**: specifies the desired type of delivery for an email report.
- - **once**: sends only one warning email for each type of disk problem detected.
- - **daily**: sends additional warning reminder emails, once per day, for each type of disk problem detected.
- - **diminishing**: sends additional warning reminder emails, after a one-day interval, then a two-day interval, then a four-day interval, and so on for each type of disk problem detected. Each interval is twice as long as the previous interval.
- - **test**: sends a single test email immediately upon smartd startup.
- - **exec PATH**: runs the executable PATH instead of the default mail command. PATH must point to an executable binary file or script. This allows to specify a desired action (beep the console, shutdown the system, and so on) when a problem is detected.
-
-Save the changes and restart smartd.
-
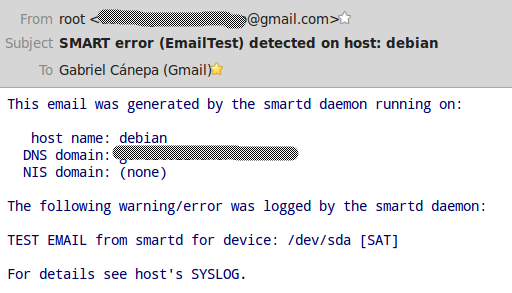
-You should expect this kind of email sent by smartd.
-
-
-
-Luckily for us, no error was detected. Had it not been so, the errors would have appeared below the line "The following warning/error was logged by the smartd daemon."
-
-Finally, you can schedule tests at your preferred schedule using the "-s" flag and the regular expression in the form of "T/MM/DD/d/HH", where:
-
-T in the regular expression indicates the kind of test:
-
-- L: long test
-- S: short test
-- C: Conveyance test (ATA only)
-- O: Offline (ATA only)
-
-and the remaining characters represent the date and time when the test should be performed:
-
-- MM is the month of the year.
-- DD is the day of the month.
-- HH is the hour of day.
-- d is the day of the week (ranging from 1=Monday through 7=Sunday).
-- MM, DD, and HH are expressed with two decimal digits.
-
-A dot in any of these places indicates all possible values. An expression inside parentheses such as ‘(A|B|C)’ denotes any one of the three possibilities A, B, or C. An expression inside square brackets such as [1-5] denotes a range (1 through 5 inclusive).
-
-For example, to perform a long test every business day at 1 pm for all disks, add the following line to /etc/smartd.conf. Make sure to restart smartd.
-
- DEVICESCAN -s (L/../../[1-5]/13)
-
-### Conclusion ###
-
-Whether you want to quickly check the electrical and mechanical performance of a disk, or perform a longer and more thorough test scans the entire disk surface, do not let yourself get so caught up in your day-to-day responsibilities as to forget to regularly check on the health of your disks. You will thank yourself later!
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/check-hard-disk-health-linux-smartmontools.html
-
-作者:[Gabriel Cánepa][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/gabriel
-[1]:http://xmodulo.com/how-to-create-secure-incremental-offsite-backup-in-linux.html
-[2]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
-[3]:http://www.smartmontools.org/
-[4]:http://en.wikipedia.org/wiki/S.M.A.R.T.
\ No newline at end of file
diff --git a/sources/tech/20141017 pidstat - Monitor and Find Statistics for Linux Procesess.md b/sources/tech/20141017 pidstat - Monitor and Find Statistics for Linux Procesess.md
deleted file mode 100644
index 401e88b7ac..0000000000
--- a/sources/tech/20141017 pidstat - Monitor and Find Statistics for Linux Procesess.md
+++ /dev/null
@@ -1,89 +0,0 @@
-johnhoow translating...
-pidstat - Monitor and Find Statistics for Linux Procesess
-================================================================================
-The **pidstat** command is used for monitoring individual tasks currently being managed by the Linux kernel. It writes to standard output activities for every task managed by the Linux kernel. The pidstat command can also be used for monitoring the child processes of selected tasks. The interval parameter specifies the amount of time in seconds between each report. A value of 0 (or no parameters at all) indicates that tasks statistics are to be reported for the time since system startup (boot).
-
-### How to Install pidstat ###
-
-pidstat is part of the sysstat suite that contains various system performance tools for Linux, it's available on the repository of most Linux distributions.
-
-To install it on Debian / Ubuntu Linux systems you can use the following command:
-
- # apt-get install sysstat
-
-If you are using CentOS / Fedora / RHEL Linux you can install the packages like this:
-
- # yum install sysstat
-
-### Using pidstat ###
-
-Running pidstat without any argument is equivalent to specifying -p ALL but only active tasks (tasks with non-zero statistics values) will appear in the report.
-
- # pidstat
-
-
-
-In the output you can see:
-
-- **PID** - The identification number of the task being monitored.
-- **%usr** - Percentage of CPU used by the task while executing at the user level (application), with or without nice priority. Note that this field does NOT include time spent running a virtual processor.
-- **%system** - Percentage of CPU used by the task while executing at the system level.
-- **%guest** - Percentage of CPU spent by the task in virtual machine (running a virtual processor).
-- **%CPU** - Total percentage of CPU time used by the task. In an SMP environment, the task's CPU usage will be divided by the total number of CPU's if option -I has been entered on the command line.
-- **CPU** - Processor number to which the task is attached.
-- **Command** - The command name of the task.
-
-### I/O Statistics ###
-
-We can use pidstat to get I/O statistics about a process using the -d flag. For example:
-
- # pidstat -d -p 8472
-
-
-
-The IO output will display a few new columns:
-
-- **kB_rd/s** - Number of kilobytes the task has caused to be read from disk per second.
-- **kB_wr/s** - Number of kilobytes the task has caused, or shall cause to be written to disk per second.
-- **kB_ccwr/s** - Number of kilobytes whose writing to disk has been cancelled by the task.
-
-### Page faults and memory usage ###
-
-Using the -r flag you can get information about memory usage and page faults.
-
-
-
-Important columns:
-
-- **minflt/s** - Total number of minor faults the task has made per second, those which have not required loading a memory page from disk.
-- **majflt/s** - Total number of major faults the task has made per second, those which have required loading a memory page from disk.
-- **VSZ** - Virtual Size: The virtual memory usage of entire task in kilobytes.
-- **RSS** - Resident Set Size: The non-swapped physical memory used by the task in kilobytes.
-
-### Examples ###
-
-**1.** You can use pidstat to find a memory leek using the following command:
-
- # pidstat -r 2 5
-
-This will give you 5 reports, one every 2 seconds, about the current page faults statistics, it should be easy to spot the problem process.
-
-**2.** To show all children of the mysql server you can use the following command
-
- # pidstat -T CHILD -C mysql
-
-**3.** To combine all statistics in a single report you can use:
-
- # pidstat -urd -h
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-command/linux-pidstat-monitor-statistics-procesess/
-
-作者:[Adrian Dinu][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/adriand/
diff --git a/sources/tech/20141021 How to create and use Python CGI scripts.md b/sources/tech/20141021 How to create and use Python CGI scripts.md
deleted file mode 100644
index fa653aeec0..0000000000
--- a/sources/tech/20141021 How to create and use Python CGI scripts.md
+++ /dev/null
@@ -1,157 +0,0 @@
-How to create and use Python CGI scripts
-================================================================================
-Have you ever wanted to create a webpage or process user input from a web-based form using Python? These tasks can be accomplished through the use of Python CGI (Common Gateway Interface) scripts with an Apache web server. CGI scripts are called by a web server when a user requests a particular URL or interacts with the webpage (such as clicking a "Submit" button). After the CGI script is called and finishes executing, the output is used by the web server to create a webpage displayed to the user.
-
-### Configuring the Apache web server to run CGI scripts ###
-
-In this tutorial we assume that an Apache web server is already set up and running. This tutorial uses an Apache web server (version 2.2.15 on CentOS release 6.5) that is hosted at the localhost (127.0.0.1) and is listening on port 80, as specified by the following Apache directives:
-
- ServerName 127.0.0.1:80
- Listen 80
-
-HTML files used in the upcoming examples are located in /var/www/html on the web server. This is specified via the DocumentRoot directive (specifies the directory that webpages are located in):
-
- DocumentRoot "/var/www/html"
-
-Consider a request for the URL: http://localhost/page1.html
-
-This will return the contents of the following file on the web server:
-
- /var/www/html/page1.html
-
-To enable use of CGI scripts, we must specify where CGI scripts are located on the web server. To do this, we use the ScriptAlias directive:
-
- ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
-
-The above directive indicates that CGI scripts are contained in the /var/www/cgi-bin directory on the web server and that inclusion of /cgi-bin/ in the requested URL will search this directory for the CGI script of interest.
-
-We must also explicitly permit the execution of CGI scripts in the /var/www/cgi-bin directory and specify the file extensions of CGI scripts. To do this, we use the following directives:
-
-
- Options +ExecCGI
- AddHandler cgi-script .py
-
-
-Consider a request for the URL: http://localhost/cgi-bin/myscript-1.py
-
-This will call the following script on the web server:
-
- /var/www/cgi-bin/myscript-1.py
-
-### Creating a CGI script ###
-
-Before creating a Python CGI script, you will need to confirm that you have Python installed (this is generally installed by default, however the installed version may vary). Scripts in this tutorial are created using Python version 2.6.6. You can check your version of Python from the command line by entering either of the following commands (the -V and --version options display the version of Python that is installed):
-
- $ python -V
- $ python --version
-
-If your Python CGI script will be used to process user-entered data (from a web-based input form), then you will need to import the Python cgi module. This module provides functionality for accessing data that users have entered into web-based input forms. You can import this module via the following statement in your script:
-
- import cgi
-
-You must also change the execute permissions for the Python CGI script so that it can be called by the web server. Add execute permissions for others via the following command:
-
- # chmod o+x myscript-1.py
-
-### Python CGI Examples ###
-
-Two scenarios involving Python CGI scripts will be considered in this tutorial:
-
-- Create a webpage using a Python script
-- Read and display user-entered data and display results in a webpage
-
-Note that the Python cgi module is required for Scenario 2 because this involves accessing user-entered data from web-based input forms.
-
-### Example 1: Create a webpage using a Python script ###
-
-For this scenario, we will start by creating a webpage /var/www/html/page1.html with a single submit button:
-
-
- Test Page 1
-
-
-
-When the "Submit" button is clicked, the /var/www/cgi-bin/myscript-1.py script is called (specified by the action parameter). A "GET" request is specified by setting the method parameter equal to "get". This requests that the web server return the specified webpage. An image of /var/www/html/page1.html as viewed from within a web browser is shown below:
-
-
-
-The contents of /var/www/cgi-bin/myscript-1.py are:
-
- #!/usr/bin/python
- print "Content-Type: text/html"
- print ""
- print ""
- print "CGI Script Output
"
- print "This page was generated by a Python CGI script.
"
- print ""
-
-The first statement indicates that this is a Python script to be run with the /usr/bin/python command. The print "Content-Type: text/html" statement is required so that the web server knows what type of output it is receiving from the CGI script. The remaining statements are used to print the text of the webpage in HTML format.
-
-When the "Submit" button is clicked in the above webpage, the following webpage is returned:
-
-
-
-The take-home point with this example is that you have the freedom to decide what information is returned by the CGI script. This could include the contents of log files, a list of users currently logged on, or today's date. The possibilities are endless given that you have the entire Python library at your disposal.
-
-### Example 2: Read and display user-entered data and display results in a webpage ###
-
-For this scenario, we will start by creating a webpage /var/www/html/page2.html with three input fields and a submit button:
-
-
- Test Page 2
-
-
-
-When the "Submit" button is clicked, the /var/www/cgi-bin/myscript-2.py script is called (specified by the action parameter). An image of /var/www/html/page2.html as viewed from within a web browser is shown below (note that the three input fields have already been filled in):
-
-
-
-The contents of /var/www/cgi-bin/myscript-2.py are:
-
- #!/usr/bin/python
- import cgi
- form = cgi.FieldStorage()
- print "Content-Type: text/html"
- print ""
- print ""
- print "CGI Script Output
"
- print ""
- print "The user entered data are:
"
- print "First Name: " + form["firstName"].value + "
"
- print "Last Name: " + form["lastName"].value + "
"
- print "Position: " + form["position"].value + "
"
- print "
"
- print ""
-
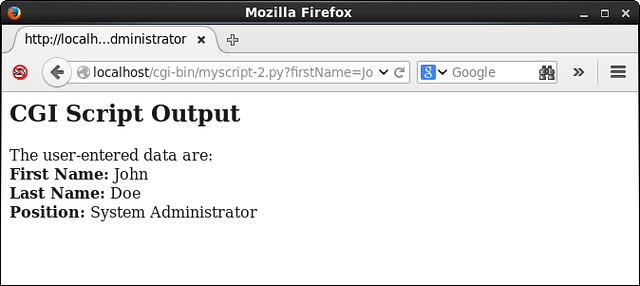
-As mentioned previously, the import cgi statement is needed to enable functionality for accessing user-entered data from web-based input forms. The web-based input form is encapsulated in the form object, which is a cgi.FieldStorage object. Once again, the "Content-Type: text/html" line is required so that the web server knows what type of output it is receiving from the CGI script. The data entered by the user are accessed in the statements that contain form["firstName"].value, form["lastName"].value, and form["position"].value. The names in the square brackets correspond to the values of the name parameters defined in the text input fields in **/var/www/html/page2.html**.
-
-When the "Submit" button is clicked in the above webpage, the following webpage is returned:
-
-
-
-The take-home point with this example is that you can easily read and display user-entered data from web-based input forms. In addition to processing data as strings, you can also use Python to convert user-entered data to numbers that can be used in numerical calculations.
-
-### Summary ###
-
-This tutorial demonstrates how Python CGI scripts are useful for creating webpages and for processing user-entered data from web-based input forms. More information about Apache CGI scripts can be found [here][1] and more information about the Python cgi module can be found [here][2].
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/create-use-python-cgi-scripts.html
-
-作者:[Joshua Reed][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/joshua
-[1]:http://httpd.apache.org/docs/2.2/howto/cgi.html
-[2]:https://docs.python.org/2/library/cgi.html#module-cgi
\ No newline at end of file
diff --git a/sources/tech/20141021 How to monitor a log file on Linux with logwatch.md b/sources/tech/20141021 How to monitor a log file on Linux with logwatch.md
index 5f00ff77df..28b9f5bfde 100644
--- a/sources/tech/20141021 How to monitor a log file on Linux with logwatch.md
+++ b/sources/tech/20141021 How to monitor a log file on Linux with logwatch.md
@@ -1,3 +1,4 @@
+(translating by runningwater)
How to monitor a log file on Linux with logwatch
================================================================================
Linux operating system and many applications create special files commonly referred to as "logs" to record their operational events. These system logs or application-specific log files are an essential tool when it comes to understanding and troubleshooting the behavior of the operating system and third-party applications. However, log files are not precisely what you would call "light" or "easy" reading, and analyzing raw log files by hand is often time-consuming and tedious. For that reason, any utility that can convert raw log files into a more user-friendly log digest is a great boon for sysadmins.
@@ -122,7 +123,7 @@ Hope this helps. Feel free to comment to share your own tips and ideas with the
via: http://xmodulo.com/monitor-log-file-linux-logwatch.html
作者:[Gabriel Cánepa][a]
-译者:[译者ID](https://github.com/译者ID)
+译者:[runningwater](https://github.com/runningwater)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/sources/tech/20141022 Linux FAQs with Answers--How to change character encoding of a text file on Linux.md b/sources/tech/20141022 Linux FAQs with Answers--How to change character encoding of a text file on Linux.md
deleted file mode 100644
index 5ce0b7be75..0000000000
--- a/sources/tech/20141022 Linux FAQs with Answers--How to change character encoding of a text file on Linux.md
+++ /dev/null
@@ -1,54 +0,0 @@
-wangjiezhe translating...
-
-Linux FAQs with Answers--How to change character encoding of a text file on Linux
-================================================================================
-> **Question**: I have an "iso-8859-1"-encoded subtitle file which shows broken characters on my Linux system, and I would like to change its text encoding to "utf-8" character set. In Linux, what is a good tool to convert character encoding in a text file?
-
-As you already know, computers can only handle binary numbers at the lowest level - not characters. When a text file is saved, each character in that file is mapped to bits, and it is those "bits" that are actually stored on disk. When an application later opens that text file, each of those binary numbers are read and mapped back to the original characters that are understood by us human. This "save and open" process is best performed when all applications that need access to a text file "understand" its encoding, meaning the way binary numbers are mapped to characters, and thus can ensure a "round trip" of understandable data.
-
-If different applications do not use the same encoding while dealing with a text file, non-readable characters will be shown wherever special characters are found in the original file. By special characters we mean those that are not part of the English alphabet, such as accented characters (e.g., ñ, á, ü).
-
-The questions then become: 1) how can I know which character encoding a certain text file is using?, and 2) how can I convert it to some other encoding of my choosing?
-
-### Step One ###
-
-In order to find out the character encoding of a file, we will use a commad-line tool called file. Since the file command is a standard UNIX program, we can expect to find it in all modern Linux distros.
-
-Run the following command:
-
- $ file --mime-encoding filename
-
-
-
-### Step Two ###
-
-The next step is to check what kinds of text encodings are supported on your Linux system. For this, we will use a tool called iconv with the "-l" flag (lowercase L), which will list all the currently supported encodings.
-
- $ iconv -l
-
-The iconv utility is part of the the GNU libc libraries, so it is available in all Linux distributions out-of-the-box.
-
-### Step Three ###
-
-Once we have selected a target encoding among those supported on our Linux system, let's run the following command to perform the conversion:
-
- $ iconv -f old_encoding -t new_encoding filename
-
-For example, to convert iso-8859-1 to utf-8:
-
- $ iconv -f iso-8859-1 -t utf-8 input.txt
-
-
-
-Knowing how to use these tools together as we have demonstrated, you can for example fix a broken subtitle file:
-
-
-
---------------------------------------------------------------------------------
-
-via: http://ask.xmodulo.com/change-character-encoding-text-file-linux.html
-
-译者:[wangjiezhe](https://github.com/wangjiezhe)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/sources/tech/20141022 Linux FAQs with Answers--How to fix sshd error--could not load host key.md b/sources/tech/20141022 Linux FAQs with Answers--How to fix sshd error--could not load host key.md
deleted file mode 100644
index 78004f1426..0000000000
--- a/sources/tech/20141022 Linux FAQs with Answers--How to fix sshd error--could not load host key.md
+++ /dev/null
@@ -1,63 +0,0 @@
-Linux FAQs with Answers--How to fix “sshd error: could not load host key”
-================================================================================
-> **Question**: When I try to SSH to a remote server, SSH client fails with "Connection closed by X.X.X.X". On the SSH server side, I see error messages: "sshd error: could not load host key." What is going on, and how can I fix this error?
-
-The detailed symptom of this SSH connection error is as follows.
-
-**SSH client side**: when you attempt to SSH to a remote host, you don't see login screen, and your SSH connection is closed right away with a message: "Connection closed by X.X.X.X"
-
-**SSH server side**: in a system log, you see the following error messages (e.g., /var/log/auth.log on Debian/Ubuntu).
-
- Oct 16 08:59:45 openstack sshd[1214]: error: Could not load host key: /etc/ssh/ssh_host_rsa_key
- Oct 16 08:59:45 openstack sshd[1214]: error: Could not load host key: /etc/ssh/ssh_host_dsa_key
- Oct 16 08:59:45 openstack sshd[1214]: error: Could not load host key: /etc/ssh/ssh_host_ecdsa_key
- Oct 16 08:59:45 openstack sshd[1214]: fatal: No supported key exchange algorithms [preauth]
-
-The root cause of this problem is that sshd daemon somehow is not able to load SSH host keys.
-
-When OpenSSH server is first installed on Linux system, SSH host keys should automatically be generated for subsequent use. If, however, key generation was not finished successfully, that can cause SSH login problems like this.
-
-Let's check if SSH host keys are found where they should be.
-
- $ ls -al /etc/ssh/ssh*key
-
-
-
-If SSH host keys are not found there, or their size is all truncated to zero (like above), you need to regenerate SSH host keys from scratch.
-
-### Regenerate SSH Host Keys ###
-
-On Debian, Ubuntu or their derivatives, you can use dpkg-reconfigure tool to regenerate SSH host keys as follows.
-
- $ sudo rm -r /etc/ssh/ssh*key
- $ sudo dpkg-reconfigure openssh-server
-
-
-
-On CentOS, RHEL or Fedora, all you have to do is to restart sshd after removing existing (problematic) keys.
-
- $ sudo rm -r /etc/ssh/ssh*key
- $ sudo systemctl restart sshd
-
-An alternative way to regenerate SSH host keys is to manually generate them using ssh-keygen command.
-
- $ sudo ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
- $ sudo ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
- $ sudo ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key
-
-
-
-Once new SSH host keys are generated, make sure that they are found in /etc/ssh directory. There is no need to restart sshd at this point.
-
- $ ls -al /etc/ssh/ssh*key
-
-Now try to SSH again to the SSH server to see if the problem is gone.
-
---------------------------------------------------------------------------------
-
-via: http://ask.xmodulo.com/sshd-error-could-not-load-host-key.html
-
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
\ No newline at end of file
diff --git a/sources/tech/20141023 What are useful Bash aliases and functions.md b/sources/tech/20141023 What are useful Bash aliases and functions.md
new file mode 100644
index 0000000000..b5d6e3b6da
--- /dev/null
+++ b/sources/tech/20141023 What are useful Bash aliases and functions.md
@@ -0,0 +1,256 @@
+luoyutiantang
+What are useful Bash aliases and functions
+================================================================================
+As a command line adventurer, you probably found yourself repeating the same lengthy commands over and over. If you always ssh into the same machine, if you always chain the same commands together, or if you constantly run a program with the same flags, you might want to save the precious seconds of your life that you spend repeating the same actions over and over.
+
+The solution to achieve that is to use an alias. As you may know, an alias is a way to tell your shell to remember a particular command and give it a new name: an alias. However, an alias is quickly limited as it is just a shortcut for a shell command, without the ability to pass or control the arguments. So to complement, bash also allows you create your own functions, which can be more lengthy and complex, and also accepts any number of arguments.
+
+Naturally, like with soup, when you have a good recipe you share it. So here is a list with some of the most useful bash aliases and functions. Note that "most useful" is loosely defined, and of course the usefulness of an alias is dependent on your everyday usage of the shell.
+
+Before you start experimenting with aliases, here is a handy tip: if you give an alias the same name as a regular command, you can choose to launch the original command and ignore the alias with the trick:
+
+ \command
+
+For example, the first alias below replaces the ls command. If you wish to use the regular ls command and not the alias, call it via:
+
+ \ls
+
+### Productivity ###
+
+So these aliases are really simple and really short, but they are mostly based on the idea that if you save yourself a fraction of a second every time, it might end up accumulating years at the end. Or maybe not.
+
+ alias ls="ls --color=auto"
+
+Simple but vital. Make the ls command output in color.
+
+ alias ll = "ls --color -al"
+
+Shortcut to display in color all the files from a directory in a list format.
+
+ alias grep='grep --color=auto'
+
+Similarly, put some color in the grep output.
+
+ mcd() { mkdir -p "$1"; cd "$1";}
+
+One of my favorite. Make a directory and cd into it in one command: mcd [name].
+
+ cls() { cd "$1"; ls;}
+
+Similar to the previous function, cd into a directory and list its content: cls [name].
+
+ backup() { cp "$1"{,.bak};}
+
+Simple way to make a backup of a file: backup [file] will create [file].bak in the same directory.
+
+ md5check() { md5sum "$1" | grep "$2";}
+
+Because I hate comparing the md5sum of a file by hand, this function computes it and compares it using grep: md5check [file] [key].
+
+
+
+ alias makescript="fc -rnl | head -1 >"
+
+Easily make a script out of the last command you ran: makescript [script.sh]
+
+ alias genpasswd="strings /dev/urandom | grep -o '[[:alnum:]]' | head -n 30 | tr -d '\n'; echo"
+
+Just to generate a strong password instantly.
+
+
+
+ alias c="clear"
+
+Cannot do simpler to clean your terminal screen.
+
+ alias histg="history | grep"
+
+To quickly search through your command history: histg [keyword]
+
+ alias ..='cd ..'
+
+No need to write cd to go up a directory.
+
+ alias ...='cd ../..'
+
+Similarly, go up two directories.
+
+ extract() {
+ if [ -f $1 ] ; then
+ case $1 in
+ *.tar.bz2) tar xjf $1 ;;
+ *.tar.gz) tar xzf $1 ;;
+ *.bz2) bunzip2 $1 ;;
+ *.rar) unrar e $1 ;;
+ *.gz) gunzip $1 ;;
+ *.tar) tar xf $1 ;;
+ *.tbz2) tar xjf $1 ;;
+ *.tgz) tar xzf $1 ;;
+ *.zip) unzip $1 ;;
+ *.Z) uncompress $1 ;;
+ *.7z) 7z x $1 ;;
+ *) echo "'$1' cannot be extracted via extract()" ;;
+ esac
+ else
+ echo "'$1' is not a valid file"
+ fi
+ }
+
+Longest but also the most useful. Extract any kind of archive: extract [archive file]
+
+### System Info ###
+
+Want to know everything about your system as quickly as possible?
+
+ alias cmount="mount | column -t"
+
+Format the output of mount into columns.
+
+
+
+ alias tree="ls -R | grep ":$" | sed -e 's/:$//' -e 's/[^-][^\/]*\//--/g' -e 's/^/ /' -e 's/-/|/'"
+
+Display the directory structure recursively in a tree format.
+
+ sbs() { du -b --max-depth 1 | sort -nr | perl -pe 's{([0-9]+)}{sprintf "%.1f%s", $1>=2**30? ($1/2**30, "G"): $1>=2**20? ($1/2**20, "M"): $1>=2**10? ($1/2**10, "K"): ($1, "")}e';}
+
+"Sort by size" to display in list the files in the current directory, sorted by their size on disk.
+
+ alias intercept="sudo strace -ff -e trace=write -e write=1,2 -p"
+
+Intercept the stdout and stderr of a process: intercept [some PID]. Note that you will need strace installed.
+
+ alias meminfo='free -m -l -t'
+
+See how much memory you have left.
+
+
+
+ alias ps? = "ps aux | grep"
+
+Easily find the PID of any process: ps? [name]
+
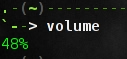
+ alias volume="amixer get Master | sed '1,4 d' | cut -d [ -f 2 | cut -d ] -f 1"
+
+Displays the current sound volume.
+
+
+
+### Networking ###
+
+For all the commands that involve the Internet or your local network, there are fancy aliases for them.
+
+ alias websiteget="wget --random-wait -r -p -e robots=off -U mozilla"
+
+Download entirely a website: websiteget [URL]
+
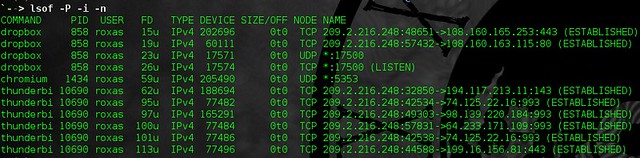
+ alias listen="lsof -P -i -n"
+
+Show which applications are connecting to the network.
+
+
+
+ alias port='netstat -tulanp'
+
+Show the active ports
+
+ gmail() { curl -u "$1" --silent "https://mail.google.com/mail/feed/atom" | sed -e 's/<\/fullcount.*/\n/' | sed -e 's/.*fullcount>//'}
+
+Rough function to display the number of unread emails in your gmail: gmail [user name]
+
+ alias ipinfo="curl ifconfig.me && curl ifconfig.me/host"
+
+Get your public IP address and host.
+
+ getlocation() { lynx -dump http://www.ip-adress.com/ip_tracer/?QRY=$1|grep address|egrep 'city|state|country'|awk '{print $3,$4,$5,$6,$7,$8}'|sed 's\ip address flag \\'|sed 's\My\\';}
+
+Returns your current location based on your IP address.
+
+### Useless ###
+
+So what if some aliases are not all that productive? They can still be fun.
+
+ kernelgraph() { lsmod | perl -e 'print "digraph \"lsmod\" {";<>;while(<>){@_=split/\s+/; print "\"$_[0]\" -> \"$_\"\n" for split/,/,$_[3]}print "}"' | dot -Tpng | display -;}
+
+To draw the kernel module dependency graph. Requires image viewer.
+
+ alias busy="cat /dev/urandom | hexdump -C | grep "ca fe""
+
+Make you look all busy and fancy in the eyes of non-technical people.
+
+
+
+To conclude, a good chunk of these aliases and functions come from my personal .bashrc, and the awesome websites [alias.sh][1] and [commandlinefu.com][2] which I already presented in my post on the [best online tools for Linux][3]. So definitely go check them out, make your own recipes, and if you are so inclined, share your wisdom in the comments.
+
+As a bonus, here is the plain text version of all the aliases and functions I mentioned, ready to be copy pasted in your bashrc.
+
+ #Productivity
+ alias ls="ls --color=auto"
+ alias ll="ls --color -al"
+ alias grep='grep --color=auto'
+ mcd() { mkdir -p "$1"; cd "$1";}
+ cls() { cd "$1"; ls;}
+ backup() { cp "$1"{,.bak};}
+ md5check() { md5sum "$1" | grep "$2";}
+ alias makescript="fc -rnl | head -1 >"
+ alias genpasswd="strings /dev/urandom | grep -o '[[:alnum:]]' | head -n 30 | tr -d '\n'; echo"
+ alias c="clear"
+ alias histg="history | grep"
+ alias ..='cd ..'
+ alias ...='cd ../..'
+ extract() {
+ if [ -f $1 ] ; then
+ case $1 in
+ *.tar.bz2) tar xjf $1 ;;
+ *.tar.gz) tar xzf $1 ;;
+ *.bz2) bunzip2 $1 ;;
+ *.rar) unrar e $1 ;;
+ *.gz) gunzip $1 ;;
+ *.tar) tar xf $1 ;;
+ *.tbz2) tar xjf $1 ;;
+ *.tgz) tar xzf $1 ;;
+ *.zip) unzip $1 ;;
+ *.Z) uncompress $1 ;;
+ *.7z) 7z x $1 ;;
+ *) echo "'$1' cannot be extracted via extract()" ;;
+ esac
+ else
+ echo "'$1' is not a valid file"
+ fi
+ }
+
+ #System info
+ alias cmount="mount | column -t"
+ alias tree="ls -R | grep ":$" | sed -e 's/:$//' -e 's/[^-][^\/]*\//--/g' -e 's/^/ /' -e 's/-/|/'"
+ sbs(){ du -b --max-depth 1 | sort -nr | perl -pe 's{([0-9]+)}{sprintf "%.1f%s", $1>=2**30? ($1/2**30, "G"): $1>=2**20? ($1/2**20, "M"): $1>=2**10? ($1/2**10, "K"): ($1, "")}e';}
+ alias intercept="sudo strace -ff -e trace=write -e write=1,2 -p"
+ alias meminfo='free -m -l -t'
+ alias ps?="ps aux | grep"
+ alias volume="amixer get Master | sed '1,4 d' | cut -d [ -f 2 | cut -d ] -f 1"
+
+ #Network
+ alias websiteget="wget --random-wait -r -p -e robots=off -U mozilla"
+ alias listen="lsof -P -i -n"
+ alias port='netstat -tulanp'
+ gmail() { curl -u "$1" --silent "https://mail.google.com/mail/feed/atom" | sed -e 's/<\/fullcount.*/\n/' | sed -e 's/.*fullcount>//'}
+ alias ipinfo="curl ifconfig.me && curl ifconfig.me/host"
+ getlocation() { lynx -dump http://www.ip-adress.com/ip_tracer/?QRY=$1|grep address|egrep 'city|state|country'|awk '{print $3,$4,$5,$6,$7,$8}'|sed 's\ip address flag \\'|sed 's\My\\';}
+
+ #Funny
+ kernelgraph() { lsmod | perl -e 'print "digraph \"lsmod\" {";<>;while(<>){@_=split/\s+/; print "\"$_[0]\" -> \"$_\"\n" for split/,/,$_[3]}print "}"' | dot -Tpng | display -;}
+ alias busy="cat /dev/urandom | hexdump -C | grep \"ca fe\""
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/useful-bash-aliases-functions.html
+
+作者:[Adrien Brochard][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/adrien
+[1]:http://alias.sh/
+[2]:http://www.commandlinefu.com/commands/browse
+[3]:http://xmodulo.com/useful-online-tools-linux.html
diff --git a/sources/tech/20141024 7 Things to Do After Installing Ubuntu 14.10 Utopic Unicorn.md b/sources/tech/20141024 7 Things to Do After Installing Ubuntu 14.10 Utopic Unicorn.md
new file mode 100644
index 0000000000..512259afa2
--- /dev/null
+++ b/sources/tech/20141024 7 Things to Do After Installing Ubuntu 14.10 Utopic Unicorn.md
@@ -0,0 +1,143 @@
+7 Things to Do After Installing Ubuntu 14.10 Utopic Unicorn
+================================================================================
+After you’ve installed or [upgraded to Ubuntu 14.10][1], known by its codename ‘Utopic Unicorn’, there are a few things you should do to get it up and running in tip-top shape.
+
+Whether you’ve performed a fresh install or upgraded an existing version, here’s our biannual checklist of post-install tasks to get started with.
+
+### 1. Get Acquainted ###
+
+
+
+The Ubuntu Browser
+
+The majority of changes rocking up in Ubuntu 14.10 aren’t immediately visible (save for some new wallpapers). That said, there are a bunch of freshly updated apps to get familiar with.
+
+Preinstalled are the latest versions of workhouse staples **Mozilla Firefox**, **Thunderbird**, and **LibreOffice**. Dig a little deeper and you’ll also find Evince 3.14, and a brand new version of the “Ubuntu Web Browser” app, used for handling web-apps.
+
+While you’re getting familiar, be sure to fire up the Software Updater tool to **check for any impromptu issues Ubuntu has found and fixed** post-release. Yes, I know: you only just upgraded. But, even so — bugs don’t adhere to deadlines like developers do!
+
+### 2. Personalise The Desktop ###
+
+
+
+New wallpapers in 14.10
+
+It’s your desktop PC, so don’t put off making it look, feel and behave how you like.
+
+Your first port of call might be changing the desktop wallpaper to one of the [twelve stunning new backgrounds][2] included in 14.10, ranging from retro record player to illustrated unicorn.
+
+Wallpapers and a host of other theme and layout options are accessible from the **Appearance Settings** pane of the System Settings app. From here you can:
+
+- Switch to a different theme
+- Adjust launcher size & behaviour
+- Enable workspaces & desktop icons
+- Put app menus back into app windows
+
+For some nifty new themes be sure to check out our **‘themes & icons’ category** here on the site.
+
+### 3. Install Graphics Card Drivers ###
+
+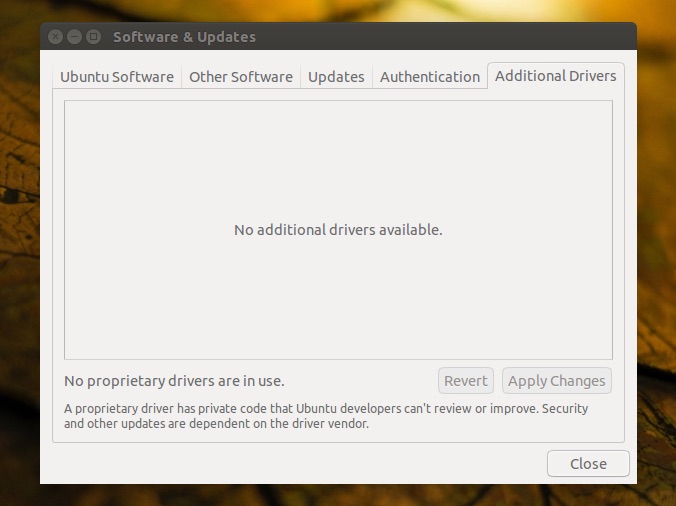
+
+If you plan on playing the [latest Steam games][3], watching high-definition video or working with graphically intensive software you’ll want to enable the latest Linux graphics drivers available for your hardware.
+
+Ubuntu makes this easy:
+
+- Open up the Software & Updates tool from the Unity Dash
+- Click the ‘Additional Drivers‘ tab
+- Follow any on-screen prompts to check, install and apply changes
+
+### 4. Enable Music & Video Codecs ###
+
+
+
+Games sorted, now to make **music and video files work just as well**.
+
+Most popular formats, .mp3, .m4a, .mov, etc., will work fine in Ubuntu — after a little cajoling. Patent-encumbered codecs cannot ship in Ubuntu for legal reasons, leaving you unable to play popular audio and video formats out of the (invisible) box.
+
+Don’t panic. To play music or watch video you can install all of the codecs you need quickly, and through the Ubuntu Software Center.
+
+- [Install Third-Party Codecs][4]
+
+### 5. Pimp Your Privacy ###
+
+
+
+The Unity Dash is a great one-stop hub for finding stuff, be it a PDF file lurking on your computer or the current weather forecast in Stockholm, Sweden.
+
+But the diversity of data surfaced through the Dash in just a few keystrokes doesn’t suit everyone’s needs. So you may want to dial down the noise and restrict what shows up.
+
+To stop certain files and folders from searched in the Dash and/or to disable all ‘online’ results returned for a query, head to the **Privacy & Security** section in System Settings.
+
+Here you’ll find all the tools, options and configuration switches you need, including options to:
+
+- Choose what apps & files can be searched from the Dash
+- Whether to require a password on waking from suspend
+- Disable sending error reports to Canonical
+- Turn off all ‘online’ features of the Dash
+
+### 6. Swap The Default Apps For Your Faves ###
+
+
+
+Make it yours
+
+Ubuntu comes preloaded with a tonne of apps, including a web browser (Mozilla Firefox), e-mail client (Thunderbird), music player (Rhythmbox), office suite (LibreOffice) and instant messenger (Empathy Instant Messenger).
+
+All well and good, they’re not everyone’s cup of tea. The Ubuntu Software Center is home to a slew of app alternatives, including:
+
+- VLC – Versatile media player
+- Steam – Games distribution platform
+- [Geary — Easy-to-use desktop e-mail app][5]
+- GIMP – Advanced image editor similar to Photoshop
+- Clementine — Stylish, fully-featured music player
+- Chromium open-source version of Google Chrome (without Flash)
+
+The Ubuntu Software Center plays host to a huge range of other apps, many of which you might not have heard of before. Since most apps are free, don’t be scared to try things out!
+
+### 7. Grab The Essentials ###
+
+
+
+Netflix in Chrome on Ubuntu
+
+Software Center apps aside, you may also wish to grab big-name apps like Skype, Spotify and Dropbox.
+
+Google Chrome is also a must if you wish to watch Netflix natively on Ubuntu or benefit from the latest, safest version of Flash.
+
+Most of these apps are available to download directly from their respective websites and can be installed on Ubuntu with a couple of clicks.
+
+- [Download Skype for Linux][6]
+- [Download Google Chrome for Linux][7]
+- [Download Dropbox for Linux][8]
+- [How to Install Spotify in Ubuntu][9]
+
+Talking of Google Chrome — did you know you can (unofficially) [install and run Android apps through it?][9] Oh yes ;)
+
+#### Finally… ####
+
+The items above are not the only ones applicable post-upgrade. Read through and follow the ones that chime with you, and feel free to ignore those that don’t.
+
+Secondly, this is a list for those who’ve upgraded to or installed Ubuntu 14.10. We’re not going walk you through carving it up into something that isn’t Ubuntu. If Unity isn’t your thing that’s fine, but be logical about it; save yourself some time and install one of the official flavours or offshoots instead.
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2014/10/7-things-to-do-after-installing-ubuntu-14-10-utopic-unicorn
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:http://www.omgubuntu.co.uk/2014/10/ubuntu-14-10-release-download-now
+[2]:http://www.omgubuntu.co.uk/2014/09/ubuntu-14-10-wallpaper-contest-winners
+[3]:http://www.omgubuntu.co.uk/category/gaming
+[4]:https://apps.ubuntu.com/cat/applications/ubuntu-restricted-extras/
+[5]:http://www.omgubuntu.co.uk/2014/09/new-shotwell-geary-stable-release-available-to-downed
+[6]:http://www.skype.com/en/download-skype/skype-for-linux/
+[7]:http://www.google.com/chrome
+[8]:https://www.dropbox.com/install?os=lnx
+[9]:http://www.omgubuntu.co.uk/2013/01/how-to-install-spotify-in-ubuntu-12-04-12-10
+[10]:http://www.omgubuntu.co.uk/2014/09/install-android-apps-ubuntu-archon
\ No newline at end of file
diff --git a/sources/tech/20141024 How To Upgrade Ubuntu 14.04 Trusty To Ubuntu 14.10 Utopic.md b/sources/tech/20141024 How To Upgrade Ubuntu 14.04 Trusty To Ubuntu 14.10 Utopic.md
new file mode 100644
index 0000000000..dee546fd1e
--- /dev/null
+++ b/sources/tech/20141024 How To Upgrade Ubuntu 14.04 Trusty To Ubuntu 14.10 Utopic.md
@@ -0,0 +1,110 @@
+johnhoow translating...
+How To Upgrade Ubuntu 14.04 Trusty To Ubuntu 14.10 Utopic
+================================================================================
+Hello all! Greetings! Today, we will discuss about how to upgrade from Ubuntu 14.04 to 14.10 final beta. As you may know, Ubuntu 14.10 final beta has already been released. According to the [Ubuntu release schedule][1], the final stable version will be available today in a couple of hours.
+
+Do you want to upgrade to Ubuntu 14.10 from Ubuntu 14.04/13.10/13,04/12,10/12.04, or older version on your system? Just follow the simple steps given below. Please note that you can’t directly upgrade from 13.10 to 14.04. First, you should upgrade from 13.10 to 14.04, and then upgrade from 14.04 to 14.10. Clear? Good. Now, Let us start the upgrade process.
+
+Though, the steps provided below are compatible for Ubuntu 14.10, It might work for other Ubuntu derivatives such as Lubuntu 14.10, Kubuntu 14.10, and Xubuntu 14.10 as well.
+
+**Important**: Before upgrading, don’t forget to backup your important data to any external device like USB hdd or CD/DVD.
+
+### Desktop Upgrade ###
+
+Before going to upgrade, we need to update the system. Open up the Terminal and enter the following commands.
+
+ sudo apt-get update && sudo apt-get dist-upgrade
+
+The above command will download and install the available latest packages.
+
+Reboot your system to finish installing updates.
+
+Now, enter the following command to upgrade to new available version.
+
+ sudo update-manager -d
+
+Software Updater will show up and search for the new release.
+
+After a few seconds, you will see a screen like below that saying: “**However, Ubuntu 14.10 is available now (you have 14.04)**”. Click on the button Upgrade to start upgrading to Ubuntu 14.10.
+
+
+
+The Software Updater will ask you to confirm still you want to upgrade. Click Start Upgrade to begin installing Ubuntu 14.10.
+
+
+
+**Please Note**: This is a beta release. Do not install it on production systems. The final stable version will be released in a couple of hours.
+
+Now, the Software Updater will prepare to start setting up new software channels.
+
+
+
+After a few minutes, the software updater will notify you the details the number of packages are going to be removed, and number of packages are going to be installed. Click **Start upgrade** to continue. Make sure you have good and stable Internet connection.
+
+
+
+Now, the updater will start to getting new packages. It will take a while depending upon your Internet connection speed.
+
+
+
+
+
+After a while, you’ll be asked to remove unnecessary applications. Finally, click **Restart** to complete the upgrade.
+
+Congratulations! Now, you have successfully upgraded to Ubuntu 14.10.
+
+
+
+That’s it.. Start using the new Ubuntu version.
+
+### Server Upgrade ###
+
+To upgrade from Ubuntu 14.04 server to Ubuntu 14.10 server, do the following steps.
+
+Install the update-manager-core package if it is not already installed:
+
+ sudo apt-get install update-manager-core
+
+Edit the file /etc/update-manager/release-upgrades,
+
+ sudo nano /etc/update-manager/release-upgrades
+
+and set Prompt=normal or Prompt=lts as shown below.
+
+ # Default behavior for the release upgrader.
+
+ [DEFAULT]
+ # Default prompting behavior, valid options:
+ #
+ # never - Never check for a new release.
+ # normal - Check to see if a new release is available. If more than one new
+ # release is found, the release upgrader will attempt to upgrade to
+ # the release that immediately succeeds the currently-running
+ # release.
+ # lts - Check to see if a new LTS release is available. The upgrader
+ # will attempt to upgrade to the first LTS release available after
+ # the currently-running one. Note that this option should not be
+ # used if the currently-running release is not itself an LTS
+ # release, since in that case the upgrader won't be able to
+ # determine if a newer release is available.
+ Prompt=normal
+
+Now, it is time to upgrade your server system to latest version using the following command:
+
+ sudo do-release-upgrade -d
+
+Follow the on-screen instructions. You’re done!!.
+
+Cheers!!
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/upgrade-ubuntu-14-04-trusty-ubuntu-14-10-utopic/
+
+作者:SK
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:https://wiki.ubuntu.com/UtopicUnicorn/ReleaseSchedule
diff --git a/sources/tech/20141027 How to download an ISO image with BitTorrent fast and safely from the command line.md b/sources/tech/20141027 How to download an ISO image with BitTorrent fast and safely from the command line.md
new file mode 100644
index 0000000000..e71c1a66cf
--- /dev/null
+++ b/sources/tech/20141027 How to download an ISO image with BitTorrent fast and safely from the command line.md
@@ -0,0 +1,127 @@
+wangjiezhe translating...
+
+How to download an ISO image with BitTorrent fast and safely from the command line
+================================================================================
+If you are one of those guys who have urge to try out every new (or even beta) release of Linux distribution to satisfy your curiosity and stay up-to-date, you will need to deal with the hassle of downloading big ISO images every now and then. ISO providers typically put up .torrent file of their ISO images to ease up on the bandwidth consumption of their servers. The benefit of peer-to-peer download is obvious for users as well (in terms of speed), especially when a new release of a popular Linux distribution is up for grab, and everyone is downloading and seeding the release at the same time.
+
+Ubuntu 14.10 (Utopic Unicorn) was just released this week. So there should be plenty of seeds to download the release from in the BitTorrent network at the moment. While there are many GUI-based BitTorrent clients out there, I am going to show you **how to download ISO images via a simple command-line interface (CLI) BitTorrent client**, which can be handy if you are on a remote headless server. Later in this tutorial, I will also demonstrate **how to verify the integrity of a downloaded ISO image**.
+
+The CLI BitTorrent client I am going to use today is transmission-cli. As you may know, [Transmission][1] is one of the most popular GUI-based BitTorrent client. transmission-cli is its stripped-down CLI version.
+
+### Install Transmission-cli on Linux ###
+
+To install **transmission-cli**, you don't need to install a full-blown GUI-based Transmission, which is nice.
+
+On Debian, Ubuntu or their derivatives:
+
+ $ sudo apt-get install transmission-cli
+
+On Fedora:
+
+ $ sudo yum install transmission-cli
+
+On CentOS or RHEL (after enabling [EPEL repository][2]):
+
+ $ sudo yum install transmission-cli
+
+### Download an ISO Image Fast with transmission-cli ###
+
+**transmission-cli** is really simple to use. If you are too lazy to study its command line options, all you have to do is to download .torrent file, and launch the command with the torrent file. It will automatically look for available peers, and download an ISO file from them.
+
+ $ wget http://releases.ubuntu.com/14.10/ubuntu-14.10-desktop-amd64.iso.torrent
+ $ transmission-cli ubuntu-14.10-desktop-amd64.iso.torrent
+
+
+
+Once an ISO image is fully downloaded, it will be stored in ~/Downloads directory by default. It took me only 5 minutes to download 1GB Ubuntu ISO image.
+
+
+
+Once it finishes downloading an ISO image, you will see the message "State changed from Incomplete to Complete" in the console. Note that transmission-cli will continue to run afterwards, becoming a seed for other downloaders. Press Ctrl+C to quit.
+
+### Customize Download Options for Repeat Use ###
+
+If you are a repeat user of **transmission-cli**, it may be worth your time to be familiar with some of its command line options.
+
+The "-w /path/to/download-directory" option specifies the directory where a downloaded file will be saved.
+
+The "-f /path/to/finish-script" option sets a script to run when current download is completed. Recall that transmission-cli, by default, continues running even after a file is fully downloaded. If you want to auto-terminate transmission-cli upon successful download, you can use this option. The following simple finish script will do.
+
+ #!/bin/sh
+ sleep 10
+ killall transmission-cli
+
+If you want to allocate limited upload/download bandwidth to transmission-cli, you can use "-d and "-u options. If you want to allow unlimited bandwidth instead, simply specify "-D" or "-U" option without any value.
+
+Here is a more advanced usage example of transmission-cli. In this example, the CLI client will automatically exit upon successful download. Download rate is unlimited while upload rate is capped at 50KB/s.
+
+ $ transmission-cli -w ~/iso -D -u 50 -f ~/finish.sh ubuntu-14.10-desktop-amd64.iso.torrent
+
+
+
+### Verify the Integrity of a Downloaded ISO Image ###
+
+When you download an ISO image, especially from many unknown peers in the BitTorrent network, it is always recommended to verify the integrity of the downloaded image.
+
+In case of Ubuntu releases, Canonical provides several checksum files (e.g., MD5SUM, SHA1SUMS and SHA256SUMS) for verification purpose. Let's use SHA256SUMS in this example.
+
+
+
+First, download the following two files.
+
+ $ wget http://releases.ubuntu.com/14.10/SHA256SUMS
+ $ wget http://releases.ubuntu.com/14.10/SHA256SUMS.gpg
+
+The first file is a SHA256 checksum file for ISO images, while the second file (*.gpg) is a signature of the checksum file. The purpose of the second file is to verify the validity of the checksum file itself.
+
+Let's verify the validity of SHA256SUMS file by running this command:
+
+ $ gpg --verify SHA256SUMS.gpg SHA256SUMS
+
+----------
+
+ gpg: Signature made Thu 23 Oct 2014 09:36:00 AM EDT using DSA key ID FBB75451
+ gpg: Can't check signature: public key not found
+
+If you are getting the above error, this is because you have not imported the public key used to generate the signature. So now let's import the required public key.
+
+To do that, you need to know the "key ID" of the public key, which is shown in the output of gpg command above. In this example, the key ID is "FBB75451". Run the following command to import the public key from the official Ubuntu keyserver.
+
+ $ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys FBB75451
+
+
+
+Now that the public key has been imported, go ahead and re-run the previous command to verify the signature.
+
+ gpg --verify SHA256SUMS.gpg SHA256SUMS
+
+
+
+This time you will not see "public key not found" error. If the SHA256SUMS file is valid, you will see "Good signature from " message. Note that you will also see a warning message saying that "This key is not certified with a trusted signature". Basically this warning message is telling you that you have not [assigned any explicit trust][3] to the imported public key. To avoid this warning, you could choose to assign your full trust to the imported public key, but you should do that only after the key has been fully vetted in some other means. Otherwise, you can ignore the warning for now.
+
+After verifying the integrity of SHA256SUMS file, the final last step is to compare the SHA256 checksum of the downloade ISO image against the corresponding checksum value in SHA256SUMS file. For that you can use sha256sum command line tool.
+
+For your convenience, the following one-liner compares the SHA256 checksums and reports the result.
+
+ $ sha256sum -c <(grep ubuntu-14.10-desktop-amd64.iso SHA256SUMS)
+
+----------
+
+ ubuntu-14.10-desktop-amd64.iso: OK
+
+If you see the above output, that means that two checksum values match. So the integrity of the downloaded ISO image has been successfully verified.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/download-iso-image-bittorrent-command-line.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:https://www.transmissionbt.com/
+[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
+[3]:http://xmodulo.com/verify-authenticity-integrity-downloaded-file.html
diff --git a/sources/tech/20141027 ntpq -p output.md b/sources/tech/20141027 ntpq -p output.md
new file mode 100644
index 0000000000..c834e43585
--- /dev/null
+++ b/sources/tech/20141027 ntpq -p output.md
@@ -0,0 +1,301 @@
+“ntpq -p” output
+================================================================================
+The [Gentoo][1] (and others?) [incomplete man pages for “ntpq -p”][2] merely give the description: “*Print a list of the peers known to the server as well as a summary of their state.*”
+
+I had not seen this documented, hence here is a summary that can be used in addition to the brief version of the man page “[man ntpq][3]“. More complete details are given on: “[ntpq – standard NTP query program][4]” (source author), and [other examples of the man ntpq pages][5].
+
+[NTP][6] is a protocol designed to synchronize the clocks of computers over a ([WAN][7] or [LAN][8]) [udp][9] network. From [Wikipedia – NTP][10]:
+
+> The Network Time Protocol (NTP) is a protocol and software implementation for synchronizing the clocks of computer systems over packet-switched, variable-latency data networks. Originally designed by David L. Mills of the University of Delaware and still maintained by him and a team of volunteers, it was first used before 1985 and is one of the oldest Internet protocols.
+
+For an awful lot more than you might ever want to know about time and NTP, see “[The NTP FAQ, Time, what Time?][11]” and the current [RFCs for NTP][12]. The earlier “Network Time Protocol (Version 3) RFC” ([txt][13], or [pdf][14], Appendix E, The NTP Timescale and its Chronometry, p70) includes an interesting explanation of the changes in, and relations between, our timekeeping systems over the past 5000 years or so. Wikipedia gives a broader view in the articles [Time][15] and [Calendar][16].
+
+The command “ntpq -p” outputs a table such as for example:
+
+ remote refid st t when poll reach delay offset jitter
+ ==============================================================================
+ LOCAL(0) .LOCL. 10 l 96h 64 0 0.000 0.000 0.000
+ *ns2.example.com 10.193.2.20 2 u 936 1024 377 31.234 3.353 3.096
+
+### Further detail: ###
+
+#### Table headings: ####
+
+
+- **remote** – The remote peer or server being synced to. “LOCAL” is this local host (included in case there are no remote peers or servers available);
+- **refid** – Where or what the remote peer or server is itself synchronised to;
+- **st** – The remote peer or server [Stratum][17]
+- **t** – Type (u: [unicast][18] or [manycast][19] client, b: [broadcast][20] or [multicast][21] client, l: local reference clock, s: symmetric peer, A: manycast server, B: broadcast server, M: multicast server, see “[Automatic Server Discovery][22]“);
+- **when** – When last polled (seconds ago, “h” hours ago, or “d” days ago);
+- **poll** – Polling frequency: [rfc5905][23] suggests this ranges in NTPv4 from 4 (16s) to 17 (36h) (log2 seconds), however observation suggests the actual displayed value is seconds for a much smaller range of 64 (26) to 1024 (210) seconds;
+- **reach** – An 8-bit left-shift shift register value recording polls (bit set = successful, bit reset = fail) displayed in [octal][24];
+- **delay** – Round trip communication delay to the remote peer or server (milliseconds);
+- **offset** – Mean offset (phase) in the times reported between this local host and the remote peer or server ([RMS][25], milliseconds);
+- **jitter** – Mean deviation (jitter) in the time reported for that remote peer or server (RMS of difference of multiple time samples, milliseconds);
+
+#### Select Field tally code: ####
+
+The first character displayed in the table (Select Field tally code) is a state flag (see [Peer Status Word][26]) that follows the sequence ” “, “x”, “-“, “#”, “+”, “*”, “o”:
+
+
+- ”** **” – No state indicated for:
+ - non-communicating remote machines,
+ - “LOCAL” for this local host,
+ - (unutilised) high stratum servers,
+ - remote machines that are themselves using this host as their synchronisation reference;
+- “**x**” – Out of tolerance, do not use (discarded by intersection algorithm);
+- “**-**” – Out of tolerance, do not use (discarded by the cluster algorithm);
+- “**#**” – Good remote peer or server but not utilised (not among the first six peers sorted by synchronization distance, ready as a backup source);
+- “**+**” – Good and a preferred remote peer or server (included by the combine algorithm);
+- “*****” – The remote peer or server presently used as the primary reference;
+- “**o**” – PPS peer (when the prefer peer is valid). The actual system synchronization is derived from a pulse-per-second (PPS) signal, either indirectly via the PPS reference clock driver or directly via kernel interface.
+
+See the [Clock Select Algorithm][27].
+
+#### “refid”: ####
+
+The **refid** can have the status values:
+
+
+- An IP address – The [IP address][28] of a remote peer or server;
+- **.LOCL.** – This local host (a place marker at the lowest stratum included in case there are no remote peers or servers available);
+- **.PPS.** – “[Pulse Per Second][29]” from a time standard;
+- **.IRIG.** – [Inter-Range Instrumentation Group][30] time code;
+- **.ACTS.** – American [NIST time standard][31] telephone modem;
+- **.NIST.** – American NIST time standard telephone modem;
+- **.PTB.** – German [PTB][32] time standard telephone modem;
+- **.USNO.** – American [USNO time standard][33] telephone modem;
+- **.CHU.** – [CHU][34] ([HF][35], Ottawa, ON, Canada) time standard radio receiver;
+- **.DCFa.** – [DCF77][36] ([LF][37], Mainflingen, Germany) time standard radio receiver;
+- **.HBG.** – [HBG][38] (LF Prangins, Switzerland) time standard radio receiver;
+- **.JJY.** – [JJY][39] (LF Fukushima, Japan) time standard radio receiver;
+- **.LORC.** – [LORAN][40]-C station ([MF][41]) time standard radio receiver. Note, [no longer operational][42] (superseded by [eLORAN][43]);
+- **.MSF.** – [MSF][44] (LF, Anthorn, Great Britain) time standard radio receiver;
+- **.TDF.** – [TDF][45] (MF, Allouis, France) time standard radio receiver;
+- **.WWV.** – [WWV][46] (HF, Ft. Collins, CO, America) time standard radio receiver;
+- **.WWVB.** – [WWVB][47] (LF, Ft. Collins, CO, America) time standard radio receiver;
+- **.WWVH.** – [WWVH][48] (HF, Kauai, HI, America) time standard radio receiver;
+- **.GOES.** – American [Geosynchronous Orbit Environment Satellite][49];
+- **.GPS.** – American [GPS][50];
+- **.GAL.** – [Galileo][51] European [GNSS][52];
+- **.ACST.** – manycast server;
+- **.AUTH.** – authentication error;
+- **.AUTO.** – Autokey sequence error;
+- **.BCST.** – broadcast server;
+- **.CRYPT.** – Autokey protocol error;
+- **.DENY.** – access denied by server;
+- **.INIT.** – association initialized;
+- **.MCST.** – multicast server;
+- **.RATE.** – (polling) rate exceeded;
+- **.TIME.** – association timeout;
+- **.STEP.** – step time change, the offset is less than the panic threshold (1000ms) but greater than the step threshold (125ms).
+
+#### Operation notes ####
+
+A time server will report time information with no time updates from clients (unidirectional updates), whereas a peer can update fellow participating peers to converge upon a mutually agreed time (bidirectional updates).
+
+During [initial startup][53]:
+
+> Unless using the iburst option, the client normally takes a few minutes to synchronize to a server. If the client time at startup happens to be more than 1000s distant from NTP time, the daemon exits with a message to the system log directing the operator to manually set the time within 1000s and restart. If the time is less than 1000s but more than 128s distant, a step correction occurs and the daemon restarts automatically.
+
+> When started for the first time and a frequency file is not present, the daemon enters a special mode in order to calibrate the frequency. This takes 900s during which the time is not [disciplined][54]. When calibration is complete, the daemon creates the frequency file and enters normal mode to amortize whatever residual offset remains.
+
+Stratum 0 devices are such as atomic (caesium, rubidium) clocks, GPS clocks, or other time standard radio clocks providing a time signal to the Stratum 1 time servers. NTP reports [UTC][55] (Coordinated Universal Time) only. Client programs/utilities then use [time zone][56] data to report local time from the synchronised UTC.
+
+The protocol is highly accurate, using a resolution of less than a nanosecond (about 2-32 seconds). The time resolution achieved and other parameters for a host (host hardware and operating system limited) is reported by the command “ntpq -c rl” (see [rfc1305][57] Common Variables and [rfc5905][58]).
+
+#### “ntpq -c rl” output parameters: ####
+
+- **precision** is rounded to give the next larger integer power of two. The achieved resolution is thus 2precision (seconds)
+- **rootdelay** – total roundtrip delay to the primary reference source at the root of the synchronization subnet. Note that this variable can take on both positive and negative values, depending on clock precision and skew (seconds)
+- **rootdisp** – maximum error relative to the primary reference source at the root of the synchronization subnet (seconds)
+- **tc** – NTP algorithm [PLL][59] (phase locked loop) or [FLL][60] (frequency locked loop) time constant (log2)
+- **mintc** – NTP algorithm PLL/FLL minimum time constant or ‘fastest response’ (log2)
+- **offset** – best and final offset determined by the combine algorithm used to discipline the system clock (ms)
+- **frequency** – system clock period (log2 seconds)
+- **sys_jitter** – best and final jitter determined by the combine algorithm used to discipline the system clock (ms)
+- **clk_jitter** – host hardware(?) system clock jitter (ms)
+- **clk_wander** – host hardware(?) system clock wander ([PPM][61] – parts per million)
+
+Jitter (also called timing jitter) refers to short-term variations in frequency with components greater than 10Hz, while wander refers to long-term variations in frequency with components less than 10Hz. (Stability refers to the systematic variation of frequency with time and is synonymous with aging, drift, trends, etc.)
+
+#### Operation notes (continued) ####
+
+The NTP software maintains a continuously updated drift correction. For a correctly configured and stable system, a reasonable expectation for modern hardware synchronising over an uncongested internet connection is for network client devices to be synchronised to within a few milliseconds of UTC at the time of synchronising to the NTP service. (What accuracy can be expected between peers on an uncongested Gigabit LAN?)
+
+Note that for UTC, a [leap second][62] can be inserted into the reported time up to twice a year to allow for variations in the Earth’s rotation. Also beware of the one hour time shifts for when local times are reported for “[daylight savings][63]” times. Also, the clock for a client device will run independently of UTC until resynchronised oncemore, unless that device is calibrated or a drift correction is applied.
+
+#### [What happens during a Leap Second?][64] ####
+
+> During a leap second, either one second is removed from the current day, or a second is added. In both cases this happens at the end of the UTC day. If a leap second is inserted, the time in UTC is specified as 23:59:60. In other words, it takes two seconds from 23:59:59 to 0:00:00 instead of one. If a leap second is deleted, time will jump from 23:59:58 to 0:00:00 in one second instead of two. See also [The Kernel Discipline][65].
+
+So… What actually is the value for the step threshold: 125ms or 128ms? And what are the PLL/FLL tc units (log2 s? ms?)? And what accuracy can be expected between peers on an uncongested Gigabit LAN?
+
+
+
+Thanks for comments from Camilo M and Chris B. Corrections and further details welcomed.
+
+Cheers,
+Martin
+
+### Apocrypha: ###
+
+- The [epoch for NTP][66] starts in year 1900 while the epoch in UNIX starts in 1970.
+- [Time corrections][67] are applied gradually, so it may take up to three hours until the frequency error is compensated.
+- [Peerstats and loopstats][68] can be logged to [summarise/plot time offsets and errors][69]
+- [RMS][70] – Root Mean Square
+- [PLL][71] – Phase locked loop
+- [FLL][72] – Frequency locked loop
+- [PPM][73] – Parts per million, used here to describe rate of time drift
+- [man ntpq (Gentoo brief version)][74]
+- [man ntpq (long version)][75]
+- [man ntpq (Gentoo long version)][76]
+
+### See: ###
+
+- [ntpq – standard NTP query program][77]
+- [The Network Time Protocol (NTP) Distribution][78]
+- A very brief [history][79] of NTP
+- A more detailed brief history: “Mills, D.L., A brief history of NTP time: confessions of an Internet timekeeper. Submitted for publication; please do not cite or redistribute” ([pdf][80])
+- [NTP RFC][81] standards documents
+- Network Time Protocol (Version 3) RFC – [txt][82], or [pdf][83]. Appendix E, The NTP Timescale and its Chronometry, p70, includes an interesting explanation of the changes in, and relations between, our timekeeping systems over the past 5000 years or so
+- Wikipedia: [Time][84] and [Calendar][85]
+- [John Harrison and the Longitude problem][86]
+- [Clock of the Long Now][87] – The 10,000 Year Clock
+- John C Taylor – [Chronophage][88]
+- [Orders of magnitude of time][89]
+- The [Greenwich Time Signal][90]
+
+### Others: ###
+
+SNTP (Simple Network Time Protocol, [RFC 4330][91]) is basically also NTP, but lacks some internal algorithms for servers where the ultimate performance of a full NTP implementation based on [RFC 1305][92] is neither needed nor justified.
+
+The W32Time [Windows Time Service][93] is a non-standard implementation of SNTP, with no accuracy guarantees, and an assumed accuracy of no better than about a 1 to 2 second range. (Is that due to there being no system clock drift correction and a time update applied only once every 24 hours assumed for a [PC][94] with typical clock drift?)
+
+There is also the [PTP (IEEE 1588)][95] Precision Time Protocol. See Wikipedia: [Precision Time Protocol][96]. A software demon is [PTPd][97]. The significant features are that it is intended as a [LAN][98] high precision master-slave synchronisation system synchronising at the microsecond scale to a master clock for [International Atomic Time][99] (TAI, [monotonic][100], no leap seconds). Data packet timestamping can be appended by hardware at the physical layer by a network interface card or switch for example. Network kit supporting PTP can timestamp data packets in and out in a way that removes the delay effect of processing within the switch/router. You can run PTP without hardware timestamping but it might not synchronise if the time errors introduced are too great. Also it will struggle to work through a router (large delays) for the same reason.
+
+### Older time synchronization protocols: ###
+
+- DTSS – Digital Time Synchronisation Service by Digital Equipment Corporation, superseded by NTP. See an example of [DTSS VMS C code c2000][101]. (Any DTSS articles/documentation anywhere?)
+- [DAYTIME protocol][102], synchronization protocol using [TCP][103] or [UDP][104] port 13
+- [ICMP Timestamp][105] and [ICMP Timestamp Reply][106], synchronization protocol using [ICMP][107]
+- [Time Protocol][108], synchronization protocol using TCP or UDP port 37
+
+--------------------------------------------------------------------------------
+
+via: http://nlug.ml1.co.uk/2012/01/ntpq-p-output/831
+
+作者:Martin L
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://www.gentoo.org/
+[2]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-brief-version/853
+[3]:http://www.thelinuxblog.com/linux-man-pages/1/ntpq
+[4]:http://www.eecis.udel.edu/~mills/ntp/html/ntpq.html
+[5]:http://linux.die.net/man/8/ntpq
+[6]:http://www.ntp.org/
+[7]:http://en.wikipedia.org/wiki/Wide_area_network
+[8]:http://en.wikipedia.org/wiki/Local_area_network
+[9]:http://en.wikipedia.org/wiki/User_Datagram_Protocol
+[10]:http://en.wikipedia.org/wiki/Network_Time_Protocol
+[11]:http://www.ntp.org/ntpfaq/NTP-s-time.htm
+[12]:http://www.ntp.org/rfc.html
+[13]:http://www.ietf.org/rfc/rfc1305.txt
+[14]:http://www.rfc-editor.org/rfc/rfc1305.pdf
+[15]:http://en.wikipedia.org/wiki/Time
+[16]:http://en.wikipedia.org/wiki/Calendar
+[17]:http://en.wikipedia.org/wiki/Network_Time_Protocol#Clock_strata
+[18]:http://en.wikipedia.org/wiki/Unicast
+[19]:http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html#mcst
+[20]:http://en.wikipedia.org/wiki/Broadcasting_%28computing%29
+[21]:http://en.wikipedia.org/wiki/Multicast
+[22]:http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html
+[23]:http://www.ietf.org/rfc/rfc5905.txt
+[24]:http://en.wikipedia.org/wiki/Octal#In_computers
+[25]:http://en.wikipedia.org/wiki/Root_mean_square
+[26]:http://www.eecis.udel.edu/~mills/ntp/html/decode.html#peer
+[27]:http://www.eecis.udel.edu/~mills/ntp/html/select.html
+[28]:http://en.wikipedia.org/wiki/Ip_address
+[29]:http://en.wikipedia.org/wiki/Pulse_per_second
+[30]:http://en.wikipedia.org/wiki/Inter-Range_Instrumentation_Group
+[31]:http://en.wikipedia.org/wiki/Standard_time_and_frequency_signal_service
+[32]:http://www.ptb.de/index_en.html
+[33]:http://en.wikipedia.org/wiki/United_States_Naval_Observatory#Time_service
+[34]:http://en.wikipedia.org/wiki/CHU_%28radio_station%29
+[35]:http://en.wikipedia.org/wiki/High_frequency
+[36]:http://en.wikipedia.org/wiki/DCF77
+[37]:http://en.wikipedia.org/wiki/Low_frequency
+[38]:http://en.wikipedia.org/wiki/HBG_%28time_signal%29
+[39]:http://en.wikipedia.org/wiki/JJY#Time_standards
+[40]:http://en.wikipedia.org/wiki/LORAN#Timing_and_synchronization
+[41]:http://en.wikipedia.org/wiki/Medium_frequency
+[42]:http://en.wikipedia.org/wiki/LORAN#The_future_of_LORAN
+[43]:http://en.wikipedia.org/wiki/LORAN#eLORAN
+[44]:http://en.wikipedia.org/wiki/Time_from_NPL#The_.27MSF_signal.27_and_the_.27Rugby_clock.27
+[45]:http://en.wikipedia.org/wiki/T%C3%A9l%C3%A9_Distribution_Fran%C3%A7aise
+[46]:http://en.wikipedia.org/wiki/WWV_%28radio_station%29#Time_signals
+[47]:http://en.wikipedia.org/wiki/WWVB
+[48]:http://en.wikipedia.org/wiki/WWVH
+[49]:http://en.wikipedia.org/wiki/GOES#Further_reading
+[50]:http://en.wikipedia.org/wiki/Gps#Timekeeping
+[51]:http://en.wikipedia.org/wiki/Galileo_%28satellite_navigation%29#The_concept
+[52]:http://en.wikipedia.org/wiki/Gnss
+[53]:http://www.eecis.udel.edu/~mills/ntp/html/debug.html
+[54]:http://www.ntp.org/ntpfaq/NTP-s-algo-kernel.htm
+[55]:http://en.wikipedia.org/wiki/Coordinated_Universal_Time
+[56]:http://en.wikipedia.org/wiki/Time_zone
+[57]:http://www.ietf.org/rfc/rfc1305.txt
+[58]:http://www.ietf.org/rfc/rfc5905.txt
+[59]:http://en.wikipedia.org/wiki/PLL
+[60]:http://en.wikipedia.org/wiki/Frequency-locked_loop
+[61]:http://en.wikipedia.org/wiki/Parts_per_million
+[62]:http://en.wikipedia.org/wiki/Leap_second
+[63]:http://en.wikipedia.org/wiki/Daylight_saving_time
+[64]:http://www.ntp.org/ntpfaq/NTP-s-time.htm#Q-TIME-LEAP-SECOND
+[65]:http://www.ntp.org/ntpfaq/NTP-s-algo-kernel.htm
+[66]:http://www.ntp.org/ntpfaq/NTP-s-algo.htm#AEN1895
+[67]:http://www.ntp.org/ntpfaq/NTP-s-algo.htm#Q-ACCURATE-CLOCK
+[68]:http://www.ntp.org/ntpfaq/NTP-s-trouble.htm#Q-TRB-MON-STATFIL
+[69]:http://www.ntp.org/ntpfaq/NTP-s-trouble.htm#AEN5086
+[70]:http://en.wikipedia.org/wiki/Root_mean_square
+[71]:http://en.wikipedia.org/wiki/PLL
+[72]:http://en.wikipedia.org/wiki/Frequency-locked_loop
+[73]:http://en.wikipedia.org/wiki/Parts_per_million
+[74]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-brief-version/853
+[75]:http://nlug.ml1.co.uk/2012/01/man-ntpq-long-version/855
+[76]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-long-version/856
+[77]:http://www.eecis.udel.edu/~mills/ntp/html/ntpq.html
+[78]:http://www.eecis.udel.edu/~mills/ntp/html/index.html
+[79]:http://www.ntp.org/ntpfaq/NTP-s-def-hist.htm
+[80]:http://www.eecis.udel.edu/~mills/database/papers/history.pdf
+[81]:http://www.ntp.org/rfc.html
+[82]:http://www.ietf.org/rfc/rfc1305.txt
+[83]:http://www.rfc-editor.org/rfc/rfc1305.pdf
+[84]:http://en.wikipedia.org/wiki/Time
+[85]:http://en.wikipedia.org/wiki/Calendar
+[86]:http://www.rmg.co.uk/harrison
+[87]:http://longnow.org/clock/
+[88]:http://johnctaylor.com/
+[89]:http://en.wikipedia.org/wiki/Orders_of_magnitude_%28time%29
+[90]:http://en.wikipedia.org/wiki/Greenwich_Time_Signal
+[91]:http://tools.ietf.org/html/rfc4330
+[92]:http://tools.ietf.org/html/rfc1305
+[93]:http://en.wikipedia.org/wiki/Network_Time_Protocol#Microsoft_Windows
+[94]:http://en.wikipedia.org/wiki/Personal_computer
+[95]:http://www.nist.gov/el/isd/ieee/ieee1588.cfm
+[96]:http://en.wikipedia.org/wiki/IEEE_1588
+[97]:http://ptpd.sourceforge.net/
+[98]:http://en.wikipedia.org/wiki/Local_area_network
+[99]:http://en.wikipedia.org/wiki/International_Atomic_Time
+[100]:http://en.wikipedia.org/wiki/Monotonic_function
+[101]:http://antinode.info/ftp/dtss_ntp/
+[102]:http://en.wikipedia.org/wiki/DAYTIME
+[103]:http://en.wikipedia.org/wiki/Transmission_Control_Protocol
+[104]:http://en.wikipedia.org/wiki/User_Datagram_Protocol
+[105]:http://en.wikipedia.org/wiki/ICMP_Timestamp
+[106]:http://en.wikipedia.org/wiki/ICMP_Timestamp_Reply
+[107]:http://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
+[108]:http://en.wikipedia.org/wiki/Time_Protocol
\ No newline at end of file
diff --git a/sources/tech/20141029 How to Install and Setup My Weather Indicator in Ubuntu 14.10.md b/sources/tech/20141029 How to Install and Setup My Weather Indicator in Ubuntu 14.10.md
new file mode 100644
index 0000000000..a5e06daef8
--- /dev/null
+++ b/sources/tech/20141029 How to Install and Setup My Weather Indicator in Ubuntu 14.10.md
@@ -0,0 +1,75 @@
+How to Install and Setup ‘My Weather Indicator’ in Ubuntu 14.10
+================================================================================
+
+
+**There’s no drought of ways to be kept abreast of the weather on the Ubuntu desktop, with the Unity Dash and desktop apps like [Typhoon][1] all offering to help.**
+
+But panel applets that offer quick glance condition and temperature stats, with a ream of detailed meteorological data never more than a quick click away, are by far the most popular weather utilities on Linux.
+
+[My Weather Indicator][2] by Atareao is one of this breed, and arguably the best.
+
+It displays current temperature and conditions on the Unity panel, and has a menu stuffed full of stats, including ‘feels like’, cloudiness and sunrise/set times. In addition, there’s a desktop widget, multiple location support, a choice of backend data providers, and plenty of configuration options.
+
+Sounds pretty comprehensive, right? Let’s walk through how to install and set it up on Ubuntu.
+
+### Install My Weather Indicator in Ubuntu ###
+
+My Weather Indicator is not available to install from the Ubuntu Software Center directly, but both a .deb installer and an officially maintained PPA (providing packages for both Ubuntu 14.04 LTS and 14.10) are provided by the developers.
+
+- Download My Weather Indicator (.deb)
+
+To ensure you’re always kept up-to-date with the latest release I recommend adding the [Atareao PPA][3] to your Software Sources and installing from there.
+
+How? **Open a new Terminal** window (Unity Dash > Terminal, or press Ctrl+Alt+T) and **enter the following two commands carefully**, entering your system password when prompted:
+
+ sudo add-apt-repository ppa:atareao/atareao
+
+ sudo apt-get update && sudo apt-get install my-weather-indicator
+
+#### Setting Up My Weather Indicator ####
+
+Regardless of how you install the tool, once you have you can launch it from the Unity Dash by searching for “weather”.
+
+
+
+The first time you open the app the following Preferences window will open. From here you can search for a location manually or set it to auto-detect using geo-ip — the latter of which can sometimes be a little imprecise, but saves the need to faff.
+
+
+
+If you’re travelling (or in need of some small talk fodder) **you can monitor a second locale**, too. This is set up in the same way as the first but in the ‘Second Location’ tab.
+
+Checking the ‘**Show Widget**’ box in the “**Widget Options**” section adds a small forecast desklet to your desktop. There are a number of different skins included, so be sure to play around to find the one you like the most (note: widget changes are applied on clicking ‘Ok’).
+
+
+
+My Weather Indicator uses [Open Weather Map][4] as its forecast backend by default, but other options can be selected from the ‘**Weather Services**’ pane (*require an API key to function):
+
+- Open Weather Map
+- Yahoo! Weather
+- Weather Underground*
+- World Weather Online*
+
+The ‘**Units**’ tab is where you can configure measurements for temperature, pressure, wind speed, etc. These are applied globally to all configured locations; you can’t have one location in Celsius and the other in Fahrenheit.
+
+
+
+Finally, in the ‘General Options‘ section you can set the refresh interval, set autostart preference, and choose from one of two panel icons.
+
+MWI not your thing? Why not try [the nerdy way to view weather forecasts on Linux][5]?
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2014/10/install-weather-indicator-ubuntu-14-10
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:https://launchpad.net/typhoon
+[2]:https://launchpad.net/my-weather-indicator
+[3]:https://launchpad.net/~atareao/+archive/ubuntu/atareao
+[4]:http://openweathermap.org/
+[5]:http://www.omgubuntu.co.uk/2014/02/get-weather-forecast-terminal-linux
\ No newline at end of file
diff --git a/sources/tech/20141029 How to create and manage LXC containers on Ubuntu.md b/sources/tech/20141029 How to create and manage LXC containers on Ubuntu.md
new file mode 100644
index 0000000000..5731a7d737
--- /dev/null
+++ b/sources/tech/20141029 How to create and manage LXC containers on Ubuntu.md
@@ -0,0 +1,141 @@
+How to create and manage LXC containers on Ubuntu
+================================================================================
+While the concept of containers was introduced more than a decade ago to manage shared hosting environments securely (e.g., FreeBSD jails), Linux containers such as LXC or [Docker][1] have gone mainstream only recently with the rising need to deploy applications for the cloud. While [Docker][2] is getting all the media spotlight these days with strong backing from major cloud providers (e.g., Amazon AWS, Microsoft Azure) and distro providers (e.g., Red Hat, Ubuntu), LXC is in fact the original container technology developed for Linux platforms.
+
+If you are an average Linux user, what good does Docker/LXC bring to you? Well, containers are actually a great means to switch between distros literally instantly. Suppose your current desktop is Debian. You want Debian's stability. At the same time, you also want to play the latest Ubuntu games. Then instead of bothering to dual boot into a Ubuntu partition, or boot up a heavyweight Ubuntu VM, simply spin off a Ubuntu container on the spot, and you are done.
+
+Even without all the goodies of Docker, what I like about LXC containers is the fact that LXC can be managed by libvirt interface, which is not the case for Docker. If you have been using libvirt-based management tools (e.g., virt-manager or virsh), you can use those same tools to manage LXC containers.
+
+In this tutorial, I focus on the command-line usage of standard LXC container tools, and demonstrate **how to create and manage LXC containers from the command line on Ubuntu**.
+
+### Install LXC on Ubuntu ###
+
+To use LXC on Ubuntu, install LXC user-space tools as follows.
+
+ $ sudo apt-get install lxc
+
+After that, check the current Linux kernel for LXC support by running lxc-checkconifg tool. If everything is enabled, kernel's LXC support is ready.
+
+ $ lxc-checkconfig
+
+
+
+After installing LXC tools, you will find that an LXC's default bridge interface (lxcbr0) is automatically created (as configured in /etc/lxc/default.conf).
+
+
+
+When you create an LXC container, the container's interface will automatically be attached to this bridge, so the container can communicate with the world.
+
+### Create an LXC Container ###
+
+To be able to create an LXC container of a particular target environment (e.g., Debian Wheezy 64bit), you need a corresponding LXC template. Fortunately, LXC user space tools on Ubuntu come with a collection of ready-made LXC templates. You can find available LXC templates in /usr/share/lxc/templates directory.
+
+ $ ls /usr/share/lxc/templates
+
+
+
+An LXC template is nothing more than a script which builds a container for a particular Linux environment. When you create an LXC container, you need to use one of these templates.
+
+To create a Ubuntu container, for example, use the following command-line:
+
+ $ sudo lxc-create -n -t ubuntu
+
+
+
+By default, it will create a minimal Ubuntu install of the same release version and architecture as the local host, in this case Saucy Salamander (13.10) 64-bit.
+
+If you want, you can create Ubuntu containers of any arbitrary version by passing the release parameter. For example, to create a Ubuntu 14.10 container:
+
+ $ sudo lxc-create -n -t ubuntu -- --release utopic
+
+It will download and validate all the packages needed by a target container environment. The whole process can take a couple of minutes or more depending on the type of container. So be patient.
+
+
+
+After a series of package downloads and validation, an LXC container image are finally created, and you will see a default login credential to use. The container is stored in /var/lib/lxc/. Its root filesystem is found in /var/lib/lxc//rootfs.
+
+All the packages downloaded during LXC creation get cached in /var/cache/lxc, so that creating additional containers with the same LXC template will take no time.
+
+Let's see a list of LXC containers on the host:
+
+ $ sudo lxc-ls --fancy
+
+----------
+
+ NAME STATE IPV4 IPV6 AUTOSTART
+ ------------------------------------
+ test-lxc STOPPED - - NO
+
+To boot up a container, use the command below. The "-d" option launches the container as a daemon. Without this option, you will directly be attached to console right after you launch the container.
+
+ $ sudo lxc-start -n -d
+
+After launching the container, let's check the state of the container again:
+
+ $ sudo lxc-ls --fancy
+
+----------
+
+ NAME STATE IPV4 IPV6 AUTOSTART
+ -----------------------------------------
+ lxc RUNNING 10.0.3.55 - NO
+
+You will see that the container is in "RUNNING" state with an IP address assigned to it.
+
+You can also verify that the container's interface (e.g., vethJ06SFL) is automatically attached to LXC's internal bridge (lxcbr0) as follows.
+
+ $ brctl show lxcbr0
+
+
+
+### Manage an LXC Container ###
+
+Now that we know how to create and start an LXC container, let's see what we can do with a running container.
+
+First of all, we want to access the container's console. For this, type this command:
+
+ $ sudo lxc-console -n
+
+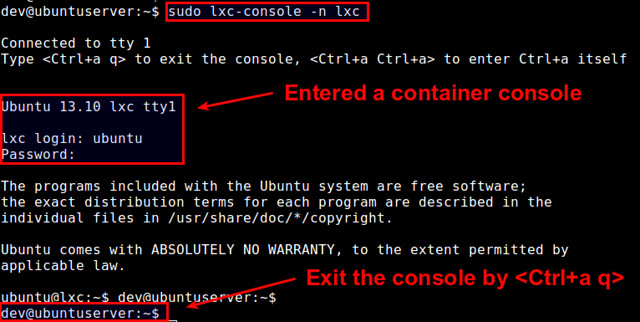
+
+Type to exit the console.
+
+To stop and destroy a container:
+
+ $ sudo lxc-stop -n
+ $ sudo lxc-destroy -n
+
+To clone an existing container to another, use these commands:
+
+ $ sudo lxc-stop -n
+ $ sudo lxc-clone -o -n
+
+### Troubleshooting ###
+
+For those of you who encounter errors with LXC, here are some troubleshooting tips.
+
+1. You fail to create an LXC container with the following error.
+
+ $ sudo lxc-create -n test-lxc -t ubuntu
+
+----------
+
+ lxc-create: symbol lookup error: /usr/lib/x86_64-linux-gnu/liblxc.so.1: undefined symbol: cgmanager_get_pid_cgroup_abs_sync
+
+This means that you are running the latest LXC, but with an older libcgmanager. To fix this problem, you need to update libcgmanager.
+
+ $ sudo apt-get install libcgmanager0
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/lxc-containers-ubuntu.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://xmodulo.com/docker-containers-centos-fedora.html
+[2]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
\ No newline at end of file
diff --git a/sources/tech/20141029 How to install LEMP stack nginx MariaDB or MySQL and php on CentOS.md b/sources/tech/20141029 How to install LEMP stack nginx MariaDB or MySQL and php on CentOS.md
new file mode 100644
index 0000000000..0554534f82
--- /dev/null
+++ b/sources/tech/20141029 How to install LEMP stack nginx MariaDB or MySQL and php on CentOS.md
@@ -0,0 +1,248 @@
+How to install LEMP stack (nginx, MariaDB/MySQL and php) on CentOS
+================================================================================
+The LEMP stack is an increasingly popular web service stack, powering mission-critical web services in many production environments. As the name implies, the LEMP stack is composed of Linux, nginx, MariaDB/MySQL and PHP. nginx is a high performance and lightweight replacement of slow and hard-to-scale Apache HTTP server used in the traditional LAMP stack. MariaDB is a community-driven fork of MySQL, with more features and better performance. PHP, a server-side language for generating dynamic content, is processed by PHP-FPM, an enhanced implementation of PHP FastCGI.
+
+In this tutorial, I demonstrate **how to set up the LEMP stack on CentOS platforms**. I target both CentOS 6 and CentOS 7 platforms, and point out differences where necessary.
+
+### Step One: Nginx ###
+
+As the first step, let's install nginx on CentOS, and do basic configuration for nginx, such as enabling auto-start and [customizing the firewall][1].
+
+#### Install Nginx ####
+
+Let's install a pre-built stable version of nginx package from its official RPM source.
+
+On CentOS 7:
+
+ $ sudo rpm --import http://nginx.org/keys/nginx_signing.key
+ $ sudo rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
+ $ sudo yum install nginx
+
+On CentOS 6:
+
+ $ sudo rpm --import http://nginx.org/keys/nginx_signing.key
+ $ sudo rpm -ivh http://nginx.org/packages/centos/6/noarch/RPMS/nginx-release-centos-6-0.el6.ngx.noarch.rpm
+ $ sudo yum install nginx
+
+Note that if you do not import the official nginx GPG key before installing nginx RPM, you will get this warning:
+
+ warning: /var/tmp/rpm-tmp.KttVHD: Header V4 RSA/SHA1 Signature, key ID 7bd9bf62: NOKEY
+
+#### Start Nginx ####
+
+After installation, nginx does not start automatically. Let's start nginx right now, and configure it to auto-start upon boot. Also, we need to open a TCP/80 port in the firewall so that you can access nginx webserver remotely. All of these are achieved by entering the following commands.
+
+On CentOS 7:
+
+ $ sudo systemctl start nginx
+ $ sudo systemctl enable nginx
+ $ sudo firewall-cmd --zone=public --add-port=80/tcp --permanent
+ $ sudo firewall-cmd --reload
+
+On CentOS 6:
+
+ $ sudo service nginx start
+ $ sudo chkconfig nginx on
+ $ sudo iptables -I INPUT -p tcp -m tcp --dport 80 -j ACCEPT
+ $ sudo service iptables save
+
+#### Test Nginx ####
+
+The default document root directory of nginx is /usr/share/nginx/html. A default index.html file must be already placed in this directory. Let's check if you can access this test web page by going to http:///
+
+
+
+If you see the above page, nginx must be set up correctly. Proceed to the next.
+
+### Step Two: MariaDB/MySQL ###
+
+The next step is to install a database component of the LEMP stack. While CentOS/RHEL 6 or earlier provides MySQL server/client packages, CentOS/RHEL 7 has adopted MariaDB as the default implementation of MySQL. As a drop-in replacement of MySQL, MariaDB ensures maximum compatibility with MySQL in terms of APIs and command-line usages. Here is how to install and configure MariaDB/MySQL on CentOS.
+
+On CentOS 7:
+
+Install MariaDB server/client package and start MariaDB server as follows.
+
+ $ sudo yum install mariadb-server
+ $ sudo systemctl start mariadb
+ $ sudo systemctl enable mariadb
+
+On CentOS 6:
+
+Install MySQL server/client package, and start MySQL server as follows.
+
+ $ sudo yum install mysql-server
+ $ sudo service mysqld start
+ $ sudo chkconfig mysqld on
+
+After launching MariaDB/MySQL server successfully, execute the following add-on script that comes with MariaDB/MySQL server package. This one-time run conducts several security hardening steps for the database server, such as setting the (non-empty) root password, removing anonymous user, and locking down remote access.
+
+ $ sudo mysql_secure_installation
+
+
+
+That's it for the database setup. Now move to the next step.
+
+### Step Three: PHP ###
+
+PHP is an important component of the LEMP stack, which is responsible for generating dynamic content from data stored in a MariaDB/MySQL server. For the LEMP stack, you need, at a minimum, to install PHP-FPM and PHP-MySQL. PHP-FPM (FastCGI Process Manager) implements an interface between nginx and PHP applications which generate dynamic content. The PHP-MySQL module allows PHP programs to access MariaDB/MySQL.
+
+#### Install PHP Modules ####
+
+On CentOS 7:
+
+ $ sudo yum php php-fpm php-mysql
+
+On CentOS 6:
+
+First you need to install REMI repository (refer to [this guide][2]), and install the packages from the repository.
+
+ $ sudo yum --enablerepo=remi install php php-fpm php-mysql
+
+
+
+Two observations worth noting while installing PHP:
+
+On CentOS 6, MySQL server and client packages will automatically be upgraded as part of dependencies of the latest php-mysql in REMI.
+
+On both CentOS 6 and 7, installing the php package will also install Apache web server (i.e., httpd) as part of its dependencies. This can cause conflicts with nginx web server. We will take care of this problem in the next section.
+
+Depending on your use cases, you may want to install any of the following additional PHP module packages with yum command to customize your PHP engine.
+
+- **php-cli**: command-line interface for PHP. Useful for testing PHP from the command line.
+- **php-gd**: image processing support for PHP.
+- **php-bcmath**: arbitrary mathematics support for PHP.
+- **php-mcrypt**: encryption algorithm support for PHP (e.g., DES, Blowfish, CBC, CFB, ECB ciphers).
+- **php-xml**: XML parsing and manipulation support for PHP.
+- **php-dba**: database abstraction layer support for PHP.
+- **php-pecl-apc**: PHP accelerator/caching support.
+
+To see a complete list of available PHP modules to install, run:
+
+ $ sudo yum search php- (CentOS 7)
+ $ sudo yum --enablerepo=remi search php- (CentOS 6)
+
+#### Start PHP-FPM ####
+
+You will need to start PHP-FPM, and add it to auto-start list.
+
+On CentOS 7:
+
+ $ sudo systemctl start php-fpm
+ $ sudo systemctl enable php-fpm
+
+On CentOS 6:
+
+ $ sudo chkconfig php-fpm on
+ $ sudo service php-fpm start
+
+### Step Four: Configure the LEMP Stack ###
+
+The final step of the tutorial is tuning the LEMP stack configuration.
+
+#### Disable Httpd ####
+
+Let's first disable httpd which was installed along with the PHP package earlier.
+
+On CentOS 7:
+
+ $ sudo systemctl disable httpd
+
+On CentOS 6:
+
+ $ sudo chkconfig httpd off
+
+#### Configure Nginx ####
+
+Next, let's configure nginx virtual hosts, so that nginx can process PHP via PHP-FPM. For that, open /etc/nginx/conf.d/default.conf with a text editor, and change it to the following.
+
+ $ sudo vi /etc/nginx/conf.d/default.conf
+
+----------
+
+ server {
+ listen 80;
+ server_name www.server_domain.com;
+ root /usr/share/nginx/html;
+ index index.php index.html index.htm;
+
+ location / {
+ }
+
+ # redirect server error pages to the static page /50x.html
+ error_page 500 502 503 504 /50x.html;
+ location = /50x.html {
+ }
+
+ # nginx passes PHP scripts to FastCGI server via a TCP/9000 socket
+ # this setting much be consistent with /etc/php-fpm.d/www.conf
+ # try_files prevents nginx from passing bad scripts to FastCGI server
+ location ~ \.php$ {
+ try_files $uri =404;
+ fastcgi_pass 127.0.0.1:9000;
+ fastcgi_index index.php;
+ fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
+ include fastcgi_params;
+ }
+ }
+
+Also, let's adjust the number of nginx worker threads (specified in /etc/nginx/nginx.conf), which is set to one by default. Typically, we create as many worker threads as the number of CPU cores you have. To check how many CPU core you have, run this command:
+
+ $ grep processor /proc/cpuinfo | wc -l
+
+If you have 4 cores, change /etc/nginx/nginx.conf as follows.
+
+ $ sudo vi /etc/nginx/nginx.conf
+
+----------
+
+ worker_processes 4;
+
+#### Configure PHP ####
+
+Next, let's customize PHP configuration in /etc/php.ini file. More specifically, add the following lines in /etc/php.ini.
+
+ cgi.fix_pathinfo=0
+ date.timezone = "America/New York"
+
+As a security precaution, we want the PHP interpreter to process only an exact file path, instead of guessing any non-existing file. The first line above achieves this goal.
+
+The second line specifies the default timezone used by date/time related PHP functions. Use [this guide][3] to find out your timezone, and set the value of **date.timezone** accordingly.
+
+#### Test PHP ####
+
+Finally, let's check if nginx can process a PHP page. Before testing, make sure to restart nginx and PHP-FPM.
+
+On CentOS 7:
+
+ $ sudo systemctl restart nginx
+ $ sudo systemctl restart php-fpm
+
+On CentOS 6:
+
+ $ sudo service nginx restart
+ $ sudo service php-fpm restart
+
+Create a PHP file named test.php with the following content, and place it in /var/www/html/
+
+
+
+Open a web browser, and go to http:///test.php.
+
+
+
+If you see the above page, you are all set with the LEMP stack!
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/install-lemp-stack-centos.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
+[2]:http://ask.xmodulo.com/install-remi-repository-centos-rhel.html
+[3]:http://ask.xmodulo.com/set-default-timezone-php.html
\ No newline at end of file
diff --git a/sources/tech/20141029 Linux FAQs with Answers--How to open a port in the firewall on CentOS or RHEL.md b/sources/tech/20141029 Linux FAQs with Answers--How to open a port in the firewall on CentOS or RHEL.md
new file mode 100644
index 0000000000..c36dcac0e8
--- /dev/null
+++ b/sources/tech/20141029 Linux FAQs with Answers--How to open a port in the firewall on CentOS or RHEL.md
@@ -0,0 +1,69 @@
+[translating by KayGuoWhu]
+Linux FAQs with Answers--How to open a port in the firewall on CentOS or RHEL
+================================================================================
+> **Question**: I am running a web/file server on my CentOS box, and to access the server remotely, I need to modify a firewall to allow access to a TCP port on the box. What is a proper way to open a TCP/UDP port in the firewall of CentOS/RHEL?
+
+Out of the box, enterprise Linux distributions such as CentOS or RHEL come with a powerful firewall built-in, and their default firewall rules are pretty restrictive. Thus if you install any custom services (e.g., web server, NFS, Samba), chances are their traffic will be blocked by the firewall rules. You need to open up necessary ports on the firewall to allow their traffic.
+
+On CentOS/RHEL 6 or earlier, the iptables service allows users to interact with netfilter kernel modules to configure firewall rules in the user space. Starting with CentOS/RHEL 7, however, a new userland interface called firewalld has been introduced to replace iptables service.
+
+To check the current firewall rules, use this command:
+
+ $ sudo iptables -L
+
+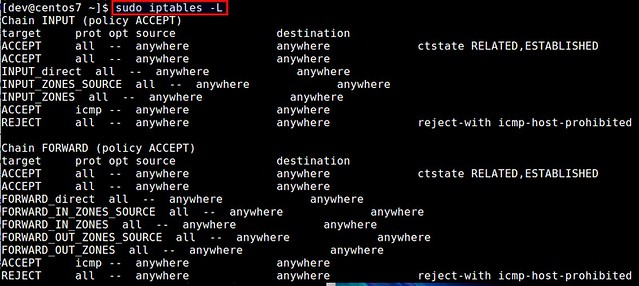
+
+Now let's see how we can update the firewall to open a port on CentOS/RHEL.
+
+### Open a Port on CentOS/RHEL 7 ###
+
+Starting with CentOS and RHEL 7, firewall rule settings are managed by firewalld service daemon. A command-line client called firewall-cmd can talk to this deamon to update firewall rules permanently.
+
+To open up a new port (e.g., TCP/80) permanently, use these commands.
+
+ $ sudo firewall-cmd --zone=public --add-port=80/tcp --permanent
+ $ sudo firewall-cmd --reload
+
+Without "--permanent" flag, the firewall rule would not persist across reboots.
+
+### Open a Port on CentOS/RHEL 6 ###
+
+On CentOS/RHEL 6 or earlier, a iptables service is responsible for maintaining firewall rules.
+
+Use iptables command to open up a new TCP/UDP port in the firewall. To save the updated rule permanently, you need the second command.
+
+ $ sudo iptables -I INPUT -p tcp -m tcp --dport 80 -j ACCEPT
+ $ sudo service iptables save
+
+Another way to open up a port on CentOS/RHEL 6 is to use a terminal-user interface (TUI) firewall client, named system-config-firewall-tui.
+
+ $ sudo system-config-firewall-tui
+
+Choose "Customize" button in the middle and press ENTER.
+
+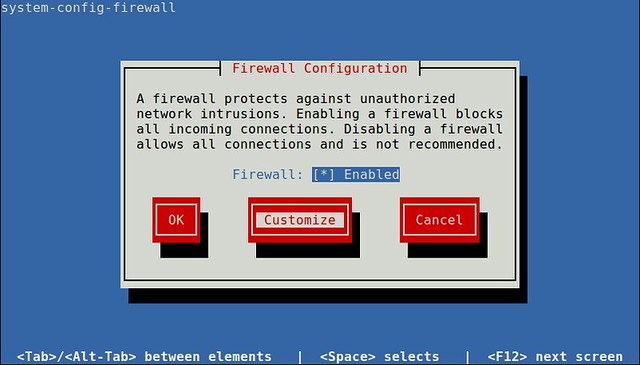
+
+If you are trying to update the firewall for any well-known service (e.g., web server), you can easily enable the firewall for the service here, and close the tool. If you are trying to open up any arbitrary TCP/UDP port, choose "Forward" button and go to a next window.
+
+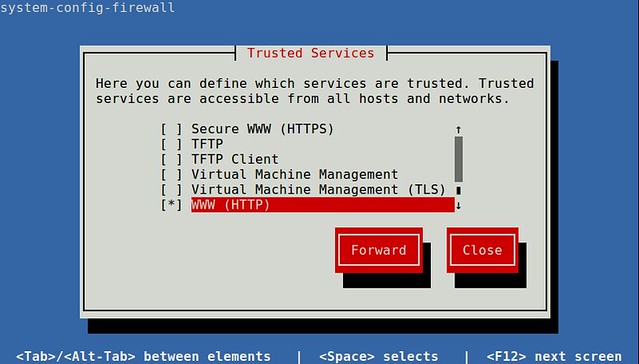
+
+Add a new rule by choosing "Add" button.
+
+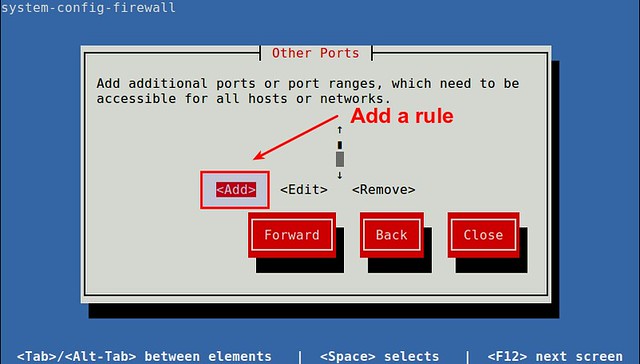
+
+Specify a port (e.g., 80) or port range (e.g., 3000-3030), and protocol (e.g., tcp or udp).
+
+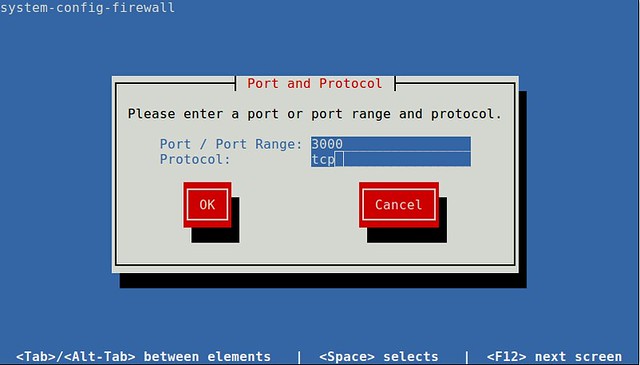
+
+Finally, save the updated configuration, and close the tool. At this point, the firewall will be saved permanently.
+
+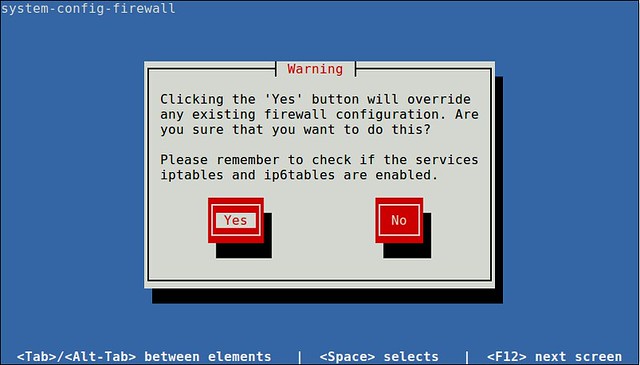
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
+
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
\ No newline at end of file
diff --git a/sources/tech/20141029 Shell Scripting--Checking Conditions with if.md b/sources/tech/20141029 Shell Scripting--Checking Conditions with if.md
new file mode 100644
index 0000000000..bcd368b908
--- /dev/null
+++ b/sources/tech/20141029 Shell Scripting--Checking Conditions with if.md
@@ -0,0 +1,147 @@
+>>> Translating by ThomazL
+Shell Scripting – Checking Conditions with if
+================================================================================
+In Bourne Shell if statement checks whether a condition is true or not. If so , the shell executes the block of code associated with the if statement. If the statement is not true , the shell jumps beyond the end of the if statement block & Continues on.
+
+### Syntax of if Statement : ###
+
+ if [ condition_command ]
+ then
+ command1
+ command2
+ ……..
+ last_command
+ fi
+
+#### Example: ####
+
+ #!/bin/bash
+ number=150
+ if [ $number -eq 150 ]
+ then
+ echo "Number is 150"
+ fi
+
+#### if-else Statement : ####
+
+In addition to the normal if statement , we can extend the if statement with an else block. The basic idea is that if the statement is true , then execute the if block. If the statement is false , then execute the else block.
+
+#### Syntax : ####
+
+ if [ condition_command ]
+ then
+ command1
+ command2
+ ……..
+ last_command
+ else
+ command1
+ command2
+ ……..
+ last_command
+ fi
+
+#### Example: ####
+
+ #!/bin/bash
+ number=150
+ if [ $number -gt 250 ]
+ then
+ echo "Number is greater"
+ else
+ echo "Number is smaller"
+ fi
+
+### If..elif..else..fi Statement (Short for else if) ###
+
+The Bourne shell syntax for the if statement allows an else block that gets executed if the test is not true. We can nest if statement , allowing for multiple conditions. As an alternative, we can use the elif construct , shot for else if.
+
+#### Syntax : ####
+
+ if [ condition_command ]
+ then
+ command1
+ command2
+ ……..
+ last_command
+ elif [ condition_command2 ]
+ then
+ command1
+ command2
+ ……..
+ last_command
+ else
+ command1
+ command2
+ ……..
+ last_command
+ fi
+
+#### Example : ####
+
+ #!/bin/bash
+ number=150
+ if [ $number -gt 300 ]
+ then
+ echo "Number is greater"
+ elif [ $number -lt 300 ]
+ then
+ echo "Number is Smaller"
+ else
+ echo "Number is equal to actual value"
+ fi
+
+### Nested if statements : ###
+
+If statement and else statement can be nested in a bash script. The keyword ‘fi’ shows the end of the inner if statement and all if statement should end with the keyword ‘fi’.
+
+Basic **syntax of nested** if is shown below :
+
+ if [ condition_command ]
+ then
+ command1
+ command2
+ ……..
+ last_command
+ else
+ if [ condition_command2 ]
+ then
+ command1
+ command2
+ ……..
+ last_command
+ else
+ command1
+ command2
+ ……..
+ last_command
+ fi
+ fi
+
+#### Example: ####
+
+ #!/bin/bash
+ number=150
+ if [ $number -eq 150 ]
+ then
+ echo "Number is 150"
+ else
+ if [ $number -gt 150 ]
+ then
+ echo "Number is greater"
+ else
+ echo "'Number is smaller"
+ fi
+ fi
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxtechi.com/shell-scripting-checking-conditions-with-if/
+
+作者:[Pradeep Kumar][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxtechi.com/author/pradeep/
diff --git a/sources/tech/20141030 8 Tips to Solve Linux and Unix Systems Hard Disk Problmes Like Disk Full Or Can't Write to the Disk.md b/sources/tech/20141030 8 Tips to Solve Linux and Unix Systems Hard Disk Problmes Like Disk Full Or Can't Write to the Disk.md
new file mode 100644
index 0000000000..1fbed0ced1
--- /dev/null
+++ b/sources/tech/20141030 8 Tips to Solve Linux and Unix Systems Hard Disk Problmes Like Disk Full Or Can't Write to the Disk.md
@@ -0,0 +1,288 @@
+8 Tips to Solve Linux & Unix Systems Hard Disk Problmes Like Disk Full Or Can’t Write to the Disk
+================================================================================
+Can't write to the hard disk on a Linux or Unix-like systems? Want to diagnose corrupt disk issues on a server? Want to find out why you are getting "disk full" messages on screen? Want to learn how to solve full/corrupt and failed disk issues. Try these eight tips to diagnose a Linux and Unix server hard disk drive problems.
+
+
+
+### #1 - Error: No space left on device ###
+
+When the Disk is full on Unix-like system you get an error message on screen. In this example, I'm running [fallocate command][1] and my system run out of disk space:
+
+ $ fallocate -l 1G test4.img
+ fallocate: test4.img: fallocate failed: No space left on device
+
+The first step is to run the df command to find out information about total space and available space on a file system including partitions:
+
+ $ df
+
+OR try human readable output format:
+
+ $ df -h
+
+Sample outputs:
+
+ Filesystem Size Used Avail Use% Mounted on
+ /dev/sda6 117G 54G 57G 49% /
+ udev 993M 4.0K 993M 1% /dev
+ tmpfs 201M 264K 200M 1% /run
+ none 5.0M 0 5.0M 0% /run/lock
+ none 1002M 0 1002M 0% /run/shm
+ /dev/sda1 1.8G 115M 1.6G 7% /boot
+ /dev/sda7 4.7G 145M 4.4G 4% /tmp
+ /dev/sda9 9.4G 628M 8.3G 7% /var
+ /dev/sda8 94G 579M 89G 1% /ftpusers
+ /dev/sda10 4.0G 4.0G 0 100% /ftpusers/tmp
+
+From the df command output it is clear that /dev/sda10 has 4.0Gb of total space of which 4.0Gb is used.
+
+#### Fixing problem when the disk is full ####
+
+1.[Compress uncompressed log and other files][2] using gzip or bzip2 or tar command:
+
+ gzip /ftpusers/tmp/*.log
+ bzip2 /ftpusers/tmp/large.file.name
+
+2.Delete [unwanted files using rm command][3] on a Unix-like system:
+
+ m -rf /ftpusers/tmp/*.bmp
+
+3.Move files to other [system or external hard disk using rsync command][4]:
+
+ rsync --remove-source-files -azv /ftpusers/tmp/*.mov /mnt/usbdisk/
+ rsync --remove-source-files -azv /ftpusers/tmp/*.mov server2:/path/to/dest/dir/
+
+4.[Find out the largest directories or files eating disk space][5] on a Unix-like systesm:
+
+ du -a /ftpusers/tmp | sort -n -r | head -n 10
+ du -cks * | sort -rn | head
+
+5.[Truncate a particular file][6]. This is useful for log file:
+
+ truncate -s 0 /ftpusers/ftp.upload.log
+ ### bash/sh etc ##
+ >/ftpusers/ftp.upload.log
+ ## perl ##
+ perl -e'truncate "filename", LENGTH'
+
+6.Find and remove large files that are open but have been deleted on Linux or Unix:
+
+ ## Works on Linux/Unix/OSX/BSD etc ##
+ lsof -nP | grep '(deleted)'
+
+ ## Only works on Linux ##
+ find /proc/*/fd -ls | grep '(deleted)'
+
+To truncate it:
+
+ ## works on Linux/Unix/BSD/OSX etc all ##
+ > "/path/to/the/deleted/file.name"
+ ## works on Linux only ##
+ > "/proc/PID-HERE/fd/FD-HERE"
+
+### #2 - Is the file system is in read-only mode? ###
+
+You may end up getting an error such as follows when you try to create a file or save a file:
+
+ $ cat > file
+ -bash: file: Read-only file system
+
+Run mount command to find out if the file system is mounted in read-only mode:
+
+ $ mount
+ $ mount | grep '/ftpusers'
+
+To fix this problem, simply remount the file system in read-write mode on a Linux based system:
+
+ # mount -o remount,rw /ftpusers/tmp
+
+Another example, from my [FreeBSD 9.x server to remount / in rw mode][7]:
+
+ # mount -o rw /dev/ad0s1a /
+
+### #3 - Am I running out of inodes? ###
+
+Sometimes, df command reports that there is enough free space but system claims file-system is full. You need to check [for the inode][8] which identifies the file and its attributes on a file systems using the following command:
+
+ $ df -i
+ $ df -i /ftpusers/
+
+Sample outputs:
+
+ Filesystem Inodes IUsed IFree IUse% Mounted on
+ /dev/sda8 6250496 11568 6238928 1% /ftpusers
+
+So /ftpusers has 62,50,496 total inodes but only 11,568 are used. You are free to create another 62,38,928 files on /ftpusers partition. If 100% of your inodes are used, try the following options:
+
+- Find unwanted files and delete or move to another server.
+- Find unwanted large files and delete or move to another server.
+
+### #4 - Is my hard drive is dying? ###
+
+[I/O errors in log file (such as /var/log/messages) indicates][9] that something is wrong with the hard disk and it may be failing. You can check hard disk for errors using smartctl command, which is control and monitor utility for SMART disks under Linux and UNIX like operating systems. The syntax is:
+
+ smartctl -a /dev/DEVICE
+ # check for /dev/sda on a Linux server
+ smartctl -a /dev/sda
+
+You can also use "Disk Utility" to get the same information
+
+[][10]
+
+Fig. 01: Gnome disk utility (Applications > System Tools > Disk Utility)
+
+> **Note**: Don't expect too much from SMART tool. It may not work in some cases. Make backup on a regular basis.
+
+### #5 - Is my hard drive and server is too hot? ###
+
+High temperatures can cause server to function poorly. So you need to maintain the proper temperature of the server and disk. High temperatures can result into server shutdown or damage to file system and disk. [Use hddtemp or smartctl utility to find out the temperature of your hard on a Linux or Unix based system][11] by reading data from S.M.A.R.T. on drives that support this feature. Only modern hard drives have a temperature sensor. hddtemp supports reading S.M.A.R.T. information from SCSI drives too. hddtemp can work as simple command line tool or as a daemon to get information from all servers:
+
+ hddtemp /dev/DISK
+ hddtemp /dev/sg0
+
+Sample outputs:
+
+[][12]
+
+Fig.02: hddtemp in action
+
+You can use the smartctl command as follows too:
+
+ smartctl -d ata -A /dev/sda | grep -i temperature
+
+#### How do I get the CPU temperature? ####
+
+You can use Linux hardware monitoring tool such as [lm_sensor to get the cpu temperature on a Linux based][13] system:
+
+ sensors
+
+Sample outputs from Debian Linux server:
+
+[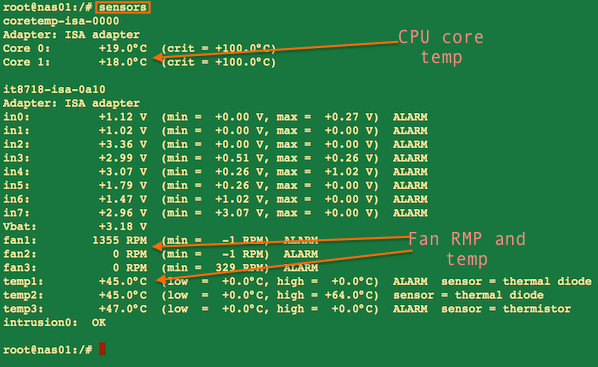][14]
+
+Fig.03: sensors command providing cpu core temperature and other info on a Linux
+
+### #6 - Dealing with corrupted file systems ###
+
+File system on server may be get corrupted due to a hard reboot or some other error such as bad blocks. You can [repair corrupted file systems with the following fsck command][15]:
+
+ umount /ftpusers
+ fsck -y /dev/sda8
+
+See [how to surviving a Linux filesystem failures][16] for more info.
+
+### #7 - Dealing with software RAID on a Linux ###
+
+To find the current status of a Linux software raid type the following command:
+
+ ## get detail on /dev/md0 raid ##
+ mdadm --detail /dev/md0
+
+ ## Find status ##
+ cat /proc/mdstat
+ watch cat /proc/mdstat
+
+Sample outputs:
+
+[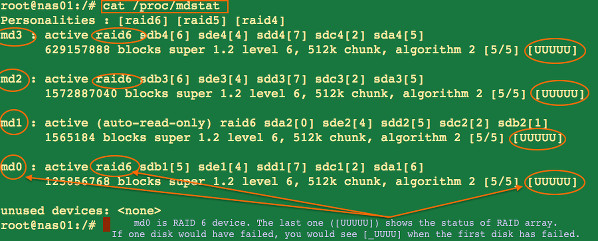][17]
+
+Fig. 04: Find the status of a Linux software raid command
+
+You need to replace a failed hard drive. You must u remove the correct failed drive. In this example, I'm going to replace /dev/sdb (2nd hard drive of RAID 6). It is not necessary to take the storage offline to repair the RAID on Linux. This only works if your server support hot-swappable hard disk:
+
+ ## remove disk from an array md0 ##
+ mdadm --manage /dev/md0 --fail /dev/sdb1
+ mdadm --manage /dev/md0 --remove /dev/sdb1
+
+ # Do the same steps again for rest of /dev/sdbX ##
+ # Power down if not hot-swappable hard disk: ##
+ shutdown -h now
+
+ ## copy partition table from /dev/sda to newly replaced /dev/sdb ##
+ sfdisk -d /dev/sda | sfdisk /dev/sdb
+ fdisk -l
+
+ ## Add it ##
+ mdadm --manage /dev/md0 --add /dev/sdb1
+ # do the same steps again for rest of /dev/sdbX ##
+
+ # Now md0 will sync again. See it on screen ##
+ watch cat /proc/mdstat
+
+See our [tips on increasing RAID sync speed on Linux][18] for more information.
+
+### #8 - Dealing with hardware RAID ###
+
+You can use the samrtctl command or vendor specific command to find out the status of RAID and disks in your controller:
+
+ ## SCSI disk
+ smartctl -d scsi --all /dev/sgX
+
+ ## Adaptec RAID array
+ /usr/StorMan/arcconf getconfig 1
+
+ ## 3ware RAID Array
+ tw_cli /c0 show
+
+See your vendor specific documentation to replace a failed disk.
+
+### Monitoring disk health ###
+
+See our previous tutorials:
+
+1. [Monitoring hard disk health with smartd under Linux or UNIX operating systems][19]
+1. [Shell script to watch the disk space][20]
+1. [UNIX get an alert when disk is full][21]
+1. [Monitor UNIX / Linux server disk space with a shell scrip][22]
+1. [Perl script to monitor disk space and send an email][23]
+1. [NAS backup server disk monitoring shell script][24]
+
+### Conclusion ###
+
+I hope these tips will help you troubleshoot system disk issue on a Linux/Unix based server. I also recommend implementing a good backup plan in order to have the ability to recover from disk failure, accidental file deletion, file corruption, or complete server destruction:
+
+- [Debian / Ubuntu: Install Duplicity for encrypted backup in cloud][25]
+- [HowTo: Backup MySQL databases, web server files to a FTP server automatically][26]
+- [How To Set Red hat & CentOS Linux remote backup / snapshot server][27]
+- [Debian / Ubuntu Linux install and configure remote filesystem snapshot with rsnapshot incremental backup utility][28]
+- [Linux Tape backup with mt And tar command tutorial][29]
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/datacenter/linux-unix-bsd-osx-cannot-write-to-hard-disk/
+
+作者:[nixCraft][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.cyberciti.biz/tips/about-us
+[1]:http://www.cyberciti.biz/faq/howto-create-lage-files-with-dd-command/
+[2]:http://www.cyberciti.biz/howto/question/general/compress-file-unix-linux-cheat-sheet.php
+[3]:http://www.cyberciti.biz/faq/howto-linux-unix-delete-remove-file/
+[4]:http://www.cyberciti.biz/faq/linux-unix-bsd-appleosx-rsync-delete-file-after-transfer/
+[5]:http://www.cyberciti.biz/faq/how-do-i-find-the-largest-filesdirectories-on-a-linuxunixbsd-filesystem/
+[6]:http://www.cyberciti.biz/faq/truncate-large-text-file-in-unix-linux/
+[7]:http://www.cyberciti.biz/faq/howto-freebsd-remount-partition/
+[8]:http://www.cyberciti.biz/tips/understanding-unixlinux-filesystem-inodes.html
+[9]:http://www.cyberciti.biz/tips/linux-find-out-if-harddisk-failing.html
+[10]:http://www.cyberciti.biz/tips/linux-find-out-if-harddisk-failing.html
+[11]:http://www.cyberciti.biz/tips/howto-monitor-hard-drive-temperature.html
+[12]:http://www.cyberciti.biz/datacenter/linux-unix-bsd-osx-cannot-write-to-hard-disk/attachment/hddtemp-on-rhel/
+[13]:http://www.cyberciti.biz/faq/howto-linux-get-sensors-information/
+[14]:http://www.cyberciti.biz/datacenter/linux-unix-bsd-osx-cannot-write-to-hard-disk/attachment/sensors-command-on-debian-server/
+[15]:http://www.cyberciti.biz/tips/repairing-linux-ext2-or-ext3-file-system.html
+[16]:http://www.cyberciti.biz/tips/surviving-a-linux-filesystem-failures.html
+[17]:http://www.cyberciti.biz/datacenter/linux-unix-bsd-osx-cannot-write-to-hard-disk/attachment/linux-mdstat-output/
+[18]:http://www.cyberciti.biz/tips/linux-raid-increase-resync-rebuild-speed.html
+[19]:http://www.cyberciti.biz/tips/monitoring-hard-disk-health-with-smartd-under-linux-or-unix-operating-systems.html
+[20]:http://www.cyberciti.biz/tips/shell-script-to-watch-the-disk-space.html
+[21]:http://www.cyberciti.biz/faq/mac-osx-unix-get-an-alert-when-my-disk-is-full/
+[22]:http://bash.cyberciti.biz/monitoring/shell-script-monitor-unix-linux-diskspace/
+[23]:http://www.cyberciti.biz/tips/howto-write-perl-script-to-monitor-disk-space.html
+[24]:http://bash.cyberciti.biz/backup/monitor-nas-server-unix-linux-shell-script/
+[25]:http://www.cyberciti.biz/faq/duplicity-installation-configuration-on-debian-ubuntu-linux/
+[26]:http://www.cyberciti.biz/tips/how-to-backup-mysql-databases-web-server-files-to-a-ftp-server-automatically.html
+[27]:http://www.cyberciti.biz/faq/redhat-cetos-linux-remote-backup-snapshot-server/
+[28]:http://www.cyberciti.biz/faq/linux-rsnapshot-backup-howto/
+[29]:http://www.cyberciti.biz/faq/linux-tape-backup-with-mt-and-tar-command-howto/
\ No newline at end of file
diff --git a/sources/tech/20141030 How to run SQL queries against Apache log files on Linux.md b/sources/tech/20141030 How to run SQL queries against Apache log files on Linux.md
new file mode 100644
index 0000000000..9ae1a5a76b
--- /dev/null
+++ b/sources/tech/20141030 How to run SQL queries against Apache log files on Linux.md
@@ -0,0 +1,138 @@
+How to run SQL queries against Apache log files on Linux
+================================================================================
+One of the distinguishing features of Linux is that, under normal circumstances, you should be able to know what is happening and has happened on your system by analyzing one or more system logs. Indeed, system logs are the first resource a system administrator tends to look to while troubleshooting system or application issues. In this article, we will focus on the Apache access log files generated by Apache HTTP web server. We will explore an alternative way of analyzing Apache access logs using [asql][1], an open-source tool that allows one to run SQL queries against the logs in order to view the same information in a more friendly format.
+
+### Background on Apache Logs ###
+
+There are two kinds of Apache logs:
+
+- **Access log**: Found at /var/log/apache2/access.log (for Debian) or /var/log/httpd/access_log (for Red Hat). Contains records of every request served by an Apache web server.
+- **Error log**: Found at /var/log/apache2/error.log (for Debian) or /var/log/httpd/error_log (for Red Hat). Contains records of all error conditions reported by an Apache web server. Error conditions include, but are not limited to, 403 (Forbidden, usually returned after a valid request missing access credentials or insufficient read permissions), and 404 (Not found, returned when the requested resource does not exist).
+
+Although the verbosity of Apache access log file can be customized through Apache's configuration files, we will assume the default format in this article, which is as follows:
+
+ Remote IP - Request date - Request type - Response code - Requested resource - Remote browser (may also include operating system)
+
+So a typical Apache log entry looks like:
+
+ 192.168.0.101 - - [22/Aug/2014:12:03:36 -0300] "GET /icons/unknown.gif HTTP/1.1" 200 519 "http://192.168.0.10/test/projects/read_json/" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:30.0) Gecko/20100101 Firefox/30.0"
+
+But what about Apache error log? Since error log entries dealing with particular requests have corresponding entries in the access log (which you can customize), you can use the access log file to obtain more information about error conditions (refer to example 5 for more details).
+
+That being said, please note that access log is a system-wide log file. To find the log files of virtual hosts, you may also need to check their corresponding configuration files (e.g., within /etc/apache2/sites-available/[virtual host name] on Debian).
+
+### Installing asql on Linux ###
+
+asql is written in Perl, and requires two Perl modules: a DBI driver for SQLite and GNU readline.
+
+#### Install asql on Debian, Ubuntu or their derivatives ####
+
+asql and its dependencies will automatically be installed with aptitude on Debian-based distributions.
+
+ # aptitude install asql
+
+#### Install asql on Fedora, CentOS or RHEL ####
+
+On CentOS or RHEL, you will need to enable [EPEL repository][2] first, and then run the commands below. On Fedora, proceed to the following commands directly.
+
+ # sudo yum install perl-DBD-SQLite perl-Term-ReadLine-Gnu
+ # wget http://www.steve.org.uk/Software/asql/asql-1.7.tar.gz
+ # tar xvfvz asql-1.7.tar.gz
+ # cd asql
+ # make install
+
+### How Does asql Work? ###
+
+As you can guess from the dependencies listed above, asql converts unstructured plain-text Apache log files into a structured SQLite database, which can be queried using standard SQL commands. This database can be populated with the contents of current and past log files - including compressed rotated logs such as access.log.X.gz. or access_log.old.
+
+First, launch asql from the command line with the following command
+
+ # asql
+
+You will be entering asql's built-in shell interface.
+
+
+
+Let's type help to list the available commands in the asql shell:
+
+
+
+We will begin by loading all the access logs in asql, which can be done with:
+
+ asql> load
+
+In case of Debian, the following command will do:
+
+ asql> load /var/log/apache2/access.*
+
+In case of CentOS/RHEL, use this command instead:
+
+ asql> load /var/log/httpd/access_log*
+
+When asql finishes loading access logs, we can start querying the database. Note that the database created after loading is "temporary," meaning that if you exit the asql shell, the database will be lost. If you want to preserve the database, you have to save it to a file first. We will see how to do that later (refer to examples 3 and 4).
+
+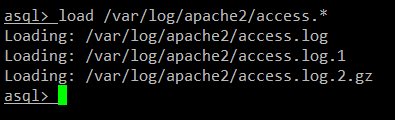
+
+The database contains a table named logs. The available fields in the logs table can be displayed using the show command:
+
+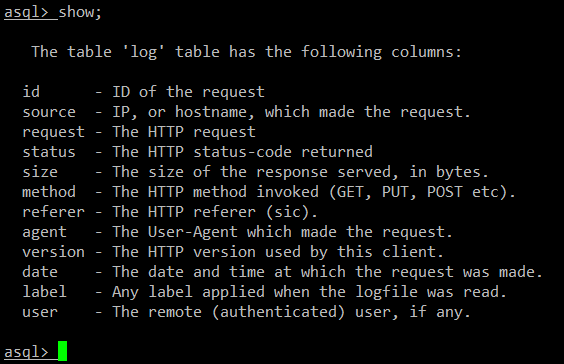
+
+The .asql hidden file, which is stored in each user's home directory, records the history of the commands that were typed by the user in an asql shell. Thus, you can browse through it using the arrow keys, and repeat previous commands by just pressing ENTER when you find the right one.
+
+### SQL Query Examples with asql ###
+
+Here a few examples of running SQL queries against Apache log files with asql.
+
+**Example 1**: Listing the request sources / dates and HTTP status codes returned during the month of October 2014.
+
+ SELECT source, date, status FROM logs WHERE date >= '2014-10-01T00:00:00' ORDER BY source;
+
+
+
+**Example 2**: Displaying the total size (in bytes) of requests served per client in descending order.
+
+ SELECT source,SUM(size) AS Number FROM logs GROUP BY source ORDER BY Number DESC;
+
+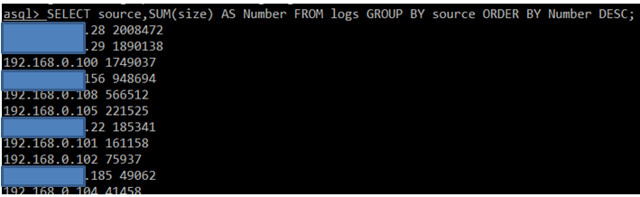
+
+**Example 3**: Saving the database to [filename] in the current working directory.
+
+ save [filename]
+
+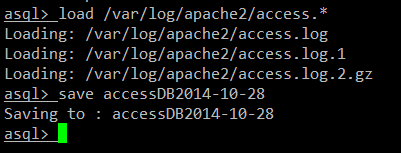
+
+This allows us to avoid the need for waiting while the log parsing is performed with the load command as shown earlier.
+
+**Example 4**: Restoring the database in a new asql session after exiting the current one.
+
+ restore [filename]
+
+
+
+**Example 5**: Returning error conditions logged in the access file. In this example, we will display all the requests that returned a 403 (access forbidden) HTTP code.
+
+ SELECT source,date,status,request FROM logs WHERE status='403' ORDER BY date
+
+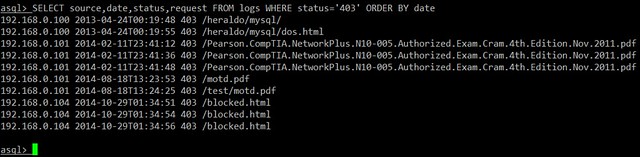
+
+This goes to show that although asql only analyzes access logs, we can use the status field of a request to display requests with error conditions.
+
+### Summary ###
+
+We have seen how asql can help us analyze Apache logs and present the results in a user friendly output format. Although you could obtain similar results by using command line utilities such as cat in conjunction with grep, uniq, sort, and wc (to name a few), in comparison asql represents a Swiss army knife due to the fact that it allows us to use standard SQL syntax to filter the logs according to our needs.
+
+Feel free to leave your questions or comments below. Hope it helps.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/sql-queries-apache-log-files-linux.html
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/gabriel
+[1]:http://www.steve.org.uk/Software/asql/
+[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
\ No newline at end of file
diff --git a/sources/tech/20141030 Test drive Linux with nothing but a flash drive.md b/sources/tech/20141030 Test drive Linux with nothing but a flash drive.md
new file mode 100644
index 0000000000..84d5b7a9d4
--- /dev/null
+++ b/sources/tech/20141030 Test drive Linux with nothing but a flash drive.md
@@ -0,0 +1,75 @@
+Test drive Linux with nothing but a flash drive
+================================================================================
+
+Image by : Opensource.com
+
+Maybe you’ve heard about Linux and are intrigued by it. So intrigued that you want to give it a try. But you might not know where to begin.
+
+You’ve probably done a bit of research online and have run across terms like dual booting and virtualization. Those terms might mean nothing to you, and you’re definitely not ready to sacrifice the operating system that you’re currently using to give Linux a try. So what can you do?
+
+If you have a USB flash drive lying around, you can test drive Linux by creating a live USB. It’s a USB flash drive that contains an operating system that can start from the flash drive. It doesn’t take much technical ability to create one. Let’s take a look at how to do that and how to run Linux using a live USB.
+
+### What you’ll need ###
+
+Aside from a desktop or laptop computer, you’ll need:
+
+- A blank USB flash drive—preferably one that has a capacity of 4 GB or more.
+- An [ISO image][1] (an archive of the contents of a hard disk) of the Linux distribution that you want to try. More about this in a moment.
+- An application called [Unetbootin][2], an open source tool, cross platform tool that creates a live USB. You don’t need to be running Linux to use it. In the instructions that below, I’m running Unetbootin on a MacBook.
+
+### Getting to work ###
+
+Plug your flash drive into a USB port on your computer and then fire up Unetbootin. You’ll be asked for the password that you use to log into your computer.
+
+
+
+Remember the ISO image that was mentioned a few moments ago? There are two ways you can get one: either by downloading it from the website of the Linux distribution that you want to try, or by having Unetbootin download it for you. To do that latter, click **Select Distribution** at the top of the window, choose the distribution that you want to download, and then click **Select Version** to select the version of the distribution that you want to try.
+
+
+
+Or, you can download the distribution yourself. Usually, the Linux distributions that I want to try aren’t in the list. If you go the second route, click **Disk image** and then click the button to search for the .iso file that you downloaded.
+
+Notice the **Space used to preserve files across reboots (Ubuntu only)** option? If you’re testing Ubuntu or one of its derivatives (like Lubuntu or Xubuntu), you can set aside a few megabytes of space on your flash drive to save files like web browser bookmarks or documents that you create. When you load Ubuntu from the flash drive again, you can reuse those files.
+
+
+
+Once the ISO image is loaded, click **OK**. It takes anywhere from a couple of minutes to 10 minutes for Unetbootin to create the live USB.
+
+
+
+### Testing out the live USB ###
+
+This is the point where you have to embrace your inner geek a bit. Not too much, but you will be taking a peek into the innards of your computer by going into the [BIOS][3]. Your computer’s BIOS starts various bits of hardware and controls where the computer’s operating system starts, or boots, from.
+
+The BIOS usually looks for the operating system in this order (or something like it): hard drive, then CD-ROM or DVD drive, and then an external drive. You’ll want to change that order so that the external drive (in this case, your live USB) is the one that the BIOS checks first.
+
+To do that, restart your computer with the flash drive plugged into a USB port. When you see the message **Press F2 to enter setup**, do just that. On some computers, the key might be F10.
+
+In the BIOS, use the right arrow key on your keyboard to navigate to the **Boot** menu. You’ll see a list of drives on your computer. Use the down arrow key on your keyboard to navigate to the item labeled **USB HDD** and then press **F6** to move that item to the top of the list.
+
+Once you’ve done that, press **F10** to save the changes. You’ll be kicked out of the BIOS and your computer will start up. After a short amount of time, you’ll be presented with a menu listing the options for starting the Linux distribution you’re trying out. Select **Run without installing** (or the menu item closest to it).
+
+Once the desktop loads, you can connect to a wireless or wired network, browse the web, and give the pre-installed software a whirl. You can also check to see if, for example, your printer or scanner works with the Linux distribution you’re testing. If you really, really want to you can also fiddle at the command line.
+
+### What to expect ###
+
+Depending on the Linux distribution you’re testing and the speed of the flash drive you’re using, the operating system might take longer to load and it might run a bit slower than it would if it was installed on your hard drive.
+
+As well, you’ll only have the basic software that the Linux distribution packs out of the box. You generally get a web browser, a word processor, a text editor, a media player, an image viewer, and a set of utilities. That should be enough to give you a feel for what it’s like to use Linux.
+
+If you decide that you like using Linux, you can install it from the flash drive by double clicking on the installer.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive
+
+作者:[Scott Nesbitt][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/scottnesbitt
+[1]:http://en.wikipedia.org/wiki/ISO_image
+[2]:http://unetbootin.sourceforge.net/
+[3]:http://en.wikipedia.org/wiki/BIOS
\ No newline at end of file
diff --git a/sources/tech/20141030 rsync Command to Exclude a List of Files and Directories in Linux.md b/sources/tech/20141030 rsync Command to Exclude a List of Files and Directories in Linux.md
new file mode 100644
index 0000000000..23bec502f8
--- /dev/null
+++ b/sources/tech/20141030 rsync Command to Exclude a List of Files and Directories in Linux.md
@@ -0,0 +1,42 @@
+rsync Command to Exclude a List of Files and Directories in Linux
+================================================================================
+**rsync** is a very useful and popular linux tool being used for backup and restoring files, but also for comparing and syncing them. We already shown you in the past [how to use rsync command in linux with examples][1] and today we will add a few more useful tricks you can use rsync at.
+
+### Exclude a list of files and directories ###
+
+Sometimes when we do large syncs we may wish to exclude a list of files and directories from syncing, in general files that can't by synced like device files and some system files, or files that would take up unnecessary disk space like temporary or cache files.
+
+First let's make a file called "excluded" (you can name it whatever you wish) and write each folder or file we would like to exclude on a separate line like this. For our example if you wish to do a full backup of your root partition you should exclude devices directories that get created at boot time and directories that hold temporary files, your list may look like this:
+
+
+
+Then you can run the following command to backup your system:
+
+ $ sudo rsync -aAXhv --exclude-from=excluded / /mnt/backup
+
+
+
+### Exclude files from the command line ###
+
+You can also exclude files directly from the command line, this is useful when you have a smaller number of files to exclude and you wish to include this in a script or crontab and don't want your script or cron to depend on another file to run successful.
+
+For example if you wish to sync /var to a backup directory but you don't wish to include cache and tmp folder that usualy don't hold important content between restarts you can use the following command:
+
+ $ sudo rsync -aAXhv --exclude={"/var/cache","/var/tmp"} /var /home/adrian/var
+
+
+
+This command will be easy to use in any script or cron and will not depend on another file.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-command/exclude-files-rsync-examples/
+
+作者:[Adrian Dinu][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/adriand/
+[1]:http://linoxide.com/how-tos/rsync-copy/
\ No newline at end of file
diff --git a/translated/share/20141027 Handy Disk Image Tools.md b/translated/share/20141027 Handy Disk Image Tools.md
new file mode 100644
index 0000000000..4f96bccede
--- /dev/null
+++ b/translated/share/20141027 Handy Disk Image Tools.md
@@ -0,0 +1,168 @@
+不得不说的磁盘镜像工具
+================================================================================
+磁盘镜像包括整个磁盘卷的文件或者是全部的存储设备的数据,比如说硬盘,光盘(DVD,CD,蓝光光碟),磁带机,USB闪存,软盘。一个完整的磁盘镜像应该像在原来的存储设备上一样完整、准确,包括数据和结构信息。
+
+磁盘镜像文件格式可以是开放的标准,像ISO格式的光盘镜像,或者是专有的特别的软件应用程序。"ISO"这个名字来源于用CD存储的ISO 9660文件系统。但是,当用户转向Linux的时候,经常遇到这样的问题,需要把专有的的镜像格式转换为开放的格式。
+
+磁盘镜像有很多不同的用处,像烧录光盘,系统备份,数据恢复,硬盘克隆,电子取证和提供操作系统(即LiveCD/DVDs)。
+
+有很多不同非方法可以把ISO镜像挂载到Linux系统下。强大的mount 命令给我们提供了一个简单的解决方案。但是如果你需要很多工具来操作磁盘镜像,你可以试一试下面的这些完美的开源工具。
+
+很多工具还没有看到最新的版本,所以如果你正在寻找一个很好用的开源工具,你也可以加入,一起来为开源做出一点贡献。
+
+----------
+
+
+
+
+
+Furius ISO Mount是一个简单易用的开源应用程序用来挂载镜像文件,它支持直接打开ISO,IMG,BIN,MDF和NRG格式的镜像而不用把他们烧录到磁盘。
+
+特性:
+
+- 支持自动挂载ISO, IMG, BIN, MDF and NRG镜像文件
+- 支持通过loop 挂载 UDF 镜像
+- 自动在根目录创建挂载点
+- 自动解挂镜像文件
+- 自动删除挂载目录,并返回到主目录之前的状态
+- 自动存档最近10次挂载历史
+- 支持挂载多个镜像文件
+- 支持烧录ISO文件及IMG文件到光盘
+- 支持MD5校验和SHA1校验
+- 自动检索之前解挂的镜像
+- 自动创建手动挂载和解挂的日志文件
+- 语言支持(目前支持保加利亚语,中文(简体),捷克语,荷兰语,法语,德语,匈牙利语,意大利语,希腊语,日语,波兰语,葡萄牙语,俄语,斯洛文尼亚语,西班牙语,瑞典语和土耳其语)
+
+- 项目网址: [launchpad.net/furiusisomount/][1]
+- 开发者: Dean Harris (Marcus Furius)
+- 许可: GNU GPL v3
+- 版本号: 0.11.3.1
+
+----------
+
+
+
+
+
+fuseiso 是用来挂载ISO文件系统的一个开源的安全模块。
+
+使用FUSE,我们完全可以在用户空间里运行一个完整的文件系统。
+
+特性:
+
+- 支持读ISO,BIN和NRG镜像,包括ISO9660文件系统
+- 支持普通的ISO9660级别1和级别2
+- 支持一些常用的扩展,想Joliet,RockRidge和zisofs
+- 支持非标准的镜像,包括CloneCD's IMGs 、Alcohol 120%'s MDFs 因为他们的格式看起来恰好像BIN镜像一样
+
+- 项目网址: [sourceforge.net/projects/fuseiso][2]
+- 开发者: Dmitry Morozhnikov
+- 许可: GNU GPL v2
+- 版本号: 20070708
+
+----------
+
+
+
+
+
+iat(Iso9660分析工具)是一个通用的开源工具,能够检测很多不同镜像格式文件的结构,包括BIN,MDF,PDI,CDI,NRG和B5I,并转化成ISO-9660格式.
+
+特性:
+
+- 支持读(输入)NRG,MDF,PDI,CDI,BIN,CUE 和B5I镜像
+- 支持用cd 刻录机直接烧录光盘镜像
+- 输出信息包括:进度条,块大小,ECC扇形分区(大小),头分区(大小),镜像偏移地址等等
+
+- 项目网址: [sourceforge.net/projects/iat.berlios][3]
+- 开发者: Salvatore Santagati
+- 许可: GNU GPL v2
+- 版本号: 0.1.3
+
+----------
+
+
+
+
+
+AcetoneISO 是一个功能丰富的开源图形化应用程序,用来挂载和管理CD/DVD镜像。
+
+当你打开这个程序,你就会看到一个图形化的文件管理器用来挂载镜像文件,包括专有的镜像格式,也包括像ISO, BIN, NRG, MDF, IMG 等等,并且允许您执行一系列的动作。
+
+AcetoneISO是用QT 4写的,也就是说,对于基于QT的桌面环境能很好的兼容,像KDE,LXQT或是Razor-qt。
+
+这个软件适用于所有正在寻找Linux版本的Daemon Tools的人。
+
+特性:
+
+- 支持挂载大多数windowns 镜像,在一个简洁易用的界面
+- 支持所有镜像格式转换到ISO,或者是从中提取内容。
+- 支持加密,压缩,解压任何类型的镜像
+- 支持转换DVD成xvid avi,支持任何格式的转换成xvid avi
+- 支持从录像里提取声音
+- 支持从不同格式中提取镜像文件,包括bin mdf nrg img daa dmg cdi b5i bwi pdi
+- 支持用Kaffeine / VLC / SMplayer播放DVD镜像,可以从Amazon 自动下载。
+- 支持从文件夹或者是CD/DVD生成ISO镜像
+- 支持文件MD5校验,或者是生成一个MD5校验码
+- 支持计算镜像的ShaSums,以128,256和384位的速度
+- 支持加密,解密一个镜像文件
+- 支持以M字节的速度,分开、合并镜像
+- 支持高比例压缩镜像成7z 格式
+- 支持翻录PSX CD成BIN格式,以便在ePSXe/pSX模拟器里运行
+- 支持修复CUE文件为BIN和IMG格式
+- 支持把MAC OS的DMG镜像转换成可挂载的镜像
+- 支持从指定的文件夹中挂载镜像
+- 支持创建数据库来管理一个大的镜像集合
+- 支持从CD/DVD 或者是ISO镜像中提取启动文件
+- 支持备份CD成BIN镜像
+- 支持简单快速的把DVD翻录成Xvid AVI
+- 支持简单快速的把常见的视频(avi, mpeg, mov, wmv, asf)转换成Xvid AVI
+- 支持简单快速的把FLV 换换成AVI 格式
+- 支持从YouTube和一些视频网站下载视频
+- 支持提取一个有密码的RAR存档
+- 支持转换任何的视频到索尼便携式PSP上
+- 国际化的语言支持支持(英语,意大利语,波兰语,西班牙语,罗马尼亚语,匈牙利语,德语,捷克语和俄语)
+
+- 项目网址: [sourceforge.net/projects/acetoneiso][4]
+- 开发者: Marco Di Antonio
+- 许可: GNU GPL v3
+- 版本号: 2.3
+
+----------
+
+
+
+
+
+ISO Master是一个开源、易用的、图形化CD 镜像编辑器,适用于Linux 和BSD 。可以从ISO 里提取文件,给ISO 添加文件,创建一个可引导的ISO,这些都是在一个可视化的用户界面完成的。可以打开ISO,NRG 和一些MDF文件,但是只能保存成ISO 格式。
+
+ISO Master 是基于bkisofs 创建的,一个简单、稳定的阅读库,修改和编写ISO 镜像,支持Joliet, RockRidge 和EL Torito扩展,
+
+特性:
+
+- 支持读ISO 格式文件(ISO9660, Joliet, RockRidge 和 El Torito),大多数的NRG 格式文件和一些单向的MDF文件,但是,只能保存成ISO 格式
+- 创建和修改一个CD/DVD 格式文件
+- 支持CD 格式文件的添加或删除文件和目录
+- 支持创建可引导的CD/DVD
+- 国际化的支持
+
+- 项目网址: [www.littlesvr.ca/isomaster/][5]
+- 开发者: Andrew Smith
+- 许可: GNU GPL v2
+- 版本号: 1.3.11
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxlinks.com/article/20141025082352476/DiskImageTools.html
+
+作者:Frazer Kline
+译者:[barney-ro](https://github.com/barney-ro)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:https://launchpad.net/furiusisomount/
+[2]:http://sourceforge.net/projects/fuseiso/
+[3]:http://sourceforge.net/projects/iat.berlios/
+[4]:http://sourceforge.net/projects/acetoneiso/
+[5]:http://www.littlesvr.ca/isomaster/
\ No newline at end of file
diff --git a/translated/talk/20140702 The People Who Support Linux--Hacking on Linux Since Age 16.md b/translated/talk/20140702 The People Who Support Linux--Hacking on Linux Since Age 16.md
new file mode 100644
index 0000000000..94ca2c688f
--- /dev/null
+++ b/translated/talk/20140702 The People Who Support Linux--Hacking on Linux Since Age 16.md
@@ -0,0 +1,62 @@
+一个 Linux 支持者:从 16 岁开始在 Linux 上 hacking
+================================================================================
+
+
+
+>翻译文章中是称主人公为 Yitao Li,还是李逸韬?他似乎是美国人,“李逸韬”是看的他的个人主页上的。
+
+在软件开发者 [Yitao Li (李逸韬) 的 GitHub 仓库][1]中,几乎所有的项目都是在他的 Linux 机器上开发完成的。它们没有一个是必须特定需要 Linux 的,但李逸韬说他使用 Linux 来做“任何事情”。
+
+举些例子:“编码/脚本设计,网页浏览,网站托管,任何云相关的,发送/接受 PGP 签名的邮件,调整防火墙规则,将 OpenWrt 镜像刷入路由器,运行某版本的 Linux kernel 的同时编译另一个版本,从事研究,完成功课(例如,用 Tex 输入数学公式),以及其他许多......” Li 在邮件里如是说。
+
+在李逸韬的 GitHub 仓库里所有项目中他的最爱是一个学校项目,调用 libpthread 和 libfuse 库使用 C++ 开发,用来理解和正确执行基于 PAXOS 的分布式加锁,键值对服务,最终实现一个分布式文件系统。他使用若干测试脚本分别在单核和多核的机器上对这个项目进行测试。
+
+“One can learn something about distributed consensus protocol by implementing the PAXOS protocol correctly (or at least mostly correctly) such that the implementation will pass all the tests,” he said. “And of course once that is accomplished, one can also earn some bragging rights. Besides, a distributed filesystem can be useful in many other programming projects.”
+
+>"One can learn something about distributed consensus protocol by implementing the PAXOS protocol correctly (or at least mostly correctly) such that the implementation will pass all the tests" 不知道翻译的是不是有点混乱
+
+"一个人可以通过正确实现(或者至少大部分正确)PAXOS 协议,让它通过所有测试,来学习关于分布式共识协议的知识,"他说,“当然一旦这完成了,他就可以获得一些炫耀的权利。除此之外,一个分布式文件系统在其他许多编程项目中也可以很有用。”
+
+Li first started using Linux at age 16, or about 7.47 years ago, he says, using the website [linuxfromscratch.org][2], with numerous hints from the free, downloadable Linux From Scratch book. Why?
+
+>with numerous hints from the free, downloadable Linux From Scratch book. 讲的应该是从 Linuxfromscratch 学习 LFS 编译安装 Linux,不知道该怎么翻译。
+
+Li 是在 16 岁的时候第一次开始使用 Linux,或是者说大约 7.47 年之前,他说,通过使用网站 [linuxfromscratch.org][2] ,从 Scratch book 中获得免费可下载的 Linux,以及大量 Hints。那么他为什么会使用 Linux?
+
+“1. Linux is very hacker-friendly and I do not see any reason for not using it,” he writes. “2. The prefrontal cortex of the brain becoming well-developed at age 16 (?).”
+
+>2. The prefrontal cortex of the brain becoming well-developed at age 16 (?). 原文里的 16 (?) 是啥意思?
+
+"1. Linux 非常黑客友好所以我没看到任何不用它的理由,"他写道,“2. 大脑的前额叶皮质在16岁时正变得发达。”
+
+[][3]
+
+他现在为 eBay工作,主要进行 Java 编程但有时也使用 Hadoop, Pig, Zookeeper, Cassandra, MongoDB,以及其他一些需要 POSIX 兼容平台的软件来工作。他主要通过给 Wikipedia 页面和 Linux 相关的论坛做贡献来支持 Linux 社区,另外当然还通过成为 Linux 基金会的个人会员。
+
+他紧跟最新的 Linux 发展动态,最近还对 GCC 4.9 及之后版本新增的 “-fstack-protector-strong” 选项印象深刻。
+
+
+"虽然这并不与我的任何项目直接相关,但它对于安全和性能问题十分重要。"他说,“这个选项比 ‘-fstack-protector-all’ 更高效的多,却在安全上几乎没有影响,同时比 ‘-fstack-protector’ 选项提供了更好的栈溢出防护覆盖。”
+
+欢迎来到 Linux 基金会,Yitao !
+
+了解更多关于成为 [Linux 基金会个人会员][3]的内容。基金会将为每位 6 月份期间的新个人会员捐赠 $25 给 Code.org。
+
+----------
+
+
+
+[Libby Clark][4]
+
+--------------------------------------------------------------------------------
+
+via: http://www.linux.com/news/featured-blogs/200-libby-clark/778559-the-people-who-support-linux-hacking-on-linux-since-age-16
+
+译者:[jabirus](https://github.com/jabirus) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:https://github.com/yl790
+[2]:http://linuxfromscratch.org/
+[3]:https://www.linuxfoundation.org/about/join/individual
+[4]:http://www.linux.com/community/forums/person/41373/catid/200-libby-clark
\ No newline at end of file
diff --git a/translated/talk/20140818 Will Linux ever be able to give consumers what they want.md b/translated/talk/20140818 Will Linux ever be able to give consumers what they want.md
new file mode 100644
index 0000000000..6e5635b12f
--- /dev/null
+++ b/translated/talk/20140818 Will Linux ever be able to give consumers what they want.md
@@ -0,0 +1,51 @@
+Linux能够提供消费者想要的东西吗?
+================================================================================
+> 由Jack Wallen提出的新观点,提供消费者想要的东西也许是收获无限成就的关键。
+
+
+
+在消费电子的世界里,如果你不能提供购买者想要的东西,那他们就会跑去别家。我们最近在Firefox浏览器上就看过类似的事情。消费者想要的是一个快速而不那么臃肿的软件,而开发者们却走到了另外的方向上。最后,用户都转移到Chrome或Chromium上去了。
+
+Linux需要深深凝视自己的水晶球,仔细体会那场浏览器大战留下的尘埃,然后留意一下这点建议:
+
+如果你不能提供他们想要的,他们就会离开。
+
+而这种事与愿违的另一个例子是Windows 8。消费者不喜欢那套界面。而微软却坚持使用,因为这是把所有东西搬到Surface平板上所必须的。相同的情况也可能发生在Canonical和Ubuntu Unity身上 -- 尽管它们的目标并不是单一独特地针对平板电脑来设计(所以,整套界面在桌面系统上仍然很实用而且直观)。
+
+一直以来,Linux开发者和设计者们看上去都按照他们自己的想法来做事情。他们过分在意“吃你自家的狗粮”这句话了。以至于他们忘记了一件非常重要的事情:
+
+没有新用户,他们的“根基”也仅仅只属于他们自己。
+
+换句话说,唱诗班不仅仅是被传道,他们也同时在宣传。让我给你看三个案例来完全掌握这一点。
+
+- 多年以来,有在Linux系统中替代活动目录(Active Directory)的需求。我很想把这个名称换成LDAP,但是你真的用过LDAP吗?那就是个噩梦。开发者们也努力了想让LDAP能易用一点,但是没一个做到了。而让我很震惊的是这样一个从多用户环境下发展起来的平台居然没有一个能和AD正面较量的功能。这需要一组开发人员,从头开始建立一个AD的开源替代。这对那些寻求从微软产品迁移的中型企业来说是非常大的福利。但是在这个产品做好之前,他们还不能开始迁移。
+- 另一个从微软激发的需求是Exchange/Outlook。是,我也知道许多人都开始用云。但是,事实上中等和大型规模生意仍然依赖于Exchange/Outlook组合,直到能有更好的产品出现。而这将非常有希望发生在开源社区。整个拼图的一小块已经摆好了(虽然还需要一些工作)- 群件客户端,Evolution。如果有人能够从Zimbra拉出一个分支,然后重新设计成可以配合Evolution(甚至Thunderbird)来提供服务实现Exchange的简单替代,那这个游戏就不是这么玩了,而消费者获得的利益将是巨大的。
+- 便宜,便宜,还是便宜。这是大多数人都得咽下去的苦药片 - 但是消费者(和生意)就是希望便宜。看看去年一年Chromebook的销量吧。现在,搜索一下Linux笔记本看能不能找到700美元以下的。而只用三分之一的价格,就可以买到一个让你够用的Chromebook(一个使用了Linux内核的平台)。但是因为Linux仍然是一个细分市场,很难降低成本。像红帽那种公司也许可以改变现状。他们也已经推出了服务器硬件。为什么不推出一些和Chromebook有类似定位但是却运行完整Linux环境的低价中档笔记本呢?(请看“[Cloudbook是Linux的未来吗?][1]”)其中的关键是这种设备要低成本并且符合普通消费者的要求。不要站在游戏玩家/开发者的角度去思考了,记住普通消费者真正的需求 - 一个网页浏览器,不会有更多了。这是Chromebook为什么可以这么轻松地成功。Google精确地知道消费者想要什么,然后推出相应的产品。而面对Linux,一些公司仍然认为他们吸引买家的唯一途径是高端昂贵的硬件。而有一点讽刺的是,口水战中最经常听到的却是Linux只能在更慢更旧的硬件上运行。
+
+最后,Linux需要看一看乔布斯传(Book Of Jobs),搞清楚如何说服消费者们他们真正要的就是Linux。在生意上和在家里 -- 每个人都可以享受到Linux带来的好处。说真的,开源社区怎么可能做不到这点呢?Linux本身就已经带有很多漂亮的时髦术语标签:稳定性,可靠性,安全性,云,免费 -- 再加上Linux实际已经进入到绝大多数人手中了(只是他们自己还不清楚罢了)。现在是时候让他们知道这一点了。如果你是用Android或者Chromebooks,那么你就在用(某种形式上的)Linux。
+
+搞清楚消费者需求一直以来都是Linux社区的绊脚石。而且我知道 -- 太多的Linux开发都基于某个开发者有个特殊的想法。这意味着这些开发都针对的“微型市场”。是时候,无论如何,让Linux开发社区能够进行全球性思考了。“一般用户有什么需求,我们怎么满足他们?”让我提几个最基本的点。
+
+一般用户想要:
+
+- 低价
+- 设备和服务能无缝衔接
+- 直观而现代的设计
+- 百分百可靠的浏览器体验
+
+把这四点放在心中,应该可以轻松地以Linux为基础开发出用户实际需要的产品。Google做到了...当然Linux社区也可以参照Google的工作并开发出更好的产品。把这些应用到集成AD这件事上,能开发出Exchange/Outlook的替代或者基于云的群件工具,就会发生一件非常特殊的事 -- 人们会为它买单。
+
+你觉得Linux社区能够提供消费者想要的东西吗?在下边的讨论区里分享一下你的看法。
+
+--------------------------------------------------------------------------------
+
+via: http://www.techrepublic.com/article/will-linux-ever-be-able-to-give-consumers-what-they-want/
+
+作者:[Jack Wallen][a]
+译者:[zpl1025](https://github.com/zpl1025)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.techrepublic.com/search/?a=jack+wallen
+[1]:http://www.techrepublic.com/article/is-the-cloudbook-the-future-of-linux/
diff --git a/translated/talk/20140915 10 Open Source Cloning Software For Linux Users.md b/translated/talk/20140915 10 Open Source Cloning Software For Linux Users.md
index 9dddef3570..1fef50289f 100644
--- a/translated/talk/20140915 10 Open Source Cloning Software For Linux Users.md
+++ b/translated/talk/20140915 10 Open Source Cloning Software For Linux Users.md
@@ -12,7 +12,7 @@ Clonezilla 是一个基于 Ubuntu 和 Debian 的 Live CD。它可以像 Windows

-### 2. [Redo Backup][2]:###
+### 2. [Redo Backup][2]:###
Redo Backup 是另一个用来方便地克隆磁盘的 Live CD。它是自由和开源的软件,使用 GPL 3 许可协议授权。它的主要功能和特点包括从 CD 引导的简单易用的 GUI、无需安装,可以恢复 Linux 和 Windows 等系统、无需登陆访问文件,以及已删除的文件等。
diff --git a/translated/talk/The history of Android/08 - The history of Android.md b/translated/talk/The history of Android/08 - The history of Android.md
new file mode 100644
index 0000000000..15dc0515d6
--- /dev/null
+++ b/translated/talk/The history of Android/08 - The history of Android.md
@@ -0,0 +1,128 @@
+安卓编年史
+================================================================================
+
+安卓1.5的虚拟键盘输入时的输入建议栏,大写状态键盘,数字与符号界面,更多符号弹窗。
+Ron Amadeo供图
+
+### Android 1.5 Cupcake——虚拟键盘打开设备设计的大门 ###
+
+在2009年4月,安卓1.1发布后将近三个月后,安卓1.5发布了。这是第一个拥有公开的,市场化代号的安卓版本:纸杯蛋糕(Cupcake)。从这个版本开始,每个版本的安卓将会拥有一个按字母表排序,以小吃为主题的代号。
+
+纸杯蛋糕新增功能中最重要的明显当属虚拟键盘。这是OEM厂商第一次有可能抛开数不清按键的实体键盘以及复杂的滑动结构,创造出平板风格的安卓设备。
+
+安卓的按键标识可以在大小写之间切换,这取决于大写锁定是否开启。尽管默认情况下它是关闭的,显示在键盘顶部的建议栏有个选项可以打开它。在按键的弹框中带有省略号的,就像“u”,上面图那样的,可以在按住的情况下可以输入弹框中的[发音符号][1]。键盘可以切换到数字和符号,长按句号键可以打开更多符号。
+
+
+1.5和1.1中的应用程序界面和通知面板的对比。
+Ron Amadeo供图
+
+“摄像机”功能加入了新图标,Google Talk从IM中分离出来成为了一个独立的应用。亚马逊MP3和浏览器的图标同样经过了重新设计。亚马逊MP3图标更改的主要原因是亚马逊即将计划推出其它的安卓应用,而“A”图标所指范围太泛了。浏览器图标无疑是安卓1.1中最糟糕的设计,所以它被重新设计了,并且不再像是一个桌面操作系统的对话框。应用抽屉的最后一个改变是“图片”,它被重新命名为了“相册”。
+
+通知面板同样经过了重新设计。面板背景加上了布纹纹理,通知的渐变效果也被平滑化了。安卓1.5在系统核心部分有许多设计上的微小改变,这些改变影响到所有的应用。在“清除通知”按钮上,你可以看到全新的系统按钮风格,相比与旧版本的按钮有了渐变,更细的边框线以及更少的阴影。
+
+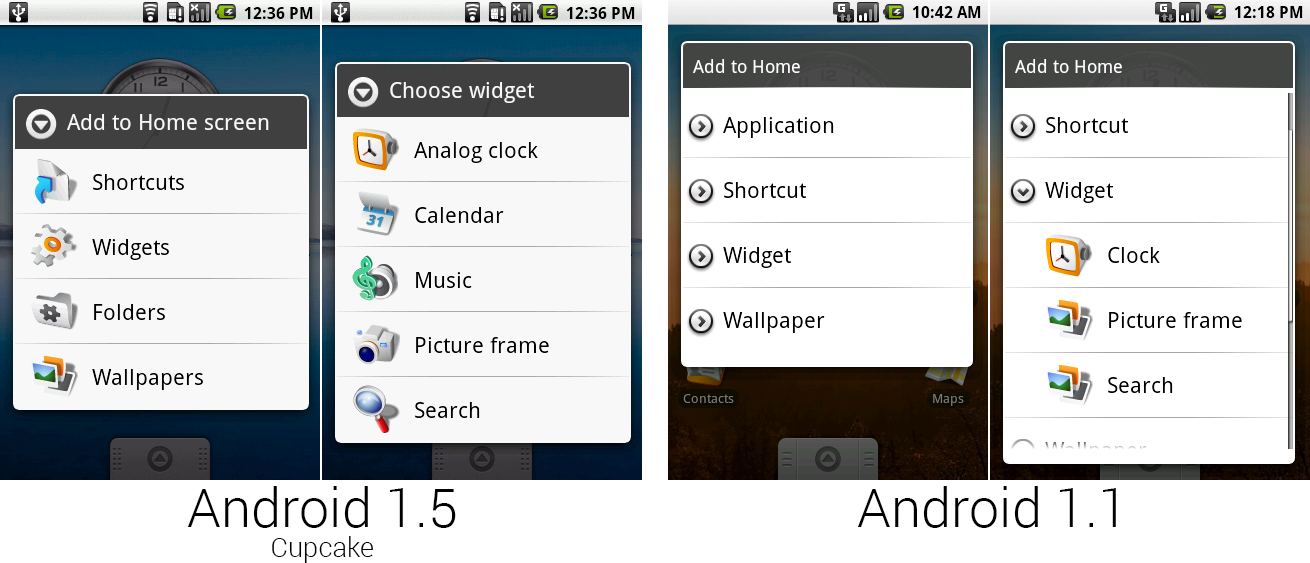
+安卓1.5和1.1中的“添加到主屏幕”对话框。
+Ron Amadeo供图
+
+第三方小部件是纸杯蛋糕的另一个头等特性,它们现在仍然是安卓的本质特征之一。无论是用来控制应用还是显示应用的信息,开发者们都可以为他们的应用捆绑一个主屏幕小部件。谷歌同样展示了一些它们自己的新的小部件,分别来自日历和音乐这两个应用。
+
+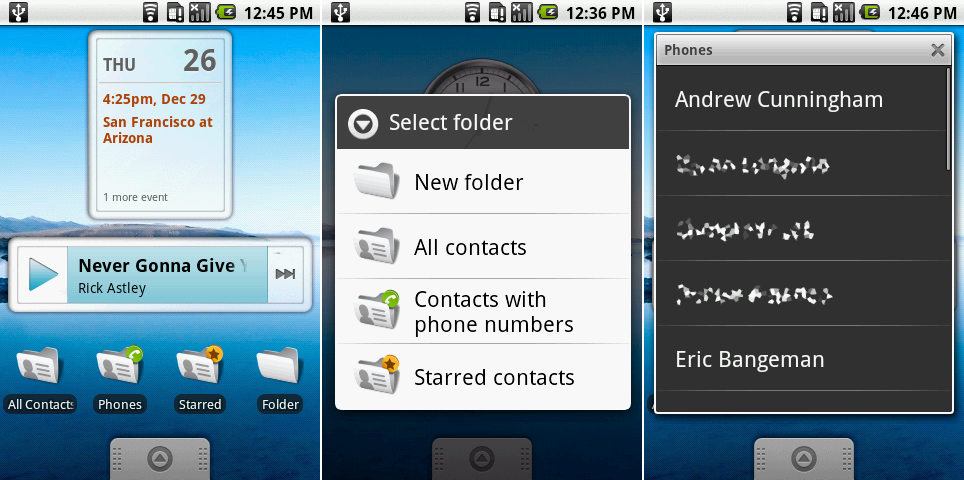
+左:日历小部件,音乐小部件以及一排实时文件夹的截图。中:文件夹列表。右:“带电话号码的联系人”实时文件夹的打开视图。
+Ron Amadeo供图
+
+在上方左边的截图里你可以看到新的日历和音乐图标。日历小部件只能显示当天的一个事件,点击它会打开日历。你不能够选择日历所显示的内容,小部件也不能够重新设置大小——它就是上面看起来的那个样子。音乐小部件是蓝色的——尽管音乐应用里没有一丁点的蓝色——它展示了歌曲名和歌手名,此外还有播放和下一曲按钮。
+
+同样在左侧截图里,底部一排的头三个文件夹是一个叫做“实时文件夹”的新特性。它们可以在“添加到主屏幕”菜单中的新顶层选项“文件夹”中被找到,就像你在中间那张图看到的那样。实时文件夹可以展示一个应用的内容而不用打开这个应用。纸杯蛋糕带来的都是和联系人相关的实时文件夹,能够显示所有联系人,带有电话号码的联系人和加星标的联系人。
+
+实时文件夹在主屏的弹窗使用了一个简单的列表视图,而不是图标。联系人只是实时文件夹的一个初级应用,它是给开发者使用的一个完整API。谷歌用Google Books应用做了个图书文件夹的演示,它可以显示RSS订阅或是一个网站的热门故事。实时文件夹是安卓没有成功实现的想法之一,这个特性最终在蜂巢(3.x)中被取消。
+
+
+摄像机和相机界面,屏幕上有触摸快门。
+Ron Amadeo供图
+
+如果你不能认出新的“摄像机”图标,这不奇怪,视频录制是在安卓1.5中才被添加进来的。相机和摄像机两个图标其实是同一个应用,你可用过菜单中的“切换至相机”和“切换至摄像机”选项在它们之间切换。T-Mobile G1上录制的视频质量并不高。一个“高”质量的测试视频输出一个.3GP格式的视频文件,其分辨率仅为352 x 288,帧率只有4FPS。
+
+除了新的视频特性,相机应用中还可以看到一些急需的UI调整。上方左侧的快照展示了最近拍摄的那张照片,点击它会跳转到相册中的相机胶卷。各个界面上方右侧的圆形图标是触摸快门,这意味着,从1.5开始,安卓设备不再需要一个实体相机按钮。
+
+这个界面相比于之后版本的相机应用实际上更加接近于安卓4.2的设计。尽管后续的设计会向相机加入愚蠢的皮革纹理毅力更多的控制设置,安卓最终还是回到了基本的设计,安卓4.2的重新设计和这里有很多共同之处。安卓1.5中的原始布局演变成了安卓4.2中的最小化的,全屏的取景器。
+
+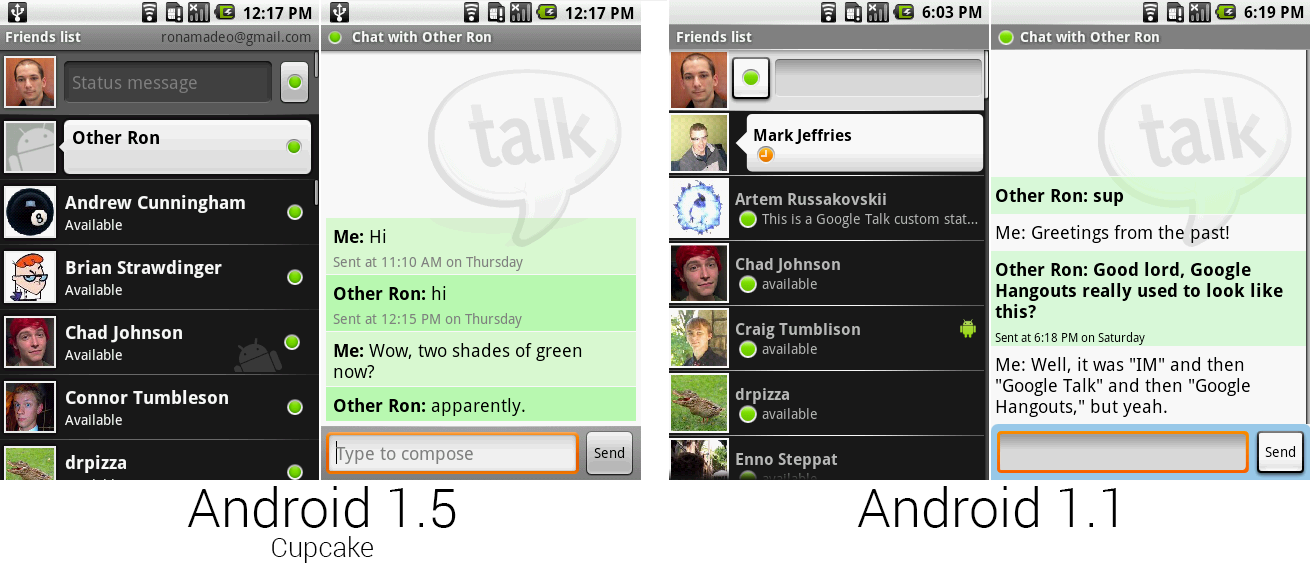
+Google Talk运行在Google Talk中vs运行在IM应用中。
+Ron Amadeo供图
+
+安卓1.0的IM即时通讯应用功能上支持Google Talk,但在安卓1.5中,Google Talk从中分离出来成为独立应用。IM应用中对其的支持已经被移除。Google Talk(上图左侧)明显是基于IM应用(上图右侧)的,但随着独立应用在1.5中的发布,在IM应用的工作被放弃了。
+
+新的Google Talk应用拥有重新设计过的状态栏,右侧状态指示灯,重新设计过的移动设备标识,是个灰色的安卓小绿人图案。聊天界面的蓝色的输入框变成了更加合理的灰色,消息的背景从淡绿和白色变成了淡绿和绿色。有了独立的应用,谷歌可以向其中添加Gtalk独有的特性,比如“不保存聊天记录”聊天,该特性可以阻止Gmail保存每个聊天记录。
+
+
+安卓1.5的日历更加明亮。
+Ron Amadeo供图
+
+日历抛弃了丑陋的黑色背景上白色方块的设计,转变为全浅色主题。所有东西的背景都变成了白色,顶部的星期日变成了蓝色。单独的约会方块从带有颜色的细条变成了拥有整个颜色背景,文字也变为白色。这将是很长一段时间内日历的最后一次改动。
+
+
+从左到右:新的浏览器控件,缩放视图,复制/粘贴文本高亮。
+Ron Amadeo供图
+
+安卓1.5从系统全局修改了缩放控件。缩放控件不再是两个大圆形,取而代之的是一个圆角的椭圆形从中间分开为左右两个按钮。这些新的控件被用在了浏览器,谷歌地图和相册之中。
+
+浏览器在缩放功能上做了很多工作。在放大或缩小之后,点击“1x”按钮可以回到正常缩放状态。底部右侧的按钮会将页面缩放整个页面并在页面上显示一个放大矩形框,就像你能在上面中间截图看到的那样。抓住矩形框并且释放会将页面的那一部分显示回“1x”视图。安卓并没有加速滚动,这使得最大滚动速度着实很慢——这就是谷歌对长网页页面导航的解决方案。
+
+浏览器的另一个新增功能就是从网页上复制文本——之前你只能从输入框中复制文本。在菜单中选择“复制文本”会激活高亮模式,在网页文本上拖动你的手指会使它们高亮。G1的轨迹球对于这种精准的移动十分的方便,并且能够控制鼠标指针。这里并没有可以拖动的光标,当你的手指离开屏幕的时候,安卓就会复制文本并且移除高亮。所以你必须做到荒谬般的精确来使用复制功能。
+
+安卓1.5中的浏览器很容易崩溃——比之前的版本经常多了。仅仅是以桌面模式浏览Ars Technica就会导致崩溃,许多其它的站点也是一样。
+
+
+Ron Amadeo供图
+
+默认的锁屏界面和图形锁屏都不再是空荡荡的黑色背景,而是和主屏幕一致的壁纸。
+
+图形解锁界面的浅色背景显示出了谷歌在圆圈对齐工作上的草率和马虎。白色圆圈在黑圆圈里从来都不是在正中心的位置——像这样基本的对齐问题对于这一时期的安卓是个频繁出现的问题。
+
+
+Youtube上传工具,内容快照,自动旋转设置,全新的音乐应用设计。
+Ron Amadeo供图
+
+安卓1.5给予了YouTube应用向其网站上传视频的能力。上传通过从相册中分享视频到YouTube应用来完成,或从YouTube应用中直接打开一个视频。这将会打开一个上传界面,用户在这里可以设置像视频标题,标签和权限这样的选项。照片可以以类似的方式上传到Picasa,一个谷歌建立的图片网站。
+
+整个系统的调整没有多少。现在喜爱的联系人在联系人列表中可以显示图片(尽管常规联系人还是没有图片)。第三张截图展示了设置中全新的自动旋转选项——这个版本同样也是第一个支持基于从设备内部传感器读取的数据自动切换方向的版本。
+
+> #### 谷歌地图是第一个登陆谷歌市场的内置应用 ####
+>
+> 尽管这篇文章为了简单起见,(主要)以安卓版本顺序来组织应用更新,但还是有一些在这时间线之外的东西值得我们特别注意一下。2009年6月14日,谷歌地图成为第一个通过谷歌市场更新的预置应用。尽管其它的所有应用更新还是要求一个完整的系统更新,地图从系统中脱离了出来,只要新特性已经就绪就可以随时接收升级周期之外的更新。
+>
+> 将应用从核心系统分离发布到安卓市场上将成为谷歌前进的主要关注点。总的来说,OTA更新是个重大的主动改进——这需要OEM厂商和运营商的合作,二者都是拖着后退的角色。更新同样没有做到到达每个设备。今天,谷歌市场给了谷歌一个与每个安卓手机之间的联系,而没有了这样的外界干扰。
+>
+> 然而,这是后来才需要考虑的问题。在2009年,谷歌只有两部裸机需要支持,而且早期的安卓运营商似乎对谷歌的升级需要反应积极。这些早期的行动对谷歌部分来说将被证明是非常积极的决定。一开始,公司只在最重要的应用——地图和Gmail上——走这条路线,但后来它将大部分预置应用导入安卓市场。后来的举措比如Google Play服务甚至将应用API从系统移除加入了谷歌商店。
+>
+> 至于这时的新地图应用,得到了一个新的路线界面,此外还有提供公共交通和步行方向的能力。现在,路线只有个朴素的黑色列表界面——逐向风格的导航很快就会登场。
+>
+> 2009年6月同时还是苹果发布第三代iPhone——3GS——以及第三版iPhone OS的时候。iPhone OS 3的主要特性大多是追赶上来的项目,比如复制/粘贴和对彩信的支持。苹果的硬件依然是更好的,软件更流畅,更整合,还有更好的设计。尽管谷歌疯狂的开发步伐使得它不得不走上追赶的道路。iPhone OS 2是在安卓0.5的Milestone 5版本之前发布的,在iOS一年的发布周期里安卓发布了五个版本。
+
+
+HTC Magic,第二部安卓设备,第一个不带实体键盘的设备。
+HTC供图
+
+纸杯蛋糕在改进安卓上做了巨大的工作,特别是从硬件方面。虚拟键盘意味着不再需要实体键盘。自动旋转使得系统更加接近iPhone,屏幕上的虚拟快门按键同样也意味着实体相机按键变成了可选选项。1.5发布后不久,第二部安卓设备的出现将会展示出这个平台未来的方向:HTC Magic。Magic(上图)没有实体键盘或相机按钮。它是没有间隙,没有滑动结构的平板状设备,依赖于安卓的虚拟按键来完成任务。
+
+安卓旗舰机开始可能有着最多按键——一个实体qwerty键盘——后来随着时间流逝开始慢慢减少按键数量。而Magic是重大的一步,去除了整个键盘和相机按钮,它仍然使用通话和挂断键,四个系统键以及轨迹球。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/8/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://en.wikipedia.org/wiki/Diacritic
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/tech/20141008 The Why and How of Ansible and Docker.md b/translated/tech/20141008 The Why and How of Ansible and Docker.md
new file mode 100644
index 0000000000..748d7eb15b
--- /dev/null
+++ b/translated/tech/20141008 The Why and How of Ansible and Docker.md
@@ -0,0 +1,103 @@
+Ansible和Docker的作用和用法
+================================================================================
+在 [Docker][1] 和 [Ansible][2] 的技术社区内存在着很多好玩的东西,我希望在你阅读完这篇文章后也能获取到我们对它们的那种热爱。当然,你也会收获一些实践知识,那就是如何通过部署 Ansible 和 Docker 来为 Rails 应用搭建一个完整的服务器环境。
+
+也许有人会问:你怎么不去用 Heroku?首先,我可以在任何供应商提供的主机上运行 Docker 和 Ansible;其次,相比于方便性,我更偏向于喜欢灵活性。我可以在这种组合中运行任何程序,而不仅仅是 web 应用。最后,我骨子里是一个工匠,我非常理解如何把零件拼凑在一起工作。Heroku 的基础模块是 Linux Container,而 Docker 表现出来的多功能性也是基于这种技术。事实上,Docker 的其中一个座右铭是:容器化是新虚拟化技术。
+
+### 为什么使用 Ansible? ###
+
+我重度使用 Chef 已经有4年了(LCTT:Chef 是与 puppet 类似的配置管理工具),**基础设施即代码**的观念让我觉得非常无聊。我花费大量时间来管理代码,而不是管理基础设施本身。不论多小的改变,都需要相当大的努力来实现它。使用 [Ansible][3],你可以一手掌握拥有可描述性数据的基础架构,另一只手掌握不同组件之间的交互作用。这种更简单的操作模式让我把精力集中在如何将我的技术设施私有化,提高了我的工作效率。与 Unix 的模式一样,Ansible 提供大量功能简单的模块,我们可以组合这些模块,达到不同的工作要求。
+
+除了 Python 和 SSH,Ansible 不再依赖其他软件,在它的远端主机上不需要部署代理,也不会留下任何运行痕迹。更厉害的是,它提供一套内建的、可扩展的模块库文件,通过它你可以控制所有:包管理器、云服务供应商、数据库等等等等。
+
+### 为什么要使用 Docker? ###
+
+[Docker][4] 的定位是:提供最可靠、最方便的方式来部署服务。这些服务可以是 mysqld,可以是 redis,可以是 Rails 应用。先聊聊 git,它的快照功能让它可以以最有效的方式发布代码,Docker 的处理方法与它类似。它保证应用可以无视主机环境,随心所欲地跑起来。
+
+一种最普遍的误解是人们总是把 Docker 容器看成是一个虚拟机,当然,我表示理解你们的误解。Docker 满足[单一功能原则][5],在一个容器里面只跑一个进程,所以一次修改只会影响一个进程,而这些进程可以被重用。这种模型参考了 Unix 的哲学思想,当前还处于试验阶段,并且正变得越来越稳定。
+
+### 设置选项 ###
+
+不需要离开终端,我就可以使用 Ansible 来生成以下实例:Amazon Web Services,Linode,Rackspace 以及 DigitalOcean。如果想要更详细的信息,我于1分25秒内在位于阿姆斯特丹的2号数据中心上创建了一个 2GB 的 DigitalOcean 虚拟机。另外的1分50秒用于系统配置,包括设置 Docker 和其他个人选项。当我完成这些基本设定后,就可以部署我的应用了。值得一提的是这个过程中我没有配置任何数据库或程序开发语言,Docker 已经帮我把应用所需要的事情都安排好了。
+
+Ansible 通过 SSH 为远端主机发送命令。我保存在本地 ssh 代理上面的 SSH 密钥会通过 Ansible 提供的 SSH 会话分享到远端主机。当我把应用代码从远端 clone 下来,或者上传到远端时,我就不再需要提供 git 所需的证书了,我的 ssh 代理会帮我通过 git 主机的身份验证程序的。
+
+### Docker 和应用的依赖性 ###
+
+我发现有一点挺有意思的:大部分开发者非常了解他们的应用需要什么版本的编程语言,这些语言依赖关系有多种形式:Python 的包、Ruby 的打包系统 gems、node.js 的模块等等,但与数据库或消息队列这种重要的概念相比起来,这些语言就处于很随便的境地了——随便给我个编程语言环境,我都能把数据库和消息队列系统跑起来。我认为这是 DevOps 运动(它旨在促进开发与运维团队的和谐相处)的动机之一,开发者负责搭建应用所需要的环境。Docker 使这个任务变得简单明了直截了当,它为现有环境加了实用的一层配置。
+
+我的应用依赖于 MySQL 5.5和 Redis 2.8,依赖关系放在“.docker_container_dependencies”文件里面:
+
+ gerhard/mysql:5.5
+ gerhard/redis:2.8
+
+Ansible 会查看这个文件,并且通知 Docker 加载正确的镜像,然后在容器中启动。它还会把这些服务容器链接到应用容器。如果你想知道 Docker 容器的链接功能是怎么工作的,可以参考[Docker 0.6.5 发布通知][6].
+
+我的应用包括一个 Dockerfile,它详细指定了 Ruby Docker 镜像的信息,这里面的步骤能够保证把正确的 Ruby 版本加载到镜像中。
+
+ FROM howareyou/ruby:2.0.0-p353
+
+ ADD ./ /terrabox
+
+ RUN \
+ . /.profile ;\
+ rm -fr /terrabox/.git ;\
+ cd /terrabox ;\
+ bundle install --local ;\
+ echo '. /.profile && cd /terrabox && RAILS_ENV=test bundle exec rake db:create db:migrate && bundle exec rspec' > /test-terrabox ;\
+ echo '. /.profile && cd /terrabox && export RAILS_ENV=production && rake db:create db:migrate && bundle exec unicorn -c config/unicorn.rails.conf.rb' > /run-terrabox ;\
+ # END RUN
+
+ ENTRYPOINT ["/bin/bash"]
+ CMD ["/run-terrabox"]
+
+ EXPOSE 3000
+
+第一步是复制应用的所有代码到 Docker 镜像,加载上一个镜像的全局环境变量。这个例子中的 Ruby Docker 镜像会加载 PATH 配置,这个配置能确保镜像加载正确的 Ruby 版本。
+
+接下来,删除 git 历史,Docker 容器不需要它们。我安装了所有 Ruby 的 gems,创建一个名为“/test-terrabox”的命令,这个命令会被名为“test-only”的容器执行。这个步骤的目的是能正确解决应用和它的依赖关系,让 Docker 容器正确链接起来,保证在真正的应用容器启动前能通过所有测试项目。
+
+CMD 这个步骤是在新的 web 应用容器启动后执行的。在测试环节结束后马上就执行`/run-terrabox`命令进行编译。
+
+最后,Dockerfile 为应用指定了一个端口号,将容器内部端口号为3000的端口映射到主机(运行着 Docker 的机器)的一个随机分配的端口上。当 Docker 容器里面的应用需要响应来自外界的请求时,这个端口可用于反向代理或负载均衡。
+
+### Docker 容器内运行 Rails 应用 ###
+
+没有本地 Docker 镜像,从零开始部署一个中级规模的 Rails 应用大概需要100个 gems,进行100次整体测试,在使用2个核心实例和2GB内存的情况下,这些操作需要花费8分16秒。装上 Ruby、MySQL 和 Redis Docker 镜像后,部署应用花费了4分45秒。另外,如果从一个已存在的主应用镜像编译出一个新的 Docker 应用镜像出来,只需花费2分23秒。综上所述,部署一套新的 Rails 应用,解决其所有依赖关系(包括 MySQL 和 Redis),只需花我2分钟多一点的时间就够了。
+
+需要指出的一点是,我的应用上运行着一套完全测试套件,跑完测试需要花费额外1分钟时间。尽管是无意的,Docker 可以变成一套简单的持续集成环境,当测试失败后,Docker 会把“test-only”这个容器保留下来,用于分析出错原因。我可以在1分钟之内和我的客户一起验证新代码,保证不同版本的应用之间是完全隔离的,同操作系统也是隔离的。传统虚拟机启动系统时需要花费好几分钟,Docker 容器只花几秒。另外,一旦一个 Dockedr 镜像编译出来,并且针对我的某个版本的应用的测试都被通过,我就可以把这个镜像提交到 Docker 私服 Registry 上,可以被其他 Docker 主机下载下来并启动一个新的 Docker 容器,而这不过需要几秒钟时间。
+
+### 总结 ###
+
+Ansible 让我重新看到管理基础设施的乐趣。Docker 让我有充分的信心能稳定处理应用部署过程中最重要的步骤——交付环节。双剑合璧,威力无穷。
+
+从无到有搭建一个完整的 Rails 应用可以在12分钟内完成,这种速度放在任何场合都是令人印象深刻的。能获得一个免费的持续集成环境,可以查看不同版本的应用之间的区别,不会影响到同主机上已经在运行的应用,这些功能强大到难以置信,让我感到很兴奋。在文章的最后,我只希望你能感受到我的兴奋。
+
+我在2014年1月伦敦 Docker 会议上讲过这个主题,[已经分享到 Speakerdeck][7]了。
+
+如果想获得更多的关于 Ansible 和 Docker 的内容,请订阅 [changlog 周报][8],它会在每周六推送一周最有价值的关于这两个主题的新闻链接。
+
+如果你想为我们的 Changlog 写一篇文章,请[使用 Draft repo][9],他们会帮到你的。
+
+下次见,[Gerhard][a]。
+
+--------------------------------------------------------------------------------
+
+via: http://thechangelog.com/ansible-docker/
+
+作者:[Gerhard Lazu][a]
+译者:[bazz2](https://github.com/bazz2)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://twitter.com/gerhardlazu
+[1]:https://www.docker.io/
+[2]:https://github.com/ansible/ansible
+[3]:http://ansible.com/
+[4]:http://docker.io/
+[5]:http://en.wikipedia.org/wiki/Single_responsibility_principle
+[6]:http://blog.docker.io/2013/10/docker-0-6-5-links-container-naming-advanced-port-redirects-host-integration/
+[7]:https://speakerdeck.com/gerhardlazu/ansible-and-docker-the-path-to-continuous-delivery-part-1
+[8]:http://thechangelog.com/weekly/
+[9]:https://github.com/thechangelog/draft
diff --git a/translated/tech/20141017 How to check hard disk health on Linux using smartmontools.md b/translated/tech/20141017 How to check hard disk health on Linux using smartmontools.md
new file mode 100644
index 0000000000..9a3a743eda
--- /dev/null
+++ b/translated/tech/20141017 How to check hard disk health on Linux using smartmontools.md
@@ -0,0 +1,150 @@
+在Linux上使用smartmontools查看硬盘的健康状态
+================================================================================
+要说Linux用户最不愿意看到的事情,莫过于在毫无警告的情况下发现硬盘崩溃了。诸如[RAID][2]的[备份][1]和存储技术可以在任何时候帮用户恢复数据,但为预防硬件突然崩溃造成数据丢失所花费的代价却是相当可观的,特别是在用户从来没有提前考虑过在这些情况下的应对措施时。
+
+为了避免遇到这种困境,用户可以试用一款叫做[smartmontools][3]的软件包程序,它通过使用自我监控(Self-Monitoring)、分析(Analysis)和报告(Reporting)三种技术(缩写为S.M.A.R.T或SMART)来管理和监控存储硬件。如今大部分的ATA/SATA、SCSI/SAS和固态硬盘都搭载内置的SMART系统。SMART的目的是监控硬盘的可靠性、预测磁盘故障和执行各种类型的磁盘自检。smartmontools由smartctl和smartd两部分工具程序组成,它们一起为Linux平台提供对磁盘退化和故障的高级警告。
+
+这篇文章会描述Linux上smartmontools的安装和配置方法。
+
+### 安装Smartmontools ###
+
+由于smartmontools在大部分Linux发行版的基本软件库中都可用,所以安装很方便。
+
+#### Debian和其衍生版:####
+
+ # aptitude install smartmontools
+
+#### 基于Red Hat的发行版:####
+
+ # yum install smartmontools
+
+### 使用Smartctl检测硬盘的健康状况 ###
+
+首先,使用下面的命令列出和系统相连的硬盘:
+
+ # ls -l /dev | grep -E 'sd|hd'
+
+输出结果和下图类似:
+
+
+
+其中sdx代表分配给机器上对应硬盘上的设备名。
+
+如果想要显示出某个指定硬盘的信息(比如设备模式、S/N、固件版本、大小、ATA版本/修订号、SMART功能的可用性和状态),在运行smartctl命令时添加"--info"选项,并按如下所示指定硬盘的设备名。
+
+在本例中,选择/dev/sda。
+
+ # smartctl --info /dev/sda
+
+
+
+尽管最开始可能不会注意到ATA(译者注:硬盘接口技术)的版本信息,但当需要替换硬盘时它确实是最重要的因素之一。每一代ATA版本都保持向下兼容。例如,老的ATA-1或ATA-2设备可以正常工作在ATA-6和ATA-7接口上,但反过来就不行了。在设备版本和接口版本两者不匹配的情况下,它们会按照两者中版本较小的规范来运行。也就是说,在这种情况下,需要替换硬盘时,ATA-7硬盘是最安全的选择。
+
+可以通过这个命令来检测某个硬盘的健康状况:
+
+ # smartctl -s on -a /dev/sda
+
+在这个命令中,"-s on"标志开启指定设备上的SMART功能。如果/dev/sda上已开启SMART支持,那就省略它。
+
+硬盘的SMART信息包含很多部分。其中,"READ SMART DATA"部分显示出硬盘的整体健康状况。
+
+ === START OF READ SMART DATA SECTION ===
+ SMART overall-health self-assessment rest result: PASSED
+
+这个测试的结果是PASSED或FAILED。后者表示即将出现硬件故障,所以需要开始备份这块磁盘上的重要数据!
+
+下一个需要关注的地方是[SMART属性][4]表,如下所示。
+
+
+
+基本上,SMART属性表列出了制造商在硬盘中定义好的属性值,以及这些属性相关的故障阈值。这个表由驱动固件自动生成和更新。
+
+- **ID**:属性ID,通常是一个1到255之间的十进制或十六进制的数字。
+- **ATTRIBUTE_NAME**:硬盘制造商定义的属性名。
+- **FLAG**:属性操作标志(可以忽略)。
+- **VALUE**:这是表格中最重要的信息之一,代表给定属性的标准化值,在1到253之间。253意味着最好情况,1意味着最坏情况。取决于属性和制造商,初始化VALUE可以被设置成100或200.
+- **WORST**:所记录的最小VALUE。
+- **THRESH**:在报告硬盘FAILED状态前,WORST可以允许的最小值。
+- **TYPE**:属性的类型(Pre-fail或Old_age)。Pre-fail类型的属性可被看成一个关键属性,表示参与磁盘的整体SMART健康评估(PASSED/FAILED)。如果任何Pre-fail类型的属性故障,那么可视为磁盘将要发生故障。另一方面,Old_age类型的属性可被看成一个非关键的属性(如正常的磁盘磨损),表示不会使磁盘本身发生故障。
+- **UPDATED**:表示属性的更新频率。Offline代表磁盘上执行离线测试的时间。
+- **WHEN_FAILED**:如果VALUE小于等于THRESH,会被设置成“FAILING_NOW”;如果WORST小于等于THRESH会被设置成“In_the_past”;如果都不是,会被设置成“-”。在“FAILING_NOW”情况下,需要备份重要文件ASAP,特别是属性是Pre-fail类型时。“In_the_past”代表属性已经故障了,但在运行测试的时候没问题。“-”代表这个属性从没故障过。
+- **RAW_VALUE**:制造商定义的原始值,从VALUE派生。
+
+这时候你可能会想,“是的,smartctl看起来是个不错的工具,但我更想知道如何避免手动运行的麻烦。”如果能够以指定的间隔运行,同时又能通知我测试结果,那不是更好吗?”
+
+好消息是,这个功能已经有了。是smartd发挥作用的时候了!
+
+### 配置Smartctl和Smartd实现实时监控 ###
+
+首先,编辑smartctl的配置文件(/etc/default/smartmontools)以便在系统启动时启动smartd,并以秒为单位指定间隔时间(如7200 = 2小时)。
+
+ start_smartd=yes
+ smartd_opts="--interval=7200"
+
+下一步,编辑smartd的配置文件(/etc/smartd.conf),添加以下行内容。
+
+ /dev/sda -m myemail@mydomain.com -M test
+
+- **-m **:指定发送测试报告到某个电子邮件地址。这里可以是系统用户比如root,或者如果服务器已经配置成发送电子邮件到系统外部,则是类似于myemail@mydomain.com的邮件地址。
+- **-M **:指定发送邮件报告的期望类型。
+ - **once**:为检测到的每种磁盘问题只发送一封警告邮件。
+ - **daily**:为检测到的每种磁盘问题每隔一天发送一封额外的警告提醒邮件。
+ - **diminishing**:为检测到的每种问题发送一封额外的警告提醒邮件,开始是每隔一天,然后每隔两天,每隔四天,以此类推。每个间隔是前一次间隔的2倍。
+ - **test**:只要smartd一启动,立即发送一封测试邮件。
+ - **exec PATH**:取代默认的邮件命令,运行PATH路径下的可执行文件。PATH必须指向一个可执行的二进制文件或脚本。当检测到一个问题时,可以指定执行一个期望的动作(闪烁控制台、关闭系统等等)。
+
+保存改动并重启smartd。
+
+smartd发送的邮件应该是这个样子。
+
+
+
+在上图中,没有检测到错误。如果实际上检测到了错误,那么错误会出现在“下列警告/错误由smartd守护进程写入日志”这一行的下面。
+
+最后,可以使用“-s”标志和形如“T/MM/DD/d/HH”的正则表达式按照想要的调度方案执行测试,其中:
+
+正则表达式中的T代表测试的类型:
+
+- L:长测试
+- S:短测试
+- C:传输测试(仅限ATA)
+- O:离线测试(仅限ATA)
+
+其它的字符代表测试执行的日期和时间:
+
+- MM是一年中的月份。
+- DD是一月中的天份。
+- HH是一天中的小时。
+- d是一个星期中的某天(从1=周一到7=周日)。
+- MM、DD和HH使用两位十进制数字表示。
+
+在上述表达中的小圆点表示所有可能的值。形如'(A|B|C)'在圆括号里的表达式表示三个可能值A、B和C中的任意一个。形如[1-5]在方括号中的表达式表示1到5的范围(包含5).
+
+例如,想要在每个工作日的下午一点为所有的磁盘执行一次长测试,在/etc/smartd.conf中添加如下行内容。确保编辑完重启smartd。
+
+ DEVICESCAN -s (L/../../[1-5]/13)
+
+### 总结 ###
+
+无论你想要快速查看磁盘的电子和机械性能,还是对整个磁盘执行一次长时间扫描测试,都不要让自己陷入日复一日地执行命令中而忘记了定期检测磁盘的健康状态。多关注磁盘的健康状况,你会受益的!
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/check-hard-disk-health-linux-smartmontools.html
+
+作者:[Gabriel Cánepa][a]
+译者:[KayGuoWhu](https://github.com/KayGuoWhu)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/gabriel
+[1]:http://xmodulo.com/how-to-create-secure-incremental-offsite-backup-in-linux.html
+[2]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
+[3]:http://www.smartmontools.org/
+[4]:http://en.wikipedia.org/wiki/S.M.A.R.T.
+
+
+
+
+
diff --git a/translated/tech/20141017 pidstat - Monitor and Find Statistics for Linux Procesess.md b/translated/tech/20141017 pidstat - Monitor and Find Statistics for Linux Procesess.md
new file mode 100644
index 0000000000..7709f77f11
--- /dev/null
+++ b/translated/tech/20141017 pidstat - Monitor and Find Statistics for Linux Procesess.md
@@ -0,0 +1,90 @@
+pidstat - 监控并统计Linux进程的数据
+================================================================================
+**pidstat**命令用来监控被Linux内核管理的独立任务(进程)。它输出每个受内核管理的任务的相关信息。pidstat命令也可以用来监控特定进程的子进程。区间参数具体说明各个报告间的时间间隔。它的值为0(或者没有参数)说明进程的统计数据的时间是从系统启动开始计算的。
+
+### 如何安装pidstat ###
+
+pidstat 是sysstat软件套件的一部分,sysstat包含很多监控linux系统行为的工具,它能够从大多数linux发行版的软件源中获得。
+
+在Debian/Ubuntu系统中可以使用下面的命令来安装
+
+ # apt-get install sysstat
+
+CentOS/Fedora/RHEL版本的linux中则使用下面的命令:
+
+ # yum install sysstat
+
+### 使用pidstat ###
+
+使用pidstat不加任何参数等价于加上-p但是只有正在活动的任务会被显示出来。
+
+ # pidstat
+
+
+
+在结果中你能看到如下内容:
+
+- **PID** - 被监控的进程的进程号
+- **%usr** - 当在用户层执行(应用程序)时这个进程的cpu使用率。注意这个字段计算的cpu时间不包括在虚拟处理器中使用花去的时间。
+- **%system** - 这个进程在系统级别使用时的cpu使用率。
+- **%guest** - 在虚拟机中的cpu使用率
+- **%CPU** - 进程总的cpu使用率。在SMP环境(多处理器)中,cpu使用率会根据cpu的数量进行划分当你在命令行中输入-I参数。
+- **CPU** - 这个进程能够使用的处理器数目
+- **Command** - 这个进程的命令名称。
+
+### I/O 统计数据 ###
+
+通过使用-d参数来得到I/O的统计数据。比如:
+
+ # pidstat -d -p 8472
+
+
+
+IO 输出会显示一些内的条目:
+
+- **kB_rd/s** - 进程从硬盘上的读取速度
+- **kB_wr/s** - 进程向硬盘中的写入速度
+- **kB_ccwr/s** - 进程写入磁盘被取消的速率
+
+### Page faults and memory usage ###
+### Page faults和内存使用 ###
+
+使用-r标记你能够得到内存使用情况的数据。
+
+
+
+重要的条目:
+
+- **minflt/s** - 从内存中加载数据时每秒钟出现的小的错误的数目
+- **majflt/s** - 从内存中加载数据时每秒出现的较大错误的数目
+- **VSZ** - 虚拟容量:整个进程的虚拟内存使用
+- **RSS** - 长期的内存使用:进程非交换物理内存的使用
+
+### 举例 ###
+
+**1.** 你可以通过使用下面的命令来监测内存使用
+
+ # pidstat -r 2 5
+
+这会给你5份关于page faults的统计数据结果,间隔2s。这将会更容易的定位出现问题的进程。
+
+**2.** 显示所有mysql server的子进程
+
+ # pidstat -T CHILD -C mysql
+
+**3.** To combine all statistics in a single report you can use:
+**3.** 将所有的统计数据结合到一个简单的结果记录中:
+
+ # pidstat -urd -h
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-command/linux-pidstat-monitor-statistics-procesess/
+
+作者:[Adrian Dinu][a]
+译者:[John](https://github.com/johnhoow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/adriand/
diff --git a/translated/tech/20141021 How to create and use Python CGI scripts.md b/translated/tech/20141021 How to create and use Python CGI scripts.md
new file mode 100644
index 0000000000..1604366d16
--- /dev/null
+++ b/translated/tech/20141021 How to create and use Python CGI scripts.md
@@ -0,0 +1,158 @@
+如何创建和使用Python CGI脚本
+===
+
+你是否想使用Python语言创建一个网页,或者处理用户从web表单输入的数据?这些任务可以通过Python CGI(公用网关接口)脚本以及一个Apache web服务器实现。当用户请求一个指定URL或者和网页交互(比如点击""提交"按钮)的时候,CGI脚本就会被web服务器启用。CGI脚本调用执行完毕后,它的输出结果就会被web服务器用来创建显示给用户的网页。
+
+### 配置Apache web服务器,让其能运行CGI脚本 ###
+
+在这个教程里,我们假设Apache web服务器已经安装好,并已运行。这篇教程使用的Apache web服务器(版本2.2.15,用于CentOS发行版6.5)运行在本地主机(127.0.0.1),并且监听80端口,如下面的Apache指令指定一样:
+
+ ServerName 127.0.0.1:80
+ Listen 80
+
+下面举例中的HTML文件存放在web服务器上的/var/www/html目录下,并通过DocumentRoot指令指定(指定网页文件所在目录):
+
+ DocumentRoot "/var/www/html"
+
+现在尝试请求URL:http://localhost/page1.html
+
+这将返回web服务器中下面文件的内容:
+
+ /var/www/html/page1.html
+
+为了启用CGI脚本,我们必须指定CGI脚本在web服务器上的位置,需要用到ScriptAlias指令:
+
+ ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
+
+以上指令表明CGI脚本保存在web服务器的/var/www/cgi-bin目录,请求URL里包含/cgi-bin/的将会搜索这个目录下的CGI脚本。
+
+我们必须还要明确CGI脚本在/var/www/cgi-bin目录下有执行权限,还要指定CGI脚本的文件扩展名。使用下面的指令:
+
+
+ Options +ExecCGI
+ AddHandler cgi-script .py
+
+
+下面访问URL:http://localhost/cgi-bin/myscript-1.py
+
+这将会调用web服务器中下面所示脚本:
+
+ /var/www/cgi-bin/myscript-1.py
+
+### 创建一个CGI脚本 ###
+
+在创建一个Python CGI脚本之前,你需要确认你已经安装了Python(这通常是默认安装的,但是安装版本可能会有所不同)。本篇教程使用的脚本是使用Python版本2.6.6编写的。你可以通过下面任意一命令(-V和--version参数将显示所安装Python的版本号)检查Python的版本。
+
+ $ python -V
+ $ python --version
+
+如果你的Python CGI脚本要用来处理用户输入的数据(从一个web输入表单),然后你将需要导入Python cgi模块。这个模块可以处理用户通过web输入表单输入的数据。你可以在你的脚本中通过下面的语句导入该脚本:
+
+ import cgi
+
+你也必须修改Python CGI脚本的执行权限,以防止web服务器不能调用。可以通过下面的命令增加执行权限:
+
+ # chmod o+x myscript-1.py
+
+### Python CGI例子 ###
+
+涉及到Python CGI脚本的两个方案将会在下面讲述:
+
+- 使用Python脚本创建一个网页
+- 读取并显示用户输入的数据,并且在网页上显示结果
+
+注意:Python cgi模块在方案2中是必需的,因为这涉及到用户从web表单输入数据。
+
+### 例子1 :使用Python脚本创建一个网页 ###
+
+对于这个方案,我们将通过创建包含一个单一提交按钮的网页/var/www/html/page1.html开始。
+
+
+ Test Page 1
+
+
+
+当"提交"按钮被点击,/var/www/cgi-bin/myscript-1.py脚本将被调用(通过action参数指定)。通过设置方法参数为"get"来指定一个"GET"请求,服务器将会返回指定的网页。/var/www/html/page1.html在浏览器中的显示情况如下:
+
+
+
+/var/www/cgi-bin/myscript-1.py的内容如下:
+
+ #!/usr/bin/python
+ print "Content-Type: text/html"
+ print ""
+ print ""
+ print "CGI Script Output
"
+ print "This page was generated by a Python CGI script.
"
+ print ""
+
+第一行声明表示这是使用 /usr/bin/python命令运行的Python脚本。"Content-Type: text/html"打印语句是必需的,这是为了让web服务器知道接受自CGI脚本的输出类型。其余的语句用来输出HTML格式的其余网页内容。
+
+当"Submit"按钮点击,下面的网页将返回:
+
+
+
+这个例子的要点是你可以决定哪些信息可以被CGI脚本返回。这可能包括日志文件的内容,当前登陆用户的列表,或者今天的日期。在你处理时拥有所有python库的可能性是无穷无尽的。
+
+### 例子2:读取并显示用户输入的数据,并将结果显示在网页上 ###
+
+对于这个方案,我们将通过创建一个含有三个输入域和一个提交按钮的网页/var/www/html/page2.html开始。
+
+
+ Test Page 2
+
+
+
+当"Submit"按钮点击,/var/www/cgi-bin/myscript-2.py脚本将被执行(通过action参数指定)。/var/www//html/page2.html显示在web浏览器中的图片如下所示(注意,三个输入域已经被填写了):
+
+
+
+/var/www/cgi-bin/myscript-2.py的内容如下:
+
+ #!/usr/bin/python
+ import cgi
+ form = cgi.FieldStorage()
+ print "Content-Type: text/html"
+ print ""
+ print ""
+ print "CGI Script Output
"
+ print ""
+ print "The user entered data are:
"
+ print "First Name: " + form["firstName"].value + "
"
+ print "Last Name: " + form["lastName"].value + "
"
+ print "Position: " + form["position"].value + "
"
+ print "
"
+ print ""
+
+正如前面提到,import cgi语句需要用来确保能够处理用户通过web输入表单输入的数据。web输入表单被封装在一个表单对象中,叫做cgi.FieldStorage对象。一旦开始,"Content-Type: text/html"是必需的,因为web服务器需要知道接受自CGI脚本的输出格式。用户输入的数据在包含form["firstName"].value,form["lastName"].value, and form["position"].value的语句中被接受。那些中括号中的名称和**/var/www/html/page2.html**文本输入域中定义的名称参数一致。
+
+当网页上的"Submit"按钮被点击,下面的网页将被返回。
+
+
+
+这个例子的要点就是你可以很容易地读取并显示用户在web表单上输入的数据。除了以字符串的方式处理数据,你也可以用Python将用户输入的数据转化为可用于数值计算的数字。
+
+### 结论 ###
+
+本教程演示了如何使用Python CGI脚本创建网页并处理用户在网页表单输入的数据。查阅更多关于Apache CGI脚本的信息,点击[这里][1]。查阅更多关于Python cgi模块的信息,点击[这里][2]。
+
+---
+
+via: http://xmodulo.com/create-use-python-cgi-scripts.html
+
+作者:[Joshua Reed][a]
+译者:[su-kaiyao](https://github.com/su-kaiyao)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/joshua
+[1]:http://httpd.apache.org/docs/2.2/howto/cgi.html
+[2]:https://docs.python.org/2/library/cgi.html#module-cgi
diff --git a/translated/tech/20141022 Linux FAQs with Answers--How to change character encoding of a text file on Linux.md b/translated/tech/20141022 Linux FAQs with Answers--How to change character encoding of a text file on Linux.md
new file mode 100644
index 0000000000..a2bec2833b
--- /dev/null
+++ b/translated/tech/20141022 Linux FAQs with Answers--How to change character encoding of a text file on Linux.md
@@ -0,0 +1,52 @@
+Linux 有问必答 -- 在 Linux 如何更改文本文件的字符编码
+================================================================================
+> **问题**:在我的 Linux 系统中有一个编码为 iso-8859-1 的字幕文件,其中部分字符无法正常显示,我想把文本改为 utf8 编码。在 Linux 张, 有没有一个好的工具来转换文本文件的字符编码?
+
+正如我们所知道的那样,电脑只能够处理低级的二进制数字,并不能直接处理字符。当一个文本文件被存储时,文件中的每一个字符都被映射成二进制数字,实际存储在硬盘中的正是这些“二进制数字”。之后当程序打开文本文件时,所有二进制数字都被读入并映射回原始的可读字符。只有当所有需要访问这个文件的程序都能够“理解”它的编码,即二进制数字到字符的映射时,这个“保存和打开”的过程才能很好地完成,这也确保了可理解数据的往返过程。
+
+如果不同的程序使用不同的编码来处理同一个文件,源文件中的特殊字符就无法正常显示。这里的特殊字符指的是非英文字母的字符,例如带重音的字符(比如 ñ,á,ü)。
+
+然后问题就来了: 1)我们如何确定一个确定的文本文件使用的是什么字符编码? 2)我们如何把文件转换成已选择的字符编码?
+
+### 步骤一 ###
+
+为了确定文件的字符编码,我们使用一个名为 “file” 的命令行工具。因为 file 命令是一个标准的 UNIX 程序,所以我们可以在所有现代的 Linux 发行版中找到它。
+
+运行下面的命令:
+
+ $ file --mime-encoding filename
+
+
+
+### 步骤二 ###
+
+下一步是查看你的 Linux 系统所支持的文件编码种类。为此,我们使用名为 iconv 短工具及 “-l” 选项(L 的小写)来列出所有当前支持的编码。
+
+ $ iconv -l
+
+iconv 工具是 GNU libc 库组成部分,因此它在所有 Linux 发行版中都是开箱即用的。
+
+### 步骤三 ###
+
+在我们在我们的 Linux 系统所支持的编码里面选定了目标编码之后,运行下面的命令来完成编码转换:
+
+ $ iconv -f old_encoding -t new_encoding filename
+
+例如,把 iso-8859-1 编码转换为 utf-8 编码:
+
+ $ iconv -f iso-8859-1 -t utf-8 input.txt
+
+
+
+了解了我们演示的如何使用这些工具之后,你可以像下面这样修复一个受损的字幕文件:
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/change-character-encoding-text-file-linux.html
+
+译者:[wangjiezhe](https://github.com/wangjiezhe)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/tech/20141022 Linux FAQs with Answers--How to fix sshd error--could not load host key.md b/translated/tech/20141022 Linux FAQs with Answers--How to fix sshd error--could not load host key.md
new file mode 100644
index 0000000000..83c2dba40e
--- /dev/null
+++ b/translated/tech/20141022 Linux FAQs with Answers--How to fix sshd error--could not load host key.md
@@ -0,0 +1,63 @@
+Linux有问必答——如何修复“sshd error: could not load host key”
+================================================================================
+> **问题**:当我尝试SSH到一台远程服务器时,SSH客户端登陆失败并提示“Connection closed by X.X.X.X”。在SSH服务器那端,我看到这样的错误消息:“sshd error: could not load host key.”。这发生了什么问题,我怎样才能修复该错误?
+
+该SSH连接错误的详细症状如下。
+
+**SSH客户端方面**:当你尝试SSH到一台远程主机时,你没有看见登录屏幕,你的SSH连接就立即关闭,并提示此消息:“Connection closed by X.X.X.X”。
+
+**SSH服务器方面**:在系统日志中,你看到如下错误消息(如,在Debian/Ubuntu上,/var/log/auth.log)。
+
+ Oct 16 08:59:45 openstack sshd[1214]: error: Could not load host key: /etc/ssh/ssh_host_rsa_key
+ Oct 16 08:59:45 openstack sshd[1214]: error: Could not load host key: /etc/ssh/ssh_host_dsa_key
+ Oct 16 08:59:45 openstack sshd[1214]: error: Could not load host key: /etc/ssh/ssh_host_ecdsa_key
+ Oct 16 08:59:45 openstack sshd[1214]: fatal: No supported key exchange algorithms [preauth]
+
+导致该问题的根源是,sshd守护进程不知怎么地不能加载SSH主机密钥了。
+
+当OpenSSH服务器第一次安装到Linux系统时,SSH主机密钥应该会自动生成以供后续使用。如果,不管怎样,密钥生成过程没有成功完成,那就会导致这样的SSH登录问题。
+
+让我们检查能否在相应的地方找到SSH主机密钥。
+
+ $ ls -al /etc/ssh/ssh*key
+
+
+
+如果SSH主机密钥在那里找不到,或者它们的大小被切短成为0(就像上面那样),你需要从头开始重新生成主机密钥。
+
+### 重新生成SSH主机密钥 ###
+
+在Debian、Ubuntu或其衍生版上,你可以使用dpkg-reconfigure工具来重新生成SSH主机密钥,过程如下:
+
+ $ sudo rm -r /etc/ssh/ssh*key
+ $ sudo dpkg-reconfigure openssh-server
+
+
+
+在CentOS、RHEL或Fedora上,你所要做的是,删除现存(有问题的)密钥,然后重启sshd服务。
+
+ $ sudo rm -r /etc/ssh/ssh*key
+ $ sudo systemctl restart sshd
+
+另外一个重新生成SSH主机密钥的方式是,使用ssh-keygen命令来手动生成。
+
+ $ sudo ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
+ $ sudo ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
+ $ sudo ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key
+
+
+
+在生成新的SSH主机密钥后,确保它们能在/etc/ssh目录中找到。此时,不必重启sshd服务。
+
+ $ ls -al /etc/ssh/ssh*key
+
+现在,再试试SSH到SSH服务器吧,看看问题是否已经离你而去了。
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/sshd-error-could-not-load-host-key.html
+
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/tech/20141023 How to turn your CentOS box into a BGP router using Quagga.md b/translated/tech/20141023 How to turn your CentOS box into a BGP router using Quagga.md
new file mode 100644
index 0000000000..261abb7767
--- /dev/null
+++ b/translated/tech/20141023 How to turn your CentOS box into a BGP router using Quagga.md
@@ -0,0 +1,365 @@
+How to turn your CentOS box into a BGP router using Quagga
+如何使用Quagga把你的CentOS系统变成一个BGP路由器?
+================================================================================
+
+
+在[之前的教程中][1](注:此文原文做过,文件名:“20140928 How to turn your CentOS box into an OSPF router using Quagga.md”,如果前面翻译发布了,可以修改此链接),我对如何简单地使用Quagga把CentOS系统变成一个不折不扣地OSPF路由器做了一些描述,Quagga是一个开源路由软件套件.在这个教程中,我将会着重**把一个Linux系统变成一个BGP路由器,又是使用Quagga**,演示如何建立BGP与其它BGP路由器对等.
+
+
+在我们进入细节之前,一些BGP的背景知识还是必要的.边界网关协议(或者BGP)是互联网的域间路由协议的实际标准。在BGP术语中,全球互联网是由成千上万相关联的自治系统(ASE)组成,其中每一个AS代表每一个特定运营商提供的一个网络管理域.
+
+
+
+为了使其网络在全球范围内路由可达,每一个AS需要知道如何在英特网中到达其它的AS.这时候BGP出来取代这个角色了.BGP作为一种语言用于一个AS去与相邻的AS交换路由信息的一种工具.这些路由信息通常被称为BGP线路或者BGP前缀,包括AS号(ASN;全球唯一号码)以及相关的IP地址块.一旦所有的BGP线路被当地的BGP路由表学习和填充,每一个AS将会知道如何到达互联网的任何公网IP.
+
+
+路由在不同域(ASes)的能力是BGP被称为外部网关协议(EGP)或者域间协议的主要原因.就如一些路由协议例如OSPF,IS-IS,RIP和EIGRP都是内部网关协议(IGPs)或者域内路由协议.
+
+
+### 测试方案 ###
+
+
+在这个教程中,让我们来关注以下拓扑.
+
+
+
+
+我们假设运营商A想要建立一个BGP来与运营商B对等交换路由.它们的AS号和IP地址空间登细节如下所示.
+
+- **运营商 A**: ASN (100), IP地址空间 (100.100.0.0/22), 分配给BGP路由器eth1网卡的IP地址(100.100.1.1)
+
+
+- **运营商 B**: ASN (200), IP地址空间 (200.200.0.0/22), 分配给BGP路由器eth1网卡的IP地址(200.200.1.1)
+
+
+路由器A和路由器B使用100.100.0.0/30子网来连接到对方.从理论上来说,任何子网从运营商那里都是可达的,可互连的.在真实场景中,建议使用掩码为30位的公网IP地址空间来实现运营商A和运营商B之间的连通.
+
+
+### 在 CentOS中安装Quagga ###
+
+如果Quagga还没被安装,我们可以使用yum来安装Quagga.
+
+ # yum install quagga
+
+
+如果你正在使用的是CentOS7系统,你需要应用一下策略来设置SELinux.否则,SElinux将会阻止Zebra守护进程写入它的配置目录.如果你正在使用的是CentOS6,你可以跳过这一步.
+
+ # setsebool -P zebra_write_config 1
+
+
+
+Quagga软件套件包含几个守护进程,这些进程可以一起工作.关于BGP路由,我们将把重点放在建立一下2个守护进程.
+
+
+- **Zebra**:一个核心守护进程用于内核接口和静态路由.
+- **BGPd**:一个BGP守护进程.
+
+
+### 配置日志记录 ###
+
+在Quagga被安装猴,下一步就是配置Zebra来管理BGP路由器的网络接口.我们通过创建一个Zebra配置文件和启用日志记录来开始第一步.
+
+ # cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
+
+
+在CentOS6系统中:
+
+ # service zebra start
+ # chkconfig zebra on
+
+
+在CentOS7系统中:
+ # systemctl start zebra
+ # systemctl enable zebra
+
+
+Quagga提供了一个叫做vtysh特有的命令行工具,你可以输入路由器厂商(例如Cisco和Juniper)兼容和支持的命令.我们将使用vtysh shell来配置BGP路由在教程的其余部分.
+
+启动vtysh shell 命令,输入:
+
+ # vtysh
+
+
+提示将被改成主机名,这表明你是在vtysh shell中.
+
+
+ Router-A#
+
+现在我们将使用以下命令来为Zebra配置日志文件:
+
+ Router-A# configure terminal
+ Router-A(config)# log file /var/log/quagga/quagga.log
+ Router-A(config)# exit
+
+永久保存Zebra配置:
+
+ Router-A# write
+
+在路由器B操作同样的步骤.
+
+
+### 配置对等的IP地址 ###
+
+
+下一步,我们将在可用的接口上配置对等的IP地址.
+
+ Router-A# show interface #显示接口信息
+
+----------
+
+ Interface eth0 is up, line protocol detection is disabled
+ . . . . .
+ Interface eth1 is up, line protocol detection is disabled
+ . . . . .
+
+配置eth0接口的参数:
+
+ site-A-RTR# configure terminal
+ site-A-RTR(config)# interface eth0
+ site-A-RTR(config-if)# ip address 100.100.0.1/30
+ site-A-RTR(config-if)# description "to Router-B"
+ site-A-RTR(config-if)# no shutdown
+ site-A-RTR(config-if)# exit
+
+
+继续配置eth1接口的参数:
+
+ site-A-RTR(config)# interface eth1
+ site-A-RTR(config-if)# ip address 100.100.1.1/24
+ site-A-RTR(config-if)# description "test ip from provider A network"
+ site-A-RTR(config-if)# no shutdown
+ site-A-RTR(config-if)# exit
+
+现在确认配置:
+
+ Router-A# show interface
+
+----------
+
+ Interface eth0 is up, line protocol detection is disabled
+ Description: "to Router-B"
+ inet 100.100.0.1/30 broadcast 100.100.0.3
+ Interface eth1 is up, line protocol detection is disabled
+ Description: "test ip from provider A network"
+ inet 100.100.1.1/24 broadcast 100.100.1.255
+
+----------
+
+ Router-A# show interface description #现实接口描述
+
+----------
+
+ Interface Status Protocol Description
+ eth0 up unknown "to Router-B"
+ eth1 up unknown "test ip from provider A network"
+
+
+如果一切看起来正常,别忘记保存配置.
+
+ Router-A# write
+
+同样地,在路由器B重复一次配置.
+
+
+在我们继续下一步之前,确认下彼此的IP是可以ping通的.
+
+ Router-A# ping 100.100.0.2
+
+----------
+
+ PING 100.100.0.2 (100.100.0.2) 56(84) bytes of data.
+ 64 bytes from 100.100.0.2: icmp_seq=1 ttl=64 time=0.616 ms
+
+下一步,我们将继续配置BGP对等和前缀设置.
+
+
+### 配置BGP对等 ###
+
+
+
+Quagga守护进程负责BGP的服务叫bgpd.首先我们来准备它的配置文件.
+
+ # cp /usr/share/doc/quagga-XXXXXXX/bgpd.conf.sample /etc/quagga/bgpd.conf
+
+
+在CentOS6系统中:
+
+ # service bgpd start
+ # chkconfig bgpd on
+
+
+在CentOS7中
+
+ # systemctl start bgpd
+ # systemctl enable bgpd
+
+现在,让我们来进入Quagga 的shell.
+
+ # vtysh
+
+
+第一步,我们要确认当前没有已经配置的BGP会话.在一些版本,我们可能会发现一个AS号为7675的BGP会话.由于我们不需要这个会话,所以把它移除.
+
+ Router-A# show running-config
+
+----------
+
+ ... ... ...
+ router bgp 7675
+ bgp router-id 200.200.1.1
+ ... ... ...
+
+
+我们将移除一些预先配置好的BGP会话,并建立我们所需的会话取而代之.
+
+ Router-A# configure terminal
+ Router-A(config)# no router bgp 7675
+ Router-A(config)# router bgp 100
+ Router-A(config)# no auto-summary
+ Router-A(config)# no synchronizaiton
+ Router-A(config-router)# neighbor 100.100.0.2 remote-as 200
+ Router-A(config-router)# neighbor 100.100.0.2 description "provider B"
+ Router-A(config-router)# exit
+ Router-A(config)# exit
+ Router-A# write
+
+
+
+路由器B将用同样的方式来进行配置,以下配置提供作为参考.
+
+ Router-B# configure terminal
+ Router-B(config)# no router bgp 7675
+ Router-B(config)# router bgp 200
+ Router-B(config)# no auto-summary
+ Router-B(config)# no synchronizaiton
+ Router-B(config-router)# neighbor 100.100.0.1 remote-as 100
+ Router-B(config-router)# neighbor 100.100.0.1 description "provider A"
+ Router-B(config-router)# exit
+ Router-B(config)# exit
+ Router-B# write
+
+
+当相关的路由器都被配置好,两台路由器之间的对等将被建立.现在让我们通过运行下面的命令来确认:
+
+ Router-A# show ip bgp summary
+
+
+
+
+从输出中,我们可以看到"State/PfxRcd"部分.如果对等关闭,输出将会现实"空闲"或者"活动'.请记住,单词'Active'这个词在路由器中总是不好的意思.它意味着路由器正在积极地寻找邻居,前缀或者路由.当对等是up状态,"State/PfxRcd"下的输出状态将会从特殊邻居接收到前缀号.
+
+在这个例子的输出中,BGP对等知识在AS100和AS200之间呈up状态.因此,没有前缀被更改,所以最右边列的数值是0.
+
+
+### 配置前缀通告 ###
+
+正如一开始提到,AS 100将以100.100.0.0/22作为通告,在我们的例子中AS 200将同样以200.200.0.0/22作为通告.这些前缀需要被添加到BGP配置如下.
+
+在路由器-A中:
+
+ Router-A# configure terminal
+ Router-A(config)# router bgp 100
+ Router-A(config)# network 100.100.0.0/22
+ Router-A(config)# exit
+ Router-A# write
+
+
+在路由器-B中:
+ Router-B# configure terminal
+ Router-B(config)# router bgp 200
+ Router-B(config)# network 200.200.0.0/22
+ Router-B(config)# exit
+ Router-B# write
+
+
+在这一点上,两个路由器会根据需要开始通告前缀.
+
+
+### 测试前缀通告 ###
+
+首先,让我们来确认前缀的数量是否被改变了.
+
+ Router-A# show ip bgp summary
+
+
+
+
+
+为了查看所接收的更多前缀细节,我们可以使用一下命令,这个命令用于显示邻居100.100.0.2所接收到的前缀总数.
+
+ Router-A# show ip bgp neighbors 100.100.0.2 advertised-routes
+
+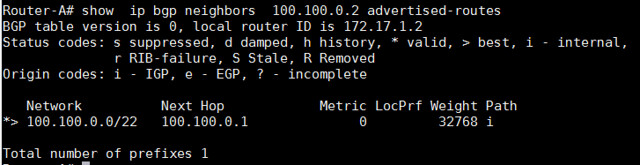
+
+
+查看哪一个前缀是我们从邻居接收到的:
+
+ Router-A# show ip bgp neighbors 100.100.0.2 routes
+
+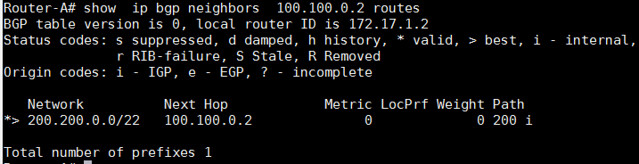
+
+
+我们也可以查看所有的BGP路由器:
+
+ Router-A# show ip bgp
+
+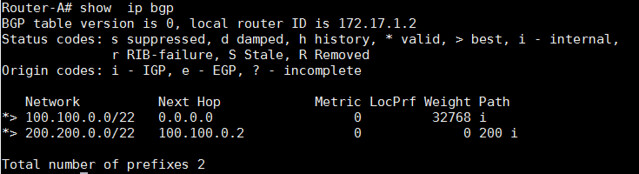
+
+
+以上的命令都可以被用于检查哪个路由器通过BGP在路由器表中被学习到.
+
+ Router-A# show ip route
+
+----------
+
+
+ 代码: K - 内核路由, C - 已链接 , S - 静态 , R - 路由信息协议 , O - 开放式最短路径优先协议,
+
+
+ I - 中间系统到中间系统的路由选择协议, B - 边界网关协议, > - 选择路由, * - FIB 路由
+
+ C>* 100.100.0.0/30 is directly connected, eth0
+ C>* 100.100.1.0/24 is directly connected, eth1
+ B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:06:45
+
+----------
+
+ Router-A# show ip route bgp
+
+----------
+
+ B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:08:13
+
+
+BGP学习到的路由也将会在Linux路由表中出现.
+
+ [root@Router-A~]# ip route
+
+----------
+
+ 100.100.0.0/30 dev eth0 proto kernel scope link src 100.100.0.1
+ 100.100.1.0/24 dev eth1 proto kernel scope link src 100.100.1.1
+ 200.200.0.0/22 via 100.100.0.2 dev eth0 proto zebra
+
+
+最后,我们将使用ping命令来测试连通.结果将成功ping通.
+
+ [root@Router-A~]# ping 200.200.1.1 -c 2
+
+
+总而言之,该教程将重点放在如何运行一个基本的BGP在CentOS系统中.当这个教程让你开始BGP的配置,那么一些更高级的设置例如设置过滤器,BGP属性调整,本地优先级和预先路径准备等.我将会在后续的教程中覆盖这些主题.
+
+希望这篇教程能给大家一些帮助.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/centos-bgp-router-quagga.html
+
+作者:[Sarmed Rahman][a]
+译者:[disylee](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/sarmed
+[1]:http://xmodulo.com/turn-centos-box-into-ospf-router-quagga.html
diff --git a/translated/tech/20141023 What is a good command-line calculator on Linux.md b/translated/tech/20141023 What is a good command-line calculator on Linux.md
new file mode 100644
index 0000000000..e86cb16ebd
--- /dev/null
+++ b/translated/tech/20141023 What is a good command-line calculator on Linux.md
@@ -0,0 +1,115 @@
+怎么样称得上是Linux下优秀的命令行计算器
+================================================================================
+每个现代的Linux桌面发行版都预装着一个带有图形界面的计算器程序。不过如果你的工作区中全是命令行窗口,那么你一定会在其中的一个命令行窗口中处理一些数字相关的问题。或许你在寻找一款基于命令行的计算器程序。如果是这样的话,[GNU bc][1](“basic calculator”的缩写)会是你不二的选择。当然Linux下又很多基于命令行的计算器应用,我认为GNU bc是功能最强大和最有用的。
+
+在GNU时代之前,bc实际上是一个著名的精密计算语言。它的诞生要追溯到70年代的Unix时期了。最初bc作为一个语法和C语言相似的编程语言而著名。随着时间的改变,最开始的bc演化成POSIX bc,最后变成了今天的GNU bc。
+
+### GNU bc的特性 ###
+
+现在的GNU bc是早期bc经过若干次改进和功能增强的结果。目前它被所有的主流GNU/Linux发行版所收纳。GNU bc支持高精度数字和多种数值类型(例如二进制、十进制、十六进制)的输入输出。
+
+如果你对C语言很熟悉的话,你会发现bc使用了和C语言一样或相似的算术操作符。受支持的操作符包括算术运算符(+,-,*,/,%,++,--)、比较运算符(<,>,==,!=,<=,>=)、逻辑运算符(!,&&,||)、位运算符(&,|,^,~,<<,>>)和复合赋值运算符(+=,-=,*=,/=,%=,&=,|=,^=,&&=,||=,<<=,>>=)。bc内置了很多有用的函数,像是平方根、正弦、余弦、反正弦、自然对数、指数等。
+
+### 如何使用GNU bc ###
+
+作为一个基于命令行的计算器,GNU bc的使用是没有限制的。在本文中,我会向大家介绍bc命令的几个常用的特性。如果你想要更加详细的指导,你可以查阅[官方指南][2]。
+
+如果你没有一个预先写好的bc脚本,那么你需要在交互模式下运行bc。在这种模式下,你输入的以回车结束的任何声明或者表达式会被立刻计算出结果。你需要输入以下命令来进入bc的交互界面。如果向退出bc,你可以输入'quit'并且按回车。
+
+ $ bc
+
+
+
+本文下面展示的例子应该在bc交互界面中输入。
+
+### 输入表达式 ###
+
+如果想要计算一个算术表达式,我们可以在闪烁的光标处输入该表达式,然后按回车确认。你也可以将该结果存储到一个变量中,然后在其他表达式中使用该变量。
+
+
+
+在一个bc的交互界面中,存在没有个数限制的命令历史记录。使用上方向键来查看之前输入的命令。如果你想限制历史记录保存的命令数量,你可以将一个名为history的特殊变量设置成你希望的数值。该变量默认为-1,也就是“历史记录数量没有限制”。
+
+### 输入输出进制切换 ###
+
+经常会发生的是,你输入一个表达式并且想使用二进制或者十六进制来显示结果。bc允许你在输入输出数字的进制间转换。输入和输出的数系基分别存储在ibase和obase变量中,默认值为10,有效的数值是2到16(或者环境变量BC_BASE_MAX的值).你只需要更改ibase和obase的值就可以在不同进制之间转换了。下面是一个求两个十六进制/二进制数和的例子:
+
+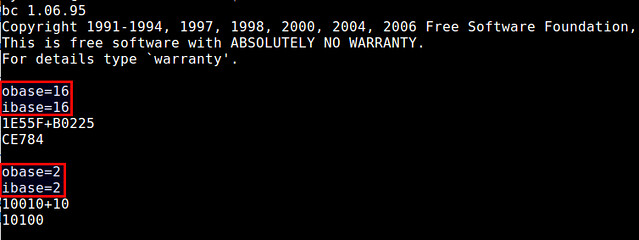
+
+需要注意的是,我有意地将obase=16放到了ibase=16前面,反过来则是不可以的。这个是因为如果我先输入ibase=16,那么随后输入的obase=16中的16会被认为是16进制的数字,也就是十进制的22。当然这个不是我们所期望的。
+
+### 调整精度 ###
+
+在bc中,数字的精度存储在一个名为scale的特殊变量中。该变量表示小数点后数字的个数。scale默认为0,意味着所有的数字和结果以整数形式储存。你可以通过改变scale这个特殊变量的值,来调整数值的精度。
+
+ scale=4
+
+
+
+### 使用内置函数 ###
+
+除了简单的算术操作符,GNU bc还通过外部的数学函数库来提供许多高级的数学函数。你可以在命令行界面使用“-l”选项来打开bc。
+
+这里描述了一些内置的函数。
+
+N的二次方根:
+
+ sqrt(N)
+
+X的正弦(X是弧度):
+
+ s(X)
+
+X的余弦(X是弧度):
+
+ c(X)
+
+X的反正弦(返回值是弧度):
+
+ a(X)
+
+X的自然对数:
+
+ l(X)
+
+X的指数对数:
+
+ e(X)
+
+### Other goodies as a language ###
+
+作为一个计算语言,GNU bc支持简单的声明(变量赋值、中断、返回等)、复合语句(if、while、for loop等)和自定义函数。在这里我不会涉及到这些特性的细节,不过你可以通过[官方指南][2]来学习如何使用这些特性。下面是一个简单的函数示例:
+
+ define dummy(x){
+ return(x * x);
+ }
+ dummy(9)
+ 81
+ dummy(4)
+ 16
+
+### 在非交互界面下使用GNU bc ###
+
+到目前为止,我们一直在交互界面下使用bc。不过更加流行的使用bc的方法是在没有交互界面的脚本中运行bc。这种情况下,你可以使用echo命令并且借助管道来向bc发送输入内容。例如:
+
+ $ echo "40*5" | bc
+ $ echo "scale=4; 10/3" | bc
+ $ echo "obase=16; ibase=2; 11101101101100010" | bc
+
+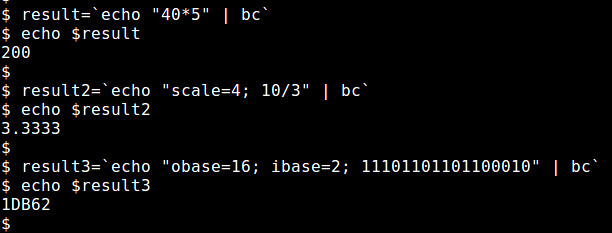
+
+总结以下,GNU bc是一款强大并且通用的基于命令行的计算器应用,因此它绝对不会让你失望。它预装在所有的现代Linux发行版中,bc可以让你不用离开命令行就可以进行高效的数学计算。所以,GNU bc一定会是你的最爱。
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/command-line-calculator-linux.html
+
+作者:[Dan Nanni][a]
+译者:[JonathanKang](https://github.com/JonathanKang)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://www.gnu.org/software/bc/
+[2]:https://www.gnu.org/software/bc/manual/bc.html
diff --git a/translated/tech/20141024 Amazing 25 Linux Performance Monitoring Tools.md b/translated/tech/20141024 Amazing 25 Linux Performance Monitoring Tools.md
new file mode 100644
index 0000000000..05b4b00e5c
--- /dev/null
+++ b/translated/tech/20141024 Amazing 25 Linux Performance Monitoring Tools.md
@@ -0,0 +1,290 @@
+25个linux性能监控工具
+================================================================================
+一段时间以来,我们在网上向读者介绍了如何为Linux以及类Linux操作系统配置多种不同的性能监控工具。在这篇文章中我们将罗列一系列使用最频繁的性能监控工具,并对介绍到的每一个工具提供了相应的简介链接,大致将其划分为两类,基于命令行的和提供图形化接口的。
+
+### 基于命令行的性能监控工具 ###
+
+#### 1. dstat - 多类型资源统计工具 ####
+
+该命令整合了**vmstat**,**iostat**和**ifstat**三种命令。同时增加了新的特性和功能允许你能够看到及时的不同的资源使用情况,从而能够使你对比和整合不同的资源使用情况。通过不同颜色和代码块布局的界面帮助你能够更加清晰容易的获取信息。它同时支持将信息数据导出到**cvs**格式文件中,从而用其他应用程序打开,或者导入到数据库中。你可以用该命令来[监控cpu,内存和网络状态随着时间的变化][1]。
+
+
+
+#### 2. atop - 相比top更好的ASCII码体验 ####
+
+使用**ASCII**码的命令行工具来显示一个性能监控工具能够记录显示所有进程活动。它不但能够展示每日的系统日志,也能够进行长期的进程活动分析,同时也能够高亮过载的系统使用资源。它包含了CPU,内存,交换空间,磁盘和网络层的度量指标。使用所用的功能只需在终端运行**atop**即可。当然你也可以使用[交互接口来显示][2]数据并进行排序。
+
+ # atop
+
+
+
+
+#### 3. Nmon - 类Unix系统的性能监控 ####
+
+Nmon为**Nigel's Monitor**缩写,它最早开发用来作为**AIX**的系统监控工具。它的特征是**在线模式**,该模式在终端中实时更新监控信息,同时使用光标操作来提高屏幕事件处理效率。使用**捕捉模式**能够将数据保存为**CSV**格式,方便进一步的处理和图形化展示。
+
+
+
+更多的信息参考我们的[nmon性能监控文章][3]。
+
+#### 4. slabtop - 显示内核slab缓存信息 ####
+
+个应用能够显示**缓存分配器**是如何管理Linux内核缓存不同类型的对象的。这个命令类似于top命令,区别是它重点实时显示内核slab缓存信息。它能够显示按照不同排序条件来显示最靠前的缓存列表。它同时也能够显示一个以slab层信息填充的统计题头。举例如下:
+
+ # slabtop --sort=a
+ # slabtop -s b
+ # slabtop -s c
+ # slabtop -s l
+ # slabtop -s v
+ # slabtop -s n
+ # slabtop -s o
+
+**更多信息参阅**[内核slab缓存文章][4]。
+
+#### 5. sar - 性能监控和瓶颈检查 ####
+
+**sar** 命令是为了标准输出在操作系统上所选的累积活动计数器内容信息。该基于计数值和时间间隔参数的**审计系统**,会按照指定的时间间隔输出指定次数的监控信息。如果时间间隔参数为设置为0,那么[sar命令将会显示系统从开机到当时时刻的平均统计信息][5]。有用的命令如下:
+
+ # sar -u 2 3
+ # sar –u –f /var/log/sa/sa05
+ # sar -P ALL 1 1
+ # sar -r 1 3
+ # sar -W 1 3
+
+#### 6. Saidar - 简单的统计监控工具 ####
+
+Saidar是一个**简单**且**轻量**的系统信息监控工具。虽然它无法提供大多性能报表,但是它能够通过一个简短友好的方式显示最有用的系统运行状况数据。你可以很容易地看到[up-time, average load,CPU,内存,进程,磁盘和网络接口][6]统计信息。
+
+ Usage: saidar [-d delay] [-c] [-v] [-h]
+
+ -d Sets the update time in seconds
+ -c Enables coloured output
+ -v Prints version number
+ -h Displays this help information.
+
+
+
+#### 7. top - 经典的Linux任务管理工具 ####
+
+作为一个广为认知的**Linux**工具,**top**出现在大多数的类Unix操作系统任务管理中。它可以显示当前正在运行的进程的列表,同时用户可以按照不同的查询条件对该列表进行排序。它主要显示了系统进程对**CPU**和内存的使用状况。top可以快速检查是哪个或哪几个进程挂起了你的系统。你可以在[这里][7]看到top使用的例子。 你可以在终端输入top来运行它并进入到交互模式:
+
+ Quick cheat sheet for interactive mode:
+
+ GLOBAL_Commands: ?, =, A, B, d, G, h, I, k, q, r, s, W, Z
+ SUMMARY_Area_Commands: l, m, t, 1
+ TASK_Area_Commands Appearance: b, x, y, z Content: c, f, H, o, S, u Size: #, i, n Sorting: <, >, F, O, R
+ COLOR_Mapping: , a, B, b, H, M, q, S, T, w, z, 0 - 7
+ COMMANDS_for_Windows: -, _, =, +, A, a, G, g, w
+
+
+
+#### 8. Sysdig - 系统进程的高级视图 ####
+
+**Sasdig**是一个能够让系统管理员和开发人员前所未有的洞察其系统行为的监控工具。其开发团队出于改善系统层次的监控方式以及通过提供关于**存储,进程,网络和内存**子系统的**统一有序**以及**粒度可见**的方式来进行错误排查,通过创建系统活动记录文件使得你可以在任何时间轻松分析。
+
+简单例子:
+
+ # sysdig proc.name=vim
+ # sysdig -p"%proc.name %fd.name" "evt.type=accept and proc.name!=httpd"
+ # sysdig evt.type=chdir and user.name=root
+ # sysdig -l
+ # sysdig -L
+ # sysdig -c topprocs_net
+ # sysdig -c fdcount_by fd.sport "evt.type=accept"
+ # sysdig -p"%proc.name %fd.name" "evt.type=accept and proc.name!=httpd"
+ # sysdig -c topprocs_file
+ # sysdig -c fdcount_by proc.name "fd.type=file"
+ # sysdig -p "%12user.name %6proc.pid %12proc.name %3fd.num %fd.typechar %fd.name" evt.type=open
+ # sysdig -c topprocs_cpu
+ # sysdig -c topprocs_cpu evt.cpu=0
+ # sysdig -p"%evt.arg.path" "evt.type=chdir and user.name=root"
+ # sysdig evt.type=open and fd.name contains /etc
+
+
+
+**更多信息** 可以在 [如何利用sysdig改善系统层次的监控和错误排查][8]
+
+#### 9. netstat - 显示开放的端口和连接 ####
+
+它是**Linux管理员**使用来显示不同网络信息的工具,如查看什么端口开放和什么网络连接已经建立以及何种进程运行在这种连接之上。同时它也显示了**Unix套接**字的信息,这些套接字在不同的程序中为打开状态。作为大多数Linux发行版本的一部分,netstat的许多命令在 [netstat和它的不同输出][9]中有详细的描述。最为常用的如下:
+
+ $ netstat | head -20
+ $ netstat -r
+ $ netstat -rC
+ $ netstat -i
+ $ netstat -ie
+ $ netstat -s
+ $ netstat -g
+ $ netstat -tapn
+
+### 10. tcpdump - 洞察网络包 ###
+
+**tcpdump**可以用来查看**网络连接**包的内容。它显示了传输过程中包内容的各种信息。为了使得输出信息更为有用,它允许使用者通过不同的过滤器获取自己想要的信息。可以参照的例子如下:
+
+ # tcpdump -i eth0 not port 22
+ # tcpdump -c 10 -i eth0
+ # tcpdump -ni eth0 -c 10 not port 22
+ # tcpdump -w aloft.cap -s 0
+ # tcpdump -r aloft.cap
+ # tcpdump -i eth0 dst port 80
+
+你可以找到详细的[描述在topdump和捕捉包][10]文章中。
+
+#### 11. vmstat - 虚拟内存统计信息 ####
+
+**vmstat**是虚拟内存(**virtual memory** statistics)的缩写,作为一个**内存监控**工具,它收集和显示概括关于**内存**,**进程**,**终端**和**分页**和**I/O阻塞**的信息。作为一个开源程序,它可以再大部分Linux发行版本中找到,包括Solaris和FreeBSD。它用来诊断大部分的内存性能问题和其他相关问题
+
+
+
+**M更多信息** 参考 [vmstat命令文章][11]。
+
+#### 12. free - 内存统计信息 ####
+
+free是另一个能够在终端中标准输出内存和交换空间使用的命令行工具。由于它的简易,它经常用于快速查看内存使用或者是应用于不同的脚本和应用程序中。在这里你可以看到[这个小程序的许多应用][12]。几乎所有的系统管理员日常都会用这个工具。:-)
+
+
+
+#### 13. Htop - 更加友好的top ####
+
+**Htop**基本上是一个top改善版本,它能够显示更多的统计信息和更加多彩的方式,同时允许你采用不同的方式进行排序,它提供了一个**用户友好**的接口。
+
+
+
+你可以找到 **更多的信息** 在 [关于htop和top的比较][13]文章中。
+
+#### 14. ss - 更现代感的网络管理替代工具 ####
+
+**ss**是**iproute2**包的一部分。iproute2趋向于替代一整套标准的**Unix网络**工具组件,它曾经用来完成[网络接口配置,路由表和管理ARP表][14]任务。ss工具用来存储套接字统计信息,也能够类似netstat一样显示信息,同时也能显示更多TCP和状态信息。一些例子如下:
+
+ # ss -tnap
+ # ss -tnap6
+ # ss -tnap
+ # ss -s
+ # ss -tn -o state established -p
+
+#### 15. lsof - 列表显示打开的文件 ####
+
+**lsof**命令,意为“**list open files**”, 用于在许多类Unix系统中显示所有打开状态的文件和打开它们的进程。在大部分Linux发行版和其他类Linux操作系统中系统管理员用它来检查不同的进程打开了哪些文件。你可以在这里找到更多的例子。
+
+ # lsof +p process_id
+ # lsof | less
+ # lsof –u username
+ # lsof /etc/passwd
+ # lsof –i TCP:ftp
+ # lsof –i TCP:80
+
+你可以找到 **更多例子** 在[lsof 文章][15]
+
+#### 16. iftop - 类似top的了网络连接工具 ####
+
+**iftop**是一个基于网络信息的类似top的程序。它能够显示当前时刻按照**带宽使用**量或者上传或者下载量排序的**网络连接**状况。它同事提供了下载文件的预估完成时间。
+
+
+
+**更多信息**可以参考[网络流量iftop文章][16]
+
+#### 17. iperf - 网络性能工具 ####
+
+**iperf**是一个**网络测试**工具,能够创建**TCP**和**UDP**数据连接和测量该网络能够传输它们的**性能**。它支持调节关于时间,协议和缓冲等不同的参数。对于每一个测试,它会报告带宽,丢包和其他的一些参数。
+
+
+
+如果你想用使用这个工具,可以参考这篇文章: [如何安装和使用iperf][17]
+
+#### 18. Smem - 高级内存报表工具 ####
+
+**Smem**是一个比较高级的**Linux**命令行工具,它提供关于系统中已经使用的和共享的实际内存,试图提供一个更为可靠地当前**内存**使用数据。
+
+ $ smem -m
+ $ smem -m -p | grep firefox
+ $ smem -u -p
+ $ smem -w -p
+
+参考我们的文章:[Smem更多的例子][18]
+
+### 图形化或基于Web的性能工具 ###
+
+#### 19. Icinga - Nagios的社区分支版本 ####
+
+**Icinga**是一个**开源免费**的网络监控程序,作为Nagios的分支,它获取了前者现存的大部分功能,同时基于这些功能又增加了社区用户要求已久的功能和补丁。
+
+
+
+**更多信息**参考[安装和配置lcinga文章][19].
+
+#### 20. Nagios - 最为流行的监控工具. ####
+
+作为在Linux上使用最为广泛和流行的**监控方案**,它有一个守护程序用来收集不同进程和远程主机的信息,这些收集到的信息都通过功能强大**的web界面**进行呈现。
+
+
+
+你可以在 **找到更多的信息** 在[如何安装nagios][20]
+
+#### 21. Linux process explorer - Linux下的procexp ####
+
+**Linux process explorer**是一个Linux下的图形化进程浏览工具。它能够显示不同的进程信息,如进程数,TCP/IP连接和每一个进程的性能指标。作为**Windows**下**procexp**在Linux的替代品,是由**Sysinternals**开发的,其目标是相比**top**和**ps**用户体验更加的友好。
+
+查看 [linux process explorer 文章][21]获取更多信息。
+
+#### 22. Collectl - 性能监控工具 ####
+
+你可以既可以通过交互的方式使用这个**性能监控**工具,也可以用它产生**报表**,并通过web服务器来访问它在磁盘上的数据。它以一种**易读易管理**的文件格式,记录了**CPU,磁盘,内存,网络,网络文件系统,进程,slabs**等统计信息于。
+
+
+
+**更多** 关于[Collectl的文章][22]。
+
+#### 23. MRTG - 经典网络流量监控图形工具 ####
+
+这是一个采用**rrdtool**的提供给用户图形化流量监控工具。作为**最早**的提供**图形化界面**的工具,它被广泛应用在类Unix的操作系统中。查看我们关于[如何使用MRTG][23]的文章获取更多关于安装和配置的信息。
+
+
+
+#### 24. Monit - 简单易用的监控工具 ####
+
+**Monit**是一个用来**监控进程**,**系统加载**,**文件系统**和**目录文件**等的开源的Linux工具。你能够让它自动化维护和修复,也能够在运行错误的情景下执行动作或者发邮件报告提醒系统管理员。如果你想要用这个工具,你可以查看[如何使用Monit的文章][24]。
+
+
+
+#### 25. Munin - 为服务器提供监控和提醒服务 ####
+
+作为一个网络资源监控工具,*Munin**能够帮助分析**资源趋势**和**查看弱节点**以及导致产生**性能问题**的原因。开发此软件的团队系统它能够易用和用户体验友好。该软件是用Perl开发的同时采用**rrdtool**来绘制图形,使用了**web接口**进行呈现。开发人员推广此应用时声称“**插件化和易用**”,目前已有500多个监控插件可结合使用。
+
+**更多信息**可以在[关于Munin的文章][25]。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/monitoring-2/linux-performance-monitoring-tools/
+
+作者:[Adrian Dinu][a]
+译者:[译者ID](https://github.com/andyxue)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/adriand/
+[1]:http://linoxide.com/monitoring-2/dstat-monitor-linux-performance/
+[2]:http://linoxide.com/monitoring-2/guide-using-linux-atop/
+[3]:http://linoxide.com/monitoring-2/install-nmon-monitor-linux-performance/
+[4]:http://linoxide.com/linux-command/kernel-slab-cache-information/
+[5]:http://linoxide.com/linux-command/linux-system-performance-monitoring-using-sar-command/
+[6]:http://linoxide.com/monitoring-2/monitor-linux-saidar-tool/
+[7]:http://linoxide.com/linux-command/linux-top-command-examples-screenshots/
+[8]:http://linoxide.com/tools/sysdig-performance-linux-tool/
+[9]:http://linoxide.com/linux-command/netstat-commad-with-all-variant-outputs/
+[10]:http://linoxide.com/linux-how-to/network-traffic-capture-tcp-dump-command/
+[11]:http://linoxide.com/linux-command/linux-vmstat-command-tool-report-virtual-memory-statistics/
+[12]:http://linoxide.com/linux-command/linux-free-command/
+[13]:http://linoxide.com/linux-command/linux-htop-command/
+[14]:http://linoxide.com/linux-command/ss-sockets-network-connection/
+[15]:http://linoxide.com/how-tos/lsof-command-list-process-id-information/
+[16]:http://linoxide.com/monitoring-2/iftop-network-traffic/
+[17]:http://linoxide.com/monitoring-2/install-iperf-test-network-speed-bandwidth/
+[18]:http://linoxide.com/tools/memory-usage-reporting-smem/
+[19]:http://linoxide.com/monitoring-2/install-configure-icinga-linux/
+[20]:http://linoxide.com/how-tos/install-configure-nagios-centos-7/
+[21]:http://sourceforge.net/projects/procexp/
+[22]:http://linoxide.com/monitoring-2/collectl-tool-install-examples/
+[23]:http://linoxide.com/tools/multi-router-traffic-grapher/
+[24]:http://linoxide.com/monitoring-2/monit-linux/
+[25]:http://linoxide.com/ubuntu-how-to/install-munin/
diff --git a/translated/tech/20141024 How To Upgrade Ubuntu 14.04 To Ubuntu 14.10.md b/translated/tech/20141024 How To Upgrade Ubuntu 14.04 To Ubuntu 14.10.md
new file mode 100644
index 0000000000..0283522090
--- /dev/null
+++ b/translated/tech/20141024 How To Upgrade Ubuntu 14.04 To Ubuntu 14.10.md
@@ -0,0 +1,51 @@
+如何从 Ubuntu 14.04 升级到 Ubuntu 14.10
+================================================================================
+
+
+Ubuntu 14.10已于前段时间发布。想知道**如何从 Ubuntu 14.04 升级到 Ubuntu 14.10 **么?别担心,这很容易做到。事实上,只要网络连接速度好,升级只是点击几下鼠标的事情而已。
+
+### 你需要从 Ubuntu 14.04 切换到 Ubuntu 14.10 么? ###
+
+在你升级到Ubuntu 14.10之前,请确定你真的想为升级 14.10 而抛弃 Ubuntu 14.04。一个很重要的原因是你不能从Ubuntu 14.10 回归到14.04。 你需要完全重新安装。
+
+Ubuntu 14.04是长期支持(LTS)版本。这意味着有更多的稳定性和更长的支持周期。如果升级到14.10,你将被迫在9个月后从Ubuntu 14.10 升级到15.04,而14.04将会持续3年以上。
+
+此外,目前Ubuntu 14.10没有很多的新功能使吸引用户切换到14.10。当然了,你肯定会得到最前沿的操作系统。所以,在这之前是否升级到Ubuntu 14.10是你自己的决定。
+
+### 从Ubuntu 14.04 升级到 Ubuntu 14.10 ###
+
+要从Ubuntu 14.04 升级到 Ubuntu 14.10,遵循下面的步骤:
+
+#### 步骤 1: ####
+
+打开 **软件和更新**.
+
+
+
+进入**更新**选项卡。这里要确保**Ubuntu有新版本时通知我** 设置成**对于任何新版本**。默认Ubuntu只会在另一个LTS发布时通知你。你必须要把它改成在任何中间版本都升级。
+
+
+
+#### 步骤 2: ####
+
+现在运行 **软件升级**。
+
+
+
+升级完成后,它应该会提示一个可用的新版本。点击升级,接着按照提示的步骤来。
+
+
+
+我希望本篇教程可以帮助你**从 Ubuntu 14.04 升级到 Ubuntu 14.10**。虽然本教程是为Ubuntu写的,但是你可以用同样的步骤升级到 Xubuntu 14.10、Kubuntu 14.10 或者Lubuntu。敬请期待下一篇Ubuntu 14.10相关文章。
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/upgrade-ubuntu-14-04-to-14-10/
+
+作者:[Abhishek][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[Caroline](https://github.com/carolinewuyan)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/Abhishek/
diff --git a/translated/tech/20141024 How to Upgrade Ubuntu 14.04 LTS to Ubuntu 14.10.md b/translated/tech/20141024 How to Upgrade Ubuntu 14.04 LTS to Ubuntu 14.10.md
new file mode 100644
index 0000000000..473bd5c72e
--- /dev/null
+++ b/translated/tech/20141024 How to Upgrade Ubuntu 14.04 LTS to Ubuntu 14.10.md
@@ -0,0 +1,32 @@
+如何从Ubuntu 14.04 LTS 升级到Ubuntu 14.10
+================================================================================
+
+
+**想知道怎样从Ubuntu 14.04 LTS 升级到Ubuntu 14.10么? 这就是我们要讲的**
+
+Canonical不会强迫14.04的用户升级到14.10这个中间版本
+
+但这并不意味着 **你**不能将你的坚如磐石的Trusty Tahr升级到(有点让人印象深刻的)Utopic Unicorn。
+
+要得到非LTS版本的Ubuntu发布通知,你需要在软件和更新工具中选择。这个很直接。
+
+- 打开 ‘**软件和更新**’
+- 选择 ‘**更新**’ 选项
+- 进入‘**有新版本Ubuntu时通知我**’的选项
+- 在下拉菜单选项中将‘**对于长期支持版本**’改成‘**对于任何版本**’
+
+切换后你会想快点更新。
+
+现在准备就绪!Canonical此刻会弹出“升级”提示给用户(想比较普通的ISO镜像而言经常延迟)可以通过软件更新工具更新到14.10了。
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2014/10/upgrade-ubuntu-14-04-to-14-10
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
\ No newline at end of file
diff --git a/translated/tech/20141024 SUSE Linux--Zypper Command Examples.md b/translated/tech/20141024 SUSE Linux--Zypper Command Examples.md
new file mode 100644
index 0000000000..3fba3b6843
--- /dev/null
+++ b/translated/tech/20141024 SUSE Linux--Zypper Command Examples.md
@@ -0,0 +1,168 @@
+SUSE Linux – Zypper 命令示例
+================================================================================
+Zypper是SUSE Linux中的命令行接口,可以用于安装,升级,卸载,管理仓库、执行不同的请求等等。本篇将会讨论zypper的几个不同命令的例子。
+
+语法:
+
+ # zypper [--global-opts] [--command-opts] [command-arguments]
+
+中括号中的部分可以不需要。执行zypper最简单的方法是 后输入他的名字。
+
+### 例子:1 列出可用的全局选项和命令 ###
+
+打开终端,输入zypper并按回车,它会显示所有可用的全局选项和命令。
+
+ linux-xa3t:~ # zypper
+
+### 例子:2 获得zypper的某个帮助 ###
+
+语法: zypper help [command]
+
+ linux-xa3t:~ # zypper help remove
+ remove (rm) [options] ...
+
+ Remove packages with specified capabilities.
+ A capability is NAME[.ARCH][OP], where OP is one of <, <=, =, >=, >.
+
+ Command options:
+ -r, --repo Load only the specified repository.
+ -t, --type Type of package (package, patch, pattern, product).
+
+ Default: package.
+ -n, --name Select packages by plain name, not by capability.
+ -C, --capability Select packages by capability.
+ --debug-solver Create solver test case for debugging.
+ -R, --no-force-resolution Do not force the solver to find solution,let it ask.
+ --force-resolution Force the solver to find a solution (even an aggressive one).
+ -u, --clean-deps Automatically remove unneeded dependencies.
+ -U, --no-clean-deps No automatic removal of unneeded dependencies.
+ -D, --dry-run Test the removal, do not actually remove.
+
+### 例子:3 打开zypper shell或者会话 ###
+
+ linux-xa3t:~ # zypper sh
+ zypper>
+
+ or
+
+ linux-xa3t:~ # zypper shell
+ zypper>
+
+### 例子:4 列出已定义的仓库 ###
+
+ linux-xa3t:~ # zypper repos
+
+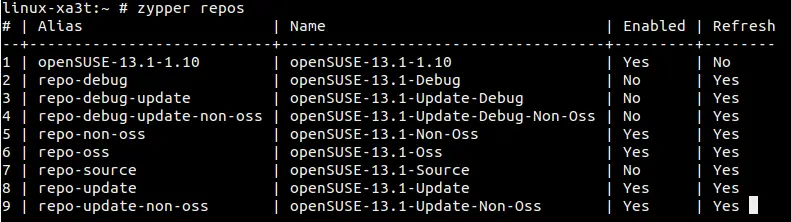
+
+or
+
+ linux-xa3t:~ # zypper lr
+
+#### 4.1) 以表格的形式列出仓库的URI ####
+
+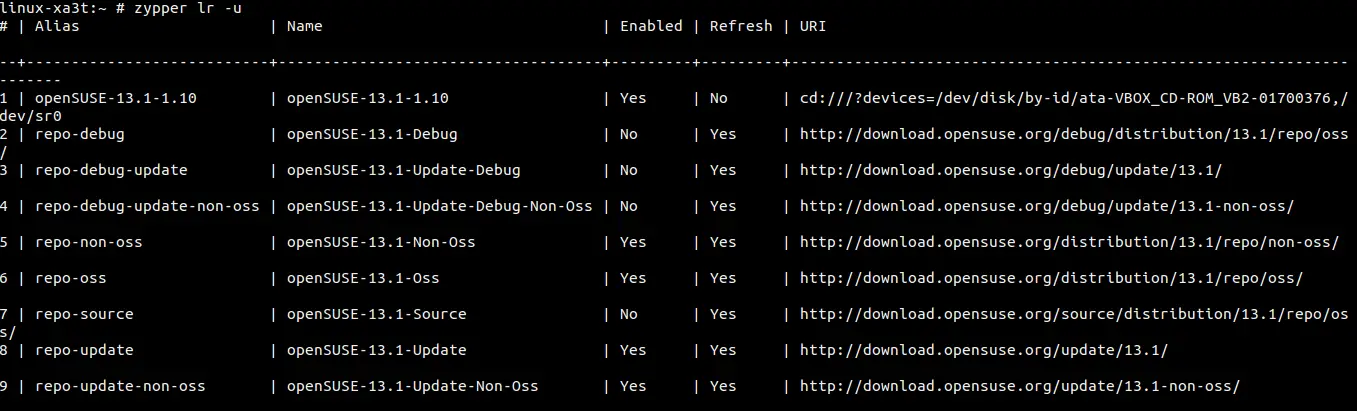
+
+#### 4.2) 以优先级列出仓库 ####
+
+ linux-xa3t:~ # zypper lr -p
+
+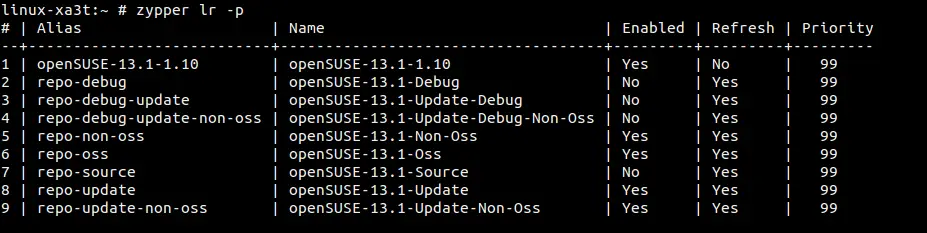
+
+### 例子:5 刷新仓库 ###
+
+ linux-xa3t:~ # zypper ref
+ Repository 'openSUSE-13.1-Non-Oss' is up to date.
+ Repository 'openSUSE-13.1-Oss' is up to date.
+ Repository 'openSUSE-13.1-Update' is up to date.
+ Repository 'openSUSE-13.1-Update-Non-Oss' is up to date.
+ All repositories have been refreshed.
+
+### 例子:6 修改zypper仓库 ###
+
+zypper仓库可以通过别名、数字或者URI或者通过‘–all、 –remote、 –local、 –medium-type’这些选项修改。
+
+linux-xa3t:~ # zypper mr -d 6 #禁用6号仓库
+linux-xa3t:~ # zypper mr -rk -p 70 upd #启用自动书信并为‘upd’仓库设置rpm文件‘缓存’,且设置它的优先级为70
+linux-xa3t:~ # zypper mr -Ka #为所有的仓库禁用rpm文件缓存
+linux-xa3t:~ # zypper mr -kt #为远程仓库设置rpm文件缓存
+
+### 例子:7 添加仓库 ###
+
+语法: zypper addrepo 或者 zypper ar
+
+ linux-xa3t:~ # zypper ar http://download.opensuse.org/update/13.1/ update
+ Adding repository 'update' .............................................[done]
+ Repository 'update' successfully added
+ Enabled: Yes
+ Autorefresh: No
+ GPG check: Yes
+ URI: http://download.opensuse.org/update/13.1/
+
+### 例子:8 移除仓库 ###
+
+语法: zypper removerepo <仓库名> <别名>
+
+或者
+
+zypper rr <仓库名> <别名>
+
+ linux-xa3t:~ # zypper rr openSUSE-13.1-1.10 openSUSE-13.1-1.10
+ Removing repository 'openSUSE-13.1-1.10' ............................[done]
+ Repository 'openSUSE-13.1-1.10' has been removed.
+
+### 例子:9 安装包 ###
+
+语法: zypper install <包名> 或者 zypper in <包名>
+
+ linux-xa3t:~ # zypper install vlc
+
+### 例子:10 卸载包 ###
+
+语法: zypper remove <包名> OR zypper rm <包名>
+
+ linux-xa3t:~ # zypper remove sqlite
+
+### 例子:11 导出和导入仓库 ###
+
+导出仓库语法 : zypper repos –export 或者 zypper lr -e
+
+ linux-xa3t:~ # zypper lr --export repo-backup/back.repo
+ Repositories have been successfully exported to repo-backup/back.repo.
+
+导入仓库语法 :
+
+ linux-xa3t:~ # zypper ar repo-backup/back.repo
+
+### 例子:12 Updating a package ###
+
+语法: zypper update <包名> 或者 zypper up <包名>
+
+ linux-xa3t:~ # zypper update bash
+
+### 例子:13 安装源码包 ###
+
+语法: zypper source-install <源码包> OR zypper si <源码包>
+
+ linux-xa3t:~ # zypper source-install zypper
+
+### 例子:只安装以来 ###
+
+例子13中的命令会安装和构建特定包的依赖。如果你想要安装源码包就用-D选项
+
+ # zypper source-install -D package_name
+
+只安装依赖就使用-d
+
+ # zypper source-install -d package_name
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxtechi.com/suse-linux-zypper-command-examples/
+
+作者:[Pradeep Kumar][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxtechi.com/author/pradeep/
\ No newline at end of file
diff --git a/translated/tech/20141027 How to encrypt files and directories with eCryptFS on Linux.md b/translated/tech/20141027 How to encrypt files and directories with eCryptFS on Linux.md
new file mode 100644
index 0000000000..655c8a27b1
--- /dev/null
+++ b/translated/tech/20141027 How to encrypt files and directories with eCryptFS on Linux.md
@@ -0,0 +1,107 @@
+在Linux上使用eCryptFS加密文件和目录
+================================================================================
+作为罪犯,你需要为自己的身份保密;而作为中情局成员,你同样也需要为自己的身份保密。但是,你却不是他们其中的任何一员,你只是不想其他人查探到你的金融数据、家庭照片、尚未出版的手稿,或者记录着你能发家致富的最初想法的私密笔记。
+
+我时常听到有人告诉我“我只是个微不足道的人,没人会查探我”或者“我没有什么东西要隐藏的。”好吧,告诉你我的想法,即便我没有什么要隐藏的,或者我也可以公开我带着狗的孩子的照片,那我也有权利不这么去做,也有权利来保护我的隐私。
+
+### 加密类型 ###
+
+我们主要有两种加密文件和目录的方法。一种是文件系统级别的加密,在这种加密中,你可以选择性地加密某些文件或者目录(如,/home/alice)。对我而言,这是个十分不错的方法,你不需要为了启用或者测试加密而把所有一切重新安装一遍。然而,文件系统级别的加密也有一些缺点。例如,许多现代应用程序会缓存(部分)文件你硬盘中未加密的部分中,比如交换分区、/tmp和/var文件夹,而这会导致隐私泄漏。
+
+另外一种方式,就是所谓的全盘加密,这意味着整个磁盘都会被加密(可能除了主引导记录外)。全盘加密工作在物理磁盘级别,写入到磁盘的每个比特都会被加密,而从磁盘中读取的任何东西都会在运行中解密。这会阻止任何潜在的对未加密数据的未经授权的访问,并且确保整个文件系统中的所有东西都被加密,包括交换分区或任何临时缓存数据。
+
+### 可用的加密工具 ###
+
+在Linux中要实施加密,有几个可供选择的工具。在本教程中,我打算介绍其中一个:**eCryptFS**,一个用户空间文件系统加密工具。下面提供了一个Linux上可用的加密工具摘要供您参考。
+
+#### 文件系统级别加密 ####
+
+- [EncFS][1]:尝试加密的最简单方式之一。EncFS工作在基于FUSE的伪文件系统上,所以你只需要创建一个加密文件夹并将它挂载到某个文件夹就可以工作了。
+- [eCryptFS][2]:一个POSIX兼容的加密文件系统,eCryptFS工作方式和EncFS相同,所以你必须挂载它。
+
+#### 磁盘级别加密 ####
+
+- [Loop-AES][3]:最古老的磁盘加密方法。它真的很快,并且适用于旧系统(如,2.0内核分支)。
+- [DMCrypt][4]:最常见的磁盘加密方案,支持现代Linux内核。
+- [CipherShed][5]:已停止的TrueCrypt磁盘加密程序的一个开源分支。
+
+### eCryptFS基础 ###
+
+eCrypFS是一个基于FUSE的用户空间加密文件系统,在Linux内核2.6.19及更高版本中可用(作为encryptfs模块)。eCryptFS加密的伪文件系统挂载到当前文件系统的顶部。它可以很好地工作在EXT文件系统家族和其它文件系统如JFS、XFS、ReiserFS、Btrfs,甚至是NFS/CIFS共享文件系统上。Ubuntu使用eCryptFS作为加密其家目录的默认方法,ChromeOS也是。在eCryptFS底层,默认使用的是AES算法,但是它也支持其它算法,如blowfish、des3、cast5、cast6。如果你是通过手工创建eCryptFS设置,你可以选择其中一种算法。
+
+就像我所的,Ubuntu让我们在安装过程中选择是否加密/home目录。好吧,这是使用eCryptFS的最简单的一种方法。
+
+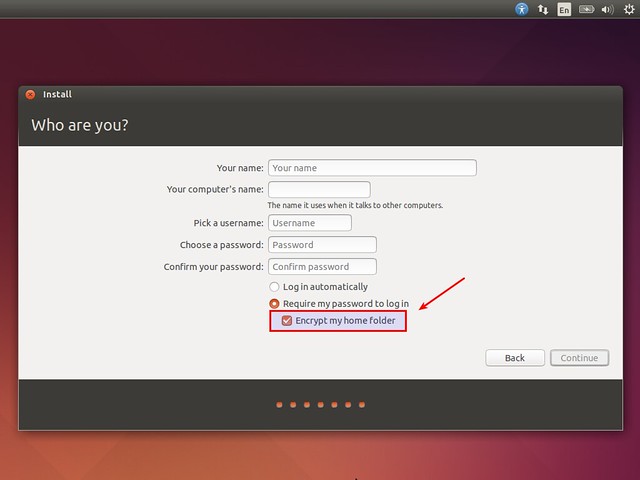
+
+Ubuntu提供了一个用户友好的工具集,通过eCryptFS可以让我们的生活更轻松,但是在Ubuntu安装过程中启用eCryptFS只创建了一个指定的预配置的设置。所以,如果默认的设置不适合你的需求,你需要进行手工设置。在本教程中,我将介绍**如何在主流Linux发行版上手工设置eCryptFS**。
+
+### eCryptFS的安装 ###
+
+Debian,Ubuntu或其衍生版:
+
+ $ sudo apt-get install ecryptfs-utils
+
+注意,如果你在Ubuntu安装过程中选择加密家目录,eCryptFS应该已经安装了。
+
+CentOS, RHEL or Fedora:
+
+ # yum install ecryptfs-utils
+
+Arch Linux:
+
+ $ sudo pacman -S ecryptfs-utils
+
+在安装完包后,加载eCryptFS内核模块当然会是一个很好的实践:
+
+ $ sudo modprobe ecryptfs
+
+### 配置eCryptFS ###
+
+现在,让我们开始加密一些目录,运行eCryptFS配置工具:
+
+ $ ecryptfs-setup-private
+
+
+
+它会要求你输入登录密码和挂载密码。登录密码和你常规登录的密码一样,而挂载密码用于派生一个文件加密主密钥。留空来生成一个,这样会更安全。登出然后重新登录。
+
+你会注意到,eCryptFS默认在你的家目录中创建了两个目录:Private和.Private。~/.Private目录包含有加密的数据,而你可以在~/Private目录中访问到相应的解密后的数据。在你登录时,~/.Private目录会自动解密并映射到~/Private目录,因此你可以访问它。当你登出时,~/Private目录会自动卸载,而~/Private目录中的内容会加密回到~/.Private目录。
+
+eCryptFS怎么会知道你拥有~/.Private目录,并自动将其解密到~/Private目录而不需要我们输入密码呢?这就是eCryptFS的PAM模块捣的鬼,它为我们提供了这项便利服务。
+
+如果你不想要~/Private目录在登录时自动挂载,只需要在运行ecryptfs-setup-private工具时添加“--noautomount”选项。同样,如果你不想要~/Private目录在登出后自动卸载,也可以自动“--noautoumount”选项。但是,那样后,你需要自己手工挂载或卸载~/Private目录:
+
+ $ ecryptfs-mount-private ~/.Private ~/Private
+ $ ecryptfs-umount-private ~/Private
+
+你可以来验证一下.Private文件夹是否被挂载,运行:
+
+ $ mount
+
+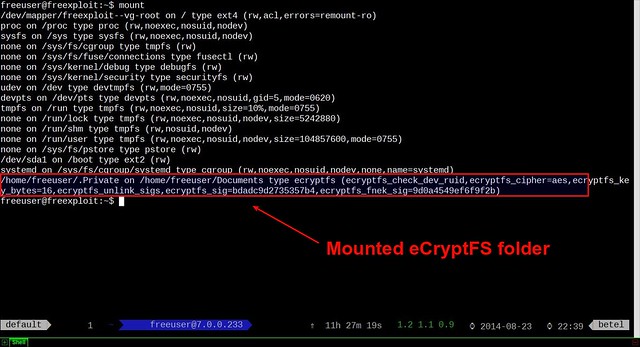
+
+现在,我们可以开始把任何敏感文件放进~/Private文件夹里头了,它们会在我们登出时自动被加密并锁在~/.Private文件内。
+
+所有这一切看起来是那么得神奇。这主要是ecryptfs-setup-private工具让一切设置变得简单。如果你想要深究一点,对eCryptFS指定的方面进行设置,那么请转到[官方文档][6]。
+
+### 结尾 ###
+
+综上所述,如果你十分关注你的隐私,最好是将基于eCryptFS文件系统级别的加密和全盘加密相结合。切记,只进行文件加密并不能保证你的隐私不受侵犯。
+
+------------------------------------------------------------------------------
+
+via: http://xmodulo.com/encrypt-files-directories-ecryptfs-linux.html
+
+作者:[Christopher Valerio][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/valerio
+[1]:http://www.arg0.net/encfs
+[2]:http://ecryptfs.org/
+[3]:http://sourceforge.net/projects/loop-aes/
+[4]:https://code.google.com/p/cryptsetup/wiki/DMCrypt
+[5]:https://ciphershed.org/
+[6]:http://ecryptfs.org/documentation.html
diff --git a/translated/tech/20141029 How to Install MariaDB in Ubuntu 14.04 LTS.md b/translated/tech/20141029 How to Install MariaDB in Ubuntu 14.04 LTS.md
new file mode 100644
index 0000000000..cbc1f4bd69
--- /dev/null
+++ b/translated/tech/20141029 How to Install MariaDB in Ubuntu 14.04 LTS.md
@@ -0,0 +1,52 @@
+如何在Ubuntu 14.04 LTS上安装MariaDB
+================================================================================
+MariaDB是一个开源数据库且100%与MySQL兼容,目标是替代MySQL数据库。
+
+### MariaDB的背景 : ###
+
+2008年,MySQL被后来被Oracle在2010年收购的**Sun Microsystems**收购了。 最初被Sun公司的收购由于符合项目的需要受到MySQL社区的欢呼,但是这种情绪并没有持续他热爱就,接下来被Oracle的收购不幸期望远远低于预期。许多MySql的开发者离开了Sun和Oracle公司开始新的项目。在他们中间就有MySQL的创建者以及项目长期技术带头人之一的**Michael ‘Monty’ Widenius**。Monty和他的团队创建了MySQL的一个fork版本并且命名它为**MariaDB**。
+
+本篇我们会讨论如何在Ubuntu上安装MariaDB。默认上MariaDB的包并没有在Ubuntu仓库中。要安装MariaDB,我们首先要设置MariaDB仓库。
+
+#### 设置 MariaDB 仓库 ####
+
+ $ sudo apt-get install software-properties-common
+ $ sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
+ $ sudo add-apt-repository 'deb http://sfo1.mirrors.digitalocean.com/mariadb/repo/10.0/ubuntu trusty main'
+
+#### 安装 MariaDB : ####
+
+ $ sudo apt-get update
+ $ sudo apt-get install mariadb-server
+
+在安装中,你会被要求设置MariaDB的root密码。
+
+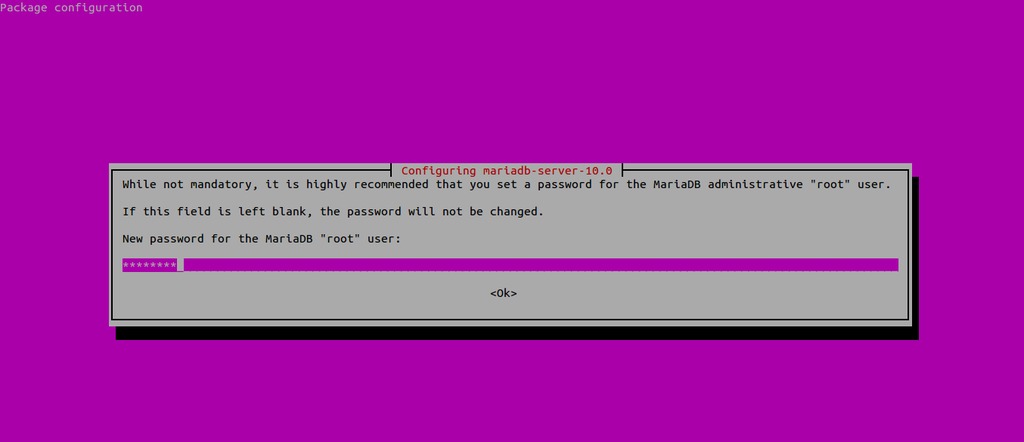
+
+#### 从命令行连接到MariaDB : ####
+
+ linuxtechi@mail:~$ mysql -uroot -p
+ Enter password:
+ Welcome to the MariaDB monitor. Commands end with ; or \g.
+ Your MariaDB connection id is 40
+ Server version: 10.0.14-MariaDB-1~trusty-log mariadb.org binary distribution
+ Copyright (c) 2000, 2014, Oracle, SkySQL Ab and others.
+ Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
+ MariaDB [(none)]>
+
+#### Maria DB 服务 ####
+
+ $ sudo /etc/init.d/mysql stop
+ $ sudo /etc/init.d/mysql start
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxtechi.com/install-mariadb-in-ubuntu/
+
+作者:[Pradeep Kumar][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxtechi.com/author/pradeep/
\ No newline at end of file
diff --git a/translated/tech/20141029 Linux FAQs with Answers--How to fix hda-duplex not supported in this QEMU binary.md b/translated/tech/20141029 Linux FAQs with Answers--How to fix hda-duplex not supported in this QEMU binary.md
new file mode 100644
index 0000000000..e3a6f3b4af
--- /dev/null
+++ b/translated/tech/20141029 Linux FAQs with Answers--How to fix hda-duplex not supported in this QEMU binary.md
@@ -0,0 +1,40 @@
+Linux 有问必答 -- 如何修复“hda-duplex not supported in this QEMU binary”(hda-duplex在此QEMU文件中不支持)
+================================================================================
+> **提问**: 当我尝试在虚拟机中安装一个新的Linux时,虚拟机不能启动且报了下面这个错误:“不支持的配置:hda-duplex在此QEMU文件中不支持。” 我该如何修复?
+
+这个错误可能来自一个当默认声卡型号不能被识别时的一个qemu bug。
+
+
+
+ 无法完成安装:‘不支持的配置:hda-duplex在此QEMU文件中不支持’
+
+要解决这个问题,按照下面的做。
+
+### 方案一: virt-manager ###
+
+在**virt-manager**中,打开虚拟机的虚拟硬件详细菜单,进入声卡选项,改变默认的设备型号为ac97。
+
+
+
+点击“应用”按钮并保存设置。看一下虚拟机现在是否可以启动了。
+
+### 方案二: Virsh ###
+
+如果你使用的是**virt-manager** 而不是**virt-manager**, 你可以编辑VM相应的配置文件。在节点中查找**sound**节点,并按照下面的默认声卡型号改成**ac97**。
+
+
+ . . .
+
+
+
+ . . .
+
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/hda-duplex-not-supported-in-this-qemu-binary.html
+
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
\ No newline at end of file
diff --git a/translated/tech/20141029 Linux FAQs with Answers--How to install REMI repository on CentOS or RHEL.md b/translated/tech/20141029 Linux FAQs with Answers--How to install REMI repository on CentOS or RHEL.md
new file mode 100644
index 0000000000..66ed92b64d
--- /dev/null
+++ b/translated/tech/20141029 Linux FAQs with Answers--How to install REMI repository on CentOS or RHEL.md
@@ -0,0 +1,52 @@
+Linux 有问必答 -- 如何在CentOS或者RHEL上安装REMI仓库
+================================================================================
+> **Question**:我该如何在CentOS或者RHEL中配置REMI仓库,并在其中安装包?
+
+[REMI 仓库][1] 提供了核心CentOS和RHEL包的更新版本,尤其是最新的PHP/MySQL系列。
+
+安装REMI仓库要记住的一件事是不要在REMI仓库中运行yum update。因为REMI仓库的包名RHEL/CentOS中的相同,运行yum update可能会触发意外的更新。一个好办法是禁用REMI仓库,在你需要安装RMEI仓库中独有的包时再启用。
+
+### 预备工作 ###
+
+安装REMI仓库之前,你首先需要启用EPEL仓库,因为REMI中的一些包依赖与EPEL。按照[这份指南][2]在CentOS或者RHEL中设置EPEL仓库。
+
+### 安装REMI仓库 ###
+
+现在按照下面的步骤安装REMI仓库。
+
+在CentOS 7上:
+
+ $ sudo rpm --import http://rpms.famillecollet.com/RPM-GPG-KEY-remi
+ $ sudo rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-7.rpm
+
+在CentOS 6上:
+
+ $ sudo rpm --import http://rpms.famillecollet.com/RPM-GPG-KEY-remi
+ $ sudo rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm
+
+默认上,REMI是禁用的。要检查REMI是否已经成功安装,使用这个命令。你会看到几个REMI仓库,比如remi、remi-php55和remi-php56。
+
+ $ yum repolist disabled | grep remi
+
+
+
+### 从REMI仓库中安装一个包 ###
+
+如上所述,最好保持禁用REMI仓库,只有在需要的时候再启用。
+
+要搜索或安装REMI仓库中的包,使用这些命令:
+
+ $ sudo yum --enablerepo=remi search
+ $ sudo yum --enablerepo=remi install
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/install-remi-repository-centos-rhel.html
+
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://rpms.famillecollet.com/
+[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
\ No newline at end of file
diff --git a/translated/tech/Linux FAQs with Answers--How to build a RPM or DEB package from the source with CheckInstall.md b/translated/tech/Linux FAQs with Answers--How to build a RPM or DEB package from the source with CheckInstall.md
deleted file mode 100644
index 372030e6d0..0000000000
--- a/translated/tech/Linux FAQs with Answers--How to build a RPM or DEB package from the source with CheckInstall.md
+++ /dev/null
@@ -1,86 +0,0 @@
-Linux 常见问题解答 --怎么用checkinstall从源码创建一个RPM或DEB包
-================================================================================
-> **问题**:我想要从源码创建安装的软件程序。有没有一种方式来创建并且从源码安装包,而不是运行“make install”?那样,以后如果我想,我可以容易的卸载程序。
-
-如果你已经从从它的源码运行“make install”安装了linux程序。想完整移除它将变得真的很麻烦,除非程序的创造者在Makefile里提供卸载的目标。你会有在你系统里文件的完整列表来和从源码安装之后比较,然后手工移除所有在制作安装过程中加入的文件
-
-
-这时候Checkinstall就可以派上使用。Checkinstall保留命令行创建或修改的所有文件的路径(例如:“make install”“make install_modules”等)并建立一个标准的二进制包,让你能用你发行版的标准包管理系统安装或卸载它,(例子:Red Hat的yum或者Debian的apt-get命令) It has been also known to work with Slackware, SuSe, Mandrake and Gentoo as well, as per the official documentation. [official documentation][1].
-
-在这篇文章中,我们只集中在红帽子和Debian为基础的发行版,并展示怎样从源码使用Checkinstall创建一个RPM和DEB软件包
-
-### 在linux上安装Checkinstall ###
-
-在Debian衍生上安装Checkinstall:
-
- # aptitude install checkinstall
-
-在红帽子的发行版上安装Checkinstall,你需要下载一个预先建立的Checkinstall rpm(例如:从 [http://rpm.pbone.net][2]),他已经从Repoforge库里删除。对于Cent OS6这个rpm包也可在Cent OS7里工作。
-
- # wget ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/ikoinoba/CentOS_CentOS-6/x86_64/checkinstall-1.6.2-3.el6.1.x86_64.rpm
- # yum install checkinstall-1.6.2-3.el6.1.x86_64.rpm
-
-一旦checkinstall安装,你可以用下列格式创建一个特定的软件包
-
- # checkinstall
-
-如果没有参数,默认安装命令“make install”将被使用
-
-### 用Checkinstall创建一个RPM或DEB包 ###
-
-在这个例子里,我们将创建一个htop包,对于linux交互式文本模式进程查看器(就像上面的 steroids)
-
-
-首先,让我们从项目的官方网站下载源代码,一个最佳的练习,我们存储源码到/usr/local/src,并解压它
-
- # cd /usr/local/src
- # wget http://hisham.hm/htop/releases/1.0.3/htop-1.0.3.tar.gz
- # tar xzf htop-1.0.3.tar.gz
- # cd htop-1.0.3
-
-让我们找出htop安装命令,那样我们就能调用Checkinstall命令,下面展示了,htop用“make install”命令安装
-
- # ./configure
- # make install
-
-因此,创建一个htop包,我们可以调用checkinstall不带任何参数安装,这将使用“make install”命令创建一个包。随着这个过程 checkinstall命令会问你一个连串的问题。
-
-总之,这个命令会创建一个htop包: **htop**:
-
- # ./configure
- # checkinstall
-
-回答“Y”“我会创建一个默认设置的包文件?”
-
-
-
-你可以输入一个包的简短描述,然后按两次ENTER
-
-
-
-输入一个数值修改下面的任何值或ENTER前进
-
-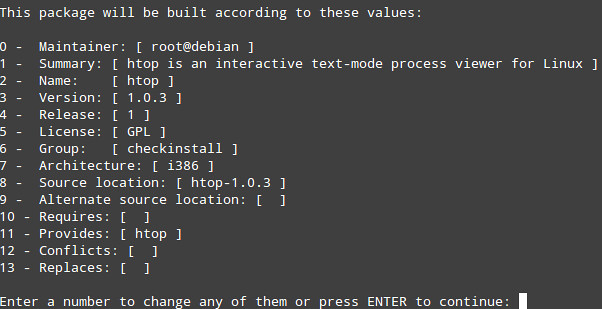
-
-然后checkinstall将自动地创建一个.rpm或者.deb包,根据你的linux系统是什么:
-
-在CentOS7:
-
-
-
-在Debian 7:
-
-
-
---------------------------------------------------------------------------------
-
-via: http://ask.xmodulo.com/build-rpm-deb-package-source-checkinstall.html
-
-译者:[luoyutiantang](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://checkinstall.izto.org/docs/README
-[2]:http://rpm.pbone.net/
-[3]:http://ask.xmodulo.com/install-htop-centos-rhel.html