mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
c498f778dc
@ -0,0 +1,70 @@
|
|||||||
|
10 个使用 Cinnamon 作为 Linux 桌面环境的理由
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> Cinnamon 是一个让人怀旧 GNOME 2 的 Linux 桌面环境,它灵活、快速,并提供了种种的功能。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
最近我安装了 Fedora 25,我觉得当前的 [KDE][3] Plasma 版本并不稳定。在我决定尝试其它的桌面之前一天崩溃了好几次。在我安装了几个其它的桌面,并每个尝试了几个小时后,我最终决定在 Plasma 打上补丁并且稳定之前就使用 Cinnamon 了。以下是我所发现的。
|
||||||
|
|
||||||
|
### Cinnamon 简介
|
||||||
|
|
||||||
|
在 2011,带有新的 GNOME Shell 的 GNOME 3 发布了,新的界面马上引来了或正或反的反馈。许多用户以及开发者非常喜欢原先的 GNOME 界面,因此有多个组织复刻了它,其中一个结果就是 Cinnamon。
|
||||||
|
|
||||||
|
开发 GNOME 3 的 GNOME shell 背后的原因之一是许多原先的 GNOME 用户界面组件不再活跃开发了。这同样也是 Cinnamon 以及其他 GNOME 复刻项目的问题。 Linux Mint 项目是 Cinnamon 的一个首要推动者,因为 GNOME 是 Mint 的官方桌面环境。Mint 开发者已经将 Cinnamon 推进到了不需要 GNOME 本身的地步,Cinnamon 已经是一个完全独立的桌面环境,它保留了许多用户喜欢的 GNOME 界面的功能。
|
||||||
|
|
||||||
|
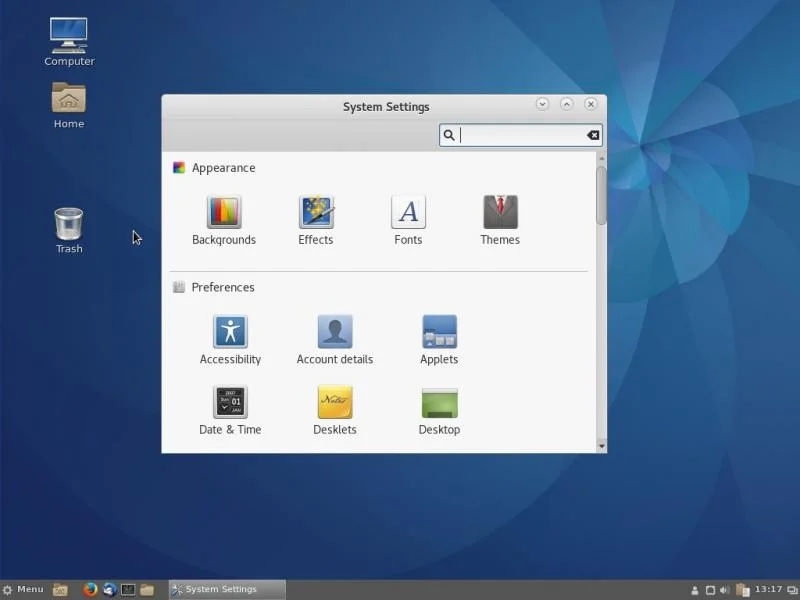
|
||||||
|
|
||||||
|
*图 1:打开系统设置工具的默认 Cinnamon 桌面。*
|
||||||
|
|
||||||
|
Cinnamon 3.2 是当前发布版本。除了 Mint,Cinnamon 还在许多发行版中可用,包括 Fedora、Arch、Gentoo、Debian 和 OpenSUSE 等。
|
||||||
|
|
||||||
|
### 使用 Cinnamon 的理由
|
||||||
|
|
||||||
|
这是我的使用 Cinnamon 的 10 个重要理由:
|
||||||
|
|
||||||
|
1. **集成。** 桌面的选择并不取决于在较长时间内是否有为它写的应用。我使用过的所有应用程序,不管它是在哪个桌面下写的,它都可以在任何其它桌面上运行正常,Cinnamon 也不例外。要运行那些为 KDE、GNOME 或其他桌面编写的程序所需要的库都有,可以在 Cinnamon 上面顺滑地使用这些程序。
|
||||||
|
2. **外观。** 让我们面对它,外观是很重要的。Cinnamon 有一个明快的、干净的外观,它使用了易于阅读的字体以及颜色的组合。桌面没有不必要的阻碍,你可以使用“系统设置” => “桌面” 菜单配置显示在桌面上的的图标。这个菜单还允许你指定是否在主监视器、次监视器或者所有监视器上显示桌面图标。
|
||||||
|
3. **桌面组件。** 桌面组件是一些小型的、可以添加到桌面的单一用途的程序。只有一些是可用的,但是你可以从 CPU 或者磁盘监视器、天气应用、便利贴、桌面相簿、时间和日期等之中选择。我喜欢时间和日期桌面组件,因为它比 Cinnamon 面板中的小程序易于阅读。
|
||||||
|
4. **速度。** Cinnamon 快速又敏捷。程序加载和显示很快。桌面自身在登录时加载也很快,虽然这只是我的主观体验,并没有基于时间测试。
|
||||||
|
5. **配置。 ** Cinnamon 不如 KDE Plasma 那样可配置,但是也要比我第一次尝试它的时候有更多的配置。Cinnamon 控制中心提供了许多桌面配置选项的集中访问。它有一个主窗口,可以从它启动特定功能的配置窗口。可以很容易地在 “系统设置” 的 “主题” 的可用外观中选择新的外观。你可以选择窗口边框、图标、控件、鼠标指针和桌面基本方案。其它选择还包括字体和背景。我发现这些配置工具中有许多是我遇到的最好的。它有适量的桌面主题,从而能够显著改变桌面的外观,而不会像 KDE 那样面临选择困难。
|
||||||
|
6. **Cinnamon 面板。** Cinnamon 面板,即工具栏,最初的配置非常简单。它包含用于启动程序的菜单、基本的系统托盘和应用程序选择器。这个面板易于配置,并且添加新的程序启动器只需要定位你想要添加到主菜单的程序,右键单击程序图标,然后选择“添加到面板”。你还可以将启动器图标添加到桌面本身,以及 Cinnamon 的 “收藏” 的启动栏中。你还可以进入面板的**编辑**模式并重新排列图标。
|
||||||
|
7. **灵活性。** 有时可能很难找到最小化或者隐藏的正在运行的程序,如果有许多正在运行的应用程序,则在工具栏的程序选择器上查找它可能会有挑战性。 在某种程度上,这是因为程序并不总是有序地排在选择器中使其易于查找,所以我最喜欢的功能之一就是可以拖动正在运行的程序的按钮并将其重新排列在选择器上。这可以使查找和显示属于程序的窗口更容易,因为现在它们现在在我放的位置上。
|
||||||
|
|
||||||
|
Cinnamon 桌面还有一个非常好的弹出菜单,你可以右键单击访问。此菜单有一些常用任务,例如访问桌面设置、添加桌面组件以及其他与桌面相关的任务。
|
||||||
|
|
||||||
|
其它菜单项之一是 “创建新文档”,它使用位于 `~/Templates` 目录中的文档模板,并列出它们中的每一个。只需点击要使用的模板,使用这个模板的文档就会使用默认的 Office 程序创建。在我的情况下,那就是 LibreOffice。
|
||||||
|
8. **多工作空间。** Cinnamon 像其他桌面环境一样提供了多个桌面。Cinnamon 称它为“工作区”。工作区选择器位于 Cinnamon 面板中并展示每个工作区的窗口概览。窗口可以在工作区之间移动或指定到所有工作区。我确实发现工作区选择器有时候会比窗口位置的显示慢一些,所以我将工作区选择器切换为显示工作区编号,而不是在工作区中显示窗口概览。
|
||||||
|
9. **Nemo。** 大部分桌面因种种目而使用它们自己偏好的默认程序,Cinnamon 也不例外。我偏好的桌面文件管理器是 Krusader,但是 Cinnamon 默认使用 Nemo,因此在测试中我就用它了。我发现我很喜欢 Nemo。它有一个美丽干净的界面,我喜欢大部分功能并经常使用。它易于使用,同时对我的需求也足够灵活。虽然 Nemo 是 Nautilus 的复刻,但是我发现 Nemo 更好地被集成进了 Cinnamon 环境。Nautilus 界面看上去没有与 Cinnamon 很好集成,与 Cinnamon 不太和谐。
|
||||||
|
10. **稳定性。** Cinnamon 非常稳定且可用。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
Cinnamon 是 GNOME 3 桌面的复刻,它看上去像一个前所未有的 GNOME 桌面。它的发展看起来是符合逻辑的改进, Cinnamon 开发者认为需要在提升和扩展 GNOME 的同时保留它的独特性以及被大家非常喜欢的特性。它不再是 GNOME 3 - 它是不同的并且是更好的。Cinnamon 看上去很棒,并且对我而言也工作得很好,并且从 KDE 这个我仍旧非常喜欢的环境切换过来也很顺畅。我花费了几天时间学习 Cinnamon 的差异如何使我的桌面体验更好,并且我非常高兴了解这个很棒的桌面。
|
||||||
|
|
||||||
|
虽然我喜欢 Cinnamon,但我仍然喜欢体验其它的环境,我目前正切换到 LXDE 桌面,并已经用了几个星期。在我使用一段时间时候,我会分享我的 LXDE 体验。
|
||||||
|
|
||||||
|
(题图: [Sam Mugraby][1],Photos8.com. [CC BY 2.0][2])
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
David Both 是一个 Linux 和开源倡导者,他居住在北卡罗莱纳州的 Raleigh。他在 IT 行业已经超过 40 年,在他工作的 IBM 公司教授 OS/2 超过 20 年,他在 1981 年为最早的 IBM PC 写了第一个培训课程。他教过 Red Hat 的 RHCE 课程,在 MCI Worldcom、 Cisco 和北卡罗莱纳州 工作过。他一直在使用 Linux 和开源软件近 20 年。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/1/cinnamon-desktop-environment
|
||||||
|
|
||||||
|
作者:[David Both][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/dboth
|
||||||
|
[1]:https://commons.wikimedia.org/wiki/File:Cinnamon-other.jpg
|
||||||
|
[2]:https://creativecommons.org/licenses/by/2.0/deed.en
|
||||||
|
[3]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||||
@ -0,0 +1,401 @@
|
|||||||
|
许多 SQL 性能问题来自于“不必要的强制性工作”
|
||||||
|
=====================================
|
||||||
|
|
||||||
|
在编写高效 SQL 时,你可能遇到的最有影响的事情就是[索引][1]。但是,一个很重要的事实就是很多 SQL 客户端要求数据库做很多**“不必要的强制性工作”**。
|
||||||
|
|
||||||
|
跟我再重复一遍:
|
||||||
|
|
||||||
|
> 不必要的强制性工作
|
||||||
|
|
||||||
|
什么是**“不必要的强制性工作”**?这个意思包括两个方面:
|
||||||
|
|
||||||
|
### 不必要的
|
||||||
|
|
||||||
|
假设你的客户端应用程序需要这些信息:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][2]
|
||||||
|
|
||||||
|
这没什么特别的。我们运行着一个电影数据库([例如 Sakila 数据库][3]),我们想要给用户显示每部电影的名称和评分。
|
||||||
|
|
||||||
|
这是能产生上面结果的查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT title, rating
|
||||||
|
FROM film
|
||||||
|
```
|
||||||
|
|
||||||
|
然而,我们的应用程序(或者我们的 ORM(LCTT 译注:Object-Relational Mapping,对象关系映射))运行的查询却是:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT *
|
||||||
|
FROM film
|
||||||
|
```
|
||||||
|
|
||||||
|
我们得到什么?猜一下。我们得到很多无用的信息:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
甚至一些复杂的 JSON 数据全程在下列环节中加载:
|
||||||
|
|
||||||
|
* 从磁盘
|
||||||
|
* 加载到缓存
|
||||||
|
* 通过总线
|
||||||
|
* 进入客户端内存
|
||||||
|
* 然后被丢弃
|
||||||
|
|
||||||
|
是的,我们丢弃了其中大部分的信息。检索它所做的工作完全就是不必要的。对吧?没错。
|
||||||
|
|
||||||
|
### 强制性
|
||||||
|
|
||||||
|
这是最糟糕的部分。现今随着优化器变得越来越聪明,这些工作对于数据库来说都是强制执行的。数据库没有办法_知道_客户端应用程序实际上不需要其中 95% 的数据。这只是一个简单的例子。想象一下如果我们连接更多的表...
|
||||||
|
|
||||||
|
你想想那会怎样呢?数据库还快吗?让我们来看看一些之前你可能没有想到的地方:
|
||||||
|
|
||||||
|
### 内存消耗
|
||||||
|
|
||||||
|
当然,单次执行时间不会变化很大。可能是慢 1.5 倍,但我们可以忍受,是吧?为方便起见,有时候确实如此。但是如果你_每次_都为了方便而牺牲性能,这事情就大了。我们不说性能问题(单个查询的速度),而是关注在吞吐量上时(系统响应时间),事情就变得困难而难以解决。你就会受阻于规模的扩大。
|
||||||
|
|
||||||
|
让我们来看看执行计划,这是 Oracle 的:
|
||||||
|
|
||||||
|
```
|
||||||
|
--------------------------------------------------
|
||||||
|
| Id | Operation | Name | Rows | Bytes |
|
||||||
|
--------------------------------------------------
|
||||||
|
| 0 | SELECT STATEMENT | | 1000 | 166K|
|
||||||
|
| 1 | TABLE ACCESS FULL| FILM | 1000 | 166K|
|
||||||
|
--------------------------------------------------
|
||||||
|
```
|
||||||
|
|
||||||
|
对比一下:
|
||||||
|
|
||||||
|
```
|
||||||
|
--------------------------------------------------
|
||||||
|
| Id | Operation | Name | Rows | Bytes |
|
||||||
|
--------------------------------------------------
|
||||||
|
| 0 | SELECT STATEMENT | | 1000 | 20000 |
|
||||||
|
| 1 | TABLE ACCESS FULL| FILM | 1000 | 20000 |
|
||||||
|
--------------------------------------------------
|
||||||
|
```
|
||||||
|
|
||||||
|
当执行 `SELECT *` 而不是 `SELECT film, rating` 的时候,我们在数据库中使用了 8 倍之多的内存。这并不奇怪,对吧?我们早就知道了。在很多我们并不需要其中全部数据的查询中我们都是这样做的。我们为数据库产生了**不必要的强制性工作**,其后果累加了起来,就是我们使用了多达 8 倍的内存(当然,数值可能有些不同)。
|
||||||
|
|
||||||
|
而现在,所有其它的步骤(比如,磁盘 I/O、总线传输、客户端内存消耗)也受到相同的影响,我这里就跳过了。另外,我还想看看...
|
||||||
|
|
||||||
|
### 索引使用
|
||||||
|
|
||||||
|
如今大部分数据库都有[涵盖索引][5](LCTT 译注:covering index,包括了你查询所需列、甚至更多列的索引,可以直接从索引中获取所有需要的数据,而无需访问物理表)的概念。涵盖索引并不是特殊的索引。但对于一个特定的查询,它可以“意外地”或人为地转变为一个“特殊索引”。
|
||||||
|
|
||||||
|
看看这个查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT *
|
||||||
|
FROM actor
|
||||||
|
WHERE last_name LIKE 'A%'
|
||||||
|
```
|
||||||
|
|
||||||
|
执行计划中没有什么特别之处。它只是个简单的查询。索引范围扫描、表访问,就结束了:
|
||||||
|
|
||||||
|
```
|
||||||
|
-------------------------------------------------------------------
|
||||||
|
| Id | Operation | Name | Rows |
|
||||||
|
-------------------------------------------------------------------
|
||||||
|
| 0 | SELECT STATEMENT | | 8 |
|
||||||
|
| 1 | TABLE ACCESS BY INDEX ROWID| ACTOR | 8 |
|
||||||
|
|* 2 | INDEX RANGE SCAN | IDX_ACTOR_LAST_NAME | 8 |
|
||||||
|
-------------------------------------------------------------------
|
||||||
|
```
|
||||||
|
|
||||||
|
这是个好计划吗?如果我们只是想要这些,那么它就不是:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][6]
|
||||||
|
|
||||||
|
当然,我们浪费了内存之类的。再来看看这个查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT first_name, last_name
|
||||||
|
FROM actor
|
||||||
|
WHERE last_name LIKE 'A%'
|
||||||
|
```
|
||||||
|
|
||||||
|
它的计划是:
|
||||||
|
|
||||||
|
```
|
||||||
|
----------------------------------------------------
|
||||||
|
| Id | Operation | Name | Rows |
|
||||||
|
----------------------------------------------------
|
||||||
|
| 0 | SELECT STATEMENT | | 8 |
|
||||||
|
|* 1 | INDEX RANGE SCAN| IDX_ACTOR_NAMES | 8 |
|
||||||
|
----------------------------------------------------
|
||||||
|
```
|
||||||
|
|
||||||
|
现在我们可以完全消除表访问,因为有一个索引涵盖了我们查询需要的所有东西……一个涵盖索引。这很重要吗?当然!这种方法可以将你的某些查询加速一个数量级(如果在某个更改后你的索引不再涵盖,可能会降低一个数量级)。
|
||||||
|
|
||||||
|
你不能总是从涵盖索引中获利。索引也有它们自己的成本,你不应该添加太多索引,例如像这种情况就是不明智的。让我们来做个测试:
|
||||||
|
|
||||||
|
```
|
||||||
|
SET SERVEROUTPUT ON
|
||||||
|
DECLARE
|
||||||
|
v_ts TIMESTAMP;
|
||||||
|
v_repeat CONSTANT NUMBER := 100000;
|
||||||
|
BEGIN
|
||||||
|
v_ts := SYSTIMESTAMP;
|
||||||
|
|
||||||
|
FOR i IN 1..v_repeat LOOP
|
||||||
|
FOR rec IN (
|
||||||
|
-- Worst query: Memory overhead AND table access
|
||||||
|
SELECT *
|
||||||
|
FROM actor
|
||||||
|
WHERE last_name LIKE 'A%'
|
||||||
|
) LOOP
|
||||||
|
NULL;
|
||||||
|
END LOOP;
|
||||||
|
END LOOP;
|
||||||
|
|
||||||
|
dbms_output.put_line('Statement 1 : ' || (SYSTIMESTAMP - v_ts));
|
||||||
|
v_ts := SYSTIMESTAMP;
|
||||||
|
|
||||||
|
FOR i IN 1..v_repeat LOOP
|
||||||
|
FOR rec IN (
|
||||||
|
-- Better query: Still table access
|
||||||
|
SELECT /*+INDEX(actor(last_name))*/
|
||||||
|
first_name, last_name
|
||||||
|
FROM actor
|
||||||
|
WHERE last_name LIKE 'A%'
|
||||||
|
) LOOP
|
||||||
|
NULL;
|
||||||
|
END LOOP;
|
||||||
|
END LOOP;
|
||||||
|
|
||||||
|
dbms_output.put_line('Statement 2 : ' || (SYSTIMESTAMP - v_ts));
|
||||||
|
v_ts := SYSTIMESTAMP;
|
||||||
|
|
||||||
|
FOR i IN 1..v_repeat LOOP
|
||||||
|
FOR rec IN (
|
||||||
|
-- Best query: Covering index
|
||||||
|
SELECT /*+INDEX(actor(last_name, first_name))*/
|
||||||
|
first_name, last_name
|
||||||
|
FROM actor
|
||||||
|
WHERE last_name LIKE 'A%'
|
||||||
|
) LOOP
|
||||||
|
NULL;
|
||||||
|
END LOOP;
|
||||||
|
END LOOP;
|
||||||
|
|
||||||
|
dbms_output.put_line('Statement 3 : ' || (SYSTIMESTAMP - v_ts));
|
||||||
|
END;
|
||||||
|
/
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
结果是:
|
||||||
|
|
||||||
|
```
|
||||||
|
Statement 1 : +000000000 00:00:02.479000000
|
||||||
|
Statement 2 : +000000000 00:00:02.261000000
|
||||||
|
Statement 3 : +000000000 00:00:01.857000000
|
||||||
|
```
|
||||||
|
|
||||||
|
注意,表 actor 只有 4 列,因此语句 1 和 2 的差别并不是太令人印象深刻,但仍然很重要。还要注意我使用了 Oracle 的提示来强制优化器为查询选择一个或其它索引。在这种情况下语句 3 明显胜利。这是一个好_很多_的查询,也是一个十分简单的查询。
|
||||||
|
|
||||||
|
当我们写 `SELECT *` 语句时,我们为数据库带来了**不必要的强制性工作**,这是无法优化的。它不会使用涵盖索引,因为比起它所使用的 `LAST_NAME` 索引,涵盖索引开销更多一点,不管怎样,它都要访问表以获取无用的 `LAST_UPDATE` 列。
|
||||||
|
|
||||||
|
使用 `SELECT *` 会变得更糟。考虑一下……
|
||||||
|
|
||||||
|
### SQL 转换
|
||||||
|
|
||||||
|
优化器工作的很好,因为它们转换了你的 SQL 查询([看我最近在 Voxxed Days Zurich 关于这方面的演讲][7])。例如,其中有一个称为“表连接消除”的转换,它真的很强大。看看这个辅助视图,我们写了这个视图是因为我们非常讨厌总是连接所有这些表:
|
||||||
|
|
||||||
|
```
|
||||||
|
CREATE VIEW v_customer AS
|
||||||
|
SELECT
|
||||||
|
c.first_name, c.last_name,
|
||||||
|
a.address, ci.city, co.country
|
||||||
|
FROM customer c
|
||||||
|
JOIN address a USING (address_id)
|
||||||
|
JOIN city ci USING (city_id)
|
||||||
|
JOIN country co USING (country_id)
|
||||||
|
```
|
||||||
|
|
||||||
|
这个视图仅仅是把 `CUSTOMER` 和他们不同的 `ADDRESS` 部分所有“对一”关系连接起来。谢天谢地,它很工整。
|
||||||
|
|
||||||
|
现在,使用这个视图一段时间之后,想象我们非常习惯这个视图,我们都忘了所有它底层的表。然后,我们运行了这个查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT *
|
||||||
|
FROM v_customer
|
||||||
|
```
|
||||||
|
|
||||||
|
我们得到了一个相当令人印象深刻的计划:
|
||||||
|
|
||||||
|
```
|
||||||
|
----------------------------------------------------------------
|
||||||
|
| Id | Operation | Name | Rows | Bytes | Cost |
|
||||||
|
----------------------------------------------------------------
|
||||||
|
| 0 | SELECT STATEMENT | | 599 | 47920 | 14 |
|
||||||
|
|* 1 | HASH JOIN | | 599 | 47920 | 14 |
|
||||||
|
| 2 | TABLE ACCESS FULL | COUNTRY | 109 | 1526 | 2 |
|
||||||
|
|* 3 | HASH JOIN | | 599 | 39534 | 11 |
|
||||||
|
| 4 | TABLE ACCESS FULL | CITY | 600 | 10800 | 3 |
|
||||||
|
|* 5 | HASH JOIN | | 599 | 28752 | 8 |
|
||||||
|
| 6 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
|
||||||
|
| 7 | TABLE ACCESS FULL| ADDRESS | 603 | 17487 | 3 |
|
||||||
|
----------------------------------------------------------------
|
||||||
|
```
|
||||||
|
|
||||||
|
当然是这样。我们运行了所有这些表连接以及全表扫描,因为这就是我们让数据库去做的:获取所有的数据。
|
||||||
|
|
||||||
|
现在,再一次想一下,对于一个特定场景,我们真正想要的是:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][8]
|
||||||
|
|
||||||
|
是啊,对吧?现在你应该知道我的意图了。但想像一下,我们确实从前面的错误中学到了东西,现在我们实际上运行下面一个比较好的查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT first_name, last_name
|
||||||
|
FROM v_customer
|
||||||
|
```
|
||||||
|
|
||||||
|
再来看看结果!
|
||||||
|
|
||||||
|
```
|
||||||
|
------------------------------------------------------------------
|
||||||
|
| Id | Operation | Name | Rows | Bytes | Cost |
|
||||||
|
------------------------------------------------------------------
|
||||||
|
| 0 | SELECT STATEMENT | | 599 | 16173 | 4 |
|
||||||
|
| 1 | NESTED LOOPS | | 599 | 16173 | 4 |
|
||||||
|
| 2 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
|
||||||
|
|* 3 | INDEX UNIQUE SCAN| SYS_C007120 | 1 | 8 | 0 |
|
||||||
|
------------------------------------------------------------------
|
||||||
|
```
|
||||||
|
|
||||||
|
这是执行计划一个_极大的_进步。我们的表连接被消除了,因为优化器可以证明它们是**不必要的**,因此一旦它可以证明这点(而且你不会因使用 `select *` 而使其成为**强制性**工作),它就可以移除这些工作并不执行它。为什么会发生这种情况?
|
||||||
|
|
||||||
|
每个 `CUSTOMER.ADDRESS_ID` 外键保证了_有且只有一个_ `ADDRESS.ADDRESS_ID` 主键值,因此可以保证 `JOIN` 操作是对一连接,它不会产生或者删除行。如果我们甚至不选择行或查询行,当然我们就不需要真正地去加载行。可以证实地移除 `JOIN` 并不会改变查询的结果。
|
||||||
|
|
||||||
|
数据库总是会做这些事情。你可以在大部分数据库上尝试它:
|
||||||
|
|
||||||
|
```
|
||||||
|
-- Oracle
|
||||||
|
SELECT CASE WHEN EXISTS (
|
||||||
|
SELECT 1 / 0 FROM dual
|
||||||
|
) THEN 1 ELSE 0 END
|
||||||
|
FROM dual
|
||||||
|
|
||||||
|
-- 更合理的 SQL 语句,例如 PostgreSQL
|
||||||
|
SELECT EXISTS (SELECT 1 / 0)
|
||||||
|
```
|
||||||
|
|
||||||
|
在这种情况下,当你运行这个查询时你可能预料到会抛出算术异常:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT 1 / 0 FROM dual
|
||||||
|
```
|
||||||
|
|
||||||
|
产生了:
|
||||||
|
|
||||||
|
```
|
||||||
|
ORA-01476: divisor is equal to zero
|
||||||
|
```
|
||||||
|
|
||||||
|
但它并没有发生。优化器(甚至解析器)可以证明 `EXISTS (SELECT ..)` 谓词内的任何 `SELECT` 列表达式不会改变查询的结果,因此也就没有必要计算它的值。呵!
|
||||||
|
|
||||||
|
### 同时……
|
||||||
|
|
||||||
|
大部分 ORM 最不幸问题就是事实上他们很随意就写出了 `SELECT *` 查询。事实上,例如 HQL / JPQL,就设置默认使用它。你甚至可以完全抛弃 `SELECT` 从句,因为毕竟你想要获取所有实体,正如声明的那样,对吧?
|
||||||
|
|
||||||
|
例如:
|
||||||
|
|
||||||
|
`FROM` `v_customer`
|
||||||
|
|
||||||
|
例如 [Vlad Mihalcea][9](一个 Hibernate 专家和 Hibernate 开发倡导者)建议你每次确定不想要在获取后进行任何更改时再使用查询。ORM 使解决对象图持久化问题变得简单。注意:持久化。真正修改对象图并持久化修改的想法是固有的。
|
||||||
|
|
||||||
|
但如果你不想那样做,为什么要抓取实体呢?为什么不写一个查询?让我们清楚一点:从性能角度,针对你正在解决的用例写一个查询_总是_会胜过其它选项。你可以不会在意,因为你的数据集很小,没关系。可以。但最终,你需要扩展并重新设计你的应用程序以便在强制实体图遍历之上支持查询语言,就会变得很困难。你也需要做其它事情。
|
||||||
|
|
||||||
|
### 计算出现次数
|
||||||
|
|
||||||
|
资源浪费最严重的情况是在只是想要检验存在性时运行 `COUNT(*)` 查询。例如:
|
||||||
|
|
||||||
|
> 这个用户有没有订单?
|
||||||
|
|
||||||
|
我们会运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT count(*)
|
||||||
|
FROM orders
|
||||||
|
WHERE user_id = :user_id
|
||||||
|
```
|
||||||
|
|
||||||
|
很简单。如果 `COUNT = 0`:没有订单。否则:是的,有订单。
|
||||||
|
|
||||||
|
性能可能不会很差,因为我们可能有一个 `ORDERS.USER_ID` 列上的索引。但是和下面的这个相比你认为上面的性能是怎样呢:
|
||||||
|
|
||||||
|
```
|
||||||
|
-- Oracle
|
||||||
|
SELECT CASE WHEN EXISTS (
|
||||||
|
SELECT *
|
||||||
|
FROM orders
|
||||||
|
WHERE user_id = :user_id
|
||||||
|
) THEN 1 ELSE 0 END
|
||||||
|
FROM dual
|
||||||
|
|
||||||
|
-- 更合理的 SQL 语句,例如 PostgreSQL
|
||||||
|
SELECT EXISTS (
|
||||||
|
SELECT *
|
||||||
|
FROM orders
|
||||||
|
WHERE user_id = :user_id
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
它不需要火箭科学家来确定,一旦它找到一个,实际存在谓词就可以马上停止寻找额外的行。因此,如果答案是“没有订单”,速度将会是差不多。但如果结果是“是的,有订单”,那么结果在我们不计算具体次数的情况下就会_大幅_加快。
|
||||||
|
|
||||||
|
因为我们_不在乎_具体的次数。我们告诉数据库去计算它(**不必要的**),而数据库也不知道我们会丢弃所有大于 1 的结果(**强制性**)。
|
||||||
|
|
||||||
|
当然,如果你在 JPA 支持的集合上调用 `list.size()` 做同样的事情,情况会变得更糟!
|
||||||
|
|
||||||
|
[近期我有关于该情况的博客以及在不同数据库上的测试。去看看吧。][10]
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
这篇文章的立场很“明显”。别让数据库做**不必要的强制性工作**。
|
||||||
|
|
||||||
|
它**不必要**,因为对于你给定的需求,你_知道_一些特定的工作不需要完成。但是,你告诉数据库去做。
|
||||||
|
|
||||||
|
它**强制性**,因为数据库无法证明它是**不必要的**。这些信息只包含在客户端中,对于服务器来说无法访问。因此,数据库需要去做。
|
||||||
|
|
||||||
|
这篇文章大部分在介绍 `SELECT *`,因为这是一个很简单的目标。但是这并不仅限于数据库。这关系到客户端要求服务器完成**不必要的强制性工作**的任何分布式算法。你的 AngularJS 应用程序平均有多少个 N+1 问题,UI 在服务结果 A 上循环,多次调用服务 B,而不是把所有对 B 的调用打包为一个调用?这是一个复发的模式。
|
||||||
|
|
||||||
|
解决方法总是相同。你给执行你命令的实体越多信息,(理论上)它能更快执行这样的命令。每次都写一个好的查询。你的整个系统都会为此感谢你的。
|
||||||
|
|
||||||
|
### 如果你喜欢这篇文章...
|
||||||
|
|
||||||
|
再看看近期我在 Voxxed Days Zurich 的演讲,其中我展示了一些在数据处理算法上为什么 SQL 总是会胜过 Java 的双曲线例子
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://blog.jooq.org/2017/03/08/many-sql-performance-problems-stem-from-unnecessary-mandatory-work
|
||||||
|
|
||||||
|
作者:[jooq][a]
|
||||||
|
译者:[ictlyh](https://github.com/ictlyh)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://blog.jooq.org/
|
||||||
|
[1]:http://use-the-index-luke.com/
|
||||||
|
[2]:https://lukaseder.files.wordpress.com/2017/03/title-rating.png
|
||||||
|
[3]:https://github.com/jOOQ/jOOQ/tree/master/jOOQ-examples/Sakila
|
||||||
|
[4]:https://lukaseder.files.wordpress.com/2017/03/useless-information.png
|
||||||
|
[5]:https://blog.jooq.org/2015/04/28/do-not-think-that-one-second-is-fast-for-query-execution/
|
||||||
|
[6]:https://lukaseder.files.wordpress.com/2017/03/first-name-last-name.png
|
||||||
|
[7]:https://www.youtube.com/watch?v=wTPGW1PNy_Y
|
||||||
|
[8]:https://lukaseder.files.wordpress.com/2017/03/first-name-last-name-customers.png
|
||||||
|
[9]:https://vladmihalcea.com/2016/09/13/the-best-way-to-handle-the-lazyinitializationexception/
|
||||||
|
[10]:https://blog.jooq.org/2016/09/14/avoid-using-count-in-sql-when-you-could-use-exists/
|
||||||
@ -0,0 +1,141 @@
|
|||||||
|
Linux GRUB2 配置简介
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 学习 GRUB 引导加载程序是如何预备你的系统并启动操作系统内核的。
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
自从上个月为我的文章《[Linux 引导和启动过程简介][2]》做研究开始,我对更深入了解 GRUB2 产生了兴趣。这篇文章提供了配置 GRUB2 的简要介绍。为了简便起见,我大多数情况下会使用 GRUB 指代 GRUB2。
|
||||||
|
|
||||||
|
### GRUB
|
||||||
|
|
||||||
|
GRUB 来自 GRand Unified Bootloader 的缩写。它的功能是在启动时从 BIOS 接管掌控、加载自身、加载 Linux 内核到内存,然后再把执行权交给内核。一旦内核开始掌控,GRUB 就完成了它的任务,也就不再需要了。
|
||||||
|
|
||||||
|
GRUB 支持多种 Linux 内核,并允许用户在启动时通过菜单在其中选择。我发现这是一种非常有用的工具,因为我有很多次遇到一个应用程序或者系统服务在特定内核版本下失败的问题。有好几次,引导到一个较旧的内核时就可以避免类似的问题。默认情况下,使用 `yum` 或 `dnf` 进行更新时会保存三个内核 - 最新的以及两个比较旧的。在被包管理器删除之前所保留的内核数目可以在 `/etc/dnf/dnf.conf` 或 `/etc/yum.conf` 文件中配置。我通常把 `installonly_limit` 的值修改为 9 以便保留 9 个内核。当我不得不恢复到低几个版本的内核时这非常有用。
|
||||||
|
|
||||||
|
### GRUB 菜单
|
||||||
|
|
||||||
|
GRUB 菜单的功能是当默认的内核不是想要的时,允许用户从已经安装的内核中选择一个进行引导。通过上下箭头键允许你选中想要的内核,敲击回车键会使用选中的内核继续引导进程。
|
||||||
|
|
||||||
|
GRUB 菜单也提供了超时机制,因此如果用户没有做任何选择,GRUB 就会在没有用户干预的情况下使用默认内核继续引导。敲击键盘上除了回车键之外的任何键会停止终端上显示的倒数计时器。立即敲击回车键会使用默认内核或者选中的内核继续引导进程。
|
||||||
|
|
||||||
|
GRUB 菜单提供了一个 “<ruby>救援<rt>rescue</rt></ruby>” 内核,用于故障排除或者由于某些原因导致的常规内核不能完成启动过程。不幸的是,这个救援内核不会引导到救援模式。文章后面会更详细介绍这方面的东西。
|
||||||
|
|
||||||
|
### grub.cfg 文件
|
||||||
|
|
||||||
|
`grub.cfg` 文件是 GRUB 配置文件。它由 `grub2-mkconfig` 程序根据用户的配置使用一组主配置文件以及 grub 默认文件而生成。`/boot/grub2/grub.cfg` 文件在 Linux 安装时会初次生成,安装新内核时又会重新生成。
|
||||||
|
|
||||||
|
`grub.cfg` 文件包括了类似 Bash 脚本的代码以及一个按照安装顺序排序的已安装内核列表。例如,如果你有 4 个已安装内核,最新的内核索引是 0,前一个内核索引是 1,最旧的内核索引是 3。如果你能访问 `grub.cfg` 文件,你应该去看看感受一下它看起来是什么样。`grub.cfg` 太大也就没有包含在这篇文章中。
|
||||||
|
|
||||||
|
### GRUB 配置文件
|
||||||
|
|
||||||
|
`grub.cfg` 的主要配置文件都在 `/etc/grub.d` 目录。该目录中的每个文件都包含了最终会整合到 `grub.cfg` 文件中的 GRUB 代码。这些配置文件的命名模式以排序方式设计,这使得最终的 `grub.cfg` 文件可以按正确的顺序整合而成。每个文件都有注释表明该部分的开始和结束,这些注释也是最终的 `grub.cfg` 文件的一部分,从而可以看出每个部分是由哪个文件生成。分隔注释看起来像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
### BEGIN /etc/grub.d/10_linux ###
|
||||||
|
|
||||||
|
### END /etc/grub.d/10_linux ###
|
||||||
|
```
|
||||||
|
|
||||||
|
不要修改这些文件,除非你是一个 GRUB 专家并明白更改会发生什么。无论如何,修改 `grub.cfg` 文件时你也总应该保留一个原始文件的备份。 `40_custom` 和 `41_custom` 这两个特别的文件用于生成用户对 GRUB 配置的修改。你仍然要注意对这些文件的更改的后果,并保存一份原始 `grub.cfg` 文件的备份。
|
||||||
|
|
||||||
|
你也可以把你自己的文件添加到 `/etc/grub.d` 目录。这样做的一个可能的原因是为非 Linux 操作系统添加菜单行。要注意遵循命名规则,确保配置文件中额外的菜单选项刚好在 `10_linux` 条目之前或之后。
|
||||||
|
|
||||||
|
### GRUB 默认文件
|
||||||
|
|
||||||
|
老版本 GRUB 的配置非常简单而明了,我只需要修改 `/boot/grub/grub.conf` 就可以了。对于新版本的 GRUB2,我虽然还可以通过更改 `/boot/grub2/grub.cfg` 来修改,但和老版本的 GRUB 相比,新版本相对更加复杂。另外,安装一个新内核时 `grub.cfg` 可能会被重写,因此任何修改都可能消失。当然,GNU.org 的 GRUB 手册确实有过直接创建和修改 `/boot/grub2/grub.cfg` 的讨论。
|
||||||
|
|
||||||
|
一旦你明白了如何做,更改 GRUB2 配置就会变得非常简单。我为之前的文章研究 GRUB2 的时候才明白这个。秘方就在 `/etc/default` 目录里面,一个自然而然称为 `grub` 的文件,它可以通过简单的终端命令操作。`/etc/default` 目录包括了一些类似 Google Chrome、 useradd、 和 grub 程序的配置文件。
|
||||||
|
|
||||||
|
`/etc/default/grub` 文件非常简单。这个 `grub` 默认文件已经列出了一些有效的键值对。你可以简单地更改现有键值或者添加其它文件中还没有的键。下面的列表 1 显示了一个没有更改过的 `/etc/default/grub` 文件。
|
||||||
|
|
||||||
|
```
|
||||||
|
GRUB_TIMEOUT=5
|
||||||
|
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g'
|
||||||
|
/etc/system-release)"
|
||||||
|
GRUB_DEFAULT=saved
|
||||||
|
GRUB_DISABLE_SUBMENU=true
|
||||||
|
GRUB_TERMINAL_OUTPUT="console"
|
||||||
|
GRUB_CMDLINE_LINUX="rd.lvm.lv=fedora_fedora25vm/root
|
||||||
|
rd.lvm.lv=fedora_fedora25vm/swap
|
||||||
|
rd.lvm.lv=fedora_fedora25vm/usr rhgb quiet"
|
||||||
|
GRUB_DISABLE_RECOVERY="true"
|
||||||
|
```
|
||||||
|
|
||||||
|
_列表 1:Fedora 25 一个原始 grub 默认文件。_
|
||||||
|
|
||||||
|
[GRUB 手册 5.1 章节][7]包括了所有可以添加到该 `grub` 文件的键的信息。我只需要修改 `grub` 默认文件已经有的一些键值就够了。让我们看看这些键值以及一些在 grub 默认文件中没有出现的每个键的意义。
|
||||||
|
|
||||||
|
* `GRUB_TIMEOUT` 这个键的值决定了显示 GRUB 选择菜单的时间长度。GRUB 提供了同时保存多个安装内核并在启动时使用 GRUB 菜单在其中选择的功能。这个键的默认值是 5 秒,但我通常修改为 10 秒使得有更多时间查看选项并作出选择。
|
||||||
|
* `GRUB_DISTRIBUTOR` 这个键定义了一个从 `/etc/system-release` 文件中提取发行版本的 [sed][3] 表达式。这个信息用于生成出现在 GRUB 菜单中的每个内核发布版的文本名称,例如 “Fedora” 等。由于不同发行版之间 `system-release` 文件结构的差异,在你的系统中这个 sed 表达式可能有些不同。
|
||||||
|
* `GRUB_DEFAULT` 决定默认引导哪个内核。如果是 `saved`,这代表最新内核。这里的其它选项如果是数字则代表了 `grub.cfg` 中列表的索引。使用索引号 3,就会总是加载列表中的第四个内核,即使安装了一个新内核之后也是。因此使用索引数字的话,在安装一个新内核后会加载不同的内核。要确保引导特定内核版本的唯一方法是设置 `GRUB_DEFAULT` 的值为想要内核的名称,例如 `4.8.13-300.fc25.x86_64`。
|
||||||
|
* `GRUB_SAVEDEFAULT` 通常,grub 默认文件中不会指定这个选项。当选择不同内核进行引导时,正常操作下该内核只会启动一次。默认内核不会改变。当其设置为 `true` 并和 `GRUB_DEFAULT=saved` 一起使用时,这个选项会保存一个不同内核作为默认值。当选择不同内核进行引导时会发生这种情况。
|
||||||
|
* `GRUB_DISABLE_SUBMENU` 一些人可能会希望为 GRUB 菜单创建一个内核的层级菜单结构。这个键和 `grub.cfg` 中一些额外内核配置允许创建这样的层级结构。例如,主菜单中可能有 `production` 和 `test` 子菜单,每个子菜单中包括了一些合适的内核。设置它为 `false` 可以启用子菜单。
|
||||||
|
* `GRUB_TERMINAL_OUTPUT` 一些环境下可能需要或者必要将输出重定向到一个不同的显示控制台或者终端。默认情况下是把输出发送到默认终端,通常 `console` 等价于 Intel 系列个人电脑的标准输出。另一个有用的选择是在使用串行终端或者 Integrated Lights Out (ILO) 终端连接的数据中心或者实验室环境中指定 `serial`。
|
||||||
|
* `GRUB_TERMINAL_INPUT` 和 `GRUB_TERMINAL_OUTPUT` 类似,可能需要或者必要重定向输入为串行终端或者 ILO 设备、而不是标准键盘输入。
|
||||||
|
* `GRUB_CMDLINE_LINUX` 这个键包括了在启动时会传递给内核的命令行参数。注意这些参数会被添加到 `grub.cfg` 所有已安装内核的内核行。这意味着所有已安装的内核在启动时都会有相同的参数。我通常删除 `rhgb` 和 `quiet` 参数以便我可以看到引导和启动时内核和 systemd 输出的所有内核信息消息。
|
||||||
|
* `GRUB_DISABLE_RECOVERY` 当这个键的值被设置为 `false`,GRUB 菜单中就会为每个已安装的内核创建一个恢复条目。当设置为 `true` 时就不会创建任何恢复条目。但不管这个设置怎样,最后的内核条目总是一个 `rescue` 选项。不过在 rescue 选项中我遇到了一个问题,下面我会详细介绍。
|
||||||
|
|
||||||
|
还有一些你可能觉得有用但我没有在这里介绍的键。它们的描述可以在 [GRUB 手册 2][8] 的 5.1 章节找到。
|
||||||
|
|
||||||
|
### 生成 grub.cfg
|
||||||
|
|
||||||
|
完成所需的配置之后,就需要生成 `/boot/grub2/grub.cfg` 文件。这通过下面的命令完成。
|
||||||
|
|
||||||
|
```
|
||||||
|
grub2-mkconfig > /boot/grub2/grub.cfg
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令按照顺序使用位于 `/etc/grub.d` 的配置文件构建 `grub.cfg` 文件,然后使用 grub 默认文件的内容修改输出以便获得最终所需的配置。`grub2-mkconfig` 命令会尝试定位所有已安装的内核并在 `grub.cfg` 文件的 `10_Linux` 部分新建条目。它还创建一个 `rescue` 条目提供一个用于从 Linux 不能启动的严重问题中恢复的方法。
|
||||||
|
|
||||||
|
强烈建议你不要手动编辑 `grub.cfg` 文件,因为任何对该文件的直接修改都会在下一次安装新内核或者手动运行 `grub2-mkconfig` 时被重写。
|
||||||
|
|
||||||
|
### 问题
|
||||||
|
|
||||||
|
我遇到一个如果没有意识到就可能导致严重后果的 GRUB2 问题。这个救援内核没有启动,反而启动了另外一个内核。我发现那是列表中索引为 1 的内核,也就是列表中的第二个内核。额外的测试发现不管使用原始的还是我生成的 `grub.cfg` 配置文件都会发生这个问题。我在虚拟机和真实硬件上都尝试过而且都发生了这个问题。我只测试了 Fedora 25,因此其它 Fedora 发行版本可能没有这个问题。
|
||||||
|
|
||||||
|
注意,从救援内核生成的 “recovery” 内核条目不能引导到维护模式。
|
||||||
|
|
||||||
|
我推荐将 grub 默认文件中 `GRUB_DISABLE_RECOVERY` 的值更改为 “false”,然后生成你自己的 `grub.cfg`。这会在 GRUB 菜单中为每个已安装的内核生成可用的恢复条目。这些恢复配置能像期望那样工作,从而从那些需要输入密码登录的内核条目中引导到运行级别 1,也就是进入(不需要密码的)单用户维护模式。你也可以按 `Ctrl-D` 继续正常的引导进入默认运行级别。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
GRUB 是引导 Linux 计算机到可用状态过程的一系列事件中,发生在 BIOS 之后的第一步。理解如何配置 GRUB 对于恢复或者处理多种类型的问题非常重要。
|
||||||
|
|
||||||
|
这么多年来我多次不得不引导到恢复或者救援模式以便解决多种类型的问题。其中的一些问题确实是类似 `/etc/fstab` 或其它配置文件中不恰当条目导致的引导问题,也有一些是由于应用程序或者系统软件和最新的内核不兼容的问题。硬件兼容性问题也可能妨碍特定的内核启动。
|
||||||
|
|
||||||
|
我希望这些信息能对你开启 GRUB 配置之旅有所帮助。
|
||||||
|
|
||||||
|
( 题图 : Internet Archive [Book][5] [Images][6]. Opensource.com 修改。 CC BY-SA 4.0)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
David Both - David Both 是一个居住在 Raleigh,北卡罗来纳州的 Linux 和开源倡导者。他在 IT 界已经有超过 40 年,并在他工作的 IBM 执教 OS/2 20 多年。在 IBM 的时候,他在 1981 年开设了第一个最初 IBM 个人电脑的培训课程。他在红帽教授过 RHCE 课程并在 MCI Worldcom、 Cisco、 和北卡罗来纳州工作过。他已经在 Linux 和开源软件方面工作将近 20 年。
|
||||||
|
|
||||||
|
|
||||||
|
----------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/3/introduction-grub2-configuration-linux
|
||||||
|
|
||||||
|
作者:[David Both][a]
|
||||||
|
译者:[ictlyh](https://github.com/ictlyh)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/dboth
|
||||||
|
[1]:https://opensource.com/article/17/2/linux-boot-and-startup
|
||||||
|
[2]:https://opensource.com/article/17/2/linux-boot-and-startup
|
||||||
|
[3]:https://en.wikipedia.org/wiki/Sed
|
||||||
|
[4]:https://opensource.com/article/17/3/introduction-grub2-configuration-linux?rate=QrIzRpQ3YhewYlBD0AFp0JiF133SvhyAq783LOxjr4c
|
||||||
|
[5]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
||||||
|
[6]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
||||||
|
[7]:https://www.gnu.org/software/grub/manual/grub.html#Simple-configuration
|
||||||
|
[8]:https://www.gnu.org/software/grub/manual/grub.html#Simple-configuration
|
||||||
|
[9]:https://opensource.com/user/14106/feed
|
||||||
|
[10]:https://opensource.com/article/17/3/introduction-grub2-configuration-linux#comments
|
||||||
|
[11]:https://opensource.com/users/dboth
|
||||||
@ -0,0 +1,454 @@
|
|||||||
|
如何用树莓派控制 GOIO 引脚并操作继电器
|
||||||
|
==========================================
|
||||||
|
|
||||||
|
> 学习如何用 PHP 和温度传感器实现树莓派控制 GPIO 并操作继电器
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
你是否曾经想知道怎样使用手机或者电脑在任何地方控制你的风扇和灯等一些家用电器?
|
||||||
|
|
||||||
|
我现在想控制我的圣诞彩灯,是使用手机呢,还是使用平板电脑呢,或者是使用笔记本电脑呢?都不是,而是仅仅使用一个树莓派。让我来告诉你如何使用 PHP 和温度传感器实现树莓派控制 GPIO 引脚并操作继电器。我使用 AJAX 把它们整合在了一起。
|
||||||
|
|
||||||
|
### 硬件要求:
|
||||||
|
|
||||||
|
* 树莓派
|
||||||
|
* 安装有 Raspbian 系统的 SD 卡(任何一张 SD 卡都可以,但是我更偏向使用大小为 32GB 等级为 class 10 的 SD 卡)
|
||||||
|
* 电源适配器
|
||||||
|
* 跳线(母对母跳线和公转母跳线)
|
||||||
|
* 继电器板(我使用一个用于 12V 继电器的继电器板)
|
||||||
|
* DS18B20 温度传感器
|
||||||
|
* 树莓派的 Wi-Fi 适配器
|
||||||
|
* 路由器(为了访问互联网,你需要有一个拥有端口转发的路由器)
|
||||||
|
* 10KΩ 的电阻
|
||||||
|
|
||||||
|
### 软件要求:
|
||||||
|
|
||||||
|
* 下载并安装 Raspbian 系统到你的 SD 卡
|
||||||
|
* 有效的互联网连接
|
||||||
|
* Apache web 服务器
|
||||||
|
* PHP
|
||||||
|
* WiringPi
|
||||||
|
* 基于 Mac 或者 Windows 的 SSH 客户端
|
||||||
|
|
||||||
|
### 一般的配置和设置
|
||||||
|
|
||||||
|
1、 插入 SD 卡到树莓派,然后使用以太网网线将它连接到路由器;
|
||||||
|
|
||||||
|
2、 连接 WiFi 适配器;
|
||||||
|
|
||||||
|
3、 使用 SSH 方式登录到树莓派,然后使用下面的命令编辑 `interfaces` 文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nano /etc/network/interfaces
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令会用一个叫做 `nano` 的编辑器打开这个文件。它是一个非常简单又易于使用的文本编辑器。如果你不熟悉基 Linux 的操作系统,可以使用键盘上的方向键来操作。
|
||||||
|
|
||||||
|
用 `nano` 打开这个文件后,你会看到这样一个界面:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
4、要配置你的无线网络,按照下面所示修改这个文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
iface lo inet loopback
|
||||||
|
iface eth0 inet dhcp
|
||||||
|
allow-hotplug wlan0
|
||||||
|
auto wlan0
|
||||||
|
iface wlan0 inet dhcp
|
||||||
|
wpa-ssid "Your Network SSID"
|
||||||
|
wpa-psk "Your Password"
|
||||||
|
```
|
||||||
|
|
||||||
|
5、 按 `CTRL+O` 保存,然后按 `CTRL+X` 退出编辑器。
|
||||||
|
|
||||||
|
到目前为止,一切都已经配置完成,接下来你需要做的就是使用命令重新加载网络:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo service networking reload
|
||||||
|
```
|
||||||
|
|
||||||
|
(警告:如果你是使用远程连接的方式连接的树莓派,连接将会中断。)
|
||||||
|
|
||||||
|
### 软件配置
|
||||||
|
|
||||||
|
#### 安装 Apache web 服务器
|
||||||
|
|
||||||
|
Apache 是一个受欢迎的服务器应用,你可以在树莓派安装这个程序让它提供网页服务。Apache 原本就可以通过 HTTP 方式提供 HTML 文件服务,添加其他模块后,Apache 还可以使用像 PHP 这样的脚本语言来提供动态网页的服务。
|
||||||
|
|
||||||
|
可以在命令行输入下面命令安装 Apache:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get install apache2 -y
|
||||||
|
```
|
||||||
|
|
||||||
|
安装完成后,可以在浏览器地址栏输入树莓派的 IP 地址来测试 web 服务器。如果你可以获得下面图片的内容,说明你已经成功地安装并设置好了你的服务器。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
要改变这个默认的页面和添加你自己的 html 文件,进入 `var/www/html` 目录:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /var/www/html
|
||||||
|
```
|
||||||
|
|
||||||
|
添加一些文件来测试是否成功。
|
||||||
|
|
||||||
|
#### 安装 PHP
|
||||||
|
|
||||||
|
PHP 是一个预处理器,这意味着它是当服务器收到网页请求时才会运行的一段代码。它开始运行,处理网页上需要被显示的内容,然后把网页发送给浏览器。不像静态的 HTML,PHP 在不同的环境下可以显示不同的内容。其他的语言也可以做到这一点,但是由于 WordPress 是用 PHP 编写的,有些时候你需要使用它。PHP 是 web 上一种非常受欢迎的语言,像 Facebok 和 Wikipeadia 这样的大型项目都是用 PHP 编写的。
|
||||||
|
|
||||||
|
使用下面的命令安装 PHP 和 Apache 软件包:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get install php5 libapache2-mod-php5 -y
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 测试 PHP
|
||||||
|
|
||||||
|
创建文件 `index.php`:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nano index.php
|
||||||
|
```
|
||||||
|
|
||||||
|
在里面写入一些 PHP 内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php echo "hello world"; ?>
|
||||||
|
```
|
||||||
|
|
||||||
|
保存文件,接下来删除 `index.html`,因为它比 `index.php` 的优先级更高:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo rm index.html
|
||||||
|
```
|
||||||
|
|
||||||
|
刷新你的浏览器,你会看到 “hello world”。这并不是动态的,但是它仍然由 PHP 提供服务。如果你在上面看到提原始的 PHP 文件而不是“hello world”,重新加载和重启 Apahce(LCTT 译注,重启即可):
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo /etc/init.d/apache2 reload
|
||||||
|
sudo /etc/init.d/apache2 restart
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 安装 WiringPi
|
||||||
|
|
||||||
|
为了可以对代码的更改进行跟踪,WiringPi 的维护采用 git。但假如你因为某些原因而没法使用 git,还有一种可以替代的方案。(通常你的防火墙会把你隔离开来,所以请先检查一下你的防火墙的设置情况!)
|
||||||
|
|
||||||
|
如果你还没有安装 git,那么在 Debian 及其衍生版本中(比如 Raspbian),你可以这样安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get install git-core
|
||||||
|
```
|
||||||
|
|
||||||
|
若是你遇到了一些错误,请确保你的树莓派是最新版本的 Raspbian 系统:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get update sudo apt-get upgrade
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 git 获取最 WiringPi:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo git clone git://git.drogon.net/wiringPi
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你之前已经使用过 clone 操作,那么可以使用下面命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd wiringPi && git pull origin
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令会将会获取更新的版本,你然后可以重新运行下面的构建脚本。
|
||||||
|
|
||||||
|
有一个新的简化的脚本来构建和安装:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd wiringPi && ./build
|
||||||
|
```
|
||||||
|
|
||||||
|
这个新的构建脚本将会为你完成编译和安装 WiringPi。它曾一度需要使用 `sudo` 命令,所以在运行这它之前你可能需要检查一下这个脚本。
|
||||||
|
|
||||||
|
#### 测试 WiringPi
|
||||||
|
|
||||||
|
运行 `gpio` 命令来检查安装成功与否:
|
||||||
|
|
||||||
|
```
|
||||||
|
gpio -v gpio readall
|
||||||
|
```
|
||||||
|
|
||||||
|
这将给你一些信心,软件运行良好。
|
||||||
|
|
||||||
|
#### 连接 DS18B20 传感器到树莓派
|
||||||
|
|
||||||
|
* 传感器上的黑线用于 GND。
|
||||||
|
* 红线用于 VCC。
|
||||||
|
* 黄线是 GPIO 线。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
连线:
|
||||||
|
|
||||||
|
* VCC 连接 3V 的 1 号引脚。
|
||||||
|
* GPIO 线连接 7 号引脚(GPIO4)。
|
||||||
|
* 地线连接 GND 的 9 号引脚。
|
||||||
|
|
||||||
|
#### 软件配置
|
||||||
|
|
||||||
|
为了用 PHP 使用 DS18B20 温度传感器模块,你需要执行下面的命令来激活用于树莓派上 GPIO 引脚和 DS18B20 的内核模块:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo modprobe w1-gpio
|
||||||
|
sudo modprobe w1-therm
|
||||||
|
```
|
||||||
|
|
||||||
|
你不想每次 Raspberry 重启后都手动执行上述命令,所以你想每次开机能自动启动这些模块。可以在文件 `/etc/modules` 中添加下面的命令行来做到:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nano /etc/modules/
|
||||||
|
```
|
||||||
|
|
||||||
|
添加下面的命令行到它里面:
|
||||||
|
|
||||||
|
```
|
||||||
|
w1-gpio
|
||||||
|
w1-therm
|
||||||
|
```
|
||||||
|
|
||||||
|
为了测试,输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /sys/bus/w1/devices/
|
||||||
|
```
|
||||||
|
|
||||||
|
现在输入 `ls`。
|
||||||
|
|
||||||
|
你会看到你的设备信息。在设备驱动程序中,你的 DS18B20 传感器应该作为一串字母和数字被列出。在本例中,设备被记录为 `28-000005e2fdc3`。然后你需要使用 `cd` 命令来访问传感器,用你自己的序列号替代我的: `cd 28-000005e2fdc3`。
|
||||||
|
|
||||||
|
DS18B20 会周期性的将数据写入文件 `w1_slave`,所以你只需要使用命令 `cat`来读出数据: `cat w1_slave`。
|
||||||
|
|
||||||
|
这会生成下面的两行文本,输出中 `t=` 表示摄氏单位的温度。在前两位数后面加上一个小数点(例如,我收到的温度读数是 30.125 摄氏度)。
|
||||||
|
|
||||||
|
### 连接继电器
|
||||||
|
|
||||||
|
1、 取两根跳线,把其中一根连接到树莓派上的 GPIO24(18 号引脚),另一根连接 GND 引脚。你可以参考下面这张图。
|
||||||
|
|
||||||
|
2、 现在将跳线的另一端连接到继电器板。GND 连接到继电器上的 GND,GPIO 输出线连接到继电器的通道引脚号,这取决于你正使用的继电器型号。记住,将树莓派上的 GND 与继电器上的 GND 连接连接起来,树莓派上的 GPIO 输出连接继电器上的输入引脚。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
注意!将继电器连接树莓派的时候小心一些,因为它可能会导致电流回流,这会造成短路。
|
||||||
|
|
||||||
|
3、 现在将电源连接继电器,可以使用 12V 的电源适配器,也可以将 VCC 引脚连接到什么破上的 3.3V 或 5.5V 引脚。
|
||||||
|
|
||||||
|
### 使用 PHP 控制继电器
|
||||||
|
|
||||||
|
让我们先写一个借助于 WiringPi 软件用来控制 Paspberry Pi 上 GPIO 引脚的 PHP 脚本。
|
||||||
|
|
||||||
|
1、在 Apache 服务器的网站根目录下创建一个文件,使用下面命令切换到该目录:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /var/www/html
|
||||||
|
```
|
||||||
|
|
||||||
|
2、 新建一个叫 `Home` 的文件夹:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo mkdir Home
|
||||||
|
```
|
||||||
|
|
||||||
|
3、 新建一个叫 `on.php`的脚本
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nano on.php
|
||||||
|
```
|
||||||
|
|
||||||
|
4、 在脚本中加入下面的代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
|
||||||
|
system("gpio-g mode 24 out");
|
||||||
|
system("gpio-g write 24 1");
|
||||||
|
|
||||||
|
?>
|
||||||
|
```
|
||||||
|
|
||||||
|
5、 使用 `CTRL+O` 保存文件,`CTRL+X` 退出。
|
||||||
|
|
||||||
|
上面的代码中,你在第一行使用命令将 24 号 GPIO引脚设置为 output 模式:
|
||||||
|
|
||||||
|
```
|
||||||
|
system("gpio-g mode 24 out") ;
|
||||||
|
```
|
||||||
|
|
||||||
|
在第二行,你使用 `1` 将 24 号引脚 GPIO 打开,在二进制中"1"表示打开,"0"表示关闭。
|
||||||
|
|
||||||
|
6、 为了关闭继电器,可以创建另外一个 `off.php` 文件,并用 `0` 替换 `1`。
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
|
||||||
|
system(" gpio-g mode 24 out ");
|
||||||
|
system(" gpio-g write 24 1 ");
|
||||||
|
|
||||||
|
?>
|
||||||
|
```
|
||||||
|
|
||||||
|
7、 如果你已经将继电器连接了树莓派,可以在浏览器中输入你的树莓派的 IP 地址,并在后面加上目录名和文件名来进行访问:
|
||||||
|
|
||||||
|
```
|
||||||
|
http://{IPADDRESS}/home/on.php
|
||||||
|
```
|
||||||
|
|
||||||
|
这将会打开继电器。
|
||||||
|
|
||||||
|
8、 要关闭它,可以访问叫 `off.php` 的文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
http://{IPADDRESS}/home/off.php
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你需要能够在一个单独的页面来控制这两样事情,而不用单独的刷新或者访问这两个页面。你可以使用 AJAX 来完成。
|
||||||
|
|
||||||
|
9、 新建一个 HTML 文件,并在其中加入下面代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
[html + php + ajax codeblock]
|
||||||
|
|
||||||
|
<html>
|
||||||
|
|
||||||
|
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.3/jquery.min.js"></script>
|
||||||
|
|
||||||
|
<script type="text/javascript">// <![CDATA[
|
||||||
|
|
||||||
|
$(document).ready(function() {
|
||||||
|
|
||||||
|
$('#on').click(function(){
|
||||||
|
|
||||||
|
var a= new XMLHttpRequest();
|
||||||
|
|
||||||
|
a.open("GET", "on.php"); a.onreadystatechange=function(){
|
||||||
|
|
||||||
|
if(a.readyState==4){ if(a.status ==200){
|
||||||
|
|
||||||
|
} else alert ("http error"); } }
|
||||||
|
|
||||||
|
a.send();
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
$(document).ready(function()
|
||||||
|
|
||||||
|
{ $('#Off').click(function(){
|
||||||
|
|
||||||
|
var a= new XMLHttpRequest();
|
||||||
|
|
||||||
|
a.open("GET", "off.php");
|
||||||
|
|
||||||
|
a.onreadystatechange=function(){
|
||||||
|
|
||||||
|
if(a.readyState==4){
|
||||||
|
|
||||||
|
if(a.status ==200){
|
||||||
|
|
||||||
|
} else alert ("http error"); } }
|
||||||
|
|
||||||
|
a.send();
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
</script>
|
||||||
|
|
||||||
|
<button id="on" type="button"``Switch Lights On </button>
|
||||||
|
|
||||||
|
<button id="off" type="button"``Switch Lights Off </button>
|
||||||
|
```
|
||||||
|
|
||||||
|
10、 保存文件,进入你的 web 浏览器目录,然后打开那个网页。你会看到两个按钮,它们可以打开和关闭灯泡。基于同样的想法,你还可以使用 bootstrap 和 CSS 来创建一个更加漂亮的 web 界面。
|
||||||
|
|
||||||
|
### 在这个网页上观察温度
|
||||||
|
|
||||||
|
1、 新建一个 `temperature.php` 的文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nano temperature.php
|
||||||
|
```
|
||||||
|
|
||||||
|
2、 在文件中加入下面的代码,用你自己的设备 ID 替换 `10-000802292522`:
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
//File to read
|
||||||
|
$file = '/sys/devices/w1_bus_master1/10-000802292522/w1_slave';
|
||||||
|
//Read the file line by line
|
||||||
|
$lines = file($file);
|
||||||
|
//Get the temp from second line
|
||||||
|
$temp = explode('=', $lines[1]);
|
||||||
|
//Setup some nice formatting (i.e., 21,3)
|
||||||
|
$temp = number_format($temp[1] / 1000, 1, ',', '');
|
||||||
|
//And echo that temp
|
||||||
|
echo $temp . " °C";
|
||||||
|
?>
|
||||||
|
```
|
||||||
|
|
||||||
|
3、 打开你刚刚创建的 HTML 文件,并创建一个新的带有 `id` 为 “screen” 的 `<div>`标签
|
||||||
|
|
||||||
|
```
|
||||||
|
<div id="screen"></div>
|
||||||
|
```
|
||||||
|
|
||||||
|
4、 在这个标签后或者这个文档的尾部下面的代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
<script>
|
||||||
|
$(document).ready(function(){
|
||||||
|
setInterval(function(){
|
||||||
|
$("#screen").load('temperature.php')
|
||||||
|
}, 1000);
|
||||||
|
});
|
||||||
|
</script>
|
||||||
|
```
|
||||||
|
|
||||||
|
其中,`#screen` 是标签 `<div>` 的 `id` ,你想在它里面显示温度。它会每隔 1000 毫秒加载一次 `temperature.php` 文件。
|
||||||
|
|
||||||
|
我使用了 bootstrap 框架来制作一个漂亮的面板来显示温度,你还可以加入多个图标和图形让网页更有吸引力。
|
||||||
|
|
||||||
|
这只是一个控制继电器板并显示温度的基础的系统,你可以通过创建基于定时和从恒温器读数等基于事件触发来进一步地对系统进行开发。
|
||||||
|
|
||||||
|
( 题图:opensource.com)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Abdul Hannan Mustajab: 我 17 岁,生活在印度。我正在追求科学,数学和计算机科学方面的教育。我在 spunkytechnology.com 上发表关于我的项目的博客。我一直在对使用不同的微控制器和电路板的基于物联网的 AI 进行研究。
|
||||||
|
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/3/operate-relays-control-gpio-pins-raspberry-pi
|
||||||
|
|
||||||
|
作者:[Abdul Hannan Mustajab][a]
|
||||||
|
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/mustajabhannan
|
||||||
|
[1]:http://www.php.net/system
|
||||||
|
[2]:http://www.php.net/system
|
||||||
|
[3]:http://www.php.net/system
|
||||||
|
[4]:http://www.php.net/system
|
||||||
|
[5]:http://www.php.net/system
|
||||||
|
[6]:http://www.php.net/file
|
||||||
|
[7]:http://www.php.net/explode
|
||||||
|
[8]:http://www.php.net/number_format
|
||||||
|
[9]:https://opensource.com/article/17/3/operate-relays-control-gpio-pins-raspberry-pi?rate=RX8QqLzmUb_wEeLw0Ee0UYdp1ehVokKZ-JbbJK_Cn5M
|
||||||
|
[10]:https://opensource.com/user/123336/feed
|
||||||
|
[11]:https://opensource.com/users/mustajabhannan
|
||||||
|
|
||||||
|
|
||||||
@ -1,27 +1,26 @@
|
|||||||
D 编程语言是用于开发的绝佳语言的 5 个理由
|
D 编程语言是用于开发的绝佳语言的 5 个理由
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
### D 语言的模块化、开发效率、可读性以及其它一些特性使其非常适合用于协同软件的开发。
|
> D 语言的模块化、开发效率、可读性以及其它一些特性使其非常适合用于协同软件的开发。
|
||||||
|
|
||||||
|
|
||||||

|

|
||||||
>图片来自: opensource.com
|
|
||||||
|
|
||||||
[D 编程语言][8]是一种静态类型的通用编程语言,它具有和 C 语言类似的语法,能够编译为本地代码。许多理由使得它很适合用于开源软件开发,下面讲到的是其中一些理由。
|
[D 编程语言][8]是一种静态类型的通用编程语言,它具有和 C 语言类似的语法,能够编译为本地代码。许多理由使得它很适合用于开源软件开发,下面讲到的是其中一些理由。
|
||||||
|
|
||||||
### 模块化能力
|
### 模块化能力
|
||||||
|
|
||||||
在大多数情况下,当你有一个好的想法,你可以完全按照你的内心所想的方式通过代码来实现它。然而,有的时候,你不得不向你的想法妥协,从而来适应代码,而不是通过模块化代码来适应想法。 D 语言支持多种[编程范式][9],包括函数式风格、命令式、面向对象、元编程、并发(演员模式)和并行集成。你可以选择任何一种方便的编程范式来模块化代码,从而适应你的想法。
|
在大多数情况下,当你有一个好的想法,你可以完全按照你的内心所想的方式通过代码来实现它。然而,有的时候,你不得让你的想法向代码妥协,而不是通过模块化代码来适应想法。D 语言支持多种[编程范式][9],包括函数式风格、命令式、面向对象、元编程、并发(演员模式),这些全都和谐共存。你可以选择任何一种方便的编程范式来将你的想法转换为代码。
|
||||||
|
|
||||||
通过使用[模板][10],可以生成额外的 D 代码并在编译的过程中把它编排进去,你可以把这些代码描述成编译器生成代码的一种模式。这是一种非常有用的设计算法,无需把它们绑定到任何特定的类型。平台无关的代码很容易加入到自然的模板中。通过将模板与[条件编译][11]结合,跨平台的应用变得更加容易实现,也更容易接受来自使用不同操作系统的开发者的贡献。有了这一点,一个程序员可以通过很少的代码,利用有限的时间实现很多东西。
|
通过使用[模板][10],可以生成额外的 D 代码并在编译的过程中把它编排进去,你可以把这些代码描述成编译器生成代码的一种模式。这是一种非常有用的设计算法,无需把它们绑定到任何特定的类型。由于模版的通用性,就很容易生成平台无关的代码。通过将模板与[条件编译][11]结合,跨平台的应用变得更加容易实现,也更容易接受来自使用不同操作系统的开发者的贡献。有了这一点,一个程序员可以通过很少的代码,利用有限的时间实现很多东西。
|
||||||
|
|
||||||
[排列][12] 已经深度集成到了 D 语言中,抽象出当和一个实际执行冲突时如何访问容器元素(比如数组、关联数组和链表等)。这个抽象使得可以在许多容器类型中设计和使用大量的算法,而无需绑定到特定的数据结构。D 的[数组切片][13]是排列的一个实现。在最后,你可以用很少的时间写很少的代码,并且只需要很低的维护成本。
|
[range][12] 已经深度集成到了 D 语言中,相对于具体实现,它抽象出容器元素(比如数组、关联数组和链表等)是如何访问的。这个抽象使得可以在许多容器类型中设计和使用大量的算法,而无需绑定到特定的数据结构。D 的[数组切片][13]是 range 的一个实现。最终,你可以用很少的时间写很少的代码,并且只需要很低的维护成本。
|
||||||
|
|
||||||
### 开发效率
|
### 开发效率
|
||||||
|
|
||||||
大多数开源软件的代码贡献者都是基于有限的时间志愿工作的。 D 语言能够极大的提高开发效率,因为你可以用更少的时间完成更多的事情。D 的模板和排列使得程序员在开发通用代码和可复用代码时效率更高,但这些仅仅是 D 开发效率高的其中几个优势。另外一个主要的吸引力是, D 的编译速度看起来感觉就像解释型语言,比如 Python、JavaScript、Ruby 和 PHP,它使得 D 能够快速成型。
|
大多数开源软件的代码贡献者都是基于有限的时间志愿工作的。 D 语言能够极大的提高开发效率,因为你可以用更少的时间完成更多的事情。D 的模板和 range 使得程序员在开发通用代码和可复用代码时效率更高,但这些仅仅是 D 开发效率高的其中几个优势。另外一个主要的吸引力是, D 的编译速度看起来感觉就像解释型语言一样,比如 Python、JavaScript、Ruby 和 PHP,它使得 D 能够快速成型。
|
||||||
|
|
||||||
D 可以很容易的与旧的代码进行对接,减少了端口的需要。它的设计目的是自然地[与 C 代码进行对接][14],毕竟, C 语言是遗留代码、精心编写和测试代码、库以及低级系统调用(特别是 Linux 系统)的主人。C++ 代码在[ D 中也是可调用的][15],从而进行更大的扩展。事实上,[Python][16]、[Objective-C][17]、[Lua][18] 和 [Fortran][19] 这些语言在技术层面上也是可以在 D 中使用的,还有许多第三方努力在把 D 语言推向这些领域。这使得大量的开源库在 D 中均可使用,这符合开源软件开发的惯例。
|
D 可以很容易的与旧的代码进行对接,减少了移植的需要。它的设计目的是[与 C 代码进行自然地对接][14],毕竟, C 语言大量用在遗留代码、精心编写而测试过的代码、库以及低级系统调用(特别是 Linux 系统)上。C++ 代码在[ D 中也是可调用的][15],从而进行更大的扩展。事实上,[Python][16]、[Objective-C][17]、[Lua][18] 和 [Fortran][19] 这些语言在技术层面上都是可以在 D 中使用的,有许多第三方正在努力在把 D 语言推向这些领域。这使得大量的开源库在 D 中均可使用,这符合开源软件开发的惯例。
|
||||||
|
|
||||||
### 可读性和可维护性
|
### 可读性和可维护性
|
||||||
|
|
||||||
@ -35,23 +34,23 @@ void main()
|
|||||||
|
|
||||||
*D 语言的 Hello, World 演示*
|
*D 语言的 Hello, World 演示*
|
||||||
|
|
||||||
对于熟悉 C 语言的人来说, D 代码很容易理解。另外, D 代码的可读性很强,即使是复杂的代码,这使得很容易发现错误。可读性对于吸引贡献者来说也是很重要的,这是开源软件成长的关键。
|
对于熟悉 C 语言的人来说, D 代码很容易理解。另外, D 代码的可读性很强,即使是复杂的代码。这使得很容易发现错误。可读性对于吸引贡献者来说也是很重要的,这是开源软件成长的关键。
|
||||||
|
|
||||||
在 D 中一个非常简单但很有用的[语法][20]是支持使用下滑线分隔数字,这使得数字的可读性更高。这在数学上很有用:
|
在 D 中一个非常简单但很有用的[语法糖][20]是支持使用下滑线分隔数字,这使得数字的可读性更高。这在数学上很有用:
|
||||||
|
|
||||||
```
|
```
|
||||||
int count = 100_000_000;
|
int count = 100_000_000;
|
||||||
double price = 20_220.00 + 10.00;
|
double price = 20_220.00 + 10.00;
|
||||||
int number = 0x7FFF_FFFF; // in hexadecimal system
|
int number = 0x7FFF_FFFF; // 16 进制系统
|
||||||
```
|
```
|
||||||
|
|
||||||
[Ddoc][21] 是一个内建的工具,它能够很容易的自动根据代码注释生成文档,而不需要使用额外的工具。文档写作、改进和更新变得更加简单,不具挑战性,因为它伴随代码同时生成。
|
[ddoc][21] 是一个内建的工具,它能够很容易的自动根据代码注释生成文档,而不需要使用额外的工具。文档写作、改进和更新变得更加简单,不具挑战性,因为它伴随代码同时生成。
|
||||||
|
|
||||||
[契约][22] 能够进行检查,从而确保 D 代码的行为能够像期望的那样。就像法律契约签订是为了确保每一方在协议中做自己该做的事情,在 D 语言中的契约式编程,能够确保实现的每一个函数、类等能够像期望的那样产生期望的结果和行为。这样一个特性对于错误检查非常实用,特别是在开源软件中,当多个人合作一个项目的时候。契约是大项目的救星。D 语言强大的契约式编程特性是内建的,而不是后期添加的。契约不仅使得使用 D 语言更加方便,也减少了正确写作和维护困难的头痛。
|
[Contract][22] 能够检查代码的实现,从而确保 D 代码的行为能够像期望的那样。就像法律契约的签订是为了确保每一方在协议中做自己该做的事情,在 D 语言中的契约式编程,能够确保实现的每一个函数、类等如期望的那样产生预期的结果和行为。这样一个特性对于错误检查非常实用,特别是在开源软件中,当多个人合作一个项目的时候。契约是大项目的救星。D 语言强大的契约式编程特性是内建的,而不是后期添加的。契约不仅使得使用 D 语言更加方便,也减少了正确写作和维护困难的头痛。
|
||||||
|
|
||||||
### 方便
|
### 方便
|
||||||
|
|
||||||
协同开发是具有挑战性的,因为代码经常发生变化,并且有许多移动部分。D 语言通过支持在本地范围内导入模块,从而缓解了一些问题:
|
协同开发是具有挑战性的,因为代码经常发生变化,并且有许多移动部分。D 语言通过支持在本地范围内导入模块,从而缓解了那些问题:
|
||||||
|
|
||||||
```
|
```
|
||||||
// 返回偶数
|
// 返回偶数
|
||||||
@ -64,11 +63,11 @@ int[] evenNumbers(int[] numbers)
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
*通过**过滤**使用 "!"运算符是[模板参数][5]的一个语法*
|
*对 filter 使用 `!` 运算符是[模板参数][5]的一个语法*
|
||||||
|
|
||||||
上面的函数可以在不破坏代码的情况下调用,因为它不依赖任何全局导入模块。像这样实现的函数都可以在后期无需破坏代码的情况下增强,这是协同开发的好东西。
|
上面的函数可以在不破坏代码的情况下调用,因为它不依赖任何全局导入模块。像这样实现的函数都可以在后期无需破坏代码的情况下增强,这是协同开发的好东西。
|
||||||
|
|
||||||
[通用函数调用语法][23]是 D 语言中的一个特殊语法,它允许像调用一个对象的成员函数那样调用正则函数。一个函数的定义如下:
|
[通用函数调用语法(UFCS)][23]是 D 语言中的一个语法糖,它允许像调用一个对象的成员函数那样调用常规函数。一个函数的定义如下:
|
||||||
|
|
||||||
```
|
```
|
||||||
void cook(string food, int quantity)
|
void cook(string food, int quantity)
|
||||||
@ -87,7 +86,7 @@ int quantity = 3;
|
|||||||
cook(food, quantity);
|
cook(food, quantity);
|
||||||
```
|
```
|
||||||
|
|
||||||
通过 UFCS,这个函数也可以像下面这样调用,看起来好像 **cook** 是一个成员函数:
|
通过 UFCS,这个函数也可以像下面这样调用,看起来好像 `cook` 是一个成员函数:
|
||||||
|
|
||||||
```
|
```
|
||||||
string food = "rice";
|
string food = "rice";
|
||||||
@ -96,7 +95,7 @@ int quantity = 3;
|
|||||||
food.cook(quantity);
|
food.cook(quantity);
|
||||||
```
|
```
|
||||||
|
|
||||||
在编译过程中,编译器会自动把 **food** 作为 **cook** 函数的第一个参数。UFCS 使得它能够连接正则函数,给你的代码产生一种函数风格编程的自然感觉。UFCS 在 D 语言中被大量使用,就像在上面的 **evenNumbers** 函数中使用的**过滤**和**数组**功能那样。结合模板、排列、条件编译和 UFCS 能够在不牺牲方便性的前提下给予你强大的力量。
|
在编译过程中,编译器会自动把 `food` 作为 `cook` 函数的第一个参数。UFCS 使得它能够链起来常规函数,给你的代码产生一种函数风格编程的自然感觉。UFCS 在 D 语言中被大量使用,就像在上面的 `evenNumbers` 函数中使用的 `filter` 和 `array` 函数那样。结合模板、range、条件编译和 UFCS 能够在不牺牲方便性的前提下给予你强大的力量。
|
||||||
|
|
||||||
`auto` 关键词可以用来代替任何类型。编译器在编译过程中会静态推断类型。这样可以省去输入很长的类型名字,让你感觉写 D 代码就像是在写动态类型语言。
|
`auto` 关键词可以用来代替任何类型。编译器在编译过程中会静态推断类型。这样可以省去输入很长的类型名字,让你感觉写 D 代码就像是在写动态类型语言。
|
||||||
|
|
||||||
@ -114,7 +113,7 @@ auto dictionary = ["one": 1, "two": 2, "three": 3]; // type of int[string]
|
|||||||
auto cook(string food) {...} // auto for a function return type
|
auto cook(string food) {...} // auto for a function return type
|
||||||
```
|
```
|
||||||
|
|
||||||
D 的[foreach][24] 循环允许遍历集合和所有不同的强调数据类型:
|
D 的[foreach][24] 循环允许遍历各种不同的底层数据类型的集合和 range:
|
||||||
|
|
||||||
```
|
```
|
||||||
foreach(name; ["John", "Yaw", "Paul", "Kofi", "Ama"])
|
foreach(name; ["John", "Yaw", "Paul", "Kofi", "Ama"])
|
||||||
@ -131,7 +130,7 @@ Student[] students = [new Student(), new Student()];
|
|||||||
foreach(student; students) {...}
|
foreach(student; students) {...}
|
||||||
```
|
```
|
||||||
|
|
||||||
D 语言中内建的[单元测试][25]不仅免除了使用外部工具的需要,也方便了程序员在自己的代码中执行测试。所有的测试用例都位于定制的 `unittest{}` 块中:
|
D 语言中内建的[单元测试][25]不仅免除了使用外部工具的需要,也方便了程序员在自己的代码中执行测试。所有的测试用例都位于可定制的 `unittest{}` 块中:
|
||||||
|
|
||||||
```
|
```
|
||||||
int[] evenNumbers(int[] numbers)
|
int[] evenNumbers(int[] numbers)
|
||||||
@ -149,17 +148,19 @@ unittest
|
|||||||
|
|
||||||
使用 D 语言的标准编译器 DMD,你可以通过增加 `-unittest` 编译器标志把所有的测试编译进可执行结果中。
|
使用 D 语言的标准编译器 DMD,你可以通过增加 `-unittest` 编译器标志把所有的测试编译进可执行结果中。
|
||||||
|
|
||||||
[Dub][26] 是 D 语言的一个内建包管理器和构建工具,使用它可以很容易的添加来自 [Dub package registry][27] 的第三方库。Dub 可以在编译过程中下载、编译和链接这些包,同时也会升级到新版本。
|
[Dub][26] 是 D 语言的一个内建包管理器和构建工具,使用它可以很容易的添加来自 [Dub package registry][27] 的第三方库。Dub 可以在编译过程中下载、编译和链接这些包,同时也会升级到新版本。
|
||||||
|
|
||||||
### 选择
|
### 选择
|
||||||
|
|
||||||
除了提供多种编程范例和功能特性外,D 还提供其他的选择。它目前有三个可用的开源编译器。官方编译器 DMD 使用它自己的后端,另外两个编译器 GDC 和 LDC,分别使用 GCC 和 LLVM 后端。DMD 以编译速度块而著称,而 LDC 和 GDC 则以在很短的编译时间内生成快速生成机器代码而著称。你可以自由选择其中一个以适应你的使用情况。
|
除了提供多种编程范例和功能特性外,D 还提供其他的选择。它目前有三个可用的开源编译器。官方编译器 DMD 使用它自己的后端,另外两个编译器 GDC 和 LDC,分别使用 GCC 和 LLVM 后端。DMD 以编译速度块而著称,而 LDC 和 GDC 则以在很短的编译时间内生成快速生成机器代码而著称。你可以自由选择其中一个以适应你的使用情况。
|
||||||
|
|
||||||
默认情况下, D 语言是采用[垃圾收集][28]的内存分配方式的。你也可以选择手动进行内存管理,如果你想的话,甚至可以进行引用计数。一切选择都是你的。
|
默认情况下,D 语言是采用[垃圾收集][28]的内存分配方式的。你也可以选择手动进行内存管理,如果你想的话,甚至可以进行引用计数。一切选择都是你的。
|
||||||
|
|
||||||
### 更多
|
### 更多
|
||||||
|
|
||||||
在这个简要的讨论中,还有许多 D 语言好的特性没有涉及到。我强烈推荐阅读 [D 语言的特性概述][29],隐藏在[标准库][30]中的宝藏,以及[ D 的使用区域][31],从而进一步了解人们用它来干什么。许多阻止已经[使用 D 语言来进行开发][32]。最后,如果你打算开始学习 D 语言,那么请看这本书 *[D 语言编程][6]*。
|
在这个简要的讨论中,还有许多 D 语言好的特性没有涉及到。我强烈推荐阅读 [D 语言的特性概述][29],这是隐藏在[标准库][30]中的宝藏,以及 [D 语言的使用区域][31],从而进一步了解人们用它来干什么。许多组织已经[使用 D 语言来进行开发][32]。最后,如果你打算开始学习 D 语言,那么请看这本书 *[D 语言编程][6]*。
|
||||||
|
|
||||||
|
(题图:opensource.com)
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -167,7 +168,7 @@ via: https://opensource.com/article/17/5/d-open-source-software-development
|
|||||||
|
|
||||||
作者:[Lawrence Aberba][a]
|
作者:[Lawrence Aberba][a]
|
||||||
译者:[ucasFL](https://github.com/ucasFL)
|
译者:[ucasFL](https://github.com/ucasFL)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
345
published/20170519 Accelerating your C++ on GPU with SYCL.md
Normal file
345
published/20170519 Accelerating your C++ on GPU with SYCL.md
Normal file
@ -0,0 +1,345 @@
|
|||||||
|
通过 SYCL 在 GPU 上加速 C++
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
在机器学习、计算机视觉以及高性能计算领域,充分利用显卡计算应用程序的能力已成为当前的热门。类似 OpenCL 的技术通过硬件无关的编程模型展现了这种能力,使得你可以编写抽象于不同体系架构的代码。它的目标是“一次编写,到处运行”,不管它是 Intel CPU、AMD 独立显卡还是 DSP 等等。不幸的是,对于日常程序员,OpenCL 的学习曲线陡峭;一个简单的 Hello World 程序可能就需要上百行晦涩难懂的代码。因此,为了减轻这种痛苦,Khronos 组织已经开发了一个称为 [SYCL][4] 的新标准,这是一个在 OpenCL 之上的 C++ 抽象层。通过 SYCL,你可以使用干净、现代的 C++ 开发出这些通用 GPU(GPGPU)应用程序,而无需拘泥于 OpenCL。下面是一个使用 SYCL 开发,通过并行 STL 实现的向量乘法事例:
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <vector>
|
||||||
|
#include <iostream>
|
||||||
|
|
||||||
|
#include <sycl/execution_policy>
|
||||||
|
#include <experimental/algorithm>
|
||||||
|
#include <sycl/helpers/sycl_buffers.hpp>
|
||||||
|
|
||||||
|
using namespace std::experimental::parallel;
|
||||||
|
using namespace sycl::helpers;
|
||||||
|
|
||||||
|
int main() {
|
||||||
|
constexpr size_t array_size = 1024*512;
|
||||||
|
std::array<cl::sycl::cl_int, array_size> a;
|
||||||
|
std::iota(begin(a),end(a),0);
|
||||||
|
|
||||||
|
{
|
||||||
|
cl::sycl::buffer<int> b(a.data(), cl::sycl::range<1>(a.size()));
|
||||||
|
cl::sycl::queue q;
|
||||||
|
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
||||||
|
transform(sycl_policy, begin(b), end(b), begin(b),
|
||||||
|
[](int x) { return x*2; });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
为了作为对比,下面是一个通过 C++ API 使用 OpenCL 编写的大概对应版本(无需花过多时间阅读,只需注意到它看起来难看而且冗长)。
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <iostream>
|
||||||
|
#include <array>
|
||||||
|
#include <numeric>
|
||||||
|
#include <CL/cl.hpp>
|
||||||
|
|
||||||
|
int main(){
|
||||||
|
std::vector<cl::Platform> all_platforms;
|
||||||
|
cl::Platform::get(&all_platforms);
|
||||||
|
if(all_platforms.size()==0){
|
||||||
|
std::cout<<" No platforms found. Check OpenCL installation!\n";
|
||||||
|
exit(1);
|
||||||
|
}
|
||||||
|
cl::Platform default_platform=all_platforms[0];
|
||||||
|
|
||||||
|
std::vector<cl::Device> all_devices;
|
||||||
|
default_platform.getDevices(CL_DEVICE_TYPE_ALL, &all_devices);
|
||||||
|
if(all_devices.size()==0){
|
||||||
|
std::cout<<" No devices found. Check OpenCL installation!\n";
|
||||||
|
exit(1);
|
||||||
|
}
|
||||||
|
|
||||||
|
cl::Device default_device=all_devices[0];
|
||||||
|
cl::Context context({default_device});
|
||||||
|
|
||||||
|
cl::Program::Sources sources;
|
||||||
|
std::string kernel_code=
|
||||||
|
" void kernel mul2(global int* A){"
|
||||||
|
" A[get_global_id(0)]=A[get_global_id(0)]*2;"
|
||||||
|
" }";
|
||||||
|
sources.push_back({kernel_code.c_str(),kernel_code.length()});
|
||||||
|
|
||||||
|
cl::Program program(context,sources);
|
||||||
|
if(program.build({default_device})!=CL_SUCCESS){
|
||||||
|
std::cout<<" Error building: "<<program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(default_device)<<"\n";
|
||||||
|
exit(1);
|
||||||
|
}
|
||||||
|
|
||||||
|
constexpr size_t array_size = 1024*512;
|
||||||
|
std::array<cl_int, array_size> a;
|
||||||
|
std::iota(begin(a),end(a),0);
|
||||||
|
|
||||||
|
cl::Buffer buffer_A(context,CL_MEM_READ_WRITE,sizeof(int)*a.size());
|
||||||
|
cl::CommandQueue queue(context,default_device);
|
||||||
|
|
||||||
|
if (queue.enqueueWriteBuffer(buffer_A,CL_TRUE,0,sizeof(int)*a.size(),a.data()) != CL_SUCCESS) {
|
||||||
|
std::cout << "Failed to write memory;n";
|
||||||
|
exit(1);
|
||||||
|
}
|
||||||
|
|
||||||
|
cl::Kernel kernel_add = cl::Kernel(program,"mul2");
|
||||||
|
kernel_add.setArg(0,buffer_A);
|
||||||
|
|
||||||
|
if (queue.enqueueNDRangeKernel(kernel_add,cl::NullRange,cl::NDRange(a.size()),cl::NullRange) != CL_SUCCESS) {
|
||||||
|
std::cout << "Failed to enqueue kernel\n";
|
||||||
|
exit(1);
|
||||||
|
}
|
||||||
|
|
||||||
|
if (queue.finish() != CL_SUCCESS) {
|
||||||
|
std::cout << "Failed to finish kernel\n";
|
||||||
|
exit(1);
|
||||||
|
}
|
||||||
|
|
||||||
|
if (queue.enqueueReadBuffer(buffer_A,CL_TRUE,0,sizeof(int)*a.size(),a.data()) != CL_SUCCESS) {
|
||||||
|
std::cout << "Failed to read result\n";
|
||||||
|
exit(1);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
在这篇博文中我会介绍使用 SYCL 加速你 GPU 上的 C++ 代码。
|
||||||
|
|
||||||
|
### GPGPU 简介
|
||||||
|
|
||||||
|
在我开始介绍如何使用 SYCL 之前,我首先给那些不熟悉这方面的人简要介绍一下为什么你可能想要在 GPU 上运行计算任务。如果已经使用过 OpenCL、CUDA 或类似的库,可以跳过这一节。
|
||||||
|
|
||||||
|
GPU 和 CPU 的一个关键不同就是 GPU 有大量小的、简单的处理单元,而不是少量(对于普通消费者桌面硬件通常是 1-8 个)复杂而强大的核。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
上面是一个 4 核 CPU 的简单漫画示意图。每个核都有一组寄存器以及不同等级的缓存(有些是共享缓存、有些不是),然后是主内存。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在 GPU 上,多个小处理单元被组成一个执行单元。每个小处理单元都附有少量内存,每个执行单元都有一些共享内存用于它的处理单元。除此之外,还有一些 GPU 范围的内存,然后是 CPU 使用的主内存。执行单元内部的单元是 _lockstep_ ,每个单元都在不同的数据片上执行相同的指令。
|
||||||
|
|
||||||
|
这可以使 GPU 同时处理大量的数据。如果是在 CPU 上,也许你可以使用多线程和向量指令在给定时间内完成大量的工作,但是 GPU 所能处理的远多于此。在 GPU 上一次性能够处理的数据规模使得它非常适合于类似图形(duh)、数学处理、神经网络等等。
|
||||||
|
|
||||||
|
GPGPU 编程的很多方面使得它和日常的 CPU 编程完全不同。例如,从主内存传输数据到 GPU 是_很慢的_。_真的_很慢。会完全干掉你的性能使你慢下来。因此,GPU 编程的权衡是尽可能多地利用加速器的高吞吐量来掩盖数据来往的延迟。
|
||||||
|
|
||||||
|
这里还有一些不那么明显的问题,例如分支的开销。由于执行单元内的处理单元按照 lockstep 工作,使它们执行不同路径(不同的控制流)的嵌套分支就是个真正的问题。这通常通过在所有单元上执行所有分支并标记出无用结果来解决。这是一个基于嵌套级别的指数级的复杂度,这当然是坏事情。当然,有一些优化方法可以拯救该问题,但需要注意:你从 CPU 领域带来的简单假设和知识在 GPU 领域可能导致大问题。
|
||||||
|
|
||||||
|
在我们回到 SYCL 之前,需要介绍一些术语。主机(host)是主 CPU 运行的机器,设备(device)是会运行你 OpenCL 代码的地方。设备可能就是主机,但也可能是你机器上的一些加速器、模拟器等。内核(kernel)是一个特殊函数,它是在你设备上运行代码的入口点。通常还会提供一些主机设置好的缓存给它用于输入和输出数据。
|
||||||
|
|
||||||
|
### 回到 SYCL
|
||||||
|
|
||||||
|
这里有两个可用的 SYCL 实现:[triSYCL](https://github.com/Xilinx/triSYCL),由 Xilinx 开发的实验性开源版本(通常作为标准的试验台使用),以及 [ComputeCpp](https://www.codeplay.com/products/computesuite/computecpp),由 Codeplay(我在 Codeplay 工作,但这篇文章是在没有我雇主建议的情况下使用我自己时间编写的) 开发的工业级实现(当前处于开发测试版)。只有 ComputeCpp 支持在 GPU 上执行内核,因此在这篇文章中我们会使用它。
|
||||||
|
|
||||||
|
第一步是在你的机器上配置以及运行 ComputeCpp。主要组件是一个实现了 SYCL API 的运行时库,以及一个基于 Clang 的编译器,它负责编译你的主机代码和设备代码。在本文写作时,已经在 Ubuntu 和 CentOS 上官方支持 Intel CPU 以及某些 AMD GPU。在其它 Linux 发行版上让它工作也非常简单(例如,我让它在我的 Arch 系统上运行)。对更多的硬件和操作系统的支持正在进行中,查看[支持平台文档][5]获取最新列表。[这里][6]列出了依赖和组件。你也可能想要下载 [SDK][7],其中包括了示例、文档、构建系统集成文件,以及其它。在这篇文章中我会使用 [SYCL 并行 STL][8],如果你想要自己在家学习的话也要下载它。
|
||||||
|
|
||||||
|
一旦你设置好了一切,我们就可以开始通用 GPU 编程了!正如简介中提到的,我的第一个示例使用 SYCL 并行 STL 实现。我们现在来看看如何使用纯 SYCL 编写代码。
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <CL/sycl.hpp>
|
||||||
|
|
||||||
|
#include <array>
|
||||||
|
#include <numeric>
|
||||||
|
#include <iostream>
|
||||||
|
|
||||||
|
int main() {
|
||||||
|
const size_t array_size = 1024*512;
|
||||||
|
std::array<cl::sycl::cl_int, array_size> in,out;
|
||||||
|
std::iota(begin(in),end(in),0);
|
||||||
|
|
||||||
|
{
|
||||||
|
cl::sycl::queue device_queue;
|
||||||
|
cl::sycl::range<1> n_items{array_size};
|
||||||
|
cl::sycl::buffer<cl::sycl::cl_int, 1> in_buffer(in.data(), n_items);
|
||||||
|
cl::sycl::buffer<cl::sycl::cl_int, 1> out_buffer(out.data(), n_items);
|
||||||
|
|
||||||
|
device_queue.submit([&](cl::sycl::handler &cgh) {
|
||||||
|
constexpr auto sycl_read = cl::sycl::access::mode::read;
|
||||||
|
constexpr auto sycl_write = cl::sycl::access::mode::write;
|
||||||
|
|
||||||
|
auto in_accessor = in_buffer.get_access<sycl_read>(cgh);
|
||||||
|
auto out_accessor = out_buffer.get_access<sycl_write>(cgh);
|
||||||
|
|
||||||
|
cgh.parallel_for<class VecScalMul>(n_items,
|
||||||
|
[=](cl::sycl::id<1> wiID) {
|
||||||
|
out_accessor[wiID] = in_accessor[wiID]*2;
|
||||||
|
});
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
我会把它划分为一个个片段。
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <CL/sycl.hpp>
|
||||||
|
```
|
||||||
|
|
||||||
|
我们做的第一件事就是包含 SYCL 头文件,它会在我们的命令中添加 SYCL 运行时库。
|
||||||
|
|
||||||
|
```
|
||||||
|
const size_t array_size = 1024*512;
|
||||||
|
std::array<cl::sycl::cl_int, array_size> in,out;
|
||||||
|
std::iota(begin(in),end(in),0);
|
||||||
|
```
|
||||||
|
|
||||||
|
这里我们构造了一个很大的整型数组并用数字 `0` 到 `array_size-1` 初始化(这就是 `std::iota` 所做的)。注意我们使用 `cl::sycl::cl_int` 确保兼容性。
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
//...
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
接着我们打开一个新的作用域,其目的为二:
|
||||||
|
|
||||||
|
1. `device_queue` 将在该作用域结束时解构,它将阻塞,直到内核完成。
|
||||||
|
2. `in_buffer` 和 `out_buffer` 也将解构,这将强制数据传输回主机并允许我们从 `in` 和 `out` 中访问数据。
|
||||||
|
```
|
||||||
|
cl::sycl::queue device_queue;
|
||||||
|
```
|
||||||
|
|
||||||
|
现在我们创建我们的命令队列。命令队列是所有工作(内核)在分发到设备之前需要入队的地方。有很多方法可以定制队列,例如说提供设备用于入队或者设置异步错误处理器,但对于这个例子默认构造器就可以了;它会查找兼容的 GPU,如果失败的话会回退到主机 CPU。
|
||||||
|
|
||||||
|
```
|
||||||
|
cl::sycl::range<1> n_items{array_size};
|
||||||
|
```
|
||||||
|
|
||||||
|
接下来我们创建一个范围,它描述了内核在上面执行的数据的形状。在我们简单的例子中,它是一个一维数组,因此我们使用 `cl::sycl::range<1>`。如果数据是二维的,我们就会使用 `cl::sycl::range<2>`,以此类推。除了 `cl::sycl::range`,还有 `cl::sycl::ndrange`,它允许你指定工作组大小以及越界范围,但在我们的例子中我们不需要使用它。
|
||||||
|
|
||||||
|
```
|
||||||
|
cl::sycl::buffer<cl::sycl::cl_int, 1> in_buffer(in.data(), n_items);
|
||||||
|
cl::sycl::buffer<cl::sycl::cl_int, 1> out_buffer(out.data(), n_items);
|
||||||
|
```
|
||||||
|
|
||||||
|
为了控制主机和设备之间的数据共享和传输,SYCL 提供了一个 `buffer` 类。我们创建了两个 SYCL 缓存用于管理我们的输入和输出数组。
|
||||||
|
|
||||||
|
```
|
||||||
|
device_queue.submit([&](cl::sycl::handler &cgh) {/*...*/});
|
||||||
|
```
|
||||||
|
|
||||||
|
设置好了我们所有数据之后,我们就可以入队真正的工作。有多种方法可以做到,但设置并行执行的一个简单方法是在我们的队列中调用 `.submit` 函数。对于这个函数我们传递了一个运行时调度该任务时会被执行的“命令组伪函数”(伪函数是规范,不是我创造的)。命令组处理器设置任何内核需要的余下资源并分发它。
|
||||||
|
|
||||||
|
```
|
||||||
|
constexpr auto sycl_read = cl::sycl::access::mode::read_write;
|
||||||
|
constexpr auto sycl_write = cl::sycl::access::mode::write;
|
||||||
|
|
||||||
|
auto in_accessor = in_buffer.get_access<sycl_read>(cgh);
|
||||||
|
auto out_accessor = out_buffer.get_access<sycl_write>(cgh);
|
||||||
|
```
|
||||||
|
|
||||||
|
为了控制到我们缓存的访问并告诉该运行时环境我们会如何使用数据,我们需要创建访问器。很显然,我们创建了一个访问器用于从 `in_buffer` 读入,一个访问器用于写到 `out_buffer`。
|
||||||
|
|
||||||
|
```
|
||||||
|
cgh.parallel_for<class VecScalMul>(n_items,
|
||||||
|
[=](cl::sycl::id<1> wiID) {
|
||||||
|
out_accessor[wiID] = in_accessor[wiID]*2;
|
||||||
|
});
|
||||||
|
```
|
||||||
|
|
||||||
|
现在我们已经完成了所有设置,我们可以真正的在我们的设备上做一些计算了。这里我们根据范围 `n_items` 在命令组处理器 `cgh` 之上分发一个内核。实际内核自身是一个使用 work-item 标识符作为输入、输出我们计算结果的 lamda 表达式。在这种情况下,我们从 `in_accessor` 使用 work-item 标识符作为索引读入,将其乘以 `2`,然后将结果保存到 `out_accessor` 相应的位置。`<class VecScalMul>` 是一个为了在标准 C++ 范围内工作的不幸的副产品,因此我们需要给内核一个唯一的类名以便编译器能完成它的工作。
|
||||||
|
|
||||||
|
```
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
在此之后,我们现在可以访问 `out` 并期望看到正确的结果。
|
||||||
|
|
||||||
|
这里有相当多的新概念在起作用,但使用这些技术你可以看到这些能力和所展现出来的东西。当然,如果你只是想在你的 GPU 上执行一些代码而不关心定制化,那么你就可以使用 SYCL 并行 STL 实现。
|
||||||
|
|
||||||
|
### SYCL 并行 STL
|
||||||
|
|
||||||
|
SYCL 并行 STL 是一个 TS 的并行化实现,它分发你的算法函数对象作为 SYCL 内核。在这个页面前面我们已经看过这样的例子,让我们来快速过一遍。
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <vector>
|
||||||
|
#include <iostream>
|
||||||
|
|
||||||
|
#include <sycl/execution_policy>
|
||||||
|
#include <experimental/algorithm>
|
||||||
|
#include <sycl/helpers/sycl_buffers.hpp>
|
||||||
|
|
||||||
|
using namespace std::experimental::parallel;
|
||||||
|
using namespace sycl::helpers;
|
||||||
|
|
||||||
|
int main() {
|
||||||
|
constexpr size_t array_size = 1024*512;
|
||||||
|
std::array<cl::sycl::cl_int, array_size> in,out;
|
||||||
|
std::iota(begin(in),end(in),0);
|
||||||
|
|
||||||
|
{
|
||||||
|
cl::sycl::buffer<int> in_buffer(in.data(), cl::sycl::range<1>(in.size()));
|
||||||
|
cl::sycl::buffer<int> out_buffer(out.data(), cl::sycl::range<1>(out.size()));
|
||||||
|
cl::sycl::queue q;
|
||||||
|
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
||||||
|
transform(sycl_policy, begin(in_buffer), end(in_buffer), begin(out_buffer),
|
||||||
|
[](int x) { return x*2; });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
constexpr size_t array_size = 1024*512;
|
||||||
|
std::array<cl::sycl::cl_int, array_size> in, out;
|
||||||
|
std::iota(begin(in),end(in),0);
|
||||||
|
```
|
||||||
|
|
||||||
|
到现在为止一切如此相似。我们再一次创建一组数组用于保存我们的输入输出数据。
|
||||||
|
|
||||||
|
```
|
||||||
|
cl::sycl::buffer<int> in_buffer(in.data(), cl::sycl::range<1>(in.size()));
|
||||||
|
cl::sycl::buffer<int> out_buffer(out.data(), cl::sycl::range<1>(out.size()));
|
||||||
|
cl::sycl::queue q;
|
||||||
|
```
|
||||||
|
|
||||||
|
这里我们创建类似上个例子的缓存和队列。
|
||||||
|
|
||||||
|
```
|
||||||
|
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
||||||
|
```
|
||||||
|
|
||||||
|
这就是有趣的部分。我们从我们的队列中创建 `sycl_execution_policy`,给它一个名称让内核使用。这个执行策略然后可以像 `std::execution::par` 或 `std::execution::seq` 那样使用。
|
||||||
|
|
||||||
|
```
|
||||||
|
transform(sycl_policy, begin(in_buffer), end(in_buffer), begin(out_buffer),
|
||||||
|
[](int x) { return x*2; });
|
||||||
|
```
|
||||||
|
|
||||||
|
现在我们的内核分发看起来像提供了一个执行策略的 `std::transform` 调用。我们传递的闭包会被编译并在设备上执行,而不需要我们做其它更加复杂的设置。
|
||||||
|
|
||||||
|
当然,除了 `transform` 你可以做更多。开发的时候,SYCL 并行 STL 支持以下算法:
|
||||||
|
|
||||||
|
* `sort`
|
||||||
|
* `transform`
|
||||||
|
* `for_each`
|
||||||
|
* `for_each_n`
|
||||||
|
* `count_if`
|
||||||
|
* `reduce`
|
||||||
|
* `inner_product`
|
||||||
|
* `transform_reduce`
|
||||||
|
|
||||||
|
|
||||||
|
这就是这篇短文需要介绍的东西。如果你想和 SYCL 的开发保持同步,那就要看 [sycl.tech][9]。最近重要的开发就是移植 [Eigen][10] 和 [Tensorflow][11] 到 SYCL ,为 OpenCL 设备带来引入关注的人工智能编程。对我个人而言,我很高兴看到高级编程模型可以用于异构程序自动优化,以及它们是怎样支持类似 [HPX][12] 或 [SkelCL][13] 等更高级的技术。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://blog.tartanllama.xyz/c++/2017/05/19/sycl/
|
||||||
|
|
||||||
|
作者:[TartanLlama][a]
|
||||||
|
译者:[ictlyh](https://github.com/ictlyh)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.twitter.com/TartanLlama
|
||||||
|
[1]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fnref:1
|
||||||
|
[2]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fn:1
|
||||||
|
[3]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fn:2
|
||||||
|
[4]:https://www.khronos.org/sycl
|
||||||
|
[5]:https://www.codeplay.com/products/computesuite/computecpp/reference/platform-support-notes
|
||||||
|
[6]:https://www.codeplay.com/products/computesuite/computecpp/reference/release-notes/
|
||||||
|
[7]:https://github.com/codeplaysoftware/computecpp-sdk
|
||||||
|
[8]:https://github.com/KhronosGroup/SyclParallelSTL
|
||||||
|
[9]:http://sycl.tech/
|
||||||
|
[10]:https://github.com/ville-k/sycl_starter
|
||||||
|
[11]:http://deep-beta.co.uk/setting-up-tensorflow-with-opencl-using-sycl/
|
||||||
|
[12]:https://github.com/STEllAR-GROUP/hpx
|
||||||
|
[13]:https://github.com/skelcl/skelcl
|
||||||
234
published/20170520 How to master the art of Git.md
Normal file
234
published/20170520 How to master the art of Git.md
Normal file
@ -0,0 +1,234 @@
|
|||||||
|
掌握 Git 之美
|
||||||
|
=====================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 使用 7 条简单的 Git 命令开始你的软件开发之旅
|
||||||
|
|
||||||
|
你是否曾经想知道如何学好 Git?你长期以来都是跌跌撞撞地在使用 Git。最终,你总需要掌握它的窍门。这就是我写这篇文章的原因,我将带你去启蒙之旅。这儿是我关于如何加快 Git 学习过程的基本指南。我将介绍 Git 的实际情况以及我使用最多的 7 条 Git 命令。本文主要针对有兴趣的开发人员和大学新生,他们需要关于 Git 的介绍以及如何掌握基础知识。
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
你可以往前继续阅读整篇文章,或者只读 TLDR; 部分,尽管这将使我很受伤。
|
||||||
|
|
||||||
|
### TLDR;
|
||||||
|
|
||||||
|
在学习 Git 的过程中,请养成下面这些步骤的习惯:
|
||||||
|
|
||||||
|
1. 随时使用 `git status`!
|
||||||
|
2. 只更改那些你真正想更改的文件。
|
||||||
|
3. `git add -A` 会是你的朋友。
|
||||||
|
4. 随时使用命令 `git commit -m "meaningful messages"`。
|
||||||
|
5. 做任何推送(push)之前先使用命令 `git pull`,但是这需要在你提交过一些更改之后。
|
||||||
|
6. 最后,`git push`推送提交的更改。
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
### 良宵莫辜负
|
||||||
|
|
||||||
|
对任何开发人员来说,通常第一步都是选择一个广泛使用的地方托管他或她的代码库。那就是,[GitHub][4]。它是一切有关代码的聚集地。要理解 GitHub 的概念,你先需要知道什么是 Git。
|
||||||
|
|
||||||
|
Git 是一款基于命令行的版本控制软件,在 Windows 和 Mac 系统上也有几款可用的桌面应用。 Git 由 Linux 之父 Linus Torvalds 开发,Linus Torvalds 还是是计算机科学中最有影响力的人物之一。因为这一优势,Git 已经成为绝大多数软件开发人员关于共享和维护代码的标准。这一大段话,让我们将其细细道来。正如它的名字所说,版本控制软件 Git 让你可以预览你写过的代码的所有版本。从字面上来说, 开发人员的每个代码库都将永远存储在其各自的仓库中,仓库可以叫做任何名字,从 *pineapple* 到 *express* 都行。在此仓库开发代码的过程中,你将进行出无数次的更改,直到第一次正式发布。这就是版本控制软件如此重要的核心原因所在。它让作为开发人员的你可以清楚地了解对代码库进行的所有更改、修订和改进。从另外一个方面说,它使协同合作更容易,下载代码进行编辑,然后将更改上传到仓库。然而,尽管有了这么多好处,然而还有一件事可以锦上添花。你可以下载并使用这些文件,即使你在整个开发过程中什么事也没有做。
|
||||||
|
|
||||||
|
让我们回到文章的 GitHub 部分。它只是所有仓库的枢纽(hub),这些仓库可以存储在其中并在线浏览。它是一个让有着共同兴趣的人相聚的地方。
|
||||||
|
|
||||||
|
### 千里之行始于足下
|
||||||
|
|
||||||
|
OK,记住,Git 是一款软件,像任何其他软件一样,你首先需要安装它:
|
||||||
|
|
||||||
|
[Git - 安装 Git,如果你希望从源代码安装 Git,你需要安装这些 Git 的依赖库: autotools —— 来自 git-scm.com][5]
|
||||||
|
|
||||||
|
*Tips:请点击上面的链接,然后按照说明开始。*
|
||||||
|
|
||||||
|
完成了安装过程,很好。现在你需要在你的浏览器地址栏输入 [github.com][7] 访问该网站。如果你还没有帐号的话需要新创建一个帐号,这就是你的起舞之处。登录并创建一个新仓库,命名为 Steve ,没有什么理由,只是想要一个名为史蒂夫的仓库好玩而已。选中 “Initialize this repository with a README” 复选框并点击创建按钮。现在你有了一个叫做 Steve 的仓库。我相信你会为你自己感到自豪。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 现在开始在使用 Git
|
||||||
|
|
||||||
|
现在是比较有趣的部分。你将把 Steve 克隆到你本地的机器上。可以把这个过程看作从 Github 上复制仓库到你的电脑上。点击 “clone or download” 按钮,你将看到一个类似下面这样的 URL:
|
||||||
|
|
||||||
|
```
|
||||||
|
https://github.com/yourGithubAccountName/Steve.git
|
||||||
|
```
|
||||||
|
|
||||||
|
复制这个 URL 并打开命令提示符窗口。现在输入并运行条命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
git clone https://github.com/yourGithubAccountName/Steve.git
|
||||||
|
```
|
||||||
|
|
||||||
|
Abrakadabra!Steve 仓库已经被自动克隆到了你的电脑上。查看你克隆这个仓库的目录,你会看到一个叫做 Steve 的文件夹。这个本地的文件夹现在已经链接到了它的 “origin” ,也就是 GitHub 上的远程仓库。
|
||||||
|
|
||||||
|
记住这个过程,在你的软件开发工程人员的职业生涯中你一定会重复这个过程很多次的。完成所有这些准备工作之后,你就可以开始使用最普通且常用的 Git 命令了。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 你现在已经开始在真实场景使用 Git 了
|
||||||
|
|
||||||
|
找到 Steve 目录并在该目录中打开命令提示符窗口,运行下面的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
git status
|
||||||
|
```
|
||||||
|
|
||||||
|
这会输出你的工作目录的状态,让你知道所有你编辑过的文件。这意味着它显示了远程库中和本地工作目录中之间的文件差异。`status` 命令被用来作为 `commit` 的模版,我将在这篇教程后面进一步谈论 `commit` 。简单的说,`[git status][1]` 告诉你你编辑过哪些文件,以给你一个你想要上传到远程库的概述。
|
||||||
|
|
||||||
|
但是,在你做任何上传之前,你首先需要做的是选择你需要发送回远程库的文件。使用下面命令完成:
|
||||||
|
|
||||||
|
```
|
||||||
|
git add
|
||||||
|
```
|
||||||
|
|
||||||
|
接着在 Steve 目录新建一个文本文件,可以取一个好玩的名字 `pineapple.txt`。在这个文件里面随便写些你想写的内容,返回命令提示符,然后再次输入 `git status`。现在,你将看到这个文件以红色出现在标记 “untracked files” 下面。
|
||||||
|
|
||||||
|
```
|
||||||
|
On branch master
|
||||||
|
Your branch is up-to-date with 'origin/master'.
|
||||||
|
Untracked files:
|
||||||
|
(use "git add <file>..." to include in what will be commited)
|
||||||
|
|
||||||
|
pineapple.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
下一步就是将它添加到暂存区(staging)。暂存区可以看作是这样的一个环境:你做过的所有更改在提交时都将捆绑为一个更改而被提交。现在,你可以将这个文件加入暂存区:
|
||||||
|
|
||||||
|
```
|
||||||
|
git add -A
|
||||||
|
```
|
||||||
|
|
||||||
|
`-A` 选项意味着所有你更改过的文件都会被加到暂存区等待提交。然而, `git add` 非常灵活,它也可以像这样一个文件一个文件的添加:
|
||||||
|
|
||||||
|
```
|
||||||
|
git add pineapple.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
这种方法让你有能力选择你想要暂存的每一个文件,而不用担心加入那些你不想改变的东西。
|
||||||
|
|
||||||
|
再次运行 `git status`,你会看到如下输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
On branch master
|
||||||
|
Your branch is up-to-date with 'origin/master'.
|
||||||
|
Changes to be committed:
|
||||||
|
(use "git reset HEAD <file>..." to unstage)
|
||||||
|
|
||||||
|
new file: pineapple.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
准备好提交更改了吗?开始吧。
|
||||||
|
|
||||||
|
```
|
||||||
|
git commit -m "Write your message here"
|
||||||
|
```
|
||||||
|
|
||||||
|
[Git commit][9] 命令会将存储在暂存区中的文件和来自用户的用于描述更改的日志信息一起存储在一个新的地方。`-m`选项加入了写在双引号内的信息。
|
||||||
|
|
||||||
|
再次检查状态,你会看到:
|
||||||
|
|
||||||
|
```
|
||||||
|
On branch master
|
||||||
|
Your branch is ahead of 'origin/master' by 1 commit.
|
||||||
|
(use "git push" to publish your local commits)
|
||||||
|
nothing to commit, working directory clean
|
||||||
|
```
|
||||||
|
|
||||||
|
所有的更改现在都被加入到一次提交当中了,同时会有一条与你所做相关的信息。现在你可以用 `git push` 将这次提交推送到远程库 “origin”了。这条命令就像字面意义所说,它会把你提交的更改从本地机器上传到 GitHub 的远程仓库中。返回到命令提示符,然后运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
git push
|
||||||
|
```
|
||||||
|
|
||||||
|
你会被要求输入你的 GitHub 帐号和密码,之后你会看到类似下面的这些内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
Counting objects: 3, done.
|
||||||
|
Delta compression using up to 4 threads.
|
||||||
|
Compressing objects: 100% (2/2), done.
|
||||||
|
Writing objects: 100% (3/3), 280 bytes | 0 bytes/s, done.
|
||||||
|
Total 3 (delta 0), reused 0 (delta 0)
|
||||||
|
To https://github.com/yourGithubUserName/Steve.git
|
||||||
|
c77a97c..08bb95a master -> master
|
||||||
|
```
|
||||||
|
|
||||||
|
就是这样。你已经成功上传了你本地的更改。看看你在 GitHub 上的仓库,你会看到它现在包含了一叫做 `pineapple.txt` 的文件。
|
||||||
|
|
||||||
|
如果你是一个开发小组的一员呢?如果他们都推送提交到 “origin”,将会发生什么?这就是 Git 真正开始发挥它的魔力的时候。你可以使用一条简单的命令轻松地将最新版本的代码库 [pull][10] 到你本地的机器上:
|
||||||
|
|
||||||
|
```
|
||||||
|
git pull
|
||||||
|
```
|
||||||
|
|
||||||
|
但是 Git 也有限制:你需要有相匹配的版本才能推送到 “origin”。这意味着你本地的版本需要和 origin 的版本大致一样。当你从 “origin” 拉取(pull)文件时,在你的工作目录中不能有文件,因为它们将会在这个过程中被覆盖。因此我给出了这条简单的建议。在学习 Git 的过程中,请养成下面这些步骤的习惯:
|
||||||
|
|
||||||
|
1. 随时使用 `git status`!
|
||||||
|
2. 只更改那些你真正想更改的文件。
|
||||||
|
3. `git add -A` 会是你的朋友。
|
||||||
|
4. 随时使用命令 `git commit -m "meaningful messages"`。
|
||||||
|
5. 做任何推送(push)之前先使用命令 `git pull`,但是这需要在你提交过一些更改之后。
|
||||||
|
6. 最后,`git push`推送提交的更改。
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
嘿!你还在看这篇文章吗?你已经看了很久了,休息一下吧!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
休息好了吗?好的!让我们来处理一些错误。如果你不小心更改了一些你本不应该更改的文件后怎么办呢?不需要担心,只需要使用 [git checkout][3]。让我们在文件 `pineapple.txt` 里更改一些内容:在文件中加入一行,比方说,“Steve is mega-awesome!” 。然后保存更改并用 `git status` 检查一下:
|
||||||
|
|
||||||
|
```
|
||||||
|
On branch master
|
||||||
|
Your branch is up-to-date with 'origin/master'.
|
||||||
|
Changes not staged for commit:
|
||||||
|
(use "git add <file>..." to update what will be committed)
|
||||||
|
(use "git checkout -- <file>..." to discard changes in working directory)
|
||||||
|
|
||||||
|
modified: pineapple.txt
|
||||||
|
|
||||||
|
no changes added to commit (use "git add" and/or "git commit -a")
|
||||||
|
```
|
||||||
|
|
||||||
|
正如预料的那样,它已经被记录为一次更改了。但是,假如 Steve 实际上并不是很优秀呢?假如 Steve 很差劲呢?不用担心!最简单的还原更改的方式是运行命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
git checkout -- pineapple.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你会看到文件已经恢复到了先前的状态。
|
||||||
|
|
||||||
|
但是假如你玩砸了呢?我是说,事情已经变得混乱,并且需要把所有东西重置到与 “origin” 一样的状态。也不需要担心,在这种紧急情况下我们可以享受 Git 的美妙之处:
|
||||||
|
|
||||||
|
```
|
||||||
|
git reset --hard
|
||||||
|
```
|
||||||
|
|
||||||
|
[Git reset][11] 命令和 `--hard` 选项一起可以抛弃自上次提交以来的所有更改,有些时候真的很好用。
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
最后,我想鼓励你尽可能多地使用 Git。这是能够熟练使用它的最好学习方式。除此之外,养成阅读 Git 文档的习惯。一开始可能会有些云里雾里,但是过段时间后你就会明白它的窍门了。
|
||||||
|
|
||||||
|
*希望你们(小伙子和姑娘们)读这篇文章的时候会和我写它时一样的开心。如果你认为这篇文章对别人有用,你尽可以与别人分享它。或者,如果你喜欢这篇文章,你可以在下面点下赞以便让更多的人看到这篇文章。*
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://hackernoon.com/how-to-master-the-art-of-git-68e1050f3147
|
||||||
|
|
||||||
|
作者:[Adnan Rahić][a]
|
||||||
|
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://hackernoon.com/@adnanrahic
|
||||||
|
[1]:https://git-scm.com/docs/git-status
|
||||||
|
[2]:https://git-scm.com/docs/git-push
|
||||||
|
[3]:https://git-scm.com/docs/git-checkout
|
||||||
|
[4]:https://github.com/
|
||||||
|
[5]:https://git-scm.com/book/en/v2/Getting-Started-Installing-Git
|
||||||
|
[6]:https://git-scm.com/book/en/v2/Getting-Started-Installing-Git
|
||||||
|
[7]:https://github.com/
|
||||||
|
[8]:https://git-scm.com/docs/git-add
|
||||||
|
[9]:https://git-scm.com/docs/git-commit
|
||||||
|
[10]:https://git-scm.com/docs/git-pull
|
||||||
|
[11]:https://git-scm.com/docs/git-reset
|
||||||
@ -1,8 +1,7 @@
|
|||||||
Linux 系统中修复 SambaCry 漏洞(CVE-2017-7494)
|
Linux 系统中修复 SambaCry 漏洞(CVE-2017-7494)
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
Samba 很久以来一直是为 *nix 系统上的 Windows 客户端提供共享文件和打印服务的标准。家庭用户,中型企业和大型公司都在使用它,它作为最佳解决方案在多种操作系统共存的环境中脱颖而出。
|
||||||
Samba 很久以来是为 *nix 系统上的 Windows 客户端提供共享文件和打印服务的标准。家庭用户,中型企业和大型公司都在使用它,它作为最佳解决方案在不同操作系统共存的环境中脱颖而出。
|
|
||||||
|
|
||||||
由于广泛使用的工具很可能发生这种情况,大多数 Samba 安装都面临着可能利用已知漏洞的攻击的风险,这个漏洞直到 WannaCry 勒索软件攻击的新闻出来之前都被认为是不重要的。
|
由于广泛使用的工具很可能发生这种情况,大多数 Samba 安装都面临着可能利用已知漏洞的攻击的风险,这个漏洞直到 WannaCry 勒索软件攻击的新闻出来之前都被认为是不重要的。
|
||||||
|
|
||||||
@ -22,13 +21,13 @@ Debian、Ubuntu、CentOS 和 Red Hat 已采取快速的行动来保护它们的
|
|||||||
|
|
||||||
如先前提到的那样,根据你之前安装的方法有两种方式更新:
|
如先前提到的那样,根据你之前安装的方法有两种方式更新:
|
||||||
|
|
||||||
如果你从发行版的仓库中安装的 Samba。
|
#### 如果你从发行版的仓库中安装的 Samba
|
||||||
|
|
||||||
让我们看下在这种情况下你需要做什么:
|
让我们看下在这种情况下你需要做什么:
|
||||||
|
|
||||||
#### 在 Debian 下修复 Sambacry
|
**在 Debian 下修复 SambaCry**
|
||||||
|
|
||||||
添加下面的行到你的源列表中(/etc/apt/sources.list)以确保 [apt][2] 能够获得最新的安全更新:
|
添加下面的行到你的源列表中(`/etc/apt/sources.list`)以确保 [apt][2] 能够获得最新的安全更新:
|
||||||
|
|
||||||
```
|
```
|
||||||
deb http://security.debian.org stable/updates main
|
deb http://security.debian.org stable/updates main
|
||||||
@ -49,11 +48,11 @@ deb-src http://security.debian.org/ stable/updates main
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
在 Debian 中修复 Sambacry
|
*在 Debian 中修复 SambaCry*
|
||||||
|
|
||||||
#### 在 Ubuntu 中修复 Sambacry
|
**在 Ubuntu 中修复 SambaCry**
|
||||||
|
|
||||||
要开始修复,如下检查新的可用软件包并更新 samba 软件包:
|
要开始修复,如下检查新的可用软件包并更新 Samba 软件包:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ sudo apt-get update
|
$ sudo apt-get update
|
||||||
@ -76,7 +75,7 @@ $ sudo apt-get install samba
|
|||||||
$ sudo apt-cache show samba
|
$ sudo apt-cache show samba
|
||||||
```
|
```
|
||||||
|
|
||||||
#### 在 CentOS/RHEL 7 中修复 Sambacry
|
**在 CentOS/RHEL 7 中修复 SambaCry**
|
||||||
|
|
||||||
在 EL 7 中打过补丁的 Samba 版本是 samba-4.4.4-14.el7_3。要安装它,这些做:
|
在 EL 7 中打过补丁的 Samba 版本是 samba-4.4.4-14.el7_3。要安装它,这些做:
|
||||||
|
|
||||||
@ -93,19 +92,19 @@ $ sudo apt-cache show samba
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
在 CentOS 中修复 Sambacry
|
*在 CentOS 中修复 SambaCry*
|
||||||
|
|
||||||
旧支持的 CentOS 以及 RHEL 更老的版本也有修复。参见 [RHSA-2017-1270][4] 获取更多。
|
旧支持的 CentOS 以及 RHEL 更老的版本也有修复。参见 [RHSA-2017-1270][4] 获取更多。
|
||||||
|
|
||||||
##### 如果你从源码安装的 Samba
|
#### 如果你从源码安装的 Samba
|
||||||
|
|
||||||
注意:下面的过程假设你先前从源码构建的 Samba。强烈建议你在部署到生产服务器之前先在测试环境尝试。
|
注意:下面的过程假设你先前从源码构建的 Samba。强烈建议你在部署到生产服务器之前先在测试环境尝试。
|
||||||
|
|
||||||
额外地,开始之前确保你备份了 smb.conf 文件。
|
此外,开始之前确保你备份了 `smb.conf` 文件。
|
||||||
|
|
||||||
在这种情况下,我们也会从源码编译并更新 Samba。然而在开始之前,我们必须先确保安装了所有的依赖。注意这也许会花费几分钟。
|
在这种情况下,我们也会从源码编译并更新 Samba。然而在开始之前,我们必须先确保安装了所有的依赖。注意这也许会花费几分钟。
|
||||||
|
|
||||||
#### 在 Debian 和 Ubuntu 中:
|
**在 Debian 和 Ubuntu 中:**
|
||||||
|
|
||||||
```
|
```
|
||||||
# aptitude install acl attr autoconf bison build-essential \
|
# aptitude install acl attr autoconf bison build-essential \
|
||||||
@ -118,7 +117,7 @@ python-all-dev python-dev python-dnspython python-crypto xsltproc \
|
|||||||
zlib1g-dev libsystemd-dev libgpgme11-dev python-gpgme python-m2crypto
|
zlib1g-dev libsystemd-dev libgpgme11-dev python-gpgme python-m2crypto
|
||||||
```
|
```
|
||||||
|
|
||||||
#### 在 CentOS 7 或相似的版本中:
|
**在 CentOS 7 或相似的版本中:**
|
||||||
|
|
||||||
```
|
```
|
||||||
# yum install attr bind-utils docbook-style-xsl gcc gdb krb5-workstation \
|
# yum install attr bind-utils docbook-style-xsl gcc gdb krb5-workstation \
|
||||||
@ -129,7 +128,7 @@ libacl-devel libaio-devel libblkid-devel libxml2-devel openldap-devel \
|
|||||||
pam-devel popt-devel python-devel readline-devel zlib-devel
|
pam-devel popt-devel python-devel readline-devel zlib-devel
|
||||||
```
|
```
|
||||||
|
|
||||||
停止服务:
|
停止服务(LCTT 译注:此处不必要):
|
||||||
|
|
||||||
```
|
```
|
||||||
# systemctl stop smbd
|
# systemctl stop smbd
|
||||||
@ -171,25 +170,24 @@ pam-devel popt-devel python-devel readline-devel zlib-devel
|
|||||||
|
|
||||||
这里返回的应该是 4.6.4。
|
这里返回的应该是 4.6.4。
|
||||||
|
|
||||||
### 概论
|
### 其它情况
|
||||||
|
|
||||||
如果你使用的是不受支持的发行版本,并且由于某些原因无法升级到最新版本,你或许要考虑下面这些建议:
|
如果你使用的是不受支持的发行版本,并且由于某些原因无法升级到最新版本,你或许要考虑下面这些建议:
|
||||||
|
|
||||||
* 如果 SELinux 是启用的,你是受保护的!
|
* 如果 SELinux 是启用的,你是处于保护之下的!
|
||||||
|
* 确保 Samba 共享是用 `noexec` 选项挂载的。这会阻止二进制文件从被挂载的文件系统中执行。
|
||||||
|
|
||||||
* 确保 Samba 共享是用 noexec 选项挂载的。这会阻止二进制文件从被挂载的文件系统中执行。
|
还有将:
|
||||||
|
|
||||||
还有将
|
|
||||||
|
|
||||||
```
|
```
|
||||||
nt pipe support = no
|
nt pipe support = no
|
||||||
```
|
```
|
||||||
|
|
||||||
添加到 smb.conf 的 [global] 字段中。你或许要记住,根据 Samba 项目,这“或许禁用 Windows 客户端的某些功能”。
|
添加到 `smb.conf` 的 `[global]` 字段中。你或许要记住,根据 Samba 项目,这“或许禁用 Windows 客户端的某些功能”。
|
||||||
|
|
||||||
重要:注意 “nt pipe support = no” 选项会禁用 Windows 客户端的共享列表。比如:当你在一台 Samba 服务器的 Windows Explorer 中输入 \\10.100.10.2\ 时,你会看到 “permission denied”。Windows 客户端不得不手动执行共享,如 \\10.100.10.2\share_name 来访问共享。
|
重要:注意 `nt pipe support = no` 选项会禁用 Windows 客户端的共享列表。比如:当你在一台 Samba 服务器的 Windows Explorer 中输入 `\\10.100.10.2\` 时,你会看到 “permission denied”。Windows 客户端不得不手动执行共享,如 `\\10.100.10.2\share_name` 来访问共享。
|
||||||
|
|
||||||
##### 总结
|
### 总结
|
||||||
|
|
||||||
在本篇中,我们已经描述了 SambaCry 漏洞以及如何减轻影响。我们希望你可以使用这个信息来保护你负责的系统。
|
在本篇中,我们已经描述了 SambaCry 漏洞以及如何减轻影响。我们希望你可以使用这个信息来保护你负责的系统。
|
||||||
|
|
||||||
@ -199,16 +197,15 @@ nt pipe support = no
|
|||||||
|
|
||||||
作者简介:
|
作者简介:
|
||||||
|
|
||||||
|
|
||||||
Gabriel Cánepa 是一名 GNU/Linux 系统管理员,阿根廷圣路易斯 Villa Mercedes 的 web 开发人员。他为一家国际大型消费品公司工作,在日常工作中使用 FOSS 工具以提高生产力,并从中获得极大乐趣。
|
Gabriel Cánepa 是一名 GNU/Linux 系统管理员,阿根廷圣路易斯 Villa Mercedes 的 web 开发人员。他为一家国际大型消费品公司工作,在日常工作中使用 FOSS 工具以提高生产力,并从中获得极大乐趣。
|
||||||
|
|
||||||
--------------
|
--------------
|
||||||
|
|
||||||
via: https://www.tecmint.com/fix-sambacry-vulnerability-cve-2017-7494-in-linux/
|
via: https://www.tecmint.com/fix-sambacry-vulnerability-cve-2017-7494-in-linux/
|
||||||
|
|
||||||
作者:[Gabriel Cánepa ][a]
|
作者:[Gabriel Cánepa][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,62 +1,70 @@
|
|||||||
安卓编年史
|
安卓编年史(21):安卓 4.2,果冻豆——全新 Nexus 设备,全新平板界面
|
||||||
================================================================================
|
================================================================================
|
||||||
### Android 4.2,果冻豆——全新 Nexus 设备,全新平板界面 ###
|
### 安卓 4.2,果冻豆——全新 Nexus 设备,全新平板界面 ###
|
||||||
|
|
||||||
安卓平台成熟的脚步越来越快,谷歌也将越来越多的应用托管到 Play 商店,需要通过系统更新来更新的应用越来越少。但是不间断的更新还是要继续的,2012 年 11 月,安卓 4.2 发布。4.2 还是叫做“果冻豆”,这个版本主要是一些少量变动。
|
安卓平台成熟的脚步越来越快,谷歌也将越来越多的应用托管到 Play 商店,需要通过系统更新来更新的应用越来越少。但是不间断的更新还是要继续的,2012 年 11 月,安卓 4.2 发布。4.2 还是叫做“果冻豆”,这个版本主要是一些少量变动。
|
||||||
|
|
||||||

|

|
||||||
LG 生产的 Nexus 4 和三星生产的 Nexus 10。
|
|
||||||
Google/Ron Amadeo 供图
|
|
||||||
|
|
||||||
和安卓 4.2 一同发布的还有两部旗舰设备,Nexus 4 和 Nexus 10,都由谷歌直接在 Play 商店出售。Nexus 4 使用了 Nexus 7 的策略,令人惊讶的低价和高质量,并且无锁设备售价 300 美元。Nexus 4 有一个 4 核 1.5GHz 骁龙 S4 Pro 处理器,2GB 内存以及 1280×768 分辨率 4.7 英寸 LCD 显示屏。谷歌的新旗舰手机由 LG 生产,并和制造商一起将关注点转向了材料和质量。Nexus 4 有着正反两面双面玻璃,这会让你爱不释手,他是有史以来触感最佳的安卓手机之一。Nexus 4 最大的缺点是没有 LTE 支持,那时候大部分手机,包括 Version Galaxy Nexus 都有更快的基带。但 Nexus 4 的需求仍大大超出了谷歌的预料——发布当日大量的流量拖垮了 Play 商店网站。手机在一小时之内销售一空。
|
*LG 生产的 Nexus 4 和三星生产的 Nexus 10。
|
||||||
|
[Google/Ron Amadeo 供图]*
|
||||||
|
|
||||||
Nexus 10 是谷歌的第一部 10 英寸 Nexus 平板。该设备的亮点是 2560×1600 分辨率的显示屏,在其等级上是分辨率最高的。这背后是双核 1.7GHz Cortex A15 处理器和 2GB 内存的强力支持。随着时间一个月一个月地流逝,Nexus 10 似乎逐渐成为了第一部也是最后一部 10 英寸 Nexus 平板。通常这些设备每年都升级,但 Nexus 10 至今面世 16 个月了,可预见的未来还没有新设备的迹象。谷歌在小尺寸的 7 英寸平板上做得很出色,它似乎更倾向于让[像三星][1]这样的合作伙伴探索更大的平板家族。
|
和安卓 4.2 一同发布的还有两部旗舰设备,Nexus 4 和 Nexus 10,都由谷歌直接在 Play 商店出售。Nexus 4 使用了 Nexus 7 的策略,令人惊讶的低价和高质量,并且无锁设备售价 300 美元。Nexus 4 有一个 4 核 1.5GHz 骁龙 S4 Pro 处理器,2GB 内存以及 1280×768 分辨率 4.7 英寸 LCD 显示屏。谷歌的新旗舰手机由 LG 生产,并和制造商一起将关注点转向了材料和质量。Nexus 4 有着正反两面双面玻璃,这会让你爱不释手,它是有史以来触感最佳的安卓手机之一。Nexus 4 最大的缺点是没有 LTE 支持,那时候大部分手机,包括 Version Galaxy Nexus 都有更快的基带。但 Nexus 4 的需求仍大大超出了谷歌的预料——发布当日大量的流量拖垮了 Play 商店网站。手机在一小时之内销售一空。
|
||||||
|
|
||||||
|
Nexus 10 是谷歌的第一部 10 英寸 Nexus 平板。该设备的亮点是 2560×1600 分辨率的显示屏,在这个等级上是分辨率最高的。这背后是双核 1.7GHz Cortex A15 处理器和 2GB 内存的强力支持。随着时间一个月一个月地流逝,Nexus 10 似乎逐渐成为了第一部也是最后一部 10 英寸 Nexus 平板。通常这些设备每年都升级,但 Nexus 10 至今面世 16 个月了,可预见的未来还没有新设备的迹象。谷歌在小尺寸的 7 英寸平板上做得很出色,它似乎更倾向于让[像三星][1]这样的合作伙伴探索更大的平板家族。
|
||||||
|
|
||||||
|

|
||||||
新的锁屏,壁纸,以及时钟小部件设计。
|
|
||||||
Ron Amadeo 供图
|
*新的锁屏,壁纸,以及时钟小部件设计。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
4.2 为锁屏带来了很多变化。文字居中,并且对小时使用了较大的字重,对分钟使用了较细的字体。锁屏现在是分页的,可以自定义小部件。锁屏不仅仅是一个简单的时钟,用户还可以将其替换成其它小部件或者添加额外的页面和更多的小部件。
|
4.2 为锁屏带来了很多变化。文字居中,并且对小时使用了较大的字重,对分钟使用了较细的字体。锁屏现在是分页的,可以自定义小部件。锁屏不仅仅是一个简单的时钟,用户还可以将其替换成其它小部件或者添加额外的页面和更多的小部件。
|
||||||
|
|
||||||
|

|
||||||
锁屏的添加小部件页面,小部件列表,锁屏上的 Gmail 部件,以及滑动到相机。
|
|
||||||
Ron Amadeo 供图
|
*锁屏的添加小部件页面,小部件列表,锁屏上的 Gmail 部件,以及滑动到相机。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
锁屏现在就像是一个精简版的主屏幕。页面轮廓会显示在锁屏的左右两侧来提示用户可以滑动到有其他小部件的页面。向左滑动页面会显示一个中间带有加号的简单空白页面,点击加号会打开兼容锁屏的小部件列表。锁屏每个页面限制一个小部件,将小部件向上或向下拖动可以展开或收起。最右侧的页面保留给了相机——一个简单的滑动就能打开相机界面,但是你没办法滑动回来。
|
锁屏现在就像是一个精简版的主屏幕。页面轮廓会显示在锁屏的左右两侧来提示用户可以滑动到有其他小部件的页面。向左滑动页面会显示一个中间带有加号的简单空白页面,点击加号会打开兼容锁屏的小部件列表。锁屏每个页面限制一个小部件,将小部件向上或向下拖动可以展开或收起。最右侧的页面保留给了相机——一个简单的滑动就能打开相机界面,但是你没办法滑动回来。
|
||||||
|
|
||||||

|

|
||||||
新的快速设置面板以及内置应用集合。
|
|
||||||
Ron Amadeo 供图
|
|
||||||
|
|
||||||
4.2 最大的新增特性之一就是“快速设置”面板。安卓 3.0 为平板引入了快速改变电源设置的途径,4.2 终于将这种能力带给了手机。通知中心右上角加入了一枚新图标,可以在正常的通知列表和新的快速设置之间切换。快速设置提供了对屏幕亮度,网络连接,电池以及数据用量更加快捷的访问,而不用打开完整的设置界面。安卓 4.1 中顶部的设置按钮移除掉了,快速设置中添加了一个按钮来替代它。
|
*新的快速设置面板以及内置应用集合。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
应用抽屉和 4.2 中的应用阵容有很多改变。得益于 Nexus 4 更宽的屏幕横纵比(5:3,Galaxy Nexus 是 16:9),应用抽屉可以显示一行五个应用图标的方阵。4.2 将自带的浏览器替换为了 Google Chrome,自带的日历换成了 Google Calendar,他们都带来了新的图标设计。时钟和相机应用在 4.2 中经过了重制,新的图标也是其中的一部分。“Google Settings”是个新应用,用于提供对系统范围内所有存在的谷歌账户设置的快捷方式,它有着和 Google Search 和 Google+ 图标一致的风格。谷歌地图拥有了新图标,谷歌纵横,以往是谷歌地图的一部分,作为对 Google+ location 的支持在这个版本退役。
|
4.2 最大的新增特性之一就是“快速设置”面板。安卓 3.0 为平板引入了快速改变电源设置的途径,4.2 终于将这种能力带给了手机。通知中心右上角加入了一枚新图标,可以在正常的通知列表和新的快速设置之间切换。快速设置提供了对屏幕亮度、网络连接、电池以及数据用量更加快捷的访问,而不用打开完整的设置界面。安卓 4.1 中顶部的设置按钮移除掉了,快速设置中添加了一个按钮来替代它。
|
||||||
|
|
||||||
|
应用抽屉和 4.2 中的应用阵容有很多改变。得益于 Nexus 4 更宽的屏幕横纵比(5:3,Galaxy Nexus 是 16:9),应用抽屉可以显示一行五个应用图标的方阵。4.2 将自带的浏览器替换为了 Google Chrome,自带的日历换成了 Google Calendar,它们都带来了新的图标设计。时钟和相机应用在 4.2 中经过了重制,新的图标也是其中的一部分。“Google Settings”是个新应用,用于提供对系统范围内所有存在的谷歌账户设置的快捷方式,它有着和 Google Search 和 Google+ 图标一致的风格。谷歌地图拥有了新图标,谷歌纵横,以往是谷歌地图的一部分,作为对 Google+ location 的支持在这个版本退役。
|
||||||
|
|
||||||
|

|
||||||
浏览器替换为 Chrome,带有全屏取景器的新相机界面。
|
|
||||||
Ron Amadeo 供图
|
|
||||||
|
|
||||||
原自带浏览器在一段时间内对 Chrome 的模仿上下了不少功夫——它引入了许多 Chrome 的界面元素,许多 Chrome 的特性,甚至还使用了 Chrome 的 javascript 引擎——但安卓 4.2 来临的时候,谷歌认为安卓版的 Chrome 已经准备好替代这个模仿者了。表面上看起来没有多大不同;界面看起来不一样,而且早期版本的 Chrome 安卓版滚动起来没有原浏览器顺畅。不过深层次来说,一切都不一样。安卓的主浏览器开发现在由 Google Chrome 团队负责,而不是作为安卓团队的子项目存在。安卓的默认浏览器从绑定安卓版本发布停滞不前的应用变成了不断更新的 Play 商店应用。现在甚至还有一个每个月接收一些更新的 beta 通道。
|
*浏览器替换为 Chrome,带有全屏取景器的新相机界面。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
|
原来的自带浏览器在一段时间内对 Chrome 的模仿上下了不少功夫——它引入了许多 Chrome 的界面元素,许多 Chrome 的特性,甚至还使用了 Chrome 的 javascript 引擎——但安卓 4.2 来临的时候,谷歌认为安卓版的 Chrome 已经准备好换下这个模仿者了。表面上看起来没有多大不同;界面看起来不一样,而且早期版本的 Chrome 安卓版滚动起来没有原浏览器顺畅。不过从深层次来说,一切都不一样。安卓的主浏览器开发现在由 Google Chrome 团队负责,而不是作为安卓团队的子项目存在。安卓的默认浏览器从绑定安卓版本发布、停滞不前的应用变成了不断更新的 Play 商店应用。现在甚至还有一个每个月接收一些更新的 beta 通道。
|
||||||
|
|
||||||
相机界面经过了重新设计。它现在完全是个全屏应用,显示摄像头的实时图像并且在上面显示控制选项。布局审美和安卓 1.5 的[相机设计][2]有很多共同之处:带对焦的最小化的控制放置在取景器显示之上。中间的控制环在你长按屏幕或点击右下角圆形按钮的时候显示。你的手指保持在屏幕上时,你可以滑动来选择环上的选项,通常是展开进入一个子菜单。在高亮的选项上释放手指选中它。这灵感很明显来自于安卓 4.0 浏览器中的快速控制,但是将选项安排在一个环上意味着你的手指几乎总会挡住一部分界面。
|
相机界面经过了重新设计。它现在完全是个全屏应用,显示摄像头的实时图像并且在上面显示控制选项。布局审美和安卓 1.5 的[相机设计][2]有很多共同之处:带对焦的最小化的控制放置在取景器显示之上。中间的控制环在你长按屏幕或点击右下角圆形按钮的时候显示。你的手指保持在屏幕上时,你可以滑动来选择环上的选项,通常是展开进入一个子菜单。在高亮的选项上释放手指选中它。这灵感很明显来自于安卓 4.0 浏览器中的快速控制,但是将选项安排在一个环上意味着你的手指几乎总会挡住一部分界面。
|
||||||
|
|
||||||
|

|
||||||
时钟应用,从一个只有两个界面的应用变成功能强大,实用的应用。
|
|
||||||
Ron Amadeo 供图
|
|
||||||
|
|
||||||
时钟应用经过了完整的改造,从一个简单的两个界面的闹钟,到一个世界时钟,闹钟,定时器,以及秒表俱全。时钟应用的设计和谷歌之前引入的完全不同,有着极简审美和红色高亮。它看起来像是谷歌的一个试验。甚至是几个版本之后,这个设计语言似乎也仅限于这个应用。
|
*时钟应用,从一个只有两个界面的应用变成功能强大,实用的应用。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
时钟的时间选择器是经过特别精心设计的。它显示一个简单的数字盘,会智能地禁用会导致无效时间的数字。设置闹钟时间也不可能没有隐式选择选择的 AM 和 PM,永远地解决了不小心将 9am 的闹钟设置成 9pm 的问题。
|
时钟应用经过了完整的改造,从一个简单的两个界面的闹钟,到一个世界时钟、闹钟、定时器,以及秒表俱全。时钟应用的设计和谷歌之前引入的完全不同,有着极简审美和红色高亮。它看起来像是谷歌的一个试验。甚至是几个版本之后,这个设计语言似乎也仅限于这个应用。
|
||||||
|
|
||||||
|
时钟的时间选择器是经过特别精心设计的。它显示一个简单的数字盘,会智能地禁用会导致无效时间的数字。设置闹钟时间也不能在没有明确选择 AM 和 PM 时设置,永远地解决了不小心将 9am 的闹钟设置成 9pm 的问题。
|
||||||
|
|
||||||
|

|
||||||
平板的新系统界面使用了延展版的手机界面。
|
|
||||||
Ron Amadeo 供图
|
*平板的新系统界面使用了延展版的手机界面。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
安卓 4.2 中最有争议的改变是平板界面,从单独一个统一的底部系统栏变成带有顶部状态栏和底部系统栏的双栏设计。新设计统一了手机和平板的界面,但批评人士说将手机界面延展到 10 英寸的横向平板上是浪费空间。因为导航按键现在拥有了整个底栏,所以他们像手机界面那样被居中。
|
安卓 4.2 中最有争议的改变是平板界面,从单独一个统一的底部系统栏变成带有顶部状态栏和底部系统栏的双栏设计。新设计统一了手机和平板的界面,但批评人士说将手机界面延展到 10 英寸的横向平板上是浪费空间。因为导航按键现在拥有了整个底栏,所以他们像手机界面那样被居中。
|
||||||
|
|
||||||
|

|
||||||
平板上的多用户,以及新的手势键盘。
|
|
||||||
Ron Amadeo 供图
|
*平板上的多用户,以及新的手势键盘。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
在平板上,安卓 4.2 带来了多用户支持。在设置里,新增了“用户”部分,你可以在这里管理一台设备上的用户。设置在每个用户账户内完成,安卓会给每个用户保存单独的设置,主屏幕,应用以及应用数据。
|
在平板上,安卓 4.2 带来了多用户支持。在设置里,新增了“用户”部分,你可以在这里管理一台设备上的用户。设置在每个用户账户内完成,安卓会给每个用户保存单独的设置,主屏幕,应用以及应用数据。
|
||||||
|
|
||||||
@ -64,17 +72,15 @@ Ron Amadeo 供图
|
|||||||
|
|
||||||
----------
|
----------
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。[@RonAmadeo][t]
|
||||||
|
|
||||||
[@RonAmadeo][t]
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/22/
|
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/22/
|
||||||
|
|
||||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,52 +1,54 @@
|
|||||||
安卓编年史
|
安卓编年史(22):周期外更新——谁需要一个新系统?
|
||||||
================================================================================
|
================================================================================
|
||||||

|

|
||||||
Play 商店又一次重新设计!这一版非常接近现在的设计,卡片结构让改变布局变得易如反掌。
|
|
||||||
Ron Amadeo 供图
|
*Play 商店又一次重新设计!这一版非常接近现在的设计,卡片结构让改变布局变得易如反掌。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
### 周期外更新——谁需要一个新系统? ###
|
### 周期外更新——谁需要一个新系统? ###
|
||||||
|
|
||||||
在安卓 4.2 和安卓 4.3 之间,谷歌进行了一次周期外更新,显示了有多少安卓可以不经过费力的 OTA 更新而得到改进。得益于[谷歌 Play 商店和 Play 服务][1],这些更新可以在不更新任何系统核心组件的前提下送达。
|
在安卓 4.2 和安卓 4.3 之间,谷歌进行了一次周期外更新,显示了有多少安卓可以不用经过费力的 OTA 更新而得到改进。得益于[谷歌 Play 商店和 Play 服务][1],这些更新可以在不更新任何系统核心组件的前提下送达。
|
||||||
|
|
||||||
2013 年 4 月,谷歌发布了谷歌 Play 商店的一个主要设计改动。就如同在这之后的大多数重新设计,新的 Play 商店完全接受了 Google Now 审美,即在灰色背景上的白色卡片。操作栏基于当前页面内容部分更改颜色,由于首屏内容以商店的各部分为主,操作栏颜色是中性的灰色。导航至内容部分的按钮指向热门付费,在那下面通常是一块促销内容或一组推荐应用。
|
2013 年 4 月,谷歌发布了谷歌 Play 商店的一个主要设计改动。就如同在这之后的大多数重新设计,新的 Play 商店完全接受了 Google Now 审美,即在灰色背景上的白色卡片。操作栏基于当前页面内容部分更改颜色,由于首屏内容以商店的各部分为主,操作栏颜色是中性的灰色。导航至内容部分的按钮指向热门付费,在那下面通常是一块促销内容或一组推荐应用。
|
||||||
|
|
||||||
|

|
||||||
独立的内容部分有漂亮的颜色。
|
|
||||||
Ron Amadeo 供图
|
*独立的内容部分有漂亮的颜色。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
新的 Play 商店展现了谷歌卡片设计语言的真正力量,在所有的屏幕尺寸上能够拥有响应式布局。一张大的卡片能够和若干小卡片组合,大屏幕设备能够显示更多的卡片,而且相对于拉伸来适应横屏模式,可以通过在一行显示更多卡片来适应。Play 商店的内容编辑们也可以自由地使用卡片布局;需要关注的大更新可以获得更大的卡片。这个设计最终会慢慢渗透向其它谷歌 Play 内容应用,最后拥有一个统一的设计。
|
新的 Play 商店展现了谷歌卡片设计语言的真正力量,在所有的屏幕尺寸上能够拥有响应式布局。一张大的卡片能够和若干小卡片组合,大屏幕设备能够显示更多的卡片,而且相对于拉伸来适应横屏模式,可以通过在一行显示更多卡片来适应。Play 商店的内容编辑们也可以自由地使用卡片布局;需要关注的大更新可以获得更大的卡片。这个设计最终会慢慢渗透向其它谷歌 Play 内容应用,最后拥有一个统一的设计。
|
||||||
|
|
||||||
|

|
||||||
Hangouts 取代了 Google Talk,现在仍由 Google+ 团队继续开发。
|
|
||||||
Ron Amadeo 供图
|
*Hangouts 取代了 Google Talk,现在仍由 Google+ 团队继续开发。
|
||||||
|
[Ron Amadeo 供图]*
|
||||||
|
|
||||||
Google I/O,谷歌的年度开发者会议,通常会宣布一个新的安卓版本。但是 2013 年的会议,谷歌只是发布了一些改进而没有系统更新。
|
Google I/O,谷歌的年度开发者会议,通常会宣布一个新的安卓版本。但是 2013 年的会议,谷歌只是发布了一些改进而没有系统更新。
|
||||||
|
|
||||||
谷歌宣布的大事件之一是 Google Talk 的更新,谷歌的即时消息平台。在很长一段时间里,谷歌随安卓附四个文本交流应用:Google Talk,Google+ Messenger,信息(短信应用),Google Voice。拥有四个应用来完成相同的任务——给某人发送文本消息——对用户来说很混乱。在 I/O 上,谷歌结束了 Google Talk 并且从头开始创建全新的消息产品 [Google Hangouts][2]。虽然最初只是想替代 Google Talk,Hangouts 的计划是统一所有谷歌的不同的消息应用到统一的界面下。
|
谷歌宣布的大事件之一是 Google Talk 的更新,谷歌的即时消息平台。在很长一段时间里,谷歌随安卓附带四个文本交流应用:Google Talk,Google+ Messenger,信息(短信应用),Google Voice。拥有四个应用来完成相同的任务——给某人发送文本消息——对用户来说很混乱。在 I/O 上,谷歌结束了 Google Talk 并且从头开始创建全新的消息产品 [Google Hangouts][2]。虽然最初只是想替代 Google Talk,Hangouts 的计划是统一所有谷歌的不同的消息应用到统一的界面下。
|
||||||
|
|
||||||
Hangouts 的用户界面布局真的和 Google Talk 没什么大的差别。主页面包含你的聊天会话,点击某一项就能进入聊天页面。界面设计上有所更新,聊天页面现在使用了卡片风格来显示每个段落,并且聊天列表是个“抽屉”风格的界面,这意味着你可以通过水平滑动打开它。Hangouts 有已读回执和输入状态指示,并且群聊现在是个主要特性。
|
Hangouts 的用户界面布局真的和 Google Talk 没什么大的差别。主页面包含你的聊天会话,点击某一项就能进入聊天页面。界面设计上有所更新,聊天页面现在使用了卡片风格来显示每个段落,并且聊天列表是个“抽屉”风格的界面,这意味着你可以通过水平滑动打开它。Hangouts 有已读回执和输入状态指示,并且群聊现在是个主要特性。
|
||||||
|
|
||||||
Google+ 是 Hangouts 的中心,所以产品的全名实际上是“Google+ Hangouts”。Hangouts 完全整合到了 Google+ 桌面站点。身份和头像直接从 Google+ 拉取,点击头像会打开用户的 Google+ 资料。和将浏览器换为 Google Chrome 类似,核心安卓功能交给了一个单独的团队——Google+ 团队——作为对应用成为繁忙的安卓工程师的副产品的反对。随着 Google+ 团队的接手,安卓的主要即时通讯客户端现在成为一个持续开发的应用。它被放进了 Play 商店并且有稳定的更新频率。
|
Google+ 是 Hangouts 的中心,所以产品的全名实际上是“Google+ Hangouts”。Hangouts 完全整合到了 Google+ 桌面站点。身份和头像直接从 Google+ 拉取,点击头像会打开用户的 Google+ 资料。和将浏览器换为 Google Chrome 类似,核心安卓功能交给了一个单独的团队——Google+ 团队,这是变得越发繁忙的安卓工程师的抗议的结果。随着 Google+ 团队的接手,安卓的主要即时通讯客户端现在成为一个持续开发的应用。它被放进了 Play 商店并且有稳定的更新频率。
|
||||||
|
|
||||||

|

|
||||||
新导航抽屉界面。
|
|
||||||
图片来自 [developer.android.com][3]
|
|
||||||
|
|
||||||
谷歌还给操作栏引入了新的设计元素:导航抽屉。这个抽屉显示为在左上角应用图标旁的三道横线。点击或从屏幕左边缘向右滑动,会出现一个侧边菜单目录。就像名字所指明的,这个是用来应用内导航的,它会显示若干应用内的顶层位置。这使得应用首屏可以用来显示内容,也给了用户一致的,易于访问的导航元素。导航抽屉基本上就是个大号的菜单,可以滚动并且固定在左侧。
|
*新导航抽屉界面。
|
||||||
|
图片来自 [developer.android.com][3]*
|
||||||
|
|
||||||
|
谷歌还给操作栏引入了新的设计元素:导航抽屉。这个抽屉显示为在左上角应用图标旁的三道横线。点击或从屏幕左边缘向右滑动,会出现一个侧边菜单目录。就像名字所指明的,这个是用来在应用内导航的,它会显示若干应用内的顶层位置。这使得应用首屏可以用来显示内容,也给了用户一致的、易于访问的导航元素。导航抽屉基本上就是个大号的菜单,可以滚动并且固定在左侧。
|
||||||
|
|
||||||
----------
|
----------
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。[@RonAmadeo][t]
|
||||||
|
|
||||||
[@RonAmadeo][t]
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/23/
|
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/23/
|
||||||
|
|
||||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
alim0x translating
|
||||||
|
|
||||||
What is open source
|
What is open source
|
||||||
===========================
|
===========================
|
||||||
|
|
||||||
|
|||||||
@ -1,3 +1,8 @@
|
|||||||
|
=====================================
|
||||||
|
翻译中 WangYueScream
|
||||||
|
======================================
|
||||||
|
|
||||||
|
|
||||||
How to get started learning to program
|
How to get started learning to program
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,60 +0,0 @@
|
|||||||
How Microsoft is becoming a Linux vendor
|
|
||||||
=====================================
|
|
||||||
|
|
||||||
|
|
||||||
>Microsoft is bridging the gap with Linux by baking it into its own products.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
Linux and open source technologies have become too dominant in data centers, cloud and IoT for Microsoft to ignore them.
|
|
||||||
|
|
||||||
On Microsoft’s own cloud, one in three machines run Linux. These are Microsoft customers who are running Linux. Microsoft needs to support the platform they use, or they will go somewhere else.
|
|
||||||
|
|
||||||
Here's how Microsoft's Linux strategy breaks down on its developer platform (Windows 10), on its cloud (Azure) and datacenter (Windows Server).
|
|
||||||
|
|
||||||
**Linux in Windows**: IT professionals managing Linux machines on public or private cloud need native UNIX tooling. Linux and macOS are the only two platforms that offer such native capabilities. No wonder all you see is MacBooks or a few Linux desktops at events like DockerCon, OpenStack Summit or CoreOS Fest.
|
|
||||||
|
|
||||||
To bridge the gap, Microsoft worked with Canonical to build a Linux subsystem within Windows that offers native Linux tooling. It’s a great compromise, where IT professionals can continue to use Windows 10 desktop while getting to run almost all Linux utilities to manage their Linux machines.
|
|
||||||
|
|
||||||
**Linux in Azure**: What good is a cloud that can’t run fully supported Linux machines? Microsoft has been working with Linux vendors that allow customers to run Linux applications and workloads on Azure.
|
|
||||||
|
|
||||||
Microsoft not only managed to sign deals with all three major Linux vendors Red Hat, SUSE and Canonical, it also worked with countless other companies to offer support for community-based distros like Debian.
|
|
||||||
|
|
||||||
**Linux in Windows Server**: This is the last missing piece of the puzzle. There is a massive ecosystem of Linux containers that are used by customers. There are over 900,000 Docker containers on Docker Hub, which can run only on Linux machines. Microsoft wanted to bring these containers to its own platform.
|
|
||||||
|
|
||||||
At DockerCon, Microsoft announced support for Linux containers on Windows Server bringing all those containers to Linux.
|
|
||||||
|
|
||||||
Things are about to get more interesting, after the success of Bash on Ubuntu on Windows 10, Microsoft is bringing Ubuntu bash to Windows Server. Yes, you heard it right. Windows Server will now have a Linux subsystem.
|
|
||||||
|
|
||||||
Rich Turner, Senior Program Manager at Microsoft told me, “WSL on the server provides admins with a preference for *NIX admin scripting & tools to have a more familiar environment in which to work.”
|
|
||||||
|
|
||||||
Microsoft said in an announcement that It will allow IT professionals “to use the same scripts, tools, procedures and container images they have been using for Linux containers on their Windows Server container host. These containers use our Hyper-V isolation technology combined with your choice of Linux kernel to host the workload while the management scripts and tools on the host use WSL.”
|
|
||||||
|
|
||||||
With all three bases covered, Microsoft has succeeded in creating an environment where its customers don't have to deal with any Linux vendor.
|
|
||||||
|
|
||||||
### What does it mean for Microsoft?
|
|
||||||
|
|
||||||
By baking Linux into its own products, Microsoft has become a Linux vendor. They are part of the Linux Foundation, they are one of the many contributors to the Linux kernel, and they now distribute Linux from their own store.
|
|
||||||
|
|
||||||
There is only one minor problem. Microsoft doesn’t own any Linux technologies. They are totally dependent on an external vendor, in this case Canonical, for their entire Linux layer. Too risky a proposition, if Canonical gets acquired by a fierce competitor.
|
|
||||||
|
|
||||||
It might make sense for Microsoft to attempt to acquire Canonical and bring the core technologies in house. It makes sense.
|
|
||||||
|
|
||||||
### What does it mean for Linux vendors
|
|
||||||
|
|
||||||
On the surface, it’s a clear victory for Microsoft as its customers can live within the Windows world. It will also contain the momentum of Linux in a datacenter. It might also affect Linux on the desktop as now IT professionals looking for *NIX tooling don’t have to run Linux desktop, they can do everything from within Windows.
|
|
||||||
|
|
||||||
Is Microsoft's victory a loss for traditional Linux vendors? To some degree, yes. Microsoft has become a direct competitor. But the clear winner here is Linux.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.cio.com/article/3197016/linux/how-microsoft-is-becoming-a-linux-vendor.html
|
|
||||||
|
|
||||||
作者:[ Swapnil Bhartiya ][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.cio.com/author/Swapnil-Bhartiya/
|
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
translating by xiaow6
|
||||||
|
|
||||||
# Go Serverless with Apex and Compose's MongoDB
|
# Go Serverless with Apex and Compose's MongoDB
|
||||||
|
|
||||||
_Apex is tooling that wraps the development and deployment experience for AWS Lambda functions. It provides a local command line tool which can create security contexts, deploy functions, and even tail cloud logs. While AWS's Lambda service treats each function as an independent unit, Apex provides a framework which treats a set of functions as a project. Plus, it even extends the service to languages beyond just Java, Javascript, and Python such as Go._
|
_Apex is tooling that wraps the development and deployment experience for AWS Lambda functions. It provides a local command line tool which can create security contexts, deploy functions, and even tail cloud logs. While AWS's Lambda service treats each function as an independent unit, Apex provides a framework which treats a set of functions as a project. Plus, it even extends the service to languages beyond just Java, Javascript, and Python such as Go._
|
||||||
@ -182,10 +184,10 @@ via: https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongo
|
|||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]:https://www.compose.com/articles/author/hays-hutton/
|
[a]:https://www.compose.com/articles/author/hays-hutton/
|
||||||
[1]:https://twitter.com/share?text=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB&url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&via=composeio
|
[1]:https://twitter.com/share?text=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB&url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&via=composeio
|
||||||
[2]:https://www.facebook.com/sharer/sharer.php?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
[2]:https://www.facebook.com/sharer/sharer.php?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
||||||
[3]:https://plus.google.com/share?url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
[3]:https://plus.google.com/share?url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
||||||
[4]:http://news.ycombinator.com/submitlink?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&t=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB
|
[4]:http://news.ycombinator.com/submitlink?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&t=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB
|
||||||
[5]:https://www.compose.com/articles/rss/
|
[5]:https://www.compose.com/articles/rss/
|
||||||
[6]:https://unsplash.com/@esaiastann
|
[6]:https://unsplash.com/@esaiastann
|
||||||
[7]:https://www.compose.com/articles
|
[7]:https://www.compose.com/articles
|
||||||
|
|||||||
@ -1,210 +0,0 @@
|
|||||||
# Network management with LXD (2.3+)
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Introduction
|
|
||||||
|
|
||||||
|
|
||||||
When LXD 2.0 shipped with Ubuntu 16.04, LXD networking was pretty simple. You could either use that “lxdbr0” bridge that “lxd init” would have you configure, provide your own or just use an existing physical interface for your containers.
|
|
||||||
|
|
||||||
While this certainly worked, it was a bit confusing because most of that bridge configuration happened outside of LXD in the Ubuntu packaging. Those scripts could only support a single bridge and none of this was exposed over the API, making remote configuration a bit of a pain.
|
|
||||||
|
|
||||||
That was all until LXD 2.3 when LXD finally grew its own network management API and command line tools to match. This post is an attempt at an overview of those new capabilities.
|
|
||||||
|
|
||||||
### Basic networking
|
|
||||||
|
|
||||||
Right out of the box, LXD 2.3 comes with no network defined at all. “lxd init” will offer to set one up for you and attach it to all new containers by default, but let’s do it by hand to see what’s going on under the hood.
|
|
||||||
|
|
||||||
To create a new network with a random IPv4 and IPv6 subnet and NAT enabled, just run:
|
|
||||||
|
|
||||||
```
|
|
||||||
stgraber@castiana:~$ lxc network create testbr0
|
|
||||||
Network testbr0 created
|
|
||||||
```
|
|
||||||
|
|
||||||
You can then look at its config with:
|
|
||||||
|
|
||||||
```
|
|
||||||
stgraber@castiana:~$ lxc network show testbr0
|
|
||||||
name: testbr0
|
|
||||||
config:
|
|
||||||
ipv4.address: 10.150.19.1/24
|
|
||||||
ipv4.nat: "true"
|
|
||||||
ipv6.address: fd42:474b:622d:259d::1/64
|
|
||||||
ipv6.nat: "true"
|
|
||||||
managed: true
|
|
||||||
type: bridge
|
|
||||||
usedby: []
|
|
||||||
```
|
|
||||||
|
|
||||||
If you don’t want those auto-configured subnets, you can go with:
|
|
||||||
|
|
||||||
```
|
|
||||||
stgraber@castiana:~$ lxc network create testbr0 ipv6.address=none ipv4.address=10.0.3.1/24 ipv4.nat=true
|
|
||||||
Network testbr0 created
|
|
||||||
```
|
|
||||||
|
|
||||||
Which will result in:
|
|
||||||
|
|
||||||
```
|
|
||||||
stgraber@castiana:~$ lxc network show testbr0
|
|
||||||
name: testbr0
|
|
||||||
config:
|
|
||||||
ipv4.address: 10.0.3.1/24
|
|
||||||
ipv4.nat: "true"
|
|
||||||
ipv6.address: none
|
|
||||||
managed: true
|
|
||||||
type: bridge
|
|
||||||
usedby: []
|
|
||||||
```
|
|
||||||
|
|
||||||
Having a network created and running won’t do you much good if your containers aren’t using it.
|
|
||||||
To have your newly created network attached to all containers, you can simply do:
|
|
||||||
|
|
||||||
```
|
|
||||||
stgraber@castiana:~$ lxc network attach-profile testbr0 default eth0
|
|
||||||
```
|
|
||||||
|
|
||||||
To attach a network to a single existing container, you can do:
|
|
||||||
|
|
||||||
```
|
|
||||||
stgraber@castiana:~$ lxc network attach my-container default eth0
|
|
||||||
```
|
|
||||||
|
|
||||||
Now, lets say you have openvswitch installed on that machine and want to convert that bridge to an OVS bridge, just change the driver property:
|
|
||||||
|
|
||||||
```
|
|
||||||
stgraber@castiana:~$ lxc network set testbr0 bridge.driver openvswitch
|
|
||||||
```
|
|
||||||
|
|
||||||
If you want to do a bunch of changes all at once, “lxc network edit” will let you edit the network configuration interactively in your text editor.
|
|
||||||
|
|
||||||
### Static leases and port security
|
|
||||||
|
|
||||||
One of the nice thing with having LXD manage the DHCP server for you is that it makes managing DHCP leases much simpler. All you need is a container-specific nic device and the right property set.
|
|
||||||
|
|
||||||
```
|
|
||||||
root@yak:~# lxc init ubuntu:16.04 c1
|
|
||||||
Creating c1
|
|
||||||
root@yak:~# lxc network attach testbr0 c1 eth0
|
|
||||||
root@yak:~# lxc config device set c1 eth0 ipv4.address 10.0.3.123
|
|
||||||
root@yak:~# lxc start c1
|
|
||||||
root@yak:~# lxc list c1
|
|
||||||
+------+---------+-------------------+------+------------+-----------+
|
|
||||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
|
||||||
+------+---------+-------------------+------+------------+-----------+
|
|
||||||
| c1 | RUNNING | 10.0.3.123 (eth0) | | PERSISTENT | 0 |
|
|
||||||
+------+---------+-------------------+------+------------+-----------+
|
|
||||||
```
|
|
||||||
|
|
||||||
And same goes for IPv6 but with the “ipv6.address” property instead.
|
|
||||||
|
|
||||||
Similarly, if you want to prevent your container from ever changing its MAC address or forwarding traffic for any other MAC address (such as nesting), you can enable port security with:
|
|
||||||
|
|
||||||
```
|
|
||||||
root@yak:~# lxc config device set c1 eth0 security.mac_filtering true
|
|
||||||
```
|
|
||||||
|
|
||||||
### DNS
|
|
||||||
|
|
||||||
LXD runs a DNS server on the bridge. On top of letting you set the DNS domain for the bridge (“dns.domain” network property), it also supports 3 different operating modes (“dns.mode”):
|
|
||||||
|
|
||||||
* “managed” will have one DNS record per container, matching its name and known IP addresses. The container cannot alter this record through DHCP.
|
|
||||||
* “dynamic” allows the containers to self-register in the DNS through DHCP. So whatever hostname the container sends during the DHCP negotiation ends up in DNS.
|
|
||||||
* “none” is for a simple recursive DNS server without any kind of local DNS records.
|
|
||||||
|
|
||||||
The default mode is “managed” and is typically the safest and most convenient as it provides DNS records for containers but doesn’t let them spoof each other’s records by sending fake hostnames over DHCP.
|
|
||||||
|
|
||||||
### Using tunnels
|
|
||||||
|
|
||||||
On top of all that, LXD also supports connecting to other hosts using GRE or VXLAN tunnels.
|
|
||||||
|
|
||||||
A LXD network can have any number of tunnels attached to it, making it easy to create networks spanning multiple hosts. This is mostly useful for development, test and demo uses, with production environment usually preferring VLANs for that kind of segmentation.
|
|
||||||
|
|
||||||
So say, you want a basic “testbr0” network running with IPv4 and IPv6 on host “edfu” and want to spawn containers using it on host “djanet”. The easiest way to do that is by using a multicast VXLAN tunnel. This type of tunnels only works when both hosts are on the same physical segment.
|
|
||||||
|
|
||||||
```
|
|
||||||
root@edfu:~# lxc network create testbr0 tunnel.lan.protocol=vxlan
|
|
||||||
Network testbr0 created
|
|
||||||
root@edfu:~# lxc network attach-profile testbr0 default eth0
|
|
||||||
```
|
|
||||||
|
|
||||||
This defines a “testbr0” bridge on host “edfu” and sets up a multicast VXLAN tunnel on it for other hosts to join it. In this setup, “edfu” will be the one acting as a router for that network, providing DHCP, DNS, … the other hosts will just be forwarding traffic over the tunnel.
|
|
||||||
|
|
||||||
```
|
|
||||||
root@djanet:~# lxc network create testbr0 ipv4.address=none ipv6.address=none tunnel.lan.protocol=vxlan
|
|
||||||
Network testbr0 created
|
|
||||||
root@djanet:~# lxc network attach-profile testbr0 default eth0
|
|
||||||
```
|
|
||||||
|
|
||||||
Now you can start containers on either host and see them getting IP from the same address pool and communicate directly with each other through the tunnel.
|
|
||||||
|
|
||||||
As mentioned earlier, this uses multicast, which usually won’t do you much good when crossing routers. For those cases, you can use VXLAN in unicast mode or a good old GRE tunnel.
|
|
||||||
|
|
||||||
To join another host using GRE, first configure the main host with:
|
|
||||||
|
|
||||||
```
|
|
||||||
root@edfu:~# lxc network set testbr0 tunnel.nuturo.protocol gre
|
|
||||||
root@edfu:~# lxc network set testbr0 tunnel.nuturo.local 172.17.16.2
|
|
||||||
root@edfu:~# lxc network set testbr0 tunnel.nuturo.remote 172.17.16.9
|
|
||||||
```
|
|
||||||
|
|
||||||
And then the “client” host with:
|
|
||||||
|
|
||||||
```
|
|
||||||
root@nuturo:~# lxc network create testbr0 ipv4.address=none ipv6.address=none tunnel.edfu.protocol=gre tunnel.edfu.local=172.17.16.9 tunnel.edfu.remote=172.17.16.2
|
|
||||||
Network testbr0 created
|
|
||||||
root@nuturo:~# lxc network attach-profile testbr0 default eth0
|
|
||||||
```
|
|
||||||
|
|
||||||
If you’d rather use vxlan, just do:
|
|
||||||
|
|
||||||
```
|
|
||||||
root@edfu:~# lxc network set testbr0 tunnel.edfu.id 10
|
|
||||||
root@edfu:~# lxc network set testbr0 tunnel.edfu.protocol vxlan
|
|
||||||
```
|
|
||||||
|
|
||||||
And:
|
|
||||||
|
|
||||||
```
|
|
||||||
root@nuturo:~# lxc network set testbr0 tunnel.edfu.id 10
|
|
||||||
root@nuturo:~# lxc network set testbr0 tunnel.edfu.protocol vxlan
|
|
||||||
```
|
|
||||||
|
|
||||||
The tunnel id is required here to avoid conflicting with the already configured multicast vxlan tunnel.
|
|
||||||
|
|
||||||
And that’s how you make cross-host networking easily with recent LXD!
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
LXD now makes it very easy to define anything from a simple single-host network to a very complex cross-host network for thousands of containers. It also makes it very simple to define a new network just for a few containers or add a second device to a container, connecting it to a separate private network.
|
|
||||||
|
|
||||||
While this post goes through most of the different features we support, there are quite a few more knobs that can be used to fine tune the LXD network experience.
|
|
||||||
A full list can be found here: [https://github.com/lxc/lxd/blob/master/doc/configuration.md][2]
|
|
||||||
|
|
||||||
# Extra information
|
|
||||||
|
|
||||||
The main LXD website is at: [https://linuxcontainers.org/lxd
|
|
||||||
][3]Development happens on Github at: [https://github.com/lxc/lxd][4]
|
|
||||||
Mailing-list support happens on: [https://lists.linuxcontainers.org][5]
|
|
||||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
|
||||||
Try LXD online: [https://linuxcontainers.org/lxd/try-it][6]
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.stgraber.org/2016/10/27/network-management-with-lxd-2-3/
|
|
||||||
|
|
||||||
作者:[Stéphane Graber][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.stgraber.org/author/stgraber/
|
|
||||||
[1]:https://www.stgraber.org/author/stgraber/
|
|
||||||
[2]:https://github.com/lxc/lxd/blob/master/doc/configuration.md#network-configuration
|
|
||||||
[3]:https://linuxcontainers.org/lxd
|
|
||||||
[4]:https://github.com/lxc/lxd
|
|
||||||
[5]:https://lists.linuxcontainers.org/
|
|
||||||
[6]:https://linuxcontainers.org/lxd/try-it
|
|
||||||
[7]:https://www.stgraber.org/2016/10/27/network-management-with-lxd-2-3/
|
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
ictlyh Translating
|
||||||
The Age of the Unikernel: 10 Projects to Know
|
The Age of the Unikernel: 10 Projects to Know
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,80 +0,0 @@
|
|||||||
10 reasons to use Cinnamon as your Linux desktop environment
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### Cinnamon is a Linux desktop environment reminiscent of GNOME 2 that offers flexibility, speed, and a slew of features.
|
|
||||||
|
|
||||||

|
|
||||||
Image credits :
|
|
||||||
|
|
||||||
[Sam Mugraby][1], Photos8.com. [CC BY 2.0][2].
|
|
||||||
|
|
||||||
Recently I installed Fedora 25, and found that the current version of [KDE][3] Plasma was unstable for me; it crashed several times a day before I decided to try to try something different. After installing a number of alternative desktops and trying them all for a couple hours each, I finally settled on using Cinnamon until Plasma is patched and stable. Here's what I found.
|
|
||||||
|
|
||||||
### Introducing Cinnamon
|
|
||||||
|
|
||||||
In 2011, GNOME 3, with the new GNOME Shell was released and the new interface immediately generated both positive and negative responses. Many users and developers liked the original GNOME interface enough that multiple groups forked it and one of those forks was Cinnamon.
|
|
||||||
|
|
||||||
One of the reasons behind the development of the GNOME shell for GNOME 3 was that many components of the original GNOME user interface were no longer being actively developed. This was also an issue for Cinnamon and some of the other forked GNOME projects. The Linux Mint project was one of the prime movers for Cinnamon because GNOME is the official desktop environment for Mint. The Mint developers have continued to develop Cinnamon to the point where GNOME itself is no longer required, and Cinnamon is a completely independent desktop environment that retains many of the interface features that users appreciated about the GNOME interface.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Figure 1: The default Cinnamon desktop with the System Settings tool open.
|
|
||||||
|
|
||||||
Cinnamon 3.2 is the current release version. Cinnamon is available for many distros besides Mint, including Fedora, Arch, Gentoo, Debian, and OpenSUSE, among others.
|
|
||||||
|
|
||||||
### Reasons for using Cinnamon
|
|
||||||
|
|
||||||
Here are my top 10 reasons for using Cinnamon.
|
|
||||||
|
|
||||||
1. **Integration.** The choice of a desktop has not been contingent upon the availability of applications written for it in a long time. All of the applications I use, regardless of the desktop for which they were written, will run just fine on any other desktop, and Cinnamon is no exception. All of the libraries required to run applications written for KDE, GNOME—or any other desktop that I use—are available and make using any application with the Cinnamon desktop a seamless experience.
|
|
||||||
|
|
||||||
2. **Looks.** Let's face it, looks are important. Cinnamon has a crisp, clean look that uses easy to read fonts and color combinations. The desktop is not hampered by unnecessary clutter, and you can configure which icons are shown on the desktop using the **System Settings => Desktop** menu. This menu also allows you to specify whether the desktop icons are shown only on the primary monitor, only on secondary monitors, or on all monitors.
|
|
||||||
|
|
||||||
3. **Desklets.** Desklets are small, usually single-purpose applications that can be added to your desktop. Only a few of these are available, but you can choose from things like CPU or disk monitors, a weather app, sticky notes, a desktop photo frame app, and time and date, among others. I like the time and date desklet because it is easier to read than the applet in the Cinnamon panel.
|
|
||||||
|
|
||||||
4. **Speed.** Cinnamon is fast and snappy. Programs load and display fast. The desktop itself loads quickly during login, though this is just my subjective experience and is not based on any timed testing.
|
|
||||||
|
|
||||||
5. **Configuration. **Cinnamon is not as configurable as KDE Plasma, but it is much more configurable than I originally thought the first time I tried it. The Cinnamon Control Center provides centralized access to many of the desktop configuration options. It has a main window from which the specific feature configuration windows can be launched. It is easy to select a new look from those available in the Themes section of System Settings. You can choose window borders, icons, controls, pointers, and the desktop basic scheme. Other choices include fonts and backgrounds. I find many of these configuration tools among the best I have encountered. A modest number of desktop themes are available, providing the ability to significantly alter the look of the desktop without the confusion of the massive numbers of choices that KDE provides.
|
|
||||||
|
|
||||||
6. **The Cinnamon Panel. **The Cinnamon Panel, i.e., the toolbar, is initially configured very simply. It contains the menu used to launch programs, a basic system tray, and an application selector. The panel is easy to configure and adding new program launchers is simply a matter of locating the program you want to add in the main Menu; right click on the program icon and select "Add to panel." You can also add the launcher icon to the desktop itself, and to the Cinnamon "Favorites" launcher bar. You can also enter the panel's **Edit** mode and rearrange the icons.
|
|
||||||
|
|
||||||
7. **Flexibility****.** It can sometimes be difficult to locate a minimized or hidden running application and finding it on the toolbar application selector can be challenging if there are a number of running applications. In part, this is because the applications are not always in a sequence on the selector that makes them easy to find. So one of my favorite features is the ability to drag the buttons for the running applications and rearrange them on the selector. This can make it much easier to find and display windows belonging to applications because they can now be where I put them on the selector.
|
|
||||||
|
|
||||||
The Cinnamon desktop also has a very nice pop-up menu that you can access with a right click. This menu has selections for some frequently used tasks such as accessing the Desktop Settings and adding Desklets, as well as other desktop-related tasks.
|
|
||||||
|
|
||||||
One of these other menu items is “Create New Document” which uses the document templates located in the ~/Templates directory and lists each of them. Simply click on the template you want to use and a new document using that template is created using the default office application. In my case, that is LibreOffice.
|
|
||||||
|
|
||||||
8. **Multiple ****workspaces****.** Cinnamon offers multiple desktops like many other desktop environments. Cinnamon calls these "workspaces." The workspace selector is located on the Cinnamon panel and shows the outlines of the windows located on each workspace. Windows can be moved between workspaces or assigned to all. I did find that the workspace selector is sometimes a bit slow to catch up with the display of window locations so I switched the workspace selector to show the workspace numbers and not shadows of the windows in the workspaces.
|
|
||||||
|
|
||||||
9. **Nemo.** Most desktops use their own preferred default applications for various purposes and Cinnamon is no exception. My preferred desktop file manager is Krusader, but Cinnamon uses Nemo as its default, so I just went with that for the duration of my test. I find that I like Nemo—a lot. It has a nice clean interface and most of the features I like and use frequently. It is easy to use while being flexible enough for my needs. Although Nemo is a fork of Nautilus, I find Nemo to be better integrated into the Cinnamon environment. The Nautilus interface seems to be somewhat poorly integrated and discordant with Cinnamon.
|
|
||||||
|
|
||||||
10. **Stability.** Cinnamon is very stable and just works.
|
|
||||||
|
|
||||||
### Conclusions
|
|
||||||
|
|
||||||
Cinnamon is a fork of the GNOME 3 desktop and appears to be intended as the GNOME desktop that never was. Its development seems to be the logical improvements that the Cinnamon developers thought were needed to improve and extend GNOME while retaining its unique and highly appreciated personality. It is no longer GNOME 3—it is different and better. Cinnamon looks good and it works very well for me and is a very nice change from KDE—which I still like very much. It took me a few days to learn how Cinnamon's differences could make my desktop experience better, and I am very glad to have learned a lot more about an excellent desktop.
|
|
||||||
|
|
||||||
Though I like Cinnamon, I would like to experiment with some others as well, and I am now going to switch to the LXDE desktop and try that out for a few weeks. I will share my experience with LXDE after I have spent some time using it.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/1/cinnamon-desktop-environment
|
|
||||||
|
|
||||||
作者:[David Both ][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/dboth
|
|
||||||
[1]:https://commons.wikimedia.org/wiki/File:Cinnamon-other.jpg
|
|
||||||
[2]:https://creativecommons.org/licenses/by/2.0/deed.en
|
|
||||||
[3]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
Translating by CherryMill
|
||||||
|
|
||||||
An introduction to the Linux boot and startup processes
|
An introduction to the Linux boot and startup processes
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,396 +0,0 @@
|
|||||||
ictlyh Translating
|
|
||||||
|
|
||||||
Many SQL Performance Problems Stem from “Unnecessary, Mandatory Work”
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
Probably the most impactful thing you could learn about when writing efficient SQL is [indexing][1]. A very close runner-up, however, is the fact that a lot of SQL clients demand tons of **“unnecessary, mandatory work”** from the database.
|
|
||||||
|
|
||||||
Repeat this after me:
|
|
||||||
|
|
||||||
> Unnecessary, Mandatory Work
|
|
||||||
|
|
||||||
What is **“unnecessary, mandatory work”**? It’s two things (duh):
|
|
||||||
|
|
||||||
### Unnecessary
|
|
||||||
|
|
||||||
Let’s assume your client application needs this information here:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][2]
|
|
||||||
|
|
||||||
Nothing out of the ordinary. We run a movie database ([e.g. the Sakila database][3]) and we want to display the title and rating of each film to the user.
|
|
||||||
|
|
||||||
This is the query that would produce the above result:
|
|
||||||
|
|
||||||
|
|
||||||
`SELECT title, rating`
|
|
||||||
`FROM film`
|
|
||||||
|
|
||||||
However, our application (or our ORM) runs this query instead:
|
|
||||||
|
|
||||||
`SELECT *`
|
|
||||||
`FROM film`
|
|
||||||
|
|
||||||
What are we getting? Guess what. We’re getting tons of useless information:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][4]
|
|
||||||
|
|
||||||
There’s even some complex JSON all the way to the right, which is loaded:
|
|
||||||
|
|
||||||
* From the disk
|
|
||||||
* Into the caches
|
|
||||||
* Over the wire
|
|
||||||
* Into the client memory
|
|
||||||
* And then discarded
|
|
||||||
|
|
||||||
Yes, we discard most of this information. The work that was performed to retrieve it was completely unnecessary. Right? Agreed.
|
|
||||||
|
|
||||||
### Mandatory
|
|
||||||
|
|
||||||
That’s the worse part. While optimisers have become quite smart these days, this work is mandatory for the database. There’s no way the database can _know_ that the client application actually didn’t need 95% of the data. And that’s just a simple example. Imagine if we joined more tables…
|
|
||||||
|
|
||||||
So what, you think? Databases are fast? Let me offer you some insight you may not have thought of, before:
|
|
||||||
|
|
||||||
### Memory consumption
|
|
||||||
|
|
||||||
Sure, the individual execution time doesn’t really change much. Perhaps, it’ll be 1.5x slower, but we can handle that right? For the sake of convenience? Sometimes that’s true. But if you’re sacrificing performance for convenience _every time_ , things add up. We’re no longer talking about performance (speed of individual queries), but throughput (system response time), and that’s when stuff gets really hairy and tough to fix. When you stop being able to scale.
|
|
||||||
|
|
||||||
Let’s look at execution plans, Oracle this time:
|
|
||||||
|
|
||||||
```
|
|
||||||
--------------------------------------------------
|
|
||||||
| Id | Operation | Name | Rows | Bytes |
|
|
||||||
--------------------------------------------------
|
|
||||||
| 0 | SELECT STATEMENT | | 1000 | 166K|
|
|
||||||
| 1 | TABLE ACCESS FULL| FILM | 1000 | 166K|
|
|
||||||
--------------------------------------------------
|
|
||||||
```
|
|
||||||
|
|
||||||
Versus
|
|
||||||
|
|
||||||
```
|
|
||||||
--------------------------------------------------
|
|
||||||
| Id | Operation | Name | Rows | Bytes |
|
|
||||||
--------------------------------------------------
|
|
||||||
| 0 | SELECT STATEMENT | | 1000 | 20000 |
|
|
||||||
| 1 | TABLE ACCESS FULL| FILM | 1000 | 20000 |
|
|
||||||
--------------------------------------------------
|
|
||||||
```
|
|
||||||
|
|
||||||
We’re using 8x as much memory in the database when doing `SELECT *`rather than `SELECT film, rating`. That’s not really surprising though, is it? We knew that. Yet we accepted it in many many of our queries where we simply didn’t need all that data. We generated **needless, mandatory work** for the database, and it does sum up. We’re using 8x too much memory (the number will differ, of course).
|
|
||||||
|
|
||||||
Now, all the other steps (disk I/O, wire transfer, client memory consumption) are also affected in the same way, but I’m skipping those. Instead, I’d like to look at…
|
|
||||||
|
|
||||||
### Index usage
|
|
||||||
|
|
||||||
Most databases these days have figured out the concept of [ _covering indexes_ ][5]. A covering index is not a special index per se. But it can turn into a “special index” for a given query, either “accidentally,” or by design.
|
|
||||||
|
|
||||||
Check out this query:
|
|
||||||
|
|
||||||
`SELECT` `*`
|
|
||||||
`FROM` `actor`
|
|
||||||
`WHERE` `last_name` `LIKE` `'A%'`
|
|
||||||
|
|
||||||
There’s no extraordinary thing to be seen in the execution plan. It’s a simple query. Index range scan, table access, done:
|
|
||||||
|
|
||||||
```
|
|
||||||
-------------------------------------------------------------------
|
|
||||||
| Id | Operation | Name | Rows |
|
|
||||||
-------------------------------------------------------------------
|
|
||||||
| 0 | SELECT STATEMENT | | 8 |
|
|
||||||
| 1 | TABLE ACCESS BY INDEX ROWID| ACTOR | 8 |
|
|
||||||
|* 2 | INDEX RANGE SCAN | IDX_ACTOR_LAST_NAME | 8 |
|
|
||||||
-------------------------------------------------------------------
|
|
||||||
```
|
|
||||||
|
|
||||||
Is it a good plan, though? Well, if what we really needed was this, then it’s not:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][6]
|
|
||||||
|
|
||||||
Sure, we’re wasting memory etc. But check out this alternative query:
|
|
||||||
|
|
||||||
| 123 | `SELECT` `first_name, last_name``FROM` `actor``WHERE` `last_name` `LIKE` `'A%'` |
|
|
||||||
|
|
||||||
Its plan is this:
|
|
||||||
|
|
||||||
```
|
|
||||||
----------------------------------------------------
|
|
||||||
| Id | Operation | Name | Rows |
|
|
||||||
----------------------------------------------------
|
|
||||||
| 0 | SELECT STATEMENT | | 8 |
|
|
||||||
|* 1 | INDEX RANGE SCAN| IDX_ACTOR_NAMES | 8 |
|
|
||||||
----------------------------------------------------
|
|
||||||
```
|
|
||||||
|
|
||||||
We could now eliminate the table access entirely, because there’s an index that covers all the needs of our query… a covering index. Does it matter? Absolutely! This approach can speed up some of your queries by an order of magnitude (or slow them down by an order of magnitude when your index stops being covering after a change).
|
|
||||||
|
|
||||||
You cannot always profit from covering indexes. Indexes come with their own cost and you shouldn’t add too many of them, but in cases like these, it’s a no-brainer. Let’s run a benchmark:
|
|
||||||
|
|
||||||
```
|
|
||||||
SET SERVEROUTPUT ON
|
|
||||||
DECLARE
|
|
||||||
v_ts TIMESTAMP;
|
|
||||||
v_repeat CONSTANT NUMBER := 100000;
|
|
||||||
BEGIN
|
|
||||||
v_ts := SYSTIMESTAMP;
|
|
||||||
|
|
||||||
FOR i IN 1..v_repeat LOOP
|
|
||||||
FOR rec IN (
|
|
||||||
-- Worst query: Memory overhead AND table access
|
|
||||||
SELECT *
|
|
||||||
FROM actor
|
|
||||||
WHERE last_name LIKE 'A%'
|
|
||||||
) LOOP
|
|
||||||
NULL;
|
|
||||||
END LOOP;
|
|
||||||
END LOOP;
|
|
||||||
|
|
||||||
dbms_output.put_line('Statement 1 : ' || (SYSTIMESTAMP - v_ts));
|
|
||||||
v_ts := SYSTIMESTAMP;
|
|
||||||
|
|
||||||
FOR i IN 1..v_repeat LOOP
|
|
||||||
FOR rec IN (
|
|
||||||
-- Better query: Still table access
|
|
||||||
SELECT /*+INDEX(actor(last_name))*/
|
|
||||||
first_name, last_name
|
|
||||||
FROM actor
|
|
||||||
WHERE last_name LIKE 'A%'
|
|
||||||
) LOOP
|
|
||||||
NULL;
|
|
||||||
END LOOP;
|
|
||||||
END LOOP;
|
|
||||||
|
|
||||||
dbms_output.put_line('Statement 2 : ' || (SYSTIMESTAMP - v_ts));
|
|
||||||
v_ts := SYSTIMESTAMP;
|
|
||||||
|
|
||||||
FOR i IN 1..v_repeat LOOP
|
|
||||||
FOR rec IN (
|
|
||||||
-- Best query: Covering index
|
|
||||||
SELECT /*+INDEX(actor(last_name, first_name))*/
|
|
||||||
first_name, last_name
|
|
||||||
FROM actor
|
|
||||||
WHERE last_name LIKE 'A%'
|
|
||||||
) LOOP
|
|
||||||
NULL;
|
|
||||||
END LOOP;
|
|
||||||
END LOOP;
|
|
||||||
|
|
||||||
dbms_output.put_line('Statement 3 : ' || (SYSTIMESTAMP - v_ts));
|
|
||||||
END;
|
|
||||||
/
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
The result is:
|
|
||||||
|
|
||||||
```
|
|
||||||
Statement 1 : +000000000 00:00:02.479000000
|
|
||||||
Statement 2 : +000000000 00:00:02.261000000
|
|
||||||
Statement 3 : +000000000 00:00:01.857000000
|
|
||||||
```
|
|
||||||
|
|
||||||
Note, the actor table only has 4 columns, so the difference between statements 1 and 2 is not too impressive, but still significant. Note also I’m using Oracle’s hints to force the optimiser to pick one or the other index for the query. Statement 3 clearly wins in this case. It’s a _much_ better query, and that’s just an extremely simple query.
|
|
||||||
|
|
||||||
Again, when we write `SELECT *`, we create **needless, mandatory work** for the database, which it cannot optimise. It won’t pick the covering index because that index has a bit more overhead than the `LAST_NAME`index that it did pick, and after all, it had to go to the table anyway to fetch the useless `LAST_UPDATE` column, for instance.
|
|
||||||
|
|
||||||
But things get worse with `SELECT *`. Consider…
|
|
||||||
|
|
||||||
### SQL transformations
|
|
||||||
|
|
||||||
Optimisers work so well, because they transform your SQL queries ([watch my recent talk at Voxxed Days Zurich about how this works][7]). For instance, there’s a SQL transformation called “`JOIN` elimination”, and it is really powerful. Consider this auxiliary view, which we wrote because we grew so incredibly tired of joining all these tables all the time:
|
|
||||||
|
|
||||||
```
|
|
||||||
CREATE VIEW v_customer AS
|
|
||||||
SELECT
|
|
||||||
c.first_name, c.last_name,
|
|
||||||
a.address, ci.city, co.country
|
|
||||||
FROM customer c
|
|
||||||
JOIN address a USING (address_id)
|
|
||||||
JOIN city ci USING (city_id)
|
|
||||||
JOIN country co USING (country_id)
|
|
||||||
```
|
|
||||||
|
|
||||||
This view just connects all the “to-one” relationships between a `CUSTOMER` and their different `ADDRESS` parts. Thanks, normalisation.
|
|
||||||
|
|
||||||
Now, after a while working with this view, imagine, we’ve become so accustomed to this view, we forgot all about the underlying tables. And now, we’re running this query:
|
|
||||||
|
|
||||||
```
|
|
||||||
SELECT *
|
|
||||||
FROM v_customer
|
|
||||||
```
|
|
||||||
|
|
||||||
We’re getting quite some impressive plan:
|
|
||||||
|
|
||||||
```
|
|
||||||
----------------------------------------------------------------
|
|
||||||
| Id | Operation | Name | Rows | Bytes | Cost |
|
|
||||||
----------------------------------------------------------------
|
|
||||||
| 0 | SELECT STATEMENT | | 599 | 47920 | 14 |
|
|
||||||
|* 1 | HASH JOIN | | 599 | 47920 | 14 |
|
|
||||||
| 2 | TABLE ACCESS FULL | COUNTRY | 109 | 1526 | 2 |
|
|
||||||
|* 3 | HASH JOIN | | 599 | 39534 | 11 |
|
|
||||||
| 4 | TABLE ACCESS FULL | CITY | 600 | 10800 | 3 |
|
|
||||||
|* 5 | HASH JOIN | | 599 | 28752 | 8 |
|
|
||||||
| 6 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
|
|
||||||
| 7 | TABLE ACCESS FULL| ADDRESS | 603 | 17487 | 3 |
|
|
||||||
----------------------------------------------------------------
|
|
||||||
```
|
|
||||||
|
|
||||||
Well, of course. We run all these joins and full table scans, because that’s what we told the database to do. Fetch all this data.
|
|
||||||
|
|
||||||
Now, again, imagine, what we really wanted on one particular screen was this:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][8]
|
|
||||||
|
|
||||||
Yeah, duh, right? By now you get my point. But imagine, we’ve learned from the previous mistakes and we’re now actually running the following, better query:
|
|
||||||
|
|
||||||
```
|
|
||||||
SELECT first_name, last_name
|
|
||||||
FROM v_customer
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
Now, check this out!
|
|
||||||
|
|
||||||
```
|
|
||||||
------------------------------------------------------------------
|
|
||||||
| Id | Operation | Name | Rows | Bytes | Cost |
|
|
||||||
------------------------------------------------------------------
|
|
||||||
| 0 | SELECT STATEMENT | | 599 | 16173 | 4 |
|
|
||||||
| 1 | NESTED LOOPS | | 599 | 16173 | 4 |
|
|
||||||
| 2 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
|
|
||||||
|* 3 | INDEX UNIQUE SCAN| SYS_C007120 | 1 | 8 | 0 |
|
|
||||||
------------------------------------------------------------------
|
|
||||||
```
|
|
||||||
|
|
||||||
That’s a _drastic_ improvement in the execution plan. Our joins were eliminated, because the optimiser could prove they were **needless**, so once it can prove this (and you don’t make the work **mandatory** by selecting *), it can remove the work and simply not do it. Why is that the case?
|
|
||||||
|
|
||||||
Each `CUSTOMER.ADDRESS_ID` foreign key guarantees that there is _exactly one_ `ADDRESS.ADDRESS_ID` primary key value, so the `JOIN` operation is guaranteed to be a to-one join which does not add rows nor remove rows. If we don’t even select rows or query rows, well, we don’t need to actually load the rows at all. Removing the `JOIN` provably won’t change the outcome of the query.
|
|
||||||
|
|
||||||
Databases do these things all the time. You can try this on most databases:
|
|
||||||
|
|
||||||
```
|
|
||||||
-- Oracle
|
|
||||||
SELECT CASE WHEN EXISTS (
|
|
||||||
SELECT 1 / 0 FROM dual
|
|
||||||
) THEN 1 ELSE 0 END
|
|
||||||
FROM dual
|
|
||||||
|
|
||||||
-- More reasonable SQL dialects, e.g. PostgreSQL
|
|
||||||
SELECT EXISTS (SELECT 1 / 0)
|
|
||||||
```
|
|
||||||
|
|
||||||
In this case, you might expect an arithmetic exception to be raised, as when you run this query:
|
|
||||||
|
|
||||||
```
|
|
||||||
SELECT 1 / 0 FROM dual
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
yielding
|
|
||||||
|
|
||||||
```
|
|
||||||
ORA-01476: divisor is equal to zero
|
|
||||||
```
|
|
||||||
|
|
||||||
But it doesn’t happen. The optimiser (or even the parser) can prove that any `SELECT` column expression in a `EXISTS (SELECT ..)` predicate will not change the outcome of a query, so there’s no need to evaluate it. Huh!
|
|
||||||
|
|
||||||
### Meanwhile…
|
|
||||||
|
|
||||||
One of most ORM’s most unfortunate problems is the fact that they make writing `SELECT *` queries so easy to write. In fact, HQL / JPQL for instance, proceeded to making it the default. You can even omit the `SELECT` clause entirely, because after all, you’re going to be fetching the entire entity, as declared, right?
|
|
||||||
|
|
||||||
For instance:
|
|
||||||
|
|
||||||
`FROM` `v_customer`
|
|
||||||
|
|
||||||
[Vlad Mihalcea for instance, a Hibernate expert and Hibernate Developer advocate][9] recommends you use queries almost every time you’re sure you don’t want to persist any modifications after fetching. ORMs make it easy to solve the object graph persistence problem. Note: Persistence. The idea of actually modifying the object graph and persisting the modifications is inherent.
|
|
||||||
|
|
||||||
But if you don’t intend to do that, why bother fetching the entity? Why not write a query? Let’s be very clear: From a performance perspective, writing a query tailored to the exact use-case you’re solving is _always_ going to outperform any other option. You may not care because your data set is small and it doesn’t matter. Fine. But eventually, you’ll need to scale and re-designing your applications to favour a query language over imperative entity graph traversal will be quite hard. You’ll have other things to do.
|
|
||||||
|
|
||||||
### Counting for existence
|
|
||||||
|
|
||||||
Some of the worst wastes of resources is when people run `COUNT(*)`queries when they simply want to check for existence. E.g.
|
|
||||||
|
|
||||||
> Did this user have any orders at all?
|
|
||||||
|
|
||||||
And we’ll run:
|
|
||||||
|
|
||||||
```
|
|
||||||
SELECT count(*)
|
|
||||||
FROM orders
|
|
||||||
WHERE user_id = :user_id
|
|
||||||
```
|
|
||||||
|
|
||||||
Easy. If `COUNT = 0`: No orders. Otherwise: Yes, orders.
|
|
||||||
|
|
||||||
The performance will not be horrible, because we probably have an index on the `ORDERS.USER_ID` column. But what do you think will be the performance of the above compared to this alternative here:
|
|
||||||
|
|
||||||
```
|
|
||||||
-- Oracle
|
|
||||||
SELECT CASE WHEN EXISTS (
|
|
||||||
SELECT *
|
|
||||||
FROM orders
|
|
||||||
WHERE user_id = :user_id
|
|
||||||
) THEN 1 ELSE 0 END
|
|
||||||
FROM dual
|
|
||||||
|
|
||||||
-- Reasonable SQL dialects, like PostgreSQL
|
|
||||||
SELECT EXISTS (
|
|
||||||
SELECT *
|
|
||||||
FROM orders
|
|
||||||
WHERE user_id = :user_id
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
It doesn’t take a rocket scientist to figure out that an actual existence predicate can stop looking for additional rows as soon as it found _one_ . So, if the answer is “no orders”, then the speed will be comparable. If, however, the answer is “yes, orders”, then the answer might be _drastically_ faster in the case where we do not calculate the exact count.
|
|
||||||
|
|
||||||
Because we _don’t care_ about the exact count. Yet, we told the database to calculate it (**needless**), and the database doesn’t know we’re discarding all results bigger than 1 (**mandatory**).
|
|
||||||
|
|
||||||
Of course, things get much worse if you call `list.size()` on a JPA-backed collection to do the same…
|
|
||||||
|
|
||||||
[I’ve blogged about this recently, and benchmarked the alternatives on different databases. Do check it out.][10]
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
This article stated the “obvious”. Don’t tell the database to perform **needless, mandatory work**.
|
|
||||||
|
|
||||||
It’s **needless** because given your requirements, you _knew_ that some specific piece of work did not need to be done. Yet, you tell the database to do it.
|
|
||||||
|
|
||||||
It’s **mandatory** because the database has no way to prove it’s **needless**. This information is contained only in the client, which is inaccessible to the server. So, the database has to do it.
|
|
||||||
|
|
||||||
This article talked about `SELECT *`, mostly, because that’s such an easy target. But this isn’t about databases only. This is about any distributed algorithm where a client instructs a server to perform **needless, mandatory work**. How many N+1 problems does your average AngularJS application have, where the UI loops over service result A, calling service B many times, instead of batching all calls to B into a single call? It’s a recurrent pattern.
|
|
||||||
|
|
||||||
The solution is always the same. The more information you give to the entity executing your command, the faster it can (in principle) execute such command. Write a better query. Every time. Your entire system will thank you for it.
|
|
||||||
|
|
||||||
### If you liked this article…
|
|
||||||
|
|
||||||
… do also check out my recent talk at Voxxed Days Zurich, where I show some hyperbolic examples of why SQL will beat Java at data processing algorithms every time:
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://blog.jooq.org/2017/03/08/many-sql-performance-problems-stem-from-unnecessary-mandatory-work
|
|
||||||
|
|
||||||
作者:[ jooq][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://blog.jooq.org/
|
|
||||||
[1]:http://use-the-index-luke.com/
|
|
||||||
[2]:https://lukaseder.files.wordpress.com/2017/03/title-rating.png
|
|
||||||
[3]:https://github.com/jOOQ/jOOQ/tree/master/jOOQ-examples/Sakila
|
|
||||||
[4]:https://lukaseder.files.wordpress.com/2017/03/useless-information.png
|
|
||||||
[5]:https://blog.jooq.org/2015/04/28/do-not-think-that-one-second-is-fast-for-query-execution/
|
|
||||||
[6]:https://lukaseder.files.wordpress.com/2017/03/first-name-last-name.png
|
|
||||||
[7]:https://www.youtube.com/watch?v=wTPGW1PNy_Y
|
|
||||||
[8]:https://lukaseder.files.wordpress.com/2017/03/first-name-last-name-customers.png
|
|
||||||
[9]:https://vladmihalcea.com/2016/09/13/the-best-way-to-handle-the-lazyinitializationexception/
|
|
||||||
[10]:https://blog.jooq.org/2016/09/14/avoid-using-count-in-sql-when-you-could-use-exists/
|
|
||||||
@ -1,138 +0,0 @@
|
|||||||
ictlyh Translating
|
|
||||||
An introduction to GRUB2 configuration for your Linux machine
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
> Learn how the GRUB boot loader works to prepare your system and launch your operating system kernel.
|
|
||||||

|
|
||||||
>Image by : Internet Archive [Book][5] [Images][6]. Modified by Opensource.com. CC BY-SA 4.0
|
|
||||||
|
|
||||||
When researching my article from last month, _[An introduction to the Linux][1][ boot and startup process][2]_ , I became interested in learning more about GRUB2\. This article provides a quick introduction to configuring GRUB2, which I will mostly refer to as GRUB for simplicity.
|
|
||||||
|
|
||||||
### GRUB
|
|
||||||
|
|
||||||
GRUB stands for _GRand Unified Bootloader_ . Its function is to take over from BIOS at boot time, load itself, load the Linux kernel into memory, and then turn over execution to the kernel. Once the kernel takes over, GRUB has done its job and it is no longer needed.
|
|
||||||
|
|
||||||
GRUB supports multiple Linux kernels and allows the user to select between them at boot time using a menu. I have found this to be a very useful tool because there have been many instances that I have encountered problems with an application or system service that fails with a particular kernel version. Many times, booting to an older kernel can circumvent issues such as these. By default, three kernels are kept–the newest and two previous–when **yum** or **dnf** are used to perform upgrades. The number of kernels to be kept before the package manager erases them is configurable in the **/etc/dnf/dnf.conf** or **/etc/yum.conf** files. I usually change the **installonly_limit** value to 9 to retain a total of nine kernels. This has come in handy on a couple occasions when I had to revert to a kernel that was several versions down-level.
|
|
||||||
|
|
||||||
### GRUB menu
|
|
||||||
|
|
||||||
The function of the GRUB menu is to allow the user to select one of the installed kernels to boot in the case where the default kernel is not the desired one. Using the up and down arrow keys allows you to select the desired kernel and pressing the **Enter** key continues the boot process using the selected kernel.
|
|
||||||
|
|
||||||
The GRUB menu also provides a timeout so that, if the user does not make any other selection, GRUB will continue to boot with the default kernel without user intervention. Pressing any key on the keyboard except the **Enter** key terminates the countdown timer which is displayed on the console. Pressing the **Enter** key immediately continues the boot process with either the default kernel or an optionally selected one.
|
|
||||||
|
|
||||||
The GRUB menu also provides a "rescue" kernel, in for use when troubleshooting or when the regular kernels don't complete the boot process for some reason. Unfortunately, this rescue kernel does not boot to rescue mode. More on this later in this article.
|
|
||||||
|
|
||||||
### The grub.cfg file
|
|
||||||
|
|
||||||
The **grub.cfg** file is the GRUB configuration file. It is generated by the **grub2-mkconfig** program using a set of primary configuration files and the grub default file as a source for user configuration specifications. The **/****boot/grub2/****grub.cfg** file is first generated during Linux installation and regenerated when a new kernel is installed.
|
|
||||||
|
|
||||||
The **grub.cfg** file contains Bash-like code and a list of installed kernels in an array ordered by sequence of installation. For example, if you have four installed kernels, the most recent kernel will be at index 0, the previous kernel will be at index 1, and the oldest kernel will be index 3\. If you have access to a **grub.****cfg** file you should look at it to get a feel for what one looks like. The **grub.cfg** file is just too large to be included in this article.
|
|
||||||
|
|
||||||
### GRUB configuration files
|
|
||||||
|
|
||||||
The main set of configuration files for **grub.cfg** is located in the **/etc/grub.d **directory. Each of the files in that directory contains GRUB code that is collected into the final grub.cfg file. The numbering scheme used in the names of these configuration files is designed to provide ordering so that the final **grub.cfg** file is assembled into the correct sequence. Each of these files has a comment to denote the beginning and end of the section, and those comments are also part of the final grub.cfg file so that it is possible to see from which file each section is generated. The delimiting comments look like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
### BEGIN /etc/grub.d/10_linux ###
|
|
||||||
|
|
||||||
### END /etc/grub.d/10_linux ###
|
|
||||||
```
|
|
||||||
|
|
||||||
These files should not be modified unless you are a GRUB expert and understand what the changes will do. Even then you should always keep a backup copy of the original, working **grub.****cfg** file. The specific files, **40_custom** and **41_custom** are intended to be used to generate user modifications to the GRUB configuration. You should still be aware of the consequences of any changes you make to these files and maintain a backup of the original **grub.****cfg** file.
|
|
||||||
|
|
||||||
You can also add your own files to the /etc/grub.d directory. One reason for doing that might be to add a menu line for a non-Linux operating system. Just be sure to follow the naming convention to ensure that the additional menu item is added either immediately before or after the **10_linux** entry in the configuration file.
|
|
||||||
|
|
||||||
### GRUB defaults file
|
|
||||||
|
|
||||||
Configuration of the original GRUB was fairly simple and straightforward. I would just modify **/boot/grub/grub.conf** and be good to go. I could still modify GRUB2 by changing **/boot/grub2/grub.****cfg**, but the new version is considerably more complex than the original GRUB. In addition, **grub.cfg** may be overwritten when a new kernel is installed, so any changes may disappear. However, the GNU.org GRUB Manual does discuss direct creation and modification of **/boot/grub2/grub.cfg**.
|
|
||||||
|
|
||||||
Changing the configuration for GRUB2 is fairly easy once you actually figure out how to do it. I only discovered this while researching GRUB2 for a previous article. The secret formula is in the **/etc/default **directory, with a file called, naturally enough, grub, which is then used in concert with a simple terminal command. The **/etc/default** directory contains configuration files for a few programs such as Google Chrome, useradd, and grub.
|
|
||||||
|
|
||||||
The **/etc/default/grub** file is very simple. The grub defaults file has a number of valid key/value pairs listed already. You can simply change the values of existing keys or add other keys that are not already in the file. Listing 1, below, shows an unmodified **/etc/default/gru**b file.
|
|
||||||
|
|
||||||
```
|
|
||||||
GRUB_TIMEOUT=5
|
|
||||||
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g'
|
|
||||||
/etc/system-release)"
|
|
||||||
GRUB_DEFAULT=saved
|
|
||||||
GRUB_DISABLE_SUBMENU=true
|
|
||||||
GRUB_TERMINAL_OUTPUT="console"
|
|
||||||
GRUB_CMDLINE_LINUX="rd.lvm.lv=fedora_fedora25vm/root
|
|
||||||
rd.lvm.lv=fedora_fedora25vm/swap
|
|
||||||
rd.lvm.lv=fedora_fedora25vm/usr rhgb quiet"
|
|
||||||
GRUB_DISABLE_RECOVERY="true"
|
|
||||||
```
|
|
||||||
|
|
||||||
_Listing 1: An original grub default file for Fedora 25._
|
|
||||||
|
|
||||||
[Section 5.1 of the GRUB Manual][7] contains information about all of the possible keys that can be included in the grub file. I have never had needed to do anything other than modifying the values of some of the keys that are already in the grub default file. Let's look at what each of these keys means as well as some that don't appear in the grub default file.
|
|
||||||
|
|
||||||
* **GRUB_TIMEOUT **The value of this key determines the length of time that the GRUB selection menu is displayed. GRUB offers the capability to keep multiple kernels installed simultaneously and choose between them at boot time using the GRUB menu. The default value for this key is 5 seconds, but I usually change that to 10 seconds to allow more time to view the choices and make a selection.
|
|
||||||
* **GRUB_DISTRIBUTOR **This key defines a [sed][3] expression that extracts the distribution release number from the /etc/system-release file. This information is used to generate the text names for each kernel release that appear in the GRUB menu, such as "Fedora". Due to variations in the structure of the data in the system-release file between distributions, this sed expression may be different on your system.
|
|
||||||
* **GRUB_DEFAULT **Determines which kernel is booted by default. That is the "saved" kernel which is the most recent kernel. Other options here are a number which represents the index of the list of kernels in **grub.cfg**. Using an index such as 3, however, to load the fourth kernel in the list will always load the fourth kernel in the list even after a new kernel is installed. So using an index will load a different kernel after a new kernel is installed. The only way to ensure that a specific kernel release is booted is to set the value of **GRUB_DEFAULT** to the name of the desired kernel, like 4.8.13-300.fc25.x86_64.
|
|
||||||
* **GRUB_SAVEDEFAULT **Normally, this option is not specified in the grub defaults file. Normal operation when a different kernel is selected for boot, that kernel is booted only that one time. The default kernel is not changed. When set to "true" and used with **GRUB_DEFAULT=saved** this option saves a different kernel as the default. This happens when a different kernel is selected for boot.
|
|
||||||
* **GRUB_DISABLE_SUBMENU **Some people may wish to create a hierarchical menu structure of kernels for the GRUB menu screen. This key, along with some additional configuration of the kernel stanzas in **grub.****cfg** allow creating such a hierarchy. For example, the one might have the main menu with "production" and "test" sub-menus where each sub-menu would contain the appropriate kernels. Setting this to "false" would enable the use of sub-menus.
|
|
||||||
* **GRUB_TERMINAL_OUTPUT **In some environments it may be desirable or necessary to redirect output to a different display console or terminal. The default is to send output to the default terminal, usually the "console" which equates to the standard display on an Intel class PC. Another useful option is to specify "serial" in a data center or lab environment in which serial terminals or Integrated Lights Out (ILO) terminal connections are in use.
|
|
||||||
* **GRUB_TERMINAL_INPUT **As with **GRUB_TERMINAL_OUTPUT**, it may be desirable or necessary to redirect input from a serial terminal or ILO device rather than the standard keyboard input.
|
|
||||||
* **GRUB_CMDLINE_LINUX **This key contains the command line arguments that will be passed to the kernel at boot time. Note that these arguments will be added to the kernel line of grub.cfg for all installed kernels. This means that all installed kernels will have the same arguments when booted. I usually remove the "rhgb" and "quiet" arguments so that I can see all of the very informative messages output by the kernel and systemd during the boot and startup.
|
|
||||||
* **GRUB_DISABLE_RECOVERY **When the value of this key is set to "false," a recovery entry is created in the GRUB menu for every installed kernel. When set to "true" no recovery entries are created. Regardless of this setting, the last kernel entry is always a "rescue" option. However, I encountered a problem with the rescue option, which I'll talk more about below.
|
|
||||||
|
|
||||||
There are other keys that I have not covered here that you might find useful. Their descriptions are located in Section 5.1 of the [GRUB Manual 2][8].
|
|
||||||
|
|
||||||
### Generate grub.cfg
|
|
||||||
|
|
||||||
After completing the desired configuration it is necessary to generate the **/boot/grub2/grub.****cfg** file. This is accomplished with the following command.
|
|
||||||
|
|
||||||
```
|
|
||||||
grub2-mkconfig > /boot/grub2/grub.cfg
|
|
||||||
```
|
|
||||||
|
|
||||||
This command takes the configuration files located in /etc/grub.d in sequence to build the **grub.****cfg** file, and uses the contents of the grub defaults file to modify the output to achieve the final desired configuration. The **grub2-mkconfig** command attempts to locate all of the installed kernels and creates an entry for each in the **10_Linux** section of the **grub.****cfg** file. It also creates a "rescue" entry to provide a method for recovering from significant problems that prevent Linux from booting.
|
|
||||||
|
|
||||||
It is strongly recommended that you do not edit the **grub.****cfg** file manually because any direct modifications to the file will be overwritten the next time a new kernel is installed or **grub2-mkconfig** is run manually.
|
|
||||||
|
|
||||||
### Issues
|
|
||||||
|
|
||||||
I encountered one problem with GRUB2 that could have serious consequences if you are not aware of it. The rescue kernel does not boot, instead, one of the other kernels boots. I found that to be the kernel at index 1 in the list, i.e., the second kernel in the list. Additional testing showed that this problem occurred whether using the original **grub.****cfg** configuration file or one that I generated. I have tried this on both virtual and real hardware and the problem is the same on each. I only tried this with Fedora 25 so it may not be an issue with other Fedora releases.
|
|
||||||
|
|
||||||
Note that the "recovery" kernel entry that is generated from the "rescue" kernel does work and boots to a maintenance mode login.
|
|
||||||
|
|
||||||
I recommend changing **GRUB_DISABLE_RECOVERY** to "false" in the grub defaults file, and generating your own **grub.cfg**. This will generate usable recovery entries in the GRUB menu for each of the installed kernels. These recovery configurations work as expected and boot to runlevel 1—according to the runlevel command—at a command line entry that requests a password to enter maintenance mode. You could also press **Ctrl-D** to continue a normal boot to the default runlevel.
|
|
||||||
|
|
||||||
### Conclusions
|
|
||||||
|
|
||||||
GRUB is the first step after BIOS in the sequence of events that boot a Linux computer to a usable state. Understanding how to configure GRUB is important to be able to recover from or to circumvent various types of problems.
|
|
||||||
|
|
||||||
I have had to boot to recovery or rescue mode many times over the years to resolve many types of problems. Some of those problems were actual boot problems due to things like improper entries in **/etc/fstab** or other configuration files, and others were due to problems with application or system software that was incompatible with the newest kernel. Hardware compatibility issues might also prevent a specific kernel from booting.
|
|
||||||
|
|
||||||
I hope this information will help you get started with GRUB configuration.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
|
||||||
|
|
||||||
|
|
||||||
----------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/3/introduction-grub2-configuration-linux
|
|
||||||
|
|
||||||
作者:[David Both ][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/dboth
|
|
||||||
[1]:https://opensource.com/article/17/2/linux-boot-and-startup
|
|
||||||
[2]:https://opensource.com/article/17/2/linux-boot-and-startup
|
|
||||||
[3]:https://en.wikipedia.org/wiki/Sed
|
|
||||||
[4]:https://opensource.com/article/17/3/introduction-grub2-configuration-linux?rate=QrIzRpQ3YhewYlBD0AFp0JiF133SvhyAq783LOxjr4c
|
|
||||||
[5]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
|
||||||
[6]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
|
||||||
[7]:https://www.gnu.org/software/grub/manual/grub.html#Simple-configuration
|
|
||||||
[8]:https://www.gnu.org/software/grub/manual/grub.html#Simple-configuration
|
|
||||||
[9]:https://opensource.com/user/14106/feed
|
|
||||||
[10]:https://opensource.com/article/17/3/introduction-grub2-configuration-linux#comments
|
|
||||||
[11]:https://opensource.com/users/dboth
|
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
ictlyh Translating
|
||||||
Introduction to functional programming
|
Introduction to functional programming
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,97 +0,0 @@
|
|||||||
8 ways to get started with open source hardware
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### Making your own hardware is easier and less expensive than ever. Here's what you need to design, build, and test your first board.
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
>Image by : Thomas Hawk on [Flickr][11]. [CC BY-NC 2.0][12]. Modified by Opensource.com
|
|
||||||
|
|
||||||
Alan Kay, famed computer scientist, once said, "People who are really serious about software should make their own hardware." I'd argue that's as true today as it was in 1982 when he said it. However, what's changed between then and now is that hardware has gotten faster, smaller, and most importantly: cheaper. it's now possible to buy a full computer for $5.
|
|
||||||
|
|
||||||
With big companies driving down prices for their own products, it's grown a manufacturing ecosystem capable of producing production-grade hardware that's cheap enough and accessible enough that it is now within reach of normal individuals. This accessibility and affordability are helping drive things like crowdfunding and the maker movement, but they're also giving way to more individuals being able to participate in open source through open source hardware.
|
|
||||||
|
|
||||||
Explore open hardware
|
|
||||||
|
|
||||||
* [What is open hardware?][1]
|
|
||||||
|
|
||||||
* [What is Raspberry Pi?][2]
|
|
||||||
|
|
||||||
* [What is an Arduino?][3]
|
|
||||||
|
|
||||||
* [Our latest open hardware articles][4]
|
|
||||||
|
|
||||||
There's some pretty big differences in what is or isn't open source hardware, but the Open Source Hardware Association (OSHWA) has a definition that most folks agree with, and if you're familiar with open source software this shouldn't sound too weird:
|
|
||||||
|
|
||||||
> "Open source hardware (OSHW) is a term for tangible artifacts—machines, devices, or other physical things—whose design has been released to the public in such a way that anyone can make, modify, distribute, and use those things."
|
|
||||||
|
|
||||||
There's lots of open source hardware around; you may not have noticed the boards you already use may, in fact, be open hardware. From the humble but ever versatile [Arduino][13] and all the way up through full computers like the [BeagleBone][14] family and the [C.H.I.P.][15] computer, there are lots of examples of open hardware around, and more designs are being made all the time.
|
|
||||||
|
|
||||||
Hardware can be complicated, and sometimes non-obvious to beginners why a design needs something. But open source hardware gives you the ability to not only see working examples, but also the ability to change those designs or strike off and replicate the pieces you need in your own designs, and it might be as simple as copy and paste.
|
|
||||||
|
|
||||||
### How can I get started?
|
|
||||||
|
|
||||||
Let's start off by pointing out that hardware is hard, it's complicated, sometimes esoteric, and the tools you may be using are not always the most user-friendly. It's also more than likely, as anyone who's played around with a microcontroller long enough can attest: you are going to fry something and let the magic smoke out at some point. It's ok, we've all done it, some of us repeatedly because we didn't learn the lesson the first 100 times we did something, but don't let this discourage you: Lessons are learned when things go wrong, and you usually get an interesting story to tell later.
|
|
||||||
|
|
||||||
### Modeling
|
|
||||||
|
|
||||||
The first thing to do is to start modeling what you want to do with an existing board, jumper wires, a breadboard, and whatever devices you want to hook up. In many cases, the simplest thing to play with is just adding more LEDs to a board and getting them to blink in novel ways. This is a great way to prototype something, and it's a fairly common thing to do. It won't look pretty, and you may find that you wire something wrong, but these are prototypes—you just want to prove things work. When things don't work, always double check everything, and don't be afraid to ask for help—sometimes a second pair of eyes will find your oddball ground short.
|
|
||||||
|
|
||||||
### Design
|
|
||||||
|
|
||||||
When you've figured out what you want to build, it's time to start taking your idea from jumper wires and breadboards to an actual design. This is where things can get a bit daunting, but start small—in fact, it's worth starting really small just to get used to the tooling and process, so why not make a printed circuit board that has a LED and a battery on it? Seriously, this might sound overly simplistic but there's a lot of new ground to cover here.
|
|
||||||
|
|
||||||
1. **Find an electronic design automation (EDA) tool to use.** There are some good open source software options out there, but they aren't always the most user-friendly. [Fritzing][5], [gEDA][6], and [KiCad ][7]are all open source in ascending order of approachability. There are also some options if you want to try more commercial offerings; Eagle has a free version available with some restrictions and a lot of open source hardware designs are done in it.
|
|
||||||
|
|
||||||
1. **Design your board in your EDA tool.** Depending on the tool you choose, this could be fairly quick, or it could be quite the exercise in learning how things work. This is one of the reasons I suggest starting small; a circuit with an LEDaan be as simple as a battery, a resistor, and an LED. The schematic capture is pretty simple, and the layout can be small and very simple.
|
|
||||||
|
|
||||||
1. **Export your design for manufacturing.** This goes hand-in-hand with the next thing on the list, but it can also be a confusing process if you haven't done it before. There's a lot of knobs and dials to twist and adjust when you do the export, and things need to be exported in certain ways to make it easier on board houses to actually figure out what you want them to make.
|
|
||||||
|
|
||||||
1. **Find a board house.** There are lots of board houses out there that can make your design, and some are more friendly and helpful than others. One place that's particularly awesome to work with is [OSH Park][8], these guys are very friendly and supportive of open source hardware. They also have a very solid process for confirming that what you are sending them is what will get built, so they are worth checking out. There are lots of other options though; take a look at [PCB Shopper][9], which lets you compare pricing, turnaround times, etc. of a number of solid PCB manufacturers.
|
|
||||||
|
|
||||||
1. **Wait.** This might be the hardest part of building your own board, as it takes time to make something digital into a physical product. Plan on two weeks from when you hit "go" to getting your boards back. This is a great time to work on your next project, ensure or acquire all the parts for your current build, or generally try not to worry. On your first board it's hard—you really want it now, but be patient.
|
|
||||||
|
|
||||||
1. **Solder up and bring up.** Once you've got your board, it's time to make it up and then test it. If you've gone with the LED option to start, it should be fairly easy to debug, and you'll have something that works. If you went more complex, be methodical and patient; sometimes things don't work and you'll need all your debugging skills to track things down.
|
|
||||||
|
|
||||||
1. **Last, if you are doing open source hardware, release it.** We are talking about open source hardware, so make sure you include a license, but release it, share it, put it somewhere people can see what you've done. You may even want to write a blog post and submit it to someplace like Hackaday.
|
|
||||||
|
|
||||||
1. **Above all, have fun.** Frankly if you are doing something and you aren't having fun, you should stop doing it. Open source hardware can be a lot of fun, though sometimes hard and complicated. Not everything may work; heck, I've had designs where half the board wasn't working or where I (accidentally) caused 12 shorts between power and ground. Were those boards bunked boards: yup. Did I learn something in the process: A LOT, and I won't make those same mistakes again. I'll make new ones, sure, but not THOSE. (I'd point and glare at those boards and their mistakes, but they wouldn't feel bad for me glaring at them, sadly).
|
|
||||||
|
|
||||||
There's a lot of open source hardware out there and lots of good examples to look at, copy, and derive from and lots of information to help make building hardware easier. That's what open source hardware is: A community of people making things and sharing them so that everyone can make their own things and build the hardware that they want—not the hardware they can get.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
John 'Warthog9' Hawley - John works for VMware in the Open Source Program Office on upstream open source projects. In a previous life he's worked on the MinnowBoard open source hardware project, led the system administration team on kernel.org, and built desktop clusters before they were cool. For fun he's built multiple star ship bridges, a replica of K-9 from a popular British TV show, done in flight computer vision processing from UAVs, designed and built a pile of his own hardware.
|
|
||||||
|
|
||||||
-------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware
|
|
||||||
|
|
||||||
作者:[John 'Warthog9' Hawley ][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware
|
|
||||||
[1]:https://opensource.com/resources/what-open-hardware?src=open_hardware_resources_menu
|
|
||||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=open_hardware_resources_menu
|
|
||||||
[3]:https://opensource.com/resources/what-arduino?src=open_hardware_resources_menu
|
|
||||||
[4]:https://opensource.com/tags/hardware?src=open_hardware_resources_menu
|
|
||||||
[5]:http://fritzing.org/home/
|
|
||||||
[6]:http://www.geda-project.org/
|
|
||||||
[7]:http://kicad-pcb.org/
|
|
||||||
[8]:https://oshpark.com/
|
|
||||||
[9]:http://pcbshopper.com/
|
|
||||||
[10]:https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware?rate=jPBGDIa2vBXW6kb837X8JWdjI2V47hZ4KecI8-GJBjQ
|
|
||||||
[11]:https://www.flickr.com/photos/thomashawk/3048157616/in/photolist-5DmB4E-BzrZ4-5aUXCN-nvBWYa-qbkwAq-fEFeDm-fuZxgC-dufA8D-oi8Npd-b6FiBp-7ChGA3-aSn7xK-7NXMyh-a9bQQr-5NG9W7-agCY7E-4QD9zm-7HLTtj-4uCiHy-bYUUtG
|
|
||||||
[12]:https://creativecommons.org/licenses/by-nc/2.0/
|
|
||||||
[13]:https://opensource.com/node/20751
|
|
||||||
[14]:https://opensource.com/node/35211
|
|
||||||
[15]:https://opensource.com/node/24891
|
|
||||||
[16]:https://opensource.com/user/130046/feed
|
|
||||||
[17]:https://opensource.com/users/warthog9
|
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
translating by ypingcn
|
||||||
|
|
||||||
Hugo vs. Jekyll: Comparing the leading static website generators
|
Hugo vs. Jekyll: Comparing the leading static website generators
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
ictlyh Translating
|
ch-cn translating
|
||||||
10 Useful Tips for Writing Effective Bash Scripts in Linux
|
10 Useful Tips for Writing Effective Bash Scripts in Linux
|
||||||
============================================================
|
============================================================
|
||||||
ch-cn translating
|
|
||||||
|
|
||||||
[Shell scripting][4] is the easiest form of programming you can learn/do in Linux. More so, it is a required skill for [system administration for automating tasks][5], developing new simple utilities/tools just to mention but a few.
|
[Shell scripting][4] is the easiest form of programming you can learn/do in Linux. More so, it is a required skill for [system administration for automating tasks][5], developing new simple utilities/tools just to mention but a few.
|
||||||
|
|
||||||
|
|||||||
@ -1,357 +0,0 @@
|
|||||||
ictlyh Translating
|
|
||||||
Accelerating your C++ on GPU with SYCL
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
|
|
||||||
### WARNING: This is an incomplete draft. There are likely many mistaeks and unfinished sections.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
Leveraging the power of graphics cards for compute applications is all the rage right now in fields such as machine learning, computer vision and high-performance computing. Technologies like OpenCL expose this power through a hardware-independent programming model, allowing you to write code which abstracts over different architecture capabilities. The dream of this is “write once, run anywhere”, be it an Intel CPU, AMD discrete GPU, DSP, etc. Unfortunately, for everyday programmers, OpenCL has something of a steep learning curve; a simple Hello World program can be a hundred or so lines of pretty ugly-looking code. However, to ease this pain, the Khronos group have developed a new standard called [SYCL][4], which is a C++ abstraction layer on top of OpenCL. Using SYCL, you can develop these general-purpose GPU (GPGPU) applications in clean, modern C++ without most of the faff associated with OpenCL. Here’s a simple vector multiplication example written in SYCL using the parallel STL implementation:
|
|
||||||
|
|
||||||
```
|
|
||||||
#include <vector>
|
|
||||||
#include <iostream>
|
|
||||||
|
|
||||||
#include <sycl/execution_policy>
|
|
||||||
#include <experimental/algorithm>
|
|
||||||
#include <sycl/helpers/sycl_buffers.hpp>
|
|
||||||
|
|
||||||
using namespace std::experimental::parallel;
|
|
||||||
using namespace sycl::helpers;
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
constexpr size_t array_size = 1024*512;
|
|
||||||
std::array<cl::sycl::cl_int, array_size> a;
|
|
||||||
std::iota(begin(a),end(a),0);
|
|
||||||
|
|
||||||
{
|
|
||||||
cl::sycl::buffer<int> b(a.data(), cl::sycl::range<1>(a.size()));
|
|
||||||
cl::sycl::queue q;
|
|
||||||
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
|
||||||
transform(sycl_policy, begin(b), end(b), begin(b),
|
|
||||||
[](int x) { return x*2; });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
For comparison, here’s a mostly equivalent version written in OpenCL using the C++ API (don’t spend much time reading this, just note that it looks ugly and is really long):
|
|
||||||
|
|
||||||
```
|
|
||||||
#include <iostream>
|
|
||||||
#include <array>
|
|
||||||
#include <numeric>
|
|
||||||
#include <CL/cl.hpp>
|
|
||||||
|
|
||||||
int main(){
|
|
||||||
std::vector<cl::Platform> all_platforms;
|
|
||||||
cl::Platform::get(&all_platforms);
|
|
||||||
if(all_platforms.size()==0){
|
|
||||||
std::cout<<" No platforms found. Check OpenCL installation!\n";
|
|
||||||
exit(1);
|
|
||||||
}
|
|
||||||
cl::Platform default_platform=all_platforms[0];
|
|
||||||
|
|
||||||
std::vector<cl::Device> all_devices;
|
|
||||||
default_platform.getDevices(CL_DEVICE_TYPE_ALL, &all_devices);
|
|
||||||
if(all_devices.size()==0){
|
|
||||||
std::cout<<" No devices found. Check OpenCL installation!\n";
|
|
||||||
exit(1);
|
|
||||||
}
|
|
||||||
|
|
||||||
cl::Device default_device=all_devices[0];
|
|
||||||
cl::Context context({default_device});
|
|
||||||
|
|
||||||
cl::Program::Sources sources;
|
|
||||||
std::string kernel_code=
|
|
||||||
" void kernel mul2(global int* A){"
|
|
||||||
" A[get_global_id(0)]=A[get_global_id(0)]*2;"
|
|
||||||
" }";
|
|
||||||
sources.push_back({kernel_code.c_str(),kernel_code.length()});
|
|
||||||
|
|
||||||
cl::Program program(context,sources);
|
|
||||||
if(program.build({default_device})!=CL_SUCCESS){
|
|
||||||
std::cout<<" Error building: "<<program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(default_device)<<"\n";
|
|
||||||
exit(1);
|
|
||||||
}
|
|
||||||
|
|
||||||
constexpr size_t array_size = 1024*512;
|
|
||||||
std::array<cl_int, array_size> a;
|
|
||||||
std::iota(begin(a),end(a),0);
|
|
||||||
|
|
||||||
cl::Buffer buffer_A(context,CL_MEM_READ_WRITE,sizeof(int)*a.size());
|
|
||||||
cl::CommandQueue queue(context,default_device);
|
|
||||||
|
|
||||||
if (queue.enqueueWriteBuffer(buffer_A,CL_TRUE,0,sizeof(int)*a.size(),a.data()) != CL_SUCCESS) {
|
|
||||||
std::cout << "Failed to write memory;n";
|
|
||||||
exit(1);
|
|
||||||
}
|
|
||||||
|
|
||||||
cl::Kernel kernel_add = cl::Kernel(program,"mul2");
|
|
||||||
kernel_add.setArg(0,buffer_A);
|
|
||||||
|
|
||||||
if (queue.enqueueNDRangeKernel(kernel_add,cl::NullRange,cl::NDRange(a.size()),cl::NullRange) != CL_SUCCESS) {
|
|
||||||
std::cout << "Failed to enqueue kernel\n";
|
|
||||||
exit(1);
|
|
||||||
}
|
|
||||||
|
|
||||||
if (queue.finish() != CL_SUCCESS) {
|
|
||||||
std::cout << "Failed to finish kernel\n";
|
|
||||||
exit(1);
|
|
||||||
}
|
|
||||||
|
|
||||||
if (queue.enqueueReadBuffer(buffer_A,CL_TRUE,0,sizeof(int)*a.size(),a.data()) != CL_SUCCESS) {
|
|
||||||
std::cout << "Failed to read result\n";
|
|
||||||
exit(1);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
In this post I’ll give an introduction on using SYCL to accelerate your C++ code on the GPU.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### Lightning intro to GPGPU
|
|
||||||
|
|
||||||
Before I get started on how to use SYCL, I’ll give a brief outline of why you might want to run compute jobs on the GPU for those who are unfamiliar. I’ve you’ve already used OpenCL, CUDA or similar, feel free to skip ahead.
|
|
||||||
|
|
||||||
The key difference between a GPU and a CPU is that, rather than having a small number of complex, powerful cores (1-8 for common consumer desktop hardware), a GPU has a huge number of small, simple processing elements.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Above is a comically simplified diagram of a CPU with four cores. Each core has a set of registers and is attached to various levels of cache (some might be shared, some not), and then main memory.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
In the GPU, tiny processing elements are grouped into execution units. Each processing element has a bit of memory attached to it, and each execution unit has some memory shared between its processing elements. After that, there’s some GPU-wide memory, then the same main memory which the CPU uses. The elements within an execution unit execute in _lockstep_ , where each element executes the same instruction on a different piece of data.
|
|
||||||
|
|
||||||
There are many aspects of GPGPU programming which make it an entirely different beast to everyday CPU programming. For example, transferring data from main memory to the GPU is _slow_ . _Really_ slow. Like, kill all your performance and get you fired slow. Therefore, the tradeoff with GPU programming is to make as much of the ridiculously high throughput of your accelerator to hide the latency of shipping the data to and from it.
|
|
||||||
|
|
||||||
There are other issues which might not be immediately apparent, like the cost of branching. Since the processing elements in an execution unit work in lockstep, nested branches which cause them to take different paths (divergent control flow) is a real problem. This is often solved by executing all branches for all elements and masking out the unneeded results. That’s a polynomial explosion in complexity based on the level of nesting, which is A Bad Thing ™. Of course, there are optimizations which can aid this, but the idea stands: simple assumptions and knowledge you bring from the CPU world might cause you big problems in the GPU world.
|
|
||||||
|
|
||||||
Before we get back to SYCL, some short pieces of terminology. The _host_ is the main CPU running on your machine which executes and the _device_ is what will be running your OpenCL code. A device could be the same as the host, or it could be some accelerator sitting in your machine, a simulator, whatever. A _kernel_ is a special function which is the entry point to the code which will run on your device. It will often be supplied with buffers for input and output data which have been set up by the host.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### Back to SYCL
|
|
||||||
|
|
||||||
There are currently two implementations of SYCL available; “triSYCL”, an experimental open source version by Xilinx (mostly used as a testbed for the standard), and “ComputeCpp”, an industry-strength implementation by Codeplay[1][2] (currently in open beta). Only ComputeCpp supports execution of kernels on the GPU, so we’ll be using that in this post.
|
|
||||||
|
|
||||||
Step 1 is to get ComputeCpp up and running on your machine. The main components are a runtime library which implements the SYCL API, and a Clang-based compiler which compiles both your host code and your device code. At the time of writing, Intel CPUs and some AMD GPUs are officially supported on Ubuntu and CentOS. It should be pretty easy to get it working on other Linux distributions (I got it running on my Arch system, for instance). Support for more hardware and operating systems is being worked on, so check the [supported platforms document][5] for an up-to-date list. The dependencies and components are listed [here][6]. You might also want to download the [SDK][7], which contains samples, documentation, build system integration files, and more. I’ll be using the [SYCL Parallel STL][8] in this post, so get that if you want to play along at home.
|
|
||||||
|
|
||||||
Once you’re all set up, we can get GPGPUing! As noted in the introduction, my first sample used the SYCL parallel STL implementation. We’ll now take a look at how to write that code with bare SYCL.
|
|
||||||
|
|
||||||
```
|
|
||||||
#include <CL/sycl.hpp>
|
|
||||||
|
|
||||||
#include <array>
|
|
||||||
#include <numeric>
|
|
||||||
#include <iostream>
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
const size_t array_size = 1024*512;
|
|
||||||
std::array<cl::sycl::cl_int, array_size> in,out;
|
|
||||||
std::iota(begin(in),end(in),0);
|
|
||||||
|
|
||||||
cl::sycl::queue device_queue;
|
|
||||||
cl::sycl::range<1> n_items{array_size};
|
|
||||||
cl::sycl::buffer<cl::sycl::cl_int, 1> in_buffer(in.data(), n_items);
|
|
||||||
cl::sycl::buffer<cl::sycl::cl_int, 1> out_buffer(out.data(), n_items);
|
|
||||||
|
|
||||||
device_queue.submit([&](cl::sycl::handler &cgh) {
|
|
||||||
constexpr auto sycl_read = cl::sycl::access::mode::read_write;
|
|
||||||
constexpr auto sycl_write = cl::sycl::access::mode::write;
|
|
||||||
|
|
||||||
auto in_accessor = in_buffer.get_access<sycl_read>(cgh);
|
|
||||||
auto out_accessor = out_buffer.get_access<sycl_write>(cgh);
|
|
||||||
|
|
||||||
cgh.parallel_for<class VecScalMul>(n_items,
|
|
||||||
[=](cl::sycl::id<1> wiID) {
|
|
||||||
out_accessor[wiID] = in_accessor[wiID]*2;
|
|
||||||
});
|
|
||||||
});
|
|
||||||
|
|
||||||
device_queue.wait();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
I’ll break this down piece-by-piece.
|
|
||||||
|
|
||||||
```
|
|
||||||
#include <CL/sycl.hpp>
|
|
||||||
```
|
|
||||||
|
|
||||||
The first thing we do is include the SYCL header file, which will put the SYCL runtime library at our command.
|
|
||||||
|
|
||||||
```
|
|
||||||
const size_t array_size = 1024*512;
|
|
||||||
std::array<cl::sycl::cl_int, array_size> in,out;
|
|
||||||
std::iota(begin(in),end(in),0);
|
|
||||||
```
|
|
||||||
|
|
||||||
Here we construct a large array of integers and initialize it with the numbers from `0` to `array_size-1` (this is what `std::iota` does). Note that we use `cl::sycl::cl_int` to ensure compatibility.
|
|
||||||
|
|
||||||
```
|
|
||||||
cl::sycl::queue device_queue;
|
|
||||||
```
|
|
||||||
|
|
||||||
Now we create our command queue. The command queue is where all work (kernels) will be enqueued before being dispatched to the device. There are many ways to customise the queue, such as providing a device to enqueue on or setting up asynchronous error handlers, but the default constructor will do for this example; it looks for a compatible GPU and falls back on the host CPU if it fails.
|
|
||||||
|
|
||||||
```
|
|
||||||
cl::sycl::range<1> n_items{array_size};
|
|
||||||
```
|
|
||||||
|
|
||||||
Next we create a range, which describes the shape of the data which the kernel will be executing on. In our simple example, it’s a one-dimensional array, so we use `cl::sycl::range<1>`. If the data was two-dimensional we would use `cl::sycl::range<2>` and so on. Alongside `cl::sycl::range`, there is `cl::sycl::ndrange`, which allows you to specify work group sizes as well as an overall range, but we don’t need that for our example.
|
|
||||||
|
|
||||||
```
|
|
||||||
cl::sycl::buffer<cl::sycl::cl_int, 1> in_buffer(in.data(), n_items);
|
|
||||||
cl::sycl::buffer<cl::sycl::cl_int, 1> out_buffer(out.data(), n_items);
|
|
||||||
```
|
|
||||||
|
|
||||||
In order to control data sharing and transfer between the host and devices, SYCL provides a `buffer` class. We create two SYCL buffers to manage our input and output arrays.
|
|
||||||
|
|
||||||
```
|
|
||||||
device_queue.submit([&](cl::sycl::handler &cgh) {/*...*/});
|
|
||||||
```
|
|
||||||
|
|
||||||
After setting up all of our data, we can enqueue our actual work. There are a few ways to do this, but a simple method for setting up a parallel execution is to call the `.submit` function on our queue. To this function we pass a _command group functor_ [2][3] which will be executed when the runtime schedules that task. A command group handler sets up any last resources needed by the kernel and dispatches it.
|
|
||||||
|
|
||||||
```
|
|
||||||
constexpr auto sycl_read = cl::sycl::access::mode::read_write;
|
|
||||||
constexpr auto sycl_write = cl::sycl::access::mode::write;
|
|
||||||
|
|
||||||
auto in_accessor = in_buffer.get_access<sycl_read>(cgh);
|
|
||||||
auto out_accessor = out_buffer.get_access<sycl_write>(cgh);
|
|
||||||
```
|
|
||||||
|
|
||||||
In order to control access to our buffers and to tell the runtime how we will be using the data, we need to create _accessors_ . It should be clear that we are creating one accessor for reading from `in_buffer`, and one accessor for writing to `out_buffer`.
|
|
||||||
|
|
||||||
```
|
|
||||||
cgh.parallel_for<class VecScalMul>(n_items,
|
|
||||||
[=](cl::sycl::id<1> wiID) {
|
|
||||||
out_accessor[wiID] = in_accessor[wiID]*2;
|
|
||||||
});
|
|
||||||
```
|
|
||||||
|
|
||||||
Now that we’ve done all the setup, we can actually do some computation on our device. Here we dispatch a kernel on the command group handler `cgh` over our range `n_items`. The actual kernel itself is a lambda which takes a work-item identifier and carries out our computation. In this case, we are reading from `in_accessor` at the index of our work-item identifier, multiplying it by `2`, then storing the result in the relevant place in `out_accessor`. That `<class VecScalMul>` is an unfortunate byproduct of how SYCL needs to work within the confines of standard C++, so we need to give a unique class name to the kernel for the compiler to be able to do its job.
|
|
||||||
|
|
||||||
```
|
|
||||||
device_queue.wait();
|
|
||||||
```
|
|
||||||
|
|
||||||
Our last line is kind of like calling `.join()` on a `std::thread`; it waits until the queue has executed all work which has been submitted. After this point, we could now access `out` and expect to see the correct results. Queues will also wait implicitly on destruction, so you could alternatively place it in some inner scope and let the synchronisation happen when the scope ends.
|
|
||||||
|
|
||||||
There are quite a few new concepts at play here, but hopefully you can see the power and expressibility we get using these techniques. However, if you just want to toss some code at your GPU and not worry about the customisation, then you can use the SYCL Parallel STL implementation.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### SYCL Parallel STL
|
|
||||||
|
|
||||||
The SYCL Parallel STL is an implementation of the Parallelism TS which dispatches your algorithm function objects as SYCL kernels. We already saw an example of this at the top of the page, so lets run through it quickly.
|
|
||||||
|
|
||||||
```
|
|
||||||
#include <vector>
|
|
||||||
#include <iostream>
|
|
||||||
|
|
||||||
#include <sycl/execution_policy>
|
|
||||||
#include <experimental/algorithm>
|
|
||||||
#include <sycl/helpers/sycl_buffers.hpp>
|
|
||||||
|
|
||||||
using namespace std::experimental::parallel;
|
|
||||||
using namespace sycl::helpers;
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
constexpr size_t array_size = 1024*512;
|
|
||||||
std::array<cl::sycl::cl_int, array_size> in,out;
|
|
||||||
std::iota(begin(in),end(in),0);
|
|
||||||
|
|
||||||
{
|
|
||||||
cl::sycl::buffer<int> in_buffer(in.data(), cl::sycl::range<1>(in.size()));
|
|
||||||
cl::sycl::buffer<int> out_buffer(out.data(), cl::sycl::range<1>(out.size()));
|
|
||||||
cl::sycl::queue q;
|
|
||||||
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
|
||||||
transform(sycl_policy, begin(in_buffer), end(in_buffer), begin(out_buffer),
|
|
||||||
[](int x) { return x*2; });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
constexpr size_t array_size = 1024*512;
|
|
||||||
std::array<cl::sycl::cl_int, array_size> in, out;
|
|
||||||
std::iota(begin(in),end(out),0);
|
|
||||||
```
|
|
||||||
|
|
||||||
So far, so similar. Again we’re creating a couple of arrays to hold our input and output data.
|
|
||||||
|
|
||||||
```
|
|
||||||
cl::sycl::buffer<int> in_buffer(in.data(), cl::sycl::range<1>(in.size()));
|
|
||||||
cl::sycl::buffer<int> out_buffer(out.data(), cl::sycl::range<1>(out.size()));
|
|
||||||
cl::sycl::queue q;
|
|
||||||
```
|
|
||||||
|
|
||||||
Here we are creating our buffers and our queue like in the last example.
|
|
||||||
|
|
||||||
```
|
|
||||||
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
|
||||||
```
|
|
||||||
|
|
||||||
Here’s where things get interesting. We create a `sycl_execution_policy` from our queue and give it a name to use for the kernel. This execution policy can then be used like `std::execution::par` or `std::execution::seq`.
|
|
||||||
|
|
||||||
```
|
|
||||||
transform(sycl_policy, begin(in_buffer), end(in_buffer), begin(out_buffer),
|
|
||||||
[](int x) { return x*2; });
|
|
||||||
```
|
|
||||||
|
|
||||||
Now our kernel dispatch looks like a call to `std::transform` with an execution policy provided. That closure we pass in will be compiled for and executed on the device without us having to do any more complex set up.
|
|
||||||
|
|
||||||
Of course, you can do more than just `transform`. At the time of writing, the SYCL Parallel STL supports these algorithms:
|
|
||||||
|
|
||||||
* `sort`
|
|
||||||
|
|
||||||
* `transform`
|
|
||||||
|
|
||||||
* `for_each`
|
|
||||||
|
|
||||||
* `for_each_n`
|
|
||||||
|
|
||||||
* `count_if`
|
|
||||||
|
|
||||||
* `reduce`
|
|
||||||
|
|
||||||
* `inner_product`
|
|
||||||
|
|
||||||
* `transform_reduce`
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
That covers things for this short introduction. If you want to keep up to date with developments in SYCL, be sure to check out [sycl.tech][9]. Notable recent developments have been porting [Eigen][10] and [Tensorflow][11] to SYCL to bring expressive artificial intelligence programming to OpenCL devices. Personally, I’m excited to see how the high-level programming models can be exploited for automatic optimization of heterogeneous programs, and how they can support even higher-level technologies like [HPX][12] or [SkelCL][13].
|
|
||||||
|
|
||||||
1. I work for Codeplay, but this post was written in my own time with no suggestion from my employer. [↩][1]
|
|
||||||
|
|
||||||
2. Hey, “functor” is in the spec, don’t @ me.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://blog.tartanllama.xyz/c++/2017/05/19/sycl/
|
|
||||||
|
|
||||||
作者:[TartanLlama ][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.twitter.com/TartanLlama
|
|
||||||
[1]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fnref:1
|
|
||||||
[2]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fn:1
|
|
||||||
[3]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fn:2
|
|
||||||
[4]:https://www.khronos.org/sycl
|
|
||||||
[5]:https://www.codeplay.com/products/computesuite/computecpp/reference/platform-support-notes
|
|
||||||
[6]:https://www.codeplay.com/products/computesuite/computecpp/reference/release-notes/
|
|
||||||
[7]:https://github.com/codeplaysoftware/computecpp-sdk
|
|
||||||
[8]:https://github.com/KhronosGroup/SyclParallelSTL
|
|
||||||
[9]:http://sycl.tech/
|
|
||||||
[10]:https://github.com/ville-k/sycl_starter
|
|
||||||
[11]:http://deep-beta.co.uk/setting-up-tensorflow-with-opencl-using-sycl/
|
|
||||||
[12]:https://github.com/STEllAR-GROUP/hpx
|
|
||||||
[13]:https://github.com/skelcl/skelcl
|
|
||||||
@ -1,261 +0,0 @@
|
|||||||
How to master the art of Git
|
|
||||||
============================================================
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Step up your software development game with 7 simple Git commands.
|
|
||||||
|
|
||||||
Have you ever wondered how one learns to use Git well? You use Git very poorly for a long time. Eventually, you’ll get the hang of it. That’s why I’m here. I’ll take you on a journey to enlightenment. These are my basic guidelines of how to speed up the process of learning Git significantly. I’ll cover what Git actually is and the 7 Git commands I use the most. This article is mainly aimed towards aspiring developers and college freshmen who are in need of an introductory explanation of what Git is and how to master the basics.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
You can go ahead and read the whole article or hurt my feelings significantly by only reading the TLDR;
|
|
||||||
|
|
||||||
#### TLDR;
|
|
||||||
|
|
||||||
When in the process of learning Git, make a habit of following these steps:
|
|
||||||
|
|
||||||
1. `git status` all the time!
|
|
||||||
|
|
||||||
2. Try only to change files you really want to change.
|
|
||||||
|
|
||||||
3. `git add -A` is your friend.
|
|
||||||
|
|
||||||
4. Feel free to `git commit -m "meaningful messages"` .
|
|
||||||
|
|
||||||
5. Always `git pull` before doing any pushing,
|
|
||||||
but after you have committed any changes.
|
|
||||||
|
|
||||||
6. Finally, `git push` the committed changes.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
#### Do not go gentle into that good night.
|
|
||||||
|
|
||||||
The universal first step for any developer is to choose a common place to host his or her code base. Voilá, [GitHub][4]! The meeting place for all things regarding code. To be able to understand the concept of GitHub you would first need to understand what Git really is.
|
|
||||||
|
|
||||||
Git is a version control software, based on the command line, with a few desktop apps available for Windows and Mac. Created by Linus Torvalds, the father of Linux and one of the most influential people in computer science, ever. Channeling this merit, Git has become a standard for a vast majority of software developers regarding sharing and maintaining code. Those were a bunch of large words. Let’s break it down. Version control software, means exactly what it says. Git allows you to have a preview of all the versions of your code you have ever written. Literally, ever! Every code base a developer has, will be stored in its respective repository, which can be named anything from _pineapple_ to _express_ . In the process of developing the code within this repository you will make countless changes, up until the first official release. Here lies the core reason why version control software is so important. It enables you, the developer, to have a clear view of all changes, revisions and improvements ever done to the code base. In turn making it much easier to collaborate, download code to make edits, and upload changes to the repository. However, in spite of all this awesomeness, one thing takes the crown as the most incredible. You can download and use the files even thought you have nothing to do with the development process!
|
|
||||||
|
|
||||||
Let’s get back to the GitHub part of the story. It’s just a hub for all repositories, where they can be stored and viewed online. A central meeting point for like minded individuals.
|
|
||||||
|
|
||||||
#### Let’s start using it already!
|
|
||||||
|
|
||||||
Okay, remember, Git is a software, and like any other software you’ll first need to install it:
|
|
||||||
|
|
||||||
[Git - Installing Git
|
|
||||||
If you do want to install Git from source, you need to have the following libraries that Git depends on: autotools…git-scm.com][5][][6]
|
|
||||||
|
|
||||||
*Anchorman voice*
|
|
||||||
_Please click on the link above, and follow the instructions stated…_
|
|
||||||
|
|
||||||
Done installing it, great. Now you will need to punch in [github.com][7] in your browsers address bar. Create an account if you don’t already have one, and you’re set to rock’n’roll! Jump in and create a new repository, name it Steve for no reason at all, just for the fun of having a repository named Steve. Go ahead and check the _Initialize this repository with a README _ checkbox and click the create button. You now have a new repository called Steve. Be proud of yourself, I sure am.
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### Starting to use Git for real this time.
|
|
||||||
|
|
||||||
Now comes the fun part. You’re ready to clone Steve to your local machine. View this process as simply copying the repository from GitHub to your computer. By clicking the _clone or download_ button you will see a URL which will look something like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
https://github.com/yourGithubAccountName/Steve.git
|
|
||||||
```
|
|
||||||
|
|
||||||
Copy this URL and open up a command prompt. Now write and run this command:
|
|
||||||
|
|
||||||
```
|
|
||||||
git clone https://github.com/yourGithubAccountName/Steve.git
|
|
||||||
```
|
|
||||||
|
|
||||||
Abrakadabra! Steve has automagically been cloned to your computer. Looking in the directory where you cloned the repository, you’ll see a folder named Steve. This local folder is now linked with it’s _origin, _ the original repository on Github.
|
|
||||||
|
|
||||||
Remember this process, you will surely repeat it many times in your career as a software developer. With all this formal stuff done, you are ready to get started with the most common and regularly used Git commands.
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
Lame video game reference
|
|
||||||
|
|
||||||
#### You’re actually just now starting to use Git for real.
|
|
||||||
|
|
||||||
Open up the Steve directory and go ahead and open a command prompt from within the same directory. Run the command:
|
|
||||||
|
|
||||||
```
|
|
||||||
git status
|
|
||||||
```
|
|
||||||
|
|
||||||
This will output the status of your working directory, showing you all the files you have edited. This means it’s showing you the difference between the files on the origin and your local working directory. The status command is designed to be used as a _commit_ template. I’ll come back to talking about commit a bit further down this tutorial. Simply put, `[git status][1]` shows you which files you have edited, in turn giving you an overview of which you wish to upload back to the origin.
|
|
||||||
|
|
||||||
But, before you do any of that, first you need to pick which files you wish to send back to the origin. This is done with:
|
|
||||||
|
|
||||||
```
|
|
||||||
git add
|
|
||||||
```
|
|
||||||
|
|
||||||
Please go ahead and create a new text file in the Steve directory. Name it _pineapple.txt_ just for the fun of it. Write whatever you would want in this file. Switch back to the command prompt, and run `git status` once again. Now, you’ll see the file show up in red under the banner _untracked files._
|
|
||||||
|
|
||||||
```
|
|
||||||
On branch master
|
|
||||||
Your branch is up-to-date with 'origin/master'.
|
|
||||||
Untracked files:
|
|
||||||
(use "git add <file>..." to include in what will be commited)
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
pineapple.txt
|
|
||||||
```
|
|
||||||
|
|
||||||
The next step is to add a file to staging. Staging can be viewed as a context where all changes you have picked will be bundled into one, when the time comes to commit them. Now you can go ahead and add this file to staging:
|
|
||||||
|
|
||||||
```
|
|
||||||
git add -A
|
|
||||||
```
|
|
||||||
|
|
||||||
The _-A _ flag means that all files that have been changed will be staged for commit. However, `git add` is very flexible and it is perfectly fine to add files one by one. Just like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
git add pineapple.txt
|
|
||||||
```
|
|
||||||
|
|
||||||
This approach gives you power to cherry pick every file you wish to stage, without the added worry that you’ll change something you weren’t supposed to.
|
|
||||||
|
|
||||||
After running `git status` once again you should see something like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
On branch master
|
|
||||||
Your branch is up-to-date with 'origin/master'.
|
|
||||||
Changes to be committed:
|
|
||||||
(use "git reset HEAD <file>..." to unstage)
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
new file: pineapple.txt
|
|
||||||
```
|
|
||||||
|
|
||||||
Ready to commit the changes? I sure am.
|
|
||||||
|
|
||||||
```
|
|
||||||
git commit -m "Write your message here"
|
|
||||||
```
|
|
||||||
|
|
||||||
The [Git commit][9] command stores the current files in staging in a new commit along with a log message from the user describing the changes. The _-m _ flag includes the message written in double quotes in the commit.
|
|
||||||
|
|
||||||
Checking the status once again will show you:
|
|
||||||
|
|
||||||
```
|
|
||||||
On branch master
|
|
||||||
Your branch is ahead of 'origin/master' by 1 commit.
|
|
||||||
(use "git push" to publish your local commits)
|
|
||||||
nothing to commit, working directory clean
|
|
||||||
```
|
|
||||||
|
|
||||||
All changes have now been bundled into one commit with one dedicated message regarding the work you have done. You’re now ready to `[git push][2]`this commit to the _origin_ . The push command does literally what it means. It will upload your committed changes from your local machine to the repository origin on GitHub. Go back to the command prompt and run:
|
|
||||||
|
|
||||||
```
|
|
||||||
git push
|
|
||||||
```
|
|
||||||
|
|
||||||
It will ask you to enter your GitHub username and password, after which you will see something like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
Counting objects: 3, done.
|
|
||||||
Delta compression using up to 4 threads.
|
|
||||||
Compressing objects: 100% (2/2), done.
|
|
||||||
Writing objects: 100% (3/3), 280 bytes | 0 bytes/s, done.
|
|
||||||
Total 3 (delta 0), reused 0 (delta 0)
|
|
||||||
To https://github.com/yourGithubUserName/Steve.git
|
|
||||||
c77a97c..08bb95a master -> master
|
|
||||||
```
|
|
||||||
|
|
||||||
That’s it. You have uploaded the local changes. Go ahead and look at your repository on GitHub and you’ll see that it now contains a file named _pineapple.txt_ .
|
|
||||||
|
|
||||||
What if you work in a team of developers? Where all of them push commits to the origin. What happens then? This is where Git starts to show it’s real power. You can just as easily [pull][10] the latest version of the code base to your local machine with one simple command.
|
|
||||||
|
|
||||||
```
|
|
||||||
git pull
|
|
||||||
```
|
|
||||||
|
|
||||||
But Git has it’s limitations. You need to have matching versions to be able to push changes to the origin. Meaning the version you have locally needs to be exactly the same as the one on the origin. When pulling from the origin you shouldn’t have files in the working directory, as they will be overwritten in the process. Hence me giving this simple advice. When in the process of learning Git, make a habit of following these steps:
|
|
||||||
|
|
||||||
1. `git status` all the time!
|
|
||||||
|
|
||||||
2. Try only to change files you really want to change.
|
|
||||||
|
|
||||||
3. `git add -A` is your friend.
|
|
||||||
|
|
||||||
4. Feel free to `git commit -m "meaningful messages"` .
|
|
||||||
|
|
||||||
5. Always `git pull` before doing any pushing,
|
|
||||||
but after you have committed any changes.
|
|
||||||
|
|
||||||
6. Finally, `git push` the committed changes.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
Phew, are you still with me? You’ve come a long way. Have a break.
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
Lame video-game references, once again…
|
|
||||||
|
|
||||||
Rested up? Great! You’re ready for some error handling. What if you accidentally changed some files your shouldn’t have touched. No need to freak out, just use `[git checkout][3]`. Let’s change something in the _pineapple.txt_ file. Add another line of text in there, let’s say, _“Steve is mega-awesome!”_ . Go ahead, save the changes and check the `git status`.
|
|
||||||
|
|
||||||
```
|
|
||||||
On branch master
|
|
||||||
Your branch is up-to-date with 'origin/master'.
|
|
||||||
Changes not staged for commit:
|
|
||||||
(use "git add <file>..." to update what will be committed)
|
|
||||||
(use "git checkout -- <file>..." to discard changes in working directory)
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
modified: pineapple.txt
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
no changes added to commit (use "git add" and/or "git commit -a")
|
|
||||||
```
|
|
||||||
|
|
||||||
As expected it has been registered as a change. But what if Steve really isn’t that mega-awesome? What if Steve is mega-lame? Worry not! The simplest way to revert the changes is to run:
|
|
||||||
|
|
||||||
```
|
|
||||||
git checkout -- pineapple.txt
|
|
||||||
```
|
|
||||||
|
|
||||||
Now you will see the file has been returned to it’s previous state.
|
|
||||||
|
|
||||||
But what if you really mess up. I mean like majorly mess things up, and need to reset everything back to the state the _origin_ is in. No need to worry, during emergencies like this we have this beauty:
|
|
||||||
|
|
||||||
```
|
|
||||||
git reset --hard
|
|
||||||
```
|
|
||||||
|
|
||||||
The [Git reset][11] command with the _--hard_ flag discards all changes since the last commit. Pretty handy sometimes.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
To wrap up, I’d like to encourage you to play around with Git as much as possible. It’s by far the best way of learning how to use it with confidence. Apart from that, make a habit of reading the Git documentation. As confusing as it may seem at first, after a few moments of reading you will get the hang of it.
|
|
||||||
|
|
||||||
_Hope you guys and girls had as much fun reading this article as I had writing it._ _Feel free to share if you believe it will be of help to someone, or if you liked it, click the 💚 below so other people will see this here on Medium._
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://hackernoon.com/how-to-master-the-art-of-git-68e1050f3147
|
|
||||||
|
|
||||||
作者:[Adnan Rahić][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://hackernoon.com/@adnanrahic
|
|
||||||
[1]:https://git-scm.com/docs/git-status
|
|
||||||
[2]:https://git-scm.com/docs/git-push
|
|
||||||
[3]:https://git-scm.com/docs/git-checkout
|
|
||||||
[4]:https://github.com/
|
|
||||||
[5]:https://git-scm.com/book/en/v2/Getting-Started-Installing-Git
|
|
||||||
[6]:https://git-scm.com/book/en/v2/Getting-Started-Installing-Git
|
|
||||||
[7]:https://github.com/
|
|
||||||
[8]:https://git-scm.com/docs/git-add
|
|
||||||
[9]:https://git-scm.com/docs/git-commit
|
|
||||||
[10]:https://git-scm.com/docs/git-pull
|
|
||||||
[11]:https://git-scm.com/docs/git-reset
|
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
Translating by ChauncyD
|
||||||
11 reasons to use the GNOME 3 desktop environment for Linux
|
11 reasons to use the GNOME 3 desktop environment for Linux
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -0,0 +1,60 @@
|
|||||||
|
微软如何正在成为一个 Linux 供应商
|
||||||
|
=====================================
|
||||||
|
|
||||||
|
|
||||||
|
>微软通过将 Linux 融入自己的产品中来弥合与 Linux 的差距。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
Linux 以及开源技术在数据中心、云以及 IoT 中变得如此主流以至于微软无法忽视他们。
|
||||||
|
|
||||||
|
在微软自己的云中,三分之一的机器运行着 Linux。这些是运行 Linux 的微软客户。微软需要支持他们使用的平台,否则他们将到别处去了。
|
||||||
|
|
||||||
|
以下就是微软如何在它的开发者平台 (Windows 10)、云 (Azure) 以及数据中心 (Windows Server) 打破 Linux 策略的。
|
||||||
|
|
||||||
|
**Windows 中的 Linux:** IT 专家管理公共或者私有 Linux 机器需要原生的 UNIX 工具。Linux 以及 macOS 是仅有的二个提供原生能力的平台。难怪你在各种会议如 DockerCon、OpenStack Summit 或者 CoreOS Fest 看到的都是 MacBook 或者少量的 Linux 桌面。
|
||||||
|
|
||||||
|
为了弥补差距,微软与 Canonical 协作在 Windows 内部构建了一个 Linux 子系统,它提供了原生的 Linux 工具。这是一个很棒的妥协,这样 IT 专家可以继续使用 Windows 10 桌面的同时能够使用大多数 Linux 工具来管理他们的 Linux 机器。
|
||||||
|
|
||||||
|
**Azure 中的 Linux:** 不能完整支持 Linux 的云有什么好呢?微软一直以来与 Linux 供应商合作来使客户能够在 Azure 中运行 Linux 程序以及负载。
|
||||||
|
|
||||||
|
微软不仅与三家主要的 Linux 供应商 Red Hat、SUSE 和 Canonical 签署了协议,还与无数的其他公司合作,为 Debian提 供了基于社区的发行版的支持。
|
||||||
|
|
||||||
|
**Windows Server 中的 Linux:** 这是剩下的最后一块披萨。客户使用的 Linux 容器是一个巨大的生态系统。Docker Hub 上有超过 90 万个 Docker 容器,它们只能在 Linux 机器上运行。微软希望把这些容器带到自己的平台上。
|
||||||
|
|
||||||
|
在 DockerCon 中,微软宣布在 Windows Server 中支持 Linux 容器,将这些容器都带到 Linux 中。
|
||||||
|
|
||||||
|
事情正变得更加有趣,在 Windows 10 上的 Bash 成功之后,微软正将 Ubuntu bash 带到 Windows Server 中。是的,你听的没错。Windows Server 将会有一个 Linux 子系统。
|
||||||
|
|
||||||
|
微软的高级项目经理 Rich Turne 告诉我:“服务器上的 WSL 为管理员提供了 *UNIX 管理脚本和工具的偏好,以便有更熟悉的工作环境。”
|
||||||
|
|
||||||
|
微软在一个通告中称它将允许 IT 专家 “使用他们在 Windows Server 容器主机上为 Linux 容器使用的相同的脚本,工具,流程和容器镜像。这些容器使用我们的 Hyper-V 隔离技术结合你选择的 Linux 内核来托管负载,而主机上的管理脚本以及工具使用 WSL。”
|
||||||
|
|
||||||
|
在覆盖了上面三个情况后,微软已经成功地创建了一个客户不必选择任何 Linux 供应商的环境。
|
||||||
|
|
||||||
|
### 它对微软意味着什么?
|
||||||
|
|
||||||
|
通过将 Linux 融入它自己的产品,微软已经成为了一个 Linux 供应商。它们是 Linux 基金会的一部分,它们是众多 Linux 贡献者之一,并且它们现在在自己的商店中分发 Linux。
|
||||||
|
|
||||||
|
还有一个小问题。微软没有拥有任何 Linux 技术。它们完全依赖于外部的厂家,目前 Canonical 是完全的 Linux 层厂商。如果 Canonical 被强力的竞争对手收购,那会是一个很大的风险。
|
||||||
|
|
||||||
|
或许对微软而言尝试收购 Canonical 是有意义的,并且会将核心技术收入囊中。这是有道理的。
|
||||||
|
|
||||||
|
### 这对 Linux 供应商意味着什么
|
||||||
|
|
||||||
|
表面上,很显然这对微软是个胜利,因为它的客户可以在 Windows 世界中存留。它还将包含 Linux 在数据中心中的势头。它或许还会影响 Linux 桌面,由于现在 IT 专家不必为了寻找 *NIX 工具使用 Linux 桌面了,它们可以在 Windows 中做任何事。
|
||||||
|
|
||||||
|
微软的成功是传统 Linux 厂家的失败么?某种程度上来说,是的,微软已经成为了一个直接竞争者。但是这里明显的赢家是 Linux。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.cio.com/article/3197016/linux/how-microsoft-is-becoming-a-linux-vendor.html
|
||||||
|
|
||||||
|
作者:[ Swapnil Bhartiya ][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.cio.com/author/Swapnil-Bhartiya/
|
||||||
212
translated/tech/20161027 Network management with LXD.md
Normal file
212
translated/tech/20161027 Network management with LXD.md
Normal file
@ -0,0 +1,212 @@
|
|||||||
|
# 使用 LXD (2.3+) 管理网络
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 介绍
|
||||||
|
|
||||||
|
|
||||||
|
当 LXD 2.0 随着 Ubuntu 16.04 一起发布时,LXD 联网就简单了。你可以使用 “lxdbr0” 桥接,配置 “lxd init”,为你的容器提供你自己或者使用一个已存在的物理接口。
|
||||||
|
|
||||||
|
虽然这确实有效,但是有点混乱,因为大部分的桥接配置发生在 Ubuntu 包的 LXD 之外。那些脚本只能支持一个桥接,并且没有通过 API 暴露,这使得远程配置有点痛苦。
|
||||||
|
|
||||||
|
直到 LXD 2.3,LXD 终于发展了自己的网络管理 API 和命令行工具来匹配。这篇文章是对这些新功能概述的尝试。
|
||||||
|
|
||||||
|
### 基础联网
|
||||||
|
|
||||||
|
在初始情况下,LXD 2.3 没有定义任何网络。“lxd init” 会为你设置一个,并且默认将所有新的容器连接到它,但是让我们亲手尝试看下究竟发生了些什么。
|
||||||
|
|
||||||
|
要创建一个新的带有随机 IPv4 和 IP6 以及启用 NAT 的网络,只需要运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
stgraber@castiana:~$ lxc network create testbr0
|
||||||
|
Network testbr0 created
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以如下查看它的配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
stgraber@castiana:~$ lxc network show testbr0
|
||||||
|
name: testbr0
|
||||||
|
config:
|
||||||
|
ipv4.address: 10.150.19.1/24
|
||||||
|
ipv4.nat: "true"
|
||||||
|
ipv6.address: fd42:474b:622d:259d::1/64
|
||||||
|
ipv6.nat: "true"
|
||||||
|
managed: true
|
||||||
|
type: bridge
|
||||||
|
usedby: []
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你不想要那些自动配置的子网,你可以这么做:
|
||||||
|
|
||||||
|
```
|
||||||
|
stgraber@castiana:~$ lxc network create testbr0 ipv6.address=none ipv4.address=10.0.3.1/24 ipv4.nat=true
|
||||||
|
Network testbr0 created
|
||||||
|
```
|
||||||
|
|
||||||
|
那就会这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
stgraber@castiana:~$ lxc network show testbr0
|
||||||
|
name: testbr0
|
||||||
|
config:
|
||||||
|
ipv4.address: 10.0.3.1/24
|
||||||
|
ipv4.nat: "true"
|
||||||
|
ipv6.address: none
|
||||||
|
managed: true
|
||||||
|
type: bridge
|
||||||
|
usedby: []
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你的容器没有使用,那么创建的网络对你也没什么用。要将你新创建的网络连接到所有容器,你可以这么做:
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
stgraber@castiana:~$ lxc network attach-profile testbr0 default eth0
|
||||||
|
```
|
||||||
|
|
||||||
|
要将一个网络连接到一个已存在的容器中,你可以这么做:
|
||||||
|
|
||||||
|
```
|
||||||
|
stgraber@castiana:~$ lxc network attach my-container default eth0
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,假设你已经在机器中安装了 openvswitch,并且要将这个桥接转换成 OVS 桥接,只需合适地更改驱动:
|
||||||
|
|
||||||
|
```
|
||||||
|
stgraber@castiana:~$ lxc network set testbr0 bridge.driver openvswitch
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想要一次性做一系列修改。“lxc network edit” 可以让你在编辑器中交互编辑网络配置。
|
||||||
|
|
||||||
|
### 静态租约及端口安全
|
||||||
|
|
||||||
|
使用 LXD 管理 DHCP 服务器的一个好处是可以使得管理 DHCP 租约很简单。你所需要的是一个容器特定的 nic 设备以及正确的属性设置。
|
||||||
|
|
||||||
|
```
|
||||||
|
root@yak:~# lxc init ubuntu:16.04 c1
|
||||||
|
Creating c1
|
||||||
|
root@yak:~# lxc network attach testbr0 c1 eth0
|
||||||
|
root@yak:~# lxc config device set c1 eth0 ipv4.address 10.0.3.123
|
||||||
|
root@yak:~# lxc start c1
|
||||||
|
root@yak:~# lxc list c1
|
||||||
|
+------+---------+-------------------+------+------------+-----------+
|
||||||
|
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||||
|
+------+---------+-------------------+------+------------+-----------+
|
||||||
|
| c1 | RUNNING | 10.0.3.123 (eth0) | | PERSISTENT | 0 |
|
||||||
|
+------+---------+-------------------+------+------------+-----------+
|
||||||
|
```
|
||||||
|
|
||||||
|
IPv6 也是相同的方法,但是换成 “ipv6.address” 属性。
|
||||||
|
|
||||||
|
相似地,如果你想要阻止你的容器更改它的 MAC 地址或者为其他 MAC 地址转发流量(比如嵌套),你可以用下面的命令启用端口安全:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@yak:~# lxc config device set c1 eth0 security.mac_filtering true
|
||||||
|
```
|
||||||
|
|
||||||
|
### DNS
|
||||||
|
|
||||||
|
LXD 在桥接中运行了一个 DNS 服务器。除了设置网桥的 DNS 域( “dns.domain” 网络属性)之外,还支持 3 种不同的操作模式(“dns.mode”):
|
||||||
|
|
||||||
|
* “managed” 为每个容器都会有一条 DNS 记录,匹配它的名字以及已知的 IP 地址。容器无法通过 DHCP 改变这条记录。
|
||||||
|
* “dynamic” 允许容器通过 DHCP 在 DNS 中自己注册。因此,在 DHCP 协商期间容器发送的任何主机名都会在 DNS 中终止。
|
||||||
|
* “none” 针对那些没有任何本地 DNS 记录的递归 DNS 服务器。
|
||||||
|
|
||||||
|
默认的模式是 “managed”,并且典型的是最安全以及最方便的,因为它为容器提供了 DNS 记录,但是不允许它们通过 DHCP 发送虚假主机名嗅探其他的记录。
|
||||||
|
|
||||||
|
### 使用隧道
|
||||||
|
|
||||||
|
除了这些,LXD 还支持使用 GRE 或者 VXLAN 隧道连接到其他主机。
|
||||||
|
|
||||||
|
LXD 网络可以连接任何数量的隧道,从而轻松地创建跨多个主机的网络。这对于开发、测试和演示非常有用,生产环境通常更喜欢使用 VLAN 进行分割。
|
||||||
|
|
||||||
|
所以说,你想在主机 “edfu” 上有一个运行 IPv4 和 IPv6 的基础 “testbr0” 网络,并希望在主机 “djanet” 上使用它来生成容器。最简单的方法是使用组播 VXLAN 隧道。这种类型的隧道仅在两个主机位于同一物理段上时才起作用。
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
root@edfu:~# lxc network create testbr0 tunnel.lan.protocol=vxlan
|
||||||
|
Network testbr0 created
|
||||||
|
root@edfu:~# lxc network attach-profile testbr0 default eth0
|
||||||
|
```
|
||||||
|
|
||||||
|
它在主机 “edfu” 上定义了一个 “testbr0” 桥接,并为其他主机能加入它设置了一个组播 VXLAN。在这个设置中,“edfu” 为这个网络扮演了一个路由器角色,提供 DHCP、DNS 等等,其他主机只是通过隧道转发流量。
|
||||||
|
|
||||||
|
```
|
||||||
|
root@djanet:~# lxc network create testbr0 ipv4.address=none ipv6.address=none tunnel.lan.protocol=vxlan
|
||||||
|
Network testbr0 created
|
||||||
|
root@djanet:~# lxc network attach-profile testbr0 default eth0
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你可以在任何一台主机上启动容器,并看它们从相同的地址池中获取 IP,通过隧道直接互相交流。
|
||||||
|
|
||||||
|
如先前所述,这个使用了组播,它通常在跨越路由器时无法很好工作。在这些情况下,你可以用单播模式使用 VXLAN 或者 GRE 隧道。
|
||||||
|
|
||||||
|
要使用 GRE 加入另一台主机,首先配置服务主机:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@edfu:~# lxc network set testbr0 tunnel.nuturo.protocol gre
|
||||||
|
root@edfu:~# lxc network set testbr0 tunnel.nuturo.local 172.17.16.2
|
||||||
|
root@edfu:~# lxc network set testbr0 tunnel.nuturo.remote 172.17.16.9
|
||||||
|
```
|
||||||
|
|
||||||
|
接着是“客户端”主机:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@nuturo:~# lxc network create testbr0 ipv4.address=none ipv6.address=none tunnel.edfu.protocol=gre tunnel.edfu.local=172.17.16.9 tunnel.edfu.remote=172.17.16.2
|
||||||
|
Network testbr0 created
|
||||||
|
root@nuturo:~# lxc network attach-profile testbr0 default eth0
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你像使用 VXLAN,只要这么做:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@edfu:~# lxc network set testbr0 tunnel.edfu.id 10
|
||||||
|
root@edfu:~# lxc network set testbr0 tunnel.edfu.protocol vxlan
|
||||||
|
```
|
||||||
|
|
||||||
|
还有:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@nuturo:~# lxc network set testbr0 tunnel.edfu.id 10
|
||||||
|
root@nuturo:~# lxc network set testbr0 tunnel.edfu.protocol vxlan
|
||||||
|
```
|
||||||
|
|
||||||
|
这里需要隧道 id 以防与已经配置的多播 VXLAN 隧道冲突。
|
||||||
|
|
||||||
|
这就是如何使用最近的 LXD 简化跨主机联网了!
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
LXD 可以容易地定义简单的单主机网络定义到数千个容器的非常复杂的跨主机网络。它也使为一些容器定义一个新网络或者给容器添加第二个设备,并连接到隔离的私有网络变得很简单。
|
||||||
|
|
||||||
|
虽然这篇文章介绍了支持的大部分功能,但仍有很有可以微调 LXD 网络体验的窍门。
|
||||||
|
|
||||||
|
可以在这里找到完整的列表:[https://github.com/lxc/lxd/blob/master/doc/configuration.md][2]
|
||||||
|
|
||||||
|
# 额外信息
|
||||||
|
|
||||||
|
LXD 主站:[https://linuxcontainers.org/lxd][3]
|
||||||
|
Github 地址: [https://github.com/lxc/lxd][4]
|
||||||
|
邮件列表支持:[https://lists.linuxcontainers.org][5]
|
||||||
|
IRC 频道:#lxcontainers on irc.freenode.net
|
||||||
|
在线尝试 LXD:[https://linuxcontainers.org/lxd/try-it][6]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.stgraber.org/2016/10/27/network-management-with-lxd-2-3/
|
||||||
|
|
||||||
|
作者:[Stéphane Graber][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.stgraber.org/author/stgraber/
|
||||||
|
[1]:https://www.stgraber.org/author/stgraber/
|
||||||
|
[2]:https://github.com/lxc/lxd/blob/master/doc/configuration.md#network-configuration
|
||||||
|
[3]:https://linuxcontainers.org/lxd
|
||||||
|
[4]:https://github.com/lxc/lxd
|
||||||
|
[5]:https://lists.linuxcontainers.org/
|
||||||
|
[6]:https://linuxcontainers.org/lxd/try-it
|
||||||
|
[7]:https://www.stgraber.org/2016/10/27/network-management-with-lxd-2-3/
|
||||||
@ -1,408 +0,0 @@
|
|||||||
如何用Raspberry Pi控制GOIO引脚并操作继电器
|
|
||||||
==========================================
|
|
||||||
|
|
||||||
> 学习如何用PHP和温度传感器实现Raspberry Pi控制GPIO并操作继电器
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
> 图片来源: opensource.com
|
|
||||||
|
|
||||||
你是否曾经想知道怎样使用手机或者电脑在任何地方控制你的风扇和等一些家用电器?
|
|
||||||
|
|
||||||
我现在想控制我的圣诞彩灯,是使用手机呢,还是使用平板电脑呢,或者是使用笔记本电脑呢?都不是,而是仅仅使用一个Raspberry Pi。让我来告诉你如何使用PHP和温度传感器实现Raspberry Pi控制GPIO引脚并操作继电器。我使用AJAX把它们整合在了一起。
|
|
||||||
|
|
||||||
### 硬件要求:
|
|
||||||
|
|
||||||
* Raspberry Pi
|
|
||||||
* 安装有Raspbian系统的SD卡(任何一张SD卡都可以,但是我更偏向使用一张大小为32GB等级为class 10的SD卡)
|
|
||||||
* 电源适配器
|
|
||||||
* 跳线(母对母跳线和公转母跳线)
|
|
||||||
* 继电器板(我使用一个用于12V继电器的继电器板)
|
|
||||||
* DS18B20温度传感器
|
|
||||||
* Raspberry Pi的Wi-Fi适配器
|
|
||||||
* 路由器(为了访问互联网,你需要有一个拥有端口转发的路由器)
|
|
||||||
* 10KΩ的电阻
|
|
||||||
|
|
||||||
### 软件要求:
|
|
||||||
* 下载并安装Raspbian系统到你的SD卡
|
|
||||||
* 有效的互联网连接
|
|
||||||
* Apache web服务器
|
|
||||||
* PHP
|
|
||||||
* WiringPi
|
|
||||||
* 基于Mac或者Windows的SSH客户端
|
|
||||||
|
|
||||||
### 一般的配置和设置
|
|
||||||
|
|
||||||
1\. 插入SD卡到Raspberry Pi,然后使用以太网网线将它连接到路由器;
|
|
||||||
|
|
||||||
2\. 连接WiFi适配器;
|
|
||||||
|
|
||||||
3\. 使用SSH方式登录到Raspberry Pi,然后使用下面的命令编辑**interfaces**文件:
|
|
||||||
|
|
||||||
> **sudo nano /etc/network/interfaces**
|
|
||||||
|
|
||||||
这个命令会用一个叫做**nano**的编辑器打开这个文件。它是一个非常简单又易于使用的文本编辑器。如果你不熟悉基于linux的操作系统,可以使用键盘上的方向键来操作。
|
|
||||||
|
|
||||||
用**nano**打开这个文件后,你会看到这样一个界面:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
4\.要配置你的无线网络,按照下面所示修改这个文件:
|
|
||||||
|
|
||||||
>**iface lo inet loopback**
|
|
||||||
|
|
||||||
>**iface eth0 inet dhcp**
|
|
||||||
|
|
||||||
>**allow-hotplug wlan0**
|
|
||||||
|
|
||||||
>**auto wlan0**
|
|
||||||
|
|
||||||
>**iface wlan0 inet dhcp**
|
|
||||||
|
|
||||||
>** wpa-ssid "Your Network SSID"**
|
|
||||||
|
|
||||||
>** wpa-psk "Your Password"**
|
|
||||||
|
|
||||||
5\. 按CTRL+O保存,然后按CTRL+X退出编辑器。
|
|
||||||
|
|
||||||
到目前为止,一切都已经配置完成,接下来你需要做的就是使用命令重新加载网络:
|
|
||||||
|
|
||||||
> **sudo service networking reload**
|
|
||||||
|
|
||||||
(警告:如果你是使用远程连接的方式连接的Raspberry Pi,连接将会中断。)
|
|
||||||
|
|
||||||
### 软件配置
|
|
||||||
|
|
||||||
#### 安装Apache web 服务器
|
|
||||||
|
|
||||||
Apache是一个受欢迎的服务器应用,你可以在Raspberry Pi安装这个程序让它提供网页服务。
|
|
||||||
Apache原本就可以通过HTTP方式提供HTML文件服务,添加其他模块后,Apache还可以使用像PHP这样的脚本语言来提供动态网页的服务。
|
|
||||||
|
|
||||||
可以在命令行输入下面命令安装Apache:
|
|
||||||
|
|
||||||
> **sudo apt-get install apache2 -y**
|
|
||||||
|
|
||||||
安装完成后,可以在浏览器地址栏输入Raspberry Pi的IP地址来测试web服务器。如果你可以获得下面图片的内容,说明你已经成功地安装并设置好了你的服务器。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
要改变这个默认的页面和添加你自己的html文件,进入**var/www/html**目录:
|
|
||||||
|
|
||||||
> **cd /var/www/html**
|
|
||||||
|
|
||||||
添加一些文件来测试是否成功。
|
|
||||||
|
|
||||||
### 安装PHP
|
|
||||||
|
|
||||||
PHP是一个预处理器,这意味着它是当服务器收到网页请求时才会运行的一段代码。它开始运行,处理网页上需要被显示的内容,然后把网页发送给浏览器。不像静态的HTML,PHP在不同的环境下可以显示不同的内容。其他的语言也可以做到这一点,但是由于WordPress是用PHP编写的,有些时候你需要使用它。PHP是web上一种非常受欢迎的语言,像Facebok和Wikipeadia这样的大型项目都是用PHP编写的。
|
|
||||||
|
|
||||||
使用下面的命令安装PHP和Apache软件包:
|
|
||||||
|
|
||||||
> **sudo apt-get install php5 libapache2-mod-php5 -y**
|
|
||||||
|
|
||||||
#### 测试PHP
|
|
||||||
|
|
||||||
创建文件:**index.php**:
|
|
||||||
|
|
||||||
> **sudo nano index.php**
|
|
||||||
|
|
||||||
在里面写入一些PHP内容:
|
|
||||||
|
|
||||||
> **<?php echo "hello world"; ?>**
|
|
||||||
|
|
||||||
保存文件,接下来删除"index.html",因为它比"index.php"的优先级更高:
|
|
||||||
|
|
||||||
> sudo rm index.html
|
|
||||||
|
|
||||||
刷新你的浏览器,你会看到"hello world"。这并不是动态的,但是它仍然由PHP提供服务。如果你在上面看到提原始的PHP文件而不是"hello world",重新加载和重启Apahce:
|
|
||||||
|
|
||||||
> **sudo /etc/init.d/apache2 reload**
|
|
||||||
|
|
||||||
> **sudo /etc/init.d/apache2 restart**
|
|
||||||
|
|
||||||
### 安装WiringPi
|
|
||||||
|
|
||||||
为了可以对代码的更改进行跟踪,WiringPi的维护采用git。但假如你因为某些原因而没法使用git,还有一种可以替代的方案B。(通常你的防火墙会把你隔离开来,所以请先检查一下你的防火墙的设置情况!)
|
|
||||||
|
|
||||||
如果你还没有安装git,那么在Debian及其衍生版本中(比如Raspbian),你可以这样安装它:
|
|
||||||
|
|
||||||
> **sudo apt-get install git-core**
|
|
||||||
|
|
||||||
若是你遇到了一些错误,请确保你的Raspberry Pi是最新版本的Raspbian系统:
|
|
||||||
|
|
||||||
> **sudo apt-get update sudo apt-get upgrade**
|
|
||||||
|
|
||||||
使用git获取最WiringPi:
|
|
||||||
|
|
||||||
> **sudo git clone git://git.drogon.net/wiringPi**
|
|
||||||
|
|
||||||
如果你之前已经使用过 clone操作,那么可以使用下面命令:
|
|
||||||
|
|
||||||
> **cd wiringPi && git pull origin**
|
|
||||||
|
|
||||||
这个命令会将会获取更新的版本,你然后可以重新运行下面的构建脚本。
|
|
||||||
|
|
||||||
有一个新的简化的脚本来构建和安装:
|
|
||||||
|
|
||||||
> cd wiringPi && ./build
|
|
||||||
|
|
||||||
这个新的构建脚本将会为你完成编译和安装WiringPi。它曾一度需要使用**sudo**命令,所以在运行这它之前你可能需要检查一下这个脚本。
|
|
||||||
|
|
||||||
### 测试WiringPi
|
|
||||||
|
|
||||||
运行 **gpio** 命令来检查安装成功与否:
|
|
||||||
|
|
||||||
> **gpio -v gpio readall**
|
|
||||||
|
|
||||||
这将给你一些信心,软件运行良好。
|
|
||||||
|
|
||||||
### 连接DS18B20传感器到Raspberry Pi
|
|
||||||
|
|
||||||
* 传感器上的黑线用于GND。
|
|
||||||
* 红线用于VCC。
|
|
||||||
* 黄线是GPIO线。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
连线:
|
|
||||||
|
|
||||||
* VCC连接3V的1号引脚。
|
|
||||||
* GPIO线连接7号引脚(GPIO4)。
|
|
||||||
* 地线连接GND的9号引脚。
|
|
||||||
|
|
||||||
### 软件配置
|
|
||||||
|
|
||||||
为了用PHP使用DS18B20温度传感器模块,你需要执行下面的命令来激活用于Raspberry Pi 上GPIO引脚和DS18B20的内核模块:
|
|
||||||
|
|
||||||
> **sudo modprobe w1-gpio**
|
|
||||||
> **sudo modprobe w1-therm**
|
|
||||||
|
|
||||||
你不想每次Raspberry重启后都手动执行上述命令,所以你想每次开机能自动启动这些模块。可以在文件**/etc/modules**中添加下面的命令行来做到:
|
|
||||||
|
|
||||||
> **sudo nano /etc/modules/**
|
|
||||||
|
|
||||||
添加下面的命令行到它里面:
|
|
||||||
|
|
||||||
> **w1-gpio**
|
|
||||||
> **w1-therm**
|
|
||||||
|
|
||||||
为了测试,输入:
|
|
||||||
|
|
||||||
> cd /sys/bus/w1/devices/
|
|
||||||
|
|
||||||
现在输入ls。
|
|
||||||
|
|
||||||
你会看到你的设备信息。在设备驱动程序中,你的DS18B20传感器应该作为一串字母和数字被列出。在本例中,设备被记录为 28-000005e2fdc3。然后你需要使用cd命令来访问传感器,用你自己的序列号替代我的: **cd 28-000005e2fdc3. **。
|
|
||||||
|
|
||||||
DS18B20会周期性的将数据写入文件**w1_slave**,所以你只需要使用命令cat来读出数据:**cat w1_slave.**。
|
|
||||||
|
|
||||||
这会生成下面的两行文本,输出中**t=** 表示摄氏单位的温度。在前两位数后面加上一个小数点(例如,我收到的温度读数是30.125摄氏度)。
|
|
||||||
|
|
||||||
### 连接继电器
|
|
||||||
|
|
||||||
1\. 取两根跳线,把其中一根连接到Pi上的GPIO24(18号引脚),另一根连接GND引脚。你可以参考下面这张图。
|
|
||||||
|
|
||||||
2\. 现在将跳线的另一端连接到继电器板。GND连接到继电器上的GND,GPIO输出线连接到继电器的通道引脚号,这取决于你正使用的继电器型号。记住,将Pi上的GND与继电器上的GND连接连接起来,Pi上的GPIO输出连接继电器上的输入引脚。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
注意!将继电器连接Pi的时候小心一些,因为它可能会导致电流回流,这会造成短路。
|
|
||||||
|
|
||||||
3\. 现在将电源连接继电器,可以使用12V的电源适配器,也可以将VCC引脚连接到Pi上的3.3V或5.5V引脚。
|
|
||||||
|
|
||||||
### 使用PHP控制继电器
|
|
||||||
|
|
||||||
让我们先写一个借助于WiringPi软件用来控制Paspberry Pi上GPIO引脚的PHP脚本。
|
|
||||||
|
|
||||||
1\. 在Apache服务器的网站根目录下创建一个文件,使用下面命令切换到该目录:
|
|
||||||
|
|
||||||
> **cd /var/www/html**
|
|
||||||
|
|
||||||
2\. 新建一个叫Home的文件夹:
|
|
||||||
|
|
||||||
> **sudo mkdir Home**
|
|
||||||
|
|
||||||
3\. 新建一个叫on.php的脚本
|
|
||||||
|
|
||||||
> **sudo nano on.php**
|
|
||||||
|
|
||||||
4\. 在脚本中加入下面的代码:
|
|
||||||
|
|
||||||
```
|
|
||||||
<?php
|
|
||||||
|
|
||||||
system("gpio-g mode 24 out");
|
|
||||||
system("gpio-g write 24 1");
|
|
||||||
|
|
||||||
?>
|
|
||||||
```
|
|
||||||
|
|
||||||
5\. 使用CTRL+O保存文件,CTRL+X退出。
|
|
||||||
|
|
||||||
上面的代码中,你在第一行使用命令将24号GPIO引脚设置为output模式:
|
|
||||||
|
|
||||||
> system(“ gpio-g mode 24 out “) ;
|
|
||||||
|
|
||||||
在第二行,你使用"1"将24号引脚GPIO打开,在二进制中"1"表示打开,"0"表示关闭。
|
|
||||||
|
|
||||||
6\. 为了关闭继电器,可以创建另外一个off.php文件,并用"0"替换"1"。
|
|
||||||
|
|
||||||
```
|
|
||||||
<?php
|
|
||||||
|
|
||||||
system(" gpio-g mode 24 out ");
|
|
||||||
system(" gpio-g write 24 1 ");
|
|
||||||
|
|
||||||
?>
|
|
||||||
```
|
|
||||||
|
|
||||||
7\. 如果你已经将继电器连接了Pi,可以在浏览器中输入你的Pi的IP地址并在后面加上目录名和文件名来进行访问:
|
|
||||||
|
|
||||||
>** http://{IPADDRESS}/home/on.php **
|
|
||||||
|
|
||||||
这将会打开继电器。
|
|
||||||
|
|
||||||
8\. 要关闭它,可以访问叫off.php的文件:
|
|
||||||
|
|
||||||
>**http://{IPADDRESS}/home/off.php**
|
|
||||||
|
|
||||||
现在你需要能够在一个单独 的页面来控制这两样事情,而不用单独的刷新或者访问这两个页面。你可以使用AJAX来完成。
|
|
||||||
|
|
||||||
9\. 新建一个HTML文件,并在其中加入下面代码:
|
|
||||||
|
|
||||||
```
|
|
||||||
[html + php + ajax codeblock]
|
|
||||||
|
|
||||||
<html>
|
|
||||||
|
|
||||||
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.3/jquery.min.js"></script>
|
|
||||||
|
|
||||||
<script type="text/javascript">// <![CDATA[
|
|
||||||
|
|
||||||
$(document).ready(function() {
|
|
||||||
|
|
||||||
$('#on').click(function(){
|
|
||||||
|
|
||||||
var a= new XMLHttpRequest();
|
|
||||||
|
|
||||||
a.open("GET", "on.php"); a.onreadystatechange=function(){
|
|
||||||
|
|
||||||
if(a.readyState==4){ if(a.status ==200){
|
|
||||||
|
|
||||||
} else alert ("http error"); } }
|
|
||||||
|
|
||||||
a.send();
|
|
||||||
|
|
||||||
});
|
|
||||||
|
|
||||||
});
|
|
||||||
|
|
||||||
$(document).ready(function()
|
|
||||||
|
|
||||||
{ $('#Off').click(function(){
|
|
||||||
|
|
||||||
var a= new XMLHttpRequest();
|
|
||||||
|
|
||||||
a.open("GET", "off.php");
|
|
||||||
|
|
||||||
a.onreadystatechange=function(){
|
|
||||||
|
|
||||||
if(a.readyState==4){
|
|
||||||
|
|
||||||
if(a.status ==200){
|
|
||||||
|
|
||||||
} else alert ("http error"); } }
|
|
||||||
|
|
||||||
a.send();
|
|
||||||
|
|
||||||
});
|
|
||||||
|
|
||||||
});
|
|
||||||
|
|
||||||
</script>
|
|
||||||
|
|
||||||
<button id="on" type="button"> Switch Lights On </button>
|
|
||||||
|
|
||||||
<button id="off" type="button"> Switch Lights Off </button>
|
|
||||||
```
|
|
||||||
|
|
||||||
10\. 保存文件,进入你的web 浏览器目录,然后打开那个网页。你会看到两个按钮,它们可以打开和关闭灯泡。基于同样的想法,你还可以使用bootstrap和CSS来创建一个更加漂亮的web界面。
|
|
||||||
|
|
||||||
### 在这个网页上观察温度
|
|
||||||
|
|
||||||
1\. 新建一个temperature.php的文件:
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo nano temperature.php
|
|
||||||
```
|
|
||||||
|
|
||||||
2\. 在文件中加入下面的代码,用你自己的设备ID替换10-000802292522:
|
|
||||||
|
|
||||||
```
|
|
||||||
<?php
|
|
||||||
//File to read
|
|
||||||
$file = '/sys/devices/w1_bus_master1/10-000802292522/w1_slave';
|
|
||||||
//Read the file line by line
|
|
||||||
$lines = file($file);
|
|
||||||
//Get the temp from second line
|
|
||||||
$temp = explode('=', $lines[1]);
|
|
||||||
//Setup some nice formatting (i.e., 21,3)
|
|
||||||
$temp = number_format($temp[1] / 1000, 1, ',', '');
|
|
||||||
//And echo that temp
|
|
||||||
echo $temp . " °C";
|
|
||||||
?>
|
|
||||||
```
|
|
||||||
|
|
||||||
3\. 打开你刚刚创建的HTML文件,并创建一个新的带有 **id** “screen”的 `<div>`标签
|
|
||||||
```
|
|
||||||
<div id="screen"></div>
|
|
||||||
```
|
|
||||||
|
|
||||||
4\. 在这个标签后或者这个文档的尾部下面的代码:
|
|
||||||
|
|
||||||
```
|
|
||||||
<script>
|
|
||||||
$(document).ready(function(){
|
|
||||||
setInterval(function(){
|
|
||||||
$("#screen").load('temperature.php')
|
|
||||||
}, 1000);
|
|
||||||
});
|
|
||||||
</script>
|
|
||||||
```
|
|
||||||
|
|
||||||
其中,`#screen`是标签`<div>`的`id`,你想在它里面显示温度。它会每隔1000毫秒加载一次`temperature.php`文件。
|
|
||||||
|
|
||||||
我使用了bootstrap框架来制作一个漂亮的面板来显示温度,你还可以加入多个icons和 glyphicons让网页更有吸引力。
|
|
||||||
|
|
||||||
这只是一个控制继电器板并显示温度的基础的系统,你可以通过创建基于定时和从恒温器读数等基于事件触发来进一步地对系统进行开发。
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Abdul Hannan Mustajab: 我17岁,生活在印度。我正在追求科学,数学和计算机科学方面的教育。我在spunkytechnology.com上发表关于我的项目的博客。我一直在对使用不同的微控制器和电路板的基于物联网的AI进行研究。
|
|
||||||
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/3/operate-relays-control-gpio-pins-raspberry-pi
|
|
||||||
|
|
||||||
作者:[ Abdul Hannan Mustajab][a]
|
|
||||||
译者:[译者ID](https://github.com/zhousiyu325)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/mustajabhannan
|
|
||||||
[1]:http://www.php.net/system
|
|
||||||
[2]:http://www.php.net/system
|
|
||||||
[3]:http://www.php.net/system
|
|
||||||
[4]:http://www.php.net/system
|
|
||||||
[5]:http://www.php.net/system
|
|
||||||
[6]:http://www.php.net/file
|
|
||||||
[7]:http://www.php.net/explode
|
|
||||||
[8]:http://www.php.net/number_format
|
|
||||||
[9]:https://opensource.com/article/17/3/operate-relays-control-gpio-pins-raspberry-pi?rate=RX8QqLzmUb_wEeLw0Ee0UYdp1ehVokKZ-JbbJK_Cn5M
|
|
||||||
[10]:https://opensource.com/user/123336/feed
|
|
||||||
[11]:https://opensource.com/users/mustajabhannan
|
|
||||||
|
|
||||||
|
|
||||||
@ -1,40 +1,40 @@
|
|||||||
ictlyh Translating
|
开发 Linux 调试器第六部分:源码级逐步执行
|
||||||
Writing a Linux Debugger Part 6: Source-level stepping
|
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
A couple of posts ago we learned about DWARF information and how it lets us relate the machine code to the high-level source. This time we’ll be putting this knowledge into practice by adding source-level stepping to our debugger.
|
在前几篇博文中我们学习了 DWARF 信息以及它如何使我们将机器码和上层源码联系起来。这一次我们通过为我们的调试器添加源码级逐步调试将该知识应用于实际。
|
||||||
|
|
||||||
* * *
|
* * *
|
||||||
|
|
||||||
### Series index
|
### 系列文章索引
|
||||||
|
|
||||||
These links will go live as the rest of the posts are released.
|
随着后面文章的发布,这些链接会逐渐生效。
|
||||||
|
|
||||||
1. [Setup][1]
|
1. [启动][1]
|
||||||
|
|
||||||
2. [Breakpoints][2]
|
2. [断点][2]
|
||||||
|
|
||||||
3. [Registers and memory][3]
|
3. [寄存器和内存][3]
|
||||||
|
|
||||||
4. [Elves and dwarves][4]
|
4. [Elves 和 dwarves][4]
|
||||||
|
|
||||||
5. [Source and signals][5]
|
5. [源码和信号][5]
|
||||||
|
|
||||||
6. [Source-level stepping][6]
|
6. [源码级逐步执行][6]
|
||||||
|
|
||||||
7. Source-level breakpoints
|
7. 源码级断点
|
||||||
|
|
||||||
8. Stack unwinding
|
8. 调用栈展开
|
||||||
|
|
||||||
9. Reading variables
|
9. 读取变量
|
||||||
|
|
||||||
10. Next steps
|
10. 下一步
|
||||||
|
|
||||||
|
译者注:ELF([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format "Executable and Linkable Format") 可执行文件格式),DWARF(一种广泛使用的调试数据格式,参考 [WIKI](https://en.wikipedia.org/wiki/DWARF "DWARF WIKI"))
|
||||||
* * *
|
* * *
|
||||||
|
|
||||||
### Exposing instruction-level stepping
|
### 暴露指令级逐步执行
|
||||||
|
|
||||||
But we’re getting ahead of ourselves. First let’s expose instruction-level single stepping through the user interface. I decided to split it between a `single_step_instruction` which can be used by other parts of the code, and a `single_step_instruction_with_breakpoint_check` which ensures that any breakpoints are disabled and re-enabled.
|
我们已经超越了自己。首先让我们通过用户接口暴露指令级单步执行。我决定将它切分为能被其它部分代码利用的 `single_step_instruction` 和确保是否启用了某个断点的 `single_step_instruction_with_breakpoint_check`。
|
||||||
|
|
||||||
```
|
```
|
||||||
void debugger::single_step_instruction() {
|
void debugger::single_step_instruction() {
|
||||||
@ -43,7 +43,7 @@ void debugger::single_step_instruction() {
|
|||||||
}
|
}
|
||||||
|
|
||||||
void debugger::single_step_instruction_with_breakpoint_check() {
|
void debugger::single_step_instruction_with_breakpoint_check() {
|
||||||
//first, check to see if we need to disable and enable a breakpoint
|
//首先,检查我们是否需要停用或者启用某个断点
|
||||||
if (m_breakpoints.count(get_pc())) {
|
if (m_breakpoints.count(get_pc())) {
|
||||||
step_over_breakpoint();
|
step_over_breakpoint();
|
||||||
}
|
}
|
||||||
@ -53,7 +53,7 @@ void debugger::single_step_instruction_with_breakpoint_check() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
As usual, another command gets lumped into our `handle_command` function:
|
正如以往,另一个命令被集成到我们的 `handle_command` 函数:
|
||||||
|
|
||||||
```
|
```
|
||||||
else if(is_prefix(command, "stepi")) {
|
else if(is_prefix(command, "stepi")) {
|
||||||
@ -63,15 +63,15 @@ else if(is_prefix(command, "stepi")) {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
With these functions added we can begin to implement our source-level stepping functions.
|
利用新增的这些函数我们可以开始实现我们的源码级逐步执行函数。
|
||||||
|
|
||||||
* * *
|
* * *
|
||||||
|
|
||||||
### Implementing the steps
|
### 实现逐步执行
|
||||||
|
|
||||||
We’re going to write very simple versions of these functions, but real debuggers tend to have the concept of a _thread plan_ which encapsulates all of the stepping information. For example, a debugger might have some complex logic to determine breakpoint sites, then have some callback which determines whether or not the step operation has completed. This is a lot of infrastructure to get in place, so we’ll just take a naive approach. We might end up accidentally stepping over breakpoints, but you can spend some time getting all the details right if you like.
|
我们打算编写这些函数非常简单的版本,但真正的调试器有 _thread plan_ 的概念,它封装了所有的单步信息。例如,调试器可能有一些复杂的逻辑去决定断点的位置,然后有一些回调函数用于判断单步操作是否完成。这其中有非常多的基础设施,我们只采用一种朴素的方法。我们可能会意外地跳过断点,但如果你愿意的话,你可以花一些时间把所有的细节都处理好。
|
||||||
|
|
||||||
For `step_out`, we’ll just set a breakpoint at the return address of the function and continue. I don’t want to get into the details of stack unwinding yet – that’ll come in a later part – but it suffices to say for now that the return address is stored 8 bytes after the start of a stack frame. So we’ll just read the frame pointer and read a word of memory at the relevant address:
|
对于跳出`step_out`,我们只是在函数的返回地址处设一个断点然后继续执行。我暂时还不想考虑调用栈展开的细节 - 这些都会在后面的部分介绍 - 但可以说返回地址就保存在栈帧开始的后 8 个字节中。因此我们会读取栈指针然后在内存相对应的地址读取值:
|
||||||
|
|
||||||
```
|
```
|
||||||
void debugger::step_out() {
|
void debugger::step_out() {
|
||||||
@ -92,7 +92,7 @@ void debugger::step_out() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
`remove_breakpoint` is a little helper function:
|
`remove_breakpoint` 是一个小的帮助函数:
|
||||||
|
|
||||||
```
|
```
|
||||||
void debugger::remove_breakpoint(std::intptr_t addr) {
|
void debugger::remove_breakpoint(std::intptr_t addr) {
|
||||||
@ -103,7 +103,7 @@ void debugger::remove_breakpoint(std::intptr_t addr) {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
Next is `step_in`. A simple algorithm is to just keep on stepping over instructions until we get to a new line.
|
接下来是跳入`step_in`。一个简单的算法是继续逐步执行指令直到新的一行。
|
||||||
|
|
||||||
```
|
```
|
||||||
void debugger::step_in() {
|
void debugger::step_in() {
|
||||||
@ -118,7 +118,7 @@ void debugger::step_in() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
`step_over` is the most difficult of the three for us. Conceptually, the solution is to just set a breakpoint at the next source line, but what is the next source line? It might not be the one directly succeeding the current line, as we could be in a loop, or some conditional construct. Real debuggers will often examine what instruction is being executed and work out all of the possible branch targets, then set breakpoints on all of them. I’d rather not implement or integrate an x86 instruction emulator for such a small project, so we’ll need to come up with a simpler solution. A couple of horrible options are to just keep stepping until we’re at a new line in the current function, or to just set a breakpoint at every line in the current function. The former would be ridiculously inefficient if we’re stepping over a function call, as we’d need to single step through every single instruction in that call graph, so I’ll go for the second solution.
|
跳过`step_over` 对于我们来说是三个中最难的。理论上,解决方法就是在下一行源码中设置一个断点,但下一行源码是什么呢?它可能不是当前行后续的那一行,因为我们可能处于一个循环、或者某种条件结构之中。真正的调试器一般会检查当前正在执行什么指令然后计算出所有可能的分支目标,然后在所有分支目标中设置断点。对于一个小的项目,我不打算实现或者集成一个 x86 指令模拟器,因此我们要想一个更简单的解决办法。有几个可怕的选项,一个是一直逐步执行直到当前函数新的一行,或者在当前函数的每一行都设置一个断点。如果我们是要跳过一个函数调用,前者将会相当的低效,因为我们需要逐步执行那个调用图中的每个指令,因此我会采用第二种方法。
|
||||||
|
|
||||||
```
|
```
|
||||||
void debugger::step_over() {
|
void debugger::step_over() {
|
||||||
@ -154,7 +154,7 @@ void debugger::step_over() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
This function is a bit more complex, so I’ll break it down a bit.
|
这个函数有一点复杂,我们将它拆开来看。
|
||||||
|
|
||||||
```
|
```
|
||||||
auto func = get_function_from_pc(get_pc());
|
auto func = get_function_from_pc(get_pc());
|
||||||
@ -162,7 +162,7 @@ This function is a bit more complex, so I’ll break it down a bit.
|
|||||||
auto func_end = at_high_pc(func);
|
auto func_end = at_high_pc(func);
|
||||||
```
|
```
|
||||||
|
|
||||||
`at_low_pc` and `at_high_pc` are functions from `libelfin` which will get us the low and high PC values for the given function DIE.
|
`at_low_pc` 和 `at_high_pc` 是 `libelfin` 中的函数,它们能给我们指定函数 DWARF 信息条目的最小和最大程序计数器值。
|
||||||
|
|
||||||
```
|
```
|
||||||
auto line = get_line_entry_from_pc(func_entry);
|
auto line = get_line_entry_from_pc(func_entry);
|
||||||
@ -179,7 +179,7 @@ This function is a bit more complex, so I’ll break it down a bit.
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We’ll need to remove any breakpoints we set so that they don’t leak out of our step function, so we keep track of them in a `std::vector`. To set all the breakpoints, we loop over the line table entries until we hit one which is outside the range of our function. For each one, we make sure that it’s not the line we are currently on, and that there’s not already a breakpoint set at that location.
|
我们需要移除我们设置的所有断点,以便不会泄露我们的逐步执行函数,为此我们把它们保存到一个 `std::vector` 中。为了设置所有断点,我们循环遍历行表条目直到找到一个不在我们函数范围内的。对于每一个,我们都要确保它不是我们当前所在的行,而且在这个位置还没有设置任何断点。
|
||||||
|
|
||||||
```
|
```
|
||||||
auto frame_pointer = get_register_value(m_pid, reg::rbp);
|
auto frame_pointer = get_register_value(m_pid, reg::rbp);
|
||||||
@ -190,7 +190,7 @@ We’ll need to remove any breakpoints we set so that they don’t leak out of o
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
Here we are setting a breakpoint on the return address of the function, just like in `step_out`.
|
这里我们在函数的返回地址处设置一个断点,正如跳出 `step_out`。
|
||||||
|
|
||||||
```
|
```
|
||||||
continue_execution();
|
continue_execution();
|
||||||
@ -200,11 +200,11 @@ Here we are setting a breakpoint on the return address of the function, just lik
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
Finally, we continue until one of those breakpoints has been hit, then remove all the temporary breakpoints we set.
|
最后,我们继续执行直到命中它们中的其中一个断点,然后移除所有我们设置的临时断点。
|
||||||
|
|
||||||
It ain’t pretty, but it’ll do for now.
|
它并不美观,但暂时先这样吧。
|
||||||
|
|
||||||
Of course, we also need to add this new functionality to our UI:
|
当然,我们还需要将这个新功能添加到用户界面:
|
||||||
|
|
||||||
```
|
```
|
||||||
else if(is_prefix(command, "step")) {
|
else if(is_prefix(command, "step")) {
|
||||||
@ -220,9 +220,9 @@ Of course, we also need to add this new functionality to our UI:
|
|||||||
|
|
||||||
* * *
|
* * *
|
||||||
|
|
||||||
### Testing it out
|
### 测试
|
||||||
|
|
||||||
I tested out my implementation with a simple program which calls a bunch of different functions:
|
我通过实现一个调用一系列不同函数的简单函数来进行测试:
|
||||||
|
|
||||||
```
|
```
|
||||||
void a() {
|
void a() {
|
||||||
@ -259,16 +259,16 @@ int main() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
You should be able to set a breakpoint on the address of `main` and then in, over, and out all over the program. Expect things to break if you try to step out of `main` or into some dynamically linked library.
|
你应该可以在 `main` 地址处设置一个断点,然后在整个程序中跳入、跳过、跳出函数。如果你尝试跳出 `main` 函数或者跳入任何动态链接库,就会出现意料之外的事情。
|
||||||
|
|
||||||
You can find the code for this post [here][7]. Next time we’ll use our newfound DWARF expertise to implement source-level breakpoints.
|
你可以在[这里][7]找到这篇博文的相关代码。下次我们会利用我们新的 DWARF 技巧来实现源码级断点。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
via: https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||||
|
|
||||||
作者:[TartanLlama ][a]
|
作者:[TartanLlama ][a]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[ictlyh](https://github.com/ictlyh)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
@ -0,0 +1,99 @@
|
|||||||
|
8 种方式开始使用开源硬件
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
### 制造自己的硬件比以往任何时候都更容易,更便宜。以下是你需要设计,构建和测试你的第一块电路板。
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
>图片提供: Thomas Hawk on [Flickr][11]. [CC BY-NC 2.0][12]. 由 Opensource.com 修改
|
||||||
|
|
||||||
|
著名的计算机科学家 Alan Kay 曾经说过:“认真对待软件的人应该制造它们自己的硬件。” 我认为今天就如 1982 年他所说的一样真实。然而,现在和那时之间的变化是硬件变得越来越快,越来越小,最重要的是:更便宜。 现在可以用 5 美元购买一台完整的电脑。
|
||||||
|
|
||||||
|
随着大公司降低自己产品的价格,它发展了一个能够生产生产级硬件的制造业生态系统,它的成本足够便宜,并且达到了普通人都可以接受的程度。这种可用性以及可负担性正在帮助推动诸如众筹和制造商运动之类的事情,但他们也让更多的个人能够通过开源硬件参与开源。
|
||||||
|
|
||||||
|
探索开放硬件
|
||||||
|
|
||||||
|
* [什么是开放硬件?][1]
|
||||||
|
|
||||||
|
* [什么是树莓派?][2]
|
||||||
|
|
||||||
|
* [什么是 Arduino?][3]
|
||||||
|
|
||||||
|
* [我们最新的开放硬件文章][4]
|
||||||
|
|
||||||
|
什么是或者不是开源硬件有很多区别,但是开源硬件联盟(OSHWA)定义了一个大多数人同意的定义,如果你熟悉开源软件,这不会听上去太奇怪:
|
||||||
|
|
||||||
|
|
||||||
|
> “开源硬件(OSHW)是有形人工机器、设备或者其他物理东西的术语-其设计像公众发布,任何人可以制造、修改、分发并使用那些。”
|
||||||
|
|
||||||
|
周围已经有很多开源硬件了。你可能没有注意到你在使用的主板可能实际上是开放的硬件。从[低调]但通用的[Arduino][13],一直到像 [BeagleBone][14] family 和 [C.H.I.P.][15] 计算机这样的完整功能的电脑,这有很多开放硬件的例子,还有更多的在设计中。
|
||||||
|
|
||||||
|
硬件可能很复杂,对初学者而言为什么设计需要这些有时不太明显。但开源硬件使你不仅可以看到工作示例,还可以更改这些设计,或者在你自己的设计中复制所需的部分,就如复制和粘贴一样简单。
|
||||||
|
|
||||||
|
### 我该如何开始?
|
||||||
|
|
||||||
|
我们先要指出硬件很难,它很复杂,有时是深奥的,你可能用到的工具并不总是最人性化的。任何一个玩微处理器的时间足够长的人都可以证明有一种可能:你会烧坏一些东西,看到神奇的烟雾在某个时刻冒出来。没关系,我们都做过,有些人还会反复做,因为我们在做一件事情的前 100 次时都不会得到教训,但不让让这阻碍你:当做错事情时,你会学到教训,而且你将来还会有有趣的故事告诉别人。
|
||||||
|
|
||||||
|
### 建模
|
||||||
|
|
||||||
|
首先要做的是开始使用现有的电路板,跳线、面包板以及你要连接的任何设备来建模你想要做的事情。在许多情况下,最简单的事情就是在板上添加更多的 LED,并以新颖的方式让它们闪烁。这是一个很好的出原型的方式,也是一个很常见的事情。它看上去不漂亮,你可能会发现你的线接错了,但这些都是原型 - 你只是想证明硬件可以工作。当硬件不工作时,一定要仔细检查一切,不要害怕寻求帮助 - 有时第二双眼睛会发现你奇怪的接地短路。
|
||||||
|
|
||||||
|
### 设计
|
||||||
|
|
||||||
|
当你弄清楚你想要构建的硬件,现在是时候把你的想法从跳线和面包板变成实际的设计了。这时事情会变得让人气馁,但是从小的开始,事情上,可以从熟悉加工和流程这样非常小的开始,所以为什么不制作一块带有 LED 和电池的印刷电路板?认真地说,这可能听起来过于简单,但在这里有很多新的基础要了解。
|
||||||
|
|
||||||
|
1. **找到一个电子设计自动化(EDA)工具来使用。** 这有很多好的开源软件可以选择,但是它们并不总是用户友好的。[Fritzing][5]、[gEDA][6] 还有 [KiCad ][7] 都是开源的,并以可用性升序排序。如果你想要尝试更多的商业软件,那么还有一些其他的选择。Eagle 有受限的免费版本使用,有许多的开源硬件是用它设计的。
|
||||||
|
|
||||||
|
2. **在 EDA 工具中设计你的电路板。** 依据你选择的工具,这可能会非常快,或者可能是学习如何设计的很好的练习。这是我建议从小的硬件开始的原因之一。一个带 LDED 的电路可以如一块电池、一个电阻、一个 LED 一样简单。电路图非常简单,并且布局也会非常小、非常简单。
|
||||||
|
|
||||||
|
3. **为制造导出设计。** 这与列表中的下一件事情紧密相连,但如果你以前没有这样做,这也可能是一个令人困惑的过程。当你在导出时,你会有很多细节需要调整,并且需要以某种方式导出以便电路板工厂能确切知道你要做的。
|
||||||
|
|
||||||
|
4. **找到一个电路板工厂。** 有许多电路板工厂可以制作你的设计,并且一些比其他更加友好及有帮助。一个特别棒的地方是 [OSH Park][8],这些人非常友好并支持开源硬件。他们也有一个非常扎实的流程来确认你发送给它的就是会被制造的,所以他们值得一试。还有很多其他选择; 看看 [PCB Shopper][9],它可以让你比较不同实体 PCB 商家的价格、周转时间等等。
|
||||||
|
|
||||||
|
5. **等待。** 这或许是在制造你自己的电路板中最难的一部分了,因为它会花费时间将数字部分变成物理产品。计划好两周时间来拿到你的电路板。这是你继续下个项目的绝好时间,确保或获取你当前制造的所有部分,或者通常上尝试不要担心。你的第一块电路板是艰难的 - 你现在非常想要,但是保持耐心。
|
||||||
|
|
||||||
|
6. **修补并提升。** 一旦拿到你的板子,是时候上电测试了。如果你是以 LED 电路开始,那么它很容易调试,并且你会得到一些可以工作的东西。如果你有更复杂的电路,那么需要有条理并且有耐心。有时候电路不会工作,并且你需要用你的调试技能来追踪问题。
|
||||||
|
|
||||||
|
7. **最后,如果你做的是开源硬件,那就发布它。*** 我们谈论的是开源硬件,因此确保包含了一个许可,但是发布它、共享它,把它放在人们可以看见你所做的地方。你或许会想写一篇博客并提交到如 Hackaday 上面。
|
||||||
|
|
||||||
|
8. **最重要的是,玩得开心。** 坦白说,如果你在说一些事但是你不开心,你应该停止这样做。开源硬件可以很有趣,虽然有时是困难而且复杂的。但是不是一切都会正常。见鬼,我已经设计了一半的电路不工作,或者我(意外地)在电源和接地之间造成了 12 次短路。这些电路板是双层板:是的。我在这个过程中学到了一些东西:非常多,并且我不会再犯同样的错误。我会做出新的板子,但不是这些。(我会支持并盯着这些板子和它们的错误,悲伤的是,它们不会在我盯着它们时感到难受)。
|
||||||
|
|
||||||
|
build the hardware that they want—not the hardware they can get.
|
||||||
|
现在有许多的开源硬件,以及从中可以查看、复制、衍生,并且有很多信息使制造硬件变得简单。这就是开源硬件:一个社区的人们制造它们,共享它们,这样每个人可以制作他们自己的东西并构建他们想要的硬件 - 而不是他们可以得到的硬件。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
John 'Warthog9' Hawley - John 在 VMWare 的开源项目办公室为上游开源项目工作。在以前的生活中,他曾在 MinnowBoard 开源硬件项目上工作,领导了 kernel.org 上的系统管理团队,并在桌面集群变得很酷之前构建了它们。为了乐趣,他构建了多个明星项目,一个受欢迎的英国电视节目 K-9 的复制品,在无人机的飞行计算机视觉处理中完成,设计并制作了一堆自己的硬件。
|
||||||
|
|
||||||
|
-------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware
|
||||||
|
|
||||||
|
作者:[John 'Warthog9' Hawley ][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware
|
||||||
|
[1]:https://opensource.com/resources/what-open-hardware?src=open_hardware_resources_menu
|
||||||
|
[2]:https://opensource.com/resources/what-raspberry-pi?src=open_hardware_resources_menu
|
||||||
|
[3]:https://opensource.com/resources/what-arduino?src=open_hardware_resources_menu
|
||||||
|
[4]:https://opensource.com/tags/hardware?src=open_hardware_resources_menu
|
||||||
|
[5]:http://fritzing.org/home/
|
||||||
|
[6]:http://www.geda-project.org/
|
||||||
|
[7]:http://kicad-pcb.org/
|
||||||
|
[8]:https://oshpark.com/
|
||||||
|
[9]:http://pcbshopper.com/
|
||||||
|
[10]:https://opensource.com/article/17/5/8-ways-get-started-open-source-hardware?rate=jPBGDIa2vBXW6kb837X8JWdjI2V47hZ4KecI8-GJBjQ
|
||||||
|
[11]:https://www.flickr.com/photos/thomashawk/3048157616/in/photolist-5DmB4E-BzrZ4-5aUXCN-nvBWYa-qbkwAq-fEFeDm-fuZxgC-dufA8D-oi8Npd-b6FiBp-7ChGA3-aSn7xK-7NXMyh-a9bQQr-5NG9W7-agCY7E-4QD9zm-7HLTtj-4uCiHy-bYUUtG
|
||||||
|
[12]:https://creativecommons.org/licenses/by-nc/2.0/
|
||||||
|
[13]:https://opensource.com/node/20751
|
||||||
|
[14]:https://opensource.com/node/35211
|
||||||
|
[15]:https://opensource.com/node/24891
|
||||||
|
[16]:https://opensource.com/user/130046/feed
|
||||||
|
[17]:https://opensource.com/users/warthog9
|
||||||
@ -1,31 +1,20 @@
|
|||||||
DevOps 的意义
|
DevOps 的意义
|
||||||
========================================
|
========================================
|
||||||
|
|
||||||
### 真正的组织文化变革有助于你弥合你原先认为无法跨过的鸿沟
|
> 真正的组织文化变革有助于你弥合你原先认为无法跨过的鸿沟
|
||||||
|
|
||||||

|

|
||||||
>图片来源 : opensource.com
|
|
||||||
|
|
||||||
回想你最近一次尝试改掉一个个人习惯,你可能遇到过这样的情形,你需要改变你思考的方式并且让不习惯成为你身体的一部分。这很艰难,你只是试着改变 _你自己的_ 思维方式。
|
|
||||||
|
|
||||||
所以你可能会努力让自己处于新的环境。新的环境实际上可帮助我们养成 _新的_ 习惯,它反过又会促成新的思维方式。
|
回想你最近一次尝试改掉一个个人习惯的事情,你可能遇到过这样的情形,你需要改变你思考的方式并且改掉之前的习惯。这很艰难,你只是试着改变 _你自己的_ 思维方式而已。
|
||||||
|
|
||||||
那就是能否成功改变的所在:看起来是那么回事,实际上它就是那么回事
|
所以你可能会努力让自己处于新的环境。新的环境实际上可帮助我们养成 _新的_ 习惯,它反过来又会促成新的思维方式。
|
||||||
。你需要知道 _为什么_ 你正在改变和你正准备去 _哪儿_ (而不是仅仅知道你要怎么做),因为改变本身往往是短暂和短视的。
|
|
||||||
|
|
||||||
现在思考你的 IT 组织需要做出的改变。也许你正在考虑采用像 DevOps 这样的东西。这个我们称之为 “DevOps” 的东西有三个组件:人、流程和工具。人和流程是 _任何_ 组织的基础。因此,采用 DevOps 需要对大多数组织的核心进行根本性的改变,而不仅仅是学习新的工具。
|
那就是能否成功改变的所在:看起来是那么回事,实际上它就是那么回事 。你需要知道 _为什么_ 你正在改变以及你的目的 _所在_ (而不是仅仅你要怎么做),因为改变本身往往是短暂和短视的。
|
||||||
|
|
||||||
开放式组织资源:
|
现在想想你的 IT 组织需要做出的改变。也许你正在考虑采用像 DevOps 这样的东西。这个我们称之为 “DevOps” 的东西有三个组件:人、流程和工具。人和流程是 _任何_ 团体组织的基础。因此,采用 DevOps 需要对大多数组织的核心进行根本性的改变,而不仅仅是学习新的工具。
|
||||||
|
|
||||||
* [下载开放式组织领导手册][1]
|
和其他改变一样,它也是短视的。如果您将注意力集中在改变作为单点解决方案——例如,“获得更好的工具进行报警”——你可能想出一个狭隘的问题。这种思维方式或许可以提供一套拥有更多铃声和口哨并且可以有一种可以更好地处理随叫随到的方式的工具,但是它不能解决这样的实际问题:警报不能到达正确的团队,或者故障得不到解决,因为实际上没有人知道如何修复服务。
|
||||||
|
|
||||||
* [下载开放式组织现场指南][2]
|
|
||||||
|
|
||||||
* [什么是开放式组织?][3]
|
|
||||||
|
|
||||||
* [什么是开放式决策][4]
|
|
||||||
|
|
||||||
和其他改变一样,它也是短视的。如果您将注意力集中在改变作为单点解决方案——例如,“获得更好的工具进行报警”——你可能想出一个狭隘的问题。这种思维方式或许可以提供一套拥有更多铃声和口哨并且可以有一种可以更好地处理随叫随到的方式的的工具,但是它不能解决这样的实际问题:警报不能到达正确的团队,或者故障得不到解决,因为实际上没有人知道如何修复服务。
|
|
||||||
|
|
||||||
新的工具(或者至少一个新工具的想法)创造了一个时刻来谈论困扰你的团队对监控的评价的潜在问题。新工具让你能够做出更大的改变——信仰和做法的改变——它们作为你组织的基础而显得更加重要。
|
新的工具(或者至少一个新工具的想法)创造了一个时刻来谈论困扰你的团队对监控的评价的潜在问题。新工具让你能够做出更大的改变——信仰和做法的改变——它们作为你组织的基础而显得更加重要。
|
||||||
|
|
||||||
@ -33,13 +22,13 @@ DevOps 的意义
|
|||||||
|
|
||||||
### 清除栅栏
|
### 清除栅栏
|
||||||
|
|
||||||
> 就改革而言,它不同于腐化。有一条明显且简单的原则,这个原则可能被称为悖论。 在这种情况下,存在某种制度或法律; 让我们说,为了简单起见,在一条路上架设了一个栅栏或门。 现代化的改革者们来到这儿,并说:“我看不到它的用处,让我们把它清除掉。”聪明的改革者会很好地回答:“如果你看不到它的用处,我肯定不会让你清除它,回去想想,然后你可以回来 告诉我你看到它的用处,我会允许你摧毁它."—G.K Chesterton, 1929
|
> 就改革而言,它不同于腐化。有一条明显且简单的原则,这个原则可能被称为悖论。在这种情况下,存在某种制度或法律;让我们说,为了简单起见,在一条路上架设了一个栅栏或门。现代化的改革者们来到这儿,并说:“我看不到它的用处,让我们把它清除掉。”聪明的改革者会很好地回答:“如果你看不到它的用处,我肯定不会让你清除它,回去想想,然后你可以回来告诉我你看到它的用处,我会允许你摧毁它。” — G.K Chesterton, 1929
|
||||||
|
|
||||||
为了了解对 DevOps 的需求——它试图将传统意义上分开的开发部门和运维部门进行重新组合——我们首先必须明白这个分开是如何产生的。一旦我们"知道了它的用处",然后我们就会知道将它们分开是为了什么,并且在必要的时候可以取消分开。
|
为了了解对 DevOps 的需求——它试图将传统意义上分开的开发部门和运维部门进行重新组合——我们首先必须明白这个分开是如何产生的。一旦我们"知道了它的用处",然后我们就会知道将它们分开是为了什么,并且在必要的时候可以取消分开。
|
||||||
|
|
||||||
今天我们没有一个单一的管理理论,但是我们可以将大多数现代管理理论的起源追溯到弗雷德里克·温斯洛·泰勒。泰勒是一名机械工程师,他创建了一个衡量钢厂工人效率的系统。泰勒认为,他可以对工厂的劳动者应用科学分析,不仅为了改进个人任务,还为了证明有一个可以发现的用来执行 _任何_ 任务最佳方法。
|
今天我们没有一个单一的管理理论,但是我们可以将大多数现代管理理论的起源追溯到弗雷德里克·温斯洛·泰勒。泰勒是一名机械工程师,他创建了一个衡量钢厂工人效率的系统。泰勒认为,他可以对工厂的劳动者应用科学分析,不仅为了改进个人任务,还为了证明有一个可以发现的用来执行 _任何_ 任务最佳方法。
|
||||||
|
|
||||||
我们可以很容易地画一个以 Taylor 为起源的历史树。基于泰勒早在18世纪80年代后期的研究而出现的时间运动研究和其他质量改进计划跨越20世纪20年代一直到今天,我们可以从中看到六西格玛、精益,等等一些。自上而下、指导式管理,再加上研究过程的有条理的方法,今天主宰主流商业文化。它主要侧重于把效率作为工人成功的测量标准。
|
我们可以很容易地画一个以 Taylor 为起源的历史树。基于泰勒早在 18 世纪 80 年代后期的研究而出现的时间运动研究和其他质量改进计划跨越 20 世纪 20 年代一直到今天,我们可以从中看到六西格玛、精益,等等一些。自上而下、指导式管理,再加上研究过程的有条理的方法,今天主宰主流商业文化。它主要侧重于把效率作为工人成功的测量标准。
|
||||||
|
|
||||||
> “开发”和“运维”的分开不是因为人的原因,不同的技能,或者放在新员工头上的一顶魔术帽,它是 Taylor 和 Sloan 的理论的副产品。
|
> “开发”和“运维”的分开不是因为人的原因,不同的技能,或者放在新员工头上的一顶魔术帽,它是 Taylor 和 Sloan 的理论的副产品。
|
||||||
|
|
||||||
@ -47,15 +36,15 @@ DevOps 的意义
|
|||||||
|
|
||||||
1920 年,通用公司正经历一场管理危机,或者说是缺乏管理的危机。Sloan 向董事会写了一份为通用汽车的多个部门提出了一个新的结构《组织研究》。这一新结构的核心概念是“集中管理下放业务”。与雪佛兰,凯迪拉克和别克等品牌相关的各个部门将独立运作,同时为中央管理层提供推动战略和控制财务的手段。
|
1920 年,通用公司正经历一场管理危机,或者说是缺乏管理的危机。Sloan 向董事会写了一份为通用汽车的多个部门提出了一个新的结构《组织研究》。这一新结构的核心概念是“集中管理下放业务”。与雪佛兰,凯迪拉克和别克等品牌相关的各个部门将独立运作,同时为中央管理层提供推动战略和控制财务的手段。
|
||||||
|
|
||||||
在 Sloan 的建议下(以及后来就任CEO的指导),通用汽车在美国汽车工业中占据了主导地位。Sloan 的计划把一个处于灾难边缘公司创造成了一个非常成功的公司。从中间来看,自治单位是黑盒子,激励和目标被设置在顶层,而团队在底层推动。
|
在 Sloan 的建议下(以及后来就任 CEO 的指导),通用汽车在美国汽车工业中占据了主导地位。Sloan 的计划把一个处于灾难边缘公司创造成了一个非常成功的公司。从中间来看,自治单位是黑盒子,激励和目标被设置在顶层,而团队在底层推动。
|
||||||
|
|
||||||
泰勒思想的“最佳实践” ——标准、可互换和可重复的行为——仍然在今天的管理理念中占有一席之地,与斯隆公司结构的层次模式相结合,主导了僵化的部门分裂和孤岛以实现最大的控制。
|
泰勒思想的“最佳实践”——标准、可互换和可重复的行为——仍然在今天的管理理念中占有一席之地,与斯隆公司结构的层次模式相结合,主导了僵化的部门分裂和孤岛以实现最大的控制。
|
||||||
|
|
||||||
我们可以指出几份管理研究来证明这一点,但商业文化不是通过阅读书籍而创造和传播的。组织文化是 *真实的* 人在 *实际的* 情形下执行推动文化规范的 *具体的* 行为的产物。这就是为何类似 Taylor 和 Sloan 的主张这样的事情变得固化而不可动摇的原因。
|
我们可以指出几份管理研究来证明这一点,但商业文化不是通过阅读书籍而创造和传播的。组织文化是 *真实的* 人在 *实际的* 情形下执行推动文化规范的 *具体的* 行为的产物。这就是为何类似 Taylor 和 Sloan 的主张这样的事情变得固化而不可动摇的原因。
|
||||||
|
|
||||||
技术部门投资就是一个例子。以下是这个周期是如何循环的:投资者只投资于他们认为可以实现 *他们的* 特定成功观点的公司。这个成功的模式并不一定源于公司本身(和它的特定的目标);它来自董事会对一家成功的公司 *应该* 如何看待的想法。许多投资者来自在经营企业的尝试和苦难中幸存下来的公司,因此他们对什么会使一个公司成功有 *不同的* 蓝图。他们为那些能够被教导模仿他们的成功模式的公司提供资金所以希望获得资金的公司学会模仿。 这样,初创公司孵化器就是一种重现理想的结构和文化的直接的方式。
|
技术部门投资就是一个例子。以下是这个周期是如何循环的:投资者只投资于他们认为可以实现 *他们的* 特定成功观点的公司。这个成功的模式并不一定源于公司本身(和它的特定的目标);它来自董事会对一家成功的公司 *应该* 如何看待的想法。许多投资者来自在经营企业的尝试和苦难中幸存下来的公司,因此他们对什么会使一个公司成功有 *不同的* 蓝图。他们为那些能够被教导模仿他们的成功模式的公司提供资金,所以希望获得资金的公司学会模仿。这样,初创公司孵化器就是一种重现理想的结构和文化的直接的方式。
|
||||||
|
|
||||||
开发和运维的分开是不是因为人原因,不同的技能,或者放在新员工头上的一顶魔术帽;它是 Taylor 和 Sloan 的理论的副产品。责任与人员之间的透明和不可渗透的界线是一个管理功能,同时也注重员工的工作效率。管理上的分开可以很容易的落在产品或者项目界线上,而不是技能上,但是通过今天的业务管理理论的历史告诉我们,基于技能的分组是“最好”的高效方式。
|
开发和运维的分开是不是因为人的原因,不同的技能,或者放在新员工头上的一顶魔术帽;它是 Taylor 和 Sloan 的理论的副产品。责任与人员之间的透明和不可渗透的界线是一个管理功能,同时也注重员工的工作效率。管理上的分开可以很容易的落在产品或者项目界线上,而不是技能上,但是通过今天的业务管理理论的历史告诉我们,基于技能的分组是“最好”的高效方式。
|
||||||
|
|
||||||
不幸的是,那些界线造成了紧张局势,这些紧张局势是由不同的管理链出于不同的目标设定的相反目标的直接结果。例如:
|
不幸的是,那些界线造成了紧张局势,这些紧张局势是由不同的管理链出于不同的目标设定的相反目标的直接结果。例如:
|
||||||
|
|
||||||
@ -65,27 +54,27 @@ DevOps 的意义
|
|||||||
* 打败竞争对手 ⟷ 保护收入
|
* 打败竞争对手 ⟷ 保护收入
|
||||||
* 修复出现的问题 ⟷ 在问题出现之前就进行预防
|
* 修复出现的问题 ⟷ 在问题出现之前就进行预防
|
||||||
|
|
||||||
今天,我们可以看到组织的高层领导人越来越认识到,现有的商业文化(并扩大了它所产生的紧张局势)是一个严重的问题。在2016年的 Gartner 报告中,57%的受访者表示,文化变革是2020年之前企业面临的主要挑战之一。像作为一种影响组织变革的的手段的敏捷和DevOps这样的新方法的兴起反映了这一认识。"[shadow IT][7]" 的出现是硬币的反面;最近的估计有将近30%的 IT 支出在IT组织的控制之外。
|
今天,我们可以看到组织的高层领导人越来越认识到,现有的商业文化(并扩大了它所产生的紧张局势)是一个严重的问题。在 2016 年的 Gartner 报告中,57% 的受访者表示,文化变革是 2020 年之前企业面临的主要挑战之一。像作为一种影响组织变革的手段的敏捷和DevOps这样的新方法的兴起反映了这一认识。"[shadow IT][7]" 的出现是硬币的反面;最近的估计有将近 30% 的 IT 支出在 IT 组织的控制之外。
|
||||||
|
|
||||||
这些只是企业正在面临的一些“文化担忧”。改变的必要性是明确的,但前进的道路仍然受到昨天的决定的约束。
|
这些只是企业正在面临的一些“文化担忧”。改变的必要性是明确的,但前进的道路仍然受到昨天的决定的约束。
|
||||||
|
|
||||||
### 抵抗并不是没用的
|
### 抵抗并不是没用的
|
||||||
|
|
||||||
> "Bert Lance 认为如果他能让政府采纳一条简单的格言“如果东西还没损坏,那就别去修理它”,他就可以为山姆拯救三十亿。他解释说:“这是政府的麻烦:'修复没有损坏的东西,而不是修复已经损坏了的东西。'” — Nation's Business, 1977.5
|
> Bert Lance 认为如果他能让政府采纳一条简单的格言“如果东西还没损坏,那就别去修理它”,他就可以为山姆拯救三十亿。他解释说:“这是政府的麻烦:‘修复没有损坏的东西,而不是修复已经损坏了的东西。’” — Nation's Business, 1977.5
|
||||||
|
|
||||||
通常,改革是组织针对所出现的错误所做的应对。 在这个意义上说,如果紧张局势(即使逆境)是变革的正常催化剂,那么 *抵抗* 变化就是成功的指标。但是过分强调成功的道路会使组织变得僵硬、衰竭和独断。 重视有效结果的政策导航是这种不断增长的僵局的症状。重视有效结果的政策导航是这种不断增长的僵局的症状。
|
通常,改革是组织针对所出现的错误所做的应对。在这个意义上说,如果紧张局势(即使逆境)是变革的正常催化剂,那么 *抵抗* 变化就是成功的指标。但是过分强调成功的道路会使组织变得僵硬、衰竭和独断。重视有效结果的政策导航是这种不断增长的僵局的症状。
|
||||||
|
|
||||||
传统IT部门的成功加剧了 IT 仓库的墙壁。其他部门现在变成了"顾客",而不是同事。试图将 IT 从成本中心转移出来创建一个新的操作模式,它可以将 IT 与其他业务目标断开。这反过来又会对敏捷性造成限制,增加摩擦,降低反应能力。合作被搁置而支持“专家方向”。结果是一个孤立主义的观点,IT 只能带来更多的伤害而不是好处。
|
传统 IT 部门的成功加剧了 IT 仓库的墙壁。其他部门现在变成了“顾客”,而不是同事。试图将 IT 从成本中心转移出来创建一个新的操作模式,它可以将 IT 与其他业务目标断开。这反过来又会对敏捷性造成限制,增加摩擦,降低反应能力。合作被搁置而支持“专家方向”。结果是一个孤立主义的观点,IT 只能带来更多的伤害而不是好处。
|
||||||
|
|
||||||
正如“软件吃掉世界”,IT 越来越成为组织整体成功的核心。具有前瞻性的IT组织认识到这一点,并且已经对其战略规划进行了有意义的改变,而不是将改变视为恐惧。
|
正如“软件吃掉世界”,IT 越来越成为组织整体成功的核心。具有前瞻性的 IT 组织认识到这一点,并且已经对其战略规划进行了有意义的改变,而不是将改变视为恐惧。
|
||||||
|
|
||||||
>改革不仅仅只是重构组织,它也是关于跨越历史上不可跨越的鸿沟的新途径。
|
> 改革不仅仅只是重构组织,它也是关于跨越历史上不可跨越的鸿沟的新途径。
|
||||||
|
|
||||||
例如,Facebook与人类学家罗宾·邓巴(Robin Dunbar)就社会团体的方法进行了磋商,而且意识到这一点对公司成长的内部团体(不仅仅是网站的外部用户)的影响。扎波斯的文化得到了很多的赞誉,该组织创立了一个部门,专注于培养他人对于核心价值观和企业文化的看法。当然,这本书是 _The Open Organization_ 的姊妹篇, 一本描述被应用于管理的开放原则——透明度、参与度和社区——可以如何为我们快节奏的有连系的时代重塑组织。
|
例如,Facebook 与人类学家罗宾·邓巴(Robin Dunbar)就社会团体的方法进行了磋商,而且意识到这一点对公司成长的内部团体(不仅仅是网站的外部用户)的影响。扎波斯的文化得到了很多的赞誉,该组织创立了一个部门,专注于培养他人对于核心价值观和企业文化的看法。当然,这本书是 _The Open Organization_ 的姊妹篇, 一本描述被应用于管理的开放原则——透明度、参与度和社区——可以如何为我们快节奏的有联系的时代重塑组织。
|
||||||
|
|
||||||
### 决心改变
|
### 决心改变
|
||||||
|
|
||||||
> "如果外界的变化率超过了内部的变化率,那末日就不远了."—Jack Welch, 2004
|
> “如果外界的变化率超过了内部的变化率,那末日就不远了。” — Jack Welch, 2004
|
||||||
|
|
||||||
一位同事曾经告诉我他可以只用 [Information Technology Infrastructure Library][9] 框架里面的词汇向一位项目经理解释 DevOps。
|
一位同事曾经告诉我他可以只用 [Information Technology Infrastructure Library][9] 框架里面的词汇向一位项目经理解释 DevOps。
|
||||||
|
|
||||||
@ -95,14 +84,15 @@ DevOps 的意义
|
|||||||
|
|
||||||
这些也不是“最佳实例”,它们只是一种检查你自己的栅栏的方式。每个组织都会有独特的由他们内部人员创造的栅栏。一旦你“知道了它的用途”,你就可以决定它是需要拆解还是掌握。
|
这些也不是“最佳实例”,它们只是一种检查你自己的栅栏的方式。每个组织都会有独特的由他们内部人员创造的栅栏。一旦你“知道了它的用途”,你就可以决定它是需要拆解还是掌握。
|
||||||
|
|
||||||
** 本文是 Opensource.com 即将推出的关于开放组织和IT文化指南的一部分。[你可以在这注册以便当它发布时收到通知][5]
|
** 本文是 Opensource.com 即将推出的关于开放组织和 IT 文化指南的一部分。[你可以在这注册以便当它发布时收到通知][5]
|
||||||
|
|
||||||
|
(题图 : opensource.com)
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
|
||||||
作者简介:
|
作者简介:
|
||||||
|
|
||||||
Matt Micene——Matt Micene 是 Red Hat 公司的 Linux 和容器传播者。他在信息技术方面拥有超过15年的经验,从架构和系统设计到数据中心设计。他对关键技术(如容器,云计算和虚拟化)有深入的了解。他目前的重点是宣传红帽企业版Linux,以及操作系统如何与计算环境的新时代相关。
|
Matt Micene——Matt Micene 是 Red Hat 公司的 Linux 和容器传播者。他在信息技术方面拥有超过 15 年的经验,从架构和系统设计到数据中心设计。他对关键技术(如容器,云计算和虚拟化)有深入的了解。他目前的重点是宣传红帽企业版 Linux,以及操作系统如何与计算环境的新时代相关。
|
||||||
|
|
||||||
------------------------------------------
|
------------------------------------------
|
||||||
|
|
||||||
@ -110,7 +100,7 @@ via: https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps
|
|||||||
|
|
||||||
作者:[Matt Micene ][a]
|
作者:[Matt Micene ][a]
|
||||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[apemost](https://github.com/apemost)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user