mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
c8522c58f9
published
20150824 How to Setup Zephyr Test Management Tool on CentOS 7.x.md20151020 how to h2 in apache.md20151104 How to Install Redis Server on CentOS 7.md20151105 Linus Torvalds Lambasts Open Source Programmers over Insecure Code.md20151204 How to Remove Banned IP from Fail2ban on CentOS 6 or CentOS 7.md
sources
news
share
20150824 Great Open Source Collaborative Editing Tools.md20150901 5 best open source board games to play online.md20151130 eSpeak--Text To Speech Tool For Linux.md
talk
tech
20150917 A Repository with 44 Years of Unix Evolution.md20151122 Doubly linked list in the Linux Kernel.md20151123 Data Structures in the Linux Kernel.md20151126 How to Install Nginx as Reverse Proxy for Apache on FreeBSD 10.2.md20151201 Backup (System Restore Point) your Ubuntu or Linux Mint with SystemBack.md20151202 How to use the Linux ftp command to up- and download files on the shell.md20151208 How to Customize Time and Date Format in Ubuntu Panel.md20151208 How to Install Bugzilla with Apache and SSL on FreeBSD 10.2.md20151210 Getting started with Docker by Dockerizing this Blog.md
Linux or UNIX grep Command Tutorial series
translated
news
share
talk
20151124 Review--5 memory debuggers for Linux coding.md
The history of Android
tech
20151104 How to Install Redis Server on CentOS 7.md20151122 Doubly linked list in the Linux Kernel.md20151123 Assign Multiple IP Addresses To One Interface On Ubuntu 15.10.md20151126 How to Install Nginx as Reverse Proxy for Apache on FreeBSD 10.2.md20151201 Backup (System Restore Point) your Ubuntu or Linux Mint with SystemBack.md20151202 How to use the Linux ftp command to up- and download files on the shell.md20151208 How to renew the ISPConfig 3 SSL Certificate.md20151208 Install Wetty on Centos or RHEL 6.X.md
Linux or UNIX grep Command Tutorial series
@ -1,6 +1,7 @@
|
||||
如何在 CentOS 7.x 上安装 Zephyr 测试管理工具
|
||||
================================================================================
|
||||
测试管理工具包括作为测试人员需要的任何东西。测试管理工具用来记录测试执行的结果、计划测试活动以及报告质量保证活动的情况。在这篇文章中我们会向你介绍如何配置 Zephyr 测试管理工具,它包括了管理测试活动需要的所有东西,不需要单独安装测试活动所需要的应用程序从而降低测试人员不必要的麻烦。一旦你安装完它,你就看可以用它跟踪 bug、缺陷,和你的团队成员协作项目任务,因为你可以轻松地共享和访问测试过程中多个项目团队的数据。
|
||||
|
||||
测试管理(Test Management)指测试人员所需要的任何的所有东西。测试管理工具用来记录测试执行的结果、计划测试活动以及汇报质量控制活动的情况。在这篇文章中我们会向你介绍如何配置 Zephyr 测试管理工具,它包括了管理测试活动需要的所有东西,不需要单独安装测试活动所需要的应用程序从而降低测试人员不必要的麻烦。一旦你安装完它,你就看可以用它跟踪 bug 和缺陷,和你的团队成员协作项目任务,因为你可以轻松地共享和访问测试过程中多个项目团队的数据。
|
||||
|
||||
### Zephyr 要求 ###
|
||||
|
||||
@ -19,21 +20,21 @@
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="140"><strong>Packages</strong></td>
|
||||
<td width="312">JDK 7 or above , Oracle JDK 6 update</td>
|
||||
<td width="209">No Prior Tomcat, MySQL installed</td>
|
||||
<td width="312">JDK 7 或更高 , Oracle JDK 6 update</td>
|
||||
<td width="209">没有事先安装的 Tomcat 和 MySQL</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="140"><strong>RAM</strong></td>
|
||||
<td width="312">4 GB</td>
|
||||
<td width="209">Preferred 8 GB</td>
|
||||
<td width="209">推荐 8 GB</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="140"><strong>CPU</strong></td>
|
||||
<td width="521" colspan="2">2.0 GHZ or Higher</td>
|
||||
<td width="521" colspan="2">2.0 GHZ 或更高</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="140"><strong>Hard Disk</strong></td>
|
||||
<td width="521" colspan="2">30 GB , Atleast 5GB must be free</td>
|
||||
<td width="521" colspan="2">30 GB , 至少 5GB </td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
@ -48,8 +49,6 @@
|
||||
|
||||
[root@centos-007 ~]# yum install java-1.7.0-openjdk-1.7.0.79-2.5.5.2.el7_1
|
||||
|
||||
----------
|
||||
|
||||
[root@centos-007 ~]# yum install java-1.7.0-openjdk-devel-1.7.0.85-2.6.1.2.el7_1.x86_64
|
||||
|
||||
安装完 java 和它的所有依赖后,运行下面的命令设置 JAVA_HOME 环境变量。
|
||||
@ -61,8 +60,6 @@
|
||||
|
||||
[root@centos-007 ~]# java –version
|
||||
|
||||
----------
|
||||
|
||||
java version "1.7.0_79"
|
||||
OpenJDK Runtime Environment (rhel-2.5.5.2.el7_1-x86_64 u79-b14)
|
||||
OpenJDK 64-Bit Server VM (build 24.79-b02, mixed mode)
|
||||
@ -71,7 +68,7 @@
|
||||
|
||||
### 安装 MySQL 5.6.x ###
|
||||
|
||||
如果的机器上有其它的 MySQL,建议你先卸载它们并安装这个版本,或者升级它们的模式到指定的版本。因为 Zephyr 前提要求这个指定的主要/最小 MySQL (5.6.x)版本要有 root 用户名。
|
||||
如果的机器上有其它的 MySQL,建议你先卸载它们并安装这个版本,或者升级它们的模式(schemas)到指定的版本。因为 Zephyr 前提要求这个指定的 5.6.x 版本的 MySQL ,要有 root 用户名。
|
||||
|
||||
可以按照下面的步骤在 CentOS-7.1 上安装 MySQL 5.6 :
|
||||
|
||||
@ -93,10 +90,7 @@
|
||||
[root@centos-007 ~]# service mysqld start
|
||||
[root@centos-007 ~]# service mysqld status
|
||||
|
||||
对于全新安装的 MySQL 服务器,MySQL root 用户的密码为空。
|
||||
为了安全起见,我们应该重置 MySQL root 用户的密码。
|
||||
|
||||
用自动生成的空密码连接到 MySQL 并更改 root 用户密码。
|
||||
对于全新安装的 MySQL 服务器,MySQL root 用户的密码为空。为了安全起见,我们应该重置 MySQL root 用户的密码。用自动生成的空密码连接到 MySQL 并更改 root 用户密码。
|
||||
|
||||
[root@centos-007 ~]# mysql
|
||||
mysql> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('your_password');
|
||||
@ -224,7 +218,7 @@ via: http://linoxide.com/linux-how-to/setup-zephyr-tool-centos-7-x/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -8,45 +8,44 @@ Copyright (C) 2015 greenbytes GmbH
|
||||
|
||||
### 源码 ###
|
||||
|
||||
你可以从[这里][1]得到 Apache 发行版。Apache 2.4.17 及其更高版本都支持 HTTP/2。我不会再重复介绍如何构建服务器的指令。在很多地方有很好的指南,例如[这里][2]。
|
||||
你可以从[这里][1]得到 Apache 版本。Apache 2.4.17 及其更高版本都支持 HTTP/2。我不会再重复介绍如何构建该服务器的指令。在很多地方有很好的指南,例如[这里][2]。
|
||||
|
||||
(有任何试验的链接?在 Twitter 上告诉我吧 @icing)
|
||||
(有任何这个试验性软件包的相关链接?在 Twitter 上告诉我吧 @icing)
|
||||
|
||||
#### 编译支持 HTTP/2 ####
|
||||
#### 编译支持 HTTP/2 ####
|
||||
|
||||
在你编译发行版之前,你要进行一些**配置**。这里有成千上万的选项。和 HTTP/2 相关的是:
|
||||
在你编译版本之前,你要进行一些**配置**。这里有成千上万的选项。和 HTTP/2 相关的是:
|
||||
|
||||
- **--enable-http2**
|
||||
|
||||
启用在 Apache 服务器内部实现协议的 ‘http2’ 模块。
|
||||
启用在 Apache 服务器内部实现该协议的 ‘http2’ 模块。
|
||||
|
||||
- **--with-nghttp2=<dir>**
|
||||
- **--with-nghttp2=\<dir>**
|
||||
|
||||
指定 http2 模块需要的 libnghttp2 模块的非默认位置。如果 nghttp2 是在默认的位置,配置过程会自动采用。
|
||||
|
||||
- **--enable-nghttp2-staticlib-deps**
|
||||
|
||||
很少用到的选项,你可能用来静态链接 nghttp2 库到服务器。在大部分平台上,只有在找不到共享 nghttp2 库时才有效。
|
||||
很少用到的选项,你可能想将 nghttp2 库静态链接到服务器里。在大部分平台上,只有在找不到共享 nghttp2 库时才有用。
|
||||
|
||||
如果你想自己编译 nghttp2,你可以到 [nghttp2.org][3] 查看文档。最新的 Fedora 以及其它发行版已经附带了这个库。
|
||||
如果你想自己编译 nghttp2,你可以到 [nghttp2.org][3] 查看文档。最新的 Fedora 以及其它版本已经附带了这个库。
|
||||
|
||||
#### TLS 支持 ####
|
||||
|
||||
大部分人想在浏览器上使用 HTTP/2, 而浏览器只在 TLS 连接(**https:// 开头的 url)时支持它。你需要一些我下面介绍的配置。但首先你需要的是支持 ALPN 扩展的 TLS 库。
|
||||
大部分人想在浏览器上使用 HTTP/2, 而浏览器只在使用 TLS 连接(**https:// 开头的 url)时才支持 HTTP/2。你需要一些我下面介绍的配置。但首先你需要的是支持 ALPN 扩展的 TLS 库。
|
||||
|
||||
ALPN 用来协商(negotiate)服务器和客户端之间的协议。如果你服务器上 TLS 库还没有实现 ALPN,客户端只能通过 HTTP/1.1 通信。那么,可以和 Apache 链接并支持它的是什么库呢?
|
||||
|
||||
ALPN 用来屏蔽服务器和客户端之间的协议。如果你服务器上 TLS 库还没有实现 ALPN,客户端只能通过 HTTP/1.1 通信。那么,和 Apache 连接的到底是什么?又是什么支持它呢?
|
||||
- **OpenSSL 1.0.2** 及其以后。
|
||||
- ??? (别的我也不知道了)
|
||||
|
||||
- **OpenSSL 1.0.2** 即将到来。
|
||||
- ???
|
||||
|
||||
如果你的 OpenSSL 库是 Linux 发行版自带的,这里使用的版本号可能和官方 OpenSSL 发行版的不同。如果不确定的话检查一下你的 Linux 发行版吧。
|
||||
如果你的 OpenSSL 库是 Linux 版本自带的,这里使用的版本号可能和官方 OpenSSL 版本的不同。如果不确定的话检查一下你的 Linux 版本吧。
|
||||
|
||||
### 配置 ###
|
||||
|
||||
另一个给服务器的好建议是为 http2 模块设置合适的日志等级。添加下面的配置:
|
||||
|
||||
# 某个地方有这样一行
|
||||
# 放在某个地方的这样一行
|
||||
LoadModule http2_module modules/mod_http2.so
|
||||
|
||||
<IfModule http2_module>
|
||||
@ -62,38 +61,37 @@ ALPN 用来屏蔽服务器和客户端之间的协议。如果你服务器上 TL
|
||||
|
||||
那么,假设你已经编译部署好了服务器, TLS 库也是最新的,你启动了你的服务器,打开了浏览器。。。你怎么知道它在工作呢?
|
||||
|
||||
如果除此之外你没有添加其它到服务器配置,很可能它没有工作。
|
||||
如果除此之外你没有添加其它的服务器配置,很可能它没有工作。
|
||||
|
||||
你需要告诉服务器在哪里使用协议。默认情况下,你的服务器并没有启动 HTTP/2 协议。因为这是安全路由,你可能要有一套部署了才能继续。
|
||||
你需要告诉服务器在哪里使用该协议。默认情况下,你的服务器并没有启动 HTTP/2 协议。因为这样比较安全,也许才能让你已有的部署可以继续工作。
|
||||
|
||||
你用 **Protocols** 命令启用 HTTP/2 协议:
|
||||
你可以用新的 **Protocols** 指令启用 HTTP/2 协议:
|
||||
|
||||
# for a https server
|
||||
# 对于 https 服务器
|
||||
Protocols h2 http/1.1
|
||||
...
|
||||
|
||||
# for a http server
|
||||
# 对于 http 服务器
|
||||
Protocols h2c http/1.1
|
||||
|
||||
你可以给一般服务器或者指定的 **vhosts** 添加这个配置。
|
||||
你可以给整个服务器或者指定的 **vhosts** 添加这个配置。
|
||||
|
||||
#### SSL 参数 ####
|
||||
|
||||
对于 TLS (SSL),HTTP/2 有一些特殊的要求。阅读 [https:// 连接][4]了解更详细的信息。
|
||||
对于 TLS (SSL),HTTP/2 有一些特殊的要求。阅读下面的“ https:// 连接”一节了解更详细的信息。
|
||||
|
||||
### http:// 连接 (h2c) ###
|
||||
|
||||
尽管现在还没有浏览器支持 HTTP/2 协议, http:// 这样的 url 也能正常工作, 因为有 mod_h[ttp]2 的支持。启用它你只需要做的一件事是在 **httpd.conf** 配置 Protocols :
|
||||
尽管现在还没有浏览器支持,但是 HTTP/2 协议也工作在 http:// 这样的 url 上, 而且 mod_h[ttp]2 也支持。启用它你唯一所要做的是在 Protocols 配置中启用它:
|
||||
|
||||
# for a http server
|
||||
# 对于 http 服务器
|
||||
Protocols h2c http/1.1
|
||||
|
||||
|
||||
这里有一些支持 **h2c** 的客户端(和客户端库)。我会在下面介绍:
|
||||
|
||||
#### curl ####
|
||||
|
||||
Daniel Stenberg 维护的网络资源命令行客户端 curl 当然支持。如果你的系统上有 curl,有一个简单的方法检查它是否支持 http/2:
|
||||
Daniel Stenberg 维护的用于访问网络资源的命令行客户端 curl 当然支持。如果你的系统上有 curl,有一个简单的方法检查它是否支持 http/2:
|
||||
|
||||
sh> curl -V
|
||||
curl 7.43.0 (x86_64-apple-darwin15.0) libcurl/7.43.0 SecureTransport zlib/1.2.5
|
||||
@ -126,11 +124,11 @@ Daniel Stenberg 维护的网络资源命令行客户端 curl 当然支持。如
|
||||
|
||||
恭喜,如果看到了有 **...101 Switching...** 的行就表示它正在工作!
|
||||
|
||||
有一些情况不会发生到 HTTP/2 的 Upgrade 。如果你的第一个请求没有内容,例如你上传一个文件,就不会触发 Upgrade。[h2c 限制][5]部分有详细的解释。
|
||||
有一些情况不会发生 HTTP/2 的升级切换(Upgrade)。如果你的第一个请求有内容数据(body),例如你上传一个文件时,就不会触发升级切换。[h2c 限制][5]部分有详细的解释。
|
||||
|
||||
#### nghttp ####
|
||||
|
||||
nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客户端,你可以简单地通过获取资源验证你的安装:
|
||||
nghttp2 可以一同编译它自己的客户端和服务器。如果你的系统中有该客户端,你可以简单地通过获取一个资源来验证你的安装:
|
||||
|
||||
sh> nghttp -uv http://<yourserver>/
|
||||
[ 0.001] Connected
|
||||
@ -151,7 +149,7 @@ nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客
|
||||
|
||||
这和我们上面 **curl** 例子中看到的 Upgrade 输出很相似。
|
||||
|
||||
在命令行参数中隐藏着一种可以使用 **h2c**:的参数:**-u**。这会指示 **nghttp** 进行 HTTP/1 Upgrade 过程。但如果我们不使用呢?
|
||||
有另外一种在命令行参数中不用 **-u** 参数而使用 **h2c** 的方法。这个参数会指示 **nghttp** 进行 HTTP/1 升级切换过程。但如果我们不使用呢?
|
||||
|
||||
sh> nghttp -v http://<yourserver>/
|
||||
[ 0.002] Connected
|
||||
@ -166,36 +164,33 @@ nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客
|
||||
:scheme: http
|
||||
...
|
||||
|
||||
连接马上显示出了 HTTP/2!这就是协议中所谓的直接模式,当客户端发送一些特殊的 24 字节到服务器时就会发生:
|
||||
连接马上使用了 HTTP/2!这就是协议中所谓的直接(direct)模式,当客户端发送一些特殊的 24 字节到服务器时就会发生:
|
||||
|
||||
0x505249202a20485454502f322e300d0a0d0a534d0d0a0d0a
|
||||
or in ASCII: PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
|
||||
|
||||
用 ASCII 表示是:
|
||||
|
||||
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
|
||||
|
||||
支持 **h2c** 的服务器在一个新的连接中看到这些信息就会马上切换到 HTTP/2。HTTP/1.1 服务器则认为是一个可笑的请求,响应并关闭连接。
|
||||
|
||||
因此 **直接** 模式只适合于那些确定服务器支持 HTTP/2 的客户端。例如,前一个 Upgrade 过程是成功的。
|
||||
因此,**直接**模式只适合于那些确定服务器支持 HTTP/2 的客户端。例如,当前一个升级切换过程成功了的时候。
|
||||
|
||||
**直接** 模式的魅力是零开销,它支持所有请求,即使没有 body 部分(查看[h2c 限制][6])。任何支持 h2c 协议的服务器默认启用了直接模式。如果你想停用它,可以添加下面的配置指令到你的服务器:
|
||||
**直接**模式的魅力是零开销,它支持所有请求,即使带有请求数据部分(查看[h2c 限制][6])。
|
||||
|
||||
注:下面这行打删除线
|
||||
|
||||
H2Direct off
|
||||
|
||||
注:下面这行打删除线
|
||||
|
||||
对于 2.4.17 发行版,默认明文连接时启用 **H2Direct** 。但是有一些模块和这不兼容。因此,在下一发行版中,默认会设置为**off**,如果你希望你的服务器支持它,你需要设置它为:
|
||||
对于 2.4.17 版本,明文连接时默认启用 **H2Direct** 。但是有一些模块和这不兼容。因此,在下一版本中,默认会设置为**off**,如果你希望你的服务器支持它,你需要设置它为:
|
||||
|
||||
H2Direct on
|
||||
|
||||
### https:// 连接 (h2) ###
|
||||
|
||||
一旦你的 mod_h[ttp]2 支持 h2c 连接,就是时候一同启用 **h2**,因为现在的浏览器支持它和 **https:** 一同使用。
|
||||
当你的 mod_h[ttp]2 可以支持 h2c 连接时,那就可以一同启用 **h2** 兄弟了,现在的浏览器仅支持它和 **https:** 一同使用。
|
||||
|
||||
HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已经提到了 ALNP 扩展。另外的一个要求是不会使用特定[黑名单][7]中的密码。
|
||||
HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已经提到了 ALNP 扩展。另外的一个要求是不能使用特定[黑名单][7]中的加密算法。
|
||||
|
||||
尽管现在版本的 **mod_h[ttp]2** 不增强这些密码(以后可能会),大部分客户端会这么做。如果你用不切当的密码在浏览器中打开 **h2** 服务器,你会看到模糊警告**INADEQUATE_SECURITY**,浏览器会拒接连接。
|
||||
尽管现在版本的 **mod_h[ttp]2** 不增强这些算法(以后可能会),但大部分客户端会这么做。如果让你的浏览器使用不恰当的算法打开 **h2** 服务器,你会看到不明确的警告**INADEQUATE_SECURITY**,浏览器会拒接连接。
|
||||
|
||||
一个可接受的 Apache SSL 配置类似:
|
||||
一个可行的 Apache SSL 配置类似:
|
||||
|
||||
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!3DES:!MD5:!PSK
|
||||
SSLProtocol All -SSLv2 -SSLv3
|
||||
@ -203,11 +198,11 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
|
||||
|
||||
(是的,这确实很长。)
|
||||
|
||||
这里还有一些应该调整的 SSL 配置参数,但不是必须:**SSLSessionCache**, **SSLUseStapling** 等,其它地方也有介绍这些。例如 Ilya Grigorik 写的一篇博客 [高性能浏览器网络][8]。
|
||||
这里还有一些应该调整,但不是必须调整的 SSL 配置参数:**SSLSessionCache**, **SSLUseStapling** 等,其它地方也有介绍这些。例如 Ilya Grigorik 写的一篇超赞的博客: [高性能浏览器网络][8]。
|
||||
|
||||
#### curl ####
|
||||
|
||||
再次回到 shell 并使用 curl(查看 [curl h2c 章节][9] 了解要求)你也可以通过 curl 用简单的命令检测你的服务器:
|
||||
再次回到 shell 使用 curl(查看上面的“curl h2c”章节了解要求),你也可以通过 curl 用简单的命令检测你的服务器:
|
||||
|
||||
sh> curl -v --http2 https://<yourserver>/
|
||||
...
|
||||
@ -220,9 +215,9 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
|
||||
|
||||
恭喜你,能正常工作啦!如果还不能,可能原因是:
|
||||
|
||||
- 你的 curl 不支持 HTTP/2。查看[检测][10]。
|
||||
- 你的 curl 不支持 HTTP/2。查看上面的“检测 curl”一节。
|
||||
- 你的 openssl 版本太低不支持 ALPN。
|
||||
- 不能验证你的证书,或者不接受你的密码配置。尝试添加命令行选项 -k 停用 curl 中的检查。如果那能工作,还要重新配置你的 SSL 和证书。
|
||||
- 不能验证你的证书,或者不接受你的算法配置。尝试添加命令行选项 -k 停用 curl 中的这些检查。如果可以工作,就重新配置你的 SSL 和证书。
|
||||
|
||||
#### nghttp ####
|
||||
|
||||
@ -246,11 +241,11 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
|
||||
The negotiated protocol: http/1.1
|
||||
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
|
||||
|
||||
这表示 ALPN 能正常工作,但并没有用 h2 协议。你需要像上面介绍的那样在服务器上选中那个协议。如果一开始在 vhost 部分选中不能正常工作,试着在通用部分选中它。
|
||||
这表示 ALPN 能正常工作,但并没有用 h2 协议。你需要像上面介绍的那样检查你服务器上的 Protocols 配置。如果一开始在 vhost 部分设置不能正常工作,试着在通用部分设置它。
|
||||
|
||||
#### Firefox ####
|
||||
|
||||
Update: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox HTTP/2 指示插件][12]。你可以看到有多少地方用到了 h2(提示:Apache Lounge 用 h2 已经有一段时间了。。。)
|
||||
更新: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox 上有个 HTTP/2 指示插件][12]。你可以看到有多少地方用到了 h2(提示:Apache Lounge 用 h2 已经有一段时间了。。。)
|
||||
|
||||
你可以在 Firefox 浏览器中打开开发者工具,在那里的网络标签页查看 HTTP/2 连接。当你打开了 HTTP/2 并重新刷新 html 页面时,你会看到类似下面的东西:
|
||||
|
||||
@ -260,9 +255,9 @@ Update: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox HTTP/2 指示
|
||||
|
||||
#### Google Chrome ####
|
||||
|
||||
在 Google Chrome 中,你在开发者工具中看不到 HTTP/2 指示器。相反,Chrome 用特殊的地址 **chrome://net-internals/#http2** 给出了相关信息。
|
||||
在 Google Chrome 中,你在开发者工具中看不到 HTTP/2 指示器。相反,Chrome 用特殊的地址 **chrome://net-internals/#http2** 给出了相关信息。(LCTT 译注:Chrome 已经有一个 “HTTP/2 and SPDY indicator” 可以很好的在地址栏识别 HTTP/2 连接)
|
||||
|
||||
如果你在服务器中打开了一个页面并在 Chrome 那个页面查看,你可以看到类似下面这样:
|
||||
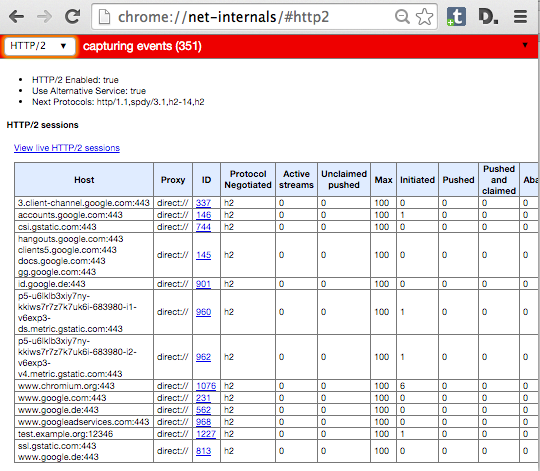
如果你打开了一个服务器的页面,可以在 Chrome 中查看那个 net-internals 页面,你可以看到类似下面这样:
|
||||
|
||||
|
||||
|
||||
@ -276,21 +271,21 @@ Windows 10 中 Internet Explorer 的继任者 Edge 也支持 HTTP/2。你也可
|
||||
|
||||
#### Safari ####
|
||||
|
||||
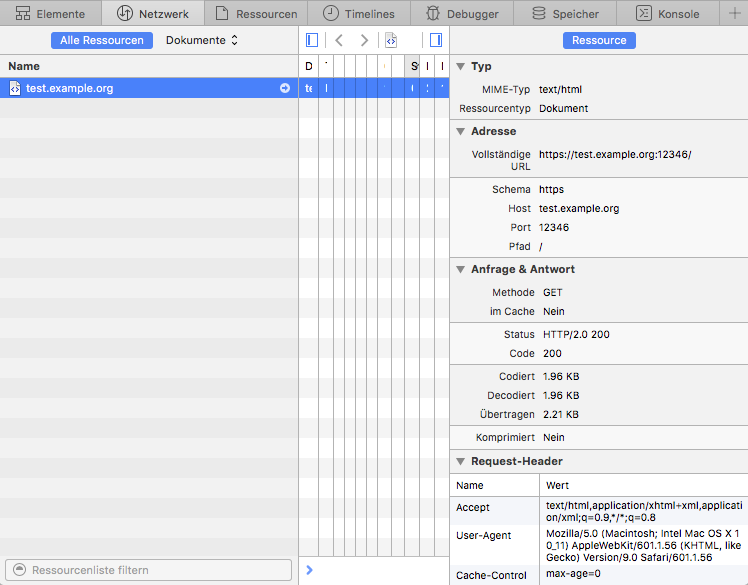
在 Apple 的 Safari 中,打开开发者工具,那里有个网络标签页。重新加载你的服务器页面并在开发者工具中选择显示了加载的行。如果你启用了在右边显示详细试图,看 **状态** 部分。那里显示了 **HTTP/2.0 200**,类似:
|
||||
在 Apple 的 Safari 中,打开开发者工具,那里有个网络标签页。重新加载你的服务器上的页面,并在开发者工具中选择显示了加载的那行。如果你启用了在右边显示详细视图,看 **Status** 部分。那里显示了 **HTTP/2.0 200**,像这样:
|
||||
|
||||
|
||||
|
||||
#### 重新协商 ####
|
||||
|
||||
https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会发生变化。在 Apache httpd 中,你可以通过目录中的配置文件修改 TLS 参数。如果一个要获取特定位置资源的请求到来,配置的 TLS 参数会和当前的 TLS 参数进行对比。如果它们不相同,就会触发重新协商。
|
||||
https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会发生变化。在 Apache httpd 中,你可以在 directory 配置中改变 TLS 参数。如果进来一个获取特定位置资源的请求,配置的 TLS 参数会和当前的 TLS 参数进行对比。如果它们不相同,就会触发重新协商。
|
||||
|
||||
这种最常见的情形是密码变化和客户端验证。你可以要求客户访问特定位置时需要通过验证,或者对于特定资源,你可以使用更安全的, CPU 敏感的密码。
|
||||
这种最常见的情形是算法变化和客户端证书。你可以要求客户访问特定位置时需要通过验证,或者对于特定资源,你可以使用更安全的、对 CPU 压力更大的算法。
|
||||
|
||||
不管你的想法有多么好,HTTP/2 中都**不可以**发生重新协商。如果有 100 多个请求到同一个地方,什么时候哪个会发生重新协商呢?
|
||||
但不管你的想法有多么好,HTTP/2 中都**不可以**发生重新协商。在同一个连接上会有 100 多个请求,那么重新协商该什么时候做呢?
|
||||
|
||||
对于这种配置,现有的 **mod_h[ttp]2** 还不能保证你的安全。如果你有一个站点使用了 TLS 重新协商,别在上面启用 h2!
|
||||
对于这种配置,现有的 **mod_h[ttp]2** 还没有办法。如果你有一个站点使用了 TLS 重新协商,别在上面启用 h2!
|
||||
|
||||
当然,我们会在后面的发行版中解决这个问题然后你就可以安全地启用了。
|
||||
当然,我们会在后面的版本中解决这个问题,然后你就可以安全地启用了。
|
||||
|
||||
### 限制 ###
|
||||
|
||||
@ -298,45 +293,45 @@ https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会
|
||||
|
||||
实现除 HTTP 之外协议的模块可能和 **mod_http2** 不兼容。这在其它协议要求服务器首先发送数据时无疑会发生。
|
||||
|
||||
**NNTP** 就是这种协议的一个例子。如果你在服务器中配置了 **mod_nntp_like_ssl**,甚至都不要加载 mod_http2。等待下一个发行版。
|
||||
**NNTP** 就是这种协议的一个例子。如果你在服务器中配置了 **mod\_nntp\_like\_ssl**,那么就不要加载 mod_http2。等待下一个版本。
|
||||
|
||||
#### h2c 限制 ####
|
||||
|
||||
**h2c** 的实现还有一些限制,你应该注意:
|
||||
|
||||
#### 在虚拟主机中拒绝 h2c ####
|
||||
##### 在虚拟主机中拒绝 h2c #####
|
||||
|
||||
你不能对指定的虚拟主机拒绝 **h2c 直连**。连接建立而没有看到请求时会触发**直连**,这使得不可能预先知道 Apache 需要查找哪个虚拟主机。
|
||||
|
||||
#### 升级请求体 ####
|
||||
##### 有请求数据时的升级切换 #####
|
||||
|
||||
对于有 body 部分的请求,**h2c** 升级不能正常工作。那些是 PUT 和 POST 请求(用于提交和上传)。如果你写了一个客户端,你可能会用一个简单的 GET 去处理请求或者用选项 * 去触发升级。
|
||||
对于有数据的请求,**h2c** 升级切换不能正常工作。那些是 PUT 和 POST 请求(用于提交和上传)。如果你写了一个客户端,你可能会用一个简单的 GET 或者 OPTIONS * 来处理那些请求以触发升级切换。
|
||||
|
||||
原因从技术层面来看显而易见,但如果你想知道:升级过程中,连接处于半疯状态。请求按照 HTTP/1.1 的格式,而响应使用 HTTP/2。如果请求有一个 body 部分,服务器在发送响应之前需要读取整个 body。因为响应可能需要从客户端处得到应答用于流控制。但如果仍在发送 HTTP/1.1 请求,客户端就还不能处理 HTTP/2 连接。
|
||||
原因从技术层面来看显而易见,但如果你想知道:在升级切换过程中,连接处于半疯状态。请求按照 HTTP/1.1 的格式,而响应使用 HTTP/2 帧。如果请求有一个数据部分,服务器在发送响应之前需要读取整个数据。因为响应可能需要从客户端处得到应答用于流控制及其它东西。但如果仍在发送 HTTP/1.1 请求,客户端就仍然不能以 HTTP/2 连接。
|
||||
|
||||
为了使行为可预测,几个服务器实现商决定不要在任何请求体中进行升级,即使 body 很小。
|
||||
为了使行为可预测,几个服务器在实现上决定不在任何带有请求数据的请求中进行升级切换,即使请求数据很小。
|
||||
|
||||
#### 升级 302s ####
|
||||
##### 302 时的升级切换 #####
|
||||
|
||||
有重定向发生时当前 h2c 升级也不能工作。看起来 mod_http2 之前的重写有可能发生。这当然不会导致断路,但你测试这样的站点也许会让你迷惑。
|
||||
有重定向发生时,当前的 h2c 升级切换也不能工作。看起来 mod_http2 之前的重写有可能发生。这当然不会导致断路,但你测试这样的站点也许会让你迷惑。
|
||||
|
||||
#### h2 限制 ####
|
||||
|
||||
这里有一些你应该意识到的 h2 实现限制:
|
||||
|
||||
#### 连接重用 ####
|
||||
##### 连接重用 #####
|
||||
|
||||
HTTP/2 协议允许在特定条件下重用 TLS 连接:如果你有带通配符的证书或者多个 AltSubject 名称,浏览器可能会重用现有的连接。例如:
|
||||
|
||||
你有一个 **a.example.org** 的证书,它还有另外一个名称 **b.example.org**。你在浏览器中打开 url **https://a.example.org/**,用另一个标签页加载 **https://b.example.org/**。
|
||||
你有一个 **a.example.org** 的证书,它还有另外一个名称 **b.example.org**。你在浏览器中打开 URL **https://a.example.org/**,用另一个标签页加载 **https://b.example.org/**。
|
||||
|
||||
在重新打开一个新的连接之前,浏览器看到它有一个到 **a.example.org** 的连接并且证书对于 **b.example.org** 也可用。因此,它在第一个连接上面向第二个标签页发送请求。
|
||||
在重新打开一个新的连接之前,浏览器看到它有一个到 **a.example.org** 的连接并且证书对于 **b.example.org** 也可用。因此,它在第一个连接上面发送第二个标签页的请求。
|
||||
|
||||
这种连接重用是刻意设计的,它使得致力于 HTTP/1 切分效率的站点能够不需要太多变化就能利用 HTTP/2。
|
||||
这种连接重用是刻意设计的,它使得使用了 HTTP/1 切分(sharding)来提高效率的站点能够不需要太多变化就能利用 HTTP/2。
|
||||
|
||||
Apache **mod_h[ttp]2** 还没有完全实现这点。如果 **a.example.org** 和 **b.example.org** 是不同的虚拟主机, Apache 不会允许这样的连接重用,并会告知浏览器状态码**421 错误请求**。浏览器会意识到它需要重新打开一个到 **b.example.org** 的连接。这仍然能工作,只是会降低一些效率。
|
||||
Apache **mod_h[ttp]2** 还没有完全实现这点。如果 **a.example.org** 和 **b.example.org** 是不同的虚拟主机, Apache 不会允许这样的连接重用,并会告知浏览器状态码 **421 Misdirected Request**。浏览器会意识到它需要重新打开一个到 **b.example.org** 的连接。这仍然能工作,只是会降低一些效率。
|
||||
|
||||
我们期望下一次的发布中能有切当的检查。
|
||||
我们期望下一次的发布中能有合适的检查。
|
||||
|
||||
Münster, 12.10.2015,
|
||||
|
||||
@ -355,7 +350,7 @@ via: https://icing.github.io/mod_h2/howto.html
|
||||
|
||||
作者:[icing][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
239
published/20151104 How to Install Redis Server on CentOS 7.md
Normal file
239
published/20151104 How to Install Redis Server on CentOS 7.md
Normal file
@ -0,0 +1,239 @@
|
||||
如何在 CentOS 7 上安装 Redis 服务器
|
||||
================================================================================
|
||||
|
||||
大家好,本文的主题是 Redis,我们将要在 CentOS 7 上安装它。编译源代码,安装二进制文件,创建、安装文件。在安装了它的组件之后,我们还会配置 redis ,就像配置操作系统参数一样,目标就是让 redis 运行的更加可靠和快速。
|
||||
|
||||

|
||||
|
||||
*Redis 服务器*
|
||||
|
||||
Redis 是一个开源的多平台数据存储软件,使用 ANSI C 编写,直接在内存使用数据集,这使得它得以实现非常高的效率。Redis 支持多种编程语言,包括 Lua, C, Java, Python, Perl, PHP 和其他很多语言。redis 的代码量很小,只有约3万行,它只做“很少”的事,但是做的很好。尽管是在内存里工作,但是数据持久化的保存还是有的,而redis 的可靠性就很高,同时也支持集群,这些可以很好的保证你的数据安全。
|
||||
|
||||
### 构建 Redis ###
|
||||
|
||||
redis 目前没有官方 RPM 安装包,我们需要从源代码编译,而为了要编译就需要安装 Make 和 GCC。
|
||||
|
||||
如果没有安装过 GCC 和 Make,那么就使用 yum 安装。
|
||||
|
||||
yum install gcc make
|
||||
|
||||
从[官网][1]下载 tar 压缩包。
|
||||
|
||||
curl http://download.redis.io/releases/redis-3.0.4.tar.gz -o redis-3.0.4.tar.gz
|
||||
|
||||
解压缩。
|
||||
|
||||
tar zxvf redis-3.0.4.tar.gz
|
||||
|
||||
进入解压后的目录。
|
||||
|
||||
cd redis-3.0.4
|
||||
|
||||
使用Make 编译源文件。
|
||||
|
||||
make
|
||||
|
||||
### 安装 ###
|
||||
|
||||
进入源文件的目录。
|
||||
|
||||
cd src
|
||||
|
||||
复制 Redis 的服务器和客户端到 /usr/local/bin。
|
||||
|
||||
cp redis-server redis-cli /usr/local/bin
|
||||
|
||||
最好也把 sentinel,benchmark 和 check 复制过去。
|
||||
|
||||
cp redis-sentinel redis-benchmark redis-check-aof redis-check-dump /usr/local/bin
|
||||
|
||||
创建redis 配置文件夹。
|
||||
|
||||
mkdir /etc/redis
|
||||
|
||||
在`/var/lib/redis` 下创建有效的保存数据的目录
|
||||
|
||||
mkdir -p /var/lib/redis/6379
|
||||
|
||||
#### 系统参数 ####
|
||||
|
||||
为了让 redis 正常工作需要配置一些内核参数。
|
||||
|
||||
配置 `vm.overcommit_memory` 为1,这可以避免数据被截断,详情[见此][2]。
|
||||
|
||||
sysctl -w vm.overcommit_memory=1
|
||||
|
||||
修改 backlog 连接数的最大值超过 redis.conf 中的 `tcp-backlog` 值,即默认值511。你可以在[kernel.org][3] 找到更多有关基于 sysctl 的 ip 网络隧道的信息。
|
||||
|
||||
sysctl -w net.core.somaxconn=512
|
||||
|
||||
取消对透明巨页内存(transparent huge pages)的支持,因为这会造成 redis 使用过程产生延时和内存访问问题。
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### redis.conf ###
|
||||
|
||||
redis.conf 是 redis 的配置文件,然而你会看到这个文件的名字是 6379.conf ,而这个数字就是 redis 监听的网络端口。如果你想要运行超过一个的 redis 实例,推荐用这样的名字。
|
||||
|
||||
复制示例的 redis.conf 到 **/etc/redis/6379.conf**。
|
||||
|
||||
cp redis.conf /etc/redis/6379.conf
|
||||
|
||||
现在编辑这个文件并且配置参数。
|
||||
|
||||
vi /etc/redis/6379.conf
|
||||
|
||||
#### daemonize ####
|
||||
|
||||
设置 `daemonize` 为 no,systemd 需要它运行在前台,否则 redis 会突然挂掉。
|
||||
|
||||
daemonize no
|
||||
|
||||
#### pidfile ####
|
||||
|
||||
设置 `pidfile` 为 /var/run/redis_6379.pid。
|
||||
|
||||
pidfile /var/run/redis_6379.pid
|
||||
|
||||
#### port ####
|
||||
|
||||
如果不准备用默认端口,可以修改。
|
||||
|
||||
port 6379
|
||||
|
||||
#### loglevel ####
|
||||
|
||||
设置日志级别。
|
||||
|
||||
loglevel notice
|
||||
|
||||
#### logfile ####
|
||||
|
||||
修改日志文件路径。
|
||||
|
||||
logfile /var/log/redis_6379.log
|
||||
|
||||
#### dir ####
|
||||
|
||||
设置目录为 /var/lib/redis/6379
|
||||
|
||||
dir /var/lib/redis/6379
|
||||
|
||||
### 安全 ###
|
||||
|
||||
下面有几个可以提高安全性的操作。
|
||||
|
||||
#### Unix sockets ####
|
||||
|
||||
在很多情况下,客户端程序和服务器端程序运行在同一个机器上,所以不需要监听网络上的 socket。如果这和你的使用情况类似,你就可以使用 unix socket 替代网络 socket,为此你需要配置 `port` 为0,然后配置下面的选项来启用 unix socket。
|
||||
|
||||
设置 unix socket 的套接字文件。
|
||||
|
||||
unixsocket /tmp/redis.sock
|
||||
|
||||
限制 socket 文件的权限。
|
||||
|
||||
unixsocketperm 700
|
||||
|
||||
现在为了让 redis-cli 可以访问,应该使用 -s 参数指向该 socket 文件。
|
||||
|
||||
redis-cli -s /tmp/redis.sock
|
||||
|
||||
#### requirepass ####
|
||||
|
||||
你可能需要远程访问,如果是,那么你应该设置密码,这样子每次操作之前要求输入密码。
|
||||
|
||||
requirepass "bTFBx1NYYWRMTUEyNHhsCg"
|
||||
|
||||
#### rename-command ####
|
||||
|
||||
想象一下如下指令的输出。是的,这会输出服务器的配置,所以你应该在任何可能的情况下拒绝这种访问。
|
||||
|
||||
CONFIG GET *
|
||||
|
||||
为了限制甚至禁止这条或者其他指令可以使用 `rename-command` 命令。你必须提供一个命令名和替代的名字。要禁止的话需要设置替代的名字为空字符串,这样禁止任何人猜测命令的名字会比较安全。
|
||||
|
||||
rename-command FLUSHDB "FLUSHDB_MY_SALT_G0ES_HERE09u09u"
|
||||
rename-command FLUSHALL ""
|
||||
rename-command CONFIG "CONFIG_MY_S4LT_GO3S_HERE09u09u"
|
||||
|
||||

|
||||
|
||||
*使用密码通过 unix socket 访问,和修改命令*
|
||||
|
||||
#### 快照 ####
|
||||
|
||||
默认情况下,redis 会周期性的将数据集转储到我们设置的目录下的 **dump.rdb** 文件。你可以使用 `save` 命令配置转储的频率,它的第一个参数是以秒为单位的时间帧,第二个参数是在数据文件上进行修改的数量。
|
||||
|
||||
每隔15分钟并且最少修改过一次键。
|
||||
|
||||
save 900 1
|
||||
|
||||
每隔5分钟并且最少修改过10次键。
|
||||
|
||||
save 300 10
|
||||
|
||||
每隔1分钟并且最少修改过10000次键。
|
||||
|
||||
save 60 10000
|
||||
|
||||
文件 `/var/lib/redis/6379/dump.rdb` 包含了从上次保存以来内存里数据集的转储数据。因为它先创建临时文件然后替换之前的转储文件,这里不存在数据破坏的问题,你不用担心,可以直接复制这个文件。
|
||||
|
||||
### 开机时启动 ###
|
||||
|
||||
你可以使用 systemd 将 redis 添加到系统开机启动列表。
|
||||
|
||||
复制示例的 init_script 文件到 `/etc/init.d`,注意脚本名所代表的端口号。
|
||||
|
||||
cp utils/redis_init_script /etc/init.d/redis_6379
|
||||
|
||||
现在我们要使用 systemd,所以在 `/etc/systems/system` 下创建一个单位文件名字为 `redis_6379.service`。
|
||||
|
||||
vi /etc/systemd/system/redis_6379.service
|
||||
|
||||
填写下面的内容,详情可见 systemd.service。
|
||||
|
||||
[Unit]
|
||||
Description=Redis on port 6379
|
||||
|
||||
[Service]
|
||||
Type=forking
|
||||
ExecStart=/etc/init.d/redis_6379 start
|
||||
ExecStop=/etc/init.d/redis_6379 stop
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
现在添加我之前在 `/etc/sysctl.conf` 里面修改过的内存过量使用和 backlog 最大值的选项。
|
||||
|
||||
vm.overcommit_memory = 1
|
||||
|
||||
net.core.somaxconn=512
|
||||
|
||||
对于透明巨页内存支持,并没有直接 sysctl 命令可以控制,所以需要将下面的命令放到 `/etc/rc.local` 的结尾。
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### 总结 ###
|
||||
|
||||
这样就可以启动了,通过设置这些选项你就可以部署 redis 服务到很多简单的场景,然而在 redis.conf 还有很多为复杂环境准备的 redis 选项。在一些情况下,你可以使用 [replication][4] 和 [Sentinel][5] 来提高可用性,或者[将数据分散][6]在多个服务器上,创建服务器集群。
|
||||
|
||||
谢谢阅读。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/install-redis-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
[1]:http://redis.io/download
|
||||
[2]:https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
|
||||
[3]:https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
|
||||
[4]:http://redis.io/topics/replication
|
||||
[5]:http://redis.io/topics/sentinel
|
||||
[6]:http://redis.io/topics/partitioning
|
||||
@ -2,9 +2,9 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
Linus 最近(LCTT 译注:其实是11月份,没有及时翻译出来,看官轻喷Orz)骂了一个 Linux 开发者,原因是他向 kernel 提交了一份不安全的代码。
|
||||
Linus 上个月骂了一个 Linux 开发者,原因是他向 kernel 提交了一份不安全的代码。
|
||||
|
||||
Linus 是个 Linux 内核项目非官方的“仁慈的独裁者(LCTT译注:英国《卫报》曾将乔布斯评价为‘仁慈的独裁者’)”,这意味着他有权决定将哪些代码合入内核,哪些代码直接丢掉。
|
||||
Linus 是个 Linux 内核项目非官方的“仁慈的独裁者(benevolent dictator)”(LCTT译注:英国《卫报》曾将乔布斯评价为‘仁慈的独裁者’),这意味着他有权决定将哪些代码合入内核,哪些代码直接丢掉。
|
||||
|
||||
在10月28号,一个开源开发者提交的代码未能符合 Torvalds 的要求,于是遭来了[一顿臭骂][1]。Torvalds 在他提交的代码下评论道:“你提交的是什么东西。”
|
||||
|
||||
@ -14,7 +14,7 @@ Torvalds 为什么会这么生气?他觉得那段代码可以写得更有效
|
||||
|
||||
Torvalds 重新写了一版代码将原来的那份替换掉,并建议所有开发者应该像他那种风格来写代码。
|
||||
|
||||
Torvalds 一直在嘲讽那些不符合他观点的人。早在1991年他就攻击过[Andrew Tanenbaum][2]——那个 Minix 操作系统的作者,而那个 Minix 操作系统被 Torvalds 描述为“脑残”。
|
||||
Torvalds 一直在嘲讽那些不符合他观点的人。早在1991年他就攻击过 [Andrew Tanenbaum][2]——那个 Minix 操作系统的作者,而那个 Minix 操作系统被 Torvalds 描述为“脑残”。
|
||||
|
||||
但是 Torvalds 在这次嘲讽中表现得更有战略性了:“我想让*每个人*都知道,像他这种代码是完全不能被接收的。”他说他的目的是提醒每个 Linux 开发者,而不是针对那个开发者。
|
||||
|
||||
@ -26,7 +26,7 @@ via: http://thevarguy.com/open-source-application-software-companies/110415/linu
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
如何在CentOS 6/7 上移除被Fail2ban禁止的IP
|
||||
如何在 CentOS 6/7 上移除被 Fail2ban 禁止的 IP
|
||||
================================================================================
|
||||

|
||||
|
||||
[Fail2ban][1]是一款用于保护你的服务器免于暴力攻击的入侵保护软件。Fail2ban用python写成,并被广泛用户大多数服务器上。Fail2ban将扫描日志文件和IP黑名单来显示恶意软件、过多的密码失败、web服务器利用、Wordpress插件攻击和其他漏洞。如果你已经安装并使用了fail2ban来保护你的web服务器,你也许会想知道如何在CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7中找到被Fail2ban阻止的IP,或者你想将ip从fail2ban监狱中移除。
|
||||
[fail2ban][1] 是一款用于保护你的服务器免于暴力攻击的入侵保护软件。fail2ban 用 python 写成,并广泛用于很多服务器上。fail2ban 会扫描日志文件和 IP 黑名单来显示恶意软件、过多的密码失败尝试、web 服务器利用、wordpress 插件攻击和其他漏洞。如果你已经安装并使用了 fail2ban 来保护你的 web 服务器,你也许会想知道如何在 CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7 中找到被 fail2ban 阻止的 IP,或者你想将 ip 从 fail2ban 监狱中移除。
|
||||
|
||||
### 如何列出被禁止的IP ###
|
||||
### 如何列出被禁止的 IP ###
|
||||
|
||||
要查看所有被禁止的ip地址,运行下面的命令:
|
||||
要查看所有被禁止的 ip 地址,运行下面的命令:
|
||||
|
||||
# iptables -L
|
||||
Chain INPUT (policy ACCEPT)
|
||||
@ -40,19 +40,19 @@
|
||||
REJECT all -- 104.194.26.205 anywhere reject-with icmp-port-unreachable
|
||||
RETURN all -- anywhere anywhere
|
||||
|
||||
### 如何从Fail2ban中移除IP ###
|
||||
### 如何从 Fail2ban 中移除 IP ###
|
||||
|
||||
# iptables -D f2b-NoAuthFailures -s banned_ip -j REJECT
|
||||
|
||||
我希望这篇教程可以给你在CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7中移除被禁止的ip一些指导。
|
||||
我希望这篇教程可以给你在 CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7 中移除被禁止的 ip 一些指导。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ehowstuff.com/how-to-remove-banned-ip-from-fail2ban-on-centos/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +0,0 @@
|
||||
Let's Encrypt:Entering Public Beta
|
||||
================================================================================
|
||||
We’re happy to announce that Let’s Encrypt has entered Public Beta. Invitations are no longer needed in order to get free
|
||||
certificates from Let’s Encrypt.
|
||||
|
||||
It’s time for the Web to take a big step forward in terms of security and privacy. We want to see HTTPS become the default.
|
||||
Let’s Encrypt was built to enable that by making it as easy as possible to get and manage certificates.
|
||||
|
||||
We’d like to thank everyone who participated in the Limited Beta. Let’s Encrypt issued over 26,000 certificates during the
|
||||
Limited Beta period. This allowed us to gain valuable insight into how our systems perform, and to be confident about moving
|
||||
to Public Beta.
|
||||
|
||||
We’d also like to thank all of our [sponsors][1] for their support. We’re happy to have announced earlier today that
|
||||
[Facebook is our newest Gold sponsor][2]/
|
||||
|
||||
We have more work to do before we’re comfortable dropping the beta label entirely, particularly on the client experience.
|
||||
Automation is a cornerstone of our strategy, and we need to make sure that the client works smoothly and reliably on a
|
||||
wide range of platforms. We’ll be monitoring feedback from users closely, and making improvements as quickly as possible.
|
||||
|
||||
Instructions for getting a certificate with the [Let’s Encrypt client][3] can be found [here][4].
|
||||
|
||||
[Let’s Encrypt Community Support][5] is an invaluable resource for our community, we strongly recommend making use of the
|
||||
site if you have any questions about Let’s Encrypt.
|
||||
|
||||
Let’s Encrypt depends on support from a wide variety of individuals and organizations. Please consider [getting involved][6]
|
||||
, and if your company or organization would like to sponsor Let’s Encrypt please email us at [sponsor@letsencrypt.org][7].
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://letsencrypt.org/2015/12/03/entering-public-beta.html
|
||||
|
||||
作者:[Josh Aas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://letsencrypt.org/2015/12/03/entering-public-beta.html
|
||||
[1]:https://letsencrypt.org/sponsors/
|
||||
[2]:https://letsencrypt.org/2015/12/03/facebook-sponsorship.html
|
||||
[3]:https://github.com/letsencrypt/letsencrypt
|
||||
[4]:https://letsencrypt.readthedocs.org/en/latest/
|
||||
[5]:https://community.letsencrypt.org/
|
||||
[6]:https://letsencrypt.org/getinvolved/
|
||||
[7]:mailto:sponsor@letsencrypt.org
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by H-mudcup
|
||||
Great Open Source Collaborative Editing Tools
|
||||
================================================================================
|
||||
In a nutshell, collaborative writing is writing done by more than one person. There are benefits and risks of collaborative working. Some of the benefits include a more integrated / co-ordinated approach, better use of existing resources, and a stronger, united voice. For me, the greatest advantage is one of the most transparent. That's when I need to take colleagues' views. Sending files back and forth between colleagues is inefficient, causes unnecessary delays and leaves people (i.e. me) unhappy with the whole notion of collaboration. With good collaborative software, I can share notes, data and files, and use comments to share thoughts in real-time or asynchronously. Working together on documents, images, video, presentations, and tasks is made less of a chore.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by tastynoodle
|
||||
5 best open source board games to play online
|
||||
================================================================================
|
||||
I have always had a fascination with board games, in part because they are a device of social interaction, they challenge the mind and, most importantly, they are great fun to play. In my misspent youth, myself and a group of friends gathered together to escape the horrors of the classroom, and indulge in a little escapism. The time provided an outlet for tension and rivalry. Board games help teach diplomacy, how to make and break alliances, bring families and friends together, and learn valuable lessons.
|
||||
|
||||
@ -1,64 +0,0 @@
|
||||
eSpeak: Text To Speech Tool For Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
[eSpeak][1] is a command line tool for Linux that converts text to speech. This is a compact speech synthesizer that provides support to English and many other languages. It is written in C.
|
||||
|
||||
eSpeak reads the text from the standard input or the input file. The voice generated, however, is nowhere close to a human voice. But it is still a compact and handy tool if you want to use it in your projects.
|
||||
|
||||
Some of the main features of eSpeak are:
|
||||
|
||||
- A command line tool for Linux and Windows
|
||||
- Speaks text from a file or from stdin
|
||||
- Shared library version for use by other programs
|
||||
- SAPI5 version for Windows, so it can be used with screen-readers and other programs that support the Windows SAPI5 interface.
|
||||
- Ported to other platforms, including Android, Mac OSX etc.
|
||||
- Several voice characteristics to choose from
|
||||
- speech output can be saved as [.WAV file][2]
|
||||
- SSML ([Speech Synthesis Markup Language][3]) is supported partially along with HTML
|
||||
- Tiny in size, the complete program with language support etc is under 2 MB.
|
||||
- Can translate text into phoneme codes, so it could be adapted as a front end for another speech synthesis engine.
|
||||
- Development tools available for producing and tuning phoneme data.
|
||||
|
||||
### Install eSpeak ###
|
||||
|
||||
To install eSpeak in Ubuntu based system, use the command below in a terminal:
|
||||
|
||||
sudo apt-get install espeak
|
||||
|
||||
eSpeak is an old tool and I presume that it should be available in the repositories of other Linux distributions such as Arch Linux, Fedora etc. You can install eSpeak easily using dnf, pacman etc.
|
||||
|
||||
To use eSpeak, just use it like: espeak and press enter to hear it aloud. Use Ctrl+C to close the running program.
|
||||
|
||||

|
||||
|
||||
There are several other options available. You can browse through them through the help section of the program.
|
||||
|
||||
### GUI version: Gespeaker ###
|
||||
|
||||
If you prefer the GUI version over the command line, you can install Gespeaker that provides a GTK front end to eSpeak.
|
||||
|
||||
Use the command below to install Gespeaker:
|
||||
|
||||
sudo apt-get install gespeaker
|
||||
|
||||
The interface is straightforward and easy to use. You can explore it all by yourself.
|
||||
|
||||

|
||||
|
||||
While such tools might not be useful for general computing need, it could be handy if you are working on some projects where text to speech conversion is required. I let you decide the usage of this speech synthesizer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/espeak-text-speech-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://espeak.sourceforge.net/
|
||||
[2]:http://en.wikipedia.org/wiki/WAV
|
||||
[3]:http://en.wikipedia.org/wiki/Speech_Synthesis_Markup_Language
|
||||
@ -1,284 +0,0 @@
|
||||
Review: 5 memory debuggers for Linux coding
|
||||
================================================================================
|
||||

|
||||
Credit: [Moini][1]
|
||||
|
||||
As a programmer, I'm aware that I tend to make mistakes -- and why not? Even programmers are human. Some errors are detected during code compilation, while others get caught during software testing. However, a category of error exists that usually does not get detected at either of these stages and that may cause the software to behave unexpectedly -- or worse, terminate prematurely.
|
||||
|
||||
If you haven't already guessed it, I am talking about memory-related errors. Manually debugging these errors can be not only time-consuming but difficult to find and correct. Also, it's worth mentioning that these errors are surprisingly common, especially in software written in programming languages like C and C++, which were designed for use with [manual memory management][2].
|
||||
|
||||
Thankfully, several programming tools exist that can help you find memory errors in your software programs. In this roundup, I assess five popular, free and open-source memory debuggers that are available for Linux: Dmalloc, Electric Fence, Memcheck, Memwatch and Mtrace. I've used all five in my day-to-day programming, and so these reviews are based on practical experience.
|
||||
|
||||
eviews are based on practical experience.
|
||||
|
||||
### [Dmalloc][3] ###
|
||||
|
||||
**Developer**: Gray Watson
|
||||
**Reviewed version**: 5.5.2
|
||||
**Linux support**: All flavors
|
||||
**License**: Creative Commons Attribution-Share Alike 3.0 License
|
||||
|
||||
Dmalloc is a memory-debugging tool developed by Gray Watson. It is implemented as a library that provides wrappers around standard memory management functions like **malloc(), calloc(), free()** and more, enabling programmers to detect problematic code.
|
||||
|
||||

|
||||
Dmalloc
|
||||
|
||||
As listed on the tool's Web page, the debugging features it provides includes memory-leak tracking, [double free][4] error tracking and [fence-post write detection][5]. Other features include file/line number reporting, and general logging of statistics.
|
||||
|
||||
#### What's new ####
|
||||
|
||||
Version 5.5.2 is primarily a [bug-fix release][6] containing corrections for a couple of build and install problems.
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
The best part about Dmalloc is that it's extremely configurable. For example, you can configure it to include support for C++ programs as well as threaded applications. A useful functionality it provides is runtime configurability, which means that you can easily enable/disable the features the tool provides while it is being executed.
|
||||
|
||||
You can also use Dmalloc with the [GNU Project Debugger (GDB)][7] -- just add the contents of the dmalloc.gdb file (located in the contrib subdirectory in Dmalloc's source package) to the .gdbinit file in your home directory.
|
||||
|
||||
Another thing that I really like about Dmalloc is its extensive documentation. Just head to the [documentation section][8] on its official website, and you'll get everything from how to download, install, run and use the library to detailed descriptions of the features it provides and an explanation of the output file it produces. There's also a section containing solutions to some common problems.
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
Like Mtrace, Dmalloc requires programmers to make changes to their program's source code. In this case you may, at the very least, want to add the **dmalloc.h** header, because it allows the tool to report the file/line numbers of calls that generate problems, something that is very useful as it saves time while debugging.
|
||||
|
||||
In addition, the Dmalloc library, which is produced after the package is compiled, needs to be linked with your program while the program is being compiled.
|
||||
|
||||
However, complicating things somewhat is the fact that you also need to set an environment variable, dubbed **DMALLOC_OPTION**, that the debugging tool uses to configure the memory debugging features -- as well as the location of the output file -- at runtime. While you can manually assign a value to the environment variable, beginners may find that process a bit tough, given that the Dmalloc features you want to enable are listed as part of that value, and are actually represented as a sum of their respective hexadecimal values -- you can read more about it [here][9].
|
||||
|
||||
An easier way to set the environment variable is to use the [Dmalloc Utility Program][10], which was designed for just that purpose.
|
||||
|
||||
#### Bottom line ####
|
||||
|
||||
Dmalloc's real strength lies in the configurability options it provides. It is also highly portable, having being successfully ported to many OSes, including AIX, BSD/OS, DG/UX, Free/Net/OpenBSD, GNU/Hurd, HPUX, Irix, Linux, MS-DOG, NeXT, OSF, SCO, Solaris, SunOS, Ultrix, Unixware and even Unicos (on a Cray T3E). Although the tool has a bit of a learning curve associated with it, the features it provides are worth it.
|
||||
|
||||
### [Electric Fence][15] ###
|
||||
|
||||
**Developer**: Bruce Perens
|
||||
**Reviewed version**: 2.2.3
|
||||
**Linux support**: All flavors
|
||||
**License**: GNU GPL (version 2)
|
||||
|
||||
Electric Fence is a memory-debugging tool developed by Bruce Perens. It is implemented in the form of a library that your program needs to link to, and is capable of detecting overruns of memory allocated on a [heap][11] ) as well as memory accesses that have already been released.
|
||||
|
||||
|
||||
Electric Fence
|
||||
|
||||
As the name suggests, Electric Fence creates a virtual fence around each allocated buffer in a way that any illegal memory access results in a [segmentation fault][12]. The tool supports both C and C++ programs.
|
||||
|
||||
#### What's new ####
|
||||
|
||||
Version 2.2.3 contains a fix for the tool's build system, allowing it to actually pass the -fno-builtin-malloc option to the [GNU Compiler Collection (GCC)][13].
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
The first thing that I liked about Electric Fence is that -- unlike Memwatch, Dmalloc and Mtrace -- it doesn't require you to make any changes in the source code of your program. You just need to link your program with the tool's library during compilation.
|
||||
|
||||
Secondly, the way the debugging tool is implemented makes sure that a segmentation fault is generated on the very first instruction that causes a bounds violation, which is always better than having the problem detected at a later stage.
|
||||
|
||||
Electric Fence always produces a copyright message in output irrespective of whether an error was detected or not. This behavior is quite useful, as it also acts as a confirmation that you are actually running an Electric Fence-enabled version of your program.
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
On the other hand, what I really miss in Electric Fence is the ability to detect memory leaks, as it is one of the most common and potentially serious problems that software written in C/C++ has. In addition, the tool cannot detect overruns of memory allocated on the stack, and is not thread-safe.
|
||||
|
||||
Given that the tool allocates an inaccessible virtual memory page both before and after a user-allocated memory buffer, it ends up consuming a lot of extra memory if your program makes too many dynamic memory allocations.
|
||||
|
||||
Another limitation of the tool is that it cannot explicitly tell exactly where the problem lies in your programs' code -- all it does is produce a segmentation fault whenever it detects a memory-related error. To find out the exact line number, you'll have to debug your Electric Fence-enabled program with a tool like [The Gnu Project Debugger (GDB)][14], which in turn depends on the -g compiler option to produce line numbers in output.
|
||||
|
||||
Finally, although Electric Fence is capable of detecting most buffer overruns, an exception is the scenario where the allocated buffer size is not a multiple of the word size of the system -- in that case, an overrun (even if it's only a few bytes) won't be detected.
|
||||
|
||||
#### Bottom line ####
|
||||
|
||||
Despite all its limitations, where Electric Fence scores is the ease of use -- just link your program with the tool once, and it'll alert you every time it detects a memory issue it's capable of detecting. However, as already mentioned, the tool requires you to use a source-code debugger like GDB.
|
||||
|
||||
### [Memcheck][16] ###
|
||||
|
||||
**Developer**: [Valgrind Developers][17]
|
||||
**Reviewed version**: 3.10.1
|
||||
**Linux support**: All flavors
|
||||
**License**: GPL
|
||||
|
||||
[Valgrind][18] is a suite that provides several tools for debugging and profiling Linux programs. Although it works with programs written in many different languages -- such as Java, Perl, Python, Assembly code, Fortran, Ada and more -- the tools it provides are largely aimed at programs written in C and C++.
|
||||
|
||||
The most popular Valgrind tool is Memcheck, a memory-error detector that can detect issues such as memory leaks, invalid memory access, uses of undefined values and problems related to allocation and deallocation of heap memory.
|
||||
|
||||
#### What's new ####
|
||||
|
||||
This [release][19] of the suite (3.10.1) is a minor one that primarily contains fixes to bugs reported in version 3.10.0. In addition, it also "backports fixes for all reported missing AArch64 ARMv8 instructions and syscalls from the trunk."
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
Memcheck, like all other Valgrind tools, is basically a command line utility. It's very easy to use: If you normally run your program on the command line in a form such as prog arg1 arg2, you just need to add a few values, like this: valgrind --leak-check=full prog arg1 arg2.
|
||||
|
||||
|
||||
Memcheck
|
||||
|
||||
(Note: You don't need to mention Memcheck anywhere in the command line because it's the default Valgrind tool. However, you do need to initially compile your program with the -g option -- which adds debugging information -- so that Memcheck's error messages include exact line numbers.)
|
||||
|
||||
What I really like about Memcheck is that it provides a lot of command line options (such as the --leak-check option mentioned above), allowing you to not only control how the tool works but also how it produces the output.
|
||||
|
||||
For example, you can enable the --track-origins option to see information on the sources of uninitialized data in your program. Enabling the --show-mismatched-frees option will let Memcheck match the memory allocation and deallocation techniques. For code written in C language, Memcheck will make sure that only the free() function is used to deallocate memory allocated by malloc(), while for code written in C++, the tool will check whether or not the delete and delete[] operators are used to deallocate memory allocated by new and new[], respectively. If a mismatch is detected, an error is reported.
|
||||
|
||||
But the best part, especially for beginners, is that the tool even produces suggestions about which command line option the user should use to make the output more meaningful. For example, if you do not use the basic --leak-check option, it will produce an output suggesting: "Rerun with --leak-check=full to see details of leaked memory." And if there are uninitialized variables in the program, the tool will generate a message that says, "Use --track-origins=yes to see where uninitialized values come from."
|
||||
|
||||
Another useful feature of Memcheck is that it lets you [create suppression files][20], allowing you to suppress certain errors that you can't fix at the moment -- this way you won't be reminded of them every time the tool is run. It's worth mentioning that there already exists a default suppression file that Memcheck reads to suppress errors in the system libraries, such as the C library, that come pre-installed with your OS. You can either create a new suppression file for your use, or edit the existing one (usually /usr/lib/valgrind/default.supp).
|
||||
|
||||
For those seeking advanced functionality, it's worth knowing that Memcheck can also [detect memory errors][21] in programs that use [custom memory allocators][22]. In addition, it also provides [monitor commands][23] that can be used while working with Valgrind's built-in gdbserver, as well as a [client request mechanism][24] that allows you not only to tell the tool facts about the behavior of your program, but make queries as well.
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
While there's no denying that Memcheck can save you a lot of debugging time and frustration, the tool uses a lot of memory, and so can make your program execution significantly slower (around 20 to 30 times, [according to the documentation][25]).
|
||||
|
||||
Aside from this, there are some other limitations, too. According to some user comments, Memcheck apparently isn't [thread-safe][26]; it doesn't detect [static buffer overruns][27]). Also, there are some Linux programs, like [GNU Emacs][28], that currently do not work with Memcheck.
|
||||
|
||||
If you're interested in taking a look, an exhaustive list of Valgrind's limitations can be found [here][29].
|
||||
|
||||
#### Bottom line ####
|
||||
|
||||
Memcheck is a handy memory-debugging tool for both beginners as well as those looking for advanced features. While it's very easy to use if all you need is basic debugging and error checking, there's a bit of learning curve if you want to use features like suppression files or monitor commands.
|
||||
|
||||
Although it has a long list of limitations, Valgrind (and hence Memcheck) claims on its site that it is used by [thousands of programmers][30] across the world -- the team behind the tool says it's received feedback from users in over 30 countries, with some of them working on projects with up to a whopping 25 million lines of code.
|
||||
|
||||
### [Memwatch][31] ###
|
||||
|
||||
**Developer**: Johan Lindh
|
||||
**Reviewed version**: 2.71
|
||||
**Linux support**: All flavors
|
||||
**License**: GNU GPL
|
||||
|
||||
Memwatch is a memory-debugging tool developed by Johan Lindh. Although it's primarily a memory-leak detector, it is also capable (according to its Web page) of detecting other memory-related issues like [double-free error tracking and erroneous frees][32], buffer overflow and underflow, [wild pointer][33] writes, and more.
|
||||
|
||||
The tool works with programs written in C. Although you can also use it with C++ programs, it's not recommended (according to the Q&A file that comes with the tool's source package).
|
||||
|
||||
#### What's new ####
|
||||
|
||||
This version adds ULONG_LONG_MAX to detect whether a program is 32-bit or 64-bit.
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
Like Dmalloc, Memwatch comes with good documentation. You can refer to the USING file if you want to learn things like how the tool works; how it performs initialization, cleanup and I/O operations; and more. Then there is a FAQ file that is aimed at helping users in case they face any common error while using Memcheck. Finally, there is a test.c file that contains a working example of the tool for your reference.
|
||||
|
||||
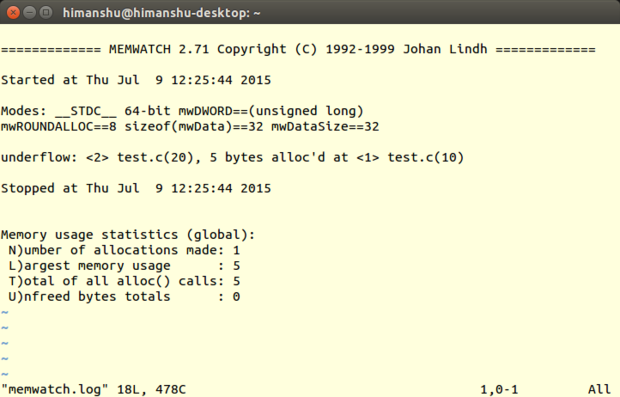
|
||||
Memwatch
|
||||
|
||||
Unlike Mtrace, the log file to which Memwatch writes the output (usually memwatch.log) is in human-readable form. Also, instead of truncating, Memwatch appends the memory-debugging output to the file each time the tool is run, allowing you to easily refer to the previous outputs should the need arise.
|
||||
|
||||
It's also worth mentioning that when you execute your program with Memwatch enabled, the tool produces a one-line output on [stdout][34] informing you that some errors were found -- you can then head to the log file for details. If no such error message is produced, you can rest assured that the log file won't contain any mistakes -- this actually saves time if you're running the tool several times.
|
||||
|
||||
Another thing that I liked about Memwatch is that it also provides a way through which you can capture the tool's output from within the code, and handle it the way you like (refer to the mwSetOutFunc() function in the Memwatch source code for more on this).
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
Like Mtrace and Dmalloc, Memwatch requires you to add extra code to your source file -- you have to include the memwatch.h header file in your code. Also, while compiling your program, you need to either compile memwatch.c along with your program's source files or include the object module from the compile of the file, as well as define the MEMWATCH and MW_STDIO variables on the command line. Needless to say, the -g compiler option is also required for your program if you want exact line numbers in the output.
|
||||
|
||||
There are some features that it doesn't contain. For example, the tool cannot detect attempts to write to an address that has already been freed or read data from outside the allocated memory. Also, it's not thread-safe. Finally, as I've already pointed out in the beginning, there is no guarantee on how the tool will behave if you use it with programs written in C++.
|
||||
|
||||
#### Bottom line ####
|
||||
|
||||
Memcheck can detect many memory-related problems, making it a handy debugging tool when dealing with projects written in C. Given that it has a very small source code, you can learn how the tool works, debug it if the need arises, and even extend or update its functionality as per your requirements.
|
||||
|
||||
### [Mtrace][35] ###
|
||||
|
||||
**Developers**: Roland McGrath and Ulrich Drepper
|
||||
**Reviewed version**: 2.21
|
||||
**Linux support**: All flavors
|
||||
**License**: GNU LGPL
|
||||
|
||||
Mtrace is a memory-debugging tool included in [the GNU C library][36]. It works with both C and C++ programs on Linux, and detects memory leaks caused by unbalanced calls to the malloc() and free() functions.
|
||||
|
||||
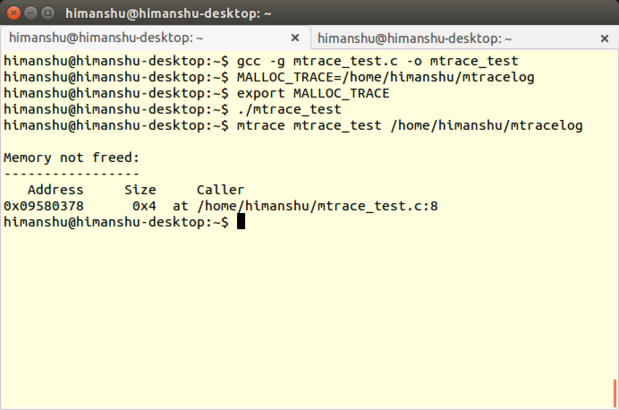
|
||||
Mtrace
|
||||
|
||||
The tool is implemented in the form of a function called mtrace(), which traces all malloc/free calls made by a program and logs the information in a user-specified file. Because the file contains data in computer-readable format, a Perl script -- also named mtrace -- is used to convert and display it in human-readable form.
|
||||
|
||||
#### What's new ####
|
||||
|
||||
[The Mtrace source][37] and [the Perl file][38] that now come with the GNU C library (version 2.21) add nothing new to the tool aside from an update to the copyright dates.
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
The best part about Mtrace is that the learning curve for it isn't steep; all you need to understand is how and where to add the mtrace() -- and the corresponding muntrace() -- function in your code, and how to use the Mtrace Perl script. The latter is very straightforward -- all you have to do is run the mtrace() <program-executable> <log-file-generated-upon-program-execution> command. (For an example, see the last command in the screenshot above.)
|
||||
|
||||
Another thing that I like about Mtrace is that it's scalable -- which means that you can not only use it to debug a complete program, but can also use it to detect memory leaks in individual modules of the program. Just call the mtrace() and muntrace() functions within each module.
|
||||
|
||||
Finally, since the tool is triggered when the mtrace() function -- which you add in your program's source code -- is executed, you have the flexibility to enable the tool dynamically (during program execution) [using signals][39].
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
Because the calls to mtrace() and mauntrace() functions -- which are declared in the mcheck.h file that you need to include in your program's source -- are fundamental to Mtrace's operation (the mauntrace() function is not [always required][40]), the tool requires programmers to make changes in their code at least once.
|
||||
|
||||
Be aware that you need to compile your program with the -g option (provided by both the [GCC][41] and [G++][42] compilers), which enables the debugging tool to display exact line numbers in the output. In addition, some programs (depending on how big their source code is) can take a long time to compile. Finally, compiling with -g increases the size of the executable (because it produces extra information for debugging), so you have to remember that the program needs to be recompiled without -g after the testing has been completed.
|
||||
|
||||
To use Mtrace, you need to have some basic knowledge of environment variables in Linux, given that the path to the user-specified file -- which the mtrace() function uses to log all the information -- has to be set as a value for the MALLOC_TRACE environment variable before the program is executed.
|
||||
|
||||
Feature-wise, Mtrace is limited to detecting memory leaks and attempts to free up memory that was never allocated. It can't detect other memory-related issues such as illegal memory access or use of uninitialized memory. Also, [there have been complaints][43] that it's not [thread-safe][44].
|
||||
|
||||
### Conclusions ###
|
||||
|
||||
Needless to say, each memory debugger that I've discussed here has its own qualities and limitations. So, which one is best suited for you mostly depends on what features you require, although ease of setup and use might also be a deciding factor in some cases.
|
||||
|
||||
Mtrace is best suited for cases where you just want to catch memory leaks in your software program. It can save you some time, too, since the tool comes pre-installed on your Linux system, something which is also helpful in situations where the development machines aren't connected to the Internet or you aren't allowed to download a third party tool for any kind of debugging.
|
||||
|
||||
Dmalloc, on the other hand, can not only detect more error types compared to Mtrace, but also provides more features, such as runtime configurability and GDB integration. Also, unlike any other tool discussed here, Dmalloc is thread-safe. Not to mention that it comes with detailed documentation, making it ideal for beginners.
|
||||
|
||||
Although Memwatch comes with even more comprehensive documentation than Dmalloc, and can detect even more error types, you can only use it with software written in the C programming language. One of its features that stands out is that it lets you handle its output from within the code of your program, something that is helpful in case you want to customize the format of the output.
|
||||
|
||||
If making changes to your program's source code is not what you want, you can use Electric Fence. However, keep in mind that it can only detect a couple of error types, and that doesn't include memory leaks. Plus, you also need to know GDB basics to make the most out of this memory-debugging tool.
|
||||
|
||||
Memcheck is probably the most comprehensive of them all. It detects more error types and provides more features than any other tool discussed here -- and it doesn't require you to make any changes in your program's source code.But be aware that, while the learning curve is not very high for basic usage, if you want to use its advanced features, a level of expertise is definitely required.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3003957/linux/review-5-memory-debuggers-for-linux-coding.html
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Himanshu-Arora/
|
||||
[1]:https://openclipart.org/detail/132427/penguin-admin
|
||||
[2]:https://en.wikipedia.org/wiki/Manual_memory_management
|
||||
[3]:http://dmalloc.com/
|
||||
[4]:https://www.owasp.org/index.php/Double_Free
|
||||
[5]:https://stuff.mit.edu/afs/sipb/project/gnucash-test/src/dmalloc-4.8.2/dmalloc.html#Fence-Post%20Overruns
|
||||
[6]:http://dmalloc.com/releases/notes/dmalloc-5.5.2.html
|
||||
[7]:http://www.gnu.org/software/gdb/
|
||||
[8]:http://dmalloc.com/docs/
|
||||
[9]:http://dmalloc.com/docs/latest/online/dmalloc_26.html#SEC32
|
||||
[10]:http://dmalloc.com/docs/latest/online/dmalloc_23.html#SEC29
|
||||
[11]:https://en.wikipedia.org/wiki/Memory_management#Dynamic_memory_allocation
|
||||
[12]:https://en.wikipedia.org/wiki/Segmentation_fault
|
||||
[13]:https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[14]:http://www.gnu.org/software/gdb/
|
||||
[15]:https://launchpad.net/ubuntu/+source/electric-fence/2.2.3
|
||||
[16]:http://valgrind.org/docs/manual/mc-manual.html
|
||||
[17]:http://valgrind.org/info/developers.html
|
||||
[18]:http://valgrind.org/
|
||||
[19]:http://valgrind.org/docs/manual/dist.news.html
|
||||
[20]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.suppfiles
|
||||
[21]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.mempools
|
||||
[22]:http://stackoverflow.com/questions/4642671/c-memory-allocators
|
||||
[23]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.monitor-commands
|
||||
[24]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.clientreqs
|
||||
[25]:http://valgrind.org/docs/manual/valgrind_manual.pdf
|
||||
[26]:http://sourceforge.net/p/valgrind/mailman/message/30292453/
|
||||
[27]:https://msdn.microsoft.com/en-us/library/ee798431%28v=cs.20%29.aspx
|
||||
[28]:http://www.computerworld.com/article/2484425/linux/5-free-linux-text-editors-for-programming-and-word-processing.html?nsdr=true&page=2
|
||||
[29]:http://valgrind.org/docs/manual/manual-core.html#manual-core.limits
|
||||
[30]:http://valgrind.org/info/
|
||||
[31]:http://www.linkdata.se/sourcecode/memwatch/
|
||||
[32]:http://www.cecalc.ula.ve/documentacion/tutoriales/WorkshopDebugger/007-2579-007/sgi_html/ch09.html
|
||||
[33]:http://c2.com/cgi/wiki?WildPointer
|
||||
[34]:https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
[35]:http://www.gnu.org/software/libc/manual/html_node/Tracing-malloc.html
|
||||
[36]:https://www.gnu.org/software/libc/
|
||||
[37]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.c;h=df10128b872b4adc4086cf74e5d965c1c11d35d2;hb=HEAD
|
||||
[38]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.pl;h=0737890510e9837f26ebee2ba36c9058affb0bf1;hb=HEAD
|
||||
[39]:http://webcache.googleusercontent.com/search?q=cache:s6ywlLtkSqQJ:www.gnu.org/s/libc/manual/html_node/Tips-for-the-Memory-Debugger.html+&cd=1&hl=en&ct=clnk&gl=in&client=Ubuntu
|
||||
[40]:http://www.gnu.org/software/libc/manual/html_node/Using-the-Memory-Debugger.html#Using-the-Memory-Debugger
|
||||
[41]:http://linux.die.net/man/1/gcc
|
||||
[42]:http://linux.die.net/man/1/g++
|
||||
[43]:https://sourceware.org/ml/libc-help/2014-05/msg00008.html
|
||||
[44]:https://en.wikipedia.org/wiki/Thread_safety
|
||||
@ -1,95 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||

|
||||
Another Market design that was nothing like the old one. This lineup shows the categories page, featured, a top apps list, and an app page.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
These screenshots give us our first look at the refined version of the Action Bar in Ice Cream Sandwich. Almost every app got a bar at the top of the screen that housed the app icon, title of the screen, several function buttons, and a menu button on the right. The right-aligned menu button was called the "overflow" button, because it housed items that didn't fit on the main action bar. The overflow menu wasn't static, though, it gave the action bar more screen real-estate—like in horizontal mode or on a tablet—and more of the overflow menu items were shown on the action bar as actual buttons.
|
||||
|
||||
New in Ice Cream Sandwich was this design style of "swipe tabs," which replaced the 2×3 interstitial navigation screen Google was previously pushing. A tab bar sat just under the Action Bar, with the center title showing the current tab and the left and right having labels for the pages to the left and right of this screen. A swipe in either direction would change tabs, or you could tap on a title to go to that tab.
|
||||
|
||||
One really cool design touch on the individual app screen was that, after the pictures, it would dynamically rearrange the page based on your history with that app. If you never installed the app before, the description would be the first box. If you used the app before, the first section would be the reviews bar, which would either invite you to review the app or remind you what you thought of the app last time you installed it. The second section for a previously used app was “What’s New," since an existing user would most likely be interested in changes.
|
||||
|
||||

|
||||
Recent apps and the browser were just like Honeycomb, but smaller.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Recent apps toned the Tron look way down. The blue outline around the thumbnails was removed, along with the eerie, uneven blue glow in the background. It now looked like a neutral UI piece that would be at home in any time period.
|
||||
|
||||
The Browser did its best to bring a tabbed experience to phones. Multi-tab browsing was placed front and center, but instead of wasting precious screen space on a tab strip, a tab button would open a Recent Apps-like interface that would show you your open tabs. Functionally, there wasn't much difference between this and the "window" view that was present in past versions of the Browser. The best addition to the Browser was a "Request desktop site" menu item, which would switch from the default mobile view to the normal site. The Browser showed off the flexibility of Google's Action Bar design, which, despite not having a top-left app icon, still functioned like any other top bar design.
|
||||
|
||||

|
||||
Gmail and Google Talk—they're like Honeycomb, but smaller!
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Gmail and Google Talk both looked like smaller versions of their Honeycomb designs, but with a few tweaks to work better on smaller screens. Gmail featured a dual Action Bar—one on the top of the screen and one on the bottom. The top of the bar showed your current folder, account, and number of unread messages, and tapping on the bar opened a navigation menu. The bottom featured all the normal buttons you would expect along with the overflow button. This dual layout was used in order display more buttons on the surface level, but in landscape mode where vertical space was at a premium, the dual bars merged into a single top bar.
|
||||
|
||||
In the message view, the blue bar was "sticky" when you scrolled down. It stuck to the top of the screen, so you could always see who wrote the current message, reply, or star it. Once in a message, the thin, dark gray bar at the bottom showed your current spot in the inbox (or whatever list brought you here), and you could swipe left and right to get to other messages.
|
||||
|
||||
Google Talk would let you swipe left and right to change chat windows, just like Gmail, but there the bar was at the top.
|
||||
|
||||

|
||||
The new dialer and the incoming call screen, both of which we haven't seen since Gingerbread.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Since Honeycomb was only for tablets, some UI pieces were directly preceded by Gingerbread instead. The new Ice Cream Sandwich dialer was, of course, black and blue, and it used smaller tabs that could be swiped through. While Ice Cream Sandwich finally did the sensible thing and separated the main phone and contacts interfaces, the phone app still had its own contacts tab. There were now two spots to view your contact list—one with a dark theme and one with a light theme. With a hardware search button no longer being a requirement, the bottom row of buttons had the voicemail shortcut swapped out for a search icon.
|
||||
|
||||
Google liked to have the incoming call interface mirror the lock screen, which meant Ice Cream Sandwich got a circle-unlock design. Besides the usual decline or accept options, a new button was added to the top of the circle, which would let you decline a call by sending a pre-defined text message to the caller. Swiping up and picking a message like "Can't talk now, call you later" was (and still is) much more informative than an endlessly ringing phone.
|
||||
|
||||

|
||||
Honeycomb didn't have folders or a texting app, so here's Ice Cream Sandwich versus Gingerbread.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Folders were now much easier to make. In Gingerbread, you had to long press on the screen, pick "folders," and then pick "new folder." In Ice Cream Sandwich, just drag one icon on top of another, and a folder is created containing those two icons. It was dead simple and much easier than finding the hidden long-press command.
|
||||
|
||||
The design was much improved, too. Gingerbread used a generic beige folder icon, but Ice Cream Sandwich actually showed you what was in the folder by stacking the first three icons on top of each other, drawing a circle around them, and using that as the folder icon. Open folder containers resized to fit the amount of icons in the folder rather than being a full-screen, mostly empty box. It looked way, way better.
|
||||
|
||||

|
||||
YouTube switched to a more modern white theme and used a list view instead of the crazy 3D scrolling
|
||||
Photo by Ron Amadeo
|
||||
|
||||
YouTube was completely redesigned and looked less like something from The Matrix and more like, well, YouTube. It was a simple white list of vertically scrolling videos, just like the website. Making videos on your phone was given prime real estate, with the first button on the action bar dedicated to recording a video. Strangely, different screens used different YouTube logos in the top left, switching between a horizontal YouTube logo and a square one.
|
||||
|
||||
YouTube used swipe tabs just about everywhere. They were placed on the main page to browse and view your account and on the video pages to switch between comments, info, and related videos. The 4.0 app showed the first signs of Google+ YouTube integration, placing a "+1" icon next to the traditional rating buttons. Eventually Google+ would completely take over YouTube, turning the comments and author pages into Google+ activity.
|
||||
|
||||

|
||||
Ice Cream Sandwich tried to make things easier on everyone. Here is a screen for tracking data usage, the new developer options with tons of analytics enabled, and the intro tutorial.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Data Usage allowed users to easily keep track of and control their data usage. The main page showed a graph of this month's data usage, and users could set thresholds to be warned about data consumption or even set a hard usage limit to avoid overage charges. All of this was done easily by dragging the horizontal orange and red threshold lines higher or lower on the chart. The vertical white bars allowed users to select a slice of time in the graph. At the bottom of the page, the data usage for the selected time was broken down by app, so users could select a spike and easily see what app was sucking up all their data. When times got really tough, in the overflow button was an option to restrict all background data. Then, only apps running in the foreground could have access to the Internet connection.
|
||||
|
||||
The Developer Options typically only housed a tiny handful of settings, but in Ice Cream Sandwich the section received a huge expansion. Google added all sorts of on-screen diagnostic overlays to help app developers understand what was happening inside their app. You could view CPU usage, pointer location, and view screen updates. There were also options to change the way the system functioned, like control over animation speed, background processing, and GPU rendering.
|
||||
|
||||
One of the biggest differences between Android and the iOS is Android's app drawer interface. In Ice Cream Sandwich's quest to be more user-friendly, the initial startup launched a small tutorial showing users where the app drawer was and how to drag icons out of the drawer and onto the homescreen. With the removal of the off-screen menu button and changes like this, Android 4.0 made a big push to be more inviting to new smartphone users and switchers.
|
||||
|
||||

|
||||
The "touch to beam" NFC support, Google Earth, and App Info, which would let you disable crapware.
|
||||
|
||||
Built into Ice Cream Sandwich was full support for [NFC][1]. While previous devices like the Nexus S had NFC, support was limited and the OS couldn't do much with the chip. 4.0 added a feature called Android Beam, which would let two NFC-equipped Android 4.0 devices transfer data back and forth. NFC would transmit data related to whatever was on the screen at the time, so tapping when a phone displayed a webpage would send that page to the other phone. You could also send contact information, directions, and YouTube links. When the two phones were put together, the screen zoomed out, and tapping on the zoomed-out display would send the information.
|
||||
|
||||
In Android, users are not allowed to uninstall system apps, which are often integral to the function of the device. Carriers and OEMs took advantage of this and started putting crapware in the system partition, which they would often stick with software they didn't want. Android 4.0 allowed users to disable any app that couldn't be uninstalled, meaning the app remained on the system but didn't show up in the app drawer and couldn't be run. If users were willing to dig through the settings, this gave them an easy way to take control of their phone.
|
||||
|
||||
Android 4.0 can be thought of as the start of the modern Android era. Most of the Google apps released around this time only worked on Android 4.0 and above. There were so many new APIs that Google wanted to take advantage of that—initially at least—support for versions below 4.0 was limited. After Ice Cream Sandwich and Honeycomb, Google was really starting to get serious about software design. In January 2012, the company [finally launched][2] *Android Design*, a design guideline site that taught Android app developers how to create apps to match the look and feel of Android. This was something iOS not only had from the start of third-party app support, but Apple enforced design so seriously that apps that did not meet the guidelines were blocked from the App Store. The fact that Android went three years without any kind of public design documents from Google shows just how bad things used to be. But with Duarte in charge of Android's design revolution, the company was finally addressing basic design needs.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/20/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2011/02/near-field-communications-a-technology-primer/
|
||||
[2]:http://arstechnica.com/business/2012/01/google-launches-style-guide-for-android-developers/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||

|
||||
@ -100,4 +102,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
[2]:http://arstechnica.com/gadgets/2012/07/divine-intervention-googles-nexus-7-is-a-fantastic-200-tablet/
|
||||
[3]:http://arstechnica.com/gadgets/2013/09/balky-carriers-and-slow-oems-step-aside-google-is-defragging-android/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -0,0 +1,155 @@
|
||||
10 tools for visual effects in Linux with Kdenlive
|
||||
================================================================================
|
||||

|
||||
Image credits : Seth Kenlon. [CC BY-SA 4.0.][1]
|
||||
|
||||
[Kdenlive][2] is one of those applications; you can use it daily for a year and wake up one morning only to realize that you still have only grazed the surface of all of its potential. That's why it's nice every once in a while to sit back and look over some of the lesser-used tricks and tools in Kdenlive. Even though something's not used as often as, say, the Spacer or Razor tools, it still may end up being just the right finishing touch on your latest masterpiece.
|
||||
|
||||
Most of the tools I'll discuss here are not officially part of Kdenlive; they are plugins from the [Frei0r][3] package. These are ubiquitous parts of video processing on Linux and Unix, and they usually get installed along with Kdenlive as distributed by most Linux distributions, so they often seem like part of the application. If your install of Kdenlive does not feature some of the tools mentioned here, make sure that you have Frei0r plugins installed.
|
||||
|
||||
Since many of the tools in this article affect the look of an image, here is the base image, without effects or adjustment:
|
||||
|
||||

|
||||
|
||||
Still image grabbed from a video by Footage Firm, Inc. [CC BY-SA 4.0.][1]
|
||||
|
||||
Let's get started.
|
||||
|
||||
### 1. Color effect ###
|
||||
|
||||

|
||||
|
||||
You can find the **Color Effect** filter in **Add Effect > Misc** context menu. As filters go, it's mostly just a preset; the only controls it has are which filter you want to use.
|
||||
|
||||
|
||||
|
||||
Normally that's the kind of filter I avoid, but I have to be honest: Sometimes a plug-and-play solution is exactly what you want. This filter has a few different settings, but the two that make it worth while (at least for me) are the Sepia and XPro effects. Admittedly, controls to adjust how sepia tone the sepia effect is would be nice, but no matter what, when you need a quick and familiar color effect, this is the filter to throw onto a clip. It's immediate, it's easy, and if your client asks for that look, this does the trick every time.
|
||||
|
||||
### 2. Colorize ###
|
||||
|
||||

|
||||
|
||||
The simplicity of the **Colorize** filter in **Add Effect > Misc** is also its strength. In some editing applications, it takes two filters and some compositing to achieve this simple color-wash effect. It's refreshing that in Kdenlive, it's a matter of one filter with three possible controls (only one of which, strictly speaking, is necessary to achieve the look).
|
||||
|
||||
|
||||
|
||||
Its use is intuitive; use the **Hue** slider to set the color. Use the other controls to adjust the luma of the base image as needed.
|
||||
|
||||
This is not a filter I use every day, but for ad spots, bumpers, dreamy sequences, or titles, it's the easiest and quickest path to a commonly needed look. Get a company's color, use it as the colorize effect, slap a logo over the top of the screen, and you've just created a winning corporate intro.
|
||||
|
||||
### 3. Dynamic Text ###
|
||||
|
||||
|
||||
|
||||
For the assistant editor, the Add Effect > Misc > Dynamic **Text** effect is worth the price of Kdenlive. With one mostly pre-set filter, you can add a running timecode burn-in to your project, which is an absolute must-have safety feature when round-tripping your footage through effects and sound.
|
||||
|
||||
The controls look more complex than they actually are.
|
||||
|
||||
|
||||
|
||||
The font settings are self-explanatory. Placement of the text is controlled by the Horizontal and Vertical Alignment settings; steer clear of the **Size** setting (it controls the size of the "canvas" upon which you are compositing the burn-in, not the size of the burn-in itself).
|
||||
|
||||
The text itself doesn't have to be timecode. From the dropdown menu, you can choose from a list of useful text, including frame count (useful for VFX, since animators work in frames), source frame rate, source dimensions, and more.
|
||||
|
||||
You are not limited to just one choice. The text field in the control panel will take whatever arbitrary text you put into it, so if you want to burn in more information than just timecode and frame rate (such as **Sc 3 - #timecode# - #meta.media.0.stream.frame_rate#**), then have at it.
|
||||
|
||||
### 4. Luminance ###
|
||||
|
||||

|
||||
|
||||
The **Add Effect > Misc > Luminance** filter is a no-options filter. Luminance does one thing and it does it well: It drops the chroma values of all pixels in an image so that they are displayed by their luma values. In simpler terms, it's a grayscale filter.
|
||||
|
||||
The nice thing about this filter is that it's quick, easy, efficient, and effective. This filter combines particularly well with other related filters (meaning that yes, I'm cheating and including three filters for one).
|
||||
|
||||
|
||||
|
||||
Combining, in this order, the **RGB Noise** for emulated grain, **Luminance** for grayscale, and **LumaLiftGainGamma** for levels can render a textured image that suggests the classic look and feel of [Kodax Tri-X][4] film.
|
||||
|
||||
### 5. Mask0mate ###
|
||||
|
||||

|
||||
Image by Footage Firm, Inc.
|
||||
|
||||
Better known as a four-point garbage mask, the **Add Effect > Alpha Manipulation > Mask0mate** tool is a quick, no-frills way to ditch parts of your frame that you don't need. There isn't much to say about it; it is what it is.
|
||||
|
||||
|
||||
|
||||
The confusing thing about the effect is that it does not imply compositing. You can pull in the edges all you want, but you won't see it unless you add the **Composite** transition to reveal what's underneath the clip (even if that's nothing). Also, use the **Invert** function for the filter to act like you think it should act (without it, the controls will probably feel backward to you).
|
||||
|
||||
### 6. Pr0file ###
|
||||
|
||||

|
||||
|
||||
The **Add Effect > Misc > Pr0file** filter is an analytical tool, not something you would actually leave on a clip for final export (unless, of course, you do). Pr0file consists of two components: the Marker, which dictates what area of the image is being analyzed, and the Graph, which displays information about the marked region.
|
||||
|
||||
Set the marker using the **X, Y, Tilt**, and **Length** controls. The graphical readout of all the relevant color channel information is displayed as a graph, superimposed over your image.
|
||||
|
||||
|
||||
|
||||
The readout displays a profile of the colors within the region marked. The result is a sort of hyper-specific vectorscope (or oscilloscope, as the case may be) that can help you zero in on problem areas during color correction, or compare regions while color matching.
|
||||
|
||||
In other editors, the way to get the same information was simply to temporarily scale your image up to the region you want to analyze, look at your readout, and then hit undo to scale back. Both ways work, but the Pr0file filter does feel a little more elegant.
|
||||
|
||||
### 7. Vectorscope ###
|
||||
|
||||
|
||||
|
||||
Kdenlive features an inbuilt vectorscope, available from the **View** menu in the main menu bar. A vectorscope is not a filter, it's just another view the footage in your Project Monitor, specifically a view of the color saturation in the current frame. If you are color correcting an image and you're not sure what colors you need to boost or counteract, looking at the vectorscope can be a huge help.
|
||||
|
||||
There are several different views available. You can render the vectorscope in traditional green monochrome (like the hardware vectorscopes you'd find in a broadcast control room), or a chromatic view (my personal preference), or subtracted from a color-wheel background, and more.
|
||||
|
||||
The vectorscope reads the entire frame, so unlike the Pr0file filter, you are not just getting a reading of one area in the frame. The result is a consolidated view of what colors are most prominent within a frame. Technically, the same sort of information can be intuited by several trial-and-error passes with color correction, or you can just leave your vectorscope open and watch the colors float along the color wheel and make adjustments accordingly.
|
||||
|
||||
Aside from how you want the vectorscope to look, there are no controls for this tool. It is a readout only.
|
||||
|
||||
### 8. Vertigo ###
|
||||
|
||||

|
||||
|
||||
There's no way around it; **Add Effect > Misc > Vertigo** is a gimmicky special effect filter. So unless you're remaking [Fear and Loathing][5] or the movie adaptation of [Dead Island][6], you probably aren't going to use it that much; however, it's one of those high-quality filters that does the exact trick you want when you happen to be looking for it.
|
||||
|
||||
The controls are simple. You can adjust how distorted the image becomes and the rate at which it distorts. The overall effect is probably more drunk or vision-quest than vertigo, but it's good.
|
||||
|
||||
|
||||
|
||||
### 9. Vignette ###
|
||||
|
||||

|
||||
|
||||
Another beautiful effect, the **Add Effect > Misc > Vignette** darkens the outer edges of the frame to provide a sort of portrait, soft-focus nouveau look. Combined with the Color Effect or the Luminance faux Tri-X trick, this can be a powerful and emotional look.
|
||||
|
||||
The softness of the border and the aspect ratio of the iris can be adjusted. The **Clear Center Size** attribute controls the size of the clear area, which has the effect of adjusting the intensity of the vignette effect.
|
||||
|
||||
|
||||
|
||||
### 10. Volume ###
|
||||
|
||||
|
||||
|
||||
I don't believe in mixing sound within the video editing application, but I do acknowledge that sometimes it's just necessary for a quick fix or, sometimes, even for a tight production schedule. And that's when the **Audio correction > Volume (Keyframable)** effect comes in handy.
|
||||
|
||||
The control panel is clunky, and no one really wants to adjust volume that way, so the effect is best when used directly in the timeline. To create a volume change, double-click the volume line over the audio clip, and then click and drag to adjust. It's that simple.
|
||||
|
||||
Should you use it? Not really. Sound mixing should be done in a sound mixing application. Will you use it? Absolutely. At some point, you'll get audio that is too loud to play as you edit, or you'll be up against a deadline without a sound engineer in sight. Use it judiciously, watch your levels, and get the show finished.
|
||||
|
||||
### Everything else ###
|
||||
|
||||
This has been 10 (OK, 13 or 14) effects and tools that Kdenlive has quietly lying around to help your edits become great. Obviously there's a lot more to Kdenlive than just these little tricks. Some are obvious, some are cliché, some are obtuse, but they're all in your toolkit. Get to know them, explore your options, and you might be surprised what a few cheap tricks will get you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/15/12/10-kdenlive-tools
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]:https://kdenlive.org/
|
||||
[3]:http://frei0r.dyne.org/
|
||||
[4]:http://www.kodak.com/global/en/professional/products/films/bw/triX2.jhtml
|
||||
[5]:https://en.wikipedia.org/wiki/Fear_and_Loathing_in_Las_Vegas_(film)
|
||||
[6]:https://en.wikipedia.org/wiki/Dead_Island
|
||||
@ -0,0 +1,96 @@
|
||||
5 great Raspberry Pi projects for the classroom
|
||||
================================================================================
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
### 1. Minecraft Pi ###
|
||||
|
||||
Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0.][1]
|
||||
|
||||
Minecraft is the favorite game of pretty much every teenager in the world—and it's one of the most creative games ever to capture the attention of young people. The version that comes with every Raspberry Pi is not only a creative thinking building game, but comes with a programming interface allowing for additional interaction with the Minecraft world through Python code.
|
||||
|
||||
Minecraft: Pi Edition is a great way for teachers to engage students with problem solving and writing code to perform tasks. You can use the Python API to build a house and have it follow you wherever you go, build a bridge wherever you walk, make it rain lava, show the temperature in the sky, and anything else your imagination can create.
|
||||
|
||||
Read more in "[Getting Started with Minecraft Pi][2]."
|
||||
|
||||
### 2. Reaction game and traffic lights ###
|
||||
|
||||

|
||||
|
||||
Courtesy of [Low Voltage Labs][3]. [CC BY-SA 4.0][1].
|
||||
|
||||
It's really easy to get started with physical computing on Raspberry Pi—just connect up LEDs and buttons to the GPIO pins, and with a few lines of code you can turn lights on and control things with button presses. Once you know the code to do the basics, it's down to your imagination as to what you do next!
|
||||
|
||||
If you know how to flash one light, you can flash three. Pick out three LEDs in traffic light colors and you can code the traffic light sequence. If you know how to use a button to a trigger an event, then you have a pedestrian crossing! Also look out for great pre-built traffic light add-ons like [PI-TRAFFIC][4], [PI-STOP][5], [Traffic HAT][6], and more.
|
||||
|
||||
It's not always about the code—this can be used as an exercise in understanding how real world systems are devised. Computational thinking is a useful skill in any walk of life.
|
||||
|
||||

|
||||
|
||||
Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0][1].
|
||||
|
||||
Next, try wiring up two buttons and an LED and making a two-player reaction game—let the light come on after a random amount of time and see who can press the button first!
|
||||
|
||||
To learn more, check out "[GPIO Zero recipes][7]. Everything you need is in [CamJam EduKit 1][8].
|
||||
|
||||
### 3. Sense HAT Pixel Pet ###
|
||||
|
||||
The Astro Pi—an augmented Raspberry Pi—is going to space this December, but you haven't missed your chance to get your hands on the hardware. The Sense HAT is the sensor board add-on used in the Astro Pi mission and it's available for anyone to buy. You can use it for data collection, science experiments, games and more. Watch this Gurl Geek Diaries video from Raspberry Pi's Carrie Anne for a great way to get started—by bringing to life an animated pixel pet of your own design on the Sense HAT display:
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" src="https://www.youtube.com/embed/gfRDFvEVz-w" allowfullscreen=""></iframe>
|
||||
|
||||
Learn more in "[Exploring the Sense HAT][9]."
|
||||
|
||||
### 4. Infrared bird box ###
|
||||
|
||||

|
||||
Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0.][1]
|
||||
|
||||
A great exercise for the whole class to get involved with—place a Raspberry Pi and the NoIR camera module inside a bird box along with some infra-red lights so you can see in the dark, then stream video from the Pi over the network or on the internet. Wait for birds to nest and you can observe them without disturbing them in their habitat.
|
||||
|
||||
Learn all about infrared and the light spectrum, and how to adjust the camera focus and control the camera in software.
|
||||
|
||||
Learn more in "[Make an infrared bird box.][10]"
|
||||
|
||||
### 5. Robotics ###
|
||||
|
||||

|
||||
|
||||
Courtesy of Low Voltage Labs. [CC BY-SA 4.0][1].
|
||||
|
||||
With a Raspberry Pi and as little as a couple of motors and a motor controller board, you can build your own robot. There is a vast range of robots you can make, from basic buggies held together by sellotape and a homemade chassis, all the way to self-aware, sensor-laden metallic stallions with camera attachments driven by games controllers.
|
||||
|
||||
Learn how to control individual motors with something straightforward like the RTK Motor Controller Board (£8/$12), or dive into the new CamJam robotics kit (£17/$25) which comes with motors, wheels and a couple of sensors—great value and plenty of learning potential.
|
||||
|
||||
Alternatively, if you'd like something more hardcore, try PiBorg's [4Borg][11] (£99/$150) or [DiddyBorg][12] (£180/$273) or go the whole hog and treat yourself to their DoodleBorg Metal edition (£250/$380)—and build a mini version of their infamous [DoodleBorg tank][13] (unfortunately not for sale).
|
||||
|
||||
Check out the [CamJam robotics kit worksheets][14].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/15/12/5-great-raspberry-pi-projects-classroom
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]:https://opensource.com/life/15/5/getting-started-minecraft-pi
|
||||
[3]:http://lowvoltagelabs.com/
|
||||
[4]:http://lowvoltagelabs.com/products/pi-traffic/
|
||||
[5]:http://4tronix.co.uk/store/index.php?rt=product/product&product_id=390
|
||||
[6]:https://ryanteck.uk/hats/1-traffichat-0635648607122.html
|
||||
[7]:http://pythonhosted.org/gpiozero/recipes/
|
||||
[8]:http://camjam.me/?page_id=236
|
||||
[9]:https://opensource.com/life/15/10/exploring-raspberry-pi-sense-hat
|
||||
[10]:https://www.raspberrypi.org/learning/infrared-bird-box/
|
||||
[11]:https://www.piborg.org/4borg
|
||||
[12]:https://www.piborg.org/diddyborg
|
||||
[13]:https://www.piborg.org/doodleborg
|
||||
[14]:http://camjam.me/?page_id=1035#worksheets
|
||||
@ -0,0 +1,94 @@
|
||||
6 creative ways to use ownCloud
|
||||
================================================================================
|
||||

|
||||
|
||||
Image by : Opensource.com
|
||||
|
||||
[ownCloud][1] is a self-hosted open source file sync and share server. Like "big boys" Dropbox, Google Drive, Box, and others, ownCloud lets you access your files, calendar, contacts, and other data. You can synchronize everything (or part of it) between your devices and share files with others. But ownCloud can do much more than its proprietary, [hosted-on-somebody-else's-computer competitors][2].
|
||||
|
||||
Let's look at six creative things ownCloud can do. Some of these are possible because ownCloud is open source, whereas others are just unique features it offers.
|
||||
|
||||
### 1. A scalable ownCloud Pi cluster ###
|
||||
|
||||
Because ownCloud is open source, you can choose between self-hosting on your own server or renting space from a provider you trust—no need to put your files at a big company that stores it who knows where. [Find some ownCloud providers here][3] or grab packages or a virtual machine for [your own server here][4].
|
||||
|
||||

|
||||
|
||||
Photo by Jörn Friedrich Dreyer. [CC BY-SA 4.0.][5]
|
||||
|
||||
The most creative things we've seen are a [Banana Pi cluster][6] and a [Raspberry Pi cluster][7]. Although ownCloud's scalability is often used to deploy to hundreds of thousands of users, some folks out there take it in a different direction, bringing multiple tiny systems together to make a super-fast ownCloud. Kudos!
|
||||
|
||||
### 2. Keep your passwords synced ###
|
||||
|
||||
To make ownCloud easier to extend, we have made it extremely modular and have an [ownCloud app store][8]. There you can find things like music and video players, calendars, contacts, productivity apps, games, a sketching app, and much more.
|
||||
|
||||
Picking only one app from the almost 200 available is hard, but managing passwords is certainly a unique feature. There are no less than three apps providing this functionality: [Passwords][9], [Secure Container][10], and [Passman][11].
|
||||
|
||||
|
||||
|
||||
### 3. Store your files where you want ###
|
||||
|
||||
External storage allows you to hook your existing data storage into ownCloud, letting you to access files stored on FTP, WebDAV, Amazon S3, and even Dropbox and Google Drive through one interface.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/uezzFDRnoPY"></iframe>
|
||||
|
||||
The "big boys" like to create their own little walled gardens—Box user can only collaborate with other Box users; and if you want to share your files from Google Drive, your mate needs a Google account or they can't do much. With ownCloud's external storage, you can break these barriers.
|
||||
|
||||
A very creative solution is adding Google Drive and Dropbox as external storage. You can work with files on both seamlessly and share them with others through a simple link—no account needed to work with you!
|
||||
|
||||
### 4. Get files uploaded ###
|
||||
|
||||
Because ownCloud is open source, people contribute interesting features without being limited by corporate requirements. Our contributors have always cared about security and privacy, so ownCloud introduced features such as protecting a public link with a password and setting an expire date [years before anybody else did][12].
|
||||
|
||||
Today, ownCloud has the ability to configure a shared link as read-write, which means visitors can seamlessly edit the files you share with them (protected with a password or not) or upload new files to your server without being forced to sign up to another web service that wants their private data.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/3GSppxEhmZY"></iframe>
|
||||
|
||||
This is great for when people want to share a large file with you. Rather than having to upload it to a third-party site, send you a link, and make you go there and download it (often requiring a login), they can just upload it to a shared folder you provide, and you can get to work right away.
|
||||
|
||||
### 5. Get free secure storage ###
|
||||
|
||||
We already talked about how many of our contributors care about security and privacy. That's why ownCloud has an app that can encrypt and decrypt stored data.
|
||||
|
||||
Using ownCloud to store your files on Dropbox or Google Drive defeats the whole idea of retaking control of your data and keeping it private. The Encryption app changes that. By encrypting data before sending it to these providers and decrypting it upon retrieval, your data is safe as kittens.
|
||||
|
||||
### 6. Share your files and stay in control ###
|
||||
|
||||
As an open source project, ownCloud has no stake in building walled gardens. Enter Federated Cloud Sharing: a protocol [developed and published by ownCloud][13] that enables different file sync and share servers to talk to one another and exchange files securely. Federated Cloud Sharing has an interesting history. [Twenty-two German universities][14] decided to build a huge cloud for their 500,000 students. But as each university wanted to stay in control of the data of their own students, a creative solution was needed: Federated Cloud Sharing. The solution now connects all these universities so the students can seamlessly work together. At the same time, the system administrators at each university stay in control of the files their students have created and can apply policies, such as storage restrictions, or limitations on what, with whom, and how files can be shared.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/9-JEmlH2DEg"></iframe>
|
||||
|
||||
And this awesome technology isn't limited to German universities: Every ownCloud user can find their [Federated Cloud ID][15] in their user settings and share it with others.
|
||||
|
||||
So there you have it. Six ways ownCloud enables people to do special and unique things, all made possible because it is open source and designed to help you liberate your data.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/15/12/6-creative-ways-use-owncloud
|
||||
|
||||
作者:[Jos Poortvliet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://owncloud.com/
|
||||
[2]:https://blogs.fsfe.org/mk/new-stickers-and-leaflets-no-cloud-and-e-mail-self-defense/
|
||||
[3]:https://owncloud.org/providers
|
||||
[4]:https://owncloud.org/install/#instructions-server
|
||||
[5]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]:http://www.owncluster.de/
|
||||
[7]:https://christopherjcoleman.wordpress.com/2013/01/05/host-your-owncloud-on-a-raspberry-pi-cluster/
|
||||
[8]:https://apps.owncloud.com/
|
||||
[9]:https://apps.owncloud.com/content/show.php/Passwords?content=170480
|
||||
[10]:https://apps.owncloud.com/content/show.php/Secure+Container?content=167268
|
||||
[11]:https://apps.owncloud.com/content/show.php/Passman?content=166285
|
||||
[12]:https://owncloud.com/owncloud45-community/
|
||||
[13]:http://karlitschek.de/2015/08/announcing-the-draft-federated-cloud-sharing-api/
|
||||
[14]:https://owncloud.com/customer/sciebo/
|
||||
[15]:https://owncloud.org/federation/
|
||||
@ -0,0 +1,79 @@
|
||||
6 useful LibreOffice extensions
|
||||
================================================================================
|
||||

|
||||
|
||||
Image by : Opensource.com
|
||||
|
||||
LibreOffice is the best free office suite around, and as such has been adopted by all major Linux distributions. Although LibreOffice is already packed with features, it can be extended by using specific add-ons, called extensions.
|
||||
|
||||
The main LibreOffice extensions website is [extensions.libreoffice.org][1]. Extensions are tools that can be added or removed independently from the main installation, and may add new functionality or make existing functionality easier to use.
|
||||
|
||||
### 1. MultiFormatSave ###
|
||||
|
||||
MultiFormatSave lets users save a document in the OpenDocument, Microsoft Office (old and new), and/or PDF formats simultaneously, according to user settings. This extension is extremely useful during the migration from Microsoft Office document formats to the [Open Document Format][2] standard, because it offers the option to save in both flavors: ODF for interoperability, and Microsoft Office for compatibility with all users sticking to legacy formats. This makes the migration process softer, and easier to administer.
|
||||
|
||||
**[Download MultiFormatSave][3]**
|
||||
|
||||
|
||||
|
||||
### 2. Alternative dialog Find & Replace for Writer (AltSearch) ###
|
||||
|
||||
This extension adds many new features to Writer's find & replace function: searched or replaced text can contain one or more paragraphs; multiple search and replacement in one step; searching: Bookmarks, Notes, Text fields, Cross-references and Reference marks to their content, name or mark and their inserting; searching and inserting Footnote and Endnote; searching object of Table, Pictures and Text frames according to their name; searching out manual page and column break and their set up or deactivation; and searching similarly formatted text, according to cursor point. It is also possible to save and load search and replacement parameters, and execute the batch on several opened documents at the same time.
|
||||
|
||||
**[Download Alternative dialog Find & Replace for Writer (AltSearch)][4]**
|
||||
|
||||
|
||||
|
||||
### 3. Pepito Cleaner ###
|
||||
|
||||
Pepito Cleaner is an extension of LibreOffice created to quickly resolve the most common formatting mistakes of old scans, PDF imports, and every digital text file. By clicking the Pepito Cleaner icon on the LibreOffice toolbar, users will open a window that will analyze the document and show the results broken down by category. This is extremely useful when converting PDF documents to ODF, as it cleans all the cruft left in place by the automatic process.
|
||||
|
||||
**[Download Pepito Cleaner][5]**
|
||||
|
||||
|
||||
|
||||
### 4. ImpressRunner ###
|
||||
|
||||
Impress Runner is a simple extension that transforms an [Impress][6] presentation into an auto-running file. The extension adds two icons, to set and remove the autostart function, which can also be added manually by editing the File | Properties | Custom Properties menu, and adding the term autostart in one of the first four text fields. This extension is especially useful for booths at conferences and events, where the slides are supposed to run unattended.
|
||||
|
||||
**[Download ImpressRunner][7]**
|
||||
|
||||
### 5. Export as Images ###
|
||||
|
||||
The Export as Images extension adds a File menu entry export as Images... in Impress and [Draw][8], to export all slides or pages as images in JPG, PNG, GIF, BMP, and TIFF format, and allows users to choose a file name for exported images, the image size, and other parameters.
|
||||
|
||||
**[Download Export as Images][9]**
|
||||
|
||||
|
||||
|
||||
### 6. Anaphraseus ###
|
||||
|
||||
Anaphraseus is a CAT (Computer-Aided Translation) tool for creating, managing, and using bilingual Translation Memories. Anaphraseus is a LibreOffice macro set available as an extension or a standalone document. Originally, Anaphraseus was developed to work with the Wordfast format, but it can also export and import files in TMX format. Anaphraseus main features are: text segmentation, fuzzy search in Translation Memory, terminology recognition, and TMX Export/Import (OmegaT translation memory format).
|
||||
|
||||
**[Download Anaphraseus][10]**
|
||||
|
||||
|
||||
|
||||
Do you have a favorite LibreOffice extension to recommend? Let us know about it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/15/12/6-useful-libreoffice-extensions
|
||||
|
||||
作者:[Italo Vignoli][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/italovignoli
|
||||
[1]:http://extensions.libreoffice.org/
|
||||
[2]:http://www.opendocumentformat.org/
|
||||
[3]:http://extensions.libreoffice.org/extension-center/multisave-1
|
||||
[4]:http://extensions.libreoffice.org/extension-center/alternative-dialog-find-replace-for-writer
|
||||
[5]:http://pepitoweb.altervista.org/pepito_cleaner/index.php
|
||||
[6]:https://www.libreoffice.org/discover/impress/
|
||||
[7]:http://extensions.libreoffice.org/extension-center/impressrunner
|
||||
[8]:https://www.libreoffice.org/discover/draw/
|
||||
[9]:http://extensions.libreoffice.org/extension-center/export-as-images
|
||||
[10]:http://anaphraseus.sourceforge.net/
|
||||
@ -0,0 +1,79 @@
|
||||
Top 5 open source community metrics to track
|
||||
================================================================================
|
||||

|
||||
|
||||
So you decided to use metrics to track your free, open source software (FOSS) community. Now comes the big question: Which metrics should I be tracking?
|
||||
|
||||
To answer this question, you must have an idea of what information you need. For example, you may want to know about the sustainability of the project community. How quickly does the community react to problems? How is the community attracting, retaining, or losing contributors? Once you decide which information you need, you can figure out which traces of community activity are available to provide it. Fortunately, FOSS projects following an open development model tend to leave loads of public data in their software development repositories, which can be analyzed to gather useful data.
|
||||
|
||||
In this article, I'll introduce metrics that help provide a multi-faceted view of your project community.
|
||||
|
||||
### 1. Activity ###
|
||||
|
||||
The overall activity of the community and how it evolves over time is a useful metric for all open source communities. Activity provides a first view of how much the community is doing, and can be used to track different kinds of activity. For example, the number of commits gives a first idea about the volume of the development effort. The number of tickets opened provides insight into how many bugs are reported or new features are proposed. The number of messages in mailing lists or posts in forums gives an idea of how much discussion is being held in public.
|
||||
|
||||
|
||||
|
||||
Number of commits and number of merged changes after code review in the OpenStack project, as found in the [OpenStack Activity Dashboard][1]. Evolution over time (weekly data).
|
||||
|
||||
### 2. Size ###
|
||||
|
||||
The size of the community is the number of people participating in it, but, depending on the kind of participation, size numbers may vary. Usually you're interested in active contributors, which is good news. Active people may leave traces in the repositories of the project, which means you can count contributors who are active in producing code by looking at the **Author** field in git repositories, or count people participating in the resolution of tickets by looking at who is contributing to them.
|
||||
|
||||
This basic idea of activity" (somebody did something) can be extended in many ways. One common way to track activity is to look at how many people did a sizable chunk of the activity. Generally most of a project's code contributions, for example, are from a small fraction of the people in the project's community. Knowing about that fraction helps provide an idea of the core group (i.e., the people who help lead the community).
|
||||
|
||||
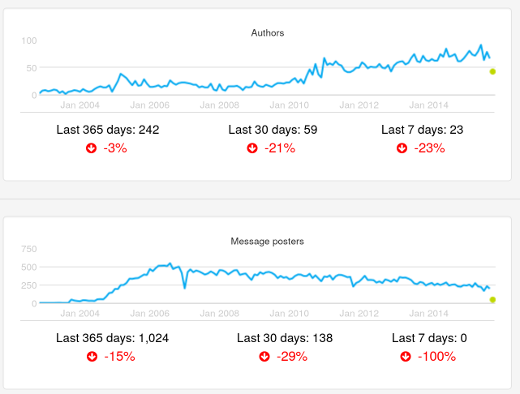
|
||||
|
||||
Number of authors and number of posters in mailing lists in the Xen project, as found in the [Xen Project Development Dashboard][2]. Evolution over time (monthly data).
|
||||
|
||||
### 3. Performance ###
|
||||
|
||||
So far, I have focused on measuring quantities of activities and contributors. You also can analyze how processes and people are performing. For example, you can measure how long processes take to finish. Time to resolve or close tickets shows how the project is reacting to new information that requires action, such as fixing a reported bug or implementing a requested new feature. Time spent in code review—from the moment when a change to the code is proposed to the moment it is accepted—shows how long upgrading a proposed change to the quality standards expected by the community takes.
|
||||
|
||||
Other metrics deal with how well the project is coping with pending work, such as the ratio of new to closed tickets, or the backlog of still non-completed code reviews. Those parameters tell us, for example, whether or not the resources put into solving issues is enough.
|
||||
|
||||
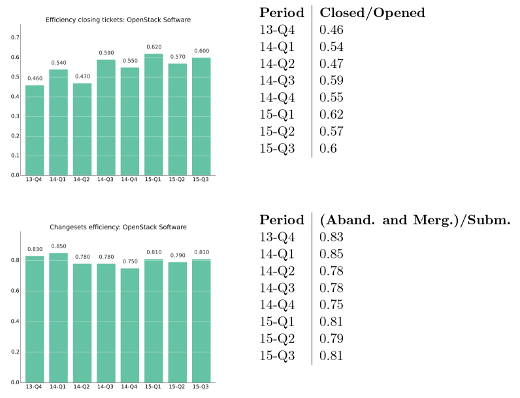
|
||||
|
||||
Ratio of tickets closed by tickets opened, and ratio of change proposals accepted or abandoned by new change proposals per quarter. OpenStack project, as shown in the [OpenStack Development Report, 2015-Q3][3] (PDF).
|
||||
|
||||
### 4. Demographics ###
|
||||
|
||||
Communities change as contributors move in and out. Depending on how people enter and leave a community over time, the age (time since members joined the community) of the community varies. The [community aging chart][4] nicely illustrates these exchanges over time. The chart is structured as a set of horizontal bars, two per "generation" of people joining the community. For each generation, the attracted bar shows how many new people joined the community during the corresponding period of time. The retained bar shows how many people are still active in the community.
|
||||
|
||||
The relationship between the two bars for each generation is the retention rate: the fraction of people of that generation who are still in the project. The complete set of attracted bars show how attractive the project was in the past. And the complete set of the retention bars shows the current age structure of the community.
|
||||
|
||||
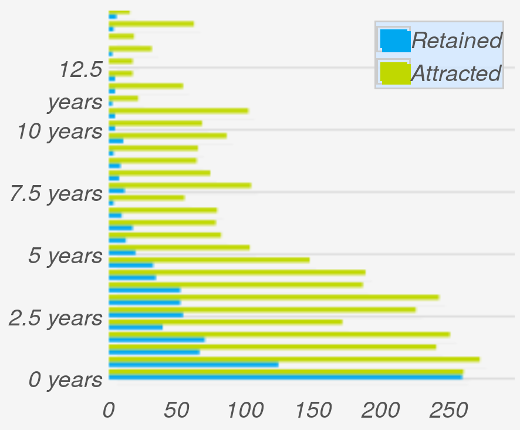
|
||||
|
||||
Community aging chart for the Eclipse community, as shown in the [Eclipse Development Dashboard][5]. Generations are defined every six months.
|
||||
|
||||
### 5. Diversity ###
|
||||
|
||||
Diversity is an important factor in the resiliency of communities. In general, the more diverse communities are—in terms of people or organizations participating—the more resilient they are. For example, when a company decides to leave a FOSS community, the potential problems the departure may cause are much smaller if its employees were contributing 5% of the work rather than 85%.
|
||||
|
||||
The [Pony Factor][6], a term defined by [Daniel Gruno][7] for the minimum number of developers performing 50% of the commits. Based on the Pony Factor, the Elephant Factor is the minimum number of companies whose employees perform 50% of the commits. Both numbers provide an indication of how many people or companies the community depends on.
|
||||
|
||||
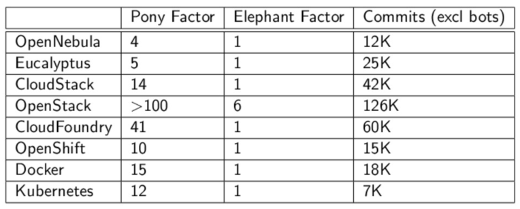
|
||||
|
||||
Pony and Elephant Factor for several FOSS projects in the area of cloud computing, as presented in [The quantitative state of the open cloud 2015][8] (slides).
|
||||
|
||||
There are many other metrics to help measure a community. When determing which metrics to collect, think about the goals of your community, and which metrics will help you reach them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/15/12/top-5-open-source-community-metrics-track
|
||||
|
||||
作者:[Jesus M. Gonzalez-Barahona][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jgbarah
|
||||
[1]:http://activity.openstack.org/
|
||||
[2]:http://projects.bitergia.com/xen-project-dashboard/
|
||||
[3]:http://activity.openstack.org/dash/reports/2015-q3/pdf/2015-q3_OpenStack_report.pdf
|
||||
[4]:http://radar.oreilly.com/2014/10/measure-your-open-source-communitys-age-to-keep-it-healthy.html
|
||||
[5]:http://dashboard.eclipse.org/demographics.html
|
||||
[6]:https://ke4qqq.wordpress.com/2015/02/08/pony-factor-math/
|
||||
[7]:https://twitter.com/humbedooh
|
||||
[8]:https://speakerdeck.com/jgbarah/the-quantitative-state-of-the-open-cloud-2015-edition
|
||||
@ -1,3 +1,4 @@
|
||||
translating wi-cuckoo
|
||||
A Repository with 44 Years of Unix Evolution
|
||||
================================================================================
|
||||
### Abstract ###
|
||||
@ -199,4 +200,4 @@ via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.htm
|
||||
[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
|
||||
[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
|
||||
@ -1,257 +0,0 @@
|
||||
Data Structures in the Linux Kernel
|
||||
================================================================================
|
||||
|
||||
Doubly linked list
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Linux kernel provides its own implementation of doubly linked list, which you can find in the [include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h). We will start `Data Structures in the Linux kernel` from the doubly linked list data structure. Why? Because it is very popular in the kernel, just try to [search](http://lxr.free-electrons.com/ident?i=list_head)
|
||||
|
||||
First of all, let's look on the main structure in the [include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h):
|
||||
|
||||
```C
|
||||
struct list_head {
|
||||
struct list_head *next, *prev;
|
||||
};
|
||||
```
|
||||
|
||||
You can note that it is different from many implementations of doubly linked list which you have seen. For example, this doubly linked list structure from the [glib](http://www.gnu.org/software/libc/) library looks like :
|
||||
|
||||
```C
|
||||
struct GList {
|
||||
gpointer data;
|
||||
GList *next;
|
||||
GList *prev;
|
||||
};
|
||||
```
|
||||
|
||||
Usually a linked list structure contains a pointer to the item. The implementation of linked list in Linux kernel does not. So the main question is - `where does the list store the data?`. The actual implementation of linked list in the kernel is - `Intrusive list`. An intrusive linked list does not contain data in its nodes - A node just contains pointers to the next and previous node and list nodes part of the data that are added to the list. This makes the data structure generic, so it does not care about entry data type anymore.
|
||||
|
||||
For example:
|
||||
|
||||
```C
|
||||
struct nmi_desc {
|
||||
spinlock_t lock;
|
||||
struct list_head head;
|
||||
};
|
||||
```
|
||||
|
||||
Let's look at some examples to understand how `list_head` is used in the kernel. As I already wrote about, there are many, really many different places where lists are used in the kernel. Let's look for an example in miscellaneous character drivers. Misc character drivers API from the [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) is used for writing small drivers for handling simple hardware or virtual devices. Those drivers share same major number:
|
||||
|
||||
```C
|
||||
#define MISC_MAJOR 10
|
||||
```
|
||||
|
||||
but have their own minor number. For example you can see it with:
|
||||
|
||||
```
|
||||
ls -l /dev | grep 10
|
||||
crw------- 1 root root 10, 235 Mar 21 12:01 autofs
|
||||
drwxr-xr-x 10 root root 200 Mar 21 12:01 cpu
|
||||
crw------- 1 root root 10, 62 Mar 21 12:01 cpu_dma_latency
|
||||
crw------- 1 root root 10, 203 Mar 21 12:01 cuse
|
||||
drwxr-xr-x 2 root root 100 Mar 21 12:01 dri
|
||||
crw-rw-rw- 1 root root 10, 229 Mar 21 12:01 fuse
|
||||
crw------- 1 root root 10, 228 Mar 21 12:01 hpet
|
||||
crw------- 1 root root 10, 183 Mar 21 12:01 hwrng
|
||||
crw-rw----+ 1 root kvm 10, 232 Mar 21 12:01 kvm
|
||||
crw-rw---- 1 root disk 10, 237 Mar 21 12:01 loop-control
|
||||
crw------- 1 root root 10, 227 Mar 21 12:01 mcelog
|
||||
crw------- 1 root root 10, 59 Mar 21 12:01 memory_bandwidth
|
||||
crw------- 1 root root 10, 61 Mar 21 12:01 network_latency
|
||||
crw------- 1 root root 10, 60 Mar 21 12:01 network_throughput
|
||||
crw-r----- 1 root kmem 10, 144 Mar 21 12:01 nvram
|
||||
brw-rw---- 1 root disk 1, 10 Mar 21 12:01 ram10
|
||||
crw--w---- 1 root tty 4, 10 Mar 21 12:01 tty10
|
||||
crw-rw---- 1 root dialout 4, 74 Mar 21 12:01 ttyS10
|
||||
crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
|
||||
crw------- 1 root root 10, 137 Mar 21 12:01 vhci
|
||||
```
|
||||
|
||||
Now let's have a close look at how lists are used in the misc device drivers. First of all, let's look on `miscdevice` structure:
|
||||
|
||||
```C
|
||||
struct miscdevice
|
||||
{
|
||||
int minor;
|
||||
const char *name;
|
||||
const struct file_operations *fops;
|
||||
struct list_head list;
|
||||
struct device *parent;
|
||||
struct device *this_device;
|
||||
const char *nodename;
|
||||
mode_t mode;
|
||||
};
|
||||
```
|
||||
|
||||
We can see the fourth field in the `miscdevice` structure - `list` which is a list of registered devices. In the beginning of the source code file we can see the definition of misc_list:
|
||||
|
||||
```C
|
||||
static LIST_HEAD(misc_list);
|
||||
```
|
||||
|
||||
which expands to the definition of variables with `list_head` type:
|
||||
|
||||
```C
|
||||
#define LIST_HEAD(name) \
|
||||
struct list_head name = LIST_HEAD_INIT(name)
|
||||
```
|
||||
|
||||
and initializes it with the `LIST_HEAD_INIT` macro, which sets previous and next entries with the address of variable - name:
|
||||
|
||||
```C
|
||||
#define LIST_HEAD_INIT(name) { &(name), &(name) }
|
||||
```
|
||||
|
||||
Now let's look on the `misc_register` function which registers a miscellaneous device. At the start it initializes `miscdevice->list` with the `INIT_LIST_HEAD` function:
|
||||
|
||||
```C
|
||||
INIT_LIST_HEAD(&misc->list);
|
||||
```
|
||||
|
||||
which does the same as the `LIST_HEAD_INIT` macro:
|
||||
|
||||
```C
|
||||
static inline void INIT_LIST_HEAD(struct list_head *list)
|
||||
{
|
||||
list->next = list;
|
||||
list->prev = list;
|
||||
}
|
||||
```
|
||||
|
||||
In the next step after a device is created by the `device_create` function, we add it to the miscellaneous devices list with:
|
||||
|
||||
```
|
||||
list_add(&misc->list, &misc_list);
|
||||
```
|
||||
|
||||
Kernel `list.h` provides this API for the addition of a new entry to the list. Let's look at its implementation:
|
||||
|
||||
```C
|
||||
static inline void list_add(struct list_head *new, struct list_head *head)
|
||||
{
|
||||
__list_add(new, head, head->next);
|
||||
}
|
||||
```
|
||||
|
||||
It just calls internal function `__list_add` with the 3 given parameters:
|
||||
|
||||
* new - new entry.
|
||||
* head - list head after which the new item will be inserted.
|
||||
* head->next - next item after list head.
|
||||
|
||||
Implementation of the `__list_add` is pretty simple:
|
||||
|
||||
```C
|
||||
static inline void __list_add(struct list_head *new,
|
||||
struct list_head *prev,
|
||||
struct list_head *next)
|
||||
{
|
||||
next->prev = new;
|
||||
new->next = next;
|
||||
new->prev = prev;
|
||||
prev->next = new;
|
||||
}
|
||||
```
|
||||
|
||||
Here we add a new item between `prev` and `next`. So `misc` list which we defined at the start with the `LIST_HEAD_INIT` macro will contain previous and next pointers to the `miscdevice->list`.
|
||||
|
||||
There is still one question: how to get list's entry. There is a special macro:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
which gets three parameters:
|
||||
|
||||
* ptr - the structure list_head pointer;
|
||||
* type - structure type;
|
||||
* member - the name of the list_head within the structure;
|
||||
|
||||
For example:
|
||||
|
||||
```C
|
||||
const struct miscdevice *p = list_entry(v, struct miscdevice, list)
|
||||
```
|
||||
|
||||
After this we can access to any `miscdevice` field with `p->minor` or `p->name` and etc... Let's look on the `list_entry` implementation:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
As we can see it just calls `container_of` macro with the same arguments. At first sight, the `container_of` looks strange:
|
||||
|
||||
```C
|
||||
#define container_of(ptr, type, member) ({ \
|
||||
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
|
||||
(type *)( (char *)__mptr - offsetof(type,member) );})
|
||||
```
|
||||
|
||||
First of all you can note that it consists of two expressions in curly brackets. The compiler will evaluate the whole block in the curly braces and use the value of the last expression.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
int i = 0;
|
||||
printf("i = %d\n", ({++i; ++i;}));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
will print `2`.
|
||||
|
||||
The next point is `typeof`, it's simple. As you can understand from its name, it just returns the type of the given variable. When I first saw the implementation of the `container_of` macro, the strangest thing I found was the zero in the `((type *)0)` expression. Actually this pointer magic calculates the offset of the given field from the address of the structure, but as we have `0` here, it will be just a zero offset along with the field width. Let's look at a simple example:
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
|
||||
struct s {
|
||||
int field1;
|
||||
char field2;
|
||||
char field3;
|
||||
};
|
||||
|
||||
int main() {
|
||||
printf("%p\n", &((struct s*)0)->field3);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
will print `0x5`.
|
||||
|
||||
The next `offsetof` macro calculates offset from the beginning of the structure to the given structure's field. Its implementation is very similar to the previous code:
|
||||
|
||||
```C
|
||||
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
|
||||
```
|
||||
|
||||
Let's summarize all about `container_of` macro. The `container_of` macro returns the address of the structure by the given address of the structure's field with `list_head` type, the name of the structure field with `list_head` type and type of the container structure. At the first line this macro declares the `__mptr` pointer which points to the field of the structure that `ptr` points to and assigns `ptr` to it. Now `ptr` and `__mptr` point to the same address. Technically we don't need this line but it's useful for type checking. The first line ensures that the given structure (`type` parameter) has a member called `member`. In the second line it calculates offset of the field from the structure with the `offsetof` macro and subtracts it from the structure address. That's all.
|
||||
|
||||
Of course `list_add` and `list_entry` is not the only functions which `<linux/list.h>` provides. Implementation of the doubly linked list provides the following API:
|
||||
|
||||
* list_add
|
||||
* list_add_tail
|
||||
* list_del
|
||||
* list_replace
|
||||
* list_move
|
||||
* list_is_last
|
||||
* list_empty
|
||||
* list_cut_position
|
||||
* list_splice
|
||||
* list_for_each
|
||||
* list_for_each_entry
|
||||
|
||||
and many more.
|
||||
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by DongShuaike
|
||||
|
||||
Data Structures in the Linux Kernel
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -1,327 +0,0 @@
|
||||
Translating by KnightJoker
|
||||
How to Install Nginx as Reverse Proxy for Apache on FreeBSD 10.2
|
||||
================================================================================
|
||||
Nginx is free and open source HTTP server and reverse proxy, as well as an mail proxy server for IMAP/POP3. Nginx is high performance web server with rich of features, simple configuration and low memory usage. Originally written by Igor Sysoev on 2002, and until now has been used by a big technology company including Netflix, Github, Cloudflare, WordPress.com etc.
|
||||
|
||||
In this tutorial we will "**install and configure nginx web server as reverse proxy for apache on freebsd 10.2**". Apache will run with php on port 8080, and then we need to configure nginx run on port 80 to receive a request from user/visitor. If user request for web page from the browser on port 80, then nginx will pass the request to apache webserver and PHP that running on port 8080.
|
||||
|
||||
#### Prerequisite ####
|
||||
|
||||
- FreeBSD 10.2.
|
||||
- Root privileges.
|
||||
|
||||
### Step 1 - Update the System ###
|
||||
|
||||
Log in to your freebsd server with ssh credential and update system with command below :
|
||||
|
||||
freebsd-update fetch
|
||||
freebsd-update install
|
||||
|
||||
### Step 2 - Install Apache ###
|
||||
|
||||
pache is open source HTTP server and the most widely used web server. Apache is not installed by default on freebsd, but we can install it from the ports or package on "/usr/ports/www/apache24" or install it from freebsd repository with pkg command. In this tutorial we will use pkg command to install from the freebsd repository :
|
||||
|
||||
pkg install apache24
|
||||
|
||||
### Step 3 - Install PHP ###
|
||||
|
||||
Once apache is installed, followed with installing php for handling a PHP file request by a user. We will install php with pkg command as below :
|
||||
|
||||
pkg install php56 mod_php56 php56-mysql php56-mysqli
|
||||
|
||||
### Step 4 - Configure Apache and PHP ###
|
||||
|
||||
Once all is installed, we will configure apache to run on port 8080, and php working with apache. To configure apache, we can edit the configuration file "httpd.conf", and for PHP we just need to copy the php configuration file php.ini on "/usr/local/etc/" directory.
|
||||
|
||||
Go to "/usr/local/etc/" directory and copy php.ini-production file to php.ini :
|
||||
|
||||
cd /usr/local/etc/
|
||||
cp php.ini-production php.ini
|
||||
|
||||
Next, configure apache by editing file "httpd.conf" on apache directory :
|
||||
|
||||
cd /usr/local/etc/apache24
|
||||
nano -c httpd.conf
|
||||
|
||||
Port configuration on line **52** :
|
||||
|
||||
Listen 8080
|
||||
|
||||
ServerName configuration on line **219** :
|
||||
|
||||
ServerName 127.0.0.1:8080
|
||||
|
||||
Add DirectoryIndex file that apache will serve it if a directory requested on line **277** :
|
||||
|
||||
DirectoryIndex index.php index.html
|
||||
|
||||
Configure apache to work with php by adding script below under line **287** :
|
||||
|
||||
<FilesMatch "\.php$">
|
||||
SetHandler application/x-httpd-php
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.phps$">
|
||||
SetHandler application/x-httpd-php-source
|
||||
</FilesMatch>
|
||||
|
||||
Save and exit.
|
||||
|
||||
Now add apache to start at boot time with sysrc command :
|
||||
|
||||
sysrc apache24_enable=yes
|
||||
|
||||
And test apache configuration with command below :
|
||||
|
||||
apachectl configtest
|
||||
|
||||
If there is no error, start apache :
|
||||
|
||||
service apache24 start
|
||||
|
||||
If all is done, verify that php is running well with apache by creating phpinfo file on "/usr/local/www/apache24/data" directory :
|
||||
|
||||
cd /usr/local/www/apache24/data
|
||||
echo "<?php phpinfo(); ?>" > info.php
|
||||
|
||||
Now visit the freebsd server IP : 192.168.1.123:8080/info.php.
|
||||
|
||||

|
||||
|
||||
Apache is working with php on port 8080.
|
||||
|
||||
### Step 5 - Install Nginx ###
|
||||
|
||||
Nginx high performance web server and reverse proxy with low memory consumption. In this step we will use nginx as reverse proxy for apache, so let's install it with pkg command :
|
||||
|
||||
pkg install nginx
|
||||
|
||||
### Step 6 - Configure Nginx ###
|
||||
|
||||
Once nginx is installed, we must configure it by replacing nginx file "**nginx.conf**" with new configuration below. Change the directory to "/usr/local/etc/nginx/" and backup default nginx.conf :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
mv nginx.conf nginx.conf.oroginal
|
||||
|
||||
Now create new nginx configuration file :
|
||||
|
||||
nano -c nginx.conf
|
||||
|
||||
and paste configuration below :
|
||||
|
||||
user www;
|
||||
worker_processes 1;
|
||||
error_log /var/log/nginx/error.log;
|
||||
|
||||
events {
|
||||
worker_connections 1024;
|
||||
}
|
||||
|
||||
http {
|
||||
include mime.types;
|
||||
default_type application/octet-stream;
|
||||
|
||||
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
|
||||
'$status $body_bytes_sent "$http_referer" '
|
||||
'"$http_user_agent" "$http_x_forwarded_for"';
|
||||
access_log /var/log/nginx/access.log;
|
||||
|
||||
sendfile on;
|
||||
keepalive_timeout 65;
|
||||
|
||||
# Nginx cache configuration
|
||||
proxy_cache_path /var/nginx/cache levels=1:2 keys_zone=my-cache:8m max_size=1000m inactive=600m;
|
||||
proxy_temp_path /var/nginx/cache/tmp;
|
||||
proxy_cache_key "$scheme$host$request_uri";
|
||||
|
||||
gzip on;
|
||||
|
||||
server {
|
||||
#listen 80;
|
||||
server_name _;
|
||||
|
||||
location /nginx_status {
|
||||
|
||||
stub_status on;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
# redirect server error pages to the static page /50x.html
|
||||
#
|
||||
error_page 500 502 503 504 /50x.html;
|
||||
location = /50x.html {
|
||||
root /usr/local/www/nginx-dist;
|
||||
}
|
||||
|
||||
# proxy the PHP scripts to Apache listening on 127.0.0.1:8080
|
||||
#
|
||||
location ~ \.php$ {
|
||||
proxy_pass http://127.0.0.1:8080;
|
||||
include /usr/local/etc/nginx/proxy.conf;
|
||||
}
|
||||
}
|
||||
|
||||
include /usr/local/etc/nginx/vhost/*;
|
||||
|
||||
}
|
||||
|
||||
Save and exit.
|
||||
|
||||
Next, create new file called **proxy.conf** for reverse proxy configuration on nginx directory :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
nano -c proxy.conf
|
||||
|
||||
Paste configuration below :
|
||||
|
||||
proxy_buffering on;
|
||||
proxy_redirect off;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
client_max_body_size 10m;
|
||||
client_body_buffer_size 128k;
|
||||
proxy_connect_timeout 90;
|
||||
proxy_send_timeout 90;
|
||||
proxy_read_timeout 90;
|
||||
proxy_buffers 100 8k;
|
||||
add_header X-Cache $upstream_cache_status;
|
||||
|
||||
Save and exit.
|
||||
|
||||
And the last, create new directory for nginx cache on "/var/nginx/cache" :
|
||||
|
||||
mkdir -p /var/nginx/cache
|
||||
|
||||
### Step 7 - Configure Nginx VirtualHost ###
|
||||
|
||||
In this step we will create new virtualhost for domain "saitama.me", with document root on "/usr/local/www/saitama.me" and the log file on "/var/log/nginx" directory.
|
||||
|
||||
First thing we must do is creating new directory to store the virtualhost file, we here use new directory called "**vhost**". Let's create it :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
mkdir vhost
|
||||
|
||||
vhost directory has been created, now go to the directory and create new file virtualhost. I'me here will create new file "**saitama.conf**" :
|
||||
|
||||
cd vhost/
|
||||
nano -c saitama.conf
|
||||
|
||||
Paste virtualhost configuration below :
|
||||
|
||||
server {
|
||||
# Replace with your freebsd IP
|
||||
listen 192.168.1.123:80;
|
||||
|
||||
# Document Root
|
||||
root /usr/local/www/saitama.me;
|
||||
index index.php index.html index.htm;
|
||||
|
||||
# Domain
|
||||
server_name www.saitama.me saitama.me;
|
||||
|
||||
# Error and Access log file
|
||||
error_log /var/log/nginx/saitama-error.log;
|
||||
access_log /var/log/nginx/saitama-access.log main;
|
||||
|
||||
# Reverse Proxy Configuration
|
||||
location ~ \.php$ {
|
||||
proxy_pass http://127.0.0.1:8080;
|
||||
include /usr/local/etc/nginx/proxy.conf;
|
||||
|
||||
# Cache configuration
|
||||
proxy_cache my-cache;
|
||||
proxy_cache_valid 10s;
|
||||
proxy_no_cache $cookie_PHPSESSID;
|
||||
proxy_cache_bypass $cookie_PHPSESSID;
|
||||
proxy_cache_key "$scheme$host$request_uri";
|
||||
|
||||
}
|
||||
|
||||
# Disable Cache for the file type html, json
|
||||
location ~* .(?:manifest|appcache|html?|xml|json)$ {
|
||||
expires -1;
|
||||
}
|
||||
|
||||
# Enable Cache the file 30 days
|
||||
location ~* .(jpg|png|gif|jpeg|css|mp3|wav|swf|mov|doc|pdf|xls|ppt|docx|pptx|xlsx)$ {
|
||||
proxy_cache_valid 200 120m;
|
||||
expires 30d;
|
||||
proxy_cache my-cache;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
Save and exit.
|
||||
|
||||
Next, create new log directory for nginx and virtualhost on "/var/log/" :
|
||||
|
||||
mkdir -p /var/log/nginx/
|
||||
|
||||
If all is done, let's create a directory for document root for saitama.me :
|
||||
|
||||
cd /usr/local/www/
|
||||
mkdir saitama.me
|
||||
|
||||
### Step 8 - Testing ###
|
||||
|
||||
This step is just test our nginx configuration and test the nginx virtualhost.
|
||||
|
||||
Test nginx configuration with command below :
|
||||
|
||||
nginx -t
|
||||
|
||||
If there is no problem, add nginx to boot time with sysrc command, and then start it and restart apache:
|
||||
|
||||
sysrc nginx_enable=yes
|
||||
service nginx start
|
||||
service apache24 restart
|
||||
|
||||
All is done, now verify the the php is working by adding new file phpinfo on saitama.me directory :
|
||||
|
||||
cd /usr/local/www/saitama.me
|
||||
echo "<?php phpinfo(); ?>" > info.php
|
||||
|
||||
Visit the domain : **www.saitama.me/info.php**.
|
||||
|
||||

|
||||
|
||||
Nginx as reverse proxy for apache is working, and php is working too.
|
||||
|
||||
And this is another results :
|
||||
|
||||
Test .html file with no-cache.
|
||||
|
||||
curl -I www.saitama.me
|
||||
|
||||

|
||||
|
||||
Test .css file with 30day cache.
|
||||
|
||||
curl -I www.saitama.me/test.css
|
||||
|
||||

|
||||
|
||||
Test .php file with cache :
|
||||
|
||||
curl -I www.saitama.me/info.php
|
||||
|
||||

|
||||
|
||||
All is done.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Nginx is most popular HTTP server and reverse proxy. Has a rich of features with high performance and low memory/RAM usage. Nginx use too for caching, we can cache a static file on the web to make the web fast load, and cache for php file if a user request for it. Nginx is easy to configure and use, use for HTTP server or act as reverse proxy for apache.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-nginx-reverse-proxy-apache-freebsd-10-2/
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arulm/
|
||||
@ -1,40 +0,0 @@
|
||||
Backup (System Restore Point) your Ubuntu/Linux Mint with SystemBack
|
||||
================================================================================
|
||||
System Restore is must have feature for any OS that allows the user to revert their computer's state (including system files, installed applications, and system settings) to that of a previous point in time, which can be used to recover from system malfunctions or other problems.
|
||||
Sometimes installing a program or driver can make your OS go to blank screen. System Restore can return your PC's system files and programs to a time when everything was working fine, potentially preventing hours of troubleshooting headaches. It won't affect your documents, pictures, or other data.
|
||||
Simple system backup and restore application with extra features. [Systemback][1] makes it easy to create backups of system and users configuration files. In case of problems you can easily restore the previous state of the system. There are extra features like system copying, system installation and Live system creation.
|
||||
|
||||
Screenshots
|
||||
|
||||
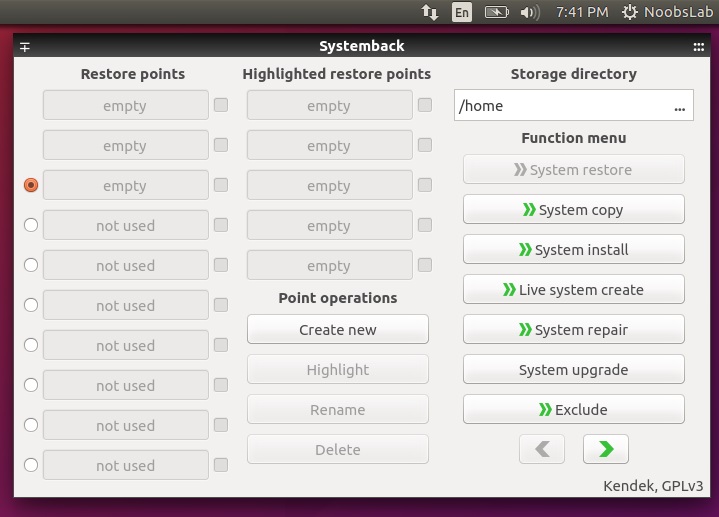
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
**Note**: Using System Restore will not restore documents, music, emails, or personal files of any kind. Depending on your perspective, this is both a positive and negative feature. The bad news is that it won't restore that accidentally deleted file you wish you could get back, though a file recovery program might solve that problem.
|
||||
If no restore point exists on your computer, System Restore has nothing to revert to so the tool won't work for you. If you're trying to recover from a major problem, you'll need to move on to another troubleshooting step.
|
||||
|
||||
>>> Available for Ubuntu 15.10 Wily/16.04/15.04 Vivid/14.04 Trusty/Linux Mint 17.x/other Ubuntu derivatives
|
||||
To install SystemBack Application in Ubuntu/Linux Mint open Terminal (Press Ctrl+Alt+T) and copy the following commands in the Terminal:
|
||||
|
||||
Terminal Commands:
|
||||
|
||||
sudo add-apt-repository ppa:nemh/systemback
|
||||
sudo apt-get update
|
||||
sudo apt-get install systemback
|
||||
|
||||
That's it
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.noobslab.com/2015/11/backup-system-restore-point-your.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://launchpad.net/systemback
|
||||
@ -1,148 +0,0 @@
|
||||
Vic020
|
||||
|
||||
How to use the Linux ftp command to up- and download files on the shell
|
||||
================================================================================
|
||||
In this tutorial, I will explain how to use the Linux ftp command on the shell. I will show you how to connect to an FTP server, up- and download files and create directories. While there are many nice desktops FTP clients available, the FTP command is still useful when you work remotely on a server over an SSH session and e.g. want to fetch a backup file from your FTP storage.
|
||||
|
||||
### Step 1: Establishing an FTP connection ###
|
||||
|
||||
To connect to the FTP server, we have to type in the terminal window '**ftp**' and then the domain name 'domain.com' or IP address of the FTP server.
|
||||
|
||||
#### Examples: ####
|
||||
|
||||
ftp domain.com
|
||||
|
||||
ftp 192.168.0.1
|
||||
|
||||
ftp user@ftpdomain.com
|
||||
|
||||
**Note: for this example we used an anonymous server.**
|
||||
|
||||
Replace the IP and domain in the above examples with the IP address or domain of your FTP server.
|
||||
|
||||
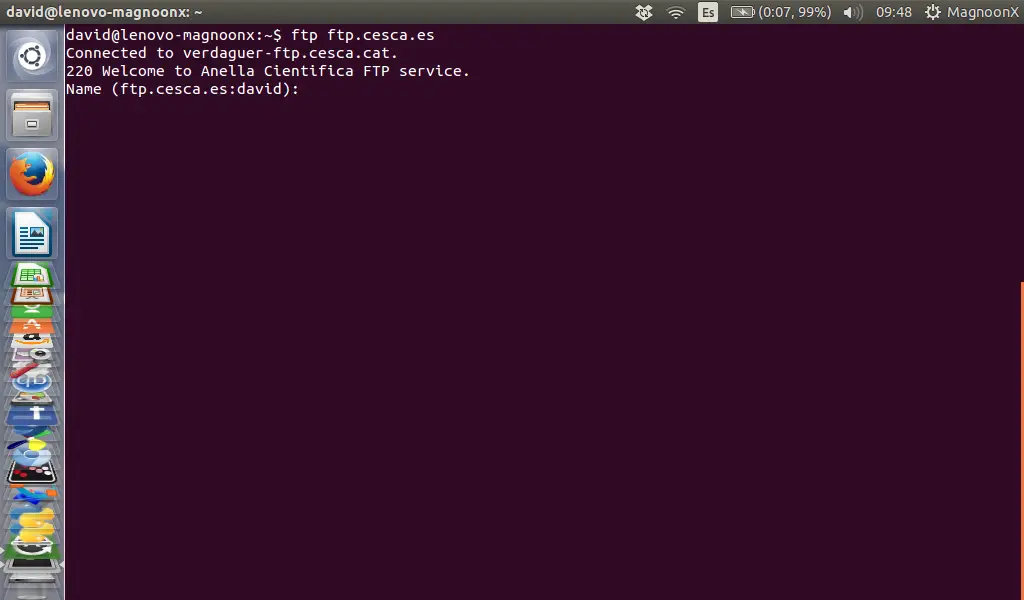
|
||||
|
||||
### Step 2: Login with User and Password ###
|
||||
|
||||
Most FTP servers logins are password protected, so the server will ask us for a '**username**' and a '**password**'.
|
||||
|
||||
If you connect to a so-called anonymous FTP server, then try to use "anonymous" as user name and a nempty password:
|
||||
|
||||
Name: anonymous
|
||||
|
||||
Password:
|
||||
|
||||
The terminal will return a message like this:
|
||||
|
||||
230 Login successful.
|
||||
Remote system type is UNIX.
|
||||
Using binary mode to transfer files.
|
||||
ftp>
|
||||
|
||||
When you are logged in successfully.
|
||||
|
||||
|
||||
|
||||
### Step 3: Working with Directories ###
|
||||
|
||||
The commands to list, move and create folders on an FTP server are almost the same as we would use locally on our computer, ls for list, cd to change directories, mkdir to create directories...
|
||||
|
||||
#### Listing directories with security settings: ####
|
||||
|
||||
ftp> ls
|
||||
|
||||
The server will return:
|
||||
|
||||
200 PORT command successful. Consider using PASV.
|
||||
150 Here comes the directory listing.
|
||||
directory list
|
||||
....
|
||||
....
|
||||
226 Directory send OK.
|
||||
|
||||
|
||||
|
||||
#### Changing Directories: ####
|
||||
|
||||
To change the directory we can type:
|
||||
|
||||
ftp> cd directory
|
||||
|
||||
The server will return:
|
||||
|
||||
250 Directory succesfully changed.
|
||||
|
||||
|
||||
|
||||
### Step 4: Downloading files with FTP ###
|
||||
|
||||
Before downloading a file, we should set the local ftp file download directory by using 'lcd' command:
|
||||
|
||||
lcd /home/user/yourdirectoryname
|
||||
|
||||
If you dont specify the download directory, the file will be downloaded to the current directory where you were at the time you started the FTP session.
|
||||
|
||||
Now, we can use the command 'get' command to download a file, the usage is:
|
||||
|
||||
get file
|
||||
|
||||
The file will be downloaded to the directory previously set with the 'lcd' command.
|
||||
|
||||
The server will return the next message:
|
||||
|
||||
local: file remote: file
|
||||
200 PORT command successful. Consider using PASV.
|
||||
150 Opening BINARY mode data connection for file (xxx bytes).
|
||||
226 File send OK.
|
||||
XXX bytes received in x.xx secs (x.xxx MB/s).
|
||||
|
||||
|
||||
|
||||
To download several files we can use wildcards. In this example I will download all files with the .xls file extension.
|
||||
|
||||
mget *.xls
|
||||
|
||||
### Step 5: Uploading Files with FTP ###
|
||||
|
||||
We can upload files that are in the local directory where we made the FTP connection.
|
||||
|
||||
To upload a file, we can use 'put' command.
|
||||
|
||||
put file
|
||||
|
||||
When the file that you want to upload is not in the local directory, you can use the absolute path starting with "/" as well:
|
||||
|
||||
put /path/file
|
||||
|
||||
To upload several files we can use the mput command similar to the mget example from above:
|
||||
|
||||
mput *.xls
|
||||
|
||||
### Step 6: Closing the FTP connection ###
|
||||
|
||||
Once we have done the FTP work, we should close the connection for security reasons. There are three commands that we can use to close the connection:
|
||||
|
||||
bye
|
||||
|
||||
exit
|
||||
|
||||
quit
|
||||
|
||||
Any of them will disconnect our PC from the FTP server and will return:
|
||||
|
||||
221 Goodbye
|
||||
|
||||

|
||||
|
||||
If you need some additional help, once you are connected to the FTP server, type 'help' and this will show you all the available FTP commands.
|
||||
|
||||
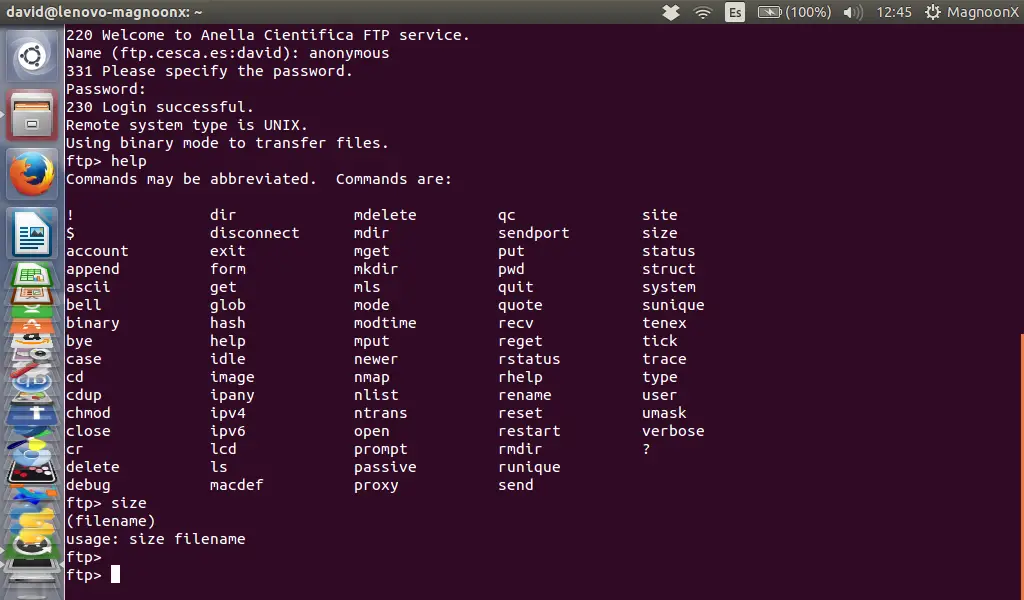
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-use-ftp-on-the-linux-shell/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,65 @@
|
||||
How to Customize Time & Date Format in Ubuntu Panel
|
||||
================================================================================
|
||||

|
||||
|
||||
This quick tutorial is going to show you how to customize your Time & Date indicator in Ubuntu panel, though there are already a few options available in the settings page.
|
||||
|
||||
|
||||
|
||||
To get started, search for and install **dconf Editor** in Ubuntu Software Center. Then launch the software and follow below steps:
|
||||
|
||||
**1.** When dconf Editor launches, navigate to **com -> canonical -> indicator -> datetime**. Set the value of **time-format** to **custom**.
|
||||
|
||||
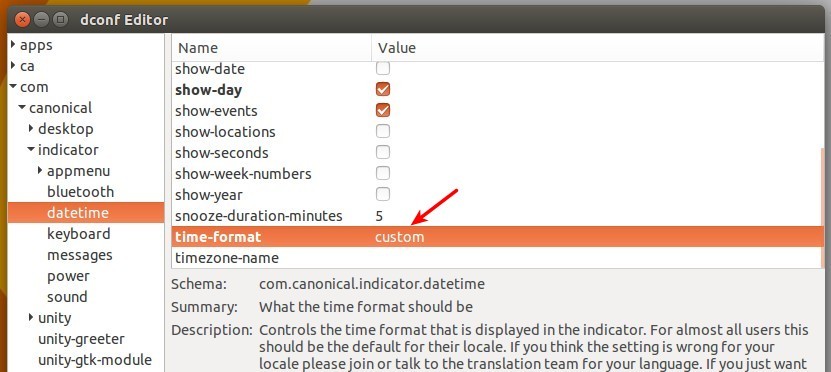
|
||||
|
||||
You can also do this via a command in terminal:
|
||||
|
||||
gsettings set com.canonical.indicator.datetime time-format 'custom'
|
||||
|
||||
**2.** Now you can customize the Time & Date format by editing the value of **custom-time-format**.
|
||||
|
||||
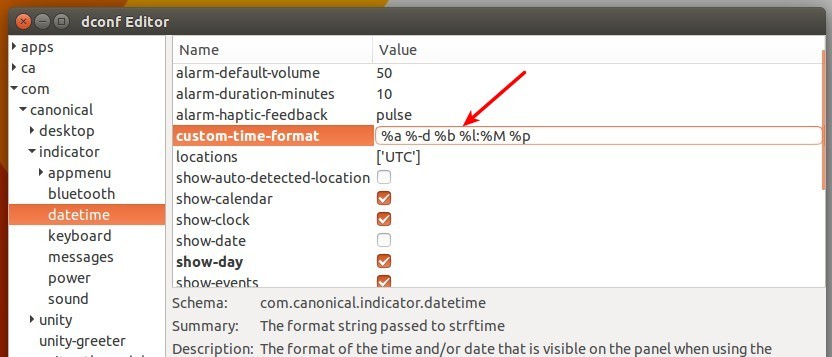
|
||||
|
||||
You can also do this via command:
|
||||
|
||||
gsettings set com.canonical.indicator.datetime custom-time-format 'FORMAT_VALUE_HERE'
|
||||
|
||||
Interpreted sequences are:
|
||||
|
||||
- %a = abbreviated weekday name
|
||||
- %A = full weekday name
|
||||
- %b = abbreviated month name
|
||||
- %B = full month name
|
||||
- %d = day of month
|
||||
- %l = hour ( 1..12), %I = hour (01..12)
|
||||
- %k = hour ( 1..23), %H = hour (01..23)
|
||||
- %M = minute (00..59)
|
||||
- %p = AM or PM, %P = am or pm.
|
||||
- %S = second (00..59)
|
||||
- open terminal and run command `man date` to get more details.
|
||||
|
||||
Some examples:
|
||||
|
||||
custom time format value: **%a %H:%M %m/%d/%Y**
|
||||
|
||||

|
||||
|
||||
**%a %r %b %d or %a %I:%M:%S %p %b %d**
|
||||
|
||||
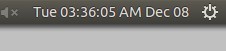
|
||||
|
||||
**%a %-d %b %l:%M %P %z**
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/12/time-date-format-ubuntu-panel/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
@ -0,0 +1,267 @@
|
||||
How to Install Bugzilla with Apache and SSL on FreeBSD 10.2
|
||||
================================================================================
|
||||
Bugzilla is open source web base application for bug tracker and testing tool, develop by mozilla project, and licensed under Mozilla Public License. It is used by high tech company like mozilla, redhat and gnome. Bugzilla was originally created by Terry Weissman in 1998. It written in perl, use MySQL as the database back-end. It is a server software designed to help you manage software development. Bugzilla has a lot of features, optimized database, excellent security, advanced search tool, integrated with email capabilities etc.
|
||||
|
||||
In this tutorial we will install bugzilla 5.0 with apache for the web server, and enable SSL for it. Then install mysql51 as the database system on freebsd 10.2.
|
||||
|
||||
#### Prerequisite ####
|
||||
|
||||
FreeBSD 10.2 - 64bit.
|
||||
Root privileges.
|
||||
|
||||
### Step 1 - Update System ###
|
||||
|
||||
Log in to the freebsd server with ssl login, and update the repository database :
|
||||
|
||||
sudo su
|
||||
freebsd-update fetch
|
||||
freebsd-update install
|
||||
|
||||
### Step 2 - Install and Configure Apache ###
|
||||
|
||||
In this step we will install apache from the freebsd repositories with pkg command. Then configure apache by editing file "httpd.conf" on apache24 directory, configure apache to use SSL, and CGI support.
|
||||
|
||||
Install apache with pkg command :
|
||||
|
||||
pkg install apache24
|
||||
|
||||
Go to the apache directory and edit the file "httpd.conf" with nanao editor :
|
||||
|
||||
cd /usr/local/etc/apache24
|
||||
nano -c httpd.conf
|
||||
|
||||
Uncomment the list line below :
|
||||
|
||||
#Line 70
|
||||
LoadModule authn_socache_module libexec/apache24/mod_authn_socache.so
|
||||
|
||||
#Line 89
|
||||
LoadModule socache_shmcb_module libexec/apache24/mod_socache_shmcb.so
|
||||
|
||||
# Line 117
|
||||
LoadModule expires_module libexec/apache24/mod_expires.so
|
||||
|
||||
#Line 141 to enabling SSL
|
||||
LoadModule ssl_module libexec/apache24/mod_ssl.so
|
||||
|
||||
# Line 162 for cgi support
|
||||
LoadModule cgi_module libexec/apache24/mod_cgi.so
|
||||
|
||||
# Line 174 to enable mod_rewrite
|
||||
LoadModule rewrite_module libexec/apache24/mod_rewrite.so
|
||||
|
||||
# Line 219 for the servername configuration
|
||||
ServerName 127.0.0.1:80
|
||||
|
||||
Save and exit.
|
||||
|
||||
Next, we need to install mod perl from freebsd repository, and then enable it :
|
||||
|
||||
pkg install ap24-mod_perl2
|
||||
|
||||
To enable mod_perl, edit httpd.conf and add to the "Loadmodule" line below :
|
||||
|
||||
nano -c httpd.conf
|
||||
|
||||
Add line below :
|
||||
|
||||
# Line 175
|
||||
LoadModule perl_module libexec/apache24/mod_perl.so
|
||||
|
||||
Save and exit.
|
||||
|
||||
And before start apache, add it to start at boot time with sysrc command :
|
||||
|
||||
sysrc apache24_enable=yes
|
||||
service apache24 start
|
||||
|
||||
### Step 3 - Install and Configure MySQL Database ###
|
||||
|
||||
We will use mysql51 for the database back-end, and it is support for perl module for mysql. Install mysql51 with pkg command below :
|
||||
|
||||
pkg install p5-DBD-mysql51 mysql51-server mysql51-client
|
||||
|
||||
Now we must add mysql to the boot time, and then start and configure the root password for mysql.
|
||||
|
||||
Run command below to do it all :
|
||||
|
||||
sysrc mysql_enable=yes
|
||||
service mysql-server start
|
||||
mysqladmin -u root password aqwe123
|
||||
|
||||
Note :
|
||||
|
||||
mysql password : aqwe123
|
||||
|
||||

|
||||
|
||||
Next, we will log in to the mysql shell with user root and password that we've configured above, then we will create new database and user for bugzilla installation.
|
||||
|
||||
Log in to the mysql shell with command below :
|
||||
|
||||
mysql -u root -p
|
||||
password: aqwe123
|
||||
|
||||
Add the database :
|
||||
|
||||
create database bugzilladb;
|
||||
create user bugzillauser@localhost identified by 'bugzillauser@';
|
||||
grant all privileges on bugzilladb.* to bugzillauser@localhost identified by 'bugzillauser@';
|
||||
flush privileges;
|
||||
\q
|
||||
|
||||

|
||||
|
||||
Database for bugzilla is created, database "bugzilladb" with user "bugzillauser" and password "bugzillauser@".
|
||||
|
||||
### Step 4 - Generate New SSL Certificate ###
|
||||
|
||||
Generate new self signed ssl certificate on directory "ssl" for bugzilla site.
|
||||
|
||||
Go to the apache24 directory and create new directory "ssl" on it :
|
||||
|
||||
cd /usr/local/etc/apache24/
|
||||
mkdir ssl; cd ssl
|
||||
|
||||
Next, generate the certificate file with openssl command, then change the permission of the certificate file :
|
||||
|
||||
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /usr/local/etc/apache24/ssl/bugzilla.key -out /usr/local/etc/apache24/ssl/bugzilla.crt
|
||||
chmod 600 *
|
||||
|
||||
### Step 5 - Configure Virtualhost ###
|
||||
|
||||
We will install bugzilla on directory "/usr/local/www/bugzilla", so we must create new virtualhost configuration for it.
|
||||
|
||||
Go to the apache directory and create new directory called "vhost" for virtualhost file :
|
||||
|
||||
cd /usr/local/etc/apache24/
|
||||
mkdir vhost; cd vhost
|
||||
|
||||
Now create new file "bugzilla.conf" for the virtualhost file :
|
||||
|
||||
nano -c bugzilla.conf
|
||||
|
||||
Paste configuration below :
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName mybugzilla.me
|
||||
ServerAlias www.mybuzilla.me
|
||||
DocumentRoot /usr/local/www/bugzilla
|
||||
Redirect permanent / https://mybugzilla.me/
|
||||
</VirtualHost>
|
||||
|
||||
Listen 443
|
||||
<VirtualHost _default_:443>
|
||||
ServerName mybugzilla.me
|
||||
DocumentRoot /usr/local/www/bugzilla
|
||||
|
||||
ErrorLog "/var/log/mybugzilla.me-error_log"
|
||||
CustomLog "/var/log/mybugzilla.me-access_log" common
|
||||
|
||||
SSLEngine On
|
||||
SSLCertificateFile /usr/local/etc/apache24/ssl/bugzilla.crt
|
||||
SSLCertificateKeyFile /usr/local/etc/apache24/ssl/bugzilla.key
|
||||
|
||||
<Directory "/usr/local/www/bugzilla">
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
DirectoryIndex index.cgi index.html
|
||||
AllowOverride Limit FileInfo Indexes Options
|
||||
Require all granted
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
Save and exit.
|
||||
|
||||
If all is done, create new directory for bugzilla installation and then enable the bugzilla virtualhost by adding the virtualhost configuration to httpd.conf file.
|
||||
|
||||
Run command below on "apache24" directory :
|
||||
|
||||
mkdir -p /usr/local/www/bugzilla
|
||||
cd /usr/local/etc/apache24/
|
||||
nano -c httpd.conf
|
||||
|
||||
In the end of the line, add configuration below :
|
||||
|
||||
Include etc/apache24/vhost/*.conf
|
||||
|
||||
Save and exit.
|
||||
|
||||
Now test the apache configuration with "apachectl" command and restart it :
|
||||
|
||||
apachectl configtest
|
||||
service apache24 restart
|
||||
|
||||
### Step 6 - Install Bugzilla ###
|
||||
|
||||
We can install bugzilla manually by downloading the source, or install it from freebsd repository. In this step we will install bugzilla from freebsd repository with pkg command :
|
||||
|
||||
pkg install bugzilla50
|
||||
|
||||
If it's done, go to the bugzilla installation directory and install all perl module that needed by bugzilla.
|
||||
|
||||
cd /usr/local/www/bugzilla
|
||||
./install-module --all
|
||||
|
||||
Wait it until all is finished, it is take the time.
|
||||
|
||||
Next, generate the configuration file "localconfig" by executing "checksetup.pl" file on bugzilla installation directory.
|
||||
|
||||
./checksetup.pl
|
||||
|
||||
You will see the error message about the database configuration, so edit the file "localconfig" with nano editor :
|
||||
|
||||
nano -c localconfig
|
||||
|
||||
Now add the database that was created on step 3.
|
||||
|
||||
#Line 57
|
||||
$db_name = 'bugzilladb';
|
||||
|
||||
#Line 60
|
||||
$db_user = 'bugzillauser';
|
||||
|
||||
#Line 67
|
||||
$db_pass = 'bugzillauser@';
|
||||
|
||||
Save and exit.
|
||||
|
||||
Then run "checksetup.pl" again :
|
||||
|
||||
./checksetup.pl
|
||||
|
||||
You will be prompt about mail and administrator account, fill all of it with your email, user and password.
|
||||
|
||||

|
||||
|
||||
In the last, we need to change the owner of the installation directory to user "www", then restart apache with service command :
|
||||
|
||||
cd /usr/local/www/
|
||||
chown -R www:www bugzilla
|
||||
service apache24 restart
|
||||
|
||||
Now Bugzilla is installed, you can see it by visiting mybugzilla.me and you will be redirect to the https connection.
|
||||
|
||||
Bugzilla home page.
|
||||
|
||||

|
||||
|
||||
Bugzilla admin panel.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Bugzilla is web based application help you to manage the software development. It is written in perl and use MySQL as the database system. Bugzilla used by mozilla, redhat, gnome etc for help their software development. Bugzilla has a lot of features and easy to configure and install.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-bugzilla-apache-ssl-freebsd-10-2/
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arulm/
|
||||
@ -0,0 +1,450 @@
|
||||
Getting started with Docker by Dockerizing this Blog
|
||||
======================
|
||||
>This article covers the basic concepts of Docker and how to Dockerize an application by creating a custom Dockerfile
|
||||
>Written by Benjamin Cane on 2015-12-01 10:00:00
|
||||
|
||||
Docker is an interesting technology that over the past 2 years has gone from an idea, to being used by organizations all over the world to deploy applications. In today's article I am going to cover how to get started with Docker by "Dockerizing" an existing application. The application in question is actually this very blog!
|
||||
|
||||
## What is Docker
|
||||
|
||||
Before we dive into learning the basics of Docker let's first understand what Docker is and why it is so popular. Docker, is an operating system container management tool that allows you to easily manage and deploy applications by making it easy to package them within operating system containers.
|
||||
|
||||
### Containers vs. Virtual Machines
|
||||
|
||||
Containers may not be as familiar as virtual machines but they are another method to provide **Operating System Virtualization**. However, they differ quite a bit from standard virtual machines.
|
||||
|
||||
Standard virtual machines generally include a full Operating System, OS Packages and eventually an Application or two. This is made possible by a Hypervisor which provides hardware virtualization to the virtual machine. This allows for a single server to run many standalone operating systems as virtual guests.
|
||||
|
||||
Containers are similar to virtual machines in that they allow a single server to run multiple operating environments, these environments however, are not full operating systems. Containers generally only include the necessary OS Packages and Applications. They do not generally contain a full operating system or hardware virtualization. This also means that containers have a smaller overhead than traditional virtual machines.
|
||||
|
||||
Containers and Virtual Machines are often seen as conflicting technology, however, this is often a misunderstanding. Virtual Machines are a way to take a physical server and provide a fully functional operating environment that shares those physical resources with other virtual machines. A Container is generally used to isolate a running process within a single host to ensure that the isolated processes cannot interact with other processes within that same system. In fact containers are closer to **BSD Jails** and `chroot`'ed processes than full virtual machines.
|
||||
|
||||
### What Docker provides on top of containers
|
||||
|
||||
Docker itself is not a container runtime environment; in fact Docker is actually container technology agnostic with efforts planned for Docker to support [Solaris Zones](https://blog.docker.com/2015/08/docker-oracle-solaris-zones/) and [BSD Jails](https://wiki.freebsd.org/Docker). What Docker provides is a method of managing, packaging, and deploying containers. While these types of functions may exist to some degree for virtual machines they traditionally have not existed for most container solutions and the ones that existed, were not as easy to use or fully featured as Docker.
|
||||
|
||||
Now that we know what Docker is, let's start learning how Docker works by first installing Docker and deploying a public pre-built container.
|
||||
|
||||
## Starting with Installation
|
||||
As Docker is not installed by default step 1 will be to install the Docker package; since our example system is running Ubuntu 14.0.4 we will do this using the Apt package manager.
|
||||
|
||||
```
|
||||
# apt-get install docker.io
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following extra packages will be installed:
|
||||
aufs-tools cgroup-lite git git-man liberror-perl
|
||||
Suggested packages:
|
||||
btrfs-tools debootstrap lxc rinse git-daemon-run git-daemon-sysvinit git-doc
|
||||
git-el git-email git-gui gitk gitweb git-arch git-bzr git-cvs git-mediawiki
|
||||
git-svn
|
||||
The following NEW packages will be installed:
|
||||
aufs-tools cgroup-lite docker.io git git-man liberror-perl
|
||||
0 upgraded, 6 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 7,553 kB of archives.
|
||||
After this operation, 46.6 MB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n] y
|
||||
```
|
||||
|
||||
To check if any containers are running we can execute the `docker` command using the `ps` option.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
The `ps` function of the `docker` command works similar to the Linux `ps `command. It will show available Docker containers and their current status. Since we have not started any Docker containers yet, the command shows no running containers.
|
||||
|
||||
## Deploying a pre-built nginx Docker container
|
||||
One of my favorite features of Docker is the ability to deploy a pre-built container in the same way you would deploy a package with `yum` or `apt-get`. To explain this better let's deploy a pre-built container running the nginx web server. We can do this by executing the `docker` command again, however, this time with the `run` option.
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
The `run` function of the `docker` command tells Docker to find a specified Docker image and start a container running that image. By default, Docker containers run in the foreground, meaning when you execute `docker run` your shell will be bound to the container's console and the process running within the container. In order to launch this Docker container in the background I included the `-d` (**detach**) flag.
|
||||
|
||||
By executing `docker ps` again we can see the nginx container running.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 nginx:latest nginx -g 'daemon off 4 seconds ago Up 3 seconds 443/tcp, 80/tcp desperate_lalande
|
||||
```
|
||||
|
||||
In the above output we can see the running container `desperate_lalande` and that this container has been built from the `nginx:latest image`.
|
||||
|
||||
### Docker Images
|
||||
Images are one of Docker's key features and is similar to a virtual machine image. Like virtual machine images, a Docker image is a container that has been saved and packaged. Docker however, doesn't just stop with the ability to create images. Docker also includes the ability to distribute those images via Docker repositories which are a similar concept to package repositories. This is what gives Docker the ability to deploy an image like you would deploy a package with `yum`. To get a better understanding of how this works let's look back at the output of the `docker run` execution.
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
```
|
||||
|
||||
The first message we see is that `docker` could not find an image named nginx locally. The reason we see this message is that when we executed `docker run` we told Docker to startup a container, a container based on an image named **nginx**. Since Docker is starting a container based on a specified image it needs to first find that image. Before checking any remote repository Docker first checks locally to see if there is a local image with the specified name.
|
||||
|
||||
Since this system is brand new there is no Docker image with the name nginx, which means Docker will need to download it from a Docker repository.
|
||||
|
||||
```
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
This is exactly what the second part of the output is showing us. By default, Docker uses the [Docker Hub](https://hub.docker.com/) repository, which is a repository service that Docker (the company) runs.
|
||||
|
||||
Like GitHub, Docker Hub is free for public repositories but requires a subscription for private repositories. It is possible however, to deploy your own Docker repository, in fact it is as easy as `docker run registry`. For this article we will not be deploying a custom registry service.
|
||||
|
||||
### Stopping and Removing the Container
|
||||
Before moving on to building a custom Docker container let's first clean up our Docker environment. We will do this by stopping the container from earlier and removing it.
|
||||
|
||||
To start a container we executed `docker` with the `run` option, in order to stop this same container we simply need to execute the `docker` with the `kill` option specifying the container name.
|
||||
|
||||
```
|
||||
# docker kill desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
If we execute `docker ps` again we will see that the container is no longer running.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
However, at this point we have only stopped the container; while it may no longer be running it still exists. By default, `docker ps` will only show running containers, if we add the `-a` (all) flag it will show all containers running or not.
|
||||
|
||||
```
|
||||
# docker ps -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 5c82215b03d1 nginx -g 'daemon off 4 weeks ago Exited (-1) About a minute ago desperate_lalande
|
||||
```
|
||||
|
||||
In order to fully remove the container we can use the `docker` command with the `rm` option.
|
||||
|
||||
```
|
||||
# docker rm desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
While this container has been removed; we still have a **nginx** image available. If we were to re-run `docker run -d nginx` again the container would be started without having to fetch the nginx image again. This is because Docker already has a saved copy on our local system.
|
||||
|
||||
To see a full list of local images we can simply run the `docker` command with the `images` option.
|
||||
|
||||
```
|
||||
# docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
nginx latest 9fab4090484a 5 days ago 132.8 MB
|
||||
```
|
||||
|
||||
## Building our own custom image
|
||||
At this point we have used a few basic Docker commands to start, stop and remove a common pre-built image. In order to "Dockerize" this blog however, we are going to have to build our own Docker image and that means creating a **Dockerfile**.
|
||||
|
||||
With most virtual machine environments if you wish to create an image of a machine you need to first create a new virtual machine, install the OS, install the application and then finally convert it to a template or image. With Docker however, these steps are automated via a Dockerfile. A Dockerfile is a way of providing build instructions to Docker for the creation of a custom image. In this section we are going to build a custom Dockerfile that can be used to deploy this blog.
|
||||
|
||||
### Understanding the Application
|
||||
Before we can jump into creating a Dockerfile we first need to understand what is required to deploy this blog.
|
||||
|
||||
The blog itself is actually static HTML pages generated by a custom static site generator that I wrote named; **hamerkop**. The generator is very simple and more about getting the job done for this blog specifically. All the code and source files for this blog are available via a public [GitHub](https://github.com/madflojo/blog) repository. In order to deploy this blog we simply need to grab the contents of the GitHub repository, install **Python** along with some **Python** modules and execute the `hamerkop` application. To serve the generated content we will use **nginx**; which means we will also need **nginx** to be installed.
|
||||
|
||||
So far this should be a pretty simple Dockerfile, but it will show us quite a bit of the [Dockerfile Syntax](https://docs.docker.com/v1.8/reference/builder/). To get started we can clone the GitHub repository and creating a Dockerfile with our favorite editor; `vi` in my case.
|
||||
|
||||
```
|
||||
# git clone https://github.com/madflojo/blog.git
|
||||
Cloning into 'blog'...
|
||||
remote: Counting objects: 622, done.
|
||||
remote: Total 622 (delta 0), reused 0 (delta 0), pack-reused 622
|
||||
Receiving objects: 100% (622/622), 14.80 MiB | 1.06 MiB/s, done.
|
||||
Resolving deltas: 100% (242/242), done.
|
||||
Checking connectivity... done.
|
||||
# cd blog/
|
||||
# vi Dockerfile
|
||||
```
|
||||
|
||||
### FROM - Inheriting a Docker image
|
||||
The first instruction of a Dockerfile is the `FROM` instruction. This is used to specify an existing Docker image to use as our base image. This basically provides us with a way to inherit another Docker image. In this case we will be starting with the same **nginx** image we were using before, if we wanted to start with a blank slate we could use the **Ubuntu** Docker image by specifying `ubuntu:latest`.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
```
|
||||
|
||||
In addition to the `FROM` instruction, I also included a `MAINTAINER` instruction which is used to show the Author of the Dockerfile.
|
||||
|
||||
As Docker supports using `#` as a comment marker, I will be using this syntax quite a bit to explain the sections of this Dockerfile.
|
||||
|
||||
### Running a test build
|
||||
Since we inherited the **nginx** Docker image our current Dockerfile also inherited all the instructions within the [Dockerfile](https://github.com/nginxinc/docker-nginx/blob/08eeb0e3f0a5ee40cbc2bc01f0004c2aa5b78c15/Dockerfile) used to build that **nginx** image. What this means is even at this point we are able to build a Docker image from this Dockerfile and run a container from that image. The resulting image will essentially be the same as the **nginx** image but we will run through a build of this Dockerfile now and a few more times as we go to help explain the Docker build process.
|
||||
|
||||
In order to start the build from a Dockerfile we can simply execute the `docker` command with the **build** option.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 23.6 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Running in c97f36450343
|
||||
---> 60a44f78d194
|
||||
Removing intermediate container c97f36450343
|
||||
Successfully built 60a44f78d194
|
||||
```
|
||||
|
||||
In the above example I used the `-t` (**tag**) flag to "tag" the image as "blog". This essentially allows us to name the image, without specifying a tag the image would only be callable via an **Image ID** that Docker assigns. In this case the **Image ID** is `60a44f78d194` which we can see from the `docker` command's build success message.
|
||||
|
||||
In addition to the `-t` flag, I also specified the directory `/root/blog`. This directory is the "build directory", which is the directory that contains the Dockerfile and any other files necessary to build this container.
|
||||
|
||||
Now that we have run through a successful build, let's start customizing this image.
|
||||
|
||||
### Using RUN to execute apt-get
|
||||
The static site generator used to generate the HTML pages is written in **Python** and because of this the first custom task we should perform within this `Dockerfile` is to install Python. To install the Python package we will use the Apt package manager. This means we will need to specify within the Dockerfile that `apt-get update` and `apt-get install python-dev` are executed; we can do this with the `RUN` instruction.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
```
|
||||
|
||||
In the above we are simply using the `RUN` instruction to tell Docker that when it builds this image it will need to execute the specified `apt-get` commands. The interesting part of this is that these commands are only executed within the context of this container. What this means is even though `python-dev` and `python-pip` are being installed within the container, they are not being installed for the host itself. Or to put it simplier, within the container the `pip` command will execute, outside the container, the `pip` command does not exist.
|
||||
|
||||
It is also important to note that the Docker build process does not accept user input during the build. This means that any commands being executed by the `RUN` instruction must complete without user input. This adds a bit of complexity to the build process as many applications require user input during installation. For our example, none of the commands executed by `RUN` require user input.
|
||||
|
||||
### Installing Python modules
|
||||
With **Python** installed we now need to install some Python modules. To do this outside of Docker, we would generally use the `pip` command and reference a file within the blog's Git repository named `requirements.txt`. In an earlier step we used the `git` command to "clone" the blog's GitHub repository to the `/root/blog` directory; this directory also happens to be the directory that we have created the `Dockerfile`. This is important as it means the contents of the Git repository are accessible to Docker during the build process.
|
||||
|
||||
When executing a build, Docker will set the context of the build to the specified "build directory". This means that any files within that directory and below can be used during the build process, files outside of that directory (outside of the build context), are inaccessible.
|
||||
|
||||
In order to install the required Python modules we will need to copy the `requirements.txt` file from the build directory into the container. We can do this using the `COPY` instruction within the `Dockerfile`.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
```
|
||||
|
||||
Within the `Dockerfile` we added 3 instructions. The first instruction uses `RUN` to create a `/build/` directory within the container. This directory will be used to copy any application files needed to generate the static HTML pages. The second instruction is the `COPY` instruction which copies the `requirements.txt` file from the "build directory" (`/root/blog`) into the `/build` directory within the container. The third is using the `RUN` instruction to execute the `pip` command; installing all the modules specified within the `requirements.txt` file.
|
||||
|
||||
`COPY` is an important instruction to understand when building custom images. Without specifically copying the file within the Dockerfile this Docker image would not contain the requirements.txt file. With Docker containers everything is isolated, unless specifically executed within a Dockerfile a container is not likely to include required dependencies.
|
||||
|
||||
### Re-running a build
|
||||
Now that we have a few customization tasks for Docker to perform let's try another build of the blog image again.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Running in bde05cf1e8fe
|
||||
---> f4b66e09fa61
|
||||
Removing intermediate container bde05cf1e8fe
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
Removing intermediate container 9aa8ff43f4b0
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Running in c50b15ddd8b1
|
||||
Downloading/unpacking jinja2 (from -r /build/requirements.txt (line 1))
|
||||
Downloading/unpacking PyYaml (from -r /build/requirements.txt (line 2))
|
||||
<truncated to reduce noise>
|
||||
Successfully installed jinja2 PyYaml mistune markdown MarkupSafe
|
||||
Cleaning up...
|
||||
---> abab55c20962
|
||||
Removing intermediate container c50b15ddd8b1
|
||||
Successfully built abab55c20962
|
||||
```
|
||||
|
||||
From the above build output we can see the build was successful, but we can also see another interesting message;` ---> Using cache`. What this message is telling us is that Docker was able to use its build cache during the build of this image.
|
||||
|
||||
#### Docker build cache
|
||||
|
||||
When Docker is building an image, it doesn't just build a single image; it actually builds multiple images throughout the build processes. In fact we can see from the above output that after each "Step" Docker is creating a new image.
|
||||
|
||||
```
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
```
|
||||
|
||||
The last line from the above snippet is actually Docker informing us of the creating of a new image, it does this by printing the **Image ID**; `cef11c3fb97c`. The useful thing about this approach is that Docker is able to use these images as cache during subsequent builds of the **blog** image. This is useful because it allows Docker to speed up the build process for new builds of the same container. If we look at the example above we can actually see that rather than installing the `python-dev` and `python-pip` packages again, Docker was able to use a cached image. However, since Docker was unable to find a build that executed the `mkdir` command, each subsequent step was executed.
|
||||
|
||||
The Docker build cache is a bit of a gift and a curse; the reason for this is that the decision to use cache or to rerun the instruction is made within a very narrow scope. For example, if there was a change to the `requirements.txt` file Docker would detect this change during the build and start fresh from that point forward. It does this because it can view the contents of the `requirements.txt` file. The execution of the `apt-get` commands however, are another story. If the **Apt** repository that provides the Python packages were to contain a newer version of the python-pip package; Docker would not be able to detect the change and would simply use the build cache. This means that an older package may be installed. While this may not be a major issue for the `python-pip` package it could be a problem if the installation was caching a package with a known vulnerability.
|
||||
|
||||
For this reason it is useful to periodically rebuild the image without using Docker's cache. To do this you can simply specify `--no-cache=True` when executing a Docker build.
|
||||
|
||||
## Deploying the rest of the blog
|
||||
With the Python packages and modules installed this leaves us at the point of copying the required application files and running the `hamerkop` application. To do this we will simply use more `COPY` and `RUN` instructions.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
|
||||
## Add blog code nd required files
|
||||
COPY static /build/static
|
||||
COPY templates /build/templates
|
||||
COPY hamerkop /build/
|
||||
COPY config.yml /build/
|
||||
COPY articles /build/articles
|
||||
|
||||
## Run Generator
|
||||
RUN /build/hamerkop -c /build/config.yml
|
||||
```
|
||||
|
||||
Now that we have the rest of the build instructions, let's run through another build and verify that the image builds successfully.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog/
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Using cache
|
||||
---> f4b66e09fa61
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> Using cache
|
||||
---> cef11c3fb97c
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Using cache
|
||||
---> abab55c20962
|
||||
Step 7 : COPY static /build/static
|
||||
---> 15cb91531038
|
||||
Removing intermediate container d478b42b7906
|
||||
Step 8 : COPY templates /build/templates
|
||||
---> ecded5d1a52e
|
||||
Removing intermediate container ac2390607e9f
|
||||
Step 9 : COPY hamerkop /build/
|
||||
---> 59efd1ca1771
|
||||
Removing intermediate container b5fbf7e817b7
|
||||
Step 10 : COPY config.yml /build/
|
||||
---> bfa3db6c05b7
|
||||
Removing intermediate container 1aebef300933
|
||||
Step 11 : COPY articles /build/articles
|
||||
---> 6b61cc9dde27
|
||||
Removing intermediate container be78d0eb1213
|
||||
Step 12 : RUN /build/hamerkop -c /build/config.yml
|
||||
---> Running in fbc0b5e574c5
|
||||
Successfully created file /usr/share/nginx/html//2011/06/25/checking-the-number-of-lwp-threads-in-linux
|
||||
Successfully created file /usr/share/nginx/html//2011/06/checking-the-number-of-lwp-threads-in-linux
|
||||
<truncated to reduce noise>
|
||||
Successfully created file /usr/share/nginx/html//archive.html
|
||||
Successfully created file /usr/share/nginx/html//sitemap.xml
|
||||
---> 3b25263113e1
|
||||
Removing intermediate container fbc0b5e574c5
|
||||
Successfully built 3b25263113e1
|
||||
```
|
||||
|
||||
### Running a custom container
|
||||
With a successful build we can now start our custom container by running the `docker` command with the `run` option, similar to how we started the nginx container earlier.
|
||||
|
||||
```
|
||||
# docker run -d -p 80:80 --name=blog blog
|
||||
5f6c7a2217dcdc0da8af05225c4d1294e3e6bb28a41ea898a1c63fb821989ba1
|
||||
```
|
||||
|
||||
Once again the `-d` (**detach**) flag was used to tell Docker to run the container in the background. However, there are also two new flags. The first new flag is `--name`, which is used to give the container a user specified name. In the earlier example we did not specify a name and because of that Docker randomly generated one. The second new flag is `-p`, this flag allows users to map a port from the host machine to a port within the container.
|
||||
|
||||
The base **nginx** image we used exposes port 80 for the HTTP service. By default, ports bound within a Docker container are not bound on the host system as a whole. In order for external systems to access ports exposed within a container the ports must be mapped from a host port to a container port using the `-p` flag. The command above maps port 80 from the host, to port 80 within the container. If we wished to map port 8080 from the host, to port 80 within the container we could do so by specifying the ports in the following syntax `-p 8080:80`.
|
||||
|
||||
From the above command it appears that our container was started successfully, we can verify this by executing `docker ps`.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
d264c7ef92bd blog:latest nginx -g 'daemon off 3 seconds ago Up 3 seconds 443/tcp, 0.0.0.0:80->80/tcp blog
|
||||
```
|
||||
|
||||
## Wrapping up
|
||||
|
||||
At this point we now have a running custom Docker container. While we touched on a few Dockerfile instructions within this article we have yet to discuss all the instructions. For a full list of Dockerfile instructions you can checkout [Docker's reference page](https://docs.docker.com/v1.8/reference/builder/), which explains the instructions very well.
|
||||
|
||||
Another good resource is their [Dockerfile Best Practices page](https://docs.docker.com/engine/articles/dockerfile_best-practices/) which contains quite a few best practices for building custom Dockerfiles. Some of these tips are very useful such as strategically ordering the commands within the Dockerfile. In the above examples our Dockerfile has the `COPY` instruction for the `articles` directory as the last `COPY` instruction. The reason for this is that the `articles` directory will change quite often. It's best to put instructions that will change oftenat the lowest point possible within the Dockerfile to optimize steps that can be cached.
|
||||
|
||||
In this article we covered how to start a pre-built container and how to build, then deploy a custom container. While there is quite a bit to learn about Docker this article should give you a good idea on how to get started. Of course, as always if you think there is anything that should be added drop it in the comments below.
|
||||
|
||||
--------------------------------------
|
||||
via:http://bencane.com/2015/12/01/getting-started-with-docker-by-dockerizing-this-blog/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+bencane%2FSAUo+%28Benjamin+Cane%29
|
||||
|
||||
作者:Benjamin Cane
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,290 +0,0 @@
|
||||
(translating by runningwater)
|
||||
Regular Expressions In grep
|
||||
================================================================================
|
||||
How do I use the Grep command with regular expressions on a Linux and Unix-like operating systems?
|
||||
|
||||
Linux comes with GNU grep, which supports extended regular expressions. GNU grep is the default on all Linux systems. The grep command is used to locate information stored anywhere on your server or workstation.
|
||||
|
||||
### Regular Expressions ###
|
||||
|
||||
Regular Expressions is nothing but a pattern to match for each input line. A pattern is a sequence of characters. Following all are examples of pattern:
|
||||
|
||||
^w1
|
||||
w1|w2
|
||||
[^ ]
|
||||
|
||||
#### grep Regular Expressions Examples ####
|
||||
|
||||
Search for 'vivek' in /etc/passswd
|
||||
|
||||
grep vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
gitevivek:x:1002:1002::/home/gitevivek:/bin/sh
|
||||
|
||||
Search vivek in any case (i.e. case insensitive search)
|
||||
|
||||
grep -i -w vivek /etc/passwd
|
||||
|
||||
Search vivek or raj in any case
|
||||
|
||||
grep -E -i -w 'vivek|raj' /etc/passwd
|
||||
|
||||
The PATTERN in last example, used as an extended regular expression.
|
||||
|
||||
### Anchors ###
|
||||
|
||||
You can use ^ and $ to force a regex to match only at the start or end of a line, respectively. The following example displays lines starting with the vivek only:
|
||||
|
||||
grep ^vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
|
||||
You can display only lines starting with the word vivek only i.e. do not display vivekgite, vivekg etc:
|
||||
|
||||
grep -w ^vivek /etc/passwd
|
||||
|
||||
Find lines ending with word foo:
|
||||
grep 'foo$' filename
|
||||
|
||||
Match line only containing foo:
|
||||
|
||||
grep '^foo$' filename
|
||||
|
||||
You can search for blank lines with the following examples:
|
||||
|
||||
grep '^$' filename
|
||||
|
||||
### Character Class ###
|
||||
|
||||
Match Vivek or vivek:
|
||||
|
||||
grep '[vV]ivek' filename
|
||||
|
||||
OR
|
||||
|
||||
grep '[vV][iI][Vv][Ee][kK]' filename
|
||||
|
||||
You can also match digits (i.e match vivek1 or Vivek2 etc):
|
||||
|
||||
grep -w '[vV]ivek[0-9]' filename
|
||||
|
||||
You can match two numeric digits (i.e. match foo11, foo12 etc):
|
||||
|
||||
grep 'foo[0-9][0-9]' filename
|
||||
|
||||
You are not limited to digits, you can match at least one letter:
|
||||
|
||||
grep '[A-Za-z]' filename
|
||||
|
||||
Display all the lines containing either a "w" or "n" character:
|
||||
|
||||
grep [wn] filename
|
||||
|
||||
Within a bracket expression, the name of a character class enclosed in "[:" and ":]" stands for the list of all characters belonging to that class. Standard character class names are:
|
||||
|
||||
- [:alnum:] - Alphanumeric characters.
|
||||
- [:alpha:] - Alphabetic characters
|
||||
- [:blank:] - Blank characters: space and tab.
|
||||
- [:digit:] - Digits: '0 1 2 3 4 5 6 7 8 9'.
|
||||
- [:lower:] - Lower-case letters: 'a b c d e f g h i j k l m n o p q r s t u v w x y z'.
|
||||
- [:space:] - Space characters: tab, newline, vertical tab, form feed, carriage return, and space.
|
||||
- [:upper:] - Upper-case letters: 'A B C D E F G H I J K L M N O P Q R S T U V W X Y Z'.
|
||||
|
||||
In this example match all upper case letters:
|
||||
|
||||
grep '[:upper:]' filename
|
||||
|
||||
### Wildcards ###
|
||||
|
||||
You can use the "." for a single character match. In this example match all 3 character word starting with "b" and ending in "t":
|
||||
|
||||
grep '\<b.t\>' filename
|
||||
|
||||
Where,
|
||||
|
||||
- \< Match the empty string at the beginning of word
|
||||
- \> Match the empty string at the end of word.
|
||||
|
||||
Print all lines with exactly two characters:
|
||||
|
||||
grep '^..$' filename
|
||||
|
||||
Display any lines starting with a dot and digit:
|
||||
|
||||
grep '^\.[0-9]' filename
|
||||
|
||||
#### Escaping the dot ####
|
||||
|
||||
The following regex to find an IP address 192.168.1.254 will not work:
|
||||
|
||||
grep '192.168.1.254' /etc/hosts
|
||||
|
||||
All three dots need to be escaped:
|
||||
|
||||
grep '192\.168\.1\.254' /etc/hosts
|
||||
|
||||
The following example will only match an IP address:
|
||||
|
||||
egrep '[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}' filename
|
||||
|
||||
The following will match word Linux or UNIX in any case:
|
||||
|
||||
egrep -i '^(linux|unix)' filename
|
||||
|
||||
### How Do I Search a Pattern Which Has a Leading - Symbol? ###
|
||||
|
||||
Searches for all lines matching '--test--' using -e option Without -e, grep would attempt to parse '--test--' as a list of options:
|
||||
|
||||
grep -e '--test--' filename
|
||||
|
||||
### How Do I do OR with grep? ###
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep 'word1|word2' filename
|
||||
|
||||
OR
|
||||
|
||||
grep 'word1\|word2' filename
|
||||
|
||||
### How Do I do AND with grep? ###
|
||||
|
||||
Use the following syntax to display all lines that contain both 'word1' and 'word2'
|
||||
|
||||
grep 'word1' filename | grep 'word2'
|
||||
|
||||
### How Do I Test Sequence? ###
|
||||
|
||||
You can test how often a character must be repeated in sequence using the following syntax:
|
||||
|
||||
{N}
|
||||
{N,}
|
||||
{min,max}
|
||||
|
||||
Match a character "v" two times:
|
||||
|
||||
egrep "v{2}" filename
|
||||
|
||||
The following will match both "col" and "cool":
|
||||
|
||||
egrep 'co{1,2}l' filename
|
||||
|
||||
The following will match any row of at least three letters 'c'.
|
||||
|
||||
egrep 'c{3,}' filename
|
||||
|
||||
The following example will match mobile number which is in the following format 91-1234567890 (i.e twodigit-tendigit)
|
||||
|
||||
grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}" filename
|
||||
|
||||
### How Do I Hightlight with grep? ###
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep --color regex filename
|
||||
|
||||
How Do I Show Only The Matches, Not The Lines?
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep -o regex filename
|
||||
|
||||
### Regular Expression Operator ###
|
||||
|
||||
注:表格
|
||||
<table border=1>
|
||||
<tr>
|
||||
<th>Regex operator</th>
|
||||
<th>Meaning</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>.</td>
|
||||
<td>Matches any single character.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>?</td>
|
||||
<td>The preceding item is optional and will be matched, at most, once.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>*</td>
|
||||
<td>The preceding item will be matched zero or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>+</td>
|
||||
<td>The preceding item will be matched one or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N}</td>
|
||||
<td>The preceding item is matched exactly N times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,}</td>
|
||||
<td>The preceding item is matched N or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,M}</td>
|
||||
<td>The preceding item is matched at least N times, but not more than M times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>-</td>
|
||||
<td>Represents the range if it's not first or last in a list or the ending point of a range in a list.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>^</td>
|
||||
<td>Matches the empty string at the beginning of a line; also represents the characters not in the range of a list.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>$</td>
|
||||
<td>Matches the empty string at the end of a line.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\b</td>
|
||||
<td>Matches the empty string at the edge of a word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\B</td>
|
||||
<td>Matches the empty string provided it's not at the edge of a word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\<</td>
|
||||
<td>Match the empty string at the beginning of word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\></td>
|
||||
<td> Match the empty string at the end of word.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
#### grep vs egrep ####
|
||||
|
||||
egrep is the same as **grep -E**. It interpret PATTERN as an extended regular expression. From the grep man page:
|
||||
|
||||
In basic regular expressions the meta-characters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{,
|
||||
\|, \(, and \).
|
||||
Traditional egrep did not support the { meta-character, and some egrep implementations support \{ instead, so portable scripts should avoid { in
|
||||
grep -E patterns and should use [{] to match a literal {.
|
||||
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification.
|
||||
For example, the command grep -E '{1' searches for the two-character string {1 instead of reporting a syntax error in the regular expression.
|
||||
POSIX.2 allows this behavior as an extension, but portable scripts should avoid it.
|
||||
|
||||
References:
|
||||
|
||||
- man page grep and regex(7)
|
||||
- info page grep`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/grep-regular-expressions/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,4 +1,4 @@
|
||||
Search Multiple Words / String Pattern Using grep Command
|
||||
(翻译中 by runningwater)Search Multiple Words / String Pattern Using grep Command
|
||||
================================================================================
|
||||
How do I search multiple strings or words using the grep command? For example I'd like to search word1, word2, word3 and so on within /path/to/file. How do I force grep to search multiple words?
|
||||
|
||||
@ -33,7 +33,7 @@ Fig.01: Linux / Unix egrep Command Search Multiple Words Demo Output
|
||||
via: http://www.cyberciti.biz/faq/searching-multiple-words-string-using-grep/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,43 @@
|
||||
|
||||
苹果编程语言Swift开始支持Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
苹果也开源了?是的,苹果编程语言Swift已经开源了。其实我们并不应该感到意外,因为[在六个月以前苹果就已经宣布了这个消息][1]。
|
||||
|
||||
苹果宣布这周将推出开源Swift社区。一个专用于开源Swift社区的[新网站][2]已经就位,网站首页显示以下信息:
|
||||
|
||||
> 我们对Swift开源感到兴奋。在苹果推出了编程语言Swift之后,它很快成为历史上增长最快的语言之一。Swift可以编写出难以置信的又快又安全的软件。目前,Swift是开源的,你能帮助做出随处可用的最好的通用编程语言。
|
||||
|
||||
[swift.org][2]这个网站将会作为一站式网站,它会提供各种资料的下载,包括各种平台,社区指南,最新消息,入门教程,贡献开源Swift的说明,文件和一些其他的指南。 如果你正期待着学习Swift,那么必须收藏这个网站。
|
||||
|
||||
在苹果的这次宣布中,一个用于方便分享和构建代码的包管理器已经可用了。
|
||||
|
||||
对于所有的Linux使用者来说,最重要的是,源代码已经可以从[Github][3]获得了.你可以从以下链接Checkout它:
|
||||
Most important of all for Linux users, the source code is now available at [Github][3]. You can check it out from the link below:
|
||||
|
||||
- [苹果Swift源代码][3]
|
||||
|
||||
除此之外,对于ubuntu 14.04和15.10版本还有预编译的二进制文件。
|
||||
|
||||
- [ubuntu系统的Swift二进制文件][4]
|
||||
|
||||
不要急着去使用它们,因为这些都是发展分支而且不适合于专用机器。因此现在避免使用,一旦发布了Linux下Swift的稳定版本,我希望ubuntu会把它包含在[umake][5]中靠近[Visual Studio][6]的地方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/swift-open-source-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/apple-open-sources-swift-programming-language-linux/
|
||||
[2]:https://swift.org/
|
||||
[3]:https://github.com/apple
|
||||
[4]:https://swift.org/download/#latest-development-snapshots
|
||||
[5]:https://wiki.ubuntu.com/ubuntu-make
|
||||
[6]:http://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
@ -0,0 +1,64 @@
|
||||
eSpeak: Linux文本转语音工具
|
||||
================================================================================
|
||||

|
||||
|
||||
[eSpeak][1]是Linux的命令行工具,能把文本转变成语音。这是一款用C语言写就的精致的语音合成器,提供英语和其它多种语言支持。
|
||||
|
||||
eSpeak从标准输入或者输入文件中读取文本。虽然语音输出与真人声音相去甚远,但是,在你项目有用得到的地方,eSpeak仍不失为一个精致快捷的工具。
|
||||
|
||||
eSpeak部分主要特性如下:
|
||||
|
||||
- 为Linux和Windows准备的命令行工具
|
||||
- 从文件或者标准输入中把文本读出来
|
||||
- 提供给其它程序使用的共享库版本
|
||||
- 为Windows提供SAPI5版本,在screen-readers或者其它支持Windows SAPI5接口程序的支持下,eSpeak仍然能正常使用
|
||||
- 可移植到其它平台,包括安卓,OSX等
|
||||
- 多种特色声音提供选择
|
||||
- 语音输出可保存为[.WAV][2]格式的文件
|
||||
- 部分SSML([Speech Synthesis Markup Language][3])能为HTML所支持
|
||||
- 体积小巧,整个程序包括语言支持等占用不足2MB
|
||||
- 可以实现文本到音素编码的转化,能被其它语音合成引擎吸纳为前端工具
|
||||
- 可作为生成和调制音素数据的开发工具
|
||||
|
||||
### 安装eSpeak ###
|
||||
|
||||
基于Ubuntu的系统中,在终端运行以下命令安装eSpeak:
|
||||
|
||||
sudo apt-get install espeak
|
||||
|
||||
eSpeak is an old tool and I presume that it should be available in the repositories of other Linux distributions such as Arch Linux, Fedora etc. You can install eSpeak easily using dnf, pacman etc.eSpeak是一个古老的工具,我推测它应该能在其它众多Linux发行版如Arch,Fedora中运行。使用dnf,pacman等命令就能轻易安装。
|
||||
|
||||
eSpeak用法如下:输入espeak按enter键运行程序。输入字符按enter转换为语音输出(译补)。使用Ctrl+C来关闭运行中的程序。
|
||||
|
||||

|
||||
|
||||
还有其它可以的选项,可以通过程序帮助进行查看。
|
||||
|
||||
### GUI版本:Gespeaker ###
|
||||
|
||||
如果你更倾向于使用GUI版本,可以安装Gespeaker,它为eSpeak提供了GTK界面。
|
||||
|
||||
使用以下命令来安装Gespeaker:
|
||||
|
||||
sudo apt-get install gespeaker
|
||||
|
||||
操作接口简明易用,你完全可以自行探索。
|
||||
|
||||

|
||||
|
||||
虽然这个工具不能为大部分计算所用,但是当你的项目需要把文本转换成语音,espeak还是挺方便使用的。需则用之吧~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/espeak-text-speech-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/soooogreen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://espeak.sourceforge.net/
|
||||
[2]:http://en.wikipedia.org/wiki/WAV
|
||||
[3]:http://en.wikipedia.org/wiki/Speech_Synthesis_Markup_Language
|
||||
@ -0,0 +1,299 @@
|
||||
点评:Linux编程中五款内存调试器
|
||||
================================================================================
|
||||

|
||||
Credit: [Moini][1]
|
||||
|
||||
作为一个程序员,我知道我总在犯错误——事实是,怎么可能会不犯错的!程序员也是人啊。有的错误能在编码过程中及时发现,而有些却得等到软件测试才显露出来。然而,有一类错误并不能在这两个时期被排除,从而导致软件不能正常运行,甚至是提前中止。
|
||||
|
||||
想到了吗?我说的就是内存相关的错误。手动调试这些错误不仅耗时,而且很难发现并纠正。值得一提的是,这种错误非常地常见,特别是在一些软件里,这些软件是用C/C++这类允许[手动管理内存][2]的语言编写的。
|
||||
|
||||
幸运的是,现行有一些编程工具能够帮你找到软件程序中这些内存相关的错误。在这些工具集中,我评定了五款Linux可用的,流行、免费并且开源的内存调试器:Dmalloc、Electric Fence、 Memcheck、 Memwatch以及Mtrace。日常编码过程中我已经把这五个调试器用了个遍,所以这些点评是建立在我的实际体验之上的。
|
||||
|
||||
### [Dmalloc][3] ###
|
||||
|
||||
**开发者**:Gray Watson
|
||||
|
||||
**点评版本**:5.5.2
|
||||
|
||||
**Linux支持**:所有种类
|
||||
|
||||
**许可**:知识共享署名-相同方式共享许可证3.0
|
||||
|
||||
Dmalloc是Gray Watson开发的一款内存调试工具。它实现成库,封装了标准内存管理函数如**malloc(), calloc(), free()**等,使得程序员得以检测出有问题的代码。
|
||||
|
||||

|
||||
Dmalloc
|
||||
|
||||
如同工具的网页所列,这个调试器提供的特性包括内存泄漏跟踪、[重复释放(double free)][4]错误跟踪、以及[越界写入(fence-post write)][5]检测。其它特性包括文件/行号报告、普通统计记录。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
5.5.2版本是一个[bug修复发行版][6],同时修复了构建和安装的问题。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
Dmalloc最大的优点是可以进行任意配置。比如说,你可以配置以支持C++程序和多线程应用。Dmalloc还提供一个有用的功能:运行时可配置,这表示在Dmalloc执行时,可以轻易地使能或者禁能它提供的特性。
|
||||
|
||||
你还可以配合[GNU Project Debugger (GDB)][7]来使用Dmalloc,只需要将dmalloc.gdb文件(位于Dmalloc源码包中的contrib子目录里)的内容添加到你的主目录中的.gdbinit文件里即可。
|
||||
|
||||
另外一个优点让我对Dmalloc爱不释手的是它有大量的资料文献。前往官网的[Documentation标签][8],可以获取任何内容,有关于如何下载、安装、运行,怎样使用库,和Dmalloc所提供特性的细节描述,及其输入文件的解释。里面还有一个章节介绍了一般问题的解决方法。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
跟Mtrace一样,Dmalloc需要程序员改动他们的源代码。比如说你可以(必须的)添加头文件**dmalloc.h**,工具就能汇报产生问题的调用的文件或行号。这个功能非常有用,因为它节省了调试的时间。
|
||||
|
||||
除此之外,还需要在编译你的程序时,把Dmalloc库(编译源码包时产生的)链接进去。
|
||||
|
||||
然而,还有点更麻烦的事,需要设置一个环境变量,命名为**DMALLOC_OPTION**,以供工具在运行时配置内存调试特性,以及输出文件的路径。可以手动为该环境变量分配一个值,不过初学者可能会觉得这个过程有点困难,因为你想使能的Dmalloc特性是存在于这个值之中的——表示为各自的十六进制值的累加。[这里][9]有详细介绍。
|
||||
|
||||
一个比较简单方法设置这个环境变量是使用[Dmalloc实用指令][10],这是专为这个目的设计的方法。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
Dmalloc真正的优势在于它的可配置选项。而且高度可移植,曾经成功移植到多种操作系统如AIX、BSD/OS、DG/UX、Free/Net/OpenBSD、GNU/Hurd、HPUX、Irix、Linux、MS-DOG、NeXT、OSF、SCO、Solaris、SunOS、Ultrix、Unixware甚至Unicos(运行在Cray T3E主机上)。虽然Dmalloc有很多东西需要学习,但是它所提供的特性值得为之付出。
|
||||
|
||||
### [Electric Fence][15] ###
|
||||
|
||||
**开发者**:Bruce Perens
|
||||
|
||||
**点评版本**:2.2.3
|
||||
|
||||
**Linux支持**:所有种类
|
||||
|
||||
**许可**:GNU 通用公共许可证 (第二版)
|
||||
|
||||
Electric Fence是Bruce Perens开发的一款内存调试工具,它以库的形式实现,你的程序需要链接它。Electric Fence能检测出[栈][11]内存溢出和访问已经释放的内存。
|
||||
|
||||

|
||||
Electric Fence
|
||||
|
||||
顾名思义,Electric Fence在每个申请的缓存边界建立了fence(防护),任何非法内存访问都会导致[段错误][12]。这个调试工具同时支持C和C++编程。
|
||||
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
2.2.3版本修复了工具的构建系统,使得-fno-builtin-malloc选项能真正传给[GNU Compiler Collection (GCC)][13]。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
我喜欢Electric Fence首要的一点是(Memwatch、Dmalloc和Mtrace所不具有的),这个调试工具不需要你的源码做任何的改动,你只需要在编译的时候把它的库链接进你的程序即可。
|
||||
|
||||
其次,Electric Fence实现一个方法,确认导致越界访问(a bounds violation)的第一个指令就是引起段错误的原因。这比在后面再发现问题要好多了。
|
||||
|
||||
不管是否有检测出错误,Electric Fence经常会在输出产生版权信息。这一点非常有用,由此可以确定你所运行的程序已经启用了Electric Fence。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
另一方面,我对Electric Fence真正念念不忘的是它检测内存泄漏的能力。内存泄漏是C/C++软件最常见也是最难隐秘的问题之一。不过,Electric Fence不能检测出堆内存溢出,而且也不是线程安全的。
|
||||
|
||||
基于Electric Fence会在用户分配内存区的前后分配禁止访问的虚拟内存页,如果你过多的进行动态内存分配,将会导致你的程序消耗大量的额外内存。
|
||||
|
||||
Electric Fence还有一个局限是不能明确指出错误代码所在的行号。它所能做只是在监测到内存相关错误时产生段错误。想要定位行号,需要借助[The Gnu Project Debugger (GDB)][14]这样的调试工具来调试你启用了Electric Fence的程序。
|
||||
|
||||
最后一点,Electric Fence虽然能检测出大部分的缓冲区溢出,有一个例外是,如果所申请的缓冲区大小不是系统字长的倍数,这时候溢出(即使只有几个字节)就不能被检测出来。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
尽管有那么多的局限,但是Electric Fence的优点却在于它的易用性。程序只要链接工具一次,Electric Fence就可以在监测出内存相关问题的时候报警。不过,如同前面所说,Electric Fence需要配合像GDB这样的源码调试器使用。
|
||||
|
||||
|
||||
### [Memcheck][16] ###
|
||||
|
||||
**开发者**:[Valgrind开发团队][17]
|
||||
|
||||
**点评版本**:3.10.1
|
||||
|
||||
**Linux支持**:所有种类
|
||||
|
||||
**许可**:通用公共许可证
|
||||
|
||||
[Valgrind][18]是一个提供好几款调试和Linux程序性能分析工具的套件。虽然Valgrind和编写语言各不相同(有Java、Perl、Python、Assembly code、ortran、Ada等等)的程序配合工作,但是它所提供的工具大部分都意在支持C/C++所编写的程序。
|
||||
|
||||
Memcheck作为内存错误检测器,是一款最受欢迎的Memcheck工具。它能够检测出诸多问题诸如内存泄漏、无效的内存访问、未定义变量的使用以及栈内存分配和释放相关的问题等。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
工具套件(3.10.1)的[发行版][19]是一个副版本,主要修复了3.10.0版本发现的bug。除此之外,从主版本backport一些包,修复了缺失的AArch64 ARMv8指令和系统调用。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
同其它所有Valgrind工具一样,Memcheck也是基本的命令行实用程序。它的操作非常简单:通常我们会使用诸如prog arg1 arg2格式的命令来运行程序,而Memcheck只要求你多加几个值即可,就像valgrind --leak-check=full prog arg1 arg2。
|
||||
|
||||

|
||||
Memcheck
|
||||
|
||||
(注意:因为Memcheck是Valgrind的默认工具所以无需提及Memcheck。但是,需要在编译程序之初带上-g参数选项,这一步会添加调试信息,使得Memcheck的错误信息会包含正确的行号。)
|
||||
|
||||
我真正倾心于Memcheck的是它提供了很多命令行选项(如上所述的--leak-check选项),如此不仅能控制工具运转还可以控制它的输出。
|
||||
|
||||
举个例子,可以开启--track-origins选项,以查看程序源码中未初始化的数据。可以开启--show-mismatched-frees选项让Memcheck匹配内存的分配和释放技术。对于C语言所写的代码,Memcheck会确保只能使用free()函数来释放内存,malloc()函数来申请内存。而对C++所写的源码,Memcheck会检查是否使用了delete或delete[]操作符来释放内存,以及new或者new[]来申请内存。
|
||||
|
||||
Memcheck最好的特点,尤其是对于初学者来说的,是它会给用户建议使用那个命令行选项能让输出更加有意义。比如说,如果你不使用基本的--leak-check选项,Memcheck会在输出时建议“使用--leak-check=full重新运行,查看更多泄漏内存细节”。如果程序有未初始化的变量,Memcheck会产生信息“使用--track-origins=yes,查看未初始化变量的定位”。
|
||||
|
||||
Memcheck另外一个有用的特性是它可以[创建抑制文件(suppression files)][20],由此可以忽略特定不能修正的错误,这样Memcheck运行时就不会每次都报警了。值得一提的是,Memcheck会去读取默认抑制文件来忽略系统库(比如C库)中的报错,这些错误在系统创建之前就已经存在了。可以选择创建一个新的抑制文件,或是编辑现有的(通常是/usr/lib/valgrind/default.supp)。
|
||||
|
||||
Memcheck还有高级功能,比如可以使用[定制内存分配器][22]来[检测内存错误][21]。除此之外,Memcheck提供[监控命令][23],当用到Valgrind的内置gdbserver,以及[客户端请求][24]机制(不仅能把程序的行为告知Memcheck,还可以进行查询)时可以使用。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
毫无疑问,Memcheck可以节省很多调试时间以及省去很多麻烦。但是它使用了很多内存,导致程序执行变慢([由资料可知][25],大概花上20至30倍时间)。
|
||||
|
||||
除此之外,Memcheck还有其它局限。根据用户评论,Memcheck明显不是[线程安全][26]的;它不能检测出 [静态缓冲区溢出][27];还有就是,一些Linux程序如[GNU Emacs][28],目前还不能使用Memcheck。
|
||||
|
||||
如果有兴趣,可以在[这里][29]查看Valgrind详尽的局限性说明。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
无论是对于初学者还是那些需要高级特性的人来说,Memcheck都是一款便捷的内存调试工具。如果你仅需要基本调试和错误核查,Memcheck会非常容易上手。而当你想要使用像抑制文件或者监控指令这样的特性,就需要花一些功夫学习了。
|
||||
|
||||
虽然罗列了大量的局限性,但是Valgrind(包括Memcheck)在它的网站上声称全球有[成千上万程序员][30]使用了此工具。开发团队称收到来自超过30个国家的用户反馈,而这些用户的工程代码有的高达2.5千万行。
|
||||
|
||||
### [Memwatch][31] ###
|
||||
|
||||
**开发者**:Johan Lindh
|
||||
|
||||
**点评版本**:2.71
|
||||
|
||||
**Linux支持**:所有种类
|
||||
|
||||
**许可**:GNU通用公共许可证
|
||||
|
||||
Memwatch是由Johan Lindh开发的内存调试工具,虽然它主要扮演内存泄漏检测器的角色,但是它也具有检测其它如[重复释放跟踪和内存错误释放][32]、缓冲区溢出和下溢、[野指针][33]写入等等内存相关问题的能力(根据网页介绍所知)。
|
||||
|
||||
Memwatch支持用C语言所编写的程序。可以在C++程序中使用它,但是这种做法并不提倡(由Memwatch源码包随附的Q&A文件中可知)。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
这个版本添加了ULONG_LONG_MAX以区分32位和64位程序。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
跟Dmalloc一样,Memwatch也有优秀的文献资料。参考USING文件,可以学习如何使用Memwatch,可以了解Memwatch是如何初始化、如何清理以及如何进行I/O操作的,等等不一而足。还有一个FAQ文件,旨在帮助用户解决使用过程遇到的一般问题。最后还有一个test.c文件提供工作案例参考。
|
||||
|
||||

|
||||
Memwatch
|
||||
|
||||
不同于Mtrace,Memwatch的输出产生的日志文件(通常是memwatch.log)是人类可阅读格式。而且,Memwatch每次运行时总会拼接内存调试输出到此文件末尾,而不是进行覆盖(译改)。如此便可在需要之时,轻松查看之前的输出信息。
|
||||
|
||||
同样值得一提的是当你执行了启用Memwatch的程序,Memwatch会在[标准输出][34]中产生一个单行输出,告知发现了错误,然后你可以在日志文件中查看输出细节。如果没有产生错误信息,就可以确保日志文件不会写入任何错误,多次运行的话能实际节省时间。
|
||||
|
||||
另一个我喜欢的优点是Memwatch同样在源码中提供一个方法,你可以据此获取Memwatch的输出信息,然后任由你进行处理(参考Memwatch源码中的mwSetOutFunc()函数获取更多有关的信息)。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
跟Mtrace和Dmalloc一样,Memwatch也需要你往你的源文件里增加代码:你需要把memwatch.h这个头文件包含进你的代码。而且,编译程序的时候,你需要连同memwatch.c一块编译;或者你可以把已经编译好的目标模块包含起来,然后在命令行定义MEMWATCH和MW_STDIO变量。不用说,想要在输出中定位行号,-g编译器选项也少不了。
|
||||
|
||||
还有一些没有具备的特性。比如Memwatch不能检测出往一块已经被释放的内存写入操作,或是在分配的内存块之外的读取操作。而且,Memwatch也不是线程安全的。还有一点,正如我在开始时指出,在C++程序上运行Memwatch的结果是不能预料的。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
Memcheck可以检测很多内存相关的问题,在处理C程序时是非常便捷的调试工具。因为源码小巧,所以可以从中了解Memcheck如何运转,有需要的话可以调试它,甚至可以根据自身需求扩展升级它的功能。
|
||||
|
||||
### [Mtrace][35] ###
|
||||
|
||||
**开发者**: Roland McGrath and Ulrich Drepper
|
||||
|
||||
**点评版本**: 2.21
|
||||
|
||||
**Linux支持**:所有种类
|
||||
|
||||
**许可**:GNU通用公共许可证
|
||||
|
||||
Mtrace是[GNU C库][36]中的一款内存调试工具,同时支持Linux C和C++程序,检测由malloc()和free()函数的不对等调用所引起的内存泄漏问题。
|
||||
|
||||

|
||||
Mtrace
|
||||
|
||||
Mtrace实现为对mtrace()函数的调用,跟踪程序中所有malloc/free调用,在用户指定的文件中记录相关信息。文件以一种机器可读的格式记录数据,所以有一个Perl脚本(同样命名为mtrace)用来把文件转换并展示为人类可读格式。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
[Mtrace源码][37]和[Perl文件][38]同GNU C库(2.21版本)一起释出,除了更新版权日期,其它别无改动。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
Mtrace最优秀的特点是非常简单易学。你只需要了解在你的源码中如何以及何处添加mtrace()及其对立的muntrace()函数,还有如何使用Mtrace的Perl脚本。后者非常简单,只需要运行指令mtrace <program-executable> <log-file-generated-upon-program-execution>(例子见开头截图最后一条指令)。
|
||||
|
||||
Mtrace另外一个优点是它的可收缩性,体现在,不仅可以使用它来调试完整的程序,还可以使用它来检测程序中独立模块的内存泄漏。只需在每个模块里调用mtrace()和muntrace()即可。
|
||||
|
||||
最后一点,因为Mtrace会在mtace()(在源码中添加的函数)执行时被触发,因此可以很灵活地[使用信号][39]动态地(在程序执行周期内)使能Mtrace。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
因为mtrace()和mauntrace()函数(在mcheck.h文件中声明,所以必须在源码中包含此头文件)的调用是Mtrace运行(mauntrace()函数并非[总是必要][40])的根本,因此Mtrace要求程序员至少改动源码一次。
|
||||
|
||||
了解需要在编译程序的时候带上-g选项([GCC][41]和[G++][42]编译器均由提供),才能使调试工具在输出展示正确的行号。除此之外,有些程序(取决于源码体积有多大)可能会花很长时间进行编译。最后,带-g选项编译会增加了可执行文件的内存(因为提供了额外的调试信息),因此记得程序需要在测试结束,不带-g选项重新进行编译。
|
||||
|
||||
使用Mtrace,你需要掌握Linux环境变量的基本知识,因为在程序执行之前,需要把用户指定文件(mtrace()函数用以记载全部信息)的路径设置为环境变量MALLOC_TRACE的值。
|
||||
|
||||
Mtrace在检测内存泄漏和尝试释放未经过分配的内存方面存在局限。它不能检测其它内存相关问题如非法内存访问、使用未初始化内存。而且,[有人抱怨][43]Mtrace不是[线程安全][44]的。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
不言自明,我在此讨论的每款内存调试器都有其优点和局限。所以,哪一款适合你取决于你所需要的特性,虽然有时候容易安装和使用也是一个决定因素。
|
||||
|
||||
要想捕获软件程序中的内存泄漏,Mtrace最适合不过了。它还可以节省时间。由于Linux系统已经预装了此工具,对于不能联网或者不可以下载第三方调试调试工具的情况,Mtrace也是极有助益的。
|
||||
|
||||
另一方面,相比Mtrace,,Dmalloc不仅能检测更多错误类型,还你呢个提供更多特性,比如运行时可配置、GDB集成。而且,Dmalloc不像这里所说的其它工具,它是线程安全的。更不用说它的详细资料了,这让Dmalloc成为初学者的理想选择。
|
||||
|
||||
虽然Memwatch的资料比Dmalloc的更加丰富,而且还能检测更多的错误种类,但是你只能在C语言写就的软件程序上使用它。一个让Memwatch脱颖而出的特性是它允许在你的程序源码中处理它的输出,这对于想要定制输出格式来说是非常有用的。
|
||||
|
||||
如果改动程序源码非你所愿,那么使用Electric Fence吧。不过,请记住,Electric Fence只能检测两种错误类型,而此二者均非内存泄漏。还有就是,需要了解GDB基础以最大程序发挥这款内存调试工具的作用。
|
||||
|
||||
Memcheck可能是这当中综合性最好的了。相比这里所说其它工具,它检测更多的错误类型,提供更多的特性,而且不需要你的源码做任何改动。但请注意,基本功能并不难上手,但是想要使用它的高级特性,就必须学习相关的专业知识了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3003957/linux/review-5-memory-debuggers-for-linux-coding.html
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/soooogreen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Himanshu-Arora/
|
||||
[1]:https://openclipart.org/detail/132427/penguin-admin
|
||||
[2]:https://en.wikipedia.org/wiki/Manual_memory_management
|
||||
[3]:http://dmalloc.com/
|
||||
[4]:https://www.owasp.org/index.php/Double_Free
|
||||
[5]:https://stuff.mit.edu/afs/sipb/project/gnucash-test/src/dmalloc-4.8.2/dmalloc.html#Fence-Post%20Overruns
|
||||
[6]:http://dmalloc.com/releases/notes/dmalloc-5.5.2.html
|
||||
[7]:http://www.gnu.org/software/gdb/
|
||||
[8]:http://dmalloc.com/docs/
|
||||
[9]:http://dmalloc.com/docs/latest/online/dmalloc_26.html#SEC32
|
||||
[10]:http://dmalloc.com/docs/latest/online/dmalloc_23.html#SEC29
|
||||
[11]:https://en.wikipedia.org/wiki/Memory_management#Dynamic_memory_allocation
|
||||
[12]:https://en.wikipedia.org/wiki/Segmentation_fault
|
||||
[13]:https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[14]:http://www.gnu.org/software/gdb/
|
||||
[15]:https://launchpad.net/ubuntu/+source/electric-fence/2.2.3
|
||||
[16]:http://valgrind.org/docs/manual/mc-manual.html
|
||||
[17]:http://valgrind.org/info/developers.html
|
||||
[18]:http://valgrind.org/
|
||||
[19]:http://valgrind.org/docs/manual/dist.news.html
|
||||
[20]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.suppfiles
|
||||
[21]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.mempools
|
||||
[22]:http://stackoverflow.com/questions/4642671/c-memory-allocators
|
||||
[23]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.monitor-commands
|
||||
[24]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.clientreqs
|
||||
[25]:http://valgrind.org/docs/manual/valgrind_manual.pdf
|
||||
[26]:http://sourceforge.net/p/valgrind/mailman/message/30292453/
|
||||
[27]:https://msdn.microsoft.com/en-us/library/ee798431%28v=cs.20%29.aspx
|
||||
[28]:http://www.computerworld.com/article/2484425/linux/5-free-linux-text-editors-for-programming-and-word-processing.html?nsdr=true&page=2
|
||||
[29]:http://valgrind.org/docs/manual/manual-core.html#manual-core.limits
|
||||
[30]:http://valgrind.org/info/
|
||||
[31]:http://www.linkdata.se/sourcecode/memwatch/
|
||||
[32]:http://www.cecalc.ula.ve/documentacion/tutoriales/WorkshopDebugger/007-2579-007/sgi_html/ch09.html
|
||||
[33]:http://c2.com/cgi/wiki?WildPointer
|
||||
[34]:https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
[35]:http://www.gnu.org/software/libc/manual/html_node/Tracing-malloc.html
|
||||
[36]:https://www.gnu.org/software/libc/
|
||||
[37]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.c;h=df10128b872b4adc4086cf74e5d965c1c11d35d2;hb=HEAD
|
||||
[38]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.pl;h=0737890510e9837f26ebee2ba36c9058affb0bf1;hb=HEAD
|
||||
[39]:http://webcache.googleusercontent.com/search?q=cache:s6ywlLtkSqQJ:www.gnu.org/s/libc/manual/html_node/Tips-for-the-Memory-Debugger.html+&cd=1&hl=en&ct=clnk&gl=in&client=Ubuntu
|
||||
[40]:http://www.gnu.org/software/libc/manual/html_node/Using-the-Memory-Debugger.html#Using-the-Memory-Debugger
|
||||
[41]:http://linux.die.net/man/1/gcc
|
||||
[42]:http://linux.die.net/man/1/g++
|
||||
[43]:https://sourceware.org/ml/libc-help/2014-05/msg00008.html
|
||||
[44]:https://en.wikipedia.org/wiki/Thread_safety
|
||||
@ -0,0 +1,93 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||

|
||||
和之前完全不同的市场设计。以上是分类,特色,热门应用以及应用详情页面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
这些截图给了我们冰淇淋三明治中新版操作栏的第一印象。几乎所有的应用顶部都有一条栏,带有应用图标,当前界面标题,一些功能按钮,右边还有一个菜单按钮。这个右对齐的菜单按钮被称为“更多操作”,因为里面存放着无法放置到主操作栏的项目。不过更多操作菜单并不是固定不变的,它给了操作栏节省了更多的屏幕空间——比如在横屏模式或在平板上时,更多操作菜单的项目会像通常的按钮一样显示在操作栏上。
|
||||
|
||||
冰淇凌三明治中新增了“滑动标签页”设计,替换掉了谷歌之前推行的2×3方阵导航屏幕。一个标签页栏放置在了操作栏下方,位于中间的标签显示的是当前页面,左右侧的两个标签显示的是对应的当前页面的左右侧页面。向左右滑动可以切换标签页,或者你可以点击指定页面的标签跳转过去。
|
||||
|
||||
应用详情页面有个很赞的设计,在应用截图后,会根据你关于那个应用的历史动态地重新布局页面。如果你从来没有安装过该应用,应用描述会优先显示。如果你曾安装过这个应用,第一部分将会是评价栏,它会邀请你评价该应用或者提醒你上次你安装该应用时的评价是什么。之前使用过的应用页面第二部分是“新特性”,因为一个老用户最关心的应该是应用有什么变化。
|
||||
|
||||

|
||||
最近应用和浏览器和蜂巢中的类似,但是是小号的。
|
||||
Ron Amadeo 供图
|
||||
|
||||
最近应用的电子风格外观被移除了。略缩图周围的蓝色的轮廓线被去除了,同时去除的还有背景怪异的,不均匀的蓝色光晕。它现在看起来是个中立型的界面,在任何时候看起来都很舒适。
|
||||
|
||||
浏览器尽了最大的努力把标签页体验带到手机上来。多标签浏览受到了关注,操作栏上引入的一个标签页按钮会打开一个类似最近应用的界面,显示你打开的标签页,而不是浪费宝贵的屏幕空间引入一个标签条。从功能上来说,这个和之前的浏览器中的“窗口”视图没什么差别。浏览器最佳的改进是菜单中的“请求桌面版站点”选项,这让你可以从默认的移动站点视图切换到正常站点。浏览器展示了谷歌的操作栏设计的灵活性,尽管这里没有左上角的应用图标,功能上来说和其他的顶栏设计相似。
|
||||
|
||||

|
||||
Gmail 和 Google Talk —— 它们和蜂巢中的相似,但是更小!
|
||||
Ron Amadeo 供图
|
||||
|
||||
Gmail 和 Google Talk 看起来都像是之前蜂巢中的设计的缩小版,但是有些小调整让它们在小屏幕上表现更佳。Gmail 以双操作栏为特色——一个在屏幕顶部,一个在底部。顶部操作栏显示当前文件夹,账户,以及未读消息数目,点击顶栏可以打开一个导航菜单。底部操作栏有你期望出现在更多操作中的选项。使用双操作栏布局是为了在界面显示更多的按钮,但是在横屏模式下纵向空间有限,双操作栏就是合并成一个顶部操作栏。
|
||||
|
||||
在邮件视图下,往下滚动屏幕时蓝色栏有“粘性”。它会固定在屏幕顶部,所以你一直可以看到该邮件是谁写的,回复它,或者给它加星标。一旦处于邮件消息界面,底部细长的,深灰色栏会显示你当前在收件箱(或你所在的某个列表)的位置,并且你可以向左或向右滑动来切换到其他邮件。
|
||||
|
||||
Google Talk 允许你像在 Gmail 中那样左右滑动来切换聊天窗口,但是这里显示栏是在顶部。
|
||||
|
||||

|
||||
新的拨号和来电界面,都是姜饼以来我们还没见过的。
|
||||
Ron Amadeo 供图
|
||||
|
||||
因为蜂巢只给平板使用,所以一些界面设计直接超前于姜饼。冰淇淋三明治的新拨号界面就是如此,黑色和蓝色相间,并且使用了可滑动切换的小标签。尽管冰淇淋三明治终于做了对的事情并将电话主体和联系人独立开来,但电话应用还是有它自己的联系人标签。现在有两个地方可以看到你的联系人列表——一个有着暗色主题,另一个有着亮色主题。由于实体搜索按钮不再是硬性要求,底部的按钮栏的语音信息快捷方式被替换为了搜索图标。
|
||||
|
||||
谷歌几乎就是把来电界面做成了锁屏界面的镜像,这意味着冰淇淋三明治有着一个环状解锁设计。除了通常的接受和挂断选项,圆环的顶部还添加了一个按钮,让你可以挂断来电并给对方发送一条预先定义好的信息。向上滑动并选择一条信息如“现在无法接听,一会回电”,相比于一直响个不停的手机而言这样做的信息交流更加丰富。
|
||||
|
||||

|
||||
蜂巢没有文件夹和信息应用,所以这里是冰淇淋三明治和姜饼的对比。
|
||||
Ron Amadeo 供图
|
||||
|
||||
现在创建文件夹更加方便了。在姜饼中,你得长按屏幕,选择“文件夹”选项,再点击“新文件夹”。在冰淇淋三明治中,你只要将一个图标拖拽到另一个图标上面,就会自动创建一个文件夹,并包含这两个图标。这简直不能更简单了,比寻找隐藏的长按命令容易多了。
|
||||
|
||||
设计上也有很大的改进。姜饼使用了一个通用的米黄色文件夹图标,但冰淇淋三明治直接显示出了文件夹中的头三个应用,把它们的图标叠在一起,在外侧画一个圆圈,并将其设置为文件夹图标。打开文件夹容器将自动调整大小以适应文件夹中的应用图标数目,而不是显示一个全屏的,大部分都是空的对话框。这看起来好得多得多。
|
||||
|
||||

|
||||
Youtube 转换到一个更加现代的白色主题,使用了列表视图替换疯狂的 3D 滚动视图。
|
||||
Ron Amadeo 供图
|
||||
|
||||
Youtube 经过了完全的重新设计,看起来没那么像是来自黑客帝国的产物,更像是,嗯,Youtube。它现在就是一个简单的垂直滚动的白色视频列表,就像网站的那样。在你手机上制作视频受到了重视,操作栏的第一个按钮专用于拍摄视频。奇怪的是,不同的界面左上角使用了不同的 Youtube 标志,在水平的 Youtube 标志和方形标志之间切换。
|
||||
|
||||
Youtube 几乎在所有地方都使用了滑动标签页。它们被放置在主页面以在浏览和账户间切换,放置在视频页面以在评论,介绍和相关视频之间切换。4.0 版本的应用显示出 Google+ Youtube 集成的第一个信号,通常的评分按钮旁边放置了 “+1” 图标。最终 Google+ 会完全占据 Youtube,将评论和作者页面变成 Google+ 活动。
|
||||
|
||||

|
||||
冰淇淋三明治试着让事情对所有人都更加简单。这里是数据使用量追踪,打开许多数据的新开发者选项,以及使用向导。
|
||||
Ron Amadeo 供图
|
||||
|
||||
数据使用量允许用户更轻松地追踪和控制他们的数据使用。主页面显示一个月度使用量图表,用户可以设置数据使用警告值或者硬性使用限制以避免超量使用产生费用。所有的这些只需简单地拖动橙色和红色水平限制线在图表上的位置即可。纵向的白色把手允许用户选择图表上的一段指定时间段。在页面底部,选定时间段内的数据使用量又细分到每个应用,所以用户可以选择一个数据使用高峰并轻松地查看哪个应用在消耗大量流量。当流量紧张的时候,更多操作按钮中有个限制所有后台流量的选项。设置之后只用在前台运行的程序有权连接互联网。
|
||||
|
||||
开发者选项通常只有一点点设置选项,但是在冰淇淋三明治中,这部分有非常多选项。谷歌添加了所有类型的屏幕诊断显示浮层来帮助开发者理解他们的应用中发生了什么。你可以看到 CPU 使用率,触摸点位置,还有视图界面更新。还有些选项可以更改系统功能,比如控制动画速度,后台处理,以及 GPU 渲染。
|
||||
|
||||
安卓和 iOS 之间最大的区别之一就是应用抽屉界面。在冰淇淋三明治对更加用户友好的追求下,设备第一次初始化启动会启动一个小教程,向用户展示应用抽屉的位置以及如何将应用图标从应用抽屉拖拽到主屏幕。随着实体菜单按键的移除和像这样的改变,安卓 4.0 做了很大的努力变得对新智能手机用户和转换过来的用户更有吸引力。
|
||||
|
||||

|
||||
“触摸分享”NFC 支持,Google Earth,以及应用信息,让你可以禁用垃圾软件。
|
||||
|
||||
冰淇淋三明治内置对 [NFC][1] 的完整支持。尽管之前的设备,比如 Nexus S 也拥有 NFC,得到的支持是有限的并且系统并不能利用芯片做太多事情。4.0 添加了一个“Android Beam”功能,两台拥有 NFC 的安卓 4.0 设备可以借此在设备间来回传输数据。NFC 会传输关于此事屏幕显示的数据,因此在手机显示一个网页的时候使用该功能会将该页面传送给另一部手机。你还可以发送联系人信息,方向导航,以及 Youtube 链接。当两台手机放在一起时,屏幕显示会缩小,点击缩小的界面会发送相关信息。
|
||||
|
||||
I在安卓中,用户不允许删除系统应用,以保证系统完整性。运营商和 OEM 利用该特性并开始将垃圾软件放入系统分区,经常有一些没用的应用存在系统中。安卓 4.0 允许用户禁用任何不能被卸载的应用,意味着该应用还存在于系统中但是不显示在应用抽屉里并且不能运行。如果用户愿意深究设置项,这给了他们一个简单的途径来拿回手机的控制权。
|
||||
|
||||
安卓 4.0 可以看做是现代安卓时代的开始。大部分这时发布的谷歌应用只能在安卓 4.0 及以上版本运行。4.0 还有许多谷歌想要好好利用的新 API——至少最初想要——对 4.0 以下的版本的支持就有限了。在冰淇淋三明治和蜂巢之后,谷歌真的开始认真对待软件设计。在2012年1月,谷歌[最终发布了][2] *Android Design*,一个教安卓开发者如何创建符合安卓外观和感觉的应用的设计指南站点。这是 iOS 在有第三方应用支持开始就在做的事情,苹果还严肃地对待应用的设计,不符合指南的应用都被 App Store 拒之门外。安卓三年以来谷歌没有给出任何公共设计规范文档的事实,足以说明事情有多糟糕。但随着在 Duarte 掌控下的安卓设计革命,谷歌终于发布了基本设计需求。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/20/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2011/02/near-field-communications-a-technology-primer/
|
||||
[2]:http://arstechnica.com/business/2012/01/google-launches-style-guide-for-android-developers/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,236 +0,0 @@
|
||||
How to Install Redis Server on CentOS 7.md
|
||||
|
||||
如何在CentOS 7上安装Redis 服务
|
||||
================================================================================
|
||||
|
||||
大家好, 本文的主题是Redis,我们将要在CentOS 7 上安装它。编译源代码,安装二进制文件,创建、安装文件。然后安装组建,我们还会配置redis ,就像配置操作系统参数一样,目标就是让redis 运行的更加可靠和快速。
|
||||
|
||||

|
||||
|
||||
Redis 服务器
|
||||
|
||||
Redis 是一个开源的多平台数据存储软件,使用ANSI C 编写,直接在内存使用数据集,这使得它得以实现非常高的效率。Redis 支持多种编程语言,包括Lua, C, Java, Python, Perl, PHP 和其他很多语言。redis 的代码量很小,只有约3万行,它只做很少的事,但是做的很好。尽管你在内存里工作,但是对数据持久化的需求还是存在的,而redis 的可靠性就很高,同时也支持集群,这儿些可以很好的保证你的数据安全。
|
||||
|
||||
### 构建 Redis ###
|
||||
|
||||
redis 目前没有官方RPM 安装包,我们需要从牙UN代码编译,而为了要编译就需要安装Make 和GCC。
|
||||
|
||||
如果没有安装过GCC 和Make,那么就使用yum 安装。
|
||||
|
||||
yum install gcc make
|
||||
|
||||
从[官网][1]下载tar 压缩包。
|
||||
|
||||
curl http://download.redis.io/releases/redis-3.0.4.tar.gz -o redis-3.0.4.tar.gz
|
||||
|
||||
解压缩。
|
||||
|
||||
tar zxvf redis-3.0.4.tar.gz
|
||||
|
||||
进入解压后的目录。
|
||||
|
||||
cd redis-3.0.4
|
||||
|
||||
使用Make 编译源文件。
|
||||
|
||||
make
|
||||
|
||||
### 安装 ###
|
||||
|
||||
进入源文件的目录。
|
||||
|
||||
cd src
|
||||
|
||||
复制 Redis server 和 client 到 /usr/local/bin
|
||||
|
||||
cp redis-server redis-cli /usr/local/bin
|
||||
|
||||
最好也把sentinel,benchmark 和check 复制过去。
|
||||
|
||||
cp redis-sentinel redis-benchmark redis-check-aof redis-check-dump /usr/local/bin
|
||||
|
||||
创建redis 配置文件夹。
|
||||
|
||||
mkdir /etc/redis
|
||||
|
||||
在`/var/lib/redis` 下创建有效的保存数据的目录
|
||||
|
||||
mkdir -p /var/lib/redis/6379
|
||||
|
||||
#### 系统参数 ####
|
||||
|
||||
为了让redis 正常工作需要配置一些内核参数。
|
||||
|
||||
配置vm.overcommit_memory 为1,它的意思是一直避免数据被截断,详情[见此][2].
|
||||
|
||||
sysctl -w vm.overcommit_memory=1
|
||||
|
||||
修改backlog 连接数的最大值超过redis.conf 中的tcp-backlog 值,即默认值511。你可以在[kernel.org][3] 找到更多有关基于sysctl 的ip 网络隧道的信息。
|
||||
|
||||
sysctl -w net.core.somaxconn=512.
|
||||
|
||||
禁止支持透明大页,,因为这会造成redis 使用过程产生延时和内存访问问题。
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### redis.conf ###
|
||||
Redis.conf 是redis 的配置文件,然而你会看到这个文件的名字是6379.conf ,而这个数字就是redis 监听的网络端口。这个名字是告诉你可以运行超过一个redis 实例。
|
||||
|
||||
复制redis.conf 的示例到 **/etc/redis/6379.conf**.
|
||||
|
||||
cp redis.conf /etc/redis/6379.conf
|
||||
|
||||
现在编辑这个文件并且配置参数。
|
||||
|
||||
vi /etc/redis/6379.conf
|
||||
|
||||
#### 守护程序 ####
|
||||
|
||||
设置daemonize 为no,systemd 需要它运行在前台,否则redis 会突然挂掉。
|
||||
|
||||
daemonize no
|
||||
|
||||
#### pidfile ####
|
||||
|
||||
设置pidfile 为/var/run/redis_6379.pid。
|
||||
|
||||
pidfile /var/run/redis_6379.pid
|
||||
|
||||
#### port ####
|
||||
|
||||
如果不准备用默认端口,可以修改。
|
||||
|
||||
port 6379
|
||||
|
||||
#### loglevel ####
|
||||
|
||||
设置日志级别。
|
||||
|
||||
loglevel notice
|
||||
|
||||
#### logfile ####
|
||||
|
||||
修改日志文件路径。
|
||||
|
||||
logfile /var/log/redis_6379.log
|
||||
|
||||
#### dir ####
|
||||
|
||||
设置目录为 /var/lib/redis/6379
|
||||
|
||||
dir /var/lib/redis/6379
|
||||
|
||||
### 安全 ###
|
||||
|
||||
下面有几个操作可以提高安全性。
|
||||
|
||||
#### Unix sockets ####
|
||||
|
||||
在很多情况下,客户端程序和服务器端程序运行在同一个机器上,所以不需要监听网络上的socket。如果这和你的使用情况类似,你就可以使用unix socket 替代网络socket ,为此你需要配置**port** 为0,然后配置下面的选项来使能unix socket。
|
||||
|
||||
设置unix socket 的套接字文件。
|
||||
|
||||
unixsocket /tmp/redis.sock
|
||||
|
||||
限制socket 文件的权限。
|
||||
|
||||
unixsocketperm 700
|
||||
|
||||
现在为了获取redis-cli 的访问权限,应该使用-s 参数指向socket 文件。
|
||||
|
||||
redis-cli -s /tmp/redis.sock
|
||||
|
||||
#### 密码 ####
|
||||
|
||||
你可能需要远程访问,如果是,那么你应该设置密码,这样子每次操作之前要求输入密码。
|
||||
|
||||
requirepass "bTFBx1NYYWRMTUEyNHhsCg"
|
||||
|
||||
#### 重命名命令 ####
|
||||
|
||||
想象一下下面一条条指令的输出。使得,这回输出服务器的配置,所以你应该在任何可能的情况下拒绝这种信息。
|
||||
|
||||
CONFIG GET *
|
||||
|
||||
为了限制甚至禁止这条或者其他指令可以使用**rename-command** 命令。你必须提供一个命令名和替代的名字。要禁止的话需要设置replacement 为空字符串,这样子禁止任何人猜测命令的名字会比较安全。
|
||||
|
||||
rename-command FLUSHDB "FLUSHDB_MY_SALT_G0ES_HERE09u09u"
|
||||
rename-command FLUSHALL ""
|
||||
rename-command CONFIG "CONFIG_MY_S4LT_GO3S_HERE09u09u"
|
||||
|
||||

|
||||
|
||||
通过密码和修改命令来访问unix socket。
|
||||
|
||||
#### 快照 ####
|
||||
|
||||
默认情况下,redis 会周期性的将数据集转储到我们设置的目录下的文件**dump.rdb**。你可以使用save 命令配置转储的频率,他的第一个参数是以秒为单位的时间帧(译注:按照下文的意思单位应该是分钟),第二个参数是在数据文件上进行修改的数量。
|
||||
|
||||
每隔15小时并且最少修改过一次键。
|
||||
save 900 1
|
||||
|
||||
每隔5小时并且最少修改过10次键。
|
||||
|
||||
save 300 10
|
||||
|
||||
每隔1小时并且最少修改过10000次键。
|
||||
|
||||
save 60 10000
|
||||
|
||||
文件**/var/lib/redis/6379/dump.rdb** 包含了内存里经过上次保存命令的转储数据。因为他创建了临时文件并且替换了源文件,这里没有被破坏的问题,而且你不用担心直接复制这个文件。
|
||||
|
||||
### 开机时启动 ###
|
||||
|
||||
You may use systemd to add Redis to the system startup
|
||||
你可以使用systemd 将redis 添加到系统开机启动列表。
|
||||
|
||||
复制init_script 示例文件到/etc/init.d,注意脚本名所代表的端口号。
|
||||
|
||||
cp utils/redis_init_script /etc/init.d/redis_6379
|
||||
|
||||
现在我们来使用systemd,所以在**/etc/systems/system** 下创建一个单位文件名字为redis_6379.service。
|
||||
|
||||
vi /etc/systemd/system/redis_6379.service
|
||||
|
||||
填写下面的内容,详情可见systemd.service。
|
||||
|
||||
[Unit]
|
||||
Description=Redis on port 6379
|
||||
|
||||
[Service]
|
||||
Type=forking
|
||||
ExecStart=/etc/init.d/redis_6379 start
|
||||
ExecStop=/etc/init.d/redis_6379 stop
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
现在添加我之前在**/etc/sysctl.conf** 里面修改多的内存过分提交和backlog 最大值的选项。
|
||||
|
||||
vm.overcommit_memory = 1
|
||||
|
||||
net.core.somaxconn=512
|
||||
|
||||
对于透明大页支持,并没有直接sysctl 命令可以控制,所以需要将下面的命令放到/etc/rc.local 的结尾。
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### 总结 ###
|
||||
|
||||
这些足够启动了,通过设置这些选项你将足够部署redis 服务到很多简单的场景,然而在redis.conf 还有很多为复杂环境准备的redis 的选项。在一些情况下,你可以使用[replication][4] 和 [Sentinel][5] 来提高可用性,或者[将数据分散][6]在多个服务器上,创建服务器集群 。谢谢阅读。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/install-redis-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
[1]:http://redis.io/download
|
||||
[2]:https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
|
||||
[3]:https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
|
||||
[4]:http://redis.io/topics/replication
|
||||
[5]:http://redis.io/topics/sentinel
|
||||
[6]:http://redis.io/topics/partitioning
|
||||
@ -0,0 +1,258 @@
|
||||
Linux 内核里的数据结构——双向链表
|
||||
================================================================================
|
||||
|
||||
双向链表
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
Linux 内核自己实现了双向链表,可以在[include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h)找到定义。我们将会从双向链表数据结构开始`内核的数据结构`。为什么?因为它在内核里使用的很广泛,你只需要在[free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
|
||||
|
||||
首先让我们看一下在[include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 里的主结构体:
|
||||
|
||||
```C
|
||||
struct list_head {
|
||||
struct list_head *next, *prev;
|
||||
};
|
||||
```
|
||||
|
||||
你可能注意到这和你以前见过的双向链表的实现方法是不同的。举个例子来说,在[glib](http://www.gnu.org/software/libc/) 库里是这样实现的:
|
||||
|
||||
```C
|
||||
struct GList {
|
||||
gpointer data;
|
||||
GList *next;
|
||||
GList *prev;
|
||||
};
|
||||
```
|
||||
|
||||
通常来说一个链表会包含一个指向某个项目的指针。但是内核的实现并没有这样做。所以问题来了:`链表在哪里保存数据呢?`。实际上内核里实现的链表实际上是`侵入式链表`。侵入式链表并不在节点内保存数据-节点仅仅包含指向前后节点的指针,然后把数据是附加到链表的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
|
||||
|
||||
比如:
|
||||
|
||||
```C
|
||||
struct nmi_desc {
|
||||
spinlock_t lock;
|
||||
struct list_head head;
|
||||
};
|
||||
```
|
||||
|
||||
让我们看几个例子来理解一下在内核里是如何使用`list_head` 的。如上所述,在内核里有实在很多不同的地方用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动API 被用来编写处理小型硬件和虚拟设备的小驱动。这些驱动共享相同的主设备号:
|
||||
|
||||
```C
|
||||
#define MISC_MAJOR 10
|
||||
```
|
||||
|
||||
但是都有各自不同的次设备号。比如:
|
||||
|
||||
```
|
||||
ls -l /dev | grep 10
|
||||
crw------- 1 root root 10, 235 Mar 21 12:01 autofs
|
||||
drwxr-xr-x 10 root root 200 Mar 21 12:01 cpu
|
||||
crw------- 1 root root 10, 62 Mar 21 12:01 cpu_dma_latency
|
||||
crw------- 1 root root 10, 203 Mar 21 12:01 cuse
|
||||
drwxr-xr-x 2 root root 100 Mar 21 12:01 dri
|
||||
crw-rw-rw- 1 root root 10, 229 Mar 21 12:01 fuse
|
||||
crw------- 1 root root 10, 228 Mar 21 12:01 hpet
|
||||
crw------- 1 root root 10, 183 Mar 21 12:01 hwrng
|
||||
crw-rw----+ 1 root kvm 10, 232 Mar 21 12:01 kvm
|
||||
crw-rw---- 1 root disk 10, 237 Mar 21 12:01 loop-control
|
||||
crw------- 1 root root 10, 227 Mar 21 12:01 mcelog
|
||||
crw------- 1 root root 10, 59 Mar 21 12:01 memory_bandwidth
|
||||
crw------- 1 root root 10, 61 Mar 21 12:01 network_latency
|
||||
crw------- 1 root root 10, 60 Mar 21 12:01 network_throughput
|
||||
crw-r----- 1 root kmem 10, 144 Mar 21 12:01 nvram
|
||||
brw-rw---- 1 root disk 1, 10 Mar 21 12:01 ram10
|
||||
crw--w---- 1 root tty 4, 10 Mar 21 12:01 tty10
|
||||
crw-rw---- 1 root dialout 4, 74 Mar 21 12:01 ttyS10
|
||||
crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
|
||||
crw------- 1 root root 10, 137 Mar 21 12:01 vhci
|
||||
```
|
||||
|
||||
现在让我们看看它是如何使用链表的。首先看一下结构体`miscdevice`:
|
||||
|
||||
```C
|
||||
struct miscdevice
|
||||
{
|
||||
int minor;
|
||||
const char *name;
|
||||
const struct file_operations *fops;
|
||||
struct list_head list;
|
||||
struct device *parent;
|
||||
struct device *this_device;
|
||||
const char *nodename;
|
||||
mode_t mode;
|
||||
};
|
||||
```
|
||||
|
||||
可以看到结构体的第四个变量`list` 是所有注册过的设备的链表。在源代码文件的开始可以看到这个链表的定义:
|
||||
|
||||
```C
|
||||
static LIST_HEAD(misc_list);
|
||||
```
|
||||
|
||||
它实际上是对用`list_head` 类型定义的变量的扩展。
|
||||
|
||||
```C
|
||||
#define LIST_HEAD(name) \
|
||||
struct list_head name = LIST_HEAD_INIT(name)
|
||||
```
|
||||
|
||||
然后使用宏`LIST_HEAD_INIT` 进行初始化,这会使用变量`name` 的地址来填充`prev`和`next` 结构体的两个变量。
|
||||
|
||||
```C
|
||||
#define LIST_HEAD_INIT(name) { &(name), &(name) }
|
||||
```
|
||||
|
||||
现在来看看注册杂项设备的函数`misc_register`。它在开始就用 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
|
||||
|
||||
```C
|
||||
INIT_LIST_HEAD(&misc->list);
|
||||
```
|
||||
|
||||
作用和宏`LIST_HEAD_INIT`一样。
|
||||
|
||||
```C
|
||||
static inline void INIT_LIST_HEAD(struct list_head *list)
|
||||
{
|
||||
list->next = list;
|
||||
list->prev = list;
|
||||
}
|
||||
```
|
||||
|
||||
在函数`device_create` 创建了设备后我们就用下面的语句将设备添加到设备链表:
|
||||
|
||||
```
|
||||
list_add(&misc->list, &misc_list);
|
||||
```
|
||||
|
||||
内核文件`list.h` 提供了项链表添加新项的API 接口。我们来看看它的实现:
|
||||
|
||||
|
||||
```C
|
||||
static inline void list_add(struct list_head *new, struct list_head *head)
|
||||
{
|
||||
__list_add(new, head, head->next);
|
||||
}
|
||||
```
|
||||
|
||||
实际上就是使用3个指定的参数来调用了内部函数`__list_add`:
|
||||
|
||||
* new - 新项。
|
||||
* head - 新项将会被添加到`head`之前.
|
||||
* head->next - `head` 之后的项。
|
||||
|
||||
`__list_add`的实现非常简单:
|
||||
|
||||
```C
|
||||
static inline void __list_add(struct list_head *new,
|
||||
struct list_head *prev,
|
||||
struct list_head *next)
|
||||
{
|
||||
next->prev = new;
|
||||
new->next = next;
|
||||
new->prev = prev;
|
||||
prev->next = new;
|
||||
}
|
||||
```
|
||||
|
||||
我们会在`prev`和`next` 之间添加一个新项。所以我们用宏`LIST_HEAD_INIT`定义的`misc` 链表会包含指向`miscdevice->list` 的向前指针和向后指针。
|
||||
|
||||
这里有一个问题:如何得到列表的内容呢?这里有一个特殊的宏:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
使用了三个参数:
|
||||
|
||||
* ptr - 指向链表头的指针;
|
||||
* type - 结构体类型;
|
||||
* member - 在结构体内类型为`list_head` 的变量的名字;
|
||||
|
||||
比如说:
|
||||
|
||||
```C
|
||||
const struct miscdevice *p = list_entry(v, struct miscdevice, list)
|
||||
```
|
||||
|
||||
然后我们就可以使用`p->minor` 或者 `p->name`来访问`miscdevice`。让我们来看看`list_entry` 的实现:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
如我们所见,它仅仅使用相同的参数调用了宏`container_of`。初看这个宏挺奇怪的:
|
||||
|
||||
```C
|
||||
#define container_of(ptr, type, member) ({ \
|
||||
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
|
||||
(type *)( (char *)__mptr - offsetof(type,member) );})
|
||||
```
|
||||
|
||||
首先你可以注意到花括号内包含两个表达式。编译器会执行花括号内的全部语句,然后返回最后的表达式的值。
|
||||
|
||||
举个例子来说:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
int i = 0;
|
||||
printf("i = %d\n", ({++i; ++i;}));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
最终会打印`2`
|
||||
|
||||
下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是`container_of`中的0.实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
|
||||
struct s {
|
||||
int field1;
|
||||
char field2;
|
||||
char field3;
|
||||
};
|
||||
|
||||
int main() {
|
||||
printf("%p\n", &((struct s*)0)->field3);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
结果显示`0x5`。
|
||||
|
||||
下一个宏`offsetof` 会计算从结构体的某个变量的相对于结构体起始地址的偏移。它的实现和上面类似:
|
||||
|
||||
```C
|
||||
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
|
||||
```
|
||||
|
||||
现在我们来总结一下宏`container_of`。只需要知道结构体里面类型为`list_head` 的变量的名字和结构体容器的类型,它可以通过结构体的变量`list_head`获得结构体的起始地址。在宏定义的第一行,声明了一个指向结构体成员变量`ptr`的指针`__mptr`,并且把`ptr` 的地址赋给它。现在`ptr` 和`__mptr` 指向了同一个地址。从技术上讲我们并不需要这一行,但是它可以方便的进行类型检查。第一行保证了特定的结构体(参数`type`)包含成员变量`member`。第二行代码会用宏`offsetof`计算成员变量相对于结构体起始地址的偏移,然后从结构体的地址减去这个偏移,最后就得到了结构体。
|
||||
|
||||
当然了`list_add` 和 `list_entry`不是`<linux/list.h>`提供的唯一功能。双向链表的实现还提供了如下API:
|
||||
|
||||
* list_add
|
||||
* list_add_tail
|
||||
* list_del
|
||||
* list_replace
|
||||
* list_move
|
||||
* list_is_last
|
||||
* list_empty
|
||||
* list_cut_position
|
||||
* list_splice
|
||||
* list_for_each
|
||||
* list_for_each_entry
|
||||
|
||||
等等很多其它API。
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
|
||||
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,18 +1,18 @@
|
||||
Assign Multiple IP Addresses To One Interface On Ubuntu 15.10
|
||||
在 Ubuntu 15.10 上为单个网卡设置多个 IP 地址
|
||||
================================================================================
|
||||
Some times you might want to use more than one IP address for your network interface card. What will you do in such cases? Buy an extra network card and assign new IP? No, It’s not necessary(at least in the small networks). We can now assign multiple IP addresses to one interface on Ubuntu systems. Curious to know how? Well, Follow me, It is not that difficult.
|
||||
有时候你可能想在你的网卡上使用多个 IP 地址。遇到这种情况你会怎么办呢?买一个新的网卡并分配一个新的 IP?不,这没有必要(至少在小网络中)。现在我们可以在 Ubuntu 系统中为一个网卡分配多个 IP 地址。想知道怎么做到的?跟着我往下看,其实并不难。
|
||||
|
||||
This method will work on Debian and it’s derivatives too.
|
||||
这个方法也适用于 Debian 以及它的衍生版本。
|
||||
|
||||
### Add additional IP addresses temporarily ###
|
||||
### 临时添加 IP 地址 ###
|
||||
|
||||
First, let us find the IP address of the network card. In my Ubuntu 15.10 server, I use only one network card.
|
||||
首先,让我们找到网卡的 IP 地址。在我的 Ubuntu 15.10 服务器版中,我只使用了一个网卡。
|
||||
|
||||
Run the following command to find out the IP address:
|
||||
运行下面的命令找到 IP 地址:
|
||||
|
||||
sudo ip addr
|
||||
|
||||
**Sample output:**
|
||||
**事例输出:**
|
||||
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
@ -27,11 +27,11 @@ Run the following command to find out the IP address:
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
Or
|
||||
或
|
||||
|
||||
sudo ifconfig
|
||||
|
||||
**Sample output:**
|
||||
**事例输出:**
|
||||
|
||||
enp0s3 Link encap:Ethernet HWaddr 08:00:27:2a:03:4b
|
||||
inet addr:192.168.1.103 Bcast:192.168.1.255 Mask:255.255.255.0
|
||||
@ -50,19 +50,19 @@ Or
|
||||
collisions:0 txqueuelen:0
|
||||
RX bytes:38793 (38.7 KB) TX bytes:38793 (38.7 KB)
|
||||
|
||||
As you see in the above output, my network card name is **enp0s3**, and its IP address is **192.168.1.103**.
|
||||
正如你在上面看到的,我的网卡名称是 **enp0s3**,它的 IP 地址是 **192.168.1.103**。
|
||||
|
||||
Now let us add an additional IP address, for example **192.168.1.104**, to the Interface card.
|
||||
现在让我们来为网卡添加一个新的 IP 地址,例如说 **192.168.1.104**。
|
||||
|
||||
Open your Terminal and run the following command to add additional IP.
|
||||
打开你的终端并运行下面的命令添加额外的 IP。
|
||||
|
||||
sudo ip addr add 192.168.1.104/24 dev enp0s3
|
||||
|
||||
Now, let us check if the IP is added using command:
|
||||
用命令检查是否启用了新的 IP:
|
||||
|
||||
sudo ip address show enp0s3
|
||||
|
||||
**Sample output:**
|
||||
**样例输出:**
|
||||
|
||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
|
||||
@ -73,13 +73,13 @@ Now, let us check if the IP is added using command:
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
Similarly, you can add as many IP addresses as you want.
|
||||
类似地,你可以添加想要的任意多的 IP 地址。
|
||||
|
||||
Let us ping the IP address to verify it.
|
||||
让我们 ping 一下这个 IP 地址验证一下。
|
||||
|
||||
sudo ping 192.168.1.104
|
||||
|
||||
**Sample output:**
|
||||
**样例输出**
|
||||
|
||||
PING 192.168.1.104 (192.168.1.104) 56(84) bytes of data.
|
||||
64 bytes from 192.168.1.104: icmp_seq=1 ttl=64 time=0.901 ms
|
||||
@ -87,17 +87,17 @@ Let us ping the IP address to verify it.
|
||||
64 bytes from 192.168.1.104: icmp_seq=3 ttl=64 time=0.521 ms
|
||||
64 bytes from 192.168.1.104: icmp_seq=4 ttl=64 time=0.524 ms
|
||||
|
||||
Yeah, It’s working!!
|
||||
好极了,它能工作!
|
||||
|
||||
To remove the IP, just run:
|
||||
要删除 IP,只需要运行:
|
||||
|
||||
sudo ip addr del 192.168.1.104/24 dev enp0s3
|
||||
|
||||
Let us check if it is removed.
|
||||
再检查一下是否删除了 IP。
|
||||
|
||||
sudo ip address show enp0s3
|
||||
|
||||
**Sample output:**
|
||||
**样例输出:**
|
||||
|
||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
|
||||
@ -106,19 +106,19 @@ Let us check if it is removed.
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
See, It’s gone!!
|
||||
可以看到已经没有了!!
|
||||
|
||||
Well, as you may know, the changes will lost after you reboot your system. How do I make it permanent? That’s easy too.
|
||||
也许你已经知道,你重启系统后会丢失这些设置。那么怎么设置才能永久有效呢?这也很简单。
|
||||
|
||||
### Add additional IP addresses permanently ###
|
||||
### 添加永久 IP 地址 ###
|
||||
|
||||
The network card configuration file of your Ubuntu system is **/etc/network/interfaces**.
|
||||
Ubuntu 系统的网卡配置文件是 **/etc/network/interfaces**。
|
||||
|
||||
Let us check the details of the above file.
|
||||
让我们来看看上面文件的具体内容。
|
||||
|
||||
sudo cat /etc/network/interfaces
|
||||
|
||||
**Sample output:**
|
||||
**输出样例:**
|
||||
|
||||
# This file describes the network interfaces available on your system
|
||||
# and how to activate them. For more information, see interfaces(5).
|
||||
@ -130,15 +130,15 @@ Let us check the details of the above file.
|
||||
auto enp0s3
|
||||
iface enp0s3 inet dhcp
|
||||
|
||||
As you see in the above output, the Interface is DHCP enabled.
|
||||
正如你在上面输出中看到的,网卡启用了 DHCP。
|
||||
|
||||
Okay, now we will assign an additional address, for example **192.168.1.104/24**.
|
||||
现在,让我们来分配一个额外的地址,例如 **192.168.1.104/24**。
|
||||
|
||||
Edit file **/etc/network/interfaces**:
|
||||
编辑 **/etc/network/interfaces**:
|
||||
|
||||
sudo nano /etc/network/interfaces
|
||||
|
||||
Add additional IP address as shown in the black letters.
|
||||
按照黑色字体标注的添加额外的 IP 地址。
|
||||
|
||||
# This file describes the network interfaces available on your system
|
||||
# and how to activate them. For more information, see interfaces(5).
|
||||
@ -152,13 +152,13 @@ Add additional IP address as shown in the black letters.
|
||||
iface enp0s3 inet static
|
||||
address 192.168.1.104/24
|
||||
|
||||
Save and close the file.
|
||||
保存并关闭文件。
|
||||
|
||||
Run the following file to take effect the changes without rebooting.
|
||||
无需重启运行下面的命令使更改生效。
|
||||
|
||||
sudo ifdown enp0s3 && sudo ifup enp0s3
|
||||
|
||||
**Sample output:**
|
||||
**样例输出:**
|
||||
|
||||
Killed old client process
|
||||
Internet Systems Consortium DHCP Client 4.3.1
|
||||
@ -182,13 +182,13 @@ Run the following file to take effect the changes without rebooting.
|
||||
DHCPACK of 192.168.1.103 from 192.168.1.1
|
||||
bound to 192.168.1.103 -- renewal in 35146 seconds.
|
||||
|
||||
**Note**: It is **very important** to run the above two commands into **one** line if you are remoting into the server because the first one will drop your connection. Given in this way the ssh-session will survive.
|
||||
**注意**:如果你从远程连接到服务器,把上面的两个命令放到**一行**中**非常重要**,因为第一个命令会断掉你的连接。而采用这种方式可以存活你的 ssh 会话。
|
||||
|
||||
Now, let us check if IP is added using command:
|
||||
现在,让我们用下面的命令来检查一下是否添加了新的 IP:
|
||||
|
||||
sudo ip address show enp0s3
|
||||
|
||||
**Sample output:**
|
||||
**输出样例:**
|
||||
|
||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
|
||||
@ -199,13 +199,13 @@ Now, let us check if IP is added using command:
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
Cool! Additional IP has been added.
|
||||
很好!我们已经添加了额外的 IP。
|
||||
|
||||
Well then let us ping the IP address to verify.
|
||||
再次 ping IP 地址进行验证。
|
||||
|
||||
sudo ping 192.168.1.104
|
||||
|
||||
**Sample output:**
|
||||
**样例输出:**
|
||||
|
||||
PING 192.168.1.104 (192.168.1.104) 56(84) bytes of data.
|
||||
64 bytes from 192.168.1.104: icmp_seq=1 ttl=64 time=0.137 ms
|
||||
@ -213,21 +213,21 @@ Well then let us ping the IP address to verify.
|
||||
64 bytes from 192.168.1.104: icmp_seq=3 ttl=64 time=0.054 ms
|
||||
64 bytes from 192.168.1.104: icmp_seq=4 ttl=64 time=0.067 ms
|
||||
|
||||
Voila! It’s working. That’s it.
|
||||
好极了!它能正常工作。就是这样。
|
||||
|
||||
Want to know how to add additional IP addresses on CentOS/RHEL/Scientific Linux/Fedora systems, check the following link.
|
||||
想知道怎么给 CentOS/RHEL/Scientific Linux/Fedora 系统添加额外的 IP 地址,可以点击下面的链接。
|
||||
|
||||
注:此篇文章以前做过选题:20150205 Linux Basics--Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7.md
|
||||
- [Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7][1]
|
||||
|
||||
Happy weekend!
|
||||
周末愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/assign-multiple-ip-addresses-to-one-interface-on-ubuntu-15-10/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,327 @@
|
||||
|
||||
如何在FreeBSD 10.2上安装Nginx作为Apache的反向代理
|
||||
================================================================================
|
||||
Nginx是一款免费的,开源的HTTP和反向代理服务器, 以及一个代理POP3/IMAP的邮件服务器. Nginx是一款高性能的web服务器,其特点是丰富的功能,简单的结构以及低内存的占用. 第一个版本由 Igor Sysoev在2002年发布,然而到现在为止很多大的科技公司都在使用,包括 Netflix, Github, Cloudflare, WordPress.com等等
|
||||
|
||||
在这篇教程里我们会 "**在freebsd 10.2系统上,安装和配置Nginx网络服务器作为Apache的反向代理**". Apache 会用PHP在8080端口上运行,并且我们需要在80端口配置Nginx的运行,用来接收用户/访问者的请求.如果网页的用户请求来自于浏览器的80端口, 那么Nginx会用Apache网络服务器和PHP来通过这个请求,并运行在8080端口.
|
||||
|
||||
#### 前提条件 ####
|
||||
|
||||
- FreeBSD 10.2.
|
||||
- Root 权限.
|
||||
|
||||
### 步骤 1 - 更新系统 ###
|
||||
|
||||
使用SSH证书登录到你的FreeBSD服务器以及使用下面命令来更新你的系统 :
|
||||
|
||||
freebsd-update fetch
|
||||
freebsd-update install
|
||||
|
||||
### 步骤 2 - 安装 Apache ###
|
||||
|
||||
Apache是现在使用范围最广的网络服务器以及开源的HTTP服务器.在FreeBSD里Apache是未被默认安装的, 但是我们可以直接从端口下载,或者解压包在"/usr/ports/www/apache24" 目录下,再或者直接从PKG命令的FreeBSD系统信息库安装。在本教程中,我们将使用PKG命令从FreeBSD的库中安装:
|
||||
|
||||
pkg install apache24
|
||||
|
||||
### 步骤 3 - 安装 PHP ###
|
||||
|
||||
一旦成功安装Apache, 接着将会安装PHP并由一个用户处理一个PHP的文件请求. 我们将会用到如下的PKG命令来安装PHP :
|
||||
|
||||
pkg install php56 mod_php56 php56-mysql php56-mysqli
|
||||
|
||||
### 步骤 4 - 配置 Apache 和 PHP ###
|
||||
|
||||
一旦所有都安装好了, 我们将会配置Apache在8080端口上运行, 并让PHP与Apache一同工作. 为了配置Apache,我们可以编辑 "httpd.conf"这个配置文件, 然而PHP我们只需要复制PHP的配置文件 php.ini 在 "/usr/local/etc/"目录下.
|
||||
|
||||
进入到 "/usr/local/etc/" 目录 并且复制 php.ini-production 文件到 php.ini :
|
||||
|
||||
cd /usr/local/etc/
|
||||
cp php.ini-production php.ini
|
||||
|
||||
下一步, 在Apache目录下通过编辑 "httpd.conf"文件来配置Apache :
|
||||
|
||||
cd /usr/local/etc/apache24
|
||||
nano -c httpd.conf
|
||||
|
||||
端口配置在第 **52**行 :
|
||||
|
||||
Listen 8080
|
||||
|
||||
服务器名称配置在第 **219** 行:
|
||||
|
||||
ServerName 127.0.0.1:8080
|
||||
|
||||
在第 **277**行,如果目录需要,添加的DirectoryIndex文件,Apache将直接作用于它 :
|
||||
|
||||
DirectoryIndex index.php index.html
|
||||
|
||||
在第 **287**行下,配置Apache通过添加脚本来支持PHP :
|
||||
|
||||
<FilesMatch "\.php$">
|
||||
SetHandler application/x-httpd-php
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.phps$">
|
||||
SetHandler application/x-httpd-php-source
|
||||
</FilesMatch>
|
||||
|
||||
保存然后退出.
|
||||
|
||||
现在用sysrc命令,来添加Apache作为开机启动项目 :
|
||||
|
||||
sysrc apache24_enable=yes
|
||||
|
||||
然后用下面的命令测试Apache的配置 :
|
||||
|
||||
apachectl configtest
|
||||
|
||||
如果到这里都没有问题的话,那么就启动Apache吧 :
|
||||
|
||||
service apache24 start
|
||||
|
||||
如果全部完毕, 在"/usr/local/www/apache24/data" 目录下,创建一个phpinfo文件是验证PHP在Apache下完美运行的好方法 :
|
||||
|
||||
cd /usr/local/www/apache24/data
|
||||
echo "<?php phpinfo(); ?>" > info.php
|
||||
|
||||
现在就可以访问 freebsd 的服务器 IP : 192.168.1.123:8080/info.php.
|
||||
|
||||

|
||||
|
||||
Apache 是使用 PHP 在 8080端口下运行的.
|
||||
|
||||
### 步骤 5 - 安装 Nginx ###
|
||||
|
||||
Nginx 以低内存的占用作为一款高性能的web服务器以及反向代理服务器.在这个步骤里,我们将会使用Nginx作为Apache的反向代理, 因此让我们用pkg命令来安装它吧 :
|
||||
|
||||
pkg install nginx
|
||||
|
||||
### 步骤 6 - 配置 Nginx ###
|
||||
|
||||
一旦 Nginx 安装完毕, 在 "**nginx.conf**" 文件里,我们需要做一个新的配置文件来替换掉原来的nginx文件. 更改到 "/usr/local/etc/nginx/"目录下 并且默认备份到 nginx.conf 文件:
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
mv nginx.conf nginx.conf.oroginal
|
||||
|
||||
现在就可以创建一个新的 nginx 配置文件了 :
|
||||
|
||||
nano -c nginx.conf
|
||||
|
||||
然后粘贴下面的配置:
|
||||
|
||||
user www;
|
||||
worker_processes 1;
|
||||
error_log /var/log/nginx/error.log;
|
||||
|
||||
events {
|
||||
worker_connections 1024;
|
||||
}
|
||||
|
||||
http {
|
||||
include mime.types;
|
||||
default_type application/octet-stream;
|
||||
|
||||
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
|
||||
'$status $body_bytes_sent "$http_referer" '
|
||||
'"$http_user_agent" "$http_x_forwarded_for"';
|
||||
access_log /var/log/nginx/access.log;
|
||||
|
||||
sendfile on;
|
||||
keepalive_timeout 65;
|
||||
|
||||
# Nginx cache configuration
|
||||
proxy_cache_path /var/nginx/cache levels=1:2 keys_zone=my-cache:8m max_size=1000m inactive=600m;
|
||||
proxy_temp_path /var/nginx/cache/tmp;
|
||||
proxy_cache_key "$scheme$host$request_uri";
|
||||
|
||||
gzip on;
|
||||
|
||||
server {
|
||||
#listen 80;
|
||||
server_name _;
|
||||
|
||||
location /nginx_status {
|
||||
|
||||
stub_status on;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
# redirect server error pages to the static page /50x.html
|
||||
#
|
||||
error_page 500 502 503 504 /50x.html;
|
||||
location = /50x.html {
|
||||
root /usr/local/www/nginx-dist;
|
||||
}
|
||||
|
||||
# proxy the PHP scripts to Apache listening on 127.0.0.1:8080
|
||||
#
|
||||
location ~ \.php$ {
|
||||
proxy_pass http://127.0.0.1:8080;
|
||||
include /usr/local/etc/nginx/proxy.conf;
|
||||
}
|
||||
}
|
||||
|
||||
include /usr/local/etc/nginx/vhost/*;
|
||||
|
||||
}
|
||||
|
||||
保存退出.
|
||||
|
||||
下一步, 在nginx目录下面,创建一个 **proxy.conf** 文件,使其作为反向代理 :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
nano -c proxy.conf
|
||||
|
||||
粘贴如下配置 :
|
||||
|
||||
proxy_buffering on;
|
||||
proxy_redirect off;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
client_max_body_size 10m;
|
||||
client_body_buffer_size 128k;
|
||||
proxy_connect_timeout 90;
|
||||
proxy_send_timeout 90;
|
||||
proxy_read_timeout 90;
|
||||
proxy_buffers 100 8k;
|
||||
add_header X-Cache $upstream_cache_status;
|
||||
|
||||
保存退出.
|
||||
|
||||
最后一步, 为 nginx 的高速缓存创建一个 "/var/nginx/cache"的新目录 :
|
||||
|
||||
mkdir -p /var/nginx/cache
|
||||
|
||||
### 步骤 7 - 配置 Nginx 的虚拟主机 ###
|
||||
|
||||
在这个步骤里面,我们需要创建一个新的虚拟主机域 "saitama.me", 以跟文件 "/usr/local/www/saitama.me" 和日志文件一同放在 "/var/log/nginx" 目录下.
|
||||
|
||||
我们必须做的第一件事情就是创建新的目录来存放虚拟主机文件, 在这里我们将用到一个"**vhost**"的新文件. 并创建它 :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
mkdir vhost
|
||||
|
||||
创建好vhost 目录, 那么我们就进入这个目录并创建一个新的虚拟主机文件. 这里我取名为 "**saitama.conf**" :
|
||||
|
||||
cd vhost/
|
||||
nano -c saitama.conf
|
||||
|
||||
粘贴如下虚拟主机的配置 :
|
||||
|
||||
server {
|
||||
# Replace with your freebsd IP
|
||||
listen 192.168.1.123:80;
|
||||
|
||||
# Document Root
|
||||
root /usr/local/www/saitama.me;
|
||||
index index.php index.html index.htm;
|
||||
|
||||
# Domain
|
||||
server_name www.saitama.me saitama.me;
|
||||
|
||||
# Error and Access log file
|
||||
error_log /var/log/nginx/saitama-error.log;
|
||||
access_log /var/log/nginx/saitama-access.log main;
|
||||
|
||||
# Reverse Proxy Configuration
|
||||
location ~ \.php$ {
|
||||
proxy_pass http://127.0.0.1:8080;
|
||||
include /usr/local/etc/nginx/proxy.conf;
|
||||
|
||||
# Cache configuration
|
||||
proxy_cache my-cache;
|
||||
proxy_cache_valid 10s;
|
||||
proxy_no_cache $cookie_PHPSESSID;
|
||||
proxy_cache_bypass $cookie_PHPSESSID;
|
||||
proxy_cache_key "$scheme$host$request_uri";
|
||||
|
||||
}
|
||||
|
||||
# Disable Cache for the file type html, json
|
||||
location ~* .(?:manifest|appcache|html?|xml|json)$ {
|
||||
expires -1;
|
||||
}
|
||||
|
||||
# Enable Cache the file 30 days
|
||||
location ~* .(jpg|png|gif|jpeg|css|mp3|wav|swf|mov|doc|pdf|xls|ppt|docx|pptx|xlsx)$ {
|
||||
proxy_cache_valid 200 120m;
|
||||
expires 30d;
|
||||
proxy_cache my-cache;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
保存退出.
|
||||
|
||||
下一步, 为nginx和虚拟主机创建一个新的日志目录 "/var/log/" :
|
||||
|
||||
mkdir -p /var/log/nginx/
|
||||
|
||||
如果一切顺利, 在文件的根目录下创建文件 saitama.me :
|
||||
|
||||
cd /usr/local/www/
|
||||
mkdir saitama.me
|
||||
|
||||
### 步骤 8 - 测试 ###
|
||||
|
||||
在这个步骤里面,我们只是测试我们的nginx和虚拟主机的配置.
|
||||
|
||||
用如下命令测试nginx的配置 :
|
||||
|
||||
nginx -t
|
||||
|
||||
如果一切都没有问题, 用 sysrc 命令添加nginx为启动项,并且启动nginx和重启apache:
|
||||
|
||||
sysrc nginx_enable=yes
|
||||
service nginx start
|
||||
service apache24 restart
|
||||
|
||||
一切完毕后, 在 saitama.me 目录下,添加一个新的phpinfo文件来验证php的正常运行 :
|
||||
|
||||
cd /usr/local/www/saitama.me
|
||||
echo "<?php phpinfo(); ?>" > info.php
|
||||
|
||||
然后便访问这个文档 : **www.saitama.me/info.php**.
|
||||
|
||||

|
||||
|
||||
Nginx 作为Apache的反向代理正在运行了,PHP也同样在进行工作了.
|
||||
|
||||
这是另一种结果 :
|
||||
|
||||
Test .html 文件无缓存.
|
||||
|
||||
curl -I www.saitama.me
|
||||
|
||||

|
||||
|
||||
Test .css 文件只有三十天的缓存.
|
||||
|
||||
curl -I www.saitama.me/test.css
|
||||
|
||||

|
||||
|
||||
Test .php 文件正常缓存 :
|
||||
|
||||
curl -I www.saitama.me/info.php
|
||||
|
||||

|
||||
|
||||
全部完成.
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Nginx 是最广泛的 HTTP 和反向代理的服务器. 拥有丰富的高性能和低内存/RAM的使用功能. Nginx使用了太多的缓存, 我们可以在网络上缓存静态文件使得网页加速, 并且在用户需要的时候再缓存php文件. 这样Nginx 的轻松配置和使用,可以让它用作HTTP服务器 或者 apache的反向代理.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-nginx-reverse-proxy-apache-freebsd-10-2/
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[KnightJoker](https://github.com/KnightJoker)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arulm/
|
||||
@ -0,0 +1,39 @@
|
||||
# 使用SystemBack备份你的Ubuntu/Linux Mint(系统还原)
|
||||
|
||||
系统还原对于任何一款允许用户还原电脑到之前状态(包括文件系统,安装的应用,以及系统设置)的操作系统来说,都是必备功能,可以处理系统故障以及其他的问题。有的时候安装一个程序或者驱动可能让你的系统黑屏。系统还原则让你电脑里面的系统文件(译者注:是系统文件,并非普通文件,详情请看**注意**部分)和程序恢复到之前工作正常时候的状态,进而让你远离那让人头痛的排障过程了。而且它也不会影响你的文件,照片或者其他数据。简单的系统备份还原工具[Systemback](https://launchpad.net/systemback)让你很容易地创建系统备份以及用户配置文件。如果遇到问题,你可以傻瓜式还原。它还有一些额外的特征包括系统复制,系统安装以及Live系统创建。
|
||||
|
||||
截图
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**注意**:使用系统还原不会还原你的文件,音乐,电子邮件或者其他任何类型的私人文件。对不同用户来讲,这既是优点又是缺点。坏消息是它不会还原你意外删除的文件,不过你可以通过一个文件恢复程序来解决这个问题。如果你的计算机上没有系统还原点,那么系统还原工具就不会奏效了。(最后一句没有太理解)
|
||||
|
||||
> > >适用于Ubuntu 15.10 Wily/16.04/15.04 Vivid/14.04 Trusty/Linux Mint 14.x/其他Ubuntu衍生版,打开终端,将下面这些命令复制过去:
|
||||
|
||||
终端命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nemh/systemback
|
||||
sudo apt-get update
|
||||
sudo apt-get install systemback
|
||||
|
||||
```
|
||||
|
||||
大功告成。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.noobslab.com/2015/11/backup-system-restore-point-your.html
|
||||
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://launchpad.net/systemback
|
||||
@ -0,0 +1,148 @@
|
||||
如何在命令行中使用ftp命令上传和下载文件
|
||||
================================================================================
|
||||
本文中,介绍在Linux shell中如何使用ftp命令。包括如何连接FTP服务器,上传或下载文件以及创建文件夹。尽管现在有许多不错的FTP桌面应用,但是在服务器、ssh、远程回话中命令行ftp命令还是有很多应用的。比如。需要服务器从ftp仓库拉取备份。
|
||||
|
||||
### 步骤 1: 建立FTP连接 ###
|
||||
|
||||
|
||||
想要连接FTP服务器,在命令上中先输入'**ftp**'然后空格跟上FTP服务器的域名'domain.com'或者IP地址
|
||||
|
||||
#### 例如: ####
|
||||
|
||||
ftp domain.com
|
||||
|
||||
ftp 192.168.0.1
|
||||
|
||||
ftp user@ftpdomain.com
|
||||
|
||||
**注意: 本次例子使用匿名服务器.**
|
||||
|
||||
替换下面例子中IP或域名为你的服务器地址。
|
||||
|
||||

|
||||
|
||||
### 步骤 2: 使用用户名密码登录 ###
|
||||
|
||||
绝大多数的FTP服务器是使用密码保护的,因此这些FTP服务器会询问'**用户名**'和'**密码**'.
|
||||
|
||||
如果你连接到被动匿名FTP服务器,可以尝试"anonymous"作为用户名以及空密码:
|
||||
|
||||
Name: anonymous
|
||||
|
||||
Password:
|
||||
|
||||
之后,终端会返回如下的信息:
|
||||
|
||||
230 Login successful.
|
||||
Remote system type is UNIX.
|
||||
Using binary mode to transfer files.
|
||||
ftp>
|
||||
|
||||
登录成功。
|
||||
|
||||

|
||||
|
||||
### 步骤 3: 目录操作 ###
|
||||
|
||||
FTP命令可以列出、移动和创建文件夹,如同我们在本地使用我们的电脑一样。ls可以打印目录列表,cd可以改变目录,mkdir可以创建文件夹。
|
||||
|
||||
#### 使用安全设置列出目录 ####
|
||||
|
||||
|
||||
ftp> ls
|
||||
|
||||
服务器将返回:
|
||||
|
||||
200 PORT command successful. Consider using PASV.
|
||||
150 Here comes the directory listing.
|
||||
directory list
|
||||
....
|
||||
....
|
||||
226 Directory send OK.
|
||||
|
||||

|
||||
|
||||
#### 改变目录: ####
|
||||
|
||||
改变目录可以输入:
|
||||
|
||||
ftp> cd directory
|
||||
|
||||
服务器将会返回:
|
||||
|
||||
250 Directory succesfully changed.
|
||||
|
||||

|
||||
|
||||
### 步骤 4: 使用FTP下载文件 ###
|
||||
|
||||
在下载一个文件之前,我们首先需要使用lcd命令设定本地接受目录位置。
|
||||
|
||||
lcd /home/user/yourdirectoryname
|
||||
|
||||
如果你不指定下载目录,文件将会下载到你登录FTP时候的工作目录。
|
||||
|
||||
现在,我们可以使用命令get来下载文件,比如:
|
||||
|
||||
get file
|
||||
|
||||
文件会保存在使用lcd命令设置的目录位置。
|
||||
|
||||
服务器返回消息:
|
||||
|
||||
local: file remote: file
|
||||
200 PORT command successful. Consider using PASV.
|
||||
150 Opening BINARY mode data connection for file (xxx bytes).
|
||||
226 File send OK.
|
||||
XXX bytes received in x.xx secs (x.xxx MB/s).
|
||||
|
||||

|
||||
|
||||
下载多个文件可以使用通配符。例如,下面这个例子我打算下载所有以.xls结尾的文件。
|
||||
|
||||
mget *.xls
|
||||
|
||||
### 步骤 5: 使用FTP上传文件 ###
|
||||
|
||||
完成FTP连接后,FTP同样可以上传文件
|
||||
|
||||
使用put命令上传文件:
|
||||
|
||||
put file
|
||||
|
||||
当文件不再当前本地目录下的时候,可以使用绝对路径:
|
||||
|
||||
put /path/file
|
||||
|
||||
同样,可以上传多个文件:
|
||||
|
||||
mput *.xls
|
||||
|
||||
### 步骤 6: 关闭FTP连接 ###
|
||||
|
||||
完成FTP工作后,为了安全起见需要关闭连接。有三个命令可以关闭连接:
|
||||
|
||||
bye
|
||||
|
||||
exit
|
||||
|
||||
quit
|
||||
|
||||
任意一个命令可以断开FTP服务器连接并返回:
|
||||
|
||||
221 Goodbye
|
||||
|
||||

|
||||
|
||||
需要更多帮助,在使用ftp命令连接到服务器后,可以使用“help”获得更多帮助。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-use-ftp-on-the-linux-shell/
|
||||
|
||||
译者:[VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,58 @@
|
||||
如何更新ISPConfig 3 SSL证书
|
||||
================================================================================
|
||||
本教程描述了如何再ISPConfig 3控制面板中更新SSL证书。有两个可选的方法:
|
||||
|
||||
- 用OpenSSL创建一个新的OpenSSL证书和CSR。
|
||||
- 用ISPConfig updater更新SSL证书
|
||||
|
||||
我将会用手工的方法更新ssl证书。
|
||||
|
||||
### 1)用OpenSSL创建一个新的ISPConfig 3 SSL 证书 ###
|
||||
|
||||
用root用户登录你的服务器。在创建一个新的SSL证书之前,备份现有的。SSL证书是安全敏感的,因此我将它存储在/root/目录下。
|
||||
|
||||
tar pcfz /root/ispconfig_ssl_backup.tar.gz /usr/local/ispconfig/interface/ssl
|
||||
chmod 600 /root/ispconfig_ssl_backup.tar.gz
|
||||
|
||||
> 现在创建一个新的SSL证书密钥,证书请求(csr)和自签发证书。
|
||||
|
||||
cd /usr/local/ispconfig/interface/ssl
|
||||
openssl genrsa -des3 -out ispserver.key 4096
|
||||
openssl req -new -key ispserver.key -out ispserver.csr
|
||||
openssl x509 -req -days 3650 -in ispserver.csr \
|
||||
-signkey ispserver.key -out ispserver.crt
|
||||
openssl rsa -in ispserver.key -out ispserver.key.insecure
|
||||
mv ispserver.key ispserver.key.secure
|
||||
mv ispserver.key.insecure ispserver.key
|
||||
|
||||
重启apache来加载新的SSL证书
|
||||
|
||||
service apache2 restart
|
||||
|
||||
### 2)用ISPConfig安装器来更新SSL证书 ###
|
||||
|
||||
另一个获取新的SSL证书的替代方案是使用ISPConfig更新脚本。下载ISPConfig到/tmp目录下,解压包并运行脚本。
|
||||
|
||||
cd /tmp
|
||||
wget http://www.ispconfig.org/downloads/ISPConfig-3-stable.tar.gz
|
||||
tar xvfz ISPConfig-3-stable.tar.gz
|
||||
cd ispconfig3_install/install
|
||||
php -q update.php
|
||||
|
||||
更新脚本会在更新时询问下面的额问题:
|
||||
|
||||
Create new ISPConfig SSL certificate (yes,no) [no]:
|
||||
|
||||
这里回答“yes”,SSL证书创建对话框就会启动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.faqforge.com/linux/how-to-renew-the-ispconfig-3-ssl-certificate/
|
||||
|
||||
作者:[Till][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.faqforge.com/author/till/
|
||||
@ -0,0 +1,62 @@
|
||||
|
||||
在 Centos/RHEL 6.X 上安装 Wetty
|
||||
================================================================================
|
||||

|
||||
|
||||
Wetty 是什么?
|
||||
|
||||
作为系统管理员,如果你是在 Linux 桌面下,你可能会使用一个软件来连接远程服务器,像 GNOME 终端(或类似的),如果你是在 Windows 下,你可能会使用像 Putty 这样的 SSH 客户端来连接,并同时可以在浏览器中查收邮件等做其他事情。
|
||||
|
||||
### 第1步: 安装 epel 源 ###
|
||||
|
||||
# wget http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
|
||||
# rpm -ivh epel-release-6-8.noarch.rpm
|
||||
|
||||
### 第2步:安装依赖 ###
|
||||
|
||||
# yum install epel-release git nodejs npm -y
|
||||
|
||||
### 第3步:在安装完依赖后,克隆 GitHub 仓库 ###
|
||||
|
||||
# git clone https://github.com/krishnasrinivas/wetty
|
||||
|
||||
### 第4步:运行 Wetty ###
|
||||
|
||||
# cd wetty
|
||||
# npm install
|
||||
|
||||
### 第5步:从 Web 浏览器启动 Wetty 并访问 Linux 终端 ###
|
||||
|
||||
# node app.js -p 8080
|
||||
|
||||
### 第6步:为 Wetty 安装 HTTPS 证书 ###
|
||||
|
||||
# openssl req -x509 -newkey rsa:2048 -keyout key.pem -out cert.pem -days 365 -nodes (complete this)
|
||||
|
||||
### Step 7: 通过 HTTPS 来使用 Wetty ###
|
||||
|
||||
# nohup node app.js --sslkey key.pem --sslcert cert.pem -p 8080 &
|
||||
|
||||
### Step 8: 为 wetty 添加一个用户 ###
|
||||
|
||||
# useradd <username>
|
||||
# Passwd <username>
|
||||
|
||||
### 第9步:访问 wetty ###
|
||||
|
||||
http://Your_IP-Address:8080
|
||||
give the credential have created before for wetty and access
|
||||
|
||||
到此结束!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-wetty-centosrhel-6-x/
|
||||
|
||||
作者:[Debojyoti Das][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/debjyoti/
|
||||
@ -0,0 +1,288 @@
|
||||
## grep 中的正则表达式
|
||||
================================================================================
|
||||
在 Linux 、类 Unix 系统中我该如何使用 Grep 命令的正则表达式呢?
|
||||
|
||||
Linux 附带有 GNU grep 命令工具,它支持正则表达式,而且 GNU grep 在所有的 Linux 系统中都是默认有的。Grep 命令被用于搜索定位存储在您服务器或工作站的信息。
|
||||
|
||||
### 正则表达式 ###
|
||||
|
||||
正则表达式仅仅是对每个输入行的匹配的一种模式,即对字符序列的匹配模式。下面是范例:
|
||||
|
||||
^w1
|
||||
w1|w2
|
||||
[^ ]
|
||||
|
||||
#### grep 正则表达式示例 ####
|
||||
|
||||
在 /etc/passswd 目录中搜索 'vivek'
|
||||
|
||||
grep vivek /etc/passwd
|
||||
|
||||
输出例子:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
gitevivek:x:1002:1002::/home/gitevivek:/bin/sh
|
||||
|
||||
摸索任何情况下的 vivek(即不区分大小写的搜索)
|
||||
|
||||
grep -i -w vivek /etc/passwd
|
||||
|
||||
摸索任何情况下的 vivek 或 raj
|
||||
|
||||
grep -E -i -w 'vivek|raj' /etc/passwd
|
||||
|
||||
上面最后的例子显示的,就是一个正则表达式扩展的模式。
|
||||
|
||||
### 锚 ###
|
||||
|
||||
你可以分别使用 ^ 和 $ 符号来正则匹配输入行的开始或结尾。下面的例子搜索显示仅仅以 vivek 开始的输入行:
|
||||
|
||||
grep ^vivek /etc/passwd
|
||||
|
||||
输出例子:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
|
||||
你可以仅仅只搜索出以单词 vivek 开始的行,即不显示 vivekgit、vivekg 等
|
||||
|
||||
grep -w ^vivek /etc/passwd
|
||||
|
||||
找出以单词 word 结尾的行:
|
||||
|
||||
grep 'foo$' 文件名
|
||||
|
||||
匹配仅仅只包含 foo 的行:
|
||||
|
||||
grep '^foo$' 文件名
|
||||
|
||||
如下所示的例子可以搜索空行:
|
||||
|
||||
grep '^$' 文件名
|
||||
|
||||
### 字符类 ###
|
||||
|
||||
匹配 Vivek 或 vivek:
|
||||
|
||||
grep '[vV]ivek' 文件名
|
||||
|
||||
或者
|
||||
|
||||
grep '[vV][iI][Vv][Ee][kK]' 文件名
|
||||
|
||||
也可以匹配数字 (即匹配 vivek1 或 Vivek2 等等):
|
||||
|
||||
grep -w '[vV]ivek[0-9]' 文件名
|
||||
|
||||
可以匹配两个数字字符(即 foo11、foo12 等):
|
||||
|
||||
grep 'foo[0-9][0-9]' 文件名
|
||||
|
||||
不仅仅局限于数字,也能匹配至少一个字母的:
|
||||
|
||||
grep '[A-Za-z]' 文件名
|
||||
|
||||
显示含有"w" 或 "n" 字符的所有行:
|
||||
|
||||
grep [wn] 文件名
|
||||
|
||||
在括号内的表达式,即包在"[:" 和 ":]" 之间的字符类的名字,它表示的是属于此类的所有字符列表。标准的字符类名称如下:
|
||||
|
||||
- [:alnum:] - 字母数字字符.
|
||||
- [:alpha:] - 字母字符
|
||||
- [:blank:] - 空字符: 空格键符 和 制表符.
|
||||
- [:digit:] - 数字: '0 1 2 3 4 5 6 7 8 9'.
|
||||
- [:lower:] - 小写字母: 'a b c d e f g h i j k l m n o p q r s t u v w x y z'.
|
||||
- [:space:] - 空格字符: 制表符、换行符、垂直制表符、换页符、回车符和空格键符.
|
||||
- [:upper:] - 大写字母: 'A B C D E F G H I J K L M N O P Q R S T U V W X Y Z'.
|
||||
|
||||
例子所示的是匹配所有大写字母:
|
||||
|
||||
grep '[:upper:]' 文件名
|
||||
|
||||
### 通配符 ###
|
||||
|
||||
你可以使用 "." 来匹配单个字符。例子中匹配以"b"开头以"t"结尾的3个字符的单词:
|
||||
|
||||
grep '\<b.t\>' 文件名
|
||||
|
||||
在这儿,
|
||||
|
||||
- \< 匹配单词前面的空字符串
|
||||
- \> 匹配单词后面的空字符串
|
||||
|
||||
打印出只有两个字符的所有行:
|
||||
|
||||
grep '^..$' 文件名
|
||||
|
||||
显示以一个点和一个数字开头的行:
|
||||
|
||||
grep '^\.[0-9]' 文件名
|
||||
|
||||
#### 点号转义 ####
|
||||
|
||||
下面要匹配到 IP 地址为 192.168.1.254 的正则式是不会工作的:
|
||||
|
||||
egrep '192.168.1.254' /etc/hosts
|
||||
|
||||
三个点符号都需要转义:
|
||||
|
||||
grep '192\.168\.1\.254' /etc/hosts
|
||||
|
||||
下面的例子仅仅匹配出 IP 地址:
|
||||
|
||||
egrep '[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}' 文件名
|
||||
|
||||
下面的例子会匹配任意大小写的 Linux 或 UNIX 这两个单词:
|
||||
|
||||
egrep -i '^(linux|unix)' 文件名
|
||||
|
||||
### 怎么样搜索以 - 符号开头的匹配模式? ###
|
||||
|
||||
要使用 -e 选项来搜索匹配 '--test--' 字符串,如果不使用 -e 选项,grep 命令会试图把 '--test--' 当作自己的选项参数来解析:
|
||||
|
||||
grep -e '--test--' 文件名
|
||||
|
||||
### 怎么使用 grep 的 OR 匹配? ###
|
||||
|
||||
使用如下的语法:
|
||||
|
||||
grep 'word1|word2' 文件名
|
||||
|
||||
或者是
|
||||
|
||||
grep 'word1\|word2' 文件名
|
||||
|
||||
### 怎么使用 grep 的 AND 匹配? ###
|
||||
|
||||
使用下面的语法来显示既包含 'word1' 又包含 'word2' 的所有行
|
||||
|
||||
grep 'word1' 文件名 | grep 'word2'
|
||||
|
||||
### 怎么样使用序列检测? ###
|
||||
|
||||
使用如下的语法,您可以检测一个字符在序列中重复出现次数:
|
||||
|
||||
{N}
|
||||
{N,}
|
||||
{min,max}
|
||||
|
||||
要匹配字符 “v" 出现两次:
|
||||
|
||||
egrep "v{2}" 文件名
|
||||
|
||||
下面的命令能匹配到 "col" 和 "cool" :
|
||||
|
||||
egrep 'co{1,2}l' 文件名
|
||||
|
||||
下面的命令将会匹配出至少有三个 'c' 字符的所有行。
|
||||
|
||||
egrep 'c{3,}' 文件名
|
||||
|
||||
下面的例子会匹配 91-1234567890(即二个数字-十个数字) 这种格式的手机号。
|
||||
|
||||
grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}" 文件名
|
||||
|
||||
### 怎么样使 grep 命令突出显示?###
|
||||
|
||||
使用如下的语法:
|
||||
|
||||
grep --color regex 文件名
|
||||
|
||||
### 怎么样仅仅只显示匹配出的字符,而不是匹配出的行? ###
|
||||
|
||||
使用如下语法:
|
||||
|
||||
grep -o regex 文件名
|
||||
|
||||
### 正则表达式限定符###
|
||||
|
||||
注:表格
|
||||
<table border=1>
|
||||
<tr>
|
||||
<th>限定符</th>
|
||||
<th>描述</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>.</td>
|
||||
<td>匹配任意的一个字符.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>?</td>
|
||||
<td>匹配前面的子表达式,最多一次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>*</td>
|
||||
<td>匹配前面的子表达式零次或多次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>+</td>
|
||||
<td>匹配前面的子表达式一次或多次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N}</td>
|
||||
<td>匹配前面的子表达式 N 次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,}</td>
|
||||
<td>匹配前面的子表达式 N 次到多次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,M}</td>
|
||||
<td>匹配前面的子表达式 N 到 M 次,至少 N 次至多 M 次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>-</td>
|
||||
<td>只要不是在序列开始、结尾或者序列的结束点上,表示序列范围</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>^</td>
|
||||
<td>匹配一行开始的空字符串;也表示字符不在要匹配的列表中。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>$</td>
|
||||
<td>匹配一行末尾的空字符串。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\b</td>
|
||||
<td>匹配一个单词前后的空字符串。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\B</td>
|
||||
<td>匹配一个单词中间的空字符串</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\<</td>
|
||||
<td>匹配单词前面的空字符串。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\></td>
|
||||
<td> 匹配单词后面的空字符串。</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
#### grep 和 egrep ####
|
||||
|
||||
egrep 跟 **grep -E** 是一样的。他会以正则表达式的模式来解释。下面是 grep 的帮助页(man):
|
||||
|
||||
基本的正则表达式元字符 ?、+、 {、 |、 ( 和 ) 已经失去了他们特殊的意义,要使用的话用反斜线的版本 \?、\+、\{、\|、\( 和 \) 来代替。
|
||||
传统的 egrep 不支持 { 元字符,一些 egrep 的实现是以 \{ 替代的,所以有 grep -E 的通用脚本应该避免使用 { 符号,要匹配字面的 { 应该使用 [}]。
|
||||
GNU grep -E 试图支持传统的用法,如果 { 出在在无效的间隔规范字符串这前,它就会假定 { 不是特殊字符。
|
||||
例如,grep -E '{1' 命令搜索包含 {1 两个字符的串,而不会报出正则表达式语法错误。
|
||||
POSIX.2 标准允许对这种操作的扩展,但在可移植脚本文件里应该避免这样使用。
|
||||
|
||||
引用:
|
||||
|
||||
- grep 和 regex 帮助手册页(7)
|
||||
- grep 的 info 页`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/grep-regular-expressions/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user