diff --git a/.github/workflows/lctt-article-badge.yml b/.github/workflows/lctt-article-badge.yml
new file mode 100644
index 0000000000..aef3d9613d
--- /dev/null
+++ b/.github/workflows/lctt-article-badge.yml
@@ -0,0 +1,27 @@
+name: LCTT Article Badge
+
+on:
+ push:
+ branches: [master]
+jobs:
+ build:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ with:
+ fetch-depth: 0
+ - name: checkout old pages branch
+ uses: actions/checkout@v2
+ with:
+ repository: lctt/translateproject
+ path: build
+ ref: gh-pages
+ - name: remove pages .git
+ run: rm -rf ./build/.git
+ - name: run badge
+ run: sh ./scripts/badge.sh;
+ - uses: crazy-max/ghaction-github-pages@v2.2.0
+ with:
+ build_dir: ./build
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
diff --git a/.github/workflows/lctt-article-checker.yml b/.github/workflows/lctt-article-checker.yml
new file mode 100644
index 0000000000..32d4354454
--- /dev/null
+++ b/.github/workflows/lctt-article-checker.yml
@@ -0,0 +1,18 @@
+name: LCTT Article Checker
+
+on:
+ pull_request:
+ branches: [master]
+jobs:
+ build:
+ runs-on: ubuntu-latest
+ env:
+ PULL_REQUEST_ID: ${{ github.event.number }}
+ steps:
+ - uses: actions/checkout@v2
+ with:
+ fetch-depth: 0
+ - name: "checkout master branch & return to pull request branch"
+ run: CURRENT=$(echo ${{github.ref}} | sed "s|refs/|refs/remotes/|") && git checkout master && git checkout $CURRENT
+ - name: run check
+ run: sh ./scripts/check.sh;
diff --git a/.github/workflows/lctt-article-status.yml b/.github/workflows/lctt-article-status.yml
new file mode 100644
index 0000000000..69ac7d5be8
--- /dev/null
+++ b/.github/workflows/lctt-article-status.yml
@@ -0,0 +1,28 @@
+name: LCTT Article Status
+
+on:
+ schedule:
+ - cron: "*/30 * * * *"
+ workflow_dispatch:
+jobs:
+ build:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ with:
+ fetch-depth: 0
+ - name: checkout old pages branch
+ uses: actions/checkout@v2
+ with:
+ repository: lctt/translateproject
+ path: build
+ ref: gh-pages
+ - name: remove pages .git
+ run: rm -rf ./build/.git
+ - name: run status
+ run: sh ./scripts/status.sh;
+ - uses: crazy-max/ghaction-github-pages@v2.2.0
+ with:
+ build_dir: ./build
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
diff --git a/.travis.yml b/.travis.yml
deleted file mode 100644
index 0b12ca6653..0000000000
--- a/.travis.yml
+++ /dev/null
@@ -1,27 +0,0 @@
-language: minimal
-install:
- - sudo apt-get install jq
- - git clone --depth=1 -b gh-pages https://github.com/LCTT/TranslateProject/ build && rm -rf build/.git
-script:
- - 'if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then sh ./scripts/check.sh; fi'
- - 'if [ "$TRAVIS_PULL_REQUEST" = "false" ]; then sh ./scripts/badge.sh; fi'
- - 'if [ "$TRAVIS_EVENT_TYPE" = "cron" ]; then sh ./scripts/status.sh; fi'
-
-branches:
- only:
- - master
- # - status
- except:
- - gh-pages
-git:
- submodules: false
- depth: false
-deploy:
- provider: pages
- skip_cleanup: true
- github_token: $GITHUB_TOKEN
- local_dir: build
- on:
- branch:
- - master
- # - status
diff --git a/published/20171025 Typeset your docs with LaTeX and TeXstudio on Fedora.md b/published/20171025 Typeset your docs with LaTeX and TeXstudio on Fedora.md
new file mode 100644
index 0000000000..8339eaf7d4
--- /dev/null
+++ b/published/20171025 Typeset your docs with LaTeX and TeXstudio on Fedora.md
@@ -0,0 +1,161 @@
+[#]: collector: (Chao-zhi)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13136-1.html)
+[#]: subject: (Typeset your docs with LaTeX and TeXstudio on Fedora)
+[#]: via: (https://fedoramagazine.org/typeset-latex-texstudio-fedora/)
+[#]: author: (Julita Inca Chiroque https://fedoramagazine.org/author/yulytas/)
+
+使用 LaTeX 和 TeXstudio 排版文档
+======
+
+
+
+LaTeX 是一个服务于高质量排版的[文档准备系统][1]。通常用于大量的技术和科学文档的排版。不过,你也可以使用 LaTex 排版各种形式的文档。教师可以编辑他们的考试和教学大纲,学生可以展示他们的论文和报告。这篇文章让你尝试使用 TeXstudio。TeXstudio 是一个便于编辑 LaTeX 文档的软件。
+
+### 启动 TeXstudio
+
+如果你使用的是 Fedora Workstation,请启动软件管理,然后输入 TeXstudio 以搜索该应用程序。然后选择安装并添加 TeXstudio 到你的系统。你可以从软件管理中启动这个程序,或者像以往一样在概览中启动这个软件。
+
+或者,如果你使用终端,请输入 `texstudio`。如果未安装该软件包,系统将提示你安装它。键入 `y` 开始安装。
+
+```
+$ texstudio
+bash: texstudio: command not found...
+Install package 'texstudio' to provide command 'texstudio'? [N/y] y
+```
+
+### 你的第一份文档
+
+LaTeX 命令通常以反斜杠 `\` 开头,命令参数用大括号 `{}` 括起来。首先声明 `documentclass` 的类型。这个例子向你展示了该文档的类是一篇文章。
+
+然后,在声明 `documentclass` 之后,用 `begin` 和 `end` 标记文档的开始和结束。在这些命令之间,写一段类似以下的内容:
+
+```
+\documentclass{article}
+\begin{document}
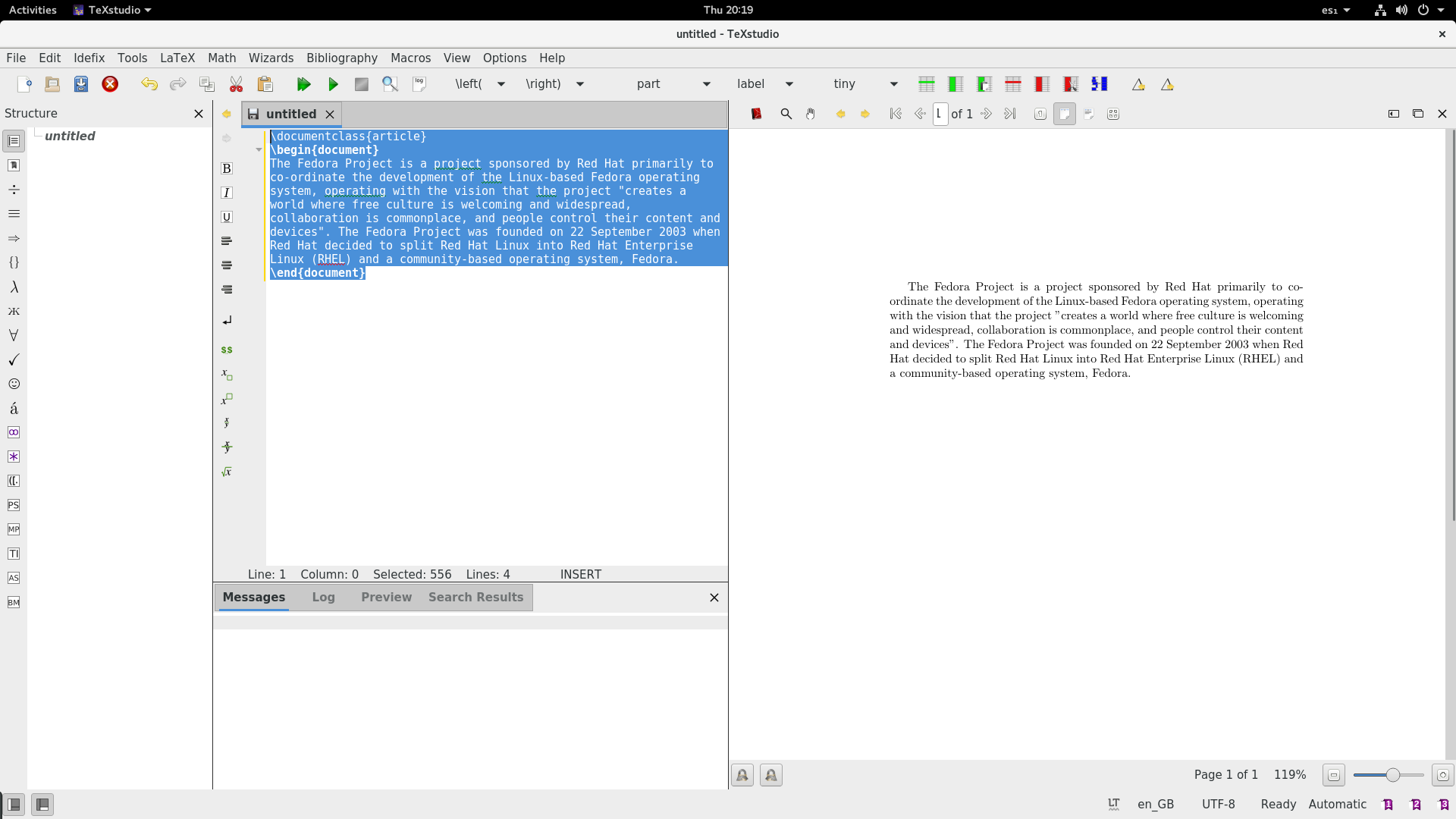
+The Fedora Project is a project sponsored by Red Hat primarily to co-ordinate the development of the Linux-based Fedora operating system, operating with the vision that the project "creates a world where free culture is welcoming and widespread, collaboration is commonplace, and people control their content and devices". The Fedora Project was founded on 22 September 2003 when Red Hat decided to split Red Hat Linux into Red Hat Enterprise Linux (RHEL) and a community-based operating system, Fedora.
+\end{document}
+```
+
+
+
+### 使用间距
+
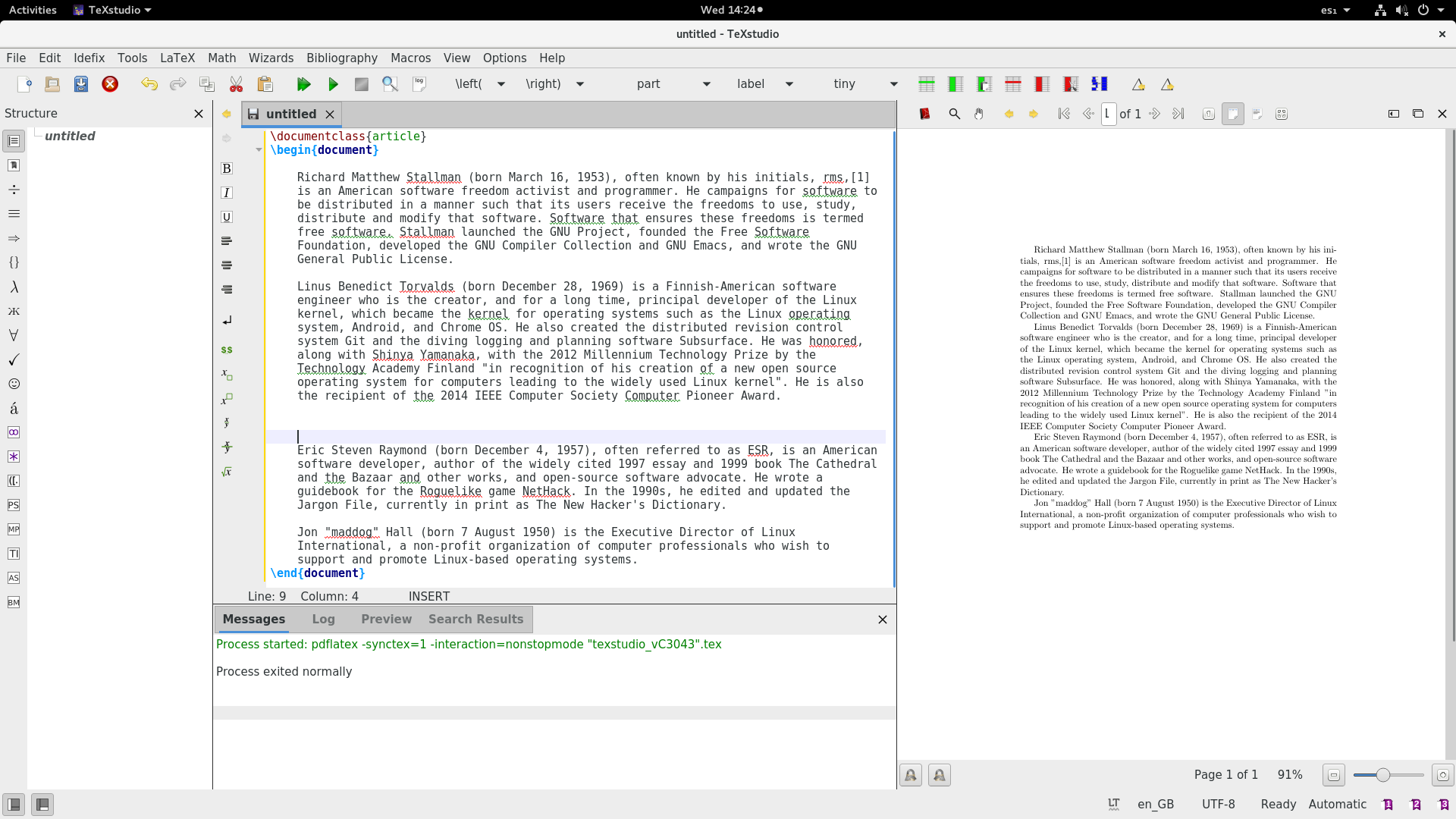
+要创建段落分隔符,请在文本之间保留一个或多个换行符。下面是一个包含四个段落的示例:
+
+
+
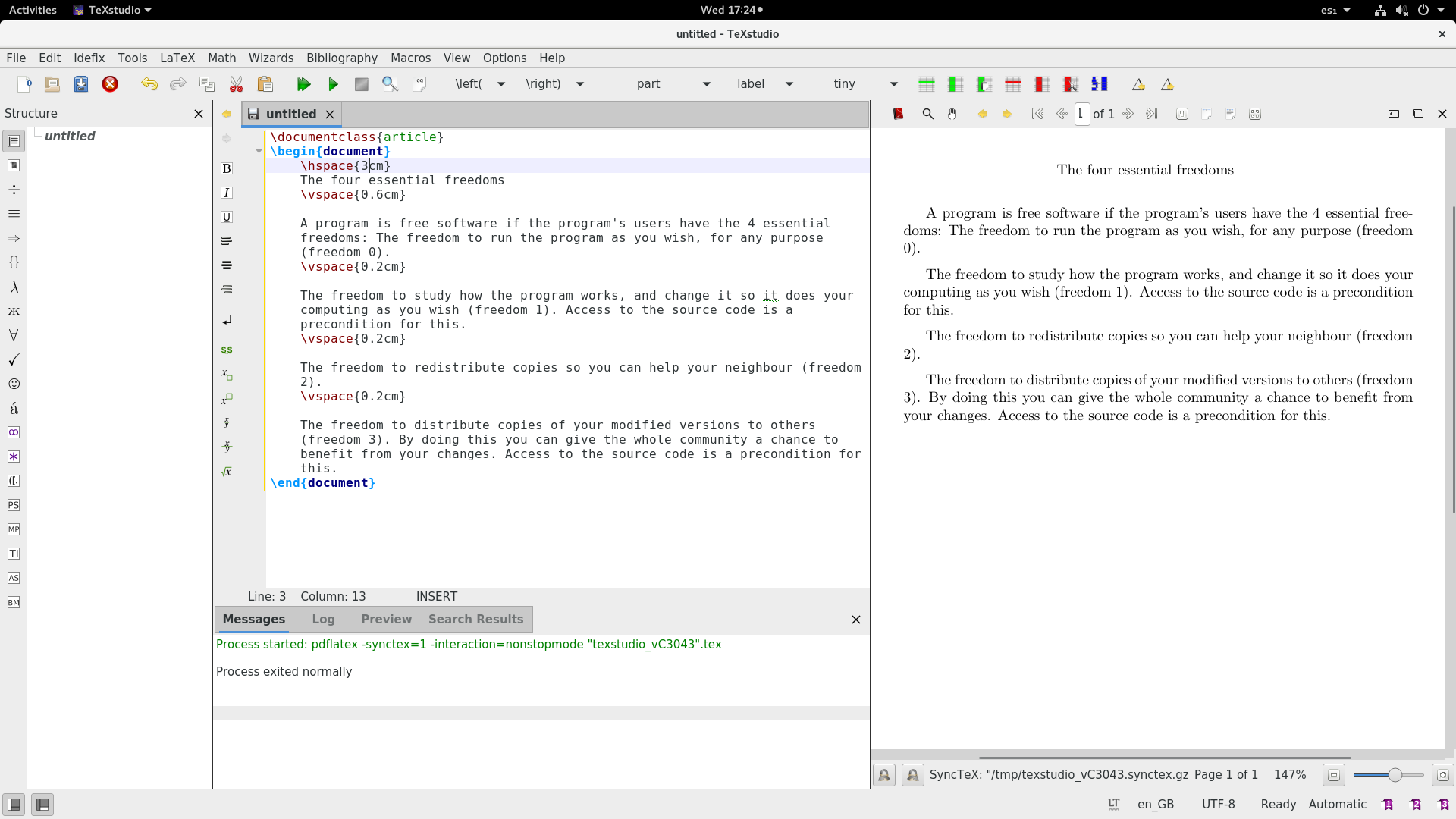
+从该示例中可以看出,多个换行符不会在段落之间创建额外的空格。但是,如果你确实需要留出额外的空间,请使用 `hspace` 和 `vspace` 命令。这两个命令分别添加水平和垂直空间。下面是一些示例代码,显示了段落周围的附加间距:
+
+```
+\documentclass{article}
+\begin{document}
+
+\hspace{2.5cm} The four essential freedoms
+
+\vspace{0.6cm}
+A program is free software if the program's users have the 4 essential freedoms:
+
+The freedom to run the program as you wish, for any purpose (freedom 0).\vspace{0.2cm}
+The freedom to study how the program works, and change it so it does your computing as you wish (freedom 1). Access to the source code is a precondition for this.\vspace{0.2cm}
+
+The freedom to redistribute copies so you can help your neighbour (freedom 2).\vspace{0.2cm}
+
+The freedom to distribute copies of your modified versions to others (freedom 3). By doing this you can give the whole community a chance to benefit from your changes. Access to the source code is a precondition for this.
+
+\end{document}
+```
+
+如果需要,你也可以使用 `noindent` 命令来避免缩进。这里是上面 LaTeX 源码的结果:
+
+
+
+### 使用列表和格式
+
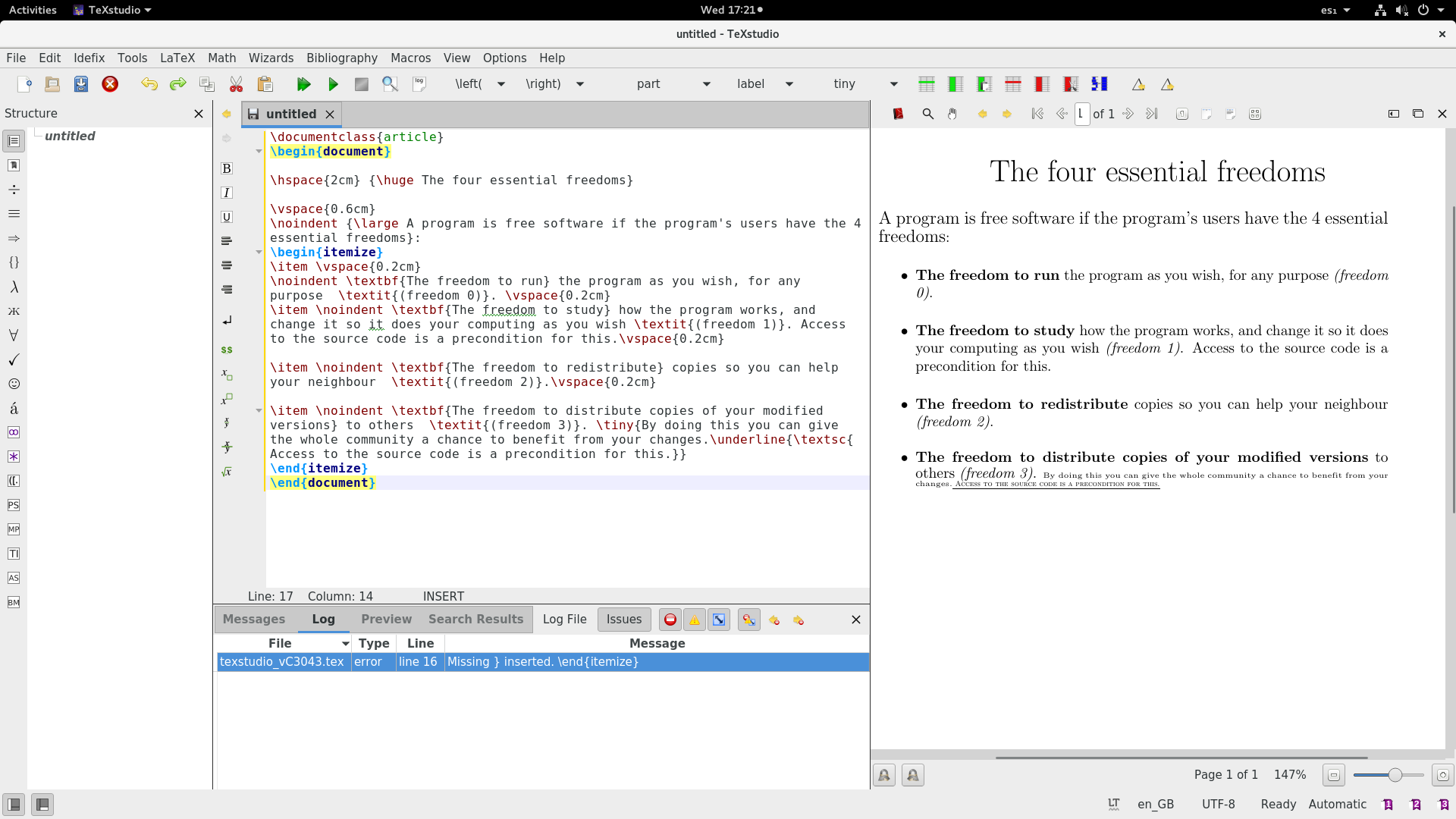
+如果把自由软件的四大基本自由列为一个清单,这个例子看起来会更好。通过在列表的开头使用`\begin{itemize}`,在末尾使用 `\end{itemize}` 来设置列表结构。在每个项目前面加上 `\item` 命令。
+
+额外的格式也有助于使文本更具可读性。用于格式化的有用命令包括粗体、斜体、下划线、超大、大、小和 textsc 以帮助强调文本:
+
+```
+\documentclass{article}
+\begin{document}
+
+\hspace{2cm} {\huge The four essential freedoms}
+
+\vspace{0.6cm}
+\noindent {\large A program is free software if the program's users have the 4 essential freedoms}:
+\begin{itemize}
+\item \vspace{0.2cm}
+\noindent \textbf{The freedom to run} the program as you wish, for any purpose \textit{(freedom 0)}. \vspace{0.2cm}
+\item \noindent \textbf{The freedom to study} how the program works, and change it so it does your computing as you wish \textit{(freedom 1)}. Access to the source code is a precondition for this.\vspace{0.2cm}
+
+\item \noindent \textbf{The freedom to redistribute} copies so you can help your neighbour \textit{(freedom 2)}.\vspace{0.2cm}
+
+\item \noindent \textbf{The freedom to distribute copies of your modified versions} to others \textit{(freedom 3)}. \tiny{By doing this you can give the whole community a chance to benefit from your changes.\underline{\textsc{ Access to the source code is a precondition for this.}}}
+\end{itemize}
+\end{document}
+```
+
+
+
+### 添加列、图像和链接
+
+列、图像和链接有助于为文本添加更多信息。LaTeX 包含一些高级功能的函数作为宏包。`\usepackage` 命令加载宏包以便你可以使用这些功能。
+
+例如,要使用图像,可以使用命令 `\usepackage{graphicx}`。或者,要设置列和链接,请分别使用 `\usepackage{multicol}` 和 `\usepackage{hyperref}`。
+
+`\includegraphics` 命令将图像内联放置在文档中。(为简单起见,请将图形文件包含在与 LaTeX 源文件相同的目录中。)
+
+下面是一个使用所有这些概念的示例。它还使用下载的两个 PNG 图片。试试你自己的图片,看看它们是如何工作的。
+
+```
+\documentclass{article}
+\usepackage{graphicx}
+\usepackage{multicol}
+\usepackage{hyperref}
+\begin{document}
+ \textbf{GNU}
+ \vspace{1cm}
+
+ GNU is a recursive acronym for "GNU's Not Unix!", chosen because GNU's design is Unix-like, but differs from Unix by being free software and containing no Unix code.
+
+ Richard Stallman, the founder of the project, views GNU as a "technical means to a social end". Stallman has written about "the social aspects of software and how Free Software can create community and social justice." in his "Free Society" book.
+ \vspace{1cm}
+
+ \textbf{Some Projects}
+
+ \begin{multicols}{2}
+ Fedora
+ \url{https://getfedora.org}
+ \includegraphics[width=1cm]{fedora.png}
+
+ GNOME
+ \url{https://getfedora.org}
+ \includegraphics[width=1cm]{gnome.png}
+ \end{multicols}
+
+\end{document}
+```
+
+
+
+这里的功能只触及 LaTeX 功能的表面。你可以在该项目的[帮助和文档站点][3]了解更多关于它们的信息。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/typeset-latex-texstudio-fedora/
+
+作者:[Julita Inca Chiroque][a]
+选题:[Chao-zhi][b]
+译者:[Chao-zhi][b]
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/yulytas/
+[b]: https://github.com/Chao-zhi
+[1]:http://www.latex-project.org/about/
+[2]:https://fedoramagazine.org/fedora-aarch64-on-the-solidrun-honeycomb-lx2k/
+[3]:https://www.latex-project.org/help/
diff --git a/published/20190312 When the web grew up- A browser story.md b/published/20190312 When the web grew up- A browser story.md
new file mode 100644
index 0000000000..a53a5babfb
--- /dev/null
+++ b/published/20190312 When the web grew up- A browser story.md
@@ -0,0 +1,59 @@
+[#]: collector: (lujun9972)
+[#]: translator: (XYenChi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13130-1.html)
+[#]: subject: (When the web grew up: A browser story)
+[#]: via: (https://opensource.com/article/19/3/when-web-grew)
+[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
+
+Web 的成长,就是一篇浏览器的故事
+======
+
+> 互联网诞生之时我的个人故事。
+
+
+
+最近,我和大家 [分享了][1] 我在 1994 年获得英国文学和神学学位离开大学后,如何在一个人们还不知道 Web 服务器是什么的世界里成功找到一份运维 Web 服务器的工作。我说的“世界”,并不仅仅指的是我工作的机构,而是泛指所有地方。Web 那时当真是全新的 —— 人们还正尝试理出头绪。
+
+那并不是说我工作的地方(一家学术出版社)特别“懂” Web。这是个大部分人还在用 28.8K 猫(调制解调器,俗称“猫”)访问网页的世界。我还记得我拿到 33.6K 猫时有多激动。至少上下行速率不对称的日子已经过去了,[^1] 以前 1200/300 的带宽描述特别常见。这意味着(在同一家机构的)印刷人员制作的设计复杂、色彩缤纷、纤毫毕现的文档是完全不可能放在 Web 上的。我不能允许在网站的首页出现大于 40k 的 GIF 图片,这对我们的许多访问者来说是很难接受的。大于大约 60k 图片的会作为独立的图片,以缩略图链接过去。
+
+如果说市场部只有这一点不喜欢,那是绝对是轻描淡写了。更糟的是布局问题。“浏览器决定如何布局文档,”我一遍又一遍地解释,“你可以使用标题或者段落,但是文档在页面上如何呈现并不取决于文档,而是取决于渲染器!”他们想控制这些,想要不同颜色的背景。后来明白了那些不能实现。我觉得我就像是参加了第一次讨论层叠样式表(CSS)的 W3C 会议,并进行了激烈地争论。关于文档编写者应控制布局的建议真令人厌恶。[^2] CSS 花了一些时间才被人们采用,与此同时,关心这些问题的人搭上了 PDF 这种到处都是安全问题的列车。
+
+如何呈现文档不是唯一的问题。作为一个实体书出版社,对于市场部来说,拥有一个网站的全部意义在于,让客户(或者说潜在的客户)不仅知道一本书的内容,而且知道买这本书需要花多少钱。但这有一个问题,你看,互联网,包括快速发展的万维网,是开放的,是所有都免费的自由之地,没有人会在意钱;事实上,在那里谈钱是要回避和避免的。
+
+我和主流“网民”的看法一致,认为没必要把价格信息放在线上。我老板,以及机构里相当多的人都持相反的意见。他们觉得消费者应该能够看到书要花多少钱。他们也觉得我的银行经理也会想看到我的账户里每个月进了多少钱,如果我不认同他们的观点的话,那我的收入就可能堪忧。
+
+幸运的是,在我被炒鱿鱼之前,我已经自己认清了一些 —— 可能是在我开始迈入 Web 的几星期之后,Web 已经发生变化,有其他人公布他们的产品价格信息。这些新来者通常被那些从早期就开始运行 Web 服务器的老派人士所看不起,[^3] 但很明显,风向是往那边吹的。然而,这并不意味着我们的网站就赢得了战争。作为一个学术出版社,我们和大学共享一个域名(在 “ac.uk” 下)。大学不太相信发布价格信息是合适的,直到出版社的一些资深人士指出,普林斯顿大学出版社正在这样做,如果我们不做……看起来是不是有点傻?
+
+有趣的事情还没完。在我担任站点管理员(“webmaster@…”)的短短几个月后,我们和其他很多网站一样开始看到了一种令人担忧的趋势。某些访问者可以轻而易举地让我们的 Web 服务器跪了。这些访问者使用了新的网页浏览器:网景浏览器(Netscape)。网景浏览器实在太恶劣了,它居然是多线程的。
+
+这为什么是个问题呢?在网景浏览器之前,所有的浏览器都是单线程。它们一次只进行一个连接,所以即使一个页面有五张 GIF 图,[^4] 也会先请求 HTML 基本文件进行解析,然后下载第一张 GIF,完成,接着第二张,完成,如此类推。事实上,GIF 的顺序经常出错,使得页面加载得非常奇怪,但这也是常规思路。而粗暴的网景公司的人决定,它们可以同时打开多个连接到 Web 服务器,比如说,可以同时请求所有的 GIF!为什么这是个问题呢?好吧,问题就在于大多数 Web 服务器都是单线程的。它们不是设计来一次进行多个连接的。确实,我们运行的 HTTP 服务的软件(MacHTTP)是单线程的。尽管我们花钱购买了它(最初是共享软件),但我们用的这版无法同时处理多个请求。
+
+互联网上爆发了大量讨论。这些网景公司的人以为他们是谁,能改变世界的运作方式?它应该如何工作?大家分成了不同阵营,就像所有的技术争论一样,双方都用各种技术热词互丢。问题是,网景浏览器不仅是多线程的,它也比其他的浏览器更好。非常多 Web 服务器代码维护者,包括 MacHTTP 作者 Chuck Shotton 在内,开始坐下来认真地在原有代码基础上更新了多线程测试版。几乎所有人立马转向测试版,它们变得稳定了,最终,浏览器要么采用了这种技术,变成多线程,要么就像所有过时产品一样销声匿迹了。[^6]
+
+对我来说,这才是 Web 真正成长起来的时候。既不是网页展示的价格,也不是设计者能定义你能在网页上看到什么,[^8] 而是浏览器变得更易用,以及成千上万的浏览者向数百万浏览者转变的网络效应,使天平向消费者而不是生产者倾斜。在我的旅程中,还有更多故事,我将留待下次再谈。但从这时起,我的雇主开始看我们的月报,然后是周报、日报,并意识到这将是一件大事,真的需要关注。
+
+[^1]: 它们又是怎么回来的?
+[^2]: 你可能不会惊讶,我还是在命令行里最开心。
+[^3]: 大约六个月前。
+[^4]: 莽撞,没错,但它确实发生了 [^5]
+[^5]: 噢,不,是 GIF 或 BMP,JPEG 还是个好主意,但还没有用上。
+[^6]: 没有真正的沉寂:总有一些坚持他们的首选解决方案具有技术上的优势,并哀叹互联网的其他人都是邪恶的死硬爱好者。 [^7]
+[^7]: 我不是唯一一个说“我还在用 Lynx”的人。
+[^8]: 我会指出,为那些有各种无障碍需求的人制造严重而持续的问题。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/when-web-grew
+
+作者:[Mike Bursell][a]
+选题:[lujun9972][b]
+译者:[XYenChi](https://github.com/XYenChi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mikecamel
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/18/11/how-web-was-won
diff --git a/published/20190404 Intel formally launches Optane for data center memory caching.md b/published/20190404 Intel formally launches Optane for data center memory caching.md
new file mode 100644
index 0000000000..f07eb56caa
--- /dev/null
+++ b/published/20190404 Intel formally launches Optane for data center memory caching.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: (ShuyRoy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13109-1.html)
+[#]: subject: (Intel formally launches Optane for data center memory caching)
+[#]: via: (https://www.networkworld.com/article/3387117/intel-formally-launches-optane-for-data-center-memory-caching.html#tk.rss_all)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+英特尔 Optane:用于数据中心内存缓存
+======
+
+
+
+> 英特尔推出了包含 3D Xpoint 内存技术的 Optane 持久内存产品线。英特尔的这个解决方案介乎于 DRAM 和 NAND 中间,以此来提升性能。
+
+![Intel][1]
+
+英特尔在 2019 年 4 月的[大规模数据中心活动][2]中正式推出 Optane 持久内存产品线。它已经问世了一段时间,但是目前的 Xeon 服务器处理器还不能充分利用它。而新的 Xeon8200 和 9200 系列可以充分利用 Optane 持久内存的优势。
+
+由于 Optane 是英特尔的产品(与美光合作开发),所以意味着 AMD 和 ARM 的服务器处理器不能够支持它。
+
+正如[我之前所说的][3],OptaneDC 持久内存采用与美光合作研发的 3D Xpoint 内存技术。3D Xpoint 是一种比 SSD 更快的非易失性内存,速度几乎与 DRAM 相近,而且它具有 NAND 闪存的持久性。
+
+第一个 3D Xpoint 产品是被称为英特尔“尺子”的 SSD,因为它们被设计成细长的样子,很像尺子的形状。它们被设计这样是为了适合 1u 的服务器机架。在发布的公告中,英特尔推出了新的利用四芯或者 QLC 3D NAND 内存的英特尔 SSD D5-P4325 [尺子][7] SSD,可以在 1U 的服务器机架上放 1PB 的存储。
+
+OptaneDC 持久内存的可用容量最初可以通过使用 128GB 的 DIMM 达到 512GB。英特尔数据中心集团执行副总裁及总经理 Navin Shenoy 说:“OptaneDC 持久内存可达到的容量是 DRAM 的 2 到 4 倍。”
+
+他说:“我们希望服务器系统的容量可以扩展到每个插槽 4.5TB 或者 8 个插槽 36TB,这是我们第一代 Xeon 可扩展芯片的 3 倍。”
+
+### 英特尔Optane内存的使用和速度
+
+Optane 有两种不同的运行模式:内存模式和应用直连模式。内存模式是将 DRAM 放在 Optane 内存之上,将 DRAM 作为 Optane 内存的缓存。应用直连模式是将 DRAM 和 OptaneDC 持久内存一起作为内存来最大化总容量。并不是每个工作负载都适合这种配置,所以应该在对延迟不敏感的应用程序中使用。正如英特尔推广的那样,Optane 的主要使用情景是内存模式。
+
+几年前,当 3D Xpoint 最初发布时,英特尔宣称 Optane 的速度是 NAND 的 1000 倍,耐用是 NAND 的 1000 倍,密度潜力是 DRAM 的 10 倍。这虽然有点夸张,但这些因素确实很令人着迷。
+
+在 256B 的连续 4 个缓存行中使用 Optane 内存可以达到 8.3GB/秒的读速度和 3.0GB/秒的写速度。与 SATA SSD 的 500MB/秒左右的读/写速度相比,可以看到性能有很大提升。请记住,Optane 充当内存,所以它会缓存被频繁访问的 SSD 中的内容。
+
+这是了解 OptaneDC 的关键。它能将非常大的数据集存储在离内存非常近的位置,因此具有很低延迟的 CPU 可以最小化访问较慢的存储子系统的访问延迟,无论存储是 SSD 还是 HDD。现在,它提供了一种可能性,即把多个 TB 的数据放在非常接近 CPU 的地方,以实现更快的访问。
+
+### Optane 内存的一个挑战
+
+唯一真正的挑战是 Optane 插进内存所在的 DIMM 插槽。现在有些主板的每个 CPU 有多达 16 个 DIMM 插槽,但是这仍然是客户和设备制造商之间需要平衡的电路板空间:Optane 还是内存。有一些 Optane 驱动采用了 PCIe 接口进行连接,可以减轻主板上内存的拥挤。
+
+3D Xpoint 由于它写数据的方式,提供了比传统的 NAND 闪存更高的耐用性。英特尔承诺 Optane 提供 5 年保修期,而很多 SSD 只提供 3 年保修期。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3387117/intel-formally-launches-optane-for-data-center-memory-caching.html#tk.rss_all
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[RiaXu](https://github.com/ShuyRoy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/06/intel-optane-persistent-memory-100760427-large.jpg
+[2]: https://www.networkworld.com/article/3386142/intel-unveils-an-epic-response-to-amds-server-push.html
+[3]: https://www.networkworld.com/article/3279271/intel-launches-optane-the-go-between-for-memory-and-storage.html
+[4]: https://www.networkworld.com/article/3290421/why-nvme-users-weigh-benefits-of-nvme-accelerated-flash-storage.html
+[5]: https://www.networkworld.com/article/3242807/data-center/top-10-data-center-predictions-idc.html#nww-fsb
+[6]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
+[7]: https://www.theregister.co.uk/2018/02/02/ruler_and_miniruler_ssd_formats_look_to_banish_diskstyle_drives/
+[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
+[9]: https://www.facebook.com/NetworkWorld/
+[10]: https://www.linkedin.com/company/network-world
diff --git a/published/20190610 Tmux Command Examples To Manage Multiple Terminal Sessions.md b/published/20190610 Tmux Command Examples To Manage Multiple Terminal Sessions.md
new file mode 100644
index 0000000000..c80af774f7
--- /dev/null
+++ b/published/20190610 Tmux Command Examples To Manage Multiple Terminal Sessions.md
@@ -0,0 +1,305 @@
+[#]: collector: (lujun9972)
+[#]: translator: (chensanle)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13107-1.html)
+[#]: subject: (Tmux Command Examples To Manage Multiple Terminal Sessions)
+[#]: via: (https://www.ostechnix.com/tmux-command-examples-to-manage-multiple-terminal-sessions/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+基于 Tmux 的多会话终端管理示例
+======
+
+
+
+我们已经了解到如何通过 [GNU Screen][2] 进行多会话管理。今天,我们将要领略另一个著名的管理会话的命令行实用工具 **Tmux**。类似 GNU Screen,Tmux 是一个帮助我们在单一终端窗口中创建多个会话,同一时间内同时运行多个应用程序或进程的终端复用工具。Tmux 自由、开源并且跨平台,支持 Linux、OpenBSD、FreeBSD、NetBSD 以及 Mac OS X。本文将讨论 Tmux 在 Linux 系统下的高频用法。
+
+### Linux 下安装 Tmux
+
+Tmux 可以在绝大多数的 Linux 官方仓库下获取。
+
+在 Arch Linux 或它的变种系统下,执行下列命令来安装:
+
+```
+$ sudo pacman -S tmux
+```
+
+Debian、Ubuntu 或 Linux Mint:
+
+```
+$ sudo apt-get install tmux
+```
+
+Fedora:
+```
+$ sudo dnf install tmux
+```
+
+RHEL 和 CentOS:
+
+```
+$ sudo yum install tmux
+```
+
+SUSE/openSUSE:
+
+```
+$ sudo zypper install tmux
+```
+
+以上,我们已经完成 Tmux 的安装。之后我们继续看看一些 Tmux 示例。
+
+### Tmux 命令示例: 多会话管理
+
+Tmux 默认所有命令的前置命令都是 `Ctrl+b`,使用前牢记这个快捷键即可。
+
+> **注意**:**Screen** 的前置命令都是 `Ctrl+a`.
+
+#### 创建 Tmux 会话
+
+在终端中运行如下命令创建 Tmux 会话并附着进入:
+
+```
+tmux
+```
+
+抑或,
+
+```
+tmux new
+```
+
+一旦进入 Tmux 会话,你将看到一个 **沉在底部的绿色的边栏**,如下图所示。
+
+![][3]
+
+*创建 Tmux 会话*
+
+这个绿色的边栏能很容易提示你当前是否身处 Tmux 会话当中。
+
+#### 退出 Tmux 会话
+
+退出当前 Tmux 会话仅需要使用 `Ctrl+b` 和 `d`。无需同时触发这两个快捷键,依次按下 `Ctrl+b` 和 `d` 即可。
+
+退出当前会话后,你将能看到如下输出:
+
+```
+[detached (from session 0)]
+```
+
+#### 创建有名会话
+
+如果使用多个会话,你很可能会混淆运行在多个会话中的应用程序。这种情况下,我们需要会话并赋予名称。譬如需要 web 相关服务的会话,就创建一个名称为 “webserver”(或任意一个其他名称) 的 Tmux 会话。
+
+```
+tmux new -s webserver
+```
+
+这里是新的 Tmux 有名会话:
+
+![][4]
+
+*拥有自定义名称的 Tmux 会话*
+
+如你所见上述截图,这个 Tmux 会话的名称已经被标注为 “webserver”。如此,你可以在多个会话中,轻易的区分应用程序的所在。
+
+退出会话,轻按 `Ctrl+b` 和 `d`。
+
+#### 查看 Tmux 会话清单
+
+查看 Tmux 会话清单,执行:
+
+```
+tmux ls
+```
+
+示例输出:
+
+![][5]
+
+*列出 Tmux 会话*
+
+如你所见,我们开启了两个 Tmux 会话。
+
+#### 创建非附着会话
+
+有时候,你可能想要简单创建会话,但是并不想自动切入该会话。
+
+创建一个非附着会话,并赋予名称 “ostechnix”,运行:
+
+```
+tmux new -s ostechnix -d
+```
+
+上述命令将会创建一个名为 “ostechnix” 的会话,但是并不会附着进入。
+
+你可以通过使用 `tmux ls` 命令验证:
+
+![][6]
+
+*创建非附着会话*
+
+#### 附着进入 Tmux 会话
+
+通过如下命令,你可以附着进入最后一个被创建的会话:
+
+```
+tmux attach
+```
+
+抑或,
+
+```
+tmux a
+```
+
+如果你想附着进入任意一个指定的有名会话,譬如 “ostechnix”,运行:
+
+```
+tmux attach -t ostechnix
+```
+
+或者,简写为:
+
+```
+tmux a -t ostechnix
+```
+
+#### 关闭 Tmux 会话
+
+当你完成或者不再需要 Tmux 会话,你可以通过如下命令关闭:
+
+```
+tmux kill-session -t ostechnix
+```
+
+当身处该会话时,使用 `Ctrl+b` 以及 `x`。点击 `y` 来关闭会话。
+
+可以通过 `tmux ls` 命令验证。
+
+关闭所有 Tmux 服务下的所有会话,运行:
+
+```
+tmux kill-server
+```
+
+谨慎!这将终止所有 Tmux 会话,并不会产生任何警告,即便会话存在运行中的任务。
+
+如果不存在活跃的 Tmux 会话,将看到如下输出:
+
+```
+$ tmux ls
+no server running on /tmp/tmux-1000/default
+```
+
+#### 切割 Tmux 窗口
+
+切割窗口成多个小窗口,在 Tmux 中,这个叫做 “Tmux 窗格”。每个窗格中可以同时运行不同的程序,并同时与所有的窗格进行交互。每个窗格可以在不影响其他窗格的前提下可以调整大小、移动位置和控制关闭。我们可以以水平、垂直或者二者混合的方式切割屏幕。
+
+##### 水平切割窗格
+
+欲水平切割窗格,使用 `Ctrl+b` 和 `"`(半个双引号)。
+
+![][7]
+
+*水平切割 Tmux 窗格*
+
+可以使用组合键进一步切割面板。
+
+##### 垂直切割窗格
+
+垂直切割面板,使用 `Ctrl+b` 和 `%`。
+
+![][8]
+
+*垂直切割 Tmux 窗格*
+
+##### 水平、垂直混合切割窗格
+
+我们也可以同时采用水平和垂直的方案切割窗格。看看如下截图:
+
+![][9]
+
+*切割 Tmux 窗格*
+
+首先,我通过 `Ctrl+b` `"` 水平切割,之后通过 `Ctrl+b` `%` 垂直切割下方的窗格。
+
+如你所见,每个窗格下我运行了不同的程序。
+
+##### 切换窗格
+
+通过 `Ctrl+b` 和方向键(上下左右)切换窗格。
+
+##### 发送命令给所有窗格
+
+之前的案例中,我们在每个窗格中运行了三个不同命令。其实,也可以发送相同的命令给所有窗格。
+
+为此,使用 `Ctrl+b` 然后键入如下命令,之后按下回车:
+
+```
+:setw synchronize-panes
+```
+
+现在在任意窗格中键入任何命令。你将看到相同命令影响了所有窗格。
+
+##### 交换窗格
+
+使用 `Ctrl+b` 和 `o` 交换窗格。
+
+##### 展示窗格号
+
+使用 `Ctrl+b` 和 `q` 展示窗格号。
+
+##### 终止窗格
+
+要关闭窗格,直接键入 `exit` 并且按下回车键。或者,按下 `Ctrl+b` 和 `x`。你会看到确认信息。按下 `y` 关闭窗格。
+
+![][10]
+
+*关闭窗格*
+
+##### 放大和缩小 Tmux 窗格
+
+我们可以将 Tmux 窗格放大到当前终端窗口的全尺寸,以获得更好的文本可视性,并查看更多的内容。当你需要更多的空间或专注于某个特定的任务时,这很有用。在完成该任务后,你可以将 Tmux 窗格缩小(取消放大)到其正常位置。更多详情请看以下链接。
+
+- [如何缩放 Tmux 窗格以提高文本可见度?](https://ostechnix.com/how-to-zoom-tmux-panes-for-better-text-visibility/)
+
+#### 自动启动 Tmux 会话
+
+当通过 SSH 与远程系统工作时,在 Tmux 会话中运行一个长期运行的进程总是一个好的做法。因为,它可以防止你在网络连接突然中断时失去对运行进程的控制。避免这个问题的一个方法是自动启动 Tmux 会话。更多详情,请参考以下链接。
+
+- [通过 SSH 登录远程系统时自动启动 Tmux 会话](https://ostechnix.com/autostart-tmux-session-on-remote-system-when-logging-in-via-ssh/)
+
+### 总结
+
+这个阶段下,你已经获得了基本的 Tmux 技能来进行多会话管理,更多细节,参阅 man 页面。
+
+```
+$ man tmux
+```
+
+GNU Screen 和 Tmux 工具都能透过 SSH 很好的管理远程服务器。学习 Screen 和 Tmux 命令,像个行家一样,彻底通过这些工具管理远程服务器。
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/tmux-command-examples-to-manage-multiple-terminal-sessions/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[chensanle](https://github.com/chensanle)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2019/06/Tmux-720x340.png
+[2]: https://www.ostechnix.com/screen-command-examples-to-manage-multiple-terminal-sessions/
+[3]: https://www.ostechnix.com/wp-content/uploads/2019/06/Tmux-session.png
+[4]: https://www.ostechnix.com/wp-content/uploads/2019/06/Named-Tmux-session.png
+[5]: https://www.ostechnix.com/wp-content/uploads/2019/06/List-Tmux-sessions.png
+[6]: https://www.ostechnix.com/wp-content/uploads/2019/06/Create-detached-sessions.png
+[7]: https://www.ostechnix.com/wp-content/uploads/2019/06/Horizontal-split.png
+[8]: https://www.ostechnix.com/wp-content/uploads/2019/06/Vertical-split.png
+[9]: https://www.ostechnix.com/wp-content/uploads/2019/06/Split-Panes.png
+[10]: https://www.ostechnix.com/wp-content/uploads/2019/06/Kill-panes.png
diff --git a/published/20190626 Where are all the IoT experts going to come from.md b/published/20190626 Where are all the IoT experts going to come from.md
new file mode 100644
index 0000000000..5b10af4a11
--- /dev/null
+++ b/published/20190626 Where are all the IoT experts going to come from.md
@@ -0,0 +1,72 @@
+[#]: collector: (lujun9972)
+[#]: translator: (scvoet)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13115-1.html)
+[#]: subject: (Where are all the IoT experts going to come from?)
+[#]: via: (https://www.networkworld.com/article/3404489/where-are-all-the-iot-experts-going-to-come-from.html)
+[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
+
+物联网专家都从何而来?
+======
+
+> 物联网(IoT)的快速发展催生了对跨职能专家进行培养的需求,这些专家可以将传统的网络和基础设施专业知识与数据库和报告技能相结合。
+
+![Kevin \(CC0\)][1]
+
+如果物联网(IoT)要实现其宏伟的诺言,它将需要大量聪明、熟练、**训练有素**的工人军团来实现这一切。而现在,这些人将从何而来尚不清楚。
+
+这就是我为什么有兴趣同资产优化软件公司 [AspenTech][2] 的产品管理、研发高级总监 Keith Flynn 通邮件的原因,他说,当处理大量属于物联网范畴的新技术时,你需要能够理解如何配置技术和解释数据的人。Flynn 认为,现有的教育机构对物联网特定课程的需求越来越大,这同时也给了以物联网为重点,提供了完善课程的新私立学院机会。
+
+Flynn 跟我说,“在未来,物联网项目将与如今普遍的数据管理和自动化项目有着巨大的不同……未来需要更全面的技能和交叉交易能力,这样我们才会说同一种语言。”
+
+Flynn 补充说,随着物联网每年增长 30%,将不再依赖于几个特定的技能,“从传统的部署技能(如网络和基础设施)到数据库和报告技能,坦白说,甚至是基础数据科学,都将需要一起理解和使用。”
+
+### 召集所有物联网顾问
+
+Flynn 预测,“受过物联网教育的人的第一个大机会将会是在咨询领域,随着咨询公司对行业趋势的适应或淘汰……有受过物联网培训的员工将有助于他们在物联网项目中的定位,并在新的业务线中提出要求——物联网咨询。”
+
+对初创企业和小型公司而言,这个问题尤为严重。“组织越大,他们越有可能雇佣到不同技术类别的人”Flynn 这样说到,“但对于较小的组织和较小的物联网项目来说,你则需要一个能同时兼顾的人。”
+
+两者兼而有之?还是**一应俱全?**物联网“需要将所有知识和技能组合在一起”,Flynn 说到,“并不是所有技能都是全新的,只是在此之前从来没有被归纳在一起或放在一起教授过。”
+
+### 未来的物联网专家
+
+Flynn 表示,真正的物联网专业技术是从基础的仪器仪表和电气技能开始的,这能帮助工人发明新的无线发射器或提升技术,以提高电池寿命和功耗。
+
+“IT 技能,如网络、IP 寻址、子网掩码、蜂窝和卫星也是物联网的关键需求”,Flynn 说。他还认为物联网需要数据库管理技能和云管理和安全专业知识,“特别是当高级过程控制(APC)将传感器数据直接发送到数据库和数据湖等事情成为常态时。”
+
+### 物联网专家又从何而来?
+
+Flynn 说,标准化的正规教育课程将是确保毕业生或证书持有者掌握一套正确技能的最佳途径。他甚至还列出了一个样本课程。“按时间顺序开始,从基础知识开始,比如 [电气仪表] 和测量。然后讲授网络知识,数据库管理和云计算课程都应在此之后开展。这个学位甚至可以循序渐进至现有的工程课程中,这可能需要两年时间……来完成物联网部分的学业。”
+
+虽然企业培训也能发挥作用,但实际上却是“说起来容易做起来难”,Flynn 这样警告,“这些培训需要针对组织的具体努力而推动。”
+
+当然,现在市面上已经有了 [大量的在线物联网培训课程和证书课程][5]。但追根到底,这一工作全都依赖于工人自身的推断。
+
+“在这个世界上,随着科技不断改变行业,提升技能是非常重要的”,Flynn 说,“如果这种提升技能的推动力并不是来源于你的雇主,那么在线课程和认证将会是提升你自己很好的一个方式。我们只需要创建这些课程……我甚至可以预见组织将与提供这些课程的高等教育机构合作,让他们的员工更好地开始。当然,物联网课程的挑战在于它需要不断发展以跟上科技的发展。”
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3404489/where-are-all-the-iot-experts-going-to-come-from.html
+
+作者:[Fredric Paul][a]
+选题:[lujun9972][b]
+译者:[Percy (@scvoet)](https://github.com/scvoet)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Fredric-Paul/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/07/programmer_certification-skills_code_devops_glasses_student_by-kevin-unsplash-100764315-large.jpg
+[2]: https://www.aspentech.com/
+[3]: https://www.networkworld.com/article/3276025/careers/20-hot-jobs-ambitious-it-pros-should-shoot-for.html
+[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fupgrading-your-technology-career
+[5]: https://www.google.com/search?client=firefox-b-1-d&q=iot+training
+[6]: https://www.networkworld.com/article/3254185/internet-of-things/tips-for-securing-iot-on-your-network.html#nww-fsb
+[7]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html#nww-fsb
+[8]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html#nww-fsb
+[9]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
+[10]: https://www.facebook.com/NetworkWorld/
+[11]: https://www.linkedin.com/company/network-world
diff --git a/published/20190810 EndeavourOS Aims to Fill the Void Left by Antergos in Arch Linux World.md b/published/20190810 EndeavourOS Aims to Fill the Void Left by Antergos in Arch Linux World.md
new file mode 100644
index 0000000000..54c752a913
--- /dev/null
+++ b/published/20190810 EndeavourOS Aims to Fill the Void Left by Antergos in Arch Linux World.md
@@ -0,0 +1,98 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13096-1.html)
+[#]: subject: (EndeavourOS Aims to Fill the Void Left by Antergos in Arch Linux World)
+[#]: via: (https://itsfoss.com/endeavouros/)
+[#]: author: (John Paul https://itsfoss.com/author/john/)
+
+EndeavourOS:填补 Antergos 在 ArchLinux 世界留下的空白
+======
+
+
+
+我相信我们的大多数读者都知道 [Antergos 项目的终结][2]。在这一消息宣布之后,Antergos 社区的成员创建了几个发行版来继承 Antergos。今天,我们将着眼于 Antergos 的“精神继承人”之一:[EndeavourOS][3]。
+
+### EndeavourOS 不是 Antergos 的分支
+
+在我们开始之前,我想非常明确地指出,EndeavourOS 并不是一个 Antergos 的复刻版本。开发者们以 Antergos 为灵感,创建了一个基于 Arch 的轻量级发行版。
+
+![Endeavouros First Boot][4]
+
+根据 [这个项目网站][5] 的说法,EndeavourOS 的诞生是因为 Antergos 社区的人们想要保持 Antergos 的精神。他们的目标很简单:“让 Arch 拥有一个易于使用的安装程序和一个友好、有帮助的社区,在掌握系统的过程中能够有一个社区可以依靠。”
+
+与许多基于 Arch 的发行版不同,EndeavourOS 打算像 [原生 Arch][5] 那样使用,“所以没有一键式安装你喜欢的应用程序的解决方案,也没有一堆你最终不需要的预装应用程序。”对于大多数人来说,尤其是那些刚接触 Linux 和 Arch 的人,会有一个学习曲线,但 EndeavourOS 的目标是建立一个大型友好的社区,鼓励人们提出问题并了解他们的系统。
+
+![Endeavouros Installing][6]
+
+### 正在进行的工作
+
+EndeavourOS 在 [2019 年 5 月 23 日首次宣布成立][8] 随后 [在 7 月 15 日发布第一个版本][7]。不幸的是,这意味着开发人员无法将他们计划的所有功能全部整合进来。(LCTT 译注:本文原文发表于 2019 年,而现在,EndeavourOS 还在持续活跃着。)
+
+例如,他们想要一个类似于 Antergos 的在线安装,但却遇到了[当前选项的问题][9]。“Cnchi 运行在 Antergos 生态系统之外会造成严重的问题,需要彻底重写才能发挥作用。RebornOS 的 Fenix 安装程序还没有完全成型,需要更多时间才能正常运行。”于是现在,EndeavourOS 将会和 [Calamares 安装程序 ][10] 一起发布。
+
+EndeavourOS 会提供 [比 Antergos 少的东西][9]:它的存储库比 Antergos 小,尽管他们会附带一些 AUR 包。他们的目标是提供一个接近 Arch 却不是原生 Arch 的系统。
+
+![Endeavouros Updating With Kalu][12]
+
+开发者[进一步声明 ][13]:
+
+> “Linux,特别是 Arch,核心精神是自由选择,我们提供了一个基本的安装,让你在一个精细的层面上方便地探索各项选择。我们永远不会强行为你作决定,比如为你安装 GUI 应用程序,如 Pamac,甚至采用沙盒解决方案,如 Flatpak 或 Snaps。想安装成什么样子完全取决于你,这是我们与 Antergos 或 Manjaro 的主要区别,但与 Antergos 一样,如果你安装的软件包遇到问题,我们会尽力帮助你。”
+
+### 体验 EndeavourOS
+
+我在 [VirtualBox][14] 中安装了 EndeavourOS,并且研究了一番。当我第一次启动时,我看到一个窗口,里面有关于安装的 EndeavourOS 网站的链接。它还有一个安装按钮和一个手动分区工具。Calamares 安装程序的安装过程非常顺利。
+
+在我重新启动到新安装的 EndeavourOS 之后,迎接我的是一个彩色主题的 XFCE 桌面。我还收到了一堆通知消息。我使用过的大多数基于 Arch 的发行版都带有一个 GUI 包管理器,比如 [pamac][15] 或 [octopi][16],以进行系统更新。EndeavourOS 配有 [kalu][17](kalu 是 “Keeping Arch Linux Up-to-date” 的缩写)。它可以更新软件包、可以看 Archlinux 新闻、可以更新 AUR 包等等。一旦它检查到有更新,它就会显示通知消息。
+
+我浏览了一下菜单,看看默认安装了什么。默认的安装并不多,连办公套件都没有。他们想让 EndeavourOS 成为一块空白画布,让任何人都可以创建他们想要的系统。他们正朝着正确的方向前进。
+
+![Endeavouros Desktop][18]
+
+### 总结思考
+
+EndeavourOS 还很年轻。第一个稳定版本都没有发布多久。它缺少一些东西,最重要的是一个在线安装程序。这就是说,我们无法估计他能够走到哪一步。(LCTT 译注:本文发表于 2019 年)
+
+虽然它不是 Antergos 的精确复刻,但 EndeavourOS 希望复制 Antergos 最重要的部分——热情友好的社区。很多时候,Linux 社区对初学者似乎是不受欢迎甚至是完全敌对的。我看到越来越多的人试图与这种消极情绪作斗争,并将更多的人引入 Linux。随着 EndeavourOS 团队把焦点放在社区建设上,我相信一个伟大的发行版将会诞生。
+
+如果你当前正在使用 Antergos,有一种方法可以让你[不用重装系统就切换到 EndeavourOS][20]
+
+如果你想要一个 Antergos 的精确复刻,我建议你去看看 [RebornOS][21]。他们目前正在开发一个名为 Fenix 的 Cnchi 安装程序的替代品。
+
+你试过 EndeavourOS 了吗?你的感受如何?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/endeavouros/
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-logo.png?ssl=1
+[2]: https://itsfoss.com/antergos-linux-discontinued/
+[3]: https://endeavouros.com/
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-first-boot.png?resize=800%2C600&ssl=1
+[5]: https://endeavouros.com/info-2/
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-installing.png?resize=800%2C600&ssl=1
+[7]: https://endeavouros.com/endeavouros-first-stable-release-has-arrived/
+[8]: https://forum.antergos.com/topic/11780/endeavour-antergos-community-s-next-stage
+[9]: https://endeavouros.com/what-to-expect-on-the-first-release/
+[10]: https://calamares.io/
+[11]: https://itsfoss.com/veltos-linux/
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-updating-with-kalu.png?resize=800%2C600&ssl=1
+[13]: https://endeavouros.com/second-week-after-the-stable-release/
+[14]: https://itsfoss.com/install-virtualbox-ubuntu/
+[15]: https://aur.archlinux.org/packages/pamac-aur/
+[16]: https://octopiproject.wordpress.com/
+[17]: https://github.com/jjk-jacky/kalu
+[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-desktop.png?resize=800%2C600&ssl=1
+[19]: https://itsfoss.com/clear-linux/
+[20]: https://forum.endeavouros.com/t/how-to-switch-from-antergos-to-endevouros/105/2
+[21]: https://rebornos.org/
diff --git a/published/20191227 The importance of consistency in your Python code.md b/published/20191227 The importance of consistency in your Python code.md
new file mode 100644
index 0000000000..5ff2d11caf
--- /dev/null
+++ b/published/20191227 The importance of consistency in your Python code.md
@@ -0,0 +1,72 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13082-1.html)
+[#]: subject: (The importance of consistency in your Python code)
+[#]: via: (https://opensource.com/article/19/12/zen-python-consistency)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+Python 代码一致性的重要性
+======
+
+> 本文是 Python 之禅特殊系列的一部分,重点是第十二、十三和十四原则:模糊性和明确性的作用。
+
+
+
+最小惊喜原则是设计用户界面时的一个 [准则][2]。它是说,当用户执行某项操作时,程序执行的事情应该使用户尽量少地感到意外。这和孩子们喜欢一遍又一遍地读同一本书的原因是一样的:没有什么比能够预测并让预测成真更让人欣慰的了。
+
+在开发 [ABC 语言][3](Python 的灵感来源)的过程中,一个重要的见解是,编程设计是用户界面,需要使用与 UI 设计者相同的工具来设计。值得庆幸的是,从那以后,越来越多的语言采用了 UI 设计中的可承受性和人体工程学的概念,即使它们的应用并不严格。
+
+这就引出了 [Python 之禅][4] 中的三个原则。
+
+### 面对歧义,要拒绝猜测的诱惑
+
+`1 + "1"` 的结果应该是什么? `"11"` 和 `2` 都是猜测。这种表达方式是*歧义的*:无论如何做都会让一些人感到惊讶。
+
+一些语言选择猜测。在 JavaScript 中,结果为 `"11"`。在 Perl 中,结果为 `2`。在 C 语言中,结果自然是空字符串。面对歧义,JavaScript、Perl 和 C 都在猜测。
+
+在 Python 中,这会引发 `TypeError`:这不是能忽略的错误。捕获 `TypeError` 是非典型的:它通常将终止程序或至少终止当前任务(例如,在大多数 Web 框架中,它将终止对当前请求的处理)。
+
+Python 拒绝猜测 `1 + "1"` 的含义。程序员必须以明确的意图编写代码:`1 + int("1")`,即 `2`;或者 `str(1) + "1"`,即 `"11"`;或 `"1"[1:]`,这将是一个空字符串。通过拒绝猜测,Python 使程序更具可预测性。
+
+### 尽量找一种,最好是唯一一种明显的解决方案
+
+预测也会出现偏差。给定一个任务,你能预知要实现该任务的代码吗?当然,不可能完美地预测。毕竟,编程是一项具有创造性的任务。
+
+但是,不必有意提供多种冗余方式来实现同一目标。从某种意义上说,某些解决方案或许 “更好” 或 “更 Python 化”。
+
+对 Python 美学欣赏部分是因为,可以就哪种解决方案更好进行健康的辩论。甚至可以持不同观点而继续编程。甚至为使其达成一致,接受不同意的观点也是可以的。但在这一切之下,必须有一种这样的认识,即正确的解决方案终将会出现。我们必须希望,通过商定实现目标的最佳方法,而最终达成真正的一致。
+
+### 虽然这种方式一开始可能并不明显(除非你是荷兰人)
+
+这是一个重要的警告:首先,实现任务的最佳方法往往*不*明显。观念在不断发展。Python 也在进化。逐块读取文件的最好方法,可能要等到 Python 3.8 时使用 [walrus 运算符][5](`:=`)。
+
+逐块读取文件这样常见的任务,在 Python 存在近 *30年* 的历史中并没有 “唯一的最佳方法”。
+
+当我在 1998 年从 Python 1.5.2 开始使用 Python 时,没有一种逐行读取文件的最佳方法。多年来,知道字典中是否有某个键的最佳方法是使用关键字 `.haskey`,直到 `in` 操作符出现才发生改变。
+
+只是要意识到找到实现目标的一种(也是唯一一种)方法可能需要 30 年的时间来尝试其它方法,Python 才可以不断寻找这些方法。这种历史观认为,为了做一件事用上 30 年是可以接受的,但对于美国这个存在仅 200 多年的国家来说,人们常常会感到不习惯。
+
+从 Python 之禅的这一部分来看,荷兰人,无论是 Python 的创造者 [Guido van Rossum][6] 还是著名的计算机科学家 [Edsger W. Dijkstra][7],他们的世界观是不同的。要理解这一部分,某种程度的欧洲人对时间的感受是必不可少的。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/12/zen-python-consistency
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_other11x_cc.png?itok=I_kCDYj0 (Two animated computers waving one missing an arm)
+[2]: https://www.uxpassion.com/blog/the-principle-of-least-surprise/
+[3]: https://en.wikipedia.org/wiki/ABC_(programming_language)
+[4]: https://www.python.org/dev/peps/pep-0020/
+[5]: https://www.python.org/dev/peps/pep-0572/#abstract
+[6]: https://en.wikipedia.org/wiki/Guido_van_Rossum
+[7]: http://en.wikipedia.org/wiki/Edsger_W._Dijkstra
diff --git a/published/20191228 The Zen of Python- Why timing is everything.md b/published/20191228 The Zen of Python- Why timing is everything.md
new file mode 100644
index 0000000000..6ebab5320a
--- /dev/null
+++ b/published/20191228 The Zen of Python- Why timing is everything.md
@@ -0,0 +1,45 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13103-1.html)
+[#]: subject: (The Zen of Python: Why timing is everything)
+[#]: via: (https://opensource.com/article/19/12/zen-python-timeliness)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+Python 之禅:时机最重要
+======
+
+> 这是 Python 之禅特别系列的一部分,重点是第十五和第十六条原则:现在与将来。
+
+
+
+Python 一直在不断发展。Python 社区对特性请求的渴求是无止境的,对现状也总是不满意的。随着 Python 越来越流行,这门语言的变化会影响到更多的人。
+
+确定什么时候该进行变化往往很难,但 [Python 之禅][2] 给你提供了指导。
+
+### 现在有总比永远没有好
+
+总有一种诱惑,就是要等到事情完美才去做,虽然,它们永远没有完美的一天。当它们看起来已经“准备”得足够好了,那就大胆采取行动吧,去做出改变吧。无论如何,变化总是发生在*某个*现在:拖延的唯一作用就是把它移到未来的“现在”。
+
+### 虽然将来总比现在好
+
+然而,这并不意味着应该急于求成。从测试、文档、用户反馈等方面决定发布的标准。在变化就绪之前的“现在”,并不是一个好时机。
+
+这不仅对 Python 这样的流行语言是个很好的经验,对你个人的小开源项目也是如此。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/12/zen-python-timeliness
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/desk_clock_job_work.jpg?itok=Nj4fuhl6 (Clock, pen, and notepad on a desk)
+[2]: https://www.python.org/dev/peps/pep-0020/
diff --git a/published/20191229 How to tell if implementing your Python code is a good idea.md b/published/20191229 How to tell if implementing your Python code is a good idea.md
new file mode 100644
index 0000000000..1a2358a77c
--- /dev/null
+++ b/published/20191229 How to tell if implementing your Python code is a good idea.md
@@ -0,0 +1,47 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13116-1.html)
+[#]: subject: (How to tell if implementing your Python code is a good idea)
+[#]: via: (https://opensource.com/article/19/12/zen-python-implementation)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+如何判断你的 Python 代码实现是否合适?
+======
+
+> 这是 Python 之禅特别系列的一部分,重点介绍第十七和十八条原则:困难和容易。
+
+
+
+一门语言并不是抽象存在的。每一个语言功能都必须用代码来实现。承诺一些功能是很容易的,但实现起来就会很麻烦。复杂的实现意味着更多潜在的 bug,甚至更糟糕的是,会带来日复一日的维护负担。
+
+对于这个难题,[Python 之禅][2] 中有答案。
+
+### 如果一个实现难以解释,那就是个坏思路
+
+编程语言最重要的是可预测性。有时我们用抽象的编程模型来解释某个结构的语义,而这些模型与实现并不完全对应。然而,最好的释义就是*解释该实现*。
+
+如果该实现很难解释,那就意味着这条路行不通。
+
+### 如果一个实现易于解释,那它可能是一个好思路
+
+仅仅因为某事容易,并不意味着它值得。然而,一旦解释清楚,判断它是否是一个好思路就容易得多。
+
+这也是为什么这个原则的后半部分故意含糊其辞的原因:没有什么可以肯定一定是好的,但总是可以讨论一下。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/12/zen-python-implementation
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/devops_confusion_wall_questions.png?itok=zLS7K2JG (Brick wall between two people, a developer and an operations manager)
+[2]: https://www.python.org/dev/peps/pep-0020/
diff --git a/published/20191230 Namespaces are the shamash candle of the Zen of Python.md b/published/20191230 Namespaces are the shamash candle of the Zen of Python.md
new file mode 100644
index 0000000000..dc98e7afc0
--- /dev/null
+++ b/published/20191230 Namespaces are the shamash candle of the Zen of Python.md
@@ -0,0 +1,58 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13123-1.html)
+[#]: subject: (Namespaces are the shamash candle of the Zen of Python)
+[#]: via: (https://opensource.com/article/19/12/zen-python-namespaces)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+命名空间是 Python 之禅的精髓
+======
+
+> 这是 Python 之禅特别系列的一部分,重点是一个额外的原则:命名空间。
+
+
+
+著名的光明节有八个晚上的庆祝活动。然而,光明节的灯台有九根蜡烛:八根普通的蜡烛和总是偏移的第九根蜡烛。它被称为 “shamash” 或 “shamos”,大致可以翻译为“仆人”或“看门人”的意思。
+
+shamos 是点燃所有其它蜡烛的蜡烛:它是唯一一支可以用火的蜡烛,而不仅仅是观看。当我们结束 Python 之禅系列时,我看到命名空间提供了类似的作用。
+
+### Python 中的命名空间
+
+Python 使用命名空间来处理一切。虽然简单,但它们是稀疏的数据结构 —— 这通常是实现目标的最佳方式。
+
+> *命名空间* 是一个从名字到对象的映射。
+>
+> —— [Python.org][2]
+
+模块是命名空间。这意味着正确地预测模块语义通常只需要熟悉 Python 命名空间的工作方式。类是命名空间,对象是命名空间。函数可以访问它们的本地命名空间、父命名空间和全局命名空间。
+
+这个简单的模型,即用 `.` 操作符访问一个对象,而这个对象又通常(但并不总是)会进行某种字典查找,这使得 Python 很难优化,但很容易解释。
+
+事实上,一些第三方模块也采取了这个准则,并以此来运行。例如,[variants][3] 包把函数变成了“相关功能”的命名空间。这是一个很好的例子,说明 [Python 之禅][4] 是如何激发新的抽象的。
+
+### 结语
+
+感谢你和我一起参加这次以光明节为灵感的 [我最喜欢的语言][5] 的探索。
+
+静心参禅,直至悟道。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/12/zen-python-namespaces
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
+[2]: https://docs.python.org/3/tutorial/classes.html
+[3]: https://pypi.org/project/variants/
+[4]: https://www.python.org/dev/peps/pep-0020/
+[5]: https://opensource.com/article/19/10/why-love-python
diff --git a/published/20200121 Ansible Automation Tool Installation, Configuration and Quick Start Guide.md b/published/20200121 Ansible Automation Tool Installation, Configuration and Quick Start Guide.md
new file mode 100644
index 0000000000..600a37c4cd
--- /dev/null
+++ b/published/20200121 Ansible Automation Tool Installation, Configuration and Quick Start Guide.md
@@ -0,0 +1,344 @@
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13142-1.html"
+[#]: subject: "Ansible Automation Tool Installation, Configuration and Quick Start Guide"
+[#]: via: "https://www.2daygeek.com/install-configure-ansible-automation-tool-linux-quick-start-guide/"
+[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
+
+Ansible 自动化工具安装、配置和快速入门指南
+======
+
+
+
+市面上有很多自动化工具。我可以举几个例子,例如 Puppet、Chef、CFEngine、Foreman、Katello、Saltstock、Space Walk,它们被许多组织广泛使用。
+
+### 自动化工具可以做什么?
+
+自动化工具可以自动执行例行任务,无需人工干预,从而使 Linux 管理员的工作变得更加轻松。这些工具允许用户执行配置管理,应用程序部署和资源调配。
+
+### 为什么喜欢 Ansible?
+
+Ansible 是一种无代理的自动化工具,使用 SSH 执行所有任务,但其它工具需要在客户端节点上安装代理。
+
+### 什么是 Ansible?
+
+Ansible 是一个开源、易于使用的功能强大的 IT 自动化工具,通过 SSH 在客户端节点上执行任务。
+
+它是用 Python 构建的,这是当今世界上最流行、最强大的编程语言之一。两端都需要使用 Python 才能执行所有模块。
+
+它可以配置系统、部署软件和安排高级 IT 任务,例如连续部署或零停机滚动更新。你可以通过 Ansible 轻松执行任何类型的自动化任务,包括简单和复杂的任务。
+
+在开始之前,你需要了解一些 Ansible 术语,这些术语可以帮助你更好的创建任务。
+
+### Ansible 如何工作?
+
+Ansible 通过在客户端节点上推送称为 ansible 模块的小程序来工作,这些模块临时存储在客户端节点中,通过 JSON 协议与 Ansible 服务器进行通信。
+
+Ansible 通过 SSH 运行这些模块,并在完成后将其删除。
+
+模块是用 Python 或 Perl 等编写的一些脚本。
+
+![][1]
+
+*控制节点,用于控制剧本的全部功能,包括客户端节点(主机)。*
+
+ * 控制节点:使用 Ansible 在受控节点上执行任务的主机。你可以有多个控制节点,但不能使用 Windows 系统主机当作控制节点。
+ * 受控节点:控制节点配置的主机列表。
+ * 清单:控制节点管理的一个主机列表,这些节点在 `/etc/ansible/hosts` 文件中配置。它包含每个节点的信息,比如 IP 地址或其主机名,还可以根据需要对这些节点进行分组。
+ * 模块:每个模块用于执行特定任务,目前有 3387 个模块。
+ * 点对点:它允许你一次性运行一个任务,它使用 `/usr/bin/ansible` 二进制文件。
+ * 任务:每个动作都有一个任务列表。任务按顺序执行,在受控节点中一次执行一个任务。
+ * 剧本:你可以使用剧本同时执行多个任务,而使用点对点只能执行一个任务。剧本使用 YAML 编写,易于阅读。将来,我们将会写一篇有关剧本的文章,你可以用它来执行复杂的任务。
+
+### 测试环境
+
+此环境包含一个控制节点(`server.2g.lab`)和三个受控节点(`node1.2g.lab`、`node2.2g.lab`、`node3.2g.lab`),它们均在虚拟环境中运行,操作系统分别为:
+
+| System Purpose | Hostname | IP Address | OS |
+|----------------------|---------------|-------------|---------------|
+| Ansible Control Node | server.2g.lab | 192.168.1.7 | Manjaro 18 |
+| Managed Node1 | node1.2g.lab | 192.168.1.6 | CentOS7 |
+| Managed Node2 | node2.2g.lab | 192.168.1.5 | CentOS8 |
+| Managed Node3 | node3.2g.lab | 192.168.1.9 | Ubuntu 18.04 |
+| User: daygeek |
+
+### 前置条件
+
+ * 在 Ansible 控制节点和受控节点之间启用无密码身份验证。
+ * 控制节点必须是 Python 2(2.7 版本) 或 Python 3(3.5 或更高版本)。
+ * 受控节点必须是 Python 2(2.6 或更高版本) 或 Python 3(3.5 或更高版本)。
+ * 如果在远程节点上启用了 SELinux,则在 Ansible 中使用任何与复制、文件、模板相关的功能之前,还需要在它们上安装 `libselinux-python`。
+
+### 如何在控制节点上安装 Ansible
+
+对于 Fedora/RHEL 8/CentOS 8 系统,使用 [DNF 命令][2] 来安装 Ansible。
+
+注意:你需要在 RHEL/CentOS 系统上启用 [EPEL 仓库][3],因为 Ansible 软件包在发行版官方仓库中不可用。
+
+```
+$ sudo dnf install ansible
+```
+
+对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][4] 或 [APT 命令][5] 来安装 Ansible。
+
+配置下面的 PPA 以便在 Ubuntu 上安装最新稳定版本的 Ansible。
+
+```
+$ sudo apt update
+$ sudo apt install software-properties-common
+$ sudo apt-add-repository --yes --update ppa:ansible/ansible
+$ sudo apt install ansible
+```
+
+对于 Debian 系统,配置以下源列表:
+
+```
+$ echo "deb http://ppa.launchpad.net/ansible/ansible/ubuntu trusty main" | sudo tee -a /etc/apt/sources.list.d/ansible.list
+$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
+$ sudo apt update
+$ sudo apt install ansible
+```
+
+对于 Arch Linux 系统,使用 [Pacman 命令][6] 来安装 Ansible:
+
+```
+$ sudo pacman -S ansible
+```
+
+对于 RHEL/CentOS 系统,使用 [YUM 命令][7] 来安装 Ansible:
+
+```
+$ sudo yum install ansible
+```
+
+对于 openSUSE 系统,使用 [Zypper 命令][8] 来安装 Ansible:
+
+```
+$ sudo zypper install ansible
+```
+
+或者,你可以使用 [Python PIP 包管理工具][9] 来安装:
+
+```
+$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
+$ sudo python get-pip.py
+$ sudo pip install ansible
+```
+
+在控制节点上检查安装的 Ansible 版本:
+
+```
+$ ansible --version
+
+ansible 2.9.2
+ config file = /etc/ansible/ansible.cfg
+ configured module search path = ['/home/daygeek/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
+ ansible python module location = /usr/lib/python3.8/site-packages/ansible
+ executable location = /usr/bin/ansible
+ python version = 3.8.1 (default, Jan 8 2020, 23:09:20) [GCC 9.2.0]
+```
+
+### 如何在受控节点上安装 Python?
+
+使用以下命令在受控节点上安装 python:
+
+```
+$ sudo yum install -y python
+$ sudo dnf install -y python
+$ sudo zypper install -y python
+$ sudo pacman -S python
+$ sudo apt install -y python
+```
+
+### 如何在 Linux 设置 SSH 密钥身份验证(无密码身份验证)
+
+使用以下命令创建 ssh 密钥,然后将其复制到远程计算机。
+
+```
+$ ssh-keygen
+$ ssh-copy-id daygeek@node1.2g.lab
+$ ssh-copy-id daygeek@node2.2g.lab
+$ ssh-copy-id daygeek@node3.2g.lab
+```
+
+具体参考这篇文章《[在 Linux 上设置 SSH 密钥身份验证(无密码身份验证)][10]》。
+
+### 如何创建 Ansible 主机清单
+
+在 `/etc/ansible/hosts` 文件中添加要管理的节点列表。如果没有该文件,则可以创建一个新文件。以下是我的测试环境的主机清单文件:
+
+```
+$ sudo vi /etc/ansible/hosts
+
+[web]
+node1.2g.lab
+node2.2g.lab
+
+[app]
+node3.2g.lab
+```
+
+让我们看看是否可以使用以下命令查找所有主机。
+
+```
+$ ansible all --list-hosts
+
+ hosts (3):
+ node1.2g.lab
+ node2.2g.lab
+ node3.2g.lab
+```
+
+对单个组运行以下命令:
+
+```
+$ ansible web --list-hosts
+
+ hosts (2):
+ node1.2g.lab
+ node2.2g.lab
+```
+
+### 如何使用点对点命令执行任务
+
+一旦完成主机清单验证检查后,你就可以上路了。干的漂亮!
+
+**语法:**
+
+```
+ansible [pattern] -m [module] -a "[module options]"
+
+Details:
+========
+ansible: A command
+pattern: Enter the entire inventory or a specific group
+-m [module]: Run the given module name
+-a [module options]: Specify the module arguments
+```
+
+使用 Ping 模块对主机清单中的所有节点执行 ping 操作:
+
+```
+$ ansible all -m ping
+
+node3.2g.lab | SUCCESS => {
+ "ansible_facts": {
+ "discovered_interpreter_python": "/usr/bin/python"
+ },
+ "changed": false,
+ "ping": "pong"
+}
+node1.2g.lab | SUCCESS => {
+ "ansible_facts": {
+ "discovered_interpreter_python": "/usr/bin/python"
+ },
+ "changed": false,
+ "ping": "pong"
+}
+node2.2g.lab | SUCCESS => {
+ "ansible_facts": {
+ "discovered_interpreter_python": "/usr/libexec/platform-python"
+ },
+ "changed": false,
+ "ping": "pong"
+}
+```
+
+所有系统都返回了成功,但什么都没有改变,只返回了 `pong` 代表成功。
+
+你可以使用以下命令获取可用模块的列表。
+
+```
+$ ansible-doc -l
+```
+
+当前有 3387 个内置模块,它们会随着 Ansible 版本的递增而增加:
+
+```
+$ ansible-doc -l | wc -l
+3387
+```
+
+使用 command 模块对主机清单中的所有节点执行命令:
+
+```
+$ ansible all -m command -a "uptime"
+
+node3.2g.lab | CHANGED | rc=0 >>
+ 18:05:07 up 1:21, 3 users, load average: 0.12, 0.06, 0.01
+node1.2g.lab | CHANGED | rc=0 >>
+ 06:35:06 up 1:21, 4 users, load average: 0.01, 0.03, 0.05
+node2.2g.lab | CHANGED | rc=0 >>
+ 18:05:07 up 1:25, 3 users, load average: 0.01, 0.01, 0.00
+```
+
+对指定组执行 command 模块。
+
+检查 app 组主机的内存使用情况:
+
+```
+$ ansible app -m command -a "free -m"
+
+node3.2g.lab | CHANGED | rc=0 >>
+ total used free shared buff/cache available
+Mem: 1993 1065 91 6 836 748
+Swap: 1425 0 1424
+```
+
+要对 web 组运行 `hostnamectl` 命令,使用以下格式:
+
+```
+$ ansible web -m command -a "hostnamectl"
+
+node1.2g.lab | CHANGED | rc=0 >>
+ Static hostname: CentOS7.2daygeek.com
+ Icon name: computer-vm
+ Chassis: vm
+ Machine ID: 002f47b82af248f5be1d67b67e03514c
+ Boot ID: dc38f9b8089d4b2d9304e526e00c6a8f
+ Virtualization: kvm
+ Operating System: CentOS Linux 7 (Core)
+ CPE OS Name: cpe:/o:centos:centos:7
+ Kernel: Linux 3.10.0-957.el7.x86_64
+ Architecture: x86-64
+node2.2g.lab | CHANGED | rc=0 >>
+ Static hostname: node2.2g.lab
+ Icon name: computer-vm
+ Chassis: vm
+ Machine ID: e39e3a27005d44d8bcbfcab201480b45
+ Boot ID: 27b46a09dde546da95ace03420fe12cb
+ Virtualization: oracle
+ Operating System: CentOS Linux 8 (Core)
+ CPE OS Name: cpe:/o:centos:centos:8
+ Kernel: Linux 4.18.0-80.el8.x86_64
+ Architecture: x86-64
+```
+
+参考:[Ansible 文档][11]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/install-configure-ansible-automation-tool-linux-quick-start-guide/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/wp-content/uploads/2020/01/ansible-architecture-2daygeek.png
+[2]: https://www.2daygeek.com/linux-dnf-command-examples-manage-packages-fedora-centos-rhel-systems/
+[3]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-oracle-linux/
+[4]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
+[5]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
+[6]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
+[7]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[8]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
+[9]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
+[10]: https://www.2daygeek.com/configure-setup-passwordless-ssh-key-based-authentication-linux/
+[11]: https://docs.ansible.com/ansible/latest/user_guide/index.html
diff --git a/published/20200419 Getting Started With Pacman Commands in Arch-based Linux Distributions.md b/published/20200419 Getting Started With Pacman Commands in Arch-based Linux Distributions.md
new file mode 100644
index 0000000000..8171a81ede
--- /dev/null
+++ b/published/20200419 Getting Started With Pacman Commands in Arch-based Linux Distributions.md
@@ -0,0 +1,244 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13099-1.html)
+[#]: subject: (Getting Started With Pacman Commands in Arch-based Linux Distributions)
+[#]: via: (https://itsfoss.com/pacman-command/)
+[#]: author: (Dimitrios Savvopoulos https://itsfoss.com/author/dimitrios/)
+
+Arch Linux 的 pacman 命令入门
+======
+
+> 这本初学者指南向你展示了在 Linux 中可以使用 pacman 命令做什么,如何使用它们来查找新的软件包,安装和升级新的软件包,以及清理你的系统。
+
+[pacman][1] 包管理器是 [Arch Linux][2] 和其他主要发行版如 Red Hat 和 Ubuntu/Debian 之间的主要区别之一。它结合了简单的二进制包格式和易于使用的 [构建系统][3]。`pacman` 的目标是方便地管理软件包,无论它是来自 [官方库][4] 还是用户自己构建的软件库。
+
+如果你曾经使用过 Ubuntu 或基于 debian 的发行版,那么你可能使用过 `apt-get` 或 `apt` 命令。`pacman` 在 Arch Linux 中是同样的命令。如果你 [刚刚安装了 Arch Linux][5],在安装 Arch Linux 后,首先要做的 [几件事][6] 之一就是学习使用 `pacman` 命令。
+
+在这个初学者指南中,我将解释一些基本的 `pacman` 命令的用法,你应该知道如何用这些命令来管理你的基于 Archlinux 的系统。
+
+### Arch Linux 用户应该知道的几个重要的 pacman 命令
+
+
+
+与其他包管理器一样,`pacman` 可以将包列表与软件库同步,它能够自动解决所有所需的依赖项,以使得用户可以通过一个简单的命令下载和安装软件。
+
+#### 通过 pacman 安装软件
+
+你可以用以下形式的代码来安装一个或者多个软件包:
+
+```
+pacman -S 软件包名1 软件包名2 ...
+```
+
+![安装一个包][8]
+
+`-S` 选项的意思是同步,它的意思是 `pacman` 在安装之前先与软件库进行同步。
+
+`pacman` 数据库根据安装的原因将安装的包分为两组:
+
+ * **显式安装**:由 `pacman -S` 或 `-U` 命令直接安装的包
+ * **依赖安装**:由于被其他显式安装的包所 [依赖][9],而被自动安装的包。
+
+#### 卸载已安装的软件包
+
+卸载一个包,并且删除它的所有依赖。
+
+```
+pacman -R 软件包名
+```
+
+![移除一个包][10]
+
+删除一个包,以及其不被其他包所需要的依赖项:
+
+```
+pacman -Rs 软件包名
+```
+
+如果需要这个依赖的包已经被删除了,这条命令可以删除所有不再需要的依赖项:
+
+```
+pacman -Qdtq | pacman -Rs -
+```
+
+#### 升级软件包
+
+`pacman` 提供了一个简单的办法来 [升级 Arch Linux][11]。你只需要一条命令就可以升级所有已安装的软件包。这可能需要一段时间,这取决于系统的新旧程度。
+
+以下命令可以同步存储库数据库,*并且* 更新系统的所有软件包,但不包括不在软件库中的“本地安装的”包:
+
+```
+pacman -Syu
+```
+
+ * `S` 代表同步
+ * `y` 代表更新本地存储库
+ * `u` 代表系统更新
+
+也就是说,同步到中央软件库(主程序包数据库),刷新主程序包数据库的本地副本,然后执行系统更新(通过更新所有有更新版本可用的程序包)。
+
+![系统更新][12]
+
+> 注意!
+>
+> 对于 Arch Linux 用户,在系统升级前,建议你访问 [Arch-Linux 主页][2] 查看最新消息,以了解异常更新的情况。如果系统更新需要人工干预,主页上将发布相关的新闻。你也可以订阅 [RSS 源][13] 或 [Arch 的声明邮件][14]。
+>
+> 在升级基础软件(如 kernel、xorg、systemd 或 glibc) 之前,请注意查看相应的 [论坛][15],以了解大家报告的各种问题。
+>
+> 在 Arch 和 Manjaro 等滚动发行版中不支持**部分升级**。这意味着,当新的库版本被推送到软件库时,软件库中的所有包都需要根据库版本进行升级。例如,如果两个包依赖于同一个库,则仅升级一个包可能会破坏依赖于该库的旧版本的另一个包。
+
+#### 用 Pacman 查找包
+
+`pacman` 使用 `-Q` 选项查询本地包数据库,使用 `-S` 选项查询同步数据库,使用 `-F` 选项查询文件数据库。
+
+`pacman` 可以在数据库中搜索包,包括包的名称和描述:
+
+```
+pacman -Ss 字符串1 字符串2 ...
+```
+
+![查找一个包][16]
+
+查找已经被安装的包:
+
+```
+pacman -Qs 字符串1 字符串2 ...
+```
+
+根据文件名在远程软包中查找它所属的包:
+
+```
+pacman -F 字符串1 字符串2 ...
+```
+
+查看一个包的依赖树:
+
+```
+pactree 软件包名
+```
+
+#### 清除包缓存
+
+`pacman` 将其下载的包存储在 `/var/cache/Pacman/pkg/` 中,并且不会自动删除旧版本或卸载的版本。这有一些优点:
+
+ 1. 它允许 [降级][17] 一个包,而不需要通过其他来源检索以前的版本。
+ 2. 已卸载的软件包可以轻松地直接从缓存文件夹重新安装。
+
+但是,有必要定期清理缓存以防止文件夹增大。
+
+[pacman contrib][19] 包中提供的 [paccache(8)][18] 脚本默认情况下会删除已安装和未安装包的所有缓存版本,但最近 3 个版本除外:
+
+```
+paccache -r
+```
+
+![清除缓存][20]
+
+要删除当前未安装的所有缓存包和未使用的同步数据库,请执行:
+
+```
+pacman -Sc
+```
+
+要从缓存中删除所有文件,请使用清除选项两次,这是最激进的方法,不会在缓存文件夹中留下任何内容:
+
+```
+pacman -Scc
+```
+
+#### 安装本地或者第三方的包
+
+安装不是来自远程存储库的“本地”包:
+
+```
+pacman -U 本地软件包路径.pkg.tar.xz
+```
+
+安装官方存储库中未包含的“远程”软件包:
+
+```
+pacman -U http://www.example.com/repo/example.pkg.tar.xz
+```
+
+### 额外内容:用 pacman 排除常见错误
+
+下面是使用 `pacman` 管理包时可能遇到的一些常见错误。
+
+#### 提交事务失败(文件冲突)
+
+如果你看到以下报错:
+
+```
+error: could not prepare transaction
+error: failed to commit transaction (conflicting files)
+package: /path/to/file exists in filesystem
+Errors occurred, no packages were upgraded.
+```
+
+这是因为 `pacman` 检测到文件冲突,不会为你覆盖文件。
+
+解决这个问题的一个安全方法是首先检查另一个包是否拥有这个文件(`pacman-Qo 文件路径`)。如果该文件属于另一个包,请提交错误报告。如果文件不属于另一个包,请重命名“存在于文件系统中”的文件,然后重新发出更新命令。如果一切顺利,文件可能会被删除。
+
+你可以显式地运行 `pacman -S –overwrite 要覆盖的文件模式**,强制 `pacman` 覆盖与 给模式匹配的文件,而不是手动重命名并在以后删除属于该包的所有文件。
+
+#### 提交事务失败(包无效或损坏)
+
+在 `/var/cache/pacman/pkg/` 中查找 `.part` 文件(部分下载的包),并将其删除。这通常是由在 `pacman.conf` 文件中使用自定义 `XferCommand` 引起的。
+
+#### 初始化事务失败(无法锁定数据库)
+
+当 `pacman` 要修改包数据库时,例如安装包时,它会在 `/var/lib/pacman/db.lck` 处创建一个锁文件。这可以防止 `pacman` 的另一个实例同时尝试更改包数据库。
+
+如果 `pacman` 在更改数据库时被中断,这个过时的锁文件可能仍然保留。如果你确定没有 `pacman` 实例正在运行,那么请删除锁文件。
+
+检查进程是否持有锁定文件:
+
+```
+lsof /var/lib/pacman/db.lck
+```
+
+如果上述命令未返回任何内容,则可以删除锁文件:
+
+```
+rm /var/lib/pacman/db.lck
+```
+
+如果你发现 `lsof` 命令输出了使用锁文件的进程的 PID,请先杀死这个进程,然后删除锁文件。
+
+我希望你喜欢我对 `pacman` 基础命令的介绍。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/pacman-command/
+
+作者:[Dimitrios Savvopoulos][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/dimitrios/
+[b]: https://github.com/lujun9972
+[1]: https://www.archlinux.org/pacman/
+[2]: https://www.archlinux.org/
+[3]: https://wiki.archlinux.org/index.php/Arch_Build_System
+[4]: https://wiki.archlinux.org/index.php/Official_repositories
+[5]: https://itsfoss.com/install-arch-linux/
+[6]: https://itsfoss.com/things-to-do-after-installing-arch-linux/
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/essential-pacman-commands.jpg?ssl=1
+[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/sudo-pacman-S.png?ssl=1
+[9]: https://wiki.archlinux.org/index.php/Dependency
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/04/sudo-pacman-R.png?ssl=1
+[11]: https://itsfoss.com/update-arch-linux/
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/sudo-pacman-Syu.png?ssl=1
+[13]: https://www.archlinux.org/feeds/news/
+[14]: https://mailman.archlinux.org/mailman/listinfo/arch-announce/
+[15]: https://bbs.archlinux.org/
+[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/sudo-pacman-Ss.png?ssl=1
+[17]: https://wiki.archlinux.org/index.php/Downgrade
+[18]: https://jlk.fjfi.cvut.cz/arch/manpages/man/paccache.8
+[19]: https://www.archlinux.org/packages/?name=pacman-contrib
+[20]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/04/sudo-paccache-r.png?ssl=1
diff --git a/published/20200529 A new way to build cross-platform UIs for Linux ARM devices.md b/published/20200529 A new way to build cross-platform UIs for Linux ARM devices.md
new file mode 100644
index 0000000000..9a742f2eb2
--- /dev/null
+++ b/published/20200529 A new way to build cross-platform UIs for Linux ARM devices.md
@@ -0,0 +1,170 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13129-1.html)
+[#]: subject: (A new way to build cross-platform UIs for Linux ARM devices)
+[#]: via: (https://opensource.com/article/20/5/linux-arm-ui)
+[#]: author: (Bruno Muniz https://opensource.com/users/brunoamuniz)
+
+一种为 Linux ARM 设备构建跨平台 UI 的新方法
+======
+
+> AndroidXML 和 TotalCross 的运用为树莓派和其他设备创建 UI 提供了更简单的方法。
+
+
+
+为应用程序创建良好的用户体验(UX)是一项艰巨的任务,尤其是在开发嵌入式应用程序时。今天,有两种图形用户界面(GUI)工具通常用于开发嵌入式软件:它们要么涉及复杂的技术,要么非常昂贵。
+
+然而,我们已经创建了一个概念验证(PoC),它提供了一种新的方法来使用现有的、成熟的工具为运行在桌面、移动、嵌入式设备和低功耗 ARM 设备上的应用程序构建用户界面(UI)。我们的方法是使用 Android Studio 绘制 UI;使用 [TotalCross][2] 在设备上呈现 Android XML;采用被称为 [KnowCode][4] 的新 [TotalCross API][3];以及使用 [树莓派 4][5] 来执行应用程序。
+
+### 选择 Android Studio
+
+可以使用 TotalCross API 为应用程序构建一个美观的响应式用户体验,但是在 Android Studio 中创建 UI 缩短了制作原型和实际应用程序之间的时间。
+
+有很多工具可以用来为应用程序构建 UI,但是 [Android Studio][6] 是全世界开发者最常使用的工具。除了它被大量采用以外,这个工具的使用也非常直观,而且它对于创建简单和复杂的应用程序都非常强大。在我看来,唯一的缺点是使用该工具所需的计算机性能,它比其他集成开发环境 (IDE) 如 VSCode 或其开源替代方案 [VSCodium][7] 要庞大得多。
+
+通过思考这些问题,我们创建了一个概念验证,使用 Android Studio 绘制 UI,并使用 TotalCross 直接在设备上运行 AndroidXML。
+
+### 构建 UI
+
+对于我们的 PoC,我们想创建一个家用电器应用程序来控制温度和其他东西,并在 Linux ARM 设备上运行。
+
+![Home appliance application to control thermostat][8]
+
+我们想为树莓派开发我们的应用程序,所以我们使用 Android 的 [ConstraintLayout][10] 来构建 848x480(树莓派的分辨率)的固定屏幕大小的 UI,不过你可以用其他布局构建响应性 UI。
+
+Android XML 为 UI 创建增加了很多灵活性,使得为应用程序构建丰富的用户体验变得容易。在下面的 XML 中,我们使用了两个主要组件:[ImageView][11] 和 [TextView][12]。
+
+```
+
+
+```
+
+TextView 元素用于向用户显示一些数据,比如建筑物内的温度。大多数 ImageView 都用作用户与 UI 交互的按钮,但它们也需要实现屏幕上组件提供的事件。
+
+### 用 TotalCross 整合
+
+这个 PoC 中的第二项技术是 TotalCross。我们不想在设备上使用 Android 的任何东西,因为:
+
+ 1。我们的目标是为 Linux ARM 提供一个出色的 UI。
+ 2。我们希望在设备上实现低占用。
+ 3。我们希望应用程序在低计算能力的低端硬件设备上运行(例如,没有 GPU、 低 RAM 等)。
+
+首先,我们使用 [VSCode 插件][13] 创建了一个空的 TotalCross 项目。接下来,我们保存了 `drawable` 文件夹中的图像副本和 `xml` 文件夹中的 Android XML 文件副本,这两个文件夹都位于 `resources` 文件夹中:
+
+![Home Appliance file structure][14]
+
+为了使用 TotalCross 模拟器运行 XML 文件,我们添加了一个名为 KnowCode 的新 TotalCross API 和一个主窗口来加载 XML。下面的代码使用 API 加载和呈现 XML:
+
+```
+public void initUI() {
+ XmlScreenAbstractLayout xmlCont = XmlScreenFactory.create("xml / homeApplianceXML.xml");
+ swap(xmlCont);
+}
+```
+
+就这样!只需两个命令,我们就可以使用 TotalCross 运行 Android XML 文件。以下是 XML 如何在 TotalCross 的模拟器上执行:
+
+![TotalCross simulator running temperature application][15]
+
+完成这个 PoC 还有两件事要做:添加一些事件来提供用户交互,并在树莓派上运行它。
+
+### 添加事件
+
+KnowCode API 提供了一种通过 ID(`getControlByID`) 获取 XML 元素并更改其行为的方法,如添加事件、更改可见性等。
+
+例如,为了使用户能够改变家中或其他建筑物的温度,我们在 UI 底部放置了加号和减号按钮,并在每次单击按钮时都会出现“单击”事件,使温度升高或降低一度:
+
+```
+Button plus = (Button) xmlCont.getControlByID("@+id/plus");
+Label insideTempLabel = (Label) xmlCont.getControlByID("@+id/insideTempLabel");
+plus.addPressListener(new PressListener() {
+ @Override
+ public void controlPressed(ControlEvent e) {
+ try {
+ String tempString = insideTempLabel.getText();
+ int temp;
+ temp = Convert.toInt(tempString);
+ insideTempLabel.setText(Convert.toString(++temp));
+ } catch (InvalidNumberException e1) {
+ e1.printStackTrace();
+ }
+ }
+});
+```
+
+### 在树莓派 4 上测试
+
+最后一步!我们在一台设备上运行了应用程序并检查了结果。我们只需要打包应用程序并在目标设备上部署和运行它。[VNC][19] 也可用于检查设备上的应用程序。
+
+整个应用程序,包括资源(图像等)、Android XML、TotalCross 和 Knowcode API,在 Linux ARM 上大约是 8MB。
+
+下面是应用程序的演示:
+
+![Application demo][20]
+
+在本例中,该应用程序仅为 Linux ARM 打包,但同一应用程序可以作为 Linux 桌面应用程序运行,在Android 设备 、Windows、windows CE 甚至 iOS 上运行。
+
+所有示例源代码和项目都可以在 [HomeApplianceXML GitHub][21] 存储库中找到。
+
+### 现有工具的新玩法
+
+为嵌入式应用程序创建 GUI 并不需要像现在这样困难。这种概念证明为如何轻松地完成这项任务提供了新的视角,不仅适用于嵌入式系统,而且适用于所有主要的操作系统,所有这些系统都使用相同的代码库。
+
+我们的目标不是为设计人员或开发人员创建一个新的工具来构建 UI 应用程序;我们的目标是为使用现有的最佳工具提供新的玩法。
+
+你对这种新的应用程序开发方式有何看法?在下面的评论中分享你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/5/linux-arm-ui
+
+作者:[Bruno Muniz][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/brunoamuniz
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_desk_home_laptop_browser.png?itok=Y3UVpY0l (Digital images of a computer desktop)
+[2]: https://totalcross.com/
+[3]: https://yourapp.totalcross.com/knowcode-app
+[4]: https://github.com/TotalCross/KnowCodeXML
+[5]: https://www.raspberrypi.org/
+[6]: https://developer.android.com/studio
+[7]: https://vscodium.com/
+[8]: https://opensource.com/sites/default/files/uploads/homeapplianceapp.png (Home appliance application to control thermostat)
+[9]: https://creativecommons.org/licenses/by-sa/4.0/
+[10]: https://codelabs.developers.google.com/codelabs/constraint-layout/index.html#0
+[11]: https://developer.android.com/reference/android/widget/ImageView
+[12]: https://developer.android.com/reference/android/widget/TextView
+[13]: https://medium.com/totalcross-community/totalcross-plugin-for-vscode-4f45da146a0a
+[14]: https://opensource.com/sites/default/files/uploads/homeappliancexml.png (Home Appliance file structure)
+[15]: https://opensource.com/sites/default/files/uploads/totalcross-simulator_0.png (TotalCross simulator running temperature application)
+[16]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+button
+[17]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+label
+[18]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
+[19]: https://tigervnc.org/
+[20]: https://opensource.com/sites/default/files/uploads/application.gif (Application demo)
+[21]: https://github.com/TotalCross/HomeApplianceXML
diff --git a/published/20200607 Top Arch-based User Friendly Linux Distributions That are Easier to Install and Use Than Arch Linux Itself.md b/published/20200607 Top Arch-based User Friendly Linux Distributions That are Easier to Install and Use Than Arch Linux Itself.md
new file mode 100644
index 0000000000..11c43fd1f5
--- /dev/null
+++ b/published/20200607 Top Arch-based User Friendly Linux Distributions That are Easier to Install and Use Than Arch Linux Itself.md
@@ -0,0 +1,201 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13104-1.html)
+[#]: subject: (Top Arch-based User Friendly Linux Distributions That are Easier to Install and Use Than Arch Linux Itself)
+[#]: via: (https://itsfoss.com/arch-based-linux-distros/)
+[#]: author: (Dimitrios Savvopoulos https://itsfoss.com/author/dimitrios/)
+
+9 个易用的基于 Arch 的用户友好型 Linux 发行版
+======
+
+在 Linux 社区中,[Arch Linux][1] 有一群狂热的追随者。这个轻量级的发行版以 DIY 的态度提供了最前沿的更新。
+
+但是,Arch 的目标用户是那些更有经验的用户。因此,它通常被认为是那些技术不够(或耐心不够)的人所无法触及的。
+
+事实上,只是最开始的步骤,[安装 Arch Linux 就足以把很多人吓跑][2]。与大多数其他发行版不同,Arch Linux 没有一个易于使用的图形安装程序。安装过程中涉及到的磁盘分区,连接到互联网,挂载驱动器和创建文件系统等只用命令行工具来操作。
+
+对于那些不想经历复杂的安装和设置的人来说,有许多用户友好的基于 Arch 的发行版。
+
+在本文中,我将向你展示一些 Arch 替代发行版。这些发行版附带了图形安装程序、图形包管理器和其他工具,比它们的命令行版本更容易使用。
+
+### 更容易设置和使用的基于 Arch 的 Linux 发行版
+
+
+
+请注意,这不是一个排名列表。这些数字只是为了计数的目的。排第二的发行版不应该被认为比排第七的发行版好。
+
+#### 1、Manjaro Linux
+
+![][4]
+
+[Manjaro][5] 不需要任何介绍。它是几年来最流行的 Linux 发行版之一,它值得拥有。
+
+Manjaro 提供了 Arch Linux 的所有优点,同时注重用户友好性和可访问性。Manjaro 既适合新手,也适合有经验的 Linux 用户。
+
+**对于新手**,它提供了一个用户友好的安装程序,系统本身也设计成可以在你[最喜爱的桌面环境 ][6](DE)或窗口管理器中直接“开箱即用”。
+
+**对于更有经验的用户**,Manjaro 还提供多种功能,以满足每个个人的口味和喜好。[Manjaro Architect][7] 提供了安装各种 Manjaro 风格的选项,并为那些想要完全自由地塑造系统的人提供了各种桌面环境、文件系统([最近推出的 ZFS][8]) 和引导程序的选择。
+
+Manjaro 也是一个滚动发布的前沿发行版。然而,与 Arch 不同的是,Manjaro 首先测试更新,然后将其提供给用户。稳定在这里也很重要。
+
+#### 2、ArcoLinux
+
+![][9]
+
+[ArcoLinux][10](以前称为 ArchMerge)是一个基于 Arch Linux 的发行版。开发团队提供了三种变体。ArcoLinux、ArcoLinuxD 和 ArcoLinuxB。
+
+ArcoLinux 是一个功能齐全的发行版,附带有 [Xfce 桌面][11]、[Openbox][12] 和 [i3 窗口管理器][13]。
+
+**ArcoLinuxD** 是一个精简的发行版,它包含了一些脚本,可以让高级用户安装任何桌面和应用程序。
+
+**ArcoLinuxB** 是一个让用户能够构建自定义发行版的项目,同时还开发了几个带有预配置桌面的社区版本,如 Awesome、bspwm、Budgie、Cinnamon、Deepin、GNOME、MATE 和 KDE Plasma。
+
+ArcoLinux 还提供了各种视频教程,因为它非常注重学习和获取 Linux 技能。
+
+#### 3、Archlabs Linux
+
+![][14]
+
+[ArchLabs Linux][15] 是一个轻量级的滚动版 Linux 发行版,基于最精简的 Arch Linux,带有 [Openbox][16] 窗口管理器。[ArchLabs][17] 在观感设计中受到 [BunsenLabs][18] 的影响和启发,主要考虑到中级到高级用户的需求。
+
+#### 4、Archman Linux
+
+![][19]
+
+[Archman][20] 是一个独立的项目。Arch Linux 发行版对于没有多少 Linux 经验的用户来说通常不是理想的操作系统。要想在最小的挫折感下让事情变得更有意义,必须要有相当的背景知识。Archman Linux 的开发人员正试图改变这种评价。
+
+Archman 的开发是基于对开发的理解,包括用户反馈和体验组件。根据团队过去的经验,将用户的反馈和要求融合在一起,确定路线图并完成构建工作。
+
+#### 5、EndeavourOS
+
+![][21]
+
+当流行的基于 Arch 的发行版 [Antergos 在 2019 结束][22] 时,它留下了一个友好且非常有用的社区。Antergos 项目结束的原因是因为该系统对于开发人员来说太难维护了。
+
+在宣布结束后的几天内,一些有经验的用户通过创建一个新的发行版来填补 Antergos 留下的空白,从而维护了以前的社区。这就是 [EndeavourOS][23] 的诞生。
+
+[EndeavourOS][24] 是轻量级的,并且附带了最少数量的预装应用程序。一块近乎空白的画布,随时可以个性化。
+
+#### 6、RebornOS
+
+![][25]
+
+[RebornOS][26] 开发人员的目标是将 Linux 的真正威力带给每个人,一个 ISO 提供了 15 个桌面环境可供选择,并提供无限的定制机会。
+
+RebornOS 还声称支持 [Anbox][27],它可以在桌面 Linux 上运行 Android 应用程序。它还提供了一个简单的内核管理器 GUI 工具。
+
+再加上 [Pacman][28]、[AUR][29],以及定制版本的 Cnchi 图形安装程序,Arch Linux 终于可以让最没有经验的用户也能够使用了。
+
+#### 7、Chakra Linux
+
+![][30]
+
+一个社区开发的 GNU/Linux 发行版,它的亮点在 KDE 和 Qt 技术。[Chakra Linux][31] 不在特定日期安排发布,而是使用“半滚动发布”系统。
+
+这意味着 Chakra Linux 的核心包被冻结,只在修复安全问题时才会更新。这些软件包是在最新版本经过彻底测试后更新的,然后再转移到永久软件库(大约每六个月更新一次)。
+
+除官方软件库外,用户还可以安装 Chakra 社区软件库 (CCR) 的软件包,该库为官方存储库中未包含的软件提供用户制作的 PKGINFOs 和 [PKGBUILD][32] 脚本,其灵感来自于 Arch 用户软件库(AUR)。
+
+#### 8、Artix Linux
+
+![Artix Mate Edition][33]
+
+[Artix Linux][34] 也是一个基于 Arch Linux 的滚动发行版,它使用 [OpenRC][35]、[runit][36] 或 [s6][37] 作为初始化工具而不是 [systemd][38]。
+
+Artix Linux 有自己的软件库,但作为一个基于 `pacman` 的发行版,它可以使用 Arch Linux 软件库或任何其他衍生发行版的软件包,甚至可以使用明确依赖于 systemd 的软件包。也可以使用 [Arch 用户软件库][29](AUR)。
+
+#### 9、BlackArch Linux
+
+![][39]
+
+BlackArch 是一个基于 Arch Linux 的 [渗透测试发行版][40],它提供了大量的网络安全工具。它是专门为渗透测试人员和安全研究人员创建的。该软件库包含 2400 多个[黑客和渗透测试工具 ][41],可以单独安装,也可以分组安装。BlackArch Linux 兼容现有的 Arch Linux 包。
+
+### 想要真正的原版 Arch Linux 吗?可以使用图形化 Arch 安装程序简化安装
+
+如果你想使用原版的 Arch Linux,但又被它困难的安装所难倒。幸运的是,你可以下载一个带有图形安装程序的 Arch Linux ISO。
+
+Arch 安装程序基本上是 Arch Linux ISO 的一个相对容易使用的基于文本的安装程序。它比裸奔的 Arch 安装容易得多。
+
+#### Anarchy Installer
+
+![][42]
+
+[Anarchy installer][43] 打算为新手和有经验的 Linux 用户提供一种简单而无痛苦的方式来安装 ArchLinux。在需要的时候安装,在需要的地方安装,并且以你想要的方式安装。这就是 Anarchy 的哲学。
+
+启动安装程序后,将显示一个简单的 [TUI 菜单][44],列出所有可用的安装程序选项。
+
+#### Zen Installer
+
+![][45]
+
+[Zen Installer][46] 为安装 Arch Linux 提供了一个完整的图形(点击式)环境。它支持安装多个桌面环境 、AUR 以及 Arch Linux 的所有功能和灵活性,并且易于图形化安装。
+
+ISO 将引导一个临场环境,然后在你连接到互联网后下载最新稳定版本的安装程序。因此,你将始终获得最新的安装程序和更新的功能。
+
+### 总结
+
+对于许多用户来说,基于 Arch 的发行版会是一个很好的无忧选择,而像 Anarchy 这样的图形化安装程序至少离原版的 Arch Linux 更近了一步。
+
+在我看来,[Arch Linux 的真正魅力在于它的安装过程][2],对于 Linux 爱好者来说,这是一个学习的机会,而不是麻烦。Arch Linux 及其衍生产品有很多东西需要你去折腾,但是在折腾的过程中你就会进入到开源软件的世界,这里是神奇的新世界。下次再见!
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/arch-based-linux-distros/
+
+作者:[Dimitrios Savvopoulos][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/dimitrios/
+[b]: https://github.com/lujun9972
+[1]: https://www.archlinux.org/
+[2]: https://itsfoss.com/install-arch-linux/
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/06/arch-based-linux-distributions.png?ssl=1
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/05/manjaro-20.jpg?ssl=1
+[5]: https://manjaro.org/
+[6]: https://itsfoss.com/best-linux-desktop-environments/
+[7]: https://itsfoss.com/manjaro-architect-review/
+[8]: https://itsfoss.com/manjaro-20-release/
+[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/05/arcolinux.png?ssl=1
+[10]: https://arcolinux.com/
+[11]: https://www.xfce.org/
+[12]: http://openbox.org/wiki/Main_Page
+[13]: https://i3wm.org/
+[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/06/Archlabs.jpg?ssl=1
+[15]: https://itsfoss.com/archlabs-review/
+[16]: https://en.wikipedia.org/wiki/Openbox
+[17]: https://archlabslinux.com/
+[18]: https://www.bunsenlabs.org/
+[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/06/Archman.png?ssl=1
+[20]: https://archman.org/en/
+[21]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/05/04_endeavouros_slide.jpg?ssl=1
+[22]: https://itsfoss.com/antergos-linux-discontinued/
+[23]: https://itsfoss.com/endeavouros/
+[24]: https://endeavouros.com/
+[25]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/06/RebornOS.png?ssl=1
+[26]: https://rebornos.org/
+[27]: https://anbox.io/
+[28]: https://itsfoss.com/pacman-command/
+[29]: https://itsfoss.com/aur-arch-linux/
+[30]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/06/Chakra_Goedel_Screenshot.png?ssl=1
+[31]: https://www.chakralinux.org/
+[32]: https://wiki.archlinux.org/index.php/PKGBUILD
+[33]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/06/Artix_MATE_edition.png?ssl=1
+[34]: https://artixlinux.org/
+[35]: https://en.wikipedia.org/wiki/OpenRC
+[36]: https://en.wikipedia.org/wiki/Runit
+[37]: https://en.wikipedia.org/wiki/S6_(software)
+[38]: https://en.wikipedia.org/wiki/Systemd
+[39]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/06/BlackArch.png?ssl=1
+[40]: https://itsfoss.com/linux-hacking-penetration-testing/
+[41]: https://itsfoss.com/best-kali-linux-tools/
+[42]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/05/anarchy.jpg?ssl=1
+[43]: https://anarchyinstaller.org/
+[44]: https://en.wikipedia.org/wiki/Text-based_user_interface
+[45]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/05/zen.jpg?ssl=1
+[46]: https://sourceforge.net/projects/revenge-installer/
diff --git a/published/20200615 LaTeX Typesetting - Part 1 (Lists).md b/published/20200615 LaTeX Typesetting - Part 1 (Lists).md
new file mode 100644
index 0000000000..b69d418b64
--- /dev/null
+++ b/published/20200615 LaTeX Typesetting - Part 1 (Lists).md
@@ -0,0 +1,260 @@
+[#]: collector: "lujun9972"
+[#]: translator: "rakino"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13112-1.html"
+[#]: subject: "LaTeX Typesetting – Part 1 (Lists)"
+[#]: via: "https://fedoramagazine.org/latex-typesetting-part-1/"
+[#]: author: "Earl Ramirez https://fedoramagazine.org/author/earlramirez/"
+
+LaTeX 排版(1):列表
+======
+
+![][1]
+
+本系列基于前文《[在 Fedora 上用 LaTex 和 TeXstudio 排版你的文档][2]》和《[LaTeX 基础][3]》,本文即系列的第一部分,是关于 LaTeX 列表的。
+
+### 列表类型
+
+LaTeX 中的列表是封闭的环境,列表中的每个项目可以取一行文字到一个完整的段落。在 LaTeX 中有三种列表类型:
+
+ * `itemize`:无序列表/项目符号列表
+ * `enumerate`:有序列表
+ * `description`:描述列表
+
+### 创建列表
+
+要创建一个列表,需要在每个项目前加上控制序列 `\item`,并在项目清单前后分别加上控制序列 `\begin{<类型>}` 和 `\end`{<类型>}`(将其中的 `<类型>` 替换为将要使用的列表类型),如下例:
+
+#### itemize(无序列表)
+
+```
+\begin{itemize}
+ \item Fedora
+ \item Fedora Spin
+ \item Fedora Silverblue
+\end{itemize}
+```
+
+![][4]
+
+#### enumerate(有序列表)
+
+```
+\begin{enumerate}
+ \item Fedora CoreOS
+ \item Fedora Silverblue
+ \item Fedora Spin
+\end{enumerate}
+```
+
+![][5]
+
+#### description(描述列表)
+
+```
+\begin{description}
+ \item[Fedora 6] Code name Zod
+ \item[Fedora 8] Code name Werewolf
+\end{description}
+```
+
+![][6]
+
+### 列表项目间距
+
+可以通过在导言区加入 `\usepackage{enumitem}` 来自定义默认的间距,宏包 `enumitem` 启用了选项 `noitemsep` 和控制序列 `\itemsep`,可以在列表中使用它们,如下例所示:
+
+#### 使用选项 noitemsep
+
+将选项 `noitemsep` 封闭在方括号内,并同下文所示放在控制序列 `\begin` 之后,该选项将移除默认的间距。
+
+```
+\begin{itemize}[noitemsep]
+ \item Fedora
+ \item Fedora Spin
+ \item Fedora Silverblue
+\end{itemize}
+```
+
+![][7]
+
+#### 使用控制序列 \itemsep
+
+控制序列 `\itemsep` 必须以一个数字作为后缀,用以表示列表项目之间应该有多少空间。
+
+```
+\begin{itemize} \itemsep0.75pt
+ \item Fedora Silverblue
+ \item Fedora CoreOS
+\end{itemize}
+```
+
+![][8]
+
+### 嵌套列表
+
+LaTeX 最多最多支持四层嵌套列表,如下例:
+
+#### 嵌套无序列表
+
+```
+\begin{itemize}[noitemsep]
+ \item Fedora Versions
+ \begin{itemize}
+ \item Fedora 8
+ \item Fedora 9
+ \begin{itemize}
+ \item Werewolf
+ \item Sulphur
+ \begin{itemize}
+ \item 2007-05-31
+ \item 2008-05-13
+ \end{itemize}
+ \end{itemize}
+ \end{itemize}
+ \item Fedora Spin
+ \item Fedora Silverblue
+\end{itemize}
+```
+
+![][9]
+
+#### 嵌套有序列表
+
+```
+\begin{enumerate}[noitemsep]
+ \item Fedora Versions
+ \begin{enumerate}
+ \item Fedora 8
+ \item Fedora 9
+ \begin{enumerate}
+ \item Werewolf
+ \item Sulphur
+ \begin{enumerate}
+ \item 2007-05-31
+ \item 2008-05-13
+ \end{enumerate}
+ \end{enumerate}
+ \end{enumerate}
+ \item Fedora Spin
+ \item Fedora Silverblue
+\end{enumerate}
+```
+
+![][10]
+
+### 每种列表类型的列表样式名称
+
+**enumerate(有序列表)** | **itemize(无序列表)**
+---|---
+`\alph*` (小写字母) | `$\bullet$` (●)
+`\Alph*` (大写字母) | `$\cdot$` (•)
+`\arabic*` (阿拉伯数字) | `$\diamond$` (◇)
+`\roman*` (小写罗马数字) | `$\ast$` (✲)
+`\Roman*` (大写罗马数字) | `$\circ$` (○)
+ | `$-$` (-)
+
+### 按嵌套深度划分的默认样式
+
+**嵌套深度** | **enumerate(有序列表)** | **itemize(无序列表)**
+---|---|---
+1 | 阿拉伯数字 | (●)
+2 | 小写字母 | (-)
+3 | 小写罗马数字 | (✲)
+4 | 大写字母 | (•)
+
+### 设置列表样式
+
+下面的例子列举了无序列表的不同样式。
+
+```
+% 无序列表样式
+\begin{itemize}
+ \item[$\ast$] Asterisk
+ \item[$\diamond$] Diamond
+ \item[$\circ$] Circle
+ \item[$\cdot$] Period
+ \item[$\bullet$] Bullet (default)
+ \item[--] Dash
+ \item[$-$] Another dash
+\end{itemize}
+```
+
+![][11]
+
+有三种设置列表样式的方式,下面将按照优先级从高到低的顺序分别举例。
+
+#### 方式一:为各项目单独设置
+
+将需要的样式名称封闭在方括号内,并放在控制序列 `\item` 之后,如下例:
+
+```
+% 方式一
+\begin{itemize}
+ \item[$\ast$] Asterisk
+ \item[$\diamond$] Diamond
+ \item[$\circ$] Circle
+ \item[$\cdot$] period
+ \item[$\bullet$] Bullet (default)
+ \item[--] Dash
+ \item[$-$] Another dash
+\end{itemize}
+```
+
+#### 方式二:为整个列表设置
+
+将需要的样式名称以 `label=` 前缀并封闭在方括号内,放在控制序列 `\begin` 之后,如下例:
+
+```
+% 方式二
+\begin{enumerate}[label=\Alph*.]
+ \item Fedora 32
+ \item Fedora 31
+ \item Fedora 30
+\end{enumerate}
+```
+
+#### 方式三:为整个文档设置
+
+该方式将改变整个文档的默认样式。使用 `\renewcommand` 来设置项目标签的值,下例分别为四个嵌套深度的项目标签设置了不同的样式。
+
+```
+% 方式三
+\renewcommand{\labelitemi}{$\ast$}
+\renewcommand{\labelitemii}{$\diamond$}
+\renewcommand{\labelitemiii}{$\bullet$}
+\renewcommand{\labelitemiv}{$-$}
+```
+
+### 总结
+
+LaTeX 支持三种列表,而每种列表的风格和间距都是可以自定义的。在以后的文章中,我们将解释更多的 LaTeX 元素。
+
+关于 LaTeX 列表的延伸阅读可以在这里找到:[LaTeX List Structures][12]
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/latex-typesetting-part-1/
+
+作者:[Earl Ramirez][a]
+选题:[lujun9972][b]
+译者:[rakino](https://github.com/rakino)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/earlramirez/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2020/06/latex-series-816x345.png
+[2]: https://fedoramagazine.org/typeset-latex-texstudio-fedora
+[3]: https://fedoramagazine.org/fedora-classroom-latex-101-beginners
+[4]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-1.png
+[5]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-2.png
+[6]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-3.png
+[7]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-4.png
+[8]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-5.png
+[9]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-7.png
+[10]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-8.png
+[11]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-9.png
+[12]: https://en.wikibooks.org/wiki/LaTeX/List_Structures
diff --git a/published/20200629 LaTeX typesetting part 2 (tables).md b/published/20200629 LaTeX typesetting part 2 (tables).md
new file mode 100644
index 0000000000..6b134a2c06
--- /dev/null
+++ b/published/20200629 LaTeX typesetting part 2 (tables).md
@@ -0,0 +1,342 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13146-1.html)
+[#]: subject: (LaTeX typesetting part 2 \(tables\))
+[#]: via: (https://fedoramagazine.org/latex-typesetting-part-2-tables/)
+[#]: author: (Earl Ramirez https://fedoramagazine.org/author/earlramirez/)
+
+LaTex 排版 (2):表格
+======
+
+![][1]
+
+LaTeX 提供了许多工具来创建和定制表格,在本系列中,我们将使用 `tabular` 和 `tabularx` 环境来创建和定制表。
+
+### 基础表格
+
+要创建表,只需指定环境 `\begin{tabular}{列选项}`:
+
+```
+\begin{tabular}{c|c}
+ Release &Codename \\ \hline
+ Fedora Core 1 &Yarrow \\
+ Fedora Core 2 &Tettnang \\
+ Fedora Core 3 &Heidelberg \\
+ Fedora Core 4 &Stentz \\
+\end{tabular}
+```
+
+![Basic Table][2]
+
+在上面的示例中,花括号中的 ”{c|c}” 表示文本在列中的位置。下表总结了位置参数及其说明。
+
+参数 | 位置
+|:---:|:---
+`c` | 将文本置于中间
+`l` | 将文本左对齐
+`r` | 将文本右对齐
+`p{宽度}` | 文本对齐单元格顶部
+`m{宽度}` | 文本对齐单元格中间
+`b{宽度}` | 文本对齐单元格底部
+
+> `m{宽度}` 和 `b{宽度}` 都要求在最前面指定数组包。
+
+使用上面的例子,让我们来详细讲解使用的要点,并描述你将在本系列中看到的更多选项:
+
+选项 | 意义
+|:-:|:-|
+`&` | 定义每个单元格,这个符号仅用于第二列
+`\\` | 这将终止该行并开始一个新行
+`|` | 指定表格中的垂直线(可选)
+`\hline` | 指定表格中的水平线(可选)
+`*{数量}{格式}` | 当你有许多列时,可以使用这个,并且是限制重复的有效方法
+`||` | 指定表格中垂直双线
+
+### 定制表格
+
+学会了这些选项,让我们使用这些选项创建一个表。
+
+```
+\begin{tabular}{*{3}{|l|}}
+\hline
+ \textbf{Version} &\textbf{Code name} &\textbf{Year released} \\
+\hline
+ Fedora 6 &Zod &2006 \\ \hline
+ Fedora 7 &Moonshine &2007 \\ \hline
+ Fedora 8 &Werewolf &2007 \\
+\hline
+\end{tabular}
+```
+
+![Customise Table][3]
+
+### 管理长文本
+
+如果列中有很多文本,那么它的格式就不好处理,看起来也不好看。
+
+下面的示例显示了文本的格式长度,我们将在导言区中使用 `blindtext`,以便生成示例文本。
+
+```
+\begin{tabular}{|l|l|}\hline
+ Summary &Description \\ \hline
+ Test &\blindtext \\
+\end{tabular}
+```
+
+![Default Formatting][4]
+
+正如你所看到的,文本超出了页面宽度;但是,有几个选项可以克服这个问题。
+
+ * 指定列宽,例如 `m{5cm}`
+ * 利用 `tablarx` 环境,这需要在导言区中引用 `tablarx` 宏包。
+
+#### 使用列宽管理长文本
+
+通过指定列宽,文本将被折行为如下示例所示的宽度。
+
+```
+\begin{tabular}{|l|m{14cm}|} \hline
+ Summary &Description \\ \hline
+ Test &\blindtext \\ \hline
+\end{tabular}\vspace{3mm}
+```
+
+![Column Width][5]
+
+#### 使用 tabularx 管理长文本
+
+在我们利用表格之前,我们需要在导言区中加上它。`tabularx` 方法见以下示例:`\begin{tabularx}{宽度}{列选项}`。
+
+```
+\begin{tabularx}{\textwidth}{|l|X|} \hline
+Summary & Tabularx Description\\ \hline
+Text &\blindtext \\ \hline
+\end{tabularx}
+```
+
+![Tabularx][6]
+
+请注意,我们需要处理长文本的列在花括号中指定了大写 `X`。
+
+### 合并行合并列
+
+有时需要合并行或列。本节描述了如何完成。要使用 `multirow` 和 `multicolumn`,请将 `multirow` 添加到导言区。
+
+#### 合并行
+
+`multirow` 采用以下参数 `\multirow{行的数量}{宽度}{文本}`,让我们看看下面的示例。
+
+```
+\begin{tabular}{|l|l|}\hline
+ Release &Codename \\ \hline
+ Fedora Core 4 &Stentz \\ \hline
+ \multirow{2}{*}{MultiRow} &Fedora 8 \\
+ &Werewolf \\ \hline
+\end{tabular}
+```
+
+![MultiRow][7]
+
+在上面的示例中,指定了两行,`*` 告诉 LaTeX 自动管理单元格的大小。
+
+#### 合并列
+
+`multicolumn` 参数是 `{multicolumn{列的数量}{单元格选项}{位置}{文本}`,下面的示例演示合并列。
+
+```
+\begin{tabular}{|l|l|l|}\hline
+ Release &Codename &Date \\ \hline
+ Fedora Core 4 &Stentz &2005 \\ \hline
+ \multicolumn{3}{|c|}{Mulit-Column} \\ \hline
+\end{tabular}
+```
+
+![Multi-Column][8]
+
+### 使用颜色
+
+可以为文本、单个单元格或整行指定颜色。此外,我们可以为每一行配置交替的颜色。
+
+在给表添加颜色之前,我们需要在导言区引用 `\usepackage[table]{xcolor}`。我们还可以使用以下颜色参考 [LaTeX Color][9] 或在颜色前缀后面添加感叹号(从 0 到 100 的阴影)来定义颜色。例如,`gray!30`。
+
+```
+\definecolor{darkblue}{rgb}{0.0, 0.0, 0.55}
+\definecolor{darkgray}{rgb}{0.66, 0.66, 0.66}
+```
+
+下面的示例演示了一个具有各种颜色的表,`\rowcolors` 采用以下选项 `\rowcolors{起始行颜色}{偶数行颜色}{奇数行颜色}`。
+
+```
+\rowcolors{2}{darkgray}{gray!20}
+\begin{tabular}{c|c}
+ Release &Codename \\ \hline
+ Fedora Core 1 &Yarrow \\
+ Fedora Core 2 &Tettnang \\
+ Fedora Core 3 &Heidelberg \\
+ Fedora Core 4 &Stentz \\
+\end{tabular}
+```
+
+![Alt colour table][10]
+
+除了上面的例子,`\rowcolor` 可以用来指定每一行的颜色,这个方法在有合并行时效果最好。以下示例显示将 `\rowColors` 与合并行一起使用的影响以及如何解决此问题。
+
+![Impact on multi-row][11]
+
+你可以看到,在合并行中,只有第一行能显示颜色。想要解决这个问题,需要这样做:
+
+```
+\begin{tabular}{|l|l|}\hline
+ \rowcolor{darkblue}\textsc{\color{white}Release} &\textsc{\color{white}Codename} \\ \hline
+ \rowcolor{gray!10}Fedora Core 4 &Stentz \\ \hline
+ \rowcolor{gray!40}&Fedora 8 \\
+ \rowcolor{gray!40}\multirow{-2}{*}{Multi-Row} &Werewolf \\ \hline
+\end{tabular}
+```
+
+![Multi-row][12]
+
+让我们讲解一下为解决合并行替换颜色问题而实施的更改。
+
+ * 第一行从合并行上方开始
+ * 行数从 `2` 更改为 `-2`,这意味着从上面的行开始读取
+ * `\rowcolor` 是为每一行指定的,更重要的是,多行必须具有相同的颜色,这样才能获得所需的结果。
+
+关于颜色的最后一个注意事项是,要更改列的颜色,需要创建新的列类型并定义颜色。下面的示例说明了如何定义新的列颜色。
+
+```
+\newcolumntype{g}{>{\columncolor{darkblue}}l}
+```
+
+我们把它分解一下:
+
+ * `\newcolumntype{g}`:将字母 `g` 定义为新列
+ * `{>{\columncolor{darkblue}}l}`:在这里我们选择我们想要的颜色,并且 `l` 告诉列左对齐,这可以用 `c` 或 `r` 代替。
+
+```
+\begin{tabular}{g|l}
+ \textsc{Release} &\textsc{Codename} \\ \hline
+ Fedora Core 4 &Stentz \\
+ &Fedora 8 \\
+ \multirow{-2}{*}{Multi-Row} &Werewolf \\
+\end{tabular}\
+```
+
+![Column Colour][13]
+
+### 横向表
+
+有时,你的表可能有许多列,纵向排列会很不好看。在导言区加入 `rotating` 包,你将能够创建一个横向表。下面的例子说明了这一点。
+
+对于横向表,我们将使用 `sidewaystable` 环境并在其中添加表格环境,我们还指定了其他选项。
+
+ * `\centering` 可以将表格放置在页面中心
+ * `\caption{}` 为表命名
+ * `\label{}` 这使我们能够引用文档中的表
+
+```
+\begin{sidewaystable}
+\centering
+\caption{Sideways Table}
+\label{sidetable}
+\begin{tabular}{ll}
+ \rowcolor{darkblue}\textsc{\color{white}Release} &\textsc{\color{white}Codename} \\
+ \rowcolor{gray!10}Fedora Core 4 &Stentz \\
+ \rowcolor{gray!40} &Fedora 8 \\
+ \rowcolor{gray!40}\multirow{-2}{*}{Multi-Row} &Werewolf \\
+\end{tabular}\vspace{3mm}
+\end{sidewaystable}
+```
+
+![Sideways Table][14]
+
+### 列表和表格
+
+要将列表包含到表中,可以使用 `tabularx`,并将列表包含在指定的列中。另一个办法是使用表格格式,但必须指定列宽。
+
+#### 用 tabularx 处理列表
+
+```
+\begin{tabularx}{\textwidth}{|l|X|} \hline
+ Fedora Version &Editions \\ \hline
+ Fedora 32 &\begin{itemize}[noitemsep]
+ \item CoreOS
+ \item Silverblue
+ \item IoT
+ \end{itemize} \\ \hline
+\end{tabularx}\vspace{3mm}
+```
+
+![List in tabularx][15]
+
+#### 用 tabular 处理列表
+
+```
+\begin{tabular}{|l|m{6cm}|}\hline
+ Fedora Version &amp;Editions \\\ \hline
+ Fedora 32 &amp;\begin{itemize}[noitemsep]
+ \item CoreOS
+ \item Silverblue
+ \item IoT
+ \end{itemize} \\\ \hline
+\end{tabular}
+```
+
+![List in tabular][16]
+
+### 总结
+
+LaTeX 提供了许多使用 `tablar` 和 `tablarx` 自定义表的方法,你还可以在表环境 (`\begin\table`) 中添加 `tablar` 和 `tablarx` 来添加表的名称和定位表。
+
+### LaTeX 宏包
+
+所需的宏包有如下这些:
+
+```
+\usepackage{fullpage}
+\usepackage{blindtext} % add demo text
+\usepackage{array} % used for column positions
+\usepackage{tabularx} % adds tabularx which is used for text wrapping
+\usepackage{multirow} % multi-row and multi-colour support
+\usepackage[table]{xcolor} % add colour to the columns
+\usepackage{rotating} % for landscape/sideways tables
+```
+
+### 额外的知识
+
+这是一堂关于表的小课,有关表和 LaTex 的更多高级信息,请访问 [LaTex Wiki][17]
+
+![][13]
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/latex-typesetting-part-2-tables/
+
+作者:[Earl Ramirez][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/earlramirez/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2020/06/latex-series-816x345.png
+[2]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-13.png
+[3]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-23.png
+[4]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-10.png
+[5]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-11.png
+[6]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-12.png
+[7]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-15.png
+[8]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-16.png
+[9]: https://latexcolor.com
+[10]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-17.png
+[11]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-18.png
+[12]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-19.png
+[13]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-24.png
+[14]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-20.png
+[15]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-21.png
+[16]: https://fedoramagazine.org/wp-content/uploads/2020/06/image-22.png
+[17]: https://en.wikibooks.org/wiki/LaTeX/Tables
diff --git a/published/20200922 Give Your GNOME Desktop a Tiling Makeover With Material Shell GNOME Extension.md b/published/20200922 Give Your GNOME Desktop a Tiling Makeover With Material Shell GNOME Extension.md
new file mode 100644
index 0000000000..a645f460fb
--- /dev/null
+++ b/published/20200922 Give Your GNOME Desktop a Tiling Makeover With Material Shell GNOME Extension.md
@@ -0,0 +1,126 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13110-1.html)
+[#]: subject: (Give Your GNOME Desktop a Tiling Makeover With Material Shell GNOME Extension)
+[#]: via: (https://itsfoss.com/material-shell/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+使用 Material Shell 扩展将你的 GNOME 桌面打造成平铺式风格
+======
+
+平铺式窗口的特性吸引了很多人的追捧。也许是因为它很好看,也许是因为它能提高 [Linux 快捷键][1] 玩家的效率。又或者是因为使用不同寻常的平铺式窗口是一种新奇的挑战。
+
+![Tiling Windows in Linux | Image Source][2]
+
+从 i3 到 [Sway][3],Linux 桌面拥有各种各样的平铺式窗口管理器。配置一个平铺式窗口管理器需要一个陡峭的学习曲线。
+
+这就是为什么像 [Regolith 桌面][4] 这样的项目会存在,给你预先配置好的平铺桌面,让你可以更轻松地开始使用平铺窗口。
+
+让我给你介绍一个类似的项目 —— Material Shell。它可以让你用上平铺式桌面,甚至比 [Regolith][5] 还简单。
+
+### Material Shell 扩展:将 GNOME 桌面转变成平铺式窗口管理器
+
+[Material Shell][6] 是一个 GNOME 扩展,这就是它最好的地方。这意味着你不需要注销并登录其他桌面环境。你只需要启用或关闭这个扩展就可以自如的切换你的工作环境。
+
+我会列出 Material Shell 的各种特性,但是也许视频更容易让你理解:
+
+- [video](https://youtu.be/Wc5mbuKrGDE)
+
+这个项目叫做 Material Shell 是因为它遵循 [Material Design][8] 原则。因此这个应用拥有一个美观的界面。这就是它最重要的一个特性。
+
+#### 直观的界面
+
+Material Shell 添加了一个左侧面板,以便快速访问。在此面板上,你可以在底部找到系统托盘,在顶部找到搜索和工作区。
+
+所有新打开的应用都会添加到当前工作区中。你也可以创建新的工作区并切换到该工作区,以将正在运行的应用分类。其实这就是工作区最初的意义。
+
+在 Material Shell 中,每个工作区都可以显示为具有多个应用程序的行列,而不是包含多个应用程序的程序框。
+
+#### 平铺式窗口
+
+在工作区中,你可以一直在顶部看到所有打开的应用程序。默认情况下,应用程序会像在 GNOME 桌面中那样铺满整个屏幕。你可以使用右上角的布局改变器来改变布局,将其分成两半、多列或多个应用网格。
+
+这段视频一目了然的显示了以上所有功能:
+
+- [video](https://player.vimeo.com/video/460050750?dnt=1&app_id=122963)
+
+#### 固定布局和工作区
+
+Material Shell 会记住你打开的工作区和窗口,这样你就不必重新组织你的布局。这是一个很好的特性,因为如果你对应用程序的位置有要求的话,它可以节省时间。
+
+#### 热建/快捷键
+
+像任何平铺窗口管理器一样,你可以使用键盘快捷键在应用程序和工作区之间切换。
+
+ * `Super+W` 切换到上个工作区;
+ * `Super+S` 切换到下个工作区;
+ * `Super+A` 切换到左边的窗口;
+ * `Super+D` 切换到右边的窗口;
+ * `Super+1`、`Super+2` … `Super+0` 切换到某个指定的工作区;
+ * `Super+Q` 关闭当前窗口;
+ * `Super+[鼠标拖动]` 移动窗口;
+ * `Super+Shift+A` 将当前窗口左移;
+ * `Super+Shift+D` 将当前窗口右移;
+ * `Super+Shift+W` 将当前窗口移到上个工作区;
+ * `Super+Shift+S` 将当前窗口移到下个工作区。
+
+### 安装 Material Shell
+
+> 警告!
+>
+> 对于大多数用户来说,平铺式窗口可能会导致混乱。你最好先熟悉如何使用 GNOME 扩展。如果你是 Linux 新手或者你害怕你的系统发生翻天覆地的变化,你应当避免使用这个扩展。
+
+Material Shell 是一个 GNOME 扩展。所以,请 [检查你的桌面环境][9],确保你运行的是 GNOME 3.34 或者更高的版本。
+
+除此之外,我注意到在禁用 Material Shell 之后,它会导致 Firefox 的顶栏和 Ubuntu 的坞站消失。你可以在 GNOME 的“扩展”应用程序中禁用/启用 Ubuntu 的坞站扩展来使其变回原来的样子。我想这些问题也应该在系统重启后消失,虽然我没试过。
+
+我希望你知道 [如何使用 GNOME 扩展][10]。最简单的办法就是 [在浏览器中打开这个链接][11],安装 GNOME 扩展浏览器插件,然后启用 Material Shell 扩展即可。
+
+![][12]
+
+如果你不喜欢这个扩展,你也可以在同样的链接中禁用它。或者在 GNOME 的“扩展”应用程序中禁用它。
+
+![][13]
+
+### 用不用平铺式?
+
+我使用多个电脑屏幕,我发现 Material Shell 不适用于多个屏幕的情况。这是开发者将来可以改进的地方。
+
+除了这个毛病以外,Material Shell 是个让你开始使用平铺式窗口的好东西。如果你尝试了 Material Shell 并且喜欢它,请 [在 GitHub 上给它一个星标或赞助它][14] 来鼓励这个项目。
+
+由于某些原因,平铺窗户越来越受欢迎。最近发布的 [Pop OS 20.04][15] 也增加了平铺窗口的功能。有一个类似的项目叫 PaperWM,也是这样做的。
+
+但正如我前面提到的,平铺布局并不适合所有人,它可能会让很多人感到困惑。
+
+你呢?你是喜欢平铺窗口还是喜欢经典的桌面布局?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/material-shell/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/ubuntu-shortcuts/
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/linux-ricing-example-800x450.jpg?resize=800%2C450&ssl=1
+[3]: https://itsfoss.com/sway-window-manager/
+[4]: https://itsfoss.com/regolith-linux-desktop/
+[5]: https://regolith-linux.org/
+[6]: https://material-shell.com
+[7]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
+[8]: https://material.io/
+[9]: https://itsfoss.com/find-desktop-environment/
+[10]: https://itsfoss.com/gnome-shell-extensions/
+[11]: https://extensions.gnome.org/extension/3357/material-shell/
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/install-material-shell.png?resize=800%2C307&ssl=1
+[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/material-shell-gnome-extension.png?resize=799%2C497&ssl=1
+[14]: https://github.com/material-shell/material-shell
+[15]: https://itsfoss.com/pop-os-20-04-review/
diff --git a/published/20201001 Navigating your Linux files with ranger.md b/published/20201001 Navigating your Linux files with ranger.md
new file mode 100644
index 0000000000..4c2387fde9
--- /dev/null
+++ b/published/20201001 Navigating your Linux files with ranger.md
@@ -0,0 +1,124 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13137-1.html)
+[#]: subject: (Navigating your Linux files with ranger)
+[#]: via: (https://www.networkworld.com/article/3583890/navigating-your-linux-files-with-ranger.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+用 ranger 在 Linux 文件的海洋中导航
+=====
+
+> ranger 是一个很好的工具,它为你的 Linux 文件提供了一个多级视图,并允许你使用方向键和一些方便的命令进行浏览和更改。
+
+
+
+`ranger` 是一款独特且非常方便的文件系统导航器,它允许你在 Linux 文件系统中移动,进出子目录,查看文本文件内容,甚至可以在不离开该工具的情况下对文件进行修改。
+
+它运行在终端窗口中,并允许你按下方向键进行导航。它提供了一个多级的文件显示,让你很容易看到你在哪里、在文件系统中移动、并选择特定的文件。
+
+要安装 `ranger`,请使用标准的安装命令(例如,`sudo apt install ranger`)。要启动它,只需键入 `ranger`。它有一个很长的、非常详细的手册页面,但开始使用 `ranger` 非常简单。
+
+### ranger 的显示方式
+
+你需要马上习惯的最重要的一件事就是 `ranger` 的文件显示方式。一旦你启动了 `ranger`,你会看到四列数据。第一列是你启动 `ranger` 的位置的上一级。例如,如果你从主目录开始,`ranger` 将在第一列中列出所有的主目录。第二列将显示你的主目录(或者你开始的目录)中的目录和文件的第一屏内容。
+
+这里的关键是超越你可能有的任何习惯,将每一行显示的细节看作是相关的。第二列中的所有条目与第一列中的单个条目相关,第四列中的内容与第二列中选定的文件或目录相关。
+
+与一般的命令行视图不同的是,目录将被列在第一位(按字母数字顺序),文件将被列在第二位(也是按字母数字顺序)。从你的主目录开始,显示的内容可能是这样的:
+
+```
+shs@dragonfly /home/shs/backups <== current selection
+ bugfarm backups 0 empty
+ dory bin 59
+ eel Buttons 15
+ nemo Desktop 0
+ shark Documents 0
+ shs Downloads 1
+ ^ ^ ^ ^
+ | | | |
+ homes directories # files listing
+ in selected in each of files in
+ home directory selected directory
+```
+
+`ranger` 显示的最上面一行告诉你在哪里。在这个例子中,当前目录是 `/home/shs/backups`。我们看到高亮显示的是 `empty`,因为这个目录中没有文件。如果我们按下方向键选择 `bin`,我们会看到一个文件列表:
+
+```
+shs@dragonfly /home/shs/bin <== current selection
+ bugfarm backups 0 append
+ dory bin 59 calcPower
+ eel Buttons 15 cap
+ nemo Desktop 0 extract
+ shark Documents 0 finddups
+ shs Downloads 1 fix
+ ^ ^ ^ ^
+ | | | |
+ homes directories # files listing
+ in selected in each of files in
+ home directory selected directory
+```
+
+每一列中高亮显示的条目显示了当前的选择。使用右方向键可移动到更深的目录或查看文件内容。
+
+如果你继续按下方向键移动到列表的文件部分,你会注意到第三列将显示文件大小(而不是文件的数量)。“当前选择”行也会显示当前选择的文件名,而最右边的一列则会尽可能地显示文件内容。
+
+```
+shs@dragonfly /home/shs/busy_wait.c <== current selection
+ bugfarm BushyRidge.zip 170 K /*
+ dory busy_wait.c 338 B * program that does a busy wait
+ eel camper.jpg 5.55 M * it's used to show ASLR, and that's it
+ nemo check_lockscreen 80 B */
+ shark chkrootkit-output 438 B #include
+ ^ ^ ^ ^
+ | | | |
+ homes files sizes file content
+```
+
+在该显示的底行会显示一些文件和目录的详细信息:
+
+```
+-rw-rw-r—- shs shs 338B 2019-01-05 14:44 1.52G, 365G free 67/488 11%
+```
+
+如果你选择了一个目录并按下回车键,你将进入该目录。然后,在你的显示屏中最左边的一列将是你的主目录的内容列表,第二列将是该目录内容的文件列表。然后你可以检查子目录的内容和文件的内容。
+
+按左方向键可以向上移动一级。
+
+按 `q` 键退出 `ranger`。
+
+### 做出改变
+
+你可以按 `?` 键,在屏幕底部弹出一条帮助行。它看起来应该是这样的:
+
+```
+View [m]an page, [k]ey bindings, [c]commands or [s]ettings? (press q to abort)
+```
+
+按 `c` 键,`ranger` 将提供你可以在该工具内使用的命令信息。例如,你可以通过输入 `:chmod` 来改变当前文件的权限,后面跟着预期的权限。例如,一旦选择了一个文件,你可以输入 `:chmod 700` 将权限设置为 `rwx------`。
+
+输入 `:edit` 可以在 `nano` 中打开该文件,允许你进行修改,然后使用 `nano` 的命令保存文件。
+
+### 总结
+
+使用 `ranger` 的方法比本篇文章所描述的更多。该工具提供了一种非常不同的方式来列出 Linux 系统上的文件并与之交互,一旦你习惯了它的多级的目录和文件列表方式,并使用方向键代替 `cd` 命令来移动,就可以很轻松地在 Linux 的文件中导航。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3583890/navigating-your-linux-files-with-ranger.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://unsplash.com/photos/mHC0qJ7l-ls
+[2]: https://creativecommons.org/publicdomain/zero/1.0/
+[3]: https://www.networkworld.com/newsletters/signup.html
+[4]: https://www.facebook.com/NetworkWorld/
+[5]: https://www.linkedin.com/company/network-world
diff --git a/published/20201013 My first day using Ansible.md b/published/20201013 My first day using Ansible.md
new file mode 100644
index 0000000000..990ddc1f24
--- /dev/null
+++ b/published/20201013 My first day using Ansible.md
@@ -0,0 +1,297 @@
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13079-1.html"
+[#]: subject: "My first day using Ansible"
+[#]: via: "https://opensource.com/article/20/10/first-day-ansible"
+[#]: author: "David Both https://opensource.com/users/dboth"
+
+使用 Ansible 的第一天
+======
+
+> 一名系统管理员分享了如何使用 Ansible 在网络中配置计算机并把其带入实际工作的信息和建议。
+
+
+
+无论是第一次还是第五十次,启动并运行一台新的物理或虚拟计算机都非常耗时,而且需要大量的工作。多年来,我一直使用我创建的一系列脚本和 RPM 来安装所需的软件包,并为我喜欢的工具配置各种选项。这种方法效果很好,简化了我的工作,而且还减少了在键盘上输入命令的时间。
+
+我一直在寻找更好的工作方式。近几年来,我一直在听到并且读到有关 [Ansible][2] 的信息,它是一个自动配置和管理系统的强大工具。Ansible 允许系统管理员在一个或多个剧本中为每个主机指定一个特定状态,然后执行各种必要的任务,使主机进入该状态。这包括安装或删除各种资源,例如 RPM 或 Apt 软件包、配置文件和其它文件、用户、组等等。
+
+因为一些琐事,我推迟了很长一段时间学习如何使用它。直到最近,我遇到了一个我认为 Ansible 可以轻松解决的问题。
+
+这篇文章并不会完整地告诉你如何入门 Ansible,相反,它只是对我遇到的问题和我在一些隐秘的地方发现的信息的做了一些记录。我在各种在线讨论和问答小组中找到的有关 Ansible 的许多信息都是错误的。错误范围包括明显的老旧信息(没有任何日期或来源的迹象),还有一些是完全错误的信息。
+
+本文所介绍的内容是有用的,尽管可能还有其它方法可以完成相同的事情,但我使用的是 Ansible 2.9.13 和 [Python][3] 3.8.5。
+
+### 我的问题
+
+我所有的最佳学习经历都始于我需要解决的问题,这次也不例外。
+
+我一直在做一个小项目,修改 [Midnight Commander][4] 文件管理器的配置文件,并将它们推送到我网络上的各种系统中进行测试。尽管我有一个脚本可以自动执行这个操作,但它仍然需要使用命令行循环来提供我想要推送新代码的系统名称。我对配置文件进行了大量的更改,这使我必须频繁推送新的配置文件。但是,就在我以为我的新配置刚刚好时,我发现了一个问题,所以我需要在修复后再进行一次推送。
+
+这种环境使得很难跟踪哪些系统有新文件,哪些没有。我还有几个主机需要区别对待。我对 Ansible 的一点了解表明,它可能能够满足我的全部或大部分工作。
+
+### 开始
+
+我读过许多有关 Ansible 的好文章和书籍,但从来没有在“我必须现在就把这个做好!”的情况下读过。而现在 —— 好吧,就是现在!
+
+在重读这些文档时,我发现它们主要是在讨论如何从 GitHub 开始安装并使用 Ansible,这很酷。但是我真的只是想尽快开始,所以我使用 DNF 和 Fedora 仓库中的版本在我的 Fedora 工作站上安装了它,非常简单。
+
+但是后来我开始寻找文件位置,并尝试确定需要修改哪些配置文件、将我的剧本保存在什么位置,甚至一个剧本怎么写以及它的作用,我脑海中有一大堆(到目前为止)悬而未决的问题。
+
+因此,不不需要进一步描述我的困难的情况下,以下是我发现的东西以及促使我继续前进的东西。
+
+### 配置
+
+Ansible 的配置文件保存在 `/etc/ansible` 中,这很有道理,因为 `/etc/` 是系统程序应该保存配置文件的地方。我需要使用的两个文件是 `ansible.cfg` 和 `hosts`。
+
+#### ansible.cfg
+
+在进行了从文档和线上找到的一些实践练习之后,我遇到了一些有关弃用某些较旧的 Python 文件的警告信息。因此,我在 `ansible.cfg` 中将 `deprecation_warnings` 设置为 `false`,这样那些愤怒的红色警告消息就不会出现了:
+
+```
+deprecation_warnings = False
+```
+
+这些警告很重要,所以我稍后将重新回顾它们,并弄清楚我需要做什么。但是现在,它们不会再扰乱屏幕,也不会让我混淆实际上需要关注的错误。
+
+#### hosts 文件
+
+与 `/etc/hosts` 文件不同,`hosts` 文件也被称为清单文件,它列出了网络上的主机。此文件允许将主机分组到相关集合中,例如“servers”、“workstations”和任何你所需的名称。这个文件包含帮助和大量示例,所以我在这里就不详细介绍了。但是,有些事情你必须知道。
+
+主机也可以列在组之外,但是组对于识别具有一个或多个共同特征的主机很有帮助。组使用 INI 格式,所以服务器组看起来像这样:
+
+```
+[servers]
+server1
+server2
+......
+```
+
+这个文件中必须有一个主机名,这样 Ansible 才能对它进行操作。即使有些子命令允许指定主机名,但除非主机名在 `hosts` 文件中,否则命令会失败。一个主机也可以放在多个组中。因此,除了 `[servers]` 组之外,`server1` 也可能是 `[webservers]` 组的成员,还可以是 `[ubuntu]` 组的成员,这样以区别于 Fedora 服务器。
+
+Ansible 很智能。如果 `all` 参数用作主机名,Ansible 会扫描 `hosts` 文件并在它列出的所有主机上执行定义的任务。Ansible 只会尝试在每个主机上工作一次,不管它出现在多少个组中。这也意味着不需要定义 `all` 组,因为 Ansible 可以确定文件中的所有主机名,并创建自己唯一的主机名列表。
+
+另一件需要注意的事情是单个主机的多个条目。我在 DNS 文件中使用 `CNAME` 记录来创建别名,这些别名指向某些主机的 [A 记录][5],这样,我可以将一个主机称为 `host1` 或 `h1` 或 `myhost`。如果你在 `hosts` 文件中为同一主机指定多个主机名,则 Ansible 将尝试在所有这些主机名上执行其任务,它无法知道它们指向同一主机。好消息是,这并不会影响整体结果;它只是多花了一点时间,因为 Ansible 会在次要主机名上工作,它会确定所有操作均已执行。
+
+### Ansible 实情
+
+我阅读过 Ansible 的大多数材料都谈到了 Ansible [实情][6],它是与远程系统相关的数据,包括操作系统、IP 地址、文件系统等等。这些信息可以通过其它方式获得,如 `lshw`、`dmidecode` 或 `/proc` 文件系统等。但是 Ansible 会生成一个包含此信息的 JSON 文件。每次 Ansible 运行时,它都会生成这些实情数据。在这个数据流中,有大量的信息,都是以键值对形式出现的:`<"variable-name": "value">`。所有这些变量都可以在 Ansible 剧本中使用,理解大量可用信息的最好方法是实际显示一下:
+
+```
+# ansible -m setup | less
+```
+
+明白了吗?你想知道的有关主机硬件和 Linux 发行版的所有内容都在这里,它们都可以在剧本中使用。我还没有达到需要使用这些变量的地步,但是我相信在接下来的几天中会用到。
+
+### 模块
+
+上面的 `ansible` 命令使用 `-m` 选项来指定 `setup` 模块。Ansible 已经内置了许多模块,所以你对这些模块不需要使用 `-m`。也可以安装许多下载的模块,但是内置模块可以完成我目前项目所需的一切。
+
+### 剧本
+
+剧本几乎可以放在任何地方。因为我需要以 root 身份运行,所以我将它放在了 `/root/ansible` 下。当我运行 Ansible 时,只要这个目录是当前的工作目录(PWD),它就可以找到我的剧本。Ansible 还有一个选项,用于在运行时指定不同的剧本和位置。
+
+剧本可以包含注释,但是我看到的文章或书籍很少提及此。但作为一个相信记录一切的系统管理员,我发现使用注释很有帮助。这并不是说在注释中做和任务名称同样的事情,而是要确定任务组的目的,并确保我以某种方式或顺序记录我做这些事情的原因。当我可能忘记最初的想法时,这可以帮助以后解决调试问题。
+
+剧本只是定义主机所需状态的任务集合。在剧本的开头指定主机名或清单组,并定义 Ansible 将在其上运行剧本的主机。
+
+以下是我的一个剧本示例:
+
+```
+################################################################################
+# This Ansible playbook updates Midnight commander configuration files. #
+################################################################################
+- name: Update midnight commander configuration files
+ hosts: all
+
+ tasks:
+ - name: ensure midnight commander is the latest version
+ dnf:
+ name: mc
+ state: present
+
+ - name: create ~/.config/mc directory for root
+ file:
+ path: /root/.config/mc
+ state: directory
+ mode: 0755
+ owner: root
+ group: root
+
+ - name: create ~/.config/mc directory for dboth
+ file:
+ path: /home/dboth/.config/mc
+ state: directory
+ mode: 0755
+ owner: dboth
+ group: dboth
+
+ - name: copy latest personal skin
+ copy:
+ src: /root/ansible/UpdateMC/files/MidnightCommander/DavidsGoTar.ini
+ dest: /usr/share/mc/skins/DavidsGoTar.ini
+ mode: 0644
+ owner: root
+ group: root
+
+ - name: copy latest mc ini file
+ copy:
+ src: /root/ansible/UpdateMC/files/MidnightCommander/ini
+ dest: /root/.config/mc/ini
+ mode: 0644
+ owner: root
+ group: root
+
+ - name: copy latest mc panels.ini file
+ copy:
+ src: /root/ansible/UpdateMC/files/MidnightCommander/panels.ini
+ dest: /root/.config/mc/panels.ini
+ mode: 0644
+ owner: root
+ group: root
+<截断>
+```
+
+剧本从它自己的名字和它将要操作的主机开始,在本文中,所有主机都在我的 `hosts` 文件中。`tasks` 部分列出了使主机达到所需状态的特定任务。这个剧本从使用 DNF 更新 Midnight Commander 开始(如果它不是最新的版本的话)。下一个任务确保创建所需的目录(如果它们不存在),其余任务将文件复制到合适的位置,这些 `file` 和 `copy` 任务还可以为目录和文件设置所有权和文件模式。
+
+剧本细节超出了本文的范围,但是我对这个问题使用了一点蛮力。还有其它方法可以确定哪些用户需要更新文件,而不是对每个用户的每个文件使用一个任务。我的下一个目标是简化这个剧本,使用一些更先进的技术。
+
+运行剧本很容易,只需要使用 `ansible-playbook` 命令。`.yml` 扩展名代表 YAML,我看到过它的几种不同含义,但我认为它是“另一种标记语言”,尽管有些人声称 YAML 不是这种语言。
+
+这个命令将会运行剧本,它会更新 Midnight Commander 文件:
+
+```
+# ansible-playbook -f 10 UpdateMC.yml
+```
+
+`-f` 选项指定 Ansible 使用 10 个线程来执行操作。这可以大大加快整个任务的完成速度,特别是在多台主机上工作时。
+
+### 输出
+
+剧本运行时会列出每个任务和执行结果。`ok` 代表任务管理的机器状态已经完成,因为在任务中定义的状态已经为真,所以 Ansible 不需要执行任何操作。
+
+`changed` 表示 Ansible 已经执行了指定的任务。在这种情况下,任务中定义的机器状态不为真,所以执行指定的操作使其为真。在彩色终端上,`TASK` 行会以彩色显示。我的终端配色为“amber-on-black”,`TASK` 行显示为琥珀色,`changed` 是棕色,`ok` 为绿色,错误是红色。
+
+下面的输出是我最终用于在新主机执行安装后配置的剧本:
+
+```
+PLAY [Post-installation updates, package installation, and configuration]
+
+TASK [Gathering Facts]
+ok: [testvm2]
+
+TASK [Ensure we have connectivity]
+ok: [testvm2]
+
+TASK [Install all current updates]
+changed: [testvm2]
+
+TASK [Install a few command line tools]
+changed: [testvm2]
+
+TASK [copy latest personal Midnight Commander skin to /usr/share]
+changed: [testvm2]
+
+TASK [create ~/.config/mc directory for root]
+changed: [testvm2]
+
+TASK [Copy the most current Midnight Commander configuration files to /root/.config/mc]
+changed: [testvm2] => (item=/root/ansible/PostInstallMain/files/MidnightCommander/DavidsGoTar.ini)
+changed: [testvm2] => (item=/root/ansible/PostInstallMain/files/MidnightCommander/ini)
+changed: [testvm2] => (item=/root/ansible/PostInstallMain/files/MidnightCommander/panels.ini)
+
+TASK [create ~/.config/mc directory in /etc/skel]
+changed: [testvm2]
+
+<截断>
+```
+
+### cowsay
+
+如果你的计算机上安装了 [cowsay][7] 程序,你会发现 `TASK` 的名字出现在奶牛的语音泡泡中:
+
+```
+ ____________________________________
+< TASK [Ensure we have connectivity] >
+ ------------------------------------
+ \ ^__^
+ \ (oo)\\_______
+ (__)\ )\/\
+ ||----w |
+ || ||
+```
+
+如果你没有这个有趣的程序,你可以使用发行版的包管理器安装 Cowsay 程序。如果你有这个程序但不想要它,可以通过在 `/etc/ansible/ansible.cfg` 文件中设置 `nocows=1` 将其禁用。
+
+我喜欢这头奶牛,它很有趣,但是它会占用我的一部分屏幕。因此,在它开始妨碍我使用时,我就把它禁用了。
+
+### 目录
+
+与我的 Midnight Commander 任务一样,经常需要安装和维护各种类型的文件。创建用于存储剧本的目录树的“最佳实践”和系统管理员一样多,至少与编写有关 Ansible 书和文章的作者数量一样多。
+
+我选择了一个对我有意义的简单结构:
+
+```bash
+/root/ansible
+└── UpdateMC
+ ├── files
+ │ └── MidnightCommander
+ │ ├── DavidsGoTar.ini
+ │ ├── ini
+ │ └── panels.ini
+ └── UpdateMC.yml
+```
+
+你可以使用任何结构。但是请注意,其它系统管理员可能需要使用你设置的剧本来工作,所以目录应该具有一定程度的逻辑。当我使用 RPM 和 Bash 脚本执行安装任务后,我的文件仓库有点分散,绝对没有任何逻辑结构。当我为许多管理任务创建剧本时,我将介绍一个更有逻辑的结构来管理我的目录。
+
+### 多次运行剧本
+
+根据需要或期望多次运行剧本是安全的。只有当主机状态与任务中指定的状态不匹配时,才会执行每个任务。这使得很容易从先前的剧本运行中遇到的错误中恢复。因为当剧本遇到错误时,它将停止运行。
+
+在测试我的第一个剧本时,我犯了很多错误并改正了它们。假设我的修正正确,那么剧本每次运行,都会跳过那些状态已与指定状态匹配的任务,执行不匹配状态的任务。当我的修复程序起作用时,之前失败的任务就会成功完成,并且会执行此任务之后的任务 —— 直到遇到另一个错误。
+
+这使得测试变得容易。我可以添加新任务,并且在运行剧本时,只有新任务会被执行,因为它们是唯一与测试主机期望状态不匹配的任务。
+
+### 一些思考
+
+有些任务不适合用 Ansible,因为有更好的方法可以实现特定的计算机状态。我想到的场景是使 VM 返回到初始状态,以便可以多次使用它来执行从已知状态开始的测试。让 VM 进入特定状态,然后对此时的计算机状态进行快照要容易得多。还原到该快照与 Ansible 将主机返回到之前状态相比,通常还原到快照通常会更容易且更快。在研究文章或测试新代码时,我每天都会做几次这样的事情。
+
+在完成用于更新 Midnight Commander 的剧本之后,我创建了一个新的剧本,用于在新安装的 Fedora 主机上执行安装任务。我已经取得了不错的进步,剧本比我第一个的更加复杂,但没有那么粗暴。
+
+在使用 Ansible 的第一天,我创建了一个解决问题的剧本,我还开始编写第二个剧本,它将解决安装后配置的大问题,在这个过程中我学到了很多东西。
+
+尽管我真的很喜欢使用 [Bash][8] 脚本来管理任务,但是我发现 Ansible 可以完成我想要的一切,并且可以使系统保持在我所需的状态。只用了一天,我就成为了 Ansible 的粉丝。
+
+### 资源
+
+我找到的最完整、最有用的参考文档是 Ansible 网站上的[用户指南][9]。本文仅供参考,不作为入门文档。
+
+多年来,我们已经发布了许多[有关 Ansible 的文章][10],我发现其中大多数对我的需求很有帮助。Enable Sysadmin 网站上也有很多对我有帮助 [Ansible 文章][11]。你可以通过查看本周(2020 年 10 月 13 日至 14 日)的 [AnsibleFest][12] 了解更多信息。该活动完全是线上的,可以免费注册。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/10/first-day-ansible
+
+作者:[David Both][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux11x_cc.png?itok=XMDOouJR "People work on a computer server with devices"
+[2]: https://www.ansible.com/
+[3]: https://www.python.org/
+[4]: https://midnight-commander.org/
+[5]: https://en.wikipedia.org/wiki/List_of_DNS_record_types
+[6]: https://docs.ansible.com/ansible/latest/user_guide/playbooks_vars_facts.html#ansible-facts
+[7]: https://en.wikipedia.org/wiki/Cowsay
+[8]: https://opensource.com/downloads/bash-cheat-sheet
+[9]: https://docs.ansible.com/ansible/latest/user_guide/index.html
+[10]: https://opensource.com/tags/ansible
+[11]: https://www.redhat.com/sysadmin/topics/ansible
+[12]: https://www.ansible.com/ansiblefest
diff --git a/published/20160302 Go channels are bad and you should feel bad.md b/published/202101/20160302 Go channels are bad and you should feel bad.md
similarity index 100%
rename from published/20160302 Go channels are bad and you should feel bad.md
rename to published/202101/20160302 Go channels are bad and you should feel bad.md
diff --git a/published/202101/20181009 GCC- Optimizing Linux, the Internet, and Everything.md b/published/202101/20181009 GCC- Optimizing Linux, the Internet, and Everything.md
new file mode 100644
index 0000000000..641a77b740
--- /dev/null
+++ b/published/202101/20181009 GCC- Optimizing Linux, the Internet, and Everything.md
@@ -0,0 +1,93 @@
+GCC:优化 Linux、互联网和一切
+======
+
+
+
+软件如果不能被电脑运行,那么它就是无用的。而在处理运行时性能的问题上,即使是最有才华的开发人员也会受编译器的支配 —— 因为如果没有可靠的编译器工具链,就无法构建任何重要的东西。GNU 编译器集合(GCC)提供了一个健壮、成熟和高性能的工具,以帮助你充分发挥你代码的潜能。经过数十年成千上万人的开发,GCC 成为了世界上最受尊敬的编译器之一。如果你在构建应用程序是没有使用 GCC,那么你可能错过了最佳解决方案。
+
+根据 LLVM.org 的说法,GCC 是“如今事实上的标准开源编译器” [^1],也是用来构建完整系统的基础 —— 从内核开始。GCC 支持超过 60 种硬件平台,包括 ARM、Intel、AMD、IBM POWER、SPARC、HP PA-RISC 和 IBM Z,以及各种操作环境,包括 GNU、Linux、Windows、macOS、FreeBSD、NetBSD、OpenBSD、DragonFly BSD、Solaris、AIX、HP-UX 和 RTEMS。它提供了高度兼容的 C/C++ 编译器,并支持流行的 C 库,如 GNU C Library(glibc)、Newlib、musl 和各种 BSD 操作系统中包含的 C 库,以及 Fortran、Ada 和 GO 语言的前端。GCC 还可以作为一个交叉编译器,可以为运行编译器的平台以外的其他平台创建可执行代码。GCC 是紧密集成的 GNU 工具链的核心组件,由 GNU 项目产生,它包括 glibc、Binutils 和 GNU 调试器(GDB)。
+
+“一直以来我最喜欢的 GNU 工具是 GCC,即GNU 编译器集合。在开发工具非常昂贵的时候,GCC 是第二个 GNU 工具,也是使社区能够编写和构建所有其他工具的工具。这个工具一手改变了这个行业,导致了自由软件运动的诞生,因为一个好的、自由的编译器是一个社区软件的先决条件。”—— Red Hat 开源和标准团队的 Dave Neary。[^2]
+
+### 优化 Linux
+
+作为 Linux 内核源代码的默认编译器,GCC 提供了可靠、稳定的性能以及正确构建内核所需的额外扩展。GCC 是流行的 Linux 发行版的标准组件,如 ArchLinux、CentOS、Debian、Fedora、openSUSE 和 Ubuntu 这些发行版中,GCC 通常用来编译支持系统的组件。这包括 Linux 使用的默认库(如 libc、libm、libintl、libssh、libssl、libcrypto、libexpat、libpthread 和 ncurses),这些库依赖于 GCC 来提供可靠性和高性能,并且使应用程序和系统程序可以访问 Linux 内核功能。发行版中包含的许多应用程序包也是用 GCC 构建的,例如 Python、Perl、Ruby、nginx、Apache HTTP 服务器、OpenStack、Docker 和 OpenShift。各个 Linux 发行版使用 GCC 构建的大量代码组成了内核、库和应用程序软件。对于 openSUSE 发行版,几乎 100% 的原生代码都是由 GCC 构建的,包括 6135 个源程序包、5705 个共享库和 38927 个可执行文件。这相当于每周编译 24540 个源代码包。[^3]
+
+Linux 发行版中包含的 GCC 的基本版本用于创建定义系统应用程序二进制接口(ABI)的内核和库。用户空间开发者可以选择下载 GCC 的最新稳定版本,以获得高级功能、性能优化和可用性改进。Linux 发行版提供安装说明或预构建的工具链,用于部署最新版本的 GCC 以及其他 GNU 工具,这些工具有助于提高开发人员的工作效率和缩短部署时间。
+
+### 优化互联网
+
+GCC 是嵌入式系统中被广泛采用的核心编译器之一,支持为日益增长的物联网设备开发软件。GCC 提供了许多扩展功能,使其非常适合嵌入式系统软件开发,包括使用编译器的内建函数、#语法、内联汇编和以应用程序为中心的命令行选项进行精细控制。GCC 支持广泛的嵌入式体系结构,包括 ARM、AMCC、AVR、Blackfin、MIPS、RISC-V、Renesas Electronics V850、NXP 和 Freescale Power 处理器,可以生成高效、高质量的代码。GCC提供的交叉编译能力对这个社区至关重要,而预制的交叉编译工具链 [^4] 是一个主要需求。例如,GNU ARM 嵌入式工具链是经过集成和验证的软件包,其中包含 ARM 嵌入式 GCC 编译器、库和其它裸机软件开发所需的工具。这些工具链可用于在 Windows、Linux 和 macOS 主机操作系统上对流行的 ARM Cortex-R 和 Cortex-M 处理器进行交叉编译,这些处理器已装载于数百亿台支持互联网的设备中。[^5]
+
+GCC 为云计算赋能,为需要直接管理计算资源的软件提供了可靠的开发平台,如数据库和 Web 服务引擎以及备份和安全软件。GCC 完全兼容 C++ 11 和 C++ 14,为 C++ 17 和 C++ 2a 提供实验支持 [^6](LCTT 译注:本文原文发布于 2018 年),可以创建性能优异的对象代码,并提供可靠的调试信息。使用 GCC 的应用程序的一些例子包括:MySQL 数据库管理系统,它需要 Linux 的 GCC [^7];Apache HTTP 服务器,它建议使用 GCC [^8];Bacula,一个企业级网络备份工具,它需要 GCC。[^9]
+
+### 优化一切
+
+对于高性能计算(HPC)中使用的科学代码的研究和开发,GCC 提供了成熟的 C、C++ 和 Fortran 前端,以及对 OpenMP 和 OpenACC API的支持,用于基于指令的并行编程。因为 GCC 提供了跨计算环境的可移植性,它使得代码能够更容易地在各种新的和传统的客户机和服务器平台上进行测试。GCC 为 C、C++ 和 Fortran 编译器提供了 OpenMP 4.0 的完整支持,为 C 和 C++ 编译器提供了 OpenMP 4.5 完整支持。对于 OpenACC、 GCC 支持大部分 2.5 规范和性能优化,并且是唯一提供 [OpenACC][1] 支持的非商业、非学术编译器。
+
+代码性能是这个社区的一个重要参数,GCC 提供了一个坚实的性能基础。Colfax Research 于 2017 年 11 月发表的一篇论文评估了 C++ 编译器在使用 OpenMP 4.x 指令并行化编译代码的速度和编译后代码的运行速度。图 1 描绘了不同编译器编译并使用单个线程运行时计算内核的相对性能。性能值经过了归一化处理,以 G++ 的性能为 1.0。
+
+![performance][3]
+
+*图 1 为由不同编译器编译的每个内核的相对性能。(单线程,越高越好)。*
+
+他的论文总结道:“GNU 编译器在我们的测试中也做得很好。G++ 在六种情况中的三种情况下生成的代码速度是第二快的,并且在编译时间方面是最快的编译器之一。”[^10]
+
+### 谁在用 GCC?
+
+在 JetBrains 2018 年的开发者生态状况调查中,在接受调查的 6000 名开发者中,66% 的 C++ 程序员和 73% 的 C 程序员经常使用 GCC。[^11] 以下简要介绍 GCC 的优点,正是这些优点使它在开发人员社区中如此受欢迎。
+
+ * 对于需要为各种新的和遗留的计算平台和操作环境编写代码的开发人员,GCC 提供了对最广泛的硬件和操作环境的支持。硬件供应商提供的编译器主要侧重于对其产品的支持,而其他开源编译器在所支持的硬件和操作系统方面则受到很大限制。[^12]
+ * 有各种各样的基于 GCC 的预构建工具链,这对嵌入式系统开发人员特别有吸引力。这包括 GNU ARM 嵌入式工具链和 Bootlin 网站上提供的 138 个预编译交叉编译器工具链。[^13] 虽然其他开源编译器(如 Clang/LLVM)可以取代现有交叉编译工具链中的 GCC,但这些工具集需要开发者完全重新构建。[^14]
+ * GCC 通过成熟的编译器平台向应用程序开发人员提供可靠、稳定的性能。《在 AMD EPYC 平台上用 GCC 8/9 与 LLVM Clang 6/7 编译器基准测试》这篇文章提供了 49 个基准测试的结果,这些测试的编译器在三个优化级别上运行。使用 `-O3 -march=native` 级别的 GCC 8.2 RC1 在 34% 的时间里排在第一位,而在相同的优化级别 LLVM Clang 6.0 在 20% 的时间里赢得了第二位。[^15]
+ * GCC 为编译调试 [^16] 提供了改进的诊断方法,并为运行时调试提供了准确而有用的信息。GCC 与 GDB 紧密集成,GDB 是一个成熟且功能齐全的工具,它提供“不间断”调试,可以在断点处停止单个线程。
+ * GCC 是一个得到良好支持的平台,它有一个活跃的、有责任感的社区,支持当前版本和以前的两个版本。由于每年都有发布计划,这为一个版本提供了两年的支持。
+
+### GCC:仍然在继续优化
+
+GCC 作为一个世界级的编译器继续向前发展。GCC 的最新版本是 8.2,于 2018 年 7 月发布(LCTT 译注:本文原文发表于 2018 年),增加了对即将推出的 Intel CPU、更多 ARM CPU 的硬件支持,并提高了 AMD 的 ZEN CPU 的性能。增加了对 C17 的初步支持,同时也对 C++2A 进行了初步工作。诊断功能继续得到增强,包括更好的发射诊断,改进了定位、定位范围和修复提示,特别是在 C++ 前端。Red Hat 的 David Malcolm 在 2018 年 3 月撰写的博客概述了 GCC 8 中的可用性改进。[^17]
+
+新的硬件平台继续依赖 GCC 工具链进行软件开发,例如 RISC-V,这是一种自由开放的 ISA,机器学习、人工智能(AI)和物联网细分市场都对其感兴趣。GCC 仍然是 Linux 系统持续开发的关键组件。针对 Intel 架构的 Clear Linux 项目是一个为云、客户端和物联网用例构建的新兴发行版,它提供了一个很好的示例,说明如何使用和改进 GCC 编译器技术来提高基于 Linux 的系统的性能和安全性。GCC 还被用于微软 Azure Sphere 的应用程序开发,这是一个基于 Linux 的物联网应用程序操作系统,最初支持基于 ARM 的联发科 MT3620 处理器。在培养下一代程序员方面,GCC 也是树莓派的 Windows 工具链的核心组件,树莓派是一种运行基于 Debian 的 GNU/Linux 的低成本嵌入式板,用于促进学校和发展中国家的基础计算机科学教学。
+
+GCC 由 GNU 项目的创始人理查德•斯托曼首次发布 于 1987 年 3 月 22 日,由于它是第一个作为自由软件发布的可移植的 ANSI C 优化编译器,因此它被认为是一个重大突破。GCC 由来自世界各地的程序员组成的社区在指导委员会的指导下维护,以确保对项目进行广泛的、有代表性的监督。GCC 的社区方法是它的优势之一,它形成了一个由开发人员和用户组成的庞大而多样化的社区,他们为项目做出了贡献并提供支持。根据 Open Hub 的说法,“GCC 是世界上最大的开源团队之一,在 Open Hub 上的所有项目团队中排名前 2%。”[^18]
+
+关于 GCC 的许可问题,人们进行了大量的讨论,其中大多数是混淆而不是启发。GCC 在 GNU 通用公共许可证(GPL)版本 3 或更高版本下发布,但运行时库例外。这是一个左版许可,这意味着衍生作品只能在相同的许可条款下分发。GPLv3 旨在保护 GCC,防止其成为专有软件,并要求对 GCC 代码的更改可以自由公开地进行。对于“最终用户”来说,这个编译器与其他编译器完全相同;使用 GCC 对你为自己的代码所选择的任何许可都没有区别。[^19]
+
+ [^1]: http://clang.llvm.org/features.html#gcccompat
+ [^2]: https://opensource.com/article/18/9/happy-birthday-gnu
+ [^3]: 由 SUSE 基于最近的构建统计提供的信息。在 openSUSE 中还有其他不生成可执行镜像的源码包,这些不包括在统计中。
+ [^4]: https://community.arm.com/tools/b/blog/posts/gnu-toolchain-performance-in-2018
+ [^5]: https://www.arm.com/products/processors/cortex-m
+ [^6]: https://gcc.gnu.org/projects/cxx-status.html#cxx17
+ [^7]: https://mysqlserverteam.com/mysql-8-0-source-code-improvements/
+ [^8]: http://httpd.apache.org/docs/2.4/install.html
+ [^9]: https://blog.bacula.org/what-is-bacula/system-requirements/
+[^10]: https://colfaxresearch.com/compiler-comparison/
+[^11]: https://www.jetbrains.com/research/devecosystem-2018/
+[^12]: http://releases.llvm.org/6.0.0/tools/clang/docs/UsersManual.html
+[^13]: https://bootlin.com/blog/free-and-ready-to-use-cross-compilation-toolchains/
+[^14]: https://clang.llvm.org/docs/Toolchain.html
+[^15]: https://www.phoronix.com/scan.php?page=article&item=gcclang-epyc-summer18&num=1
+[^16]: https://gcc.gnu.org/wiki/ClangDiagnosticsComparison
+[^17]: https://developers.redhat.com/blog/2018/03/15/gcc-8-usability-improvements/
+[^18]: https://www.openhub.net/p/gcc/factoids#FactoidTeamSizeVeryLarge
+[^19]: https://www.gnu.org/licenses/gcc-exception-3.1-faq.en.html
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2018/10/gcc-optimizing-linux-internet-and-everything
+
+作者:[Margaret Lewis][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/margaret-lewis
+[b]: https://github.com/lujun9972
+[1]: https://www.openacc.org/tools
+[2]: /files/images/gccjpg-0
+[3]: https://lcom.static.linuxfound.org/sites/lcom/files/gcc_0.jpg?itok=HbGnRqWX "performance"
+[4]: https://www.linux.com/licenses/category/used-permission
diff --git a/published/20181123 Three SSH GUI Tools for Linux.md b/published/202101/20181123 Three SSH GUI Tools for Linux.md
similarity index 100%
rename from published/20181123 Three SSH GUI Tools for Linux.md
rename to published/202101/20181123 Three SSH GUI Tools for Linux.md
diff --git a/published/20190104 Search, Study And Practice Linux Commands On The Fly.md b/published/202101/20190104 Search, Study And Practice Linux Commands On The Fly.md
similarity index 100%
rename from published/20190104 Search, Study And Practice Linux Commands On The Fly.md
rename to published/202101/20190104 Search, Study And Practice Linux Commands On The Fly.md
diff --git a/published/20190204 Getting started with Git- Terminology 101.md b/published/202101/20190204 Getting started with Git- Terminology 101.md
similarity index 100%
rename from published/20190204 Getting started with Git- Terminology 101.md
rename to published/202101/20190204 Getting started with Git- Terminology 101.md
diff --git a/published/202101/20190205 5 Streaming Audio Players for Linux.md b/published/202101/20190205 5 Streaming Audio Players for Linux.md
new file mode 100644
index 0000000000..82babefc3c
--- /dev/null
+++ b/published/202101/20190205 5 Streaming Audio Players for Linux.md
@@ -0,0 +1,134 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13029-1.html)
+[#]: subject: (5 Streaming Audio Players for Linux)
+[#]: via: (https://www.linux.com/blog/2019/2/5-streaming-audio-players-linux)
+[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
+
+5 个适用于 Linux 的流式音频播放器
+======
+
+
+
+当我工作的时候,我会一直在后台播放音乐。大多数情况下,这些音乐是以黑胶唱片的形式在转盘上旋转。但有时我不想用这种单纯的方法听音乐时,我会选择听流媒体音频应用程序的方式。然而,由于我工作在 Linux 平台上,所以我只可以使用在我的操作系统上运行良好的软件。幸运的是,对于想在 Linux 桌面听流式音频的人来说,有很多工具可以选择。
+
+事实上,Linux 为音乐流媒体提供了许多可靠的产品,我将重点介绍我最喜欢的五种用于此任务的工具。警告一句,并不是所有的玩意都是开源的。但是如果你不介意在你的开源桌面上运行一个专有的应用程序,你有一些非常棒的选择。让我们来看看有什么可用的。
+
+### Spotify
+
+Linux 版的 Spotify 不是那种在你启动就闪退的愚蠢的、半生不熟的应用程序,也没有阉割什么功能。事实上,Spotify 的 Linux 版本与其他平台上的版本完全相同。使用 Spotify 流媒体客户端,你可以收听音乐和播客、创建播放列表、发现新的艺术家等等。Spotify 界面(图 1)非常易于导航和使用。
+
+![Spotify][2]
+
+*图 1:Spotify 界面可以很容易地找到新的音乐和旧的收藏。*
+
+你可以使用 snap(使用 `sudo snap install Spotify` 命令)安装 Spotify,也可以使用以下命令从官方存储库安装 Spotify:
+
+```
+sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 931FF8E79F0876134EDDBDCCA87FF9DF48BF1C90
+sudo echo deb http://repository.spotify.com stable non-free | sudo tee /etc/apt/sources.list.d/spotify.list
+sudo apt-get update
+sudo apt-get install spotify-client
+```
+
+一旦安装,你就可以登录你的 Spotify 帐户,这样你就可以开始听好听的音乐,以帮助激励你完成你的工作。如果你已在其他设备上安装了 Spotify(并登录到同一帐户),则可以指定音乐应该流式传输到哪个设备(通过单击 Spotify 窗口右下角附近的“可用设备”图标)。
+
+### Clementine
+
+Clementine 是 Linux 平台上最好的音乐播放器之一。Clementine 不仅允许用户播放本地存储的音乐,还可以连接到许多流媒体音频服务,例如:
+
+ * Amazon Cloud Drive
+ * Box
+ * Dropbox
+ * Icecast
+ * Jamendo
+ * Magnatune
+ * RockRadio.com
+ * Radiotunes.com
+ * SomaFM
+ * SoundCloud
+ * Spotify
+ * Subsonic
+ * Vk.com
+ * 或其他有趣的电台
+
+使用 Clementine 有两个注意事项。首先,你必须使用最新版本(因为某些软件库中可用的构建版本已过时,并且不会安装必要的流式处理插件)。第二,即使是最新的构建版本,一些流媒体服务也不会像预期的那样工作。例如,接入 Spotify 频道时,你只能使用最热门的曲目(而无法使用播放列表,或搜索歌曲的功能)。
+
+使用 Clementine 互联网流媒体服务时,你会发现其中有很多你从来没有听说过的音乐家和乐队(图 2)。
+
+![Clementine][5]
+
+*图 2:Clementine 互联网广播是寻找新音乐的好方法。*
+
+### Odio
+
+Odio 是一个跨平台的专有应用程序(可用于 Linux、MacOS 和 Windows),它允许你流式传输各种类型的互联网音乐站。广播的内容是取自 [www.radio-browser.info][6],而应用程序本身在为你呈现流方面做了令人难以置信的工作(图 3)。
+
+![Odio][8]
+
+*图 3:Odio 接口是你能找到的最好的接口之一。*
+
+Odio 让你很容易找到独特的互联网广播电台,甚至可以把你找到并收藏的电台添加到你的库中。目前,在 Linux 上安装 Odio 的唯一方法是通过 Snap。如果你的发行版支持 snap 软件包,请使用以下命令安装此流应用程序:
+
+```
+sudo snap install odio
+```
+
+安装后,你可以打开应用程序并开始使用它。无需登录(或创建)帐户。Odio 的设置非常有限。实际上,它只提供了在设置窗口中选择暗色主题或亮色主题的选项。然而,尽管它可能功能有限,但 Odio 是在 Linux 上播放互联网广播的最佳选择之一。
+
+### StreamTuner2
+
+Streamtuner2 是一个优秀的互联网电台 GUI 工具。使用它,你可以流式播放以下音乐:
+
+ * Internet radio stations
+ * Jameno
+ * MyOggRadio
+ * Shoutcast.com
+ * SurfMusic
+ * TuneIn
+ * Xiph.org
+ * YouTube
+
+Streamtuner2 提供了一个很好的界面(如果不是有点过时的话),可以很容易地找到和播放你喜爱的音乐。StreamTuner2 的一个警告是,它实际上只是一个用于查找你想要听到的流媒体的 GUI。当你找到一个站点时,双击它打开与流相关的应用程序。这意味着你必须安装必要的应用程序,才能播放流媒体。如果你没有合适的应用程序,你就不能播放流媒体。因此,你将花费大量的时间来确定要为某些流媒体安装哪些应用程序(图 4)。
+
+![Streamtuner2][10]
+
+*图4:配置 Streamtuner2 需要一个坚强的心脏。*
+
+### VLC
+
+很长一段时间以来,VLC 一直被称为 Linux 最好的媒体播放工具。这是有充分理由的,因为几乎所有你丢给它的东西它都能播放。其中包括流媒体广播电台。虽然你无法让 VLC 连接到 Spotify 这样的网站,但你可以直接访问互联网广播,点击播放列表,而 VLC 毫无疑问可以打开它。考虑到目前有很多互联网广播电台,你在寻找适合自己口味的音乐方面不会有任何问题。VLC 还包括可视化工具、均衡器(图 5)等工具。
+
+![VLC ][12]
+
+*图 5:VLC 可视化工具和均衡器特性。*
+
+VLC 唯一需要注意的是,你必须有一个你希望听到的互联网广播的 URL,因为这个工具本身并不能进行管理。但是有了这些链接,你就找不到比 VLC 更好的媒体播放器了。
+
+### 这些工具软件怎么来的
+
+如果这五个工具都不太不适合你的需要,我建议你打开你发行版的应用商店,搜索一个适合你的。有很多工具可以制作流媒体音乐、播客等等,不仅可以在 Linux 上实现,而且很简单。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2019/2/5-streaming-audio-players-linux
+
+作者:[Jack Wallen][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[b]: https://github.com/lujun9972
+[2]: https://lcom.static.linuxfound.org/sites/lcom/files/spotify_0.jpg?itok=8-Ym-R61 (Spotify)
+[3]: https://www.linux.com/licenses/category/used-permission
+[5]: https://lcom.static.linuxfound.org/sites/lcom/files/clementine_0.jpg?itok=5oODJO3b (Clementine)
+[6]: http://www.radio-browser.info
+[8]: https://lcom.static.linuxfound.org/sites/lcom/files/odio.jpg?itok=sNPTSS3c (Odio)
+[10]: https://lcom.static.linuxfound.org/sites/lcom/files/streamtuner2.jpg?itok=1MSbafWj (Streamtuner2)
+[12]: https://lcom.static.linuxfound.org/sites/lcom/files/vlc_0.jpg?itok=QEOsq7Ii (VLC )
+[13]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/published/202101/20190205 Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS.md b/published/202101/20190205 Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS.md
new file mode 100644
index 0000000000..4f74e02e9e
--- /dev/null
+++ b/published/202101/20190205 Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS.md
@@ -0,0 +1,436 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13041-1.html)
+[#]: subject: (Install Apache, MySQL, PHP \(LAMP\) Stack On Ubuntu 18.04 LTS)
+[#]: via: (https://www.ostechnix.com/install-apache-mysql-php-lamp-stack-on-ubuntu-18-04-lts/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+在 Ubuntu 中安装 Apache、MySQL、PHP(LAMP)套件
+======
+
+
+
+**LAMP** 套件是一种流行的开源 Web 开发平台,可用于运行和部署动态网站和基于 Web 的应用程序。通常,LAMP 套件由 Apache Web 服务器、MariaDB/MySQL 数据库、PHP/Python/Perl 程序设计(脚本)语言组成。 LAMP 是 **L**inux,**M**ariaDB/**M**YSQL,**P**HP/**P**ython/**P**erl 的缩写。 本教程描述了如何在 Ubuntu 18.04 LTS 服务器中安装 Apache、MySQL、PHP(LAMP 套件)。
+
+就本教程而言,我们将使用以下 Ubuntu 测试。
+
+ * **操作系统**:Ubuntu 18.04.1 LTS Server Edition
+ * **IP 地址** :192.168.225.22/24
+
+### 1. 安装 Apache Web 服务器
+
+首先,利用下面命令更新 Ubuntu 服务器:
+
+```
+$ sudo apt update
+$ sudo apt upgrade
+```
+
+然后,安装 Apache Web 服务器(命令如下):
+
+```
+$ sudo apt install apache2
+```
+
+检查 Apache Web 服务器是否已经运行:
+
+```
+$ sudo systemctl status apache2
+```
+
+输出结果大概是这样的:
+
+```
+● apache2.service - The Apache HTTP Server
+ Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: en
+ Drop-In: /lib/systemd/system/apache2.service.d
+ └─apache2-systemd.conf
+ Active: active (running) since Tue 2019-02-05 10:48:03 UTC; 1min 5s ago
+ Main PID: 2025 (apache2)
+ Tasks: 55 (limit: 2320)
+ CGroup: /system.slice/apache2.service
+ ├─2025 /usr/sbin/apache2 -k start
+ ├─2027 /usr/sbin/apache2 -k start
+ └─2028 /usr/sbin/apache2 -k start
+
+Feb 05 10:48:02 ubuntuserver systemd[1]: Starting The Apache HTTP Server...
+Feb 05 10:48:03 ubuntuserver apachectl[2003]: AH00558: apache2: Could not reliably
+Feb 05 10:48:03 ubuntuserver systemd[1]: Started The Apache HTTP Server.
+```
+
+祝贺你! Apache 服务已经启动并运行了!!
+
+#### 1.1 调整防火墙允许 Apache Web 服务器
+
+默认情况下,如果你已在 Ubuntu 中启用 UFW 防火墙,则无法从远程系统访问 Apache Web 服务器。 必须按照以下步骤开启 `http` 和 `https` 端口。
+
+首先,使用以下命令列出 Ubuntu 系统上可用的应用程序配置文件:
+
+```
+$ sudo ufw app list
+```
+
+输出结果:
+
+```
+Available applications:
+Apache
+Apache Full
+Apache Secure
+OpenSSH
+```
+
+如你所见,Apache 和 OpenSSH 应用程序已安装 UFW 配置文件。你可以使用 `ufw app info "Profile Name"` 命令列出有关每个配置文件及其包含的规则的信息。
+
+让我们研究一下 “Apache Full” 配置文件。 为此,请运行:
+
+```
+$ sudo ufw app info "Apache Full"
+```
+
+输出结果:
+
+```
+Profile: Apache Full
+Title: Web Server (HTTP,HTTPS)
+Description: Apache v2 is the next generation of the omnipresent Apache web
+server.
+
+Ports:
+80,443/tcp
+```
+
+如你所见,“Apache Full” 配置文件包含了启用经由端口 **80** 和 **443** 的传输规则:
+
+现在,运行以下命令配置允许 HTTP 和 HTTPS 传入通信:
+
+```
+$ sudo ufw allow in "Apache Full"
+Rules updated
+Rules updated (v6)
+```
+
+如果你不想允许 HTTP 通信,而只允许 HTTP(80) 通信,请运行:
+
+```
+$ sudo ufw app info "Apache"
+```
+
+#### 1.2 测试 Apache Web 服务器
+
+现在,打开 Web 浏览器并导航到 或 来访问 Apache 测试页。
+
+
+
+如果看到上面类似的显示内容,那就成功了。 Apache 服务器正在工作!
+
+### 2. 安装 MySQL
+
+在 Ubuntu 安装 MySQL 请运行:
+
+```
+$ sudo apt install mysql-server
+```
+
+使用以下命令验证 MySQL 服务是否正在运行:
+
+```
+$ sudo systemctl status mysql
+```
+
+输出结果:
+
+```
+● mysql.service - MySQL Community Server
+Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enab
+Active: active (running) since Tue 2019-02-05 11:07:50 UTC; 17s ago
+Main PID: 3423 (mysqld)
+Tasks: 27 (limit: 2320)
+CGroup: /system.slice/mysql.service
+└─3423 /usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid
+
+Feb 05 11:07:49 ubuntuserver systemd[1]: Starting MySQL Community Server...
+Feb 05 11:07:50 ubuntuserver systemd[1]: Started MySQL Community Server.
+```
+
+MySQL 正在运行!
+
+#### 2.1 配置数据库管理用户(root)密码
+
+默认情况下,MySQL root 用户密码为空。你需要通过运行以下脚本使你的 MySQL 服务器安全:
+
+```
+$ sudo mysql_secure_installation
+```
+
+系统将询问你是否要安装 “VALIDATE PASSWORD plugin(密码验证插件)”。该插件允许用户为数据库配置强密码凭据。如果启用,它将自动检查密码的强度并强制用户设置足够安全的密码。**禁用此插件是安全的**。但是,必须为数据库使用唯一的强密码凭据。如果不想启用此插件,只需按任意键即可跳过密码验证部分,然后继续其余步骤。
+
+如果回答是 `y`,则会要求你选择密码验证级别。
+
+```
+Securing the MySQL server deployment.
+
+Connecting to MySQL using a blank password.
+
+VALIDATE PASSWORD PLUGIN can be used to test passwords
+and improve security. It checks the strength of password
+and allows the users to set only those passwords which are
+secure enough. Would you like to setup VALIDATE PASSWORD plugin?
+
+Press y|Y for Yes, any other key for No y
+```
+
+可用的密码验证有 “low(低)”、 “medium(中)” 和 “strong(强)”。只需输入适当的数字(0 表示低,1 表示中,2 表示强密码)并按回车键。
+
+```
+There are three levels of password validation policy:
+
+LOW Length >= 8
+MEDIUM Length >= 8, numeric, mixed case, and special characters
+STRONG Length >= 8, numeric, mixed case, special characters and dictionary file
+
+Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG:
+```
+
+现在,输入 MySQL root 用户的密码。请注意,必须根据上一步中选择的密码策略,为 MySQL root 用户使用密码。如果你未启用该插件,则只需使用你选择的任意强度且唯一的密码即可。
+
+```
+Please set the password for root here.
+
+New password:
+
+Re-enter new password:
+
+Estimated strength of the password: 50
+Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) : y
+```
+
+两次输入密码后,你将看到密码强度(在此示例情况下为 50)。如果你确定可以,请按 `y` 继续提供的密码。如果对密码长度不满意,请按其他任意键并设置一个强密码。我现在的密码可以,所以我选择了`y`。
+
+对于其余的问题,只需键入 `y` 并按回车键。这将删除匿名用户、禁止 root 用户远程登录并删除 `test`(测试)数据库。
+
+```
+Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
+Success.
+
+Normally, root should only be allowed to connect from
+'localhost'. This ensures that someone cannot guess at
+the root password from the network.
+
+Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
+Success.
+
+By default, MySQL comes with a database named 'test' that
+anyone can access. This is also intended only for testing,
+and should be removed before moving into a production
+environment.
+
+Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
+- Dropping test database...
+Success.
+
+- Removing privileges on test database...
+Success.
+
+Reloading the privilege tables will ensure that all changes
+made so far will take effect immediately.
+
+Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
+Success.
+
+All done!
+```
+
+以上就是为 MySQL root 用户设置密码。
+
+#### 2.2 更改 MySQL 超级用户的身份验证方法
+
+默认情况下,Ubuntu 系统的 MySQL root 用户为 MySQL 5.7 版本及更新的版本使用插件 `auth_socket` 设置身份验证。尽管它增强了安全性,但是当你使用任何外部程序(例如 phpMyAdmin)访问数据库服务器时,也会变得更困难。要解决此问题,你需要将身份验证方法从 `auth_socket` 更改为 `mysql_native_password`。为此,请使用以下命令登录到你的 MySQL 提示符下:
+
+```
+$ sudo mysql
+```
+
+在 MySQL 提示符下运行以下命令,找到所有 MySQL 当前用户帐户的身份验证方法:
+
+```
+SELECT user,authentication_string,plugin,host FROM mysql.user;
+```
+
+输出结果:
+
+```
++------------------|-------------------------------------------|-----------------------|-----------+
+| user | authentication_string | plugin | host |
++------------------|-------------------------------------------|-----------------------|-----------+
+| root | | auth_socket | localhost |
+| mysql.session | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | mysql_native_password | localhost |
+| mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | mysql_native_password | localhost |
+| debian-sys-maint | *F126737722832701DD3979741508F05FA71E5BA0 | mysql_native_password | localhost |
++------------------|-------------------------------------------|-----------------------|-----------+
+4 rows in set (0.00 sec)
+```
+
+![][2]
+
+如你所见,Mysql root 用户使用 `auth_socket` 插件进行身份验证。
+
+要将此身份验证更改为 `mysql_native_password` 方法,请在 MySQL 提示符下运行以下命令。 别忘了用你选择的强大唯一的密码替换 `password`。 如果已启用 VALIDATION 插件,请确保已根据当前策略要求使用了强密码。
+
+```
+ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
+```
+
+使用以下命令更新数据库:
+
+```
+FLUSH PRIVILEGES;
+```
+
+使用命令再次检查身份验证方法是否已更改:
+
+```
+SELECT user,authentication_string,plugin,host FROM mysql.user;
+```
+
+输出结果:
+
+![][3]
+
+好!MySQL root 用户就可以使用密码进行身份验证来访问 `mysql shell`。
+
+从 MySQL 提示符下退出:
+
+```
+exit
+```
+
+### 3. 安装 PHP
+
+安装 PHP 请运行:
+
+```
+$ sudo apt install php libapache2-mod-php php-mysql
+```
+
+安装 PHP 后,在 Apache 文档根目录中创建 `info.php` 文件。通常,在大多数基于 Debian 的 Linux 发行版中,Apache 文档根目录为 `/var/www/html/` 或 `/var/www/`。Ubuntu 18.04 LTS 系统下,文档根目录是 `/var/www/html/`。
+
+在 Apache 根目录中创建 `info.php` 文件:
+
+```
+$ sudo vi /var/www/html/info.php
+```
+
+在此文件中编辑如下内容:
+
+```
+
+```
+
+然后按下 `ESC` 键并且输入 `:wq` 保存并退出此文件。重新启动 Apache 服务使更改生效。
+
+```
+$ sudo systemctl restart apache2
+```
+
+#### 3.1 测试 PHP
+
+打开 Web 浏览器,然后导航到 URL 。
+
+你就将看到 PHP 测试页面。
+
+
+
+通常,当用户向 Web 服务器发出请求时,Apache 首先会在文档根目录中查找名为 `index.html` 的文件。如果你想将 Apache 更改为 `php` 文件提供服务而不是其他文件,请将 `dir.conf` 配置文件中的 `index.php` 移至第一个位置,如下所示:
+
+```
+$ sudo vi /etc/apache2/mods-enabled/dir.conf
+```
+
+上面的配置文件(`dir.conf`) 内容如下:
+
+```
+
+DirectoryIndex index.html index.cgi index.pl index.php index.xhtml index.htm
+
+
+# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
+```
+
+将 `index.php` 移动到最前面。更改后,`dir.conf` 文件内容看起来如下所示。
+
+```
+
+DirectoryIndex index.php index.html index.cgi index.pl index.xhtml index.htm
+
+
+# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
+```
+
+然后按下 `ESC` 键并且输入 `:wq` 保存并关闭此文件。重新启动 Apache 服务使更改生效。
+
+```
+$ sudo systemctl restart apache2
+```
+
+#### 3.2 安装 PHP 模块
+
+为了增加 PHP 的功能,可以安装一些其他的 PHP 模块。
+
+要列出可用的 PHP 模块,请运行:
+
+```
+$ sudo apt-cache search php- | less
+```
+
+输出结果:
+
+![][4]
+
+使用方向键浏览结果。要退出,请输入 `q` 并按下回车键。
+
+要查找任意 `php` 模块的详细信息,例如 `php-gd`,请运行:
+
+```
+$ sudo apt-cache show php-gd
+```
+
+安装 PHP 模块请运行:
+
+```
+$ sudo apt install php-gd
+```
+
+安装所有的模块(虽然没有必要),请运行:
+
+```
+$ sudo apt-get install php*
+```
+
+安装任何 `php` 模块后,请不要忘记重新启动 Apache 服务。要检查模块是否已加载,请在浏览器中打开 `info.php` 文件并检查是否存在。
+
+接下来,你可能需要安装数据库管理工具,以通过 Web 浏览器轻松管理数据库。如果是这样,请按照以下链接中的说明安装 `phpMyAdmin`。
+
+祝贺你!我们已经在 Ubuntu 服务器中成功配置了 LAMP 套件。
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/install-apache-mysql-php-lamp-stack-on-ubuntu-18-04-lts/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: http://www.ostechnix.com/wp-content/uploads/2019/02/mysql-1.png
+[3]: http://www.ostechnix.com/wp-content/uploads/2019/02/mysql-2.png
+[4]: http://www.ostechnix.com/wp-content/uploads/2016/06/php-modules.png
diff --git a/published/202101/20190215 Make websites more readable with a shell script.md b/published/202101/20190215 Make websites more readable with a shell script.md
new file mode 100644
index 0000000000..a84cdfaa40
--- /dev/null
+++ b/published/202101/20190215 Make websites more readable with a shell script.md
@@ -0,0 +1,261 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13052-1.html)
+[#]: subject: (Make websites more readable with a shell script)
+[#]: via: (https://opensource.com/article/19/2/make-websites-more-readable-shell-script)
+[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
+
+利用 Shell 脚本让网站更具可读性
+======
+
+> 测算网站的文本和背景之间的对比度,以确保站点易于阅读。
+
+
+
+如果希望人们发现你的网站实用,那么他们需要能够阅读它。为文本选择的颜色可能会影响网站的可读性。不幸的是,网页设计中的一种流行趋势是在打印输出文本时使用低对比度的颜色,就像在白色背景上的灰色文本。对于 Web 设计师来说,这也许看起来很酷,但对于许多阅读它的人来说确实很困难。
+
+W3C 提供了《Web 内容可访问性指南》,其中包括帮助 Web 设计人员选择易于区分文本和背景色的指导。z这就是所谓的“对比度”。 W3C 定义的对比度需要进行一些计算:给定两种颜色,首先计算每种颜色的相对亮度,然后计算对比度。对比度在 1 到 21 的范围内(通常写为 1:1 到 21:1)。对比度越高,文本在背景下的突出程度就越高。例如,白色背景上的黑色文本非常醒目,对比度为 21:1。对比度为 1:1 的白色背景上的白色文本不可读。
+
+[W3C 说,正文][1] 的对比度至少应为 4.5:1,标题至少应为 3:1。但这似乎是最低限度的要求。W3C 还建议正文至少 7:1,标题至少 4.5:1。
+
+计算对比度可能比较麻烦,因此最好将其自动化。我已经用这个方便的 Bash 脚本做到了这一点。通常,脚本执行以下操作:
+
+ 1. 获取文本颜色和背景颜色
+ 2. 计算相对亮度
+ 3. 计算对比度
+
+### 获取颜色
+
+你可能知道显示器上的每种颜色都可以用红色、绿色和蓝色(R、G 和 B)来表示。要计算颜色的相对亮度,脚本需要知道颜色的红、绿和蓝的各个分量。理想情况下,脚本会将这些信息读取为单独的 R、G 和 B 值。 Web 设计人员可能知道他们喜欢的颜色的特定 RGB 代码,但是大多数人不知道不同颜色的 RGB 值。作为一种替代的方法是,大多数人通过 “red” 或 “gold” 或 “maroon” 之类的名称来引用颜色。
+
+幸运的是,GNOME 的 [Zenity][2] 工具有一个颜色选择器应用程序,可让你使用不同的方法选择颜色,然后用可预测的格式 `rgb(R,G,B)` 返回 RGB 值。使用 Zenity 可以轻松获得颜色值:
+
+```
+color=$( zenity --title 'Set text color' --color-selection --color='black' )
+```
+
+如果用户(意外地)单击 “Cancel(取消)” 按钮,脚本将假定一种颜色:
+
+```
+if [ $? -ne 0 ] ; then
+ echo '** color canceled .. assume black'
+ color='rgb(0,0,0)'
+fi
+```
+
+脚本对背景颜色值也执行了类似的操作,将其设置为 `$background`。
+
+### 计算相对亮度
+
+一旦你在 `$color` 中设置了前景色,并在 `$background` 中设置了背景色,下一步就是计算每种颜色的相对亮度。 [W3C 提供了一个算法][3] 用以计算颜色的相对亮度。
+
+> 对于 sRGB 色彩空间,一种颜色的相对亮度定义为:
+>
+> L = 0.2126 * R + 0.7152 * G + 0.0722 * B
+>
+> R、G 和 B 定义为:
+>
+> if $R_{sRGB}$ <= 0.03928 then R = $R_{sRGB}$/12.92
+>
+> else R = (($R_{sRGB}$+0.055)/1.055) $^{2.4}$
+>
+> if $G_{sRGB}$ <= 0.03928 then G = $G_{sRGB}$/12.92
+>
+> else G = (($G_{sRGB}$+0.055)/1.055) $^{2.4}$
+>
+> if $B_{sRGB}$ <= 0.03928 then B = $B_{sRGB}$/12.92
+>
+> else B = (($B_{sRGB}$+0.055)/1.055) $^{2.4}$
+>
+> $R_{sRGB}$、$G_{sRGB}$ 和 $B_{sRGB}$ 定义为:
+>
+> $R_{sRGB}$ = $R_{8bit}$/255
+>
+> $G_{sRGB}$ = $G_{8bit}$/255
+>
+> $B_{sRGB}$ = $B_{8bit}$/255
+
+由于 Zenity 以 `rgb(R,G,B)` 的格式返回颜色值,因此脚本可以轻松拉取分隔开的 R、B 和 G 的值以计算相对亮度。AWK 可以使用逗号作为字段分隔符(`-F,`),并使用 `substr()` 字符串函数从 `rgb(R,G,B)` 中提取所要的颜色值:
+
+```
+R=$( echo $color | awk -F, '{print substr($1,5)}' )
+G=$( echo $color | awk -F, '{print $2}' )
+B=$( echo $color | awk -F, '{n=length($3); print substr($3,1,n-1)}' )
+```
+
+*有关使用 AWK 提取和显示数据的更多信息,[查看 AWK 备忘表][4]*
+
+最好使用 BC 计算器来计算最终的相对亮度。BC 支持计算中所需的简单 `if-then-else`,这使得这一过程变得简单。但是由于 BC 无法使用非整数指数直接计算乘幂,因此需要使用自然对数替代它做一些额外的数学运算:
+
+```
+echo "scale=4
+rsrgb=$R/255
+gsrgb=$G/255
+bsrgb=$B/255
+if ( rsrgb <= 0.03928 ) r = rsrgb/12.92 else r = e( 2.4 * l((rsrgb+0.055)/1.055) )
+if ( gsrgb <= 0.03928 ) g = gsrgb/12.92 else g = e( 2.4 * l((gsrgb+0.055)/1.055) )
+if ( bsrgb <= 0.03928 ) b = bsrgb/12.92 else b = e( 2.4 * l((bsrgb+0.055)/1.055) )
+0.2126 * r + 0.7152 * g + 0.0722 * b" | bc -l
+```
+
+这会将一些指令传递给 BC,包括作为相对亮度公式一部分的 `if-then-else` 语句。接下来 BC 打印出最终值。
+
+### 计算对比度
+
+利用文本颜色和背景颜色的相对亮度,脚本就可以计算对比度了。 [W3C 确定对比度][5] 是使用以下公式:
+
+> (L1 + 0.05) / (L2 + 0.05),这里的
+> L1 是颜色较浅的相对亮度,
+> L2 是颜色较深的相对亮度。
+
+给定两个相对亮度值 `$r1` 和 `$r2`,使用 BC 计算器很容易计算对比度:
+
+```
+echo "scale=2
+if ( $r1 > $r2 ) { l1=$r1; l2=$r2 } else { l1=$r2; l2=$r1 }
+(l1 + 0.05) / (l2 + 0.05)" | bc
+```
+
+使用 `if-then-else` 语句确定哪个值(`$r1` 或 `$r2`)是较浅还是较深的颜色。BC 执行结果计算并打印结果,脚本可以将其存储在变量中。
+
+### 最终脚本
+
+通过以上内容,我们可以将所有内容整合到一个最终脚本。 我使用 Zenity 在文本框中显示最终结果:
+
+```
+#!/bin/sh
+# script to calculate contrast ratio of colors
+
+# read color and background color:
+# zenity returns values like 'rgb(255,140,0)' and 'rgb(255,255,255)'
+
+color=$( zenity --title 'Set text color' --color-selection --color='black' )
+if [ $? -ne 0 ] ; then
+ echo '** color canceled .. assume black'
+ color='rgb(0,0,0)'
+fi
+
+background=$( zenity --title 'Set background color' --color-selection --color='white' )
+if [ $? -ne 0 ] ; then
+ echo '** background canceled .. assume white'
+ background='rgb(255,255,255)'
+fi
+
+# compute relative luminance:
+
+function luminance()
+{
+ R=$( echo $1 | awk -F, '{print substr($1,5)}' )
+ G=$( echo $1 | awk -F, '{print $2}' )
+ B=$( echo $1 | awk -F, '{n=length($3); print substr($3,1,n-1)}' )
+
+ echo "scale=4
+rsrgb=$R/255
+gsrgb=$G/255
+bsrgb=$B/255
+if ( rsrgb <= 0.03928 ) r = rsrgb/12.92 else r = e( 2.4 * l((rsrgb+0.055)/1.055) )
+if ( gsrgb <= 0.03928 ) g = gsrgb/12.92 else g = e( 2.4 * l((gsrgb+0.055)/1.055) )
+if ( bsrgb <= 0.03928 ) b = bsrgb/12.92 else b = e( 2.4 * l((bsrgb+0.055)/1.055) )
+0.2126 * r + 0.7152 * g + 0.0722 * b" | bc -l
+}
+
+lum1=$( luminance $color )
+lum2=$( luminance $background )
+
+# compute contrast
+
+function contrast()
+{
+ echo "scale=2
+if ( $1 > $2 ) { l1=$1; l2=$2 } else { l1=$2; l2=$1 }
+(l1 + 0.05) / (l2 + 0.05)" | bc
+}
+
+rel=$( contrast $lum1 $lum2 )
+
+# print results
+
+( cat< 容器构建有两大趋势:使用基本镜像和从头开始构建。每个都有工程上的权衡。
+
+
+
+有人说 Linux 发行版不再与容器有关。像 distroless 和 scratch 容器等可替代的方法,似乎是风靡一时。看来,我们在考虑和做出技术决策时,更多的是基于时尚感和即时的情感满足,而不是考虑我们选择的次要影响。我们应该问这样的问题:这些选择将如何影响未来六个月的维护?工程权衡是什么?这种范式转换如何影响我们的大规模构建系统?
+
+这真让人沮丧。如果我们忘记了工程是一个零和游戏,有可衡量的利弊权衡,有不同方法的成本和收益 —— 这样对我们自己不利,对雇主不利,对最终维护我们的代码的同事不利。最后,我们对所有的维护人员([向维护人员致敬!][1] )都是一种伤害,因为我们不欣赏他们所做的工作。
+
+### 理解问题所在
+
+为了理解这个问题,我们必须首先研究为什么我们使用 Linux 发行版。我将把原因分为两大类:内核和其他包。编译内核实际上相当容易。Slackware 和 Gentoo( 我的小心脏还是有点害怕)教会了我们这一点。
+
+另一方面,对于一个可用的 Linux 系统需要打包大量的开发软件和应用软件,这可能会让人望而生畏。此外,确保数百万个程序包可以一起安装和工作的唯一方法是使用旧的范例:即编译它并将它作为一个工件(即 Linux 发行版)一起发布。那么,为什么 Linux 发行版要将内核和所有包一起编译呢?很简单:确保事情协调一致。
+
+首先,我们来谈谈内核。内核很特别。在没有编译好的内核的情况下引导 Linux 系统有点困难。它是 Linux 操作系统的核心,也是我们在系统启动时首先依赖的。内核在编译时有很多不同的配置选项,这些选项会对硬件和软件如何在一个内核上运行产生巨大影响。这方面中的第二个问题是,系统软件(如编译器 、C 库和解释器)必须针对内核中内置的选项进行调优。Gentoo 的维基以一种发自内心的方式教我们这一点,它把每个人都变成了一个微型的开发版维护者。
+
+令人尴尬的是(因为我在过去五年里一直在使用容器),我必须承认我最近才编译过内核。我必须让嵌套的 KVM 在 RHEL7 上工作,这样我才能在笔记本电脑上的 KVM 虚拟机中运行 [OpenShift on OpenStack][2] 虚拟机,以及我的 [Container Development Kit(CDK)][3]。我只想说,当时我在一个全新的 4.X 内核上启动了 RHEL7。和任何优秀的系统管理员一样,我有点担心自己错过了一些重要的配置选项和补丁。当然,我也的确错过了一些东西。比如睡眠模式无法正常工作,我的扩展底座无法正常工作,还有许多其他小的随机错误。但它在我的笔记本电脑上的一个 KVM 虚拟机上,对于 OpenStack 上的 OpenShift 的实时演示来说已经足够好了。来吧,这很有趣,对吧?但我离题了……
+
+现在,我们来谈谈其他的软件包。虽然内核和相关的系统软件可能很难编译,但从工作负载的角度来看,更大的问题是编译成千上万的包,以提供一个可用的 Linux 系统。每个软件包都需要专业知识。有些软件只需要运行三个命令:`./configure`、`make` 和 `make install`。另一些则需要大量的专业知识,从在 `etc` 中添加用户和配置特定的默认值到运行安装后脚本和添加 systemd 单元文件。对于任何一个人来说,调试好你可能用得到的成千上万种不同软件所需要的一套技能都是令人望而生畏的。但是,如果你想要一个可以随时尝试新软件的可用系统,你必须学会如何编译和安装新软件,然后才能开始学习使用它。这就是没有 Linux 发行版的 Linux。当你放弃使用 Linux 发行版时,那么你就得自己编译软件。
+
+关键是,你必须将所有内容构建在一起,以确保它能够以任何合理的可靠性级别协同工作,而且构建一个可用的包群需要大量的知识。这是任何一个开发人员或系统管理员都无法合理地学习和保留的知识。我描述的每个问题都适用于你的 [容器主机][4](内核和系统软件)和 [容器镜像][5](系统软件和所有其他包)——请注意:在容器镜像中还包含有编译器 、C 库、解释器和 JVM。
+
+### 解决方案
+
+所以你也看到了,其实使用 Linux 发行版就是解决方案。别再看了,给离你最近的软件包维护者(再次向维护人员致敬!)发张电子卡吧(等等,我是不是把我的年龄告诉别人了?)。不过说真的,这些人做了大量的工作,这真的是被低估了。Kubernetes、Istio、Prometheus,还有 Knative:我在看着你们。你们的时代要来了,到时候你们会进入维护模式,被过度使用,被低估。大约七到十年后,我将再次写这篇文章,可能是关于 Kubernetes 的。
+
+### 容器构建的首要原则
+
+从零开始构建和从基础镜像构建之间存在权衡。
+
+#### 从基础镜像构建
+
+从基础镜像构建的优点是,大多数构建操作只不过是安装或更新包。它依赖于 Linux 发行版中包维护人员所做的大量工作。它还有一个优点,即六个月甚至十年后的修补事件(使用 RHEL)是运维/系统管理员事件 (`yum update`),而不是开发人员事件(这需要通过代码找出某些函数参数不再工作的原因)。
+
+你想想,应用程序代码依赖于许多库,从 JSON mung 库到对象关系映射器。与 Linux 内核和 Glibc 不同,这些类型的库很少改变 API 兼容性。这意味着三年后你的修补事件可能会变成代码更改事件,而不是 yum 更新事件。因此让他自己深入下去吧。开发人员,如果安全团队找不到防火墙黑客来阻止攻击,你将在凌晨 2 点收到短信。
+
+从基础镜像构建不是完美的;还有一些缺点,比如所有被拖入的依赖项的大小。这几乎总是会使容器镜像比从头开始构建的镜像更大。另一个缺点是你并不总是能够访问最新的上游代码。这可能会让开发人员感到沮丧,尤其是当你只想使用依赖项中的一部分功能时,但是你仍然不得不将你根本用不着的东西一起打包带走,因为上游的维护人员一直在改变这个库。
+
+如果你是一个 web 开发人员,正在对我翻白眼,我有一个词可以形容你:DevOps。那意味着你带着寻呼机,我的朋友。
+
+#### Scratch 构建
+
+Scratch 构建的优点是镜像非常小。当你不依赖容器中的 Linux 发行版时,你有很多控制权,这意味着你可以根据需要定制所有内容。这是一个最佳模型,在某些用例中是很有效的。另一个优势是你可以访问最新的软件包。你不必等待 Linux 发行版更新任何内容。是你自己在控制,所以你可以自行选择什么时候去费功夫纳入新的软件。
+
+记住,控制一切都是有代价的。通常,更新到具有新特性的新库会拖如不必要的 API 更改,这意味着修复代码中的不兼容(换句话说,这就像[给牦牛剪毛][6])。在凌晨 2 点应用程序不起作用的时候给牦牛剪毛是不好玩的。幸运的是,使用容器,你可以在下一个工作日回滚并给牦牛剪毛,但它仍会占用你为业务提供新价值、为应用程序提供新功能的时间。欢迎来到系统管理员的生活。
+
+好吧,也就是说,有些时候,Scratch 构建是有意义的。我完全承认,静态编译的 Golang 程序和 C 程序是 scratch/distorless 构建的两个不错的候选程序。对于这些类型的程序,每个容器构建都是一个编译事件。三年后你仍然需要担心 API 的损坏,但是如果你是一个 Golang 商店,你应该有能力随着时间的推移修复问题。
+
+### 结论
+
+基本上,Linux 发行版做了大量工作来节省你在常规 Linux 系统或容器上的时间。维护人员所拥有的知识是巨大的,而且没有得到真正的赞赏。容器的采用使得问题更加严重,因为它被进一步抽象了。
+
+通过容器主机,Linux 发行版可以让你访问广泛的硬件生态系统,从微型 ARM 系统到 128 核 CPU x86 巨型机箱,再到云服务商的虚拟机。他们提供可工作的容器引擎和开箱即用的容器运行时环境,所以你只需启动你的容器,让其他人担心事情的进展。
+
+对于容器镜像,Linux 发行版为你的项目提供了对大量软件的轻松访问。即使你从头开始构建,你也可能会看到一个包维护人员是如何构建和运送东西的 —— 一个好的艺术家是一个好的偷学者,所以不要低估这项工作的价值。
+
+所以,感谢 Fedora、RHEL(Frantisek,你是我的英雄 )、Debian、Gentoo 和其他 Linux 发行版的所有维护人员。我很感激你所做的工作,尽管我是个“容器工人”
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/linux-distributions-still-matter-containers
+
+作者:[Scott McCarty][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/fatherlinux
+[b]: https://github.com/lujun9972
+[1]: https://aeon.co/essays/innovation-is-overvalued-maintenance-often-matters-more
+[2]: https://blog.openshift.com/openshift-on-openstack-delivering-applications-better-together/
+[3]: https://developers.redhat.com/blog/2018/02/13/red-hat-cdk-nested-kvm/
+[4]: https://developers.redhat.com/blog/2018/02/22/container-terminology-practical-introduction/#h.8tyd9p17othl
+[5]: https://developers.redhat.com/blog/2018/02/22/container-terminology-practical-introduction/#h.dqlu6589ootw
+[6]: https://en.wiktionary.org/wiki/yak_shaving
diff --git a/published/20190322 Printing from the Linux command line.md b/published/202101/20190322 Printing from the Linux command line.md
similarity index 100%
rename from published/20190322 Printing from the Linux command line.md
rename to published/202101/20190322 Printing from the Linux command line.md
diff --git a/published/20190516 Monitor and Manage Docker Containers with Portainer.io (GUI tool) - Part-2.md b/published/202101/20190516 Monitor and Manage Docker Containers with Portainer.io (GUI tool) - Part-2.md
similarity index 100%
rename from published/20190516 Monitor and Manage Docker Containers with Portainer.io (GUI tool) - Part-2.md
rename to published/202101/20190516 Monitor and Manage Docker Containers with Portainer.io (GUI tool) - Part-2.md
diff --git a/published/202101/20190924 Integrate online documents editors, into a Python web app using ONLYOFFICE.md b/published/202101/20190924 Integrate online documents editors, into a Python web app using ONLYOFFICE.md
new file mode 100644
index 0000000000..b1404ac687
--- /dev/null
+++ b/published/202101/20190924 Integrate online documents editors, into a Python web app using ONLYOFFICE.md
@@ -0,0 +1,391 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13037-1.html)
+[#]: subject: (Integrate online documents editors, into a Python web app using ONLYOFFICE)
+[#]: via: (https://opensourceforu.com/2019/09/integrate-online-documents-editors-into-a-python-web-app-using-onlyoffice/)
+[#]: author: (Aashima Sharma https://opensourceforu.com/author/aashima-sharma/)
+
+利用 ONLYOFFICE 将在线文档编辑器集成到 Python Web 应用程序中
+======
+
+![][1]
+
+[ONLYOFFICE][3] 是根据 GNU AGPL v.3 许可证条款分发的开源协作办公套件。它包含三个用于文本文档、电子表格和演示文稿的编辑器,并具有以下功能:
+
+ * 查看,编辑和协同编辑 `.docx`、`.xlsx`、`.pptx` 文件。OOXML 作为一种核心格式,可确保与 Microsoft Word、Excel 和 PowerPoint 文件的高度兼容性。
+ * 通过内部转换为 OOXML,编辑其他流行格式(`.odt`、`.rtf`、`.txt`、`.html`、`.ods`、`.csv`、`.odp`)。
+ * 熟悉的选项卡式界面。
+ * 协作工具:两种协同编辑模式(快速和严谨),跟踪更改,评论和集成聊天。
+ * 灵活的访问权限管理:完全访问权限、只读、审阅、表单填写和评论。
+ * 使用 API 构建附加组件。
+ * 250 种可用语言和象形字母表。
+
+通过 API,开发人员可以将 ONLYOFFICE 编辑器集成到网站和利用程序设计语言编写的应用程序中,并能配置和管理编辑器。
+
+要集成 ONLYOFFICE 编辑器,我们需要一个集成应用程序来连接编辑器(ONLYOFFICE 文档服务器)和服务。 要在你的界面中使用编辑器,因该授予 ONLYOFFICE 以下权限:
+
+ * 添加并执行自定义代码。
+ * 用于下载和保存文件的匿名访问权限。这意味着编辑器仅与服务器端的服务通信,而不包括客户端的任何用户授权数据(浏览器 cookies)。
+ * 在用户界面添加新按钮(例如,“在 ONLYOFFICE 中打开”、“在 ONLYOFFICE 中编辑”)。
+ * 开启一个新页面,ONLYOFFICE 可以在其中执行脚本以添加编辑器。
+ * 能够指定文档服务器连接设置。
+
+流行的协作解决方案的成功集成案例有很多,如 Nextcloud、ownCloud、Alfresco、Confluence 和 SharePoint,都是通过 ONLYOFFICE 提供的官方即用型连接器实现的。
+
+实际的集成案例之一是 ONLYOFFICE 编辑器与以 C# 编写的开源协作平台的集成。该平台具有文档和项目管理、CRM、电子邮件聚合器、日历、用户数据库、博客、论坛、调查、Wiki 和即时通讯程序的功能。
+
+将在线编辑器与 CRM 和项目模块集成,你可以:
+
+ * 文档关联到 CRM 时机和容器、项目任务和讨论,甚至创建一个单独的文件夹,其中包含与项目相关的文档、电子表格和演示文稿。
+ * 直接在 CRM 或项目模块中创建新的文档、工作表和演示文稿。
+ * 打开和编辑关联的文档,或者下载和删除。
+ * 将联系人从 CSV 文件批量导入到 CRM 中,并将客户数据库导出为 CSV 文件。
+
+在“邮件”模块中,你可以关联存储在“文档模块”中的文件,或者将指向所需文档的链接插入到邮件正文中。 当 ONLYOFFICE 用户收到带有附件的文档的消息时,他们可以:下载附件、在浏览器中查看文件、打开文件进行编辑或将其保存到“文档模块”。 如上所述,如果格式不同于 OOXML ,则文件将自动转换为 `.docx`、`.xlsx`、`.pptx`,并且其副本也将以原始格式保存。
+
+在本文中,你将看到 ONLYOFFICE 与最流行的编程语言之一的 Python 编写的文档管理系统的集成过程。 以下步骤将向你展示如何创建所有必要的部分,以使在 DMS(文档管理系统)界面内的文档中可以进行协同工作成为可能:查看、编辑、协同编辑、保存文件和用户访问管理,并可以作为服务的示例集成到 Python 应用程序中。
+
+### 1、前置需求
+
+首先,创建集成过程的关键组件:[ONLYOFFICE 文档服务器][4] 和用 Python 编写的文件管理系统。
+
+#### 1.1、ONLYOFFICE 文档服务器
+
+要安装 ONLYOFFICE 文档服务器,你可以从多个安装选项中进行选择:编译 GitHub 上可用的源代码,使用 `.deb` 或 `.rpm` 软件包亦或 Docker 镜像。
+
+我们推荐使用下面这条命令利用 Docker 映像安装文档服务器和所有必需的依赖。请注意,选择此方法,你需要安装最新的 Docker 版本。
+
+```
+docker run -itd -p 80:80 onlyoffice/documentserver-de
+```
+
+#### 1.2、利用 Python 开发 DMS
+
+如果已经拥有一个,请检查它是否满足以下条件:
+
+ * 包含需要打开以查看/编辑的保留文件
+ * 允许下载文件
+
+对于该应用程序,我们将使用 Bottle 框架。我们将使用以下命令将其安装在工作目录中:
+
+```
+pip install bottle
+```
+
+然后我们创建应用程序代码 `main.py` 和模板 `index.tpl`。
+
+我们将以下代码添加到 `main.py` 文件中:
+
+```
+from bottle import route, run, template, get, static_file # connecting the framework and the necessary components
+@route('/') # setting up routing for requests for /
+def index():
+ return template('index.tpl') # showing template in response to request
+
+run(host="localhost", port=8080) # running the application on port 8080
+```
+
+一旦我们运行该应用程序,点击 就会在浏览器上呈现一个空白页面 。
+为了使文档服务器能够创建新文档,添加默认文件并在模板中生成其名称列表,我们应该创建一个文件夹 `files` 并将3种类型文件(`.docx`、`.xlsx` 和 `.pptx`)放入其中。
+
+要读取这些文件的名称,我们使用 `listdir` 组件(模块):
+
+```
+from os import listdir
+```
+
+现在让我们为文件夹中的所有文件名创建一个变量:
+
+```
+sample_files = [f for f in listdir('files')]
+```
+
+要在模板中使用此变量,我们需要通过 `template` 方法传递它:
+
+```
+def index():
+ return template('index.tpl', sample_files=sample_files)
+```
+
+这是模板中的这个变量:
+
+```
+% for file in sample_files:
+
+ {{file}}
+
+% end
+```
+
+我们重新启动应用程序以查看页面上的文件名列表。
+
+使这些文件可用于所有应用程序用户的方法如下:
+
+```
+@get("/files/")
+def show_sample_files(filepath):
+ return static_file(filepath, root="files")
+```
+
+### 2、查看文档
+
+所有组件准备就绪后,让我们添加函数以使编辑者可以利用应用接口操作。
+
+第一个选项使用户可以打开和查看文档。连接模板中的文档编辑器 API :
+
+```
+
+```
+
+`editor_url` 是文档编辑器的链接接口。
+
+打开每个文件以供查看的按钮:
+
+```
+
+```
+
+现在我们需要添加带有 `id` 的 `div` 标签,打开文档编辑器:
+
+```
+
+```
+
+要打开编辑器,必须调用调用一个函数:
+
+```
+
+```
+
+DocEditor 函数有两个参数:将在其中打开编辑器的元素 `id` 和带有编辑器设置的 `JSON`。
+在此示例中,使用了以下必需参数:
+
+ * `documentType` 由其格式标识(`.docx`、`.xlsx`、`.pptx` 用于相应的文本、电子表格和演示文稿)
+ * `document.url` 是你要打开的文件链接。
+ * `editorConfig.mode`。
+
+我们还可以添加将在编辑器中显示的 `title`。
+
+接下来,我们可以在 Python 应用程序中查看文档。
+
+### 3、编辑文档
+
+首先,添加 “Edit”(编辑)按钮:
+
+```
+
+```
+
+然后创建一个新功能,打开文件进行编辑。类似于查看功能。
+
+现在创建 3 个函数:
+
+```
+
+```
+
+`destroyEditor` 被调用以关闭一个打开的编辑器。
+
+你可能会注意到,`edit()` 函数中缺少 `editorConfig` 参数,因为默认情况下它的值是:`{"mode":"edit"}`。
+
+现在,我们拥有了打开文档以在 Python 应用程序中进行协同编辑的所有功能。
+
+### 4、如何在 Python 应用中利用 ONLYOFFICE 协同编辑文档
+
+通过在编辑器中设置对同一文档使用相同的 `document.key` 来实现协同编辑。 如果没有此键值,则每次打开文件时,编辑器都会创建编辑会话。
+
+为每个文档设置唯一键,以使用户连接到同一编辑会话时进行协同编辑。 密钥格式应为以下格式:`filename +"_key"`。下一步是将其添加到当前文档的所有配置中。
+
+```
+document: {
+ url: "host_url" + '/' + filepath,
+ title: filename,
+ key: filename + '_key'
+},
+```
+
+### 5、如何在 Python 应用中利用 ONLYOFFICE 保存文档
+
+每次我们更改并保存文件时,ONLYOFFICE 都会存储其所有版本。 让我们仔细看看它是如何工作的。 关闭编辑器后,文档服务器将构建要保存的文件版本并将请求发送到 `callbackUrl` 地址。 该请求包含 `document.key`和指向刚刚构建的文件的链接。
+
+`document.key` 用于查找文件的旧版本并将其替换为新版本。 由于这里没有任何数据库,因此仅使用 `callbackUrl` 发送文件名。
+
+在 `editorConfig.callbackUrl` 的设置中指定 `callbackUrl` 参数并将其添加到 `edit()` 方法中:
+
+```
+ function edit(filename) {
+ const filepath = 'files/' + filename;
+ if (editor) {
+ editor.destroyEditor()
+ }
+ editor = new DocsAPI.DocEditor("editor",
+ {
+ documentType: get_file_type(filepath),
+ document: {
+ url: "host_url" + '/' + filepath,
+ title: filename,
+ key: filename + '_key'
+ }
+ ,
+ editorConfig: {
+ mode: 'edit',
+ callbackUrl: "host_url" + '/callback' + '&filename=' + filename // add file name as a request parameter
+ }
+ });
+ }
+```
+
+编写一种方法,在获取到 POST 请求发送到 `/callback` 地址后将保存文件:
+
+```
+@post("/callback") # processing post requests for /callback
+def callback():
+ if request.json['status'] == 2:
+ file = requests.get(request.json['url']).content
+ with open('files/' + request.query['filename'], 'wb') as f:
+ f.write(file)
+ return "{\"error\":0}"
+
+```
+
+`# status 2` 是已生成的文件,当我们关闭编辑器时,新版本的文件将保存到存储器中。
+
+### 6、管理用户
+
+如果应用中有用户,并且你需要查看谁在编辑文档,请在编辑器的配置中输入其标识符(`id`和`name`)。
+
+在界面中添加选择用户的功能:
+
+```
+
+```
+
+如果在标记 `
+
+
+
+