mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
c593244d04
@ -1,12 +1,11 @@
|
||||
Linux 中如何打印和管理打印机
|
||||
完全指南:在 Linux 中如何打印和管理打印机
|
||||
======
|
||||
|
||||
|
||||
### Linux 中的打印
|
||||
|
||||
虽然现在大量的沟通都是电子化和无纸化的,但是在我们的公司中还有大量的材料需要打印。银行结算单、公用事业帐单、财务和其它报告、以及收益结算单等一些东西还是需要打印的。本教程将介绍在 Linux 中如何使用 CUPS 去打印。
|
||||
|
||||
CUPS,是通用 Unix 打印系统(Common UNIX Printing System)的首字母缩写,它是 Linux 中的打印机和打印任务的管理者。早期计算机上的打印机一般是在特定的字符集和字体大小下打印文本文件行。现在的图形打印机可以打印各种字体和大小的文本和图形。尽管如此,现在你所使用的一些命令,在它们以前的历史上仍旧使用的是古老的行打印守护进程(LPD)技术。
|
||||
CUPS,是<ruby>通用 Unix 打印系统<rt>Common UNIX Printing System</rt></ruby>的首字母缩写,它是 Linux 中的打印机和打印任务的管理者。早期计算机上的打印机一般是在特定的字符集和字体大小下打印文本文件行。现在的图形打印机可以打印各种字体和大小的文本和图形。尽管如此,现在你所使用的一些命令,在古老的行式打印守护进程(LPD)技术的历史中仍能找到它们。
|
||||
|
||||
本教程将帮你了解 Linux 服务器专业考试(LPIC-1)的第 108 号主题的 108.4 目标。这个目标的权重为 2。
|
||||
|
||||
@ -20,38 +19,39 @@ CUPS,是通用 Unix 打印系统(Common UNIX Printing System)的首字母
|
||||
|
||||
这一小部分历史并不是 LPI 目标的,但它有助于你理解这个目标的相关环境。
|
||||
|
||||
早期的计算机大都使用行打印机。这些都是击打式打印机,一段时间以来,它们使用固定间距的字符和单一的字体来打印文本行。为提升整个系统性能,早期的主机都对慢速的外围设备如读卡器、卡片穿孔机、和运行其它工作的行打印进行交叉工作。因此就产生了在行上或者假脱机上的同步外围操作,这一术语目前在谈到计算机打印时仍然在使用。
|
||||
早期的计算机大都使用行式打印机。这些都是击打式打印机,那时,它们使用固定间距的字符和单一的字体来打印文本行。为提升整个系统性能,早期的主机要与慢速的外围设备(如读卡器、卡片穿孔机、和运行其它工作的行式打印机)交叉进行工作。因此就产生了在线的或者假脱机的同步外围操作,这一术语目前在谈到计算机打印时仍然在使用。
|
||||
|
||||
在 UNIX 和 Linux 系统上,打印初始化使用的是 BSD(Berkeley Software Distribution)打印子系统,它是由一个作为服务器运行的行打印守护程序(LPD)组成,而客户端命令如 `lpr` 是用于提交打印作业。这个协议后来被 IETF 标准化为 RFC 1179 —— **行打印机守护协议**。
|
||||
在 UNIX 和 Linux 系统上,打印初始化使用的是 BSD(<ruby>伯克利软件分发版<rt>Berkeley Software Distribution</rt></ruby>)打印子系统,它是由一个作为服务器运行的行式打印守护程序(LPD)组成,而客户端命令如 `lpr` 是用于提交打印作业。这个协议后来被 IETF 标准化为 RFC 1179 —— **行式打印机守护进程协议**。
|
||||
|
||||
系统也有一个打印守护程序。它的功能与BSD 的 LPD 守护程序类似,但是它们的命令集不一样。你在后面会经常看到完成相同的任务使用不同选项的两个命令。例如,对于打印文件的命令,`lpr` 是伯克利实现的,而 `lp` 是 System V 实现的。
|
||||
System V 也有一个打印守护程序。它的功能与BSD 的 LPD 守护程序类似,但是它们的命令集不一样。你在后面会经常看到完成相同的任务使用不同选项的两个命令。例如,对于打印文件的命令,伯克利实现版本是 `lpr`,而 System V 实现版本是 `lp`。
|
||||
|
||||
随着打印机技术的进步,在一个页面上混合出现不同字体成为可能,并且可以将图片像文字一样打印。可变间距字体,以及更多先进的打印技术,比如 kerning 和 ligatures,现在都已经标准化。它们对基本的 lpd/lpr 方法进行了改进设计,比如 LPRng,下一代的 LPR、以及 CUPS。
|
||||
随着打印机技术的进步,在一个页面上混合出现不同字体成为可能,并且可以将图片像文字一样打印。可变间距字体,以及更多先进的打印技术,比如间距和连字符,现在都已经标准化。出现了几种对基本的 lpd/lpr 方法等改进设计,比如 LPRng,下一代的 LPR,以及 CUPS。
|
||||
|
||||
许多可以打印图形的打印机,使用 Adobe PostScript 语言进行初始化。一个 PostScript 打印机有一个解释器引擎,它可以解释打印任务中的命令并从这些命令中生成最终的页面。PostScript 经常被用做原始文件和打印机之间的中间层,比如一个文本文件或者一个图像文件,以及没有适合 PostScript 功能的特定打印机的最终格式。转换这些特定的打印任务,比如一个 ASCII 文本文件或者一个 JPEG 图像转换为 PostScript,然后再使用过滤器转换 PostScript 到非 PostScript 打印机所需要的最终光栅格式。
|
||||
许多可以打印图形的打印机,使用 Adobe PostScript 语言进行初始化。一个 PostScript 打印机有一个解释器引擎,它可以解释打印任务中的命令并从这些命令中生成最终的页面。PostScript 经常被用做原始文件(比如一个文本文件或者一个图像文件)和最终格式没有适合的 PostScript 功能的特定打印机之间的中间层。转换这些特定的打印任务,比如将一个 ASCII 文本文件或者一个 JPEG 图像转换为 PostScript,然后再使用过滤器转换 PostScript 到非 PostScript 打印机所需要的最终光栅格式。
|
||||
|
||||
现在的便携式文档格式(PDF),它就是基于 PostScript 的,已经替换了传统的原始 PostScript。PDF 设计为与硬件和软件无关,它封装了要打印的页面的完整描述。你可以查看 PDF 文件,同时也可以打印它们。
|
||||
现在的<ruby>便携式文档格式<rt>Portable Document Format</rt></ruby>(PDF),它就是基于 PostScript 的,已经替换了传统的原始 PostScript。PDF 设计为与硬件和软件无关,它封装了要打印的页面的完整描述。你可以查看 以及打印 PDF 文件。
|
||||
|
||||
### 管理打印队列
|
||||
|
||||
用户直接打印作业到一个名为打印队列的逻辑实体。在单用户系统中,一个打印队列和一个打印机通常是几乎相同的意思。但是,CUPS 允许系统对最终在一个远程系统上的打印,并不附属打印机到一个队列打印作业上,而是通过使用类,允许将打印作业重定向到该类第一个可用的打印机上。
|
||||
用户直接打印作业到一个名为<ruby>打印队列<rt>print queue</rt></ruby>的逻辑实体。在单用户系统中,打印队列和打印机通常是几乎相同的意思。但是,CUPS 允许系统不用连接到一个打印机上,而最终在一个远程系统上的排队打印作业,并且通过使用分类,允许将定向到一个分类的打印作业在该分类第一个可用的打印机上打印。
|
||||
|
||||
你可以检查和管理打印队列。对于 CUPS 来说,其中一些命令还是很新的。另外的一些是源于 LPD 的兼容命令,不过现在的一些选项通常是原始 LPD 打印系统选项的有限子集。
|
||||
你可以检查和管理打印队列。对于 CUPS 来说,其中一些命令实现了一些新操作。另外的一些是源于 LPD 的兼容命令,不过现在的一些选项通常是最初的 LPD 打印系统选项的有限子集。
|
||||
|
||||
你可以使用 CUPS 的 `lpstat` 命令去检查队列,以了解打印系统。一些常见命令如下表 1。
|
||||
|
||||
###### 表 1. lpstat 命令的选项
|
||||
| 选项 | 作用 |
|
||||
| -a | 显示打印机状态 |
|
||||
| -c | 显示打印类 |
|
||||
| -p | 显示打印状态:enabled 或者 disabled. |
|
||||
| -s | 显示默认打印机、打印机和类。相当于 -d -c -v。**注意:为指定多个选项,这些选项必须像值一样分隔开。**|
|
||||
| -s | 显示打印机和它们的设备。 |
|
||||
你可以使用 CUPS 的 `lpstat` 命令去检查队列,以了解打印系统。一些常见选项如下表 1。
|
||||
|
||||
|
||||
你也可以使用 LPD 的 `lpc` 命令,它可以在 /usr/sbin 中找到,使用它的 `status` 选项。如果你不想指定打印机名字,将列出所有的队列。列表 1 展示了命令的一些示例。
|
||||
| 选项 | 作用 |
|
||||
| --- | --- |
|
||||
| `-a` | 显示打印机状态 |
|
||||
| `-c` | 显示打印分类 |
|
||||
| `-p` | 显示打印状态:`enabled` 或者 `disabled` |
|
||||
| `-s` | 显示默认打印机、打印机和类。相当于 `-d -c -v`。**注意:要指定多个选项,这些选项必须像值一样分隔开。**|
|
||||
| `-v` | 显示打印机和它们的设备。|
|
||||
|
||||
*表 1. lpstat 命令的选项*
|
||||
|
||||
你也可以使用 LPD 的 `lpc` 命令(它可以在 `/usr/sbin` 中找到)使用它的 `status` 选项。如果你不想指定打印机名字,将列出所有的队列。列表 1 展示了命令的一些示例。
|
||||
|
||||
###### 列表 1. 显示可用打印队列
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -d
|
||||
system default destination: HL-2280DW
|
||||
@ -77,11 +77,12 @@ HL-2280DW:
|
||||
|
||||
```
|
||||
|
||||
这个示例展示了两台打印机 —— HL-2280DW 和 XP-610,和一个类 `anyprint`,它允许打印作业定向到这两台打印机中的第一个可用打印机。
|
||||
*列表 1. 显示可用打印队列*
|
||||
|
||||
在这个示例中,已经禁用了打印到 HL-2280DW 队列,但是打印是启用的,这样便于打印机脱机维护之前可以完成打印队列中的任务。无论队列是启用还是禁用,都可以使用 `cupsaccept` 和 `cupsreject` 命令来管理它们。你或许可能在 /usr/sbin 中找到这些命令,它们现在都是链接到新的命令上。同样,无论打印是启用还是禁用,你都可以使用 `cupsenable` 和 `cupsdisable` 命令来管理它们。在早期版本的 CUPS 中,这些被称为 `enable` 和 `disable`,它也许会与 bash shell 内置的 `enable` 混淆。列表 2 展示了如何去启用打印机 HL-2280DW 上的队列,不过它的打印还是禁止的。CUPS 的几个命令支持使用一个 `-r` 选项去提供一个动作的理由。这个理由会在你使用 `lpstat` 时显示,但是如果你使用的是 `lpc` 命令则不会显示它。
|
||||
这个示例展示了两台打印机 —— HL-2280DW 和 XP-610,和一个分类 `anyprint`,它允许打印作业定向到这两台打印机中的第一个可用打印机。
|
||||
|
||||
在这个示例中,已经禁用了打印到 HL-2280DW 队列,但是打印功能是启用的,这样便于将打印机脱机维护之前可以完成打印队列中的任务。启用还是禁用队列,可以使用 `cupsaccept` 和 `cupsreject` 命令来管理。以前它们叫做 `accept` 和 `reject`,你或许可能在 `/usr/sbin` 中找到这些命令,但它们现在都是符号链接到新的命令上了。同样,启用还是禁用打印,你可以使用 `cupsenable` 和 `cupsdisable` 命令来管理。在早期版本的 CUPS 中,这些被称为 `enable` 和 `disable`,它也许会与 bash shell 内置的 `enable` 混淆。列表 2 展示了如何去启用打印机 HL-2280DW 上的队列,而禁止它的打印。CUPS 的几个命令支持使用 `-r` 选项去提供一个该操作的理由。这个理由会在你使用 `lpstat` 时显示,但是如果你使用的是 `lpc` 命令则不会显示它。
|
||||
|
||||
###### 列表 2. 启用队列和禁用打印
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -a -p HL-2280DW
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
@ -100,16 +101,16 @@ printer XP-610 is idle. enabled since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Mon 29 Jan 2018 04:03:50 PM EST
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
|
||||
```
|
||||
|
||||
注意:用户执行这些任务必须经过授权。它可能要求是 root 用户或者其它的授权用户。在 /etc/cups/cups-files.conf 中可以看到 SystemGroup 的条目,cups-files.conf 的 man 页面有更多授权用户组的信息。
|
||||
*列表 2. 启用队列和禁用打印*
|
||||
|
||||
注意:用户执行这些任务必须经过授权。它可能要求是 root 用户或者其它的授权用户。在 `/etc/cups/cups-files.conf` 中可以看到 `SystemGroup` 的条目,`cups-files.conf` 的 man 页面有更多授权用户组的信息。
|
||||
|
||||
### 管理用户打印作业
|
||||
|
||||
现在,你已经知道了一些如何去检查打印队列和类的方法,我将给你展示如何管理打印队列上的作业。你要做的第一件事是,如何找到一个特定打印机或者全部打印机上排队的任意作业。完成上述工作要使用 `lpq` 命令。如果没有指定任何选项,`lpq` 将显示默认打印机上的队列。使用 `-P` 选项和一个打印机名字将指定打印机,或者使用 `-a` 选项去指定所有的打印机,如下面的列表 3 所示。
|
||||
|
||||
###### 列表 3. 使用 lpq 检查打印队列
|
||||
```
|
||||
[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lpq
|
||||
@ -132,16 +133,16 @@ Rank Owner Job File(s) Total Size
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 8 .bashrc 1024 bytes
|
||||
5th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
在这个示例中,共有五个作业,它们是 4、6、7、8、和 9,并且它是名为 HL-2280DW 的打印机的队列,而不是 XP-610 的。在这个示例中使用 `-P` 选项,可简单地显示那个打印机已经准备好,但是没有队列任务。注意,CUPS 的打印机命名,大小写是不敏感的。还要注意的是,用户 ian 提交了同样的作业两次,当一个作业第一次没有打印时,经常能看到用户的这种动作。
|
||||
*列表 3. 使用 lpq 检查打印队列*
|
||||
|
||||
一般情况下,你可能查看或者维护你自己的打印作业,但是,root 用户或者其它授权的用户通常会去管理其它打印作业。大多数 CUPS 命令都可以使用一个 `-E` 选项,对 CUPS 服务器与客户端之间的通讯进行加密。
|
||||
在这个示例中,共有五个作业,它们是 4、6、7、8、和 9,并且它是名为 HL-2280DW 的打印机的队列,而不是 XP-610 的。在这个示例中使用 `-P` 选项,可简单地显示哪个打印机已经准备好,但是没有队列任务。注意,CUPS 的打印机命名,是大小写不敏感的。还要注意的是,用户 ian 提交了同样的作业两次,当一个作业没有第一时间打印时,经常能看到用户的这种动作。
|
||||
|
||||
使用 `lprm` 命令从队列中去删除 .bashrc 作业。如果不使用选项,将删除当前的作业。使用 `-` 选项,将删除全部的作业。要么就如列表 4 那样,指定一个要删除的作业列表。
|
||||
一般情况下,你可能会查看或者维护你自己的打印作业,但是,root 用户或者其它授权的用户通常会去管理其它打印作业。大多数 CUPS 命令都可以使用一个 `-E` 选项,对 CUPS 服务器与客户端之间的通讯进行加密。
|
||||
|
||||
使用 `lprm` 命令从队列中去删除一个 `.bashrc` 作业。如果不使用选项,将删除当前的作业。使用 `-` 选项,将删除全部的作业。要么就如列表 4 那样,指定一个要删除的作业列表。
|
||||
|
||||
###### 列表 4. 使用 lprm 删除打印作业
|
||||
```
|
||||
[[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lprm
|
||||
@ -156,14 +157,14 @@ Rank Owner Job File(s) Total Size
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
*列表 4. 使用 lprm 删除打印作业*
|
||||
|
||||
注意,用户 pat 不能删除队列中的第一个作业,因为它是用户 ian 的。但是,ian 可以删除他自己的 8 号作业。
|
||||
|
||||
另外的可以帮你操作打印队列中的作业的命令是 `lp`。使用它可以去修改作业属性,比如打印数量或者优先级。我们假设用户 ian 希望他的作业 9 在用户 pat 的作业之前打印,并且希望打印两份。作业优先级的默认值是 50,它的优先级范围从最低的 1 到最高的 100 之间。用户 ian 可以使用 `-i`、`-n`、以及 `-q` 选项去指定一个要修改的作业,而新的打印数量和优先级可以如下面的列表 5 所示的那样去修改。注意,使用 `-l` 选项的 `lpq` 命令可以提供更详细的输出。
|
||||
|
||||
###### 列表 5. 使用 lp 去改变打印数量和优先级
|
||||
```
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
@ -180,12 +181,12 @@ Rank Owner Job File(s) Total Size
|
||||
2nd ian 4 permutation.C 6144 bytes
|
||||
3rd pat 6 bitlib.h 6144 bytes
|
||||
4th pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
最后,`lpmove` 命令可以允许一个作业从一个队列移动到另一个队列。例如,我们可能因为打印机 HL-2280DW 现在不能使用,而想去移动一个作业到另外的队列上。你可以指定一个作业编号,比如 9,或者你可以用一个队列名加一个连字符去限定它,比如,HL-2280DW-0。`lpmove` 命令的操作要求一个授权用户。列表 6 展示了如何去从一个队列移动作业到另外的队列,通过打印机和作业 ID 指定第一个,然后指定打印机的所有作业都移动到第二个队列。稍后我们可以去再次检查队列,其中一个作业已经在打印中了。
|
||||
*列表 5. 使用 lp 去改变打印数量和优先级*
|
||||
|
||||
最后,`lpmove` 命令可以允许一个作业从一个队列移动到另一个队列。例如,我们可能因为打印机 HL-2280DW 现在不能使用,而想去移动一个作业到另外的队列上。你可以指定一个作业编号,比如 9,或者你可以用一个队列名加一个连字符去限定它,比如,HL-2280DW-0。`lpmove` 命令的操作要求是授权用户。列表 6 展示了如何去从一个队列移动作业到另外的队列,先是指定打印机和作业 ID 移动,然后是移动指定打印机的所有作业。稍后我们可以去再次检查队列,其中一个作业已经在打印中了。
|
||||
|
||||
###### 列表 6. 使用 lpmove 移动作业到另外一个打印队列
|
||||
```
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW-9 anyprint
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW xp-610
|
||||
@ -200,44 +201,46 @@ active ian 9 .bashrc 1024 bytes
|
||||
Rank Owner Job File(s) Total Size
|
||||
active pat 6 bitlib.h 6144 bytes
|
||||
1st pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是打印服务器而不是 CUPS,比如 LPD 或者 LPRng,大多数的队列管理功能是由 `lpc` 命令的子命令来处理的。例如,你可以使用 `lpc topq` 去移动一个作业到队列的顶端。其它的 `lpc` 子命令包括 `disable`、`down`、`enable`、`hold`、`move`、`redirect`、`release`、和 `start`。这些子命令在 CUPS 的兼容命令中没有实现。
|
||||
*列表 6. 使用 lpmove 移动作业到另外一个打印队列*
|
||||
|
||||
如果你使用的是 CUPS 之外的打印服务器,比如 LPD 或者 LPRng,大多数的队列管理功能是由 `lpc` 命令的子命令来处理的。例如,你可以使用 `lpc topq` 去移动一个作业到队列的顶端。其它的 `lpc` 子命令包括 `disable`、`down`、`enable`、`hold`、`move`、`redirect`、`release`、和 `start`。这些子命令在 CUPS 的兼容命令中没有实现。
|
||||
|
||||
#### 打印文件
|
||||
|
||||
如何去打印创建的作业?大多数图形界面程序都提供了一个打印方法,通常是 **文件** 菜单下面的选项。这些程序为选择打印机、设置页边距、彩色或者黑白打印、打印数量、选择每张纸打印的页面数(每张纸打印两个页面,通常用于讲义)等等,都提供了图形化的工具。现在,我将为你展示如何使用命令行工具去管理这些功能,然后和图形化实现进行比较。
|
||||
|
||||
打印文件最简单的方法是使用 `lpr` 命令,然后提供一个文件名字。这将在默认打印机上打印这个文件。`lp` 命令不仅可以打印文件,也可以修改打印作业。列表 7 展示了使用这个命令的一个简单示例。注意,`lpr` 会静默处理这个作业,但是 `lp` 会显示处理后的作业的 ID。
|
||||
打印文件最简单的方法是使用 `lpr` 命令,然后提供一个文件名字。这将在默认打印机上打印这个文件。而 `lp` 命令不仅可以打印文件,也可以修改打印作业。列表 7 展示了使用这个命令的一个简单示例。注意,`lpr` 会静默处理这个作业,但是 `lp` 会显示处理后的作业的 ID。
|
||||
|
||||
###### 列表 7. 使用 lpr 和 lp 打印
|
||||
```
|
||||
[ian@atticf27 ~]$ echo "Print this text" > printexample.txt
|
||||
[ian@atticf27 ~]$ lpr printexample.txt
|
||||
[ian@atticf27 ~]$ lp printexample.txt
|
||||
request id is HL-2280DW-12 (1 file(s))
|
||||
|
||||
```
|
||||
|
||||
*列表 7. 使用 lpr 和 lp 打印*
|
||||
|
||||
表 2 展示了 `lpr` 上你可以使用的一些选项。注意, `lp` 的选项和 `lpr` 的很类似,但是名字可能不一样;例如,`-#` 在 `lpr` 上是相当于 `lp` 的 `-n` 选项。查看 man 页面了解更多的信息。
|
||||
|
||||
###### 表 2. lpr 的选项
|
||||
|
||||
| 选项 | 作用 |
|
||||
| -C, -J, or -T | 设置一个作业名字。 |
|
||||
| -P | 选择一个指定的打印机。 |
|
||||
| -# | 指定打印数量。注意它与 lp 命令的 -n 有点差别。|
|
||||
| -m | 在作业完成时发送电子邮件。 |
|
||||
| -l | 表示打印文件已经为打印做好格式准备。相当于 -o raw。 |
|
||||
| -o | 设置一个作业选项。 |
|
||||
| -p | 格式化一个带有阴影标题的文本文件。相关于 -o prettyprint。 |
|
||||
| -q | 暂缓(或排队)最后的打印作业。 |
|
||||
| -r | 在文件进入打印池之后,删除文件。 |
|
||||
| 选项 | 作用 |
|
||||
|---|---|
|
||||
| `-C`, `-J` 或 `-T` | 设置一个作业名字。 |
|
||||
| `-P` | 选择一个指定的打印机。|
|
||||
| `-#` | 指定打印数量。注意这不同于 `lp` 命令的 `-n` 选项。|
|
||||
| `-m` | 在作业完成时发送电子邮件。|
|
||||
| `-l` | 表示打印文件已经为打印做好格式准备。相当于 `-o raw`。 |
|
||||
| `-o` | 设置一个作业选项。|
|
||||
| `-p` | 格式化一个带有阴影标题的文本文件。相关于 `-o prettyprint`。|
|
||||
| `-q` | 暂缓(或排队)后面的打印作业。|
|
||||
| `-r` | 在文件进入打印池之后,删除文件。 |
|
||||
|
||||
*表 2. lpr 的选项*
|
||||
|
||||
列表 8 展示了一些选项。我要求打印之后给我发确认电子邮件,那个作业被暂缓执行,并且在打印之后删除文件。
|
||||
|
||||
###### 列表 8. 使用 lpr 打印
|
||||
```
|
||||
[ian@atticf27 ~]$ lpr -P HL-2280DW -J "Ian's text file" -#2 -m -p -q -r printexample.txt
|
||||
[[ian@atticf27 ~]$ lpq -l
|
||||
@ -248,20 +251,20 @@ ian: 1st [job 13 localhost]
|
||||
2 copies of Ian's text file 1024 bytes
|
||||
[ian@atticf27 ~]$ ls printexample.txt
|
||||
ls: cannot access 'printexample.txt': No such file or directory
|
||||
|
||||
```
|
||||
|
||||
我现在有一个在 HL-2280DW 打印队列上暂缓执行的作业。怎么做到这样?`lp` 命令有一个选项可以暂缓或者投放作业,使用 `-H` 选项是使用各种值。列表 9 展示了如何投放被暂缓的作业。检查 `lp` 命令的 man 页面了解其它选项的信息。
|
||||
*列表 8. 使用 lpr 打印*
|
||||
|
||||
我现在有一个在 HL-2280DW 打印队列上暂缓执行的作业。然后怎么做?`lp` 命令可以通过使用 `-H` 的各种选项来暂缓或者投放作业。列表 9 展示了如何投放被暂缓的作业。查看 `lp` 命令的 man 页面了解其它选项的信息。
|
||||
|
||||
###### 列表 9. 重启一个暂缓的打印作业
|
||||
```
|
||||
[ian@atticf27 ~]$ lp -i 13 -H resume
|
||||
|
||||
```
|
||||
|
||||
*列表 9. 重启一个暂缓的打印作业*
|
||||
|
||||
并不是所有的可用打印机都支持相同的选项集。使用 `lpoptions` 命令去查看一个打印机的常用选项。添加 `-l` 选项去显示打印机专用的选项。列表 10 展示了两个示例。许多常见的选项涉及到人像/风景打印、页面大小和输出在纸张上的布局。详细信息查看 man 页面。
|
||||
|
||||
###### 列表 10. 检查打印机选项
|
||||
```
|
||||
[ian@atticf27 ~]$ lpoptions -p HL-2280DW
|
||||
copies=1 device-uri=dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
@ -296,21 +299,22 @@ StpImageType/Image Type: None Text Graphics *TextGraphics Photo LineArt
|
||||
|
||||
```
|
||||
|
||||
大多数的 GUI 应用程序有一个打印对话框,通常你可以使用 **文件 >打印** 菜单去选择它。图 1 展示了在 GIMP 中的一个示例,GIMP 是一个图像处理程序。
|
||||
*列表 10. 检查打印机选项*
|
||||
|
||||
###### 图 1. 在 GIMP 中打印
|
||||
大多数的 GUI 应用程序有一个打印对话框,通常你可以使用 **文件 >打印** 菜单去选择它。图 1 展示了在 GIMP 中的一个示例,GIMP 是一个图像处理程序。
|
||||
|
||||
![Printing from the GIMP][3]
|
||||
|
||||
到目前为止,我们所有的命令都是隐式指向到本地的 CUPS 打印服务器上。你也可以通过指定 `-h` 选项和一个端口号(如果不是 CUPS 的默认端口号 631的话)将打印转向到另外一个系统上的服务器。
|
||||
*图 1. 在 GIMP 中打印*
|
||||
|
||||
到目前为止,我们所有的命令都是隐式指向到本地的 CUPS 打印服务器上。你也可以通过指定 `-h` 选项和一个端口号(如果不是 CUPS 的默认端口号 631 的话)将打印转向到另外一个系统上的服务器。
|
||||
|
||||
### CUPS 和 CUPS 服务器
|
||||
|
||||
CUPS 打印系统的核心是 `cupsd` 打印服务器,它是一个运行的守护进程。CUPS 配置文件一般位于 /etc/cups/cupsd.conf。/etc/cups 目录也有与 CUPS 相关的其它的配置文件。CUPS 一般在系统初始化期间启动,根据你的发行版不同,它也可能通过位于 /etc/rc.d/init.d 或者 /etc/init.d 目录中的 CUPS 脚本来控制。对于 最新使用 systemd 来初始化的系统,CUPS 服务脚本可能在 /usr/lib/systemd/system/cups.service 中。和大多数使用脚本的服务一样,你可以停止、启动、或者重启守护程序。查看我们的教程:[学习 Linux,101:运行级别、引导目标、关闭、和重启动][4],了解使用初始化脚本的更多信息。
|
||||
CUPS 打印系统的核心是 `cupsd` 打印服务器,它是一个运行的守护进程。CUPS 配置文件一般位于 `/etc/cups/cupsd.conf`。`/etc/cups` 目录也有与 CUPS 相关的其它的配置文件。CUPS 一般在系统初始化期间启动,根据你的发行版不同,它也可能通过位于 `/etc/rc.d/init.d` 或者 `/etc/init.d` 目录中的 CUPS 脚本来控制。对于 最新使用 systemd 来初始化的系统,CUPS 服务脚本可能在 `/usr/lib/systemd/system/cups.service` 中。和大多数使用脚本的服务一样,你可以停止、启动、或者重启守护程序。查看我们的教程:[学习 Linux,101:运行级别、引导目标、关闭、和重启动][4],了解使用初始化脚本的更多信息。
|
||||
|
||||
配置文件 /etc/cups/cupsd.conf 包含管理一些事情的参数,比如访问打印系统、是否允许远程打印、本地打印池文件等等。在一些系统上,一个辅助的部分单独描述打印队列,它一般是由配置工具自动生成的。列表 11 展示了一个默认的 cupsd.conf 文件中的一些条目。注意,注释是以 # 字符开头的。默认值通常以注释的方式显示,并且可以通过删除前面的 # 字符去改变默认值。
|
||||
配置文件 `/etc/cups/cupsd.conf` 包含一些管理参数,比如访问打印系统、是否允许远程打印、本地打印池文件等等。在一些系统上,第二部分单独描述了打印队列,它一般是由配置工具自动生成的。列表 11 展示了一个默认的 `cupsd.conf` 文件中的一些条目。注意,注释是以 `#` 字符开头的。默认值通常以注释的方式显示,并且可以通过删除前面的 `#` 字符去改变默认值。
|
||||
|
||||
###### Listing 11. 默认的 /etc/cups/cupsd.conf 文件的部分内容
|
||||
```
|
||||
# Only listen for connections from the local machine.
|
||||
Listen localhost:631
|
||||
@ -338,12 +342,12 @@ WebInterface Yes
|
||||
<Limit Create-Job Print-Job Print-URI Validate-Job>
|
||||
Order deny,allow
|
||||
</Limit>
|
||||
|
||||
```
|
||||
|
||||
能够允许在 cupsd.conf 中使用的文件、目录、和用户配置命令,现在都存储在作为替代的 cups-files.conf 中。这是为了防范某些类型的提权攻击。列表 12 展示了 cups-files.conf 文件中的一些条目。注意,正如在文件层次结构标准(FHS)中所期望的那样,打印池文件默认保存在文件系统的 /var/spool 目录中。查看 man 页面了解 cupsd.conf 和 cups-files.conf 配置文件的更多信息。
|
||||
*列表 11. 默认的 /etc/cups/cupsd.conf 文件的部分内容*
|
||||
|
||||
可以用在 `cupsd.conf` 中使用的文件、目录、和用户配置命令,现在都存储在作为替代的 `cups-files.conf` 中。这是为了防范某些类型的提权攻击。列表 12 展示了 `cups-files.conf` 文件中的一些条目。注意,正如在文件层次结构标准(FHS)中所期望的那样,打印池文件默认保存在文件系统的 `/var/spool` 目录中。查看 man 页面了解 `cupsd.conf` 和 `cups-files.conf` 配置文件的更多信息。
|
||||
|
||||
###### 列表 12. 默认的 /etc/cups/cups-files.conf 配置文件的部分内容
|
||||
```
|
||||
# Location of the file listing all of the local printers...
|
||||
#Printcap /etc/printcap
|
||||
@ -364,12 +368,13 @@ WebInterface Yes
|
||||
|
||||
# Location of other configuration files...
|
||||
#ServerRoot /etc/cups
|
||||
|
||||
```
|
||||
|
||||
列表 12 引用了 /etc/printcap 文件。这是 LPD 打印服务器的配置文件的名字,并且一些应用程序仍然使用它去确定可用的打印机和它们的属性。它通常是在 CUPS 系统上自动生成的,因此,你可能没有必要去修改它。但是,如果你在诊断用户打印问题,你可能需要去检查它。列表 13 展示了一个示例。
|
||||
*列表 12. 默认的 /etc/cups/cups-files.conf 配置文件的部分内容*
|
||||
|
||||
|
||||
列表 12 提及了 `/etc/printcap` 文件。这是 LPD 打印服务器的配置文件的名字,并且一些应用程序仍然使用它去确定可用的打印机和它们的属性。它通常是在 CUPS 系统上自动生成的,因此,你可能没有必要去修改它。但是,如果你在诊断用户打印问题,你可能需要去检查它。列表 13 展示了一个示例。
|
||||
|
||||
###### 列表 13. 自动生成的 /etc/printcap
|
||||
```
|
||||
# This file was automatically generated by cupsd(8) from the
|
||||
# /etc/cups/printers.conf file. All changes to this file
|
||||
@ -377,18 +382,19 @@ WebInterface Yes
|
||||
HL-2280DW|Brother HL-2280DW:rm=atticf27:rp=HL-2280DW:
|
||||
anyprint|Any available printer:rm=atticf27:rp=anyprint:
|
||||
XP-610|EPSON XP-610 Series:rm=atticf27:rp=XP-610:
|
||||
|
||||
```
|
||||
|
||||
这个文件中的每一行都有一个打印机名字、打印机描述,远程机器(rm)的名字、以及那个远程机器上的远程打印机(rp)。老的 /etc/printcap 文件也描述了打印机的能力。
|
||||
*列表 13. 自动生成的 /etc/printcap*
|
||||
|
||||
这个文件中的每一行都有一个打印机名字、打印机描述,远程机器(`rm`)的名字、以及那个远程机器上的远程打印机(`rp`)。老的 `/etc/printcap` 文件也描述了打印机的能力。
|
||||
|
||||
#### 文件转换过滤器
|
||||
|
||||
你可以使用 CUPS 打印许多类型的文件,包括明文的文本文件、PDF、PostScript、和各种格式的图像文件,你只需要提供要打印的文件名,除此之外你再无需向 `lpr` 或 `lp` 命令提供更多的信息。这个神奇的壮举是通过使用过滤器来实现的。实际上,这些年来最流行的过滤器就命名为 magicfilter。
|
||||
你可以使用 CUPS 打印许多类型的文件,包括明文的文本文件、PDF、PostScript、和各种格式的图像文件,你只需要提供要打印的文件名,除此之外你再无需向 `lpr` 或 `lp` 命令提供更多的信息。这个神奇的壮举是通过使用过滤器来实现的。实际上,这些年来最流行的过滤器就就叫做 magicfilter(神奇的过滤器)。
|
||||
|
||||
当打印一个文件时,CUPS 使用多用途因特网邮件扩展(MIME)类型去决定合适的转换过滤器。其它的打印包可能使用由 `file` 命令使用的神奇数字机制。关于 `file` 或者 `magic` 的更多信息可以查看它们的 man 页面。
|
||||
当打印一个文件时,CUPS 使用多用途因特网邮件扩展(MIME)类型去决定合适的转换过滤器。其它的打印数据包可能使用由 `file` 命令使用的神奇数字机制。关于 `file` 或者神奇数的更多信息可以查看它们的 man 页面。
|
||||
|
||||
输入文件被过滤器转换成中间层的光栅格式或者 PostScript 格式。一些作业信息,比如打印数量也会被添加进去。数据最终通过一个 bechend 发送到目标打印机。还有一些可以用手动过滤的输入文件的过滤器。你可以通过这些过滤器获得特殊格式的结果,或者去处理一些 CUPS 原生并不支持的文件格式。
|
||||
输入文件被过滤器转换成中间层的光栅格式或者 PostScript 格式。一些作业信息,比如打印数量也会被添加进去。数据最终通过一个后端发送到目标打印机。还有一些可以用手动过滤的输入文件的过滤器(如 a2ps 或 dvips)。你可以通过这些过滤器获得特殊格式的结果,或者去处理一些 CUPS 原生并不支持的文件格式。
|
||||
|
||||
#### 添加打印机
|
||||
|
||||
@ -401,25 +407,22 @@ CUPS 支持多种打印机,包括:
|
||||
* 使用 NCP 的 Novell 打印机
|
||||
* HP Jetdirect 打印机
|
||||
|
||||
|
||||
|
||||
当系统启动或者设备连接时,现在的大多数系统都会尝试自动检测和自动配置本地硬件。同样,许多网络打印机也可以被自动检测到。使用 CUPS 的 web 管理工具(<http://localhost:631> 或者 <http://127.0.0.1:631>)去搜索或添加打印机。许多发行版都包含它们自己的配置工具,比如,在 SUSE 系统上的 YaST。图 2 展示了使用 localhost:631 的 CUPS 界面,图 3 展示了 Fedora 27 上的 GNOME 打印机设置对话框。
|
||||
|
||||
###### 图 2. 使用 CUPS 的 web 界面
|
||||
|
||||
|
||||
![Using the CUPS web interface][5]
|
||||
|
||||
###### 图 3. Fedora 27 上的打印机设置
|
||||
*图 2. 使用 CUPS 的 web 界面*
|
||||
|
||||
|
||||
![Using printer settings on Fedora 27][6]
|
||||
|
||||
*图 3. Fedora 27 上的打印机设置*
|
||||
|
||||
你也可以从命令行配置打印机。在配置打印机之前,你需要一些关于打印机和它的连接方式的基本信息。如果是一个远程系统,你还需要一个用户 ID 和密码。
|
||||
|
||||
你需要去知道你的打印机使用什么样的驱动程序。不是所有的打印机都支持 Linux,有些打印机在 Linux 上压根就不能使用,或者功能受限。你可以去 OpenPrinting.org(查看相关主题)去查看是否有你的特定的打印机的驱动程序。`lpinfo` 命令也可以帮你识别有效的设备类型和驱动程序。使用 `-v` 选项去列出支持的设备,使用 `-m` 选项去列出驱动程序,如列表 14 所示。
|
||||
你需要去知道你的打印机使用什么样的驱动程序。不是所有的打印机都支持 Linux,有些打印机在 Linux 上压根就不能使用,或者功能受限。你可以去 OpenPrinting.org 去查看是否有你的特定的打印机的驱动程序。`lpinfo` 命令也可以帮你识别有效的设备类型和驱动程序。使用 `-v` 选项去列出支持的设备,使用 `-m` 选项去列出驱动程序,如列表 14 所示。
|
||||
|
||||
###### 列表 14. 可用的打印机驱动程序
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i xp-610
|
||||
lsb/usr/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
@ -443,16 +446,16 @@ network dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
network dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
network lpd://BRN001BA98A1891/BINARY_P1
|
||||
network lpd://192.168.1.38:515/PASSTHRU
|
||||
|
||||
```
|
||||
|
||||
Epson-XP-610_Series-epson-escpr-en.ppd.gz 驱动程序在我的系统上位于 /usr/share/ppd/Epson/epson-inkjet-printer-escpr/ 目录中。
|
||||
*列表 14. 可用的打印机驱动程序*
|
||||
|
||||
如果你找不到驱动程序,你可以到打印机生产商的网站看看,说不上会有专用的驱动程序。例如,在写这篇文章的时候,Brother 就有一个我的 HL-2280DW 打印机的驱动程序,但是,这个驱动程序在 OpenPrinting.org 上还没有列出来。
|
||||
这个 Epson-XP-610_Series-epson-escpr-en.ppd.gz 驱动程序在我的系统上位于 `/usr/share/ppd/Epson/epson-inkjet-printer-escpr/` 目录中。
|
||||
|
||||
如果你找不到驱动程序,你可以到打印机生产商的网站看看,说不定会有专用的驱动程序。例如,在写这篇文章的时候,Brother 就有一个我的 HL-2280DW 打印机的驱动程序,但是,这个驱动程序在 OpenPrinting.org 上还没有列出来。
|
||||
|
||||
如果你收集齐了基本信息,你可以如列表 15 所示的那样,使用 `lpadmin` 命令去配置打印机。为此,我将为我的 HL-2280DW 打印机创建另外一个实例,以便于双面打印。
|
||||
|
||||
###### 列表 15. 配置一台打印机
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i "hl.*2280"
|
||||
HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
@ -465,16 +468,16 @@ anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Tue 30 Jan 2018 10:56:10 AM EST
|
||||
HL-2280DW-duplex accepting requests since Wed 31 Jan 2018 11:41:16 AM EST
|
||||
HXP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
你可以使用带 `-c` 选项的 `lpadmin` 命令去创建一个仅用于双面打印的新类,而不用为了双面打印去创建一个打印机的副本。
|
||||
*列表 15. 配置一台打印机*
|
||||
|
||||
你可以使用带 `-c` 选项的 `lpadmin` 命令去创建一个仅用于双面打印的新分类,而不用为了双面打印去创建一个打印机的副本。
|
||||
|
||||
如果你需要删除一台打印机,使用带 `-x` 选项的 `lpadmin` 命令。
|
||||
|
||||
列表 16 展示了如何去删除打印机和创建一个替代类。
|
||||
|
||||
###### 列表 16. 删除一个打印机和创建一个类
|
||||
```
|
||||
[ian@atticf27 ~]$ lpadmin -x HL-2280DW-duplex
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW -c duplex -E -D "Duplex printing" -o sides=two-sided-long-edge
|
||||
@ -485,34 +488,33 @@ anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
duplex accepting requests since Wed 31 Jan 2018 12:12:05 PM EST
|
||||
HL-2280DW accepting requests since Wed 31 Jan 2018 11:51:16 AM EST
|
||||
XP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
*列表 16. 删除一个打印机和创建一个类*
|
||||
|
||||
你也可以使用 `lpadmin` 或者 `lpoptions` 命令去设置各种打印机选项。详细信息请查看 man 页面。
|
||||
|
||||
### 排错
|
||||
|
||||
如果你有一个打印问题,尝试下列的提示:
|
||||
如果你有打印问题,尝试下列的提示:
|
||||
|
||||
* 确保 CUPS 服务器正在运行。你可以使用 `lpstat` 命令,如果它不能连接到 cupsd 守护程序,它将会报告一个错误。或者,你可以使用 `ps -ef` 命令在输出中去检查是否有 cupsd。
|
||||
* 如果你尝试为打印去排队一个作业,而得到一个错误信息,指示打印机不接受这个作业,你可以使用 `lpstat -a` 或者 `lpc status` 去检查那个打印机可接受的作业。
|
||||
* 如果你试着排队一个打印作业而得到一个错误信息,指示打印机不接受这个作业,你可以使用 `lpstat -a` 或者 `lpc status` 去检查那个打印机是否接受作业。
|
||||
* 如果一个队列中的作业没有打印,使用 `lpstat -p` 或 `lpc status` 去检查那个打印机是否接受作业。如前面所讨论的那样,你可能需要将这个作业移动到其它的打印机。
|
||||
* 如果这个打印机是远程的,检查它在远程系统上是否存在,并且是可操作的。
|
||||
* 检查配置文件,确保特定的用户或者远程系统允许在这个打印机上打印。
|
||||
* 确保防火墙允许远程打印请求,是否允许从其它系统到你的系统,或者从你的系统到其它系统的数据包通讯。
|
||||
* 验证是否有正确的驱动程序。
|
||||
|
||||
|
||||
|
||||
正如你所见,打印涉及到你的系统中的几个组件,甚至还有网络。在本教程中,基于篇幅的考虑,我们仅为诊断给你提供了几个着手点。大多数的 CUPS 系统也有实现我们所讨论的命令行功能的图形界面。一般情况下,这个界面是从本地主机使用浏览器指向 631 端口(<http://localhost:631> 或 <http://127.0.0.1:631>)来访问的,如前面的图 2 所示。
|
||||
正如你所见,打印涉及到你的系统中的几个组件,甚至还有网络。在本教程中,基于篇幅的考虑,我们仅能给你的诊断提供了几个着手点。大多数的 CUPS 系统也有实现我们所讨论的命令行功能的图形界面。一般情况下,这个界面是从本地主机使用浏览器指向 631 端口(<http://localhost:631> 或 <http://127.0.0.1:631>)来访问的,如前面的图 2 所示。
|
||||
|
||||
你可以通过将 CUPS 运行在前台而不是做为一个守护进程来诊断它的问题。如果有需要,你也可以通过这种方式去测试替代的配置文件。运行 `cupsd -h` 获得更多信息,或者查看 man 页面。
|
||||
|
||||
CUPS 也管理一个访问日志和错误日志。你可以在 cupsd.conf 中使用 LogLevel 语句来改变日志级别。默认情况下,日志是保存在 /var/log/cups 目录。它们可以在浏览器界面(<http://localhost:631>)下,从 **Administration** 选项卡中查看。使用不带任何选项的 `cupsctl` 命令可以显示日志选项。也可以编辑 cupsd.conf 或者使用 `cupsctl` 去调整各种日志参数。查看 `cupsctl` 命令的 man 页面了解更多信息。
|
||||
CUPS 也带有一个访问日志和错误日志。你可以在 `cupsd.conf` 中使用 `LogLevel` 语句来改变日志级别。默认情况下,日志是保存在 `/var/log/cups` 目录。它们可以在浏览器界面(<http://localhost:631>)下,从 **Administration** 选项卡中查看。使用不带任何选项的 `cupsctl` 命令可以显示日志选项。也可以编辑 `cupsd.conf` 或者使用 `cupsctl` 去调整各种日志参数。查看 `cupsctl` 命令的 man 页面了解更多信息。
|
||||
|
||||
在 Ubuntu 的 Wiki 页面上的 [调试打印问题][7] 页面也是一个非常好的学习的地方。
|
||||
|
||||
它包含了打印和 CUPS 的介绍。
|
||||
这就是关于打印和 CUPS 的介绍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -520,7 +522,7 @@ via: https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,13 @@
|
||||
开始使用 SQL
|
||||
SQL 入门
|
||||
======
|
||||
|
||||
> 使用 SQL 构建一个关系数据库比你想的更容易。
|
||||
|
||||

|
||||
|
||||
使用 SQL 构建数据库比大多数人想象得要简单。实际上,你甚至不需要成为一个有经验的程序员来使用 SQL 创建数据库。在本文中,我将解释如何使用 MySQL 5.6 来创建简单的关系型数据库管理系统(RDMS)。在开始之前,我想快速地感谢 [SQL Fiddle][1],这是我用来运行脚本的工具。它提供了一个用于测试简单脚本的有用的沙箱。
|
||||
使用 SQL 构建数据库比大多数人想象得要简单。实际上,你甚至不需要成为一个有经验的程序员就可以使用 SQL 创建数据库。在本文中,我将解释如何使用 MySQL 5.6 来创建简单的关系型数据库管理系统(RDMS)。在开始之前,我想顺便感谢一下 [SQL Fiddle][1],这是我用来运行脚本的工具。它提供了一个用于测试简单脚本的有用的沙箱。
|
||||
|
||||
在本教程中,我将构建一个使用下面实体关系图(ERD)中显示的简单架构的数据库。数据库列出了学生和正在学习的课程。为了保持简单,我使用了两个实体(即表),只有一种关系和依赖关系。这两个实体称为 `dbo_students` 和 `dbo_courses`。
|
||||
在本教程中,我将构建一个使用如下实体关系图(ERD)中显示的简单架构的数据库。数据库列出了学生和正在学习的课程。为了保持简单,我使用了两个实体(即表),只有一种关系和依赖。这两个实体称为 `dbo_students` 和 `dbo_courses`。
|
||||
|
||||
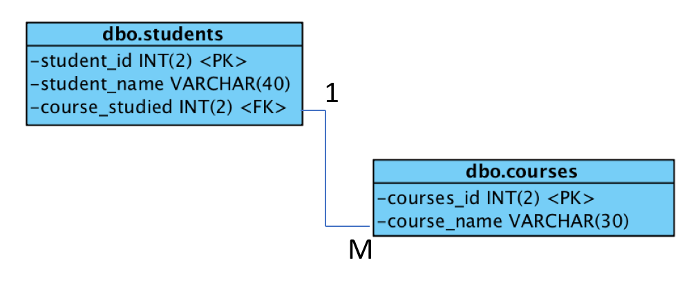
|
||||
|
||||
@ -20,87 +22,62 @@
|
||||
|
||||
### 构建架构
|
||||
|
||||
要构建数据库,使用 `CREATE TABLE <表名>` 命令,然后定义每个字段的名称和数据类型。数据库使用 `VARCHAR(n)` (字符串)和 `INT(n)` (整数),其中 n 表示可以存储的值的长度。例如 `INT(2)` 可能是 01。
|
||||
要构建数据库,使用 `CREATE TABLE <表名>` 命令,然后定义每个字段的名称和数据类型。数据库使用 `VARCHAR(n)` (字符串)和 `INT(n)` (整数),其中 `n` 表示可以存储的值的长度。例如 `INT(2)` 可以是 `01`。
|
||||
|
||||
这是用于创建两个表的代码:
|
||||
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
student_name VARCHAR(50),
|
||||
course_studied INT(2),
|
||||
PRIMARY KEY (student_id)
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
course_name VARCHAR(30),
|
||||
PRIMARY KEY (course_id)
|
||||
);
|
||||
```
|
||||
|
||||
`NOT NULL` 意味着字段不能为空,`AUTO_INCREMENT` 意味着当一个新的元组被添加时,ID 号将自动生成,并将 1 添加到先前存储的 ID 号,来强化各实体之间的完整参照性。 `PRIMARY KEY` 是每个表的惟一标识符属性。这意味着每个元组都有自己的不同的标识。
|
||||
`NOT NULL` 意味着字段不能为空,`AUTO_INCREMENT` 意味着当一个新的元组被添加时,ID 号将自动生成,是对先前存储的 ID 号加 1,以强化各实体之间的完整参照性。 `PRIMARY KEY` 是每个表的惟一标识符属性。这意味着每个元组都有自己的不同的标识。
|
||||
|
||||
### 关系作为一种约束
|
||||
|
||||
就目前来看,这两张表格是独立存在的,没有任何联系或关系。要连接它们,必须标识一个外键。在 `dbo_students` 中,外键是 `course_studied`,其来源在 `dbo_courses` 中,意味着该字段被引用。SQL 中的特定命令为 `CONSTRAINT`,并且将使用另一个名为 `ALTER TABLE` 的命令添加这种关系,这样即使在架构构建完毕后,也可以编辑表。
|
||||
|
||||
以下代码将关系添加到数据库构造脚本中:
|
||||
|
||||
```
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
```
|
||||
|
||||
使用 `CONSTRAINT` 命令实际上并不是必要的,但这是一个好习惯,因为它意味着约束可以被命名并且使维护更容易。现在数据库已经完成了,是时候添加一些数据了。
|
||||
|
||||
### 将数据添加到数据库
|
||||
|
||||
`INSERT INTO <表名>`是用于直接选择将数据添加到哪些属性(即字段)的命令。首先声明实体名称,然后声明属性。命令下边是添加到实体的数据,从而创建一个元组。如果指定了 `NOT NULL`,这表示该属性不能留空。以下代码将展示如何向表中添加记录:
|
||||
`INSERT INTO <表名>` 是用于直接选择要添加哪些属性(即字段)数据的命令。首先声明实体名称,然后声明属性,下边是添加到实体的数据,从而创建一个元组。如果指定了 `NOT NULL`,这表示该属性不能留空。以下代码将展示如何向表中添加记录:
|
||||
|
||||
```
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
```
|
||||
|
||||
@ -109,128 +86,89 @@ VALUES(004,'student4',003);
|
||||
### 查询
|
||||
|
||||
查询遵循使用以下命令的集合结构:
|
||||
|
||||
```
|
||||
SELECT <attributes>
|
||||
|
||||
FROM <entity>
|
||||
|
||||
WHERE <condition>
|
||||
```
|
||||
|
||||
要显示 `dbo_courses` 实体内的所有记录并显示课程代码和课程名称,请使用 * 。 这是一个通配符,它消除了键入所有属性名称的需要。(在生产数据库中不建议使用它。)此处查询的代码是:
|
||||
要显示 `dbo_courses` 实体内的所有记录并显示课程代码和课程名称,请使用 `*` 。 这是一个通配符,它消除了键入所有属性名称的需要。(在生产数据库中不建议使用它。)此处查询的代码是:
|
||||
|
||||
```
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
```
|
||||
|
||||
此处查询的输出显示表中的所有元组,因此可显示所有可用课程:
|
||||
|
||||
```
|
||||
| course_id | course_name |
|
||||
|
||||
|-----------|----------------------|
|
||||
|
||||
| 1 | Software Engineering |
|
||||
|
||||
| 2 | Computer Science |
|
||||
|
||||
| 3 | Computing |
|
||||
```
|
||||
|
||||
在以后的文章中,我将使用三种类型的连接之一来解释更复杂的查询:Inner,Outer 或 Cross。
|
||||
在后面的文章中,我将使用三种类型的连接之一来解释更复杂的查询:内连接、外连接和交叉连接。
|
||||
|
||||
这是完整的脚本:
|
||||
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
student_name VARCHAR(50),
|
||||
course_studied INT(2),
|
||||
PRIMARY KEY (student_id)
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
course_name VARCHAR(30),
|
||||
PRIMARY KEY (course_id)
|
||||
);
|
||||
|
||||
|
||||
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
|
||||
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
```
|
||||
|
||||
### 学习更多
|
||||
|
||||
SQL 并不困难;我认为它比编程简单,并且该语言对于不同的数据库系统是通用的。 请注意,`dbo.<实体>` (译者注:文章中使用的是 `dbo_<实体>`) 不是必需的实体命名约定;我之所以使用,仅仅是因为它是 Microsoft SQL Server 中的标准。
|
||||
SQL 并不困难;我认为它比编程简单,并且该语言对于不同的数据库系统是通用的。 请注意,实体关系图中 `dbo.<实体>` (LCTT 译注:文章中使用的是 `dbo_<实体>`)不是必需的实体命名约定;我之所以使用,仅仅是因为它是 Microsoft SQL Server 中的标准。
|
||||
|
||||
如果你想了解更多,在网络上这方面的最佳指南是 [W3Schools.com][2] 中对所有数据库平台的 SQL 综合指南。
|
||||
|
||||
请随意使用我的数据库。另外,如果你有任何建议或疑问,请在评论中回复。(译注:请点击原文地址进行评论回应)
|
||||
请随意使用我的数据库。另外,如果你有任何建议或疑问,请在评论中回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://opensource.com/article/18/2/getting-started-sql](https://opensource.com/article/18/2/getting-started-sql)
|
||||
via: https://opensource.com/article/18/2/getting-started-sql
|
||||
|
||||
作者:[Aaron Cocker][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,106 @@
|
||||
5 steps to building a cloud that meets your users' needs
|
||||
======
|
||||
|
||||

|
||||
This article was co-written with [Ian Tewksbury][1].
|
||||
|
||||
However you define it, a cloud is simply another tool for your users to perform their part of your organization's value stream. It can be easy when talking about any new paradigm or technology (the cloud is arguably both) to get distracted by the shiny newness of it. Conversations can quickly devolve into feature wish lists set off by a series of never-ending questions, all of which you probably have already considered:
|
||||
|
||||
* Will it be public, private, or hybrid?
|
||||
* Will it use virtual machines or containers, or both?
|
||||
* Will it be self-service?
|
||||
* Will it be fully automated from development to production, or will it have manual gates?
|
||||
* How fast can we make it?
|
||||
* What about tool X, Y, or Z?
|
||||
|
||||
|
||||
|
||||
The list goes on.
|
||||
|
||||
The usual approach to beginning IT modernization, or digital transformation, or whatever you call it is to start answering high-level questions in the higher-level echelons of management. The outcome of this approach is predictable: failure. After extensively researching and spending months, if not years, deploying the fanciest new technology, the new cloud is never used and falls into disrepair until it is eventually scrapped or forgotten in the dustier corners of the datacenter and budget.
|
||||
|
||||
That's because whatever was delivered was not the tool the users wanted or needed. Worse yet, it likely was a single tool when users really needed a collection of tools that could be swapped out over time as newer, shinier, upgraded tools come along that better meet their needs.
|
||||
|
||||
### Focus on what matters
|
||||
|
||||
The problem is focus, which has traditionally been on the tools. But the tools are not what add to your organization's value stream; end users making use of tools are what do that. You need to shift your focus from building your cloud—for example, the technology and the tools, to your people, your users.
|
||||
|
||||
Beyond the fact that users using tools (not the tools themselves) are what drive value, there are other reasons to focus attention on the users. The tools are for the users to use to solve their problems and allow them to create value, so it follows that if those tools don't meet those users' needs, then those tools won't be used. If you deliver tools that your users don't like, they won't use them. This is natural human behavior.
|
||||
|
||||
The IT industry got away with providing a single solution to users for decades because there were only one or two options, and the users had no power to change that. That is no longer the case. We now live in the world of technological choice. It is no longer acceptable to users to not be given a choice; they have choices in their personal technological lives, and they expect it in the workplace, too. Today's users are educated and know there are better options than the ones you've been providing.
|
||||
|
||||
As a result, outside the most physically secure locations, there is no way to stop them from just doing what they want, which we call "shadow IT." If your organization has such strict security and compliance polices that shadow IT is impossible, many of your best people will grow frustrated and leave for other organizations that offer them choices.
|
||||
|
||||
For all of these reasons, you must design your expensive and time-consuming cloud project with your end user foremost in mind.
|
||||
|
||||
### Five-step process to build a cloud for users' needs
|
||||
|
||||
Now that we know the why, let's talk about the how. How do you build a cloud for the end user? How do you start refocusing your attention from the technology to the people using that technology?
|
||||
|
||||
Through experience, we've learned that the best approach involves two things: getting constant feedback from your users, and building things iteratively.
|
||||
|
||||
Your cloud environment will continually evolve with your organization. The following five-step process will help you create a cloud that meets your users' needs.
|
||||
|
||||
#### 1\. Identify who your users will be.
|
||||
|
||||
Before you can start asking users questions, you first must identify who the users of your new cloud will be. They will likely include developers who build applications on the cloud; the operations team who will operate, maintain, and likely build the cloud; and the security team who protects your organization. For the first iteration, scope down your users to a smaller group so you're less overwhelmed by feedback. Ask each of your identified user groups to appoint two liaisons (a primary and a secondary) who will represent their team on this journey. This will also keep your first delivery small in both size and time.
|
||||
|
||||
#### 2\. Talk to your users face-to-face to get valuable input.
|
||||
|
||||
The best way to get users' feedback is through direct communication. Mass emails asking for input will self-select respondents—if you even get a response. Group discussions can be helpful, but people tend to be more candid when they have a private, attentive audience.
|
||||
|
||||
Schedule in-person, individual meetings with your first set of users to ask them questions like the following:
|
||||
|
||||
* What do you need in order to accomplish your tasks?
|
||||
* What do you want in order to accomplish your tasks?
|
||||
* What is your current, most annoying technological pain?
|
||||
* What is your current, most annoying policy or procedural pain?
|
||||
* What ideas do you have to address any of your needs, wants, or pains?
|
||||
|
||||
|
||||
|
||||
These questions are guidelines and not ideal for every organization. They should not be the only questions you ask, and they should lead to further discussion. Be sure to tell people that anything said or asked is taken as feedback, and all feedback is helpful, whether positive or negative. The outcome of these conversations will help set your development priorities.
|
||||
|
||||
Gathering this level of personalized feedback is another reason to keep your initial group of users small: It takes a lot of time to sit down with each user, but we have found it is absolutely worth the investment.
|
||||
|
||||
#### 3\. Design and deliver your first iteration of the solution.
|
||||
|
||||
Once you've collected feedback from your initial users, it is time to design and deliver a piece of functionality. We do not recommend trying to deliver the entire solution. The design and delivery phase should be short; this is to avoid making the huge mistake of spending a year building what you think is the correct solution, only to have your users reject it because it isn't beneficial to them. The specific tools you choose for building your cloud will depend on your organization and its specific needs. Just make sure that the solution you build is based on your users' feedback and that you deliver it in small chunks to solicit feedback from them as often as possible.
|
||||
|
||||
#### 4\. Ask users for feedback on the first iteration.
|
||||
|
||||
Great, now you've designed and delivered the first iteration of your fancy new cloud to your end users! You didn't spend a year doing it but instead tackled it in small pieces. Why is it important to do things in small chunks? It's because you're going back to your user groups and collecting feedback about your design and delivery. What do they like? What don't they like? Did you properly address their concerns? Is the technology great, but the process or policy side of the system still lacking?
|
||||
|
||||
Again, the questions you'll ask depend on your organization; the key here is to continue the discussions from the earlier phases. You're building this cloud for users after all, so make sure it's useful for them and a productive use of everyone's time.
|
||||
|
||||
#### 5\. Return to step 1.
|
||||
|
||||
This is an iterative process. Your first delivery should have been quick and small, and all future iterations should be, too. Don't expect to be able to follow this process once, twice, or even three times and be done. As you iterate, you will introduce more users and get better at the process. You will get more buy-in from users. You will be able to iterate faster and more reliably. And, finally, you will change your process to meet your users' needs.
|
||||
|
||||
Users are the most important part of this process, but the iteration is the second most important part because it allows you to keep going back to the users and getting more information. Throughout each phase, take note of what worked and what didn't. Be introspective and honest with yourself. Are we providing the most value possible for the time we spent? If not, try something different in the next phase. The great part about not spending too much time in each cycle is that, if something doesn't work this time, you can easily tweak it for next time, until you find an approach that works for your organization.
|
||||
|
||||
### This is just the beginning
|
||||
|
||||
Through many customer engagements, feedback gathered from users, and experiences from peers in the field, we've found time and time again that the most important thing you can do when building a cloud is to talk to your users. It seems obvious, but it is surprising how many organizations will go off and build something for months or years, then find out it isn't even useful to end users.
|
||||
|
||||
Now you know why you should keep your focus on the end users and have a process for building a cloud with them at the center. The remaining piece is the part that we all enjoy, the part where you go out and do it.
|
||||
|
||||
This article is based on "[Design your hybrid cloud for the end user—or fail][2]," a talk the authors will be giving at [Red Hat Summit 2018][3], which will be held May 8-10 in San Francisco.
|
||||
|
||||
[Register by May 7][3] to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly
|
||||
|
||||
作者:[Cameron Wyatt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cameronmwyatt
|
||||
[1]:https://opensource.com/users/itewk
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
61
sources/talk/20180410 Microservices Explained.md
Normal file
61
sources/talk/20180410 Microservices Explained.md
Normal file
@ -0,0 +1,61 @@
|
||||
Microservices Explained
|
||||
======
|
||||
|
||||

|
||||
Microservices is not a new term. Like containers, the concept been around for a while, but it’s become a buzzword recently as many companies embark on their cloud native journey. But, what exactly does the term microservices mean? Who should care about it? In this article, we’ll take a deep dive into the microservices architecture.
|
||||
|
||||
### Evolution of microservices
|
||||
|
||||
Patrick Chanezon, Chief Developer Advocate for Docker provided a brief history lesson during our conversation: In the late 1990s, developers started to structure their applications into monoliths where massive apps hadall features and functionalities baked into them. Monoliths were easy to write and manage. Companies could have a team of developers who built their applications based on customer feedback through sales and marketing teams. The entire developer team would work together to build tightly glued pieces as an app that can be run on their own app servers. It was a popular way of writing and delivering web applications.
|
||||
|
||||
There is a flip side to the monolithic coin. Monoliths slow everything and everyone down. It’s not easy to update one service or feature of the application. The entire app needs to be updated and a new version released. It takes time. There is a direct impact on businesses. Organizations could not respond quickly to keep up with new trends and changing market dynamics. Additionally, scalability was challenging.
|
||||
|
||||
Around 2011, SOA (Service Oriented Architecture) became popular where developers could cram multi-tier web applications as software services inside a VM (virtual machine). It did allow them to add or update services independent of each other. However, scalability still remained a problem.
|
||||
|
||||
“The scale out strategy then was to deploy multiple copies of the virtual machine behind a load balancer. The problems with this model are several. Your services can not scale or be upgraded independently as the VM is your lowest granularity for scale. VMs are bulky as they carry extra weight of an operating system, so you need to be careful about simply deploying multiple copies of VMs for scaling,” said Madhura Maskasky, co-founder and VP of Product at Platform9.
|
||||
|
||||
Some five years ago when Docker hit the scene and containers became popular, SOA faded out in favor of “microservices” architecture. “Containers and microservices fix a lot of these problems. Containers enable deployment of microservices that are focused and independent, as containers are lightweight. The Microservices paradigm, combined with a powerful framework with native support for the paradigm, enables easy deployment of independent services as one or more containers as well as easy scale out and upgrade of these,” said Maskasky.
|
||||
|
||||
### What’s are microservices?
|
||||
|
||||
Basically, a microservice architecture is a way of structuring applications. With the rise of containers, people have started to break monoliths into microservices. “The idea is that you are building your application as a set of loosely coupled services that can be updated and scaled separately under the container infrastructure,” said Chanezon.
|
||||
|
||||
“Microservices seem to have evolved from the more strictly defined service-oriented architecture (SOA), which in turn can be seen as an expression object oriented programming concepts for networked applications. Some would call it just a rebranding of SOA, but the term “microservices” often implies the use of even smaller functional components than SOA, RESTful APIs exchanging JSON, lighter-weight servers (often containerized, and modern web technologies and protocols,” said Troy Topnik, SUSE Senior Product Manager, Cloud Application Platform.
|
||||
|
||||
Microservices provides a way to scale development and delivery of large, complex applications by breaking them down that allows the individual components to evolve independently from each other.
|
||||
|
||||
“Microservices architecture brings more flexibility through the independence of services, enabling organizations to become more agile in how they deliver new business capabilities or respond to changing market conditions. Microservices allows for using the ‘right tool for the right task’, meaning that apps can be developed and delivered by the technology that will be best for the task, rather than being locked into a single technology, runtime or framework,” said Christian Posta, senior principal application platform specialist, Red Hat.
|
||||
|
||||
### Who consumes microservices?
|
||||
|
||||
“The main consumers of microservices architecture patterns are developers and application architects,” said Topnik. As far as admins and DevOps engineers are concerned their role is to build and maintain the infrastructure and processes that support microservices.
|
||||
|
||||
“Developers have been building their applications traditionally using various design patterns for efficient scale out, high availability and lifecycle management of their applications. Microservices done along with the right orchestration framework help simplify their lives by providing a lot of these features out of the box. A well-designed application built using microservices will showcase its benefits to the customers by being easy to scale, upgrade, debug, but without exposing the end customer to complex details of the microservices architecture,” said Maskasky.
|
||||
|
||||
### Who needs microservices?
|
||||
|
||||
Everyone. Microservices is the modern approach to writing and deploying applications more efficiently. If an organization cares about being able to write and deploy its services at a faster rate they should care about it. If you want to stay ahead of your competitors, microservices is the fastest route. Security is another major benefit of the microservices architecture, as this approach allows developers to keep up with security and bug fixes, without having to worry about downtime.
|
||||
|
||||
“Application developers have always known that they should build their applications in a modular and flexible way, but now that enough of them are actually doing this, those that don’t risk being left behind by their competitors,” said Topnik.
|
||||
|
||||
If you are building a new application, you should design it as microservices. You never have to hold up a release if one team is late. New functionalities are available when they're ready, and the overall system never breaks.
|
||||
|
||||
“We see customers using this as an opportunity to also fix other problems around their application deployment -- such as end-to-end security, better observability, deployment and upgrade issues,” said Maskasky.
|
||||
|
||||
Failing to do so means you would be stuck in the traditional stack, which means microservices won’t be able to add any value to it. If you are building new applications, microservices is the way to go.
|
||||
|
||||
Learn more about cloud-native at [KubeCon + CloudNativeCon Europe][1], coming up May 2-4 in Copenhagen, Denmark.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/4/microservices-explained
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://events.linuxfoundation.org/events/kubecon-cloudnativecon-europe-2018/attend/register/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Create, Revert and Delete KVM Virtual machine snapshot with virsh command
|
||||
======
|
||||
[![KVM-VirtualMachine-Snapshot][1]![KVM-VirtualMachine-Snapshot][2]][2]
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Use WSL Like a Linux Pro
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,60 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to add fonts to Fedora
|
||||
===================
|
||||
|
||||

|
||||
|
||||
Fonts help you express your thoughts in creative ways through design. Whether you’re captioning an image, building a presentation, or designing a greeting or advertisement, fonts can boost your idea to the next level. It’s easy to fall in love with them just for their own aesthetic qualities. Fortunately, Fedora makes installation easy. Here’s how to do it.
|
||||
|
||||
### System-wide installation
|
||||
|
||||
If you install a font system-wide, it becomes available to all users. The best way to take advantage of this method is by using RPM packages from the official software repositories.
|
||||
|
||||
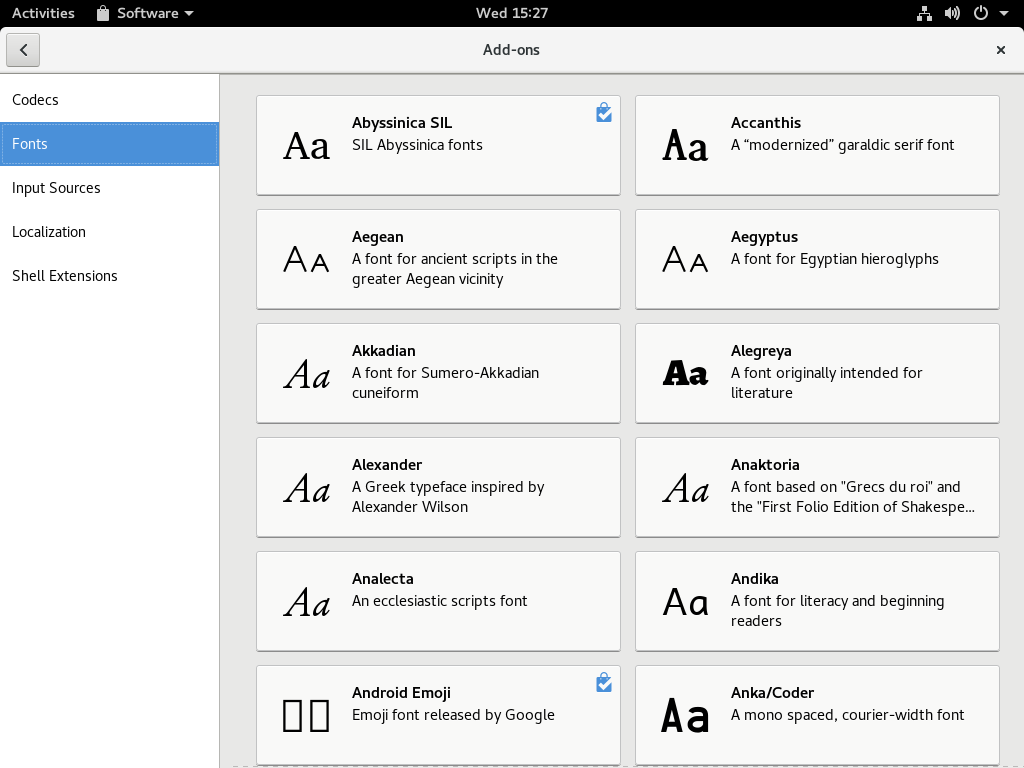
To get started, open the _Software_ tool in your Fedora Workstation, or other tool that uses the official repositories. Choose the _Add-ons_ category in the group of banners shown. Then in the add-on categories, select _Fonts._ You’ll see a list of available fonts similar to this screenshot:
|
||||
|
||||
[][1]
|
||||
|
||||
When you select a font, some details appear. Depending on several conditions, you may be able to preview how the font looks with some example text. Select the _Install_ button to add it to your system. It may take a few moments for the process to complete, based on your system speed and network bandwidth.
|
||||
|
||||
You can also remove previously installed font packages, shown with a check mark, with the _Remove_ button shown in the font details.
|
||||
|
||||
### Personal installation
|
||||
|
||||
This method works better if you have a font you’ve downloaded in a compatible format: _.ttf_ , _otf_ , _.ttc_ , _.pfa_ , _.pfb_ or . _pcf._ These font extensions shouldn’t be installed system-wide by dropping them into a system folder. Non-packaged fonts of this type can’t be updated automatically. They also can potentially interfere with some software operations later. The best way to install these fonts is in your own personal data directory.
|
||||
|
||||
Open the _Files_ application in your Fedora Workstation, or a similar file manager app of your choice. If you’re using _Files_ , you may need to use the _Ctrl+H_ key combination to show hidden files and folders. Look for the _.fonts_ folder and open it. If you don’t have a _.fonts_ folder, create it. (Remember the leading dot and to use all lowercase.)
|
||||
|
||||
Copy the font file you’ve downloaded to your _.fonts_ folder. You can close the file manager at this point. Open a terminal and type the following command:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
```
|
||||
|
||||
This will rebuild font caches that help Fedora locate and reference the fonts it can use. You may also need to restart an application such as Inkscape or LibreOffice in which you want to use the new font. Once you restart, the new font should be available.
|
||||
|
||||
* * *
|
||||
|
||||
Photo by [Raphael Schaller][2] on [Unsplash][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Paul W. Frields
|
||||
Paul W. Frields has been a Linux user and enthusiast since 1997, and joined the Fedora Project in 2003, shortly after launch. He was a founding member of the Fedora Project Board, and has worked on documentation, website publishing, advocacy, toolchain development, and maintaining software. He joined Red Hat as Fedora Project Leader from February 2008 to July 2010, and remains with Red Hat as an engineering manager. He currently lives with his wife and two children in Virginia.
|
||||
|
||||
-----------------------------
|
||||
|
||||
via: https://fedoramagazine.org/add-fonts-fedora/
|
||||
|
||||
作者:[ Paul W. Frields ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2017/11/Software-fonts.png
|
||||
[2]:https://unsplash.com/photos/GkinCd2enIY?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://unsplash.com/search/photos/fonts?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -1,82 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Reliable IoT event logging with syslog-ng
|
||||
======
|
||||
|
||||

|
||||
For any device connected to the internet or a network, it's essential that you log events so you know what the device is doing and can address any potential problems. Increasingly those devices include Internet of Things (IoT) devices and embedded systems.
|
||||
|
||||
One monitoring tool to consider is the open source [syslog-ng][1] application, an enhanced logging daemon with a focus on portability and central log collection. It collects logs from many different sources, processes and filters them, and stores or routes them for further analysis. Most of syslog-ng is written in efficient and highly portable C code. It's suitable for a wide range of scenarios, whether you need something simple enough to run with a really small footprint on underpowered devices or a solution powerful enough to reside in your data center and collect logs from tens of thousands of devices.
|
||||
|
||||
You probably noticed the abundance of buzzwords I wrote in that single paragraph. To clarify what this all means, let's go over them, but this time slower and in more depth.
|
||||
|
||||
### Logging
|
||||
|
||||
First things first. Logging is the recording of events on a computer. On a typical Linux machine, you can find these log messages in the `/var/log` directory. For example, if you log into your machine through SSH, you will find a message similar to this in one of the files:
|
||||
|
||||
`Jan 14 11:38:48 ``linux``-0jbu sshd[7716]: Accepted ``publickey`` for root from 127.0.0.1 port 48806 ssh2`
|
||||
|
||||
It could be about your CPU running too hot, a document downloaded through HTTP, or just about anything one of your applications considers important.
|
||||
|
||||
### syslog-ng
|
||||
|
||||
As I wrote above, the syslog-ng application is an enhanced logging daemon with a focus on portability and central log collection. Daemon means syslog-ng is an application running continuously in the background; in this case, it's collecting log messages.
|
||||
|
||||
While Linux testing for many of today's applications is limited to x86_64 machines, syslog-ng also works on many BSD and commercial UNIX variants. What is even more important from the embedded/IoT standpoint is that it runs on many different CPU architectures, including 32- and 64-bit ARM, PowerPC, MIPS, and more. (Sometimes I learn about new architectures just by reading about how syslog-ng is used.)
|
||||
|
||||
Why is central collection of logs such a big deal? One reason is ease of use, as it creates a single place to check instead of tens or thousands of devices. Another reason is availability—you can check a device's log messages even if the device is unavailable for any reason. A third reason is security; when your device is hacked, checking the logs can uncover traces of the hack.
|
||||
|
||||
### Four roles of syslog-ng
|
||||
|
||||
Syslog-ng has four major roles: collecting, processing, filtering, and storing log messages.
|
||||
|
||||
**Collecting messages:** syslog-ng can collect from a wide variety of [platform-specific sources][2], like `/dev/log`, `journal`, or `sun-streams`. As a central log collector, it speaks both the legacy (`rfc3164`) and the new (`rfc5424`) syslog protocols and all their variants over User Datagram Protocol (UDP), TCP, and encrypted connections. You can also collect log messages (or any kind of text data) from pipes, sockets, files, and even application output.
|
||||
|
||||
**Processing log messages:** The possibilities here are almost endless. You can classify, normalize, and structure log messages with built-in parsers. You can even write your own parser in Python if none of the available parsers suits your needs. You can also enrich messages with geolocation data or additional fields based on the message content. Log messages can be reformatted to suit the requirements of the application processing the logs. You can also rewrite log messages—not to falsify messages, of course—for things such as anonymizing log messages as required by many compliance regulations.
|
||||
|
||||
**Filtering logs:** There are two main uses for filtering logs: To discard surplus log messages—like debug-level messages—to save on storage, and for log routing—making sure the right logs reach the right destinations. An example of the latter is forwarding all authentication-related messages to a security information and event management (SIEM) system.
|
||||
|
||||
**Storing messages:** Traditionally, files were saved locally or sent to a central syslog server; either way, they'd be sent to [flat files][3]. Over the years, syslog-ng began supporting SQL databases, and in the past few years Big Data destinations, including HDFS, Kafka, MongoDB, and Elasticsearch, were added to syslog-ng.
|
||||
|
||||
### Message formats
|
||||
|
||||
When you look at your log messages under the `/var/log` directory, you will see (like in the SSH message above) most are in the form:
|
||||
|
||||
`date + host name + application name + an almost complete English sentence`
|
||||
|
||||
Where each application event is described by a different sentence, creating a report based on this data is quite a painful job.
|
||||
|
||||
The solution to this mess is to use structured logging. In this case, events are represented as name-value pairs instead of freeform log messages. For example, an SSH login can be described by the application name, source IP address, username, authentication method, and so on.
|
||||
|
||||
You can take a structured approach for your log messages right from the beginning. When working with legacy log messages, you can use the different parsers in syslog-ng to turn unstructured (and some of the structured) message formats into name-value pairs. Once you have your logs available as name-value pairs, reporting, alerting, and simply finding the information you are looking for becomes a lot easier.
|
||||
|
||||
### Logging IoT
|
||||
|
||||
Let's start with a tricky question: Which version of syslog-ng is the most popular? Before you answer, consider these facts: The project started 20 years ago, Red Hat Enterprise Linux EPEL has version 3.5, and the current version is 3.14. When I ask this question during my presentations, the audience members usually suggest the one in their favorite Linux distribution. Surprisingly, the correct answer is version 1.6, almost 15 years old. That's because it is the version included in the Amazon Kindle e-book readers, so it's running on over 100 million devices worldwide. Another example of a consumer device running syslog-ng is the BMW i3 all-electric car.
|
||||
|
||||
The Kindle uses syslog-ng to collect all possible information about what the user is doing on the device. On the BMW, syslog-ng does very complex, content-based filtering of log messages, and most it likely records only the most important logs.
|
||||
|
||||
Networking and storage are other categories of devices that often use syslog-ng. Networking and storage are other categories of devices that often use syslog-ng. Some better known examples are the Turris Omnia open source Linux router and Synology NAS devices. In most cases, syslog-ng started out as a logging client on these devices, but in some cases it's evolved into a central logging server with a rich web interface.
|
||||
|
||||
You can find syslog-ng in industrial devices, as well. It runs on all real-time Linux devices from National Instruments doing measurements and automation. It is also used to collect logs from customer-developed applications. Configuration is done from the command line, but a nice GUI is available to browse the logs.
|
||||
|
||||
Finally, there are some large-scale projects, such as cars and airplanes, where syslog-ng runs on both the client and server side. The common theme here is that syslog-ng collects all log and metrics data, sends it to a central cluster of servers where logs are processed, and saves it to one of the supported Big Data destinations where it waits for further analysis.
|
||||
|
||||
### Overall benefits for IoT
|
||||
|
||||
There are several benefits of using syslog-ng in an IoT environment. First, it delivers high performance and reliable log collection. It also simplifies the architecture, as system and application logs and metrics data can be collected together. Third, it makes it easier to use data, as data is parsed and presented in a ready-to-use format. Finally, efficient routing and filtering by syslog-ng can significantly decrease processing load.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/logging-iot-events-syslog-ng
|
||||
|
||||
作者:[Peter Czanik][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/czanik
|
||||
[1]:https://syslog-ng.com/open-source-log-management
|
||||
[2]:https://syslog-ng.com/documents/html/syslog-ng-ose-latest-guides/en/syslog-ng-ose-guide-admin/html/sources.html
|
||||
[3]:https://en.wikipedia.org/wiki/Flat_file_database
|
||||
@ -0,0 +1,172 @@
|
||||
12 Best GTK Themes for Ubuntu and other Linux Distributions
|
||||
======
|
||||
**Brief: Let’s have a look at some of the beautiful GTK themes that you can use not only in Ubuntu but other Linux distributions that use GNOME.**
|
||||
|
||||
For those of us that use Ubuntu proper, the move from Unity to Gnome as the default desktop environment has made theming and customizing easier than ever. Gnome has a fairly large tweaking community, and there is no shortage of fantastic GTK themes for users to choose from. With that in mind, I went ahead and found some of my favorite themes that I have come across in recent months. These are what I believe offer some of the best experiences that you can find.
|
||||
|
||||
### Best themes for Ubuntu and other Linux distributions
|
||||
|
||||
This is not an exhaustive list and may exclude some of the themes you already use and love, but hopefully, you find at least one theme that you enjoy that you did not already know about. All themes present should work on any Gnome 3 setup, Ubuntu or not. I lost some screenshots so I have taken images from the official websites.
|
||||
|
||||
The themes listed here are in no particular order.
|
||||
|
||||
But before you see the best GNOME themes, you should learn [how to install themes in Ubuntu GNOME][1].
|
||||
|
||||
#### 1\. Arc-Ambiance
|
||||
|
||||
![][2]
|
||||
|
||||
Arc and Arc variant themes have been around for quite some time now, and are widely regarded as some of the best themes you can find. In this example, I have selected Arc-Ambiance because of its modern take on the default Ambiance theme in Ubuntu.
|
||||
|
||||
I am a fan of both the Arc theme and the default Ambiance theme, so needless to say, I was pumped when I came across a theme that merged the best of both worlds. If you are a fan of the arc themes but not a fan of this one in particular, Gnome look has plenty of other options that will most certainly suit your taste.
|
||||
|
||||
[Arc-Ambiance Theme][3]
|
||||
|
||||
#### 2\. Adapta Colorpack
|
||||
|
||||
![][4]
|
||||
|
||||
The Adapta theme has been one of my favorite flat themes I have ever found. Like Arc, Adapata is widely adopted by many-a-linux user. I have selected this color pack because in one download you have several options to choose from. In fact, there are 19 to choose from. Yep. You read that correctly. 19!
|
||||
|
||||
So, if you are a fan of the flat/material design language that we see a lot of today, then there is most likely a variant in this theme pack that will satisfy you.
|
||||
|
||||
[Adapta Colorpack Theme][5]
|
||||
|
||||
#### 3\. Numix Collection
|
||||
|
||||
![][6]
|
||||
|
||||
Ah, Numix! Oh, the years we have spent together! For those of us that have been theming our DE for the last couple of years, you must have come across the Numix themes or icon packs at some point in time. Numix was probably the first modern theme for Linux that I fell in love with, and I am still in love with it today. And after all these years, it still hasn’t lost its charm.
|
||||
|
||||
The gray tone throughout the theme, especially with the default pinkish-red highlight color, makes for a genuinely clean and complete experience. You would be hard pressed to find a theme pack as polished as Numix. And in this offering, you have plenty of options to choose from, so go crazy!
|
||||
|
||||
[Numix Collection Theme][7]
|
||||
|
||||
#### 4\. Hooli
|
||||
|
||||
![][8]
|
||||
|
||||
Hooli is a theme that has been out for some time now, but only recently came across my radar. I am a fan of most flat themes but have usually strayed away from themes that come to close to the material design language. Hooli, like Adapta, takes notes from that design language, but does it in a way that I think sets it apart from the rest. The green highlight color is one of my favorite parts about the theme, and it does a good job at not overpowering the entire theme.
|
||||
|
||||
[Hooli Theme][9]
|
||||
|
||||
#### 5\. Arrongin/Telinkrin
|
||||
|
||||
![][10]
|
||||
|
||||
Bonus: Two themes in one! And they are relatively new contenders in the theming realm. They both take notes from Ubuntu’s soon to be finished “[communitheme][11]” and bring it to your desktop today. The only real difference I can find between the offerings are the colors. Arrongin is centered around an Ubuntu-esq orange color, while Telinkrin uses a slightly more KDE Breeze-esq blue. I personally prefer the blue, but both are great options!
|
||||
|
||||
[Arrongin/Telinkrin Themes][12]
|
||||
|
||||
#### 6\. Gnome-osx
|
||||
|
||||
![][13]
|
||||
|
||||
I have to admit, usually, when I see that a theme has “osx” or something similar in the title, I don’t expect much. Most Apple inspired themes seem to have so much in common that I can’t really find a reason to use them. There are two themes I can think of that break this mold: the Arc-osc them and the Gnome-osx theme that we have here.
|
||||
|
||||
The reason I like the Gnome-osx theme is because it truly does look at home on the Gnome desktop. It does a great job at blending into the DE without being too flat. So for those of you that enjoy a slightly less flat theme, and you like the red, yellow, and green button scheme for the close, minimize, and maximize buttons, than this theme is perfect for you.
|
||||
|
||||
[Gnome-osx Theme][14]
|
||||
|
||||
#### 7\. Ultimate Maia
|
||||
|
||||
![][15]
|
||||
|
||||
There was a time when I used Manjaro Gnome. Since then I have reverted back to Ubuntu, but one thing I wish I could have brought with me was the Manjaro theme. If you feel the same about the Manjaro theme as I do, then you are in luck because you can bring it to ANY distro you want that is running Gnome!
|
||||
|
||||
The rich green color, the Breeze-esq close, minimize, maximize buttons, and the over-all polish of the theme makes for one compelling option. It even offers some other color variants of you are not a fan of the green. But let’s be honest…who isn’t a fan of that Manjaro green color?
|
||||
|
||||
[Ultimate Maia Theme][16]
|
||||
|
||||
#### 8\. Vimix
|
||||
|
||||
![][17]
|
||||
|
||||
This was a theme I easily got excited about. It is modern, pulls from the macOS red, yellow, green buttons without directly copying them, and tones down the vibrancy of the theme, making for one unique alternative to most other themes. It comes with three dark variants and several colors to choose from so most of us will find something we like.
|
||||
|
||||
[Vimix Theme][18]
|
||||
|
||||
#### 9\. Ant
|
||||
|
||||
![][19]
|
||||
|
||||
Like Vimix, Ant pulls inspiration from macOS for the button colors without directly copying the style. Where Vimix tones down the color options, Ant adds a richness to the colors that looks fantastic on my System 76 Galago Pro screen. The variation between the three theme options is pretty dramatic, and though it may not be to everyone’s taste, it is most certainly to mine.
|
||||
|
||||
[Ant Theme][20]
|
||||
|
||||
#### 10\. Flat Remix
|
||||
|
||||
![][21]
|
||||
|
||||
If you haven’t noticed by this point, I am a sucker for someone who pays attention to the details in the close, minimize, maximize buttons. The color theme that Flat Remix uses is one I have not seen anywhere else, with a red, blue, and orange color way. Add that on top of a theme that looks almost like a mix between Arc and Adapta, and you have Flat Remix.
|
||||
|
||||
I am personally a fan of the dark option, but the light alternative is very nice as well. So if you like subtle transparencies, a cohesive dark theme, and a touch of color here and there, Flat Remix is for you.
|
||||
|
||||
[Flat Remix Theme][22]
|
||||
|
||||
#### 11\. Paper
|
||||
|
||||
![][23]
|
||||
|
||||
[Paper][24] has been around for some time now. I remember using it for the first back in 2014. I would say, at this point, Paper is more known for its icon pack than for its GTK theme, but that doesn’t mean that the theme isn’t a wonderful option in and of its self. Even though I adored the Paper icons from the beginning, I can’t say that I was a huge fan of the Paper theme when I first tried it out.
|
||||
|
||||
I felt like the bright colors and fun approach to a theme made for an “immature” experience. Now, years later, Paper has grown on me, to say the least, and the light hearted approach that the theme takes is one I greatly appreciate.
|
||||
|
||||
[Paper Theme][25]
|
||||
|
||||
#### 12\. Pop
|
||||
|
||||
![][26]
|
||||
|
||||
Pop is one of the newer offerings on this list. Created by the folks over at [System 76][27], the Pop GTK theme is a fork of the Adapta theme listed earlier and comes with a matching icon pack, which is a fork of the previously mentioned Paper icon pack.
|
||||
|
||||
The theme was released soon after System 76 announced that they were releasing [their own distribution,][28] Pop!_OS. You can read my [Pop!_OS review][29] to know more about it. Needless to say, I think Pop is a fantastic theme with a superb amount of polish and offers a fresh feel to any Gnome desktop.
|
||||
|
||||
[Pop Theme][30]
|
||||
|
||||
#### Conclusion
|
||||
|
||||
Obviously, there way more themes to choose from than we could feature in one article, but these are some of the most complete and polished themes I have used in recent months. If you think we missed any that you really like or you just really dislike one that I featured above, then feel free to let me know in the comment section below and share why you think your favorite themes are better!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-gtk-themes/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[2]:https://itsfoss.com/wp-content/uploads/2018/03/arcambaince-300x225.png
|
||||
[3]:https://www.gnome-look.org/p/1193861/
|
||||
[4]:https://itsfoss.com/wp-content/uploads/2018/03/adapta-300x169.jpg
|
||||
[5]:https://www.gnome-look.org/p/1190851/
|
||||
[6]:https://itsfoss.com/wp-content/uploads/2018/03/numix-300x169.png
|
||||
[7]:https://www.gnome-look.org/p/1170667/
|
||||
[8]:https://itsfoss.com/wp-content/uploads/2018/03/hooli2-800x500.jpg
|
||||
[9]:https://www.gnome-look.org/p/1102901/
|
||||
[10]:https://itsfoss.com/wp-content/uploads/2018/03/AT-800x590.jpg
|
||||
[11]:https://itsfoss.com/ubuntu-community-theme/
|
||||
[12]:https://www.gnome-look.org/p/1215199/
|
||||
[13]:https://itsfoss.com/wp-content/uploads/2018/03/gosx-800x473.jpg
|
||||
[14]:https://www.opendesktop.org/s/Gnome/p/1171688/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2018/03/ultimatemaia-800x450.jpg
|
||||
[16]:https://www.opendesktop.org/s/Gnome/p/1193879/
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2018/03/vimix-800x450.jpg
|
||||
[18]:https://www.gnome-look.org/p/1013698/
|
||||
[19]:https://itsfoss.com/wp-content/uploads/2018/03/ant-800x533.png
|
||||
[20]:https://www.opendesktop.org/p/1099856/
|
||||
[21]:https://itsfoss.com/wp-content/uploads/2018/03/flatremix-800x450.png
|
||||
[22]:https://www.opendesktop.org/p/1214931/
|
||||
[23]:https://itsfoss.com/wp-content/uploads/2018/04/paper-800x450.jpg
|
||||
[24]:https://itsfoss.com/install-paper-theme-linux/
|
||||
[25]:https://snwh.org/paper/download
|
||||
[26]:https://itsfoss.com/wp-content/uploads/2018/04/pop-800x449.jpg
|
||||
[27]:https://system76.com/
|
||||
[28]:https://itsfoss.com/system76-popos-linux/
|
||||
[29]:https://itsfoss.com/pop-os-linux-review/
|
||||
[30]:https://github.com/pop-os/gtk-theme/blob/master/README.md
|
||||
@ -0,0 +1,99 @@
|
||||
A Kernel Module That Forcibly Shutdown Your System
|
||||
======
|
||||
|
||||

|
||||
I know that staying up late is bad for the health. But, who cares? I have been a night owl for years. I usually go to bed after 12 am, sometimes after 1 am. The next morning, I snooze my alarm at least three times, wake up tired and grumpy. Everyday, I promise myself I will go to bed earlier, but ended up going to bed very late as usual. And, this cycle continues! If you’re anything like me, here is a good news. A fellow late nighter has developed a Kernel module named **“Kgotobed”** that forces you to go to bed at a specific time. That said it will forcibly shutdown your system.
|
||||
|
||||
Why should I use this? I have plenty of other options. I can set a cron job to schedule system shutdown at a specific time. I can set up a reminder or alarm clock. I can use a browser plugin or a software. You might ask! However, they all are can easily be ignored or bypassed. Kgotobed is something that you can’t ignore. Something that **can’t be disabled even if you’re a root user**. Yes, it will forcibly power off your system at the specified time. There is no snooze option. You can’t postpone the power off process or you can’t cancel it either. Your system will go down at the specified time no matter what. You have been warned!!
|
||||
|
||||
### Install Kgotobed
|
||||
|
||||
Make sure you have installed **dkms**. It is available in the default repositories of most Linux distributions.
|
||||
|
||||
For example on Fedora, you can install it using the following command:
|
||||
```
|
||||
$ sudo dnf install kernel-devel-$(uname -r) dkms
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, linux Mint:
|
||||
```
|
||||
$ sudo apt install dkms
|
||||
|
||||
```
|
||||
|
||||
Once installed the prerequisites, git clone Kgotobed project.
|
||||
```
|
||||
$ git clone https://github.com/nikital/kgotobed.git
|
||||
|
||||
```
|
||||
|
||||
This command will clone all contents of Kgotobed repository in a folder named “kgotobed” in your current working directory. Cd to that directory:
|
||||
```
|
||||
$ cd kgotobed/
|
||||
|
||||
```
|
||||
|
||||
And, install Kgotobed driver using command:
|
||||
```
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
The above command will register **kgotobed.ko** module with **DKMS** (so that it will be rebuilt for every kernel you run) and Install **gotobed** utility in **/usr/local/bin/** location and then register, enable and start kgotobed service.
|
||||
|
||||
### How it works
|
||||
|
||||
By default, Kgotobed sets bedtime to **1:00 AM**. That said, your computer will shutdown at 1:00 AM no matter what you’re doing.
|
||||
|
||||
To view the current bed time, run:
|
||||
```
|
||||
$ gotobed
|
||||
Current bedtime is 2018-04-10 01:00:00
|
||||
|
||||
```
|
||||
|
||||
To move the bed time earlier, for example 22:00 (10 PM), run:
|
||||
```
|
||||
$ sudo gotobed 22:00
|
||||
[sudo] password for sk:
|
||||
Current bedtime is 2018-04-10 00:58:00
|
||||
Setting bedtime to 2018-04-09 22:00:00
|
||||
Bedtime will be in 2 hours 16 minutes
|
||||
|
||||
```
|
||||
|
||||
This can be helpful when you want to sleep earlier!
|
||||
|
||||
However, you can’t move the bed time later i.e after 1:00 AM. You can’t unload the module, and adjusting system clock won’t help either. The only way out is a reboot!!
|
||||
|
||||
To set different default time, you need to customize **kgotobed.service** (by editing it or by using systemd drop-in).
|
||||
|
||||
### Uninstall Kgotobed
|
||||
|
||||
Not happy with Kgotobed? No worries! Go to the “kgotobed” folder which we cloned earlier and run the following command to uninstall it.
|
||||
```
|
||||
$ sudo make uninstall
|
||||
|
||||
```
|
||||
|
||||
Again, I warn you there is no way to snooze, postpone, or cancel the power off process, even if you’re a root user. Your system will go down forcibly at the specified time. This is not for everyone! It may drive you nuts when you’re working on an important task. In such cases, make sure you have saved the work from time to time or use some advanced utilities that help you to auto shutdown, reboot, suspend, and hibernate your system at a specific time as described in the following link.
|
||||
|
||||
And, that’s for now. Hope you find this guide useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/kgotobed-a-kernel-module-that-forcibly-shutdown-your-system/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,281 @@
|
||||
How to create LaTeX documents with Emacs
|
||||
======
|
||||

|
||||
|
||||
In his excellent article, [An introduction to creating documents in LaTeX][1], author [Aaron Cocker][2] introduces the [LaTeX typesetting system][3] and explains how to create a LaTeX document using [TeXstudio][4]. He also lists a few LaTeX editors that many users find helpful in creating LaTeX documents.
|
||||
|
||||
This comment on the article by [Greg Pittman][5] caught my attention: "LaTeX seems like an awful lot of typing when you first start...". This is true. LaTeX involves a lot of typing and debugging, if you missed a special character like an exclamation mark, which can discourage many users, especially beginners. In this article, I will introduce you to [GNU Emacs][6] and describe how to use it to create LaTeX documents.
|
||||
|
||||
### Creating your first document
|
||||
|
||||
Launch Emacs by typing:
|
||||
```
|
||||
emacs -q --no-splash helloworld.org
|
||||
|
||||
```
|
||||
|
||||
The `-q` flag ensures that no Emacs initializations will load. The `--no-splash-screen` flag prevents splash screens to ensure that only one window is open, with the file `helloworld.org`.
|
||||
|
||||
![Emacs startup screen][8]
|
||||
|
||||
GNU Emacs with the helloworld.org file opened in a buffer window
|
||||
|
||||
Let's add some LaTeX headers the Emacs way: Go to **Org** in the menu bar and select **Export/Publish**.
|
||||
|
||||
![template_flow.png][10]
|
||||
|
||||
Inserting a default template
|
||||
|
||||
In the next window, Emacs offers options to either export or insert a template. Insert the template by entering **#** ([#] Insert template). This will move a cursor to a mini-buffer, where the prompt reads **Options category:**. At this time you may not know the category names; press Tab to see possible completions. Type "default" and press Enter. The following content will be inserted:
|
||||
```
|
||||
#+TITLE: helloworld
|
||||
|
||||
#+DATE: <2018-03-12 Mon>
|
||||
|
||||
#+AUTHOR:
|
||||
|
||||
#+EMAIL: makerpm@nubia
|
||||
|
||||
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
|
||||
|
||||
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
|
||||
|
||||
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
|
||||
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:t todo:t |:t
|
||||
|
||||
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
|
||||
|
||||
#+DESCRIPTION:
|
||||
|
||||
#+EXCLUDE_TAGS: noexport
|
||||
|
||||
#+KEYWORDS:
|
||||
|
||||
#+LANGUAGE: en
|
||||
|
||||
#+SELECT_TAGS: export
|
||||
|
||||
```
|
||||
|
||||
Change the title, date, author, and email as you wish. Mine looks like this:
|
||||
```
|
||||
#+TITLE: Hello World! My first LaTeX document
|
||||
|
||||
#+DATE: \today
|
||||
|
||||
#+AUTHOR: Sachin Patil
|
||||
|
||||
#+EMAIL: psachin@redhat.com
|
||||
|
||||
```
|
||||
|
||||
We don't want to create a Table of Contents yet, so change the value of `toc` from `t` to `nil` inline, as shown below:
|
||||
```
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
|
||||
|
||||
```
|
||||
|
||||
Let's add a section and paragraphs. A section starts with an asterisk (*). We'll copy the content of some paragraphs from Aaron's post (from the [Lipsum Lorem Ipsum generator][11]):
|
||||
```
|
||||
* Introduction
|
||||
|
||||
|
||||
|
||||
\paragraph{}
|
||||
|
||||
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras lorem
|
||||
|
||||
nisi, tincidunt tempus sem nec, elementum feugiat ipsum. Nulla in
|
||||
|
||||
diam libero. Nunc tristique ex a nibh egestas sollicitudin.
|
||||
|
||||
|
||||
|
||||
\paragraph{}
|
||||
|
||||
Mauris efficitur vitae ex id egestas. Vestibulum ligula felis,
|
||||
|
||||
pulvinar a posuere id, luctus vitae leo. Sed ac imperdiet orci, non
|
||||
|
||||
elementum leo. Nullam molestie congue placerat. Phasellus tempor et
|
||||
|
||||
libero maximus commodo.
|
||||
|
||||
```
|
||||
|
||||
|
||||
![helloworld_file.png][13]
|
||||
|
||||
The helloworld.org file
|
||||
|
||||
With the content in place, we'll export the content as a PDF. Select **Export/Publish** from the **Org** menu again, but this time, type **l** (export to LaTeX), followed by **o** (as PDF file and open). This not only opens PDF file for you to view, but also saves the file as `helloworld.pdf` in the same path as `helloworld.org`.
|
||||
|
||||
![org_to_pdf.png][15]
|
||||
|
||||
Exporting helloworld.org to helloworld.pdf
|
||||
|
||||
![org_and_pdf_file.png][17]
|
||||
|
||||
Opening the helloworld.pdf file
|
||||
|
||||
You can also export org to PDF by pressing `Alt + x`, then typing "org-latex-export-to-pdf". Use Tab to auto-complete.
|
||||
|
||||
Emacs also creates the `helloworld.tex` file to give you control over the content.
|
||||
|
||||
![org_tex_pdf.png][19]
|
||||
|
||||
Emacs with LaTeX, org, and PDF files open in three different windows
|
||||
|
||||
You can compile the `.tex` file to `.pdf` using the command:
|
||||
```
|
||||
pdflatex helloworld.tex
|
||||
|
||||
```
|
||||
|
||||
You can also export the `.org` file to HTML or as a simple text file. What I like about .org files is they can be pushed to [GitHub][20], where they are rendered just like any other markdown formats.
|
||||
|
||||
### Creating a LaTeX Beamer presentation
|
||||
|
||||
Let's go a step further and create a LaTeX [Beamer][21] presentation using the same file with some modifications as shown below:
|
||||
```
|
||||
#+TITLE: LaTeX Beamer presentation
|
||||
|
||||
#+DATE: \today
|
||||
|
||||
#+AUTHOR: Sachin Patil
|
||||
|
||||
#+EMAIL: psachin@redhat.com
|
||||
|
||||
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
|
||||
|
||||
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
|
||||
|
||||
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
|
||||
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
|
||||
|
||||
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
|
||||
|
||||
#+DESCRIPTION:
|
||||
|
||||
#+EXCLUDE_TAGS: noexport
|
||||
|
||||
#+KEYWORDS:
|
||||
|
||||
#+LANGUAGE: en
|
||||
|
||||
#+SELECT_TAGS: export
|
||||
|
||||
#+LATEX_CLASS: beamer
|
||||
|
||||
#+BEAMER_THEME: Frankfurt
|
||||
|
||||
#+BEAMER_INNER_THEME: rounded
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* Introduction
|
||||
|
||||
*** Programming
|
||||
|
||||
- Python
|
||||
|
||||
- Ruby
|
||||
|
||||
|
||||
|
||||
*** Paragraph one
|
||||
|
||||
|
||||
|
||||
Lorem ipsum dolor sit amet, consectetur adipiscing
|
||||
|
||||
elit. Cras lorem nisi, tincidunt tempus sem nec, elementum feugiat
|
||||
|
||||
ipsum. Nulla in diam libero. Nunc tristique ex a nibh egestas
|
||||
|
||||
sollicitudin.
|
||||
|
||||
|
||||
|
||||
*** Paragraph two
|
||||
|
||||
|
||||
|
||||
Mauris efficitur vitae ex id egestas. Vestibulum
|
||||
|
||||
ligula felis, pulvinar a posuere id, luctus vitae leo. Sed ac
|
||||
|
||||
imperdiet orci, non elementum leo. Nullam molestie congue
|
||||
|
||||
placerat. Phasellus tempor et libero maximus commodo.
|
||||
|
||||
|
||||
|
||||
* Thanks
|
||||
|
||||
*** Links
|
||||
|
||||
- Link one
|
||||
|
||||
- Link two
|
||||
|
||||
```
|
||||
|
||||
We have added three more lines to the header:
|
||||
```
|
||||
#+LATEX_CLASS: beamer
|
||||
|
||||
#+BEAMER_THEME: Frankfurt
|
||||
|
||||
#+BEAMER_INNER_THEME: rounded
|
||||
|
||||
```
|
||||
|
||||
To export to PDF, press `Alt + x` and type "org-beamer-export-to-pdf".
|
||||
|
||||
![latex_beamer_presentation.png][23]
|
||||
|
||||
The Latex Beamer presentation, created using Emacs and Org mode
|
||||
|
||||
I hope you enjoyed creating this LaTeX and Beamer document using Emacs (note that it's faster to use keyboard shortcuts than a mouse). Emacs Org-mode offers much more than I can cover in this post; you can learn more at [orgmode.org][24].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/how-create-latex-documents-emacs
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psachin
|
||||
[1]:https://opensource.com/article/17/6/introduction-latex
|
||||
[2]:https://opensource.com/users/aaroncocker
|
||||
[3]:https://www.latex-project.org
|
||||
[4]:http://www.texstudio.org/
|
||||
[5]:https://opensource.com/users/greg-p
|
||||
[6]:https://www.gnu.org/software/emacs/
|
||||
[7]:/file/392261
|
||||
[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/emacs_startup.png?itok=UnT4PgK5 (Emacs startup screen)
|
||||
[9]:/file/392266
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/insert_template_flow.png?itok=V_c2KipO (template_flow.png)
|
||||
[11]:https://www.lipsum.com/feed/html
|
||||
[12]:/file/392271
|
||||
[13]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/helloworld_file.png?itok=o8IX0TsJ (helloworld_file.png)
|
||||
[14]:/file/392276
|
||||
[15]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_to_pdf.png?itok=fNnC1Y-L (org_to_pdf.png)
|
||||
[16]:/file/392281
|
||||
[17]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_and_pdf_file.png?itok=HEhtw-cu (org_and_pdf_file.png)
|
||||
[18]:/file/392286
|
||||
[19]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_tex_pdf.png?itok=poZZV_tj (org_tex_pdf.png)
|
||||
[20]:https://github.com
|
||||
[21]:https://www.sharelatex.com/learn/Beamer
|
||||
[22]:/file/392291
|
||||
[23]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/latex_beamer_presentation.png?itok=rsPSeIuM (latex_beamer_presentation.png)
|
||||
[24]:https://orgmode.org/worg/org-tutorials/org-latex-export.html
|
||||
@ -0,0 +1,136 @@
|
||||
Yet Another TUI Graphical Activity Monitor, Written In Go
|
||||
======
|
||||
|
||||

|
||||
You already know about “top” command, don’t you? Yes, It provides dynamic real-time information about running processes in any Unix-like operating systems. A few developers have built graphical front-ends for top command, so the users can easily find out their system’s activity in a graphical window. One of them is **Gotop**. As the name implies, Gotop is a TUI graphical activity monitor, written in **Go** language. It is completely free, open source and inspired by [gtop][1] and [vtop][2] programs.
|
||||
|
||||
In this brief guide, we are going to discuss how to install and use Gotop program to monitor a Linux system’s activity.
|
||||
|
||||
### Installing Gotop
|
||||
|
||||
Gotop is written using Go, so we need to install it first. To install Go programming language in Linux, refer the following guide.
|
||||
|
||||
After installing Go, download the latest Gotop binary using the following command.
|
||||
```
|
||||
$ sh -c "$(curl https://raw.githubusercontent.com/cjbassi/gotop/master/download.sh)"
|
||||
|
||||
```
|
||||
|
||||
And, then move the downloaded binary to your $PATH, for example **/usr/local/bin/**.
|
||||
```
|
||||
$ cp gotop /usr/local/bin
|
||||
|
||||
```
|
||||
|
||||
Finally, make it executable using command:
|
||||
```
|
||||
$ chmod +x /usr/local/bin/gotop
|
||||
|
||||
```
|
||||
|
||||
If you’re using Arch-based systems, Gotop is available in **AUR** , so you can install it using any AUR helper programs.
|
||||
|
||||
Using [**Cower**][3]:
|
||||
```
|
||||
$ cower -S gotop
|
||||
|
||||
```
|
||||
|
||||
Using [**Pacaur**][4]:
|
||||
```
|
||||
$ pacaur -S gotop
|
||||
|
||||
```
|
||||
|
||||
Using [**Packer**][5]:
|
||||
```
|
||||
$ packer -S gotop
|
||||
|
||||
```
|
||||
|
||||
Using [**Trizen**][6]:
|
||||
```
|
||||
$ trizen -S gotop
|
||||
|
||||
```
|
||||
|
||||
Using [**Yay**][7]:
|
||||
```
|
||||
$ yay -S gotop
|
||||
|
||||
```
|
||||
|
||||
Using [yaourt][8]:
|
||||
```
|
||||
$ yaourt -S gotop
|
||||
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Gotop usage is easy! All you have to do is to run the following command from the Terminal.
|
||||
```
|
||||
$ gotop
|
||||
|
||||
```
|
||||
|
||||
There you go! You will see the usage of your system’s CPU, disk, memory, network, cpu temperature and process list in a simple TUI window.
|
||||
|
||||
![][10]
|
||||
|
||||
To show only CPU, Mem and Process widgets, use **-m** flag like below.
|
||||
```
|
||||
$ gotop -m
|
||||
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
You can sort the process table by using the following keyboard shortcuts.
|
||||
|
||||
* **c** – CPU
|
||||
* **m** – Mem
|
||||
* **p** – PID
|
||||
|
||||
|
||||
|
||||
For process navigation, use the following keys.
|
||||
|
||||
* **UP/DOWN** arrows or **j/k** keys to go up and down.
|
||||
* **Ctrl-d** and **Ctrl-u** – up and down half a page.
|
||||
* **Ctrl-f** and **Ctrl-b** – up and down a full page.
|
||||
* **gg** and **G** – iump to top and bottom.
|
||||
|
||||
|
||||
|
||||
Press **< TAB>** to toggle process grouping. To kill the selected process or process group, type **dd**. To select a process, just click on it. To scroll down/up, use the mouse scroll button. To zoom in and zoom out CPU and memory graphs, use **h** and **l**. To display the help menu at anytime, just press **?**.
|
||||
|
||||
**Recommended read:**
|
||||
|
||||
And, that’s all for now. Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/gotop-yet-another-tui-graphical-activity-monitor-written-in-go/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/aksakalli/gtop
|
||||
[2]:https://github.com/MrRio/vtop
|
||||
[3]:https://www.ostechnix.com/cower-simple-aur-helper-arch-linux/
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/04/Gotop-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/04/Gotop-2.png
|
||||
@ -0,0 +1,156 @@
|
||||
Top 9 open source ERP systems to consider | Opensource.com
|
||||
======
|
||||
|
||||
Businesses with more than a handful of employees have a lot to balance including pricing, product planning, accounting and finance, managing payroll, dealing with inventory, and more. Stitching together a set of disparate tools to handle those jobs is a quick, cheap, and dirty way to get things done.
|
||||
|
||||
That approach isn't scalable. It's difficult to efficiently move data between the various pieces of such an ad-hoc system. As well, it can be difficult to maintain.
|
||||
|
||||
Instead, most growing businesses turn to an [enterprise resource planning][1] (ERP) system.
|
||||
|
||||
The big guns in that space are Oracle, SAP, and Microsoft Dynamics. Their offerings are comprehensive, but also expensive. What happens if your business can't afford one of those big implementations or if your needs are simple? You turn to the open source alternatives.
|
||||
|
||||
### What to look for in an ERP system
|
||||
|
||||
Obviously, you want a system that suits your needs. Depending on those needs, more features doesn't always mean better. However, your needs might change as your business grows, so you'll want to find an ERP system that can expand to meet your new needs. That could mean the system has additional modules or just supports plugins and add-ons.
|
||||
|
||||
Most open source ERP systems are web applications. You can download and install them on your server. But if you don't want (or don't have the skills or staff) to maintain a system yourself, then make sure there's a hosted version of the application available.
|
||||
|
||||
Finally, you'll want to make sure the application has good documentation and good support—either in the form of paid support or an active user community.
|
||||
|
||||
There are a number of flexible, feature-rich, and cost-effective open source ERP systems out there. Here are nine to check out if you're in the market for such a system.
|
||||
|
||||
### ADempiere
|
||||
|
||||
Like most other open source ERP solutions, [ADempiere][2] is targeted at small and midsized businesses. It's been around awhile—the project was formed in 2006 as a fork from the Compiere ERP software.
|
||||
|
||||
Its Italian name means to achieve or satisfy, and its "multidimensional" ERP features aim to help businesses satisfy a wide range of needs. It adds supply chain management (SCM) and customer relationship management (CRM) features to its ERP suite to help manage sales, purchasing, inventory, and accounting processes in one piece of software. Its latest release, v.3.9.0, updated its user interface, point-of-sale, HR, payroll, and other features.
|
||||
|
||||
As a multiplatform, Java-based cloud solution, ADempiere is accessible on Linux, Unix, Windows, MacOS, smartphones, and tablets. It is licensed under [GPLv2][3]. If you'd like to learn more, take its [demo][4] for a test run or access its [source code][5] on GitHub.
|
||||
|
||||
### Apache OFBiz
|
||||
|
||||
[Apache OFBiz][6]'s suite of related business tools is built on a common architecture that enables organizations to customize the ERP to their needs. As a result, it's best suited for midsize or large enterprises that have the internal development resources to adapt and integrate it within their existing IT and business processes.
|
||||
|
||||
OFBiz is a mature open source ERP system; its website says it's been a top-level Apache project for a decade. [Modules][7] are available for accounting, manufacturing, HR, inventory management, catalog management, CRM, and e-commerce. You can also try out its e-commerce web store and backend ERP applications on its [demo page][8].
|
||||
|
||||
Apache OFBiz's source code can be found in the [project's repository][9]. It is written in Java and licensed under an [Apache 2.0 license][10].
|
||||
|
||||
### Dolibarr
|
||||
|
||||
[Dolibarr][11] offers end-to-end management for small and midsize businesses—from keeping track of invoices, contracts, inventory, orders, and payments to managing documents and supporting electronic point-of-sale system. It's all wrapped in a fairly clean interface.
|
||||
|
||||
If you're wondering what Dolibarr can't do, [here's some documentation about that][12].
|
||||
|
||||
In addition to an [online demo][13], Dolibarr also has an [add-ons store][14] where you can buy software that extends its features. You can check out its [source code][15] on GitHub; it's licensed under [GPLv3][16] or any later version.
|
||||
|
||||
### ERPNext
|
||||
|
||||
[ERPNext][17] is one of those classic open source projects; in fact, it was [featured on Opensource.com][18] way back in 2014. It was designed to scratch a particular itch, in this case replacing a creaky and expensive proprietary ERP implementation.
|
||||
|
||||
ERPNext was built for small and midsized businesses. It includes modules for accounting, managing inventory, sales, purchase, and project management. The applications that make up ERPNext are form-driven—you fill information in a set of fields and let the application do the rest. The whole suite is easy to use.
|
||||
|
||||
If you're interested, you can request a [demo][19] before taking the plunge and [downloading it][20] or [buying a subscription][21] to the hosted service.
|
||||
|
||||
### Metasfresh
|
||||
|
||||
[Metasfresh][22]'s name reflects its commitment to keeping its code "fresh." It's released weekly updates since late 2015, when its founders forked the code from the ADempiere project. Like ADempiere, it's an open source ERP based on Java targeted at the small and midsize business market.
|
||||
|
||||
While it's a younger project than most of the other software described here, it's attracted some early, positive attention, such as being named a finalist for the Initiative Mittelstand "best of open source" IT innovation award.
|
||||
|
||||
Metasfresh is free when self-hosted or for one user via the cloud, or on a monthly subscription fee basis as a cloud-hosted solution for 1-100 users. Its [source code][23] is available under the [GPLv2][24] license at GitHub and its cloud version is licensed under GPLv3.
|
||||
|
||||
### Odoo
|
||||
|
||||
[Odoo][25] is an integrated suite of applications that includes modules for project management, billing, accounting, inventory management, manufacturing, and purchasing. Those modules can communicate with each other to efficiently and seamlessly exchange information.
|
||||
|
||||
While ERP can be complex, Odoo makes it friendlier with a simple, almost spartan interface. The interface is reminiscent of Google Drive, with just the functions you need visible. You can [give Odoo a try][26] before you decide to sign up.
|
||||
|
||||
Odoo is a web-based tool. Subscriptions to individual modules will set you back $20 (USD) a month for each one. You can also [download it][27] or grab the [source code][28] from GitHub. It's licensed under [LGPLv3][29].
|
||||
|
||||
### Opentaps
|
||||
|
||||
[Opentaps][30], one of the few open source ERP solutions designed for larger businesses, packs a lot of power and flexibility. This is no surprise because it's built on top of Apache OFBiz.
|
||||
|
||||
You get the expected set of modules that help you manage inventory, manufacturing, financials, and purchasing. You also get an analytics feature that helps you analyze all aspects of your business. You can use that information to better plan into the future. Opentaps also packs a powerful reporting function.
|
||||
|
||||
On top of that, you can [buy add-ons and additional modules][31] to enhance Opentaps' capabilities. They include integration with Amazon Marketplace Services and FedEx. Before you [download Opentaps][32], give the [online demo][33] a try. It's licensed under [GPLv3][34].
|
||||
|
||||
### WebERP
|
||||
|
||||
[WebERP][35] is exactly as it sounds: An ERP system that operates through a web browser. The only other software you need is a PDF reader to view reports.
|
||||
|
||||
Specifically, its an accounting and business management solution geared toward wholesale, distribution, and manufacturing businesses. It also integrates with [third-party business software][36], including a point-of-sale system for multi-branch retail management, an e-commerce module, and wiki software for building a business knowledge base. It's written in PHP and aims to be a low-footprint, efficient, fast, and platform-independent system that's easy for general business users.
|
||||
|
||||
WebERP is actively being developed and has an active [forum][37], where you can ask questions or learn more about using the application. You can also try a [demo][38] or download the [source code][39] (licensed under [GPLv2][40]) on GitHub.
|
||||
|
||||
### xTuple PostBooks
|
||||
|
||||
If your manufacturing, distribution, or e-commerce business has outgrown its small business roots and is looking for an ERP to grow with you, you may want to check out [xTuple PostBooks][41]. It's a comprehensive solution built around its core ERP, accounting, and CRM features that adds inventory, distribution, purchasing, and vendor reporting capabilities.
|
||||
|
||||
xTuple is available under the Common Public Attribution License ([CPAL][42]), and the project welcomes developers to fork it to create other business software for inventory-based manufacturers. Its web app core is written in JavaScript, and its [source code][43] can be found on GitHub. To see if it's right for you, register for a free [demo][44] on xTuple's website.
|
||||
|
||||
There are many other open source ERP options you can choose from—others you might want to check out include [Tryton][45], which is written in Python and uses the PostgreSQL database engine, or the Java-based [Axelor][46], which touts users' ability to create or modify business apps with a drag-and-drop interface. And, if your favorite open source ERP solution isn't on the list, please share it with us in the comments. You might also check out our list of top [supply chain management tools][47].
|
||||
|
||||
This article is updated from a [previous version][48] authored by Opensource.com moderator [Scott Nesbitt][49].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/tools/enterprise-resource-planning
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:http://en.wikipedia.org/wiki/Enterprise_resource_planning
|
||||
[2]:http://www.adempiere.net/welcome
|
||||
[3]:http://wiki.adempiere.net/License
|
||||
[4]:http://www.adempiere.net/web/guest/demo
|
||||
[5]:https://github.com/adempiere/adempiere
|
||||
[6]:http://ofbiz.apache.org/
|
||||
[7]:https://ofbiz.apache.org/business-users.html#UsrModules
|
||||
[8]:http://ofbiz.apache.org/ofbiz-demos.html
|
||||
[9]:http://ofbiz.apache.org/source-repositories.html
|
||||
[10]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[11]:http://www.dolibarr.org/
|
||||
[12]:http://wiki.dolibarr.org/index.php/What_Dolibarr_can%27t_do
|
||||
[13]:http://www.dolibarr.org/onlinedemo
|
||||
[14]:http://www.dolistore.com/
|
||||
[15]:https://github.com/Dolibarr/dolibarr
|
||||
[16]:https://github.com/Dolibarr/dolibarr/blob/develop/COPYING
|
||||
[17]:https://erpnext.com/
|
||||
[18]:https://opensource.com/business/14/11/building-open-source-erp
|
||||
[19]:https://frappe.erpnext.com/request-a-demo
|
||||
[20]:https://erpnext.com/download
|
||||
[21]:https://erpnext.com/pricing
|
||||
[22]:http://metasfresh.com/en/
|
||||
[23]:https://github.com/metasfresh/metasfresh
|
||||
[24]:https://github.com/metasfresh/metasfresh/blob/master/LICENSE.md
|
||||
[25]:https://www.odoo.com/
|
||||
[26]:https://www.odoo.com/page/start
|
||||
[27]:https://www.odoo.com/page/download
|
||||
[28]:https://github.com/odoo
|
||||
[29]:https://github.com/odoo/odoo/blob/11.0/LICENSE
|
||||
[30]:http://www.opentaps.org/
|
||||
[31]:http://shop.opentaps.org/
|
||||
[32]:http://www.opentaps.org/products/download
|
||||
[33]:http://www.opentaps.org/products/online-demo
|
||||
[34]:https://www.gnu.org/licenses/agpl-3.0.html
|
||||
[35]:http://www.weberp.org/
|
||||
[36]:http://www.weberp.org/Links.html
|
||||
[37]:http://www.weberp.org/forum/
|
||||
[38]:http://www.weberp.org/weberp/
|
||||
[39]:https://github.com/webERP-team/webERP
|
||||
[40]:https://github.com/webERP-team/webERP#legal
|
||||
[41]:https://xtuple.com/
|
||||
[42]:https://xtuple.com/products/license-options#cpal
|
||||
[43]:http://xtuple.github.io/
|
||||
[44]:https://xtuple.com/free-demo
|
||||
[45]:http://www.tryton.org/
|
||||
[46]:https://www.axelor.com/
|
||||
[47]:https://opensource.com/tools/supply-chain-management
|
||||
[48]:https://opensource.com/article/16/3/top-4-open-source-erp-systems
|
||||
[49]:https://opensource.com/users/scottnesbitt
|
||||
58
translated/tech/20180301 How to add fonts to Fedora.md
Normal file
58
translated/tech/20180301 How to add fonts to Fedora.md
Normal file
@ -0,0 +1,58 @@
|
||||
如何将字体添加到 Fedora
|
||||
===================
|
||||
|
||||

|
||||
|
||||
字体可帮助你通过设计以创意的方式表达你的想法。无论给图片加标题、编写演示文稿,还是设计问候语或广告,字体都可以将你的想法提升到更高水平。很容易仅仅为了它们的审美品质而爱上它们。幸运的是,Fedora 使安装变得简单。以下是如何做的。
|
||||
|
||||
### 全系统安装
|
||||
|
||||
如果你在系统范围内安装字体,那么它可以让所有用户使用。此方式的最佳方法是使用官方软件库中的 RPM 软件包。
|
||||
|
||||
开始前打开 Fedora Workstation 中的 _Software_ 工具,或者其他使用官方仓库的工具。选择横栏中选择 _Add-ons_ 类别。接着在 add-on 类别中选择 _Fonts_。你会看到类似于下面截图中的可用字体:
|
||||
|
||||
[][1]
|
||||
|
||||
当你选择一种字体时,会出现一些细节。根据几种情况,你可能能够预览字体的一些示例文本。点击 _Install_ 按钮将其添加到你的系统。根据系统速度和网络带宽,完成此过程可能需要一些时间。
|
||||
|
||||
你还可以在字体细节中通过 _Remove_ 按钮删除前面带有勾的已经安装的字体。
|
||||
|
||||
### 个人安装
|
||||
|
||||
如果你以兼容格式:_.ttf_、 _otf_ 、_.ttc_、_.pfa_ 、_.pfb_ 或者 . _pcf_ 下载了字体,则此方法效果更好。这些字体扩展名不应通过将它们放入系统文件夹来安装在系统范围内。这种类型的非打包字体不能自动更新。他们也可能会在稍后干扰一些软件操作。安装这些字体的最佳方法是在你自己的个人数据目录中。
|
||||
|
||||
打开 Fedora Workstation 中的 _Files_ 应用或你选择的类似文件管理器应用。如果你使用 _Files_,那么可能需要使用 _Ctrl+H_ 组合键来显示隐藏的文件和文件夹。查找 _.fonts_ 文件夹并将其打开。如果你没有 _.fonts_ 文件夹,请创建它。 (记住最前面的点并全部使用小写。)
|
||||
|
||||
将已下载的字体文件复制到 _.fonts_ 文件夹中。此时你可以关闭文件管理器。打开一个终端并输入以下命令:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
```
|
||||
|
||||
这将重建字体缓存,帮助 Fedora 可以找到并引用它。你可能还需要重新启动需要使用新字体的应用程序,例如 Inkscape 或 LibreOffice。你重新启动后,新的字体应该就可以使用了。
|
||||
|
||||
* * *
|
||||
|
||||
照片由 [Raphael Schaller][2] 发布在 [Unsplash][3] 中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Paul W. Frields
|
||||
Paul W. Frields 自 1997 年以来一直是 Linux 用户和爱好者,并于 2003 年 Fedora 发布不久后加入项目。他是 Fedora 项目委员会的创始成员之一,并从事文档、网站发布、倡导、工具链开发和维护软件工作。他于 2008 年 2 月至 2010 年 7 月在红帽担任 Fedora 项目负责人,现任红帽公司工程部经理。他目前和他的妻子和两个孩子一起住在弗吉尼亚州。
|
||||
|
||||
-----------------------------
|
||||
|
||||
via: https://fedoramagazine.org/add-fonts-fedora/
|
||||
|
||||
作者:[ Paul W. Frields ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2017/11/Software-fonts.png
|
||||
[2]:https://unsplash.com/photos/GkinCd2enIY?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://unsplash.com/search/photos/fonts?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,81 @@
|
||||
使用 syslog-ng 可靠地记录物联网事件
|
||||
======
|
||||
|
||||

|
||||
现在,物联网设备和嵌入式系统越来越多。对于许多连接到因特网或者一个网络的设备来说,记录事件很有必要,因为你需要知道这些设备都做了些什么事情,这样你才能够解决可能出现的问题。
|
||||
|
||||
可以考虑去使用的一个监视工具是开源的 [syslog-ng][1] 应用程序,它是一个强化的、致力于可移植的、中心化的日志收集守护程序。它可以从许多不同种类的源、进程来收集日志,并且可以对这些日志进行过滤、存储、或者路由,以便于做进一步的分析。syslog-ng 的大多数代码是用高效率的、高可移植的 C 代码写成的。它能够适用于各种场景,无论你是将它运行在一个处理能力很弱的设备上做一些简单的事情,还是运行在数据中心从成千上万的机器中收集日志的强大应用,它都能够胜任。
|
||||
|
||||
你可能注意到在这个段落中,我使用了大量的溢美词汇。为了让你更清晰地了解它,我们来复习一下,但这将花费更多的时间,也了解的更深入一些。
|
||||
|
||||
### 日志
|
||||
|
||||
首先解释一下日志。日志是记录一台计算机上事件的东西。在一个典型的 Linux 机器上,你可以在 `/var/log` 目录中找到这些信息。例如,如果你通过 SSH 登陆到机器中,你将可以在其中一个日志文件中找到类似于如下内容的信息:
|
||||
|
||||
`Jan 14 11:38:48 ``linux``-0jbu sshd[7716]: Accepted ``publickey`` for root from 127.0.0.1 port 48806 ssh2`
|
||||
|
||||
它的内容可能是关于你的 CPU 过热,通过 HTTP 下载了一个文档,或者你的应用程序认为重要的任何东西。
|
||||
|
||||
### syslog-ng
|
||||
|
||||
正如我在上面所写的那样,syslog-ng 应用程序是一个强化的、致力于可移植性、和中心化的日志收集守护程序。守护程序的意思是,syslog-ng 是一个持续运行在后台的应用程序,用于收集日志信息。
|
||||
|
||||
虽然现在大多数应用程序的 Linux 测试是限制在 x86_64 的机器上,但是,syslog-ng 也可以运行在大多数 BSD 和商业 UNIX 变种版本上的。从嵌入式/物联网的角度来看,这种能够运行在不同的 CPU 架构(包括 32 位和 64 位的 ARM、PowerPC、MIPS 等等)的能力甚至更为重要。(有时候,我通过阅读关于 syslog-ng 如何使用它们来学习新架构)
|
||||
|
||||
为什么中心化的日志收集如此重要?其中一个很重要的原因是易于使用,因为它放在一个地方,不用到成百上千的机器上挨个去检查它们的日志。另一个原因是可用性 —— 如果一个设备不论是什么原因导致了它不可用,你可以检查这个设备的日志信息。第三个原因是安全性;当你的设备被黑,检查设备日志可以发现攻击的踪迹。
|
||||
|
||||
### syslog-ng 的四种用法
|
||||
|
||||
Syslog-ng 有四种主要的用法:收集、处理、过滤、和保存日志信息。
|
||||
|
||||
**收集信息:** syslog-ng 能够从各种各样的 [特定平台源][2] 上收集信息,比如 `/dev/log`,`journal`,或者 `sun-streams`。作为一个中心化的日志收集器,传统的(`rfc3164`)和最新的(`rfc5424`)系统日志协议、以及它们 基于 UDP、TCP、和加密连接的各种变种,它都是支持的。你也可以从管道、套接字、文件、甚至应用程序输出来收集日志信息(或者各种文本数据)。
|
||||
|
||||
**处理日志信息:** 它的处理能力几乎是无限的。你可以用它内置的解析器来分类、规范、以及结构化日志信息。如果它没有为你提供在你的应用场景中所需要的解析器,你甚至可以用 Python 来自己写一个解析器。你也可以使用地理数据来丰富信息,或者基于信息内容来附加一些字段。日志信息可以按处理它的应用程序所要求的格式进行重新格式化。你也可以重写日志信息 —— 当然了,你不能篡改日志内容 —— 比如在某些情况下,需要满足匿名要求的信息。
|
||||
|
||||
**过滤日志:** 过滤日志的用法主要有两种:丢弃不需要保存的日志信息 —— 像调试级别的信息;和路由日志信息—— 确保正确的日志到达正确的目的地。后一种用法的一个例子是,转发所有的认证相关的信息到一个安全信息与事件管理系统(SIEM)。
|
||||
|
||||
**保存信息:** 传统的做法是,将文件保存在本地或者发送到中心化日志服务器;不论是哪种方式,它们都被发送到一个[平面文件][3]。经过这些年的改进,syslog-ng 已经开始支持 SQL 数据库,并且在过去的几年里,大数据目的地,包括 HDFS、Kafka、MongoDB、和 Elasticsearch,都被加入到 syslog-ng 的支持中。
|
||||
|
||||
### 消息格式
|
||||
|
||||
当在你的 `/var/log` 目录中查看消息时,你将看到(如上面的 SSH 信息)大量的消息都是如下格式的内容:
|
||||
|
||||
`date + host name + application name + an almost complete English sentence`
|
||||
|
||||
在这里的每个应用程序事件都是用不同的语法描述的,基于这些数据去创建一个报告是个痛苦的任务。
|
||||
|
||||
解决这种混乱信息的一个方案是使用结构化日志。在这种情况下,事件被表示为键-值对,而不是随意的日志信息。比如,一个 SSH 日志能够按应用程序名字、源 IP 地址、用户名、认证方法等等来描述。
|
||||
|
||||
你可以从一开始就对你的日志信息按合适的格式进行结构化处理。当处理传统的日志信息时,你可以在 syslog-ng 中使用不同的解析器,转换非结构化(和部分结构化)的信息为键-值对格式。一旦你的日志信息表示为键-值对,那么,报告、报警、以及简单查找信息将变得很容易。
|
||||
|
||||
### 物联网日志
|
||||
|
||||
我们从一个棘手的问题开始:哪个版本的 syslog-ng 最流行?在你回答之前,想想如下这些事实:这个项目启动于 20 年以前,Red Hat 企业版 Linux EPEL 已经有了 3.5 版,并且当前版本是 3.14。当我在我的演讲中问到这个问题时,观众通常回答他们喜欢的 Linux 发行版。你们绝对想不到的是,正确答案竟然是 1.6 版最流行,这个版本已经有 15 年的历史的。这什么这个版本是最为流行的,因为它是包含在亚马逊 Kindle 阅读器中的版本,它是电子书阅读器,因为它运行在全球范围内超过 1 亿台的设备上。另外一个在消费类设备上运行 syslog-ng 的例子是 BMW i3 电动汽车。
|
||||
|
||||
Kindle 使用 syslog-ng 去收集关于用户在这台设备上都做了些什么事情的所有可能的信息。在 BMW 电动汽车上,syslog-ng 所做的事情更复杂,基于内容过滤日志信息,并且在大多数情况下,只记录最重要的日志。
|
||||
|
||||
使用 syslog-ng 的其它类别设备还有网络和存储。一些比较知名的例子有,Turris Omnia 开源 Linux 路由器和群晖 NAS 设备。在大多数案例中,syslog-ng 是在设备上作为一个日志客户端来运行,但是在有些案例中,它运行为一个有富 Web 界面的中心日志服务器。
|
||||
|
||||
你还可以在一些行业服务中找到 syslog-ng 的身影。它运行在来自美国国家仪器有限公司(NI)的实时 Linux 设备上,执行测量和自动化任务。它也被用于从定制开发的应用程序中收集日志。从命令行就可以做配置,但是一个漂亮的 GUI 可用于浏览日志。
|
||||
|
||||
最后,这里还有大量的项目,比如,汽车和飞机,syslog-ng 在它们上面既可以运行为客户端,也可以运行为服务端。在这种使用案例中,syslog-ng 一般用来收集所有的日志和测量数据,然后发送它们到处理这些日志的中心化服务器集群上,然后保存它们到支持大数据的目的地,以备进一步分析。
|
||||
|
||||
### 对物联网的整体益处
|
||||
|
||||
在物联网环境中使用 syslog-ng 有几个好处。第一,它的分发性能很高,并且是一个可靠的日志收集器。第二,它的架构也很简单,因此,系统、应用程序日志、以及测量数据可以被一起收集。第三,它使数据易于使用,因为,数据可以被解析和表示为易于使用的格式。最后,通过 syslog-ng 的高效路由和过滤功能,可以显著降低处理程序的负载水平。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/logging-iot-events-syslog-ng
|
||||
|
||||
作者:[Peter Czanik][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[qhwdw](https://github.com/qhwdw)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/czanik
|
||||
[1]:https://syslog-ng.com/open-source-log-management
|
||||
[2]:https://syslog-ng.com/documents/html/syslog-ng-ose-latest-guides/en/syslog-ng-ose-guide-admin/html/sources.html
|
||||
[3]:https://en.wikipedia.org/wiki/Flat_file_database
|
||||
Loading…
Reference in New Issue
Block a user