mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
cab6bc7b56
@ -1,103 +0,0 @@
|
||||
pinewall translating
|
||||
|
||||
How do private keys work in PKI and cryptography?
|
||||
======
|
||||
|
||||

|
||||
|
||||
In [a previous article][1], I gave an overview of cryptography and discussed the core concepts of confidentiality (keeping data secret), integrity (protecting data from tampering), and authentication (knowing the identity of the data's source). Since authentication relates so closely to all the messiness of identity in the real world, a complex technological ecosystem has evolved around establishing that someone is who they claim to be. In this article, I'll describe in broad strokes how these systems work.
|
||||
|
||||
### A quick review of public key cryptography and digital signatures
|
||||
|
||||
Authentication in the online world relies on public key cryptography where a key has two parts: a private key kept secret by the owner and a public key shared with the world. After the public key encrypts data, only the private key can decrypt it. This feature is useful if a whistleblower wanted to establish contact with a [journalist][2], for example. More importantly for this article, a private key can be combined with a message to create a digital signature that provides integrity and authentication.
|
||||
|
||||
In practice, what is signed is not the actual message, but a digest of a message attained by sending the message through a cryptographic hash function. Instead of signing an entire zip file of source code, the sender signs the 256-bit [SHA-256][3] digest of that zip file and sends the zip file in the clear. Recipients independently calculate the SHA-256 digest of the file they received. They input their digest, the signature they received, and the sender's public key into a signature verification algorithm. The verification process varies depending on the encryption algorithm, and there are enough subtleties that signature verification [vulnerabilities][4] still [pop up][5] . If the verification succeeds, the file has not been modified in transit and must have originated from the sender since only the sender has the private key that created the signature.
|
||||
|
||||
### The missing piece of the puzzle
|
||||
|
||||
There's one major detail missing from this scenario. Where do we get the sender's public key? The sender could send the public key along with a message, but then we have no proof of their identity beyond their own assertion. Imagine being a bank teller and a customer walks up and says, "Hello, I'm Jane Doe, and I'd like to make a withdrawal." When you ask for identification, she points to a name tag sticker on her shirt that says "Jane Doe." Personally, I would politely turn "Jane" away.
|
||||
|
||||
If you already know the sender, you could meet in person and exchange public keys. If you don't, you could meet in person, examine their passport, and once you are satisfied it is authentic, accept their public key. To make the process more efficient, you could throw a [party][6], invite a bunch of people, examine all their passports, and accept all their public keys. Building off that, if you know Jane Doe and trust her (despite her unusual banking practices), Jane could go to the party, get the public keys, and give them to you. In fact, Jane could just sign the other public keys using her own private key, and then you could use [an online repository][7] of public keys, trusting the ones signed by Jane. If a person's public key is signed by multiple people you trust, then you might decide to trust that person as well (even though you don't know them). In this fashion, you can build a [web of trust][8].
|
||||
|
||||
But now things have gotten complicated: We need to decide on a standard way to encode a key and the identity associated with that key into a digital bundle we can sign. More properly, these digital bundles are called certificates. We'll also need tooling that can create, use, and manage these certificates. The way we solve these and other requirements is what constitutes a public key infrastructure (PKI).
|
||||
|
||||
### Beyond the web of trust
|
||||
|
||||
You can think of the web of trust as a network of people. A network with many interconnections between the people makes it easy to find a short path of trust: a social circle, for example. [GPG][9]-encrypted email relies on a web of trust, and it functions ([in theory][10]) since most of us communicate primarily with a relatively small group of friends, family, and co-workers.
|
||||
|
||||
In practice, the web of trust has some [significant problems][11], many of them around scaling. When the network starts to get larger and there are few connections between people, the web of trust starts to break down. If the path of trust is attenuated across a long chain of people, you face a higher chance of encountering someone who carelessly or maliciously signed a key. And if there is no path at all, you have to create one by contacting the other party and verifying their key to your satisfaction. Imagine going to an online store that you and your friends have never used. Before you establish a secure communications channel to place an order, you'd need to verify the site's public key belongs to the company and not an impostor. That vetting would entail going to a physical store, making telephone calls, or some other laborious process. Online shopping would be a lot less convenient (or a lot less secure since many people would cut corners and accept the key without verifying it).
|
||||
|
||||
What if the world had some exceptionally trustworthy people constantly verifying and signing keys for websites? You could just trust them, and browsing the internet would be much smoother. At a high level, that's how things work today. These "exceptionally trustworthy people" are companies called certificate authorities (CAs). When a website wants to get its public key signed, it submits a certificate signing request (CSR) to the CA.
|
||||
|
||||
CSRs are like stub certificates that contain a public key and an identity (in this case, the hostname of the server), but are not signed by a CA. Before signing, the CA performs some verification steps. In some cases, the CA merely verifies that the requester controls the domain for the hostname listed in the CSR (via a challenge-and-response email exchange with the address in the WHOIS entry, for example). [In other cases][12], the CA inspects legal documents, like business licenses. Once the CA is satisfied (and usually after the requester has paid a fee), it takes the data from the CSR and signs it with its own private key to create a certificate. The CA then sends the certificate to the requester. The requester installs the certificate on their site's web server, and the certificate is delivered to users when they connect over HTTPS (or any other protocol secured with [TLS][13]).
|
||||
|
||||
When users connect to the site, their browser looks at the certificate, checks that the hostname in the certificate is the same as the hostname it is connected to (more on this in a moment), and verifies the CA's signature. If any of these steps fail, the browser will show a warning and break off the connection. Otherwise, the browser uses the public key in the certificate to verify some signed information sent from the server to ensure that the server possesses the certificate's private key. These messages also serve as steps in one of several algorithms used to establish a shared secret key that will encrypt subsequent messages. Key exchange algorithms are beyond the scope of this article, but there's a good discussion of one of them in [this video][14].
|
||||
|
||||
### Creating trust
|
||||
|
||||
You're probably wondering, "If the CA's private key signs a certificate, that means to verify a certificate we need the CA's public key. Where does it come from and who signs it?" The answer is the CA signs for itself! A certificate can be signed using the private key associated with the same certificate's public key. These certificates are said to be self-signed; they are the PKI equivalent of saying, "Trust me." (People often say, as a form of shorthand, that a certificate has signed something even though it's the private key—which isn't in the certificate at all—doing the actual signing.)
|
||||
|
||||
By adhering to policies established by [web browser][15] and [operating system][16] vendors, CAs demonstrate they are trustworthy enough to be placed into a group of self-signed certificates built into the browser or operating system. These certificates are called trust anchors or root CA certificates, and they are placed in a root certificate store where they are trusted implicitly.
|
||||
|
||||
A CA can also issue a certificate endowed with the ability to act as a CA itself. In this way, they can create a chain of certificates. To verify the chain, a program starts at the trust anchor and verifies (among other things) the signature on the next certificate using the public key of the current certificate. It continues down the chain, verifying each link until it reaches the end. If there are no problems along the way, a chain of trust is established. When a website pays a CA to sign a certificate for it, they are paying for the privilege of being placed at the end of that chain. CAs mark certificates sold to websites as not being allowed to sign subsequent certificates; this is so they can terminate the chain of trust at the appropriate place.
|
||||
|
||||
Why would a chain ever be more than two links long? After all, a site just needs its certificate signed by a CA's root certificate. In practice, CAs create intermediate CA certificates for convenience (among other reasons). The private keys for a CA's root certificates are so valuable that they reside in a specialized device, a [hardware security module][17] (HSM), that requires multiple people to unlock it, is completely offline, and is kept inside a [vault][18] wired with alarms and cameras.
|
||||
|
||||
CAB Forum, the association that governs CAs, [requires][19] any interaction with a CA's root certificate to be performed directly by a human. Issuing certificates for dozens of websites a day would be tedious if every certificate request required an employee to place the request on secure media, enter a vault, unlock the HSM with a coworker, sign the certificate, exit the vault, and then copy the signed certificate off the media. Instead, CAs create internal, intermediate CAs used to sign certificates automatically.
|
||||
|
||||
You can see this chain in Firefox by clicking the lock icon in the URL bar, opening up the page information, and clicking the "View Certificate" button on the "Security" tab. As of this writing, [opensource.com][20] had the following chain:
|
||||
```
|
||||
DigiCert High Assurance EV Root CA
|
||||
|
||||
DigiCert SHA2 High Assurance Server CA
|
||||
|
||||
opensource.com
|
||||
|
||||
```
|
||||
|
||||
### The man in the middle
|
||||
|
||||
I mentioned earlier that a browser needs to check that the hostname in the certificate is the same as the hostname it connected to. Why? The answer has to do with what's called a [man-in-the-middle (MITM) attack][21]. These are [network attacks][22] that allow an attacker to insert itself between a client and a server, masquerading as the server to the client and vice versa. If the traffic is over HTTPS, it's encrypted and eavesdropping is fruitless. Instead, the attacker can create a proxy that will accept HTTPS connections from the victim, decrypt the information, and then form an HTTPS connection with the original destination. To create the phony HTTPS connection, the proxy must return a certificate that our attacker has the private key for. Our attacker could generate self-signed certificates, but the victim's browser won't trust anything not signed by a CA's root certificate in the browser's root certificate store. What if instead, the attacker uses a certificate signed by a trusted CA for a domain it owns?
|
||||
|
||||
Imagine we're back to our job in the bank. A man walks in and asks to withdraw money from Jane Doe's account. When asked for identification, the man hands us a valid driver's license for Joe Smith. We would be rightfully fired if we allowed the transaction to continue. If a browser detects a mismatch between the certificate hostname and the connection hostname, it will show a warning that says something like "Your connection is not secure" and an option to show additional details. In Firefox, this error is called SSL_ERROR_BAD_CERT_DOMAIN.
|
||||
|
||||
If there's one lesson I want you to remember from this article, it's: If you see these warnings, **do not disregard them**! They signal that the site is either configured so erroneously that you shouldn't use it or that you're the potential victim of a MITM attack.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
I've only scratched the surface of the PKI world in this article, but I hope that I've given you a map that you can use to guide your further explorations. Cryptography and PKI are fractal-like in their beauty and complexity. The further you dive in, the more there is to discover.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/private-keys
|
||||
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/awood
|
||||
[1]:https://opensource.com/article/18/5/cryptography-pki
|
||||
[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
|
||||
[3]:https://en.wikipedia.org/wiki/SHA-2
|
||||
[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
|
||||
[5]:https://www.imperialviolet.org/2014/09/26/pkcs1.html
|
||||
[6]:https://en.wikipedia.org/wiki/Key_signing_party
|
||||
[7]:https://en.wikipedia.org/wiki/Key_server_(cryptographic)
|
||||
[8]:https://en.wikipedia.org/wiki/Web_of_trust
|
||||
[9]:https://www.gnupg.org/gph/en/manual/x547.html
|
||||
[10]:https://blog.cryptographyengineering.com/2014/08/13/whats-matter-with-pgp/
|
||||
[11]:https://lists.torproject.org/pipermail/tor-talk/2013-September/030235.html
|
||||
[12]:https://en.wikipedia.org/wiki/Extended_Validation_Certificate
|
||||
[13]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[14]:https://www.youtube.com/watch?v=YEBfamv-_do
|
||||
[15]:https://www.mozilla.org/en-US/about/governance/policies/security-group/certs/policy/
|
||||
[16]:https://technet.microsoft.com/en-us/library/cc751157.aspx
|
||||
[17]:https://en.wikipedia.org/wiki/Hardware_security_module
|
||||
[18]:https://arstechnica.com/information-technology/2012/11/inside-symantecs-ssl-certificate-vault/
|
||||
[19]:https://cabforum.org/baseline-requirements-documents/
|
||||
[20]:http://opensource.com
|
||||
[21]:https://en.wikipedia.org/wiki/Man-in-the-middle_attack
|
||||
[22]:http://www.shortestpathfirst.net/2010/11/18/man-in-the-middle-mitm-attacks-explained-arp-poisoining/
|
||||
@ -0,0 +1,78 @@
|
||||
Joplin: Encrypted Open Source Note Taking And To-Do Application
|
||||
======
|
||||
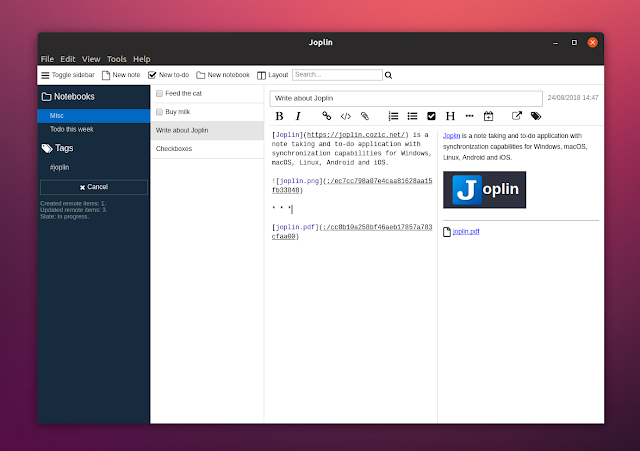
**[Joplin][1] is a free and open source note taking and to-do application available for Linux, Windows, macOS, Android and iOS. Its key features include end-to-end encryption, Markdown support, and synchronization via third-party services like NextCloud, Dropbox, OneDrive or WebDAV.**
|
||||
|
||||
|
||||
|
||||
With Joplin you can write your notes in the **Markdown format** (with support for math notations and checkboxes) and the desktop app comes with 3 views: Markdown code, Markdown preview, or both side by side. **You can add attachments to your notes (with image previews) or edit them in an external Markdown editor** and have them automatically updated in Joplin each time you save the file.
|
||||
|
||||
The application should handle a large number of notes pretty well by allowing you to **organizing notes into notebooks, add tags, and search in notes**. You can also sort notes by updated date, creation date or title. **Each notebook can contain notes, to-do items, or both** , and you can easily add links to other notes (in the desktop app right click on a note and select `Copy Markdown link` , then paste the link in a note).
|
||||
|
||||
**Do-do items in Joplin support alarms** , but this feature didn't work for me on Ubuntu 18.04.
|
||||
|
||||
**Other Joplin features include:**
|
||||
|
||||
* **Optional Web Clipper extension** for Firefox and Chrome (in the Joplin desktop application go to `Tools > Web clipper options` to enable the clipper service and find download links for the Chrome / Firefox extension) which can clip simplified or complete pages, clip a selection or screenshot.
|
||||
|
||||
* **Optional command line client**.
|
||||
|
||||
* **Import Enex files (Evernote export format) and Markdown files**.
|
||||
|
||||
* **Export JEX files (Joplin Export format), PDF and raw files**.
|
||||
|
||||
* **Offline first, so the entire data is always available on the device even without an internet connection**.
|
||||
|
||||
* **Geolocation support**.
|
||||
|
||||
|
||||
|
||||
[![Joplin notes checkboxes link to other note][2]][3]
|
||||
Joplin with hidden sidebar showing checkboxes and a link to another note
|
||||
|
||||
While it doesn't offer as many features as Evernote, Joplin is a robust open source Evernote alternative. Joplin includes all the basic features, and on top of that it's open source software, it includes encryption support, and you also get to choose the service you want to use for synchronization.
|
||||
|
||||
The application was actually designed as an Evernote alternative so it can import complete Evernote notebooks, notes, tags, attachments, and note metadata like the author, creation and updated time, or geolocation.
|
||||
|
||||
Another aspect on which the Joplin development was focused was to avoid being tied to a particular company or service. This is why the application offers multiple synchronization solutions, like NextCloud, Dropbox, oneDrive and WebDav, while also making it easy to support new services. It's also easy to switch from one service to another if you change your mind.
|
||||
|
||||
**I should note that Joplin doesn't use encryption by default and you must enable this from its settings. Go to** `Tools > Encryption options` and enable the Joplin end-to-end encryption from there.
|
||||
|
||||
### Download Joplin
|
||||
|
||||
[Download Joplin][7]
|
||||
|
||||
**Joplin is available for Linux, Windows, macOS, Android and iOS. On Linux, there's an AppImage as well as an Aur package available.**
|
||||
|
||||
To run the Joplin AppImage on Linux, double click it and select `Make executable and run` if your file manager supports this. If not, you'll need to make it executable either using your file manager (should be something like: `right click > Properties > Permissions > Allow executing file as program` , but this may vary depending on the file manager you use), or from the command line:
|
||||
```
|
||||
chmod +x /path/to/Joplin-*-x86_64.AppImage
|
||||
|
||||
```
|
||||
|
||||
Replacing `/path/to/` with the path to where you downloaded Joplin. Now you can double click the Joplin Appimage file to launch it.
|
||||
|
||||
**TIP:** If you integrate Joplin to your menu and `~/.local/share/applications/appimagekit-joplin.desktop`) and adding `StartupWMClass=Joplin` at the end of the file on a new line, without modifying anything else.
|
||||
|
||||
Joplin has a **command line client** that can be [installed using npm][5] (for Debian, Ubuntu or Linux Mint, see [how to install and configure Node.js and npm][6] ).
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://joplin.cozic.net/
|
||||
[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
|
||||
[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
|
||||
[4]:https://github.com/laurent22/joplin/issues/338
|
||||
[5]:https://joplin.cozic.net/terminal/
|
||||
[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
|
||||
|
||||
[7]: https://joplin.cozic.net/#installation
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
An introduction to diffs and patches
|
||||
======
|
||||

|
||||
|
||||
@ -0,0 +1,85 @@
|
||||
How to scale your website across all mobile devices
|
||||
======
|
||||
|
||||

|
||||
|
||||
Most of us surf the internet, make online purchases, and even pay bills using our mobile devices because they are handy and easily accessible. According to a Forrester study, [The Digital Business Imperative][1], 43% of banking customers in the US used mobile phones to complete banking transactions in a three-month period.
|
||||
|
||||
The significant year-over-year growth of online business transactions done via mobile devices has encouraged companies to build websites and e-commerce sites that look, feel, and function identically on computers and smart mobile devices. However, many users still find the experience of browsing a website on a smartphone isn’t the same as on a computer. In order to develop websites that scale effectively and smoothly across different devices, it's important to understand what causes these differences across platforms.
|
||||
|
||||
Web pages are usually composed of one or more of the following components: Header and footer, main content (text), images, forms, videos, and tables. Devices differ on features such as screen dimension (length x width), screen resolution (pixel density), compute power (CPU and memory), and operating system (iOS, Android, Windows, etc.). These differences contribute significantly to the overall performance and rendering of web components such as images, videos, and text across different devices. Another important factor is that mobile users may not always be connected to a high-speed network, so web pages should be carefully designed to work effectively on low-bandwidth connections.
|
||||
|
||||
### The most troublesome issues on mobile platforms
|
||||
|
||||
Here are some of the most common issues that can affect the performance and scalability of websites across devices:
|
||||
|
||||
* **Sites do not automatically adapt to different screen sizes.** Some websites are designed to format for variable screen sizes, but their elements may not auto-scale. This would result in the site automatically adjusting itself for various screen sizes, but the elements in the site may look too large on smaller devices. Some sites may not be designed to adjust for variable screen sizes, causing the elements to look extremely small on devices with smaller screens.
|
||||
* **Sites have too much content for mobile devices.** Some websites are loaded with content to fill empty space on a desktop screen. Websites developed without considering mobile users generally fall under this category. These sites take more time and bandwidth to load, and if the pages aren’t designed appropriately for mobile devices, some content may not even appear.
|
||||
* **Sites take too long to load images.** Websites with too many images or heavy image files are likely to take a long time to load, especially if the images were not optimized during the design phase.
|
||||
* **Data in tables looks complex and takes too long to load.** Many websites present data in a tabular fashion (for example, comparisons of competing products, airfare data from different travel sites, flight schedules, etc.), and on mobile devices, these tables can be slow and difficult to comprehend.
|
||||
* **Websites host videos that don’t play on some devices.** Not all mobile devices support all video formats. Some websites host media that require licenses, Adobe Flash, or other players that some mobile devices may not support. This causes frustration and a poor overall user experience.
|
||||
|
||||
|
||||
|
||||
### Design your sites to adapt to different devices
|
||||
|
||||
All these issues can be addressed through proper design and by adopting a [mobile-first][2] approach. When working with limitations such as screen size, bandwidth, etc., focus on the right quantity and quality of content. A mobile-first strategy places content as the primary object and designs for the smallest devices, ensuring that a site includes only the most essential features. Address the design challenges for mobile devices first, and then progressively enhance the design for larger devices.
|
||||
|
||||
Here are a few best practices to consider when designing websites that need to scale on different devices.
|
||||
|
||||
* **Adapting to any screen size**. At a minimum, a web page needs to be scaled to fit the screen size of any mobile device. Today's mobile devices come with very high screen resolutions. The pixel density on mobile devices is much higher than that of desktop screens, so it is important to format pages to match the mobile screen’s width in device-independent pixels. The “meta viewport” tag included in the HTML document addresses this requirement.
|
||||
|
||||
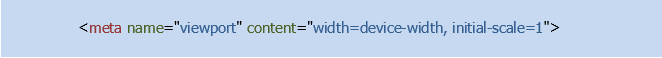
|
||||
|
||||
The meta viewport value, as shown above, helps format the entire HTML page and render the content to match any screen size.
|
||||
|
||||
* **" Content is king."** Content should determine the design of a website, not vice versa. Websites with too many elements such as tables, forms, charts, etc., become challenging when they need to scale on mobile devices. Developers end up hiding content for mobile users, and the desktop version and the mobile version become inconsistent. The design should focus on the core structure and content rather than decorative elements. The mobile-first methodology ensures a single version of content for both desktop and mobile users, so web designers should carefully consider, craft, and optimize content so that it not only satisfies business goals but also appeals to mobile users. Content that doesn’t appear in the mobile version may not even need to appear in the desktop version.
|
||||
* **Responsive images**. The design should consider small hand-held devices operating in areas with low signal strength. Large photos and complex graphics are not suitable for mobile devices operating under such conditions. Make sure all images are optimized for different sizes of viewports and pixel densities. A recommended approach is [resolution switching][3], which enables the browser to select an appropriately sized image file, depending on the screen size of a device. Resolution switching uses two attributes—`srcset` and `sizes` (shown in the code snippet shown below)—which enable the browser to use the device width to select the most suitable media condition provided in the sizes list, choose the slot size based on that condition, and load the image referenced in the `srcset` that most closely matches the chosen slot size.
|
||||
|
||||

|
||||
|
||||
For example, if a device with a viewport of 320px loads the page, the media condition (max-width: 320px) in the sizes list will be true, and the corresponding 280px slot will be chosen. The width of the first image listed in `srcset` (elephant-320w.jpg) is the closest to this slot. Browsers that don’t support resolution switching display the image listed in the src attribute as the default image. This approach not only picks the right image for your device viewport, but it also prevents loading unnecessarily large images that consume significant bandwidth.
|
||||
|
||||
|
||||
|
||||
* **Responsive tables.** As the world becomes more data-driven, bringing critical, time-sensitive data to handheld devices provides power and freedom to users. The challenge is to present data in a way that is easy to load and read on mobile devices. Some data needs to be presented in the form of a table, but when data tables get too large and unwieldy, it can be frustrating for users to interpret them on a mobile device with a small screen. If the screen is much narrower than the width of the table, for example, users are forced to zoom out, making the text too small to read. Conversely, if the screen is wider than the table, users must zoom in to view the data, which requires constant vertical and horizontal scrolling.
|
||||
|
||||
Fortunately, there are several ways to build [responsive tables][4]. Here is one of the most effective:
|
||||
|
||||
* The table's columns are transposed into rows. Each column is sized to the same width as the screen, preventing the need to scroll horizontally. Use of color helps users clearly distinguish each individual row of data. In this case, for each “cell,” the CSS-generated content `(:before)` should be used to apply the label so that each piece of data can be identified clearly.
|
||||
* Another approach is to display the data in one of two formats, based on screen width: chart format (for narrow screens) or complete table format (for wider screens). If the user wants to click the chart to see the complete table, the approach described above can be used to show the data in tabular form.(:before)
|
||||
* A third approach is to show a mini-graphic in a narrow screen to indicate the presence of a table. The user can click on the graphic to expand and display the table.
|
||||
* **Videos that always play.** [Video files][5] generally won’t play on mobile devices if their formats are unsupported or if they require a proprietary video player. The recommended approach is to use standard HTML5 tags for videos and animations. The video element in HTML5 can be used to load, decode, and play videos on your website. Produce video in multiple formats to suit different mobile platforms, and be sure to size videos appropriately so that they play within their containers.
|
||||
|
||||
The example below shows the use of tags to specify different video formats (indicated by the type element). In this approach, the switch to the correct format happens at the client side, and only one request is made to the server. This reduces network latency and lets the browser select the most appropriate video format without first downloading it.
|
||||
|
||||

|
||||
|
||||
The `videoWidth` and `videoHeight` properties of the video element help identify the encoded size of a video. Video dimensions can be controlled using JavaScript or CSS. `max-width: 100%` helps size the videos to fit the screen. CSS media queries can be used to set the size based on the viewport dimensions. There are also several JavaScript libraries and plugins that can maintain the aspect ratio and size of videos.
|
||||
|
||||
### All things considered…
|
||||
|
||||
These days, users regularly surf the web and perform business transactions with their smartphones and tablets. The web is becoming the primary business channel for many businesses worldwide. Consequently, it is important to develop websites that work and scale well on mobile devices. The goal is to enhance the mobile user experience so that it mirrors the functionality and performance of desktop computers and large monitors.
|
||||
|
||||
The mobile-first approach helps web designers create sites that operate well on small mobile devices. Design should focus on content that satisfies business requirements while also considering technical limitations such as screen size, processor speed, memory, and operating conditions (e.g., poor network signal strength). It must also ensure that pictures, videos, and data are responsive across all mobile devices while remaining sensitive to breakpoints, touch targets, etc.
|
||||
|
||||
A well-designed website that works and scales on a small device can always be progressively enhanced to work on larger devices.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/how-scale-your-website-across-all-devices
|
||||
|
||||
作者:[Sridhar Asvathanarayanan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sasvathanarayanangmailcom
|
||||
[1]: https://www.forrester.com/report/The+Digital+Business+Imperative/-/E-RES115784#
|
||||
[2]: https://www.uxpin.com/studio/blog/a-hands-on-guide-to-mobile-first-design/
|
||||
[3]: https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images
|
||||
[4]: https://css-tricks.com/responsive-data-tables/
|
||||
[5]: https://developers.google.com/web/fundamentals/media/video
|
||||
@ -0,0 +1,160 @@
|
||||
A Cross-platform High-quality GIF Encoder
|
||||
======
|
||||
|
||||

|
||||
|
||||
As a content writer, I needed to add images in my articles. Sometimes, it is better to add videos or gif images to explain the concept a bit easier. The readers can easily understand the guide much better by watching the output in video or gif format than the text. The day before, I have written about [**Flameshot**][1], a feature-rich and powerful screenshot tool for Linux. Today, I will show you how to make high quality gif images either from a video or set of images. Meet **Gifski** , a cross-platform, open source, command line High-quality GIF encoder based on **Pngquant**.
|
||||
|
||||
For those wondering, pngquant is a command line lossy PNG image compressor. Trust me, pngquant is one of the best loss-less PNG compressor that I ever use. It compresses PNG images **upto 70%** without losing the original quality and and preserves full alpha transparency. The compressed images are compatible with all web browsers and operating systems. Since Gifski is based on Pngquant, it uses pngquant’s features for creating efficient GIF animations. Gifski is capable of creating animated GIFs that use thousands of colors per frame. Gifski is also requires **ffmpeg** to convert video into PNG images.
|
||||
|
||||
### **Installing Gifski**
|
||||
|
||||
Make sure you have installed FFMpeg and Pngquant.
|
||||
|
||||
FFmpeg is available in the default repositories of most Linux distributions, so you can install it using the default package manager. For installation instructions, refer the following guide.
|
||||
|
||||
Pngquant is available in [**AUR**][2]. To install it in Arch-based systems, use any AUR helper programs like [**Yay**][3].
|
||||
```
|
||||
$ yay -S pngquant
|
||||
|
||||
```
|
||||
|
||||
On Debian-based systems, run:
|
||||
```
|
||||
$ sudo apt install pngquant
|
||||
|
||||
```
|
||||
|
||||
If pngquant is not available for your distro, compile and install it from source. You will need **`libpng-dev`** package installed with development headers.
|
||||
```
|
||||
$ git clone --recursive https://github.com/kornelski/pngquant.git
|
||||
|
||||
$ make
|
||||
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
After installing the prerequisites, install Gifski. You can install it using **cargo** if you have installed [**Rust**][4] programming language.
|
||||
```
|
||||
$ cargo install gifski
|
||||
|
||||
```
|
||||
|
||||
You can also get it with [**Linuxbrew**][5] package manager.
|
||||
```
|
||||
$ brew install gifski
|
||||
|
||||
```
|
||||
|
||||
If you don’t want to install cargo or Linuxbrew, download the latest binary executables from [**releases page**][6] and compile and install gifski manually.
|
||||
|
||||
### Create high-quality GIF animations using Gifski high-quality GIF encoder
|
||||
|
||||
Go to the location where you have kept the PNG images and run the following command to create GIF animation from the set of images:
|
||||
```
|
||||
$ gifski -o file.gif *.png
|
||||
|
||||
```
|
||||
|
||||
Here file.gif is the final output gif animation.
|
||||
|
||||
Gifski has also some other additional features, like;
|
||||
|
||||
* Create GIF animation with specific dimension
|
||||
* Show specific number of animations per second
|
||||
* Encode with a specific quality
|
||||
* Encode faster
|
||||
* Encode images exactly in the order given, rather than sorted
|
||||
|
||||
|
||||
|
||||
To create GIF animation with specific dimension, for example width=800 and height=400, use the following command:
|
||||
```
|
||||
$ gifski -o file.gif -W 800 -H 400 *.png
|
||||
|
||||
```
|
||||
|
||||
You can set how many number of animation frames per second you want in the gif animation. The default value is **20**. To do so, run:
|
||||
```
|
||||
$ gifski -o file.gif --fps 1 *.png
|
||||
|
||||
```
|
||||
|
||||
In the above example, I have used one animation frame per second.
|
||||
|
||||
We can encode with specific quality on the scale of 1-100. Obviously, the lower quality may give smaller file and higher quality give bigger seize gif animation.
|
||||
```
|
||||
$ gifski -o file.gif --quality 50 *.png
|
||||
|
||||
```
|
||||
|
||||
Gifski will take more time when you encode large number of images. To make the encoding process 3 times faster than usual speed, run:
|
||||
```
|
||||
$ gifski -o file.gif --fast *.png
|
||||
|
||||
```
|
||||
|
||||
Please note that it will reduce quality to 10% and create bigger animation file.
|
||||
|
||||
To encode images exactly in the order given (rather than sorted), use **`--nosort`** option.
|
||||
```
|
||||
$ gifski -o file.gif --nosort *.png
|
||||
|
||||
```
|
||||
|
||||
If you do not to loop the GIF, simple use **`--once`** option.
|
||||
```
|
||||
$ gifski -o file.gif --once *.png
|
||||
|
||||
```
|
||||
|
||||
**Create GIF animation from Video file**
|
||||
|
||||
Some times you might want to an animated file from a video. It is also possible. This is where FFmpeg comes in help. First convert the video into PNG frames first like below.
|
||||
```
|
||||
$ ffmpeg -i video.mp4 frame%04d.png
|
||||
|
||||
```
|
||||
|
||||
The above command makes image files namely “frame0001.png”, “frame0002.png”, “frame0003.png”…, etc. from video.mp4 (%04d makes the frame number) and save them in the current working directory.
|
||||
|
||||
After converting the image files, simply run the following command to make the animated GIF file.
|
||||
```
|
||||
$ gifski -o file.gif *.png
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section.
|
||||
```
|
||||
$ gifski -h
|
||||
|
||||
```
|
||||
|
||||
Here is the sample animated file created using Gifski.
|
||||
|
||||
As you can see, the quality of the GIF file is really great.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/gifski-a-cross-platform-high-quality-gif-encoder/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/
|
||||
[2]: https://aur.archlinux.org/packages/pngquant/
|
||||
[3]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]: https://www.ostechnix.com/install-rust-programming-language-in-linux/
|
||||
[5]: https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[6]: https://github.com/ImageOptim/gifski/releases
|
||||
@ -0,0 +1,343 @@
|
||||
Turn your vi editor into a productivity powerhouse
|
||||
======
|
||||
|
||||

|
||||
|
||||
A versatile and powerful editor, vi includes a rich set of potent commands that make it a popular choice for many users. This article specifically looks at commands that are not enabled by default in vi but are nevertheless useful. The commands recommended here are expected to be set in a vi configuration file. Though it is possible to enable commands individually from each vi session, the purpose of this article is to create a highly productive environment out of the box.
|
||||
|
||||
### Before you begin
|
||||
|
||||
While "vim" is the technically correct name of the newer version of the vi editor, this article refers to it as "vi." vimrc is the configuration file used by vim.
|
||||
|
||||
The commands or configurations discussed here go into the vi startup configuration file, vimrc, located in the user home directory. Follow the instructions below to set the commands in vimrc:
|
||||
|
||||
(Note: The vimrc file is also used for system-wide configurations in Linux, such as `/etc/vimrc` or `/etc/vim/vimrc`. In this article, we'll consider only user-specific vimrc, present in user home folder.)
|
||||
|
||||
In Linux:
|
||||
|
||||
* Open the file with `vi $HOME/.vimrc`
|
||||
* Type or copy/paste the commands in the cheat sheet at the end of this article
|
||||
* Save and close (`:wq`)
|
||||
|
||||
|
||||
|
||||
In Windows:
|
||||
|
||||
* First, [install gvim][1]
|
||||
* Open gvim
|
||||
* Click Edit --> Startup settings, which opens the _vimrc file
|
||||
* Type or copy/paste the commands in the cheat sheet at the end of this article
|
||||
* Click File --> Save
|
||||
|
||||
|
||||
|
||||
Let's delve into the individual vi productivity commands. These commands are classified into the following categories:
|
||||
|
||||
1. Indentation & Tabs
|
||||
2. Display & Format
|
||||
3. Search
|
||||
4. Browse & Scroll
|
||||
5. Spell
|
||||
6. Miscellaneous
|
||||
|
||||
|
||||
|
||||
### 1\. Indentation & Tabs
|
||||
|
||||
To automatically align the indentation of a line in a file:
|
||||
```
|
||||
set autoindent
|
||||
|
||||
```
|
||||
|
||||
Smart Indent uses the code syntax and style to align:
|
||||
```
|
||||
set smartindent
|
||||
|
||||
```
|
||||
|
||||
Tip: vi is language-aware and provides a default setting that works efficiently based on the programming language used in your file. There are many default configuration commands, including `axs cindent`, `cinoptions`, `indentexpr`, etc., which are not explained here. `syn` is a helpful command that shows or sets the file syntax.
|
||||
|
||||
To set the number of spaces to display for a tab:
|
||||
```
|
||||
set tabstop=4
|
||||
|
||||
```
|
||||
|
||||
To set the number of spaces to display for a “shift operation” (such as ‘>>’ or ‘<<’):
|
||||
```
|
||||
set shiftwidth=4
|
||||
|
||||
```
|
||||
|
||||
If you prefer to use spaces instead of tabs, this option inserts spaces when the Tab key is pressed. This may cause problems for languages such as Python that rely on tabs instead of spaces. In such cases, you may set this option based on the file type (see `autocmd`).
|
||||
```
|
||||
set expandtab
|
||||
|
||||
```
|
||||
|
||||
### 2\. Display & Format
|
||||
|
||||
To show line numbers:
|
||||
```
|
||||
set number
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
To wrap text when it crosses the maximum line width:
|
||||
```
|
||||
set textwidth=80
|
||||
|
||||
```
|
||||
|
||||
To wrap text based on a number of columns from the right side:
|
||||
```
|
||||
set wrapmargin=2
|
||||
|
||||
```
|
||||
|
||||
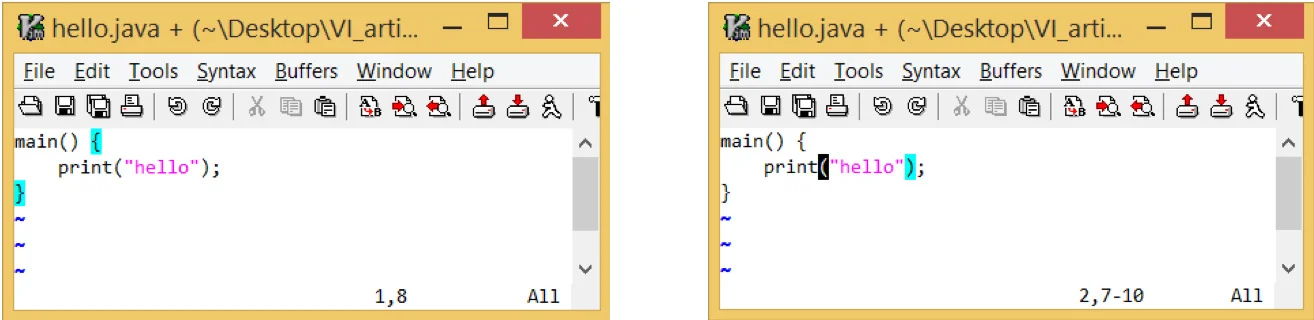
To identify open and close brace positions when you traverse through the file:
|
||||
```
|
||||
set showmatch
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 3\. Search
|
||||
|
||||
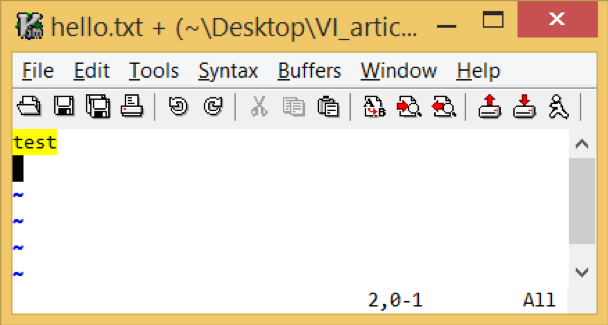
To highlight the searched term in a file:
|
||||
```
|
||||
set hlsearch
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
To perform incremental searches as you type:
|
||||
```
|
||||
set incsearch
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
To search ignoring case (many users prefer not to use this command; set it only if you think it will be useful):
|
||||
```
|
||||
set ignorecase
|
||||
|
||||
```
|
||||
|
||||
To search without considering `ignorecase` when both `ignorecase` and `smartcase` are set and the search pattern contains uppercase:
|
||||
```
|
||||
set smartcase
|
||||
|
||||
```
|
||||
|
||||
For example, if the file contains:
|
||||
|
||||
test
|
||||
Test
|
||||
|
||||
When both `ignorecase` and `smartcase` are set, a search for “test” finds and highlights both:
|
||||
|
||||
test
|
||||
Test
|
||||
|
||||
A search for “Test” highlights or finds only the second line:
|
||||
|
||||
test
|
||||
Test
|
||||
|
||||
### 4. Browse & Scroll
|
||||
|
||||
For a better visual experience, you may prefer to have the cursor somewhere in the middle rather than on the first line. The following option sets the cursor position to the 5th row.
|
||||
```
|
||||
set scrolloff=5
|
||||
|
||||
```
|
||||
|
||||
Example:
|
||||
|
||||
The first image is with scrolloff=0 and the second image is with scrolloff=5.
|
||||
|
||||
|
||||
|
||||
Tip: `set sidescrolloff` is useful if you also set `nowrap.`
|
||||
|
||||
To display a permanent status bar at the bottom of the vi screen showing the filename, row number, column number, etc.:
|
||||
```
|
||||
set laststatus=2
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 5. Spell
|
||||
|
||||
vi has a built-in spell-checker that is quite useful for text editing as well as coding. vi recognizes the file type and checks the spelling of comments only in code. Use the following command to turn on spell-check for the English language:
|
||||
```
|
||||
set spell spelllang=en_us
|
||||
|
||||
```
|
||||
|
||||
### 6. Miscellaneous
|
||||
|
||||
Disable creating backup file: When this option is on, vi creates a backup of the previous edit. If you do not want this feature, disable it as shown below. Backup files are named with a tilde (~) at the end of the filename.
|
||||
```
|
||||
set nobackup
|
||||
|
||||
```
|
||||
|
||||
Disable creating a swap file: When this option is on, vi creates a swap file that exists until you start editing the file. Swapfile is used to recover a file in the event of a crash or a use conflict. Swap files are hidden files that begin with `.` and end with `.swp`.
|
||||
```
|
||||
set noswapfile
|
||||
|
||||
```
|
||||
|
||||
Suppose you need to edit multiple files in the same vi session and switch between them. An annoying feature that's not readily apparent is that the working directory is the one from which you opened the first file. Often it is useful to automatically switch the working directory to that of the file being edited. To enable this option:
|
||||
```
|
||||
set autochdir
|
||||
|
||||
```
|
||||
|
||||
vi maintains an undo history that lets you undo changes. By default, this history is active only until the file is closed. vi includes a nifty feature that maintains the undo history even after the file is closed, which means you may undo your changes even after the file is saved, closed, and reopened. The undo file is a hidden file saved with the `.un~` extension.
|
||||
```
|
||||
set undofile
|
||||
|
||||
```
|
||||
|
||||
To set audible alert bells (which sound a warning if you try to scroll beyond the end of a line):
|
||||
```
|
||||
set errorbells
|
||||
|
||||
```
|
||||
|
||||
If you prefer, you may set visual alert bells:
|
||||
```
|
||||
set visualbell
|
||||
|
||||
```
|
||||
|
||||
### Bonus
|
||||
|
||||
vi provides long-format as well as short-format commands. Either format can be used to set or unset the configuration.
|
||||
|
||||
Long format for the `autoindent` command:
|
||||
```
|
||||
set autoindent
|
||||
|
||||
```
|
||||
|
||||
Short format for the `autoindent` command:
|
||||
```
|
||||
set ai
|
||||
|
||||
```
|
||||
|
||||
To see the current configuration setting of a command without changing its current value, use `?` at the end:
|
||||
```
|
||||
set autoindent?
|
||||
|
||||
```
|
||||
|
||||
To unset or turn off a command, most commands take `no` as a prefix:
|
||||
```
|
||||
set noautoindent
|
||||
|
||||
```
|
||||
|
||||
It is possible to set a command for one file but not for the global configuration. To do this, open the file and type `:`, followed by the `set` command. This configuration is effective only for the current file editing session.
|
||||
|
||||
|
||||
|
||||
For help on a command:
|
||||
```
|
||||
:help autoindent
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
Note: The commands listed here were tested on Linux with Vim version 7.4 (2013 Aug 10) and Windows with Vim 8.0 (2016 Sep 12).
|
||||
|
||||
These useful commands are sure to enhance your vi experience. Which other commands do you recommend?
|
||||
|
||||
### Cheat sheet
|
||||
|
||||
Copy/paste this list of commands in your vimrc file:
|
||||
```
|
||||
" Indentation & Tabs
|
||||
|
||||
set autoindent
|
||||
|
||||
set smartindent
|
||||
|
||||
set tabstop=4
|
||||
|
||||
set shiftwidth=4
|
||||
|
||||
set expandtab
|
||||
|
||||
set smarttab
|
||||
|
||||
" Display & format
|
||||
|
||||
set number
|
||||
|
||||
set textwidth=80
|
||||
|
||||
set wrapmargin=2
|
||||
|
||||
set showmatch
|
||||
|
||||
" Search
|
||||
|
||||
set hlsearch
|
||||
|
||||
set incsearch
|
||||
|
||||
set ignorecase
|
||||
|
||||
set smartcase
|
||||
|
||||
" Browse & Scroll
|
||||
|
||||
set scrolloff=5
|
||||
|
||||
set laststatus=2
|
||||
|
||||
" Spell
|
||||
|
||||
set spell spelllang=en_us
|
||||
|
||||
" Miscellaneous
|
||||
|
||||
set nobackup
|
||||
|
||||
set noswapfile
|
||||
|
||||
set autochdir
|
||||
|
||||
set undofile
|
||||
|
||||
set visualbell
|
||||
|
||||
set errorbells
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/vi-editor-productivity-powerhouse
|
||||
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gammay
|
||||
[1]: https://www.vim.org/download.php#pc
|
||||
@ -0,0 +1,101 @@
|
||||
PKI 和 密码学中的私钥的角色
|
||||
======
|
||||
|
||||

|
||||
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密),<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
|
||||
### 公钥密码学及数字签名快速回顾
|
||||
|
||||
互联网世界中的身份认证依赖于公钥密码学,其中密钥分为两部分:拥有者需要保密的私钥和可以对外公开的公钥。经过公钥加密过的数据,只能用对应的私钥解密。举个例子,对于希望与[记者][2]建立联系的举报人来说,这个特性非常有用。但就本文介绍的内容而言,私钥更重要的用途是与一个消息一起创建一个<ruby>数字签名<rt>digital signature</rt></ruby>,用于提供完整性和身份认证。
|
||||
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,由于不断发现微妙的触发条件,签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
|
||||
### 方案中缺失的环节
|
||||
|
||||
上述方案中缺失了一个重要的环节:我们从哪里获得发送者的公钥?发送者可以将公钥与消息一起发送,但除了发送者的自我宣称,我们无法核验其身份。假设你是一名银行柜员,一名顾客走过来向你说,“你好,我是 Jane Doe,我要取一笔钱”。当你要求其证明身份时,她指着衬衫上贴着的姓名标签说道,“看,Jane Doe!”。如果我是这个柜员,我会礼貌的拒绝她的请求。
|
||||
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办聚会并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe (尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个[<ruby>信任网络<rt>Web of Trust</rt></ruby>][8]。
|
||||
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificates</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure, PKI</rt></ruby>。
|
||||
|
||||
### 比信任网络更进一步
|
||||
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:不妨以社交圈为例。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
|
||||
(LCTT 译注:作者提到的“短信任链”应该是暗示“六度空间理论”,即任意两个陌生人之间所间隔的人一般不会超过 6 个。对 GPG 的唱衰,一方面是因为密钥管理的复杂性没有改善,另一方面 Yahoo 和 Google 都提出了更便利的端到端加密方案。)
|
||||
|
||||
在实际应用中,信任网络有一些[<ruby>"硬伤"<rt>significant problems</rt></ruby>][11],主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接逐渐降低时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链;具体而言,你与其它组织建立联系,验证它们的密钥符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authorities, CAs</rt></ruby>的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>。
|
||||
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>DV<rt>Domain Validated</rt></ruby> 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>EV<rt>Extended Validated</rt></ruby> 类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥核验服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>Key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
|
||||
### 建立信任
|
||||
|
||||
你可能会问,“如果 CA 使用其私钥对证书进行签名,也就意味着我们需要使用 CA 的公钥验证证书。那么 CA 的公钥从何而来,谁对其进行签名呢?” 答案是 CA 对自己签名!可以使用证书公钥对应的私钥,对证书本身进行签名!这类签名证书被称为是<ruby>自签名的<rt>self-signed</rt></ruby>;在 PKI 体系下,这意味着对你说“相信我”。(为了表达方便,人们通常说用证书进行了签名,虽然真正用于签名的私钥并不在证书中。)
|
||||
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchors</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificates</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
|
||||
CA 也可以签发一种特殊的证书,该证书自身可以作为 CA。在这种情况下,它们可以生成一个证书链。要核验证书链,需要从“信任锚”(也就是 CA 根证书)开始,使用当前证书的公钥核验下一层证书的签名(或其它一些信息)。按照这个方式依次核验下一层证书,直到证书链底部。如果整个核验过程没有问题,信任链也建立完成。当向 CA 付费为网站签发证书时,实际购买的是将证书放置在证书链下的权利。CA 将卖出的证书标记为“不可签发子证书”,这样它们可以在适当的长度终止信任链(防止其继续向下扩展)。
|
||||
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module, HSM</rt></ruby>,该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
|
||||
<ruby>CA/浏览器论坛<rt>CAB Forum, CA/Browser Forum</rt></ruby>负责管理 CA,[要求][19]任何与 CA 根证书(LCTT 译注:就像前文提到的那样,这里是指对应的私钥)相关的操作必须由人工完成。设想一下,如果每个证书请求都需要员工将请求内容拷贝到保密介质中、进入地下室、与同事一起解锁 HSM、(使用 CA 根证书对应的私钥)签名证书,最后将签名证书从保密介质中拷贝出来;那么每天为大量网站签发证书是相当繁重乏味的工作。因此,CA 创建内部使用的中间 CA,用于证书签发自动化。
|
||||
|
||||
如果想查看证书链,可以在 Firefox 中点击地址栏的锁型图标,接着打开页面信息,然后点击“安全”面板中的“查看证书”按钮。在本文写作时,[opensource.com][20] 使用的证书链如下:
|
||||
|
||||
```
|
||||
DigiCert High Assurance EV Root CA
|
||||
DigiCert SHA2 High Assurance Server CA
|
||||
opensource.com
|
||||
```
|
||||
|
||||
### 中间人
|
||||
|
||||
我之前提到,浏览器需要核验证书中的主机名与已经建立连接的主机名一致。为什么需要这一步呢?要回答这个问题,需要了解所谓的[<ruby>中间人攻击<rt>man-in-the-middle, MIMT</rt></ruby>][22]。有一类[网络攻击][22]可以让攻击者将自己置身于客户端和服务端中间,冒充客户端与服务端连接,同时冒充服务端与客户端连接。如果网络流量是通过 HTTPS 传输的,加密的流量无法被窃听。此时,攻击者会创建一个代理,接收来自受害者的 HTTPS 连接,解密信息后构建一个新的 HTTPS 连接到原始目的地(即服务端)。为了建立假冒的 HTTPS 连接,代理必须返回一个攻击者具有对应私钥的证书。攻击者可以生成自签名证书,但受害者的浏览器并不会信任该证书,因为它并不是根证书库中的 CA 根证书签发的。换一个方法,攻击者使用一个受信任 CA 签发但主机名对应其自有域名的证书,结果会怎样呢?
|
||||
|
||||
再回到银行的那个例子,我们是银行柜员,一位男性顾客进入银行要求从 Jane Doe 的账户上取钱。当被要求提供身份证明时,他给出了 Joe Smith 的有效驾驶执照。如果这个交易可以完成,我们无疑会被银行开除。类似的,如果检测到证书中的主机名与连接对应的主机名不一致,浏览器会给出类似“连接不安全”的警告和查看更多内容的选项。在 Firefox 中,这类错误被标记为 `SSL_ERROR_BAD_CERT_DOMAIN`。
|
||||
|
||||
我希望你阅读完本文起码记住这一点:如果看到这类警告,**不要无视它们**!它们出现意味着,或者该网站配置存在严重问题(不推荐访问),或者你已经是中间人攻击的潜在受害者。
|
||||
|
||||
### 总结
|
||||
|
||||
虽然本文只触及了 PKI 世界的一些皮毛,我希望我已经为你展示了便于后续探索的大致蓝图。密码学和 PKI 是美与复杂性的结合体。越深入研究,越能发现更多的美和复杂性,就像分形那样。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/private-keys
|
||||
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/awood
|
||||
[1]:https://opensource.com/article/18/5/cryptography-pki
|
||||
[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
|
||||
[3]:https://en.wikipedia.org/wiki/SHA-2
|
||||
[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
|
||||
[5]:https://www.imperialviolet.org/2014/09/26/pkcs1.html
|
||||
[6]:https://en.wikipedia.org/wiki/Key_signing_party
|
||||
[7]:https://en.wikipedia.org/wiki/Key_server_(cryptographic)
|
||||
[8]:https://en.wikipedia.org/wiki/Web_of_trust
|
||||
[9]:https://www.gnupg.org/gph/en/manual/x547.html
|
||||
[10]:https://blog.cryptographyengineering.com/2014/08/13/whats-matter-with-pgp/
|
||||
[11]:https://lists.torproject.org/pipermail/tor-talk/2013-September/030235.html
|
||||
[12]:https://en.wikipedia.org/wiki/Extended_Validation_Certificate
|
||||
[13]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[14]:https://www.youtube.com/watch?v=YEBfamv-_do
|
||||
[15]:https://www.mozilla.org/en-US/about/governance/policies/security-group/certs/policy/
|
||||
[16]:https://technet.microsoft.com/en-us/library/cc751157.aspx
|
||||
[17]:https://en.wikipedia.org/wiki/Hardware_security_module
|
||||
[18]:https://arstechnica.com/information-technology/2012/11/inside-symantecs-ssl-certificate-vault/
|
||||
[19]:https://cabforum.org/baseline-requirements-documents/
|
||||
[20]:http://opensource.com
|
||||
[21]:https://en.wikipedia.org/wiki/Man-in-the-middle_attack
|
||||
[22]:http://www.shortestpathfirst.net/2010/11/18/man-in-the-middle-mitm-attacks-explained-arp-poisoining/
|
||||
Loading…
Reference in New Issue
Block a user