mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
c004c0a5a4
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# PR 检查脚本
|
||||
set -e
|
||||
|
||||
|
||||
@ -22,7 +22,12 @@ do_analyze() {
|
||||
# 统计每个类别的每个操作
|
||||
REGEX="$(get_operation_regex "$STAT" "$TYPE")"
|
||||
OTHER_REGEX="${OTHER_REGEX}|${REGEX}"
|
||||
eval "${TYPE}_${STAT}=\"\$(grep -Ec '$REGEX' /tmp/changes)\"" || true
|
||||
CHANGES_FILE="/tmp/changes_${TYPE}_${STAT}"
|
||||
eval "grep -E '$REGEX' /tmp/changes" \
|
||||
| sed 's/^[^\/]*\///g' \
|
||||
| sort > "$CHANGES_FILE" || true
|
||||
sed 's/^.*\///g' "$CHANGES_FILE" > "${CHANGES_FILE}_basename"
|
||||
eval "${TYPE}_${STAT}=$(wc -l < "$CHANGES_FILE")"
|
||||
eval echo "${TYPE}_${STAT}=\$${TYPE}_${STAT}"
|
||||
done
|
||||
done
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# 检查脚本状态
|
||||
set -e
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# PR 文件变更收集
|
||||
set -e
|
||||
|
||||
@ -31,7 +31,16 @@ git --no-pager show --summary "${MERGE_BASE}..HEAD"
|
||||
|
||||
echo "[收集] 写出文件变更列表……"
|
||||
|
||||
git diff "$MERGE_BASE" HEAD --no-renames --name-status > /tmp/changes
|
||||
RAW_CHANGES="$(git diff "$MERGE_BASE" HEAD --no-renames --name-status -z \
|
||||
| tr '\0' '\n')"
|
||||
[ -z "$RAW_CHANGES" ] && {
|
||||
echo "[收集] 无变更,退出……"
|
||||
exit 1
|
||||
}
|
||||
echo "$RAW_CHANGES" | while read -r STAT; do
|
||||
read -r NAME
|
||||
echo "${STAT} ${NAME}"
|
||||
done > /tmp/changes
|
||||
echo "[收集] 已写出文件变更列表:"
|
||||
cat /tmp/changes
|
||||
{ [ -z "$(cat /tmp/changes)" ] && echo "(无变更)"; } || true
|
||||
|
||||
@ -10,9 +10,10 @@ export TSL_DIR='translated' # 已翻译
|
||||
export PUB_DIR='published' # 已发布
|
||||
|
||||
# 定义匹配规则
|
||||
export CATE_PATTERN='(news|talk|tech)' # 类别
|
||||
export CATE_PATTERN='(talk|tech)' # 类别
|
||||
export FILE_PATTERN='[0-9]{8} [a-zA-Z0-9_.,() -]*\.md' # 文件名
|
||||
|
||||
# 获取用于匹配操作的正则表达式
|
||||
# 用法:get_operation_regex 状态 类型
|
||||
#
|
||||
# 状态为:
|
||||
@ -26,5 +27,50 @@ export FILE_PATTERN='[0-9]{8} [a-zA-Z0-9_.,() -]*\.md' # 文件名
|
||||
get_operation_regex() {
|
||||
STAT="$1"
|
||||
TYPE="$2"
|
||||
|
||||
echo "^${STAT}\\s+\"?$(eval echo "\$${TYPE}_DIR")/"
|
||||
}
|
||||
|
||||
# 确保两个变更文件一致
|
||||
# 用法:ensure_identical X类型 X状态 Y类型 Y状态 是否仅比较文件名
|
||||
#
|
||||
# 状态为:
|
||||
# - A:添加
|
||||
# - M:修改
|
||||
# - D:删除
|
||||
# 类型为:
|
||||
# - SRC:未翻译
|
||||
# - TSL:已翻译
|
||||
# - PUB:已发布
|
||||
ensure_identical() {
|
||||
TYPE_X="$1"
|
||||
STAT_X="$2"
|
||||
TYPE_Y="$3"
|
||||
STAT_Y="$4"
|
||||
NAME_ONLY="$5"
|
||||
SUFFIX=
|
||||
[ -n "$NAME_ONLY" ] && SUFFIX="_basename"
|
||||
|
||||
X_FILE="/tmp/changes_${TYPE_X}_${STAT_X}${SUFFIX}"
|
||||
Y_FILE="/tmp/changes_${TYPE_Y}_${STAT_Y}${SUFFIX}"
|
||||
|
||||
cmp "$X_FILE" "$Y_FILE" 2> /dev/null
|
||||
}
|
||||
|
||||
# 检查文章分类
|
||||
# 用法:check_category 类型 状态
|
||||
#
|
||||
# 状态为:
|
||||
# - A:添加
|
||||
# - M:修改
|
||||
# - D:删除
|
||||
# 类型为:
|
||||
# - SRC:未翻译
|
||||
# - TSL:已翻译
|
||||
check_category() {
|
||||
TYPE="$1"
|
||||
STAT="$2"
|
||||
|
||||
CHANGES="/tmp/changes_${TYPE}_${STAT}"
|
||||
! grep -Eqv "^${CATE_PATTERN}/" "$CHANGES"
|
||||
}
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# 匹配 PR 规则
|
||||
set -e
|
||||
|
||||
@ -27,31 +27,39 @@ rule_bypass_check() {
|
||||
# 添加原文:添加至少一篇原文
|
||||
rule_source_added() {
|
||||
[ "$SRC_A" -ge 1 ] \
|
||||
&& check_category SRC A \
|
||||
&& [ "$TOTAL" -eq "$SRC_A" ] && echo "匹配规则:添加原文 ${SRC_A} 篇"
|
||||
}
|
||||
|
||||
# 申领翻译:只能申领一篇原文
|
||||
rule_translation_requested() {
|
||||
[ "$SRC_M" -eq 1 ] \
|
||||
&& check_category SRC M \
|
||||
&& [ "$TOTAL" -eq 1 ] && echo "匹配规则:申领翻译"
|
||||
}
|
||||
|
||||
# 提交译文:只能提交一篇译文
|
||||
rule_translation_completed() {
|
||||
[ "$SRC_D" -eq 1 ] && [ "$TSL_A" -eq 1 ] \
|
||||
&& ensure_identical SRC D TSL A \
|
||||
&& check_category SRC D \
|
||||
&& check_category TSL A \
|
||||
&& [ "$TOTAL" -eq 2 ] && echo "匹配规则:提交译文"
|
||||
}
|
||||
|
||||
# 校对译文:只能校对一篇
|
||||
rule_translation_revised() {
|
||||
[ "$TSL_M" -eq 1 ] \
|
||||
&& check_category TSL M \
|
||||
&& [ "$TOTAL" -eq 1 ] && echo "匹配规则:校对译文"
|
||||
}
|
||||
|
||||
# 发布译文:发布多篇译文
|
||||
rule_translation_published() {
|
||||
[ "$TSL_D" -ge 1 ] && [ "$PUB_A" -ge 1 ] && [ "$TSL_D" -eq "$PUB_A" ] \
|
||||
&& [ "$TOTAL" -eq $(($TSL_D + $PUB_A)) ] \
|
||||
&& ensure_identical SRC D TSL A 1 \
|
||||
&& check_category TSL D \
|
||||
&& [ "$TOTAL" -eq $((TSL_D + PUB_A)) ] \
|
||||
&& echo "匹配规则:发布译文 ${PUB_A} 篇"
|
||||
}
|
||||
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
For your first HTML code, let’s help Batman write a love letter
|
||||
============================================================
|
||||
|
||||
@ -553,360 +556,4 @@ We want to apply our styles to the specific div and img that we are using right
|
||||
<div id="letter-container">
|
||||
```
|
||||
|
||||
and here’s how to use this id in our embedded style as a selector:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
Notice the “#” symbol. It indicates that it is an id, and the styles inside {…} should apply to the element with that specific id only.
|
||||
|
||||
Let’s apply this to our code:
|
||||
|
||||
```
|
||||
<style>
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
```
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
Our HTML is ready with embedded styling.
|
||||
|
||||
However, you can see that as we include more styles, the <style></style> will get bigger. This can quickly clutter our main html file. So let’s go one step further and use linked styling by copying the content inside our style tag to a new file.
|
||||
|
||||
Create a new file in the project root directory and save it as style.css:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
```
|
||||
|
||||
We don’t need to write `<style>` and `</style>` in our CSS file.
|
||||
|
||||
We need to link our newly created CSS file to our HTML file using the `<link>`tag in our html file. Here’s how we can do that:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
```
|
||||
|
||||
We use the link element to include external resources inside your HTML document. It is mostly used to link Stylesheets. The three attributes that we are using are:
|
||||
|
||||
* rel: Relation. What relationship the linked file has to the document. The file with the .css extension is called a stylesheet, and so we keep rel=“stylesheet”.
|
||||
|
||||
* type: the Type of the linked file; it’s “text/css” for a CSS file.
|
||||
|
||||
* href: Hypertext Reference. Location of the linked file.
|
||||
|
||||
There is no </link> at the end of the link element. So, <link> is also a self-closing tag.
|
||||
|
||||
```
|
||||
<link rel="gf" type="cute" href="girl.next.door">
|
||||
```
|
||||
|
||||
If only getting a Girlfriend was so easy :D
|
||||
|
||||
Nah, that’s not gonna happen, let’s move on.
|
||||
|
||||
Here’s the content of our loveletter.html:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
and our style.css:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
```
|
||||
|
||||
Save both the files and refresh, and your output in the browser should remain the same.
|
||||
|
||||
### A Few Formalities
|
||||
|
||||
Our love letter is almost ready to deliver to Batman, but there are a few formal pieces remaining.
|
||||
|
||||
Like any other programming language, HTML has also gone through many versions since its birth year(1990). The current version of HTML is HTML5.
|
||||
|
||||
So, how would the browser know which version of HTML you are using to code your page? To tell the browser that you are using HTML5, you need to include `<!DOCTYPE html>` at top of the page. For older versions of HTML, this line used to be different, but you don’t need to learn that because we don’t use them anymore.
|
||||
|
||||
Also, in previous HTML versions, we used to encapsulate the entire document inside `<html></html>` tag. The entire file was divided into two major sections: Head, inside `<head></head>`, and Body, inside `<body></body>`. This is not required in HTML5, but we still do this for compatibility reasons. Let’s update our code with `<Doctype>`, `<html>`, `<head>` and `<body>`:
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
</head>
|
||||
<body>
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
The main content goes inside `<body>` and meta information goes inside `<head>`. So we keep the div inside `<body>` and load the stylesheets inside `<head>`.
|
||||
|
||||
Save and refresh, and your HTML page should display the same as earlier.
|
||||
|
||||
### Title in HTML
|
||||
|
||||
This is the last change. I promise.
|
||||
|
||||
You might have noticed that the title of the tab is displaying the path of the HTML file:
|
||||
|
||||
|
||||
|
||||
|
||||
We can use `<title>` tag to define a title for our HTML file. The title tag also, like the link tag, goes inside head. Let’s put “Bat Letter” in our title:
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title>Bat Letter</title>
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
</head>
|
||||
<body>
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
Save and refresh, and you will see that instead of the file path, “Bat Letter” is now displayed on the tab.
|
||||
|
||||
Batman’s Love Letter is now complete.
|
||||
|
||||
Congratulations! You made Batman’s Love Letter in HTML.
|
||||
|
||||
|
||||

|
||||
|
||||
### What we learned
|
||||
|
||||
We learned the following new concepts:
|
||||
|
||||
* The structure of an HTML document
|
||||
|
||||
* How to write elements in HTML (<p></p>)
|
||||
|
||||
* How to write styles inside the element using the style attribute (this is called inline styling, avoid this as much as you can)
|
||||
|
||||
* How to write styles of an element inside <style>…</style> (this is called embedded styling)
|
||||
|
||||
* How to write styles in a separate file and link to it in HTML using <link> (this is called a linked stylesheet)
|
||||
|
||||
* What is a tag name, attribute, opening tag, and closing tag
|
||||
|
||||
* How to give an id to an element using id attribute
|
||||
|
||||
* Tag selectors and id selectors in CSS
|
||||
|
||||
We learned the following HTML tags:
|
||||
|
||||
* <p>: for paragraphs
|
||||
|
||||
* <br>: for line breaks
|
||||
|
||||
* <ul>, <li>: to display lists
|
||||
|
||||
* <div>: for grouping elements of our letter
|
||||
|
||||
* <h1>, <h2>: for heading and sub heading
|
||||
|
||||
* <img>: to insert an image
|
||||
|
||||
* <strong>, <em>: for bold and italic text styling
|
||||
|
||||
* <style>: for embedded styling
|
||||
|
||||
* <link>: for including external an stylesheet
|
||||
|
||||
* <html>: to wrap the entire HTML document
|
||||
|
||||
* <!DOCTYPE html>: to let the browser know that we are using HTML5
|
||||
|
||||
* <head>: to wrap meta info, like <link> and <title>
|
||||
|
||||
* <body>: for the body of the HTML page that is actually displayed
|
||||
|
||||
* <title>: for the title of the HTML page
|
||||
|
||||
We learned the following CSS properties:
|
||||
|
||||
* width: to define the width of an element
|
||||
|
||||
* CSS units: “px” and “%”
|
||||
|
||||
That’s it for the day friends, see you in the next tutorial.
|
||||
|
||||
* * *
|
||||
|
||||
Want to learn Web Development with fun and engaging tutorials?
|
||||
|
||||
[Click here to get new Web Development tutorials every week.][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Developer + Writer | supersarkar.com | twitter.com/supersarkar
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: https://medium.freecodecamp.org/for-your-first-html-code-lets-help-batman-write-a-love-letter-64c203b9360b
|
||||
|
||||
作者:[Kunal Sarkar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@supersarkar
|
||||
[1]:https://www.pexels.com/photo/batman-black-and-white-logo-93596/
|
||||
[2]:https://code.visualstudio.com/
|
||||
[3]:https://www.pexels.com/photo/batman-black-and-white-logo-93596/
|
||||
[4]:http://supersarkar.com/
|
||||
and here’s how to use th
|
||||
|
||||
@ -1,258 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Build a bikesharing app with Redis and Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
I travel a lot on business. I'm not much of a car guy, so when I have some free time, I prefer to walk or bike around a city. Many of the cities I've visited on business have bikeshare systems, which let you rent a bike for a few hours. Most of these systems have an app to help users locate and rent their bikes, but it would be more helpful for users like me to have a single place to get information on all the bikes in a city that are available to rent.
|
||||
|
||||
To solve this problem and demonstrate the power of open source to add location-aware features to a web application, I combined publicly available bikeshare data, the [Python][1] programming language, and the open source [Redis][2] in-memory data structure server to index and query geospatial data.
|
||||
|
||||
The resulting bikeshare application incorporates data from many different sharing systems, including the [Citi Bike][3] bikeshare in New York City. It takes advantage of the General Bikeshare Feed provided by the Citi Bike system and uses its data to demonstrate some of the features that can be built using Redis to index geospatial data. The Citi Bike data is provided under the [Citi Bike data license agreement][4].
|
||||
|
||||
### General Bikeshare Feed Specification
|
||||
|
||||
The General Bikeshare Feed Specification (GBFS) is an [open data specification][5] developed by the [North American Bikeshare Association][6] to make it easier for map and transportation applications to add bikeshare systems into their platforms. The specification is currently in use by over 60 different sharing systems in the world.
|
||||
|
||||
The feed consists of several simple [JSON][7] data files containing information about the state of the system. The feed starts with a top-level JSON file referencing the URLs of the sub-feed data:
|
||||
```
|
||||
{
|
||||
|
||||
"data": {
|
||||
|
||||
"en": {
|
||||
|
||||
"feeds": [
|
||||
|
||||
{
|
||||
|
||||
"name": "system_information",
|
||||
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
|
||||
|
||||
},
|
||||
|
||||
{
|
||||
|
||||
"name": "station_information",
|
||||
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
|
||||
|
||||
},
|
||||
|
||||
. . .
|
||||
|
||||
]
|
||||
|
||||
}
|
||||
|
||||
},
|
||||
|
||||
"last_updated": 1506370010,
|
||||
|
||||
"ttl": 10
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The first step is loading information about the bikesharing stations into Redis using data from the `system_information` and `station_information` feeds.
|
||||
|
||||
The `system_information` feed provides the system ID, which is a short code that can be used to create namespaces for Redis keys. The GBFS spec doesn't specify the format of the system ID, but does guarantee it is globally unique. Many of the bikeshare feeds use short names like coast_bike_share, boise_greenbike, or topeka_metro_bikes for system IDs. Others use familiar geographic abbreviations such as NYC or BA, and one uses a universally unique identifier (UUID). The bikesharing application uses the identifier as a prefix to construct unique keys for the given system.
|
||||
|
||||
The `station_information` feed provides static information about the sharing stations that comprise the system. Stations are represented by JSON objects with several fields. There are several mandatory fields in the station object that provide the ID, name, and location of the physical bike stations. There are also several optional fields that provide helpful information such as the nearest cross street or accepted payment methods. This is the primary source of information for this part of the bikesharing application.
|
||||
|
||||
### Building the database
|
||||
|
||||
I've written a sample application, [load_station_data.py][8], that mimics what would happen in a backend process for loading data from external sources.
|
||||
|
||||
### Finding the bikeshare stations
|
||||
|
||||
Loading the bikeshare data starts with the [systems.csv][9] file from the [GBFS repository on GitHub][5].
|
||||
|
||||
The repository's [systems.csv][9] file provides the discovery URL for registered bikeshare systems with an available GBFS feed. The discovery URL is the starting point for processing bikeshare information.
|
||||
|
||||
The `load_station_data` application takes each discovery URL found in the systems file and uses it to find the URL for two sub-feeds: system information and station information. The system information feed provides a key piece of information: the unique ID of the system. (Note: the system ID is also provided in the systems.csv file, but some of the identifiers in that file do not match the identifiers in the feeds, so I always fetch the identifier from the feed.) Details on the system, like bikeshare URLs, phone numbers, and emails, could be added in future versions of the application, so the data is stored in a Redis hash using the key `${system_id}:system_info`.
|
||||
|
||||
### Loading the station data
|
||||
|
||||
The station information provides data about every station in the system, including the system's location. The `load_station_data` application iterates over every station in the station feed and stores the data about each into a Redis hash using a key of the form `${system_id}:station:${station_id}`. The location of each station is added to a geospatial index for the bikeshare using the `GEOADD` command.
|
||||
|
||||
### Updating data
|
||||
|
||||
On subsequent runs, I don't want the code to remove all the feed data from Redis and reload it into an empty Redis database, so I carefully considered how to handle in-place updates of the data.
|
||||
|
||||
The code starts by loading the dataset with information on all the bikesharing stations for the system being processed into memory. When information is loaded for a station, the station (by key) is removed from the in-memory set of stations. Once all station data is loaded, we're left with a set containing all the station data that must be removed for that system.
|
||||
|
||||
The application iterates over this set of stations and creates a transaction to delete the station information, remove the station key from the geospatial indexes, and remove the station from the list of stations for the system.
|
||||
|
||||
### Notes on the code
|
||||
|
||||
There are a few interesting things to note in [the sample code][8]. First, items are added to the geospatial indexes using the `GEOADD` command but removed with the `ZREM` command. As the underlying implementation of the geospatial type uses sorted sets, items are removed using `ZREM`. A word of caution: For simplicity, the sample code demonstrates working with a single Redis node; the transaction blocks would need to be restructured to run in a cluster environment.
|
||||
|
||||
If you are using Redis 4.0 (or later), you have some alternatives to the `DELETE` and `HMSET` commands in the code. Redis 4.0 provides the [`UNLINK`][10] command as an asynchronous alternative to the `DELETE` command. `UNLINK` will remove the key from the keyspace, but it reclaims the memory in a separate thread. The [`HMSET`][11] command is [deprecated in Redis 4.0 and the `HSET` command is now variadic][12] (that is, it accepts an indefinite number of arguments).
|
||||
|
||||
### Notifying clients
|
||||
|
||||
At the end of the process, a notification is sent to the clients relying on our data. Using the Redis pub/sub mechanism, the notification goes out over the `geobike:station_changed` channel with the ID of the system.
|
||||
|
||||
### Data model
|
||||
|
||||
When structuring data in Redis, the most important thing to think about is how you will query the information. The two main queries the bikeshare application needs to support are:
|
||||
|
||||
* Find stations near us
|
||||
* Display information about stations
|
||||
|
||||
|
||||
|
||||
Redis provides two main data types that will be useful for storing our data: hashes and sorted sets. The [hash type][13] maps well to the JSON objects that represent stations; since Redis hashes don't enforce a schema, they can be used to store the variable station information.
|
||||
|
||||
Of course, finding stations geographically requires a geospatial index to search for stations relative to some coordinates. Redis provides [several commands][14] to build up a geospatial index using the [sorted set][15] data structure.
|
||||
|
||||
We construct keys using the format `${system_id}:station:${station_id}` for the hashes containing information about the stations and keys using the format `${system_id}:stations:location` for the geospatial index used to find stations.
|
||||
|
||||
### Getting the user's location
|
||||
|
||||
The next step in building out the application is to determine the user's current location. Most applications accomplish this through built-in services provided by the operating system. The OS can provide applications with a location based on GPS hardware built into the device or approximated from the device's available WiFi networks.
|
||||
|
||||
|
||||
|
||||
### Finding stations
|
||||
|
||||
After the user's location is found, the next step is locating nearby bikesharing stations. Redis' geospatial functions can return information on stations within a given distance of the user's current coordinates. Here's an example of this using the Redis command-line interface.
|
||||
|
||||
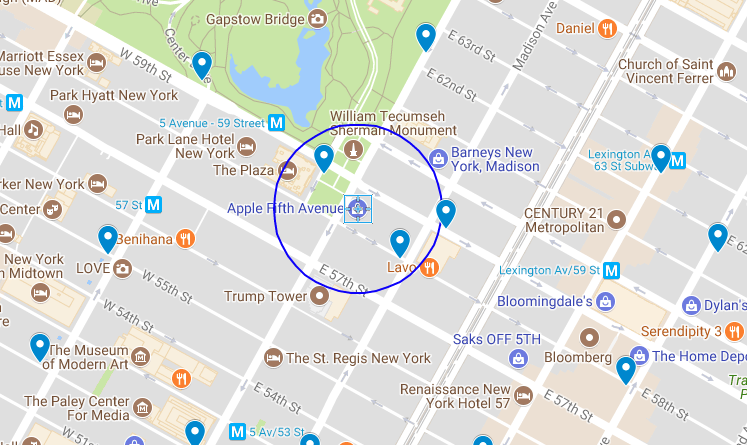
Imagine I'm at the Apple Store on Fifth Avenue in New York City, and I want to head downtown to Mood on West 37th to catch up with my buddy [Swatch][16]. I could take a taxi or the subway, but I'd rather bike. Are there any nearby sharing stations where I could get a bike for my trip?
|
||||
|
||||
The Apple store is located at 40.76384, -73.97297. According to the map, two bikeshare stations—Grand Army Plaza & Central Park South and East 58th St. & Madison—fall within a 500-foot radius (in blue on the map above) of the store.
|
||||
|
||||
I can use Redis' `GEORADIUS` command to query the NYC system index for stations within a 500-foot radius:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
|
||||
|
||||
1) "NYC:station:3457"
|
||||
|
||||
2) "NYC:station:281"
|
||||
|
||||
```
|
||||
|
||||
Redis returns the two bikeshare locations found within that radius, using the elements in our geospatial index as the keys for the metadata about a particular station. The next step is looking up the names for the two stations:
|
||||
```
|
||||
127.0.0.1:6379> hget NYC:station:281 name
|
||||
|
||||
"Grand Army Plaza & Central Park S"
|
||||
|
||||
|
||||
|
||||
127.0.0.1:6379> hget NYC:station:3457 name
|
||||
|
||||
"E 58 St & Madison Ave"
|
||||
|
||||
```
|
||||
|
||||
Those keys correspond to the stations identified on the map above. If I want, I can add more flags to the `GEORADIUS` command to get a list of elements, their coordinates, and their distance from our current point:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
|
||||
|
||||
1) 1) "NYC:station:281"
|
||||
|
||||
2) "289.1995"
|
||||
|
||||
3) 1) "-73.97371262311935425"
|
||||
|
||||
2) "40.76439830559216659"
|
||||
|
||||
2) 1) "NYC:station:3457"
|
||||
|
||||
2) "383.1782"
|
||||
|
||||
3) 1) "-73.97209256887435913"
|
||||
|
||||
2) "40.76302702144496237"
|
||||
|
||||
```
|
||||
|
||||
Looking up the names associated with those keys generates an ordered list of stations I can choose from. Redis doesn't provide directions or routing capability, so I use the routing features of my device's OS to plot a course from my current location to the selected bike station.
|
||||
|
||||
The `GEORADIUS` function can be easily implemented inside an API in your favorite development framework to add location functionality to an app.
|
||||
|
||||
### Other query commands
|
||||
|
||||
In addition to the `GEORADIUS` command, Redis provides three other commands for querying data from the index: `GEOPOS`, `GEODIST`, and `GEORADIUSBYMEMBER`.
|
||||
|
||||
The `GEOPOS` command can provide the coordinates for a given element from the geohash. For example, if I know there is a bikesharing station at West 38th and 8th and its ID is 523, then the element name for that station is NYC🚉523. Using Redis, I can find the station's longitude and latitude:
|
||||
```
|
||||
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
|
||||
|
||||
1) 1) "-73.99138301610946655"
|
||||
|
||||
2) "40.75466497634030105"
|
||||
|
||||
```
|
||||
|
||||
The `GEODIST` command provides the distance between two elements of the index. If I wanted to find the distance between the station at Grand Army Plaza & Central Park South and the station at East 58th St. & Madison, I would issue the following command:
|
||||
```
|
||||
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
|
||||
|
||||
"671.4900"
|
||||
|
||||
```
|
||||
|
||||
Finally, the `GEORADIUSBYMEMBER` command is similar to the `GEORADIUS` command, but instead of taking a set of coordinates, the command takes the name of another member of the index and returns all the members within a given radius centered on that member. To find all the stations within 1,000 feet of the Grand Army Plaza & Central Park South, enter the following:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
|
||||
|
||||
1) 1) "NYC:station:281"
|
||||
|
||||
2) "0.0000"
|
||||
|
||||
2) 1) "NYC:station:3132"
|
||||
|
||||
2) "793.4223"
|
||||
|
||||
3) 1) "NYC:station:2006"
|
||||
|
||||
2) "911.9752"
|
||||
|
||||
4) 1) "NYC:station:3136"
|
||||
|
||||
2) "940.3399"
|
||||
|
||||
5) 1) "NYC:station:3457"
|
||||
|
||||
2) "671.4900"
|
||||
|
||||
```
|
||||
|
||||
While this example focused on using Python and Redis to parse data and build an index of bikesharing system locations, it can easily be generalized to locate restaurants, public transit, or any other type of place developers want to help users find.
|
||||
|
||||
This article is based on [my presentation][17] at Open Source 101 in Raleigh this year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools
|
||||
|
||||
作者:[Tague Griffith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tague
|
||||
[1]:https://www.python.org/
|
||||
[2]:https://redis.io/
|
||||
[3]:https://www.citibikenyc.com/
|
||||
[4]:https://www.citibikenyc.com/data-sharing-policy
|
||||
[5]:https://github.com/NABSA/gbfs
|
||||
[6]:http://nabsa.net/
|
||||
[7]:https://www.json.org/
|
||||
[8]:https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15
|
||||
[9]:https://github.com/NABSA/gbfs/blob/master/systems.csv
|
||||
[10]:https://redis.io/commands/unlink
|
||||
[11]:https://redis.io/commands/hmset
|
||||
[12]:https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
|
||||
[13]:https://redis.io/topics/data-types#Hashes
|
||||
[14]:https://redis.io/commands#geo
|
||||
[15]:https://redis.io/topics/data-types-intro#redis-sorted-sets
|
||||
[16]:https://twitter.com/swatchthedog
|
||||
[17]:http://opensource101.com/raleigh/talks/building-location-aware-apps-open-source-tools/
|
||||
@ -1,80 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Joplin: Encrypted Open Source Note Taking And To-Do Application
|
||||
======
|
||||
**[Joplin][1] is a free and open source note taking and to-do application available for Linux, Windows, macOS, Android and iOS. Its key features include end-to-end encryption, Markdown support, and synchronization via third-party services like NextCloud, Dropbox, OneDrive or WebDAV.**
|
||||
|
||||
|
||||
|
||||
With Joplin you can write your notes in the **Markdown format** (with support for math notations and checkboxes) and the desktop app comes with 3 views: Markdown code, Markdown preview, or both side by side. **You can add attachments to your notes (with image previews) or edit them in an external Markdown editor** and have them automatically updated in Joplin each time you save the file.
|
||||
|
||||
The application should handle a large number of notes pretty well by allowing you to **organizing notes into notebooks, add tags, and search in notes**. You can also sort notes by updated date, creation date or title. **Each notebook can contain notes, to-do items, or both** , and you can easily add links to other notes (in the desktop app right click on a note and select `Copy Markdown link` , then paste the link in a note).
|
||||
|
||||
**Do-do items in Joplin support alarms** , but this feature didn't work for me on Ubuntu 18.04.
|
||||
|
||||
**Other Joplin features include:**
|
||||
|
||||
* **Optional Web Clipper extension** for Firefox and Chrome (in the Joplin desktop application go to `Tools > Web clipper options` to enable the clipper service and find download links for the Chrome / Firefox extension) which can clip simplified or complete pages, clip a selection or screenshot.
|
||||
|
||||
* **Optional command line client**.
|
||||
|
||||
* **Import Enex files (Evernote export format) and Markdown files**.
|
||||
|
||||
* **Export JEX files (Joplin Export format), PDF and raw files**.
|
||||
|
||||
* **Offline first, so the entire data is always available on the device even without an internet connection**.
|
||||
|
||||
* **Geolocation support**.
|
||||
|
||||
|
||||
|
||||
[![Joplin notes checkboxes link to other note][2]][3]
|
||||
Joplin with hidden sidebar showing checkboxes and a link to another note
|
||||
|
||||
While it doesn't offer as many features as Evernote, Joplin is a robust open source Evernote alternative. Joplin includes all the basic features, and on top of that it's open source software, it includes encryption support, and you also get to choose the service you want to use for synchronization.
|
||||
|
||||
The application was actually designed as an Evernote alternative so it can import complete Evernote notebooks, notes, tags, attachments, and note metadata like the author, creation and updated time, or geolocation.
|
||||
|
||||
Another aspect on which the Joplin development was focused was to avoid being tied to a particular company or service. This is why the application offers multiple synchronization solutions, like NextCloud, Dropbox, oneDrive and WebDav, while also making it easy to support new services. It's also easy to switch from one service to another if you change your mind.
|
||||
|
||||
**I should note that Joplin doesn't use encryption by default and you must enable this from its settings. Go to** `Tools > Encryption options` and enable the Joplin end-to-end encryption from there.
|
||||
|
||||
### Download Joplin
|
||||
|
||||
[Download Joplin][7]
|
||||
|
||||
**Joplin is available for Linux, Windows, macOS, Android and iOS. On Linux, there's an AppImage as well as an Aur package available.**
|
||||
|
||||
To run the Joplin AppImage on Linux, double click it and select `Make executable and run` if your file manager supports this. If not, you'll need to make it executable either using your file manager (should be something like: `right click > Properties > Permissions > Allow executing file as program` , but this may vary depending on the file manager you use), or from the command line:
|
||||
```
|
||||
chmod +x /path/to/Joplin-*-x86_64.AppImage
|
||||
|
||||
```
|
||||
|
||||
Replacing `/path/to/` with the path to where you downloaded Joplin. Now you can double click the Joplin Appimage file to launch it.
|
||||
|
||||
**TIP:** If you integrate Joplin to your menu and `~/.local/share/applications/appimagekit-joplin.desktop`) and adding `StartupWMClass=Joplin` at the end of the file on a new line, without modifying anything else.
|
||||
|
||||
Joplin has a **command line client** that can be [installed using npm][5] (for Debian, Ubuntu or Linux Mint, see [how to install and configure Node.js and npm][6] ).
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://joplin.cozic.net/
|
||||
[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
|
||||
[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
|
||||
[4]:https://github.com/laurent22/joplin/issues/338
|
||||
[5]:https://joplin.cozic.net/terminal/
|
||||
[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
|
||||
|
||||
[7]: https://joplin.cozic.net/#installation
|
||||
@ -1,512 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Lab 6: Network Driver
|
||||
======
|
||||
### Lab 6: Network Driver (default final project)
|
||||
|
||||
**Due on Thursday, December 6, 2018
|
||||
**
|
||||
|
||||
### Introduction
|
||||
|
||||
This lab is the default final project that you can do on your own.
|
||||
|
||||
Now that you have a file system, no self respecting OS should go without a network stack. In this the lab you are going to write a driver for a network interface card. The card will be based on the Intel 82540EM chip, also known as the E1000.
|
||||
|
||||
##### Getting Started
|
||||
|
||||
Use Git to commit your Lab 5 source (if you haven't already), fetch the latest version of the course repository, and then create a local branch called `lab6` based on our lab6 branch, `origin/lab6`:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'my solution to lab5'
|
||||
nothing to commit (working directory clean)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab6 origin/lab6
|
||||
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
|
||||
Switched to a new branch "lab6"
|
||||
athena% git merge lab5
|
||||
Merge made by recursive.
|
||||
fs/fs.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
The network card driver, however, will not be enough to get your OS hooked up to the Internet. In the new lab6 code, we have provided you with a network stack and a network server. As in previous labs, use git to grab the code for this lab, merge in your own code, and explore the contents of the new `net/` directory, as well as the new files in `kern/`.
|
||||
|
||||
In addition to writing the driver, you will need to create a system call interface to give access to your driver. You will implement missing network server code to transfer packets between the network stack and your driver. You will also tie everything together by finishing a web server. With the new web server you will be able to serve files from your file system.
|
||||
|
||||
Much of the kernel device driver code you will have to write yourself from scratch. This lab provides much less guidance than previous labs: there are no skeleton files, no system call interfaces written in stone, and many design decisions are left up to you. For this reason, we recommend that you read the entire assignment write up before starting any individual exercises. Many students find this lab more difficult than previous labs, so please plan your time accordingly.
|
||||
|
||||
##### Lab Requirements
|
||||
|
||||
As before, you will need to do all of the regular exercises described in the lab and _at least one_ challenge problem. Write up brief answers to the questions posed in the lab and a description of your challenge exercise in `answers-lab6.txt`.
|
||||
|
||||
#### QEMU's virtual network
|
||||
|
||||
We will be using QEMU's user mode network stack since it requires no administrative privileges to run. QEMU's documentation has more about user-net [here][1]. We've updated the makefile to enable QEMU's user-mode network stack and the virtual E1000 network card.
|
||||
|
||||
By default, QEMU provides a virtual router running on IP 10.0.2.2 and will assign JOS the IP address 10.0.2.15. To keep things simple, we hard-code these defaults into the network server in `net/ns.h`.
|
||||
|
||||
While QEMU's virtual network allows JOS to make arbitrary connections out to the Internet, JOS's 10.0.2.15 address has no meaning outside the virtual network running inside QEMU (that is, QEMU acts as a NAT), so we can't connect directly to servers running inside JOS, even from the host running QEMU. To address this, we configure QEMU to run a server on some port on the _host_ machine that simply connects through to some port in JOS and shuttles data back and forth between your real host and the virtual network.
|
||||
|
||||
You will run JOS servers on ports 7 (echo) and 80 (http). To avoid collisions on shared Athena machines, the makefile generates forwarding ports for these based on your user ID. To find out what ports QEMU is forwarding to on your development host, run make which-ports. For convenience, the makefile also provides make nc-7 and make nc-80, which allow you to interact directly with servers running on these ports in your terminal. (These targets only connect to a running QEMU instance; you must start QEMU itself separately.)
|
||||
|
||||
##### Packet Inspection
|
||||
|
||||
The makefile also configures QEMU's network stack to record all incoming and outgoing packets to `qemu.pcap` in your lab directory.
|
||||
|
||||
To get a hex/ASCII dump of captured packets use `tcpdump` like this:
|
||||
|
||||
```
|
||||
tcpdump -XXnr qemu.pcap
|
||||
```
|
||||
|
||||
Alternatively, you can use [Wireshark][2] to graphically inspect the pcap file. Wireshark also knows how to decode and inspect hundreds of network protocols. If you're on Athena, you'll have to use Wireshark's predecessor, ethereal, which is in the sipbnet locker.
|
||||
|
||||
##### Debugging the E1000
|
||||
|
||||
We are very lucky to be using emulated hardware. Since the E1000 is running in software, the emulated E1000 can report to us, in a user readable format, its internal state and any problems it encounters. Normally, such a luxury would not be available to a driver developer writing with bare metal.
|
||||
|
||||
The E1000 can produce a lot of debug output, so you have to enable specific logging channels. Some channels you might find useful are:
|
||||
|
||||
| Flag | Meaning |
|
||||
| --------- | ---------------------------------------------------|
|
||||
| tx | Log packet transmit operations |
|
||||
| txerr | Log transmit ring errors |
|
||||
| rx | Log changes to RCTL |
|
||||
| rxfilter | Log filtering of incoming packets |
|
||||
| rxerr | Log receive ring errors |
|
||||
| unknown | Log reads and writes of unknown registers |
|
||||
| eeprom | Log reads from the EEPROM |
|
||||
| interrupt | Log interrupts and changes to interrupt registers. |
|
||||
|
||||
To enable "tx" and "txerr" logging, for example, use make E1000_DEBUG=tx,txerr ....
|
||||
|
||||
Note: `E1000_DEBUG` flags only work in the 6.828 version of QEMU.
|
||||
|
||||
You can take debugging using software emulated hardware one step further. If you are ever stuck and do not understand why the E1000 is not responding the way you would expect, you can look at QEMU's E1000 implementation in `hw/e1000.c`.
|
||||
|
||||
#### The Network Server
|
||||
|
||||
Writing a network stack from scratch is hard work. Instead, we will be using lwIP, an open source lightweight TCP/IP protocol suite that among many things includes a network stack. You can find more information on lwIP [here][3]. In this assignment, as far as we are concerned, lwIP is a black box that implements a BSD socket interface and has a packet input port and packet output port.
|
||||
|
||||
The network server is actually a combination of four environments:
|
||||
|
||||
* core network server environment (includes socket call dispatcher and lwIP)
|
||||
* input environment
|
||||
* output environment
|
||||
* timer environment
|
||||
|
||||
|
||||
|
||||
The following diagram shows the different environments and their relationships. The diagram shows the entire system including the device driver, which will be covered later. In this lab, you will implement the parts highlighted in green.
|
||||
|
||||
![Network server architecture][4]
|
||||
|
||||
##### The Core Network Server Environment
|
||||
|
||||
The core network server environment is composed of the socket call dispatcher and lwIP itself. The socket call dispatcher works exactly like the file server. User environments use stubs (found in `lib/nsipc.c`) to send IPC messages to the core network environment. If you look at `lib/nsipc.c` you will see that we find the core network server the same way we found the file server: `i386_init` created the NS environment with NS_TYPE_NS, so we scan `envs`, looking for this special environment type. For each user environment IPC, the dispatcher in the network server calls the appropriate BSD socket interface function provided by lwIP on behalf of the user.
|
||||
|
||||
Regular user environments do not use the `nsipc_*` calls directly. Instead, they use the functions in `lib/sockets.c`, which provides a file descriptor-based sockets API. Thus, user environments refer to sockets via file descriptors, just like how they referred to on-disk files. A number of operations (`connect`, `accept`, etc.) are specific to sockets, but `read`, `write`, and `close` go through the normal file descriptor device-dispatch code in `lib/fd.c`. Much like how the file server maintained internal unique ID's for all open files, lwIP also generates unique ID's for all open sockets. In both the file server and the network server, we use information stored in `struct Fd` to map per-environment file descriptors to these unique ID spaces.
|
||||
|
||||
Even though it may seem that the IPC dispatchers of the file server and network server act the same, there is a key difference. BSD socket calls like `accept` and `recv` can block indefinitely. If the dispatcher were to let lwIP execute one of these blocking calls, the dispatcher would also block and there could only be one outstanding network call at a time for the whole system. Since this is unacceptable, the network server uses user-level threading to avoid blocking the entire server environment. For every incoming IPC message, the dispatcher creates a thread and processes the request in the newly created thread. If the thread blocks, then only that thread is put to sleep while other threads continue to run.
|
||||
|
||||
In addition to the core network environment there are three helper environments. Besides accepting messages from user applications, the core network environment's dispatcher also accepts messages from the input and timer environments.
|
||||
|
||||
##### The Output Environment
|
||||
|
||||
When servicing user environment socket calls, lwIP will generate packets for the network card to transmit. LwIP will send each packet to be transmitted to the output helper environment using the `NSREQ_OUTPUT` IPC message with the packet attached in the page argument of the IPC message. The output environment is responsible for accepting these messages and forwarding the packet on to the device driver via the system call interface that you will soon create.
|
||||
|
||||
##### The Input Environment
|
||||
|
||||
Packets received by the network card need to be injected into lwIP. For every packet received by the device driver, the input environment pulls the packet out of kernel space (using kernel system calls that you will implement) and sends the packet to the core server environment using the `NSREQ_INPUT` IPC message.
|
||||
|
||||
The packet input functionality is separated from the core network environment because JOS makes it hard to simultaneously accept IPC messages and poll or wait for a packet from the device driver. We do not have a `select` system call in JOS that would allow environments to monitor multiple input sources to identify which input is ready to be processed.
|
||||
|
||||
If you take a look at `net/input.c` and `net/output.c` you will see that both need to be implemented. This is mainly because the implementation depends on your system call interface. You will write the code for the two helper environments after you implement the driver and system call interface.
|
||||
|
||||
##### The Timer Environment
|
||||
|
||||
The timer environment periodically sends messages of type `NSREQ_TIMER` to the core network server notifying it that a timer has expired. The timer messages from this thread are used by lwIP to implement various network timeouts.
|
||||
|
||||
### Part A: Initialization and transmitting packets
|
||||
|
||||
Your kernel does not have a notion of time, so we need to add it. There is currently a clock interrupt that is generated by the hardware every 10ms. On every clock interrupt we can increment a variable to indicate that time has advanced by 10ms. This is implemented in `kern/time.c`, but is not yet fully integrated into your kernel.
|
||||
|
||||
```
|
||||
Exercise 1. Add a call to `time_tick` for every clock interrupt in `kern/trap.c`. Implement `sys_time_msec` and add it to `syscall` in `kern/syscall.c` so that user space has access to the time.
|
||||
```
|
||||
|
||||
Use make INIT_CFLAGS=-DTEST_NO_NS run-testtime to test your time code. You should see the environment count down from 5 in 1 second intervals. The "-DTEST_NO_NS" disables starting the network server environment because it will panic at this point in the lab.
|
||||
|
||||
#### The Network Interface Card
|
||||
|
||||
Writing a driver requires knowing in depth the hardware and the interface presented to the software. The lab text will provide a high-level overview of how to interface with the E1000, but you'll need to make extensive use of Intel's manual while writing your driver.
|
||||
|
||||
```
|
||||
Exercise 2. Browse Intel's [Software Developer's Manual][5] for the E1000. This manual covers several closely related Ethernet controllers. QEMU emulates the 82540EM.
|
||||
|
||||
You should skim over chapter 2 now to get a feel for the device. To write your driver, you'll need to be familiar with chapters 3 and 14, as well as 4.1 (though not 4.1's subsections). You'll also need to use chapter 13 as reference. The other chapters mostly cover components of the E1000 that your driver won't have to interact with. Don't worry about the details right now; just get a feel for how the document is structured so you can find things later.
|
||||
|
||||
While reading the manual, keep in mind that the E1000 is a sophisticated device with many advanced features. A working E1000 driver only needs a fraction of the features and interfaces that the NIC provides. Think carefully about the easiest way to interface with the card. We strongly recommend that you get a basic driver working before taking advantage of the advanced features.
|
||||
```
|
||||
|
||||
##### PCI Interface
|
||||
|
||||
The E1000 is a PCI device, which means it plugs into the PCI bus on the motherboard. The PCI bus has address, data, and interrupt lines, and allows the CPU to communicate with PCI devices and PCI devices to read and write memory. A PCI device needs to be discovered and initialized before it can be used. Discovery is the process of walking the PCI bus looking for attached devices. Initialization is the process of allocating I/O and memory space as well as negotiating the IRQ line for the device to use.
|
||||
|
||||
We have provided you with PCI code in `kern/pci.c`. To perform PCI initialization during boot, the PCI code walks the PCI bus looking for devices. When it finds a device, it reads its vendor ID and device ID and uses these two values as a key to search the `pci_attach_vendor` array. The array is composed of `struct pci_driver` entries like this:
|
||||
|
||||
```
|
||||
struct pci_driver {
|
||||
uint32_t key1, key2;
|
||||
int (*attachfn) (struct pci_func *pcif);
|
||||
};
|
||||
```
|
||||
|
||||
If the discovered device's vendor ID and device ID match an entry in the array, the PCI code calls that entry's `attachfn` to perform device initialization. (Devices can also be identified by class, which is what the other driver table in `kern/pci.c` is for.)
|
||||
|
||||
The attach function is passed a _PCI function_ to initialize. A PCI card can expose multiple functions, though the E1000 exposes only one. Here is how we represent a PCI function in JOS:
|
||||
|
||||
```
|
||||
struct pci_func {
|
||||
struct pci_bus *bus;
|
||||
|
||||
uint32_t dev;
|
||||
uint32_t func;
|
||||
|
||||
uint32_t dev_id;
|
||||
uint32_t dev_class;
|
||||
|
||||
uint32_t reg_base[6];
|
||||
uint32_t reg_size[6];
|
||||
uint8_t irq_line;
|
||||
};
|
||||
```
|
||||
|
||||
The above structure reflects some of the entries found in Table 4-1 of Section 4.1 of the developer manual. The last three entries of `struct pci_func` are of particular interest to us, as they record the negotiated memory, I/O, and interrupt resources for the device. The `reg_base` and `reg_size` arrays contain information for up to six Base Address Registers or BARs. `reg_base` stores the base memory addresses for memory-mapped I/O regions (or base I/O ports for I/O port resources), `reg_size` contains the size in bytes or number of I/O ports for the corresponding base values from `reg_base`, and `irq_line` contains the IRQ line assigned to the device for interrupts. The specific meanings of the E1000 BARs are given in the second half of table 4-2.
|
||||
|
||||
When the attach function of a device is called, the device has been found but not yet _enabled_. This means that the PCI code has not yet determined the resources allocated to the device, such as address space and an IRQ line, and, thus, the last three elements of the `struct pci_func` structure are not yet filled in. The attach function should call `pci_func_enable`, which will enable the device, negotiate these resources, and fill in the `struct pci_func`.
|
||||
|
||||
```
|
||||
Exercise 3. Implement an attach function to initialize the E1000. Add an entry to the `pci_attach_vendor` array in `kern/pci.c` to trigger your function if a matching PCI device is found (be sure to put it before the `{0, 0, 0}` entry that mark the end of the table). You can find the vendor ID and device ID of the 82540EM that QEMU emulates in section 5.2. You should also see these listed when JOS scans the PCI bus while booting.
|
||||
|
||||
For now, just enable the E1000 device via `pci_func_enable`. We'll add more initialization throughout the lab.
|
||||
|
||||
We have provided the `kern/e1000.c` and `kern/e1000.h` files for you so that you do not need to mess with the build system. They are currently blank; you need to fill them in for this exercise. You may also need to include the `e1000.h` file in other places in the kernel.
|
||||
|
||||
When you boot your kernel, you should see it print that the PCI function of the E1000 card was enabled. Your code should now pass the `pci attach` test of make grade.
|
||||
```
|
||||
|
||||
##### Memory-mapped I/O
|
||||
|
||||
Software communicates with the E1000 via _memory-mapped I/O_ (MMIO). You've seen this twice before in JOS: both the CGA console and the LAPIC are devices that you control and query by writing to and reading from "memory". But these reads and writes don't go to DRAM; they go directly to these devices.
|
||||
|
||||
`pci_func_enable` negotiates an MMIO region with the E1000 and stores its base and size in BAR 0 (that is, `reg_base[0]` and `reg_size[0]`). This is a range of _physical memory addresses_ assigned to the device, which means you'll have to do something to access it via virtual addresses. Since MMIO regions are assigned very high physical addresses (typically above 3GB), you can't use `KADDR` to access it because of JOS's 256MB limit. Thus, you'll have to create a new memory mapping. We'll use the area above MMIOBASE (your `mmio_map_region` from lab 4 will make sure we don't overwrite the mapping used by the LAPIC). Since PCI device initialization happens before JOS creates user environments, you can create the mapping in `kern_pgdir` and it will always be available.
|
||||
|
||||
```
|
||||
Exercise 4. In your attach function, create a virtual memory mapping for the E1000's BAR 0 by calling `mmio_map_region` (which you wrote in lab 4 to support memory-mapping the LAPIC).
|
||||
|
||||
You'll want to record the location of this mapping in a variable so you can later access the registers you just mapped. Take a look at the `lapic` variable in `kern/lapic.c` for an example of one way to do this. If you do use a pointer to the device register mapping, be sure to declare it `volatile`; otherwise, the compiler is allowed to cache values and reorder accesses to this memory.
|
||||
|
||||
To test your mapping, try printing out the device status register (section 13.4.2). This is a 4 byte register that starts at byte 8 of the register space. You should get `0x80080783`, which indicates a full duplex link is up at 1000 MB/s, among other things.
|
||||
```
|
||||
|
||||
Hint: You'll need a lot of constants, like the locations of registers and values of bit masks. Trying to copy these out of the developer's manual is error-prone and mistakes can lead to painful debugging sessions. We recommend instead using QEMU's [`e1000_hw.h`][6] header as a guideline. We don't recommend copying it in verbatim, because it defines far more than you actually need and may not define things in the way you need, but it's a good starting point.
|
||||
|
||||
##### DMA
|
||||
|
||||
You could imagine transmitting and receiving packets by writing and reading from the E1000's registers, but this would be slow and would require the E1000 to buffer packet data internally. Instead, the E1000 uses _Direct Memory Access_ or DMA to read and write packet data directly from memory without involving the CPU. The driver is responsible for allocating memory for the transmit and receive queues, setting up DMA descriptors, and configuring the E1000 with the location of these queues, but everything after that is asynchronous. To transmit a packet, the driver copies it into the next DMA descriptor in the transmit queue and informs the E1000 that another packet is available; the E1000 will copy the data out of the descriptor when there is time to send the packet. Likewise, when the E1000 receives a packet, it copies it into the next DMA descriptor in the receive queue, which the driver can read from at its next opportunity.
|
||||
|
||||
The receive and transmit queues are very similar at a high level. Both consist of a sequence of _descriptors_. While the exact structure of these descriptors varies, each descriptor contains some flags and the physical address of a buffer containing packet data (either packet data for the card to send, or a buffer allocated by the OS for the card to write a received packet to).
|
||||
|
||||
The queues are implemented as circular arrays, meaning that when the card or the driver reach the end of the array, it wraps back around to the beginning. Both have a _head pointer_ and a _tail pointer_ and the contents of the queue are the descriptors between these two pointers. The hardware always consumes descriptors from the head and moves the head pointer, while the driver always add descriptors to the tail and moves the tail pointer. The descriptors in the transmit queue represent packets waiting to be sent (hence, in the steady state, the transmit queue is empty). For the receive queue, the descriptors in the queue are free descriptors that the card can receive packets into (hence, in the steady state, the receive queue consists of all available receive descriptors). Correctly updating the tail register without confusing the E1000 is tricky; be careful!
|
||||
|
||||
The pointers to these arrays as well as the addresses of the packet buffers in the descriptors must all be _physical addresses_ because hardware performs DMA directly to and from physical RAM without going through the MMU.
|
||||
|
||||
#### Transmitting Packets
|
||||
|
||||
The transmit and receive functions of the E1000 are basically independent of each other, so we can work on one at a time. We'll attack transmitting packets first simply because we can't test receive without transmitting an "I'm here!" packet first.
|
||||
|
||||
First, you'll have to initialize the card to transmit, following the steps described in section 14.5 (you don't have to worry about the subsections). The first step of transmit initialization is setting up the transmit queue. The precise structure of the queue is described in section 3.4 and the structure of the descriptors is described in section 3.3.3. We won't be using the TCP offload features of the E1000, so you can focus on the "legacy transmit descriptor format." You should read those sections now and familiarize yourself with these structures.
|
||||
|
||||
##### C Structures
|
||||
|
||||
You'll find it convenient to use C `struct`s to describe the E1000's structures. As you've seen with structures like the `struct Trapframe`, C `struct`s let you precisely layout data in memory. C can insert padding between fields, but the E1000's structures are laid out such that this shouldn't be a problem. If you do encounter field alignment problems, look into GCC's "packed" attribute.
|
||||
|
||||
As an example, consider the legacy transmit descriptor given in table 3-8 of the manual and reproduced here:
|
||||
|
||||
```
|
||||
63 48 47 40 39 32 31 24 23 16 15 0
|
||||
+---------------------------------------------------------------+
|
||||
| Buffer address |
|
||||
+---------------|-------|-------|-------|-------|---------------+
|
||||
| Special | CSS | Status| Cmd | CSO | Length |
|
||||
+---------------|-------|-------|-------|-------|---------------+
|
||||
```
|
||||
|
||||
The first byte of the structure starts at the top right, so to convert this into a C struct, read from right to left, top to bottom. If you squint at it right, you'll see that all of the fields even fit nicely into a standard-size types:
|
||||
|
||||
```
|
||||
struct tx_desc
|
||||
{
|
||||
uint64_t addr;
|
||||
uint16_t length;
|
||||
uint8_t cso;
|
||||
uint8_t cmd;
|
||||
uint8_t status;
|
||||
uint8_t css;
|
||||
uint16_t special;
|
||||
};
|
||||
```
|
||||
|
||||
Your driver will have to reserve memory for the transmit descriptor array and the packet buffers pointed to by the transmit descriptors. There are several ways to do this, ranging from dynamically allocating pages to simply declaring them in global variables. Whatever you choose, keep in mind that the E1000 accesses physical memory directly, which means any buffer it accesses must be contiguous in physical memory.
|
||||
|
||||
There are also multiple ways to handle the packet buffers. The simplest, which we recommend starting with, is to reserve space for a packet buffer for each descriptor during driver initialization and simply copy packet data into and out of these pre-allocated buffers. The maximum size of an Ethernet packet is 1518 bytes, which bounds how big these buffers need to be. More sophisticated drivers could dynamically allocate packet buffers (e.g., to reduce memory overhead when network usage is low) or even pass buffers directly provided by user space (a technique known as "zero copy"), but it's good to start simple.
|
||||
|
||||
```
|
||||
Exercise 5. Perform the initialization steps described in section 14.5 (but not its subsections). Use section 13 as a reference for the registers the initialization process refers to and sections 3.3.3 and 3.4 for reference to the transmit descriptors and transmit descriptor array.
|
||||
|
||||
Be mindful of the alignment requirements on the transmit descriptor array and the restrictions on length of this array. Since TDLEN must be 128-byte aligned and each transmit descriptor is 16 bytes, your transmit descriptor array will need some multiple of 8 transmit descriptors. However, don't use more than 64 descriptors or our tests won't be able to test transmit ring overflow.
|
||||
|
||||
For the TCTL.COLD, you can assume full-duplex operation. For TIPG, refer to the default values described in table 13-77 of section 13.4.34 for the IEEE 802.3 standard IPG (don't use the values in the table in section 14.5).
|
||||
```
|
||||
|
||||
Try running make E1000_DEBUG=TXERR,TX qemu. If you are using the course qemu, you should see an "e1000: tx disabled" message when you set the TDT register (since this happens before you set TCTL.EN) and no further "e1000" messages.
|
||||
|
||||
Now that transmit is initialized, you'll have to write the code to transmit a packet and make it accessible to user space via a system call. To transmit a packet, you have to add it to the tail of the transmit queue, which means copying the packet data into the next packet buffer and then updating the TDT (transmit descriptor tail) register to inform the card that there's another packet in the transmit queue. (Note that TDT is an _index_ into the transmit descriptor array, not a byte offset; the documentation isn't very clear about this.)
|
||||
|
||||
However, the transmit queue is only so big. What happens if the card has fallen behind transmitting packets and the transmit queue is full? In order to detect this condition, you'll need some feedback from the E1000. Unfortunately, you can't just use the TDH (transmit descriptor head) register; the documentation explicitly states that reading this register from software is unreliable. However, if you set the RS bit in the command field of a transmit descriptor, then, when the card has transmitted the packet in that descriptor, the card will set the DD bit in the status field of the descriptor. If a descriptor's DD bit is set, you know it's safe to recycle that descriptor and use it to transmit another packet.
|
||||
|
||||
What if the user calls your transmit system call, but the DD bit of the next descriptor isn't set, indicating that the transmit queue is full? You'll have to decide what to do in this situation. You could simply drop the packet. Network protocols are resilient to this, but if you drop a large burst of packets, the protocol may not recover. You could instead tell the user environment that it has to retry, much like you did for `sys_ipc_try_send`. This has the advantage of pushing back on the environment generating the data.
|
||||
|
||||
```
|
||||
Exercise 6. Write a function to transmit a packet by checking that the next descriptor is free, copying the packet data into the next descriptor, and updating TDT. Make sure you handle the transmit queue being full.
|
||||
```
|
||||
|
||||
Now would be a good time to test your packet transmit code. Try transmitting just a few packets by directly calling your transmit function from the kernel. You don't have to create packets that conform to any particular network protocol in order to test this. Run make E1000_DEBUG=TXERR,TX qemu to run your test. You should see something like
|
||||
|
||||
```
|
||||
e1000: index 0: 0x271f00 : 9000002a 0
|
||||
...
|
||||
```
|
||||
|
||||
as you transmit packets. Each line gives the index in the transmit array, the buffer address of that transmit descriptor, the cmd/CSO/length fields, and the special/CSS/status fields. If QEMU doesn't print the values you expected from your transmit descriptor, check that you're filling in the right descriptor and that you configured TDBAL and TDBAH correctly. If you get "e1000: TDH wraparound @0, TDT x, TDLEN y" messages, that means the E1000 ran all the way through the transmit queue without stopping (if QEMU didn't check this, it would enter an infinite loop), which probably means you aren't manipulating TDT correctly. If you get lots of "e1000: tx disabled" messages, then you didn't set the transmit control register right.
|
||||
|
||||
Once QEMU runs, you can then run tcpdump -XXnr qemu.pcap to see the packet data that you transmitted. If you saw the expected "e1000: index" messages from QEMU, but your packet capture is empty, double check that you filled in every necessary field and bit in your transmit descriptors (the E1000 probably went through your transmit descriptors, but didn't think it had to send anything).
|
||||
|
||||
```
|
||||
Exercise 7. Add a system call that lets you transmit packets from user space. The exact interface is up to you. Don't forget to check any pointers passed to the kernel from user space.
|
||||
```
|
||||
|
||||
#### Transmitting Packets: Network Server
|
||||
|
||||
Now that you have a system call interface to the transmit side of your device driver, it's time to send packets. The output helper environment's goal is to do the following in a loop: accept `NSREQ_OUTPUT` IPC messages from the core network server and send the packets accompanying these IPC message to the network device driver using the system call you added above. The `NSREQ_OUTPUT` IPC's are sent by the `low_level_output` function in `net/lwip/jos/jif/jif.c`, which glues the lwIP stack to JOS's network system. Each IPC will include a page consisting of a `union Nsipc` with the packet in its `struct jif_pkt pkt` field (see `inc/ns.h`). `struct jif_pkt` looks like
|
||||
|
||||
```
|
||||
struct jif_pkt {
|
||||
int jp_len;
|
||||
char jp_data[0];
|
||||
};
|
||||
```
|
||||
|
||||
`jp_len` represents the length of the packet. All subsequent bytes on the IPC page are dedicated to the packet contents. Using a zero-length array like `jp_data` at the end of a struct is a common C trick (some would say abomination) for representing buffers without pre-determined lengths. Since C doesn't do array bounds checking, as long as you ensure there's enough unused memory following the struct, you can use `jp_data` as if it were an array of any size.
|
||||
|
||||
Be aware of the interaction between the device driver, the output environment and the core network server when there is no more space in the device driver's transmit queue. The core network server sends packets to the output environment using IPC. If the output environment is suspended due to a send packet system call because the driver has no more buffer space for new packets, the core network server will block waiting for the output server to accept the IPC call.
|
||||
|
||||
```
|
||||
Exercise 8. Implement `net/output.c`.
|
||||
```
|
||||
|
||||
You can use `net/testoutput.c` to test your output code without involving the whole network server. Try running make E1000_DEBUG=TXERR,TX run-net_testoutput. You should see something like
|
||||
|
||||
```
|
||||
Transmitting packet 0
|
||||
e1000: index 0: 0x271f00 : 9000009 0
|
||||
Transmitting packet 1
|
||||
e1000: index 1: 0x2724ee : 9000009 0
|
||||
...
|
||||
```
|
||||
|
||||
and tcpdump -XXnr qemu.pcap should output
|
||||
|
||||
|
||||
```
|
||||
reading from file qemu.pcap, link-type EN10MB (Ethernet)
|
||||
-5:00:00.600186 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 30 Packet.00
|
||||
-5:00:00.610080 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 31 Packet.01
|
||||
...
|
||||
```
|
||||
|
||||
To test with a larger packet count, try make E1000_DEBUG=TXERR,TX NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput. If this overflows your transmit ring, double check that you're handling the DD status bit correctly and that you've told the hardware to set the DD status bit (using the RS command bit).
|
||||
|
||||
Your code should pass the `testoutput` tests of make grade.
|
||||
|
||||
```
|
||||
Question
|
||||
|
||||
1. How did you structure your transmit implementation? In particular, what do you do if the transmit ring is full?
|
||||
```
|
||||
|
||||
|
||||
### Part B: Receiving packets and the web server
|
||||
|
||||
#### Receiving Packets
|
||||
|
||||
Just like you did for transmitting packets, you'll have to configure the E1000 to receive packets and provide a receive descriptor queue and receive descriptors. Section 3.2 describes how packet reception works, including the receive queue structure and receive descriptors, and the initialization process is detailed in section 14.4.
|
||||
|
||||
```
|
||||
Exercise 9. Read section 3.2. You can ignore anything about interrupts and checksum offloading (you can return to these sections if you decide to use these features later), and you don't have to be concerned with the details of thresholds and how the card's internal caches work.
|
||||
```
|
||||
|
||||
The receive queue is very similar to the transmit queue, except that it consists of empty packet buffers waiting to be filled with incoming packets. Hence, when the network is idle, the transmit queue is empty (because all packets have been sent), but the receive queue is full (of empty packet buffers).
|
||||
|
||||
When the E1000 receives a packet, it first checks if it matches the card's configured filters (for example, to see if the packet is addressed to this E1000's MAC address) and ignores the packet if it doesn't match any filters. Otherwise, the E1000 tries to retrieve the next receive descriptor from the head of the receive queue. If the head (RDH) has caught up with the tail (RDT), then the receive queue is out of free descriptors, so the card drops the packet. If there is a free receive descriptor, it copies the packet data into the buffer pointed to by the descriptor, sets the descriptor's DD (Descriptor Done) and EOP (End of Packet) status bits, and increments the RDH.
|
||||
|
||||
If the E1000 receives a packet that is larger than the packet buffer in one receive descriptor, it will retrieve as many descriptors as necessary from the receive queue to store the entire contents of the packet. To indicate that this has happened, it will set the DD status bit on all of these descriptors, but only set the EOP status bit on the last of these descriptors. You can either deal with this possibility in your driver, or simply configure the card to not accept "long packets" (also known as _jumbo frames_ ) and make sure your receive buffers are large enough to store the largest possible standard Ethernet packet (1518 bytes).
|
||||
|
||||
```
|
||||
Exercise 10. Set up the receive queue and configure the E1000 by following the process in section 14.4. You don't have to support "long packets" or multicast. For now, don't configure the card to use interrupts; you can change that later if you decide to use receive interrupts. Also, configure the E1000 to strip the Ethernet CRC, since the grade script expects it to be stripped.
|
||||
|
||||
By default, the card will filter out _all_ packets. You have to configure the Receive Address Registers (RAL and RAH) with the card's own MAC address in order to accept packets addressed to that card. You can simply hard-code QEMU's default MAC address of 52:54:00:12:34:56 (we already hard-code this in lwIP, so doing it here too doesn't make things any worse). Be very careful with the byte order; MAC addresses are written from lowest-order byte to highest-order byte, so 52:54:00:12 are the low-order 32 bits of the MAC address and 34:56 are the high-order 16 bits.
|
||||
|
||||
The E1000 only supports a specific set of receive buffer sizes (given in the description of RCTL.BSIZE in 13.4.22). If you make your receive packet buffers large enough and disable long packets, you won't have to worry about packets spanning multiple receive buffers. Also, remember that, just like for transmit, the receive queue and the packet buffers must be contiguous in physical memory.
|
||||
|
||||
You should use at least 128 receive descriptors
|
||||
```
|
||||
|
||||
You can do a basic test of receive functionality now, even without writing the code to receive packets. Run make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput. `testinput` will transmit an ARP (Address Resolution Protocol) announcement packet (using your packet transmitting system call), which QEMU will automatically reply to. Even though your driver can't receive this reply yet, you should see a "e1000: unicast match[0]: 52:54:00:12:34:56" message, indicating that a packet was received by the E1000 and matched the configured receive filter. If you see a "e1000: unicast mismatch: 52:54:00:12:34:56" message instead, the E1000 filtered out the packet, which means you probably didn't configure RAL and RAH correctly. Make sure you got the byte ordering right and didn't forget to set the "Address Valid" bit in RAH. If you don't get any "e1000" messages, you probably didn't enable receive correctly.
|
||||
|
||||
Now you're ready to implement receiving packets. To receive a packet, your driver will have to keep track of which descriptor it expects to hold the next received packet (hint: depending on your design, there's probably already a register in the E1000 keeping track of this). Similar to transmit, the documentation states that the RDH register cannot be reliably read from software, so in order to determine if a packet has been delivered to this descriptor's packet buffer, you'll have to read the DD status bit in the descriptor. If the DD bit is set, you can copy the packet data out of that descriptor's packet buffer and then tell the card that the descriptor is free by updating the queue's tail index, RDT.
|
||||
|
||||
If the DD bit isn't set, then no packet has been received. This is the receive-side equivalent of when the transmit queue was full, and there are several things you can do in this situation. You can simply return a "try again" error and require the caller to retry. While this approach works well for full transmit queues because that's a transient condition, it is less justifiable for empty receive queues because the receive queue may remain empty for long stretches of time. A second approach is to suspend the calling environment until there are packets in the receive queue to process. This tactic is very similar to `sys_ipc_recv`. Just like in the IPC case, since we have only one kernel stack per CPU, as soon as we leave the kernel the state on the stack will be lost. We need to set a flag indicating that an environment has been suspended by receive queue underflow and record the system call arguments. The drawback of this approach is complexity: the E1000 must be instructed to generate receive interrupts and the driver must handle them in order to resume the environment blocked waiting for a packet.
|
||||
|
||||
```
|
||||
Exercise 11. Write a function to receive a packet from the E1000 and expose it to user space by adding a system call. Make sure you handle the receive queue being empty.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! If the transmit queue is full or the receive queue is empty, the environment and your driver may spend a significant amount of CPU cycles polling, waiting for a descriptor. The E1000 can generate an interrupt once it is finished with a transmit or receive descriptor, avoiding the need for polling. Modify your driver so that processing the both the transmit and receive queues is interrupt driven instead of polling.
|
||||
|
||||
Note that, once an interrupt is asserted, it will remain asserted until the driver clears the interrupt. In your interrupt handler make sure to clear the interrupt as soon as you handle it. If you don't, after returning from your interrupt handler, the CPU will jump back into it again. In addition to clearing the interrupts on the E1000 card, interrupts also need to be cleared on the LAPIC. Use `lapic_eoi` to do so.
|
||||
```
|
||||
|
||||
#### Receiving Packets: Network Server
|
||||
|
||||
In the network server input environment, you will need to use your new receive system call to receive packets and pass them to the core network server environment using the `NSREQ_INPUT` IPC message. These IPC input message should have a page attached with a `union Nsipc` with its `struct jif_pkt pkt` field filled in with the packet received from the network.
|
||||
|
||||
```
|
||||
Exercise 12. Implement `net/input.c`.
|
||||
```
|
||||
|
||||
Run `testinput` again with make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput. You should see
|
||||
|
||||
```
|
||||
Sending ARP announcement...
|
||||
Waiting for packets...
|
||||
e1000: index 0: 0x26dea0 : 900002a 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001
|
||||
input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202
|
||||
input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000
|
||||
input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
|
||||
```
|
||||
|
||||
The lines beginning with "input:" are a hexdump of QEMU's ARP reply.
|
||||
|
||||
Your code should pass the `testinput` tests of make grade. Note that there's no way to test packet receiving without sending at least one ARP packet to inform QEMU of JOS' IP address, so bugs in your transmitting code can cause this test to fail.
|
||||
|
||||
To more thoroughly test your networking code, we have provided a daemon called `echosrv` that sets up an echo server running on port 7 that will echo back anything sent over a TCP connection. Use make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv to start the echo server in one terminal and make nc-7 in another to connect to it. Every line you type should be echoed back by the server. Every time the emulated E1000 receives a packet, QEMU should print something like the following to the console:
|
||||
|
||||
```
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
e1000: index 2: 0x26ea7c : 9000036 0
|
||||
e1000: index 3: 0x26f06a : 9000039 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
```
|
||||
|
||||
At this point, you should also be able to pass the `echosrv` test.
|
||||
|
||||
```
|
||||
Question
|
||||
|
||||
2. How did you structure your receive implementation? In particular, what do you do if the receive queue is empty and a user environment requests the next incoming packet?
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
Challenge! Read about the EEPROM in the developer's manual and write the code to load the E1000's MAC address out of the EEPROM. Currently, QEMU's default MAC address is hard-coded into both your receive initialization and lwIP. Fix your initialization to use the MAC address you read from the EEPROM, add a system call to pass the MAC address to lwIP, and modify lwIP to the MAC address read from the card. Test your change by configuring QEMU to use a different MAC address.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Modify your E1000 driver to be "zero copy." Currently, packet data has to be copied from user-space buffers to transmit packet buffers and from receive packet buffers back to user-space buffers. A zero copy driver avoids this by having user space and the E1000 share packet buffer memory directly. There are many different approaches to this, including mapping the kernel-allocated structures into user space or passing user-provided buffers directly to the E1000. Regardless of your approach, be careful how you reuse buffers so that you don't introduce races between user-space code and the E1000.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Take the zero copy concept all the way into lwIP.
|
||||
|
||||
A typical packet is composed of many headers. The user sends data to be transmitted to lwIP in one buffer. The TCP layer wants to add a TCP header, the IP layer an IP header and the MAC layer an Ethernet header. Even though there are many parts to a packet, right now the parts need to be joined together so that the device driver can send the final packet.
|
||||
|
||||
The E1000's transmit descriptor design is well-suited to collecting pieces of a packet scattered throughout memory, like the packet fragments created inside lwIP. If you enqueue multiple transmit descriptors, but only set the EOP command bit on the last one, then the E1000 will internally concatenate the packet buffers from these descriptors and only transmit the concatenated buffer when it reaches the EOP-marked descriptor. As a result, the individual packet pieces never need to be joined together in memory.
|
||||
|
||||
Change your driver to be able to send packets composed of many buffers without copying and modify lwIP to avoid merging the packet pieces as it does right now.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Augment your system call interface to service more than one user environment. This will prove useful if there are multiple network stacks (and multiple network servers) each with their own IP address running in user mode. The receive system call will need to decide to which environment it needs to forward each incoming packet.
|
||||
|
||||
Note that the current interface cannot tell the difference between two packets and if multiple environments call the packet receive system call, each respective environment will get a subset of the incoming packets and that subset may include packets that are not destined to the calling environment.
|
||||
|
||||
Sections 2.2 and 3 in [this][7] Exokernel paper have an in-depth explanation of the problem and a method of addressing it in a kernel like JOS. Use the paper to help you get a grip on the problem, chances are you do not need a solution as complex as presented in the paper.
|
||||
```
|
||||
|
||||
#### The Web Server
|
||||
|
||||
A web server in its simplest form sends the contents of a file to the requesting client. We have provided skeleton code for a very simple web server in `user/httpd.c`. The skeleton code deals with incoming connections and parses the headers.
|
||||
|
||||
```
|
||||
Exercise 13. The web server is missing the code that deals with sending the contents of a file back to the client. Finish the web server by implementing `send_file` and `send_data`.
|
||||
```
|
||||
|
||||
Once you've finished the web server, start the webserver (make run-httpd-nox) and point your favorite browser at http:// _host_ : _port_ /index.html, where _host_ is the name of the computer running QEMU (If you're running QEMU on athena use `hostname.mit.edu` (hostname is the output of the `hostname` command on athena, or `localhost` if you're running the web browser and QEMU on the same computer) and _port_ is the port number reported for the web server by make which-ports . You should see a web page served by the HTTP server running inside JOS.
|
||||
|
||||
At this point, you should score 105/105 on make grade.
|
||||
|
||||
```
|
||||
Challenge! Add a simple chat server to JOS, where multiple people can connect to the server and anything that any user types is transmitted to the other users. To do this, you will have to find a way to communicate with multiple sockets at once _and_ to send and receive on the same socket at the same time. There are multiple ways to go about this. lwIP provides a MSG_DONTWAIT flag for recv (see `lwip_recvfrom` in `net/lwip/api/sockets.c`), so you could constantly loop through all open sockets, polling them for data. Note that, while `recv` flags are supported by the network server IPC, they aren't accessible via the regular `read` function, so you'll need a way to pass the flags. A more efficient approach is to start one or more environments for each connection and to use IPC to coordinate them. Conveniently, the lwIP socket ID found in the struct Fd for a socket is global (not per-environment), so, for example, the child of a `fork` inherits its parents sockets. Or, an environment can even send on another environment's socket simply by constructing an Fd containing the right socket ID.
|
||||
```
|
||||
|
||||
```
|
||||
Question
|
||||
|
||||
3. What does the web page served by JOS's web server say?
|
||||
4. How long approximately did it take you to do this lab?
|
||||
```
|
||||
|
||||
|
||||
**This completes the lab.** As usual, don't forget to run make grade and to write up your answers and a description of your challenge exercise solution. Before handing in, use git status and git diff to examine your changes and don't forget to git add answers-lab6.txt. When you're ready, commit your changes with git commit -am 'my solutions to lab 6', then make handin and follow the directions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://wiki.qemu.org/download/qemu-doc.html#Using-the-user-mode-network-stack
|
||||
[2]: http://www.wireshark.org/
|
||||
[3]: http://www.sics.se/~adam/lwip/
|
||||
[4]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/ns.png
|
||||
[5]: https://pdos.csail.mit.edu/6.828/2018/readings/hardware/8254x_GBe_SDM.pdf
|
||||
[6]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/e1000_hw.h
|
||||
[7]: http://pdos.csail.mit.edu/papers/exo:tocs.pdf
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Create a containerized machine learning model
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Create A Bootable Linux USB Drive From Windows OS 7,8 and 10?
|
||||
======
|
||||
If you would like to learn about Linux, the first thing you have to do is install the Linux OS on your system.
|
||||
|
||||
@ -1,229 +0,0 @@
|
||||
translating by dianbanjiu Commandline quick tips: How to locate a file
|
||||
======
|
||||
|
||||

|
||||
|
||||
We all have files on our computers — documents, photos, source code, you name it. So many of them. Definitely more than I can remember. And if not challenging, it might be time consuming to find the right one you’re looking for. In this post, we’ll have a look at how to make sense of your files on the command line, and especially how to quickly find the ones you’re looking for.
|
||||
|
||||
Good news is there are few quite useful utilities in the Linux commandline designed specifically to look for files on your computer. We’ll have a look at three of those: ls, tree, and find.
|
||||
|
||||
### ls
|
||||
|
||||
If you know where your files are, and you just need to list them or see information about them, ls is here for you.
|
||||
|
||||
Just running ls lists all visible files and directories in the current directory:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Documents Music Pictures Videos notes.txt
|
||||
```
|
||||
|
||||
Adding the **-l** option shows basic information about the files. And together with the **-h** option you’ll see file sizes in a human-readable format:
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
total 60K
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
|
||||
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
|
||||
```
|
||||
|
||||
**Is** can also search a specific place:
|
||||
|
||||
```
|
||||
$ ls Pictures/
|
||||
trees.png wallpaper.png
|
||||
```
|
||||
|
||||
Or a specific file — even with just a part of the name:
|
||||
|
||||
```
|
||||
$ ls *.txt
|
||||
notes.txt
|
||||
```
|
||||
|
||||
Something missing? Looking for a hidden file? No problem, use the **-a** option:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
. .bash_logout .bashrc Documents Pictures notes.txt
|
||||
.. .bash_profile .vimrc Music Videos
|
||||
```
|
||||
|
||||
There are many other useful options for **ls** , and you can combine them together to achieve what you need. Learn about them by running:
|
||||
|
||||
```
|
||||
$ man ls
|
||||
```
|
||||
|
||||
### tree
|
||||
|
||||
If you want to see, well, a tree structure of your files, tree is a good choice. It’s probably not installed by default which you can do yourself using the package manager DNF:
|
||||
|
||||
```
|
||||
$ sudo dnf install tree
|
||||
```
|
||||
|
||||
Running tree without any options or parameters shows the whole tree starting at the current directory. Just a warning, this output might be huge, because it will include all files and directories:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| | `-- christmas-presents.txt
|
||||
| `-- work
|
||||
| |-- project-abc
|
||||
| | |-- README.md
|
||||
| | |-- do-things.sh
|
||||
| | `-- project-notes.txt
|
||||
| `-- status-reports.txt
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
If that’s too much, I can limit the number of levels it goes using the -L option followed by a number specifying the number of levels I want to see:
|
||||
|
||||
```
|
||||
$ tree -L 2
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| `-- work
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
You can also display a tree of a specific path:
|
||||
|
||||
```
|
||||
$ tree Documents/work/
|
||||
Documents/work/
|
||||
|-- project-abc
|
||||
| |-- README.md
|
||||
| |-- do-things.sh
|
||||
| `-- project-notes.txt
|
||||
`-- status-reports.txt
|
||||
```
|
||||
|
||||
To browse and search a huge tree, you can use it together with less:
|
||||
|
||||
```
|
||||
$ tree | less
|
||||
```
|
||||
|
||||
Again, there are other options you can use with three, and you can combine them together for even more power. The manual page has them all:
|
||||
|
||||
```
|
||||
$ man tree
|
||||
```
|
||||
|
||||
### find
|
||||
|
||||
And what about files that live somewhere in the unknown? Let’s find them!
|
||||
|
||||
In case you don’t have find on your system, you can install it using DNF:
|
||||
|
||||
```
|
||||
$ sudo dnf install findutils
|
||||
```
|
||||
|
||||
Running find without any options or parameters recursively lists all files and directories in the current directory.
|
||||
|
||||
```
|
||||
$ find
|
||||
.
|
||||
./Documents
|
||||
./Documents/secret
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc
|
||||
./Documents/work/project-abc/README.md
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./.bash_logout
|
||||
./.bashrc
|
||||
./Videos
|
||||
./.bash_profile
|
||||
./.vimrc
|
||||
./Pictures
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
./notes.txt
|
||||
./Music
|
||||
```
|
||||
|
||||
But the true power of find is that you can search by name:
|
||||
|
||||
```
|
||||
$ find -name do-things.sh
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
```
|
||||
|
||||
Or just a part of a name — like the file extension. Let’s find all .txt files:
|
||||
|
||||
```
|
||||
$ find -name "*.txt"
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./notes.txt
|
||||
```
|
||||
|
||||
You can also look for files by size. That might be especially useful if you’re running out of space. Let’s list all files larger than 1 MB:
|
||||
|
||||
```
|
||||
$ find -size +1M
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
```
|
||||
|
||||
Searching a specific directory is also possible. Let’s say I want to find a file in my Documents directory, and I know it has the word “project” in its name:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*"
|
||||
Documents/work/project-abc
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
Ah! That also showed the directory. One thing I can do is to limit the search query to files only:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*" -type f
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
And again, find have many more options you can use, the man page might definitely help you:
|
||||
|
||||
```
|
||||
$ man find
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-locate-file/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,171 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Introducing pydbgen: A random dataframe/database table generator
|
||||
======
|
||||
Simple tool generates large database files with multiple tables to practice SQL commands for data science.
|
||||
|
||||

|
||||
|
||||
When you start learning data science, often your biggest worry is not the algorithms or techniques but getting access to raw data. While there are many high-quality, real-life datasets available on the web for trying out cool machine learning techniques, I've found that the same is not true when it comes to learning SQL.
|
||||
|
||||
For data science, having a basic familiarity with SQL is almost as important as knowing how to write code in Python or R. But it's far easier to find toy datasets on Kaggle than it is to access a large enough database with real data (such as name, age, credit card, social security number, address, birthday, etc.) specifically designed or curated for machine learning tasks.
|
||||
|
||||
Wouldn't it be great to have a simple tool or library to generate a large database with multiple tables filled with data of your own choice?
|
||||
|
||||
Aside from beginners in data science, even seasoned software testers may find it useful to have a simple tool where, with a few lines of code, they can generate arbitrarily large data sets with random (fake), yet meaningful entries.
|
||||
|
||||
For this reason, I am glad to introduce a lightweight Python library called **[pydbgen][1]**. In this article, I'll briefly share some information about the package, and you can learn much more [by reading the docs][2].
|
||||
|
||||
### What is pydbgen?
|
||||
|
||||
Pydbgen is a lightweight, pure-Python library to generate random useful entries (e.g., name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in a Pandas dataframe object, as an SQLite table in a database file, or in a Microsoft Excel file.
|
||||
|
||||
### How to install pydbgen
|
||||
|
||||
The current version (1.0.5) is hosted on PyPI (the Python Package Index repository). You need to have [Faker][3] installed to make this work. To install Pydbgen, enter:
|
||||
|
||||
```
|
||||
pip install pydbgen
|
||||
```
|
||||
|
||||
It has been tested on Python 3.6 and won't work on Python 2 installations.
|
||||
|
||||
### How to use it
|
||||
|
||||
To start using Pydbgen, initiate a **pydb** object.
|
||||
|
||||
```
|
||||
import pydbgen
|
||||
from pydbgen import pydbgen
|
||||
myDB=pydbgen.pydb()
|
||||
```
|
||||
|
||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||
|
||||
```
|
||||
myDB.city_real()
|
||||
>> 'Otterville'
|
||||
for _ in range(10):
|
||||
print(myDB.license_plate())
|
||||
>> 8NVX937
|
||||
6YZH485
|
||||
XBY-564
|
||||
SCG-2185
|
||||
XMR-158
|
||||
6OZZ231
|
||||
CJN-850
|
||||
SBL-4272
|
||||
TPY-658
|
||||
SZL-0934
|
||||
```
|
||||
|
||||
By the way, if you enter **city** instead of **city_real** , it will return fictitious city names.
|
||||
|
||||
```
|
||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||
>>
|
||||
New Michelle
|
||||
Robinborough
|
||||
Leebury
|
||||
Kaylatown
|
||||
Hamiltonfort
|
||||
Lake Christopher
|
||||
Hannahstad
|
||||
West Adamborough
|
||||
```
|
||||
|
||||
### Generate a Pandas dataframe with random entries
|
||||
|
||||
You can choose how many and what data types will be generated. Note that everything returns as string/texts.
|
||||
|
||||
```
|
||||
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
||||
testdf
|
||||
```
|
||||
|
||||
The resulting dataframe looks like the following image.
|
||||
|
||||
|
||||
|
||||
### Generate a database table
|
||||
|
||||
You can choose how many and what data types will be generated. Everything is returned in the text/VARCHAR data type for the database. You can specify the database filename and the table name.
|
||||
|
||||
```
|
||||
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
||||
|
||||
fields=['name','city','street_address','email'])
|
||||
```
|
||||
|
||||
This generates a .db file which can be used with MySQL or the SQLite database server. The following image shows a database table opened in DB Browser for SQLite.
|
||||
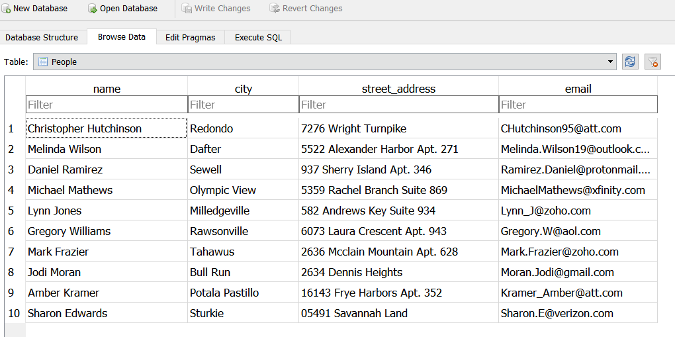
|
||||
|
||||
### Generate an Excel file
|
||||
|
||||
Similar to the examples above, the following code will generate an Excel file with random data. Note that **phone_simple** is set to **False** so it can generate complex, long-form phone numbers. This can come in handy when you want to experiment with more involved data extraction codes.
|
||||
|
||||
```
|
||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||
phone_simple=False,filename='TestExcel.xlsx')
|
||||
```
|
||||
|
||||
The resulting file looks like this image:
|
||||
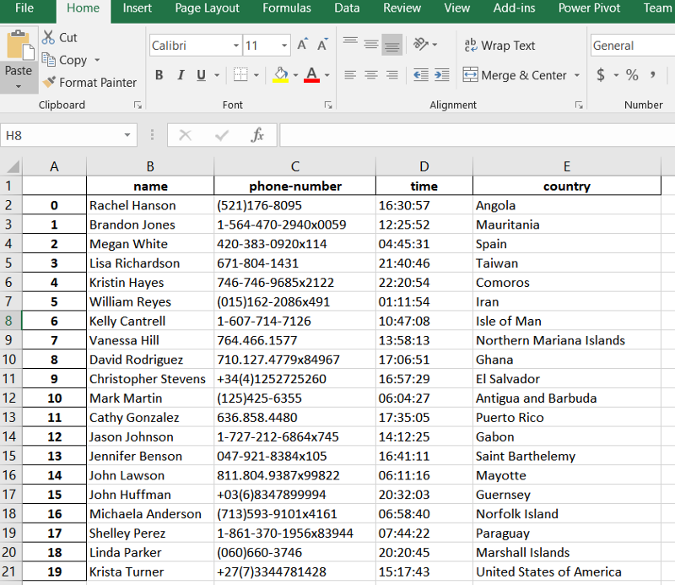
|
||||
|
||||
### Generate random email IDs for scrap use
|
||||
|
||||
A built-in method in pydbgen is **realistic_email** , which generates random email IDs from a seed name. This is helpful when you don't want to use your real email address on the web—but something close.
|
||||
|
||||
```
|
||||
for _ in range(10):
|
||||
print(myDB.realistic_email('Tirtha Sarkar'))
|
||||
>>
|
||||
Tirtha_Sarkar@gmail.com
|
||||
Sarkar.Tirtha@outlook.com
|
||||
Tirtha_S48@verizon.com
|
||||
Tirtha_Sarkar62@yahoo.com
|
||||
Tirtha.S46@yandex.com
|
||||
Tirtha.S@att.com
|
||||
Sarkar.Tirtha60@gmail.com
|
||||
TirthaSarkar@zoho.com
|
||||
Sarkar.Tirtha@protonmail.com
|
||||
Tirtha.S@comcast.net
|
||||
```
|
||||
|
||||
### Future improvements and user contributions
|
||||
|
||||
There may be many bugs in the current version—if you notice any and your program crashes during execution (except for a crash due to your incorrect entry), please let me know. Also, if you have a cool idea to contribute to the source code, the [GitHub repo][1] is open. Some questions readily come to mind:
|
||||
|
||||
* Can we integrate some machine learning/statistical modeling with this random data generator?
|
||||
* Should a visualization function be added to the generator?
|
||||
|
||||
|
||||
|
||||
The possibilities are endless and exciting!
|
||||
|
||||
If you have any questions or ideas to share, please contact me at [tirthajyoti[AT]gmail.com][4]. If you are, like me, passionate about machine learning and data science, please [add me on LinkedIn][5] or [follow me on Twitter][6]. Also, check my [GitHub repo][7] for other fun code snippets in Python, R, or MATLAB and some machine learning resources.
|
||||
|
||||
Originally published on [Towards Data Science][8]. Licensed under [CC BY-SA 4.0][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tirthajyoti/pydbgen
|
||||
[2]: http://pydbgen.readthedocs.io/en/latest/
|
||||
[3]: https://faker.readthedocs.io/en/latest/index.html
|
||||
[4]: mailto:tirthajyoti@gmail.com
|
||||
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[6]: https://twitter.com/tirthajyotiS
|
||||
[7]: https://github.com/tirthajyoti?tab=repositories
|
||||
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
@ -0,0 +1,206 @@
|
||||
使用Redis和Python构建一个共享单车的应用程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
我经常出差。但不是一个汽车狂热分子,所以当我有空闲时,我更喜欢在城市中散步或者骑单车。我参观过的许多城市都有共享单车系统,你可以租个单车用几个小时。大多数系统都有一个应用程序来帮助用户定位和租用他们的单车,但对于像我这样的用户来说,在一个地方可以获得可租赁的城市中所有单车的信息会更有帮助。
|
||||
|
||||
为了解决这个问题并且展示开源的强大还有为 Web 应用程序添加位置感知的功能,我组合了可用的公开的共享单车数据,[Python][1] 编程语言以及开源的 [Redis][2] 内存数据结构服务,用来索引和查询地理空间数据。
|
||||
|
||||
由此诞生的共享单车应用程序包含来自很多不同的共享系统的数据,包括纽约市的 [Citi Bike][3] 共享单车系统(LCTT 译注:Citi Bike 是纽约市的一个私营公共单车系统。在2013年5月27日正式营运,是美国最大的公共单车系统。Citi Bike 的名称有两层意思。Citi 是计划赞助商花旗银行(CitiBank)的名字。同时,Citi 和英文中“城市(city)”一词的读音相同)。它利用了花旗单车系统提供的 <ruby>通用共享单车数据流<rt>General Bikeshare Feed</rt></ruby>,并利用其数据演示了一些使用 Redis 地理空间数据索引的功能。 花旗单车数据可以在 [花旗单车数据许可协议][4] 下提供。
|
||||
|
||||
### 通用共享单车数据流规范
|
||||
|
||||
通用共享单车数据流规范(GBFS)是由 [北美共享单车协会][6] 开发的 [开放数据规范][5],旨在使地图程序和运输程序更容易的将共享单车系统添加到对应平台中。 目前世界上有 60 多个不同的共享系统使用该规范。
|
||||
|
||||
Feed 流由几个简单的 [JSON][7] 数据文件组成,其中包含系统状态的信息。 Feed 流以引用了子 Feed 流数据的URL 的顶级 JSON 文件开头:
|
||||
|
||||
```
|
||||
{
|
||||
"data": {
|
||||
"en": {
|
||||
"feeds": [
|
||||
{
|
||||
"name": "system_information",
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
|
||||
},
|
||||
{
|
||||
"name": "station_information",
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
|
||||
},
|
||||
. . .
|
||||
]
|
||||
}
|
||||
},
|
||||
"last_updated": 1506370010,
|
||||
"ttl": 10
|
||||
}
|
||||
```
|
||||
|
||||
第一步是使用 `system_information` 和 `station_information` 的数据将共享单车站的信息加载到Redis中。
|
||||
|
||||
`system_information` 提供系统 ID,系统 ID 可用于为 Redis 密钥创建命名空间的简短编码。 GBFS 规范没有指定系统 ID 的格式,但需要确保它是全局唯一的。许多共享单车数据流使用诸如coast_bike_share,boise_greenbike 或者 topeka_metro_bikes 这样的短名称作为系统 ID。其他的使用常见的地理缩写,例如 NYC 或者 BA,并且使用通用唯一标识符(UUID)。 共享单车应用程序使用标识符作为前缀来为指定系统构造唯一键。
|
||||
|
||||
`station_information feed` 提供组成整个系统的共享单车站的静态信息。车站由具有多个字段的 JSON 对象表示。车站对象中有几个必填字段,用于提供物理单车站的 ID,名称和位置。还有几个可选字段提供有用的信息,例如最近的十字路口,可接受的付款方式。这是共享单车应用程序这一部分的主要信息来源。
|
||||
|
||||
### 建立数据库
|
||||
|
||||
我编写了一个示例应用程序 [load_station_data.py][8],它模仿后端进程中从外部源加载数据时会发生什么。
|
||||
|
||||
### 查找共享单车站
|
||||
|
||||
从 [GitHub 上 GBFS 仓库][5]中的 [systems.csv][9] 文件开始加载共享单车数据。
|
||||
|
||||
仓库中的 [systems.csv][9] 文件为已注册的共享单车系统提供可用的 GBFS 源发现的 URL。 发现的URL是处理共享单车信息的起点。
|
||||
|
||||
`load_station_data` 程序获取系统文件中找到的每个 URL,并使用它来查找两个子数据流的URL:系统信息和车站信息。 系统信息提供提供了一条关键信息:系统的唯一 ID。 (注意:系统 ID 也在 systems.csv 文件中提供,但文件中的某些标识符与数据流中的标识符不匹配,因此我总是从数据流中获取标识符。)系统上的详细信息,比如共享单车 URLS,电话号码和电子邮件, 可以在程序的后续版本中添加,因此使用 `${system_id}:system_info` 这个键将数据存储在 Redis 中。
|
||||
|
||||
### 载入车站数据
|
||||
|
||||
车站信息提供系统中每个车站的数据,包括系统的位置。 load_station_data 程序遍历车站数据流中的每个车站,并使用 `${system_id}:station:${station_id}` 形式的键将每个车站的数据存储到 Redis 中。 使用 `GEOADD` 命令将每个车站的位置添加到共享单车的地理空间索引中。
|
||||
|
||||
### 更新数据
|
||||
|
||||
在后续运行中,我不希望代码从 Redis 中删除所有 Feed 数据并将其重新加载到空的 Redis 数据库中,因此我仔细考虑了如何处理数据的原地更新。
|
||||
|
||||
代码首先将所有共享单车站的信息数据集加载到正在处理到内存中的系统中的。 为单个车站加载信息时,将从内存中的车站集合按照存储在 Redis 的键中删除该站。 加载完所有车站数据后,我们将留下一个包含该系统必须删除的所有车站数据的集合。
|
||||
|
||||
程序创建一个事务删除这组车站的信息,从地理空间索引中删除车站的键,并从系统的车站列表中删除车站。
|
||||
|
||||
### 代码注意点
|
||||
|
||||
需要注意在[示例代码][8]中有一些有趣的事情。 首先,使用 `GEOADD` 命令将所有数据项添加到地理空间索引中,使用 `ZREM` 命令将其删除。 由于地理空间类型的底层实现使用了有序集合,因此需要使用ZREM删除数据项。 需要注意的是:为简单起见,示例代码演示了如何使用单个 Redis 节点; 为了在集群环境中运行,需要重新构建事务块。
|
||||
|
||||
如果你使用的是 Redis 4.0(或更高版本),则可以在代码中使用 `DELETE` 和 `HMSET` 命令。 Redis 4.0 提供 `UNLINK` 命令作为 `DELETE` 命令的异步版本的替代。 `UNLINK` 命令将从键空间中删除键,但它会在单独的线程中回收内存。 在 Redis 4.0 中 [`HMSET` 命令已经被弃用了而且`HSET` 命令现在接收可变参数][12](即,它接受的参数个数不定)。
|
||||
|
||||
### 通知客户端
|
||||
|
||||
处理结束时,会向依赖我们数据的客户发送通知。 使用 Redis 发布/订阅机制,通知将通过 `geobike:station_changed` 通道和系统 ID 一起发出。
|
||||
|
||||
### 数据模型
|
||||
|
||||
在 Redis 中构建数据时,最重要的考虑因素是如何查询信息。 共享单车程序需要支持的两个主要查询是:
|
||||
|
||||
- 找到我们附近的车站
|
||||
- 显示车站相关的信息
|
||||
|
||||
Redis 提供了两种主要数据类型用于存储数据:哈希和有序集。 哈希类型很好地映射到表示车站的 JSON 对象; 由于 Redis 哈希不使用固定结构,因此它们可用于存储可变的车站信息。
|
||||
|
||||
当然,在地理位置上寻找站点需要地理空间索引来搜索相对于某些坐标的站点。 Redis 提供了几个使用有序集数据结构构建地理空间索引的命令。
|
||||
|
||||
我们使用 `${system_id}:station:${station_id}` 这种格式的键存储车站相关的信息,使用格 `${system_id}:stations:location` 这种格式的键查找车站的地理空间索引。
|
||||
|
||||
### 获取用户位置
|
||||
|
||||
构建应用程序的下一步是确定用户的当前位置。 大多数应用程序通过操作系统提供的内置服务来实现此目的。 操作系统可以基于设备内置的 GPS 硬件为应用程序提供定位,或者从设备的可用 WiFi 网络提供近似的定位。
|
||||
|
||||

|
||||
|
||||
### 查找车站
|
||||
|
||||
找到用户的位置后,下一步是找到附近的共享单车站。 Redis 的地理空间功能可以返回用户当前坐标在给定距离内的所有车站信息。 以下是使用 Redis 命令行界面的示例。
|
||||
|
||||
想象一下,我正在纽约市第五大道的苹果零售店,我想要向市中心方向前往位于西 37 街的 MOOD 布料店,与我的好友 [Swatch][16] 相遇。 我可以坐出租车或地铁,但我更喜欢骑单车。 附近有没有我可以使用的单车共享站呢?
|
||||
|
||||
苹果零售店位于 40.76384,-73.97297。 根据地图显示,在零售店 500 英尺半径范围内(地图上方的蓝色)有两个单车站,分别是陆军广场中央公园南单车站和东 58 街麦迪逊单车站。
|
||||
|
||||
我可以使用 Redis 的 `GEORADIUS` 命令查询 500 英尺半径范围内的车站的 NYC 系统索引:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
|
||||
1) "NYC:station:3457"
|
||||
2) "NYC:station:281"
|
||||
```
|
||||
|
||||
Redis 使用地理空间索引中的元素作为特定车站的元数据的键,返回在该半径内找到的两个共享单车站。 下一步是查找两个站的名称:
|
||||
```
|
||||
127.0.0.1:6379> hget NYC:station:281 name
|
||||
"Grand Army Plaza & Central Park S"
|
||||
|
||||
127.0.0.1:6379> hget NYC:station:3457 name
|
||||
"E 58 St & Madison Ave"
|
||||
```
|
||||
|
||||
这些键对应于上面地图上标识的车站。 如果需要,可以在 `GEORADIUS` 命令中添加更多标志来获取元素列表,每个元素的坐标以及它们与当前点的距离:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
|
||||
1) 1) "NYC:station:281"
|
||||
2) "289.1995"
|
||||
3) 1) "-73.97371262311935425"
|
||||
2) "40.76439830559216659"
|
||||
2) 1) "NYC:station:3457"
|
||||
2) "383.1782"
|
||||
3) 1) "-73.97209256887435913"
|
||||
2) "40.76302702144496237"
|
||||
```
|
||||
|
||||
查找与这些键关联的名称会生成一个我可以从中选择的车站的有序列表。 Redis 不提供路线的功能,因此我使用设备操作系统的路线功能绘制从当前位置到所选单车站的路线。
|
||||
|
||||
`GEORADIUS` 函数可以很轻松的在你喜欢的开发框架的 API 里实现,就可以向应用程序添加位置功能了。
|
||||
|
||||
### 其他的查询命令
|
||||
|
||||
除了 `GEORADIUS` 命令外,Redis 还提供了另外三个用于查询索引数据的命令:`GEOPOS`,`GEODIST` 和 `GEORADIUSBYMEMBER`。
|
||||
|
||||
`GEOPOS` 命令可以为 <ruby>地理哈希<rt>geohash</rt></ruby> 中的给定元素提供坐标(LCTT译注:geohash 是一种将二维的经纬度编码为一位的字符串的一种算法,常用于基于距离的查找算法和推荐算法)。 例如,如果我知道西 38 街 8 号有一个共享单车站,ID 是 523,那么该站的元素名称是`NYC:station:523`。 使用 Redis,我可以找到该站的经度和纬度:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
|
||||
1) 1) "-73.99138301610946655"
|
||||
2) "40.75466497634030105"
|
||||
```
|
||||
|
||||
`GEODIST` 命令提供两个索引元素之间的距离。 如果我想找到陆军广场中央公园南单车站与东 58 街麦迪逊单车站之间的距离,我会使用以下命令:
|
||||
```
|
||||
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
|
||||
"671.4900"
|
||||
```
|
||||
|
||||
最后,`GEORADIUSBYMEMBER` 命令与 `GEORADIUS` 命令类似,但该命令不是采用一组坐标,而是采用索引的另一个成员的名称,并返回以该成员为中心的给定半径内的所有成员。 要查找陆军广场中央公园南单车站 1000 英尺范围内的所有车站,请输入以下内容:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
|
||||
1) 1) "NYC:station:281"
|
||||
2) "0.0000"
|
||||
2) 1) "NYC:station:3132"
|
||||
2) "793.4223"
|
||||
3) 1) "NYC:station:2006"
|
||||
2) "911.9752"
|
||||
4) 1) "NYC:station:3136"
|
||||
2) "940.3399"
|
||||
5) 1) "NYC:station:3457"
|
||||
2) "671.4900"
|
||||
```
|
||||
|
||||
虽然此示例侧重于使用 Python 和 Redis 来解析数据并构建共享单车系统位置的索引,但可以很容易地衍生为定位餐馆,公共交通或者是开发人员希望帮助用户找到的任何其他类型的场所。
|
||||
|
||||
本文基于今年我在北卡罗来纳州罗利市的开源 101 会议上的[演讲][17]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools
|
||||
|
||||
作者:[Tague Griffith][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tague
|
||||
[1]: https://www.python.org/
|
||||
[2]: https://redis.io/
|
||||
[3]: https://www.citibikenyc.com/
|
||||
[4]: https://www.citibikenyc.com/data-sharing-policy
|
||||
[5]: https://github.com/NABSA/gbfs
|
||||
[6]: http://nabsa.net/
|
||||
[7]: https://www.json.org/
|
||||
[8]: https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15
|
||||
[9]: https://github.com/NABSA/gbfs/blob/master/systems.csv
|
||||
[10]: https://redis.io/commands/unlink
|
||||
[11]: https://redis.io/commands/hmset
|
||||
[12]: https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
|
||||
[13]: https://redis.io/topics/data-types#Hashes
|
||||
[14]: https://redis.io/commands#geo
|
||||
[15]: https://redis.io/topics/data-types-intro#redis-sorted-sets
|
||||
[16]: https://twitter.com/swatchthedog
|
||||
[17]: http://opensource101.com/raleigh/talks/building-location-aware-apps-open-source-tools/
|
||||
@ -0,0 +1,78 @@
|
||||
Joplin:开源加密笔记及待办事项应用
|
||||
======
|
||||
**[Joplin][1] 是一个免费开源的笔记和待办事项应用,可用于 Linux、Windows、macOS、Android 和 iOS。它的主要功能包括端到端加密,Markdown 支持以及通过 NextCloud、Dropbox、OneDrive 或 WebDAV 等第三方服务进行同步。**
|
||||
|
||||

|
||||
|
||||
在 Joplin 中你可以用 **Markdown格式**(支持数学符号和复选框)记笔记,桌面程序有 3 种视图:Markdown 代码、Markdown 预览或两者并排。**你可以在笔记中添加附件(使用图像预览)或在外部 Markdown 编辑器中编辑它们**并在每次保存文件时自动在 Joplin 中更新它们。
|
||||
|
||||
这个应用应该可以很好地处理大量笔记,它允许你**将笔记组织到笔记本中、添加标签和搜索**。你还可以按更新日期、创建日期或标题对笔记进行排序。**每个笔记本可以包含笔记、待办事项或两者**,你可以轻松添加其他笔记的链接(在桌面应用中右键单击笔记并选择 `Copy Markdown link`,然后在笔记中添加链接)。
|
||||
|
||||
**Joplin 中的待办事项支持警报**,但在 Ubuntu 18.04 上,此功能我无法使用。
|
||||
|
||||
**其他 Joplin 功能包括:**
|
||||
|
||||
* **Firefox 和 Chrome 中可选的 Web Clipper 扩展**(在 Joplin 桌面应用中进入 `Tools > Web clipper options` 以启用剪切服务并找到 Chrome/Firefox 扩展程序的下载链接),它可以剪切简单或完整的页面、剪切选中的区域或者截图。
|
||||
|
||||
* **可选命令行客户端**。
|
||||
|
||||
* **导入 Enex 文件(Evernote 导出格式)和 Markdown 文件**。
|
||||
|
||||
* **导出 JEX 文件(Joplin 导出格式)、PDF 和原始文件**。
|
||||
|
||||
* **离线优先,因此即使没有互联网连接,所有数据也始终可在设备上查看**。
|
||||
|
||||
* **地理位置支持**。
|
||||
|
||||
|
||||
|
||||
[![Joplin notes checkboxes link to other note][2]][3]
|
||||
Joplin 带有显示复选框和指向另一个笔记链接的隐藏侧边栏
|
||||
|
||||
虽然它没有提供与 Evernote 一样多的功能,但 Joplin 是一个强大的开源 Evernote 替代品。Joplin 包含所有基本功能,除了它是开源软件之外,它还包括加密支持,你还可以选择用于同步的服务。
|
||||
|
||||
该应用实际上被设计为 Evernote 替代品,因此它可以导入完整的 Evernote 笔记本、笔记、标签、附件和笔记元数据,如作者、创建和更新时间或地理位置。
|
||||
|
||||
Joplin 开发重点关注的另一个方面是避免与特定公司或服务挂钩。这就是为什么该应用提供多种同步方案,如 NextCloud、Dropbox、oneDrive 和 WebDav,同时也容易支持新的服务。如果你改变主意,也很容易从一种服务切换到另一种服务。
|
||||
|
||||
**我注意到 Joplin 默认情况下不使用加密,你必须在设置中启用此功能。进入**`Tools> Encryption options` 并在这里启用 Joplin 端到端加密。
|
||||
|
||||
### 下载 Joplin
|
||||
|
||||
[Download Joplin][7]
|
||||
|
||||
**Joplin 适用于 Linux、Windows、macOS、Android 和 iOS。在 Linux 上,还有 AppImage 和 Aur 包。**
|
||||
|
||||
要在 Linux 上运行 Joplin AppImage,请双击它并选择 `Make executable and run` (如果文件管理器支持这个)。如果不支持,你需要使用你的文件管理器使它可执行(应该类似这样:`右键单击>属性>权限>允许作为程序执行`,但这可能会因你使用的文件管理器而有所不同),或者从命令行:
|
||||
```
|
||||
chmod +x /path/to/Joplin-*-x86_64.AppImage
|
||||
|
||||
```
|
||||
|
||||
用你下载 Joplin 的路径替换 `/path/to/`。现在,你可以双击 Joplin Appimage 文件来启动它。
|
||||
|
||||
**提示:**如果你将 Joplin 集成到你的菜单中,而它的图标没有显示在你 dock/应用切换器中,你可以打开 Joplin 的桌面文件(如果你使用 appimagekit 集成,它应该在 `~/.local/share/applications/appimagekit-joplin.desktop`)并在文件末尾添加 `StartupWMClass=Joplin` 其他不变来修复。
|
||||
|
||||
Joplin 有一个**命令行客户端**,它可以[使用 npm 安装][5](对于 Debian、Ubuntu 或 Linux Mint,请参阅[如何安装和配置 Node.js 和 npm][6])。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://joplin.cozic.net/
|
||||
[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
|
||||
[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
|
||||
[4]:https://github.com/laurent22/joplin/issues/338
|
||||
[5]:https://joplin.cozic.net/terminal/
|
||||
[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
|
||||
|
||||
[7]: https://joplin.cozic.net/#installation
|
||||
507
translated/tech/20181016 Lab 6- Network Driver.md
Normal file
507
translated/tech/20181016 Lab 6- Network Driver.md
Normal file
@ -0,0 +1,507 @@
|
||||
实验 6:网络驱动程序
|
||||
======
|
||||
### 实验 6:网络驱动程序(缺省的最终设计)
|
||||
|
||||
### 简介
|
||||
|
||||
这个实验是缺省的最终项目中你自己能够做的最后的实验。
|
||||
|
||||
现在你有了一个文件系统,一个典型的操作系统都应该有一个网络栈。在本实验中,你将继续为一个网卡去写一个驱动程序。这个网卡基于 Intel 82540EM 芯片,也就是众所周知的 E1000 芯片。
|
||||
|
||||
##### 预备知识
|
||||
|
||||
使用 Git 去提交你的实验 5 的源代码(如果还没有提交的话),获取课程仓库的最新版本,然后创建一个名为 `lab6` 的本地分支,它跟踪我们的远程分支 `origin/lab6`:
|
||||
|
||||
```c
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'my solution to lab5'
|
||||
nothing to commit (working directory clean)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab6 origin/lab6
|
||||
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
|
||||
Switched to a new branch "lab6"
|
||||
athena% git merge lab5
|
||||
Merge made by recursive.
|
||||
fs/fs.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
然后,仅有网卡驱动程序并不能够让你的操作系统接入因特网。在新的实验 6 的代码中,我们为你提供了网络栈和一个网络服务器。与以前的实验一样,使用 git 去拉取这个实验的代码,合并到你自己的代码中,并去浏览新的 `net/` 目录中的内容,以及在 `kern/` 中的新文件。
|
||||
|
||||
除了写这个驱动程序以外,你还需要去创建一个访问你的驱动程序的系统调用。你将要去实现那些在网络服务器中缺失的代码,以便于在网络栈和你的驱动程序之间传输包。你还需要通过完成一个 web 服务器来将所有的东西连接到一起。你的新 web 服务器还需要你的文件系统来提供所需要的文件。
|
||||
|
||||
大部分的内核设备驱动程序代码都需要你自己去从头开始编写。本实验提供的指导比起前面的实验要少一些:没有框架文件、没有现成的系统调用接口、并且很多设计都由你自己决定。因此,我们建议你在开始任何单独练习之前,阅读全部的编写任务。许多学生都反应这个实验比前面的实验都难,因此请根据你的实际情况计划你的时间。
|
||||
|
||||
##### 实验要求
|
||||
|
||||
与以前一样,你需要做实验中全部的常规练习和至少一个挑战问题。在实验中写出你的详细答案,并将挑战问题的方案描述写入到 `answers-lab6.txt` 文件中。
|
||||
|
||||
#### QEMU 的虚拟网络
|
||||
|
||||
我们将使用 QEMU 的用户模式网络栈,因为它不需要以管理员权限运行。QEMU 的文档的[这里][1]有更多关于用户网络的内容。我们更新后的 makefile 启用了 QEMU 的用户模式网络栈和虚拟的 E1000 网卡。
|
||||
|
||||
缺省情况下,QEMU 提供一个运行在 IP 地址 10.2.2.2 上的虚拟路由器,它给 JOS 分配的 IP 地址是 10.0.2.15。为了简单起见,我们在 `net/ns.h` 中将这些缺省值硬编码到网络服务器上。
|
||||
|
||||
虽然 QEMU 的虚拟网络允许 JOS 随意连接因特网,但 JOS 的 10.0.2.15 的地址并不能在 QEMU 中的虚拟网络之外使用(也就是说,QEMU 还得做一个 NAT),因此我们并不能直接连接到 JOS 上运行的服务器,即便是从运行 QEMU 的主机上连接也不行。为解决这个问题,我们配置 QEMU 在主机的某些端口上运行一个服务器,这个服务器简单地连接到 JOS 中的一些端口上,并在你的真实主机和虚拟网络之间传递数据。
|
||||
|
||||
你将在端口 7(echo)和端口 80(http)上运行 JOS,为避免在共享的 Athena 机器上发生冲突,makefile 将为这些端口基于你的用户 ID 来生成转发端口。你可以运行 `make which-ports` 去找出是哪个 QEMU 端口转发到你的开发主机上。为方便起见,makefile 也提供 `make nc-7` 和 `make nc-80`,它允许你在终端上直接与运行这些端口的服务器去交互。(这些目标仅能连接到一个运行中的 QEMU 实例上;你必须分别去启动它自己的 QEMU)
|
||||
|
||||
##### 包检查
|
||||
|
||||
makefile 也可以配置 QEMU 的网络栈去记录所有的入站和出站数据包,并将它保存到你的实验目录中的 `qemu.pcap` 文件中。
|
||||
|
||||
使用 `tcpdump` 命令去获取一个捕获的 hex/ASCII 包转储:
|
||||
|
||||
```
|
||||
tcpdump -XXnr qemu.pcap
|
||||
```
|
||||
|
||||
或者,你可以使用 [Wireshark][2] 以图形化界面去检查 pcap 文件。Wireshark 也知道如何去解码和检查成百上千的网络协议。如果你在 Athena 上,你可以使用 Wireshark 的前辈:ethereal,它运行在加锁的保密互联网协议网络中。
|
||||
|
||||
##### 调试 E1000
|
||||
|
||||
我们非常幸运能够去使用仿真硬件。由于 E1000 是在软件中运行的,仿真的 E1000 能够给我们提供一个人类可读格式的报告、它的内部状态以及它遇到的任何问题。通常情况下,对祼机上做驱动程序开发的人来说,这是非常难能可贵的。
|
||||
|
||||
E1000 能够产生一些调试输出,因此你可以去打开一个专门的日志通道。其中一些对你有用的通道如下:
|
||||
|
||||
| 标志 | 含义 |
|
||||
| --------- | :----------------------- |
|
||||
| tx | 包发送日志 |
|
||||
| txerr | 包发送错误日志 |
|
||||
| rx | 到 RCTL 的日志通道 |
|
||||
| rxfilter | 入站包过滤日志 |
|
||||
| rxerr | 接收错误日志 |
|
||||
| unknown | 未知寄存器的读写日志 |
|
||||
| eeprom | 读取 EEPROM 的日志 |
|
||||
| interrupt | 中断和中断寄存器变更日志 |
|
||||
|
||||
例如,你可以使用 `make E1000_DEBUG=tx,txerr` 去打开 "tx" 和 "txerr" 日志功能。
|
||||
|
||||
注意:`E1000_DEBUG` 标志仅能在打了 6.828 补丁的 QEMU 版本上工作。
|
||||
|
||||
你可以使用软件去仿真硬件,来做进一步的调试工作。如果你使用它时卡壳了,不明白为什么 E1000 没有如你预期那样响应你,你可以查看在 `hw/e1000.c` 中的 QEMU 的 E1000 实现。
|
||||
|
||||
#### 网络服务器
|
||||
|
||||
从头开始写一个网络栈是很困难的。因此我们将使用 lwIP,它是一个开源的、轻量级 TCP/IP 协议套件,它能做包括一个网络栈在内的很多事情。你能在 [这里][3] 找到很多关于 IwIP 的信息。在这个任务中,对我们而言,lwIP 就是一个实现了一个 BSD 套接字接口和拥有一个包输入端口和包输出端口的黑盒子。
|
||||
|
||||
一个网络服务器其实就是一个有以下四个环境的混合体:
|
||||
|
||||
* 核心网络服务器环境(包括套接字调用派发器和 lwIP)
|
||||
* 输入环境
|
||||
* 输出环境
|
||||
* 定时器环境
|
||||
|
||||
|
||||
|
||||
下图展示了各个环境和它们之间的关系。下图展示了包括设备驱动的整个系统,我们将在后面详细讲到它。在本实验中,你将去实现图中绿色高亮的部分。
|
||||
|
||||
![Network server architecture][4]
|
||||
|
||||
##### 核心网络服务器环境
|
||||
|
||||
核心网络服务器环境由套接字调用派发器和 IwIP 自身组成的。套接字调用派发器就像一个文件服务器一样。用户环境使用 stubs(可以在 `lib/nsipc.c` 中找到它)去发送 IPC 消息到核心网络服务器环境。如果你看了 `lib/nsipc.c`,你就会发现核心网络服务器与我们创建的文件服务器 `i386_init` 的工作方式是一样的,`i386_init` 是使用 NS_TYPE_NS 创建的 NS 环境,因此我们检查 `envs`,去查找这个特殊的环境类型。对于每个用户环境的 IPC,网络服务器中的派发器将调用相应的、由 IwIP 提供的、代表用户的 BSD 套接字接口函数。
|
||||
|
||||
普通用户环境不能直接使用 `nsipc_*` 调用。而是通过在 `lib/sockets.c` 中的函数来使用它们,这些函数提供了基于文件描述符的套接字 API。以这种方式,用户环境通过文件描述符来引用套接字,就像它们引用磁盘上的文件一样。一些操作(`connect`、`accept`、等等)是特定于套接字的,但 `read`、`write`、和 `close` 是通过 `lib/fd.c` 中一般的文件描述符设备派发代码的。就像文件服务器对所有的打开的文件维护唯一的内部 ID 一样,lwIP 也为所有的打开的套接字生成唯一的 ID。不论是文件服务器还是网络服务器,我们都使用存储在 `struct Fd` 中的信息去映射每个环境的文件描述符到这些唯一的 ID 空间上。
|
||||
|
||||
尽管看起来文件服务器的网络服务器的 IPC 派发器行为是一样的,但它们之间还有很重要的差别。BSD 套接字调用(像 `accept` 和 `recv`)能够无限期阻塞。如果派发器让 lwIP 去执行其中一个调用阻塞,派发器也将被阻塞,并且在整个系统中,同一时间只能有一个未完成的网络调用。由于这种情况是无法接受的,所以网络服务器使用用户级线程以避免阻塞整个服务器环境。对于每个入站 IPC 消息,派发器将创建一个线程,然后在新创建的线程上来处理请求。如果线程被阻塞,那么只有那个线程被置入休眠状态,而其它线程仍然处于运行中。
|
||||
|
||||
除了核心网络环境外,还有三个辅助环境。核心网络服务器环境除了接收来自用户应用程序的消息之外,它的派发器也接收来自输入环境和定时器环境的消息。
|
||||
|
||||
##### 输出环境
|
||||
|
||||
在为用户环境套接字调用提供服务时,lwIP 将为网卡生成用于发送的包。IwIP 将使用 `NSREQ_OUTPUT` 去发送在 IPC 消息页参数中附加了包的 IPC 消息。输出环境负责接收这些消息,并通过你稍后创建的系统调用接口来转发这些包到设备驱动程序上。
|
||||
|
||||
##### 输入环境
|
||||
|
||||
网卡接收到的包需要传递到 lwIP 中。输入环境将每个由设备驱动程序接收到的包拉进内核空间(使用你将要实现的内核系统调用),并使用 `NSREQ_INPUT` IPC 消息将这些包发送到核心网络服务器环境。
|
||||
|
||||
包输入功能是独立于核心网络环境的,因为在 JOS 上同时实现接收 IPC 消息并从设备驱动程序中查询或等待包有点困难。我们在 JOS 中没有实现 `select` 系统调用,这是一个允许环境去监视多个输入源以识别准备处理哪个输入的系统调用。
|
||||
|
||||
如果你查看了 `net/input.c` 和 `net/output.c`,你将会看到在它们中都需要去实现那个系统调用。这主要是因为实现它要依赖你的系统调用接口。在你实现了驱动程序和系统调用接口之后,你将要为这两个辅助环境写这个代码。
|
||||
|
||||
##### 定时器环境
|
||||
|
||||
定时器环境周期性发送 `NSREQ_TIMER` 类型的消息到核心服务器,以提醒它那个定时器已过期。IwIP 使用来自线程的定时器消息来实现各种网络超时。
|
||||
|
||||
### Part A:初始化和发送包
|
||||
|
||||
你的内核还没有一个时间概念,因此我们需要去添加它。这里有一个由硬件产生的每 10 ms 一次的时钟中断。每收到一个时钟中断,我们将增加一个变量值,以表示时间已过去 10 ms。它在 `kern/time.c` 中已实现,但还没有完全集成到你的内核中。
|
||||
|
||||
```markdown
|
||||
练习 1、为 `kern/trap.c` 中的每个时钟中断增加一个到 `time_tick` 的调用。实现 `sys_time_msec` 并增加到 `kern/syscall.c` 中的 `syscall`,以便于用户空间能够访问时间。
|
||||
```
|
||||
|
||||
使用 `make INIT_CFLAGS=-DTEST_NO_NS run-testtime` 去测试你的代码。你应该会看到环境计数从 5 开始以 1 秒为间隔减少。"-DTEST_NO_NS” 参数禁止在网络服务器环境上启动,因为在当前它将导致 JOS 崩溃。
|
||||
|
||||
#### 网卡
|
||||
|
||||
写驱动程序要求你必须深入了解硬件和软件中的接口。本实验将给你提供一个如何使用 E1000 接口的高度概括的文档,但是你在写驱动程序时还需要大量去查询 Intel 的手册。
|
||||
|
||||
```markdown
|
||||
练习 2、为开发 E1000 驱动,去浏览 Intel 的 [软件开发者手册][5]。这个手册涵盖了几个与以太网控制器紧密相关的东西。QEMU 仿真了 82540EM。
|
||||
|
||||
现在,你应该去浏览第 2 章,以对设备获得一个整体概念。写驱动程序时,你需要熟悉第 3 到 14 章,以及 4.1(不包括 4.1 的子节)。你也应该去参考第 13 章。其它章涵盖了 E1000 的组件,你的驱动程序并不与这些组件去交互。现在你不用担心过多细节的东西;只需要了解文档的整体结构,以便于你后面需要时容易查找。
|
||||
|
||||
在阅读手册时,记住,E1000 是一个拥有很多高级特性的很复杂的设备,一个能让 E1000 工作的驱动程序仅需要它一小部分的特性和 NIC 提供的接口即可。仔细考虑一下,如何使用最简单的方式去使用网卡的接口。我们强烈推荐你在使用高级特性之前,只去写一个基本的、能够让网卡工作的驱动程序即可。
|
||||
```
|
||||
|
||||
##### PCI 接口
|
||||
|
||||
E1000 是一个 PCI 设备,也就是说它是插到主板的 PCI 总线插槽上的。PCI 总线有地址、数据、和中断线,并且 PCI 总线允许 CPU 与 PCI 设备通讯,以及 PCI 设备去读取和写入内存。一个 PCI 设备在它能够被使用之前,需要先发现它并进行初始化。发现 PCI 设备是 PCI 总线查找已安装设备的过程。初始化是分配 I/O 和内存空间、以及协商设备所使用的 IRQ 线的过程。
|
||||
|
||||
我们在 `kern/pci.c` 中已经为你提供了使用 PCI 的代码。PCI 初始化是在引导期间执行的,PCI 代码遍历PCI 总线来查找设备。当它找到一个设备时,它读取它的供应商 ID 和设备 ID,然后使用这两个值作为关键字去搜索 `pci_attach_vendor` 数组。这个数组是由像下面这样的 `struct pci_driver` 条目组成:
|
||||
|
||||
```c
|
||||
struct pci_driver {
|
||||
uint32_t key1, key2;
|
||||
int (*attachfn) (struct pci_func *pcif);
|
||||
};
|
||||
```
|
||||
|
||||
如果发现的设备的供应商 ID 和设备 ID 与数组中条目匹配,那么 PCI 代码将调用那个条目的 `attachfn` 去执行设备初始化。(设备也可以按类别识别,那是通过 `kern/pci.c` 中其它的驱动程序表来实现的。)
|
||||
|
||||
绑定函数是传递一个 _PCI 函数_ 去初始化。一个 PCI 卡能够发布多个函数,虽然这个 E1000 仅发布了一个。下面是在 JOS 中如何去表示一个 PCI 函数:
|
||||
|
||||
```c
|
||||
struct pci_func {
|
||||
struct pci_bus *bus;
|
||||
|
||||
uint32_t dev;
|
||||
uint32_t func;
|
||||
|
||||
uint32_t dev_id;
|
||||
uint32_t dev_class;
|
||||
|
||||
uint32_t reg_base[6];
|
||||
uint32_t reg_size[6];
|
||||
uint8_t irq_line;
|
||||
};
|
||||
```
|
||||
|
||||
上面的结构反映了在 Intel 开发者手册里第 4.1 节的表 4-1 中找到的一些条目。`struct pci_func` 的最后三个条目我们特别感兴趣的,因为它们将记录这个设备协商的内存、I/O、以及中断资源。`reg_base` 和 `reg_size` 数组包含最多六个基址寄存器或 BAR。`reg_base` 为映射到内存中的 I/O 区域(对于 I/O 端口而言是基 I/O 端口)保存了内存的基地址,`reg_size` 包含了以字节表示的大小或来自 `reg_base` 的相关基值的 I/O 端口号,而 `irq_line` 包含了为中断分配给设备的 IRQ 线。在表 4-2 的后半部分给出了 E1000 BAR 的具体涵义。
|
||||
|
||||
当设备调用了绑定函数后,设备已经被发现,但没有被启用。这意味着 PCI 代码还没有确定分配给设备的资源,比如地址空间和 IRQ 线,也就是说,`struct pci_func` 结构的最后三个元素还没有被填入。绑定函数将调用 `pci_func_enable`,它将去启用设备、协商这些资源、并在结构 `struct pci_func` 中填入它。
|
||||
|
||||
```markdown
|
||||
练习 3、实现一个绑定函数去初始化 E1000。添加一个条目到 `kern/pci.c` 中的数组 `pci_attach_vendor` 上,如果找到一个匹配的 PCI 设备就去触发你的函数(确保一定要把它放在表末尾的 `{0, 0, 0}` 条目之前)。你在 5.2 节中能找到 QEMU 仿真的 82540EM 的供应商 ID 和设备 ID。在引导期间,当 JOS 扫描 PCI 总线时,你也可以看到列出来的这些信息。
|
||||
|
||||
到目前为止,我们通过 `pci_func_enable` 启用了 E1000 设备。通过本实验我们将添加更多的初始化。
|
||||
|
||||
我们已经为你提供了 `kern/e1000.c` 和 `kern/e1000.h` 文件,这样你就不会把构建系统搞糊涂了。不过它们现在都是空的;你需要在本练习中去填充它们。你还可能在内核的其它地方包含这个 `e1000.h` 文件。
|
||||
|
||||
当你引导你的内核时,你应该会看到它输出的信息显示 E1000 的 PCI 函数已经启用。这时你的代码已经能够通过 `make grade` 的 `pci attach` 测试了。
|
||||
```
|
||||
|
||||
##### 内存映射的 I/O
|
||||
|
||||
软件与 E1000 通过内存映射的 I/O(MMIO) 来沟通。你在 JOS 的前面部分可能看到过 MMIO 两次:CGA 控制台和 LAPIC 都是通过写入和读取“内存”来控制和查询设备的。但这些读取和写入不是去往内存芯片的,而是直接到这些设备的。
|
||||
|
||||
`pci_func_enable` 为 E1000 协调一个 MMIO 区域,来存储它在 BAR 0 的基址和大小(也就是 `reg_base[0]` 和 `reg_size[0]`),这是一个分配给设备的一段物理内存地址,也就是说你可以通过虚拟地址访问它来做一些事情。由于 MMIO 区域一般分配高位物理地址(一般是 3GB 以上的位置),因此你不能使用 `KADDR` 去访问它们,因为 JOS 被限制为最大使用 256MB。因此,你可以去创建一个新的内存映射。我们将使用 `MMIOBASE`(从实验 4 开始,你的 `mmio_map_region` 区域应该确保不能被 LAPIC 使用的映射所覆盖)以上的部分。由于在 JOS 创建用户环境之前,PCI 设备就已经初始化了,因此你可以在 `kern_pgdir` 处创建映射,并且让它始终可用。
|
||||
|
||||
```markdown
|
||||
练习 4、在你的绑定函数中,通过调用 `mmio_map_region`(它就是你在实验 4 中写的,是为了支持 LAPIC 内存映射)为 E1000 的 BAR 0 创建一个虚拟地址映射。
|
||||
|
||||
你将希望在一个变量中记录这个映射的位置,以便于后面访问你映射的寄存器。去看一下 `kern/lapic.c` 中的 `lapic` 变量,它就是一个这样的例子。如果你使用一个指针指向设备寄存器映射,一定要声明它为 `volatile`;否则,编译器将允许缓存它的值,并可以在内存中再次访问它。
|
||||
|
||||
为测试你的映射,尝试去输出设备状态寄存器(第 12.4.2 节)。这是一个在寄存器空间中以字节 8 开头的 4 字节寄存器。你应该会得到 `0x80080783`,它表示以 1000 MB/s 的速度启用一个全双工的链路,以及其它信息。
|
||||
```
|
||||
|
||||
提示:你将需要一些常数,像寄存器位置和掩码位数。如果从开发者手册中复制这些东西很容易出错,并且导致调试过程很痛苦。我们建议你使用 QEMU 的 [`e1000_hw.h`][6] 头文件做为基准。我们不建议完全照抄它,因为它定义的值远超过你所需要,并且定义的东西也不见得就是你所需要的,但它仍是一个很好的参考。
|
||||
|
||||
##### DMA
|
||||
|
||||
你可能会认为是从 E1000 的寄存器中通过写入和读取来传送和接收数据包的,其实这样做会非常慢,并且还要求 E1000 在其中去缓存数据包。相反,E1000 使用直接内存访问(DMA)从内存中直接读取和写入数据包,而且不需要 CPU 参与其中。驱动程序负责为发送和接收队列分配内存、设置 DMA 描述符、以及配置 E1000 使用的队列位置,而在这些设置完成之后的其它工作都是异步方式进行的。发送包的时候,驱动程序复制它到发送队列的下一个 DMA 描述符中,并且通知 E1000 下一个发送包已就绪;当轮到这个包发送时,E1000 将从描述符中复制出数据。同样,当 E1000 接收一个包时,它从接收队列中将它复制到下一个 DMA 描述符中,驱动程序将能在下一次读取到它。
|
||||
|
||||
总体来看,接收队列和发送队列非常相似。它们都是由一系列的描述符组成。虽然这些描述符的结构细节有所不同,但每个描述符都包含一些标志和包含了包数据的一个缓存的物理地址(发送到网卡的数据包,或网卡将接收到的数据包写入到由操作系统分配的缓存中)。
|
||||
|
||||
队列被实现为一个环形数组,意味着当网卡或驱动到达数组末端时,它将重新回到开始位置。它有一个头指针和尾指针,队列的内容就是这两个指针之间的描述符。硬件就是从头开始移动头指针去消费描述符,在这期间驱动程序不停地添加描述符到尾部,并移动尾指针到最后一个描述符上。发送队列中的描述符表示等待发送的包(因此,在平静状态下,发送队列是空的)。对于接收队列,队列中的描述符是表示网卡能够接收包的空描述符(因此,在平静状态下,接收队列是由所有的可用接收描述符组成的)。正确的更新尾指针寄存器而不让 E1000 产生混乱是很有难度的;要小心!
|
||||
|
||||
指向到这些数组及描述符中的包缓存地址的指针都必须是物理地址,因为硬件是直接在物理内存中且不通过 MMU 来执行 DMA 的读写操作的。
|
||||
|
||||
#### 发送包
|
||||
|
||||
E1000 中的发送和接收功能本质上是独立的,因此我们可以同时进行发送接收。我们首先去攻克简单的数据包发送,因为我们在没有先去发送一个 “I'm here!" 包之前是无法测试接收包功能的。
|
||||
|
||||
首先,你需要初始化网卡以准备发送,详细步骤查看 14.5 节(不必着急看子节)。发送初始化的第一步是设置发送队列。队列的详细结构在 3.4 节中,描述符的结构在 3.3.3 节中。我们先不要使用 E1000 的 TCP offload 特性,因此你只需专注于 “传统的发送描述符格式” 即可。你应该现在就去阅读这些章节,并要熟悉这些结构。
|
||||
|
||||
##### C 结构
|
||||
|
||||
你可以用 C `struct` 很方便地描述 E1000 的结构。正如你在 `struct Trapframe` 中所看到的结构那样,C `struct` 可以让你很方便地在内存中描述准确的数据布局。C 可以在字段中插入数据,但是 E1000 的结构就是这样布局的,这样就不会是个问题。如果你遇到字段对齐问题,进入 GCC 查看它的 "packed” 属性。
|
||||
|
||||
查看手册中表 3-8 所给出的一个传统的发送描述符,将它复制到这里作为一个示例:
|
||||
|
||||
```
|
||||
63 48 47 40 39 32 31 24 23 16 15 0
|
||||
+---------------------------------------------------------------+
|
||||
| Buffer address |
|
||||
+---------------|-------|-------|-------|-------|---------------+
|
||||
| Special | CSS | Status| Cmd | CSO | Length |
|
||||
+---------------|-------|-------|-------|-------|---------------+
|
||||
```
|
||||
|
||||
从结构右上角第一个字节开始,我们将它转变成一个 C 结构,从上到下,从右到左读取。如果你从右往左看,你将看到所有的字段,都非常适合一个标准大小的类型:
|
||||
|
||||
```c
|
||||
struct tx_desc
|
||||
{
|
||||
uint64_t addr;
|
||||
uint16_t length;
|
||||
uint8_t cso;
|
||||
uint8_t cmd;
|
||||
uint8_t status;
|
||||
uint8_t css;
|
||||
uint16_t special;
|
||||
};
|
||||
```
|
||||
|
||||
你的驱动程序将为发送描述符数组去保留内存,并由发送描述符指向到包缓冲区。有几种方式可以做到,从动态分配页到在全局变量中简单地声明它们。无论你如何选择,记住,E1000 是直接访问物理内存的,意味着它能访问的任何缓存区在物理内存中必须是连续的。
|
||||
|
||||
处理包缓存也有几种方式。我们推荐从最简单的开始,那就是在驱动程序初始化期间,为每个描述符保留包缓存空间,并简单地将包数据复制进预留的缓冲区中或从其中复制出来。一个以太网包最大的尺寸是 1518 字节,这就限制了这些缓存区的大小。主流的成熟驱动程序都能够动态分配包缓存区(即:当网络使用率很低时,减少内存使用量),或甚至跳过缓存区,直接由用户空间提供(就是“零复制”技术),但我们还是从简单开始为好。
|
||||
|
||||
```markdown
|
||||
练习 5、执行一个 14.5 节中的初始化步骤(它的子节除外)。对于寄存器的初始化过程使用 13 节作为参考,对发送描述符和发送描述符数组参考 3.3.3 节和 3.4 节。
|
||||
|
||||
要记住,在发送描述符数组中要求对齐,并且数组长度上有限制。因为 TDLEN 必须是 128 字节对齐的,而每个发送描述符是 16 字节,你的发送描述符数组必须是 8 个发送描述符的倍数。并且不能使用超过 64 个描述符,以及不能在我们的发送环形缓存测试中溢出。
|
||||
|
||||
对于 TCTL.COLD,你可以假设为全双工操作。对于 TIPG、IEEE 802.3 标准的 IPG(不要使用 14.5 节中表上的值),参考在 13.4.34 节中表 13-77 中描述的缺省值。
|
||||
```
|
||||
|
||||
尝试运行 `make E1000_DEBUG=TXERR,TX qemu`。如果你使用的是打了 6.828 补丁的 QEMU,当你设置 TDT(发送描述符尾部)寄存器时你应该会看到一个 “e1000: tx disabled" 的信息,并且不会有更多 "e1000” 信息了。
|
||||
|
||||
现在,发送初始化已经完成,你可以写一些代码去发送一个数据包,并且通过一个系统调用使它可以访问用户空间。你可以将要发送的数据包添加到发送队列的尾部,也就是说复制数据包到下一个包缓冲区中,然后更新 TDT 寄存器去通知网卡在发送队列中有另外的数据包。(注意,TDT 是一个进入发送描述符数组的索引,不是一个字节偏移量;关于这一点文档中说明的不是很清楚。)
|
||||
|
||||
但是,发送队列只有这么大。如果网卡在发送数据包时卡住或发送队列填满时会发生什么状况?为了检测这种情况,你需要一些来自 E1000 的反馈。不幸的是,你不能只使用 TDH(发送描述符头)寄存器;文档上明确说明,从软件上读取这个寄存器是不可靠的。但是,如果你在发送描述符的命令字段中设置 RS 位,那么,当网卡去发送在那个描述符中的数据包时,网卡将设置描述符中状态字段的 DD 位,如果一个描述符中的 DD 位被设置,你就应该知道那个描述符可以安全地回收,并且可以用它去发送其它数据包。
|
||||
|
||||
如果用户调用你的发送系统调用,但是下一个描述符的 DD 位没有设置,表示那个发送队列已满,该怎么办?在这种情况下,你该去决定怎么办了。你可以简单地丢弃数据包。网络协议对这种情况的处理很灵活,但如果你丢弃大量的突发数据包,协议可能不会去重新获得它们。可能需要你替代网络协议告诉用户环境让它重传,就像你在 `sys_ipc_try_send` 中做的那样。在环境上回推产生的数据是有好处的。
|
||||
|
||||
```
|
||||
练习 6、写一个函数去发送一个数据包,它需要检查下一个描述符是否空闲、复制包数据到下一个描述符并更新 TDT。确保你处理的发送队列是满的。
|
||||
```
|
||||
|
||||
现在,应该去测试你的包发送代码了。通过从内核中直接调用你的发送函数来尝试发送几个包。在测试时,你不需要去创建符合任何特定网络协议的数据包。运行 `make E1000_DEBUG=TXERR,TX qemu` 去测试你的代码。你应该看到类似下面的信息:
|
||||
|
||||
```c
|
||||
e1000: index 0: 0x271f00 : 9000002a 0
|
||||
...
|
||||
```
|
||||
|
||||
在你发送包时,每行都给出了在发送数组中的序号、那个发送的描述符的缓存地址、`cmd/CSO/length` 字段、以及 `special/CSS/status` 字段。如果 QEMU 没有从你的发送描述符中输出你预期的值,检查你的描述符中是否有合适的值和你配置的正确的 TDBAL 和 TDBAH。如果你收到的是 "e1000: TDH wraparound @0, TDT x, TDLEN y" 的信息,意味着 E1000 的发送队列持续不断地运行(如果 QEMU 不去检查它,它将是一个无限循环),这意味着你没有正确地维护 TDT。如果你收到了许多 "e1000: tx disabled" 的信息,那么意味着你没有正确设置发送控制寄存器。
|
||||
|
||||
一旦 QEMU 运行,你就可以运行 `tcpdump -XXnr qemu.pcap` 去查看你发送的包数据。如果从 QEMU 中看到预期的 "e1000: index” 信息,但你捕获的包是空的,再次检查你发送的描述符,是否填充了每个必需的字段和位。(E1000 或许已经遍历了你的发送描述符,但它认为不需要去发送)
|
||||
|
||||
```
|
||||
练习 7、添加一个系统调用,让你从用户空间中发送数据包。详细的接口由你来决定。但是不要忘了检查从用户空间传递给内核的所有指针。
|
||||
```
|
||||
|
||||
#### 发送包:网络服务器
|
||||
|
||||
现在,你已经有一个系统调用接口可以发送包到你的设备驱动程序端了。输出辅助环境的目标是在一个循环中做下面的事情:从核心网络服务器中接收 `NSREQ_OUTPUT` IPC 消息,并使用你在上面增加的系统调用去发送伴随这些 IPC 消息的数据包。这个 `NSREQ_OUTPUT` IPC 是通过 `net/lwip/jos/jif/jif.c` 中的 `low_level_output` 函数来发送的。它集成 lwIP 栈到 JOS 的网络系统。每个 IPC 将包含一个页,这个页由一个 `union Nsipc` 和在 `struct jif_pkt pkt` 字段中的一个包组成(查看 `inc/ns.h`)。`struct jif_pkt` 看起来像下面这样:
|
||||
|
||||
```c
|
||||
struct jif_pkt {
|
||||
int jp_len;
|
||||
char jp_data[0];
|
||||
};
|
||||
```
|
||||
|
||||
`jp_len` 表示包的长度。在 IPC 页上的所有后续字节都是为了包内容。在结构的结尾处使用一个长度为 0 的数组来表示缓存没有一个预先确定的长度(像 `jp_data` 一样),这是一个常见的 C 技巧(也有人说这是一个令人讨厌的做法)。因为 C 并不做数组边界的检查,只要你确保结构后面有足够的未使用内存即可,你可以把 `jp_data` 作为一个任意大小的数组来使用。
|
||||
|
||||
当设备驱动程序的发送队列中没有足够的空间时,一定要注意在设备驱动程序、输出环境和核心网络服务器之间的交互。核心网络服务器使用 IPC 发送包到输出环境。如果输出环境在由于一个发送包的系统调用而挂起,导致驱动程序没有足够的缓存去容纳新数据包,这时核心网络服务器将阻塞以等待输出服务器去接收 IPC 调用。
|
||||
|
||||
```markdown
|
||||
练习 8、实现 `net/output.c`。
|
||||
```
|
||||
|
||||
你可以使用 `net/testoutput.c` 去测试你的输出代码而无需整个网络服务器参与。尝试运行 `make E1000_DEBUG=TXERR,TX run-net_testoutput`。你将看到如下的输出:
|
||||
|
||||
```c
|
||||
Transmitting packet 0
|
||||
e1000: index 0: 0x271f00 : 9000009 0
|
||||
Transmitting packet 1
|
||||
e1000: index 1: 0x2724ee : 9000009 0
|
||||
...
|
||||
```
|
||||
|
||||
运行 `tcpdump -XXnr qemu.pcap` 将输出:
|
||||
|
||||
|
||||
```c
|
||||
reading from file qemu.pcap, link-type EN10MB (Ethernet)
|
||||
-5:00:00.600186 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 30 Packet.00
|
||||
-5:00:00.610080 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 31 Packet.01
|
||||
...
|
||||
```
|
||||
|
||||
使用更多的数据包去测试,可以运行 `make E1000_DEBUG=TXERR,TX NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput`。如果它导致你的发送队列溢出,再次检查你的 DD 状态位是否正确,以及是否告诉硬件去设置 DD 状态位(使用 RS 命令位)。
|
||||
|
||||
你的代码应该会通过 `make grade` 的 `testoutput` 测试。
|
||||
|
||||
```
|
||||
问题
|
||||
|
||||
1、你是如何构造你的发送实现的?在实践中,如果发送缓存区满了,你该如何处理?
|
||||
```
|
||||
|
||||
|
||||
### Part B:接收包和 web 服务器
|
||||
|
||||
#### 接收包
|
||||
|
||||
就像你在发送包中做的那样,你将去配置 E1000 去接收数据包,并提供一个接收描述符队列和接收描述符。在 3.2 节中描述了接收包的操作,包括接收队列结构和接收描述符、以及在 14.4 节中描述的详细的初始化过程。
|
||||
|
||||
```
|
||||
练习 9、阅读 3.2 节。你可以忽略关于中断和 offload 校验和方面的内容(如果在后面你想去使用这些特性,可以再返回去阅读),你现在不需要去考虑阈值的细节和网卡内部缓存是如何工作的。
|
||||
```
|
||||
|
||||
除了接收队列是由一系列的等待入站数据包去填充的空缓存包以外,接收队列的其它部分与发送队列非常相似。所以,当网络空闲时,发送队列是空的(因为所有的包已经被发送出去了),而接收队列是满的(全部都是空缓存包)。
|
||||
|
||||
当 E1000 接收一个包时,它首先与网卡的过滤器进行匹配检查(例如,去检查这个包的目标地址是否为这个 E1000 的 MAC 地址),如果这个包不匹配任何过滤器,它将忽略这个包。否则,E1000 尝试从接收队列头部去检索下一个接收描述符。如果头(RDH)追上了尾(RDT),那么说明接收队列已经没有空闲的描述符了,所以网卡将丢弃这个包。如果有空闲的接收描述符,它将复制这个包的数据到描述符指向的缓存中,设置这个描述符的 DD 和 EOP 状态位,并递增 RDH。
|
||||
|
||||
如果 E1000 在一个接收描述符中接收到了一个比包缓存还要大的数据包,它将按需从接收队列中检索尽可能多的描述符以保存数据包的全部内容。为表示发生了这种情况,它将在所有的这些描述符上设置 DD 状态位,但仅在这些描述符的最后一个上设置 EOP 状态位。在你的驱动程序上,你可以去处理这种情况,也可以简单地配置网卡拒绝接收这种”长包“(这种包也被称为”巨帧“),你要确保接收缓存有足够的空间尽可能地去存储最大的标准以太网数据包(1518 字节)。
|
||||
|
||||
```markdown
|
||||
练习 10、设置接收队列并按 14.4 节中的流程去配置 E1000。你可以不用支持 ”长包“ 或多播。到目前为止,我们不用去配置网卡使用中断;如果你在后面决定去使用接收中断时可以再去改。另外,配置 E1000 去除以太网的 CRC 校验,因为我们的评级脚本要求必须去掉校验。
|
||||
|
||||
默认情况下,网卡将过滤掉所有的数据包。你必须使用网卡的 MAC 地址去配置接收地址寄存器(RAL 和 RAH)以接收发送到这个网卡的数据包。你可以简单地硬编码 QEMU 的默认 MAC 地址 52:54:00:12:34:56(我们已经在 lwIP 中硬编码了这个地址,因此这样做不会有问题)。使用字节顺序时要注意;MAC 地址是从低位字节到高位字节的方式来写的,因此 52:54:00:12 是 MAC 地址的低 32 位,而 34:56 是它的高 16 位。
|
||||
|
||||
E1000 的接收缓存区大小仅支持几个指定的设置值(在 13.4.22 节中描述的 RCTL.BSIZE 值)。如果你的接收包缓存够大,并且拒绝长包,那你就不用担心跨越多个缓存区的包。另外,要记住的是,和发送一样,接收队列和包缓存必须是连接的物理内存。
|
||||
|
||||
你应该使用至少 128 个接收描述符。
|
||||
```
|
||||
|
||||
现在,你可以做接收功能的基本测试了,甚至都无需写代码去接收包了。运行 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput`。`testinput` 将发送一个 ARP(地址解析协议)通告包(使用你的包发送的系统调用),而 QEMU 将自动回复它,即便是你的驱动尚不能接收这个回复,你也应该会看到一个 "e1000: unicast match[0]: 52:54:00:12:34:56" 的消息,表示 E1000 接收到一个包,并且匹配了配置的接收过滤器。如果你看到的是一个 "e1000: unicast mismatch: 52:54:00:12:34:56” 消息,表示 E1000 过滤掉了这个包,意味着你的 RAL 和 RAH 的配置不正确。确保你按正确的顺序收到了字节,并不要忘记设置 RAH 中的 "Address Valid” 位。如果你没有收到任何 "e1000” 消息,或许是你没有正确地启用接收功能。
|
||||
|
||||
现在,你准备去实现接收数据包。为了接收数据包,你的驱动程序必须持续跟踪希望去保存下一下接收到的包的描述符(提示:按你的设计,这个功能或许已经在 E1000 中的一个寄存器来实现了)。与发送类似,官方文档上表示,RDH 寄存器状态并不能从软件中可靠地读取,因为确定一个包是否被发送到描述符的包缓存中,你需要去读取描述符中的 DD 状态位。如果 DD 位被设置,你就可以从那个描述符的缓存中复制出这个数据包,然后通过更新队列的尾索引 RDT 来告诉网卡那个描述符是空闲的。
|
||||
|
||||
如果 DD 位没有被设置,表明没有接收到包。这就与发送队列满的情况一样,这时你可以有几种做法。你可以简单地返回一个 ”重传“ 错误来要求对端重发一次。对于满的发送队列,由于那是个临时状况,这种做法还是很好的,但对于空的接收队列来说就不太合理了,因为接收队列可能会保持好长一段时间的空的状态。第二个方法是挂起调用环境,直到在接收队列中处理了这个包为止。这个策略非常类似于 `sys_ipc_recv`。就像在 IPC 的案例中,因为我们每个 CPU 仅有一个内核栈,一旦我们离开内核,栈上的状态就会被丢弃。我们需要设置一个标志去表示那个环境由于接收队列下溢被挂起并记录系统调用参数。这种方法的缺点是过于复杂:E1000 必须被指示去产生接收中断,并且驱动程序为了恢复被阻塞等待一个包的环境,必须处理这个中断。
|
||||
|
||||
```
|
||||
练习 11、写一个函数从 E1000 中接收一个包,然后通过一个系统调用将它发布到用户空间。确保你将接收队列处理成空的。
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!如果发送队列是满的或接收队列是空的,环境和你的驱动程序可能会花费大量的 CPU 周期是轮询、等待一个描述符。一旦完成发送或接收描述符,E1000 能够产生一个中断,以避免轮询。修改你的驱动程序,处理发送和接收队列是以中断而不是轮询的方式进行。
|
||||
|
||||
注意,一旦确定为中断,它将一直处于中断状态,直到你的驱动程序明确处理完中断为止。在你的中断服务程序中,一旦处理完成要确保清除掉中断状态。如果你不那样做,从你的中断服务程序中返回后,CPU 将再次跳转到你的中断服务程序中。除了在 E1000 网卡上清除中断外,也需要使用 `lapic_eoi` 在 LAPIC 上清除中断。
|
||||
```
|
||||
|
||||
#### 接收包:网络服务器
|
||||
|
||||
在网络服务器输入环境中,你需要去使用你的新的接收系统调用以接收数据包,并使用 `NSREQ_INPUT` IPC 消息将它传递到核心网络服务器环境。这些 IPC 输入消息应该会有一个页,这个页上绑定了一个 `union Nsipc`,它的 `struct jif_pkt pkt` 字段中有从网络上接收到的包。
|
||||
|
||||
```markdown
|
||||
练习 12、实现 `net/input.c`。
|
||||
```
|
||||
|
||||
使用 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput` 再次运行 `testinput`,你应该会看到:
|
||||
|
||||
```c
|
||||
Sending ARP announcement...
|
||||
Waiting for packets...
|
||||
e1000: index 0: 0x26dea0 : 900002a 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001
|
||||
input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202
|
||||
input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000
|
||||
input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
|
||||
```
|
||||
|
||||
"input:” 打头的行是一个 QEMU 的 ARP 回复的十六进制转储。
|
||||
|
||||
你的代码应该会通过 `make grade` 的 `testinput` 测试。注意,在没有发送至少一个包去通知 QEMU 中的 JOS 的 IP 地址上时,是没法去测试包接收的,因此在你的发送代码中的 bug 可能会导致测试失败。
|
||||
|
||||
为彻底地测试你的网络代码,我们提供了一个称为 `echosrv` 的守护程序,它在端口 7 上设置运行 `echo` 的服务器,它将回显通过 TCP 连接发送给它的任何内容。使用 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv` 在一个终端中启动 `echo` 服务器,然后在另一个终端中通过 `make nc-7` 去连接它。你输入的每一行都被这个服务器回显出来。每次在仿真的 E1000 上接收到一个包,QEMU 将在控制台上输出像下面这样的内容:
|
||||
|
||||
```c
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
e1000: index 2: 0x26ea7c : 9000036 0
|
||||
e1000: index 3: 0x26f06a : 9000039 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
```
|
||||
|
||||
做到这一点后,你应该也就能通过 `echosrv` 的测试了。
|
||||
|
||||
```
|
||||
问题
|
||||
|
||||
2、你如何构造你的接收实现?在实践中,如果接收队列是空的并且一个用户环境要求下一个入站包,你怎么办?
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
小挑战!在开发者手册中阅读关于 EEPROM 的内容,并写出从 EEPROM 中加载 E1000 的 MAC 地址的代码。目前,QEMU 的默认 MAC 地址是硬编码到你的接收初始化代码和 lwIP 中的。修复你的初始化代码,让它能够从 EEPROM 中读取 MAC 地址,和增加一个系统调用去传递 MAC 地址到 lwIP 中,并修改 lwIP 去从网卡上读取 MAC 地址。通过配置 QEMU 使用一个不同的 MAC 地址去测试你的变更。
|
||||
```
|
||||
|
||||
```
|
||||
小挑战!修改你的 E1000 驱动程序去使用 "零复制" 技术。目前,数据包是从用户空间缓存中复制到发送包缓存中,和从接收包缓存中复制回到用户空间缓存中。一个使用 ”零复制“ 技术的驱动程序可以通过直接让用户空间和 E1000 共享包缓存内存来实现。还有许多不同的方法去实现 ”零复制“,包括映射内容分配的结构到用户空间或直接传递用户提供的缓存到 E1000。不论你选择哪种方法,都要注意你如何利用缓存的问题,因为你不能在用户空间代码和 E1000 之间产生争用。
|
||||
```
|
||||
|
||||
```
|
||||
小挑战!把 ”零复制“ 的概念用到 lwIP 中。
|
||||
|
||||
一个典型的包是由许多头构成的。用户发送的数据被发送到 lwIP 中的一个缓存中。TCP 层要添加一个 TCP 包头,IP 层要添加一个 IP 包头,而 MAC 层有一个以太网头。甚至还有更多的部分增加到包上,这些部分要正确地连接到一起,以便于设备驱动程序能够发送最终的包。
|
||||
|
||||
E1000 的发送描述符设计是非常适合收集分散在内存中的包片段的,像在 IwIP 中创建的包的帧。如果你排队多个发送描述符,但仅设置最后一个描述符的 EOP 命令位,那么 E1000 将在内部把这些描述符串成包缓存,并在它们标记完 EOP 后仅发送串起来的缓存。因此,独立的包片段不需要在内存中把它们连接到一起。
|
||||
|
||||
修改你的驱动程序,以使它能够发送由多个缓存且无需复制的片段组成的包,并且修改 lwIP 去避免它合并包片段,因为它现在能够正确处理了。
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!增加你的系统调用接口,以便于它能够为多于一个的用户环境提供服务。如果有多个网络栈(和多个网络服务器)并且它们各自都有自己的 IP 地址运行在用户模式中,这将是非常有用的。接收系统调用将决定它需要哪个环境来转发每个入站的包。
|
||||
|
||||
注意,当前的接口并不知道两个包之间有何不同,并且如果多个环境去调用包接收的系统调用,各个环境将得到一个入站包的子集,而那个子集可能并不包含调用环境指定的那个包。
|
||||
|
||||
在 [这篇][7] 外内核论文的 2.2 节和 3 节中对这个问题做了深度解释,并解释了在内核中(如 JOS)处理它的一个方法。用这个论文中的方法去解决这个问题,你不需要一个像论文中那么复杂的方案。
|
||||
```
|
||||
|
||||
#### Web 服务器
|
||||
|
||||
一个最简单的 web 服务器类型是发送一个文件的内容到请求的客户端。我们在 `user/httpd.c` 中提供了一个非常简单的 web 服务器的框架代码。这个框架内码处理入站连接并解析请求头。
|
||||
|
||||
```markdown
|
||||
练习 13、这个 web 服务器中缺失了发送一个文件的内容到客户端的处理代码。通过实现 `send_file` 和 `send_data` 完成这个 web 服务器。
|
||||
```
|
||||
|
||||
在你完成了这个 web 服务器后,启动这个 web 服务器(`make run-httpd-nox`),使用你喜欢的浏览器去浏览 http:// _host_ : _port_ /index.html 地址。其中 _host_ 是运行 QEMU 的计算机的名字(如果你在 athena 上运行 QEMU,使用 `hostname.mit.edu`(其中 hostname 是在 athena 上运行 `hostname` 命令的输出,或者如果你在运行 QEMU 的机器上运行 web 浏览器的话,直接使用 `localhost`),而 _port_ 是 web 服务器运行 `make which-ports` 命令报告的端口号。你应该会看到一个由运行在 JOS 中的 HTTP 服务器提供的一个 web 页面。
|
||||
|
||||
到目前为止,你的评级测试得分应该是 105 分(满分为105)。
|
||||
|
||||
```markdown
|
||||
小挑战!在 JOS 中添加一个简单的聊天服务器,多个人可以连接到这个服务器上,并且任何用户输入的内容都被发送到其它用户。为实现它,你需要找到一个一次与多个套接字通讯的方法,并且在同一时间能够在同一个套接字上同时实现发送和接收。有多个方法可以达到这个目的。lwIP 为 `recv`(查看 `net/lwip/api/sockets.c` 中的 `lwip_recvfrom`)提供了一个 MSG_DONTWAIT 标志,以便于你不断地轮询所有打开的套接字。注意,虽然网络服务器的 IPC 支持 `recv` 标志,但是通过普通的 `read` 函数并不能访问它们,因此你需要一个方法来传递这个标志。一个更高效的方法是为每个连接去启动一个或多个环境,并且使用 IPC 去协调它们。而且碰巧的是,对于一个套接字,在结构 Fd 中找到的 lwIP 套接字 ID 是全局的(不是每个环境私有的),因此,比如一个 `fork` 的子环境继承了它的父环境的套接字。或者,一个环境通过构建一个包含了正确套接字 ID 的 Fd 就能够发送到另一个环境的套接字上。
|
||||
```
|
||||
|
||||
```
|
||||
问题
|
||||
|
||||
3、由 JOS 的 web 服务器提供的 web 页面显示了什么?
|
||||
4. 你做这个实验大约花了多长的时间?
|
||||
```
|
||||
|
||||
**本实验到此结束了。**一如既往,不要忘了运行 `make grade` 并去写下你的答案和挑战问题的解决方案的描述。在你动手之前,使用 `git status` 和 `git diff` 去检查你的变更,并不要忘了去 `git add answers-lab6.txt`。当你完成之后,使用 `git commit -am 'my solutions to lab 6’` 去提交你的变更,然后 `make handin` 并关注它的动向。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://wiki.qemu.org/download/qemu-doc.html#Using-the-user-mode-network-stack
|
||||
[2]: http://www.wireshark.org/
|
||||
[3]: http://www.sics.se/~adam/lwip/
|
||||
[4]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/ns.png
|
||||
[5]: https://pdos.csail.mit.edu/6.828/2018/readings/hardware/8254x_GBe_SDM.pdf
|
||||
[6]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/e1000_hw.h
|
||||
[7]: http://pdos.csail.mit.edu/papers/exo:tocs.pdf
|
||||
@ -0,0 +1,228 @@
|
||||
命令行快捷提示:如何定位一个文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们都会有文件存储在电脑里 —— 目录,相片,源代码等等。它们是如此之多。也无疑超出了我的记忆范围。要是毫无目标,找到正确的那一个可能会很费时间。在这篇文章里我们来看一下如何在命令行里找到需要的文件,特别是快速找到你想要的那一个。
|
||||
|
||||
好消息是 Linux 命令行专门设计了很多非常有用的命令行工具在你的电脑上查找文件。下面我们看一下它们其中三个:ls、tree 和 tree。
|
||||
|
||||
### ls
|
||||
|
||||
如果你知道文件在哪里,你只需要列出它们或者查看有关它们的信息,ls 就是为此而生的。
|
||||
|
||||
只需运行 ls 就可以列出当下目录中所有可见的文件和目录:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Documents Music Pictures Videos notes.txt
|
||||
```
|
||||
|
||||
添加 **-l** 选项可以查看文件的相关信息。同时再加上 **-h** 选项,就可以用一种人们易读的格式查看文件的大小:
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
total 60K
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
|
||||
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
|
||||
```
|
||||
|
||||
**ls** 也可以搜索一个指定位置:
|
||||
|
||||
```
|
||||
$ ls Pictures/
|
||||
trees.png wallpaper.png
|
||||
```
|
||||
|
||||
或者一个指定文件 —— 即便只跟着名字的一部分:
|
||||
|
||||
```
|
||||
$ ls *.txt
|
||||
notes.txt
|
||||
```
|
||||
|
||||
少了点什么?想要查看一个隐藏文件?没问题,使用 **-a** 选项:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
. .bash_logout .bashrc Documents Pictures notes.txt
|
||||
.. .bash_profile .vimrc Music Videos
|
||||
```
|
||||
|
||||
**ls** 还有很多其他有用的选项,你可以把它们组合在一起获得你想要的效果。可以使用以下命令了解更多:
|
||||
|
||||
```
|
||||
$ man ls
|
||||
```
|
||||
|
||||
### tree
|
||||
|
||||
如果你想查看你的文件的树状结构,tree 是一个不错的选择。可能你的系统上没有默认安装它,你可以使用包管理 DNF 手动安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install tree
|
||||
```
|
||||
|
||||
如果不带任何选项或者参数地运行 tree,将会以当前目录开始,显示出包含其下所有目录和文件的一个树状图。提醒一下,这个输出可能会非常大,因为它包含了这个目录下的所有目录和文件:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| | `-- christmas-presents.txt
|
||||
| `-- work
|
||||
| |-- project-abc
|
||||
| | |-- README.md
|
||||
| | |-- do-things.sh
|
||||
| | `-- project-notes.txt
|
||||
| `-- status-reports.txt
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
如果列出的太多了,使用 -L 选项,并在其后加上你想查看的层级数,可以限制列出文件的层级:
|
||||
|
||||
```
|
||||
$ tree -L 2
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| `-- work
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
你也可以显示一个指定目录的树状图:
|
||||
|
||||
```
|
||||
$ tree Documents/work/
|
||||
Documents/work/
|
||||
|-- project-abc
|
||||
| |-- README.md
|
||||
| |-- do-things.sh
|
||||
| `-- project-notes.txt
|
||||
`-- status-reports.txt
|
||||
```
|
||||
|
||||
如果使用 tree 列出的是一个很大的树状图,你可以把它跟 less 组合使用:
|
||||
|
||||
```
|
||||
$ tree | less
|
||||
```
|
||||
|
||||
再一次,tree 有很多其他的选项可以使用,你可以把他们组合在一起发挥更强大的作用。man 手册页有所有这些选项:
|
||||
|
||||
```
|
||||
$ man tree
|
||||
```
|
||||
|
||||
### find
|
||||
|
||||
那么如果不知道文件在哪里呢?就让我们来找到它们吧!
|
||||
|
||||
要是你的系统中没有 find,你可以使用 DNF 安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install findutils
|
||||
```
|
||||
|
||||
运行 find 时如果没有添加任何选项或者参数,它将会递归列出当前目录下的所有文件和目录。
|
||||
|
||||
```
|
||||
$ find
|
||||
.
|
||||
./Documents
|
||||
./Documents/secret
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc
|
||||
./Documents/work/project-abc/README.md
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./.bash_logout
|
||||
./.bashrc
|
||||
./Videos
|
||||
./.bash_profile
|
||||
./.vimrc
|
||||
./Pictures
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
./notes.txt
|
||||
./Music
|
||||
```
|
||||
|
||||
但是 find 真正强大的是你可以使用文件名进行搜索:
|
||||
|
||||
```
|
||||
$ find -name do-things.sh
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
```
|
||||
|
||||
或者仅仅是名字的一部分 —— 像是文件后缀。我们来找一下所有的 .txt 文件:
|
||||
|
||||
```
|
||||
$ find -name "*.txt"
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./notes.txt
|
||||
```
|
||||
你也可以根据大小寻找文件。如果你的空间不足的时候,这种方法也许特别有用。现在来列出所有大于 1 MB 的文件:
|
||||
|
||||
```
|
||||
$ find -size +1M
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
```
|
||||
|
||||
当然也可以搜索一个具体的目录。假如我想在我的 Documents 文件夹下找一个文件,而且我知道它的名字里有 “project” 这个词:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*"
|
||||
Documents/work/project-abc
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
除了文件它还显示目录。你可以限制仅搜索查询文件:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*" -type f
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
最后再一次,find 还有很多供你使用的选项,要是你想使用它们,man 手册页绝对可以帮到你:
|
||||
|
||||
```
|
||||
$ man find
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-locate-file/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,169 @@
|
||||
pydbgen:一个数据库随机生成器
|
||||
======
|
||||
> 用这个简单的工具生成大型数据库,让你更好地研究数据科学。
|
||||
|
||||

|
||||
|
||||
在研究数据科学的过程中,最麻烦的往往不是算法或者技术,而是如何获取到一批原始数据。尽管网上有很多真实优质的数据集可以用于机器学习,然而在学习 SQL 时却不是如此。
|
||||
|
||||
对于数据科学来说,熟悉 SQL 的重要性不亚于了解 Python 或 R 编程。如果想收集诸如姓名、年龄、信用卡信息、地址这些信息用于机器学习任务,在 Kaggle 上查找专门的数据集比使用足够大的真实数据库要容易得多。
|
||||
|
||||
如果有一个简单的工具或库来帮助你生成一个大型数据库,表里还存放着大量你需要的数据,岂不美哉?
|
||||
|
||||
不仅仅是数据科学的入门者,即使是经验丰富的软件测试人员也会需要这样一个简单的工具,只需编写几行代码,就可以通过随机(但是是假随机)生成任意数量但有意义的数据集。
|
||||
|
||||
因此,我要推荐这个名为 [pydbgen][1] 的轻量级 Python 库。在后文中,我会简要说明这个库的相关内容,你也可以[阅读它的文档][2]详细了解更多信息。
|
||||
|
||||
### pydbgen 是什么
|
||||
|
||||
`pydbgen` 是一个轻量的纯 Python 库,它可以用于生成随机但有意义的数据记录(包括姓名、地址、信用卡号、日期、时间、公司名称、职位、车牌号等等),存放在 Pandas Dataframe 对象中,并保存到 SQLite 数据库或 Excel 文件。
|
||||
|
||||
### 如何安装 pydbgen
|
||||
|
||||
目前 1.0.5 版本的 pydbgen 托管在 PyPI(<ruby>Python 包索引存储库<rt>Python Package Index repository</rt></ruby>)上,并且对 [Faker][3] 有依赖关系。安装 pydbgen 只需要执行命令:
|
||||
|
||||
```
|
||||
pip install pydbgen
|
||||
```
|
||||
|
||||
已经在 Python 3.6 环境下测试安装成功,但在 Python 2 环境下无法正常安装。
|
||||
|
||||
### 如何使用 pydbgen
|
||||
|
||||
在使用 `pydbgen` 之前,首先要初始化 `pydb` 对象。
|
||||
|
||||
```
|
||||
import pydbgen
|
||||
from pydbgen import pydbgen
|
||||
myDB=pydbgen.pydb()
|
||||
```
|
||||
|
||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||
随后就可以调用 `pydb` 对象公开的各种内部函数了。可以按照下面的例子,输出随机的美国城市和车牌号码:
|
||||
|
||||
```
|
||||
myDB.city_real()
|
||||
>> 'Otterville'
|
||||
for _ in range(10):
|
||||
print(myDB.license_plate())
|
||||
>> 8NVX937
|
||||
6YZH485
|
||||
XBY-564
|
||||
SCG-2185
|
||||
XMR-158
|
||||
6OZZ231
|
||||
CJN-850
|
||||
SBL-4272
|
||||
TPY-658
|
||||
SZL-0934
|
||||
```
|
||||
|
||||
另外,如果你输入的是 city 而不是 city_real,返回的将会是虚构的城市名。
|
||||
|
||||
```
|
||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||
>>
|
||||
New Michelle
|
||||
Robinborough
|
||||
Leebury
|
||||
Kaylatown
|
||||
Hamiltonfort
|
||||
Lake Christopher
|
||||
Hannahstad
|
||||
West Adamborough
|
||||
```
|
||||
|
||||
### 生成随机的 Pandas Dataframe
|
||||
|
||||
你可以指定生成数据的数量和种类,但需要注意的是,返回结果均为字符串或文本类型。
|
||||
|
||||
```
|
||||
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
||||
testdf
|
||||
```
|
||||
|
||||
最终产生的 Dataframe 类似下图所示。
|
||||
|
||||

|
||||
|
||||
### 生成数据库表
|
||||
|
||||
你也可以指定生成数据的数量和种类,而返回结果是数据库中的文本或者变长字符串类型。在生成过程中,你可以指定对应的数据库文件名和表名。
|
||||
|
||||
```
|
||||
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
||||
|
||||
fields=['name','city','street_address','email'])
|
||||
```
|
||||
|
||||
上面的例子种生成了一个能被 MySQL 和 SQLite 支持的 `.db` 文件。下图则显示了这个文件中的数据表在 SQLite 可视化客户端中打开的画面。
|
||||

|
||||
|
||||
### 生成 Excel 文件
|
||||
|
||||
和上面的其它示例类似,下面的代码可以生成一个具有随机数据的 Excel 文件。值得一提的是,通过将`phone_simple` 参数设为 `False` ,可以生成较长较复杂的电话号码。如果你想要提高自己在数据提取方面的能力,不妨尝试一下这个功能。
|
||||
|
||||
```
|
||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||
phone_simple=False,filename='TestExcel.xlsx')
|
||||
```
|
||||
|
||||
最终的结果类似下图所示:
|
||||

|
||||
|
||||
### 生成随机电子邮箱地址
|
||||
|
||||
`pydbgen` 内置了一个 `realistic_email` 方法,它基于种子来生成随机的电子邮箱地址。如果你不想在网络上使用真实的电子邮箱地址时,这个功能可以派上用场。
|
||||
|
||||
```
|
||||
for _ in range(10):
|
||||
print(myDB.realistic_email('Tirtha Sarkar'))
|
||||
>>
|
||||
Tirtha_Sarkar@gmail.com
|
||||
Sarkar.Tirtha@outlook.com
|
||||
Tirtha_S48@verizon.com
|
||||
Tirtha_Sarkar62@yahoo.com
|
||||
Tirtha.S46@yandex.com
|
||||
Tirtha.S@att.com
|
||||
Sarkar.Tirtha60@gmail.com
|
||||
TirthaSarkar@zoho.com
|
||||
Sarkar.Tirtha@protonmail.com
|
||||
Tirtha.S@comcast.net
|
||||
```
|
||||
|
||||
### 未来的改进和用户贡献
|
||||
|
||||
目前的版本中并不完美。如果你发现了 pydbgen 的 bug 导致 pydbgen 在运行期间发生崩溃,请向我反馈。如果你打算对这个项目贡献代码,[也随时欢迎你][1]。当然现在也还有很多改进的方向:
|
||||
|
||||
* pydbgen 作为随机数据生成器,可以集成一些机器学习或统计建模的功能吗?
|
||||
* pydbgen 是否会添加可视化功能?
|
||||
|
||||
一切皆有可能!
|
||||
|
||||
如果你有任何问题或想法想要分享,都可以通过 [tirthajyoti@gmail.com][4] 与我联系。如果你像我一样对机器学习和数据科学感兴趣,也可以添加我的 [LinkedIn][5] 或在 [Twitter][6] 上关注我。另外,还可以在我的 [GitHub][7] 上找到更多 Python、R 或 MATLAB 的有趣代码和机器学习资源。
|
||||
|
||||
本文以 [CC BY-SA 4.0][9] 许可在 [Towards Data Science][8] 首发。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tirthajyoti/pydbgen
|
||||
[2]: http://pydbgen.readthedocs.io/en/latest/
|
||||
[3]: https://faker.readthedocs.io/en/latest/index.html
|
||||
[4]: mailto:tirthajyoti@gmail.com
|
||||
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[6]: https://twitter.com/tirthajyotiS
|
||||
[7]: https://github.com/tirthajyoti?tab=repositories
|
||||
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user