mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
bfcff006f5
@ -0,0 +1,216 @@
|
||||
8 个优秀的开源 Markdown 编辑器
|
||||
============================================================
|
||||
|
||||
### Markdown
|
||||
|
||||
首先,对 Markdown 进行一个简单的介绍。Markdown 是由 John Gruber 和 Aaron Swartz 共同创建的一种轻量级纯文本格式语法。Markdown 可以让用户“以易读、易写的纯文本格式来进行写作,然后可以将其转换为有效格式的 XHTML(或 HTML)“。Markdown 语法只包含一些非常容易记住的符号。其学习曲线平缓;你可以在炒蘑菇的同时一点点学习 Markdown 语法(大约 10 分钟)。通过使用尽可能简单的语法,错误率达到了最小化。除了拥有友好的语法,它还具有直接输出干净、有效的(X)HTML 文件的强大功能。如果你看过我的 HTML 文件,你就会知道这个功能是多么的重要。
|
||||
|
||||
Markdown 格式语法的主要目标是实现最大的可读性。用户能够以纯文本的形式发布一份 Markdown 格式的文件。用 Markdown 进行文本写作的一个优点是易于在计算机、智能手机和个人之间共享。几乎所有的内容管理系统都支持 Markdown 。它作为一种网络写作格式流行起来,其产生一些被许多服务采用的变种,比如 GitHub 和 Stack Exchange 。
|
||||
|
||||
你可以使用任何文本编辑器来写 Markdown 文件。但我建议使用一个专门为这种语法设计的编辑器。这篇文章中所讨论的软件允许你使用 Markdown 语法来写各种格式的专业文档,包括博客文章、演示文稿、报告、电子邮件以及幻灯片等。另外,所有的应用都是在开源许可证下发布的,在 Linux、OS X 和 Windows 操作系统下均可用。
|
||||
|
||||
|
||||
### Remarkable
|
||||
|
||||

|
||||
|
||||
让我们从 Remarkable 开始。Remarkable 是一个 apt 软件包的名字,它是一个相当有特色的 Markdown 编辑器 — 它并不支持 Markdown 的全部功能特性,但该有的功能特性都有。它使用和 GitHub Markdown 类似的语法。
|
||||
|
||||
你可以使用 Remarkable 来写 Markdown 文档,并在实时预览窗口查看更改。你可以把你的文件导出为 PDF 格式(带有目录)和 HTML 格式文件。它有强大的配置选项,从而具有许多样式,因此,你可以把它配置成你最满意的 Markdown 编辑器。
|
||||
|
||||
其他一些特性:
|
||||
|
||||
* 语法高亮
|
||||
* 支持 [GitHub 风味的 Markdown](https://linux.cn/article-8399-1.html)
|
||||
* 支持 MathJax - 通过高级格式呈现丰富文档
|
||||
* 键盘快捷键
|
||||
|
||||
在 Debian、Ubuntu、Fedora、SUSE 和 Arch 系统上均有 Remarkable 的可用的简易安装程序。
|
||||
|
||||
主页: [https://remarkableapp.github.io/][4]
|
||||
许可证: MIT 许可
|
||||
|
||||
### Atom
|
||||
|
||||

|
||||
|
||||
毫无疑问, Atom 是一个神话般的文本编辑器。超过 50 个开源包集合在一个微小的内核上,从而构成 Atom 。伴有 Node.js 的支持,以及全套功能特性,Atom 是我最喜欢用来写代码的编辑器。Atom 的特性在[杀手级开源应用][5]的文章中有更详细介绍,它是如此的强大。但是作为一个 Markdown 编辑器,Atom 还有许多不足之处,它的默认包不支持 Markdown 的特性。例如,正如上图所展示的,它不支持等价渲染。
|
||||
|
||||
但是,开源拥有强大的力量,这是我强烈提倡开源的一个重要原因。Atom 上有许多包以及一些复刻,从而添加了缺失的功能特性。比如,Markdown Preview Plus 提供了 Markdown 文件的实时预览,并伴有数学公式渲染和实时重加载。另外,你也可以尝试一下 [Markdown Preview Enhanced][6]。如果你需要自动滚动特性,那么 [markdown-scroll-sync][7] 可以满足你的需求。我是 [Markdown-Writer][8]和 [Markdown-pdf][9]的忠实拥趸,后者支持将 Markdown 快速转换为 PDF、PNG 以及 JPEG 文件。
|
||||
|
||||
这个方式体现了开源的理念:允许用户通过添加扩展来提供所需的特性。这让我想起了 Woolworths 的 n 种杂拌糖果的故事。虽然需要多付出一些努力,但能收获最好的回报。
|
||||
|
||||
主页: [https://atom.io/][10]
|
||||
许可证: MIT 许可
|
||||
|
||||
### Haroopad
|
||||
|
||||

|
||||
|
||||
Haroopad 是一个优秀的 Markdown 编辑器,是一个用于创建适宜 Web 的文档的处理器。使用 Haroopad 可以创作各种格式的文档,比如博客文章、幻灯片、演示文稿、报告和电子邮件等。Haroopad 在 Windows、Mac OS X 和 Linux 上均可用。它有 Debian/Ubuntu 的软件包,也有 Windows 和 Mac 的二进制文件。该应用程序使用 node-webkit、CodeMirror,marked,以及 Twitter 的 Bootstrap 。
|
||||
|
||||
Haroo 在韩语中的意思是“一天”。
|
||||
|
||||
它的功能列表非常可观。请看下面:
|
||||
|
||||
* 主题、皮肤和 UI 组件
|
||||
* 超过 30 种不同的编辑主题 - tomorrow-night-bright 和 zenburn 是近期刚添加的
|
||||
* 编辑器中的代码块的语法高亮
|
||||
* Ruby、Python、PHP、Javascript、C、HTML 和 CSS 的语法高亮支持
|
||||
* 基于 CodeMirror,这是一个在浏览器中使用 JavaScript 实现的通用文本编辑器
|
||||
* 实时预览主题
|
||||
* 基于 markdown-css 的 7 个主题
|
||||
* 语法高亮
|
||||
* 基于 hightlight.js 的 112 种语言以及 49 种样式
|
||||
* 定制主题
|
||||
* 基于 CSS (层叠样式表)的样式
|
||||
* 演示模式 - 对于现场演示非常有用
|
||||
* 绘图 - 流程图和序列图
|
||||
* 任务列表
|
||||
* 扩展 Markdown 语法,支持 TOC(目录)、 GitHub 风味 Markdown 以及数学表达式、脚注和任务列表等
|
||||
* 字体大小
|
||||
* 使用首选窗口和快捷键来设置编辑器和预览字体大小
|
||||
* 嵌入富媒体内容
|
||||
* 视频、音频、3D、文本、开放图形以及 oEmbed
|
||||
* 支持大约 100 种主要的网络服务(YouTude、SoundCloud、Flickr 等)
|
||||
* 支持拖放
|
||||
* 显示模式
|
||||
* 默认:编辑器|预览器,倒置:预览器|编辑器,仅编辑器,仅预览器(View -> Mode)
|
||||
* 插入当前日期和时间
|
||||
* 多种格式支持(Insert -> Data & Time)
|
||||
* HtML 到 Markdown
|
||||
* 拖放你在 Web 浏览器中选择好的文本
|
||||
* Markdown 解析选项
|
||||
* 大纲预览
|
||||
* 纯粹主义者的 Vim 键位绑定
|
||||
* Markdown 自动补全
|
||||
* 导出为 PDF 和 HTML
|
||||
* 带有样式的 HTML 复制到剪切板可用于所见即所得编辑器
|
||||
* 自动保存和恢复
|
||||
* 文件状态信息
|
||||
* 换行符或空格缩进
|
||||
* (一、二、三)列布局视图
|
||||
* Markdown 语法帮助对话框
|
||||
* 导入和导出设置
|
||||
* 通过 MathJax 支持 LaTex 数学表达式
|
||||
* 导出文件为 HTML 和 PDF
|
||||
* 创建扩展来构建自己的功能
|
||||
* 高效地将文件转换进博客系统:WordPress、Evernote 和 Tumblr 等
|
||||
* 全屏模式-尽管该模式不能隐藏顶部菜单栏和顶部工具栏
|
||||
* 国际化支持:英文、韩文、西班牙文、简体中文、德文、越南文、俄文、希腊文、葡萄牙文、日文、意大利文、印度尼西亚文土耳其文和法文
|
||||
|
||||
主页 [http://pad.haroopress.com/][11]
|
||||
许可证: GNU GPL v3 许可
|
||||
|
||||
### StackEdit
|
||||
|
||||

|
||||
|
||||
StackEdit 是一个功能齐全的 Markdown 编辑器,基于 PageDown(该 Markdown 库被 Stack Overflow 和其他一些 Stack 交流网站使用)。不同于在这个列表中的其他编辑器,StackEdit 是一个基于 Web 的编辑器。在 Chrome 浏览器上即可使用 StackEdit 。
|
||||
|
||||
特性包括:
|
||||
|
||||
* 实时预览 HTML,并通过绑定滚动连接特性来将编辑器和预览的滚动条相绑定
|
||||
* 支持 Markdown Extra 和 GitHub 风味 Markdown,Prettify/Highlight.js 语法高亮
|
||||
* 通过 MathJax 支持 LaTex 数学表达式
|
||||
* 所见即所得的控制按键
|
||||
* 布局配置
|
||||
* 不同风格的主题支持
|
||||
* la carte 扩展
|
||||
* 离线编辑
|
||||
* 可以与 Google 云端硬盘(多帐户)和 Dropbox 在线同步
|
||||
* 一键发布到 Blogger、Dropbox、Gist、GitHub、Google Drive、SSH 服务器、Tumblr 和 WordPress
|
||||
|
||||
主页: [https://stackedit.io/][12]
|
||||
许可证: Apache 许可
|
||||
|
||||
### MacDown
|
||||
|
||||

|
||||
|
||||
MacDown 是在这个列表中唯一一个只运行在 macOS 上的全特性编辑器。具体来说,它需要在 OX S 10.8 或更高的版本上才能使用。它在内部使用 Hoedown 将 Markdown 渲染成 HTML,这使得它的特性更加强大。Heodown 是 Sundown 的一个复活复刻。它完全符合标准,无依赖,具有良好的扩展支持和 UTF-8 感知。
|
||||
|
||||
MacDown 基于 Mou,这是专为 Web 开发人员设计的专用解决方案。
|
||||
|
||||
它提供了良好的 Markdown 渲染,通过 Prism 提供的语言识别渲染实现代码块级的语法高亮,MathML 和 LaTex 渲染,GTM 任务列表,Jekyll 前端以及可选的高级自动补全。更重要的是,它占用资源很少。想在 OS X 上写 Markdown?MacDown 是我针对 Web 开发者的开源推荐。
|
||||
|
||||
主页: [https://macdown.uranusjr.com/][13]
|
||||
许可证: MIT 许可
|
||||
|
||||
|
||||
### ghostwriter
|
||||
|
||||

|
||||
|
||||
ghostwriter 是一个跨平台的、具有美感的、无干扰的 Markdown 编辑器。它内建了 Sundown 处理器支持,还可以自动检测 pandoc、MultiMarkdown、Discount 和 cmark 处理器。它试图成为一个朴实的编辑器。
|
||||
|
||||
ghostwriter 有许多很好的功能设置,包括语法高亮、全屏模式、聚焦模式、主题、通过 Hunspell 进行拼写检查、实时字数统计、实时 HTML 预览、HTML 预览自定义 CSS 样式表、图片拖放支持以及国际化支持。Hemingway 模式按钮可以禁用退格键和删除键。一个新的 “Markdown cheat sheet” HUD 窗口是一个有用的新增功能。主题支持很基本,但在 [GitHub 仓库上][14]也有一些可用的试验性主题。
|
||||
|
||||
ghostwriter 的功能有限。我越来越欣赏这个应用的通用性,部分原因是其简洁的界面能够让写作者完全集中在策划内容上。这一应用非常值得推荐。
|
||||
|
||||
ghostwirter 在 Linux 和 Windows 系统上均可用。在 Windows 系统上还有一个便携式的版本可用。
|
||||
|
||||
主页: [https://github.com/wereturtle/ghostwriter][15]
|
||||
许可证: GNU GPL v3 许可
|
||||
|
||||
### Abricotine
|
||||
|
||||

|
||||
|
||||
Abricotine 是一个为桌面构建的、旨在跨平台且开源的 Markdown 编辑器。它在 Linux、OS X 和 Windows 上均可用。
|
||||
|
||||
该应用支持 Markdown 语法以及一些 GitHub 风味的 Markdown 增强(比如表格)。它允许用户直接在文本编辑器中预览文档,而不是在侧窗栏。
|
||||
|
||||
该应用有一系列有用的特性,包括拼写检查、以 HTML 格式保存文件或把富文本复制粘贴到邮件客户端。你也可以在侧窗中显示文档目录,展示语法高亮代码、以及助手、锚点和隐藏字符等。它目前正处于早期的开发阶段,因此还有一些很基本的 bug 需要修复,但它值得关注。它有两个主题可用,如果有能力,你也可以添加你自己的主题。
|
||||
|
||||
主页: [http://abricotine.brrd.fr/][16]
|
||||
许可证: GNU 通用公共许可证 v3 或更高许可
|
||||
|
||||
### ReText
|
||||
|
||||

|
||||
|
||||
ReText 是一个简单而强大的 Markdown 和 reStructureText 文本编辑器。用户可以控制所有输出的格式。它编辑的文件是纯文本文件,但可以导出为 PDF、HTML 和其他格式的文件。ReText 官方仅支持 Linux 系统。
|
||||
|
||||
特性包括:
|
||||
|
||||
* 全屏模式
|
||||
* 实时预览
|
||||
* 同步滚动(针对 Markdown)
|
||||
* 支持数学公式
|
||||
* 拼写检查
|
||||
* 分页符
|
||||
* 导出为 HTML、ODT 和 PDF 格式
|
||||
* 使用其他标记语言
|
||||
|
||||
主页: [https://github.com/retext-project/retext][17]
|
||||
许可证: GNU GPL v2 或更高许可
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/markdown-editors/
|
||||
|
||||
作者:[Steve Emms][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://www.ossblog.org/author/steve/
|
||||
[2]:https://www.ossblog.org/markdown-editors/#comments
|
||||
[3]:https://www.ossblog.org/category/utilities/
|
||||
[4]:https://remarkableapp.github.io/
|
||||
[5]:https://www.ossblog.org/top-software/2/
|
||||
[6]:https://atom.io/packages/markdown-preview-enhanced
|
||||
[7]:https://atom.io/packages/markdown-scroll-sync
|
||||
[8]:https://atom.io/packages/markdown-writer
|
||||
[9]:https://atom.io/packages/markdown-pdf
|
||||
[10]:https://atom.io/
|
||||
[11]:http://pad.haroopress.com/
|
||||
[12]:https://stackedit.io/
|
||||
[13]:https://macdown.uranusjr.com/
|
||||
[14]:https://github.com/jggouvea/ghostwriter-themes
|
||||
[15]:https://github.com/wereturtle/ghostwriter
|
||||
[16]:http://abricotine.brrd.fr/
|
||||
[17]:https://github.com/retext-project/retext
|
||||
@ -0,0 +1,111 @@
|
||||
AI 正快速入侵我们生活的五个方面
|
||||
============================================================
|
||||
|
||||
> 让我们来看看我们已经被人工智能包围的五个真实存在的方面。
|
||||
|
||||

|
||||
|
||||
> 图片来源: opensource.com
|
||||
|
||||
开源项目[正在助推][2]人工智能(AI)进步,而且随着技术的成熟,我们将听到更多关于 AI 如何影响我们生活的消息。你有没有考虑过 AI 是如何改变你周围的世界的?让我们来看看我们日益被我们所改变的世界,以及大胆预测一下 AI 对未来影响。
|
||||
|
||||
### 1. AI 影响你的购买决定
|
||||
|
||||
最近 [VentureBeat][3] 上的一篇文章,[“AI 将如何帮助我们解读千禧一代”][4]吸引了我的注意。我承认我对人工智能没有思考太多,也没有费力尝试解读千禧一代,所以我很好奇,希望了解更多。事实证明,文章标题有点误导人,“如何卖东西给千禧一代”或许会是一个更准确的标题。
|
||||
|
||||
根据这篇文章,千禧一代是“一个令人垂涎的年龄阶段的人群,全世界的市场经理都在争抢他们”。通过分析网络行为 —— 无论是购物、社交媒体或其他活动 - 机器学习可以帮助预测行为模式,这将可以变成有针对性的广告。文章接着解释如何对物联网和社交媒体平台进行挖掘形成数据点。“使用机器学习挖掘社交媒体数据,可以让公司了解千禧一代如何谈论其产品,他们对一个产品类别的看法,他们对竞争对手的广告活动如何响应,还可获得很多数据,用于设计有针对性的广告,"这篇文章解释说。AI 和千禧一代成为营销的未来并不是什么很令人吃惊的事,但是 X 一代和婴儿潮一代,你们也逃不掉呢!(LCTT 译注:X 一代指出生于 20 世纪 60 年代中期至 70 年代末的美国人,婴儿潮是指二战结束后,1946 年初至 1964 年底出生的人)
|
||||
|
||||
> 人工智能根据行为变化,将包括城市人在内的整个人群设为目标群体。
|
||||
|
||||
例如, [Raconteur 上][23]的一篇文章 —— “AI 将怎样改变购买者的行为”中解释说,AI 在网上零售行业最大的力量是它能够迅速适应客户行为不断变化的形势。人工智能创业公司 [Fluid AI][25] 首席执行官 Abhinav Aggarwal 表示,他公司的软件被一个客户用来预测顾客行为,有一次系统注意到在暴风雪期间发生了一个变化。“那些通常会忽略在一天中发送的电子邮件或应用内通知的用户现在正在打开它们,因为他们在家里没有太多的事情可做。一个小时之内,AI 系统就适应了新的情况,并在工作时间开始发送更多的促销材料。”他解释说。
|
||||
|
||||
AI 正在改变我们怎样花钱和为什么花钱,但是 AI 是怎样改变我们挣钱的方式的呢?
|
||||
|
||||
### 2. 人工智能正在改变我们如何工作
|
||||
|
||||
[Fast 公司][5]最近的一篇文章“2017 年人工智能将如何改变我们的生活”中说道,求职者将会从人工智能中受益。作者解释说,除更新薪酬趋势之外,人工智能将被用来给求职者发送相关职位空缺信息。当你应该升职的时候,你很可能会得到一个升职的机会。
|
||||
|
||||
人工智能也可以被公司用来帮助新入职的员工。文章解释说:“许多新员工在刚入职的几天内会获得大量信息,其中大部分都留不下来。” 相反,机器人可能会随着时间的推移,当新员工需要相关信息时,再向他一点点“告知信息”。
|
||||
|
||||
[Inc.][7] 有一篇文章[“没有偏见的企业:人工智能将如何重塑招聘机制”][8],观察了人才管理解决方案提供商 [SAP SuccessFactors][9] 是怎样利用人工智能作为一个工作描述“偏见检查器”,以及检查员工赔偿金的偏见。
|
||||
|
||||
[《Deloitte 2017 人力资本趋势报告》][10]显示,AI 正在激励组织进行重组。Fast 公司的文章[“AI 是怎样改变公司组织的方式”][11]审查了这篇报告,该报告是基于全球 10,000 多名人力资源和商业领袖的调查结果。这篇文章解释说:"许多公司现在更注重文化和环境的适应性,而不是聘请最有资格的人来做某个具体任务,因为知道个人角色必须随 AI 的实施而发展。" 为了适应不断变化的技术,组织也从自上而下的结构转向多学科团队,文章说。
|
||||
|
||||
### 3. AI 正在改变教育
|
||||
|
||||
> AI 将使所有教育生态系统的利益相关者受益。
|
||||
|
||||
尽管教育预算正在缩减,但是教室的规模却正在增长。因此利用技术的进步有助于提高教育体系的生产率和效率,并在提高教育质量和负担能力方面发挥作用。根据 VentureBeat 上的一篇文章[“2017 年人工智能将怎样改变教育”][26],今年我们将看到 AI 对学生们的书面答案进行评分,机器人回答学生的问题,虚拟个人助理辅导学生等等。文章解释说:“AI 将惠及教育生态系统的所有利益相关者。学生将能够通过即时的反馈和指导学习地更好,教师将获得丰富的学习分析和对个性化教学的见解,父母将以更低的成本看到他们的孩子的更好的职业前景,学校能够规模化优质的教育,政府能够向所有人提供可负担得起的教育。"
|
||||
|
||||
### 4. 人工智能正在重塑医疗保健
|
||||
|
||||
2017 年 2 月 [CB Insights][12] 的一篇文章挑选了 106 个医疗保健领域的人工智能初创公司,它们中的很多在过去几年中提高了第一次股权融资。这篇文章说:“在 24 家成像和诊断公司中,19 家公司自 2015 年 1 月起就首次公开募股。”这份名单上有那些从事于远程病人监测,药物发现和肿瘤学方面人工智能的公司。”
|
||||
|
||||
3 月 16 日发表在 TechCrunch 上的一篇关于 AI 进步如何重塑医疗保健的文章解释说:“一旦对人类的 DNA 有了更好的理解,就有机会更进一步,并能根据他们特殊的生活习性为他们提供个性化的见解。这种趋势预示着‘个性化遗传学’的新纪元,人们能够通过获得关于自己身体的前所未有的信息来充分控制自己的健康。”
|
||||
|
||||
本文接着解释说,AI 和机器学习降低了研发新药的成本和时间。部分得益于广泛的测试,新药进入市场需要 12 年以上的时间。这篇文章说:“机器学习算法可以让计算机根据先前处理的数据来‘学习’如何做出预测,或者选择(在某些情况下,甚至是产品)需要做什么实验。类似的算法还可用于预测特定化合物对人体的副作用,这样可以加快审批速度。”这篇文章指出,2015 年旧金山的一个创业公司 [Atomwise][15] 一天内完成了可以减少埃博拉感染的两种新药物的分析,而不是花费数年时间。
|
||||
|
||||
> AI 正在帮助发现、诊断和治疗新疾病。
|
||||
|
||||
另外一个位于伦敦的初创公司 [BenevolentAI][27] 正在利用人工智能寻找科学文献中的模式。这篇文章说:“最近,这家公司找到了两种可能对 Alzheimer 起作用的化合物,引起了很多制药公司的关注。"
|
||||
|
||||
除了有助于研发新药,AI 正在帮助发现、诊断和治疗新疾病。TechCrunch 上的文章解释说,过去是根据显示的症状诊断疾病,但是现在 AI 正在被用于检测血液中的疾病特征,并利用对数十亿例临床病例分析进行深度学习获得经验来制定治疗计划。这篇文章说:“IBM 的 Watson 正在与纽约的 Memorial Sloan Kettering 合作,消化理解数十年来关于癌症患者和治疗方面的数据,为了向治疗疑难的癌症病例的医生提供和建议治疗方案。”
|
||||
|
||||
### 5. AI 正在改变我们的爱情生活
|
||||
|
||||
有 195 个国家的超过 5000 万活跃用户通过一个在 2012 年推出的约会应用程序 [Tinder][16] 找到潜在的伴侣。在一个 [Forbes 采访播客][17]中,Tinder 的创始人兼董事长 Sean Rad spoke 与 Steven Bertoni 对人工智能是如何正在改变人们约会进行过讨论。在[关于此次采访的文章][18]中,Bertoni 引用了 Rad 说的话,他说:“可能有这样一个时刻,Tinder 可以很好的推测你会感兴趣的人,在组织约会中还可能会做很多跑腿的工作”,所以,这个 app 会向用户推荐一些附近的同伴,并更进一步,协调彼此的时间安排一次约会,而不只是向用户显示一些有可能的同伴。
|
||||
|
||||
> 我们的后代真的可能会爱上人工智能。
|
||||
|
||||
你爱上了 AI 吗?我们的后代真的可能会爱上人工智能。Raya Bidshahri 发表在 [Singularity Hub][19] 的一篇文章“AI 将如何重新定义爱情”说,几十年的后,我们可能会认为爱情不再受生物学的限制。
|
||||
|
||||
Bidshahri 解释说:“我们的技术符合摩尔定律,正在以惊人的速度增长 —— 智能设备正在越来越多地融入我们的生活。”,他补充道:“到 2029 年,我们将会有和人类同等智慧的 AI,而到 21 世纪 40 年代,AI 将会比人类聪明无数倍。许多人预测,有一天我们会与强大的机器合并,我们自己可能会变成人工智能。”他认为在这样一个世界上那些是不可避免的,人们将会接受与完全的非生物相爱。
|
||||
|
||||
这听起来有点怪异,但是相比较于未来机器人将统治世界,爱上 AI 会是一个更乐观的结果。Bidshahri 说:“对 AI 进行编程,让他们能够感受到爱,这将使我们创造出更富有同情心的 AI,这可能也是避免很多人忧虑的 AI 大灾难的关键。”
|
||||
|
||||
这份 AI 正在入侵我们生活各领域的清单只是涉及到了我们身边的人工智能的表面。哪些 AI 创新是让你最兴奋的,或者是让你最烦恼的?大家可以在文章评论区写下你们的感受。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Rikki Endsley - Rikki Endsley 是开源社区 Opensource.com 的管理员。在过去,她曾做过 Red Hat 开源和标准(OSAS)团队社区传播者;自由技术记者;USENIX 协会的社区管理员;linux 权威杂志 ADMIN 和 Ubuntu User 的合作出版者,还是杂志 Sys Admin 和 UnixReview.com 的主编。在 Twitter 上关注她:@rikkiends。
|
||||
|
||||
----
|
||||
|
||||
via: https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives?rate=ORfqhKFu9dpA9aFfg-5Za9ZWGcBcx-f0cUlf_VZNeQs
|
||||
[2]:https://www.linux.com/news/open-source-projects-are-transforming-machine-learning-and-ai
|
||||
[3]:https://twitter.com/venturebeat
|
||||
[4]:http://venturebeat.com/2017/03/16/how-ai-will-help-us-decipher-millennials/
|
||||
[5]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
[6]:https://www.fastcompany.com/3066620/this-is-how-ai-will-change-your-work-in-2017
|
||||
[7]:https://twitter.com/Inc
|
||||
[8]:http://www.inc.com/bill-carmody/businesses-beyond-bias-how-ai-will-reshape-hiring-practices.html
|
||||
[9]:https://www.successfactors.com/en_us.html
|
||||
[10]:https://dupress.deloitte.com/dup-us-en/focus/human-capital-trends.html?id=us:2el:3pr:dup3575:awa:cons:022817:hct17
|
||||
[11]:https://www.fastcompany.com/3068492/how-ai-is-changing-the-way-companies-are-organized
|
||||
[12]:https://twitter.com/CBinsights
|
||||
[13]:https://www.cbinsights.com/blog/artificial-intelligence-startups-healthcare/
|
||||
[14]:https://techcrunch.com/2017/03/16/advances-in-ai-and-ml-are-reshaping-healthcare/
|
||||
[15]:http://www.atomwise.com/
|
||||
[16]:https://twitter.com/Tinder
|
||||
[17]:https://www.forbes.com/podcasts/the-forbes-interview/#5e962e5624e1
|
||||
[18]:https://www.forbes.com/sites/stevenbertoni/2017/02/14/tinders-sean-rad-on-how-technology-and-artificial-intelligence-will-change-dating/#4180fc2e5b99
|
||||
[19]:https://twitter.com/singularityhub
|
||||
[20]:https://singularityhub.com/2016/08/05/how-ai-will-redefine-love/
|
||||
[21]:https://opensource.com/user/23316/feed
|
||||
[22]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives#comments
|
||||
[23]:https://twitter.com/raconteur
|
||||
[24]:https://www.raconteur.net/technology/how-ai-will-change-buyer-behaviour
|
||||
[25]:http://www.fluid.ai/
|
||||
[26]:http://venturebeat.com/2017/02/04/how-ai-will-transform-education-in-2017/
|
||||
[27]:https://twitter.com/benevolent_ai
|
||||
[28]:https://opensource.com/users/rikki-endsley
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
T-UI Launcher:将你的 Android 设备变成 Linux 命令行界面
|
||||
============================================================
|
||||
|
||||
不管你是一位命令行大师,还是只是不想让你的朋友和家人使用你的 Android 设备,那就看下 T-UI Launcher 这个程序。Unix/Linux 用户一定会喜欢这个。
|
||||
|
||||
T-UI Launcher 是一个免费的轻量级 Android 程序,具有类似 Linux 的命令行界面,它可将你的普通 Android 设备变成一个完整的命令行界面。对于喜欢使用基于文本的界面的人来说,这是一个简单、快速、智能的启动器。
|
||||
|
||||
#### T-UI Launcher 功能
|
||||
|
||||
下面是一些重要的功能:
|
||||
|
||||
* 第一次启动后展示快速使用指南。
|
||||
* 快速且可完全定制。
|
||||
* 提供自动补全菜单及快速、强大的别名系统。
|
||||
* 此外,提供预测建议,并提供有用的搜索功能。
|
||||
|
||||
它是免费的,你可以从 Google Play 商店[下载并安装它][1],接着在 Android 设备中运行。
|
||||
|
||||
安装完成后,第一次启动时你会看到一个快速指南。阅读完成之后,你可以如下面那样使用简单的命令开始使用了。
|
||||
|
||||
[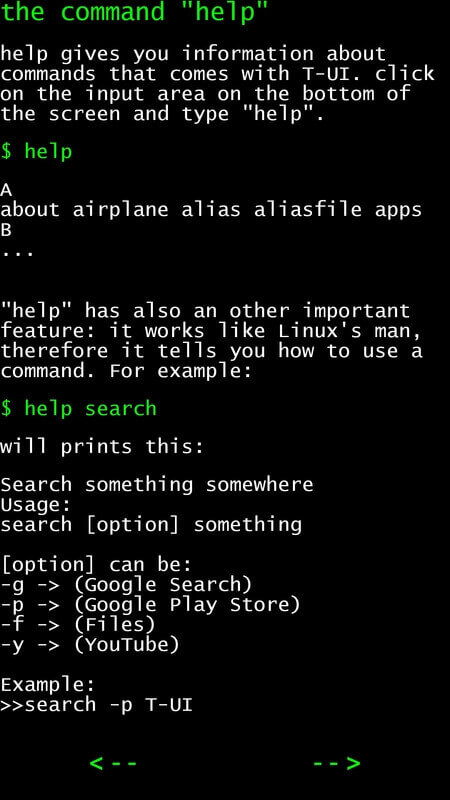][2]
|
||||
|
||||
*T-UI 命令行帮助指南*
|
||||
|
||||
要启动一个 app,只要输入几个字母,自动补全功能会在屏幕中展示可用的 app。接着点击你想打开的程序。
|
||||
|
||||
```
|
||||
$ Telegram ### 启动 telegram
|
||||
$ WhatsApp ### 启动 whatsapp
|
||||
$ Chrome ### 启动 chrome
|
||||
```
|
||||
|
||||
[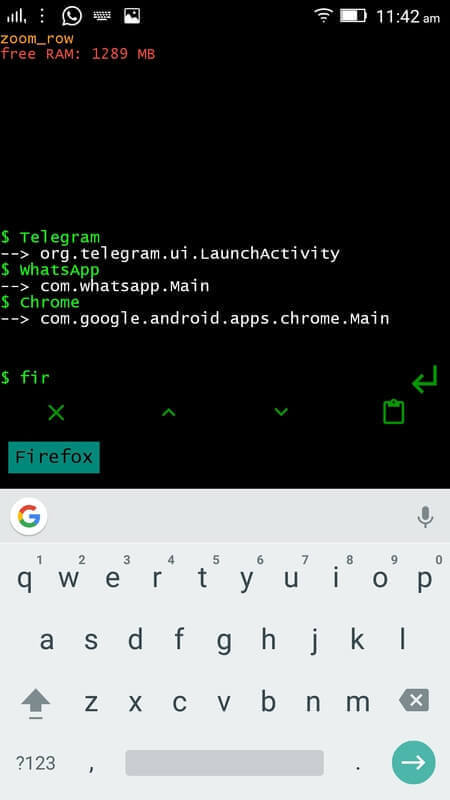][3]
|
||||
|
||||
*T-UI 命令行使用*
|
||||
|
||||
要浏览你的 Android 设备状态(电池电量、wifi、移动数据),输入:
|
||||
|
||||
```
|
||||
$ status
|
||||
```
|
||||
|
||||
[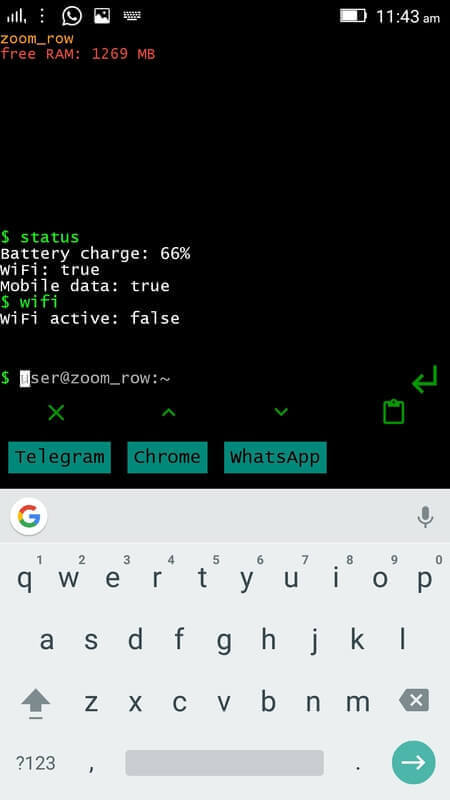][4]
|
||||
|
||||
*Android 电话状态*
|
||||
|
||||
其它的有用命令。
|
||||
|
||||
```
|
||||
$ uninstall telegram ### 卸载 telegram
|
||||
$ search [google, playstore, youtube, files] ### 搜索在线应用或本地文件
|
||||
$ wifi ### 打开或关闭 WIFI
|
||||
$ cp Downloads/* Music ### 从 Download 文件夹复制所有文件到 Music 文件夹
|
||||
$ mv Downloads/* Music ### 从 Download 文件夹移动所有文件到 Music 文件夹
|
||||
```
|
||||
|
||||
就是这样了!在本篇中,我们展示了一个带有类似 Linux CLI(命令界面)的简单而有用的 Android 程序,它可以将你的常规 Android 设备变成一个完整的命令行界面。尝试一下并在下面的评论栏分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux 系统管理员和网络开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/t-ui-launcher-turns-android-device-into-linux-cli/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://play.google.com/store/apps/details?id=ohi.andre.consolelauncher
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Help.jpg
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Usage.jpg
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Status.jpg
|
||||
[5]:https://www.tecmint.com/author/aaronkili/
|
||||
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
101
sources/talk/20170421 A Window Into the Linux Desktop.md
Normal file
101
sources/talk/20170421 A Window Into the Linux Desktop.md
Normal file
@ -0,0 +1,101 @@
|
||||
A Window Into the Linux Desktop
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
"What can it do that Windows can't?"
|
||||
|
||||
That is the first question many people ask when considering Linux for their desktop. While the open source philosophy that underpins Linux is a good enough draw for some, others want to know just how different its look, feel and functionality can get. To a degree, that depends on whether you choose a desktop environment or a window manager.
|
||||
|
||||
If you want a desktop experience that is lightning fast and uncompromisingly efficient, foregoing the classic desktop environment for a window manager might be for you.
|
||||
|
||||
### What's What
|
||||
|
||||
"Desktop environment" is the technical term for a typical, full-featured desktop -- that is, the complete graphical layout of your system. Besides displaying your programs, the desktop environment includes accoutrements such as app launchers, menu panels and widgets.
|
||||
|
||||
In Microsoft Windows, the desktop environment consists of, among other things, the Start menu, the taskbar of open applications and notification center, all the Windows programs that come bundled with the OS, and the frames enclosing open applications (with a dash, square and X in the upper right corner).
|
||||
|
||||
There are many similarities in Linux.
|
||||
|
||||
The Linux [Gnome][3] desktop environment, for instance, has a slightly different design, but it shares all of the Microsoft Windows basics -- from an app menu to a panel showing open applications, to a notification bar, to the windows framing programs.
|
||||
|
||||
Window program frames rely on a component for drawing them and letting you move and resize them: It's called the "window manager." So, as they all have windows, every desktop environment includes a window manager.
|
||||
|
||||
However, not every window manager is part of a desktop environment. You can run window managers by themselves, and there are reasons to consider doing just that.
|
||||
|
||||
### Out of Your Environment
|
||||
|
||||
For the purpose of this column, references to "window manager" refer to those that can stand alone. If you install a window manager on an existing Linux system, you can log out without shutting down, choose the new window manager on your login screen, and log back in.
|
||||
|
||||
You might not want to do this without researching your window manager first, though, because you will be greeted by a blank screen and sparse status bar that may or may not be clickable.
|
||||
|
||||
There typically is a straightforward way to bring up a terminal in a window manager, because that's how you edit its configuration file. There you will find key- and mouse-bindings to launch programs, at which point you actually can use your new setup.
|
||||
|
||||
In the popular i3 window manager, for instance, you can launch a terminal by hitting the Super (i.e., Windows) key plus Enter -- or press Super plus D to bring up the app launcher. There you can type an app name and hit Enter to open it. All the existing apps can be found that way, and they will open to full screen once selected.
|
||||
|
||||
[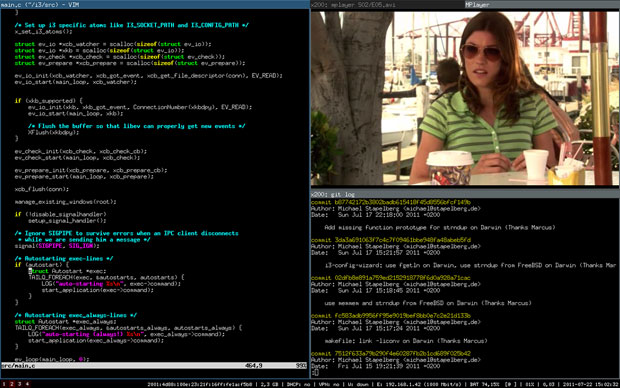][4] (Click Image to Enlarge)
|
||||
|
||||
i3 is also a tiling window manager, meaning it ensures that all windows expand to evenly fit the screen, neither overlapping nor wasting space. When a new window pops up, it reduces the existing windows, nudging them aside to make room. Users can toggle to open the next window either vertically or horizontally adjacent.
|
||||
|
||||
### Features Can Be Friends or Foes
|
||||
|
||||
Desktop environments have their advantages, of course. First and foremost, they provide a feature-rich, recognizable interface. Each has its signature style, but overall they provide unobtrusive default settings out of the box, which makes desktop environments ready to use right from the start.
|
||||
|
||||
Another strong point is that desktop environments come with a constellation of programs and media codecs, allowing users to accomplish simple tasks immediately. Further, they include handy features like battery monitors, wireless widgets and system notifications.
|
||||
|
||||
As comprehensive as desktop environments are, the large software base and user experience philosophy unique to each means there are limits on how far they can go. That means they are not always very configurable. With desktop environments that emphasize flashy looks, oftentimes what you see is what you get.
|
||||
|
||||
Many desktop environments are notoriously heavy on system resources, so they're not friendly to lower-end hardware. Because of the visual effects running on them, there are more things that can go wrong, too. I once tried tweaking networking settings that were unrelated to the desktop environment I was running, and the whole thing crashed. When I started a window manager, I was able to change the settings.
|
||||
|
||||
Those prioritizing security may want to avoid desktop environments, since more programs means greater attack surface -- that is, entry points where malicious actors can break in.
|
||||
|
||||
However, if you want to give a desktop environment a try, XFCE is a good place to start, as its smaller software base trims some bloat, leaving less clutter behind if you don't stick with it.
|
||||
|
||||
It's not the prettiest at first sight, but after downloading some GTK theme packs (every desktop environment serves up either these or Qt themes, and XFCE is in the GTK camp) and enabling them in the Appearance section of settings, you easily can touch it up. You can even shop around at this [centralized gallery][5] to find the theme you like best.
|
||||
|
||||
### You Can Save a Lot of Time... if You Take the Time First
|
||||
|
||||
If you'd like to see what you can do outside of a desktop environment, you'll find a window manager allows plenty of room to maneuver.
|
||||
|
||||
More than anything, window managers are about customization. In fact, their customizability has spawned numerous galleries hosting a vibrant community of users whose palette of choice is a window manager.
|
||||
|
||||
The modest resource needs of window managers make them ideal for lower specs, and since most window managers don't come with any programs, they allow users who appreciate modularity to add only those they want.
|
||||
|
||||
Perhaps the most noticeable distinction from desktop environments is that window managers generally focus on efficiency by emphasizing mouse movements and keyboard hotkeys to open programs or launchers.
|
||||
|
||||
Keyboard-driven window managers are especially streamlined, since you can bring up new windows, enter text or more keyboard commands, move them around, and close them again -- all without moving your hands from the home row. Once you acculturate to the design logic, you will be amazed at how quickly you can blaze through your tasks.
|
||||
|
||||
In spite of the freedom they provide, window managers have their drawbacks. Most significantly, they are extremely bare-bones out of the box. Before you can make much use of one, you'll have to spend time reading your window manager's documentation for configuration syntax, and probably some more time getting the hang of said syntax.
|
||||
|
||||
Although you will have some user programs if you switched from a desktop environment (the likeliest scenario), you also will start out missing familiar things like battery indicators and network widgets, and it will take some time to set up new ones.
|
||||
|
||||
If you want to dive into window managers, i3 has [thorough documentation][6] and straightforward configuration syntax. The configuration file doesn't use any programming language -- it simply defines a variable-value pair on each line. Creating a hotkey is as easy as writing "bindsym", the key combination, and the action for that combination to launch.
|
||||
|
||||
While window managers aren't for everyone, they offer a distinctive computing experience, and Linux is one of the few OSes that allows them. No matter which paradigm you ultimately go with, I hope this overview gives you enough information to feel confident about the choice you've made -- or confident enough to venture out of your familiar zone and see what else is available.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
**Jonathan Terrasi** has been an ECT News Network columnist since 2017\. His main interests are computer security (particularly with the Linux desktop), encryption, and analysis of politics and current affairs. He is a full-time freelance writer and musician. His background includes providing technical commentaries and analyses in articles published by the Chicago Committee to Defend the Bill of Rights.
|
||||
|
||||
|
||||
-----------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84473.html?rss=1
|
||||
|
||||
作者:[ ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:http://www.linuxinsider.com/story/84473.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84473
|
||||
[3]:http://en.wikipedia.org/wiki/GNOME
|
||||
[4]:http://www.linuxinsider.com/article_images/2017/84473_1200x750.jpg
|
||||
[5]:http://www.xfce-look.org/
|
||||
[6]:https://i3wm.org/docs/
|
||||
@ -0,0 +1,52 @@
|
||||
Faster machine learning is coming to the Linux kernel
|
||||
============================================================
|
||||
|
||||
### The addition of heterogenous memory management to the Linux kernel will unlock new ways to speed up GPUs, and potentially other kinds of machine learning hardware
|
||||
|
||||
|
||||

|
||||
>Credit: Thinkstock
|
||||
|
||||
It's been a long time in the works, but a memory management feature intended to give machine learning or other GPU-powered applications a major performance boost is close to making it into one of the next revisions of the kernel.
|
||||
|
||||
Heterogenous memory management (HMM) allows a device’s driver to mirror the address space for a process under its own memory management. As Red Hat developer Jérôme Glisse [explains][10], this makes it easier for hardware devices like GPUs to directly access the memory of a process without the extra overhead of copying anything. It also doesn't violate the memory protection features afforded by modern OSes.
|
||||
|
||||
|
||||
One class of application that stands to benefit most from HMM is GPU-based machine learning. Libraries like OpenCL and CUDA would be able to get a speed boost from HMM. HMM does this in much the same way as [speedups being done to GPU-based machine learning][11], namely by leaving data in place near the GPU, operating directly on it there, and moving it around as little as possible.
|
||||
|
||||
These kinds of speed-ups for CUDA, Nvidia’s library for GPU-based processing, would only benefit operations on Nvidia GPUs, but those GPUs currently constitute the vast majority of the hardware used to accelerate number crunching. However, OpenCL was devised to write code that could target multiple kinds of hardware—CPUs, GPUs, FPGAs, and so on—so HMM could provide much broader benefits as that hardware matures.
|
||||
|
||||
|
||||
There are a few obstacles to getting HMM into a usable state in Linux. First is kernel support, which has been under wraps for quite some time. HMM was first proposed as a Linux kernel patchset [back in 2014][12], with Red Hat and Nvidia both involved as key developers. The amount of work involved wasn’t trivial, but the developers believe code could be submitted for potential inclusion within the next couple of kernel releases.
|
||||
|
||||
The second obstacle is video driver support, which Nvidia has been working on separately. According to Glisse’s notes, AMD GPUs are likely to support HMM as well, so this particular optimization won’t be limited to Nvidia GPUs. AMD has been trying to ramp up its presence in the GPU market, potentially by [merging GPU and CPU processing][13] on the same die. However, the software ecosystem still plainly favors Nvidia; there would need to be a few more vendor-neutral projects like HMM, and OpenCL performance on a par with what CUDA can provide, to make real choice possible.
|
||||
|
||||
The third obstacle is hardware support, since HMM requires the presence of a replayable page faults hardware feature to work. Only Nvidia’s Pascal line of high-end GPUs supports this feature. In a way that’s good news, since it means Nvidia will only need to provide driver support for one piece of hardware—requiring less work on its part—to get HMM up and running.
|
||||
|
||||
Once HMM is in place, there will be pressure on public cloud providers with GPU instances to [support the latest-and-greatest generation of GPU][14]. Not just by swapping old-school Nvidia Kepler cards for bleeding-edge Pascal GPUs; as each succeeding generation of GPU pulls further away from the pack, support optimizations like HMM will provide strategic advantages.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3196884/linux/faster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&via=infoworld&text=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[3]:http://www.linkedin.com/shareArticle?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&title=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[4]:https://plus.google.com/share?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[5]:http://reddit.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&title=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[6]:http://www.stumbleupon.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[7]:http://www.infoworld.com/article/3196884/linux/faster-machine-learning-is-coming-to-the-linux-kernel.html#email
|
||||
[8]:http://www.infoworld.com/article/3152565/linux/5-rock-solid-linux-distros-for-developers.html#tk.ifw-infsb
|
||||
[9]:http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
[10]:https://lkml.org/lkml/2017/4/21/872
|
||||
[11]:http://www.infoworld.com/article/3195437/machine-learning-analytics-get-a-boost-from-gpu-data-frame-project.html
|
||||
[12]:https://lwn.net/Articles/597289/
|
||||
[13]:http://www.infoworld.com/article/3099204/hardware/amd-mulls-a-cpugpu-super-chip-in-a-server-reboot.html
|
||||
[14]:http://www.infoworld.com/article/3126076/artificial-intelligence/aws-machine-learning-vms-go-faster-but-not-forward.html
|
||||
136
sources/talk/20170515 How I got started with bash scripting.md
Normal file
136
sources/talk/20170515 How I got started with bash scripting.md
Normal file
@ -0,0 +1,136 @@
|
||||
How I got started with bash scripting
|
||||
============================================================
|
||||
|
||||
### With a few simple Google searches, a programming novice learned to write code that automates a previously tedious and time-consuming task.
|
||||
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
I wrote a script the other day. For some of you, that sentence sounds like no big deal. For others, and I know you're out there, that sentence is significant. You see, I'm not a programmer. I'm a writer.
|
||||
|
||||
### What I needed to solve
|
||||
|
||||
My problem was fairly simple: I had to juggle files from engineering into our documentation. The files were available in a .zip format from a web URL. I was copying them to my desktop manually, then moving them into a different directory structure to match my documentation needs. A fellow writer gave me this advice: _"Why don't you just write a script to do this for you?"_
|
||||
|
||||
Programming and development
|
||||
|
||||
* [New Python content][1]
|
||||
|
||||
* [Our latest JavaScript articles][2]
|
||||
|
||||
* [Recent Perl posts][3]
|
||||
|
||||
* [Red Hat Developers Blog][4]
|
||||
|
||||
|
||||
|
||||
I thought _"just write a script?!?"_ —as if it was the easiest thing in the world to do.
|
||||
|
||||
### How Google came to the rescue
|
||||
|
||||
My colleague's question got me thinking, and as I thought, I googled.
|
||||
|
||||
**What scripting languages are on Linux?**
|
||||
|
||||
This was my first Google search criteria, and many of you are probably thinking, "She's pretty clueless." Well, I was, but it did set me on a path to solving my problem. The most common result was Bash. Hmm, I've seen Bash. Heck, one of the files I had to document had Bash in it, that ubiquitous line **#!/bin/bash**. I took another look at that file, and I knew what it was doing because I had to document it.
|
||||
|
||||
So that led me to my next Google search request.
|
||||
|
||||
**How to download a zip file from a URL?**
|
||||
|
||||
That was my basic task really. I had a URL with a .zip file containing all the files I needed to include in my documentation, so I asked the All Powerful Google to help me out. That search gem, and a few more, led me to Curl. But here's the best part: Not only did I find Curl, one of the top search hits showed me a Bash script that used Curl to download a .zip file and extract it. That was more than I asked for, but that's when I realized being specific in my Google search requests could give me the information I needed to write this script. So, momentum in my favor, I wrote the simplest of scripts:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
curl http://rather.long.url | tar -xz -C my_directory --strip-components=1
|
||||
```
|
||||
|
||||
What a moment to see that thing run! But then I realized one gotcha: The URL can change, depending on which set of files I'm trying to access. I had another problem to solve, which led me to my next search.
|
||||
|
||||
**How to pass parameters into a Bash script?**
|
||||
|
||||
I needed to be able to run this script with different URLs and different end directories. Google showed me how to put in **$1**, **$2**, etc., to replace what I typed on the command line with my script. For example:
|
||||
|
||||
```
|
||||
bash myscript.sh http://rather.long.url my_directory
|
||||
```
|
||||
|
||||
That was much better. Everything was working as I needed it to, I had flexibility, I had a working script, and most of all, I had a short command to type and save myself 30 minutes of copy-paste grunt work. That was a morning well spent.
|
||||
|
||||
Then I realized I had one more problem. You see, my memory is short, and I knew I'd run this script only every couple of months. That left me with two issues:
|
||||
|
||||
* How would I remember what to type for my script (URL first? directory first?)?
|
||||
|
||||
* How would another writer know how to run my script if I got hit by a truck?
|
||||
|
||||
I needed a usage message—something the script would display if I didn't use it correctly. For example:
|
||||
|
||||
```
|
||||
usage: bash yaml-fetch.sh <'snapshot_url'> <directory>
|
||||
```
|
||||
|
||||
Otherwise, run the script. My next search was:
|
||||
|
||||
**How to write "if/then/else" in a Bash script?**
|
||||
|
||||
Fortunately I already knew **if/then/else** existed in programming. I just had to find out how to do that. Along the way, I also learned to print from a Bash script using **echo**. What I ended up with was something like this:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
URL=$1
|
||||
DIRECTORY=$2
|
||||
|
||||
if [ $# -eq 0 ];
|
||||
then
|
||||
echo "usage: bash yaml-fetch.sh <'snapshot_url'> <directory>".
|
||||
else
|
||||
|
||||
# make the directory if it doesn't already exist
|
||||
echo 'create directory'
|
||||
|
||||
mkdir $DIRECTORY
|
||||
|
||||
# fetch and untar the yaml files
|
||||
echo 'fetch and untar the yaml files'
|
||||
|
||||
curl $URL | tar -xz -C $DIRECTORY --strip-components=1
|
||||
fi
|
||||
```
|
||||
|
||||
### How Google and scripting rocked my world
|
||||
|
||||
Okay, slight exaggeration there, but this being the 21st century, learning new things (especially somewhat simple things) is a whole lot easier than it used to be. What I learned (besides how to write a short, self-documented Bash script) is that if I have a question, there's a good chance someone else had the same or a similar question before. When I get stumped, I can ask the next question, and the next question. And in the end, not only do I have a script, I have the start of a new skill that I can hold onto and use to simplify other tasks I've been avoiding.
|
||||
|
||||
Don't let that first script (or programming step) get the best of you. It's a skill, like any other, and there's a wealth of information out there to help you along the way. You don't need to read a massive book or take a month-long course. You can do it a simpler way with baby steps and baby scripts that get you started, then build on that skill and your confidence. There will always be a need for folks to write those thousands-of-lines-of-code programs with all the branching and merging and bug-fixing.
|
||||
|
||||
But there is also a strong need for simple scripts and other ways to automate/simplify tasks. And that's where a little script and a little confidence can give you a kickstart.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Sandra McCann - Sandra McCann is a Linux and open source advocate. She's worked as a software developer, content architect for learning resources, and content creator. Sandra is currently a content creator for Red Hat in Westford, MA focusing on OpenStack and NFV techology.
|
||||
|
||||
----
|
||||
|
||||
via: https://opensource.com/article/17/5/how-i-learned-bash-scripting
|
||||
|
||||
作者:[ Sandra McCann ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sandra-mccann
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://opensource.com/article/17/5/how-i-learned-bash-scripting?rate=s_R-jmOxcMvs9bi41yRwenl7GINDvbIFYrUMIJ8OBYk
|
||||
[6]:https://opensource.com/user/39771/feed
|
||||
[7]:https://opensource.com/article/17/5/how-i-learned-bash-scripting#comments
|
||||
[8]:https://opensource.com/users/sandra-mccann
|
||||
@ -0,0 +1,60 @@
|
||||
How Microsoft is becoming a Linux vendor
|
||||
=====================================
|
||||
|
||||
|
||||
>Microsoft is bridging the gap with Linux by baking it into its own products.
|
||||
|
||||

|
||||
|
||||
|
||||
Linux and open source technologies have become too dominant in data centers, cloud and IoT for Microsoft to ignore them.
|
||||
|
||||
On Microsoft’s own cloud, one in three machines run Linux. These are Microsoft customers who are running Linux. Microsoft needs to support the platform they use, or they will go somewhere else.
|
||||
|
||||
Here's how Microsoft's Linux strategy breaks down on its developer platform (Windows 10), on its cloud (Azure) and datacenter (Windows Server).
|
||||
|
||||
**Linux in Windows**: IT professionals managing Linux machines on public or private cloud need native UNIX tooling. Linux and macOS are the only two platforms that offer such native capabilities. No wonder all you see is MacBooks or a few Linux desktops at events like DockerCon, OpenStack Summit or CoreOS Fest.
|
||||
|
||||
To bridge the gap, Microsoft worked with Canonical to build a Linux subsystem within Windows that offers native Linux tooling. It’s a great compromise, where IT professionals can continue to use Windows 10 desktop while getting to run almost all Linux utilities to manage their Linux machines.
|
||||
|
||||
**Linux in Azure**: What good is a cloud that can’t run fully supported Linux machines? Microsoft has been working with Linux vendors that allow customers to run Linux applications and workloads on Azure.
|
||||
|
||||
Microsoft not only managed to sign deals with all three major Linux vendors Red Hat, SUSE and Canonical, it also worked with countless other companies to offer support for community-based distros like Debian.
|
||||
|
||||
**Linux in Windows Server**: This is the last missing piece of the puzzle. There is a massive ecosystem of Linux containers that are used by customers. There are over 900,000 Docker containers on Docker Hub, which can run only on Linux machines. Microsoft wanted to bring these containers to its own platform.
|
||||
|
||||
At DockerCon, Microsoft announced support for Linux containers on Windows Server bringing all those containers to Linux.
|
||||
|
||||
Things are about to get more interesting, after the success of Bash on Ubuntu on Windows 10, Microsoft is bringing Ubuntu bash to Windows Server. Yes, you heard it right. Windows Server will now have a Linux subsystem.
|
||||
|
||||
Rich Turner, Senior Program Manager at Microsoft told me, “WSL on the server provides admins with a preference for *NIX admin scripting & tools to have a more familiar environment in which to work.”
|
||||
|
||||
Microsoft said in an announcement that It will allow IT professionals “to use the same scripts, tools, procedures and container images they have been using for Linux containers on their Windows Server container host. These containers use our Hyper-V isolation technology combined with your choice of Linux kernel to host the workload while the management scripts and tools on the host use WSL.”
|
||||
|
||||
With all three bases covered, Microsoft has succeeded in creating an environment where its customers don't have to deal with any Linux vendor.
|
||||
|
||||
### What does it mean for Microsoft?
|
||||
|
||||
By baking Linux into its own products, Microsoft has become a Linux vendor. They are part of the Linux Foundation, they are one of the many contributors to the Linux kernel, and they now distribute Linux from their own store.
|
||||
|
||||
There is only one minor problem. Microsoft doesn’t own any Linux technologies. They are totally dependent on an external vendor, in this case Canonical, for their entire Linux layer. Too risky a proposition, if Canonical gets acquired by a fierce competitor.
|
||||
|
||||
It might make sense for Microsoft to attempt to acquire Canonical and bring the core technologies in house. It makes sense.
|
||||
|
||||
### What does it mean for Linux vendors
|
||||
|
||||
On the surface, it’s a clear victory for Microsoft as its customers can live within the Windows world. It will also contain the momentum of Linux in a datacenter. It might also affect Linux on the desktop as now IT professionals looking for *NIX tooling don’t have to run Linux desktop, they can do everything from within Windows.
|
||||
|
||||
Is Microsoft's victory a loss for traditional Linux vendors? To some degree, yes. Microsoft has become a direct competitor. But the clear winner here is Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cio.com/article/3197016/linux/how-microsoft-is-becoming-a-linux-vendor.html
|
||||
|
||||
作者:[ Swapnil Bhartiya ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cio.com/author/Swapnil-Bhartiya/
|
||||
103
sources/talk/20170517 Security Debt is an Engineers Problem.md
Normal file
103
sources/talk/20170517 Security Debt is an Engineers Problem.md
Normal file
@ -0,0 +1,103 @@
|
||||
Security Debt is an Engineer’s Problem
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||

|
||||
>Keziah Plattner of AirBnBSecurity.
|
||||
|
||||
Just like organizations can build up technical debt, so too can they also build up something called “security debt,” if they don’t plan accordingly, attendees learned at the [WomenWhoCode Connect ][5]event at Twitter headquarters in San Francisco last month.
|
||||
|
||||
Security has got to be integral to every step of the software development process, stressed [Mary Ann Davidson][6], Oracle’s Chief Security Officer, in a keynote talk with about security for developers with [Zassmin Montes de Oca][7] of [WomenWhoCode][8].
|
||||
|
||||
In the past, security used to be ignored by pretty much everyone, except banks. But security is more critical than it has ever been because there are so many access points. We’ve entered the era of [Internet of Things][9], where thieves can just hack your fridge to see that you’re not home.
|
||||
|
||||
Davidson is in charge of assurance at Oracle, “making sure we build security into everything we build, whether it’s an on-premise product, whether it’s a cloud service, even devices we have that support group builds at customer sites and reports data back to us, helping us do diagnostics — every single one of those things has to have security engineered into it.”
|
||||
|
||||

|
||||
|
||||
Plattner talking to a capacity crowd at #WWCConnect
|
||||
|
||||
AirBnB’s [Keziah Plattner][10] echoed that sentiment in her breakout session. “Most developers don’t see security as their job,” she said, “but this has to change.”
|
||||
|
||||
She shared four basic security principles for engineers. First, security debt is expensive. There’s a lot of talk about [technical debt ][11]and she thinks security debt should be included in those conversations.
|
||||
|
||||
“This historical attitude is ‘We’ll think about security later,’” Plattner said. As companies grab the low-hanging fruit of software efficiency and growth, they ignore security, but an initial insecure design can cause problems for years to come.
|
||||
|
||||
It’s very hard to add security to an existing vulnerable system, she said. Even when you know where the security holes are and have budgeted the time and resources to make the changes, it’s time-consuming and difficult to re-engineer a secure system.
|
||||
|
||||
So it’s key, she said, to build security into your design from the start. Think of security as part of the technical debt to avoid. And cover all possibilities.
|
||||
|
||||
Most importantly, according to Plattner, is the difficulty in getting to people to change their behavior. No one will change voluntarily, she said, even when you point out that the new behavior is more secure. We all nodded.
|
||||
|
||||
Davidson said engineers need to start thinking about how their code could be attacked, and design from that perspective. She said she only has two rules. The first is never trust any unvalidated data and rule two is see rule one.
|
||||
|
||||
“People do this all the time. They say ‘My client sent me the data so it will be fine.’ Nooooooooo,” she said, to laughs.
|
||||
|
||||
The second key to security, Plattner said, is “never trust users.”
|
||||
|
||||
Davidson put it another way: “My job is to be a professional paranoid.” She worries all the time about how someone might breach her systems even inadvertently. This is not academic, there has been recent denial of service attacks through IoT devices.
|
||||
|
||||
### Little Bobby Tables
|
||||
|
||||
If part of your security plan is trusting users to do the right thing, your system is inherently insecure regardless of whatever other security measures you have in place, said Plattner.
|
||||
|
||||
It’s important to properly sanitize all user input, she explained, showing the [XKCD cartoon][12] where a mom wiped out an entire school database because her son’s middle name was “DropTable Students.”
|
||||
|
||||
So sanitize all user input. Check.
|
||||
|
||||
She showed an example of JavaScript developers using Eval on open source. “A good ground rule is ‘Never use eval(),’” she cautioned. The [eval() ][13]function evaluates JavaScript code. “You’re opening your system to random users if you do.”
|
||||
|
||||
Davidson cautioned that her paranoia extends to including security testing your example code in documentation. “Because we all know no one ever copies sample code,” she said to laughter. She underscored the point that any code should be subject to security checks.
|
||||
|
||||

|
||||
|
||||
Make it easy
|
||||
|
||||
Plattner’s suggestion three: Make security easy. Take the path of least resistance, she suggested.
|
||||
|
||||
Externally, make users opt out of security instead of opting in, or, better yet, make it mandatory. Changing people’s behavior is the hardest problem in tech, she said. Once users get used to using your product in a non-secure way, getting them to change in the future is extremely difficult.
|
||||
|
||||
Internal to your company, she suggested make tools that standardize security so it’s not something individual developers need to think about. For example, encrypting data as a service so engineers can just call the service to encrypt or decrypt data.
|
||||
|
||||
Make sure that your company is focused on good security hygiene, she said. Switch to good security habits across the company.
|
||||
|
||||
You’re only secure as your weakest link, so it’s important that each individual also has good personal security hygiene as well as having good corporate security hygiene.
|
||||
|
||||
At Oracle, they’ve got this covered. Davidson said she got tired of explaining security to engineers who graduated college with absolutely no security training, so she wrote the first coding standards at Oracle. There are now hundreds of pages with lots of contributors, and there are classes that are mandatory. They have metrics for compliance to security requirements and measure it. The classes are not just for engineers, but for doc writers as well. “It’s a cultural thing,” she said.
|
||||
|
||||
And what discussion about security would be secure without a mention of passwords? While everyone should be using a good password manager, Plattner said, but they should be mandatory for work, along with two-factor authentication.
|
||||
|
||||
Basic password principles should be a part of every engineer’s waking life, she said. What matters most in passwords is their length and entropy — making the collection of keystrokes as random as possible. A robust password entropy checker is invaluable for this. She recommends [zxcvbn][14], the Dropbox open-source entropy checker.
|
||||
|
||||
Another trick is to use something intentionally slow like [bcrypt][15] when authenticating user input, said Plattner. The slowness doesn’t bother most legit users but irritates hackers who try to force password attempts.
|
||||
|
||||
All of this adds up to job security for anyone wanting to get into the security side of technology, said Davidson. We’re putting more code more places, she said, and that creates systemic risk. “I don’t think anybody is not going to have a job in security as long as we keep doing interesting things in technology.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://thenewstack.io/security-engineers-problem/
|
||||
|
||||
作者:[TC Currie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://thenewstack.io/author/tc/
|
||||
[1]:http://twitter.com/share?url=https://thenewstack.io/security-engineers-problem/&text=Security+Debt+is+an+Engineer%E2%80%99s+Problem+
|
||||
[2]:http://www.facebook.com/sharer.php?u=https://thenewstack.io/security-engineers-problem/
|
||||
[3]:http://www.linkedin.com/shareArticle?mini=true&url=https://thenewstack.io/security-engineers-problem/
|
||||
[4]:https://thenewstack.io/security-engineers-problem/#disqus_thread
|
||||
[5]:http://connect2017.womenwhocode.com/
|
||||
[6]:https://www.linkedin.com/in/mary-ann-davidson-235ba/
|
||||
[7]:https://www.linkedin.com/in/zassmin/
|
||||
[8]:https://www.womenwhocode.com/
|
||||
[9]:https://www.thenewstack.io/tag/Internet-of-Things
|
||||
[10]:https://twitter.com/ittskeziah
|
||||
[11]:https://martinfowler.com/bliki/TechnicalDebt.html
|
||||
[12]:https://xkcd.com/327/
|
||||
[13]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/eval
|
||||
[14]:https://blogs.dropbox.com/tech/2012/04/zxcvbn-realistic-password-strength-estimation/
|
||||
[15]:https://en.wikipedia.org/wiki/Bcrypt
|
||||
[16]:https://thenewstack.io/author/tc/
|
||||
@ -1,79 +1,54 @@
|
||||
|
||||
朝鲜180局的网络战部门让西方国家忧虑。
|
||||
|
||||
Translating by hwlog
|
||||
North Korea's Unit 180, the cyber warfare cell that worries the West
|
||||
|
||||
============================================================
|
||||
[][13] [**PHOTO:** 脱北者说, 平壤的网络战攻击目的在于一个叫做“180局”的部门来筹集资金。(Reuters: Damir Sagolj, file)][14]
|
||||
据叛逃者,官方和网络安全专家称,朝鲜的情报机关有一个叫做180局的特殊部门, 这个部门已经发起过多起勇敢且成功的网络战。
|
||||
近几年朝鲜被美国,韩国,和周边几个国家指责对多数的金融网络发起过一系列在线袭击。
|
||||
网络安全技术人员称他们找到了这个月感染了150多个国家30多万台计算机的全球想哭勒索病毒"ransomware"和朝鲜网络战有关联的技术证据。
|
||||
平壤称该指控是“荒谬的”。
|
||||
对朝鲜的关键指控是指朝鲜与一个叫做拉撒路的黑客组织有联系,这个组织是在去年在孟加拉国中央银行网络抢劫8000万美元并在2014年攻击了索尼的好莱坞工作室的网路。
|
||||
美国政府指责朝鲜对索尼公司的黑客袭击,同时美国政府对平壤在孟加拉国银行的盗窃行为提起公诉并要求立案。
|
||||
由于没有确凿的证据,没有犯罪指控并不能够立案。朝鲜之后也否认了Sony公司和银行的袭击与其有关。
|
||||
朝鲜是世界上最封闭的国家之一,它秘密行动的一些细节很难获得。
|
||||
但研究这个封闭的国家和流落到韩国和一些西方国家的的叛逃者已经给出了或多或少的提示。
|
||||
|
||||
### 黑客们喜欢用雇员来作为掩护
|
||||
金恒光,朝鲜前计算机教授,2004叛逃到韩国,他仍然有着韩国内部的消息,他说平壤的网络战目的在于通过侦察总局下属的一个叫做180局来筹集资金,这个局主要是负责海外的情报机构。
|
||||
金教授称,“180局负责入侵金融机构通过漏洞从银行账户提取资金”。
|
||||
他之前也说过,他以前的一些学生已经加入了朝鲜的网络战略司令部-朝鲜的网络部队。
|
||||
|
||||
[][13] [**PHOTO:** Defectors say Pyongyang's cyberattacks aimed at raising cash are likely organised by the special cell — Unit 180. (Reuters: Damir Sagolj, file)][14]
|
||||
>"黑客们到海外寻找比朝鲜更好的互联网服务的地方,以免留下痕迹," 金教授补充说。
|
||||
他说他们经常用贸易公司,朝鲜的海外分公司和在中国和东南亚合资企业的雇员来作为掩护
|
||||
位于华盛顿的战略与国际研究中心的叫做James Lewis的朝鲜专家称,平壤首先用黑客作为间谍活动的工具然后对韩国和美国的目的进行政治干扰。
|
||||
索尼公司事件之后,他们改变方法,通过用黑客来支持犯罪活动来形成国内坚挺的货币经济政策。
|
||||
“目前为止,网上毒品,假冒伪劣,走私,都是他们惯用的伎俩”。
|
||||
Media player: 空格键播放,“M”键静音,“左击”和“右击”查看。
|
||||
|
||||
North Korea's main spy agency has a special cell called Unit 180 that is likely to have launched some of its most daring and successful cyberattacks, according to defectors, officials and internet security experts.
|
||||
[**VIDEO:** 你遇到过勒索病毒吗? (ABC News)][16]
|
||||
|
||||
### 韩国声称拥有大量的“证据”
|
||||
美国国防部称在去年提交给国会的一个报告中显示,朝鲜可能有作为有效成本的,不对称的,可拒绝的工具,它能够应付来自报复性袭击很小的风险,因为它的“网络”大部分是和因特网分离的。
|
||||
|
||||
> 报告中说," 它可能从第三方国家使用互联网基础设施"。
|
||||
韩国政府称,他们拥有朝鲜网络战行动的大量证据。
|
||||
“朝鲜进行网络战通过第三方国家来掩护网络袭击的来源,并且使用他们的信息和通讯技术设施”,Ahn Chong-ghee,韩国外交部副部长,在书面评论中告诉路透社。
|
||||
除了孟加拉银行抢劫案,他说平壤也被怀疑与菲律宾,越南和波兰的银行袭击有关。
|
||||
去年六月,警察称朝鲜袭击了160个韩国公司和政府机构,入侵了大约14万台计算机,暗中在他的对手的计算机中植入恶意代码作为长期计划的一部分来进行大规模网络攻击。
|
||||
朝鲜也被怀疑在2014年对韩国核反应堆操作系统进行阶段性网络攻击,尽管朝鲜否认与其无关。
|
||||
根据在一个韩国首尔的杀毒软件厂商“hauri”的高级安全研究员Simon Choi的说法,网络袭击是来自于他在中国的一个基地。
|
||||
Choi先生,一个有着对朝鲜的黑客能力进行了广泛的研究的人称,“他们在那里行动以至于不论他们做什么样的计划,他们拥有中国的ip地址”。
|
||||
|
||||
North Korea has been blamed in recent years for a series of online attacks, mostly on financial networks, in the United States, South Korea and over a dozen other countries.
|
||||
|
||||
Cyber security researchers have also said they found technical evidence that could l[ink North Korea with the global WannaCry "ransomware" cyberattack][15] that infected more than 300,000 computers in 150 countries this month.
|
||||
|
||||
Pyongyang has called the allegation "ridiculous".
|
||||
|
||||
The crux of the allegations against North Korea is its connection to a hacking group called Lazarus that is linked to last year's $US81 million cyber heist at the Bangladesh central bank and the 2014 attack on Sony's Hollywood studio.
|
||||
|
||||
The US Government has blamed North Korea for the Sony hack and some US officials have said prosecutors are building a case against Pyongyang in the Bangladesh Bank theft.
|
||||
|
||||
No conclusive proof has been provided and no criminal charges have yet been filed. North Korea has also denied being behind the Sony and banking attacks.
|
||||
|
||||
North Korea is one of the most closed countries in the world and any details of its clandestine operations are difficult to obtain.
|
||||
|
||||
But experts who study the reclusive country and defectors who have ended up in South Korea or the West have provided some clues.
|
||||
|
||||
### Hackers likely under cover as employees
|
||||
|
||||
Kim Heung-kwang, a former computer science professor in North Korea who defected to the South in 2004 and still has sources inside North Korea, said Pyongyang's cyberattacks aimed at raising cash are likely organised by Unit 180, a part of the Reconnaissance General Bureau (RGB), its main overseas intelligence agency.
|
||||
|
||||
"Unit 180 is engaged in hacking financial institutions (by) breaching and withdrawing money out of bank accounts," Mr Kim said.
|
||||
|
||||
|
||||
He has previously said that some of his former students have joined join North Korea's Strategic Cyber Command, its cyber-army.
|
||||
|
||||
> "The hackers go overseas to find somewhere with better internet services than North Korea so as not to leave a trace," Mr Kim added.
|
||||
|
||||
He said it was likely they went under the cover of being employees of trading firms, overseas branches of North Korean companies, or joint ventures in China or South-East Asia.
|
||||
|
||||
James Lewis, a North Korea expert at the Washington-based Centre for Strategic and International Studies, said Pyongyang first used hacking as a tool for espionage and then political harassment against South Korean and US targets.
|
||||
|
||||
"They changed after Sony by using hacking to support criminal activities to generate hard currency for the regime," he said.
|
||||
|
||||
"So far, it's worked as well or better as drugs, counterfeiting, smuggling — all their usual tricks."
|
||||
|
||||
Media player: "Space" to play, "M" to mute, "left" and "right" to seek.
|
||||
|
||||
[**VIDEO:** Have you been hit by ransomware? (ABC News)][16]
|
||||
|
||||
### South Korea purports to have 'considerable evidence'
|
||||
|
||||
The US Department of Defence said in a report submitted to Congress last year that North Korea likely "views cyber as a cost-effective, asymmetric, deniable tool that it can employ with little risk from reprisal attacks, in part because its networks are largely separated from the internet".
|
||||
|
||||
> "It is likely to use internet infrastructure from third-party nations," the report said.
|
||||
|
||||
South Korean officials said they had considerable evidence of North Korea's cyber warfare operations.
|
||||
|
||||
|
||||
"North Korea is carrying out cyberattacks through third countries to cover up the origin of the attacks and using their information and communication technology infrastructure," Ahn Chong-ghee, South Korea's Vice-Foreign Minister, told Reuters in written comments.
|
||||
|
||||
Besides the Bangladesh Bank heist, he said Pyongyang was also suspected in attacks on banks in the Philippines, Vietnam and Poland.
|
||||
|
||||
In June last year, police said the North hacked into more than 140,000 computers at 160 South Korean companies and government agencies, planting malicious code as part of a long-term plan to lay the groundwork for a massive cyberattack on its rival.
|
||||
|
||||
North Korea was also suspected of staging cyberattacks against the South Korean nuclear reactor operator in 2014, although it denied any involvement.
|
||||
|
||||
That attack was conducted from a base in China, according to Simon Choi, a senior security researcher at Seoul-based anti-virus company Hauri Inc.
|
||||
|
||||
"They operate there so that regardless of what kind of project they do, they have Chinese IP addresses," said Mr Choi, who has conducted extensive research into North Korea's hacking capabilities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.abc.net.au/news/2017-05-21/north-koreas-unit-180-cyber-warfare-cell-hacking/8545106
|
||||
|
||||
作者:[www.abc.net.au ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[译者ID](https://github.com/hwlog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,231 +0,0 @@
|
||||
ucasFL translating
|
||||
WRITE MARKDOWN WITH 8 EXCEPTIONAL OPEN SOURCE EDITORS
|
||||
============================================================
|
||||
|
||||
### Markdown
|
||||
|
||||
By way of a succinct introduction, Markdown is a lightweight plain text formatting syntax created by John Gruber together with Aaron Swartz. Markdown offers individuals “to write using an easy-to-read, easy-to-write plain text format, then convert it to structurally valid XHTML (or HTML)”. Markdown’s syntax consists of easy to remember symbols. It has a gentle learning curve; you can literally learn the Markdown syntax in the time it takes to fry some mushrooms (that’s about 10 minutes). By keeping the syntax as simple as possible, the risk of errors is minimized. Besides being a friendly syntax, it has the virtue of producing clean and valid (X)HTML output. If you have seen my HTML, you would know that’s pretty essential.
|
||||
|
||||
The main goal for the formatting syntax is to make it extremely readable. Users should be able to publish a Markdown-formatted document as plain text. Text written in Markdown has the virtue of being easy to share between computers, smart phones, and individuals. Almost all content management systems support Markdown. It’s popularity as a format for writing for the web has also led to variants being adopted by many services such as GitHub and Stack Exchange.
|
||||
|
||||
Markdown can be composed in any text editor. But I recommend an editor purposely designed for this syntax. The software featured in this roundup allows an author to write professional documents of various formats including blog posts, presentations, reports, email, slides and more. All of the applications are, of course, released under an open source license. Linux, OS X and Windows’ users are catered for.
|
||||
|
||||
* * *
|
||||
|
||||
### Remarkable
|
||||
|
||||

|
||||
|
||||
Let’s start with Remarkable. An apt name. Remarkable is a reasonably featured Markdown editor – it doesn’t have all the bells and whistles, but there’s nothing critical missing. It has a syntax like Github flavoured markdown.
|
||||
|
||||
With this editor you can write Markdown and view the changes as you make them in the live preview window. You can export your files to PDF (with a TOC) and HTML. There are multiple styles available along with extensive configuration options so you can configure it to your heart’s content.
|
||||
|
||||
Other features include:
|
||||
|
||||
* Syntax highlighting
|
||||
* GitHub Flavored Markdown support
|
||||
* MathJax support – render rich documents with advanced formatting
|
||||
* Keyboard shortcuts
|
||||
|
||||
There are easy installers available for Debian, Ubuntu, Fedora, SUSE and Arch systems.
|
||||
|
||||
Homepage: [https://remarkableapp.github.io/][4]
|
||||
License: MIT License
|
||||
|
||||
* * *
|
||||
|
||||
### Atom
|
||||
|
||||

|
||||
|
||||
Make no bones about it, Atom is a fabulous text editor. Atom consists of over 50 open source packages integrated around a minimal core. With Node.js support, and a full set of features, Atom is my preferred way to edit code. It features in our [Killer Open Source Apps][5], it is that masterly. But as a Markdown editor Atom leaves a lot to be desired – its default packages are bereft of Markdown specific features; for example, it doesn’t render equations, as illustrated in the graphic above.
|
||||
|
||||
But here lies the power of open source and one of the reasons I’m a strong advocate of openness. There are a plethora of packages, some forks, which add the missing functionality. For example, Markdown Preview Plus provides a real-time preview of markdown documents, with math rendering and live reloading. Alternatively, you might try [Markdown Preview Enhanced][6]. If you need an auto-scroll feature, there’s [markdown-scroll-sync][7]. I’m a big fan of [Markdown-Writer][8] and [markdown-pdf][9] the latter converts markdown to PDF, PNG and JPEG on the fly.
|
||||
|
||||
The approach embodies the open source mentality, allowing the user to add extensions to provide only the features needed. Reminds me of Woolworths pick ‘n’ mix sweets. A bit more effort, but the best outcome.
|
||||
|
||||
Homepage: [https://atom.io/][10]
|
||||
License: MIT License
|
||||
|
||||
* * *
|
||||
|
||||
### Haroopad
|
||||
|
||||

|
||||
|
||||
Haroopad is an excellent markdown enabled document processor for creating web-friendly documents. Author various formats of documents such as blog articles, slides, presentations, reports, and e-mail. Haroopad runs on Windows, Mac OS X, and Linux. There are Debian/Ubuntu packages, and binaries for Windows and Mac. The application uses node-webkit, CodeMirror, marked, and Twitter Bootstrap.
|
||||
|
||||
Haroo means “A Day” in Korean.
|
||||
|
||||
The feature list is rather impressive; take a look below:
|
||||
|
||||
* Themes, Skins and UI Components
|
||||
* Over 30 different themes to edit – tomorrow-night-bright and zenburn are recent additions
|
||||
* Syntax highlighting in fenced code block on editor
|
||||
* Ruby, Python, PHP, Javascript, C, HTML, CSS
|
||||
* Based on CodeMirror, a versatile text editor implemented in JavaScript for the browser
|
||||
* Live Preview themes
|
||||
* 7 themes based markdown-css
|
||||
* Syntax Highlighting
|
||||
* 112 languages & 49 styles based on highlight.js
|
||||
* Custom Theme
|
||||
* Style based on CSS (Cascading Style Sheet)
|
||||
* Presentation Mode – useful for on the spot presentations
|
||||
* Draw diagrams – flowcharts, and sequence diagrams
|
||||
* Tasklist
|
||||
* Enhanced Markdown syntax with TOC, GitHub Flavored Markdown and extensions, mathematical expressions, footnotes, tasklists, and more
|
||||
* Font Size
|
||||
* Editor and Viewer font size control using Preference Window & Shortcuts
|
||||
* Embedding Rich Media Contents
|
||||
* Video, Audio, 3D, Text, Open Graph and oEmbed
|
||||
* About 100 major internet services (YouTube, SoundCloud, Flickr …) Support
|
||||
* Drag & Drop support
|
||||
* Display Mode
|
||||
* Default (Editor:Viewer), Reverse (Viewer:Editor), Only Editor, Only Viewer (View > Mode)
|
||||
* Insert Current Date & Time
|
||||
* Various Format support (Insert > Date & Time)
|
||||
* HTML to Markdown
|
||||
* Drag & Drop your selected text on Web Browser
|
||||
* Options for markdown parsing
|
||||
* Outline View
|
||||
* Vim Key-binding for purists
|
||||
* Markdown Auto Completion
|
||||
* Export to PDF, HTML
|
||||
* Styled HTML copy to clipboard for WYSIWYG editors
|
||||
* Auto Save & Restore
|
||||
* Document state information
|
||||
* Tab or Spaces for Indentation
|
||||
* Column (Single, Two and Three) Layout View
|
||||
* Markdown Syntax Help Dialog.
|
||||
* Import and Export settings
|
||||
* Support for LaTex mathematical expressions using MathJax
|
||||
* Export documents to HTML and PDF
|
||||
* Build extensions for making your own feature
|
||||
* Effortlessly transform documents into a blog system: WordPress, Evernote and Tumblr,
|
||||
* Full screen mode – although the mode fails to hide the top menu bar or the bottom toolbar
|
||||
* Internationalization support: English, Korean, Spanish, Chinese Simplified, German, Vietnamese, Russian, Greek, Portuguese, Japanese, Italian, Indonesian, Turkish, and French
|
||||
|
||||
Homepage: [http://pad.haroopress.com/][11]
|
||||
License: GNU GPL v3
|
||||
|
||||
* * *
|
||||
|
||||
### StackEdit
|
||||
|
||||

|
||||
|
||||
StackEdit is a full-featured Markdown editor based on PageDown, the Markdown library used by Stack Overflow and the other Stack Exchange sites. Unlike the other editors in this roundup, StackEdit is a web based editor. A Chrome app is also available.
|
||||
|
||||
Features include:
|
||||
|
||||
* Real-time HTML preview with Scroll Link feature to bind editor and preview scrollbars
|
||||
* Markdown Extra/GitHub Flavored Markdown support and Prettify/Highlight.js syntax highlighting
|
||||
* LaTeX mathematical expressions using MathJax
|
||||
* WYSIWYG control buttons
|
||||
* Configurable layout
|
||||
* Theming support with different themes available
|
||||
* A la carte extensions
|
||||
* Offline editing
|
||||
* Online synchronization with Google Drive (multi-accounts) and Dropbox
|
||||
* One click publish on Blogger, Dropbox, Gist, GitHub, Google Drive, SSH server, Tumblr, and WordPress
|
||||
|
||||
Homepage: [https://stackedit.io/][12]
|
||||
License: Apache License
|
||||
|
||||
* * *
|
||||
|
||||
### MacDown
|
||||
|
||||

|
||||
|
||||
MacDown is the only editor featured in this roundup which only runs on macOS. Specifically, it requires OS X 10.8 or later. Hoedown is used internally to render Markdown into HTML which gives an edge to its performance. Hoedown is a revived fork of Sundown, it is fully standards compliant with no dependencies, good extension support, and UTF-8 aware.
|
||||
|
||||
MacDown is based on Mou, a proprietary solution designed for web developers.
|
||||
|
||||
It offers good Markdown rendering, syntax highlighting for fenced code blocks with language identifiers rendered by Prism, MathML and LaTeX rendering, GTM task lists, Jekyll front-matter, and optional advanced auto-completion. And above all, it isn’t a resource hog. Want to write Markdown on OS X? MacDown is my open source recommendation for web developers.
|
||||
|
||||
Homepage: [https://macdown.uranusjr.com/][13]
|
||||
License: MIT License
|
||||
|
||||
* * *
|
||||
|
||||
### ghostwriter
|
||||
|
||||

|
||||
|
||||
ghostwriter is a cross-platform, aesthetic, distraction-free Markdown editor. It has built-in support for the Sundown processor, but can also auto-detect Pandoc, MultiMarkdown, Discount and cmark processors. It seeks to be an unobtrusive editor.
|
||||
|
||||
ghostwriter has a good feature set which includes syntax highlighting, a full-screen mode, a focus mode, themes, spell checking with Hunspell, a live word count, live HTML preview, and custom CSS style sheets for HTML preview, drag and drop support for images, and internalization support. A Hemingway mode button disables backspace and delete keys. A new Markdown cheat sheet HUD window is a useful addition. Theme support is pretty basic, but there are some experimental themes available at this [GitHub repository][14].
|
||||
|
||||
ghostwriter is an under-rated utility. I have come to appreciate the versatility of this application more and more, in part because of its spartan interface helps the writer fully concentrate on curating content. Recommended.
|
||||
|
||||
ghostwriter is available for Linux and Windows. There is also a portable version available for Windows.
|
||||
|
||||
Homepage: [https://github.com/wereturtle/ghostwriter][15]
|
||||
License: GNU GPL v3
|
||||
|
||||
* * *
|
||||
|
||||
### Abricotine
|
||||
|
||||

|
||||
|
||||
Abricotine is a promising cross-platform open-source markdown editor built for the desktop. It is available for Linux, OS X and Windows.
|
||||
|
||||
The application supports markdown syntax combined with some Github-flavored Markdown enhancements (such as tables). It lets users preview documents directly in the text editor as opposed to a side pane.
|
||||
|
||||
The tool has a reasonable set of features including a spell checker, the ability to save documents as HTML or copy rich text to paste in your email client. You can also display a document table of content in the side pane, display syntax highlighting for code, as well as helpers, anchors and hidden characters. It is at a fairly early stage of development with some basic bugs that need fixing, but it is one to keep an eye on. There are 2 themes, with the ability to add your own.
|
||||
|
||||
Homepage: [http://abricotine.brrd.fr/][16]
|
||||
License: GNU General Public License v3 or later
|
||||
|
||||
* * *
|
||||
|
||||
### ReText
|
||||
|
||||

|
||||
|
||||
ReText is a simple but powerful editor for Markdown and reStructuredText. It gives users the power to control all output formatting. The files it works with are plain text files, however it can export to PDF, HTML and other formats. ReText is officially supported on Linux only.
|
||||
|
||||
Features include:
|
||||
|
||||
* Full screen mode
|
||||
* Live previews
|
||||
* Synchronised scrolling (for Markdown)
|
||||
* Support for math formulas
|
||||
* Spell checking
|
||||
* Page breaks
|
||||
* Export to HTML, ODT and PDF
|
||||
* Use other markup languages
|
||||
|
||||
Homepage: [https://github.com/retext-project/retext][17]
|
||||
License: GNU GPL v2 or higher
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/markdown-editors/
|
||||
|
||||
作者:[Steve Emms ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://www.ossblog.org/author/steve/
|
||||
[2]:https://www.ossblog.org/markdown-editors/#comments
|
||||
[3]:https://www.ossblog.org/category/utilities/
|
||||
[4]:https://remarkableapp.github.io/
|
||||
[5]:https://www.ossblog.org/top-software/2/
|
||||
[6]:https://atom.io/packages/markdown-preview-enhanced
|
||||
[7]:https://atom.io/packages/markdown-scroll-sync
|
||||
[8]:https://atom.io/packages/markdown-writer
|
||||
[9]:https://atom.io/packages/markdown-pdf
|
||||
[10]:https://atom.io/
|
||||
[11]:http://pad.haroopress.com/
|
||||
[12]:https://stackedit.io/
|
||||
[13]:https://macdown.uranusjr.com/
|
||||
[14]:https://github.com/jggouvea/ghostwriter-themes
|
||||
[15]:https://github.com/wereturtle/ghostwriter
|
||||
[16]:http://abricotine.brrd.fr/
|
||||
[17]:https://github.com/retext-project/retext
|
||||
@ -0,0 +1,346 @@
|
||||
ictlyh Translating
|
||||
Writing a Linux Debugger Part 3: Registers and memory
|
||||
============================================================
|
||||
|
||||
In the last post we added simple address breakpoints to our debugger. This time we’ll be adding the ability to read and write registers and memory, which will allow us to screw around with our program counter, observe state and change the behaviour of our program.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][3]
|
||||
|
||||
2. [Breakpoints][4]
|
||||
|
||||
3. [Registers and memory][5]
|
||||
|
||||
4. [Elves and dwarves][6]
|
||||
|
||||
5. [Source and signals][7]
|
||||
|
||||
6. [Source-level stepping][8]
|
||||
|
||||
7. Source-level breakpoints
|
||||
|
||||
8. Stack unwinding
|
||||
|
||||
9. Reading variables
|
||||
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### Registering our registers
|
||||
|
||||
Before we actually read any registers, we need to teach our debugger a bit about our target, which is x86_64\. Alongside sets of general and special purpose registers, x86_64 has floating point and vector registers available. I’ll be omitting the latter two for simplicity, but you can choose to support them if you like. x86_64 also allows you to access some 64 bit registers as 32, 16, or 8 bit registers, but I’ll just be sticking to 64\. Due to these simplifications, for each register we just need its name, its DWARF register number, and where it is stored in the structure returned by `ptrace`. I chose to have a scoped enum for referring to the registers, then I laid out a global register descriptor array with the elements in the same order as in the `ptrace` register structure.
|
||||
|
||||
```
|
||||
enum class reg {
|
||||
rax, rbx, rcx, rdx,
|
||||
rdi, rsi, rbp, rsp,
|
||||
r8, r9, r10, r11,
|
||||
r12, r13, r14, r15,
|
||||
rip, rflags, cs,
|
||||
orig_rax, fs_base,
|
||||
gs_base,
|
||||
fs, gs, ss, ds, es
|
||||
};
|
||||
|
||||
constexpr std::size_t n_registers = 27;
|
||||
|
||||
struct reg_descriptor {
|
||||
reg r;
|
||||
int dwarf_r;
|
||||
std::string name;
|
||||
};
|
||||
|
||||
const std::array<reg_descriptor, n_registers> g_register_descriptors {{
|
||||
{ reg::r15, 15, "r15" },
|
||||
{ reg::r14, 14, "r14" },
|
||||
{ reg::r13, 13, "r13" },
|
||||
{ reg::r12, 12, "r12" },
|
||||
{ reg::rbp, 6, "rbp" },
|
||||
{ reg::rbx, 3, "rbx" },
|
||||
{ reg::r11, 11, "r11" },
|
||||
{ reg::r10, 10, "r10" },
|
||||
{ reg::r9, 9, "r9" },
|
||||
{ reg::r8, 8, "r8" },
|
||||
{ reg::rax, 0, "rax" },
|
||||
{ reg::rcx, 2, "rcx" },
|
||||
{ reg::rdx, 1, "rdx" },
|
||||
{ reg::rsi, 4, "rsi" },
|
||||
{ reg::rdi, 5, "rdi" },
|
||||
{ reg::orig_rax, -1, "orig_rax" },
|
||||
{ reg::rip, -1, "rip" },
|
||||
{ reg::cs, 51, "cs" },
|
||||
{ reg::rflags, 49, "eflags" },
|
||||
{ reg::rsp, 7, "rsp" },
|
||||
{ reg::ss, 52, "ss" },
|
||||
{ reg::fs_base, 58, "fs_base" },
|
||||
{ reg::gs_base, 59, "gs_base" },
|
||||
{ reg::ds, 53, "ds" },
|
||||
{ reg::es, 50, "es" },
|
||||
{ reg::fs, 54, "fs" },
|
||||
{ reg::gs, 55, "gs" },
|
||||
}};
|
||||
```
|
||||
|
||||
You can typically find the register data structure in `/usr/include/sys/user.h` if you’d like to look at it yourself, and the DWARF register numbers are taken from the [System V x86_64 ABI][11].
|
||||
|
||||
Now we can write a bunch of functions to interact with registers. We’d like to be able to read registers, write to them, retrieve a value from a DWARF register number, and lookup registers by name and vice versa. Let’s start with implementing `get_register_value`:
|
||||
|
||||
```
|
||||
uint64_t get_register_value(pid_t pid, reg r) {
|
||||
user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, nullptr, ®s);
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
Again, `ptrace` gives us easy access to the data we want. We just construct an instance of `user_regs_struct` and give that to `ptrace` alongside the `PTRACE_GETREGS` request.
|
||||
|
||||
Now we want to read `regs` depending on which register was requested. We could write a big switch statement, but since we’ve laid out our `g_register_descriptors` table in the same order as `user_regs_struct`, we can just search for the index of the register descriptor, and access `user_regs_struct` as an array of `uint64_t`s.[1][9]
|
||||
|
||||
```
|
||||
auto it = std::find_if(begin(g_register_descriptors), end(g_register_descriptors),
|
||||
[r](auto&& rd) { return rd.r == r; });
|
||||
|
||||
return *(reinterpret_cast<uint64_t*>(®s) + (it - begin(g_register_descriptors)));
|
||||
```
|
||||
|
||||
The cast to `uint64_t` is safe because `user_regs_struct` is a standard layout type, but I think the pointer arithmetic is technically UB. No current compilers even warn about this and I’m lazy, but if you want to maintain utmost correctness, write a big switch statement.
|
||||
|
||||
`set_register_value` is much the same, we just write to the location and write the registers back at the end:
|
||||
|
||||
```
|
||||
void set_register_value(pid_t pid, reg r, uint64_t value) {
|
||||
user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, nullptr, ®s);
|
||||
auto it = std::find_if(begin(g_register_descriptors), end(g_register_descriptors),
|
||||
[r](auto&& rd) { return rd.r == r; });
|
||||
|
||||
*(reinterpret_cast<uint64_t*>(®s) + (it - begin(g_register_descriptors))) = value;
|
||||
ptrace(PTRACE_SETREGS, pid, nullptr, ®s);
|
||||
}
|
||||
```
|
||||
|
||||
Next is lookup by DWARF register number. This time I’ll actually check for an error condition just in case we get some weird DWARF information:
|
||||
|
||||
```
|
||||
uint64_t get_register_value_from_dwarf_register (pid_t pid, unsigned regnum) {
|
||||
auto it = std::find_if(begin(g_register_descriptors), end(g_register_descriptors),
|
||||
[regnum](auto&& rd) { return rd.dwarf_r == regnum; });
|
||||
if (it == end(g_register_descriptors)) {
|
||||
throw std::out_of_range{"Unknown dwarf register"};
|
||||
}
|
||||
|
||||
return get_register_value(pid, it->r);
|
||||
}
|
||||
```
|
||||
|
||||
Nearly finished, now he have register name lookups:
|
||||
|
||||
```
|
||||
std::string get_register_name(reg r) {
|
||||
auto it = std::find_if(begin(g_register_descriptors), end(g_register_descriptors),
|
||||
[r](auto&& rd) { return rd.r == r; });
|
||||
return it->name;
|
||||
}
|
||||
|
||||
reg get_register_from_name(const std::string& name) {
|
||||
auto it = std::find_if(begin(g_register_descriptors), end(g_register_descriptors),
|
||||
[name](auto&& rd) { return rd.name == name; });
|
||||
return it->r;
|
||||
}
|
||||
```
|
||||
|
||||
And finally we’ll add a simple helper to dump the contents of all registers:
|
||||
|
||||
```
|
||||
void debugger::dump_registers() {
|
||||
for (const auto& rd : g_register_descriptors) {
|
||||
std::cout << rd.name << " 0x"
|
||||
<< std::setfill('0') << std::setw(16) << std::hex << get_register_value(m_pid, rd.r) << std::endl;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
As you can see, iostreams has a very concise interface for outputting hex data nicely[2][10]. Feel free to make an I/O manipulator to get rid of this mess if you like.
|
||||
|
||||
This gives us enough support to handle registers easily in the rest of the debugger, so we can now add this to our UI.
|
||||
|
||||
* * *
|
||||
|
||||
### Exposing our registers
|
||||
|
||||
All we need to do here is add a new command to the `handle_command` function. With the following code, users will be able to type `register read rax`, `register write rax 0x42` and so on.
|
||||
|
||||
```
|
||||
else if (is_prefix(command, "register")) {
|
||||
if (is_prefix(args[1], "dump")) {
|
||||
dump_registers();
|
||||
}
|
||||
else if (is_prefix(args[1], "read")) {
|
||||
std::cout << get_register_value(m_pid, get_register_from_name(args[2])) << std::endl;
|
||||
}
|
||||
else if (is_prefix(args[1], "write")) {
|
||||
std::string val {args[3], 2}; //assume 0xVAL
|
||||
set_register_value(m_pid, get_register_from_name(args[2]), std::stol(val, 0, 16));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Where is my mind?
|
||||
|
||||
We’ve already read from and written to memory when setting our breakpoints, so we just need to add a couple of functions to hide the `ptrace` call a bit.
|
||||
|
||||
```
|
||||
uint64_t debugger::read_memory(uint64_t address) {
|
||||
return ptrace(PTRACE_PEEKDATA, m_pid, address, nullptr);
|
||||
}
|
||||
|
||||
void debugger::write_memory(uint64_t address, uint64_t value) {
|
||||
ptrace(PTRACE_POKEDATA, m_pid, address, value);
|
||||
}
|
||||
```
|
||||
|
||||
You might want to add support for reading and writing more than a word at a time, which you can do by just incrementing the address each time you want to read another word. You could also use [`process_vm_readv` and `process_vm_writev`][12] or `/proc/<pid>/mem` instead of `ptrace` if you like.
|
||||
|
||||
Now we’ll add commands for our UI:
|
||||
|
||||
```
|
||||
else if(is_prefix(command, "memory")) {
|
||||
std::string addr {args[2], 2}; //assume 0xADDRESS
|
||||
|
||||
if (is_prefix(args[1], "read")) {
|
||||
std::cout << std::hex << read_memory(std::stol(addr, 0, 16)) << std::endl;
|
||||
}
|
||||
if (is_prefix(args[1], "write")) {
|
||||
std::string val {args[3], 2}; //assume 0xVAL
|
||||
write_memory(std::stol(addr, 0, 16), std::stol(val, 0, 16));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Patching `continue_execution`
|
||||
|
||||
Before we test out our changes, we’re now in a position to implement a more sane version of `continue_execution`. Since we can get the program counter, we can check our breakpoint map to see if we’re at a breakpoint. If so, we can disable the breakpoint and step over it before continuing.
|
||||
|
||||
First we’ll add for couple of helper functions for clarity and brevity:
|
||||
|
||||
```
|
||||
uint64_t debugger::get_pc() {
|
||||
return get_register_value(m_pid, reg::rip);
|
||||
}
|
||||
|
||||
void debugger::set_pc(uint64_t pc) {
|
||||
set_register_value(m_pid, reg::rip, pc);
|
||||
}
|
||||
```
|
||||
|
||||
Then we can write a function to step over a breakpoint:
|
||||
|
||||
```
|
||||
void debugger::step_over_breakpoint() {
|
||||
// - 1 because execution will go past the breakpoint
|
||||
auto possible_breakpoint_location = get_pc() - 1;
|
||||
|
||||
if (m_breakpoints.count(possible_breakpoint_location)) {
|
||||
auto& bp = m_breakpoints[possible_breakpoint_location];
|
||||
|
||||
if (bp.is_enabled()) {
|
||||
auto previous_instruction_address = possible_breakpoint_location;
|
||||
set_pc(previous_instruction_address);
|
||||
|
||||
bp.disable();
|
||||
ptrace(PTRACE_SINGLESTEP, m_pid, nullptr, nullptr);
|
||||
wait_for_signal();
|
||||
bp.enable();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
First we check to see if there’s a breakpoint set for the value of the current PC. If there is, we first put execution back to before the breakpoint, disable it, step over the original instruction, and re-enable the breakpoint.
|
||||
|
||||
`wait_for_signal` will encapsulate our usual `waitpid` pattern:
|
||||
|
||||
```
|
||||
void debugger::wait_for_signal() {
|
||||
int wait_status;
|
||||
auto options = 0;
|
||||
waitpid(m_pid, &wait_status, options);
|
||||
}
|
||||
```
|
||||
|
||||
Finally we rewrite `continue_execution` like this:
|
||||
|
||||
```
|
||||
void debugger::continue_execution() {
|
||||
step_over_breakpoint();
|
||||
ptrace(PTRACE_CONT, m_pid, nullptr, nullptr);
|
||||
wait_for_signal();
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Testing it out
|
||||
|
||||
Now that we can read and modify registers, we can have a bit of fun with our hello world program. As a first test, try setting a breakpoint on the call instruction again and continue from it. You should see `Hello world` being printed out. For the fun part, set a breakpoint just after the output call, continue, then write the address of the call argument setup code to the program counter (`rip`) and continue. You should see `Hello world` being printed a second time due to this program counter manipulation. Just in case you aren’t sure where to set the breakpoint, here’s my `objdump` output from the last post again:
|
||||
|
||||
```
|
||||
0000000000400936 <main>:
|
||||
400936: 55 push rbp
|
||||
400937: 48 89 e5 mov rbp,rsp
|
||||
40093a: be 35 0a 40 00 mov esi,0x400a35
|
||||
40093f: bf 60 10 60 00 mov edi,0x601060
|
||||
400944: e8 d7 fe ff ff call 400820 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
|
||||
400949: b8 00 00 00 00 mov eax,0x0
|
||||
40094e: 5d pop rbp
|
||||
40094f: c3 ret
|
||||
|
||||
```
|
||||
|
||||
You’ll want to move the program counter back to `0x40093a` so that the `esi` and `edi` registers are set up properly.
|
||||
|
||||
In the next post, we’ll take our first look at DWARF information and add various kinds of single stepping to our debugger. After that, we’ll have a mostly functioning tool which can step through code, set breakpoints wherever we like, modify data and so forth. As always, drop a comment below if you have any questions!
|
||||
|
||||
You can find the code for this post [here][13].
|
||||
|
||||
* * *
|
||||
|
||||
1. You could also reorder the `reg` enum and cast them to the underlying type to use as indexes, but I wrote it this way in the first place, it works, and I’m too lazy to change it. [↩][1]
|
||||
|
||||
2. Ahahahahahahahahahahahahahahahaha [↩][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
|
||||
作者:[ TartanLlama ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/#fnref:2
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/#fnref:1
|
||||
[3]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[7]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[8]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[9]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/#fn:2
|
||||
[10]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/#fn:1
|
||||
[11]:https://www.uclibc.org/docs/psABI-x86_64.pdf
|
||||
[12]:http://man7.org/linux/man-pages/man2/process_vm_readv.2.html
|
||||
[13]:https://github.com/TartanLlama/minidbg/tree/tut_registers
|
||||
@ -0,0 +1,329 @@
|
||||
ictlyh Translating
|
||||
Writing a Linux Debugger Part 4: Elves and dwarves
|
||||
============================================================
|
||||
|
||||
Up until now you’ve heard whispers of dwarves, of debug information, of a way to understand the source code without just parsing the thing. Today we’ll be going into the details of source-level debug information in preparation for using it in following parts of this tutorial.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][1]
|
||||
|
||||
2. [Breakpoints][2]
|
||||
|
||||
3. [Registers and memory][3]
|
||||
|
||||
4. [Elves and dwarves][4]
|
||||
|
||||
5. [Source and signals][5]
|
||||
|
||||
6. [Source-level stepping][6]
|
||||
|
||||
7. Source-level breakpoints
|
||||
|
||||
8. Stack unwinding
|
||||
|
||||
9. Reading variables
|
||||
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### Introduction to ELF and DWARF
|
||||
|
||||
ELF and DWARF are two components which you may not have heard of, but probably use most days. ELF (Executable and Linkable Format) is the most widely used object file format in the Linux world; it specifies a way to store all of the different parts of a binary, like the code, static data, debug information, and strings. It also tells the loader how to take the binary and ready it for execution, which involves noting where different parts of the binary should be placed in memory, which bits need to be fixed up depending on the position of other components ( _relocations_ ) and more. I won’t cover much more of ELF in these posts, but if you’re interested, you can have a look at [this wonderful infographic][7] or [the standard][8].
|
||||
|
||||
DWARF is the debug information format most commonly used with ELF. It’s not necessarily tied to ELF, but the two were developed in tandem and work very well together. This format allows a compiler to tell a debugger how the original source code relates to the binary which is to be executed. This information is split across different ELF sections, each with its own piece of information to relay. Here are the different sections which are defined, taken from this highly informative if slightly out of date [Introduction to the DWARF Debugging Format][9]:
|
||||
|
||||
* `.debug_abbrev` Abbreviations used in the `.debug_info` section
|
||||
|
||||
* `.debug_aranges` A mapping between memory address and compilation
|
||||
|
||||
* `.debug_frame` Call Frame Information
|
||||
|
||||
* `.debug_info` The core DWARF data containing DWARF Information Entries (DIEs)
|
||||
|
||||
* `.debug_line` Line Number Program
|
||||
|
||||
* `.debug_loc` Location descriptions
|
||||
|
||||
* `.debug_macinfo` Macro descriptions
|
||||
|
||||
* `.debug_pubnames` A lookup table for global objects and functions
|
||||
|
||||
* `.debug_pubtypes` A lookup table for global types
|
||||
|
||||
* `.debug_ranges` Address ranges referenced by DIEs
|
||||
|
||||
* `.debug_str` String table used by `.debug_info`
|
||||
|
||||
* `.debug_types` Type descriptions
|
||||
|
||||
We are most interested in the `.debug_line` and `.debug_info` sections, so lets have a look at some DWARF for a simple program.
|
||||
|
||||
```
|
||||
int main() {
|
||||
long a = 3;
|
||||
long b = 2;
|
||||
long c = a + b;
|
||||
a = 4;
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### DWARF line table
|
||||
|
||||
If you compile this program with the `-g` option and run the result through `dwarfdump`, you should see something like this for the line number section:
|
||||
|
||||
```
|
||||
.debug_line: line number info for a single cu
|
||||
Source lines (from CU-DIE at .debug_info offset 0x0000000b):
|
||||
|
||||
NS new statement, BB new basic block, ET end of text sequence
|
||||
PE prologue end, EB epilogue begin
|
||||
IS=val ISA number, DI=val discriminator value
|
||||
<pc> [lno,col] NS BB ET PE EB IS= DI= uri: "filepath"
|
||||
0x00400670 [ 1, 0] NS uri: "/home/simon/play/MiniDbg/examples/variable.cpp"
|
||||
0x00400676 [ 2,10] NS PE
|
||||
0x0040067e [ 3,10] NS
|
||||
0x00400686 [ 4,14] NS
|
||||
0x0040068a [ 4,16]
|
||||
0x0040068e [ 4,10]
|
||||
0x00400692 [ 5, 7] NS
|
||||
0x0040069a [ 6, 1] NS
|
||||
0x0040069c [ 6, 1] NS ET
|
||||
|
||||
```
|
||||
|
||||
The first bunch of lines is some information on how to understand the dump – the main line number data starts at the line starting with `0x00400670`. Essentially this maps a code memory address with a line and column number in some file. `NS` means that the address marks the beginning of a new statement, which is often used for setting breakpoints or stepping. `PE`marks the end of the function prologue, which is helpful for setting function entry breakpoints. `ET` marks the end of the translation unit. The information isn’t actually encoded like this; the real encoding is a very space-efficient program of sorts which can be executed to build up this line information.
|
||||
|
||||
So, say we want to set a breakpoint on line 4 of variable.cpp, what do we do? We look for entries corresponding to that file, then we look for a relevant line entry, look up the address which corresponds to it, and set a breakpoint there. In our example, that’s this entry:
|
||||
|
||||
```
|
||||
0x00400686 [ 4,14] NS
|
||||
|
||||
```
|
||||
|
||||
So we want to set a breakpoint at address `0x00400686`. You could do so by hand with the debugger you’ve already written if you want to give it a try.
|
||||
|
||||
The reverse works just as well. If we have a memory location – say, a program counter value – and want to find out where that is in the source, we just find the closest mapped address in the line table information and grab the line from there.
|
||||
|
||||
* * *
|
||||
|
||||
### DWARF debug info
|
||||
|
||||
The `.debug_info` section is the heart of DWARF. It gives us information about the types, functions, variables, hopes, and dreams present in our program. The fundamental unit in this section is the DWARF Information Entry, affectionately known as DIEs. A DIE consists of a tag telling you what kind of source-level entity is being represented, followed by a series of attributes which apply to that entity. Here’s the `.debug_info` section for the simple example program I posted above:
|
||||
|
||||
```
|
||||
|
||||
.debug_info
|
||||
|
||||
COMPILE_UNIT<header overall offset = 0x00000000>:
|
||||
< 0><0x0000000b> DW_TAG_compile_unit
|
||||
DW_AT_producer clang version 3.9.1 (tags/RELEASE_391/final)
|
||||
DW_AT_language DW_LANG_C_plus_plus
|
||||
DW_AT_name /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_stmt_list 0x00000000
|
||||
DW_AT_comp_dir /super/secret/path/MiniDbg/build
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
|
||||
LOCAL_SYMBOLS:
|
||||
< 1><0x0000002e> DW_TAG_subprogram
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
DW_AT_name main
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000001
|
||||
DW_AT_type <0x00000077>
|
||||
DW_AT_external yes(1)
|
||||
< 2><0x0000004c> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -8
|
||||
DW_AT_name a
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000002
|
||||
DW_AT_type <0x0000007e>
|
||||
< 2><0x0000005a> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -16
|
||||
DW_AT_name b
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000003
|
||||
DW_AT_type <0x0000007e>
|
||||
< 2><0x00000068> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -24
|
||||
DW_AT_name c
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000004
|
||||
DW_AT_type <0x0000007e>
|
||||
< 1><0x00000077> DW_TAG_base_type
|
||||
DW_AT_name int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000004
|
||||
< 1><0x0000007e> DW_TAG_base_type
|
||||
DW_AT_name long int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000008
|
||||
|
||||
```
|
||||
|
||||
The first DIE represents a compilation unit (CU), which is essentially a source file with all of the `#includes` and such resolved. Here are the attributes annotated with their meaning:
|
||||
|
||||
```
|
||||
DW_AT_producer clang version 3.9.1 (tags/RELEASE_391/final) <-- The compiler which produced
|
||||
this binary
|
||||
DW_AT_language DW_LANG_C_plus_plus <-- The source language
|
||||
DW_AT_name /super/secret/path/MiniDbg/examples/variable.cpp <-- The name of the file which
|
||||
this CU represents
|
||||
DW_AT_stmt_list 0x00000000 <-- An offset into the line table
|
||||
which tracks this CU
|
||||
DW_AT_comp_dir /super/secret/path/MiniDbg/build <-- The compilation directory
|
||||
DW_AT_low_pc 0x00400670 <-- The start of the code for
|
||||
this CU
|
||||
DW_AT_high_pc 0x0040069c <-- The end of the code for
|
||||
this CU
|
||||
|
||||
```
|
||||
|
||||
The other DIEs follow a similar scheme, and you can probably intuit what the different attributes mean.
|
||||
|
||||
Now we can try and solve a few practical problems with our new-found knowledge of DWARF.
|
||||
|
||||
### Which function am I in?
|
||||
|
||||
Say we have a program counter value and want to figure out what function we’re in. A simple algorithm for this is:
|
||||
|
||||
```
|
||||
for each compile unit:
|
||||
if the pc is between DW_AT_low_pc and DW_AT_high_pc:
|
||||
for each function in the compile unit:
|
||||
if the pc is between DW_AT_low_pc and DW_AT_high_pc:
|
||||
return function information
|
||||
|
||||
```
|
||||
|
||||
This will work for many purposes, but things get a bit more difficult in the presence of member functions and inlining. With inlining, for example, once we’ve found the function whose range contains our PC, we’ll need to recurse over the children of that DIE to see if there are any inlined functions which are a better match. I won’t deal with inlining in my code for this debugger, but you can add support for this if you like.
|
||||
|
||||
### How do I set a breakpoint on a function?
|
||||
|
||||
Again, this depends on if you want to support member functions, namespaces and suchlike. For free functions you can just iterate over the functions in different compile units until you find one with the right name. If your compiler is kind enough to fill in the `.debug_pubnames` section, you can do this a lot more efficiently.
|
||||
|
||||
Once the function has been found, you can set a breakpoint on the memory address given by `DW_AT_low_pc`. However, that’ll break at the start of the function prologue, but it’s preferable to break at the start of the user code. Since the line table information can specify the memory address which specifies the prologue end, you could just lookup the value of `DW_AT_low_pc` in the line table, then keep reading until you get to the entry marked as the prologue end. Some compilers won’t output this information though, so another option is to just set a breakpoint on the address given by the second line entry for that function.
|
||||
|
||||
Say we want to set a breakpoint on `main` in our example program. We search for the function called `main`, and get this DIE:
|
||||
|
||||
```
|
||||
< 1><0x0000002e> DW_TAG_subprogram
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
DW_AT_name main
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000001
|
||||
DW_AT_type <0x00000077>
|
||||
DW_AT_external yes(1)
|
||||
|
||||
```
|
||||
|
||||
This tells us that the function begins at `0x00400670`. If we look this up in our line table, we get this entry:
|
||||
|
||||
```
|
||||
0x00400670 [ 1, 0] NS uri: "/super/secret/path/MiniDbg/examples/variable.cpp"
|
||||
|
||||
```
|
||||
|
||||
We want to skip the prologue, so we read ahead an entry:
|
||||
|
||||
```
|
||||
0x00400676 [ 2,10] NS PE
|
||||
|
||||
```
|
||||
|
||||
Clang has included the prologue end flag on this entry, so we know to stop here and set a breakpoint on address `0x00400676`.
|
||||
|
||||
### How do I read the contents of a variable?
|
||||
|
||||
Reading variables can be very complex. They are elusive things which can move around throughout a function, sit in registers, be placed in memory, be optimised out, hide in the corner, whatever. Fortunately our simple example is, well, simple. If we want to read the contents of variable `a`, we have a look at its `DW_AT_location` attribute:
|
||||
|
||||
```
|
||||
DW_AT_location DW_OP_fbreg -8
|
||||
|
||||
```
|
||||
|
||||
This says that the contents are stored at an offset of `-8` from the base of the stack frame. To work out where this base is, we look at the `DW_AT_frame_base` attribute on the containing function.
|
||||
|
||||
```
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
|
||||
```
|
||||
|
||||
`reg6` on x86 is the frame pointer register, as specified by the [System V x86_64 ABI][10]. Now we read the contents of the frame pointer, subtract 8 from it, and we’ve found our variable. If we actually want to make sense of the thing, we’ll need to look at its type:
|
||||
|
||||
```
|
||||
< 2><0x0000004c> DW_TAG_variable
|
||||
DW_AT_name a
|
||||
DW_AT_type <0x0000007e>
|
||||
|
||||
```
|
||||
|
||||
If we look up this type in the debug information, we get this DIE:
|
||||
|
||||
```
|
||||
< 1><0x0000007e> DW_TAG_base_type
|
||||
DW_AT_name long int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000008
|
||||
|
||||
```
|
||||
|
||||
This tells us that the type is a 8 byte (64 bit) signed integer type, so we can go ahead and interpret those bytes as an `int64_t` and display it to the user.
|
||||
|
||||
Of course, types can get waaaaaaay more complex than that, as they have to be able to express things like C++ types, but this gives you a basic idea of how they work.
|
||||
|
||||
Coming back to that frame base for a second, Clang was nice enough to track the frame base with the frame pointer register. Recent versions of GCC tend to prefer `DW_OP_call_frame_cfa`, which involves parsing the `.eh_frame` ELF section, and that’s an entirely different article which I won’t be writing. If you tell GCC to use DWARF 2 instead of more recent versions, it’ll tend to output location lists, which are somewhat easier to read:
|
||||
|
||||
```
|
||||
DW_AT_frame_base <loclist at offset 0x00000000 with 4 entries follows>
|
||||
low-off : 0x00000000 addr 0x00400696 high-off 0x00000001 addr 0x00400697>DW_OP_breg7+8
|
||||
low-off : 0x00000001 addr 0x00400697 high-off 0x00000004 addr 0x0040069a>DW_OP_breg7+16
|
||||
low-off : 0x00000004 addr 0x0040069a high-off 0x00000031 addr 0x004006c7>DW_OP_breg6+16
|
||||
low-off : 0x00000031 addr 0x004006c7 high-off 0x00000032 addr 0x004006c8>DW_OP_breg7+8
|
||||
|
||||
```
|
||||
|
||||
A location list gives different locations depending on where the program counter is. This example says that if the PC is at an offset of `0x0` from `DW_AT_low_pc` then the frame base is an offset of 8 away from the value stored in register 7, if it’s between `0x1` and `0x4` away, then it’s at an offset of 16 away from the same, and so on.
|
||||
|
||||
* * *
|
||||
|
||||
### Take a breath
|
||||
|
||||
That’s a lot of information to get your head round, but the good news is that in the next few posts we’re going to have a library do the hard work for us. It’s still useful to understand the concepts at play, particularly when something goes wrong or when you want to support some DWARF concept which isn’t implemented in whatever DWARF library you use.
|
||||
|
||||
If you want to learn more about DWARF, then you can grab the standard [here][11]. At the time of writing, DWARF 5 has just been released, but DWARF 4 is more commonly supported.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
|
||||
作者:[ TartanLlama ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/corkami/pics/raw/master/binary/elf101/elf101-64.pdf
|
||||
[8]:http://www.skyfree.org/linux/references/ELF_Format.pdf
|
||||
[9]:http://www.dwarfstd.org/doc/Debugging%20using%20DWARF-2012.pdf
|
||||
[10]:https://www.uclibc.org/docs/psABI-x86_64.pdf
|
||||
[11]:http://dwarfstd.org/Download.php
|
||||
@ -0,0 +1,302 @@
|
||||
ictlyh Translating
|
||||
Writing a Linux Debugger Part 5: Source and signals
|
||||
============================================================
|
||||
|
||||
In the the last part we learned about DWARF information and how it can be used to read variables and associate our high-level source code with the machine code which is being executed. In this part we’ll put this into practice by implementing some DWARF primitives which will be used by the rest of our debugger. We’ll also take this opportunity to get our debugger to print out the current source context when a breakpoint is hit.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][1]
|
||||
|
||||
2. [Breakpoints][2]
|
||||
|
||||
3. [Registers and memory][3]
|
||||
|
||||
4. [Elves and dwarves][4]
|
||||
|
||||
5. [Source and signals][5]
|
||||
|
||||
6. [Source-level stepping][6]
|
||||
|
||||
7. Source-level breakpoints
|
||||
|
||||
8. Stack unwinding
|
||||
|
||||
9. Reading variables
|
||||
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### Setting up our DWARF parser
|
||||
|
||||
As I noted way back at the start of this series, we’ll be using [`libelfin`][7] to handle our DWARF information. Hopefully you got this set up in the first post, but if not, do so now, and make sure that you use the `fbreg` branch of my fork.
|
||||
|
||||
Once you have `libelfin` building, it’s time to add it to our debugger. The first step is to parse the ELF executable we’re given and extract the DWARF from it. This is very easy with `libelfin`, just make these changes to `debugger`:
|
||||
|
||||
```
|
||||
class debugger {
|
||||
public:
|
||||
debugger (std::string prog_name, pid_t pid)
|
||||
: m_prog_name{std::move(prog_name)}, m_pid{pid} {
|
||||
auto fd = open(m_prog_name.c_str(), O_RDONLY);
|
||||
|
||||
m_elf = elf::elf{elf::create_mmap_loader(fd)};
|
||||
m_dwarf = dwarf::dwarf{dwarf::elf::create_loader(m_elf)};
|
||||
}
|
||||
//...
|
||||
|
||||
private:
|
||||
//...
|
||||
dwarf::dwarf m_dwarf;
|
||||
elf::elf m_elf;
|
||||
};
|
||||
```
|
||||
|
||||
`open` is used instead of `std::ifstream` because the elf loader needs a UNIX file descriptor to pass to `mmap` so that it can just map the file into memory rather than reading it a bit at a time.
|
||||
|
||||
* * *
|
||||
|
||||
### Debug information primitives
|
||||
|
||||
Next we can implement functions to retrieve line entries and function DIEs from PC values. We’ll start with `get_function_from_pc`:
|
||||
|
||||
```
|
||||
dwarf::die debugger::get_function_from_pc(uint64_t pc) {
|
||||
for (auto &cu : m_dwarf.compilation_units()) {
|
||||
if (die_pc_range(cu.root()).contains(pc)) {
|
||||
for (const auto& die : cu.root()) {
|
||||
if (die.tag == dwarf::DW_TAG::subprogram) {
|
||||
if (die_pc_range(die).contains(pc)) {
|
||||
return die;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
throw std::out_of_range{"Cannot find function"};
|
||||
}
|
||||
```
|
||||
|
||||
Here I take a naive approach of just iterating through compilation units until I find one which contains the program counter, then iterating through the children until we find the relevant function (`DW_TAG_subprogram`). As mentioned in the last post, you could handle things like member functions and inlining here if you wanted.
|
||||
|
||||
Next is `get_line_entry_from_pc`:
|
||||
|
||||
```
|
||||
dwarf::line_table::iterator debugger::get_line_entry_from_pc(uint64_t pc) {
|
||||
for (auto &cu : m_dwarf.compilation_units()) {
|
||||
if (die_pc_range(cu.root()).contains(pc)) {
|
||||
auto < = cu.get_line_table();
|
||||
auto it = lt.find_address(pc);
|
||||
if (it == lt.end()) {
|
||||
throw std::out_of_range{"Cannot find line entry"};
|
||||
}
|
||||
else {
|
||||
return it;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
throw std::out_of_range{"Cannot find line entry"};
|
||||
}
|
||||
```
|
||||
|
||||
Again, we simply find the correct compilation unit, then ask the line table to get us the relevant entry.
|
||||
|
||||
* * *
|
||||
|
||||
### Printing source
|
||||
|
||||
When we hit a breakpoint or step around our code, we’ll want to know where in the source we end up.
|
||||
|
||||
```
|
||||
void debugger::print_source(const std::string& file_name, unsigned line, unsigned n_lines_context) {
|
||||
std::ifstream file {file_name};
|
||||
|
||||
//Work out a window around the desired line
|
||||
auto start_line = line <= n_lines_context ? 1 : line - n_lines_context;
|
||||
auto end_line = line + n_lines_context + (line < n_lines_context ? n_lines_context - line : 0) + 1;
|
||||
|
||||
char c{};
|
||||
auto current_line = 1u;
|
||||
//Skip lines up until start_line
|
||||
while (current_line != start_line && file.get(c)) {
|
||||
if (c == '\n') {
|
||||
++current_line;
|
||||
}
|
||||
}
|
||||
|
||||
//Output cursor if we're at the current line
|
||||
std::cout << (current_line==line ? "> " : " ");
|
||||
|
||||
//Write lines up until end_line
|
||||
while (current_line <= end_line && file.get(c)) {
|
||||
std::cout << c;
|
||||
if (c == '\n') {
|
||||
++current_line;
|
||||
//Output cursor if we're at the current line
|
||||
std::cout << (current_line==line ? "> " : " ");
|
||||
}
|
||||
}
|
||||
|
||||
//Write newline and make sure that the stream is flushed properly
|
||||
std::cout << std::endl;
|
||||
}
|
||||
```
|
||||
|
||||
Now that we can print out source, we’ll need to hook this into our debugger. A good place to do this is when the debugger gets a signal from a breakpoint or (eventually) single step. While we’re at this, we might want to add some better signal handling to our debugger.
|
||||
|
||||
* * *
|
||||
|
||||
### Better signal handling
|
||||
|
||||
We want to be able to tell what signal was sent to the process, but we also want to know how it was produced. For example, we want to be able to tell if we just got a `SIGTRAP` because we hit a breakpoint, or if it was because a step completed, or a new thread spawned, etc. Fortunately, `ptrace` comes to our rescue again. One of the possible commands to `ptrace` is `PTRACE_GETSIGINFO`, which will give you information about the last signal which the process was sent. We use it like so:
|
||||
|
||||
```
|
||||
siginfo_t debugger::get_signal_info() {
|
||||
siginfo_t info;
|
||||
ptrace(PTRACE_GETSIGINFO, m_pid, nullptr, &info);
|
||||
return info;
|
||||
}
|
||||
```
|
||||
|
||||
This gives us a `siginfo_t` object, which provides the following information:
|
||||
|
||||
```
|
||||
siginfo_t {
|
||||
int si_signo; /* Signal number */
|
||||
int si_errno; /* An errno value */
|
||||
int si_code; /* Signal code */
|
||||
int si_trapno; /* Trap number that caused
|
||||
hardware-generated signal
|
||||
(unused on most architectures) */
|
||||
pid_t si_pid; /* Sending process ID */
|
||||
uid_t si_uid; /* Real user ID of sending process */
|
||||
int si_status; /* Exit value or signal */
|
||||
clock_t si_utime; /* User time consumed */
|
||||
clock_t si_stime; /* System time consumed */
|
||||
sigval_t si_value; /* Signal value */
|
||||
int si_int; /* POSIX.1b signal */
|
||||
void *si_ptr; /* POSIX.1b signal */
|
||||
int si_overrun; /* Timer overrun count;
|
||||
POSIX.1b timers */
|
||||
int si_timerid; /* Timer ID; POSIX.1b timers */
|
||||
void *si_addr; /* Memory location which caused fault */
|
||||
long si_band; /* Band event (was int in
|
||||
glibc 2.3.2 and earlier) */
|
||||
int si_fd; /* File descriptor */
|
||||
short si_addr_lsb; /* Least significant bit of address
|
||||
(since Linux 2.6.32) */
|
||||
void *si_lower; /* Lower bound when address violation
|
||||
occurred (since Linux 3.19) */
|
||||
void *si_upper; /* Upper bound when address violation
|
||||
occurred (since Linux 3.19) */
|
||||
int si_pkey; /* Protection key on PTE that caused
|
||||
fault (since Linux 4.6) */
|
||||
void *si_call_addr; /* Address of system call instruction
|
||||
(since Linux 3.5) */
|
||||
int si_syscall; /* Number of attempted system call
|
||||
(since Linux 3.5) */
|
||||
unsigned int si_arch; /* Architecture of attempted system call
|
||||
(since Linux 3.5) */
|
||||
}
|
||||
```
|
||||
|
||||
I’ll just be using `si_signo` to work out which signal was sent, and `si_code` to get more information about the signal. The best place to put this code is in our `wait_for_signal` function:
|
||||
|
||||
```
|
||||
void debugger::wait_for_signal() {
|
||||
int wait_status;
|
||||
auto options = 0;
|
||||
waitpid(m_pid, &wait_status, options);
|
||||
|
||||
auto siginfo = get_signal_info();
|
||||
|
||||
switch (siginfo.si_signo) {
|
||||
case SIGTRAP:
|
||||
handle_sigtrap(siginfo);
|
||||
break;
|
||||
case SIGSEGV:
|
||||
std::cout << "Yay, segfault. Reason: " << siginfo.si_code << std::endl;
|
||||
break;
|
||||
default:
|
||||
std::cout << "Got signal " << strsignal(siginfo.si_signo) << std::endl;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Now to handle `SIGTRAP`s. It suffices to know that `SI_KERNEL` or `TRAP_BRKPT` will be sent when a breakpoint is hit, and `TRAP_TRACE` will be sent on single step completion:
|
||||
|
||||
```
|
||||
void debugger::handle_sigtrap(siginfo_t info) {
|
||||
switch (info.si_code) {
|
||||
//one of these will be set if a breakpoint was hit
|
||||
case SI_KERNEL:
|
||||
case TRAP_BRKPT:
|
||||
{
|
||||
set_pc(get_pc()-1); //put the pc back where it should be
|
||||
std::cout << "Hit breakpoint at address 0x" << std::hex << get_pc() << std::endl;
|
||||
auto line_entry = get_line_entry_from_pc(get_pc());
|
||||
print_source(line_entry->file->path, line_entry->line);
|
||||
return;
|
||||
}
|
||||
//this will be set if the signal was sent by single stepping
|
||||
case TRAP_TRACE:
|
||||
return;
|
||||
default:
|
||||
std::cout << "Unknown SIGTRAP code " << info.si_code << std::endl;
|
||||
return;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
There are a bunch of different signals and flavours of signals which you could handle. See `man sigaction` for more information.
|
||||
|
||||
Since we now correct the program counter when we get the `SIGTRAP`, we can remove this coded from `step_over_breakpoint`, so it now looks like:
|
||||
|
||||
```
|
||||
void debugger::step_over_breakpoint() {
|
||||
if (m_breakpoints.count(get_pc())) {
|
||||
auto& bp = m_breakpoints[get_pc()];
|
||||
if (bp.is_enabled()) {
|
||||
bp.disable();
|
||||
ptrace(PTRACE_SINGLESTEP, m_pid, nullptr, nullptr);
|
||||
wait_for_signal();
|
||||
bp.enable();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Testing it out
|
||||
|
||||
Now you should be able to set a breakpoint at some address, run the program and see the source code printed out with the currently executing line marked with a cursor.
|
||||
|
||||
Next time we’ll be adding the ability to set source-level breakpoints. In the meantime, you can get the code for this post [here][8].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
|
||||
作者:[TartanLlama ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
||||
[8]:https://github.com/TartanLlama/minidbg/tree/tut_source
|
||||
@ -0,0 +1,94 @@
|
||||
Linux's Big Bang: One Kernel, Countless Distros
|
||||
============================================================[Print][1][Email][2]By Jonathan Terrasi
|
||||
Apr 27, 2017 3:24 PM PT
|
||||

|
||||
|
||||
Even if you're a newcomer to Linux, you've probably figured out that it is not a single, monolithic operating system, but a constellation of projects. The different "stars" in this constellation take the form of "distributions," or "distros." Each offers its own take on the Linux model.
|
||||
|
||||
To gain an appreciation of the plethora of options offered by the range of distributions, it helps to understand how Linux started out and subsequently proliferated. With that in mind, here's a brief introduction to Linux's history.
|
||||
|
||||
### Linus Torvalds, Kernel Builder
|
||||
|
||||
Most people with any familiarity with Linux have heard of its creator, Linus Torvalds (pictured above), but not many know why he created it in the first place. In 1991, Torvalds was a university student in Finland studying computers. As an independent personal project, he wanted to create a Unix-like kernel to build a system for his unique hardware.
|
||||
|
||||
The "kernel" is the part of an operating system that mediates between the hardware, via its firmware, and the OS. Essentially, it is the heart of the system. Developing a kernel is no small feat, but Torvalds was eager for the challenge and found he had a rare knack for it.
|
||||
|
||||
As he was new to kernels, he wanted input from others to ensure he was on the right track, so he solicited the experience of veteran tinkerers on Usenet, the foremost among early Internet forums, by publishing the code for his kernel. Contributions flooded in.
|
||||
|
||||
After establishing a process for reviewing forum-submitted patches and selectively integrating them, Torvalds realized he had amassed an informal development team. It quickly became a somewhat formal development team once the project took off.
|
||||
|
||||
### Richard Stallman's Role
|
||||
|
||||
Though Torvalds and his team created the Linux kernel, there would have been no subsequent spread of myriad Linux distributions without the work of Richard Stallman, who had launched the free software movement a decade earlier.
|
||||
|
||||
Frustrated with the lack of transparency in many core Unix programming and system utilities, Stallman had decided to write his own -- and to share the source code freely with anyone who wanted it and also was committed to openness. He created a considerable body of core programs, collectively dubbed the "GNU Project," which he launched in 1983.
|
||||
|
||||
Without them, a kernel would not have been of much use. Early designers of Linux-based OSes readily incorporated the GNU tools into their projects.
|
||||
|
||||
Different teams began to emerge -- each with its own philosophy regarding computing functions and architecture. They combined the Linux kernel, GNU utilities, and their own original software, and "distributed" variants of the Linux operating system.
|
||||
|
||||
### Server Distros
|
||||
|
||||
Each distro has its own design logic and purpose, but to appreciate their nuances it pays to understand the difference between upstream and downstream developers. An "upstream developer" is responsible for actually creating the program and releasing it for individual download, or for including it in other projects. By contrast, a "downstream developer," or "package maintainer," is one who takes each release of the upstream program and tweaks it to fit the use case of a downstream project.
|
||||
|
||||
While most Linux distributions include some original projects, the majority of distribution development is "downstream" work on the Linux kernel, GNU tools, and the vast ecosystem of user programs.
|
||||
|
||||
Many distros make their mark by optimizing for specific use cases. For instance, some projects are designed to run as servers. Distributions tailored for deployment as servers often will shy away from quickly pushing out the latest features from upstream projects in favor of releasing a thoroughly tested, stable base of essential software that system administrators can depend on to run smoothly.
|
||||
|
||||
Development teams for server-focused distros often are large and are staffed with veteran programmers who can provide years of support for each release.
|
||||
|
||||
### Desktop Distros
|
||||
|
||||
There is also a wide array of distributions meant to run as user desktops. In fact, some of the more well-known of these are designed to compete with major commercial OSes by offering a simple installation and intuitive interface. These distributions usually include enormous software repositories containing every user program imaginable, so that users can make their systems their own.
|
||||
|
||||
As usability is key, they are likely to devote a large segment of their staff to creating a signature, distro-specific desktop, or to tweaking existing desktops to fit their design philosophy. User-focused distributions tend to speed up the downstream development timetable a bit to offer their users new features in a timely fashion.
|
||||
|
||||
"Rolling release" projects -- a subset of desktop distributions -- are crafted to be on the bleeding edge. Instead of waiting until all the desired upstream programs reach a certain point of development and then integrating them into a single release, package maintainers for rolling release projects release a new version of each upstream program separately, once they finish tweaking it.
|
||||
|
||||
One advantage to this approach is security, as critical patches will be available faster than non-rolling release distros. Another upside is the immediate availability of new features that users otherwise would have to wait for. The drawback for rolling release distributions is that they require more manual intervention and careful maintenance, as certain upgrades can conflict with others, breaking a system.
|
||||
|
||||
### Embedded Systems
|
||||
|
||||
Yet another class of Linux distros is known as "embedded systems," which are extremely trimmed down (compared to server and desktop distros) to fit particular use cases.
|
||||
|
||||
We often forget that anything that connects to the Internet or is more complex than a simple calculator is a computer, and computers need operating systems. Because Linux is free and highly modular, it's usually the one that hardware manufacturers choose.
|
||||
|
||||
In the vast majority of cases, if you see a smart TV, an Internet-connected camera, or even a car, you're looking at a Linux device. Practically every smartphone that's not an iPhone runs a specialized variety of embedded Linux too.
|
||||
|
||||
### Linux Live
|
||||
|
||||
Finally, there are certain Linux distros that aren't meant to be installed permanently in a computer, but instead reside on a USB stick and allow other computers to boot them up without touching the computer's onboard hard drive.
|
||||
|
||||
These "live" systems can be optimized to perform a number of tasks, ranging from repairing damaged systems, to conducting security evaluations, to browsing the Internet with high security.
|
||||
|
||||
As these live Linux distros usually are meant for tackling very specific problems, they generally include specialized tools like hard drive analysis and recovery programs, network monitoring applications, and encryption tools. They also keep a light footprint so they can be booted up quickly.
|
||||
|
||||
### How Do You Choose?
|
||||
|
||||
This is by no means an exhaustive list of Linux distribution types, but it should give you an idea of the scope and variety of the Linux ecosystem.
|
||||
|
||||
Within each category, there are many choices, so how do you choose the one that might best suit your needs?
|
||||
|
||||
One way is to experiment. It is very common in the Linux community to go back and forth between distros to try them out, or for users to run different ones on different machines, according to their needs.
|
||||
|
||||
In a future post, I'll showcase a few examples of each type of distribution so you can try them for yourself and begin your journey to discovering the one you like best.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jonathan Terrasi has been an ECT News Network columnist since 2017. His main interests are computer security (particularly with the Linux desktop), encryption, and analysis of politics and current affairs. He is a full-time freelance writer and musician. His background includes providing technical commentaries and analyses in articles published by the Chicago Committee to Defend the Bill of Rights.
|
||||
|
||||
------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84489.html?rss=1
|
||||
|
||||
作者:[ Jonathan Terrasi ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxinsider.com/story/84489.html?rss=1#searchbyline
|
||||
[1]:http://www.linuxinsider.com/story/84489.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84489
|
||||
@ -1,83 +0,0 @@
|
||||
T-UI Launcher – Turns Android Device into Linux Command Line Interface
|
||||
============================================================
|
||||
|
||||
Are you a command line guru, or do you simply want to make your Android device unusable for friends and family, then check out T-UI Launcher app. Unix/Linux users will definitely love this.
|
||||
|
||||
T-UI Launcher is a free lightweight Android app with a Linux-like CLI (Command Line Interface) that turns your regular Android device into a complete command line interface. It is a simple, quick and smart launcher for those who love to work with text-based interfaces.
|
||||
|
||||
#### T-UI Launcher Features
|
||||
|
||||
Below are some of its notable features:
|
||||
|
||||
* Shows quick usage guide after the first launch.
|
||||
|
||||
* It’s fast and fully customizable.
|
||||
|
||||
* Offers to autocomplete menu with fast, powerful alias system.
|
||||
|
||||
* Also, provides predictive suggestions and offers a serviceable search function.
|
||||
|
||||
It is free, and you can [download and install][1] it from Google Play Store, then run it on your Android device.
|
||||
|
||||
Once you have installed it, you’ll be shown a quick usage guide when you first launch it. After reading the guide, you can start using it with simple commands as the ones explained below.
|
||||
|
||||
[][2]
|
||||
|
||||
T-UI Commandline Help Guide
|
||||
|
||||
To launch an app, simply type the first few letter in its name and the auto completion functionality will show all the available apps on the screen. Then click on the one you want to open.
|
||||
|
||||
```
|
||||
$ Telegram #launch telegram
|
||||
$ WhatsApp #launch whatsapp
|
||||
$ Chrome #launch chrome
|
||||
```
|
||||
[][3]
|
||||
|
||||
T-UI Commandline Usage
|
||||
|
||||
To view your Android device status (battery charge, wifi, mobile data), type.
|
||||
|
||||
```
|
||||
$ status
|
||||
```
|
||||
[][4]
|
||||
|
||||
Android Phone Status
|
||||
|
||||
Other useful commands you can use.
|
||||
|
||||
```
|
||||
$ uninstall telegram #uninstall telegram
|
||||
$ search [google, playstore, youtube, files] #search online apps or for a local file
|
||||
$ wifi #trun wifi on or off
|
||||
$ cp Downloads/* Music #copy all files from Download folder to Music
|
||||
$ mv Downloads/* Music #move all files from Download folder to Music
|
||||
```
|
||||
|
||||
That’s all! In this article, we reviewed simple yet useful Android app with a Linux-like CLI (Command Line Interface) that turns your regular Android device into a complete command line interface. Give it a try and share your thoughts with us via the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/t-ui-launcher-turns-android-device-into-linux-cli/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://play.google.com/store/apps/details?id=ohi.andre.consolelauncher
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Help.jpg
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Usage.jpg
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Status.jpg
|
||||
[5]:https://www.tecmint.com/author/aaronkili/
|
||||
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,283 @@
|
||||
ictlyh Translating
|
||||
Writing a Linux Debugger Part 6: Source-level stepping
|
||||
============================================================
|
||||
|
||||
A couple of posts ago we learned about DWARF information and how it lets us relate the machine code to the high-level source. This time we’ll be putting this knowledge into practice by adding source-level stepping to our debugger.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][1]
|
||||
|
||||
2. [Breakpoints][2]
|
||||
|
||||
3. [Registers and memory][3]
|
||||
|
||||
4. [Elves and dwarves][4]
|
||||
|
||||
5. [Source and signals][5]
|
||||
|
||||
6. [Source-level stepping][6]
|
||||
|
||||
7. Source-level breakpoints
|
||||
|
||||
8. Stack unwinding
|
||||
|
||||
9. Reading variables
|
||||
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### Exposing instruction-level stepping
|
||||
|
||||
But we’re getting ahead of ourselves. First let’s expose instruction-level single stepping through the user interface. I decided to split it between a `single_step_instruction` which can be used by other parts of the code, and a `single_step_instruction_with_breakpoint_check` which ensures that any breakpoints are disabled and re-enabled.
|
||||
|
||||
```
|
||||
void debugger::single_step_instruction() {
|
||||
ptrace(PTRACE_SINGLESTEP, m_pid, nullptr, nullptr);
|
||||
wait_for_signal();
|
||||
}
|
||||
|
||||
void debugger::single_step_instruction_with_breakpoint_check() {
|
||||
//first, check to see if we need to disable and enable a breakpoint
|
||||
if (m_breakpoints.count(get_pc())) {
|
||||
step_over_breakpoint();
|
||||
}
|
||||
else {
|
||||
single_step_instruction();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
As usual, another command gets lumped into our `handle_command` function:
|
||||
|
||||
```
|
||||
else if(is_prefix(command, "stepi")) {
|
||||
single_step_instruction_with_breakpoint_check();
|
||||
auto line_entry = get_line_entry_from_pc(get_pc());
|
||||
print_source(line_entry->file->path, line_entry->line);
|
||||
}
|
||||
```
|
||||
|
||||
With these functions added we can begin to implement our source-level stepping functions.
|
||||
|
||||
* * *
|
||||
|
||||
### Implementing the steps
|
||||
|
||||
We’re going to write very simple versions of these functions, but real debuggers tend to have the concept of a _thread plan_ which encapsulates all of the stepping information. For example, a debugger might have some complex logic to determine breakpoint sites, then have some callback which determines whether or not the step operation has completed. This is a lot of infrastructure to get in place, so we’ll just take a naive approach. We might end up accidentally stepping over breakpoints, but you can spend some time getting all the details right if you like.
|
||||
|
||||
For `step_out`, we’ll just set a breakpoint at the return address of the function and continue. I don’t want to get into the details of stack unwinding yet – that’ll come in a later part – but it suffices to say for now that the return address is stored 8 bytes after the start of a stack frame. So we’ll just read the frame pointer and read a word of memory at the relevant address:
|
||||
|
||||
```
|
||||
void debugger::step_out() {
|
||||
auto frame_pointer = get_register_value(m_pid, reg::rbp);
|
||||
auto return_address = read_memory(frame_pointer+8);
|
||||
|
||||
bool should_remove_breakpoint = false;
|
||||
if (!m_breakpoints.count(return_address)) {
|
||||
set_breakpoint_at_address(return_address);
|
||||
should_remove_breakpoint = true;
|
||||
}
|
||||
|
||||
continue_execution();
|
||||
|
||||
if (should_remove_breakpoint) {
|
||||
remove_breakpoint(return_address);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`remove_breakpoint` is a little helper function:
|
||||
|
||||
```
|
||||
void debugger::remove_breakpoint(std::intptr_t addr) {
|
||||
if (m_breakpoints.at(addr).is_enabled()) {
|
||||
m_breakpoints.at(addr).disable();
|
||||
}
|
||||
m_breakpoints.erase(addr);
|
||||
}
|
||||
```
|
||||
|
||||
Next is `step_in`. A simple algorithm is to just keep on stepping over instructions until we get to a new line.
|
||||
|
||||
```
|
||||
void debugger::step_in() {
|
||||
auto line = get_line_entry_from_pc(get_pc())->line;
|
||||
|
||||
while (get_line_entry_from_pc(get_pc())->line == line) {
|
||||
single_step_instruction_with_breakpoint_check();
|
||||
}
|
||||
|
||||
auto line_entry = get_line_entry_from_pc(get_pc());
|
||||
print_source(line_entry->file->path, line_entry->line);
|
||||
}
|
||||
```
|
||||
|
||||
`step_over` is the most difficult of the three for us. Conceptually, the solution is to just set a breakpoint at the next source line, but what is the next source line? It might not be the one directly succeeding the current line, as we could be in a loop, or some conditional construct. Real debuggers will often examine what instruction is being executed and work out all of the possible branch targets, then set breakpoints on all of them. I’d rather not implement or integrate an x86 instruction emulator for such a small project, so we’ll need to come up with a simpler solution. A couple of horrible options are to just keep stepping until we’re at a new line in the current function, or to just set a breakpoint at every line in the current function. The former would be ridiculously inefficient if we’re stepping over a function call, as we’d need to single step through every single instruction in that call graph, so I’ll go for the second solution.
|
||||
|
||||
```
|
||||
void debugger::step_over() {
|
||||
auto func = get_function_from_pc(get_pc());
|
||||
auto func_entry = at_low_pc(func);
|
||||
auto func_end = at_high_pc(func);
|
||||
|
||||
auto line = get_line_entry_from_pc(func_entry);
|
||||
auto start_line = get_line_entry_from_pc(get_pc());
|
||||
|
||||
std::vector<std::intptr_t> to_delete{};
|
||||
|
||||
while (line->address < func_end) {
|
||||
if (line->address != start_line->address && !m_breakpoints.count(line->address)) {
|
||||
set_breakpoint_at_address(line->address);
|
||||
to_delete.push_back(line->address);
|
||||
}
|
||||
++line;
|
||||
}
|
||||
|
||||
auto frame_pointer = get_register_value(m_pid, reg::rbp);
|
||||
auto return_address = read_memory(frame_pointer+8);
|
||||
if (!m_breakpoints.count(return_address)) {
|
||||
set_breakpoint_at_address(return_address);
|
||||
to_delete.push_back(return_address);
|
||||
}
|
||||
|
||||
continue_execution();
|
||||
|
||||
for (auto addr : to_delete) {
|
||||
remove_breakpoint(addr);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This function is a bit more complex, so I’ll break it down a bit.
|
||||
|
||||
```
|
||||
auto func = get_function_from_pc(get_pc());
|
||||
auto func_entry = at_low_pc(func);
|
||||
auto func_end = at_high_pc(func);
|
||||
```
|
||||
|
||||
`at_low_pc` and `at_high_pc` are functions from `libelfin` which will get us the low and high PC values for the given function DIE.
|
||||
|
||||
```
|
||||
auto line = get_line_entry_from_pc(func_entry);
|
||||
auto start_line = get_line_entry_from_pc(get_pc());
|
||||
|
||||
std::vector<std::intptr_t> breakpoints_to_remove{};
|
||||
|
||||
while (line->address < func_end) {
|
||||
if (line->address != start_line->address && !m_breakpoints.count(line->address)) {
|
||||
set_breakpoint_at_address(line->address);
|
||||
breakpoints_to_remove.push_back(line->address);
|
||||
}
|
||||
++line;
|
||||
}
|
||||
```
|
||||
|
||||
We’ll need to remove any breakpoints we set so that they don’t leak out of our step function, so we keep track of them in a `std::vector`. To set all the breakpoints, we loop over the line table entries until we hit one which is outside the range of our function. For each one, we make sure that it’s not the line we are currently on, and that there’s not already a breakpoint set at that location.
|
||||
|
||||
```
|
||||
auto frame_pointer = get_register_value(m_pid, reg::rbp);
|
||||
auto return_address = read_memory(frame_pointer+8);
|
||||
if (!m_breakpoints.count(return_address)) {
|
||||
set_breakpoint_at_address(return_address);
|
||||
to_delete.push_back(return_address);
|
||||
}
|
||||
```
|
||||
|
||||
Here we are setting a breakpoint on the return address of the function, just like in `step_out`.
|
||||
|
||||
```
|
||||
continue_execution();
|
||||
|
||||
for (auto addr : to_delete) {
|
||||
remove_breakpoint(addr);
|
||||
}
|
||||
```
|
||||
|
||||
Finally, we continue until one of those breakpoints has been hit, then remove all the temporary breakpoints we set.
|
||||
|
||||
It ain’t pretty, but it’ll do for now.
|
||||
|
||||
Of course, we also need to add this new functionality to our UI:
|
||||
|
||||
```
|
||||
else if(is_prefix(command, "step")) {
|
||||
step_in();
|
||||
}
|
||||
else if(is_prefix(command, "next")) {
|
||||
step_over();
|
||||
}
|
||||
else if(is_prefix(command, "finish")) {
|
||||
step_out();
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Testing it out
|
||||
|
||||
I tested out my implementation with a simple program which calls a bunch of different functions:
|
||||
|
||||
```
|
||||
void a() {
|
||||
int foo = 1;
|
||||
}
|
||||
|
||||
void b() {
|
||||
int foo = 2;
|
||||
a();
|
||||
}
|
||||
|
||||
void c() {
|
||||
int foo = 3;
|
||||
b();
|
||||
}
|
||||
|
||||
void d() {
|
||||
int foo = 4;
|
||||
c();
|
||||
}
|
||||
|
||||
void e() {
|
||||
int foo = 5;
|
||||
d();
|
||||
}
|
||||
|
||||
void f() {
|
||||
int foo = 6;
|
||||
e();
|
||||
}
|
||||
|
||||
int main() {
|
||||
f();
|
||||
}
|
||||
```
|
||||
|
||||
You should be able to set a breakpoint on the address of `main` and then in, over, and out all over the program. Expect things to break if you try to step out of `main` or into some dynamically linked library.
|
||||
|
||||
You can find the code for this post [here][7]. Next time we’ll use our newfound DWARF expertise to implement source-level breakpoints.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
|
||||
作者:[TartanLlama ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/TartanLlama/minidbg/tree/tut_dwarf_step
|
||||
@ -0,0 +1,111 @@
|
||||
ttyload – Shows a Color-coded Graph of Linux Load Average in Terminal
|
||||
============================================================
|
||||
|
||||
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][12] | [4 Free Shell Scripting eBooks][13]
|
||||
|
||||
ttyload is a lightweight utility which is intended to offer a color-coded graph of load averages over time on Linux and other Unix-like systems. It enables a graphical tracking of system load average in a terminal (“tty“).
|
||||
|
||||
It is known to run on systems such as Linux, IRIX, Solaris, FreeBSD, MacOS X (Darwin) and Isilon OneFS. It is designed to be easy to port to other platforms, but this comes with some hard work.
|
||||
|
||||
Some of its notable features are: it uses fairly standard, but hard-coded, ANSI escape sequences for screen manipulation and colorization. And also comes with (but doesn’t install, or even build by default) a relatively self-contained load bomb, if you want to view how things work on an otherwise unloaded system.
|
||||
|
||||
**Suggested Read:** [GoTTY – Share Your Linux Terminal (TTY) as a Web Application][1]
|
||||
|
||||
In this article, we will show you how to install and use ttyload in Linux to view a color-coded graph of your system load average in a terminal.
|
||||
|
||||
### How to Install ttyload in Linux Systems
|
||||
|
||||
On Debian/Ubuntu based distributions, you can install ttyload from the default system respositores by typing the following [apt-get command][2].
|
||||
|
||||
```
|
||||
$ sudo apt-get install ttyload
|
||||
```
|
||||
|
||||
On Other Linux distributions you can install ttyload from the source as shown.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/lindes/ttyload.git
|
||||
$ cd ttyload
|
||||
$ make
|
||||
$ ./ttyload
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
Once installed, you can start it by typing the following command.
|
||||
|
||||
```
|
||||
$ ttyload
|
||||
```
|
||||
[][3]
|
||||
|
||||
ttyload – Graphical View of Linux Load Average
|
||||
|
||||
Note: To close the program simply press `[Ctrl+C]` keys.
|
||||
|
||||
You can also define the number of seconds in the interval between refreshes. Default value is 4, and the minimum is 1.
|
||||
|
||||
```
|
||||
$ ttyload -i 5
|
||||
$ ttyload -i 1
|
||||
```
|
||||
|
||||
To run it in a monochrome mode which turns off ANSI escapes, use the `-m` as follows.
|
||||
|
||||
```
|
||||
$ ttyload -m
|
||||
```
|
||||
[][4]
|
||||
|
||||
ttyload – Monochrome Mode
|
||||
|
||||
To get the ttyload usage info and help, type.
|
||||
|
||||
```
|
||||
$ ttyload -h
|
||||
```
|
||||
|
||||
Below are some of its important features yet to be added:
|
||||
|
||||
* Support for arbitrary sizing.
|
||||
|
||||
* Make an X front end using the same basic engine, to have “3xload”.
|
||||
|
||||
* Logging-oriented mode.
|
||||
|
||||
For more information, check out the ttyload Homepage: [http://www.daveltd.com/src/util/ttyload/][5]
|
||||
|
||||
Thats all for now! In this article, we showed you how to install and use ttyload in Linux. Write back to us via the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
|
||||
|
||||
-------------------
|
||||
|
||||
via: https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/gotty-share-linux-terminal-in-web-browser/
|
||||
[2]:https://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2017/05/ttyload-Graphical-View-of-Linux-Load-Average-.png
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/05/ttyload-monochrome-mode.png
|
||||
[5]:http://www.daveltd.com/src/util/ttyload/
|
||||
[6]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#
|
||||
[7]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#
|
||||
[8]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#
|
||||
[9]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#
|
||||
[10]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#comments
|
||||
[11]:https://www.tecmint.com/author/aaronkili/
|
||||
[12]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[13]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,5 +1,6 @@
|
||||
How to Password Protect a Vim File in Linux
|
||||
============================================================
|
||||
ch-cn translating
|
||||
|
||||
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][16] | [4 Free Shell Scripting eBooks][17]
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
wcnnbdk1 translating
|
||||
ssh_scan – Verifies Your SSH Server Configuration and Policy in Linux
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,358 @@
|
||||
How to Configure and Integrate iRedMail Services to Samba4 AD DC – Part 11
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
In this tutorial will learn how to modify iRedMail main daemons which provide mail services, respectively, [Postfix used for mail transfer and Dovecot][4] which delivers mail to accounts mailboxes, in order to integrate them both in [Samba4 Active Directory Domain Controller][5].
|
||||
|
||||
By integrating iRedMail to a Samba4 AD DC you will benefit from the following features: user authentication, management, and status via Samba AD DC, create mail lists with the help of AD groups and Global LDAP Address Book in Roundcube.
|
||||
|
||||
#### Requirements
|
||||
|
||||
1. [Install iRedMail on CentOS 7 for Samba4 AD Integration][1]
|
||||
|
||||
### Step 1: Prepare iRedMail System for Sama4 AD Integration
|
||||
|
||||
1. On the first step, you need to [assign a static IP address for your machine][6] in case you’re using a dynamic IP address provided by a DHCP server.
|
||||
|
||||
Run [ifconfig command][7] to list your machine network interfaces names and edit the proper network interface with your custom IP settings by issuing [nmtui-edit][8] command against the correct NIC.
|
||||
|
||||
Run nmtui-edit command with root privileges.
|
||||
|
||||
```
|
||||
# ifconfig
|
||||
# nmtui-edit eno16777736
|
||||
```
|
||||
[][9]
|
||||
|
||||
Find Network Interface Name
|
||||
|
||||
2. Once the network interface is opened for editing, add the proper static IP settings, make sure you add the DNS servers IP addresses of your Samba4 AD DC and the name of your domain in order to query the realm from your machine. Use the below screenshot as a guide.
|
||||
|
||||
[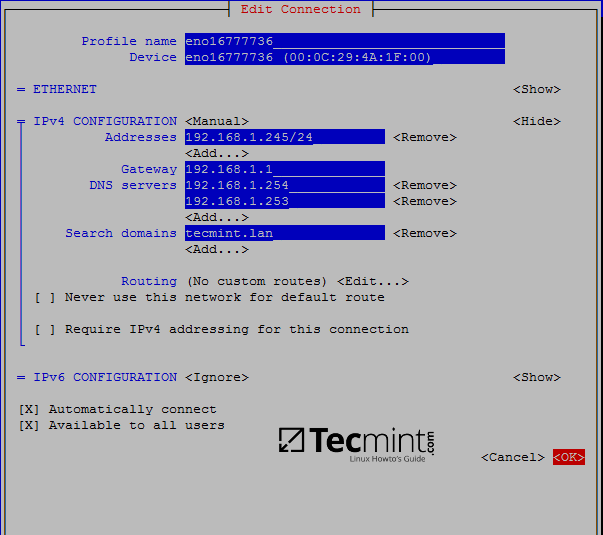][10]
|
||||
|
||||
Configure Network Settings
|
||||
|
||||
3. After you finish configuring the network interface, restart the network daemon to apply changes and issue a series of ping commands against the domain name and samba4 domain controllers FQDNs.
|
||||
|
||||
```
|
||||
# systemctl restart network.service
|
||||
# cat /etc/resolv.conf # verify DNS resolver configuration if the correct DNS servers IPs are queried for domain resolution
|
||||
# ping -c2 tecmint.lan # Ping domain name
|
||||
# ping -c2 adc1 # Ping first AD DC
|
||||
# ping -c2 adc2 # Ping second AD DC
|
||||
```
|
||||
[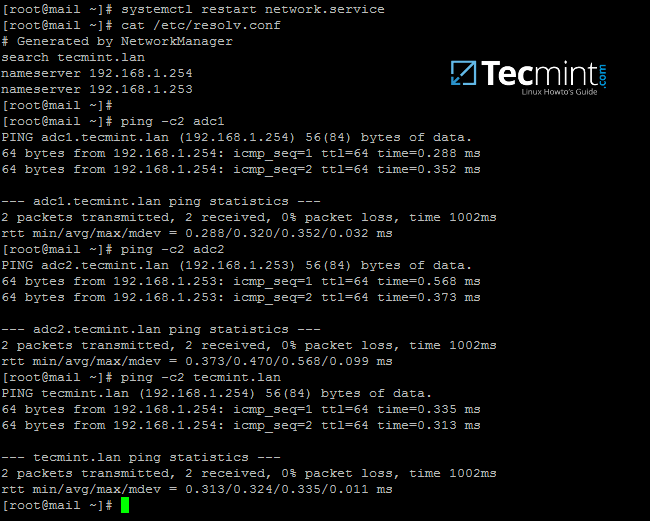][11]
|
||||
|
||||
Verify Network DNS Configuration
|
||||
|
||||
4. Next, sync time with samba domain controller by installing the ntpdate package and query Samba4 machine NTP server by issuing the below commands:
|
||||
|
||||
```
|
||||
# yum install ntpdate
|
||||
# ntpdate -qu tecmint.lan # querry domain NTP servers
|
||||
# ntpdate tecmint.lan # Sync time with the domain
|
||||
```
|
||||
[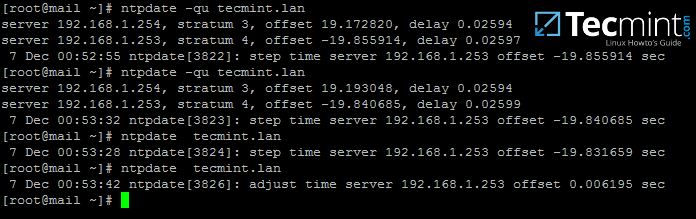][12]
|
||||
|
||||
Sync Time with Samba NTP Server
|
||||
|
||||
5. You might want the local time to be automatically synchronized with samba AD time server. In order to achieve this setting, add a scheduled job to run every hour by issuing [crontab -e command][13] and append the following line:
|
||||
|
||||
```
|
||||
0 */1 * * * /usr/sbin/ntpdate tecmint.lan > /var/log/ntpdate.lan 2>&1
|
||||
```
|
||||
[][14]
|
||||
|
||||
Auto Sync Time with Samba NTP
|
||||
|
||||
### Step 2: Prepare Samba4 AD DC for iRedMail Integration
|
||||
|
||||
6. Now, move to a [Windows machine with RSAT tools installed][15] to manage Samba4 Active Directory as described in this tutorial [here][16].
|
||||
|
||||
Open DNS Manager, go to your domain Forward Lookup Zones and add a new A record, an MX record and a PTR record to point to your iRedMail system IP address. Use the below screenshots as a guide.
|
||||
|
||||
Add A record (replace the name and the IP Address of iRedMail machine accordingly).
|
||||
|
||||
[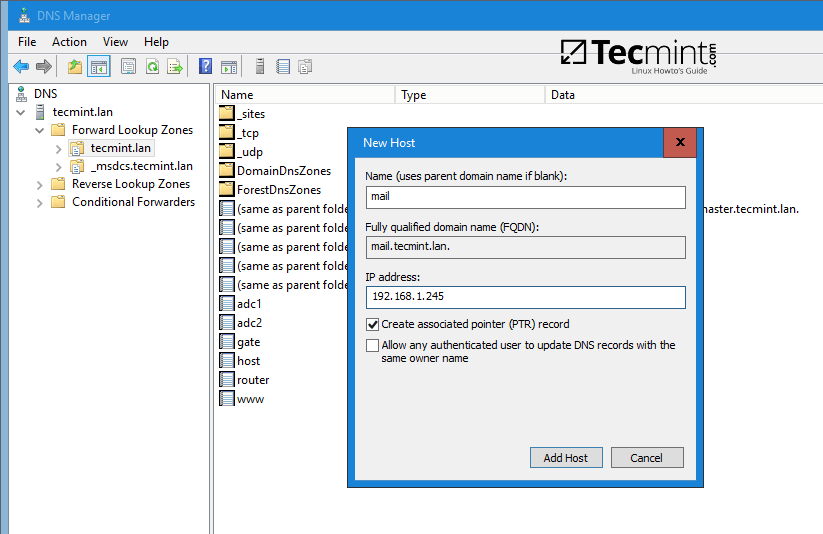][17]
|
||||
|
||||
Create DNS A Record for iRedMail
|
||||
|
||||
Add MX record (leave child domain blank and add a 10 priority for this mail server).
|
||||
|
||||
[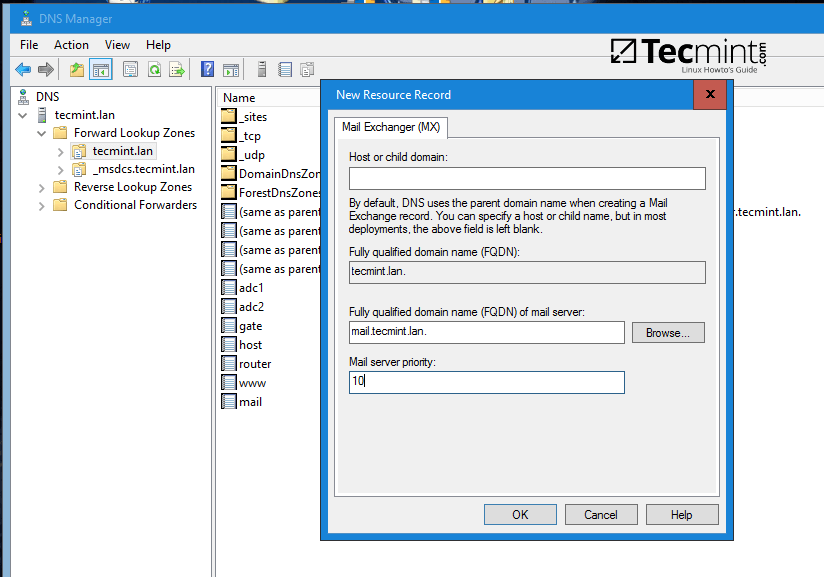][18]
|
||||
|
||||
Create DNS MX Record for iRedMail
|
||||
|
||||
Add PTR record by expanding to Reverse Lookup Zones (replace IP address of iRedMail server accordingly). In case you haven’t configured a reverse zone for your domain controller so far, read the following tutorial:
|
||||
|
||||
1. [Manage Samba4 DNS Group Policy from Windows][2]
|
||||
|
||||
[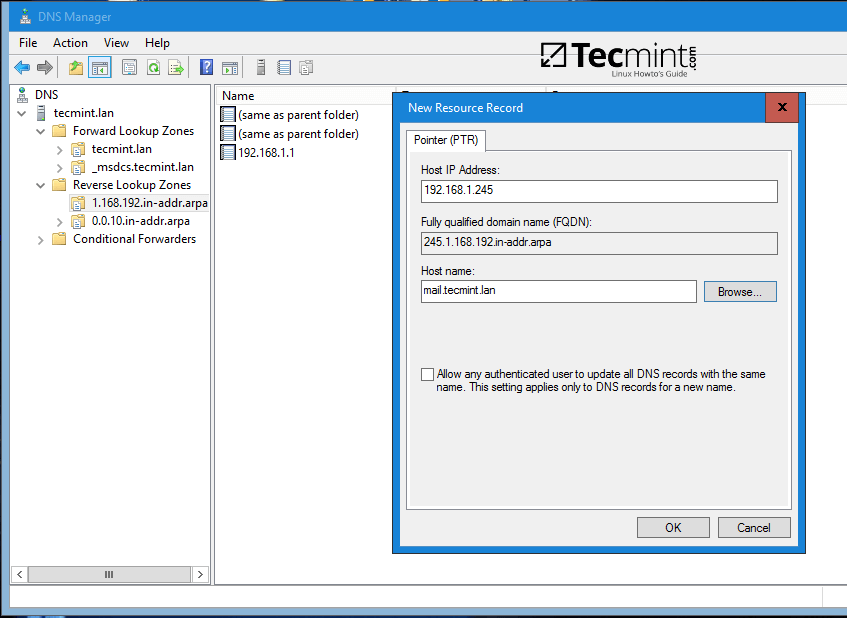][19]
|
||||
|
||||
Create DNS PTR Record for iRedMail
|
||||
|
||||
7. After you’ve added the basic DNS records which make a mail server to function properly, move to the iRedMail machine, install bind-utils package and query the newly added mail records as suggested on the below excerpt.
|
||||
|
||||
Samba4 AD DC DNS server should respond with the DNS records added in the previous step.
|
||||
|
||||
```
|
||||
# yum install bind-utils
|
||||
# host tecmint.lan
|
||||
# host mail.tecmint.lan
|
||||
# host 192.168.1.245
|
||||
```
|
||||
[][20]
|
||||
|
||||
Install Bind and Query Mail Records
|
||||
|
||||
From a Windows machine, open a Command Prompt window and issue [nslookup command][21] against the above mail server records.
|
||||
|
||||
8. As a final pre-requirement, create a new user account with minimal privileges in Samba4 AD DC with the name vmail, choose a strong password for this user and make sure the password for this user never expires.
|
||||
|
||||
The vmail user account will be used by iRedMail services to query Samba4 AD DC LDAP database and pull the email accounts.
|
||||
|
||||
To create the vmail account, use ADUC graphical tool from a Windows machine joined to the realm with RSAT tools installed as illustrated on the below screenshots or use samba-tool command line directly from a domain controller as explained on the following topic.
|
||||
|
||||
1. [Manage Samba4 Active Directory from Linux Command Line][3]
|
||||
|
||||
In this guide, we’ll use the first method mentioned above.
|
||||
|
||||
[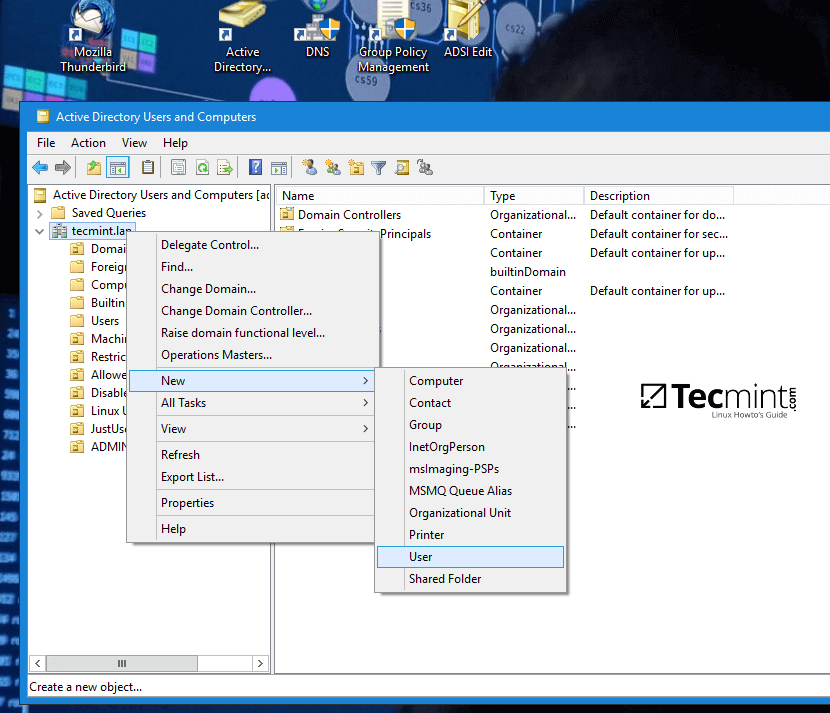][22]
|
||||
|
||||
Active Directory Users and Computers
|
||||
|
||||
[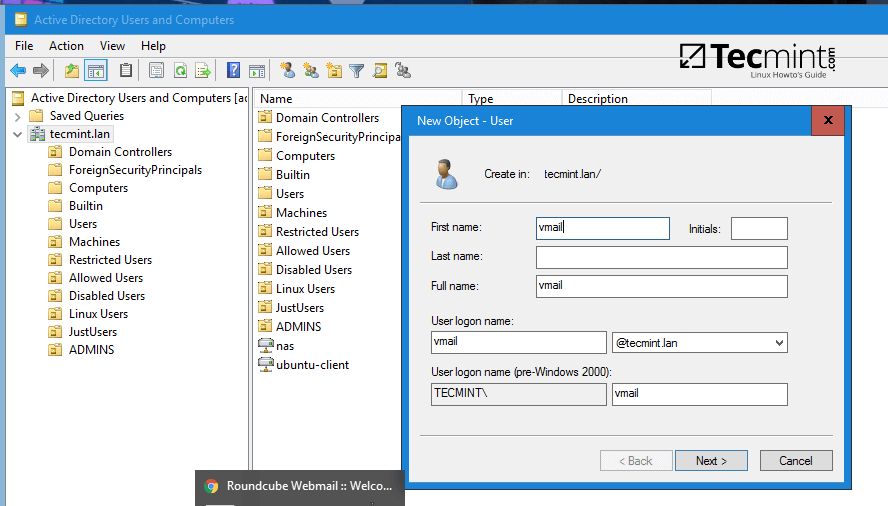][23]
|
||||
|
||||
Create New User for iRedMail
|
||||
|
||||
[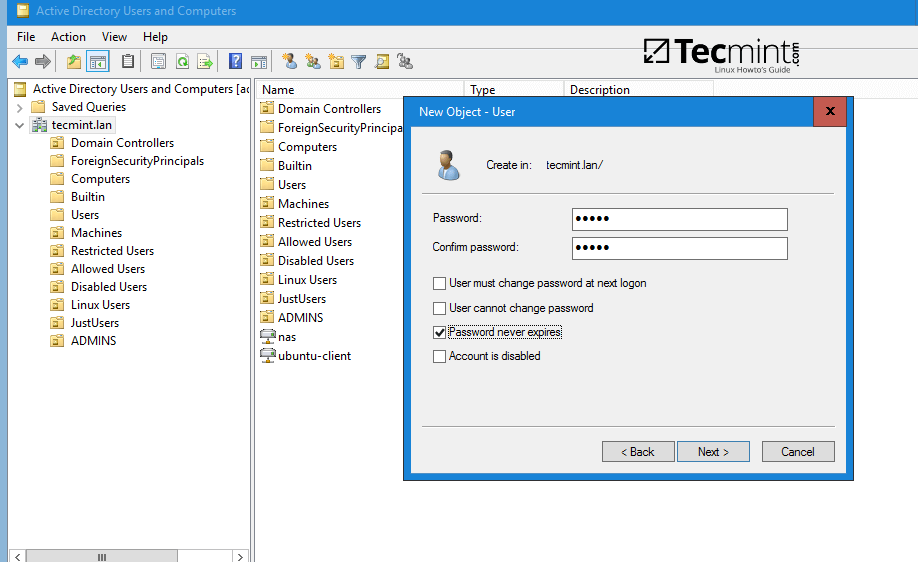][24]
|
||||
|
||||
Set Strong Password for User
|
||||
|
||||
9. From iRedMail system, test the vmail user ability to query Samba4 AD DC LDAP database by issuing the below command. The returned result should be a total number of objects entries for your domain as illustrated on the below screenshots.
|
||||
|
||||
```
|
||||
# ldapsearch -x -h tecmint.lan -D 'vmail@tecmint.lan' -W -b 'cn=users,dc=tecmint,dc=lan'
|
||||
```
|
||||
|
||||
Note: Replace the domain name and the LDAP base dn in Samba4 AD (‘cn=users,dc=tecmint,dc=lan‘) accordingly.
|
||||
|
||||
[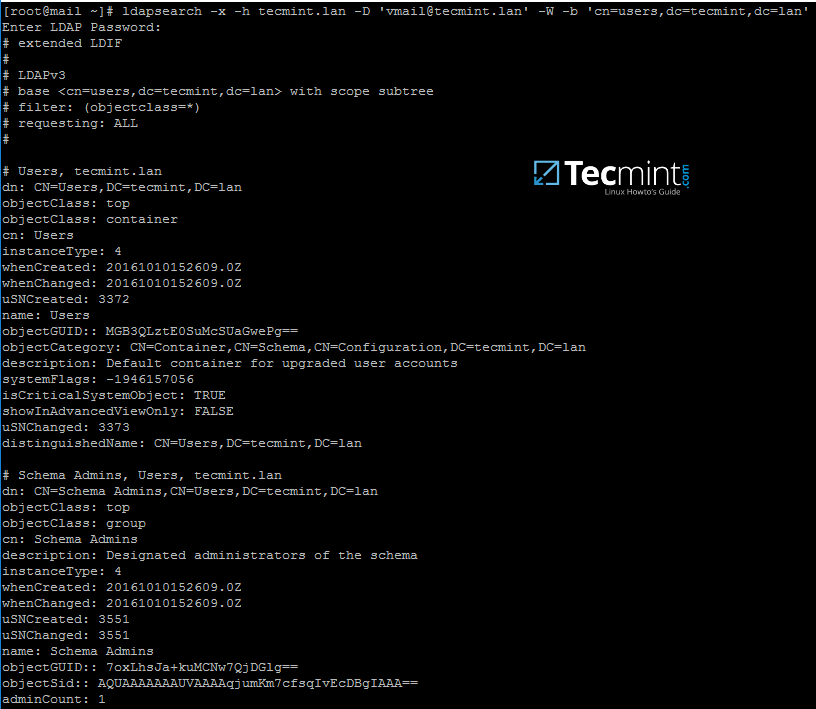][25]
|
||||
|
||||
Query Samba4 AD DC LDAP
|
||||
|
||||
### Step 3: Integrate iRedMail Services to Samba4 AD DC
|
||||
|
||||
10. Now it’s time to tamper with iRedMail services (Postfix, Dovecot and Roundcube) in order to query Samba4 Domain Controller for mail accounts.
|
||||
|
||||
The first service to be modified will be the MTA agent, Postfix. Issue the following commands to disable a series of MTA settings, add your domain name to Postfix local domain and mailbox domains and use Dovecot agent to deliver received mails locally to user mailboxes.
|
||||
|
||||
```
|
||||
# postconf -e virtual_alias_maps=' '
|
||||
# postconf -e sender_bcc_maps=' '
|
||||
# postconf -e recipient_bcc_maps= ' '
|
||||
# postconf -e relay_domains=' '
|
||||
# postconf -e relay_recipient_maps=' '
|
||||
# postconf -e sender_dependent_relayhost_maps=' '
|
||||
# postconf -e smtpd_sasl_local_domain='tecmint.lan' #Replace with your own domain
|
||||
# postconf -e virtual_mailbox_domains='tecmint.lan' #Replace with your own domain
|
||||
# postconf -e transport_maps='hash:/etc/postfix/transport'
|
||||
# postconf -e smtpd_sender_login_maps='proxy:ldap:/etc/postfix/ad_sender_login_maps.cf' # Check SMTP senders
|
||||
# postconf -e virtual_mailbox_maps='proxy:ldap:/etc/postfix/ad_virtual_mailbox_maps.cf' # Check local mail accounts
|
||||
# postconf -e virtual_alias_maps='proxy:ldap:/etc/postfix/ad_virtual_group_maps.cf' # Check local mail lists
|
||||
# cp /etc/postfix/transport /etc/postfix/transport.backup # Backup transport conf file
|
||||
# echo "tecmint.lan dovecot" > /etc/postfix/transport # Add your domain with dovecot transport
|
||||
# cat /etc/postfix/transport # Verify transport file
|
||||
# postmap hash:/etc/postfix/transport
|
||||
```
|
||||
|
||||
11. Next, create Postfix `/etc/postfix/ad_sender_login_maps.cf` configuration file with your favorite text editor and add the below configuration.
|
||||
|
||||
```
|
||||
server_host = tecmint.lan
|
||||
server_port = 389
|
||||
version = 3
|
||||
bind = yes
|
||||
start_tls = no
|
||||
bind_dn = vmail@tecmint.lan
|
||||
bind_pw = ad_vmail_account_password
|
||||
search_base = dc=tecmint,dc=lan
|
||||
scope = sub
|
||||
query_filter = (&(userPrincipalName=%s)(objectClass=person)(!(userAccountControl:1.2.840.113556.1.4.803:=2)))
|
||||
result_attribute= userPrincipalName
|
||||
debuglevel = 0
|
||||
```
|
||||
|
||||
12. Create `/etc/postfix/ad_virtual_mailbox_maps.cf` with the following configuration.
|
||||
|
||||
```
|
||||
server_host = tecmint.lan
|
||||
server_port = 389
|
||||
version = 3
|
||||
bind = yes
|
||||
start_tls = no
|
||||
bind_dn = vmail@tecmint.lan
|
||||
bind_pw = ad_vmail_account_password
|
||||
search_base = dc=tecmint,dc=lan
|
||||
scope = sub
|
||||
query_filter = (&(objectclass=person)(userPrincipalName=%s))
|
||||
result_attribute= userPrincipalName
|
||||
result_format = %d/%u/Maildir/
|
||||
debuglevel = 0
|
||||
```
|
||||
|
||||
13. Create `/etc/postfix/ad_virtual_group_maps.cf` with the below configuration.
|
||||
|
||||
```
|
||||
server_host = tecmint.lan
|
||||
server_port = 389
|
||||
version = 3
|
||||
bind = yes
|
||||
start_tls = no
|
||||
bind_dn = vmail@tecmint.lan
|
||||
bind_pw = ad_vmail_account_password
|
||||
search_base = dc=tecmint,dc=lan
|
||||
scope = sub
|
||||
query_filter = (&(objectClass=group)(mail=%s))
|
||||
special_result_attribute = member
|
||||
leaf_result_attribute = mail
|
||||
result_attribute= userPrincipalName
|
||||
debuglevel = 0
|
||||
```
|
||||
|
||||
On all three configuration files replace the values from server_host, bind_dn, bind_pw and search_base to reflect your own domain custom settings.
|
||||
|
||||
14. Next, open Postfix main configuration file and search and disable iRedAPD check_policy_service and smtpd_end_of_data_restrictions by adding a comment `#` in front of the following lines.
|
||||
|
||||
```
|
||||
# nano /etc/postfix/main.cf
|
||||
```
|
||||
|
||||
Comment the following lines:
|
||||
|
||||
```
|
||||
#check_policy_service inet:127.0.0.1:7777
|
||||
#smtpd_end_of_data_restrictions = check_policy_service inet:127.0.0.1:7777
|
||||
```
|
||||
|
||||
15. Now, verify Postfix binding to Samba AD using an existing domain user and a domain group by issuing a series of queries as presented in the following examples.
|
||||
|
||||
The result should be similar as illustrated on the bellow screenshot.
|
||||
|
||||
```
|
||||
# postmap -q tecmint_user@tecmint.lan ldap:/etc/postfix/ad_virtual_mailbox_maps.cf
|
||||
# postmap -q tecmint_user@tecmint.lan ldap:/etc/postfix/ad_sender_login_maps.cf
|
||||
# postmap -q linux_users@tecmint.lan ldap:/etc/postfix/ad_virtual_group_maps.cf
|
||||
```
|
||||
[][26]
|
||||
|
||||
Verify Postfix Binding to Samba AD
|
||||
|
||||
Replace AD user and group accounts accordingly. Also, assure that the AD group you’re using has some AD users members assigned to it.
|
||||
|
||||
16. On the next step modify Dovecot configuration file in order to query Samba4 AD DC. Open file `/etc/dovecot/dovecot-ldap.conf` for editing and add the following lines.
|
||||
|
||||
```
|
||||
hosts = tecmint.lan:389
|
||||
ldap_version = 3
|
||||
auth_bind = yes
|
||||
dn = vmail@tecmint.lan
|
||||
dnpass = ad_vmail_password
|
||||
base = dc=tecmint,dc=lan
|
||||
scope = subtree
|
||||
deref = never
|
||||
user_filter = (&(userPrincipalName=%u)(objectClass=person)(!(userAccountControl:1.2.840.113556.1.4.803:=2)))
|
||||
pass_filter = (&(userPrincipalName=%u)(objectClass=person)(!(userAccountControl:1.2.840.113556.1.4.803:=2)))
|
||||
pass_attrs = userPassword=password
|
||||
default_pass_scheme = CRYPT
|
||||
user_attrs = =home=/var/vmail/vmail1/%Ld/%Ln/Maildir/,=mail=maildir:/var/vmail/vmail1/%Ld/%Ln/Maildir/
|
||||
```
|
||||
|
||||
The mailbox of a Samba4 AD account will be stored in /var/vmail/vmail1/your_domain.tld/your_domain_user/Maildir/ location on the Linux system.
|
||||
|
||||
17. Make sure pop3 and imap protocols are enabled in dovecot main configuration file. Verify if quota and acl mail plugins are also enabled by opening file `/etc/dovecot/dovecot.conf` and check if these values are present.
|
||||
|
||||
[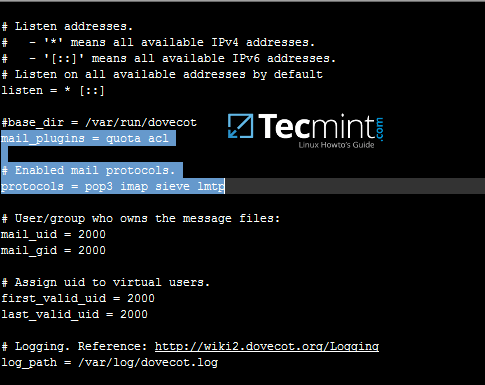][27]
|
||||
|
||||
Enable Pop3 and Imap in Dovecot
|
||||
|
||||
18. Optionally, if you want to set a global hard quota to not exceed the maximum of 500 MB of storage for each domain user, add the following line in /etc/dovecot/dovecot.conf file.
|
||||
|
||||
```
|
||||
quota_rule = *:storage=500M
|
||||
```
|
||||
|
||||
19. Finally, in order to apply all changes made so far, restart and verify the status of Postfix and Dovecot daemons by issuing the below commands with root privileges.
|
||||
|
||||
```
|
||||
# systemctl restart postfix dovecot
|
||||
# systemctl status postfix dovecot
|
||||
```
|
||||
|
||||
20. In order to test mail server configuration from the command line using IMAP protocol use telnet or [netcat command][28] as presented in the below example.
|
||||
|
||||
```
|
||||
# nc localhost 143
|
||||
a1 LOGIN ad_user@your_domain.tld ad_user_password
|
||||
a2 LIST “” “*”
|
||||
a3 LOGOUT
|
||||
```
|
||||
[][29]
|
||||
|
||||
Test iRedMail Configuration
|
||||
|
||||
If you can perform an IMAP login from the command line with a Samba4 user account then iRedMail server seems ready to send and receive mail for Active Directory accounts.
|
||||
|
||||
On the next tutorial will discuss how to integrate Roundcube webmail with Samba4 AD DC and enable Global LDAP Address Book, customize Roudcube, access Roundcube web interface from a browser and disable some unneeded iRedMail services.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
|
||||
-----
|
||||
|
||||
via: https://www.tecmint.com/integrate-iredmail-to-samba4-ad-dc-on-centos-7/
|
||||
|
||||
作者:[ Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/install-iredmail-on-centos-7-for-samba4-ad-integration/
|
||||
[2]:https://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/
|
||||
[3]:https://www.tecmint.com/manage-samba4-active-directory-linux-command-line/
|
||||
[4]:https://www.tecmint.com/setup-postfix-mail-server-and-dovecot-with-mariadb-in-centos/
|
||||
[5]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[6]:https://www.tecmint.com/set-add-static-ip-address-in-linux/
|
||||
[7]:https://www.tecmint.com/ifconfig-command-examples/
|
||||
[8]:https://www.tecmint.com/configure-network-connections-using-nmcli-tool-in-linux/
|
||||
[9]:https://www.tecmint.com/wp-content/uploads/2017/05/Find-Network-Interface-Name.png
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/05/Configure-Network-Settings.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/05/Verify-Network-DNS-Configuration.png
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/05/Sync-Time-with-Samba-NTP-Server.png
|
||||
[13]:https://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/05/Auto-Sync-Time-with-Samba-NTP.png
|
||||
[15]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[16]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[17]:https://www.tecmint.com/wp-content/uploads/2017/05/Create-DNS-A-Record-for-iRedMail.png
|
||||
[18]:https://www.tecmint.com/wp-content/uploads/2017/05/Create-DNS-MX-Record-for-iRedMail.png
|
||||
[19]:https://www.tecmint.com/wp-content/uploads/2017/05/Create-DNS-PTR-Record-for-iRedMail.png
|
||||
[20]:https://www.tecmint.com/wp-content/uploads/2017/05/Install-Bind-and-Query-Mail-Records.png
|
||||
[21]:https://www.tecmint.com/8-linux-nslookup-commands-to-troubleshoot-dns-domain-name-server/
|
||||
[22]:https://www.tecmint.com/wp-content/uploads/2017/05/Active-Directory-Users-and-Computers.png
|
||||
[23]:https://www.tecmint.com/wp-content/uploads/2017/05/Create-New-User-for-iRedMail.png
|
||||
[24]:https://www.tecmint.com/wp-content/uploads/2017/05/Set-Strong-Password-for-User.png
|
||||
[25]:https://www.tecmint.com/wp-content/uploads/2017/05/Query-Samba4-AD-DC-LDAP.png
|
||||
[26]:https://www.tecmint.com/wp-content/uploads/2017/05/Verify-Postfix-Binding-to-Samba-AD.png
|
||||
[27]:https://www.tecmint.com/wp-content/uploads/2017/05/Enable-Pop3-Imap-in-Dovecot.png
|
||||
[28]:https://www.tecmint.com/check-remote-port-in-linux/
|
||||
[29]:https://www.tecmint.com/wp-content/uploads/2017/05/Test-iRedMail-Configuration.png
|
||||
[30]:https://www.tecmint.com/author/cezarmatei/
|
||||
[31]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[32]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,87 +0,0 @@
|
||||
How to Delete HUGE (100-200GB) Files in Linux
|
||||
============================================================
|
||||
|
||||
by [Aaron Kili][11] | Published: May 11, 2017 | Last Updated: May 11, 2017
|
||||
|
||||
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][12] | [4 Free Shell Scripting eBooks][13]
|
||||
|
||||
Usually, to [delete/remove a file from Linux terminal][1], we use the rm command (delete files), shred command (securely delete a file), wipe command (securely erase a file) or secure-deletion toolkit (a collection of [secure file deletion tools][2]).
|
||||
|
||||
We can use any of the above utilities to deal with relatively small files. What if we want to delete/remove a huge file/directory say of about 100-200GB. This may not be as easy as it seems, in terms of the time taken to remove the file (I/O scheduling) as well as the amount of RAM consumed while carrying out the operation.
|
||||
|
||||
In this tutorial, we will explain how to efficiently and reliably delete huge files/directories in Linux.
|
||||
|
||||
**Suggested Read:** [5 Ways to Empty or Delete a Large File Content in Linux][3]
|
||||
|
||||
The main aim here is to use a technique that will not slow down the system while removing a huge file, resulting to reasonable I/O. We can achieve this using the ionice command.
|
||||
|
||||
### Deleting HUGE (200GB) Files in Linux Using ionice Command
|
||||
|
||||
ionice is a useful program which sets or gets the I/O scheduling class and priority for another program. If no arguments or just `-p` is given, ionice will query the current I/O scheduling class and priority for that process.
|
||||
|
||||
If we give a command name such as rm command, it will run this command with the given arguments. To specify the [process IDs of running processes][4] for which to get or set the scheduling parameters, run this:
|
||||
|
||||
```
|
||||
# ionice -p PID
|
||||
```
|
||||
|
||||
To specify the name or number of the scheduling class to use (0 for none, 1 for real time, 2 for best-effort, 3 for idle) the command below.
|
||||
|
||||
This means that rm will belong to idle I/O class and only uses I/O when any other process does not need it:
|
||||
|
||||
```
|
||||
---- Deleting Huge Files in Linux -----
|
||||
# ionice -c 3 rm /var/logs/syslog
|
||||
# ionice -c 3 rm -rf /var/log/apache
|
||||
```
|
||||
|
||||
If there won’t be much idle time on the system, then we may want to use the best-effort scheduling class and set a low priority like this:
|
||||
|
||||
```
|
||||
# ionice -c 2 -n 6 rm /var/logs/syslog
|
||||
# ionice -c 2 -n 6 rm -rf /var/log/apache
|
||||
```
|
||||
|
||||
Note: To delete huge files using a secure method, we may use the shred, wipe and various tools in the secure-deletion toolkit mentioned earlier on, instead of rm command.
|
||||
|
||||
**Suggested Read:** [3 Ways to Permanently and Securely Delete Files/Directories’ in Linux][5]
|
||||
|
||||
For more info, look through the ionice man page:
|
||||
|
||||
```
|
||||
# man ionice
|
||||
```
|
||||
|
||||
That’s it for now! What other methods do you have in mind for the above purpose? Use the comment section below to share with us.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/delete-huge-files-in-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||
[2]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||
[3]:https://www.tecmint.com/empty-delete-file-content-linux/
|
||||
[4]:https://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[5]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||
[6]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||
[7]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||
[8]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||
[9]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||
[10]:https://www.tecmint.com/delete-huge-files-in-linux/#comments
|
||||
[11]:https://www.tecmint.com/author/aaronkili/
|
||||
[12]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[13]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,281 @@
|
||||
How to Integrate iRedMail Roundcube with Samba4 AD DC – Part 12
|
||||
============================================================
|
||||
|
||||
by [Matei Cezar][15] | Published: May 13, 2017 | Last Updated: May 14, 2017
|
||||
|
||||
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][16] | [4 Free Shell Scripting eBooks][17]
|
||||
|
||||
[Roundcube][3], one of the most used webmail user agent in Linux, offers a modern web interface for end users to interact with all mail services in order to read, compose and send e-mails. Roundcube supports a variety of mail protocols, including the secured ones, such IMAPS, POP3S or submission.
|
||||
|
||||
In this topic we’ll discuss how to configure Roundcube in iRedMail with IMAPS and submission secured ports to retrieve and send emails for Samba4 AD accounts, how to access iRedMail Roundcube web interface from a browser and add a web address alias, how to enable Samba4 AD integration for Global LDAP Address Book and how to disable some unneeded iRedMail services.
|
||||
|
||||
#### Requirements
|
||||
|
||||
1. [How to Install iRedMail on CentOS 7 for Samba4 AD Integration][1]
|
||||
|
||||
2. [Configure iRedMail on CentOS 7 for Samba4 AD Integration][2]
|
||||
|
||||
### Step 1: Declare E-mail Address for Domain Accounts in Samba4 AD DC
|
||||
|
||||
1. In order send and receive mail for Samba4 AD DC domain accounts, you need to edit each user account and explicitly set email filed with the proper e-mail address by opening ADUC tool from a [Windows machine with RSAT tools installed][4] and joined to Samba4 AD as illustrated in the below image.
|
||||
|
||||
[][5]
|
||||
|
||||
Add Email Account to Join Samba4 AD DC
|
||||
|
||||
2. Similarly, to use mail lists, you need to create groups in ADUC, add the corresponding e-mail address for each group and assign the proper user accounts as members of the group.
|
||||
|
||||
With this setup created as a mail list, all members mailboxes of a Samba4 AD group will receive mail destined for an AD group e-mail address. Use the below screenshots as a guide to declare e-mail filed for a Samba4 group account and add domain users as members of the group.
|
||||
|
||||
Make sure all accounts members added to a group have their e-mail address declared.
|
||||
|
||||
[][6]
|
||||
|
||||
Create Group Admin for Samba4 AD DC
|
||||
|
||||
[][7]
|
||||
|
||||
Add Users to Group
|
||||
|
||||
In this example, all mails sent to admins@tecmint.lan e-mail address declared for ‘Domain Admins’ group will be received by each member mailbox of this group.
|
||||
|
||||
3. An alternative method that you can use to declare the e-mail address for a Samba4 AD account is by creating a user or a group with samba-tool command line directly from one of the AD DC console and specify the e-mail address with the `--mail-address` flag.
|
||||
|
||||
Use one of the following command syntax to create a user with e-mail address specified:
|
||||
|
||||
```
|
||||
# samba-tool user add --mail-address=user_email@domain.tld --surname=your_surname --given-name=your_given_name your_ad_user
|
||||
```
|
||||
|
||||
Create a group with e-mail address specified:
|
||||
|
||||
```
|
||||
# samba-tool group add --mail-address=group_email@domain.tld your_ad_group
|
||||
```
|
||||
|
||||
To add members to a group:
|
||||
|
||||
```
|
||||
# samba-tool group addmembers your_group user1,user2,userX
|
||||
```
|
||||
|
||||
To list all available samba-tool command fields for a user or a group use the following syntax:
|
||||
|
||||
```
|
||||
# samba-tool user add -h
|
||||
# samba-tool group add -h
|
||||
```
|
||||
|
||||
### Step 3: Secure Roundcube Webmail
|
||||
|
||||
4. Before modifying Roundcube configuration file, first, use [netstat command][8] piped through egrep filter to list the sockets that [Dovecot and Postfix][9] listen to and assure that the properly secured ports (993 for IMAPS and 587 for submission) are active and enabled.
|
||||
|
||||
```
|
||||
# netstat -tulpn| egrep 'dovecot|master'
|
||||
```
|
||||
|
||||
5. To enforce mail reception and transfer between Roundcube and iRedMail services on secured IMAP and SMTP ports, open Roundcube configuration file located in /var/www/roundcubemail/config/config.inc.php and make sure you change the following lines, for localhost in this case, as shown in the below excerpt:
|
||||
|
||||
```
|
||||
// For IMAPS
|
||||
$config['default_host'] = 'ssl://127.0.0.1';
|
||||
$config['default_port'] = 993;
|
||||
$config['imap_auth_type'] = 'LOGIN';
|
||||
// For SMTP
|
||||
$config['smtp_server'] = 'tls://127.0.0.1';
|
||||
$config['smtp_port'] = 587;
|
||||
$config['smtp_user'] = '%u';
|
||||
$config['smtp_pass'] = '%p';
|
||||
$config['smtp_auth_type'] = 'LOGIN';
|
||||
```
|
||||
|
||||
This setup is highly recommended in case Roudcube is installed on a remote host than the one that provides mail services (IMAP, POP3 or SMTP daemons).
|
||||
|
||||
6. Next, don’t close the configuration file, search and make the following small changes in order for Roundcube to be visited only via HTTPS protocol, to hide the version number and to automatically append the domain name for accounts who login in the web interface.
|
||||
|
||||
```
|
||||
$config['force_https'] = true;
|
||||
$config['useragent'] = 'Your Webmail'; // Hide version number
|
||||
$config['username_domain'] = 'domain.tld'
|
||||
```
|
||||
|
||||
7. Also, disable the following plugins: managesieve and password by adding a comment `(//)` in front of the line that starts with $config[‘plugins’].
|
||||
|
||||
Users will change their password from a Windows or Linux machine joined to Samba4 AD DC once they login and authenticate to the domain. A sysadmin will globally manage all sieve rules for domain accounts.
|
||||
|
||||
```
|
||||
// $config['plugins'] = array('managesieve', 'password');
|
||||
```
|
||||
|
||||
8. Finally, save and close the configuration file and visit Roundcube Webmail by opening a browser and navigate to iRedMail IP address or FQDN/mail location via HTTPS protocol.
|
||||
|
||||
The first time when you visit Roundcube an alert should appear on the browser due to the Self-Signed Certificate the web server uses. Accept the certificate and login with a Samba AD account credentials.
|
||||
|
||||
```
|
||||
https://iredmail-FQDN/mail
|
||||
```
|
||||
[][10]
|
||||
|
||||
Roundcube Webmail Login
|
||||
|
||||
### Step 3: Enable Samba AD Contacts in Roundcube
|
||||
|
||||
9. To configure Samba AD Global LDAP Address Book to appear Roundcube Contacts, open Roundcube configuration file again for editing and make the following changes:
|
||||
|
||||
Navigate to the bottom of the file and identify the section that begins with ‘# Global LDAP Address Book with AD’, delete all its content until the end of the file and replace it with the following code block:
|
||||
|
||||
```
|
||||
# Global LDAP Address Book with AD.
|
||||
#
|
||||
$config['ldap_public']["global_ldap_abook"] = array(
|
||||
'name' => 'tecmint.lan',
|
||||
'hosts' => array("tecmint.lan"),
|
||||
'port' => 389,
|
||||
'use_tls' => false,
|
||||
'ldap_version' => '3',
|
||||
'network_timeout' => 10,
|
||||
'user_specific' => false,
|
||||
'base_dn' => "dc=tecmint,dc=lan",
|
||||
'bind_dn' => "vmail@tecmint.lan",
|
||||
'bind_pass' => "your_password",
|
||||
'writable' => false,
|
||||
'search_fields' => array('mail', 'cn', 'sAMAccountName', 'displayname', 'sn', 'givenName'),
|
||||
'fieldmap' => array(
|
||||
'name' => 'cn',
|
||||
'surname' => 'sn',
|
||||
'firstname' => 'givenName',
|
||||
'title' => 'title',
|
||||
'email' => 'mail:*',
|
||||
'phone:work' => 'telephoneNumber',
|
||||
'phone:mobile' => 'mobile',
|
||||
'department' => 'departmentNumber',
|
||||
'notes' => 'description',
|
||||
),
|
||||
'sort' => 'cn',
|
||||
'scope' => 'sub',
|
||||
'filter' => '(&(mail=*)(|(&(objectClass=user)(!(objectClass=computer)))(objectClass=group)))',
|
||||
'fuzzy_search' => true,
|
||||
'vlv' => false,
|
||||
'sizelimit' => '0',
|
||||
'timelimit' => '0',
|
||||
'referrals' => false,
|
||||
);
|
||||
```
|
||||
|
||||
On this block of code replace name, hosts, base_dn, bind_dn and bind_pass values accordingly.
|
||||
|
||||
10. After you’ve made all the required changes, save and close the file, login to Roundcube webmail interface and go to Address Book menu.
|
||||
|
||||
Hit on your Global Address Book chosen name and a contact list of all domain accounts (users and groups) with their specified e-mail address should be visible.
|
||||
|
||||
[][11]
|
||||
|
||||
Roundcube User Contact List
|
||||
|
||||
### Step 4: Add an Alias for Roundcube Webmail Interface
|
||||
|
||||
11. To visit Roundcube at a web address with the following form https://webmail.domain.tld instead of the old address provided by default by iRedMail you need to make the following changes.
|
||||
|
||||
From a joined Windows machine with RSAT tools installed, open DNS Manager and add a new CNAME record for iRedMail FQDN, named webmail, as illustrated in the following image.
|
||||
|
||||
[][12]
|
||||
|
||||
DNS Webmail Properties
|
||||
|
||||
12. Next, on iRedMail machine, open Apache web server SSL configuration file located in /etc/httpd/conf.d/ssl.conf and change DocumentRoot directive to point to /var/www/roundcubemail/ system path.
|
||||
|
||||
file /etc/httpd/conf.d/ssl.conf excerpt:
|
||||
|
||||
```
|
||||
DocumentRoot “/var/www/roundcubemail/”
|
||||
```
|
||||
|
||||
Restart Apache daemon to apply changes.
|
||||
|
||||
```
|
||||
# systemctl restart httpd
|
||||
```
|
||||
|
||||
13. Now, point the browser to the following address and Roundcube interface should appear. Accept the Self-Signed Cerificate error to continue to login page. Replace domain.tld from this example with your own domain name.
|
||||
|
||||
```
|
||||
https://webmail.domain.tld
|
||||
```
|
||||
|
||||
### Step 5: Disable iRedMail Unused Services
|
||||
|
||||
14. Since iRedMail daemons are configured to query Samba4 AD DC LDAP server for account information and other resources, you can safely stop and disable some local services on iRedMail machine, such as LDAP database server and iredpad service by issuing the following commands.
|
||||
|
||||
```
|
||||
# systemctl stop slapd iredpad
|
||||
# systemctl disable slapd iredpad
|
||||
```
|
||||
|
||||
15. Also, disable some scheduled tasks performed by iRedMail, such as LDAP database backup and iRedPad tracking records by adding a comment (#) in front of each line from crontab file as illustrated on the below screenshot.
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
```
|
||||
[][13]
|
||||
|
||||
Disable iRedMail Tasks
|
||||
|
||||
### Step 6: Use Mail Alias in Postfix
|
||||
|
||||
16. To redirect all locally generated mail (destined for postmaster and subsequently redirected to root account) to a specific Samba4 AD account, open Postfix aliases configuration file located in /etc/postfix/aliases and modify root line as follows:
|
||||
|
||||
```
|
||||
root: your_AD_email_account@domain.tld
|
||||
```
|
||||
|
||||
17. Apply the aliases configuration file so that Postfix can read it in its own format by executing newaliases command and test if the mail gets sent to the proper domain e-email account by issuing the following command.
|
||||
|
||||
```
|
||||
# echo “Test mail” | mail -s “This is root’s email” root
|
||||
```
|
||||
|
||||
18. After the mail has been sent, login to Roundcube webmail with the domain account you’ve setup for mail redirection and verify the previously sent mail should be received in your account Inbox.
|
||||
|
||||
[][14]
|
||||
|
||||
Verify User Mail
|
||||
|
||||
That’all! Now, you have a fully working mail server integrated with Samba4 Active Directory. Domain accounts can send and receive mail for their internal domain or for other external domains.
|
||||
|
||||
The configurations used in this tutorial can be successfully applied to integrate an iRedMail server to a Windows Server 2012 R2 or 2016 Active Directory.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
-----------
|
||||
|
||||
|
||||
via: https://www.tecmint.com/integrate-iredmail-roundcube-with-samba4-ad-dc/
|
||||
|
||||
作者:[ ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/install-iredmail-on-centos-7-for-samba4-ad-integration/
|
||||
[2]:https://www.tecmint.com/integrate-iredmail-to-samba4-ad-dc-on-centos-7/
|
||||
[3]:https://www.tecmint.com/install-and-configure-roundcube-webmail-for-postfix-mail-server/
|
||||
[4]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/05/Active-Directory-User-and-Computers.jpg
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/05/Create-Group-Admin-for-Samba4-AD-DC.png
|
||||
[7]:https://www.tecmint.com/wp-content/uploads/2017/05/Add-Users-to-Group.png
|
||||
[8]:https://www.tecmint.com/20-netstat-commands-for-linux-network-management/
|
||||
[9]:https://www.tecmint.com/configure-postfix-and-dovecot-with-virtual-domain-users-in-linux/
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/05/Roundcube-Webmail-Login.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/05/Roundcube-User-Contact-List.png
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/05/DNS-Webmail-Properties.jpg
|
||||
[13]:https://www.tecmint.com/wp-content/uploads/2017/05/Disable-iRedMail-Tasks.png
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/05/Verify-User-Mail.png
|
||||
[15]:https://www.tecmint.com/author/cezarmatei/
|
||||
[16]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[17]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
72
sources/tech/20170516 What Fuchsia could mean for Android.md
Normal file
72
sources/tech/20170516 What Fuchsia could mean for Android.md
Normal file
@ -0,0 +1,72 @@
|
||||
What Fuchsia could mean for Android
|
||||
============================================================
|
||||
|
||||
Fuchsia could be next replacement for Android, or Android and Chrome OS. Speculation abounds, and Jack Wallen adds to this speculation some kudos and caveats for Google to consider.
|
||||
|
||||
In this white paper, you’ll learn why legacy IT systems create drag on businesses, and how companies can transform their operations and reap the benefits of hybrid IT by partnering with the right managed services provider. [Download Now][9]
|
||||
|
||||
 Image: Jack Wallen
|
||||
|
||||
Google has never been one to settle or to do things in a way that is not decidedly "Google". So it should have come as no surprise to anyone that they began working on a project that had many scratching their heads. The project is called [Fuschia][6] and most people that follow Google and Android closely, know of this new platform.
|
||||
|
||||
For those that haven't been following the latest and greatest from Google, Fuschia is a new, real-time, open source operating system that first popped up on the radar in August, 2016\. Back then, Fuchsia was nothing more than a command line. Less than a year has zipped by and the platform already has a rather interesting GUI.
|
||||
|
||||
Much to the chagrin of the Linux faithful, Fuchsia does not use the Linux kernel. This project is all Google and uses a Google-developed microkernel, named "Magenta." Why would they do this? Consider the fact that Google's newest device, the Pixel, runs kernel 3.18 and you have your answer. The 3.18 Linux kernel was released in 2014 (which, in tech terms is ancient). With that in mind, why wouldn't Google want to break out completely on their own to keep their mobile platform as up to date as possible?
|
||||
|
||||
Although it pains me to think that Linux might not be (in some unknown future date) powering the most widely-used ecosystem on the planet, I believe this is the right move for Google, with one major caveat.
|
||||
|
||||
### First, a couple of kudos
|
||||
|
||||
I have to first say, bravo to Google for open sourcing Fuchsia. This was the right move. Android has benefitted from the open source Linux kernel for years, so it only makes sense that Google would open up their latest project. To be perfectly honest, had it not been for open source and the Linux kernel, Android would not have risen nearly as quickly as it did. In fact, I would venture a guess to say that, had it not been for Android being propped up by Linux and open source, the mobile market share would show a very different, apple-shaped, picture at the moment.
|
||||
|
||||
The next bit of bravo comes by way of necessity. Operating systems need to be completely rethought now and then. Android is an amazing platform that serves the mobile world quite well. However, there's only so much evolution one can squeeze out of it; and considering the consuming world is always looking for next big thing, Android (and iOS) can only deliver so many times before they have been wrung dry. Couple that with a sorely out of date kernel and you have a perfect storm ready for the likes of Fuchsia.
|
||||
|
||||
Google has never been one to remain stagnant and this new platform is proof.
|
||||
|
||||
### That darned caveat
|
||||
|
||||
I will preface this by reminding everyone of my open source background. I have been a user of Linux since the late 90s and have covered nearly every aspect of open source to be found. Over the last few years, I've been watching and commenting on the goings on with Ubuntu and their (now) failed attempt at convergence. With that said, here's my concern with Fuchsia.
|
||||
|
||||
My suspicion is that Google's big plan for Fucshia is to create a single operating system for all devices: Smartphones, IoT, Chromebooks. On the surface, that sounds like an idea that would bear significant fruit; but if you examine the struggles Canonical endured with Unity 8/Mir/Convergence, you cringe at the idea of "one platform to rule them all". Of course, this isn't quite the same. I doubt Google is creating a single platform that will allow you to "converge" all of your devices. After all, what benefit would there be to converging IoT with your smartphone? It's not like we need to start exchanging data between a phone and a thermostat. Right? Right???
|
||||
|
||||
Even so, should that be the plan for Google, I would caution them to look closely at what befell Canonical and Unity 8\. It was an outstanding idea that simply couldn't come to fruition.
|
||||
|
||||
I could be wrong about this. Google might be thinking of Fuchsia as nothing more than a replacement for Android. It is quite possible this was Google needing to replace the outdated Linux kernel and deciding they may as well go "all in". But considering Armadillo (the Fuchsia UI) has been written in the cross-platform [Flutter SDK][7], the idea of crossing the platform boundary starts to fall into the realm of the possible.
|
||||
|
||||
Or, maybe Fuchsia is simply just Google saying "Let's rebuild our smartphone platform with the knowledge we have today and see where it goes." If that's the case, I would imagine the Google mobile OS will be primed for major success. However, there's one elephant in the room that many have yet to address that hearkens back to "one platform to rule them all". Google has been teasing Android apps on Chromebooks for quite some time. Unfortunately, the success with this idea has been moderate (at best). With Microsoft going out of their way to compete with Chromebooks, Google knows they have to expand that ecosystem, or else lose precious ground (such as within the education arena). One way to combat this is with a single OS to drive both smartphones and Chromebooks. It would mean all apps would work on both platforms (which would be a serious boon) and a universality to the ecosystem (again, massive boon).
|
||||
|
||||
### Speculation
|
||||
|
||||
Google is very good at keeping this sort of thing close to the vest; which translates to a lot of speculation on the part of pundits. Generally speaking, at least with Android, Google has always seemed to make the right moves. If they believe Fuchsia is the way to go, then I'm inclined to believe them. However, there are so many uncertainties surrounding this platform that one is left constantly scratching one's head in wonder.
|
||||
|
||||
What do you think? What will Fuchsia become? Speculate with me.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack Wallen is an award-winning writer for TechRepublic and Linux.com. He’s an avid promoter of open source and the voice of The Android Expert. For more news about Jack Wallen, visit his website jackwallen.com.
|
||||
|
||||
-------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/
|
||||
|
||||
作者:[About Jack Wallen ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/#modal-bio
|
||||
[1]:http://www.techrepublic.com/article/biometric-mobile-payments-will-hit-2b-this-year/
|
||||
[2]:http://www.techrepublic.com/article/apple-invests-200m-in-us-manufacturing-to-help-corning-produce-new-state-of-the-art-glass/
|
||||
[3]:http://www.techrepublic.com/article/google-will-soon-require-android-for-work-profiles-for-enterprise-users/
|
||||
[4]:http://www.techrepublic.com/newsletters/
|
||||
[5]:http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/#postComments
|
||||
[6]:https://github.com/fuchsia-mirror
|
||||
[7]:https://flutter.io/
|
||||
[8]:http://intent.cbsi.com/redir?tag=medc-content-top-leaderboard&siteId=11&rsid=cbsitechrepublicsite&pagetype=article&sl=en&sc=us&topicguid=09288d3a-8606-11e2-a661-024c619f5c3d&assetguid=714cb8ff-ebf0-4584-a421-e8464aae66cf&assettype=content_article&ftag_cd=LGN3588bd2&devicetype=desktop&viewguid=4c47ca57-283d-4861-a131-09e058b652ac&q=&ctype=docids;promo&cval=33109435;7205&ttag=&ursuid=&bhid=&destUrl=http%3A%2F%2Fwww.techrepublic.com%2Fresource-library%2Fwhitepapers%2Ftaming-it-complexity-with-managed-services-japanese%2F%3Fpromo%3D7205%26ftag%3DLGN3588bd2%26cval%3Dcontent-top-leaderboard
|
||||
[9]:http://intent.cbsi.com/redir?tag=medc-content-top-leaderboard&siteId=11&rsid=cbsitechrepublicsite&pagetype=article&sl=en&sc=us&topicguid=09288d3a-8606-11e2-a661-024c619f5c3d&assetguid=714cb8ff-ebf0-4584-a421-e8464aae66cf&assettype=content_article&ftag_cd=LGN3588bd2&devicetype=desktop&viewguid=4c47ca57-283d-4861-a131-09e058b652ac&q=&ctype=docids;promo&cval=33109435;7205&ttag=&ursuid=&bhid=&destUrl=http%3A%2F%2Fwww.techrepublic.com%2Fresource-library%2Fwhitepapers%2Ftaming-it-complexity-with-managed-services-japanese%2F%3Fpromo%3D7205%26ftag%3DLGN3588bd2%26cval%3Dcontent-top-leaderboard
|
||||
[10]:http://www.techrepublic.com/rssfeeds/topic/android/
|
||||
[11]:http://www.techrepublic.com/meet-the-team/us/jack-wallen/
|
||||
[12]:https://twitter.com/intent/user?screen_name=jlwallen
|
||||
@ -0,0 +1,75 @@
|
||||
How to make Vim user-friendly with Cream
|
||||
============================================================
|
||||
|
||||
### The Cream add-on makes the Vim text editor easier to use by putting a more familiar face on its functionality.
|
||||
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
About 10 years ago, I split my text editing time between Emacs and Vim. That said, I was and definitely still am an Emacs guy. But while Emacs has always had an edge in my affections, I know that Vim is no slouch.
|
||||
|
||||
So do other people—even those who, like me, are all thumbs technically. Over the years, I've talked to a few new Linux users who wanted to use Vim but were a bit disappointed that it doesn't act like the text editors they've used on other operating systems.
|
||||
|
||||
That disappointment changed to satisfaction when I introduced them to Cream, an add-on for Vim that makes it easier to use. Cream turned each of them into diehard Vim users.
|
||||
|
||||
Let's take a look at Cream and how it makes Vim easier to use.
|
||||
|
||||
### Getting going with Cream
|
||||
|
||||
Before you can install Cream, you'll need Vim and GVim GUI components installed on your computer. I find the easiest way to do that is to use your Linux distribution's package manager.
|
||||
|
||||
Once you have Vim installed, grab [the installer][2] for Cream or, again, turn to your distribution's package manager.
|
||||
|
||||
Once Cream is installed, you can fire it up by selecting the entry from the application menu (for example, **Applications > Cream**) or by typing **cream** into your program launcher.
|
||||
|
||||

|
||||
|
||||
### Using Cream
|
||||
|
||||
If you've used GVim before, you'll notice that Cream doesn't change the editor's look and feel too much. The biggest cosmetic differences are Cream's menu bar and toolbar, which replace the stock GVim menu bar and toolbar with ones that look and group functions like their counterparts in other applications.
|
||||
|
||||
Cream's menus hide a lot of the more techie options—like the ability to specify a compiler and the **Make** command—from the user. As you get more familiar with Vim by using Cream, however, you can make more of those features more easily accessible by selecting an option from the **Settings > Preferences > Behavior** menu. With those options, you could (if you want to) wind up with an editor that behaves as a hybrid of Cream and traditional Vim.
|
||||
|
||||
Cream isn't only driven by its menus. While the editor's functions are only a click or two away, you can also use common keyboard shortcuts to perform actions—for example, **CTRL-O** (to open a file) or **CTRL-C** (to copy text). There's no need to shift between modes or remember Vim's somewhat cryptic commands.
|
||||
|
||||
With Cream running, get to work by opening a file or creating a new one. Then start typing. A couple or three of the people I've introduced to Cream have said that while it retains much of the classic styling of Vim, Cream feels more comfortable to use.
|
||||
|
||||

|
||||
|
||||
That's not to say Cream dumbs down or waters down Vim. Far from it. You still retain all of Vim's features, along with [a long list of others][3]. Some of the features of Cream that I find useful include:
|
||||
|
||||
* A tabbed interface
|
||||
|
||||
* Syntax highlighting (especially when working with Markdown, LaTeX, and HTML)
|
||||
|
||||
* Auto correction of spelling mistakes
|
||||
|
||||
* Word count
|
||||
|
||||
* Built-in file explorer
|
||||
|
||||
Cream also comes with a number of add-ons that give the editor some additional features. Those features include the ability to encrypt text and to clean up the body of emails, and there's even a typing tutor. To be honest, I haven't found any of the add-ons to be all that useful. Your mileage might vary, though.
|
||||
|
||||
I've heard a few Vi/Vim purists pooh-pooh Cream for "dumbing down _"_ (their words) the editor. Let's be honest: Cream isn't for them. It's for someone who wants to quickly get up and running with Vim while retaining the look and feel of the editors they're used to. In that way, Cream succeeds admirably. It makes Vim a lot more accessible and usable to a wider range of people.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/stir-bit-cream-make-vim-friendlier
|
||||
|
||||
作者:[ Scott Nesbitt ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/5/stir-bit-cream-make-vim-friendlier?rate=sPQVOnwWoNwyyQX4wV2SZ_7Ly_KXd_Gu9pBu16LRyhU
|
||||
[2]:http://cream.sourceforge.net/download.html
|
||||
[3]:http://cream.sourceforge.net/featurelist.html
|
||||
[4]:https://opensource.com/user/14925/feed
|
||||
[5]:https://opensource.com/article/17/5/stir-bit-cream-make-vim-friendlier#comments
|
||||
[6]:https://opensource.com/users/scottnesbitt
|
||||
@ -0,0 +1,101 @@
|
||||
Hugo vs. Jekyll: Comparing the leading static website generators
|
||||
============================================================
|
||||
|
||||
### If you're building a new website, a static site generator may be the right platform for you.
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
Unless your spirit animal is Emily Dickinson, when you make a thing, you want to share it with the world. Sharing your work means that you need a website. Of course, you could simply partake in digital sharecropping and use any of the various social media sites to get your work in front of an audience. There sure are plenty to choose from... and not just "conventional" social media sites. With places like Artstation, Flickr, Soundcloud, and Wattpad, there's an outlet for you, whatever your medium.
|
||||
|
||||
And actually, you _should_ use those sites. It's where the people are, after all. However, none of those places is truly yours. None is a home base that _you_ control and that you can ensure will be there for people to find regardless of the waxing and waning trends of social media.
|
||||
|
||||
Programming and development
|
||||
|
||||
* [New Python content][1]
|
||||
|
||||
* [Our latest JavaScript articles][2]
|
||||
|
||||
* [Recent Perl posts][3]
|
||||
|
||||
* [Red Hat Developers Blog][4]
|
||||
|
||||
Control. That's the value of having your own place on the web.
|
||||
|
||||
But this article isn't about setting up a domain name and hosting for your website. It's for the step _after_ that, the actual making of that site. The typical choice for a lot of people would be to use something like [WordPress][6]. It's a one-click install on most hosting providers, and there's a gigantic market of plugins and themes available to choose from, depending on the type of site you're trying to build. But not only is WordPress a bit overkill for most websites, it also gives you a dynamically generated site with a lot of moving parts. If you don't keep all of those pieces up to date, they can pose a significant security risk and your site could get hijacked.
|
||||
|
||||
The alternative would be to have a static website, with nothing dynamically generated on the server side. Just good old HTML and CSS (and perhaps a bit of Javascript for flair). The downside to that option has been that you've been relegated to coding the whole thing by hand yourself. It's doable, but you just want a place to share your work. You shouldn't have to know all the idiosyncrasies of low-level web design (and the monumental headache of cross-browser compatibility) to do that.
|
||||
|
||||
Enter static site generators. You get the speed and security of static HTML pages, but with a workflow that's closer to the convenience of a dynamic site. The two frontrunners in the static site generator world are [Hugo][7] and [Jekyll][8]. (By the way, Paolo Bonzini has a great article on [getting started with Jekyll][9].) But which one is the right choice for you? Hopefully by the end of this article, you'll have a better idea. We're evaluating both static site generators based on how quickly you can get started, availability of themes, editing workflow, and extensibility.
|
||||
|
||||
### Getting started
|
||||
|
||||
Fair warning, both of these tools will require you to work with them from the command line. Most of the commands are straightforward and easy to remember, but let's adjust our expectations accordingly. This is not a point-and-click interface.
|
||||
|
||||
Installation for both Jekyll and Hugo is pretty simple. Jekyll installs as a RubyGem, and Hugo offers a very handy all-in-one binary to get you started quickly. Because of the single install package, Hugo edges ahead here slightly. Although the RubyGems install method for Jekyll is easy in its own right, it _does_ require that you already have a properly installed and configured Ruby environment on your computer. Outside of the community of designers and developers for the web, most folks don't already have that setup.
|
||||
|
||||
Once installed, though, both Hugo and Jekyll are pretty evenly matched. They both have great documentation and quick-start guides. You start a new site with a single command (in Jekyll, it's **jekyll new <your_site>** and in Hugo, **hugo new site <your_site>**). This sets up a general directory structure and scaffolding for your site. Directory structures and basic configuration are pretty similar. Jekyll uses a **_config.yml** file and Hugo uses **config.toml** (although you _can_ use YAML or even JSON syntax with Hugo's config if you're more comfortable with either of those). The front matter metadata at the top of each content file uses the same syntax as the config. After that, all page content is written in Markdown.
|
||||
|
||||
I will say that in terms of getting you started with your very first statically generated site, Jekyll has a slight advantage over Hugo because it starts with some basic content and a default theme. You can use these as example templates as you start building your site. Hugo has no example content or even a default theme. That said, example content and default themes are usually the first things I delete when I'm making a new site with any tool, so Hugo actually saves me a step.
|
||||
|
||||
### Themes
|
||||
|
||||
As I mentioned, Hugo doesn't ship with a default theme at all, so that's probably one of the first things you're going to want to set up. Jekyll has a decent default theme, though it's pretty bare bones. You'll probably want to go theme hunting with your Jekyll site, too.
|
||||
|
||||
Both Hugo and Jekyll have a pretty diverse assortment of themes for all manners of website types from single-page ID themes to full-blown multipage sites with blog posts and comments. Despite that, it's not exactly easy to find a theme that suits your needs. In either case, the place to go for themes—[themes.gohugo.io][10] for Hugo and [jekyllthemes.org][11] for Jekyll—is basically a single large page full of theme screenshots. Once you click on a theme, you can get some pretty detailed information about it, but that initial search is pretty rough. Hugo's theme page has some basic tagging built into it, but in general, theme searching and presentation is something I feel both projects really need to work on.
|
||||
|
||||
Theme management is also an interesting topic. In both cases, nearly every theme is a Git repository (often hosted on GitHub) that you clone into your website scaffolding. In Jekyll, there's an additional step of using RubyGems' **bundle** to ensure that the theme is managed with the site. Most themes already come with a **Gemfile**, making this step relatively painless. If the theme doesn't already have a **Gemfile**, it's fairly easy to add. In Hugo there's no bundling step. Just point to the theme from your **config.toml,** and you're good to go.
|
||||
|
||||
I've found that I'm partial to the way that Hugo handles themes. You clone (or create) themes into their own space in a **themes** subdirectory. Not only does it make it relatively easy to switch between themes when you're first starting out, but it also gives you the ability to override any component file of a theme with your own file. This means you can customize a theme to your tastes without messing too much with the source of the original theme, allowing it to stay generic enough for other people to use. Of course, if you have a change that you feel other users of the theme may find worthwhile, you can still edit that source and submit a pull request to the theme maintainer.
|
||||
|
||||
### Workflow
|
||||
|
||||
The workflows for building your site in Jekyll and Hugo are pretty similar once you have your initial configuration set up. Both have a live **serve** command that runs a small, lightweight web server on your computer so you can test your site locally without needing to upload it anywhere. The really nice thing is that whether you're running **jekyll serve** or **hugo serve**, both are configured by default to watch for any changes you make to your site as you work on it. When you look at the locally served version of your site in a browser, it automatically updates with any change you make, regardless of whether that change is to content, configuration, theme, or just an image. It's really quite handy and a great time-saver.
|
||||
|
||||
You write the content for your site in both systems using [Markdown][12] syntax. If you don't happen to be familiar with Markdown, it's a very simplified means of writing in plain text while still allowing for some nice formatting marks. It's very easy to work in and human-readable. And because it's in plain text, your content (and therefore your site) is easily version controlled. It's pretty much the main way I write almost everything these days.
|
||||
|
||||
New content can be added to your site scaffolding by manually creating files in the right place. It just needs to be a Markdown file with the appropriate "front matter" metadata at the top of the file. As with the configuration file, Jekyll uses YAML syntax for front matter, while Hugo will accept TOML, YAML, or JSON (default is TOML). That new page file needs to be placed in the correct directory within your site's scaffolding. In Jekyll, you have separate **_drafts** and **_posts** directories for storing your work in progress and your completed content pages, respectively. In Hugo, there's only a single **content** directory. You specify whether a post is a draft or not within that content file's front matter.
|
||||
|
||||
Now, although it's possible to do all of this manually, Hugo does offer some convenience functions to ensure that your new file is created in the correct spot in the scaffolding and that files are pre-populated with appropriate front matter. It's simply a matter of going to your site's directory in a terminal and typing **hugo new content/<page.md>** where **<page.md>** is the new page you want to create. You can even set up templates called **archetypes** that hold customized front matter for pages of different types (like if you have both a blog and a podcast on your website).
|
||||
|
||||
When your site is ready to ship, you can shut down your preview server and issue a command to build the actual pages of the site. In Jekyll, that would be **jekyll build**. In Hugo, it's just **hugo**. Jekyll puts the completed site in the **_site** subdirectory, while Hugo puts them in a subdirectory named **public**. In either case, once you do that, you have a completed static website that you can upload and have hosted nearly anywhere.
|
||||
|
||||
### Extensibility
|
||||
|
||||
Both Hugo and Jekyll give you the ability to customize your site down to the smallest thing. However, in terms of extensibility, Jekyll currently leads in a big way because of its plugin API. Because of this plugin architecture, it's relatively easy to add functionality to your Jekyll-generated site with reasonably short snippets of code available through the Jekyll community or that you write yourself.
|
||||
|
||||
Hugo does not currently have a plugin API at all, so adding that kind of functionality is a bit tougher. There's hope that the ability to write and include plugins will be added in the future, but it doesn't appear that anyone is working on that yet.
|
||||
|
||||
### Conclusion
|
||||
|
||||
By and large, Hugo and Jekyll are pretty similar. It really comes down to determining how you're most comfortable working and what your site needs. If you already have a RubyGems environment set up and you need the extensibility of plugins, then Jekyll is the way to go. However, if you value a simple workflow and a straightforward means of customizing your site, then Hugo would be your top pick.
|
||||
|
||||
I find that I'm more drawn to Hugo's approach, and in building a small handful of sites, I haven't yet had a need for any plugins. Of course, everyone's needs are a little bit different. Which static site generator would you choose for your site?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/hugo-vs-jekyll
|
||||
|
||||
作者:[Jason van Gumster ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-van-gumster
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://opensource.com/article/17/5/hugo-vs-jekyll?rate=lZDKuqOQ7lVUon-ZKebR5SUCyXDz5oCQ_zoCSBPolOQ
|
||||
[6]:http://wordpress.org/
|
||||
[7]:http://gohugo.io/
|
||||
[8]:https://jekyllrb.com/
|
||||
[9]:https://opensource.com/article/17/4/getting-started-jekyll
|
||||
[10]:https://themes.gohugo.io/
|
||||
[11]:http://jekyllthemes.org/
|
||||
[12]:https://daringfireball.net/projects/markdown/
|
||||
[13]:https://opensource.com/user/26430/feed
|
||||
[14]:https://opensource.com/article/17/5/hugo-vs-jekyll#comments
|
||||
[15]:https://opensource.com/users/jason-van-gumster
|
||||
@ -1,130 +0,0 @@
|
||||
Linfo – Shows Linux Server Health Status in Real-Time
|
||||
============================================================
|
||||
|
||||
|
||||
Linfo is a free and open source, cross-platform server statistics UI/library which displays a great deal of system information. It is extensible, easy-to-use (via composer) PHP5 library to get extensive system statistics programmatically from your PHP application. It’s a Ncurses CLI view of Web UI, which works in Linux, Windows, *BSD, Darwin/Mac OSX, Solaris, and Minix.
|
||||
|
||||
It displays system info including [CPU type/speed][2]; architecture, mount point usage, hard/optical/flash drives, hardware devices, network devices and stats, uptime/date booted, hostname, memory usage (RAM and swap, if possible), temperatures/voltages/fan speeds and RAID arrays.
|
||||
|
||||
#### Requirements:
|
||||
|
||||
* PHP 5.3
|
||||
|
||||
* pcre extension
|
||||
|
||||
* Linux – /proc and /sys mounted and readable by PHP and Tested with the 2.6.x/3.x kernels
|
||||
|
||||
### How to Install Linfo Server Stats UI/library in Linux
|
||||
|
||||
First, create a Linfo directory in your Apache or Nginx web root directory, then clone and move repository files into `/var/www/html/linfo` using the [rsync command][3] as shown below:
|
||||
|
||||
```
|
||||
$ sudo mkdir -p /var/www/html/linfo
|
||||
$ git clone git://github.com/jrgp/linfo.git
|
||||
$ sudo rsync -av linfo/ /var/www/html/linfo/
|
||||
```
|
||||
|
||||
Then rename sample.config.inc.php to config.inc.php. This is the Linfo config file, you can define your own values in it:
|
||||
|
||||
```
|
||||
$ sudo mv sample.config.inc.php config.inc.php
|
||||
```
|
||||
|
||||
Now open the URL `http://SERVER_IP/linfo` in web browser to see the Web UI as shown in the screenshots below.
|
||||
|
||||
This screenshot shows the Linfo Web UI displaying core system info, hardware components, RAM stats, network devices, drives and file system mount points.
|
||||
|
||||
[][4]
|
||||
|
||||
Linux Server Health Information
|
||||
|
||||
You can add the line below in the config file `config.inc.php` to yield useful error messages for troubleshooting purposes:
|
||||
|
||||
```
|
||||
$settings['show_errors'] = true;
|
||||
```
|
||||
|
||||
### Running Linfo in Ncurses Mode
|
||||
|
||||
Linfo has a simple ncurses-based interface, which rely on php’s ncurses extension.
|
||||
|
||||
```
|
||||
# yum install php-pecl-ncurses [On CentOS/RHEL]
|
||||
# dnf install php-pecl-ncurses [On Fedora]
|
||||
$ sudo apt-get install php5-dev libncurses5-dev [On Debian/Ubuntu]
|
||||
```
|
||||
|
||||
Now compile the php extension as follows
|
||||
|
||||
```
|
||||
$ wget http://pecl.php.net/get/ncurses-1.0.2.tgz
|
||||
$ tar xzvf ncurses-1.0.2.tgz
|
||||
$ cd ncurses-1.0.2
|
||||
$ phpize # generate configure script
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
Next, if you successfully compiled and installed the php extension, run the commands below.
|
||||
|
||||
```
|
||||
$ sudo echo extension=ncurses.so > /etc/php5/cli/conf.d/ncurses.ini
|
||||
```
|
||||
|
||||
Verify the ncurses.
|
||||
|
||||
```
|
||||
$ php -m | grep ncurses
|
||||
```
|
||||
|
||||
Now run the Linfo.
|
||||
|
||||
```
|
||||
$ cd /var/www/html/linfo/
|
||||
$ ./linfo-curses
|
||||
```
|
||||
[][5]
|
||||
|
||||
Linux Server Information
|
||||
|
||||
The following features yet to be added in Linfo:
|
||||
|
||||
1. Support for more Unix operating systems (such as Hurd, IRIX, AIX, HP UX, etc)
|
||||
|
||||
2. Support for less known operating systems: Haiku/BeOS
|
||||
|
||||
3. Extra superfluous features/extensions
|
||||
|
||||
4. Support for [htop-like][1] features in ncurses mode
|
||||
|
||||
For more information, visit Linfo Github repository: [https://github.com/jrgp/linfo][6]
|
||||
|
||||
That’s all! From now on, you can view a Linux system’s information from within a web browser using Linfo. Try it out and share with us your thoughts in the comments. Additionally, have you come across any similar useful tools/libraries? If yes, then give us some info about them as well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
---------------
|
||||
|
||||
via: https://www.tecmint.com/linfo-shows-linux-server-health-status-in-real-time/
|
||||
|
||||
作者:[ Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||
[2]:https://www.tecmint.com/corefreq-linux-cpu-monitoring-tool/
|
||||
[3]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-Server-Health-Information.png
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-Server-Information.png
|
||||
[6]:https://github.com/jrgp/linfo
|
||||
[7]:https://www.tecmint.com/author/aaronkili/
|
||||
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,5 +1,6 @@
|
||||
10 Useful Tips for Writing Effective Bash Scripts in Linux
|
||||
============================================================
|
||||
ch-cn translating
|
||||
|
||||
[Shell scripting][4] is the easiest form of programming you can learn/do in Linux. More so, it is a required skill for [system administration for automating tasks][5], developing new simple utilities/tools just to mention but a few.
|
||||
|
||||
|
||||
@ -0,0 +1,218 @@
|
||||
5 reasons the D programming language is a great choice for development
|
||||
============================================================
|
||||
|
||||
### D's modeling, productivity, readability, and other features make it a good fit for collaborative software development.
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
The [D programming language][8] is a statically typed, general purpose programming language with C-like syntax that compiles to native code. It's a good fit in open source software development for many reasons; here are some of them.
|
||||
|
||||
### Modeling power
|
||||
|
||||
It's not uncommon to find yourself in a situation where you have an idea and you want to implement it in code exactly the way you are thinking about it in your mind. However, sometimes you have to compromise the idea to fit the code, instead of modeling the code to fit the idea. D supports several [programming paradigms][9], including functional style, imperative, object oriented, metaprogramming, and concurrent (actor model), all harmoniously integrated. You have the option to choose whichever paradigm is convenient for modeling code to fit your idea.
|
||||
|
||||
Programming and development
|
||||
|
||||
* [New Python content][1]
|
||||
|
||||
* [Our latest JavaScript articles][2]
|
||||
|
||||
* [Recent Perl posts][3]
|
||||
|
||||
* [Red Hat Developers Blog][4]
|
||||
|
||||
By using [templates][10], a feature to generate additional D code and weave it in during compilation, you can describe code as a pattern for the compiler to generate the code. This is especially useful for designing algorithms without tying them to specific types. Platform-agnostic code becomes easy with the generic nature of templates. By combining templates with [conditional compilation][11], cross-platform apps become much easier to implement and are more likely to receive contributions from developers using different operating systems. With this, a single programmer can achieve a lot with less code and limited time.
|
||||
|
||||
[Ranges][12], deeply integrated into D, abstract how container elements (e.g., arrays, associative arrays, linked lists, etc.) are accessed as opposed to an actual implementation. This abstraction enables the design and use of a great number of algorithms over a great number of container types without tying them to a specific data structure. D's [array slicing][13] is an implementation of a range. In the end, you write less code in less time and have lower maintenance costs.
|
||||
|
||||
### Productivity
|
||||
|
||||
Most code contributors to open source software work on a voluntary basis with limited time. D allows you be more productive because you can do more in less time. Templates and ranges in D make programmers more productive as they write generic and reusable code, but those are only a couple of D's strengths in terms of productivity. Another main appeal is that D's compilation speed feels like interpreted languages such as Python, JavaScript, Ruby, and PHP, making D good for quick prototyping.
|
||||
|
||||
D can easily interface with legacy code, alleviating the need to port. It was designed to make [interfacing directly with C code][14] natural: After all, C is the master of legacy, well-written and tested code, libraries, and low-level system calls (especially in Linux). C++ code is also [callable in D][15] to a greater extent. In fact, [Python][16], [Objective-C][17], [Lua][18], and [Fortran][19] are some of the languages that are technically usable in D, and there are a number of third-party efforts pushing D in those areas. This makes the huge number of open source libraries usable in D code, which aligns with conventions of open source software development.
|
||||
|
||||
### Readable and maintainable
|
||||
|
||||
```
|
||||
import std.stdio; // import standard I/O module
|
||||
void main()
|
||||
{
|
||||
writeln("Hello, World!");
|
||||
}
|
||||
```
|
||||
|
||||
HelloWorld demo in D
|
||||
|
||||
D code is easy to understand by anyone familiar with C-like programming languages. Moreover, D is very readable, even for sophisticated code, which makes bugs easy to spot. Readability is also critical for engaging contributors, which is key to the growth of open source software.
|
||||
|
||||
One simple but very useful [syntactic sugar][20] in D is support for using an underscore to separate numbers, making them more readable. This is especially useful for math:
|
||||
|
||||
```
|
||||
int count = 100_000_000;
|
||||
double price = 20_220.00 + 10.00;
|
||||
int number = 0x7FFF_FFFF; // in hexadecimal system
|
||||
```
|
||||
|
||||
[Ddoc][21], a built-in tool, makes it easy to automatically generate documentation out of code comments without the need for an external tool. Documentation becomes less challenging to write, improve, and update as it goes side by side with the code.
|
||||
|
||||
[Contracts][22] are checks put in place to ensure D code behaves exactly as expected. Just like legal contracts are signed to ensure each party does their part in an agreement, contract programming in D ensures that the implementation of a function, class, etc. always produces the desired results or behaves as expected. Such a feature is practically useful for bug checks, especially in open source software where several people collaborate on a project. Contracts can be a lifesaver for large projects. D's powerful contract programming features are built-in rather than added as an afterthought. Contracts not only add to the convenience of using D but also make writing correct and maintainable code less of a headache.
|
||||
|
||||
### Convenient
|
||||
|
||||
Collaborative development can be challenging, as code is frequently changing and has many moving parts. D alleviates some of these issues, with support for importing modules locally within a scope:
|
||||
|
||||
```
|
||||
// returns even numbers
|
||||
int[] evenNumbers(int[] numbers)
|
||||
{
|
||||
// "filter" and "array" are only accessible locally
|
||||
import std.algorithm: filter;
|
||||
import std.array: array;
|
||||
return numbers.filter!(n => n%2 == 0).array;
|
||||
}
|
||||
```
|
||||
|
||||
The "!" operator used with **filter** is the syntax of a [template argument][5].
|
||||
|
||||
The function above can be tossed around without breaking code because it does not rely on any globally imported module. Any function implemented like this can be later enhanced without breaking code, which is a good thing for collaborative development.
|
||||
|
||||
[Universal Function Call Syntax][23] (UFCS), is a syntactic sugar in D that allows the call of regular functions, like member functions of an object. A function is defined as:
|
||||
|
||||
```
|
||||
void cook(string food, int quantity)
|
||||
{
|
||||
import std.stdio: writeln;
|
||||
writeln(food, " in quantity of ", quantity);
|
||||
}
|
||||
```
|
||||
|
||||
It can be called in the usual way like:
|
||||
|
||||
```
|
||||
string food = "rice";
|
||||
int quantity = 3;
|
||||
|
||||
cook(food, quantity);
|
||||
```
|
||||
|
||||
With UFCS, this same function can be called as if **cook** is a member function:
|
||||
|
||||
```
|
||||
string food = "rice";
|
||||
int quantity = 3;
|
||||
|
||||
food.cook(quantity);
|
||||
```
|
||||
|
||||
During compilation, the compiler automatically places **food** as the first argument to the function **cook**. UFCS makes it possible to **chain** regular functions—giving your code the natural feel of functional style programming. UFCS is heavily used in D, as it was in the case of the **filter** and **array** functions used in the **evenNumbers** function above. Combining templates, ranges, conditional compilation, and UFCS gives you massive power without sacrificing convenience.
|
||||
|
||||
The **auto** keyword can be used in place of a type. The compiler will statically infer the type during compilation. This saves you from long type names and makes writing D code feel like a dynamically typed language.
|
||||
|
||||
```
|
||||
// Nope. Do you?
|
||||
VeryLongTypeHere variable = new VeryLongTypeHere();
|
||||
|
||||
// using auto keyword
|
||||
auto variable = new VeryLongTypeHere();
|
||||
auto name = "John Doe";
|
||||
auto age = 12;
|
||||
auto letter = 'e';
|
||||
auto anArray = [1, 2.0, 3, 0, 1.5]; // type of double[]
|
||||
auto dictionary = ["one": 1, "two": 2, "three": 3]; // type of int[string]
|
||||
auto cook(string food) {...} // auto for a function return type
|
||||
```
|
||||
|
||||
D's [foreach][24] loop allows looping over collections and ranges of varying underlining data types:
|
||||
|
||||
```
|
||||
foreach(name; ["John", "Yaw", "Paul", "Kofi", "Ama"])
|
||||
{
|
||||
writeln(name);
|
||||
}
|
||||
|
||||
foreach(number; [1, 2, 3, 4, 4, 6]) {...}
|
||||
|
||||
foreach(number; 0..10) {...} // 0..10 is the syntax for number range
|
||||
|
||||
class Student {...}
|
||||
Student[] students = [new Student(), new Student()];
|
||||
foreach(student; students) {...}
|
||||
```
|
||||
|
||||
Built-in [unit test][25] support in D not only alleviates the need for an external tool, but also makes it convenient for programmers to implement tests in their code. All test cases go inside the customizable **unittest {}** block:
|
||||
|
||||
```
|
||||
int[] evenNumbers(int[] numbers)
|
||||
{
|
||||
import std.algorithm: filter;
|
||||
import std.array: array;
|
||||
return numbers.filter!(n => n%2 == 0).array;
|
||||
}
|
||||
|
||||
unittest
|
||||
{
|
||||
assert( evenNumbers([1, 2, 3, 4]) == [2, 4] );
|
||||
}
|
||||
```
|
||||
|
||||
Using DMD, D's reference compiler, you can compile all tests into the resulting executable by adding the **-unittest** compiler flag.
|
||||
|
||||
[Dub][26], a built-in package manager and build tool for D, makes it easy to use the increasing number of third-party packages (libraries) from the [Dub package registry][27]. Dub takes care of downloading, compiling, and linking those packages during compilation, as well as upgrading to future versions.
|
||||
|
||||
### Choice
|
||||
|
||||
In addition to providing several programming paradigms and features, D offers other choices. It currently has three compilers, all open source. The reference compiler, DMD, comes with its own backend, while the other two, GDC and LDC, use GCC and LLVM backends, respectively. DMD is noted for its fast compilation speeds, while LDC and GDC are noted for generating fast machine code at the cost of a little compilation time. You are free to choose whichever fits your use case.
|
||||
|
||||
Certain parts of D, when used, are [garbage-collected][28] by default. You can also choose manual memory management or even reference counting if you wish. The choice is all yours.
|
||||
|
||||
### And much more
|
||||
|
||||
There a several sugars in D that I haven't covered in this brief discussion. I highly recommend you check out [D's feature overview][29], the hidden treasures in the [standard library][30], and [areas of D usage][31] to see more of what people are doing with it. Many organizations are already [using D in production][32]. Finally, if you are ready to start learning D, check out the book _[Programming in D][6]_ .
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/d-open-source-software-development
|
||||
|
||||
作者:[Lawrence Aberba][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aberba
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:http://ddili.org/ders/d.en/templates.html
|
||||
[6]:http://ddili.org/ders/d.en/index.html
|
||||
[7]:https://opensource.com/article/17/5/d-open-source-software-development?rate=2NrC12X6cAUXB18h8bLBYUkDmF2GR1nuiAdeMCFCvh8
|
||||
[8]:https://dlang.org/
|
||||
[9]:https://en.wikipedia.org/wiki/Programming_paradigm
|
||||
[10]:http://ddili.org/ders/d.en/templates.html
|
||||
[11]:https://dlang.org/spec/version.html
|
||||
[12]:http://ddili.org/ders/d.en/ranges.html
|
||||
[13]:https://dlang.org/spec/arrays.html#slicing
|
||||
[14]:https://dlang.org/spec/interfaceToC.html
|
||||
[15]:https://dlang.org/spec/cpp_interface.html
|
||||
[16]:https://code.dlang.org/packages/pyd
|
||||
[17]:https://dlang.org/spec/objc_interface.html
|
||||
[18]:http://beza1e1.tuxen.de/into_luad.html
|
||||
[19]:http://www.active-analytics.com/blog/interface-d-with-c-fortran/
|
||||
[20]:https://en.wikipedia.org/wiki/Syntactic_sugar
|
||||
[21]:https://dlang.org/spec/ddoc.html
|
||||
[22]:http://ddili.org/ders/d.en/contracts.html
|
||||
[23]:http://ddili.org/ders/d.en/ufcs.html
|
||||
[24]:http://ddili.org/ders/d.en/foreach.html
|
||||
[25]:https://dlang.org/spec/unittest.html
|
||||
[26]:http://code.dlang.org/getting_started
|
||||
[27]:https://code.dlang.org/
|
||||
[28]:https://dlang.org/spec/garbage.html
|
||||
[29]:https://dlang.org/comparison.html
|
||||
[30]:https://dlang.org/phobos/index.html
|
||||
[31]:https://dlang.org/areas-of-d-usage.html
|
||||
[32]:https://dlang.org/orgs-using-d.html
|
||||
[33]:https://opensource.com/user/129491/feed
|
||||
[34]:https://opensource.com/users/aberba
|
||||
356
sources/tech/20170519 Accelerating your C++ on GPU with SYCL.md
Normal file
356
sources/tech/20170519 Accelerating your C++ on GPU with SYCL.md
Normal file
@ -0,0 +1,356 @@
|
||||
Accelerating your C++ on GPU with SYCL
|
||||
============================================================
|
||||
|
||||
|
||||
### WARNING: This is an incomplete draft. There are likely many mistaeks and unfinished sections.
|
||||
|
||||
* * *
|
||||
|
||||
Leveraging the power of graphics cards for compute applications is all the rage right now in fields such as machine learning, computer vision and high-performance computing. Technologies like OpenCL expose this power through a hardware-independent programming model, allowing you to write code which abstracts over different architecture capabilities. The dream of this is “write once, run anywhere”, be it an Intel CPU, AMD discrete GPU, DSP, etc. Unfortunately, for everyday programmers, OpenCL has something of a steep learning curve; a simple Hello World program can be a hundred or so lines of pretty ugly-looking code. However, to ease this pain, the Khronos group have developed a new standard called [SYCL][4], which is a C++ abstraction layer on top of OpenCL. Using SYCL, you can develop these general-purpose GPU (GPGPU) applications in clean, modern C++ without most of the faff associated with OpenCL. Here’s a simple vector multiplication example written in SYCL using the parallel STL implementation:
|
||||
|
||||
```
|
||||
#include <vector>
|
||||
#include <iostream>
|
||||
|
||||
#include <sycl/execution_policy>
|
||||
#include <experimental/algorithm>
|
||||
#include <sycl/helpers/sycl_buffers.hpp>
|
||||
|
||||
using namespace std::experimental::parallel;
|
||||
using namespace sycl::helpers;
|
||||
|
||||
int main() {
|
||||
constexpr size_t array_size = 1024*512;
|
||||
std::array<cl::sycl::cl_int, array_size> a;
|
||||
std::iota(begin(a),end(a),0);
|
||||
|
||||
{
|
||||
cl::sycl::buffer<int> b(a.data(), cl::sycl::range<1>(a.size()));
|
||||
cl::sycl::queue q;
|
||||
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
||||
transform(sycl_policy, begin(b), end(b), begin(b),
|
||||
[](int x) { return x*2; });
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
For comparison, here’s a mostly equivalent version written in OpenCL using the C++ API (don’t spend much time reading this, just note that it looks ugly and is really long):
|
||||
|
||||
```
|
||||
#include <iostream>
|
||||
#include <array>
|
||||
#include <numeric>
|
||||
#include <CL/cl.hpp>
|
||||
|
||||
int main(){
|
||||
std::vector<cl::Platform> all_platforms;
|
||||
cl::Platform::get(&all_platforms);
|
||||
if(all_platforms.size()==0){
|
||||
std::cout<<" No platforms found. Check OpenCL installation!\n";
|
||||
exit(1);
|
||||
}
|
||||
cl::Platform default_platform=all_platforms[0];
|
||||
|
||||
std::vector<cl::Device> all_devices;
|
||||
default_platform.getDevices(CL_DEVICE_TYPE_ALL, &all_devices);
|
||||
if(all_devices.size()==0){
|
||||
std::cout<<" No devices found. Check OpenCL installation!\n";
|
||||
exit(1);
|
||||
}
|
||||
|
||||
cl::Device default_device=all_devices[0];
|
||||
cl::Context context({default_device});
|
||||
|
||||
cl::Program::Sources sources;
|
||||
std::string kernel_code=
|
||||
" void kernel mul2(global int* A){"
|
||||
" A[get_global_id(0)]=A[get_global_id(0)]*2;"
|
||||
" }";
|
||||
sources.push_back({kernel_code.c_str(),kernel_code.length()});
|
||||
|
||||
cl::Program program(context,sources);
|
||||
if(program.build({default_device})!=CL_SUCCESS){
|
||||
std::cout<<" Error building: "<<program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(default_device)<<"\n";
|
||||
exit(1);
|
||||
}
|
||||
|
||||
constexpr size_t array_size = 1024*512;
|
||||
std::array<cl_int, array_size> a;
|
||||
std::iota(begin(a),end(a),0);
|
||||
|
||||
cl::Buffer buffer_A(context,CL_MEM_READ_WRITE,sizeof(int)*a.size());
|
||||
cl::CommandQueue queue(context,default_device);
|
||||
|
||||
if (queue.enqueueWriteBuffer(buffer_A,CL_TRUE,0,sizeof(int)*a.size(),a.data()) != CL_SUCCESS) {
|
||||
std::cout << "Failed to write memory;n";
|
||||
exit(1);
|
||||
}
|
||||
|
||||
cl::Kernel kernel_add = cl::Kernel(program,"mul2");
|
||||
kernel_add.setArg(0,buffer_A);
|
||||
|
||||
if (queue.enqueueNDRangeKernel(kernel_add,cl::NullRange,cl::NDRange(a.size()),cl::NullRange) != CL_SUCCESS) {
|
||||
std::cout << "Failed to enqueue kernel\n";
|
||||
exit(1);
|
||||
}
|
||||
|
||||
if (queue.finish() != CL_SUCCESS) {
|
||||
std::cout << "Failed to finish kernel\n";
|
||||
exit(1);
|
||||
}
|
||||
|
||||
if (queue.enqueueReadBuffer(buffer_A,CL_TRUE,0,sizeof(int)*a.size(),a.data()) != CL_SUCCESS) {
|
||||
std::cout << "Failed to read result\n";
|
||||
exit(1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
In this post I’ll give an introduction on using SYCL to accelerate your C++ code on the GPU.
|
||||
|
||||
* * *
|
||||
|
||||
### Lightning intro to GPGPU
|
||||
|
||||
Before I get started on how to use SYCL, I’ll give a brief outline of why you might want to run compute jobs on the GPU for those who are unfamiliar. I’ve you’ve already used OpenCL, CUDA or similar, feel free to skip ahead.
|
||||
|
||||
The key difference between a GPU and a CPU is that, rather than having a small number of complex, powerful cores (1-8 for common consumer desktop hardware), a GPU has a huge number of small, simple processing elements.
|
||||
|
||||

|
||||
|
||||
Above is a comically simplified diagram of a CPU with four cores. Each core has a set of registers and is attached to various levels of cache (some might be shared, some not), and then main memory.
|
||||
|
||||

|
||||
|
||||
In the GPU, tiny processing elements are grouped into execution units. Each processing element has a bit of memory attached to it, and each execution unit has some memory shared between its processing elements. After that, there’s some GPU-wide memory, then the same main memory which the CPU uses. The elements within an execution unit execute in _lockstep_ , where each element executes the same instruction on a different piece of data.
|
||||
|
||||
There are many aspects of GPGPU programming which make it an entirely different beast to everyday CPU programming. For example, transferring data from main memory to the GPU is _slow_ . _Really_ slow. Like, kill all your performance and get you fired slow. Therefore, the tradeoff with GPU programming is to make as much of the ridiculously high throughput of your accelerator to hide the latency of shipping the data to and from it.
|
||||
|
||||
There are other issues which might not be immediately apparent, like the cost of branching. Since the processing elements in an execution unit work in lockstep, nested branches which cause them to take different paths (divergent control flow) is a real problem. This is often solved by executing all branches for all elements and masking out the unneeded results. That’s a polynomial explosion in complexity based on the level of nesting, which is A Bad Thing ™. Of course, there are optimizations which can aid this, but the idea stands: simple assumptions and knowledge you bring from the CPU world might cause you big problems in the GPU world.
|
||||
|
||||
Before we get back to SYCL, some short pieces of terminology. The _host_ is the main CPU running on your machine which executes and the _device_ is what will be running your OpenCL code. A device could be the same as the host, or it could be some accelerator sitting in your machine, a simulator, whatever. A _kernel_ is a special function which is the entry point to the code which will run on your device. It will often be supplied with buffers for input and output data which have been set up by the host.
|
||||
|
||||
* * *
|
||||
|
||||
### Back to SYCL
|
||||
|
||||
There are currently two implementations of SYCL available; “triSYCL”, an experimental open source version by Xilinx (mostly used as a testbed for the standard), and “ComputeCpp”, an industry-strength implementation by Codeplay[1][2] (currently in open beta). Only ComputeCpp supports execution of kernels on the GPU, so we’ll be using that in this post.
|
||||
|
||||
Step 1 is to get ComputeCpp up and running on your machine. The main components are a runtime library which implements the SYCL API, and a Clang-based compiler which compiles both your host code and your device code. At the time of writing, Intel CPUs and some AMD GPUs are officially supported on Ubuntu and CentOS. It should be pretty easy to get it working on other Linux distributions (I got it running on my Arch system, for instance). Support for more hardware and operating systems is being worked on, so check the [supported platforms document][5] for an up-to-date list. The dependencies and components are listed [here][6]. You might also want to download the [SDK][7], which contains samples, documentation, build system integration files, and more. I’ll be using the [SYCL Parallel STL][8] in this post, so get that if you want to play along at home.
|
||||
|
||||
Once you’re all set up, we can get GPGPUing! As noted in the introduction, my first sample used the SYCL parallel STL implementation. We’ll now take a look at how to write that code with bare SYCL.
|
||||
|
||||
```
|
||||
#include <CL/sycl.hpp>
|
||||
|
||||
#include <array>
|
||||
#include <numeric>
|
||||
#include <iostream>
|
||||
|
||||
int main() {
|
||||
const size_t array_size = 1024*512;
|
||||
std::array<cl::sycl::cl_int, array_size> in,out;
|
||||
std::iota(begin(in),end(in),0);
|
||||
|
||||
cl::sycl::queue device_queue;
|
||||
cl::sycl::range<1> n_items{array_size};
|
||||
cl::sycl::buffer<cl::sycl::cl_int, 1> in_buffer(in.data(), n_items);
|
||||
cl::sycl::buffer<cl::sycl::cl_int, 1> out_buffer(out.data(), n_items);
|
||||
|
||||
device_queue.submit([&](cl::sycl::handler &cgh) {
|
||||
constexpr auto sycl_read = cl::sycl::access::mode::read_write;
|
||||
constexpr auto sycl_write = cl::sycl::access::mode::write;
|
||||
|
||||
auto in_accessor = in_buffer.get_access<sycl_read>(cgh);
|
||||
auto out_accessor = out_buffer.get_access<sycl_write>(cgh);
|
||||
|
||||
cgh.parallel_for<class VecScalMul>(n_items,
|
||||
[=](cl::sycl::id<1> wiID) {
|
||||
out_accessor[wiID] = in_accessor[wiID]*2;
|
||||
});
|
||||
});
|
||||
|
||||
device_queue.wait();
|
||||
}
|
||||
```
|
||||
|
||||
I’ll break this down piece-by-piece.
|
||||
|
||||
```
|
||||
#include <CL/sycl.hpp>
|
||||
```
|
||||
|
||||
The first thing we do is include the SYCL header file, which will put the SYCL runtime library at our command.
|
||||
|
||||
```
|
||||
const size_t array_size = 1024*512;
|
||||
std::array<cl::sycl::cl_int, array_size> in,out;
|
||||
std::iota(begin(in),end(in),0);
|
||||
```
|
||||
|
||||
Here we construct a large array of integers and initialize it with the numbers from `0` to `array_size-1` (this is what `std::iota` does). Note that we use `cl::sycl::cl_int` to ensure compatibility.
|
||||
|
||||
```
|
||||
cl::sycl::queue device_queue;
|
||||
```
|
||||
|
||||
Now we create our command queue. The command queue is where all work (kernels) will be enqueued before being dispatched to the device. There are many ways to customise the queue, such as providing a device to enqueue on or setting up asynchronous error handlers, but the default constructor will do for this example; it looks for a compatible GPU and falls back on the host CPU if it fails.
|
||||
|
||||
```
|
||||
cl::sycl::range<1> n_items{array_size};
|
||||
```
|
||||
|
||||
Next we create a range, which describes the shape of the data which the kernel will be executing on. In our simple example, it’s a one-dimensional array, so we use `cl::sycl::range<1>`. If the data was two-dimensional we would use `cl::sycl::range<2>` and so on. Alongside `cl::sycl::range`, there is `cl::sycl::ndrange`, which allows you to specify work group sizes as well as an overall range, but we don’t need that for our example.
|
||||
|
||||
```
|
||||
cl::sycl::buffer<cl::sycl::cl_int, 1> in_buffer(in.data(), n_items);
|
||||
cl::sycl::buffer<cl::sycl::cl_int, 1> out_buffer(out.data(), n_items);
|
||||
```
|
||||
|
||||
In order to control data sharing and transfer between the host and devices, SYCL provides a `buffer` class. We create two SYCL buffers to manage our input and output arrays.
|
||||
|
||||
```
|
||||
device_queue.submit([&](cl::sycl::handler &cgh) {/*...*/});
|
||||
```
|
||||
|
||||
After setting up all of our data, we can enqueue our actual work. There are a few ways to do this, but a simple method for setting up a parallel execution is to call the `.submit` function on our queue. To this function we pass a _command group functor_ [2][3] which will be executed when the runtime schedules that task. A command group handler sets up any last resources needed by the kernel and dispatches it.
|
||||
|
||||
```
|
||||
constexpr auto sycl_read = cl::sycl::access::mode::read_write;
|
||||
constexpr auto sycl_write = cl::sycl::access::mode::write;
|
||||
|
||||
auto in_accessor = in_buffer.get_access<sycl_read>(cgh);
|
||||
auto out_accessor = out_buffer.get_access<sycl_write>(cgh);
|
||||
```
|
||||
|
||||
In order to control access to our buffers and to tell the runtime how we will be using the data, we need to create _accessors_ . It should be clear that we are creating one accessor for reading from `in_buffer`, and one accessor for writing to `out_buffer`.
|
||||
|
||||
```
|
||||
cgh.parallel_for<class VecScalMul>(n_items,
|
||||
[=](cl::sycl::id<1> wiID) {
|
||||
out_accessor[wiID] = in_accessor[wiID]*2;
|
||||
});
|
||||
```
|
||||
|
||||
Now that we’ve done all the setup, we can actually do some computation on our device. Here we dispatch a kernel on the command group handler `cgh` over our range `n_items`. The actual kernel itself is a lambda which takes a work-item identifier and carries out our computation. In this case, we are reading from `in_accessor` at the index of our work-item identifier, multiplying it by `2`, then storing the result in the relevant place in `out_accessor`. That `<class VecScalMul>` is an unfortunate byproduct of how SYCL needs to work within the confines of standard C++, so we need to give a unique class name to the kernel for the compiler to be able to do its job.
|
||||
|
||||
```
|
||||
device_queue.wait();
|
||||
```
|
||||
|
||||
Our last line is kind of like calling `.join()` on a `std::thread`; it waits until the queue has executed all work which has been submitted. After this point, we could now access `out` and expect to see the correct results. Queues will also wait implicitly on destruction, so you could alternatively place it in some inner scope and let the synchronisation happen when the scope ends.
|
||||
|
||||
There are quite a few new concepts at play here, but hopefully you can see the power and expressibility we get using these techniques. However, if you just want to toss some code at your GPU and not worry about the customisation, then you can use the SYCL Parallel STL implementation.
|
||||
|
||||
* * *
|
||||
|
||||
### SYCL Parallel STL
|
||||
|
||||
The SYCL Parallel STL is an implementation of the Parallelism TS which dispatches your algorithm function objects as SYCL kernels. We already saw an example of this at the top of the page, so lets run through it quickly.
|
||||
|
||||
```
|
||||
#include <vector>
|
||||
#include <iostream>
|
||||
|
||||
#include <sycl/execution_policy>
|
||||
#include <experimental/algorithm>
|
||||
#include <sycl/helpers/sycl_buffers.hpp>
|
||||
|
||||
using namespace std::experimental::parallel;
|
||||
using namespace sycl::helpers;
|
||||
|
||||
int main() {
|
||||
constexpr size_t array_size = 1024*512;
|
||||
std::array<cl::sycl::cl_int, array_size> in,out;
|
||||
std::iota(begin(in),end(in),0);
|
||||
|
||||
{
|
||||
cl::sycl::buffer<int> in_buffer(in.data(), cl::sycl::range<1>(in.size()));
|
||||
cl::sycl::buffer<int> out_buffer(out.data(), cl::sycl::range<1>(out.size()));
|
||||
cl::sycl::queue q;
|
||||
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
||||
transform(sycl_policy, begin(in_buffer), end(in_buffer), begin(out_buffer),
|
||||
[](int x) { return x*2; });
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
constexpr size_t array_size = 1024*512;
|
||||
std::array<cl::sycl::cl_int, array_size> in, out;
|
||||
std::iota(begin(in),end(out),0);
|
||||
```
|
||||
|
||||
So far, so similar. Again we’re creating a couple of arrays to hold our input and output data.
|
||||
|
||||
```
|
||||
cl::sycl::buffer<int> in_buffer(in.data(), cl::sycl::range<1>(in.size()));
|
||||
cl::sycl::buffer<int> out_buffer(out.data(), cl::sycl::range<1>(out.size()));
|
||||
cl::sycl::queue q;
|
||||
```
|
||||
|
||||
Here we are creating our buffers and our queue like in the last example.
|
||||
|
||||
```
|
||||
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
|
||||
```
|
||||
|
||||
Here’s where things get interesting. We create a `sycl_execution_policy` from our queue and give it a name to use for the kernel. This execution policy can then be used like `std::execution::par` or `std::execution::seq`.
|
||||
|
||||
```
|
||||
transform(sycl_policy, begin(in_buffer), end(in_buffer), begin(out_buffer),
|
||||
[](int x) { return x*2; });
|
||||
```
|
||||
|
||||
Now our kernel dispatch looks like a call to `std::transform` with an execution policy provided. That closure we pass in will be compiled for and executed on the device without us having to do any more complex set up.
|
||||
|
||||
Of course, you can do more than just `transform`. At the time of writing, the SYCL Parallel STL supports these algorithms:
|
||||
|
||||
* `sort`
|
||||
|
||||
* `transform`
|
||||
|
||||
* `for_each`
|
||||
|
||||
* `for_each_n`
|
||||
|
||||
* `count_if`
|
||||
|
||||
* `reduce`
|
||||
|
||||
* `inner_product`
|
||||
|
||||
* `transform_reduce`
|
||||
|
||||
* * *
|
||||
|
||||
That covers things for this short introduction. If you want to keep up to date with developments in SYCL, be sure to check out [sycl.tech][9]. Notable recent developments have been porting [Eigen][10] and [Tensorflow][11] to SYCL to bring expressive artificial intelligence programming to OpenCL devices. Personally, I’m excited to see how the high-level programming models can be exploited for automatic optimization of heterogeneous programs, and how they can support even higher-level technologies like [HPX][12] or [SkelCL][13].
|
||||
|
||||
1. I work for Codeplay, but this post was written in my own time with no suggestion from my employer. [↩][1]
|
||||
|
||||
2. Hey, “functor” is in the spec, don’t @ me.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/05/19/sycl/
|
||||
|
||||
作者:[TartanLlama ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fnref:1
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fn:1
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/05/19/sycl/#fn:2
|
||||
[4]:https://www.khronos.org/sycl
|
||||
[5]:https://www.codeplay.com/products/computesuite/computecpp/reference/platform-support-notes
|
||||
[6]:https://www.codeplay.com/products/computesuite/computecpp/reference/release-notes/
|
||||
[7]:https://github.com/codeplaysoftware/computecpp-sdk
|
||||
[8]:https://github.com/KhronosGroup/SyclParallelSTL
|
||||
[9]:http://sycl.tech/
|
||||
[10]:https://github.com/ville-k/sycl_starter
|
||||
[11]:http://deep-beta.co.uk/setting-up-tensorflow-with-opencl-using-sycl/
|
||||
[12]:https://github.com/STEllAR-GROUP/hpx
|
||||
[13]:https://github.com/skelcl/skelcl
|
||||
@ -0,0 +1,203 @@
|
||||
How to Kill a Process from the Command Line
|
||||
============================================================
|
||||
|
||||

|
||||
>Linux has all the tools you need to stop running processes at the command line. Jack Wallen has details.[Creative Commons Zero][4]
|
||||
|
||||
Picture this: You’ve launched an application (be it from your favorite desktop menu or from the command line) and you start using that launched app, only to have it lock up on you, stop performing, or unexpectedly die. You try to run the app again, but it turns out the original never truly shut down completely.
|
||||
|
||||
What do you do? You kill the process. But how? Believe it or not, your best bet most often lies within the command line. Thankfully, Linux has every tool necessary to empower you, the user, to kill an errant process. However, before you immediately launch that command to kill the process, you first have to know what the process is. How do you take care of this layered task? It’s actually quite simple...once you know the tools at your disposal.
|
||||
|
||||
Let me introduce you to said tools.
|
||||
|
||||
The steps I’m going to outline will work on almost every Linux distribution, whether it is a desktop or a server. I will be dealing strictly with the command line, so open up your terminal and prepare to type.
|
||||
|
||||
### Locating the process
|
||||
|
||||
The first step in killing the unresponsive process is locating it. There are two commands I use to locate a process: _top _ and _ps_ . Top is a tool every administrator should get to know. With _top_ , you get a full listing of currently running process. From the command line, issue _top_ to see a list of your running processes (Figure 1).
|
||||
|
||||
### [killa.jpg][5]
|
||||
|
||||

|
||||
|
||||
Figure 1: The top command gives you plenty of information.[Used with permission][1]
|
||||
|
||||
From this list you will see some rather important information. Say, for example, Chrome has become unresponsive. According to our _top_ display, we can discern there are four instances of chrome running with Process IDs (PID) 3827, 3919, 10764, and 11679\. This information will be important to have with one particular method of killing the process.
|
||||
|
||||
Although _top_ is incredibly handy, it’s not always the most efficient means of getting the information you need. Let’s say you know the Chrome process is what you need to kill, and you don’t want to have to glance through the real-time information offered by _top_ . For that, you can make use of the _ps_ command and filter the output through _grep_ . The _ps_ command reports a snapshot of a current process and _grep _ prints lines matching a pattern. The reason why we filter _ps_ through _grep_ is simple: If you issue the _ps_ command by itself, you will get a snapshot listing of all current processes. We only want the listing associated with Chrome. So this command would look like:
|
||||
|
||||
```
|
||||
ps aux | grep chrome
|
||||
```
|
||||
|
||||
The _aux_ options are as follows:
|
||||
|
||||
* a = show processes for all users
|
||||
|
||||
* u = display the process's user/owner
|
||||
|
||||
* x = also show processes not attached to a terminal
|
||||
|
||||
The _x_ option is important when you’re hunting for information regarding a graphical application.
|
||||
|
||||
When you issue the command above, you’ll be given more information than you need (Figure 2) for the killing of a process, but it is sometimes more efficient than using top.
|
||||
|
||||
### [killb.jpg][6]
|
||||
|
||||

|
||||
|
||||
Figure 2: Locating the necessary information with the ps command.[Used with permission][2]
|
||||
|
||||
### Killing the process
|
||||
|
||||
Now we come to the task of killing the process. We have two pieces of information that will help us kill the errant process:
|
||||
|
||||
* Process name
|
||||
|
||||
* Process ID
|
||||
|
||||
Which you use will determine the command used for termination. There are two commands used to kill a process:
|
||||
|
||||
* kill - Kill a process by ID
|
||||
|
||||
* killall - Kill a process by name
|
||||
|
||||
There are also different signals that can be sent to both kill commands. What signal you send will be determined by what results you want from the kill command. For instance, you can send the HUP (hang up) signal to the kill command, which will effectively restart the process. This is always a wise choice when you need the process to immediately restart (such as in the case of a daemon). You can get a list of all the signals that can be sent to the kill command by issuing kill -l. You’ll find quite a large number of signals (Figure 3).
|
||||
|
||||
### [killc.jpg][7]
|
||||
|
||||

|
||||
|
||||
Figure 3: The available kill signals.[Used with permission][3]
|
||||
|
||||
The most common kill signals are:
|
||||
|
||||
|
|
||||
|
||||
Signal Name
|
||||
|
||||
|
|
||||
|
||||
Single Value
|
||||
|
||||
|
|
||||
|
||||
Effect
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGHUP
|
||||
|
||||
|
|
||||
|
||||
1
|
||||
|
||||
|
|
||||
|
||||
Hangup
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGINT
|
||||
|
||||
|
|
||||
|
||||
2
|
||||
|
||||
|
|
||||
|
||||
Interrupt from keyboard
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGKILL
|
||||
|
||||
|
|
||||
|
||||
9
|
||||
|
||||
|
|
||||
|
||||
Kill signal
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGTERM
|
||||
|
||||
|
|
||||
|
||||
15
|
||||
|
||||
|
|
||||
|
||||
Termination signal
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGSTOP
|
||||
|
||||
|
|
||||
|
||||
17, 19, 23
|
||||
|
||||
|
|
||||
|
||||
Stop the process
|
||||
|
||||
|
|
||||
|
||||
What’s nice about this is that you can use the Signal Value in place of the Signal Name. So you don’t have to memorize all of the names of the various signals.
|
||||
So, let’s now use the _kill _ command to kill our instance of chrome. The structure for this command would be:
|
||||
|
||||
```
|
||||
kill SIGNAL PID
|
||||
```
|
||||
|
||||
Where SIGNAL is the signal to be sent and PID is the Process ID to be killed. We already know, from our _ps_ command that the IDs we want to kill are 3827, 3919, 10764, and 11679\. So to send the kill signal, we’d issue the commands:
|
||||
|
||||
```
|
||||
kill -9 3827
|
||||
|
||||
kill -9 3919
|
||||
|
||||
kill -9 10764
|
||||
|
||||
kill -9 11679
|
||||
```
|
||||
|
||||
Once we’ve issued the above commands, all of the chrome processes will have been successfully killed.
|
||||
|
||||
Let’s take the easy route! If we already know the process we want to kill is named chrome, we can make use of the _killall _ command and send the same signal the process like so:
|
||||
|
||||
_killall -9 chrome_
|
||||
|
||||
The only caveat to the above command is that it may not catch all of the running chrome processes. If, after running the above command, you issue the ps aux|grep chrome command and see remaining processes running, your best bet is to go back to the _kill _ command and send signal 9 to terminate the process by PID.
|
||||
|
||||
### Ending processes made easy
|
||||
|
||||
As you can see, killing errant processes isn’t nearly as challenging as you might have thought. When I wind up with a stubborn process, I tend to start off with the _killall _ command as it is the most efficient route to termination. However, when you wind up with a really feisty process, the _kill _ command is the way to go.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/5/how-kill-process-command-line
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[5]:https://www.linux.com/files/images/killajpg
|
||||
[6]:https://www.linux.com/files/images/killbjpg
|
||||
[7]:https://www.linux.com/files/images/killcjpg
|
||||
[8]:https://www.linux.com/files/images/stop-processesjpg
|
||||
@ -0,0 +1,71 @@
|
||||
朝鲜180局的网络战部门让西方国家忧虑。
|
||||
|
||||
Translated by hwlog
|
||||
North Korea's Unit 180, the cyber warfare cell that worries the West
|
||||
|
||||
============================================================
|
||||
[][13] [**PHOTO:** 脱北者说, 平壤的网络战攻击目的在于一个叫做“180局”的部门来筹集资金。(Reuters: Damir Sagolj, file)][14]
|
||||
据叛逃者,官方和网络安全专家称,朝鲜的情报机关有一个叫做180局的特殊部门, 这个部门已经发起过多起勇敢且成功的网络战。
|
||||
近几年朝鲜被美国,韩国,和周边几个国家指责对多数的金融网络发起过一系列在线袭击。
|
||||
网络安全技术人员称他们找到了这个月感染了150多个国家30多万台计算机的全球想哭勒索病毒"ransomware"和朝鲜网络战有关联的技术证据。
|
||||
平壤称该指控是“荒谬的”。
|
||||
对朝鲜的关键指控是指朝鲜与一个叫做拉撒路的黑客组织有联系,这个组织是在去年在孟加拉国中央银行网络抢劫8000万美元并在2014年攻击了索尼的好莱坞工作室的网路。
|
||||
美国政府指责朝鲜对索尼公司的黑客袭击,同时美国政府对平壤在孟加拉国银行的盗窃行为提起公诉并要求立案。
|
||||
由于没有确凿的证据,没有犯罪指控并不能够立案。朝鲜之后也否认了Sony公司和银行的袭击与其有关。
|
||||
朝鲜是世界上最封闭的国家之一,它秘密行动的一些细节很难获得。
|
||||
但研究这个封闭的国家和流落到韩国和一些西方国家的的叛逃者已经给出了或多或少的提示。
|
||||
|
||||
### 黑客们喜欢用雇员来作为掩护
|
||||
金恒光,朝鲜前计算机教授,2004叛逃到韩国,他仍然有着韩国内部的消息,他说平壤的网络战目的在于通过侦察总局下属的一个叫做180局来筹集资金,这个局主要是负责海外的情报机构。
|
||||
金教授称,“180局负责入侵金融机构通过漏洞从银行账户提取资金”。
|
||||
他之前也说过,他以前的一些学生已经加入了朝鲜的网络战略司令部-朝鲜的网络部队。
|
||||
|
||||
>"黑客们到海外寻找比朝鲜更好的互联网服务的地方,以免留下痕迹," 金教授补充说。
|
||||
他说他们经常用贸易公司,朝鲜的海外分公司和在中国和东南亚合资企业的雇员来作为掩护
|
||||
位于华盛顿的战略与国际研究中心的叫做James Lewis的朝鲜专家称,平壤首先用黑客作为间谍活动的工具然后对韩国和美国的目的进行政治干扰。
|
||||
索尼公司事件之后,他们改变方法,通过用黑客来支持犯罪活动来形成国内坚挺的货币经济政策。
|
||||
“目前为止,网上毒品,假冒伪劣,走私,都是他们惯用的伎俩”。
|
||||
Media player: 空格键播放,“M”键静音,“左击”和“右击”查看。
|
||||
|
||||
[**VIDEO:** 你遇到过勒索病毒吗? (ABC News)][16]
|
||||
|
||||
### 韩国声称拥有大量的“证据”
|
||||
美国国防部称在去年提交给国会的一个报告中显示,朝鲜可能有作为有效成本的,不对称的,可拒绝的工具,它能够应付来自报复性袭击很小的风险,因为它的“网络”大部分是和因特网分离的。
|
||||
|
||||
> 报告中说," 它可能从第三方国家使用互联网基础设施"。
|
||||
韩国政府称,他们拥有朝鲜网络战行动的大量证据。
|
||||
“朝鲜进行网络战通过第三方国家来掩护网络袭击的来源,并且使用他们的信息和通讯技术设施”,Ahn Chong-ghee,韩国外交部副部长,在书面评论中告诉路透社。
|
||||
除了孟加拉银行抢劫案,他说平壤也被怀疑与菲律宾,越南和波兰的银行袭击有关。
|
||||
去年六月,警察称朝鲜袭击了160个韩国公司和政府机构,入侵了大约14万台计算机,暗中在他的对手的计算机中植入恶意代码作为长期计划的一部分来进行大规模网络攻击。
|
||||
朝鲜也被怀疑在2014年对韩国核反应堆操作系统进行阶段性网络攻击,尽管朝鲜否认与其无关。
|
||||
根据在一个韩国首尔的杀毒软件厂商“hauri”的高级安全研究员Simon Choi的说法,网络袭击是来自于他在中国的一个基地。
|
||||
Choi先生,一个有着对朝鲜的黑客能力进行了广泛的研究的人称,“他们在那里行动以至于不论他们做什么样的计划,他们拥有中国的ip地址”。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.abc.net.au/news/2017-05-21/north-koreas-unit-180-cyber-warfare-cell-hacking/8545106
|
||||
|
||||
作者:[www.abc.net.au ][a]
|
||||
译者:[译者ID](https://github.com/hwlog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.abc.net.au
|
||||
[1]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||
[2]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||
[3]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||
[4]:http://www.abc.net.au/news/2017-05-16/researchers-link-wannacry-to-north-korea/8531110
|
||||
[5]:http://www.abc.net.au/news/2017-05-18/adylkuzz-cyberattack-could-be-far-worse-than-wannacry:-expert/8537502
|
||||
[6]:http://www.google.com/maps/place/Korea,%20Democratic%20People%20S%20Republic%20Of/@40,127,5z
|
||||
[7]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||
[8]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||
[9]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||
[10]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||
[11]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||
[12]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||
[13]:http://www.abc.net.au/news/2017-05-21/military-trucks-trhough-pyongyang/8545134
|
||||
[14]:http://www.abc.net.au/news/2017-05-21/military-trucks-trhough-pyongyang/8545134
|
||||
[15]:http://www.abc.net.au/news/2017-05-16/researchers-link-wannacry-to-north-korea/8531110
|
||||
[16]:http://www.abc.net.au/news/2017-05-15/have-you-been-hit-by-ransomware/8527854
|
||||
@ -1,111 +0,0 @@
|
||||
|
||||
AI 正快速入侵我们生活的五个方面
|
||||
============================================================
|
||||
|
||||
> 让我们来看看我们已经被人工智能包围的五个真实存在的方面。
|
||||
|
||||

|
||||
> 图片来源: opensource.com
|
||||
|
||||
开源项目[正在帮助推动][2]人工智能进步,而且随着技术的成熟,我们将听到更多关于 AI 如何影响我们生活的消息。你有没有考虑过 AI 是如何改变你周围的世界的?让我们来看看我们日益人为增强的世界,以及 AI 对未来影响的大胆预测。
|
||||
|
||||
### 1. AI 影响你的购买决定
|
||||
|
||||
最近 [VentureBeat][3] 上的一篇文章,[“AI 将如何帮助我们解读千禧一代”][4]吸引了我的注意。我承认我对人工智能没有思考太多,也没有费力尝试解读千禧一代,所以我很好奇,渴望了解更多。事实证明,文章标题有点误导;“如何卖东西给千禧一代”会是一个更准确的标题。
|
||||
|
||||
根据这篇文章,千禧一代是“一个年龄阶段的人群,被人觊觎,以至于来自全世界的市场经理都在争抢他们”。通过分析网络行为 —— 无论是购物、社交媒体或其他活动 - 机器学习可以帮助预测行为模式,这将可以变成有针对性的广告。文章接着解释如何对物联网和社交媒体平台进行挖掘形成数据点。“使用机器学习挖掘社交媒体数据,可以让公司了解千禧一代如何谈论其产品,他们对一个产品类别的看法,他们对竞争对手的广告活动如何响应,还可获得很多数据,用于设计有针对性的广告,"这篇文章解释说。AI 和千禧一代成为营销的未来并不是什么很令人吃惊的事,但是 X 一代和婴儿潮一代,你们也逃不掉呢!
|
||||
|
||||
> 人工智能被用来根据行为变化来定位包括城市人在内的整个人群。
|
||||
|
||||
例如, [Raconteur上][23]的一篇文章——"AI将怎样改变购买者的行为"解释说,AI 在网上零售行业最大的力量是它能够迅速适应流动的情况下改变客户行为。人工智能创业公司 [Fluid AI][25]首席执行官 Abhinav Aggarwal 表示,他的公司的软件被客户用来预测客户行为,并且系统注意到在暴风雪期间发生了变化。“那些通常会忽略在一天中发送的电子邮件或应用内通知的用户现在正在打开它们,因为他们在家里没有太多的事情可做。一个小时,AI 系统就适应了新的情况,并在工作时间发送更多的促销材料。"他解释说。
|
||||
|
||||
AI正在改变了我们怎样花钱和为什么花钱,但是AI是怎样改变我们挣钱的方式的呢?
|
||||
|
||||
### 2. 人工智能正在改变我们如何工作
|
||||
|
||||
[Fast 公司][5]最近的一篇文章《这就是在 2017 年人工智能如何改变我们的生活》说道,求职者将会从人工智能中受益。作者解释说,除薪酬趋势更新之外,人工智能将被用来给求职者发送相关职位空缺信息。当你应该升职的时候,你就会得到一个升职的机会。
|
||||
|
||||
人造智能也将被公司用来帮助新入职的员工。文章解释说:“许多新员工在头几天内获得了大量信息,其中大部分不会被保留。” 相反,机器人可能会随着时间的推移向一名新员工“滴滴”,因为它变得更加相关。
|
||||
|
||||
[Inc.][7]的一篇文章[《没有偏见的企业:人工智能将如何重塑招聘机制》][8]着眼于人才管理解决方案提供商 [SAP SuccessFactors][9] 是怎样利用人工智能作为一个工作描述偏差检查器”和检查员工赔偿金的偏差。
|
||||
|
||||
[《Deloitte 2017 人力资本趋势报告》][10]显示,AI 正在激励组织进行重组。Fast公司的文章[《AI 是怎样改变公司组织的方式》][11]审查了这篇报告,该文章是基于全球 10,000 多名人力资源和商业领袖的调查结果。这篇文章解释说:"许多公司现在更注重文化和环境的适应性,而不是聘请最有资格的人来做某个具体任务,因为知道个人角色必须随 AI 的实施而发展 。" 为了适应不断变化的技术,组织也从自上而下的结构转向多学科团队,文章说。
|
||||
|
||||
###3. AI 正在改变教育
|
||||
|
||||
> AI 将使所有教育生态系统的利益相关者受益。
|
||||
|
||||
尽管教育的预算正在缩减,但是教室的规模却正在增长。因此利用技术的进步有助于提高教育体系的生产率和效率,并在提高教育质量和负担能力方面发挥作用。根据VentureBeat上的一篇文章[《2017 年人工智能是怎样改变教育》][26],今年我们将看到 AI 对学生们的书面答案进行评分,机器人回答学生的答案,虚拟个人助理辅导学生等等。文章解释说:“AI 将惠及教育生态系统的所有利益相关者。学生将能够通过即时的反馈和指导学习地更好,教师将获得丰富的学习分析和对个性化教学的见解,父母将以更低的成本看到他们的孩子的更好的职业前景,学校能够规模化优质的教育,政府能够向所有人提供可负担得起的教育。"
|
||||
|
||||
### 4. 人工智能正在重塑医疗保健
|
||||
|
||||
2017 年 2 月[CB Insights][12]的一篇文章挑选了 106 个医疗保健领域的人工智能初创公司,它们中的很多在过去几年中提高了第一次股权融资。这篇文章说:“在24 家成像和诊断公司中,19 家公司自 2015 年 1 月起就首次公开募股。”这份名单上了有那些从事于远程病人监测,药物发现和肿瘤学方面人工智能的公司。
|
||||
|
||||
3 月 16 日发表在 TechCrunch 上的一篇关于 AI 进步如何重塑医疗保健的文章解释说:"一旦对人类的 DNA 有了更好的理解,就有机会更进一步,并能根据他们特殊的生活习性为他们提供个性化的见解"。这种趋势预示着“个性化遗传学”的新纪元,人们能够通过获得关于自己身体的前所未有的信息来充分控制自己的健康。"
|
||||
|
||||
本文接着解释说,AI 和机器学习降低了研发新药的成本和时间。部分得益于广泛的测试,新药进入市场需要 12年 以上的时间。这篇文章说:“机器学习算法可以让计算机根据先前处理的数据来"学习"如何做出预测,或者选择(在某些情况下,甚至是产品)需要做什么实验。类似的算法还可用于预测特定化合物对人体的副作用,这样可以加快审批速度。"这篇文章指出,2015 年旧金山的一个创业公司 [Atomwise][15] 完成了对两种可以减少一天内 Ebola 感染的新药物。
|
||||
|
||||
> AI 正在帮助发现、诊断和治疗新疾病。
|
||||
|
||||
另外一个位于伦敦的初创公司 [BenevolentAI][27] 正在利用人工智能寻找科学文献中的模式。这篇文章说:"最近,这家公司找到了两种可能对 Alzheimer 起作用的化合物,引起了很多制药公司的关注。"
|
||||
|
||||
除了有助于研发新药,AI正在帮助发现、诊断和治疗新疾病。TechCrunch 上 文章解释说,过去是根据显示的症状诊断疾病,但是现在 AI 正在被用于检测血液中的疾病特征,并利用对数十亿例临床病例分析进行深度学习获得经验来制定治疗计划。这篇文章说:“IBM 的 Watson 正在与纽约的 Memorial Sloan Kettering 合作,消化理解数十年来关于癌症患者和治疗方面的数据,为了向治疗疑难的癌症病例的医生提供和建议治疗方案。”
|
||||
|
||||
### 5. AI正在改变我们的爱情生活
|
||||
|
||||
有 195 个国家的超过 5000 万活跃用户通过一个在 2012 年推出的约会应用程序 [Tinder][16] 找到潜在的伴侣。在一篇 [Forbes 采访播客][17]中,Tinder 的创始人兼董事长 Sean Rad spoke 与 Steven Bertoni 对人工智能是如何正在改变人们约会进行过讨论。在一篇[关于采访的文章][18]中,Bertoni 引用了 Rad 说的话,他说:"可能有这样一个时刻,这时 Tinder 非常擅长推测你会感兴趣的人,Tinder 在组织一次约会中可能会做很多跑腿的工作,对吧?"所以,这个 app 会向用户推荐一些附近的同伴,并更进一步,协调彼此的时间安排一次约会,而不只是向用户显示一些有可能的同伴。
|
||||
|
||||
> 我们的后代真的可能会爱上人工智能。
|
||||
|
||||
你爱上了 AI 吗?我们的后代真的可能会爱上人工智能。Raya Bidshahri 发表在 [Singularity Hub][19] 的一篇文章《AI 将如何重新定义爱情》说,几十年的后,我们可能会认为爱情不再受生物学的限制。
|
||||
|
||||
Bidshahri 解释说:"我们的技术符合摩尔定律,正在以惊人的速度增长——智能设备正在越来越多地融入我们的生活。",他补充道:"到 2029 年,我们将会有和人类同等智慧的 AI,而到 21 世纪 40 年代,AI 将会比人类聪明无数倍。许多人预测,有一天我们会与强大的机器合并,我们自己可能会变成人工智能。"他认为在这样一个世界上那些是不可避免的,人们将会接受与完全的非生物相爱。
|
||||
|
||||
这听起来有点怪异,但是相比较于未来机器人将统治世界,爱上AI会是一个更乐观的结果。Bidshahri说:"对AI进行编程,让他们能够感受到爱,这将使我们创造出更富有同情心的AI,这可能也是避免很多人忧虑的AI大灾难的关键。"
|
||||
|
||||
这份 AI 正在入侵我们生活各领域的其中五个方面的清单仅仅只是涉及到了我们身边的人工智能的表面。哪些 AI 创新是让你最兴奋的,或者是让你最烦恼的?大家可以在文章评论区写下你们的感受。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Rikki Endsley - Rikki Endsley 是开源社区 Opensource.com 的管理员。在过去,她曾做过 Red Hat 开源和标准(OSAS)团队社区传播者;自由技术记者;USENIX 协会的社区管理员; linux 权威杂志 ADMIN 和 Ubuntu User 的合作出版者,还是杂志 Sys Admin 和 UnixReview.com 的主编。在 Twitter上关注她:@rikkiends。
|
||||
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
|
||||
作者:[Rikki Endsley ][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives?rate=ORfqhKFu9dpA9aFfg-5Za9ZWGcBcx-f0cUlf_VZNeQs
|
||||
[2]:https://www.linux.com/news/open-source-projects-are-transforming-machine-learning-and-ai
|
||||
[3]:https://twitter.com/venturebeat
|
||||
[4]:http://venturebeat.com/2017/03/16/how-ai-will-help-us-decipher-millennials/
|
||||
[5]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives
|
||||
[6]:https://www.fastcompany.com/3066620/this-is-how-ai-will-change-your-work-in-2017
|
||||
[7]:https://twitter.com/Inc
|
||||
[8]:http://www.inc.com/bill-carmody/businesses-beyond-bias-how-ai-will-reshape-hiring-practices.html
|
||||
[9]:https://www.successfactors.com/en_us.html
|
||||
[10]:https://dupress.deloitte.com/dup-us-en/focus/human-capital-trends.html?id=us:2el:3pr:dup3575:awa:cons:022817:hct17
|
||||
[11]:https://www.fastcompany.com/3068492/how-ai-is-changing-the-way-companies-are-organized
|
||||
[12]:https://twitter.com/CBinsights
|
||||
[13]:https://www.cbinsights.com/blog/artificial-intelligence-startups-healthcare/
|
||||
[14]:https://techcrunch.com/2017/03/16/advances-in-ai-and-ml-are-reshaping-healthcare/
|
||||
[15]:http://www.atomwise.com/
|
||||
[16]:https://twitter.com/Tinder
|
||||
[17]:https://www.forbes.com/podcasts/the-forbes-interview/#5e962e5624e1
|
||||
[18]:https://www.forbes.com/sites/stevenbertoni/2017/02/14/tinders-sean-rad-on-how-technology-and-artificial-intelligence-will-change-dating/#4180fc2e5b99
|
||||
[19]:https://twitter.com/singularityhub
|
||||
[20]:https://singularityhub.com/2016/08/05/how-ai-will-redefine-love/
|
||||
[21]:https://opensource.com/user/23316/feed
|
||||
[22]:https://opensource.com/article/17/3/5-big-ways-ai-rapidly-invading-our-lives#comments
|
||||
[23]:https://twitter.com/raconteur
|
||||
[24]:https://www.raconteur.net/technology/how-ai-will-change-buyer-behaviour
|
||||
[25]:http://www.fluid.ai/
|
||||
[26]:http://venturebeat.com/2017/02/04/how-ai-will-transform-education-in-2017/
|
||||
[27]:https://twitter.com/benevolent_ai
|
||||
[28]:https://opensource.com/users/rikki-endsley
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
如何在 Linux 中删除大(100-200GB)文件
|
||||
============================================================
|
||||
|
||||
作者:[Aaron Kili][11] | 发布日期: May 11, 2017 | 最后更新:May 11, 2017
|
||||
|
||||
立即下载你的免费电子书 - [10 本为管理员的免费 Linux 电子书][12] | [4 本免费 Shell 脚本电子书][13]
|
||||
|
||||
通常,要[在 Linux 终端删除一个文件][1],我们使用 rm 命令(删除文件)、shred 命令(安全删除文件)、wipe 命令(安全擦除文件)或者 secure-deletion 工具包(一个[安全文件删除工具][2]集合)。
|
||||
|
||||
我们可以使用下面任意的工具来处理相对较小的文件。如果我们想要删除大的文件/文件夹,比如大概 100-200GB。这个方法在删除文件(I/O 调度)所花费的时间以及 RAM 占用量方面看起来可能并不容易。
|
||||
|
||||
在本教程中,我们会解释如何在 Linux 中有效率并可靠地删除大文件/文件夹。
|
||||
|
||||
**建议阅读:** [5 个在 Linux 中清空或者删除大文件的方法][3]
|
||||
|
||||
主要的目标是使用一种不会在删除大文件时拖慢系统的技术,并有合理的 I/O 占用。我么可以用 ionice 命令实现这个目标。
|
||||
|
||||
### 在 Linux 中使用 ionice 命令删除大(200GB)文件
|
||||
|
||||
ionice 是一个可以为另一个程序设置或获取 I/O 调度级别和优先级的有用程序。如果没有给出参数或者只有 `-p`,那么 ionice 将会查询该进程的当前的 I/O 调度级别以及优先级。
|
||||
|
||||
如果我们给出命令名称,如 rm 命令,它将使用给定的参数运行此命令。要指定要获取或设置调度参数的[进程的进程 ID],运行这个:
|
||||
|
||||
```
|
||||
# ionice -p PID
|
||||
```
|
||||
|
||||
要指定名字或者调度的数字,使用(0 表示无、1 表示实时、2 表示尽力、3 表示空闲)下面的命令。
|
||||
|
||||
这意味这 rm 会属于空闲 I/O 级别,并且只在其他进程不使用的时候使用 I/O:
|
||||
|
||||
```
|
||||
---- Deleting Huge Files in Linux -----
|
||||
# ionice -c 3 rm /var/logs/syslog
|
||||
# ionice -c 3 rm -rf /var/log/apache
|
||||
```
|
||||
|
||||
如果系统中没有很多空闲时间,那么我们希望使用尽力调度级别,并且使用低优先级:
|
||||
|
||||
```
|
||||
# ionice -c 2 -n 6 rm /var/logs/syslog
|
||||
# ionice -c 2 -n 6 rm -rf /var/log/apache
|
||||
```
|
||||
|
||||
注意:要使用安全的方法删除大文件,我们可以使用先前提到的 shred、wipe 以及 secure-deletion 工具包中的不同工具,而不是 rm 命令。
|
||||
|
||||
**建议阅读:**[3 个在 Linux 中永久/安全删除文件/文件夹的方法][5]
|
||||
|
||||
要获取更多信息,查阅 ionice 的手册页:
|
||||
|
||||
```
|
||||
# man ionice
|
||||
```
|
||||
|
||||
就是这样了!你脑海里还有其他的方法么?在评论栏中与我们分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux 系统管理员和网络开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/delete-huge-files-in-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||
[2]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||
[3]:https://www.tecmint.com/empty-delete-file-content-linux/
|
||||
[4]:https://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[5]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||
[6]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||
[7]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||
[8]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||
[9]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||
[10]:https://www.tecmint.com/delete-huge-files-in-linux/#comments
|
||||
[11]:https://www.tecmint.com/author/aaronkili/
|
||||
[12]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[13]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,131 @@
|
||||
Linfo — 实时显示你的 Linux 服务器运行状况
|
||||
============================================================
|
||||
|
||||
|
||||
Linfo 是一个免费且开源的跨平台服务器统计 UI/库,它可以显示大量的系统信息。Linfo 是可扩展的,通过 `composer`,很容易使用 PHP5 库以程序化方式获取来自 PHP 应用的扩展系统统计。它是 `Web UI` 的一个 `Ncurses CLI view`,在 Linux、Windows、BSD、Darwin/Mac OSX、Solaris 和 Minix 系统上均可用。
|
||||
|
||||
Linfo 显示的系统信息包括 [CPU 类型/速度][2]、服务器的体系结构、挂载点使用量、硬盘/光纤/flash 驱动器、硬件设备、网络设备和统计信息、运行时间/启动日期、主机名、内存使用量(RAM 和 swap)、温度/电压/风扇速度和 RAID 阵列等。
|
||||
|
||||
#### 环境要求:
|
||||
|
||||
* PHP 5.3
|
||||
|
||||
* pcre 扩展
|
||||
|
||||
* Linux – /proc 和 /sys 已挂载且可对 `PHP` 可读,已经在 2.6.x/3.x 内核中测试过
|
||||
|
||||
### 如何在 Linux 中安装服务器统计 UI/库 Info
|
||||
|
||||
首先,在 `Apache` 或 `Nginx` 的 Web 根目录下创建一个 `Linfo` 目录,然后,克隆仓库文件并使用下面展示的 [rsync 命令][3]将其移动到目录 `/var/www/html/linfo` 下:
|
||||
|
||||
```
|
||||
$ sudo mkdir -p /var/www/html/linfo
|
||||
$ git clone git://github.com/jrgp/linfo.git
|
||||
$ sudo rsync -av linfo/ /var/www/html/linfo/
|
||||
```
|
||||
|
||||
接下来,将 `sample.config.inc.php` 重命名为 `config.inc.php`。这是 Linfo 的配置文件,你可以在里面定义你想要的值:
|
||||
|
||||
```
|
||||
$ sudo mv sample.config.inc.php config.inc.php
|
||||
```
|
||||
|
||||
现在,在 Web 浏览器中打开链接 `http://SERVER_IP/linfo` 来查看这个 Web UI,正如下面的截图所展示的。
|
||||
|
||||
从截图中可以看到, Linfo 显示了系统内核信息、硬件组成、RAM 统计、网络设备、驱动器以及文件系统挂载点。
|
||||
|
||||
[][4]
|
||||
|
||||
*Linux 服务器运行信息*
|
||||
|
||||
你可以将下面一行内容加入配置文件 `config.inc.php` 中,从而可以产生错误信息,以便进行故障排查。
|
||||
|
||||
```
|
||||
$settings['show_errors'] = true;
|
||||
```
|
||||
|
||||
### 以 Ncurses 模式运行 Linfo
|
||||
|
||||
Linfo 有一个基于 `ncurses` 的简单界面,它依赖于 `php` 的 `ncurses` 扩展。
|
||||
|
||||
```
|
||||
# yum install php-pecl-ncurses [在 CentOS/RHEL 上]
|
||||
# dnf install php-pecl-ncurses [在 Fedora 上]
|
||||
$ sudo apt-get install php5-dev libncurses5-dev [在 Debian/Ubuntu 上]
|
||||
```
|
||||
|
||||
现在,像下面这样编译这个 `php` 扩展:
|
||||
|
||||
```
|
||||
$ wget http://pecl.php.net/get/ncurses-1.0.2.tgz
|
||||
$ tar xzvf ncurses-1.0.2.tgz
|
||||
$ cd ncurses-1.0.2
|
||||
$ phpize # generate configure script
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
接下来,如果编译成功并安装好了该 `php` 扩展,运行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo echo extension=ncurses.so > /etc/php5/cli/conf.d/ncurses.ini
|
||||
```
|
||||
|
||||
验证 ncurse:
|
||||
|
||||
```
|
||||
$ php -m | grep ncurses
|
||||
```
|
||||
|
||||
Now run the Linfo.
|
||||
现在,运行 Info:
|
||||
|
||||
```
|
||||
$ cd /var/www/html/linfo/
|
||||
$ ./linfo-curses
|
||||
```
|
||||
[][5]
|
||||
|
||||
*Linux 服务器信息*
|
||||
|
||||
Info 中尚未加入下面这些功能:
|
||||
|
||||
1. 支持更多 Unix 操作系统(比如 Hurd、IRIX、AIX 和 HP UX 等)
|
||||
|
||||
2. 支持不太出名的操作系统 Haiku/BeOS
|
||||
|
||||
3. 额外功能/扩展
|
||||
|
||||
5. 在 ncurses 模式中支持 [htop-like][1] 特性
|
||||
|
||||
如果想了解更多信息,请访问 Info 的 GitHub 仓库: [https://github.com/jrgp/linfo][6]
|
||||
|
||||
这就是本文的全部内容了。从现在起,你可以使用 Info 在 Web 浏览器中查看 Linux 系统的信息。尝试一下,并在评论中和我们分享你的想法。另外,你是否还知道与之类似的有用工具/库?如果有,请给我们提供一些相关信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux 系统管理员和网络开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识
|
||||
|
||||
---------------
|
||||
|
||||
via: https://www.tecmint.com/linfo-shows-linux-server-health-status-in-real-time/
|
||||
|
||||
作者:[ Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||
[2]:https://www.tecmint.com/corefreq-linux-cpu-monitoring-tool/
|
||||
[3]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-Server-Health-Information.png
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-Server-Information.png
|
||||
[6]:https://github.com/jrgp/linfo
|
||||
[7]:https://www.tecmint.com/author/aaronkili/
|
||||
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
Loading…
Reference in New Issue
Block a user