mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
c5bfa4536d
82
README.md
82
README.md
@ -11,7 +11,7 @@
|
||||
简介
|
||||
-------------------------------
|
||||
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux 中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
|
||||
LCTT 已经拥有几百名活跃成员,并欢迎更多的 Linux 志愿者加入我们的团队。
|
||||
|
||||
@ -31,14 +31,14 @@ LCTT 的组成
|
||||
加入我们
|
||||
-------------------------------
|
||||
|
||||
请首先加入翻译组的 QQ 群,群号是:198889102,加群时请说明是“志愿者”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
请首先加入翻译组的 QQ 群,群号是:**198889102**,加群时请说明是“*志愿者*”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
|
||||
加入的成员,请先阅读 [WIKI 如何开始](https://github.com/LCTT/TranslateProject/wiki/01-如何开始)。
|
||||
|
||||
如何开始
|
||||
-------------------------------
|
||||
|
||||
请阅读 [WIKI](https://github.com/LCTT/TranslateProject/wiki)。
|
||||
请阅读 [WIKI](https://github.com/LCTT/TranslateProject/wiki)。如需要协助,请在群内发问。
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
@ -79,44 +79,52 @@ LCTT 的组成
|
||||
* 2018/08/17 提升 pityonline 为核心成员,担任校对,并接受他的建议采用 PR 审核模式。
|
||||
* 2018/09/10 [LCTT 五周年](https://linux.cn/article-9999-1.html)。
|
||||
* 2018/10/25 重构了 CI,感谢 vizv、lujun9972、bestony。
|
||||
* 2018/11/13 [成立了项目管理委员会(PMC)](https://linux.cn/article-10279-1.html),初始成员为:@wxy (主席)、@oska874、@lujun9972、@bestony、@pityonline、@geekpi、@qhwdw。
|
||||
|
||||
核心成员
|
||||
|
||||
项目管理委员及核心成员
|
||||
-------------------------------
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
LCTT 现由项目管理委员会(PMC)进行管理,成员如下:
|
||||
|
||||
- 组长 @wxy,
|
||||
- 选题 @oska874,
|
||||
- 选题 @lujun9972,
|
||||
- 技术 @bestony,
|
||||
- 校对 @jasminepeng,
|
||||
- 校对 @pityonline,
|
||||
- 钻石译者 @geekpi,
|
||||
- 钻石译者 @qhwdw,
|
||||
- 钻石译者 @GOLinux,
|
||||
- 核心成员 @GHLandy,
|
||||
- 核心成员 @martin2011qi,
|
||||
- 核心成员 @ictlyh,
|
||||
- 核心成员 @strugglingyouth,
|
||||
- 核心成员 @FSSlc,
|
||||
- 核心成员 @zpl1025,
|
||||
- 核心成员 @runningwater,
|
||||
- 核心成员 @bazz2,
|
||||
- 核心成员 @Vic020,
|
||||
- 核心成员 @alim0x,
|
||||
- 核心成员 @tinyeyeser,
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @MjSeven
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
- 前任校对 @carolinewuyan,
|
||||
- 功勋成员 @vito-L,
|
||||
- 功勋成员 @willqian,
|
||||
- 功勋成员 @vizv,
|
||||
- 功勋成员 @dongfengweixiao,
|
||||
- 🎩 主席 @wxy
|
||||
- 🎩 选题 @oska874
|
||||
- 🎩 选题 @lujun9972
|
||||
- 🎩 技术 @bestony
|
||||
- 🎩 校对 @pityonline
|
||||
- 🎩 译者 @geekpi
|
||||
- 🎩 译者 @qhwdw
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
|
||||
- ❤️ 核心成员 @vizv
|
||||
- ❤️ 核心成员 @zpl1025
|
||||
- ❤️ 核心成员 @runningwater
|
||||
- ❤️ 核心成员 @FSSlc
|
||||
- ❤️ 核心成员 @Vic020
|
||||
- ❤️ 核心成员 @alim0x
|
||||
- ❤️ 核心成员 @martin2011qi
|
||||
- ❤️ 核心成员 @Locez
|
||||
- ❤️ 核心成员 @ucasFL
|
||||
- ❤️ 核心成员 @MjSeven
|
||||
|
||||
曾经做出了巨大贡献的核心成员,被列入荣誉榜:
|
||||
|
||||
- 🏆 前任选题 @DeadFire
|
||||
- 🏆 前任校对 @reinoir222
|
||||
- 🏆 前任校对 @PurlingNayuki
|
||||
- 🏆 前任校对 @carolinewuyan
|
||||
- 🏆 前任校对 @jasminepeng
|
||||
- 🏆 功勋成员 @tinyeyeser
|
||||
- 🏆 功勋成员 @vito-L
|
||||
- 🏆 功勋成员 @willqian
|
||||
- 🏆 功勋成员 @GOLinux
|
||||
- 🏆 功勋成员 @bazz2
|
||||
- 🏆 功勋成员 @ictlyh
|
||||
- 🏆 功勋成员 @dongfengweixiao
|
||||
- 🏆 功勋成员 @strugglingyouth
|
||||
- 🏆 功勋成员 @GHLandy
|
||||
- 🏆 功勋成员 @rusking
|
||||
|
||||
全部成员列表请参见: https://linux.cn/lctt-list/ 。
|
||||
|
||||
|
||||
@ -0,0 +1,401 @@
|
||||
学习 Linux/*BSD/Unix 的 30 个最佳在线文档
|
||||
======
|
||||
|
||||
手册页(man)是由系统管理员和 IT 技术开发人员写的,更多的是为了作为参考而不是教你如何使用。手册页对于已经熟悉使用 Linux、Unix 和 BSD 操作系统的人来说是非常有用的。如果你仅仅需要知道某个命令或者某个配置文件的格式那么你可以使用手册页,但是手册页对于 Linux 新手来说并没有太大的帮助。想要通过使用手册页来学习一些新东西不是一个好的选择。这里有将提供 30 个学习 Linux 和 Unix 操作系统的最佳在线网页文档。
|
||||
|
||||
![Dennis Ritchie and Ken Thompson working with UNIX PDP11][1]
|
||||
|
||||
值得一提的是,相对于 Linux,BSD 的手册页更好。
|
||||
|
||||
### #1:Red Hat Enterprise Linux(RHEL)
|
||||
|
||||
![Red hat Enterprise Linux 文档][2]
|
||||
|
||||
RHEL 是由红帽公司开发的面向商业市场的 Linux 发行版。红帽的文档是最好的文档之一,涵盖从 RHEL 的基础到一些高级主题比如安全、SELinux、虚拟化、目录服务器、服务器集群、JBOSS 应用程序服务器、高可用性集群(HPC)等。红帽的文档已经被翻译成 22 种语言,发布成多页面 HTML、单页面 HTML、PDF、EPUB 等文件格式。好消息同样的文档你可以用于 Centos 和 Scientific Linux(社区企业发行版)。这些文档随操作系统一起下载提供,也就是说当你没有网络的时候,你也可以使用它们。RHEL 的文档**涵盖从安装到配置器群的所有内容**。唯一的缺点是你需要成为付费用户。当然这对于企业公司来说是一件完美的事。
|
||||
|
||||
1. RHEL 文档:[HTML/PDF格式][3](LCTT 译注:**此链接**需要付费用户才可以访问)
|
||||
2. 是否支持论坛:只能通过红帽公司的用户网站提交支持案例。
|
||||
|
||||
#### 关于 CentOS Wiki 和论坛的说明
|
||||
|
||||
![Centos Linux Wiki][4]
|
||||
|
||||
CentOS(<ruby>社区企业操作系统<rt>Community ENTerprise Operating System</rt></ruby>)是由 RHEL 提供的自由源码包免费重建的。它为个人电脑或其它用途提供了可靠的、免费的企业级 Linux。你可以不用付出任何支持和认证费用就可以获得 RHEL 的稳定性。CentOS的 wiki 分为 Howto、技巧等等部分,链接如下:
|
||||
|
||||
1. 文档:[wiki 格式][87]
|
||||
2. 是否支持论坛:[是][88]
|
||||
|
||||
### #2:Arch 的 Wiki 和论坛
|
||||
|
||||
![Arch Linux wiki 和教程][5]
|
||||
|
||||
Arch linux 是一个独立开发的 Linux 操作系统,它有基于 wiki 网站形式的非常不错的文档。它是由 Arch 社区的一些用户共同协作开发出来的,并且允许任何用户添加或修改内容。这些文档教程被分为几类比如说优化、软件包管理、系统管理、X window 系统还有获取安装 Arch Linux 等。它的[官方论坛][7]在解决许多问题的时候也非常有用。它有总共 4 万多个注册用户、超过 1 百万个帖子。 该 wiki 包含一些 **其它 Linux 发行版也适用的通用信息**。
|
||||
|
||||
1. Arch 社区文档:[Wiki 格式][8]
|
||||
2. 是否支持论坛:[是][7]
|
||||
|
||||
### #3:Gentoo Linux Wiki 和论坛
|
||||
|
||||
![Gentoo Linux 手册和 Wiki][9]
|
||||
|
||||
Gentoo Linux 基于 Portage 包管理系统。Gentoo Linux 用户根据它们选择的配置在本地编译源代码。多数 Gentoo Linux 用户都会定制自己独有的程序集。 Gentoo Linux 的文档会给你一些有关 Gentoo Linux 操作系统的说明和一些有关安装、软件包、网络和其它等主要出现的问题的解决方法。Gentoo 有对你来说 **非常有用的论坛**,论坛中有超过 13 万 4 千的用户,总共发了有 5442416 个文章。
|
||||
|
||||
1. Gentoo 社区文档:[手册][10] 和 [Wiki 格式][11]
|
||||
2. 是否支持论坛:[是][12]
|
||||
|
||||
### #4:Ubuntu Wiki 和文档
|
||||
|
||||
![Ubuntu Linux Wiki 和论坛][14]
|
||||
|
||||
Ubuntu 是领先的台式机和笔记本电脑发行版之一。其官方文档由 Ubuntu 文档工程开发维护。你可以在从官方文档中查看大量的信息,比如如何开始使用 Ubuntu 的教程。最好的是,此处包含的这些信息也可用于基于 Debian 的其它系统。你可能会找到由 Ubuntu 的用户们创建的社区文档,这是一份有关 Ubuntu 的使用教程和技巧等。Ubuntu Linux 有着网络上最大的 Linux 社区的操作系统,它对新用户和有经验的用户均有助益。
|
||||
|
||||
1. Ubuntu 社区文档:[wiki 格式][15]
|
||||
2. Ubuntu 官方文档:[wiki 格式][16]
|
||||
3. 是否支持论坛:[是][17]
|
||||
|
||||
### #5:IBM Developer Works
|
||||
|
||||
![IBM: Linux 程序员和系统管理员用到的技术][18]
|
||||
|
||||
IBM Developer Works 为 Linux 程序员和系统管理员提供技术资源,其中包含数以百计的文章、教程和技巧来协助 Linux 程序员的编程工作和应用开发还有系统管理员的日常工作。
|
||||
|
||||
1. IBM 开发者项目文档:[HTML 格式][19]
|
||||
2. 是否支持论坛:[是][20]
|
||||
|
||||
### #6:FreeBSD 文档和手册
|
||||
|
||||
![Freebsd Documentation][21]
|
||||
|
||||
FreeBSD 的手册是由 <ruby>FreeBSD 文档项目<rt>FreeBSD Documentation Project</rt></ruby>所创建的,它介绍了 FreeBSD 操作系统的安装、管理和一些日常使用技巧等内容。FreeBSD 的手册页通常比 GNU Linux 的手册页要好一点。FreeBSD **附带有全部最新手册页的文档**。 FreeBSD 手册涵盖任何你想要的内容。手册包含一些通用的 Unix 资料,这些资料同样适用于其它的 Linux 发行版。FreeBSD 官方论坛会在你遇到棘手问题时给予帮助。
|
||||
|
||||
1. FreeBSD 文档:[HTML/PDF 格式][90]
|
||||
2. 是否支持论坛:[是][91]
|
||||
|
||||
### #7:Bash Hackers Wiki
|
||||
|
||||
![Bash Hackers wiki][22]
|
||||
|
||||
这是一个对于 bash 使用者来说非常好的资源。Bash 使用者的 wiki 是为了归纳所有类型的 GNU Bash 文档。这个项目的动力是为了提供可阅读的文档和资料来避免用户被迫一点一点阅读 Bash 的手册,有时候这是非常麻烦的。Bash Hackers Wiki 分为各个类,比如说脚本和通用资料、如何使用、代码风格、bash 命令格式和其它。
|
||||
|
||||
1. Bash 用户教程:[wiki 格式][23]
|
||||
|
||||
### #8:Bash 常见问题
|
||||
|
||||
![Bash 常见问题:一些有关 GNU/BASH 常见问题的解决方法][24]
|
||||
|
||||
这是一个为 bash 新手设计的一个 wiki。它收集了 IRC 网络的 #bash 频道里常见问题的解决方法,这些解决方法是由该频道的普通成员提供。当你遇到问题的时候不要忘了在 [BashPitfalls][25] 部分检索查找答案。这些常见问题的解决方法可能会倾向于 Bash,或者偏向于最基本的 Bourne Shell,这决定于是谁给出的答案。大多数情况会尽力提供可移植的(Bourne)和高效的(Bash,在适当情况下)的两类答案。
|
||||
|
||||
1. Bash 常见问题:[wiki 格式][26]
|
||||
|
||||
### #9: Howtoforge - Linux 教程
|
||||
|
||||
![Howtoforge][27]
|
||||
|
||||
博客作者 Falko 在 Howtoforge 上有一些非常不错的东西。这个网站提供了 Linux 关于各种各样主题的教程,比如说其著名的“最佳服务器系列”,网站将主题分为几类,比如说 web 服务器、linux 发行版、DNS 服务器、虚拟化、高可用性、电子邮件和反垃圾邮件、FTP 服务器、编程主题还有一些其它的内容。这个网站也支持德语。
|
||||
|
||||
1. Howtoforge: [html 格式][28]
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #10:OpenBSD 常见问题和文档
|
||||
|
||||
![OpenBSD 文档][29]
|
||||
|
||||
OpenBSD 是另一个基于 BSD 的类 Unix 计算机操作系统。OpenBSD 是由 NetBSD 项目分支而来。OpenBSD 因高质量的代码和文档、对软件许可协议的坚定立场和强烈关注安全问题而闻名。OpenBSD 的文档分为多个主题类别,比如说安装、包管理、防火墙设置、用户管理、网络、磁盘和磁盘阵列管理等。
|
||||
|
||||
1. OpenBSD:[html 格式][30]
|
||||
2. 是否支持论坛:否,但是可以通过 [邮件列表][31] 来咨询
|
||||
|
||||
### #11: Calomel - 开源研究和参考文档
|
||||
|
||||
![开源研究和参考文档][32]
|
||||
|
||||
这个极好的网站是专门作为开源软件和那些特别专注于 OpenBSD 的软件的文档来使用的。这是最简洁的引导网站之一,专注于高质量的内容。网站内容分为多个类,比如说 DNS、OpenBSD、安全、web 服务器、Samba 文件服务器、各种工具等。
|
||||
|
||||
1. Calomel 官网:[html 格式][33]
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #12:Slackware 书籍项目
|
||||
|
||||
![Slackware Linux 手册和文档][34]
|
||||
|
||||
Slackware Linux 是我的第一个 Linux 发行版。Slackware 是基于 Linux 内核的最早的发行版之一,也是当前正在维护的最古老的 Linux 发行版。 这个发行版面向专注于稳定性的高级用户。 Slackware 也是很少有的的“类 Unix” 的 Linux 发行版之一。官方的 Slackware 手册是为了让用户快速开始了解 Slackware 操作系统的使用方法而设计的。 这不是说它将包含发行版的每一个方面,而是为了说明它的实用性和给使用者一些有关系统的基础工作使用方法。手册分为多个主题,比如说安装、网络和系统配置、系统管理、包管理等。
|
||||
|
||||
1. Slackware Linux 手册:[html 格式][35]、pdf 和其它格式
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #13:Linux 文档项目(TLDP)
|
||||
|
||||
![Linux 学习网站和文档][36]
|
||||
|
||||
<ruby>Linux 文档项目<rt>Linux Documentation Project</rt></ruby>旨在给 Linux 操作系统提供自由、高质量文档。网站是由志愿者创建和维护的。网站分为具体主题的帮助、由浅入深的指南等。在此我想推荐一个非常好的[文档][37],这个文档既是一个教程也是一个 shell 脚本编程的参考文档,对于新用户来说这个 HOWTO 的[列表][38]也是一个不错的开始。
|
||||
|
||||
1. Linux [文档工程][39] 支持多种查阅格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #14:Linux Home Networking
|
||||
|
||||
![Linux Home Networking][40]
|
||||
|
||||
Linux Home Networking 是学习 linux 的另一个比较好的资源,这个网站包含了 Linux 软件认证考试的内容比如 RHCE,还有一些计算机培训课程。网站包含了许多主题,比如说网络、Samba 文件服务器、无线网络、web 服务器等。
|
||||
|
||||
1. Linux [home networking][41] 可通过 html 格式和 PDF(少量费用)格式查阅
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #15:Linux Action Show
|
||||
|
||||
![Linux 播客][42]
|
||||
|
||||
Linux Action Show(LAS) 是一个关于 Linux 的播客。这个网站是由 Bryan Lunduke、Allan Jude 和 Chris Fisher 共同管理的。它包含了 FOSS 的最新消息。网站内容主要是评论一些应用程序和 Linux 发行版。有时候也会发布一些和开源项目著名人物的采访视频。
|
||||
|
||||
1. Linux [action show][43] 支持音频和视频格式
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #16:Commandlinefu
|
||||
|
||||
![Commandlinefu 的最优 Unix / Linux 命令][45]
|
||||
|
||||
Commandlinefu 列出了各种有用或有趣的 shell 命令。这里所有命令都可以评论、讨论和投票(支持或反对)。对于所有 Unix 命令行用户来说是一个极好的资源。不要忘了查看[评选出来的最佳命令][44]。
|
||||
|
||||
1. [Commandlinefu][46] 支持 html 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #17:Debian 管理技巧和资源
|
||||
|
||||
![Debian Linux 管理: 系统管理员技巧和教程][48]
|
||||
|
||||
这个网站包含一些只和 Debian GNU/Linux 相关的主题、技巧和教程,特别是包含了关于系统管理的有趣和有用的信息。你可以在上面贡献文章、建议和问题。提交了之后不要忘记查看[最佳文章列表][47]里有没有你的文章。
|
||||
|
||||
1. Debian [系统管理][49] 支持 html 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #18: Catonmat - Sed、Awk、Perl 教程
|
||||
|
||||
![Sed 流编辑器、 Awk 文本处理工具、 Perl 语言教程][50]
|
||||
|
||||
这个网站是由博客作者 Peteris Krumins 维护的。主要关注命令行和 Unix 编程主题,比如说 sed 流编辑器、perl 语言、AWK 文本处理工具等。不要忘了查看 [sed 介绍][51]、sed 含义解释,还有命令行历史的[权威介绍][53]。
|
||||
|
||||
1. [catonmat][55] 支持 html 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #19:Debian GNU/Linux 文档和 Wiki
|
||||
|
||||
![Debian Linux 教程和 Wiki][56]
|
||||
|
||||
Debian 是另外一个 Linux 操作系统,其主要使用的软件以 GNU 许可证发布。Debian 因严格坚持 Unix 和自由软件的理念而闻名,它也是很受欢迎并且有一定影响力的 Linux 发行版本之一。 Ubuntu 等发行版本都是基于 Debian 的。Debian 项目以一种易于访问的形式提供给用户合适的文档。这个网站分为 Wiki、安装指导、常见问题、支持论坛几个模块。
|
||||
|
||||
1. Debian GNU/Linux [文档][57] 支持 html 和其它格式访问
|
||||
2. Debian GNU/Linux [wiki][58]
|
||||
3. 是否支持论坛:[是][59]
|
||||
|
||||
### #20:Linux Sea
|
||||
|
||||
Linux Sea 这本书提供了比较通俗易懂但充满技术(从最终用户角度来看)的 Linux 操作系统的介绍,使用 Gentoo Linux 作为例子。它既没有谈论 Linux 内核或 Linux 发行版的历史,也没有谈到 Linux 用户不那么感兴趣的细节。
|
||||
|
||||
1. Linux [sea][60] 支持 html 格式访问
|
||||
2. 是否支持论坛: 否
|
||||
|
||||
### #21:O'reilly Commons
|
||||
|
||||
![免费 Linux / Unix / Php / Javascript / Ubuntu 学习笔记][61]
|
||||
|
||||
O'reilly 出版社发布了不少 wiki 格式的文章。这个网站主要是为了给那些喜欢创作、参考、使用、修改、更新和修订来自 O'Reilly 或者其它来源的素材的社区提供资料。这个网站包含关于 Ubuntu、PHP、Spamassassin、Linux 等的免费书籍。
|
||||
|
||||
1. Oreilly [commons][62] 支持 Wiki 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #22:Ubuntu 袖珍指南
|
||||
|
||||
![Ubuntu 新手书籍][63]
|
||||
|
||||
这本书的作者是 Keir Thomas。这本指南(或者说是书籍)对于所有 ubuntu 用户来说都值得一读。这本书旨在向用户介绍 Ubuntu 操作系统和其所依赖的理念。你可以从官网下载这本书的 PDF 版本,也可以在亚马逊买印刷版。
|
||||
|
||||
1. Ubuntu [pocket guide][64] 支持 PDF 和印刷版本.
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #23: Linux: Rute User's Tutorial and Exposition
|
||||
|
||||
![GNU/LINUX system administration book][65]
|
||||
|
||||
这本书涵盖了 GNU/LINUX 系统管理,主要是对主流的发布版本比如红帽和 Debian 的说明,可以作为新用户的教程和高级管理员的参考。这本书旨在给出 Unix 系统的每个面的简明彻底的解释和实践性的例子。想要全面了解 Linux 的人都不需要再看了 —— 这里没有涉及的内容。
|
||||
|
||||
1. Linux: [Rute User's Tutorial and Exposition][66] 支持印刷版和 html 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #24:高级 Linux 编程
|
||||
|
||||
![高级 Linux 编程][67]
|
||||
|
||||
这本书是写给那些已经熟悉了 C 语言编程的程序员的。这本书采取一种教程式的方式来讲述大多数在 GNU/Linux 系统应用编程中重要的概念和功能特性。如果你是一个已经对 GNU/Linux 系统编程有一定经验的开发者,或者是对其它类 Unix 系统编程有一定经验的开发者,或者对 GNU/Linux 软件开发有兴趣,或者想要从非 Unix 系统环境转换到 Unix 平台并且已经熟悉了优秀软件的开发原则,那你很适合读这本书。另外,你会发现这本书同样适合于 C 和 C++ 编程。
|
||||
|
||||
1. [高级 Linux 编程][68] 支持印刷版和 PDF 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #25: LPI 101 Course Notes
|
||||
|
||||
![Linux 国际专业协会认证书籍][69]
|
||||
|
||||
LPIC 1、2、3 级是用于 Linux 系统管理员认证的。这个网站提供了 LPI 101 和 LPI 102 的测试训练。这些是根据 <ruby>GNU 自由文档协议<rt>GNU Free Documentation Licence</rt></ruby>(FDL)发布的。这些课程材料基于 Linux 国际专业协会的 LPI 101 和 102 考试的目标。这个课程是为了提供给你一些必备的 Linux 系统的操作和管理的技能。
|
||||
|
||||
1. LPI [训练手册][70] 支持 PDF 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #26: FLOSS 手册
|
||||
|
||||
![FLOSS Manuals is a collection of manuals about free and open source software][72]
|
||||
|
||||
FLOSS 手册是一系列关于自由和开源软件以及用于创建它们的工具和使用这些工具的社区的手册。社区的成员包含作者、编辑、设计师、软件开发者、积极分子等。这些手册中说明了怎样安装使用一些自由和开源软件,如何操作(比如设计和维持在线安全)开源软件,这其中也包含如何使用或支持自由软件和格式的自由文化服务手册。你也会发现关于一些像 VLC、 [Linux 视频编辑][71]、 Linux、 OLPC / SUGAR、 GRAPHICS 等软件的手册。
|
||||
|
||||
1. 你可以浏览 [FOSS 手册][73] 支持 Wiki 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #27:Linux 入门包
|
||||
|
||||
![Linux 入门包][74]
|
||||
|
||||
刚接触 Linux 这个美好世界?想找一个简单的入门方式?你可以下载一个 130 页的指南来入门。这个指南会向你展示如何在你的个人电脑上安装 Linux,如何浏览桌面,掌握最主流行的 Linux 程序和修复可能出现的问题的方法。
|
||||
|
||||
1. [Linux 入门包][75]支持 PDF 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #28:Linux.com - Linux 信息来源
|
||||
|
||||
Linux.com 是 Linux 基金会的一个产品。这个网站上提供一些新闻、指南、教程和一些关于 Linux 的其它信息。利用全球 Linux 用户的力量来通知、写作、连接 Linux 的事务。
|
||||
|
||||
1. 在线访问 [Linux.com][76]
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #29: LWN
|
||||
|
||||
LWN 是一个注重自由软件及用于 Linux 和其它类 Unix 操作系统的软件的网站。这个网站有周刊、基本上每天发布的单独文章和文章的讨论对话。该网站提供有关 Linux 和 FOSS 相关的开发、法律、商业和安全问题的全面报道。
|
||||
|
||||
1. 在线访问 [lwn.net][77]
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #30:Mac OS X 相关网站
|
||||
|
||||
与 Mac OS X 相关网站的快速链接:
|
||||
|
||||
* [Mac OS X 提示][78] —— 这个网站专用于苹果的 Mac OS X Unix 操作系统。网站有很多有关 Bash 和 Mac OS X 的使用建议、技巧和教程
|
||||
* [Mac OS 开发库][79] —— 苹果拥有大量和 OS X 开发相关的优秀系列内容。不要忘了看一看 [bash shell 脚本入门][80]
|
||||
* [Apple 知识库][81] - 这个有点像 RHN 的知识库。这个网站提供了所有苹果产品包括 OS X 相关的指南和故障报修建议。
|
||||
|
||||
### #30: NetBSD
|
||||
|
||||
(LCTT 译注:没错,又一个 30)
|
||||
|
||||
NetBSD 是另一个基于 BSD Unix 操作系统的自由开源操作系统。NetBSD 项目专注于系统的高质量设计、稳定性和性能。由于 NetBSD 的可移植性和伯克利式的许可证,NetBSD 常用于嵌入式系统。这个网站提供了一些 NetBSD 官方文档和各种第三方文档的链接。
|
||||
|
||||
1. 在线访问 [netbsd][82] 文档,支持 html、PDF 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### 你要做的事
|
||||
|
||||
这是我的个人列表,这可能并不完全是权威的,因此如果你有你自己喜欢的独特 Unix/Linux 网站,可以在下方参与评论分享。
|
||||
|
||||
// 图片来源: [Flickr photo][83] PanelSwitchman。一些连接是用户在我们的 Facebook 粉丝页面上建议添加的。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者和经验丰富的系统管理员以及 Linux 操作系统 / Unix shell 脚本的培训师。它曾与全球客户及各行各业合作,包括 IT、教育,国防和空间研究以及一些非营利部门。可以关注作者的 [Twitter][84]、[Facebook][85]、[Google+][86]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-documentations.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[ScarboroughCoral](https://github.com/ScarboroughCoral)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2011/12/unix-pdp11.jpg "Dennis Ritchie and Ken Thompson working with UNIX PDP11"
|
||||
[2]:https://www.cyberciti.biz/media/new/tips/2011/12/redhat-enterprise-linux-docs.png "Red hat Enterprise Linux Docs"
|
||||
[3]:https://access.redhat.com/documentation/en-us/
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2011/12/centos-linux-wiki.png "Centos Linux Wiki, Support, Documents"
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2011/12/arch-linux-wiki.png "Arch Linux wiki and tutorials "
|
||||
[6]:https://wiki.archlinux.org/index.php/Category:Networking_%28English%29
|
||||
[7]:https://bbs.archlinux.org/
|
||||
[8]:https://wiki.archlinux.org/
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2011/12/gentoo-linux-wiki1.png "Gentoo Linux Handbook and Wiki"
|
||||
[10]:http://www.gentoo.org/doc/en/handbook/
|
||||
[11]:https://wiki.gentoo.org
|
||||
[12]:https://forums.gentoo.org/
|
||||
[13]:http://gentoo-wiki.com
|
||||
[14]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-linux-wiki.png "Ubuntu Linux Wiki and Forums"
|
||||
[15]:https://help.ubuntu.com/community
|
||||
[16]:https://help.ubuntu.com/
|
||||
[17]:https://ubuntuforums.org/
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2011/12/ibm-devel.png "IBM: Technical for Linux programmers and system administrators"
|
||||
[19]:https://www.ibm.com/developerworks/learn/linux/index.html
|
||||
[20]:https://www.ibm.com/developerworks/community/forums/html/public?lang=en
|
||||
[21]:https://www.cyberciti.biz/media/new/tips/2011/12/freebsd-docs.png "Freebsd Documentation"
|
||||
[22]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-hackers-wiki.png "Bash hackers wiki for bash users"
|
||||
[23]:http://wiki.bash-hackers.org/doku.php
|
||||
[24]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-faq.png "Bash FAQ: Answers to frequently asked questions about GNU/BASH"
|
||||
[25]:http://mywiki.wooledge.org/BashPitfalls
|
||||
[26]:https://mywiki.wooledge.org/BashFAQ
|
||||
[27]:https://www.cyberciti.biz/media/new/tips/2011/12/howtoforge.png "Howtoforge tutorials"
|
||||
[28]:https://howtoforge.com/
|
||||
[29]:https://www.cyberciti.biz/media/new/tips/2011/12/openbsd-faq.png "OpenBSD Documenation"
|
||||
[30]:https://www.openbsd.org/faq/index.html
|
||||
[31]:https://www.openbsd.org/mail.html
|
||||
[32]:https://www.cyberciti.biz/media/new/tips/2011/12/calomel_org.png "Open Source Research and Reference Documentation"
|
||||
[33]:https://calomel.org
|
||||
[34]:https://www.cyberciti.biz/media/new/tips/2011/12/slackware-linux-book.png "Slackware Linux Book and Documentation "
|
||||
[35]:http://www.slackbook.org/
|
||||
[36]:https://www.cyberciti.biz/media/new/tips/2011/12/tldp.png "Linux Learning Site and Documentation "
|
||||
[37]:http://tldp.org/LDP/abs/html/index.html
|
||||
[38]:http://tldp.org/HOWTO/HOWTO-INDEX/howtos.html
|
||||
[39]:http://tldp.org/
|
||||
[40]:https://www.cyberciti.biz/media/new/tips/2011/12/linuxhomenetworking.png "Linux Home Networking "
|
||||
[41]:http://www.linuxhomenetworking.com/
|
||||
[42]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-action-show.png "Linux Podcast "
|
||||
[43]:http://www.jupiterbroadcasting.com/show/linuxactionshow/
|
||||
[44]:https://www.commandlinefu.com/commands/browse/sort-by-votes
|
||||
[45]:https://www.cyberciti.biz/media/new/tips/2011/12/commandlinefu.png "The best Unix / Linux Commands "
|
||||
[46]:https://commandlinefu.com/
|
||||
[47]:https://www.debian-administration.org/hof
|
||||
[48]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-admin.png "Debian Linux Adminstration: Tips and Tutorial For Sys Admin"
|
||||
[49]:https://www.debian-administration.org/
|
||||
[50]:https://www.cyberciti.biz/media/new/tips/2011/12/catonmat.png "Sed, Awk, Perl Tutorials"
|
||||
[51]:http://www.catonmat.net/blog/worlds-best-introduction-to-sed/
|
||||
[52]:https://www.catonmat.net/blog/sed-one-liners-explained-part-one/
|
||||
[53]:https://www.catonmat.net/blog/the-definitive-guide-to-bash-command-line-history/
|
||||
[54]:https://www.catonmat.net/blog/awk-one-liners-explained-part-one/
|
||||
[55]:https://catonmat.net/
|
||||
[56]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-wiki.png "Debian Linux Tutorials and Wiki"
|
||||
[57]:https://www.debian.org/doc/
|
||||
[58]:https://wiki.debian.org/
|
||||
[59]:https://www.debian.org/support
|
||||
[60]:http://swift.siphos.be/linux_sea/
|
||||
[61]:https://www.cyberciti.biz/media/new/tips/2011/12/orelly.png "Oreilly Free Linux / Unix / Php / Javascript / Ubuntu Books"
|
||||
[62]:http://commons.oreilly.com/wiki/index.php/O%27Reilly_Commons
|
||||
[63]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-guide.png "Ubuntu Book For New Users"
|
||||
[64]:http://ubuntupocketguide.com/
|
||||
[65]:https://www.cyberciti.biz/media/new/tips/2011/12/rute.png "GNU/LINUX system administration free book"
|
||||
[66]:https://web.archive.org/web/20160204213406/http://rute.2038bug.com/rute.html.gz
|
||||
[67]:https://www.cyberciti.biz/media/new/tips/2011/12/advanced-linux-programming.png "Download Advanced Linux Programming PDF version"
|
||||
[68]:https://github.com/MentorEmbedded/advancedlinuxprogramming
|
||||
[69]:https://www.cyberciti.biz/media/new/tips/2011/12/lpic.png "Download Linux Professional Institute Certification PDF Book"
|
||||
[70]:http://academy.delmar.edu/Courses/ITSC1358/eBooks/LPI-101.LinuxTrainingCourseNotes.pdf
|
||||
[71]://www.cyberciti.biz/faq/top5-linux-video-editing-system-software/
|
||||
[72]:https://www.cyberciti.biz/media/new/tips/2011/12/floss-manuals.png "Download manuals about free and open source software"
|
||||
[73]:https://flossmanuals.net/
|
||||
[74]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-starter.png "New to Linux? Start Linux starter book [ PDF version ]"
|
||||
[75]:http://www.tuxradar.com/linuxstarterpack
|
||||
[76]:https://linux.com
|
||||
[77]:https://lwn.net/
|
||||
[78]:http://hints.macworld.com/
|
||||
[79]:https://developer.apple.com/library/mac/navigation/
|
||||
[80]:https://developer.apple.com/library/mac/#documentation/OpenSource/Conceptual/ShellScripting/Introduction/Introduction.html
|
||||
[81]:https://support.apple.com/kb/index?page=search&locale=en_US&q=
|
||||
[82]:https://www.netbsd.org/docs/
|
||||
[83]:https://www.flickr.com/photos/9479603@N02/3311745151/in/set-72157614479572582/
|
||||
[84]:https://twitter.com/nixcraft
|
||||
[85]:https://facebook.com/nixcraft
|
||||
[86]:https://plus.google.com/+CybercitiBiz
|
||||
[87]:https://wiki.centos.org/
|
||||
[88]:https://www.centos.org/forums/
|
||||
[90]: https://www.freebsd.org/docs.html
|
||||
[91]: https://forums.freebsd.org/
|
||||
108
published/20171108 Continuous infrastructure- The other CI.md
Normal file
108
published/20171108 Continuous infrastructure- The other CI.md
Normal file
@ -0,0 +1,108 @@
|
||||
持续基础设施:另一个 CI
|
||||
======
|
||||
|
||||
> 想要提升你的 DevOps 效率吗?将基础设施当成你的 CI 流程中的重要的一环。
|
||||
|
||||

|
||||
|
||||
持续交付(CD)和持续集成(CI)是 DevOps 的两个众所周知的方面。但在 CI 大肆流行的今天却忽略了另一个关键性的 "I":<ruby>基础设施<rt>infrastructure</rt></ruby>。
|
||||
|
||||
曾经有一段时间 “基础设施”就意味着<ruby>无头<rt>headless</rt></ruby>的黑盒子、庞大的服务器,和高耸的机架 —— 更不用说漫长的采购流程和对盈余负载的错误估计。后来到了虚拟机时代,把基础设施处理得很好,虚拟化 —— 以前的世界从未有过这样。我们不再需要管理实体的服务器。仅仅是简单的点击,我们就可以创建和销毁、开始和停止、升级和降级我们的服务器。
|
||||
|
||||
有一个关于银行的流行故事:它们实现了数字化,并且引入了在线表格,用户需要手动填写表格、打印,然后邮寄回银行(LCTT 译注:我真的遇到过有人问我这样的需求怎么办)。这就是我们今天基础设施遇到的情况:使用新技术来做和以前一样的事情。
|
||||
|
||||
在这篇文章中,我们会看到在基础设施管理方面的进步,将基础设施视为一个版本化的组件并试着探索<ruby>不可变服务器<rt>immutable server</rt></ruby>的概念。在后面的文章中,我们将了解如何使用开源工具来实现持续的基础设施。
|
||||
|
||||
![continuous infrastructure pipeline][2]
|
||||
|
||||
*实践中的持续集成流程*
|
||||
|
||||
这是我们熟悉的 CI,尽早发布、经常发布的循环流程。这个流程缺少一个关键的组件:基础设施。
|
||||
|
||||
突击小测试:
|
||||
|
||||
* 你怎样创建和升级你的基础设施?
|
||||
* 你怎样控制和追溯基础设施的改变?
|
||||
* 你的基础设施是如何与你的业务进行匹配的?
|
||||
* 你是如何确保在正确的基础设施配置上进行测试的?
|
||||
|
||||
要回答这些问题,就要了解<ruby>持续基础设施<rt>continuous infrastructure</rt></ruby>。把 CI 构建流程分为<ruby>代码持续集成<rt>continuous integration code</rt></ruby>(CIc)和<ruby>基础设施持续集成<rt>continuous integration infrastructure</rt></ruby>(CIi)来并行开发和构建代码和基础设施,再将两者融合到一起进行测试。把基础设施构建视为 CI 流程中的重要的一环。
|
||||
|
||||
![pipeline with infrastructure][4]
|
||||
|
||||
*包含持续基础设施的 CI 流程*
|
||||
|
||||
关于 CIi 定义的几个方面:
|
||||
|
||||
1. 代码
|
||||
|
||||
通过代码来创建基础设施架构,而不是通过安装。<ruby>基础设施如代码<rt>Infrastructure as code</rt></ruby>(IaC)是使用配置脚本创建基础设施的现代最流行的方法。这些脚本遵循典型的编码和单元测试周期(请参阅下面关于 Terraform 脚本的示例)。
|
||||
2. 版本
|
||||
|
||||
IaC 组件在源码仓库中进行版本管理。这让基础设施的拥有了版本控制的所有好处:一致性,可追溯性,分支和标记。
|
||||
3. 管理
|
||||
|
||||
通过编码和版本化的基础设施管理,你可以使用你所熟悉的测试和发布流程来管理基础设施的开发。
|
||||
|
||||
CIi 提供了下面的这些优势:
|
||||
|
||||
1. <ruby>一致性<rt>Consistency</rt></ruby>
|
||||
|
||||
版本化和标记化的基础设施意味着你可以清楚的知道你的系统使用了哪些组件和配置。这建立了一个非常好的 DevOps 实践,用来鉴别和管理基础设施的一致性。
|
||||
2. <ruby>可重现性<rt>Reproducibility</rt></ruby>
|
||||
|
||||
通过基础设施的标记和基线,重建基础设施变得非常容易。想想你是否经常听到这个:“但是它在我的机器上可以运行!”现在,你可以在本地的测试平台中快速重现类似生产环境,从而将环境像变量一样在你的调试过程中删除。
|
||||
3. <ruby>可追溯性<rt>Traceability</rt></ruby>
|
||||
|
||||
你是否还记得曾经有过多少次寻找到底是谁更改了文件夹权限的经历,或者是谁升级了 `ssh` 包?代码化的、版本化的,发布的基础设施消除了临时性变更,为基础设施的管理带来了可追踪性和可预测性。
|
||||
4. <ruby>自动化<rt>Automation</rt></ruby>
|
||||
|
||||
借助脚本化的基础架构,自动化是下一个合乎逻辑的步骤。自动化允许你按需创建基础设施,并在使用完成后销毁它,所以你可以将更多宝贵的时间和精力用在更重要的任务上。
|
||||
5. <ruby>不变性<rt>Immutability</rt></ruby>
|
||||
|
||||
CIi 带来了不可变基础设施等创新。你可以创建一个新的基础设施组件而不是通过升级(请参阅下面有关不可变设施的说明)。
|
||||
|
||||
持续基础设施是从运行基础环境到运行基础组件的进化。像处理代码一样,通过证实的 DevOps 流程来完成。对传统的 CI 的重新定义包含了缺少的那个 “i”,从而形成了连贯的 CD 。
|
||||
|
||||
**(CIc + CIi) = CI -> CD**
|
||||
|
||||
### 基础设施如代码 (IaC)
|
||||
|
||||
CIi 流程的一个关键推动因素是<ruby>基础设施如代码<rt>infrastructure as code</rt></ruby>(IaC)。IaC 是一种使用配置文件进行基础设施创建和升级的机制。这些配置文件像其他的代码一样进行开发,并且使用版本管理系统进行管理。这些文件遵循一般的代码开发流程:单元测试、提交、构建和发布。IaC 流程拥有版本控制带给基础设施开发的所有好处,如标记、版本一致性,和修改可追溯。
|
||||
|
||||
这有一个简单的 Terraform 脚本用来在 AWS 上创建一个双层基础设施的简单示例,包括虚拟私有云(VPC)、弹性负载(ELB),安全组和一个 NGINX 服务器。[Terraform][5] 是一个通过脚本创建和更改基础设施架构和开源工具。
|
||||
|
||||
![terraform script][7]
|
||||
|
||||
*Terraform 脚本创建双层架构设施的简单示例*
|
||||
|
||||
完整的脚本请参见 [GitHub][8]。
|
||||
|
||||
### 不可变基础设施
|
||||
|
||||
你有几个正在运行的虚拟机,需要更新安全补丁。一个常见的做法是推送一个远程脚本单独更新每个系统。
|
||||
|
||||
要是不更新旧系统,如何才能直接丢弃它们并部署安装了新安全补丁的新系统呢?这就是<ruby>不可变基础设施<rt>immutable infrastructure</rt></ruby>。因为之前的基础设施是版本化的、标签化的,所以安装补丁就只是更新该脚本并将其推送到发布流程而已。
|
||||
|
||||
现在你知道为什么要说基础设施在 CI 流程中特别重要了吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/continuous-infrastructure-other-ci
|
||||
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Jamskr](https://github.com/Jamskr)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/gammay
|
||||
[1]:/file/376916
|
||||
[2]:https://opensource.com/sites/default/files/images/life-uploads/figure1.jpg (continuous infrastructure pipeline in use)
|
||||
[3]:/file/376921
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/figure2.jpg (CI pipeline with infrastructure)
|
||||
[5]:https://github.com/hashicorp/terraform
|
||||
[6]:/file/376926
|
||||
[7]:https://opensource.com/sites/default/files/images/life-uploads/figure3_0.png (sample terraform script)
|
||||
[8]:https://github.com/terraform-providers/terraform-provider-aws/tree/master/examples/two-tier
|
||||
@ -1,17 +1,15 @@
|
||||
对于你的第一行 HTML 代码,让我们来帮助蝙蝠侠写一封情书
|
||||
编写你的第一行 HTML 代码,来帮助蝙蝠侠写一封情书
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Image Credit][1]
|
||||
|
||||
在一个美好的夜晚,你的肚子拒绝消化你在晚餐吃的大块披萨,所以你不得不在睡梦中冲进洗手间。
|
||||
|
||||
在浴室里,当你在思考为什么会发生这种情况时,你听到一个来自通风口的低沉声音:“嘿,我是蝙蝠侠。”
|
||||
|
||||
这时,你会怎么做呢?
|
||||
|
||||
在你恐慌并处于关键节点之前,蝙蝠侠说:“我需要你的帮助。我是一个超级极客,但我不懂 HTML。我需要用 HTML 写一封情书,你愿意帮助我吗?”
|
||||
在你恐慌并处于关键时刻之前,蝙蝠侠说:“我需要你的帮助。我是一个超级极客,但我不懂 HTML。我需要用 HTML 写一封情书,你愿意帮助我吗?”
|
||||
|
||||
谁会拒绝蝙蝠侠的请求呢,对吧?所以让我们用 HTML 来写一封蝙蝠侠的情书。
|
||||
|
||||
@ -21,9 +19,9 @@ HTML 网页与你电脑上的其它文件一样。就同一个 .doc 文件以 MS
|
||||
|
||||
那么,让我们来创建一个 .html 文件。你可以在 Notepad 或其它任何编辑器中完成此任务,但我建议使用 VS Code。[在这里下载并安装 VS Code][2]。它是免费的,也是我唯一喜欢的微软产品。
|
||||
|
||||
在系统中创建一个目录,将其命名为 “HTML Practice”(不带引号)。在这个目录中,再创建一个名为 “Batman’s Love Letter”(不带引号)的目录,这将是我们的项目根目录。这意味着我们所有与这个项目相关的文件都会在这里。
|
||||
在系统中创建一个目录,将其命名为 “HTML Practice”(不带引号)。在这个目录中,再创建一个名为 “Batman's Love Letter”(不带引号)的目录,这将是我们的项目根目录。这意味着我们所有与这个项目相关的文件都会在这里。
|
||||
|
||||
打开 VS Code,按下 ctrl+n 创建一个新文件,按下 ctrl+s 保存文件。切换到 “Batman’s Love Letter” 文件夹并将其命名为 “loveletter.html”,然后单击保存。
|
||||
打开 VS Code,按下 `ctrl+n` 创建一个新文件,按下 `ctrl+s` 保存文件。切换到 “Batman's Love Letter” 文件夹并将其命名为 “loveletter.html”,然后单击保存。
|
||||
|
||||
现在,如果你在文件资源管理器中双击它,它将在你的默认浏览器中打开。我建议使用 Firefox 来进行 web 开发,但 Chrome 也可以。
|
||||
|
||||
@ -37,7 +35,7 @@ HTML 网页与你电脑上的其它文件一样。就同一个 .doc 文件以 MS
|
||||
|
||||
“After all the battles we fought together, after all the difficult times we saw together, and after all the good and bad moments we’ve been through, I think it’s time I let you know how I feel about you.”
|
||||
|
||||
复制这些到 VS Code 中的 loveletter.html。单击 View -> Toggle Word Wrap (alt+z) 自动换行。
|
||||
复制这些到 VS Code 中的 loveletter.html。单击 “View -> Toggle Word Wrap (alt+z)” 自动换行。
|
||||
|
||||
保存并在浏览器中打开它。如果它已经打开,单击浏览器中的刷新按钮。
|
||||
|
||||
@ -61,7 +59,7 @@ HTML 网页与你电脑上的其它文件一样。就同一个 .doc 文件以 MS
|
||||
|
||||
我们不希望这样。没有人想要阅读这么长的行。让我们设定段落宽度为 550px。
|
||||
|
||||
我们可以通过使用元素的 “style” 属性来实现。你可以在其 style 属性中定义元素的样式(例如,在我们的示例中为宽度)。以下行将在 “p” 元素上创建一个空样式属性:
|
||||
我们可以通过使用元素的 `style` 属性来实现。你可以在其 `style` 属性中定义元素的样式(例如,在我们的示例中为宽度)。以下行将在 `p` 元素上创建一个空样式属性:
|
||||
|
||||
```
|
||||
<p style="">...</p>
|
||||
@ -75,23 +73,25 @@ HTML 网页与你电脑上的其它文件一样。就同一个 .doc 文件以 MS
|
||||
</p>
|
||||
```
|
||||
|
||||
我们将 “width” 属性设置为 550px,用冒号 “:” 分隔,以分号 “;” 结束。
|
||||
我们将 `width` 属性设置为 `550px`,用冒号 `:` 分隔,以分号 `;` 结束。
|
||||
|
||||
另外,注意我们如何将 `<p>` 和 `</p>` 放在单独的行中,文本内容用一个 tab 缩进。像这样设置代码使其更具可读性。
|
||||
另外,注意我们如何将 `<p>` 和 `</p>` 放在单独的行中,文本内容用一个制表符缩进。像这样设置代码使其更具可读性。
|
||||
|
||||
### HTML 中的列表
|
||||
|
||||
接下来,蝙蝠侠希望列出他所钦佩的人的一些优点,例如:
|
||||
|
||||
“ You complete my darkness with your light. I love:
|
||||
```
|
||||
You complete my darkness with your light. I love:
|
||||
- the way you see good in the worst things
|
||||
- the way you handle emotionally difficult situations
|
||||
- the way you look at Justice
|
||||
I have learned a lot from you. You have occupied a special place in my heart over time.”
|
||||
I have learned a lot from you. You have occupied a special place in my heart over time.
|
||||
```
|
||||
|
||||
这看起来很简单。
|
||||
|
||||
让我们继续,在 `</p>:` 下面复制所需的文本:
|
||||
让我们继续,在 `</p>` 下面复制所需的文本:
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
@ -137,11 +137,11 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
|
||||
另外,注意我们没有写一个 `</br>`。有些标签不需要结束标签(它们被称为自闭合标签)。
|
||||
|
||||
还有一件事:我们没有在两个段落之间使用 `<br>`,但第二个段落仍然是从一个新行开始,这是因为 “p” 元素会自动插入换行符。
|
||||
还有一件事:我们没有在两个段落之间使用 `<br>`,但第二个段落仍然是从一个新行开始,这是因为 `<p>` 元素会自动插入换行符。
|
||||
|
||||
我们使用纯文本编写列表,但是有两个标签可以供我们使用来达到相同的目的:`<ul>` and `<li>`。
|
||||
|
||||
为了得到命名(to 校正:这里不太理解):ul 代表无序列表,li 代表列表项目。让我们使用它们来展示我们的列表:
|
||||
让我们解释一下名字的意思:ul 代表<ruby>无序列表<rt>Unordered List</rt></ruby>,li 代表<ruby>列表项目<rt>List Item</rt></ruby>。让我们使用它们来展示我们的列表:
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
@ -164,12 +164,9 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
在复制代码之前,注意差异部分:
|
||||
|
||||
* 我们删除了所有的 `<br>`,因为每个 `<li>` 会自动显示在新行中
|
||||
|
||||
* 我们将每个列表项包含在 `<li>` 和 `</li>` 之间
|
||||
|
||||
* 我们将所有列表项的集合包裹在 `<ul>` 和 `</ul>` 之间
|
||||
|
||||
* 我们没有像 “p” 元素那样定义 “ul” 元素的宽度。这是因为 “ul” 是 “p” 的子节点,“p” 已经被约束到 550px,所以 “ul” 不会超出这个范围。
|
||||
* 我们没有像 `<p>` 元素那样定义 `<ul>` 元素的宽度。这是因为 `<ul>` 是 `<p>` 的子节点,`<p>` 已经被约束到 550px,所以 `<ul>` 不会超出这个范围。
|
||||
|
||||
让我们保存文件并刷新浏览器以查看结果:
|
||||
|
||||
@ -177,7 +174,7 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
|
||||
你会立即注意到在每个列表项之前显示了重点标志。我们现在不需要在每个列表项之前写 “-”。
|
||||
|
||||
经过仔细检查,你会注意到最后一行超出 550px 宽度。这是为什么?因为 HTML 不允许 “ul” 元素出现在 "p" 元素中。让我们将第一行和最后一行放在单独的 “p” 元素中:
|
||||
经过仔细检查,你会注意到最后一行超出 550px 宽度。这是为什么?因为 HTML 不允许 `<ul>` 元素出现在 `<p>` 元素中。让我们将第一行和最后一行放在单独的 `<p>` 元素中:
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
@ -207,11 +204,11 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
|
||||
保存并刷新。
|
||||
|
||||
注意,这次我们还定义了 “ul” 元素的宽度。那是因为我们现在已经将 “ul” 元素放在了 “p” 元素之外。
|
||||
注意,这次我们还定义了 `<ul>` 元素的宽度。那是因为我们现在已经将 `<ul>` 元素放在了 `<p>` 元素之外。
|
||||
|
||||
定义情书中所有元素的宽度会变得很麻烦。我们有一个特定的元素用于此目的:“div” 元素。一个 “div” 元素就是一个通用容器,用于对内容进行分组,以便轻松设置样式。
|
||||
定义情书中所有元素的宽度会变得很麻烦。我们有一个特定的元素用于此目的:`<div>` 元素。一个 `<div>` 元素就是一个通用容器,用于对内容进行分组,以便轻松设置样式。
|
||||
|
||||
让我们用 div 元素包装整个情书,并为其赋予宽度:550px
|
||||
让我们用 `<div>` 元素包装整个情书,并为其赋予宽度:550px 。
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
@ -238,11 +235,11 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
|
||||
到目前为止,蝙蝠侠对结果很高兴,他希望在情书上标题。他想写一个标题: “Bat Letter”。当然,你已经看到这个名字了,不是吗?:D
|
||||
|
||||
你可以使用 ht, h2, h3, h4, h5 和 h6 标签来添加标题,h1 是最大的标题和最主要的标题,h6 是最小的标题。
|
||||
你可以使用 `<h1>`、`<h2>`、`<h3>`、`<h4>`、`<h5>` 和 `<h6>` 标签来添加标题,`<h1>` 是最大的标题和最主要的标题,`<h6>` 是最小的标题。
|
||||
|
||||

|
||||
|
||||
让我们在第二段之前使用 h1 做主标题和一个副标题:
|
||||
让我们在第二段之前使用 `<h1>` 做主标题和一个副标题:
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
@ -280,9 +277,9 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
|
||||
所以,让我们在情书中添加一个蝙蝠侠标志。
|
||||
|
||||
在 HTML 中包含图像就像在一个 Word 文件中包含图像一样。在 MS Word 中,你到 菜单 -> 插入 -> 图像 -> 然后导航到图像位置为止 -> 选择图像 -> 单击插入。
|
||||
在 HTML 中包含图像就像在一个 Word 文件中包含图像一样。在 MS Word 中,你到 “菜单 -> 插入 -> 图像 -> 然后导航到图像位置为止 -> 选择图像 -> 单击插入”。
|
||||
|
||||
在 HTML 中,我们使用 `<img>` 标签让浏览器知道我们需要加载的图像,而不是单击菜单。我们在 “src” 属性中写入文件的位置和名称。如果图像在项目根目录中,我们可以简单地在 src 属性中写入图像文件的名称。
|
||||
在 HTML 中,我们使用 `<img>` 标签让浏览器知道我们需要加载的图像,而不是单击菜单。我们在 `src` 属性中写入文件的位置和名称。如果图像在项目根目录中,我们可以简单地在 `src` 属性中写入图像文件的名称。
|
||||
|
||||
在我们深入编码之前,从[这里][3]下载蝙蝠侠标志。你可能希望裁剪图像中的额外空白区域。复制项目根目录中的图像并将其重命名为 “bat-logo.jpeg”。
|
||||
|
||||
@ -311,7 +308,7 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
</div>
|
||||
```
|
||||
|
||||
我们在第 3 行包含了 img 标签。这个标签也是一个自闭合的标签,所以我们不需要写 `</img>`。在 src 属性中,我们给出了图像文件的名称。这个名称应与图像名称完全相同,包括扩展名(.jpeg)及其大小写。
|
||||
我们在第 3 行包含了 `<img>` 标签。这个标签也是一个自闭合的标签,所以我们不需要写 `</img>`。在 `src` 属性中,我们给出了图像文件的名称。这个名称应与图像名称完全相同,包括扩展名(.jpeg)及其大小写。
|
||||
|
||||
保存并刷新,查看结果。
|
||||
|
||||
@ -319,7 +316,7 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
|
||||
该死的!刚刚发生了什么?
|
||||
|
||||
当使用 img 标签包含图像时,默认情况下,图像将以其原始分辨率显示。在我们的例子中,图像比 550px 宽得多。让我们使用 style 属性定义它的宽度:
|
||||
当使用 `<img>` 标签包含图像时,默认情况下,图像将以其原始分辨率显示。在我们的例子中,图像比 550px 宽得多。让我们使用 `style` 属性定义它的宽度:
|
||||
|
||||
|
||||
```
|
||||
@ -353,7 +350,7 @@ I have learned a lot from you. You have occupied a special place in my heart ove
|
||||
|
||||
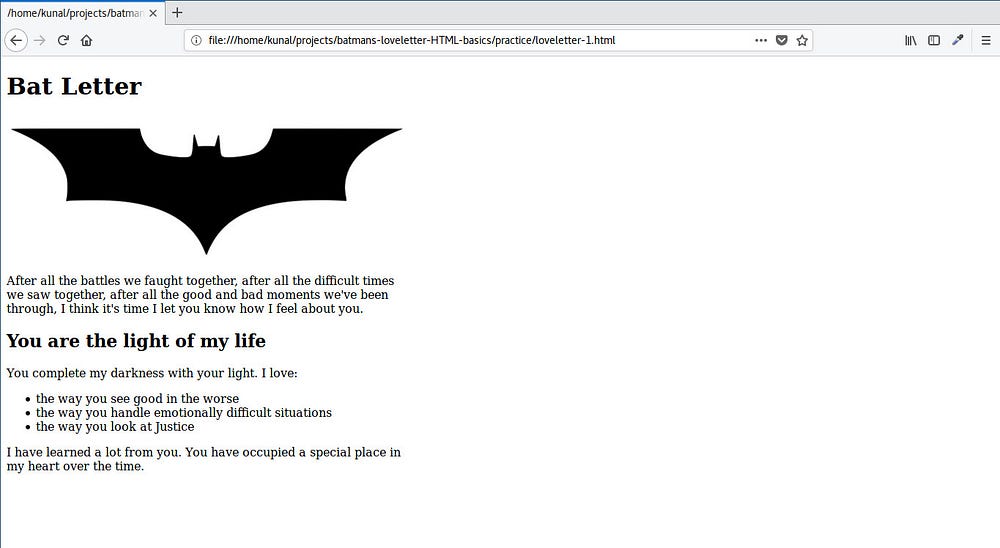
|
||||
|
||||
太棒了!这给蝙蝠侠的脸带来了胆怯的微笑 :)。(to 校正:这里什么意思)
|
||||
太棒了!这让蝙蝠侠的脸露出了羞涩的微笑 :)。
|
||||
|
||||
### HTML 中的粗体和斜体
|
||||
|
||||
@ -373,7 +370,7 @@ I don’t show my emotions, but I think this man behind the mask is falling for
|
||||
|
||||
你说:哦!我还以为是给神奇女侠的呢。
|
||||
|
||||
蝙蝠侠说:不,这是给超人的,请在最后写上“I love you Superman.”。
|
||||
蝙蝠侠说:不,这是给超人的,请在最后写上 “I love you Superman.”。
|
||||
|
||||
好的,我们来写:
|
||||
|
||||
@ -462,13 +459,11 @@ I don’t show my emotions, but I think this man behind the mask is falling for
|
||||
|
||||
你可以通过三种方式设置样式或定义 HTML 元素的外观:
|
||||
|
||||
* 内联样式:我们使用元素的 “style” 属性来编写样式。这是我们迄今为止使用的,但这不是一个好的实践。
|
||||
|
||||
* 嵌入式样式:我们在由 <style> 和 </style> 包裹的 “style” 元素中编写所有样式。
|
||||
|
||||
* 内联样式:我们使用元素的 `style` 属性来编写样式。这是我们迄今为止使用的,但这不是一个好的实践。
|
||||
* 嵌入式样式:我们在由 `<style>` 和 `</style>` 包裹的 “style” 元素中编写所有样式。
|
||||
* 链接样式表:我们在具有 .css 扩展名的单独文件中编写所有元素的样式。此文件称为样式表。
|
||||
|
||||
让我们来看看如何定义 “div” 的内联样式:
|
||||
让我们来看看如何定义 `<div>` 的内联样式:
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
@ -484,9 +479,9 @@ div{
|
||||
|
||||
在嵌入式样式中,我们编写的样式是与元素分开的。所以我们需要一种方法来关联元素及其样式。第一个单词 “div” 就做了这样的活。它让浏览器知道花括号 `{...}` 里面的所有样式都属于 “div” 元素。由于这种语法确定要应用样式的元素,因此它称为一个选择器。
|
||||
|
||||
我们编写样式的方式保持不变:属性(宽度)和值(550px)用冒号(:)分隔,以分号(;)结束。
|
||||
我们编写样式的方式保持不变:属性(`width`)和值(`550px`)用冒号(`:`)分隔,以分号(`;`)结束。
|
||||
|
||||
让我们从 “div” 和 “img” 元素中删除内联样式,将其写入 `<style>` 元素:
|
||||
让我们从 `<div>` 和 `<img>` 元素中删除内联样式,将其写入 `<style>` 元素:
|
||||
|
||||
```
|
||||
<style>
|
||||
@ -538,11 +533,11 @@ div{
|
||||
|
||||
保存并刷新,结果应保持不变。
|
||||
|
||||
但是有一个大问题,如果我们的 HTML 文件中有多个 “div” 和 “img” 元素该怎么办?这样我们在 “style” 元素中为 div 和 img 定义的样式就会应用于页面上的每个 div 和 img。
|
||||
但是有一个大问题,如果我们的 HTML 文件中有多个 `<div>` 和 `<img>` 元素该怎么办?这样我们在 `<style>` 元素中为 div 和 img 定义的样式就会应用于页面上的每个 div 和 img。
|
||||
|
||||
如果你在以后的代码中添加另一个 div,那么该 div 也将变为 550px 宽。我们并不希望这样。
|
||||
|
||||
我们想要将我们的样式应用于现在正在使用的特定 div 和 img。为此,我们需要为 div 和 img 元素提供唯一的 id。以下是使用 “id” 属性为元素赋予 id 的方法:
|
||||
我们想要将我们的样式应用于现在正在使用的特定 div 和 img。为此,我们需要为 div 和 img 元素提供唯一的 id。以下是使用 `id` 属性为元素赋予 id 的方法:
|
||||
|
||||
```
|
||||
<div id="letter-container">
|
||||
@ -556,7 +551,7 @@ div{
|
||||
}
|
||||
```
|
||||
|
||||
注意 “#” 符号。它表示它是一个 id,{...} 中的样式应该只应用于具有该特定 id 的元素。
|
||||
注意 `#` 符号。它表示它是一个 id,`{...}` 中的样式应该只应用于具有该特定 id 的元素。
|
||||
|
||||
让我们来应用它:
|
||||
|
||||
@ -610,11 +605,11 @@ div{
|
||||
|
||||
HTML 已经准备好了嵌入式样式。
|
||||
|
||||
但是,你可以看到,随着我们包含越来越多的样式,<style></style> 将变得很大。这可能很快会混乱我们的主 HTML 文件。
|
||||
但是,你可以看到,随着我们包含越来越多的样式,`<style></style>` 将变得很大。这可能很快会混乱我们的主 HTML 文件。
|
||||
|
||||
因此,让我们更进一步,通过将 style 标签内的内容复制到一个新文件来使用链接样式。
|
||||
因此,让我们更进一步,通过将 `<style>` 标签内的内容复制到一个新文件来使用链接样式。
|
||||
|
||||
在项目根目录中创建一个新文件,将其另存为 style.css:
|
||||
在项目根目录中创建一个新文件,将其另存为 “style.css”:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
@ -633,15 +628,13 @@ HTML 已经准备好了嵌入式样式。
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
```
|
||||
|
||||
我们使用 link 元素在 HTML 文档中包含外部资源,它主要用于链接样式表。我们使用的三个属性是:
|
||||
我们使用 `<link>` 元素在 HTML 文档中包含外部资源,它主要用于链接样式表。我们使用的三个属性是:
|
||||
|
||||
* rel:关系。链接文件与文档的关系。具有 .css 扩展名的文件称为样式表,因此我们保留 rel=“stylesheet”。
|
||||
* `rel`:关系。链接文件与文档的关系。具有 .css 扩展名的文件称为样式表,因此我们保留 rel=“stylesheet”。
|
||||
* `type`:链接文件的类型;对于一个 CSS 文件来说它是 “text/css”。
|
||||
* `href`:超文本参考。链接文件的位置。
|
||||
|
||||
* type:链接文件的类型;对于一个 CSS 文件来说它是 “text/css”。
|
||||
|
||||
* href:超文本参考。链接文件的位置。
|
||||
|
||||
link 元素的结尾没有 </link>。因此,<link> 也是一个自闭合的标签。
|
||||
link 元素的结尾没有 `</link>`。因此,`<link>` 也是一个自闭合的标签。
|
||||
|
||||
```
|
||||
<link rel="gf" type="cute" href="girl.next.door">
|
||||
@ -651,7 +644,7 @@ link 元素的结尾没有 </link>。因此,<link> 也是一个自闭合的标
|
||||
|
||||
可惜没有那么简单,让我们继续前进。
|
||||
|
||||
这是我们 loveletter.html 的内容:
|
||||
这是我们 “loveletter.html” 的内容:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
@ -688,7 +681,7 @@ link 元素的结尾没有 </link>。因此,<link> 也是一个自闭合的标
|
||||
</div>
|
||||
```
|
||||
|
||||
style.css 内容:
|
||||
“style.css” 内容:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
@ -701,7 +694,6 @@ style.css 内容:
|
||||
|
||||
保存文件并刷新,浏览器中的输出应保持不变。
|
||||
|
||||
|
||||
### 一些手续
|
||||
|
||||
我们的情书已经准备好给蝙蝠侠,但还有一些正式的片段。
|
||||
@ -710,7 +702,7 @@ style.css 内容:
|
||||
|
||||
那么,浏览器如何知道你使用哪个版本的 HTML 来编写页面呢?要告诉浏览器你正在使用 HTML5,你需要在页面顶部包含 `<!DOCTYPE html>`。对于旧版本的 HTML,这行不同,但你不需要了解它们,因为我们不再使用它们了。
|
||||
|
||||
此外,在之前的 HTML 版本中,我们曾经将整个文档封装在 `<html></html>` 标签内。整个文件分为两个主要部分:Head 在 `<head></head>` 里面,Body 在 `<body></body>` 里面。这在 HTML5 中不是必须的,但由于兼容性原因,我们仍然这样做。让我们用 `<Doctype>`, `<html>`, `<head>` 和 `<body>` 更新我们的代码:
|
||||
此外,在之前的 HTML 版本中,我们曾经将整个文档封装在 `<html></html>` 标签内。整个文件分为两个主要部分:头部在 `<head></head>` 里面,主体在 `<body></body>` 里面。这在 HTML5 中不是必须的,但由于兼容性原因,我们仍然这样做。让我们用 `<Doctype>`, `<html>`、 `<head>` 和 `<body>` 更新我们的代码:
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
@ -754,7 +746,7 @@ style.css 内容:
|
||||
</html>
|
||||
```
|
||||
|
||||
主要内容在 `<body>` 里面,元信息在 `<head>` 里面。所以我们把 div 保存在 `<body>` 里面并加载 `<head>` 里面的样式表。
|
||||
主要内容在 `<body>` 里面,元信息在 `<head>` 里面。所以我们把 `<div>` 保存在 `<body>` 里面并加载 `<head>` 里面的样式表。
|
||||
|
||||
保存并刷新,你的 HTML 页面应显示与之前相同的内容。
|
||||
|
||||
@ -766,7 +758,7 @@ style.css 内容:
|
||||
|
||||
|
||||
|
||||
我们可以使用 `<title>` 标签来定义 HTML 文件的标题。标题标签也像链接标签一样在 head 内部。让我们我们在标题中加上 “Bat Letter”:
|
||||
我们可以使用 `<title>` 标签来定义 HTML 文件的标题。标题标签也像链接标签一样在 `<head>` 内部。让我们我们在标题中加上 “Bat Letter”:
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
@ -824,70 +816,41 @@ style.css 内容:
|
||||
我们学习了以下新概念:
|
||||
|
||||
* 一个 HTML 文档的结构
|
||||
|
||||
* 在 HTML 中如何写元素(\<p>\</p>)
|
||||
|
||||
* 在 HTML 中如何写元素(`<p></p>`)
|
||||
* 如何使用 style 属性在元素内编写样式(这称为内联样式,尽可能避免这种情况)
|
||||
|
||||
* 如何在 <style>...</style> 中编写元素的样式(这称为嵌入式样式)
|
||||
|
||||
* 在 HTML 中如何使用 <link> 在单独的文件中编写样式并链接它(这称为链接样式表)
|
||||
|
||||
* 如何在 `<style>...</style>` 中编写元素的样式(这称为嵌入式样式)
|
||||
* 在 HTML 中如何使用 `<link>` 在单独的文件中编写样式并链接它(这称为链接样式表)
|
||||
* 什么是标签名称,属性,开始标签和结束标签
|
||||
|
||||
* 如何使用 id 属性为一个元素赋予 id
|
||||
|
||||
* CSS 中的标签选择器和 id 选择器
|
||||
|
||||
我们学习了以下 HTML 标签:
|
||||
|
||||
* \<p>:用于段落
|
||||
* `<p>`:用于段落
|
||||
* `<br>`:用于换行
|
||||
* `<ul>`、`<li>`:显示列表
|
||||
* `<div>`:用于分组我们信件的元素
|
||||
* `<h1>`、`<h2>`:用于标题和子标题
|
||||
* `<img>`:用于插入图像
|
||||
* `<strong>`、`<em>`:用于粗体和斜体文字样式
|
||||
* `<style>`:用于嵌入式样式
|
||||
* `<link>`:用于包含外部样式表
|
||||
* `<html>`:用于包裹整个 HTML 文档
|
||||
* `<!DOCTYPE html>`:让浏览器知道我们正在使用 HTML5
|
||||
* `<head>`:包裹元信息,如 `<link>` 和 `<title>`
|
||||
* `<body>`:用于实际显示的 HTML 页面的主体
|
||||
* `<title>`:用于 HTML 页面的标题
|
||||
|
||||
* \<br>:用于换行
|
||||
|
||||
* \<ul>, \<li>:显示列表
|
||||
|
||||
* \<div>:用于分组我们信件的元素
|
||||
|
||||
* \<h1>, \<h2>:用于标题和子标题
|
||||
|
||||
* \<img>:用于插入图像
|
||||
|
||||
* \<strong>, \<em>:用于粗体和斜体文字样式
|
||||
|
||||
* \<style>:用于嵌入式样式
|
||||
|
||||
* \<link>:用于包含外部样式表
|
||||
|
||||
* \<html>:用于包裹整个 HTML 文档
|
||||
|
||||
* \<!DOCTYPE html>:让浏览器知道我们正在使用 HTML5
|
||||
|
||||
* \<head>:包裹元信息,如 \<link> 和 \<title>
|
||||
|
||||
* \<body>:用于实际显示的 HTML 页面的主体
|
||||
|
||||
* \<title>:用于 HTML 页面的标题
|
||||
|
||||
我们学习了以下 CSS 属性:
|
||||
我们学习了以下 CSS 属性:
|
||||
|
||||
* width:用于定义元素的宽度
|
||||
|
||||
* CSS 单位:“px” 和 “%”
|
||||
|
||||
朋友们,这就是今天的全部了,下一个教程中见。
|
||||
|
||||
***
|
||||
|
||||
想通过有趣且引人入胜的教程学习 Web 开发?
|
||||
|
||||
[点击这里获取每周新的 Web 开发教程][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
开发者 + 作者 | supersarkar.com | twitter.com/supersarkar
|
||||
作者简介:开发者 + 作者 | supersarkar.com | twitter.com/supersarkar
|
||||
|
||||
-------------
|
||||
|
||||
@ -895,7 +858,8 @@ via: https://medium.freecodecamp.org/for-your-first-html-code-lets-help-batman-w
|
||||
|
||||
作者:[Kunal Sarkar][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@supersarkar
|
||||
177
published/20180228 Emacs -2- Introducing org-mode.md
Normal file
177
published/20180228 Emacs -2- Introducing org-mode.md
Normal file
@ -0,0 +1,177 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (Emacs #2: Introducing org-mode)
|
||||
[#]: via: (https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode)
|
||||
[#]: author: (John Goerzen http://changelog.complete.org/archives/author/jgoerzen)
|
||||
[#]: url: (https://linux.cn/article-10312-1.html)
|
||||
|
||||
Emacs 系列(二):org 模式介绍
|
||||
======
|
||||
|
||||
在我 Emacs 系列中的[第一篇文章][1]里,我介绍了我在用了几十年的 vim 后转向了 Emacs,org 模式就是我为什么这样做的原因。
|
||||
|
||||
org 模式的精简和高效真的震惊了我,它真的是个“杀手”应用。
|
||||
|
||||
### 所以,org 模式到底是什么呢?
|
||||
|
||||
这是我昨天写的:
|
||||
|
||||
> 它是一个组织信息的平台,它的主页上这样写着:“一切都是纯文本:org 模式用于记笔记、维护待办事项列表、计划项目和使用快速有效的纯文本系统编写文档。”
|
||||
|
||||
这是事实,但并不是很准确。org 模式是一个你用来组织事务的小工具。它有一些非常合理的默认设置,但也允许你自己定制。
|
||||
|
||||
主要突出在这几件事上:
|
||||
|
||||
* **维护待办事项列表**:项目可以分散在 org 文件中,包含附件,有标签、截止日期、时间表。有一个方便的“日程”视图,显示需要做什么。项目也可以重复。
|
||||
* **编写文档**:org 模式有个特殊的功能来生成 HTML、LaTeX、幻灯片(用 LaTeX beamer)和其他所有的格式。它也支持直接在缓冲区中运行和以 Emacs 所支持的的语言进行<ruby>文学编程<rt>literate programming</rt></ruby>。如果你想要深入了解这项功能的话,参阅[这篇文学式 DevOps 的文章][2]。而 [整个 Worg 网站][3] 是用 org 模式开发的。
|
||||
* **记笔记**:对,它也能做笔记。通过全文搜索,文件的交叉引用(类似 wiki),UUID,甚至可以与其他的系统进行交互(通过 Message-ID 与 mu4e 交互,通过 ERC 的日志等等……)。
|
||||
|
||||
### 入门
|
||||
|
||||
我强烈建议去阅读 [Carsten Dominik 关于 org 模式的一篇很棒的 Google 讲话][4]。那篇文章真的很赞。
|
||||
|
||||
在 Emacs 中带有 org 模式,但如果你想要个比较新的版本的话,Debian 用户可以使用命令 `apt-get install org-mode` 来更新,或者使用 Emacs 的包管理系统命令 `M-x package-install RET org-mode RET`。
|
||||
|
||||
现在,你可能需要阅读一下 org 模式的精简版教程中的[导读部分][5],特别注意,你要设置下[启动部分][6]中提到的那些键的绑定。
|
||||
|
||||
### 一份好的教程
|
||||
|
||||
我会给出一些好的教程和介绍的链接,但这篇文章不会是一篇教程。特别是在本文末尾,有两个很不错的视频链接。
|
||||
|
||||
### 我的一些配置
|
||||
|
||||
我将在这里记录下一些我的配置并介绍它的作用。你没有必要每行每句将它拷贝到你的配置中 —— 这只是一个参考,告诉你哪些可以配置,要怎么在手册中查找,或许只是一个“我现在该怎么做”的参考。
|
||||
|
||||
首先,我将 Emacs 的编码默认设置为 UTF-8。
|
||||
|
||||
```
|
||||
(prefer-coding-system 'utf-8)
|
||||
(set-language-environment "UTF-8")
|
||||
```
|
||||
|
||||
org 模式中可以打开 URL。默认的,它会在 Firefox 中打开,但我喜欢用 Chromium。
|
||||
|
||||
```
|
||||
(setq browse-url-browser-function 'browse-url-chromium)
|
||||
```
|
||||
|
||||
我把基本的键的绑定和设为教程里的一样,再加上 `M-RET` 的操作的配置。
|
||||
|
||||
```
|
||||
(global-set-key "\C-cl" 'org-store-link)
|
||||
(global-set-key "\C-ca" 'org-agenda)
|
||||
(global-set-key "\C-cc" 'org-capture)
|
||||
(global-set-key "\C-cb" 'org-iswitchb)
|
||||
|
||||
(setq org-M-RET-may-split-line nil)
|
||||
```
|
||||
|
||||
|
||||
### 捕获配置
|
||||
|
||||
我可以在 Emacs 的任何模式中按 `C-c c`,按下后它就会[帮我捕获某些事][7],其中包括一个指向我正在处理事务的链接。
|
||||
|
||||
你可以通过定义[捕获模板][8]来配置它。我将保存两个日志文件,作为会议、电话等的通用记录。一个是私人用的,一个是办公用的。如果我按下 `C-c c j`,它就会帮我捕获为私人项. 下面包含 `%a` 的配置是表示我当前的位置(或是我使用 `C-c l` 保存的链接)的链接。
|
||||
|
||||
```
|
||||
(setq org-default-notes-file "~/org/tasks.org")
|
||||
(setq org-capture-templates
|
||||
'(
|
||||
("t" "Todo" entry (file+headline "inbox.org" "Tasks")
|
||||
"* TODO %?\n %i\n %u\n %a")
|
||||
("n" "Note/Data" entry (file+headline "inbox.org" "Notes/Data")
|
||||
"* %? \n %i\n %u\n %a")
|
||||
("j" "Journal" entry (file+datetree "~/org/journal.org")
|
||||
"* %?\nEntered on %U\n %i\n %a")
|
||||
("J" "Work-Journal" entry (file+datetree "~/org/wjournal.org")
|
||||
"* %?\nEntered on %U\n %i\n %a")
|
||||
))
|
||||
(setq org-irc-link-to-logs t)
|
||||
```
|
||||
|
||||
我喜欢通过 UUID 来建立链接,这让我在文件之间移动而不会破坏位置。当我要 org 存储一个链接目标以便将来插入时,以下配置有助于生成 UUID。
|
||||
|
||||
```
|
||||
(require 'org-id)
|
||||
(setq org-id-link-to-org-use-id 'create-if-interactive)
|
||||
```
|
||||
|
||||
### 议程配置
|
||||
|
||||
我喜欢将星期天作为一周的开始,当我将某件事标记为完成时,我也喜欢记下时间。
|
||||
|
||||
```
|
||||
(setq org-log-done 'time)
|
||||
(setq org-agenda-start-on-weekday 0)
|
||||
```
|
||||
|
||||
### 文件归档配置
|
||||
|
||||
在这我将配置它,让它知道在议程中该使用哪些文件,而且在纯文本的搜索中添加一点点小功能。我喜欢保留一个通用的文件夹(我可以从其中移动或“重新归档”内容),然后将个人和工作项的任务、日志和知识库分开。
|
||||
|
||||
```
|
||||
(setq org-agenda-files (list "~/org/inbox.org"
|
||||
"~/org/email.org"
|
||||
"~/org/tasks.org"
|
||||
"~/org/wtasks.org"
|
||||
"~/org/journal.org"
|
||||
"~/org/wjournal.org"
|
||||
"~/org/kb.org"
|
||||
"~/org/wkb.org"
|
||||
))
|
||||
(setq org-agenda-text-search-extra-files
|
||||
(list "~/org/someday.org"
|
||||
"~/org/config.org"
|
||||
))
|
||||
|
||||
(setq org-refile-targets '((nil :maxlevel . 2)
|
||||
(org-agenda-files :maxlevel . 2)
|
||||
("~/org/someday.org" :maxlevel . 2)
|
||||
("~/org/templates.org" :maxlevel . 2)
|
||||
)
|
||||
)
|
||||
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
|
||||
(setq org-refile-use-outline-path 'file)
|
||||
```
|
||||
|
||||
### 外观配置
|
||||
|
||||
我喜欢一个较漂亮的的屏幕。在你开始习惯 org 模式之后,你可以试试这个。
|
||||
|
||||
```
|
||||
(add-hook 'org-mode-hook
|
||||
(lambda ()
|
||||
(org-bullets-mode t)))
|
||||
(setq org-ellipsis "⤵")
|
||||
```
|
||||
|
||||
### 下一篇
|
||||
|
||||
希望这篇文章展示了 org 模式的一些功能。接下来,我将介绍如何定制 `TODO` 关键字和标记、归档旧任务、将电子邮件转发到 org 模式,以及如何使用 `git` 在不同电脑之间进行同步。
|
||||
|
||||
你也可以查看[本系列的所有文章列表][9]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://changelog.complete.org/archives/author/jgoerzen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10297-1.html
|
||||
[2]: http://www.howardism.org/Technical/Emacs/literate-devops.html
|
||||
[3]: https://orgmode.org/worg/
|
||||
[4]: https://www.youtube.com/watch?v=oJTwQvgfgMM
|
||||
[5]: https://orgmode.org/guide/Introduction.html#Introduction
|
||||
[6]: https://orgmode.org/guide/Activation.html#Activation
|
||||
[7]: https://orgmode.org/guide/Capture.html#Capture
|
||||
[8]: https://orgmode.org/guide/Capture-templates.html#Capture-templates
|
||||
[9]: https://changelog.complete.org/archives/tag/emacs2018
|
||||
@ -0,0 +1,221 @@
|
||||
如何在 Linux 中从一个 PDF 文件中移除密码
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我碰巧分享一个受密码保护的 PDF 文件给我的一个朋友。我知道这个 PDF 文件的密码,但是我不想透露密码。作为代替,我只想移除密码并发送文件给他。我开始在因特网上查找一些简单的方法来从 PDF 文件中移除密码保护。在快速 google 搜索后,在 Linux 中,我带来四种方法来从一个 PDF 文件中移除密码。有趣的事是,在几年以前我已经做过这事情但是我忘记了。如果你想知道,如何在 Linux 中从一个 PDF 文件移除密码,继续读!它是不难的。
|
||||
|
||||
### 在Linux中从一个PDF文件中移除密码
|
||||
|
||||
#### 方法 1 – 使用 Qpdf
|
||||
|
||||
**Qpdf** 是一个 PDF 转换软件,它被用于加密和解密 PDF 文件,转换 PDF 文件到其他等效的 PDF 文件。 Qpdf 在大多数 Linux 发行版中的默认存储库中是可用的,所以你可以使用默认的软件包安装它。
|
||||
|
||||
例如,Qpdf 可以被安装在 Arch Linux 和它的衍生版,使用 [pacman][1] ,像下面显示。
|
||||
|
||||
```
|
||||
$ sudo pacman -S qpdf
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install qpdf
|
||||
```
|
||||
|
||||
现在,让我们使用 qpdf 从一个 pdf 文件移除密码。
|
||||
|
||||
我有一个受密码保护的 PDF 文件,名为 `secure.pdf`。每当我打开这个文件时,它提示我输入密码来显示它的内容。
|
||||
|
||||
![][3]
|
||||
|
||||
我知道上面 PDF 文件的密码。然而,我不想与任何人共享密码。所以,我将要做的事是简单地移除 PDF 文件的密码,使用 Qpdf 功能带有下面的命令。
|
||||
|
||||
```
|
||||
$ qpdf --password='123456' --decrypt secure.pdf output.pdf
|
||||
```
|
||||
|
||||
相当简单,不是吗?是的,它是!这里,`123456` 是 `secure.pdf` 文件的密码。用你自己的密码替换。
|
||||
|
||||
#### 方法 2 – 使用 Pdftk
|
||||
|
||||
**Pdftk** 是另一个用于操作 PDF 文件的好软件。 Pdftk 可以做几乎所有的 PDF 操作,例如:
|
||||
|
||||
* 加密和解密 PDF 文件。
|
||||
* 合并 PDF 文档。
|
||||
* 整理 PDF 页扫描。
|
||||
* 拆分 PDF 页。
|
||||
* 旋转 PDF 文件或页。
|
||||
* 用 X/FDF 数据 填充 PDF 表单,和/或摧毁表单。
|
||||
* 从 PDF 表单中生成 PDF数据模板。
|
||||
* 应用一个背景水印,或一个前景印记。
|
||||
* 报告 PDF 度量标准、书签和元数据。
|
||||
* 添加/更新 PDF 书签或元数据。
|
||||
* 附加文件到 PDF 页,或 PDF 文档。
|
||||
* 解包 PDF 附件。
|
||||
* 拆解一个 PDF 文件到单页中。
|
||||
* 压缩和解压缩页流。
|
||||
* 修复破损的 PDF 文件。
|
||||
|
||||
Pddftk 在 AUR 中是可用的,所以你可以在 Arch Linux 和它的衍生版上使用任意 AUR 帮助程序安装它。
|
||||
|
||||
使用 [Pacaur][4]:
|
||||
|
||||
```
|
||||
$ pacaur -S pdftk
|
||||
```
|
||||
|
||||
使用 [Packer][5]:
|
||||
|
||||
```
|
||||
$ packer -S pdftk
|
||||
```
|
||||
|
||||
使用 [Trizen][6]:
|
||||
|
||||
```
|
||||
$ trizen -S pdftk
|
||||
```
|
||||
|
||||
使用 [Yay][7]:
|
||||
|
||||
```
|
||||
$ yay -S pdftk
|
||||
```
|
||||
|
||||
使用 [Yaourt][8]:
|
||||
|
||||
```
|
||||
$ yaourt -S pdftk
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上,运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get instal pdftk
|
||||
```
|
||||
|
||||
在 CentOS、Fedora、Red Hat 上:
|
||||
|
||||
首先,安装 EPEL 仓库:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
$ sudo dnf install epel-release
|
||||
```
|
||||
|
||||
然后,安装 PDFtk 应用程序,使用命令:
|
||||
|
||||
```
|
||||
$ sudo yum install pdftk
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ sudo dnf install pdftk
|
||||
```
|
||||
|
||||
一旦 pdftk 安装,你可以从一个 PDF 文档移除密码,使用命令:
|
||||
|
||||
```
|
||||
$ pdftk secure.pdf input_pw 123456 output output.pdf
|
||||
```
|
||||
|
||||
用你正确的密码替换 `123456`。这个命令解密 `secure.pdf` 文件,并创建一个相同的名为 `output.pdf` 的无密码保护的文件。
|
||||
|
||||
**参阅:**
|
||||
|
||||
- [How To Merge PDF Files In Command Line On Linux][9]
|
||||
- [How To Split or Extract Particular Pages From A PDF File][10]
|
||||
|
||||
#### 方法 3 – 使用 Poppler
|
||||
|
||||
**Poppler** 是一个基于 xpdf-3.0 代码库的 PDF 渲染库。它包含下列用于操作 PDF 文档的命令行功能集。
|
||||
|
||||
* `pdfdetach` – 列出或提取嵌入的文件。
|
||||
* `pdffonts` – 字体分析器。
|
||||
* `pdfimages` – 图片提取器。
|
||||
* `pdfinfo` – 文档信息。
|
||||
* `pdfseparate` – 页提取工具。
|
||||
* `pdfsig` – 核查数字签名。
|
||||
* `pdftocairo` – PDF 到 PNG/JPEG/PDF/PS/EPS/SVG 转换器,使用 Cairo 。
|
||||
* `pdftohtml` – PDF 到 HTML 转换器。
|
||||
* `pdftoppm` – PDF 到 PPM/PNG/JPEG 图片转换器。
|
||||
* `pdftops` – PDF 到 PostScript (PS) 转换器。
|
||||
* `pdftotext` – 文本提取。
|
||||
* `pdfunite` – 文档合并工具。
|
||||
|
||||
因这个指南的目的,我们仅使用 `pdftops` 功能。
|
||||
|
||||
在基于 Arch Linux 的发行版上,安装 Poppler,运行:
|
||||
|
||||
```
|
||||
$ sudo pacman -S poppler
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install poppler-utils
|
||||
```
|
||||
|
||||
在 RHEL、CentOS、Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo yum install poppler-utils
|
||||
```
|
||||
|
||||
一旦 Poppler 安装,运行下列命令来解密密码保护的 PDF 文件,并创建一个新的相同的名为 `output.pdf` 的文件。
|
||||
|
||||
```
|
||||
$ pdftops -upw 123456 secure.pdf output.pdf
|
||||
|
||||
```
|
||||
|
||||
再一次,用你的 pdf 密码替换 `123456` 。
|
||||
|
||||
正如你在上面方法中可能注意到,我们仅转换密码保护的名为 `secure.pdf` 的 PDF 文件到另一个相同的名为 `output.pdf` 的 PDF 文件。技术上讲,我们并没有真的从源文件中移除密码,作为代替,我们解密它,并保存它为另一个相同的没有密码保护的 PDF 文件。
|
||||
|
||||
#### 方法 4 – 打印到一个文件
|
||||
|
||||
这是在所有上面方法中的最简单的方法。你可以使用你存在的 PDF 查看器,例如 Atril 文档查看器、Evince 等等,并打印密码保护的 PDF 文件到另一个文件。
|
||||
|
||||
在你的 PDF 查看器应用程序中打开密码保护的文件。转到 “File - > Print” 。并在你选择的某个位置保存 PDF 文件。
|
||||
|
||||
![][2]
|
||||
|
||||
于是,这是全部。希望这是有用的。你知道/使用一些其它方法来从从 PDF 文件中移除密码保护吗?在下面的评价区让我们知道。
|
||||
|
||||
更多好东西来了。敬请期待!
|
||||
|
||||
谢谢!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-remove-password-from-a-pdf-file-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:https://www.ostechnix.com/wp-content/uploads/2018/04/Remove-Password-From-A-PDF-File-2.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/04/Remove-Password-From-A-PDF-File-1.png
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[9]: https://www.ostechnix.com/how-to-merge-pdf-files-in-command-line-on-linux/
|
||||
[10]: https://www.ostechnix.com/extract-particular-pages-pdf-file/
|
||||
@ -1,38 +1,40 @@
|
||||
如何实现 Linux + Windows 双系统启动
|
||||
=====
|
||||
> 设置你的计算机根据需要启动 Windows 10 或 Ubuntu 18.04。
|
||||
|
||||

|
||||
|
||||
尽管 Linux 是一个有着广泛的硬件和软件支持的操作系统,但事实上有时你仍需要使用 Windows,也许是因为有些不能在 Linux 下运行的重要软件。但幸运地是, 双启动 Windows 和 Linux 是很简单的—在这篇文章中我将会向你展示如何实现 Windows 10 + Ubuntu 18.04 双系统启动。
|
||||
尽管 Linux 是一个有着广泛的硬件和软件支持的操作系统,但事实上有时你仍需要使用 Windows,也许是因为有些不能在 Linux 下运行的重要软件。但幸运地是,双启动 Windows 和 Linux 是很简单的 —— 在这篇文章中我将会向你展示如何实现 Windows 10 + Ubuntu 18.04 双系统启动。
|
||||
|
||||
在你开始之前,确保你已经备份了你的电脑文件。 虽然设置双启动过程不是非常复杂,但意外有可能仍会发生。所以花一点时间来备份你的重要文件以防混沌理论发挥作用。除了备份你的文件之外,考虑制作一份备份镜像也是个不错的选择,虽然这不是必需的且会变成一个更高级的过程。
|
||||
在你开始之前,确保你已经备份了你的电脑文件。虽然设置双启动过程不是非常复杂,但意外有可能仍会发生。所以花一点时间来备份你的重要文件以防混沌理论发挥作用。除了备份你的文件之外,考虑制作一份备份镜像也是个不错的选择,虽然这不是必需的且会变成一个更高级的过程。
|
||||
|
||||
### 要求
|
||||
|
||||
为了开始,你将需要以下5项东西:
|
||||
为了开始,你将需要以下 5 项东西:
|
||||
|
||||
#### 1\. 两个 USB 闪存盘(或者 DVD-Rs)
|
||||
#### 1、两个 USB 闪存盘(或者 DVD-R)
|
||||
|
||||
我推荐用 USB 闪存盘来安装 Windows 和 Ubuntu,因为他们比 DVDs 更快。这通常是毋庸置疑的, 但是创建一个可启动的介质会抹除闪存盘上的一切东西。因此,确保闪存盘是空的或者其包含的文件是你不再需要的。
|
||||
我推荐用 USB 闪存盘来安装 Windows 和 Ubuntu,因为他们比 DVD 更快。这通常是毋庸置疑的, 但是创建一个可启动的介质会抹除闪存盘上的一切东西。因此,确保闪存盘是空的或者其包含的文件是你不再需要的。
|
||||
|
||||
如果你的电脑不支持从 USB 启动,你可以创建 DVD 介质来代替。不幸的是, 因为没有两台电脑似乎有相同的 DVD 烧录软件,所以我无法引导这一过程。 然而,如果你的 DVD 烧录软件有从一个 ISO 镜像中烧录的选项,这个选项是你需要的。
|
||||
如果你的电脑不支持从 USB 启动,你可以创建 DVD 介质来代替。不幸的是,因为电脑上的 DVD 烧录软件似乎各有不同,所以我无法使用这一过程。然而,如果你的 DVD 烧录软件有从一个 ISO 镜像中烧录的选项,这个选项是你需要的。
|
||||
|
||||
#### 2\. 一份 Windows 10 许可证
|
||||
#### 2、一份 Windows 10 许可证
|
||||
|
||||
如果你的电脑已经安装 Windows 10,那么许可证将会被安装到你的电脑中,所以你不需要担心在安装过程中输入它。如果你购买的是零售版,你应该拥有一个需要在安装过程中输入的产品密钥。
|
||||
|
||||
#### 3\. Windows 10介质创建工具
|
||||
#### 3、Windows 10 介质创建工具
|
||||
|
||||
下载并运行 Windows 10 [介质创建工具][1]。一旦你运行这个工具,它将会引导你完成在一个 USB 或者 DVD-R 上创建 Windows 安装介质的所需步骤。注意: 即使你已经安装了 Windows 10 。总之创建一个可引导的介质是一个不错的主意,万一刚好系统出错了且需要你重新安装。
|
||||
下载并运行 Windows 10 [介质创建工具][1]。一旦你运行这个工具,它将会引导你完成在一个 USB 或者 DVD-R 上创建 Windows 安装介质的所需步骤。注意:即使你已经安装了 Windows 10,创建一个可引导的介质也是一个不错的主意,万一刚好系统出错了且需要你重新安装。
|
||||
|
||||
#### 4\. Ubuntu 18.04 安装介质
|
||||
#### 4、Ubuntu 18.04 安装介质
|
||||
|
||||
下载 [Ubuntu 18.04][2] ISO 镜像。
|
||||
|
||||
#### 5\. Etcher 软件(用于制作一个可引导 Ubuntu 的 USB 驱动器)
|
||||
用于为任何 Linux 发型版本创建可启动的介质的工具,我推荐 [Etcher][3]。Etcher 可以在三大主流操作系统(Linux,MacOS,和 Windows)上运行且不会让你覆盖当前操作系统的分区。
|
||||
#### 5、Etcher 软件(用于制作一个可引导 Ubuntu 的 USB 驱动器)
|
||||
|
||||
一旦你下载完成并运行 Etcher,点击选择镜像并指向你在步骤4中下载的 Ubuntu ISO 镜像, 接下来, 点击驱动器以选择你的闪存驱动器,然后点击 ` Flash!` 开始将闪存驱动器转化为一个 Ubuntu 安装器的过程。 (如果你正使用一个 DVD-R, 使用你电脑中的 DVD 烧录软件来完成此过程。)
|
||||
用于为任何 Linux 发行版创建可启动的介质的工具,我推荐 [Etcher][3]。Etcher 可以在三大主流操作系统(Linux、MacOS 和 Windows)上运行且不会让你覆盖当前操作系统的分区。
|
||||
|
||||
一旦你下载完成并运行 Etcher,点击选择镜像并指向你在步骤 4 中下载的 Ubuntu ISO 镜像, 接下来,点击驱动器以选择你的闪存驱动器,然后点击 “Flash!” 开始将闪存驱动器转化为一个 Ubuntu 安装器的过程。 (如果你正使用一个 DVD-R,使用你电脑中的 DVD 烧录软件来完成此过程。)
|
||||
|
||||
### 安装 Windows 和 Ubuntu
|
||||
|
||||
@ -42,124 +44,95 @@
|
||||
* 创建 Windows 安装介质
|
||||
* 创建 Ubuntu 安装介质
|
||||
|
||||
|
||||
|
||||
有两种方法可以进行安装。首先,如果你已经安装了 WIndows 10 ,你可以让 Ubuntu 安装程序调整分区大小,然后在空白区域上进行安装。或者,如果你尚未安装 Windows 10,你可以在安装过程中将它安装在一个更小的分区上(下面我将描述如何去做)。第二种方法是首选的且出错率较低。很有可能你不会遇到任何问题。但是手动安装 Windows 并给它一个更小的分区,然后再安装 Ubuntu 是最简单的方法。
|
||||
有两种方法可以进行安装。首先,如果你已经安装了 Windows 10 ,你可以让 Ubuntu 安装程序调整分区大小,然后在空白区域上进行安装。或者,如果你尚未安装 Windows 10,你可以在安装过程中将它(Windows)安装在一个较小的分区上(下面我将描述如何去做)。第二种方法是首选的且出错率较低。很有可能你不会遇到任何问题,但是手动安装 Windows 并给它一个较小的分区,然后再安装 Ubuntu 是最简单的方法。
|
||||
|
||||
如果你的电脑上已经安装了 Windows 10,那么请跳过以下的 Windows 安装说明并继续安装 Ubuntu。
|
||||
|
||||
#### 安装 Windows
|
||||
|
||||
将创建的 Windows 安装介质插入你的电脑中并引导其启动。这如何做取决于你的电脑。但大多数有一个可以按下以启动启动菜单的快捷键。例如,在戴尔的电脑上就是 F12键。如果闪存盘并未作为一个选项显示,那么你可能需要重新启动你的电脑。有时候,只有在启动电脑前插入介质才能使其显示出来。如果看到类似‘’请按任意键以从安装介质中启动“的信息,请按下任意一个键。然后你应该会看到如下的界面。选择你的语言和键盘样式,然后单击`Next`。
|
||||
|
||||
将创建的 Windows 安装介质插入你的电脑中并引导其启动。这如何做取决于你的电脑。但大多数有一个可以按下以显示启动菜单的快捷键。例如,在戴尔的电脑上就是 F12 键。如果闪存盘并未作为一个选项显示,那么你可能需要重新启动你的电脑。有时候,只有在启动电脑前插入介质才能使其显示出来。如果看到类似“请按任意键以从安装介质中启动”的信息,请按下任意一个键。然后你应该会看到如下的界面。选择你的语言和键盘样式,然后单击 “Next”。
|
||||
|
||||
![Windows 安装][5]
|
||||
|
||||
点击“现在安装”启动 Windows 安装程序。
|
||||
|
||||
点击`现在安装`启动 Windows 安装程序
|
||||
|
||||
在下一个屏幕上,它会询问你的产品密钥。如果因你的电脑在出厂时已经安装了 Windows 10 而没有密钥的话,请选择‘’我没有一个产品密钥”。一旦赶上更新,它会在安装完成后自动激活。如果你有一个产品密钥,输入密钥并单击`下一步`。
|
||||
![现在安装][6]
|
||||
|
||||
在下一个屏幕上,它会询问你的产品密钥。如果因你的电脑在出厂时已经安装了 Windows 10 而没有密钥的话,请选择“我没有一个产品密钥”。在安装完成后更新该密码后会自动激活。如果你有一个产品密钥,输入密钥并单击“下一步”。
|
||||
|
||||
![输入产品密钥][7]
|
||||
|
||||
|
||||
选择你想要安装的 Windows 版本。如果你有一个零售版,标签(LCTT 译者注:类似于 CPU 型号 的 logo 贴标,)会告诉你你有什么版本。否则,它通常与计算机的附带文档放在一起。在大多数情况下,它要么是 Windows 10 家庭版 或者 Windows 10 专业版。大多数带有 家庭版的电脑都有一个简单的标签,上面写着"Windows 10",而专业版则有明确的标签。
|
||||
|
||||
选择你想要安装的 Windows 版本。如果你有一个零售版,封面标签(LCTT 译注:类似于 CPU 型号的 logo 贴标)会告诉你你有什么版本。否则,它通常在你的计算机的附带文档中可以找到。在大多数情况下,它要么是 Windows 10 家庭版或者 Windows 10 专业版。大多数带有 家庭版的电脑都有一个简单的标签,上面写着“Windows 10”,而专业版则会明确标明。
|
||||
|
||||
![选择 Windows 版本][10]
|
||||
|
||||
|
||||
勾选复选框以接受许可协议,然后单击`下一步`。
|
||||
|
||||
勾选复选框以接受许可协议,然后单击“下一步”。
|
||||
|
||||
![接受许可协议][12]
|
||||
|
||||
|
||||
在接受协议后,你有两种可用的安装选项。选择第二个选项`自定义:只安装 Windows (高级)`。
|
||||
|
||||
在接受协议后,你有两种可用的安装选项。选择第二个选项“自定义:只安装 Windows (高级)”。
|
||||
|
||||
![选择 Windows 的安装方式][14]
|
||||
|
||||
|
||||
接下来应该会显示你当前的硬盘配置。
|
||||
|
||||
|
||||
![硬盘配置][16]
|
||||
|
||||
|
||||
你的结果可能看起来和我的不一样。我以前从来没有用过这个硬盘,所以它是完全未分配的。你可能会看到你当前操作系统的一个或多个分区。
|
||||
你的结果可能看起来和我的不一样。我以前从来没有用过这个硬盘,所以它是完全未分配的。你可能会看到你当前操作系统的一个或多个分区。选中每个分区并移除它。(LCTT 译注:确保这些分区中没有你需要的数据!!)
|
||||
|
||||
此时,你的电脑屏幕将显示未分配的整个磁盘。创建一个新的分区以继续安装。
|
||||
|
||||
|
||||
![创建一个新分区][18]
|
||||
|
||||
|
||||
你可以看到我通过创建一个81920MB 大小的分区(接近 160GB 的一半)将驱动器分成了一半(或者说分得足够近)。给 Windows 至少 40GB,最好 64GB 或者更多。把剩下的硬盘留着不要分配,作为以后安装 Ubuntu 的分区
|
||||
你可以看到我通过创建一个 81920MB 大小的分区(接近 160GB 的一半)将驱动器分成了一半(或者说接近一半)。给 Windows 至少 40GB,最好 64GB 或者更多。把剩下的硬盘留着不要分配,作为以后安装 Ubuntu 的分区。
|
||||
|
||||
你的结果应该看起来像这样:
|
||||
|
||||
|
||||
![保留未分配空间的分区][20]
|
||||
|
||||
|
||||
确认分区看起来很好,然后单击`下一步`。现在将开始安装 Windows。
|
||||
|
||||
确认分区看起来合理,然后单击“下一步”。现在将开始安装 Windows。
|
||||
|
||||
![安装 Windows][22]
|
||||
|
||||
|
||||
如果你的电脑成功地引导进入了 Windows 桌面环境,你就可以进入下一步了。
|
||||
|
||||
![Windows 桌面][24]
|
||||
|
||||
|
||||
#### 安装 Ubuntu
|
||||
|
||||
无论你是已经安装了 Windows,还是完成了上面的步骤,现在你已经安装了 Windows。现在用你之前创建的 Ubuntu 安装介质来引导进入 Ubuntu。继续插入安装介质并从中引导你的电脑,同样,启动引导菜单的快捷键因计算机型号而异,因此如果你不确定,请查阅你的文档。如果一切顺利的话,当安装介质加载完成之后,你将会看到以下界面:
|
||||
|
||||
|
||||
![Ubuntu 安装欢迎屏幕][26]
|
||||
|
||||
|
||||
在这里,你可以选择 `尝试 Ubuntu` 或者 `安装 Ubuntu`。现在不要安装,相反,点击 `尝试 Ubuntu`。当完成加载之后,你应该可以看到 Ubuntu 桌面。
|
||||
在这里,你可以选择 “尝试 Ubuntu” 或者 “安装 Ubuntu”。现在不要安装,相反,点击 “尝试 Ubuntu”。当完成加载之后,你应该可以看到 Ubuntu 桌面。
|
||||
|
||||
![Ubuntu 桌面][28]
|
||||
|
||||
通过单击`尝试 Ubuntu`,你已经选择在安装之前试用 Ubuntu。 在 Live 模式下,你可以试用 Ubuntu,确保在你安装之前一切正常。Ubuntu 能兼容大多数 PC 硬件,但最好提前测试一下。确保你可以访问互联网并可以正常播放音频和视频。登录 YouTube 播放视频是一次性完成所有这些工作的好方法。如果你需要连接到无线网络,请单击屏幕右上角的网络图标。在那里,你可以找到一个无线网络列表并连接到你的无线网络。
|
||||
通过单击“尝试 Ubuntu”,你已经选择在安装之前试用 Ubuntu。 在 Live 模式下,你可以试用 Ubuntu,确保在你安装之前一切正常。Ubuntu 能兼容大多数 PC 硬件,但最好提前测试一下。确保你可以访问互联网并可以正常播放音频和视频。登录 YouTube 播放视频是一次性完成所有这些工作的好方法(LCTT 译注:国情所限,这个方法在这里并不奏效)。如果你需要连接到无线网络,请单击屏幕右上角的网络图标。在那里,你可以找到一个无线网络列表并连接到你的无线网络。
|
||||
|
||||
准备好之后,双击桌面上的 `安装 Ubuntu 18.04 LTS`图标启动安装程序。
|
||||
|
||||
选择要用于安装过程的语言,然后单击 `继续`。
|
||||
准备好之后,双击桌面上的 “安装 Ubuntu 18.04 LTS” 图标启动安装程序。
|
||||
|
||||
选择要用于安装过程的语言,然后单击 “继续”。
|
||||
|
||||
![选择 Ubuntu 的语言][30]
|
||||
|
||||
|
||||
接下来,选择键盘布局。完成后选择后,单击`继续`。
|
||||
|
||||
接下来,选择键盘布局。完成后选择后,单击“继续”。
|
||||
|
||||
![选择 Ubuntu 的键盘][32]
|
||||
|
||||
在下面的屏幕上有一些选项。一,你可以选择一个正常安装或最小化安装。对大多数人来说,普通安装是理想的。高级用户可能想要默认安装应用程序比较少的最小化安装。此外,你还可以选择下载更新以及是否包含第三方软件和驱动程序。我建议同时检查这两个方框。完成后,单击`继续`。
|
||||
|
||||
在下面的屏幕上有一些选项。你可以选择一个正常安装或最小化安装。对大多数人来说,普通安装是理想的。高级用户可能想要默认安装应用程序比较少的最小化安装。此外,你还可以选择下载更新以及是否包含第三方软件和驱动程序。我建议同时检查这两个方框。完成后,单击“继续”。
|
||||
|
||||
![选择 Ubuntu 安装选项][34]
|
||||
|
||||
下一个屏幕将询问你是要擦除磁盘还是设置双启动。由于你是双启动,因此请选择`安装 Ubuntu,与 Windows 10共存`,单击`现在安装`。
|
||||
|
||||
下一个屏幕将询问你是要擦除磁盘还是设置双启动。由于你是双启动,因此请选择“安装 Ubuntu,与 Windows 10共存”,单击“现在安装”。
|
||||
|
||||
![安装 Ubuntu,与 Windows 10共存][36]
|
||||
|
||||
|
||||
可能会出现以下屏幕。如果你从头开始安装 Windows 并在磁盘上保留了未分区的空间, Ubuntu 将会自动在空白区域中自行设置分区,因此你将看不到此屏幕。如果你已经安装了 Windows 10 并且它占用了整个驱动器,则会出现此屏幕,并在顶部为你提供一个选择磁盘的选项。如果你只有一个磁盘,则可以选择从 Windows 窃取多少空间给 Ubuntu。你可以使用鼠标左右拖动中间的垂直线以从其中一个分区中拿走一些空间并给另一个分区,按照你自己想要的方式调整它,然后单击`现在安装`。
|
||||
|
||||
可能会出现以下屏幕。如果你从头开始安装 Windows 并在磁盘上保留了未分区的空间,Ubuntu 将会自动在空白区域中自行设置分区,因此你将看不到此屏幕。如果你已经安装了 Windows 10 并且它占用了整个驱动器,则会出现此屏幕,并在顶部为你提供一个选择磁盘的选项。如果你只有一个磁盘,则可以选择从 Windows 窃取多少空间给 Ubuntu。你可以使用鼠标左右拖动中间的垂直线以从其中一个分区中拿走一些空间并给另一个分区,按照你自己想要的方式调整它,然后单击“现在安装”。
|
||||
|
||||
![分配驱动器空间][38]
|
||||
|
||||
|
||||
你应该会看到一个显示 Ubuntu 计划将要做什么的确认屏幕,如果一切正常,请单击`继续`。
|
||||
你应该会看到一个显示 Ubuntu 计划将要做什么的确认屏幕,如果一切正常,请单击“继续”。
|
||||
|
||||
![确认屏幕][39]
|
||||
|
||||
@ -167,7 +140,7 @@ Ubuntu 正在后台安装。不过,你仍需要进行一些配置。当 Ubuntu
|
||||
|
||||
![选择地理位置][40]
|
||||
|
||||
接下来,填写用户账户信息:你的姓名、计算机名、用户名和密码。完成后单击`继续`。
|
||||
接下来,填写用户账户信息:你的姓名、计算机名、用户名和密码。完成后单击“继续”。
|
||||
|
||||
![账户设置][41]
|
||||
|
||||
@ -188,7 +161,7 @@ via: https://opensource.com/article/18/5/dual-boot-linux
|
||||
作者:[Jay LaCroix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -198,9 +171,8 @@ via: https://opensource.com/article/18/5/dual-boot-linux
|
||||
[3]:http://www.etcher.io
|
||||
[4]:/file/397066
|
||||
[5]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_01.png "Windows setup"
|
||||
[6]:/file/397076
|
||||
[6]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_02a.png
|
||||
[7]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_03.png "Enter product key"
|
||||
[8]:data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw== "Click and drag to move"
|
||||
[9]:/file/397081
|
||||
[10]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_04.png "Select Windows version"
|
||||
[11]:/file/397086
|
||||
@ -1,8 +1,9 @@
|
||||
如何在 Linux 中为每个屏幕设置不同的壁纸
|
||||
======
|
||||
**简介:如果你想在 Ubuntu 18.04 或任何其他 Linux 发行版上使用 GNOME、MATE 或 Budgie 桌面环境在多个显示器上显示不同的壁纸,这个小工具将帮助你实现这一点。**
|
||||
|
||||
多显示器设置通常会在 Linux 上出现多个问题,但我不打算在本文中讨论这些问题。我有一篇关于 Linux 上多显示器支持的文章。
|
||||
> 如果你想在 Ubuntu 18.04 或任何其他 Linux 发行版上使用 GNOME、MATE 或 Budgie 桌面环境在多个显示器上显示不同的壁纸,这个小工具将帮助你实现这一点。
|
||||
|
||||
多显示器设置通常会在 Linux 上出现多个问题,但我不打算在本文中讨论这些问题。我有另外一篇关于 Linux 上多显示器支持的文章。
|
||||
|
||||
如果你使用多台显示器,也许你想为每台显示器设置不同的壁纸。我不确定其他 Linux 发行版和桌面环境,但是 [GNOME 桌面][1] 的 Ubuntu 本身并不提供此功能。
|
||||
|
||||
@ -18,11 +19,11 @@
|
||||
|
||||
#### 使用 FlatPak 在 Linux 上安装 HydraPaper
|
||||
|
||||
使用 [FlatPak][9] 可以轻松安装 HydraPaper。Ubuntu 18.04已 经提供对 FlatPaks 的支持,所以你需要做的就是下载应用文件并双击在 GNOME 软件中心中打开它。
|
||||
使用 [FlatPak][9] 可以轻松安装 HydraPaper。Ubuntu 18.04 已 经提供对 FlatPaks 的支持,所以你需要做的就是下载应用文件并双击在 GNOME 软件中心中打开它。
|
||||
|
||||
你可以参考这篇文章来了解如何在你的发行版[启用 FlatPak 支持][10]。启用 FlatPak 支持后,只需从 [FlatHub][11] 下载并安装即可。
|
||||
|
||||
[Download HydraPaper][12]
|
||||
- [下载 HydraPaper][12]
|
||||
|
||||
#### 使用 HydraPaper 在不同的显示器上设置不同的背景
|
||||
|
||||
@ -65,13 +66,13 @@ via: https://itsfoss.com/wallpaper-multi-monitor/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.gnome.org/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/multi-monitor-wallpaper-setup-800x450.jpeg
|
||||
[2]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/05/multi-monitor-wallpaper-setup.jpeg?w=800&ssl=1
|
||||
[3]:https://github.com/GabMus/HydraPaper
|
||||
[4]:https://www.gtk.org/
|
||||
[5]:https://itsfoss.com/gnome-tricks-ubuntu/
|
||||
@ -82,8 +83,8 @@ via: https://itsfoss.com/wallpaper-multi-monitor/
|
||||
[10]:https://flatpak.org/setup/
|
||||
[11]:https://flathub.org
|
||||
[12]:https://flathub.org/apps/details/org.gabmus.hydrapaper
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-2-800x631.jpeg
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-1.jpeg
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-3.jpeg
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/hydra-paper-dual-monitor-800x450.jpeg
|
||||
[17]:https://www.reddit.com/r/LinuxUsersGroup/
|
||||
[13]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-2.jpeg?w=800&ssl=1
|
||||
[14]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-1.jpeg?w=799&ssl=1
|
||||
[15]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-3.jpeg?w=799&ssl=1
|
||||
[16]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/hydra-paper-dual-monitor.jpeg?w=800&ssl=1
|
||||
[17]:https://www.reddit.com/r/LinuxUsersGroup/
|
||||
324
published/20180707 Version Control Before Git with CVS.md
Normal file
324
published/20180707 Version Control Before Git with CVS.md
Normal file
@ -0,0 +1,324 @@
|
||||
Git 前时代:使用 CVS 进行版本控制
|
||||
======
|
||||
|
||||
GitHub 网站发布于 2008 年。如果你的软件工程师职业生涯跟我一样,也是晚于此时间的话,Git 可能是你用过的唯一版本控制软件。虽然其陡峭的学习曲线和不直观地用户界面时常会遭人抱怨,但不可否认的是,Git 已经成为学习版本控制的每个人的选择。Stack Overflow 2015 年进行的开发者调查显示,69.3% 的被调查者在使用 Git,几乎是排名第二的 Subversion 版本控制系统使用者数量的两倍。[^1] 2015 年之后,也许是因为 Git 太受欢迎了,大家对此话题不再感兴趣,所以 Stack Overflow 停止了关于开发人员使用的版本控制系统的问卷调查。
|
||||
|
||||
GitHub 的发布时间距离 Git 自身发布时间很近。2005 年,Linus Torvalds 发布了 Git 的首个版本。现在的年经一代开发者可能很难想象“版本控制软件”一词所代表的世界并不仅仅只有 Git,虽然这样的世界诞生的时间并不长。除了 Git 外,还有很多可供选择。那时,开源开发者较喜欢 Subversion,企业和视频游戏公司使用 Perforce (到如今有些仍在用),而 Linux 内核项目依赖于名为 BitKeeper 的版本控制系统。
|
||||
|
||||
其中一些系统,特别是 BitKeeper,会让年经一代的 Git 用户感觉很熟悉,上手也很快,但大多数相差很大。除了 BitKeeper,Git 之前的版本控制系统都是以不同的架构模型为基础运行的。《[Version Control By Example][8]》一书的作者 Eric Sink 在他的书中对版本控制进行了分类,按其说法,Git 属于第三代版本控制系统,而大多数 Git 的前身,即流行于二十世纪九零年代和二十一世纪早期的系统,都属于第二代版本控制系统。[^2] 第三代版本控制系统是分布式的,第二代是集中式。你们以前大概都听过 Git 被描述为一款“分布式”版本控制系统。我一直都不明白分布式/集中式之间的区别,随后自己亲自安装了一款第二代的集中式版本控件系统,并做了相关实验,至少明白了一些。
|
||||
|
||||
我安装的版本系统是 CVS。CVS,即 “<ruby>并发版本系统<rt>Concurrent Versions System</rt></ruby>” 的缩写,是最初的第二代版本控制系统。大约十年间,它是最为流行的版本控制系统,直到 2000 年被 Subversion 所取代。即便如此,Subversion 被认为是 “更好的 CVS”,这更进一步突出了 CVS 在二十世纪九零年代的主导地位。
|
||||
|
||||
CVS 最早是由一位名叫 Dick Grune 的荷兰科学家在 1986 年开发的,当时有一个编译器项目,他正在寻找一种能与其学生合作的方法。[^3] CVS 最初仅仅只是一个包装了 RCS(<ruby>修订控制系统<rt>Revision Control System</rt></ruby>) 的 Shell 脚本集合,Grune 想改进这个第一代的版本控制系统。 RCS 是按悲观锁模式工作的,这意味着两个程序员不可以同时处理同一个文件。需要编辑一个文件话,首先得向 RCS 系统请求一个排它锁,锁定此文件直到完成编辑,如果你想编辑的文件有人正在编辑,你就必须等待。CVS 在 RCS 基础上改进,并把悲观锁模型替换成乐观锁模型,迎来了第二代版本控制系统的时代。现在,程序员可以同时编辑同一个文件、合并编辑部分,随后解决合并冲突问题。(后来接管 CVS 项目的工程师 Brian Berliner 于 1990 年撰写了一篇非常易读的关于 CVS 创新的 [论文][1]。)
|
||||
|
||||
从这个意义上来讲,CVS 与 Git 并无差异,因为 Git 也是运行于乐观锁模式的,但也仅仅只有此点相似。实际上,Linus Torvalds 开发 Git 时,他的一个指导原则是 WWCVSND,即 “<ruby>CVS 不能做的<rt>What Would CVS
|
||||
Not Do</rt></ruby>”。每当他做决策时,他都会力争选择那些在 CVS 设计里没有使用的功能选项。[^4] 所以即使 CVS 要早于 Git 十多年,但它对 Git 的影响是反面的。
|
||||
|
||||
我非常喜欢折腾 CVS。我认为要弄明白为什么 Git 的分布式特性是对以前的版本控制系统的极大改善的话,除了折腾 CVS 外,没有更好的办法。因此,我邀请你跟我一起来一段激动人心的旅程,并在接下来的十分钟内了解下这个近十年来无人使用的软件。(可以看看文末“修正”部分)
|
||||
|
||||
### CVS 入门
|
||||
|
||||
CVS 的安装教程可以在其 [项目主页][2] 上找到。MacOS 系统的话,可以使用 Homebrew 安装。
|
||||
|
||||
由于 CVS 是集中式的,所以它有客户端和服务端之区分,这种模式 Git 是没有的。两端分别有不同的可执行文件,其区别不太明显。但要开始使用 CVS 的话,即使只在你的本地机器上使用,也必须设置 CVS 的服务后端。
|
||||
|
||||
CVS 的后端,即所有代码的中央存储区,被叫做<ruby>存储库<rt> repository</rt></ruby>。在 Git 中每一个项目都有一个存储库,而 CVS 中一个存储库就包含所有的项目。尽管有办法保证一次只能访问一个项目,但一个中央存储库包含所有东西是改变不了的。
|
||||
|
||||
要在本地创建存储库的话,请运行 `init` 命令。你可以像如下所示在家目录创建,也可以在你本地的任何地方创建。
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox init
|
||||
```
|
||||
|
||||
CVS 允许你将选项传递给 `cvs` 命令本身或 `init` 子命令。出现在 `cvs` 命令之后的选项默认是全局的,而出现在子命令之后的是子命令特有选项。上面所示例子中,`-d` 标志是全局选项。在这儿是告诉 CVS 我们想要创建存储库路径在哪里,但一般 `-d` 标志指的是我们想要使用的且已经存在的存储库位置。一直使用 `-d` 标志很单调乏味,所以可以设置 `CVSROOT` 环境变量来代替。
|
||||
|
||||
因为我们只是在本地操作,所以仅仅使用 `-d` 参考来传递路径就可以,但也可以包含个主机名。
|
||||
|
||||
此命令在你的家目录创建了一个名叫 `sandbox` 的目录。 如果你列出 `sandbox` 内容,会发现下面包含有名为 `CVSROOT` 的目录。请不要把此目录与我们的环境变量混淆,它保存存储库的管理文件。
|
||||
|
||||
恭喜! 你刚刚创建了第一个 CVS 存储库。
|
||||
|
||||
### 检入代码
|
||||
|
||||
假设你决定留存下自己喜欢的颜色清单。因为你是一个有艺术倾向但很健忘的人,所以你键入颜色列表清单,并保存到一个叫 `favorites.txt` 的文件中:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
我们也假设你把文件保存到一个叫 `colors` 的目录中。现在你想要把喜欢的颜色列表清单置于版本控制之下,因为从现在起的五十年间你会回顾下,随着时间的推移自己的品味怎么变化,这件事很有意思。
|
||||
|
||||
为此,你必须将你的目录导入为新的 CVS 项目。可以使用 `import` 命令:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox import -m "" colors colors initial
|
||||
N colors/favorites.txt
|
||||
|
||||
No conflicts created by this import
|
||||
```
|
||||
|
||||
这里我们再次使用 `-d` 标志来指定存储库的位置,其余的参数是传输给 `import` 子命令的。必须要提供一条消息,但这儿没必要,所以留空。下一个参数 `colors`,指定了存储库中新目录的名字,这儿给的名字跟检入的目录名称一致。最后的两个参数分别指定了 “vendor” 标签和 “release” 标签。我们稍后就会谈论标签。
|
||||
|
||||
我们刚将 `colors` 项目拉入 CVS 存储库。将代码引入 CVS 有很多种不同的方法,但这是 《[Pragmatic Version Control Using CVS][3]》 一书所推荐方法,这是一本关于 CVS 的程序员实用指导书籍。使用这种方法有点尴尬的就是你得重新<ruby>检出<rt>check out</rt></ruby>工作项目,即使已经存在有 `colors` 此项目了。不要使用该目录,首先删除它,然后从 CVS 中检出刚才的版本,如下示:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox co colors
|
||||
cvs checkout: Updating colors
|
||||
U colors/favorites.txt
|
||||
```
|
||||
|
||||
这个过程会创建一个新的目录,也叫做 `colors`。此目录里会发现你的源文件 `favorites.txt`,还有一个叫 `CVS` 的目录。这个 `CVS` 目录基本上与每个 Git 存储库的 `.git` 目录等价。
|
||||
|
||||
### 做出改动
|
||||
|
||||
准备旅行。
|
||||
|
||||
和 Git 一样,CVS 也有 `status` 命令:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
|
||||
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: fD7GYxt035GNg8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
到这儿事情开始陌生起来了。CVS 没有提交对象这一概念。如上示,有一个叫 “<ruby>提交标识符<rt>Commit Identifier</rt></ruby>” 的东西,但这可能是一个较新版本的标识,在 2003 年出版的《Pragmatic Version Control Using CVS》一书中并没有提到 “提交标识符” 这个概念。 (CVS 的最新版本于 2008 年发布的。[^5] )
|
||||
|
||||
在 Git 中,我们所谈论某文件版本其实是在谈论如 `commit 45de392` 相关的东西,而 CVS 中文件是独立版本化的。文件的第一个版本为 1.1 版本,下一个是 1.2 版本,依此类推。涉及分支时,会在后面添加扩展数字。因此你会看到如上所示的 `1.1.1.1` 的内容,这就是示例的版本号,即使我们没有创建分支,似乎默认的会给加上。
|
||||
|
||||
一个项目中会有很多的文件和很多次的提交,如果你运行 `cvs log` 命令(等同于 `git log`),会看到每个文件提交历史信息。同一个项目中,有可能一个文件处于 1.2 版本,一个文件处于 1.14 版本。
|
||||
|
||||
继续,我们对 1.1 版本的 `favorites.txt` 文件做些修改(LCTT 译注:原文此处示例有误):
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
cyan
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
修改完成,就可以运行 `cvs diff` 来看看 CVS 发生了什么:
|
||||
|
||||
```
|
||||
$ cvs diff
|
||||
cvs diff: Diffing .
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.1.1.1
|
||||
diff -r1.1.1.1 favorites.txt
|
||||
3a4
|
||||
> cyan
|
||||
```
|
||||
|
||||
CVS 识别出我们我在文件中添加了一个包含颜色 “cyan” 的新行。(实际上,它说我们已经对 “RCS” 文件进行了更改;你可以看到,CVS 底层使用的还是 RCS。) 此差异指的是当前工作目录中的 `favorites.txt` 副本与存储库中 1.1.1.1 版本的文件之间的差异。
|
||||
|
||||
为了更新存储库中的版本,我们必须提交更改。Git 中,这个操作要好几个步骤。首先,暂存此修改,使其在索引中出现,然后提交此修改,最后,为了使此修改让其他人可见,我们必须把此提交推送到源存储库中。
|
||||
|
||||
而 CVS 中,只需要运行 `cvs commit` 命令就搞定一切。CVS 会汇集它所找到的变化,然后把它们放到存储库中:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Add cyan to favorites."
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.2; previous revision: 1.1
|
||||
```
|
||||
|
||||
我已经习惯了 Git,所以这种操作会让我感到十分恐惧。因为没有变更暂存区的机制,工作目录下任何你动过的东西都会一股脑给提交到公共存储库中。你有过因为不爽,私下里重写了某个同事不佳的函数实现,但仅仅只是自我宣泄一下并不想让他知道的时候吗?如果不小心提交上去了,就太糟糕了,他会认为你是个混蛋。在推送它们之前,你也不能对提交进行编辑,因为提交就是推送。还是你愿意花费 40 分钟的时间来反复运行 `git rebase -i` 命令,以使得本地提交历史记录跟数学证明一样清晰严谨?很遗憾,CVS 里不支持,结果就是,大家都会看到你没有先写测试用例。
|
||||
|
||||
不过,到现在我终于理解了为什么那么多人都觉得 Git 没必要搞那么复杂。对那些早已经习惯直接 `cvs commit` 的人来说,进行暂存变更和推送变更操作确实是毫无意义的差事。
|
||||
|
||||
人们常谈论 Git 是一个 “分布式” 系统,其中分布式与非分布式的主要区别为:在 CVS 中,无法进行本地提交。提交操作就是向中央存储库提交代码,所以没有网络连接,就无法执行操作,你本地的那些只是你的工作目录而已;在 Git 中,会有一个完完全全的本地存储库,所以即使断网了也可以无间断执行提交操作。你还可以编辑那些提交、回退、分支,并选择你所要的东西,没有任何人会知道他们必须知道的之外的东西。
|
||||
|
||||
因为提交是个大事,所以 CVS 用户很少做提交。提交会包含很多的内容修改,就像如今我们能在一个含有十次提交的拉取请求中看到的一样多。特别是在提交触发了 CI 构建和自动测试程序时如此。
|
||||
|
||||
现在我们运行 `cvs status`,会看到产生了文件的新版本:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.2 2018-07-06 21:18:59 -0400
|
||||
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: pQx5ooyNk90wW8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
### 合并
|
||||
|
||||
如上所述,在 CVS 中,你可以同时编辑其他人正在编辑的文件。这是 CVS 对 RCS 的重大改进。当需要将更改的部分重新组合在一起时会发生什么?
|
||||
|
||||
假设你邀请了一些朋友来将他们喜欢的颜色添加到你的列表中。在他们添加的时候,你确定了不再喜欢绿色,然后把它从列表中删除。
|
||||
|
||||
当你提交更新的时候,会发现 CVS 报出了个问题:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Remove green"
|
||||
cvs commit: Examining .
|
||||
cvs commit: Up-to-date check failed for `favorites.txt'
|
||||
cvs [commit aborted]: correct above errors first!
|
||||
```
|
||||
|
||||
这看起来像是朋友们首先提交了他们的变化。所以你的 `favorites.txt` 文件版本没有更新到存储库中的最新版本。此时运行 `cvs status` 就可以看到,本地的 `favorites.txt` 文件副本有一些本地变更且是 1.2 版本的,而存储库上的版本号是 1.3,如下示:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Needs Merge
|
||||
|
||||
Working revision: 1.2 2018-07-07 10:42:43 -0400
|
||||
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: 2oZ6n0G13bDaldJA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
你可以运行 `cvs diff` 来了解 1.2 版本与 1.3 版本的确切差异:
|
||||
|
||||
```
|
||||
$ cvs diff -r HEAD favorites.txt
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.3
|
||||
diff -r1.3 favorites.txt
|
||||
3d2
|
||||
< green
|
||||
7,10d5
|
||||
<
|
||||
< pink
|
||||
< hot pink
|
||||
< bubblegum pink
|
||||
```
|
||||
|
||||
看来我们的朋友是真的喜欢粉红色,但好在他们编辑的是此文件的不同部分,所以很容易地合并此修改。跟 `git pull` 类似,只要运行 `cvs update` 命令,CVS 就可以为我们做合并操作,如下示:
|
||||
|
||||
```
|
||||
$ cvs update
|
||||
cvs update: Updating .
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.2
|
||||
retrieving revision 1.3
|
||||
Merging differences between 1.2 and 1.3 into favorites.txt
|
||||
M favorites.txt
|
||||
```
|
||||
|
||||
此时查看 `favorites.txt` 文件内容的话,你会发现你的朋友对文件所做的更改已经包含进去了,你的修改也在里面。现在你可以自由的提交文件了,如下示:
|
||||
|
||||
```
|
||||
$ cvs commit
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.4; previous revision: 1.3
|
||||
```
|
||||
|
||||
最终的结果就跟在 Git 中运行 `git pull --rebase` 一样。你的修改是添加在你朋友的修改之后的,所以没有 “合并提交” 这操作。
|
||||
|
||||
某些时候,对同一文件的修改可能导致冲突。例如,如果你的朋友把 “green” 修改成 “olive”,同时你完全删除 “green”,就会出现冲突。CVS 早期的时候,正是这种情况导致人们担心 CVS 不安全,而 RCS 的悲观锁机制可以确保此情况永不会发生。但 CVS 提供了一个安全保障机制,可以确保不会自动的覆盖任何人的修改。因此,当运行 `cvs update` 的时候,你必须告诉 CVS 想要保留哪些修改才能继续下一步操作。CVS 会标记文件的所有变更,这跟 Git 检测到合并冲突时所做的方式一样,然后,你必须手工编辑文件,选择需要保留的变更进行合并。
|
||||
|
||||
这儿需要注意的有趣事情就是在进行提交之前必须修复并合并冲突。这是 CVS 集中式特性的另一个结果。而在 Git 里,在推送本地的提交内容之前,你都不用担心合并冲突问题。
|
||||
|
||||
### 标记与分支
|
||||
|
||||
由于 CVS 没有易于寻址的提交对象,因此对变更集合进行分组的唯一方法就是对于特定的工作目录状态打个标记。
|
||||
|
||||
创建一个标记是很容易的:
|
||||
|
||||
```
|
||||
$ cvs tag VERSION_1_0
|
||||
cvs tag: Tagging .
|
||||
T favorites.txt
|
||||
```
|
||||
|
||||
稍后,运行 `cvs update` 命令并把标签传输给 `-r` 标志就可以把文件恢复到此状态,如下示:
|
||||
|
||||
```
|
||||
$ cvs update -r VERSION_1_0
|
||||
cvs update: Updating .
|
||||
U favorites.txt
|
||||
```
|
||||
|
||||
因为你需要一个标记来回退到早期的工作目录状态,所以 CVS 鼓励创建大量的抢先标记。例如,在重大的重构之前,你可以创建一个 `BEFORE_REFACTOR_01` 标记,如果重构出错,就可以使用此标记回退。你如果想生成整个项目的差异文件的话,也可以使用标记。基本上,如今我们惯常使用提交的哈希值完成的事情都必须在 CVS 中提前计划,因为你必须首先有个标签才行。
|
||||
|
||||
可以在 CVS 中创建分支。分支只是一种特殊的标记,如下示:
|
||||
|
||||
```
|
||||
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
|
||||
cvs rtag: Tagging colors
|
||||
```
|
||||
|
||||
这命令仅仅只是创建了分支(每个人都这样觉得吧),所以还需要使用 `cvs update` 命令来切换分支,如下示:
|
||||
|
||||
```
|
||||
$ cvs update -r TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
上面的命令就会把你的当前工作目录切换到新的分支,但《Pragmatic Version Control Using CVS》一书实际上是建议创建一个新的目录来房子你的新分支。估计,其作者发现在 CVS 里切换目录要比切换分支来得更简单吧。
|
||||
|
||||
此书也建议不要从现有分支创建分支,而只在主线分支(Git 中被叫做 `master`)上创建分支。一般来说,分支在 CVS 中主认为是 “高级” 技能。而在 Git 中,你几乎可以任性创建新分支,但 CVS 中要在真正需要的时候才能创建,比如发布项目。
|
||||
|
||||
稍后可以使用 `cvs update` 和 `-j` 标志将分支合并回主线:
|
||||
|
||||
```
|
||||
$ cvs update -j TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
### 感谢历史上的贡献者
|
||||
|
||||
2007 年,Linus Torvalds 在 Google 进行了一场关于 Git 的 [演讲][4](LCTT 译注:[已搬运][9])。当时 Git 是很新的东西,整场演讲基本上都是在说服满屋子都持有怀疑态度的程序员们:尽管 Git 是如此的与众不同,也应该使用 Git。如果没有看过这个视频的话,我强烈建议你去看看。Linus 是个有趣的演讲者,即使他有些傲慢。他非常出色地解释了为什么分布式的版本控制系统要比集中式的优秀。他的很多评论是直接针对 CVS 的。
|
||||
|
||||
Git 是一个 [相当复杂的工具][5]。学习起来是一个令人沮丧的经历,但也不断的给我惊喜:Git 还能做这样的事情。相比之下,CVS 简单明了,但是,许多我们认为理所当然的操作都做不了。想要对 Git 的强大功能和灵活性有全新的认识的话,就回过头来用用 CVS 吧,这是种很好的学习方式。这很好的诠释了为什么理解软件的开发历史可以让人受益匪浅。重拾过期淘汰的工具可以让我们理解今天所使用的工具后面所隐藏的哲理。
|
||||
|
||||
如果你喜欢此博文的话,每两周会有一次更新!请在 Twitter 上关注 [@TwoBitHistory][6] 或都通过 [RSS feed][7] 订阅,新博文出来会有通知。
|
||||
|
||||
### 修正
|
||||
|
||||
有人告诉我,有很多组织企业,特别是像做医疗设备软件等这种规避风险类的企业,仍在使用 CVS。这些企业中的程序员通过使用一些小技巧来解决 CVS 的限制,例如为几乎每个更改创建一个新分支以避免直接提交给 `HEAD`。 (感谢 Michael Kohne 指出这一点。)
|
||||
|
||||
[^1]: “2015 Developer Survey,” Stack Overflow, accessed July 7, 2018, https://insights.stackoverflow.com/survey/2015#tech-sourcecontrol.
|
||||
[^2]: Eric Sink, “A History of Version Control,” Version Control By Example, 2011, accessed July 7, 2018, https://ericsink.com/vcbe/html/history_of_version_control.html.
|
||||
[^3]: Dick Grune, “Concurrent Versions System CVS,” dickgrune.com, accessed July 7, 2018, https://dickgrune.com/Programs/CVS.orig/#History.
|
||||
[^4]: “Tech Talk: Linus Torvalds on Git,” YouTube, May 14, 2007, accessed July 7, 2018, https://www.youtube.com/watch?v=4XpnKHJAok8.
|
||||
[^5]: “Concurrent Versions System - News,” Savannah, accessed July 7, 2018, http://savannah.nongnu.org/news/?group=cvs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/07/07/cvs.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.freebsd.org/44doc/psd/28.cvs/paper.pdf
|
||||
[2]: https://www.nongnu.org/cvs/
|
||||
[3]: http://shop.oreilly.com/product/9780974514000.do
|
||||
[4]: https://www.youtube.com/watch?v=4XpnKHJAok8
|
||||
[5]: https://xkcd.com/1597/
|
||||
[6]: https://twitter.com/TwoBitHistory
|
||||
[7]: https://twobithistory.org/feed.xml
|
||||
[8]: https://ericsink.com/vcbe/index.html
|
||||
[9]: https://v.qq.com/x/page/o0772kqh5iv.html
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (5 Firefox extensions to protect your privacy)
|
||||
[#]: via: (https://opensource.com/article/18/7/firefox-extensions-protect-privacy)
|
||||
[#]: author: ( Chris Short https://opensource.com/users/chrisshort)
|
||||
[#]: url: (https://linux.cn/article-10316-1.html)
|
||||
|
||||
5 个保护你隐私的 Firefox 扩展
|
||||
======
|
||||
> 用这些关注隐私的工具使你的浏览器免于泄露数据。
|
||||
|
||||

|
||||
|
||||
在<ruby>剑桥分析公司<rt>Cambridge Analytica</rt></ruby>这件事后,我仔细研究了我让 Facebook 渗透到我的网络生活的程度。由于我一般担心单点故障,我不是一个使用社交登录的人。我使用密码管理器为每个站点创建唯一的登录(你也应该这样做)。
|
||||
|
||||
我最担心的 Facebook 对我的数字生活的普遍侵扰。在深入了解剑桥分析公司这件事后,我几乎立即卸载了 Facebook 的移动程序。我还从 Facebook [断开了对所有应用、游戏和网站的连接][1]。是的,这将改变你在 Facebook 上的体验,但它也将保护您的隐私。作为一名有遍布全球朋友的人,保持 Facebook 的社交连接对我来说非常重要。
|
||||
|
||||
我还仔细审查了其他服务。我检查了 Google、Twitter、GitHub 以及任何未使用的连接应用。但我知道这还不够。我需要我的浏览器主动防止侵犯我隐私的行为。我开始研究如何做到最好。当然,我可以锁定浏览器,但是我需要使我用的网站和工具正常使用,同时试图防止它们泄露数据。
|
||||
|
||||
以下是五种可在使用浏览器时保护你隐私的工具。前三个扩展可用于 Firefox 和 Chrome,而后两个仅适用于 Firefox。
|
||||
|
||||
### Privacy Badger
|
||||
|
||||
我已经使用 [Privacy Badger][2] 有一段时间了。其他内容或广告拦截器做得更好吗?也许。很多内容拦截器的问题在于它们的“付费显示”。这意味着他们有收费的“合作伙伴”白名单。这就站在了为什么存在内容拦截器这件事的对立面。Privacy Badger 是由电子前沿基金会 (EFF) 制作的,这是一家以捐赠为基础的商业模式的非营利实体。Privacy Badger 承诺从你的浏览习惯中学习,并且很少需要调整。例如,我只需将一些网站列入白名单。Privacy Badger 允许精确控制在哪些站点上启用哪些跟踪器。这是我无论在哪个浏览器必须安装的头号扩展。
|
||||
|
||||
### DuckDuckGo Privacy Essentials
|
||||
|
||||
搜索引擎 DuckDuckGo 通常有隐私意识。[DuckDuckGo Privacy Essentials][3] 适用于主流的移动设备和浏览器。它的独特之处在于它根据你提供的设置对网站进行评分。例如,即使启用了隐私保护,Facebook 也会获得 D。同时,[chrisshort.net][4] 在启用隐私保护时获得 B 和禁用时获得 C。如果你因任何原因不喜欢 EFF 或 Privacy Badger,我会推荐 DuckDuckGo Privacy Essentials(选择一个,而不是两个,因为它们基本上做同样的事情)。
|
||||
|
||||
### HTTPS Everywhere
|
||||
|
||||
[HTTPS Everywhere][5] 是 EFF 的另一个扩展。根据 HTTPS Everywhere 的说法,“网络上的许多网站都通过 HTTPS 提供一些有限的加密支持,但使它难以使用。例如,它们可能默认为未加密的 HTTP 或在加密的页面里面使用返回到未加密站点的链接。HTTPS Everywhere 扩展通过使用聪明的技术将对这些站点的请求重写为 HTTPS 来解决这些问题。“虽然许多网站和浏览器在实施 HTTPS 方面越来越好,但仍有很多网站仍需要帮助。HTTPS Everywhere 将尽力确保你的流量已加密。
|
||||
|
||||
### NoScript Security Suite
|
||||
|
||||
[NoScript Security Suite][6] 不适合胆小的人。虽然这个 Firefox 独有扩展“允许 JavaScript、Java、Flash 和其他插件只能由你选择的受信任网站执行”,但它并不能很好地确定你的选择。但是,毫无疑问,防止泄漏数据的可靠方法是不执行可能会泄露数据的代码。NoScript 通过其“基于白名单的抢占式脚本阻止”实现了这一点。这意味着你需要为尚未加入白名单的网站构建白名单。请注意,NoScript 仅适用于 Firefox。
|
||||
|
||||
### Facebook Container
|
||||
|
||||
[Facebook Container][7] 使 Firefox 成为我在使用 Facebook 时的唯一浏览器。 “Facebook Container 的工作原理是将你的 Facebook 身份隔离到一个单独的容器中,这使得 Facebook 更难以使用第三方 Cookie 跟踪你访问其他网站。” 这意味着 Facebook 无法窥探浏览器中其他地方发生的活动。 突然间,这些令人毛骨悚然的广告将停止频繁出现(假设你在移动设备上卸载了 Facebook 应用)。 在隔离的空间中使用 Facebook 将阻止任何额外的数据收集。 请记住,你已经提供了 Facebook 数据,而 Facebook Container 无法阻止这些数据被共享。
|
||||
|
||||
这些是我浏览器隐私的首选扩展。 你的是什么? 请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/firefox-extensions-protect-privacy
|
||||
|
||||
作者:[Chris Short][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/chrisshort
|
||||
[1]:https://www.facebook.com/help/211829542181913
|
||||
[2]:https://www.eff.org/privacybadger
|
||||
[3]:https://duckduckgo.com/app
|
||||
[4]:https://chrisshort.net
|
||||
[5]:https://www.eff.org/https-everywhere
|
||||
[6]:https://noscript.net/
|
||||
[7]:https://addons.mozilla.org/en-US/firefox/addon/facebook-container/
|
||||
@ -1,46 +1,46 @@
|
||||
GPaste 是 Gnome Shell 中优秀的剪贴板管理器
|
||||
GPaste:Gnome Shell 中优秀的剪贴板管理器
|
||||
======
|
||||
**[GPaste][1] 是一个剪贴板管理系统,它包含了库、守护程序以及命令行和 Gnome 的接口(使用原生 Gnome Shell 扩展)。**
|
||||
|
||||
[GPaste][1] 是一个剪贴板管理系统,它包含了库、守护程序以及命令行和 Gnome 界面(使用原生 Gnome Shell 扩展)。
|
||||
|
||||
剪贴板管理器能够跟踪你正在复制和粘贴的内容,从而能够访问以前复制的项目。GPaste 带有原生的 Gnome Shell 扩展,是那些寻找 Gnome 剪贴板管理器的人的完美补充。
|
||||
|
||||
[![GPaste Gnome Shell extension Ubuntu 18.04][2]][3]
|
||||
GPaste Gnome Shell扩展
|
||||
|
||||
**在 Gnome 中使用 GPaste,你只需单击顶部面板即可得到可配置的、可搜索的剪贴板历史记录。GPaste 不仅会记住你复制的文本,还能记住文件路径和图像**(后者需要在设置中启用,因为默认情况下它被禁用)。
|
||||
*GPaste Gnome Shell扩展*
|
||||
|
||||
不仅如此,GPaste 还可以检测到增长的行,这意味着当检测到新文本是另一个文本的扩展时,它会替换它,这对于保持剪贴板整洁非常有用。
|
||||
在 Gnome 中使用 GPaste,你只需单击顶部面板即可得到可配置的、可搜索的剪贴板历史记录。GPaste 不仅会记住你复制的文本,还能记住文件路径和图像(后者需要在设置中启用,因为默认情况下它被禁用)。
|
||||
|
||||
不仅如此,GPaste 还可以检测到增长的行,这意味着当检测到新文本是另一个文本的增长时,它会替换它,这对于保持剪贴板整洁非常有用。
|
||||
|
||||
在扩展菜单中,你可以暂停 GPaste 跟踪剪贴板,并从剪贴板历史记录或整个历史记录中删除项目。你还会发现一个启动 GPaste 用户界面窗口的按钮。
|
||||
|
||||
**如果你更喜欢使用键盘,你可以使用快捷键从顶栏开启 GPaste 历史记录** (`Ctrl + Alt + H`) **或打开全部的 GPaste GUI**(`Ctrl + Alt + G`)。
|
||||
如果你更喜欢使用键盘,你可以使用快捷键从顶栏开启 GPaste 历史记录(`Ctrl + Alt + H`)或打开全部的 GPaste GUI(`Ctrl + Alt + G`)。
|
||||
|
||||
该工具还包含这些键盘快捷键(可以更改):
|
||||
|
||||
* 从历史记录中删除活动项目: `Ctrl + Alt + V`
|
||||
|
||||
* **将活动项目显示为密码(在 GPaste 中混淆剪贴板条目):** `Ctrl + Alt + S`
|
||||
|
||||
* 将剪贴板同步到主选择: `Ctrl + Alt + O`
|
||||
|
||||
* 将主选择同步到剪贴板:`Ctrl + Alt + P`
|
||||
|
||||
* 将活动项目上传到 pastebin 服务:`Ctrl + Alt + U`
|
||||
* 从历史记录中删除活动项目: `Ctrl + Alt + V`
|
||||
* 将活动项目显示为密码(在 GPaste 中混淆剪贴板条目): `Ctrl + Alt + S`
|
||||
* 将剪贴板同步到主选择: `Ctrl + Alt + O`
|
||||
* 将主选择同步到剪贴板:`Ctrl + Alt + P`
|
||||
* 将活动项目上传到 pastebin 服务:`Ctrl + Alt + U`
|
||||
|
||||
[![][4]][5]
|
||||
GPaste GUI
|
||||
|
||||
*GPaste GUI*
|
||||
|
||||
GPaste 窗口界面提供可供搜索的剪贴板历史记录(包括清除、编辑或上传项目的选项)、暂停 GPaste 跟踪剪贴板的选项、重启 GPaste 守护程序,备份当前剪贴板历史记录,还有它的设置。
|
||||
|
||||
[![][6]][7]
|
||||
GPaste GUI
|
||||
|
||||
在 GPaste UI 中,你可以更改以下设置:
|
||||
*GPaste GUI*
|
||||
|
||||
在 GPaste 界面中,你可以更改以下设置:
|
||||
|
||||
* 启用或禁用 Gnome Shell 扩展
|
||||
* 将守护程序状态与扩展程序的状态同步
|
||||
* 主选择影响历史
|
||||
* 使剪贴板与主选择同步
|
||||
* 主选区生效历史
|
||||
* 使剪贴板与主选区同步
|
||||
* 图像支持
|
||||
* 修整条目
|
||||
* 检测增长行
|
||||
@ -48,11 +48,9 @@ GPaste GUI
|
||||
* 历史记录设置,如最大历史记录大小、内存使用情况、最大文本长度等
|
||||
* 键盘快捷键
|
||||
|
||||
|
||||
|
||||
### 下载 GPaste
|
||||
|
||||
[Download GPaste](https://github.com/Keruspe/GPaste)
|
||||
- [下载 GPaste](https://github.com/Keruspe/GPaste)
|
||||
|
||||
Gpaste 项目页面没有链接到任何 GPaste 二进制文件,它只有源码安装说明。非 Debian 或 Ubuntu 的 Linux 发行版的用户(你可以在下面找到 GPaste 安装说明)可以在各自的发行版仓库中搜索 GPaste。
|
||||
|
||||
@ -60,17 +58,17 @@ Gpaste 项目页面没有链接到任何 GPaste 二进制文件,它只有源
|
||||
|
||||
#### 在 Ubuntu(18.04、16.04)或 Debian(Jessie 和更新版本)中安装 GPaste
|
||||
|
||||
**对于 Debian,GPaste 可用于 Jessie 和更新版本,而对于 Ubuntu,GPaste 在 16.04 及更新版本的仓库中(因此可在 Ubuntu 18.04 Bionic Beaver 中使用)。**
|
||||
对于 Debian,GPaste 可用于 Jessie 和更新版本,而对于 Ubuntu,GPaste 在 16.04 及更新版本的仓库中(因此可在 Ubuntu 18.04 Bionic Beaver 中使用)。
|
||||
|
||||
你可以使用以下命令在 Debian 或 Ubuntu 中安装 GPaste(守护程序和 Gnome Shell 扩展):
|
||||
|
||||
**你可以使用以下命令在 Debian 或 Ubuntu 中安装 GPaste(守护程序和 Gnome Shell 扩展):**
|
||||
```
|
||||
sudo apt install gnome-shell-extensions-gpaste gpaste
|
||||
|
||||
```
|
||||
|
||||
安装完成后,按下 `Alt + F2` 并输入 `r` 重新启动 Gnome Shell,然后按`回车`键。现在应该启用了 GPaste Gnome Shell 扩展,其图标应显示在顶部 Gnome Shell 面板上。如果没有,请使用 Gnome Tweaks(Gnome Tweak Tool)启用扩展。
|
||||
安装完成后,按下 `Alt + F2` 并输入 `r` 重新启动 Gnome Shell,然后按回车键。现在应该启用了 GPaste Gnome Shell 扩展,其图标应显示在顶部 Gnome Shell 面板上。如果没有,请使用 Gnome Tweaks(Gnome Tweak Tool)启用扩展。
|
||||
|
||||
**[Debian][8] 和 [Ubuntu][9] 的 GPaste 3.28.0 中有一个错误,如果启用了图像支持选项会导致它崩溃,所以现在不要启用此功能。** 这在 GPaste 3.28.2 中被标记为[已修复][10],但 Debian 和 Ubuntu 仓库中尚未提供此包。
|
||||
[Debian][8] 和 [Ubuntu][9] 的 GPaste 3.28.0 中有一个错误,如果启用了图像支持选项会导致它崩溃,所以现在不要启用此功能。这在 GPaste 3.28.2 中被标记为[已修复][10],但 Debian 和 Ubuntu 仓库中尚未提供此包。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -80,7 +78,7 @@ via: https://www.linuxuprising.com/2018/08/gpaste-is-great-clipboard-manager-for
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -94,4 +92,4 @@ via: https://www.linuxuprising.com/2018/08/gpaste-is-great-clipboard-manager-for
|
||||
[7]:https://4.bp.blogspot.com/-047ShYc6RrQ/W2gyz5FCf_I/AAAAAAAABTA/-o6jaWzwNpsSjG0QRwRJ5Xurq_A6dQ0sQCLcBGAs/s1600/gpaste-gui_2.png
|
||||
[8]:https://packages.debian.org/buster/gpaste
|
||||
[9]:https://launchpad.net/ubuntu/+source/gpaste
|
||||
[10]:https://www.imagination-land.org/posts/2018-04-13-gpaste-3.28.2-released.html
|
||||
[10]:https://www.imagination-land.org/posts/2018-04-13-gpaste-3.28.2-released.html
|
||||
@ -1,13 +1,16 @@
|
||||
Systemd 定时器: 三种使用场景
|
||||
Systemd 定时器:三种使用场景
|
||||
======
|
||||
|
||||
> 继续 systemd 教程,这些特殊的例子可以展示给你如何更好的利用 systemd 定时器单元。
|
||||
|
||||

|
||||
|
||||
在这个 systemd 系列教程中,我们[已经在某种程度上讨论了 systemd 定时器单元][1]。不过,在我们开始讨论 socket 之前,我们先来看三个例子,这些例子展示了如何最佳化利用这些单元。
|
||||
在这个 systemd 系列教程中,我们[已经在某种程度上讨论了 systemd 定时器单元][1]。不过,在我们开始讨论 sockets 之前,我们先来看三个例子,这些例子展示了如何最佳化利用这些单元。
|
||||
|
||||
### 简单的类 _cron_ 行为
|
||||
### 简单的类 cron 行为
|
||||
|
||||
我每周都要去收集 [Debian popcon 数据][2],如果每次都能在同一时间收集更好,这样我就能看到某些应用程序的下载趋势。这是一个可以使用 cron 任务来完成的典型事例,但 systemd 定时器同样能做到:
|
||||
|
||||
我每周都要去收集 [Debian popcon 数据][2],如果每次都能在同一时间收集更好,这样我就能看到某些应用程序的下载趋势。这是一个可以使用 _cron_ 任务来完成的典型事例,但 systemd 定时器同样能做到:
|
||||
```
|
||||
# 类 cron 的 popcon.timer
|
||||
|
||||
@ -20,14 +23,14 @@ Unit= popcon.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
实际的 _popcon.service_ 会执行一个常规的 _wget_ 任务,并没有什么特别之处。这里的新内容是 `OnCalendar=` 指令。这个指令可以让你在一个特定日期的特定时刻来运行某个服务。在这个例子中,`Thu` 表示“_在周四运行_”,`*-*-*` 表示“_具体年份、月份和日期无关紧要_”,这些可以翻译成“不管年月日,只在每周四运行”。
|
||||
实际的 `popcon.service` 会执行一个常规的 `wget` 任务,并没有什么特别之处。这里的新内容是 `OnCalendar=` 指令。这个指令可以让你在一个特定日期的特定时刻来运行某个服务。在这个例子中,`Thu` 表示 “在周四运行”,`*-*-*` 表示“具体年份、月份和日期无关紧要”,这些可以翻译成 “不管年月日,只在每周四运行”。
|
||||
|
||||
这样,你就设置了这个服务的运行时间。我选择在欧洲中部夏令时区的上午 5:30 左右运行,那个时候服务器不是很忙。
|
||||
|
||||
如果你的服务器关闭了,而且刚好错过了每周的截止时间,你还可以在同一个计时器中使用像 _anacron_ 一样的功能。
|
||||
如果你的服务器关闭了,而且刚好错过了每周的截止时间,你还可以在同一个计时器中使用像 anacron 一样的功能。
|
||||
|
||||
```
|
||||
# 具备类似 anacron 功能的 popcon.timer
|
||||
|
||||
@ -41,26 +44,26 @@ Persistent=true
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
当你将 `Persistent=` 指令设为真值时,它会告诉 systemd,如果服务器在本该它运行的时候关闭了,那么在启动后就要立刻运行服务。这意味着,如果机器在周四凌晨停机了(比如说维护),一旦它再次启动后,_popcon.service_ 将会立刻执行。在这之后,它的运行时间将会回到例行性的每周四早上 5:32.
|
||||
当你将 `Persistent=` 指令设为真值时,它会告诉 systemd,如果服务器在本该它运行的时候关闭了,那么在启动后就要立刻运行服务。这意味着,如果机器在周四凌晨停机了(比如说维护),一旦它再次启动后,`popcon.service` 将会立刻执行。在这之后,它的运行时间将会回到例行性的每周四早上 5:32.
|
||||
|
||||
到目前为止,就是这么直白。
|
||||
到目前为止,就是这么简单直白。
|
||||
|
||||
### 延迟执行
|
||||
|
||||
但是,我们提升一个档次,来“改进”这个[基于 systemd 的监控系统][3]。你应该记得,当你接入摄像头的时候,系统就会开始拍照。假设你并不希望它在你安装摄像头的时候拍下你的脸。你希望将拍照服务的启动时间向后推迟一两分钟,这样你就有时间接入摄像头,然后走到画框外面。
|
||||
|
||||
为了完成这件事,首先你要更改 Udev 规则,将它指向一个定时器:
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
|
||||
SYMLINK+="mywebcam", MODE="0666"
|
||||
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
|
||||
SYMLINK+="mywebcam", MODE="0666"
|
||||
```
|
||||
|
||||
这个定时器看起来像这样:
|
||||
|
||||
```
|
||||
# picchanged.timer
|
||||
|
||||
@ -73,10 +76,9 @@ Unit= picchanged.path
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
在你接入摄像头后,Udev 规则被触发,它会调用定时器。这个定时器启动后会等上一分钟(`OnActiveSec= 1 m`),然后运行 _picchanged.path_,它会[监视主图片的变化][4]。_picchanged.path_ 还会负责接触 _webcan.service_,这个实际用来拍照的服务。
|
||||
在你接入摄像头后,Udev 规则被触发,它会调用定时器。这个定时器启动后会等上一分钟(`OnActiveSec= 1 m`),然后运行 `picchanged.path`,它会[监视主图片的变化][4]。`picchanged.path` 还会负责接触 `webcan.service`,这个实际用来拍照的服务。
|
||||
|
||||
### 在每天的特定时刻启停 Minetest 服务器
|
||||
|
||||
@ -85,6 +87,7 @@ WantedBy= basic.target
|
||||
你有个为你的孩子设置的 Minetest 服务。不过,你还想要假装关心一下他们的教育和成长,要让他们做作业和家务活。所以你要确保 Minetest 只在每天晚上的一段时间内可用,比如五点到七点。
|
||||
|
||||
这个跟之前的“_在特定时间启动服务_”不太一样。写个定时器在下午五点启动服务很简单…:
|
||||
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
@ -97,12 +100,12 @@ Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
…可是编写一个对应的定时器,让它在特定时刻关闭服务,则需要更大剂量的横向思维。
|
||||
|
||||
我们从最明显的东西开始 —— 设置定时器:
|
||||
|
||||
```
|
||||
# stopminetest.timer
|
||||
|
||||
@ -115,16 +118,16 @@ Unit= stopminetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
这里棘手的部分是如何去告诉 _stopminetest.service_ 去 —— 你知道的 —— 停止 Minetest. 我们无法从 _minetest.service_ 中传递 Minetest 服务器的 PID. 而且 systemd 的单元词汇表中也没有明显的命令来停止或禁用正在运行的服务。
|
||||
这里棘手的部分是如何去告诉 `stopminetest.service` 去 —— 你知道的 —— 停止 Minetest. 我们无法从 `minetest.service` 中传递 Minetest 服务器的 PID. 而且 systemd 的单元词汇表中也没有明显的命令来停止或禁用正在运行的服务。
|
||||
|
||||
我们的诀窍是使用 systemd 的 `Conflicts=` 指令。它和 systemd 的 `Wants=` 指令类似,不过它所做的事情_正相反_。如果你有一个 _b.service_ 单元,其中包含一个 `Wants=a.service` 指令,在这个单元启动时,如果 _a.service_ 没有运行,则 _b.service_ 会运行它。同样,如果你的 _b.service_ 单元中有一行写着 `Conflicts= a.service`,那么在 _b.service_ 启动时,systemd 会停止 _a.service_.
|
||||
我们的诀窍是使用 systemd 的 `Conflicts=` 指令。它和 systemd 的 `Wants=` 指令类似,不过它所做的事情_正相反_。如果你有一个 `b.service` 单元,其中包含一个 `Wants=a.service` 指令,在这个单元启动时,如果 `a.service` 没有运行,则 `b.service` 会运行它。同样,如果你的 `b.service` 单元中有一行写着 `Conflicts= a.service`,那么在 `b.service` 启动时,systemd 会停止 `a.service`.
|
||||
|
||||
这种机制用于两个服务在尝试同时控制同一资源时会发生冲突的场景,例如当两个服务要同时访问打印机的时候。通过在首选服务中设置 `Conflicts=`,你就可以确保它会覆盖掉最不重要的服务。
|
||||
|
||||
不过,你会在一个稍微不同的场景中来使用 `Conflicts=`. 你将使用 `Conflicts=` 来干净地关闭 _minetest.service_:
|
||||
不过,你会在一个稍微不同的场景中来使用 `Conflicts=`. 你将使用 `Conflicts=` 来干净地关闭 `minetest.service`:
|
||||
|
||||
```
|
||||
# stopminetest.service
|
||||
|
||||
@ -135,12 +138,12 @@ Conflicts= minetest.service
|
||||
[Service]
|
||||
Type= oneshot
|
||||
ExecStart= /bin/echo "Closing down minetest.service"
|
||||
|
||||
```
|
||||
|
||||
_stopminetest.service_ 并不会做特别的东西。事实上,它什么都不会做。不过因为它包含那行 `Conflicts=`,所以在它启动时,systemd 会关掉 _minetest.service_.
|
||||
`stopminetest.service` 并不会做特别的东西。事实上,它什么都不会做。不过因为它包含那行 `Conflicts=`,所以在它启动时,systemd 会关掉 `minetest.service`.
|
||||
|
||||
在你完美的 Minetest 设置中,还有最后一点涟漪:你下班晚了,错过了服务器的开机时间,可当你开机的时候游戏时间还没结束,这该怎么办?`Persistent=` 指令(如上所述)在错过开始时间后仍然可以运行服务,但这个方案还是不行。如果你在早上十一点把服务器打开,它就会启动 Minetest,而这不是你想要的。你真正需要的是一个确保 systemd 只在晚上五到七点启动 Minetest 的方法:
|
||||
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
@ -153,12 +156,12 @@ Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
`OnCalendar= *-*-* 17..19:*:00` 这一行有两个有趣的地方:(1) `17..19` 并不是一个时间点,而是一个时间段,在这个场景中是 17 到 19 点;以及,(2) 分钟字段中的 `*` 表示服务每分钟都要运行。因此,你会把它读做 “_在下午五到七点间的每分钟,运行 minetest.service_”
|
||||
`OnCalendar= *-*-* 17..19:*:00` 这一行有两个有趣的地方:(1) `17..19` 并不是一个时间点,而是一个时间段,在这个场景中是 17 到 19 点;以及,(2) 分钟字段中的 `*` 表示服务每分钟都要运行。因此,你会把它读做 “在下午五到七点间的每分钟,运行 minetest.service”
|
||||
|
||||
不过还有一个问题:一旦 `minetest.service` 启动并运行,你会希望 `minetest.timer` 不要再次尝试运行它。你可以在 `minetest.service` 中包含一条 `Conflicts=` 指令:
|
||||
|
||||
不过还有一个问题:一旦 _minetest.service_ 启动并运行,你会希望 _minetest.timer_ 不要再次尝试运行它。你可以在 _minetest.service_ 中包含一条 `Conflicts=` 指令:
|
||||
```
|
||||
# minetest.service
|
||||
|
||||
@ -175,19 +178,18 @@ ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.targe
|
||||
|
||||
```
|
||||
|
||||
上面的 `Conflicts=` 指令会保证在 _minstest.service_ 成功运行后,_minetest.timer_ 就会立即停止。
|
||||
上面的 `Conflicts=` 指令会保证在 `minstest.service` 成功运行后,`minetest.timer` 就会立即停止。
|
||||
|
||||
现在,启用并启动 `minetest.timer`:
|
||||
|
||||
现在,启用并启动 _minetest.timer_:
|
||||
```
|
||||
systemctl enable minetest.timer
|
||||
systemctl start minetest.timer
|
||||
|
||||
```
|
||||
|
||||
而且,如果你在六点钟启动了服务器,_minetest.timer_ 会启用;到了五到七点,_minetest.timer_ 每分钟都会尝试启动 _minetest.service_. 不过,一旦 _minetest.service_ 开始运行,systemd 会停止 _minetest.timer_,因为它会与 _minetest.service_“冲突”,从而避免计时器在服务已经运行的情况下还会不断尝试启动服务。
|
||||
而且,如果你在六点钟启动了服务器,`minetest.timer` 会启用;到了五到七点,`minetest.timer` 每分钟都会尝试启动 `minetest.service`。不过,一旦 `minetest.service` 开始运行,systemd 会停止 `minetest.timer`,因为它会与 `minetest.service` “冲突”,从而避免计时器在服务已经运行的情况下还会不断尝试启动服务。
|
||||
|
||||
在首先启动某个服务时杀死启动它的计时器,这么做有点反直觉,但它是有效的。
|
||||
|
||||
@ -197,7 +199,7 @@ systemctl start minetest.timer
|
||||
|
||||
但是,这个系列文章的目的不是为任何具体问题提供最佳解决方案。它的目的是为了尽可能多地使用 systemd 来解决问题,甚至会到荒唐的程度。它的目的是展示大量的例子,来说明如何利用不同类型的单位及其包含的指令。我们的读者,也就是你,可以从这篇文章中找到所有这些的可实践范例。
|
||||
|
||||
尽管如此,我们还有一件事要做:下回中,我们会关注 _sockets_ 和 _targets_,然后我们将完成对 systemd 单元的介绍。
|
||||
尽管如此,我们还有一件事要做:下回中,我们会关注 sockets 和 targets,然后我们将完成对 systemd 单元的介绍。
|
||||
|
||||
你可以在 Linux 基金会和 edX 中,通过免费的 [Linux 介绍][5]课程中,学到更多关于 Linux 的知识。
|
||||
|
||||
@ -208,12 +210,12 @@ via: https://www.linux.com/blog/intro-to-linux/2018/8/systemd-timers-two-use-cas
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
[1]:https://linux.cn/article-10182-1.html
|
||||
[2]:https://popcon.debian.org/
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
@ -0,0 +1,73 @@
|
||||
混合软件开发角色效果更佳
|
||||
======
|
||||
|
||||
> 为什么在工程中混合角色对用户更好的三个原因。
|
||||
|
||||

|
||||
|
||||
大多数开源社区没有很多正式的角色。当然,也有一些固定人员帮助处理系统管理员任务、测试、编写文档以及翻译或开发代码。但开源社区的人员通常在不同的角色之间流动,往往同时履行几个角色的职责。
|
||||
|
||||
相反,大多数传统公司的团队成员都定义了角色,例如,负责文档、技术支持、质量检验和其他领域。
|
||||
|
||||
为什么开源社区采取共享角色的方法,更重要的是,这种协作方式如何影响产品和客户?
|
||||
|
||||
[Nextcloud][1] 采用了这种社区式的混合角色的做法,我们看到了我们的客户和用户受益颇多。
|
||||
|
||||
### 1、更好的产品测试
|
||||
|
||||
每个测试人员都会说测试是一项困难的工作。你需要了解工程师开发的产品,并且需要设计测试案例、执行测试案例并将结果返回给开发人员。完成该过程后,开发人员将进行更改,然后重复该过程,根据需要来回进行多次,直到任务完成。
|
||||
|
||||
在社区中,贡献者通常会对他们开发的项目负责,因此他们会对这些项目进行广泛的测试和记录,然后再将其交给用户。贴近项目的用户通常会与开发人员协作,帮助测试、翻译和编写文档。这将创建一个更紧密、更快的反馈循环,从而加快开发速度并提高质量。
|
||||
|
||||
当开发人员不断面对他们的工作结果时,会鼓励他们以最大限度地减少测试和调试的方式去书写。自动化测试是开发中的一个重要元素,反馈循环可以确保正确地完成操作:开发人员主观能动的来实现自动化 —— 而不过于简化也不过于复杂。当然,他们可能希望别人做更多的测试或自动化的测试,但当测试是正确的选择时,他们就会这样做。此外,他们还审查对方的代码,因为他们知道问题往往会在以后让他们付出代价。
|
||||
|
||||
因此,虽然我不认为放弃专用测试人员更好,但在没有社区志愿者进行测试的项目中,测试人员应该是开发人员,并密切嵌入到开发团队中。结果如何?客户得到的产品是由 100% 有动机的人测试和开发的,以确保它是稳定和可靠的。
|
||||
|
||||
### 2、开发和客户需求之间的密切协作
|
||||
|
||||
要使产品开发与客户需求保持一致是非常困难的。每个客户都有自己独特的需求,有长期和短期的因素需要考虑 —— 当然,作为一家公司,你对你的发展方向有想法。你如何整合所有这些想法和愿景?
|
||||
|
||||
公司通常会创建与工程和产品开发分开的角色,如产品管理、支持、质量检测等。这背后的想法是,人们在专攻的时候做得最好,工程师不应该为测试或支持等 “简单” 的任务而烦恼。
|
||||
|
||||
实际上,这种角色分离是一项削减成本的措施。它使管理层能够进行微观管理,并更能掌握全局,因为他们可以简单地进行产品管理,例如,确定路线图项目的优先次序。(它还创建了更多的会议!)
|
||||
|
||||
另一方面,在社区,“决定权在工作者手上”。开发人员通常也是用户(或由用户支付报酬),因此他们自然地与用户的需求保持一致。当用户帮助进行测试时(如上所述),开发人员会不断地与他们合作,因此双方都完全了解什么是可行的,什么是需要的。
|
||||
|
||||
这种开放的合作方式使用户和项目紧密协作。在没有管理层干涉和指手画脚的情况下,用户最迫切的需求可以迅速得到满足,因为工程师已经非常了解这些需求。
|
||||
|
||||
在 nextcloud 中,客户永远不需要解释两次,也不需要依靠初级支持团队成员将问题准确地传达给工程师。我们的工程师根据客户的实际需求不断调整他们的优先级。同时,基于对客户的深入了解,合作制定长期目标。
|
||||
|
||||
### 3、最佳支持
|
||||
|
||||
与专有的或 <ruby>[开放源核心][2]<rt>open core</rt></ruby>的供应商不同,开源供应商有强大的动力提供尽可能最好的支持:这是与其他公司在其生态系统中的关键区别。
|
||||
|
||||
为什么项目背后的推动者(比如 [Collabora][3] 在 [LibreOffice][4] 背后,[The Qt Company][5] 在 [Qt][6] 背后,或者 [Red Hat][7] 在 [RHEL][8] 背后)是客户支持的最佳来源呢?
|
||||
|
||||
当然是直接接触工程师。这些公司并不阻断来自工程团队的支持,而是为客户提供了获得工程师专业知识的机会。这有助于确保客户始终尽快获得最佳答案。虽然一些工程师可能比其他人在支持上花费更多的时间,但整个工程团队在客户成功方面发挥着作用。专有供应商可能会为客户提供一个专门的现场工程师,费用相当高,但一个开源公司,如 [OpenNMS][9] 可以在您的支持合同中提供相同级别的服务,即使您不是财富 500 强客户也是如此。
|
||||
|
||||
还有一个好处,那就是与测试和客户协作有关:共享角色可确保工程师每天处理客户问题和愿望,从而促使他们快速解决最常见的问题。他们还倾向于构建额外的工具和功能,以满足客户预期。
|
||||
|
||||
简单地说,将质量检测、支持、产品管理和其他工程角色合并为一个团队,可确保优秀开发人员的三大优点 —— <ruby>[从简、精益求精、高度自我要求][10]<rt>laziness,impatience,and hubris</rt></ruby> —— 与客户紧密保持一致。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/mixing-roles-engineering
|
||||
|
||||
作者:[Jos Poortvliet][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lixinyuxx](https://github.com/lixinyuxx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://nextcloud.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Open_core
|
||||
[3]:https://www.collaboraoffice.com/
|
||||
[4]:https://www.libreoffice.org/
|
||||
[5]:https://www.qt.io/
|
||||
[6]:https://www.qt.io/developers/
|
||||
[7]:https://www.redhat.com/en
|
||||
[8]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[9]:https://www.opennms.org/en
|
||||
[10]:http://threevirtues.com/
|
||||
@ -1,23 +1,24 @@
|
||||
使用 MDwiki 将 Markdown 发布成 HTML
|
||||
======
|
||||
> 用这个有用工具从 Markdown 文件创建一个基础的网站。
|
||||
|
||||

|
||||
|
||||
有很多理由喜欢 Markdown,这是一门简单的语言,有易于学习的语法,它可以与任何文本编辑器一起使用。使用像 [Pandoc][1] 这样的工具,你可以将 Markdown 文本转换为[各种流行格式][2],包括 HTML。你还可以在 Web 服务器中自动执行转换过程。由 TimoDörr 创建的名为 [MDwiki][3]的 HTML5 和 JavaScript 应用可以将一堆 Markdown 文件在浏览器请求它们时转换为网站。MDwiki 网站包含一个操作指南和其他信息可帮助你入门:
|
||||
有很多理由喜欢 Markdown,这是一门简单的语言,有易于学习的语法,它可以与任何文本编辑器一起使用。使用像 [Pandoc][1] 这样的工具,你可以将 Markdown 文本转换为[各种流行格式][2],包括 HTML。你还可以在 Web 服务器中自动执行转换过程。由 TimoDörr 创建的名为 [MDwiki][3] 的 HTML5 和 JavaScript 应用可以将一堆 Markdown 文件在浏览器请求它们时转换为网站。MDwiki 网站包含一个操作指南和其他信息可帮助你入门:
|
||||
|
||||
![MDwiki site getting started][5]
|
||||
|
||||
Mdwiki 网站的样子。
|
||||
*Mdwiki 网站的样子。*
|
||||
|
||||
在 Web 服务器内部,基本的 MDwiki 站点如下所示:
|
||||
|
||||
![MDwiki site inside web server][7]
|
||||
|
||||
该站点的 web 服务器文件夹的样子
|
||||
*该站点的 web 服务器文件夹的样子*
|
||||
|
||||
我将此项目的 MDwiki HTML 文件重命名为 `START.HTML`。还有一个处理导航的 Markdown 文件和一个 JSON 文件来保存一些配置设置。其他的都是网站内容。
|
||||
|
||||
虽然整个网站设计被 MDwiki 固定了,但内容、样式和页面数量却没有。你可以在 [MDwiki 站点][8]查看由 MDwiki 生成的一系列不同站点。公平地说,MDwiki 网站缺乏网页设计师可以实现的视觉吸引力 - 但它们是功能性的,用户应该平衡其简单的外观与创建和编辑它们的速度和简易性。
|
||||
虽然整个网站设计被 MDwiki 固定了,但内容、样式和页面数量却没有。你可以在 [MDwiki 站点][8]查看由 MDwiki 生成的一系列不同站点。公平地说,MDwiki 网站缺乏网页设计师可以实现的视觉吸引力 —— 但它们是功能性的,用户应该平衡其简单的外观与创建和编辑它们的速度和简易性。
|
||||
|
||||
Markdown 有不同的风格,可以针对不同的特定目的扩展稳定的核心功能。MDwiki 使用 GitHub 风格 [Markdown][9],它为流行的编程语言添加了格式化代码块和语法高亮等功能,使其非常适合生成程序文档和教程。
|
||||
|
||||
@ -29,13 +30,14 @@ MDwiki 的默认配色方案并非适用于所有项目,但你可以将其替
|
||||
|
||||
![MDwiki screen with Bootswatch Superhero theme][12]
|
||||
|
||||
MDwiki 页面使用 Bootswatch Superhero 主题
|
||||
*MDwiki 页面使用 Bootswatch Superhero 主题*
|
||||
|
||||
MDwiki、Markdown 文件和静态图像可以用于许多目的。但是,你有时可能希望包含 JavaScript 幻灯片或反馈表单。Markdown 文件可以包含 HTML 代码,但将 Markdown 与 HTML 混合会让人感到困惑。一种解决方案是在单独的 HTML 文件中创建所需的功能,并将其显示在带有 iframe 标记的 Markdown 文件中。我从 [Twine Cookbook][13] 知道了这个想法,它是 Twine 交互式小说引擎的支持站点。Twine Cookbook 实际上并没有使用 MDwiki,但结合 Markdown 和 iframe 标签开辟了广泛的创作可能性。
|
||||
|
||||
这是一个例子:
|
||||
|
||||
此 HTML 将显示由 Markdown 文件中的 Twine 交互式小说引擎创建的 HTML 页面。
|
||||
|
||||
```
|
||||
<iframe height="400" src="sugarcube_dungeonmoving_example.html" width="90%"></iframe>
|
||||
```
|
||||
@ -53,7 +55,7 @@ via: https://opensource.com/article/18/8/markdown-html-publishing
|
||||
作者:[Peter Cheer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
48
published/20180904 Why schools of the future are open.md
Normal file
48
published/20180904 Why schools of the future are open.md
Normal file
@ -0,0 +1,48 @@
|
||||
为什么未来的学校是开放式的
|
||||
======
|
||||
> 一个学生对现代教育并不那么悲观的观点。
|
||||
|
||||

|
||||
|
||||
最近有些人和我说现代教育会是什么样子,我回答说:就像过去一百年一样。我们为什么会对我们的教育体系保持悲观态度呢?
|
||||
|
||||
这不是一个悲观的观点,而是一个务实的观点。任何花时间在学校的人都会有同样的感觉,我们对教导年轻人的方式固执地抵制变革。随着美国学校开始新的一年,大多数学生回到了桌子排成一排排的教室。教学环境主要以教师为中心,学生的进步由卡内基单位和 A-F 评分来衡量,而合作通常被认为是作弊。
|
||||
|
||||
我们从哪能够找到证据指出这种工业化模式正在产生所预想的结果?每个孩子都得到个人关注,以培养对学习的热爱,并发展出当今创新经济中茁壮成长所需的技能,我们很可能对现状非常满意。 但是,任何真实客观地看待当前的指标都表明要从基本开始改变。
|
||||
|
||||
但我的观点并非悲观。 事实上,非常乐观。
|
||||
|
||||
尽管我们可以很容易的阐述现代教育的问题所在,但我也知道一个例子,教育利益相关者愿意走出那些舒适的环境,并挑战这个对变革无动于衷的体系。教师要与同龄人进行更多的合作,并采取更多方式公开透明的对原型创意进行展示,从而为学生带来真正的创新 —— 而不是通过技术重新包装传统方法。管理员通过以社区为中心,基于项目的学习,实现更深入、更紧密的学习实际的应用程序 —— 不仅仅是在孤立的教室中“做项目”。 父母们想把学习的快乐回归到学校的文化,这些文化因强调考试而受到损害。
|
||||
|
||||
所有文化变革向来都不容易,特别是在面对任何考试成绩下降(无论统计意义如何重要)都面临政治反弹的环境中,因此人们不愿意承担风险。
|
||||
那么为什么我乐观地认为我们正在接近一个临界点,我们所需要的变化确实可以克服长期挫败它们的惯性呢?
|
||||
|
||||
因为在我们的现代时代,社会中还有其他东西在以前没有出现过:开放的精神,由数字技术催化。
|
||||
|
||||
想一想:如果你需要为即将到来的法国旅行学习基本的法语,你该怎么办? 您可以在当地社区学院注册一门课程或者从图书馆借书,但很有可能,您会用免费在线视频并了解旅行所需的基本知识。人类历史上从未有过免费的按需学习。事实上,人们可以参加麻省理工学院关于“[应用数学的专题:线性代数和变异微积分][1]的免费在线课程。报名参加吧!
|
||||
|
||||
为什么麻省理工学院、斯坦福大学和哈佛大学等学校提供免费课程? 为什么人们和公司愿意公开分享曾经严格控制的知识产权?为什么全球各地的人们都愿意花时间,无偿地帮助公民科学项目呢?
|
||||
|
||||
David Price 在他那本很棒的书《[开放:我们将如何在未来工作和学习][2]》中,清楚地描述了非正式的社交学习如何成为新的学习规范,尤其是习惯于能够及时获取他们需要的知识学习的年轻人。通过一系列案例研究,Price 清楚地描绘了当传统制度不适应这种新现实并因此变得越来越不相关时会发生什么。这是缺失的元素,它能让众包产生积极的颠覆性的影响。
|
||||
|
||||
Price 指出(以及人们现在对基层的要求)正是一场开放的运动,人们认识到开放式合作和自由交换思想已经破坏了从音乐到软件再到出版的生态系统。 而且,除了任何自上而下推动的“改革”之外,这种对开放性的期望有可能从根本上改变长期以来一直抵制变革的教育体系。事实上,开放精神的标志之一是,它期望知识的透明和公平民主化,造福所有人。那么,对于这样一种精神而言,还有什么生态系统能比试图让年轻人做好准备,继承这个世界、让这个世界变得更好呢?
|
||||
|
||||
当然,也有另一种悲观的声音说,我早期关于教育未来的预测可能确实是短期未来的教育状况。但我也非常乐观地认为,这种说法将被证明是错误的。 我知道我和许多其他志趣相投的教育工作者每天都在努力证明这是错误的。 当我们开始帮助我们的学校[转变为开放式组织][3] —— 从过时的传统模式过渡到更开放、灵活,响应每个学生和他们服务的社区需要的时候,你会加入我吗?
|
||||
|
||||
这是适合现代时代的真正教育模式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/9/modern-education-open-education
|
||||
|
||||
作者:[Ben Owens][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hkurj](https://github.com/hkurj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/engineerteacher
|
||||
[1]: https://ocw.mit.edu/courses/mechanical-engineering/2-035-special-topics-in-mathematics-with-applications-linear-algebra-and-the-calculus-of-variations-spring-2007/
|
||||
[2]: https://www.goodreads.com/book/show/18730272-open
|
||||
[3]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
116
published/20181004 Archiving web sites.md
Normal file
116
published/20181004 Archiving web sites.md
Normal file
@ -0,0 +1,116 @@
|
||||
对网站进行归档
|
||||
======
|
||||
|
||||
我最近深入研究了网站归档,因为有些朋友担心遇到糟糕的系统管理或恶意删除时失去对放在网上的内容的控制权。这使得网站归档成为系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难归档。本文介绍了对传统网站进行归档的过程,并阐述在面对最新流行单页面应用程序(SPA)的现代网站时,它有哪些不足。
|
||||
|
||||
### 转换为简单网站
|
||||
|
||||
手动编码 HTML 网站的日子早已不复存在。现在的网站是动态的,并使用最新的 JavaScript、PHP 或 Python 框架即时构建。结果,这些网站更加脆弱:数据库崩溃、升级出错或者未修复的漏洞都可能使数据丢失。在我以前是一名 Web 开发人员时,我不得不接受客户这样的想法:希望网站基本上可以永久工作。这种期望与 web 开发“快速行动和破除陈规”的理念不相符。在这方面,使用 [Drupal][2] 内容管理系统(CMS)尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担的起高昂的升级成本。解决方案是将这些网站归档:以实时动态的网站为基础,将其转换为任何 web 服务器可以永久服务的纯 HTML 文件。此过程对你自己的动态网站非常有用,也适用于你想保护但无法控制的第三方网站。
|
||||
|
||||
对于简单的静态网站,古老的 [Wget][3] 程序就可以胜任。然而镜像保存一个完整网站的命令却是错综复杂的:
|
||||
|
||||
```
|
||||
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
|
||||
--backup-converted --page-requisites --adjust-extension \
|
||||
--base=./ --directory-prefix=./ --span-hosts \
|
||||
--domains=www.example.com,example.com http://www.example.com/
|
||||
```
|
||||
|
||||
以上命令下载了网页的内容,也抓取了指定域名中的所有内容。在对你喜欢的网站执行此操作之前,请考虑此类抓取可能对网站产生的影响。上面的命令故意忽略了 `robots.txt` 规则,就像现在[归档者的习惯做法][4],并以尽可能快的速度归档网站。大多数抓取工具都可以选择在两次抓取间暂停并限制带宽使用,以避免使网站瘫痪。
|
||||
|
||||
上面的命令还将获取 “页面所需(LCTT 译注:单页面所需的所有元素)”,如样式表(CSS)、图像和脚本等。下载的页面内容将会被修改,以便链接也指向本地副本。任何 web 服务器均可托管生成的文件集,从而生成原始网站的静态副本。
|
||||
|
||||
以上所述是事情一切顺利的时候。任何使用过计算机的人都知道事情的进展很少如计划那样;各种各样的事情可以使程序以有趣的方式脱离正轨。比如,在网站上有一段时间很流行日历块。内容管理系统会动态生成这些内容,这会使爬虫程序陷入死循环以尝试检索所有页面。灵巧的归档者可以使用正则表达式(例如 Wget 有一个 `--reject-regex` 选项)来忽略有问题的资源。如果可以访问网站的管理界面,另一个方法是禁用日历、登录表单、评论表单和其他动态区域。一旦网站变成静态的,(那些动态区域)也肯定会停止工作,因此从原始网站中移除这些杂乱的东西也不是全无意义。
|
||||
|
||||
### JavaScript 噩梦
|
||||
|
||||
很不幸,有些网站不仅仅是纯 HTML 文件构建的。比如,在单页面网站中,web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将难以重建这些网站的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用[渐进增强][5]技术,在不使用 JavaScript 的情况下提供内容和实现功能,但这些指引很少被人遵循 —— 使用过 [NoScript][6] 或 [uMatrix][7] 等插件的人都知道。
|
||||
|
||||
传统的归档方法有时会以最愚蠢的方式失败。在尝试为一个本地报纸网站([pamplemousse.ca][8])创建备份时,我发现 WordPress 在包含 的 JavaScript 末尾添加了查询字符串(例如:`?ver=1.12.4`)。这会使提供归档服务的 web 服务器不能正确进行内容类型检测,因为其靠文件扩展名来发送正确的 `Content-Type` 头部信息。在 web 浏览器加载此类归档时,这些脚本会加载失败,导致动态网站受损。
|
||||
|
||||
随着 web 向使用浏览器作为执行任意代码的虚拟机转化,依赖于纯 HTML 文件解析的归档方法也需要随之适应。这个问题的解决方案是在抓取时记录(以及重现)服务器提供的 HTTP 头部信息,实际上专业的归档者就使用这种方法。
|
||||
|
||||
### 创建和显示 WARC 文件
|
||||
|
||||
在 <ruby>[互联网档案馆][9]<rt>Internet Archive</rt></ruby> 网站,Brewster Kahle 和 Mike Burner 在 1996 年设计了 [ARC][10] (即 “ARChive”)文件格式,以提供一种聚合其归档工作所产生的百万个小文件的方法。该格式最终标准化为 WARC(“Web ARChive”)[规范][11],并在 2009 年作为 ISO 标准发布,2017 年修订。标准化工作由<ruby>[国际互联网保护联盟][12]<rt>International Internet Preservation Consortium</rt></ruby>(IIPC)领导,据维基百科称,这是一个“*为了协调为未来而保护互联网内容的努力而成立的国际图书馆组织和其他组织*”;它的成员包括<ruby>美国国会图书馆<rt>US Library of Congress</rt></ruby>和互联网档案馆等。后者在其基于 Java 的 [Heritrix crawler][13](LCTT 译注:一种爬虫程序)内部使用了 WARC 格式。
|
||||
|
||||
WARC 在单个压缩文件中聚合了多种资源,像 HTTP 头部信息、文件内容,以及其他元数据。方便的是,Wget 实际上提供了 `--warc` 参数来支持 WARC 格式。不幸的是,web 浏览器不能直接显示 WARC 文件,所以为了访问归档文件,一个查看器或某些格式转换是很有必要的。我所发现的最简单的查看器是 [pywb][14],它以 Python 包的形式运行一个简单的 web 服务器提供一个像“<ruby>时光倒流机网站<rt>Wayback Machine</rt></ruby>”的界面,来浏览 WARC 文件的内容。执行以下命令将会在 `http://localhost:8080/` 地址显示 WARC 文件的内容:
|
||||
|
||||
```
|
||||
$ pip install pywb
|
||||
$ wb-manager init example
|
||||
$ wb-manager add example crawl.warc.gz
|
||||
$ wayback
|
||||
```
|
||||
|
||||
顺便说一句,这个工具是由 [Webrecorder][15] 服务提供者建立的,Webrecoder 服务可以使用 web 浏览器保存动态页面的内容。
|
||||
|
||||
很不幸,pywb 无法加载 Wget 生成的 WARC 文件,因为它[遵循][16]的 [1.0 规范不一致][17],[1.1 规范修复了此问题][17]。就算 Wget 或 pywb 修复了这些问题,Wget 生成的 WARC 文件对我的使用来说不够可靠,所以我找了其他的替代品。引起我注意的爬虫程序简称 [crawl][19]。以下是它的调用方式:
|
||||
|
||||
```
|
||||
$ crawl https://example.com/
|
||||
```
|
||||
|
||||
(它的 README 文件说“非常简单”。)该程序支持一些命令行参数选项,但大多数默认值都是最佳的:它会从其他域获取页面所需(除非使用 `-exclude-related` 参数),但肯定不会递归出域。默认情况下,它会与远程站点建立十个并发连接,这个值可以使用 `-c` 参数更改。但是,最重要的是,生成的 WARC 文件可以使用 pywb 完美加载。
|
||||
|
||||
### 未来的工作和替代方案
|
||||
|
||||
这里还有更多有关使用 WARC 文件的[资源][20]。特别要提的是,这里有一个专门用来归档网站的 Wget 的直接替代品,叫做 [Wpull][21]。它实验性地支持了 [PhantomJS][22] 和 [youtube-dl][23] 的集成,即允许分别下载更复杂的 JavaScript 页面以及流媒体。该程序是一个叫做 [ArchiveBot][24] 的复杂归档工具的基础,ArchiveBot 被那些在 [ArchiveTeam][25] 的“*零散离群的归档者、程序员、作家以及演说家*”使用,他们致力于“*在历史永远丢失之前保存它们*”。集成 PhantomJS 好像并没有如团队期望的那样良好工作,所以 ArchiveTeam 也用其它零散的工具来镜像保存更复杂的网站。例如,[snscrape][26] 将抓取一个社交媒体配置文件以生成要发送到 ArchiveBot 的页面列表。该团队使用的另一个工具是 [crocoite][27],它使用无头模式的 Chrome 浏览器来归档 JavaScript 较多的网站。
|
||||
|
||||
如果没有提到称做“网站复制者”的 [HTTrack][28] 项目,那么这篇文章算不上完整。它工作方式和 Wget 相似,HTTrack 可以对远程站点创建一个本地的副本,但是不幸的是它不支持输出 WRAC 文件。对于不熟悉命令行的小白用户来说,它在人机交互方面显得更有价值。
|
||||
|
||||
同样,在我的研究中,我发现了叫做 [Wget2][29] 的 Wget 的完全重制版本,它支持多线程操作,这可能使它比前身更快。和 Wget 相比,它[舍弃了一些功能][30],但是最值得注意的是拒绝模式、WARC 输出以及 FTP 支持,并增加了 RSS、DNS 缓存以及改进的 TLS 支持。
|
||||
|
||||
最后,我个人对这些工具的愿景是将它们与我现有的书签系统集成起来。目前我在 [Wallabag][31] 中保留了一些有趣的链接,这是一种自托管式的“稍后阅读”服务,意在成为 [Pocket][32](现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 在设计上只保留了文章的“可读”副本,而不是一个完整的拷贝。在某些情况下,“可读版本”实际上[不可读][33],并且 Wallabag 有时[无法解析文章][34]。恰恰相反,像 [bookmark-archiver][35] 或 [reminiscence][36] 这样其他的工具会保存页面的屏幕截图以及完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件所以没有办法更可信的重现网页内容。
|
||||
|
||||
我所经历的有关镜像保存和归档的悲剧就是死数据。幸运的是,业余的归档者可以利用工具将有趣的内容保存到网上。对于那些不想麻烦的人来说,“互联网档案馆”看起来仍然在那里,并且 ArchiveTeam 显然[正在为互联网档案馆本身做备份][37]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-10-04-archiving-web-sites/
|
||||
|
||||
作者:[Anarcat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://anarc.at
|
||||
[1]: https://anarc.at/blog
|
||||
[2]: https://drupal.org
|
||||
[3]: https://www.gnu.org/software/wget/
|
||||
[4]: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
|
||||
[5]: https://en.wikipedia.org/wiki/Progressive_enhancement
|
||||
[6]: https://noscript.net/
|
||||
[7]: https://github.com/gorhill/uMatrix
|
||||
[8]: https://pamplemousse.ca/
|
||||
[9]: https://archive.org
|
||||
[10]: http://www.archive.org/web/researcher/ArcFileFormat.php
|
||||
[11]: https://iipc.github.io/warc-specifications/
|
||||
[12]: https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium
|
||||
[13]: https://github.com/internetarchive/heritrix3/wiki
|
||||
[14]: https://github.com/webrecorder/pywb
|
||||
[15]: https://webrecorder.io/
|
||||
[16]: https://github.com/webrecorder/pywb/issues/294
|
||||
[17]: https://github.com/iipc/warc-specifications/issues/23
|
||||
[18]: https://github.com/iipc/warc-specifications/pull/24
|
||||
[19]: https://git.autistici.org/ale/crawl/
|
||||
[20]: https://archiveteam.org/index.php?title=The_WARC_Ecosystem
|
||||
[21]: https://github.com/chfoo/wpull
|
||||
[22]: http://phantomjs.org/
|
||||
[23]: http://rg3.github.io/youtube-dl/
|
||||
[24]: https://www.archiveteam.org/index.php?title=ArchiveBot
|
||||
[25]: https://archiveteam.org/
|
||||
[26]: https://github.com/JustAnotherArchivist/snscrape
|
||||
[27]: https://github.com/PromyLOPh/crocoite
|
||||
[28]: http://www.httrack.com/
|
||||
[29]: https://gitlab.com/gnuwget/wget2
|
||||
[30]: https://gitlab.com/gnuwget/wget2/wikis/home
|
||||
[31]: https://wallabag.org/
|
||||
[32]: https://getpocket.com/
|
||||
[33]: https://github.com/wallabag/wallabag/issues/2825
|
||||
[34]: https://github.com/wallabag/wallabag/issues/2914
|
||||
[35]: https://pirate.github.io/bookmark-archiver/
|
||||
[36]: https://github.com/kanishka-linux/reminiscence
|
||||
[37]: http://iabak.archiveteam.org
|
||||
@ -1,89 +1,86 @@
|
||||
实验 3:用户环境
|
||||
Caffeinated 6.828:实验 3:用户环境
|
||||
======
|
||||
### 实验 3:用户环境
|
||||
|
||||
#### 简介
|
||||
### 简介
|
||||
|
||||
在本实验中,你将要实现一个基本的内核功能,要求它能够保护运行的用户模式环境(即:进程)。你将去增强这个 JOS 内核,去配置数据结构以便于保持对用户环境的跟踪、创建一个单一用户环境、将程序镜像加载到用户环境中、并将它启动运行。你也要写出一些 JOS 内核的函数,用来处理任何用户环境生成的系统调用,以及处理由用户环境引进的各种异常。
|
||||
|
||||
**注意:** 在本实验中,术语**_“环境”_** 和**_“进程”_** 是可互换的 —— 它们都表示同一个抽象概念,那就是允许你去运行的程序。我在介绍中使用术语**“环境”**而不是使用传统术语**“进程”**的目的是为了强调一点,那就是 JOS 的环境和 UNIX 的进程提供了不同的接口,并且它们的语义也不相同。
|
||||
**注意:** 在本实验中,术语**“环境”** 和**“进程”** 是可互换的 —— 它们都表示同一个抽象概念,那就是允许你去运行的程序。我在介绍中使用术语**“环境”**而不是使用传统术语**“进程”**的目的是为了强调一点,那就是 JOS 的环境和 UNIX 的进程提供了不同的接口,并且它们的语义也不相同。
|
||||
|
||||
##### 预备知识
|
||||
#### 预备知识
|
||||
|
||||
使用 Git 去提交你自实验 2 以后的更改(如果有的话),获取课程仓库的最新版本,以及创建一个命名为 `lab3` 的本地分支,指向到我们的 lab3 分支上 `origin/lab3` :
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
实验 3 包含一些你将探索的新源文件:
|
||||
|
||||
```c
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
```
|
||||
|
||||
另外,一些在实验 2 中的源文件在实验 3 中将被修改。如果想去查看有什么更改,可以运行:
|
||||
|
||||
```
|
||||
$ git diff lab2
|
||||
|
||||
$ git diff lab2
|
||||
```
|
||||
|
||||
你也可以另外去看一下 [实验工具指南][1],它包含了与本实验有关的调试用户代码方面的信息。
|
||||
|
||||
##### 实验要求
|
||||
#### 实验要求
|
||||
|
||||
本实验分为两部分:Part A 和 Part B。Part A 在本实验完成后一周内提交;你将要提交你的更改和完成的动手实验,在提交之前要确保你的代码通过了 Part A 的所有检查(如果你的代码未通过 Part B 的检查也可以提交)。只需要在第二周提交 Part B 的期限之前代码检查通过即可。
|
||||
|
||||
由于在实验 2 中,你需要做实验中描述的所有正则表达式练习,并且至少通过一个挑战(是指整个实验,不是每个部分)。写出详细的问题答案并张贴在实验中,以及一到两个段落的关于你如何解决你选择的挑战问题的详细描述,并将它放在一个名为 `answers-lab3.txt` 的文件中,并将这个文件放在你的 `lab` 目标的根目录下。(如果你做了多个问题挑战,你仅需要提交其中一个即可)不要忘记使用 `git add answers-lab3.txt` 提交这个文件。
|
||||
|
||||
##### 行内汇编语言
|
||||
#### 行内汇编语言
|
||||
|
||||
在本实验中你可能找到使用了 GCC 的行内汇编语言特性,虽然不使用它也可以完成实验。但至少你需要去理解这些行内汇编语言片段,这些汇编语言("`asm`" 语句)片段已经存在于提供给你的源代码中。你可以在课程 [参考资料][2] 的页面上找到 GCC 行内汇编语言有关的信息。
|
||||
在本实验中你可能发现使用了 GCC 的行内汇编语言特性,虽然不使用它也可以完成实验。但至少你需要去理解这些行内汇编语言片段,这些汇编语言(`asm` 语句)片段已经存在于提供给你的源代码中。你可以在课程 [参考资料][2] 的页面上找到 GCC 行内汇编语言有关的信息。
|
||||
|
||||
#### Part A:用户环境和异常处理
|
||||
### Part A:用户环境和异常处理
|
||||
|
||||
新文件 `inc/env.h` 中包含了在 JOS 中关于用户环境的基本定义。现在就去阅读它。内核使用数据结构 `Env` 去保持对每个用户环境的跟踪。在本实验的开始,你将只创建一个环境,但你需要去设计 JOS 内核支持多环境;实验 4 将带来这个高级特性,允许用户环境去 `fork` 其它环境。
|
||||
|
||||
正如你在 `kern/env.c` 中所看到的,内核维护了与环境相关的三个全局变量:
|
||||
|
||||
```
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
```
|
||||
|
||||
一旦 JOS 启动并运行,`envs` 指针指向到一个数组,即数据结构 `Env`,它保存了系统中全部的环境。在我们的设计中,JOS 内核将同时支持最大值为 `NENV` 个的活动的环境,虽然在一般情况下,任何给定时刻运行的环境很少。(`NENV` 是在 `inc/env.h` 中用 `#define` 定义的一个常量)一旦它被分配,对于每个 `NENV` 可能的环境,`envs` 数组将包含一个数据结构 `Env` 的单个实例。
|
||||
@ -92,38 +89,38 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
|
||||
内核使用符号 `curenv` 来保持对任意给定时刻的 _当前正在运行的环境_ 进行跟踪。在系统引导期间,在第一个环境运行之前,`curenv` 被初始化为 `NULL`。
|
||||
|
||||
##### 环境状态
|
||||
#### 环境状态
|
||||
|
||||
数据结构 `Env` 被定义在文件 `inc/env.h` 中,内容如下:(在后面的实验中将添加更多的字段):
|
||||
|
||||
```c
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
```
|
||||
|
||||
以下是数据结构 `Env` 中的字段简介:
|
||||
|
||||
* **env_tf**:
|
||||
* `env_tf`:
|
||||
这个结构定义在 `inc/trap.h` 中,它用于在那个环境不运行时保持它保存在寄存器中的值,即:当内核或一个不同的环境在运行时。当从用户模式切换到内核模式时,内核将保存这些东西,以便于那个环境能够在稍后重新运行时回到中断运行的地方。
|
||||
* **env_link**:
|
||||
* `env_link`:
|
||||
这是一个链接,它链接到在 `env_free_list` 上的下一个 `Env` 上。`env_free_list` 指向到列表上第一个空闲的环境。
|
||||
* **env_id**:
|
||||
* `env_id`:
|
||||
内核在数据结构 `Env` 中保存了一个唯一标识当前环境的值(即:使用数组 `envs` 中的特定槽位)。在一个用户环境终止之后,内核可能给另外的环境重新分配相同的数据结构 `Env` —— 但是新的环境将有一个与已终止的旧的环境不同的 `env_id`,即便是新的环境在数组 `envs` 中复用了同一个槽位。
|
||||
* **env_parent_id**:
|
||||
* `env_parent_id`:
|
||||
内核使用它来保存创建这个环境的父级环境的 `env_id`。通过这种方式,环境就可以形成一个“家族树”,这对于做出“哪个环境可以对谁做什么”这样的安全决策非常有用。
|
||||
* **env_type**:
|
||||
* `env_type`:
|
||||
它用于去区分特定的环境。对于大多数环境,它将是 `ENV_TYPE_USER` 的。在稍后的实验中,针对特定的系统服务环境,我们将引入更多的几种类型。
|
||||
* **env_status**:
|
||||
* `env_status`:
|
||||
这个变量持有以下几个值之一:
|
||||
* `ENV_FREE`:
|
||||
表示那个 `Env` 结构是非活动的,并且因此它还在 `env_free_list` 上。
|
||||
@ -135,59 +132,64 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
表示那个 `Env` 结构所代表的是一个当前活动的环境,但不是当前准备去运行的:例如,因为它正在因为一个来自其它环境的进程间通讯(IPC)而处于等待状态。
|
||||
* `ENV_DYING`:
|
||||
表示那个 `Env` 结构所表示的是一个僵尸环境。一个僵尸环境将在下一次被内核捕获后被释放。我们在实验 4 之前不会去使用这个标志。
|
||||
* **env_pgdir**:
|
||||
* `env_pgdir`:
|
||||
这个变量持有这个环境的内核虚拟地址的页目录。
|
||||
|
||||
|
||||
|
||||
就像一个 Unix 进程一样,一个 JOS 环境耦合了“线程”和“地址空间”的概念。线程主要由保存的寄存器来定义(`env_tf` 字段),而地址空间由页目录和 `env_pgdir` 所指向的页表所定义。为运行一个环境,内核必须使用保存的寄存器值和相关的地址空间去设置 CPU。
|
||||
|
||||
我们的 `struct Env` 与 xv6 中的 `struct proc` 类似。它们都在一个 `Trapframe` 结构中持有环境(即进程)的用户模式寄存器状态。在 JOS 中,单个的环境并不能像 xv6 中的进程那样拥有它们自己的内核栈。在这里,内核中任意时间只能有一个 JOS 环境处于活动中,因此,JOS 仅需要一个单个的内核栈。
|
||||
|
||||
##### 为环境分配数组
|
||||
#### 为环境分配数组
|
||||
|
||||
在实验 2 的 `mem_init()` 中,你为数组 `pages[]` 分配了内存,它是内核用于对页面分配与否的状态进行跟踪的一个表。你现在将需要去修改 `mem_init()`,以便于后面使用它分配一个与结构 `Env` 类似的数组,这个数组被称为 `envs`。
|
||||
|
||||
```markdown
|
||||
练习 1、修改在 `kern/pmap.c` 中的 `mem_init()`,以用于去分配和映射 `envs` 数组。这个数组完全由 `Env` 结构分配的实例 `NENV` 组成,就像你分配的 `pages` 数组一样。与 `pages` 数组一样,由内存支持的数组 `envs` 也将在 `UENVS`(它的定义在 `inc/memlayout.h` 文件中)中映射用户只读的内存,以便于用户进程能够从这个数组中读取。
|
||||
```
|
||||
> **练习 1**、修改在 `kern/pmap.c` 中的 `mem_init()`,以用于去分配和映射 `envs` 数组。这个数组完全由 `Env` 结构分配的实例 `NENV` 组成,就像你分配的 `pages` 数组一样。与 `pages` 数组一样,由内存支持的数组 `envs` 也将在 `UENVS`(它的定义在 `inc/memlayout.h` 文件中)中映射用户只读的内存,以便于用户进程能够从这个数组中读取。
|
||||
|
||||
你应该去运行你的代码,并确保 `check_kern_pgdir()` 是没有问题的。
|
||||
|
||||
##### 创建和运行环境
|
||||
#### 创建和运行环境
|
||||
|
||||
现在,你将在 `kern/env.c` 中写一些必需的代码去运行一个用户环境。因为我们并没有做一个文件系统,因此,我们将设置内核去加载一个嵌入到内核中的静态的二进制镜像。JOS 内核以一个 ELF 可运行镜像的方式将这个二进制镜像嵌入到内核中。
|
||||
现在,你将在 `kern/env.c` 中写一些必需的代码去运行一个用户环境。因为我们并没有做一个文件系统,因此,我们将设置内核去加载一个嵌入到内核中的静态的二进制镜像。JOS 内核以一个 ELF 可运行镜像的方式将这个二进制镜像嵌入到内核中。
|
||||
|
||||
在实验 3 中,`GNUmakefile` 将在 `obj/user/` 目录中生成一些二进制镜像。如果你看到 `kern/Makefrag`,你将注意到一些奇怪的的东西,它们“链接”这些二进制直接进入到内核中运行,就像 `.o` 文件一样。在链接器命令行上的 `-b binary` 选项,将因此把它们链接为“原生的”不解析的二进制文件,而不是由编译器产生的普通的 `.o` 文件。(就链接器而言,这些文件压根就不是 ELF 镜像文件 —— 它们可以是任何东西,比如,一个文本文件或图片!)如果你在内核构建之后查看 `obj/kern/kernel.sym` ,你将会注意到链接器很奇怪的生成了一些有趣的、命名很费解的符号,比如像 `_binary_obj_user_hello_start`、`_binary_obj_user_hello_end`、以及 `_binary_obj_user_hello_size`。链接器通过改编二进制文件的命令来生成这些符号;这种符号为普通内核代码使用一种引入嵌入式二进制文件的方法。
|
||||
|
||||
在 `kern/init.c` 的 `i386_init()` 中,你将写一些代码在环境中运行这些二进制镜像中的一种。但是,设置用户环境的关键函数还没有实现;将需要你去完成它们。
|
||||
|
||||
```markdown
|
||||
练习 2、在文件 `env.c` 中,写完以下函数的代码:
|
||||
> **练习 2**、在文件 `env.c` 中,写完以下函数的代码:
|
||||
|
||||
* `env_init()`
|
||||
初始化 `envs` 数组中所有的 `Env` 结构,然后把它们添加到 `env_free_list` 中。也称为 `env_init_percpu`,它通过配置硬件,在硬件上为 level 0(内核)权限和 level 3(用户)权限使用单独的段。
|
||||
* `env_setup_vm()`
|
||||
为一个新环境分配一个页目录,并初始化新环境的地址空间的内核部分。
|
||||
* `region_alloc()`
|
||||
为一个新环境分配和映射物理内存
|
||||
* `load_icode()`
|
||||
你将需要去解析一个 ELF 二进制镜像,就像引导加载器那样,然后加载它的内容到一个新环境的用户地址空间中。
|
||||
* `env_create()`
|
||||
使用 `env_alloc` 去分配一个环境,并调用 `load_icode` 去加载一个 ELF 二进制
|
||||
* `env_run()`
|
||||
在用户模式中开始运行一个给定的环境
|
||||
> * `env_init()`
|
||||
|
||||
> 初始化 `envs` 数组中所有的 `Env` 结构,然后把它们添加到 `env_free_list` 中。也称为 `env_init_percpu`,它通过配置硬件,在硬件上为 level 0(内核)权限和 level 3(用户)权限使用单独的段。
|
||||
|
||||
> * `env_setup_vm()`
|
||||
|
||||
在你写这些函数时,你可能会发现新的 cprintf 动词 `%e` 非常有用 -- 它可以输出一个错误代码的相关描述。比如:
|
||||
> 为一个新环境分配一个页目录,并初始化新环境的地址空间的内核部分。
|
||||
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
> * `region_alloc()`
|
||||
|
||||
中 panic 将输出消息 "env_alloc: out of memory"。
|
||||
> 为一个新环境分配和映射物理内存
|
||||
|
||||
> * `load_icode()`
|
||||
|
||||
> 你将需要去解析一个 ELF 二进制镜像,就像引导加载器那样,然后加载它的内容到一个新环境的用户地址空间中。
|
||||
|
||||
> * `env_create()`
|
||||
|
||||
> 使用 `env_alloc` 去分配一个环境,并调用 `load_icode` 去加载一个 ELF 二进制
|
||||
|
||||
> * `env_run()`
|
||||
|
||||
> 在用户模式中开始运行一个给定的环境
|
||||
|
||||
> 在你写这些函数时,你可能会发现新的 cprintf 动词 `%e` 非常有用 -- 它可以输出一个错误代码的相关描述。比如:
|
||||
|
||||
> ```
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
```
|
||||
|
||||
> 中 panic 将输出消息 "env_alloc: out of memory"。
|
||||
|
||||
下面是用户代码相关的调用图。确保你理解了每一步的用途。
|
||||
|
||||
* `start` (`kern/entry.S`)
|
||||
@ -200,107 +202,94 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
* `env_run`
|
||||
* `env_pop_tf`
|
||||
|
||||
|
||||
|
||||
在完成以上函数后,你应该去编译内核并在 QEMU 下运行它。如果一切正常,你的系统将进入到用户空间并运行二进制的 `hello` ,直到使用 `int` 指令生成一个系统调用为止。在那个时刻将存在一个问题,因为 JOS 尚未设置硬件去允许从用户空间到内核空间的各种转换。当 CPU 发现没有系统调用中断的服务程序时,它将生成一个一般保护异常,找到那个异常并去处理它,还将生成一个双重故障异常,同样也找到它并处理它,并且最后会出现所谓的“三重故障异常”。通常情况下,你将随后看到 CPU 复位以及系统重引导。虽然对于传统的应用程序(在 [这篇博客文章][3] 中解释了原因)这是重大的问题,但是对于内核开发来说,这是一个痛苦的过程,因此,在打了 6.828 补丁的 QEMU 上,你将可以看到转储的寄存器内容和一个“三重故障”的信息。
|
||||
|
||||
我们马上就会去处理这些问题,但是现在,我们可以使用调试器去检查我们是否进入了用户模式。使用 `make qemu-gdb` 并在 `env_pop_tf` 处设置一个 GDB 断点,它是你进入用户模式之前到达的最后一个函数。使用 `si` 单步进入这个函数;处理器将在 `iret` 指令之后进入用户模式。然后你将会看到在用户环境运行的第一个指令,它将是在 `lib/entry.S` 中的标签 `start` 的第一个指令 `cmpl`。现在,在 `hello` 中的 `sys_cputs()` 的 `int $0x30` 处使用 `b *0x...`(关于用户空间的地址,请查看 `obj/user/hello.asm` )设置断点。这个指令 `int` 是系统调用去显示一个字符到控制台。如果到 `int` 还没有运行,那么可能在你的地址空间设置或程序加载代码时发生了错误;返回去找到问题并解决后重新运行。
|
||||
|
||||
##### 处理中断和异常
|
||||
#### 处理中断和异常
|
||||
|
||||
到目前为止,在用户空间中的第一个系统调用指令 `int $0x30` 已正式寿终正寝了:一旦处理器进入用户模式,将无法返回。因此,现在,你需要去实现基本的异常和系统调用服务程序,因为那样才有可能让内核从用户模式代码中恢复对处理器的控制。你所做的第一件事情就是彻底地掌握 x86 的中断和异常机制的使用。
|
||||
|
||||
```
|
||||
练习 3、如果你对中断和异常机制不熟悉的话,阅读 80386 程序员手册的第 9 章(或 IA-32 开发者手册的第 5 章)。
|
||||
```
|
||||
> **练习 3**、如果你对中断和异常机制不熟悉的话,阅读 80386 程序员手册的第 9 章(或 IA-32 开发者手册的第 5 章)。
|
||||
|
||||
在这个实验中,对于中断、异常、以其它类似的东西,我们将遵循 Intel 的术语习惯。由于如<ruby>异常<rt>exception</rt></ruby>、<ruby>陷阱<rt>trap</rt></ruby>、<ruby>中断<rt>interrupt</rt></ruby>、<ruby>故障<rt>fault</rt></ruby>和<ruby>中止<rt>abort</rt></ruby>这些术语在不同的架构和操作系统上并没有一个统一的标准,我们经常在特定的架构下(如 x86)并不去考虑它们之间的细微差别。当你在本实验以外的地方看到这些术语时,它们的含义可能有细微的差别。
|
||||
|
||||
##### 受保护的控制转移基础
|
||||
#### 受保护的控制转移基础
|
||||
|
||||
异常和中断都是“受保护的控制转移”,它将导致处理器从用户模式切换到内核模式(CPL=0)而不会让用户模式的代码干扰到内核的其它函数或其它的环境。在 Intel 的术语中,一个中断就是一个“受保护的控制转移”,它是由于处理器以外的外部异步事件所引发的,比如外部设备 I/O 活动通知。而异常正好与之相反,它是由当前正在运行的代码所引发的同步的、受保护的控制转移,比如由于发生了一个除零错误或对无效内存的访问。
|
||||
异常和中断都是“受保护的控制转移”,它将导致处理器从用户模式切换到内核模式(`CPL=0`)而不会让用户模式的代码干扰到内核的其它函数或其它的环境。在 Intel 的术语中,一个中断就是一个“受保护的控制转移”,它是由于处理器以外的外部异步事件所引发的,比如外部设备 I/O 活动通知。而异常正好与之相反,它是由当前正在运行的代码所引发的同步的、受保护的控制转移,比如由于发生了一个除零错误或对无效内存的访问。
|
||||
|
||||
为了确保这些受保护的控制转移是真正地受到保护,处理器的中断/异常机制设计是:当中断/异常发生时,当前运行的代码不能随意选择进入内核的位置和方式。而是,处理器在确保内核能够严格控制的条件下才能进入内核。在 x86 上,有两种机制协同来提供这种保护:
|
||||
|
||||
1. **中断描述符表** 处理器确保中断和异常仅能够导致内核进入几个特定的、由内核本身定义好的、明确的入口点,而不是去运行中断或异常发生时的代码。
|
||||
1. **中断描述符表** 处理器确保中断和异常仅能够导致内核进入几个特定的、由内核本身定义好的、明确的入口点,而不是去运行中断或异常发生时的代码。
|
||||
|
||||
x86 允许最多有 256 个不同的中断或异常入口点去进入内核,每个入口点都使用一个不同的中断向量。一个向量是一个介于 0 和 255 之间的数字。一个中断向量是由中断源确定的:不同的设备、错误条件、以及应用程序去请求内核使用不同的向量生成中断。CPU 使用向量作为进入处理器的中断描述符表(IDT)的索引,它是内核设置的内核私有内存,GDT 也是。从这个表中的适当的条目中,处理器将加载:
|
||||
x86 允许最多有 256 个不同的中断或异常入口点去进入内核,每个入口点都使用一个不同的中断向量。一个向量是一个介于 0 和 255 之间的数字。一个中断向量是由中断源确定的:不同的设备、错误条件、以及应用程序去请求内核使用不同的向量生成中断。CPU 使用向量作为进入处理器的中断描述符表(IDT)的索引,它是内核设置的内核私有内存,GDT 也是。从这个表中的适当的条目中,处理器将加载:
|
||||
|
||||
* 将值加载到指令指针寄存器(EIP),指向内核代码设计好的,用于处理这种异常的服务程序。
|
||||
* 将值加载到代码段寄存器(CS),它包含运行权限为 0—1 级别的、要运行的异常服务程序。(在 JOS 中,所有的异常处理程序都运行在内核模式中,运行级别为 level 0。)
|
||||
2. **任务状态描述符表** 处理器在中断或异常发生时,需要一个地方去保存旧的处理器状态,比如,处理器在调用异常服务程序之前的 `EIP` 和 `CS` 的原始值,这样那个异常服务程序就能够稍后通过还原旧的状态来回到中断发生时的代码位置。但是对于已保存的处理器的旧状态必须被保护起来,不能被无权限的用户模式代码访问;否则代码中的 bug 或恶意用户代码将危及内核。
|
||||
* 将值加载到代码段寄存器(CS),它包含运行权限为 0—1 级别的、要运行的异常服务程序。(在 JOS 中,所有的异常处理程序都运行在内核模式中,运行级别为 0。)
|
||||
|
||||
基于这个原因,当一个 x86 处理器产生一个中断或陷阱时,将导致权限级别的变更,从用户模式转换到内核模式,它也将导致在内核的内存中发生栈切换。有一个被称为 TSS 的任务状态描述符表规定段描述符和这个栈所处的地址。处理器在这个新栈上推送 `SS`、`ESP`、`EFLAGS`、`CS`、`EIP`、以及一个可选的错误代码。然后它从中断描述符上加载 `CS` 和 `EIP` 的值,然后设置 `ESP` 和 `SS` 去指向新的栈。
|
||||
2. **任务状态描述符表** 处理器在中断或异常发生时,需要一个地方去保存旧的处理器状态,比如,处理器在调用异常服务程序之前的 `EIP` 和 `CS` 的原始值,这样那个异常服务程序就能够稍后通过还原旧的状态来回到中断发生时的代码位置。但是对于已保存的处理器的旧状态必须被保护起来,不能被无权限的用户模式代码访问;否则代码中的 bug 或恶意用户代码将危及内核。
|
||||
|
||||
虽然 TSS 很大并且默默地为各种用途服务,但是 JOS 仅用它去定义当从用户模式到内核模式的转移发生时,处理器即将切换过去的内核栈。因为在 JOS 中的“内核模式”仅运行在 x86 的 level 0 权限上,当进入内核模式时,处理器使用 TSS 上的 `ESP0` 和 `SS0` 字段去定义内核栈。JOS 并不去使用 TSS 的任何其它字段。
|
||||
基于这个原因,当一个 x86 处理器产生一个中断或陷阱时,将导致权限级别的变更,从用户模式转换到内核模式,它也将导致在内核的内存中发生栈切换。有一个被称为 TSS 的任务状态描述符表规定段描述符和这个栈所处的地址。处理器在这个新栈上推送 `SS`、`ESP`、`EFLAGS`、`CS`、`EIP`、以及一个可选的错误代码。然后它从中断描述符上加载 `CS` 和 `EIP` 的值,然后设置 `ESP` 和 `SS` 去指向新的栈。
|
||||
|
||||
虽然 TSS 很大并且默默地为各种用途服务,但是 JOS 仅用它去定义当从用户模式到内核模式的转移发生时,处理器即将切换过去的内核栈。因为在 JOS 中的“内核模式”仅运行在 x86 的运行级别 0 权限上,当进入内核模式时,处理器使用 TSS 上的 `ESP0` 和 `SS0` 字段去定义内核栈。JOS 并不去使用 TSS 的任何其它字段。
|
||||
|
||||
|
||||
|
||||
##### 异常和中断的类型
|
||||
#### 异常和中断的类型
|
||||
|
||||
所有的 x86 处理器上的同步异常都能够产生一个内部使用的、介于 0 到 31 之间的中断向量,因此它映射到 IDT 就是条目 0-31。例如,一个页故障总是通过向量 14 引发一个异常。大于 31 的中断向量仅用于软件中断,它由 `int` 指令生成,或异步硬件中断,当需要时,它们由外部设备产生。
|
||||
|
||||
在这一节中,我们将扩展 JOS 去处理向量为 0-31 之间的、内部产生的 x86 异常。在下一节中,我们将完成 JOS 的 48(0x30)号软件中断向量,JOS 将(随意选择的)使用它作为系统调用中断向量。在实验 4 中,我们将扩展 JOS 去处理外部生成的硬件中断,比如时钟中断。
|
||||
|
||||
##### 一个示例
|
||||
#### 一个示例
|
||||
|
||||
我们把这些片断综合到一起,通过一个示例来巩固一下。我们假设处理器在用户环境下运行代码,遇到一个除零问题。
|
||||
|
||||
1. 处理器去切换到由 TSS 中的 `SS0` 和 `ESP0` 定义的栈,在 JOS 中,它们各自保存着值 `GD_KD` 和 `KSTACKTOP`。
|
||||
|
||||
2. 处理器在内核栈上推入异常参数,起始地址为 `KSTACKTOP`:
|
||||
1. 处理器去切换到由 TSS 中的 `SS0` 和 `ESP0` 定义的栈,在 JOS 中,它们各自保存着值 `GD_KD` 和 `KSTACKTOP`。
|
||||
2. 处理器在内核栈上推入异常参数,起始地址为 `KSTACKTOP`:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
|
||||
```
|
||||
|
||||
3. 由于我们要处理一个除零错误,它将在 x86 上产生一个中断向量 0,处理器读取 IDT 的条目 0,然后设置 `CS:EIP` 去指向由条目描述的处理函数。
|
||||
|
||||
4. 处理服务程序函数将接管控制权并处理异常,例如中止用户环境。
|
||||
|
||||
|
||||
|
||||
3. 由于我们要处理一个除零错误,它将在 x86 上产生一个中断向量 0,处理器读取 IDT 的条目 0,然后设置 `CS:EIP` 去指向由条目描述的处理函数。
|
||||
4. 处理服务程序函数将接管控制权并处理异常,例如中止用户环境。
|
||||
|
||||
对于某些类型的 x86 异常,除了以上的五个“标准的”寄存器外,处理器还推入另一个包含错误代码的寄存器值到栈中。页故障异常,向量号为 14,就是一个重要的示例。查看 80386 手册去确定哪些异常推入一个错误代码,以及错误代码在那个案例中的意义。当处理器推入一个错误代码后,当从用户模式中进入内核模式,异常处理服务程序开始时的栈看起来应该如下所示:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
##### 嵌套的异常和中断
|
||||
#### 嵌套的异常和中断
|
||||
|
||||
处理器能够处理来自用户和内核模式中的异常和中断。当收到来自用户模式的异常和中断时才会进入内核模式中,而且,在推送它的旧寄存器状态到栈中和通过 IDT 调用相关的异常服务程序之前,x86 处理器会自动切换栈。如果当异常或中断发生时,处理器已经处于内核模式中(`CS` 寄存器低位两个比特为 0),那么 CPU 只是推入一些值到相同的内核栈中。在这种方式中,内核可以优雅地处理嵌套的异常,嵌套的异常一般由内核本身的代码所引发。在实现保护时,这种功能是非常重要的工具,我们将在稍后的系统调用中看到它。
|
||||
|
||||
如果处理器已经处于内核模式中,并且发生了一个嵌套的异常,由于它并不需要切换栈,它也就不需要去保存旧的 `SS` 或 `ESP` 寄存器。对于不推入错误代码的异常类型,在进入到异常服务程序时,它的内核栈看起来应该如下图:
|
||||
|
||||
```
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
对于需要推入一个错误代码的异常类型,处理器将在旧的 `EIP` 之后,立即推入一个错误代码,就和前面一样。
|
||||
|
||||
关于处理器的异常嵌套的功能,这里有一个重要的警告。如果处理器正处于内核模式时发生了一个异常,并且不论是什么原因,比如栈空间泄漏,都不会去推送它的旧的状态,那么这时处理器将不能做任何的恢复,它只是简单地重置。毫无疑问,内核应该被设计为禁止发生这种情况。
|
||||
|
||||
##### 设置 IDT
|
||||
#### 设置 IDT
|
||||
|
||||
到目前为止,你应该有了在 JOS 中为了设置 IDT 和处理异常所需的基本信息。现在,我们去设置 IDT 以处理中断向量 0-31(处理器异常)。我们将在本实验的稍后部分处理系统调用,然后在后面的实验中增加中断 32-47(设备 IRQ)。
|
||||
|
||||
@ -311,102 +300,94 @@ x86 允许最多有 256 个不同的中断或异常入口点去进入内核,
|
||||
你将要实现的完整的控制流如下图所描述:
|
||||
|
||||
```c
|
||||
IDT trapentry.S trap.c
|
||||
IDT trapentry.S trap.c
|
||||
|
||||
+----------------+
|
||||
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
| &handler1 |----> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
+----------------+
|
||||
| &handler2 |--------> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
| &handler2 |----> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
.
|
||||
.
|
||||
.
|
||||
+----------------+
|
||||
| &handlerX |--------> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
| &handlerX |----> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
```
|
||||
|
||||
每个异常或中断都应该在 `trapentry.S` 中有它自己的处理程序,并且 `trap_init()` 应该使用这些处理程序的地址去初始化 IDT。每个处理程序都应该在栈上构建一个 `struct Trapframe`(查看 `inc/trap.h`),然后使用一个指针调用 `trap()`(在 `trap.c` 中)到 `Trapframe`。`trap()` 接着处理异常/中断或派发给一个特定的处理函数。
|
||||
|
||||
```markdown
|
||||
练习 4、编辑 `trapentry.S` 和 `trap.c`,然后实现上面所描述的功能。在 `trapentry.S` 中的宏 `TRAPHANDLER` 和 `TRAPHANDLER_NOEC` 将会帮你,还有在 `inc/trap.h` 中的 T_* defines。你需要在 `trapentry.S` 中为每个定义在 `inc/trap.h` 中的陷阱添加一个入口点(使用这些宏),并且你将有 t、o 提供的 `_alltraps`,这是由宏 `TRAPHANDLER`指向到它。你也需要去修改 `trap_init()` 来初始化 `idt`,以使它指向到每个在 `trapentry.S` 中定义的入口点;宏 `SETGATE` 将有助你实现它。
|
||||
> 练习 4、编辑 `trapentry.S` 和 `trap.c`,然后实现上面所描述的功能。在 `trapentry.S` 中的宏 `TRAPHANDLER` 和 `TRAPHANDLER_NOEC` 将会帮你,还有在 `inc/trap.h` 中的 T_* defines。你需要在 `trapentry.S` 中为每个定义在 `inc/trap.h` 中的陷阱添加一个入口点(使用这些宏),并且你将有 t、o 提供的 `_alltraps`,这是由宏 `TRAPHANDLER`指向到它。你也需要去修改 `trap_init()` 来初始化 `idt`,以使它指向到每个在 `trapentry.S` 中定义的入口点;宏 `SETGATE` 将有助你实现它。
|
||||
|
||||
你的 `_alltraps` 应该:
|
||||
> 你的 `_alltraps` 应该:
|
||||
|
||||
1. 推送值以使栈看上去像一个结构 Trapframe
|
||||
2. 加载 `GD_KD` 到 `%ds` 和 `%es`
|
||||
3. `pushl %esp` 去传递一个指针到 Trapframe 以作为一个 trap() 的参数
|
||||
4. `call trap` (`trap` 能够返回吗?)
|
||||
> 1. 推送值以使栈看上去像一个结构 Trapframe
|
||||
> 2. 加载 `GD_KD` 到 `%ds` 和 `%es`
|
||||
> 3. `pushl %esp` 去传递一个指针到 Trapframe 以作为一个 trap() 的参数
|
||||
> 4. `call trap` (`trap` 能够返回吗?)
|
||||
|
||||
> 考虑使用 `pushal` 指令;它非常适合 `struct Trapframe` 的布局。
|
||||
|
||||
> 使用一些在 `user` 目录中的测试程序来测试你的陷阱处理代码,这些测试程序在生成任何系统调用之前能引发异常,比如 `user/divzero`。在这时,你应该能够成功完成 `divzero`、`softint`、以有 `badsegment` 测试。
|
||||
|
||||
考虑使用 `pushal` 指令;它非常适合 `struct Trapframe` 的布局。
|
||||
.
|
||||
|
||||
使用一些在 `user` 目录中的测试程序来测试你的陷阱处理代码,这些测试程序在生成任何系统调用之前能引发异常,比如 `user/divzero`。在这时,你应该能够成功完成 `divzero`、`softint`、以有 `badsegment` 测试。
|
||||
> **小挑战!**目前,在 `trapentry.S` 中列出的 `TRAPHANDLER` 和他们安装在 `trap.c` 中可能有许多代码非常相似。清除它们。修改 `trapentry.S` 中的宏去自动为 `trap.c` 生成一个表。注意,你可以直接使用 `.text` 和 `.data` 在汇编器中切换放置其中的代码和数据。
|
||||
|
||||
.
|
||||
|
||||
> **问题**
|
||||
|
||||
> 在你的 `answers-lab3.txt` 中回答下列问题:
|
||||
|
||||
> 1. 为每个异常/中断设置一个独立的服务程序函数的目的是什么?(即:如果所有的异常/中断都传递给同一个服务程序,在我们的当前实现中能否提供这样的特性?)
|
||||
> 2. 你需要做什么事情才能让 `user/softint` 程序正常运行?评级脚本预计将会产生一个一般保护故障(trap 13),但是 `softint` 的代码显示为 `int $14`。为什么它产生的中断向量是 13?如果内核允许 `softint` 的 `int $14` 指令去调用内核页故障的服务程序(它的中断向量是 14)会发生什么事情?
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!目前,在 `trapentry.S` 中列出的 `TRAPHANDLER` 和他们安装在 `trap.c` 中可能有许多代码非常相似。清除它们。修改 `trapentry.S` 中的宏去自动为 `trap.c` 生成一个表。注意,你可以直接使用 `.text` 和 `.data` 在汇编器中切换放置其中的代码和数据。
|
||||
```
|
||||
|
||||
```markdown
|
||||
问题
|
||||
|
||||
在你的 `answers-lab3.txt` 中回答下列问题:
|
||||
|
||||
1. 为每个异常/中断设置一个独立的服务程序函数的目的是什么?(即:如果所有的异常/中断都传递给同一个服务程序,在我们的当前实现中能否提供这样的特性?)
|
||||
2. 你需要做什么事情才能让 `user/softint` 程序正常运行?评级脚本预计将会产生一个一般保护故障(trap 13),但是 `softint` 的代码显示为 `int $14`。为什么它产生的中断向量是 13?如果内核允许 `softint` 的 `int $14` 指令去调用内核页故障的服务程序(它的中断向量是 14)会发生什么事情?
|
||||
```
|
||||
|
||||
|
||||
本实验的 Part A 部分结束了。不要忘了去添加 `answers-lab3.txt` 文件,提交你的变更,然后在 Part A 作业的提交截止日期之前运行 `make handin`。
|
||||
|
||||
#### Part B:页故障、断点异常、和系统调用
|
||||
### Part B:页故障、断点异常、和系统调用
|
||||
|
||||
现在,你的内核已经有了最基本的异常处理能力,你将要去继续改进它,来提供依赖异常服务程序的操作系统原语。
|
||||
|
||||
##### 处理页故障
|
||||
#### 处理页故障
|
||||
|
||||
页故障异常,中断向量为 14(`T_PGFLT`),它是一个非常重要的东西,我们将通过本实验和接下来的实验来大量练习它。当处理器产生一个页故障时,处理器将在它的一个特定的控制寄存器(`CR2`)中保存导致这个故障的线性地址(即:虚拟地址)。在 `trap.c` 中我们提供了一个专门处理它的函数的一个雏形,它就是 `page_fault_handler()`,我们将用它来处理页故障异常。
|
||||
|
||||
```markdown
|
||||
练习 5、修改 `trap_dispatch()` 将页故障异常派发到 `page_fault_handler()` 上。你现在应该能够成功测试 `faultread`、`faultreadkernel`、`faultwrite`、和 `faultwritekernel` 了。如果它们中的任何一个不能正常工作,找出问题并修复它。记住,你可以使用 make run- _x_ 或 make run- _x_ -nox 去重引导 JOS 进入到一个特定的用户程序。比如,你可以运行 make run-hello-nox 去运行 the _hello_ user 程序。
|
||||
```
|
||||
> **练习 5**、修改 `trap_dispatch()` 将页故障异常派发到 `page_fault_handler()` 上。你现在应该能够成功测试 `faultread`、`faultreadkernel`、`faultwrite` 和 `faultwritekernel` 了。如果它们中的任何一个不能正常工作,找出问题并修复它。记住,你可以使用 `make run-x` 或 `make run-x-nox` 去重引导 JOS 进入到一个特定的用户程序。比如,你可以运行 `make run-hello-nox` 去运行 `hello` 用户程序。
|
||||
|
||||
下面,你将进一步细化内核的页故障服务程序,因为你要实现系统调用了。
|
||||
|
||||
##### 断点异常
|
||||
#### 断点异常
|
||||
|
||||
断点异常,中断向量为 3(`T_BRKPT`),它一般用在调试上,它在一个程序代码中插入断点,从而使用特定的 1 字节的 `int3` 软件中断指令来临时替换相应的程序指令。在 JOS 中,我们将稍微“滥用”一下这个异常,通过将它打造成一个伪系统调用原语,使得任何用户环境都可以用它来调用 JOS 内核监视器。如果我们将 JOS 内核监视认为是原始调试器,那么这种用法是合适的。例如,在 `lib/panic.c` 中实现的用户模式下的 `panic()` ,它在显示它的 `panic` 消息后运行一个 `int3` 中断。
|
||||
|
||||
```markdown
|
||||
练习 6、修改 `trap_dispatch()`,让它在调用内核监视器时产生一个断点异常。你现在应该可以在 `breakpoint` 上成功完成测试。
|
||||
```
|
||||
> **练习 6**、修改 `trap_dispatch()`,让它在调用内核监视器时产生一个断点异常。你现在应该可以在 `breakpoint` 上成功完成测试。
|
||||
|
||||
```markdown
|
||||
小挑战!修改 JOS 内核监视器,以便于你能够从当前位置(即:在 `int3` 之后,断点异常调用了内核监视器) '继续' 异常,并且因此你就可以一次运行一个单步指令。为了实现单步运行,你需要去理解 `EFLAGS` 寄存器中的某些比特的意义。
|
||||
.
|
||||
|
||||
可选:如果你富有冒险精神,找一些 x86 反汇编的代码 —— 即通过从 QEMU 中、或从 GNU 二进制工具中分离、或你自己编写 —— 然后扩展 JOS 内核监视器,以使它能够反汇编,显示你的每步的指令。结合实验 1 中的符号表,这将是你写的一个真正的内核调试器。
|
||||
```
|
||||
> **小挑战!**修改 JOS 内核监视器,以便于你能够从当前位置(即:在 `int3` 之后,断点异常调用了内核监视器) '继续' 异常,并且因此你就可以一次运行一个单步指令。为了实现单步运行,你需要去理解 `EFLAGS` 寄存器中的某些比特的意义。
|
||||
|
||||
```markdown
|
||||
问题
|
||||
> 可选:如果你富有冒险精神,找一些 x86 反汇编的代码 —— 即通过从 QEMU 中、或从 GNU 二进制工具中分离、或你自己编写 —— 然后扩展 JOS 内核监视器,以使它能够反汇编,显示你的每步的指令。结合实验 1 中的符号表,这将是你写的一个真正的内核调试器。
|
||||
|
||||
3. 在断点测试案例中,根据你在 IDT 中如何初始化断点条目的不同情况(即:你的从 `trap_init` 到 `SETGATE` 的调用),既有可能产生一个断点异常,也有可能产生一个一般保护故障。为什么?为了能够像上面的案例那样工作,你需要如何去设置它,什么样的不正确设置才会触发一个一般保护故障?
|
||||
4. 你认为这些机制的意义是什么?尤其是要考虑 `user/softint` 测试程序的工作原理。
|
||||
```
|
||||
.
|
||||
|
||||
> **问题**
|
||||
|
||||
##### 系统调用
|
||||
> 3. 在断点测试案例中,根据你在 IDT 中如何初始化断点条目的不同情况(即:你的从 `trap_init` 到 `SETGATE` 的调用),既有可能产生一个断点异常,也有可能产生一个一般保护故障。为什么?为了能够像上面的案例那样工作,你需要如何去设置它,什么样的不正确设置才会触发一个一般保护故障?
|
||||
|
||||
> 4. 你认为这些机制的意义是什么?尤其是要考虑 `user/softint` 测试程序的工作原理。
|
||||
|
||||
#### 系统调用
|
||||
|
||||
用户进程请求内核为它做事情就是通过系统调用来实现的。当用户进程请求一个系统调用时,处理器首先进入内核模式,处理器和内核配合去保存用户进程的状态,内核为了完成系统调用会运行有关的代码,然后重新回到用户进程。用户进程如何获得内核的关注以及它如何指定它需要的系统调用的具体细节,这在不同的系统上是不同的。
|
||||
|
||||
@ -414,45 +395,43 @@ x86 允许最多有 256 个不同的中断或异常入口点去进入内核,
|
||||
|
||||
应用程序将在寄存器中传递系统调用号和系统调用参数。通过这种方式,内核就不需要去遍历用户环境的栈或指令流。系统调用号将放在 `%eax` 中,而参数(最多五个)将分别放在 `%edx`、`%ecx`、`%ebx`、`%edi`、和 `%esi` 中。内核将在 `%eax` 中传递返回值。在 `lib/syscall.c` 中的 `syscall()` 中已为你编写了使用一个系统调用的汇编代码。你可以通过阅读它来确保你已经理解了它们都做了什么。
|
||||
|
||||
```markdown
|
||||
练习 7、在内核中为中断向量 `T_SYSCALL` 添加一个服务程序。你将需要去编辑 `kern/trapentry.S` 和 `kern/trap.c` 的 `trap_init()`。还需要去修改 `trap_dispatch()`,以便于通过使用适当的参数来调用 `syscall()` (定义在 `kern/syscall.c`)以处理系统调用中断,然后将系统调用的返回值安排在 `%eax` 中传递给用户进程。最后,你需要去实现 `kern/syscall.c` 中的 `syscall()`。如果系统调用号是无效值,确保 `syscall()` 返回值一定是 `-E_INVAL`。为确保你理解了系统调用的接口,你应该去阅读和掌握 `lib/syscall.c` 文件(尤其是行内汇编的动作),对于在 `inc/syscall.h` 中列出的每个系统调用都需要通过调用相关的内核函数来处理A。
|
||||
> **练习 7**、在内核中为中断向量 `T_SYSCALL` 添加一个服务程序。你将需要去编辑 `kern/trapentry.S` 和 `kern/trap.c` 的 `trap_init()`。还需要去修改 `trap_dispatch()`,以便于通过使用适当的参数来调用 `syscall()` (定义在 `kern/syscall.c`)以处理系统调用中断,然后将系统调用的返回值安排在 `%eax` 中传递给用户进程。最后,你需要去实现 `kern/syscall.c` 中的 `syscall()`。如果系统调用号是无效值,确保 `syscall()` 返回值一定是 `-E_INVAL`。为确保你理解了系统调用的接口,你应该去阅读和掌握 `lib/syscall.c` 文件(尤其是行内汇编的动作),对于在 `inc/syscall.h` 中列出的每个系统调用都需要通过调用相关的内核函数来处理A。
|
||||
|
||||
在你的内核中运行 `user/hello` 程序(make run-hello)。它应该在控制台上输出 "`hello, world`",然后在用户模式中产生一个页故障。如果没有产生页故障,可能意味着你的系统调用服务程序不太正确。现在,你应该有能力成功通过 `testbss` 测试。
|
||||
> 在你的内核中运行 `user/hello` 程序(make run-hello)。它应该在控制台上输出 `hello, world`,然后在用户模式中产生一个页故障。如果没有产生页故障,可能意味着你的系统调用服务程序不太正确。现在,你应该有能力成功通过 `testbss` 测试。
|
||||
|
||||
.
|
||||
|
||||
> 小挑战!使用 `sysenter` 和 `sysexit` 指令而不是使用 `int 0x30` 和 `iret` 来实现系统调用。
|
||||
|
||||
> `sysenter/sysexit` 指令是由 Intel 设计的,它的运行速度要比 `int/iret` 指令快。它使用寄存器而不是栈来做到这一点,并且通过假定了分段寄存器是如何使用的。关于这些指令的详细内容可以在 Intel 参考手册 2B 卷中找到。
|
||||
|
||||
> 在 JOS 中添加对这些指令支持的最容易的方法是,在 `kern/trapentry.S` 中添加一个 `sysenter_handler`,在它里面保存足够多的关于用户环境返回、设置内核环境、推送参数到 `syscall()`、以及直接调用 `syscall()` 的信息。一旦 `syscall()` 返回,它将设置好运行 `sysexit` 指令所需的一切东西。你也将需要在 `kern/init.c` 中添加一些代码,以设置特殊模块寄存器(MSRs)。在 AMD 架构程序员手册第 2 卷的 6.1.2 节中和 Intel 参考手册的 2B 卷的 SYSENTER 上都有关于 MSRs 的很详细的描述。对于如何去写 MSRs,在[这里][4]你可以找到一个添加到 `inc/x86.h` 中的 `wrmsr` 的实现。
|
||||
|
||||
> 最后,`lib/syscall.c` 必须要修改,以便于支持用 `sysenter` 来生成一个系统调用。下面是 `sysenter` 指令的一种可能的寄存器布局:
|
||||
|
||||
> ```
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!使用 `sysenter` 和 `sysexit` 指令而不是使用 `int 0x30` 和 `iret` 来实现系统调用。
|
||||
> GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的值。不要忘了同时去保存(`push`)和恢复(`pop`)你使用的其它寄存器,或告诉内联汇编器你正在使用它们。内联汇编器不支持保存 `%ebp`,因此你需要自己去增加一些代码来保存和恢复它们,返回地址可以使用一个像 `leal after_sysenter_label, %%esi` 的指令置入到 `%esi` 中。
|
||||
|
||||
`sysenter/sysexit` 指令是由 Intel 设计的,它的运行速度要比 `int/iret` 指令快。它使用寄存器而不是栈来做到这一点,并且通过假定了分段寄存器是如何使用的。关于这些指令的详细内容可以在 Intel 参考手册 2B 卷中找到。
|
||||
> 注意,它仅支持 4 个参数,因此你需要保留支持 5 个参数的系统调用的旧方法。而且,因为这个快速路径并不更新当前环境的 trap 帧,因此,在我们添加到后续实验中的一些系统调用上,它并不适合。
|
||||
|
||||
在 JOS 中添加对这些指令支持的最容易的方法是,在 `kern/trapentry.S` 中添加一个 `sysenter_handler`,在它里面保存足够多的关于用户环境返回、设置内核环境、推送参数到 `syscall()`、以及直接调用 `syscall()` 的信息。一旦 `syscall()` 返回,它将设置好运行 `sysexit` 指令所需的一切东西。你也将需要在 `kern/init.c` 中添加一些代码,以设置特殊模块寄存器(MSRs)。在 AMD 架构程序员手册第 2 卷的 6.1.2 节中和 Intel 参考手册的 2B 卷的 SYSENTER 上都有关于 MSRs 的很详细的描述。对于如何去写 MSRs,在[这里][4]你可以找到一个添加到 `inc/x86.h` 中的 `wrmsr` 的实现。
|
||||
> 在接下来的实验中我们启用了异步中断,你需要再次去评估一下你的代码。尤其是,当返回到用户进程时,你需要去启用中断,而 `sysexit` 指令并不会为你去做这一动作。
|
||||
|
||||
最后,`lib/syscall.c` 必须要修改,以便于支持用 `sysenter` 来生成一个系统调用。下面是 `sysenter` 指令的一种可能的寄存器布局:
|
||||
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
|
||||
GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的值。不要忘了同时去保存(push)和恢复(pop)你使用的其它寄存器,或告诉内联汇编器你正在使用它们。内联汇编器不支持保存 `%ebp`,因此你需要自己去增加一些代码来保存和恢复它们,返回地址可以使用一个像 `leal after_sysenter_label, %%esi` 的指令置入到 `%esi` 中。
|
||||
|
||||
注意,它仅支持 4 个参数,因此你需要保留支持 5 个参数的系统调用的旧方法。而且,因为这个快速路径并不更新当前环境的 trap 帧,因此,在我们添加到后续实验中的一些系统调用上,它并不适合。
|
||||
|
||||
在接下来的实验中我们启用了异步中断,你需要再次去评估一下你的代码。尤其是,当返回到用户进程时,你需要去启用中断,而 `sysexit` 指令并不会为你去做这一动作。
|
||||
```
|
||||
|
||||
##### 启动用户模式
|
||||
#### 启动用户模式
|
||||
|
||||
一个用户程序是从 `lib/entry.S` 的顶部开始运行的。在一些配置之后,代码调用 `lib/libmain.c` 中的 `libmain()`。你应该去修改 `libmain()` 以初始化全局指针 `thisenv`,使它指向到这个环境在数组 `envs[]` 中的 `struct Env`。(注意那个 `lib/entry.S` 中已经定义 `envs` 去指向到在 Part A 中映射的你的设置。)提示:查看 `inc/env.h` 和使用 `sys_getenvid`。
|
||||
|
||||
`libmain()` 接下来调用 `umain`,在 hello 程序的案例中,`umain` 是在 `user/hello.c` 中。注意,它在输出 "`hello, world`” 之后,它尝试去访问 `thisenv->env_id`。这就是为什么前面会发生故障的原因了。现在,你已经正确地初始化了 `thisenv`,它应该不会再发生故障了。如果仍然会发生故障,或许是因为你没有映射 `UENVS` 区域为用户可读取(回到前面 Part A 中 查看 `pmap.c`);这是我们第一次真实地使用 `UENVS` 区域)。
|
||||
|
||||
```markdown
|
||||
练习 8、添加要求的代码到用户库,然后引导你的内核。你应该能够看到 `user/hello` 程序会输出 "`hello, world`" 然后输出 "`i am environment 00001000`"。`user/hello` 接下来会通过调用 `sys_env_destroy()`(查看`lib/libmain.c` 和 `lib/exit.c`)尝试去"退出"。由于内核目前仅支持一个用户环境,它应该会报告它毁坏了唯一的环境,然后进入到内核监视器中。现在你应该能够成功通过 `hello` 的测试。
|
||||
```
|
||||
> **练习 8**、添加要求的代码到用户库,然后引导你的内核。你应该能够看到 `user/hello` 程序会输出 `hello, world` 然后输出 `i am environment 00001000`。`user/hello` 接下来会通过调用 `sys_env_destroy()`(查看`lib/libmain.c` 和 `lib/exit.c`)尝试去“退出”。由于内核目前仅支持一个用户环境,它应该会报告它毁坏了唯一的环境,然后进入到内核监视器中。现在你应该能够成功通过 `hello` 的测试。
|
||||
|
||||
##### 页故障和内存保护
|
||||
#### 页故障和内存保护
|
||||
|
||||
内存保护是一个操作系统中最重要的特性,通过它来保证一个程序中的 bug 不会破坏其它程序或操作系统本身。
|
||||
|
||||
@ -462,10 +441,8 @@ GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的
|
||||
|
||||
对于内存保护,系统调用中有一个非常有趣的问题。许多系统调用接口让用户程序传递指针到内核中。这些指针指向用户要读取或写入的缓冲区。然后内核在执行系统调用时废弃这些指针。这样就有两个问题:
|
||||
|
||||
1. 内核中的页故障可能比用户程序中的页故障多的多。如果内核在维护它自己的数据结构时发生页故障,那就是一个内核 bug,而故障服务程序将使整个内核(和整个系统)崩溃。但是当内核废弃了由用户程序传递给它的指针后,它就需要一种方式去记住那些废弃指针所导致的页故障其实是代表用户程序的。
|
||||
2. 一般情况下内核拥有比用户程序更多的权限。用户程序可以传递一个指针到系统调用,而指针指向的区域有可能是内核可以读取或写入而用户程序不可访问的区域。内核必须要非常小心,不能被废弃的这种指针欺骗,因为这可能导致泄露私有信息或破坏内核的完整性。
|
||||
|
||||
|
||||
1. 内核中的页故障可能比用户程序中的页故障多的多。如果内核在维护它自己的数据结构时发生页故障,那就是一个内核 bug,而故障服务程序将使整个内核(和整个系统)崩溃。但是当内核废弃了由用户程序传递给它的指针后,它就需要一种方式去记住那些废弃指针所导致的页故障其实是代表用户程序的。
|
||||
2. 一般情况下内核拥有比用户程序更多的权限。用户程序可以传递一个指针到系统调用,而指针指向的区域有可能是内核可以读取或写入而用户程序不可访问的区域。内核必须要非常小心,不能被废弃的这种指针欺骗,因为这可能导致泄露私有信息或破坏内核的完整性。
|
||||
|
||||
由于以上的原因,内核在处理由用户程序提供的指针时必须格外小心。
|
||||
|
||||
@ -473,32 +450,33 @@ GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的
|
||||
|
||||
这样,内核在废弃一个用户提供的指针时就绝不会发生页故障。如果内核出现这种页故障,它应该崩溃并终止。
|
||||
|
||||
```markdown
|
||||
练习 9、如果在内核模式中发生一个页故障,修改 `kern/trap.c` 去崩溃。
|
||||
> **练习 9**、如果在内核模式中发生一个页故障,修改 `kern/trap.c` 去崩溃。
|
||||
|
||||
提示:判断一个页故障是发生在用户模式还是内核模式,去检查 `tf_cs` 的低位比特即可。
|
||||
> 提示:判断一个页故障是发生在用户模式还是内核模式,去检查 `tf_cs` 的低位比特即可。
|
||||
|
||||
阅读 `kern/pmap.c` 中的 `user_mem_assert` 并在那个文件中实现 `user_mem_check`。
|
||||
> 阅读 `kern/pmap.c` 中的 `user_mem_assert` 并在那个文件中实现 `user_mem_check`。
|
||||
|
||||
修改 `kern/syscall.c` 去常态化检查传递给系统调用的参数。
|
||||
> 修改 `kern/syscall.c` 去常态化检查传递给系统调用的参数。
|
||||
|
||||
引导你的内核,运行 `user/buggyhello`。环境将被毁坏,而内核将不会崩溃。你将会看到:
|
||||
> 引导你的内核,运行 `user/buggyhello`。环境将被毁坏,而内核将不会崩溃。你将会看到:
|
||||
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
最后,修改在 `kern/kdebug.c` 中的 `debuginfo_eip`,在 `usd`、`stabs`、和 `stabstr` 上调用 `user_mem_check`。如果你现在运行 `user/breakpoint`,你应该能够从内核监视器中运行回溯,然后在内核因页故障崩溃前看到回溯进入到 `lib/libmain.c`。是什么导致了这个页故障?你不需要去修复它,但是你应该明白它是如何发生的。
|
||||
> ```
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
```
|
||||
|
||||
> 最后,修改在 `kern/kdebug.c` 中的 `debuginfo_eip`,在 `usd`、`stabs`、和 `stabstr` 上调用 `user_mem_check`。如果你现在运行 `user/breakpoint`,你应该能够从内核监视器中运行回溯,然后在内核因页故障崩溃前看到回溯进入到 `lib/libmain.c`。是什么导致了这个页故障?你不需要去修复它,但是你应该明白它是如何发生的。
|
||||
|
||||
注意,刚才实现的这些机制也同样适用于恶意用户程序(比如 `user/evilhello`)。
|
||||
|
||||
```
|
||||
练习 10、引导你的内核,运行 `user/evilhello`。环境应该被毁坏,并且内核不会崩溃。你应该能看到:
|
||||
> **练习 10**、引导你的内核,运行 `user/evilhello`。环境应该被毁坏,并且内核不会崩溃。你应该能看到:
|
||||
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
> ```
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
```
|
||||
|
||||
**本实验到此结束。**确保你通过了所有的等级测试,并且不要忘记去写下问题的答案,在 `answers-lab3.txt` 中详细描述你的挑战练习的解决方案。提交你的变更并在 `lab` 目录下输入 `make handin` 去提交你的工作。
|
||||
@ -512,13 +490,13 @@ via: https://pdos.csail.mit.edu/6.828/2018/labs/lab3/
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pdos.csail.mit.edu/6.828/2018/labs/labguide.html
|
||||
[1]: https://linux.cn/article-10273-1.html
|
||||
[2]: https://pdos.csail.mit.edu/6.828/2018/labs/reference.html
|
||||
[3]: http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx
|
||||
[4]: http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c
|
||||
@ -0,0 +1,147 @@
|
||||
如何用 Python 编写你喜爱的 R 函数
|
||||
======
|
||||
> R 还是 Python ? Python 脚本模仿易使用的 R 风格函数,使得数据统计变得简单易行。
|
||||
|
||||

|
||||
|
||||
“Python vs. R” 是数据科学和机器学习的现代战争之一。毫无疑问,近年来这两者发展迅猛,成为数据科学、预测分析和机器学习领域的顶级编程语言。事实上,根据 IEEE 最近的一篇文章,Python 已在 [最受欢迎编程语言排行榜][1] 中超越 C++ 成为排名第一的语言,并且 R 语言也稳居前 10 位。
|
||||
|
||||
但是,这两者之间存在一些根本区别。[R][2] 语言设计的初衷主要是作为统计分析和数据分析问题的快速原型设计的工具,另一方面,Python 是作为一种通用的、现代的面向对象语言而开发的,类似 C++ 或 Java,但具有更简单的学习曲线和更灵活的语言风格。因此,R 仍在统计学家、定量生物学家、物理学家和经济学家中备受青睐,而 Python 已逐渐成为日常脚本、自动化、后端 Web 开发、分析和通用机器学习框架的顶级语言,拥有广泛的支持基础和开源开发社区。
|
||||
|
||||
### 在 Python 环境中模仿函数式编程
|
||||
|
||||
[R 作为函数式编程语言的本质][3]为用户提供了一个极其简洁的用于快速计算概率的接口,还为数据分析问题提供了必不可少的描述统计和推论统计方法(LCTT 译注:统计学从功能上分为描述统计学和推论统计学)。例如,只用一个简洁的函数调用来解决以下问题难道不是很好吗?
|
||||
|
||||
* 如何计算数据向量的平均数 / 中位数 / 众数。
|
||||
* 如何计算某些服从正态分布的事件的累积概率。如果服<ruby>从泊松分布<rt>Poisson distribution</rt></ruby>又该怎样计算呢?
|
||||
* 如何计算一系列数据点的四分位距。
|
||||
* 如何生成服从学生 t 分布的一些随机数(LCTT 译注: 在概率论和统计学中,学生 t-分布(Student's t-distribution)可简称为 t 分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值)。
|
||||
|
||||
R 编程环境可以完成所有这些工作。
|
||||
|
||||
另一方面,Python 的脚本编写能力使分析师能够在各种分析流程中使用这些统计数据,具有无限的复杂性和创造力。
|
||||
|
||||
要结合二者的优势,你只需要一个简单的 Python 封装的库,其中包含与 R 风格定义的概率分布和描述性统计相关的最常用函数。 这使你可以非常快速地调用这些函数,而无需转到正确的 Python 统计库并理解整个方法和参数列表。
|
||||
|
||||
### 便于调用 R 函数的 Python 包装脚本
|
||||
|
||||
[我编写了一个 Python 脚本][4] ,用 Python 简单统计分析定义了最简洁和最常用的 R 函数。导入此脚本后,你将能够原生地使用这些 R 函数,就像在 R 编程环境中一样。
|
||||
|
||||
此脚本的目标是提供简单的 Python 函数,模仿 R 风格的统计函数,以快速计算密度估计和点估计、累积分布和分位数,并生成重要概率分布的随机变量。
|
||||
|
||||
为了延续 R 风格,脚本不使用类结构,并且只在文件中定义原始函数。因此,用户可以导入这个 Python 脚本,并在需要单个名称调用时使用所有功能。
|
||||
|
||||
请注意,我使用 mimic 这个词。 在任何情况下,我都声称要模仿 R 的真正的函数式编程范式,该范式包括深层环境设置以及这些环境和对象之间的复杂关系。 这个脚本允许我(我希望无数其他的 Python 用户)快速启动 Python 程序或 Jupyter 笔记本程序、导入脚本,并立即开始进行简单的描述性统计。这就是目标,仅此而已。
|
||||
|
||||
如果你已经写过 R 代码(可能在研究生院)并且刚刚开始学习并使用 Python 进行数据分析,那么你将很高兴看到并在 Jupyter 笔记本中以类似在 R 环境中一样使用一些相同的知名函数。
|
||||
|
||||
无论出于何种原因,使用这个脚本很有趣。
|
||||
|
||||
### 简单的例子
|
||||
|
||||
首先,只需导入脚本并开始处理数字列表,就好像它们是 R 中的数据向量一样。
|
||||
|
||||
```
|
||||
from R_functions import *
|
||||
lst=[20,12,16,32,27,65,44,45,22,18]
|
||||
<more code, more statistics...>
|
||||
```
|
||||
|
||||
假设你想从数据向量计算 [Tuckey 五数][5]摘要。 你只需要调用一个简单的函数 `fivenum`,然后将向量传进去。 它将返回五数摘要,存在 NumPy 数组中。
|
||||
|
||||
```
|
||||
lst=[20,12,16,32,27,65,44,45,22,18]
|
||||
fivenum(lst)
|
||||
> array([12. , 18.5, 24.5, 41. , 65. ])
|
||||
```
|
||||
|
||||
或许你想要知道下面问题的答案:
|
||||
|
||||
> 假设一台机器平均每小时输出 10 件成品,标准偏差为 2。输出模式遵循接近正态的分布。 机器在下一个小时内输出至少 7 个但不超过 12 个单位的概率是多少?
|
||||
|
||||
答案基本上是这样的:
|
||||
|
||||
|
||||
|
||||
使用 `pnorm` ,你可以只用一行代码就能获得答案:
|
||||
|
||||
```
|
||||
pnorm(12,10,2)-pnorm(7,10,2)
|
||||
> 0.7745375447996848
|
||||
```
|
||||
|
||||
或者你可能需要回答以下问题:
|
||||
|
||||
> 假设你有一个不公平硬币,每次投它时有 60% 可能正面朝上。 你正在玩 10 次投掷游戏。 你如何绘制并给出这枚硬币所有可能的胜利数(从 0 到 10)的概率?
|
||||
|
||||
只需使用一个函数 `dbinom` 就可以获得一个只有几行代码的美观条形图:
|
||||
|
||||
```
|
||||
probs=[]
|
||||
import matplotlib.pyplot as plt
|
||||
for i in range(11):
|
||||
probs.append(dbinom(i,10,0.6))
|
||||
plt.bar(range(11),height=probs)
|
||||
plt.grid(True)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 简单的概率计算接口
|
||||
|
||||
R 提供了一个非常简单直观的接口,可以从基本概率分布中快速计算。 接口如下:
|
||||
|
||||
* **d** 分布:给出点 **x** 处的密度函数值
|
||||
* **p** 分布:给出 **x** 点的累积值
|
||||
* **q** 分布:以概率 **p** 给出分位数函数值
|
||||
* **r** 分布:生成一个或多个随机变量
|
||||
|
||||
在我们的实现中,我们坚持使用此接口及其关联的参数列表,以便你可以像在 R 环境中一样执行这些函数。
|
||||
|
||||
### 目前已实现的函数
|
||||
|
||||
脚本中实现了以下 R 风格函数,以便快速调用。
|
||||
|
||||
* 平均数、中位数、方差、标准差
|
||||
* Tuckey 五数摘要、<ruby>四分位距<rt>interquartile range</rt></ruby>(IQR)
|
||||
* 矩阵的协方差或两个向量之间的协方差
|
||||
* 以下分布的密度、累积概率、分位数函数和随机变量生成:正态、均匀、二项式、<ruby>泊松<rt>Poisson</rt></ruby>、F、<ruby>学生 t<rt>Student's t</rt></ruby>、<ruby>卡方<rt>Chi-square</rt></ruby>、<ruby>贝塔<rt>beta</rt></ruby>和<ruby>伽玛<rt>gamma</rt></ruby>
|
||||
|
||||
### 进行中的工作
|
||||
|
||||
显然,这是一项正在进行的工作,我计划在此脚本中添加一些其他方便的R函数。 例如,在 R 中,单行命令 `lm` 可以为数字数据集提供一个简单的最小二乘拟合模型,其中包含所有必要的推理统计(P 值,标准误差等)。 这非常简洁! 另一方面,Python 中的标准线性回归问题经常使用 [Scikit-learn][6] 库来处理,此用途需要更多的脚本,所以我打算使用 Python 的 [statsmodels][7] 库合并这个单函数线性模型来拟合功能。
|
||||
|
||||
如果你喜欢这个脚本,并且愿意在工作中使用,请在 [GitHub 仓库][8]点个 star 或者 fork 帮助其他人找到它。 另外,你可以查看我其他的 [GitHub 仓库][9],了解 Python、R 或 MATLAB 中的有趣代码片段以及一些机器学习资源。
|
||||
|
||||
如果你有任何问题或想法要分享,请通过 [tirthajyoti [AT] gmail.com][10] 与我联系。 如果你像我一样热衷于机器学习和数据科学,请 [在 LinkedIn 上加我为好友][11]或者[在 Twitter 上关注我][12]。
|
||||
|
||||
本篇文章最初发表于[走向数据科学][13]。 请在 [CC BY-SA 4.0][14] 协议下转载。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/write-favorite-r-functions-python
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[Flowsnow](https://github.com/Flowsnow)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://spectrum.ieee.org/at-work/innovation/the-2018-top-programming-languages
|
||||
[2]: https://www.coursera.org/lecture/r-programming/overview-and-history-of-r-pAbaE
|
||||
[3]: http://adv-r.had.co.nz/Functional-programming.html
|
||||
[4]: https://github.com/tirthajyoti/StatsUsingPython/blob/master/R_Functions.py
|
||||
[5]: https://en.wikipedia.org/wiki/Five-number_summary
|
||||
[6]: http://scikit-learn.org/stable/
|
||||
[7]: https://www.statsmodels.org/stable/index.html
|
||||
[8]: https://github.com/tirthajyoti/StatsUsingPython
|
||||
[9]: https://github.com/tirthajyoti?tab=repositories
|
||||
[10]: mailto:tirthajyoti@gmail.com
|
||||
[11]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[12]: https://twitter.com/tirthajyotiS
|
||||
[13]: https://towardsdatascience.com/how-to-write-your-favorite-r-functions-in-python-11e1e9c29089
|
||||
[14]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
@ -1,15 +1,15 @@
|
||||
流量引导:网络世界的负载均衡解密
|
||||
======
|
||||
|
||||
均衡网络流量的常用技术,它们的优势和利弊权衡。
|
||||
> 均衡网络流量的常用技术,它们的优势和利弊权衡。
|
||||
|
||||

|
||||
|
||||
大型的多站点互联网系统,包括内容分发网络(CDN)和云服务提供商,用一些方法来均衡来访的流量。这篇文章我们讲一下常见的流量均衡设计,包括它们的技术手段和利弊权衡。
|
||||
|
||||
如果你很早就用云计算技术来提供服务的话,你可能在单台云服务器上搭建 web 服务,分配一个 IP 地址,然后配置一个给人读的域名(DNS)指向这个 IP 地址,再将 IP 地址通过边界网关协议(BGP)宣告出去,BGP 是在不同网络之间交换路由信息的标准方式。
|
||||
早期的云计算服务提供商,可以提供单一一台客户 Web 服务器,分配一个 IP 地址,然后用一个便于人读的域名配置一个 DNS 记录指向这个 IP 地址,再将 IP 地址通过边界网关协议(BGP)宣告出去,BGP 是在不同网络之间交换路由信息的标准方式。
|
||||
|
||||
这本身并不是负载均衡,但是在冗余的多条网络路径中,很可能是有流量分发的,而且利用网络技术让流量绕过不可用的网络,从而提高了可用性(也引起了[非对称路由][1]的现象)。
|
||||
这本身并不是负载均衡,但是能在冗余的多条网络路径中进行流量分发,而且可以利用网络技术让流量绕过不可用的网络,从而提高了可用性(也引起了[非对称路由][1]的现象)。
|
||||
|
||||
### 简单的 DNS 负载均衡
|
||||
|
||||
@ -25,9 +25,9 @@
|
||||
|
||||
![Layer 4 load balancers balance connections across webservers.][5]
|
||||
|
||||
四层负载均衡器能够均衡用户和两台 web 服务器的连接
|
||||
*四层负载均衡器能够均衡用户和两台 web 服务器的连接*
|
||||
|
||||
四层均衡器将网络流量均衡地引导至后端服务器。通常这是基于对 IP 数据包的五元组做散列(数学函数)来完成的,五元组包括:源地址,源端口,目的地址,目的端口,协议(比如 TCP 或 UDP)。这种方法是快速和高效的(还维持了 TCP 的基本属性),而且不需要均衡器维持每个连接的状态。(更多信息请阅读[谷歌发表的 Maglev 论文][6],这篇论文详细讨论了四层软件负载均衡器的实现细节。)
|
||||
四层均衡器将网络流量均衡地引导至后端服务器。通常这是基于对 IP 数据包的五元组做散列(数学函数)来完成的,五元组包括:源地址、源端口、目的地址、目的端口、协议(比如 TCP 或 UDP)。这种方法是快速和高效的(还维持了 TCP 的基本属性),而且不需要均衡器维持每个连接的状态。(更多信息请阅读[谷歌发表的 Maglev 论文][6],这篇论文详细讨论了四层软件负载均衡器的实现细节。)
|
||||
|
||||
四层均衡器可以对后端服务做健康检查,只把流量分发到健康的机器上。和使用 DNS 做负载均衡不同的是,在某个后端 web 服务故障的时候,它可以很快地把流量重新分发到其他机器上,虽然故障机器的已有连接会被重置。
|
||||
|
||||
@ -35,29 +35,29 @@
|
||||
|
||||
### 扩展到多站点
|
||||
|
||||
系统规模在持续增长。你的客户希望能一直使用服务,即使数据中心发生故障的时候。所以你建设了一个新的数据中心,独立部署了一套服务和四层负载均衡器集群,仍然使用同样的 VIP。DNS 的设置不变。
|
||||
系统规模在持续增长。你的客户希望能一直使用服务,即使是数据中心发生故障的时候。所以你建设了一个新的数据中心,另外独立部署了一套服务和四层负载均衡器集群,仍然使用同样的 VIP。DNS 的设置不变。
|
||||
|
||||
两个站点的边缘路由器都把自己的地址空间宣告出去,包括 VIP 地址。发往该 VIP 的请求可能到达任何一个站点,取决于用户和系统之间的网络是如何连接的,以及各个网络的路由策略是如何配置的。这就是泛播。大部分时候这种机制可以很好的工作。如果一个站点出问题了,你可以停止通过 BGP 宣告 VIP 地址,客户的请求就会迅速地转移到另外一个站点去。
|
||||
|
||||
![Serving from multiple sites using anycast][8]
|
||||
|
||||
多个站点使用泛播提供服务
|
||||
*多个站点使用泛播提供服务*
|
||||
|
||||
这种设置有一些问题。最大的问题是,不能控制请求流向哪个站点,或者限制某个站点的流量。也没有一个明确的方式把用户的请求转到距离他最近的站点(为了降低网络延迟),不过,网络协议和路由选路配置在大部分情况下应该能把用户请求路由到最近的站点。
|
||||
|
||||
### 控制多站点系统中的入方向请求
|
||||
### 控制多站点系统中的入站请求
|
||||
|
||||
为了维持稳定性,需要能够控制每个站点的流量大小。要实现这种控制,可以给每个站点分配不同的 VIP 地址,然后用简单的或者有权重的 DNS [轮询][9]来做负载均衡。
|
||||
|
||||
![Serving from multiple sites using a primary VIP][11]
|
||||
|
||||
多站点提供服务,每个站点使用一个主 VIP,另外一个站点作为备份。基于能感知地理位置的 DNS。
|
||||
*多站点提供服务,每个站点使用一个主 VIP,另外一个站点作为备份。基于能感知地理位置的 DNS。*
|
||||
|
||||
现在有两个问题。
|
||||
|
||||
第一,使用 DNS 均衡意味着会有被缓存的记录,如果你要快速重定向流量的话就麻烦了。
|
||||
第一、使用 DNS 均衡意味着会有被缓存的记录,如果你要快速重定向流量的话就麻烦了。
|
||||
|
||||
第二,用户每次做新的 DNS 查询,都可能连上任意一个站点,可能不是距离最近的。如果你的服务运行在分布广泛的很多站点上,用户会感受到响应时间有明显的变化,取决于用户和提供服务的站点之间有多大的网络延迟。
|
||||
第二、用户每次做新的 DNS 查询,都可能连上任意一个站点,可能不是距离最近的。如果你的服务运行在分布广泛的很多站点上,用户会感受到响应时间有明显的变化,取决于用户和提供服务的站点之间有多大的网络延迟。
|
||||
|
||||
让每个站点都配置上其他所有站点的 VIP 地址,并宣告出去(因此也会包含故障的站点),这样可以解决第一个问题。有一些网络上的小技巧,比如备份站点宣告路由时,不像主站点使用那么具体的目的地址,这样可以保证每个 VIP 的主站点只要可用就会优先提供服务。这是通过 BGP 来实现的,所以我们应该可以看到,流量在 BGP 更新后的一两分钟内就开始转移了。
|
||||
|
||||
@ -69,13 +69,13 @@
|
||||
|
||||
虽然四层负载均衡可以高效地在多个 web 服务器之间分发流量,但是它们只针对源地址、目标地址、协议和端口来操作,请求的内容是什么就不得而知了,所以很多高级功能在四层负载均衡上实现不了。而七层(L7)负载均衡知道请求的内容和结构,所以能做更多的事情。
|
||||
|
||||
七层负载均衡可以实现缓存,限速,错误注入,做负载均衡时可以感知到请求的代价(有些请求需要服务器花更多的时间去处理)。
|
||||
七层负载均衡可以实现缓存、限速、错误注入,做负载均衡时可以感知到请求的代价(有些请求需要服务器花更多的时间去处理)。
|
||||
|
||||
七层负载均衡还可以基于请求的属性(比如 HTTP cookies)来分发流量,可以终结 SSL 连接,还可以帮助防御应用层的拒绝服务(DoS)攻击。规模大的 L7 负载均衡的缺点是成本——处理请求需要更多的计算,而且每个活跃的请求都占用一些系统资源。在一个或者多个 L7 均衡器前面运行 L4 均衡器集群,对扩展规模有帮助。
|
||||
七层负载均衡还可以基于请求的属性(比如 HTTP cookies)来分发流量,可以终结 SSL 连接,还可以帮助防御应用层的拒绝服务(DoS)攻击。规模大的 L7 负载均衡的缺点是成本 —— 处理请求需要更多的计算,而且每个活跃的请求都占用一些系统资源。在一个或者多个 L7 均衡器前面运行 L4 均衡器集群,对扩展规模有帮助。
|
||||
|
||||
### 结论
|
||||
|
||||
负载均衡是一个复杂的难题。除了上面说过的策略,还有不同的[负载均衡算法][13],用来实现负载均衡器的高可用技术,客户端负载均衡技术,以及最近兴起的服务网络等等。
|
||||
负载均衡是一个复杂的难题。除了上面说过的策略,还有不同的[负载均衡算法][13],用来实现负载均衡器的高可用技术、客户端负载均衡技术,以及最近兴起的服务网络等等。
|
||||
|
||||
核心的负载均衡模式随着云计算的发展而不断发展,而且,随着大型 web 服务商致力于让负载均衡技术更可控和更灵活,这项技术会持续发展下去。
|
||||
|
||||
@ -86,7 +86,7 @@ via: https://opensource.com/article/18/10/internet-scale-load-balancing
|
||||
作者:[Laura Nolan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[BeliteX](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
提高 Linux 网络浏览器安全性的 5 个建议
|
||||
提高 Linux 的网络浏览器安全性的 5 个建议
|
||||
======
|
||||

|
||||
> 这些简单的步骤可以大大提高您的在线安全性。
|
||||
|
||||

|
||||
|
||||
如果你使用 Linux 桌面但从来不使用网络浏览器,那你算得上是百里挑一。网络浏览器是绝大多数人最常用的工具之一,无论是工作、娱乐、看新闻、社交、理财,对网络浏览器的依赖都比本地应用要多得多。因此,我们需要知道如何使用网络浏览器才是安全的。一直以来都有不法的犯罪分子以及他们建立的网页试图窃取私密的信息。正是由于我们需要通过网络浏览器收发大量的敏感信息,安全性就更是至关重要。
|
||||
|
||||
@ -8,17 +10,14 @@
|
||||
|
||||
### 正确选择浏览器
|
||||
|
||||
尽管我我提出的建议具有普适性,但是正确选择网络浏览器也是很必要的。网络浏览器的更新频率是它安全性的一个重要体现。网络浏览器会不断暴露出新的问题,因此版本越新的网络浏览器修复的问题就越多,也越安全。在主流的网络浏览器当中,2017 年版本更新的发布量排行榜如下:
|
||||
尽管我提出的建议具有普适性,但是正确选择网络浏览器也是很必要的。网络浏览器的更新频率是它安全性的一个重要体现。网络浏览器会不断暴露出新的问题,因此版本越新的网络浏览器修复的问题就越多,也越安全。在主流的网络浏览器当中,2017 年版本更新的发布量排行榜如下:
|
||||
|
||||
1. Chrome 发布了 8 个更新(Chromium 全年跟进发布了大量安全补丁)。
|
||||
2. Firefox 发布了 7 个更新。
|
||||
3. Edge 发布了 2 个更新。
|
||||
4. Safari 发布了 1 个更新(苹果也会每年发布 5 到 6 个安全补丁)。
|
||||
1. Chrome 发布了 8 个更新(Chromium 全年跟进发布了大量安全补丁)。
|
||||
2. Firefox 发布了 7 个更新。
|
||||
3. Edge 发布了 2 个更新。
|
||||
4. Safari 发布了 1 个更新(苹果也会每年发布 5 到 6 个安全补丁)。
|
||||
|
||||
|
||||
|
||||
|
||||
网络浏览器会经常发布更新,同时用户方面也要及时升级到最新的版本,否则毫无意义了。尽管大部分流行的 Linux 发行版都会自动更新网络浏览器到最新版本,但还是有一些 Linux 发行版不会自动进行更新,所以最好还是手动保持浏览器更新到最新版本。这就意味着你所使用的 Linux 发行版对应的标准软件库中存放的很可能就不是最新版本的网络浏览器,在这种情况下,你可以随时从网络浏览器开发者提供的最新版本下载页中进行下载安装。
|
||||
网络浏览器会经常发布更新,同时用户也要及时升级到最新的版本,否则毫无意义了。尽管大部分流行的 Linux 发行版都会自动更新网络浏览器到最新版本,但还是有一些 Linux 发行版不会自动进行更新,所以最好还是手动保持浏览器更新到最新版本。这就意味着你所使用的 Linux 发行版对应的标准软件库中存放的很可能就不是最新版本的网络浏览器,在这种情况下,你可以随时从网络浏览器开发者提供的最新版本下载页中进行下载安装。
|
||||
|
||||
如果你是一个勇于探索的人,你还可以尝试使用测试版或者<ruby>每日构建<rt>daily build</rt></ruby>版的网络浏览器,不过,这些版本将伴随着不能稳定运行的可能性。在基于 Ubuntu 的发行版中,你可以使用到每日构建版的 Firefox,只需要执行以下命令添加所需的存储库:
|
||||
|
||||
@ -43,60 +42,47 @@ sudo apt-get install firefox
|
||||
|
||||
### 保护好密码
|
||||
|
||||
有的人可能会认为,每次都需要重复输入密码,这样的操作太麻烦了。在 Firefox 中,如果你既想保护好自己的密码,又不想经常输入密码,就可以通过 Master Password 这一款内置的工具来实现你的需求。起用了这个工具之后,需要输入正确的主密码,才能后续使用保存在浏览器中的其它密码。你可以按照以下步骤进行操作:
|
||||
|
||||
1. 打开 Firefox。
|
||||
|
||||
2. 点击菜单按钮。
|
||||
|
||||
3. 点击“偏好设置”。
|
||||
|
||||
4. 在偏好设置页面,点击“隐私与安全”。
|
||||
|
||||
5. 在页面中勾选“使用主密码”选项(图 1)。
|
||||
|
||||
6. 确认以后,输入新的主密码(图 2)。
|
||||
|
||||
7. 重启 Firefox。
|
||||
|
||||
|
||||
有的人可能会认为,每次都需要重复输入密码,这样的操作太麻烦了。在 Firefox 中,如果你既想保护好自己的密码,又不想经常输入密码,就可以通过<ruby>主密码<rt>Master Password</rt></ruby>这一款内置的工具来实现你的需求。起用了这个工具之后,需要输入正确的主密码,才能后续使用保存在浏览器中的其它密码。你可以按照以下步骤进行操作:
|
||||
|
||||
1. 打开 Firefox。
|
||||
2. 点击菜单按钮。
|
||||
3. 点击“偏好设置”。
|
||||
4. 在偏好设置页面,点击“隐私与安全”。
|
||||
5. 在页面中勾选“使用主密码”选项(图 1)。
|
||||
6. 确认以后,输入新的主密码(图 2)。
|
||||
7. 重启 Firefox。
|
||||
|
||||
![Master Password][3]
|
||||
|
||||
图 1: Firefox 偏好设置页中的主密码设置。
|
||||
*图 1: Firefox 偏好设置页中的主密码设置。*
|
||||
|
||||
![Setting password][6]
|
||||
|
||||
图 2:在 Firefox 中设置主密码。
|
||||
*图 2:在 Firefox 中设置主密码。*
|
||||
|
||||
### 了解你使用的扩展和插件
|
||||
|
||||
大多数网络浏览器在保护隐私方面都有很多扩展,你可以根据自己的需求选择不同的扩展。而我自己则选择了一下这些扩展:
|
||||
|
||||
* [Firefox Multi-Account Containers][7] \- 允许将某些站点配置为在容器化选项卡中打开。
|
||||
* [Facebook Container][8] \- 始终在容器化选项卡中打开 Facebook(这个扩展需要 Firefox Multi-Account Containers)。
|
||||
* [Avast Online Security][9] \- 识别并拦截已知的钓鱼网站,并显示网站的安全评级(由超过 4 亿用户的 Avast 社区支持)。
|
||||
* [Mining Blocker][10] \- 拦截所有使用 CPU 的挖矿工具。
|
||||
* [PassFF][11] \- 通过集成 `pass` (一个 UNIX 密码管理器)以安全存储密码。
|
||||
* [Privacy Badger][12] \- 自动拦截网站跟踪。
|
||||
* [uBlock Origin][13] \- 拦截已知的网站跟踪。
|
||||
|
||||
* [Firefox Multi-Account Containers][7] —— 允许将某些站点配置为在容器化选项卡中打开。
|
||||
* [Facebook Container][8] —— 始终在容器化选项卡中打开 Facebook(这个扩展需要 Firefox Multi-Account Containers)。
|
||||
* [Avast Online Security][9] —— 识别并拦截已知的钓鱼网站,并显示网站的安全评级(由超过 4 亿用户的 Avast 社区支持)。
|
||||
* [Mining Blocker][10] —— 拦截所有使用 CPU 的挖矿工具。
|
||||
* [PassFF][11] —— 通过集成 `pass` (一个 UNIX 密码管理器)以安全存储密码。
|
||||
* [Privacy Badger][12] —— 自动拦截网站跟踪。
|
||||
* [uBlock Origin][13] —— 拦截已知的网站跟踪。
|
||||
|
||||
除此以外,以下这些浏览器还有很多安全方面的扩展:
|
||||
|
||||
+ [Firefox][2]
|
||||
|
||||
+ [Chrome、Chromium,、Vivaldi][5]
|
||||
|
||||
+ [Opera][14]
|
||||
|
||||
|
||||
但并非每一个网络浏览器都会向用户提供扩展或插件。例如 Midoria 就只有少量可以开启或关闭的内置插件(图 3),同时这些轻量级浏览器的第三方插件也相当缺乏。
|
||||
|
||||
![Midori Browser][15]
|
||||
|
||||
图 3:Midori 浏览器的插件窗口。
|
||||
*图 3:Midori 浏览器的插件窗口。*
|
||||
|
||||
### 虚拟化
|
||||
|
||||
@ -115,7 +101,7 @@ via: https://www.linux.com/learn/intro-to-linux/2018/11/5-easy-tips-linux-web-br
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
如何在 Linux 上对驱动器进行分区和格式化
|
||||
======
|
||||
这里有所有你想知道的关于设置存储器而又不敢问的一切。
|
||||
|
||||
> 这里有所有你想知道的关于设置存储器而又不敢问的一切。
|
||||
|
||||

|
||||
|
||||
@ -10,27 +11,26 @@
|
||||
|
||||
### 什么是块设备?
|
||||
|
||||
硬盘驱动器通常被称为“块设备”,因为硬盘驱动器以固定大小的块进行读写。这就可以区分硬盘驱动器和其它可能插入到您计算机的一些设备,如打印机,游戏手柄,麦克风,或相机。一个简单的方法用来列出连接到你 Linux 系统上的块设备就是使用 `lsblk` (list block devices)命令:
|
||||
硬盘驱动器通常被称为“块设备”,因为硬盘驱动器以固定大小的块进行读写。这就可以区分硬盘驱动器和其它可能插入到您计算机的一些设备,如打印机、游戏手柄、麦克风,或相机。一个简单的方法用来列出连接到你 Linux 系统上的块设备就是使用 `lsblk` (list block devices)命令:
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 238.5G 0 disk
|
||||
├─sda1 8:1 0 1G 0 part /boot
|
||||
└─sda2 8:2 0 237.5G 0 part
|
||||
└─luks-e2bb...e9f8 253:0 0 237.5G 0 crypt
|
||||
├─fedora-root 253:1 0 50G 0 lvm /
|
||||
├─fedora-swap 253:2 0 5.8G 0 lvm [SWAP]
|
||||
└─fedora-home 253:3 0 181.7G 0 lvm /home
|
||||
sdb 8:16 1 14.6G 0 disk
|
||||
└─sdb1 8:17 1 14.6G 0 part
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 238.5G 0 disk
|
||||
├─sda1 8:1 0 1G 0 part /boot
|
||||
└─sda2 8:2 0 237.5G 0 part
|
||||
└─luks-e2bb...e9f8 253:0 0 237.5G 0 crypt
|
||||
├─fedora-root 253:1 0 50G 0 lvm /
|
||||
├─fedora-swap 253:2 0 5.8G 0 lvm [SWAP]
|
||||
└─fedora-home 253:3 0 181.7G 0 lvm /home
|
||||
sdb 8:16 1 14.6G 0 disk
|
||||
└─sdb1 8:17 1 14.6G 0 part
|
||||
```
|
||||
|
||||
最左列是设备标识符,每个都是以 `sd` 开头,并以一个字母结尾,字母从 `a` 开始。每个块设备上的分区分配一个数字,从 1 开始。例如,第一个设备上的第二个分区用 `sda2` 表示。如果你不确定到底是哪个分区,那也不要紧,只需接着往下读。
|
||||
最左列是设备标识符,每个都是以 `sd` 开头,并以一个字母结尾,字母从 `a` 开始。每个块设备上的分区分配一个数字,从 `1` 开始。例如,第一个设备上的第二个分区用 `sda2` 表示。如果你不确定到底是哪个分区,那也不要紧,只需接着往下读。
|
||||
|
||||
`lsblk` 命令是无损的,仅仅用于检测,所以你可以放心的使用而不用担心破坏你驱动器上的数据。
|
||||
|
||||
### 使用 `dmesg` 进行测试
|
||||
### 使用 dmesg 进行测试
|
||||
|
||||
如果你有疑问,你可以通过在 `dmesg` 命令的最后几行查看驱动器的卷标,这个命令显示了操作系统最近的日志(比如说插入或移除一个驱动器)。一句话,如果你想确认你插入的设备是不是 `/dev/sdc` ,那么,把设备插到你的计算机上,然后运行这个 `dmesg` 命令:
|
||||
|
||||
@ -40,20 +40,20 @@ $ sudo dmesg | tail
|
||||
|
||||
显示中列出的最新的驱动器就是你刚刚插入的那个。如果你拔掉它,并再运行这个命令一次,你可以看到,这个设备已经被移除。如果你再插上它再运行命令,这个设备又会出现在那里。换句话说,你可以监控内核对驱动器的识别。
|
||||
|
||||
### 解理文件系统
|
||||
### 理解文件系统
|
||||
|
||||
如果你只需要设备卷标,那么你的工作就完成了。但是如果你的目的是想创建一个可用的驱动器,那你还必须给这个驱动器做一个文件系统。
|
||||
|
||||
如果你还不知道什么是文件系统,那么通过了解当没有文件系统时会发生什么,可能会更容易理解这个概念。如果你有多余的设备驱动器,并且上面没有什么重要的数据资料,你可以跟着做一下下面的这个实验。否则,请不要尝试,因为根据设计,这个肯定会删除您的资料。
|
||||
如果你还不知道什么是文件系统,那么通过了解当没有文件系统时会发生什么可能会更容易理解这个概念。如果你有多余的设备驱动器,并且上面没有什么重要的数据资料,你可以跟着做一下下面的这个实验。否则,请不要尝试,因为根据其设计目的,这个肯定会删除您的资料。
|
||||
|
||||
当一个驱动器没有文件系统时也是可以使用的。一旦你已经肯定,正解识别了一个驱动器,并且已经确定上面没有任何重要的资料,那就可以把它插到你的计算机上——但是不要挂载它,如果它被自动挂载上了,那就请手动卸载掉它。
|
||||
当一个驱动器没有文件系统时也是可以使用的。一旦你已经肯定,正确识别了一个驱动器,并且已经确定上面没有任何重要的资料,那就可以把它插到你的计算机上 —— 但是不要挂载它,如果它被自动挂载上了,那就请手动卸载掉它。
|
||||
|
||||
```
|
||||
$ su -
|
||||
# umount /dev/sdx{,1}
|
||||
```
|
||||
|
||||
为了防止灾难性的复制-粘贴错误,下面的例子将使用不太可能出现的 `sdx` 来作为驱动器的卷标。
|
||||
为了防止灾难性的复制 —— 粘贴错误,下面的例子将使用不太可能出现的 `sdx` 来作为驱动器的卷标。
|
||||
|
||||
现在,这个驱动器已经被卸载了,尝试使用下面的命令:
|
||||
|
||||
@ -70,7 +70,7 @@ $ su -
|
||||
hello world
|
||||
```
|
||||
|
||||
这看起来工作得很好,但是想象一下如果 "hello world" 这个短语是一个文件,如果你想要用这种方法写入一个新的文件,则必须:
|
||||
这看起来工作得很好,但是想象一下如果 “hello world” 这个短语是一个文件,如果你想要用这种方法写入一个新的文件,则必须:
|
||||
|
||||
1. 知道第 1 行已经存在一个文件了
|
||||
2. 知道已经存在的文件只占用了 1 行
|
||||
@ -105,7 +105,7 @@ this is a second file
|
||||
|
||||
分区是硬盘驱动器的一种边界,用来告诉文件系统它可以占用哪些空间。举例来说,你有一个 4GB 的 USB 驱动器,你可以只分一个分区占用一个驱动器 (4GB),或两个分区,每个 2GB (又或者是一个 1GB,一个 3GB,只要你愿意),或者三个不同的尺寸大小,等等。这种组合将是无穷无尽的。
|
||||
|
||||
假设你的驱动器是 4GB,你可以 GNU `parted` 命令来创建一个大的分区。
|
||||
假设你的驱动器是 4GB,你可以使用 GNU `parted` 命令来创建一个大的分区。
|
||||
|
||||
```
|
||||
# parted /dev/sdx --align opt mklabel msdos 0 4G
|
||||
@ -113,11 +113,11 @@ this is a second file
|
||||
|
||||
按 `parted` 命令的要求,首先指定了驱动器的路径。
|
||||
|
||||
`\--align` 选项让 `parted` 命令自动选择一个最佳的开始点和结束点。
|
||||
`--align` 选项让 `parted` 命令自动选择一个最佳的开始点和结束点。
|
||||
|
||||
`mklabel` 命令在驱动器上创建了一个分区表 (称为磁盘卷标)。这个例子使用了 msdos 磁盘卷标,因为它是一个非常兼容和流行的卷标,虽然 gpt 正变得越来越普遍。
|
||||
|
||||
最后定义了分区所需的起点和终点。因为使用了 `\--align opt` 标志,所以 `parted` 将根据需要调整大小以优化驱动器的性能,但这些数字仍然可以做为参考。
|
||||
最后定义了分区所需的起点和终点。因为使用了 `--align opt` 标志,所以 `parted` 将根据需要调整大小以优化驱动器的性能,但这些数字仍然可以做为参考。
|
||||
|
||||
接下来,创建实际的分区。如果你开始点和结束点的选择并不是最优的, `parted` 会向您发出警告并让您做出调整。
|
||||
|
||||
@ -135,7 +135,7 @@ Ignore/Cancel? C
|
||||
|
||||
我们有很多文件系统可以使用。有些是开源和免费的,另外的一些并不是。一些公司拒绝支持开源文件系统,所以他们的用户无法使用开源的文件系统读取,而开源的用户也无法在不对其进行逆向工程的情况下从封闭的文件系统中读取。
|
||||
|
||||
尽管有这种特殊的情况存在,还是仍然有很多操作系统可以使用,选择哪个取决于驱动器的用途。如果你希望你的驱动器兼容多个系统,那么你唯一的选择是 exFAT 文件系统。然而微软尚未向任何开源内核提交 exFAT 的代码,因此你可能必须在软件包管理器中安装 exFAT 支持,但是 Windows 和 MacOS 都支持 exFAT 文件系统。
|
||||
尽管有这种特殊的情况存在,还是仍然有很多文件系统可以使用,选择哪个取决于驱动器的用途。如果你希望你的驱动器兼容多个系统,那么你唯一的选择是 exFAT 文件系统。然而微软尚未向任何开源内核提交 exFAT 的代码,因此你可能必须在软件包管理器中安装 exFAT 支持,但是 Windows 和 MacOS 都支持 exFAT 文件系统。
|
||||
|
||||
一旦你安装了 exFAT 支持,你可以在驱动器上你创建好的分区中创建一个 exFAT 文件系统。
|
||||
|
||||
@ -155,31 +155,31 @@ Linux 中常见的文件系统是 [ext4][1]。但对于便携式的设备来说
|
||||
|
||||
### 使用桌面工具
|
||||
|
||||
很高兴知道了在只有一个 Linux shell的时候,如何操作和处理你的块设备,但是,有时候你仅仅是想让一个驱动器可用,而不需要进行那么多的检测。 GNOME 的 KDE 的开发者们提供了这样的一些优秀的工具让这个过程变得简单。
|
||||
很高兴知道了在只有一个 Linux shell 的时候如何操作和处理你的块设备,但是,有时候你仅仅是想让一个驱动器可用,而不需要进行那么多的检测。 GNOME 的 KDE 的开发者们提供了这样的一些优秀的工具让这个过程变得简单。
|
||||
|
||||
[GNOME 磁盘][2] 和 [KDE 分区管理器][3] 是一个图形化的工具,为本文到目前为止提到的一切提供了一个一体化的解决方案。启动其中的任何一个,来查看所有连接的设备(在左侧列表中),创建和调整分区大小,和创建文件系统。
|
||||
|
||||
![KDE 分区管理器][5]
|
||||
|
||||
KDE 分区管理器
|
||||
*KDE 分区管理器*
|
||||
|
||||
可以预见的是,GNOME 版本会比 KDE 版本更加简单,因此,我将使用复杂的版本进行演示——如果你愿意动手的话,很容易弄清楚 GNOME 磁盘工具的使用。
|
||||
|
||||
启动 KDE 分区管理工具,然后输入你的 root 密码。
|
||||
|
||||
在最左边的一列,选择你想要格式化的驱动器。如果你的驱动器并没有列出来,确认下是否已经插好,然后选择 Tools > Refresh devices (或使用键盘上的 F5 键)。
|
||||
在最左边的一列,选择你想要格式化的驱动器。如果你的驱动器并没有列出来,确认下是否已经插好,然后选择 “Tools > Refresh devices” (或使用键盘上的 F5 键)。
|
||||
|
||||
除非你想销毁驱动器已经存在的分区表,否则请勿继续。选择好驱动器后,单击顶部工具栏中的 New Partition Table 。系统会提示你为该分区选择一个卷标: gpt 或 msdos 。前者更加灵活可以处理更大的驱动器,而后者像很多微软的技术一样,是占据大量市场份额的事实上的标准。
|
||||
除非你想销毁驱动器已经存在的分区表,否则请勿继续。选择好驱动器后,单击顶部工具栏中的 “New Partition Table” 。系统会提示你为该分区选择一种卷标:gpt 或 msdos 。前者更加灵活可以处理更大的驱动器,而后者像很多微软的技术一样,是占据大量市场份额的事实上的标准。
|
||||
|
||||
现在您有了一个新的分区表,在右侧的面板中右键单击你的设备,然后选择 New 来创建新的分区,按照提示设置分区的类型和大小。此操作包括了分区步骤和创建文件系统。
|
||||
现在您有了一个新的分区表,在右侧的面板中右键单击你的设备,然后选择 “New” 来创建新的分区,按照提示设置分区的类型和大小。此操作包括了分区步骤和创建文件系统。
|
||||
|
||||
![创建一个新分区][7]
|
||||
|
||||
创建一个新分区
|
||||
*创建一个新分区*
|
||||
|
||||
要将更改应用于你的驱动器,单击窗口左上角的 Apply 按钮。
|
||||
要将更改应用于你的驱动器,单击窗口左上角的 “Apply” 按钮。
|
||||
|
||||
### 硬盘驱动器, 容易驱动
|
||||
### 硬盘驱动器,轻松驱动
|
||||
|
||||
在 Linux 上处理硬盘驱动器很容易,甚至如果你理解硬盘驱动器的语言就更容易了。自从切换到 Linux 系统以来,我已经能够以任何我想要的方式来处理我的硬盘驱动器了。由于 Linux 在处理存储提供的透明性,因此恢复数据也变得更加容易了。
|
||||
|
||||
@ -198,7 +198,7 @@ via: https://opensource.com/article/18/11/partition-format-drive-linux
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Jamskr](https://github.com/Jamskr)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,36 +1,35 @@
|
||||
使用 Selenium 自动化 Web 浏览器
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Selenium][1] 是浏览器自动化的绝佳工具。使用 Selenium IDE,你可以录制命令序列(如单击、拖动和输入),验证结果并最终存储此自动化测试供日后使用。这非常适合在浏览器中进行积极开发。但是当你想要将这些测试与 CI/CD 流集成时,是时候使用 Selenium WebDriver 了。
|
||||
[Selenium][1] 是浏览器自动化的绝佳工具。使用 Selenium IDE,你可以录制命令序列(如单击、拖动和输入),验证结果并最终存储此自动化测试供日后使用。这非常适合在浏览器中进行活跃开发。但是当你想要将这些测试与 CI/CD 流集成时,是时候使用 Selenium WebDriver 了。
|
||||
|
||||
WebDriver 公开了一个绑定了许多编程语言的 API,它允许你将浏览器测试与其他测试集成。这篇文章向你展示了如何在容器中运行 WebDriver 并将其与 Python 程序一起使用。
|
||||
|
||||
### 使用 Podman 运行 Selenium
|
||||
|
||||
Podman是下面例子的容器运行时。有关如何开始使用 Podman 的信息,请参见[此前文章][2]。
|
||||
Podman 是下面例子的容器运行时。有关如何开始使用 Podman 的信息,请参见[此前文章][2]。
|
||||
|
||||
此例使用了 Selenium 的独立容器,其中包含 WebDriver 服务器和浏览器本身。要在后台启动服务器容器,请运行以下命令:
|
||||
|
||||
```
|
||||
$ podman run -d --network host --privileged --name server \
|
||||
docker.io/selenium/standalone-firefox
|
||||
$ podman run -d --network host --privileged --name server docker.io/selenium/standalone-firefox
|
||||
```
|
||||
|
||||
当你使用特权标志和主机网络运行容器时,你可以稍后从在 Python 中连接到此容器。你不需要使用 sudo。
|
||||
当你使用特权标志和主机网络运行容器时,你可以稍后从在 Python 中连接到此容器。你不需要使用 `sudo`。
|
||||
|
||||
### 在 Python 中使用 Selenium
|
||||
|
||||
现在你可以提供一个使用此服务器的简单程序。这个程序很小,但应该会让你知道可以做什么:
|
||||
|
||||
```
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
|
||||
server ="http://127.0.0.1:4444/wd/hub"
|
||||
|
||||
driver = webdriver.Remote(command_executor=server,
|
||||
desired_capabilities=DesiredCapabilities.FIREFOX)
|
||||
desired_capabilities=DesiredCapabilities.FIREFOX)
|
||||
|
||||
print("Loading page...")
|
||||
driver.get("https://fedoramagazine.org/")
|
||||
@ -77,7 +76,7 @@ Done.
|
||||
|
||||
上面的示例程序是最小的,也许没那么有用。但这仅仅是最表面的东西!查看 [Selenium][3] 和 [Python 绑定][4] 的文档。在那里,你将找到有关如何在页面中查找元素、处理弹出窗口或填写表单的示例。拖放也是可能的,当然还有等待事件。
|
||||
|
||||
在实现一些不错的测试后,你可能希望将它们包含在 CI/CD pipeline 中。幸运的是,这是相当直接的,因为一切都是容器化的。
|
||||
在实现一些不错的测试后,你可能希望将它们包含在 CI/CD 流程中。幸运的是,这是相当直接的,因为一切都是容器化的。
|
||||
|
||||
你可能也有兴趣设置 [grid][5] 来并行运行测试。这不仅有助于加快速度,还允许你同时测试多个不同的浏览器。
|
||||
|
||||
@ -108,14 +107,14 @@ via: https://fedoramagazine.org/automate-web-browser-selenium/
|
||||
作者:[Lennart Jern][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/lennartj/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.seleniumhq.org/
|
||||
[2]: https://fedoramagazine.org/running-containers-with-podman/
|
||||
[2]: https://linux.cn/article-10156-1.html
|
||||
[3]: https://www.seleniumhq.org/docs/
|
||||
[4]: https://selenium-python.readthedocs.io
|
||||
[5]: https://www.seleniumhq.org/docs/07_selenium_grid.jsp
|
||||
@ -0,0 +1,163 @@
|
||||
有所为,有所不为:在 Linux 中使用超级用户权限
|
||||
======
|
||||
|
||||
> sudo 命令允许特权用户以 root 用户身份运行全部或部分命令,但是理解其能做什么和不能做什么很有帮助。
|
||||
|
||||

|
||||
|
||||
在你想要使用超级权限临时运行一条命令时,`sudo` 命令非常方便,但是当它不能如你期望的工作时,你也会遇到一些麻烦。比如说你想在某些日志文件结尾添加一些重要的信息,你可能会尝试这样做:
|
||||
|
||||
```
|
||||
$ echo "Important note" >> /var/log/somelog
|
||||
-bash: /var/log/somelog: Permission denied
|
||||
```
|
||||
|
||||
好吧,看起来你似乎需要一些额外的特权。一般来说,你不能使用你的用户账号向系统日志中写入东西。我们使用 `sudo` 再尝试一次吧。
|
||||
|
||||
```
|
||||
$ sudo !!
|
||||
sudo echo "Important note" >> /var/log/somelog
|
||||
-bash: /var/log/somelog: Permission denied
|
||||
```
|
||||
|
||||
嗯,它还是没有啥反应。我们来试点不同的吧。
|
||||
|
||||
```
|
||||
$ sudo 'echo "Important note" >> /var/log/somelog'
|
||||
sudo: echo "Important note" >> /var/log/somelog: command not found
|
||||
```
|
||||
|
||||
也可以查看:[在 Linux 下排查故障的宝贵提示和技巧][1]。
|
||||
|
||||
### 接下来该干什么?
|
||||
|
||||
上面在执行完第一条命令后的回应显示,我们缺少向日志文件写入时必须的特权。第二次,我们使用 root 权限运行了第一次的命令,但是返回了一个“没有权限”的错误。第三次,我们把整个命令放在一个引号里面再运行了一遍,返回了一个“没有发现命令”的错误。所以,到底错在哪里了呢?
|
||||
|
||||
* 第一条命令:没有 root 特权,你无法向这个日志中写入东西。
|
||||
* 第二条命令:你的超级权限没有延伸到重定向。
|
||||
* 第三条命令:`sudo` 不理解你用引号括起来的整个 “命令”。
|
||||
|
||||
而且如果你的用户还未添加到 sudo 用户组的时候,如果尝试使用 `sudo`,你可能已经看到过像下面的这么一条错误了:
|
||||
|
||||
```
|
||||
nemo is not in the sudoers file. This incident will be reported.
|
||||
```
|
||||
|
||||
### 你可以做什么?
|
||||
|
||||
一个相当简单的选择就是使用 `sudo` 命令暂时成为 root。鉴于你已经有了 sudo 特权,你可以使用下面的命令执行此操作:
|
||||
|
||||
```
|
||||
$ sudo su
|
||||
[sudo] password for nemo:
|
||||
#
|
||||
```
|
||||
|
||||
注意这个改变的提示符表明了你的新身份。然后你就可以以 root 运行之前的命令了:
|
||||
|
||||
```
|
||||
# echo "Important note" >> /var/log/somelog
|
||||
```
|
||||
|
||||
接着你可以输入 `^d` 返回你之前的身份。当然了,一些 sudo 的配置可能会阻止你使用 `sudo` 命令成为 root。
|
||||
|
||||
另一个切换用户为 root 的方法是仅用 `su` 命令,但是这需要你知道 root 密码。许多人被赋予了访问 sudo 的权限,而并不知道 root 密码,所以这并不是总是可行。
|
||||
|
||||
(采用 su 直接)切换到 root 之后,你就可以以 root 的身份运行任何你想执行的命令了。这种方式的问题是:1) 每个想要使用 root 特权的人都需要事先知道 root 的密码(这样不很安全);2) 如果在运行需要 root 权限的特定命令后未能退出特权状态,你的系统可能会受到一些重大错误的波及。`sudo` 命令旨在允许您仅在真正需要时使用 root 权限,并控制每个 sudo 用户应具有的 root 权限。它也可以使你在使用完 root 特权之后轻松地回到普通用户的状态。
|
||||
|
||||
另外请注意,整个讨论的前提是你可以正常地访问 sudo,并且你的访问权限没有受限。详细的内容后面会介绍到。
|
||||
|
||||
还有一个选择就是使用一个不同的命令。如果通过编辑文件从而在其后添加内容是一种选择的话,你也许可以使用 `sudo vi /var/log/somelog`,虽然编辑一个活跃的日志文件通常不是一个好主意,因为系统可能会频繁的向这个文件中进行写入操作。
|
||||
|
||||
最后一个但是有点复杂的选择是,使用下列命令之一可以解决我们之前看到的问题,但是它们涉及到了很多复杂的语法。第一个命令允许你在得到 “没有权限” 的拒绝之后可以使用 `!!` 重复你的命令:
|
||||
|
||||
```
|
||||
$ sudo echo "Important note" >> /var/log/somelog
|
||||
-bash: /var/log/somelog: Permission denied
|
||||
$ !!:gs/>/|sudo tee -a / <=====
|
||||
$ tail -1 /var/log/somelog
|
||||
Important note
|
||||
```
|
||||
|
||||
第二种是通过 `sudo` 命令,把你想要添加的信息传递给 `tee`。注意,`-a` 指定了你要**附加**文本到目标文件:
|
||||
|
||||
```
|
||||
$ echo "Important note" | sudo tee -a /var/log/somelog
|
||||
$ tail -1 /var/log/somelog
|
||||
Important note
|
||||
```
|
||||
|
||||
### sudo 有多可控?
|
||||
|
||||
回答这个问题最快速的回答就是,它取决于管理它的人。大多数 Linux 的默认设置都非常简单。如果一个用户被安排到了一个特别的组中,例如 `wheel` 或者 `admin` 组,那这个用户无需知道 root 的密码就可以拥有运行任何命令的能力。这就是大多数 Linux 系统中的默认设置。一旦在 `/etc/group` 中添加了一个用户到了特权组中,这个用户就可以以 root 的权力运行任何命令。另一方面,可以配置 sudo,以便一些用户只能够以 root 身份运行单一指令或者一组命令中的任何一个。
|
||||
|
||||
如果把像下面展示的这些行添加到了 `/etc/sudoers` 文件中,例如 “nemo” 这个用户可以以 root 身份运行 `whoami` 命令。在现实中,这可能不会造成任何影响,它非常适合作为一个例子。
|
||||
|
||||
```
|
||||
# User alias specification
|
||||
nemo ALL=(root) NOPASSWD: WHOAMI
|
||||
|
||||
# Cmnd alias specification
|
||||
Cmnd_Alias WHOAMI = /usr/bin/whoami
|
||||
```
|
||||
|
||||
注意,我们添加了一个命令别名(`Cmnd_Alias`),它指定了一个可以运行的命令的全路径,以及一个用户别名,允许这个用户无需密码就可以使用 `sudo` 执行的单个命令。
|
||||
|
||||
当 nemo 运行 `sudo whoami` 命令的时候,他将会看到这个:
|
||||
|
||||
```
|
||||
$ sudo whoami
|
||||
root
|
||||
```
|
||||
|
||||
注意这个,因为 nemo 使用 `sudo` 执行了这条命令,`whoami` 会显示该命令运行时的用户是 `root`。
|
||||
|
||||
至于其他的命令,nemo 将会看到像这样的一些内容:
|
||||
|
||||
```
|
||||
$ sudo date
|
||||
[sudo] password for nemo:
|
||||
Sorry, user nemo is not allowed to execute '/bin/date' as root on butterfly.
|
||||
```
|
||||
|
||||
### sudo 的默认设置
|
||||
|
||||
在默认路径中,我们会利用像下面展示的 `/etc/sudoers` 文件中的几行:
|
||||
|
||||
```
|
||||
$ sudo egrep "admin|sudo" /etc/sudoers
|
||||
# Members of the admin group may gain root privileges
|
||||
%admin ALL=(ALL) ALL <=====
|
||||
# Allow members of group sudo to execute any command
|
||||
%sudo ALL=(ALL:ALL) ALL <=====
|
||||
```
|
||||
|
||||
在这几行中,`%admin` 和 `%sudo` 都说明了任何添加到这些组中的人都可以使用 `sudo` 命令以 root 的身份运行任何命令。
|
||||
|
||||
下面列出的是 `/etc/group` 中的一行,它意味着每一个在该组中列出的成员,都拥有了 sudo 特权,而无需在 `/etc/sudoers` 中进行任何修改。
|
||||
|
||||
```
|
||||
sudo:x:27:shs,nemo
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
`sudo` 命令意味着你可以根据需要轻松地部署超级用户的访问权限,而且只有在需要的时候才能赋予用户非常有限的特权访问权限。你可能会遇到一些与简单的 `sudo command` 不同的问题,不过在 `sudo` 的回应中应该会显示你遇到了什么问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3322504/linux/selectively-deploying-your-superpowers-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (Standalone web applications with GNOME Web)
|
||||
[#]: via: (https://fedoramagazine.org/standalone-web-applications-gnome-web/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
|
||||
[#]: url: (https://linux.cn/article-10317-1.html)
|
||||
|
||||
使用 GNOME Web “安装”独立 Web 应用
|
||||
======
|
||||
|
||||

|
||||
|
||||
你是否经常使用单页 Web 应用(SPA),但失去了一些完整桌面应用的好处? GNOME Web 浏览器,简称为 Web(又名 Epiphany)有一个非常棒的功能,它允许你“安装” 一个 Web 应用。安装完成后,Web 应用将显示在应用菜单、GNOME shell 搜索中,并且它在切换窗口时是一个单独的项目。这个简短的教程将引导你完成使用 GNOME Web “安装” Web 应用的步骤。
|
||||
|
||||
### 安装 GNOME Web
|
||||
|
||||
GNOME Web 未包含在默认的 Fedora 安装中。要安装它,请在软件中心搜索 “web”,然后安装。
|
||||
|
||||
![][1]
|
||||
|
||||
或者,在终端中使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf install epiphany
|
||||
```
|
||||
|
||||
### 安装为 Web 应用
|
||||
|
||||
接下来,启动 GNOME Web,然后去浏览要安装的 Web 应用。使用浏览器连接到应用,然后从菜单中选择“将站点安装为 Web 应用”:
|
||||
|
||||
![][2]
|
||||
|
||||
GNOME Web 接下来会出现一个用于编辑应用名称的对话框。将其保留为默认值 (URL) 或更改为更具描述性的内容:
|
||||
|
||||
![][3]
|
||||
|
||||
最后,按下“创建”以 “安装” 你的新 Web 应用。创建 Web 应用后,关闭 GNOME Web。
|
||||
|
||||
### 使用新的 Web 应用
|
||||
|
||||
像使用任何典型的桌面应用一样启动 Web 应用。在 GNOME Shell Overview 中搜索它:
|
||||
|
||||
![][4]
|
||||
|
||||
此外,Web 应用将在 `alt-tab` 应用切换器中显示为单独的应用:
|
||||
|
||||
![][5]
|
||||
|
||||
另一个额外的功能是来自“已安装”的 Web 应用的所有 Web 通知都显示为常规 GNOME 通知。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/standalone-web-applications-gnome-web/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2018/11/gnome-web-in-gnome-software.png
|
||||
[2]: https://fedoramagazine.org/wp-content/uploads/2018/11/freenode-page-in-gnome-web.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/11/edit-web-application-in-GNOME-web.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/11/web-application-in-overview.jpg
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/11/web-app-in-app-switcher.jpg
|
||||
95
published/20181129 4 open source Markdown editors.md
Normal file
95
published/20181129 4 open source Markdown editors.md
Normal file
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxfminions)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (4 open source Markdown editors)
|
||||
[#]: via: (https://opensource.com/article/18/11/markdown-editors)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
[#]: url: (https://linux.cn/article-10320-1.html)
|
||||
|
||||
4 个 Markdown 开源编辑器
|
||||
======
|
||||
|
||||
> 如果你正在寻找一种简便的方法去格式化 Markdown 文本,那么这些编辑器可能会满足你的需求。
|
||||
|
||||

|
||||
|
||||
我的文章、散文、博客等等基本上都是在文本编辑器上使用 [Markdown][1] 写作的。当然,我不是唯一使用 Markdown 写作的人。不仅仅无数的人在使用 Markdown,而且也产生了许多服务于 Markdown 的工具。
|
||||
|
||||
谁能想到由 John Gruber 和之后的 Aaron Schwartz 创造的一种格式化网页文档的简便的方法如此的受欢迎呢?
|
||||
|
||||
我的大多数协作都是在文本编辑器上进行,我能理解为什么 Markdown 编辑器会如此受欢迎 —— 可以快速格式化,可以轻便的将文档转换为其他的格式,可以实时预览。
|
||||
|
||||
如果你想用 Markdown 和寻找一个专用的 Markdown 编辑器,那么这里有四个开源编辑器可能会让你写作更加轻松。
|
||||
|
||||
### Ghostwriter
|
||||
|
||||
在我使用过的或试过的 Markdown 编辑器中 [Ghostwriter][2] 能排进前三。我已经使用或试了不少。
|
||||
|
||||
|
||||
|
||||
作为一个编辑器,Ghostwriter 就像一个画布,你可以手动进行编辑和添加格式。如果你不想这么做或者只想学习 Markdown 或者不知道如何添加,你可以从 Ghostwriter 的格式化菜单中选择你想要的格式。
|
||||
|
||||
一般的,它只有一个基本的格式:列表、字符格式化和缩进。所以你必须手动的添加标题、代码。而且它有一个有趣的任务列表选项,很多人都在用 Markdown 去创造任务列表,这个功能可以让你更加容易去创造和维护任务列表。
|
||||
|
||||
Ghostwriter 区别于其他的 Markdown 编辑器的是它有更多的导出选项。你可以选择你想使用的 Markdown 编译器,包括 [Sundown][3]、[Pandoc][4] 或 [Discount][5]。只需要点击两次,你可以轻松的将你写的内容转换为 HTML5、ODT、EPUB、LaTeX、PDF 或 Word 文档。
|
||||
|
||||
### Abricotine
|
||||
|
||||
如果喜欢简洁的 Markdown 编辑器,你会爱上 [Abricotine][6]。但是不要让它的简单性欺骗了你;Abricotine 包含了很多强大的功能。
|
||||
|
||||
|
||||
|
||||
与其他的编辑器一样,你可以手动格式化文档或使用它的格式化菜单或插入菜单。Abricotine 有一个插入 [GitHub 式 Markdown][7] 表格的菜单。它预装了 16 个表样式,你可以在你需要的地方添加行或列。如果这个表看起来有点复杂,你可以使用 `Ctrl+Shift+B` 去使它看起来更整洁优美。
|
||||
|
||||
Abricotine 可以自动显示图片、连接和数学公式。当然你也可以关闭这些选项。可惜的是,这个编辑器只能导出为 HTML 格式。
|
||||
|
||||
### Mark Text
|
||||
|
||||
像 Abricotine 一样,[Mark Text][8] 也是一个简洁的 Markdown 编辑器。它有一些你可能没有预料到但能够很好的处理 Markdown 文档的功能。
|
||||
|
||||
|
||||
|
||||
Mark Text 有点奇怪,它没有菜单或工具条。你需要点击编辑器左上角的弹出式菜单得到命令和功能。它就是让你专注于你的内容。
|
||||
|
||||
虽然当你添加内容后,可以在预览区实时看到你所写的内容,但它仍然是一个半所见即所得的编辑器。Mark Text 支持 GitHub 式 Markdown 格式,所以你可以添加表和语法高亮的代码块。在缺省的预览中,编辑器会显示你文档的所有图片。
|
||||
|
||||
与 Ghostwriter 相比,你只能将你的文档保存为 HTML 或 PDF 格式。这个输出看起来也不是很糟糕。
|
||||
|
||||
### Remarkable
|
||||
|
||||
[Remarkable][9] 复杂性介乎于 Ghostwriter 和 Abricotine 或 Mark Text 之间。它有一个带点现代风格的双栏界面。它有一些有用的特点。
|
||||
|
||||
|
||||
|
||||
你注意到的第一件事是它受到 [Material Design][10] 启发的界面外观。它不是每一个人都能习惯的,老实说:我花费了很多时间去适应它。一旦你适应了,它使用起来很简单。
|
||||
|
||||
你可以在工具条和菜单上快速访问格式化功能。你可以使用内置的 11 种 CSS 样式或你自己创造的去定制预览框的样式。
|
||||
|
||||
Remarkable 的导出选项是有限的 —— 你只能导出为 HTML 或 PDF 格式文件。然而你可以复制整个文档或挑选一部分作为 HTML,粘贴到另一个文档或编辑器中。
|
||||
|
||||
你有最喜爱的 Markdown 编辑器吗?为什么不在评论区分享它呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/markdown-editors
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxfminions](https://github.com/lxfminions)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Markdown
|
||||
[2]: https://wereturtle.github.io/ghostwriter/
|
||||
[3]: https://github.com/vmg/sundown
|
||||
[4]: https://pandoc.org
|
||||
[5]: https://www.pell.portland.or.us/~orc/Code/discount/
|
||||
[6]: http://abricotine.brrd.fr/
|
||||
[7]: https://guides.github.com/features/mastering-markdown/
|
||||
[8]: https://marktext.github.io/website/
|
||||
[9]: https://remarkableapp.github.io/
|
||||
[10]: https://en.wikipedia.org/wiki/Material_Design
|
||||
@ -49,11 +49,11 @@ for catalog in "$@";do
|
||||
num=$(count_files_under_dir "${catalog}" "[0-9]*.md")
|
||||
;;
|
||||
translating)
|
||||
num=$(git grep -niE "translat|fanyi|翻译" sources/*.md |awk -F ":" '{if ($2<=3) print $1}' |wc -l)
|
||||
num=$(git grep -niE "^[^[].*translat|^\[#\]: translator: \([^[:space:]]+\)|fanyi|翻译" sources/*.md |awk -F ":" '{if ($2<=3) print $1}'|wc -l)
|
||||
;;
|
||||
sources)
|
||||
total=$(count_files_under_dir "${catalog}" "[0-9]*.md")
|
||||
translating_num=$(git grep -niE "translat|fanyi|翻译" sources/*.md |awk -F ":" '{if ($2<=3) print $1}' |wc -l)
|
||||
translating_num=$(git grep -niE "^[^[].*translat|^\[#\]: translator: \([^[:space:]]+\)|fanyi|翻译" sources/*.md |awk -F ":" '{if ($2<=3) print $1}'|wc -l)
|
||||
num=$((${total} - ${translating_num}))
|
||||
;;
|
||||
*)
|
||||
|
||||
@ -47,20 +47,26 @@ rule_translation_completed() {
|
||||
&& [ "$TOTAL" -eq 2 ] && echo "匹配规则:提交译文"
|
||||
}
|
||||
|
||||
# 校对译文:只能校对一篇
|
||||
# 校对译文:只能校对一篇译文
|
||||
rule_translation_revised() {
|
||||
[ "$TSL_M" -eq 1 ] \
|
||||
&& check_category TSL M \
|
||||
&& [ "$TOTAL" -eq 1 ] && echo "匹配规则:校对译文"
|
||||
}
|
||||
|
||||
# 发布译文:发布多篇译文
|
||||
# 发布译文:只能发布一篇译文
|
||||
rule_translation_published() {
|
||||
[ "$TSL_D" -ge 1 ] && [ "$PUB_A" -ge 1 ] && [ "$TSL_D" -eq "$PUB_A" ] \
|
||||
&& ensure_identical SRC D TSL A 1 \
|
||||
[ "$TSL_D" -eq 1 ] && [ "$PUB_A" -eq 1 ] \
|
||||
&& ensure_identical TSL D PUB A 1 \
|
||||
&& check_category TSL D \
|
||||
&& [ "$TOTAL" -eq $((TSL_D + PUB_A)) ] \
|
||||
&& echo "匹配规则:发布译文 ${PUB_A} 篇"
|
||||
&& echo "匹配规则:发布译文"
|
||||
}
|
||||
|
||||
# 校对已发布译文:只能校对一篇已发布的译文
|
||||
rule_published_translation_revised() {
|
||||
[ "$PUB_M" -eq 1 ] \
|
||||
&& [ "$TOTAL" -eq 1 ] && echo "匹配规则:校对已发布译文"
|
||||
}
|
||||
|
||||
# 定义常见错误
|
||||
@ -73,7 +79,13 @@ error_undefined() {
|
||||
# 申领多篇
|
||||
error_translation_requested_multiple() {
|
||||
[ "$SRC_M" -gt 1 ] \
|
||||
&& echo "匹配错误:申领多篇,请一次仅申领一篇"
|
||||
&& echo "匹配错误:请勿申领多篇,请一次仅申领一篇"
|
||||
}
|
||||
|
||||
# 提交多篇
|
||||
error_translation_completed_multiple() {
|
||||
[ "$TSL_A" -gt 1 ] \
|
||||
&& echo "匹配错误:请勿提交多篇,请一次仅提交一篇"
|
||||
}
|
||||
|
||||
# 执行检查并输出匹配项目
|
||||
@ -84,8 +96,10 @@ do_check() {
|
||||
|| rule_translation_completed \
|
||||
|| rule_translation_revised \
|
||||
|| rule_translation_published \
|
||||
|| rule_published_translation_revised \
|
||||
|| {
|
||||
error_translation_requested_multiple \
|
||||
|| error_translation_completed_multiple \
|
||||
|| error_undefined
|
||||
exit 1
|
||||
}
|
||||
|
||||
@ -1,4 +1,11 @@
|
||||
thecyanbird translating
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (runningwater)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (The Rise and Rise of JSON)
|
||||
[#]: via: ( https://twobithistory.org/2017/09/21/the-rise-and-rise-of-json.html)
|
||||
[#]: author: (https://twobithistory.org)
|
||||
[#]: url: ( )
|
||||
|
||||
The Rise and Rise of JSON
|
||||
======
|
||||
@ -82,7 +89,7 @@ via: https://twobithistory.org/2017/09/21/the-rise-and-rise-of-json.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,61 +0,0 @@
|
||||
translating by valonia
|
||||
|
||||
How Creative Commons benefits artists and big business
|
||||
======
|
||||
|
||||
|
||||
I attended film school, and later I taught at a film school, and even later I worked at a major film studio. There was a common thread through all these different angles of the creative industry: creators need content. Interestingly, one movement kept providing the solution, and that was free culture, or, as it has been formalized, Creative Commons.
|
||||
|
||||
### Showpieces and demos
|
||||
|
||||
Like anything else in life, creativity requires practice. I luckily stumbled into open source early in my experience with computers, through an article in a trade magazine about render farms. I didn't yet understand what "open source" meant, but I knew that the tools labeled open source were the only tools that provided me reliable access to the technology I wanted to explore. The same has been true for the Creative Commons content that I use. Creative Commons provides artists an entire studio full of artistic resources.
|
||||
|
||||
When I was teaching in film and needed sample footage for students to edit, overdub, foley, grade, or score, I always had what I needed from films like Jim Munroe's independent masterpiece [Infest Wisely][1] or from the Creative Commons content on [Vimeo][2]. These provide realistic footage, spanning the whole spectrum from indie productions to expensive, high-quality crane (actually drone, usually) shots.
|
||||
|
||||
For experimentalist art, the possibilities are truly endless. Creative Commons provides a wealth of stock footage to integrate into video art, video DJ mixes, and whatever else a visual pioneer dreams up.
|
||||
|
||||
Before Creative Commons, the only ways to get experience with real-world footage were either to use footage that former students or professors generated, assuming you were at a university, or to use copyrighted footage despite the restrictions.
|
||||
|
||||
### It's all about the bottom line
|
||||
|
||||
There's a more business-centric use for all of this, as well. When working deep in the render farms of a large computer company, I was tasked with performing render tests on some hardware that was under the threat of being discontinued. For this job, I used the assets of [Big Buck Bunny][3] because not just the movie itself, but also its components, are free to use and share. If it hadn't been for this short film, I could not have done my tests until I'd acquired realistic assets, which would likely never have happened because computer companies are busy places that don't typically employ a team of 3D artists to compose a scene on call.
|
||||
|
||||
It struck me that, much like open source itself, Creative Commons is already propping up big companies in ways no one really thinks about. The use of Creative Commons in a company may or may not make or break the daily process, but it's filling gaps and making people's jobs and workflows move smoothly. I don't think anyone's accounting for this benefit in their books, but Creative Commons content is everywhere.
|
||||
|
||||
I've even seen Blender open movies, like [Sintel][4], as the demo films playing on the latest television screens when a TV resolution exceeds what is currently available on standard media.
|
||||
|
||||
### Raw materials
|
||||
|
||||
Artists need raw materials. A painter needs paint, brushes, and a canvas. Sculptors need clay and modeling tools. And digital content creators need digital content, whether it's clipart or sound effects or ready-made sprites for a video game.
|
||||
|
||||
The digital medium has bestowed upon one individual creator the power to apparently make works of art that should take a group of people to complete. The reality is, though, that most of us like to think big. We want to make projects that look and sound good. We want big worlds, intense stories, evocative works, but we don't have the time or the variety of skills to make it all happen.
|
||||
|
||||
It's here that Creative Commons saves the day, yet again, with the little bits and pieces of free art that abound on sites like [Freesound.org][5], [Openclipart.org][6], [OpenGameArt.org][7], and many, many more. Artists are able, through the Commons, to use raw material that they could not have produced themselves to produce works they couldn't otherwise make alone.
|
||||
|
||||
Possibly even more significantly, though, is the fact that your raw material that you put up on the internet for reuse can bring you, without any further investment, into amazing works of art that you'd never dream of producing yourself. I have contributed to countless musical albums and video games with sound clips I've added to the Commons. Sometimes the artist notifies me, others I find on my own, and probably even more exist than I know about. I've seen icons that I've drawn pop up in software projects that I never knew existed. I've seen articles I've written for [Opensource.com][8] published elsewhere, and things I've written in the bibliographies of thesis projects, white papers, and reference materials.
|
||||
|
||||
### Free culture is culture
|
||||
|
||||
"Free culture" is a redundant term that shouldn't be part of our vocabulary. Culture, conceptually, is an organic process. It's the way a society develops and grows, from one person to another. It's about the interactions and the ideas that people share. It's a unique product of the modern world that culture is not free by default.
|
||||
|
||||
If you want to combat that, and prefer to share your culture with your fellow human beings across the globe, support Creative Commons by contributing to it, using it, and supporting those who do.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/creative-commons-real-world
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:http://infestwisely.com
|
||||
[2]:https://vimeo.com/creativecommons
|
||||
[3]:https://peach.blender.org/
|
||||
[4]:https://durian.blender.org/
|
||||
[5]:http://freesound.org
|
||||
[6]:http://openclipart.org
|
||||
[7]:http://opengameart.org
|
||||
[8]:https://opensource.com/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by valoniakim
|
||||
|
||||
What NASA Has Been Doing About Open Science
|
||||
======
|
||||
![][1]
|
||||
|
||||
@ -1,82 +0,0 @@
|
||||
Translating by hopefully2333
|
||||
|
||||
A new approach to security instrumentation
|
||||
======
|
||||
|
||||

|
||||
|
||||
How many of us have ever uttered the following phrase: “I hope this works!”?
|
||||
|
||||
Without a doubt, most of us have, likely more than once. It’s not a phrase that inspires confidence, as it reveals doubts about our abilities or the functionality of whatever we are testing. Unfortunately, this very phrase defines our traditional security model all too well. We operate based on the assumption and the hope that the controls we put in place—from vulnerability scanning on web applications to anti-virus on endpoints—prevent malicious actors and software from entering our systems and damaging or stealing our information.
|
||||
|
||||
Penetration testing took a step to combat relying on assumptions by actively trying to break into the network, inject malicious code into a web application, or spread “malware” by sending out phishing emails. Composed of finding and poking holes in our different security layers, pen testing fails to account for situations in which holes are actively opened. In security experimentation, we intentionally create chaos in the form of controlled, simulated incident behavior to objectively instrument our ability to detect and deter these types of activities.
|
||||
|
||||
> “Security experimentation provides a methodology for the experimentation of the security of distributed systems to build confidence in the ability to withstand malicious conditions.”
|
||||
|
||||
When it comes to security and complex distributed systems, a common adage in the chaos engineering community reiterates that “hope is not an effective strategy.” How often do we proactively instrument what we have designed or built to determine if the controls are failing? Most organizations do not discover that their security controls are failing until a security incident results from that failure. We believe that “Security incidents are not detective measures” and “Hope is not an effective strategy” should be the mantras of IT professionals operating effective security practices.
|
||||
|
||||
The industry has traditionally emphasized preventative security measures and defense-in-depth, whereas our mission is to drive new knowledge and insights into the security toolchain through detective experimentation. With so much focus on the preventative mechanisms, we rarely attempt beyond one-time or annual pen testing requirements to validate whether or not those controls are performing as designed.
|
||||
|
||||
With all of these constantly changing, stateless variables in modern distributed systems, it becomes next to impossible for humans to adequately understand how their systems behave, as this can change from moment to moment. One way to approach this problem is through robust systematic instrumentation and monitoring. For instrumentation in security, you can break down the domain into two primary buckets: **testing** , and what we call **experimentation**. Testing is the validation or assessment of a previously known outcome. In plain terms, we know what we are looking for before we go looking for it. On the other hand, experimentation seeks to derive new insights and information that was previously unknown. While testing is an important practice for mature security teams, the following example should help further illuminate the differences between the two, as well as provide a more tangible depiction of the added value of experimentation.
|
||||
|
||||
### Example scenario: Craft beer delivery
|
||||
|
||||
Consider a simple web service or web application that takes orders for craft beer deliveries.
|
||||
|
||||
This is a critical service for this craft beer delivery company, whose orders come in from its customers' mobile devices, the web, and via its API from restaurants that serve its craft beer. This critical service runs in the company's AWS EC2 environment and is considered by the company to be secure. The company passed its PCI compliance with flying colors last year and annually performs third-party penetration tests, so it assumes that its systems are secure.
|
||||
|
||||
This company also prides itself on its DevOps and continuous delivery practices by deploying sometimes twice in the same day.
|
||||
|
||||
After learning about chaos engineering and security experimentation, the company's development teams want to determine, on a continuous basis, how resilient and effective its security systems are to real-world events, and furthermore, to ensure that they are not introducing new problems into the system that the security controls are not able to detect.
|
||||
|
||||
The team wants to start small by evaluating port security and firewall configurations for their ability to detect, block, and alert on misconfigured changes to the port configurations on their EC2 security groups.
|
||||
|
||||
* The team begins by performing a summary of their assumptions about the normal state.
|
||||
* Develops a hypothesis for port security in their EC2 instances
|
||||
* Selects and configures the YAML file for the Unauthorized Port Change experiment.
|
||||
* This configuration would designate the objects to randomly select from for targeting, as well as the port ranges and number of ports that should be changed.
|
||||
* The team also configures when to run the experiment and shrinks the scope of its blast radius to ensure minimal business impact.
|
||||
* For this first test, the team has chosen to run the experiment in their stage environments and run a single run of the test.
|
||||
* In true Game Day style, the team has elected a Master of Disaster to run the experiment during a predefined two-hour window. During that window of time, the Master of Disaster will execute the experiment on one of the EC2 Instance Security Groups.
|
||||
* Once the Game Day has finished, the team begins to conduct a thorough, blameless post-mortem exercise where the focus is on the results of the experiment against the steady state and the original hypothesis. The questions would be something similar to the following:
|
||||
|
||||
|
||||
|
||||
### Post-mortem questions
|
||||
|
||||
* Did the firewall detect the unauthorized port change?
|
||||
* If the change was detected, was it blocked?
|
||||
* Did the firewall report log useful information to the log aggregation tool?
|
||||
* Did the SIEM throw an alert on the unauthorized change?
|
||||
* If the firewall did not detect the change, did the configuration management tool discover the change?
|
||||
* Did the configuration management tool report good information to the log aggregation tool?
|
||||
* Did the SIEM finally correlate an alert?
|
||||
* If the SIEM threw an alert, did the Security Operations Center get the alert?
|
||||
* Was the SOC analyst who got the alert able to take action on the alert, or was necessary information missing?
|
||||
* If the SOC alert determined the alert to be credible, was Security Incident Response able to conduct triage activities easily from the data?
|
||||
|
||||
|
||||
|
||||
The acknowledgment and anticipation of failure in our systems have already begun unraveling our assumptions about how our systems work. Our mission is to take what we have learned and apply it more broadly to begin to truly address security weaknesses proactively, going beyond the reactive processes that currently dominate traditional security models.
|
||||
|
||||
As we continue to explore this new domain, we will be sure to post our findings. For those interested in learning more about the research or getting involved, please feel free to contact [Aaron Rinehart][1] or [Grayson Brewer][2].
|
||||
|
||||
Special thanks to Samuel Roden for the insights and thoughts provided in this article.
|
||||
|
||||
**[See our related story,[Is the term DevSecOps necessary?][3]]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/new-approach-security-instrumentation
|
||||
|
||||
作者:[Aaron Rinehart][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaronrinehart
|
||||
[1]:https://twitter.com/aaronrinehart
|
||||
[2]:https://twitter.com/BrewerSecurity
|
||||
[3]:https://opensource.com/article/18/4/devsecops
|
||||
@ -1,47 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (How a university network assistant used Linux in the 90s)
|
||||
[#]: via: (https://opensource.com/article/18/5/my-linux-story-student)
|
||||
[#]: author: ([Alan Formy-Duva](https://opensource.com/users/alanfdoss)
|
||||
[#]: url: ( )
|
||||
|
||||
How a university network assistant used Linux in the 90s
|
||||
======
|
||||

|
||||
In the mid-1990s, I was enrolled in computer science classes. My university’s computer science department provided a SunOS server—a multi-user, multitasking Unix system—for its students. We logged into it and wrote source code for the programming languages we were learning, such as C, C++, and ADA. In those days, well before social networks and instant messaging, we also used the system to communicate with each other, sending emails and using utilities such as `write` and `talk`. We were each also allowed to host a personal website. I enjoyed being able to complete my assignments and contact other users.
|
||||
|
||||
It was my first experience with this type of operating environment, but I soon learned about another operating system that could do the same thing: Linux.
|
||||
|
||||
While I was a student, I also worked part-time at the university. My first position was as a network installer in the Department of Housing and Residence (H&R). This involved connecting student dormitories to the campus network. As this was the university's first dormitory network service, only two buildings and about 75 students had been connected.
|
||||
|
||||
In my second year, the network expanded to cover an additional two buildings. H&R decided to let the university’s Office of Information Technology (OIT) manage this growing operation. I transferred to OIT and started the position of Student Assistant to the OIT Network Manager. That is how I discovered Linux. One of my new responsibilities was to manage the firewall systems that provided network and internet access to the dormitories.
|
||||
|
||||
Each student was registered with their hardware MAC address. Registered students could connect to the dorm network and receive an IP address and a route to the internet. Unlike the other expensive SunOS and VMS servers used by the university, these firewalls used low-cost computers running the free and open source Linux operating system. By the end of the year, the system had registered nearly 500 students.
|
||||
|
||||
![Red hat Linux install disks][1]
|
||||
|
||||
The OIT network staff members were using Linux for HTTP, FTP, and other services. They also used Linux on their personal desktops. That's when I realized I had my hands on a computer system that looked and acted just like the expensive SunOS box in the CS department but without the high cost. Linux could run on commodity x86 hardware, such as a Dell Latitude with 8 MB of RAM and a 133Mhz Intel Pentium CPU. That was the selling point for me! I installed Red Hat Linux 5.2 on a box scavenged from the surplus warehouse and gave my friends login accounts.
|
||||
|
||||
While I used my new Linux server to host my website and provide accounts to my friends, it also offered graphics capabilities over the CS department server. Using the X Windows system, I could browse the web with Netscape Navigator, play music with [XMMS][2], and try out different window managers. I could also download and compile other open source software and write my own code.
|
||||
|
||||
I learned that Linux offered some pretty advanced features, many of which were more convenient than or superior to more mainstream operating systems. For example, many operating systems did not yet offer simple ways to apply updates. In Linux, this was easy, thanks to [autoRPM][3], an update manager written by Kirk Bauer, which sent the root user a daily email with available updates. It had an intuitive interface for reviewing and selecting software updates to install—pretty amazing for the mid-'90s.
|
||||
|
||||
Linux may not have been well-known back then, and it was often received with skepticism, but I was convinced it would survive. And survive it did!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/my-linux-story-student
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alanfdoss
|
||||
[1]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/red_hat_linux_install_disks.png?itok=VSw6Cke9 (Red hat Linux install disks)
|
||||
[2]:http://www.xmms.org/
|
||||
[3]:http://www.ccp14.ac.uk/solution/linux/autorpm_redhat7_3.html
|
||||
@ -1,49 +0,0 @@
|
||||
hkurj translating
|
||||
Why schools of the future are open
|
||||
======
|
||||
|
||||

|
||||
|
||||
Someone recently asked me what education will look like in the modern era. My response: Much like it has for the last 100 years. How's that for a pessimistic view of our education system?
|
||||
|
||||
It's not a pessimistic view as much as it is a pragmatic one. Anyone who spends time in schools could walk away feeling similarly, given that the ways we teach young people are stubbornly resistant to change. As schools in the United States begin a new year, most students are returning to classrooms where desks are lined-up in rows, the instructional environment is primarily teacher-centred, progress is measured by Carnegie units and A-F grading, and collaboration is often considered cheating.
|
||||
|
||||
Were we able to point to evidence that this industrialized model was producing the kind of results that are required, where every child is given the personal attention needed to grow a love of learning and develop the skills needed to thrive in today's innovation economy, then we could very well be satisfied with the status quo. But any honest and objective look at current metrics speaks to the need for fundamental change.
|
||||
|
||||
But my view isn't a pessimistic one. In fact, it's quite optimistic.
|
||||
|
||||
For as easy as it is to dwell on what's wrong with our current education model, I also know of example after example of where education stakeholders are willing to step out of what's comfortable and challenge this system that is so immune to change. Teachers are demanding more collaboration with peers and more ways to be open and transparent about prototyping ideas that lead to true innovation for students—not just repackaging of traditional methods with technology. Administrators are enabling deeper, more connected learning to real-world applications through community-focused, project-based learning—not just jumping through hoops of "doing projects" in isolated classrooms. And parents are demanding that the joy and wonder of learning return to the culture of their schools that have been corrupted by an emphasis on test prep.
|
||||
|
||||
These and other types of cultural changes are never easy, especially in an environment so reluctant to take risks in the face of political backlash from any dip in test scores (regardless of statistical significance). So why am I optimistic that we are approaching a tipping point where the type of changes we desperately need can indeed overcome the inertia that has thwarted them for too long?
|
||||
|
||||
Because there is something else in water at this point in our modern era that was not present before: an ethos of openness, catalyzed by digital technology.
|
||||
|
||||
Think for a moment: If you need to learn how to speak basic French for an upcoming trip to France, where do you turn? You could sign up for a course at a local community college or check out a book from the library, but in all likelihood, you'll access a free online video and learn the basics you will need for your trip. Never before in human history has free, on-demand learning been so accessible. In fact, one can sign up right now for a free, online course from MIT on "[Special Topics in Mathematics with Applications: Linear Algebra and the Calculus of Variations][1]." Sign me up!
|
||||
|
||||
Why do schools such as MIT, Stanford, and Harvard offer free access to their courses? Why are people and corporations willing to openly share what was once tightly controlled intellectual property? Why are people all over the planet willing to invest their time—for no pay—to help with citizen science projects?
|
||||
|
||||
There is something else in water at this point in our modern era that was not present before: an ethos of openness, catalyzed by digital technology.
|
||||
|
||||
In his wonderful book [Open: How We'll Work Live and Learn in the Future][2], author David Price clearly describes how informal, social learning is becoming the new norm of learning, especially among young people accustomed to being able to get the "just in time" knowledge they need. Through a series of case studies, Price paints a clear picture of what happens when traditional institutions don't adapt to this new reality and thus become less and less relevant. That's the missing ingredient that has the crowdsourced power of creating positive disruption.
|
||||
|
||||
What Price points out (and what people are now demanding at a grassroots level) is nothing short of an open movement, one recognizing that open collaboration and free exchange of ideas have already disrupted ecosystems from music to software to publishing. And more than any top-down driven "reform," this expectation for openness has the potential to fundamentally alter an educational system that has resisted change for too long. In fact, one of the hallmarks of the open ethos is that it expects the transparent and fair democratization of knowledge for the benefit of all. So what better ecosystem for such an ethos to thrive than within the one that seeks to prepare young people to inherit the world and make it better?
|
||||
|
||||
Sure, the pessimist in me says that my earlier prediction about the future of education may indeed be the state of education in the short term future. But I am also very optimistic that this prediction will be proven to be dead wrong. I know that I and many other kindred-spirit educators are working every day to ensure that it's wrong. Won't you join me as we start a movement to help our schools [transform into open organizations][3]—to transition from from an outdated, legacy model to one that is more open, nimble, and responsive to the needs of every student and the communities in which they serve?
|
||||
|
||||
That's a true education model appropriate for the modern era.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/9/modern-education-open-education
|
||||
|
||||
作者:[Ben Owens][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/engineerteacher
|
||||
[1]: https://ocw.mit.edu/courses/mechanical-engineering/2-035-special-topics-in-mathematics-with-applications-linear-algebra-and-the-calculus-of-variations-spring-2007/
|
||||
[2]: https://www.goodreads.com/book/show/18730272-open
|
||||
[3]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
@ -1,59 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
A Free Guide for Setting Your Open Source Strategy
|
||||
======
|
||||
|
||||

|
||||
|
||||
The majority of companies using open source understand its business value, but they may lack the tools to strategically implement an open source program and reap the full rewards. According to a recent survey from [The New Stack][1], “the top three benefits of open source programs are 1) increased awareness of open source, 2) more speed and agility in the development cycle, and 3) better license compliance.”
|
||||
|
||||
Running an open source program office involves creating a strategy to help you define and implement your approach as well as measure your progress. The [Open Source Guides to the Enterprise][2], developed by The Linux Foundation in partnership with the TODO Group, offer open source expertise based on years of experience and practice.
|
||||
|
||||
The most recent guide, [Setting an Open Source Strategy][3], details the essential steps in creating a strategy and setting you on the path to success. According to the guide, “your open source strategy connects the plans for managing, participating in, and creating open source software with the business objectives that the plans serve. This can open up many opportunities and catalyze innovation.” The guide covers the following topics:
|
||||
|
||||
1. Why create a strategy?
|
||||
2. Your strategy document
|
||||
3. Approaches to strategy
|
||||
4. Key considerations
|
||||
5. Other components
|
||||
6. Determine ROI
|
||||
7. Where to invest
|
||||
|
||||
|
||||
|
||||
The critical first step here is creating and documenting your open source strategy, which will “help you maximize the benefits your organization gets from open source.” At the same time, your detailed strategy can help you avoid difficulties that may arise from mistakes such as choosing the wrong license or improperly maintaining code. According to the guide, this document can also:
|
||||
|
||||
* Get leaders excited and involved
|
||||
* Help obtain buy-in within the company
|
||||
* Facilitate decision-making in diffuse, multi-departmental organizations
|
||||
* Help build a healthy community
|
||||
* Explain your company’s approach to open source and support of its use
|
||||
* Clarify where your company invests in community-driven, external R&D and where your company will focus on its value added differentiation
|
||||
|
||||
|
||||
|
||||
“At Salesforce, we have internal documents that we circulate to our engineering team, providing strategic guidance and encouragement around open source. These encourage the creation and use of open source, letting them know in no uncertain terms that the strategic leaders at the company are fully behind it. Additionally, if there are certain kinds of licenses we don’t want engineers using, or other open source guidelines for them, our internal documents need to be explicit,” said Ian Varley, Software Architect at Salesforce and contributor to the guide.
|
||||
|
||||
Open source programs help promote an enterprise culture that can make companies more productive, and, according to the guide, a strong strategy document can “help your team understand the business objectives behind your open source program, ensure better decision-making, and minimize risks.”
|
||||
|
||||
Learn how to align your goals for managing and creating open source software with your organization’s business objectives using the tips and proven practices in the new guide to [Setting an Open Source Strategy][3]. And, check out all 12 [Open Source Guides for the Enterprise][2] for more information on achieving success with open source.
|
||||
|
||||
This article originally appeared on [The Linux Foundation][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/11/free-guide-setting-your-open-source-strategy
|
||||
|
||||
作者:[Amber Ankerholz][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/aankerholz
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://thenewstack.io/open-source-culture-starts-with-programs-and-policies/
|
||||
[2]: https://www.linuxfoundation.org/resources/open-source-guides/
|
||||
[3]: https://www.linuxfoundation.org/resources/open-source-guides/setting-an-open-source-strategy/
|
||||
[4]: https://www.linuxfoundation.org/blog/2018/11/a-free-guide-for-setting-your-open-source-strategy/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (10 ways to give thanks to open source and free software maintainers)
|
||||
|
||||
108
sources/talk/20181129 9 top tech-recruiting mistakes to avoid.md
Normal file
108
sources/talk/20181129 9 top tech-recruiting mistakes to avoid.md
Normal file
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (9 top tech-recruiting mistakes to avoid)
|
||||
[#]: via: (https://opensource.com/article/18/11/top-tech-recruiting-mistakes-avoid)
|
||||
[#]: author: (Rikki Endsley https://opensource.com/users/rikki-endsley)
|
||||
[#]: url: ( )
|
||||
|
||||
9 top tech-recruiting mistakes to avoid
|
||||
======
|
||||
We round up common mistakes tech recruiters make and a few best practices to adopt instead.
|
||||

|
||||
|
||||
Some of my best friends and colleagues are tech recruiters, and a bunch of my favorite humans are on the job hunt. With these fine folks in mind, I decided to help them connect by finding out what kinds of recruiting efforts stand out to potential hires. I reached out to my colleagues and contacts and asked them what they like (and hate) when it comes to recruiting, then I rounded up a list of top tech-recruiting mistakes to avoid and best practices to use instead.
|
||||
|
||||
### 9 common tech recruiting mistakes to avoid
|
||||
|
||||
Don’t even think about reaching out to a potential candidate without doing due diligence on their background, experience, and expertise. Not knowing what skills a recruit has and what kind of work they’ve done in the past instantly turns off job seekers. Recruiters who make it clear that they’ve done their homework signal that they aren’t planning to waste a candidate’s time and stand a better chance of piquing their interest from the beginning. Common recruiting mistakes also include:
|
||||
|
||||
**1\. Sending form letters — or even worse, broken form letters.**
|
||||
|
||||
Unless someone is job-seeking and not getting many offers, chances are your form letter won’t stand out or get much interest. And if your form letter is broken and has [NAME] where a candidate’s name should appear, forget about getting any qualified candidate responses.
|
||||
|
||||
**2\. Blowing the salutation.**
|
||||
|
||||
Be sure to spell the candidate’s name correctly, and typing “Mr.” or “Miss” in the greeting could be a big mistake. For example, I can’t tell you how many “Mr. Endsley” messages I get every month, and “Miss Endsley” won’t sit well with me, either.
|
||||
|
||||
**3\. Not understanding what the recruit does.**
|
||||
|
||||
Potential candidates can tell whether you’ve done your homework, dug through their LinkedIn profiles, and have a grasp of their backgrounds, experiences, and areas of interest. Reaching out to a UX designer about an engineering role won’t get you good results.
|
||||
|
||||
**4\. Sending unsolicited contact requests.**
|
||||
|
||||
Don’t send LinkedIn connection requests to people you don’t know. Just don’t do it.
|
||||
|
||||
**5\. Being too general about the job position.**
|
||||
|
||||
Kill the coy. Share as many details you can about the role, including any must-have and nice-to-have skills. Draw potential recruits a picture of what the work looks like to make qualified candidates take notice.
|
||||
|
||||
**6\. Being too vague or mysterious about the team and company.**
|
||||
|
||||
Tech professionals with in-demand skills and experience are being more selective about what kind of team dynamics they walk into and [organizational ethics][1]. Letting potential hires know right away what the team looks like (e.g., small vs. large, remote vs. on-site) and which company you represent can save everyone a lot of time.
|
||||
|
||||
**7\. Having unrealistic or overly specific requirements.**
|
||||
|
||||
Does the right candidate really need to be an expert in every technology and programming language and hold multiple degrees? Be clear about what skills a candidate needs vs. what skills might come in handy or can be acquired on the job.
|
||||
|
||||
**8\. Getting too cutesy or culture-y in a description.**
|
||||
|
||||
Not all of us consider office puppies, free booze, and ping pong to be job perks. If this is the messaging you lead with, you’re going to attract a pretty specific kind of applicant and quickly narrow down your list of potential candidates.
|
||||
|
||||
Also [avoid terms][2] like “guys,” “rock star,” and “recent graduate,” which can translate to “women, minorities, and anyone over 25 need not apply.” Ouch.
|
||||
|
||||
**9\. Asking for referrals to other potential candidates.**
|
||||
|
||||
This is a no-win for recruiters. For example, I’m happy to recommend job seekers in my network for roles, but lots of other folks working in tech see this as lazy recruiting. The safest approach might be to ask a candidate later in the process, after you’ve developed a friendly working relationship and you've both agreed that this role doesn’t quite fit their interests or expertise. Then they might have other contacts in mind for it.
|
||||
|
||||
### 6 best practices for tech recruiters
|
||||
|
||||
**1\. Provide a sincere and personalized greeting.**
|
||||
|
||||
A personalized greeting goes a long way. Let potential candidates know you understand their previous work experience, you’re familiar with what they do, and that you have an idea of what they want to be doing.
|
||||
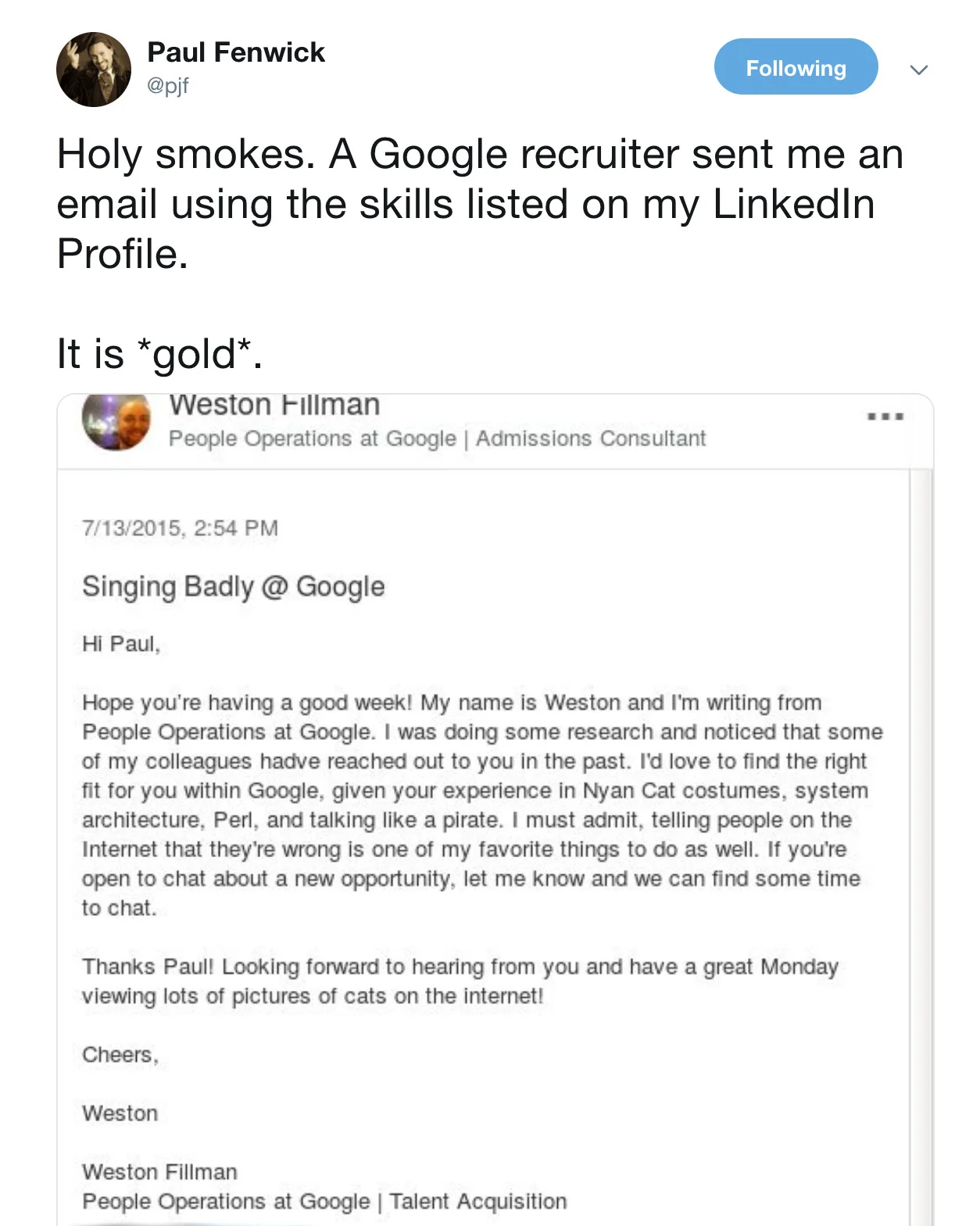
|
||||
|
||||
**2\. Offer a transparent description of the team and the role.**
|
||||
|
||||
Be as clear as you can when describing the team and the role. Using words like “rock star” or “fast-paced team” does nothing to help the potential candidate visualize what they’d be walking into. Is this a small team? Remote team?
|
||||
|
||||
Being mysterious about the role won’t build intrigue, so opt for transparency.
|
||||
|
||||
**3\. Give the company name.**
|
||||
|
||||
Telling job candidates that the organization is a startup or a Fortune 500 company also won’t work as well being transparent about the organization from the beginning. How can anyone know whether they’re interested in a role if they don’t know which organization they’d be joining?
|
||||
|
||||
**4\. Be persistent and specific.**
|
||||
|
||||
In addition to providing the job description and company name, specifying the salary range and why you think the potential candidate is a good fit for the role stands out. Also consider specifying the work authorization and whether the organization provides visa sponsorships, relocation, and additional benefits beyond an hourly or annual salary. If you have a good feeling about a candidate who might not be a 100% technical fit with the job posting, let them know and open those lines of communication.
|
||||
|
||||
**5\. Invite potential candidates to local recruiting events.**
|
||||
|
||||
The event should provide brief presentations about the company, refreshments, and a networking opportunity. Here’s your chance to show off the culture (i.e., people) part of your organization in person.
|
||||
|
||||
**6\. Maintain a relationship with potential recruits.**
|
||||
|
||||
If you talk to a candidate who isn’t the right fit for a role, but who would be a great addition to your organization, keep the lines of communication open. If candidates have a good experience with a recruiter, they’ll also be more inclined to join the organization later or send other job seekers their way in the future.
|
||||
|
||||
### Bonus advice for tech recruits
|
||||
|
||||
Keep in mind that recruiters, like you, are just trying to do their jobs. If you're tired of hearing from recruiters and annoyed when they contact you, step back and get a little perspective. Although you might be in the fortunate spot of being happily employed and in-demand, not everyone else is. Grumbling about recruiters on social media is a great way to humble brag, but not the best way to show empathy for the job-seekers or win any friends.
|
||||
|
||||
_Thank you to the many people who contributed to this article! What would you add to these lists? Let us know in the comments._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/top-tech-recruiting-mistakes-avoid
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rikki-endsley
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://spectrum.ieee.org/view-from-the-valley/at-work/tech-careers/engineers-say-no-thanks-to-silicon-valley-recruiters-citing-ethical-concerns
|
||||
[2]: https://www.theladders.com/career-advice/job-descriptions-driving-away-women
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Why giving back is important to the DevOps culture)
|
||||
[#]: via: (https://opensource.com/article/18/11/why-sharing-important-devops-culture)
|
||||
[#]: author: (Matty Stratton https://opensource.com/users/mattstratton)
|
||||
[#]: url: ( )
|
||||
|
||||
Why giving back is important to the DevOps culture
|
||||
======
|
||||
Our habit of not sharing knowledge is doing us harm.
|
||||

|
||||
In the DevOps [CALMS][1] model (which stands for Culture, Automation, Lean, Measurement, and Sharing), Sharing is often overlooked or misunderstood. While each element of CALMS is just as important as the others, sharing knowledge is something that we often neglect.
|
||||
|
||||
### What happens if we don't share?
|
||||
|
||||
[Jeff Smith][2], director of production operations at [Centro][3], tells this story:
|
||||
|
||||
> A change to the level of granularity that gets stored in one of our reporting tables was made. The change increased the disk space usage on the database instance by 8x. Not only did this cause our existing database instance to rapidly fill up, but it also made operations question if the design pattern made sense. Because they weren't included in such an impactful change, all of the design decisions that went into the new process architecture were viewed as suspect and underwent a constant re-examination from ops. In a nutshell, a little bit of faith and trust was lost.
|
||||
|
||||
The damage caused by eroding faith can't be understated. Collaboration is based on trust. Every time this trust is chipped away, energy is spent on questioning the validity of decisions made by others.
|
||||
|
||||
### What are the benefits of sharing?
|
||||
|
||||
Today's systems are incredibly complex. The days when one person could hold an entire infrastructure and system interdependencies in their head are long gone. Communicating across boundaries of expertise makes our entire organization more robust and resilient.
|
||||
|
||||
Sharing isn't just about the technical data or access, though. "Inter-team communication should always start with the goal, not with one team's proposed solution to a problem," Jeff says. "When you start with a solution, the conversation veers in the wrong direction."
|
||||
|
||||
[Emily Freeman][4], CloudOps advocate at [Microsoft][5] says "Collaboration is impossible without sharing information." She points out that having a "mental map" of the skills and knowledge of other teams "enables people to ask questions more efficiently and reduces the fear they're asking too many questions or look stupid."
|
||||
|
||||
### How can we share better?
|
||||
|
||||
"Sharing doesn't have to be a drum circle every Tuesday at 10:30am," Emily says. "It's openness and authenticity. It's removing the shadows from your organization and ensuring everyone is honest and forthright and accountable."
|
||||
|
||||
At a minimum, there should be read-only access to logs, code, and after-incident reports for everyone. Before you cry "separation of concerns," please consider that the data that cannot be shared with everyone in the organization is a much smaller set than we usually think it is. It might require some additional effort to scrub and protect this small subset than to default to "nobody can see anything but their small part of it," but the benefits outweigh the effort.
|
||||
|
||||
"If anyone's excluded, they aren't part of your team, no matter what the org chart says," Emily reminds us.
|
||||
|
||||
It's more than the logs and the tooling, though. "The 'S' is often just seen as knowledge sharing, training, etc.," Jeff says. "But if it doesn't include the sharing of responsibility and ownership, it can be difficult to get your organization to that next level of productivity."
|
||||
|
||||
### Why don't we share?
|
||||
|
||||
There are many reasons that sharing information and knowledge isn't the default position for knowledge workers, but both Emily and Jeff agree it usually comes down to fear.
|
||||
|
||||
"Teams may feel that only their circle is capable of performing a particular task with the zeal and delicacy it deserves," Jeff says. "So information gets siloed, access gets restricted, and gates get constructed. But that diminishes our responsibility to build safe systems, instead leaning on 'operator expertise' as a crutch."
|
||||
|
||||
Emily agrees. "DevOps cultures never look to change the past," she says. "Instead, the companies that thrive at embracing the DevOps philosophy are realistic about where they are and work toward continuously improving their process so everyone on the team can thrive."
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/why-sharing-important-devops-culture
|
||||
|
||||
作者:[Matty Stratton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mattstratton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://whatis.techtarget.com/definition/CALMS
|
||||
[2]: https://twitter.com/DarkAndNerdy
|
||||
[3]: https://www.centro.net/
|
||||
[4]: https://twitter.com/editingemily
|
||||
[5]: http://dev.azure.com/
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (3 emerging tipping points in open source)
|
||||
[#]: via: (https://opensource.com/article/18/11/3-new-tipping-points-open-source)
|
||||
[#]: author: (Bilgin lbryam https://opensource.com/users/bibryam)
|
||||
[#]: url: ( )
|
||||
|
||||
3 emerging tipping points in open source
|
||||
======
|
||||
Understand the factors advancing the open source model's evolution.
|
||||

|
||||
|
||||
Over the last two decades, open source has been expanding into all aspects of technology—from software to [hardware][1]; from small, disruptive startups to large, boring enterprises; from open standards to open [patents][2].
|
||||
|
||||
As movements evolve, they reach tipping points—stages that move the model in new directions. Following are three things that I believe are now reaching a tipping point in open source.
|
||||
|
||||
### Open for non-coders
|
||||
|
||||
As the name suggests, the open source model has mainly been focused on the source code. On the surface, that's probably because open source communities are usually made up of developers working on the source code, and the tools used in open source projects, such as source control systems, issue trackers, mailing list names, chat channel names, etc., all assume that developers are the center of the universe.
|
||||
|
||||
This has created big losses because it prevents creative people, designers, document writers, event organizers, community managers, lawyers, accountants, and many others from participating in open source communities. We need and want non-code contributors, but we don't have processes and tools to include them, means to measure their value, nor ways for their peers, the community, or their employers to reward their efforts. As a result, it has been a lose-lose for decades. We can see the implications in all the ugly websites, amateur logos, badly written and formatted documentation, disorganized events, etc., in open source projects.
|
||||
|
||||
The good news is that we are getting signals that change is on the way:
|
||||
|
||||
* [Linus Torvalds apologized][3] for his "bad behavior." While this wasn't specifically focused on non-coders, it symbolizes making open source a non-hostile place for less-technical contributors.
|
||||
* The Cloud Native Computing Foundation (CNCF) introduced the [Non-Code Contributor's Guide][4]. In addition to showing the many ways people can contribute to open source projects, it also set a baseline for non-code contributions that other open source projects and foundations will end up following.
|
||||
* The Apache Software Foundation (ASF) is working in the same direction. We've been holding long discussions, and we will have some concrete output very soon (note that is "ASF soon").
|
||||
|
||||
|
||||
|
||||
There is a little-known secret that is great news for non-coders and others new to open source: One of the easiest ways to be recognized as part of an established open source project is to do non-coding activities. Nowadays, with complex software stacks and tough competition, there is a pretty high bar for entering a project as a committer. Performing non-coding activities is less popular, and it opens a fast backdoor to open source communities.
|
||||
|
||||
|
||||
|
||||
### Macro acquisitions
|
||||
|
||||
Open source may have started in the hacker community as a way of scratching developers' personal itches, but today it is the place where innovation happens. Even the world's largest software companies are transitioning to the model to continue dominating their market.
|
||||
|
||||
Here are some good reasons enterprises have become so interested in contributing to open source:
|
||||
|
||||
* It multiplies the company's investments through contributions.
|
||||
* They can benefit from the most recent technology advances and avoid reinventing the wheel.
|
||||
* It helps spread knowledge of their software and its broader adoption.
|
||||
* It increases the developer base and hiring pool.
|
||||
* Internal developers' skills grow by learning from top coders in the field.
|
||||
* It builds a company's reputation—developers want to work for organizations they can boast about.
|
||||
* It aids recruitment and retention—developers want to work on exciting projects that affect large groups of people.
|
||||
* New companies and projects can start faster through the open source networking effect.
|
||||
|
||||
|
||||
|
||||
Many enterprises are trying to shortcut the process by acquiring open source companies—which leads to even more open source adoption. Building an open source company takes many years of effort done out in the open. Hiring good developers who are willing to work in the open, building a community around a project, and creating a successful business model require delicate effort. Companies that manage to do this are very attractive for investment and acquisition, as they serve as a catalyst to turn the acquirer into an open source company at scale. The number of [successful open source companies][5] that is acquired seems to get bigger every day, and this trend is only getting stronger.
|
||||
|
||||
### Micro-funding of open source software
|
||||
|
||||
In addition to macro investments through acquisitions of open source companies, there has also been an increase in decentralized [micro-funding of self-sustaining][6] open source projects.
|
||||
|
||||
On one end of the spectrum, there are open source projects that are maintained primarily by intrinsically motivated developers. On the other end, large companies are hiring developers to work on open source projects driven by company roadmaps and strategies. That leaves a large number of open source projects that are not exciting enough for accidental contributors nor on enterprise companies' radar.
|
||||
|
||||
In recent years, there has been an increase in [platforms for funding and sustaining][7] these open source projects through bug bounties, micro-payments, recurring donations, one-time contributions, subscriptions, etc. These open source funding platforms allow individuals to take responsibility for open source sustainability in their own hands by paying maintainers directly. This enables people to contribute to the open source model through value transfer rather than code contributions.
|
||||
|
||||
There are three basic channels for open source contributions:
|
||||
|
||||
* Hobbyists contribute to open source projects because of intrinsic motivations rather than monetary value.
|
||||
* Companies with open source business models (open core, SaaS, support, services, etc.) monetize open source projects directly with regular, planned, and centralized subsidization.
|
||||
* Independent open source users provide irregular, micro, decentralized subsidization through [OSS funding][7] platforms.
|
||||
|
||||
|
||||
|
||||
While hobbyists and hackers started the open source movement, it's turned into an enterprise monetization model. Having a model to sustain the remaining open source projects is welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/3-new-tipping-points-open-source
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bibryam
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/resources/what-open-hardware
|
||||
[2]: https://www.redhat.com/en/blog/red-hat-welcomes-milestone-addition-open-invention-network-microsoft-joins-safeguard-linux-patent-attacks
|
||||
[3]: https://lkml.org/lkml/2018/9/16/167
|
||||
[4]: https://kubernetes.io/blog/2018/10/04/introducing-the-non-code-contributors-guide/
|
||||
[5]: http://oss.cash/
|
||||
[6]: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
[7]: http://oss.fund/
|
||||
60
sources/talk/20181204 3 implications of serverless.md
Normal file
60
sources/talk/20181204 3 implications of serverless.md
Normal file
@ -0,0 +1,60 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (3 implications of serverless)
|
||||
[#]: via: (https://opensource.com/article/18/12/serverless-podcast-command-line-heros)
|
||||
[#]: author: (Jen Wike Huger https://opensource.com/users/remyd)
|
||||
[#]: url: ( )
|
||||
|
||||
3 implications of serverless
|
||||
======
|
||||
Plus, when to go serverless and when to not?
|
||||

|
||||
|
||||
If you strip away all of the modern conveniences and features that make up your internet experience today, what you're left with is the client-server model. This distributed network was what the internet was built on in the beginning, and that part hasn't changed. You could say, it is still serving us well.
|
||||
|
||||
So, when people talk about serverless, what does it mean? Well, it doesn't mean servers are GONE. Of course not: That "client-server model" is still the backbone of how things are getting done.
|
||||
|
||||
Serverless refers to a developer's ability to code, deploy, and create applications without having to know how to do the rest of it, like rack the servers, patch the operating system, and create container images.
|
||||
|
||||
### Top 3 implications of serverless
|
||||
|
||||
1. People who might not have been before are becoming developers now. Why? They have to learn less of that kind of stuff and get to do more of the creative stuff.
|
||||
2. Developers don't have the recreate the wheel. Why? They let serverless providers do what they do best: run and maintain the servers, patch the operating systems, and build containers.
|
||||
3. Reality check: Someone on your team still has to think about the big picture, about operations. Why? Because when your server crashes or any decision at all needs to be made about the server-side of your project or product, your phone will ring and someone has to pick up. Preferably someone who knows the gameplan, your strategy for going serverless.
|
||||
|
||||
|
||||
|
||||
### When to serverless and when to not?
|
||||
|
||||
So, serverless is great, right? But, the truth is it isn't always the right call. What are the factors that should be considered?
|
||||
|
||||
1. Cost
|
||||
2. Scale
|
||||
3. Time
|
||||
4. Control
|
||||
|
||||
|
||||
|
||||
The last one, control, is where things get interesting. Projects like [Apache OpenWhisk][1] have developed processes and tools to make it possible for you, as a developer, to operate and control your serverless computing environments.
|
||||
|
||||
### Why open source serverless?
|
||||
|
||||
For more on this, check out conversations with leading serverless thinkers and host Saron Yitbarek in [Episode 7 of Command Line Heroes podcast][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/serverless-podcast-command-line-heros
|
||||
|
||||
作者:[Jen Wike Huger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/remyd
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/11/developing-functions-service-apache-openwhisk
|
||||
[2]: https://www.redhat.com/en/command-line-heroes
|
||||
@ -1,464 +0,0 @@
|
||||
ScarboroughCoral translating!
|
||||
|
||||
|
||||
30 Best Sources For Linux / *BSD / Unix Documentation On the Web
|
||||
======
|
||||
|
||||
|
||||
|
||||
Man pages are written by sys-admin and developers for IT techs, and are intended more as a reference than as a how to. Man pages are very useful for people who are already familiar with Linux, Unix, and BSD operating systems. Use man pages when you just need to know the syntax for particular commands or configuration file, but they are not helpful for new Linux users. Man pages are not good for learning something new for the first time. Here are thirty best documentation sites on the web for learning Linux and Unix like operating systems.
|
||||
|
||||
![Dennis Ritchie and Ken Thompson working with UNIX PDP11][1]
|
||||
|
||||
Please note that BSD manpages are usually better as compare to Linux.
|
||||
|
||||
## #1: Red Hat Enterprise Linux
|
||||
|
||||
![Red hat Enterprise Linux Docs][2]
|
||||
|
||||
RHEL is developed by Red Hat and targeted toward the commercial market. It has one of the best documentations covering basis of RHEL to advanced topics like security, SELinux, virtualization, directory server, clustering, JBOSS, HPC, and much more. Red Hat documentation has been translated into twenty-two languages and is available in multi-page HTML, single-page HTML, PDF, and EPUB formats. The good news is you can use the same documentation for CentOS or Scientific Linux (community enterprise distros). All of these documents ship with the OS, so if you don't have a network connection, then you have them there as well. The RHEL docs **covers everything from installation to configuring clusters**. The only downside is you need to be a paid customer. This is perfect for an enterprise company.
|
||||
|
||||
1. RHEL Documentation: [in HTML/PDF format][3]
|
||||
2. Support forums: Only available to Red Hat customer portal to submit a support case.
|
||||
|
||||
|
||||
|
||||
### A Note About CentOS Wiki and Forums
|
||||
|
||||
![Centos Linux Wiki][4]
|
||||
|
||||
CentOS (Community ENTerprise Operating System) is a free rebuild of source packages freely available from a RHEL. It provides truly reliable, free enterprise Linux for personal and other usage. You will get RHEL stability without the cost of certification and support. CentOS wiki divided into Howtos, Tips & Tricks, and much more at the following locations:
|
||||
|
||||
1. [Documentation Wiki][87]
|
||||
2. [Support forum][88]
|
||||
|
||||
## #2: Arch Wiki and Forums
|
||||
|
||||
![Arch Linux wiki and tutorials][5]
|
||||
|
||||
Arch Linux is an independently developed, Linux operating system and it comes with pretty good documentation in form of wiki based site. It is developed collaboratively by a community of Arch users, allowing any user to add and edit content. The articles are divided into various categories like [networking][6], optimization, package management, system administration, X window system, and getting & installing Arch Linux. The official [forums][7] are useful for solving many issues. It has total 40k+ registered users with over 1 million posts. The wiki contains some **general information that can also apply in other Linux distros**.
|
||||
|
||||
1. Arch community Documentation: [Wiki format][8]
|
||||
2. Support forums: [Yes][7]
|
||||
|
||||
|
||||
|
||||
## #3: Gentoo Linux Wiki and Forums
|
||||
|
||||
![Gentoo Linux Handbook and Wiki][9]
|
||||
|
||||
Gentoo Linux is based on the Portage package management system. The Gentoo user compiles the source code locally according to their chosen configuration. The majority of users have configurations and sets of installed programs which are unique to themselves. The Gentoo give you some explanation about the Gentoo Linux and answer most of your questions regarding installations, packages, networking, and much more. Gentoo has **very helpful forum** with over one hundred thirty-four thousand plus users who have posted a total of 5442416 articles.
|
||||
|
||||
1. Gentoo community documentation: [Handbook][10] and [Wiki format][11]
|
||||
2. Support forums: [Yes][12]
|
||||
3. User-supplied documentation available at [gentoo-wiki.com][13]
|
||||
|
||||
|
||||
|
||||
## #4: Ubuntu Wiki and Documentation
|
||||
|
||||
Ubuntu is one of the leading desktop and laptop distro. The official documentation developed and maintained by the Ubuntu Documentation Project. You can access a wealth of information including a getting started Guide. The best part is information contained herein may also work with other Debian-based systems. You will also find the community documentation for Ubuntu created by its users. This is a reference for Ubuntu-related 'Howtos, Tips, Tricks, and Hacks'. Ubuntu Linux has one of the biggest Linux communities on the web. It offers help to the both new and experienced users.
|
||||
|
||||
![Ubuntu Linux Wiki and Forums][14]
|
||||
|
||||
1. Ubuntu community documentation: [wiki format][15].
|
||||
2. Ubuntu official documentation: [wiki format][16].
|
||||
3. Support forums: [Yes][17].
|
||||
|
||||
|
||||
|
||||
## #5: IBM Developer Works
|
||||
|
||||
IBM developer works offers technical resources for Linux programmers and system administrators. It contains hundreds of articles, tutorials, and tips to help developers with Linux programming and application development, as well as Linux system administration.
|
||||
|
||||
![IBM: Technical for Linux programmers and system administrators][18]
|
||||
|
||||
1. IBM Developer Works Documentation: [HTML format][19]
|
||||
2. Support forums: [Yes][20].
|
||||
|
||||
|
||||
|
||||
## #6: FreeBSD Documentation and Handbook
|
||||
|
||||
The FreeBSD handbook is created by the FreeBSD Documentation Project. It describes the installation, administration and day-to-day use of the FreeBSD OS. BSD manpages are usually better as compare to GNU/Linux man pages. The FreeBSD **comes with all the documents** with upto date man pages. The FreeBSD Handbook **covers everything**. The handbook contains some general Unix information that can also apply in other Linux distros. The official FreeBSD forums also provides helps whenever you will get stuck with problems.
|
||||
|
||||
![Freebsd Documentation][21]
|
||||
|
||||
1. FreeBSD Documentation: [HTML/PDF format][90]
|
||||
2. Support forums: [Yes][91].
|
||||
|
||||
|
||||
## #7: Bash Hackers Wiki
|
||||
|
||||
![Bash hackers wiki for bash users][22]
|
||||
This is an excellent resource for bash user. The bash hackers wiki is intended to hold documentations of any kind about the GNU Bash. The main motivation was to provide human-readable documentation and information to not force users to read every bit of the Bash manpage - which is hard sometimes. The wiki is divided into various sections such as - scripting and general information, howtos, coding style, bash syntax, and much more.
|
||||
|
||||
1. Bash hackers [wiki][23] in wiki format
|
||||
|
||||
|
||||
|
||||
## #8: Bash FAQ
|
||||
|
||||
![Bash FAQ: Answers to frequently asked questions about GNU/BASH][24]
|
||||
A wiki designed for new bash users. It has good collections to frequently asked questions on channel #bash on the freenode IRC network. These answers are contributed by the regular members of the channel. Don't forget to check out common mistakes made by Bash programmers, in [BashPitfalls][25] section. The answers given in this FAQ may be slanted toward Bash, or they may be slanted toward the lowest common denominator Bourne shell, depending on who wrote the answer. In most cases, an effort is made to provide both a portable (Bourne) and an efficient (Bash, where appropriate) answer.
|
||||
|
||||
1. Bash FAQ [in wiki ][26] format.
|
||||
|
||||
|
||||
|
||||
## #9: Howtoforge - Linux Tutorials
|
||||
|
||||
![Howtoforge][27]
|
||||
|
||||
Fellow blogger Falko has some great stuff over at How-To Forge. The site provides Linux tutorials about various topic including its famous "The Perfect Server" series. The site is divided into various topics such as web-server, Linux distros, DNS servers, Virtualization, High-availability, Email and anti-spam, FTP servers, programming topics, and much more. The site is also available in German language.
|
||||
|
||||
1. Howtoforge [in html][28] format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #10: OpenBSD FAQ and Documentation
|
||||
|
||||
![OpenBSD Documenation][29]
|
||||
|
||||
OpenBSD is another Unix-like computer operating system based on Berkeley Software Distribution (BSD). It was forked from NetBSD by project. The OpenBSD is well known for the **quality code, documentation** , uncompromising position on software licensing, with strong focus on security. The documenation is divided into various topics such as - installations, package management, firewall setup, user management, networking, disk / RAID management and much more.
|
||||
|
||||
1. OpenBSD [in html][30] format.
|
||||
2. Support forums: No, but [mail lists][31] are available.
|
||||
|
||||
|
||||
|
||||
## #11: Calomel - Open Source Research and Reference
|
||||
|
||||
This amazing site dedicated to documenting open source software, and programs with special focus on OpenBSD. This is one of the cleanest and easy to to navigate website, with focus on the quality content. The site is divided into various server topic such as DNS, OpeBSD, security, web-server, Samba file server, various tools, and much more.
|
||||
|
||||
![Open Source Research and Reference Documentation][32]
|
||||
|
||||
1. Calomel Org [in html][33] format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #12: Slackware Book Project
|
||||
|
||||
![Slackware Linux Book and Documentation ][34]
|
||||
Slackware Linux was my first distro. It was one of the earliest distro based on the Linux kernel and is the oldest currently being maintained. The distro is targeted towards power users with strong focus on stability. Slackware is one of few the most "Unix-like" Linux distribution. The official slackware book is designed to get you started with the Slackware Linux operating system. It's not meant to cover every single aspect of the distribution, but rather to show what it is capable of and give you a basic working knowledge of the system. The book is divided into various topics such as Installation, Network & System Configuration, System administration, Package management, and much more.
|
||||
|
||||
1. Slackware [Linux books in html][35], pdf, and other format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #13: The Linux Documentation Project (TLDP)
|
||||
|
||||
![Linux Learning Site and Documentation ][36]
|
||||
|
||||
The Linux Documentation Project is working towards developing free, high quality documentation for the Linux operating system. The site is created and maintained by volunteers. The site is divided into subject-specific help, longer and in-depth guide books, and much more. I recommend [this document][37] which is both a tutorial and a reference on shell scripting with Bash. The [single list][38] of HOWTOs is also a good starting point for new users.
|
||||
|
||||
1. The Linux [documentation project][39] available in multiple formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #14: Linux Home Networking
|
||||
|
||||
![Linux Home Networking ][40]
|
||||
|
||||
Linux home networking is another good resource for learning Linux. This site covers topics needed for Linux software certification exams, such as the RHCE, and many computer training courses. The site is divided into various topics such as networking, samba file server, wirless networking, web-server, and much more.
|
||||
|
||||
1. Linux [home networking][41] available in html and PDF (with small fee) formats.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #15: Linux Action Show
|
||||
|
||||
![Linux Podcast ][42]
|
||||
|
||||
Linux Action Show ("LAS") is a podcast about Linux. The show is hosted by Bryan Lunduke, Allan Jude, and Chris Fisher. It covers the latest news in the FOSS world. The show reviews various apps and Linux distros. Sometime an interview with a major personal in the open source world is posted on the show.
|
||||
|
||||
1. Linux [action show][43] available in audio/video format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #16: Commandlinefu
|
||||
|
||||
Commandlinefu lists various shell commands that you may find interesting and useful. All commands can be commented on, discussed and voted up or down. Ths is an awesome resource for all Unix command line users. Don't forget to checkout all [top voted][44] commands here.
|
||||
|
||||
![The best Unix / Linux Commands By Commandlinefu][45]
|
||||
|
||||
1. [Commandlinefu][46] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #17: Debian Administration Tips and Resources
|
||||
|
||||
This site covers topics, tips, and tutorial only related to Debian GNU/Linux. It contain interesting and useful information related to the System Administration. You can contribute an article, tip, or question here. Don't forget to checkout [top articles][47] posted in the hall of fame section.
|
||||
![Debian Linux Adminstration: Tips and Tutorial For Sys Admin][48]
|
||||
|
||||
1. Debian [administration][49] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #18: Catonmat - Sed, Awk, Perl Tutorials
|
||||
|
||||
![Sed, Awk, Perl Tutorials][50]
|
||||
|
||||
This site run by a fellow blogger Peteris Krumins. The main focus is on command line and Unix programming topics such as sed, perl, awk, and others. Don't forget to check out [introduction to sed][51], sed [one liner][52] explained, the definitive [guide][53] to Bash Command line history, and [awk][54] liner explained.
|
||||
|
||||
1. [catonmat][55] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #19: Debian GNU/Linux Documentation and Wiki
|
||||
|
||||
![Debian Linux Tutorials and Wiki][56]
|
||||
|
||||
Debian is another Linux based operating system that primarily uses software released under the GNU General Public. Debian is well known for strict adherence to the philosophies of Unix and free software. It is also one of popular and influential Linux distribution. It is also used as a base for many other distributions such as Ubuntu and others. The Debian project provides its users with proper documentation in an easily accessible form. The site is divided into wiki, installation guide, faqs, and support forum.
|
||||
|
||||
1. Debian GNU/Linux [documentation][57] available in html and other format.
|
||||
2. Debian GNU/Linux [wiki][58]
|
||||
3. Support forums: [Yes][59]
|
||||
|
||||
|
||||
|
||||
## #20: Linux Sea
|
||||
|
||||
The book "Linux Sea" offers a gentle yet technical (from end-user perspective) introduction to the Linux operating system, using Gentoo Linux as the example Linux distribution. It does not nor will it ever talk about the history of the Linux kernel or Linux distributions or dive into details that are less interesting for Linux users.
|
||||
|
||||
1. Linux [sea][60] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #21: Oreilly Commons
|
||||
|
||||
![Oreilly Free Linux / Unix / Php / Javascript / Ubuntu Books][61]
|
||||
|
||||
The oreilly publishing house has posted quite a few titles in wiki format for all. The purpose of this site is to provide content to communities that would like to create, reference, use, modify, update and revise material from O'Reilly or other sources. The site includes books about Ubuntu, Php, Spamassassin, Linux, and much more all for free.
|
||||
|
||||
1. Oreilly [commons][62] available in wiki format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #22: Ubuntu Pocket Guide
|
||||
|
||||
![Ubuntu Book For New Users][63]
|
||||
|
||||
This book is written by Keir Thomas. This guide/book is a good read for everyday Ubuntu user. The purpose of this book is to introduce you to the Ubuntu operating system, and the philosophy that underpins it. You can download a pdf version from the official site or order a print version using Amazon.
|
||||
|
||||
1. Ubuntu [pocket guide][64] available in pdf and print formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #23: Linux: Rute User's Tutorial and Exposition
|
||||
|
||||
![GNU/LINUX system administration book][65]
|
||||
|
||||
This book covers GNU/LINUX system administration, for popular distributions like RedHat and Debian, as a tutorial for new users and a reference for advanced administrators. It aims to give concise, thorough explanations and practical examples of each aspect of a UNIX system. Anyone who wants a comprehensive text on (what is commercially called) LINUX need look no further-there is little that is not covered here.
|
||||
|
||||
1. Linux: [Rute User's Tutorial and Exposition][66] available in print and html formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #24: Advanced Linux Programming
|
||||
|
||||
![Advanced Linux Programming][67]
|
||||
|
||||
This book is intended for the programmer already familiar with the C programming language. It take a tutorial approach and teach the most important concepts and power features of the GNU/Linux system in application programs. If you're a developer already experienced with programming for the GNU/Linux system, are experienced with another UNIX-like system and are interested in developing GNU/Linux software, or want to make the transition for a non-UNIX environment and are already familiar with the general principles of writing good software, this book is for you. In addition, you will find that this book is equally applicable to C and C++ programming.
|
||||
|
||||
1. Advanced [Linux programming][68] available in print and pdf formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #25: LPI 101 Course Notes
|
||||
|
||||
![Linux Professional Institute Certification Books][69]
|
||||
|
||||
LPIC-1/2/3 levels are certification for Linux administrators. This site provides training manuals for LPI 101 and 102 exams. These are licenced under the GNU Free Documentation Licence (FDL). This course material is based on the objectives for the Linux Professionals Institutea€™s LPI 101 and 102 examination. The course is intended to provide you with the skills required for operating and administering Linux systems.
|
||||
|
||||
1. Download LPI [training manuals][70] in pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #26: FOSS Manuals
|
||||
|
||||
FLOSS Manuals is a collection of manuals about free and open source software together with the tools used to create them and the community that uses those tools. They include authors, editors, artists, software developers, activists, and many others. There are manuals that explain how to install and use a range of free and open source softwares, about how to do things (like design or stay safe online) with open source software, and manuals about free culture services that use or support free software and formats. You will find manuals about software such as VLC, [Linux video editing][71], Linux, OLPC / SUGAR, GRAPHICS, and much more.
|
||||
|
||||
![FLOSS Manuals is a collection of manuals about free and open source software][72]
|
||||
|
||||
1. You can browse [FOSS manuals][73] in wiki format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #27: Linux Starter Pack
|
||||
|
||||
![The Linux Starter Pack][74]
|
||||
|
||||
New to the wonderful world of Linux? Looking for an easy way to get started? You can download 130-page guide and get to grips with the OS. This will show you how to install Linux onto your PC, navigate around the desktop, master the most popular Linux programs and fix any problems that may arise.
|
||||
|
||||
1. Download [Linux starter][75] pack in pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #28: Linux.com - The Source of Linux Info
|
||||
|
||||
Linux.com is a product of the Linux Foundation. The side provides news, guides, tutorials and other information about Linux by harnessing the power of Linux users worldwide to inform, collaborate and connect on all matters Linux.
|
||||
|
||||
1. Visit [Linux.com][76] online.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #29: LWN
|
||||
|
||||
LWN is a site with an emphasis on free software and software for Linux and other Unix-like operating systems. It consists of a weekly issue, separate stories which are published most days, and threaded discussion attached to every story. The site provide comprehensive coverage of development, legal, commercial, and security issues related to Linux and FOSS.
|
||||
|
||||
1. Visit [lwn.net][77] online.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #30: Mac OS X Related sites
|
||||
|
||||
A quick links to Max OS X related sites:
|
||||
|
||||
* [Mac OS X Hints][78] - This site is dedicated to the Apple's Mac OS X unix operating systems. It has tons of tips, tricks and tutorial about Bash, and OS X
|
||||
* [Mac OS development library][79] - Apple has good collection related to OS X development. Don't forget to checkout [bash shell scripting primer][80].
|
||||
* [Apple kbase][81] - This is like RHN kbase. It provides guides and troublshooting tips for all apple products including OS X.
|
||||
|
||||
|
||||
|
||||
## #30: NetBSD
|
||||
|
||||
NetBSD is another free open source operating system based upon the Berkeley Software Distribution (BSD) Unix operating system. The NetBSD project is primarily focused on high quality design, stability and performance of the system. Due to its portability and Berkeley-style license, NetBSD is often used in embedded systems. This site provides links to the official NetBSD documentation and also links to various external documents.
|
||||
|
||||
1. View [netbsd][82] documentation online in html / pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## Your Turn:
|
||||
|
||||
This is my personal list and it is not absolutely definitive, so if you've got your own favorite Unix/Linux specific site, share in the comments below.
|
||||
|
||||
// Image credit: [Flickr photo][83] by PanelSwitchman. Some links are suggested by user on our facebook fan page.
|
||||
|
||||
// For those who celebrate, Merry Christmas! For everyone else, enjoy the weekend.
|
||||
|
||||
## About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][84], [Facebook][85], [Google+][86].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-documentations.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2011/12/unix-pdp11.jpg "Dennis Ritchie and Ken Thompson working with UNIX PDP11"
|
||||
[2]:https://www.cyberciti.biz/media/new/tips/2011/12/redhat-enterprise-linux-docs-150x150.png "Red hat Enterprise Linux Docs"
|
||||
[3]:https://access.redhat.com/documentation/en-us/
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2011/12/centos-linux-wiki-150x150.png "Centos Linux Wiki, Support, Documents"
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2011/12/arch-linux-wiki-150x150.png "Arch Linux wiki and tutorials "
|
||||
[6]:https://wiki.archlinux.org/index.php/Category:Networking_%28English%29
|
||||
[7]:https://bbs.archlinux.org/
|
||||
[8]:https://wiki.archlinux.org/
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2011/12/gentoo-linux-wiki1-150x150.png "Gentoo Linux Handbook and Wiki"
|
||||
[10]:http://www.gentoo.org/doc/en/handbook/
|
||||
[11]:https://wiki.gentoo.org
|
||||
[12]:https://forums.gentoo.org/
|
||||
[13]:http://gentoo-wiki.com
|
||||
[14]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-linux-wiki.png "Ubuntu Linux Wiki and Forums"
|
||||
[15]:https://help.ubuntu.com/community
|
||||
[16]:https://help.ubuntu.com/
|
||||
[17]:https://ubuntuforums.org/
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2011/12/ibm-devel.png "IBM: Technical for Linux programmers and system administrators"
|
||||
[19]:https://www.ibm.com/developerworks/learn/linux/index.html
|
||||
[20]:https://www.ibm.com/developerworks/community/forums/html/public?lang=en
|
||||
[21]:https://www.cyberciti.biz/media/new/tips/2011/12/freebsd-docs.png "Freebsd Documentation"
|
||||
[22]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-hackers-wiki-150x150.png "Bash hackers wiki for bash users"
|
||||
[23]:http://wiki.bash-hackers.org/doku.php
|
||||
[24]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-faq-150x150.png "Bash FAQ: Answers to frequently asked questions about GNU/BASH"
|
||||
[25]:http://mywiki.wooledge.org/BashPitfalls
|
||||
[26]:https://mywiki.wooledge.org/BashFAQ
|
||||
[27]:https://www.cyberciti.biz/media/new/tips/2011/12/howtoforge-150x150.png "Howtoforge tutorials"
|
||||
[28]:https://howtoforge.com/
|
||||
[29]:https://www.cyberciti.biz/media/new/tips/2011/12/openbsd-faq-150x150.png "OpenBSD Documenation"
|
||||
[30]:https://www.openbsd.org/faq/index.html
|
||||
[31]:https://www.openbsd.org/mail.html
|
||||
[32]:https://www.cyberciti.biz/media/new/tips/2011/12/calomel_org.png "Open Source Research and Reference Documentation"
|
||||
[33]:https://calomel.org
|
||||
[34]:https://www.cyberciti.biz/media/new/tips/2011/12/slackware-linux-book-150x150.png "Slackware Linux Book and Documentation "
|
||||
[35]:http://www.slackbook.org/
|
||||
[36]:https://www.cyberciti.biz/media/new/tips/2011/12/tldp-150x150.png "Linux Learning Site and Documentation "
|
||||
[37]:http://tldp.org/LDP/abs/html/index.html
|
||||
[38]:http://tldp.org/HOWTO/HOWTO-INDEX/howtos.html
|
||||
[39]:http://tldp.org/
|
||||
[40]:https://www.cyberciti.biz/media/new/tips/2011/12/linuxhomenetworking-150x150.png "Linux Home Networking "
|
||||
[41]:http://www.linuxhomenetworking.com/
|
||||
[42]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-action-show-150x150.png "Linux Podcast "
|
||||
[43]:http://www.jupiterbroadcasting.com/show/linuxactionshow/
|
||||
[44]:https://www.commandlinefu.com/commands/browse/sort-by-votes
|
||||
[45]:https://www.cyberciti.biz/media/new/tips/2011/12/commandlinefu.png "The best Unix / Linux Commands "
|
||||
[46]:https://commandlinefu.com/
|
||||
[47]:https://www.debian-administration.org/hof
|
||||
[48]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-admin.png "Debian Linux Adminstration: Tips and Tutorial For Sys Admin"
|
||||
[49]:https://www.debian-administration.org/
|
||||
[50]:https://www.cyberciti.biz/media/new/tips/2011/12/catonmat-150x150.png "Sed, Awk, Perl Tutorials"
|
||||
[51]:http://www.catonmat.net/blog/worlds-best-introduction-to-sed/
|
||||
[52]:https://www.catonmat.net/blog/sed-one-liners-explained-part-one/
|
||||
[53]:https://www.catonmat.net/blog/the-definitive-guide-to-bash-command-line-history/
|
||||
[54]:https://www.catonmat.net/blog/awk-one-liners-explained-part-one/
|
||||
[55]:https://catonmat.net/
|
||||
[56]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-wiki-150x150.png "Debian Linux Tutorials and Wiki"
|
||||
[57]:https://www.debian.org/doc/
|
||||
[58]:https://wiki.debian.org/
|
||||
[59]:https://www.debian.org/support
|
||||
[60]:http://swift.siphos.be/linux_sea/
|
||||
[61]:https://www.cyberciti.biz/media/new/tips/2011/12/orelly-150x150.png "Oreilly Free Linux / Unix / Php / Javascript / Ubuntu Books"
|
||||
[62]:http://commons.oreilly.com/wiki/index.php/O%27Reilly_Commons
|
||||
[63]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-guide-150x150.png "Ubuntu Book For New Users"
|
||||
[64]:http://ubuntupocketguide.com/
|
||||
[65]:https://www.cyberciti.biz/media/new/tips/2011/12/rute-150x150.png "GNU/LINUX system administration free book"
|
||||
[66]:https://web.archive.org/web/20160204213406/http://rute.2038bug.com/rute.html.gz
|
||||
[67]:https://www.cyberciti.biz/media/new/tips/2011/12/advanced-linux-programming-150x150.png "Download Advanced Linux Programming PDF version"
|
||||
[68]:https://github.com/MentorEmbedded/advancedlinuxprogramming
|
||||
[69]:https://www.cyberciti.biz/media/new/tips/2011/12/lpic-150x150.png "Download Linux Professional Institute Certification PDF Book"
|
||||
[70]:http://academy.delmar.edu/Courses/ITSC1358/eBooks/LPI-101.LinuxTrainingCourseNotes.pdf
|
||||
[71]://www.cyberciti.biz/faq/top5-linux-video-editing-system-software/
|
||||
[72]:https://www.cyberciti.biz/media/new/tips/2011/12/floss-manuals.png "Download manuals about free and open source software"
|
||||
[73]:https://flossmanuals.net/
|
||||
[74]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-starter-150x150.png "New to Linux? Start Linux starter book [ PDF version ]"
|
||||
[75]:http://www.tuxradar.com/linuxstarterpack
|
||||
[76]:https://linux.com
|
||||
[77]:https://lwn.net/
|
||||
[78]:http://hints.macworld.com/
|
||||
[79]:https://developer.apple.com/library/mac/navigation/
|
||||
[80]:https://developer.apple.com/library/mac/#documentation/OpenSource/Conceptual/ShellScripting/Introduction/Introduction.html
|
||||
[81]:https://support.apple.com/kb/index?page=search&locale=en_US&q=
|
||||
[82]:https://www.netbsd.org/docs/
|
||||
[83]:https://www.flickr.com/photos/9479603@N02/3311745151/in/set-72157614479572582/
|
||||
[84]:https://twitter.com/nixcraft
|
||||
[85]:https://facebook.com/nixcraft
|
||||
[86]:https://plus.google.com/+CybercitiBiz
|
||||
[87]:https://wiki.centos.org/
|
||||
[88]:https://www.centos.org/forums/
|
||||
[90]: https://www.freebsd.org/docs.html
|
||||
[91]: https://forums.freebsd.org/
|
||||
@ -1,279 +0,0 @@
|
||||
[#]:translator:(oneforalone)
|
||||
A CEO's Guide to Emacs
|
||||
============================================================
|
||||
|
||||
Years—no, decades—ago, I lived in Emacs. I wrote code and documents, managed email and calendar, and shelled all in the editor/OS. I was quite happy. Years went by and I moved to newer, shinier things. As a result, I forgot how to do tasks as basic as efficiently navigating files without a mouse. About three months ago, noticing just how much of my time was spent switching between applications and computers, I decided to give Emacs another try. It was a good decision for several reasons that will be covered in this post. Covered too are `.emacs` and Dropbox tips so that you can set up a good, movable environment.
|
||||
|
||||
For those who haven't used Emacs, it's something you'll likely hate, but may love. It's sort of a Rube Goldberg machine the size of a house that, at first glance, performs all the functions of a toaster. That hardly sounds like an endorsement, but the key phrase is "at first glance." Once you grok Emacs, you realize that it's a thermonuclear toaster that can also serve as the engine for... well, just about anything you want to do with text. When you think about how much your computing life revolves around text, this is a rather bold statement. Bold, but true.
|
||||
|
||||
Perhaps more importantly to me though, it's the one application I've ever used that makes me feel like I really own it instead of casting me as an anonymous "user" whose wallet is cleverly targeted by product marketing departments in fancy offices somewhere near [Soma][30] or Redmond. Modern productivity and authoring applications (e.g., Pages or IDEs) are like carbon fiber racing bikes. They come kitted out very nicely and fully assembled. Emacs is like a box of classic [Campagnolo][31] parts and a beautiful lugged steel frame that's missing one crank arm and a brake lever that you have to find in some tiny subculture on the Internet. The first one is faster and complete. The second is a source of endless joy or annoyance depending on your personality—and will last until your dying day. I'm the sort of person who feels equal joy at finding an old stash of Campy parts or tweaking my editor with eLisp. YMMV.
|
||||
|
||||

|
||||
A 1933 steel bicycle that I still ride. Check out this comparison of frame tubes: [https://www.youtube.com/watch?v=khJQgRLKMU0][6].
|
||||
|
||||
This may give the impression that Emacs is anachronistic or old-fashioned. It's not. It's powerful and timeless, but demands that you patiently understand it on its terms. The terms are pretty far off the beaten path and seem odd, but there is a logic to them that is both compelling and charming. To me, Emacs feels like the future rather than the past. Just as the lugged steel frame will be useful and comfortable in decades to come and the carbon fiber wunderbike will be in a landfill, having shattered on impact, so will Emacs persist as a useful tool when the latest trendy app is long forgotten.
|
||||
|
||||
If the notion of building your own personal working environment by editing Lisp code and having that fits-like-a-glove environment follow you to any computer is appealing to you, you may really like Emacs. If you like the new and shiny and want to get straight to work without much investment of time and mental cycles, it's likely not for you. I don't write code any more (other than Ludwig and Emacs Lisp), but many of the engineers at Fugue use Emacs to good effect. I'd say our engineers are about 30% Emacs, 40% IDEs, and 30% Vim users. But, this post is about Emacs for CEOs and other [Pointy-Haired Bosses][32] (PHB)[1][7] (and, hey, anyone who’s curious), so I'm going to explain and/or rationalize why I love it and how I use it. I also hope to provide you with enough detail that you can have a successful experience with it, without hours of Googling.
|
||||
|
||||
### Lasting Advantages
|
||||
|
||||
The long-term advantages that come with using Emacs just make life easier. The net gain makes the initial lift entirely worthwhile. Consider these:
|
||||
|
||||
### No More Context Switching
|
||||
|
||||
Org Mode alone is worth investing some serious time in, but if you are like me, you are usually working on a dozen or so documents—from blog posts to lists of what you need to do for a conference to employee reviews. In the modern world of computing, this generally means using several applications, all of which have distracting user interfaces and different ways to store, sort, and search. The result is that you need to constantly switch mental contexts and remember minutiae. I hate context switching because it is an imposition put on me due to a broken interface model[2][8] and I hate having to remember things my computer should remember for me in any rational world. In providing a single environment, Emacs is even more powerful for the PHB than the programmer, since programmers tend to spend a greater percentage of their day in a single application. Switching mental contexts has a higher cost than is often apparent. OS and application vendors have tarted up interfaces to distract us from this reality. If you’re technical, having access to a powerful [language interpreter][33] in a single keyboard shortcut (`M-:`) is especially useful.[3][9]
|
||||
|
||||
Many applications can be full screened all day and used to edit text. Emacs is singular because it is both an editor and a Lisp interpreter. In essence, you have a Turing complete machine a keystroke or two away at all times, while you go about your business. If you know a little or a lot about programming, you'll recognize that this means you can do _anything_ in Emacs. The full power of your computer is available to you in near real time while you work, once you have the commands in memory. You won't want to re-create Excel in eLisp, but most things you might do in Excel are smaller in scope and easy to accomplish in a line or two of code. If I need to crunch numbers, I'm more likely to jump over to the scratch buffer and write a little code than open a spreadsheet. Even if I have an email to write that isn't a one-liner, I'll usually just write it in Emacs and paste it into my email client. Why context switch when you can just flow? You might start with a simple calculation or two, but, over time, anything you need computed can be added with relative ease to Emacs. This is perhaps unique in applications that also provide rich features for creating things for other humans. Remember those magical terminals in Isaac Asimov's books? Emacs is the closest thing I've encountered to them.[4][10] I no longer decide what app to use for this or that thing. Instead, I just work. There is real power and efficiency to having a great tool and committing to it.
|
||||
|
||||
### Creating Things in Peace and Quiet
|
||||
|
||||
What’s the end result of having the best text editing features I've ever found? Having a community of people making all manner of useful additions? Having the full power of Lisp a keychord away? It’s that I use Emacs for all my creative work, aside from making music or images.
|
||||
|
||||
I have a dual monitor set up at my desk. One of them is in portrait mode with Emacs full screened all day long. The other one has web browsers for researching and reading; it usually has a terminal open as well. I keep my calendar, email, etc., on another desktop in OS X, which is hidden while I'm in Emacs, and I keep all notifications turned off. This allows me to actually concentrate on what I'm doing. I've found eliminating distractions to be almost impossible in the more modern UI applications due to their efforts to be helpful and easy to use. I don't need to be constantly reminded how to do operations I've done tens of thousands of times, but I do need a nice, clean white sheet of paper to be thoughtful. Maybe I'm just bad at living in noisy environments due to age and abuse, but I’d suggest it’s worth a try for anyone. See what it's like to have some actual peace and quiet in your computing environment. Of course, lots of apps now have modes that hide the interface and, thankfully, both Apple and Microsoft now have meaningful full-screen modes. But, no other application is powerful enough to “live in” for most things. Unless you are writing code all day or perhaps working on a very long document like a book, you're still going to face the noise of other apps. Also, most modern applications seem simultaneously patronizing and lacking in functionality and usability.[5][11] The only applications I dislike more than office apps are the online versions.
|
||||
|
||||

|
||||
My desktop arrangement. Emacs on the left.
|
||||
|
||||
But what about communicating? The difference between creating and communicating is substantial. I'm much more productive at both when I set aside distinct time for each. We use Slack at Fugue, which is both wonderful and hellish. I keep it on a messaging desktop alongside my calendar and email, so that, while I'm actually making things, I'm blissfully unaware of all the chatter in the world. It takes just one Slackstorm or an email from a VC or Board Director to immediately throw me out of my work. But, most things can usually wait an hour or two.
|
||||
|
||||
### Taking Everything with You and Keeping It Forever
|
||||
|
||||
The third reason I find Emacs more advantageous than other environments is that it's easy to take all your stuff with you. By this, I mean that, rather than having a plethora of apps interacting and syncing in their own ways, all you need is one or two directories syncing via Dropbox or the like. Then, you can have all your work follow you anywhere in the environment you have crafted to suit your purposes. I do this across OS X, Windows, and sometimes Linux. It's dead simple and reliable. I've found this capability to be so useful that I dread dealing with Pages, GDocs, Office, or other kinds of files and applications that force me back into finding stuff somewhere on the filesystem or in the cloud.
|
||||
|
||||
The limiting factor in keeping things forever on a computer is file format. Assuming that humans have now solved the problem of storage [6][12] for good, the issue we face over time is whether we can continue to access the information we've created. Text files are the most long-lived format for computing. You easily can open a text file from 1970 in Emacs. That’s not so true for Office applications. Text files are also nice and small—radically smaller than Office application data files. As a digital pack rat and as someone who makes lots of little notes as things pop into my head, having a simple, light, permanent collection of stuff that is always available is important to me.
|
||||
|
||||
If you’re feeling ready to give Emacs a try, read on! The sections that follow don’t take the place of a full tutorial, but will have you operational by the time you finish reading.
|
||||
|
||||
### Learning To Ride Emacs - A Technical Setup
|
||||
|
||||
The price of all this power and mental peace and quiet is that you have a steep learning curve with Emacs and it does everything differently than you're used to. At first, this will make you feel like you’re wasting time on an archaic and strange application that the modern world passed by. It’s a bit like learning to ride a bicycle[7][13]if you've only driven cars.
|
||||
|
||||
### Which Emacs?
|
||||
|
||||
I use the plain vanilla Emacs from GNU for OS X and Windows. You can get the OS X version at [][34][http://emacsformacosx.com/][35] and the Windows version at [][36][http://www.gnu.org/software/emacs/][37]. There are a bunch of other versions out there, especially for the Mac, but I've found the learning curve for doing powerful stuff (which involves Lisp and lots of modes) to be much lower with the real deal. So download it, and we can get started![8][14]
|
||||
|
||||
### First, You'll Need To Learn How To Navigate
|
||||
|
||||
I use the Emacs conventions for keys and combinations in this document. These are 'C' for control, 'M' for meta (which is usually mapped to Alt or Option), and the hyphen for holding down the keys in combination. So `C-h t` means to hold down control and type h, then release control and type t. This is the command for bringing up the tutorial, which you should go ahead and do.
|
||||
|
||||
Don't use the arrow keys or the mouse. They work, but you should give yourself a week of using the native navigation commands in Emacs. Once you have them committed to muscle memory, you'll likely enjoy them and miss them badly everywhere else you go. The Emacs tutorial does a pretty good job of walking you through them, but I'll summarize so you don't need to read the whole thing. The boring stuff is that, instead of arrows, you use `C-b` for back, `C-f` for forward, `C-p` for previous (up), and `C-n` for next (down). You may be thinking "why in the world would I do that, when I have perfectly good arrow keys?" There are several reasons. First, you don't have to move your hands from the typing position, and the forward and back keys used with Alt (or Meta in Emacspeak) navigate a word at a time. This is more handy than is obvious. The third good reason is that, if you want to repeat a command, you can precede it with a number. I often use this when editing documents by estimating how many words I need to go back or lines up or down and doing something like `C-9 C-p` or `M-5 M-b`. The other really important navigation commands are based on `a` for the beginning of a thing and `e` for the end of a thing. Using `C-a|e` are on lines, and using `M-a|e`, are on sentences. For the sentence commands to work properly, you'll need to double space after periods, which simultaneously provides a useful feature and takes a shibboleth of [opinion][38] off the mental table. If you need to export the document to a single space [publication environment][39], you can write a macro in moments to do so.
|
||||
|
||||
It genuinely is worth going through the tutorial that ships with Emacs. I'll cover a few important commands for the truly impatient, but the tutorial is gold. Reminder: `C-h t` for the tutorial.
|
||||
|
||||
### Learn To Copy and Paste
|
||||
|
||||
You can put Emacs into `CUA` mode, which will work in familiar ways, but the native Emacs way is pretty great and plenty easy once you learn it. You mark regions (like selecting) by using Shift with the navigation commands. So `C-F` selects one character forward from the cursor, etc. You copy with `M-w`, you cut with `C-w`, and you paste with `C-y`. These are actually called killing and yanking, but it's very similar to cut and paste. There is magic under the hood here in the kill ring, but for now, just worry about cut, copy, and paste. If you start fumbling around at this point, `C-x u` is undo...
|
||||
|
||||
### Next, Learn Ido Mode
|
||||
|
||||
Trust me. Ido makes working with files much easier. You don't generally use a separate Finder|Explorer window to work with files in Emacs. Instead you use the editor's commands to create, open, and save files. This is a bit of a pain without Ido, so I recommend installing it before learning the other way. Ido comes with Emacs beginning with version 22, but you'll want to make some tweaks to your `.emacs` file so that it is always used. This is a good excuse to get your environment set up.
|
||||
|
||||
Most features in Emacs come in modes. To install any given mode, you'll need to do two things. Well, at first you'll need to do a few extra things, but these only need to be done once, and thereafter only two things. So the extra things are that you'll need a single place to put all your eLisp files and you'll need to tell Emacs where that place is. I suggest you make a single directory in, say, Dropbox that is your Emacs home. Inside this, you'll want to create an `.emacs` file and an `.emacs.d` directory. Inside the `.emacs.d`, make a directory called `lisp`. So you should have:
|
||||
|
||||
```
|
||||
home
|
||||
|
|
||||
+.emacs
|
||||
|
|
||||
-.emacs.d
|
||||
|
|
||||
-lisp
|
||||
```
|
||||
|
||||
You'll put the `.el` files for things like modes into the `home/.emacs.d/lisp`directory, and you'll point to that in your `.emacs` like so:
|
||||
|
||||
`(add-to-list 'load-path "~/.emacs.d/lisp/")`
|
||||
|
||||
Ido Mode comes with Emacs, so you won't need to put an `.el` file into your Lisp directory for this, but you'll be adding other stuff soon that will go in there.
|
||||
|
||||
### Symlinks are Your Friend
|
||||
|
||||
But wait, that says that `.emacs` and `.emacs.d` are in your home directory, and we put them in some dumb folder in Dropbox! Correct. This is how you make it easy to have your environment anywhere you go. Keep everything in Dropbox and make symbolic links to `.emacs`, `.emacs.d`, and your main document directories in `~`. On OS X, this is super easy with the `ln -s` command, but on Windows this is a pain. Fortunately, Emacs provides an easy alternative to symlinking on Windows, the HOME environment variable. Go into Environment Variables in Windows (as of Windows 10, you can just hit the Windows key and type "Environment Variables" to find this with search, which is the best part of Windows 10), and make a HOME environment variable in your account that points to the Dropbox folder you made for Emacs. If you want to make it easy to navigate to local files that aren't in Dropbox, you may instead want to make a symbolic link to the Dropbox Emacs home in your actual home directory.
|
||||
|
||||
So now you've done all the jiggery-pokery needed to get any machine pointed to your Emacs setup and files. If you get a new computer or use someone else's for an hour or a day, you get your entire work environment. This seems a little difficult the first time you do it, but it's about a ten minute (at most) operation once you know what you're doing.
|
||||
|
||||
But we were configuring Ido...
|
||||
|
||||
`C-x` `C-f` and type `~/.emacs RET RET` to create your `.emacs` file. Add these lines to it:
|
||||
|
||||
```
|
||||
;; set up ido mode
|
||||
(require `ido)
|
||||
(setq ido-enable-flex-matching t)
|
||||
(setq ido-everywhere t)
|
||||
(ido-mode 1)
|
||||
```
|
||||
|
||||
With the `.emacs` buffer open, do an `M-x evaluate-buffer` command, and you'll either get an error if you munged something or you'll get Ido. Ido changes how the minibuffer works when doing file operations. There is great documentation on it, but I'll point out a few tips. Use the `~/` effectively; you can just type `~/` at any point in the minibuffer and it'll jump back to home. Implicit in this is that you should have most of your stuff a short hop off your home. I use `~/org` for all my non-code stuff and `~/code` for code. Once you’re in the right directory, you'll often have a collection of files with different extensions, especially if you use Org Mode and publish from it. You can type period and the extension you want no matter where you are in the file name and Ido will limit the choices to files with that extension. For example, I'm writing this blog post in Org Mode, so the main file is:
|
||||
|
||||
`~/org/blog/emacs.org`
|
||||
|
||||
I also occasionally push it out to HTML using Org Mode publishing, so I've got an `emacs.html` file in the same directory. When I want to open the Org file, I will type:
|
||||
|
||||
`C-x C-f ~/o[RET]/bl[RET].or[RET]`
|
||||
|
||||
The [RET]s are me hitting return for auto completion for Ido Mode. So, that’s 12 characters typed and, if you're used to it, a _lot_ less time than opening Finder|Explorer and clicking around. Ido Mode is plenty useful, but really is a utility mode for operating Emacs. Let's explore some modes that are useful for getting work done.
|
||||
|
||||
### Fonts and Styles
|
||||
|
||||
I recommend getting the excellent input family of typefaces for use in Emacs. They are customizable with different braces, zeroes, and other characters. You can build in extra line spacing into the font files themselves. I recommend a 1.5X line spacing and using their excellent proportional fonts for code and data. I use Input Serif for my writing, which has a funky but modern feel. You can find them on [http://input.fontbureau.com/][40] where you can customize to your preferences. You can manually set the fonts using menus in Emacs, but this puts code into your `.emacs`file and, if you use multiple devices, you may find you want some different settings. I've set up my `.emacs` to look for the machine I'm using by name and configure the screen appropriately. The code for this is:
|
||||
|
||||
```
|
||||
;; set up fonts for different OSes. OSX toggles to full screen.
|
||||
(setq myfont "InputSerif")
|
||||
(cond
|
||||
((string-equal system-name "Sampo.local")
|
||||
(set-face-attribute 'default nil :font myfont :height 144)
|
||||
(toggle-frame-fullscreen))
|
||||
((string-equal system-name "Morpheus.local")
|
||||
(set-face-attribute 'default nil :font myfont :height 144))
|
||||
((string-equal system-name "ILMARINEN")
|
||||
(set-face-attribute 'default nil :font myfont :height 106))
|
||||
((string-equal system-name "UKKO")
|
||||
(set-face-attribute 'default nil :font myfont :height 104)))
|
||||
```
|
||||
|
||||
You should replace the `system-name` values with what you get when you evaluate `(system-name)` in your copy of Emacs. Note that on Sampo (my MacBook), I also set Emacs to full screen. I'd like to do this on Windows as well, but Windows and Emacs don't really love each other and it always ends up in some wonky state when I try this. Instead, I just fullscreen it manually after launch.
|
||||
|
||||
I also recommend getting rid of the awful toolbar that Emacs got sometime in the 90s when the cool thing to do was to have toolbars in your application. I also got rid of some other "chrome" so that I have a simple, productive interface. Add these to your `.emacs` file to get rid of the toolbar and scroll bars, but to keep your menu available (on OS X, it'll be hidden unless you mouse to the top of the screen anyway):
|
||||
|
||||
```
|
||||
(if (fboundp 'scroll-bar-mode) (scroll-bar-mode -1))
|
||||
(if (fboundp 'tool-bar-mode) (tool-bar-mode -1))
|
||||
(if (fboundp 'menu-bar-mode) (menu-bar-mode 1))
|
||||
```
|
||||
|
||||
### Org Mode
|
||||
|
||||
I pretty much live in Org Mode. It is my go-to environment for authoring documents, keeping notes, making to-do lists and 90% of everything else I do. Org was originally conceived as a combination note-taking and to-do list utility by a fellow who is a laptop-in-meetings sort. I am against use of laptops in meetings and don't do it myself, so my use cases are a little different than his. For me, Org is primarily a way to handle all manner of content within a structure. There are heads and subheads, etc., in Org Mode, and they function like an outline. Org allows you to expand or hide the contents of the tree and also to rearrange the tree. This fits how I think very nicely and I find it to be just a pleasure to use in this way.
|
||||
|
||||
Org Mode also has a lot of little things that make life pleasant. For example, the footnote handling is excellent and the LaTeX/PDF output is great. Org has the ability to generate agendas based on the to-do's in all your documents and a nice way to relate them to dates/times. I don't use this for any sort of external commitments, which are handled on a shared calendar, but for creating things and keeping track of what I need to create in the future, it's invaluable. Installing it is as easy as adding the `org-mode.el` to your Lisp directory and adding these lines to your `.emacs`, if you want it to indent based on tree location and to open documents fully expanded:
|
||||
|
||||
```
|
||||
;; set up org mode
|
||||
(setq org-startup-indented t)
|
||||
(setq org-startup-folded "showall")
|
||||
(setq org-directory "~/org")
|
||||
```
|
||||
|
||||
The last line is there so that Org knows where to look for files to include in agendas and some other things. I keep Org right in my home directory, i.e., a symlink to the directory that lives in Dropbox, as described earlier.
|
||||
|
||||
I have a `stuff.org` file that is always open in a buffer. I use it like a notepad. Org makes it easy to extract things like TODOs and stuff with deadlines. It's especially useful when you can inline Lisp code and evaluate it whenever you need. Having code with content is super handy. Again, you have access to the actual computer with Emacs, and this is a liberation.
|
||||
|
||||
#### Publishing with Org Mode
|
||||
|
||||
I care about the appearance and formatting of my documents. I started my career as a designer, and I think information can and should be presented clearly and beautifully. Org has great support for generating PDFs via LaTeX, which has a bit of its own learning curve, but doing simple things is pretty easy.
|
||||
|
||||
If you want to use fonts and styles other than the typical LaTeX ones, you've got a few things to do. First, you'll want XeLaTeX so you can use normal system fonts rather than LaTeX specific fonts. Next, you'll want to add this to `.emacs`:
|
||||
|
||||
```
|
||||
(setq org-latex-pdf-process
|
||||
'("xelatex -interaction nonstopmode %f"
|
||||
"xelatex -interaction nonstopmode %f"))
|
||||
```
|
||||
|
||||
I put this right at the end of my Org section of `.emacs` to keep things tidy. This will allow you to use more formatting options when publishing from Org. For example, I often use:
|
||||
|
||||
```
|
||||
#+LaTeX_HEADER: \usepackage{fontspec}
|
||||
#+LATEX_HEADER: \setmonofont[Scale=0.9]{Input Mono}
|
||||
#+LATEX_HEADER: \setromanfont{Maison Neue}
|
||||
#+LATEX_HEADER: \linespread{1.5}
|
||||
#+LATEX_HEADER: \usepackage[margin=1.25in]{geometry}
|
||||
|
||||
#+TITLE: Document Title Here
|
||||
```
|
||||
|
||||
These simply go somewhere in your `.org` file. Our corporate font for body copy is Maison Neue, but you can put whatever is appropriate here. I strongly discourage the use of Maison Neue. It’s a terrible font and no one should ever use it.
|
||||
|
||||
This file is an example of PDF output using these settings. This is what out-of-the-box LaTeX always looks like. It's fine I suppose, but the fonts are boring and a little odd. Also, if you use the standard format, people will assume they are reading something that is or pretends to be an academic paper. You've been warned.
|
||||
|
||||
### Ace Jump Mode
|
||||
|
||||
This is more of a gem than a major feature, but you want it. It works a bit like Jef Raskin's Leap feature from days gone by.[9][15] The way it works is you type `C-c` `C-SPC`and then type the first letter of the word you want to jump to. It highlights all occurrences of words with that initial character, replacing it with a letter of the alphabet. You simply type the letter of the alphabet for the location you want and your cursor jumps to it. I find myself using this as often as the more typical nav keys or search. Download the `.el` to your Lisp directory and put this in your `.emacs`:
|
||||
|
||||
```
|
||||
;; set up ace-jump-mode
|
||||
(add-to-list 'load-path "which-folder-ace-jump-mode-file-in/")
|
||||
(require 'ace-jump-mode)
|
||||
(define-key global-map (kbd "C-c C-SPC" ) 'ace-jump-mode)
|
||||
```
|
||||
|
||||
### More Later
|
||||
|
||||
That's enough for one post—this may get you somewhere you'd like to be. I'd love to hear about your uses for Emacs aside from programming (or for programming!) and whether this was useful at all. There are likely some boneheaded PHBisms in how I use Emacs, and if you want to point them out, I'd appreciate it. I'll probably write some updates over time to introduce additional features or modes. I'll certainly show you how to use Fugue with Emacs and Ludwig-mode as we evolve it into something more useful than code highlighting. Send your thoughts to [@fugueHQ][41] on Twitter.
|
||||
|
||||
* * *
|
||||
|
||||
#### Footnotes
|
||||
|
||||
1. [^][16] If you are now a PHB of some sort, but were never technical, Emacs likely isn’t for you. There may be a handful of folks for whom Emacs will form a path into the more technical aspects of computing, but this is probably a small population. It’s helpful to know how to use a Unix or Windows terminal, to have edited a dotfile or two, and to have written some code at some point in your life for Emacs to make much sense.
|
||||
|
||||
2. [^][17] [][18][http://archive.wired.com/wired/archive/2.08/tufte.html][19]
|
||||
|
||||
3. [^][20] I mainly use this to perform calculations while writing. For example, I was writing an offer letter to a new employee and wanted to calculate how many options to include in the offer. Since I have a variable defined in my `.emacs` for outstanding-shares, I can simply type `M-: (* .001 outstanding-shares)`and get a tenth of a point without opening a calculator or spreadsheet. I keep _lots_ of numbers in variables like this so I can avoid context switching.
|
||||
|
||||
4. [^][21] The missing piece of this is the web. There is an Emacs web browser called eww that will allow you to browse in Emacs. I actually use this, as it is both a great ad-blocker and removes most of the poor choices in readability from the web designer's hands. It's a bit like Reading Mode in Safari. Unfortunately, most websites have lots of annoying cruft and navigation that translates poorly into text.
|
||||
|
||||
5. [^][22] Usability is often confused with learnability. Learnability is how difficult it is to learn a tool. Usability is how useful the tool is. Often, these are at odds, such as with the mouse and menus. Menus are highly learnable, but have poor usability, so there have been keyboard shortcuts from the earliest days. Raskin was right on many points where he was ignored about GUIs in general. Now, OSes are putting things like decent search onto a keyboard shortcut. On OS X and Windows, my default method of navigation is search. Ubuntu's search is badly broken, as is the rest of its GUI.
|
||||
|
||||
6. [^][23] AWS S3 has effectively solved file storage for as long as we have the Internet. Trillions of objects are stored in S3 and they've never lost one of them. Most every service out there that offers cloud storage is built on S3 or imitates it. No one has the scale of S3, so I keep important stuff there, via Dropbox.
|
||||
|
||||
7. [^][24] By now, you might be thinking "what is it with this guy and bicycles?" ... I love them on every level. They are the most mechanically efficient form of transportation ever invented. They can be objects of real beauty. And, with some care, they can last a lifetime. I had Rivendell Bicycle Works build a frame for me back in 2001 and it still makes me happy every time I look at it. Bicycles and UNIX are the two best inventions I've interacted with. Well, they and Emacs.
|
||||
|
||||
8. [^][25] This is not a tutorial for Emacs. It comes with one and it's excellent. I do walk through some of the things that I find most important to getting a useful Emacs setup, but this is not a replacement in any way.
|
||||
|
||||
9. [^][26] Jef Raskin designed the Canon Cat computer in the 1980s after falling out with Steve Jobs on the Macintosh project, which he originally led. The Cat had a document-centric interface (as all computers should) and used the keyboard in innovative ways that you can now imitate with Emacs. If I could have a modern, powerful Cat with a giant high-res screen and Unix underneath, I'd trade my Mac for it right away. [][27][https://youtu.be/o_TlE_U_X3c?t=19s][28]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.fugue.co/2015-11-11-guide-to-emacs.html
|
||||
|
||||
作者:[Josh Stella ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.fugue.co/authors/josh.html
|
||||
[1]:https://blog.fugue.co/2013-10-16-vpc-on-aws-part3.html
|
||||
[2]:https://blog.fugue.co/2013-10-02-vpc-on-aws-part2.html
|
||||
[3]:http://ww2.fugue.co/2017-05-25_OS_AR_GartnerCoolVendor2017_01-LP-Registration.html
|
||||
[4]:https://blog.fugue.co/authors/josh.html
|
||||
[5]:https://twitter.com/joshstella
|
||||
[6]:https://www.youtube.com/watch?v=khJQgRLKMU0
|
||||
[7]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#phb
|
||||
[8]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#tufte
|
||||
[9]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#interpreter
|
||||
[10]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#eww
|
||||
[11]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#usability
|
||||
[12]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#s3
|
||||
[13]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#bicycles
|
||||
[14]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#nottutorial
|
||||
[15]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#canoncat
|
||||
[16]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#phbOrigin
|
||||
[17]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#tufteOrigin
|
||||
[18]:http://archive.wired.com/wired/archive/2.08/tufte.html
|
||||
[19]:http://archive.wired.com/wired/archive/2.08/tufte.html
|
||||
[20]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#interpreterOrigin
|
||||
[21]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#ewwOrigin
|
||||
[22]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#usabilityOrigin
|
||||
[23]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#s3Origin
|
||||
[24]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#bicyclesOrigin
|
||||
[25]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#nottutorialOrigin
|
||||
[26]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#canoncatOrigin
|
||||
[27]:https://youtu.be/o_TlE_U_X3c?t=19s
|
||||
[28]:https://youtu.be/o_TlE_U_X3c?t=19s
|
||||
[29]:https://blog.fugue.co/authors/josh.html
|
||||
[30]:http://www.huffingtonpost.com/zachary-ehren/soma-isnt-a-drug-san-fran_b_987841.html
|
||||
[31]:http://www.campagnolo.com/US/en
|
||||
[32]:http://www.businessinsider.com/best-pointy-haired-boss-moments-from-dilbert-2013-10
|
||||
[33]:http://www.webopedia.com/TERM/I/interpreter.html
|
||||
[34]:http://emacsformacosx.com/
|
||||
[35]:http://emacsformacosx.com/
|
||||
[36]:http://www.gnu.org/software/emacs/
|
||||
[37]:http://www.gnu.org/software/emacs/
|
||||
[38]:http://www.huffingtonpost.com/2015/05/29/two-spaces-after-period-debate_n_7455660.html
|
||||
[39]:http://practicaltypography.com/one-space-between-sentences.html
|
||||
[40]:http://input.fontbureau.com/
|
||||
[41]:https://twitter.com/fugueHQ
|
||||
@ -0,0 +1,201 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Celebrate Christmas In Linux Way With These Wallpapers)
|
||||
[#]: via: (https://itsfoss.com/christmas-linux-wallpaper/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
[#]: url: ( )
|
||||
|
||||
Celebrate Christmas In Linux Way With These Wallpapers
|
||||
======
|
||||
|
||||
It’s the holiday season and many of you might be celebrating Christmas already. From the team of It’s FOSS, I would like to wish you a Merry Christmas and a happy new year.
|
||||
|
||||
To continue the festive mood, I’ll show you some really awesome [Linux wallpapers][1] on Christmas theme. But before we see that, how about a Christmas Tree in Linux terminal.
|
||||
|
||||
### Display Christmas Tree in Linux Terminal
|
||||
|
||||
<https://giphy.com/embed/xUNda6KphvbpYxL3tm>
|
||||
|
||||
If you want to display an animated Christmas tree in the terminal, you can use the command below:
|
||||
|
||||
```
|
||||
curl https://raw.githubusercontent.com/sergiolepore/ChristBASHTree/master/tree-EN.sh | bash
|
||||
```
|
||||
|
||||
If you don’t want to get it from the internet all the time, you can get the shell script from its GitHub repository, change the permission and run it like a normal shell script.
|
||||
|
||||
[ChristBASHTree][2]
|
||||
|
||||
### Display Christmas Tree in Linux terminal using Perl
|
||||
|
||||
[![Christmas Tree in Linux terminal by NixCraft][3]][4]
|
||||
|
||||
This trick was originally shared by [NixCraft][5]. You’ll need to install a Perl module for this.
|
||||
|
||||
To be honest, I don’t like using Perl modules because uninstalling them is a real pain. So **use this Perl module knowing that you’ll have to manually remove it**.
|
||||
|
||||
```
|
||||
perl -MCPAN -e 'install Acme::POE::Tree'
|
||||
```
|
||||
|
||||
You can read the original article [here][5] to know more about it.
|
||||
|
||||
## Download Linux Christmas Wallpapers
|
||||
|
||||
All these Linux Christmas wallpapers are created by Mark Riedesel and you can find plenty of other artwork on [his website][6].
|
||||
|
||||
He has been making such wallpapers almost every year since 2002. Quite understandably some of the earliest wallpapers don’t have modern aspect ratio. I have put them up in reverse chronological order.
|
||||
|
||||
One tiny note. The images displayed here are highly compressed so download the wallpapers from the provided link only.
|
||||
|
||||
![Christmas Linux Wallpaper][7]
|
||||
|
||||
[Download This Wallpaper][8]
|
||||
|
||||
[![Christmas Linux Wallpapers][9]][10]
|
||||
|
||||
[Download This Wallpaper][11]
|
||||
|
||||
[![Christmas Linux Wallpapers][12]][13]
|
||||
|
||||
[Download This Wallpaper][14]
|
||||
|
||||
[![Christmas Linux Wallpapers][15]][16]
|
||||
|
||||
[Download This Wallpaper][17]
|
||||
|
||||
[![Christmas Linux Wallpapers][18]][19]
|
||||
|
||||
[Download This Wallpaper][20]
|
||||
|
||||
[![Christmas Linux Wallpapers][21]][22]
|
||||
|
||||
[Download This Wallpaper][23]
|
||||
|
||||
[![Christmas Linux Wallpapers][24]][25]
|
||||
|
||||
[Download This Wallpaper][26]
|
||||
|
||||
[![Christmas Linux Wallpapers][27]][28]
|
||||
|
||||
[Download This Wallpaper][29]
|
||||
|
||||
[![Christmas Linux Wallpapers][30]][31]
|
||||
|
||||
[Download This Wallpaper][32]
|
||||
|
||||
[![Christmas Linux Wallpapers][33]][34]
|
||||
|
||||
[Download This Wallpaper][35]
|
||||
|
||||
[![Christmas Linux Wallpapers][36]][37]
|
||||
|
||||
[Download This Wallpaper][38]
|
||||
|
||||
[![Christmas Linux Wallpapers][39]][40]
|
||||
|
||||
[Download This Wallpaper][41]
|
||||
|
||||
[![Christmas Linux Wallpapers][42]][43]
|
||||
|
||||
[Download This Wallpaper][44]
|
||||
|
||||
[![Christmas Linux Wallpapers][45]][46]
|
||||
|
||||
[Download This Wallpaper][47]
|
||||
|
||||
[![Christmas Linux Wallpapers][48]][49]
|
||||
|
||||
[Download This Wallpaper][50]
|
||||
|
||||
### Bonus: Linux Christmas carols
|
||||
|
||||
Here is a bonus for you. Christmas carols Linuxified for Linux lovers like us.
|
||||
|
||||
In [an article on Computer World][51], [Sandra Henry-Stocker][52] shared such Christmas carols. An excerpt:
|
||||
|
||||
To the tune of: [Chestnuts Roasting on an Open Fire][53]
|
||||
|
||||
> Running merrily on open source
|
||||
> With users happy as can be
|
||||
> We’re using Linux and getting lots done
|
||||
> And happy everything is free
|
||||
|
||||
To the tune of: [The Twelve Days of Christmas][54]
|
||||
|
||||
> On my first day with Linux, my admin gave to me a password and a login ID
|
||||
> On my second day with Linux my admin gave to me two new commands and a password and a login ID
|
||||
|
||||
You can read full carols [here][51].
|
||||
|
||||
Merry Linux to you!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/christmas-linux-wallpaper/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/beautiful-linux-wallpapers/
|
||||
[2]: https://github.com/sergiolepore/ChristBASHTree
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2016/12/perl-tree.gif?resize=600%2C622&ssl=1
|
||||
[4]: https://itsfoss.com/christmas-linux-wallpaper/perl-tree/
|
||||
[5]: https://www.cyberciti.biz/open-source/command-line-hacks/linux-unix-desktop-fun-christmas-tree-for-your-terminal/
|
||||
[6]: http://www.klowner.com/
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/12/christmas-linux-wallpaper-featured.jpeg?resize=800%2C450&ssl=1
|
||||
[8]: http://klowner.com/wallery/christmas_tux_2017/download/ChristmasTux2017_3840x2160.png
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2016_3840x2160_result.jpg?resize=800%2C450&ssl=1
|
||||
[10]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2016_3840x2160_result/
|
||||
[11]: http://www.klowner.com/wallpaper/christmas_tux_2016/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2015_2560x1920_result.jpg?resize=800%2C600&ssl=1
|
||||
[13]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2015_2560x1920_result/
|
||||
[14]: http://www.klowner.com/wallpaper/christmas_tux_2015/
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2014_2560x1440_result.jpg?resize=800%2C450&ssl=1
|
||||
[16]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2014_2560x1440_result/
|
||||
[17]: http://www.klowner.com/wallpaper/christmas_tux_2014/
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/12/christmastux2013_result.jpg?resize=800%2C450&ssl=1
|
||||
[19]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2013_result/
|
||||
[20]: http://www.klowner.com/wallpaper/christmas_tux_2013/
|
||||
[21]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2012_2560x1440_result.jpg?resize=800%2C450&ssl=1
|
||||
[22]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2012_2560x1440_result/
|
||||
[23]: http://www.klowner.com/wallpaper/christmas_tux_2012/
|
||||
[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/12/christmastux2011_2560x1440_result.jpg?resize=800%2C450&ssl=1
|
||||
[25]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2011_2560x1440_result/
|
||||
[26]: http://www.klowner.com/wallpaper/christmas_tux_2011/
|
||||
[27]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2016/12/christmastux2010_5120x2880_result.jpg?resize=800%2C450&ssl=1
|
||||
[28]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2010_5120x2880_result/
|
||||
[29]: http://www.klowner.com/wallpaper/christmas_tux_2010/
|
||||
[30]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2009_1600x1200_result.jpg?resize=800%2C600&ssl=1
|
||||
[31]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2009_1600x1200_result/
|
||||
[32]: http://www.klowner.com/wallpaper/christmas_tux_2009/
|
||||
[33]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2008_2560x1600_result.jpg?resize=800%2C500&ssl=1
|
||||
[34]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2008_2560x1600_result/
|
||||
[35]: http://www.klowner.com/wallpaper/christmas_tux_2008/
|
||||
[36]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2007_2560x1600_result.jpg?resize=800%2C500&ssl=1
|
||||
[37]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2007_2560x1600_result/
|
||||
[38]: http://www.klowner.com/wallpaper/christmas_tux_2007/
|
||||
[39]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2006_1024x768_result.jpg?resize=800%2C600&ssl=1
|
||||
[40]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2006_1024x768_result/
|
||||
[41]: http://www.klowner.com/wallpaper/christmas_tux_2006/
|
||||
[42]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2005_1600x1200_result.jpg?resize=800%2C600&ssl=1
|
||||
[43]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2005_1600x1200_result/
|
||||
[44]: http://www.klowner.com/wallpaper/christmas_tux_2005/
|
||||
[45]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2004_1600x1200_result.jpg?resize=800%2C600&ssl=1
|
||||
[46]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2004_1600x1200_result/
|
||||
[47]: http://www.klowner.com/wallpaper/christmas_tux_2004/
|
||||
[48]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2016/12/ChristmasTux2002_1600x1200_result.jpg?resize=800%2C600&ssl=1
|
||||
[49]: https://itsfoss.com/christmas-linux-wallpaper/christmastux2002_1600x1200_result/
|
||||
[50]: http://www.klowner.com/wallpaper/christmas_tux_2002/
|
||||
[51]: http://www.computerworld.com/article/3151076/linux/merry-linux-to-you.html
|
||||
[52]: https://twitter.com/bugfarm
|
||||
[53]: https://www.youtube.com/watch?v=dhzxQCTCI3E
|
||||
[54]: https://www.youtube.com/watch?v=oyEyMjdD2uk
|
||||
@ -1,3 +1,4 @@
|
||||
robsean translating
|
||||
Graphics and music tools for game development
|
||||
======
|
||||
|
||||
|
||||
@ -1,220 +0,0 @@
|
||||
How To Remove Password From A PDF File in Linux
|
||||
======
|
||||
|
||||

|
||||
Today I happen to share a password protected PDF file to one of my friend. I knew the password of that PDF file, but I didn’t want to disclose it. Instead, I just wanted to remove the password and send the file to him. I started to looking for some easy ways to remove the password protection from the pdf files on Internet. After a quick google search, I came up with four methods to remove password from a PDF file in Linux. The funny thing is I had already done it few years ago and I almost forgot it. If you’re wondering how to remove password from a PDF file in Linux, read on! It is not that difficult.
|
||||
|
||||
### Remove Password From A PDF File in Linux
|
||||
|
||||
**Method 1 – Using Qpdf**
|
||||
|
||||
The **Qpdf** is a PDF transformation software which is used to encrypt and decrypt PDF files, convert PDF files to another equivalent pdf files. Qpdf is available in the default repositories of most Linux distributions, so you can install it using the default package manager.
|
||||
|
||||
For example, Qpdf can be installed on Arch Linux and its variants using [**pacman**][1] as shown below.
|
||||
```
|
||||
$ sudo pacman -S qpdf
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt-get install qpdf
|
||||
|
||||
```
|
||||
|
||||
Now let us remove the password from a pdf file using qpdf.
|
||||
|
||||
I have a password-protected PDF file named **“secure.pdf”**. Whenever I open this file, it prompts me to enter the password to display its contents.
|
||||
|
||||
![][3]
|
||||
|
||||
I know the password of the above pdf file. However, I don’t want to share the password with anyone. So what I am going to do is to simply remove the password of the PDF file using Qpdf utility with following command.
|
||||
```
|
||||
$ qpdf --password='123456' --decrypt secure.pdf output.pdf
|
||||
|
||||
```
|
||||
|
||||
Quite easy, isn’t it? Yes, it is! Here, **123456** is the password of the **secure.pdf** file. Replace the password with your own.
|
||||
|
||||
**Method 2 – Using Pdftk**
|
||||
|
||||
**Pdftk** is yet another great software for manipulating pdf documents. Pdftk can do almost all sort of pdf operations, such as;
|
||||
|
||||
* Encrypt and decrypt pdf files.
|
||||
* Merge PDF documents.
|
||||
* Collate PDF page Scans.
|
||||
* Split PDF pages.
|
||||
* Rotate PDF files or pages.
|
||||
* Fill PDF forms with X/FDF data and/or flatten forms.
|
||||
* Generate FDF data stencils from PDF forms.
|
||||
* Apply a background watermark or a foreground stamp.
|
||||
* Report PDF metrics, bookmarks and metadata.
|
||||
* Add/update PDF bookmarks or metadata.
|
||||
* Attach files to PDF pages or the PDF document.
|
||||
* Unpack PDF attachments.
|
||||
* Burst a PDF file into single pages.
|
||||
* Compress and decompress page streams.
|
||||
* Repair corrupted PDF file.
|
||||
|
||||
|
||||
|
||||
Pddftk is available in AUR, so you can install it using any AUR helper programs on Arch Linux its derivatives.
|
||||
|
||||
Using [**Pacaur**][4]:
|
||||
```
|
||||
$ pacaur -S pdftk
|
||||
|
||||
```
|
||||
|
||||
Using [**Packer**][5]:
|
||||
```
|
||||
$ packer -S pdftk
|
||||
|
||||
```
|
||||
|
||||
Using [**Trizen**][6]:
|
||||
```
|
||||
$ trizen -S pdftk
|
||||
|
||||
```
|
||||
|
||||
Using [**Yay**][7]:
|
||||
```
|
||||
$ yay -S pdftk
|
||||
|
||||
```
|
||||
|
||||
Using [**Yaourt**][8]:
|
||||
```
|
||||
$ yaourt -S pdftk
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint, run:
|
||||
```
|
||||
$ sudo apt-get instal pdftk
|
||||
|
||||
```
|
||||
|
||||
On CentOS, Fedora, Red Hat:
|
||||
|
||||
First, Install EPEL repository:
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
```
|
||||
|
||||
Or
|
||||
```
|
||||
$ sudo dnf install epel-release
|
||||
|
||||
```
|
||||
|
||||
Then install PDFtk application using command:
|
||||
```
|
||||
$ sudo yum install pdftk
|
||||
|
||||
```
|
||||
|
||||
Or
|
||||
```
|
||||
$ sudo dnf install pdftk
|
||||
|
||||
```
|
||||
|
||||
Once pdftk installed, you can remove the password from a pdf document using command:
|
||||
```
|
||||
$ pdftk secure.pdf input_pw 123456 output output.pdf
|
||||
|
||||
```
|
||||
|
||||
Replace ‘123456’ with your correct password. This command decrypts the “secure.pdf” file and create an equivalent non-password protected file named “output.pdf”.
|
||||
|
||||
**Also read:**
|
||||
|
||||
**Method 3 – Using Poppler**
|
||||
|
||||
**Poppler** is a PDF rendering library based on the xpdf-3.0 code base. It contains the following set of command line utilities for manipulating PDF documents.
|
||||
|
||||
* **pdfdetach** – lists or extracts embedded files.
|
||||
* **pdffonts** – font analyzer.
|
||||
* **pdfimages** – image extractor.
|
||||
* **pdfinfo** – document information.
|
||||
* **pdfseparate** – page extraction tool.
|
||||
* **pdfsig** – verifies digital signatures.
|
||||
* **pdftocairo** – PDF to PNG/JPEG/PDF/PS/EPS/SVG converter using Cairo.
|
||||
* **pdftohtml** – PDF to HTML converter.
|
||||
* **pdftoppm** – PDF to PPM/PNG/JPEG image converter.
|
||||
* **pdftops** – PDF to PostScript (PS) converter.
|
||||
* **pdftotext** – text extraction.
|
||||
* **pdfunite** – document merging tool.
|
||||
|
||||
|
||||
|
||||
For the purpose of this guide, we only use the “pdftops” utility.
|
||||
|
||||
To install Poppler on Arch Linux based distributions, run:
|
||||
```
|
||||
$ sudo pacman -S poppler
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt-get install poppler-utils
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS, Fedora:
|
||||
```
|
||||
$ sudo yum install poppler-utils
|
||||
|
||||
```
|
||||
|
||||
Once Poppler installed, run the following command to decrypt the password protected pdf file and create a new equivalent file named output.pdf.
|
||||
```
|
||||
$ pdftops -upw 123456 secure.pdf output.pdf
|
||||
|
||||
```
|
||||
|
||||
Again, replace ‘123456’ with your pdf password.
|
||||
|
||||
As you might noticed in all above methods, we just converted the password protected pdf file named “secure.pdf” to another equivalent pdf file named “output.pdf”. Technically speaking, we really didn’t remove the password from the source file, instead we decrypted it and saved it as another equivalent pdf file without password protection.
|
||||
|
||||
**Method 4 – Print to a file
|
||||
**
|
||||
|
||||
This is the easiest method in all of the above methods. You can use your existing PDF viewer such as Atril document viewer, Evince etc., and print the password protected pdf file to another file.
|
||||
|
||||
Open the password protected file in your PDF viewer application. Go to **File - > Print**. And save the pdf file in any location of your choice.
|
||||
|
||||
![][9]
|
||||
|
||||
And, that’s all. Hope this was useful. Do you know/use any other methods to remove the password protection from PDF files? Let us know in the comment section below.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-remove-password-from-a-pdf-file-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/04/Remove-Password-From-A-PDF-File-1.png
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
@ -1,4 +1,4 @@
|
||||
Command Line Tricks For Data Scientists • kade killary
|
||||
GraveAccent翻译中 Command Line Tricks For Data Scientists • kade killary
|
||||
======
|
||||
|
||||

|
||||
|
||||
@ -1,145 +0,0 @@
|
||||
How to Manage Fonts in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Not only do I write technical documentation, I write novels. And because I’m comfortable with tools like GIMP, I also create my own book covers (and do graphic design for a few clients). That artistic endeavor depends upon a lot of pieces falling into place, including fonts.
|
||||
|
||||
Although font rendering has come a long way over the past few years, it continues to be an issue in Linux. If you compare the look of the same fonts on Linux vs. macOS, the difference is stark. This is especially true when you’re staring at a screen all day. But even though the rendering of fonts has yet to find perfection in Linux, one thing that the open source platform does well is allow users to easily manage their fonts. From selecting, adding, scaling, and adjusting, you can work with fonts fairly easily in Linux.
|
||||
|
||||
Here, I’ll share some of the tips I’ve depended on over the years to help extend my “font-ability” in Linux. These tips will especially help those who undertake artistic endeavors on the open source platform. Because there are so many desktop interfaces available for Linux (each of which deal with fonts in a different way), when a desktop environment becomes central to the management of fonts, I’ll be focusing primarily on GNOME and KDE.
|
||||
|
||||
With that said, let’s get to work.
|
||||
|
||||
### Adding new fonts
|
||||
|
||||
For the longest time, I have been a collector of fonts. Some might say I have a bit of an obsession. And since my early days of using Linux, I’ve always used the same process for adding fonts to my desktops. There are two ways to do this:
|
||||
|
||||
* Make the fonts available on a per-user basis.
|
||||
|
||||
* Make the fonts available system-wide.
|
||||
|
||||
|
||||
|
||||
|
||||
Because my desktops never have other users (besides myself), I only ever work with fonts on a per-user basis. However, I will show you how to do both. First, let’s see how to add fonts on a per-user basis. The first thing you must do is find fonts. Both True Type Fonts (TTF) and Open Type Fonts (OTF) can be added. I add fonts manually. Do this is, I create a new hidden directory in ~/ called ~/.fonts. This can be done with the command:
|
||||
```
|
||||
mkdir ~/.fonts
|
||||
|
||||
```
|
||||
|
||||
With that folder created, I then move all of my TTF and OTF files into the directory. That’s it. Every font you add into that directory will now be available for use to your installed apps. But remember, those fonts will only be available to that one user.
|
||||
|
||||
If you want to make that collection of fonts available to all, here’s what you do:
|
||||
|
||||
1. Open up a terminal window.
|
||||
|
||||
2. Change into the directory housing all of your fonts.
|
||||
|
||||
3. Copy all of those fonts with the commands sudo cp *.ttf *.TTF /usr/share/fonts/truetype/ and sudo cp *.otf *.OTF /usr/share/fonts/opentype
|
||||
|
||||
|
||||
|
||||
|
||||
The next time a user logs in, they’ll have access to all those glorious fonts.
|
||||
|
||||
### GUI Font Managers
|
||||
|
||||
There are a few ways to manage your fonts in Linux, via GUI. How it’s done will depend on your desktop environment. Let’s examine KDE first. With the KDE that ships with Kubuntu 18.04, you’ll find a Font Management tool pre-installed. Open that tool and you can easily add, remove, enable, and disable fonts (as well as get information about all of the installed fonts. This tool also makes it easy for you to add and remove fonts for personal and system-wide use. Let’s say you want to add a particular font for personal usage. To do this, download your font and then open up the Font Management tool. In this tool (Figure 1), click on Personal Fonts and then click the + Add button.
|
||||
|
||||
|
||||
![adding fonts][2]
|
||||
|
||||
Figure 1: Adding personal fonts in KDE.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Navigate to the location of your fonts, select them, and click Open. Your fonts will then be added to the Personal section and are immediately available for you to use (Figure 2).
|
||||
|
||||
|
||||
![KDE Font Manager][5]
|
||||
|
||||
Figure 2: Fonts added with the KDE Font Manager.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
To do the same thing in GNOME requires the installation of an application. Open up either GNOME Software or Ubuntu Software (depending upon the distribution you’re using) and search for Font Manager. Select Font Manager and then click the Install button. Once the software is installed, launch it from the desktop menu. With the tool open, let’s install fonts on a per-user basis. Here’s how:
|
||||
|
||||
1. Select User from the left pane (Figure 3).
|
||||
|
||||
2. Click the + button at the top of the window.
|
||||
|
||||
3. Navigate to and select the downloaded fonts.
|
||||
|
||||
4. Click Open.
|
||||
|
||||
|
||||
|
||||
|
||||
![Adding fonts ][7]
|
||||
|
||||
Figure 3: Adding fonts in GNOME.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### Tweaking fonts
|
||||
|
||||
There are three concepts you must first understand:
|
||||
|
||||
* **Font Hinting:** The use of mathematical instructions to adjust the display of a font outline so that it lines up with a rasterized grid.
|
||||
|
||||
* **Anti-aliasing:** The technique used to add greater realism to a digital image by smoothing jagged edges on curved lines and diagonals.
|
||||
|
||||
* **Scaling factor:** **** A scalable unit that allows you to multiple the point size of a font. So if you’re font is 12pt and you have an scaling factor of 1, the font size will be 12pt. If your scaling factor is 2, the font size will be 24pt.
|
||||
|
||||
|
||||
|
||||
|
||||
Let’s say you’ve installed your fonts, but they don’t look quite as good as you’d like. How do you tweak the appearance of fonts? In both the KDE and GNOME desktops, you can make a few adjustments. One thing to consider with the tweaking of fonts is that taste is very much subjective. You might find yourself having to continually tweak until you get the fonts looking exactly how you like (dictated by your needs and particular taste). Let’s first look at KDE.
|
||||
|
||||
Open up the System Settings tool and clock on Fonts. In this section, you can not only change various fonts, you can also enable and configure both anti-aliasing and enable font scaling factor (Figure 4).
|
||||
|
||||
|
||||
![Configuring fonts][9]
|
||||
|
||||
Figure 4: Configuring fonts in KDE.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
To configure anti-aliasing, select Enabled from the drop-down and then click Configure. In the resulting window (Figure 5), you can configure an exclude range, sub-pixel rendering type, and hinting style.
|
||||
|
||||
Once you’ve made your changes, click Apply. Restart any running applications and the new settings will take effect.
|
||||
|
||||
To do this in GNOME, you have to have either use Font Manager or GNOME Tweaks installed. For this, GNOME Tweaks is the better tool. If you open the GNOME Dash and cannot find Tweaks installed, open GNOME Software (or Ubuntu Software), and install GNOME Tweaks. Once installed, open it and click on the Fonts section. Here you can configure hinting, anti-aliasing, and scaling factor (Figure 6).
|
||||
|
||||
![Tweaking fonts][11]
|
||||
|
||||
Figure 6: Tweaking fonts in GNOME.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### Make your fonts beautiful
|
||||
|
||||
And that’s the gist of making your fonts look as beautiful as possible in Linux. You may not see a macOS-like rendering of fonts, but you can certainly improve the look. Finally, the fonts you choose will have a large impact on how things look. Make sure you’re installing clean, well-designed fonts; otherwise, you’re fighting a losing battle.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/5/how-manage-fonts-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[2]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_1.jpg?itok=7yTTe6o3 (adding fonts)
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_2.jpg?itok=_g0dyVYq (KDE Font Manager)
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_3.jpg?itok=8o884QKs (Adding fonts )
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_4.jpg?itok=QJpPzFED (Configuring fonts)
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_6.jpg?itok=4cQeIW9C (Tweaking fonts)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,313 +0,0 @@
|
||||
(translating by runningwater)
|
||||
Version Control Before Git with CVS
|
||||
======
|
||||
Github was launched in 2008. If your software engineering career, like mine, is no older than Github, then Git may be the only version control software you have ever used. While people sometimes grouse about its steep learning curve or unintuitive interface, Git has become everyone’s go-to for version control. In Stack Overflow’s 2015 developer survey, 69.3% of respondents used Git, almost twice as many as used the second-most-popular version control system, Subversion. After 2015, Stack Overflow stopped asking developers about the version control systems they use, perhaps because Git had become so popular that the question was uninteresting.
|
||||
|
||||
Git itself is not much older than Github. Linus Torvalds released the first version of Git in 2005. Though today younger developers might have a hard time conceiving of a world where the term “version control software” didn’t more or less just mean Git, such a world existed not so long ago. There were lots of alternatives to choose from. Open source developers preferred Subversion, enterprises and video game companies used Perforce (some still do), while the Linux kernel project famously relied on a version control system called BitKeeper.
|
||||
|
||||
Some of these systems, particularly BitKeeper, might feel familiar to a young Git user transported back in time. Most would not. BitKeeper aside, the version control systems that came before Git worked according to a fundamentally different paradigm. In a taxonomy offered by Eric Sink, author of Version Control by Example, Git is a third-generation version control system, while most of Git’s predecessors, the systems popular in the 1990s and early 2000s, are second-generation version control systems. Where third-generation version control systems are distributed, second-generation version control systems are centralized. You have almost certainly heard Git described as a “distributed” version control system before. I never quite understood the distributed/centralized distinction, at least not until I installed and experimented with a centralized second-generation version control system myself.
|
||||
|
||||
The system I installed was CVS. CVS, short for Concurrent Versions System, was the very first second-generation version control system. It was also the most popular version control system for about a decade until it was replaced in 2000 by Subversion. Even then, Subversion was supposed to be “CVS but better,” which only underscores how dominant CVS had become throughout the 1990s.
|
||||
|
||||
CVS was first developed in 1986 by a Dutch computer scientist named Dick Grune, who was looking for a way to collaborate with his students on a compiler project. CVS was initially little more than a collection of shell scripts wrapping RCS (Revision Control System), a first-generation version control system that Grune wanted to improve. RCS works according to a pessimistic locking model, meaning that no two programmers can work on a single file at once. In order to edit a file, you have to first ask RCS for an exclusive lock on the file, which you keep until you are finished editing. If someone else is already editing a file you need to edit, you have to wait. CVS improved on RCS and ushered in the second generation of version control systems by trading the pessimistic locking model for an optimistic one. Programmers could now edit the same file at the same time, merging their edits and resolving any conflicts later. (Brian Berliner, an engineer who later took over the CVS project, wrote a very readable [paper][1] about CVS’ innovations in 1990.)
|
||||
|
||||
In that sense, CVS wasn’t all that different from Git, which also works according to an optimistic model. But that’s where the similarities end. In fact, when Linus Torvalds was developing Git, one of his guiding principles was WWCVSND, or “What Would CVS Not Do.” Whenever he was in doubt about a decision, he strove to choose the option that had not been chosen in the design of CVS. So even though CVS predates Git by over a decade, it influenced Git as a kind of negative template.
|
||||
|
||||
I’ve really enjoyed playing around with CVS. I think there’s no better way to understand why Git’s distributed nature is such an improvement on what came before. So I invite you to come along with me on an exciting journey and spend the next ten minutes of your life learning about a piece of software nobody has used in the last decade. (See correction.)
|
||||
|
||||
### Getting Started with CVS
|
||||
|
||||
Instructions for installing CVS can be found on the [project’s homepage][2]. On MacOS, you can install CVS using Homebrew.
|
||||
|
||||
Since CVS is centralized, it distinguishes between the client-side universe and the server-side universe in a way that something like Git does not. The distinction is not so pronounced that there are different executables. But in order to start using CVS, even on your own machine, you’ll have to set up the CVS backend.
|
||||
|
||||
The CVS backend, the central store for all your code, is called the repository. Whereas in Git you would typically have a repository for every project, in CVS the repository holds all of your projects. There is one central repository for everything, though there are ways to work with only a project at a time.
|
||||
|
||||
To create a local repository, you run the `init` command. You would do this somewhere global like your home directory.
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox init
|
||||
```
|
||||
|
||||
CVS allows you to pass options to either the `cvs` command itself or to the `init` subcommand. Options that appear after the `cvs` command are global in nature, while options that appear after the subcommand are specific to the subcommand. In this case, the `-d` flag is global. Here it happens to tell CVS where we want to create our repository, but in general the `-d` flag points to the location of the repository we want to use for any given action. It can be tedious to supply the `-d` flag all the time, so the `CVSROOT` environment variable can be set instead.
|
||||
|
||||
Since we’re working locally, we’ve just passed a path for our `-d` argument, but we could also have included a hostname.
|
||||
|
||||
The command creates a directory called `sandbox` in your home directory. If you list the contents of `sandbox`, you’ll find that it contains another directory called `CVSROOT`. This directory, not to be confused with the environment variable, holds administrative files for the repository.
|
||||
|
||||
Congratulations! You’ve just created your first CVS repository.
|
||||
|
||||
### Checking In Code
|
||||
|
||||
Let’s say that you’ve decided to keep a list of your favorite colors. You are an artistically inclined but extremely forgetful person. You type up your list of colors and save it as a file called `favorites.txt`:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
Let’s also assume that you’ve saved your file in a new directory called `colors`. Now you’d like to put your favorite color list under version control, because fifty years from now it will be interesting to look back and see how your tastes changed through time.
|
||||
|
||||
In order to do that, you will have to import your directory as a new CVS project. You can do that using the `import` command:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox import -m "" colors colors initial
|
||||
N colors/favorites.txt
|
||||
|
||||
No conflicts created by this import
|
||||
```
|
||||
|
||||
Here we are specifying the location of our repository with the `-d` flag again. The remaining arguments are passed to the `import` subcommand. We have to provide a message, but here we don’t really need one, so we’ve left it blank. The next argument, `colors`, specifies the name of our new directory in the repository; here we’ve just used the same name as the directory we are in. The last two arguments specify the vendor tag and the release tag respectively. We’ll talk more about tags in a minute.
|
||||
|
||||
You’ve just pulled your “colors” project into the CVS repository. There are a couple different ways to go about bringing code into CVS, but this is the method recommended by [Pragmatic Version Control Using CVS][3], the Pragmatic Programmer book about CVS. What makes this method a little awkward is that you then have to check out your work fresh, even though you’ve already got an existing `colors` directory. Instead of using that directory, you’re going to delete it and then check out the version that CVS already knows about:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox co colors
|
||||
cvs checkout: Updating colors
|
||||
U colors/favorites.txt
|
||||
```
|
||||
|
||||
This will create a new directory, also called `colors`. In this directory you will find your original `favorites.txt` file along with a directory called `CVS`. The `CVS` directory is basically CVS’ equivalent of the `.git` directory in every Git repository.
|
||||
|
||||
### Making Changes
|
||||
|
||||
Get ready for a trip.
|
||||
|
||||
Just like Git, CVS has a `status` subcommand:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
|
||||
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: fD7GYxt035GNg8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
This is where things start to look alien. CVS doesn’t have commit objects. In the above, there is something called a “Commit Identifier,” but this might be only a relatively recent edition—no mention of a “Commit Identifier” appears in Pragmatic Version Control Using CVS, which was published in 2003. (The last update to CVS was released in 2008.)
|
||||
|
||||
Whereas with Git you’d talk about the version of a file associated with commit `45de392`, in CVS files are versioned separately. The first version of your file is version 1.1, the next version is 1.2, and so on. When branches are involved, extra numbers are appended, so you might end up with something like the `1.1.1.1` above, which appears to be the default in our case even though we haven’t created any branches.
|
||||
|
||||
If you were to run `cvs log` (equivalent to `git log`) in a project with lots of files and commits, you’d see an individual history for each file. You might have a file at version 1.2 and a file at version 1.14 in the same project.
|
||||
|
||||
Let’s go ahead and make a change to version 1.1 of our `favorites.txt` file:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
+cyan
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
Once we’ve made the change, we can run `cvs diff` to see what CVS thinks we’ve done:
|
||||
|
||||
```
|
||||
$ cvs diff
|
||||
cvs diff: Diffing .
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.1.1.1
|
||||
diff -r1.1.1.1 favorites.txt
|
||||
3a4
|
||||
> cyan
|
||||
```
|
||||
|
||||
CVS recognizes that we added a new line containing the color “cyan” to the file. (Actually, it says we’ve made changes to the “RCS” file; you can see that CVS never fully escaped its original association with RCS.) The diff we are being shown is the diff between the copy of `favorites.txt` in our working directory and the 1.1.1.1 version stored in the repository.
|
||||
|
||||
In order to update the version stored in the repository, we have to commit the change. In Git, this would be a multi-step process. We’d have to stage the change so that it appears in our index. Then we’d commit the change. Finally, to make the change visible to anyone else, we’d have to push the commit up to the origin repository.
|
||||
|
||||
In CVS, all of these things happen when you run `cvs commit`. CVS just bundles up all the changes it can find and puts them in the repository:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Add cyan to favorites."
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.2; previous revision: 1.1
|
||||
```
|
||||
|
||||
I’m so used to Git that this strikes me as terrifying. Without an opportunity to stage changes, any old thing that you’ve touched in your working directory might end up as part of the public repository. Did you passive-aggressively rewrite a coworker’s poorly implemented function out of cathartic necessity, never intending for him to know? Too bad, he now thinks you’re a dick. You also can’t edit your commits before pushing them, since a commit is a push. Do you enjoy spending 40 minutes repeatedly running `git rebase -i` until your local commit history flows like the derivation of a mathematical proof? Sorry, you can’t do that here, and everyone is going to find out that you don’t actually write your tests first.
|
||||
|
||||
But I also now understand why so many people find Git needlessly complicated. If `cvs commit` is what you were used to, then I’m sure staging and pushing changes would strike you as a pointless chore.
|
||||
|
||||
When people talk about Git being a “distributed” system, this is primarily the difference they mean. In CVS, you can’t make commits locally. A commit is a submission of code to the central repository, so it’s not something you can do without a connection. All you’ve got locally is your working directory. In Git, you have a full-fledged local repository, so you can make commits all day long even while disconnected. And you can edit those commits, revert, branch, and cherry pick as much as you want, without anybody else having to know.
|
||||
|
||||
Since commits were a bigger deal, CVS users often made them infrequently. Commits would contain as many changes as today we might expect to see in a ten-commit pull request. This was especially true if commits triggered a CI build and an automated test suite.
|
||||
|
||||
If we now run `cvs status`, we can see that we have a new version of our file:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.2 2018-07-06 21:18:59 -0400
|
||||
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: pQx5ooyNk90wW8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
### Merging
|
||||
|
||||
As mentioned above, in CVS you can edit a file that someone else is already editing. That was CVS’ big improvement on RCS. What happens when you need to bring your changes back together?
|
||||
|
||||
Let’s say that you have invited some friends to add their favorite colors to your list. While they are adding their colors, you decide that you no longer like the color green and remove it from the list.
|
||||
|
||||
When you go to commit your changes, you might discover that CVS notices a problem:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Remove green"
|
||||
cvs commit: Examining .
|
||||
cvs commit: Up-to-date check failed for `favorites.txt'
|
||||
cvs [commit aborted]: correct above errors first!
|
||||
```
|
||||
|
||||
It looks like your friends committed their changes first. So your version of `favorites.txt` is not up-to-date with the version in the repository. If you run `cvs status`, you’ll see that your local copy of `favorites.txt` is version 1.2 with some local changes, but the repository version is 1.3:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Needs Merge
|
||||
|
||||
Working revision: 1.2 2018-07-07 10:42:43 -0400
|
||||
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: 2oZ6n0G13bDaldJA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
You can run `cvs diff` to see exactly what the differences between 1.2 and 1.3 are:
|
||||
|
||||
```
|
||||
$ cvs diff -r HEAD favorites.txt
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.3
|
||||
diff -r1.3 favorites.txt
|
||||
3d2
|
||||
< green
|
||||
7,10d5
|
||||
<
|
||||
< pink
|
||||
< hot pink
|
||||
< bubblegum pink
|
||||
```
|
||||
|
||||
It seems that our friends really like pink. In any case, they’ve edited a different part of the file than we have, so the changes are easy to merge. CVS can do that for us when we run `cvs update`, which is similar to `git pull`:
|
||||
|
||||
```
|
||||
$ cvs update
|
||||
cvs update: Updating .
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.2
|
||||
retrieving revision 1.3
|
||||
Merging differences between 1.2 and 1.3 into favorites.txt
|
||||
M favorites.txt
|
||||
```
|
||||
|
||||
If you now take a look at `favorites.txt`, you’ll find that it has been modified to include the changes that your friends made to the file. Your changes are still there too. Now you are free to commit the file:
|
||||
|
||||
```
|
||||
$ cvs commit
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.4; previous revision: 1.3
|
||||
```
|
||||
|
||||
The end result is what you’d get in Git by running `git pull --rebase`. Your changes have been added on top of your friends’ changes. There is no “merge commit.”
|
||||
|
||||
Sometimes, changes to the same file might be incompatible. If your friends had changed “green” to “olive,” for example, that would have conflicted with your change removing “green” altogether. In the early days of CVS, this was exactly the kind of case that caused people to worry that CVS wasn’t safe; RCS’ pessimistic locking ensured that such a case could never arise. But CVS guarantees safety by making sure that nobody’s changes get overwritten automatically. You have to tell CVS which change you want to keep going forward, so when you run `cvs update`, CVS marks up the file with both changes in the same way that Git does when Git detects a merge conflict. You then have to manually edit the file and pick the change you want to keep.
|
||||
|
||||
The interesting thing to note here is that merge conflicts have to be fixed before you can commit. This is another consequence of CVS’ centralized nature. In Git, you don’t have to worry about resolving merges until you push the commits you’ve got locally.
|
||||
|
||||
Since CVS doesn’t have easily addressable commit objects, the only way to group a collection of changes is to mark a particular working directory state with a tag.
|
||||
|
||||
Creating a tag is easy:
|
||||
|
||||
```
|
||||
$ cvs tag VERSION_1_0
|
||||
cvs tag: Tagging .
|
||||
T favorites.txt
|
||||
```
|
||||
|
||||
You’ll later be able to return files to this state by running `cvs update` and passing the tag to the `-r` flag:
|
||||
|
||||
```
|
||||
$ cvs update -r VERSION_1_0
|
||||
cvs update: Updating .
|
||||
U favorites.txt
|
||||
```
|
||||
|
||||
Because you need a tag to rewind to an earlier working directory state, CVS encourages a lot of preemptive tagging. Before major refactors, for example, you might create a `BEFORE_REFACTOR_01` tag that you could later use if the refactor went wrong. People also used tags if they wanted to generate project-wide diffs. Basically, all the things we routinely do today with commit hashes have to be anticipated and planned for with CVS, since you needed to have the tags available already.
|
||||
|
||||
Branches can be created in CVS, sort of. Branches are just a special kind of tag:
|
||||
|
||||
```
|
||||
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
|
||||
cvs rtag: Tagging colors
|
||||
```
|
||||
|
||||
That only creates the branch (in full view of everyone, by the way), so you still need to switch to it using `cvs update`:
|
||||
|
||||
```
|
||||
$ cvs update -r TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
The above commands switch onto the new branch in your current working directory, but Pragmatic Version Control Using CVS actually advises that you create a new directory to hold your new branch. Presumably its authors found switching directories easier than switching branches in CVS.
|
||||
|
||||
Pragmatic Version Control Using CVS also advises against creating branches off of an existing branch. They recommend only creating branches off of the mainline branch, which in Git is known as `master`. In general, branching was considered an “advanced” CVS skill. In Git, you might start a new branch for almost any trivial reason, but in CVS branching was typically used only when really necessary, such as for releases.
|
||||
|
||||
A branch could later be merged back into the mainline using `cvs update` and the `-j` flag:
|
||||
|
||||
```
|
||||
$ cvs update -j TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
### Thanks for the Commit Histories
|
||||
|
||||
In 2007, Linus Torvalds gave [a talk][4] about Git at Google. Git was very new then, so the talk was basically an attempt to persuade a roomful of skeptical programmers that they should use Git, even though Git was so different from anything then available. If you haven’t already seen the talk, I highly encourage you to watch it. Linus is an entertaining speaker, even if he never fails to be his brash self. He does an excellent job of explaining why the distributed model of version control is better than the centralized one. A lot of his criticism is reserved for CVS in particular.
|
||||
|
||||
Git is a [complex tool][5]. Learning it can be a frustrating experience. But I’m also continually amazed at the things that Git can do. In comparison, CVS is simple and straightforward, though often unable to do many of the operations we now take for granted. Going back and using CVS for a while is an excellent way to find yourself with a new appreciation for Git’s power and flexibility. It illustrates well why understanding the history of software development can be so beneficial—picking up and re-examining obsolete tools will teach you volumes about the why behind the tools we use today.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][6] on Twitter or subscribe to the [RSS feed][7] to make sure you know when a new post is out.
|
||||
|
||||
#### Correction
|
||||
|
||||
I’ve been told that there are many organizations, particularly risk-adverse organizations that do things like make medical device software, that still use CVS. Programmers in these organizations have developed little tricks for working around CVS’ limitations, such as making a new branch for almost every change to avoid committing directly to `HEAD`. (Thanks to Michael Kohne for pointing this out.)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/07/07/cvs.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.freebsd.org/44doc/psd/28.cvs/paper.pdf
|
||||
[2]: https://www.nongnu.org/cvs/
|
||||
[3]: http://shop.oreilly.com/product/9780974514000.do
|
||||
[4]: https://www.youtube.com/watch?v=4XpnKHJAok8
|
||||
[5]: https://xkcd.com/1597/
|
||||
[6]: https://twitter.com/TwoBitHistory
|
||||
[7]: https://twobithistory.org/feed.xml
|
||||
@ -1,56 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
5 Firefox extensions to protect your privacy
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the wake of the Cambridge Analytica story, I took a hard look at how far I had let Facebook penetrate my online presence. As I'm generally concerned about single points of failure (or compromise), I am not one to use social logins. I use a password manager and create unique logins for every site (and you should, too).
|
||||
|
||||
What I was most perturbed about was the pervasive intrusion Facebook was having on my digital life. I uninstalled the Facebook mobile app almost immediately after diving into the Cambridge Analytica story. I also [disconnected all apps, games, and websites][1] from Facebook. Yes, this will change your experience on Facebook, but it will also protect your privacy. As a veteran with friends spread out across the globe, maintaining the social connectivity of Facebook is important to me.
|
||||
|
||||
I went about the task of scrutinizing other services as well. I checked Google, Twitter, GitHub, and more for any unused connected applications. But I know that's not enough. I need my browser to be proactive in preventing behavior that violates my privacy. I began the task of figuring out how best to do that. Sure, I can lock down a browser, but I need to make the sites and tools I use work while trying to keep them from leaking data.
|
||||
|
||||
Following are five tools that will protect your privacy while using your browser. The first three extensions are available for Firefox and Chrome, while the latter two are only available for Firefox.
|
||||
|
||||
### Privacy Badger
|
||||
|
||||
[Privacy Badger][2] has been my go-to extension for quite some time. Do other content or ad blockers do a better job? Maybe. The problem with a lot of content blockers is that they are "pay for play." Meaning they have "partners" that get whitelisted for a fee. That is the antithesis of why content blockers exist. Privacy Badger is made by the Electronic Frontier Foundation (EFF), a nonprofit entity with a donation-based business model. Privacy Badger promises to learn from your browsing habits and requires minimal tuning. For example, I have only had to whitelist a handful of sites. Privacy Badger also allows granular controls of exactly which trackers are enabled on what sites. It's my #1, must-install extension, no matter the browser.
|
||||
|
||||
### DuckDuckGo Privacy Essentials
|
||||
|
||||
The search engine DuckDuckGo has typically been privacy-conscious. [DuckDuckGo Privacy Essentials][3] works across major mobile devices and browsers. It's unique in the sense that it grades sites based on the settings you give them. For example, Facebook gets a D, even with Privacy Protection enabled. Meanwhile, [chrisshort.net][4] gets a B with Privacy Protection enabled and a C with it disabled. If you're not keen on EFF or Privacy Badger for whatever reason, I would recommend DuckDuckGo Privacy Essentials (choose one, not both, as they essentially do the same thing).
|
||||
|
||||
### HTTPS Everywhere
|
||||
|
||||
[HTTPS Everywhere][5] is another extension from the EFF. According to HTTPS Everywhere, "Many sites on the web offer some limited support for encryption over HTTPS, but make it difficult to use. For instance, they may default to unencrypted HTTP or fill encrypted pages with links that go back to the unencrypted site. The HTTPS Everywhere extension fixes these problems by using clever technology to rewrite requests to these sites to HTTPS." While a lot of sites and browsers are getting better about implementing HTTPS, there are a lot of sites that still need help. HTTPS Everywhere will try its best to make sure your traffic is encrypted.
|
||||
|
||||
### NoScript Security Suite
|
||||
|
||||
[NoScript Security Suite][6] is not for the faint of heart. While the Firefox-only extension "allows JavaScript, Java, Flash, and other plugins to be executed only by trusted websites of your choice," it doesn't do a great job at figuring out what your choices are. But, make no mistake, a surefire way to prevent leaking data is not executing code that could leak it. NoScript enables that via its "whitelist-based preemptive script blocking." This means you will need to build the whitelist as you go for sites not already on it. Note that NoScript is only available for Firefox.
|
||||
|
||||
### Facebook Container
|
||||
|
||||
[Facebook Container][7] makes Firefox the only browser where I will use Facebook. "Facebook Container works by isolating your Facebook identity into a separate container that makes it harder for Facebook to track your visits to other websites with third-party cookies." This means Facebook cannot snoop on activity happening elsewhere in your browser. Suddenly those creepy ads will stop appearing so frequently (assuming you uninstalled the Facebook app from your mobile devices). Using Facebook in an isolated space will prevent any additional collection of data. Remember, you've given Facebook data already, and Facebook Container can't prevent that data from being shared.
|
||||
|
||||
These are my go-to extensions for browser privacy. What are yours? Please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/firefox-extensions-protect-privacy
|
||||
|
||||
作者:[Chris Short][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/chrisshort
|
||||
[1]:https://www.facebook.com/help/211829542181913
|
||||
[2]:https://www.eff.org/privacybadger
|
||||
[3]:https://duckduckgo.com/app
|
||||
[4]:https://chrisshort.net
|
||||
[5]:https://www.eff.org/https-everywhere
|
||||
[6]:https://noscript.net/
|
||||
[7]:https://addons.mozilla.org/en-US/firefox/addon/facebook-container/
|
||||
@ -1,7 +1,3 @@
|
||||
**translating by [erlinux](https://github.com/erlinux)**
|
||||
**PROJECT MANAGEMENT TOOL called [gn2.sh](https://github.com/lctt/lctt-cli)**
|
||||
|
||||
|
||||
How to analyze your system with perf and Python
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
### translating by way-ww
|
||||
|
||||
4 Must-Have Tools for Monitoring Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Create a containerized machine learning model
|
||||
======
|
||||
|
||||
|
||||
163
sources/tech/20181105 5 Minimal Web Browsers for Linux.md
Normal file
163
sources/tech/20181105 5 Minimal Web Browsers for Linux.md
Normal file
@ -0,0 +1,163 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (5 Minimal Web Browsers for Linux)
|
||||
[#]: via: (https://www.linux.com/blog/intro-to-linux/2018/11/5-minimal-web-browsers-linux)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
[#]: url: ( )
|
||||
|
||||
5 Minimal Web Browsers for Linux
|
||||
======
|
||||

|
||||
|
||||
There are so many reasons to enjoy the Linux desktop. One reason I often state up front is the almost unlimited number of choices to be found at almost every conceivable level. From how you interact with the operating system (via a desktop interface), to how daemons run, to what tools you use, you have a multitude of options.
|
||||
|
||||
The same thing goes for web browsers. You can use anything from open source favorites, such as [Firefox][1] and [Chromium][2], or closed sourced industry darlings like [Vivaldi][3] and [Chrome][4]. Those options are full-fledged browsers with every possible bell and whistle you’ll ever need. For some, these feature-rich browsers are perfect for everyday needs.
|
||||
|
||||
There are those, however, who prefer using a web browser without all the frills. In fact, there are many reasons why you might prefer a minimal browser over a standard browser. For some, it’s about browser security, while others look at a web browser as a single-function tool (as opposed to a one-stop shop application). Still others might be running low-powered machines that cannot handle the requirements of, say, Firefox or Chrome. Regardless of the reason, Linux has you covered.
|
||||
|
||||
Let’s take a look at five of the minimal browsers that can be installed on Linux. I’ll be demonstrating these browsers on the Elementary OS platform, but each of these browsers are available to nearly every distribution in the known Linuxverse. Let’s dive in.
|
||||
|
||||
### GNOME Web
|
||||
|
||||
GNOME Web (codename Epiphany, which means [“a usually sudden manifestation or perception of the essential nature or meaning of something”][5]) is the default web browser for Elementary OS, but it can be installed from the standard repositories. (Note, however, that the recommended installation of Epiphany is via Flatpak or Snap). If you choose to install via the standard package manager, issue a command such as sudo apt-get install epiphany-browser -y for successful installation.
|
||||
|
||||
Epiphany uses the WebKit rendering engine, which is the same engine used in Apple’s Safari browser. Couple that rendering engine with the fact that Epiphany has very little in terms of bloat to get in the way, you will enjoy very fast page-rendering speeds. Epiphany development follows strict adherence to the following guidelines:
|
||||
|
||||
* Simplicity - Feature bloat and user interface clutter are considered evil.
|
||||
|
||||
* Standards compliance - No non-standard features will ever be introduced to the codebase.
|
||||
|
||||
* Software freedom - Epiphany will always be released under a license that respects freedom.
|
||||
|
||||
* Human interface - Epiphany follows the [GNOME Human Interface Guidelines][6].
|
||||
|
||||
* Minimal preferences - Preferences are only added when they make sense and after careful consideration.
|
||||
|
||||
* Target audience - Non-technical users are the primary target audience (which helps to define the types of features that are included).
|
||||
|
||||
|
||||
|
||||
|
||||
GNOME Web is as clean and simple a web browser as you’ll find (Figure 1).
|
||||
|
||||
![GNOME Web][8]
|
||||
|
||||
Figure 1: The GNOME Web browser displaying a minimal amount of preferences for the user.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
The GNOME Web manifesto reads:
|
||||
|
||||
A web browser is more than an application: it is a way of thinking, a way of seeing the world. Epiphany's principles are simplicity, standards compliance, and software freedom.
|
||||
|
||||
### Netsurf
|
||||
|
||||
The [Netsurf][10] minimal web browser opens almost faster than you can release the mouse button. Netsurf uses its own layout and rendering engine (designed completely from scratch), which is rather hit and miss in its rendering (Figure 2).
|
||||
|
||||

|
||||
|
||||
Although you might find Netsurf to suffer from rendering issues on certain sites, understand the Hubbub HTML parser is following the work-in-progress HTML5 specification, so there will be issues popup now and then. To ease those rendering headaches, Netsurf does include HTTPS support, web page thumbnailing, URL completion, scale view, bookmarks, full-screen mode, keyboard shorts, and no particular GUI toolkit requirements. That last bit is important, especially when you switch from one desktop to another.
|
||||
|
||||
For those curious as to the requirements for Netsurf, the browser can run on a machine as slow as a 30Mhz ARM 6 computer with 16MB of RAM. That’s impressive, by today’s standard.
|
||||
|
||||
### QupZilla
|
||||
|
||||
If you’re looking for a minimal browser that uses the Qt Framework and the QtWebKit rendering engine, [QupZilla][11] might be exactly what you’re looking for. QupZilla does include all the standard features and functions you’d expect from a web browser, such as bookmarks, history, sidebar, tabs, RSS feeds, ad blocking, flash blocking, and CA Certificates management. Even with those features, QupZilla still manages to remain a very fast lightweight web browser. Other features include: Fast startup, speed dial homepage, built-in screenshot tool, browser themes, and more.
|
||||
One feature that should appeal to average users is that QupZilla has a more standard preferences tools than found in many lightweight browsers (Figure 3). So, if going too far outside the lines isn’t your style, but you still want something lighter weight, QupZilla is the browser for you.
|
||||
|
||||
![QupZilla][13]
|
||||
|
||||
Figure 3: The QupZilla preferences tool.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
### Otter Browser
|
||||
|
||||
Otter Browser is a free, open source attempt to recreate the closed-source offerings found in the Opera Browser. Otter Browser uses the WebKit rendering engine and has an interface that should be immediately familiar with any user. Although lightweight, Otter Browser does include full-blown features such as:
|
||||
|
||||
* Passwords manager
|
||||
|
||||
* Add-on manager
|
||||
|
||||
* Content blocking
|
||||
|
||||
* Spell checking
|
||||
|
||||
* Customizable GUI
|
||||
|
||||
* URL completion
|
||||
|
||||
* Speed dial (Figure 4)
|
||||
|
||||
* Bookmarks and various related features
|
||||
|
||||
* Mouse gestures
|
||||
|
||||
* User style sheets
|
||||
|
||||
* Built-in Note tool
|
||||
|
||||
|
||||
![Otter][15]
|
||||
|
||||
Figure 4: The Otter Browser Speed Dial tab.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Otter Browser can be run on nearly any Linux distribution from an [AppImage][16], so there’s no installation required. Just download the AppImage file, give the file executable permissions (with the command chmod u+x otter-browser-*.AppImage), and then launch the app with the command ./otter-browser*.AppImage.
|
||||
|
||||
Otter Browser does an outstanding job of rendering websites and could function as your go-to minimal browser with ease.
|
||||
|
||||
### Lynx
|
||||
|
||||
Let’s get really minimal. When I first started using Linux, back in ‘97, one of the web browsers I often turned to was a text-only take on the app called [Lynx][17]. It should come as no surprise that Lynx is still around and available for installation from the standard repositories. As you might expect, Lynx works from the terminal window and doesn’t display pretty pictures or render much in the way of advanced features (Figure 5). In fact, Lynx is as bare-bones a browser as you will find available. Because of how bare-bones this web browser is, it’s not recommended for everyone. But if you happen to have a gui-less web server and you have a need to be able to read the occasional website, Lynx can be a real lifesaver.
|
||||
|
||||
![Lynx][19]
|
||||
|
||||
Figure 5: The Lynx browser rendering the Linux.com page.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
I have also found Lynx an invaluable tool when troubleshooting certain aspects of a website (or if some feature on a website is preventing me from viewing the content in a regular browser). Another good reason to use Lynx is when you only want to view the content (and not the extraneous elements).
|
||||
|
||||
### Plenty More Where This Came From
|
||||
|
||||
There are plenty more minimal browsers than this. But the list presented here should get you started down the path of minimalism. One (or more) of these browsers are sure to fill that need, whether you’re running it on a low-powered machine or not.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/11/5-minimal-web-browsers-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.mozilla.org/en-US/firefox/new/
|
||||
[2]: https://www.chromium.org/
|
||||
[3]: https://vivaldi.com/
|
||||
[4]: https://www.google.com/chrome/
|
||||
[5]: https://www.merriam-webster.com/dictionary/epiphany
|
||||
[6]: https://developer.gnome.org/hig/stable/
|
||||
[7]: /files/images/minimalbrowsers1jpg
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minimalbrowsers_1.jpg?itok=Q7wZLF8B (GNOME Web)
|
||||
[9]: /licenses/category/used-permission
|
||||
[10]: https://www.netsurf-browser.org/
|
||||
[11]: https://qupzilla.com/
|
||||
[12]: /files/images/minimalbrowsers3jpg
|
||||
[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minimalbrowsers_3.jpg?itok=O8iMALWO (QupZilla)
|
||||
[14]: /files/images/minimalbrowsers4jpg
|
||||
[15]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minimalbrowsers_4.jpg?itok=5bCa0z-e (Otter)
|
||||
[16]: https://sourceforge.net/projects/otter-browser/files/
|
||||
[17]: https://lynx.browser.org/
|
||||
[18]: /files/images/minimalbrowsers5jpg
|
||||
[19]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minimalbrowsers_5.jpg?itok=p_Lmiuxh (Lynx)
|
||||
[20]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,342 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (How To Check The List Of Packages Installed From Particular Repository?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-check-the-list-of-packages-installed-from-particular-repository/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
[#]: url: ( )
|
||||
|
||||
How To Check The List Of Packages Installed From Particular Repository?
|
||||
======
|
||||
|
||||
If you would like to check the list of package installed from particular repository then you are in the right place to get it done.
|
||||
|
||||
Why we need this detail? It may helps you to isolate the installed packages list based on the repository.
|
||||
|
||||
Like, it’s coming from distribution official repository or these are coming from PPA or these are coming from other resources, etc.,
|
||||
|
||||
You may want to know what are the packages came from third party repositories to keep eye on those to avoid any damages on your system.
|
||||
|
||||
So many third party repositories and PPAs are available for Linux. These repositories are included set of packages which is not available in distribution repository due to some limitation.
|
||||
|
||||
It helps administrator to easily install some of the important packages which is not available in the distribution official repository. Installing third party repository on production system is not advisable as this may not properly maintained by the repository maintainer due to many reasons.
|
||||
|
||||
So, you have to decide whether you want to install or not. I can say, we can believe some of the third party repositories which is well maintained and suggested by Linux distributions like [EPEL repository][1], Copr (Cool Other Package Repo), etc,.
|
||||
|
||||
If you would like to see the list of package was installed from the corresponding repo, use the following commands based on your distributions.
|
||||
|
||||
[List of Major repositories][2] and it’s details are below.
|
||||
|
||||
* **`CentOS:`** [EPEL][1], [ELRepo][3], etc is [CentOS Community Approved Repositories][4].
|
||||
* **`Fedora:`** [RPMfusion repo][5] is commonly used by most of the [Fedora][6] users.
|
||||
* **`ArchLinux:`** ArchLinux community repository contains packages that have been adopted by Trusted Users from the Arch User Repository.
|
||||
* **`openSUSE:`** [Packman repo][7] offers various additional packages for openSUSE, especially but not limited to multimedia related applications and libraries that are on the openSUSE Build Service application blacklist. It’s the largest external repository of openSUSE packages.
|
||||
* **`Ubuntu:`** Personal Package Archives (PPAs) are a kind of repository. Developers create them in order to distribute their software. You can find this information on the PPA’s Launchpad page. Also, you can enable Cananical partners repositories.
|
||||
|
||||
|
||||
|
||||
### What Is Repository?
|
||||
|
||||
A software repository is a central place which stores the software packages for the particular application.
|
||||
|
||||
All the Linux distributions are maintaining their own repositories and they allow users to retrieve and install packages on their machine.
|
||||
|
||||
Each vendor offered a unique package management tool to manage their repositories such as search, install, update, upgrade, remove, etc.
|
||||
|
||||
Most of the Linux distributions comes as freeware except RHEL and SUSE. To access their repositories you need to buy a subscriptions.
|
||||
|
||||
### How To Check The List Of Packages Installed From Particular Repository on RHEL/CentOS Systems?
|
||||
|
||||
This can be done in multiple ways. Here we will be giving you all the possible options and you can choose which one is best for you.
|
||||
|
||||
### Method-1: Using Yum Command
|
||||
|
||||
RHEL & CentOS systems are using RPM packages hence we can use the [Yum Package Manager][8] to get this information.
|
||||
|
||||
YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
|
||||
|
||||
Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
|
||||
|
||||
```
|
||||
[[email protected] ~]# yum list installed | grep @epel
|
||||
apachetop.x86_64 0.15.6-1.el7 @epel
|
||||
aria2.x86_64 1.18.10-2.el7.1 @epel
|
||||
atop.x86_64 2.3.0-8.el7 @epel
|
||||
axel.x86_64 2.4-9.el7 @epel
|
||||
epel-release.noarch 7-11 @epel
|
||||
lighttpd.x86_64 1.4.50-1.el7 @epel
|
||||
```
|
||||
|
||||
Alternatively, you can use the yum command with other option to get the same details like above.
|
||||
|
||||
```
|
||||
# yum repo-pkgs epel list installed
|
||||
Loaded plugins: fastestmirror
|
||||
Loading mirror speeds from cached hostfile
|
||||
* epel: epel.mirror.constant.com
|
||||
Installed Packages
|
||||
apachetop.x86_64 0.15.6-1.el7 @epel
|
||||
aria2.x86_64 1.18.10-2.el7.1 @epel
|
||||
atop.x86_64 2.3.0-8.el7 @epel
|
||||
axel.x86_64 2.4-9.el7 @epel
|
||||
epel-release.noarch 7-11 @epel
|
||||
lighttpd.x86_64 1.4.50-1.el7 @epel
|
||||
```
|
||||
|
||||
### Method-2: Using Yumdb Command
|
||||
|
||||
Yumdb info provides information similar to yum info but additionally it provides package checksum data, type, user info (who installed the package). Since yum 3.2.26 yum has started storing additional information outside of the rpmdatabase (where user indicates it was installed by the user, and dep means it was brought in as a dependency).
|
||||
|
||||
```
|
||||
# yumdb search from_repo epel* |egrep -v '(from_repo|^$)'
|
||||
Loaded plugins: fastestmirror
|
||||
apachetop-0.15.6-1.el7.x86_64
|
||||
aria2-1.18.10-2.el7.1.x86_64
|
||||
atop-2.3.0-8.el7.x86_64
|
||||
axel-2.4-9.el7.x86_64
|
||||
epel-release-7-11.noarch
|
||||
lighttpd-1.4.50-1.el7.x86_64
|
||||
```
|
||||
|
||||
### Method-3: Using Repoquery Command
|
||||
|
||||
repoquery is a program for querying information from YUM repositories similarly to rpm queries.
|
||||
|
||||
```
|
||||
# repoquery -a --installed --qf "%{ui_from_repo} %{name}" | grep '^@epel'
|
||||
@epel apachetop
|
||||
@epel aria2
|
||||
@epel atop
|
||||
@epel axel
|
||||
@epel epel-release
|
||||
@epel lighttpd
|
||||
```
|
||||
|
||||
### How To Check The List Of Packages Installed From Particular Repository on Fedora System?
|
||||
|
||||
DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for back-end. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
|
||||
|
||||
[Dnf command][9] is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
|
||||
|
||||
```
|
||||
# dnf list installed | grep @updates
|
||||
NetworkManager.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-adsl.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-bluetooth.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-libnm.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-libreswan.x86_64 1.2.10-1.fc29 @updates
|
||||
NetworkManager-libreswan-gnome.x86_64 1.2.10-1.fc29 @updates
|
||||
NetworkManager-openvpn.x86_64 1:1.8.8-1.fc29 @updates
|
||||
NetworkManager-openvpn-gnome.x86_64 1:1.8.8-1.fc29 @updates
|
||||
NetworkManager-ovs.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-ppp.x86_64 1:1.12.4-2.fc29 @updates
|
||||
.
|
||||
.
|
||||
```
|
||||
|
||||
Alternatively, you can use the dnf command with other option to get the same details like above.
|
||||
|
||||
```
|
||||
# dnf repo-pkgs updates list installed
|
||||
Installed Packages
|
||||
NetworkManager.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-adsl.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-bluetooth.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-libnm.x86_64 1:1.12.4-2.fc29 @updates
|
||||
NetworkManager-libreswan.x86_64 1.2.10-1.fc29 @updates
|
||||
NetworkManager-libreswan-gnome.x86_64 1.2.10-1.fc29 @updates
|
||||
NetworkManager-openvpn.x86_64 1:1.8.8-1.fc29 @updates
|
||||
NetworkManager-openvpn-gnome.x86_64 1:1.8.8-1.fc29 @updates
|
||||
NetworkManager-ovs.x86_64 1:1.12.4-2.fc29 @updates
|
||||
.
|
||||
.
|
||||
```
|
||||
|
||||
### How To Check The List Of Packages Installed From Particular Repository on openSUSE System?
|
||||
|
||||
Zypper is a command line package manager which makes use of libzypp. [Zypper command][10] provides functions like repository access, dependency solving, package installation, etc.
|
||||
|
||||
```
|
||||
zypper search -ir "Update Repository (Non-Oss)"
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
S | Name | Summary | Type
|
||||
---+----------------------------+---------------------------------------------------+--------
|
||||
i | gstreamer-0_10-fluendo-mp3 | GStreamer plug-in from Fluendo for MP3 support | package
|
||||
i+ | openSUSE-2016-615 | Test-update for openSUSE Leap 42.2 Non Free | patch
|
||||
i+ | openSUSE-2017-724 | Security update for unrar | patch
|
||||
i | unrar | A program to extract, test, and view RAR archives | package
|
||||
```
|
||||
|
||||
Alternatively, we can use repo id instead of repo name.
|
||||
|
||||
```
|
||||
zypper search -ir 2
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
S | Name | Summary | Type
|
||||
---+----------------------------+---------------------------------------------------+--------
|
||||
i | gstreamer-0_10-fluendo-mp3 | GStreamer plug-in from Fluendo for MP3 support | package
|
||||
i+ | openSUSE-2016-615 | Test-update for openSUSE Leap 42.2 Non Free | patch
|
||||
i+ | openSUSE-2017-724 | Security update for unrar | patch
|
||||
i | unrar | A program to extract, test, and view RAR archives | package
|
||||
```
|
||||
|
||||
### How To Check The List Of Packages Installed From Particular Repository on ArchLinux System?
|
||||
|
||||
[Pacman command][11] stands for package manager utility. pacman is a simple command-line utility to install, build, remove and manage Arch Linux packages. Pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
|
||||
|
||||
```
|
||||
$ paclist community
|
||||
acpi 1.7-2
|
||||
acpid 2.0.30-1
|
||||
adapta-maia-theme 3.94.0.149-1
|
||||
android-tools 9.0.0_r3-1
|
||||
blueman 2.0.6-1
|
||||
brotli 1.0.7-1
|
||||
.
|
||||
.
|
||||
ufw 0.35-5
|
||||
unace 2.5-10
|
||||
usb_modeswitch 2.5.2-1
|
||||
viewnior 1.7-1
|
||||
wallpapers-2018 1.0-1
|
||||
xcursor-breeze 5.11.5-1
|
||||
xcursor-simpleandsoft 0.2-8
|
||||
xcursor-vanilla-dmz-aa 0.4.5-1
|
||||
xfce4-whiskermenu-plugin-gtk3 2.3.0-1
|
||||
zeromq 4.2.5-1
|
||||
```
|
||||
|
||||
### How To Check The List Of Packages Installed From Particular Repository on Debian Based Systems?
|
||||
|
||||
For Debian based systems, it can be done using grep command.
|
||||
|
||||
If you want to know the list of installed repositories on your system, use the following command.
|
||||
|
||||
```
|
||||
$ ls -lh /var/lib/apt/lists/ | uniq
|
||||
total 370M
|
||||
-rw-r--r-- 1 root root 10K Oct 26 10:53 archive.canonical.com_ubuntu_dists_bionic_InRelease
|
||||
-rw-r--r-- 1 root root 6.4K Oct 26 10:53 archive.canonical.com_ubuntu_dists_bionic_partner_binary-amd64_Packages
|
||||
-rw-r--r-- 1 root root 6.4K Oct 26 10:53 archive.canonical.com_ubuntu_dists_bionic_partner_binary-i386_Packages
|
||||
-rw-r--r-- 1 root root 3.2K Jun 12 21:19 archive.canonical.com_ubuntu_dists_bionic_partner_i18n_Translation-en
|
||||
drwxr-xr-x 2 _apt root 4.0K Jul 25 08:44 auxfiles
|
||||
-rw-r--r-- 1 root root 3.7K Oct 16 15:13 download.virtualbox.org_virtualbox_debian_dists_bionic_contrib_binary-amd64_Packages
|
||||
-rw-r--r-- 1 root root 7.2K Oct 16 15:13 download.virtualbox.org_virtualbox_debian_dists_bionic_contrib_Contents-amd64.lz4
|
||||
-rw-r--r-- 1 root root 4.4K Oct 16 15:13 download.virtualbox.org_virtualbox_debian_dists_bionic_InRelease
|
||||
-rw-r--r-- 1 root root 34 Mar 19 2018 download.virtualbox.org_virtualbox_debian_dists_bionic_non-free_Contents-amd64.lz4
|
||||
-rw-r--r-- 1 root root 6.4K Sep 21 09:42 in.archive.ubuntu.com_ubuntu_dists_bionic-backports_Contents-amd64.lz4
|
||||
-rw-r--r-- 1 root root 6.4K Sep 21 09:42 in.archive.ubuntu.com_ubuntu_dists_bionic-backports_Contents-i386.lz4
|
||||
-rw-r--r-- 1 root root 73K Nov 6 11:16 in.archive.ubuntu.com_ubuntu_dists_bionic-backports_InRelease
|
||||
.
|
||||
.
|
||||
-rw-r--r-- 1 root root 29 May 11 06:39 security.ubuntu.com_ubuntu_dists_bionic-security_main_dep11_icons-64x64.tar.gz
|
||||
-rw-r--r-- 1 root root 747K Nov 5 23:57 security.ubuntu.com_ubuntu_dists_bionic-security_main_i18n_Translation-en
|
||||
-rw-r--r-- 1 root root 2.8K Oct 9 22:37 security.ubuntu.com_ubuntu_dists_bionic-security_multiverse_binary-amd64_Packages
|
||||
-rw-r--r-- 1 root root 3.7K Oct 9 22:37 security.ubuntu.com_ubuntu_dists_bionic-security_multiverse_binary-i386_Packages
|
||||
-rw-r--r-- 1 root root 1.8K Jul 24 23:06 security.ubuntu.com_ubuntu_dists_bionic-security_multiverse_i18n_Translation-en
|
||||
-rw-r--r-- 1 root root 519K Nov 5 20:12 security.ubuntu.com_ubuntu_dists_bionic-security_universe_binary-amd64_Packages
|
||||
-rw-r--r-- 1 root root 517K Nov 5 20:12 security.ubuntu.com_ubuntu_dists_bionic-security_universe_binary-i386_Packages
|
||||
-rw-r--r-- 1 root root 11K Nov 6 05:36 security.ubuntu.com_ubuntu_dists_bionic-security_universe_dep11_Components-amd64.yml.gz
|
||||
-rw-r--r-- 1 root root 8.9K Nov 6 05:36 security.ubuntu.com_ubuntu_dists_bionic-security_universe_dep11_icons-48x48.tar.gz
|
||||
-rw-r--r-- 1 root root 16K Nov 6 05:36 security.ubuntu.com_ubuntu_dists_bionic-security_universe_dep11_icons-64x64.tar.gz
|
||||
-rw-r--r-- 1 root root 315K Nov 5 20:12 security.ubuntu.com_ubuntu_dists_bionic-security_universe_i18n_Translation-en
|
||||
```
|
||||
|
||||
To get the list of installed packages from the `security.ubuntu.com` repository.
|
||||
|
||||
```
|
||||
$ grep Package /var/lib/apt/lists/security.ubuntu.com_*_Packages | awk '{print $2;}'
|
||||
amd64-microcode
|
||||
apache2
|
||||
apache2-bin
|
||||
apache2-data
|
||||
apache2-dbg
|
||||
apache2-dev
|
||||
.
|
||||
.
|
||||
znc
|
||||
znc-dev
|
||||
znc-perl
|
||||
znc-python
|
||||
znc-tcl
|
||||
zsh-static
|
||||
zziplib-bin
|
||||
```
|
||||
|
||||
The security repository containing multiple branches (main, multiverse and universe) and if you would like to list out the installed packages from the particular repository `universe` then use the following format.
|
||||
|
||||
```
|
||||
$ grep Package /var/lib/apt/lists/security.ubuntu.com_ubuntu_dists_bionic-security_universe*_Packages | awk '{print $2;}'
|
||||
ant
|
||||
ant-doc
|
||||
ant-optional
|
||||
apache2-suexec-custom
|
||||
apache2-suexec-pristine
|
||||
apparmor-easyprof
|
||||
apport-kde
|
||||
apport-noui
|
||||
apport-valgrind
|
||||
apt-transport-https
|
||||
.
|
||||
.
|
||||
xul-ext-gdata-provider
|
||||
xul-ext-lightning
|
||||
xvfb
|
||||
znc
|
||||
znc-dev
|
||||
znc-perl
|
||||
znc-python
|
||||
znc-tcl
|
||||
zsh-static
|
||||
zziplib-bin
|
||||
```
|
||||
|
||||
one more example for `ppa.launchpad.net` repository.
|
||||
|
||||
```
|
||||
$ grep Package /var/lib/apt/lists/ppa.launchpad.net_*_Packages | awk '{print $2;}'
|
||||
notepadqq
|
||||
notepadqq-gtk
|
||||
notepadqq-common
|
||||
notepadqq
|
||||
notepadqq-gtk
|
||||
notepadqq-common
|
||||
numix-gtk-theme
|
||||
numix-icon-theme
|
||||
numix-icon-theme-circle
|
||||
numix-icon-theme-square
|
||||
numix-gtk-theme
|
||||
numix-icon-theme
|
||||
numix-icon-theme-circle
|
||||
numix-icon-theme-square
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-the-list-of-packages-installed-from-particular-repository/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[2]: https://www.2daygeek.com/category/repository/
|
||||
[3]: https://www.2daygeek.com/install-enable-elrepo-on-rhel-centos-scientific-linux/
|
||||
[4]: https://www.2daygeek.com/additional-yum-repositories-for-centos-rhel-fedora-systems/
|
||||
[5]: https://www.2daygeek.com/install-enable-rpm-fusion-repository-on-centos-fedora-rhel/
|
||||
[6]: https://fedoraproject.org/wiki/Third_party_repositories
|
||||
[7]: https://www.2daygeek.com/install-enable-packman-repository-on-opensuse-leap/
|
||||
[8]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[9]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[11]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
@ -1,324 +0,0 @@
|
||||
Top 30 OpenStack Interview Questions and Answers
|
||||
======
|
||||
Now a days most of the firms are trying to migrate their IT infrastructure and Telco Infra into private cloud i.e OpenStack. If you planning to give interviews on Openstack admin profile, then below list of interview questions might help you to crack the interview.
|
||||
|
||||

|
||||
|
||||
### Q:1 Define OpenStack and its key components?
|
||||
|
||||
Ans: It is a bundle of opensource software, which all in combine forms a provide cloud software known as OpenStack.OpenStack is known as Stack of Open source Software or Projects.
|
||||
|
||||
Following are the key components of OpenStack
|
||||
|
||||
* **Nova** – It handles the Virtual machines at compute level and performs other computing task at compute or hypervisor level.
|
||||
* **Neutron** – It provides the networking functionality to VMs, Compute and Controller Nodes.
|
||||
* **Keystone** – It provides the identity service for all cloud users and openstack services. In other words, we can say Keystone a method to provide access to cloud users and services.
|
||||
* **Horizon** – It provides a GUI (Graphical User Interface), using the GUI Admin can all day to day operations task at ease.
|
||||
* **Cinder** – It provides the block storage functionality, generally in OpenStack Cinder is integrated with Chef and ScaleIO to service block storage to Compute & Controller nodes.
|
||||
* **Swift** – It provides the object storage functionality. Generally, Glance images are on object storage. External storage like ScaleIO can work as Object storage too and can easily be integrated with Glance Service.
|
||||
* **Glance** – It provides Cloud image services, using glance admin used to upload and download cloud images.
|
||||
* **Heat** – It provides an orchestration service or functionality. Using Heat admin can easily VMs as stack and based on requirements VMs in the stack can be scale-in and Scale-out
|
||||
* **Ceilometer** – It provides the telemetry and billing services.
|
||||
|
||||
|
||||
|
||||
### Q:2 What are services generally run on a controller node?
|
||||
|
||||
Ans: Following services run on a controller node:
|
||||
|
||||
* Identity Service ( KeyStone)
|
||||
* Image Service ( Glance)
|
||||
* Nova Services like Nova API, Nova Scheduler & Nova DB
|
||||
* Block & Object Service
|
||||
* Ceilometer Service
|
||||
* MariaDB / MySQL and RabbitMQ Service
|
||||
* Management services of Networking (Neutron) and Networking agents
|
||||
* Orchestration Service (Heat)
|
||||
|
||||
|
||||
|
||||
### Q:3 What are the services generally run on a Compute Node?
|
||||
|
||||
Ans: Following services run on a compute node,
|
||||
|
||||
* Nova-Compute
|
||||
* Networking Services like OVS
|
||||
|
||||
|
||||
|
||||
### Q:4 What is the default location of VMs on the Compute Nodes?
|
||||
|
||||
Ans: VMs in the Compute node are stored at “ **/var/lib/nova/instances** ”
|
||||
|
||||
### Q:5 What is default location of glance images?
|
||||
|
||||
Ans: As the Glance service runs on a controller node, all the glance images are store under the folder “ **/var/lib/glance/images** ” on a controller node.
|
||||
|
||||
Read More : [**How to Create and Delete Virtual Machine(VM) from Command line in OpenStack**][1]
|
||||
|
||||
### Q:6 Tell me the command how to spin a VM from Command Line?
|
||||
|
||||
Ans: We can easily spin a new VM using the following openstack command,
|
||||
|
||||
```
|
||||
# openstack server create --flavor {flavor-name} --image {Image-Name-Or-Image-ID} --nic net-id={Network-ID} --security-group {Security_Group_ID} –key-name {Keypair-Name} <VM_Name>
|
||||
```
|
||||
|
||||
### Q:7 How to list the network namespace of a tenant in OpenStack?
|
||||
|
||||
Ans: Network namespace of a tenant can be listed using “ip net ns” command
|
||||
|
||||
```
|
||||
~# ip netns list
|
||||
qdhcp-a51635b1-d023-419a-93b5-39de47755d2d
|
||||
haproxy
|
||||
vrouter
|
||||
```
|
||||
|
||||
### Q:8 How to execute command inside network namespace in openstack?
|
||||
|
||||
Ans: Let’s assume we want to execute “ifconfig” command inside the network namespace “qdhcp-a51635b1-d023-419a-93b5-39de47755d2d”, then run the beneath command,
|
||||
|
||||
Syntax : ip netns exec {network-space} <command>
|
||||
|
||||
```
|
||||
~# ip netns exec qdhcp-a51635b1-d023-419a-93b5-39de47755d2d "ifconfig"
|
||||
```
|
||||
|
||||
### Q:9 How to upload and download a cloud image in Glance from command line?
|
||||
|
||||
Ans: A Cloud image can be uploaded in glance from command using beneath openstack command,
|
||||
|
||||
```
|
||||
~# openstack image create --disk-format qcow2 --container-format bare --public --file {Name-Cloud-Image}.qcow2 <Cloud-Image-Name>
|
||||
```
|
||||
|
||||
Use below openstack command to download a cloud image from command line,
|
||||
|
||||
```
|
||||
~# glance image-download --file <Cloud-Image-Name> --progress <Image-ID>
|
||||
```
|
||||
|
||||
### Q:10 How to reset error state of a VM into active in OpenStack env?
|
||||
|
||||
Ans: There are some scenarios where some VMs went to error state and this error state can be changed into active state using below commands,
|
||||
|
||||
```
|
||||
~# nova reset-state --active {Instance_id}
|
||||
```
|
||||
|
||||
### Q:11 How to get list of available Floating IPs from command line?
|
||||
|
||||
Ans: Available floating ips can be listed using the below command,
|
||||
|
||||
```
|
||||
~]# openstack ip floating list | grep None | head -10
|
||||
```
|
||||
|
||||
### Q:12 How to provision a virtual machine in specific availability zone and compute Host?
|
||||
|
||||
Ans: Let’s assume we want to provision a VM on the availability zone NonProduction in compute-02, use the beneath command to accomplish this,
|
||||
|
||||
```
|
||||
~]# openstack server create --flavor m1.tiny --image cirros --nic net-id=e0be93b8-728b-4d4d-a272-7d672b2560a6 --security-group NonProd_SG --key-name linuxtec --availability-zone NonProduction:compute-02 nonprod_testvm
|
||||
```
|
||||
|
||||
### Q:13 How to get list of VMs which are provisioned on a specific Compute node?
|
||||
|
||||
Ans: Let’s assume we want to list the vms which are provisioned on compute-0-19, use below
|
||||
|
||||
Syntax: openstack server list –all-projects –long -c Name -c Host | grep -i {Compute-Node-Name}
|
||||
|
||||
```
|
||||
~# openstack server list --all-projects --long -c Name -c Host | grep -i compute-0-19
|
||||
```
|
||||
|
||||
### Q:14 How to view the console log of an openstack instance from command line?
|
||||
|
||||
Ans: Console logs of an instance can be viewed from the command line using the following commands,
|
||||
|
||||
First get the ID of an instance and then use the below command,
|
||||
|
||||
```
|
||||
~# openstack console log show {Instance-id}
|
||||
```
|
||||
|
||||
### Q:15 How to get console URL of an openstack instance?
|
||||
|
||||
Ans: Console URL of an instance can be retrieved from command line using the below openstack command,
|
||||
|
||||
```
|
||||
~# openstack console url show {Instance-id}
|
||||
```
|
||||
|
||||
### Q:16 How to create a bootable cinder / block storage volume from command line?
|
||||
|
||||
Ans: To Create a bootable cinder or block storage volume (assume 8 GB) , refer the below steps:
|
||||
|
||||
* Get Image list using below
|
||||
|
||||
|
||||
|
||||
```
|
||||
~# openstack image list | grep -i cirros
|
||||
| 89254d46-a54b-4bc8-8e4d-658287c7ee92 | cirros | active |
|
||||
```
|
||||
|
||||
* Create bootable volume of size 8 GB using cirros image
|
||||
|
||||
|
||||
|
||||
```
|
||||
~# cinder create --image-id 89254d46-a54b-4bc8-8e4d-658287c7ee92 --display-name cirros-bootable-vol 8
|
||||
```
|
||||
|
||||
### Q:17 How to list all projects or tenants that has been created in your opentstack?
|
||||
|
||||
Ans: Projects or tenants list can be retrieved from the command using the below openstack command,
|
||||
|
||||
```
|
||||
~# openstack project list --long
|
||||
```
|
||||
|
||||
### Q:18 How to list the endpoints of openstack services?
|
||||
|
||||
Ans: Openstack service endpoints are classified into three categories,
|
||||
|
||||
* Public Endpoint
|
||||
* Internal Endpoint
|
||||
* Admin Endpoint
|
||||
|
||||
|
||||
|
||||
Use below openstack command to view endpoints of each openstack service,
|
||||
|
||||
```
|
||||
~# openstack catalog list
|
||||
```
|
||||
|
||||
To list the endpoint of a specific service like keystone use below,
|
||||
|
||||
```
|
||||
~# openstack catalog show keystone
|
||||
```
|
||||
|
||||
Read More : [**Step by Step Instance Creation Flow in OpenStack**][2]
|
||||
|
||||
### Q:19 In which order we should restart nova services on a controller node?
|
||||
|
||||
Ans: Following order should be followed to restart the nova services on openstack controller node,
|
||||
|
||||
* service nova-api restart
|
||||
* service nova-cert restart
|
||||
* service nova-conductor restart
|
||||
* service nova-consoleauth restart
|
||||
* service nova-scheduler restart
|
||||
|
||||
|
||||
|
||||
### Q:20 Let’s assume DPDK ports are configured on compute node for data traffic, now how you will check the status of dpdk ports?
|
||||
|
||||
Ans: As DPDK ports are configured via openvSwitch (OVS), use below commands to check the status,
|
||||
|
||||
### Q:21 How to add new rules to the existing SG(Security Group) from command line in openstack?
|
||||
|
||||
Ans: New rules to the existing SG in openstack can be added using the neutron command,
|
||||
|
||||
```
|
||||
~# neutron security-group-rule-create --protocol <tcp or udp> --port-range-min <port-number> --port-range-max <port-number> --direction <ingress or egress> --remote-ip-prefix <IP-address-or-range> Security-Group-Name
|
||||
```
|
||||
|
||||
### Q:22 How to view the OVS bridges configured on Controller and Compute Nodes?
|
||||
|
||||
Ans: OVS bridges on Controller and Compute nodes can be viewed using below command,
|
||||
|
||||
```
|
||||
~]# ovs-vsctl show
|
||||
```
|
||||
|
||||
### Q:23 What is the role of Integration Bridge(br-int) on the Compute Node ?
|
||||
|
||||
Ans: The integration bridge (br-int) performs VLAN tagging and untagging for the traffic coming from and to the instance running on the compute node.
|
||||
|
||||
Packets leaving the n/w interface of an instance goes through the linux bridge (qbr) using the virtual interface qvo. The interface qvb is connected to the Linux Bridge & interface qvo is connected to integration bridge (br-int). The qvo port on integration bridge has an internal VLAN tag that gets appended to packet header when a packet reaches to the integration bridge.
|
||||
|
||||
### Q:24 What is the role of Tunnel Bridge (br-tun) on the compute node?
|
||||
|
||||
Ans: The tunnel bridge (br-tun) translates the VLAN tagged traffic from integration bridge to the tunnel ids using OpenFlow rules.
|
||||
|
||||
br-tun (tunnel bridge) allows the communication between the instances on different networks. Tunneling helps to encapsulate the traffic travelling over insecure networks, br-tun supports two overlay networks i.e GRE and VXLAN
|
||||
|
||||
### Q:25 What is the role of external OVS bridge (br-ex)?
|
||||
|
||||
Ans: As the name suggests, this bridge forwards the traffic coming to and from the network to allow external access to instances. br-ex connects to the physical interface like eth2, so that floating IP traffic for tenants networks is received from the physical network and routed to the tenant network ports.
|
||||
|
||||
### Q:26 What is function of OpenFlow rules in OpenStack Networking?
|
||||
|
||||
Ans: OpenFlow rules is a mechanism that define how a packet will reach to destination starting from its source. OpenFlow rules resides in flow tables. The flow tables are part of OpenFlow switch.
|
||||
|
||||
When a packet arrives to a switch, it is processed by the first flow table, if it doesn’t match any flow entries in the table then packet is dropped or forwarded to another table.
|
||||
|
||||
### Q:27 How to display the information about a OpenFlow switch (like ports, no. of tables, no of buffer)?
|
||||
|
||||
Ans: Let’s assume we want to display the information about OpenFlow switch (br-int), run the following command,
|
||||
|
||||
```
|
||||
root@compute-0-15# ovs-ofctl show br-int
|
||||
OFPT_FEATURES_REPLY (xid=0x2): dpid:0000fe981785c443
|
||||
n_tables:254, n_buffers:256
|
||||
capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP
|
||||
actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst
|
||||
1(patch-tun): addr:3a:c6:4f:bd:3e:3b
|
||||
config: 0
|
||||
state: 0
|
||||
speed: 0 Mbps now, 0 Mbps max
|
||||
2(qvob35d2d65-f3): addr:b2:83:c4:0b:42:3a
|
||||
config: 0
|
||||
state: 0
|
||||
current: 10GB-FD COPPER
|
||||
speed: 10000 Mbps now, 0 Mbps max
|
||||
………………………………………
|
||||
```
|
||||
|
||||
### Q:28 How to display the entries for all the flows in a switch?
|
||||
|
||||
Ans: Flows entries of a switch can be displayed using the command ‘ **ovs-ofctl dump-flows** ‘
|
||||
|
||||
Let’s assume we want to display flow entries of OVS integration bridge (br-int),
|
||||
|
||||
### Q:29 What are Neutron Agents and how to list all neutron agents?
|
||||
|
||||
Ans: OpenStack neutron server acts as the centralized controller, the actual network configurations are executed either on compute and network nodes. Neutron agents are software entities that carry out configuration changes on compute or network nodes. Neutron agents communicate with the main neutron service via Neuron API and message queue.
|
||||
|
||||
Neutron agents can be listed using the following command,
|
||||
|
||||
```
|
||||
~# openstack network agent list -c ‘Agent type’ -c Host -c Alive -c State
|
||||
```
|
||||
|
||||
### Q:30 What is CPU pinning?
|
||||
|
||||
Ans: CPU pinning refers to reserving the physical cores for specific virtual machine. It is also known as CPU isolation or processor affinity. The configuration is in two parts:
|
||||
|
||||
* it ensures that virtual machine can only run on dedicated cores
|
||||
* it also ensures that common host processes don’t run on those cores
|
||||
|
||||
|
||||
|
||||
In other words we can say pinning is one to one mapping of a physical core to a guest vCPU.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/openstack-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxtechi.com/create-delete-virtual-machine-command-line-openstack/
|
||||
[2]: https://www.linuxtechi.com/step-by-step-instance-creation-flow-in-openstack/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by seriouszyx
|
||||
|
||||
A Free, Secure And Cross-platform Password Manager
|
||||
======
|
||||
|
||||
|
||||
@ -1,228 +0,0 @@
|
||||
An introduction to Udev: The Linux subsystem for managing device events
|
||||
======
|
||||
Create a script that triggers your computer to do a specific action when a specific device is plugged in.
|
||||

|
||||
|
||||
Udev is the Linux subsystem that supplies your computer with device events. In plain English, that means it's the code that detects when you have things plugged into your computer, like a network card, external hard drives (including USB thumb drives), mouses, keyboards, joysticks and gamepads, DVD-ROM drives, and so on. That makes it a potentially useful utility, and it's well-enough exposed that a standard user can manually script it to do things like performing certain tasks when a certain hard drive is plugged in.
|
||||
|
||||
This article teaches you how to create a [udev][1] script triggered by some udev event, such as plugging in a specific thumb drive. Once you understand the process for working with udev, you can use it to do all manner of things, like loading a specific driver when a gamepad is attached, or performing an automatic backup when you attach your backup drive.
|
||||
|
||||
### A basic script
|
||||
|
||||
The best way to work with udev is in small chunks. Don't write the entire script upfront, but instead start with something that simply confirms that udev triggers some custom event.
|
||||
|
||||
Depending on your goal for your script, you can't guarantee you will ever see the results of a script with your own eyes, so make sure your script logs that it was successfully triggered. The usual place for log files is in the **/var** directory, but that's mostly the root user's domain. For testing, use **/tmp** , which is accessible by normal users and usually gets cleaned out with a reboot.
|
||||
|
||||
Open your favorite text editor and enter this simple script:
|
||||
|
||||
```
|
||||
#!/usr/bin/bash
|
||||
|
||||
echo $date > /tmp/udev.log
|
||||
```
|
||||
|
||||
Place this in **/usr/local/bin** or some such place in the default executable path. Call it **trigger.sh** and, of course, make it executable with **chmod +x**.
|
||||
|
||||
```
|
||||
$ sudo mv trigger.sh /usr/local/bin
|
||||
$ sudo chmod +x /usr/local/bin/trigger.sh
|
||||
```
|
||||
|
||||
This script has nothing to do with udev. When it executes, the script places a timestamp in the file **/tmp/udev.log**. Test the script yourself:
|
||||
|
||||
```
|
||||
$ /usr/local/bin/trigger.sh
|
||||
$ cat /tmp/udev.log
|
||||
Tue Oct 31 01:05:28 NZDT 2035
|
||||
```
|
||||
|
||||
The next step is to make udev trigger the script.
|
||||
|
||||
### Unique device identification
|
||||
|
||||
In order for your script to be triggered by a device event, udev must know under what conditions it should call the script. In real life, you can identify a thumb drive by its color, the manufacturer, and the fact that you just plugged it into your computer. Your computer, however, needs a different set of criteria.
|
||||
|
||||
Udev identifies devices by serial numbers, manufacturers, and even vendor ID and product ID numbers. Since this is early in your udev script's lifespan, be as broad, non-specific, and all-inclusive as possible. In other words, you want first to catch nearly any valid udev event to trigger your script.
|
||||
|
||||
With the **udevadm monitor** command, you can tap into udev in real time and see what it sees when you plug in different devices. Become root and try it.
|
||||
|
||||
```
|
||||
$ su
|
||||
# udevadm monitor
|
||||
```
|
||||
|
||||
The monitor function prints received events for:
|
||||
|
||||
* UDEV: the event udev sends out after rule processing
|
||||
* KERNEL: the kernel uevent
|
||||
|
||||
|
||||
|
||||
With **udevadm monitor** running, plug in a thumb drive and watch as all kinds of information is spewed out onto your screen. Notice that the type of event is an **ADD** event. That's a good way to identify what type of event you want.
|
||||
|
||||
The **udevadm monitor** command provides a lot of good info, but you can see it with prettier formatting with the command **udevadm info** , assuming you know where your thumb drive is currently located in your **/dev** tree. If not, unplug and plug your thumb drive back in, then immediately issue this command:
|
||||
|
||||
```
|
||||
$ su -c 'dmesg | tail | fgrep -i sd*'
|
||||
```
|
||||
|
||||
If that command returned **sdb: sdb1** , for instance, you know the kernel has assigned your thumb drive the **sdb** label.
|
||||
|
||||
Alternately, you can use the **lsblk** command to see all drives attached to your system, including their sizes and partitions.
|
||||
|
||||
Now that you have established where your drive is located in your filesystem, you can view udev information about that device with this command:
|
||||
|
||||
```
|
||||
# udevadm info -a -n /dev/sdb | less
|
||||
```
|
||||
|
||||
This returns a lot of information. Focus on the first block of info for now.
|
||||
|
||||
Your job is to pick out parts of udev's report about a device that are most unique to that device, then tell udev to trigger your script when those unique attributes are detected.
|
||||
|
||||
The **udevadm info** process reports on a device (specified by the device path), then "walks" up the chain of parent devices. For every device found, it prints all possible attributes using a key-value format. You can compose a rule to match according to the attributes of a device plus attributes from one single parent device.
|
||||
|
||||
```
|
||||
looking at device '/devices/000:000/blah/blah//block/sdb':
|
||||
KERNEL=="sdb"
|
||||
SUBSYSTEM=="block"
|
||||
DRIVER==""
|
||||
ATTR{ro}=="0"
|
||||
ATTR{size}=="125722368"
|
||||
ATTR{stat}==" 2765 1537 5393"
|
||||
ATTR{range}=="16"
|
||||
ATTR{discard\_alignment}=="0"
|
||||
ATTR{removable}=="1"
|
||||
ATTR{blah}=="blah"
|
||||
```
|
||||
|
||||
A udev rule must contain one attribute from one single parent device.
|
||||
|
||||
Parent attributes are things that describe a device from the most basic level, such as it's something that has been plugged into a physical port or it is something with a size or this is a removable device.
|
||||
|
||||
Since the KERNEL label of **sdb** can change depending upon how many other drives were plugged in before you plugged that thumb drive in, that's not the optimal parent attribute for a udev rule. However, it works for a proof of concept, so you could use it. An even better candidate is the SUBSYSTEM attribute, which identifies that this is a "block" system device (which is why the **lsblk** command lists the device).
|
||||
|
||||
Open a file called **80-local.rules** in **/etc/udev/rules.d** and enter this code:
|
||||
|
||||
```
|
||||
SUBSYSTEM=="block", ACTION=="add", RUN+="/usr/local/bin/trigger.sh"
|
||||
```
|
||||
|
||||
Save the file, unplug your test thumb drive, and reboot.
|
||||
|
||||
Wait, reboot on a Linux machine?
|
||||
|
||||
Theoretically, you can just issue **udevadm control --reload** , which should load all rules, but at this stage in the game, it's best to eliminate all variables. Udev is complex enough, and you don't want to be lying in bed all night wondering if that rule didn't work because of a syntax error or if you just should have rebooted. So reboot regardless of what your POSIX pride tells you.
|
||||
|
||||
When your system is back online, switch to a text console (with Ctl+Alt+F3 or similar) and plug in your thumb drive. If you are running a recent kernel, you will probably see a bunch of output in your console when you plug in the drive. If you see an error message such as Could not execute /usr/local/bin/trigger.sh, you probably forgot to make the script executable. Otherwise, hopefully all you see is a device was plugged in, it got some kind of kernel device assignment, and so on.
|
||||
|
||||
Now, the moment of truth:
|
||||
|
||||
```
|
||||
$ cat /tmp/udev.log
|
||||
Tue Oct 31 01:35:28 NZDT 2035
|
||||
```
|
||||
|
||||
If you see a very recent date and time returned from **/tmp/udev.log** , udev has successfully triggered your script.
|
||||
|
||||
### Refining the rule into something useful
|
||||
|
||||
The problem with this rule is that it's very generic. Plugging in a mouse, a thumb drive, or someone else's thumb drive will indiscriminately trigger your script. Now is the time to start focusing on the exact thumb drive you want to trigger your script.
|
||||
|
||||
One way to do this is with the vendor ID and product ID. To get these numbers, you can use the **lsusb** command.
|
||||
|
||||
```
|
||||
$ lsusb
|
||||
Bus 001 Device 002: ID 8087:0024 Slacker Corp. Hub
|
||||
Bus 002 Device 002: ID 8087:0024 Slacker Corp. Hub
|
||||
Bus 003 Device 005: ID 03f0:3307 TyCoon Corp.
|
||||
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 hub
|
||||
Bus 001 Device 003: ID 13d3:5165 SBo Networks
|
||||
```
|
||||
|
||||
In this example, the **03f0:3307** before **TyCoon Corp.** denotes the idVendor and idProduct attributes. You can also see these numbers in the output of **udevadm info -a -n /dev/sdb | grep vendor** , but I find the output of **lsusb** a little easier on the eyes.
|
||||
|
||||
You can now include these attributes in your rule.
|
||||
|
||||
```
|
||||
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", RUN+="/usr/local/bin/thumb.sh"
|
||||
```
|
||||
|
||||
Test this (yes, you should still reboot, just to make sure you're getting fresh reactions from udev), and it should work the same as before, only now if you plug in, say, a thumb drive manufactured by a different company (therefore with a different idVendor) or a mouse or a printer, the script won't be triggered.
|
||||
|
||||
Keep adding new attributes to further focus in on that one unique thumb drive you want to trigger your script. Using **udevadm info -a -n /dev/sdb** , you can find out things like the vendor name, sometimes a serial number, or the product name, and so on.
|
||||
|
||||
For your own sanity, be sure to add only one new attribute at a time. Most mistakes I have made (and have seen other people online make) is to throw a bunch of attributes into their udev rule and wonder why the thing no longer works. Testing attributes one by one is the safest way to ensure udev can identify your device successfully.
|
||||
|
||||
### Security
|
||||
|
||||
This brings up the security concerns of writing udev rules to automatically do something when a drive is plugged in. On my machines, I don't even have auto-mount turned on, and yet this article proposes scripts and rules that execute commands just by having something plugged in.
|
||||
|
||||
Two things to bear in mind here.
|
||||
|
||||
1. Focus your udev rules once you have them working so they trigger scripts only when you really want them to. Executing a script that blindly copies data to or from your computer is a bad idea in case anyone who happens to be carrying the same brand of thumb drive plugs it into your box.
|
||||
2. Do not write your udev rule and scripts and forget about them. I know which computers have my udev rules on them, and those boxes are most often my personal computers, not the ones I take around to conferences or have in my office at work. The more "social" a computer is, the less likely it is to get a udev rule on it that could potentially result in my data ending up on someone else's device or someone else's data or malware on my device.
|
||||
|
||||
|
||||
|
||||
In other words, as with so much of the power provided by a GNU system, it is your job to be mindful of how you are wielding that power. If you abuse it or fail to treat it with respect, it very well could go horribly wrong.
|
||||
|
||||
### Udev in the real world
|
||||
|
||||
Now that you can confirm that your script is triggered by udev, you can turn your attention to the function of the script. Right now, it is useless, doing nothing more than logging the fact that it has been executed.
|
||||
|
||||
I use udev to trigger [automated backups][2] of my thumb drives. The idea is that the master copies of my active documents are on my thumb drive (since it goes everywhere I go and could be worked on at any moment), and those master documents get backed up to my computer each time I plug the drive into that machine. In other words, my computer is the backup drive and my production data is mobile. The source code is available, so feel free to look at the code of attachup for further examples of constraining your udev tests.
|
||||
|
||||
Since that's what I use udev for the most, it's the example I'll use here, but udev can grab lots of other things, like gamepads (this is useful on systems that aren't set to load the xboxdrv module when a gamepad is attached) and cameras and microphones (useful to set inputs when a specific mic is attached), so realize that it's good for a lot more than this one example.
|
||||
|
||||
A simple version of my backup system is a two-command process:
|
||||
|
||||
```
|
||||
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", SYMLINK+="safety%n"
|
||||
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", RUN+="/usr/local/bin/trigger.sh"
|
||||
```
|
||||
|
||||
The first line detects my thumb drive with the attributes already discussed, then assigns the thumb drive a symlink within the device tree. The symlink it assigns is **safety%n**. The **%n** is a udev macro that resolves to whatever number the kernel gives to the device, such as sdb1, sdb2, sdb3, and so on. So **%n** would be the 1 or the 2 or the 3.
|
||||
|
||||
This creates a symlink in the dev tree, so it does not interfere with the normal process of plugging in a device. This means that if you use a desktop environment that likes to auto-mount devices, you won't be causing problems for it.
|
||||
|
||||
The second line runs the script.
|
||||
|
||||
My backup script looks like this:
|
||||
|
||||
```
|
||||
#!/usr/bin/bash
|
||||
|
||||
mount /dev/safety1 /mnt/hd
|
||||
sleep 2
|
||||
rsync -az /mnt/hd/ /home/seth/backups/ && umount /dev/safety1
|
||||
```
|
||||
|
||||
The script uses the symlink, which avoids the possibility of udev naming the drive something unexpected (for instance, if I have a thumb drive called DISK plugged into my computer already, and I plug in my other thumb drive also called DISK, the second one will be labeled DISK_, which would foil my script). It mounts **safety1** (the first partition of the drive) at my preferred mount point of **/mnt/hd**.
|
||||
|
||||
Once safely mounted, it uses [rsync][3] to back up the drive to my backup folder (my actual script uses rdiff-backup, and yours can use whatever automated backup solution you prefer).
|
||||
|
||||
### Udev is your dev
|
||||
|
||||
Udev is a very flexible system and enables you to define rules and functions in ways that few other systems dare provide users. Learn it and use it, and enjoy the power of POSIX.
|
||||
|
||||
This article builds on content from the [Slackermedia Handbook][4], which is licensed under the [GNU Free Documentation License 1.3][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/udev
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.die.net/man/8/udev
|
||||
[2]: https://gitlab.com/slackermedia/attachup
|
||||
[3]: https://opensource.com/article/17/1/rsync-backup-linux
|
||||
[4]: http://slackermedia.info/handbook/doku.php?id=backup
|
||||
[5]: http://www.gnu.org/licenses/fdl-1.3.html
|
||||
@ -1,461 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (How to Build a Netboot Server, Part 1)
|
||||
[#]: via: (https://fedoramagazine.org/how-to-build-a-netboot-server-part-1/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
[#]: url: ( )
|
||||
|
||||
How to Build a Netboot Server, Part 1
|
||||
======
|
||||
|
||||

|
||||
|
||||
Some computer networks need to maintain identical software installations and configurations on several physical machines. One such environment would be a school computer lab. A [netboot][1] server can be set up to serve an entire operating system over a network so that the client computers can be configured from one central location. This tutorial will show one method of building a netboot server.
|
||||
|
||||
Part 1 of this tutorial will cover creating a netboot server and image. Part 2 will show how to add Kerberos-authenticated home directories to the netboot configuration.
|
||||
|
||||
### Initial Configuration
|
||||
|
||||
Start by downloading one of Fedora Server’s [netinst][2] images, burning it to a CD, and booting the server that will be reformatted from it. We just need a typical “Minimal Install” of Fedora Server for our starting point and we will use the command line to add any additional packages that are needed after the installation is finished.
|
||||
|
||||
![][3]
|
||||
|
||||
> NOTE: For this tutorial we will be using Fedora 28. Other versions may include a slightly different set of packages in their “Minimal Install”. If you start with a different version of Fedora, then you may need to do some troubleshooting if an expected file or command is not available.
|
||||
|
||||
Once you have your minimal installation of Fedora Server up and running, log in as root and set the hostname:
|
||||
|
||||
```
|
||||
$ MY_HOSTNAME=server-01.example.edu
|
||||
$ hostnamectl set-hostname $MY_HOSTNAME
|
||||
```
|
||||
|
||||
> NOTE: Red Hat recommends that both static and transient names match the fully-qualified domain name (FQDN) used for the machine in DNS, such as host.example.com ([Understanding Host Names][4]).
|
||||
>
|
||||
> NOTE: This guide is meant to be copy-and-paste friendly. Any value that you might need to customize will be stated as a MY_* variable that you can tweak before running the remaining commands. Beware that if you log out, the variable assignments will be cleared.
|
||||
>
|
||||
> NOTE: Fedora 28 Server tends to dump a lot of logging output to the console by default. You may want to disable the console logging temporarily by running: sysctl -w kernel.printk=0
|
||||
|
||||
Next, we need a static network address on our server. The following sequence of commands should find and reconfigure your default network connection appropriately:
|
||||
|
||||
```
|
||||
$ MY_DNS1=192.0.2.91
|
||||
$ MY_DNS2=192.0.2.92
|
||||
$ MY_IP=192.0.2.158
|
||||
$ MY_PREFIX=24
|
||||
$ MY_GATEWAY=192.0.2.254
|
||||
$ DEFAULT_DEV=$(ip route show default | awk '{print $5}')
|
||||
$ DEFAULT_CON=$(nmcli d show $DEFAULT_DEV | sed -n '/^GENERAL.CONNECTION:/s!.*:\s*!! p')
|
||||
$ nohup bash << END
|
||||
nmcli con mod "$DEFAULT_CON" connection.id "$DEFAULT_DEV"
|
||||
nmcli con mod "$DEFAULT_DEV" connection.interface-name "$DEFAULT_DEV"
|
||||
nmcli con mod "$DEFAULT_DEV" ipv4.method disabled
|
||||
nmcli con up "$DEFAULT_DEV"
|
||||
nmcli con add con-name br0 ifname br0 type bridge
|
||||
nmcli con mod br0 bridge.stp no
|
||||
nmcli con mod br0 ipv4.dns $MY_DNS1,$MY_DNS2
|
||||
nmcli con mod br0 ipv4.addresses $MY_IP/$MY_PREFIX
|
||||
nmcli con mod br0 ipv4.gateway $MY_GATEWAY
|
||||
nmcli con mod br0 ipv4.method manual
|
||||
nmcli con up br0
|
||||
nmcli con add con-name br0-slave0 ifname "$DEFAULT_DEV" type bridge-slave master br0
|
||||
nmcli con up br0-slave0
|
||||
END
|
||||
```
|
||||
|
||||
> NOTE: The last set of commands above is wrapped in a “nohup” script because it will disable networking temporarily. The nohup command should allow the nmcli commands to finish running even while your ssh connection is down. Beware that it may take 10 or so seconds for the connection to come back up and that you will have to start a new ssh connection if you changed the server’s IP address.
|
||||
>
|
||||
> NOTE: The above network configuration creates a [network bridge][5] on top of the default connection so that we can run a virtual machine instance directly on the server for testing later. If you do not want to test the netboot image directly on the server, you can skip creating the bridge and set the static IP address directly on your default network connection.
|
||||
|
||||
### Install and Configure NFS4
|
||||
|
||||
Start by installing the nfs-utils package:
|
||||
|
||||
```
|
||||
$ dnf install -y nfs-utils
|
||||
```
|
||||
|
||||
Create a top-level [pseudo filesystem][6] for the NFS exports and share it out to your network:
|
||||
|
||||
```
|
||||
$ MY_SUBNET=192.0.2.0
|
||||
$ mkdir /export
|
||||
$ echo "/export -fsid=0,ro,sec=sys,root_squash $MY_SUBNET/$MY_PREFIX" > /etc/exports
|
||||
```
|
||||
|
||||
SELinux will interfere with the netboot server’s operation. Configuring exceptions for it is beyond the scope of this tutorial, so we will disable it:
|
||||
|
||||
```
|
||||
$ sed -i '/GRUB_CMDLINE_LINUX/s/"$/ audit=0 selinux=0"/' /etc/default/grub
|
||||
$ grub2-mkconfig -o /boot/grub2/grub.cfg
|
||||
$ sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
|
||||
$ setenforce 0
|
||||
```
|
||||
|
||||
> NOTE: Editing the grub command line should not be necessary, but simply editing /etc/sysconfig/selinux proved ineffective across reboots of Fedora Server 28 during testing, so the “selinux=0” flag has been set here to be doubly sure.
|
||||
|
||||
Now, add an exception for the NFS service to the local firewall and start the NFS service:
|
||||
|
||||
```
|
||||
$ firewall-cmd --add-service nfs
|
||||
$ firewall-cmd --runtime-to-permanent
|
||||
$ systemctl enable nfs-server.service
|
||||
$ systemctl start nfs-server.service
|
||||
```
|
||||
|
||||
### Create the Netboot Image
|
||||
|
||||
Now that our NFS server is up and running, we need to supply it with an operating system image to serve to the client computers. We will start with a very minimal image and add to it after everything is working.
|
||||
|
||||
First, create a new directory where our image will be stored:
|
||||
|
||||
```
|
||||
$ mkdir /fc28
|
||||
```
|
||||
|
||||
Use the “dnf” command to build the image under the new directory with only a few base packages:
|
||||
|
||||
```
|
||||
$ dnf -y --releasever=28 --installroot=/fc28 install fedora-release systemd passwd rootfiles sudo dracut dracut-network nfs-utils vim-minimal dnf
|
||||
```
|
||||
|
||||
It is important that the “kernel” packages were omitted from the above command. Before they are installed, we need to tweak the set of drivers that will be included in the “initramfs” image that is built automatically when the kernel is first installed. In particular, we need to disable “hostonly” mode so that the initramfs image will work on a wider set of hardware platforms and we need to add support for networking and NFS:
|
||||
|
||||
```
|
||||
$ echo 'hostonly=no' > /fc28/etc/dracut.conf.d/hostonly.conf
|
||||
$ echo 'add_dracutmodules+=" network nfs "' > /fc28/etc/dracut.conf.d/netboot.conf
|
||||
```
|
||||
|
||||
Now, install the kernel:
|
||||
|
||||
```
|
||||
$ dnf -y --installroot=/fc28 install kernel
|
||||
```
|
||||
|
||||
Set a rule to prevent the kernel from being updated:
|
||||
|
||||
```
|
||||
$ echo 'exclude=kernel-*' >> /fc28/etc/dnf/dnf.conf
|
||||
```
|
||||
|
||||
Set the locale:
|
||||
|
||||
```
|
||||
$ echo 'LANG="en_US.UTF-8"' > /fc28/etc/locale.conf
|
||||
```
|
||||
|
||||
> NOTE: Some programs (e.g. GNOME Terminal) will not function if the locale is not properly configured.
|
||||
|
||||
Blank root’s passwd:
|
||||
|
||||
```
|
||||
$ sed -i 's/^root:\*/root:/' /fc28/etc/shadow
|
||||
```
|
||||
|
||||
Set the client’s hostname:
|
||||
|
||||
```
|
||||
$ MY_CLIENT_HOSTNAME=client-01.example.edu
|
||||
$ echo $MY_CLIENT_HOSTNAME > /fc28/etc/hostname
|
||||
```
|
||||
|
||||
Disable logging to the console:
|
||||
|
||||
```
|
||||
$ echo 'kernel.printk = 0 4 1 7' > /fc28/etc/sysctl.d/00-printk.conf
|
||||
```
|
||||
|
||||
Define a local “liveuser” in the netboot image:
|
||||
|
||||
```
|
||||
$ echo 'liveuser:x:1000:1000::/home/liveuser:/bin/bash' >> /fc28/etc/passwd
|
||||
$ echo 'liveuser::::::::' >> /fc28/etc/shadow
|
||||
$ echo 'liveuser:x:1000:' >> /fc28/etc/group
|
||||
$ echo 'liveuser:!::' >> /fc28/etc/gshadow
|
||||
```
|
||||
|
||||
Allow “liveuser” to sudo:
|
||||
|
||||
```
|
||||
$ echo 'liveuser ALL=(ALL) NOPASSWD: ALL' > /fc28/etc/sudoers.d/liveuser
|
||||
```
|
||||
|
||||
Enable automatic home directory creation:
|
||||
|
||||
```
|
||||
$ dnf install -y --installroot=/fc28 authselect oddjob-mkhomedir
|
||||
$ echo 'dirs /home' > /fc28/etc/rwtab.d/home
|
||||
$ chroot /fc28 authselect select sssd with-mkhomedir --force
|
||||
$ chroot /fc28 systemctl enable oddjobd.service
|
||||
```
|
||||
|
||||
Since multiple clients will be mounting our image concurrently, we need to configure the image so that it will operate in read-only mode:
|
||||
|
||||
```
|
||||
$ sed -i 's/^READONLY=no$/READONLY=yes/' /fc28/etc/sysconfig/readonly-root
|
||||
```
|
||||
|
||||
Configure logging to go to RAM rather than permanent storage:
|
||||
|
||||
```
|
||||
$ sed -i 's/^#Storage=auto$/Storage=volatile/' /fc28/etc/systemd/journald.conf
|
||||
```
|
||||
|
||||
Configure DNS:
|
||||
|
||||
```
|
||||
$ MY_DNS1=192.0.2.91
|
||||
$ MY_DNS2=192.0.2.92
|
||||
$ cat << END > /fc28/etc/resolv.conf
|
||||
nameserver $MY_DNS1
|
||||
nameserver $MY_DNS2
|
||||
END
|
||||
```
|
||||
|
||||
Work-around a few bugs that exist for read-only root mounts at the time this tutorial is being written ([BZ1542567][7]):
|
||||
|
||||
```
|
||||
$ echo 'dirs /var/lib/gssproxy' > /fc28/etc/rwtab.d/gssproxy
|
||||
$ cat << END > /fc28/etc/rwtab.d/systemd
|
||||
dirs /var/lib/systemd/catalog
|
||||
dirs /var/lib/systemd/coredump
|
||||
END
|
||||
```
|
||||
|
||||
Finally, we can create the NFS filesystem for our image and share it out to our subnet:
|
||||
|
||||
```
|
||||
$ mkdir /export/fc28
|
||||
$ echo '/fc28 /export/fc28 none bind 0 0' >> /etc/fstab
|
||||
$ mount /export/fc28
|
||||
$ echo "/export/fc28 -ro,sec=sys,no_root_squash $MY_SUBNET/$MY_PREFIX" > /etc/exports.d/fc28.exports
|
||||
$ exportfs -vr
|
||||
```
|
||||
|
||||
### Create the Boot Loader
|
||||
|
||||
Now that we have an operating system available to netboot, we need a boot loader to kickstart it on the client systems. For this setup, we will be using [iPXE][8].
|
||||
|
||||
> NOTE: This section and the following section — Testing with QEMU — can be done on a separate computer; they do not have to be run on the netboot server.
|
||||
|
||||
Install git and use it to download iPXE:
|
||||
|
||||
```
|
||||
$ dnf install -y git
|
||||
$ git clone http://git.ipxe.org/ipxe.git $HOME/ipxe
|
||||
```
|
||||
|
||||
Now we need to create a special startup script for our bootloader:
|
||||
|
||||
```
|
||||
$ cat << 'END' > $HOME/ipxe/init.ipxe
|
||||
#!ipxe
|
||||
|
||||
prompt --key 0x02 --timeout 2000 Press Ctrl-B for the iPXE command line... && shell ||
|
||||
|
||||
dhcp || exit
|
||||
set prefix file:///linux
|
||||
chain ${prefix}/boot.cfg || exit
|
||||
END
|
||||
```
|
||||
|
||||
Enable the “file” download protocol:
|
||||
|
||||
```
|
||||
$ echo '#define DOWNLOAD_PROTO_FILE' > $HOME/ipxe/src/config/local/general.h
|
||||
```
|
||||
|
||||
Install the C compiler and related tools and libraries:
|
||||
|
||||
```
|
||||
$ dnf groupinstall -y "C Development Tools and Libraries"
|
||||
```
|
||||
|
||||
Build the boot loader:
|
||||
|
||||
```
|
||||
$ cd $HOME/ipxe/src
|
||||
$ make clean
|
||||
$ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe
|
||||
```
|
||||
|
||||
Make note of where the where the newly-compiled boot loader is. We will need it for the next section:
|
||||
|
||||
```
|
||||
$ IPXE_FILE="$HOME/ipxe/src/bin-x86_64-efi/ipxe.efi"
|
||||
```
|
||||
|
||||
### Testing with QEMU
|
||||
|
||||
This section is optional, but you will need to duplicate the file layout of the [EFI system partition][9] that is shown below on your physical machines to configure them for netbooting.
|
||||
|
||||
> NOTE: You could also copy the files to a TFTP server and reference that server from DHCP if you wanted a fully diskless system.
|
||||
|
||||
In order to test our boot loader with QEMU, we are going to create a small disk image containing only an EFI system partition and our startup files.
|
||||
|
||||
Start by creating the required directory layout for the EFI system partition and copying the boot loader that we created in the previous section to it:
|
||||
|
||||
```
|
||||
$ mkdir -p $HOME/esp/efi/boot
|
||||
$ mkdir $HOME/esp/linux
|
||||
$ cp $IPXE_FILE $HOME/esp/efi/boot/bootx64.efi
|
||||
```
|
||||
|
||||
The below command should identify the kernel version that our netboot image is using and store it in a variable for use in the remaining configuration directives:
|
||||
|
||||
```
|
||||
$ DEFAULT_VER=$(ls -c /fc28/lib/modules | head -n 1)
|
||||
```
|
||||
|
||||
Define the boot configuration that our client computers will be using:
|
||||
|
||||
```
|
||||
$ MY_DNS1=192.0.2.91
|
||||
$ MY_DNS2=192.0.2.92
|
||||
$ MY_NFS4=server-01.example.edu
|
||||
$ cat << END > $HOME/esp/linux/boot.cfg
|
||||
#!ipxe
|
||||
|
||||
kernel --name kernel.efi \${prefix}/vmlinuz-$DEFAULT_VER initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=nfs4:$MY_NFS4:/fc28 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
|
||||
initrd --name initrd.img \${prefix}/initramfs-$DEFAULT_VER.img
|
||||
boot || exit
|
||||
END
|
||||
```
|
||||
|
||||
> NOTE: The above boot script shows a minimal example of how to get iPXE to netboot Linux. Much more complex configurations are possible. Most notably, iPXE has support for interactive boot menus which can be configured with a default selection and a timeout. A more advanced iPXE script could, for example, default to booting an operation system from the local disk and only go to the netboot operation if a user pressed a key before a countdown timer reached zero.
|
||||
|
||||
Copy the Linux kernel and its associated initramfs to the EFI system partition:
|
||||
|
||||
```
|
||||
$ cp $(find /fc28/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $DEFAULT_VER) $HOME/esp/linux/vmlinuz-$DEFAULT_VER
|
||||
$ cp $(find /fc28/boot -name 'init*' | grep -m 1 $DEFAULT_VER) $HOME/esp/linux/initramfs-$DEFAULT_VER.img
|
||||
```
|
||||
|
||||
Our resulting directory layout should look like this:
|
||||
|
||||
```
|
||||
esp
|
||||
├── efi
|
||||
│ └── boot
|
||||
│ └── bootx64.efi
|
||||
└── linux
|
||||
├── boot.cfg
|
||||
├── initramfs-4.18.18-200.fc28.x86_64.img
|
||||
└── vmlinuz-4.18.18-200.fc28.x86_64
|
||||
```
|
||||
|
||||
To use our EFI system partition with QEMU, we need to create a small “uefi.img” disk image containing it and then connect that to QEMU as the primary boot drive.
|
||||
|
||||
Begin by installing the necessary tools:
|
||||
|
||||
```
|
||||
$ dnf install -y parted dosfstools
|
||||
```
|
||||
|
||||
Now create the “uefi.img” file and copy the files from the “esp” directory into it:
|
||||
|
||||
```
|
||||
$ ESP_SIZE=$(du -ks $HOME/esp | cut -f 1)
|
||||
$ dd if=/dev/zero of=$HOME/uefi.img count=$((${ESP_SIZE}+5000)) bs=1KiB
|
||||
$ UEFI_DEV=$(losetup --show -f $HOME/uefi.img)
|
||||
$ parted ${UEFI_DEV} -s mklabel gpt mkpart EFI FAT16 1MiB 100% toggle 1 boot
|
||||
$ mkfs -t msdos ${UEFI_DEV}p1
|
||||
$ mkdir -p $HOME/mnt
|
||||
$ mount ${UEFI_DEV}p1 $HOME/mnt
|
||||
$ cp -r $HOME/esp/* $HOME/mnt
|
||||
$ umount $HOME/mnt
|
||||
$ losetup -d ${UEFI_DEV}
|
||||
```
|
||||
|
||||
> NOTE: On a physical computer, you need only copy the files from the “esp” directory to the computer’s existing EFI system partition. You do not need the “uefi.img” file to boot a physical computer.
|
||||
>
|
||||
> NOTE: On a physical computer you can rename the “bootx64.efi” file if a file by that name already exists, but if you do so, you will probably have to edit the computer’s BIOS settings and add the renamed efi file to the boot list.
|
||||
|
||||
Next we need to install the qemu package:
|
||||
|
||||
```
|
||||
$ dnf install -y qemu-system-x86
|
||||
```
|
||||
|
||||
Allow QEMU to access the bridge that we created in the “Initial Configuration” section of this tutorial:
|
||||
|
||||
```
|
||||
$ echo 'allow br0' > /etc/qemu/bridge.conf
|
||||
```
|
||||
|
||||
Create a copy of the “OVMF_VARS.fd” image to store our virtual machine’s persistent BIOS settings:
|
||||
|
||||
```
|
||||
$ cp /usr/share/edk2/ovmf/OVMF_VARS.fd $HOME
|
||||
```
|
||||
|
||||
Now, start the virtual machine:
|
||||
|
||||
```
|
||||
$ qemu-system-x86_64 -machine accel=kvm -nographic -m 1024 -drive if=pflash,format=raw,unit=0,file=/usr/share/edk2/ovmf/OVMF_CODE.fd,readonly=on -drive if=pflash,format=raw,unit=1,file=$HOME/OVMF_VARS.fd -drive if=ide,format=raw,file=$HOME/uefi.img -net bridge,br=br0 -net nic,model=virtio
|
||||
```
|
||||
|
||||
If all goes well, you should see results similar to what is shown in the below image:
|
||||
|
||||
![][10]
|
||||
You can use the “shutdown” command to get out of the virtual machine and back to the server:
|
||||
|
||||
```
|
||||
$ sudo shutdown -h now
|
||||
```
|
||||
|
||||
> NOTE: If something goes wrong and the virtual machine hangs, you may need to start a new ssh session to the server and use the “kill” command to terminate the “qemu-system-x86_64” process.
|
||||
|
||||
### Adding to the Image
|
||||
|
||||
Adding to the image should be a simple matter of chroot’ing into the image on the server and running “dnf install <package_name>”.
|
||||
|
||||
There is no limit to what can be installed on the netboot image. A full graphical installation should function perfectly.
|
||||
|
||||
Here is an example of how to bring our minimal netboot image up to a complete graphical installation:
|
||||
|
||||
```
|
||||
$ for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done
|
||||
$ chroot /fc28 /usr/bin/bash --login
|
||||
$ dnf -y groupinstall "Fedora Workstation"
|
||||
$ dnf -y remove gnome-initial-setup
|
||||
$ systemctl disable sshd.service
|
||||
$ systemctl enable gdm.service
|
||||
$ systemctl set-default graphical.target
|
||||
$ sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
|
||||
$ logout
|
||||
$ for i in run sys proc dev/shm dev/pts dev; do umount /fc28/$i; done
|
||||
```
|
||||
|
||||
Optionally, you may want to enable automatic login for the “liveuser” account:
|
||||
|
||||
```
|
||||
$ sed -i '/daemon/a AutomaticLoginEnable=true' /fc28/etc/gdm/custom.conf
|
||||
$ sed -i '/daemon/a AutomaticLogin=liveuser' /fc28/etc/gdm/custom.conf
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-to-build-a-netboot-server-part-1/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Network_booting
|
||||
[2]: https://dl.fedoraproject.org/pub/fedora/linux/releases/28/Server/x86_64/iso/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/11/installation-summary-1024x768.png
|
||||
[4]: https://docs.fedoraproject.org/en-US/Fedora/25/html/Networking_Guide/ch-Configure_Host_Names.html#sec_Understanding_Host_Names
|
||||
[5]: https://en.wikipedia.org/wiki/Bridging_(networking)
|
||||
[6]: https://www.centos.org/docs/5/html/5.1/Deployment_Guide/s3-nfs-server-config-exportfs-nfsv4.html
|
||||
[7]: https://bugzilla.redhat.com/show_bug.cgi?id=1542567
|
||||
[8]: https://ipxe.org/
|
||||
[9]: https://en.wikipedia.org/wiki/EFI_system_partition
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/11/netboot-liveuser-1024x641.png
|
||||
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Bio-Linux: A stable, portable scientific research Linux distribution)
|
||||
[#]: via: (https://opensource.com/article/18/11/bio-linux)
|
||||
[#]: author: (Matt Calverley https://opensource.com/users/mattcalverley)
|
||||
[#]: url: ( )
|
||||
|
||||
Bio-Linux: A stable, portable scientific research Linux distribution
|
||||
======
|
||||
Linux distro's integrated software approach offers powerful bioinformatic data analysis with a familiar look and feel.
|
||||
|
||||
|
||||
Bio-Linux was introduced and detailed in a [Nature Biotechnology paper in July 2006][1]. The distribution was a group effort by the Natural Environment Research Council in the UK. As the creators and authors point out, the analysis demands of high-throughput “-omic” (genomic, proteomic, metabolomic) science has necessitated the development of integrated computing solutions to analyze the resultant mountains of experimental data.
|
||||
|
||||
From this need, Bio-Linux was born. The distribution, [according to its creators][2], serves as a “free bioinformatics workstation platform that can be installed on anything from a laptop to a large server.” The current distro version, Bio-Linux 8, is built on an Ubuntu 14.04 LTS base. Thus, the general look and feel of Bio-Linux is similar to that of Ubuntu.
|
||||
|
||||
In my own work as a research immunologist, I can attest to both the need for and success of the integrated software approach in Bio-Linux's design and development. Bio-Linux functions as a true turnkey solution to data pipeline requirements of modern science. As the website mentions, Bio-Linux includes [more than 250 pre-installed software packages][3], many of which are specific to the requirements of bioinformatic data analysis.
|
||||
|
||||
The power of this approach becomes immediately evident when you try to duplicate the software installation process under another operating system. Integrating all software components and installing all required dependencies is immensely time-consuming, and in some instances is not even possible outside of the Linux operating system. The Bio-Linux distro provides a portable, stable, integrated environment with pre-installed software sufficient to begin a vast array of bioinformatic analysis tasks.
|
||||
|
||||
By now you’re probably saying, “I’m sold—how do I get this amazing distro?”
|
||||
|
||||
I’m glad you asked. I'll start by saying that there is excellent documentation on the Bio-Linux website. This [documentation][4] covers both installation instructions and a very thorough overview of using the distro.
|
||||
|
||||
The distro can be installed and run locally, run off a CD/DVD or USB, installed on a server, or run out of a virtual machine environment. To begin the installation process for local installation, [download the disk image or ISO][5] for the Bio-Linux distro. The disk image is a 3.3GB file, and depending on your internet download speed, this may be a good time to get a cup of coffee or take a nice nap.
|
||||
|
||||
Once the ISO has been downloaded, the Bio-Linux developers recommend using [UNetBootin][6], a freely available cross-platform software package used to make bootable USBs. There is a link provided for UNetBootin on the Bio-Linux website. I can attest to the effectiveness of UNetBootin in both Mac and Linux operating systems.
|
||||
|
||||
On Unix family operating systems (Mac OS and Linux), it is also possible to make a bootable USB from the command line using the `dd `command:
|
||||
|
||||
```
|
||||
sudo umount “USB location”
|
||||
|
||||
sudo dd bs=4M if=”ISO location” of =”USB location” conv=fdatasync
|
||||
```
|
||||
Regardless of the method you use, this might be another good time for a coffee break.
|
||||
|
||||
At this point in my installation, UNetBootin appeared to freeze at the `squashfs` file transfer during bootable USB creation. However, a quick check of the Ubuntu disks application confirmed that the file was still being written to the USB. In other words, be patient—it takes quite some time to make the bootable USB.
|
||||
|
||||
Once you’ve had your coffee and you have a finished USB in hand, you are ready to use Bio-Linux. As the Bio-Linux website points out, if you are trying to use a bootable USB with a Mac computer (particularly newer hardware versions), you may not be able to boot from the USB. There are workarounds, but they involve configuring the system for dual boot. Likewise, on Windows-based machines, it may be necessary to make changes to the boot order and possibly the secure boot settings for the machine from within BIOS.
|
||||
|
||||
From this point, how you use the distro is up to you. You can run the distro from the USB to test it. You can install the distro to your computer. You can even follow the instructions on the Bio-Linux website to make a VM instance of the distro or run it on a server. Regardless of how you use it, you have a high-powered bioinformatic data analysis workstation at your disposal.
|
||||
|
||||
Maybe you have a professional need for such a workstation, but even if you never use Bio-Linux as a professional researcher, it could provide a great resource for biology teaching professionals at all levels to introduce students to modern bioinformatics principles. For the price of a laptop and a USB, every school can have an in silico teaching resource to complement classroom lessons in the “-omics” age. Your only limitations are your creativity and the performance of your hardware.
|
||||
|
||||
### More on Linux
|
||||
|
||||
As an open source operating system with strong community support, the Linux kernel shares many of the strengths common to other successful open source software endeavors. Linux tends to be both stable and amenable to customization. It is also fairly hardware-agnostic, capable of running alongside other operating systems on a wide array of hardware configurations. In fact, installing Linux is a common method of regaining usability from dated hardware that is incapable of running other modern operating systems. Linux is also highly portable and can be run from any bootable external storage device, such as a USB drive, without the need to permanently install the operating system.
|
||||
|
||||
It is this combination of stability, customizability, and portability that initially drew me to Linux. Each Linux operating system variant is referred to as a distribution (or distro), and it seems as though there is a Linux distribution for every imaginable computing scenario or desire. The options can actually be rather intimidating, and I suspect they may often discourage people from trying Linux.
|
||||
|
||||
“How many different distributions can there possibly be?” you might wonder. If you have a few minutes, or even a few hours, have a look at [DistroWatch.com][7]. As its name implies, this site is devoted to the cataloging of all things Linux distribution-related. For visual learners, there is an amazing [Linux family tree][8] that really puts it into perspective.
|
||||
|
||||
While [entire books][9] are devoted to the topic of Linux distributions, the differences often depend on what software is included in the base installation, how the software is managed, and graphical differences affecting the “look and feel” of the distribution. Certainly, there are also subtleties of hardware compatibility, speed, and stability.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/bio-linux
|
||||
|
||||
作者:[Matt Calverley][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mattcalverley
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.nature.com/articles/nbt0706-801
|
||||
[2]: http://environmentalomics.org/bio-linux/
|
||||
[3]: http://environmentalomics.org/bio-linux-software-list/
|
||||
[4]: http://nebc.nerc.ac.uk/downloads/courses/Bio-Linux/bl8_latest.pdf
|
||||
[5]: http://environmentalomics.org/bio-linux-download/
|
||||
[6]: https://unetbootin.github.io/
|
||||
[7]: https://distrowatch.com/
|
||||
[8]: https://distrowatch.com/images/other/distro-family-tree.png
|
||||
[9]: https://www.amazon.com/Introducing-Linux-Distros-Dieguez-Castro/dp/1484213939
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux)
|
||||
[#]: via: (https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
[#]: url: ( )
|
||||
|
||||
Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux
|
||||
======
|
||||
|
||||
We have to make the system up-to date to minimize the downtime and issues.
|
||||
|
||||
It’s one of the routine task for Linux administrator to patch the system once in a month or 60 days once or 90 days at maximum.
|
||||
|
||||
It would be sufficient schedule and we can’t do it this less than a month as it’s involve multiple activities and environments.
|
||||
|
||||
Basically infrastructure comes with Test, Development, QA a.k.a Staging & Prod environments.
|
||||
|
||||
Initially we will deploy the patches in the Test environment and corresponding team will be monitoring the system a week then they will give a status report like good or bad.
|
||||
|
||||
If it’s success then we will move forward to other environments. If everything is good then finally we will patch production servers.
|
||||
|
||||
Many of the organization has prepare to patch entire system. i mean full system update. It is a general patching schedule for a typical infrastructure.
|
||||
|
||||
In some of the infrastructure they may have only production environment so, we should not prepare for the full system update instead we can go with security patch to make the system more stable and secure.
|
||||
|
||||
Since Arch Linux and its derivatives distributions are fall under rolling release can be considered to be always up-to-date, as it uses the latest versions of software packages from the upstream.
|
||||
|
||||
In some cases if you want to update security patch alone then you have to use arch-audit tool to identify and fix the security patches.
|
||||
|
||||
### What is a Vulnerability?
|
||||
|
||||
A vulnerability is a security weakness in a software program or hardware components (firmware). It’s a flaw that can leave it open to attack.
|
||||
|
||||
To mitigate this we need to patch accordingly like for application/hardware it could be a code changes or config changes or parameter changes.
|
||||
|
||||
### What is Arch-Audit Tool?
|
||||
|
||||
[Arch-audit][1] is a tool like pkg-audit for Arch Linux system. It Uses data collected by the awesome Arch Security Team. It wont scan and find the vulnerable packages on your system like **yum –security check-update & yum updateinfo list available** and it will simply parse the <https://security.archlinux.org/> page and display the results in terminal. So, it would show the accurate data.
|
||||
|
||||
The Arch Security Team is a group of volunteers whose goal is to track security issues with Arch Linux packages. All issues are tracked on the Arch Linux security tracker.
|
||||
|
||||
The team was formerly known as the Arch CVE Monitoring Team. The mission of the Arch Security Team is to contribute to the improvement of the security of Arch Linux.
|
||||
|
||||
### How to Install arch-audit tool in Arch Linux
|
||||
|
||||
The arch-audit tool is available in community repository so you can use the Pacman Package Manager to install it.
|
||||
|
||||
```
|
||||
$ sudo pacman -S arch-audit
|
||||
```
|
||||
|
||||
Run the `arch-audit` tool to find the open vulnerable packages on Arch based distributions.
|
||||
|
||||
```
|
||||
$ arch-audit
|
||||
Package cairo is affected by CVE-2017-7475. Low risk!
|
||||
Package exiv2 is affected by CVE-2017-11592, CVE-2017-11591, CVE-2017-11553, CVE-2017-17725, CVE-2017-17724, CVE-2017-17723, CVE-2017-17722. Medium risk!
|
||||
Package libtiff is affected by CVE-2018-18661, CVE-2018-18557, CVE-2017-9935, CVE-2017-11613. High risk!. Update to 4.0.10-1!
|
||||
Package openssl is affected by CVE-2018-0735, CVE-2018-0734. Low risk!
|
||||
Package openssl-1.0 is affected by CVE-2018-5407, CVE-2018-0734. Low risk!
|
||||
Package patch is affected by CVE-2018-6952, CVE-2018-1000156. High risk!. Update to 2.7.6-7!
|
||||
Package pcre is affected by CVE-2017-11164. Low risk!
|
||||
Package systemd is affected by CVE-2018-6954, CVE-2018-15688, CVE-2018-15687, CVE-2018-15686. Critical risk!. Update to 239.300-1!
|
||||
Package unzip is affected by CVE-2018-1000035. Medium risk!
|
||||
Package webkit2gtk is affected by CVE-2018-4372. Critical risk!. Update to 2.22.4-1!
|
||||
```
|
||||
|
||||
The above result shows the vulnerability risk status as well such as Low, Medium and Critical.
|
||||
|
||||
To Show only vulnerable package names and their versions.
|
||||
|
||||
```
|
||||
$ arch-audit -q
|
||||
cairo
|
||||
exiv2
|
||||
libtiff>=4.0.10-1
|
||||
openssl
|
||||
openssl-1.0
|
||||
patch>=2.7.6-7
|
||||
pcre
|
||||
systemd>=239.300-1
|
||||
unzip
|
||||
webkit2gtk>=2.22.4-1
|
||||
```
|
||||
|
||||
To show only packages that have already been fixed.
|
||||
|
||||
```
|
||||
$ arch-audit --upgradable --quiet
|
||||
libtiff>=4.0.10-1
|
||||
patch>=2.7.6-7
|
||||
systemd>=239.300-1
|
||||
webkit2gtk>=2.22.4-1
|
||||
```
|
||||
|
||||
To cross check the above results, i’m going to test one of the package which is listed above in <https://www.archlinux.org/packages/> to confirm whether the vulnerability is still open or fixed it. Yes, it’s fixed and published the updated package in repository on yesterday.
|
||||
![][3]
|
||||
|
||||
To print only package names and associated CVEs alone.
|
||||
|
||||
```
|
||||
$ arch-audit -uf "%n|%c"
|
||||
libtiff|CVE-2018-18661,CVE-2018-18557,CVE-2017-9935,CVE-2017-11613
|
||||
patch|CVE-2018-6952,CVE-2018-1000156
|
||||
systemd|CVE-2018-6954,CVE-2018-15688,CVE-2018-15687,CVE-2018-15686
|
||||
webkit2gtk|CVE-2018-4372
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/ilpianista/arch-audit
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2018/11/A-Tool-To-Check-Vulnerable-Packages-In-Arch-Linux.png
|
||||
@ -1,145 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (OpenSnitch – an Application Firewall for Linux [Review])
|
||||
[#]: via: (https://itsfoss.com/opensnitch-firewall-linux/)
|
||||
[#]: author: ([John Paul](https://itsfoss.com/author/john/))
|
||||
[#]: url: ( )
|
||||
|
||||
OpenSnitch – an Application Firewall for Linux [Review]
|
||||
======
|
||||
|
||||
Just because Linux is a lot more secure than Windows, there is no reason you should not be cautious. There are a number of firewalls available for Linux that you can use to make your Linux system more secure. Today we will be taking a look at one of such firewall tool called OpenSnitch.
|
||||
|
||||
### What is OpenSnitch?
|
||||
|
||||
![Linux firewall and security][1]
|
||||
|
||||
[OpenSnitch][2] is a port of Little Snitch. Little Snitch, in turn, is an application firewall designed solely for Mac OS. OpenSnitch is created by [Simone Margaritelli][3], also known as [evilsocket][4].
|
||||
|
||||
The main thing that OpenSnitch does is track internet requests made by applications you have installed. OpenSnitch allows you to create rules for which apps to allow to access the internet and which to block. Each time an application that does not have a rule in place tries to access the internet, a dialog box appears. This dialog box gives you the option to allow or block the connection.
|
||||
|
||||
You can also decide whether this new rule applies to the process, the exact URL it is attempting to reach, the domain that it is attempting to reach, to this single instance, to this session or forever.
|
||||
|
||||
![OpenSnitch firewall app in Linux][5]OpenSnatch rule request
|
||||
|
||||
All of the rules that you create are stored as [JSON files][6] so you can change them later if you need to. For example, if you incorrectly blocked an application.
|
||||
|
||||
OpenSnitch also has a nice graphical user interface that lets you see at a glance:
|
||||
|
||||
* What applications are accessing the web
|
||||
* What IP address they are using
|
||||
* What User owns it
|
||||
* What port is being used
|
||||
|
||||
|
||||
|
||||
You can also export the information to a CSV file if you wish.
|
||||
|
||||
OpenSnitch is available under the GPL v3 license.
|
||||
|
||||
![OpenSnitch firewall interface][7]OpenSnitch processes tab
|
||||
|
||||
### Installing OpenSnitch in Linux
|
||||
|
||||
The installation instructions on the [OpenSnitch GitHub page][8] are aimed at Ubuntu users. If you are using another distro, you will have to adjust the commands. As far as I know, this application is only packaged in the [Arch User Repository][9].
|
||||
|
||||
Before you start, you need to have Go properly installed and the `$GOPATH` environment variable is defined.
|
||||
|
||||
First, install the necessary dependencies.
|
||||
|
||||
```
|
||||
sudo apt-get install protobuf-compiler libpcap-dev libnetfilter-queue-dev python3-pip
|
||||
|
||||
go get github.com/golang/protobuf/protoc-gen-go
|
||||
|
||||
go get -u github.com/golang/dep/cmd/dep
|
||||
|
||||
python3 -m pip install --user grpcio-tools
|
||||
```
|
||||
|
||||
Next, you will need to clone the OpenSnitch repo. There will probably be a message that no Go files where found. Ignore it. If you get a message that git is missing, just install it.
|
||||
|
||||
```
|
||||
go get github.com/evilsocket/opensnitch
|
||||
|
||||
cd $GOPATH/src/github.com/evilsocket/opensnitch
|
||||
```
|
||||
|
||||
If the `$GOPATH` environment variable is not setup correctly, you will get a “no such folder found” error on the previous command. just `cd` into the location of the “evilsocket/opensnitch” folder that was listed when you cloned it to your system.
|
||||
|
||||
Now, we build and install it.
|
||||
|
||||
```
|
||||
make
|
||||
|
||||
sudo make install
|
||||
```
|
||||
|
||||
If you get an error that the `dep` command could not be found, add `GOPATH/bin` is in the `PATH`.
|
||||
|
||||
Once that is finished, we will initiate the daemon and start the graphical user environment.
|
||||
|
||||
```
|
||||
sudo systemctl enable opensnitchd
|
||||
|
||||
sudo service opensnitchd start
|
||||
|
||||
opensnitch-ui
|
||||
```
|
||||
|
||||
![OpenSnitch firewall interface][10]OpenSnitch on Manjaro
|
||||
|
||||
### Experience
|
||||
|
||||
I’ll be honest: my experience with OpenSnitch was not great. I started by trying to install it on Fedora. I had trouble finding some of the dependencies. I switched over to Manjaro and was happy to find it in the Arch User Repository.
|
||||
|
||||
Unfortunately, after I ran the installation, I could not launch the graphical user interface. So I ran the last three steps by hand. Everything seemed to be working fine. The dialog box popped up asking me if I wanted to let Firefox visit the Manjaro website.
|
||||
|
||||
Interestingly, when I ran an [AUR tool][11] `yay` to update my system, the dialog box requested rules for `yay`, `pacman`, `pamac`, and `git`. Later, I had to close and restart the GUI because it was acting up. When I restart it, it stopped asking me to create rules. I installed Falkon and OpenSnitch did not ask me to give it any permissions. It did not even list Falkon in the OpenSnithch GUI. I reinstalled OpenSnitch. Same issue.
|
||||
|
||||
Then I moved to Ubuntu Mate. Since the installation instructions were written for Ubuntu, things went easier. However, I ran into a couple issues. I tweaked the installation instructions above to fix the problems I encountered.
|
||||
|
||||
Installation was not the only issue that I ran into. The dialog box that appeared every time a new app created a connection only lasted for 10 seconds. That was barely enough time to explore the available options. Most of the time, I only had time to allow an application (only the ones I trust) to access the web forever.
|
||||
|
||||
The GUI also left a bit to be desired. For some reason, the window was set to be on top all of the time. On top of that, there are no setting to change it. It would also have been nice to have the option to change rules from the GUI.
|
||||
|
||||
![][12]OpenSnitch hosts tab
|
||||
|
||||
### Final Thoughts on OpenSnitch
|
||||
|
||||
I like what OpenSnitch is aiming for: any easy way to control what information leaves your computer. However, it has too many rough edges for me to recommend it to a regular or hobby user. If you are a power user, who likes to tinker and dig for answers then maybe this is for you.
|
||||
|
||||
It’s kinda disappointing. I would have hoped that an application that recently hit 1.0 would be in a little better shape.
|
||||
|
||||
Have you ever used OpenSnitch? If not, what is your favorite firewall app? How do you make your Linux system more secure? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/opensnitch-firewall-linux/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/linux-firewall-security.jpg?fit=800%2C450&ssl=1
|
||||
[2]: https://www.opensnitch.io/
|
||||
[3]: https://github.com/evilsocket
|
||||
[4]: https://twitter.com/evilsocket
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/opensnitch-dialog.jpg?fit=800%2C421&ssl=1
|
||||
[6]: https://www.json.org/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/opensnitch-processes.jpg?fit=800%2C651&ssl=1
|
||||
[8]: https://github.com/evilsocket/opensnitch
|
||||
[9]: https://aur.archlinux.org/packages/opensnitch-git
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/opensnitch-manjaro.jpg?fit=800%2C651&ssl=1
|
||||
[11]: https://itsfoss.com/best-aur-helpers/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/opensnitch-hosts.jpg?fit=800%2C651&ssl=1
|
||||
[13]: http://reddit.com/r/linuxusersgroup
|
||||
@ -1,70 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Standalone web applications with GNOME Web)
|
||||
[#]: via: (https://fedoramagazine.org/standalone-web-applications-gnome-web/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
|
||||
[#]: url: ( )
|
||||
|
||||
Standalone web applications with GNOME Web
|
||||
======
|
||||

|
||||
|
||||
Do you regularly use a single-page web application, but miss some of the benefits of a full-fledged desktop application? The GNOME Web browser, simply named Web (aka Epiphany) has an awesome feature that allows you to ‘install’ a web application. By doing this, the web application is then presented in the applications menus, GNOME shell search, and is a separate item when switching windows. This short tutorial walks you through the steps of ‘installing’ a web application with GNOME Web.
|
||||
|
||||
### Install GNOME Web
|
||||
|
||||
GNOME Web is not included in the default Fedora install. To install, search in the Software application for ‘web’, and install.
|
||||
|
||||
![][1]
|
||||
|
||||
Alternatively, use the following command in the terminal:
|
||||
|
||||
```
|
||||
sudo dnf install epiphany
|
||||
```
|
||||
|
||||
### Install as Web Application
|
||||
|
||||
Next, launch GNOME Web, and browse to the web application you wish to install. Connect to the application using the browser, and choose ‘Install site as Web Application’ from the menu:
|
||||
|
||||
![][2]
|
||||
|
||||
GNOME Web next presents a dialog to edit the name of the application. Either leave it as the default (the URL) or change to something more descriptive:
|
||||
|
||||
![][3]
|
||||
|
||||
Finally, press **Create** to ‘install’ your new web application. After creating the web application, close GNOME Web.
|
||||
|
||||
### Using the new web application
|
||||
|
||||
Launch the web application as you would with any typical desktop application. Search for it in the GNOME Shell Overview:
|
||||
|
||||
![][4]
|
||||
|
||||
Additionally, the web application will appear as a separate application in the alt-tab application switcher:
|
||||
|
||||
![][5]
|
||||
|
||||
One additional feature this adds is that all web notifications from the ‘installed’ web application are presented as regular GNOME notifications.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/standalone-web-applications-gnome-web/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2018/11/gnome-web-in-gnome-software.png
|
||||
[2]: https://fedoramagazine.org/wp-content/uploads/2018/11/freenode-page-in-gnome-web.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/11/edit-web-application-in-GNOME-web.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/11/web-application-in-overview.jpg
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/11/web-app-in-app-switcher.jpg
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (SMPlayer in Linux: Features, Download and Installation)
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Boxing yourself in on the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-boxes)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
[#]: url: ( )
|
||||
|
||||
Boxing yourself in on the Linux command line
|
||||
======
|
||||
Learn how to use the boxes utility to draw shapes with characters at the Linux terminal and make your words stand out.
|
||||

|
||||
|
||||
It's the holiday season, and every Linux terminal user deserves a little gift. It doesn't matter whether you celebrate Christmas, another holiday, or nothing at all. So I'm gathering together a collection of 24 Linux command-line toys over the next few weeks for you to enjoy and share with your friends. Let's have a little fun and add a little joy to a month that, at least here in the northern hemisphere, can be a little bit cold and dreary.
|
||||
|
||||
Chances are, there will be a few that you've heard of before. But, hopefully, we'll all have a chance to learn something new. (I know I did when doing some research to make sure I could make it to 24.)
|
||||
|
||||
The first of our 24 Linux terminal toys is a program called boxes. Why start with boxes? Because it's going to be hard to wrap up all of our other command-line presents to you without it!
|
||||
|
||||
On my Fedora machine, boxes wasn't installed by default, but it was in my normal repositories, so installing it was as simple as
|
||||
|
||||
```
|
||||
$ sudo dnf install boxes -y
|
||||
```
|
||||
|
||||
If you're on a different distribution, there's a good chance you'll find it in your default repositories as well.
|
||||
|
||||
Boxes a utility I really wish I had in my high school and college computer science courses, where well-intentioned teachers insisted I provide very specific looking comment at the beginning of every source file, function, code block, etc.
|
||||
|
||||
```
|
||||
/***************/
|
||||
/* Hello World */
|
||||
/***************/
|
||||
```
|
||||
|
||||
It turns out, once you add a few lines of text inside, formatting them can get, well, tedious. Enter boxes. Boxes is a simple utility for surrounding a block of text with an ASCII art-style box. It comes with defaults for source code commenting, as well as other options.
|
||||
|
||||
It's really easy to use. Using pipes, I can push a short greeting into a box.
|
||||
|
||||
```
|
||||
$ cat greeting.txt | boxes -d diamonds -a c
|
||||
```
|
||||
|
||||
Which will give us the output as follows:
|
||||
|
||||
```
|
||||
/\ /\ /\
|
||||
/\//\\/\ /\//\\/\ /\//\\/\
|
||||
/\//\\\///\\/\//\\\///\\/\//\\\///\\/\
|
||||
//\\\//\/\\///\\\//\/\\///\\\//\/\\///\\
|
||||
\\//\/ \/\\//
|
||||
\/ \/
|
||||
/\ I'm wishing you all a /\
|
||||
//\\ joyous holiday season //\\
|
||||
\\// and a Happy Gnu Year! \\//
|
||||
\/ \/
|
||||
/\ /\
|
||||
//\\/\ /\//\\
|
||||
\\///\\/\//\\\///\\/\//\\\///\\/\//\\\//
|
||||
\/\\///\\\//\/\\///\\\//\/\\///\\\//\/
|
||||
\/\\//\/ \/\\//\/ \/\\//\/
|
||||
\/ \/ \/
|
||||
```
|
||||
|
||||
Or perhaps something more fun, like:
|
||||
|
||||
```
|
||||
echo "I am a dog" | boxes -d dog -a c
|
||||
```
|
||||
|
||||
Which will, unsurprisingly, give you the following:
|
||||
|
||||
```
|
||||
__ _,--="=--,_ __
|
||||
/ \." .-. "./ \
|
||||
/ ,/ _ : : _ \/` \
|
||||
\ `| /o\ :_: /o\ |\__/
|
||||
`-'| :="~` _ `~"=: |
|
||||
\` (_) `/
|
||||
.-"-. \ | / .-"-.
|
||||
.---{ }--| /,.-'-.,\ |--{ }---.
|
||||
) (_)_)_) \_/`~-===-~`\_/ (_(_(_) (
|
||||
( I am a dog )
|
||||
) (
|
||||
'---------------------------------------'
|
||||
```
|
||||
|
||||
Boxes comes with [lots of options][1] for padding, position, and even processing regular expressions. You can learn more about boxes on the [project's homepage][2], or head over to [GitHub][3] to download the source code or contribute your own box. In fact, if you're looking for an idea to submit, I've got an idea for you: why not a holiday present?
|
||||
|
||||
```
|
||||
_ _
|
||||
/_\/_\
|
||||
_______\_\/_/_______
|
||||
| ///\\\ |
|
||||
| /// \\\ |
|
||||
| |
|
||||
| "Happy pull |
|
||||
| request!" |
|
||||
|____________________|
|
||||
```
|
||||
|
||||
Boxes is open source under a GPLv2 license.
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Or check out tomorrow's command-line toy, [Drive a locomotive through your Linux terminal][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-boxes
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://boxes.thomasjensen.com/examples.html
|
||||
[2]: https://boxes.thomasjensen.com/
|
||||
[3]: https://github.com/ascii-boxes/boxes
|
||||
[4]: https://opensource.com/article/18/12/linux-toy-sl
|
||||
266
sources/tech/20181202 How To Customize The GNOME 3 Desktop.md
Normal file
266
sources/tech/20181202 How To Customize The GNOME 3 Desktop.md
Normal file
@ -0,0 +1,266 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (How To Customize The GNOME 3 Desktop?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-customize-the-gnome-3-desktop/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
[#]: url: ( )
|
||||
|
||||
How To Customize The GNOME 3 Desktop?
|
||||
======
|
||||
|
||||
We have got many emails from user to write an article about GNOME 3 desktop customization but we don’t get a time to write this topic.
|
||||
|
||||
I was using Ubuntu operating system since long time in my primary laptop and i got bored so, i would like to test some other distro which is related to Arch Linux.
|
||||
|
||||
I prefer to go with Majaro so, i have installed Manjaro 18.0 with GNOME 3 desktop in my laptop.
|
||||
|
||||
I’m customizing my desktop, how i want it. So, i would like to take this opportunity to write up this article in detailed way to help others.
|
||||
|
||||
This article helps others to customize their desktop without headache.
|
||||
|
||||
I’m not going to include all my customization and i will be adding a necessary things which will be mandatory and useful for Linux desktop users.
|
||||
|
||||
If you feel some tweak is missing in this article, i would request you to mention that in comment sections. It will be very helpful for other users.
|
||||
|
||||
### 1) How to Launch Activities Overview in GNOME 3 Desktop?
|
||||
|
||||
The Activities Overview will display all the running applications or launched/opened windows by clicking `Super Key` or by clicking `Activities` button in the topmost left corner.
|
||||
|
||||
It allows you to launch a new applications, switch windows, and move windows between workspaces.
|
||||
|
||||
You can simply exit the Activities Overview by choosing the following any of the one actions like selecting a window, application or workspace, or by pressing the `Super Key` or `Esc Key`.
|
||||
|
||||
Activities Overview Screenshot.
|
||||
![][2]
|
||||
|
||||
### 2) How to Resize Windows in GNOME 3 Desktop?
|
||||
|
||||
The Launched windows can be maximized, unmaximized and snapped to one side of the screen (Left or Right) by using the following key combinations.
|
||||
|
||||
* `Super Key+Down Arrow:` To unmaximize the window.
|
||||
* `Super Key+Up Arrow:` To maximize the window.
|
||||
* `Super Key+Right Arrow:` To fill a window in the right side of the half screen.
|
||||
* `Super Key+Left Arrow:` To fill a window in the left side of the half screen
|
||||
|
||||
|
||||
|
||||
Use `Super Key+Down Arrow` to unmaximize the window.
|
||||
![][3]
|
||||
|
||||
Use `Super Key+Up Arrow` to maximize the window.
|
||||
![][4]
|
||||
|
||||
Use `Super Key+Right Arrow` to fill a window in the right side of the half screen.
|
||||
![][5]
|
||||
|
||||
Use `Super Key+Left Arrow` to fill a window in the left side of the half screen.
|
||||
![][6]
|
||||
|
||||
This feature will help you to view two applications at a time a.k.a splitting screen.
|
||||
![][7]
|
||||
|
||||
### 3) How to Display Applications in GNOME 3 Desktop?
|
||||
|
||||
Click on the `Show Application Grid` button in the Dash to display all the installed applications on your system.
|
||||
![][8]
|
||||
|
||||
### 4) How to Add Applications on Dash in GNOME 3 Desktop?
|
||||
|
||||
To speed up your day to day activity you may want to add frequently used application into Dash or Drag the application launcher to the Dash.
|
||||
|
||||
It will allow you to directly launch your favorite applications without searching them. To do so, simply right click on it and use the option `Add to Favorites`.
|
||||
![][9]
|
||||
|
||||
To remove a application launcher a.k.a favorite from Dash, either drag it from the Dash to the grid button or simply right click on it and use the option `Remove from Favorites`.
|
||||
![][10]
|
||||
|
||||
### 5) How to Switch Between Workspaces in GNOME 3 Desktop?
|
||||
|
||||
Workspaces allow you to group windows together. It will helps you to segregate your work properly. If you are working on Multiple things and you want to group each work and related things separately then it will be very handy and perfect option for you.
|
||||
|
||||
You can switch workspaces in two ways, Open the Activities Overview and select a workspace from the right-hand side or use the following key combinations.
|
||||
|
||||
* Use `Ctrl+Alt+Up` Switch to the workspace above.
|
||||
* Use `Ctrl+Alt+Down` Switch to the workspace below.
|
||||
|
||||
|
||||
|
||||
![][11]
|
||||
|
||||
### 6) How to Switch Between Applications (Application Switcher) in GNOME 3 Desktop?
|
||||
|
||||
Use either `Alt+Tab` or `Super+Tab` to switch between applications. To launch Application Switcher, use either `Alt+Tab` or `Super+Tab`.
|
||||
|
||||
Once launched, just keep holding the Alt or Super key and hit the tab key to move to the next application from left to right order.
|
||||
|
||||
### 7) How to Add UserName to Top Panel in GNOME 3 Desktop?
|
||||
|
||||
If you would like to add your UserName to Top Panel then install the following [Add Username to Top Panel][12] GNOME Extension.
|
||||
![][13]
|
||||
|
||||
### 8) How to Add Microsoft Bing’s wallpaper in GNOME 3 Desktop?
|
||||
|
||||
Install the following [Bing Wallpaper Changer][14] GNOME shell extension to change your wallpaper every day to Microsoft Bing’s wallpaper.
|
||||
![][15]
|
||||
|
||||
### 9) How to Enable Night Light in GNOME 3 Desktop?
|
||||
|
||||
Night light app is one of the famous app which reduces strain on the eyes by turning your screen a dim yellow from blue light after sunset.
|
||||
|
||||
It is available in smartphones. The other known apps for the same purpose are flux and **[redshift][16]**.
|
||||
|
||||
To enable this, navigate to **System Settings** >> **Devices** >> **Displays** and turn Nigh Light on.
|
||||
![][17]
|
||||
|
||||
Once it’s enabled and status icon will be placed on the top panel.
|
||||
![][18]
|
||||
|
||||
### 10) How to Show the Battery Percentage in GNOME 3 Desktop?
|
||||
|
||||
Battery percentage will show you the exact battery usage. To enable this follow the below steps.
|
||||
|
||||
Start GNOME Tweaks >> **Top Bar** >> **Battery Percentage** and switch it on.
|
||||
![][19]
|
||||
|
||||
After modification you can able to see the battery percentage icon on the top panel.
|
||||
![][20]
|
||||
|
||||
### 11) How to Enable Mouse Right Click in GNOME 3 Desktop?
|
||||
|
||||
By default right click is disabled on GNOME 3 desktop environment. To enable this follow the below steps.
|
||||
|
||||
Start GNOME Tweaks >> **Keyboard & Mouse** >> Mouse Click Emulation and select “Area” option.
|
||||
![][21]
|
||||
|
||||
### 12) How to Enable Minimize On Click in GNOME 3 Desktop?
|
||||
|
||||
Enable one-click minimize feature which will help us to minimize opened window without using minimize option.
|
||||
|
||||
```
|
||||
$ gsettings set org.gnome.shell.extensions.dash-to-dock click-action 'minimize'
|
||||
```
|
||||
|
||||
### 13) How to Customize Dock in GNOME 3 Desktop?
|
||||
|
||||
If you would like to change your Dock similar to Deepin desktop or Mac then use the following set of commands.
|
||||
|
||||
```
|
||||
$ gsettings set org.gnome.shell.extensions.dash-to-dock dock-position BOTTOM
|
||||
$ gsettings set org.gnome.shell.extensions.dash-to-dock extend-height false
|
||||
$ gsettings set org.gnome.shell.extensions.dash-to-dock transparency-mode FIXED
|
||||
$ gsettings set org.gnome.shell.extensions.dash-to-dock dash-max-icon-size 50
|
||||
```
|
||||
|
||||
![][22]
|
||||
|
||||
### 14) How to Show Desktop in GNOME 3 Desktop?
|
||||
|
||||
By default `Super Key+D` shortcut doesn’t show your desktop. To configure this follow the below steps.
|
||||
|
||||
Settings >> **Devices** >> **Keyboard** >> Click **Hide all normal windows** under Navigation then Press `Super Key+D` finally hit `Set` button to enable it.
|
||||
![][23]
|
||||
|
||||
### 15) How to Customize Date and Time Format?
|
||||
|
||||
By default GNOME 3 shows date and time with `Sun 04:48`. It’s not clear and if you want to get the output with following format `Sun Dec 2 4:49 AM` follow the below steps.
|
||||
|
||||
**For Date Modification:** Start GNOME Tweaks >> **Top Bar** and enable `Weekday` option under Clock.
|
||||
![][24]
|
||||
|
||||
**For Time Modification:** Settings >> **Details** >> **Date & Time** then choose `AM/PM` option in the time format.
|
||||
![][25]
|
||||
|
||||
After modification you can able to see the date and time format same as below.
|
||||
![][26]
|
||||
|
||||
### 16) How to Permanently Disable Unused Services in Boot?
|
||||
|
||||
In my case, i’m not going to use **Bluetooth** & **cpus a.k.a Printer service**. Hence, disabling these services on my laptop. To disable services on Arch based systems use **[Pacman Package Manager][27]**.
|
||||
For Bluetooth
|
||||
|
||||
```
|
||||
$ sudo systemctl stop bluetooth.service
|
||||
$ sudo systemctl disable bluetooth.service
|
||||
$ sudo systemctl mask bluetooth.service
|
||||
$ systemctl status bluetooth.service
|
||||
```
|
||||
|
||||
For cups
|
||||
|
||||
```
|
||||
$ sudo systemctl stop org.cups.cupsd.service
|
||||
$ sudo systemctl disable org.cups.cupsd.service
|
||||
$ sudo systemctl mask org.cups.cupsd.service
|
||||
$ systemctl status org.cups.cupsd.service
|
||||
```
|
||||
|
||||
Finally verify whether these services are disabled or not in the boot using the following command. If you want to double confirm this, you can reboot once and check the same. Navigate to the following link to know more about **[systemctl][28]** usage,
|
||||
|
||||
```
|
||||
$ systemctl list-unit-files --type=service | grep enabled
|
||||
[email protected] enabled
|
||||
dbus-org.freedesktop.ModemManager1.service enabled
|
||||
dbus-org.freedesktop.NetworkManager.service enabled
|
||||
dbus-org.freedesktop.nm-dispatcher.service enabled
|
||||
display-manager.service enabled
|
||||
gdm.service enabled
|
||||
[email protected] enabled
|
||||
linux-module-cleanup.service enabled
|
||||
ModemManager.service enabled
|
||||
NetworkManager-dispatcher.service enabled
|
||||
NetworkManager-wait-online.service enabled
|
||||
NetworkManager.service enabled
|
||||
systemd-fsck-root.service enabled-runtime
|
||||
tlp-sleep.service enabled
|
||||
tlp.service enabled
|
||||
```
|
||||
|
||||
### 17) Install Icons & Themes in GNOME 3 Desktop?
|
||||
|
||||
Bunch of Icons and Themes are available for GNOME Desktop so, choose the desired **[GTK Themes][29]** and **[Icons Themes][30]** for you. To configure this further, navigate to the below links which makes your Desktop more elegant.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-customize-the-gnome-3-desktop/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-activities-overview-screenshot.jpg
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-activities-unmaximize-the-window.jpg
|
||||
[4]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-activities-maximize-the-window.jpg
|
||||
[5]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-activities-fill-a-window-right-side.jpg
|
||||
[6]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-activities-fill-a-window-left-side.jpg
|
||||
[7]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-activities-split-screen.jpg
|
||||
[8]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-display-applications.jpg
|
||||
[9]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-add-applications-on-dash.jpg
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-remove-applications-from-dash.jpg
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-workspaces-screenshot.jpg
|
||||
[12]: https://extensions.gnome.org/extension/1108/add-username-to-top-panel/
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-add-username-to-top-panel.jpg
|
||||
[14]: https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-add-microsoft-bings-wallpaper.jpg
|
||||
[16]: https://www.2daygeek.com/install-redshift-reduce-prevent-protect-eye-strain-night-linux/
|
||||
[17]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-enable-night-light.jpg
|
||||
[18]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-enable-night-light-1.jpg
|
||||
[19]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-display-battery-percentage.jpg
|
||||
[20]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-display-battery-percentage-1.jpg
|
||||
[21]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-enable-mouse-right-click.jpg
|
||||
[22]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-dock-customization.jpg
|
||||
[23]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-enable-show-desktop.jpg
|
||||
[24]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-customize-date.jpg
|
||||
[25]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-customize-time.jpg
|
||||
[26]: https://www.2daygeek.com/wp-content/uploads/2018/12/how-to-customize-the-gnome-3-desktop-customize-date-time.jpg
|
||||
[27]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[28]: https://www.2daygeek.com/sysvinit-vs-systemd-cheatsheet-systemctl-command-usage/
|
||||
[29]: https://www.2daygeek.com/category/gtk-theme/
|
||||
[30]: https://www.2daygeek.com/category/icon-theme/
|
||||
149
sources/tech/20181204 Have a cow at the Linux command line.md
Normal file
149
sources/tech/20181204 Have a cow at the Linux command line.md
Normal file
@ -0,0 +1,149 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Have a cow at the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-cowsay)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
[#]: url: ( )
|
||||
|
||||
Have a cow at the Linux command line
|
||||
======
|
||||
Bring a bovine voice to your terminal output with the cowsay utility.
|
||||
|
||||
|
||||
Welcome to the fourth day of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself, what’s a command-line toy. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
|
||||
|
||||
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone. Because just about everyone who I’ve mentioned this series to has asked me about it already, today’s selection is an obligatory one.
|
||||
|
||||
You didn’t think we’d make it through this series without mentioning cowsay, did you?
|
||||
|
||||
Cowsay is an udderly fantastic utility that takes text and outputs it as the spoken text of an ASCII-art bovine.
|
||||
|
||||
You’ll likely find cowsay packaged in your default repositories, and perhaps even already installed. For me, in Fedora, all it took to install was:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y cowsay
|
||||
```
|
||||
|
||||
Then, invoke it with cowsay followed by your message. Perhaps you’d like to pipe in the [fortune][1] [utility][1] we talked about yesterday.
|
||||
|
||||
```
|
||||
$ fortune | cowsay
|
||||
_________________________________________
|
||||
/ If at first you do succeed, try to hide \
|
||||
\ your astonishment. /
|
||||
-----------------------------------------
|
||||
\ ^__^
|
||||
\ (oo)\_______
|
||||
(__)\ )\/\
|
||||
||----w |
|
||||
|| ||
|
||||
```
|
||||
|
||||
That’s it! **Cowsay** ships with few variations, called cow files, that can usually be found in **/usr/share/cowsay.** To see the cow file options available on your system, use **-l** flag after cowsay. Then, use the **-f** flag to try one out.
|
||||
|
||||
```
|
||||
$ cowsay -f dragon "Run for cover, I feel a sneeze coming on."
|
||||
_______________________________________
|
||||
/ Run for cover, I feel a sneeze coming \
|
||||
\ on. /
|
||||
---------------------------------------
|
||||
\ / \ //\
|
||||
\ |\___/| / \// \\
|
||||
/0 0 \__ / // | \ \
|
||||
/ / \/_/ // | \ \
|
||||
@_^_@'/ \/_ // | \ \
|
||||
//_^_/ \/_ // | \ \
|
||||
( //) | \/// | \ \
|
||||
( / /) _|_ / ) // | \ _\
|
||||
( // /) '/,_ _ _/ ( ; -. | _ _\.-~ .-~~~^-.
|
||||
(( / / )) ,-{ _ `-.|.-~-. .~ `.
|
||||
(( // / )) '/\ / ~-. _ .-~ .-~^-. \
|
||||
(( /// )) `. { } / \ \
|
||||
(( / )) .----~-.\ \-' .~ \ `. \^-.
|
||||
///.----..> \ _ -~ `. ^-` ^-_
|
||||
///-._ _ _ _ _ _ _}^ - - - - ~ ~-- ,.-~
|
||||
/.-~
|
||||
```
|
||||
|
||||
My real beef with **cowsay** is that I don’t have enough time today to really milk the cow puns for all they are worth. The steaks are just too high, and I might butcher the joke.
|
||||
|
||||
On a more serious note, I had completely forgotten about **cowsay** until I re-encountered it when learning Ansible playbooks. If you happen to have **cowsay** installed, when you run a playbook, you’ll get your output from a series of cows. For example, running this playbook:
|
||||
|
||||
```
|
||||
- hosts:
|
||||
- localhost
|
||||
tasks:
|
||||
- action: ping
|
||||
```
|
||||
|
||||
Might give you the following:
|
||||
|
||||
```
|
||||
$ ansible-playbook playbook.yml
|
||||
__________________
|
||||
< PLAY [localhost] >
|
||||
------------------
|
||||
\ ^__^
|
||||
\ (oo)\_______
|
||||
(__)\ )\/\
|
||||
||----w |
|
||||
|| ||
|
||||
|
||||
________________________
|
||||
< TASK [Gathering Facts] >
|
||||
------------------------
|
||||
\ ^__^
|
||||
\ (oo)\_______
|
||||
(__)\ )\/\
|
||||
||----w |
|
||||
|| ||
|
||||
|
||||
ok: [localhost]
|
||||
_____________
|
||||
< TASK [ping] >
|
||||
-------------
|
||||
\ ^__^
|
||||
\ (oo)\_______
|
||||
(__)\ )\/\
|
||||
||----w |
|
||||
|| ||
|
||||
|
||||
ok: [localhost]
|
||||
____________
|
||||
< PLAY RECAP >
|
||||
------------
|
||||
\ ^__^
|
||||
\ (oo)\_______
|
||||
(__)\ )\/\
|
||||
||----w |
|
||||
|| ||
|
||||
|
||||
localhost : ok=2 changed=0 unreachable=0 failed=0
|
||||
```
|
||||
|
||||
**Cowsay** is available under a GPLv3 license, and you can find the Perl [source code][2] on GitHub. I’ve also seen versions floating around in other languages, so take a look around for other variants; here’s [one in R][3], for example. Implementing your own version in your language of choice might even be a fun programming learning task.
|
||||
|
||||
Now that **cowsay** is out of the way, we can move on to greener pastures.
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Check out yesterday's toy, [How to bring good fortune to your Linux terminal][1], and check back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-cowsay
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/12/linux-toy-fortune
|
||||
[2]: https://github.com/tnalpgge/rank-amateur-cowsay
|
||||
[3]: https://github.com/sckott/cowsay
|
||||
@ -0,0 +1,92 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Easily Convert Audio File Formats with SoundConverter in Linux)
|
||||
[#]: via: (https://itsfoss.com/sound-converter-linux/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
[#]: url: ( )
|
||||
|
||||
Easily Convert Audio File Formats with SoundConverter in Linux
|
||||
======
|
||||
|
||||
**If you are looking for converting audio file formats to wav, mp3, ogg or any other format, SoundConverter is the tool you need in Linux.**
|
||||
|
||||
![Audio Converter in Linux][1]
|
||||
|
||||
So recently I purchased some DRM-free music. I got it from [SaReGaMa][2], the oldest and the largest music labels in India. The downloaded files were in HD quality and in WAV format.
|
||||
|
||||
Unfortunately, Rhythmbox doesn’t play the WAV files. On top of that, a single file was around 70 MB in size. Imagine transferring such large music files to smartphones. It would eat up a lot of space unnecessarily.
|
||||
|
||||
So I thought it was time to convert the WAV files to MP3, the evergreen and the most popular music file format.
|
||||
|
||||
And for this task, I needed an audio converter in Linux. In this quick tutorial, I’ll show you how can you convert your audio files from one format to another easily with a GUI tool called SoundCoverter.
|
||||
|
||||
### Installing SoundConverter in Linux
|
||||
|
||||
[SoundConverter][3] is a popular free and open source software. It should be available in the official repository of most Linux distributions.
|
||||
|
||||
Ubuntu/Linux Mint users can simply search for SoundConverter in the software center and install it from there.
|
||||
|
||||
![SoundConverter application in Software Center of Ubuntu][4]SoundConverter can be installed from Software Center
|
||||
|
||||
Alternatively, you can use the command line way. In Debian and Ubuntu based systems, you can use the following command:
|
||||
|
||||
```
|
||||
sudo apt install soundconverter
|
||||
```
|
||||
|
||||
For Arch, Fedora and other non-Debian based distributions, you can use the software center or the package manager of your distribution.
|
||||
|
||||
### Using SoundConverter to convert audio file formats in Linux
|
||||
|
||||
Once you have installed SoundConverter, search for it in the menu and start it.
|
||||
|
||||
The default interface looks like this and it cannot be more simple than this:
|
||||
|
||||
![SoundConverter application interface in Linux][5]Simple Interface
|
||||
|
||||
Converting audio file format is as easy as selecting the file and clicking on convert.
|
||||
|
||||
However, I would advise you to check the default settings at least on the first run. By default it converts the audio file to OGG file format and you may not want that.
|
||||
|
||||
![Preferences in SoundConverter][6]Default output settings can be changed in Preferences
|
||||
|
||||
To change the default output settings, click on the Preferences icon visible on the interface. You’ll see plenty of options to change here.
|
||||
|
||||
You can change the default output format, bitrate, quality etc. You can also choose if you want to keep the converted files in the same folder as the original or not.
|
||||
|
||||
There is also an option of automatically deleting the original file after conversion. I don’t think you should use that option.
|
||||
|
||||
You can also change the output file name. By default, it will just change the suffix but you can also choose to name it based on track number, title, artist etc. For that to happen, you should have proper metadata on the original file.
|
||||
|
||||
Speaking of metadata, have you heard of [MusicBrainz Picard][7]? This tool helps you automatically updates the metadata of your local music files.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I have discussed [recording audio in Linux][8] previously with a similar tiny application. Such nifty tools actually make life easier with their focused aim of completing a certain task. You may use full-fledged and a lot better audio editing tool like [Audacity][9] but that may be complicated to use for smaller tasks like converting audio file formats.
|
||||
|
||||
I hope you like SoundConverter. If you use some other tool, do mention that in the comments and I may cover it here on It’s FOSS. Enjoy!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/sound-converter-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/12/Convert-audio-file-format-linux.png?resize=800%2C450&ssl=1
|
||||
[2]: https://en.wikipedia.org/wiki/Saregama
|
||||
[3]: http://soundconverter.org/
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/12/sound-converter-software-center.png?ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/sound-converter-app-linux.jpeg?ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/12/sound-converter-app-linux-preferences.jpeg?resize=800%2C431&ssl=1
|
||||
[7]: https://itsfoss.com/musicbrainz-picard/
|
||||
[8]: https://itsfoss.com/record-streaming-audio/
|
||||
[9]: https://www.audacityteam.org/
|
||||
@ -0,0 +1,59 @@
|
||||
知识共享是怎样造福艺术家和大企业的
|
||||
======
|
||||

|
||||
|
||||
我毕业于电影学院,毕业后在一所电影学校教书,之后进入一家主流电影工作室,我一直在从事电影相关的工作。创造业的方方面面面临着同一个问题:创造者需要原材料。有趣的是,自由文化运动提出了解决方案,具体来说是在自由文化运动中出现的知识共享组织。
|
||||
|
||||
###知识共享能够为我们提供展示片段和小样
|
||||
|
||||
和其他事情一样,创造力也需要反复练习。幸运的是,在我刚开始接触电脑时,就在一本渲染工场的专业杂志中接触到了开源这个存在。当时我并不理解所谓的“开源”是什么,但我知道只有开源工具能帮助我在领域内稳定发展。对我来说,知识共享也是如此。知识共享可以为艺术家们提供充满丰富艺术资源的工作室。
|
||||
|
||||
我在电影学院任教时,经常需要给学生们准备练习编辑、录音、拟音、分级、评分的脚本。在 Jim Munroe 的独立作品 [Infest Wisely][1] 中和 [Vimeo][2] 上的知识共享里我总能找到我想要的。这些写实的脚本覆盖内容十分广泛,从独立影院出品到昂贵的高质的升降镜头(一般都会用无人机代替)都有。
|
||||
|
||||
对实验艺术来说,确有无尽可能。知识共享提供了丰富的底片材料,这些材料可以用来整合,混剪等等,可以满足一位视觉先锋能够想到的任何用途。
|
||||
|
||||
在接触知识共享之前,如果我想要使用写实脚本,我只能用之前的学生和老师拍摄的或者直接使用版权库里的脚本,但这些都有很多局限性。
|
||||
|
||||
###坚守版权的底线很重要
|
||||
|
||||
知识共享同样能够创造经济效益。在某大型计算机公司的渲染工场工作时,我负责在某些硬件设施上测试渲染的运行情况,而这个测试时刻面临着被搁置的风险。做这些测试时,我用的都是[大雄兔][3]的资源,因为这个电影和它的组件都是可以免费使用和分享的。如果没有这个小短片,在接触写实资源之前我都没法完成我的实验,因为对于一个计算机公司来说,雇佣一只3D艺术家来应召布景是不太现实的。
|
||||
|
||||
令我震惊的是,与开源类似,知识共享已经用我们难以想象的方式支撑起了大公司。知识共享的使用或有或无地影响着公司的日常程序,但它填补了不足,让工作流程顺利进行。我没见到谁在他们的书中将流畅工作归功于知识共享的应用,但它确实无处不在。
|
||||
|
||||
我也见过一些开放版权的电影,比如[辛特尔][4],在最近的电视节目中播放了它的短片,那时的电视比现在的网络媒体要火得多。
|
||||
|
||||
###知识共享可以提供大量原材料
|
||||
|
||||
艺术家需要原材料。画家需要颜料,画笔和画布。雕塑家需要陶土和工具。数字内容编辑师需要数字内容,无论它是剪贴画还是音效或者是电子游戏里的成品精灵。
|
||||
|
||||
数字媒介赋予了人们超能力,让一个人就能完成需要一组人员才能完成的工作。事实上,我们大部分都好高骛远。我们想做高大上的项目,想让我们的成果不论是视觉上还是听觉上都无与伦比。我们想塑造的是宏大的世界,紧张的情节,能引起共鸣的作品,但我们所拥有的时间精力和技能与之都不匹配,达不到想要的效果。
|
||||
|
||||
是知识共享再一次拯救了我们,用 [Freesound.org][5], [Openclipart.org][6], [OpenGameArt.org][7] 等等网站上那些细小的开放版权艺术材料。通过知识共享,艺术家可以使用各种他们自己没办法创造的原材料,来完成他们原本完不成的工作。
|
||||
|
||||
最神奇的是,不用自己投资,你放在网上给大家使用的原材料就能变成精美的作品,而这是你从没想过的。我在知识共享上面分享了很多音乐素材,它们现在用于无数的专辑和电子游戏里。有些人用了我的材料会通知我,有些是我自己发现的,所以这些材料的应用可能比我知道的还有多得多。有时我会偶然看到我亲手画的标志出现在我从没听说过的软件里。我见到过我为[开源网站][8]写的文章在别处发表,有的是论文的参考文献,白皮书或者参考资料中。
|
||||
|
||||
###知识共享所代表的自由文化也是一种文化
|
||||
|
||||
“自由文化”这个说法过于累赘,文化,从概念上来说,是一个有机的整体。在这种文化中社会逐渐成长发展,从一个人到另一个。它是人与人之间的互动和思想交流。自由文化是自由缺失的现代世界里的特殊产物。
|
||||
|
||||
如果你也想对这样的局限进行反抗,想把你的思想、作品,你自己的文化分享给全世界的人,那么就来和我们一起,使用知识共享吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/creative-commons-real-world
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:http://infestwisely.com
|
||||
[2]:https://vimeo.com/creativecommons
|
||||
[3]:https://peach.blender.org/
|
||||
[4]:https://durian.blender.org/
|
||||
[5]:http://freesound.org
|
||||
[6]:http://openclipart.org
|
||||
[7]:http://opengameart.org
|
||||
[8]:https://opensource.com/
|
||||
@ -0,0 +1,80 @@
|
||||
一种新的用于安全检测的方法
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们当中有多少人曾说出过下面这句话:“我希望这能起到作用!”?
|
||||
|
||||
毫无疑问,我们中的大多数人可能都不止一次地说过这句话。这句话不是用来激发信心的,相反它揭示了我们对自身能力和当前正在测试功能的怀疑。不幸的是,这句话非常好地描述了我们传统的安全模型。我们的运营基于这样的假设,并希望我们实施的控制措施——从 web 应用的漏扫到终端上的杀毒软件——防止恶意的病毒和软件进入我们的系统,损坏或偷取我们的信息。
|
||||
|
||||
渗透测试通过积极地尝试侵入网络、向 web 应用注入恶意代码或者通过发送钓鱼邮件来传播病毒等等这些步骤来避免我们对假设的依赖。由于我们在不同的安全层面上来发现和渗透漏洞,手动测试无法解决漏洞被主动打开的情况。在安全实验中,我们故意在受控的情形下创造混乱,模拟事故的情形,来客观地检测我们检测、阻止这类问题的能力。
|
||||
|
||||
> “安全实验为分布式系统的安全性实验提供了一种方法,以建立对抗恶意攻击的能力的信心。”
|
||||
|
||||
在分布式系统的安全性和复杂性方面,需要反复地重申混沌工程界的一句名言,“希望不是一种有效的策略”。我们多久会主动测试一次我们设计或构建的系统,来确定我们是否已失去对它的控制?大多数组织都不会发现他们的安全控制措施失效了,直到安全事件的发生。我们相信“安全事件不是侦察措施”,而且“希望不要出事也不是一个有效的策略”应该是 IT 专业人士执行有效安全实践的口号。
|
||||
|
||||
工业在传统上强调预防性的安全措施和纵深防御,但我们的任务是通过侦探实验来驱动对安全工具链新的知识和见解。因为过于专注于预防机制,我们很少尝试一次以上地或者年度性地手动测试要求的安全措施,来验证这些控件是否按设计的那样执行。
|
||||
|
||||
随着现代分布式系统中的无状态变量的不断改变,人们很难充分理解他们的系统的行为,因为会随时变化。解决这个问题的一种途径是通过强大的系统性的设备进行检测,对于安全性检测,你可以将这个问题分成两个主要方面,测试,和我们称之为实验的部分。测试是对我们已知部分的验证和评估,简单来说,就是我们在开始找之前,要先弄清楚我们在找什么。另一方面,实验是去寻找获得我们之前并不清楚的见解和知识。虽然测试对于一个成熟的安全团队来说是一项重要实践,但以下示例会有助于进一步地阐述两者之间的差异,并对实验的附加价值提供一个更为贴切的描述。
|
||||
|
||||
### 示例场景:精酿啤酒
|
||||
|
||||
思考一个用于接收精酿啤酒订单的 web 服务或者 web 应用。
|
||||
|
||||
这是这家精酿啤酒运输公司的一项重要服务,这些订单来自客户的移动设备,网页,和通过为这家公司精酿啤酒提供服务的餐厅的 API。这项重要服务运行在 AWS EC2 环境上,并且公司认为它是安全的。这家公司去年成功地通过了 PCI 规则,并且每年都会请第三方进行渗透测试,所以公司认为这个系统是安全的。
|
||||
|
||||
这家公司有时一天两次部署来进行 DevOps 和持续交付工作,公司为其感到自豪。
|
||||
|
||||
在了解了混沌工程和安全实验方面的东西后,该公司的开发团队希望能确定,在一个连续不断的基础上,他们的安全系统对真实世界事件的有效性和快速恢复性怎么样。与此同时,确保他们不会把安全控件不能检测到的新问题引入到系统中。
|
||||
|
||||
该团队希望能小规模地通过评估端口安全和防火墙设置来让他们能够检测、阻止和警告他们 EC2 安全组上端口设置的错误配置更改。
|
||||
|
||||
* 该团队首先对他们正常状态下的假设进行总结。
|
||||
* 在 EC2 实例里为端口安全进行一个假设。
|
||||
* 为未认证的端口改变实验选择和配置 YAML 文件。
|
||||
* 该配置会从已选择的目标中随机指定对象,同时端口的范围和数量也会被改变。
|
||||
* 团队还会设置进行实验的时间并缩小爆破攻击的范围,来确保对业务的影响最小。
|
||||
* 对于第一次测试,团队选择在他们的测试环境中运行实验并运行一个单独的测试。
|
||||
* 在真实的游戏日风格里,团队在预先计划好的两个小时的窗口期内,选择灾难大师来运行实验。在那段窗口期内,灾难大师会在 EC2 实例安全组中的一个上执行这次实验。
|
||||
* 一旦游戏日结束,团队就会开始进行一个彻底的、无可指责的事后练习。它的重点在于针对稳定状态和原始假设的实验结果。问题会类似于下面这些:
|
||||
|
||||
|
||||
|
||||
### 事后验证问题
|
||||
|
||||
* 防火墙是否检测到未经授权的端口更改?
|
||||
* 如果更改被检测到,更改是否会被阻止?
|
||||
* 防火墙是否会将有用的日志信息记录到日志聚合工具中?
|
||||
* SIEM 是否会对未经授权的更改发出警告?
|
||||
* 如果防火墙没有检测到未经授权的更改,那么配置的管理工具是否发现了这次更改?
|
||||
* 配置管理工具是否向日志聚合工具报告了完善的信息?
|
||||
* SIEM 最后是否进行了关联报警?
|
||||
* 如果 SIEM 发出了警报,安全运营中心是否能收到这个警报?
|
||||
* 获得警报的 SOC 分析师是否能对警报采取措施,还是缺少必要的信息?
|
||||
* 如果 SOC 确定警报是真实的,那么安全事件响应是否能简单地从数据中进行分类活动?
|
||||
|
||||
|
||||
|
||||
我们系统中对失败的承认和预期已经开始揭示我们对系统工作的假设。我们的使命是利用我们所学到的,并更加广泛地应用它。以此来真正主动地解决安全问题,来超越当前传统主流的被动处理问题的安全模型。
|
||||
|
||||
随着我们继续在这个新领域内进行探索,我们一定会发布我们的研究成果。如果您有兴趣想了解更多有关研究的信息或是想参与进来,请随时联系 Aaron Rinehart 或者 Grayson Brewer。
|
||||
|
||||
特别感谢 Samuel Roden 对本文提供的见解和想法。
|
||||
|
||||
**[看我们相关的文章,是否需要 DevSecOps 这个词?][3]]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/new-approach-security-instrumentation
|
||||
|
||||
作者:[Aaron Rinehart][a]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaronrinehart
|
||||
[1]:https://twitter.com/aaronrinehart
|
||||
[2]:https://twitter.com/BrewerSecurity
|
||||
[3]:https://opensource.com/article/18/4/devsecops
|
||||
@ -0,0 +1,47 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (How a university network assistant used Linux in the 90s)
|
||||
[#]: via: (https://opensource.com/article/18/5/my-linux-story-student)
|
||||
[#]: author: ([Alan Formy-Duva](https://opensource.com/users/alanfdoss)
|
||||
[#]: url: ( )
|
||||
|
||||
大学网络助理如何在 90 年代使用 Linux
|
||||
======
|
||||

|
||||
在 20 世纪 90 年代中期,我报名了计算机科学课。我大学的计算机科学系为学生提供了一台 SunOS 服务器,它是一个多用户、多任务的 Unix 系统。我们登录它并编写我们在学习的编程语言代码,例如 C、C++ 和 ADA。在那些日子里,在社交网络和 IM 出现之前,我们还使用该系统相互通信,发送电子邮件和使用诸如 `write` 和 `talk` 之类的程序。我们每个人被允许托管一个个人网站。我很高兴它能够完成我的作业并联系其他用户。
|
||||
|
||||
这是我第一次体验这种类型的操作环境,但我很快就了解了另一个可以做同样事情的操作系统:Linux。
|
||||
|
||||
当我还是一名学生的时候,我还在大学兼职工作。我的第一个职位是住房和住宅部 (H&R) 的网络安装人员。这包含将学生宿舍与校园网络连接起来。由于这是该大学的第一个宿舍网络服务,因此只有两幢楼和大约 75 名学生已经连接。
|
||||
|
||||
在我工作的第二年,该网络扩展到另外两幢楼。H&R 决定让该大学的信息技术办公室 (OIT) 管理这不断增长的业务。我进入 OIT 并开始担任 OIT 网络经理的学生助理。这就是我发现 Linux 的方式。我的新职责之一是管理防火墙系统,它为宿舍提供网络和互联网访问。
|
||||
|
||||
每个学生都注册了他们硬件的 MAC 地址。注册学生可以连接到宿舍网络并获得 IP 地址及访问互联网。与大学使用的其他昂贵的 SunOS 和 VMS 服务器不同,这些防火墙使用运行着免费和开源 Linux 操作系统的低成本计算机。截至年底,该系统已注册近 500 名学生。
|
||||
|
||||
![Red hat Linux install disks][1]
|
||||
|
||||
OIT 网络工作人员使用 Linux 运行 HTTP、FTP 和其他服务。他们还在个人桌面上使用 Linux。就在那时,我意识到我手上的计算机看起来和运行起来就像 CS 系昂贵的 SunOS 机器一样但没有高昂的成本。Linux 可以在商用 x86 硬件上运行,例如有 8 MB RAM 和 133Mhz Intel Pentium CPU 的 Dell Latitude。那对我来说是个卖点!我在从一个剩余的仓库中清理出来的机器上安装了 Red Hat Linux 5.2,并给了我的朋友登录帐户。
|
||||
|
||||
我使用我的新 Linux 服务器来托管我的网站并向我的朋友提供帐户,同时它还提供 CS 系服务器没有的图形功能。它使用了 X Windows 系统,我可以使用 Netscape Navigator 浏览网页,使用 [XMMS][2] 播放音乐,并尝试不同的窗口管理器。我也可以下载并编译其他开源软件并编写自己的代码。
|
||||
|
||||
我了解到 Linux 提供了一些非常先进的功能,其中许多功能比更主流的操作系统更方便或更优越。例如,许多操作系统尚未提供应用更新的简单方法。在 Linux 中,这很简单,感谢 [autoRPM][3],一个由 Kirk Bauer 编写的更新管理器,它向 root 用户每日发送邮件,其中包含可用的更新。它有一个直观的界面,用于审查和选择要安装的软件更新 - 这对于 90 年代中期来说非常了不起。
|
||||
|
||||
Linux may not have been well-known back then, and it was often received with skepticism, but I was convinced it would survive. And survive it did!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/my-linux-story-student
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alanfdoss
|
||||
[1]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/red_hat_linux_install_disks.png?itok=VSw6Cke9 (Red hat Linux install disks)
|
||||
[2]:http://www.xmms.org/
|
||||
[3]:http://www.ccp14.ac.uk/solution/linux/autorpm_redhat7_3.html
|
||||
@ -1,71 +0,0 @@
|
||||
混合软件开发角色效果更佳
|
||||
======
|
||||
|
||||

|
||||
|
||||
大多数开源社区没有很多正式的角色。当然, 也有一些固定人员帮助处理系统管理员任务、测试、编写文档以及翻译或开发代码。但开源社区的人员通常在不同的角色之间流动, 往往同时履行几个角色的职责。
|
||||
|
||||
相反, 大多数传统公司的团队成员都定义了角色,例如, 负责文档、技术支持、质量检验和其他领域。
|
||||
|
||||
为什么开源社区采取共享角色的方法, 更重要的是, 这种协作方式如何影响产品和客户?
|
||||
|
||||
[Nextcloud][1] 采用了这种社区式的混合角色的做法, 我们看到了我们的客户和用户受益颇多。
|
||||
|
||||
### 1\.更好的产品测试
|
||||
|
||||
任何测试人员都会说测试是一项困难的工作。你需要了解工程师开发的产品, 并且需要设计测试案例、执行测试案例并将结果返回给开发人员。完成该过程后, 开发人员将进行更改, 然后重复该过程, 根据需要来回进行多次,直到任务完成。
|
||||
|
||||
在社区中, 贡献者通常会对他们开发的项目负责, 因此他们会对这些项目进行广泛的测试和记录, 然后再将其交给用户。贴近项目的用户通常会与开发人员协作, 帮助测试、翻译和编写文档。这将创建一个更紧密、更快的反馈循环, 从而加快开发速度并提高质量。
|
||||
|
||||
当开发人员不断面对他们的工作结果时, 它鼓励他们以最大限度地减少测试和调试的方式去书写。自动化测试是开发中的一个重要元素, 反馈循环可以确保正确地完成操作: 开发人员主观能动的来实现自动化--而不过于简化也不过于复杂。当然, 他们可能希望别人做更多的测试或自动化的测试 但当测试是正确的选择时, 他们就会这样做。此外, 他们还审查对方的代码, 因为他们知道问题往往会在以后让他们付出代价。
|
||||
|
||||
因此, 虽然我不认为放弃专用测试人员更好, 但在没有社区志愿者进行测试的项目中, 测试人员应该是开发人员, 并密切嵌入到开发团队中。结果如何?客户得到的产品是由100% 有动机的人测试和开发的, 以确保它是稳定和可靠的。
|
||||
|
||||
### 2\. 开发和客户需求之间的密切协作
|
||||
|
||||
要使产品开发与客户需求保持一致是非常困难的。每个客户都有自己独特的需求, 有长期和短期的因素需要考虑--当然, 作为一家公司, 你对你的方向有想法。你如何整合所有这些想法和愿景?
|
||||
|
||||
公司通常创建与工程和产品开发分开的角色, 如产品管理、支持、质量检测等。这背后的想法是, 人们在专攻的时候做得最好, 工程师不应该为测试或支持等 "简单" 的任务而烦恼。
|
||||
|
||||
实际上, 这种角色分离是一项削减成本的措施。它使管理层能够进行微观管理, 并更能掌握全局, 因为他们可以简单地进行产品管理, 例如, 确定路线图项目的优先次序。(它还创建了更多的会议!)
|
||||
|
||||
另一方面, 在社区, "决定权在工作者手上"。开发人员通常也是用户 (或由用户支付报酬), 因此他们自然地与用户的需求保持一致。当用户帮助进行测试时 (如上所述), 开发人员会不断地与他们合作, 因此双方都完全了解什么是可行的, 什么是需要的。
|
||||
|
||||
这种开放的合作方式使用户和项目紧密协作。在没有管理层干涉和指手画脚的情况下, 用户最迫切的需求可以迅速得到满足, 因为工程师已经非常了解这些需求。
|
||||
|
||||
在 nextcloud 中, 客户永远不需要解释两次, 也不需要依靠初级支持团队成员将问题准确地传达给工程师。我们的工程师根据客户的实际需求不断调整他们的优先级。同时, 基于对客户的深入了解, 合作制定长期目标。
|
||||
|
||||
### 3\. 最佳支持
|
||||
|
||||
与专有的或 [open core][2](开放源核心)的开发商不同, 开源供应商有强大的动力提供尽可能最好的支持: 它是与其他公司在其生态系统中的关键区别。
|
||||
|
||||
为什么项目背后有动力?—比如 [Collabora][3] 在 [LibreOffice][4] 背后, [The Qt Company][5] 在 [Qt][6] 背后, 或者 [Red Hat][7] 在 [RHEL][8] 背后—最佳来源于客户的支持?
|
||||
|
||||
当然, 直接接触工程师。许多公司并阻断工程的支持, 而是为客户提供了获得工程师专业知识的机会。这有助于确保客户始终尽快获得最佳答案。虽然一些工程师可能比其他人在支持上花费更多的时间, 但整个工程团队在客户成功方面发挥着作用。自营供应商可能会为客户提供一个专门的现场工程师, 费用相当高, 例如,但一个开源公司, 如 [OpenNMS][9] 在您的支持合同中提供相同级别的服务, 即使您不是财富500强客户也是如此。
|
||||
|
||||
还有一个好处, 那就是与测试和客户协作有关: 共享角色可确保工程师每天处理客户问题和愿望, 从而促使他们快速解决最常见的问题。他们还倾向于构建额外的工具和功能, 以满足客户预期。
|
||||
|
||||
简单地说, 将 质量检测、支持、产品管理和其他工程角色合并为一个团队, 可确保优秀开发人员的三大优点--[laziness, impatience, and hubris][10](从简,精益求精,高度自我要求)—与客户紧密保持一致。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/mixing-roles-engineering
|
||||
|
||||
作者:[Jos Poortvliet][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lixinyuxx](https://github.com/lixinyuxx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://nextcloud.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Open_core
|
||||
[3]:https://www.collaboraoffice.com/
|
||||
[4]:https://www.libreoffice.org/
|
||||
[5]:https://www.qt.io/
|
||||
[6]:https://www.qt.io/developers/
|
||||
[7]:https://www.redhat.com/en
|
||||
[8]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[9]:https://www.opennms.org/en
|
||||
[10]:http://threevirtues.com/
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (A Free Guide for Setting Your Open Source Strategy)
|
||||
[#]: via: (https://www.linux.com/blog/2018/11/free-guide-setting-your-open-source-strategy)
|
||||
[#]: author: ([Amber Ankerholz](https://www.linux.com/users/aankerholz)
|
||||
[#]: url: ( )
|
||||
|
||||
制定开源战略的免费指南
|
||||
======
|
||||
|
||||

|
||||
|
||||
大多数使用开源的公司都了解其商业价值,但他们可能缺乏战略性地实施开源计划和获得全部回报的工具。根据 [The New Stack][1] 最近的一项调查,“开源计划的三大好处是1)提高了对开源的认识,2)提高了开发周期的速度和灵活性,以及 3)更好的许可证合规性“。
|
||||
|
||||
运营开源计划办公点涉及创建策略来帮助你定义和实施你的方法,并衡量你的进度。由 Linux 基金会与 TODO 集团合作开发的[企业开源指南][2]基于多年的经验和实践提供了专业开源知识。
|
||||
|
||||
最新的指南中,[设置开源战略][3]详细介绍了制定战略和确保成功之路的基本步骤。根据该指南,“你的开源战略将管理、参与和创建开源软件的计划与计划所服务的业务目标联系起来。这可以开辟许多机会并促进创新。“该指南涵盖以下主题:
|
||||
|
||||
1. 为什么制定战略?
|
||||
2. 你的战略文件
|
||||
3. 战略方法
|
||||
4. 关键考虑因素
|
||||
5. 其他组成
|
||||
6. 确定投资回报率
|
||||
7. 投资目标
|
||||
|
||||
|
||||
|
||||
这里关键的第一步是创建和记录你的开源策略,该策略将“帮助你最大限度地提高组织从开源中获得的利益。”同时,你详细的策略可以帮助你避免因错误而导致的困难,例如:选择错误的许可证或不正确地维护代码。根据指南,该文件还可以:
|
||||
|
||||
* 让领导者感到兴奋并参与
|
||||
* 帮助在公司内获得支持
|
||||
* 促进分散的多部门组织的决策
|
||||
* 帮助建立一个健康的社区
|
||||
* 解释贵公司的开源方式和对其使用的支持
|
||||
* 明确贵公司在社区驱动的外部研发中投资的地方,以及贵公司将重点放在增值差异化的地方
|
||||
|
||||
|
||||
|
||||
Salesforce 的软件架构师兼指南的撰稿人 Ian Varley 说:“在 Salesforce 内,我们有内部文件,我们将这些围绕开源战略指导和鼓励的文件分发给我们的工程团队。其中鼓励创建和使用开源,这让他们毫不含糊地知道公司的战略领导者完全支持它。此外,如果有某些我们不希望工程师使用的许可证或有其他开源指南,我们的内部文档需要明确。“
|
||||
|
||||
开源计划有助于促进企业文化,使企业更高效,并且根据指南,强有力的战略文档可以“帮助你的团队了解开源计划背后的业务目标,确保更好的决策,并最大限度地降低风险“。
|
||||
|
||||
了解如何使用[设置开源策略][3]新指南中的提示和经过验证的实践,将管理和创建开源软件的目标与组织的业务目标保持一致。然后,查看所有 12 个[企业开源指南][2],了解有关使用开源获得成功的更多信息。
|
||||
|
||||
本文最初发表在 [Linux基金会][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/11/free-guide-setting-your-open-source-strategy
|
||||
|
||||
作者:[Amber Ankerholz][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/aankerholz
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://thenewstack.io/open-source-culture-starts-with-programs-and-policies/
|
||||
[2]: https://www.linuxfoundation.org/resources/open-source-guides/
|
||||
[3]: https://www.linuxfoundation.org/resources/open-source-guides/setting-an-open-source-strategy/
|
||||
[4]: https://www.linuxfoundation.org/blog/2018/11/a-free-guide-for-setting-your-open-source-strategy/
|
||||
@ -1,111 +0,0 @@
|
||||
持续基础设施: 另一个 CI
|
||||
======
|
||||
|
||||

|
||||
|
||||
持续交付(CD)和持续集成(CI)是 DevOps 的两个众所周知的方面。但在 CI 大肆流行的今天却忽略了另一个关键性的 "I":基础设施(infrastructure)。
|
||||
|
||||
曾经有一段时间 “基础设施”就意味着无头的黑盒子,庞大的服务器,和高耸的机架——更不用说漫长的采购流程和对盈余负载的错误估计。后来到了虚拟机时代,把基础设施处理得很好,虚拟化——以前的世界从未有过这样。我们不再需要管理实体的服务器。仅仅是简单的点击,我们就可以创建和销毁,开始和停止,升级和降级我们的服务器。
|
||||
|
||||
有一个关于银行的流行的故事,它们实现了数字化,并且引入了在线表格,用户需要手动填写表格,打印,然后邮寄回银行。这就是我们今天要说的基础设施:使用新技术来做和以前一样的事情。
|
||||
|
||||
在这篇文章中,我们会看到在基础设施管理方面的进步,将基础设施视为一个版本化的组件并试着探索服务器一致性的概念。在后面的文章中,我们将了解如何使用开源工具来实现持续的基础设施。
|
||||
|
||||
![continuous infrastructure pipeline][2]
|
||||
|
||||
实践中的持续集成管道
|
||||
|
||||
这是我们熟悉的 CI,尽早发布,经常发布的循环管道。这个管道缺少一个关键的组件:基础设施。
|
||||
|
||||
突击小测试:
|
||||
|
||||
* 你怎样创建和升级你的基础设施?
|
||||
* 你怎样控制和追溯基础设施的改变?
|
||||
* 你的基础设施是如何与你的业务进行匹配的?
|
||||
* 你是如何确保在正确的基础设施配置上进行测试的?
|
||||
|
||||
要回答这些问题,就要了解持续基础设施。把 CI 构建流程分为代码持续集成(CIc)和基础设施持续集成(CIi)来并行开发代码和基础设施,再将两者融合到一起进行测试 。把基础设施构建视为CI流程中的重要的一环。
|
||||
|
||||
![pipeline with infrastructure][4]
|
||||
|
||||
包含持续基础设施的 CI 管道流程
|
||||
|
||||
关于 CIi 定义的几个方面:
|
||||
|
||||
**1\. 代码**
|
||||
|
||||
通过代码来创建基础设施架构,而不是通过安装。使用配置脚代码是现代最流行的创建基础设施(IaC)的方法。这些脚本遵循典型的编码和单元测试周期(请参阅下面关于 Terraform 脚本的示例)。
|
||||
|
||||
**2\. 版本**
|
||||
|
||||
IaC 组件在源码仓库中进行版本管理。这让基础设施的拥有了版本控制的所有好处:一致性,可追溯性,分支和标记。
|
||||
|
||||
**3\. 管理**
|
||||
|
||||
通过编码和版本化的基础设施管理,你可以使用你所熟悉的测试和发布流程来管理基础设施的开发。
|
||||
|
||||
CIi 提供了下面的这些优势:
|
||||
|
||||
**1\. 一致性**
|
||||
|
||||
版本化和标记基础设施意味着你可以清楚的知道你的系统使用了哪些组件和配置。这是建立了一个非常好的 DevOps 实践,用来鉴定和管理基础设施的一致性。
|
||||
|
||||
**2\. 可重现性**
|
||||
|
||||
通过基础设施的标记和基线,重建基础设施变得非常容易。想想你是否经常听到这个:“但是它在我的机器上可以运行!”现在,你可以在本地的测试平台中快速重现类似生产环境,从而将环境像变量一样在你的调试过程中删除。
|
||||
|
||||
**3\. 可追溯性性**
|
||||
|
||||
你是否还记得曾经有过多少次寻找到底是谁更改了文件夹权限的经历,或者是谁升级了 `ssh` 包?编码,版本化,发布的基础设施消除了临时的变更,为基础设施的管理带来了可追踪性和可预测性。
|
||||
|
||||
**4\. 自动化**
|
||||
|
||||
借助脚本化的基础架构,自动化是下一个合乎逻辑的步骤。自动化允许你按需创建基础设施,并在使用完成后删除它,所以你可以将更多宝贵的时间和精力用在更重要的任务上。
|
||||
|
||||
**5\. 不变性**
|
||||
|
||||
CIi 不可变基础设施等创新。你可以创建一个新的基础设施组件而不是通过升级(请参阅下面有关不可变设施的说明)。
|
||||
|
||||
持续基础设施是从运行基础环境到运行基础组件的进化。像处理代码一样,通过认证的 DevOps 流程来完成。对传统的 CI 的重新定义包含了缺少的那个 “i”,从而形成了连贯的 CD 。
|
||||
|
||||
**(CIc + CIi) = CI -> CD**
|
||||
|
||||
## 基础设施代码 (IaC)
|
||||
|
||||
CIi 管道的一个关键推动因素是基础设施代码(IaC)。IaC 是一种使用配置文件进行基础设施创建和升级的机制。这些配置文件像其他的代码一样进行开发,并且使用版本管理系统进行管理。这些文件遵循一般的代码开发流程:单元测试,提交,构建,和发布。IaC 流程拥有版本控制带给基础设施开发的所有好处,像标记,版本一致性,和修改可追溯。
|
||||
|
||||
这有一个简单的 Terraform 脚本用来用来在 AWS 上创建一个双层基础设施的简单示例,包括虚拟私有云(VPC),弹性负载(ELB),安全组和一个 NGINX 服务器。Terraform 是一个通过通过脚本创建和更改基础设施架构和开源工具。
|
||||
|
||||
![terraform script][7]
|
||||
|
||||
Terraform 脚本创建双层架构设施的简单示例
|
||||
|
||||
完整的脚本请参见 [GitHub][8]。
|
||||
|
||||
## 基础设施架构的不变性
|
||||
|
||||
你有几个正在运行的 VM 需要更新安全补丁。一个常见的做法是推送一个远程脚本单独更新每个系统。
|
||||
|
||||
如何更新一个旧系统,如何丢弃它们并布置安装了新安全补丁的新系统?这就是基础设施的不变性。通过之前对基础设施的版本控制和标记,所以安装补丁只需要更新下脚本并将其推送到发布管道即可。
|
||||
|
||||
现在你知道为什么要说基础设施在 CI 管道中特别重要了吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/continuous-infrastructure-other-ci
|
||||
|
||||
作者:[About The Author;Girish Managoli;With About Years;Experience In The Software It Industry;Girish Presently Holds Chief Architect Capacity At Mindtree;A Global It Services Organization;Based In India. Specialising In Paas;Saas Platforms;Girish Is Architect Of;I Got][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[Jamskr](https://github.com/Jamskr)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:/file/376916
|
||||
[2]:https://opensource.com/sites/default/files/images/life-uploads/figure1.jpg (continuous infrastructure pipeline in use)
|
||||
[3]:/file/376921
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/figure2.jpg (CI pipeline with infrastructure)
|
||||
[5]:https://github.com/hashicorp/terraform
|
||||
[6]:/file/376926
|
||||
[7]:https://opensource.com/sites/default/files/images/life-uploads/figure3_0.png (sample terraform script)
|
||||
[8]:https://github.com/terraform-providers/terraform-provider-aws/tree/master/examples/two-tier
|
||||
278
translated/tech/20171111 A CEOs Guide to Emacs.md
Normal file
278
translated/tech/20171111 A CEOs Guide to Emacs.md
Normal file
@ -0,0 +1,278 @@
|
||||
一位 CEO 的 Emacs 指南
|
||||
============================================================
|
||||
|
||||
几年前,不,是几十年前,我就在用 Emacs。不论是码代码、编写文档,还是管理邮件和日程,我都用这个编辑器或者是说操作系统,而且我还乐此不疲。多年过去了,我也转向了其他更新,更好的工具。结果,我已经忘了如何在不用鼠标的情况下来浏览文件。大约三个月前,我意识到我在应用程序和计算机之间切换上耗费了大量的时间,于是就决定再试一次 Emacs。这是个很正确的决定,原因有以下几个。其中包括了 `.emacs` 和 Dropbox 的技巧,可以让你建立一个良好的,可移植的环境。
|
||||
|
||||
对于那先还没用过 Emacs 的人来说,你可能会讨厌它,但也可能喜欢上它。它有点像一个房子大小的 Rube Goldberg 机器,乍一看,它具备烤面包机的所有功能。这听起来不像是一种认可,但关键短语是“乍一看”。一旦你了解了Emacs,你就会意识到它其实是一种可以作为发动机的热核烤面包机。好吧,你想对文字做什么都可以。当考虑到计算寿命在很大程度上与文本有关时,这是一个相当大胆的声明,真的很大胆。
|
||||
|
||||
也许对我来说更重要的是,它是我曾经使用过的一个应用程序,并让我觉得我真正的拥有它,而不是把我塑造成一个匿名的“用户”,就好像位于 [Soma][30] 或 Redmond 附近某个高档办公室的产品营销部门把钱作为明确的目标一样。现代生产力和创作应用程序(如文件或 `IDE`)就像碳纤维赛车,他们装备得很好,也很完整。而Emacs 就像一盒经典的 [Campagnolo][31] 零件和一个漂亮的拖钢框架,缺少曲柄臂和刹车杆,你必须在网上某个小众文化中找到它们。第二点就是它会给你带来无尽的快乐或烦恼,这取决于你自己,而且会一直持续到你生命的最后一天。我是那种在找到一堆老古董或用 `Emacs Lisp` 配置编辑器时同样感到高兴的人,具体情况因人而异。
|
||||
|
||||

|
||||
一辆我还在骑的1933年产的钢制自行车。你可以从查看框架管差别: [https://www.youtube.com/watch?v=khJQgRLKMU0][6].
|
||||
|
||||
这可能给人一种 Emacs 已经过气或过时的印象。但它不是,它是强大和永恒的,只要你耐心地去理解它的一些规则。他的规则很另类,也很奇怪,但其中的逻辑却引人注目,且很有魅力。对于我来说, Emacs 更像是未来而不是过去。就像牵引式钢框架在未来几十年里将会变得好用和舒适,而神奇的碳纤维自行车将会被扔进垃圾场,在撞击中粉碎一样,Emacs 也将会作为一种在最新的流行应用早已被遗忘的时候的好用的工具继续存在这。
|
||||
|
||||
如果通过编辑 `Lisp` 代码来构建自己的个人工作环境,并将这种非常适合自己的环境移植到任何计算机的想法吸引了你,那么你可能会爱上 Emacs。如果你喜欢很潮、很炫的,又不想投入太多时间和精力的情况下就能直接工作的话,那么它可能不适合你。我已经不再写代码了(除了 `Ludwig` 和 `Emacs Lisp`),但是 `Fugue` 的很多工程师都使用 Emacs 来提高码代码的效率。我公司有 30% 的工程师用 Emacs, 40% 用 `IDE` 和 30% 的用 vim。但这篇文章是关于 CEO 和其他[聪明的老板][32](PHB<sup>[1][7]</sup>)的 Emacs 指南,所以我将解释或者说辩解我为什么喜欢它以及我如何使用它。同时我也希望我能介绍清楚从而让你能有个良好的体验,而不是花上几个小时去 Google。
|
||||
|
||||
### 最后的优点
|
||||
|
||||
使用 Emacs 带来的长期优势是让生活更轻松。与最后的收获相比,最开始的付出完全值得。想想这些:
|
||||
|
||||
### 无需上下文切换
|
||||
|
||||
`Org` 模式本身就值得花时间,但如果你像我一样,你通常要处理十几份左右的文件 —— 从博客帖子到会议需要做什么的清单,再到员工评论。在现代计算世界中,这通常意味着要使用多个应用程序,所有这些应用程序都有不同的用户界面,保存方式、排序和搜索方式。结果就是你需要不断转换思维环境,记住细节。我讨厌上下文切换,因为它是一种强加到我身上的方式,原因是破坏了接口模型<sup>[2][8]</sup>,并且我讨厌记住计算机的命令,这本该是计算机要记住的东西。在单个环境下,Emacs 对 PHB 甚至比对于程序员更有用,因为程序员更多时候只需要专注于一个程序。转换思维环境的成本比通常看起来的要高。操作系统和应用程序供应商已经构建了各种接口,以分散我们对这一现实的注意力。如果你是技术人员,通过快捷键(`M-:`)来访问功能强大的[语言解释器][33]会方便的多<sup>[3][9]</sup>。
|
||||
|
||||
许多应用程序可以全天全屏并用于编辑文本。Emacs 是惟一的,因为它既是编辑器也是 `Emacs Lisp` 解释器。从本质上说,你工作时只要用电脑上的一两个键就能完成。如果你对编程略知一二,就能发现这一位置你可以在 Emacs 中做 _任何事情_。一旦你在内存中有了这些命令,你的电脑就可以在你工作时几乎实时地为你提供高效的运转。你不会想用 `Emacs Lisp` 来重建 Excel,只要用简单的一两行代码就能实现 Excel 中大多数的功能。如果我需要处理数字,我更有可能转到 scratch 缓冲区,编写一些代码,而不是打开电子表格。即便是我有一封多行的邮件要写,我通常也会先在 Emacs 中写完,然后再复制粘贴到邮件客户端中。当你可以流畅的书写时,为什么要去切换呢?你可以先从一两个简单的计算开始,随着时间的推移,你可以很容易的在 Emacs 中添加你所需要处理的计算。这在应用程序中可能是独一无二的,同时还提供了让为其他的人创造的丰富特性。还记得 Isaac Asimov 书中那些神奇的终端吗<sup>[4][10]</sup>? Emacs 是我所遇到的最接近他们的东西。我决定不再用什么应用程序来做这个或那个。相反,我只是工作。拥有一个伟大的工具并致力于此,这才是真正的动力和效率。
|
||||
|
||||
### 在安静中创造事情
|
||||
|
||||
拥有我所发现的最好的文本编辑功能的最终结果是什么?有一群人在做各种各样有用的补充吗?拥有 `Lisp` 键盘的全部功能?这就是我用 Emacs 来完成所有的创作性工作,处理音乐和图片除外。
|
||||
|
||||
我的办公桌上有两个显示器。其中一块竖屏是将 Emacs 全天全屏显示,另一个显示浏览器,用来搜索和阅读,通常也会打开一个终端。我将日历、邮件等保存在 OS X 的另一个桌面上,当我使用 Emacs 时,这个桌面是隐藏的,同时我也会关掉所有通知。这样就能让我专注于我手头上在做的事了。我发现,在更现代的 UI 应用程序中,消除干扰几乎是不可能的,因为这些应用程序努力提供帮助并使其易于使用。我不需要经常被提醒该如何操作,我已经做了成千上万次了,我真正需要的是一张干净整洁的白纸用来思考。也许因为年龄和自己的“恶习”,我不太喜欢处在嘈杂的环境中,但我认为这值得一试。看看在你电脑环境中有一些真正的宁静是怎样的。当然,现在很多应用程序都有隐藏界面的模式,谢天谢地,苹果和微软现在都有了真正意义上的全屏模式。但是,没有并没有应用程序可以强大到足以“处理”大多数事务。除非你整天写代码,或者像写一本书一样处理很长的文档,否则你仍然会面临其他应用程序的干扰。而且,大多数现代应用程序似乎同时显得自视甚高,缺乏功能和可用性<sup>[5][11]</sup>。比其 office 应用程序,我更讨厌在线版的应用程序。
|
||||
|
||||

|
||||
我的桌面布局, Emacs 在左边
|
||||
|
||||
但是交流呢?创造和交流之间的差别很大。当我为两者留出不同的时间时,我的效率会更高。在 `Fugue` 中使用了 `Slack`,痛并快乐着。我把它和我的日历、电子邮件放在一个即时通讯的桌面上,这样,当我正在做事时,我很高兴地能够忽略所有的聊天。仅仅是风投或董事会董事的一次懈怠,或一封电子邮件,就能让我立刻丢掉手头工作。但是,大多数事情通常可以等上一两个小时。
|
||||
|
||||
### 带上一切,并保留着
|
||||
|
||||
第三个原因是,我发现 Emacs 比其它的环境更有优势的是你可以很容易的用它来处理事务。我的意思是,你所需要的只是通过 `Dropbox` 类似的网站同步一两个目录,而不是让大量的应用程序以它们自己的方式进行交互和同步。然后,你可以在任何地方,任何环境下工作了,因为你已经精心制作了适合目的套件了。我在 OS X,Windows,或有时在 Linux 都是这样做的。它非常简单可靠。这种功能很有用,以至于我害怕处理页面、Google Docs、Office 或其他类型的文件和应用程序,这些文件和应用程序会迫使我回到文件系统或云中的某个地方去寻找。
|
||||
|
||||
永久存储在计算机上的限制是文件格式。假设人类已经解决了存储<sup>[6][12]</sup>的问题,随着时间的推移,我们面临的问题是我们能否够继续访问我们创建的信息。文本文件是最持久的计算格式。你可以用 Emacs 轻松地打开 1970 年的文本文件。然而对于办公应用程序却并非如此。同时文本文件要比 Office 应用程序数据文件小得多,也要好的多。作为一个数码背包迷,作为一个在脑子里一闪而过就会做很多小笔记的人,拥有一个简单、轻便、永久、随时可用的东西对我来说很重要。
|
||||
|
||||
如果你准备尝试 Emacs,请继续阅读!下面的部分不会取代完整的教程,但是在完成阅读时,就可以操作了。
|
||||
|
||||
### 学会驾驭 Emacs —— 一个专业的配置
|
||||
|
||||
所有这些强大、精神上的平静和安宁的代价是,Emacs 有一个陡峭的学习曲线,它的一切都与你以前所习惯的不同。一开始,这会让你觉得你是在浪费时间在一个过时和奇怪的应用程序上,就好像现代世界已经过去了。这有点像你只开过车,却要你去学骑自行车<sup>[7][13]</sup>。
|
||||
|
||||
### 该选哪个 Emacs
|
||||
|
||||
我用的是 GNU 中 OS X 和 Windows 的通用版本的 Emacs。你可以在 [][34][http://emacsformacos.com/][35] 获取 OS X 版本,在[][36][http://www.gnu.org/software/emacs/][37]获取 Windows 版本。市面上还有很多其他版本,尤其是 Mac 版本,但我发现,要做一些功能强大的东西(包括 `Lisp` 和许多模式),学习曲线要比实际操作低得多。下载,然后我们就可以开始了<sup>[8][14]</sup>!
|
||||
|
||||
### 首先,学会浏览
|
||||
|
||||
在本文中,我将约定 Emacs 中的键和组合。`C` 表示 `Control` 键,`M` 表示 `meta`(通常是 `Alt` 或 `Option` 键),以及用于组合键的连字符。因此,`C-h t` 表示同时按下 `Control` 和 `h` 键,然后释放,再按下 `t`。这个组快捷键会指向一个教程,这是你首先要做的一件事。
|
||||
|
||||
不要使用方向键或鼠标。它们可以工作,但是你应该给自己一周的时间来使用 Emacs 教程中的原生命令。一旦你这些命令变为了肌肉记忆,你可能就会乐在其中,无论到哪里,你都会非常想念它们。Emacs 教程在介绍它们方面做得很好,但是我将进行总结,所以您不需要阅读全部内容。最无聊的是,不用方向键,用 `C-b` 向前移动,用 `C-f` 向后移动,上一行用 `C-p`,下一行用 `C-n`。你可能会想:“我用方向键就很好,为什么还要这样做?” 有几个原因。首先,你不需要从主键盘区将你的手移开。第二,使用 `Alt`(或用 Emacs 的说法 `Meta`)键来向前或向后移动一个单词。显而易见这样更方便。第三,如果想重复某个命令,可以在命令前面加上一个数字。在编辑文档时,我经常使用这种方法,通过估计向前多少个单词或向上或线下移动多少行,然后按下 `C-9 C-p` 或 `M-5 M-b` 之类的快捷键。其他真正重要的浏览命令基于开头用 `a` 和结尾用 `e`。在行中使用 `C-a|e`,在句中使用 `M-a|e`。为了让句中的命令正常工作,需要在句号后增加两个空格,这同时提供了一个有用的特性,并消除了脑中的[希伯列][38]。如果需要将文档导出到单个空间[发布环境][39],可以编写一个宏来执行此操作。
|
||||
|
||||
Emacs 附带的教程很值得去看。对于真正缺乏耐心的人,我将介绍一些重要的命令,但那个教程非常有用。记住:用 `C-h t` 进入教程。
|
||||
|
||||
### 学会复制和粘贴
|
||||
|
||||
你可以叫 Emacs 设为 `CUA` 模式,这将会以熟悉的方式工作来操作复制粘贴,但是原生的 Emacs 方法更好,而且你一旦学会了它,就很容易。你可以使用 `Shift` 这样的浏览命令来标记区域(如选择)。所以 `C-F` 是选中管标前的一个字符,等等。亦可以用 `M-w` 来复制,用 `C-w` 剪切,然后用 `C-y` 粘贴。这些实际上叫做删除和召回,但它非常类似于剪切和粘贴。在删除的环中有些小技巧,但是现在,你只需要关注剪切、复制和粘贴。如果你在这开始摸索, `C-x u` 是撤销。
|
||||
|
||||
### 下一步,学会用 `Ido` 模式
|
||||
|
||||
相信我,`Ido` 会让文件的工作变得很简单。通常,你在 Emacs 中处理文件不需要使用一个单独分开的查找或文件资源管理器的窗口。相反的,你可以用编辑器的命令来创建、打开和保存文件。如果没有 `Ido` 的话,这将有点麻烦,所以我建议你在学习其他之前安装好它。 `Ido` 是 Emacs 的 22 版时开发出来的,但是需要对你的 `.emacs` 文件做一些调整,来确保它一直开启着。这是个配置环境的好理由。
|
||||
|
||||
Emacs 中的大多数功能都表现在模式上。要安装制定的模式,需要做两件事。嗯,一开始你需要做一些额外的事情,但这些只需要做一次,然后再做这两件事。那么,额外的事情是你需要一个单独的位置来放置所有 `Emacs Lisp` 文件,并且你需要告诉 Emacs 这个位置在哪。我建议你在 Dropbox 上创建一个单独的目录,那是你 Emacs 主目录。在这里,你需要创建一个 `.emacs` 文件和 `.emacs.d` 目录。在 `.emacs.d` 目录下,创建一个 `lisp` 的目录。就像这样:
|
||||
|
||||
```
|
||||
home
|
||||
|
|
||||
+.emacs
|
||||
|
|
||||
-.emacs.d
|
||||
|
|
||||
-lisp
|
||||
```
|
||||
|
||||
你可以将那些像模式的 `.el` 文件放到 `home/.emacs.d/lis` 目录下,然后在你的 `.emacs` 文件中添加以下代码来指明该路径:
|
||||
|
||||
`(add-to-list 'load-path "~/.emacs.d/lisp/")`
|
||||
|
||||
`Ido` 模式是 Emacs 自带的,所以你不需要在你的 `lisp` 目录中放 `.el` 文件,但你仍然需要添加上面代码,因为下面的介绍会使用到它.
|
||||
|
||||
### 符号链接是你的好伙伴
|
||||
|
||||
等等,这里写的 `.emacs` 和 `.emacs.d` 都是存放在你的主目录下,但我们把他们放到了 Dropbox 的某些愚蠢的文件夹!对,这就让你的环境在任何地方都很容易使用。把所有东西都保存在 Dropbox 上,并链接到 `.emacs` 和 `.emacs.d`,以及主目录 `~`。在 OS X 上,使用 `ln -s` 命令非常简单,但在 Windows 上却很麻烦。幸运的是,Emacs 提供了一种简单的方法来替代 Windows 上的符号链接,Windows 的 `HOME` 环境变量。转到 Windows 的环境变量(Windows 10,你可以按 Windows 键然后输入 “环境变量” 来搜索,这是 Windows 10 最好的一部分了),在你的帐户下创建一个指向你在 Dropbox 中 Emacs 的文件家的 `HOME` 环境变量。如果你想方便地浏览 Dropbox 之外的本地文件,你可能想在你的实际主目录下建立一个到 Dropbox 下 Emacs 主目录的符号链接。
|
||||
|
||||
至此,你已经完成了在任意机器上指向 Emacs 配置和配置文件所需的技巧。如果你买了一台新电脑,或者用别人的电脑一小时或一天,你就得到了你的整个工作环境。第一次做这个似乎有点困难,但是一旦你知道你在做什么,就只需要10分钟(最多)。
|
||||
|
||||
但我们现在是在配置 `Ido`……
|
||||
|
||||
按下 `C-x` `C-f` 然后输入 `~/.emacs RET RET` 来创建 `.emacs` 文件,将下面几行添加进去:
|
||||
|
||||
```
|
||||
;; set up ido mode
|
||||
(require `ido)
|
||||
(setq ido-enable-flex-matching t)
|
||||
(setq ido-everywhere t)
|
||||
(ido-mode 1)
|
||||
```
|
||||
|
||||
在 `.emacs` 窗口开着的时候,执行 `M-x evaluate-buffer` 命令。如果某处弄错了的话,将得到一个错误,或者你将得到 `Ido`。`Ido` 改变了在 `minibuffer` 中操作文件操方式。有一篇比较好的文档,但是我也会指出一些技巧。有效地使用 `~/`;你可以在 `minibuffer` 的任何地方输入 `~/`,它就会跳转到主目录。这就意味着,你应该让你的大部分东西就近的放在主目录下。我用 `~/org` 目录来保存所有非代码的东西,用 `~/code` 保存代码。一旦你进入到正确的目录,通常会拥有一组具有不同扩展名的文件,特别是当你使用 `Org` 模式并从中发布的话。你可以输入 `period` 和想要的扩展名,无论你的在文件名的什么位置,`Ido` 都会将选择限制在具有该扩展名的文件中。例如,我在 `Org` 模式下写这篇博客,所以该文件是:
|
||||
|
||||
`~/org/blog/emacs.org`
|
||||
|
||||
我偶尔也会用 `Org` 模式发布成 HTML 格式,所以我将在同一目录下得到 `emacs.html` 文件。当我想打开 `Org` 文件时,我会输入:
|
||||
|
||||
`C-x C-f ~/o[RET]/bl[RET].or[RET]`
|
||||
|
||||
其中 `[RET]` 是我使用 `Ido` 模式的自动补全而按下的回车键。所以,这只需要按 12 个键,如果你习惯了的话, 这将比打开查找或文件资源管理器再用鼠标点要节省 _很_ 多时间。 `Ido` 模式很有用, 这真的是操作 Emacs 的一种实用的模式。下面让我们去探索一些其他对完成工作很有帮助的模式吧。
|
||||
|
||||
### 字体及风格
|
||||
|
||||
我推荐在 Emacs 中使用很棒的字体系列。它们可以使用不同的括号、0和其他字符进行自定义。你可以在字体文件本身中构建额外的行间距。我推荐 1\.5 倍的行间距,并在代码和数据中使用它们适应比例的字体。写作中我用 `Serif` 字体,它有一种紧凑但时髦的感觉。你可以在 [http://input.fontbureau.com/][40] 上找到它们,在那里你可以根据自己的喜好进行定制。你可以使用 Emacs 中的菜单手动设置字体,但这会将代码保存到你的 `.emacs` 文件中,如果您使用多个设备,您可能需要一些不同的设置。我我将我的 `.emacs` 设置位根据使用的机器的名称,并配置适当的屏幕机字体。代码如下:
|
||||
|
||||
```
|
||||
;; set up fonts for different OSes. OSX toggles to full screen.
|
||||
(setq myfont "InputSerif")
|
||||
(cond
|
||||
((string-equal system-name "Sampo.local")
|
||||
(set-face-attribute 'default nil :font myfont :height 144)
|
||||
(toggle-frame-fullscreen))
|
||||
((string-equal system-name "Morpheus.local")
|
||||
(set-face-attribute 'default nil :font myfont :height 144))
|
||||
((string-equal system-name "ILMARINEN")
|
||||
(set-face-attribute 'default nil :font myfont :height 106))
|
||||
((string-equal system-name "UKKO")
|
||||
(set-face-attribute 'default nil :font myfont :height 104)))
|
||||
```
|
||||
|
||||
您应该将你的 Emacs 副本中 `system-name` 的值替换成你使用命令 `(system-name)` 得到的值。注意,在 Sampo (我的 MacBook)上,我还将 Emacs 设置为全屏。我也想在 Windows 实现这个,但是 Windows 和 Emacs 并不真正喜欢对方,当我尝试这个时,它总是不稳定。相反,我只是在启动后手动全屏。
|
||||
|
||||
我还建议去掉 Emacs 中在 90 年代获得的难看的工具栏,当时最酷的事情是在应用程序中使用工具栏。我还去掉了一些其他的 `chrome`,这样我就有了一个简单、高效的界面。把这些加到你的 `.emacs` 的文件中,来去掉工具栏和滚动条,但要保留菜单 (在 OS X 上,它将被隐藏,除非你将鼠标到屏幕顶部):
|
||||
|
||||
```
|
||||
(if (fboundp 'scroll-bar-mode) (scroll-bar-mode -1))
|
||||
(if (fboundp 'tool-bar-mode) (tool-bar-mode -1))
|
||||
(if (fboundp 'menu-bar-mode) (menu-bar-mode 1))
|
||||
```
|
||||
|
||||
### Org 模式
|
||||
|
||||
我基本上 `Org` 模式下处理工作的。它是我创作文档、记笔记、列任务清单以及 90% 其他工作的首选环境。`Org` 最初是由一个在会议中使用笔记本电脑的家伙构想出来的,它是笔记和待办事项列表的组合工具。我反对在会议中使用笔记本电脑,自己也不使用,所以我的用法与他的有些不同。对我来说,`Org` 主要是一种处理结构中内容的方式。在 `Org` 模式中有标题和副标题等,它们的作用就像一个大纲。`Org` 允许你展开或隐藏文本内容,还可以重新排列文本。这非常很符合我的想法,而且我发现用这种方式使用它是一种乐趣。
|
||||
|
||||
`Org` 模式也有很多让生活愉快的小功能。例如,脚注处理非常好,`LaTeX/PDF` 输出也很好。`Org` 能够根据所有文档中的待办事项生成议程,并能很好地将它们与日期/时间联系起来。我不把它用在任何形式的外部任务上,这些任务都是在一个共享的日历上处理的,但是在创建事物和跟踪我未来需要创建的东西时,它是无价的。安装它,你只要将 `org-mode.el` 放到你的 `lisp` 目录下,然后再在你的 `.emacs` 文件中添加如下代码,如果你想要它基于文档的结构进行缩进并在打开时全部展开的话:
|
||||
|
||||
```
|
||||
;; set up org mode
|
||||
(setq org-startup-indented t)
|
||||
(setq org-startup-folded "showall")
|
||||
(setq org-directory "~/org")
|
||||
```
|
||||
|
||||
最后一行是让 `Org` 知道在哪里查找要包含在议程和其他事情中的文件。我把 `Org` 保存在我的主目录中,也就是说,像前面介绍的一样,它是 Dropbox 目录的一个符号链接。
|
||||
|
||||
我有一个总是在缓冲区中打开的 `stuff.org` 文件。我把它当作记事本。`Org` 使得提取待办事项和有期限的事情变得很容易。当你在内联 `Lisp` 代码并在需要计算它时,它特别有用。拥有包含内容的代码非常方便。同样,你可以使用 Emacs 访问实际的计算机,这是一种解放。
|
||||
|
||||
#### 用 `Org` 模式进行发布
|
||||
|
||||
我关心的是文档的外观和格式。我我刚开始工作时是个设计师,而且我认为信息可以,也应该表现得清晰和美丽。`Org` 对将 `LaTeX` 生成 PDF 支持的很好, `LaTeX` 有自己的学习曲线,但是做简单的事情非常简单。
|
||||
|
||||
如果你想使用字体和样式,而不是典型的 `LaTeX` 字体和样式,你需要做些事。首先,你要用到 `XeLaTeX`,这样就可以使用普通的系统字体,而不是 `LaTeX` 的特殊字体。接下来,您需要将一下代码添加到 `.emacs` 中:
|
||||
|
||||
```
|
||||
(setq org-latex-pdf-process
|
||||
'("xelatex -interaction nonstopmode %f"
|
||||
"xelatex -interaction nonstopmode %f"))
|
||||
```
|
||||
|
||||
我把这个放在 `.emacs` 中 `Org` 配置部分的末尾来保持整洁。这让你在从 `Org` 发布时使用更多格式化选项。例如,我经常使用:
|
||||
|
||||
```
|
||||
#+LaTeX_HEADER: \usepackage{fontspec}
|
||||
#+LATEX_HEADER: \setmonofont[Scale=0.9]{Input Mono}
|
||||
#+LATEX_HEADER: \setromanfont{Maison Neue}
|
||||
#+LATEX_HEADER: \linespread{1.5}
|
||||
#+LATEX_HEADER: \usepackage[margin=1.25in]{geometry}
|
||||
|
||||
#+TITLE: Document Title Here
|
||||
```
|
||||
|
||||
这些都可以在你的 `.org` 文件中找到。我们的公司规定的正文字体是 `Maison Neue`,但你也可以在这写上任何适当的东西。我强烈反对使用 `Maison Neue`。它是一种糟糕的字体,任何人都不应该使用它。
|
||||
|
||||
这个文件是一个使用该配置输出为 PDF 的实例。这就是开箱即用的 `LaTeX` 一样。在我看来这还不错,但是字体很无聊,而且有点奇怪。此外,如果你使用标准格式,人们会认为他们正在阅读的东西是或假装是一篇学术论文。别怪我没提醒你。
|
||||
|
||||
### `Ace Jump` 模式
|
||||
|
||||
如果你想使用的话,这是个辅助而不是主要功能。它的工作原理有点像 Jef Raskin 的 `Leap` 功能<sup>[9][15]</sup>。 按下 `C-c` `C-SPC`,然后输入要跳转到单词的第一个字母。它会高亮显示所有以该字母开头的单词,并将其替换为字母表中的字母。您只需键入所需位置的字母,光标就会跳转到该位置。我自己经常用这个作为导航键或搜索。将 `.el` 文件下到你的 `Lisp` 目录下,并在 `.emacs` 文件添加如下代码:
|
||||
|
||||
```
|
||||
;; set up ace-jump-mode
|
||||
(add-to-list 'load-path "which-folder-ace-jump-mode-file-in/")
|
||||
(require 'ace-jump-mode)
|
||||
(define-key global-map (kbd "C-c C-SPC" ) 'ace-jump-mode)
|
||||
```
|
||||
|
||||
### 更多
|
||||
|
||||
这篇文章已经够详细了,你能在其中的到你所想要的。我很想了解除编程(或编程)之外你对 Emacs 的使用,以及这是否有用。在我使用 Emacs 的过程中,可能存在一些自作聪明的想法,如果你能指出它们,我将感激不尽。之后,我可能会写一些更新来引入其他特性或模式。我很确定我将会向你展示如何在 Emacs 和 `Ludwig` 模式下使用 `Fugue`,因为我会将它发展成比代码突出显示更有用的东西。把你的想法发到 [@fugueHQ][41] 上。
|
||||
|
||||
* * *
|
||||
|
||||
#### 附注
|
||||
|
||||
1. [^][16] If you are now a PHB of some sort, but were never technical, Emacs likely isn’t for you. There may be a handful of folks for whom Emacs will form a path into the more technical aspects of computing, but this is probably a small population. It’s helpful to know how to use a Unix or Windows terminal, to have edited a dotfile or two, and to have written some code at some point in your life for Emacs to make much sense.
|
||||
|
||||
2. [^][17] [][18][http://archive.wired.com/wired/archive/2.08/tufte.html][19]
|
||||
|
||||
3. [^][20] I mainly use this to perform calculations while writing. For example, I was writing an offer letter to a new employee and wanted to calculate how many options to include in the offer. Since I have a variable defined in my `.emacs` for outstanding-shares, I can simply type `M-: (* .001 outstanding-shares)`and get a tenth of a point without opening a calculator or spreadsheet. I keep _lots_ of numbers in variables like this so I can avoid context switching.
|
||||
|
||||
4. [^][21] The missing piece of this is the web. There is an Emacs web browser called eww that will allow you to browse in Emacs. I actually use this, as it is both a great ad-blocker and removes most of the poor choices in readability from the web designer's hands. It's a bit like Reading Mode in Safari. Unfortunately, most websites have lots of annoying cruft and navigation that translates poorly into text.
|
||||
|
||||
5. [^][22] Usability is often confused with learnability. Learnability is how difficult it is to learn a tool. Usability is how useful the tool is. Often, these are at odds, such as with the mouse and menus. Menus are highly learnable, but have poor usability, so there have been keyboard shortcuts from the earliest days. Raskin was right on many points where he was ignored about GUIs in general. Now, OSes are putting things like decent search onto a keyboard shortcut. On OS X and Windows, my default method of navigation is search. Ubuntu's search is badly broken, as is the rest of its GUI.
|
||||
|
||||
6. [^][23] AWS S3 has effectively solved file storage for as long as we have the Internet. Trillions of objects are stored in S3 and they've never lost one of them. Most every service out there that offers cloud storage is built on S3 or imitates it. No one has the scale of S3, so I keep important stuff there, via Dropbox.
|
||||
|
||||
7. [^][24] By now, you might be thinking "what is it with this guy and bicycles?" ... I love them on every level. They are the most mechanically efficient form of transportation ever invented. They can be objects of real beauty. And, with some care, they can last a lifetime. I had Rivendell Bicycle Works build a frame for me back in 2001 and it still makes me happy every time I look at it. Bicycles and UNIX are the two best inventions I've interacted with. Well, they and Emacs.
|
||||
|
||||
8. [^][25] This is not a tutorial for Emacs. It comes with one and it's excellent. I do walk through some of the things that I find most important to getting a useful Emacs setup, but this is not a replacement in any way.
|
||||
|
||||
9. [^][26] Jef Raskin designed the Canon Cat computer in the 1980s after falling out with Steve Jobs on the Macintosh project, which he originally led. The Cat had a document-centric interface (as all computers should) and used the keyboard in innovative ways that you can now imitate with Emacs. If I could have a modern, powerful Cat with a giant high-res screen and Unix underneath, I'd trade my Mac for it right away. [][27][https://youtu.be/o_TlE_U_X3c?t=19s][28]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.fugue.co/2015-11-11-guide-to-emacs.html
|
||||
|
||||
作者:[Josh Stella ][a]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.fugue.co/authors/josh.html
|
||||
[1]:https://blog.fugue.co/2013-10-16-vpc-on-aws-part3.html
|
||||
[2]:https://blog.fugue.co/2013-10-02-vpc-on-aws-part2.html
|
||||
[3]:http://ww2.fugue.co/2017-05-25_OS_AR_GartnerCoolVendor2017_01-LP-Registration.html
|
||||
[4]:https://blog.fugue.co/authors/josh.html
|
||||
[5]:https://twitter.com/joshstella
|
||||
[6]:https://www.youtube.com/watch?v=khJQgRLKMU0
|
||||
[7]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#phb
|
||||
[8]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#tufte
|
||||
[9]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#interpreter
|
||||
[10]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#eww
|
||||
[11]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#usability
|
||||
[12]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#s3
|
||||
[13]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#bicycles
|
||||
[14]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#nottutorial
|
||||
[15]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#canoncat
|
||||
[16]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#phbOrigin
|
||||
[17]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#tufteOrigin
|
||||
[18]:http://archive.wired.com/wired/archive/2.08/tufte.html
|
||||
[19]:http://archive.wired.com/wired/archive/2.08/tufte.html
|
||||
[20]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#interpreterOrigin
|
||||
[21]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#ewwOrigin
|
||||
[22]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#usabilityOrigin
|
||||
[23]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#s3Origin
|
||||
[24]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#bicyclesOrigin
|
||||
[25]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#nottutorialOrigin
|
||||
[26]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#canoncatOrigin
|
||||
[27]:https://youtu.be/o_TlE_U_X3c?t=19s
|
||||
[28]:https://youtu.be/o_TlE_U_X3c?t=19s
|
||||
[29]:https://blog.fugue.co/authors/josh.html
|
||||
[30]:http://www.huffingtonpost.com/zachary-ehren/soma-isnt-a-drug-san-fran_b_987841.html
|
||||
[31]:http://www.campagnolo.com/US/en
|
||||
[32]:http://www.businessinsider.com/best-pointy-haired-boss-moments-from-dilbert-2013-10
|
||||
[33]:http://www.webopedia.com/TERM/I/interpreter.html
|
||||
[34]:http://emacsformacosx.com/
|
||||
[35]:http://emacsformacosx.com/
|
||||
[36]:http://www.gnu.org/software/emacs/
|
||||
[37]:http://www.gnu.org/software/emacs/
|
||||
[38]:http://www.huffingtonpost.com/2015/05/29/two-spaces-after-period-debate_n_7455660.html
|
||||
[39]:http://practicaltypography.com/one-space-between-sentences.html
|
||||
[40]:http://input.fontbureau.com/
|
||||
[41]:https://twitter.com/fugueHQ
|
||||
131
translated/tech/20180302 Emacs -3- More on org-mode.md
Normal file
131
translated/tech/20180302 Emacs -3- More on org-mode.md
Normal file
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Emacs #3: More on org-mode)
|
||||
[#]: via: (https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode)
|
||||
[#]: author: (John Goerzen http://changelog.complete.org/archives/author/jgoerzen)
|
||||
[#]: url: ( )
|
||||
|
||||
Emacs 系列(三): `Org` 模式的补充
|
||||
======
|
||||
|
||||
这是 [Emacs 和 `Org` 模式系列][1]的第三篇。
|
||||
|
||||
**Todo 的跟进及关键字**
|
||||
|
||||
当你使用 `Org` 模式来跟进的的 TODO 时,它有多种状态。你可以用 `C-c C-t` 来快速切换状态。我将它设为这样:
|
||||
|
||||
```
|
||||
(setq org-todo-keywords '(
|
||||
(sequence "TODO(t!)" "NEXT(n!)" "STARTED(a!)" "WAIT(w@/!)" "OTHERS(o!)" "|" "DONE(d)" "CANCELLED(c)")
|
||||
))
|
||||
```
|
||||
|
||||
在这里,我设置了一个任务未完成的五种状态:`TODO`、`NEXT`、`STARTED`、`WAIT` 及 `OTHERS`。每一个状态都单个字的快捷键(t,n,a 等)。这些符号之后的状态被认为是“完成”的状态。我有两个“完成”状态:`DONE`(已经完成)及 `CANCELLED`(还没完成,但由于其它的原因无法完成)。
|
||||
|
||||
`!` 的含义是记录某项更改为状态的时间。我不把这个添加到完成的状态,是因为它们已经被记录了。`@` 符号表示带理由的提示,所以当切换到 `WAIT` 时,`Org` 会问我为什么,并将这个添加到笔记中。
|
||||
|
||||
以下是项目状态发生变化的例子:
|
||||
|
||||
```
|
||||
** DONE This is a test
|
||||
CLOSED: [2018-03-02 Fri 03:05]
|
||||
|
||||
- State "DONE" from "WAIT" [2018-03-02 Fri 03:05]
|
||||
- State "WAIT" from "TODO" [2018-03-02 Fri 03:05] \\
|
||||
waiting for pigs to fly
|
||||
- State "TODO" from "NEXT" [2018-03-02 Fri 03:05]
|
||||
- State "NEXT" from "TODO" [2018-03-02 Fri 03:05]
|
||||
```
|
||||
|
||||
在这里,最新的项目在最上面。
|
||||
|
||||
**议程模式,日程及期限**
|
||||
|
||||
当你处在一个待办项时,`C-c C-s` 或 `C-c C-d` 可以为其设置相应的日程或期限。这些都是在议程模式中的功能。区别在于意图和表现。日程是你希望在某个时候完成的事情,而期限是在某个特定的时间应该完成的事情。默认情况下,议程视图将在项目的截止日期前提醒你。
|
||||
|
||||
在此过程中,[议程视图][3]将显示即将出现的项目,提供了一种基于纯文本或标记搜索项目的方法,甚至可以进行跨多个文件处理项目的批量操作。我在本系列的[第 2 部分][4]中介绍了为议程模式配置。
|
||||
|
||||
**标签**
|
||||
|
||||
`Org` 模式当然也支持标签了。你可以通过 `C-c C-q` 快速的建立标签。
|
||||
|
||||
你可能会想为一些常用的标签设置快捷键。就像这样:
|
||||
|
||||
```
|
||||
(setq org-tag-persistent-alist
|
||||
'(("@phone" . ?p)
|
||||
("@computer" . ?c)
|
||||
("@websurfing" . ?w)
|
||||
("@errands" . ?e)
|
||||
("@outdoors" . ?o)
|
||||
("MIT" . ?m)
|
||||
("BIGROCK" . ?b)
|
||||
("CONTACTS" . ?C)
|
||||
("INBOX" . ?i)
|
||||
))
|
||||
```
|
||||
|
||||
你还可以根据每个文件向该列表添加标记,也可以根据每个文件为某些内容设置标记。我就在我的 `inbox.org` 和 `email.org` 文件中设置了一个 `INBOX` 的标签。然后我可以每天从日程视图中查看所有标记为 `INBOX` 的项目,像将它们重新归档到其他文件中的简单操作将让它们去掉 `INBOX` 标记。
|
||||
|
||||
**重新归档**
|
||||
|
||||
“重新归档”就是在文件中或其他地方移动。它是使用标来题完成。`C-c C-w` 就是做这个的。我设置成这样:
|
||||
|
||||
```
|
||||
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
|
||||
(setq org-refile-use-outline-path 'file)
|
||||
```
|
||||
|
||||
**归档分类**
|
||||
|
||||
一段时间后,你的文件就会被已经完成的事情弄得乱七八糟。`Org` 模式有一个[归档][6]特性,可以将主 `.org` 文件移到其他文件中,以备将来参考。如果你在 `git` 或其他软件中 有 `Org` 文件,你可能希望删除这些其他文件,因为无论如何都会在历史中拥有这些文件,但是我发现它们对于 `grepping` 和搜索非常方便。
|
||||
|
||||
我会定期检查并归档文件中的所有内容。基于 [stackoverflow 的讨论][7],我有以下代码:
|
||||
|
||||
```
|
||||
(defun org-archive-done-tasks ()
|
||||
(interactive)
|
||||
(org-map-entries
|
||||
(lambda ()
|
||||
(org-archive-subtree)
|
||||
(setq org-map-continue-from (outline-previous-heading)))
|
||||
"/DONE" 'file)
|
||||
(org-map-entries
|
||||
(lambda ()
|
||||
(org-archive-subtree)
|
||||
(setq org-map-continue-from (outline-previous-heading)))
|
||||
"/CANCELLED" 'file)
|
||||
)
|
||||
```
|
||||
|
||||
这基于[一个特定的答案][8]——你可以从评论那获得一些额外的提示。现在你可以运行 `M-x org-archive-done-tasks`,当前文件中所有标记为 `DONE` 或 `CANCELED` 的内容都将放到另一个文件中。
|
||||
|
||||
**下一篇**
|
||||
|
||||
我将通过讨论在 `Org` 模式中自动接受邮件以及在不同的机子上同步来对 `Org` 模式进行总结。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://changelog.complete.org/archives/author/jgoerzen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://changelog.complete.org/archives/tag/emacs2018
|
||||
[2]: https://orgmode.org/guide/TODO-Items.html#TODO-Items
|
||||
[3]: https://orgmode.org/guide/Agenda-Views.html#Agenda-Views
|
||||
[4]: https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode
|
||||
[5]: https://orgmode.org/guide/Tags.html#Tags
|
||||
[6]: https://orgmode.org/guide/Archiving.html#Archiving
|
||||
[7]: https://stackoverflow.com/questions/6997387/how-to-archive-all-the-done-tasks-using-a-single-command
|
||||
[8]: https://stackoverflow.com/a/27043756
|
||||
145
translated/tech/20180518 How to Manage Fonts in Linux.md
Normal file
145
translated/tech/20180518 How to Manage Fonts in Linux.md
Normal file
@ -0,0 +1,145 @@
|
||||
如何在 Linux 上管理字体
|
||||
======
|
||||
|
||||

|
||||
|
||||
我不仅写技术文档,还写小说。并且因为我对 GIMP 等工具感到满意,所以我也(译者注:此处应指使用 GIMP)创建了自己的书籍封面(并为少数客户做了图形设计)。艺术创作取决于很多东西,包括字体。
|
||||
|
||||
虽然字体渲染已经在过去的几年里取得了长足进步,但它在 Linux 平台上仍是个问题。如果你在 Linux 和 macOS 平台上比较相同字体的外观,差别是显而易见的,尤其是你要盯着屏幕一整天的时候。虽然在 Linux 平台上尚未找到完美的字体渲染方案,开源平台做得好的一件事是允许用户轻松地管理他们的字体。通过选择、添加、缩放和调整,你可以在 Linux 平台上相当轻松地使用字体。
|
||||
|
||||
此处,我将分享一些这些年来我赖于在 Linux 上帮助我扩展“字体能力”的技巧。这些技巧将对那些在开源平台上进行艺术创作的人有特别的帮助。因为 Linux 平台上有非常多可用的桌面界面(每种界面以不同的方式处理字体),因此当桌面环境成为字体管理的中心时,我将主要聚焦在 GNOME 和 KDE 上。
|
||||
|
||||
话虽如此,让我们开始吧。
|
||||
|
||||
### 添加新字体
|
||||
|
||||
在相当长的一段时间里,我都是一个字体收藏家,甚至有些人会说我有些痴迷。从我使用 Linux 的早期开始,我就总是用相同的方法向我的桌面添加字体。有两种方法可以做到这一点:
|
||||
|
||||
* 使字体针对每个用户可用;
|
||||
|
||||
* 使字体在系统范围内可用。
|
||||
|
||||
|
||||
|
||||
|
||||
因为我的桌面从没有其他用户(除了我自己),我只使用了每个用户的字体设置。然而,我会向你演示如何完成这两种设置。首先,让我们来看一下如何向每个用户添加新字体。你首先要做的是找到字体文件,真实类型字体(TTF)和开源类型字体(OTF)都可以被添加。我选择手动添加字体,也就是说,我在 ~/ 目录下新建了一个名为 ~/.fonts 的隐藏目录。该操作可由以下命令完成:
|
||||
```
|
||||
mkdir ~/.fonts
|
||||
|
||||
```
|
||||
|
||||
当此文件夹新建完成,我将所有 TTF 和 OTF 字体文件移动到此文件夹中。也就是说,你在此文件夹中添加的所有字体都可以在已安装的应用中使用了。但是要记住,这些字体只会对这一个用户可用。
|
||||
|
||||
如果你想要使这个字体集合对所有用户可用,你可以如下操作:
|
||||
|
||||
1. 打开一个终端窗口;
|
||||
|
||||
2. 切换路径到包含你所有字体的目录中;
|
||||
|
||||
3. 使用 `sudo cp *.ttf *.TTF /usr/share/fonts/truetype/` 和 `sudo cp *.otf *.OTF /usr/share/fonts/opentype` 命令拷贝所有字体。
|
||||
|
||||
|
||||
|
||||
|
||||
当下次用户登录时,他们就将可以使用所有这些漂亮的字体。
|
||||
|
||||
### 图形界面字体管理
|
||||
|
||||
在 Linux 上你有许多方式来管理你的字体,如何完成取决于你的桌面环境。让我们以 KDE 为例。使用以 KDE 作为桌面环境的 Kubuntu 18.04,你能够找到一个预装的字体管理工具。打开此工具,你就能轻松地添加、移除、启用或禁用字体(当然也包括获得所有已安装字体的详细信息)。这个工具也能让你轻松地针对每个用户或在系统范围内添加和删除字体。假如你想要为用户添加一个特定的字体,你需要下载该字体并打开字体管理工具。在此工具中(图 1),点击个人字体并点击“+”号添加按钮。
|
||||
|
||||
|
||||
![添加字体][2]
|
||||
|
||||
图 1: 在 KDE 中添加个人字体。
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
导航至你的字体路径,选择它们,然后点击打开。你的字体就会被添加进了个人区域,并且立即可用(图 2)。
|
||||
|
||||
|
||||
![KDE 字体管理][5]
|
||||
|
||||
图 2: 使用 KDE 字体管理添加字体
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
在 GNOME 中做同样的事需要安装一个应用。打开 GNOME 软件中心或者 Ubuntu 软件中心(取决于你使用的发行版)并搜索字体管理器。选择 Font Manager 并点击安装按钮。一但安装完成,你就可以从桌面菜单中启动它,然后让我们安装个人字体。下面是如何安装:
|
||||
|
||||
1. 从左侧窗格选择“用户”(图 3);
|
||||
|
||||
2. 点击窗口顶部的 + 按钮;
|
||||
|
||||
3. 浏览并选择已下载的字体;
|
||||
|
||||
4. 点击“打开”。
|
||||
|
||||
|
||||
|
||||
|
||||
![添加字体][7]
|
||||
|
||||
图 3: 在 GNOME 中添加字体
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
### 调整字体
|
||||
|
||||
首先你需要理解 3 条概念:
|
||||
|
||||
* **字体提示:** 使用数学指令调整字体轮廓显示,使其与光栅化网格对齐。
|
||||
|
||||
* **抗锯齿:** 一种通过使曲线和斜线锯齿状边缘光滑化,提高数字图像真实性的技术。
|
||||
|
||||
* **缩放因子:** **** 一个允许你倍增字体大小的缩放单元。也就是说如果你的字体是 12pt 并且缩放因子为 1,那么字体大小将会是 12pt。如果你的缩放因子为 2,那么字体将会是 24pt。
|
||||
|
||||
|
||||
|
||||
|
||||
假设你已经安装好了你的字体,但他们看起来并不像你想的那么好。你将如何调整字体的外观?在 KDE 和 GNOME 中,你都可以做一些调整。在调整字体时需要考虑的一件事是,关于字体的口味是非常主观的。你也许会发现你只得不停地调整,直到你得到了看起来确实满意的字体(由你的需求和特殊口味决定)。让我们先看一下 KDE 下的情况吧。
|
||||
|
||||
打开系统设置工具并点击“字体”。在此节中,你不仅能切换不同字体,你也能够启用或配置抗锯齿或启用字体缩放因子(图 4)。
|
||||
|
||||
|
||||
![配置字体][9]
|
||||
|
||||
图 4: 在 KDE 中配置字体
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
要配置抗锯齿,在下拉菜单中选择“启用”并点击“配置”。在结果窗口中(图 5),你可以配置排除范围、子像素渲染类型和提示类型。
|
||||
|
||||
一但你做了更改,点击“应用”。重启所有正在运行的程序,然后新的设置就会生效。
|
||||
|
||||
要在 GNOME 中这么做,你需要安装 Font Manager或 GNOME Tweaks。在此处,GNOME Tweaks 是更好的工具。如果你打开 GNOME Dash 菜单但没有找到 Tweaks,打开 GNOME Software(或 Ubuntu Software)并安装 GNOME Tweaks。安装完毕,打开并点击“字体”,此处你可以配置提示、抗锯齿和缩放因子(图 6)。
|
||||
|
||||
![调整字体][11]
|
||||
|
||||
图 6: 在 GNOME 中调整字体
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
### 美化你的字体
|
||||
|
||||
以上便是使你的 Linux 字体尽可能漂亮的要旨。你可能得不到像 macOS 那样渲染的字体,但你一定可以提升字体外观。最后,你选择的字体会很大程度地影响视觉效果,因此请确保你安装的字体是干净并且完整适配的,否则你将输掉这次对抗。
|
||||
|
||||
通过 The Linux Foundation 和 edX 平台的免费课程 [初识 Linux][12] 了解更多关于 Linux 的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/5/how-manage-fonts-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[2]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_1.jpg?itok=7yTTe6o3 (adding fonts)
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_2.jpg?itok=_g0dyVYq (KDE Font Manager)
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_3.jpg?itok=8o884QKs (Adding fonts )
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_4.jpg?itok=QJpPzFED (Configuring fonts)
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_6.jpg?itok=4cQeIW9C (Tweaking fonts)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,37 +1,38 @@
|
||||
yongshouzhang translating
|
||||
|
||||
HTTP request routing and validation with gorilla/mux
|
||||
使用 gorilla/mux 进行HTTP请求路由和验证
|
||||
======
|
||||
|
||||

|
||||
|
||||
The Go networking library includes the `http.ServeMux` structure type, which supports HTTP request multiplexing (routing): A web server routes an HTTP request for a hosted resource, with a URI such as /sales4today, to a code handler; the handler performs the appropriate logic before sending an HTTP response, typically an HTML page. Here’s a sketch of the architecture:
|
||||
Go 网络库包括 `http.ServeMux` 结构类型,它支持 HTTP 请求多路复用(路由):Web 服务器将托管资源的 HTTP 请求与诸如 sales4today 之类的 URI 路由到代码处理程序; 处理程序在发送 HTTP 响应(通常是 HTML 页面)之前执行适当的逻辑。 这是该体系的草图:
|
||||
|
||||
```
|
||||
+------------+ +--------+ +---------+
|
||||
HTTP request---->| web server |---->| router |---->| handler |
|
||||
HTTP 请求---->| web 服务器 |---->| 路由 |---->| 处理程序|
|
||||
+------------+ +--------+ +---------+
|
||||
```
|
||||
|
||||
In a call to the `ListenAndServe` method to start an HTTP server
|
||||
调用 `ListenAndServe` 方法后启动 HTTP 服务器
|
||||
|
||||
```
|
||||
http.ListenAndServe(":8888", nil) // args: port & router
|
||||
```
|
||||
|
||||
a second argument of `nil` means that the `DefaultServeMux` is used for request routing.
|
||||
|
||||
The `gorilla/mux` package has a `mux.Router` type as an alternative to either the `DefaultServeMux` or a customized request multiplexer. In the `ListenAndServe` call, a `mux.Router` instance would replace `nil` as the second argument. What makes the `mux.Router` so appealing is best shown through a code example:
|
||||
第二个参数 `nil` 意味着 `DefaultServeMux` 用于请求路由。
|
||||
|
||||
`gorilla/mux` 库包含 `mux.Router` 类型,可替代 `DefaultServeMux` 或自定义请求多路复用器。 在 `ListenAndServe` 调用中,`mux.Router` 实例将代替 `nil` 作为第二个参数。 下面的示例代码很好的说明了为什么 `mux.Router`如此吸引人:
|
||||
|
||||
### 1\. A sample crud web app
|
||||
|
||||
The crud web application (see below) supports the four CRUD (Create Read Update Delete) operations, which match four HTTP request methods: POST, GET, PUT, and DELETE, respectively. In the crud app, the hosted resource is a list of cliche pairs, each a cliche and a conflicting cliche such as this pair:
|
||||
crud web 应用程序(见下文)支持四种 CRUD(创建读取更新删除)操作,它们分别对应四种 HTTP 请求方法:POST,GET,PUT 和 DELETE。 在 crud 应用程序中,托管资源是陈词滥调对的列表,每个陈词滥调都是陈词滥调和冲突的陈词滥调,例如这对:
|
||||
```
|
||||
Out of sight, out of mind. Absence makes the heart grow fonder.
|
||||
|
||||
```
|
||||
|
||||
New cliche pairs can be added, and existing ones can be edited or deleted.
|
||||
可以添加新的陈词滥调对,可以编辑或删除现有的陈词滥调对。
|
||||
|
||||
**The crud web app**
|
||||
**crud web 应用程序**
|
||||
```
|
||||
package main
|
||||
|
||||
@ -446,43 +447,45 @@ func populateClichesList() {
|
||||
|
||||
```
|
||||
|
||||
To focus on request routing and validation, the crud app does not use HTML pages as responses to requests. Instead, requests result in plaintext response messages: A list of the cliche pairs is the response to a GET request, confirmation that a new cliche pair has been added to the list is a response to a POST request, and so on. This simplification makes it easy to test the app, in particular, the `gorilla/mux` components, with a command-line utility such as [curl][1].
|
||||
为了专注于请求路由和验证,crud 应用程序不使用 HTML 页面作为请求响应。 相反,请求会产生明文响应消息:陈词滥调对的列表是对 GET 请求的响应,确认新的陈词滥调对已添加到列表中是对 POST 请求的响应,依此类推。 这种简化使得使用命令行实用程序(如 [curl] [1])可以轻松地测试应用程序,尤其是 `gorilla/mux` 组件。
|
||||
|
||||
The `gorilla/mux` package can be installed from [GitHub][2]. The crud app runs indefinitely; hence, it should be terminated with a Control-C or equivalent. The code for the crud app, together with a README and sample curl tests, is available on [my website][3].
|
||||
`gorilla/mux` 包可以从 [GitHub] [2] 安装。 crud app 无限期运行; 因此,应使用 Control-C 或同等命令终止。 crud 应用程序的代码,以及自述文件和简单的 curl 测试,可以在[我的网站] [3]上找到。
|
||||
|
||||
### 2\. Request routing
|
||||
### 2\. 请求路由
|
||||
|
||||
`mux.Router` 扩展了 REST 风格的路由,它赋给 HTTP 方法(例如,GET)和 URL 末尾的 URI 或路径(例如/cliches)相同的权重。 URI 用作 HTTP 动词(方法)的名词。 例如,在HTTP请求中有一个起始行,例如
|
||||
|
||||
The `mux.Router` extends REST-style routing, which gives equal weight to the HTTP method (e.g., GET) and the URI or path at the end of a URL (e.g., /cliches). The URI serves as the noun for the HTTP verb (method). For example, in an HTTP request a startline such as
|
||||
```
|
||||
GET /cliches
|
||||
|
||||
```
|
||||
|
||||
means get all of the cliche pairs, whereas a startline such as
|
||||
意味着得到所有的陈词滥调对,而一个起始线,如
|
||||
|
||||
```
|
||||
POST /cliches
|
||||
|
||||
```
|
||||
|
||||
means create a cliche pair from data in the HTTP body.
|
||||
意味着从HTTP正文中的数据创建一个陈词滥调对。
|
||||
|
||||
In the crud web app, there are five functions that act as request handlers for five variations of an HTTP request:
|
||||
在 crud web 应用程序中,有五个函数充当HTTP请求的五种变体的请求处理程序:
|
||||
```
|
||||
ClichesAll(...) # GET: get all of the cliche pairs
|
||||
ClichesAll(...) # GET: 获取所有的陈词滥调对
|
||||
|
||||
ClichesOne(...) # GET: get a specified cliche pair
|
||||
ClichesOne(...) # GET: 获取指定的陈词滥调对
|
||||
|
||||
ClichesCreate(...) # POST: create a new cliche pair
|
||||
ClichesCreate(...) # POST: 创建新的陈词滥调对
|
||||
|
||||
ClichesEdit(...) # PUT: edit an existing cliche pair
|
||||
ClichesEdit(...) # PUT: 编辑现有的陈词滥调对
|
||||
|
||||
ClichesDelete(...) # DELETE: delete a specified cliche pair
|
||||
ClichesDelete(...) # DELETE: 删除指定的陈词滥调对
|
||||
|
||||
```
|
||||
|
||||
Each function takes two arguments: an `http.ResponseWriter` for sending a response back to the requester, and a pointer to an `http.Request`, which encapsulates information from the underlying HTTP request. The `gorilla/mux` package makes it easy to register these request handlers with the web server, and to perform regex-based validation.
|
||||
每个函数都有两个参数:一个 `http.ResponseWriter` 用于向请求者发送一个响应,一个指向 `http.Request` 的指针,该指针封装了底层 HTTP 请求的信息。 使用 `gorilla/mux` 包可以轻松地将这些请求处理程序注册到Web服务器,并执行基于正则表达式的验证。
|
||||
|
||||
The `startServer` function in the crud app registers the request handlers. Consider this pair of registrations, with `router` as a `mux.Router` instance:
|
||||
crud 应用程序中的 `startServer` 函数注册请求处理程序。 考虑这对注册,`router` 作为 `mux.Router` 实例:
|
||||
```
|
||||
router.HandleFunc("/", ClichesAll).Methods("GET")
|
||||
|
||||
@ -490,13 +493,14 @@ router.HandleFunc("/cliches", ClichesAll).Methods("GET")
|
||||
|
||||
```
|
||||
|
||||
These statements mean that a GET request for either the single slash / or /cliches should be routed to the `ClichesAll` function, which then handles the request. For example, the curl request (with % as the command-line prompt)
|
||||
这些语句意味着对单斜线/ 或 /cliches 的 GET 请求应该路由到 `ClichesAll` 函数,然后处理请求。 例如,curl 请求(使用%作为命令行提示符)
|
||||
|
||||
```
|
||||
% curl --request GET localhost:8888/
|
||||
|
||||
```
|
||||
|
||||
produces this response:
|
||||
会产生如下结果
|
||||
```
|
||||
1: Out of sight, out of mind. Absence makes the heart grow fonder.
|
||||
|
||||
@ -506,9 +510,10 @@ produces this response:
|
||||
|
||||
```
|
||||
|
||||
The three cliche pairs are the initial data in the crud app.
|
||||
三个陈词滥调对是 crud 应用程序中的初始数据。
|
||||
|
||||
In this pair of registration statements
|
||||
|
||||
在这句注册语句中
|
||||
```
|
||||
router.HandleFunc("/cliches", ClichesAll).Methods("GET")
|
||||
|
||||
@ -516,84 +521,85 @@ router.HandleFunc("/cliches", ClichesCreate).Methods("POST")
|
||||
|
||||
```
|
||||
|
||||
the URI is the same (/cliches) but the verbs differ: GET in the first case, and POST in the second. This registration exemplifies REST-style routing because the difference in the verbs alone suffices to dispatch the requests to two different handlers.
|
||||
URI是相同的(/cliches),但动词不同:第一种情况下为 GET 请求,第二种情况下为 POST 请求。 此注册举例说明了 REST 样式的路由,因为仅动词的不同就足以将请求分派给两个不同的处理程序。
|
||||
|
||||
注册中允许多个 HTTP 方法,尽管这会影响 REST 风格路由的精髓:
|
||||
|
||||
More than one HTTP method is allowed in a registration, although this strains the spirit of REST-style routing:
|
||||
```
|
||||
router.HandleFunc("/cliches", DoItAll).Methods("POST", "GET")
|
||||
|
||||
```
|
||||
除了动词和 URI 之外,还可以在功能上路由 HTTP 请求。 例如,注册
|
||||
|
||||
HTTP requests can be routed on features besides the verb and the URI. For example, the registration
|
||||
```
|
||||
router.HandleFunc("/cliches", ClichesCreate).Schemes("https").Methods("POST")
|
||||
|
||||
```
|
||||
|
||||
requires HTTPS access for a POST request to create a new cliche pair. In similar fashion, a registration might require a request to have a specified HTTP header element (e.g., an authentication credential).
|
||||
要求对 POST 请求进行 HTTPS 访问以创建新的陈词滥调对。 以类似的方式,注册可能需要具有指定的 HTTP 头元素(例如,认证凭证)的请求。
|
||||
|
||||
### 3\. Request validation
|
||||
|
||||
The `gorilla/mux` package takes an easy, intuitive approach to request validation through regular expressions. Consider this request handler for a get one operation:
|
||||
`gorilla/mux` 包采用简单,直观的方法通过正则表达式进行请求验证。 考虑此请求处理程序以获取一个操作:
|
||||
```
|
||||
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesOne).Methods("GET")
|
||||
|
||||
```
|
||||
|
||||
This registration rules out HTTP requests such as
|
||||
此注册排除了 HTTP 请求,例如
|
||||
```
|
||||
% curl --request GET localhost:8888/cliches/foo
|
||||
|
||||
```
|
||||
|
||||
because foo is not a decimal numeral. The request results in the familiar 404 (Not Found) status code. Including the regex pattern in this handler registration ensures that the `ClichesOne` function is called to handle a request only if the request URI ends with a decimal integer value:
|
||||
因为 foo 不是十进制数字。 该请求导致熟悉的 404(未找到)状态码。 在此处理程序注册中包含正则表达式模式可确保仅在请求 URI 以十进制整数值结束时才调用 `ClichesOne` 函数来处理请求:
|
||||
|
||||
```
|
||||
% curl --request GET localhost:8888/cliches/3 # ok
|
||||
|
||||
```
|
||||
|
||||
As a second example, consider the request
|
||||
另一个例子,请求如下
|
||||
```
|
||||
% curl --request PUT --data "..." localhost:8888/cliches
|
||||
|
||||
```
|
||||
此请求导致状态代码为 405(错误方法),因为 /cliches URI 在 crud 应用程序中仅在 GET 和 POST 请求中注册。 像 GET 请求一样,PUT 请求必须在 URI 的末尾包含一个数字id:
|
||||
|
||||
This request results in a status code of 405 (Bad Method) because the /cliches URI is registered, in the crud app, only for GET and POST requests. A PUT request, like a GET one request, must include a numeric id at the end of the URI:
|
||||
```
|
||||
router.HandleFunc("/cliches/{id:[0-9]+}", ClichesEdit).Methods("PUT")
|
||||
|
||||
```
|
||||
|
||||
### 4\. Concurrency issues
|
||||
### 4\. 并发问题
|
||||
|
||||
`gorilla/mux` 路由器作为单独的 goroutine 执行对已注册的请求处理程序的每次调用,这意味着并发性被烘焙到包中。 例如,如果有十个同时发出的请求,例如
|
||||
|
||||
The `gorilla/mux` router executes each call to a registered request handler as a separate goroutine, which means that concurrency is baked into the package. For example, if there are ten simultaneous requests such as
|
||||
```
|
||||
% curl --request POST --data "..." localhost:8888/cliches
|
||||
|
||||
```
|
||||
|
||||
then the `mux.Router` launches ten goroutines to execute the `ClichesCreate` handler.
|
||||
然后 `mux.Router` 启动十个 goroutines 来执行 `ClichesCreate` 处理程序。
|
||||
|
||||
Of the five request operations GET all, GET one, POST, PUT, and DELETE, the last three alter the requested resource, the shared `clichesList` that houses the cliche pairs. Accordingly, the crudapp needs to guarantee safe concurrency by coordinating access to the `clichesList`. In different but equivalent terms, the crud app must prevent a race condition on the `clichesList`. In a production environment, a database system might be used to store a resource such as the `clichesList`, and safe concurrency then could be managed through database transactions.
|
||||
GET all,GET one,POST,PUT 和 DELETE 中的五个请求操作中,最后三个改变了所请求的资源,即包含陈词滥调对的共享 `clichesList`。 因此,crudapp 需要通过协调对`clichesList` 的访问来保证安全的并发性。 在不同但等效的术语中,crud app 必须防止 `clichesList` 上的竞争条件。 在生产环境中,可以使用数据库系统来存储诸如 `clichesList` 之类的资源,然后可以通过数据库事务来管理安全并发。
|
||||
|
||||
The crud app takes the recommended Go approach to safe concurrency:
|
||||
crud 应用程序采用推荐的Go方法来实现安全并发:
|
||||
|
||||
* Only a single goroutine, the resource manager started in the crud app `startServer` function, has access to the `clichesList` once the web server starts listening for requests.
|
||||
* The request handlers such as `ClichesCreate` and `ClichesAll` send a (pointer to) a `crudRequest` instance to a Go channel (thread-safe by default), and the resource manager alone reads from this channel. The resource manager then performs the requested operation on the `clichesList`.
|
||||
* 只有一个 goroutine,资源管理器在 crud app`startServer` 函数中启动,一旦 Web 服务器开始侦听请求,就可以访问 `clichesList`。
|
||||
* 诸如 `ClichesCreate` 和 `ClichesAll` 之类的请求处理程序向 Go 通道发送(指向)`crudRequest` 实例(默认情况下是线程安全的),并且资源管理器单独从该通道读取。 然后,资源管理器对 `clichesList` 执行请求的操作。
|
||||
|
||||
安全并发体系结构绘制如下:
|
||||
|
||||
|
||||
The safe-concurrency architecture can be sketched as follows:
|
||||
```
|
||||
crudRequest read/write
|
||||
crudRequest 读/写
|
||||
|
||||
request handlers------------->resource manager------------>clichesList
|
||||
请求处理程序 -------------> 资源托管者 ------------> 陈词滥调列表
|
||||
|
||||
```
|
||||
|
||||
With this architecture, no explicit locking of the `clichesList` is needed because only one goroutine, the resource manager, accesses the `clichesList` once CRUD requests start coming in.
|
||||
在这种架构中,不需要显式锁定 `clichesList`,因为一旦 CRUD 请求开始进入,只有一个 goroutine(资源管理器)访问 `clichesList`。
|
||||
|
||||
为了使 crud 应用程序尽可能保持并发,在一方请求处理程序与另一方的单一资源管理器之间进行有效的分工至关重要。 在这里,为了审查,是 `ClichesCreate` 请求处理程序:
|
||||
|
||||
To keep the crud app as concurrent as possible, it’s essential to have an efficient division of labor between the request handlers, on the one side, and the single resource manager, on the other side. Here, for review, is the `ClichesCreate` request handler:
|
||||
```
|
||||
func ClichesCreate(res http.ResponseWriter, req *http.Request) {
|
||||
|
||||
@ -612,42 +618,40 @@ func ClichesCreate(res http.ResponseWriter, req *http.Request) {
|
||||
}ClichesCreateres httpResponseWriterreqclichecountergetDataFromRequestreqcpclichePaircpClicheclichecpCountercountercr&crudRequestverbPOSTcpcpconfirmcompleteRequestcrres
|
||||
|
||||
```
|
||||
`ClichesCreate` 调用实用函数 `getDataFromRequest`,它从 POST 请求中提取新的陈词滥调和反陈词滥调。 然后 `ClichesCreate` 函数创建一个新的 `ClichePair`,设置两个字段,并创建一个 `crudRequest` 发送给单个资源管理器。 此请求包括一个确认通道,资源管理器使用该通道将信息返回给请求处理程序。 所有设置工作都可以在不涉及资源管理器的情况下完成,因为尚未访问 `clichesList`。
|
||||
|
||||
`ClichesCreate` calls the utility function `getDataFromRequest`, which extracts the new cliche and counter-cliche from the POST request. The `ClichesCreate` function then creates a new `ClichePair`, sets two fields, and creates a `crudRequest` to be sent to the single resource manager. This request includes a confirmation channel, which the resource manager uses to return information back to the request handler. All of the setup work can be done without involving the resource manager because the `clichesList` is not being accessed yet.
|
||||
请求处理程序调用实用程序函数,该函数从 POST 请求中提取新的陈词滥调和反陈词滥调。 然后,该函数创建一个新的,设置两个字段,并创建 ato 发送到单个资源管理器。 此请求包括一个确认通道,资源管理器使用该通道将信息返回给请求处理程序。 所有设置工作都可以在不涉及资源管理器的情况下完成,因为尚未访问它。
|
||||
|
||||
The request handlercalls the utility function, which extracts the new cliche and counter-cliche from the POST request. Thefunction then creates a new, sets two fields, and creates ato be sent to the single resource manager. This request includes a confirmation channel, which the resource manager uses to return information back to the request handler. All of the setup work can be done without involving the resource manager because theis not being accessed yet.
|
||||
|
||||
The `completeRequest` utility function called at the end of the `ClichesCreate` function and the other request handlers
|
||||
`completeRequest` 实用程序函数在 `ClichesCreate` 函数和其他请求处理程序的末尾调用
|
||||
```
|
||||
completeRequest(cr, res, "create") // shown above
|
||||
|
||||
```
|
||||
|
||||
brings the resource manager into play by putting a `crudRequest` into the `crudRequests` channel:
|
||||
通过将 `crudRequest` 放入 `crudRequests` 频道,使资源管理器发挥作用:
|
||||
```
|
||||
func completeRequest(cr *crudRequest, res http.ResponseWriter, logMsg string) {
|
||||
|
||||
crudRequests<-cr // send request to resource manager
|
||||
crudRequests<-cr // 向资源托管者发送请求
|
||||
|
||||
msg := <-cr.confirm // await confirmation string
|
||||
msg := <-cr.confirm // 等待确认
|
||||
|
||||
res.Write([]byte(msg)) // send confirmation back to requester
|
||||
res.Write([]byte(msg)) // 向请求方发送确认
|
||||
|
||||
logIt(logMsg) // print to the standard output
|
||||
logIt(logMsg) // 打印到标准输出
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
For a POST request, the resource manager calls the utility function `addPair`, which changes the `clichesList` resource:
|
||||
对于 POST 请求,资源管理器调用实用程序函数 `addPair`,它会更改 `clichesList` 资源:
|
||||
```
|
||||
func addPair(cp *clichePair) string {
|
||||
|
||||
cp.Id = masterId // assign a unique ID
|
||||
cp.Id = masterId // 分配一个唯一的 ID
|
||||
|
||||
masterId++ // update the ID counter
|
||||
masterId++ // 更新 ID 计数器
|
||||
|
||||
clichesList = append(clichesList, cp) // update the list
|
||||
clichesList = append(clichesList, cp) // 更新列表
|
||||
|
||||
return "\nCreated: " + cp.Cliche + " " + cp.Counter + "\n"
|
||||
|
||||
@ -655,9 +659,9 @@ func addPair(cp *clichePair) string {
|
||||
|
||||
```
|
||||
|
||||
The resource manager calls similar utility functions for the other CRUD operations. It’s worth repeating that the resource manager is the only goroutine to read or write the `clichesList` once the web server starts accepting requests.
|
||||
资源管理器为其他CRUD操作调用类似的实用程序函数。 值得重复的是,一旦 Web 服务器开始接受请求,资源管理器就是唯一可以读取或写入 `clichesList` 的 goroutine。
|
||||
|
||||
For web applications of any type, the `gorilla/mux` package provides request routing, request validation, and related services in a straightforward, intuitive API. The crud web app highlights the package’s main features. Give the package a test drive, and you’ll likely be a buyer.
|
||||
对于任何类型的 Web 应用程序,`gorilla/mux` 包在简单直观的API中提供请求路由,请求验证和相关服务。 crud web 应用程序突出了软件包的主要功能。 给包裹一个测试驱动,你可能会成为买主。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -665,7 +669,7 @@ via: https://opensource.com/article/18/8/http-request-routing-validation-gorilla
|
||||
|
||||
作者:[Marty Kalin][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,119 +0,0 @@
|
||||
存档网站
|
||||
======
|
||||
|
||||
我最近深入研究了网站存档,因为有些朋友担心遇到糟糕的系统管理或恶意入侵时失去对在线托管的工作的控制。这使得网站存档成为任意系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难存档。本文介绍了对传统网站进行存档的过程,并阐述在面对最新流行的单页面应用程序的现代网站时,它有哪些不足。
|
||||
|
||||
### 转换为简单网站
|
||||
|
||||
手动开发 HTML 网站的日子早已不复存在。现在的网站是动态的,并使用最新的 JavaScript,PHP 或 Python 框架即时构建。结果,这些网站更加脆弱:数据库崩溃,升级出错或者未修复的漏洞都可能使数据丢失。在我以前是一名 Web 开发人员时,我不得不接受客户希望网站基本上可以永久工作的想法。这种期望与 web 开发“快速行动和破除陈规”的理念不相符。在这方面,使用 [Drupal][2] 内容管理系统(CMS)尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担的起高昂的升级成本。解决方案是将这些网站存档:以实时动态的网站为基础,将其转换为任何 web 服务器可以永久服务的纯 HTML 文件。此过程对你自己的动态网站非常有用,也适用于你想保护但无法控制的第三方网站。
|
||||
|
||||
对于简单的静态网站,古老的 [Wget][3] 程序就可以胜任。然而,镜像保存一个完整页面的方法,虽然复杂但很固定:
|
||||
|
||||
```
|
||||
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
|
||||
--backup-converted --page-requisites --adjust-extension \
|
||||
--base=./ --directory-prefix=./ --span-hosts \
|
||||
--domains=www.example.com,example.com http://www.example.com/
|
||||
|
||||
```
|
||||
|
||||
以上命令下载了网页的内容,但也抓取了指定域名中的所有内容。在对你喜欢的网站执行此操作之前,请考虑此类抓取可能对网站产生的影响。上面的命令故意忽略了 `robots.txt` 规则,就像现在[档案管理者的习惯做法][4],并尽可能快的存档网站。大多数抓取工具都可以选择点击暂停并限制带宽使用,以避免使网站瘫痪。
|
||||
|
||||
上面的命令还将获取 “page requisites(译者注:单页面所需的所有元素)”,像样式表(CSS),图像和脚本等。下载的页面内容将会被修改,以便链接也指向本地副本。任意 web 服务器均可托管生成的文件集,从而生成原始网站的静态副本。
|
||||
|
||||
以上所述是事情一切顺利的时候。任意使用过计算机的人都知道事情的进展很少如计划那样;各种各样的事情可以使程序以有趣的方式脱离正规。比如,在网站上有一个日历块很流行。内容管理系统会动态生成这些内容,这会使爬虫程序陷入死循环以尝试检索所有页面。灵巧的存档者可以使用正则表达式(例如 Wget 有一个 `--reject-regex` 选项)来忽略有问题的资源。如果可以访问网站的管理界面,另一个方法是禁用日历、登录表单、评论表单和其他动态区域。一旦网站变成静态的,(那些动态区域)也肯定会停止工作,因此从原始网站中移除这些杂乱的东西也不是全无意义。
|
||||
|
||||
### JavaScript 的厄运
|
||||
|
||||
很不幸,有些网站不仅仅是纯 HTML 文件构建的。比如,在单页面网站中,web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将难以重建这些网站的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用[渐进增强][5]技术,在不使用 JavaScript 的情况下提供内容和实现功能,但这些指示很少被遵循,因为使用 [NoScript][6] 或 [uMatrix][7] 等插件的人都很确定。
|
||||
|
||||
传统的存档方法有时是最愚蠢的方式,会导致失败。在尝试为一个本地报纸网站([pamplemousse.ca][8])创建备份时,我发现 WordPress 在末尾包含 JavaScript,且添加了查询字符串(例如:`?ver=1.12.4`)。这会使提供存档服务的 web 服务器不能正确进行内容类型检测,因为其靠文件扩展名来发送正确的 `Content-Type` 头部信息。在 web 浏览器加载此类存档时,这些脚本将无法加载,导致动态网站受损。
|
||||
|
||||
随着 web 向使用浏览器作为虚拟机执行任意代码转化,依赖于纯 HTML 文件解析的存档方法也需要随之适应。这个问题的解决方案是在抓取时记录(以及重现)服务器提供的 HTTP 头部信息,实际上专业的档案管理者就使用这种方法。
|
||||
|
||||
### 创建和显示 WARC 文件Creating and displaying WARC files
|
||||
|
||||
在 [Internet Archive][9] 网站,Brewster Kahle 和 Mike Burner 在 1996 年设计了 [ARC][10] (用于 "ARChive")文件格式,以提供一种聚合档案工作产生的百万个小文件的方法。该格式最终标准化为 WARC(“Web ARChive”)[规范][11],并在 2009 年作为 ISO 标准发布,2017 年修订。标准化工作由[国际互联网保护联盟][12](IIPC)领导,据维基百科称,这是一个“为共同保护未来互联网内容而建立的图书馆和国际组织”;它有美国国会图书馆和互联网档案馆等成员。后者内部在其基于 Java 的 [Heritrix crawler][13](译者注:一种爬虫程序)上使用 WARC 格式。
|
||||
|
||||
WARC 在单个压缩文件中聚合了多种资源,像 HTTP 头部信息,文件内容,以及其他元数据。方便的是实际上 Wget 提供了 `--warc` 参数来支持 WARC 格式。不幸的是 web 浏览器不能直接显示 WARC 文件,所以为了访问存档文件,一个查看器或某些格式转换是很有必要的。我所发现的最简单的查看器是 [pywb][14],它以 Python 包的形式运行一个简单的 web 服务器提供一个像网站时光倒流机网站的界面,来浏览 WARC 文件的内容。执行以下命令将会在 `http://localhost:8080/` 地址显示 WARC 文件的内容:
|
||||
|
||||
```
|
||||
$ pip install pywb
|
||||
$ wb-manager init example
|
||||
$ wb-manager add example crawl.warc.gz
|
||||
$ wayback
|
||||
|
||||
```
|
||||
|
||||
顺便说一句,这个工具是由 [Webrecorder][15] 服务提供者建立的,Webrecoder 服务可以使用 web 浏览器保存动态页面的内容。
|
||||
|
||||
很不幸,pywb 无法加载 Wget 生成的 WARC 文件,因为它[遵循][16][不一致的 1.0 规范][17],[1.1 规范修复了此问题][17]。就算 Wget 或 pywb 修复了这些问题,Wget 生成的 WARC 文件对我的使用来说不够可靠,所以我找了其他的替代品。引起我注意的爬虫程序简称 [crawl][19]。以下是它的调用方式:
|
||||
|
||||
```
|
||||
$ crawl https://example.com/
|
||||
|
||||
```
|
||||
|
||||
(它的 README 文件说“非常简单”。)该程序确实支持一些命令行参数选项,但大多数默认值都是最佳的:它会从其他域获取页面需求(除非使用 `-exclude-related` 参数),但肯定不会递归出域。默认情况下,它会与远程站点建立十个并发连接,这个值可以使用 `-c` 参数更改。但是,最重要的是,生成的 WARC 文件可以使用 pywb 完美加载。
|
||||
|
||||
### 未来的工作和替代方案
|
||||
|
||||
这里还有更多有关使用 WARC 文件的[资源][20]。特别要提的是,这里有一个专门用来存档网站的 Wget 的直接替代品,叫做 [Wpull][21]。它实验性地支持了 [PhantomJS][22] 和 [youtube-dl][23] 的集成,即允许分别下载更复杂的 JavaScript 页面以及流媒体。该程序是一个叫做 [ArchiveBot][24] 的复杂档案工具的基础,ArchiveBot 被那些在 [ArchiveTeam][25] 的“零散离群的档案管理者、程序员、作家以及演说家”使用,他们致力于“在历史永远丢失之前保存他们”。集成 PhantomJS 好像并没有如团队期望的那样良好工作,所以 ArchiveTeam 也用其他的低等工具来镜像保存更复杂的网站。例如,[snscrape][26] 将抓取社交媒体配置文件以生成要发送到 ArchiveBot 的页面列表。团队使用的另一个工具是 [crocoite][27],它在 Chrome 浏览器下以无头文件信息的模式来存档 JavaScript 较多的网站。
|
||||
|
||||
如果没有提到称做“网站复制者”的 [HTTrack][28] 项目,那么这篇文章算不上完整。工作方式和 Wget 相似,HTTrack 可以对远程站点创建一个本地的副本,但是不幸的是它不支持输出 WRAC 文件。对于不熟悉命令行的小白用户来说,它在人机交互方面显得更有价值。
|
||||
|
||||
同样,在我的研究中,我发现了叫做 [Wget2][29] 的 Wget 的完全重制版本,它支持多线程操作,这可能使它比前身更快。和 Wget 相比,它[舍弃了一些功能][30],但是最值得注意的是拒绝模式、WARC 输出以及 FTP 支持,并增加了 RSS、DNS 缓存以及改进的 TLS 支持。
|
||||
|
||||
最后,我个人对这些工具的愿景是将他们与现有的书签系统集成起来。目前我在 [Wallabag][31] 中保留了一些有趣的链接,这是一种自托管式的“稍后阅读”服务,意在成为 [Pocket][32](现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 在设计上只保留了文章的“可读”副本,而不是一个完整的拷贝。在某些情况下,“可读版本”实际上[不可读][33],并且 Wallabag 有时[无法解析文章][34]。恰恰相反,像 [bookmark-archiver][35] 或 [reminiscence][36] 这样其他的工具会保存页面的屏幕截图以及完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件所以没有办法更可信的重现网页内容。
|
||||
|
||||
我所经历的有关镜像保存和存档的悲剧就是死数据。幸运的是,业余档案管理者可以利用工具将有趣的内容保存到网上。对于那些不想麻烦的人来说,互联网档案馆依然要留在这里,并且存档团队显然[正在为互联网档案馆本身做备份][37]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-10-04-archiving-web-sites/
|
||||
|
||||
作者:[Anarcat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://anarc.at
|
||||
[1]: https://anarc.at/blog
|
||||
[2]: https://drupal.org
|
||||
[3]: https://www.gnu.org/software/wget/
|
||||
[4]: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
|
||||
[5]: https://en.wikipedia.org/wiki/Progressive_enhancement
|
||||
[6]: https://noscript.net/
|
||||
[7]: https://github.com/gorhill/uMatrix
|
||||
[8]: https://pamplemousse.ca/
|
||||
[9]: https://archive.org
|
||||
[10]: http://www.archive.org/web/researcher/ArcFileFormat.php
|
||||
[11]: https://iipc.github.io/warc-specifications/
|
||||
[12]: https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium
|
||||
[13]: https://github.com/internetarchive/heritrix3/wiki
|
||||
[14]: https://github.com/webrecorder/pywb
|
||||
[15]: https://webrecorder.io/
|
||||
[16]: https://github.com/webrecorder/pywb/issues/294
|
||||
[17]: https://github.com/iipc/warc-specifications/issues/23
|
||||
[18]: https://github.com/iipc/warc-specifications/pull/24
|
||||
[19]: https://git.autistici.org/ale/crawl/
|
||||
[20]: https://archiveteam.org/index.php?title=The_WARC_Ecosystem
|
||||
[21]: https://github.com/chfoo/wpull
|
||||
[22]: http://phantomjs.org/
|
||||
[23]: http://rg3.github.io/youtube-dl/
|
||||
[24]: https://www.archiveteam.org/index.php?title=ArchiveBot
|
||||
[25]: https://archiveteam.org/
|
||||
[26]: https://github.com/JustAnotherArchivist/snscrape
|
||||
[27]: https://github.com/PromyLOPh/crocoite
|
||||
[28]: http://www.httrack.com/
|
||||
[29]: https://gitlab.com/gnuwget/wget2
|
||||
[30]: https://gitlab.com/gnuwget/wget2/wikis/home
|
||||
[31]: https://wallabag.org/
|
||||
[32]: https://getpocket.com/
|
||||
[33]: https://github.com/wallabag/wallabag/issues/2825
|
||||
[34]: https://github.com/wallabag/wallabag/issues/2914
|
||||
[35]: https://pirate.github.io/bookmark-archiver/
|
||||
[36]: https://github.com/kanishka-linux/reminiscence
|
||||
[37]: http://iabak.archiveteam.org
|
||||
@ -1,147 +0,0 @@
|
||||
如何在 Python 中写你喜爱的 R 函数
|
||||
======
|
||||
R 还是 Python ? 这个 Python 脚本模仿方便的 R 风格函数,使统计数据变得简单易行。
|
||||
|
||||

|
||||
|
||||
“Python vs. R” 是数据科学和机器学习的现代战争之一。毫无疑问,近年来两者发展迅猛并成为数据科学,预测分析和机器学习领域的顶级编程语言。事实上,根据 IEEE 最近一篇文章,Python 已在 [最受欢迎编程语言排行榜][1] 中超越 C++ 并且 R 语言也稳居前 10 位。
|
||||
|
||||
但是,这两者之间存在一些根本区别。[R] 主要作为统计分析和数据分析问题的快速原型设计的工具而开发的。另一方面,Python 开发为一种通用的,现代的面向对象语言,类似 C++ 或 Java,但具有更简单的学习曲线和更灵活的语言风格。因此,R 仍在统计学家,定量生物学家,物理学家和经济学家中备受青睐,而 Python 已逐渐成为日常脚本,自动化,后端Web开发,分析和通用机器学习框架的顶级语言并拥有广泛的支持基础和开源开发社区。
|
||||
|
||||
###在 Python 环境中模仿函数式编程
|
||||
|
||||
[R] 作为函数式编程语言的天性为用户提供了一个极其简单和紧凑的借口,用于快速计算概率和数据分析问题的基本描述/推论统计。例如,只用一个紧凑的函数调用来解决以下问题难道不是很好吗?
|
||||
|
||||
* 如何计算数据向量的均值 / 中值 / 众数。
|
||||
* 如何计算某些服从正态分布事件的累积概率。如果服从 Poisson 分布会怎样?
|
||||
* 如何计算一系列数据点的四分差。
|
||||
* 如何生成服从学生 t 分布的一些随机数。
|
||||
|
||||
R编程环境可以完成所有这些工作。
|
||||
|
||||
另一方面,Python的脚本编写能力使分析师能够在各种分析流程中使用这些统计数据,具有无限的复杂性和创造力。
|
||||
|
||||
要结合二者的优势,您只需要一个简单的基于 Python 的包装器库,其中包含与 R 风格定义的概率分布和描述性统计相关的最常用函数。 这使您可以非常快速地调用这些函数,而无需转到正确的 Python 统计库并理解整个方法和参数列表。
|
||||
|
||||
|
||||
### 便于调用 R 函数的 Python 包装脚本
|
||||
|
||||
[我编写了一个Python脚本] [4] 在 Python 中定义了简单统计分析中方便广泛使用的 R 函数。
|
||||
|
||||
此脚本的目标是提供简单的 Python 子例程,模仿 R 风格的统计函数,以快速计算密度/点估计,累积分布和分位数,并生成重要概率分布的随机变量。
|
||||
|
||||
为了保持 R 风格的精髓,脚本不使用类层次结构,并且只在文件中定义原始函数。 因此,用户可以导入这个 Python 脚本,并在需要单个名称调用时使用所有功能。
|
||||
|
||||
请注意,我使用 mimic 这个词。 在任何情况下,我都声称要模仿 R 的真正的函数式编程范例,该范式包括深层环境设置以及这些环境和对象之间的复杂关系。 这个脚本允许我(我希望无数其他 Python 用户)快速启动P ython 程序或 Jupyter 笔记本,导入脚本,并立即开始进行简单的描述性统计。 这就是目标,仅此而已。
|
||||
|
||||
如果您已经写过 R 代码(可能在研究生院)并且刚刚开始学习并使用 Python 进行数据分析,那么您将很高兴看到并在 Jupyter 笔记本中以类似在 R 环境中一样使用一些相同的知名函数。
|
||||
|
||||
无论出于何种原因,使用这个脚本很有趣。
|
||||
|
||||
### 简单的例子
|
||||
|
||||
首先,只需导入脚本并开始处理数字列表,就好像它们是 R 中的数据向量一样。
|
||||
|
||||
```
|
||||
from R_functions import *
|
||||
lst=[20,12,16,32,27,65,44,45,22,18]
|
||||
<more code, more statistics...>
|
||||
```
|
||||
|
||||
假设您想从数据点向量计算[Tuckey五数] [5]摘要。 你只需要调用一个简单的函数 ** fivenum **,然后传递向量。 它将返回 NumPy 数组中的五数摘要。
|
||||
|
||||
```
|
||||
lst=[20,12,16,32,27,65,44,45,22,18]
|
||||
fivenum(lst)
|
||||
> array([12. , 18.5, 24.5, 41. , 65. ])
|
||||
```
|
||||
|
||||
或许你想要知道下面问题的解答
|
||||
|
||||
假设一台机器平均每小时输出 10 件成品,标准偏差为 2。输出模式遵循接近正态的分布。 机器在下一个小时内输出至少 7 个但不超过 12 个单位的概率是多少?
|
||||
|
||||
答案基本上是这样的:
|
||||
|
||||

|
||||
|
||||
您可以使用 **pnorm** 只用一行代码获得答案:
|
||||
|
||||
```
|
||||
pnorm(12,10,2)-pnorm(7,10,2)
|
||||
> 0.7745375447996848
|
||||
```
|
||||
或者您可能需要回答以下问题:
|
||||
|
||||
假设你有一个不正的硬币,每次投它时有 60% 可能正面朝上。 你正在玩10次投掷游戏。 你如何绘制并给出这枚硬币所有可能的胜利数(从0到10)?
|
||||
|
||||
只需使用一个函数 **dbinom** 就可以获得一个只有几行代码的漂亮条形图:
|
||||
|
||||
```
|
||||
probs=[]
|
||||
import matplotlib.pyplot as plt
|
||||
for i in range(11):
|
||||
probs.append(dbinom(i,10,0.6))
|
||||
plt.bar(range(11),height=probs)
|
||||
plt.grid(True)
|
||||
plt.show()
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 简单概率计算接口
|
||||
|
||||
R 提供了一个非常简单直观的界面,可以从基本概率分布中快速计算。 接口如下:
|
||||
|
||||
* **d** {distribution} 给出点 **x** 处的密度函数值
|
||||
* **p** {distribution} 给出 **x**点的累积值
|
||||
* **q** {distribution} 以概率 **p**给出分位数函数值
|
||||
* **r** {distribution} 生成一个或多个随机变量
|
||||
|
||||
在我们的实现中,我们坚持使用此接口及其关联的参数列表,以便您可以像在 R 环境中一样执行这些函数。
|
||||
|
||||
### 目前实现的函数
|
||||
|
||||
脚本中实现了以下R风格函数,以便快速调用。
|
||||
|
||||
* 均值,中位数,方差,标准差
|
||||
* Tuckey 五数总结,IQR
|
||||
* 矩阵的协方差或两个向量之间的协方差
|
||||
* 以下分布的密度,累积概率,分位数函数和随机变量生成:正态,均匀,二项式,泊松,F,学生t,卡方,β和伽马
|
||||
|
||||
### 进行中的工作
|
||||
|
||||
显然,这是一项正在进行的工作,我计划在此脚本中添加一些其他方便的R函数。 例如,在 R 中,单行命令 ** lm ** 可以为数字数据集提供一个普通的最小二乘拟合模型,其中包含所有必要的推理统计量(P 值,标准误差等)。 这是有力的简洁和紧凑! 另一方面,Python 中的标准线性回归问题经常使用 [Scikit-learn] [6] 来处理,这需要更多的脚本用于此用途,所以我打算使用 Python 的 [statsmodels] 合并这个单函数线性模型拟合特征 [7]后端。
|
||||
|
||||
如果您喜欢并在工作中使用此脚本,请通过主演或分析其 [GitHub存储库] [8]帮助其他人找到它。 另外,您可以查看我的其他 [GitHub repos] [9],了解 Python,R 或 MATLAB 中的有趣代码片段以及一些机器学习资源。
|
||||
|
||||
如果您有任何问题或想法要分享,请通过 [tirthajyoti [AT] gmail.com] [10]与我联系。 如果你像我一样热衷于机器学习和数据科学,请 [加我在LinkedIn] [11]或[在Twitter上关注我。] [12]
|
||||
|
||||
最初发表于[走向数据科学] [13]。 转载于[CC BY-SA 4.0] [14]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/write-favorite-r-functions-python
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://spectrum.ieee.org/at-work/innovation/the-2018-top-programming-languages
|
||||
[2]: https://www.coursera.org/lecture/r-programming/overview-and-history-of-r-pAbaE
|
||||
[3]: http://adv-r.had.co.nz/Functional-programming.html
|
||||
[4]: https://github.com/tirthajyoti/StatsUsingPython/blob/master/R_Functions.py
|
||||
[5]: https://en.wikipedia.org/wiki/Five-number_summary
|
||||
[6]: http://scikit-learn.org/stable/
|
||||
[7]: https://www.statsmodels.org/stable/index.html
|
||||
[8]: https://github.com/tirthajyoti/StatsUsingPython
|
||||
[9]: https://github.com/tirthajyoti?tab=repositories
|
||||
[10]: mailto:tirthajyoti@gmail.com
|
||||
[11]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[12]: https://twitter.com/tirthajyotiS
|
||||
[13]: https://towardsdatascience.com/how-to-write-your-favorite-r-functions-in-python-11e1e9c29089
|
||||
[14]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
@ -0,0 +1,339 @@
|
||||
|
||||
Openstack 30个经典面试问题和解答
|
||||
======
|
||||
|
||||
现在,大多数公司都试图将它们的 IT 基础设施和 Telco Infra 迁移到私有云,即OpenStack。如果你打算面试 OpenStack 管理员这个岗位,那么下面列出的这些面试问题可能会帮助你通过面试。
|
||||
|
||||

|
||||
|
||||
### Q:1 说一下 OpenStack 及其主要组件?
|
||||
|
||||
Ans: OpenStack 是一系列开源软件,这些软件组成了一个云提供软件,也就是 OpenStack,被称为开源软件或项目栈。
|
||||
|
||||
下面是 OpenStack 的主要关键组件:
|
||||
|
||||
* **Nova** – 用于计算级别管理虚拟机,并在计算或管理程序级别执行其他计算任务。
|
||||
* **Neutron** – 为虚拟机、计算和控制节点提供网络功能。
|
||||
* **Keystone** – 为所有云用户和 OpenStack 云服务提供身份认证服务。换句话说,我们可以说 Keystone 是一个提供给云用户和云服务访问权限的方法。
|
||||
* **Horizon** – 用于提供图形用户界面。使用图形化管理界面可以很轻松地完成各种日常操作任务。
|
||||
* **Cinder** – 用于提供块存储功能。通常来说 OpenStack 的 Cinder 中集成了 Chef 和 ScaleIO 来共同为计算和控制节点提供块存储服务。
|
||||
* **Swift** – 用于提供对象存储功能。通常来说,Glance 管理的镜像是存储在对象存储空间的。扩展存储就像 ScaleIO 也可以提供对象存储,可以很容易的集成 Glance 服务。
|
||||
* **Glance** – 用于提供镜像服务。使用 Glance 的管理平台来上传和下载云镜像。
|
||||
* **Heat** – 用于提供编排服务或功能。使用 Heat 管理平台可以轻松地将虚拟机作为堆栈,并且根据需要可以将虚拟机扩展或收缩。
|
||||
* **Ceilometer** – 用于提供计量与监控功能。
|
||||
|
||||
|
||||
|
||||
### Q:2 什么服务通常在控制节点上运行?
|
||||
|
||||
Ans: 以下服务通常在控制节点上运行:
|
||||
|
||||
* 认证服务 ( KeyStone)
|
||||
* 镜像服务 ( Glance)
|
||||
* Nova 服务比如 Nova API, Nova Scheduler 和 Nova DB
|
||||
* 块存储和对象存储服务
|
||||
* Ceilometer 服务
|
||||
* MariaDB / MySQL 和 RabbitMQ 服务
|
||||
* 网络(Neutron)和网络代理的管理服务
|
||||
* 编排服务 (Heat)
|
||||
|
||||
|
||||
|
||||
### Q:3 什么服务通常在计算节点上运行?
|
||||
|
||||
Ans: 以下服务通常在计算节点运行:
|
||||
|
||||
* Nova 计算
|
||||
* 网络服务,比如 OVS
|
||||
|
||||
|
||||
|
||||
### Q:4 计算节点上虚拟机的默认地址是什么?
|
||||
|
||||
Ans: 虚拟机存储在计算节点的 “ **/var/lib/nova/instances** ”
|
||||
|
||||
### Q:5 Glance 镜像的默认地址是什么?
|
||||
|
||||
Ans: 因为Glance 服务运行在控制节点上,所以 Glance 镜像都被存储在控制节点的“ **/var/lib/glance/images** ”文件夹下。
|
||||
|
||||
想了解更多请访问 : [**在 OpenStack 中如何使用命令行创建和删除虚拟机**][1]
|
||||
|
||||
### Q:6 说一下如何使用命令行启动一个虚拟机?
|
||||
|
||||
Ans: 我们可以使用如下 OpenStack 命令来启动一个新的虚拟机:
|
||||
|
||||
```
|
||||
# openstack server create --flavor {flavor-name} --image {Image-Name-Or-Image-ID} --nic net-id={Network-ID} --security-group {Security_Group_ID} –key-name {Keypair-Name} <VM_Name>
|
||||
```
|
||||
|
||||
### Q:7 如何在 OpenStack 中显示用户的网络命名空间列表?
|
||||
|
||||
Ans: 可以使用 “ip net ns” 命令来列出用户的网络命名空间。
|
||||
|
||||
```
|
||||
~# ip netns list
|
||||
qdhcp-a51635b1-d023-419a-93b5-39de47755d2d
|
||||
haproxy
|
||||
vrouter
|
||||
```
|
||||
|
||||
### Q:8 如何在 OpenStack 中执行网络命名空间内的命令?
|
||||
|
||||
Ans: 假设我们想在 “qdhcp-a51635b1-d023-419a-93b5-39de47755d2d” 网络命名空间中执行 “ifconfig” 命令,我们可以执行如下命令。
|
||||
|
||||
命令格式 : ip netns exec {network-space} <command>
|
||||
|
||||
```
|
||||
~# ip netns exec qdhcp-a51635b1-d023-419a-93b5-39de47755d2d "ifconfig"
|
||||
```
|
||||
|
||||
### Q:9 在 Glance 服务中如何使用命令行上传和下载镜像?
|
||||
|
||||
Ans: Glance 服务中云镜像上传可以使用如下 OpenStack 命令:
|
||||
|
||||
```
|
||||
~# openstack image create --disk-format qcow2 --container-format bare --public --file {Name-Cloud-Image}.qcow2 <Cloud-Image-Name>
|
||||
```
|
||||
|
||||
下载云镜像则使用如下命令:
|
||||
|
||||
```
|
||||
~# glance image-download --file <Cloud-Image-Name> --progress <Image-ID>
|
||||
```
|
||||
|
||||
### Q:10 OpenStack 如何将虚拟机从错误状态转换为活动状态?
|
||||
|
||||
Ans: 在某些情况下虚拟机可能会进入错误状态,可以使用如下命令将错误状态转换为活动状态:
|
||||
|
||||
```
|
||||
~# nova reset-state --active {Instance_id}
|
||||
```
|
||||
|
||||
### Q:11 如何使用命令行来获取可使用的浮动 IP 列表?
|
||||
|
||||
Ans: 可使用如下命令来显示可用浮动 IP 列表:
|
||||
|
||||
```
|
||||
~]# openstack ip floating list | grep None | head -10
|
||||
```
|
||||
|
||||
### Q:12 如何在特定可用区域中或在计算主机上配置虚拟机?
|
||||
|
||||
Ans: 假设我们想在 compute-02 中的可用区 NonProduction 上配置虚拟机,可以使用如下命令:
|
||||
|
||||
```
|
||||
~]# openstack server create --flavor m1.tiny --image cirros --nic net-id=e0be93b8-728b-4d4d-a272-7d672b2560a6 --security-group NonProd_SG --key-name linuxtec --availability-zone NonProduction:compute-02 nonprod_testvm
|
||||
```
|
||||
|
||||
### Q:13 如何在特定计算节点上获取配置的虚拟机列表?
|
||||
|
||||
Ans: 假设我们想要获取在 compute-0-19 中配置的虚拟机列表,可以使用如下命令:
|
||||
|
||||
命令格式: openstack server list –all-projects –long -c Name -c Host | grep -i {Compute-Node-Name}
|
||||
|
||||
```
|
||||
~# openstack server list --all-projects --long -c Name -c Host | grep -i compute-0-19
|
||||
```
|
||||
|
||||
### Q:14 如何使用命令行查看 OpenStack 实例的打印信息?
|
||||
|
||||
Ans: 使用如下命令可查看实例的命令行打印信息:
|
||||
|
||||
首先获取实例的 ID,然后使用如下命令:
|
||||
|
||||
```
|
||||
~# openstack console log show {Instance-id}
|
||||
```
|
||||
|
||||
### Q:15 如何获取 OpenStack 实例的控制台的 URL 地址?
|
||||
|
||||
Ans: 可以使用以下 OpenStack 命令从命令行检索实例的控制台 URL 地址:
|
||||
|
||||
```
|
||||
~# openstack console url show {Instance-id}
|
||||
```
|
||||
|
||||
### Q:16 如何使用命令行创建可启动的 cinder / block 存储卷?
|
||||
|
||||
Ans: 假设创建一个 8GB 可启动存储卷,可参考如下步骤:
|
||||
|
||||
* 使用如下命令获取镜像列表
|
||||
|
||||
|
||||
|
||||
```
|
||||
~# openstack image list | grep -i cirros
|
||||
| 89254d46-a54b-4bc8-8e4d-658287c7ee92 | cirros | active |
|
||||
```
|
||||
|
||||
* 使用 cirros 镜像创建 8GB 的可启动存储卷
|
||||
|
||||
|
||||
|
||||
```
|
||||
~# cinder create --image-id 89254d46-a54b-4bc8-8e4d-658287c7ee92 --display-name cirros-bootable-vol 8
|
||||
```
|
||||
|
||||
### Q:17 如何列出所有在你的 OpenStack 中创建的项目或用户?
|
||||
|
||||
Ans: 可以使用如下命令来检索所有项目和用户:
|
||||
|
||||
```
|
||||
~# openstack project list --long
|
||||
```
|
||||
|
||||
### Q:18 如何显示 OpenStack 服务端点列表?
|
||||
|
||||
Ans: OpenStack 服务端点被分为 3 类:
|
||||
|
||||
* 公共端点
|
||||
* 内部端点
|
||||
* 管理端点
|
||||
|
||||
|
||||
|
||||
使用如下 OpenStack 命令来查看各种 OpenStack 服务端点:
|
||||
|
||||
```
|
||||
~# openstack catalog list
|
||||
```
|
||||
|
||||
可通过以下命令来显示特定服务端点(比如说 keystone)列表:
|
||||
|
||||
```
|
||||
~# openstack catalog show keystone
|
||||
```
|
||||
|
||||
想了解更多请访问 : [**OpenStack 中的实例创建流程**][2]
|
||||
|
||||
### Q:19 在控制节点上你应该按照什么步骤来重启 nova 服务?
|
||||
|
||||
Ans: 应该按照如下步骤来重启 OpenStack 控制节点的 nova 服务:
|
||||
|
||||
* service nova-api restart
|
||||
* service nova-cert restart
|
||||
* service nova-conductor restart
|
||||
* service nova-consoleauth restart
|
||||
* service nova-scheduler restart
|
||||
|
||||
|
||||
|
||||
### Q:20 假如计算节点上为数据流量配置了一些 DPDK 端口,你如何检查 DPDK 端口的状态呢?
|
||||
|
||||
Ans: 因为我们使用 openvSwitch (OVS) 来配置 DPDK 端口,因此可以使用如下命令来检查端口的状态:
|
||||
|
||||
```
|
||||
root@compute-0-15:~# ovs-appctl bond/show | grep dpdk
|
||||
active slave mac: 90:38:09:ac:7a:99(dpdk0)
|
||||
slave dpdk0: enabled
|
||||
slave dpdk1: enabled
|
||||
root@compute-0-15:~#
|
||||
root@compute-0-15:~# dpdk-devbind.py --status
|
||||
```
|
||||
|
||||
### Q:21 How to add new rules to the existing SG(Security Group) from command line in openstack?如何使用命令行在 OpenStack 中向存在的安全组 SG(Security Group)中添加新规则?
|
||||
|
||||
Ans: 可以使用 neutron 命令向 OpenStack 已存在的安全组中添加新规则:
|
||||
|
||||
```
|
||||
~# neutron security-group-rule-create --protocol <tcp or udp> --port-range-min <port-number> --port-range-max <port-number> --direction <ingress or egress> --remote-ip-prefix <IP-address-or-range> Security-Group-Name
|
||||
```
|
||||
|
||||
### Q:22 如何查看控制节点和计算节点的 OVS 桥配置?
|
||||
|
||||
Ans: 控制节点和计算节点的 OVS 桥配置可使用以下命令来查看:
|
||||
|
||||
```
|
||||
~]# ovs-vsctl show
|
||||
```
|
||||
|
||||
### Q:23 计算节点上的集成桥(br-int)的作用是什么?
|
||||
|
||||
Ans: 集成桥(br-int)对来自和运行在计算节点上的实例的流量执行 VLAN 标记和取消标记。
|
||||
|
||||
数据包从实例的 n/w 接口发出使用虚拟接口 qvo 通过 linux 桥(qbr)。qvb接口是用来连接 Linux 桥的,qvo 接口是用来连接集成桥(br-int)的。集成桥上的 qvo 端口有一个内部 VLAN 标签,这个标签是用于当数据包到达集成桥的时候贴到数据包头部的。
|
||||
|
||||
### Q:24 隧道桥(br-tun)在计算节点上的作用是什么?
|
||||
|
||||
Ans: 隧道网桥(br-tun)根据 OpenFlow 规则将 VLAN 标记的流量从集成网桥转换为隧道 ID。
|
||||
|
||||
br-tun(tunnel bridge,即隧道桥)允许不同网络的实例彼此进行通信。隧道有利于封装在非安全网络上传输的流量,br-tun 支持两层网络,即 GRE 和 VXLAN。
|
||||
|
||||
### Q:25 外部 OVS 桥(br-ex)的作用是什么?
|
||||
|
||||
Ans: 顾名思义,此网桥转发来往网络的流量,以允许外部访问实例。br-ex 连接物理接口比如 eth2,这样用户网络的浮动 IP 数据从物理网络接收并路由到用户网络端口。
|
||||
|
||||
### Q:26 OpenStack 网络中 OpenFlow 规则的作用是什么?
|
||||
|
||||
Ans: OpenFlow 规则是一种机制,这种机制定义了一个数据包如何从源到达目的地。OpenFlow 规则存储在 flow 表中。flow 表是 OpenFlow 交换机的一部分。
|
||||
|
||||
当一个数据包到达交换机就会被第一个 flow 表检查,如果不匹配 flow 表中的任何入口,那这个数据包就会被丢弃或者转发到其他 flow 表中。
|
||||
|
||||
### Q:27 怎样查看 OpenFlow 交换机的信息(比如端口、表编号、缓存编号等)?
|
||||
|
||||
Ans: 假如我们要显示 OpenFlow 交换机的信息(br-int),需要执行如下命令:
|
||||
|
||||
```
|
||||
root@compute-0-15# ovs-ofctl show br-int
|
||||
OFPT_FEATURES_REPLY (xid=0x2): dpid:0000fe981785c443
|
||||
n_tables:254, n_buffers:256
|
||||
capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP
|
||||
actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst
|
||||
1(patch-tun): addr:3a:c6:4f:bd:3e:3b
|
||||
config: 0
|
||||
state: 0
|
||||
speed: 0 Mbps now, 0 Mbps max
|
||||
2(qvob35d2d65-f3): addr:b2:83:c4:0b:42:3a
|
||||
config: 0
|
||||
state: 0
|
||||
current: 10GB-FD COPPER
|
||||
speed: 10000 Mbps now, 0 Mbps max
|
||||
………………………………………
|
||||
```
|
||||
|
||||
### Q:28 如何显示交换机中的所有 flow 的入口?
|
||||
|
||||
Ans: 可以使用命令 ‘ **ovs-ofctl dump-flows** ‘ 来查看交换机的 flow 入口
|
||||
|
||||
假设我们想显示 OVS 集成桥(br-int)的所有 flow 入口,可以使用如下命令:
|
||||
|
||||
```
|
||||
[root@compute01 ~]# ovs-ofctl dump-flows br-int
|
||||
```
|
||||
|
||||
### Q:29 什么是 Neutron 代理?如何显示所有 Neutron 代理?
|
||||
|
||||
Ans: OpenStack Neutron 服务器充当中心控制器,实际网络配置是在计算节点或者网络节点上执行的。Neutron 代理是计算节点或者网络节点上进行配置更新的软件实体。Neutron 代理通过 Neuron 服务和消息队列来和中心 Neutron 服务通信。
|
||||
|
||||
可通过如下命令查看 Neutron 代理列表:
|
||||
|
||||
```
|
||||
~# openstack network agent list -c ‘Agent type’ -c Host -c Alive -c State
|
||||
```
|
||||
|
||||
### Q:30 CPU Pinning 是什么?
|
||||
|
||||
Ans: CPU Pinning 是指为某个虚拟机保留物理核心。它也称为 CPU 隔离或处理器关联。有两个目的:
|
||||
|
||||
* 它确保虚拟机只能在专用核心上运行
|
||||
* 它还确保公共主机进程不在这些核心上运行
|
||||
|
||||
|
||||
|
||||
我们也可以认为 Pinning 是物理核心到一个用户虚拟 CPU(vCPU) 的一对一映射。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/openstack-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ScarboroughCoral](https://github.com/ScarboroughCoral)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxtechi.com/create-delete-virtual-machine-command-line-openstack/
|
||||
[2]: https://www.linuxtechi.com/step-by-step-instance-creation-flow-in-openstack/
|
||||
@ -0,0 +1,228 @@
|
||||
Udev 入门:管理设备事件的 Linux 子系统
|
||||
======
|
||||
创建这样一个脚本,当指定的设备插入时触发你的计算机去做一个指定动作。
|
||||

|
||||
|
||||
Udev 是一个让你的计算机使用设备事件的 Linux 子系统。通俗来讲就是,当你的计算机上插入了像网卡、外置硬盘(包括 U 盘)、鼠标、键盘、游戏操纵杆和手柄、DVD-ROM 驱动器等等设备时,代码能够检测到它们。这样就能写出很多可能非常有用的实用程序,而它已经很好了,普通用户就可以写出脚本去做一些事情,比如当某个硬盘驱动器插入时,执行某个任务。
|
||||
|
||||
这篇文章教你去如何写一个由一些 udev 事件触发的 [udev][1] 脚本,比如插入了一个 U 盘。当你理解了 udev 的工作原理,你就可以用它去做各种事情,比如当一个游戏手柄连接后加载一个指定的驱动程序,或者当你用于备份的驱动器连接后,自动执行备份工作。
|
||||
|
||||
### 一个初级的脚本
|
||||
|
||||
使用 udev 的最佳方式是让它工作在一个小的代码块中。不要指望从一开始就写出完整的脚本,而是从最简单的确认 udev 触发了某些指定的事件开始。
|
||||
|
||||
对于你的脚本,依据你的目标,并不是在任何情况下都能保证你亲眼看到你的脚本运行结果的,因此需要在你的脚本日志中确认它成功触发了。而日志文件通常放在 **/var** 目录下,但那个目录通常是 root 用户的领地。对于测试目的,可以使用 **/tmp**,它可以被普通用户访问并且在重启动后就被清除了。
|
||||
|
||||
打开你喜欢的文本编辑器,然后输入下面的简单脚本:
|
||||
|
||||
```
|
||||
#!/usr/bin/bash
|
||||
|
||||
echo $date > /tmp/udev.log
|
||||
```
|
||||
|
||||
把这个脚本放在 **/usr/local/bin** 或缺省可运行路径的位置中。将它命名为 **trigger.sh**,并运行 **chmod +x** 授予可运行权限:
|
||||
|
||||
```
|
||||
$ sudo mv trigger.sh /usr/local/bin
|
||||
$ sudo chmod +x /usr/local/bin/trigger.sh
|
||||
```
|
||||
|
||||
udev 用这个脚本并不做任何事情。当它运行时,这个脚本将在文件 **/tmp/udev.log** 中放入当前的时间戳。你可以自己测试一下这个脚本:
|
||||
|
||||
```
|
||||
$ /usr/local/bin/trigger.sh
|
||||
$ cat /tmp/udev.log
|
||||
Tue Oct 31 01:05:28 NZDT 2035
|
||||
```
|
||||
|
||||
接下来让 udev 去触发这个脚本。
|
||||
|
||||
### 唯一设备识别
|
||||
|
||||
为了让你的脚本能够被一个设备事件触发,udev 必须要知道在什么情况下调用该脚本。在现实中,你可以通过它的颜色、制造商、以及插入到你的计算机这一事实来识别一个 U 盘。而你的计算机,它需要一系列不同的标准。
|
||||
|
||||
Udev 通过序列号、制造商、以及提供商 ID 和产品 ID 号来识别设备。由于现在你的 udev 脚本还处于它的生命周期的早期阶段,因此要尽可能地宽泛、非特定和全包括。换句话说就是,你希望首先去捕获尽可能多的有效 udev 事件来触发你的脚本。
|
||||
|
||||
使用 **udevadm monitor** 命令你可以实时利用 udev,并且可以看到当你插入不同设备时发生了什么。用 root 权限试一试。
|
||||
|
||||
```
|
||||
$ su
|
||||
# udevadm monitor
|
||||
```
|
||||
|
||||
监视函数输出接收到的事件:
|
||||
|
||||
* UDEV:在规则处理之后发出 udev 事件
|
||||
* KERNEL:内核发送 uevent 事件
|
||||
|
||||
|
||||
|
||||
在 **udevadm monitor** 命令运行时,插入一个 U 盘,你将看到各种信息在你的屏幕上滚动而出。注意那一个 **ADD** 事件的事件类型。这是你所需要的识别事件类型的一个好方法。
|
||||
|
||||
**udevadm monitor** 命令提供了许多很好的信息,但是你可以使用 **udevadm info** 命令以更好看的格式来看到它,假如你知道你的 U 盘当前已经位于你的 **/dev** 树。如果不在这个树下,拔下它并重新插入,然后立即运行这个命令:
|
||||
|
||||
```
|
||||
$ su -c 'dmesg | tail | fgrep -i sd*'
|
||||
```
|
||||
|
||||
举例来说,如果那个命令返回 **sdb: sdb1**,说明内核已经给你的 U 盘分配了 **sdb** 卷标。
|
||||
|
||||
或者,你可以使用 **lsblk** 命令去查看所有附加到你的系统上的驱动器,包括它的大小和分区。
|
||||
|
||||
现在,你的驱动器已经处于你的文件系统中了,你可以使用下面的命令去查看那个设备的相关 udev 信息:
|
||||
|
||||
```
|
||||
# udevadm info -a -n /dev/sdb | less
|
||||
```
|
||||
|
||||
这个命令将返回许多信息。现在我们只关心信息中的第一个块。
|
||||
|
||||
你的任务是从 udev 的报告中找出能唯一标识那个设备的部分,然后当计算机检测到这些唯一属性时,告诉 udev 去触发你的脚本。
|
||||
|
||||
**udevadm info** 命令处理一个(由设备路径指定的)设备上的报告,接着“遍历”父级设备链。对于找到的大多数设备,它以一个“键值对”格式输出所有可能的属性。你可以写一个规则,从一个单个的父级设备属性上去匹配插入设备的属性。
|
||||
|
||||
```
|
||||
looking at device '/devices/000:000/blah/blah//block/sdb':
|
||||
KERNEL=="sdb"
|
||||
SUBSYSTEM=="block"
|
||||
DRIVER==""
|
||||
ATTR{ro}=="0"
|
||||
ATTR{size}=="125722368"
|
||||
ATTR{stat}==" 2765 1537 5393"
|
||||
ATTR{range}=="16"
|
||||
ATTR{discard\_alignment}=="0"
|
||||
ATTR{removable}=="1"
|
||||
ATTR{blah}=="blah"
|
||||
```
|
||||
|
||||
一个 udev 规则必须包含来自单个父级设备的一个属性。
|
||||
|
||||
父级属性是描述一个设备的最基本的东西,比如它是插入到一个物理端口的东西、或是一个多大的东西、或这是一个可移除的设备。
|
||||
|
||||
由于内核卷标 **sdb** 可能会由于分配给在它之前插入的其它驱动器而发生变化,因此卷标并不是一个 udev 规则的父级属性的好选择。但是,在做概念论证时你可以使用它。一个事件的最佳候选者是 SUBSYSTEM 属性,它表示那个设备是一个 “block” 系统设备(也就是为什么我们要使用 **lsblk** 命令来列出设备的原因)。
|
||||
|
||||
在 **/etc/udev/rules.d** 目录中打开一个名为 **80-local.rules** 的文件,然后输入如下代码:
|
||||
|
||||
```
|
||||
SUBSYSTEM=="block", ACTION=="add", RUN+="/usr/local/bin/trigger.sh"
|
||||
```
|
||||
|
||||
保存文件,拔下你的测试 U 盘,然后重启动系统。
|
||||
|
||||
等等,重启动 Linux 机器?
|
||||
|
||||
理论上说,你只需要运行 **udevadm control —reload** 即可,它将重新加载所有规则,但是在我们实验的现阶段,最好要排除可能影响实验结果的所有因素。Udev 是非常复杂的,为了不让你躺在床上整晚都在思考为什么这个规则不能正常工作,是因为语法错误吗?还是应该重启动一下。所以,不管 POSIX 自负地告诉你过什么,你都应该去重启动一下。
|
||||
|
||||
当你的系统重启动完毕之后,(使用 Ctl+Alt+F3 或类似快捷键)切换到一个文本控制台,并插入你的 U 盘。如果你运行了一个最新的内核,当你插入 U 盘后你或许可以看到一大堆输出。如果看到一个错误信息,比如 “Could not execute /usr/local/bin/trigger.sh”,或许是因为你忘了授予这个脚本可运行的权限。否则你将看到的是,一个设备插入,它得到内核设备分配的一些东西,等等。
|
||||
|
||||
现在,见证奇迹的时刻到了。
|
||||
|
||||
```
|
||||
$ cat /tmp/udev.log
|
||||
Tue Oct 31 01:35:28 NZDT 2035
|
||||
```
|
||||
|
||||
如果你在 **/tmp/udev.log** 中看到了最新的日期和时间,那么说明 udev 已经成功触发了你的脚本。
|
||||
|
||||
### 改进规则做一些有用的事情
|
||||
|
||||
现在的问题是使用的规则太通用了。插入一个鼠标、一个 U 盘、或某个人的 U 盘都将盲目地触发这个脚本。现在,我们开始专注于希望触发你的脚本的是确定的某个 U 盘。
|
||||
|
||||
实现上述目标的一种方式是使用提供商 ID 和产品 ID。你可以使用 **lsusb** 命令去得到这些数字。
|
||||
|
||||
```
|
||||
$ lsusb
|
||||
Bus 001 Device 002: ID 8087:0024 Slacker Corp. Hub
|
||||
Bus 002 Device 002: ID 8087:0024 Slacker Corp. Hub
|
||||
Bus 003 Device 005: ID 03f0:3307 TyCoon Corp.
|
||||
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 hub
|
||||
Bus 001 Device 003: ID 13d3:5165 SBo Networks
|
||||
```
|
||||
|
||||
在这个例子中,**TyCoon Corp** 前面的 **03f0:3307** 就表示了提供商 ID 和产品 ID 的属性。你也可以通过 **udevadm info -a -n /dev/sdb | grep vendor** 的输出来查看这些数字,但是从 **lsusb** 的输出中可以很容易地一眼找到这些数字。
|
||||
|
||||
现在,可以在你的脚本中包含这些属性了。
|
||||
|
||||
```
|
||||
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", RUN+="/usr/local/bin/thumb.sh"
|
||||
```
|
||||
|
||||
测试它(是的,为了确保不会有来自 udev 的影响因素,我们仍然建议先重新启动一下),它应该会像前面一样工作,现在,如果你插入一个不同公司制造的 U 盘(因为它们的提供商 ID 不一样)、或插入一个鼠标、或插入一个打印机,这个脚本将不会被触发。
|
||||
|
||||
继续添加新属性来进一步专注于你希望去触发你的脚本的那个唯一的 U 盘。使用 **udevadm info -a -n /dev/sdb** 命令,你可以找出像提供商名字、序列号、或产品名这样的东西。
|
||||
|
||||
为了保证思路清晰,确保每次只添加一个新属性。我们(和在网上看到的其他人)在 udev 规则中所遇到的大多数错误都是因为一次添加了太多的属性,而奇怪为什么不能正常工作了。逐个测试属性是最安全的作法,这样可以确保 udev 能够成功识别到你的设备。
|
||||
|
||||
### 安全
|
||||
|
||||
编写 udev 规则当插入一个驱动器后自动去做一些事情,将带来安全方面的担忧。在我的机器上,我甚至都没有打开自动挂载功能,而基于本文的目的,当设备插入时,脚本和规则可以运行一些命令来做一些事情。
|
||||
|
||||
在这里需要记住两个事情。
|
||||
|
||||
1. 聚焦于你的 udev 规则,当你真实地使用它们时,一旦让规则发挥作用将触发脚本。执行一个脚本去盲目地复制数据到你的计算上,或从你的计算机上复制出数据,是一个很糟糕的主意,因为有可能会遇到一个人拿着和你相同品牌的 U 盘插入到你的机器上的情况。
|
||||
2. 不要在写了 udev 规则和脚本后忘记了它们的存在。我知道哪个计算上有我的 udev 规则,这些机器一般是我的个人计算机,而不是那些我带着去开会或办公室工作的计算机。一台计算机的 “社交” 程度越高,它就越不能有 udev 规则存在于它上面,因为它将潜在地导致我的数据最终可能会出现在某个人的设备、或某个人的数据中、或在我的设备上出现恶意程序。
|
||||
|
||||
|
||||
|
||||
换句话说就是,随着一个 GNU 系统提供了一个这么强大的功能,你的任务是小心地如何使用它们的强大功能。如果你滥用它或不小心谨慎地使用它,最终将让你出问题,它非常可能会导致可怕的问题。
|
||||
|
||||
### 现实中的 Udev
|
||||
|
||||
现在,你可以确认你的脚本是由 udev 触发的,那么,可以将你的关注点转到脚本功能上了。到目前为止,这个脚本是没有用的,它除了记录脚本已经运行过了这一事实外,再没有做更多的事情。
|
||||
|
||||
我使用 udev 去触发我的 U 盘的 [自动备份][2] 。这个创意是,将我正在处理的文档的主复本保存在我的 U 盘上(因为我随身带着它,这样就可以随时处理它),并且在我每次将 U 盘插入到那台机器上时,这些主文档将备份回我的计算机上。换句话说就是,我的计算机是备份驱动器,而产生的数据是移动的。源代码是可用的,你可以随意查看 attachup 的代码,以进一步限制你的 udev 的测试示例。
|
||||
|
||||
虽然我使用 udev 最多的情况就是这个例子,但是 udev 能抓取很多的事件,像游戏手柄(当连接游戏手柄时,让系统去加载 xboxdrv 模块)、摄像头、麦克风(当指定的麦克风连接时用于去设置输入),所以应该意识到,它能做的事情远比这个示例要多。
|
||||
|
||||
我的备份系统的一个简化版本是由两个命令组成的一个过程:
|
||||
|
||||
```
|
||||
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", SYMLINK+="safety%n"
|
||||
SUBSYSTEM=="block", ATTRS{idVendor}=="03f0", ACTION=="add", RUN+="/usr/local/bin/trigger.sh"
|
||||
```
|
||||
|
||||
第一行使用属性去检测我的 U 盘,这在前面已经讨论过了,接着在设备树中为我的 U 盘分配一个符号链接,给它分配的符号连接是 **safety%n**。这个 **%n** 是一个 udev 宏,它是内核分配给这个设备的任意数字,比如 sdb1、sdb2、sdb3、等等。因此 **%n** 应该是 1 或 2 或 3。
|
||||
|
||||
这将在 dev 树中创建一个符号链接,因此它不会干涉插入一个设备的正常过程。这意味着,如果你在自动挂载设备的桌面环境中使用它,将不会出现问题。
|
||||
|
||||
第二行运行这个脚本。
|
||||
|
||||
我的备份脚本如下:
|
||||
|
||||
```
|
||||
#!/usr/bin/bash
|
||||
|
||||
mount /dev/safety1 /mnt/hd
|
||||
sleep 2
|
||||
rsync -az /mnt/hd/ /home/seth/backups/ && umount /dev/safety1
|
||||
```
|
||||
|
||||
这个脚本使用符号链接,这将避免出现 udev 命名导致的意外情况(例如,假设一个命名为 DISK 的 U 盘已经插入到我的计算机上,而我插入的其它 U 盘恰好名字也是 DISK,那么第二个 U 盘的卷标将被命名为 `DISK_`,这将导致我的脚本不会正常运行),它在我喜欢的挂载点 **/mnt/hd** 上挂载了 **safety1**(驱动器的第一个分区)。
|
||||
|
||||
一旦 safely 挂载之后,它将使用 [rsync][3] 将驱动器备份到我的备份文件夹(我真实使用的脚本用的是 rdiff-backup,而你可以使用任何一个你喜欢的自动备份解决方案)。
|
||||
|
||||
### Udev 让你的设备你做主
|
||||
|
||||
Udev 是一个非常灵活的系统,它可以让你用其它系统很少敢提供给用户的方式去定义规则和功能。学习它,使用它,去享受 POSIX 的强大吧。
|
||||
|
||||
本文内容来自 [Slackermedia Handbook][4],它以 [GNU Free Documentation License 1.3][5] 许可证授权使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/udev
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.die.net/man/8/udev
|
||||
[2]: https://gitlab.com/slackermedia/attachup
|
||||
[3]: https://opensource.com/article/17/1/rsync-backup-linux
|
||||
[4]: http://slackermedia.info/handbook/doku.php?id=backup
|
||||
[5]: http://www.gnu.org/licenses/fdl-1.3.html
|
||||
@ -0,0 +1,462 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer:
|
||||
[#]: publisher:
|
||||
[#]: subject: (How to Build a Netboot Server, Part 1)
|
||||
|
||||
[#]: via: (https://fedoramagazine.org/how-to-build-a-netboot-server-part-1/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
[#]: url:
|
||||
|
||||
如何构建一台网络引导服务器(第一部分)
|
||||
======
|
||||
|
||||

|
||||
|
||||
有些计算机网络需要在各个物理机器上维护相同的软件和配置。学校的计算机实验室就是这样的一个环境。一台 [网络引导][1] 服务器能够被配置为基于网络去提供一个完整的操作系统,以便于客户端计算机从一个中央位置获取配置。本教程将向你展示构建一台网络引导服务器的一种方法。
|
||||
|
||||
本教程的第一部分将包括创建一台网络引导服务器和镜像。第二部分将展示如何去添加 Kerberos 验证的 home 目录到网络引导配置中。
|
||||
|
||||
### 初始化配置
|
||||
|
||||
首先去下载 Fedora 服务器的 [netinst][2] 镜像,将它刻录到一张光盘上,然后它将引导服务器去重新格式化。我们只需要一个典型的 Fedora Server 的“最小化安装”来作为我们的开端,安装完成后,我们可以使用命令行去添加我们需要的任何额外的包。
|
||||
|
||||
![][3]
|
||||
|
||||
> 注意:本教程中我们将使用 Fedora 28。其它版本在“最小化安装”中包含的包可能略有不同。如果你使用的是不同的 Fedora 版本,如果一个预期的文件或命令不可用,你可能需要做一些调试。
|
||||
|
||||
最小化安装的 Fedora Server 运行起来之后,以 root 用户登入并设置主机名字:
|
||||
|
||||
```javascript
|
||||
$ MY_HOSTNAME=server-01.example.edu
|
||||
$ hostnamectl set-hostname $MY_HOSTNAME
|
||||
```
|
||||
|
||||
> 注意:Red Hat 建议静态和临时名字应都要与这个机器在 DNS 中的完全合格域名相匹配,比如 host.example.com([了解主机名字][4])。
|
||||
>
|
||||
> 注意:本指南为了你“复制粘贴”友好。需要自定义的任何值都声明为一个 MY_* 变量,在你运行剩余命令之前,你可能需要调整它。如果你注销之后,变量的赋值将被清除。
|
||||
>
|
||||
> 注意:Fedora 28 Server 在默认情况下往往会转储大量的日志到控制台上。你可以通过运行命令:sysctl -w kernel.printk=0 去禁用控制台日志输出。
|
||||
|
||||
接下来,我们需要在我们的服务器上配置一个静态网络地址。运行下面的一系列命令将找到并重新配置你的默认网络连接:
|
||||
|
||||
```javascript
|
||||
$ MY_DNS1=192.0.2.91
|
||||
$ MY_DNS2=192.0.2.92
|
||||
$ MY_IP=192.0.2.158
|
||||
$ MY_PREFIX=24
|
||||
$ MY_GATEWAY=192.0.2.254
|
||||
$ DEFAULT_DEV=$(ip route show default | awk '{print $5}')
|
||||
$ DEFAULT_CON=$(nmcli d show $DEFAULT_DEV | sed -n '/^GENERAL.CONNECTION:/s!.*:\s*!! p')
|
||||
$ nohup bash << END
|
||||
nmcli con mod "$DEFAULT_CON" connection.id "$DEFAULT_DEV"
|
||||
nmcli con mod "$DEFAULT_DEV" connection.interface-name "$DEFAULT_DEV"
|
||||
nmcli con mod "$DEFAULT_DEV" ipv4.method disabled
|
||||
nmcli con up "$DEFAULT_DEV"
|
||||
nmcli con add con-name br0 ifname br0 type bridge
|
||||
nmcli con mod br0 bridge.stp no
|
||||
nmcli con mod br0 ipv4.dns $MY_DNS1,$MY_DNS2
|
||||
nmcli con mod br0 ipv4.addresses $MY_IP/$MY_PREFIX
|
||||
nmcli con mod br0 ipv4.gateway $MY_GATEWAY
|
||||
nmcli con mod br0 ipv4.method manual
|
||||
nmcli con up br0
|
||||
nmcli con add con-name br0-slave0 ifname "$DEFAULT_DEV" type bridge-slave master br0
|
||||
nmcli con up br0-slave0
|
||||
END
|
||||
```
|
||||
|
||||
> 注意:上面最后的一组命令被封装到一个 “nohup” 脚本中,因为它将临时禁用网络。这个 nohup 命令将允许 nmcli 命令去完成运行,直到你的 SSH 连接断开。注意,连接恢复可能需要 10 秒左右的时间,如果你改变了服务器 IP 地址,你将需要重新启动一个新的 SSH 连接。
|
||||
>
|
||||
> 注意:上面的网络配置在默认的连接之上创建了一个 [网桥][5],这样我们在后面的测试中就可以直接运行一个虚拟机实例。如果你不想在这台服务器上去直接测试网络引导镜像,你可以跳过创建网桥的命令,并直接在你的默认网络连接上配置静态 IP 地址。
|
||||
|
||||
### 安装和配置 NFS4
|
||||
|
||||
从安装 nfs-utils 包开始:
|
||||
|
||||
```
|
||||
$ dnf install -y nfs-utils
|
||||
```
|
||||
|
||||
为发布 NFS 去创建一个顶级的 [伪文件系统][6],然后在你的网络上共享它:
|
||||
|
||||
```javascript
|
||||
$ MY_SUBNET=192.0.2.0
|
||||
$ mkdir /export
|
||||
$ echo "/export -fsid=0,ro,sec=sys,root_squash $MY_SUBNET/$MY_PREFIX" > /etc/exports
|
||||
```
|
||||
|
||||
SELinux 将干扰网络引导服务器的运行。在本教程中我们将不涉及为它配置例外的部分,因此我们直接禁用它:
|
||||
|
||||
```javascript
|
||||
$ sed -i '/GRUB_CMDLINE_LINUX/s/"$/ audit=0 selinux=0"/' /etc/default/grub
|
||||
$ grub2-mkconfig -o /boot/grub2/grub.cfg
|
||||
$ sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
|
||||
$ setenforce 0
|
||||
```
|
||||
|
||||
> 注意:编辑 grub 命令行应该是不需要的,但在测试过程中发现,简单地编辑 /etc/sysconfig/selinux 被证明重启后是无效的,因此再次确保设置了 “selinux=0” 标志。
|
||||
|
||||
现在,在本地防火墙中为 NFS 服务添加一个例外,然后启动 NFS 服务:
|
||||
|
||||
```javascript
|
||||
$ firewall-cmd --add-service nfs
|
||||
$ firewall-cmd --runtime-to-permanent
|
||||
$ systemctl enable nfs-server.service
|
||||
$ systemctl start nfs-server.service
|
||||
```
|
||||
|
||||
### 创建网络引导镜像
|
||||
|
||||
现在我们的 NFS 服务器已经启动运行了,我们需要为它提供一个操作系统镜像,以便于它提供给客户端计算机。我们将从一个非常小的镜像开始,等一切顺利之后再添加。
|
||||
|
||||
首先,创建一个存放我们镜像的新目录:
|
||||
|
||||
```
|
||||
$ mkdir /fc28
|
||||
```
|
||||
|
||||
使用 “dnf” 命令在新目录下用几个基础包去构建镜像:
|
||||
|
||||
```javascript
|
||||
$ dnf -y --releasever=28 --installroot=/fc28 install fedora-release systemd passwd rootfiles sudo dracut dracut-network nfs-utils vim-minimal dnf
|
||||
```
|
||||
|
||||
在上面的命令中省略了很重要的 “kernel” 包。在它们被安装完成之前,我们需要去调整一下 “initramfs” 镜像中包含的驱动程序集,“kernel” 首次安装时将自动构建这个镜像。尤其是,我们需要禁用 “hostonly” 模式,以便于 initramfs 镜像能够在各种硬件平台上正常工作,并且我们还需要添加对网络和 NFS 的支持:
|
||||
|
||||
```javascript
|
||||
$ echo 'hostonly=no' > /fc28/etc/dracut.conf.d/hostonly.conf
|
||||
$ echo 'add_dracutmodules+=" network nfs "' > /fc28/etc/dracut.conf.d/netboot.conf
|
||||
```
|
||||
|
||||
现在,安装 kernel:
|
||||
|
||||
```javascript
|
||||
$ dnf -y --installroot=/fc28 install kernel
|
||||
```
|
||||
|
||||
设置一个阻止 kernel 被更新的规则:
|
||||
|
||||
```javascript
|
||||
$ echo 'exclude=kernel-*' >> /fc28/etc/dnf/dnf.conf
|
||||
```
|
||||
|
||||
设置 locale:
|
||||
|
||||
```javascript
|
||||
$ echo 'LANG="en_US.UTF-8"' > /fc28/etc/locale.conf
|
||||
```
|
||||
|
||||
> 注意:如果 locale 没有正确配置,一些程序(如 GNOME Terminal)将无法正常工作。
|
||||
|
||||
root 用户密码留空:
|
||||
|
||||
```javascript
|
||||
$ sed -i 's/^root:\*/root:/' /fc28/etc/shadow
|
||||
```
|
||||
|
||||
设置客户端的主机名字:
|
||||
|
||||
```javascript
|
||||
$ MY_CLIENT_HOSTNAME=client-01.example.edu
|
||||
$ echo $MY_CLIENT_HOSTNAME > /fc28/etc/hostname
|
||||
```
|
||||
|
||||
禁用控制台日志输出:
|
||||
|
||||
```javascript
|
||||
$ echo 'kernel.printk = 0 4 1 7' > /fc28/etc/sysctl.d/00-printk.conf
|
||||
```
|
||||
|
||||
定义网络引导镜像中的本地 “liveuser” 用户:
|
||||
|
||||
```javascript
|
||||
$ echo 'liveuser:x:1000:1000::/home/liveuser:/bin/bash' >> /fc28/etc/passwd
|
||||
$ echo 'liveuser::::::::' >> /fc28/etc/shadow
|
||||
$ echo 'liveuser:x:1000:' >> /fc28/etc/group
|
||||
$ echo 'liveuser:!::' >> /fc28/etc/gshadow
|
||||
```
|
||||
|
||||
在 sudo 中启用 “liveuser”:
|
||||
|
||||
```javascript
|
||||
$ echo 'liveuser ALL=(ALL) NOPASSWD: ALL' > /fc28/etc/sudoers.d/liveuser
|
||||
```
|
||||
|
||||
启用自动 home 目录创建:
|
||||
|
||||
```livescript
|
||||
$ dnf install -y --installroot=/fc28 authselect oddjob-mkhomedir
|
||||
$ echo 'dirs /home' > /fc28/etc/rwtab.d/home
|
||||
$ chroot /fc28 authselect select sssd with-mkhomedir --force
|
||||
$ chroot /fc28 systemctl enable oddjobd.service
|
||||
```
|
||||
|
||||
由于多个客户端将会同时挂载我们的镜像,我们需要去配置镜像工作在只读模式中:
|
||||
|
||||
```livescript
|
||||
$ sed -i 's/^READONLY=no$/READONLY=yes/' /fc28/etc/sysconfig/readonly-root
|
||||
```
|
||||
|
||||
配置日志输出到内存而不是持久存储中:
|
||||
|
||||
```livescript
|
||||
$ sed -i 's/^#Storage=auto$/Storage=volatile/' /fc28/etc/systemd/journald.conf
|
||||
```
|
||||
|
||||
配置 DNS:
|
||||
|
||||
```livescript
|
||||
$ MY_DNS1=192.0.2.91
|
||||
$ MY_DNS2=192.0.2.92
|
||||
$ cat << END > /fc28/etc/resolv.conf
|
||||
nameserver $MY_DNS1
|
||||
nameserver $MY_DNS2
|
||||
END
|
||||
```
|
||||
|
||||
解决编写本教程时存在的只读 root 挂载 bug([BZ1542567][7]):
|
||||
|
||||
```livescript
|
||||
$ echo 'dirs /var/lib/gssproxy' > /fc28/etc/rwtab.d/gssproxy
|
||||
$ cat << END > /fc28/etc/rwtab.d/systemd
|
||||
dirs /var/lib/systemd/catalog
|
||||
dirs /var/lib/systemd/coredump
|
||||
END
|
||||
```
|
||||
|
||||
最后,为我们镜像创建 NFS 文件系统,并将它共享到我们的子网中:
|
||||
|
||||
```livescript
|
||||
$ mkdir /export/fc28
|
||||
$ echo '/fc28 /export/fc28 none bind 0 0' >> /etc/fstab
|
||||
$ mount /export/fc28
|
||||
$ echo "/export/fc28 -ro,sec=sys,no_root_squash $MY_SUBNET/$MY_PREFIX" > /etc/exports.d/fc28.exports
|
||||
$ exportfs -vr
|
||||
```
|
||||
|
||||
### 创建引导加载器
|
||||
|
||||
现在,我们已经有了可以进行网络引导的操作系统,我们需要一个引导加载器去从客户端系统上启动它。在本教程中我们使用的是 [iPXE][8].
|
||||
|
||||
> 注意:本节和接下来的节 — 使用 QEMU 测试 — 能在另外一台单独的计算机上来完成;它们不需要在网络引导服务器上来运行。
|
||||
|
||||
安装 git 并使用它去下载 iPXE:
|
||||
|
||||
```livescript
|
||||
$ dnf install -y git
|
||||
$ git clone http://git.ipxe.org/ipxe.git $HOME/ipxe
|
||||
```
|
||||
|
||||
现在我们需要去为我们的引导加载器创建一个指定的启动脚本:
|
||||
|
||||
```livescript
|
||||
$ cat << 'END' > $HOME/ipxe/init.ipxe
|
||||
#!ipxe
|
||||
|
||||
prompt --key 0x02 --timeout 2000 Press Ctrl-B for the iPXE command line... && shell ||
|
||||
|
||||
dhcp || exit
|
||||
set prefix file:///linux
|
||||
chain ${prefix}/boot.cfg || exit
|
||||
END
|
||||
```
|
||||
|
||||
启动 “file” 下载协议:
|
||||
|
||||
```livescript
|
||||
$ echo '#define DOWNLOAD_PROTO_FILE' > $HOME/ipxe/src/config/local/general.h
|
||||
```
|
||||
|
||||
安装 C 编译器以及相关的工具和库:
|
||||
|
||||
```livescript
|
||||
$ dnf groupinstall -y "C Development Tools and Libraries"
|
||||
```
|
||||
|
||||
构建引导加载器:
|
||||
|
||||
```livescript
|
||||
$ cd $HOME/ipxe/src
|
||||
$ make clean
|
||||
$ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe
|
||||
```
|
||||
|
||||
记下新编译的引导加载器的存储位置。我们将在接下来的节中用到它:
|
||||
|
||||
```livescript
|
||||
$ IPXE_FILE="$HOME/ipxe/src/bin-x86_64-efi/ipxe.efi"
|
||||
```
|
||||
|
||||
### 用 QEMU 测试
|
||||
|
||||
这一节是可选的,但是你需要去复制下面显示在物理机器上的 [EFI 系统分区][9] 的布局,在网络引导时需要去配置它们。
|
||||
|
||||
> 注意:如果你想实现一个完全的无盘系统,你也可以复制那个文件到一个 TFTP 服务器,然后从 DHCP 上引用那台服务器。
|
||||
|
||||
为了使用 QEMU 去测试我们的引导加载器,我们继续去创建一个仅包含一个 EFI 系统分区和我们的启动文件的、很小的磁盘镜像。
|
||||
|
||||
从创建 EFI 系统分区所需要的目录布局开始,然后把我们在前面节中创建的引导加载器复制进去:
|
||||
|
||||
```livescript
|
||||
$ mkdir -p $HOME/esp/efi/boot
|
||||
$ mkdir $HOME/esp/linux
|
||||
$ cp $IPXE_FILE $HOME/esp/efi/boot/bootx64.efi
|
||||
```
|
||||
|
||||
下面的命令将识别我们的引导加载器镜像正在使用的内核版本,并将它保存到一个变量中,以备后续的配置命令去使用它:
|
||||
|
||||
```livescript
|
||||
$ DEFAULT_VER=$(ls -c /fc28/lib/modules | head -n 1)
|
||||
```
|
||||
|
||||
定义我们的客户端计算机将使用的引导配置:
|
||||
|
||||
```livescript
|
||||
$ MY_DNS1=192.0.2.91
|
||||
$ MY_DNS2=192.0.2.92
|
||||
$ MY_NFS4=server-01.example.edu
|
||||
$ cat << END > $HOME/esp/linux/boot.cfg
|
||||
#!ipxe
|
||||
|
||||
kernel --name kernel.efi \${prefix}/vmlinuz-$DEFAULT_VER initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=$MY_DNS1 nameserver=$MY_DNS2 root=nfs4:$MY_NFS4:/fc28 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
|
||||
initrd --name initrd.img \${prefix}/initramfs-$DEFAULT_VER.img
|
||||
boot || exit
|
||||
END
|
||||
```
|
||||
|
||||
> 注意:上面的引导脚本展示了如何使用 iPXE 去网络引导 Linux 的最小示例。还可以做更多更复杂的配置。值得注意的是,iPXE 支持交互式引导菜单,它可以让你配置默认选项和超时时间。比如,一个更高级一点 iPXE 脚本可以默认从本地磁盘引导一个操作系统,如果在倒计时结束之前用户按下了一个键,才会去网络引导一个操作系统。
|
||||
|
||||
复制 Linux 内核并分配 initramfs 给 EFI 系统分区:
|
||||
|
||||
```livescript
|
||||
$ cp $(find /fc28/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $DEFAULT_VER) $HOME/esp/linux/vmlinuz-$DEFAULT_VER
|
||||
$ cp $(find /fc28/boot -name 'init*' | grep -m 1 $DEFAULT_VER) $HOME/esp/linux/initramfs-$DEFAULT_VER.img
|
||||
```
|
||||
|
||||
我们最终的目录布局应该看起来像下面的样子:
|
||||
|
||||
```livescript
|
||||
esp
|
||||
├── efi
|
||||
│ └── boot
|
||||
│ └── bootx64.efi
|
||||
└── linux
|
||||
├── boot.cfg
|
||||
├── initramfs-4.18.18-200.fc28.x86_64.img
|
||||
└── vmlinuz-4.18.18-200.fc28.x86_64
|
||||
```
|
||||
|
||||
使用 QEMU 去使用我们的 EFI 系统分区,我们需要去创建一个小的 “uefi.img” 磁盘镜像来包含它,然后将它连接到 QEMU 作为主引导驱动器。
|
||||
|
||||
开始安装必需的工具:
|
||||
|
||||
```livescript
|
||||
$ dnf install -y parted dosfstools
|
||||
```
|
||||
|
||||
现在创建 “uefi.img” 文件,并将 “esp” 目录中文件复制进去:
|
||||
|
||||
```livescript
|
||||
$ ESP_SIZE=$(du -ks $HOME/esp | cut -f 1)
|
||||
$ dd if=/dev/zero of=$HOME/uefi.img count=$((${ESP_SIZE}+5000)) bs=1KiB
|
||||
$ UEFI_DEV=$(losetup --show -f $HOME/uefi.img)
|
||||
$ parted ${UEFI_DEV} -s mklabel gpt mkpart EFI FAT16 1MiB 100% toggle 1 boot
|
||||
$ mkfs -t msdos ${UEFI_DEV}p1
|
||||
$ mkdir -p $HOME/mnt
|
||||
$ mount ${UEFI_DEV}p1 $HOME/mnt
|
||||
$ cp -r $HOME/esp/* $HOME/mnt
|
||||
$ umount $HOME/mnt
|
||||
$ losetup -d ${UEFI_DEV}
|
||||
```
|
||||
|
||||
> 注意:在物理计算机上,你只需要从 “esp” 目录中复制文件到计算机上已存在的 EFI 系统分区中。你不需要使用 “uefi.img” 文件去引导物理计算机。
|
||||
>
|
||||
> 注意:在一个物理计算机上,如果文件名已存在,你可以重命名 “bootx64.efi” 文件,如果你重命名了它,就需要去编辑计算机的 BIOS 设置,并添加重命令后的 efi 文件到引导列表中。
|
||||
|
||||
接下来我们需要去安装 qemu 包:
|
||||
|
||||
```livescript
|
||||
$ dnf install -y qemu-system-x86
|
||||
```
|
||||
|
||||
允许 QEMU 访问我们在本教程“初始化配置”一节中创建的网桥:
|
||||
|
||||
```livescript
|
||||
$ echo 'allow br0' > /etc/qemu/bridge.conf
|
||||
```
|
||||
|
||||
创建一个 “OVMF_VARS.fd” 镜像的副本去保存我们虚拟机的持久 BIOS 配置:
|
||||
|
||||
```livescript
|
||||
$ cp /usr/share/edk2/ovmf/OVMF_VARS.fd $HOME
|
||||
```
|
||||
|
||||
现在,启动虚拟机:
|
||||
|
||||
```livescript
|
||||
$ qemu-system-x86_64 -machine accel=kvm -nographic -m 1024 -drive if=pflash,format=raw,unit=0,file=/usr/share/edk2/ovmf/OVMF_CODE.fd,readonly=on -drive if=pflash,format=raw,unit=1,file=$HOME/OVMF_VARS.fd -drive if=ide,format=raw,file=$HOME/uefi.img -net bridge,br=br0 -net nic,model=virtio
|
||||
```
|
||||
|
||||
如果一切顺利,你将看到类似下图所示的结果:
|
||||
|
||||
![][10]
|
||||
你可以使用 “shutdown” 命令关闭虚拟机回到我们的服务器上:
|
||||
|
||||
```livescript
|
||||
$ sudo shutdown -h now
|
||||
```
|
||||
|
||||
> 注意:如果出现了错误或虚拟机挂住了,你可能需要启动一个新的 SSH 会话去连接服务器,使用 “kill” 命令去终止 “qemu-system-x86_64” 进程。
|
||||
|
||||
### 镜像中添加包
|
||||
|
||||
镜像中添加包应该是一个很简单的问题,在服务器上 chroot 进镜像,然后运行 “dnf install <package_name>”。
|
||||
|
||||
在网络引导镜像中并不限制你能安装什么包。一个完整的图形化安装应该能够完美地工作。
|
||||
|
||||
下面是一个如何将最小化安装的网络引导镜像变成完整的图形化安装的示例:
|
||||
|
||||
```livescript
|
||||
$ for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done
|
||||
$ chroot /fc28 /usr/bin/bash --login
|
||||
$ dnf -y groupinstall "Fedora Workstation"
|
||||
$ dnf -y remove gnome-initial-setup
|
||||
$ systemctl disable sshd.service
|
||||
$ systemctl enable gdm.service
|
||||
$ systemctl set-default graphical.target
|
||||
$ sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
|
||||
$ logout
|
||||
$ for i in run sys proc dev/shm dev/pts dev; do umount /fc28/$i; done
|
||||
```
|
||||
|
||||
可选,你可能希望去启用 “liveuser” 用户的自动登陆:
|
||||
|
||||
```livescript
|
||||
$ sed -i '/daemon/a AutomaticLoginEnable=true' /fc28/etc/gdm/custom.conf
|
||||
$ sed -i '/daemon/a AutomaticLogin=liveuser' /fc28/etc/gdm/custom.conf
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-to-build-a-netboot-server-part-1/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Network_booting
|
||||
[2]: https://dl.fedoraproject.org/pub/fedora/linux/releases/28/Server/x86_64/iso/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/11/installation-summary-1024x768.png
|
||||
[4]: https://docs.fedoraproject.org/en-US/Fedora/25/html/Networking_Guide/ch-Configure_Host_Names.html#sec_Understanding_Host_Names
|
||||
[5]: https://en.wikipedia.org/wiki/Bridging_(networking)
|
||||
[6]: https://www.centos.org/docs/5/html/5.1/Deployment_Guide/s3-nfs-server-config-exportfs-nfsv4.html
|
||||
[7]: https://bugzilla.redhat.com/show_bug.cgi?id=1542567
|
||||
[8]: https://ipxe.org/
|
||||
[9]: https://en.wikipedia.org/wiki/EFI_system_partition
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/11/netboot-liveuser-1024x641.png
|
||||
@ -1,162 +0,0 @@
|
||||
如何使用 sudo 命令在 Linux 中部署超级用户权限
|
||||
======
|
||||
|
||||

|
||||
|
||||
**sudo** 命令在你想要使用超级权限运行一条林临时的命令时非常方便,但是当它不能做到你期望的所有事的时候,你也会遇到一些麻烦。比如说你想在某些日志文件结尾添加一些重要的信息,你可能会尝试这样做:
|
||||
|
||||
```
|
||||
$ echo "Important note" >> /var/log/somelog
|
||||
-bash: /var/log/somelog: Permission denied
|
||||
```
|
||||
|
||||
好吧,看起来你似乎需要一些额外的特权。一般来说,你不能使用你的用户账号向系统日志中写入东西。我们使用 **sudo** 再尝试一次吧。
|
||||
|
||||
```
|
||||
$ sudo !!
|
||||
sudo echo "Important note" >> /var/log/somelog
|
||||
-bash: /var/log/somelog: Permission denied
|
||||
```
|
||||
|
||||
emmm,它还是没有啥反应。我们来试点不同的吧。
|
||||
|
||||
```
|
||||
$ sudo 'echo "Important note" >> /var/log/somelog'
|
||||
sudo: echo "Important note" >> /var/log/somelog: command not found
|
||||
```
|
||||
|
||||
**[ 也可以查看:[在 Linux 下排查故障的宝贵提示和技巧][1] ]**
|
||||
|
||||
### 接下来该干什么?
|
||||
|
||||
上面在执行完第一条命令后的回应显示,我们缺少向日志文件写入时必须的特权。第二次,我们使用 root 权限运行了第一次的命令,但是返回了一个 **没有权限** 的错误。第三次,我们把整个命令放在一个引号里面再运行了一遍,返回了一个 **没有发现命令** 的错误。 。所以,到底错在哪里了呢?
|
||||
|
||||
* 第一条命令:没有 root 特权,你无法向这个日志中写入东西。
|
||||
* 第二条命令:你的超级权限没有被正确重定位。
|
||||
* 第三条命令:Sudo 不理解你用引号括起来的整个 “命令”。
|
||||
|
||||
|
||||
|
||||
在你的用户还未添加到 sudo 用户组的时候,如果尝试使用 sudo,你可能已经看到过像下面的这么一条命令了:
|
||||
|
||||
```
|
||||
nemo is not in the sudoers file. This incident will be reported.
|
||||
```
|
||||
|
||||
### 你可以做什么?
|
||||
|
||||
一个相当简单的选择就是使用 sudo 命令成为 root。鉴于你已经有了 sudo 特权,你可以使用下面的命令执行此操作:
|
||||
|
||||
```
|
||||
$ sudo su
|
||||
[sudo] password for nemo:
|
||||
#
|
||||
```
|
||||
注意这个改变的符号表明了你的新身份。然后你就可以以 root 运行之前的命令了:
|
||||
|
||||
```
|
||||
# echo "Important note" >> /var/log/somelog
|
||||
```
|
||||
接着你可以输入 **^d** 返回你之前的身份。当然了,一些 sudo 的配置可能会阻止你使用 sudo 命令成为 root。
|
||||
|
||||
用 **su** 命令是另一个切换用户为 root 的选择,但是这需要你知道 root 密码许多人被赋予了访问 sudo 的权限,而且无需提供 root 密码,所以这并不是总有用。
|
||||
|
||||
切换到 root 之后,你就可以以 root 的身份运行任何你想执行的命令了。要想通过这种途径有三个问题 1) 每个想要使用 root 特权的人都需要事先知道 root 的密码(这样很不安全) 2) 如果在运行需要 root 权限的特定命令后未能退出特权状态,你的系统可能会受到一些重大错误的波及。最好 _只有_ 当你真的需要 root 特权,以及能控制好每个 sudo 用户可以拥有多少 root 权限的时候再去使用它。在使用完 root 特权之后,最好及时恢复到普通用户的状态。
|
||||
|
||||
另外请注意,整个讨论的前提是你可以正常地访问 sudo,并且你的访问权限没有受限。详细的内容后面会介绍到。
|
||||
|
||||
还有一个选择就是使用一个不同的命令。如果通过编辑文件从而在其后添加内容是一种选择的话,你也许可以使用 “sudo vi /var/log/somelog”,通过编辑一个活跃的日志文件通常不是一个好办法,因为系统可能会频繁的向这个文件中进行写入操作。
|
||||
|
||||
最后一个但是有点复杂的选择是,使用下列可以解决我们之前看到的问题的命令之一,但是它们涉及到了很多复杂的语法。第一个命令允许你在得到 “没有权限” 的拒绝之后可以使用 !! 重复你的命令:
|
||||
|
||||
```
|
||||
$ sudo echo "Important note" >> /var/log/somelog
|
||||
-bash: /var/log/somelog: Permission denied
|
||||
$ !!:gs/>/|sudo tee -a / <=====
|
||||
$ tail -1 /var/log/somelog
|
||||
Important note
|
||||
```
|
||||
|
||||
第二种是通过 sudo 命令,把你想要添加的信息传递给 **tee**。注意,**-a** 指定了你要添加文本的目标文件:
|
||||
|
||||
```
|
||||
$ echo "Important note" | sudo tee -a /var/log/somelog
|
||||
$ tail -1 /var/log/somelog
|
||||
Important note
|
||||
```
|
||||
|
||||
### sudo 有多可控?
|
||||
|
||||
回答这个问题最快速的回答就是,它取决于管理它的人。大多数 Linux 的默认设置都非常简单。如果一个用户被安排到了一个特别的组中,例如 **wheel** 或者 **admin** 组,那这个用户无需知道 root 的密码就可以拥有运行任何命令的能力。这就是大多数 Linux 系统中的默认设置。一旦在 **/etc/group** 中添加了一个用户到了特权组中,这个用户就可以以 root 的权力运行任何命令。另一方面,可以配置 sudo,以便一些用户只能够以 root 身份运行单一指令或者一组命令中的任何一个。
|
||||
|
||||
如果把像下面展示的这些行添加到了 **/etc/sudoers** 文件中,例如 “nemo” 这个用户可以以 root 身份运行 **whoami** 命令。在现实中,这可能不会造成任何影响,作为一个例子,它做的非常好。
|
||||
|
||||
```
|
||||
# User alias specification
|
||||
nemo ALL=(root) NOPASSWD: WHOAMI
|
||||
|
||||
# Cmnd alias specification
|
||||
Cmnd_Alias WHOAMI = /usr/bin/whoami
|
||||
```
|
||||
|
||||
注意,我们添加了一个命令别名(Cmnd_Alias),它指定了一个可以运行的命令的全路径,以及一个用户别名,允许这个用户无需密码就可以使用 sudo 执行的单个命令。
|
||||
|
||||
当 nemo 运行 **sudo whoami** 命令的时候,他将会看到这个:
|
||||
|
||||
```
|
||||
$ sudo whoami
|
||||
root
|
||||
```
|
||||
|
||||
注意这个,一旦 nemo 使用 sudo 执行了这条命令,**whoami** 会显示此时的用户是 **root**。
|
||||
|
||||
至于其他的命令,nemo 将会看到像这样的一些内容:
|
||||
|
||||
```
|
||||
$ sudo date
|
||||
[sudo] password for nemo:
|
||||
Sorry, user nemo is not allowed to execute '/bin/date' as root on butterfly.
|
||||
```
|
||||
|
||||
### sudo 的默认设置
|
||||
|
||||
在默认路径中,我们会利用像下面展示的 **/etc/sudoers** 文件中的几行:
|
||||
|
||||
```
|
||||
$ sudo egrep "admin|sudo" /etc/sudoers
|
||||
# Members of the admin group may gain root privileges
|
||||
%admin ALL=(ALL) ALL <=====
|
||||
# Allow members of group sudo to execute any command
|
||||
%sudo ALL=(ALL:ALL) ALL <=====
|
||||
```
|
||||
|
||||
在这几行中,**%admin** 和 **%sudo** 都说明了任何添加到这些组中的人都可以使用 sudo 命令 以 root 的身份运行任何命令。
|
||||
|
||||
下面列出的是 /etc/group 中的一行,它意味着每一个在该组中列出的成员,都拥有了 sudo 特权,而无需在 /etc/sudoers 中进行任何修改。
|
||||
|
||||
```
|
||||
sudo:x:27:shs,nemo
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
sudo 命令意味着你可以根据需要轻松地部署超级用户的访问权限,而且只有在需要的时候才能赋予用户非常有限的特权访问权限。你可能会遇到一些与简单的 "sudo command" 不同的问题,不过在 **sudo** 的回应中应该会显示你遇到了什么问题。
|
||||
|
||||
欢迎加入 [Facebook][2] 和 [LinkedIn][3] 上的 Network World 社区,并在其中重要的主题下进行留言评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3322504/linux/selectively-deploying-your-superpowers-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "qhwdw"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: subject: "OpenSnitch – an Application Firewall for Linux [Review]"
|
||||
[#]: via: "https://itsfoss.com/opensnitch-firewall-linux/"
|
||||
[#]: author: "[John Paul](https://itsfoss.com/author/john/)"
|
||||
[#]: url: " "
|
||||
|
||||
OpenSnitch – 一个 Linux 上的应用程序防火墙
|
||||
======
|
||||
|
||||
不能因为 Linux 比 Windows 更安全,就可以在 Linux 上放松警惕。Linux 上可以使用的防火墙很多,它们可以让你的 Linux 系统更安全。今天,我们将带你了解一个这样的防火墙工具,它就是 OpenSnitch。
|
||||
|
||||
### OpenSnitch 是什么?
|
||||
|
||||
![Linux firewall and security][1]
|
||||
|
||||
[OpenSnitch][2] 是从 Little Snitch 上移植过来的。而 Little Snitch 是专门为 Mac OS 设计的一款应用程序防火墙。OpenSnitch 是由 [Simone Margaritelli][3] 设计,也称为 [evilsocket][4]。
|
||||
|
||||
OpenSnitch 所做的主要事情就是跟踪你机器上安装的应用程序所发起的互联网请求。OpenSnitch 允许你去创建规则以同意或阻止那个应用程序发起的互联网访问。当一个应用程序尝试去访问互联网而没有相应的访问规则存在时,就会出现一个对话框,这个对话框让你去选择允许还是阻止那个连接。
|
||||
|
||||
你也可以决定这个新规则是应用到进程上、精确的 URL 上、域名上、单个实例上,以及本次会话还是永久有效。
|
||||
|
||||
![OpenSnitch firewall app in Linux][5]OpenSnatch 规则请求
|
||||
|
||||
你创建的所有规则都保存为 [JSON 文件][6],如果以后需要修改它,就可以去修改这个文件。比如说,你错误地阻止了一个应用程序。
|
||||
|
||||
OpenSnitch 也有一个漂亮的、一目了然的图形用户界面:
|
||||
|
||||
* 是什么应用程序访问 web
|
||||
* 它们使用哪个 IP 地址
|
||||
* 属主用户是谁
|
||||
* 使用哪个端口
|
||||
|
||||
|
||||
|
||||
如果你愿意,也可以将这些信息导出到一个 CSV 文件中。
|
||||
|
||||
OpenSnitch 遵循 GPL v3 许可证使用。
|
||||
|
||||
![OpenSnitch firewall interface][7]OpenSnitch 进程标签页
|
||||
|
||||
### 在 Linux 中安装 OpenSnitch
|
||||
|
||||
[OpenSnitch GitHub 页面][8] 上的安装介绍是针对 Ubuntu 用户的。如果你使用的是其它发行版,你需要调整一下相关的命令。据我所知,这个应用程序仅打包到 [Arch User Repository][9] 中。
|
||||
|
||||
在你开始之前,你必须正确安装了 Go,并且已经定义好了 `$GOPATH` 环境变量。
|
||||
|
||||
首先,安装必需的依赖。
|
||||
|
||||
```
|
||||
sudo apt-get install protobuf-compiler libpcap-dev libnetfilter-queue-dev python3-pip
|
||||
|
||||
go get github.com/golang/protobuf/protoc-gen-go
|
||||
|
||||
go get -u github.com/golang/dep/cmd/dep
|
||||
|
||||
python3 -m pip install --user grpcio-tools
|
||||
```
|
||||
|
||||
接下来,克隆 OpenSnitch 仓库。这里可能会出现一个没有 Go 文件的信息,不用理它。如果出现 git 没有找到的信息,那么你需要首先去安装 Git。
|
||||
|
||||
```
|
||||
go get github.com/evilsocket/opensnitch
|
||||
|
||||
cd $GOPATH/src/github.com/evilsocket/opensnitch
|
||||
```
|
||||
|
||||
如果没有正确设置 `$GOPATH` 环境变量,运行上面的命令时将会出现一个 “no such folder found” 的错误信息。只需要进入到你刚才克隆仓库位置的 “evilsocket/opensnitch” 文件夹中即可。
|
||||
|
||||
现在,我们构建并安装它。
|
||||
|
||||
```
|
||||
make
|
||||
|
||||
sudo make install
|
||||
```
|
||||
|
||||
如果出现 “`dep` command could not be found” 的错误信息,在 `PATH` 中添加 `GOPATH/bin` 即可。
|
||||
|
||||
安装完成后,我们将要启动它的守护程序和图形用户界面。
|
||||
|
||||
```
|
||||
sudo systemctl enable opensnitchd
|
||||
|
||||
sudo service opensnitchd start
|
||||
|
||||
opensnitch-ui
|
||||
```
|
||||
|
||||
![OpenSnitch firewall interface][10]
|
||||
运行在 Manjaro 上的 OpenSnitch
|
||||
|
||||
### 使用体验
|
||||
|
||||
实话实说:我使用 OpenSnitch 的体验并不好。我开始在 Fedora 上尝试安装它。遇到了许多依赖问题。我又转到 Manjaro 上,在 Arch User Repository 上我很容易地找到了这些依赖。
|
||||
|
||||
不幸的是,我安装之后,不能启动图形用户界面。因此,我手动去运行最后三个步骤。一切似乎很顺利。如果我想让 Firefox 去访问 Manjaro 的网站,对话框就会弹出来询问我。
|
||||
|
||||
有趣的是,当我运行一个 [AUR 工具][11] `yay` 去更新我的系统时,弹出对话框要求了 `yay`、`pacman`、`pamac`、和 `git` 的访问规则。后来,我关闭并重启动 GUI,因为它是活动的。当我重启动它时,它不再要求我去创建规则了。我安装了 Falkon,而 OpenSnitch 并没有询问我去授予它任何权限。它甚至在 OpenSnitch 的 GUI 中没有列出 Falkon。我重新安装了 OpenSnitch 后,这个问题依旧存在。
|
||||
|
||||
然后,我转到 Ubuntu Mate 上安装 OpenSnitch,因为安装介绍就是针对 Ubuntu 所写的,进展很顺利。但是,我遇到了几个问题。我调整了一下上面介绍的安装过程以解决我遇到的问题。
|
||||
|
||||
安装的问题并不是我遇到的唯一问题。每次一个新的应用程序创建一个连接时弹出的对话框仅存在 10 秒钟。这么短的时间根本不够去浏览所有的可用选项。大多数情况下,这点时间只够我去永久允许一个(我信任的)应用程序访问 web。
|
||||
|
||||
GUI 也有一点需要去改进。由于某些原因,每次窗口都被放在顶部。而且不能通过设置来修改这个问题。如果能够从 GUI 中改变规则将是一个不错的选择。
|
||||
|
||||
![][12]OpenSnitch 的 hosts 标签
|
||||
|
||||
### 对 OpenSnitch 的最后意见
|
||||
|
||||
我很喜欢 OpenSnitch 的目标:用任何简单的方式控制离开你的计算机的信息。但是,它还很粗糙,我不能将它推荐给普通或业余用户。如果你是一个高级用户,很乐意去摆弄或挖掘这些问题,那么它可能很适合你。
|
||||
|
||||
这有点令人失望。我希望即将到来的 1.0 版本能够做的更好。
|
||||
|
||||
你以前用过 OpenSnitch 吗?如果没有,你最喜欢的防火墙应用是什么?你是如何保护你的 Linux 系统的?在下面的评论区告诉我们吧。
|
||||
|
||||
如果你对本文感兴趣,请花一点时间将它分享到社交媒体上吧,Hacker News 或 [Reddit][13] 都行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/opensnitch-firewall-linux/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/linux-firewall-security.jpg?fit=800%2C450&ssl=1
|
||||
[2]: https://www.opensnitch.io/
|
||||
[3]: https://github.com/evilsocket
|
||||
[4]: https://twitter.com/evilsocket
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/opensnitch-dialog.jpg?fit=800%2C421&ssl=1
|
||||
[6]: https://www.json.org/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/opensnitch-processes.jpg?fit=800%2C651&ssl=1
|
||||
[8]: https://github.com/evilsocket/opensnitch
|
||||
[9]: https://aur.archlinux.org/packages/opensnitch-git
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/opensnitch-manjaro.jpg?fit=800%2C651&ssl=1
|
||||
[11]: https://itsfoss.com/best-aur-helpers/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/opensnitch-hosts.jpg?fit=800%2C651&ssl=1
|
||||
[13]: http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,307 @@
|
||||
关于 top 工具的 6 个替代方案
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 GitHub 和 GitLab 上,不断有来自世界各地的开源应用程序和工具涌现。其中有全新的应用程序,也有针对现有各种被广泛使用的 Linux 程序的替代方案。在本文档中,我会介绍一些针对 [`top`][1] 工具(也就是命令行任务管理器程序)的替代方案。
|
||||
|
||||
### top 工具的替代方案
|
||||
|
||||
在本文中,将会介绍以下 6 种 `top` 工具的替代方案:
|
||||
|
||||
1. Htop
|
||||
2. Vtop
|
||||
3. Gtop
|
||||
4. Gotop
|
||||
5. Ptop
|
||||
6. Hegemon
|
||||
|
||||
如果后续有更多类似的工具,原作者会在原文进行更新。如果你对此有兴趣,可以持续关注。
|
||||
|
||||
#### Htop
|
||||
|
||||
`htop` 是一个流行的开源跨平台交互式进程管理器,也是我最喜欢的系统活动监控工具。`htop` 是对原版 `top` 工具的扩展。它最初只是用于 Linux 系统,后来开发者们不断为其添加对其它类 Unix 操作系统的支持,包括 FreeBSD 和 Mac OS。`htop` 还是一个自由开源软件,它基于 ncurses 并按照 GPLv2 发布。
|
||||
|
||||
和原版的 `top` 工具相比,`htop` 工具有这些优势:
|
||||
|
||||
* `htop` 比 `top` 启动更快
|
||||
* `htop` 支持横向滚动和纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行
|
||||
* 在 `top` 工具中进行杀死进程、更改进程优先级这些操作时,需要输入进程 ID,而在 `htop` 工具中则不需要输入
|
||||
* 在 `htop` 中可以同时杀死多个进程
|
||||
* 在 `top` 中每次输入一个未预设的键都要等待一段时间,尤其是在多个键组成转义字符串的时候就更麻烦了
|
||||
|
||||
在很多 Linux 发行版的默认软件仓库中,都带有了 `htop`。
|
||||
|
||||
在基于 Arch 的操作系统中则可以执行以下命令来安装 `htop`:
|
||||
|
||||
```
|
||||
$ sudo pacman -S htop
|
||||
```
|
||||
|
||||
在基于 Debian 的操作系统使用以下命令:
|
||||
|
||||
```
|
||||
$ sudo apt install htop
|
||||
```
|
||||
|
||||
在使用 RPM 软件管理的操作系统使用以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install htop
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ sudo yum install htop
|
||||
```
|
||||
|
||||
在 openSUSE 系统中:
|
||||
|
||||
```
|
||||
$ sudo zypper in htop
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
不带任何参数执行 `htop` 时,会显示如下画面:
|
||||
|
||||
```
|
||||
$ htop
|
||||
```
|
||||

|
||||
|
||||
从图上可以看出,`htop` 会在界面顶部显示内存、交换空间、任务总数、系统平均负载、系统正常运行时间这些常用指标,在下方则和 `top` 一样显示进程列表,并且将进程的 ID、用户、进程优先级、进程 nice 值、虚拟内存使用情况、CPU 使用情况、内存使用情况等信息以多列显示出来。如果你想详细了解这些数据的含义,可以在[这里][1]阅读参考。
|
||||
|
||||
和 `top` 不同的是,`htop` 支持对不同的操作使用专有的按键。以下列出一些用于与 `htop` 交互的快捷键:
|
||||
|
||||
* `F1`、`h`、`?`:进入帮助界面。
|
||||
* `F2`、`Shift+s`:进入设置界面。在设置界面中可以配置仪表板界面顶部显示哪些数据,以及设置颜色方案、显示列、显示顺序等等多种参数。
|
||||
* `F3`、`/`:在进程列表中进行搜索。
|
||||
* `F4`、`\`:进入筛选模式。输入一个字符串,筛选出包含这个字符串的进程。进入筛选模式后再按一次 `F4` 或者 `ESC` 可以退出筛选模式。
|
||||
* `F5`、`t`:切换默认显示模式和树型显示模式,在树型显示模式下按 `+` 可以查看子树。
|
||||
* `F6`、`<`、`>`:依次按照进程 ID、用户、进程优先级、进程 nice 值、CPU 使用率、内存使用率排序显示。
|
||||
* `F7`、`]`:提高所选进程的优先级。
|
||||
* `F8`、`[`:降低所选进程的优先级。
|
||||
* `F9`、`k`:杀死所选进程。可以用 `↑` / `↓` 键选择不同的进程并按 `F9` 杀死进程。
|
||||
* `F10`、`q`: 退出 `htop`
|
||||
|
||||
|
||||
|
||||
以上这些快捷键都在 `htop` 界面底部显示。
|
||||
|
||||
需要注意的是,这其中有一些快捷键可能会与已有的快捷键发生冲突。例如按 `F2` 之后可能没有进入 `htop` 的设置界面,而是开始了对终端窗口的重命名。在这种情况下,你可能要更改一下快捷键的设置。
|
||||
|
||||
除了以上列出的快捷键以外,还有一些带有其它功能的快捷键,例如:
|
||||
|
||||
* `u` 可以选择显示某个用户的进程。
|
||||
* `Shift+m` 可以按照内存使用量对进程列表排序。
|
||||
* `Shift+p` 可以按照 CPU 使用量对进程列表排序。
|
||||
* `Shit+t` 可以按照进程启动时间对进程列表排序。
|
||||
* `CTRL+l` 刷新界面。
|
||||
|
||||
|
||||
|
||||
`htop` 的所有功能都可以在启动后通过快捷键来调用,而不需要在启动的时候带上某个参数。当然,`htop` 也支持带参数启动。
|
||||
|
||||
例如按照以下方式启动 `htop` 就可以只显示某个用户的进程:
|
||||
|
||||
```
|
||||
$ htop -u <username>
|
||||
```
|
||||
|
||||
更改界面自动刷新的时间间隔:
|
||||
|
||||
```kan
|
||||
$ htop -d 10
|
||||
```
|
||||
|
||||
看,`htop` 确实比 `top` 好用多了。
|
||||
|
||||
想了解 `htop` 的更多细节,可以查阅它的手册页面:
|
||||
|
||||
```
|
||||
$ man htop
|
||||
```
|
||||
|
||||
也可以查看它的[项目主页](http://hisham.hm/htop/)和 [GitHub 仓库](https://github.com/hishamhm/htop)。
|
||||
|
||||
#### Vtop
|
||||
|
||||
`vtop` 是 `top` 工具的另一个替代方案。它是一个使用 NodeJS 编写的、自由开源的命令行界面系统活动监视器,并使用 MIT 许可发布。`vtop` 通过使用 unicode 中的盲文字符来绘制 CPU 和内存使用情况的可视化图表。
|
||||
|
||||
在安装 `vtop` 之前,需要先安装 NodeJS。如果还没有安装 NodeJS,可以按照[这个教程](https://www.ostechnix.com/install-node-js-linux/)进行安装。
|
||||
|
||||
NodeJS 安装完毕之后,执行以下命令安装 `vtop`:
|
||||
|
||||
```
|
||||
$ npm install -g vtop
|
||||
```
|
||||
|
||||
安装好 `vtop` 就可以执行以下命令开始监控了。
|
||||
|
||||
```
|
||||
$ vtop
|
||||
```
|
||||
|
||||
显示界面如下:
|
||||
|
||||
![][3]
|
||||
|
||||
如上图所示,`vtop` 界面和 `top`、`htop` 都有所不同,它将不同的内容分别以多个盒子的布局显示。另外在界面底部也展示了用于与 `vtop` 交互的所有快捷键。
|
||||
|
||||
`vtop` 有这些快捷键:
|
||||
|
||||
* `dd` :杀死一个进程。
|
||||
* `↑`、`k`:向上移动。
|
||||
* `↓`、`j`:向下移动。
|
||||
* `←`、`h` :放大图表。
|
||||
* `→`、`l`:缩小图表。
|
||||
* `g` :跳转到进程列表顶部。
|
||||
* `Shift+g` :跳转到进程列表底部。
|
||||
* `c` :以 CPU 使用量对进程排序。
|
||||
* `m` :以内存使用量对进程排序。
|
||||
|
||||
|
||||
|
||||
想要了解更多关于 `vtop` 的细节,可以查阅它的[项目主页](http://parall.ax/vtop)或者 [GitHub 仓库](https://github.com/MrRio/vtop)。
|
||||
|
||||
#### Gtop
|
||||
|
||||
`gtop` 和 `vtop` 一样,都是一个使用 NodeJS 编写、在 MIT 许可下发布的系统活动监视器。
|
||||
|
||||
执行以下命令安装 `gtop`:
|
||||
|
||||
```
|
||||
$ npm install gtop -g
|
||||
```
|
||||
|
||||
然后执行以下命令启动:
|
||||
|
||||
```
|
||||
$ gtop
|
||||
```
|
||||
|
||||
显示界面如下:
|
||||
|
||||

|
||||
|
||||
`gtop` 有一个好,就是它会以不同的颜色来显示不同的模块,这种表现形式非常清晰明了。
|
||||
|
||||
主要的快捷键包括:
|
||||
|
||||
* `p`:按照进程 ID 对进程排序。
|
||||
* `c`:按照 CPU 使用量对进程排序。
|
||||
* `m`:按照内存使用量对进程排序。
|
||||
* `q`、`Ctrl+c`:退出。
|
||||
|
||||
|
||||
|
||||
想要了解更多关于 `gtop` 的细节,可以查阅它的 [GitHub 仓库](https://github.com/aksakalli/gtop)。
|
||||
|
||||
#### Gotop
|
||||
|
||||
`gotop` 也是一个完全自由和开源的图表式系统活动监视器。顾名思义,它是在受到 `gtop` 和 `vtop` 的启发之后用 Go 语言编写的,因此也不再对其展开过多的赘述了。如果你有兴趣了解这个项目,可以阅读《[gotop:又一个图表式系统活动监视器](https://www.ostechnix.com/manage-python-packages-using-pip/)》这篇文章。
|
||||
|
||||
#### Ptop
|
||||
|
||||
有些人对 NodeJS 和 Go 语言的项目可能不太感冒。如果你也是其中之一,你可以试一下使用 Python 编写的 `ptop`。它同样是一个自由开源的、在 MIT 许可下发布的系统活动监视器。
|
||||
|
||||
`ptop` 同时兼容 Python2.x 和 Python3.x,因此可以使用 Python 的软件包管理器 `pip` 轻松安装。如果你没有安装 `pip`,也可以参考[这个教程](https://www.ostechnix.com/manage-python-packages-using-pip/)进行安装。
|
||||
|
||||
安装 `pip` 之后,执行以下命令就可以安装 `ptop`:
|
||||
|
||||
```
|
||||
$ pip install ptop
|
||||
```
|
||||
|
||||
又或者按照以下方式通过源代码安装:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/darxtrix/ptop
|
||||
$ cd ptop/
|
||||
$ pip install -r requirements.txt # install requirements
|
||||
$ sudo python setup.py install
|
||||
```
|
||||
|
||||
如果需要对 `ptop` 进行更新,可以这样操作:
|
||||
|
||||
```
|
||||
$ pip install --upgrade ptop
|
||||
```
|
||||
|
||||
即使你不执行更新,`ptop` 也会在第一次启动的时候提示你是否需要更新到最新的版本。
|
||||
|
||||
现在可以看一下启动 `ptop` 后的界面。
|
||||
|
||||
```
|
||||
$ ptop
|
||||
```
|
||||
|
||||
就像下面这样:
|
||||

|
||||
|
||||
`ptop` 的快捷键包括以下这些:
|
||||
|
||||
* `Ctrl+k`:杀死一个进程。
|
||||
* `Ctrl+n`:按照内存使用量对进程排序。
|
||||
* `Ctrl+t`:按照进程启动时间对进程排序。
|
||||
* `Ctrl+r`:重置所有数据。
|
||||
* `Ctrl+f`:对进程进行筛选,输入进程的名称就能够筛选出符合条件的进程。
|
||||
* `Ctrl+l`:查看所选进程的详细信息。
|
||||
* `g`:跳转到进程列表顶部。
|
||||
* `Ctrl+q`:退出。
|
||||
|
||||
|
||||
|
||||
`ptop` 还支持更改显示主题。如果你想让 `ptop` 更好看,可以选择你喜欢的主题。可用的主题包括以下这些:
|
||||
|
||||
* colorful
|
||||
* elegant
|
||||
* simple
|
||||
* dark
|
||||
* light
|
||||
|
||||
|
||||
|
||||
如果需要更换主题(例如更换到 colorful 主题),可以执行以下命令:
|
||||
|
||||
```
|
||||
$ ptop -t colorful
|
||||
```
|
||||
|
||||
使用 `-h` 参数可以查看帮助页面:
|
||||
|
||||
```
|
||||
$ ptop -h
|
||||
```
|
||||
|
||||
想要了解更多关于 `ptop` 的细节,可以查阅它的 [GitHub 仓库](https://github.com/darxtrix/ptop)。
|
||||
|
||||
#### Hegemon
|
||||
|
||||
`hegemon` 是一个使用 Rust 编写的系统活动监视器,如果你对 Rust 感兴趣,也可以了解一下。我们最近有一篇关于 `hegemon` 的[文章](https://www.ostechnix.com/hegemon-a-modular-system-monitor-application-written-in-rust/),想要详细了解的读者不妨阅读。
|
||||
|
||||
### 总结
|
||||
|
||||
以上就是关于 `top` 工具的 6 个替代方案。我并不会说它们比 `top` 更好或者可以完全替代 `top`,但多了解一些类似的工具总是好的。你有使用过这些工具吗?哪个是你最喜欢的?欢迎在评论区留言。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/some-alternatives-to-top-command-line-utility-you-might-want-to-know/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/the-top-command-tutorial-with-examples-for-beginners/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2018/11/vtop.png
|
||||
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Drive a locomotive through your Linux terminal)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-sl)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
[#]: url: ( )
|
||||
|
||||
在 Linux 终端中开火车
|
||||
======
|
||||
使用 sl 命令,你可以让自己坐上火车,有一个有趣的命令行体验。
|
||||
|
||||
|
||||
现在是 12 月,每个 Linux 终端用户都值得这一年的奖励。因此, 我们将为你带来一个 Linux 命令行玩具的出现日历。什么是命令行玩具?它可能是一个游戏、一个小的无意义的打发时间的东西,或者为你在终端带来快乐的东西。
|
||||
|
||||
今天的 Linux 命令行玩具是来自 Opensource.com 社区版主 [Ben Cotton][1] 的建议。Ben 建议 `sl`,它是蒸汽机车的简称。
|
||||
|
||||
对于 Linux **ls** 命令来说,它也是一个常见的错误,而不是巧合。想要不再打错吗?尝试安装 **sl**。它可能已经在默认仓库中打包。对我而言,在 Fedora 中,这意味着安装起来很简单:
|
||||
|
||||
```
|
||||
$ sudo dnf install sl -y
|
||||
```
|
||||
|
||||
现在,只需键入**sl** 即可测试。
|
||||
|
||||

|
||||
|
||||
你可能会像我一样注意到,**Ctrl+C** 不会让你的火车脱轨,所以你必须等待整列火车通过。这会让你知道打错了 **ls**!
|
||||
|
||||
|
||||
想查看 **sl** 源码?它已经在[在 GitHub 上][2]。
|
||||
|
||||
**sl** 也是分享关于开源许可的个人 PSA 的绝佳机会。虽然它的[许可证][3]“足够开源”以便为我的发行版打包,但技术上而言,它并不是 [OSI 批准][4]的许可证。在版权行之后,许可证的内容很简单:
|
||||
|
||||
```
|
||||
Everyone is permitted to do anything on this program including copying,
|
||||
modifying, and improving, unless you try to pretend that you wrote it.
|
||||
i.e., the above copyright notice has to appear in all copies.
|
||||
THE AUTHOR DISCLAIMS ANY RESPONSIBILITY WITH REGARD TO THIS SOFTWARE.
|
||||
```
|
||||
|
||||
遗憾的是,当你选择未经 OSI 批准的许可证时,你可能会意外地为你的用户带来额外的工作,因为他们必须要弄清楚你的许可证是否适用于他们的情况。他们的公司政策是否允许他们做贡献?甚至他们可以合法地使用该程序吗?许可证是否与他们希望与之集成的其他程序的许可证相匹配?
|
||||
|
||||
除非你是律师(也许,即使你是律师),否则在非标准许可证范围内选择可能会很棘手。因此,如果你仍在寻找新年的方案,为什么不把仅 OSI 批准的许可证作为你 2019 年新项目的选择呢。
|
||||
|
||||
这并不是对作者的不尊重。**sl** 仍然是一个很棒的小命令行玩具。
|
||||
|
||||
你有一个你认为我应该介绍的最喜欢的命令行玩具吗?这个系列的日历大部分已经完成,但我还剩下几个空余。请在下面的评论中告诉我,我会了解一下。如果有空间,我会尝试包含它。如果没有,但我得到了一些好的投稿,我会在最后做一些荣誉介绍。
|
||||
|
||||
了解昨天的玩具,[在 Linux 命令行中装饰字符][5],还有记得明天再来!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-sl
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/users/bcotton
|
||||
[2]: https://github.com/mtoyoda/sl
|
||||
[3]: https://github.com/mtoyoda/sl/blob/master/LICENSE
|
||||
[4]: https://opensource.org/licenses
|
||||
[5]: https://opensource.com/article/18/12/linux-toy-boxes
|
||||
Loading…
Reference in New Issue
Block a user