mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
commit
ca45cca373
@ -0,0 +1,261 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13052-1.html)
|
||||
[#]: subject: (Make websites more readable with a shell script)
|
||||
[#]: via: (https://opensource.com/article/19/2/make-websites-more-readable-shell-script)
|
||||
[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
|
||||
|
||||
利用 Shell 脚本让网站更具可读性
|
||||
======
|
||||
|
||||
> 测算网站的文本和背景之间的对比度,以确保站点易于阅读。
|
||||
|
||||

|
||||
|
||||
如果希望人们发现你的网站实用,那么他们需要能够阅读它。为文本选择的颜色可能会影响网站的可读性。不幸的是,网页设计中的一种流行趋势是在打印输出文本时使用低对比度的颜色,就像在白色背景上的灰色文本。对于 Web 设计师来说,这也许看起来很酷,但对于许多阅读它的人来说确实很困难。
|
||||
|
||||
W3C 提供了《<ruby>Web 内容可访问性指南<rt>Web Content Accessibility Guidelines</rt></ruby>》,其中包括帮助 Web 设计人员选择易于区分文本和背景色的指导。z这就是所谓的“<ruby>对比度<rt>contrast ratio</rt></ruby>”。 W3C 定义的对比度需要进行一些计算:给定两种颜色,首先计算每种颜色的相对亮度,然后计算对比度。对比度在 1 到 21 的范围内(通常写为 1:1 到 21:1)。对比度越高,文本在背景下的突出程度就越高。例如,白色背景上的黑色文本非常醒目,对比度为 21:1。对比度为 1:1 的白色背景上的白色文本不可读。
|
||||
|
||||
[W3C 说,正文][1] 的对比度至少应为 4.5:1,标题至少应为 3:1。但这似乎是最低限度的要求。W3C 还建议正文至少 7:1,标题至少 4.5:1。
|
||||
|
||||
计算对比度可能比较麻烦,因此最好将其自动化。我已经用这个方便的 Bash 脚本做到了这一点。通常,脚本执行以下操作:
|
||||
|
||||
1. 获取文本颜色和背景颜色
|
||||
2. 计算相对亮度
|
||||
3. 计算对比度
|
||||
|
||||
### 获取颜色
|
||||
|
||||
你可能知道显示器上的每种颜色都可以用红色、绿色和蓝色(R、G 和 B)来表示。要计算颜色的相对亮度,脚本需要知道颜色的红、绿和蓝的各个分量。理想情况下,脚本会将这些信息读取为单独的 R、G 和 B 值。 Web 设计人员可能知道他们喜欢的颜色的特定 RGB 代码,但是大多数人不知道不同颜色的 RGB 值。作为一种替代的方法是,大多数人通过 “red” 或 “gold” 或 “maroon” 之类的名称来引用颜色。
|
||||
|
||||
幸运的是,GNOME 的 [Zenity][2] 工具有一个颜色选择器应用程序,可让你使用不同的方法选择颜色,然后用可预测的格式 `rgb(R,G,B)` 返回 RGB 值。使用 Zenity 可以轻松获得颜色值:
|
||||
|
||||
```
|
||||
color=$( zenity --title 'Set text color' --color-selection --color='black' )
|
||||
```
|
||||
|
||||
如果用户(意外地)单击 “Cancel(取消)” 按钮,脚本将假定一种颜色:
|
||||
|
||||
```
|
||||
if [ $? -ne 0 ] ; then
|
||||
echo '** color canceled .. assume black'
|
||||
color='rgb(0,0,0)'
|
||||
fi
|
||||
```
|
||||
|
||||
脚本对背景颜色值也执行了类似的操作,将其设置为 `$background`。
|
||||
|
||||
### 计算相对亮度
|
||||
|
||||
一旦你在 `$color` 中设置了前景色,并在 `$background` 中设置了背景色,下一步就是计算每种颜色的相对亮度。 [W3C 提供了一个算法][3] 用以计算颜色的相对亮度。
|
||||
|
||||
> 对于 sRGB 色彩空间,一种颜色的相对亮度定义为:
|
||||
>
|
||||
> L = 0.2126 * R + 0.7152 * G + 0.0722 * B
|
||||
>
|
||||
> R、G 和 B 定义为:
|
||||
>
|
||||
> if $R_{sRGB}$ <= 0.03928 then R = $R_{sRGB}$/12.92
|
||||
>
|
||||
> else R = (($R_{sRGB}$+0.055)/1.055) $^{2.4}$
|
||||
>
|
||||
> if $G_{sRGB}$ <= 0.03928 then G = $G_{sRGB}$/12.92
|
||||
>
|
||||
> else G = (($G_{sRGB}$+0.055)/1.055) $^{2.4}$
|
||||
>
|
||||
> if $B_{sRGB}$ <= 0.03928 then B = $B_{sRGB}$/12.92
|
||||
>
|
||||
> else B = (($B_{sRGB}$+0.055)/1.055) $^{2.4}$
|
||||
>
|
||||
> $R_{sRGB}$、$G_{sRGB}$ 和 $B_{sRGB}$ 定义为:
|
||||
>
|
||||
> $R_{sRGB}$ = $R_{8bit}$/255
|
||||
>
|
||||
> $G_{sRGB}$ = $G_{8bit}$/255
|
||||
>
|
||||
> $B_{sRGB}$ = $B_{8bit}$/255
|
||||
|
||||
由于 Zenity 以 `rgb(R,G,B)` 的格式返回颜色值,因此脚本可以轻松拉取分隔开的 R、B 和 G 的值以计算相对亮度。AWK 可以使用逗号作为字段分隔符(`-F,`),并使用 `substr()` 字符串函数从 `rgb(R,G,B)` 中提取所要的颜色值:
|
||||
|
||||
```
|
||||
R=$( echo $color | awk -F, '{print substr($1,5)}' )
|
||||
G=$( echo $color | awk -F, '{print $2}' )
|
||||
B=$( echo $color | awk -F, '{n=length($3); print substr($3,1,n-1)}' )
|
||||
```
|
||||
|
||||
*有关使用 AWK 提取和显示数据的更多信息,[查看 AWK 备忘表][4]*
|
||||
|
||||
最好使用 BC 计算器来计算最终的相对亮度。BC 支持计算中所需的简单 `if-then-else`,这使得这一过程变得简单。但是由于 BC 无法使用非整数指数直接计算乘幂,因此需要使用自然对数替代它做一些额外的数学运算:
|
||||
|
||||
```
|
||||
echo "scale=4
|
||||
rsrgb=$R/255
|
||||
gsrgb=$G/255
|
||||
bsrgb=$B/255
|
||||
if ( rsrgb <= 0.03928 ) r = rsrgb/12.92 else r = e( 2.4 * l((rsrgb+0.055)/1.055) )
|
||||
if ( gsrgb <= 0.03928 ) g = gsrgb/12.92 else g = e( 2.4 * l((gsrgb+0.055)/1.055) )
|
||||
if ( bsrgb <= 0.03928 ) b = bsrgb/12.92 else b = e( 2.4 * l((bsrgb+0.055)/1.055) )
|
||||
0.2126 * r + 0.7152 * g + 0.0722 * b" | bc -l
|
||||
```
|
||||
|
||||
这会将一些指令传递给 BC,包括作为相对亮度公式一部分的 `if-then-else` 语句。接下来 BC 打印出最终值。
|
||||
|
||||
### 计算对比度
|
||||
|
||||
利用文本颜色和背景颜色的相对亮度,脚本就可以计算对比度了。 [W3C 确定对比度][5] 是使用以下公式:
|
||||
|
||||
> (L1 + 0.05) / (L2 + 0.05),这里的
|
||||
> L1 是颜色较浅的相对亮度,
|
||||
> L2 是颜色较深的相对亮度。
|
||||
|
||||
给定两个相对亮度值 `$r1` 和 `$r2`,使用 BC 计算器很容易计算对比度:
|
||||
|
||||
```
|
||||
echo "scale=2
|
||||
if ( $r1 > $r2 ) { l1=$r1; l2=$r2 } else { l1=$r2; l2=$r1 }
|
||||
(l1 + 0.05) / (l2 + 0.05)" | bc
|
||||
```
|
||||
|
||||
使用 `if-then-else` 语句确定哪个值(`$r1` 或 `$r2`)是较浅还是较深的颜色。BC 执行结果计算并打印结果,脚本可以将其存储在变量中。
|
||||
|
||||
### 最终脚本
|
||||
|
||||
通过以上内容,我们可以将所有内容整合到一个最终脚本。 我使用 Zenity 在文本框中显示最终结果:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# script to calculate contrast ratio of colors
|
||||
|
||||
# read color and background color:
|
||||
# zenity returns values like 'rgb(255,140,0)' and 'rgb(255,255,255)'
|
||||
|
||||
color=$( zenity --title 'Set text color' --color-selection --color='black' )
|
||||
if [ $? -ne 0 ] ; then
|
||||
echo '** color canceled .. assume black'
|
||||
color='rgb(0,0,0)'
|
||||
fi
|
||||
|
||||
background=$( zenity --title 'Set background color' --color-selection --color='white' )
|
||||
if [ $? -ne 0 ] ; then
|
||||
echo '** background canceled .. assume white'
|
||||
background='rgb(255,255,255)'
|
||||
fi
|
||||
|
||||
# compute relative luminance:
|
||||
|
||||
function luminance()
|
||||
{
|
||||
R=$( echo $1 | awk -F, '{print substr($1,5)}' )
|
||||
G=$( echo $1 | awk -F, '{print $2}' )
|
||||
B=$( echo $1 | awk -F, '{n=length($3); print substr($3,1,n-1)}' )
|
||||
|
||||
echo "scale=4
|
||||
rsrgb=$R/255
|
||||
gsrgb=$G/255
|
||||
bsrgb=$B/255
|
||||
if ( rsrgb <= 0.03928 ) r = rsrgb/12.92 else r = e( 2.4 * l((rsrgb+0.055)/1.055) )
|
||||
if ( gsrgb <= 0.03928 ) g = gsrgb/12.92 else g = e( 2.4 * l((gsrgb+0.055)/1.055) )
|
||||
if ( bsrgb <= 0.03928 ) b = bsrgb/12.92 else b = e( 2.4 * l((bsrgb+0.055)/1.055) )
|
||||
0.2126 * r + 0.7152 * g + 0.0722 * b" | bc -l
|
||||
}
|
||||
|
||||
lum1=$( luminance $color )
|
||||
lum2=$( luminance $background )
|
||||
|
||||
# compute contrast
|
||||
|
||||
function contrast()
|
||||
{
|
||||
echo "scale=2
|
||||
if ( $1 > $2 ) { l1=$1; l2=$2 } else { l1=$2; l2=$1 }
|
||||
(l1 + 0.05) / (l2 + 0.05)" | bc
|
||||
}
|
||||
|
||||
rel=$( contrast $lum1 $lum2 )
|
||||
|
||||
# print results
|
||||
|
||||
( cat<<EOF
|
||||
Color is $color on $background
|
||||
|
||||
Contrast ratio is $rel
|
||||
Contrast ratios can range from 1 to 21 (commonly written 1:1 to 21:1).
|
||||
|
||||
EOF
|
||||
|
||||
if [ ${rel%.*} -ge 4 ] ; then
|
||||
echo "Ok for body text"
|
||||
else
|
||||
echo "Not good for body text"
|
||||
fi
|
||||
if [ ${rel%.*} -ge 3 ] ; then
|
||||
echo "Ok for title text"
|
||||
else
|
||||
echo "Not good for title text"
|
||||
fi
|
||||
|
||||
cat<<EOF
|
||||
|
||||
W3C 说明:
|
||||
|
||||
1.4.3 对比度(最小值):文本和文本图像的视觉呈现方式的对比度至少为 4.5:1,但以下情况除外:(AA 级)
|
||||
|
||||
大文本:大文本和大文本图像的对比度至少为 3:1;
|
||||
|
||||
附带说明:作为非活动用户界面组件一部分,纯装饰的,任何人都不可见或图片的一部分包含特定的其他可视内容的文本或文本图像没有对比度要求。
|
||||
|
||||
小示意图:徽标或商标名称中的文本没有最低对比度要求。
|
||||
|
||||
1.4.6 对比度(增强):文本和文本图像的视觉表示具有至少 7:1 的对比度,但以下情况除外:(AAA 级)
|
||||
|
||||
大文本:大文本和大文本图像的对比度至少为 4.5:1;
|
||||
|
||||
附带说明:作为非活动用户界面组件一部分,纯装饰的,任何人都不可见或图片的一部分包含特定的其他可视内容的文本或文本图像没有对比度要求。
|
||||
|
||||
小示意图:徽标或商标名称中的文本没有最低对比度要求。
|
||||
EOF
|
||||
) | zenity --text-info --title='Relative Luminance' --width=800 --height=600
|
||||
```
|
||||
|
||||
最后,我希望提供有关 W3C 建议的参考信息,以提醒自己。
|
||||
|
||||
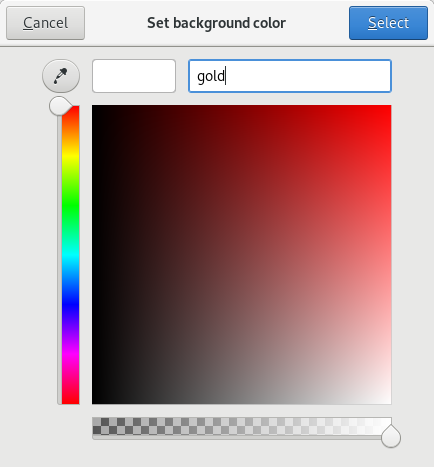
Zenity 颜色选择器完成了所有解释颜色的艰苦工作,用户可以通过单击色轮或输入值来选择颜色。 Zenity 接受网站上使用的标准十六进制颜色值,例如 `#000000` 或 `#000`或 `rgb(0,0,0)`(所有这些均为黑色)。这是白色背景上的黑色文本的示例计算:
|
||||
|
||||
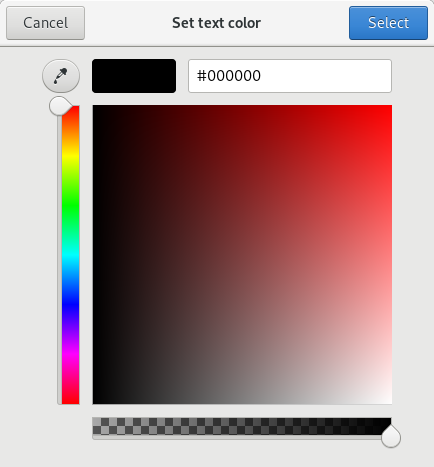
|
||||
|
||||
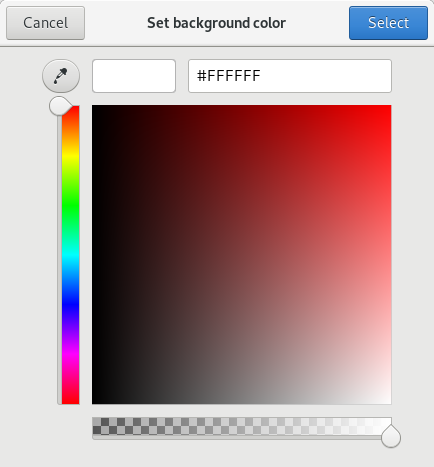
|
||||
|
||||

|
||||
|
||||
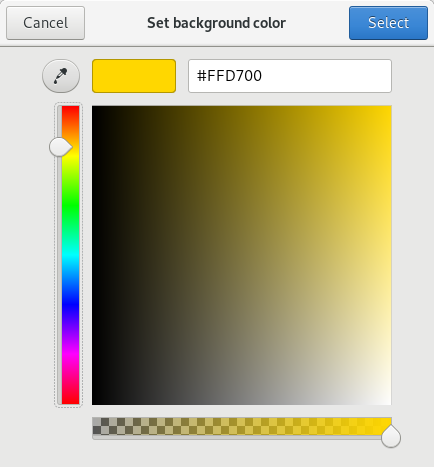
Zenity 还识别标准的颜色名称,如“cadetblue”、“orange”或“gold”。在Zenity 中输入颜色名称,然后点击 `Tab` 键,Zenity 会将颜色名称转换为十六进制颜色值,如以下示例中对金色背景上的黑色文本的计算:
|
||||
|
||||
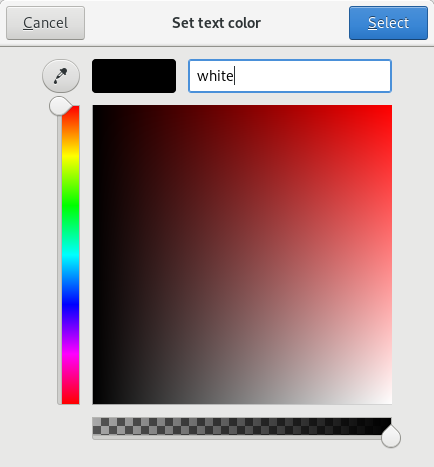
|
||||
|
||||
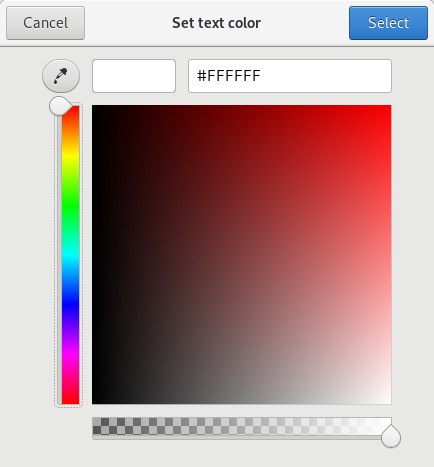
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/make-websites-more-readable-shell-script
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.w3.org/TR/2008/REC-WCAG20-20081211/#visual-audio-contrast
|
||||
[2]: https://wiki.gnome.org/Projects/Zenity
|
||||
[3]: https://www.w3.org/TR/2008/REC-WCAG20-20081211/#relativeluminancedef
|
||||
[4]: https://opensource.com/article/18/7/cheat-sheet-awk
|
||||
[5]: https://www.w3.org/TR/2008/REC-WCAG20-20081211/#contrast-ratiodef
|
||||
@ -0,0 +1,44 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Zen of Python: Why timing is everything)
|
||||
[#]: via: (https://opensource.com/article/19/12/zen-python-timeliness)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
The Zen of Python: Why timing is everything
|
||||
======
|
||||
This is part of a special series about the Zen of Python focusing on the
|
||||
15th and 16th principles: now vs. never.
|
||||
![Clock, pen, and notepad on a desk][1]
|
||||
|
||||
Python is always evolving. The Python community has an unending appetite for feature requests but also an unending bias toward the status quo. As Python gets more popular, changes to the language affect more people.
|
||||
|
||||
The exact timing for when a change happens is often hard, but the [Zen of Python][2] offers guidance.
|
||||
|
||||
### Now is better than never.
|
||||
|
||||
There is always the temptation to delay things until they are perfect. They will never be perfect, though. When they look "ready" enough, that is when it is time to take the plunge and put them out there. Ultimately, a change always happens at _some_ now: the only thing that delaying does is move it to a future person's "now."
|
||||
|
||||
### Although never is often better than _right now_.
|
||||
|
||||
This, however, does not mean things should be rushed. Decide the criteria for release in terms of testing, documentation, user feedback, and so on. "Right now," as in before the change is ready, is not a good time.
|
||||
|
||||
This is a good lesson not just for popular languages like Python, but also for your personal little open source project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/zen-python-timeliness
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/desk_clock_job_work.jpg?itok=Nj4fuhl6 (Clock, pen, and notepad on a desk)
|
||||
[2]: https://www.python.org/dev/peps/pep-0020/
|
||||
@ -0,0 +1,46 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to tell if implementing your Python code is a good idea)
|
||||
[#]: via: (https://opensource.com/article/19/12/zen-python-implementation)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
How to tell if implementing your Python code is a good idea
|
||||
======
|
||||
This is part of a special series about the Zen of Python focusing on the
|
||||
17th and 18th principles: hard vs. easy.
|
||||
![Brick wall between two people, a developer and an operations manager][1]
|
||||
|
||||
A language does not exist in the abstract. Every single language feature has to be implemented in code. It is easy to promise some features, but the implementation can get hairy. Hairy implementation means more potential for bugs, and, even worse, a maintenance burden for the ages.
|
||||
|
||||
The [Zen of Python][2] has answers for this conundrum.
|
||||
|
||||
### If the implementation is hard to explain, it's a bad idea.
|
||||
|
||||
The most important thing about programming languages is predictability. Sometimes we explain the semantics of a certain construct in terms of abstract programming models, which do not correspond exactly to the implementation. However, the best of all explanations just _explains the implementation_.
|
||||
|
||||
If the implementation is hard to explain, it means the avenue is impossible.
|
||||
|
||||
### If the implementation is easy to explain, it may be a good idea.
|
||||
|
||||
Just because something is easy does not mean it is worthwhile. However, once it is explained, it is much easier to judge whether it is a good idea.
|
||||
|
||||
This is why the second half of this principle intentionally equivocates: nothing is certain to be a good idea, but it always allows people to have that discussion.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/zen-python-implementation
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/devops_confusion_wall_questions.png?itok=zLS7K2JG (Brick wall between two people, a developer and an operations manager)
|
||||
[2]: https://www.python.org/dev/peps/pep-0020/
|
||||
@ -0,0 +1,55 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Namespaces are the shamash candle of the Zen of Python)
|
||||
[#]: via: (https://opensource.com/article/19/12/zen-python-namespaces)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
Namespaces are the shamash candle of the Zen of Python
|
||||
======
|
||||
This is part of a special series about the Zen of Python focusing on one
|
||||
bonus principle: namespaces.
|
||||
![Person programming on a laptop on a building][1]
|
||||
|
||||
Hanukkah famously has eight nights of celebration. The Hanukkah menorah, however, has nine candles: eight regular candles and a ninth that is always offset. It is called the **shamash** or **shamos**, which loosely translates to meaning "servant" or "janitor."
|
||||
|
||||
The shamos is the candle that lights all the others: it is the only candle whose fire can be used, not just watched. As we wrap up our series on the Zen of Python, I see how namespaces provide a similar service.
|
||||
|
||||
### Namespaces in Python
|
||||
|
||||
Python uses namespaces for everything. Though simple, they are sparse data structures—which is often the best way to achieve a goal.
|
||||
|
||||
> A _namespace_ is a mapping from names to objects.
|
||||
>
|
||||
> — [Python.org][2]
|
||||
|
||||
Modules are namespaces. This means that correctly predicting module semantics often just requires familiarity with how Python namespaces work. Classes are namespaces. Objects are namespaces. Functions have access to their local namespace, their parent namespace, and the global namespace.
|
||||
|
||||
The simple model, where the **.** operator accesses an object, which in turn will usually, but not always, do some sort of dictionary lookup, makes Python hard to optimize, but easy to explain.
|
||||
|
||||
Indeed, some third-party modules take this guideline and run with it. For example, the** [variants][3]** package turns functions into namespaces of "related functionality." It is a good example of how the [Zen of Python][4] can inspire new abstractions.
|
||||
|
||||
### In conclusion
|
||||
|
||||
Thank you for joining me on this Hanukkah-inspired exploration of [my favorite language][5]. Go forth and meditate on the Zen until you reach enlightenment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/zen-python-namespaces
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
|
||||
[2]: https://docs.python.org/3/tutorial/classes.html
|
||||
[3]: https://pypi.org/project/variants/
|
||||
[4]: https://www.python.org/dev/peps/pep-0020/
|
||||
[5]: https://opensource.com/article/19/10/why-love-python
|
||||
@ -1,251 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ()
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding 52-bit virtual address support in the Arm64 kernel)
|
||||
[#]: via: (https://opensource.com/article/20/12/52-bit-arm64-kernel)
|
||||
[#]: author: (Bhupesh Sharma https://opensource.com/users/bhsharma)
|
||||
|
||||
Understanding 52-bit virtual address support in the Arm64 kernel
|
||||
======
|
||||
The introduction of 64-bit hardware increased the need to handle larger
|
||||
address spaces.
|
||||
![Puzzle pieces coming together to form a computer screen][1]
|
||||
|
||||
After 64-bit hardware became available, the need to handle larger address spaces (greater than 232 bytes) became obvious. With some vendors now offering servers with 64TiB (or more) of memory, x86_64 and arm64 now allow addressing adress spaces greater than 248 bytes (available with the default 48-bit address support).
|
||||
|
||||
x86_64 addressed these use cases by enabling support for five-level page tables in both hardware and software. This enables addressing address spaces equal to 257 bytes (see [x86: 5-level paging enabling for v4.12][2] for details). It bumps the limits to 128PiB of virtual address space and 4PiB of physical address space.
|
||||
|
||||
arm64 achieved the same thing by introducing two new architecture extensions—ARMv8.2 LVA (Large Virtual Addressing) and ARMv8.2 LPA (Large Physical Addressing). These allow 4PiB of virtual address space and 4 PiB of physical address space (i.e., 252 bits each, respectively).
|
||||
|
||||
With ARMv8.2 architecture extensions available in new arm64 CPUs, the two new hardware extensions are now supported in open source software.
|
||||
|
||||
Starting with Linux kernel version 5.4, the 52-bit (Large) Virtual Address (VA) and Physical Address (PA) support was introduced for arm64 architecture. Although the [kernel documentation][3] describes these features and how they impact the new kernels running on older CPUs (which don't support 52-bit VA extension in hardware) and newer CPUs (which support 52-bit VA extensions in hardware), it can be complex for average users to understand them and how they can "opt-in" to receiving VAs from a 52-bit space.
|
||||
|
||||
Therefore, I will introduce these relatively new concepts in this article:
|
||||
|
||||
1. How the kernel memory layout got "flipped" for Arm64 after the support for these features was added
|
||||
2. The impact on userspace applications, especially the ones that provide debugging support (e.g., kexec-tools, makedumpfile, and crash-utility)
|
||||
3. How userspace applications can "opt-in" to receiving VAs from a 52-bit space by specifying an mmap hint parameter that is larger than 48 bits
|
||||
|
||||
|
||||
|
||||
### ARMv8.2 architecture LVA and LPA extensions
|
||||
|
||||
The ARMv8.2 architecture provides two important extensions: Large Virtual Addressing (LVA) and Large Physical Addressing (LPA).
|
||||
|
||||
ARMv8.2-LVA supports a larger VA space for each translation table base register of up to 52 bits when using the 64KB translation granule.
|
||||
|
||||
ARMv8.2-LPA allows:
|
||||
|
||||
* A larger intermediate physical address (IPA) and PA space of up to 52 bits when using the 64KB translation granule
|
||||
* A level 1 block size where the block covers a 4TB address range for the 64KB translation granule if the implementation supports 52 bits of PA
|
||||
|
||||
|
||||
|
||||
_Note that these features are supported only in the AArch64 state._
|
||||
|
||||
Currently, the following Arm64 Cortex-A processors support ARMv8.2 extensions:
|
||||
|
||||
* Cortex-A55
|
||||
* Cortex-A75
|
||||
* Cortex-A76
|
||||
|
||||
|
||||
|
||||
For more details, see the [Armv8 Architecture Reference Manual][4].
|
||||
|
||||
### Kernel memory layout on Arm64
|
||||
|
||||
With the ARMv8.2 extension adding support for LVA space (which is only available when running with a 64KB page size), the number of descriptors gets expanded in the first level of translation.
|
||||
|
||||
User addresses have bits 63:48 set to 0, while the kernel addresses have the same bits set to 1. TTBRx selection is given by bit 63 of the virtual address. The `swapper_pg_dir` contains only kernel (global) mappings, while the user `pgd` contains only user (non-global) mappings. The `swapper_pg_dir` address is written to TTBR1 and never written to TTBR0.
|
||||
|
||||
**AArch64 Linux memory layout with 64KB pages plus three levels (52-bit with hardware support):**
|
||||
|
||||
|
||||
```
|
||||
Start End Size Use
|
||||
-----------------------------------------------------------------------
|
||||
0000000000000000 000fffffffffffff 4PB user
|
||||
fff0000000000000 fff7ffffffffffff 2PB kernel logical memory map
|
||||
fff8000000000000 fffd9fffffffffff 1440TB [gap]
|
||||
fffda00000000000 ffff9fffffffffff 512TB kasan shadow region
|
||||
ffffa00000000000 ffffa00007ffffff 128MB bpf jit region
|
||||
ffffa00008000000 ffffa0000fffffff 128MB modules
|
||||
ffffa00010000000 fffff81ffffeffff ~88TB vmalloc
|
||||
fffff81fffff0000 fffffc1ffe58ffff ~3TB [guard region]
|
||||
fffffc1ffe590000 fffffc1ffe9fffff 4544KB fixed mappings
|
||||
fffffc1ffea00000 fffffc1ffebfffff 2MB [guard region]
|
||||
fffffc1ffec00000 fffffc1fffbfffff 16MB PCI I/O space
|
||||
fffffc1fffc00000 fffffc1fffdfffff 2MB [guard region]
|
||||
fffffc1fffe00000 ffffffffffdfffff 3968GB vmemmap
|
||||
ffffffffffe00000 ffffffffffffffff 2MB [guard region]
|
||||
```
|
||||
|
||||
**Translation table lookup with 4KB pages:**
|
||||
|
||||
|
||||
```
|
||||
+--------+--------+--------+--------+--------+--------+--------+--------+
|
||||
|63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0|
|
||||
+--------+--------+--------+--------+--------+--------+--------+--------+
|
||||
| | | | | |
|
||||
| | | | | v
|
||||
| | | | | [11:0] in-page offset
|
||||
| | | | +-> [20:12] L3 index
|
||||
| | | +-----------> [29:21] L2 index
|
||||
| | +---------------------> [38:30] L1 index
|
||||
| +-------------------------------> [47:39] L0 index
|
||||
+-------------------------------------------------> [63] TTBR0/1
|
||||
```
|
||||
|
||||
**Translation table lookup with 64KB pages:**
|
||||
|
||||
|
||||
```
|
||||
+--------+--------+--------+--------+--------+--------+--------+--------+
|
||||
|63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0|
|
||||
+--------+--------+--------+--------+--------+--------+--------+--------+
|
||||
| | | | |
|
||||
| | | | v
|
||||
| | | | [15:0] in-page offset
|
||||
| | | +----------> [28:16] L3 index
|
||||
| | +--------------------------> [41:29] L2 index
|
||||
| +-------------------------------> [47:42] L1 index (48-bit)
|
||||
| [51:42] L1 index (52-bit)
|
||||
+-------------------------------------------------> [63] TTBR0/1
|
||||
```
|
||||
|
||||
|
||||
|
||||
![][5]
|
||||
|
||||
opensource.com
|
||||
|
||||
### 52-bit VA support in the kernel
|
||||
|
||||
Since the newer kernels with the LVA support should run well on older CPUs (which don't support LVA extension in hardware) and the newer CPUs (which support LVA extension in hardware), the chosen design approach is to have a single binary that supports 52 bit (and must be able to fall back to 48 bit at early boot time if the hardware feature is not present). That is, the VMEMMAP must be sized large enough for 52-bit VAs and also must be sized large enough to accommodate a fixed `PAGE_OFFSET`.
|
||||
|
||||
This design approach requires the kernel to support the following variables for the new virtual address space:
|
||||
|
||||
|
||||
```
|
||||
VA_BITS constant the *maximum* VA space size
|
||||
|
||||
vabits_actual variable the *actual* VA space size
|
||||
```
|
||||
|
||||
So, while `VA_BITS` denotes the maximum VA space size, the actual VA space supported (depending on the switch made at boot time) is indicated by `vabits_actual`.
|
||||
|
||||
#### Flipping the kernel memory layout
|
||||
|
||||
The design approach of keeping a single kernel binary requires the kernel .text to be in the higher addresses, such that they are invariant to 48/52-bit VAs. Due to the Kernel Address Sanitizer (KASAN) shadow being a fraction of the entire kernel VA space, the end of the KASAN shadow must also be in the higher half of the kernel VA space for both 48 and 52 bit. (Switching from 48 bit to 52 bit, the end of the KASAN shadow is invariant and dependent on `~0UL`, while the start address will "grow" towards the lower addresses).
|
||||
|
||||
To optimize `phys_to_virt()` and `virt_to_phys()`, the `PAGE_OFFSET` is kept constant at `0xFFF0000000000000` (corresponding to 52 bit), this obviates the need for an extra variable read. The `physvirt` and `vmemmap` offsets are computed at early boot to enable this logic.
|
||||
|
||||
Consider the following physical vs. virtual RAM address space conversion:
|
||||
|
||||
|
||||
```
|
||||
/*
|
||||
* The linear kernel range starts at the bottom of the virtual address
|
||||
* space. Testing the top bit for the start of the region is a
|
||||
* sufficient check and avoids having to worry about the tag.
|
||||
*/
|
||||
|
||||
#define virt_to_phys(addr) ({ \
|
||||
if (!(((u64)addr) & BIT(vabits_actual - 1))) \
|
||||
(((addr) & ~PAGE_OFFSET) + PHYS_OFFSET)
|
||||
})
|
||||
|
||||
#define phys_to_virt(addr) ((unsigned long)((addr) - PHYS_OFFSET) | PAGE_OFFSET)
|
||||
|
||||
where:
|
||||
PAGE_OFFSET - the virtual address of the start of the linear map, at the
|
||||
start of the TTBR1 address space,
|
||||
PHYS_OFFSET - the physical address of the start of memory, and
|
||||
vabits_actual - the *actual* VA space size
|
||||
```
|
||||
|
||||
### Impact on userspace applications used to debug kernel
|
||||
|
||||
Several userspace applications are used to debug running/live kernels or analyze the vmcore dump from a crashing system (e.g., to determine the root cause of the kernel crash): kexec-tools, makedumpfile, and crash-utility.
|
||||
|
||||
When these are used for debugging the Arm64 kernel, there is also an impact on them because of the Arm64 kernel memory map getting "flipped." These applications also need to perform a translation table walk for determining a physical address corresponding to a virtual address (similar to how it is done in the kernel).
|
||||
|
||||
Accordingly, userspace applications must be modified as they are broken upstream after the "flip" was introduced in the kernel memory map.
|
||||
|
||||
I have proposed fixes in the three affected userspace applications; while some have been accepted upstream, others are still pending:
|
||||
|
||||
* [Proposed makedumpfile upstream fix][6]
|
||||
* [Proposed kexec-tools upstream fix][7]
|
||||
* [Fix accepted in crash-utility][8]
|
||||
|
||||
|
||||
|
||||
Unless these changes are made in userspace applications, they will remain broken for debugging running/live kernels or analyzing the vmcore dump from a crashing system.
|
||||
|
||||
### 52-bit userspace VAs
|
||||
|
||||
To maintain compatibility with userspace applications that rely on the ARMv8.0 VA space maximum size of 48 bits, the kernel will, by default, return virtual addresses to userspace from a 48-bit range.
|
||||
|
||||
Userspace applications can "opt-in" to receiving VAs from a 52-bit space by specifying an mmap hint parameter larger than 48 bits.
|
||||
|
||||
For example:
|
||||
|
||||
|
||||
```
|
||||
.mmap_high_addr.c
|
||||
\----
|
||||
|
||||
maybe_high_address = mmap(~0UL, size, prot, flags,...);
|
||||
```
|
||||
|
||||
It is also possible to build a debug kernel that returns addresses from a 52-bit space by enabling the following kernel config options:
|
||||
|
||||
|
||||
```
|
||||
` CONFIG_EXPERT=y && CONFIG_ARM64_FORCE_52BIT=y`
|
||||
```
|
||||
|
||||
_Note that this option is only intended for debugging applications and should **not** be used in production._
|
||||
|
||||
### Conclusions
|
||||
|
||||
To summarize:
|
||||
|
||||
1. Starting with Linux kernel version 5.14, the new Armv8.2 hardware extensions LVA and LPA are now well-supported in the Linux kernel.
|
||||
2. Userspace applications like kexec-tools and makedumpfile used for debugging the kernel are broken _right now_ and awaiting acceptance of upstream fixes.
|
||||
3. Legacy userspace applications that rely on Arm64 kernel providing it a 48-bit VA will continue working as-is, whereas newer userspace applications can "opt-in" to receiving VAs from a 52-bit space by specifying an mmap hint parameter that is larger than 48 bits.
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_This article draws on [Memory Layout on AArch64 Linux][9] and [Linux kernel documentation v5.9.12][10]. Both are licensed under GPLv2.0._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/12/52-bit-arm64-kernel
|
||||
|
||||
作者:[Bhupesh Sharma][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[萌新阿岩](https://github.com/mengxinayan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bhsharma
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||
[2]: https://lwn.net/Articles/716916/
|
||||
[3]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/arm64/memory.rst
|
||||
[4]: https://developer.arm.com/documentation/ddi0487/latest/
|
||||
[5]: https://opensource.com/sites/default/files/arm64-multi-level-translation_0.png (arm64 Multi-level Translation)
|
||||
[6]: http://lists.infradead.org/pipermail/kexec/2020-September/021372.html
|
||||
[7]: http://lists.infradead.org/pipermail/kexec/2020-September/021333.html
|
||||
[8]: https://github.com/crash-utility/crash/commit/1c45cea02df7f947b4296c1dcaefa1024235ef10
|
||||
[9]: https://www.kernel.org/doc/html/latest/arm64/memory.html
|
||||
[10]: https://elixir.bootlin.com/linux/latest/source/arch/arm64/include/asm/memory.h
|
||||
@ -1,69 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why keeping a journal improves productivity)
|
||||
[#]: via: (https://opensource.com/article/21/1/open-source-journal)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
Why keeping a journal improves productivity
|
||||
======
|
||||
Journaling has a long history. Here are three open source tools to help
|
||||
make your journaling life a little easier.
|
||||
![Note taking hand writing][1]
|
||||
|
||||
In previous years, this annual series covered individual apps. This year, we are looking at all-in-one solutions in addition to strategies to help in 2021. Welcome to day 10 of 21 Days of Productivity in 2021.
|
||||
|
||||
When I was in primary school in the days before the commercial internet, teachers would often give my class an assignment to keep a journal. Sometimes it was targeted at something particular, like a specifically formatted list of bugs and descriptions or a weekly news article summary for a civics class.
|
||||
|
||||
People have been keeping journals for centuries. They are a handy way of storing information. They come in many forms, like the Italian [Zibaldone][2], [Commonplace Books][3], or a diary of events that logs what got done today.
|
||||
|
||||
![Notebook folders][4]
|
||||
|
||||
(Kevin Sonney, [CC BY-SA 4.0][5])
|
||||
|
||||
Why should we keep a journal of some sort? The first reason is so that we aren't keeping everything in our heads. Not many of us have an [Eidetic memory][6], and maintaining a running log or set of notes makes it easier to reference something we did before. Journals are also easier to share since they can be copy/pasted in chat, email, and so on. "Knowledge is Power. Knowledge shared is Power Multiplied," as [Robert Boyce][7] famously said, and the sharing of knowledge is an intrinsic part of Open Source.
|
||||
|
||||
![Today's journal][8]
|
||||
|
||||
Today's journal (Kevin Sonney, [CC BY-SA 4.0][5])
|
||||
|
||||
One of the critical points when journaling events is to make it fast, simple, and easy. The easiest way is to open a document, add a line with the current date and the note, and save.
|
||||
|
||||
Several programs or add-ons are available to make this easier. [The GNote Note of the Day Plugin][9] automatically creates a note titled with the date and can be used to store content for just that day.
|
||||
|
||||
Emacs Org has a hotkey combination to "capture" things and put them into a document. Combined with the [org-journal][10] add-on, this will create entries in a document for the day it was created.
|
||||
|
||||
The KNotes component of Kontact automatically adds the date and time to new notes.
|
||||
|
||||
![Finding a note][11]
|
||||
|
||||
Finding a note (Kevin Sonney, [CC BY-SA 4.0][5])
|
||||
|
||||
Keeping a journal or record of things is a handy way of keeping track of what and how something was done. And it can be useful for more than just "I did this" - it can also include a list of books read, foods eaten, places visited, and a whole host of information that is often useful in the future.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/1/open-source-journal
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/note-taking.jpeg?itok=fiF5EBEb (Note taking hand writing)
|
||||
[2]: https://en.wikipedia.org/wiki/Zibaldone
|
||||
[3]: https://en.wikipedia.org/wiki/Commonplace_book
|
||||
[4]: https://opensource.com/sites/default/files/pictures/day10-image1.png (Notebook folders)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://en.wikipedia.org/wiki/Eidetic_memory
|
||||
[7]: https://en.wikipedia.org/wiki/Robert_Boyce
|
||||
[8]: https://opensource.com/sites/default/files/pictures/day10-image2.png (Today's journal)
|
||||
[9]: https://help.gnome.org/users/gnote/unstable/addin-noteoftheday.html.en
|
||||
[10]: https://github.com/bastibe/org-journal
|
||||
[11]: https://opensource.com/sites/default/files/pictures/day10-image3.png (Finding a note)
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 stress-free steps to tackling your task list)
|
||||
[#]: via: (https://opensource.com/article/21/1/break-down-tasks)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
3 stress-free steps to tackling your task list
|
||||
======
|
||||
Break your larger tasks into small steps to keep from being overwhelmed.
|
||||
![Team checklist][1]
|
||||
|
||||
In prior years, this annual series covered individual apps. This year, we are looking at all-in-one solutions in addition to strategies to help in 2021. Welcome to day 14 of 21 Days of Productivity in 2021.
|
||||
|
||||
At the start of the week, I like to review my schedule and look at the things I either need or would like to accomplish. And often, there are some items on that list that are relatively big. Whether it is an issue for work, a series of articles on productivity, or maybe an improvement to the chicken enclosures, the task can seem really daunting when taken as a single job. The odds are good that I will not be able to sit down and finish something like (just as an example, mind you) 21 articles in a single block of time, or even a single day.
|
||||
|
||||
![21 Days of Productivity project screenshot][2]
|
||||
|
||||
21 Days of Productivity (Kevin Sonney, [CC BY-SA 4.0][3])
|
||||
|
||||
So the first thing I do when I have something like this on my list is to break it down into smaller pieces. As Nobel laureate [William Faulkner][4] famously said, "The man who removes a mountain begins by carrying away small stones." We need to take our big tasks (the mountain) and find the individual steps (the small stones) that need to be done.
|
||||
|
||||
I use the following steps to break down my big tasks into little ones:
|
||||
|
||||
1. I usually have a fair idea of what needs to be done to complete a task. If not, I do a little research to figure that out.
|
||||
2. I write down the steps I think it will take, in order.
|
||||
3. Finally, I sit down with my calendar and the list and start to spread the tasks out across several days (or weeks, or months) to get an idea of when I might finish it.
|
||||
|
||||
|
||||
|
||||
Now I have not only a plan but an idea of how long it is going to take. As I complete each step, I can see that big task get not only a little smaller but closer to completion.
|
||||
|
||||
There is an old military saying that goes, "No plan survives contact with the enemy." It is almost certain that there will be a point or two (or five) where I realize that something as simple as "take a screenshot" needs to be expanded into something _much_ more complex. In fact, taking the screenshots of [Easy!Appointments][5] turned out to be:
|
||||
|
||||
1. Install and configure Easy!Appointments.
|
||||
2. Install and configure the Easy!Appointments WordPress plugin.
|
||||
3. Generate the API keys needed to sync the calendar.
|
||||
4. Take screenshots.
|
||||
|
||||
|
||||
|
||||
Even then, I had to break these tasks down into smaller pieces—download the software, configure NGINX, validate the installs…you get the idea. And that's OK. A plan, or set of tasks, is not set in stone and can be changed as needed.
|
||||
|
||||
![project completion pie chart][6]
|
||||
|
||||
About 2/3 done for this year! (Kevin Sonney, [CC BY-SA 4.0][3])
|
||||
|
||||
This is a learned skill and will take some effort the first few times. Learning how to break big tasks into smaller steps allows you to track progress towards a goal or completion of something big without getting overwhelmed in the process.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/1/break-down-tasks
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_todo_clock_time_team.png?itok=1z528Q0y (Team checklist)
|
||||
[2]: https://opensource.com/sites/default/files/day14-image1.png
|
||||
[3]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[4]: https://en.wikipedia.org/wiki/William_Faulkner
|
||||
[5]: https://opensource.com/article/21/1/open-source-scheduler
|
||||
[6]: https://opensource.com/sites/default/files/day14-image2_1.png
|
||||
@ -1,256 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Make websites more readable with a shell script)
|
||||
[#]: via: (https://opensource.com/article/19/2/make-websites-more-readable-shell-script)
|
||||
[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
|
||||
|
||||
利用 Shell 脚本让网站更具可读性
|
||||
|
||||
======
|
||||
|
||||
测算对比网站文本和背景之间的对比度,以确保站点易于阅读。
|
||||
|
||||

|
||||
|
||||
如果希望人们发现你的网站实用,那么他们需要能够阅读它。为文本选择的颜色可能会影响网站的可读性。不幸的是,网页设计中的一种流行趋势是在打印输出文本时使用低对比度的颜色,就像在白色背景上的灰色文本。对于 Web 设计师来说,这也许看起来很酷,但对于许多阅读它的人来说确实很困难。
|
||||
|
||||
W3C 提供了 Web 内容可访问性指南,其中包括帮助 Web 设计人员选择易于区分文本和背景色的指南。称为“对比度”。 W3C 定义的对比度需要进行一些计算:给定两种颜色,首先计算每种颜色的相对亮度,然后计算对比度。对比度在 1 到 21 的范围内(通常写为1:1到21:1)。对比度越高,文本在背景下的突出程度就越高。例如,白色背景上的黑色文本非常醒目,对比度为 21:1。对比度为 1:1 的白色背景上的白色文本不可读。
|
||||
|
||||
[W3C 说文本显示][1] 的对比度至少应为 4.5:1,标题至少应为 3:1。但这似乎是最低要求。 W3C 还建议正文至少 7:1,标题至少 4.5:1。
|
||||
|
||||
计算对比度可能比较麻烦,因此最好将其自动化。我已经用这个方便的 Bash 脚本做到了这一点。通常,脚本执行以下操作:
|
||||
|
||||
1. 获取文本颜色和背景颜色
|
||||
2. 计算相对亮度
|
||||
3. 计算对比度
|
||||
|
||||
|
||||
### 获取颜色
|
||||
|
||||
你可能知道显示器上的每种颜色都可以用红色,绿色和蓝色(R,G 和 B)表示。要计算颜色的相对亮度,脚本需要知道颜色的红,绿和蓝的各个分量。理想情况下,脚本会将这些信息读取为单独的 R,G 和 B 值。 Web 设计人员可能知道他们喜欢的颜色的特定 RGB 代码,但是大多数人不知道不同颜色的 RGB 值。作为一种替代的方法是,大多数人通过 “红色” 或 “金色” 或 “栗色” 之类的名称来引用颜色。
|
||||
|
||||
幸运的是,GNOME [Zenity][2] 工具有一个颜色选择器应用程序,可让您使用不同的方法选择颜色,然后用可预测的格式“rgb(**R**,**G**,**B**)” 返回 RGB 值。使用 Zenity 可以轻松获得颜色值:
|
||||
|
||||
```
|
||||
color=$( zenity --title 'Set text color' --color-selection --color='black' )
|
||||
```
|
||||
|
||||
如果用户(意外地)单击 “Cancel(取消)” 按钮,脚本将采用一种颜色:
|
||||
|
||||
```
|
||||
if [ $? -ne 0 ] ; then
|
||||
echo '** color canceled .. assume black'
|
||||
color='rgb(0,0,0)'
|
||||
fi
|
||||
```
|
||||
|
||||
我的脚本执行了类似的操作,将背景颜色值设置为 **$background**。
|
||||
### 计算相对亮度
|
||||
|
||||
一旦您在 **$color** 中设置了前景色,并在 **$background** 中设置了背景色,下一步就是计算每种颜色的相对亮度。 [W3C 提供算法][3] 用以计算颜色的相对亮度。
|
||||
|
||||
>对于 sRGB 色彩空间,一种颜色的相对亮度定义为
|
||||
>
|
||||
> **L = 0.2126 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated R + 0.7152 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated G + 0.0722 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated B** R,G 和 B 定义为:
|
||||
>
|
||||
> if RsRGB <= 0.03928 then R = RsRGB/12.92
|
||||
> else R = ((RsRGB+0.055)/1.055) ^ 2.4
|
||||
>
|
||||
> if GsRGB <= 0.03928 then G = GsRGB/12.92
|
||||
> else G = ((GsRGB+0.055)/1.055) ^ 2.4
|
||||
>
|
||||
> if BsRGB <= 0.03928 then B = BsRGB/12.92
|
||||
> else B = ((BsRGB+0.055)/1.055) ^ 2.4
|
||||
>
|
||||
> RsRGB, GsRGB, 和 BsRGB 定义为:
|
||||
>
|
||||
> RsRGB = R8bit/255
|
||||
>
|
||||
> GsRGB = G8bit/255
|
||||
>
|
||||
> BsRGB = B8bit/255
|
||||
|
||||
由于 Zenity 以 “rgb(**R**,**G**,**B**)”的格式返回颜色值,因此脚本可以轻松拉取分隔开的 R,B 和 G 的值以计算相对亮度。 AWK 使用逗号作为字段分隔符(**-F,**),并使用 **substr()** 字符串函数从 “rgb(**R**,**G**,**B**)中提取所要的颜色值:
|
||||
|
||||
```
|
||||
R=$( echo $color | awk -F, '{print substr($1,5)}' )
|
||||
G=$( echo $color | awk -F, '{print $2}' )
|
||||
B=$( echo $color | awk -F, '{n=length($3); print substr($3,1,n-1)}' )
|
||||
```
|
||||
|
||||
**(有关使用 AWK 提取和显示数据的更多信息,[获取 AWK 备忘表][4].)**
|
||||
|
||||
最好使用 BC 计算器来计算最终的相对亮度。 BC 支持计算中所需的简单 `if-then-else`,这使得这一过程变得简单。 但是由于 BC 无法使用非整数指数直接计算乘幂,因此需要使用自然对数替代它做一些额外的数学运算:
|
||||
|
||||
```
|
||||
echo "scale=4
|
||||
rsrgb=$R/255
|
||||
gsrgb=$G/255
|
||||
bsrgb=$B/255
|
||||
if ( rsrgb <= 0.03928 ) r = rsrgb/12.92 else r = e( 2.4 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated l((rsrgb+0.055)/1.055) )
|
||||
if ( gsrgb <= 0.03928 ) g = gsrgb/12.92 else g = e( 2.4 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated l((gsrgb+0.055)/1.055) )
|
||||
if ( bsrgb <= 0.03928 ) b = bsrgb/12.92 else b = e( 2.4 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated l((bsrgb+0.055)/1.055) )
|
||||
0.2126 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated r + 0.7152 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated g + 0.0722 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated b" | bc -l
|
||||
```
|
||||
|
||||
这会将一些指令传递给 BC,包括作为相对亮度公式一部分的 `if-then-else` 语句。接下来 BC 打印出最终值。
|
||||
### 计算对比度
|
||||
|
||||
利用文本颜色和背景颜色的相对亮度,脚本就可以计算对比度了。 [W3C 确定对比度][5] 使用以下公式:
|
||||
|
||||
> (L1 + 0.05) / (L2 + 0.05), 这里的
|
||||
> L1是颜色较浅的相对亮度,
|
||||
> L2是颜色较深的相对亮度
|
||||
|
||||
给定两个相对亮度值 **$r1** 和 **$r2**,使用 BC 计算器很容易计算对比度:
|
||||
|
||||
```
|
||||
echo "scale=2
|
||||
if ( $r1 > $r2 ) { l1=$r1; l2=$r2 } else { l1=$r2; l2=$r1 }
|
||||
(l1 + 0.05) / (l2 + 0.05)" | bc
|
||||
```
|
||||
|
||||
使用 `if-then-else` 语句确定哪个值(**$r1** 或 **$r2**)是较浅还是较深的颜色。 BC 执行结果计算并打印结果,脚本可以将其存储在变量中。
|
||||
|
||||
### 最终脚本
|
||||
|
||||
通过以上内容,我们可以将所有内容整合到一个最终脚本。 我使用 Zenity 在文本框中显示最终结果:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# script to calculate contrast ratio of colors
|
||||
|
||||
# read color and background color:
|
||||
# zenity returns values like 'rgb(255,140,0)' and 'rgb(255,255,255)'
|
||||
|
||||
color=$( zenity --title 'Set text color' --color-selection --color='black' )
|
||||
if [ $? -ne 0 ] ; then
|
||||
echo '** color canceled .. assume black'
|
||||
color='rgb(0,0,0)'
|
||||
fi
|
||||
|
||||
background=$( zenity --title 'Set background color' --color-selection --color='white' )
|
||||
if [ $? -ne 0 ] ; then
|
||||
echo '** background canceled .. assume white'
|
||||
background='rgb(255,255,255)'
|
||||
fi
|
||||
|
||||
# compute relative luminance:
|
||||
|
||||
function luminance()
|
||||
{
|
||||
R=$( echo $1 | awk -F, '{print substr($1,5)}' )
|
||||
G=$( echo $1 | awk -F, '{print $2}' )
|
||||
B=$( echo $1 | awk -F, '{n=length($3); print substr($3,1,n-1)}' )
|
||||
|
||||
echo "scale=4
|
||||
rsrgb=$R/255
|
||||
gsrgb=$G/255
|
||||
bsrgb=$B/255
|
||||
if ( rsrgb <= 0.03928 ) r = rsrgb/12.92 else r = e( 2.4 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated l((rsrgb+0.055)/1.055) )
|
||||
if ( gsrgb <= 0.03928 ) g = gsrgb/12.92 else g = e( 2.4 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated l((gsrgb+0.055)/1.055) )
|
||||
if ( bsrgb <= 0.03928 ) b = bsrgb/12.92 else b = e( 2.4 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated l((bsrgb+0.055)/1.055) )
|
||||
0.2126 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated r + 0.7152 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated g + 0.0722 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated b" | bc -l
|
||||
}
|
||||
|
||||
lum1=$( luminance $color )
|
||||
lum2=$( luminance $background )
|
||||
|
||||
# compute contrast
|
||||
|
||||
function contrast()
|
||||
{
|
||||
echo "scale=2
|
||||
if ( $1 > $2 ) { l1=$1; l2=$2 } else { l1=$2; l2=$1 }
|
||||
(l1 + 0.05) / (l2 + 0.05)" | bc
|
||||
}
|
||||
|
||||
rel=$( contrast $lum1 $lum2 )
|
||||
|
||||
# print results
|
||||
|
||||
( cat<<EOF
|
||||
Color is $color on $background
|
||||
|
||||
Contrast ratio is $rel
|
||||
Contrast ratios can range from 1 to 21 (commonly written 1:1 to 21:1).
|
||||
|
||||
EOF
|
||||
|
||||
if [ ${rel%.*} -ge 4 ] ; then
|
||||
echo "Ok for body text"
|
||||
else
|
||||
echo "Not good for body text"
|
||||
fi
|
||||
if [ ${rel%.*} -ge 3 ] ; then
|
||||
echo "Ok for title text"
|
||||
else
|
||||
echo "Not good for title text"
|
||||
fi
|
||||
|
||||
cat<<EOF
|
||||
|
||||
W3C 说明:
|
||||
|
||||
1.4.3 对比度(最小值):文本和文本图像的视觉呈现方式的对比度至少为4.5:1,但以下情况除外:(AA级)
|
||||
|
||||
大文本:大文本和大文本图像的对比度至少为 3:1;
|
||||
|
||||
附带说明:作为非活动用户界面组件一部分,纯装饰的,任何人都不可见或图片的一部分包含特定的其他可视内容的文本或文本图像没有对比度要求。
|
||||
|
||||
小示意图:徽标或商标名称中的文本没有最低对比度要求。
|
||||
|
||||
1.4.6 对比度(增强):文本和文本图像的视觉表示具有至少 7:1 的对比度,但以下情况除外:(AAA级)
|
||||
|
||||
大文本:大文本和大文本图像的对比度至少为 4.5:1;
|
||||
|
||||
附带说明:作为非活动用户界面组件一部分,纯装饰的,任何人都不可见或图片的一部分包含特定的其他可视内容的文本或文本图像没有对比度要求。
|
||||
|
||||
小示意图:徽标或商标名称中的文本没有最低对比度要求。
|
||||
EOF
|
||||
) | zenity --text-info --title='Relative Luminance' --width=800 --height=600
|
||||
```
|
||||
|
||||
最后,我希望提供有关 W3C 建议的参考信息,以提醒自己。
|
||||
|
||||
Zenity 颜色选择器完成了所有解释颜色的艰苦工作,用户可以通过单击色轮或输入值来选择颜色。 Zenity 接受网站上使用的标准十六进制颜色值,例如 `#000000` 或 `#000`或 `rgb(0,0,0)`(所有这些均为黑色)。这是白色背景上的黑色文本的示例计算:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Zenity 还识别标准的颜色名称,如深蓝色,橙色或金色。在Zenity 中输入颜色名称,然后点击 Tab 键,Zenity 会将颜色名称转换为十六进制颜色值,如以下示例中对金色背景上的黑色文本的计算:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/make-websites-more-readable-shell-script
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.w3.org/TR/2008/REC-WCAG20-20081211/#visual-audio-contrast
|
||||
[2]: https://wiki.gnome.org/Projects/Zenity
|
||||
[3]: https://www.w3.org/TR/2008/REC-WCAG20-20081211/#relativeluminancedef
|
||||
[4]: https://opensource.com/article/18/7/cheat-sheet-awk
|
||||
[5]: https://www.w3.org/TR/2008/REC-WCAG20-20081211/#contrast-ratiodef
|
||||
@ -0,0 +1,226 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mengxinayan)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding 52-bit virtual address support in the Arm64 kernel)
|
||||
[#]: via: (https://opensource.com/article/20/12/52-bit-arm64-kernel)
|
||||
[#]: author: (Bhupesh Sharma https://opensource.com/users/bhsharma)
|
||||
|
||||
理解 ARM64 内核中对 52 比特虚拟地址的支持
|
||||
======
|
||||
随着 64 比特硬件的普及,增加了处理更大地址空间的需求。
|
||||
![拼图碎片聚在一起形成计算机屏幕][1]
|
||||
|
||||
当 64 比特硬件变得可用之后,处理更大地址空间(大于232字节)的需求变得显而易见。现如今一些公司已经提供 64TiB 或更大内存的服务器,x86_64 架构和 arm64 架构现在允许寻址的地址空间大于 248 字节(可以使用默认的 48 比特地址支持)。
|
||||
|
||||
x86_64 架构通过让硬件和软件支持五级页表以支持这些用例。它允许寻址的地址空间等于 257 字节(详情见 [x86:在 4.12 内核中启用 5 级页表][2])。它突破了过去虚拟地址空间 128PiB 和 物理地址空间 4PiB 的上限。
|
||||
|
||||
arm64 架构通过引入两个新的体系结构拓展来实现相同的功能—ARMv8.2 LVA(更大的虚拟寻址) 和 ARMv8.2 LPA(更大的物理地址寻址)。这允许使用 4PiB 的虚拟地址空间和 4PiB 的物理地址空间(即分别为 252 比特)。
|
||||
|
||||
在新的 arm64 CPU 中已经支持了 ARMv8.2 体系结构拓展,同时现在开源软件也支持了这两种新的硬件拓展。
|
||||
|
||||
从 5.4 内核开始, arm64 架构中的52 比特(大)虚拟地址(VA)和物理地址(PA)得到支持。尽管[内核文档][3]描述了这些特性和新的内核运行时对旧的 CPU(硬件层面不支持 52 比特虚拟地址拓展)和新的 CPU(硬件层面支持 52 比特虚拟地址拓展)的影响,但对普通用户而言理解这些并且如何“选择使用”52比特的地址空间可能会很复杂。
|
||||
|
||||
因此,我会在本文中介绍下面这些比较新的概念:
|
||||
|
||||
1. 在增加了对这些功能的支持后,内核的内存布局如何“翻转”到 Arm64 架构
|
||||
2. 对用户态应用的影响,尤其是对提供调试支持的程序(例如:kexec-tools, makedumpfile 和 crash-utility)
|
||||
3. 如何通过指定大于 48 比特的 mmap 参数,使用户态应用“选择”接收 52 比特地址?
|
||||
|
||||
### ARMv8.2 架构的 LVA 和 LPA 拓展
|
||||
|
||||
ARMv8.2 架构提供两种重要的拓展:更大的虚拟地址(LVA)和更大的物理地址(LPA)。
|
||||
|
||||
当使用 64 KB 转换粒度时,ARMv8.2-LVA 为每个基地址寄存器提供了一个更大的 52 比特虚拟地址空间。
|
||||
|
||||
在 ARMv8.2-LVA 中包含:
|
||||
|
||||
* 当使用 64 KB 转换粒度时,中间物理地址(IPA)和物理地址空间拓展为 52 比特。
|
||||
* 如果使用 64 KB 转换粒度来实现对 52 比特物理地址的支持,那么一级块将会覆盖 4TB 的地址空间。
|
||||
|
||||
_需要注意的是这些特性仅在 AArch64 架构中支持。_
|
||||
|
||||
目前下列的 Arm64 Cortex-A 处理器支持 ARMv8.2 拓展:
|
||||
|
||||
* Cortex-A55
|
||||
* Cortex-A75
|
||||
* Cortex-A76
|
||||
|
||||
更多细节请参考 [Armv8 架构参考手册][4]。
|
||||
|
||||
### Arm64 中的内核内存布局
|
||||
|
||||
伴随着 ARMv8.2 拓展增加了对 LVA 地址的支持(仅当页大小为 64 KB 是可用),在第一级翻译中,描述符的数量会增加。
|
||||
|
||||
用户地址将 63-48 比特位置为 0,然而内核地址将这些比特位置为 1。TTBRx 选择由虚拟地址的 63 比特位决定。`swapper_pg_dir` 仅包含内核全局映射,然而 `pgd` 仅包含用户(非全局)的映射。`swapper_pg_dir` 地址会写入 TTBR1 且永远不会写入 TTBR0。
|
||||
|
||||
**页面大小为 64 KB 和三个级别的(具有 52 比特硬件支持)的 AArch64 架构下 Linux 内存布局如下:**
|
||||
|
||||
```
|
||||
开始 结束 大小 用途
|
||||
-----------------------------------------------------------------------
|
||||
0000000000000000 000fffffffffffff 4PB 用户
|
||||
fff0000000000000 fff7ffffffffffff 2PB 内核逻辑内存映射
|
||||
fff8000000000000 fffd9fffffffffff 1440TB [间隙]
|
||||
fffda00000000000 ffff9fffffffffff 512TB Kasan 阴影区
|
||||
ffffa00000000000 ffffa00007ffffff 128MB bpf jit 区域
|
||||
ffffa00008000000 ffffa0000fffffff 128MB 模块
|
||||
ffffa00010000000 fffff81ffffeffff ~88TB vmalloc 区
|
||||
fffff81fffff0000 fffffc1ffe58ffff ~3TB [保护区域]
|
||||
fffffc1ffe590000 fffffc1ffe9fffff 4544KB 固定映射
|
||||
fffffc1ffea00000 fffffc1ffebfffff 2MB [保护区域]
|
||||
fffffc1ffec00000 fffffc1fffbfffff 16MB PCI I/O 空间
|
||||
fffffc1fffc00000 fffffc1fffdfffff 2MB [保护区域]
|
||||
fffffc1fffe00000 ffffffffffdfffff 3968GB vmemmap
|
||||
ffffffffffe00000 ffffffffffffffff 2MB [保护区域]
|
||||
```
|
||||
|
||||
**4 KB 页面的转换查询表如下:**
|
||||
|
||||
```
|
||||
+--------+--------+--------+--------+--------+--------+--------+--------+
|
||||
|63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0|
|
||||
+--------+--------+--------+--------+--------+--------+--------+--------+
|
||||
| | | | | |
|
||||
| | | | | v
|
||||
| | | | | [11:0] 页内偏移量
|
||||
| | | | +-> [20:12] L3 索引
|
||||
| | | +-----------> [29:21] L2 索引
|
||||
| | +---------------------> [38:30] L1 索引
|
||||
| +-------------------------------> [47:39] L0 索引
|
||||
+-------------------------------------------------> [63] TTBR0/1
|
||||
```
|
||||
|
||||
**64 KB 页面的转换查询表如下:**
|
||||
|
||||
```
|
||||
+--------+--------+--------+--------+--------+--------+--------+--------+
|
||||
|63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0|
|
||||
+--------+--------+--------+--------+--------+--------+--------+--------+
|
||||
| | | | |
|
||||
| | | | v
|
||||
| | | | [15:0] 页内偏移量
|
||||
| | | +----------> [28:16] L3 索引
|
||||
| | +--------------------------> [41:29] L2 索引
|
||||
| +-------------------------------> [47:42] L1 索引 (48 比特)
|
||||
| [51:42] L1 索引 (52 比特)
|
||||
+-------------------------------------------------> [63] TTBR0/1
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
### 内核对 52 比特虚拟地址的支持
|
||||
|
||||
因为支持 LVA 的较新的内核应在旧的CPU(硬件不支持 LVA 拓展)和新的CPU(硬件支持 LVA 拓展)上都可以正常运行,因此采用的设计方法是使用单个二进制文件来支持 52 比特(如果硬件不支持该特性,则必须在刚开始启动时能回到 48 比特)。也就是说,为了满足 52 比特的虚拟地址以及固定大小的 `PAGE_OFFSET`,VMEMMAP 必须设置得足够大。
|
||||
|
||||
这样的设计方式要求内核为了新的虚拟地址空间而支持下面的变量:
|
||||
|
||||
```
|
||||
VA_BITS 常量 *最大的* 虚拟地址空间大小
|
||||
|
||||
vabits_actual 变量 *实际的* 虚拟地址空间大小
|
||||
```
|
||||
|
||||
因此,尽管 `VA_BITS` 设置了最大的虚拟地址空间大小,但实际上支持的虚拟地址空间大小由 `vabits_actual` 确定(具体取决于启动时的切换)
|
||||
|
||||
#### 翻转内核内存布局
|
||||
|
||||
保持一个单内核二进制文件的设计方法要求内核的 .text 文件位于高位地址中,因此它们对于 48/52 比特虚拟地址都不变。因为内核地址检测器(KASAN)区域仅占整个内核虚拟地址空间的一小部分,因此对于 48 比特或 52 比特的虚拟地址空间,KASAN 区域的末尾也必须在内核虚拟地址空间的上半部分。(从 48 比特切换到 52 比特,KASAN 区域的末尾是不变的且依赖于 `~0UL`,而起始地址将“增长”到低位地址)
|
||||
|
||||
为了优化 `phys_to_virt()` 和 `virt_to_phys()`,页偏移量将被保持在 `0xFFF0000000000000` (对应于 52 比特),这消除了读取额外变量的需求。在早期启动时将会计算 `physvirt` 和 `vmemmap` 偏移量以启用这个逻辑。
|
||||
|
||||
考虑下面的物理和虚拟 RAM 地址空间的转换:
|
||||
|
||||
```
|
||||
/*
|
||||
* 内核线性地址开始于虚拟地址空间的底部
|
||||
* 测试区域开始处的最高位已经是一个足够的检查,并且避免了担心标签的麻烦
|
||||
*/
|
||||
|
||||
#define virt_to_phys(addr) ({ \
|
||||
if (!(((u64)addr) & BIT(vabits_actual - 1))) \
|
||||
(((addr) & ~PAGE_OFFSET) + PHYS_OFFSET)
|
||||
})
|
||||
|
||||
#define phys_to_virt(addr) ((unsigned long)((addr) - PHYS_OFFSET) | PAGE_OFFSET)
|
||||
|
||||
在上面的代码中:
|
||||
PAGE_OFFSET — 线性映射的虚拟地址的起始位置位于 TTBR1 地址空间
|
||||
PHYS_OFFSET — 物理地址的起始位置以及 vabits_actual — *实际的*虚拟地址空间大小
|
||||
```
|
||||
|
||||
### 对用于调试内核的用户态程序的影响
|
||||
|
||||
一些用户空间应用程序用于调试正在运行的/活动中的内核或者分析系统崩溃时的 vmcore 转储(例如确定内核奔溃的根本原因):kexec-tools, makedumpfile, 和 crash-utility。
|
||||
|
||||
当用它们来调试 Arm64 内核时,因为 Arm64 内核内存映射被“翻转”,因此也会对它们产生影响。这些应用程序还需要遍历转换表以确定与虚拟地址相应的物理地址(类似于内核中的完成方式)。
|
||||
|
||||
相应地,在将“翻转”引入内核内存映射之后,由于上游中断了用户态应用程序,因此必须对其进行修改。
|
||||
|
||||
我已经提议了对三个受影响的用户态应用程序的修复;有一些已经被上游接受,但其他仍在等待中:
|
||||
|
||||
* [提议 makedumpfile 上游的修复][6]
|
||||
* [提议 kexec-tools 上游的修复][7]
|
||||
* [已接受的 crash-utility 的修复][8]
|
||||
|
||||
除非在用户空间应用程序进行了这些修改,否则它们将仍然无法调试运行/活动中的内核或分析系统崩溃时的 vmcore 转储。
|
||||
|
||||
### 52 比特用户态虚拟地址
|
||||
|
||||
为了保持与依赖 ARMv8.0 虚拟地址空间的最大为 48 比特的用户空间应用程序的兼容性,在默认情况下内核会将虚拟地址从 48 比特范围返回给用户空间。
|
||||
|
||||
通过指定大于48位的mmap提示参数,用户态程序可以“选择”从 52 比特空间接收虚拟地址。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
.mmap_high_addr.c
|
||||
\----
|
||||
|
||||
maybe_high_address = mmap(~0UL, size, prot, flags,...);
|
||||
```
|
||||
|
||||
通过启用以下的内核配置选项,还可以构建一个从 52 比特空间返回地址的调试内核:
|
||||
|
||||
```
|
||||
` CONFIG_EXPERT=y && CONFIG_ARM64_FORCE_52BIT=y`
|
||||
```
|
||||
|
||||
_请注意此选项仅用于调试应用程序,不应在实际生产中使用。_
|
||||
|
||||
### 结论
|
||||
|
||||
总结一下:
|
||||
|
||||
1. 内核版本从 5.14 开始,新的 Armv8.2 硬件拓展 LVA 和 LPA 在内核中得到很好的拓展。
|
||||
2. 像 kexec-tools 和 makedumpfile 被用来调试内核的用户态应用程序现在无法支持新拓展,仍在等待上游接受修补。
|
||||
3. 过去的用户态应用程序依赖于 Arm64 内核提供的 48 比特虚拟地址将继续原样工作,而较新的用户态应用程序通构指定超过 48 比特更大的 mmap 提示参数来 “选择加入”已接受来自 52 比特的虚拟地址。
|
||||
|
||||
* * *
|
||||
|
||||
_这篇文章参考了 [AArch64 架构下的 Linux 内存布局][9] 和 [Linux 5.9.12 内核文档][10]。它们均为 GPLv2.0 许可。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/12/52-bit-arm64-kernel
|
||||
|
||||
作者:[Bhupesh Sharma][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[萌新阿岩](https://github.com/mengxinayan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bhsharma
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||
[2]: https://lwn.net/Articles/716916/
|
||||
[3]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/arm64/memory.rst
|
||||
[4]: https://developer.arm.com/documentation/ddi0487/latest/
|
||||
[5]: https://opensource.com/sites/default/files/arm64-multi-level-translation_0.png (arm64 Multi-level Translation)
|
||||
[6]: http://lists.infradead.org/pipermail/kexec/2020-September/021372.html
|
||||
[7]: http://lists.infradead.org/pipermail/kexec/2020-September/021333.html
|
||||
[8]: https://github.com/crash-utility/crash/commit/1c45cea02df7f947b4296c1dcaefa1024235ef10
|
||||
[9]: https://www.kernel.org/doc/html/latest/arm64/memory.html
|
||||
[10]: https://elixir.bootlin.com/linux/latest/source/arch/arm64/include/asm/memory.h
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why keeping a journal improves productivity)
|
||||
[#]: via: (https://opensource.com/article/21/1/open-source-journal)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
为什么写日志能提高效率
|
||||
======
|
||||
写日志有着悠久的历史。这里有三个开源工具,可以帮助你写日志变得更轻松。
|
||||
![Note taking hand writing][1]
|
||||
|
||||
在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的第十天。
|
||||
|
||||
在商业互联网还没有出现的我的小学时代,老师经常会给我们班级布置一个让我们写日志的作业。有时会针对一些特定的内容,例如特定格式的虫子列表和说明,或者是公民课的每周新闻摘要。
|
||||
|
||||
几个世纪以来,人们一直在写日志。它们是一种方便的信息保存方式。它们有很多形式,比如意大利的 [Zibaldone][2]、[备忘录][3],或者记录今天做了什么的事件日志。
|
||||
|
||||
![Notebook folders][4]
|
||||
|
||||
(Kevin Sonney, [CC BY-SA 4.0][5])
|
||||
|
||||
为什么我们要写某种日志呢?第一个原因是为了让我们不至于把所有的事情都记在脑子里。我们中没有多少人有[遗觉记忆][6],维护运行日志或一组笔记可以让我们更容易地参考我们之前做的一些事情。日志也更容易分享,因为它们可以在聊天、邮件中复制/粘贴。正如 [Robert Boyce][7]的名言:”知识就是力量。知识共享就是力量倍增。“知识的共享是开源的一个内在组成部分。
|
||||
|
||||
![Today's journal][8]
|
||||
|
||||
今天的日志 (Kevin Sonney, [CC BY-SA 4.0][5])
|
||||
|
||||
在写事件日志的时候,有一个很关键的点就是要快速、简单、方便。最简单的方法是打开文档,添加一行当前日期和备注,然后保存。
|
||||
|
||||
有几个程序或附加软件可以让这一切变得更简单。[GNote 的 Note of the Day 插件][9]会自动创建一个以日期为标题的笔记,可以用来保存当天的内容。
|
||||
|
||||
Emacs Org 有一个热键组合,可以”捕捉“事物并将其放入文档中。结合 [org-journal][10] 附加组件,这将在文档中创建当天的条目。
|
||||
|
||||
Kontact 的 KNotes 组件会自动将日期和时间添加到新笔记中。
|
||||
|
||||
![Finding a note][11]
|
||||
|
||||
查找笔记 (Kevin Sonney, [CC BY-SA 4.0][5])
|
||||
|
||||
写日志或记录事情是一种方便的方法,可以记录做了什么和怎么做的。它的作用不仅仅是”我做了什么“,它还可以包括阅读的书籍、吃过的食物、去过的地方,以及一大堆对未来有用的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/1/open-source-journal
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/note-taking.jpeg?itok=fiF5EBEb (Note taking hand writing)
|
||||
[2]: https://en.wikipedia.org/wiki/Zibaldone
|
||||
[3]: https://en.wikipedia.org/wiki/Commonplace_book
|
||||
[4]: https://opensource.com/sites/default/files/pictures/day10-image1.png (Notebook folders)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://en.wikipedia.org/wiki/Eidetic_memory
|
||||
[7]: https://en.wikipedia.org/wiki/Robert_Boyce
|
||||
[8]: https://opensource.com/sites/default/files/pictures/day10-image2.png (Today's journal)
|
||||
[9]: https://help.gnome.org/users/gnote/unstable/addin-noteoftheday.html.en
|
||||
[10]: https://github.com/bastibe/org-journal
|
||||
[11]: https://opensource.com/sites/default/files/pictures/day10-image3.png (Finding a note)
|
||||
Loading…
Reference in New Issue
Block a user