mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
c59186e080
@ -1,8 +1,8 @@
|
||||
CentOS上配置rsyslog客户端用以远程记录日志
|
||||
================================================================================
|
||||
**rsyslog**是一个开源工具,被广泛用于Linux系统以通过TCP/UDP协议转发或接收日志消息。rsyslog守护进程可以被配置称两种环境,一种是配置成日志收集服务器,rsyslog进程可以从网络中收集所有其它主机上的日志数据,这些主机已经将日志配置为发送到服务器。rsyslog的另外一个角色,就是可以配置为客户端,用来过滤和发送内部日志消息到本地文件夹(如/var/log)或一台可以路由到的远程rsyslog服务器上。
|
||||
**rsyslog**是一个开源工具,被广泛用于Linux系统以通过TCP/UDP协议转发或接收日志消息。rsyslog守护进程可以被配置成两种环境,一种是配置成日志收集服务器,rsyslog进程可以从网络中收集其它主机上的日志数据,这些主机会将日志配置为发送到另外的远程服务器。rsyslog的另外一个用法,就是可以配置为客户端,用来过滤和发送内部日志消息到本地文件夹(如/var/log)或一台可以路由到的远程rsyslog服务器上。
|
||||
|
||||
假定你的网络中已经有一台rsyslog服务器[已经起来并且处于运行中][1],本指南将为你展示如何来设置CentOS系统将其内部日志消息路由到一台远程rsyslog服务器上。这将大大改善你的系统磁盘空间的使用,尤其是你还没有一个独立的用于/var目录的大分区。
|
||||
假定你的网络中已经有一台[已经配置好并启动的][1]rsyslog服务器,本指南将为你展示如何来设置CentOS系统将其内部日志消息路由到一台远程rsyslog服务器上。这将大大改善你的系统磁盘空间的使用,尤其是当你还没有一个用于/var目录的独立的大分区。
|
||||
|
||||
### 步骤一: 安装Rsyslog守护进程 ###
|
||||
|
||||
@ -35,9 +35,9 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
*.* @@192.168.1.25:514
|
||||
|
||||
注意,你也可以将rsyslog服务器的IP地址替换成它的DNS名称(FQDN)。
|
||||
注意,你也可以将rsyslog服务器的IP地址替换成它的主机名(FQDN)。
|
||||
|
||||
如果你只想要转发指定设备的日志消息,比如说内核设备,那么你可以在rsyslog配置文件中使用以下声明。
|
||||
如果你只想要转发服务器上的指定设备的日志消息,比如说内核设备,那么你可以在rsyslog配置文件中使用以下声明。
|
||||
|
||||
kern.* @192.168.1.25:514
|
||||
|
||||
@ -51,9 +51,11 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
在另外一种环境中,让我们假定你已经在机器上安装了一个名为“foobar”的应用程序,它会在/var/log下生成foobar.log日志文件。现在,你只想要将它的日志定向到rsyslog服务器,这可以通过像下面这样在rsyslog配置文件中加载imfile模块来实现。
|
||||
####非 syslog 日志的转发
|
||||
|
||||
首先,加载imfile模块,这必须只做一次。
|
||||
在另外一种环境中,让我们假定你已经在机器上安装了一个名为“foobar”的应用程序,它会在/var/log下生成foobar.log日志文件。现在,你想要将它的日志定向到rsyslog服务器,这可以通过像下面这样在rsyslog配置文件中加载imfile模块来实现。
|
||||
|
||||
首先,加载imfile模块,这只需做一次。
|
||||
|
||||
module(load="imfile" PollingInterval="5")
|
||||
|
||||
@ -73,8 +75,7 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
### 步骤三: 让Rsyslog进程自动启动 ###
|
||||
|
||||
To automatically start rsyslog client after every system reboot, run the following command to enable it system-wide:
|
||||
要让rsyslog客户端在每次系统重启后自动启动,请运行以下命令来在系统范围启用:
|
||||
要让rsyslog客户端在每次系统重启后自动启动,请运行以下命令:
|
||||
|
||||
**CentOS 7:**
|
||||
|
||||
@ -86,7 +87,7 @@ To automatically start rsyslog client after every system reboot, run the followi
|
||||
|
||||
### 小结 ###
|
||||
|
||||
在本教程中,我演示了如何将CentOS系统转变成rsyslog客户端以强制它发送日志消息到远程rsyslog服务器。这里我假定rsyslog客户端和服务器之间的连接是安全的(如,在有防火墙保护的公司网络中)。不管在任何情况下,都不要配置rsyslog客户端将日志消息通过不安全的网络转发,或者,特别是通过互联网转发,因为syslog协议是一个明文协议。要进行安全传输,可以考虑使用[TLS/SSL][2]来加密日志消息。
|
||||
在本教程中,我演示了如何将CentOS系统转变成rsyslog客户端以强制它发送日志消息到远程rsyslog服务器。这里我假定rsyslog客户端和服务器之间的连接是安全的(如,在有防火墙保护的公司网络中)。不管在任何情况下,都不要配置rsyslog客户端将日志消息通过不安全的网络转发,或者,特别是通过互联网转发,因为syslog协议是一个明文协议。要进行安全传输,可以考虑使用[TLS/SSL][2]来加密日志消息的传输。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -94,7 +95,7 @@ via: http://xmodulo.com/configure-rsyslog-client-centos.html
|
||||
|
||||
作者:[Caezsar M][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
Linux有问必答:如何检查Linux的内存使用状况
|
||||
================================================================================
|
||||
|
||||
>**问题**:我想要监测Linux系统的内存使用状况。有哪些可用的图形界面或者命令行工具来检查当前内存使用情况?
|
||||
|
||||
当涉及到Linux系统性能优化的时候,物理内存是一个最重要的因素。自然的,Linux提供了丰富的选择来监测珍贵的内存资源的使用情况。不同的工具,在监测粒度(例如:全系统范围,每个进程,每个用户),接口方式(例如:图形用户界面,命令行,ncurses)或者运行模式(交互模式,批量处理模式)上都不尽相同。
|
||||
|
||||
下面是一个可供选择的,但并不全面的图形或命令行工具列表,这些工具用来检查Linux平台中已用和可用的内存。
|
||||
|
||||
### 1. /proc/meminfo ###
|
||||
|
||||
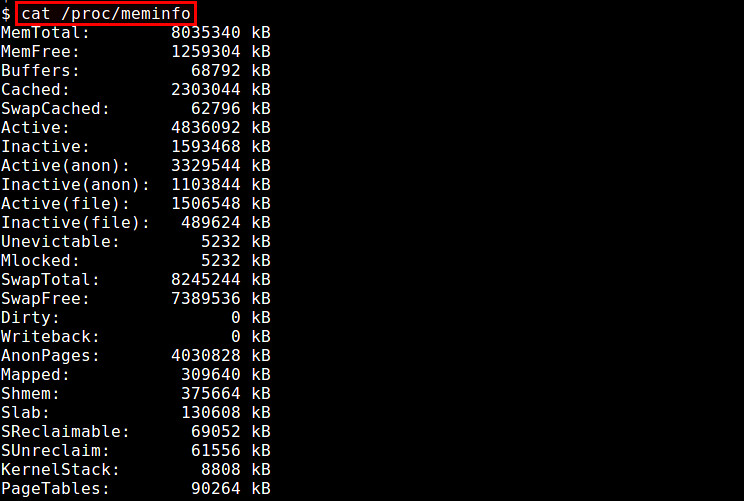
一种最简单的方法是通过“/proc/meminfo”来检查内存使用状况。这个动态更新的虚拟文件事实上是诸如free,top和ps这些与内存相关的工具的信息来源。从可用/闲置物理内存数量到等待被写入缓存的数量或者已写回磁盘的数量,只要是你想要的关于内存使用的信息,“/proc/meminfo”应有尽有。特定进程的内存信息也可以通过“/proc/\<pid>/statm”和“/proc/\<pid>/status”来获取。
|
||||
|
||||
$ cat /proc/meminfo
|
||||
|
||||
|
||||
|
||||
### 2. atop ###
|
||||
|
||||
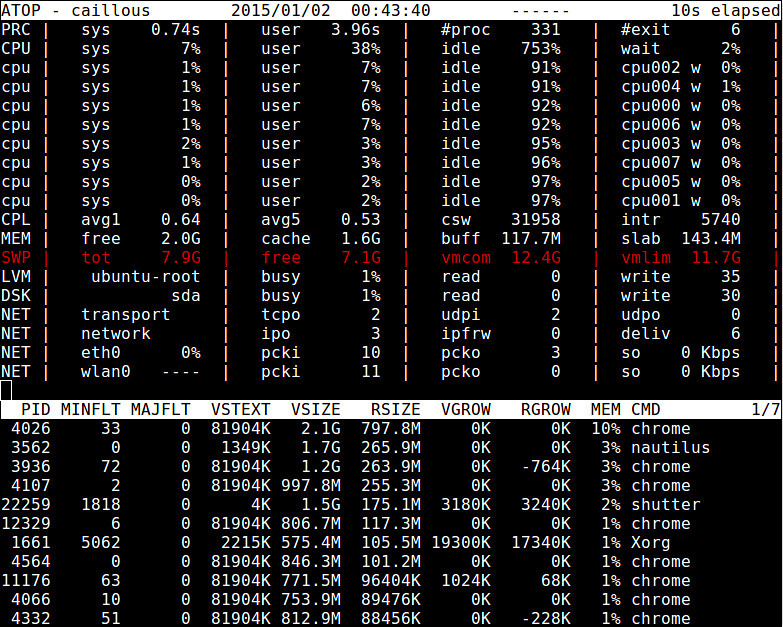
atop命令是用于终端环境的基于ncurses的交互式的系统和进程监测工具。它展示了动态更新的系统资源摘要(CPU, 内存, 网络, 输入/输出, 内核),并且用醒目的颜色把系统高负载的部分以警告信息标注出来。它同样提供了类似于top的线程(或用户)资源使用视图,因此系统管理员可以找到哪个进程或者用户导致的系统负载。内存统计报告包括了总计/闲置内存,缓存的/缓冲的内存和已提交的虚拟内存。
|
||||
|
||||
$ sudo atop
|
||||
|
||||
|
||||
|
||||
### 3. free ###
|
||||
|
||||
free命令是一个用来获得内存使用概况的快速简单的方法,这些信息从“/proc/meminfo”获取。它提供了一个快照,用于展示总计/闲置的物理内存和系统交换区,以及已使用/闲置的内核缓冲区。
|
||||
|
||||
$ free -h
|
||||
|
||||

|
||||
|
||||
### 4. GNOME System Monitor ###
|
||||
|
||||
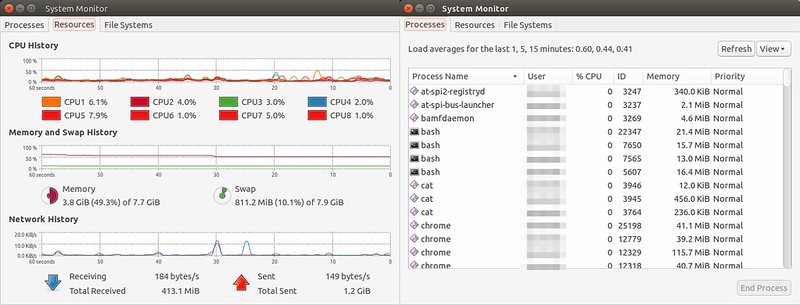
GNOME System Monitor 是一个图形界面应用,它展示了包括CPU,内存,交换区和网络在内的系统资源使用率的较近历史信息。它同时也可以提供一个带有CPU和内存使用情况的进程视图。
|
||||
|
||||
$ gnome-system-monitor
|
||||
|
||||
|
||||
|
||||
### 5. htop ###
|
||||
|
||||
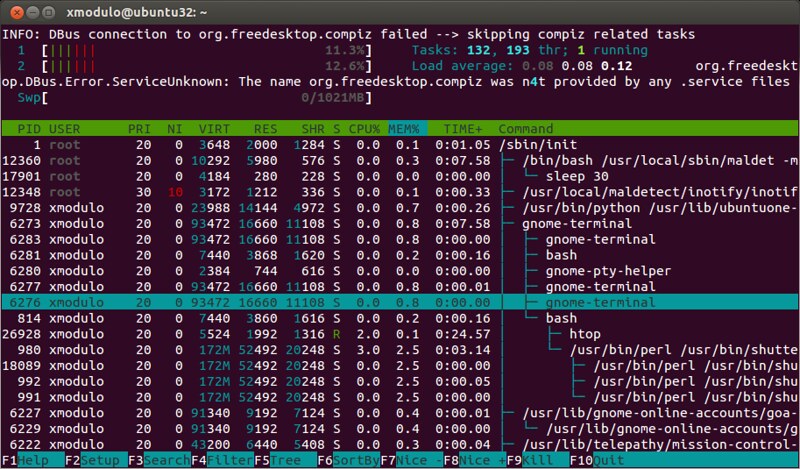
htop命令是一个基于ncurses的交互式的进程视图,它实时展示了每个进程的内存使用情况。它可以报告所有运行中进程的常驻内存大小(RSS)、内存中程序的总大小、库大小、共享页面大小和脏页面大小。你可以横向或者纵向滚动进程列表进行查看。
|
||||
|
||||
$ htop
|
||||
|
||||
|
||||
|
||||
### 6. KDE System Monitor ###
|
||||
|
||||
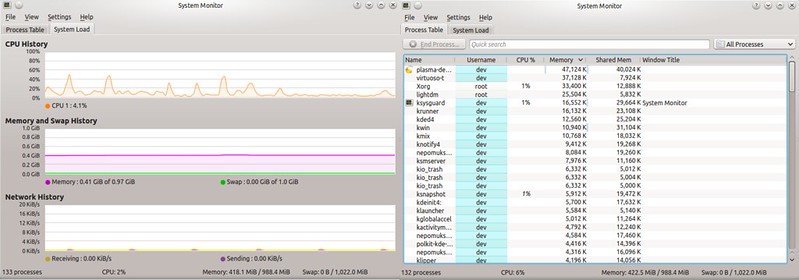
就像GNOME桌面拥有GNOME System Monitor一样,KDE桌面也有它自己的对口应用:KDE System Monitor。这个工具的功能与GNOME版本极其相似,也就是说,它同样展示了一个关于系统资源使用情况,以及带有每个进程的CPU/内存消耗情况的实时历史记录。
|
||||
|
||||
$ ksysguard
|
||||
|
||||
|
||||
|
||||
### 7. memstat ###
|
||||
|
||||
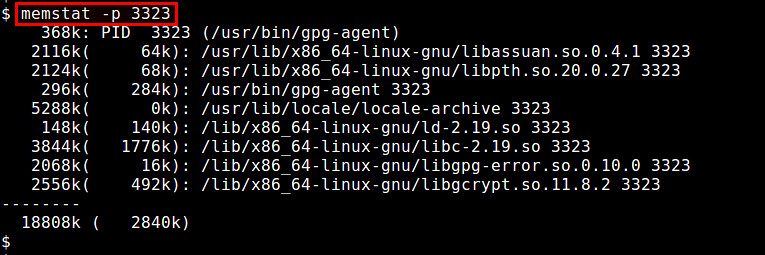
memstat工具对于识别正在消耗虚拟内存的可执行部分、进程和共享库非常有用。给出一个进程识别号,memstat即可识别出与之相关联的可执行部分、数据和共享库究竟使用了多少虚拟内存。
|
||||
|
||||
$ memstat -p <PID>
|
||||
|
||||
|
||||
|
||||
### 8. nmon ###
|
||||
|
||||
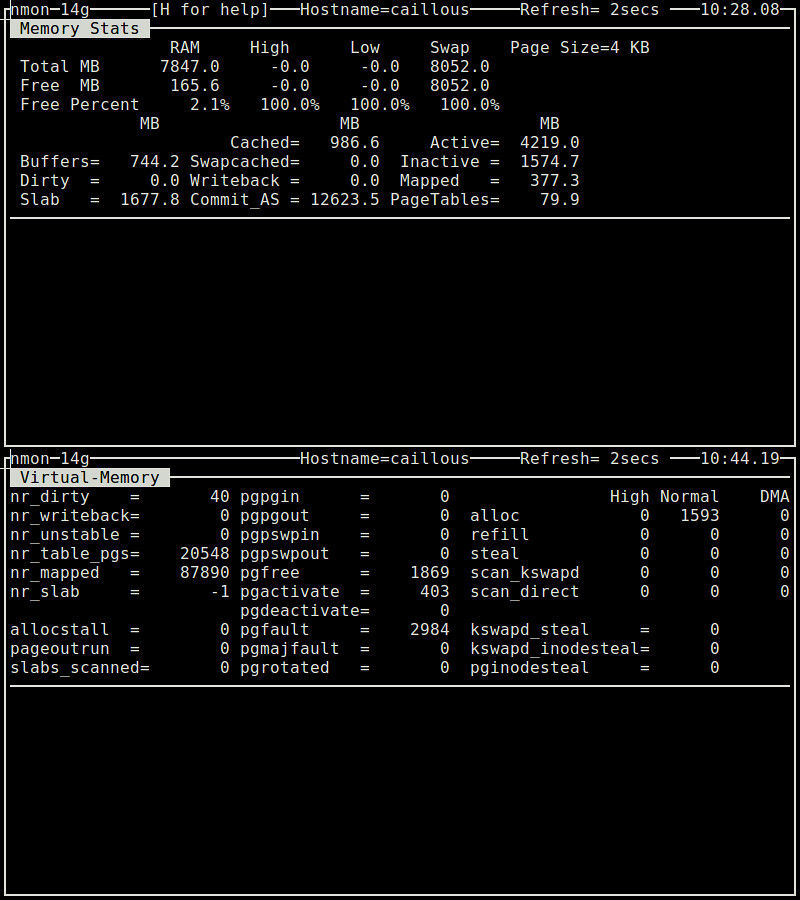
nmon工具是一个基于ncurses系统基准测试工具,它能够以交互方式监测CPU、内存、磁盘I/O、内核、文件系统以及网络资源。对于内存使用状况而言,它能够展示像总计/闲置内存、交换区、缓冲的/缓存的内存,虚拟内存页面换入换出的统计,所有这些都是实时的。
|
||||
|
||||
$ nmon
|
||||
|
||||
|
||||
|
||||
### 9. ps ###
|
||||
|
||||
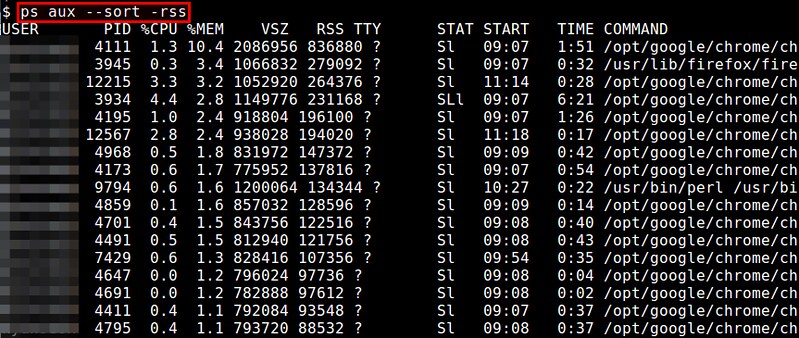
ps命令能够实时展示每个进程的内存使用状况。内存使用报告里包括了 %MEM (物理内存使用百分比), VSZ (虚拟内存使用总量), 和 RSS (物理内存使用总量)。你可以使用“--sort”选项来对进程列表排序。例如,按照RSS降序排序:
|
||||
|
||||
$ ps aux --sort -rss
|
||||
|
||||
|
||||
|
||||
### 10. smem ###
|
||||
|
||||
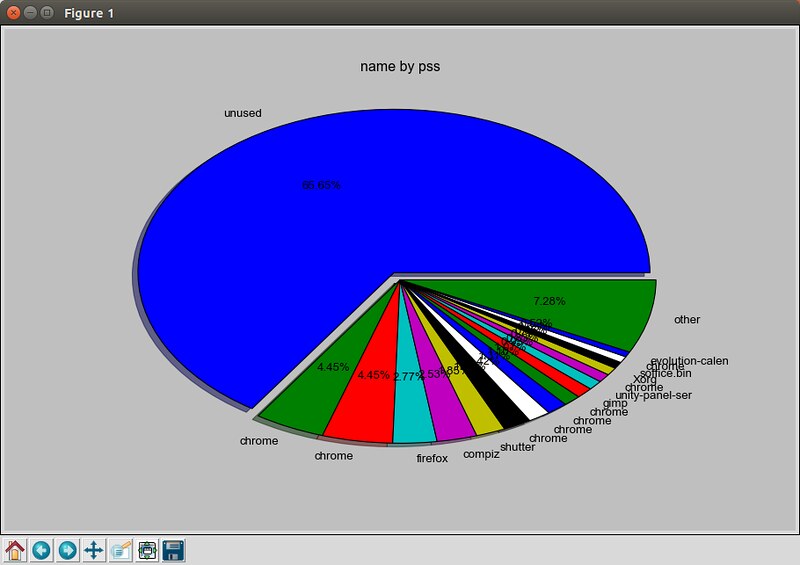
[smem][1]命令允许你测定不同进程和用户的物理内存使用状况,这些信息来源于“/proc”目录。它利用“按比例分配大小(PSS)”指标来精确量化Linux进程的有效内存使用情况。内存使用分析结果能够输出为柱状图或者饼图类的图形化图表。
|
||||
|
||||
$ sudo smem --pie name -c "pss"
|
||||
|
||||
|
||||
|
||||
### 11. top ###
|
||||
|
||||
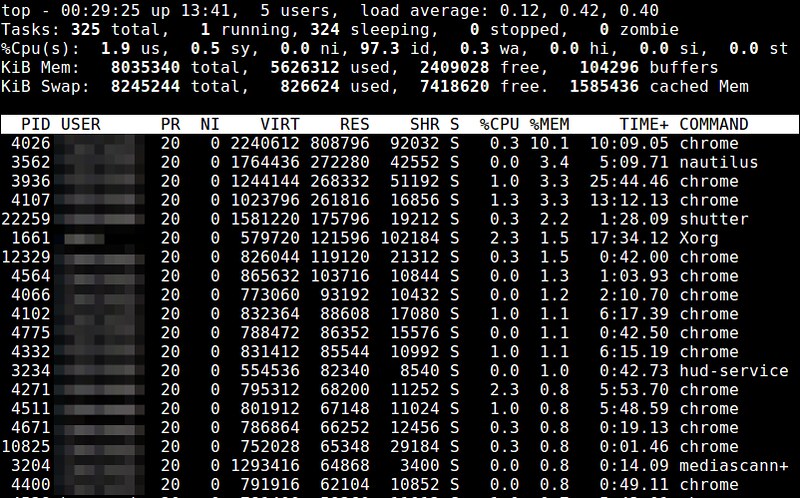
top命令提供了一个运行中进程的实时视图,以及特定进程的各种资源使用统计信息。与内存相关的信息包括 %MEM (内存使用率), VIRT (虚拟内存使用总量), SWAP (换出的虚拟内存使用量), CODE (分配给代码执行的物理内存数量), DATA (分配给非执行的数据的物理内存数量), RES (物理内存使用总量; CODE+DATA), 和 SHR (有可能与其他进程共享的内存数量)。你能够基于内存使用情况或者大小对进程列表进行排序。
|
||||
|
||||
|
||||
|
||||
### 12. vmstat ###
|
||||
|
||||
vmstat命令行工具显示涵盖了CPU、内存、中断和磁盘I/O在内的各种系统活动的瞬时和平均统计数据。对于内存信息而言,命令不仅仅展示了物理内存使用情况(例如总计/已使用内存和缓冲的/缓存的内存),还同样展示了虚拟内存统计数据(例如,内存页的换入/换出,虚拟内存页的换入/换出)
|
||||
|
||||
$ vmstat -s
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-memory-usage-linux.html
|
||||
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/visualize-memory-usage-linux.html
|
||||
@ -1,67 +0,0 @@
|
||||
Translating by shipsw
|
||||
What is a good EPUB reader on Linux
|
||||
================================================================================
|
||||
If the habit on reading books on electronic tablets is still on its way, reading books on a computer is even rarer. It is hard enough to focus on the classics of the 16th century literature, so who needs the Facebook chat pop up sound in the background in addition? But if for some reasons you wish to open an electronic book in your computer, chances are that you will need specific software. Indeed, most editors agreed with using the EPUB format for electronic books (for "Electronic PUBlication"). Hopefully, Linux is not deprived of good programs capable of dealing with such format. In short, here is a non-exhaustive list of good EPUB readers on Linux.
|
||||
|
||||
### 1. Calibre ###
|
||||
|
||||
|
||||
|
||||
Let's dive in with maybe the biggest name of that list: [Calibre][1]. More than just an ebook reader, Calibre is a fully packaged e-library. It supports a plethora of formats (almost every I can think of), integrates a reader, a manager, a meta-data editor which can download covers from the Internet, an EPUB editor, a news reader, and a search engine to download additional books. To top it all, the interface is slick and has nothing to envy to other professional software. The only potential downside is that if you are looking for an EPUB reader, and are not interested in the whole library manager aspect, the program is too heavy for your needs.
|
||||
|
||||
### 2. FBReader ###
|
||||
|
||||
|
||||
|
||||
[FBReader][2] is also a library manager, but in a lighter way than Calibre. The interface is more sober, and is clearly cut in two: (1) the library aspect where you can add files, edit the meta-data, or download new books, and (2) the reader aspect. If you like simplicity, you might enjoy this program. I personally appreciate its straightforward tag and series system for classifying books.
|
||||
|
||||
### 3. Cool Reader ###
|
||||
|
||||

|
||||
|
||||
For all of you who are just looking for a way to visualize the content of an EPUB file, I recommend [Cool Reader][5]. In the spirit of Linux applications which do only one thing and do it well, Cool Reader is optimized to just open an EPUB file, and navigate through it via handy shortcuts. And since it is based on Qt, it also follows Qt's mentality by giving a ton of settings to mess around with.
|
||||
|
||||
### 4. Okular ###
|
||||
|
||||

|
||||
|
||||
Since we were talking about Qt applications, one of KDE's main document viewer, [Okular][3], also has the capacity to view EPUB files, once an EPUB library has been installed on the system. However, this is probably not a very good option if you are not a KDE user.
|
||||
|
||||
### 5. pPub ###
|
||||
|
||||

|
||||
|
||||
[pPub][4] is an old project that you can still find on Github. Its latest change seems to have been made two years ago. However, pPub is one of those programs that really deserve a second life. Written in Python and based on GTK3 and WebKit, pPub is lightweight and intuitive. The interface probably needs a little updating and is beyond sober, but the core is very good. It even supports JavaScript. So please, someone kick that up again.
|
||||
|
||||
### 6. epub ###
|
||||
|
||||
|
||||
|
||||
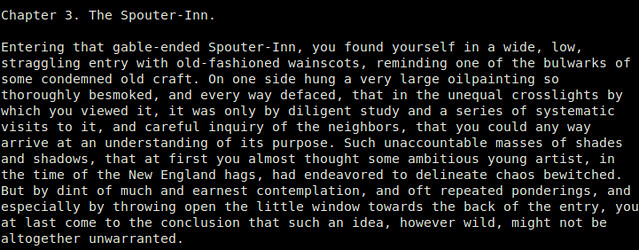
If all you need is a quick and easy way to check the content of an EPUB file, without caring about any fancy GUI, maybe an EPUB reader with command line interface might just do. [epub][6] is a minimalistic EPUB reader written in Python, which allows you to read an EPUB file in a terminal environment. You can switch between chapter/TOC views, up/down a page, and nothing more. This is as simple as any EPUB reader can possibly get.
|
||||
|
||||
### 7. Sigil ###
|
||||
|
||||
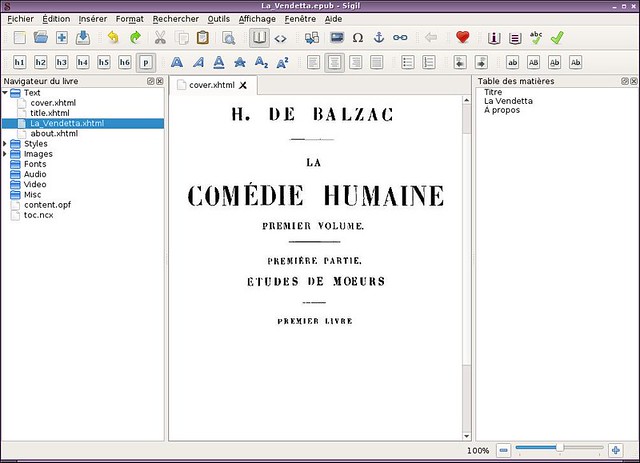
|
||||
|
||||
Finally, last of the list is not actually an EPUB reader, but more of a standalone editor. [Sigil][7] is able to extract the content of an EPUB file, and break it down for what it really is: xhtml text, images, styles, and sometimes audio. The interface is a lot more complex than the one for a basic reader, but remains clear and well thought, on par with the features it provides. I particularly appreciate the tab system. If you are familiar with editing web pages, you will be in know territory here.
|
||||
|
||||
To conclude, there are a lot of open source EPUB readers out there. Some do nothing more, while others go way beyond that. As usual, I recommend using the one that makes the most sense for you to use. If you know more good EPUB readers on Linux that you like, please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/good-epub-reader-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calibre-ebook.com/
|
||||
[2]:http://fbreader.org/
|
||||
[3]:http://okular.kde.org/
|
||||
[4]:https://github.com/sakisds/pPub
|
||||
[5]:http://crengine.sourceforge.net/
|
||||
[6]:https://github.com/rupa/epub
|
||||
[7]:https://github.com/user-none/Sigil
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by FSSlc
|
||||
|
||||
Best GNOME Shell Themes For Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
@ -108,4 +110,4 @@ via: http://itsfoss.com/gnome-shell-themes-ubuntu-1404/
|
||||
[7]:http://mokaproject.com/
|
||||
[8]:https://github.com/vivaeltopo/gnome-shell-theme-viva
|
||||
[9]:http://zagortenay333.deviantart.com/art/Ciliora-Prima-Shell-451947568
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
|
||||
@ -1,223 +0,0 @@
|
||||
How to create a software RAID-1 array with mdadm on Linux
|
||||
================================================================================
|
||||
Redundant Array of Independent Disks (RAID) is a storage technology that combines multiple hard disks into a single logical unit to provide fault-tolerance and/or improve disk I/O performance. Depending on how data is stored in an array of disks (e.g., with striping, mirroring, parity, or any combination thereof), different RAID levels are defined (e.g., RAID-0, RAID-1, RAID-5, etc). RAID can be implemented either in software or with a hardware RAID card. On modern Linux, basic software RAID functionality is available by default.
|
||||
|
||||
In this post, we'll discuss the software setup of a RAID-1 array (also known as a "mirroring" array), where identical data is written to the two devices that form the array. While it is possible to implement RAID-1 with partitions on a single physical hard drive (as with other RAID levels), it won't be of much use if that single hard drive fails. In fact, that's why most RAID levels normally use multiple physical drives to provide redundancy. In the event of any single drive failure, the virtual RAID block device should continue functioning without issues, and allow us to replace the faulty drive without significant production downtime and, more importantly, with no data loss. However, it does not replace the need to save periodic system backups in external storage.
|
||||
|
||||
Since the actual storage capacity (size) of a RAID-1 array is the size of the smallest drive, normally (if not always) you will find two identical physical drives in RAID-1 setup.
|
||||
|
||||
### Installing mdadm on Linux ###
|
||||
|
||||
The tool that we are going to use to create, assemble, manage, and monitor our software RAID-1 is called mdadm (short for **m**ultiple **d**isks **adm**in). On Linux distros such as Fedora, CentOS, RHEL or Arch Linux, mdadm is available by default. On Debian-based distros, mdadm can be installed with aptitude or apt-get.
|
||||
|
||||
#### Fedora, CentOS or RHEL ####
|
||||
|
||||
As mdadm comes pre-installed, all you have to do is to start RAID monitoring service, and configure it to auto-start upon boot:
|
||||
|
||||
# systemctl start mdmonitor
|
||||
# systemctl enable mdmonitor
|
||||
|
||||
For CentOS/RHEL 6, use these commands instead:
|
||||
|
||||
# service mdmonitor start
|
||||
# chkconfig mdmonitor on
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
On Debian and its derivatives, mdadm can be installed with **aptitude or apt-get**:
|
||||
|
||||
# aptitude install mdadm
|
||||
|
||||
On Ubuntu, you will be asked to configure postfix MTA for sending out email notifications (as part of RAID monitoring). You can skip it for now.
|
||||
|
||||
On Debian, the installation will start with the following explanatory message to help us decide whether or not we are going to install the root filesystem on a RAID array. What we need to enter on the next screen will depend on this decision. Read it carefully:
|
||||
|
||||
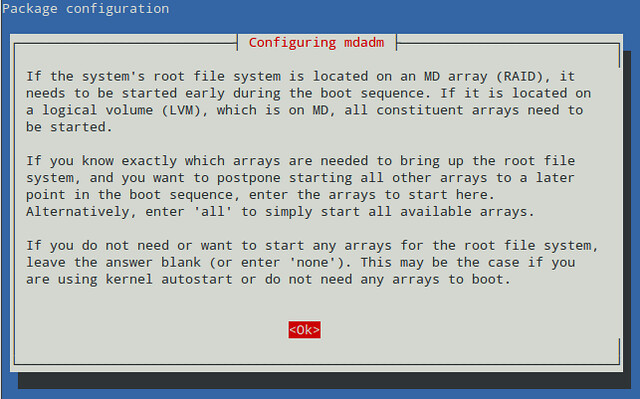
|
||||
|
||||
Since we will not use our RAID-1 for the root filesystem, we will leave the answer blank:
|
||||
|
||||
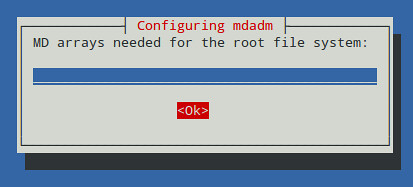
|
||||
|
||||
When asked whether we want to start (reassemble) our array automatically during each boot, choose "Yes". Note that we will need to add an entry to the /etc/fstab file later in order for the array to be properly mounted during the boot process as well.
|
||||
|
||||

|
||||
|
||||
### Partitioning Hard Drives ###
|
||||
|
||||
Now it's time to prepare the physical devices that will be used in our array. For this setup, I have plugged in two 8 GB USB drives that have been identified as /dev/sdb and /dev/sdc from dmesg output:
|
||||
|
||||
# dmesg | less
|
||||
|
||||
----------
|
||||
|
||||
[ 60.014863] sd 3:0:0:0: [sdb] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
|
||||
[ 75.066466] sd 4:0:0:0: [sdc] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
|
||||
|
||||
We will use fdisk to create a primary partition on each disk that will occupy its entire size. The following steps show how to perform this task on /dev/sdb, and assume that this drive hasn't been partitioned yet (otherwise, we can delete the existing partition(s) to start off with a clean disk):
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
Press 'p' to print the current partition table:
|
||||
|
||||

|
||||
|
||||
(if one or more partitions are found, they can be deleted with 'd' option. Then 'w' option is used to apply the changes).
|
||||
|
||||
Since no partitions are found, we will create a new primary partition ['n'] as a primary partition ['p'], assign the partition number = ['1'] to it, and then indicate its size. You can press Enter key to accept the proposed default values, or enter a value of your choosing, as shown in the image below.
|
||||
|
||||

|
||||
|
||||
Now repeat the same process for /dev/sdc.
|
||||
|
||||
If we have two drives of different sizes, say 750 GB and 1 TB for example, we should create a primary partition of 750 GB on each of them, and use the remaining space on the bigger drive for another purpose, independent of the RAID array.
|
||||
|
||||
### Create a RAID-1 Array ###
|
||||
|
||||
Once you are done with creating the primary partition on each drive, use the following command to create a RAID-1 array:
|
||||
|
||||
# mdadm -Cv /dev/md0 -l1 -n2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
Where:
|
||||
|
||||
- **-Cv**: creates an array and produce verbose output.
|
||||
- **/dev/md0**: is the name of the array.
|
||||
- **-l1** (l as in "level"): indicates that this will be a RAID-1 array.
|
||||
- **-n2**: indicates that we will add two partitions to the array, namely /dev/sdb1 and /dev/sdc1.
|
||||
|
||||
The above command is equivalent to:
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
If alternatively you want to add a spare device in order to replace a faulty disk in the future, you can add '--spare-devices=1 /dev/sdd1' to the above command.
|
||||
|
||||
Answer "y" when prompted if you want to continue creating an array, then press Enter:
|
||||
|
||||
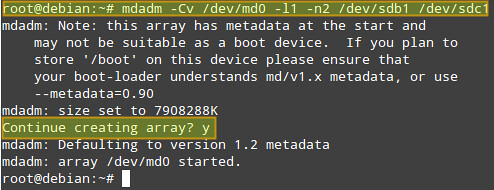
|
||||
|
||||
You can check the progress with the following command:
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
Another way to obtain more information about a RAID array (both while it's being assembled and after the process is finished) is:
|
||||
|
||||
# mdadm --query /dev/md0
|
||||
# mdadm --detail /dev/md0 (or mdadm -D /dev/md0)
|
||||
|
||||
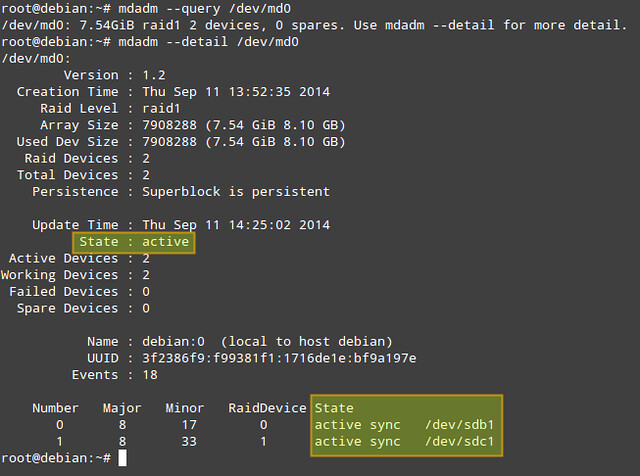
|
||||
|
||||
Of the information provided by 'mdadm -D', perhaps the most useful is that which shows the state of the array. The active state means that there is currently I/O activity happening. Other possible states are clean (all I/O activity has been completed), degraded (one of the devices is faulty or missing), resyncing (the system is recovering from an unclean shutdown such as a power outage), or recovering (a new drive has been added to the array, and data is being copied from the other drive onto it), to name the most common states.
|
||||
|
||||
### Formatting and Mounting a RAID Array ###
|
||||
|
||||
The next step is formatting (with ext4 in this example) the array:
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||
|
||||
|
||||
Now let's mount the array, and verify that it was mounted correctly:
|
||||
|
||||
# mount /dev/md0 /mnt
|
||||
# mount
|
||||
|
||||
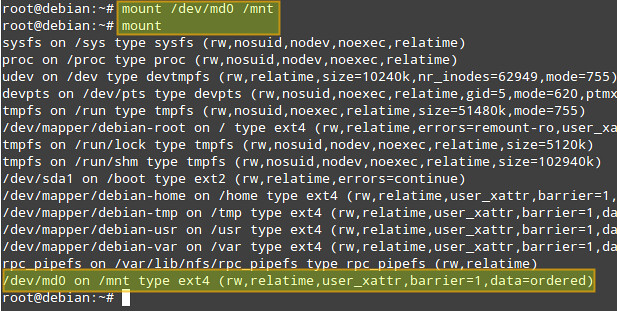
|
||||
|
||||
### Monitor a RAID Array ###
|
||||
|
||||
The mdadm tool comes with RAID monitoring capability built in. When mdadm is set to run as a daemon (which is the case with our RAID setup), it periodically polls existing RAID arrays, and reports on any detected events via email notification or syslog logging. Optionally, it can also be configured to invoke contingency commands (e.g., retrying or removing a disk) upon detecting any critical errors.
|
||||
|
||||
By default, mdadm scans all existing partitions and MD arrays, and logs any detected event to /var/log/syslog. Alternatively, you can specify devices and RAID arrays to scan in mdadm.conf located in /etc/mdadm/mdadm.conf (Debian-based) or /etc/mdadm.conf (Red Hat-based), in the following format. If mdadm.conf does not exist, create one.
|
||||
|
||||
DEVICE /dev/sd[bcde]1 /dev/sd[ab]1
|
||||
|
||||
ARRAY /dev/md0 devices=/dev/sdb1,/dev/sdc1
|
||||
ARRAY /dev/md1 devices=/dev/sdd1,/dev/sde1
|
||||
.....
|
||||
|
||||
# optional email address to notify events
|
||||
MAILADDR your@email.com
|
||||
|
||||
After modifying mdadm configuration, restart mdadm daemon:
|
||||
|
||||
On Debian, Ubuntu or Linux Mint:
|
||||
|
||||
# service mdadm restart
|
||||
|
||||
On Fedora, CentOS/RHEL 7:
|
||||
|
||||
# systemctl restart mdmonitor
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
# service mdmonitor restart
|
||||
|
||||
### Auto-mount a RAID Array ###
|
||||
|
||||
Now we will add an entry in the /etc/fstab to mount the array in /mnt automatically during boot (you can specify any other mount point):
|
||||
|
||||
# echo "/dev/md0 /mnt ext4 defaults 0 2" << /etc/fstab
|
||||
|
||||
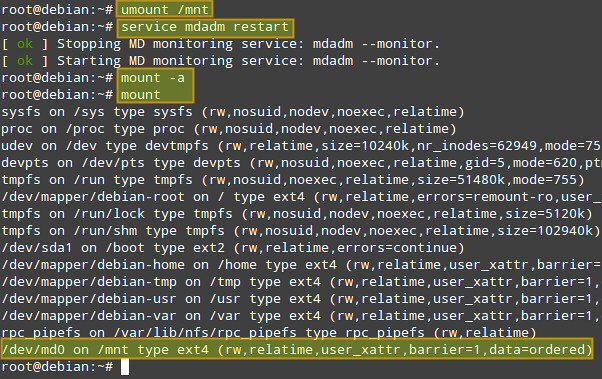
To verify that mount works okay, we now unmount the array, restart mdadm, and remount. We can see that /dev/md0 has been mounted as per the entry we just added to /etc/fstab:
|
||||
|
||||
# umount /mnt
|
||||
# service mdadm restart (on Debian, Ubuntu or Linux Mint)
|
||||
or systemctl restart mdmonitor (on Fedora, CentOS/RHEL7)
|
||||
or service mdmonitor restart (on CentOS/RHEL6)
|
||||
# mount -a
|
||||
|
||||
|
||||
|
||||
Now we are ready to access the RAID array via /mnt mount point. To test the array, we'll copy the /etc/passwd file (any other file will do) into /mnt:
|
||||
|
||||
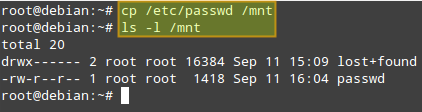
|
||||
|
||||
On Debian, we need to tell the mdadm daemon to automatically start the RAID array during boot by setting the AUTOSTART variable to true in the /etc/default/mdadm file:
|
||||
|
||||
AUTOSTART=true
|
||||
|
||||
### Simulating Drive Failures ###
|
||||
|
||||
We will simulate a faulty drive and remove it with the following commands. Note that in a real life scenario, it is not necessary to mark a device as faulty first, as it will already be in that state in case of a failure.
|
||||
|
||||
First, unmount the array:
|
||||
|
||||
# umount /mnt
|
||||
|
||||
Now, notice how the output of 'mdadm -D /dev/md0' indicates the changes after performing each command below.
|
||||
|
||||
# mdadm /dev/md0 --fail /dev/sdb1 #Marks /dev/sdb1 as faulty
|
||||
# mdadm --remove /dev/md0 /dev/sdb1 #Removes /dev/sdb1 from the array
|
||||
|
||||
Afterwards, when you have a new drive for replacement, re-add the drive again:
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdb1
|
||||
|
||||
The data is then immediately started to be rebuilt onto /dev/sdb1:
|
||||
|
||||

|
||||
|
||||
Note that the steps detailed above apply for systems with hot-swappable disks. If you do not have such technology, you will also have to stop a current array, and shutdown your system first in order to replace the part:
|
||||
|
||||
# mdadm --stop /dev/md0
|
||||
# shutdown -h now
|
||||
|
||||
Then add the new drive and re-assemble the array:
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdb1
|
||||
# mdadm --assemble /dev/md0 /dev/sdb1 /dev/sdc1
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-software-raid1-array-mdadm-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
Get back your privacy and control over your data in just a few hours: build your own cloud for you and your friends
|
||||
================================================================================
|
||||
40'000+ searches over 8 years! That's my Google Search history. How about yours? (you can find out for yourself [here][1]) With so many data points across such a long time, Google has a very precise idea of what you've been interested in, what's been on your mind, what you are worried about, and how that all changed over the years since you first got that Google account.
|
||||
@ -1110,4 +1111,4 @@ via: https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/
|
||||
[35]:http://owncloud.org/
|
||||
[36]:http://owncloud.org/install/
|
||||
[37]:https://code.google.com/p/k9mail/
|
||||
[38]:http://doc.owncloud.org/server/7.0/user_manual/files/files.html
|
||||
[38]:http://doc.owncloud.org/server/7.0/user_manual/files/files.html
|
||||
|
||||
@ -1,116 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
Linux FAQs with Answers--How to check CPU info on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to know detailed information about the CPU processor of my computer. What are the available methods to check CPU information on Linux?
|
||||
|
||||
Depending on your need, there are various pieces of information you may need to know about the CPU processor(s) of your computer, such as CPU vendor name, model name, clock speed, number of sockets/cores, L1/L2/L3 cache configuration, available processor capabilities (e.g., hardware virtualization, AES, MMX, SSE), and so on. In Linux, there are many command line or GUI-based tools that are used to show detailed information about your CPU hardware.
|
||||
|
||||
### 1. /proc/cpuinfo ###
|
||||
|
||||
The simpliest method is to check /proc/cpuinfo. This virtual file shows the configuration of available CPU hardware.
|
||||
|
||||
$ more /proc/cpuinfo
|
||||
|
||||
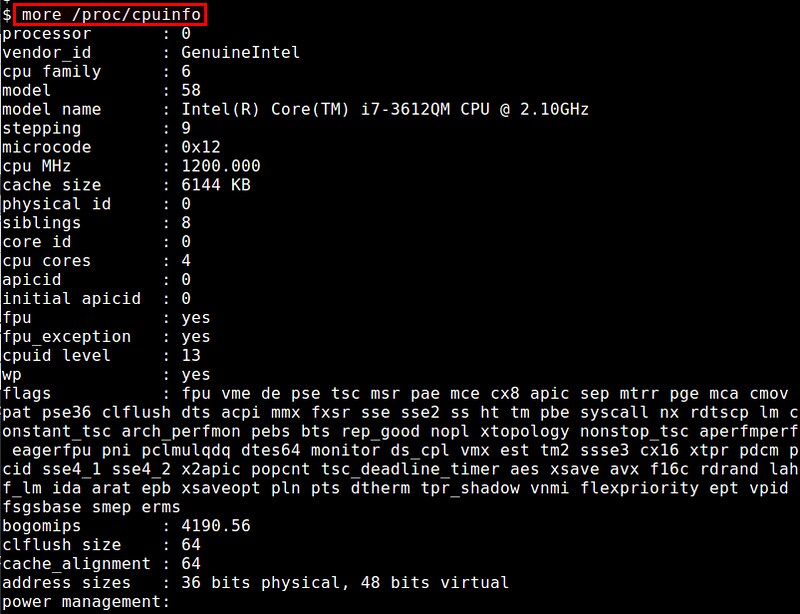
|
||||
|
||||
By inspecting this file, you can [identify][1] the number of physical processors, the number of cores per CPU, available CPU flags, and a number of other things.
|
||||
|
||||
### 2. cpufreq-info ###
|
||||
|
||||
The cpufreq-info command (which is part of **cpufrequtils** package) collects and reports CPU frequency information from the kernel/hardware. The command shows the hardware frequency that the CPU currently runs at, as well as the minimum/maximum CPU frequency allowed, CPUfreq policy/statistics, and so on. To check up on CPU #0:
|
||||
|
||||
$ cpufreq-info -c 0
|
||||
|
||||

|
||||
|
||||
### 3. cpuid ###
|
||||
|
||||
The cpuid command-line utility is a dedicated CPU information tool that displays verbose information about CPU hardware by using [CPUID functions][2]. Reported information includes processor type/family, CPU extensions, cache/TLB configuration, power management features, etc.
|
||||
|
||||
$ cpuid
|
||||
|
||||
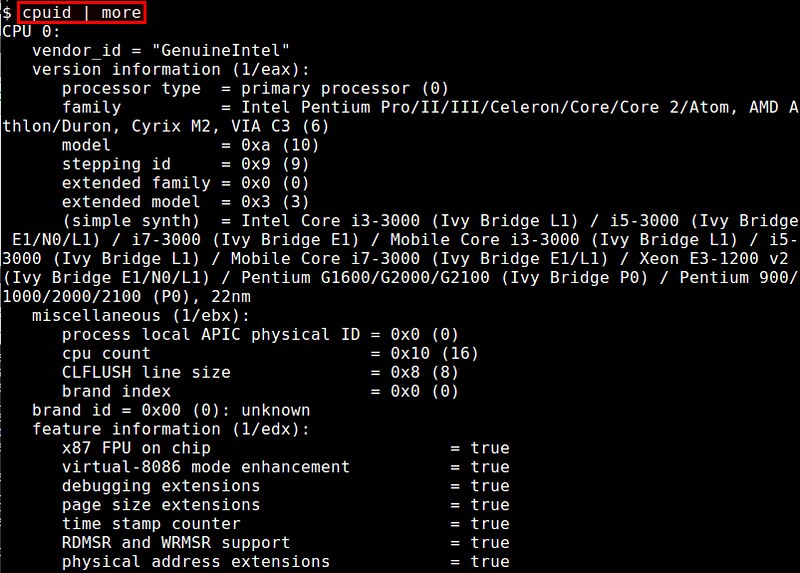
|
||||
|
||||
### 4. dmidecode ###
|
||||
|
||||
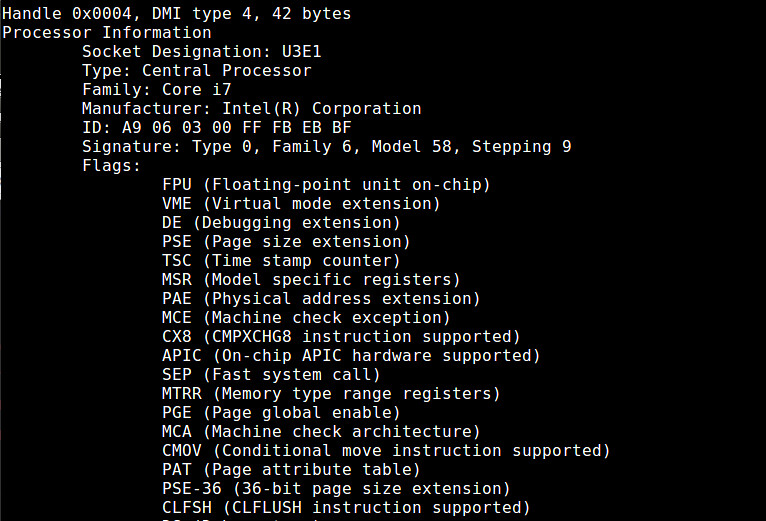
The dmidecode command collects detailed information about system hardware directly from DMI data of the BIOS. Reported CPU information includes CPU vendor, version, CPU flags, maximum/current clock speed, (enabled) core count, L1/L2/L3 cache configuration, and so on.
|
||||
|
||||
$ sudo dmidecode
|
||||
|
||||
|
||||
|
||||
### 5. hardinfo ###
|
||||
|
||||
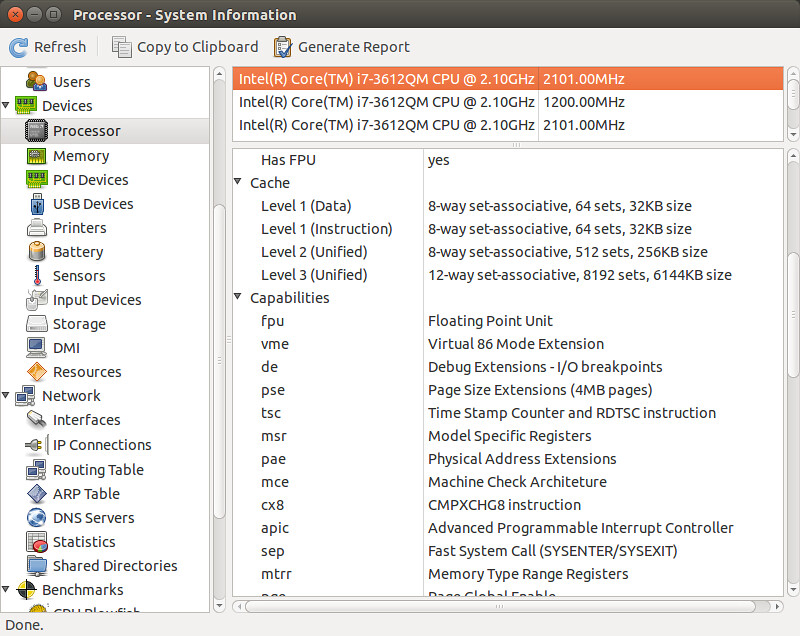
The hardinfo is a GUI-based system information tool which can give you an easy-to-understand summary of your CPU hardware, as well as other hardware components of your system.
|
||||
|
||||
$ hardinfo
|
||||
|
||||
|
||||
|
||||
### 6. i7z ###
|
||||
|
||||
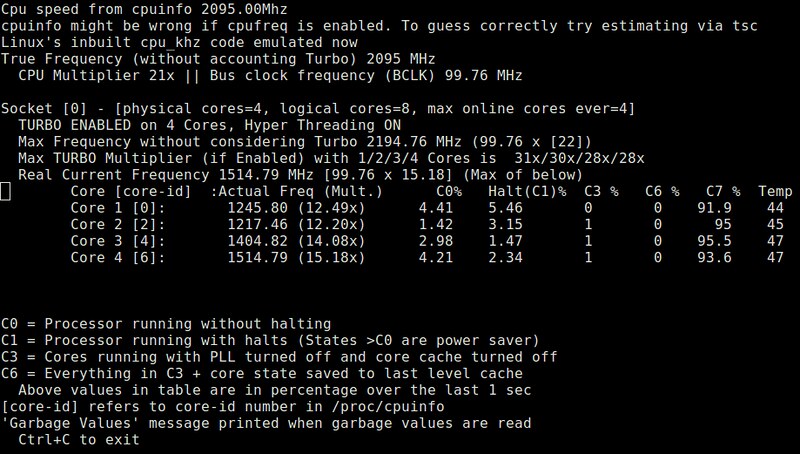
i7z is a real-time CPU reporting tool dedicated to Intel Core i3, i5 and i7 CPUs. It can display various per-core information in real time, such as Turbo Boost states, CPU frequencies, CPU power states, temperature measurements, and so on. i7z runs in either ncurses-based console mode or QT based GUI.
|
||||
|
||||
$ sudo i7z
|
||||
|
||||
|
||||
|
||||
### 8. likwid-topology ###
|
||||
|
||||
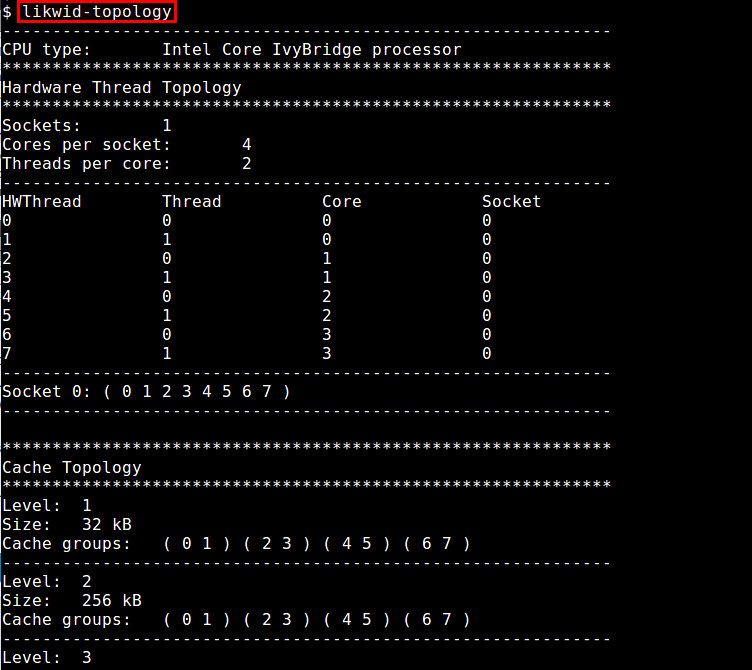
[likwid][3] (Like I Knew What I'm Doing) is a collection of command-line tools to measure, configure and display hardware related properties. Among them is likwid-topology which shows CPU hardware (thread/cache/NUMA) topology information. It can also identify processor families (e.g., Intel Core 2, AMD Shanghai).
|
||||
|
||||
|
||||
|
||||
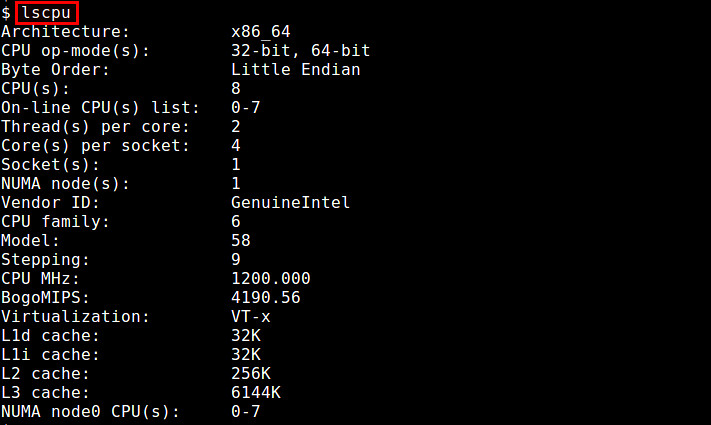
### 9. lscpu ###
|
||||
|
||||
The lscpu command summarizes /etc/cpuinfo content in a more user-friendly format, e.g., the number of (online/offline) CPUs, cores, sockets, NUMA nodes.
|
||||
|
||||
$ lscpu
|
||||
|
||||
|
||||
|
||||
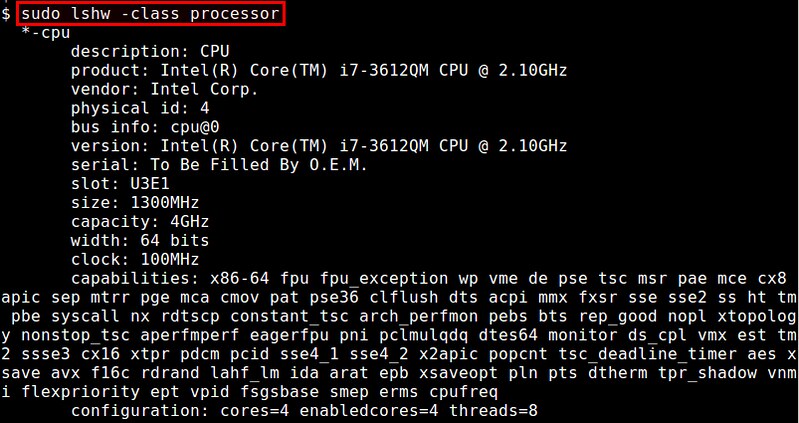
### 10. lshw ###
|
||||
|
||||
The **lshw** command is a comprehensive hardware query tool. Unlike other tools, lshw requires root privilege because it query DMI information in system BIOS. It can report the total number of cores and enabled cores, but miss out on information such as L1/L2/L3 cache configuration. The GTK version lshw-gtk is also available.
|
||||
|
||||
$ sudo lshw -class processor
|
||||
|
||||
|
||||
|
||||
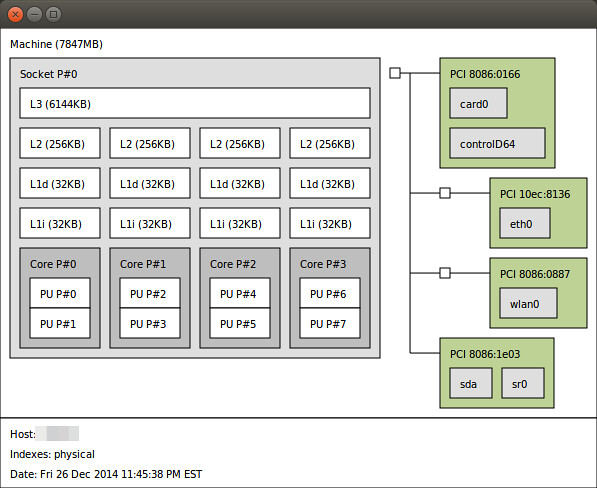
### 11. lstopo ###
|
||||
|
||||
The lstopo command (contained in [hwloc][4] package) visualizes the topology of the system which is composed of CPUs, cache, memory and I/O devices. This command is useful to identify the processor architecture and NUMA topology of the system.
|
||||
|
||||
$ lstopo
|
||||
|
||||
|
||||
|
||||
### 12. numactl ###
|
||||
|
||||
Originally developed to set the NUMA scheduling and memeory placement policy of Linux processes, the numactl command can also show information about NUMA topology of the CPU hardware from the command line.
|
||||
|
||||
$ numactl --hardware
|
||||
|
||||

|
||||
|
||||
### 13. x86info ###
|
||||
|
||||
x86info is a command-line tool for showing x86-based CPU information. Reported information includes CPU model, number of threads/cores, clock speed, TLB cache configuration, supported feature flags, etc.
|
||||
|
||||
$ x86info --all
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-cpu-info-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-find-number-of-cpu-cores-on.html
|
||||
[2]:http://en.wikipedia.org/wiki/CPUID
|
||||
[3]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[4]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
Linux FAQs with Answers--How to install Go language on Linux
|
||||
================================================================================
|
||||
Go (also called "golang") is an open-source programming language initially developed by Google. It was born with several design principles in mind: simplicity, safety, and speed. The Go language distribution comes with various tools for debugging, testing, profiling and code-vetting. Nowadays the Go language and its tool chain are available in the base repositories of most Linux distributions, making it easy to install them with a default package manager.
|
||||
@ -93,4 +95,4 @@ via: http://ask.xmodulo.com/install-go-language-linux.html
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://golang.org/dl/
|
||||
[1]:https://golang.org/dl/
|
||||
|
||||
@ -0,0 +1,67 @@
|
||||
Linux版EPUB阅读器
|
||||
================================================================================
|
||||
|
||||
如果说用平板电脑看书尚属主流的话,那么在电脑上读书就非常少见了。专注阅读16世纪的书是非常困难的了,没人希望后台蹦出Facebook聊天窗口。但是如果你非要在电脑上打开电子书的话,那么你需要一个电子书阅读软件。大多数编辑支持使用EPUB格式来存放电子书(电子出版物)。幸运的书,linux上从不缺乏此类软件。以下书一些Linux上比较好的EPUB阅读软件。
|
||||
|
||||
### 1. Calibre ###
|
||||
|
||||

|
||||
|
||||
先从列表中最有名的软件开始: [Calibre][1]。Calibre 不仅仅是个阅读器,他还是个电子图书馆。软件支持几乎所有的格式,集成了阅读器,管理器,一个可以从互联网下载书籍封面的元数据编辑器,一个EPUB编辑器,新闻阅读器和一个用来下载电子书的搜索引擎。可喜的是,界面丝毫不逊色专业的阅读软件。唯一的缺点书如果你只想要一个EPUB阅读器的话,这个软件还是太大了。
|
||||
|
||||
### 2. FBReader ###
|
||||
|
||||

|
||||
|
||||
[FBReader][2] 也是一个图书馆管理软件,但是比Calibre小。界面简洁分为两个部分:左边书文件管理、元数据编辑、和下载新书等功能;右边书阅读区。如果你喜欢简洁,这个软件挺不错。我个人非常喜欢这类直观标记书籍和分类的做法。
|
||||
|
||||
### 3. Cool Reader ###
|
||||
|
||||

|
||||
|
||||
对于那些只想想看EPUB书内容的用户,我推荐 [Cool Reader][5]。遵循Linux应用程序的规则,Cool Reader 做了优化,每次只打开一个EPUB文件,可以使用简单的快捷键进行阅读和导航。由于程序书基于Qt开发的,所以他也遵循Qt的规则,需要大量的设置项。
|
||||
|
||||
### 4. Okular ###
|
||||
|
||||

|
||||
|
||||
除了Qt应用程序,如果安装了EPUB库的话,KDE的文档阅读器[Okular][3] 也能打开EPUB文件。尽管如此,如果你不是个KDE用户的话,不推荐这个软件。
|
||||
|
||||
### 5. pPub ###
|
||||
|
||||

|
||||
|
||||
[pPub][4]是个老项目,Github上可以找到这个项目,他最后的更新已经是在两年前了。尽管如此,这个软件还是值得使用的,pPub是用Python编写的,基于GTK3和WebKit,是个简单轻量的软件。界面可能需要一些更新,不够简洁,但是内部却非常好。软件支持JavaScript。所以,谁来捡起这个项目呢?
|
||||
|
||||
### 6. epub ###
|
||||
|
||||

|
||||
|
||||
如果你只是想快速简单的查看EPUB文件的内容,不关心任何图形化界面功能的话,最好使用命令行模式打开EPUB。[epub][6] 是一个用Python编写的阅读器,可以在终端环境读取EPUB文件的内容。软件可以在章节、页面见切换,没有其他的功能。这是最简洁的EPUB阅读器了。
|
||||
|
||||
### 7. Sigil ###
|
||||
|
||||

|
||||
|
||||
最后介绍的这个实际上不是个EPUB阅读器,应该是个独立的编辑器。[Sigil][7] 可以提取EPUB文件的内容并转换成其他格式:xhtml文本,图像,格式,还有其他的内容,比如音频等。界面比基本的阅读器复杂,但是功能还是比较丰富的。我很喜欢他的标签体系,如果你对网页比较熟悉的话,这个软件书很好使用的。
|
||||
|
||||
总结,有很多的开源的EPUB阅读器,有一些只有最基本的功能, 另外一些功能却太多了。一般来说,我建议你选择一个最合适的使用。如果你有更好的EPUB阅读器,请在评论里告诉我们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/good-epub-reader-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calibre-ebook.com/
|
||||
[2]:http://fbreader.org/
|
||||
[3]:http://okular.kde.org/
|
||||
[4]:https://github.com/sakisds/pPub
|
||||
[5]:http://crengine.sourceforge.net/
|
||||
[6]:https://github.com/rupa/epub
|
||||
[7]:https://github.com/user-none/Sigil
|
||||
@ -2,39 +2,39 @@
|
||||
================================================================================
|
||||
Linux 与 Mac 用户至少有一个共同点:他们都不太喜欢用 Windows。但除了这点外,二者再也无法达成其他共识,只得分道扬镳。为什么 Mac 用户不选择 Linux 呢?是什么因素致使 Mac 用户做出了这种选择的?
|
||||
|
||||
[Datamation 就此问题做了一番调查][1],并试图进行解答。Datamation 的结论是,所有原因都只归结于众多应用及工作区,而非操作系统的关系:
|
||||
[Datamation 就此问题做了一番调查][1],并试图进行解答。Datamation 的结论是,所有原因都只归结于众多应用及工作流程,而非操作系统的关系:
|
||||
|
||||
> …某些事例表明,尝试用新应用接替现有应用,并非会是很糟糕的体验 - 对工作区和实用性来说都是如此。但不幸的是,苹果在这些方面做得非常好。因此,在几乎不可能改变这些事实的情况下,想要拉拢那些 Mac忠实用户实在是很大的挑战。
|
||||
> …某些事例表明,尝试用新应用代替现有应用,并不是很实际 - 对工作流程和整体实用性来说都是如此。但不幸的是,苹果在这些方面做得非常好。因此,在几乎不可能改变这些事实的情况下,想要拉拢那些 Mac忠实用户实在是很大的挑战。
|
||||
|
||||
> 不过老实来说,除了 Web 开发者,我还没见过 Mac 用户仅仅为了避免升级到 OS X Yosemite 而 “
|
||||
en masse”(法语:共同,一起) 尝试变更他们的工作区。诚然,经历过 Yosemite 更新后 - 考虑过权限的用户应该会发现这方面已经变得非常令人讨厌。并且,OS X 除了在 UI 方面几乎没有变化,针对现有 Mac 用户的核心工作区也在最大程度上保持了原样。
|
||||
en masse”(法语:共同,一起) 尝试变更他们的工作流程。诚然,经历过 Yosemite 更新后 - 考虑过权限的用户应该会发现这方面已经变得非常令人讨厌。并且,OS X 除了在 UI 方面的微小变化,几乎没有改变,针对现有 Mac 用户的核心工作流程也在最大程度上保持了原样。
|
||||
|
||||
> 但,我相信 Linux 在未来将会继续保持多样化特点。Linux 会继续成长,但绝不是经过精确计量般得一成不变。
|
||||
|
||||
我大体上同意 Datamation 关于应用和工作区的重要性的结论,在选择操作系统时这两方面是必须要考虑顾及的。但我认为对 Mac 用户来说,选择 Mac 有比这两方面更重要的因素。我相信是不同的心态造就了 Linux 和 Mac 用户,并且我认为这才是为什么 Mac 用户不选择 Linux 的真实原因。
|
||||
我大体上同意 Datamation 关于应用和工作流程重要性的结论,在选择操作系统时这两方面是必须要考虑顾及的。但我认为对 Mac 用户来说,选择 Mac 有比这两方面更重要的因素。我相信是不同的心态造就了 Linux 和 Mac 用户,并且我认为这才是为什么 Mac 用户不选择 Linux 的真实原因。
|
||||
|
||||

|
||||
|
||||
### 控制权才是 Linux 用户最看重的地方 ###
|
||||
Linux 用户倾向于控制电脑上的所有细节,他们试图作出一切能做的努力使操作系统变成他们想要的样子。但这种方式并不适用于 OS X 以及其他任何苹果的产品。如果你使用了苹果的产品,就意味着绝大多数情况下,你只能按照苹果预先设定的模式来使用它们。
|
||||
|
||||
对 Mac(以及 iOS)用户来说这没什么,因为他们似乎并不在乎生活在苹果那围墙高筑的花园里,仅仅使用那些苹果给予他们的标准和选择。但这对绝大多数 Linux 用户来说是完全不能接受的。Linux 的新用户通常来自 Windows,正是从那里,他们开始厌恶那些告诉他们什么才叫操作系统,并试图限制操作系统权限的东西的。
|
||||
对 Mac(以及 iOS)用户来说这没什么,因为他们似乎并不在乎生活在苹果那围墙高筑的花园里,仅仅使用那些苹果给予他们的标准和选择。但这对绝大多数 Linux 用户来说是完全不能接受的。Linux 的新用户通常来自 Windows,正是从那里,他们开始厌恶那些告诉他们什么才叫操作系统,并试图限制操作系统权限的东西。
|
||||
|
||||
自从他们尝到使用自由的 Linux 系统所带来的甜头之后,他们就再也不会再回到苹果或者微软的监牢里去了。即使你在他们死后,把 Linux 从他们那冰冷僵硬的手指下撬出来,他们也不会接受苹果和微软那种糟糕的操作系统。
|
||||
自从他们尝到使用自由的 Linux 系统所带来的甜头之后,他们就再也不会回到苹果或者微软的监牢里去了。即使在他们死后,把 Linux 从他们那冰冷僵硬的手指中撬出来,他们也不会接受苹果和微软为他们定制的操作系统。
|
||||
|
||||
但绝大部分 Mac 用户不会有这样的意志和决心。对他们来说当苹果升级 OS X 时放弃他们现有的习惯方式是非常容易的。在苹果那围墙高筑的花园里,即使他们不满意苹果的变化,他们也会迅速地接受。
|
||||
|
||||
因此,对控制权的渴望是 Mac 用户与 Linux 用户的最大不同。但我并未把它视为一个问题,尽管这反映出使用电脑的两类人的截然不同的态度。
|
||||
因此,对控制权的渴望是 Mac 用户与 Linux 用户的最大不同。但我并未把它视为一个问题,尽管这反映出使用电脑的两类用户截然不同的态度。
|
||||
|
||||
### Mac 用户离不开苹果的技术支持 ###
|
||||
|
||||
Linux 用户与 Mac 用户的区别也体现在 Linux 用户并不介意亲自维护自己的电脑。虽然维护电脑及控制操作系统都是很大的责任,但 Linux 用户还是愿意独自承担,愿意通过自己的力量使他们的系统工作得更棒更有效率,并且深入了解操作系统是每一位 Linux 用户都乐衷的事情。
|
||||
|
||||
当 Linux 用户遇到问题的时,他们会迅速地尝试自己来解决问题。如果这不奏效的话,他们会在网上寻找其他用户在遇到类似问题是怎么解决的,并不断进行尝试,直到问题解决。
|
||||
当 Linux 用户遇到问题时,他们会迅速地尝试自己来解决问题。如果这不奏效的话,他们会在网上搜索其他Linux用户的解决方案,并不断进行尝试,直到问题解决。
|
||||
|
||||
但 Mac 用户却不大会这样。这也许是为什么苹果零售店如此火爆、为什么如此多的 Mac 用户在拿到新 Mac 的时候会选择购买苹果维护服务的原因。Mac 用户会很轻易得带着 TA 的电脑去苹果零售店,走进天才吧并要求苹果的工作人员为其查看和修复电脑。
|
||||
|
||||
绝大多数 Linux 用户连想都不会像这种事情。谁会愿意让一个你都不认识的家伙碰你的电脑并维修它呢?
|
||||
绝大多数 Linux 用户连想都不会想这种事情。谁会愿意让一个你都不认识的家伙碰你的电脑并维修它呢?
|
||||
|
||||
因此对 Mac 用户来说,很难抛弃过去可以从苹果那里得到的技术支持,转而使用 Linux。这种选择会令某些 Mac 用户觉得自己的电脑将变得非常脆弱、容易被攻击,他们如同离开母亲怀抱的婴儿般充满了无助感。
|
||||
|
||||
@ -42,7 +42,7 @@ Linux 用户与 Mac 用户的区别也体现在 Linux 用户并不介意亲自
|
||||
|
||||
Datamation 发表的文章中主要研究了软件方面的原因,但我认为硬件因素同样对 Mac 用户有很大影响。绝大部分 Mac 用户非常喜爱苹果的硬件。TA 们购买 Mac 并不仅仅是为了 OS X。苹果那精美的工艺设计也是 Mac 用户购买时着重考虑的一点。Mac 用户愿意支付高价购买电脑,因为他们认为这样绝对是物有所值的。
|
||||
|
||||
另一方面,Linux 用户似乎并不会考虑这些东西。我认为他们更偏向于在他们的电脑外观上花费较少的金钱。对他们来说,花费最少的金钱来获取尽可能好的硬件才是最重要的。他们并不像 Mac 用户一样热衷于电脑的外观,因此这一点并不是他们在购买电脑时考虑的地方。
|
||||
另一方面,Linux 用户似乎并不会考虑这些东西。我认为他们更关注电脑的花费,而不太在意电脑的外观和设计。对他们来说,花费最少的金钱来获取尽可能好的硬件才是最重要的。他们并不像 Mac 用户一样热衷于电脑的外观,因此这一点并不是他们在购买电脑时考虑的地方。
|
||||
|
||||
我认为对于硬件的两种不同观点是没有高低之分的。这仅仅和用户的不同需求有关,仅仅会在他们购买电脑时影响他们,或者对某些 Linux 用户来说只是因为他们想要自己组装电脑而已。两种观点只是因为出发点不同、对于电脑的真正价值体现所在之处的理解不同罢了。
|
||||
|
||||
@ -50,19 +50,19 @@ Datamation 发表的文章中主要研究了软件方面的原因,但我认为
|
||||
|
||||
### Linux 发行版太多了不知道选哪个? ###
|
||||
|
||||
另一个让 Mac 用户无法选择 Linux 的原因是:要从从众多 Linux 发行版当中选择一个实在是太困难了。在大多数 Linux 并不抗拒的多元化发行版时代,没有任何相关知识的 Mac 用户感到十分困惑。
|
||||
另一个让 Mac 用户无法选择 Linux 的原因是:要从众多 Linux 发行版当中选择一个实在是太困难了。在大多数 Linuxer 并不抗拒的多元化发行版时代,没有相关知识的 Mac 用户会对如何选择感到十分困惑。
|
||||
|
||||
我认为,随着时间的推移,Mac 用户是可以找出不适应最适合自己的发行版的。但在短时间内,尤其是在长时期得使用 OS X 之后,这是一个艰巨的任务。我不认为这个问题是无法克服的,但却有必要在这里提一下。
|
||||
我认为,随着时间的推移,Mac 用户可以学习并找出最适合自己的发行版。但在短时间内,尤其是长时期得使用 OS X 之后,这是一个艰巨的任务。我不认为这个问题是无法克服的,但却有必要在这里提一下。
|
||||
|
||||
当然我们可以给 Mac 用户指明道路,推荐参考 [DistroWatch][3] 还有我们人的博客 [Desktop Linux Reviews][4],这都有助于 Mac 用户找到正确的 Linux 发行版。再说一条,网上有很多诸如“最好的 Linux 发行版”等类似的文章,当 Mac 用户想要寻找适合自己使用的发行版时可以参考一下。
|
||||
当然我们可以给大家提供资源,推荐参考 [DistroWatch][3] 还有我们的博客 [Desktop Linux Reviews][4],这都有助于 Mac 用户找到适合的 Linux 发行版。再说一条,网上有很多诸如“最好的 Linux 发行版”等类似的文章,当 Mac 用户想要寻找适合自己使用的发行版时可以参考一下。
|
||||
|
||||
但有苹果顾客购买 Mac 的其中一个原因是苹果硬件软件协调统一起来的简便性和易用性。所以我不确定有多少 Mac 用户愿意花费时间找出适合自己的 Linux 发行版。也许是否要使用 Linux 确实会令 TA 们考虑一阵子了。
|
||||
但有苹果顾客购买 Mac 的其中一个原因是苹果硬件软件协调统一起来的简便性和易用性。所以我不确定有多少 Mac 用户愿意花费时间找出适合自己的 Linux 发行版。也许是否要使用 Linux 确实会令TA们考虑一阵子了。
|
||||
|
||||
### Mac 用户是苹果,Linux 用户是橘子 ###
|
||||
|
||||
Mac 用户与 Linux 用户分道扬镳我认为并没有什么不妥。我认为我们只是在谈论两类完全不同的人群,这是一件好事,因为两类人群都在按自己四环的方式去使用操作系统和软件。让 Mac 用户和 Linux 用户各自沉浸在 OS X 和 Linux 中吧,希望他们都能高兴,都能对自己的电脑满意。
|
||||
Mac 用户与 Linux 用户分道扬镳我认为并没有什么不妥。我认为我们只是在谈论两类完全不同的人群,这是一件好事,因为两类人群都在按自己喜欢的方式去使用操作系统和软件。让 Mac 用户和 Linux 用户各自沉浸在 OS X 和 Linux 中吧,希望他们都能高兴,都能对自己的电脑满意。
|
||||
|
||||
也许 Mac 用户会偶然走入 Linux 的世界并开始转向 Linux,但我认为绝大多数时候,两类人都愿意呆在在不同的世界并不与对方接触。通常来说我并不会随意比较二者,尤其是你已经自己拿定主意的时候,况且这只不过是选苹果还是选橘子的问题罢了。
|
||||
也许 Mac 用户会偶然走入 Linux 的世界并开始转向 Linux,但我认为绝大多数时候,两类人都愿意呆在不同的世界并不与对方接触。通常来说我并不会随意比较二者,尤其是你已经自己拿定主意的时候,况且这只不过是选苹果还是选橘子的问题罢了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -70,7 +70,7 @@ via: http://jimlynch.com/linux-articles/why-mac-users-dont-switch-to-linux/
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -78,4 +78,4 @@ via: http://jimlynch.com/linux-articles/why-mac-users-dont-switch-to-linux/
|
||||
[1]:http://www.datamation.com/open-source/why-linux-isnt-winning-over-mac-users-1.html
|
||||
[2]:http://www.howtogeek.com/187410/how-to-install-and-dual-boot-linux-on-a-mac/
|
||||
[3]:http://distrowatch.com/
|
||||
[4]:http://desktoplinuxreviews.com/
|
||||
[4]:http://desktoplinuxreviews.com/
|
||||
|
||||
@ -0,0 +1,223 @@
|
||||
如何使用linux程序mdadm创建软件RAID1软阵列
|
||||
================================================================================
|
||||
磁盘冗余阵列(RAID)是将多个物理磁盘结合成一个逻辑磁盘的技术,该技术可以提高磁盘容错性能,提高磁盘的读写速度。根据数据存储的排列(如 条带存储,镜像存储,奇偶或者他们的组合),定义了几个不同级别的RAID(RAID-0,RAID-1,RAID-5 等等)。磁盘阵列可以使用软件或者硬件方式实现。现代Linux操作系统中,基本的软件RAID功能是默认安装的。
|
||||
|
||||
本文中,我们将介绍软件方式构建RAID-1阵列(镜像阵列),RAID-1将相同的数据写到不同的设备中。虽然可以使用同一个磁盘的两个分区实现RAID-1,但是如果磁盘坏了的话数据就都丢了,所以没什么意义。实际上,这也是为什么大多数RAID级别都使用多个物理磁盘提供冗余。当单盘失效后不影响整个阵列的运行,并且可以在线更换磁盘,最重要的是数据不会丢失。尽管如此,阵列不能取代外部存储的定期备份。
|
||||
|
||||
由于RAID-1阵列的大小是最小磁盘的大小,一般来说应该使用两个大小相同的磁盘来组建RAID-1。
|
||||
|
||||
### 安装mdadm ###
|
||||
|
||||
我们将使用mdadm(简称多盘管理)工具创建、组装、管理和监控软件RAID-1。在诸如Fedora、CentOS、RHEL或者Arch Linux 的发行版中,mdadm是默认安装的。在基于Debian的发行版中,可以使用aptitude 或者 apt-get 安装mdadm。
|
||||
|
||||
#### Fedora, CentOS 或 RHEL ####
|
||||
|
||||
由于adadm是预装的,所以我们只需要开启RAID守护服务,并将其配置成开机启动即可:
|
||||
|
||||
# systemctl start mdmonitor
|
||||
# systemctl enable mdmonitor
|
||||
|
||||
对于CentOS/RHEL 6系统,使用以下命令:
|
||||
|
||||
# service mdmonitor start
|
||||
# chkconfig mdmonitor on
|
||||
|
||||
#### Debian, Ubuntu 或 Linux Mint ####
|
||||
|
||||
在Debian或类Debian系统中,mdadm可以使用 **aptitude 或者 apt-get** 安装:
|
||||
|
||||
# aptitude install mdadm
|
||||
|
||||
Ubuntu系统中,会要求为电子邮件通知配置后缀MTA。你可以跳过去。
|
||||
|
||||
Debian系统中,安装程序会显示以下解释信息,用来帮助我们去判断是否将根目录安装到RAID阵列中。下面的所有操作都有赖于这一步,所以应该仔细阅读他。
|
||||
|
||||

|
||||
|
||||
我们不在根目录使用RAID-1,所以留空。
|
||||
|
||||

|
||||
|
||||
提示是否开机启动阵列的时候,选择是。注意,这里需要往/etc/fstab 文件中添加一个条目使得系统启动的时候正确挂载阵列。
|
||||
|
||||

|
||||
|
||||
### 硬盘分区 ###
|
||||
|
||||
现在开始准备建立阵列需要的硬盘。这里往插入两个8GB的usb磁盘,使用dmesg命令设备显示设备 /dev/sdb 和 /dev/sdc
|
||||
|
||||
# dmesg | less
|
||||
|
||||
----------
|
||||
|
||||
[ 60.014863] sd 3:0:0:0: [sdb] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
|
||||
[ 75.066466] sd 4:0:0:0: [sdc] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
|
||||
|
||||
我们使用fdisk为每个磁盘建立一个大小为8G的主分区。以下步骤是如何在/dev/sdb上建立分区,假设次磁盘从未被分区(如果有其他分区的话,可以删掉):
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
按p键输出现在的分区表:
|
||||
|
||||

|
||||
|
||||
(如果有分区的话,可以使用 d 选项删除,w 选项应用更改)。
|
||||
|
||||
磁盘上没有分区,所以我们使用命令 ['n'] 创建一个主分区['p'], 分配分区号为['1'] 并且指定大小。你可以按回车使用默认值,或者输入一个你想设置的值。如下图:
|
||||
|
||||

|
||||
|
||||
用同样的方法为/dev/sdc 分区。
|
||||
|
||||
如果我们有两个不同容量的硬盘,比如 750GB 和 1TB的话,我们需要在每个磁盘上分出一个750GB的主分区,大盘剩下的空间可以用作他用,不加入磁盘阵列。
|
||||
|
||||
### 创建 RAID-1 阵列 ###
|
||||
|
||||
磁盘分区完成后,我们可以使用以下命令创建 RAID-1 阵列:
|
||||
|
||||
# mdadm -Cv /dev/md0 -l1 -n2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
说明:
|
||||
|
||||
- **-Cv**: 创建一个阵列并打印出详细信息。
|
||||
- **/dev/md0**: 阵列名称。
|
||||
- **-l1** (l as in "level"): 指定阵列类型为 RAID-1 。
|
||||
- **-n2**: 指定我们将两个分区加入到阵列中去,分别为/dev/sdb1 和 /dev/sdc1
|
||||
|
||||
以上命令和下面的等价:
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
如果你想在在磁盘失效时添加另外一个磁盘到阵列中,可以指定 '--spare-devices=1 /dev/sdd1' 到以上命令。
|
||||
|
||||
输入 “y” 继续创建阵列,回车:
|
||||
|
||||

|
||||
|
||||
可以使用以下命令查看进度:
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
另外一个获取阵列信息的方法是:
|
||||
|
||||
# mdadm --query /dev/md0
|
||||
# mdadm --detail /dev/md0 (or mdadm -D /dev/md0)
|
||||
|
||||

|
||||
|
||||
'mdadm -D'命令提供的信息中,最重要就是阵列状态类。激活状态说明阵列正在进行读写操作。其他几个状态分别为 完成(读写完成)、降级(有一块磁盘失效或丢失)或者恢复中(一张新盘已插入,系统正在写入数据)。这几个状态涵盖类大多数情况。
|
||||
|
||||
### 格式化或加载磁盘阵列 ###
|
||||
|
||||
下一步就是格式化阵列了,本例中使用ext4格式:
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
现在可以加载阵列并验证其正常加载:
|
||||
|
||||
# mount /dev/md0 /mnt
|
||||
# mount
|
||||
|
||||

|
||||
|
||||
### 监控磁盘阵列 ###
|
||||
|
||||
mdadm工具内置有磁盘阵列监控功能。当mdadm作为守护程序运行的时候(就像我们上文那样),会周期性的检测阵列运行状态,将检测到的信息通过电子邮件或者系统日志报告上来。当然,也可以配置其在发生致命性错误的时候调用紧急命令。
|
||||
|
||||
mdadm默认会记录所有已知分区和阵列的事件,并将他们记录到 /var/log/syslog中。或者你可以在配置文件中(/etc/mdadm/mdadm.conf debian系统 /etc/mdadm.conf 红帽子系统)以以下格式指定监控设备或者阵列。如果mdadm.conf文件不存在,你可以创建一个。
|
||||
|
||||
DEVICE /dev/sd[bcde]1 /dev/sd[ab]1
|
||||
|
||||
ARRAY /dev/md0 devices=/dev/sdb1,/dev/sdc1
|
||||
ARRAY /dev/md1 devices=/dev/sdd1,/dev/sde1
|
||||
.....
|
||||
|
||||
# optional email address to notify events
|
||||
MAILADDR your@email.com
|
||||
|
||||
编辑完毕mdadm配置文件后,重启mdadm服务:
|
||||
|
||||
Debian系统,Ubuntu或者Linux Mint:
|
||||
|
||||
# service mdadm restart
|
||||
|
||||
Fedora, CentOS 或 RHEL 7:
|
||||
|
||||
# systemctl restart mdmonitor
|
||||
|
||||
CentOS或者RHEL 6:
|
||||
|
||||
# service mdmonitor restart
|
||||
|
||||
### 自动加载阵列 ###
|
||||
|
||||
现在我们在/etc/fstab中加入条目使得系统启动的时候将阵列挂载到/mnt目录下:
|
||||
|
||||
# echo "/dev/md0 /mnt ext4 defaults 0 2" << /etc/fstab
|
||||
|
||||
为了验证挂载脚本工作正常,我们首先卸载阵列,重启mdadm,然后重新加载。可以看到/dev/md0已经安装我们添加到/etc/fstab中的条目加载了:
|
||||
|
||||
# umount /mnt
|
||||
# service mdadm restart (on Debian, Ubuntu or Linux Mint)
|
||||
or systemctl restart mdmonitor (on Fedora, CentOS/RHEL7)
|
||||
or service mdmonitor restart (on CentOS/RHEL6)
|
||||
# mount -a
|
||||
|
||||

|
||||
|
||||
现在我们的阵列已经可以访问类,拷贝文件/etc/passwd到/mnt中测试一下:
|
||||
|
||||

|
||||
|
||||
Debian系统中,需要在/etc/default/mdadm 设置 AUTOSTART 变量为 true 才能使mdadm守护程序在开机时自动加载阵列:
|
||||
|
||||
AUTOSTART=true
|
||||
|
||||
### 模拟磁盘丢失故障 ###
|
||||
|
||||
我们将使用以下命令卸载磁盘来模拟磁盘故障。注意,在实际应用中,磁盘已经上故障状态了,不需要卸载。
|
||||
|
||||
首先,卸载阵列:
|
||||
|
||||
# umount /mnt
|
||||
|
||||
现在注意每次执行命令后 'mdadm -D /dev/md0' 的输出。
|
||||
|
||||
# mdadm /dev/md0 --fail /dev/sdb1 #Marks /dev/sdb1 as faulty
|
||||
# mdadm --remove /dev/md0 /dev/sdb1 #Removes /dev/sdb1 from the array
|
||||
|
||||
然后,如果你有个备用盘的话,重新添加以下:
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdb1
|
||||
|
||||
数据会被自动添加到备用盘 /dev/sdb1 上:
|
||||
|
||||

|
||||
|
||||
注意以上所述步骤只适合支持磁盘热拔插的系统,在不支持热拔插的系统中,还是得停止阵列并关机后更换备用盘:
|
||||
|
||||
# mdadm --stop /dev/md0
|
||||
# shutdown -h now
|
||||
|
||||
最后将新驱动器重新添加到阵列中:
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdb1
|
||||
# mdadm --assemble /dev/md0 /dev/sdb1 /dev/sdc1
|
||||
|
||||
希望本文对你有所帮助
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-software-raid1-array-mdadm-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
@ -0,0 +1,115 @@
|
||||
Linux有问必答时间--如何查看Linux系统的CPU信息
|
||||
================================================================================
|
||||
> **问题**: 我想要了解我的电脑关于CPU处理器的详细信息,查看CPU信息比较有效地方法是什么?
|
||||
|
||||
根据你的需要,有各种各样的关于你的CPU处理器信息你需要了解,比如CPU供应商名、模型名、时钟频率、套接字/内核的数量, L1/L2/L3缓存配置、可用的处理器能力(比如:硬件虚拟化、AES, MMX, SSE)等等。在Linux中,有许多命令行或基于GUI的工具就能来展示你的CPU硬件的相关具体信息。
|
||||
|
||||
### 1. /proc/cpuinfo ###
|
||||
|
||||
最简单的方法就是查看 /proc/cpuinfo ,这个虚拟文件展示的是可用CPU硬件的配置。
|
||||
|
||||
$ more /proc/cpuinfo
|
||||
|
||||

|
||||
|
||||
通过查看这个文件,你能[识别出][1]物理处理器数、每个CPU核心数、可用的CPU标志寄存器以及其它东西的数量。
|
||||
|
||||
### 2. cpufreq-info ###
|
||||
|
||||
cpufreq-info命令(**cpufrequtils**包的一部分)从内核/硬件中收集并报告CPU频率信息。这条命令展示了CPU当前运行的硬件频率,包括CPU所允许的最小/最大频率、CPUfreq策略/统计数据等等。来看下CPU #0上的信息:
|
||||
|
||||
$ cpufreq-info -c 0
|
||||
|
||||

|
||||
|
||||
### 3. cpuid ###
|
||||
|
||||
cpuid命令的功能就相当于一个专用的CPU信息工具,它能通过使用[CPUID功能][2]来显示详细的关于CPU硬件的信息。信息报告包括处理器类型/家族、CPU扩展指令集、缓存/TLB(译者注:传输后备缓冲器)配置、电源管理功能等等。
|
||||
|
||||
$ cpuid
|
||||
|
||||

|
||||
|
||||
### 4. dmidecode ###
|
||||
|
||||
dmidecode命令直接从BIOS的DMI(译者注:桌面管理接口)数据收集关于系统硬件的具体信息。CPU信息报告包括CPU供应商、版本、CPU标志寄存器、最大/最近的时钟速度、(所允许的)核心总数、L1/L2/L3缓存配置等等。
|
||||
|
||||
$ sudo dmidecode
|
||||
|
||||

|
||||
|
||||
### 5. hardinfo ###
|
||||
|
||||
hardinfo是一个基于GUI的系统信息工具,它能展示给你一个易于理解的CPU硬件信息的概况,也包括你的系统其它的一些硬件组成部分。
|
||||
|
||||
$ hardinfo
|
||||
|
||||

|
||||
|
||||
### 6. i7z ###
|
||||
|
||||
i7z是一个专供英特尔酷睿i3、i5和i7 CPU的实时CPU报告工具。它能实时显示每个核心的各类信息,比如睿频加速状态、CPU频率、CPU电源状态、温度检测等等。i7z运行在基于ncurses的控制台模式或基于QT的GUI的其中之一上。
|
||||
|
||||
$ sudo i7z
|
||||
|
||||

|
||||
|
||||
### 8. likwid-topology ###
|
||||
|
||||
[likwid][3] (Like I Knew What I'm Doing) 是一个用来测量、配置并显示硬件相关特性的命令行收集工具。其中的likwid拓扑结构能显示CPU硬件(线程/缓存/NUMA)的拓扑结构信息,还能识别处理器家族(比如:Intel Core 2, AMD Shanghai)。
|
||||
|
||||

|
||||
|
||||
### 9. lscpu ###
|
||||
|
||||
lscpu命令用一个更加用户友好的格式统计了 /etc/cpuinfo 的内容,比如CPU、核心、套接字、NUMA节点的数量(线上/线下)。
|
||||
|
||||
$ lscpu
|
||||
|
||||

|
||||
|
||||
### 10. lshw ###
|
||||
|
||||
**lshw**命令是一个综合性硬件查询工具。不同于其它工具,lshw需要root特权才能运行因为它是在BIOS系统里查询DMI(译者注:桌面管理接口)信息。它能报告总核心数和可用核心数,但是会遗漏掉一些信息比如L1/L2/L3缓存配置。GTK版本的lshw-gtk也是可用的。
|
||||
|
||||
$ sudo lshw -class processor
|
||||
|
||||

|
||||
|
||||
### 11. lstopo ###
|
||||
|
||||
lstopo命令 (包括 [hwloc][4] 包) 使由CPU、缓存、内存和I/O设备组成的拓扑结构可见。这个命令用来识别处理器结构和系统的NUMA拓扑结构。
|
||||
|
||||
$ lstopo
|
||||
|
||||

|
||||
|
||||
### 12. numactl ###
|
||||
|
||||
其被开发的起初是为了设置NUMA的时序安排和Linux处理器的内存布局策略,numactl命令也能通过命令行来展示关于CPU硬件的NUMA拓扑结构信息。
|
||||
|
||||
$ numactl --hardware
|
||||
|
||||

|
||||
|
||||
### 13. x86info ###
|
||||
|
||||
x86info是一个为了展示基于x86架构的CPU信息的命令行工具。信息报告包括CPU型号、线程/核心数、时钟速度、TLB(译者注:传输后备缓冲器)缓存配置、支持的特征标志寄存器等等。
|
||||
|
||||
$ x86info --all
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-cpu-info-linux.html
|
||||
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-find-number-of-cpu-cores-on.html
|
||||
[2]:http://en.wikipedia.org/wiki/CPUID
|
||||
[3]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[4]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
@ -1,113 +0,0 @@
|
||||
Linux有问必答:如何检查Linux的内存使用状况
|
||||
================================================================================
|
||||
|
||||
>**问题**:我想要监测Linux系统的内存使用状况。有哪些可用的图形界面或者命令行工具来检查当前内存使用情况?
|
||||
|
||||
当涉及到Linux系统性能优化的时候,物理内存是一个最重要的因素。自然的,Linux提供了丰富的选择来监测对于珍贵的内存资源的使用。不同的工具,在监测粒度(例如:全系统范围, 每个进程, 每个用户),接口(例如:图形用户界面, 命令行, ncurses)或者运行模式(交互模式, 批量处理模式)上都不尽相同。
|
||||
|
||||
下面是一个可供选择的但并不全面的图形或命令行工具列表,这些工具用来检查并且释放Linux平台中内存。
|
||||
|
||||
### 1. /proc/meminfo ###
|
||||
|
||||
一种最简单的方法是通过“/proc/meminfo”来检查内存使用状况。这个动态更新的虚拟文件事实上是许多信息资源的集中展示,这些资源来自于诸如free,top和ps这些与内存相关的工具。从可用/闲置物理内存数量到等待被写入缓存的数量或者已写回磁盘的数量,只要是你想要的关于内存使用的信息,“/proc/meminfo”应有尽有。特定进程的内存信息也可以通过“/proc/<pid>/statm”和“/proc/<pid>/status”来获取。
|
||||
|
||||
$ cat /proc/meminfo
|
||||
|
||||

|
||||
|
||||
### 2. atop ###
|
||||
|
||||
atop命令是用于终端环境的基于ncurses的交互系统和进程监测工具。它展示了动态更新的系统资源(中央处理器, 内存, 网络, 输入/输出, 内核)摘要,并且用醒目的颜色将高系统负载的警告信息标注出来。它同样提供了类似于top的线程(或用户)资源使用视图,因此系统管理员可以指出哪个进程或者用户对系统负载负责。内存统计报告包括了总计/闲置内存,缓存的/缓冲的内存 和 提交的虚拟内存。
|
||||
|
||||
$ sudo atop
|
||||
|
||||

|
||||
|
||||
### 3. free ###
|
||||
|
||||
free命令是一个用来获得内存使用概况的快速简单的方法,这些信息从“/proc/meminfo”获取。它提供了一个快照用于展示总计/闲置的物理内存和系统交换区,以及已使用/闲置的内核缓冲区。
|
||||
|
||||
$ free -h
|
||||
|
||||

|
||||
|
||||
### 4. GNOME System Monitor ###
|
||||
|
||||
GNOME System Monitor 是一个图形界面应用,它展示了包括中央处理器,内存,交换区和网络在内的系统资源使用率的短暂历史记录。它同时也可以提供一个带有中央处理器和内存使用情况的进程视图。
|
||||
|
||||
$ gnome-system-monitor
|
||||
|
||||

|
||||
|
||||
### 5. htop ###
|
||||
|
||||
htop命令是一个基于ncurses的交互处理视图,它实时展示了每个进程的内存使用情况。它可以报告所有运行中进程的常驻内存大小(RSS)、内存中程序的总大小、库大小、共享文件大小、和脏页面大小。你可以横向或者纵向滚动进程列表进行查看。
|
||||
|
||||
$ htop
|
||||
|
||||

|
||||
|
||||
### 6. KDE System Monitor ###
|
||||
|
||||
就像GNOME桌面拥有GNOME System Monitor一样,KDE桌面也有它自己的对口应用:KDE System Monitor。这个工具的功能与GNOME版本极其相似,也就是说,它同样展示了一个关于系统资源使用情况,以及带有每个进程的中央处理器/内存消耗情况的实时历史记录。
|
||||
|
||||
$ ksysguard
|
||||
|
||||

|
||||
|
||||
### 7. memstat ###
|
||||
|
||||
memstat工具对于识别正在消耗虚拟内存的可执行文件、进程和共享库非常有用。给出一个进程识别号,memstat即可识别出与之相关联的可执行文件、数据和共享库究竟使用了多少虚拟内存。
|
||||
|
||||
$ memstat -p <PID>
|
||||
|
||||

|
||||
|
||||
### 8. nmon ###
|
||||
|
||||
nmon工具是一个基于ncurses系统基准测试工具,它能够以交互方式监测中央处理器、内存、磁盘输入/输出、内核、文件系统以及网络资源。对于内存使用状况而言,它能够展示像总计/闲置内存、交换区、缓冲的/缓存的内存,虚拟内存页面输入输出统计,所有这些都是实时的。
|
||||
|
||||
$ nmon
|
||||
|
||||

|
||||
|
||||
### 9. ps ###
|
||||
|
||||
ps命令能够实时展示每个进程的内存使用状况。内存使用报告里包括了 %MEM (物理内存使用百分比), VSZ (虚拟内存使用总量), and RSS (物理内存使用总量)。你可以使用“--sort”选项来对进程列表排序。例如,按照RSS降序排序:
|
||||
|
||||
$ ps aux --sort -rss
|
||||
|
||||

|
||||
|
||||
### 10. smem ###
|
||||
|
||||
[smem][1]命令允许你测定不同进程和用户的物理内存使用状况,这些信息来源于“/proc”目录。它利用比例设置大小(PSS)指标来精确量化Linux进程的有效内存使用情况。内存使用分析能够扩展成为柱状图或者饼图类的图形化图表。
|
||||
|
||||
$ sudo smem --pie name -c "pss"
|
||||
|
||||

|
||||
|
||||
### 11. top ###
|
||||
|
||||
top命令提供了一个运行中进程的实时视图,以及特定进程的各种资源使用统计信息。与内存相关的信息包括 %MEM (内存使用率), VIRT (虚拟内存使用总量), SWAP (交换出的虚拟内存使用量), CODE (分配给代码执行的物理内存数量), DATA (分配给无需执行的数据的物理内存数量), RES (物理内存使用总量; CODE+DATA), and SHR (有可能与其他进程共享的内存数量).你能够基于内存使用情况或者大小对进程列表进行排序。
|
||||
|
||||

|
||||
|
||||
### 12. vmstat ###
|
||||
|
||||
vmstat命令行工具显示涵盖了中央处理器、内存、中断和磁盘输入/输出在内的各种系统活动的瞬时和平均统计数据。对于内存信息而言,命令不仅仅展示了物理内存使用情况(例如总计/已使用内存和缓冲的/缓存的内存),还同样展示了虚拟内存统计数据(例如,内存的页输入/输出,交换输入/输出)
|
||||
|
||||
$ vmstat -s
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-memory-usage-linux.html
|
||||
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/visualize-memory-usage-linux.html
|
||||
Loading…
Reference in New Issue
Block a user