Ubuntu 下修改用户密码][9]
|
||||
|
||||
做好这些后,点击上面的 “Change” 按钮,这样就完成了。你已经成功地在 Ubuntu 下修改了用户密码。
|
||||
|
||||
我希望这篇快速精简的小教程能够帮助你在 Ubuntu 下修改用户密码。如果你对此还有一些问题或建议,请在下方留下评论。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/change-password-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[An-DJ](https://github.com/An-DJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ubuntu.com/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-password-ubuntu-linux.png?resize=800%2C450&ssl=1
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-linux-1.jpg?resize=800%2C253&ssl=1
|
||||
[4]: https://itsfoss.com/how-to-hack-ubuntu-password/
|
||||
[5]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-ubuntu-gui-2.jpg?resize=800%2C484&ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-ubuntu-gui-3.jpg?resize=800%2C488&ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-ubuntu-gui-4.jpg?resize=800%2C555&ssl=1
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-user-password-ubuntu-gui-1.jpg?ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/change-password-ubuntu-linux.png?fit=800%2C450&ssl=1
|
||||
194
published/20190219 Logical - in Bash.md
Normal file
194
published/20190219 Logical - in Bash.md
Normal file
@ -0,0 +1,194 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "zero-mk"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10596-1.html"
|
||||
[#]: subject: "Logical & in Bash"
|
||||
[#]: via: "https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash"
|
||||
[#]: author: "Paul Brown https://www.linux.com/users/bro66"
|
||||
|
||||
Bash 中的逻辑和(&)
|
||||
======
|
||||
> 在 Bash 中,你可以使用 & 作为 AND(逻辑和)操作符。
|
||||
|
||||

|
||||
|
||||
有人可能会认为两篇文章中的 `&` 意思差不多,但实际上并不是。虽然 [第一篇文章讨论了如何在命令末尾使用 & 来将命令转到后台运行][1],在之后剖析了流程管理,第二篇文章将 [ & 看作引用文件描述符的方法][2],这些文章让我们知道了,与 `<` 和 `>` 结合使用后,你可以将输入或输出引导到别的地方。
|
||||
|
||||
但我们还没接触过作为 AND 操作符使用的 `&`。所以,让我们来看看。
|
||||
|
||||
### & 是一个按位运算符
|
||||
|
||||
如果你十分熟悉二进制数操作,你肯定听说过 AND 和 OR 。这些是按位操作,对二进制数的各个位进行操作。在 Bash 中,使用 `&` 作为 AND 运算符,使用 `|` 作为 OR 运算符:
|
||||
|
||||
**AND**:
|
||||
|
||||
```
|
||||
0 & 0 = 0
|
||||
0 & 1 = 0
|
||||
1 & 0 = 0
|
||||
1 & 1 = 1
|
||||
```
|
||||
|
||||
**OR**:
|
||||
|
||||
```
|
||||
0 | 0 = 0
|
||||
0 | 1 = 1
|
||||
1 | 0 = 1
|
||||
1 | 1 = 1
|
||||
```
|
||||
|
||||
你可以通过对任何两个数字进行 AND 运算并使用 `echo` 输出结果:
|
||||
|
||||
```
|
||||
$ echo $(( 2 & 3 )) # 00000010 AND 00000011 = 00000010
|
||||
2
|
||||
$ echo $(( 120 & 97 )) # 01111000 AND 01100001 = 01100000
|
||||
96
|
||||
```
|
||||
|
||||
OR(`|`)也是如此:
|
||||
|
||||
```
|
||||
$ echo $(( 2 | 3 )) # 00000010 OR 00000011 = 00000011
|
||||
3
|
||||
$ echo $(( 120 | 97 )) # 01111000 OR 01100001 = 01111001
|
||||
121
|
||||
```
|
||||
|
||||
说明:
|
||||
|
||||
1. 使用 `(( ... ))` 告诉 Bash 双括号之间的内容是某种算术或逻辑运算。`(( 2 + 2 ))`、 `(( 5 % 2 ))` (`%` 是[求模][3]运算符)和 `((( 5 % 2 ) + 1))`(等于 3)都可以工作。
|
||||
2. [像变量一样][4],使用 `$` 提取值,以便你可以使用它。
|
||||
3. 空格并没有影响:`((2+3))` 等价于 `(( 2+3 ))` 和 `(( 2 + 3 ))`。
|
||||
4. Bash 只能对整数进行操作。试试这样做: `(( 5 / 2 ))` ,你会得到 `2`;或者这样 `(( 2.5 & 7 ))` ,但会得到一个错误。然后,在按位操作中使用除了整数之外的任何东西(这就是我们现在所讨论的)通常是你不应该做的事情。
|
||||
|
||||
**提示:** 如果你想看看十进制数字在二进制下会是什么样子,你可以使用 `bc` ,这是一个大多数 Linux 发行版都预装了的命令行计算器。比如:
|
||||
|
||||
```
|
||||
bc <<< "obase=2; 97"
|
||||
```
|
||||
|
||||
这个操作将会把 `97` 转换成十二进制(`obase` 中的 `o` 代表 “output” ,也即,“输出”)。
|
||||
|
||||
```
|
||||
bc <<< "ibase=2; 11001011"
|
||||
```
|
||||
|
||||
这个操作将会把 `11001011` 转换成十进制(`ibase` 中的 `i` 代表 “input”,也即,“输入”)。
|
||||
|
||||
### && 是一个逻辑运算符
|
||||
|
||||
虽然它使用与其按位表达相同的逻辑原理,但 Bash 的 `&&` 运算符只能呈现两个结果:`1`(“真值”)和`0`(“假值”)。对于 Bash 来说,任何不是 `0` 的数字都是 “真值”,任何等于 `0` 的数字都是 “假值”。什么也是 “假值”同时也不是数字呢:
|
||||
|
||||
```
|
||||
$ echo $(( 4 && 5 )) # 两个非零数字,两个为 true = true
|
||||
1
|
||||
$ echo $(( 0 && 5 )) # 有一个为零,一个为 false = false
|
||||
0
|
||||
$ echo $(( b && 5 )) # 其中一个不是数字,一个为 false = false
|
||||
0
|
||||
```
|
||||
|
||||
与 `&&` 类似, OR 对应着 `||` ,用法正如你想的那样。
|
||||
|
||||
以上这些都很简单……直到它用在命令的退出状态时。
|
||||
|
||||
### && 是命令退出状态的逻辑运算符
|
||||
|
||||
[正如我们在之前的文章中看到的][2],当命令运行时,它会输出错误消息。更重要的是,对于今天的讨论,它在结束时也会输出一个数字。此数字称为“返回码”,如果为 0,则表示该命令在执行期间未遇到任何问题。如果是任何其他数字,即使命令完成,也意味着某些地方出错了。
|
||||
|
||||
所以 0 意味着是好的,任何其他数字都说明有问题发生,并且,在返回码的上下文中,0 意味着“真”,其他任何数字都意味着“假”。对!这 **与你所熟知的逻辑操作完全相反** ,但是你能用这个做什么? 不同的背景,不同的规则。这种用处很快就会显现出来。
|
||||
|
||||
让我们继续!
|
||||
|
||||
返回码 *临时* 储存在 [特殊变量][5] `?` 中 —— 是的,我知道:这又是一个令人迷惑的选择。但不管怎样,[别忘了我们在讨论变量的文章中说过][4],那时我们说你要用 `$` 符号来读取变量中的值,在这里也一样。所以,如果你想知道一个命令是否顺利运行,你需要在命令结束后,在运行别的命令之前马上用 `$?` 来读取 `?` 变量的值。
|
||||
|
||||
试试下面的命令:
|
||||
|
||||
```
|
||||
$ find /etc -iname "*.service"
|
||||
find: '/etc/audisp/plugins.d': Permission denied
|
||||
/etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service
|
||||
/etc/systemd/system/dbus-org.freedesktop.ModemManager1.service
|
||||
[......]
|
||||
```
|
||||
|
||||
[正如你在上一篇文章中看到的一样][2],普通用户权限在 `/etc` 下运行 `find` 通常将抛出错误,因为它试图读取你没有权限访问的子目录。
|
||||
|
||||
所以,如果你在执行 `find` 后立马执行……
|
||||
|
||||
```
|
||||
echo $?
|
||||
```
|
||||
|
||||
……,它将打印 `1`,表明存在错误。
|
||||
|
||||
(注意:当你在一行中运行两遍 `echo $?` ,你将得到一个 `0` 。这是因为 `$?` 将包含第一个 `echo $?` 的返回码,而这条命令按理说一定会执行成功。所以学习如何使用 `$?` 的第一课就是: **单独执行 `$?`** 或者将它保存在别的安全的地方 —— 比如保存在一个变量里,不然你会很快丢失它。)
|
||||
|
||||
一个直接使用 `?` 变量的用法是将它并入一串链式命令列表,这样 Bash 运行这串命令时若有任何操作失败,后面命令将终止。例如,你可能熟悉构建和编译应用程序源代码的过程。你可以像这样手动一个接一个地运行它们:
|
||||
|
||||
```
|
||||
$ configure
|
||||
.
|
||||
.
|
||||
.
|
||||
$ make
|
||||
.
|
||||
.
|
||||
.
|
||||
$ make install
|
||||
.
|
||||
.
|
||||
.
|
||||
```
|
||||
|
||||
你也可以把这三行合并成一行……
|
||||
|
||||
```
|
||||
$ configure; make; make install
|
||||
```
|
||||
|
||||
…… 但你要希望上天保佑。
|
||||
|
||||
为什么这样说呢?因为你这样做是有缺点的,比方说 `configure` 执行失败了, Bash 将仍会尝试执行 `make` 和 `sudo make install`——就算没东西可 `make` ,实际上,是没东西会安装。
|
||||
|
||||
聪明一点的做法是:
|
||||
|
||||
```
|
||||
$ configure && make && make install
|
||||
```
|
||||
|
||||
这将从每个命令中获取退出码,并将其用作链式 `&&` 操作的操作数。
|
||||
|
||||
但是,没什么好抱怨的,Bash 知道如果 `configure` 返回非零结果,整个过程都会失败。如果发生这种情况,不必运行 `make` 来检查它的退出代码,因为无论如何都会失败的。因此,它放弃运行 `make`,只是将非零结果传递给下一步操作。并且,由于 `configure && make` 传递了错误,Bash 也不必运行`make install`。这意味着,在一长串命令中,你可以使用 `&&` 连接它们,并且一旦失败,你可以节省时间,因为其他命令会立即被取消运行。
|
||||
|
||||
你可以类似地使用 `||`,OR 逻辑操作符,这样就算只有一部分命令成功执行,Bash 也能运行接下来链接在一起的命令。
|
||||
|
||||
鉴于所有这些(以及我们之前介绍过的内容),你现在应该更清楚地了解我们在 [这篇文章开头][1] 出现的命令行:
|
||||
|
||||
```
|
||||
mkdir test_dir 2>/dev/null || touch backup/dir/images.txt && find . -iname "*jpg" > backup/dir/images.txt &
|
||||
```
|
||||
|
||||
因此,假设你从具有读写权限的目录运行上述内容,它做了什么以及如何做到这一点?它如何避免不合时宜且可能导致执行中断的错误?下周,除了给你这些答案的结果,我们将讨论圆括号,不要错过了哟!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zero-MK](https://github.com/zero-mk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10587-1.html
|
||||
[2]: https://linux.cn/article-10591-1.html
|
||||
[3]: https://en.wikipedia.org/wiki/Modulo_operation
|
||||
[4]: https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-otherwise
|
||||
[5]: https://www.gnu.org/software/bash/manual/html_node/Special-Parameters.html
|
||||
@ -0,0 +1,135 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10600-1.html)
|
||||
[#]: subject: (An Automated Way To Install Essential Applications On Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/an-automated-way-to-install-essential-applications-on-ubuntu/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
在 Ubuntu 上自动化安装基本应用的方法
|
||||
======
|
||||
|
||||

|
||||
|
||||
默认安装的 Ubuntu 并未预先安装所有必需的应用。你可能需要在网上花几个小时或者向其他 Linux 用户寻求帮助才能找到并安装 Ubuntu 所需的应用。如果你是新手,那么你肯定需要花更多的时间来学习如何从命令行(使用 `apt-get` 或 `dpkg`)或从 Ubuntu 软件中心搜索和安装应用。一些用户,特别是新手,可能希望轻松快速地安装他们喜欢的每个应用。如果你是其中之一,不用担心。在本指南中,我们将了解如何使用名为 “Alfred” 的简单命令行程序在 Ubuntu 上安装基本应用。
|
||||
|
||||
Alfred 是用 Python 语言编写的自由、开源脚本。它使用 Zenity 创建了一个简单的图形界面,用户只需点击几下鼠标即可轻松选择和安装他们选择的应用。你不必花费数小时来搜索所有必要的应用程序、PPA、deb、AppImage、snap 或 flatpak。Alfred 将所有常见的应用、工具和小程序集中在一起,并自动安装所选的应用。如果你是最近从 Windows 迁移到 Ubuntu Linux 的新手,Alfred 会帮助你在新安装的 Ubuntu 系统上进行无人值守的软件安装,而无需太多用户干预。请注意,还有一个名称相似的 Mac OS 应用,但两者有不同的用途。
|
||||
|
||||
### 在 Ubuntu 上安装 Alfred
|
||||
|
||||
Alfred 安装很简单!只需下载脚本并启动它。就这么简单。
|
||||
|
||||
```
|
||||
$ wget https://raw.githubusercontent.com/derkomai/alfred/master/alfred.py
|
||||
$ python3 alfred.py
|
||||
```
|
||||
|
||||
或者,使用 `wget` 下载脚本,如上所示,只需将 `alfred.py` 移动到 `$PATH` 中:
|
||||
|
||||
```
|
||||
$ sudo cp alfred.py /usr/local/bin/alfred
|
||||
```
|
||||
|
||||
使其可执行:
|
||||
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/alfred
|
||||
```
|
||||
|
||||
并使用命令启动它:
|
||||
|
||||
```
|
||||
$ alfred
|
||||
```
|
||||
|
||||
### 使用 Alfred 脚本轻松快速地在 Ubuntu 上安装基本应用程序
|
||||
|
||||
按照上面所说启动 Alfred 脚本。这就是 Alfred 默认界面的样子。
|
||||
|
||||
![][2]
|
||||
|
||||
如你所见,Alfred 列出了许多最常用的应用类型,例如:
|
||||
|
||||
* 网络浏览器,
|
||||
* 邮件客户端,
|
||||
* 消息,
|
||||
* 云存储客户端,
|
||||
* 硬件驱动程序,
|
||||
* 编解码器,
|
||||
* 开发者工具,
|
||||
* Android,
|
||||
* 文本编辑器,
|
||||
* Git,
|
||||
* 内核更新工具,
|
||||
* 音频/视频播放器,
|
||||
* 截图工具,
|
||||
* 录屏工具,
|
||||
* 视频编码器,
|
||||
* 流媒体应用,
|
||||
* 3D 建模和动画工具,
|
||||
* 图像查看器和编辑器,
|
||||
* CAD 软件,
|
||||
* PDF 工具,
|
||||
* 游戏模拟器,
|
||||
* 磁盘管理工具,
|
||||
* 加密工具,
|
||||
* 密码管理器,
|
||||
* 存档工具,
|
||||
* FTP 软件,
|
||||
* 系统资源监视器,
|
||||
* 应用启动器等。
|
||||
|
||||
你可以选择任何一个或多个应用并立即安装它们。在这里,我将安装 “Developer bundle”,因此我选择它并单击 OK 按钮。
|
||||
|
||||
![][3]
|
||||
|
||||
现在,Alfred 脚本将自动你的 Ubuntu 系统上添加必要仓库、PPA 并开始安装所选的应用。
|
||||
|
||||
![][4]
|
||||
|
||||
安装完成后,你将看到以下消息。
|
||||
|
||||
![][5]
|
||||
|
||||
恭喜你!已安装选定的软件包。
|
||||
|
||||
你可以使用以下命令[在 Ubuntu 上查看最近安装的应用][6]:
|
||||
|
||||
```
|
||||
$ grep " install " /var/log/dpkg.log
|
||||
```
|
||||
|
||||
你可能需要重启系统才能使用某些已安装的应用。类似地,你可以方便地安装列表中的任何程序。
|
||||
|
||||
提示一下,还有一个由不同的开发人员编写的类似脚本,名为 `post_install.sh`。它与 Alfred 完全相同,但提供了一些不同的应用。请查看以下链接获取更多详细信息。
|
||||
|
||||
- [Ubuntu Post Installation Script](https://www.ostechnix.com/ubuntu-post-installation-script/)
|
||||
|
||||
这两个脚本能让懒惰的用户,特别是新手,只需点击几下鼠标就能够轻松快速地安装他们想要在 Ubuntu Linux 中使用的大多数常见应用、工具、更新、小程序,而无需依赖官方或者非官方文档的帮助。
|
||||
|
||||
就是这些了。希望这篇文章有用。还有更多好东西。敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/an-automated-way-to-install-essential-applications-on-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2019/02/alfred-1.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/02/alfred-2.png
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2019/02/alfred-4.png
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2019/02/alfred-5-1.png
|
||||
[6]: https://www.ostechnix.com/list-installed-packages-sorted-installation-date-linux/
|
||||
@ -0,0 +1,188 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "zero-mk"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10593-1.html"
|
||||
[#]: subject: "Bash-Insulter : A Script That Insults An User When Typing A Wrong Command"
|
||||
[#]: via: "https://www.2daygeek.com/bash-insulter-insults-the-user-when-typing-wrong-command/"
|
||||
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||
|
||||
Bash-Insulter:一个在输入错误命令时嘲讽用户的脚本
|
||||
======
|
||||
|
||||
这是一个非常有趣的脚本,每当用户在终端输入错误的命令时,它都会嘲讽用户。
|
||||
|
||||
它让你在解决一些问题时会感到快乐。有的人在受到终端嘲讽的时候感到不愉快。但是,当我受到终端的批评时,我真的很开心。
|
||||
|
||||
这是一个有趣的 CLI 工具,在你弄错的时候,会用随机短语嘲讽你。此外,它允许你添加自己的短语。
|
||||
|
||||
### 如何在 Linux 上安装 Bash-Insulter?
|
||||
|
||||
在安装 Bash-Insulter 之前,请确保你的系统上安装了 git。如果没有,请使用以下命令安装它。
|
||||
|
||||
对于 Fedora 系统, 请使用 [DNF 命令][1] 安装 git。
|
||||
|
||||
```
|
||||
$ sudo dnf install git
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,请使用 [APT-GET 命令][2] 或者 [APT 命令][3] 安装 git。
|
||||
|
||||
```
|
||||
$ sudo apt install git
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,请使用 [Pacman 命令][4] 安装 git。
|
||||
|
||||
```
|
||||
$ sudo pacman -S git
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,请使用 [YUM 命令][5] 安装 git。
|
||||
|
||||
```
|
||||
$ sudo yum install git
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,请使用 [Zypper 命令][6] 安装 git。
|
||||
|
||||
```
|
||||
$ sudo zypper install git
|
||||
```
|
||||
|
||||
我们可以通过<ruby>克隆<rt>clone</rt></ruby>开发人员的 GitHub 存储库轻松地安装它。
|
||||
|
||||
首先克隆 Bash-insulter 存储库。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/hkbakke/bash-insulter.git bash-insulter
|
||||
```
|
||||
|
||||
将下载的文件移动到文件夹 `/etc` 下。
|
||||
|
||||
```
|
||||
$ sudo cp bash-insulter/src/bash.command-not-found /etc/
|
||||
```
|
||||
|
||||
将下面的代码添加到 `/etc/bash.bashrc` 文件中。
|
||||
|
||||
```
|
||||
$ vi /etc/bash.bashrc
|
||||
|
||||
#Bash Insulter
|
||||
if [ -f /etc/bash.command-not-found ]; then
|
||||
. /etc/bash.command-not-found
|
||||
fi
|
||||
```
|
||||
|
||||
运行以下命令使更改生效。
|
||||
|
||||
```
|
||||
$ sudo source /etc/bash.bashrc
|
||||
```
|
||||
|
||||
你想测试一下安装是否生效吗?你可以试试在终端上输入一些错误的命令,看看它如何嘲讽你。
|
||||
|
||||
```
|
||||
$ unam -a
|
||||
|
||||
$ pin 2daygeek.com
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
如果你想附加你自己的短语,则导航到以下文件并更新它。你可以在 `messages` 部分中添加短语。
|
||||
|
||||
```
|
||||
# vi /etc/bash.command-not-found
|
||||
|
||||
print_message () {
|
||||
|
||||
local messages
|
||||
local message
|
||||
|
||||
messages=(
|
||||
"Boooo!"
|
||||
"Don't you know anything?"
|
||||
"RTFM!"
|
||||
"Haha, n00b!"
|
||||
"Wow! That was impressively wrong!"
|
||||
"Pathetic"
|
||||
"The worst one today!"
|
||||
"n00b alert!"
|
||||
"Your application for reduced salary has been sent!"
|
||||
"lol"
|
||||
"u suk"
|
||||
"lol... plz"
|
||||
"plz uninstall"
|
||||
"And the Darwin Award goes to.... ${USER}!"
|
||||
"ERROR_INCOMPETENT_USER"
|
||||
"Incompetence is also a form of competence"
|
||||
"Bad."
|
||||
"Fake it till you make it!"
|
||||
"What is this...? Amateur hour!?"
|
||||
"Come on! You can do it!"
|
||||
"Nice try."
|
||||
"What if... you type an actual command the next time!"
|
||||
"What if I told you... it is possible to type valid commands."
|
||||
"Y u no speak computer???"
|
||||
"This is not Windows"
|
||||
"Perhaps you should leave the command line alone..."
|
||||
"Please step away from the keyboard!"
|
||||
"error code: 1D10T"
|
||||
"ACHTUNG! ALLES TURISTEN UND NONTEKNISCHEN LOOKENPEEPERS! DAS KOMPUTERMASCHINE IST NICHT FÜR DER GEFINGERPOKEN UND MITTENGRABEN! ODERWISE IST EASY TO SCHNAPPEN DER SPRINGENWERK, BLOWENFUSEN UND POPPENCORKEN MIT SPITZENSPARKEN. IST NICHT FÜR GEWERKEN BEI DUMMKOPFEN. DER RUBBERNECKEN SIGHTSEEREN KEEPEN DAS COTTONPICKEN HÄNDER IN DAS POCKETS MUSS. ZO RELAXEN UND WATSCHEN DER BLINKENLICHTEN."
|
||||
"Pro tip: type a valid command!"
|
||||
"Go outside."
|
||||
"This is not a search engine."
|
||||
"(╯°□°)╯︵ ┻━┻"
|
||||
"¯\_(ツ)_/¯"
|
||||
"So, I'm just going to go ahead and run rm -rf / for you."
|
||||
"Why are you so stupid?!"
|
||||
"Perhaps computers is not for you..."
|
||||
"Why are you doing this to me?!"
|
||||
"Don't you have anything better to do?!"
|
||||
"I am _seriously_ considering 'rm -rf /'-ing myself..."
|
||||
"This is why you get to see your children only once a month."
|
||||
"This is why nobody likes you."
|
||||
"Are you even trying?!"
|
||||
"Try using your brain the next time!"
|
||||
"My keyboard is not a touch screen!"
|
||||
"Commands, random gibberish, who cares!"
|
||||
"Typing incorrect commands, eh?"
|
||||
"Are you always this stupid or are you making a special effort today?!"
|
||||
"Dropped on your head as a baby, eh?"
|
||||
"Brains aren't everything. In your case they're nothing."
|
||||
"I don't know what makes you so stupid, but it really works."
|
||||
"You are not as bad as people say, you are much, much worse."
|
||||
"Two wrongs don't make a right, take your parents as an example."
|
||||
"You must have been born on a highway because that's where most accidents happen."
|
||||
"If what you don't know can't hurt you, you're invulnerable."
|
||||
"If ignorance is bliss, you must be the happiest person on earth."
|
||||
"You're proof that god has a sense of humor."
|
||||
"Keep trying, someday you'll do something intelligent!"
|
||||
"If shit was music, you'd be an orchestra."
|
||||
"How many times do I have to flush before you go away?"
|
||||
)
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bash-insulter-insults-the-user-when-typing-wrong-command/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zero-mk](https://github.com/zero-mk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[2]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[5]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[7]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]: https://www.2daygeek.com/wp-content/uploads/2019/02/bash-insulter-insults-the-user-when-typing-wrong-command-1.png
|
||||
59
published/20190223 Regex groups and numerals.md
Normal file
59
published/20190223 Regex groups and numerals.md
Normal file
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10594-1.html)
|
||||
[#]: subject: (Regex groups and numerals)
|
||||
[#]: via: (https://leancrew.com/all-this/2019/02/regex-groups-and-numerals/)
|
||||
[#]: author: (Dr.Drang https://leancrew.com)
|
||||
|
||||
正则表达式的分组和数字
|
||||
======
|
||||
|
||||
大约一周前,我在编辑一个程序时想要更改一些变量名。我之前认为这将是一个简单的正则表达式查找/替换。只是这没有我想象的那么简单。
|
||||
|
||||
变量名为 `a10`、`v10` 和 `x10`,我想分别将它们改为 `a30`、`v30` 和 `x30`。我想到使用 BBEdit 的查找窗口并输入:
|
||||
|
||||
![Mistaken BBEdit replacement pattern][2]
|
||||
|
||||
我不能简单地 `30` 替换为 `10`,因为代码中有一些与变量无关的数字 `10`。我认为我很聪明,所以我不想写三个非正则表达式替换,`a10`、`v10` 和 `x10`,每个一个。但是我却没有注意到替换模式中的蓝色。如果我这样做了,我会看到 BBEdit 将我的替换模式解释为“匹配组 13,后面跟着 `0`,而不是”匹配组 1,后面跟着 `30`,后者是我想要的。由于匹配组 13 是空白的,因此所有变量名都会被替换为 `0`。
|
||||
|
||||
你看,BBEdit 可以在搜索模式中匹配多达 99 个分组,严格来说,我们应该在替换模式中引用它们时使用两位数字。但在大多数情况下,我们可以使用 `\1` 到 `\9` 而不是 `\01` 到 `\09`,因为这没有歧义。换句话说,如果我尝试将 `a10`、`v10` 和 `x10` 更改为 `az`、`vz` 和 `xz`,那么使用 `\1z`的替换模式就可以了。因为后面的 `z` 意味着不会误解释该模式中 `\1`。
|
||||
|
||||
因此,在撤消替换后,我将模式更改为这样:
|
||||
|
||||
![Two-digit BBEdit replacement pattern][3]
|
||||
|
||||
它可以正常工作。
|
||||
|
||||
还有另一个选择:命名组。这是使用 `var` 作为模式名称:
|
||||
|
||||
![Named BBEdit replacement pattern][4]
|
||||
|
||||
我从来都没有使用过命名组,无论正则表达式是在文本编辑器还是在脚本中。我的总体感觉是,如果模式复杂到我必须使用变量来跟踪所有组,那么我应该停下来并将问题分解为更小的部分。
|
||||
|
||||
顺便说一下,你可能已经听说 BBEdit 正在庆祝它诞生[25周年][5]。当一个有良好文档的应用有如此长的历史时,手册的积累能让人愉快地回到过去的日子。当我在 BBEdit 手册中查找命名组的表示法时,我遇到了这个说明:
|
||||
|
||||
![BBEdit regex manual excerpt][6]
|
||||
|
||||
BBEdit 目前的版本是 12.5。第一次出现于 2001 年的 V6.5。但手册希望确保长期客户(我记得是在 V4 的时候第一次购买)不会因行为变化而感到困惑,即使这些变化几乎发生在二十年前。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://leancrew.com/all-this/2019/02/regex-groups-and-numerals/
|
||||
|
||||
作者:[Dr.Drang][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[s](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://leancrew.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://leancrew.com/all-this/2019/02/automation-evolution/
|
||||
[2]: https://leancrew.com/all-this/images2019/20190223-Mistaken%20BBEdit%20replacement%20pattern.png (Mistaken BBEdit replacement pattern)
|
||||
[3]: https://leancrew.com/all-this/images2019/20190223-Two-digit%20BBEdit%20replacement%20pattern.png (Two-digit BBEdit replacement pattern)
|
||||
[4]: https://leancrew.com/all-this/images2019/20190223-Named%20BBEdit%20replacement%20pattern.png (Named BBEdit replacement pattern)
|
||||
[5]: https://merch.barebones.com/
|
||||
[6]: https://leancrew.com/all-this/images2019/20190223-BBEdit%20regex%20manual%20excerpt.png (BBEdit regex manual excerpt)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user