mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
commit
c715af888b
published
20160604 How to Build Your First Slack Bot with Python.md20160913 Monitoring Docker Containers with Elasticsearch and cAdvisor.md
sources
talk
tech
translated/tech
20160604 How to Build Your First Slack Bot with Python.md20160622 Part III - How to apply Advanced Mathematical Processing Effects on Audio files with Octave 4.0 on Ubuntu.md20160823 The infrastructure behind Twitter - efficiency and optimization.md20160913 Monitoring Docker Containers with Elasticsearch and cAdvisor.md
317
published/20160604 How to Build Your First Slack Bot with Python.md
Executable file
317
published/20160604 How to Build Your First Slack Bot with Python.md
Executable file
@ -0,0 +1,317 @@
|
||||
如何运用 Python 建立你的第一个 Slack 聊天机器人?
|
||||
============
|
||||
|
||||
[聊天机器人(Bot)](https://www.fullstackpython.com/bots.html) 是一种像 [Slack](https://slack.com/) 一样的实用的互动聊天服务方式。如果你之前从来没有建立过聊天机器人,那么这篇文章提供了一个简单的入门指南,告诉你如何用 Python 结合 [Slack API](https://api.slack.com/) 建立你第一个聊天机器人。
|
||||
|
||||
我们通过搭建你的开发环境, 获得一个 Slack API 的聊天机器人令牌,并用 Pyhon 开发一个简单聊天机器人。
|
||||
|
||||
### 我们所需的工具
|
||||
|
||||
我们的聊天机器人我们将它称作为“StarterBot”,它需要 Python 和 Slack API。要运行我们的 Python 代码,我们需要:
|
||||
|
||||
* [Python 2 或者 Python 3](https://www.fullstackpython.com/python-2-or-3.html)
|
||||
* [pip](https://pip.pypa.io/en/stable/) 和 [virtualenv](https://virtualenv.pypa.io/en/stable/) 来处理 Python [应用程序依赖关系](https://www.fullstackpython.com/application-dependencies.html)
|
||||
* 一个可以访问 API 的[免费 Slack 账号](https://slack.com/),或者你可以注册一个 [Slack Developer Hangout team](http://dev4slack.xoxco.com/)。
|
||||
* 通过 Slack 团队建立的官方 Python [Slack 客户端](https://github.com/slackhq/python-slackclient)代码库
|
||||
* [Slack API 测试令牌](https://api.slack.com/tokens)
|
||||
|
||||
当你在本教程中进行构建时,[Slack API 文档](https://api.slack.com/) 是很有用的。
|
||||
|
||||
本教程中所有的代码都放在 [slack-starterbot](https://github.com/mattmakai/slack-starterbot) 公共库里,并以 MIT 许可证开源。
|
||||
|
||||
### 搭建我们的环境
|
||||
|
||||
我们现在已经知道我们的项目需要什么样的工具,因此让我们来搭建我们所的开发环境吧。首先到终端上(或者 Windows 上的命令提示符)并且切换到你想要存储这个项目的目录。在那个目录里,创建一个新的 virtualenv 以便和其他的 Python 项目相隔离我们的应用程序依赖关系。
|
||||
|
||||
```
|
||||
virtualenv starterbot
|
||||
|
||||
```
|
||||
|
||||
激活 virtualenv:
|
||||
|
||||
```
|
||||
source starterbot/bin/activate
|
||||
|
||||
```
|
||||
|
||||
你的提示符现在应该看起来如截图:
|
||||
|
||||

|
||||
|
||||
这个官方的 slack 客户端 API 帮助库是由 Slack 建立的,它可以通过 Slack 通道发送和接收消息。通过这个 `pip` 命令安装 slackclient 库:
|
||||
|
||||
```
|
||||
pip install slackclient
|
||||
|
||||
```
|
||||
|
||||
当 `pip` 命令完成时,你应该看到类似这样的输出,并返回提示符。
|
||||
|
||||

|
||||
|
||||
我们也需要为我们的 Slack 项目获得一个访问令牌,以便我们的聊天机器人可以用它来连接到 Slack API。
|
||||
|
||||
### Slack 实时消息传递(RTM)API
|
||||
|
||||
Slack 允许程序通过一个 [Web API](https://www.fullstackpython.com/application-programming-interfaces.html) 来访问他们的消息传递通道。去这个 [Slack Web API 页面](https://api.slack.com/) 注册建立你自己的 Slack 项目。你也可以登录一个你拥有管理权限的已有账号。
|
||||
|
||||

|
||||
|
||||
登录后你会到达 [聊天机器人用户页面](https://api.slack.com/bot-users)。
|
||||
|
||||

|
||||
|
||||
给你的聊天机器人起名为“starterbot”然后点击 “Add bot integration” 按钮。
|
||||
|
||||

|
||||
|
||||
这个页面将重新加载,你将看到一个新生成的访问令牌。你还可以将标志改成你自己设计的。例如我给的这个“Full Stack Python”标志。
|
||||
|
||||

|
||||
|
||||
在页面底部点击“Save Integration”按钮。你的聊天机器人现在已经准备好连接 Slack API。
|
||||
|
||||
Python 开发人员的一个常见的做法是以环境变量输出秘密令牌。输出的 Slack 令牌名字为`SLACK_BOT_TOKEN`:
|
||||
|
||||
```
|
||||
export SLACK_BOT_TOKEN='你的 slack 令牌粘帖在这里'
|
||||
|
||||
```
|
||||
|
||||
好了,我们现在得到了将这个 Slack API 用作聊天机器人的授权。
|
||||
|
||||
我们建立聊天机器人还需要更多信息:我们的聊天机器人的 ID。接下来我们将会写一个简短的脚本,从 Slack API 获得该 ID。
|
||||
|
||||
### 获得我们聊天机器人的 ID
|
||||
|
||||
这是最后写一些 Python 代码的时候了! 我们编写一个简短的 Python 脚本获得 StarterBot 的 ID 来热身一下。这个 ID 基于 Slack 项目而不同。
|
||||
|
||||
我们需要该 ID,当解析从 Slack RTM 上发给 StarterBot 的消息时,它用于对我们的应用验明正身。我们的脚本也会测试我们 `SLACK_BOT_TOKEN` 环境变量是否设置正确。
|
||||
|
||||
建立一个命名为 print_bot_id.py 的新文件,并且填入下面的代码:
|
||||
|
||||
```
|
||||
import os
|
||||
from slackclient import SlackClient
|
||||
|
||||
|
||||
BOT_NAME = 'starterbot'
|
||||
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
api_call = slack_client.api_call("users.list")
|
||||
if api_call.get('ok'):
|
||||
# retrieve all users so we can find our bot
|
||||
users = api_call.get('members')
|
||||
for user in users:
|
||||
if 'name' in user and user.get('name') == BOT_NAME:
|
||||
print("Bot ID for '" + user['name'] + "' is " + user.get('id'))
|
||||
else:
|
||||
print("could not find bot user with the name " + BOT_NAME)
|
||||
|
||||
```
|
||||
|
||||
我们的代码导入 SlackClient,并用我们设置的环境变量 `SLACK_BOT_TOKEN` 实例化它。 当该脚本通过 python 命令执行时,我们通过会访问 Slack API 列出所有的 Slack 用户并且获得匹配一个名字为“satrterbot”的 ID。
|
||||
|
||||
这个获得聊天机器人的 ID 的脚本我们仅需要运行一次。
|
||||
|
||||
```
|
||||
python print_bot_id.py
|
||||
|
||||
```
|
||||
|
||||
当它运行为我们提供了聊天机器人的 ID 时,脚本会打印出简单的一行输出。
|
||||
|
||||

|
||||
|
||||
复制这个脚本打印出的唯一 ID。并将该 ID 作为一个环境变量 `BOT_ID` 输出。
|
||||
|
||||
```
|
||||
(starterbot)$ export BOT_ID='bot id returned by script'
|
||||
|
||||
```
|
||||
|
||||
这个脚本仅仅需要运行一次来获得聊天机器人的 ID。 我们现在可以在我们的运行 StarterBot 的 Python应用程序中使用这个 ID 。
|
||||
|
||||
### 编码我们的 StarterBot
|
||||
|
||||
现在我们拥有了写我们的 StarterBot 代码所需的一切。 创建一个新文件命名为 starterbot.py ,它包括以下代码。
|
||||
|
||||
```
|
||||
import os
|
||||
import time
|
||||
from slackclient import SlackClient
|
||||
|
||||
```
|
||||
|
||||
对 `os` 和 `SlackClient` 的导入我们看起来很熟悉,因为我们已经在 theprint_bot_id.py 中用过它们了。
|
||||
|
||||
通过我们导入的依赖包,我们可以使用它们获得环境变量值,并实例化 Slack 客户端。
|
||||
|
||||
```
|
||||
# starterbot 的 ID 作为一个环境变量
|
||||
BOT_ID = os.environ.get("BOT_ID")
|
||||
|
||||
# 常量
|
||||
AT_BOT = "<@" + BOT_ID + ">:"
|
||||
EXAMPLE_COMMAND = "do"
|
||||
|
||||
# 实例化 Slack 和 Twilio 客户端
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
```
|
||||
|
||||
该代码通过我们以输出的环境变量 `SLACK_BOT_TOKEN 实例化 `SlackClient` 客户端。
|
||||
|
||||
```
|
||||
if __name__ == "__main__":
|
||||
READ_WEBSOCKET_DELAY = 1 # 1 从 firehose 读取延迟 1 秒
|
||||
if slack_client.rtm_connect():
|
||||
print("StarterBot connected and running!")
|
||||
while True:
|
||||
command, channel = parse_slack_output(slack_client.rtm_read())
|
||||
if command and channel:
|
||||
handle_command(command, channel)
|
||||
time.sleep(READ_WEBSOCKET_DELAY)
|
||||
else:
|
||||
print("Connection failed. Invalid Slack token or bot ID?")
|
||||
|
||||
```
|
||||
|
||||
Slack 客户端会连接到 Slack RTM API WebSocket,然后当解析来自 firehose 的消息时会不断循环。如果有任何发给 StarterBot 的消息,那么一个被称作 `handle_command` 的函数会决定做什么。
|
||||
|
||||
接下来添加两个函数来解析 Slack 的输出并处理命令。
|
||||
|
||||
```
|
||||
def handle_command(command, channel):
|
||||
"""
|
||||
Receives commands directed at the bot and determines if they
|
||||
are valid commands. If so, then acts on the commands. If not,
|
||||
returns back what it needs for clarification.
|
||||
"""
|
||||
response = "Not sure what you mean. Use the *" + EXAMPLE_COMMAND + \
|
||||
"* command with numbers, delimited by spaces."
|
||||
if command.startswith(EXAMPLE_COMMAND):
|
||||
response = "Sure...write some more code then I can do that!"
|
||||
slack_client.api_call("chat.postMessage", channel=channel,
|
||||
text=response, as_user=True)
|
||||
|
||||
def parse_slack_output(slack_rtm_output):
|
||||
"""
|
||||
The Slack Real Time Messaging API is an events firehose.
|
||||
this parsing function returns None unless a message is
|
||||
directed at the Bot, based on its ID.
|
||||
"""
|
||||
output_list = slack_rtm_output
|
||||
if output_list and len(output_list) > 0:
|
||||
for output in output_list:
|
||||
if output and 'text' in output and AT_BOT in output['text']:
|
||||
# 返回 @ 之后的文本,删除空格
|
||||
return output['text'].split(AT_BOT)[1].strip().lower(), \
|
||||
output['channel']
|
||||
return None, None
|
||||
|
||||
```
|
||||
|
||||
`parse_slack_output` 函数从 Slack 接受信息,并且如果它们是发给我们的 StarterBot 时会作出判断。消息以一个给我们的聊天机器人 ID 的直接命令开始,然后交由我们的代码处理。目前只是通过 Slack 管道发布一个消息回去告诉用户去多写一些 Python 代码!
|
||||
|
||||
这是整个程序组合在一起的样子 (你也可以 [在 GitHub 中查看该文件](https://github.com/mattmakai/slack-starterbot/blob/master/starterbot.py)):
|
||||
|
||||
```
|
||||
import os
|
||||
import time
|
||||
from slackclient import SlackClient
|
||||
|
||||
# starterbot 的 ID 作为一个环境变量
|
||||
BOT_ID = os.environ.get("BOT_ID")
|
||||
|
||||
# 常量
|
||||
AT_BOT = "<@" + BOT_ID + ">:"
|
||||
EXAMPLE_COMMAND = "do"
|
||||
|
||||
# 实例化 Slack 和 Twilio 客户端
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
def handle_command(command, channel):
|
||||
"""
|
||||
Receives commands directed at the bot and determines if they
|
||||
are valid commands. If so, then acts on the commands. If not,
|
||||
returns back what it needs for clarification.
|
||||
"""
|
||||
response = "Not sure what you mean. Use the *" + EXAMPLE_COMMAND + \
|
||||
"* command with numbers, delimited by spaces."
|
||||
if command.startswith(EXAMPLE_COMMAND):
|
||||
response = "Sure...write some more code then I can do that!"
|
||||
slack_client.api_call("chat.postMessage", channel=channel,
|
||||
text=response, as_user=True)
|
||||
|
||||
def parse_slack_output(slack_rtm_output):
|
||||
"""
|
||||
The Slack Real Time Messaging API is an events firehose.
|
||||
this parsing function returns None unless a message is
|
||||
directed at the Bot, based on its ID.
|
||||
"""
|
||||
output_list = slack_rtm_output
|
||||
if output_list and len(output_list) > 0:
|
||||
for output in output_list:
|
||||
if output and 'text' in output and AT_BOT in output['text']:
|
||||
# 返回 @ 之后的文本,删除空格
|
||||
return output['text'].split(AT_BOT)[1].strip().lower(), \
|
||||
output['channel']
|
||||
return None, None
|
||||
|
||||
if __name__ == "__main__":
|
||||
READ_WEBSOCKET_DELAY = 1 # 1 second delay between reading from firehose
|
||||
if slack_client.rtm_connect():
|
||||
print("StarterBot connected and running!")
|
||||
while True:
|
||||
command, channel = parse_slack_output(slack_client.rtm_read())
|
||||
if command and channel:
|
||||
handle_command(command, channel)
|
||||
time.sleep(READ_WEBSOCKET_DELAY)
|
||||
else:
|
||||
print("Connection failed. Invalid Slack token or bot ID?")
|
||||
|
||||
```
|
||||
|
||||
现在我们的代码已经有了,我们可以通过 `python starterbot.py` 来运行我们 StarterBot 的代码了。
|
||||
|
||||

|
||||
|
||||
在 Slack 中创建新通道,并且把 StarterBot 邀请进来,或者把 StarterBot 邀请进一个已经存在的通道中。
|
||||
|
||||

|
||||
|
||||
现在在你的通道中给 StarterBot 发命令。
|
||||
|
||||

|
||||
|
||||
如果你从聊天机器人得到的响应中遇见问题,你可能需要做一个修改。正如上面所写的这个教程,其中一行 `AT_BOT = "<@" + BOT_ID + ">:"`,在“@starter”(你给你自己的聊天机器人起的名字)后需要一个冒号。从`AT_BOT` 字符串后面移除`:`。Slack 似乎需要在 `@` 一个人名后加一个冒号,但这好像是有些不协调的。
|
||||
|
||||
### 结束
|
||||
|
||||
好吧,你现在已经获得一个简易的聊天机器人,你可以在代码中很多地方加入你想要创建的任何特性。
|
||||
|
||||
我们能够使用 Slack RTM API 和 Python 完成很多功能。看看通过这些文章你还可以学习到什么:
|
||||
|
||||
* 附加一个持久的[关系数据库](https://www.fullstackpython.com/databases.html) 或者 [NoSQL 后端](https://www.fullstackpython.com/no-sql-datastore.html) 比如 [PostgreSQL](https://www.fullstackpython.com/postgresql.html)、[MySQL](https://www.fullstackpython.com/mysql.html) 或者 [SQLite](https://www.fullstackpython.com/sqlite.html) ,来保存和检索用户数据
|
||||
* 添加另外一个与聊天机器人互动的通道,比如 [短信](https://www.twilio.com/blog/2016/05/build-sms-slack-bot-python.html) 或者[电话呼叫](https://www.twilio.com/blog/2016/05/add-phone-calling-slack-python.html)
|
||||
* [集成其它的 web API](https://www.fullstackpython.com/api-integration.html),比如 [GitHub](https://developer.github.com/v3/)、[Twilio](https://www.twilio.com/docs) 或者 [api.ai](https://docs.api.ai/)
|
||||
|
||||
有问题? 通过 Twitter 联系我 [@fullstackpython](https://twitter.com/fullstackpython) 或 [@mattmakai](https://twitter.com/mattmakai)。 我在 GitHub 上的用户名是 [mattmakai](https://github.com/mattmakai)。
|
||||
|
||||
这篇文章感兴趣? Fork 这个 [GitHub 上的页面](https://github.com/mattmakai/fullstackpython.com/blob/gh-pages/source/content/posts/160604-build-first-slack-bot-python.markdown)吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.fullstackpython.com/blog/build-first-slack-bot-python.html
|
||||
|
||||
作者:[Matt Makai][a]
|
||||
译者:[jiajia9llinuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出aa
|
||||
|
||||
[a]: https://www.fullstackpython.com/about-author.html
|
||||
@ -0,0 +1,476 @@
|
||||
使用 Elasticsearch 和 cAdvisor 监控 Docker 容器
|
||||
=======
|
||||
|
||||
如果你正在运行 Swarm 模式的集群,或者只运行单台 Docker,你都会有下面的疑问:
|
||||
|
||||
> 我如何才能监控到它们都在干些什么?
|
||||
|
||||
这个问题的答案是“很不容易”。
|
||||
|
||||
你需要监控下面的参数:
|
||||
|
||||
1. 容器的数量和状态。
|
||||
2. 一台容器是否已经移到另一个节点了,如果是,那是在什么时候,移动到哪个节点?
|
||||
3. 给定节点上运行着的容器数量。
|
||||
4. 一段时间内的通信峰值。
|
||||
5. 孤儿卷和网络(LCTT 译注:孤儿卷就是当你删除容器时忘记删除它的卷,这个卷就不会再被使用,但会一直占用资源)。
|
||||
6. 可用磁盘空间、可用 inode 数。
|
||||
7. 容器数量与连接在 `docker0` 和 `docker_gwbridge` 上的虚拟网卡数量不一致(LCTT 译注:当 docker 启动时,它会在宿主机器上创建一个名为 docker0 的虚拟网络接口)。
|
||||
8. 开启和关闭 Swarm 节点。
|
||||
9. 收集并集中处理日志。
|
||||
|
||||
本文的目标是介绍 [Elasticsearch][1] + [Kibana][2] + [cAdvisor][3] 的用法,使用它们来收集 Docker 容器的参数,分析数据并产生可视化报表。
|
||||
|
||||
阅读本文后你可以发现有一个监控仪表盘能够部分解决上述列出的问题。但如果只是使用 cAdvisor,有些参数就无法显示出来,比如 Swarm 模式的节点。
|
||||
|
||||
如果你有一些 cAdvisor 或其他工具无法解决的特殊需求,我建议你开发自己的数据收集器和数据处理器(比如 [Beats][4]),请注意我不会演示如何使用 Elasticsearch 来集中收集 Docker 容器的日志。
|
||||
|
||||
> [“你要如何才能监控到 Swarm 模式集群里面发生了什么事情?要做到这点很不容易。” —— @fntlnz][5]
|
||||
|
||||
### 我们为什么要监控容器?
|
||||
|
||||
想象一下这个经典场景:你在管理一台或多台虚拟机,你把 tmux 工具用得很溜,用各种 session 事先设定好了所有基础的东西,包括监控。然后生产环境出问题了,你使用 `top`、`htop`、`iotop`、`jnettop` 各种 top 来排查,然后你准备好修复故障。
|
||||
|
||||
现在重新想象一下你有 3 个节点,包含 50 台容器,你需要在一个地方查看整洁的历史数据,这样你知道问题出在哪个地方,而不是把你的生命浪费在那些字符界面来赌你可以找到问题点。
|
||||
|
||||
### 什么是 Elastic Stack ?
|
||||
|
||||
Elastic Stack 就一个工具集,包括以下工具:
|
||||
|
||||
- Elasticsearch
|
||||
- Kibana
|
||||
- Logstash
|
||||
- Beats
|
||||
|
||||
我们会使用其中一部分工具,比如使用 Elasticsearch 来分析基于 JSON 格式的文本,以及使用 Kibana 来可视化数据并产生报表。
|
||||
|
||||
另一个重要的工具是 [Beats][4],但在本文中我们还是把精力放在容器上,官方的 Beats 工具不支持 Docker,所以我们选择原生兼容 Elasticsearch 的 cAdvisor。
|
||||
|
||||
[cAdvisor][3] 工具负责收集、整合正在运行的容器数据,并导出报表。在本文中,这些报表被到入到 Elasticsearch 中。
|
||||
|
||||
cAdvisor 有两个比较酷的特性:
|
||||
|
||||
- 它不只局限于 Docker 容器。
|
||||
- 它有自己的 Web 服务器,可以简单地显示当前节点的可视化报表。
|
||||
|
||||
### 设置测试集群,或搭建自己的基础架构
|
||||
|
||||
和我[以前的文章][9]一样,我习惯提供一个简单的脚本,让读者不用花很多时间就能部署好和我一样的测试环境。你可以使用以下(非生产环境使用的)脚本来搭建一个 Swarm 模式的集群,其中一个容器运行着 Elasticsearch。
|
||||
|
||||
> 如果你有充足的时间和经验,你可以搭建自己的基础架构 (Bring Your Own Infrastructure,BYOI)。
|
||||
|
||||
如果要继续阅读本文,你需要:
|
||||
|
||||
- 运行 Docker 进程的一个或多个节点(docker 版本号大于等于 1.12)。
|
||||
- 至少有一个独立运行的 Elasticsearch 节点(版本号 2.4.X)。
|
||||
|
||||
重申一下,此 Elasticsearch 集群环境不能放在生产环境中使用。生产环境也不推荐使用单节点集群,所以如果你计划安装一个生产环境,请参考 [Elastic 指南][6]。
|
||||
|
||||
### 对喜欢尝鲜的用户的友情提示
|
||||
|
||||
我就是一个喜欢尝鲜的人(当然我也已经在生产环境中使用了最新的 alpha 版本),但是在本文中,我不会使用最新的 Elasticsearch 5.0.0 alpha 版本,我还不是很清楚这个版本的功能,所以我不想成为那个引导你们出错的关键。
|
||||
|
||||
所以本文中涉及的 Elasticsearch 版本为最新稳定版 2.4.0。
|
||||
|
||||
### 测试集群部署脚本
|
||||
|
||||
前面已经说过,我提供这个脚本给你们,让你们不必费神去部署 Swarm 集群和 Elasticsearch,当然你也可以跳过这一步,用你自己的 Swarm 模式引擎和你自己的 Elasticserch 节点。
|
||||
|
||||
执行这段脚本之前,你需要:
|
||||
|
||||
- [Docker Machine][7] – 最终版:在 DigitalOcean 中提供 Docker 引擎。
|
||||
- [DigitalOcean API Token][8]: 让 docker 机器按照你的意思来启动节点。
|
||||
|
||||

|
||||
|
||||
### 创建集群的脚本
|
||||
|
||||
现在万事俱备,你可以把下面的代码拷到 create-cluster.sh 文件中:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
#
|
||||
# Create a Swarm Mode cluster with a single master and a configurable number of workers
|
||||
|
||||
workers=${WORKERS:-"worker1 worker2"}
|
||||
|
||||
#######################################
|
||||
# Creates a machine on Digital Ocean
|
||||
# Globals:
|
||||
# DO_ACCESS_TOKEN The token needed to access DigitalOcean's API
|
||||
# Arguments:
|
||||
# $1 the actual name to give to the machine
|
||||
#######################################
|
||||
create_machine() {
|
||||
docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token=$DO_ACCESS_TOKEN \
|
||||
--digitalocean-size 2gb \
|
||||
$1
|
||||
}
|
||||
|
||||
#######################################
|
||||
# Executes a command on the specified machine
|
||||
# Arguments:
|
||||
# $1 The machine on which to run the command
|
||||
# $2..$n The command to execute on that machine
|
||||
#######################################
|
||||
machine_do() {
|
||||
docker-machine ssh $@
|
||||
}
|
||||
|
||||
main() {
|
||||
|
||||
if [ -z "$DO_ACCESS_TOKEN" ]; then
|
||||
echo "Please export a DigitalOcean Access token: https://cloud.digitalocean.com/settings/api/tokens/new"
|
||||
echo "export DO_ACCESS_TOKEN=<yourtokenhere>"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -z "$WORKERS" ]; then
|
||||
echo "You haven't provided your workers by setting the \$WORKERS environment variable, using the default ones: $workers"
|
||||
fi
|
||||
|
||||
# Create the first and only master
|
||||
echo "Creating the master"
|
||||
|
||||
create_machine master1
|
||||
|
||||
master_ip=$(docker-machine ip master1)
|
||||
|
||||
# Initialize the swarm mode on it
|
||||
echo "Initializing the swarm mode"
|
||||
machine_do master1 docker swarm init --advertise-addr $master_ip
|
||||
|
||||
# Obtain the token to allow workers to join
|
||||
worker_tkn=$(machine_do master1 docker swarm join-token -q worker)
|
||||
echo "Worker token: ${worker_tkn}"
|
||||
|
||||
# Create and join the workers
|
||||
for worker in $workers; do
|
||||
echo "Creating worker ${worker}"
|
||||
create_machine $worker
|
||||
machine_do $worker docker swarm join --token $worker_tkn $master_ip:2377
|
||||
done
|
||||
}
|
||||
|
||||
main $@
|
||||
```
|
||||
|
||||
赋予它可执行权限:
|
||||
|
||||
```
|
||||
chmod +x create-cluster.sh
|
||||
```
|
||||
|
||||
### 创建集群
|
||||
|
||||
如文件名所示,我们可以用它来创建集群。默认情况下这个脚本会创建一个 master 和两个 worker,如果你想修改 worker 个数,可以设置环境变量 WORKERS。
|
||||
|
||||
现在就来创建集群吧。
|
||||
|
||||
```
|
||||
./create-cluster.sh
|
||||
```
|
||||
|
||||
你可以出去喝杯咖啡,因为这需要花点时间。
|
||||
|
||||
最后集群部署好了。
|
||||
|
||||

|
||||
|
||||
现在为了验证 Swarm 模式集群已经正常运行,我们可以通过 ssh 登录进 master:
|
||||
|
||||
```
|
||||
docker-machine ssh master1
|
||||
```
|
||||
|
||||
然后列出集群的节点:
|
||||
|
||||
```
|
||||
docker node ls
|
||||
```
|
||||
|
||||
```
|
||||
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||
26fi3wiqr8lsidkjy69k031w2 * master1 Ready Active Leader
|
||||
dyluxpq8sztj7kmwlzs51u4id worker2 Ready Active
|
||||
epglndegvixag0jztarn2lte8 worker1 Ready Active
|
||||
```
|
||||
|
||||
### 安装 Elasticsearch 和 Kibana
|
||||
|
||||
> 注意,从现在开始所有的命令都运行在主节点 master1 上。
|
||||
|
||||
在生产环境中,你可能会把 Elasticsearch 和 Kibana 安装在一个单独的、[大小合适][14]的实例集合中。但是在我们的实验中,我们还是把它们和 Swarm 模式集群安装在一起。
|
||||
|
||||
为了将 Elasticsearch 和 cAdvisor 连通,我们需要创建一个自定义的网络,因为我们使用了集群,并且容器可能会分布在不同的节点上,我们需要使用 [overlay][10] 网络(LCTT 译注:overlay 网络是指在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在 IP 报文之上的新的数据格式,是目前最主流的容器跨节点数据传输和路由方案)。
|
||||
|
||||
也许你会问,“为什么还要网络?我们不是可以用 link 吗?” 请考虑一下,自从引入*用户定义网络*后,link 机制就已经过时了。
|
||||
|
||||
以下内容摘自[ Docker 文档][11]:
|
||||
|
||||
> 在 Docker network 特性出来以前,你可以使用 Docker link 特性实现容器互相发现、安全通信。而在 network 特性出来以后,你还可以使用 link,但是当容器处于默认桥接网络或用户自定义网络时,它们的表现是不一样的。
|
||||
|
||||
现在创建 overlay 网络,名称为 monitoring:
|
||||
|
||||
```
|
||||
docker network create monitoring -d overlay
|
||||
```
|
||||
|
||||
### Elasticsearch 容器
|
||||
|
||||
```
|
||||
docker service create --network=monitoring \
|
||||
--mount type=volume,target=/usr/share/elasticsearch/data \
|
||||
--constraint node.hostname==worker1 \
|
||||
--name elasticsearch elasticsearch:2.4.0
|
||||
```
|
||||
|
||||
注意 Elasticsearch 容器被限定在 worker1 节点,这是因为它运行时需要依赖 worker1 节点上挂载的卷。
|
||||
|
||||
### Kibana 容器
|
||||
|
||||
```
|
||||
docker service create --network=monitoring --name kibana -e ELASTICSEARCH_URL="http://elasticsearch:9200" -p 5601:5601 kibana:4.6.0
|
||||
```
|
||||
|
||||
如你所见,我们启动这两个容器时,都让它们加入 monitoring 网络,这样一来它们可以通过名称(如 Kibana)被相同网络的其他服务访问。
|
||||
|
||||
现在,通过 [routing mesh][12] 机制,我们可以使用浏览器访问服务器的 IP 地址来查看 Kibana 报表界面。
|
||||
|
||||
获取 master1 实例的公共 IP 地址:
|
||||
|
||||
```
|
||||
docker-machine ip master1
|
||||
```
|
||||
|
||||
打开浏览器输入地址:`http://[master1 的 ip 地址]:5601/status`
|
||||
|
||||
所有项目都应该是绿色:
|
||||
|
||||

|
||||
|
||||
让我们接下来开始收集数据!
|
||||
|
||||
### 收集容器的运行数据
|
||||
|
||||
收集数据之前,我们需要创建一个服务,以全局模式运行 cAdvisor,为每个有效节点设置一个定时任务。
|
||||
|
||||
这个服务与 Elasticsearch 处于相同的网络,以便于 cAdvisor 可以推送数据给 Elasticsearch。
|
||||
|
||||
```
|
||||
docker service create --network=monitoring --mode global --name cadvisor \
|
||||
--mount type=bind,source=/,target=/rootfs,readonly=true \
|
||||
--mount type=bind,source=/var/run,target=/var/run,readonly=false \
|
||||
--mount type=bind,source=/sys,target=/sys,readonly=true \
|
||||
--mount type=bind,source=/var/lib/docker/,target=/var/lib/docker,readonly=true \
|
||||
google/cadvisor:latest \
|
||||
-storage_driver=elasticsearch \
|
||||
-storage_driver_es_host="http://elasticsearch:9200"
|
||||
```
|
||||
|
||||
> 注意:如果你想配置 cAdvisor 选项,参考[这里][13]。
|
||||
|
||||
现在 cAdvisor 在发送数据给 Elasticsearch,我们通过定义一个索引模型来检索 Kibana 中的数据。有两种方式可以做到这一点:通过 Kibana 或者通过 API。在这里我们使用 API 方式实现。
|
||||
|
||||
我们需要在一个连接到 monitoring 网络的正在运行的容器中运行索引创建命令,你可以在 cAdvisor 容器中拿到 shell,不幸的是 Swarm 模式在开启服务时会在容器名称后面附加一个唯一的 ID 号,所以你需要手动指定 cAdvisor 容器的名称。
|
||||
|
||||
拿到 shell:
|
||||
|
||||
```
|
||||
docker exec -ti <cadvisor-container-name> sh
|
||||
```
|
||||
|
||||
创建索引:
|
||||
|
||||
```
|
||||
curl -XPUT http://elasticsearch:9200/.kibana/index-pattern/cadvisor -d '{"title" : "cadvisor*", "timeFieldName": "container_stats.timestamp"}'
|
||||
```
|
||||
|
||||
如果你够懒,可以只执行下面这一句:
|
||||
|
||||
```
|
||||
docker exec $(docker ps | grep cadvisor | awk '{print $1}' | head -1) curl -XPUT http://elasticsearch:9200/.kibana/index-pattern/cadvisor -d '{"title" : "cadvisor*", "timeFieldName": "container_stats.timestamp"}'
|
||||
```
|
||||
|
||||
### 把数据汇总成报表
|
||||
|
||||
你现在可以使用 Kibana 来创建一份美观的报表了。但是不要着急,我为你们建了一份报表和一些图形界面来方便你们入门。
|
||||
|
||||

|
||||
|
||||
访问 Kibana 界面 => Setting => Objects => Import,然后选择包含以下内容的 JSON 文件,就可以导入我的配置信息了:
|
||||
|
||||
```
|
||||
[
|
||||
{
|
||||
"_id": "cAdvisor",
|
||||
"_type": "dashboard",
|
||||
"_source": {
|
||||
"title": "cAdvisor",
|
||||
"hits": 0,
|
||||
"description": "",
|
||||
"panelsJSON": "[{\"id\":\"Filesystem-usage\",\"type\":\"visualization\",\"panelIndex\":1,\"size_x\":6,\"size_y\":3,\"col\":1,\"row\":1},{\"id\":\"Memory-[Node-equal->Container]\",\"type\":\"visualization\",\"panelIndex\":2,\"size_x\":6,\"size_y\":4,\"col\":7,\"row\":4},{\"id\":\"memory-usage-by-machine\",\"type\":\"visualization\",\"panelIndex\":3,\"size_x\":6,\"size_y\":6,\"col\":1,\"row\":4},{\"id\":\"CPU-Total-Usage\",\"type\":\"visualization\",\"panelIndex\":4,\"size_x\":6,\"size_y\":5,\"col\":7,\"row\":8},{\"id\":\"Network-RX-TX\",\"type\":\"visualization\",\"panelIndex\":5,\"size_x\":6,\"size_y\":3,\"col\":7,\"row\":1}]",
|
||||
"optionsJSON": "{\"darkTheme\":false}",
|
||||
"uiStateJSON": "{}",
|
||||
"version": 1,
|
||||
"timeRestore": false,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"filter\":[{\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}}}]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "Network",
|
||||
"_type": "search",
|
||||
"_source": {
|
||||
"title": "Network",
|
||||
"description": "",
|
||||
"hits": 0,
|
||||
"columns": [
|
||||
"machine_name",
|
||||
"container_Name",
|
||||
"container_stats.network.name",
|
||||
"container_stats.network.interfaces",
|
||||
"container_stats.network.rx_bytes",
|
||||
"container_stats.network.rx_packets",
|
||||
"container_stats.network.rx_dropped",
|
||||
"container_stats.network.rx_errors",
|
||||
"container_stats.network.tx_packets",
|
||||
"container_stats.network.tx_bytes",
|
||||
"container_stats.network.tx_dropped",
|
||||
"container_stats.network.tx_errors"
|
||||
],
|
||||
"sort": [
|
||||
"container_stats.timestamp",
|
||||
"desc"
|
||||
],
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"analyze_wildcard\":true,\"query\":\"*\"}},\"highlight\":{\"pre_tags\":[\"@kibana-highlighted-field@\"],\"post_tags\":[\"@/kibana-highlighted-field@\"],\"fields\":{\"*\":{}},\"fragment_size\":2147483647},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "Filesystem-usage",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "Filesystem usage",
|
||||
"visState": "{\"title\":\"Filesystem usage\",\"type\":\"histogram\",\"params\":{\"addLegend\":true,\"addTimeMarker\":false,\"addTooltip\":true,\"defaultYExtents\":false,\"mode\":\"stacked\",\"scale\":\"linear\",\"setYExtents\":false,\"shareYAxis\":true,\"times\":[],\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.filesystem.usage\",\"customLabel\":\"USED\"}},{\"id\":\"2\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":false}},{\"id\":\"3\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.filesystem.capacity\",\"customLabel\":\"AVAIL\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.filesystem.device\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{\"vis\":{\"colors\":{\"Average container_stats.filesystem.available\":\"#E24D42\",\"Average container_stats.filesystem.base_usage\":\"#890F02\",\"Average container_stats.filesystem.capacity\":\"#3F6833\",\"Average container_stats.filesystem.usage\":\"#E24D42\",\"USED\":\"#BF1B00\",\"AVAIL\":\"#508642\"}}}",
|
||||
"description": "",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"analyze_wildcard\":true,\"query\":\"*\"}},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "CPU-Total-Usage",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "CPU Total Usage",
|
||||
"visState": "{\"title\":\"CPU Total Usage\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.cpu.usage.total\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"container_Name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":true}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{}",
|
||||
"description": "",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "memory-usage-by-machine",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "Memory [Node]",
|
||||
"visState": "{\"title\":\"Memory [Node]\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.memory.usage\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{}",
|
||||
"description": "",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "Network-RX-TX",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "Network RX TX",
|
||||
"visState": "{\"title\":\"Network RX TX\",\"type\":\"histogram\",\"params\":{\"addLegend\":true,\"addTimeMarker\":true,\"addTooltip\":true,\"defaultYExtents\":false,\"mode\":\"stacked\",\"scale\":\"linear\",\"setYExtents\":false,\"shareYAxis\":true,\"times\":[],\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.network.rx_bytes\",\"customLabel\":\"RX\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"s\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.network.tx_bytes\",\"customLabel\":\"TX\"}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{\"vis\":{\"colors\":{\"RX\":\"#EAB839\",\"TX\":\"#BF1B00\"}}}",
|
||||
"description": "",
|
||||
"savedSearchId": "Network",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"_id": "Memory-[Node-equal->Container]",
|
||||
"_type": "visualization",
|
||||
"_source": {
|
||||
"title": "Memory [Node=>Container]",
|
||||
"visState": "{\"title\":\"Memory [Node=>Container]\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.memory.usage\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"container_Name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":true}}],\"listeners\":{}}",
|
||||
"uiStateJSON": "{}",
|
||||
"description": "",
|
||||
"version": 1,
|
||||
"kibanaSavedObjectMeta": {
|
||||
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"* NOT container_Name.raw: \\\\\\\"/\\\\\\\" AND NOT container_Name.raw: \\\\\\\"/docker\\\\\\\"\",\"analyze_wildcard\":true}},\"filter\":[]}"
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
这里还有很多东西可以玩,你也许想自定义报表界面,比如添加内存页错误状态,或者收发包的丢包数。如果你能实现开头列表处我没能实现的项目,那也是很好的。
|
||||
|
||||
### 总结
|
||||
|
||||
正确监控需要大量时间和精力,容器的 CPU、内存、IO、网络和磁盘,监控的这些参数还只是整个监控项目中的沧海一粟而已。
|
||||
|
||||
我不知道你做到了哪一阶段,但接下来的任务也许是:
|
||||
|
||||
- 收集运行中的容器的日志
|
||||
- 收集应用的日志
|
||||
- 监控应用的性能
|
||||
- 报警
|
||||
- 监控健康状态
|
||||
|
||||
如果你有意见或建议,请留言。祝你玩得开心。
|
||||
|
||||
现在你可以关掉这些测试系统了:
|
||||
|
||||
```
|
||||
docker-machine rm master1 worker{1,2}
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
|
||||
作者:[Lorenzo Fontana][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.codeship.com/author/lorenzofontana/
|
||||
|
||||
[1]: https://github.com/elastic/elasticsearch
|
||||
[2]: https://github.com/elastic/kibana
|
||||
[3]: https://github.com/google/cadvisor
|
||||
[4]: https://github.com/elastic/beats
|
||||
[5]: https://twitter.com/share?text=%22How+do+you+keep+track+of+all+that%27s+happening+in+a+Swarm+Mode+cluster%3F+Not+easily.%22+via+%40fntlnz&url=https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
[6]: https://www.elastic.co/guide/en/elasticsearch/guide/2.x/deploy.html
|
||||
[7]: https://docs.docker.com/machine/install-machine/
|
||||
[8]: https://cloud.digitalocean.com/settings/api/tokens/new
|
||||
[9]: https://blog.codeship.com/nginx-reverse-proxy-docker-swarm-clusters/
|
||||
[10]: https://docs.docker.com/engine/userguide/networking/get-started-overlay/
|
||||
[11]: https://docs.docker.com/engine/userguide/networking/default_network/dockerlinks/
|
||||
[12]: https://docs.docker.com/engine/swarm/ingress/
|
||||
[13]: https://github.com/google/cadvisor/blob/master/docs/runtime_options.md
|
||||
[14]: https://www.elastic.co/blog/found-sizing-elasticsearch
|
||||
@ -1,5 +1,3 @@
|
||||
GHLandy Translating
|
||||
|
||||
Linux vs. Windows device driver model : architecture, APIs and build environment comparison
|
||||
============================================================================================
|
||||
|
||||
@ -179,7 +177,7 @@ Download this article as ad-free PDF (made possible by [your kind donation][2]):
|
||||
via: http://xmodulo.com/linux-vs-windows-device-driver-model.html
|
||||
|
||||
作者:[Dennis Turpitka][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,139 +0,0 @@
|
||||
translating by theArcticOcean.
|
||||
|
||||
Part III - How to apply Advanced Mathematical Processing Effects on Audio files with Octave 4.0 on Ubuntu
|
||||
=====
|
||||
|
||||
The third part of our Digital Audio processing tutorial series covers the signal Modulation, we explain how to apply Amplitude Modulation, Tremolo Effect, and Frequency Variation.
|
||||
|
||||
### Modulation
|
||||
|
||||
#### Amplitude Modulation
|
||||
|
||||
As its name implies, this effect varies the amplitude of a sinusoid according to the message to be transmitted. A sine wave is called a carrier because it carries the information. This type of modulation is used in some commercial broadcasting and transmission citizen bands (AM).
|
||||
|
||||
#### Why use the Amplitude Modulation?
|
||||
|
||||
**Modulation Radiation.**
|
||||
|
||||
If the communication channel is a free space, then antennas are required to radiate and receive the signal. It requires an efficient electromagnetic radiation antenna whose dimensions are of the same order of magnitude as the wavelength of the signal being radiated. Many signals, including audio components, have often 100 Hz or less. For these signals, it would be necessary to build antennas about 300 km in length if the signal were to be radiated directly. If signal modulation is used to print the message on a high-frequency carrier, let's say 100 MHz, then the antenna needs to have a length of over a meter (transverse length) only.
|
||||
|
||||
**Concentration modulation or multi-channeling.**
|
||||
|
||||
If more than one signal uses a single channel, modulation can be used for transferring different signals to different spectral positions allowing the receiver to select the desired signal. Applications that use concentration ("multiplexing") include telemetry data, stereo FM radio and long-distance telephony.
|
||||
|
||||
**Modulation to Overcome Limitations on equipment.**
|
||||
|
||||
The performance of signal processing devices such as filters and amplifiers, and the ease with which these devices can be constructed, depends on the situation of the signal in the frequency domain and the relationship between the higher frequency and low signal. Modulation can be used to transfer the signal to a position in the frequency domain where design requirements are met easier. The modulation can also be used to convert a "broadband signal" (a signal for which the ratio between the highest and lowest frequency is large) into a sign of "narrow band".
|
||||
|
||||
**Audio Effects**
|
||||
|
||||
Many audio effects use amplitude modulation due to the striking and ease with which it can handle such signals. We can name a few such as tremolo, chorus, flanger, etc. This utility is where we focus in this tutorial series.
|
||||
|
||||
### Tremolo effect
|
||||
|
||||
The tremolo effect is one of the simplest applications of amplitude modulation, to achieve this effect, we have to vary (multiply) the audio signal by a periodic signal, either sinusoidal or otherwise.
|
||||
|
||||
```
|
||||
>> tremolo='tremolo.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> wo=2*pi*440*t;
|
||||
>> wa=2*pi*1.2*t;
|
||||
>> audiowrite(tremolo, cos(wa).*cos(wo),fs);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremolo.png)
|
||||
|
||||
This will generate a sinusoid-shaped signal which effect is like a 'tremolo'.
|
||||
|
||||
[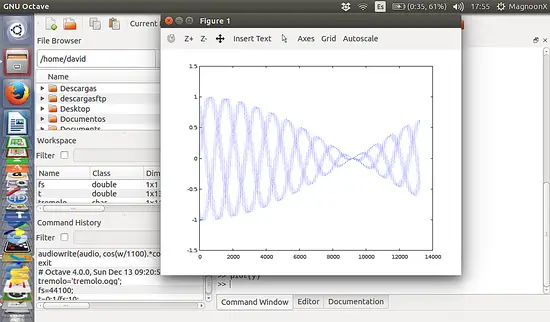](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremoloshape.png)
|
||||
|
||||
### Tremolo on real Audio Files
|
||||
|
||||
Now we will show the tremolo effect in the real world, First, we use a file previously recorded by a male voice saying 'A'. The plot for this signal is the following:
|
||||
|
||||
```
|
||||
>> [y,fs]=audioread('A.ogg');
|
||||
>> plot(y);
|
||||
```
|
||||
|
||||
[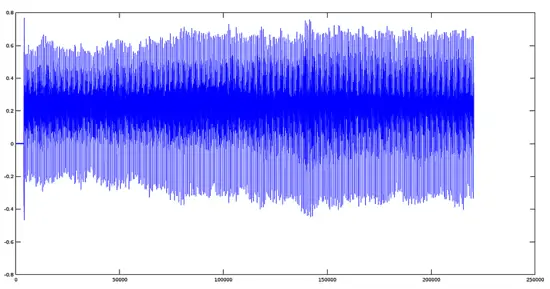](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/avocalmale.png)
|
||||
|
||||
Now we have to create an enveloping sinusoidal signal with the following parameters:
|
||||
|
||||
```
|
||||
Amplitude = 1
|
||||
Frequency= 1.5Hz
|
||||
Phase = 0
|
||||
```
|
||||
|
||||
```
|
||||
>> t=0:1/fs:4.99999999;
|
||||
>> t=t(:);
|
||||
>> w=2*pi*1.5*t;
|
||||
>> q=cos(w);
|
||||
>> plot(q);
|
||||
```
|
||||
|
||||
Note: when we create an array of values of the time, by default, this is created in the form of columns, ie, 1x220500 values. To multiply this set of values must transpose it in rows (220500x1). This is the t=t(:) command
|
||||
|
||||
[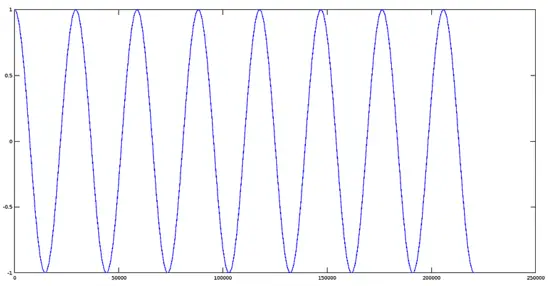](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/sinusoidal.png)
|
||||
|
||||
We will create a second ogg file which contains the resulting modulated signal:
|
||||
|
||||
```
|
||||
>> tremolo='tremolo.ogg';
|
||||
>> audiowrite(tremolo, q.*y,fs);
|
||||
```
|
||||
|
||||
[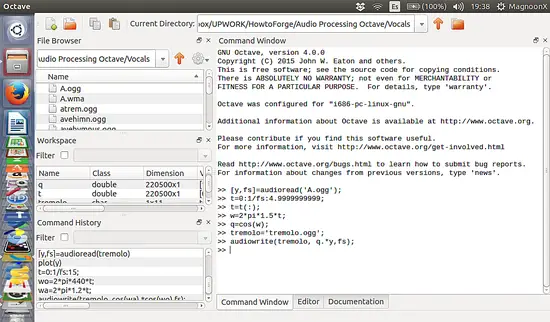](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremsignal1.png)[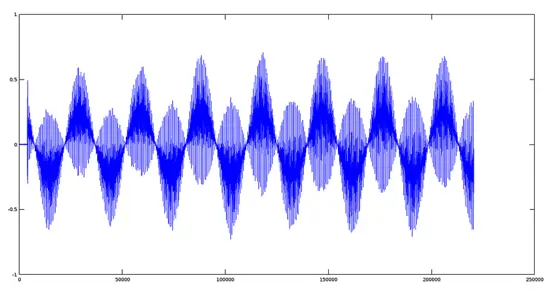](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremolsignal1.png)
|
||||
|
||||
### Frequency Variation
|
||||
|
||||
We can vary the frequency to obtain quite interesting musical effects such as distortion, sound effects for movies and games among others.
|
||||
|
||||
#### Effect of sinusoidal frequency modulation
|
||||
|
||||
This is the code where the sinusoidal modulation frequency is shown, according to equation:
|
||||
|
||||
```
|
||||
Y=Ac*Cos(wo*Cos(wo/k))
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
```
|
||||
Ac = Amplitude
|
||||
|
||||
wo = fundamental frequency
|
||||
|
||||
k = scalar divisor
|
||||
```
|
||||
|
||||
```
|
||||
>> fm='fm.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> w=2*pi*442*t;
|
||||
>> audiowrite(fm, cos(cos(w/1500).*w), fs);
|
||||
>> [y,fs]=audioread('fm.ogg');
|
||||
>> figure (); plot (y);
|
||||
```
|
||||
|
||||
The plot of the signal is:
|
||||
|
||||
[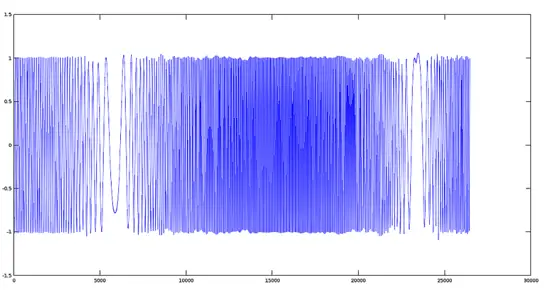](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/fmod.png)
|
||||
|
||||
You can use almost any type of periodic function as the frequency modulator. For this example, we only used a sine function here. Please feel free to experiment with changing the frequencies of the functions, mixing with other functions or change, even, the type of function.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/ubuntu-octave-audio-processing-part-3/
|
||||
|
||||
作者:[David Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/ubuntu-octave-audio-processing-part-3/
|
||||
@ -1,4 +1,4 @@
|
||||
Being translated by ChrisLeeGit
|
||||
Being translated by Bestony
|
||||
How to Monitor Docker Containers using Grafana on Ubuntu
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
firstadream is translating
|
||||
|
||||
Ryver: Why You Should Be Using It instead of Slack
|
||||
=====
|
||||
|
||||
|
||||
@ -1,315 +0,0 @@
|
||||
# 如何运用Python建立你的第一个Slack Bot?
|
||||
|
||||
[Bots](https://www.fullstackpython.com/bots.html) 是一种像 [Slack](https://slack.com/) 一样实用的互动聊天服务方式. 如果你之前从来没有建立过bot, 这篇文章提供了一个简单的用Python建立你第一个bot的关于 [Slack API](https://api.slack.com/) 集合的入门教程.
|
||||
|
||||
我们通过设置你的开发环境, 获得一个Slack API bot标记和我们用Pyhon编码的简单bot.
|
||||
|
||||
### 我们所需的工具
|
||||
|
||||
我们的bot, 我们将它称作为 "StarterBot", 它需要 Python 和 the Slack API. 然后运行我们需要的Python代码:
|
||||
|
||||
* [Python 2 或者 Python 3](https://www.fullstackpython.com/python-2-or-3.html)
|
||||
* [pip](https://pip.pypa.io/en/stable/) 和 [virtualenv](https://virtualenv.pypa.io/en/stable/) 处理 Python [应用程序依赖关系](https://www.fullstackpython.com/application-dependencies.html)
|
||||
* 一个你可以拥有API访问和注册Slack Developer Hangout team](http://dev4slack.xoxco.com/)的[免费Slack账号](https://slack.com/)
|
||||
* 通过Slack团队建立的官方Python [Slack客户端](https://github.com/slackhq/python-slackclient)代码库
|
||||
* [Slack API 测试标志](https://api.slack.com/tokens)
|
||||
|
||||
这也是一个方便你建立本教程的有用[Slack API 文档](https://api.slack.com/)
|
||||
|
||||
对于本教程,所有的代码都是在[slack-starterbot](https://github.com/mattmakai/slack-starterbot)公共库里通过MIT许可证的可获得的开放源码.
|
||||
|
||||
### 搭建我们的环境
|
||||
|
||||
我们现在已经知道我们的项目需要什么样的工具,因此我们要获得我们所建立的开发环境。首先到终端上(或者用Windows上的命令提示符)并且改变你想要存储这个项目的目录。在那个目录里,创建一个新的virtualenv以便从其他的Python项目来隔离我们的应用程序依赖关系。
|
||||
|
||||
```
|
||||
virtualenv starterbot
|
||||
|
||||
```
|
||||
|
||||
Activate the virtualenv 激活virtualenv:
|
||||
|
||||
```
|
||||
source starterbot/bin/activate
|
||||
|
||||
```
|
||||
|
||||
你的提示现在应该看起来像在一个这样的截图里。
|
||||
|
||||

|
||||
|
||||
|
||||
这个官方的slackclient API帮助库是通过Slack可以发送和接收消息的Slack通道所建立的。安装slackclient库是通过这个pip命令:
|
||||
|
||||
```
|
||||
pip install slackclient
|
||||
|
||||
```
|
||||
|
||||
当pip命令完成时,你应该看到这样的输出和你将返回的提示.
|
||||
|
||||

|
||||
|
||||
我们也需要从Slack项目获得一个访问提示,因此我们的bot可以用它来连接这个Slack API.
|
||||
|
||||
### Slack实时消息传递(RTM)API
|
||||
|
||||
Slack同意程序通过一个 [网络应用程序API](https://www.fullstackpython.com/application-programming-interfaces.html)访问他们的消息传递通道. 去这个[Slack网络应用程序API页面](https://api.slack.com/) 并且注册建立你自己的Slack项目.你也可以通过一个你拥有管理权限的有效账号登陆.
|
||||
|
||||

|
||||
|
||||
然后你可以到[Bot用户页面](https://api.slack.com/bot-users)登陆.
|
||||
|
||||

|
||||
|
||||
给你的bot起名为 "starterbot" 然后点击 “Add bot integration” 按钮.
|
||||
|
||||

|
||||
|
||||
这个页面将重新加载,你将看到一个新生成的访问令牌。你还可以将标志改成自定义设计。例如我给的这个“Full Stack Python”标志.
|
||||
|
||||

|
||||
|
||||
在页面底部点击 "Save Integration"按钮. 你的 bot 现在已经准备好连接Slack's API.
|
||||
|
||||
Python开发人员的一个常见的做法是输出秘密令牌提示作为环境变量。输出的Slack令牌名字为“SLACK_BOT_TOKEN”.:
|
||||
|
||||
```
|
||||
export SLACK_BOT_TOKEN='your slack token pasted here'
|
||||
|
||||
```
|
||||
|
||||
好了,我们现在将被作为bot授权使用这个Slack API .
|
||||
|
||||
这个是一个更多的我们需要建立我们的bot的信息: 我们的bot的ID. 接下来我们将会写一个简短的脚本来从这个Slack API获得ID.
|
||||
|
||||
### 获得我们Bot的ID
|
||||
|
||||
这是最后一次写的一些Python代码! 我们将会在编译一个简短的Python脚本来获得StarterBot的ID时获得热身. 这个ID基于Slack项目而改变.
|
||||
|
||||
我们需要ID,因为当消息被解析为从Slcak RTM在StarterBot上指导的,他会允许我们的应用程序作出终止.我们的脚本也会测试我们SLACK_BOT_TOKEN环境变量是否设置正确.
|
||||
|
||||
建立一个新文件并命名为print_bot_id.py 并且填写下面的代码.
|
||||
|
||||
```
|
||||
import os调用外部程序
|
||||
from slackclient import SlackClient从slackclient调用SlackClient
|
||||
|
||||
BOT_NAME = 'starterbot'
|
||||
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
if __name__ == "__main__":
|
||||
api_call = slack_client.api_call("users.list")
|
||||
if api_call.get('ok'):
|
||||
# retrieve all users so we can find our bot检索所有的用户以便我们可以找到我们的bot
|
||||
users = api_call.get('members')
|
||||
for user in users:
|
||||
if 'name' in user and user.get('name') == BOT_NAME:
|
||||
print("Bot ID for '" + user['name'] + "' is " + user.get('id'))
|
||||
else:
|
||||
print("could not find bot user with the name " + BOT_NAME)
|
||||
|
||||
```
|
||||
|
||||
当我们设置为一个环境变量时,我们的代码调用于SlackClient并且为我们的SLACK_BOT_TOKEN而将它实例化. 当脚本通过pyhon命令执行时,我们通过会访问Slack API列出所有的Slack用户并且获得匹配一个名字为"satrterbot"的ID.
|
||||
|
||||
我们仅仅需要运行一次脚本来获得我们bot的ID.
|
||||
|
||||
```
|
||||
python print_bot_id.py
|
||||
|
||||
```
|
||||
|
||||
当它运行为我们提供我们bot的ID时,脚本会打印出简单的一行输出.
|
||||
|
||||

|
||||
|
||||
复制脚本打印出的唯一ID.并将ID作为一个环境变量命名为BOT_ID输出.
|
||||
|
||||
```
|
||||
(starterbot)$ export BOT_ID='bot id returned by script'
|
||||
|
||||
```
|
||||
|
||||
这个脚本仅仅需要运行一次来获得bot的ID. 我们现在可以使用这个ID在我们的Python应用程序中来运行StarterBot.
|
||||
|
||||
### 编码我们的StarterBot
|
||||
|
||||
我们通过我们拥有的一切来写我们需要书写的StarterBot代码. 创建一个新文件命名为starterbot.py ,它包括以下代码.
|
||||
|
||||
```
|
||||
import os
|
||||
import time
|
||||
from slackclient import SlackClient
|
||||
|
||||
```
|
||||
|
||||
操作系统和SlackClient调用将会看起来很熟悉,因为我们会使用它们在theprint_bot_id.py中.
|
||||
|
||||
在我们的依赖关系调用中,我们可以使用它们获得环境变量值并且在Slack client中将它们实例化.
|
||||
|
||||
```
|
||||
# starterbot's ID as an environment variable starterbot的ID作为一个环境变量
|
||||
BOT_ID = os.environ.get("BOT_ID")
|
||||
|
||||
# constants 常量
|
||||
AT_BOT = "<@" + BOT_ID + ">:"
|
||||
EXAMPLE_COMMAND = "do"
|
||||
|
||||
# instantiate Slack & Twilio clients 实例化Slack和Twilio clients
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
```
|
||||
|
||||
代码在我们的SLACK_BOT_TOKEN中将SlackClient client实例化并且作为一个环境变量输出.
|
||||
|
||||
```
|
||||
if __name__ == "__main__":
|
||||
READ_WEBSOCKET_DELAY = 1 # 1 second delay between reading from firehose 从firehose阅读间延迟1秒
|
||||
if slack_client.rtm_connect():
|
||||
print("StarterBot connected and running!")
|
||||
while True:
|
||||
command, channel = parse_slack_output(slack_client.rtm_read())
|
||||
if command and channel:
|
||||
handle_command(command, channel)
|
||||
time.sleep(READ_WEBSOCKET_DELAY)
|
||||
else:
|
||||
print("Connection failed. Invalid Slack token or bot ID?")
|
||||
|
||||
```
|
||||
|
||||
Slack client连接到Slack RTM API WebSocket(Slack RTM API 双向通信),然后当解析信息来自firehose时会不断循环.如果任何这些消息都指向StarterBot,那么一个被称作handle_command的函数会决定做什么.
|
||||
|
||||
接下来添加两个函数来解析Slack输出和handle commands.
|
||||
|
||||
```
|
||||
def handle_command(command, channel):
|
||||
"""
|
||||
Receives commands directed at the bot and determines if they
|
||||
are valid commands. If so, then acts on the commands. If not,
|
||||
returns back what it needs for clarification.
|
||||
"""
|
||||
response = "Not sure what you mean. Use the *" + EXAMPLE_COMMAND + \
|
||||
"* command with numbers, delimited by spaces."
|
||||
if command.startswith(EXAMPLE_COMMAND):
|
||||
response = "Sure...write some more code then I can do that!"
|
||||
slack_client.api_call("chat.postMessage", channel=channel,
|
||||
text=response, as_user=True)
|
||||
|
||||
def parse_slack_output(slack_rtm_output):
|
||||
"""
|
||||
The Slack Real Time Messaging API is an events firehose.
|
||||
this parsing function returns None unless a message is
|
||||
directed at the Bot, based on its ID.
|
||||
"""
|
||||
output_list = slack_rtm_output
|
||||
if output_list and len(output_list) > 0:
|
||||
for output in output_list:
|
||||
if output and 'text' in output and AT_BOT in output['text']:
|
||||
# return text after the @ mention, whitespace removed 在@之后提到返回文本,空格删除
|
||||
return output['text'].split(AT_BOT)[1].strip().lower(), \
|
||||
output['channel']
|
||||
return None, None
|
||||
|
||||
```
|
||||
|
||||
parse_slack_output函数从Slack接受信息并且如果他们指向我们的StarterBot时会作出判断.消息通过给我们bot的ID一个直接命令启动,然后交由我们的代码处理.-目前只是通过SLack管道发布一个消息回去告诉用户去多写一些Python代码!
|
||||
|
||||
这是整个程序看上去应该如何组合在一起 (你也可以 [在GitHub中查看文件](https://github.com/mattmakai/slack-starterbot/blob/master/starterbot.py)):
|
||||
|
||||
```
|
||||
import os
|
||||
import time
|
||||
from slackclient import SlackClient
|
||||
|
||||
# 把 starterbot 的 ID作为一个环境变量
|
||||
BOT_ID = os.environ.get("BOT_ID")
|
||||
|
||||
# constants 常量
|
||||
AT_BOT = "<@" + BOT_ID + ">:"
|
||||
EXAMPLE_COMMAND = "do"
|
||||
|
||||
# 实例化Slack和Twilio clients
|
||||
slack_client = SlackClient(os.environ.get('SLACK_BOT_TOKEN'))
|
||||
|
||||
def handle_command(command, channel):
|
||||
"""
|
||||
Receives commands directed at the bot and determines if they
|
||||
are valid commands. If so, then acts on the commands. If not,
|
||||
returns back what it needs for clarification.
|
||||
"""
|
||||
response = "Not sure what you mean. Use the *" + EXAMPLE_COMMAND + \
|
||||
"* command with numbers, delimited by spaces."
|
||||
if command.startswith(EXAMPLE_COMMAND):
|
||||
response = "Sure...write some more code then I can do that!"
|
||||
slack_client.api_call("chat.postMessage", channel=channel,
|
||||
text=response, as_user=True)
|
||||
|
||||
def parse_slack_output(slack_rtm_output):
|
||||
"""
|
||||
The Slack Real Time Messaging API is an events firehose.
|
||||
this parsing function returns None unless a message is
|
||||
directed at the Bot, based on its ID.
|
||||
"""
|
||||
output_list = slack_rtm_output
|
||||
if output_list and len(output_list) > 0:
|
||||
for output in output_list:
|
||||
if output and 'text' in output and AT_BOT in output['text']:
|
||||
# 在@之后提到返回文本,空格删除
|
||||
return output['text'].split(AT_BOT)[1].strip().lower(), \
|
||||
output['channel']
|
||||
return None, None
|
||||
|
||||
if __name__ == "__main__":
|
||||
READ_WEBSOCKET_DELAY = 1 # 1 second delay between reading from firehose
|
||||
if slack_client.rtm_connect():
|
||||
print("StarterBot connected and running!")
|
||||
while True:
|
||||
command, channel = parse_slack_output(slack_client.rtm_read())
|
||||
if command and channel:
|
||||
handle_command(command, channel)
|
||||
time.sleep(READ_WEBSOCKET_DELAY)
|
||||
else:
|
||||
print("Connection failed. Invalid Slack token or bot ID?")
|
||||
|
||||
```
|
||||
|
||||
现在这是我们在这里所有的在命令行上通过python starterbot.py可以启动我们StarterBot的代码.
|
||||
|
||||

|
||||
|
||||
在 Slack 中创建新管道并且把 StarterBot 添加进来,或者直接把 StarterBot 添加进一个已经存在的管道。
|
||||
|
||||

|
||||
|
||||
现在在管道中启动 StarterBot。
|
||||
|
||||

|
||||
|
||||
当你从bot得到的响应中遇见问题时,这是你一种可能你想去做的修改.正如上面所写的这个教程,其中一行AT_BOT = "<@" + BOT_ID + ">:",在"@starter"后需要一个冒号(或者任何你自己所命名的特定bot).移除这些:从AT_BOT结束后的字符串.Slack clients似乎需要在@一个人名后加一个冒号,但这好像是有些不协调的.
|
||||
|
||||
### 结束
|
||||
|
||||
好吧,你现在已经获得一个简易的你可以在代码中很多地方加入你想创建任何特性的StarterBot.
|
||||
|
||||
这里有很多你可以使用的Slack RTM API 和 Python.看看通过这些文章你还可以学习到什么:
|
||||
|
||||
* 附加一个持久的[relational database 关系数据库](https://www.fullstackpython.com/databases.html) 或者 [NoSQL back-end](https://www.fullstackpython.com/no-sql-datastore.html) 比如 [PostgreSQL](https://www.fullstackpython.com/postgresql.html),[MySQL](https://www.fullstackpython.com/mysql.html) 或者 [SQLite](https://www.fullstackpython.com/sqlite.html) 用来保存和检索用户数据
|
||||
* 添加另外一个与bot互动的通道 [via SMS](https://www.twilio.com/blog/2016/05/build-sms-slack-bot-python.html) 或者 [phone calls](https://www.twilio.com/blog/2016/05/add-phone-calling-slack-python.html)
|
||||
* [Integrate other web APIs](https://www.fullstackpython.com/api-integration.html) 比如 [GitHub](https://developer.github.com/v3/), [Twilio](https://www.twilio.com/docs) 或者 [api.ai](https://docs.api.ai/)
|
||||
|
||||
有问题? 通过Twitter联系我 [@fullstackpython](https://twitter.com/fullstackpython) or [@mattmakai](https://twitter.com/mattmakai). 这是我在GitHub上的用户名 [mattmakai](https://github.com/mattmakai).
|
||||
|
||||
这篇文章还有问题? Fork [this page's source on GitHub 这是在GitHub上的页面源](https://github.com/mattmakai/fullstackpython.com/blob/gh-pages/source/content/posts/160604-build-first-slack-bot-python.markdown).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.fullstackpython.com/blog/build-first-slack-bot-python.html
|
||||
|
||||
作者: [Matt Makai][a]
|
||||
译者:[jiajia9llinuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出aa
|
||||
|
||||
[a]: https://www.fullstackpython.com/about-author.html
|
||||
@ -0,0 +1,136 @@
|
||||
第3部分 - 如何使用Ubuntu系统上Octave 4.0的先进数学技术处理音频文件
|
||||
=====
|
||||
|
||||
我们的数字音频处理技术第三部分涵盖了信号调制内容,将解释如何进行调幅,颤音效果,和频率变化。
|
||||
### 调制
|
||||
|
||||
#### 调幅
|
||||
|
||||
正如它的名字暗示的那样, 影响正弦信号的振幅变化依据传递的信息不断改变。正弦波因为承载者大量的信息被称作载波。这种调制技术被用于许多的商业广播和市民信息传输波段(AM).
|
||||
|
||||
#### 为何要使用调幅技术?
|
||||
|
||||
**调制发射.**
|
||||
|
||||
假设信道是免费资源,我们需要天线发射和接收信号。这要求有效的电磁信号发射天线,它的大小和要被发射的信号的波长应该是同一数量级。很多信号,包括音频成分,通常100赫兹或更少。对于这些信号,如果直接发射,我们就需要建立300公里的天线。如果信号调制用于在100MZ的高频载波中打印信息,那么天线仅仅需要1米(横向长度)。
|
||||
|
||||
**集中调制与多通道.**
|
||||
|
||||
假设多个信号占用一个通道,可以调制不同的信号到接收特定信号的不同位置。使用集中调制(“复用”)的应用有遥感探测数据,立体声调频收音机和长途电话。
|
||||
|
||||
**克服设备限制的调制.**
|
||||
|
||||
信号处理设备,比如过滤器,放大器,以及可以被重新创建的设备它们的性能依赖于信号在频域中的境况以及高频率和低频信号的关系。调制可以用于传递信号在频域中的位置,更容易满足设计的要求。调制也可以将“宽带信号“(高频和低频的比例很大的信号)转换成”窄带“信号
|
||||
|
||||
**音频特效**
|
||||
|
||||
许多音频特效由于引人注目和处理信号的便捷性使用了调幅技术。我们可以说出很多,比如颤音、合唱、镶边等等。这种实用性就是我们关注它的原因。
|
||||
|
||||
### 颤音效果
|
||||
|
||||
颤音效果是调幅最简单的应用,为实现这样的效果,我们会用周期信号改变(乘)音频信号,使用正弦或其他。
|
||||
|
||||
```
|
||||
>> tremolo='tremolo.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> wo=2*pi*440*t;
|
||||
>> wa=2*pi*1.2*t;
|
||||
>> audiowrite(tremolo, cos(wa).*cos(wo),fs);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremolo.png)
|
||||
|
||||
这将创造一个正弦形状的信号,它的效果就像‘颤音’。
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremoloshape.png)
|
||||
|
||||
### 在真实音频文件中的颤音
|
||||
|
||||
现在我们将展示真实世界中的颤音效果。首先,我们使用之前记录过男性发声‘A’的音频文件。这个信号图就像下面这样:
|
||||
|
||||
```
|
||||
>> [y,fs]=audioread('A.ogg');
|
||||
>> plot(y);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/avocalmale.png)
|
||||
|
||||
现在我们将创建一个完整的正弦信号,使用如下的参数:
|
||||
|
||||
```
|
||||
Amplitude = 1
|
||||
Frequency= 1.5Hz
|
||||
Phase = 0
|
||||
```
|
||||
|
||||
```
|
||||
>> t=0:1/fs:4.99999999;
|
||||
>> t=t(:);
|
||||
>> w=2*pi*1.5*t;
|
||||
>> q=cos(w);
|
||||
>> plot(q);
|
||||
```
|
||||
|
||||
注意: 当我们创建一组时间值时,默认情况下,它是以列的格式呈现,如, 1x220500的值。为了乘以这样的值,必须将其变成行的形式(220500x1). 这就是t=t(:)命令的作用。
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/sinusoidal.png)
|
||||
|
||||
我们将创建第二份ogg音频格式的文件,它包含了如下的调制信号:
|
||||
|
||||
```
|
||||
>> tremolo='tremolo.ogg';
|
||||
>> audiowrite(tremolo, q.*y,fs);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremsignal1.png)[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/tremolsignal1.png)
|
||||
|
||||
### 频率变化
|
||||
|
||||
我们可以改变频率保持一些有趣的音效,比如原音变形,电影音效,多人比赛。
|
||||
|
||||
#### 正弦频率调制的影响
|
||||
|
||||
这是正弦调制频率变化的演示代码,根据方程:
|
||||
|
||||
```
|
||||
Y=Ac*Cos(wo*Cos(wo/k))
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
```
|
||||
Ac = Amplitude
|
||||
|
||||
wo = fundamental frequency
|
||||
|
||||
k = scalar divisor
|
||||
```
|
||||
|
||||
```
|
||||
>> fm='fm.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> w=2*pi*442*t;
|
||||
>> audiowrite(fm, cos(cos(w/1500).*w), fs);
|
||||
>> [y,fs]=audioread('fm.ogg');
|
||||
>> figure (); plot (y);
|
||||
```
|
||||
|
||||
信号图:
|
||||
|
||||
[](https://www.howtoforge.com/images/ubuntu-octave-audio-processing-part-3/big/fmod.png)
|
||||
|
||||
你可以使用几乎任何类型的周期函数频率调制。本例中,我们仅仅用了一个正弦函数。请大胆的改变函数频率,用复合函数,甚至改变函数的类型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
经由: https://www.howtoforge.com/tutorial/ubuntu-octave-audio-processing-part-3/
|
||||
|
||||
作者:[David Duarte][a]
|
||||
译者:[theArcticOcean](https://github.com/theArcticOcean)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/ubuntu-octave-audio-processing-part-3/
|
||||
@ -1,26 +1,26 @@
|
||||
Twitter背后的基础设施:效率与优化
|
||||
揭秘 Twitter 背后的基础设施:效率与优化篇
|
||||
===========
|
||||
|
||||
过去我们曾经发布过一些关于 [Finagle](https://twitter.github.io/finagle/) , [Manhattan](https://blog.twitter.com/2014/manhattan-our-real-time-multi-tenant-distributed-database-for-twitter-scale) 这些项目的文章,还写过一些针对大型事件活动的架构优化的文章,例如天空之城,超级碗, 2014 世界杯,全球新年夜庆祝活动等。在这篇基础设施系列文章中,我主要聚焦于 Twitter 的一些关键设施和组件。我也会写一些我们在系统的扩展性,可靠性,效率性方面的做过的改进,例如我们基础设施的历史,遇到过的挑战,学到的教训,做过的升级,以及我们现在前进的方向等等。
|
||||
过去我们曾经发布过一些关于 [Finagle](https://twitter.github.io/finagle/) 、[Manhattan](https://blog.twitter.com/2014/manhattan-our-real-time-multi-tenant-distributed-database-for-twitter-scale) 这些项目的文章,还写过一些针对大型事件活动的[架构优化](https://blog.twitter.com/2013/new-tweets-per-second-record-and-how)的文章,例如天空之城、超级碗、2014 世界杯、全球新年夜庆祝活动等。在这篇基础设施系列文章中,我主要聚焦于 Twitter 的一些关键设施和组件。我也会写一些我们在系统的扩展性、可靠性、效率方面的做过的改进,例如我们基础设施的历史,遇到过的挑战,学到的教训,做过的升级,以及我们现在前进的方向等等。
|
||||
|
||||
> 天空之城:2013年8月2日,宫崎骏的《天空之城》在NTV迎来其第14次电视重播,剧情发展到高潮之时,Twitter的TPS(Tweets Per Second)也被推上了新的高度——143,199 TPS,是平均值的25倍,这个记录保持至今 -- 译者注。
|
||||
> 天空之城:2013 年 8 月 2 日,宫崎骏的《天空之城(Castle in the Sky)》在 NTV 迎来其第 14 次电视重播,剧情发展到高潮之时,Twitter 的 TPS(Tweets Per Second)也被推上了新的高度——143,199 TPS,是平均值的 25 倍,这个记录保持至今。-- LCTT 译注
|
||||
|
||||
### 数据中心的效率优化
|
||||
|
||||
#### 历史
|
||||
|
||||
当前Twitter硬件和数据中心的规模已经超过大多数公司。但达到这样的规模不是一蹴而就的,系统是随着软硬件的升级优化一步步成熟起来的,过程中我们也曾经犯过很多错误。
|
||||
当前 Twitter 硬件和数据中心的规模已经超过大多数公司。但达到这样的规模不是一蹴而就的,系统是随着软硬件的升级优化一步步成熟起来的,过程中我们也曾经犯过很多错误。
|
||||
|
||||
有个一时期我们的系统故障不断。软件问题,硬件问题,甚至底层设备问题不断爆发,常常导致系统运营中断。随着 Twitter 在客户、服务、媒体上的影响力不断扩大,构建一个高效、可靠的系统来提供服务成为我们的战略诉求。
|
||||
有个一时期我们的系统故障不断。软件问题、硬件问题,甚至底层设备问题不断爆发,常常导致系统运营中断。出现故障的地方存在于各个方面,必须综合考虑才能确定其风险和受到影响的服务。随着 Twitter 在客户、服务、媒体上的影响力不断扩大,构建一个高效、可靠的系统来提供服务成为我们的战略诉求。
|
||||
|
||||
> Twitter系统故障的界面被称为失败鲸(Fail Whale),如下图 -- 译者注
|
||||

|
||||
> Twitter系统故障的界面被称为失败鲸(Fail Whale),如下图 -- LCTT 译注
|
||||
> 
|
||||
|
||||
#### 挑战
|
||||
|
||||
一开始,我们的软件是直接安装在服务器,这意味着软件可靠性依赖硬件,电源、网络以及其他的环境因素都是威胁。这种情况下,如果要增加容错能力,就需要统筹考虑物理设备和在上面运行的服务。
|
||||
一开始,我们的软件是直接安装在服务器,这意味着软件可靠性依赖硬件,电源、网络以及其他的环境因素都是威胁。这种情况下,如果要增加容错能力,就需要统筹考虑这些互不关联的物理设备因素及在上面运行的服务。
|
||||
|
||||
最早采购数据中心方案的时候,我们都还是菜鸟,对于站点选择、运营和设计都非常不专业。我们先直接租用主机,业务增长后我们改用主机托管。早期遇到的问题主要是因为设备故障、数据中心设计问题、维护问题以及人为操作失误。我们也在持续迭代我们的硬件设计,从而增强硬件和数据中心的容错性。
|
||||
最早采购数据中心方案的时候,我们都还是菜鸟,对于站点选择、运营和设计都非常不专业。我们先直接托管主机,业务增长后我们改用租赁机房。早期遇到的问题主要是因为设备故障、数据中心设计问题、维护问题以及人为操作失误。我们也在持续迭代我们的硬件设计,从而增强硬件和数据中心的容错性。
|
||||
|
||||
服务中断的原因有很多,其中硬件故障常发生在服务器、机架交换机、核心交换机这地方。举一个我们曾经犯过的错误,硬件团队最初在设计服务器的时候,认为双路电源对减少供电问题的意义不大 -- 他们真的就移除了一块电源。然而数据中心一般给机架提供两路供电来提高冗余性,防止电网故障传导到服务器,而这需要两块电源。最终我们不得不在机架上增加了一个 ATS 单元(AC transfer switch 交流切换开关)来接入第二路供电。
|
||||
|
||||
@ -28,9 +28,9 @@ Twitter背后的基础设施:效率与优化
|
||||
|
||||
#### 我们学到的教训以及技术的升级、迁移和选型
|
||||
|
||||
我们学到的第一个教训就是要先建模,将可能出故障的地方(例如建筑的供电和冷却系统、硬件、光线网络等)和运行在上面的服务之间的依赖关系弄清楚,这样才能更好地分析,从而优化设计提升容错能力。
|
||||
我们学到的第一个教训就是要先建模,将可能出故障的地方(例如建筑的供电和冷却系统、硬件、光纤网络等)和运行在上面的服务之间的依赖关系弄清楚,这样才能更好地分析,从而优化设计提升容错能力。
|
||||
|
||||
我们增加了更多的数据中心提升地理容灾能力,减少自然灾害的影响。而且这种站点隔离也降低了软件的风险,减少了例如软件部署升级和系统故障的风险。这种多活的数据中心架构提供了代码灰度发布的能力,减少代码首次上线时候的影响。
|
||||
我们增加了更多的数据中心提升地理容灾能力,减少自然灾害的影响。而且这种站点隔离也降低了软件的风险,减少了例如软件部署升级和系统故障的风险。这种多活的数据中心架构提供了代码灰度发布(staged code deployment)的能力,减少代码首次上线时候的影响。
|
||||
|
||||
我们设计新硬件使之能够在更高温度下正常运行,数据中心的能源效率因此有所提升。
|
||||
|
||||
@ -46,9 +46,9 @@ Twitter背后的基础设施:效率与优化
|
||||
|
||||
Twitter 是一个很大的公司,它对硬件的要求对任何团队来说都是一个不小的挑战。为了满足整个公司的需求,我们的首要工作是能检测并保证购买的硬件的品质。团队重点关注的是性能和可靠性这两部分。对于硬件我们会做系统性的测试来保证其性能可预测,保证尽量不引入新的问题。
|
||||
|
||||
随着我们一些关键组件的负荷越来越大(如 Mesos , Hadoop , Manhattan , MySQL 等),市面上的产品已经无法满足我们的需求。同时供应商提供的一些高级服务器功能,例如 Raid 管理或者电源热切换等,可靠性提升很小,反而会拖累系统性能而且价格高昂,例如一些 Raid 控制器价格高达系统总报价的三分之一,还拖累了 SSD 的性能。
|
||||
随着我们一些关键组件的负荷越来越大(如 Mesos、Hadoop、Manhattan、MySQL 等),市面上的产品已经无法满足我们的需求。同时供应商提供的一些高级服务器功能,例如 Raid 管理或者电源热切换等,可靠性提升很小,反而会拖累系统性能而且价格高昂,例如一些 Raid 控制器价格高达系统总报价的三分之一,还拖累了 SSD 的性能。
|
||||
|
||||
那时,我们也是 MySQL 数据库的一个大型用户。SAS(Serial Attached SCSI,串行连接 SCSI )设备的供应和性能都有很大的问题。我们大量使用 1 u 的服务器,它的驱动器和回写缓存一起也只能支撑每秒 2000 次顺序 IO。为了获得更好的效果,我们只得不断增加 CPU 核心数并加强磁盘能力。我们那时候找不到更节省成本的方案。
|
||||
那时,我们也是 MySQL 数据库的一个大型用户。SAS(Serial Attached SCSI,串行连接 SCSI )设备的供应和性能都有很大的问题。我们大量使用 1U 规格的服务器,它的磁盘和回写缓存一起也只能支撑每秒 2000 次的顺序 IO。为了获得更好的效果,我们只得不断增加 CPU 核心数并加强磁盘能力。我们那时候找不到更节省成本的方案。
|
||||
|
||||
后来随着我们对硬件需求越来越大,我们可以成立了一个硬件团队,从而自己来设计更便宜更高效的硬件。
|
||||
|
||||
@ -58,62 +58,59 @@ Twitter 是一个很大的公司,它对硬件的要求对任何团队来说都
|
||||
|
||||
- 2012 - 采用 SSD 作为我们 MySQL 和 Key-Value 数据库的主要存储。
|
||||
- 2013 - 我们开发了第一个定制版 Hadoop 工作站,它现在是我们主要的大容量存储方案。
|
||||
- 2013 - 我们定制的解决方案应用在 Mesos 、 TFE( Twitter Front-End )以及缓存设备上。
|
||||
- 2013 - 我们定制的解决方案应用在 Mesos、TFE( Twitter Front-End )以及缓存设备上。
|
||||
- 2014 - 我们定制的 SSD Key-Value 服务器完成开发。
|
||||
- 2015 - 我们定制的数据库解决方案完成开发。
|
||||
- 2016 - 我们开发了一个 GPU 系统来做模糊推理和训练机器学习。
|
||||
|
||||
#### 学到的教训
|
||||
|
||||
硬件团队的工作本质是通过做取舍来优化TCO(总体拥有成本),最终达到达到降低 CAPEX(资本支出)和 OPEX(运营支出)的目的。概括来说,服务器降成本就是:
|
||||
硬件团队的工作本质是通过做取舍来优化 TCO(总体拥有成本),最终达到达到降低 CAPEX(资本支出)和 OPEX(运营支出)的目的。概括来说,服务器降成本就是:
|
||||
|
||||
1. 删除无用的功能和组件
|
||||
2. 提升利用率
|
||||
|
||||
Twitter 的设备总体来说有这四大类:存储设备、计算设备、数据库和 GPU 。 Twitter 对每一类都定义了详细的需求,让硬件工程师更针对性地设计产品,从而优化掉那些用不到或者极少用的冗余部分。例如,我们的存储设备就专门为 Hadoop 优化,设备的购买和运营成本相比于 OEM 产品降低了 20% 。同时,这样做减法还提高了设备的性能和可靠性。同样的,对于计算设备,硬件工程师们也通过移除无用的特性获得了效率提升。
|
||||
Twitter 的设备总体来说有这四大类:存储设备、计算设备、数据库和 GPU 。 Twitter 对每一类都定义了详细的需求,让硬件工程师更针对性地设计产品,从而优化掉那些用不到或者极少用的冗余部分。例如,我们的存储设备就专门为 Hadoop 优化过,设备的购买和运营成本相比于 OEM 产品降低了 20% 。同时,这样做减法还提高了设备的性能和可靠性。同样的,对于计算设备,硬件工程师们也通过移除无用的特性获得了效率提升。
|
||||
|
||||
一个服务器可以移除的组件总是有限的,我们很快就把能移除的都扔掉了。于是我们想出了其他办法,例如在存储设备里,我们认为降低成本最好的办法是用一个节点替换多个节点,并通过 Aurora/Mesos 来管理任务负载。这就是我们现在正在做的东西。
|
||||
|
||||
对于这个我们自己新设计的服务器,首先要通过一系列的标准测试,然后会再做一系列负载测试,我们的目标是一台新设备至少能替换两台旧设备。大多数的提升都比较简单,例如增加 CPU 的进程数,同时我们的测试也比较出新 CPU 的 单线程能力提高了 20~50% ,对应能耗降低了 25% ,这都是我们测试环节需要做的工作。
|
||||
对于这个我们自己新设计的服务器,首先要通过一系列的标准测试,然后会再做一系列负载测试,我们的目标是一台新设备至少能替换两台旧设备。最大的性能提升来自增加 CPU 的线程数,我们的测试结果表示新 CPU 的 单线程能力提高了 20~50% 。同时由于整个服务器的线程数增加,我们看到单线程能效提升了 25%。
|
||||
|
||||
这个新设备首次部署的时候,监控发现新设备只能替换 1.5 台旧设备,这比我们的目标低了很多。对性能数据检查后发现,我们之前新硬件的部分指标是错的,而这正是我们在做性能测试需要发现的问题。
|
||||
这个新设备首次部署的时候,监控发现新设备只能替换 1.5 台旧设备,这比我们的目标低了很多。对性能数据检查后发现,我们之前对负载特性的一些假定是有问题的,而这正是我们在做性能测试需要发现的问题。
|
||||
|
||||
对此我们硬件团队开发了一个模型,用来预测在不同的硬件配置下当前 Aurora 任务的打包效率。这个模型正确的预测了新旧硬件的性能比例。模型还指出了我们一开始没有考虑到的存储需求,并因此建议我们增加 CPU 核心数。另外,它还预测,如果我们修改内存的配置,那系统的性能还会有较大提高。
|
||||
对此我们硬件团队开发了一个模型,用来预测在不同的硬件配置下当前 Aurora 任务的填充效率。这个模型正确的预测了新旧硬件的性能比例。模型还指出了我们一开始没有考虑到的存储需求,并因此建议我们增加 CPU 核心数。另外,它还预测,如果我们修改内存的配置,那系统的性能还会有较大提高。
|
||||
|
||||
硬件配置的改变都需要花时间去操作,所以我们的硬件工程师们就首先找出几个关键痛点。例如我们和站点工程团队一起调整任务顺序来降低存储需求,这种修改很简单也很有效,新设备可以代替 1.85 个旧设备了。
|
||||
硬件配置的改变都需要花时间去操作,所以我们的硬件工程师们就首先找出几个关键痛点。例如我们和 SRE(Site Reliability Engineer,网站可靠性工程师)团队一起调整任务顺序来降低存储需求,这种修改很简单也很有效,新设备可以代替 1.85 个旧设备了。
|
||||
|
||||
为了更好的优化效率,我们对新硬件的配置做了修改,扩大了内存和磁盘容量就将 CPU 利用率提高了20% ,而这只增加了非常小的成本。同时我们的硬件工程师也和生产的伙伴一起优化发货顺序来降低货运成本。后续的观察发现我们的自己的新设备实际上可以代替 2.4 台旧设备,这个超出了预定的目标。
|
||||
为了更好的优化效率,我们对新硬件的配置做了修改,只是扩大了内存和磁盘容量就将 CPU 利用率提高了20% ,而这只增加了非常小的成本。同时我们的硬件工程师也和合作生产厂商一起为那些服务器的最初出货调整了物料清单。后续的观察发现我们的自己的新设备实际上可以代替 2.4 台旧设备,这个超出了预定的目标。
|
||||
|
||||
### 从裸设备迁移到 mesos 集群
|
||||
|
||||
直到2012年为止,软件团队在 Twitter 开通一个新服务还需要自己操心硬件:配置硬件的规格需求,研究机架尺寸,开发部署脚本以及处理硬件故障。同时,系统中没有所谓的“服务发现”机制,当一个服务需要调用一个另一个服务时候,需要读取一个 YAML 配置文件,这个配置文件中有目标服务对应的主机 IP 和端口信息(端口信息是由一个公共 wiki 页面维护的)。随着硬件的替换和更新,YAML 配置文件里的内容也会不断的编辑更新。每次更新都需要花几个小时甚至几天来重启在各个服务,从而将新配置刷新到所有服务的缓存里,所以我们只能尽量一次增加多个配置并且按次序分别重启。我们经常遇到重启过程中 cache 不一致导致的问题,因为有的主机在使用旧的配置有的主机在用新的。有时候一台主机的异常(例如它正在重启)会导致整个站点都无法正常工作。
|
||||
直到 2012 年为止,软件团队在 Twitter 开通一个新服务还需要自己操心硬件:配置硬件的规格需求,研究机架尺寸,开发部署脚本以及处理硬件故障。同时,系统中没有所谓的“服务发现”机制,当一个服务需要调用一个另一个服务时候,需要读取一个 YAML 配置文件,这个配置文件中有目标服务对应的主机 IP 和端口信息(预留的端口信息是由一个公共 wiki 页面维护的)。随着硬件的替换和更新,YAML 配置文件里的内容也会不断的编辑更新。在缓存层做修改意味着我们可以按小时或按天做很多次部署,每次添加少量主机并按阶段部署。我们经常遇到在部署过程中 cache 不一致导致的问题,因为有的主机在使用旧的配置有的主机在用新的。有时候一台主机的异常(例如在部署过程中它临时宕机了)会导致整个站点都无法正常工作。
|
||||
|
||||
在 2012/2013 年的时候,Twitter 开始尝试两个新事物:服务发现(来自 ZooKeeper 集群和 Finagle 核心模块中的一个库)和 Mesos(包括基于 Mesos 的一个自研的计划任务框架 Aurora ,它现在也是 Apache 基金会的一个项目)。
|
||||
在 2012/2013 年的时候,Twitter 开始尝试两个新事物:服务发现(来自 ZooKeeper 集群和 [Finagle](https://twitter.github.io/finagle/) 核心模块中的一个库)和 [Mesos](http://mesos.apache.org/)(包括基于 Mesos 的一个自研的计划任务框架 Aurora ,它现在也是 Apache 基金会的一个项目)。
|
||||
|
||||
服务发现功能意味着不需要再维护一个静态 YAML 主机列表了。服务或者在启动后主动注册,或者自动被 mesos 接入到一个“服务集”(就是一个 ZooKeeper 中的 znode 列表,包含角色、环境和服务名信息)中。任何想要访问这个服务的组件都只需要监控这个路径就可以实时获取到一个正在工作的服务列表。
|
||||
|
||||
现在我们通过 Mesos/Aurora ,而不是使用脚本(我们曾经是 Capistrano 的重度用户)来获取一个主机列表、分发代码并规划重启任务。现在软件团队如果想部署一个新服务,只需要将软件包上传到一个叫 Packer 的工具上(它是一个基于 HDFS 的服务),再在 Aurora 配置上描述文件(需要多少 CPU ,多少内存,多少个实例,启动的命令行代码),然后 Aurora 就会自动完成整个部署过程。 Aurora 先找到可用的主机,从 Packer 下载代码,注册到“服务发现”,最后启动这个服务。如果整个过程中遇到失败(硬件故障、网络中断等等), Mesos/Aurora 会自动重选一个新主机并将服务部署上去。
|
||||
现在我们通过 Mesos/Aurora ,而不是使用脚本(我们曾经是 [Capistrano](https://github.com/capistrano/capistrano) 的重度用户)来获取一个主机列表、分发代码并规划重启任务。现在软件团队如果想部署一个新服务,只需要将软件包上传到一个叫 Packer 的工具上(它是一个基于 HDFS 的服务),再在 Aurora 配置上描述文件(需要多少 CPU ,多少内存,多少个实例,启动的命令行代码),然后 Aurora 就会自动完成整个部署过程。 Aurora 先找到可用的主机,从 Packer 下载代码,注册到“服务发现”,最后启动这个服务。如果整个过程中遇到失败(硬件故障、网络中断等等), Mesos/Aurora 会自动重选一个新主机并将服务部署上去。
|
||||
|
||||
#### Twitter 的私有 PaaS 云平台
|
||||
|
||||
Mesos/Aurora 和服务发现这两个功能给我们带了革命性的变化。虽然在接下来几年里,我们碰到了无数 bug ,伤透了无数脑筋,学到了分布式系统里的无数教训,但是这套架还是非常赞的。以前大家一直忙于处理硬件搭配和管理,而现在,大家只需要考虑如何优化业务以及需要多少系统能力就可以了。同时,我们也从根本上解决了 CPU 利用率低的问题,以前服务直接安装在服务器上,这种方式无法充分利用服务器资源,任务协调能力也很差。现在 Mesos 允许我们把多个服务打包成一个服务包,增加一个新服务只需要修改硬件配额,再改一行配置就可以了。
|
||||
Mesos/Aurora 和服务发现这两个功能给我们带了革命性的变化。虽然在接下来几年里,我们碰到了无数 bug ,伤透了无数脑筋,学到了分布式系统里的无数教训,但是这套架还是非常赞的。以前大家一直忙于处理硬件搭配和管理,而现在,大家只需要考虑如何优化业务以及需要多少系统能力就可以了。同时,我们也从根本上解决了 Twitter 之前经历过的 CPU 利用率低的问题,以前服务直接安装在服务器上,这种方式无法充分利用服务器资源,任务协调能力也很差。现在 Mesos 允许我们把多个服务打包成一个服务包,增加一个新服务只需要修改配额,再改一行配置就可以了。
|
||||
|
||||
在两年时间里,多数“无状态”服务迁移到了 Mesos 平台。一些大型且重要的服务(包括我们的用户服务和广告服务)是最先迁移上去的。因为它们的体量巨大,所以他们从这些服务里获得的好处也最多。
|
||||
在两年时间里,多数“无状态”服务迁移到了 Mesos 平台。一些大型且重要的服务(包括我们的用户服务和广告服务系统)是最先迁移上去的。因为它们的体量巨大,所以它们从这些服务里获得的好处也最多,这也降低了它们的服务压力。
|
||||
|
||||
我们一直在不断追求效率提升和架构优化的最佳实践。我们会定期去测试公有云的产品,和我们自己产品的 TCO 以及性能做对比。我们也拥抱公有云的服务,事实上我们现在正在使用公有云产品。最后,这个系列的下一篇将会主要聚焦于我们基础设施的体量方面。
|
||||
|
||||
特别感谢 Jennifer Fraser, David Barr, Geoff Papilion, Matt Singer, Lam Dong 对这篇文章的贡献。
|
||||
|
||||
|
||||
|
||||
特别感谢 [Jennifer Fraser][1]、[David Barr][2]、[Geoff Papilion][3]、 [Matt Singer][4]、[Lam Dong][5] 对这篇文章的贡献。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.twitter.com/2016/the-infrastructure-behind-twitter-efficiency-and-optimization?utm_source=webopsweekly&utm_medium=email
|
||||
via: https://blog.twitter.com/2016/the-infrastructure-behind-twitter-efficiency-and-optimization
|
||||
|
||||
作者:[mazdakh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[eriwoon](https://github.com/eriwoon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -121,9 +118,5 @@ via: https://blog.twitter.com/2016/the-infrastructure-behind-twitter-efficiency-
|
||||
[1]: https://twitter.com/jenniferfraser
|
||||
[2]: https://twitter.com/davebarr
|
||||
[3]: https://twitter.com/gpapilion
|
||||
[4]: https://twitter.com/lamdong
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[4]: https://twitter.com/mattbytes
|
||||
[5]: https://twitter.com/lamdong
|
||||
@ -1,200 +0,0 @@
|
||||
使用 Elasticsearch 和 cAdvisor 监控 Docker 容器
|
||||
=======
|
||||
|
||||
如果你正在运行 Swarm 模式的集群,或者只运行单台 Docker,你都会有下面的疑问:
|
||||
|
||||
> 我如何才能监控到它们都在干些什么?
|
||||
|
||||
这个问题的答案是“很不容易”。
|
||||
|
||||
你需要监控下面的参数:
|
||||
|
||||
1. 容器的数量和状态。
|
||||
2. 一台容器是否已经移到另一个节点了,如果是,那是在什么时候,移动到哪个节点?
|
||||
3. 给定节点上运行着的容器数量。
|
||||
4. 一段时间内的通信峰值。
|
||||
5. 孤儿卷和网络(LCTT 译注:孤儿卷就是当你删除容器时忘记删除它的卷,这个卷就不会再被使用,但会一直占用资源)。
|
||||
6. 可用磁盘空间、可用 inode 数。
|
||||
7. 容器数量与连接在 docker0 和 docker_gwbridge 上的虚拟网卡数量不一致(LCTT 译注:当 docker 启动时,它会在宿主机器上创建一个名为 docker0 的虚拟网络接口)。
|
||||
8. 开启和关闭 Swarm 节点。
|
||||
9. 收集并集中处理日志。
|
||||
|
||||
本文的目标是介绍 [Elasticsearch][1] + [Kibana][2] + [cAdvisor][3] 的用法,使用它们来收集 Docker 容器的参数,分析数据并产生可视化报表。
|
||||
|
||||
阅读本文后你可以发现有一个监控仪表盘能够部分解决上述列出的问题。但如果只是使用 cAdvisor,有些参数就无法显示出来,比如 Swarm 模式的节点。
|
||||
|
||||
如果你有一些 cAdvisor 或其他工具无法解决的特殊需求,我建议你开发自己的数据收集器和数据处理器(比如 [Beats][4]),请注意我不会演示如何使用 Elasticsearch 来集中收集 Docker 容器的日志。
|
||||
|
||||
> [“你要如何才能监控到 Swarm 模式集群里面发生了什么事情?要做到这点很不容易。” —— @fntlnz][5]
|
||||
|
||||
### 我们为什么要监控容器?
|
||||
|
||||
想象一下这个经典场景:你在管理一台或多台虚拟机,你把 tmux 工具用得很溜,用各种 session 事先设定好了所有基础的东西,包括监控。然后生产环境出问题了,你使用 `top`、`htop`、`iotop`、`jnettop` 各种 top 来排查,然后你准备好修复故障。
|
||||
|
||||
现在重新想象一下你有 3 个节点,包含 50 台容器,你需要在一个地方查看整洁的历史数据,这样你知道问题出在哪个地方,而不是把你的生命浪费在那些字符界面来赌你可以找到问题点。
|
||||
|
||||
### 什么是 Elastic Stack ?
|
||||
|
||||
Elastic Stack 就一个工具集,包括以下工具:
|
||||
|
||||
- Elasticsearch
|
||||
- Kibana
|
||||
- Logstash
|
||||
- Beats
|
||||
|
||||
我们会使用其中一部分工具,比如使用 Elasticsearch 来分析基于 JSON 格式的文本,以及使用 Kibana 来可视化数据并产生报表。
|
||||
|
||||
另一个重要的工具是 [Beats][4],但在本文中我们还是把精力放在容器上,官方的 Beats 工具不支持 Docker,所以我们选择原生兼容 Elasticsearch 的 cAdvisor。
|
||||
|
||||
[cAdvisor][3] 工具负责收集、整合正在运行的容器数据,并导出报表。在本文中,这些报表被到入到 Elasticsearch 中。
|
||||
|
||||
cAdvisor 有两个比较酷的特性:
|
||||
|
||||
- 它不只局限于 Docker 容器。
|
||||
- 它有自己的 Web 服务器,可以简单地显示当前节点的可视化报表。
|
||||
|
||||
### 设置测试集群,或搭建自己的基础架构
|
||||
|
||||
和我[以前的文章][9]一样,我习惯提供一个简单的脚本,让读者不用花很多时间就能部署好和我一样的测试环境。你可以使用以下(非生产环境使用的)脚本来搭建一个 Swarm 模式的集群,其中一个容器运行着 Elasticsearch。
|
||||
|
||||
> 如果你有充足的时间和经验,你可以搭建自己的基础架构 (Bring Your Own Infrastructure,BYOI)。
|
||||
|
||||
如果要继续阅读本文,你需要:
|
||||
|
||||
- 运行 Docker 进程的一个或多个节点(docker 版本号大于等于 1.12)。
|
||||
- 至少有一个独立运行的 Elasticsearch 节点(版本号 2.4.X)。
|
||||
|
||||
重申一下,此 Elasticsearch 集群环境不能放在生产环境中使用。生产环境也不推荐使用单节点集群,所以如果你计划安装一个生产环境,请参考 [Elastic 指南][6]。
|
||||
|
||||
### 对喜欢尝鲜的用户的友情提示
|
||||
|
||||
我就是一个喜欢尝鲜的人(当然我也已经在生产环境中使用了最新的 alpha 版本),但是在本文中,我不会使用最新的 Elasticsearch 5.0.0 alpha 版本,我还不是很清楚这个版本的功能,所以我不想成为那个引导你们出错的关键。
|
||||
|
||||
所以本文中涉及的 Elasticsearch 版本为最新稳定版 2.4.0。
|
||||
|
||||
### 测试集群部署脚本
|
||||
|
||||
前面已经说过,我提供这个脚本给你们,让你们不必费神去部署 Swarm 集群和 Elasticsearch,当然你也可以跳过这一步,用你自己的 Swarm 模式引擎和你自己的 Elasticserch 节点。
|
||||
|
||||
执行这段脚本之前,你需要:
|
||||
|
||||
- [Docker Machine][7] – 最终版:在 DigitalOcean 中提供 Docker 引擎。
|
||||
- [DigitalOcean API Token][8]: 让 docker 机器按照你的意思来启动节点。
|
||||
|
||||

|
||||
|
||||
### 创建集群的脚本
|
||||
|
||||
现在万事俱备,你可以把下面的代码拷到 create-cluster.sh 文件中:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
#
|
||||
# Create a Swarm Mode cluster with a single master and a configurable number of workers
|
||||
|
||||
workers=${WORKERS:-"worker1 worker2"}
|
||||
|
||||
#######################################
|
||||
# Creates a machine on Digital Ocean
|
||||
# Globals:
|
||||
# DO_ACCESS_TOKEN The token needed to access DigitalOcean's API
|
||||
# Arguments:
|
||||
# $1 the actual name to give to the machine
|
||||
#######################################
|
||||
create_machine() {
|
||||
docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token=$DO_ACCESS_TOKEN \
|
||||
--digitalocean-size 2gb \
|
||||
$1
|
||||
}
|
||||
|
||||
#######################################
|
||||
# Executes a command on the specified machine
|
||||
# Arguments:
|
||||
# $1 The machine on which to run the command
|
||||
# $2..$n The command to execute on that machine
|
||||
#######################################
|
||||
machine_do() {
|
||||
docker-machine ssh $@
|
||||
}
|
||||
|
||||
main() {
|
||||
|
||||
if [ -z "$DO_ACCESS_TOKEN" ]; then
|
||||
echo "Please export a DigitalOcean Access token: https://cloud.digitalocean.com/settings/api/tokens/new"
|
||||
echo "export DO_ACCESS_TOKEN=<yourtokenhere>"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -z "$WORKERS" ]; then
|
||||
echo "You haven't provided your workers by setting the \$WORKERS environment variable, using the default ones: $workers"
|
||||
fi
|
||||
|
||||
# Create the first and only master
|
||||
echo "Creating the master"
|
||||
|
||||
create_machine master1
|
||||
|
||||
master_ip=$(docker-machine ip master1)
|
||||
|
||||
# Initialize the swarm mode on it
|
||||
echo "Initializing the swarm mode"
|
||||
machine_do master1 docker swarm init --advertise-addr $master_ip
|
||||
|
||||
# Obtain the token to allow workers to join
|
||||
worker_tkn=$(machine_do master1 docker swarm join-token -q worker)
|
||||
echo "Worker token: ${worker_tkn}"
|
||||
|
||||
# Create and join the workers
|
||||
for worker in $workers; do
|
||||
echo "Creating worker ${worker}"
|
||||
create_machine $worker
|
||||
machine_do $worker docker swarm join --token $worker_tkn $master_ip:2377
|
||||
done
|
||||
}
|
||||
|
||||
main $@
|
||||
```
|
||||
|
||||
赋予它可执行权限:
|
||||
|
||||
```
|
||||
chmod +x create-cluster.sh
|
||||
```
|
||||
|
||||
### 创建集群
|
||||
|
||||
如文件名所示,我们可以用它来创建集群。默认情况下这个脚本会创建一个 master 和两个 worker,如果你想修改 worker 个数,可以设置环境变量 WORKERS。
|
||||
|
||||
现在就来创建集群吧。
|
||||
|
||||
```
|
||||
./create-cluster.sh
|
||||
```
|
||||
|
||||
你可以出去喝杯咖啡,因为这需要花点时间。
|
||||
|
||||
最后集群部署好了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
|
||||
作者:[Lorenzo Fontana][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.codeship.com/author/lorenzofontana/
|
||||
|
||||
[1]: https://github.com/elastic/elasticsearch
|
||||
[2]: https://github.com/elastic/kibana
|
||||
[3]: https://github.com/google/cadvisor
|
||||
[4]: https://github.com/elastic/beats
|
||||
[5]: https://twitter.com/share?text=%22How+do+you+keep+track+of+all+that%27s+happening+in+a+Swarm+Mode+cluster%3F+Not+easily.%22+via+%40fntlnz&url=https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
[6]: https://www.elastic.co/guide/en/elasticsearch/guide/2.x/deploy.html
|
||||
[7]: https://docs.docker.com/machine/install-machine/
|
||||
[8]: https://cloud.digitalocean.com/settings/api/tokens/new
|
||||
[9]: https://blog.codeship.com/nginx-reverse-proxy-docker-swarm-clusters/
|
||||
Loading…
Reference in New Issue
Block a user