mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
commit
c492008733
61
published/20150810 For Linux, Supercomputers R Us.md
Normal file
61
published/20150810 For Linux, Supercomputers R Us.md
Normal file
@ -0,0 +1,61 @@
|
||||
有了 Linux,你就可以搭建自己的超级计算机
|
||||
================================================================================
|
||||
|
||||
> 几乎所有超级计算机上运行的系统都是 Linux,其中包括那些由树莓派(Raspberry Pi)板卡和 PlayStation 3游戏机组成的计算机。
|
||||
|
||||

|
||||
|
||||
*题图来源:By Michel Ngilen,[ CC BY 2.0 ], via Wikimedia Commons*
|
||||
|
||||
超级计算机是一种严肃的工具,做的都是高大上的计算。它们往往从事于严肃的用途,比如原子弹模拟、气候模拟和高等物理学。当然,它们的花费也很高大上。在最新的超级计算机 [Top500][1] 排名中,中国国防科技大学研制的天河 2 号位居第一,而天河 2 号的建造耗资约 3.9 亿美元!
|
||||
|
||||
但是,也有一个超级计算机,是由博伊西州立大学电气和计算机工程系的一名在读博士 Joshua Kiepert [用树莓派构建完成][2]的,其建造成本低于2000美元。
|
||||
|
||||
不,这不是我编造的。它一个真实的超级计算机,由超频到 1GHz 的 [B 型树莓派][3]的 ARM11 处理器与 VideoCore IV GPU 组成。每个都配备了 512MB 的内存、一对 USB 端口和 1 个 10/100 BaseT 以太网端口。
|
||||
|
||||
那么天河 2 号和博伊西州立大学的超级计算机有什么共同点吗?它们都运行 Linux 系统。世界最快的超级计算机[前 500 强中有 486][4] 个也同样运行的是 Linux 系统。这是从 20 多年前就开始的格局。而现在的趋势是超级计算机开始由廉价单元组成,因为 Kiepert 的机器并不是唯一一个无所谓预算的超级计算机。
|
||||
|
||||
麻省大学达特茅斯分校的物理学副教授 Gaurav Khanna 创建了一台超级计算机仅用了[不足 200 台的 PlayStation3 视频游戏机][5]。
|
||||
|
||||
PlayStation 游戏机由一个 3.2 GHz 的基于 PowerPC 的 Power 处理器所驱动。每个都配有 512M 的内存。你现在仍然可以花 200 美元买到一个,尽管索尼将在年底逐步淘汰它们。Khanna 仅用了 16 个 PlayStation 3 构建了他第一台超级计算机,所以你也可以花费不到 4000 美元就拥有你自己的超级计算机。
|
||||
|
||||
这些机器可能是用玩具建成的,但他们不是玩具。Khanna 已经用它做了严肃的天体物理学研究。一个白帽子黑客组织使用了类似的 [PlayStation 3 超级计算机在 2008 年破解了 SSL 的 MD5 哈希算法][6]。
|
||||
|
||||
两年后,美国空军研究实验室研制的 [Condor Cluster,使用了 1760 个索尼的 PlayStation 3 的处理器][7]和168 个通用的图形处理单元。这个低廉的超级计算机,每秒运行约 500 TFLOP ,即每秒可进行 500 万亿次浮点运算。
|
||||
|
||||
其他的一些便宜且适用于构建家庭超级计算机的构件包括,专业并行处理板卡,比如信用卡大小的 [99 美元的 Parallella 板卡][8],以及高端显卡,比如 [Nvidia 的 Titan Z][9] 和 [ AMD 的 FirePro W9100][10]。这些高端板卡的市场零售价约 3000 美元,一些想要一台梦幻般的机器的玩家为此参加了[英特尔极限大师赛:英雄联盟世界锦标赛][11],要是甚至有机会得到了第一名的话,能获得超过 10 万美元奖金。另一方面,一个能够自己提供超过 2.5TFLOPS 计算能力的计算机,对于科学家和研究人员来说,这为他们提供了一个可以拥有自己专属的超级计算机的经济的方法。
|
||||
|
||||
而超级计算机与 Linux 的连接,这一切都始于 1994 年戈达德航天中心的第一个名为 [Beowulf 超级计算机][13]。
|
||||
|
||||
按照我们的标准,Beowulf 不能算是最优越的。但在那个时期,作为第一台自制的超级计算机,它的 16 个英特尔486DX 处理器和 10Mbps 的以太网总线,是个伟大的创举。[Beowulf 是由美国航空航天局的承建商 Don Becker 和 Thomas Sterling 所设计的][14],是第一台“创客”超级计算机。它的“计算部件” 486DX PC,成本仅有几千美元。尽管它的速度只有个位数的 GFLOPS (吉拍,每秒10亿次)浮点运算,[Beowulf][15] 表明了你可以用商用现货(COTS)硬件和 Linux 创建超级计算机。
|
||||
|
||||
我真希望我参与创建了一部分,但是我 1994 年就离开了戈达德,开始了作为一名全职的科技记者的职业生涯。该死。
|
||||
|
||||
但是尽管我只是使用笔记本的记者,我依然能够体会到 COTS 和开源软件是如何永远的改变了超级计算机。我希望现在读这篇文章的你也能。因为,无论是 Raspberry Pi 集群,还是超过 300 万个英特尔的 Ivy Bridge 和 Xeon Phi 芯片的庞然大物,几乎所有当代的超级计算机都可以追溯到 Beowulf。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/2960701/linux/for-linux-supercomputers-r-us.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.top500.org/
|
||||
[2]:http://www.zdnet.com/article/build-your-own-supercomputer-out-of-raspberry-pi-boards/
|
||||
[3]:https://www.raspberrypi.org/products/model-b/
|
||||
[4]:http://www.zdnet.com/article/linux-still-rules-supercomputing/
|
||||
[5]:http://www.nytimes.com/2014/12/23/science/an-economical-way-to-save-progress.html?smid=fb-nytimes&smtyp=cur&bicmp=AD&bicmlukp=WT.mc_id&bicmst=1409232722000&bicmet=1419773522000&_r=4
|
||||
[6]:http://www.computerworld.com/article/2529932/cybercrime-hacking/researchers-hack-verisign-s-ssl-scheme-for-securing-web-sites.html
|
||||
[7]:http://phys.org/news/2010-12-air-playstation-3s-supercomputer.html
|
||||
[8]:http://www.zdnet.com/article/parallella-the-99-linux-supercomputer/
|
||||
[9]:http://blogs.nvidia.com/blog/2014/03/25/titan-z/
|
||||
[10]:http://www.amd.com/en-us/press-releases/Pages/amd-flagship-professional-2014apr7.aspx
|
||||
[11]:http://en.intelextrememasters.com/news/check-out-the-intel-extreme-masters-katowice-prize-money-distribution/
|
||||
|
||||
[13]:http://www.beowulf.org/overview/history.html
|
||||
[14]:http://yclept.ucdavis.edu/Beowulf/aboutbeowulf.html
|
||||
[15]:http://www.beowulf.org/
|
||||
@ -1,349 +0,0 @@
|
||||
translating wi-cuckoo
|
||||
Shilpa Nair Shares Her Interview Experience on RedHat Linux Package Management
|
||||
================================================================================
|
||||
**Shilpa Nair has just graduated in the year 2015. She went to apply for Trainee position in a National News Television located in Noida, Delhi. When she was in the last year of graduation and searching for help on her assignments she came across Tecmint. Since then she has been visiting Tecmint regularly.**
|
||||
|
||||

|
||||
|
||||
Linux Interview Questions on RPM
|
||||
|
||||
All the questions and answers are rewritten based upon the memory of Shilpa Nair.
|
||||
|
||||
> “Hi friends! I am Shilpa Nair from Delhi. I have completed my graduation very recently and was hunting for a Trainee role soon after my degree. I have developed a passion for UNIX since my early days in the collage and I was looking for a role that suits me and satisfies my soul. I was asked a lots of questions and most of them were basic questions related to RedHat Package Management.”
|
||||
|
||||
Here are the questions, that I was asked and their corresponding answers. I am posting only those questions that are related to RedHat GNU/Linux Package Management, as they were mainly asked.
|
||||
|
||||
### 1. How will you find if a package is installed or not? Say you have to find if ‘nano’ is installed or not, what will you do? ###
|
||||
|
||||
> **Answer** : To find the package nano, weather installed or not, we can use rpm command with the option -q is for query and -a stands for all the installed packages.
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> Also the package name must be complete, an incomplete package name will return the prompt without printing anything which means that package (incomplete package name) is not installed. It can be understood easily by the example below:
|
||||
>
|
||||
> We generally substitute vim command with vi. But if we find package vi/vim we will get no result on the standard output.
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> However we can clearly see that the package is installed by firing vi/vim command. Here is culprit is incomplete file name. If we are not sure of the exact file-name we can use wildcard as:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> This way we can find information about any package, if installed or not.
|
||||
|
||||
### 2. How will you install a package XYZ using rpm? ###
|
||||
|
||||
> **Answer** : We can install any package (*.rpm) using rpm command a shown below, here options -i (install), -v (verbose or display additional information) and -h (print hash mark during package installation).
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> If upgrading a package from earlier version -U switch should be used, option -v and -h follows to make sure we get a verbose output along with hash Mark, that makes it readable.
|
||||
|
||||
### 3. You have installed a package (say httpd) and now you want to see all the files and directories installed and created by the above package. What will you do? ###
|
||||
|
||||
> **Answer** : We can list all the files (Linux treat everything as file including directories) installed by the package httpd using options -l (List all the files) and -q (is for query).
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. You are supposed to remove a package say postfix. What will you do? ###
|
||||
|
||||
> **Answer** : First we need to know postfix was installed by what package. Find the package name that installed postfix using options -e erase/uninstall a package) and –v (verbose output).
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> and then remove postfix as:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. Get detailed information about an installed package, means information like Version, Release, Install Date, Size, Summary and a brief description. ###
|
||||
|
||||
> **Answer** : We can get detailed information about an installed package by using option -qa with rpm followed by package name.
|
||||
>
|
||||
> For example to find details of package openssh, all I need to do is:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. You are not sure about what are the configuration files provided by a specific package say httpd. How will you find list of all the configuration files provided by httpd and their location. ###
|
||||
|
||||
> **Answer** : We need to run option -c followed by package name with rpm command and it will list the name of all the configuration file and their location.
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> Similarly we can list all the associated document files as:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> also, we can list the associated License file as:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> Not to mention that the option -d and option -L in the above command stands for ‘documents‘ and ‘License‘, respectively.
|
||||
|
||||
### 7. You came across a configuration file located at ‘/usr/share/alsa/cards/AACI.conf’ and you are not sure this configuration file is associated with what package. How will you find out the parent package name? ###
|
||||
|
||||
> **Answer** : When a package is installed, the relevant information gets stored in the database. So it is easy to trace what provides the above package using option -qf (-f query packages owning files).
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> Similarly we can find (what provides) information about any sub-packge, document files and License files.
|
||||
|
||||
### 8. How will you find list of recently installed software’s using rpm? ###
|
||||
|
||||
> **Answer** : As said earlier, everything being installed is logged in database. So it is not difficult to query the rpm database and find the list of recently installed software’s.
|
||||
>
|
||||
> We can do this by running the below commands using option –last (prints the most recent installed software’s).
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> The above command will print all the packages installed in a order such that, the last installed software appears at the top.
|
||||
>
|
||||
> If our concern is to find out specific package, we can grep that package (say sqlite) from the list, simply as:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> We can also get a list of 10 most recently installed software simply as:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> We can refine the result to output a more custom result simply as:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> In the above command -n represents number followed by a numeric value. The above command prints a list of 2 most recent installed software.
|
||||
|
||||
### 9. Before installing a package, you are supposed to check its dependencies. What will you do? ###
|
||||
|
||||
> **Answer** : To check the dependencies of a rpm package (XYZ.rpm), we can use switches -q (query package), -p (query a package file) and -R (Requires / List packages on which this package depends i.e., dependencies).
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. Is rpm a front-end Package Management Tool? ###
|
||||
|
||||
> **Answer** : No! rpm is a back-end package management for RPM based Linux Distribution.
|
||||
>
|
||||
> [YUM][1] which stands for Yellowdog Updater Modified is the front-end for rpm. YUM automates the overall process of resolving dependencies and everything else.
|
||||
>
|
||||
> Very recently [DNF][2] (Dandified YUM) replaced YUM in Fedora 22. Though YUM is still available to be used in RHEL and CentOS, we can install dnf and use it alongside of YUM. DNF is said to have a lots of improvement over YUM.
|
||||
>
|
||||
> Good to know, you keep yourself updated. Lets move to the front-end part.
|
||||
|
||||
### 11. How will you list all the enabled repolist on a system. ###
|
||||
|
||||
> **Answer** : We can list all the enabled repos on a system simply using following commands.
|
||||
>
|
||||
> # yum repolist
|
||||
> or
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> The above command will only list those repos that are enabled. If we need to list all the repos, enabled or not, we can do.
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. How will you list all the available and installed packages on a system? ###
|
||||
|
||||
> **Answer** : To list all the available packages on a system, we can do:
|
||||
>
|
||||
> # yum list available
|
||||
> or
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> To list all the installed Packages on a system, we can do.
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> To list all the available and installed packages on a system, we can do.
|
||||
>
|
||||
> # yum list
|
||||
> or
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. How will you install and update a package and a group of packages separately on a system using YUM/DNF? ###
|
||||
|
||||
> Answer : To Install a package (say nano), we can do,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> To Install a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> To update a package (say nano), we can do.
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> To update a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. How will you SYNC all the installed packages on a system to stable release? ###
|
||||
|
||||
> **Answer** : We can sync all the packages on a system (say CentOS or Fedora) to stable release as,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/RHEL]
|
||||
> or
|
||||
> # dnf distro-sync [On Fedora 20 Onwards]
|
||||
|
||||
Seems you have done a good homework before coming for the interview,Good!. Before proceeding further I just want to ask one more question.
|
||||
|
||||
### 15. Are you familiar with YUM local repository? Have you tried making a Local YUM repository? Let me know in brief what you will do to create a local YUM repo. ###
|
||||
|
||||
> **Answer** : First I would like to Thank you Sir for appreciation. Coming to question, I must admit that I am quiet familiar with Local YUM repositories and I have already implemented it for testing purpose in my local machine.
|
||||
>
|
||||
> 1. To set up Local YUM repository, we need to install the below three packages as:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. Create a directory (say /home/$USER/rpm) and copy all the RPMs from RedHat/CentOS DVD to that folder.
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. Create base repository headers as.
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. Create the .repo file (say abc.repo) at the location /etc/yum.repos.d simply as:
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**Important**: Make sure to remove $USER with user_name.
|
||||
|
||||
That’s all we need to do to create a Local YUM repository. We can now install applications from here, that is relatively fast, secure and most important don’t need an Internet connection.
|
||||
|
||||
Okay! It was nice interviewing you. I am done. I am going to suggest your name to HR. You are a young and brilliant candidate we would like to have in our organization. If you have any question you may ask me.
|
||||
|
||||
**Me**: Sir, it was really a very nice interview and I feel very lucky today, to have cracked the interview..
|
||||
|
||||
Obviously it didn’t end here. I asked a lots of questions like the project they are handling. What would be my role and responsibility and blah..blah..blah
|
||||
|
||||
Friends, by the time all these were documented I have been called for HR round which is 3 days from now. Hope I do my best there as well. All your blessings will count.
|
||||
|
||||
Thankyou friends and Tecmint for taking time and documenting my experience. Mates I believe Tecmint is doing some really extra-ordinary which must be praised. When we share ours experience with other, other get to know many things from us and we get to know our mistakes.
|
||||
|
||||
It enhances our confidence level. If you have given any such interview recently, don’t keep it to yourself. Spread it! Let all of us know that. You may use the below form to share your experience with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -0,0 +1,62 @@
|
||||
Darkstat is a Web Based Network Traffic Analyzer – Install it on Linux
|
||||
================================================================================
|
||||
Darkstat is a simple, web based network traffic analyzer application. It works on many popular operating systems like Linux, Solaris, Mac and AIX. It keeps running in the background as a daemon and continues collecting and sniffing network data and presents it in easily understandable format within its web interface. It can generate traffic reports for hosts, identify which ports are open on some particular host and is IPV 6 complaint application. Let’s see how we can install and configure it on Linux operating system.
|
||||
|
||||
### Installing Darkstat on Linux ###
|
||||
|
||||
**Install Darkstat on Fedora/CentOS/RHEL:**
|
||||
|
||||
In order to install it on Fedora/RHEL and CentOS Linux distributions, run following command on the terminal.
|
||||
|
||||
sudo yum install darkstat
|
||||
|
||||
**Install Darkstat on Ubuntu/Debian:**
|
||||
|
||||
Run following on the terminal to install it on Ubuntu and Debian.
|
||||
|
||||
sudo apt-get install darkstat
|
||||
|
||||
Congratulations, Darkstat has been installed on your Linux system now.
|
||||
|
||||
### Configuring Darkstat ###
|
||||
|
||||
In order to run this application properly, we need to perform some basic configurations. Edit /etc/darkstat/init.cfg file in Gedit text editor by running the following command on the terminal.
|
||||
|
||||
sudo gedit /etc/darkstat/init.cfg
|
||||
|
||||

|
||||
Edit Darkstat
|
||||
|
||||
Change START_DARKSTAT parameter to “yes” and provide your network interface in “INTERFACE”. Make sure to uncomment DIR, PORT, BINDIP, and LOCAL parameters here. If you wish to bind the web interface for Darkstat to some specific IP, provide it in BINDIP section.
|
||||
|
||||
### Starting Darkstat Daemon ###
|
||||
|
||||
Once the installation and configuration for Darkstat is complete, run following command to start its daemon.
|
||||
|
||||
sudo /etc/init.d/darkstat start
|
||||
|
||||

|
||||
|
||||
You can configure Darkstat to start on system boot by running the following command:
|
||||
|
||||
chkconfig darkstat on
|
||||
|
||||
Launch your browser and load **http://localhost:666** and it will display the web based graphical interface for Darkstat. Start using this tool to analyze your network traffic.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
It is a lightweight tool with very low memory footprints. The key reason for the popularity of this tool is simplicity, ease of configuration and usage. It is a must-have application for System and Network Administrators.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-darkstat-on-ubuntu-linux/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
How to download apk files from Google Play Store on Linux
|
||||
================================================================================
|
||||
Suppose you want to install an Android app on your Android device. However, for whatever reason, you cannot access Google Play Store on the Android device. What can you do then? One way to install the app without Google Play Store access is to download its APK file using some other means, and then [install the APK][1] file on the Android device manually.
|
||||
@ -96,4 +98,4 @@ via: http://xmodulo.com/download-apk-files-google-play-store.html
|
||||
[3]:https://addons.mozilla.org/en-us/firefox/addon/apk-downloader/
|
||||
[4]:http://codingteam.net/project/googleplaydownloader
|
||||
[5]:http://packages.ubuntu.com/vivid/python-ndg-httpsclient
|
||||
[6]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
[6]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
|
||||
@ -0,0 +1,143 @@
|
||||
Linux Tricks: Play Game in Chrome, Text-to-Speech, Schedule a Job and Watch Commands in Linux
|
||||
================================================================================
|
||||
Here again, I have compiled a list of four things under [Linux Tips and Tricks][1] series you may do to remain more productive and entertained with Linux Environment.
|
||||
|
||||

|
||||
|
||||
Linux Tips and Tricks Series
|
||||
|
||||
The topics I have covered includes Google-chrome inbuilt small game, Text-to-speech in Linux Terminal, Quick job scheduling using ‘at‘ command and watch a command at regular interval.
|
||||
|
||||
### 1. Play A Game in Google Chrome Browser ###
|
||||
|
||||
Very often when there is a power shedding or no network due to some other reason, I don’t put my Linux box into maintenance mode. I keep myself engage in a little fun game by Google Chrome. I am not a gamer and hence I have not installed third-party creepy games. Security is another concern.
|
||||
|
||||
So when there is Internet related issue and my web page seems something like this:
|
||||
|
||||

|
||||
|
||||
Unable to Connect Internet
|
||||
|
||||
You may play the Google-chrome inbuilt game simply by hitting the space-bar. There is no limitation for the number of times you can play. The best thing is you need not break a sweat installing and using it.
|
||||
|
||||
No third-party application/plugin required. It should work well on other platforms like Windows and Mac but our niche is Linux and I’ll talk about Linux only and mind it, it works well on Linux. It is a very simple game (a kind of time pass).
|
||||
|
||||
Use Space-Bar/Navigation-up-key to jump. A glimpse of the game in action.
|
||||
|
||||

|
||||
|
||||
Play Game in Google Chrome
|
||||
|
||||
### 2. Text to Speech in Linux Terminal ###
|
||||
|
||||
For those who may not be aware of espeak utility, It is a Linux command-line text to speech converter. Write anything in a variety of languages and espeak utility will read it loud for you.
|
||||
|
||||
Espeak should be installed in your system by default, however it is not installed for your system, you may do:
|
||||
|
||||
# apt-get install espeak (Debian)
|
||||
# yum install espeak (CentOS)
|
||||
# dnf install espeak (Fedora 22 onwards)
|
||||
|
||||
You may ask espeak to accept Input Interactively from standard Input device and convert it to speech for you. You may do:
|
||||
|
||||
$ espeak [Hit Return Key]
|
||||
|
||||
For detailed output you may do:
|
||||
|
||||
$ espeak --stdout | aplay [Hit Return Key][Double - Here]
|
||||
|
||||
espeak is flexible and you can ask espeak to accept input from a text file and speak it loud for you. All you need to do is:
|
||||
|
||||
$ espeak --stdout /path/to/text/file/file_name.txt | aplay [Hit Enter]
|
||||
|
||||
You may ask espeak to speak fast/slow for you. The default speed is 160 words per minute. Define your preference using switch ‘-s’.
|
||||
|
||||
To ask espeak to speak 30 words per minute, you may do:
|
||||
|
||||
$ espeak -s 30 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
To ask espeak to speak 200 words per minute, you may do:
|
||||
|
||||
$ espeak -s 200 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
To use another language say Hindi (my mother tongue), you may do:
|
||||
|
||||
$ espeak -v hindi --stdout 'टेकमिंट विश्व की एक बेहतरीन लाइंक्स आधारित वेबसाइट है|' | aplay
|
||||
|
||||
You may choose any language of your preference and ask to speak in your preferred language as suggested above. To get the list of all the languages supported by espeak, you need to run:
|
||||
|
||||
$ espeak --voices
|
||||
|
||||
### 3. Quick Schedule a Job ###
|
||||
|
||||
Most of us are already familiar with [cron][2] which is a daemon to execute scheduled commands.
|
||||
|
||||
Cron is an advanced command often used by Linux SYSAdmins to schedule a job such as Backup or practically anything at certain time/interval.
|
||||
|
||||
Are you aware of ‘at’ command in Linux which lets you schedule a job/command to run at specific time? You can tell ‘at’ what to do and when to do and everything else will be taken care by command ‘at’.
|
||||
|
||||
For an example, say you want to print the output of uptime command at 11:02 AM, All you need to do is:
|
||||
|
||||
$ at 11:02
|
||||
uptime >> /home/$USER/uptime.txt
|
||||
Ctrl+D
|
||||
|
||||

|
||||
|
||||
Schedule Job in Linux
|
||||
|
||||
To check if the command/script/job has been set or not by ‘at’ command, you may do:
|
||||
|
||||
$ at -l
|
||||
|
||||

|
||||
|
||||
View Scheduled Jobs
|
||||
|
||||
You may schedule more than one command in one go using at, simply as:
|
||||
|
||||
$ at 12:30
|
||||
Command – 1
|
||||
Command – 2
|
||||
…
|
||||
command – 50
|
||||
…
|
||||
Ctrl + D
|
||||
|
||||
### 4. Watch a Command at Specific Interval ###
|
||||
|
||||
We need to run some command for specified amount of time at regular interval. Just for example say we need to print the current time and watch the output every 3 seconds.
|
||||
|
||||
To see current time we need to run the below command in terminal.
|
||||
|
||||
$ date +"%H:%M:%S
|
||||
|
||||

|
||||
|
||||
Check Date and Time in Linux
|
||||
|
||||
and to check the output of this command every three seconds, we need to run the below command in Terminal.
|
||||
|
||||
$ watch -n 3 'date +"%H:%M:%S"'
|
||||
|
||||

|
||||
|
||||
Watch Command in Linux
|
||||
|
||||
The switch ‘-n’ in watch command is for Interval. In the above example we defined Interval to be 3 sec. You may define yours as required. Also you may pass any command/script with watch command to watch that command/script at the defined interval.
|
||||
|
||||
That’s all for now. Hope you are like this series that aims at making you more productive with Linux and that too with fun inside. All the suggestions are welcome in the comments below. Stay tuned for more such posts. Keep connected and Enjoy…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/text-to-speech-in-terminal-schedule-a-job-and-watch-commands-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
@ -0,0 +1,227 @@
|
||||
Part 1 - RHCE Series: How to Setup and Test Static Network Routing
|
||||
================================================================================
|
||||
RHCE (Red Hat Certified Engineer) is a certification from Red Hat company, which gives an open source operating system and software to the enterprise community, It also gives training, support and consulting services for the companies.
|
||||
|
||||

|
||||
|
||||
RHCE Exam Preparation Guide
|
||||
|
||||
This RHCE (Red Hat Certified Engineer) is a performance-based exam (codename EX300), who possesses the additional skills, knowledge, and abilities required of a senior system administrator responsible for Red Hat Enterprise Linux (RHEL) systems.
|
||||
|
||||
**Important**: [Red Hat Certified System Administrator][1] (RHCSA) certification is required to earn RHCE certification.
|
||||
|
||||
Following are the exam objectives based on the Red Hat Enterprise Linux 7 version of the exam, which will going to cover in this RHCE series:
|
||||
|
||||
- Part 1: How to Setup and Test Static Routing in RHEL 7
|
||||
- Part 2: How to Perform Packet Filtering, Network Address Translation and Set Kernel Runtime Parameters
|
||||
- Part 3: How to Produce and Deliver System Activity Reports Using Linux Toolsets
|
||||
- Part 4: Automate System Maintenance Tasks Using Shell Scripts
|
||||
- Part 5: How to Configure Local and Remote System Logging
|
||||
- Part 6: How to Configure a Samba Server and a NFS Server
|
||||
- Part 7: Setting Up Complete SMTP Server for Mailing
|
||||
- Part 8: Setting Up HTTPS and TLS on RHEL 7
|
||||
- Part 9: Setting Up Network Time Protocol
|
||||
- Part 10: How to Configure a Cache-Only DNS Server
|
||||
|
||||
To view fees and register for an exam in your country, check the [RHCE Certification][2] page.
|
||||
|
||||
In this Part 1 of the RHCE series and the next, we will present basic, yet typical, cases where the principles of static routing, packet filtering, and network address translation come into play.
|
||||
|
||||

|
||||
|
||||
RHCE: Setup and Test Network Static Routing – Part 1
|
||||
|
||||
Please note that we will not cover them in depth, but rather organize these contents in such a way that will be helpful to take the first steps and build from there.
|
||||
|
||||
### Static Routing in Red Hat Enterprise Linux 7 ###
|
||||
|
||||
One of the wonders of modern networking is the vast availability of devices that can connect groups of computers, whether in relatively small numbers and confined to a single room or several machines in the same building, city, country, or across continents.
|
||||
|
||||
However, in order to effectively accomplish this in any situation, network packets need to be routed, or in other words, the path they follow from source to destination must be ruled somehow.
|
||||
|
||||
Static routing is the process of specifying a route for network packets other than the default, which is provided by a network device known as the default gateway. Unless specified otherwise through static routing, network packets are directed to the default gateway; with static routing, other paths are defined based on predefined criteria, such as the packet destination.
|
||||
|
||||
Let us define the following scenario for this tutorial. We have a Red Hat Enterprise Linux 7 box connecting to router #1 [192.168.0.1] to access the Internet and machines in 192.168.0.0/24.
|
||||
|
||||
A second router (router #2) has two network interface cards: enp0s3 is also connected to router #1 to access the Internet and to communicate with the RHEL 7 box and other machines in the same network, whereas the other (enp0s8) is used to grant access to the 10.0.0.0/24 network where internal services reside, such as a web and / or database server.
|
||||
|
||||
This scenario is illustrated in the diagram below:
|
||||
|
||||

|
||||
|
||||
Static Routing Network Diagram
|
||||
|
||||
In this article we will focus exclusively on setting up the routing table on our RHEL 7 box to make sure that it can both access the Internet through router #1 and the internal network via router #2.
|
||||
|
||||
In RHEL 7, you will use the [ip command][3] to configure and show devices and routing using the command line. These changes can take effect immediately on a running system but since they are not persistent across reboots, we will use ifcfg-enp0sX and route-enp0sX files inside /etc/sysconfig/network-scripts to save our configuration permanently.
|
||||
|
||||
To begin, let’s print our current routing table:
|
||||
|
||||
# ip route show
|
||||
|
||||

|
||||
|
||||
Check Current Routing Table
|
||||
|
||||
From the output above, we can see the following facts:
|
||||
|
||||
- The default gateway’s IP address is 192.168.0.1 and can be accessed via the enp0s3 NIC.
|
||||
- When the system booted up, it enabled the zeroconf route to 169.254.0.0/16 (just in case). In few words, if a machine is set to obtain an IP address through DHCP but fails to do so for some reason, it is automatically assigned an address in this network. Bottom line is, this route will allow us to communicate, also via enp0s3, with other machines who have failed to obtain an IP address from a DHCP server.
|
||||
- Last, but not least, we can communicate with other boxes inside the 192.168.0.0/24 network through enp0s3, whose IP address is 192.168.0.18.
|
||||
|
||||
These are the typical tasks that you would have to perform in such a setting. Unless specified otherwise, the following tasks should be performed in router #2:
|
||||
|
||||
Make sure all NICs have been properly installed:
|
||||
|
||||
# ip link show
|
||||
|
||||
If one of them is down, bring it up:
|
||||
|
||||
# ip link set dev enp0s8 up
|
||||
|
||||
and assign an IP address in the 10.0.0.0/24 network to it:
|
||||
|
||||
# ip addr add 10.0.0.17 dev enp0s8
|
||||
|
||||
Oops! We made a mistake in the IP address. We will have to remove the one we assigned earlier and then add the right one (10.0.0.18):
|
||||
|
||||
# ip addr del 10.0.0.17 dev enp0s8
|
||||
# ip addr add 10.0.0.18 dev enp0s8
|
||||
|
||||
Now, please note that you can only add a route to a destination network through a gateway that is itself already reachable. For that reason, we need to assign an IP address within the 192.168.0.0/24 range to enp0s3 so that our RHEL 7 box can communicate with it:
|
||||
|
||||
# ip addr add 192.168.0.19 dev enp0s3
|
||||
|
||||
Finally, we will need to enable packet forwarding:
|
||||
|
||||
# echo "1" > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
and stop / disable (just for the time being – until we cover packet filtering in the next article) the firewall:
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||
Back in our RHEL 7 box (192.168.0.18), let’s configure a route to 10.0.0.0/24 through 192.168.0.19 (enp0s3 in router #2):
|
||||
|
||||
# ip route add 10.0.0.0/24 via 192.168.0.19
|
||||
|
||||
After that, the routing table looks as follows:
|
||||
|
||||
# ip route show
|
||||
|
||||

|
||||
|
||||
Confirm Network Routing Table
|
||||
|
||||
Likewise, add the corresponding route in the machine(s) you’re trying to reach in 10.0.0.0/24:
|
||||
|
||||
# ip route add 192.168.0.0/24 via 10.0.0.18
|
||||
|
||||
You can test for basic connectivity using ping:
|
||||
|
||||
In the RHEL 7 box, run
|
||||
|
||||
# ping -c 4 10.0.0.20
|
||||
|
||||
where 10.0.0.20 is the IP address of a web server in the 10.0.0.0/24 network.
|
||||
|
||||
In the web server (10.0.0.20), run
|
||||
|
||||
# ping -c 192.168.0.18
|
||||
|
||||
where 192.168.0.18 is, as you will recall, the IP address of our RHEL 7 machine.
|
||||
|
||||
Alternatively, we can use [tcpdump][4] (you may need to install it with yum install tcpdump) to check the 2-way communication over TCP between our RHEL 7 box and the web server at 10.0.0.20.
|
||||
|
||||
To do so, let’s start the logging in the first machine with:
|
||||
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
and from another terminal in the same system let’s telnet to port 80 in the web server (assuming Apache is listening on that port; otherwise, indicate the right port in the following command):
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
|
||||
The tcpdump log should look as follows:
|
||||
|
||||

|
||||
|
||||
Check Network Communication between Servers
|
||||
|
||||
Where the connection has been properly initialized, as we can tell by looking at the 2-way communication between our RHEL 7 box (192.168.0.18) and the web server (10.0.0.20).
|
||||
|
||||
Please remember that these changes will go away when you restart the system. If you want to make them persistent, you will need to edit (or create, if they don’t already exist) the following files, in the same systems where we performed the above commands.
|
||||
|
||||
Though not strictly necessary for our test case, you should know that /etc/sysconfig/network contains system-wide network parameters. A typical /etc/sysconfig/network looks as follows:
|
||||
|
||||
# Enable networking on this system?
|
||||
NETWORKING=yes
|
||||
# Hostname. Should match the value in /etc/hostname
|
||||
HOSTNAME=yourhostnamehere
|
||||
# Default gateway
|
||||
GATEWAY=XXX.XXX.XXX.XXX
|
||||
# Device used to connect to default gateway. Replace X with the appropriate number.
|
||||
GATEWAYDEV=enp0sX
|
||||
|
||||
When it comes to setting specific variables and values for each NIC (as we did for router #2), you will have to edit /etc/sysconfig/network-scripts/ifcfg-enp0s3 and /etc/sysconfig/network-scripts/ifcfg-enp0s8.
|
||||
|
||||
Following our case,
|
||||
|
||||
TYPE=Ethernet
|
||||
BOOTPROTO=static
|
||||
IPADDR=192.168.0.19
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NAME=enp0s3
|
||||
ONBOOT=yes
|
||||
|
||||
and
|
||||
|
||||
TYPE=Ethernet
|
||||
BOOTPROTO=static
|
||||
IPADDR=10.0.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=10.0.0.1
|
||||
NAME=enp0s8
|
||||
ONBOOT=yes
|
||||
|
||||
for enp0s3 and enp0s8, respectively.
|
||||
|
||||
As for routing in our client machine (192.168.0.18), we will need to edit /etc/sysconfig/network-scripts/route-enp0s3:
|
||||
|
||||
10.0.0.0/24 via 192.168.0.19 dev enp0s3
|
||||
|
||||
Now reboot your system and you should see that route in your table.
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have covered the essentials of static routing in Red Hat Enterprise Linux 7. Although scenarios may vary, the case presented here illustrates the required principles and the procedures to perform this task. Before wrapping up, I would like to suggest you to take a look at [Chapter 4][5] of the Securing and Optimizing Linux section in The Linux Documentation Project site for further details on the topics covered here.
|
||||
|
||||
Free ebook on Securing & Optimizing Linux: The Hacking Solution (v.3.0) – This 800+ eBook contains comprehensive collection of Linux security tips and how to use them safely and easily to configure Linux-based applications and services.
|
||||
|
||||

|
||||
|
||||
Linux Security and Optimization Book
|
||||
|
||||
[Download Now][6]
|
||||
|
||||
In the next article we will talk about packet filtering and network address translation to sum up the networking basic skills needed for the RHCE certification.
|
||||
|
||||
As always, we look forward to hearing from you, so feel free to leave your questions, comments, and suggestions using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[2]:https://www.redhat.com/en/services/certification/rhce
|
||||
[3]:http://www.tecmint.com/ip-command-examples/
|
||||
[4]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[5]:http://www.tldp.org/LDP/solrhe/Securing-Optimizing-Linux-RH-Edition-v1.3/net-manage.html
|
||||
[6]:http://tecmint.tradepub.com/free/w_opeb01/prgm.cgi
|
||||
@ -0,0 +1,177 @@
|
||||
Part 2 - How to Perform Packet Filtering, Network Address Translation and Set Kernel Runtime Parameters
|
||||
================================================================================
|
||||
As promised in Part 1 (“[Setup Static Network Routing][1]”), in this article (Part 2 of RHCE series) we will begin by introducing the principles of packet filtering and network address translation (NAT) in Red Hat Enterprise Linux 7, before diving into setting runtime kernel parameters to modify the behavior of a running kernel if certain conditions change or needs arise.
|
||||
|
||||

|
||||
|
||||
RHCE: Network Packet Filtering – Part 2
|
||||
|
||||
### Network Packet Filtering in RHEL 7 ###
|
||||
|
||||
When we talk about packet filtering, we refer to a process performed by a firewall in which it reads the header of each data packet that attempts to pass through it. Then, it filters the packet by taking the required action based on rules that have been previously defined by the system administrator.
|
||||
|
||||
As you probably know, beginning with RHEL 7, the default service that manages firewall rules is [firewalld][2]. Like iptables, it talks to the netfilter module in the Linux kernel in order to examine and manipulate network packets. Unlike iptables, updates can take effect immediately without interrupting active connections – you don’t even have to restart the service.
|
||||
|
||||
Another advantage of firewalld is that it allows us to define rules based on pre-configured service names (more on that in a minute).
|
||||
|
||||
In Part 1, we used the following scenario:
|
||||
|
||||

|
||||
|
||||
Static Routing Network Diagram
|
||||
|
||||
However, you will recall that we disabled the firewall on router #2 to simplify the example since we had not covered packet filtering yet. Let’s see now how we can enable incoming packets destined for a specific service or port in the destination.
|
||||
|
||||
First, let’s add a permanent rule to allow inbound traffic in enp0s3 (192.168.0.19) to enp0s8 (10.0.0.18):
|
||||
|
||||
# firewall-cmd --permanent --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
The above command will save the rule to /etc/firewalld/direct.xml:
|
||||
|
||||
# cat /etc/firewalld/direct.xml
|
||||
|
||||

|
||||
|
||||
Check Firewalld Saved Rules
|
||||
|
||||
Then enable the rule for it to take effect immediately:
|
||||
|
||||
# firewall-cmd --direct --add-rule ipv4 filter FORWARD 0 -i enp0s3 -o enp0s8 -j ACCEPT
|
||||
|
||||
Now you can telnet to the web server from the RHEL 7 box and run [tcpdump][3] again to monitor the TCP traffic between the two machines, this time with the firewall in router #2 enabled.
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# tcpdump -qnnvvv -i enp0s3 host 10.0.0.20
|
||||
|
||||
What if you want to only allow incoming connections to the web server (port 80) from 192.168.0.18 and block connections from other sources in the 192.168.0.0/24 network?
|
||||
|
||||
In the web server’s firewall, add the following rules:
|
||||
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.18/24" service name="http" accept'
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.18/24" service name="http" accept' --permanent
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.0/24" service name="http" drop'
|
||||
# firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.0.0/24" service name="http" drop' --permanent
|
||||
|
||||
Now you can make HTTP requests to the web server, from 192.168.0.18 and from some other machine in 192.168.0.0/24. In the first case the connection should complete successfully, whereas in the second it will eventually timeout.
|
||||
|
||||
To do so, any of the following commands will do the trick:
|
||||
|
||||
# telnet 10.0.0.20 80
|
||||
# wget 10.0.0.20
|
||||
|
||||
I strongly advise you to check out the [Firewalld Rich Language][4] documentation in the Fedora Project Wiki for further details on rich rules.
|
||||
|
||||
### Network Address Translation in RHEL 7 ###
|
||||
|
||||
Network Address Translation (NAT) is the process where a group of computers (it can also be just one of them) in a private network are assigned an unique public IP address. As result, they are still uniquely identified by their own private IP address inside the network but to the outside they all “seem” the same.
|
||||
|
||||
In addition, NAT makes it possible that computers inside a network sends requests to outside resources (like the Internet) and have the corresponding responses be sent back to the source system only.
|
||||
|
||||
Let’s now consider the following scenario:
|
||||
|
||||

|
||||
|
||||
Network Address Translation
|
||||
|
||||
In router #2, we will move the enp0s3 interface to the external zone, and enp0s8 to the internal zone, where masquerading, or NAT, is enabled by default:
|
||||
|
||||
# firewall-cmd --list-all --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external
|
||||
# firewall-cmd --change-interface=enp0s3 --zone=external --permanent
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal
|
||||
# firewall-cmd --change-interface=enp0s8 --zone=internal --permanent
|
||||
|
||||
For our current setup, the internal zone – along with everything that is enabled in it will be the default zone:
|
||||
|
||||
# firewall-cmd --set-default-zone=internal
|
||||
|
||||
Next, let’s reload firewall rules and keep state information:
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
Finally, let’s add router #2 as default gateway in the web server:
|
||||
|
||||
# ip route add default via 10.0.0.18
|
||||
|
||||
You can now verify that you can ping router #1 and an external site (tecmint.com, for example) from the web server:
|
||||
|
||||
# ping -c 2 192.168.0.1
|
||||
# ping -c 2 tecmint.com
|
||||
|
||||

|
||||
|
||||
Verify Network Routing
|
||||
|
||||
### Setting Kernel Runtime Parameters in RHEL 7 ###
|
||||
|
||||
In Linux, you are allowed to change, enable, and disable the kernel runtime parameters, and RHEL is no exception. The /proc/sys interface (sysctl) lets you set runtime parameters on-the-fly to modify the system’s behavior without much hassle when operating conditions change.
|
||||
|
||||
To do so, the echo shell built-in is used to write to files inside /proc/sys/<category>, where <category> is most likely one of the following directories:
|
||||
|
||||
- dev: parameters for specific devices connected to the machine.
|
||||
- fs: filesystem configuration (quotas and inodes, for example).
|
||||
- kernel: kernel-specific configuration.
|
||||
- net: network configuration.
|
||||
- vm: use of the kernel’s virtual memory.
|
||||
|
||||
To display the list of all the currently available values, run
|
||||
|
||||
# sysctl -a | less
|
||||
|
||||
In Part 1, we changed the value of the net.ipv4.ip_forward parameter by doing
|
||||
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
in order to allow a Linux machine to act as router.
|
||||
|
||||
Another runtime parameter that you may want to set is kernel.sysrq, which enables the Sysrq key in your keyboard to instruct the system to perform gracefully some low-level functions, such as rebooting the system if it has frozen for some reason:
|
||||
|
||||
# echo 1 > /proc/sys/kernel/sysrq
|
||||
|
||||
To display the value of a specific parameter, use sysctl as follows:
|
||||
|
||||
# sysctl <parameter.name>
|
||||
|
||||
For example,
|
||||
|
||||
# sysctl net.ipv4.ip_forward
|
||||
# sysctl kernel.sysrq
|
||||
|
||||
Some parameters, such as the ones mentioned above, require only one value, whereas others (for example, fs.inode-state) require multiple values:
|
||||
|
||||

|
||||
|
||||
Check Kernel Parameters
|
||||
|
||||
In either case, you need to read the kernel’s documentation before making any changes.
|
||||
|
||||
Please note that these settings will go away when the system is rebooted. To make these changes permanent, we will need to add .conf files inside the /etc/sysctl.d as follows:
|
||||
|
||||
# echo "net.ipv4.ip_forward = 1" > /etc/sysctl.d/10-forward.conf
|
||||
|
||||
(where the number 10 indicates the order of processing relative to other files in the same directory).
|
||||
|
||||
and enable the changes with
|
||||
|
||||
# sysctl -p /etc/sysctl.d/10-forward.conf
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial we have explained the basics of packet filtering, network address translation, and setting kernel runtime parameters on a running system and persistently across reboots. I hope you have found this information useful, and as always, we look forward to hearing from you!
|
||||
Don’t hesitate to share with us your questions, comments, or suggestions using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/perform-packet-filtering-network-address-translation-and-set-kernel-runtime-parameters-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
[2]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[3]:http://www.tecmint.com/12-tcpdump-commands-a-network-sniffer-tool/
|
||||
[4]:https://fedoraproject.org/wiki/Features/FirewalldRichLanguage
|
||||
@ -0,0 +1,182 @@
|
||||
Part 3 - How to Produce and Deliver System Activity Reports Using Linux Toolsets
|
||||
================================================================================
|
||||
As a system engineer, you will often need to produce reports that show the utilization of your system’s resources in order to make sure that: 1) they are being utilized optimally, 2) prevent bottlenecks, and 3) ensure scalability, among other reasons.
|
||||
|
||||

|
||||
|
||||
RHCE: Monitor Linux Performance Activity Reports – Part 3
|
||||
|
||||
Besides the well-known native Linux tools that are used to check disk, memory, and CPU usage – to name a few examples, Red Hat Enterprise Linux 7 provides two additional toolsets to enhance the data you can collect for your reports: sysstat and dstat.
|
||||
|
||||
In this article we will describe both, but let’s first start by reviewing the usage of the classic tools.
|
||||
|
||||
### Native Linux Tools ###
|
||||
|
||||
With df, you will be able to report disk space and inode usage of by filesystem. You need to monitor both because a lack of space will prevent you from being able to save further files (and may even cause the system to crash), just like running out of inodes will mean you can’t link further files with their corresponding data structures, thus producing the same effect: you won’t be able to save those files to disk.
|
||||
|
||||
# df -h [Display output in human-readable form]
|
||||
# df -h --total [Produce a grand total]
|
||||
|
||||
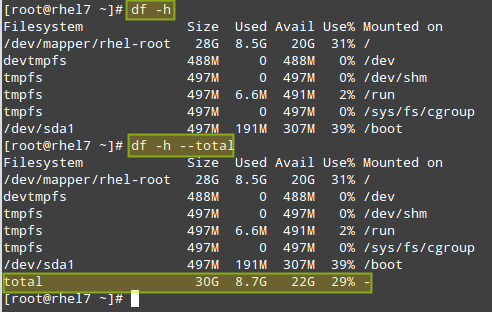
|
||||
|
||||
Check Linux Total Disk Usage
|
||||
|
||||
# df -i [Show inode count by filesystem]
|
||||
# df -i --total [Produce a grand total]
|
||||
|
||||

|
||||
|
||||
Check Linux Total inode Numbers
|
||||
|
||||
With du, you can estimate file space usage by either file, directory, or filesystem.
|
||||
|
||||
For example, let’s see how much space is used by the /home directory, which includes all of the user’s personal files. The first command will return the overall space currently used by the entire /home directory, whereas the second will also display a disaggregated list by sub-directory as well:
|
||||
|
||||
# du -sch /home
|
||||
# du -sch /home/*
|
||||
|
||||

|
||||
|
||||
Check Linux Directory Disk Size
|
||||
|
||||
Don’t Miss:
|
||||
|
||||
- [12 ‘df’ Command Examples to Check Linux Disk Space Usage][1]
|
||||
- [10 ‘du’ Command Examples to Find Disk Usage of Files/Directories][2]
|
||||
|
||||
Another utility that can’t be missing from your toolset is vmstat. It will allow you to see at a quick glance information about processes, CPU and memory usage, disk activity, and more.
|
||||
|
||||
If run without arguments, vmstat will return averages since the last reboot. While you may use this form of the command once in a while, it will be more helpful to take a certain amount of system utilization samples, one after another, with a defined time separation between samples.
|
||||
|
||||
For example,
|
||||
|
||||
# vmstat 5 10
|
||||
|
||||
will return 10 samples taken every 5 seconds:
|
||||
|
||||

|
||||
|
||||
Check Linux System Performance
|
||||
|
||||
As you can see in the above picture, the output of vmstat is divided by columns: procs (processes), memory, swap, io, system, and cpu. The meaning of each field can be found in the FIELD DESCRIPTION sections in the man page of vmstat.
|
||||
|
||||
Where can vmstat come in handy? Let’s examine the behavior of the system before and during a yum update:
|
||||
|
||||
# vmstat -a 1 5
|
||||
|
||||

|
||||
|
||||
Vmstat Linux Performance Monitoring
|
||||
|
||||
Please note that as files are being modified on disk, the amount of active memory increases and so does the number of blocks written to disk (bo) and the CPU time that is dedicated to user processes (us).
|
||||
|
||||
Or during the saving process of a large file directly to disk (caused by dsync):
|
||||
|
||||
# vmstat -a 1 5
|
||||
# dd if=/dev/zero of=dummy.out bs=1M count=1000 oflag=dsync
|
||||
|
||||

|
||||
|
||||
VmStat Linux Disk Performance Monitoring
|
||||
|
||||
In this case, we can see a yet larger number of blocks being written to disk (bo), which was to be expected, but also an increase of the amount of CPU time that it has to wait for I/O operations to complete before processing tasks (wa).
|
||||
|
||||
**Don’t Miss**: [Vmstat – Linux Performance Monitoring][3]
|
||||
|
||||
### Other Linux Tools ###
|
||||
|
||||
As mentioned in the introduction of this chapter, there are other tools that you can use to check the system status and utilization (they are not only provided by Red Hat but also by other major distributions from their officially supported repositories).
|
||||
|
||||
The sysstat package contains the following utilities:
|
||||
|
||||
- sar (collect, report, or save system activity information).
|
||||
- sadf (display data collected by sar in multiple formats).
|
||||
- mpstat (report processors related statistics).
|
||||
- iostat (report CPU statistics and I/O statistics for devices and partitions).
|
||||
- pidstat (report statistics for Linux tasks).
|
||||
- nfsiostat (report input/output statistics for NFS).
|
||||
- cifsiostat (report CIFS statistics) and
|
||||
- sa1 (collect and store binary data in the system activity daily data file.
|
||||
- sa2 (write a daily report in the /var/log/sa directory) tools.
|
||||
|
||||
whereas dstat adds some extra features to the functionality provided by those tools, along with more counters and flexibility. You can find an overall description of each tool by running yum info sysstat or yum info dstat, respectively, or checking the individual man pages after installation.
|
||||
|
||||
To install both packages:
|
||||
|
||||
# yum update && yum install sysstat dstat
|
||||
|
||||
The main configuration file for sysstat is /etc/sysconfig/sysstat. You will find the following parameters in that file:
|
||||
|
||||
# How long to keep log files (in days).
|
||||
# If value is greater than 28, then log files are kept in
|
||||
# multiple directories, one for each month.
|
||||
HISTORY=28
|
||||
# Compress (using gzip or bzip2) sa and sar files older than (in days):
|
||||
COMPRESSAFTER=31
|
||||
# Parameters for the system activity data collector (see sadc manual page)
|
||||
# which are used for the generation of log files.
|
||||
SADC_OPTIONS="-S DISK"
|
||||
# Compression program to use.
|
||||
ZIP="bzip2"
|
||||
|
||||
When sysstat is installed, two cron jobs are added and enabled in /etc/cron.d/sysstat. The first job runs the system activity accounting tool every 10 minutes and stores the reports in /var/log/sa/saXX where XX is the day of the month.
|
||||
|
||||
Thus, /var/log/sa/sa05 will contain all the system activity reports from the 5th of the month. This assumes that we are using the default value in the HISTORY variable in the configuration file above:
|
||||
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
|
||||
The second job generates a daily summary of process accounting at 11:53 pm every day and stores it in /var/log/sa/sarXX files, where XX has the same meaning as in the previous example:
|
||||
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
|
||||
For example, you may want to output system statistics from 9:30 am through 5:30 pm of the sixth of the month to a .csv file that can easily be viewed using LibreOffice Calc or Microsoft Excel (this approach will also allow you to create charts or graphs):
|
||||
|
||||
# sadf -s 09:30:00 -e 17:30:00 -dh /var/log/sa/sa06 -- | sed 's/;/,/g' > system_stats20150806.csv
|
||||
|
||||
You could alternatively use the -j flag instead of -d in the sadf command above to output the system stats in JSON format, which could be useful if you need to consume the data in a web application, for example.
|
||||
|
||||

|
||||
|
||||
Linux System Statistics
|
||||
|
||||
Finally, let’s see what dstat has to offer. Please note that if run without arguments, dstat assumes -cdngy by default (short for CPU, disk, network, memory pages, and system stats, respectively), and adds one line every second (execution can be interrupted anytime with Ctrl + C):
|
||||
|
||||
# dstat
|
||||
|
||||

|
||||
|
||||
Linux Disk Statistics Monitoring
|
||||
|
||||
To output the stats to a .csv file, use the –output flag followed by a file name. Let’s see how this looks on LibreOffice Calc:
|
||||
|
||||

|
||||
|
||||
Monitor Linux Statistics Output
|
||||
|
||||
I strongly advise you to check out the man page of dstat, included with this article along with the man page of sysstat in PDF format for your reading convenience. You will find several other options that will help you create custom and detailed system activity reports.
|
||||
|
||||
**Don’t Miss**: [Sysstat – Linux Usage Activity Monitoring Tool][4]
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this guide we have explained how to use both native Linux tools and specific utilities provided with RHEL 7 in order to produce reports on system utilization. At one point or another, you will come to rely on these reports as best friends.
|
||||
|
||||
You will probably have used other tools that we have not covered in this tutorial. If so, feel free to share them with the rest of the community along with any other suggestions / questions / comments that you may have- using the form below.
|
||||
|
||||
We look forward to hearing from you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[2]:http://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
[3]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[4]:http://www.tecmint.com/install-sysstat-in-linux/
|
||||
@ -1,59 +0,0 @@
|
||||
Linux:称霸超级计算机系统
|
||||
================================================================================
|
||||

|
||||
首图来源:By Michel Ngilen,[ CC BY 2.0 ], via Wikimedia Commons
|
||||
|
||||
> 几乎所有超级计算机上运行的系统都是Linux,其中包括那些由树莓派(Raspberry Pi)板和PlayStation 3游戏机板组成的计算机。
|
||||
|
||||
超级计算机是很正经的工具,目的是做严肃的计算。它们往往从事于严肃的追求,比如原子弹的模拟,气候模拟和高级物理学。当然,它们也需要大笔资金的投资。在最新的超级计算机[500强][1]排名中,中国国防科大研制的天河2号位居第一。天河2号耗资约3.9亿美元。
|
||||
|
||||
但是,也有一个超级计算机,是由博伊西州立大学电气和计算机工程系的一名在读博士Joshua Kiepert[用树莓派构建完成][2]的。其创建成本低于2000美元。
|
||||
|
||||
不,这不是我编造的。这是一个真实的超级计算机,由超频1GHz的[B型树莓派][3]ARM11处理器与VideoCore IV GPU组成。每个都配备了512MB的RAM,一对USB端口和1个10/100 BaseT以太网端口。
|
||||
|
||||
那么天河2号和博伊西州立大学的超级计算机有什么共同点?它们都运行Linux系统。世界最快的超级计算机[前500强中有486][4]个也同样运行的是Linux系统。这是20多年前就开始的一种覆盖。现在Linux开始建立于廉价的超级计算机。因为Kiepert的机器并不是唯一的预算数字计算机。
|
||||
|
||||
Gaurav Khanna,麻省大学达特茅斯分校的物理学副教授,创建了一台超级计算机仅用了[不足200的PlayStation3视频游戏机][5]。
|
||||
|
||||
PlayStation游戏机是由一个3.2 GHz的基于PowerPC的电源处理单元供电。每个都配有512M的RAM。你现在仍然可以花200美元买到一个,尽管索尼将在年底逐步淘汰它们。Khanna仅用16个PlayStation 3s构建了他第一台超级计算机,所以你也可以花费不到4000美元就拥有你自己的超级计算机。
|
||||
|
||||
这些机器可能是从玩具建成的,但他们不是玩具。Khanna已经用它做了严肃的天体物理学研究。一个白帽子黑客组织使用了类似的[PlayStation 3超级计算机在2008年破解了SSL的MD5哈希算法][6]。
|
||||
|
||||
两年后,美国空军研究实验室研制的[Condor Cluster,使用了1,760个索尼的PlayStation3的处理器][7]和168个通用的图形处理单元。这个低廉的超级计算机,每秒运行约500TFLOPs,或500万亿次浮点运算。
|
||||
|
||||
其他的一些便宜且适用于构建家庭超级计算机的构件包括,专业并行处理板比如信用卡大小[99美元的Parallella板][8],以及高端显卡比如[Nvidia的 Titan Z][9] 以及[ AMD的 FirePro W9100][10].这些高端主板市场零售价约3000美元,被一些[英特尔极限大师赛世界锦标赛英雄联盟参赛][11]玩家觊觎能够赢得的梦想的机器,c[传说][12]这项比赛第一名能获得超过10万美元奖金。另一方面,一个人能够独自提供超过2.5TFLOPS,并且他们为科学家和研究人员提供了一个经济的方法,使得他们拥有自己专属的超级计算机。
|
||||
|
||||
作为Linux的连接,这一切都开始于1994年戈达德航天中心的第一个名为[Beowulf超级计算机][13]。
|
||||
|
||||
按照我们的标准,Beowulf不能算是最优越的。但在那个时期,作为第一台自制的超级计算机,其16英特尔486DX处理器和10Mbps的以太网总线,是伟大的创举。由[美国航空航天局承包人Don Becker和Thomas Sterling设计的Beowulf][14],是第一个“制造者”超级计算机。它的“计算部件”486DX PCs,成本仅有几千美元。尽管它的速度只有一位数的浮点运算,[Beowulf][15]表明了你可以用商用现货(COTS)硬件和Linux创建超级计算机。
|
||||
|
||||
我真希望我参与创作了一部分,但是我1994年就离开了戈达德,开始了作为一名全职的科技记者的职业生涯。该死。
|
||||
|
||||
但是尽管我只是使用笔记本的记者,我依然能够体会到COTS和开源软件是如何永远的改变了超级计算机。我希望现在读这篇文章的你也能。因为,无论是Raspberry Pis集群,还是超过300万英特尔的Ivy Bridge和Xeon Phi芯片的庞然大物,几乎所有当代的超级计算机都可以追溯到Beowulf。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.top500.org/
|
||||
[2]:http://www.zdnet.com/article/build-your-own-supercomputer-out-of-raspberry-pi-boards/
|
||||
[3]:https://www.raspberrypi.org/products/model-b/
|
||||
[4]:http://www.zdnet.com/article/linux-still-rules-supercomputing/
|
||||
[5]:http://www.nytimes.com/2014/12/23/science/an-economical-way-to-save-progress.html?smid=fb-nytimes&smtyp=cur&bicmp=AD&bicmlukp=WT.mc_id&bicmst=1409232722000&bicmet=1419773522000&_r=4
|
||||
[6]:http://www.computerworld.com/article/2529932/cybercrime-hacking/researchers-hack-verisign-s-ssl-scheme-for-securing-web-sites.html
|
||||
[7]:http://phys.org/news/2010-12-air-playstation-3s-supercomputer.html
|
||||
[8]:http://www.zdnet.com/article/parallella-the-99-linux-supercomputer/
|
||||
[9]:http://blogs.nvidia.com/blog/2014/03/25/titan-z/
|
||||
[10]:http://www.amd.com/en-us/press-releases/Pages/amd-flagship-professional-2014apr7.aspx
|
||||
[11]:http://en.intelextrememasters.com/news/check-out-the-intel-extreme-masters-katowice-prize-money-distribution/
|
||||
[12]:http://www.google.com/url?q=http%3A%2F%2Fen.intelextrememasters.com%2Fnews%2Fcheck-out-the-intel-extreme-masters-katowice-prize-money-distribution%2F&sa=D&sntz=1&usg=AFQjCNE6yoAGGz-Hpi2tPF4gdhuPBEckhQ
|
||||
[13]:http://www.beowulf.org/overview/history.html
|
||||
[14]:http://yclept.ucdavis.edu/Beowulf/aboutbeowulf.html
|
||||
[15]:http://www.beowulf.org/
|
||||
@ -0,0 +1,348 @@
|
||||
Shilpa Nair 分享了她面试 RedHat Linux 包管理方面的经验
|
||||
========================================================================
|
||||
**Shilpa Nair 刚于2015年毕业。她之后去了一家位于 Noida,Delhi 的国家新闻电视台,应聘实习生的岗位。在她去年毕业季的时候,常逛 Tecmint 寻求作业上的帮助。从那时开始,她就常去 Tecmint。**
|
||||
|
||||

|
||||
|
||||
有关 RPM 方面的 Linux 面试题
|
||||
|
||||
所有的问题和回答都是 Shilpa Nair 根据回忆重写的。
|
||||
|
||||
> “大家好!我是来自 Delhi 的Shilpa Nair。我不久前才顺利毕业,正寻找一个实习的机会。在大学早期的时候,我就对 UNIX 十分喜爱,所以我也希望这个机会能适合我,满足我的兴趣。我被提问了很多问题,大部分都是关于 RedHat 包管理的基础问题。”
|
||||
|
||||
下面就是我被问到的问题,和对应的回答。我仅贴出了与 RedHat GNU/Linux 包管理相关的,也是主要被提问的。
|
||||
|
||||
### 1,里如何查找一个包安装与否?假设你需要确认 ‘nano’ 有没有安装,你怎么做? ###
|
||||
|
||||
> **回答**:为了确认 nano 软件包有没有安装,我们可以使用 rpm 命令,配合 -q 和 -a 选项来查询所有已安装的包
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> 同时包的名字必须是完成的,不完整的包名返回提示,不打印任何东西,就是说这包(包名字不全)未安装。下面的例子会更好理解些:
|
||||
>
|
||||
> 我们通常使用 vim 替代 vi 命令。当时如果我们查找安装包 vi/vim 的时候,我们就会看到标准输出上没有任何结果。
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> 尽管如此,我们仍然可以通过使用 vi/vim 命令来清楚地知道包有没有安装。Here is ... name(这句不知道)。如果我们不确切知道完整的文件名,我们可以使用通配符:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> 通过这种方式,我们可以获得任何软件包的信息,安装与否。
|
||||
|
||||
### 2. 你如何使用 rpm 命令安装 XYZ 软件包? ###
|
||||
|
||||
> **回答**:我们可以使用 rpm 命令安装任何的软件包(*.rpm),像下面这样,选项 -i(install),-v(冗余或者显示额外的信息)和 -h(打印#号显示进度,在安装过程中)。
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> 如果要升级一个早期版本的包,应加上 -U 选项,选项 -v 和 -h 可以确保我们得到用 # 号表示的冗余输出,这增加了可读性。
|
||||
|
||||
### 3. 你已经安装了一个软件包(假设是 httpd),现在你想看看软件包创建并安装的所有文件和目录,你会怎么做? ###
|
||||
|
||||
> **回答**:使用选项 -l(列出所有文件)和 -q(查询)列出 httpd 软件包安装的所有文件(Linux哲学:所有的都是文件,包括目录)。
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. 假如你要移除一个软件包,叫 postfix。你会怎么做? ###
|
||||
|
||||
> **回答**:首先我们需要知道什么包安装了 postfix。查找安装 postfix 的包名后,使用 -e(擦除/卸载软件包)和 -v(冗余输出)两个选项来实现。
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> 然后移除 postfix,如下:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. 获得一个已安装包的具体信息,如版本,发行号,安装日期,大小,总结和一个间短的描述。 ###
|
||||
|
||||
> **回答**:我们通过使用 rpm 的选项 -qi,后面接包名,可以获得关于一个已安装包的具体信息。
|
||||
>
|
||||
> 举个例子,为了获得 openssh 包的具体信息,我需要做的就是:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. 假如你不确定一个指定包的配置文件在哪,比如 httpd。你如何找到所有 httpd 提供的配置文件列表和位置。 ###
|
||||
|
||||
> **回答**: 我们需要用选项 -c 接包名,这会列出所有配置文件的名字和他们的位置。
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> 相似地,我们可以列出所有相关的文档文件,如下:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> 我们也可以列出所有相关的证书文件,如下:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> 忘了说明上面的选项 -d 和 -L 分别表示 “文档” 和 “证书”,抱歉。
|
||||
|
||||
### 7. 你进入了一个配置文件,位于‘/usr/share/alsa/cards/AACI.conf’,现在你不确定该文件属于哪个包。你如何查找出包的名字? ###
|
||||
|
||||
> **回答**:当一个包被安装后,相关的信息就存储在了数据库里。所以使用选项 -qf(-f 查询包拥有的文件)很容易追踪谁提供了上述的包。
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> 类似地,我们可以查找(谁提供的)关于任何子包,文档和证书文件的信息。
|
||||
|
||||
### 8. 你如何使用 rpm 查找最近安装的软件列表? ###
|
||||
|
||||
> **回答**:如刚刚说的,每一样被安装的文件都记录在了数据库里。所以这并不难,通过查询 rpm 的数据库,找到最近安装软件的列表。
|
||||
>
|
||||
> 我们通过运行下面的命令,使用选项 -last(打印出最近安装的软件)达到目的。
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> 上面的命令会打印出所有安装的软件,最近一次安装的软件在列表的顶部。
|
||||
>
|
||||
> 如果我们关心的是找出特定的包,我们可以使用 grep 命令从列表中匹配包(假设是 sqlite ),简单如下:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> 我们也可以获得10个最近安装的软件列表,简单如下:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> 我们可以重定义一下,输出想要的结果,简单如下:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> 上面的命令中,-n 代表数目,后面接一个常数值。该命令是打印2个最近安装的软件的列表。
|
||||
|
||||
### 9. 安装一个包之前,你如果要检查其依赖。你会怎么做? ###
|
||||
|
||||
> **回答**:检查一个 rpm 包(XYZ.rpm)的依赖,我们可以使用选项 -q(查询包),-p(指定包名)和 -R(查询/列出该包依赖的包,嗯,就是依赖)。
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. rpm 是不是一个前端的包管理工具呢? ###
|
||||
|
||||
> **回答**:不是!rpm 是一个后端管理工具,适用于基于 Linux 发行版的 RPM (此处指 Redhat Package Management)。
|
||||
>
|
||||
> [YUM][1],全称 Yellowdog Updater Modified,是一个 RPM 的前端工具。YUM 命令自动完成所有工作,包括解决依赖和其他一切事务。
|
||||
>
|
||||
> 最近,[DNF][2](YUM命令升级版)在Fedora 22发行版中取代了 YUM。尽管 YUM 仍然可以在 RHEL 和 CentOS 平台使用,我们也可以安装 dnf,与 YUM 命令共存使用。据说 DNF 较于 YUM 有很多提高。
|
||||
>
|
||||
> 知道更多总是好的,保持自我更新。现在我们移步到前端部分来谈谈。
|
||||
|
||||
### 11. 你如何列出一个系统上面所有可用的仓库列表。 ###
|
||||
|
||||
> **回答**:简单地使用下面的命令,我们就可以列出一个系统上所有可用的仓库列表。
|
||||
>
|
||||
> # yum repolist
|
||||
> 或
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> 上面的命令仅会列出可用的仓库。如果你需要列出所有的仓库,不管可用与否,可以这样做。
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. 你如何列出一个系统上所有可用并且安装了的包? ###
|
||||
|
||||
> **回答**:列出一个系统上所有可用的包,我们可以这样做:
|
||||
>
|
||||
> # yum list available
|
||||
> 或
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> 而列出一个系统上所有已安装的包,我们可以这样做。
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> 而要同时满足两个要求的时候,我们可以这样做。
|
||||
>
|
||||
> # yum list
|
||||
> 或
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. 你会怎么分别安装和升级一个包与一组包,在一个系统上面使用 YUM/DNF? ###
|
||||
|
||||
> **回答**:安装一个包(假设是 nano),我们可以这样做,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> 而安装一组包(假设是 Haskell),我们可以这样做,
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> 升级一个包(还是 nano),我们可以这样做,
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> 而为了升级一组包(还是 haskell),我们可以这样做,
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. 你会如何同步一个系统上面的所有安装软件到稳定发行版? ###
|
||||
|
||||
> **回答**:我们可以一个系统上(假设是 CentOS 或者 Fedora)的所有包到稳定发行版,如下,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/ RHEL]
|
||||
> 或
|
||||
> # dnf distro-sync [On Fedora 20之后版本]
|
||||
|
||||
似乎来面试之前你做了相当不多的功课,很好!在进一步交谈前,我还想问一两个问题。
|
||||
|
||||
### 15. 你对 YUM 本地仓库熟悉吗?你尝试过建立一个本地 YUM 仓库吗?让我们简单看看你会怎么建立一个本地 YUM 仓库。 ###
|
||||
|
||||
> **回答**:首先,感谢你的夸奖。回到问题,我必须承认我对本地 YUM 仓库十分熟悉,并且在我的本地主机上也部署过,作为测试用。
|
||||
>
|
||||
> 1. 为了建立本地 YUM 仓库,我们需要安装下面三个包:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. 新建一个目录(假设 /home/$USER/rpm),然后复制 RedHat/CentOS DVD 上的 RPM 包到这个文件夹下
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. 新建基本的库头文件如下。
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. 在路径 /etc/yum.repo.d 下创建一个 .repo 文件(如 abc.repo):
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**重要**:用你的用户名替换掉 $USER。
|
||||
|
||||
以上就是创建一个本地 YUM 仓库所要做的全部工作。我们现在可以从这里安装软件了,相对快一些,安全一些,并且最重要的是不需要 Internet 连接。
|
||||
|
||||
好了!面试过程很愉快。我已经问完了。我会将你推荐给 HR。你是一个年轻且十分聪明的候选者,我们很愿意你加入进来。如果你有任何问题,你可以问我。
|
||||
|
||||
**我**:谢谢,这确实是一次愉快的面试,我感到非常幸运今天,然后这次面试就毁了。。。
|
||||
|
||||
显然,不会在这里结束。我问了很多问题,比如他们正在做的项目。我会担任什么角色,负责什么,,,balabalabala
|
||||
|
||||
小伙伴们,3天以前 HR 轮的所有问题到时候也会被写成文档。希望我当时表现不错。感谢你们所有的祝福。
|
||||
|
||||
谢谢伙伴们和 Tecmint,花时间来编辑我的面试经历。我相信 Tecmint 好伙伴们做了很大的努力,必要要赞一个。当我们与他人分享我们的经历的时候,其他人从我们这里知道了更多,而我们自己则发现了自己的不足。
|
||||
|
||||
这增加了我们的信心。如果你最近也有任何类似的面试经历,别自己蔵着。分享出来!让我们所有人都知道。你可以使用如下的格式来与我们分享你的经历。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -0,0 +1,263 @@
|
||||
fdupes——Linux中查找并删除重复文件的命令行工具
|
||||
================================================================================
|
||||
对于大多数计算机用户而言,查找并替换重复的文件是一个常见的需求。查找并移除重复文件真是一项领人不胜其烦的工作,它耗时又耗力。如果你的机器上跑着GNU/Linux,那么查找重复文件会变得十分简单,这多亏了`**fdupes**`工具。
|
||||
|
||||

|
||||
|
||||
Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
### fdupes是啥东东? ###
|
||||
|
||||
**Fdupes**是Linux下的一个工具,它由**Adrian Lopez**用C编程语言编写并基于MIT许可证发行,该应用程序可以在指定的目录及子目录中查找重复的文件。Fdupes通过对比文件的MD5签名,以及逐字节比较文件来识别重复内容,可以为Fdupes指定大量的选项以实现对文件的列出、删除、替换到文件副本的硬链接等操作。
|
||||
|
||||
对比以下列顺序开始:
|
||||
|
||||
**大小对比 > 部分 MD5 签名对比 > 完整 MD5 签名对比 > 逐字节对比**
|
||||
|
||||
### 安装 fdupes 到 Linux ###
|
||||
|
||||
在基于**Debian**的系统上,如**Ubuntu**和**Linux Mint**,安装最新版fdupes,用下面的命令手到擒来。
|
||||
|
||||
$ sudo apt-get install fdupes
|
||||
|
||||
在基于CentOS/RHEL和Fedora的系统上,你需要开启[epel仓库][1]来安装fdupes包。
|
||||
|
||||
# yum install fdupes
|
||||
# dnf install fdupes [On Fedora 22 onwards]
|
||||
|
||||
**注意**:自Fedora 22之后,默认的包管理器yum被dnf取代了。
|
||||
|
||||
### fdupes命令咋个搞? ###
|
||||
1.作为演示的目的,让我们来在某个目录(比如 tecmint)下创建一些重复文件,命令如下:
|
||||
|
||||
$ mkdir /home/"$USER"/Desktop/tecmint && cd /home/"$USER"/Desktop/tecmint && for i in {1..15}; do echo "I Love Tecmint. Tecmint is a very nice community of Linux Users." > tecmint${i}.txt ; done
|
||||
|
||||
在执行以上命令后,让我们使用ls[命令][2]验证重复文件是否创建。
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 60
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint10.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint11.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint12.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint13.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint14.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint15.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint1.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint2.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint3.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint4.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint5.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint6.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint7.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint8.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9.txt
|
||||
|
||||
上面的脚本创建了**15**个文件,名称分别为tecmint1.txt,tecmint2.txt……tecmint15.txt,并且每个文件的数据相同,如
|
||||
|
||||
"I Love Tecmint. Tecmint is a very nice community of Linux Users."
|
||||
|
||||
2.现在在**tecmint**文件夹内搜索重复的文件。
|
||||
|
||||
$ fdupes /home/$USER/Desktop/tecmint
|
||||
|
||||
/home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
3.使用**-r**选项在每个目录包括其子目录中递归搜索重复文件。
|
||||
|
||||
它会递归搜索所有文件和文件夹,花一点时间来扫描重复文件,时间的长短取决于文件和文件夹的数量。在此其间,终端中会显示全部过程,像下面这样。
|
||||
|
||||
$ fdupes -r /home
|
||||
|
||||
Progress [37780/54747] 69%
|
||||
|
||||
4.使用**-S**选项来查看某个文件夹内找到的重复文件的大小。
|
||||
|
||||
$ fdupes -S /home/$USER/Desktop/tecmint
|
||||
|
||||
65 bytes each:
|
||||
/home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
5.你可以同时使用**-S**和**-r**选项来查看所有涉及到的目录和子目录中的重复文件的大小,如下:
|
||||
|
||||
$ fdupes -Sr /home/avi/Desktop/
|
||||
|
||||
65 bytes each:
|
||||
/home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
107 bytes each:
|
||||
/home/tecmint/Desktop/resume_files/r-csc.html
|
||||
/home/tecmint/Desktop/resume_files/fc.html
|
||||
|
||||
6.不同于在一个或所有文件夹内递归搜索,你可以选择按要求有选择性地在两个或三个文件夹内进行搜索。不必再提醒你了吧,如有需要,你可以使用**-S**和/或**-r**选项。
|
||||
|
||||
$ fdupes /home/avi/Desktop/ /home/avi/Templates/
|
||||
|
||||
7.要删除重复文件,同时保留一个副本,你可以使用`**-d**`选项。使用该选项,你必须额外小心,否则最终结果可能会是文件/数据的丢失。郑重提醒,此操作不可恢复。
|
||||
|
||||
$ fdupes -d /home/$USER/Desktop/tecmint
|
||||
|
||||
[1] /home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
[2] /home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
[3] /home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
[4] /home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
[5] /home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
[6] /home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
[7] /home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
[8] /home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
[9] /home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
[10] /home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
[11] /home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
[12] /home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
[13] /home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
[14] /home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
[15] /home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
Set 1 of 1, preserve files [1 - 15, all]:
|
||||
|
||||
你可能注意到了,所有重复的文件被列了出来,并给出删除提示,一个一个来,或者指定范围,或者一次性全部删除。你可以选择一个范围,就像下面这样,来删除指定范围内的文件。
|
||||
|
||||
Set 1 of 1, preserve files [1 - 15, all]: 2-15
|
||||
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
[+] /home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
8.从安全角度出发,你可能想要打印`**fdupes**`的输出结果到文件中,然后检查文本文件来决定要删除什么文件。这可以降低意外删除文件的风险。你可以这么做:
|
||||
|
||||
$ fdupes -Sr /home > /home/fdupes.txt
|
||||
|
||||
**注意**:你可以替换`**/home**`为你想要的文件夹。同时,如果你想要递归搜索并打印大小,可以使用`**-r**`和`**-S**`选项。
|
||||
|
||||
9.你可以使用`**-f**`选项来忽略每个匹配集中的首个文件。
|
||||
|
||||
首先列出该目录中的文件。
|
||||
|
||||
$ ls -l /home/$USER/Desktop/tecmint
|
||||
|
||||
total 20
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9 (3rd copy).txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9 (4th copy).txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9 (another copy).txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9 (copy).txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9.txt
|
||||
|
||||
然后,忽略掉每个匹配集中的首个文件。
|
||||
|
||||
$ fdupes -f /home/$USER/Desktop/tecmint
|
||||
|
||||
/home/tecmint/Desktop/tecmint9 (copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (3rd copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (another copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (4th copy).txt
|
||||
|
||||
10.检查已安装的fdupes版本。
|
||||
|
||||
$ fdupes --version
|
||||
|
||||
fdupes 1.51
|
||||
|
||||
11.如果你需要关于fdupes的帮助,可以使用`**-h**`开关。
|
||||
|
||||
$ fdupes -h
|
||||
|
||||
Usage: fdupes [options] DIRECTORY...
|
||||
|
||||
-r --recurse for every directory given follow subdirectories
|
||||
encountered within
|
||||
-R --recurse: for each directory given after this option follow
|
||||
subdirectories encountered within (note the ':' at
|
||||
the end of the option, manpage for more details)
|
||||
-s --symlinks follow symlinks
|
||||
-H --hardlinks normally, when two or more files point to the same
|
||||
disk area they are treated as non-duplicates; this
|
||||
option will change this behavior
|
||||
-n --noempty exclude zero-length files from consideration
|
||||
-A --nohidden exclude hidden files from consideration
|
||||
-f --omitfirst omit the first file in each set of matches
|
||||
-1 --sameline list each set of matches on a single line
|
||||
-S --size show size of duplicate files
|
||||
-m --summarize summarize dupe information
|
||||
-q --quiet hide progress indicator
|
||||
-d --delete prompt user for files to preserve and delete all
|
||||
others; important: under particular circumstances,
|
||||
data may be lost when using this option together
|
||||
with -s or --symlinks, or when specifying a
|
||||
particular directory more than once; refer to the
|
||||
fdupes documentation for additional information
|
||||
-N --noprompt together with --delete, preserve the first file in
|
||||
each set of duplicates and delete the rest without
|
||||
prompting the user
|
||||
-v --version display fdupes version
|
||||
-h --help display this help message
|
||||
|
||||
到此为止了。让我知道你到现在为止你是怎么在Linux中查找并删除重复文件的?同时,也让我知道你关于这个工具的看法。在下面的评论部分中提供你有价值的反馈吧,别忘了为我们点赞并分享,帮助我们扩散哦。
|
||||
|
||||
我正在使用另外一个移除重复文件的工具,它叫**fslint**。很快就会把使用心得分享给大家哦,你们一定会喜欢看的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/fdupes-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user