mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
commit
c12fe990b3
@ -0,0 +1,86 @@
|
||||
页面缓存、内存和文件之间的那些事
|
||||
============================================================
|
||||
|
||||
|
||||
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而没有提及文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
|
||||
|
||||
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘寻道][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间*共享*文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLL。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLL 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 ld.so 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
|
||||
|
||||
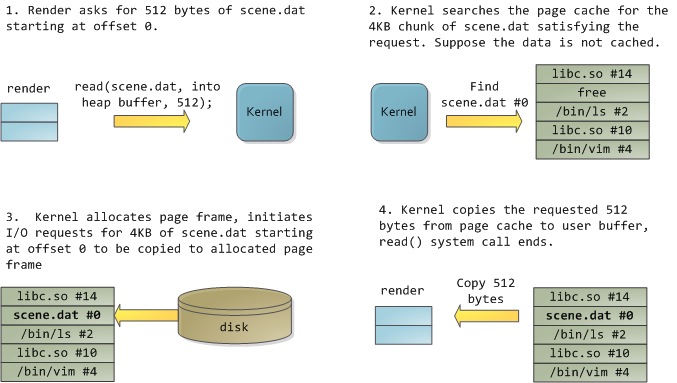
幸运的是,这两个问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 `render` 的 Linux 程序,它打开了文件 `scene.dat`,并且一次读取 512 字节,并将文件内容存储到一个分配到堆中的块上。第一次读取的过程如下:
|
||||
|
||||
|
||||
|
||||
1. `render` 请求 `scene.dat` 从位移 0 开始的 512 字节。
|
||||
2. 内核搜寻页面缓存中 `scene.dat` 的 4kb 块,以满足该请求。假设该数据没有缓存。
|
||||
3. 内核分配页面帧,初始化 I/O 请求,将 `scend.dat` 从位移 0 开始的 4kb 复制到分配的页面帧。
|
||||
4. 内核从页面缓存复制请求的 512 字节到用户缓冲区,系统调用 `read()` 结束。
|
||||
|
||||
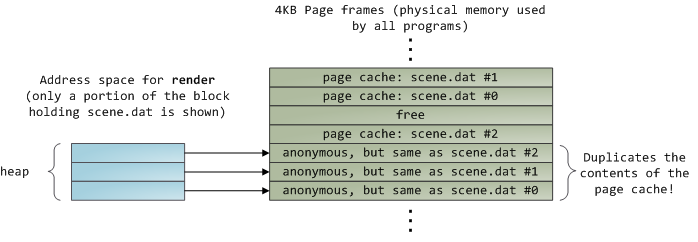
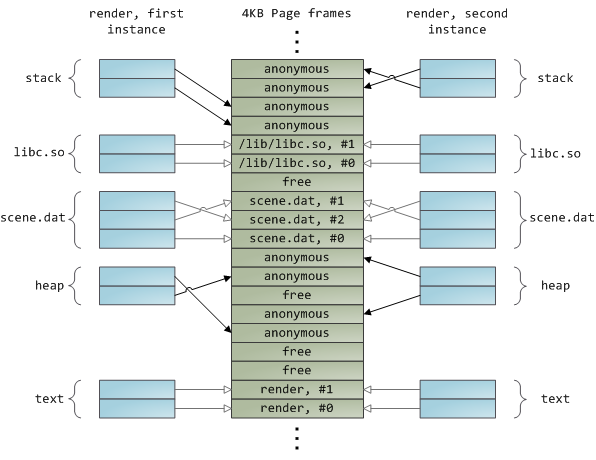
读取完 12KB 的文件内容以后,`render` 程序的堆和相关的页面帧如下图所示:
|
||||
|
||||
|
||||
|
||||
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取(`read`)调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,**普通的文件 I/O 就是这样通过页面缓存来进行的**。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序一般也不会从磁盘区域仅仅读取几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 `#0`、`#1` 等等来描述。Windows 使用 256KB 大小的<ruby>视图<rt>view</rt></ruby>,类似于 Linux 的页面缓存中的<ruby>页面<rt>page</rt></ruby>。
|
||||
|
||||
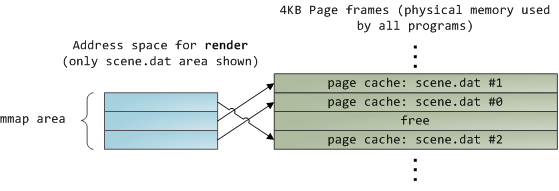
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到用户缓冲区中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],**在复制数据时也浪费物理内存**。如前面的图示,`scene.dat` 的内存被存储了两次,并且,程序中的每个实例都用另外的时间去存储内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
|
||||
|
||||
|
||||
|
||||
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 报告指出,在相关的普通文件读取上运行时性能提升多达 30% ,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。这取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
|
||||
|
||||
对高性能的追求是永恒不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。这个 API 提供了非常好用的实现方式,它允许你在内存中按字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄 [映射你的虚拟页面][14] 到页面缓存上。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
|
||||
|
||||
现在出现一个突发的状况,假设我们的 `render` 程序的最后一个实例退出了。在页面缓存中保存着 `scene.dat` 内容的页面要立刻释放掉吗?人们通常会如此考虑,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该保持全满。并且,这一原则适用于所有的进程。如果你现在运行 `render` 一周后, `scene.dat` 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(LCTT 译注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
|
||||
|
||||
由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“脏”页面。磁盘 I/O 通常并**不会**立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。副作用是,如果这时候发生了电脑死机,你的写入将不会完成,因此,对于至关重要的文件,像数据库事务日志,要求必须进行 [fsync()][17](仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,直到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows 缓存提示][20] ),你可以通过<ruby>提示<rt>hint</rt></ruby>帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是我不确定 Windows 的行为。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
|
||||
|
||||
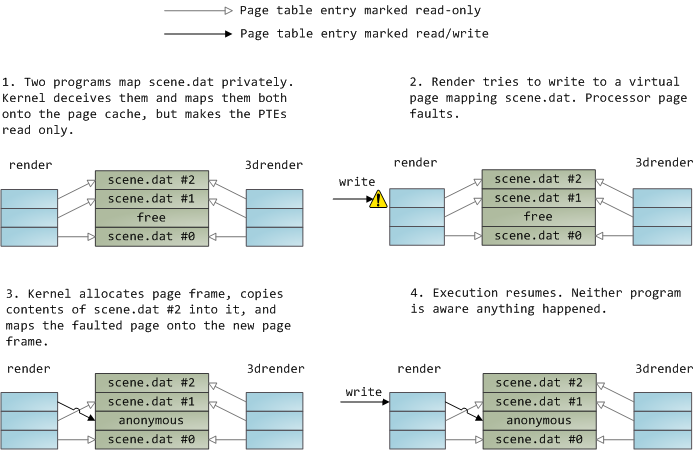
一个文件映射可以是私有的,也可以是共享的。当然,这只是针对内存中内容的**更新**而言:在一个私有的内存映射上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核使用<ruby>写时复制<rt>copy on write</rt></ruby>(CoW)机制,这是通过<ruby>页面表条目<rt>page table entry</rt></ruby>(PTE)来实现这种私有的映射。在下面的例子中,`render` 和另一个被称为 `render3d` 的程序都私有映射到 `scene.dat` 上。然后 `render` 去写入映射的文件的虚拟内存区域:
|
||||
|
||||
|
||||
|
||||
1. 两个程序私有地映射 `scene.dat`,内核误导它们并将它们映射到页面缓存,但是使该页面表条目只读。
|
||||
2. `render` 试图写入到映射 `scene.dat` 的虚拟页面,处理器发生页面故障。
|
||||
3. 内核分配页面帧,复制 `scene.dat` 的第二块内容到其中,并映射故障的页面到新的页面帧。
|
||||
4. 继续执行。程序就当做什么都没发生。
|
||||
|
||||
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
|
||||
|
||||
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 API 为你提供与私有文件映射相同的效果。下面的示例展示了映射文件的 `render` 程序的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
|
||||
|
||||
|
||||
|
||||
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://linux.cn/article-9393-1.html
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
@ -1,4 +1,4 @@
|
||||
用 PGP 保护代码完整性 - 第二部分:生成你的主密钥
|
||||
用 PGP 保护代码完整性(二):生成你的主密钥
|
||||
======
|
||||
|
||||

|
||||
@ -7,127 +7,101 @@
|
||||
|
||||
### 清单
|
||||
|
||||
1. 生成一个 4096 位的 RSA 主密钥 (ESSENTIAL)
|
||||
|
||||
2. 使用 paperkey 备份你的 RSA 主密钥 (ESSENTIAL)
|
||||
|
||||
3. 添加所有相关的身份 (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
1. 生成一个 4096 位的 RSA 主密钥 (必要)
|
||||
2. 使用 paperkey 备份你的 RSA 主密钥 (必要)
|
||||
3. 添加所有相关的身份 (必要)
|
||||
|
||||
### 考虑事项
|
||||
|
||||
#### 理解“主”(认证)密钥
|
||||
### 理解“主”(认证)密钥
|
||||
|
||||
在本节和下一节中,我们将讨论“主密钥”和“子密钥”。理解以下内容很重要:
|
||||
|
||||
1. 在“主密钥”和“子密钥”之间没有技术上的区别。
|
||||
|
||||
2. 在创建时,我们赋予每个密钥特定的能力来分配功能限制
|
||||
|
||||
1. 在“主密钥”和“子密钥”之间没有技术上的区别。
|
||||
2. 在创建时,我们赋予每个密钥特定的能力来分配功能限制。
|
||||
3. 一个 PGP 密钥有四项能力
|
||||
|
||||
* [S] 密钥可以用于签名
|
||||
|
||||
* [E] 密钥可以用于加密
|
||||
|
||||
* [A] 密钥可以用于身份认证
|
||||
|
||||
* \[A] 密钥可以用于身份认证
|
||||
* [C] 密钥可以用于认证其他密钥
|
||||
|
||||
4. 一个密钥可能有多种能力
|
||||
|
||||
|
||||
|
||||
|
||||
带有[C] (认证)能力的密钥被认为是“主”密钥,因为它是唯一可以用来表明与其他密钥关系的密钥。只有[C]密钥可以被用于:
|
||||
带有 [C] (认证)能力的密钥被认为是“主”密钥,因为它是唯一可以用来表明与其他密钥关系的密钥。只有 [C] 密钥可以被用于:
|
||||
|
||||
* 添加或撤销其他密钥(子密钥)的 S/E/A 能力
|
||||
|
||||
* 添加,更改或撤销密钥关联的身份(uids)
|
||||
|
||||
* 添加、更改或撤销密钥关联的身份(uid)
|
||||
* 添加或更改本身或其他子密钥的到期时间
|
||||
|
||||
* 为了网络信任目的为其它密钥签名
|
||||
|
||||
在自由软件的世界里,[C] 密钥就是你的数字身份。一旦你创建该密钥,你应该格外小心地保护它并且防止它落入坏人的手中。
|
||||
|
||||
|
||||
|
||||
在自由软件的世界里,[C]密钥就是你的数字身份。一旦你创建该密钥,你应该格外小心地保护它并且防止它落入坏人的手中。
|
||||
|
||||
#### 在你创建主密钥前
|
||||
### 在你创建主密钥前
|
||||
|
||||
在你创建的你的主密钥前,你需要选择你的主要身份和主密码。
|
||||
|
||||
##### 主要身份
|
||||
#### 主要身份
|
||||
|
||||
身份使用邮件中发件人一栏相同格式的字符串:
|
||||
|
||||
```
|
||||
Alice Engineer <alice.engineer@example.org>
|
||||
|
||||
```
|
||||
|
||||
你可以在任何时候创建新的身份,取消旧的,并且更改你的“主要”身份。由于主要身份在所有 GnuPG 操作中都展示,你应该选择正式的和最有可能用于 PGP 保护通信的名字和邮件地址,比如你的工作地址或者用于在项目提交(commit)时签名的地址。
|
||||
你可以在任何时候创建新的身份,取消旧的,并且更改你的“主要”身份。由于主要身份在所有 GnuPG 操作中都展示,你应该选择正式的和最有可能用于 PGP 保护通信的名字和邮件地址,比如你的工作地址或者用于在项目<ruby>提交<rt>commit</rt></ruby>时签名的地址。
|
||||
|
||||
##### 密码
|
||||
#### 密码
|
||||
|
||||
密码(passphrase)专用于在存储在磁盘上时使用对称加密算法对私钥进行加密。如果你的 .gnupg 目录的内容被泄露,那么一个好的密码就是小偷能够在线模拟你的最后一道防线,这就是为什么设置一个好的密码很重要的原因。
|
||||
<ruby>密码<rt>passphrase</rt></ruby>专用于私钥存储在磁盘上时使用对称加密算法对其进行加密。如果你的 `.gnupg` 目录的内容被泄露,那么一个好的密码就是小偷能够在线假冒你的最后一道防线,这就是为什么设置一个好的密码很重要的原因。
|
||||
|
||||
一个强密码的好的指导是用丰富或混合的词典的 3-4 个词,而不引用自流行来源(歌曲,书籍,口号)。由于你将相当频繁地使用该密码,所以它应当易于 输入和记忆。
|
||||
一个强密码最好使用丰富或混合的词典的 3-4 个词,而不引用自流行来源(歌曲、书籍、口号)。由于你将相当频繁地使用该密码,所以它应当易于输入和记忆。
|
||||
|
||||
##### 算法和密钥强度
|
||||
#### 算法和密钥强度
|
||||
|
||||
尽管现在 GnuPG 已经支持椭圆曲线加密一段时间了,我们仍坚持使用 RSA 密钥,至少稍长一段时间。虽然现在就可以开始使用 ED25519 密钥,但你可能会碰到无法正确处理它们的工具和硬件设备。
|
||||
尽管现在 GnuPG 已经支持椭圆曲线加密一段时间了,但我们仍坚持使用 RSA 密钥,至少较长一段时间会这样。虽然现在就可以开始使用 ED25519 密钥,但你可能会碰到无法正确处理它们的工具和硬件设备。
|
||||
|
||||
如果后续的指南中我们说 2048 位的密钥对 RSA 公钥加密的生命周期已经足够,你可能也会好奇主密钥为什么是 4096 位。 原因很大程度是由于社会因素而非技术上的:主密钥在密钥链上恰好是最明显的,同时如果你的主密钥位数比一些你交互的开发者的少,他们将不可避免地负面评价你。
|
||||
在后续的指南中我们说 2048 位的密钥对 RSA 公钥加密的生命周期已经足够,你可能也会好奇主密钥为什么是 4096 位。 原因很大程度是由于社会因素而非技术上的:主密钥在密钥链上是最显眼的,如果你的主密钥位数比一些和你交互的开发者的少,他们肯定会鄙视你。
|
||||
|
||||
#### 生成主密钥
|
||||
|
||||
为了生成你的主密钥,请使用以下命令,并且将“Alice Engineer:”替换为正确值
|
||||
为了生成你的主密钥,请使用以下命令,并且将 “Alice Engineer” 替换为正确值。
|
||||
|
||||
```
|
||||
$ gpg --quick-generate-key 'Alice Engineer <alice@example.org>' rsa4096 cert
|
||||
|
||||
```
|
||||
|
||||
一个要求输入密码的对话框将弹出。然后,你可能需要移动鼠标或输入一些密钥才能生成足够的熵,直到命令完成。
|
||||
这将弹出一个要求输入密码的对话框。然后,你可能需要移动鼠标或随便按一些键才能生成足够的熵,直到该命令完成。
|
||||
|
||||
查看命令输出,它就像这样:
|
||||
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid Alice Engineer <alice@example.org>
|
||||
|
||||
```
|
||||
|
||||
注意第二行的长字符串 -- 它是你新生成的密钥的完整指纹。密钥 ID(key IDs)可以用以下三种不同形式表达:
|
||||
注意第二行的长字符串 —— 它是你新生成的密钥的完整指纹。密钥 ID(Key ID)可以用以下三种不同形式表达:
|
||||
|
||||
* Fingerprint,一个完整的 40 个字符的密钥标识符
|
||||
|
||||
* Long,指纹的最后 16 个字符(AAAABBBBCCCCDDDD)
|
||||
|
||||
* Short,指纹的最后 8 个字符(CCCCDDDD)
|
||||
* <ruby>指纹<rt>Fingerprint</rt></ruby>,一个完整的 40 个字符的密钥标识符
|
||||
* <ruby>长密钥 ID<rt>Long</rt></ruby>,指纹的最后 16 个字符(AAAABBBBCCCCDDDD)
|
||||
* <ruby>短密钥 ID<rt>Short</rt></ruby>,指纹的最后 8 个字符(CCCCDDDD)
|
||||
|
||||
|
||||
|
||||
|
||||
你应该避免使用 8 个字符的短密钥 ID(short key IDs),因为它们不足够唯一。
|
||||
你应该避免使用 8 个字符的短密钥 ID,因为它们不足够唯一。
|
||||
|
||||
这里,我建议你打开一个文本编辑器,复制你新密钥的指纹并粘贴。你需要在接下来几步中用到它,所以将它放在旁边会很方便。
|
||||
|
||||
#### 备份你的主密钥
|
||||
|
||||
出于灾后恢复的目的 -- 同时特别的如果你试图使用 Web of Trust 并且收集来自其他项目开发者的密钥签名 -- 你应该创建你的私钥的 硬拷贝备份。万一所有其它的备份机制都失败了,这应当是最后的补救措施。
|
||||
出于灾后恢复的目的 —— 同时特别的如果你试图使用 Web of Trust 并且收集来自其他项目开发者的密钥签名 —— 你应该创建你的私钥的硬拷贝备份。万一所有其它的备份机制都失败了,这应当是最后的补救措施。
|
||||
|
||||
创建一个你的私钥的可打印的硬拷贝的最好方法是使用为此而写的软件 paperkey。Paperkey 在所有 Linux 发行版上可用,在 Mac 上也可以通过 brew 安装 paperkey。
|
||||
创建一个你的私钥的可打印的硬拷贝的最好方法是使用为此而写的软件 `paperkey`。`paperkey` 在所有 Linux 发行版上可用,在 Mac 上也可以通过 brew 安装 `paperkey`。
|
||||
|
||||
运行以下命令,用你密钥的完整指纹替换 `[fpr]`:
|
||||
|
||||
运行以下命令,用你密钥的完整指纹替换[fpr]:
|
||||
```
|
||||
$ gpg --export-secret-key [fpr] | paperkey -o /tmp/key-backup.txt
|
||||
|
||||
```
|
||||
|
||||
输出将采用易于 OCR 或手动输入的格式,以防如果你需要恢复它的话。打印出该文件,然后拿支笔,并在纸的边缘写下密钥的密码。这是必要的一步,因为密钥输出仍然使用密码加密,并且如果你更改了密钥的密码,你不会记得第一次创建的密钥是什么 -- 我保证。
|
||||
输出将采用易于 OCR 或手动输入的格式,以防如果你需要恢复它的话。打印出该文件,然后拿支笔,并在纸的边缘写下密钥的密码。这是必要的一步,因为密钥输出仍然使用密码加密,并且如果你更改了密钥的密码,你不会记得第一次创建的密钥是什么 —— 我保证。
|
||||
|
||||
将打印结果和手写密码放入信封中,并存放在一个安全且保护好的地方,最好远离你家,例如银行保险库。
|
||||
|
||||
@ -135,26 +109,26 @@ $ gpg --export-secret-key [fpr] | paperkey -o /tmp/key-backup.txt
|
||||
|
||||
#### 添加相关身份
|
||||
|
||||
如果你有多个相关的邮件地址(个人,工作,开源项目等),你应该将其添加到主密钥中。你不需要为任何你不希望用于 PGP 的地址(例如,可能不是你的校友地址)这样做。
|
||||
如果你有多个相关的邮件地址(个人、工作、开源项目等),你应该将其添加到主密钥中。你不需要为任何你不希望用于 PGP 的地址(例如,可能不是你的校友地址)这样做。
|
||||
|
||||
该命令是(用你完整的密钥指纹替换 `[fpr]`):
|
||||
|
||||
该命令是(用你完整的密钥指纹替换[fpr]):
|
||||
```
|
||||
$ gpg --quick-add-uid [fpr] 'Alice Engineer <allie@example.net>'
|
||||
|
||||
```
|
||||
|
||||
你可以查看你已经使用的 UIDs:
|
||||
你可以查看你已经使用的 UID:
|
||||
|
||||
```
|
||||
$ gpg --list-key [fpr] | grep ^uid
|
||||
|
||||
```
|
||||
|
||||
##### 选择主 UID
|
||||
#### 选择主 UID
|
||||
|
||||
GnuPG 将会把你最近添加的 UID 作为你的主 UID,如果这与你想的不同,你应该改回来:
|
||||
|
||||
```
|
||||
$ gpg --quick-set-primary-uid [fpr] 'Alice Engineer <alice@example.org>'
|
||||
|
||||
```
|
||||
|
||||
下次,我们将介绍如何生成 PGP 子密钥,它是你实际用于日常工作的密钥。
|
||||
@ -167,10 +141,10 @@ via: https://www.linux.com/blog/learn/PGP/2018/2/protecting-code-integrity-pgp-p
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[1]:https://linux.cn/article-9524-1.html
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,83 +0,0 @@
|
||||
pinewall Translating
|
||||
How to tell when moving to blockchain is a bad idea
|
||||
======
|
||||
|
||||

|
||||
So, there's this thing called "blockchain" that is quite popular…
|
||||
|
||||
You know that already, of course. I keep wondering whether we've hit "peak hype" for blockchain and related technologies yet, but so far there's no sign of it. When I'm talking about blockchain here, I'm including distributed ledger technologies (DLTs), which are, by some tight definitions of the term, not really blockchains at all. I'm particularly interested, from a professional point of view, in permissioned blockchains. You can read more about how that's defined in my article [Is blockchain a security topic?][1] The key point here is that I'm interested in business applications of blockchain beyond cryptocurrency.1
|
||||
|
||||
And, if the hype is to be believed—and some of it probably should be2—then there is an almost infinite set of applications for blockchain. That's probably correct, but it doesn't mean all of them are good applications for blockchain. Some, in fact, are likely to be very bad applications for blockchain.
|
||||
|
||||
The hype associated with blockchain, however, means that businesses are rushing to embrace this new technology3 without really understanding what they're doing. The drivers towards this are arguably three-fold:
|
||||
|
||||
1. You can, if you try, make almost any application with multiple users that stores data into a blockchain-enabled application.
|
||||
2. There are lots of conferences and "gurus" telling people that if they don't embrace blockchain now, they'll go out of business within six months4.
|
||||
3. It's not easy technology to understand fully, and lots of its proponents "on-the-ground" in organisations are techies.
|
||||
|
||||
|
||||
|
||||
I want to unpack that last statement before I get a hail of trolls flaming me.5 I have nothing against techies—I'm one myself—but one of our characteristics tends to be enormous enthusiasm about new things ("shinies") that we understand, but whose impact on the business we don't always fully grok.6 That's not always a positive for business leaders.
|
||||
|
||||
The danger, then, is that the confluence of those three drivers may lead to businesses moving to blockchain applications without fully understanding whether it's a good idea. I wrote in another post ([Blockchain: should we all play?][2]) about some tests to decide when a process is a good fit for blockchain and when it's not. They were useful, but the more I think about it, the more I'm convinced that we need some simple tests to tell us when we should definitely not move a process or an application to a blockchain. I present my three tests. If your answer to any of these questions is "yes," then you almost certainly don't need a blockchain.
|
||||
|
||||
### Test 1: Does it have a centralised controller or authority?
|
||||
|
||||
If the answer is "yes," then you don't need a blockchain.
|
||||
|
||||
If, for instance, you're selling, I don't know, futons, and you have a single ordering system, then you have a single authority for deciding when to send out a futon. You almost certainly don't need to make this a blockchain. If you are a purveyor of content that has to pass through a single editorial and publishing process, you almost certainly don't need to make this a blockchain.
|
||||
|
||||
The lesson is: Blockchains really don't make sense unless the tasks required in the process execution—and the trust associated with those tasks—is distributed among multiple entities.
|
||||
|
||||
### Test 2: Could it work fine with a standard database?
|
||||
|
||||
If the answer to this question is "yes," then you don't need a blockchain.
|
||||
|
||||
This and the previous question are somewhat intertwined but don't need to be. There are applications where you have distributed processes but need to store information centrally, or you have centralised authorities but distributed data, where one answer may be "yes" and the other is "no." But if your answer to this question is "yes," use a standard database.
|
||||
|
||||
Databases are good at what they do, they are cheaper in terms of design and operations than running a blockchain or distributed ledger, and we know how to make them work. Blockchains are about letting everybody8 see and hold data, but the overheads can be high and the implications costly.
|
||||
|
||||
### Test 3: Is adoption going to be costly or annoying to some stakeholders?
|
||||
|
||||
If the answer to this question is "yes," then you don't need a blockchain.
|
||||
|
||||
I've heard assertions that blockchains always benefit all users. This is patently false. If you are creating an application for a process and changing the way your stakeholders interact with you and it, you need to consider whether that change is in their best interests. It's very easy to create and introduce an application, blockchain or not, that reduces business friction for the owner of the process but increases it for other stakeholders.
|
||||
|
||||
If I make engine parts for the automotive industry, it may benefit me immensely to be able to track and manage the parts on a blockchain. I may be able to see at a glance who supplied what, when, and the quality of the steel used in the (for example) ball bearings I buy. On the other hand, if I'm a ball-bearing producer with an established process that works for the 40 other companies to whom I sell ball bearings, adopting a new process for one company—with associated changes to my method of work, systems, storage, and security requirements—is unlikely to be in my best interests. It's going to be both costly and annoying.
|
||||
|
||||
### In summary
|
||||
|
||||
Tests are guidelines; they're not fixed in stone. One of these tests looks like a technical test (the database one), but it's really as much about business roles and responsibilities as the other two. All of them, hopefully, can be used as a counterbalance to the three drivers of blockchain adoption I mentioned.
|
||||
|
||||
1\. Which, don't get me wrong, is definitely interesting and a business application—it's just not what I'm going to talk about in this post.
|
||||
|
||||
2\. The trick is knowing which bits. Let me know if you work out how, OK?
|
||||
|
||||
3\. It's actually quite a large set of technologies, to be honest.
|
||||
|
||||
4\. Which is patently untrue, unless the word "they" refers to the conferences and gurus, in which case it's probably correct.
|
||||
|
||||
5\. Which may happen anyway due to my egregious mixing of metaphors.
|
||||
|
||||
6\. There's a word to love. I've put it in to exhibit my techie credentials.7
|
||||
|
||||
7\. And before you doubt them, yes, I've read the book, in both cut and uncut versions.
|
||||
|
||||
8\. Within reason.
|
||||
|
||||
This article originally appeared on [Alice, Eve, and Bob – a security blog][3] and is republished with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/3-tests-not-moving-blockchain
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://opensource.com/article/17/12/blockchain-security-topic
|
||||
[2]:https://aliceevebob.com/2017/09/12/blockchain-should-we-all-play/
|
||||
[3]:https://aliceevebob.com/2018/02/13/3-tests-for-not-moving-to-blockchain/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Understanding Linux filesystems: ext4 and beyond
|
||||
======
|
||||
|
||||
|
||||
51
sources/talk/20180404 Is the term DevSecOps necessary.md
Normal file
51
sources/talk/20180404 Is the term DevSecOps necessary.md
Normal file
@ -0,0 +1,51 @@
|
||||
Is the term DevSecOps necessary?
|
||||
======
|
||||
|
||||

|
||||
First came the term "DevOps."
|
||||
|
||||
It has many different aspects. For some, [DevOps][1] is mostly about a culture valuing collaboration, openness, and transparency. Others focus more on key practices and principles such as automating everything, constantly iterating, and instrumenting heavily. And while DevOps isn’t about specific tools, certain platforms and tooling make it a more practical proposition. Think containers and associated open source cloud-native technologies like [Kubernetes][2] and CI/CD pipeline tools like [Jenkins][3]—as well as native Linux capabilities.
|
||||
|
||||
However, one of the earliest articulated concepts around DevOps was the breaking down of the “wall of confusion” specifically between developers and operations teams. This was rooted in the idea that developers didn’t think much about operational concerns and operators didn’t think much about application development. Add the fact that developers want to move quickly and operators care more about (and tend to be measured on) stability than speed, and it’s easy to see why it was difficult to get the two groups on the same page. Hence, DevOps came to symbolize developers and operators working more closely together, or even merging roles to some degree.
|
||||
|
||||
Of course, calls for improved communications and better-integrated workflows were never just about dev and ops. Business owners should be part of conversations as well. And there are the actual users of the software. Indeed, you can write up an almost arbitrarily long list of stakeholders concerned with the functionality, cost, reliability, and other aspects of software and its associated infrastructure. Which raises the question that many have asked: “What’s so special about security that we need a DevSecOps term?”
|
||||
|
||||
I’m glad you asked.
|
||||
|
||||
The first is simply that it serves as a useful reminder. If developers and operations were historically two of the most common silos in IT organizations, security was (and often still is) another. Security people are often thought of as conservative gatekeepers for whom “no” often seems the safest response to new software releases and technologies. Security’s job is to protect the company, even if that means putting the brakes on a speedy development process.
|
||||
|
||||
Many aspects of traditional security, and even its vocabulary, can also seem arcane to non-specialists. This has also contributed to the notion that security is something apart from mainstream IT. I often share the following anecdote: A year or two ago I was leading a security discussion at a [DevOpsDays][4] event in London in which we were talking about traditional security roles. One of the participants raised his hand and admitted that he was one of those security gatekeepers. He went on to say that this was the first time in his career that he had ever been to a conference that wasn’t a traditional security conference like RSA. (He also noted that he was going to broaden both his and his team’s horizons more.)
|
||||
|
||||
So DevSecOps perhaps shouldn’t be a needed term. But explicitly calling it out seems like a good practice at a time when software security threats are escalating.
|
||||
|
||||
The second reason is that the widespread introduction of cloud-native technologies, particularly those built around containers, are closely tied to DevOps practices. These new technologies are both leading to and enabling greater scale and more dynamic infrastructures. Static security policies and checklists no longer suffice. Security must become a continuous activity. And it must be considered at every stage of your application and infrastructure lifecycle.
|
||||
|
||||
**Here are a few examples:**
|
||||
|
||||
You need to secure the pipeline and applications. You need to use trusted sources for content so that you know who has signed off on container images and that they’re up-to-date with the most recent patches. Your continuous integration system must integrate automated security testing. You’ll sometimes hear people talking about “shifting security left,” which means earlier in the process so that problems can be dealt with sooner. But it’s actually better to think about embedding security throughout the entire pipeline at each step of the testing, integration, deployment, and ongoing management process.
|
||||
|
||||
You need to secure the underlying infrastructure. This means securing the host Linux kernel from container escapes and securing containers from each other. It means using a container orchestration platform with integrated security features. It means defending the network by using network namespaces to isolate applications from other applications within a cluster and isolate environments (such as dev, test, and production) from each other.
|
||||
|
||||
And it means taking advantage of the broader security ecosystem such as container content scanners and vulnerability management tools.
|
||||
|
||||
In short, it’s DevSecOps because modern application development and container platforms require a new type of Dev and a new type of Ops. But they also require a new type of Sec. Thus, DevSecOps.
|
||||
|
||||
**[See our related story,[Security and the SRE: How chaos engineering can play a key role][5].]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/devsecops
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://opensource.com/resources/devops
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://jenkins.io/
|
||||
[4]:https://www.devopsdays.org/
|
||||
[5]:https://opensource.com/article/18/3/through-looking-glass-security-sre
|
||||
@ -0,0 +1,125 @@
|
||||
Rethinking "ownership" across the organization
|
||||
======
|
||||
|
||||

|
||||
Differences in organizational design don't necessarily make some organizations better than others—just better suited to different purposes. Any style of organization must account for its models of ownership (the way tasks get delegated, assumed, executed) and responsibility (the way accountability for those tasks gets distributed and enforced). Conventional organizations and open organizations treat these issues differently, however, and those difference can be jarring for anyone hopping transitioning from one organizational model to another. But transitions are ripe for stumbling over—oops, I mean, learning from.
|
||||
|
||||
Let's do that.
|
||||
|
||||
### Ownership explained
|
||||
|
||||
In most organizations (and according to typical project management standards), work on projects proceeds in five phases:
|
||||
|
||||
* Initiation: Assess project feasibility, identify deliverables and stakeholders, assess benefits
|
||||
* Planning (Design): Craft project requirements, scope, and schedule; develop communication and quality plans
|
||||
* Executing: Manage task execution, implement plans, maintain stakeholder relationships
|
||||
* Monitoring/Controlling: Manage project performance, risk, and quality of deliverables
|
||||
* Closing: Sign-off on completion requirements, release resources
|
||||
|
||||
|
||||
|
||||
The list above is not exhaustive, but I'd like to add one phase that is often overlooked: the "Adoption" phase, frequently needed for strategic projects where a change to the culture or organization is required for "closing" or completion.
|
||||
|
||||
* Adoption: Socializing the work of the project; providing communication, training, or integration into processes and standard workflows.
|
||||
|
||||
|
||||
|
||||
Examining project phases is one way contrast the expression of ownership and responsibility in organizations.
|
||||
|
||||
### Two models, contrasted
|
||||
|
||||
In my experience, "ownership" in a traditional software organization works like this.
|
||||
|
||||
A manager or senior technical associate initiates a project with senior stakeholders and, with the authority to champion and guide the project, they bestow the project on an associate at some point during the planning and execution stages. Frequently, but not always, the groundwork or fundamental design of the work has already been defined and approved—sometimes even partially solved. Employees are expected to see the project through execution and monitoring to completion.
|
||||
|
||||
Employees cut their teeth on a "starter project," where they prove their abilities to a management chain (for example, I recall several such starter projects that were already defined by a manager and architect, and I was assigned to help implement them). Employees doing a good job on a project for which they're responsible get rewarded with additional opportunities, like a coveted assignment, a new project, or increased responsibility.
|
||||
|
||||
An associate acting as "owner" of work is responsible and accountable for that work (if someone, somewhere, doesn't do their job, then the responsible employee either does the necessary work herself or alerts a manager to the problem.) A sense of ownership begins to feel stable over time: Employees generally work on the same projects, and in the same areas for an extended period. For some employees, it means the development of deep expertise. That's because the social network has tighter integration between people and the work they do, so moving around and changing roles and projects is rather difficult.
|
||||
|
||||
This process works differently in an open organization.
|
||||
|
||||
Associates continually define the parameters of responsibility and ownership in an open organization—typically in light of their interests and passions. Associates have more agency to perform all the stages of the project themselves, rather than have pre-defined projects assigned to them. This places additional emphasis on leadership skills in an open organization, because the process is less about one group of people making decisions for others, and more about how an associate manages responsibilities and ownership (whether or not they roughly follow the project phases while being inclusive, adaptable, and community-focused, for example).
|
||||
|
||||
Being responsible for all project phases can make ownership feel more risky for associates in an open organization. Proposing a new project, designing it, and leading its implementation takes initiative and courage—especially when none of this is pre-defined by leadership. It's important to get continuous buy-in, which comes with questions, criticisms, and resistance not only from leaders but also from peers. By default, in open organizations this makes associates leaders; they do much the same work that higher-level leaders do in conventional organizations. And incidentally, this is why Jim Whitehurst, in The Open Organization, cautions us about the full power of "transparency" and the trickiness of getting people's real opinions and thoughts whether we like them or not. The risk is not as high in a traditional organization, because in those organizations leaders manage some of it by shielding associates from heady discussions that arise.
|
||||
|
||||
The reward in an Open Organization is more opportunity—offers of new roles, promotions, raises, etc., much like in a conventional organization. Yet in the case of open organizations, associates have developed reputations of excellence based on their own initiatives, rather than on pre-sanctioned opportunities from leadership.
|
||||
|
||||
### Thinking about adoption
|
||||
|
||||
Any discussion of ownership and responsibility involves addressing the issue of buy-in, because owning a project means we are accountable to our sponsors and users—our stakeholders. We need our stakeholders to buy-into our idea and direction, or we need users to adopt an innovation we've created with our stakeholders. Achieving buy-in for ideas and work is important in each type of organization, and it's difficult in both traditional and open systems—but for different reasons.
|
||||
|
||||
Open organizations better allow highly motivated associates, who are ambitious and skilled, to drive their careers. But support for their ideas is required across the organization, rather than from leadership alone.
|
||||
|
||||
Penetrating a traditional organization's closely knit social ties can be difficult, and it takes time. In such "command-and-control" environments, one would think that employees are simply "forced" to do whatever leaders want them to do. In some cases that's true (e.g., a travel reimbursement system). However, with more innovative programs, this may not be the case; the adoption of a program, tool, or process can be difficult to achieve by fiat, just like in an open organization. And yet these organizations tend to reduce redundancies of work and effort, because "ownership" here involves leaders exerting responsibility over clearly defined "domains" (and because those domains don't change frequently, knowing "who's who"—who's in charge, who to contact with a request or inquiry or idea—can be easier).
|
||||
|
||||
Open organizations better allow highly motivated associates, who are ambitious and skilled, to drive their careers. But support for their ideas is required across the organization, rather than from leadership alone. Points of contact and sources of immediate support can be less obvious, and this means achieving ownership of a project or acquiring new responsibility takes more time. And even then someone's idea may never get adopted. A project's owner can change—and the idea of "ownership" itself is more flexible. Ideas that don't get adopted can even be abandoned, leaving a great idea unimplemented or incomplete. Because any associate can "own" an idea in an open organization, these organizations tend to exhibit more redundancy. (Some people immediately think this means "wasted effort," but I think it can augment the implementation and adoption of innovative solutions. By comparing these organizations, we can also see why Jim Whitehurst calls this kind of culture "chaotic" in The Open Organization).
|
||||
|
||||
### Two models of ownership
|
||||
|
||||
In my experience, I've seen very clear differences between conventional and open organizations when it comes to the issues of ownership and responsibility.
|
||||
|
||||
In an traditional organization:
|
||||
|
||||
* I couldn't "own" things as easily
|
||||
* I felt frustrated, wanting to take initiative and always needing permission
|
||||
* I could more easily see who was responsible because stakeholder responsibility was more clearly sanctioned and defined
|
||||
* I could more easily "find" people, because the organizational network was more fixed and stable
|
||||
* I more clearly saw what needed to happen (because leadership was more involved in telling me).
|
||||
|
||||
|
||||
|
||||
Over time, I've learned the following about ownership and responsibility in an open organization:
|
||||
|
||||
* People can feel good about what they are doing because the structure rewards behavior that's more self-driven
|
||||
* Responsibility is less clear, especially in situations where there's no leader
|
||||
* In cases where open organizations have "shared responsibility," there is the possibility that no one in the group identified with being responsible; often there is lack of role clarity ("who should own this?")
|
||||
* More people participate
|
||||
* Someone's leadership skills must be stronger because everyone is "on their own"; you are the leader.
|
||||
|
||||
|
||||
|
||||
### Making it work
|
||||
|
||||
On the subject of ownership, each type of organization can learn from the other. The important thing to remember here: Don't make changes to one open or conventional value without considering all the values in both organizations.
|
||||
|
||||
Sound confusing? Maybe these tips will help.
|
||||
|
||||
If you're a more conventional organization trying to act more openly:
|
||||
|
||||
* Allow associates to take ownership out of passion or interest that align with the strategic goals of the organization. This enactment of meritocracy can help them build a reputation for excellence and execution.
|
||||
* But don't be afraid sprinkle in a bit of "high-level perspective" in the spirit of transparency; that is, an associate should clearly communicate plans to their leadership, so the initiative doesn't create irrelevant or unneeded projects.
|
||||
* Involving an entire community (as when, for example, the associate gathers feedback from multiple stakeholders and user groups) aids buy-in and creates beneficial feedback from the diversity of perspectives, and this helps direct the work.
|
||||
* Exploring the work with the community [doesn't mean having to come to consensus with thousands of people][1]. Use the [Open Decision Framework][2] to set limits and be transparent about what those limits are so that feedback and participation is organized ad boundaries are understood.
|
||||
|
||||
|
||||
|
||||
If you're already an open organization, then you should remember:
|
||||
|
||||
* Although associates initiate projects from "the bottom up," leadership needs to be involved to provide guidance, input to the vision, and circulate centralized knowledge about ownership and responsibility creating a synchronicity of engagement that is transparent to the community.
|
||||
* Ownership creates responsibility, and the definition and degree of these should be something both associates and leaders agree upon, increasing the transparency of expectations and accountability during the project. Don't make this a matter of oversight or babysitting, but rather [a collaboration where both parties give and take][3]—associates initiate, leaders guide; associates own, leaders support.
|
||||
|
||||
|
||||
|
||||
Leadership education and mentorship, as it pertains to a particular organization, needs to be available to proactive associates, especially since there is often a huge difference between supporting individual contributors and guiding and coordinating a multiplicity of contributions.
|
||||
|
||||
["Owning your own career"][4] can be difficult when "ownership" isn't a concept an organization completely understands.
|
||||
|
||||
[Subscribe to our weekly newsletter][5] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/4/rethinking-ownership-across-organization
|
||||
|
||||
作者:[Heidi Hess von Ludewig][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/heidi-hess-von-ludewig
|
||||
[1]:https://opensource.com/open-organization/17/8/achieving-alignment-in-openorg
|
||||
[2]:https://opensource.com/open-organization/resources/open-decision-framework
|
||||
[3]:https://opensource.com/open-organization/17/11/what-is-collaboration
|
||||
[4]:https://opensource.com/open-organization/17/12/drive-open-career-forward
|
||||
[5]:https://opensource.com/open-organization/resources/newsletter
|
||||
178
sources/tech/20140119 10 Killer Tips To Speed Up Ubuntu Linux.md
Normal file
178
sources/tech/20140119 10 Killer Tips To Speed Up Ubuntu Linux.md
Normal file
@ -0,0 +1,178 @@
|
||||
10 Killer Tips To Speed Up Ubuntu Linux
|
||||
======
|
||||
**Brief** : Some practical **tips to speed up Ubuntu** Linux. Tips here are valid for most versions of Ubuntu and can also be applied in Linux Mint and other Ubuntu based distributions.
|
||||
|
||||
You might have experienced that after using Ubuntu for some time, the system starts running slow. In this article, we shall see several tweaks and **tips to make Ubuntu run faster**.
|
||||
|
||||
Before we see how to improve overall system performance in Ubuntu, first let’s ponder on why the system gets slower over time. There could be several reasons for it. You may have a humble computer with basic configuration. You might have installed several applications which are eating up resources at boot time. Endless reasons in fact.
|
||||
|
||||
Here I have listed several small tweaks that will help you speed up Ubuntu a little. There are some best practices as well which you can employ to get a smoother and improved system performance. You can choose to follow all or some of it. All of them adds up a little to give you a smoother, quicker and faster Ubuntu.
|
||||
|
||||
### Tips to make Ubuntu faster:
|
||||
|
||||
![Tips to speed up Ubuntu][1]
|
||||
|
||||
I have used these tweaks with an older version of Ubuntu but I believe that the same can be used in other Ubuntu versions as well as other Linux distributions which are based on Ubuntu such as Linux Mint, Elementary OS Luna etc.
|
||||
|
||||
#### 1\. Reduce the default grub load time:
|
||||
|
||||
The grub gives you 10 seconds to change between dual boot OS or to go in recovery etc. To me, it’s too much. It also means you will have to sit beside your computer and press the enter key to boot into Ubuntu as soon as possible. A little time taking, ain’t it? The first trick would be to change this boot time. If you are more comfortable with a GUI tool, read this article to [change grub time and boot order with Grub Customizer][2].
|
||||
|
||||
For the rest of us, you can simply use the following command to open grub configuration:
|
||||
```
|
||||
sudo gedit /etc/default/grub &
|
||||
|
||||
```
|
||||
|
||||
And change **GRUB_TIMEOUT=10** to **GRUB_TIMEOUT=2**. This will change the boot time to 2 seconds. Prefer not to put 0 here as you will lose the privilege to change between OS and recovery options. Once you have changed the grub configuration, use the following command to make the change count:
|
||||
```
|
||||
sudo update-grub
|
||||
|
||||
```
|
||||
|
||||
#### 2\. Manage startup applications:
|
||||
|
||||
Over the time you tend to start installing applications. If you are a regular It’s FOSS reader, you might have installed many apps from [App of the week][3] series.
|
||||
|
||||
Some of these apps are started at each startup and of course resources will be busy in running these applications. Result: a slow computer for a significant time duration at each boot. Go in Unity Dash and look for **Startup Applications** :
|
||||
|
||||

|
||||
In here, look at what applications are loaded at startup. Now think if there are any applications which you don’t require to be started up every time you boot in to Ubuntu. Feel free to remove them:
|
||||
|
||||

|
||||
But what if you don’t want to remove the applications from startup? For example, if you installed one of the [best indicator applets for Ubuntu][4], you will want them to be started automatically at each boot.
|
||||
|
||||
What you can do here is to delay some the start of some of the programs. This way you will free up the resource at boot time and your applications will be started automatically, after some time. In the previous picture click on Edit and change the run command with a sleep option.
|
||||
|
||||
For example, if you want to delay the running of Dropbox indicator for let’s say 20 seconds, you just need to **add a command** like this in the existing command:
|
||||
```
|
||||
sleep 10;
|
||||
|
||||
```
|
||||
|
||||
So, the command ‘ **dropbox start -i** ‘ changes to ‘ **sleep 20; drobox start -i** ‘. Which means that now Dropbox will start with a 20 seconds delay. You can change the start time of another start up applications in the similar fashion.
|
||||
|
||||

|
||||
|
||||
#### 3\. Install preload to speed up application load time:
|
||||
|
||||
Preload is a daemon that runs in the background and analyzes user behavior and frequently run applications. Open a terminal and use the following command to install preload:
|
||||
```
|
||||
sudo apt-get install preload
|
||||
|
||||
```
|
||||
|
||||
After installing it, restart your computer and forget about it. It will be working in the background. [Read more about preload.][5]
|
||||
|
||||
#### 4\. Choose the best mirror for software updates:
|
||||
|
||||
It’s good to verify that you are using the best mirror to update the software. Ubuntu software repository are mirrored across the globe and it is quite advisable to use the one which is nearest to you. This will result in a quicker system update as it reduces the time to get the packages from the server.
|
||||
|
||||
In **Software & Updates->Ubuntu Software tab->Download From** choose **Other** and thereafter click on **Select Best Server** :
|
||||
|
||||

|
||||
It will run a test and tell you which is the best mirror for you. Normally, the best mirror is already set but as I said, no harm in verifying it. Also, this may result in some delay in getting the updates if the nearest mirror where the repository is cached is not updated frequently. This is useful for people with a relatively slower internet connection. You can also these tips to [speed up wifi speed in Ubuntu][6].
|
||||
|
||||
#### 5\. Use apt-fast instead of apt-get for a speedy update:
|
||||
|
||||
apt-fast is a shell script wrapper for “apt-get” that improves updated and package download speed by downloading packages from multiple connections simultaneously. If you frequently use terminal and apt-get to install and update the packages, you may want to give apt-fast a try. Install apt-fast via official PPA using the following commands:
|
||||
```
|
||||
sudo add-apt-repository ppa:apt-fast/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install apt-fast
|
||||
|
||||
```
|
||||
|
||||
#### 6\. Remove language related ign from apt-get update:
|
||||
|
||||
Have you ever noticed the output of sudo apt-get update? There are three kinds of lines in it, **hit** , **ign** and **get**. You can read their meaning [here][7]. If you look at IGN lines, you will find that most of them are related to language translation. If you use all the applications, packages in English, there is absolutely no need for a translation of package database from English to English.
|
||||
|
||||
If you suppress this language related updates from apt-get, it will slightly increase the apt-get update speed. To do that, open the following file:
|
||||
```
|
||||
sudo gedit /etc/apt/apt.conf.d/00aptitude
|
||||
|
||||
```
|
||||
|
||||
And add the following line at the end of this file:
|
||||
```
|
||||
Acquire::Languages "none";
|
||||
|
||||
```
|
||||
[![speed up apt get update in Ubuntu][8]][9]
|
||||
|
||||
#### 7\. Reduce overheating:
|
||||
|
||||
Overheating is a common problem in computers these days. An overheated computer runs quite slow. It takes ages to open a program when your CPU fan is running like [Usain Bolt][10]. There are two tools which you can use to reduce overheating and thus get a better system performance in Ubuntu, TLP and CPUFREQ.
|
||||
|
||||
To install and use TLP, use the following commands in a terminal:
|
||||
```
|
||||
sudo add-apt-repository ppa:linrunner/tlp
|
||||
sudo apt-get update
|
||||
sudo apt-get install tlp tlp-rdw
|
||||
sudo tlp start
|
||||
|
||||
```
|
||||
|
||||
You don’t need to do anything after installing TLP. It works in the background.
|
||||
|
||||
To install CPUFREQ indicator use the following command:
|
||||
```
|
||||
sudo apt-get install indicator-cpufreq
|
||||
|
||||
```
|
||||
|
||||
Restart your computer and use the **Powersave** mode in it:
|
||||
|
||||

|
||||
|
||||
#### 8\. Tweak LibreOffice to make it faster:
|
||||
|
||||
If you are a frequent user of office product, then you may want to tweak the default LibreOffice a bit to make it faster. You will be tweaking memory option here. Open LibreOffice and go to **Tools- >Options**. In there, choose **Memory** from the left sidebar and enable **Systray Quickstarter** along with increasing memory allocation.
|
||||
|
||||

|
||||
You can read more about [how to speed up LibreOffice][11] in detail.
|
||||
|
||||
#### 9\. Use a lightweight desktop environment (if you can)
|
||||
|
||||
If you chose to install the default Unity of GNOME desktop environment, you may choose to opt for a lightweight desktop environment like [Xfce][12] or [LXDE][13].
|
||||
|
||||
These desktop environments use less RAM and consume less CPU. They also come with their own set of lightweight applications that further helps in running Ubuntu faster. You can refer to this detailed guide to learn [how to install Xfce on Ubuntu][14].
|
||||
|
||||
Of course, the desktop might not look as modern as Unity or GNOME. That’s a compromise you have to make.
|
||||
|
||||
#### 10\. Use lighter alternatives for different applications:
|
||||
|
||||
This is more of a suggestion and liking. Some of the default or popular applications are resource heavy and may not be suitable for a low-end computer. What you can do is to use some alternates to these applications. For example, use [AppGrid][15] instead of Ubuntu Software Center. Use [Gdebi][16] to install packages. Use AbiWord instead of LibreOffice Writer etc.
|
||||
|
||||
That concludes the collection of tips to make Ubuntu 14.04, 16.04 and other versions faster. I am sure these tips would provide overall a better system performance.
|
||||
|
||||
Do you have some tricks up your sleeves as well to **speed up Ubuntu**? Did these tips help you as well? Do share your views. Questions, suggestions are always welcomed. Feel free to drop to the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2017/07/speed-up-ubuntu-featured-800x450.jpeg
|
||||
[2]:https://itsfoss.com/windows-default-os-dual-boot-ubuntu-1304-easy/ (Make Windows Default OS In Dual Boot With Ubuntu 13.04: The Easy Way)
|
||||
[3]:https://itsfoss.com/tag/app-of-the-week/
|
||||
[4]:https://itsfoss.com/best-indicator-applets-ubuntu/ (7 Best Indicator Applets For Ubuntu 13.10)
|
||||
[5]:https://itsfoss.com/improve-application-startup-speed-with-preload-in-ubuntu/ (Improve Application Startup Speed With Preload in Ubuntu)
|
||||
[6]:https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/ (Speed Up Slow WiFi Connection In Ubuntu 13.04)
|
||||
[7]:http://ubuntuforums.org/showthread.php?t=231300
|
||||
[8]:https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update-e1510129903529.jpeg
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update.jpeg
|
||||
[10]:http://en.wikipedia.org/wiki/Usain_Bolt
|
||||
[11]:https://itsfoss.com/speed-libre-office-simple-trick/ (Speed Up LibreOffice With This Simple Trick)
|
||||
[12]:https://xfce.org/
|
||||
[13]:https://lxde.org/
|
||||
[14]:https://itsfoss.com/install-xfce-desktop-xubuntu/
|
||||
[15]:https://itsfoss.com/app-grid-lighter-alternative-ubuntu-software-center/ (App Grid: Lighter Alternative Of Ubuntu Software Center)
|
||||
[16]:https://itsfoss.com/install-deb-files-easily-and-quickly-in-ubuntu-12-10-quick-tip/ (Install .deb Files Easily And Quickly In Ubuntu 12.10 [Quick Tip])
|
||||
@ -1,3 +1,4 @@
|
||||
#fuyongXu 翻译中
|
||||
# [Google launches TensorFlow-based vision recognition kit for RPi Zero W][26]
|
||||
|
||||
|
||||
|
||||
@ -1,106 +0,0 @@
|
||||
Linux LAN Routing for Beginners: Part 1
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Carla Schroder offers an overview of hardware and operating systems, plus IPv4 addressing basics, in this tutorial.[Creative Commons Attribution][1][Wikimedia Commons: Public Domain][2]
|
||||
|
||||
Once upon a time we learned about [IPv6 routing][4]. Now we're going to dig into the basics of IPv4 routing with Linux. We'll start with an overview of hardware and operating systems, and IPv4 addressing basics, and next week we'll setup and test routing.
|
||||
|
||||
### LAN Router Hardware
|
||||
|
||||
Linux is a real networking operating system, and always has been, with network functionality built-in from the beginning. Building a LAN router is simple compared to building a gateway router that connects your LAN to the Internet. You don't have to hassle with security or firewall rules, which are still complicated by having to deal with NAT, network address translation, an affliction of IPv4\. Why do we not drop IPv4 and migrate to IPv6? The life of the network administrator would be ever so much simpler.
|
||||
|
||||
But I digress. Ideally, your Linux router is a small machine with at least two network interfaces. Linux Gizmos has a great roundup of single-board computers here: [Catalog of 98 open-spec, hacker friendly SBCs][5]. You could use an old laptop or desktop PC. You could use a compact computer, like the ZaReason Zini or the System76 Meerkat, though these are a little pricey at nearly $600\. But they are stout and reliable, and you're not wasting money on a Windows license.
|
||||
|
||||
The Raspberry Pi 3 Model B is great for lower-demand routing. It has a single 10/100 Ethernet port, onboard 2.4GHz 802.11n wireless, and four USB ports, so you can plug in more USB network interfaces. USB 2.0 and the slower onboard network interfaces make the Pi a bit of a network bottleneck, but you can't beat the price ($35 without storage or power supply). It supports a couple dozen Linux flavors, so chances are you can have your favorite. The Debian-based Raspbian is my personal favorite.
|
||||
|
||||
### Operating System
|
||||
|
||||
You might as well stuff the smallest version of your favorite Linux on your chosen hardware thingy, because the specialized router operating systems such as OpenWRT, Tomato, DD-WRT, Smoothwall, Pfsense, and so on all have their own non-standard interfaces. In my admirable opinion this is an unnecessary complication that gets in the way rather than helping. Use the standard Linux tools and learn them once.
|
||||
|
||||
The Debian net install image is about 300MB and supports multiple architectures, including ARM, i386, amd64, and armhf. Ubuntu's server net installation image is under 50MB, giving you even more control over what packages you install. Fedora, Mageia, and openSUSE all offer compact net install images. If you need inspiration browse [Distrowatch][6].
|
||||
|
||||
### What Routers Do
|
||||
|
||||
Why do we even need network routers? A router connects different networks. Without routing every network space is isolated, all sad and alone with no one to talk to but the same boring old nodes. Suppose you have a 192.168.1.0/24 and a 192.168.2.0/24 network. Your two networks cannot talk to each other without a router connecting them. These are Class C private networks with 254 usable addresses each. Use ipcalc to get nice visual information about them:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.1.0/24
|
||||
Address: 192.168.1.0 11000000.10101000.00000001\. 00000000
|
||||
Netmask: 255.255.255.0 = 24 11111111.11111111.11111111\. 00000000
|
||||
Wildcard: 0.0.0.255 00000000.00000000.00000000\. 11111111
|
||||
=>
|
||||
Network: 192.168.1.0/24 11000000.10101000.00000001\. 00000000
|
||||
HostMin: 192.168.1.1 11000000.10101000.00000001\. 00000001
|
||||
HostMax: 192.168.1.254 11000000.10101000.00000001\. 11111110
|
||||
Broadcast: 192.168.1.255 11000000.10101000.00000001\. 11111111
|
||||
Hosts/Net: 254 Class C, Private Internet
|
||||
```
|
||||
|
||||
I like that ipcalc's binary output makes a visual representation of how the netmask works. The first three octets are the network address, and the fourth octet is the host address, so when you are assigning host addresses you "mask" out the network portion and use the leftover. Your two networks have different network addresses, and that is why they cannot communicate without a router in between them.
|
||||
|
||||
Each octet is 256 bytes, but that does not give you 256 host addresses because the first and last values, 0 and 255, are reserved. 0 is the network identifier, and 255 is the broadcast address, so that leaves 254 host addresses. ipcalc helpfully spells all of this out.
|
||||
|
||||
This does not mean that you never have a host address that ends in 0 or 255\. Suppose you have a 16-bit prefix:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.0.0/16
|
||||
Address: 192.168.0.0 11000000.10101000\. 00000000.00000000
|
||||
Netmask: 255.255.0.0 = 16 11111111.11111111\. 00000000.00000000
|
||||
Wildcard: 0.0.255.255 00000000.00000000\. 11111111.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/16 11000000.10101000\. 00000000.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000\. 00000000.00000001
|
||||
HostMax: 192.168.255.254 11000000.10101000\. 11111111.11111110
|
||||
Broadcast: 192.168.255.255 11000000.10101000\. 11111111.11111111
|
||||
Hosts/Net: 65534 Class C, Private Internet
|
||||
```
|
||||
|
||||
ipcalc lists your first and last host addresses, 192.168.0.1 and 192.168.255.254\. You may have host addresses that end in 0 and 255, for example 192.168.1.0 and 192.168.0.255, because those fall in between the HostMin and HostMax.
|
||||
|
||||
The same principles apply regardless of your address blocks, whether they are private or public, and don't be shy about using ipcalc to help you understand.
|
||||
|
||||
### CIDR
|
||||
|
||||
CIDR (Classless Inter-Domain Routing) was created to extend IPv4 by providing variable-length subnet masking. CIDR allows finer slicing-and-dicing of your network space. Let ipcalc demonstrate:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.1.0/22
|
||||
Address: 192.168.1.0 11000000.10101000.000000 01.00000000
|
||||
Netmask: 255.255.252.0 = 22 11111111.11111111.111111 00.00000000
|
||||
Wildcard: 0.0.3.255 00000000.00000000.000000 11.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/22 11000000.10101000.000000 00.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000.000000 00.00000001
|
||||
HostMax: 192.168.3.254 11000000.10101000.000000 11.11111110
|
||||
Broadcast: 192.168.3.255 11000000.10101000.000000 11.11111111
|
||||
Hosts/Net: 1022 Class C, Private Internet
|
||||
```
|
||||
|
||||
The netmask is not limited to whole octets, but rather crosses the boundary between the third and fourth octets, and the subnet portion ranges from 0 to 3, and not from 0 to 255\. The number of available hosts is not a multiple of 8 as it is when the netmask is defined by whole octets.
|
||||
|
||||
Your homework is to review CIDR and how the IPv4 address space is allocated between public, private, and reserved blocks, as this is essential to understanding routing. Setting up routes is not complicated as long as you have a good knowledge of addressing.
|
||||
|
||||
Start with [Understanding IP Addressing and CIDR Charts][7], [IPv4 Private Address Space and Filtering][8], and [IANA IPv4 Address Space Registry][9]. Then come back next week to learn how to create and manage routes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[2]:https://commons.wikimedia.org/wiki/File:Traffic_warder.jpeg
|
||||
[3]:https://www.linux.com/files/images/trafficwarderjpeg
|
||||
[4]:https://www.linux.com/learn/intro-to-linux/2017/7/practical-networking-linux-admins-ipv6-routing
|
||||
[5]:http://linuxgizmos.com/catalog-of-98-open-spec-hacker-friendly-sbcs/#catalog
|
||||
[6]:http://distrowatch.org/
|
||||
[7]:https://www.ripe.net/about-us/press-centre/understanding-ip-addressing
|
||||
[8]:https://www.arin.net/knowledge/address_filters.html
|
||||
[9]:https://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xhtml
|
||||
@ -1,120 +0,0 @@
|
||||
Linux LAN Routing for Beginners: Part 2
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
In this tutorial, we show how to manually configure LAN routers.[Creative Commons Zero][1]
|
||||
|
||||
Last week [we reviewed IPv4 addressing][3] and using the network admin's indispensible ipcalc tool: Now we're going to make some nice LAN routers.
|
||||
|
||||
VirtualBox and KVM are wonderful for testing routing, and the examples in this article are all performed in KVM. If you prefer to use physical hardware, then you need three computers: one to act as the router, and the other two to represent two different networks. You also need two Ethernet switches and cabling.
|
||||
|
||||
The examples assume a wired Ethernet LAN, and we shall pretend there are some bridged wireless access points for a realistic scenario, although we're not going to do anything with them. (I have not yet tried all-WiFi routing and have had mixed success with connecting a mobile broadband device to an Ethernet LAN, so look for those in a future installment.)
|
||||
|
||||
### Network Segments
|
||||
|
||||
The simplest network segment is two computers in the same address space connected to the same switch. These two computers do not need a router to communicate with each other. A useful term is _broadcast domain_ , which describes a group of hosts that are all in the same network. They may be all connected to a single Ethernet switch, or multiple switches. A broadcast domain may include two different networks connected by an Ethernet bridge, which makes the two networks behave as a single network. Wireless access points are typically bridged to a wired Ethernetwork.
|
||||
|
||||
A broadcast domain can talk to a different broadcast domain only when they are connected by a network router.
|
||||
|
||||
### Simple Network
|
||||
|
||||
The following example commands are not persistent, and your changes will vanish with a restart.
|
||||
|
||||
A broadcast domain needs a router to talk to other broadcast domains. Let's illustrate this with two computers and the `ip` command. Our two computers are 192.168.110.125 and 192.168.110.126, and they are plugged into the same Ethernet switch. In VirtualBox or KVM, you automatically create a virtual switch when you configure a new network, so when you assign a network to a virtual machine it's like plugging it into a switch. Use `ip addr show` to see your addresses and network interface names. The two hosts can ping each other.
|
||||
|
||||
Now add an address in a different network to one of the hosts:
|
||||
|
||||
```
|
||||
# ip addr add 192.168.120.125/24 dev ens3
|
||||
```
|
||||
|
||||
You have to specify the network interface name, which in the example is ens3\. It is not required to add the network prefix, in this case /24, but it never hurts to be explicit. Check your work with `ip`. The example output is trimmed for clarity:
|
||||
|
||||
```
|
||||
$ ip addr show
|
||||
ens3:
|
||||
inet 192.168.110.125/24 brd 192.168.110.255 scope global dynamic ens3
|
||||
valid_lft 875sec preferred_lft 875sec
|
||||
inet 192.168.120.125/24 scope global ens3
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
The host at 192.168.120.125 can ping itself (`ping 192.168.120.125`), and that is a good basic test to verify that your configuration is working correctly, but the second computer can't ping that address.
|
||||
|
||||
Now we need to do bit of network juggling. Start by adding a third host to act as the router. This needs two virtual network interfaces and a second virtual network. In real life you want your router to have static IP addresses, but for now we'll let the KVM DHCP server do the work of assigning addresses, so you only need these two virtual networks:
|
||||
|
||||
* First network: 192.168.110.0/24
|
||||
|
||||
* Second network: 192.168.120.0/24
|
||||
|
||||
Then your router must be configured to forward packets. Packet forwarding should be disabled by default, which you can check with `sysctl`:
|
||||
|
||||
```
|
||||
$ sysctl net.ipv4.ip_forward
|
||||
net.ipv4.ip_forward = 0
|
||||
```
|
||||
|
||||
The zero means it is disabled. Enable it with this command:
|
||||
|
||||
```
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
```
|
||||
|
||||
Then configure one of your other hosts to play the part of the second network by assigning the 192.168.120.0/24 virtual network to it in place of the 192.168.110.0/24 network, and then reboot the two "network" hosts, but not the router. (Or restart networking; I'm old and lazy and don't care what weird commands are required to restart services when I can just reboot.) The addressing should look something like this:
|
||||
|
||||
* Host 1: 192.168.110.125
|
||||
|
||||
* Host 2: 192.168.120.135
|
||||
|
||||
* Router: 192.168.110.126 and 192.168.120.136
|
||||
|
||||
Now go on a ping frenzy, and ping everyone from everyone. There are some quirks with virtual machines and the various Linux distributions that produce inconsistent results, so some pings will succeed and some will not. Not succeeding is good, because it means you get to practice creating a static route. First, view the existing routing tables. The first example is from Host 1, and the second is from the router:
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link src 192.168.110.164 metric 100
|
||||
```
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
default via 192.168.120.1 dev ens3 proto static metric 101
|
||||
169.254.0.0/16 dev ens3 scope link metric 1000
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link
|
||||
src 192.168.110.126 metric 100
|
||||
192.168.120.0/24 dev ens9 proto kernel scope link
|
||||
src 192.168.120.136 metric 100
|
||||
```
|
||||
|
||||
This shows us that the default routes are the ones assigned by KVM. The 169.* address is the automatic link local address, and we can ignore it. Then we see two more routes, the two that belong to our router. You can have multiple routes, and this example shows how to add a non-default route to Host 1:
|
||||
|
||||
```
|
||||
# ip route add 192.168.120.0/24 via 192.168.110.126 dev ens3
|
||||
```
|
||||
|
||||
This means Host 1 can access the 192.168.110.0/24 network via the router interface 192.168.110.126\. See how it works? Host 1 and the router need to be in the same address space to connect, then the router forwards to the other network.
|
||||
|
||||
This command deletes a route:
|
||||
|
||||
```
|
||||
# ip route del 192.168.120.0/24
|
||||
```
|
||||
|
||||
In real life, you're not going to be setting up routes manually like this, but rather using a router daemon and advertising your router via DHCP but understanding the fundamentals is key. Come back next week to learn how to set up a nice easy router daemon that does the work for you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginners-part-2
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/dortmund-hbf-12595591920jpg
|
||||
[3]:https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
How to apply Machine Learning to IoT using Android Things and TensorFlow
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
How To Edit Multiple Files Using Vim Editor
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Transfer Files From Computer To Mobile Devices By Scanning QR Codes
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
Memories of writing a parser for man pages
|
||||
======
|
||||
|
||||
I generally enjoy being bored, but sometimes enough is enough—that was the case a Sunday afternoon of 2015 when I decided to start an open source project to overcome my boredom.
|
||||
|
||||
In my quest for ideas, I stumbled upon a request to build a [“Man page viewer built with web standards”][1] by [Mathias Bynens][2] and without thinking too much, I started coding a man page parser in JavaScript, which after a lot of back and forths, ended up being [Jroff][3].
|
||||
|
||||
Back then, I was familiar with manual pages as a concept and used them a fair amount of times, but that was all I knew, I had no idea how they were generated or if there was a standard in place. Two years later, here are some thoughts on the matter.
|
||||
|
||||
### How man pages are written
|
||||
|
||||
The first thing that surprised me at the time, was the notion that manpages at their core are just plain text files stored somewhere in the system (you can check this directory using the `manpath` command).
|
||||
|
||||
This files not only contain the documentation, but also formatting information using a typesetting system from the 1970s called `troff`.
|
||||
|
||||
> troff, and its GNU implementation groff, are programs that process a textual description of a document to produce typeset versions suitable for printing. **It’s more ‘What you describe is what you get’ rather than WYSIWYG.**
|
||||
>
|
||||
> — extracted from [troff.org][4]
|
||||
|
||||
If you are totally unfamiliar with typesetting formats, you can think of them as Markdown on steroids, but in exchange for the flexibility you have a more complex syntax:
|
||||
|
||||
![groff-compressor][5]
|
||||
|
||||
The `groff` file can be written manually, or generated from other formats such as Markdown, Latex, HTML, and so on with many different tools.
|
||||
|
||||
Why `groff` and man pages are tied together has to do with history, the format has [mutated along time][6], and his lineage is composed of a chain of similarly-named programs: RUNOFF > roff > nroff > troff > groff.
|
||||
|
||||
But this doesn’t necessarily mean that `groff` is strictly related to man pages, it’s a general-purpose format that has been used to [write books][7] and even for [phototypesetting][8].
|
||||
|
||||
Moreover, It’s worth noting that `groff` can also call a postprocessor to convert its intermediate output to a final format, which is not necessarily ascii for terminal display! some of the supported formats are: TeX DVI, HTML, Canon, HP LaserJet4 compatible, PostScript, utf8 and many more.
|
||||
|
||||
### Macros
|
||||
|
||||
Other of the cool features of the format is its extensibility, you can write macros that enhance the basic functionalities.
|
||||
|
||||
With the vast history of *nix systems, there are several macro packages that group useful macros together for specific functionalities according to the output that you want to generate, examples of macro packages are `man`, `mdoc`, `mom`, `ms`, `mm`, and the list goes on.
|
||||
|
||||
Manual pages are conventionally written using `man` and `mdoc`.
|
||||
|
||||
You can easily distinguish native `groff` commands from macros by the way standard `groff` packages capitalize their macro names. For `man`, each macro’s name is uppercased, like .PP, .TH, .SH, etc. For `mdoc`, only the first letter is uppercased: .Pp, .Dt, .Sh.
|
||||
|
||||
![groff-example][9]
|
||||
|
||||
### Challenges
|
||||
|
||||
Whether you are considering to write your own `groff` parser, or just curious, these are some of the problems that I have found more challenging.
|
||||
|
||||
#### Context-sensitive grammar
|
||||
|
||||
Formally, `groff` has a context-free grammar, unfortunately, since macros describe opaque bodies of tokens, the set of macros in a package may not itself implement a context-free grammar.
|
||||
|
||||
This kept me away (for good or bad) from the parser generators that were available at the time.
|
||||
|
||||
#### Nested macros
|
||||
|
||||
Most of the macros in `mdoc` are callable, this roughly means that macros can be used as arguments of other macros, for example, consider this:
|
||||
|
||||
* The macro `Fl` (Flag) adds a dash to its argument, so `Fl s` produces `-s`
|
||||
* The macro `Ar` (Argument) provides facilities to define arguments
|
||||
* The `Op` (Optional) macro wraps its argument in brackets, as this is the standard idiom to define something as optional.
|
||||
* The following combination `.Op Fl s Ar file` produces `[-s file]` because `Op` macros can be nested.
|
||||
|
||||
|
||||
|
||||
#### Lack of beginner-friendly resources
|
||||
|
||||
Something that really confused me was the lack of a canonical, well defined and clear source to look at, there’s a lot of information in the web which assumes a lot about the reader that it takes time to grasp.
|
||||
|
||||
### Interesting macros
|
||||
|
||||
To wrap up, I will offer to you a very short list of macros that I found interesting while developing jroff:
|
||||
|
||||
**man**
|
||||
|
||||
* TH: when writing manual pages with `man` macros, your first line that is not a comment must be this macro, it accepts five parameters: title section date source manual
|
||||
* BI: bold alternating with italics (especially useful for function specifications)
|
||||
* BR: bold alternating with Roman (especially useful for referring to other manual pages)
|
||||
|
||||
|
||||
|
||||
**mdoc**
|
||||
|
||||
* .Dd, .Dt, .Os: similar to how `man` macros require the `.TH` the `mdoc` macros require these three macros, in that particular order. Their initials stand for: Document date, Document title and Operating system.
|
||||
* .Bl, .It, .El: these three macros are used to create list, their names are self-explanatory: Begin list, Item and End list.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/memories-writing-parser-man-pages/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://github.com/h5bp/lazyweb-requests/issues/114
|
||||
[2]:https://mathiasbynens.be/
|
||||
[3]:jroff
|
||||
[4]:https://www.troff.org/
|
||||
[5]:https://user-images.githubusercontent.com/4419992/37868021-2e74027c-2f7f-11e8-894b-80829ce39435.gif
|
||||
[6]:https://manpages.bsd.lv/history.html
|
||||
[7]:https://rkrishnan.org/posts/2016-03-07-how-is-gopl-typeset.html
|
||||
[8]:https://en.wikipedia.org/wiki/Phototypesetting
|
||||
[9]:https://user-images.githubusercontent.com/4419992/37866838-e602ad78-2f6e-11e8-97a9-2a4494c766ae.jpg
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
How to build a digital pinhole camera with a Raspberry Pi
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Reliable IoT event logging with syslog-ng
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Build a baby monitor with a Raspberry Pi
|
||||
======
|
||||
|
||||
|
||||
@ -1,69 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Use Instagram In Terminal
|
||||
======
|
||||

|
||||
Instagram doesn’t need introduction. It is one of a popular social network platform, like Facebook and Twitter, to share photos and videos either publicly or privately to pre-approved followers. It was launched in 2010 by two entrepreneurs namely **Kevin Systrom** and **Mike Krieger**. In 2012, the social network giant Facebook has acquired Instagram. Instagram is available for free on Android and iOS devices. We can also use it in desktop systems via a web browser. And, the cool thing is now you can use Instagram in Terminal on any Unix-like operating systems. Are you excited? Well, read on to know how to view your Instagram feed on your Terminal.
|
||||
|
||||
### Instagram In Terminal
|
||||
|
||||
First, install **pip3** as described in the following link.
|
||||
|
||||
Then, git clone the repository of “instagram-terminal-news-feed” script.
|
||||
```
|
||||
$ git clone https://github.com/billcccheng/instagram-terminal-news-feed.git
|
||||
|
||||
```
|
||||
|
||||
The above command will clone the contents of instagram script in a directory named “instagram-terminal-news-feed” in your current working directory. Cd to that directory:
|
||||
```
|
||||
$ cd instagram-terminal-news-feed/
|
||||
|
||||
```
|
||||
|
||||
Then, run the following command to install instagram terminal feed:
|
||||
```
|
||||
$ pip3 install -r requirements.txt
|
||||
|
||||
```
|
||||
|
||||
Now, run the following command to launch instagram in terminal in your Linux box.
|
||||
```
|
||||
$ python3 start.py
|
||||
|
||||
```
|
||||
|
||||
Enter your Instagram username and password and browse your Instagram feed right from the Terminal. Your instragram username and password will only be stored locally in the file called **credential.json**. So, you don’t need to worry about it. You can also just don’t save your credentials which is the default option.
|
||||
|
||||
Here is some screenshots of [**My Instagram page**][1].
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
![][5]
|
||||
|
||||
Please note that you can only view your feed. You can’t follow anyone, like or comment posts. This is just a instagram feed reader.
|
||||
|
||||
This project is freely available on GitHub, so you can view the source code, improve it, add more features, fix any bugs if there are any.
|
||||
|
||||
Have fun! Cheers!!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-use-instagram-in-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.instagram.com/ostechnix/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/instagram-in-terminal-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/instagram-in-terminal-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/instagram-in-terminal-3-2.png
|
||||
@ -1,3 +1,5 @@
|
||||
pinewall translating
|
||||
|
||||
Protect Your Websites with Let's Encrypt
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
How to build a plotter with Arduino
|
||||
======
|
||||
|
||||
|
||||
77
sources/tech/20180403 Why I love ARM and PowerPC.md
Normal file
77
sources/tech/20180403 Why I love ARM and PowerPC.md
Normal file
@ -0,0 +1,77 @@
|
||||
Why I love ARM and PowerPC
|
||||
======
|
||||
|
||||

|
||||
Recently I've been asked why I mention [ARM][1] and [PowerPC][2] so often on my blogs and in my tweets. I have two answers: one is personal, the other technical.
|
||||
|
||||
### The personal
|
||||
|
||||
Once upon a time, I studied environmental protection. While working on my PhD, I was looking for a new computer. As an environmentally aware person, I wanted a high-performing computer that was also efficient. That is how I first became interested in the PowerPC and discovered [Pegasos][3], a PowerPC workstation created by [Genesi][4].
|
||||
|
||||
I had already used [RS/6000][5] (PowerPC), [SGI][6] (MIPS), [HP-UX][7] (PA-RISC), and [VMS][8] (Alpha) both as a server and a workstation, and on my PC I used Linux, not Windows, so using a different CPU architecture was not a barrier. [Pegasos][9], which was small and efficient enough for home use, was my first workstation.
|
||||
|
||||
Soon I was working for Genesi, enabling [openSUSE][10], Ubuntu, and various other Linux distributions on Pegasos and providing quality assurance and community support. Pegasos was followed by [EFIKA][11], another PowerPC board. It felt strange at first to use an embedded system after using workstations. But as one of the first affordable developer boards, it was the start of a revolution.
|
||||
|
||||
I was working on some large-scale server projects when I received another interesting piece of hardware from Genesi: a [Smarttop][12] and a [Smartbook][13] based on ARM. My then-favorite Linux distribution, openSUSE, also received a dozen of these machines. This gave a big boost to ARM-related openSUSE developments at a time when very few ARM machines were available.
|
||||
|
||||
Although I have less time available these days, I try to stay up-to-date on ARM and PowerPC news. This helps me support syslog-ng users on non-x86 platforms. And when I have half an hour free, I hack one of my ARM machines. I did some benchmarks on the [Raspberry Pi 2][14] with [syslog-ng][15], and the [results were quite surprising][16]. Recently, I built a music player using a Raspberry Pi, a USB sound card, and the [Music Player Daemon][17], and I use it regularly.
|
||||
|
||||
### The technical
|
||||
|
||||
Diversity is good: It creates competition, and competition creates better products. While x86 is a solid generic workhorse, chips like ARM and PowerPC (and many others) are better suited in various situations.
|
||||
|
||||
If you have an [Android][18] mobile device or an [Apple][19] iPhone or iPad, there's a good chance it is running on an ARM SoC (system on chip). Same with a network-attached storage server. The reason is quite simple: power efficiency. You don't want to constantly recharge batteries or pay more for electricity than you did for your router.
|
||||
|
||||
ARM is also conquering the enterprise server world with its 64-bit ARMv8 chips. Many tasks require minimal computing capacity; on the other hand, power efficiency and fast I/O are key— think storage, static web content, email, and other storage- and network-intensive functions. A prime example is [Ceph][20], a distributed object storage and file system. [SoftIron][21], which uses CentOS as reference software on its ARMv8 developer hardware, is working on Ceph-based turnkey storage appliances.
|
||||
|
||||
Most people know PowerPC as the former CPU of [Apple Mac][22] machines. While it is no longer used as a generic desktop CPU, it still functions in routers, telecommunications equipment. And [IBM][23] continued to produce chips for high-performance servers. A few years ago, with the introduction of POWER8, IBM opened up the architecture under the aegis of the [OpenPOWER Foundation][24]. POWER8 is an ideal platform for HPC, big data, and analytics, where memory bandwidth is key. POWER9 is right around the corner.
|
||||
|
||||
These are all server applications, but there are plans for end-user devices. Raptor Engineering is working on a [POWER9 workstation][25], and there is also an initiative to [create a notebook][26] based on a Freescale/NXP QorIQ e6500 chip. Of course, these machines are not for everybody—you can't install your favorite Windows game or commercial application on them. But they are great for PowerPC developers and enthusiasts, or anyone wanting a fully open system, from hardware to firmware to applications.
|
||||
|
||||
### The dream
|
||||
|
||||
My dream is a completely x86-free environment—not because I don't like x86, but because I like diversity and always use the most suitable tool for the job. If you look at the [graph][27] on Raptor Engineering's page, you will see that, depending on your use case, ARM and POWER can replace most of x86. Right now I compile, package, and test syslog-ng in x86 virtual machines running on my laptop. Using a strong enough ARMv8 or PowerPC machine, either as a workstation or a server, I could avoid x86 for this kind of tasks.
|
||||
|
||||
Right now I am waiting for the next generation of [Pinebook][28] to arrive, as I was told at [FOSDEM][29] in February that the next version is expected to offer much higher performance. Unlike Chromebooks, this ARM-powered laptop runs Linux by design, not as a hack. For a desktop, I am looking for ARMv8 workstation-class hardware. Some are already available—like the [ThunderX Desktop][30] from Avantek—but they do not yet feature the latest, fastest, and more importantly, most energy-efficient ARMv8 CPU generations. Until these arrive, I'll use my Pixel C laptop running Android. It's not as easy and flexible as Linux, but it has a powerful ARM SoC and a Linux kernel at its heart.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/why-i-love-arm-and-powerpc
|
||||
|
||||
作者:[Peter Czanik][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/czanik
|
||||
[1]:https://en.wikipedia.org/wiki/ARM_architecture
|
||||
[2]:https://en.wikipedia.org/wiki/PowerPC
|
||||
[3]:https://genesi.company/products/opendesktop
|
||||
[4]:https://genesi.company/
|
||||
[5]:https://en.wikipedia.org/wiki/RS/6000
|
||||
[6]:https://en.wikipedia.org/wiki/Silicon_Graphics#Workstations
|
||||
[7]:https://en.wikipedia.org/wiki/HP-UX
|
||||
[8]:https://en.wikipedia.org/wiki/OpenVMS#Port_to_DEC_Alpha
|
||||
[9]:https://en.wikipedia.org/wiki/Pegasos
|
||||
[10]:https://www.opensuse.org/
|
||||
[11]:https://genesi.company/products/efika/5200b
|
||||
[12]:https://genesi.company/products/efika
|
||||
[13]:https://genesi.company/products/smartbook
|
||||
[14]:https://www.raspberrypi.org/products/raspberry-pi-2-model-b/
|
||||
[15]:https://syslog-ng.com/open-source-log-management
|
||||
[16]:https://syslog-ng.com/blog/syslog-ng-raspberry-pi-2/
|
||||
[17]:https://www.musicpd.org/
|
||||
[18]:https://www.android.com/
|
||||
[19]:http://www.apple.com/
|
||||
[20]:http://ceph.com/
|
||||
[21]:http://softiron.co.uk/
|
||||
[22]:https://en.wikipedia.org/wiki/Power_Macintosh
|
||||
[23]:https://www.ibm.com/us-en/
|
||||
[24]:http://openpowerfoundation.org/
|
||||
[25]:https://www.raptorcs.com/TALOSII/
|
||||
[26]:http://www.powerpc-notebook.org/en/
|
||||
[27]:https://secure.raptorengineering.com/TALOS/power_advantages.php
|
||||
[28]:https://www.pine64.org/?page_id=3707
|
||||
[29]:https://fosdem.org/2018/
|
||||
[30]:https://www.avantek.co.uk/store/avantek-32-core-cavium-thunderx-arm-desktop.html
|
||||
@ -0,0 +1,88 @@
|
||||
Containerization, Atomic Distributions, and the Future of Linux
|
||||
======
|
||||
|
||||

|
||||
Linux has come a long way since Linus Torvalds announced it in 1991. It has become the dominant operating system in the enterprise space. And, although we’ve seen improvements and tweaks in the desktop environment space, the model of a typical Linux distribution has largely remained the same over the past 25+ years. The traditional package management based model has dominated both the desktop and server space.
|
||||
|
||||
However, things took an interesting turn when Google launched Linux-based Chrome OS, which deployed an image-based model. Core OS (now owned by Red Hat) came out with an operating system (Container Linux) that was inspired by Google but targeted at enterprise customers.
|
||||
|
||||
Container Linux changed the way operating systems update. It changed the way applications were delivered and updated. Is this the future of Linux distributions? Will it replace the traditional package-based distribution model?
|
||||
|
||||
### Three models
|
||||
|
||||
Matthias Eckermann, Director of Product Management for SUSE Linux Enterprise, thinks there are not two but three models. “Outside of the traditional (RHEL/SLE) and the image-based model (RH Atomic Host), there is a third model: transactional. This is where [SUSE CaaS Platform][1] and its SUSE MicroOS lives,” said Eckermann.
|
||||
|
||||
### What’s the difference?
|
||||
|
||||
Those who live in Linux land are very well aware of the traditional model. It’s made up of single packages and shared libraries. This model has its own benefit as application developers don’t have to worry about bundling libraries with their apps. There is no duplication, which keeps the system lean and thin. It also saves bandwidth as users don’t have to download a lot of packages. Distributions have total control over packages so security issues can be fixed easily by pushing updates at the system level.
|
||||
|
||||
“Traditional packaging continues to provide the opportunity to carefully craft and tune an operating system to support mission-critical workloads that need to stand the test of time,” said Ron Pacheco, Director of Product Management at Red Hat Enterprise Linux.
|
||||
|
||||
But the traditional model has some disadvantages, too. App developers must restrict themselves to the libraries shipped with the distro, which means they can’t take advantage of new packages for their apps if the distro doesn’t support them. It could also lead to conflict between two different versions. As a result, it creates administration challenges as they are often difficult to keep updated and in sync.
|
||||
|
||||
### Image-based Model
|
||||
|
||||
That’s where the image based model comes to the rescue. “The image-based model solves the problems of the traditional model as it replaces the operating system at every reiteration and doesn't work with single packages,” said Eckermann.
|
||||
|
||||
“When we talk about the operating system as an image, what we’re really talking about is developing and deploying in a programmatic way and with better integrated life cycle management,” said Pacheco, giving the example of OpenShift, which is built on top of Red Hat Enterprise Linux.
|
||||
|
||||
Pacheco sees the image-based OS as a continuum, from hand-tooling a deployed image to a heavily automated infrastructure that can be managed at a large scale; regardless of where a customer is on this range, the same applications have to run. “You don't want to create a silo by using a wholly different deployment model,” he said.
|
||||
|
||||
The image-based model replaces the entire OS with new libraries and packages, which introduces its own set of problems. The image-based model has to be reconstructed to meet the needs of specific environments. For example, if the user has a specific need for installing a specific hardware driver or low-level monitoring option, the image model fails, or options to have finer granularity have to be re-invented.
|
||||
|
||||
### Transactional model
|
||||
|
||||
The third model is transactional updates, which follows the traditional package-based updates, but instead handles all packages as if they were images, updating all the packages that belong together in one shot like an image.
|
||||
|
||||
“The difference is because they are single packages that are grouped together as well as on descending and the installation, the customer has the option to influence this if necessary. This gives the user extra flexibility by combining the benefits of both and avoiding the disadvantages associated with the traditional or image model,” said Eckermann.
|
||||
|
||||
Pacheco said that it’s becoming increasingly common for carefully crafted workloads to be deployed as images in order to deploy consistently, reliably, and to do so with elasticity. “This is what we see our customers do today when they create and deploy virtual machines on premises or on public/private clouds as well as on traditional bare metal deployments,” he said.
|
||||
|
||||
Pacheco suggests that we should not look at these models as strictly a “compare and contrast scenario,” but rather as an evolution and expansion of the operating system’s role.
|
||||
|
||||
### Arrival of Atomic Updates
|
||||
|
||||
Google’s Chrome OS and the Core OS popularized the concept of transactional updates, a model followed by both Red Hat and SUSE.
|
||||
|
||||
“The real problem is the operating system underlining the container host operating system is not in focus anymore -- at least not in a way the administrator should care about. Both RH Atomic Host and SUSE CaaS Platform solve this problem similarly from a user experience perspective,” said Eckermann.
|
||||
|
||||
[Immutable infrastructure][2], such as that provided by SUSE CaaS Platform, Red Hat Atomic Host, and Container Linux (formerly Core OS), encourages the use of transactional updates. “Having a model where the host always moves to a ‘known good’ state enables better confidence with updates, which in turn enables a faster flow of features, security benefits, and an easier-to-adopt operational model,” said Ben Breard, senior technology product manager, Red Hat.
|
||||
|
||||
These newer OSes isolate the applications from the underlying host with Linux containers thereby removing many of the traditional limitations associated with infrastructure updates.
|
||||
|
||||
“The real power and benefits are realized when the orchestration layer is intelligently handling the updates, deployments, and, ultimately, seamless operations,” added Breard.
|
||||
|
||||
### The Future
|
||||
|
||||
What does the future hold for Linux? The answer really depends on who you ask. Container players will say the future belongs to containerized OS, but Linux vendors who still have a huge market may disagree.
|
||||
|
||||
When asked if, in the long run, atomic distros will replace traditional distributions, Eckermann said, “If I say yes, then I am following the trend; if I say no, I will be considered old-fashioned. Nevertheless, I say no: atomic distros will not replace traditional distros in the long run -- but traditional workloads and containerized workloads will live together in data centers as well as private and public cloud environments.”
|
||||
|
||||
Pacheco maintained that the growth in Linux deployments, in general, makes it difficult to imagine one model replacing the other. He said that instead of looking at them as competing models, we should look at atomic distributions as part of the evolution and deployment of the operating system.
|
||||
|
||||
Additionally, there are many use-cases that may need a mix of both species of Linux distributions. “Imagine the large number of PL/1 and Cobol systems in banks and insurance companies. Think about in-memory databases and core data bus systems,” said Eckermann.
|
||||
|
||||
Most of these applications can’t be containerized. As much as we would like to think, containerization is not a silver bullet that solves every problem. There will always be a mix of different technologies.
|
||||
|
||||
Eckermann believes that over time, a huge number of new developments and deployments will go into containerization, but there is still good reason to keep traditional deployment methods and applications in the enterprise.
|
||||
|
||||
“Customers need to undergo business, design, and cultural transformations in order to maximize the advantages that container-based deployments are delivering. The good news is that the industry understands this, as a similar transformation at scale occurred with the historical moves from mainframes to UNIX to x86 to virtualization,” said Pacheco.
|
||||
|
||||
### Conclusion
|
||||
|
||||
It’s apparent that the volume of containerized workloads will increase in the future, which translates into more demand for atomic distros. In the meantime, a substantial percentage of workloads may remain on traditional distros that will keep them running. What really matters is that both players have invested heavily in new models and are ready to tweak their strategy as the market evolves. An external observer can clearly see that the future belongs to transactional/atomic models. We have seen the evolution of datacenter; we have come a long way from one application per server to function-as-a-service model. It is not far fetched to see Linux distros entering the atomic phase.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/4/containerization-atomic-distributions-and-future-linux
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.suse.com/products/caas-platform/
|
||||
[2]:https://www.digitalocean.com/community/tutorials/what-is-immutable-infrastructure
|
||||
@ -0,0 +1,177 @@
|
||||
Emacs #5: Documents and Presentations with org-mode
|
||||
======
|
||||
|
||||
### 1 About org-mode exporting
|
||||
|
||||
#### 1.1 Background
|
||||
|
||||
org-mode isn't just an agenda-making program. It can also export to lots of formats: LaTeX, PDF, Beamer, iCalendar (agendas), HTML, Markdown, ODT, plain text, man pages, and more complicated formats such as a set of web pages.
|
||||
|
||||
This isn't just some afterthought either; it's a core part of the system and integrates very well.
|
||||
|
||||
One file can be source code, automatically-generated output, task list, documentation, and presentation, all at once.
|
||||
|
||||
Some use org-mode as their preferred markup format, even for things like LaTeX documents. The org-mode manual has an extensive [section on exporting][13].
|
||||
|
||||
#### 1.2 Getting started
|
||||
|
||||
From any org-mode document, just hit C-c C-e. From there will come up a menu, letting you choose various export formats and options. These are generally single-key options so it's easy to set and execute. For instance, to export a document to a PDF, use C-c C-e l p or for HTML export, C-c C-e h h.
|
||||
|
||||
There are lots of settings available for all of these export options; see the manual. It is, in fact, quite possible to use LaTeX-format equations in both LaTeX and HTML modes, to insert arbitrary preambles and settings for different modes, etc.
|
||||
|
||||
#### 1.3 Add-on packages
|
||||
|
||||
ELPA containts many addition exporters for org-mode as well. Check there for details.
|
||||
|
||||
### 2 Beamer slides with org-mode
|
||||
|
||||
#### 2.1 About Beamer
|
||||
|
||||
[Beamer][14] is a LaTeX environment for making presentations. Its features include:
|
||||
|
||||
* Automated generating of structural elements in the presentation (see, for example, [the Marburg theme][1]). This provides a visual reference for the audience of where they are in the presentation.
|
||||
|
||||
* Strong help for structuring the presentation
|
||||
|
||||
* Themes
|
||||
|
||||
* Full LaTeX available
|
||||
|
||||
#### 2.2 Benefits of Beamer in org-mode
|
||||
|
||||
org-mode has a lot of benefits for working with Beamer. Among them:
|
||||
|
||||
* org-mode's very easy and strong support for visualizing and changing the structure makes it very quick to reorganize your material.
|
||||
|
||||
* Combined with org-babel, live source code (with syntax highlighting) and results can be embedded.
|
||||
|
||||
* The syntax is often easier to work with.
|
||||
|
||||
I have completely replaced my usage of LibreOffice/Powerpoint/GoogleDocs with org-mode and beamer. It is, in fact, rather frustrating when I have to use one of those tools, as they are nowhere near as strong as org-mode for visualizing a presentation structure.
|
||||
|
||||
#### 2.3 Headline Levels
|
||||
|
||||
org-mode's Beamer export will convert sections of your document (defined by headings) into slides. The question, of course, is: which sections? This is governed by the H [export setting][15] (org-export-headline-levels).
|
||||
|
||||
There are many ways to go, which suit people. I like to have my presentation like this:
|
||||
|
||||
```
|
||||
#+OPTIONS: H:2
|
||||
#+BEAMER_HEADER: \AtBeginSection{\frame{\sectionpage}}
|
||||
```
|
||||
|
||||
This gives a standalone section slide for each major topic, to highlight major transitions, and then takes the level 2 (two asterisks) headings to set the slide. Many Beamer themes expect a third level of indirection, so you would set H:3 for them.
|
||||
|
||||
#### 2.4 Themes and settings
|
||||
|
||||
You can configure many Beamer and LaTeX settings in your document by inserting lines at the top of your org file. This document, for instance, defines:
|
||||
|
||||
```
|
||||
#+TITLE: Documents and presentations with org-mode
|
||||
#+AUTHOR: John Goerzen
|
||||
#+BEAMER_HEADER: \institute{The Changelog}
|
||||
#+PROPERTY: comments yes
|
||||
#+PROPERTY: header-args :exports both :eval never-export
|
||||
#+OPTIONS: H:2
|
||||
#+BEAMER_THEME: CambridgeUS
|
||||
#+BEAMER_COLOR_THEME: default
|
||||
```
|
||||
|
||||
#### 2.5 Advanced settings
|
||||
|
||||
I like to change some colors, bullet formatting, and the like. I round out my document with:
|
||||
|
||||
```
|
||||
# We can't just +BEAMER_INNER_THEME: default because that picks the theme default.
|
||||
# Override per https://tex.stackexchange.com/questions/11168/change-bullet-style-formatting-in-beamer
|
||||
#+BEAMER_INNER_THEME: default
|
||||
#+LaTeX_CLASS_OPTIONS: [aspectratio=169]
|
||||
#+BEAMER_HEADER: \definecolor{links}{HTML}{0000A0}
|
||||
#+BEAMER_HEADER: \hypersetup{colorlinks=,linkcolor=,urlcolor=links}
|
||||
#+BEAMER_HEADER: \setbeamertemplate{itemize items}[default]
|
||||
#+BEAMER_HEADER: \setbeamertemplate{enumerate items}[default]
|
||||
#+BEAMER_HEADER: \setbeamertemplate{items}[default]
|
||||
#+BEAMER_HEADER: \setbeamercolor*{local structure}{fg=darkred}
|
||||
#+BEAMER_HEADER: \setbeamercolor{section in toc}{fg=darkred}
|
||||
#+BEAMER_HEADER: \setlength{\parskip}{\smallskipamount}
|
||||
```
|
||||
|
||||
Here, aspectratio=169 sets a 16:9 aspect ratio, and the remaining are standard LaTeX/Beamer configuration bits.
|
||||
|
||||
#### 2.6 Shrink (to fit)
|
||||
|
||||
Sometimes you've got some really large code examples and you might prefer to just shrink the slide to fit.
|
||||
|
||||
Just type C-c C-x p, set the BEAMER_opt property to shrink=15\.
|
||||
|
||||
(Or a larger value of shrink). The previous slide uses this here.
|
||||
|
||||
#### 2.7 Result
|
||||
|
||||
Here's the end result:
|
||||
|
||||
[][16]
|
||||
|
||||
### 3 Interactive Slides
|
||||
|
||||
#### 3.1 Interactive Emacs Slideshows
|
||||
|
||||
With the [org-tree-slide package][17], you can display your slideshow from right within Emacs. Just run M-x org-tree-slide-mode. Then, use C-> and C-< to move between slides.
|
||||
|
||||
You might find C-c C-x C-v (which is org-toggle-inline-images) helpful to cause the system to display embedded images.
|
||||
|
||||
#### 3.2 HTML Slideshows
|
||||
|
||||
There are a lot of ways to export org-mode presentations to HTML, with various levels of JavaScript integration. See the [non-beamer presentations section][18] of the org-mode wiki for details.
|
||||
|
||||
### 4 Miscellaneous
|
||||
|
||||
#### 4.1 Additional resources to accompany this post
|
||||
|
||||
* [orgmode.org beamer tutorial][2]
|
||||
|
||||
* [LaTeX wiki][3]
|
||||
|
||||
* [Generating section title slides][4]
|
||||
|
||||
* [Shrinking content to fit on slide][5]
|
||||
|
||||
* A great resource: refcard-org-beamer See its [Github repo][6] Make sure to check out both the PDF and the .org file
|
||||
|
||||
* A nice [Theme matrix][7]
|
||||
|
||||
#### 4.2 Up next in my Emacs series…
|
||||
|
||||
mu4e for email!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9900-emacs-5-documents-and-presentations-with-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://hartwork.org/beamer-theme-matrix/all/beamer-albatross-Marburg-1.png
|
||||
[2]:https://orgmode.org/worg/exporters/beamer/tutorial.html
|
||||
[3]:https://en.wikibooks.org/wiki/LaTeX/Presentations
|
||||
[4]:https://tex.stackexchange.com/questions/117658/automatically-generate-section-title-slides-in-beamer/117661
|
||||
[5]:https://tex.stackexchange.com/questions/78514/content-doesnt-fit-in-one-slide
|
||||
[6]:https://github.com/fniessen/refcard-org-beamer
|
||||
[7]:https://hartwork.org/beamer-theme-matrix/
|
||||
[8]:https://changelog.complete.org/archives/tag/emacs2018
|
||||
[9]:https://github.com/jgoerzen/public-snippets/blob/master/emacs/emacs-org-beamer/emacs-org-beamer.org
|
||||
[10]:http://changelog.complete.org/archives/9900-emacs-5-documents-and-presentations-with-org-mode
|
||||
[11]:https://github.com/jgoerzen/public-snippets/raw/master/emacs/emacs-org-beamer/emacs-org-beamer.pdf
|
||||
[12]:https://github.com/jgoerzen/public-snippets/raw/master/emacs/emacs-org-beamer/emacs-org-beamer-document.pdf
|
||||
[13]:https://orgmode.org/manual/Exporting.html#Exporting
|
||||
[14]:https://en.wikipedia.org/wiki/Beamer_(LaTeX)
|
||||
[15]:https://orgmode.org/manual/Export-settings.html#Export-settings
|
||||
[16]:https://www.flickr.com/photos/jgoerzen/26366340577/in/dateposted/
|
||||
[17]:https://orgmode.org/worg/org-tutorials/non-beamer-presentations.html#org-tree-slide
|
||||
[18]:https://orgmode.org/worg/org-tutorials/non-beamer-presentations.html
|
||||
164
sources/tech/20180405 Getting started with Vagrant.md
Normal file
164
sources/tech/20180405 Getting started with Vagrant.md
Normal file
@ -0,0 +1,164 @@
|
||||
Getting started with Vagrant
|
||||
======
|
||||
|
||||
|
||||
If you're like me, you probably have a "sandbox" somewhere, a place where you hack on whatever projects you're working on. Over time, the sandbox will get crufty and cluttered with bits and pieces of ideas, toolchain elements, code modules you aren't using, and other stuff you don't need. When you finish something, this can complicate your deployment, because you may be unsure of the actual dependencies of your project—you've had some tool in your sandbox for so long that you forget it must be installed. You need a clean environment, with all your dependencies in one place, to make things easier later.
|
||||
|
||||
Or maybe you're in DevOps, and the developers you serve hand you code with muddy dependencies, and it makes testing that much harder. You need a way to have a clean box to pull in the code and run it through its paces. You want these environments to be disposable and repeatable.
|
||||
|
||||
Enter [Vagrant][1]. Created by HashiCorp under the [MIT License][2], Vagrant acts as a wrapper and frontend for VirtualBox, Microsoft Hyper-V, or Docker containers, and it is extensible with plugins for [a great many other providers][3]. You can configure Vagrant to provide repeatably clean environments with needed infrastructure already installed. The configuration script is portable, so if your repository and Vagrant configuration script are on cloud-based storage, you can spin up and work on multiple machines with just a few limitations. Let's take a look.
|
||||
|
||||
### Installation
|
||||
|
||||
For this installation, I'm working on my Linux Mint desktop, version 18.3 Cinnamon 64-bit. Installation is very similar on most other Debian-derived systems, and there are similar installers for RPM-based systems on most distributions. Vagrant's [installation page][4] provides downloads for Debian, Windows, CentOS, MacOS, and Arch Linux, but I found it in my package manager, so I'll install that.
|
||||
|
||||
The easiest install uses VirtualBox for the virtualization provider, so I'll need to install that, as well.
|
||||
```
|
||||
sudo apt-get install virtualbox vagrant
|
||||
|
||||
```
|
||||
|
||||
The installer will pick up the dependencies—mostly Ruby stuff—and install them.
|
||||
|
||||
### Setting up a project
|
||||
|
||||
Before setting up your project, you'll need to know a bit about the environment where you want to run it. You can find a whole bunch of preconfigured boxes for many virtualization providers at the [Vagrant Boxes repository][5]. Many will be pre-configured with some core infrastructure you might need, like PHP, MySQL, and Apache, but for this test, I'm going to install a bare Debian 8 64-bit "Jessie" box and manually install a few things, just so you can see how.
|
||||
```
|
||||
mkdir ~/myproject
|
||||
|
||||
cd ~/myproject
|
||||
|
||||
vagrant init debian/contrib-jessie64
|
||||
|
||||
vagrant up
|
||||
|
||||
```
|
||||
|
||||
The last command will fetch or update the VirtualBox image from the library, as needed, then pull the starter, and you'll have a running box on your system! The next time you start the box, it won't take as long, unless the image has been updated in the repository.
|
||||
|
||||
To access the box, just enter `vagrant ssh`. You'll be dropped into a fully functional SSH session on the virtual machine. You'll be user `vagrant`, but you're a member of the `sudo` group, so you can change to root and do whatever you want from here.
|
||||
|
||||
You'll see a directory named `/vagrant` on the box. Be careful with this directory, as it'll be synced with the `~/myproject` folder on the host machine. Touch a file in `/vagrant` on the virtual machine, and it's immediately copied out to the host, and vice versa. Be aware that some boxes do not have the VirtualBox guest additions installed, so the copy works only one-way and only at boot time! There are some command-line tools for manual syncing, which might be a really useful feature in a testing environment. I tend to stick to boxes that have the additions in place, so this directory syncing just works without me having to think about it.
|
||||
|
||||
The benefits of this scheme become quickly apparent: If you have a code-editing toolchain on the host and don't want it on the virtual machine for any reason, that's not a problem—edit on the host, and the VM sees the change at once. Make a quick change on the VM, and it's synced to the "official" copy on the host, as well.
|
||||
|
||||
Let's shut the box down so we can provision some things we'll need on this box: `vagrant halt`.
|
||||
|
||||
### Installing additional software on the VM, consistently
|
||||
|
||||
For this example, I'm going to work on a project using [Apache][6], [PostgreSQL][7], and the [Dancer][8] web framework for Perl. I'll modify the Vagrant configuration script so that the things I need are already installed. Just to make things easy to keep it updated later, I'll create a script at the top of `~/myproject/Vagrantfile`:
|
||||
```
|
||||
$provision_script = <<SCRIPT
|
||||
|
||||
export DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get -y install \
|
||||
|
||||
apache2 \
|
||||
|
||||
postgresql-client-9.4 \
|
||||
|
||||
postgresql-9.4 \
|
||||
|
||||
libdbd-pg-perl \
|
||||
|
||||
libapache2-mod-fastcgi \
|
||||
|
||||
libdata-validate-email-perl \
|
||||
|
||||
libexception-class-perl \
|
||||
|
||||
libexception-class-trycatch-perl \
|
||||
|
||||
libtemplate-perl \
|
||||
|
||||
libtemplate-plugin-json-escape-perl \
|
||||
|
||||
libdbix-class-perl \
|
||||
|
||||
libyaml-tiny-perl \
|
||||
|
||||
libcrypt-saltedhash-perl \
|
||||
|
||||
libdancer2-perl \
|
||||
|
||||
libtemplate-plugin-gravatar-perl \
|
||||
|
||||
libtext-csv-perl \
|
||||
|
||||
libstring-tokenizer-perl \
|
||||
|
||||
cpanminus
|
||||
|
||||
cpanm -f -n \
|
||||
|
||||
Dancer2::Session::Cookie \
|
||||
|
||||
Dancer2::Plugin::DBIC \
|
||||
|
||||
Dancer2::Plugin::Auth::Extensible::Provider::DBIC \
|
||||
|
||||
Dancer2::Plugin::Locale \
|
||||
|
||||
Dancer2::Plugin::Growler
|
||||
|
||||
sudo a2enmod rewrite fastcgi
|
||||
|
||||
sudo apache2ctl restart
|
||||
|
||||
SCRIPT
|
||||
|
||||
```
|
||||
|
||||
Down near the end of the Vagrantfile, you'll find a line for the `config.vm.provision` variable. You could do that inline here, as you see in the example, merely by uncommenting these lines:
|
||||
```
|
||||
# config.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
# sudo apt-get update
|
||||
|
||||
# sudo apt-get install -y apache2
|
||||
|
||||
# SHELL
|
||||
|
||||
```
|
||||
|
||||
But instead, replace those four lines to use the provisioning script you defined as a variable at the top of the file:
|
||||
```
|
||||
config.vm.provision "shell", inline: $provision_script
|
||||
|
||||
```
|
||||
|
||||
`forwarded_port` and uncomment it. You can change the port from 8080 to something else, if you want, as well. I normally use port 5000, and accessing `http://localhost:5000` in my browser gets me to the Apache server on the virtual machine.
|
||||
|
||||
You'll probably also want to set the forwarded port to access Apache on the VM from your host machine. Look for the line containingand uncomment it. You can change the port from 8080 to something else, if you want, as well. I normally use port 5000, and accessingin my browser gets me to the Apache server on the virtual machine.
|
||||
|
||||
Here's a setup tip: if your repository is on cloud storage, in order to use Vagrant on multiple machines, you'll probably want to set the `VAGRANT_HOME` environment variable on different machines to different things. With the way VirtualBox works, you'll want to store state information separately for these systems. Make sure the directories being used for this are ignored by your version control—I add `.vagrant.d*` to my `.gitignore` file for the repository. I do let the Vagrantfile be part of the repository, though!
|
||||
|
||||
### All done!
|
||||
|
||||
I enter `vagrant up`, and I'm ready to start writing code. Once you've done this once or twice, you'll probably come up with some Vagrantfile boilerplates you'll recycle a lot (like the one I just used), and that's one of the strengths of Vagrant. You get to the actual coding work quicker and spend less time on infrastructure!
|
||||
|
||||
There's a lot more you can do with Vagrant. Provisioning tools exist for many toolchains, so no matter what environment you need to replicate, it's quick and easy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/getting-started-vagrant
|
||||
|
||||
作者:[Ruth Holloway][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/druthb
|
||||
[1]:https://vagrantup.com
|
||||
[2]:https://opensource.org/licenses/MIT
|
||||
[3]:https://github.com/hashicorp/vagrant/wiki/Available-Vagrant-Plugins#providers
|
||||
[4]:https://www.vagrantup.com/downloads.html
|
||||
[5]:https://app.vagrantup.com/boxes/search
|
||||
[6]:https://httpd.apache.org/
|
||||
[7]:https://postgresql.org
|
||||
[8]:https://perldancer.org
|
||||
74
sources/tech/20180405 How to find files in Linux.md
Normal file
74
sources/tech/20180405 How to find files in Linux.md
Normal file
@ -0,0 +1,74 @@
|
||||
How to find files in Linux
|
||||
======
|
||||
|
||||

|
||||
If you're a Windows user or a non-power-user of OSX, you probably use a GUI to find files. You may also find the interface limited, frustrating, or both, and have learned to excel at organizing things and remembering the exact order of your files. You can do that in Linux, too—but you don't have to.
|
||||
|
||||
One of the best things about Linux is that it offers a variety of ways to do things. You can open any file manager and `ctrl`+`f`, you can use the program you are in to open files manually, or you can simply start typing letters and it'll filter the current directory listing.
|
||||
|
||||
![Screenshot of how to find files in Linux with Ctrl+F][2]
|
||||
|
||||
Screenshot of how to find files in Linux with Ctrl+F
|
||||
|
||||
But what if you don't know where your file is and don't want to search the entire disk? Linux is well-tooled for this and a variety of other use-cases.
|
||||
|
||||
### Finding program locations by command name
|
||||
|
||||
The Linux file system can seem daunting if you're used to putting things wherever you like. For me, one of the hardest things to get used to was finding where programs are supposed to live.
|
||||
|
||||
For example, `which bash` will usually return `/bin/bash`, but if you download a program and it doesn't appear in your menus, the `which` command can be a great tool.
|
||||
|
||||
A similar utility is the `locate` command, which I find useful for finding configuration files. I don't like typing in program names because simple ones like `locate php` often offer many results that need to be filtered further.
|
||||
|
||||
For more information about `locate` and `which`, see the `man` pages:
|
||||
|
||||
* `man which`
|
||||
* `man locate`
|
||||
|
||||
|
||||
|
||||
### Find
|
||||
|
||||
The `find` utility offers much more advanced functionality. Below is an example from a script I've installed on a number of servers that I administer to ensure that a specific pattern of file (also known as a glob) exists for only five days and all files older than that are deleted. (Since its last modification, a decimal is used to account for up to 240 minutes difference.)
|
||||
```
|
||||
find ./backup/core-files*.tar.gz -mtime +4.9 -exec rm {} \;
|
||||
|
||||
```
|
||||
|
||||
The `find` utility has many advanced use-cases, but most common is executing commands on results without chaining and filtering files by type, creation, and modification date.
|
||||
|
||||
Another interesting use of `find` is to find all files with executable permissions. This can help ensure that nobody is installing bitcoin miners or botnets on your expensive servers.
|
||||
```
|
||||
find / -perm /+x
|
||||
|
||||
```
|
||||
|
||||
For more information on `find`, see the `man` page using `man find.`
|
||||
|
||||
### Grep
|
||||
|
||||
Want to find a file by its contents? Linux has it covered. You can use many Linux utilities to efficiently search for files that match a pattern, but `grep` is one that I use often.
|
||||
|
||||
Suppose you have an application that's delivering error messages with a code reference and stack trace. You find these in your logs. Grepping is not always the go-to, but I always `grep -R` if the issue is with a supplied value.
|
||||
|
||||
An increasing number of IDEs are implementing find functions, but if you're accessing a remote system or for whatever reason don't have a GUI, or if you want to iterate in-place, then use: `grep -R {searchterm}` or on systems supporting `egrep` alias; just add `-e` flag to command `egrep -r {regex-pattern}`.
|
||||
|
||||
I used this technique when patching the `dhcpcd5` in [Raspbian][3] last year so I could continue to operate a network access point on newer Debian releases from the [Raspberry Pi Foundation][4].
|
||||
|
||||
What tips help you search for files more efficiently on Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/how-find-files-linux
|
||||
|
||||
作者:[Lewis Cowles][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/lewiscowles1986
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/find-files-in-linux-ctrlf.png?itok=1gf9kIut (Screenshot of how to find files in Linux with Ctrl+F)
|
||||
[3]:https://www.raspbian.org/
|
||||
[4]:https://www.raspberrypi.org/
|
||||
@ -0,0 +1,310 @@
|
||||
The fc Command Tutorial With Examples For Beginners
|
||||
======
|
||||
|
||||

|
||||
The **fc** command, short for **f** ix **c** ommands, is a shell built-in command used to list, edit and re-execute the most recently entered commands in to an interactive shell. You can edit the recently entered commands in your favorite editor and run them without having to retype the entire commands. This command can be helpful to correct the spelling mistakes in the previously entered commands and avoids the repetition of long and complicated commands. Since it is shell-builtin, it is available in most shells, including Bash, Zsh, Ksh etc. In this brief tutorial, we are going to learn to use fc command in Linux.
|
||||
|
||||
### The fc Command Tutorial With Examples
|
||||
|
||||
**List the recently executed commands**
|
||||
|
||||
If you run “fc -l” command with no arguments, it will display the last **16** commands.
|
||||
```
|
||||
$ fc -l
|
||||
507 fish
|
||||
508 fc -l
|
||||
509 sudo netctl restart wlp9s0sktab
|
||||
510 ls -l
|
||||
511 pwd
|
||||
512 uname -r
|
||||
513 uname -a
|
||||
514 touch ostechnix.txt
|
||||
515 vi ostechnix.txt
|
||||
516 echo "Welcome to OSTechNix"
|
||||
517 sudo apcman -Syu
|
||||
518 sudo pacman -Syu
|
||||
519 more ostechnix.txt
|
||||
520 wc -l ostechnix.txt
|
||||
521 cat ostechnix.txt
|
||||
522 clear
|
||||
|
||||
```
|
||||
|
||||
To reverse the order of the commands, use **-r** flag.
|
||||
```
|
||||
$ fc -l
|
||||
|
||||
```
|
||||
|
||||
You can suppress the line numbers using “-n” parameter.
|
||||
```
|
||||
$ fc -ln
|
||||
nano ~/.profile
|
||||
source ~/.profile
|
||||
source ~/.profile
|
||||
fc -ln
|
||||
fc -l
|
||||
sudo netctl restart wlp9s0sktab
|
||||
ls -l
|
||||
pwd
|
||||
uname -r
|
||||
uname -a
|
||||
echo "Welcome to OSTechNix"
|
||||
sudo apcman -Syu
|
||||
cat ostechnix.txt
|
||||
wc -l ostechnix.txt
|
||||
more ostechnix.txt
|
||||
clear
|
||||
|
||||
```
|
||||
|
||||
Now you won’t see the line numbers.
|
||||
|
||||
To list the result staring from a specific command, simply use the line number along with **-l** option. For instance, to display the commands starting from line number 520 up to the present, we do:
|
||||
```
|
||||
$ fc -l 520
|
||||
520 ls -l
|
||||
521 pwd
|
||||
522 uname -r
|
||||
523 uname -a
|
||||
524 echo "Welcome to OSTechNix"
|
||||
525 sudo apcman -Syu
|
||||
526 cat ostechnix.txt
|
||||
527 wc -l ostechnix.txt
|
||||
528 more ostechnix.txt
|
||||
529 clear
|
||||
530 fc -ln
|
||||
531 fc -l
|
||||
|
||||
```
|
||||
|
||||
To list a commands within a specific range, for example 520 to 525, do:
|
||||
```
|
||||
$ fc -l 520 525
|
||||
520 ls -l
|
||||
521 pwd
|
||||
522 uname -r
|
||||
523 uname -a
|
||||
524 echo "Welcome to OSTechNix"
|
||||
525 sudo apcman -Syu
|
||||
|
||||
```
|
||||
|
||||
Instead of using the line numbers, we can also use strings. For example, list the commands starting from “pwd” command up to the resent, just use the staring letter of that command (i.e **p** ) like below.
|
||||
```
|
||||
$ fc -l p
|
||||
521 pwd
|
||||
522 uname -r
|
||||
523 uname -a
|
||||
524 echo "Welcome to OSTechNix"
|
||||
525 sudo apcman -Syu
|
||||
526 cat ostechnix.txt
|
||||
527 wc -l ostechnix.txt
|
||||
528 more ostechnix.txt
|
||||
529 clear
|
||||
530 fc -ln
|
||||
531 fc -l
|
||||
532 fc -l 520
|
||||
533 fc -l 520 525
|
||||
534 fc -l 520
|
||||
535 fc -l 522
|
||||
536 fc -l l
|
||||
|
||||
```
|
||||
|
||||
To see everything between “pwd” to “more” command, you could use either:
|
||||
```
|
||||
$ fc -l p m
|
||||
|
||||
```
|
||||
|
||||
Or, use combination of first letter of the starting command command and line number of the ending command:
|
||||
```
|
||||
$ fc -l p 528
|
||||
|
||||
```
|
||||
|
||||
Or, just line numbers of starting and ending commands:
|
||||
```
|
||||
$ fc -l 521 528
|
||||
|
||||
```
|
||||
|
||||
All of these three commands will display the same result.
|
||||
|
||||
**Edit and re-run the last command automatically**
|
||||
|
||||
At times, you might misspelled a previous command. In such situations, you can easily edit the spelling mistakes of the command using your default editor and execute it without having to retype again.
|
||||
|
||||
To edit the last command and re-run it again, do:
|
||||
```
|
||||
$ fc
|
||||
|
||||
```
|
||||
|
||||
This will open your last command in the default editor.
|
||||
|
||||
![][2]
|
||||
|
||||
As you see in the above screenshot, my last command was “fc -l”. You can make any changes in the command and re-run it automatically again once you save and quit the editor. This can be useful when you use long and complicated commands or arguments. Please be mindful that this also can be a **destructive**. For example, if the previous command was a deadly command like “rm -fr <some-path>”, it will automatically execute and you may lost your important data. So, be very careful before using command.
|
||||
|
||||
**Change the default editor to edit commands**
|
||||
|
||||
Another notable option of fc is **“e”** to choose a different editor to edit the commands. For example, we can use “nano” editor to edit the last command like below.
|
||||
```
|
||||
$ fc -e nano
|
||||
|
||||
```
|
||||
|
||||
This command will open the nano editor(instead of the default editor) to edit last command.
|
||||
|
||||
![][3]
|
||||
|
||||
You may find it time consuming to use **-e** option for each command. To make the new editor as your default, just set the environment variable **FCEDIT** to the name of the editor you want **fc** to use.
|
||||
|
||||
For example, to set “nano” as the new default editor, edit your **~/.profile** or environment file:
|
||||
```
|
||||
$ vi ~/.profile
|
||||
|
||||
```
|
||||
|
||||
Add the following line:
|
||||
```
|
||||
FCEDIT=nano
|
||||
|
||||
```
|
||||
|
||||
You can also use the full path of the editor like below.
|
||||
```
|
||||
FCEDIT=/usr/local/bin/emacs
|
||||
|
||||
```
|
||||
|
||||
Type **:wq** to save and close the file. To update the changes, run:
|
||||
```
|
||||
$ source ~/.profile
|
||||
|
||||
```
|
||||
|
||||
Now, you can just type to “fc” to edit the last command using “nano” editor.
|
||||
|
||||
**Re-run the last command without editing it**
|
||||
|
||||
We already knew if we run “fc” without any arguments, it loads the editor with the most recent command. At times, you may not want to edit, but simply execute the last command. To do so, use hyphen (-) symbol at the end as shown below.
|
||||
```
|
||||
$ echo "Welcome to OSTechNix"
|
||||
Welcome to OSTechNix
|
||||
|
||||
$ fc -e -
|
||||
echo "Welcome to OSTechNix"
|
||||
Welcome to OSTechNix
|
||||
|
||||
```
|
||||
|
||||
As you see, fc didn’t edit the last command (i.e echo “Welcome to OSTechNix”) even if I used **-e** option.
|
||||
|
||||
Please note that some of the options are shell-specific. They may not work in other shells. For example the following options can be used in **zsh** shell. It won’t work in Bash or Ksh shells.
|
||||
|
||||
**Display when the commands were executed**
|
||||
|
||||
To view when the commands were run, use **-d** like below.
|
||||
```
|
||||
fc -ld
|
||||
1 18:41 exit
|
||||
2 18:41 clear
|
||||
3 18:42 fc -l
|
||||
4 18:42 sudo netctl restart wlp9s0sktab
|
||||
5 18:42 ls -l
|
||||
6 18:42 pwd
|
||||
7 18:42 uname -r
|
||||
8 18:43 uname -a
|
||||
9 18:43 cat ostechnix.txt
|
||||
10 18:43 echo "Welcome to OSTechNix"
|
||||
11 18:43 more ostechnix.txt
|
||||
12 18:43 wc -l ostechnix.txt
|
||||
13 18:43 cat ostechnix.txt
|
||||
14 18:43 clear
|
||||
15 18:43 fc -l
|
||||
|
||||
```
|
||||
|
||||
Now you see the execution time of most recently executed commands.
|
||||
|
||||
We can also display the full timestamp of each command using **-f** option.
|
||||
```
|
||||
fc -lf
|
||||
1 4/5/2018 18:41 exit
|
||||
2 4/5/2018 18:41 clear
|
||||
3 4/5/2018 18:42 fc -l
|
||||
4 4/5/2018 18:42 sudo netctl restart wlp9s0sktab
|
||||
5 4/5/2018 18:42 ls -l
|
||||
6 4/5/2018 18:42 pwd
|
||||
7 4/5/2018 18:42 uname -r
|
||||
8 4/5/2018 18:43 uname -a
|
||||
9 4/5/2018 18:43 cat ostechnix.txt
|
||||
10 4/5/2018 18:43 echo "Welcome to OSTechNix"
|
||||
11 4/5/2018 18:43 more ostechnix.txt
|
||||
12 4/5/2018 18:43 wc -l ostechnix.txt
|
||||
13 4/5/2018 18:43 cat ostechnix.txt
|
||||
14 4/5/2018 18:43 clear
|
||||
15 4/5/2018 18:43 fc -l
|
||||
16 4/5/2018 18:43 fc -ld
|
||||
|
||||
```
|
||||
|
||||
Of course, the European folks can use european date format using **-E** option.
|
||||
```
|
||||
fc -lE
|
||||
2 5.4.2018 18:41 clear
|
||||
3 5.4.2018 18:42 fc -l
|
||||
4 5.4.2018 18:42 sudo netctl restart wlp9s0sktab
|
||||
5 5.4.2018 18:42 ls -l
|
||||
6 5.4.2018 18:42 pwd
|
||||
7 5.4.2018 18:42 uname -r
|
||||
8 5.4.2018 18:43 uname -a
|
||||
9 5.4.2018 18:43 cat ostechnix.txt
|
||||
10 5.4.2018 18:43 echo "Welcome to OSTechNix"
|
||||
11 5.4.2018 18:43 more ostechnix.txt
|
||||
12 5.4.2018 18:43 wc -l ostechnix.txt
|
||||
13 5.4.2018 18:43 cat ostechnix.txt
|
||||
14 5.4.2018 18:43 clear
|
||||
15 5.4.2018 18:43 fc -l
|
||||
16 5.4.2018 18:43 fc -ld
|
||||
17 5.4.2018 18:49 fc -lf
|
||||
|
||||
```
|
||||
|
||||
### TL;DR
|
||||
|
||||
* When running without any arguments, fc will load the most recent command in the default text editor.
|
||||
* When running with a numeric argument, fc loads the editor with the command with that specified number.
|
||||
* When running with a string argument, fc loads the most recent command starting with that specified string.
|
||||
* When running with two arguments to fc , the arguments specify the beginning and end of a range of commands.
|
||||
|
||||
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man fc
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for today. Hope you find this article useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-fc-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/04/fc-command-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/04/fc-command-2.png
|
||||
@ -0,0 +1,302 @@
|
||||
How To Register The Oracle Linux System With The Unbreakable Linux Network (ULN)
|
||||
======
|
||||
Most of us knows about RHEL subscription but only few of them knows about Oracle subscription and its details.
|
||||
|
||||
Even i don’t know the information about this and i recently came to know about this and wants to share this with others so, i’m going to write a article which will guide you to register the Oracle Linux system with the Unbreakable Linux Network (ULN).
|
||||
|
||||
This allows the register systems to get software update and other patches ASAP.
|
||||
|
||||
### What Is Unbreakable Linux Network
|
||||
|
||||
ULN stands for Unbreakable Linux Network which is owned by Oracle. If you have a active subscription to Oracle OS Support, you can register your system with Unbreakable Linux Network (ULN).
|
||||
|
||||
ULN offers software patches, updates, and fixes for Oracle Linux and Oracle VM, as well as information on yum, Ksplice, and support policies. You can also download useful packages that are not included in the original distribution.
|
||||
|
||||
The ULN Alert Notification Tool periodically checks with ULN and alerts you when updates are available.
|
||||
|
||||
If you want to use ULN repository with yum to manage your systems, make sure your system should registered with ULN and subscribe each system to one or more ULN channels. When you register a system with ULN, automatically it will choose latest version of channel based on the system architecture and OS.
|
||||
|
||||
### How To Register As A ULN User
|
||||
|
||||
To register as a ULN user, make sure you have a valid customer support identifier (CSI) for Oracle Linux support or Oracle VM support.
|
||||
|
||||
Follow the below steps to register as a ULN user.
|
||||
|
||||
Visit @ [linux.oracle.com][1]
|
||||
![][3]
|
||||
|
||||
If you already have an SSO account, click Sign On.
|
||||
![][4]
|
||||
|
||||
If you don’t have a account, click Create New Single Signon Account and follow the onscreen instructions to create one.
|
||||
![][5]
|
||||
|
||||
Verify your email address to complete your account setup.
|
||||
|
||||
Log in using your SSO user name and password. On the Create New ULN User page, enter your CSI and click Create New User.
|
||||
![][6]
|
||||
|
||||
**Note :**
|
||||
|
||||
* If no administrator is currently assigned to manage the CSI, you are prompted to click Confirm to become the CSI administrator.
|
||||
* If your user name already exists on the system, you are prompted to proceed to ULN by clicking the link Unbreakable Linux Network.
|
||||
|
||||
|
||||
|
||||
### How To Register The Oracle Linux 6/7 System With ULN
|
||||
|
||||
Just run the below command and follow the instruction to register the system.
|
||||
```
|
||||
# uln_register
|
||||
|
||||
```
|
||||
|
||||
Make sure your system is having active internet connection. Also keep ready your Oracle Single Sign-On Login & password (SSO) details then hit `Next`.
|
||||
```
|
||||
Copyright © 2006--2010 Red Hat, Inc. All rights reserved.
|
||||
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââââââââ⤠Setting up software updates âââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
â This assistant will guide you through connecting your system to Unbreakable Linux Network (ULN) to receive software updates, â
|
||||
â including security updates, to keep your system supported and compliant. You will need the following at this time: â
|
||||
â â
|
||||
â * A network connection â
|
||||
â * Your Oracle Single Sign-On Login & password â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â ââââââââââââââââââââââââââââââââââââ ââââââââ ââââââââââ â
|
||||
â â Why Should I Connect to ULN? ... â â Next â â Cancel â â
|
||||
â ââââââââââââââââââââââââââââââââââââ ââââââââ ââââââââââ â
|
||||
â â
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
|
||||
```
|
||||
|
||||
Input your login information for Unbreakable Linux Network, then hit `Next`.
|
||||
```
|
||||
Copyright © 2006--2010 Red Hat, Inc. All rights reserved.
|
||||
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââââââââ⤠Setting up software updates âââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
â â
|
||||
â Please enter your login information for Unbreakable Linux Network (http://linux.oracle.com/): â
|
||||
â â
|
||||
â â
|
||||
â Oracle Single Sign-On Login: [email protected] â
|
||||
â Password: **********__________ â
|
||||
â CSI: 12345678____________ â
|
||||
â Tip: Forgot your login or password? Visit: http://www.oracle.com/corporate/contact/getaccthelp.html â
|
||||
â â
|
||||
â ââââââââ ââââââââ ââââââââââ â
|
||||
â â Next â â Back â â Cancel â â
|
||||
â ââââââââ ââââââââ ââââââââââ â
|
||||
â â
|
||||
â â
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
|
||||
```
|
||||
|
||||
Register a System Profile – Hardware information, then hit `Next`.
|
||||
```
|
||||
Copyright © 2006--2010 Red Hat, Inc. All rights reserved.
|
||||
|
||||
âââââââââââââââââââââââââââââââââââââââââââââ⤠Register a System Profile - Hardware ââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
â â
|
||||
â A Profile Name is a descriptive name that you choose to identify this â
|
||||
â System Profile on the Unbreakable Linux Network web pages. Optionally, â
|
||||
â include a computer serial or identification number. â
|
||||
â Profile name: 2g-oracle-sys___________________________ â
|
||||
â â
|
||||
â [*] Include the following information about hardware and network: â
|
||||
â Press to deselect the option. â
|
||||
â â
|
||||
â Version: 6 CPU model: Intel(R) Xeon(R) CPU E5-5650 0 @ 2.00GHz â
|
||||
â Hostname: 2g-oracle-sys â
|
||||
â CPU speed: 1199 MHz IP Address: 192.168.1.101 Memory: â
|
||||
â â
|
||||
â Additional hardware information including PCI devices, disk sizes and mount points will be included in the profile. â
|
||||
â â
|
||||
â ââââââââ ââââââââ ââââââââââ â
|
||||
â â Next â â Back â â Cancel â â
|
||||
â ââââââââ ââââââââ ââââââââââ â
|
||||
â â
|
||||
â â
|
||||
âââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
|
||||
```
|
||||
|
||||
Register a System Profile – Packages configuration, then hit `Next`.
|
||||
```
|
||||
Copyright © 2006--2010 Red Hat, Inc. All rights reserved.
|
||||
|
||||
âââââââââââââââââââââââââââââââââââââââââââââ⤠Register a System Profile - Packages âââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
â â
|
||||
â RPM information is important to determine what updated software packages are relevant to this system. â
|
||||
â â
|
||||
â [*] Include RPM packages installed on this system in my System Profile â
|
||||
â â
|
||||
â You may deselect individual packages by unchecking them below. â
|
||||
â [*] ConsoleKit-0.4.1-6.el6 â â
|
||||
â [*] ConsoleKit-libs-0.4.1-6.el6 â â
|
||||
â [*] ConsoleKit-x11-0.4.1-6.el6 â â
|
||||
â [*] DeviceKit-power-014-3.el6 â â
|
||||
â [*] GConf2-2.28.0-7.el6 â â
|
||||
â [*] GConf2-2.28.0-7.el6 â â
|
||||
â [*] GConf2-devel-2.28.0-7.el6 â â
|
||||
â [*] GConf2-gtk-2.28.0-7.el6 â â
|
||||
â [*] MAKEDEV-3.24-6.el6 â â
|
||||
â [*] MySQL-python-1.2.3-0.3.c1.1.el6 â â
|
||||
â [*] NessusAgent-7.0.3-es6 â â
|
||||
â [*] ORBit2-2.14.17-6.el6_8 â â
|
||||
â [*] ORBit2-2.14.17-6.el6_8 â â
|
||||
â [*] ORBit2-devel-2.14.17-6.el6_8 â â
|
||||
â [*] PackageKit-0.5.8-26.0.1.el6 â â
|
||||
â [*] PackageKit-device-rebind-0.5.8-26.0.1.el6 â â
|
||||
â [*] PackageKit-glib-0.5.8-26.0.1.el6 â â
|
||||
â â
|
||||
â ââââââââ ââââââââ ââââââââââ â
|
||||
â â Next â â Back â â Cancel â â
|
||||
â ââââââââ ââââââââ ââââââââââ â
|
||||
â â
|
||||
â â
|
||||
âââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
|
||||
```
|
||||
|
||||
Press “Next” to send this System Profile to Unbreakable Linux Network.
|
||||
```
|
||||
Copyright © 2006--2010 Red Hat, Inc. All rights reserved.
|
||||
|
||||
âââââââââââââââââââââââââââââââââââ⤠Send Profile Information to Unbreakable Linux Network âââââââââââââââââââââââââââââââââââââ
|
||||
â â
|
||||
â We are finished collecting information for the System Profile. â
|
||||
â â
|
||||
â Press "Next" to send this System Profile to Unbreakable Linux Network. Click "Cancel" and no information will be sent. You â
|
||||
â can run the registration program later by typing `uln_register` at the command line. â
|
||||
â â
|
||||
â ââââââââ ââââââââ ââââââââââ â
|
||||
â â Next â â Back â â Cancel â â
|
||||
â ââââââââ ââââââââ ââââââââââ â
|
||||
â â
|
||||
â â
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
|
||||
```
|
||||
|
||||
Sending Profile to Unbreakable Linux Network is under processing.
|
||||
```
|
||||
Copyright © 2006--2010 Red Hat, Inc. All rights reserved.
|
||||
|
||||
|
||||
|
||||
â⤠Sending Profile to Unbreakable Linux Network â
|
||||
â â
|
||||
â 75% â
|
||||
â â
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
|
||||
```
|
||||
|
||||
ULN registration has been done and review system subscription details. If everything is fine, then hit `ok`.
|
||||
```
|
||||
Copyright © 2006--2010 Red Hat, Inc. All rights reserved.
|
||||
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââââââ⤠Review system subscription details ââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
â â
|
||||
â â
|
||||
â Note: yum-rhn-plugin has been enabled. â
|
||||
â â
|
||||
â Please review the subscription details below: â
|
||||
â â
|
||||
â Software channel subscriptions: â
|
||||
â This system will receive updates from the following Unbreakable Linux Network software channels: â
|
||||
â Oracle Linux 6 Latest (x86_64) â
|
||||
â Unbreakable Enterprise Kernel Release 4 for Oracle Linux 6 (x86_64) â
|
||||
â â
|
||||
â Warning: If an installed product on this system is not listed above, you will not receive updates or support for that product. If â
|
||||
â you would like to receive updates for that product, please visit http://linux.oracle.com/ and subscribe this system to the â
|
||||
â appropriate software channels to get updates for that product. â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â â
|
||||
â ââââââ â
|
||||
â â OK â â
|
||||
â ââââââ â
|
||||
â â
|
||||
â â
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
|
||||
```
|
||||
|
||||
Finally hit `Finish` to complete the registration.
|
||||
```
|
||||
Copyright © 2006--2010 Red Hat, Inc. All rights reserved.
|
||||
|
||||
|
||||
ââââââââââââââââââââââââââââââââââââââââââââââ⤠Finish setting up software updates âââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
â â
|
||||
â You may now run 'yum update' from this system's command line to get the latest software updates from Unbreakable Linux Network. â
|
||||
â You will need to run this periodically to get the latest updates. â
|
||||
â â
|
||||
â ââââââââââ â
|
||||
â â Finish â â
|
||||
â ââââââââââ â
|
||||
â â
|
||||
â â
|
||||
âââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââââ
|
||||
|
||||
```
|
||||
|
||||
ULN registration has been done successfully, in order to get repository from ULN run the following command.
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: aliases, changelog, presto, refresh-packagekit, rhnplugin, security, tmprepo, ulninfo, verify, versionlock
|
||||
This system is receiving updates from ULN.
|
||||
ol6_x86_64_UEKR3_latest | 1.2 kB 00:00
|
||||
ol6_x86_64_UEKR3_latest/primary | 35 MB 00:14
|
||||
ol6_x86_64_UEKR3_latest 874/874
|
||||
repo id repo name status
|
||||
ol6_x86_64_UEKR3_latest Unbreakable Enterprise Kernel Release 3 for Oracle Linux 6 (x86_64) - Latest 874
|
||||
ol6_x86_64_latest Oracle Linux 6 Latest (x86_64) 40,092
|
||||
repolist: 40,966
|
||||
|
||||
```
|
||||
|
||||
Also, you can check the same in ULN website. Go to the `System` tab to view the list of registered systems.
|
||||
![][7]
|
||||
|
||||
To view list of the enabled repositories. Go to the `System` tab then hit the corresponding system. Also, you can able to see the available updates for the system for errata.
|
||||
![][8]
|
||||
|
||||
To manage subscription channel. Go to the `System` tab, then hit appropriate `system name` and finally hit `Manage Subscriptions`.
|
||||
![][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-register-the-oracle-linux-system-with-the-unbreakable-linux-network-uln/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/vinoth/
|
||||
[1]:https://linux.oracle.com/register
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2018/04/How-To-Register-The-Oracle-Linux-System-With-The-Unbreakable-Linux-Network-ULN-1.png
|
||||
[4]:https://www.2daygeek.com/wp-content/uploads/2018/04/How-To-Register-The-Oracle-Linux-System-With-The-Unbreakable-Linux-Network-ULN-3.png
|
||||
[5]:https://www.2daygeek.com/wp-content/uploads/2018/04/How-To-Register-The-Oracle-Linux-System-With-The-Unbreakable-Linux-Network-ULN-2.png
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2018/04/How-To-Register-The-Oracle-Linux-System-With-The-Unbreakable-Linux-Network-ULN-4.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2018/04/How-To-Register-The-Oracle-Linux-System-With-The-Unbreakable-Linux-Network-ULN-5a.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2018/04/How-To-Register-The-Oracle-Linux-System-With-The-Unbreakable-Linux-Network-ULN-6a.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2018/04/How-To-Register-The-Oracle-Linux-System-With-The-Unbreakable-Linux-Network-ULN-7a.png
|
||||
@ -0,0 +1,147 @@
|
||||
MX Linux: A Mid-Weight Distro Focused on Simplicity
|
||||
======
|
||||
|
||||

|
||||
There are so many distributions of Linux. Some of those distributions go a very long way to differentiate themselves. In other cases, the differences are so minimal, you wonder why anyone would have bothered reinventing that particular wheel. It’s that latter concern that had me wondering why [antiX][1] and [MEPIS][2] communities would come together to create yet another distribution—especially given that the results would be an Xfce edition of antiX, built by the MEPIS community.
|
||||
|
||||
Does building antiX with an Xfce desktop warrant its own distribution? After all, antiX claims to be a “fast, lightweight and easy to install systemd-free linux live CD distribution based on Debian Stable.” The antiX desktop of choice is [LXDE][3], which does certainly fit the bill for a lightweight desktop. So why retool antiX into another lightweight distribution, only this time with Xfce? Well, as anyone within the Linux community knows, variance adds flavor and a good lightweight distribution is a worthwhile endeavor (especially in preventing old hardware from making its way to the landfill). Of course, LXDE and Xfce aren’t quite in the same category. LXDE should be considered a true lightweight desktop, whereas Xfce should be considered more a mid-weight desktop. And that, my friends, is key to why MX Linux is an important iteration of antiX. A mid-weight distribution, built on Debian, that includes all the tools you need to get your work done.
|
||||
|
||||
But there’s something really keen within MX Linux—something directly borrowed from antiX—and that is the installation tool. When I first set up a VirtualBox VM to install MX Linux, I assumed the installation would be the typical, incredibly easy Linux installation I’d grown accustomed to. Much to my surprise, that antiX installer MX Linux uses could be a real game changer, especially for those on the fence about giving Linux a try.
|
||||
|
||||
So even before I began kicking the tires of MX Linux, I was impressed. Let’s take a look at what makes the installation of this distribution so special, and then finally have a go with the desktop.
|
||||
|
||||
You can download MX Linux 17.1 from [here][4]. The minimum system requirements are:
|
||||
|
||||
* A CD/DVD drive (and BIOS capable of booting from that drive), or a live USB (and BIOS capable of booting from USB)
|
||||
|
||||
* A modern i486 Intel or AMD processor
|
||||
|
||||
* 512 MB of RAM memory
|
||||
|
||||
* 5 GB free hard drive space
|
||||
|
||||
* A SoundBlaster, AC97 or HDA-compatible sound card
|
||||
|
||||
* For use as a LiveUSB, 4 GB free
|
||||
|
||||
|
||||
|
||||
|
||||
### Installation
|
||||
|
||||
Out of the gate, the MX Linux installer makes installing Linux a breeze. Although it may not be the most modern-looking installation tool, there’s little to second-guess. The heart of the installation begins with choosing the disks and selecting the installation type (Figure 1).
|
||||
|
||||
|
||||
![install][6]
|
||||
|
||||
Figure 1: One of the first installer screens for MX Linux.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
The next important screen (Figure 2) requires you to set a computer name, domain, and (if necessary) a workgroup for MS Networking.
|
||||
|
||||
That ability to configure a workgroup is the first bit to really stand out. This is the first distribution I can remember that offers this option during installation. It also should clue you in that MX Linux offers the ability to share directories out of the box. It does, and it does so with aplomb. It’s not perfect, but it works without having to install any extra package (more on this in a bit).
|
||||
|
||||
The last important installation screen (that requires user-interaction) is the creation of the user account and root password (Figure 3).
|
||||
|
||||
|
||||
![user][9]
|
||||
|
||||
Figure 3: Setting up your user account details and the root user password.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
Once you’ve taken care of this final screen, the installation will complete and ask you to reboot. Upon rebooting, you’ll be greeted with the login screen. Login and enjoy the MX Linux experience.
|
||||
|
||||
### Usage
|
||||
|
||||
The Xfce desktop is quite an easy interface to get up to speed with. The default places the panel on the left edge of the screen (Figure 4).
|
||||
|
||||
|
||||
![desktop ][11]
|
||||
|
||||
Figure 4: The default MX Linux desktop.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
If you want to move the panel to a more traditional location, right click a blank spot on the panel and click Panel > Panel Preferences. In the resulting window (Figure 5), click the Mode drop-down to select from between Deskbar, Vertical, or Horizontal.
|
||||
|
||||
|
||||
![panel][13]
|
||||
|
||||
Figure 5: Configuring the MX Linux Panel.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
The difference between the Deskbar and Vertical options is that, in the Deskbar mode, the panel is aligned vertically, just like in the vertical mode, but the plugins are laid out horizontally. This means you can create much wider panels (for widescreen layouts). If you opt for a horizontal layout, it will default to the top—you will have to then uncheck the Lock panel check box, click Close, and then (using the drag handle on the left edge of the panel) drag it to the bottom. You can then go back into the Panel Settings window and re-lock the panel.
|
||||
|
||||
Beyond that, using the Xfce desktop should be a no-brainer for nearly any experience level … it’s that easy. You’ll find software to cover productivity (LibreOffice, Orage Calendar, PDF-Shuffler), graphics (GIMP), communication (Firefox, Thunderbird, HexChat), multimedia (Clementine, guvcview, SMTube, VLC media player), and a number of tools specific to MX Linux (called MX Tools, that range from a live-USB drive creator, a network assistant, package installer, repo manager, live ISO snapshot creator, and more).
|
||||
|
||||
![sharing][15]
|
||||
|
||||
Figure 6: Sharing out a directory to your network.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
### Samba
|
||||
|
||||
Let’s talk about sharing folders to your network. As I mentioned, you won’t have to install any extra packages to get this to function. You simply open up the file manager, right-click anywhere, and select Share a folder on your network. You will be prompted for the administrative password (set during installation). Upon successful authentication, the Samba Server Configuration Tool will open (Figure 6).
|
||||
|
||||
![sharing][17]
|
||||
|
||||
Figure 7: Configuring the share on MX Linux.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
Click the + button and configure your share. You will be asked to locate the directory, give the share a name/description, and then decide if the share is writeable and visible (Figure 7).
|
||||
|
||||
When you click the Access tab, you have the choice between giving everyone access to the share or just specific users. Here’s where the problem arises. At this point, no users will be available for sharing. Why? They haven’t been added. In order to add them, there are two possibilities: From the command line or using the tool we already have open. Let’s take the obvious route. From the main window of the Samba Server Configuration Tool, click Preferences > Samba Users. In the resulting window, click Add user.
|
||||
|
||||
A new window will appear (Figure 8), where you need to select the user from the drop-down, enter a Windows username, and type/retype a password for the user.
|
||||
|
||||
![Samba][19]
|
||||
|
||||
Figure 8: Adding a user to Samba.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
Once you’ve clicked OK, the user will be added and the share will be accessible, to that user, across your network. Creating Samba shares really can be that easy.
|
||||
|
||||
### The conclusion
|
||||
|
||||
MX Linux makes transitioning from just about any desktop operating system simple. Although some might find the desktop interface to be a bit less-than-modern, the distribution’s primary focus isn’t on beauty, but simplicity. To that end, MX Linux succeeds in stellar fashion. This flavor of Linux can make anyone feel right at home on Linux. Spin up this mid-weight distribution and see if it can’t serve as your daily driver.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/4/mx-linux-mid-weight-distro-focused-simplicity
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://antixlinux.com/
|
||||
[2]:https://en.wikipedia.org/wiki/MEPIS
|
||||
[3]:https://lxde.org/
|
||||
[4]:https://mxlinux.org/download-links
|
||||
[5]:/files/images/mxlinux1jpg
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mxlinux_1.jpg?itok=i9bNScjH (install)
|
||||
[7]:/licenses/category/used-permission
|
||||
[8]:/files/images/mxlinux3jpg
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mxlinux_3.jpg?itok=ppf2l_bm (user)
|
||||
[10]:/files/images/mxlinux4jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/mxlinux_4.jpg?itok=mS1eBy9m (desktop)
|
||||
[12]:/files/images/mxlinux5jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/mxlinux_5.jpg?itok=wsN1hviN (panel)
|
||||
[14]:/files/images/mxlinux6jpg
|
||||
[15]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/mxlinux_6.jpg?itok=vw8mIp9T (sharing)
|
||||
[16]:/files/images/mxlinux7jpg
|
||||
[17]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/mxlinux_7.jpg?itok=tRIWdcEk (sharing)
|
||||
[18]:/files/images/mxlinux8jpg
|
||||
[19]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/mxlinux_8.jpg?itok=ZS6lhZN2 (Samba)
|
||||
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
150
sources/tech/20180407 12 Git tips for Git-s 12th birthday.md
Normal file
150
sources/tech/20180407 12 Git tips for Git-s 12th birthday.md
Normal file
@ -0,0 +1,150 @@
|
||||
12 Git tips for Git's 12th birthday
|
||||
======
|
||||

|
||||
[Git][1], the distributed revision-control system that's become the default tool for source code control in the open source world, turns 12 on April 7. One of the more frustrating things about using Git is how much you need to know to use it effectively. This can also be one of the more awesome things about using Git, because there's nothing quite like discovering a new tip or trick that can streamline or improve your workflow.
|
||||
|
||||
In honor of Git's 12th birthday, here are 12 tips and tricks to make your Git experience more useful and powerful, starting with some basics you might have overlooked and scaling up to some real power-user tricks!
|
||||
|
||||
### 1\. Your ~/.gitconfig file
|
||||
|
||||
The first time you tried to use the `git` command to commit a change to a repository, you might have been greeted with something like this:
|
||||
```
|
||||
*** Please tell me who you are.
|
||||
|
||||
Run
|
||||
|
||||
git config --global user.email "you@example.com"
|
||||
|
||||
git config --global user.name "Your Name"
|
||||
|
||||
to set your account's default identity.
|
||||
|
||||
```
|
||||
|
||||
What you might not have realized is that those commands are modifying the contents of `~/.gitconfig`, which is where Git stores global configuration options. There are a vast array of things you can do via your `~/.gitconfig` file, including defining aliases, turning particular command options on (or off!) on a permanent basis, and modifying aspects of how Git works (e.g., which diff algorithm `git diff` uses or what type of merge strategy is used by default). You can even conditionally include other config files based on the path to a repository! See `man git-config` for all the details.
|
||||
|
||||
### 2\. Your repo's .gitconfig file
|
||||
|
||||
In the previous tip, you may have wondered what that `--global` flag on the `git config` command was doing. It tells Git to update the "global" configuration, the one found in `~/.gitconfig`. Of course, having a global config also implies a local configuration, and sure enough, if you omit the `--global` flag, `git config` will instead update the repository-specific configuration, which is stored in `.git/config`.
|
||||
|
||||
Options that are set in the `.git/config` file will override any setting in the `~/.gitconfig` file. So, for example, if you need to use a different email address for a particular repository, you can run `git config user.email "also_you@example.com"`. Then, any commits in that repository will use your other email address. This can be super useful if you work on open source projects from a work laptop and want them to show up with a personal email address while still using your work email for your main Git configuration.
|
||||
|
||||
Pretty much anything you can set in `~/.gitconfig`, you can also set in `.git/config` to make it specific to the given repository. In any of the following tips, when I mention adding something to your `~/.gitconfig`, just remember you could also set that option for just one repository by adding it to `.git/config` instead.
|
||||
|
||||
### 3\. Aliases
|
||||
|
||||
Aliases are another thing you can put in your `~/.gitconfig`. These work just like aliases in the command shell—they set up a new command name that can invoke one or more other commands, often with a particular set of options or flags. They're super useful for longer, more complicated commands you use frequently.
|
||||
|
||||
You can define aliases using the `git config` command—for example, running `git config --global --add alias.st status` will make running `git st` do the same thing as running `git status`—but I find when defining aliases, it's frequently easier to just edit the `~/.gitconfig` file directly.
|
||||
|
||||
If you choose to go this route, you'll find that the `~/.gitconfig` file is an [INI file][2]. INI is basically a key-value file format with particular sections. When adding an alias, you'll be changing the `[alias]` section. For example, to define the same `git st` alias as above, add this to the file:
|
||||
```
|
||||
[alias]
|
||||
|
||||
st = status
|
||||
|
||||
```
|
||||
|
||||
(If there's already an `[alias]` section, just add the second line to that existing section.)
|
||||
|
||||
### 4\. Aliases to shell commands
|
||||
|
||||
Aliases aren't limited to just running other Git subcommands—you can also define aliases that run other shell commands. This is a fantastic way to deal with a recurring, infrequent, and complicated task: Once you've figured out how to do it once, preserve the command under an alias. For example, I have a few repositories where I've forked an open source project and made some local modifications that don't need to be contributed back to the project. I want to keep up-to-date with ongoing development work in the project but also maintain my local changes. To accomplish this, I need to periodically merge the changes from the upstream repo into my fork—which I do by using an alias I call `upstream-merge`. It's defined like this:
|
||||
```
|
||||
upstream-merge = !"git fetch origin -v && git fetch upstream -v && git merge upstream/master && git push"
|
||||
|
||||
```
|
||||
|
||||
The `!` at the beginning of the alias definition tells Git to run the command via the shell. This example involves running a number of `git` commands, but aliases defined in this way can run any shell command.
|
||||
|
||||
(Note that if you want to copy my `upstream-merge` alias, you'll need to make sure you have a Git remote named `upstream` pointed at the upstream repository you've forked from. You can add this by running `git remote add upstream <URL to repo>`.)
|
||||
|
||||
### 5\. Visualizing the commit graph
|
||||
|
||||
If you work on a project with a lot of branching activity, sometimes it can be difficult to get a handle on all the work that's happening and how it's all related. Various GUI tools allow you to get a picture of different branches and commits in what's called the "commit graph." For example, here's a section of one of my repositories visualized with the [GitLab][3] commit graph viewer:
|
||||
|
||||
|
||||
![GitLab commit graph viewer][5]
|
||||
|
||||
John Anderson, CC BY
|
||||
|
||||
If you're a dedicated command-line user or somebody who finds switching tools to be distracting, it's nice to get a similar view of the commit graph from the command line. That's where the `--graph` argument to the `git log` command comes in:
|
||||
|
||||
![Repository visualized with --graph command][7]
|
||||
|
||||
John Anderson, CC BY
|
||||
|
||||
This is the same section of the same repo visualized with the following command:
|
||||
```
|
||||
git log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --date=relative
|
||||
|
||||
```
|
||||
|
||||
The `--graph` option adds the graph to the left side of the log, `--abbrev-commit` shortens the commit [SHAs][8], `--date=relative` expresses the dates in relative terms, and the `--pretty` bit handles all the other custom formatting. I have this aliased to `git lg`, and it is one of my top 10 most frequently run commands.
|
||||
|
||||
### 6\. A nicer force-push
|
||||
|
||||
Sometimes, as hard as you try to avoid it, you'll find that you need to run `git push --force` to overwrite the history on a remote copy of your repository. You may have gotten some feedback that caused you to do an interactive rebase, or you may simply have messed up and want to hide the evidence.
|
||||
|
||||
One of the hazards with force pushes happens when somebody else has made changes on top of the same branch in the remote copy of the repository. When you force-push your rewritten history, those commits will be lost. This is where `git push --force-with-lease` comes in—it will not allow you to force-push if the remote branch has been updated, which will ensure you don't throw away someone else's work.
|
||||
|
||||
### 7\. git add -N
|
||||
|
||||
Have you ever used `git commit -a` to stage and commit all your outstanding changes in a single move, only to discover after you've pushed your commit that `git commit -a` ignores newly added files? You can work around this by using the `git add -N` (think "notify") to tell Git about newly added files you'd like to be included in commits before you actually commit them for the first time.
|
||||
|
||||
### 8\. git add -p
|
||||
|
||||
A best practice when using Git is to make sure each commit consists of only a single logical change—whether that's a fix for a bug or a new feature. Sometimes when you're working, however, you'll end up with more than one commit's worth of change in your repository. How can you manage to divide things up so that each commit contains only the appropriate changes? `git add --patch` to the rescue!
|
||||
|
||||
This flag will cause the `git add` command to look at all the changes in your working copy and, for each one, ask if you'd like to stage it to be committed, skip over it, or defer the decision (as well as a few other more powerful options you can see by selecting `?` after running the command). `git add -p` is a fantastic tool for producing well-structured commits.
|
||||
|
||||
### 9\. git checkout -p
|
||||
|
||||
Similar to `git add -p`, the `git checkout` command will take a `--patch` or `-p` option, which will cause it to present each "hunk" of change in your local working copy and allow you to discard it—basically reverting your local working copy to what was there before your change.
|
||||
|
||||
This is fantastic when, for example, you've introduced a bunch of debug logging statements while chasing down a bug. After the bug is fixed, you can first use `git checkout -p` to remove all the new debug logging, then you `git add -p` to add the bug fix. Nothing is more satisfying than putting together a beautiful, well-structured commit!
|
||||
|
||||
### 10\. Rebase with command execution
|
||||
|
||||
Some projects have a rule that each commit in the repository must be in a working state—that is, at each commit, it should be possible to compile the code or the test suite should run without failure. This is not too difficult when you're working on a branch over time, but if you end up needing to rebase for whatever reason, it can be a little tedious to step through each rebased commit to make sure you haven't accidentally introduced a break.
|
||||
|
||||
Fortunately, `git rebase` has you covered with the `-x` or `--exec` option. `git rebase -x <cmd>` will run that command after each commit is applied in the rebase. So, for example, if you have a project where `npm run tests` runs your test suite, `git rebase -x npm run tests` would run the test suite after each commit was applied during the rebase. This allows you to see if the test suite fails at any of the rebased commits so you can confirm that the test suite is still passing at each commit.
|
||||
|
||||
### 11\. Time-based revision references
|
||||
|
||||
Many Git subcommands take a revision argument to specify what part of the repository to work on. This can be the SHA1 of a particular commit, a branch name, or even a symbolic name like `HEAD` (which refers to the most recent commit on the currently checked out branch). In addition to these simple forms, you can also append a specific date or time to mean "this reference, at this time."
|
||||
|
||||
This becomes very useful when you're dealing with a newly introduced bug and find yourself saying, "I know this worked yesterday! What changed?" Instead of staring at the output of `git log` trying to figure out what commit was changed when, you can simply run `git diff HEAD@{yesterday}`, and see all the changes that have happened since then. This also works with longer time periods (e.g., `git diff HEAD@{'2 months ago'}`) as well as exact dates (e.g., `git diff HEAD@{'2010-01-01 12:00:00'}`).
|
||||
|
||||
You can also use these date-based revision arguments with any Git subcommand that takes a revision argument. Find full details about which format to use in the man page for `gitrevisions`.
|
||||
|
||||
### 12\. The all-seeing reflog
|
||||
|
||||
Have you ever rebased away a commit, then discovered there was something in that commit you wanted to keep? You may have thought that information was lost forever and would need to be recreated. But if you committed it in your local working copy, it was added to the reference log (reflog), and you should still be able to access it.
|
||||
|
||||
Running `git reflog` will show you a list of all the activity for the current branch in your local working copy and also give you the SHA1 of each commit. Once you've found the commit you rebased away, you can run `git checkout <SHA1>` to check out that commit, copy any information you need, and run `git checkout HEAD` to return to the most recent commit in the branch.
|
||||
|
||||
### That's all folks!
|
||||
|
||||
Hopefully at least one of these tips has taught you something new about Git, a 12-year-old project that's continuing to innovate and add new features. What's your favorite Git trick?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/12-git-tips-gits-12th-birthday
|
||||
|
||||
作者:[John SJ Anderson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/genehack
|
||||
[1]:https://git-scm.com/
|
||||
[2]:https://en.wikipedia.org/wiki/INI_file
|
||||
[3]:https://gitlab.com/
|
||||
[4]:/file/392941
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gui_graph.png?itok=3GovYfG1 (GitLab commit graph viewer)
|
||||
[6]:/file/392936
|
||||
[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/console_graph.png?itok=XogY1P8M (Repository visualized with --graph command)
|
||||
[8]:https://en.wikipedia.org/wiki/Secure_Hash_Algorithms
|
||||
@ -0,0 +1,82 @@
|
||||
区块链不适用的若干场景
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
不错,区块链这个概念异常的火热。
|
||||
|
||||
众所周知,我一直关注区块链及相关技术的成熟度发展情况,思考其是否达到过高期望的峰值(peak hype);但从目前的情况来看,还没有这个迹象。我在文中提到的区块链技术是广义上的,包含了狭义上不属于区块链的分布式账本技术(DLTs)。我对私有链更感兴趣,其中私有链的定义可以参考我的文章[区块链是安全性方面的话题吗?][1]。简而言之,我对加密货币之外的区块链业务应用特别感兴趣<sup>[1](#footnote1)</sup>。
|
||||
|
||||
我们对区块链的技术成熟度的判断应该有一部分可以得到证实<sup>[2](#footnote2)</sup>。如果我们判断正确,未来将会出现海量的区块链应用。这很可能会变成现实,但并不是所有的应用都是优秀的区块链应用,其中一部分很可能是非常糟糕的。
|
||||
|
||||
但区块链所处的技术成熟度意味着,大量业务将快速拥抱新技术<sup>[3](#footnote3)</sup>,但对于可能的前景却一知半解。促成这种情况的原因可以大致分为三种:
|
||||
|
||||
1. 对于涉及多用户数据存储的业务应用,在投入精力的情况下,几乎都可以改造为基于区块链的版本;
|
||||
2. 很多区块链相关的会议和“专家”呼吁尽快拥抱区块链,否则可能会在半年内被淘汰<sup>[4](#footnote4)</sup>;
|
||||
3. 完全理解区块链技术是很难的,支持其在企业中落地的往往是工程师。
|
||||
|
||||
对于最后一条,我必须补充几句,不然很容易被引起众怒<sup>[5](#footnote5)</sup>。作为一名工程师,我显然无意贬低工程师。但工程师的天性使然,我们对见到的新鲜事物(亮点)热情澎湃,却对业务本身神交<sup>[6](#footnote6)</sup>不足,故对于新技术给业务带来的影响理解可能并不深刻。在业务领导者看来,这些影响不一定是有利的。
|
||||
|
||||
上面提到的三种促因可能导致一种风险,即在没有充分评估利弊的情况下,将业务改造为区块链应用。在另一文([区块链:每个人都应该参与进来吗?][2])中提到几个场景,用于判断一个业务什么情况下适合采用区块链技术。这些场景是有益的,但更进一步,我坚信人们更加需要的是,业务完全不适用区块链的几种简单的场景判定。我总结了三种场景判定,如果对于其中任何一个问题你给出了肯定的回答,那么很大概率上区块链不适合你。
|
||||
|
||||
### 场景判定1:业务是否需要集中式的管控或授权?
|
||||
|
||||
如果你给出了肯定的回答,那么区块链不适合你。
|
||||
|
||||
例如,假设你是一个蒲团销售商,具有唯一的订单系统,那么对于何时发货你有唯一的授权,显然区块链不适合你。假设你是一个内容提供商,所有提供的内容都会经过唯一的编辑和发布过程,显然区块链不适合你。
|
||||
|
||||
经验总结:只有当任务对应的执行流程及相应的认证流程是分布于众多主体时,区块链是有价值的。
|
||||
|
||||
### 场景判定2:业务使用经典数据库是否工作良好?
|
||||
|
||||
如果你给出了肯定的回答,那么区块链不适合你。
|
||||
|
||||
该场景似乎与上一个场景是强相关的,但并不总是如此。在一些应用中,处理流程是分布的,但信息存储是中心化的;在另外一些应用中,处理流程需要中心化的授权,但信息存储是分布的,即总有一个并不是分布式的。但如果业务使用经典数据库可以工作量良好的话,使用经典数据库是一个好主意。
|
||||
|
||||
经典数据库不仅性能良好,在设计与运营成本方面低比区块链或分布式账本,而且我们在这方面技术积累丰厚。区块链让所有人<sup>[8](#footnote8)</sup>可以查看和持有数据,但间接成本和潜在成本都比较高昂。
|
||||
|
||||
### 场景判定3:业务采用新技术是否成本高昂或对合作伙伴有负面效果?
|
||||
|
||||
如果你给出了肯定的回答,那么区块链不适合你。
|
||||
|
||||
我曾听过这种观点,即区块链会让所有人获益。但这显然是不可能的。假设你正在为某个流程设计一个应用,改变合作伙伴与你及应用的交互方式,那么你需要判断这个改变是否符合合作伙伴的兴趣。不论是否涉及区块链,可以很容易的设计并引入一个应用,虽然降低了你自己的业务阻力,但与此同时增加了合作伙伴的业务阻力。
|
||||
|
||||
假设我为汽车行业生产发动机配件,那么使用区块链追溯和管理配件会让我受益匪浅。例如,我可以查看购买的滚珠轴承的生产商、生产时间和钢铁材料供应商等。换一个角度,假设我是滚珠轴承生产商,已经为40多个客户公司建立了处理流程。为一家客户引入新的流程会涉及工作方式、系统体系、储藏和安全性标准等方面的变更,这无法让我感兴趣,相反,这会导致复杂性和高开销。
|
||||
|
||||
### 总结
|
||||
|
||||
这几个场景判定用于提纲挈领,并不是一成不变的。其中数据库相关的那个场景判定更像是技术方面的,但也是紧密结合业务定位和功能的。希望这几个判定可以为区块链技术引进促因带来的过热进行降温。
|
||||
|
||||
<a name="footnote1">1</a>\. 请不要误解我的意思,加密货币显然是一种有趣的区块链业务应用,只是不在本文的讨论范畴而已。
|
||||
|
||||
<a name="footnote2">2</a>\. 知道具体是哪些部分是很有意义的,如果你知道,请告诉我好吗?
|
||||
|
||||
<a name="footnote3">3</a>\. 坦率的说,它其实更像是一大堆技术的集合体。
|
||||
|
||||
<a name="footnote4">4</a>\. 这显然是不太可能的,如果被淘汰的主体是这些会议和“专家”本身倒十分有可能。
|
||||
|
||||
<a name="footnote5">5</a>\. 由于比方打得有些不恰当,估计还是会引起众怒。
|
||||
|
||||
<a name="footnote6">6</a>\. 我太喜欢grok这个单词了,我把它放在这里作为我的工程师标志<sup>[7](#footnote7)</sup>。
|
||||
|
||||
<a name="footnote7">7</a>\. 你可能已经想到了,我读过*Stranger in a Strange Land*一书,包括删减版和原版。
|
||||
|
||||
<a name="footnote8">8</a>\. 在合理的情况下。
|
||||
|
||||
原文最初发表于[爱丽丝, 夏娃和鲍勃 – 一个安全性主题博客][3],已获得转载许可。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
原文链接: https://opensource.com/article/18/3/3-tests-not-moving-blockchain
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://opensource.com/article/17/12/blockchain-security-topic
|
||||
[2]:https://aliceevebob.com/2017/09/12/blockchain-should-we-all-play/
|
||||
[3]:https://aliceevebob.com/2018/02/13/3-tests-for-not-moving-to-blockchain/
|
||||
@ -1,76 +0,0 @@
|
||||
[页面缓存,内存和文件之间的那些事][1]
|
||||
============================================================
|
||||
|
||||
|
||||
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而忽略了文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
|
||||
|
||||
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘查找][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间共享文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLLs。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLLs 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 [ld.so][5] 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
|
||||
|
||||
幸运的是,所有的这些问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 Render 的 Linux 程序,它打开了文件 scene.dat,并且一次读取 512 字节,并将文件内容存储到一个分配的堆块中。第一次读取的过程如下:
|
||||
|
||||

|
||||
|
||||
读取完 12KB 的文件内容以后,Render 程序的堆和相关的页面帧如下图所示:
|
||||
|
||||

|
||||
|
||||
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,普通的文件 I/O 就是这样通过页面缓存来进行的。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序读取的磁盘区域也不仅仅只保存几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 #0、#1、等等来描述。Windows 也是类似的,使用 256KB 大小的页面缓存。
|
||||
|
||||
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到一个用户缓存中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],在复制数据时也浪费物理内存。如前面的图示,scene.dat 的内存被保存了两次,并且,程序中的每个实例都在另外的时间中去保存了内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
|
||||
|
||||

|
||||
|
||||
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 的报告指出,在相关的普通文件读取上运行时性能有多达 30% 的提升,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
|
||||
|
||||
对高性能的追求是永衡不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。而 API 提供了非常好用的实现方式,它允许你通过内存中的字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄在页面缓存上 [映射你的虚拟页面][14] 。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
|
||||
|
||||
假设我们的 Reader 程序是持续存在的实例,现在出现一个突发的状况。在页面缓存中保存着 scene.dat 内容的页面要立刻释放掉吗?这是一个人们经常要考虑的问题,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该始终完整保存。并且,这一原则适用于所有的进程。如果你现在运行 Render,一周后 scene.dat 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(译者注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
|
||||
|
||||
由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“赃”页面。磁盘 I/O 通常并不会立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。如果这时候发生了电脑死机,你的写入将不会被标记,因此,对于至关重要的文件,像数据库事务日志,必须要求 [fsync()][17]ed(仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,走到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows cache hints][20] ),你可以通过提示(hint)帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是,在 Windows 上并不能确保被内存映射的文件也会预读。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
|
||||
|
||||
一个内存映射的文件可以是私有的,也可以是共享的。当然,这只是针对内存中内容的更新而言:在一个私有的内存映射文件上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射文件,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核在写机制上使用拷贝,这是通过页面表条目来实现这种私有的映射。在下面的例子中,Render 和另一个被称为 render3d 都私有映射到 scene.dat 上。然后 Render 去写入映射的文件的虚拟内存区域:
|
||||
|
||||

|
||||
|
||||
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于去共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
|
||||
|
||||
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 APIs 为你提供与私有文件映射相同的效果。下面的示例展示了 Reader 程序映射的文件的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
|
||||
|
||||

|
||||
|
||||
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://manybutfinite.com/post/how-the-kernel-manages-your-memory
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
66
translated/tech/20180328 How To Use Instagram In Terminal.md
Normal file
66
translated/tech/20180328 How To Use Instagram In Terminal.md
Normal file
@ -0,0 +1,66 @@
|
||||
如何在终端中使用 Instagram
|
||||
======
|
||||

|
||||
Instagram 不需要介绍。它是像 Facebook 和 Twitter 之类的流行社交网络平台之一,它可以公开或私下分享照片和视频给确认过的粉丝。它是由两位企业家于 2010 年发起的,分别是 **Kevin Systrom** and **Mike Krieger**。2012 年,社交网络巨头 Facebook 收购了 Instagram。Android 和 iOS 设备上免费提供 Instagram。我们也可以通过网络浏览器在桌面系统中使用它。而且,最酷的是现在你可以在任何类 Unix 操作系统上的终端中使用 Instagram。你兴奋了吗?那么,请阅读以下内容了解如何在终端上查看你的Instagram feed。
|
||||
|
||||
### 终端中的 Instagram
|
||||
|
||||
首先,按照以下链接中的说明安装 **pip3**。
|
||||
|
||||
然后,git clone “instagram-terminal-news-feed” 脚本仓库。
|
||||
```
|
||||
$ git clone https://github.com/billcccheng/instagram-terminal-news-feed.git
|
||||
|
||||
```
|
||||
|
||||
以上命令会将 instagram 脚本的内容克隆到当前工作目录中名为 “instagram-terminal-news-feed” 的目录中。cd 到该目录:
|
||||
```
|
||||
$ cd instagram-terminal-news-feed/
|
||||
|
||||
```
|
||||
|
||||
然后,运行以下命令安装 instagram 终端 feed:
|
||||
```
|
||||
$ pip3 install -r requirements.txt
|
||||
|
||||
```
|
||||
|
||||
现在,运行以下命令在 Linux 终端中启动 instagram。
|
||||
```
|
||||
$ python3 start.py
|
||||
|
||||
```
|
||||
|
||||
输入你的 Instagram 用户名和密码,并直接从终端中浏览你的 Instagram feed。你的 instragram 用户名和密码将仅本地存储在名为 **credential.json** 的文件中。所以,你不必担心它。你也可以选择不保存默认保存的凭证。
|
||||
|
||||
下面是[**我的 Instagram 页面**][1]的一些截图。
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
![][5]
|
||||
|
||||
请注意,你只能查看你的 feed。你不能关注任何人,喜欢或评论帖子。这只是一个 instagram feed 阅读器。
|
||||
|
||||
该项目可在 GitHub 上免费获得,因此你可以查看源代码,改进它,添加更多功能,修复任何 bug。
|
||||
|
||||
玩得开心!干杯!!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-use-instagram-in-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.instagram.com/ostechnix/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/instagram-in-terminal-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/instagram-in-terminal-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/instagram-in-terminal-3-2.png
|
||||
Loading…
Reference in New Issue
Block a user