mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
c50cd50df5
@ -1,3 +1,5 @@
|
||||
[su-kaiyao] translating
|
||||
|
||||
How To Run Linux Programs From The Terminal In Background Mode
|
||||
================================================================================
|
||||

|
||||
@ -83,4 +85,4 @@ via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-The-Te
|
||||
[2]:http://linux.about.com/od/commands/l/blcmdl1_locate.htm
|
||||
[3]:http://linux.about.com/library/cmd/blcmdl1_less.htm
|
||||
[4]:http://linux.about.com/library/cmd/blcmdl1_more.htm
|
||||
[5]:http://linux.about.com/od/commands/l/blcmdl8_sudo.htm
|
||||
[5]:http://linux.about.com/od/commands/l/blcmdl8_sudo.htm
|
||||
|
||||
@ -0,0 +1,154 @@
|
||||
How to configure a syslog server with rsyslog on Linux
|
||||
================================================================================
|
||||
A syslog server represents a central log monitoring point on a network, to which all kinds of devices including Linux or Windows servers, routers, switches or any other hosts can send their logs over network. By setting up a syslog server, you can filter and consolidate logs from different hosts and devices into a single location, so that you can view and archive important log messages more easily.
|
||||
|
||||
On most Linux distributions, **rsyslog** is the standard syslog daemon that comes pre-installed. Configured in a client/server architecture, **rsyslog** can play both roles; as a syslog server **rsyslog** can gather logs from other devices, and as a syslog client, **rsyslog** can transmit its internal logs to a remote syslog server.
|
||||
|
||||
In this tutorial, we cover how to configure a centralized syslog server using **rsyslog** on Linux. Before we go into the details, it is instructive to go over syslog standard first.
|
||||
|
||||
### Basic of Syslog Standard ###
|
||||
|
||||
When logs are collected with syslog mechanism, three important things must be taken into consideration:
|
||||
|
||||
- **Facility level**: what type of processes to monitor
|
||||
- **Severity (priority) level**: what type of log messages to collect
|
||||
- **Destination**: where to send or record log messages
|
||||
|
||||
Let's take a look at how the configuration is defined in more detail.
|
||||
|
||||
The facility levels define a way to categorize internal system processes. Some of the common standard facilities in Linux are:
|
||||
|
||||
- **auth**: messages related to authentication (login)
|
||||
- **cron**: messages related to scheduled processes or applications
|
||||
- **daemon**: messages related to daemons (internal servers)
|
||||
- **kernel**: messages related to the kernel
|
||||
- **mail**: messages related to internal mail servers
|
||||
- **syslog**: messages related to the syslog daemon itself
|
||||
- **lpr**: messages related to print servers
|
||||
- **local0 - local7**: messages defined by user (local7 is usually used by Cisco and Windows servers)
|
||||
|
||||
The severity (priority) levels are standardized, and defined by using standard abbreviation and an assigned number with number 7 being the highest level of all. These levels are:
|
||||
|
||||
- emerg: Emergency - 0
|
||||
- alert: Alerts - 1
|
||||
- crit: Critical - 2
|
||||
- err: Errors - 3
|
||||
- warn: Warnings - 4
|
||||
- notice: Notification - 5
|
||||
- info: Information - 6
|
||||
- debug: Debugging - 7
|
||||
|
||||
Finally, the destination statement enforces a syslog client to perform one of three following tasks: (1) save log messages on a local file, (2) route them to a remote syslog server over TCP/UDP, or (3) send them to stdout such as a console.
|
||||
|
||||
In rsyslog, syslog configuration is structured based on the following schema.
|
||||
|
||||
[facility-level].[severity-level] [destination]
|
||||
|
||||
### Configure Rsyslog on Linux ###
|
||||
|
||||
Now that we understand syslog, it's time to configure a Linux server as a central syslog server using rsyslog. We will also see how to configure a Windows based system as a syslog client to send internal logs to the syslog server.
|
||||
|
||||
#### Step One: Initial System Requirements ####
|
||||
|
||||
To set up a Linux host as a central log server, we need to create a separate /var partition, and allocate a large enough disk size or create a LVM special volume group. That way, the syslog server will be able to sustain the exponential growth of collected logs over time.
|
||||
|
||||
#### Step Two: Enable Rsyslog Daemon ####
|
||||
|
||||
rsyslog daemon comes pre-installed on modern Linux distributions, but is not enabled by default. To enable rsyslog daemon to receive external messages, edit its configuration file located in /etc/rsyslog.conf.
|
||||
|
||||
Once the file is opened for editing, search and uncomment the below two lines by removing the # sign from the beginning of lines.
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
|
||||
This will enable rsyslog daemon to receive log messages on UDP port 514. UDP is way faster than TCP, but does not provide reliability on data flow the same way as TCP does. If you need to reliable delivery, you can enable TCP by uncommenting the following lines.
|
||||
|
||||
$ModLoad imtcp
|
||||
$InputTCPServerRun 514
|
||||
|
||||
Note that both TCP and UDP can be set on the server simultaneously to listen on TCP/UDP connections.
|
||||
|
||||
#### Step Three: Create a Template for Log Receipt ####
|
||||
|
||||
In the next step we need to create a template for remote messages, and tell rsyslog daemon how to record messages received from other client machines.
|
||||
|
||||
Open /etc/rsyslog.conf with a text editor, and append the following template before the GLOBAL DIRECTIVES block:
|
||||
|
||||
$template RemoteLogs,"/var/log/%HOSTNAME%/%PROGRAMNAME%.log" *
|
||||
*.* ?RemoteLogs
|
||||
& ~
|
||||
|
||||
This template needs a little explanation. The $template RemoteLogs directive ("RemoteLogs" string can be changed to any other descriptive name) forces rsyslog daemon to write log messages to separate local log files in /var/log/, where log file names are defined based on the hostname of the remote sending machine as well as the remote application that generated the logs. The second line ("*.* ?RemoteLogs") implies that we apply RemoteLogs template to all received logs.
|
||||
|
||||
The "& ~" sign represents a redirect rule, and is used to tell rsyslog daemon to stop processing log messages further, and not write them locally. If this redirection is not used, all the remote messages would be also written on local log files besides the log files described above, which means they would practically be written twice. Another consequence of using this rule is that the syslog server's own log messages would only be written to dedicated files named after machine's hostname.
|
||||
|
||||
If you want, you can direct log messages with a specific facility or severity level to this new template using the following schema.
|
||||
|
||||
[facility-level].[severity-level] ?RemoteLogs
|
||||
|
||||
For example:
|
||||
|
||||
Direct all internal authentication messages of all priority levels to RemoteLogs template:
|
||||
|
||||
authpriv.* ?RemoteLogs
|
||||
|
||||
Direct informational messages generated by all system processes, except mail, authentication and cron messages to RemoteLogs template:
|
||||
|
||||
*.info,mail.none,authpriv.none,cron.none ?RemoteLogs
|
||||
|
||||
If we want all received messages from remote clients written to a single file named after their IP address, you can use the following template. We assign a new name "IpTemplate" to this template.
|
||||
|
||||
$template IpTemplate,"/var/log/%FROMHOST-IP%.log"
|
||||
*.* ?IpTemplate
|
||||
& ~
|
||||
|
||||
After we have enabled rsyslog daemon and edited its configuration file, we need to restart the daemon.
|
||||
|
||||
On Debian, Ubuntu or CentOS/RHEL 6:
|
||||
|
||||
$ sudo service rsyslog restart
|
||||
|
||||
On Fedora or CentOS/RHEL 7:
|
||||
|
||||
$ sudo systemctl restart rsyslog
|
||||
|
||||
We can verify that rsyslog daemon is functional by using netstat command.
|
||||
|
||||
$ sudo netstat -tulpn | grep rsyslog
|
||||
|
||||
The output should look like the following in case rsyslog daemon listens on UDP port.
|
||||
|
||||
udp 0 0 0.0.0.0:514 0.0.0.0:* 551/rsyslogd
|
||||
udp6 0 0 :::514 :::* 551/rsyslogd
|
||||
|
||||
If rsyslog daemon is set up to listen on TCP connections, the output should look like this.
|
||||
|
||||
tcp 0 0 0.0.0.0:514 0.0.0.0:* LISTEN 1891/rsyslogd
|
||||
tcp6 0 0 :::514 :::* LISTEN 1891/rsyslogd
|
||||
|
||||
#### Send Windows Logs to a Remote Rsyslog Server ####
|
||||
|
||||
To forward a Windows based client's log messages to our rsyslog server, we need a Windows syslog agent. While there are a multitude of syslog agents that can run on Windows, we can use [Datagram SyslogAgent][1], which is a freeware program.
|
||||
|
||||
After downloading and installing the syslog agent, we need to configure it to run as a service. Specify the protocol though which it will send data, the IP address and port of a remote rsyslog server, and what type of event logs should be transmitted as follows.
|
||||
|
||||
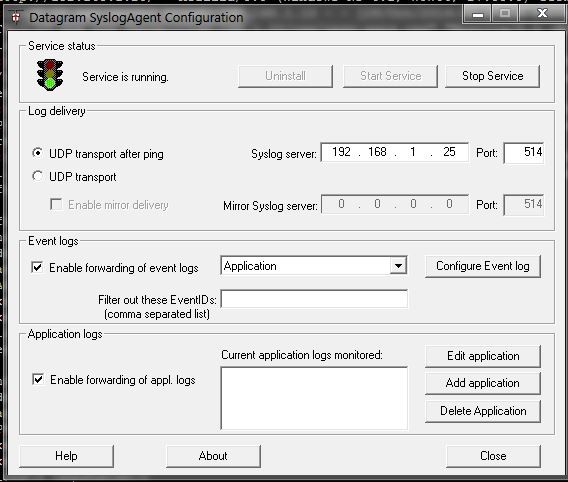
|
||||
|
||||
After we have set up all the configurations, we can start the service and watch the log files on the central rsyslog server using tailf command line utility.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
By creating a central rsyslog server that can collect log files of local or remote hosts, we can get a better idea on what is going on internally in their systems, and can debug their problems more easily should any of them become unresponsive or crash.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-syslog-server-linux.html
|
||||
|
||||
作者:[Caezsar M][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/caezsar
|
||||
[1]:http://www.syslogserver.com/download.html
|
||||
@ -0,0 +1,248 @@
|
||||
SPccman translating
|
||||
How to create a custom backup plan for Debian with backupninja
|
||||
================================================================================
|
||||
Backupninja is a powerful and highly-configurable backup tool for Debian based distributions. In the [previous tutorial][1], we explored how to install backupninja and how to set up two backup actions for the program to perform. However, we should note that those examples were only "the tip of the iceberg," so to speak. In this post we will discuss how to leverage custom handlers and helpers that allow this program to be customized in order to accomplish almost any backup need that you can think of.
|
||||
|
||||
And believe me - that is not an overstatement, so let's begin.
|
||||
|
||||
### A Quick Review of Backupninja ###
|
||||
|
||||
One of backupninja's distinguishing features is the fact that you can just drop plain text configuration or action files in /etc/backup.d, and the program will take care of the rest. In addition, we can write custom scripts (aka "handlers") and place them in /usr/share/backupninja to handle each type of backup action. Furthermore, we can have these scripts be executed via ninjahelper's ncurses-based interactive menus (aka "helpers") to guide us to create the configuration files we mentioned earlier, minimizing the chances of human error.
|
||||
|
||||
### Creating a Custom Handler and Helper ###
|
||||
|
||||
Our goal in this case is to create a script to handle the backup of chosen home directories into a tarball with either **gzip** or **bzip2** compression, excluding music and video files. We will simply name this script home, and place it under /usr/backup/ninja.
|
||||
|
||||
Although you could achieve the same objective with the default tar handler (refer to /usr/share/backupninja/tar and /usr/share/backupninja/tar.helper), we will use this approach to show how to create a useful handler script and ncurses-based helper from scratch. You can then decide how to apply the same principles depending on your specific needs.
|
||||
|
||||
Note that since handlers are sourced from the main script, there is no need to start with #!/bin/bash at the top.
|
||||
|
||||
Our proposed handler (/usr/share/backupninja/home) is as follows. It is heavily commented for clarification. The getconf function is used to read the backup action's configuration file. If you specify a value for a variable here, it will override the corresponding value present in the configuration file:
|
||||
|
||||
# home handler script for backupninja
|
||||
|
||||
# Every backup file will identify the host by its FQDN
|
||||
getconf backupname
|
||||
|
||||
# Directory to store backups
|
||||
getconf backupdir
|
||||
|
||||
# Default compression
|
||||
getconf compress
|
||||
|
||||
# Include /home directory
|
||||
getconf includes
|
||||
|
||||
# Exclude files with *.mp3 and *.mp4 extensions
|
||||
getconf excludes
|
||||
|
||||
# Default extension for the packaged backup file
|
||||
getconf EXTENSION
|
||||
|
||||
# Absolute path to date binary
|
||||
getconf TAR `which tar`
|
||||
|
||||
# Absolute path to date binary
|
||||
getconf DATE `which date`
|
||||
|
||||
# Chosen date format
|
||||
DATEFORMAT="%Y-%m-%d"
|
||||
|
||||
# If backupdir does not exist, exit with fatal error
|
||||
if [ ! -d "$backupdir" ]
|
||||
then
|
||||
mkdir -p "$backupdir" || fatal "Can not make directory $backupdir"
|
||||
fi
|
||||
|
||||
# If backupdir is not writeable, exit with fatal error as well
|
||||
if [ ! -w "$backupdir" ]
|
||||
then
|
||||
fatal "Directory $backupdir is not writable"
|
||||
fi
|
||||
|
||||
# Set the right tar option as per the chosen compression format
|
||||
case $compress in
|
||||
"gzip")
|
||||
compress_option="-z"
|
||||
EXTENSION="tar.gz"
|
||||
;;
|
||||
"bzip")
|
||||
compress_option="-j"
|
||||
EXTENSION="tar.bz2"
|
||||
;;
|
||||
"none")
|
||||
compress_option=""
|
||||
;;
|
||||
*)
|
||||
warning "Unknown compress filter ($tar_compress)"
|
||||
compress_option=""
|
||||
EXTENSION="tar.gz"
|
||||
;;
|
||||
esac
|
||||
|
||||
# Exclude the following file types / directories
|
||||
exclude_options=""
|
||||
for i in $excludes
|
||||
do
|
||||
exclude_options="$exclude_options --exclude $i"
|
||||
done
|
||||
|
||||
# Debugging messages, performing backup
|
||||
debug "Running backup: " $TAR -c -p -v $compress_option $exclude_options \
|
||||
-f "$backupdir/$backupname-"`$DATE "+$DATEFORMAT"`".$EXTENSION" \
|
||||
$includes
|
||||
|
||||
# Redirect standard output to a file with .list extension
|
||||
# and standard error to a file with .err extension
|
||||
$TAR -c -p -v $compress_option $exclude_options \
|
||||
-f "$backupdir/$backupname-"`$DATE "+$DATEFORMAT"`".$EXTENSION" \
|
||||
$includes \
|
||||
> "$backupdir/$backupname-"`$DATE "+$DATEFORMAT"`.list \
|
||||
2> "$backupdir/$backupname-"`$DATE "+$DATEFORMAT"`.err
|
||||
|
||||
[ $? -ne 0 ] && fatal "Tar backup failed"
|
||||
|
||||
Next, we will create our helper file (/usr/share/backupninja/home.helper) so that our handlers shows up as a menu in **ninjahelper**:
|
||||
|
||||
# Backup action's description. Separate words with underscores.
|
||||
HELPERS="$HELPERS home:backup_of_home_directories"
|
||||
|
||||
home_wizard() {
|
||||
home_title="Home action wizard"
|
||||
|
||||
backupname=`hostname --fqdn`
|
||||
|
||||
# Specify default value for the time when this backup actions is supposed to run
|
||||
inputBox "$home_title" "When to run this action?" "everyday at 01"
|
||||
[ $? = 1 ] && return
|
||||
home_when_run="when = $REPLY"
|
||||
|
||||
# Specify default value for backup file name
|
||||
inputBox "$home_title" "\"Name\" of backups" "$backupname"
|
||||
[ $? = 1 ] && return
|
||||
home_backupname="backupname = $REPLY"
|
||||
backupname="$REPLY"
|
||||
|
||||
# Specify default directory to store the backups
|
||||
inputBox "$home_title" "Directory where to store the backups" "/var/backups/home"
|
||||
[ $? = 1 ] && return
|
||||
home_backupdir="backupdir = $REPLY"
|
||||
|
||||
# Specify default values for the radiobox
|
||||
radioBox "$home_title" "Compression" \
|
||||
"none" "No compression" off \
|
||||
"gzip" "Compress with gzip" on \
|
||||
"bzip" "Compress with bzip" off
|
||||
[ $? = 1 ] && return;
|
||||
result="$REPLY"
|
||||
home_compress="compress = $REPLY "
|
||||
|
||||
REPLY=
|
||||
while [ -z "$REPLY" ]; do
|
||||
formBegin "$home_title: Includes"
|
||||
formItem "Include:" /home/gacanepa
|
||||
formDisplay
|
||||
[ $? = 0 ] || return 1
|
||||
home_includes="includes = "
|
||||
for i in $REPLY; do
|
||||
[ -n "$i" ] && home_includes="$home_includes $i"
|
||||
done
|
||||
done
|
||||
|
||||
REPLY=
|
||||
while [ -z "$REPLY" ]; do
|
||||
formBegin "$home_title: Excludes"
|
||||
formItem "Exclude:" *.mp3
|
||||
formItem "Exclude:" *.mp4
|
||||
# Add as many “Exclude” text boxes as needed to specify other exclude options
|
||||
formItem "Exclude:"
|
||||
formItem "Exclude:"
|
||||
formDisplay
|
||||
[ $? = 0 ] || return 1
|
||||
home_excludes="excludes = "
|
||||
for i in $REPLY; do
|
||||
[ -n "$i" ] && home_excludes="$home_excludes $i"
|
||||
done
|
||||
done
|
||||
|
||||
# Save the config
|
||||
get_next_filename $configdirectory/10.home
|
||||
cat > $next_filename <<EOF
|
||||
$home_when_run
|
||||
$home_backupname
|
||||
$home_backupdir
|
||||
$home_compress
|
||||
$home_includes
|
||||
$home_excludes
|
||||
|
||||
# tar binary - have to be GNU tar
|
||||
TAR `which tar`
|
||||
DATE `which date`
|
||||
DATEFORMAT "%Y-%m-%d"
|
||||
EXTENSION tar
|
||||
|
||||
EOF
|
||||
# Backupninja requires that configuration files be chmoded to 600
|
||||
chmod 600 $next_filename
|
||||
}
|
||||
|
||||
### Running Ninjahelper ###
|
||||
|
||||
Once we have created our handler script named home and the corresponding helper named home.helper, let's run ninjahelper command to create a new backup action:
|
||||
|
||||
# ninjahelper
|
||||
|
||||
And choose create a new backup action.
|
||||
|
||||

|
||||
|
||||
We will now be presented with the available action types. Let's select "backup of home directories":
|
||||
|
||||

|
||||
|
||||
The next screens will display the default values as set in the helper (only 3 of them are shown here). Feel free to edit the values in the text box. Particularly, refer to the scheduling section of the documentation for the right syntax for the when variable.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
When you are done creating the backup action, it will show in ninjahelper's initial menu:
|
||||
|
||||

|
||||
|
||||
Then you can press ENTER to show the options available for this action. Feel free to experiment with them, as their description is quite straightforward.
|
||||
|
||||
Particularly, "run this action now" will execute the backup action in debug mode immediately regardless of the scheduled time:
|
||||
|
||||

|
||||
|
||||
Should the backup action fail for some reason, the debug will display an informative message to help you locate the error and correct it. Consider, for example, the following error messages that were displayed after running a backup action with bugs that have not been corrected yet:
|
||||
|
||||

|
||||
|
||||
The image above tells you that the connection needed to complete the backup action could not be completed because the remote host seems to be down. In addition, the destination directory specified in the helper file does not exist. Once you correct the problems, re-run the backup action.
|
||||
|
||||
A few things to remember:
|
||||
|
||||
- If you create a custom script in /usr/share/backupninja (e.g., foobar) to handle a specific backup action, you also need to write a corresponding helper (e.g., foobar.helper) in order to create, through ninjahelper, a file named 10.foobar (11 and onward for further actions as well) in /etc/backup.d, which is the actual configuration file for the backup action.
|
||||
- You can execute your backups at any given time via ninjahelper as explained earlier, or have them run as per the specified frequency in the when variable.
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this post we have discussed how to create our own backup actions from scratch and how to add a related menu in ninjahelper to facilitate the creation of configuration files. With the previous [backupninja article][2] and the present one I hope I've given you enough good reasons to go ahead and at least try it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/create-custom-backup-plan-debian.html
|
||||
|
||||
作者:[ Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/backup-debian-system-backupninja.html
|
||||
[2]:http://xmodulo.com/backup-debian-system-backupninja.html
|
||||
@ -0,0 +1,152 @@
|
||||
How to use matplotlib for scientific plotting on Linux
|
||||
================================================================================
|
||||
If you want an efficient, automatable solution for producing high-quality scientific plots in Linux, then consider using matplotlib. Matplotlib is a Python-based open-source scientific plotting package with a license based on the Python Software Foundation license. The extensive documentation and examples, integration with Python and the NumPy scientific computing package, and automation capability are just a few reasons why this package is a solid choice for scientific plotting in a Linux environment. This tutorial will provide several example plots created with matplotlib.
|
||||
|
||||
### Features ###
|
||||
|
||||
- Numerous plot types (bar, box, contour, histogram, scatter, line plots...)
|
||||
- Python-based syntax
|
||||
- Integration with the NumPy scientific computing package
|
||||
- Source data can be Python lists, Python tuples, or NumPy arrays
|
||||
- Customizable plot format (axes scales, tick positions, tick labels...)
|
||||
- Customizable text (font, size, position...)
|
||||
- TeX formatting (equations, symbols, Greek characters...)
|
||||
- Compatible with IPython (allows interactive plotting from a Python shell)
|
||||
- Automation use Python loops to iteratively create plots
|
||||
- Save plots to image files (png, pdf, ps, eps, and svg format)
|
||||
|
||||
The Python-based syntax of matplotlib serves as the foundation for many of its features and enables an efficient workflow. There are many scientific plotting packages that can produce quality plots, but do they allow you to do it directly from within your Python code? On top of that, do they allow you to create automated routines for iterative creation of plots that can be saved as image files? Matplotlib allows you to accomplish all of these tasks. You can now look forward to saving time that would have otherwise been spent manually creating multiple plots.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Installation of Python and the NumPy package is a prerequisite for use of matplotlib. Instructions for installing NumPy can be found [here][1].
|
||||
|
||||
To install matplotlib in Debian or Ubuntu, run the following command:
|
||||
|
||||
$ sudo apt-get install python-matplotlib
|
||||
|
||||
To install matplotlib in Fedora or CentOS/RHEL, run the following command:
|
||||
|
||||
$ sudo yum install python-matplotlib
|
||||
|
||||
### Matplotlib Examples ###
|
||||
|
||||
This tutorial will provide several plotting examples that demonstrate how to use matplotlib:
|
||||
|
||||
- Scatter and line plot
|
||||
- Histogram plot
|
||||
- Pie chart
|
||||
|
||||
In these examples we will use Python scripts to execute matplotlib commands. Note that the numpy and matplotlib modules must be imported from within the scripts via the import command. np is specified as a reference to the numpy module and plt is specified as a reference to the matplotlib.pyplot namespace:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
### Example 1: Scatter and Line Plot ###
|
||||
|
||||
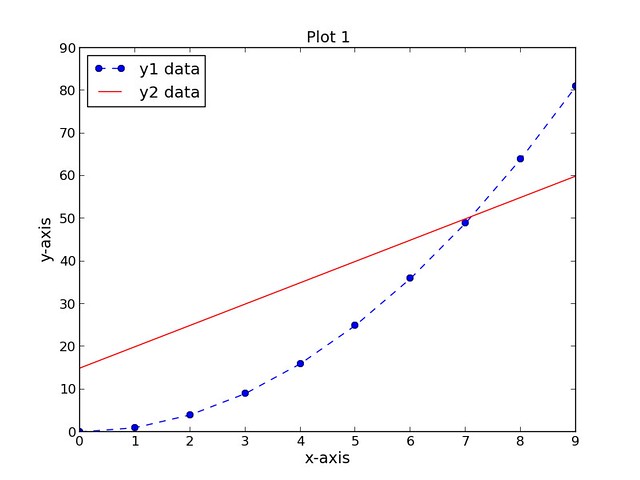
The first script, **script1.py** completes the following tasks:
|
||||
|
||||
- Creates three data sets (xData, yData1, and yData2)
|
||||
- Creates a new figure (assigned number 1) with a width and height of 8 inches and 6 inches, respectively
|
||||
- Sets the plot title, x-axis label, and y-axis label (all with font size of 14)
|
||||
- Plots the first data set, yData1, as a function of the xData dataset as a dotted blue line with circular markers and a label of "y1 data"
|
||||
- Plots the second data set, yData2, as a function of the xData dataset as a solid red line with no markers and a label of "y2 data".
|
||||
- Positions the legend in the upper left-hand corner of the plot
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of **script1.py**:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
xData = np.arange(0, 10, 1)
|
||||
yData1 = xData.__pow__(2.0)
|
||||
yData2 = np.arange(15, 61, 5)
|
||||
plt.figure(num=1, figsize=(8, 6))
|
||||
plt.title('Plot 1', size=14)
|
||||
plt.xlabel('x-axis', size=14)
|
||||
plt.ylabel('y-axis', size=14)
|
||||
plt.plot(xData, yData1, color='b', linestyle='--', marker='o', label='y1 data')
|
||||
plt.plot(xData, yData2, color='r', linestyle='-', label='y2 data')
|
||||
plt.legend(loc='upper left')
|
||||
plt.savefig('images/plot1.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Example 2: Histogram Plot ###
|
||||
|
||||
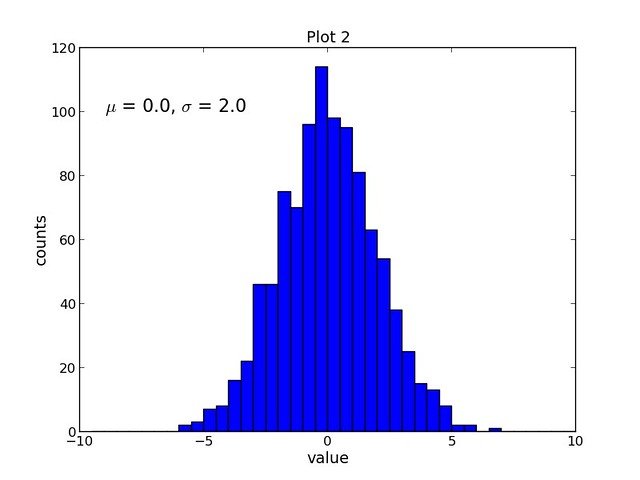
The second script, **script2.py** completes the following tasks:
|
||||
|
||||
- Creates a data set containing 1000 random samples from a Normal distribution
|
||||
- Creates a new figure (assigned number 1) with a width and height of 8 inches and 6 inches, respectively
|
||||
- Sets the plot title, x-axis label, and y-axis label (all with font size of 14)
|
||||
- Plots the data set, samples, as a histogram with 40 bins and an upper and lower bound of -10 and 10, respectively
|
||||
- Adds text to the plot and uses TeX formatting to display the Greek letters mu and sigma (font size of 16)
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of **script2.py**:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
mu = 0.0
|
||||
sigma = 2.0
|
||||
samples = np.random.normal(loc=mu, scale=sigma, size=1000)
|
||||
plt.figure(num=1, figsize=(8, 6))
|
||||
plt.title('Plot 2', size=14)
|
||||
plt.xlabel('value', size=14)
|
||||
plt.ylabel('counts', size=14)
|
||||
plt.hist(samples, bins=40, range=(-10, 10))
|
||||
plt.text(-9, 100, r'$\mu$ = 0.0, $\sigma$ = 2.0', size=16)
|
||||
plt.savefig('images/plot2.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Example 3: Pie Chart ###
|
||||
|
||||
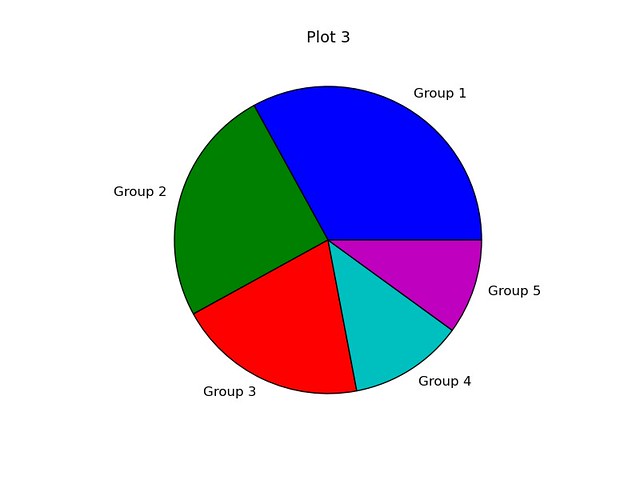
The third script, **script3.py** completes the following tasks:
|
||||
|
||||
- Creates data set containing five integers
|
||||
- Creates a new figure (assigned number 1) with a width and height of 6 inches and 6 inches, respectively
|
||||
- Adds an axes to the figure with an aspect ratio of 1
|
||||
- Sets the plot title (font size of 14)
|
||||
- Plots the data set, data, as a pie chart with labels included
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of **script3.py**:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
data = [33, 25, 20, 12, 10]
|
||||
plt.figure(num=1, figsize=(6, 6))
|
||||
plt.axes(aspect=1)
|
||||
plt.title('Plot 3', size=14)
|
||||
plt.pie(data, labels=('Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5'))
|
||||
plt.savefig('images/plot3.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Summary ###
|
||||
|
||||
This tutorial provides several examples of plots that can be created with the matplotlib scientific plotting package. Matplotlib is a great solution for scientific plotting in a Linux environment given its natural integration with Python and NumPy, its ability to be automated, and its production of a wide variety of customizable high quality plots. Documentation and examples for the matplotlib package can be found [here][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/matplotlib-scientific-plotting-linux.html
|
||||
|
||||
作者:[Joshua Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/joshua
|
||||
[1]:http://xmodulo.com/numpy-scientific-computing-linux.html
|
||||
[2]:http://matplotlib.org/
|
||||
@ -0,0 +1,155 @@
|
||||
What is a good free control panel for VPS
|
||||
================================================================================
|
||||
Anyone with a reasonable level of Linux skills knows that no control panel can beat the plain-old command line interface for managing a [virtual private server][1] (VPS). One can still argue that there is a place for a good server control panel though, due to the streamlined interface for getting routine administration tasks done easily with a few mouse clicks.
|
||||
|
||||
As far as control panels are concerned, even with the feature-rich commercial control panels with all the bells and whistles, there are viable free open-source alternatives which can be as powerful and versatile. Standing out among them is [Ajenti][2] server administration panel.
|
||||
|
||||
Ajenti allows you to easily configure a variety of common server programs such as Apache/nginx, Samba, BIND, Squid, MySQL, cron, firewall, and so on, making it a great time saver for administering common VPS instances. For production environments, Ajenti also offers add-ons and platform support for virtual web hosting management and custom web UI development.
|
||||
|
||||
Ajenti comes with a [dual license][3]; It is free to use (AGPLv3) for your personal servers, a company's internal hardware boxes, or educational institutions. However, if you are a hosting company or a hardware vendor, you need to purchase a commercial license to use Ajenti as part of commercial offerings.
|
||||
|
||||
### Install Ajenti on Linux ###
|
||||
|
||||
For easy of installation, Ajenti offers its own repository for major Linux distros. All it takes to install Ajenti on Linux is to configure a target repository and install it with a default package manager.
|
||||
|
||||
Upon installation, a RSA private key and certificate will be automatically generated for SSL, and Ajenti will listen on HTTPS port 8000 for secure web access. If you are using firewall, you need to allow TCP/8000 port in the firewall. For security, it is a good idea to block access to port 8000 by default, and add only selected few IP addresses to the white list.
|
||||
|
||||
#### Install Ajenti on Debian ####
|
||||
|
||||
$ wget http://repo.ajenti.org/debian/key -O- | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://repo.ajenti.org/debian main main debian" >> /etc/apt/sources.list'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install ajenti
|
||||
|
||||
#### Install Ajenti on Ubuntu ####
|
||||
|
||||
$ wget http://repo.ajenti.org/debian/key -O- | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://repo.ajenti.org/ng/debian main main ubuntu" >> /etc/apt/sources.list'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install ajenti
|
||||
|
||||
#### Install Ajenti on CentOS/RHEL or Fedora ####
|
||||
|
||||
On CentOS/RHEL, [configure][4] EPEL repository first, and then run the following. On Fedora, use the following commands directly.
|
||||
|
||||
$ wget http://repo.ajenti.org/ajenti-repo-1.0-1.noarch.rpm
|
||||
$ sudo rpm -ivh ajenti-repo-1.0-1.noarch.rpm
|
||||
$ sudo yum install ajenti
|
||||
|
||||
Next, configure the firewall.
|
||||
|
||||
On Fedora or CentOS/RHEL 7:
|
||||
|
||||
$ sudo firewall-cmd --zone=public --add-port=8000/tcp --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
$ sudo iptables -I INPUT -p tcp -m tcp --dport 8000 -j ACCEPT
|
||||
$ sudo service iptables save
|
||||
|
||||
### Access Ajenti Web Interface ###
|
||||
|
||||
Before accessing Ajenti's web interface, make sure to start ajenti service.
|
||||
|
||||
$ sudo service ajenti restart
|
||||
|
||||
Direct your web browser to https://<server-ip-address>:8000, and you will see the following Ajenti login interface.
|
||||
|
||||

|
||||
|
||||
The default login credential is "root" for username and "admin" for password. Once you log in, you will see the initial Ajengi menu.
|
||||
|
||||
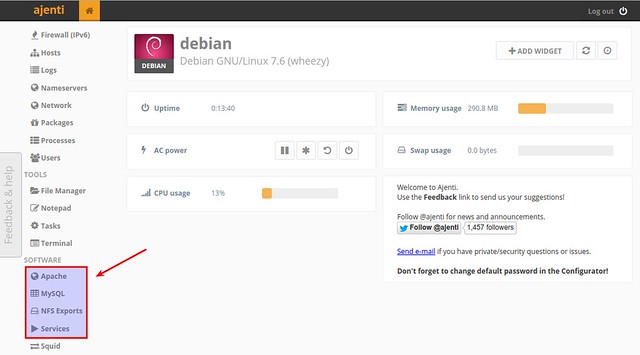
|
||||
|
||||
Under "SOFTWARE" section in the left panel, you will see a list of installed services. When you install any new server software supported by Ajenti, the software will be automatically added to the list once you restart ajenti service.
|
||||
|
||||
$ sudo service ajenti restart
|
||||
|
||||
### VPS Management via Ajenti Web Interface ###
|
||||
|
||||
Ajenti's web interface is extremely intuitive and easy to use. Here are a few examples of Ajenti functionality.
|
||||
|
||||
#### Pluggable Architecture ####
|
||||
|
||||
Ajenti comes with a number of application-specific plugins, which makes Ajenti highly extensible. When you install a new software on your VPS, a corresponding Ajenti plugin (if any) will be automatically enabled to manage the software. The "Plugins" menu will show what plugins are available/enabled, and which plugin is associated with what software.
|
||||
|
||||
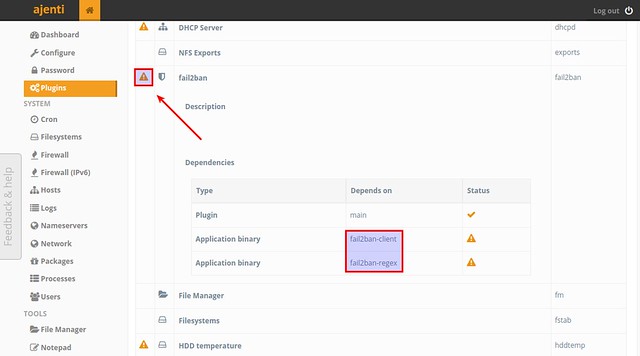
|
||||
|
||||
#### Package Management ####
|
||||
|
||||
Ajenti offers a web interface for installing and upgrading packages on VPS.
|
||||
|
||||
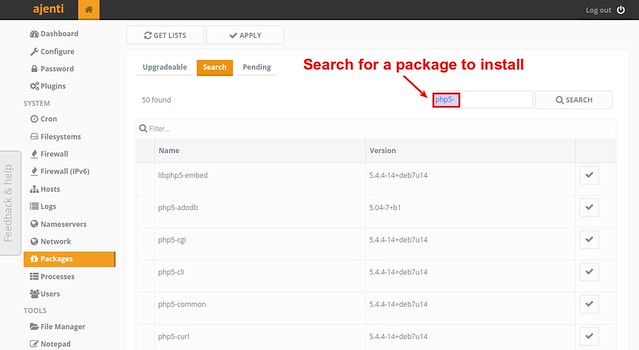
|
||||
|
||||
#### Firewall Configuration ####
|
||||
|
||||
Ajenti allows you to manage firewall rules (iptables or CSF) in two ways. One is to use a user-friendly web panel interface, and the other is to edit raw firewall rules directly.
|
||||
|
||||
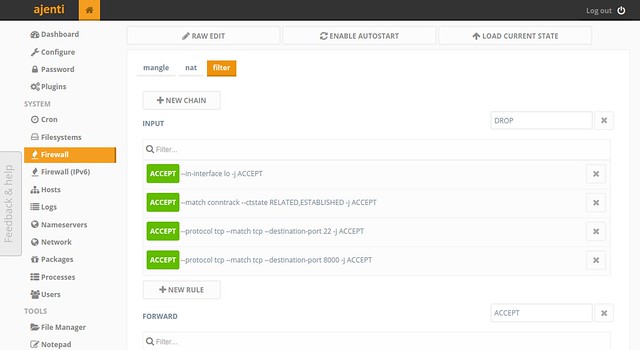
|
||||
|
||||
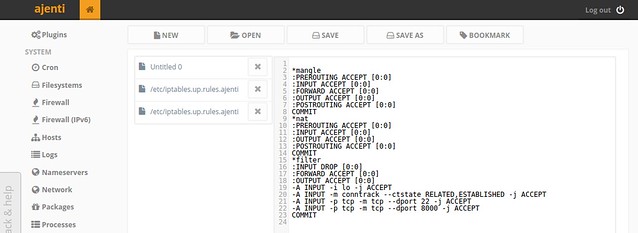
|
||||
|
||||
#### Log Inspection ####
|
||||
|
||||
You can browse system logs in /var/log via Ajenti's web interface.
|
||||
|
||||
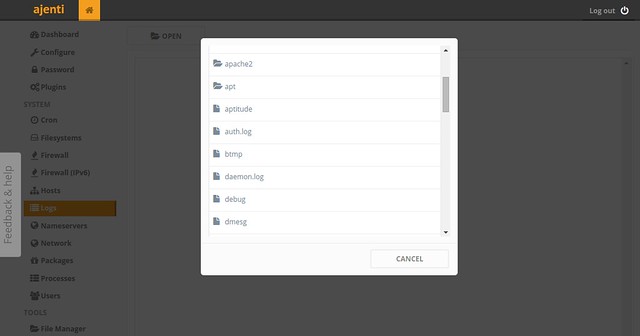
|
||||
|
||||
#### Process Monitoring ####
|
||||
|
||||
You can see a list of processes sorted by CPU or RAM usage, and can kill them as needed.
|
||||
|
||||
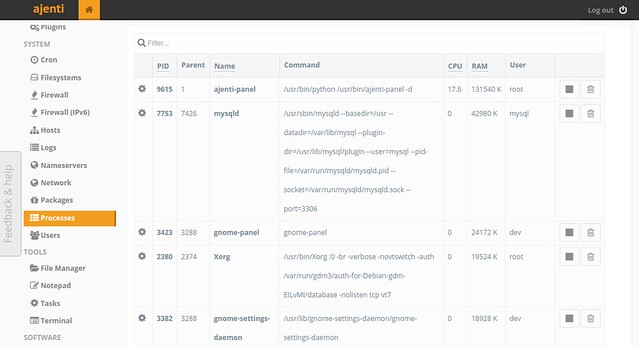
|
||||
|
||||
#### Terminal Access ####
|
||||
|
||||
For low-level VPS access, Ajenti offers a web-based terminal interface where you can type Linux commands. You can open multiple terminal tabs within a web panel as shown below.
|
||||
|
||||
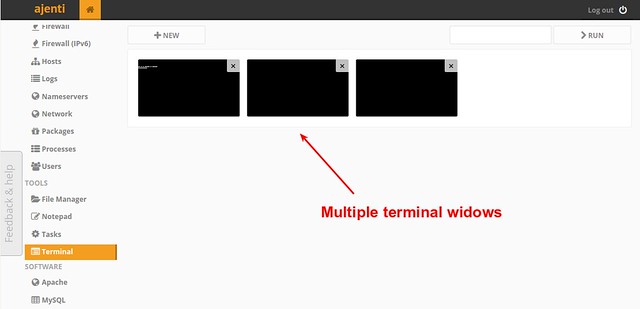
|
||||
|
||||
#### Apache Web Server Administration ####
|
||||
|
||||
You can edit Apache configuration file, and manage apache2 service.
|
||||
|
||||
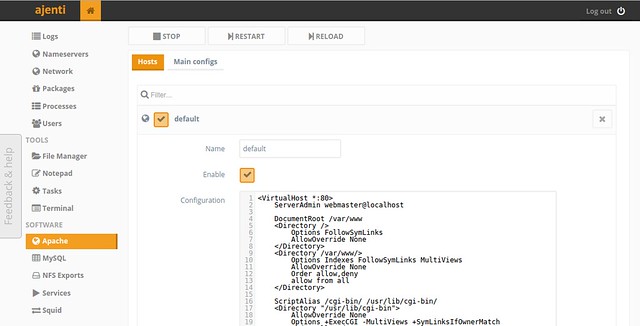
|
||||
|
||||
#### MySQL/MariaDB Management ####
|
||||
|
||||
You can access MySQL/MariaDB server and execute raw SQL commands on it.
|
||||
|
||||
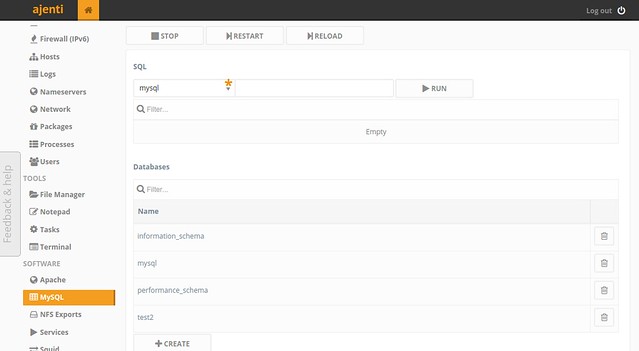
|
||||
|
||||
#### Squid Configuration ####
|
||||
|
||||
You can configure ACL, HTTP access rules, filtering ports for Squid proxy server.
|
||||
|
||||
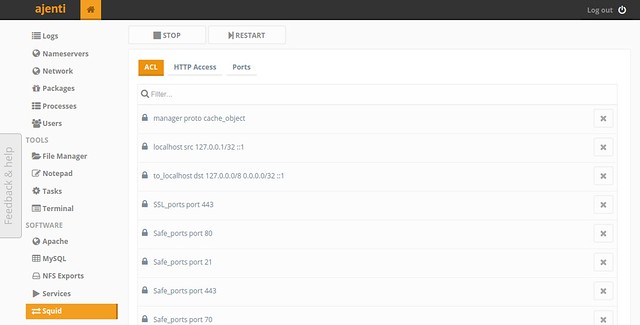
|
||||
|
||||
#### Startup Service Management ####
|
||||
|
||||
You can view, start, stop and restart installed services.
|
||||
|
||||
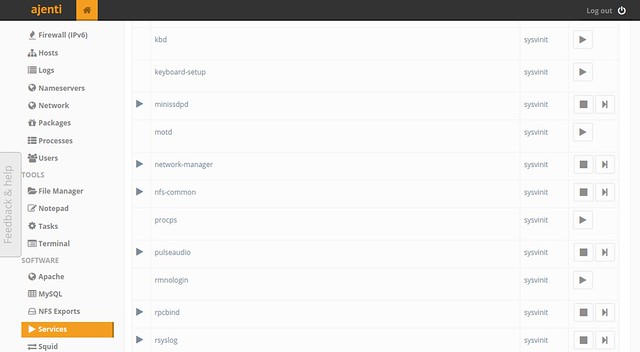
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Ajenti is a convenient and easy-to-use web control panel for common server administration, with the possibility to add [custom plugins][5] that you can develop. However, remember that any good control panel does not obviate the need for you to learn what's happening behind the scene on your [VPS][6]. A control panel will become a real time saver only when you fully understand what you are doing, and be able to handle the consequence of your action without relying on the control panel.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/free-control-panel-for-vps.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://ajenti.org/
|
||||
[3]:http://ajenti.org/licensing
|
||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://docs.ajenti.org/en/latest/dev/intro.html
|
||||
[6]:http://xmodulo.com/go/digitalocean
|
||||
@ -1,17 +1,18 @@
|
||||
Vic020
|
||||
|
||||
How To Drop Database In Oracle 11 Without Using DBCA
|
||||
如何不使用DBCA在Oracle 11中删除数据库
|
||||
================================================================================
|
||||
In this small tutorial, I want to show you how to drop the database without using the GUI tool DBCA
|
||||
本文简短的教程,将会向你展示如何不使用DBCA(数据库配置助手)在Oracle 11中删除数据
|
||||
|
||||
#### 1- Export database SID if not yet Already defined ####
|
||||
#### 1- 导入数据库的SID,如果没有定义的话 ####
|
||||
|
||||
命令:
|
||||
export ORACLE_SID=database
|
||||
|
||||
#### 2- Connect as sysdba ####
|
||||
#### 2- 以操作系统认证连接数据库 ####
|
||||
|
||||
命令:
|
||||
[oracle@Oracle11 ~]$ sqlplus / as sysdba
|
||||
|
||||
提示:
|
||||
----------
|
||||
|
||||
SQL*Plus: Release 11.2.0.1.0 Production on Mon Dec 1 17:38:02 2014
|
||||
@ -24,9 +25,11 @@ In this small tutorial, I want to show you how to drop the database without usin
|
||||
|
||||
Connected to an idle instance.
|
||||
|
||||
#### 3- Start The database ####
|
||||
#### 3- 启动数据库实例 ####
|
||||
|
||||
命令:
|
||||
SQL> startup
|
||||
提示:
|
||||
ORACLE instance started.
|
||||
Total System Global Area 3340451840 bytes
|
||||
Fixed Size 2217952 bytes
|
||||
@ -36,16 +39,20 @@ In this small tutorial, I want to show you how to drop the database without usin
|
||||
Database mounted.
|
||||
Database opened.
|
||||
|
||||
#### 4- Shutdown the database ####
|
||||
#### 4- 关闭数据库 ####
|
||||
|
||||
命令:
|
||||
SQL> shutdown immediate;
|
||||
提示:
|
||||
Database closed.
|
||||
Database dismounted.
|
||||
ORACLE instance shut down.
|
||||
|
||||
#### 5- Start in Exclusive mode ####
|
||||
#### 5- 启动独占模式 ####
|
||||
|
||||
命令:
|
||||
SQL> startup mount exclusive restrict
|
||||
提示:
|
||||
ORACLE instance started.
|
||||
|
||||
----------
|
||||
@ -57,10 +64,12 @@ In this small tutorial, I want to show you how to drop the database without usin
|
||||
Redo Buffers 16343040 bytes
|
||||
Database mounted.
|
||||
|
||||
#### 6- Drop the database ####
|
||||
#### 6- 删除数据库 ####
|
||||
|
||||
命令:
|
||||
SQL> drop database;
|
||||
|
||||
提示:
|
||||
----------
|
||||
|
||||
Database dropped.
|
||||
@ -71,14 +80,14 @@ In this small tutorial, I want to show you how to drop the database without usin
|
||||
With the Partitioning, OLAP, Data Mining and Real Application Testing options
|
||||
SQL>
|
||||
|
||||
Cheers!
|
||||
完成!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/drop-database-oracle-11-without-using-dcba/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[VicYu/Vic020](http://vicyu.net/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user