mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
commit
ca565be3d2
@ -1,12 +1,12 @@
|
||||
在命令行中管理 Wifi 连接
|
||||
================================================================================
|
||||
无论何时要安装一款新的 Linux 发行系统,一般的建议都是让您通过有线连接来接到互联网的。这主要的原因有两条:第一,您的无线网卡也许安装的驱动不正确而不能用;第二,如果您是从命令行中来安装系统的,管理 WiFi 就非常可怕。我总是试图避免在命令行中处理 WiFi 。但 Linux 的世界,应具有无所畏惧的精神。如果您不知道怎样操作,您需要继续往下来学习之,这就是写这篇文章的唯一原因。所以我强迫自己学习如何在命令行中管理 WiFi 连接。
|
||||
无论何时要安装一款新的 Linux 发行系统,一般的建议都是让您通过有线连接来接到互联网的。这主要的原因有两条:第一,您的无线网卡也许安装的驱动不正确而不能用;第二,如果您是从命令行中来安装系统的,管理 WiFi 就非常可怕。我总是试图避免在命令行中处理 WiFi 。但 Linux 的世界,应具有无所畏惧的精神。如果您不知道怎样操作,您需要继续往下来学习之,这就是写这篇文章的唯一原因。所以我迫使自己学习如何在命令行中管理 WiFi 连接。
|
||||
|
||||
通过命令行来设置连接到 WiFi 当然有很多种方法,但在这篇文章里,也是一个建议,我将会作用最基本的方法:那就是使用在任何发布版本中都有的包含在“默认包”里的程序和工具。或者我偏向于使用这一种方法。使用此方法显而易见的好处是这个操作过程能在任意有 Linux 系统的机器上复用。不好的一点是它相对来说比较复杂。
|
||||
通过命令行来设置连接到 WiFi 当然有很多种方法,但在这篇文章里,同时也是一个建议,我使用最基本的方法:那就是使用在任何发布版本中都有的包含在“默认包”里的程序和工具。或者说我偏向于使用这一种方法。使用此方法显而易见的好处是这个操作过程能在任意有 Linux 系统的机器上复用。不好的一点是它相对来说比较复杂。
|
||||
|
||||
首先,我假设您们都已经正确安装了无线网卡的驱动程序。没有这前提,后续的一切都如镜花水月。如果您你机器确实没有正确安装上,您应该看看关于您的发布版本的维基和文档。
|
||||
|
||||
然后您就可以用如下命令来检查是哪一个接口来支持无线连接的
|
||||
然后您就可以用如下命令来检查是哪一个接口来支持无线连接的:
|
||||
|
||||
$ iwconfig
|
||||
|
||||
@ -24,21 +24,21 @@
|
||||
|
||||
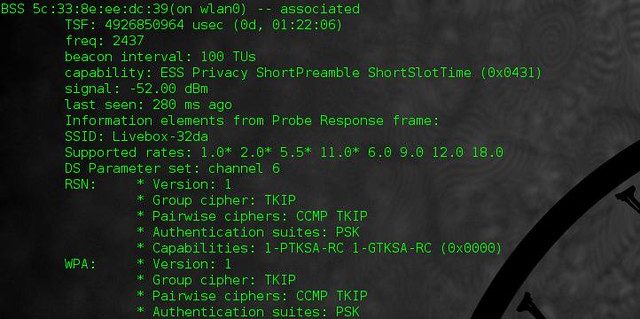
|
||||
|
||||
根据扫描出的结果,可以得到网络的名字(它的 SSID),它的信息强度,以及它使用的是哪个安全加密的(如:WEP、WPA/WPA2)。从此时起,将会分成两条路线:情况很好的和容易的以及情况稍微复杂的。
|
||||
根据扫描出的结果,可以得到网络的名字(它的 SSID),它的信息强度,以及它使用的是哪个安全加密的(如:WEP、WPA/WPA2)。从此时起,将会分成两条路线:情况很好、很容易的以及情况稍微复杂的。
|
||||
|
||||
如果您想连接的网络是没有加密的,您可以用下面的命令直接连接:
|
||||
|
||||
$ sudo iw dev wlan0 connect [network SSID]
|
||||
$ sudo iw dev wlan0 connect [网络 SSID]
|
||||
|
||||
如果网络是用 WEP 加密的,也非常容易:
|
||||
|
||||
$ sudo iw dev wlan0 connect [network SSID] key 0:[WEP key]
|
||||
$ sudo iw dev wlan0 connect [网络 SSID] key 0:[WEP 密钥]
|
||||
|
||||
但网络使用的是 WPA 或 WPA2 协议的话,事情就不好办了。这种情况,您就得使用叫做 wpa_supplicant 的工具,它默认是没有启用的。需要修改 /etc/wpa_supplicant/wpa_supplicant.conf 文件,增加如下行:
|
||||
但网络使用的是 WPA 或 WPA2 协议的话,事情就不好办了。这种情况,您就得使用叫做 wpa_supplicant 的工具,它默认是没有的。然后需要修改 /etc/wpa_supplicant/wpa_supplicant.conf 文件,增加如下行:
|
||||
|
||||
network={
|
||||
ssid="[network ssid]"
|
||||
psk="[the passphrase]"
|
||||
ssid="[网络 ssid]"
|
||||
psk="[密码]"
|
||||
priority=1
|
||||
}
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux FAQ -- 如何修复“X11 forwarding request failed on channel 0”错误
|
||||
Linux有问必答:如何修复“X11 forwarding request failed on channel 0”错误
|
||||
================================================================================
|
||||
> **问题**: 当我尝试使用SSH的X11转发选项连接到远程主机时, 我在登录时遇到了一个 "X11 forwarding request failed on channel 0" (X11 转发请求在通道0上失败)的错误。 我为什么会遇到这个错误,并且该如何修复它
|
||||
|
||||
@ -26,9 +26,9 @@ X11客户端不能正确处理X11转发,这会导致报告中的错误。要
|
||||
$ sudo systemctl restart ssh.service (Debian 7, CentOS/RHEL 7, Fedora)
|
||||
$ sudo service sshd restart (CentOS/RHEL 6)
|
||||
|
||||
### 方案而 ###
|
||||
### 方案二 ###
|
||||
|
||||
如果远程主机的SSH服务禁止了IPv6,那么X11转发失败的错误也有可能发生。要解决这个情况下的错误。打开/etc/ssh/sshd配置文件,打开"AddressFamily all" (如果有的话)的注释。接着加入下面这行。这会强制SSH服务只使用IPv4而不是IPv6。
|
||||
如果远程主机的SSH服务禁止了IPv6,那么X11转发失败的错误也有可能发生。要解决这个情况下的错误。打开/etc/ssh/sshd配置文件,取消对"AddressFamily all" (如果有这条的话)的注释。接着加入下面这行。这会强制SSH服务只使用IPv4而不是IPv6。(LCTT 译注:此处恐有误,AddressFamily 没有 all 这个参数,而 any 代表同时支持 IPv6和 IPv4,以此处的场景而言,应该是关闭IPv6支持,只支持 IPv4,所以此处应该是“注释掉 AddressFamily any”才对。)
|
||||
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
|
||||
@ -43,7 +43,7 @@ X11客户端不能正确处理X11转发,这会导致报告中的错误。要
|
||||
via: http://ask.xmodulo.com/fix-broken-x11-forwarding-ssh.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Ubuntu 14.04历史文件清理
|
||||
如何清理 Ubuntu 14.04 的最近打开文件历史列表
|
||||
================================================================================
|
||||
这个简明教程对Ubuntu 14.04历史文件清理进行了说明,它用于初学者。
|
||||
|
||||
@ -21,6 +21,6 @@ Ubuntu 14.04历史文件清理
|
||||
via: http://www.ubuntugeek.com/how-to-delete-recently-opened-files-history-in-ubuntu-14-04.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,48 +0,0 @@
|
||||
Red Hat designs RHEL for a decade-long run
|
||||
================================================================================
|
||||
> The newly released RHEL 7 includes Docker containers and the new terabyte-scaled XFS file system
|
||||
|
||||
IDG News Service - Knowing how system administrators enjoy continuity, Red Hat has designed the latest release of its flagship Linux distribution to be run, with support, until 2024.
|
||||
|
||||
Red Hat Enterprise Linux 7 (RHEL 7), the completed version of which was shipped Tuesday, also features a number of new technologies that the company sees as instrumental for the next decade, including the Docker Linux Container system and the advanced XFS file system.
|
||||
|
||||
"XFS opens the door for a new class of business analytics, big data and data analytics," said Mark Coggin, Red Hat senior director of product marketing.
|
||||
|
||||
The last major update to RHEL, RHEL 6, was released in November 2010. Since then, server software has been used in an increasingly wide variety of operational scenarios, including providing the basis for bare metal servers, virtual machines, IaaS (infrastructure-as-a-service) and PaaS (platform-as-a-service) cloud packages.
|
||||
|
||||
Red Hat will support RHEL 7 with bug fixes and commercial support for up to 10 years. The company generally releases a major version of RHEL every three years.
|
||||
|
||||
In contrast, Canonical's Ubuntu LTS (long-term support) distributions are supported for five years. Suse Enterprise Linux [is also supported][1], in most aspects, for up to 10 years,
|
||||
|
||||
This is the first edition to include Docker, a container technology [that could act as a nimbler replacement][2] to full virtual machines used in cloud operations. Docker provides a way to package an application in a virtual container so that it can be run across different Linux servers.
|
||||
|
||||
Red Hat expects that containers will be widely deployed over the next few years as a way to package and run applications, thanks to their portable nature.
|
||||
|
||||
"Customers have told us they are looking for a lighter weight version of developing applications. The applications themselves don't need a full operating system or a virtual machine," Coggin said. The system calls are answered by the server's OS and the container includes only the necessary support libraries and the application. "We only put into that container what we need," he said.
|
||||
|
||||
Containers are also easier to maintain because users don't have to worry about updating or patching the full OS within a virtual machine, Coggin said.
|
||||
|
||||
Red Hat is also planning a special stripped-down release of RHEL, now code-named RHEL Atomic, which will be a distribution for just running containers. Containers that run on the regular RHEL can easily be transferred to RHEL Atomic, once that OS is available. They will also run on Red Hat OpenShift PaaS.
|
||||
|
||||
Red Hat is also supporting Docker through its switch in RHEL 7 to the systemd process manager, replacing Linux's long used init process manager. Systemd "gives the administrator a lot of additional flexibility in managing the underlying processes inside of RHEL. It also has a tie back to the container initiative and is very integral to the way the processes are stood up and managed in containers," Coggin said.
|
||||
|
||||
Red Hat has switched the default file system in RHEL 7 to XFS, which is able to keep track of up to 500TBs on a single partition. The previous default file system, ext4, was only able to support 50TBs. Ext4 is still available as an option, as well as another of other file systems such as GFS2 and Btrfs (under technology preview).
|
||||
|
||||
Red Hat has added greater interoperability with the Microsoft Windows environment. Organizations can now use Microsoft Active Directory to securely authenticate users on Red Hat systems. Tools are also included in RHEL 7 to offer Red Hat credentials for Windows servers.
|
||||
|
||||
"Customers have thousands of Windows servers and thousands of RHEL servers, and they to need ways to integrate the two," Coggin said.
|
||||
|
||||
The installation process has been sped up as well, thanks to an update to the Anaconda installer, which now allows administrators to preselect server configurations on the start of the installation process. The inclusion of the industry standard OpenLMI (Open Linux Management Infrastructure), which allows the administrator to manage services at a granular level through a standardized API (application programming interface).
|
||||
|
||||
"OpenLMI is another important way of improving stability and efficiency by helping to manage systems better," Coggin said.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/s/article/9248988/Red_Hat_designs_RHEL_for_a_decade_long_run?taxonomyId=122
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.suse.com/support/policy.html
|
||||
[2]:http://www.infoworld.com/d/virtualization/docker-all-geared-the-enterprise-244020
|
||||
@ -1,99 +0,0 @@
|
||||
What will your business look like in 2030?
|
||||
================================================================================
|
||||

|
||||
|
||||
lya Pozin is a serial entrepreneur, writer, and investor. He is the founder of online video entertainment platform [Pluto.TV][1], social greeting card company [Open Me][2], and digital marketing agency [Ciplex][3].
|
||||
|
||||
The year is 2030, and you’re walking into the front doors of your company. What will it look like, what functions will your employees be performing and how will you stack up against the competition?
|
||||
|
||||
You might not be considering the future, but remember that [25 years ago][4], only 15 percent of US households had a personal computer. While 73 percent of online adults currently have a social media account, social media barely existed 15 years ago.
|
||||
|
||||
Technology is always changing, and with it come disruptions to industries, companies and the employment marketplace. The future is closing in, but is your company ready?
|
||||
|
||||
### Why should you be worried? ###
|
||||
|
||||
In business, to stop moving forward means your company is stagnating; for many companies, stagnation equates to eventual death. Companies clinging to outmoded and outdated business practices eventually run into major problems. There are examples everywhere in the marketplace, from struggling BlackBerry phones to Kodak slowly shuttering its film business.
|
||||
|
||||
According to [futurist and TED talk speaker Thomas Frey][5], two billion jobs will disappear by 2030 thanks to shifting technologies and changing needs. You can’t afford to be behind the pack when the future comes calling.
|
||||
|
||||
### What will 2030 look like? ###
|
||||
|
||||

|
||||
|
||||
Recently, the [Canadian Scholarship Trust][6], as part of its Inspired Minds campaign, [put together a list of the jobs][7] we might all be hiring for in 2030. These jobs range from “Company Culture Ambassador” to – get this! – “Nostalgist.”
|
||||
|
||||
Taking CST’s lead, I spoke to some entrepreneurs and innovators in different fields, from medicine to marketing, to see their predictions for how businesses will be run in the future. Hopping in our time travel machine, here’s a glimpse at what 2030 might look like:
|
||||
|
||||
### Cloud-based ###
|
||||
|
||||
“Everything will be cloud-based with faster speeds,” said Marjorie Adams, [AQB][8] CEO and President. “The technologies coming out now will be better defined and connected. While innovation from the business side could be a lot slower-going than the consumer side, we will have a lot more data to understand real needs.”
|
||||
|
||||
### Automated ###
|
||||
|
||||
Google is already leading the way with the self-driving car, but automation might creep into other aspects of our lives in the future.
|
||||
|
||||
“Home automation will be very different in 2030,” said Andrew Thomas, co-founder of [SkyBell Technologies, Inc][9] .“We’ll all have brain-sensing headbands and glasses and we’ll just ‘think’ about locking the door or turning off the lights. Our fridge will email the store when we’re low on food and our self-driving cars will go pick up the groceries for us!”
|
||||
|
||||
### Human curated ###
|
||||
|
||||
As more and more options become available to consumers, we’ll all become overwhelmed by choice. Human curation will come back into vogue for everything from music to online video.
|
||||
|
||||
We’re already seeing the trend start now with [Apple’s acquisition][10] of human curated music service Beats. After all, do you really think apps are [smarter than you][11]?
|
||||
|
||||
### Socially-connected ###
|
||||
|
||||
If you can’t watch the latest episode of Scandal or Game of Thrones, it’s common sense to stay off your Facebook and Twitter feeds.
|
||||
|
||||
“Imagine a media environment 15 years into the future where no object or entertainment venue is out of reach for second-screen integration with social media,” said Jared Feldman, CEO and founder of [Mashwork][12]. “Social platforms like Facebook and Twitter might as well be agnostic at this point in time since consumers will have aggregated all of their digital social life into consolidated user profiles designed to curate multiple feeds and allow for single-source user engagement.”
|
||||
|
||||
### Targeted ###
|
||||
|
||||
Already advertising is becoming more and more targeted to consumers needs thanks to big data and algorithms. Don’t expect this trend to move backwards, at least according to [FlexOne][13] CEO Matthijs Keij.
|
||||
|
||||
“Advertisers will know more about you than you yourself. Which products you like, how to improve your personal and work life, and even how to be more healthy. Sounds a little like Huxley’s Brave New World? Maybe…but consumers might actually like it.”
|
||||
|
||||
### How do your prepare? ###
|
||||
|
||||

|
||||
|
||||
Preparing for the future might seem impossible, but you don’t need a crystal ball to keep abreast of changes. It’s important to always keep up with trends and emerging technology, both in the economy in general and within your industry in particular.
|
||||
|
||||
Go to conferences, attend industry talks, and make time for industry trade shows. Pay attention to the new technology entering your sector, and don’t turn your nose up at something new just because it’s different than the way things have always been.
|
||||
|
||||
Understand your customers and know what they need, because the future is looking more consumer-focused than ever before, even in segments like healthcare. “The paradigm is shifting to a more “consumer-centric” model,” said Robert Grajewski, CEO of [Edison Nation Medical][14]. “Healthcare as a whole will shift to this individual care focus.”
|
||||
|
||||
Companies that understand their core competencies and their consumer needs will have a leg up on the competition.
|
||||
|
||||
As more digital natives come of age and flock into the economy, some highly skilled fields will see consumers picking up additional skills.
|
||||
|
||||
“By 2030 virtually everyone will be a designer, equipped with knowledge of the hottest mega trends and ripe and ready to replace those who can’t keep up with the latest software,” said Ashley Mady, CEO of [Brandberry][15].
|
||||
|
||||
“The best way to prepare for this inevitable shift in the design world is to focus on creative, big picture thinking over production, which will soon become a commodity. Designers should remain innovative by developing their own adaptable brands and technology that will grow alongside the quickly evolving world we live in.”
|
||||
|
||||
Finally, it’s important to be open, curious, and willing to pivot. New technologies are going to come along to improve, and sometimes complicate, your business. You need to be willing to embrace these new paradigms, or you risk your company becoming obsolete.
|
||||
|
||||
What do you think? How do you plan to prepare for the future? Share in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thenextweb.com/entrepreneur/2014/06/18/will-business-look-like-2030/?utm_campaign=share%20button&utm_content=What%20will%20your%20business%20look%20like%20in%202030?&awesm=tnw.to_q3L0P&utm_source=copypaste&utm_medium=referral
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://pluto.tv/
|
||||
[2]:http://www.openme.com/
|
||||
[3]:http://www.ciplex.com/
|
||||
[4]:http://www.cnbc.com/id/101611509
|
||||
[5]:http://www.futuristspeaker.com/2012/02/2-billion-jobs-to-disappear-by-2030/
|
||||
[6]:http://www.cst.org/
|
||||
[7]:http://careers2030.cst.org/jobs/
|
||||
[8]:http://www.aqb.com/
|
||||
[9]:http://www.skybell.com/
|
||||
[10]:http://thenextweb.com/apple/2014/05/28/apple-confirms-acquisition-beats/
|
||||
[11]:http://thenextweb.com/apps/2013/10/19/i-let-apps-tell-me-how-to-live-for-a-day/
|
||||
[12]:http://mashwork.com/
|
||||
[13]:http://www.flxone.com/
|
||||
[14]:http://www.edisonnationmedical.com/
|
||||
[15]:http://www.brandberry.com/
|
||||
@ -1,3 +1,4 @@
|
||||
2q1w2007翻译中
|
||||
How to convert image, audio and video formats on Ubuntu
|
||||
================================================================================
|
||||
If you need to work with a variety of image, audio and video files encoded in all sorts of different formats, you are probably using more than one tools to convert among all those heterogeneous media formats. If there is a versatile all-in-one media conversion tool that is capable of dealing with all different image/audio/video formats, that will be awesome.
|
||||
@ -83,4 +84,4 @@ via: http://xmodulo.com/how-to-convert-image-audio-and-video-formats-on-ubuntu.h
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://launchpad.net/format-junkie
|
||||
[2]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
[2]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
|
||||
@ -1,60 +0,0 @@
|
||||
su-kaiyao translating
|
||||
|
||||
Simple guide to forks in GitHub and Git
|
||||
==========================================
|
||||
|
||||
In my experience, one of the most confusing parts about getting started in Git and GitHub is trying to figure out the following: **What do I do in Git, and what do I do in GitHub?**
|
||||
|
||||
Git tutorials tend not to address this question, since they are (purposefully) focused on teaching you Git commands and concepts, and do not presume you will use GitHub. [GitHub help articles](https://help.github.com/) bridge this gap somewhat, but each article is narrowly focused and ultimately doesn't provide a conceptual overview of the "Git vs GitHub" question.
|
||||
|
||||
**If you are the type of learner that benefits from understanding concepts before diving into code**, and you are new to Git and GitHub, I suggest that the first step is to understand forking. Why?
|
||||
|
||||
1. Forking is a common way to get started in GitHub.
|
||||
2. Forking requires very few Git commands, but the ones it does use are very important.
|
||||
3. Forking provides a foundational understanding of Git and GitHub that will benefit you later.
|
||||
|
||||
**This guide uses two simple diagrams to teach you the two main workflows for forks.** I'm not going to cover any code, but in the Conclusion I'll link to the code you should use.
|
||||
|
||||
###Forking and updating a repo
|
||||
|
||||
Let's say there's a programmer named Joe who built a game you would like to improve, and he is hosting his code in a GitHub repository. Here's what you do:
|
||||

|
||||
*Diagram of forking and updating a GitHub repo*
|
||||
|
||||
1. **Fork his repo**: This is a GitHub operation, in which you are making a copy of Joe's repository (including the files, commit history, issues, and more). This repository now lives in your GitHub account. Nothing has yet happened to your local computer.
|
||||
|
||||
2. **Clone your repo**: This is a Git operation, in which you are using Git to tell GitHub "please send me a copy of my repo." The repo is now stored on your local computer.
|
||||
|
||||
3. **Update some files**: You can now make updates to the files in whatever program or environment you like.
|
||||
|
||||
4. **Commit your changes**: This is a Git operation, in which you are telling Git to record the file changes you have made. This is an operation on your local computer only.
|
||||
|
||||
5. **Push your changes to your GitHub repo**: This is a Git operation, in which you are using Git to tell GitHub "here are my changes." Pushing does not happen automatically, so until you do this step, GitHub does not know about your commits.
|
||||
|
||||
6. **Send a pull request to Joe**: If you think that Joe might like to incorporate your changes, you send him a pull request. This is a GitHub operation, in which you are communicating your changes to Joe, and "requesting" that he "pull" from your repo. It is up to him whether he pulls from you or not.
|
||||
|
||||
If Joe accepts your pull request, he will pull your changes into his repo. Victory!
|
||||
|
||||
###Syncing a fork
|
||||
|
||||
Let's say that Joe and other contributors have made some more updates to the game, and you've thought of some more updates you'd like to make. Before you do anything else, it's best to "sync your fork" so that you are working on the latest copy of the files. Here's what you do:
|
||||
|
||||

|
||||
|
||||
*Diagram of syncing a GitHub fork*
|
||||
|
||||
1. **Fetch changes from Joe's repo**: This is a Git operation, in which you are using Git to tell GitHub that you would like to retrieve the latest files from Joe's repo.
|
||||
|
||||
2. **Merge those changes into your repo**: This is a Git operation, in which you are updating the repo on your local computer with those changes (which have been temporarily stored in a "branch"). Note: Steps 1 and 2 are often combined into a single Git operation called a "pull."
|
||||
|
||||
3. **Push the updates to your GitHub repo** (optional): Remember that your local computer does not automatically update your GitHub repo. Therefore, the only way to get your GitHub repo up-to-date is by pushing up the latest changes. You can either do this right away, or you can wait until you have made some updates of your own and committed them locally.
|
||||
|
||||
**Take note of the contrast between the workflow for forking and the workflow for syncing**: When you initially fork a repo, the flow of information is from Joe's repo to your repo, and then down to your local computer. But after that initial process, the flow of information is from Joe's repo to your local computer, and then up to your repo.
|
||||
|
||||
###Conclusion
|
||||
|
||||
I hope this was a helpful overview of [forking](https://help.github.com/articles/fork-a-repo) in GitHub and Git. Now that you understand the concepts, you should be much better prepared to actually execute the code! The GitHub articles on forking and [syncing](https://help.github.com/articles/syncing-a-fork) will give you most of the code you need.
|
||||
|
||||
If you are new to Git and this style of learning appeals to you, I highly recommend the first two chapters of the book [Pro Git](http://git-scm.com/book), which is available online for free.
|
||||
|
||||
If you enjoy learning via videos, I created a [11-part video series](http://www.dataschool.io/git-and-github-videos-for-beginners/) (36 minutes total) introducing Git and GitHub to beginners.
|
||||
@ -1,90 +0,0 @@
|
||||
Linux FAQs with Answers--How to change default location of libvirt VM images
|
||||
================================================================================
|
||||
> **Question**: I am using libvirt and virt-manager to create VMs on my Linux system. I noticed that the VM images are stored in /var/lib/libvirt/images directory. Is there a way to change the default location of VM image directory to something else?
|
||||
|
||||
**libvirt** and its GUI front-end **virt-manager** can create and manage VMs using different hypervisors such as KVM and Xen. By default, all the VM images created via **libvirt** go to /var/lib/libvirt/images directory. However, this may not be desirable in some cases. For example, the disk partition where /var/lib/libvirt/images lives may have limited free space. Or you may want to store all VM images in a specific repository for management purposes.
|
||||
|
||||
In fact, you can easily change the default location of the libvirt image directory, or what they call a "storage pool."
|
||||
|
||||
There are two ways to change the default storage pool.
|
||||
|
||||
### Method One: Virt-Manager GUI ###
|
||||
|
||||
If you are using virt-manager GUI program, changing the default storage pool is very easy.
|
||||
|
||||
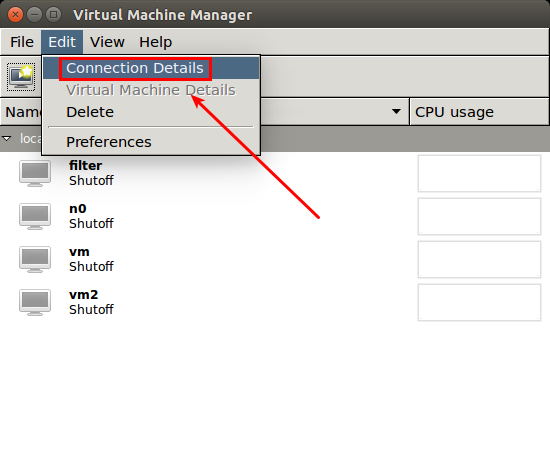
Go to "Edit" -> "Connection Details" in **virt-manager** menu GUI.
|
||||
|
||||
|
||||
|
||||
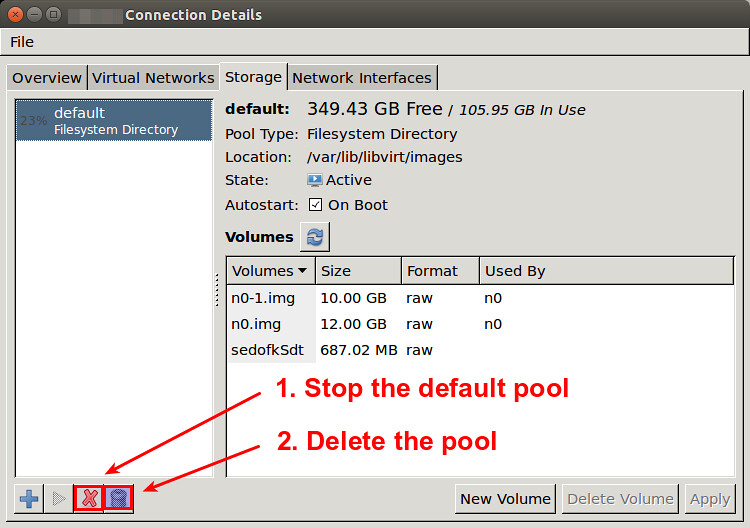
You will see the default storage pool as shown below. On the left bottom of the window, click on the cross icon, which will stop the default storage pool. Once the pool is stopped, click on the trash bin icon on the right, which will delete the pool. Note that this action will NOT remove the VM images inside the pool.
|
||||
|
||||
Now click on the plus icon on the far left to add a new storage pool.
|
||||
|
||||
|
||||
|
||||
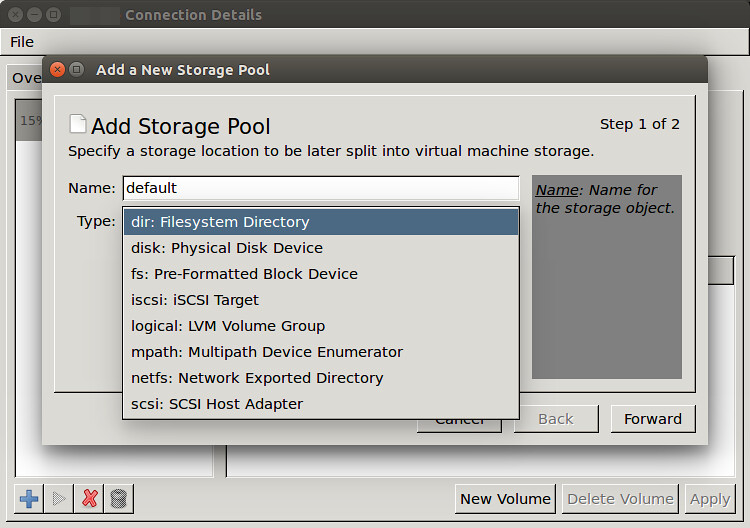
Type in the name of a new storage pool (e.g., default), and choose the type of the pool. In this case, choose a "filesystem directory" type since we are simply changing a storage pool directory.
|
||||
|
||||
|
||||
|
||||
Type in the path of a new storage pool (e.g., /storage).
|
||||
|
||||
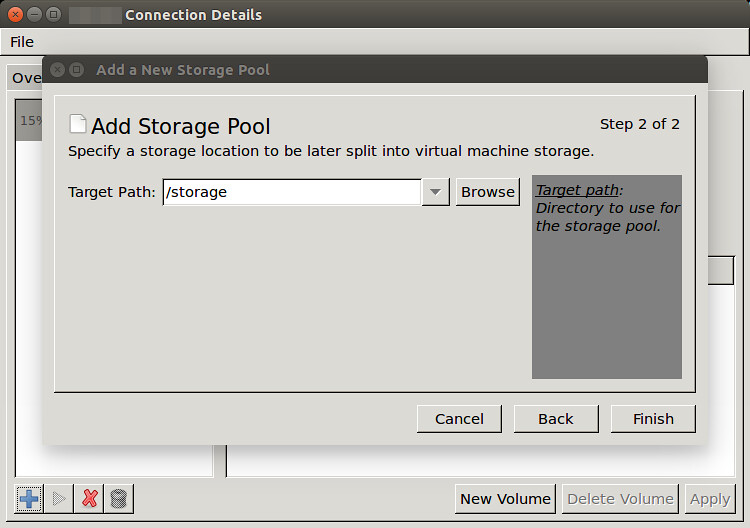
|
||||
|
||||
At this point, the new storage pool should be started, and automatically used when you create a new VM.
|
||||
|
||||
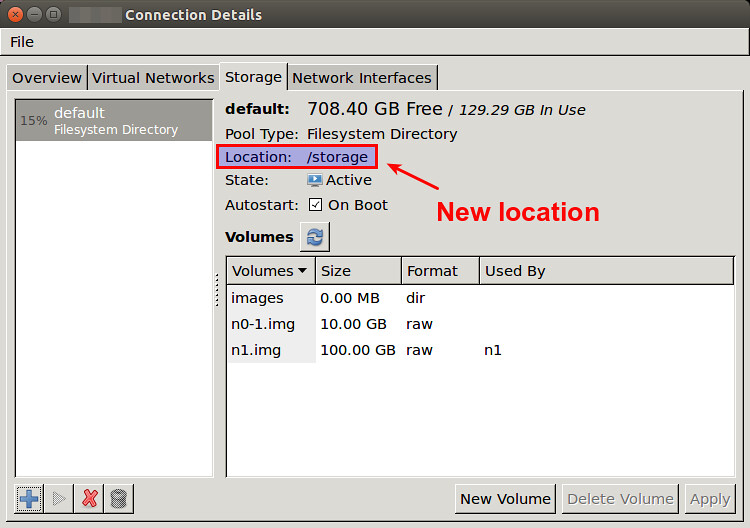
|
||||
|
||||
### Method One: Virsh Command-Line ###
|
||||
|
||||
Another method to change the default storage pool directory is to use **virsh** command line utility which comes with **libvirt** package.
|
||||
|
||||
First, run the following command to dump XML definition of the default storage pool.
|
||||
|
||||
$ virsh pool-dumpxml default > pool.xml
|
||||
|
||||
Open this XML file with a text editor, and change <path> element from /var/lib/libvirt/images to a new location.
|
||||
|
||||
<pool type='dir'>
|
||||
<name>default</name>
|
||||
<uuid>0ec0e393-28a2-e975-feec-0c7356f38d08</uuid>
|
||||
<capacity unit='bytes'>975762788352</capacity>
|
||||
<allocation unit='bytes'>530052247552</allocation>
|
||||
<available unit='bytes'>445710540800</available>
|
||||
<source>
|
||||
</source>
|
||||
<target>
|
||||
<path>/var/lib/libvirt/images</path>
|
||||
<permissions>
|
||||
<mode>0711</mode>
|
||||
<owner>-1</owner>
|
||||
<group>-1</group>
|
||||
</permissions>
|
||||
</target>
|
||||
</pool>
|
||||
|
||||
Remove the current default pool.
|
||||
|
||||
$ virsh pool-destroy default
|
||||
|
||||
----------
|
||||
|
||||
Pool default destroyed
|
||||
|
||||
Now create a new storage pool based on the updated XML file.
|
||||
|
||||
$ virsh pool-create pool.xml
|
||||
|
||||
----------
|
||||
|
||||
Pool default created from pool.xml
|
||||
|
||||
At this point, a default pool has been changed to a new location, and is ready for use.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-default-location-libvirt-vm-images.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,37 @@
|
||||
Ubuntu Unity 4岁了,生日快乐!
|
||||
================================================================================
|
||||
> Unity桌面环境在Ubuntu 10.04 Netbook Remix版本中加入,这是一个不再存在的版本。
|
||||
|
||||
**Canonical开发着以及Ubuntu社区这些天有一个很好的理由来庆祝,因为Unity桌面环境已经4岁了**
|
||||
|
||||
Unity是Ubuntu的默认桌面环境,并且已经有4年了,虽然这并不是发行版的桌面版本。它首次用于Ubuntu Netbook Remix,是专为笔记本使用的版本。实际上Ubuntu Netbook Remix 10.10 Maverick市场首次接受Unity桌面。
|
||||
|
||||
常规的Ubuntu 10.10 发行版桌面仍旧使用GNOME 2.x,这也是为什么有用户说10.10 仍是Canonical做的最好的版本。
|
||||
|
||||
### Unity 是没人想要的替代品 ###
|
||||
|
||||
Canonical决定用他们自己的软件替代GNOME 2.x桌面环境,但是它的设计对用户而言很陌生。一些人喜欢它,但是许多人并不这样并且还被不同的用户在他们决定放弃Ubuntu的时候还时不时地提到这个。
|
||||
|
||||
Unit设计视角上和GNOME不同,但是Ubuntu开发者并没有替换GNOME所有的包,并且还保留了很多(他们现在仍旧这样)。之前不喜欢Unity方向的Ubuntu的粉丝一定对GNOME 2.x被很快抛弃且被完全不同的同样引发相同质疑的GNOME 3.0替换感到很失望。
|
||||
|
||||
### 为什么Unity替换GNOME ###
|
||||
|
||||
回到还在Ubuntu 10.10 的时光,Canonical和GNOME团队习惯与非常紧密地一起工作,但是事情在Ubuntu变得越来越流行后发生了改变。其中一个驱使Canonical构建Unity的理由是GNOME团队的是叫不再和他们一致了。
|
||||
|
||||
用户在抱怨GMOME的问题或者他们想要特定的功能。Ubuntu团队会发给上游一些补丁,对于GNOME,它不会接受或者会花很长的时间去实现。在同时,Canonical和Ubuntu被一下额他们不能解决的问题受到了很多的批评,但是用户并不知道这些。
|
||||
|
||||
因此,一个与GNOME捆绑不太紧的桌面环境的需求变得非常清晰了。Unity最终在Ubuntu 11.10中引入。因此官方的发布日期是 2010年10月10日,这让Unity已经4岁了。
|
||||
|
||||
Unity还没有被全社区的拥抱,虽然有很多用户已经接受了这是一个有用且是一个生产桌面环境。虽然桌面的大修已经逾期了很久且势必会在一两年内完成,但是它在每个新的发行后都会获得了更多的支持和停留。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Ubuntu-s-Unity-Turns-4-Happy-Birthday--461840.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[gekepi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
@ -0,0 +1,67 @@
|
||||
在Github和Git上fork之简单指南
|
||||
===
|
||||
|
||||
以我的经验来看,刚接触Git和GitHub时,最困扰的一件事情就是尝试解决下面的问题:**在Git和GitHub上,我能做什么?**
|
||||
|
||||
Git教程往往不会解决这个问题,因为它集中篇幅来教你Git命令和概念,并且不认为你会使用GitHub。[GitHub帮助教程](https://help.github.com/)一定程度上弥补了这一缺陷,但是它每篇文章的关注点都较为狭隘,而且没有提供关于"Git vs GitHub"问题的概念性概述。
|
||||
|
||||
**如果你是习惯于先理解概念,再着手代码的学习者**,而且你也是Git和GitHub的初学者,我建议你先理解清楚什么是fork,为什么?
|
||||
|
||||
1. Fork是在GitHub起步最普遍的方式。
|
||||
2. Fork只需要很少的Git命令,但是起得作用却非常大。
|
||||
3. Fork提供了对Git和GitHub最基础的了解,有益于你之后的工作。
|
||||
|
||||
**本篇指南使用两张简单的图表,来教会你fork的两种主要工作流程。**我并不打算涉及任何代码,但是在结论中,我会把你需要使用的代码的链接给你。
|
||||
|
||||
### fork并且更新一个仓库
|
||||
|
||||
现在有这样一种情形:有一个叫做Joe的程序猿写了一个游戏程序,而你可能要去改进它。并且Joe将他的代码放在了GitHub仓库上。下面是你要做的事情:
|
||||
|
||||

|
||||
|
||||
**fork并且更新GitHub仓库的图表演示**
|
||||
|
||||
1. **Fork他的仓库**:这是GitHub操作,这个操作会复制Joe的仓库(包括文件,提交历史,issues,和其余一些东西)。复制后的仓库在你自己的GitHub帐号下。目前,你本地计算机对这个仓库没有任何操作。
|
||||
|
||||
2. **Clone你的仓库**:这是Git操作。使用该操作让你发送"请给我发一份我仓库的复制文件"的命令给GitHub。现在这个仓库就会存储在你本地计算机上。
|
||||
|
||||
3. **更新某些文件**:现在,你可以在任何程序或者环境下更新仓库里的文件。
|
||||
|
||||
4. **提交你的更改**:这是Git操作。使用该操作让你发送"记录我的更改"的命令至GitHub。此操作只在你的本地计算机上完成。
|
||||
|
||||
5. **将你的更改push到你的GitHub仓库**:这是Git操作。使用该操作让你发送"这是我的修改"的信息给GitHub。Push操作不会自动完成,所以直到你做了push操作,GitHub才知道你的提交。
|
||||
|
||||
6. **给Joe发送一个pull request**:如果你认为Joe会接受你的修改,你就可以给他发送一个pull request。这是GitHub操作,使用此操作可以帮助你和Joe交流你的修改,并且询问Joe是否愿意接受你的"pull request",当然,接不接受完全取决于他自己。
|
||||
|
||||
如果Joe接受了你的pull request,他将把那些修改拉到自己的仓库。胜利!
|
||||
|
||||
### 同步一个fork
|
||||
|
||||
Joe和其余贡献者已经对这个项目做了一些修改,而你将在他们的修改的基础上,还要再做一些修改。在你开始之前,你最好"同步你的fork",以确保在最新的复制版本里工作。下面是你要做的:
|
||||
|
||||

|
||||
|
||||
*同步GitHub fork的图表示意图*
|
||||
|
||||
1. **从Joe的仓库中取出那些变化的文件**:这是Git操作,使用该命令让你可以从Joe的仓库获取最新的文件。
|
||||
|
||||
2. **将这些修改合并到你自己的仓库**:这是Git操作,使用该命令使得那些修改更新到你的本地计算机(那些修改暂时存放在一个"分支"中)。记住:步骤1和2经常结合为一个命令使用,合并后的Git命令叫做"pull"。
|
||||
|
||||
3. **将那些修改更新推送到你的GitHub仓库**(可选):记住,你本地计算机不会自动更新你的GitHub仓库。所以,唯一更新GitHub仓库的办法就是将那些修改推送上去。你可以在步骤2完成后立即执行push,也可以等到你做了自己的一些修改,并已经本地提交后再执行推送操作。
|
||||
|
||||
**比较一下fork和同步工作流程的区别**:当你最初fork一个仓库的时候,信息的流向是从Joe的仓库到你的仓库,然后再到你本地计算机。但是最初的过程之后,信息的流向是从Joe的仓库到你的本地计算机,之后再到你的仓库。
|
||||
|
||||
### 结论
|
||||
|
||||
我希望这是一篇关于GitHub和Git [fork](https://help.github.com/articles/fork-a-repo)有用概述。现在,你已经理解了那些概念,你将会更容易地在实际中执行你的代码。GitHub关于fork和[同步](https://help.github.com/articles/syncing-a-fork)的文章将会给你大部分你需要的代码。
|
||||
|
||||
如果你是Git的初学者,而且你很喜欢这种学习方式,那么我极力推荐书籍[Pro Git](http://git-scm.com/book)的前两个章节,网上是可以免费查阅的。
|
||||
|
||||
如果你喜欢视频学习,我创建了一个[11部分的视频系列](http://www.dataschool.io/git-and-github-videos-for-beginners/)(总共36分钟),来向初学者介绍Git和GitHub。
|
||||
|
||||
---
|
||||
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,16 +1,16 @@
|
||||
Linux有问必答——如何在Linux命令行中刻录ISO或NRG镜像到DVD
|
||||
================================================================================
|
||||
> **问题**:我需要在Linux盒子上使用DVD刻录机刻录一个镜像文件(.iso或.nrg)到DVD,有没有一个既快捷又简易的方法,最好是使用命令行工具,来刻录.iso或.nrg镜像到DVD?
|
||||
> **问题**:我需要在Linux盒子上使用DVD刻录机刻录一个镜像文件(.iso或.nrg)到DVD,有没有一个既快捷又简易的方法,最好是使用命令行工具?
|
||||
|
||||
最常见的两种镜像文件格式是ISO(.iso为文件扩展名)和NRG(.nrg为文件扩展名)。ISO格式是一个由ISO(国际标准组)创立的全球标准,因此被大多数操作系统所支持,它提供了很高的便携性。另一方面,NRG格式是由Nero AG开发的私有格式,Nero AG是一个很大众的磁盘镜像和刻录软件公司。
|
||||
最常见的两种镜像文件格式是ISO(.iso为文件扩展名)和NRG(.nrg为文件扩展名)。ISO格式是一个由ISO(国际标准组织)创立的全球标准,因此被大多数操作系统所支持,它提供了很高的便携性。另一方面,NRG格式是由Nero AG开发的私有格式,Nero AG是一个很大众的磁盘镜像和刻录软件公司。
|
||||
|
||||
下面来解答怎样从Linux命令行刻录.iso或.nrg镜像到DVD。
|
||||
|
||||
### 转换NRG镜像到ISO格式 ###
|
||||
### 把NRG镜像转换为ISO格式 ###
|
||||
|
||||
由于ISO被广为采用,刻录.iso镜像到CD/DVD就非常简单。但是,要刻录一个.nrg镜像则首先需要将它转换为.iso格式。
|
||||
|
||||
要转换一个.nrg镜像文件到.iso格式,你可以使用nrg2iso这个工具。它是一个开源程序,用来将Nero Burning Rom创建的镜像转换到标准的.iso(ISO9660)文件。
|
||||
把一个.nrg镜像文件转换到.iso格式,你可以使用nrg2iso这个工具。它是一个开源程序,用来将Nero Burning Rom创建的镜像转换到标准的.iso(ISO9660)文件。
|
||||
|
||||
在Debian及其衍生版上安装**nrg2iso**:
|
||||
|
||||
@ -32,13 +32,13 @@ Linux有问必答——如何在Linux命令行中刻录ISO或NRG镜像到DVD
|
||||
|
||||

|
||||
|
||||
### 刻录.ISO镜像文件到DVD ###
|
||||
### 刻录.ISO镜像文件到DVD ###
|
||||
|
||||
为了刻录.iso镜像文件到DVD,我们将使用**growisofs**这个工具:
|
||||
|
||||
# growisofs -dvd-compat -speed=4 -Z /dev/dvd1=WindowsXPProfessionalSP3Original.iso
|
||||
|
||||
在上面的命令行中,“-dvd-compat”选项提供了与DVD-ROM/-Video的最大介质兼容性。在一次写入DVD+R或DVD-R上下文中,这会导致不可添加记录(关闭磁盘)。
|
||||
在上面的命令行中,“-dvd-compat”选项提供了与DVD-ROM/-Video的最大介质兼容性。在一次写入式 DVD+R 或 DVD-R 上下文中,导致不可添加记录(关闭磁盘)。
|
||||
|
||||
“-Z /dev/dvd1=filename.iso”选项表示我们刻录.iso文件到设备选单(/dev/dvd1)中选择的介质中。
|
||||
|
||||
@ -46,6 +46,8 @@ Linux有问必答——如何在Linux命令行中刻录ISO或NRG镜像到DVD
|
||||
|
||||
你可以根据[此教程][2]找出你的DVD刻录机的设备名称和它所支持的写入速度。
|
||||
注:此文在另一篇原文中(20141014 Linux FAQs with Answers--How to detect DVD writer' s device name and its writing speed from the command line on Linux.md),如果也翻译发布了,可修改此链接.
|
||||
校对注:这篇的原文还没翻译,翻译完一起发布
|
||||
|
||||

|
||||
|
||||
刻录进程完成后,磁盘会自动弹出。
|
||||
@ -54,13 +56,13 @@ Linux有问必答——如何在Linux命令行中刻录ISO或NRG镜像到DVD
|
||||
|
||||
关于这一点,你可以通过将刻录的DVD的校验和与原始.iso文件的md5校验和进行对比,以检查所刻录介质的完整性。如果两者相同,你就可以放心了,因为刻录成功了。
|
||||
|
||||
然而,当你使用nrg2iso来将.nrg镜像转换为.iso格式后,你需要明白一点,nrg2iso创建的.iso文件的大小不是2048的倍数(通常,.iso文件的大小是它的倍数)。因此,常规的校验和对比,结果一般是该.iso文件和刻录介质的内容不一样。
|
||||
然而,当你使用nrg2iso来将.nrg镜像转换为.iso格式后,你需要明白一点,nrg2iso创建的.iso文件的大小不是2048的倍数(通常,.iso文件的大小是它的倍数)。因此,常规的校验和对比,该.iso文件和刻录介质的内容不一样。
|
||||
|
||||
另一方面,如果你已经刻录了一个不是由.nrg文件转换而来的.iso镜像,你可以使用以下命令来检查记录到DVD中的数据的完整性。替换“/dev/dvd1”为你的设备名。
|
||||
|
||||
# md5sum filename.iso; dd if=/dev/dvd1 bs=2048 count=$(($(stat -c "%s" filename.iso) / 2048)) | md5sum
|
||||
|
||||
命令的第一部分计算.iso文件的md5校验和,而第二部分则读取/dev/dvd1中的磁盘的内容,然后通过管道输出给md5sum工具。“bs=2048”表示dd命令将使用2048字节块为单位检查,因为原始iso文件以2048为单位划分。
|
||||
命令的第一部分计算.iso文件的md5校验和,而第二部分则读取/dev/dvd1中的磁盘内容,然后通过管道输出给md5sum工具。“bs=2048”表示dd命令将使用2048字节块为单位检查,因为原始iso文件以2048为单位划分。
|
||||
|
||||

|
||||
|
||||
@ -71,7 +73,7 @@ Linux有问必答——如何在Linux命令行中刻录ISO或NRG镜像到DVD
|
||||
via: http://ask.xmodulo.com/burn-iso-nrg-image-dvd-command-line.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,90 @@
|
||||
Linux 有问必答 -- 如何改变libvirt VM镜像的默认位置
|
||||
================================================================================
|
||||
> **提问**: 我使用libvirt和virt-manager在我的Linux系统上创建虚拟机。我注意到虚拟机镜像位于/var/lib/libvirt/images目录。有没有办法改变虚拟机镜像的默认路径?
|
||||
|
||||
**libvirt**和它的GUI前端**virt-manager**可以使用不同的虚拟机管理程序创建和管理VM,例如LVM和Xen。默认上所有的虚拟机镜像通过**libvirt**创建到/var/lib/libvirt/images目录。然而,这有时并不是我们希望的。比如/var/lib/libvirt/images此处的磁盘分区大小有限。或者你想要存储所有的虚拟机镜像到一个特定的用于管理的仓库中。
|
||||
|
||||
实际上,你可以非常容易地改变libvirt镜像的默认目录,或者称之为“存储池”。
|
||||
|
||||
有两种方法可以改变默认存储池。
|
||||
|
||||
### 方法一: Virt-Manager GUI ###
|
||||
|
||||
如果你正在使用virt-manager GUI程序,改变默认存储池非常容易。
|
||||
|
||||
进入**virt-manager**的菜单GUI “编辑” -> "连接细节"。
|
||||
|
||||

|
||||
|
||||
你可以看到如下所是的默认存储池。在窗口的左下角,点击叉形按钮,将会停止默认的存储池。存储池一旦停止后,点击右边的垃圾桶,将会删除存储池。注意这个动作不会删除池中的镜像。
|
||||
|
||||
现在点击左边的加号增加一个新的存储池。
|
||||
|
||||

|
||||
|
||||
输入新的存储池的名字(比如:default),并且选择存储池的类型。本例中,因为我们只是改变存储池目录所以选择“文件系统目录”。
|
||||
|
||||

|
||||
|
||||
输入新的存储池路径(比如,/storage)。
|
||||
|
||||

|
||||
|
||||
这时,新的存储池应该启动了,并且自动在你创建一个新的虚拟机的时候使用。
|
||||
|
||||

|
||||
|
||||
### 方法二: Virsh 命令行 ###
|
||||
|
||||
另外一个改变默认存储池目录的方法是使用来自**libvirt**包的**virsh** 命令行工具。
|
||||
|
||||
首先,运行下面的命令来导出默认存储池的XML定义。
|
||||
|
||||
$ virsh pool-dumpxml default > pool.xml
|
||||
|
||||
用文本编辑器打开XML文件,并且改变<path>节点中的/var/lib/libvirt/images改成新的地址。
|
||||
|
||||
<pool type='dir'>
|
||||
<name>default</name>
|
||||
<uuid>0ec0e393-28a2-e975-feec-0c7356f38d08</uuid>
|
||||
<capacity unit='bytes'>975762788352</capacity>
|
||||
<allocation unit='bytes'>530052247552</allocation>
|
||||
<available unit='bytes'>445710540800</available>
|
||||
<source>
|
||||
</source>
|
||||
<target>
|
||||
<path>/var/lib/libvirt/images</path>
|
||||
<permissions>
|
||||
<mode>0711</mode>
|
||||
<owner>-1</owner>
|
||||
<group>-1</group>
|
||||
</permissions>
|
||||
</target>
|
||||
</pool>
|
||||
|
||||
移除现在的默认池。
|
||||
|
||||
$ virsh pool-destroy default
|
||||
|
||||
----------
|
||||
|
||||
Pool default destroyed
|
||||
|
||||
现在创建一个基于更新后的XML文件的新存储池。
|
||||
|
||||
$ virsh pool-create pool.xml
|
||||
|
||||
----------
|
||||
|
||||
Pool default created from pool.xml
|
||||
|
||||
这时,默认池已经改变到新的地址了,并且可以使用了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-default-location-libvirt-vm-images.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -30,7 +30,7 @@ SNMPv3提供了重要的安全特征:
|
||||
|
||||
###配置SNMPv3###
|
||||
|
||||
获得守护进程的权限
|
||||
获得守护进程的权限
|
||||
|
||||
默认的安装仅提供本地的访问权限,如果想要获得外部访问权限的话编辑文件 /etc/default/snmpd。
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user