mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
bda6535bd3
@ -0,0 +1,140 @@
|
||||
如何在MacBook Pro Retina上安装Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
MacBook Pros拥有非常强大的配置,但是有些人想强上加强,他们想用Linux系统。
|
||||
|
||||
不管您是想要更开放和个性化的操作系统又或者是您只想要使用某些在Linux特有的软件,您都会想要在您的MacBook上安装Linux。 可惜的是MacBook Pro们可是一块块密不透风砖头,让您想装其他系统又无从下手。尤其是Linux,比在MacBook上装Windows还难。 Boot Camp对于Linux来说也没有什么用处。 虽然如此,但并不代表您完全不能做到,装机走起!
|
||||
|
||||
### 为什么要在MacBook Pro Retina上装Linux? ###
|
||||
|
||||
买MacBook不就是为了OS X吗?为何要装Linux? 其实买MacBook的原因不仅仅只是因为它的操作系统, 其极致的硬件性能,超长的电池寿命,以及抗操抗造都是购买它的原因。 这些这么好的硬件再加上一块能让您体验到HiDPI的清晰度Retina显示屏,其不皆是买入的理由乎?
|
||||
|
||||
但是如果您对OS X无爱,又或者您真心想要使用Linux,为何不将这自由、开源、小巧、个性化的Linux塞进您的高大上的硬件呢?苹果可能有话要说了,可谁在乎呢~
|
||||
|
||||
注:在本期教程我们将会使用[最流行的Linux发行版][1] - Ubuntu来作为我们这次安装的选择。您也可以用自己想用的的Linux发行版,但相关的步骤会和本教程略有出入。 如果您把自己的系统玩坏了,我们将不承担任何责任。 本教程将教您如何 Linux 和 OS X 双系统启动,另外只有在OS X才能升级固件,所以我们建议您不要将OS X 删除。
|
||||
|
||||
但在我们开始之前,请您用您喜欢的方法(比如Time Machine 或 CrashPlan)将您的电脑彻底备份,以防万一。
|
||||
|
||||
### 下载 Ubuntu ###
|
||||
|
||||
首先您需要下载一份[Ubuntu桌面版安装镜像][2] 。 务必选择64位的桌面版,虽然该镜像并不是为Mac提供的。该镜像在BIOS和EFI模式下都能启动,而Mac的镜像却只能在BIOS启动。Mac是专门设计成这样的,但是我们要使之以EFI模式下启动。
|
||||
|
||||
### 写到U盘(USB) ###
|
||||
|
||||
其次, 找个2GB以上的USB, 我们将会用该USB作为Ubuntu的安装启动盘。 你可以按照 [Ubuntu官方指导的步骤][3] 或者 [使用专用的图形化工具][4] 来准备安装盘.
|
||||
|
||||
### 调整分区大小 ###
|
||||
|
||||

|
||||
|
||||
当你完成上一步后,你的Mac Book Pro就做好安装的准备了。 打开Disk Utility(磁盘工具), 点击左边选择你的硬盘, 选择Partitions(分区)标签页。 把Mac分区缩小到你喜欢的大小 - 我们将会用新创建的可用空间来安装Ubuntu。
|
||||
|
||||
### 启动Ubuntu镜像 ###
|
||||
|
||||

|
||||
|
||||
上述步骤完成后,将U盘插入并重启Mac Book Pro。当关机之后屏幕一黑时,请按住Option键(alt)直到你看到不同的启动选项。选择EFI选项(如果有两个的话选择左边的哪一个)来从USB启动Ubuntu.
|
||||
|
||||
当你看到“Try Ubuntu" 和 "Install Ubuntu" 两个选项的时候, 选择 "Try Ubuntu" 因为我们需要在安装完成之后重启之前弄一些其他的东西。
|
||||
|
||||
### 安装器 ###
|
||||
|
||||
当Ubuntu的桌面加载好之后,一路向下走直到你看到分区的这一步。 如果你连接不上WiFi的话就代表你的Ubuntu还暂时不知道如何跟你这位高大上Mac做朋友, 不过不用担心, 我们暂时还不需要网络, 在你迟些重启的时候会自动识别你的驱动。
|
||||
|
||||

|
||||
|
||||
到分区这个步骤之后, 选择 "Do Something else" 这个选项。 然后请确保那块大约128MB左右的分区已经被识别为EFI启动分区(你可以点击它然后选择Option来确定一下; 另外,那个分区应该是 /dev/sda1)。下一步, 你要在新建的空间里创建一个 ext4分区,在其上挂载“/”路径。 如果你知道你自己在干嘛的话也可以创建几个不同的分区(切记这不是Windows啊孩纸)。
|
||||
|
||||
在你开始下一步之前,请确保你的安装引导程序(boot loader)是选择了 /dev/sda1,GRUB也是装到该分区的。 然后按照平常一样该咋装咋装。
|
||||
|
||||
### 修改 EFI 引导 ###
|
||||
|
||||

|
||||
|
||||
当你的安装器装完Ubuntu之后,不要按重启!!! 我们还需要弄这么点东西才能使用GRUB。 请运行下列的指令:
|
||||
|
||||
sudo apt-get install efibootmgr
|
||||
|
||||
这个将会暂时地安装一个EFI boot的配置工具,然后 运行:
|
||||
|
||||
sudo efibootmgr
|
||||
|
||||
这个将会显示出当前的启动设置, 你应该看到的是 "ubuntu" 和 "Boot0000*",当前的EFI设置是把系统指向 Boot0080*,这样的话就会跳过GRUB然后直接跳入OS X,所以我们要用以下指令来修复它:
|
||||
|
||||
sudo efibootmgr -o 0,80
|
||||
|
||||
现在就可以重启了!
|
||||
|
||||
恭喜你啦~你的Ubuntu现在应该就可以用了哦!不过下列的一些调整会让性能提升哦!
|
||||
|
||||
### 坑爹地调整设置 ###
|
||||
|
||||
首先你需要改一下GRUB的设置,这样你的SSD盘才不会偶尔死机, 在Terminal输入:
|
||||
|
||||
sudo nano /etc/default/grub
|
||||
|
||||
找到 **GRUB\_CMDLINE\_LINUX**那一行 , 把它改成 **GRUB\_CMDLINE\_LINUX="libata.force=noncq"** 。 按下CTRL + X保存,然后按Y来确定保存。 接下来你要在Terminal输入:
|
||||
|
||||
sudo nano /etc/grub.d/40_custom
|
||||
|
||||
打开一个新的文件,请使用真丶精准手指准确地一字一字输入:
|
||||
|
||||
menuentry "Mac OS X" {
|
||||
exit
|
||||
}
|
||||
|
||||
这将会让你boot到你安装好的Mac OS X(GRUB的32-bit和64-bit项不能用)。然后CTRL+X 和 Y 保存退出,然后输入:
|
||||
|
||||
sudo update-grub
|
||||
|
||||
最后必须要重启才能生效。
|
||||
|
||||

|
||||
|
||||
在极其高清的Retina显示屏上神马都这么小,坑爹啊啊? 去Setting -> Display 里把 Scaling Factor弄大一点吧,不然妈妈又要担心你的近视眼了。
|
||||
|
||||
你也可能觉得在边边上改变窗口大小是一件极其困难的事情,坑爹啊啊? 去Terminal输入:
|
||||
|
||||
sudo nano /usr/share/themes/Ambiance/metacity-1/metacity-theme-1.xml
|
||||
|
||||
然后在里面修改成下面的参数:
|
||||
|
||||
<distance name="left_width" value="4"/>
|
||||
<distance name="right_width" value="4"/>
|
||||
<distance name="bottom_height" value="4"/>
|
||||
|
||||
如果还是太小,把上面的东西改成6吧!
|
||||
|
||||
最后,如果你觉得你的Linux把你那Retina鲜艳的颜色洗掉了,请到你的OS X盘,找到以下的文件:
|
||||
|
||||
/Library/ColorSync/Profiles/Displays/Color LCD-xxxxxx.icc
|
||||
|
||||
xxxxxx只是一串随机的字符,不过这路径应该只有一个文件。把他搬到你Ubuntu的Home folder, 然后到 System Settings –> Color 选择 Add New Profile 并选择你那刚弄过来的icc文件。
|
||||
|
||||
### 总结 ###
|
||||
|
||||

|
||||
|
||||
恭喜你啦, 现在终于有一台属于你的Linux MacBook Pro Retina啦!如果你想把你的Ubuntu弄得更手熟,请按 [让你的Ubuntu 像家一样舒服][5] 尽情地修改配置吧! 该教程也可用于其他的Mac系统,当然每种Mac都有不同的好处和坏处。 如果你用的是其他的Mac,请翻一翻[这篇为Ubuntu写的文档][6]
|
||||
|
||||
另外,你还可以看一下其他可以在Mac安装的[Linux 发行包][7]哦!
|
||||
|
||||
Image Credits: [K?rlis Dambr?ns][8] Via Flickr
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/install-linux-macbook-pro/
|
||||
|
||||
译者:[213edu](https://github.com/213edu) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.makeuseof.com/tag/windows-xp-users-switch-ubuntu-14-04-lts-trusty-tahr/
|
||||
[2]:http://www.ubuntu.com/download/desktop/
|
||||
[3]:http://www.ubuntu.com/download/desktop/create-a-usb-stick-on-mac-osx
|
||||
[4]:http://www.makeuseof.com/tag/how-to-boot-a-linux-live-usb-stick-on-your-mac/
|
||||
[5]:http://www.makeuseof.com/tag/11-tweaks-perform-ubuntu-installation/
|
||||
[6]:https://help.ubuntu.com/community/MacBookPro
|
||||
[7]:http://www.makeuseof.com/pages/best-linux-distributions
|
||||
[8]:https://www.flickr.com/photos/janitors/10037346335
|
||||
@ -8,15 +8,15 @@ APP Grid:一个优秀的Ubuntu软件中心替代品
|
||||
|
||||
### App Grid:Ubuntu软件中心替代品 ###
|
||||
|
||||
自从2011年的彻底改造后,Ubuntu的旗舰应用商店的界面就没怎么变过。这并不是说它在此期间被完全忽略了,12.04的开发周期中可以看到[在启动时间上的工作][1]已经做了一些。
|
||||
自从2011年的彻底改造后,Ubuntu的旗舰应用商店的界面就没怎么变过。这并不是说它在此期间被完全忽略了,在12.04的开发周期中可以看到已经做了一些[减少打开耗时的工作][1]。
|
||||
|
||||
撇开那个不算,ol’ USC还是一如既往:一篮子的潜力还没被开发。
|
||||
撇开那个不算,Ubuntu软件中心还是一如既往,还有许多潜在功能还没被开发。
|
||||
|
||||
App Grid的目标时解决这些问题。从零开始,它要求更快的启动时间,更快的反应时间,而且“不感觉混乱,不让人失望”。
|
||||
App Grid的目标是解决这些问题。从零开始,它要求更快的启动时间,更快的反应时间,而且“不感觉混乱,不让人失望”。
|
||||
|
||||
在大部分这些方面,App Grid取得了成功。它几乎可以立即打开,而在界面上点击也确实反应迅速。“不感觉混乱”这一承诺,或许有一点小小的争议。该应用有时候要你横向滚动,而另外的时候,又要你纵向滚动。也有人禁不住会想,如果这个应用能把它的网格背景样式扔了,可能看起来会显得更专业一些。
|
||||
|
||||
作为在Ubuntu上从筛选应用程序的一个方式,App Grid做出了极大的努力。它支持Ubuntu One上的订购、评级和评论,作为Ubuntu默认应用商店的替代品,它更好用。
|
||||
作为在Ubuntu上筛选应用程序的一个方式,App Grid做出了极大的努力。它支持Ubuntu One上的订购、评级和评论,作为Ubuntu默认应用商店的替代品,它更好用。
|
||||
|
||||
如果非要说点什么缺点的话,那就是它不是一个开源的应用程序,第一次运行时会显示以下免责声明:
|
||||
|
||||
@ -27,18 +27,19 @@ App Grid的目标时解决这些问题。从零开始,它要求更快的启动
|
||||
App Grid可运行在Ubuntu 12.04 LTS,13.10以及14.04 LTS版本下。可以通过添加以下PPA软件源来安装:
|
||||
|
||||
sudo add-apt-repository -y ppa:appgrid/stable
|
||||
sudo apt-get update && sudo apt-get install app grid
|
||||
sudo apt-get update && sudo apt-get install appgrid
|
||||
|
||||
或者,也可以[从项目网站][2]抓取一个.deb安装包来安装。
|
||||
|
||||
- [下载用于Ubuntu 14.04的App Grid安装包][3]
|
||||
|
||||
试试吧,试过后请到我们开的空间里来发表一下你的看法吧……
|
||||
试试吧,试过后请发表一下你的看法吧……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/05/appgrid-ubuntu-software-centre-alternative
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
370
published/20140603 Write your first Linux Kernel module.md
Normal file
370
published/20140603 Write your first Linux Kernel module.md
Normal file
@ -0,0 +1,370 @@
|
||||
黑客内核:编写属于你的第一个Linux内核模块
|
||||
================================================================================
|
||||
> 曾经多少次想要在内核游荡?曾经多少次茫然不知方向?你不要再对着它迷惘,让我们指引你走向前方……
|
||||
|
||||
内核编程常常看起来像是黑魔法,而在亚瑟 C 克拉克的眼中,它八成就是了。Linux内核和它的用户空间是大不相同的:抛开漫不经心,你必须小心翼翼,因为你编程中的一个bug就会影响到整个系统。浮点运算做起来可不容易,堆栈固定而狭小,而你写的代码总是异步的,因此你需要想想并发会导致什么。而除了所有这一切之外,Linux内核只是一个很大的、很复杂的C程序,它对每个人开放,任何人都去读它、学习它并改进它,而你也可以是其中之一。
|
||||
|
||||
学习内核编程的最简单的方式也许就是写个内核模块:一段可以动态加载进内核的代码。模块所能做的事是有限的——例如,他们不能在类似进程描述符这样的公共数据结构中增减字段(LCTT译注:可能会破坏整个内核及系统的功能)。但是,在其它方面,他们是成熟的内核级的代码,可以在需要时随时编译进内核(这样就可以摒弃所有的限制了)。完全可以在Linux源代码树以外来开发并编译一个模块(这并不奇怪,它称为树外开发),如果你只是想稍微玩玩,而并不想提交修改以包含到主线内核中去,这样的方式是很方便的。
|
||||
|
||||
在本教程中,我们将开发一个简单的内核模块用以创建一个**/dev/reverse**设备。写入该设备的字符串将以相反字序的方式读回(“Hello World”读成“World Hello”)。这是一个很受欢迎的程序员面试难题,当你利用自己的能力在内核级别实现这个功能时,可以使你得到一些加分。在开始前,有一句忠告:你的模块中的一个bug就会导致系统崩溃(虽然可能性不大,但还是有可能的)和数据丢失。在开始前,请确保你已经将重要数据备份,或者,采用一种更好的方式,在虚拟机中进行试验。
|
||||
|
||||
### 尽可能不要用root身份 ###
|
||||
|
||||
> 默认情况下,**/dev/reverse**只有root可以使用,因此你只能使用**sudo**来运行你的测试程序。要解决该限制,可以创建一个包含以下内容的**/lib/udev/rules.d/99-reverse.rules**文件:
|
||||
>
|
||||
> SUBSYSTEM=="misc", KERNEL=="reverse", MODE="0666"
|
||||
>
|
||||
> 别忘了重新插入模块。让非root用户访问设备节点往往不是一个好主意,但是在开发其间却是十分有用的。这并不是说以root身份运行二进制测试文件也不是个好主意。
|
||||
|
||||
#### 模块的构造 ####
|
||||
|
||||
由于大多数的Linux内核模块是用C写的(除了底层的特定于体系结构的部分),所以推荐你将你的模块以单一文件形式保存(例如,reverse.c)。我们已经把完整的源代码放在GitHub上——这里我们将看其中的一些片段。开始时,我们先要包含一些常见的文件头,并用预定义的宏来描述模块:
|
||||
|
||||
#include <linux/init.h>
|
||||
#include <linux/kernel.h>
|
||||
#include <linux/module.h>
|
||||
|
||||
MODULE_LICENSE("GPL");
|
||||
MODULE_AUTHOR("Valentine Sinitsyn <valentine.sinitsyn@gmail.com>");
|
||||
MODULE_DESCRIPTION("In-kernel phrase reverser");
|
||||
|
||||
这里一切都直接明了,除了**MODULE\_LICENSE()**:它不仅仅是一个标记。内核坚定地支持GPL兼容代码,因此如果你把许可证设置为其它非GPL兼容的(如,“Proprietary”[专利]),某些特定的内核功能将在你的模块中不可用。
|
||||
|
||||
### 什么时候不该写内核模块 ###
|
||||
|
||||
> 内核编程很有趣,但是在现实项目中写(尤其是调试)内核代码要求特定的技巧。通常来讲,在没有其它方式可以解决你的问题时,你才应该在内核级别解决它。以下情形中,可能你在用户空间中解决它更好:
|
||||
|
||||
> - 你要开发一个USB驱动 —— 请查看[libusb][1]。
|
||||
> - 你要开发一个文件系统 —— 试试[FUSE][2]。
|
||||
> - 你在扩展Netfilter —— 那么[libnetfilter\_queue][3]对你有所帮助。
|
||||
|
||||
> 通常,内核里面代码的性能会更好,但是对于许多项目而言,这点性能丢失并不严重。
|
||||
|
||||
由于内核编程总是异步的,没有一个**main()**函数来让Linux顺序执行你的模块。取而代之的是,你要为各种事件提供回调函数,像这个:
|
||||
|
||||
static int __init reverse_init(void)
|
||||
{
|
||||
printk(KERN_INFO "reverse device has been registered\n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
static void __exit reverse_exit(void)
|
||||
{
|
||||
printk(KERN_INFO "reverse device has been unregistered\n");
|
||||
}
|
||||
|
||||
module_init(reverse_init);
|
||||
module_exit(reverse_exit);
|
||||
|
||||
这里,我们定义的函数被称为模块的插入和删除。只有第一个的插入函数是必要的。目前,它们只是打印消息到内核环缓冲区(可以在用户空间通过**dmesg**命令访问);**KERN\_INFO**是日志级别(注意,没有逗号)。**\_\_init**和**\_\_exit**是属性 —— 联结到函数(或者变量)的元数据片。属性在用户空间的C代码中是很罕见的,但是内核中却很普遍。所有标记为**\_\_init**的,会在初始化后释放内存以供重用(还记得那条过去内核的那条“Freeing unused kernel memory…[释放未使用的内核内存……]”信息吗?)。**\_\_exit**表明,当代码被静态构建进内核时,该函数可以安全地优化了,不需要清理收尾。最后,**module\_init()**和**module\_exit()**这两个宏将**reverse\_init()**和**reverse_exit()**函数设置成为我们模块的生命周期回调函数。实际的函数名称并不重要,你可以称它们为**init()**和**exit()**,或者**start()**和**stop()**,你想叫什么就叫什么吧。他们都是静态声明,你在外部模块是看不到的。事实上,内核中的任何函数都是不可见的,除非明确地被导出。然而,在内核程序员中,给你的函数加上模块名前缀是约定俗成的。
|
||||
|
||||
这些都是些基本概念 - 让我们来做更多有趣的事情吧。模块可以接收参数,就像这样:
|
||||
|
||||
# modprobe foo bar=1
|
||||
|
||||
**modinfo**命令显示了模块接受的所有参数,而这些也可以在**/sys/module//parameters**下作为文件使用。我们的模块需要一个缓冲区来存储参数 —— 让我们把这大小设置为用户可配置。在**MODULE_DESCRIPTION()**下添加如下三行:
|
||||
|
||||
static unsigned long buffer_size = 8192;
|
||||
module_param(buffer_size, ulong, (S_IRUSR | S_IRGRP | S_IROTH));
|
||||
MODULE_PARM_DESC(buffer_size, "Internal buffer size");
|
||||
|
||||
这儿,我们定义了一个变量来存储该值,封装成一个参数,并通过sysfs来让所有人可读。这个参数的描述(最后一行)出现在modinfo的输出中。
|
||||
|
||||
由于用户可以直接设置**buffer\_size**,我们需要在**reverse\_init()**来清除无效取值。你总该检查来自内核之外的数据 —— 如果你不这么做,你就是将自己置身于内核异常或安全漏洞之中。
|
||||
|
||||
static int __init reverse_init()
|
||||
{
|
||||
if (!buffer_size)
|
||||
return -1;
|
||||
printk(KERN_INFO
|
||||
"reverse device has been registered, buffer size is %lu bytes\n",
|
||||
buffer_size);
|
||||
return 0;
|
||||
}
|
||||
|
||||
来自模块初始化函数的非0返回值意味着模块执行失败。
|
||||
|
||||
### 导航 ###
|
||||
|
||||
> 但你开发模块时,Linux内核就是你所需一切的源头。然而,它相当大,你可能在查找你所要的内容时会有困难。幸运的是,在庞大的代码库面前,有许多工具使这个过程变得简单。首先,是Cscope —— 在终端中运行的一个比较经典的工具。你所要做的,就是在内核源代码的顶级目录中运行**make cscope && cscope**。Cscope和Vim以及Emacs整合得很好,因此你可以在你最喜爱的编辑器中使用它。
|
||||
|
||||
> 如果基于终端的工具不是你的最爱,那么就访问[http://lxr.free-electrons.com][4]吧。它是一个基于web的内核导航工具,即使它的功能没有Cscope来得多(例如,你不能方便地找到函数的用法),但它仍然提供了足够多的快速查询功能。
|
||||
|
||||
现在是时候来编译模块了。你需要你正在运行的内核版本头文件(**linux-headers**,或者等同的软件包)和**build-essential**(或者类似的包)。接下来,该创建一个标准的Makefile模板:
|
||||
|
||||
obj-m += reverse.o
|
||||
all:
|
||||
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
|
||||
clean:
|
||||
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
|
||||
|
||||
现在,调用**make**来构建你的第一个模块。如果你输入的都正确,在当前目录内会找到reverse.ko文件。使用**sudo insmod reverse.ko**插入内核模块,然后运行如下命令:
|
||||
|
||||
$ dmesg | tail -1
|
||||
[ 5905.042081] reverse device has been registered, buffer size is 8192 bytes
|
||||
|
||||
恭喜了!然而,目前这一行还只是假象而已 —— 还没有设备节点呢。让我们来搞定它。
|
||||
|
||||
#### 混杂设备 ####
|
||||
|
||||
在Linux中,有一种特殊的字符设备类型,叫做“混杂设备”(或者简称为“misc”)。它是专为单一接入点的小型设备驱动而设计的,而这正是我们所需要的。所有混杂设备共享同一个主设备号(10),因此一个驱动(**drivers/char/misc.c**)就可以查看它们所有设备了,而这些设备用次设备号来区分。从其他意义来说,它们只是普通字符设备。
|
||||
|
||||
要为该设备注册一个次设备号(以及一个接入点),你需要声明**struct misc\_device**,填上所有字段(注意语法),然后使用指向该结构的指针作为参数来调用**misc\_register()**。为此,你也需要包含**linux/miscdevice.h**头文件:
|
||||
|
||||
static struct miscdevice reverse_misc_device = {
|
||||
.minor = MISC_DYNAMIC_MINOR,
|
||||
.name = "reverse",
|
||||
.fops = &reverse_fops
|
||||
};
|
||||
static int __init reverse_init()
|
||||
{
|
||||
...
|
||||
misc_register(&reverse_misc_device);
|
||||
printk(KERN_INFO ...
|
||||
}
|
||||
|
||||
这儿,我们为名为“reverse”的设备请求一个第一个可用的(动态的)次设备号;省略号表明我们之前已经见过的省略的代码。别忘了在模块卸下后注销掉该设备。
|
||||
|
||||
static void __exit reverse_exit(void)
|
||||
{
|
||||
misc_deregister(&reverse_misc_device);
|
||||
...
|
||||
}
|
||||
|
||||
‘fops’字段存储了一个指针,指向一个**file\_operations**结构(在Linux/fs.h中声明),而这正是我们模块的接入点。**reverse\_fops**定义如下:
|
||||
|
||||
static struct file_operations reverse_fops = {
|
||||
.owner = THIS_MODULE,
|
||||
.open = reverse_open,
|
||||
...
|
||||
.llseek = noop_llseek
|
||||
};
|
||||
|
||||
另外,**reverse\_fops**包含了一系列回调函数(也称之为方法),当用户空间代码打开一个设备,读写或者关闭文件描述符时,就会执行。如果你要忽略这些回调,可以指定一个明确的回调函数来替代。这就是为什么我们将**llseek**设置为**noop\_llseek()**,(顾名思义)它什么都不干。这个默认实现改变了一个文件指针,而且我们现在并不需要我们的设备可以寻址(这是今天留给你们的家庭作业)。
|
||||
|
||||
#### 关闭和打开 ####
|
||||
|
||||
让我们来实现该方法。我们将给每个打开的文件描述符分配一个新的缓冲区,并在它关闭时释放。这实际上并不安全:如果一个用户空间应用程序泄漏了描述符(也许是故意的),它就会霸占RAM,并导致系统不可用。在现实世界中,你总得考虑到这些可能性。但在本教程中,这种方法不要紧。
|
||||
|
||||
我们需要一个结构函数来描述缓冲区。内核提供了许多常规的数据结构:链接列表(双联的),哈希表,树等等之类。不过,缓冲区常常从头设计。我们将调用我们的“struct buffer”:
|
||||
|
||||
struct buffer {
|
||||
char *data, *end, *read_ptr;
|
||||
unsigned long size;
|
||||
};
|
||||
|
||||
**data**是该缓冲区存储的一个指向字符串的指针,而**end**指向字符串结尾后的第一个字节。**read_ptr**是**read()**开始读取数据的地方。缓冲区的size是为了保证完整性而存储的 —— 目前,我们还没有使用该区域。你不能假设使用你结构体的用户会正确地初始化所有这些东西,所以最好在函数中封装缓冲区的分配和收回。它们通常命名为**buffer\_alloc()**和**buffer\_free()**。
|
||||
|
||||
static struct buffer *buffer_alloc(unsigned long size)
|
||||
{
|
||||
struct buffer *buf;
|
||||
buf = kzalloc(sizeof(*buf), GFP_KERNEL);
|
||||
if (unlikely(!buf))
|
||||
goto out;
|
||||
...
|
||||
out:
|
||||
return buf;
|
||||
}
|
||||
|
||||
内核内存使用**kmalloc()**来分配,并使用**kfree()**来释放;**kzalloc()**的风格是将内存设置为全零。不同于标准的**malloc()**,它的内核对应部分收到的标志指定了第二个参数中请求的内存类型。这里,**GFP_KERNEL**是说我们需要一个普通的内核内存(不是在DMA或高内存区中)以及如果需要的话函数可以睡眠(重新调度进程)。**sizeof(*buf)**是一种常见的方式,它用来获取可通过指针访问的结构体的大小。
|
||||
|
||||
你应该随时检查**kmalloc()**的返回值:访问NULL指针将导致内核异常。同时也需要注意**unlikely()**宏的使用。它(及其相对宏**likely()**)被广泛用于内核中,用于表明条件几乎总是真的(或假的)。它不会影响到控制流程,但是能帮助现代处理器通过分支预测技术来提升性能。
|
||||
|
||||
最后,注意**goto**语句。它们常常为认为是邪恶的,但是,Linux内核(以及一些其它系统软件)采用它们来实施集中式的函数退出。这样的结果是减少嵌套深度,使代码更具可读性,而且非常像更高级语言中的**try-catch**区块。
|
||||
|
||||
有了**buffer\_alloc()**和**buffer\_free()**,**open**和**close**方法就变得很简单了。
|
||||
|
||||
static int reverse_open(struct inode *inode, struct file *file)
|
||||
{
|
||||
int err = 0;
|
||||
file->private_data = buffer_alloc(buffer_size);
|
||||
...
|
||||
return err;
|
||||
}
|
||||
|
||||
**struct file**是一个标准的内核数据结构,用以存储打开的文件的信息,如当前文件位置(**file->f\_pos**)、标志(**file->f\_flags**),或者打开模式(**file->f\_mode**)等。另外一个字段**file->privatedata**用于关联文件到一些专有数据,它的类型是void *,而且它在文件拥有者以外,对内核不透明。我们将一个缓冲区存储在那里。
|
||||
|
||||
如果缓冲区分配失败,我们通过返回否定值(**-ENOMEM**)来为调用的用户空间代码标明。一个C库中调用的**open(2)**系统调用(如 **glibc**)将会检测这个并适当地设置**errno** 。
|
||||
|
||||
#### 学习如何读和写 ####
|
||||
|
||||
“read”和“write”方法是真正完成工作的地方。当数据写入到缓冲区时,我们放弃之前的内容和反向地存储该字段,不需要任何临时存储。**read**方法仅仅是从内核缓冲区复制数据到用户空间。但是如果缓冲区还没有数据,**revers\_eread()**会做什么呢?在用户空间中,**read()**调用会在有可用数据前阻塞它。在内核中,你就必须等待。幸运的是,有一项机制用于处理这种情况,就是‘wait queues’。
|
||||
|
||||
想法很简单。如果当前进程需要等待某个事件,它的描述符(**struct task_struct**存储‘current’信息)被放进非可运行(睡眠中)状态,并添加到一个队列中。然后**schedule()**就被调用来选择另一个进程运行。生成事件的代码通过使用队列将等待进程放回**TASK\_RUNNING**状态来唤醒它们。调度程序将在以后在某个地方选择它们之一。Linux有多种非可运行状态,最值得注意的是**TASK\_INTERRUPTIBLE**(一个可以通过信号中断的睡眠)和**TASK\_KILLABLE**(一个可被杀死的睡眠中的进程)。所有这些都应该正确处理,并等待队列为你做这些事。
|
||||
|
||||
一个用以存储读取等待队列头的天然场所就是结构缓冲区,所以从为它添加**wait\_queue\_head_t read\_queue**字段开始。你也应该包含**linux/sched.h**头文件。可以使用DECLARE\_WAITQUEUE()宏来静态声明一个等待队列。在我们的情况下,需要动态初始化,因此添加下面这行到**buffer\_alloc()**:
|
||||
|
||||
init_waitqueue_head(&buf->read_queue);
|
||||
|
||||
我们等待可用数据;或者等待**read\_ptr != end**条件成立。我们也想要让等待操作可以被中断(如,通过Ctrl+C)。因此,“read”方法应该像这样开始:
|
||||
|
||||
static ssize_t reverse_read(struct file *file, char __user * out,
|
||||
size_t size, loff_t * off)
|
||||
{
|
||||
struct buffer *buf = file->private_data;
|
||||
ssize_t result;
|
||||
while (buf->read_ptr == buf->end) {
|
||||
if (file->f_flags & O_NONBLOCK) {
|
||||
result = -EAGAIN;
|
||||
goto out;
|
||||
}
|
||||
if (wait_event_interruptible
|
||||
(buf->read_queue, buf->read_ptr != buf->end)) {
|
||||
result = -ERESTARTSYS;
|
||||
goto out;
|
||||
}
|
||||
}
|
||||
...
|
||||
|
||||
我们让它循环,直到有可用数据,如果没有则使用**wait\_event\_interruptible()**(它是一个宏,不是函数,这就是为什么要通过值的方式给队列传递)来等待。好吧,如果**wait\_event\_interruptible()**被中断,它返回一个非0值,这个值代表**-ERESTARTSYS**。这段代码意味着系统调用应该重新启动。**file->f\_flags**检查以非阻塞模式打开的文件数:如果没有数据,返回**-EAGAIN**。
|
||||
|
||||
我们不能使用**if()**来替代**while()**,因为可能有许多进程正等待数据。当**write**方法唤醒它们时,调度程序以不可预知的方式选择一个来运行,因此,在这段代码有机会执行的时候,缓冲区可能再次空出。现在,我们需要将数据从**buf->data** 复制到用户空间。**copy\_to\_user()**内核函数就干了此事:
|
||||
|
||||
size = min(size, (size_t) (buf->end - buf->read_ptr));
|
||||
if (copy_to_user(out, buf->read_ptr, size)) {
|
||||
result = -EFAULT;
|
||||
goto out;
|
||||
}
|
||||
|
||||
如果用户空间指针错误,那么调用可能会失败;如果发生了此事,我们就返回**-EFAULT**。记住,不要相信任何来自内核外的事物!
|
||||
|
||||
buf->read_ptr += size;
|
||||
result = size;
|
||||
out:
|
||||
return result;
|
||||
}
|
||||
|
||||
为了使数据在任意块可读,需要进行简单运算。该方法返回读入的字节数,或者一个错误代码。
|
||||
|
||||
写方法更简短。首先,我们检查缓冲区是否有足够的空间,然后我们使用**copy\_from\_userspace()**函数来获取数据。再然后**read\_ptr**和结束指针会被重置,并且反转存储缓冲区内容:
|
||||
|
||||
buf->end = buf->data + size;
|
||||
buf->read_ptr = buf->data;
|
||||
if (buf->end > buf->data)
|
||||
reverse_phrase(buf->data, buf->end - 1);
|
||||
|
||||
这里, **reverse\_phrase()**干了所有吃力的工作。它依赖于**reverse\_word()**函数,该函数相当简短并且标记为内联。这是另外一个常见的优化;但是,你不能过度使用。因为过多的内联会导致内核映像徒然增大。
|
||||
|
||||
最后,我们需要唤醒**read\_queue**中等待数据的进程,就跟先前讲过的那样。**wake\_up\_interruptible()**就是用来干此事的:
|
||||
|
||||
wake_up_interruptible(&buf->read_queue);
|
||||
|
||||
耶!你现在已经有了一个内核模块,它至少已经编译成功了。现在,是时候来测试了。
|
||||
|
||||
### 调试内核代码 ###
|
||||
|
||||
> 或许,内核中最常见的调试方法就是打印。如果你愿意,你可以使用普通的**printk()** (假定使用**KERN\_DEBUG**日志等级)。然而,那儿还有更好的办法。如果你正在写一个设备驱动,这个设备驱动有它自己的“struct device”,可以使用**pr\_debug()**或者**dev\_dbg()**:它们支持动态调试(**dyndbg**)特性,并可以根据需要启用或者禁用(请查阅**Documentation/dynamic-debug-howto.txt**)。对于单纯的开发消息,使用**pr\_devel()**,除非设置了DEBUG,否则什么都不会做。要为我们的模块启用DEBUG,请添加以下行到Makefile中:
|
||||
|
||||
> CFLAGS_reverse.o := -DDEBUG
|
||||
>
|
||||
> 完了之后,使用**dmesg**来查看**pr_debug()**或**pr_devel()**生成的调试信息。
|
||||
> 或者,你可以直接发送调试信息到控制台。要想这么干,你可以设置**console_loglevel**内核变量为8或者更大的值(**echo 8 /proc/sys/kernel/printk**),或者在高日志等级,如**KERN_ERR**,来临时打印要查询的调试信息。很自然,在发布代码前,你应该移除这样的调试声明。
|
||||
|
||||
> 注意内核消息出现在控制台,不要在Xterm这样的终端模拟器窗口中去查看;这也是在内核开发时,建议你不在X环境下进行的原因。
|
||||
|
||||
### 惊喜,惊喜! ###
|
||||
|
||||
编译模块,然后加载进内核:
|
||||
|
||||
$ make
|
||||
$ sudo insmod reverse.ko buffer_size=2048
|
||||
$ lsmod
|
||||
reverse 2419 0
|
||||
$ ls -l /dev/reverse
|
||||
crw-rw-rw- 1 root root 10, 58 Feb 22 15:53 /dev/reverse
|
||||
|
||||
一切似乎就位。现在,要测试模块是否正常工作,我们将写一段小程序来翻转它的第一个命令行参数。**main()**(再三检查错误)可能看上去像这样:
|
||||
|
||||
int fd = open("/dev/reverse", O_RDWR);
|
||||
write(fd, argv[1], strlen(argv[1]));
|
||||
read(fd, argv[1], strlen(argv[1]));
|
||||
printf("Read: %s\n", argv[1]);
|
||||
|
||||
像这样运行:
|
||||
|
||||
$ ./test 'A quick brown fox jumped over the lazy dog'
|
||||
Read: dog lazy the over jumped fox brown quick A
|
||||
|
||||
它工作正常!玩得更逗一点:试试传递单个单词或者单个字母的短语,空的字符串或者是非英语字符串(如果你有这样的键盘布局设置),以及其它任何东西。
|
||||
|
||||
现在,让我们让事情变得更好玩一点。我们将创建两个进程,它们共享一个文件描述符(及其内核缓冲区)。其中一个会持续写入字符串到设备,而另一个将读取这些字符串。在下例中,我们使用了**fork(2)**系统调用,而pthreads也很好用。我也省略打开和关闭设备的代码,并在此检查代码错误(又来了):
|
||||
|
||||
char *phrase = "A quick brown fox jumped over the lazy dog";
|
||||
if (fork())
|
||||
/* Parent is the writer */
|
||||
while (1)
|
||||
write(fd, phrase, len);
|
||||
else
|
||||
/* child is the reader */
|
||||
while (1) {
|
||||
read(fd, buf, len);
|
||||
printf("Read: %s\n", buf);
|
||||
}
|
||||
|
||||
你希望这个程序会输出什么呢?下面就是在我的笔记本上得到的东西:
|
||||
|
||||
Read: dog lazy the over jumped fox brown quick A
|
||||
Read: A kcicq brown fox jumped over the lazy dog
|
||||
Read: A kciuq nworb xor jumped fox brown quick A
|
||||
Read: A kciuq nworb xor jumped fox brown quick A
|
||||
...
|
||||
|
||||
这里发生了什么呢?就像举行了一场比赛。我们认为**read**和**write**是原子操作,或者从头到尾一次执行一个指令。然而,内核确实无序并发的,随便就重新调度了**reverse\_phrase()**函数内部某个地方运行着的写入操作的内核部分。如果在写入操作结束前就调度了**read()**操作呢?就会产生数据不完整的状态。这样的bug非常难以找到。但是,怎样来处理这个问题呢?
|
||||
|
||||
基本上,我们需要确保在写方法返回前没有**read**方法能被执行。如果你曾经编写过一个多线程的应用程序,你可能见过同步原语(锁),如互斥锁或者信号。Linux也有这些,但有些细微的差别。内核代码可以运行进程上下文(用户空间代码的“代表”工作,就像我们使用的方法)和终端上下文(例如,一个IRQ处理线程)。如果你已经在进程上下文中和并且你已经得到了所需的锁,你只需要简单地睡眠和重试直到成功为止。在中断上下文时你不能处于休眠状态,因此代码会在一个循环中运行直到锁可用。关联原语被称为自旋锁,但在我们的环境中,一个简单的互斥锁 —— 在特定时间内只有唯一一个进程能“占有”的对象 —— 就足够了。处于性能方面的考虑,现实的代码可能也会使用读-写信号。
|
||||
|
||||
锁总是保护某些数据(在我们的环境中,是一个“struct buffer”实例),而且也常常会把它们嵌入到它们所保护的结构体中。因此,我们添加一个互斥锁(‘struct mutex lock’)到“struct buffer”中。我们也必须用**mutex\_init()**来初始化互斥锁;**buffer\_alloc**是用来处理这件事的好地方。使用互斥锁的代码也必须包含**linux/mutex.h**。
|
||||
|
||||
互斥锁很像交通信号灯 —— 要是司机不看它和不听它的,它就没什么用。因此,在对缓冲区做操作并在操作完成时释放它之前,我们需要更新**reverse\_read()**和**reverse\_write()**来获取互斥锁。让我们来看看**read**方法 —— **write**的工作原理相同:
|
||||
|
||||
static ssize_t reverse_read(struct file *file, char __user * out,
|
||||
size_t size, loff_t * off)
|
||||
{
|
||||
struct buffer *buf = file->private_data;
|
||||
ssize_t result;
|
||||
if (mutex_lock_interruptible(&buf->lock)) {
|
||||
result = -ERESTARTSYS;
|
||||
goto out;
|
||||
}
|
||||
|
||||
我们在函数一开始就获取锁。**mutex\_lock\_interruptible()**要么得到互斥锁然后返回,要么让进程睡眠,直到有可用的互斥锁。就像前面一样,**\_interruptible**后缀意味着睡眠可以由信号来中断。
|
||||
|
||||
while (buf->read_ptr == buf->end) {
|
||||
mutex_unlock(&buf->lock);
|
||||
/* ... wait_event_interruptible() here ... */
|
||||
if (mutex_lock_interruptible(&buf->lock)) {
|
||||
result = -ERESTARTSYS;
|
||||
goto out;
|
||||
}
|
||||
}
|
||||
|
||||
下面是我们的“等待数据”循环。当获取互斥锁时,或者发生称之为“死锁”的情境时,不应该让进程睡眠。因此,如果没有数据,我们释放互斥锁并调用**wait\_event\_interruptible()**。当它返回时,我们重新获取互斥锁并像往常一样继续:
|
||||
|
||||
if (copy_to_user(out, buf->read_ptr, size)) {
|
||||
result = -EFAULT;
|
||||
goto out_unlock;
|
||||
}
|
||||
...
|
||||
out_unlock:
|
||||
mutex_unlock(&buf->lock);
|
||||
out:
|
||||
return result;
|
||||
|
||||
最后,当函数结束,或者在互斥锁被获取过程中发生错误时,互斥锁被解锁。重新编译模块(别忘了重新加载),然后再次进行测试。现在你应该没发现毁坏的数据了。
|
||||
|
||||
### 接下来是什么? ###
|
||||
|
||||
现在你已经尝试了一次内核黑客。我们刚刚为你揭开了这个话题的外衣,里面还有更多东西供你探索。我们的第一个模块有意识地写得简单一点,在从中学到的概念在更复杂的环境中也一样。并发、方法表、注册回调函数、使进程睡眠以及唤醒进程,这些都是内核黑客们耳熟能详的东西,而现在你已经看过了它们的运作。或许某天,你的内核代码也将被加入到主线Linux源代码树中 —— 如果真这样,请联系我们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/be-a-kernel-hacker/
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux) [disylee](https://github.com/disylee) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.libusb.org/
|
||||
[2]:http://fuse.sf.net/
|
||||
[3]:http://www.linuxvoice.com/be-a-kernel-hacker/www.netfilter.org/projects/libnetfilter_queue
|
||||
[4]:http://lxr.free-electrons.com/
|
||||
@ -0,0 +1,135 @@
|
||||
在linux桌面上观看2014年巴西世界杯比赛!
|
||||
================================================================================
|
||||
足球是世界上受众最广和观众最多的运动,现代足球起源于英国。足球运动员平均每场比赛要跑6个多英里。上届南非世界杯有近10亿的电视观众,而今年的的观赛数量预计还要增加。
|
||||
|
||||
2014年第20界世界杯在巴西举行,时间安排为从6月12号开始持续到7月13号,共有32个国家参加这项赛事。
|
||||
|
||||
爱足球的小伙子们,我们将要介绍一款可以提供最新的赛况以及你喜欢的球队的进球数信息的应用程序,它叫做“icup 2014 Brazil”。下面让我们介绍它的特点,用法和安装等。
|
||||
|
||||

|
||||
|
||||
*iCup 2014 Brazil*
|
||||
|
||||
### 什么是“icup 2014 Brazil” ###
|
||||
|
||||
“icup 2014 Brazil”简单的说是一个应用程序,在linux桌面为你提供2014年世界杯的最新比赛赛况。
|
||||
|
||||
### “icup 2014 Brazil”的特点###
|
||||
|
||||
- 自适应的用户界面,比如自动缩放
|
||||
- 迅速查看战绩
|
||||
- 支持Facebook、twitter和Google+社交分享功能
|
||||
- 支持Retina显示输出
|
||||
- 实时跟踪比赛结果
|
||||
- 包括32个国家的国歌小工具配合露天广场效果很不错
|
||||
- 内置日历和时区工具,实时的显示当天数据,图像化展示最新的战况和得分
|
||||
- 支持代理
|
||||
|
||||
|
||||
### 平台和框架支持 ###
|
||||
|
||||
这款软件可以运行在Mac、windows和linux上,特别提醒,在Linux上,它是为x86的CPU设计的,虽然它也可以在x64的平台上安装,不过我们需要做一下设置。
|
||||
|
||||
#### 在不同平台的技术规范 ####
|
||||
|
||||
- 实时结果,日历,数据分组,第二阶段整合,社交网络连接和多语言支持,这些支持全平台
|
||||
- Retina显示支持,这个不支持windows和linux,仅支持Mac OS
|
||||
- 详细的统计-支持linux。在windows和Mac需要捐赠才行
|
||||
- 声音小工具-支持MAC和linux,windows不确定
|
||||
|
||||
**重要**: 上面的特点都支持,一些具体的特性除了linux外都不是免费提供的,这是为了支付服务器和带宽费用。对于linux用户来说,任何细节不需要关心,高兴的用去吧。
|
||||
|
||||
### Linux下安装“icup 2014 Brazil” ###
|
||||
|
||||
首先去[“icup 2014 Brazil”官方下载页面][1]下载你电脑平台的软件版本
|
||||
|
||||
#### 32位下的安装步骤 ####
|
||||
|
||||
# cd Downloads/
|
||||
# tar xvf iCup_2014_FREE-Brazil_1.1_linux.tar.bz2
|
||||
# cd iCup\ 2014\ FREE\ -\ Brazil\ 1.1/
|
||||
# chmod 755 iCup\ 2014\ FREE\ -\ Brazil
|
||||
|
||||
如上文所说,这个应用程序只为X86架构设计,为了在64位架构下安装32位的软件,我们需要在系统上安装一些软件包:**GTK+2**和**libstdc++.so.6**。
|
||||
|
||||
不只是这款软件,一大堆Linux下的软件不支持64位架构,例如**Skype**,我们也需要这样调整我们的系统来安装这些软件。
|
||||
|
||||
#### 在64位系统下 ####
|
||||
|
||||
安装**GTK+2**和**libstdc++so.6**,用如下apt或者yum命令
|
||||
|
||||
$ sudo apt-get install libgtk2.0-0 libstdc++6 [在基于Debian系统上执行这个命令]
|
||||
|
||||
如果有报错的话,运行下面的命令来解决
|
||||
|
||||
$ sudo apt-get -f install
|
||||
|
||||
----------
|
||||
|
||||
# yum install gtk2 libstdc++ [在基于Redhat系统上执行这个命令]
|
||||
|
||||
需要的软件包安装完后,就可以在64位系统下安装32位的软件了,进入你的下载目录,找到“**icup 2014 Brazil**”安装包然后执行下面的命令
|
||||
|
||||
# cd Downloads/
|
||||
# tar xvf iCup_2014_FREE-Brazil_1.1_linux.tar.bz2
|
||||
# cd iCup\ 2014\ FREE\ -\ Brazil\ 1.1/
|
||||
# chmod 755 iCup\ 2014\ FREE\ -\ Brazil
|
||||
|
||||
然后,进入软件所在目录,双击可执行文件启动软件。下面的截屏图中看不到所有的信息,**因为本文写作时2014年世界杯现在还没开始呢,开始后我们就能看到结果了**。
|
||||
|
||||

|
||||
|
||||
iCup Brazil 2014
|
||||
|
||||
无具体信息,世界杯尚未开始。
|
||||
|
||||

|
||||
|
||||
Match Detailed Information
|
||||
|
||||
分组和队伍
|
||||
|
||||

|
||||
|
||||
Groups and Teams
|
||||
|
||||
第二阶段详细信息
|
||||
|
||||

|
||||
|
||||
2nd stage Detailed Information
|
||||
|
||||
比赛细节,尚未完整
|
||||
|
||||

|
||||
|
||||
Match Summary
|
||||
|
||||
集成语言切换和社交分享按钮
|
||||
|
||||

|
||||
|
||||
Language Change
|
||||
|
||||
Linux上捐赠是可选的,你可以贡献你的心意。
|
||||
|
||||

|
||||
|
||||
Donation
|
||||
|
||||
### 总结 ###
|
||||
|
||||
上面的这个软件有望成为足球粉丝的一大福利,赶快在线试用吧。
|
||||
|
||||
好了,我马上又有一个有趣的文章了。请保持关注Tecmint.com。请在评论区对我们的工作给予反馈。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/view-fifa-world-cup-matche-results/
|
||||
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.e-link.it/icup/brazil2014/icup-brazil-2014-desktop-app.php
|
||||
33
published/20140607 How To Install iCup 2014 In Linux.md
Normal file
33
published/20140607 How To Install iCup 2014 In Linux.md
Normal file
@ -0,0 +1,33 @@
|
||||
在Linux上用iCup追世界杯
|
||||
================================================================================
|
||||

|
||||
|
||||
嗨,Linux 极客们,
|
||||
|
||||
在本文简短的叙述中,我将教您如何在Linux中安装一个非常棒的2014FIFA世界杯APP。这个应用叫iCup,支持Windows,Mac以及伟大的Linux。
|
||||
|
||||
我看足球比赛已经有很长的时间了,所以我得在我的电脑上装个这样的应用来保持更新2014世界杯的最新情况。我可不想在我朋友们面前看起来像一无所知的笨货。iCup应用正好提供了每一场赛程、比分、球队教练组等信息。更有提供实时比赛更新,给您提供 正在进行的比赛的最新数据。
|
||||
|
||||
### 支持以下功能: ###
|
||||
|
||||
- 30种语言支持,完全本地化(使用语言菜单选择)
|
||||
- 独家的灵活界面可随意调整窗口大小
|
||||
- 可按日期或阶段检索比赛日历
|
||||
- 可视化分组
|
||||
- 支持自动转变比赛时间来适应本地时间和格式
|
||||
- 一键化社交网络发表比赛评论(支持Facebook,Google+和Twitter)
|
||||
- 支持代理(支持基本认证和摘要认证方法)
|
||||
|
||||
我已经在Ubuntu12.04LTS上用过而且真的很好用!目前为止,这款软件还没有出错或者崩溃过。通过[官方网站][1]您可以下载到压缩包并且十分轻松地安装这个很棒的应用,然后您可以解压到任何您喜欢的地方。解压完成后,双击iCup 2014 FREE- Brazil运行。
|
||||
|
||||
iCup真心好用,我希望您也能用其享受世界杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-icup-2014-linux/
|
||||
|
||||
译者:[Vic020](http://www.vicyu.net) 校对:[213edu](http://ryanhu.me/)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.e-link.it/icup/brazil2014/icup-brazil-2014-desktop-app.php
|
||||
@ -1,16 +1,17 @@
|
||||
用笔记本模式工具1.65来延长电池续航
|
||||
用笔记本模式工具1.65来延长电池续航能力
|
||||
================================================================================
|
||||
|
||||
|
||||
|
||||
笔记本模式工具是一个Liunx省电工具包,它可以让用户以多种方式延长笔记本电池续航,现在它已经升级到1.65。
|
||||
笔记本模式工具是一个Liunx电源管理工具包,它可以让用户以多种方式延长笔记本电池续航能力,现在它已经升级到1.65。
|
||||
|
||||
笔记本模式工具的版本曾经很少而且间隔很长,但开发者在最新的版本中做了一些很有意思的改变,虽然此次更新与以前不同。
|
||||
笔记本模式工具的发布的版本曾经很少而且间隔很长,但开发者在最新的版本中做了一些很有意思的改变,虽然此次更新与以前不同。
|
||||
|
||||
根据更新日志,grep找不到$device/uevent的错误已得到修复、 sysfs/enabled已被"ip link down"所取代、 添加了对iwlwifi的支持,运行时电源管理框架现在更健壮,并且usb-autosuspend模块已被去除。
|
||||
|
||||
此外,当笔记本电脑恢复时,笔记本模式工具将强制以初始化模式运行,最新版本已添加英特尔 PState 驱动程序的模块,并已实现挂起/休眠接口。
|
||||
|
||||
用户不须更改自动设置。更改自动设置可能会导致更多的问题但一般准期望他们总是要打开。此外,要注意到每个功能所做的因为你可能会搞出更多问题。
|
||||
用户不须更改自动设置。更改自动设置可能会导致更多的问题,但通常看来他们总是会去动它。此外,要注意到每个功能究竟是做什么的,否则你可能会搞出更多问题。
|
||||
|
||||
看官方[公告][1]来了解更多细节。
|
||||
|
||||
@ -22,7 +23,7 @@
|
||||
|
||||
via: http://news.softpedia.com/news/Improve-Battery-Life-with-Laptop-Mode-Tools-1-65-447397.shtml
|
||||
|
||||
译者:[2q1w2007](https://github.com/2q1w2007) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[2q1w2007](https://github.com/2q1w2007) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,26 +1,27 @@
|
||||
红帽携手eNovance,共进OpenStack市场
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
正在OpenStack峰会于亚特兰大举办的同时,红帽确认了数项与OpenStack相关的项目。其中一项是,红帽正与开源云计算市场的领导者eNovance进行 [合作][1] 。双方将推动网络功能虚拟(Network Functions Virtualization)和电信功能融入OpenStack. 红帽 [宣布][2] 将以七千万欧元或九千五百万美金的现金和股票,购买eNovance.
|
||||
正在OpenStack峰会于亚特兰大举办的同时,红帽确认了数项与OpenStack相关的项目。其中一项是,红帽正与开源云计算市场的领导者eNovance进行[合作][1] 。双方将推动网络功能虚拟化(Network Functions Virtualization)及将电信功能融入OpenStack中。红帽[宣布][2]将以七千万欧元或九千五百万美金的现金和股票投资eNovance。
|
||||
|
||||
eNovance 是OpenStack市场上重要的角色, 特别以其和电信公司的合作而为人所知。eNovance帮助服务提供商和大型私企搭建部署云基础架构,快速且成本低廉。这也将为红帽开创新的产品线。
|
||||
|
||||
IDC 分析员 Laura DuBois and Ashish Nadkarni 在2014春季OpenStack 峰会上指出 “像eNovance这样的集成商将继续助力云服务提供商和企业,建立OpenStack云。OpenStack的前景开起来十分光明。"
|
||||
IDC 分析员 Laura DuBois 和 Ashish Nadkarni 在2014春季OpenStack 峰会上指出 “像eNovance这样的集成商将继续助力云服务提供商和企业,建立OpenStack云。OpenStack的前景开起来十分光明。"
|
||||
|
||||
eNovance 是OpenStack十大上游贡献者之一, 也是OpenStack 基金唯一的欧洲金牌合作商。 该公司在全球有超过150家客户,包括 Alcatel-Lucent, AXA, Cisco, Cloudwatt, and Ericsson. 在巴黎、蒙特利尔、班加罗尔、印度,都设有办公室。
|
||||
eNovance 是OpenStack十大上游贡献者之一, 也是OpenStack 基金唯一的欧洲金牌合作商。 该公司在全球有超过150家客户,包括 Alcatel-Lucent、 AXA,、 Cisco、 Cloudwatt 和 Ericsson. 在巴黎、蒙特利尔、班加罗尔、印度,都设有办公室。
|
||||
|
||||
2013年,红帽和 eNovance 第一次展开[合作][3] ,为其共同客户,提供OpenStack 部署和集成服务。该服务基于Red Hat Enterprise Linux OpenStack 平台。 五月的OpenStack峰会上, 两家公司宣布了 [进一步的合作][4] ,推动网络功能虚拟(NFV) 和电信在OpenStack上的创新, 意在提供业界最完整、电信级的 通讯服务,基于Linux, 基于内核的虚拟机 (KVM), 和 OpenStack.
|
||||
2013年,红帽和 eNovance 第一次展开[合作][3] ,为其共同客户提供OpenStack 部署和集成服务。该服务基于Red Hat Enterprise Linux OpenStack 平台。 今年五月的OpenStack峰会上, 两家公司宣布了[进一步的合作][4] ,推动网络功能虚拟(NFV) 和电信在OpenStack上的创新,意在提供业界最完整、电信级的 通讯服务,基于Linux、内核级虚拟机 (KVM)和 OpenStack。
|
||||
|
||||
eNovance的联合创始人、首席执行官Raphaël Ferreira, 在声明中说:
|
||||
eNovance的联合创始人、首席执行官Raphaël Ferreira, 在声明中说:
|
||||
|
||||
> “和红帽一样,eNovance理解OpenStack改变企业市场的力量,当其正确部署且集成时。 我们非常高兴能成为红帽的一部分。红帽不仅仅提供一流的OpenStack发行版本, 也和我们一样坚信: 最好以连续、无缝的方式部署、集成OpenStack."
|
||||
> “和红帽一样,eNovance也认为部署和集成OpenStack已成趋势,这是企业市场上的变革力量。 我们非常高兴能成为红帽的一部分。红帽不仅仅提供一流的OpenStack发行版本,也和我们一样坚信: 最好以连续、无缝的方式部署、集成OpenStack。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/red-hat-to-acquire-enovance-focus-together-on-openstack
|
||||
|
||||
译者:[tengpeng](https://github.com/tengpeng) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[tengpeng](https://github.com/tengpeng) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
34
published/20140620 Celebrating 30 Years of X.md
Normal file
34
published/20140620 Celebrating 30 Years of X.md
Normal file
@ -0,0 +1,34 @@
|
||||
X 窗口系统已经30岁了!
|
||||
================================================================================
|
||||
X.org基金会很自豪地宣布一个特别的日子:30年前,1984年六月19日,Bob Scheifler发布了X窗口系统。
|
||||
|
||||
有关X窗口系统的介绍参见: [https://en.wikipedia.org/wiki/X11#Introduction][1]
|
||||
|
||||
在这30年中,X作为UNIX桌面无处不在。在今天,数以百万计的用户使用着桌面环境如GNOME,KDE,Xfce,Unity,Enlightenment等等,而这些都使用X作为其底层技术。
|
||||
|
||||
X的开发者们做出了巨大的突破,把X从原本为VAX VS100 CPU编写的一个程序发展成为在今天可在笔记本电脑上进行3D渲染的图形用户界面。事实上,X的出现早于图形处理单元(GPU)概念的出现,甚至是比推广这项技术公司——于1999上市的Nvidia更早。
|
||||
|
||||

|
||||
|
||||
尽管X已经服务了很长时间,但是X仍将做出改进并继续陪伴我们。
|
||||
|
||||
请不要感到惊奇, X的出现早于:
|
||||
|
||||
- Linux, FreeBSD, NetBSD, OpenBSD, Solaris, Microsoft Windows
|
||||
- POSIX, C89, C99, C++, Java
|
||||
- 互联网
|
||||
- GPL 和 FSF
|
||||
|
||||
X是第一个主要的开源软件项目,比Free Software 和 Open Source Software更早。和我们一起庆祝吧,因为没有X,桌面就不会是今天这个样子。
|
||||
|
||||
- X.Org 品牌总监
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://comments.gmane.org/gmane.comp.freedesktop.xorg.announce/2177
|
||||
|
||||
译者:[2q1w2007](https://github.com/2q1w2007) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://en.wikipedia.org/wiki/X11#Introduction
|
||||
@ -0,0 +1,69 @@
|
||||
使用DNSCrypt来加密您与OpenDNS之间的通信
|
||||
================================================================================
|
||||
**正如SSL能将HTTP通信变为加密过的HTTPS通信,DNSCrypt, 物如其名, 是一款能加密您电脑与OpenDNS之间的通信的小神器。**
|
||||
|
||||
DNSCrypt刚问世的时候,官方公布它只是一款Mac才能用的工具,但根据最近一篇由OpenDNS发的[文章][1]表明,虽然还没有用户界面,但其实当Mac版DNSCrypt推出的时候源码已经放到了Github上了, Linux的用户也可以安装以及使用哦!
|
||||
|
||||
### 为神马要使用 DNSCrypt? ###
|
||||
|
||||
**DNSCrypt可以加密您电脑与OpenDNS服务器的所有通信,加密可以防止中间人攻击,信息窥觑,DNS劫持。更能防止网络供应商对某些网站的封锁。**
|
||||
|
||||
这是世界上第一款加密DNS通信的工具,虽然TOR可以加密DNS的请求,但毕竟它们只是在出口节点加密而已。
|
||||
|
||||
> 这款工具并不需要对域名或其工作方式做任何的改变,它只是提供了个该工具的用户与机房里的DNS服务器之间的加密方式而已。
|
||||
|
||||
您可以在[GitHub][3]的[OpenSND DNSCrypt][2]页面阅读更多的相关信息。
|
||||
|
||||
### 如何在Linux使用DNSCrypt ###
|
||||
|
||||
首先下载安装[Download DNSCrypt][4], 然后在Terminal里输入这个命令:
|
||||
|
||||
sudo /usr/sbin/dnscrypt-proxy --daemonize
|
||||
|
||||
|
||||
|
||||
然后把您的DNS服务器调成"127.0.0.1" - 在GNOME界面下的话,只要到Network Connections(网络连接)选项然后选择"Edit"并在"DNS servers"输入"127.0.0.1"就好了。如果您用的是DHCP的话,请选择Automatic (DHCP) addresses only", 这样的话才能输入DNS服务器。然后只要重连网络便可。
|
||||
|
||||
您可以访问这条[链接][5]来测试您连接到了OpenDNS了没。
|
||||
|
||||
如果您想设置开机启动DNSCrypt,可以自建一个init的脚本,如果您用的是Ubuntu,可以参考下面的。
|
||||
|
||||
**Arch Linux的用户可以通过[AUR][6]来安装DNSCrypt-proxy** (内含rc.d脚本)
|
||||
|
||||
### Ubuntu下的DNSCrypt ###
|
||||
|
||||
如果您想在Ubuntu设置开机启动,您可以使用这个[Upstart脚本][7]。
|
||||
|
||||
注: 在Ubuntu 12.04版在127.0.0.1有个本地的DNS cache 服务器(dnsmasq)在跑,所以已经把改脚本改成让DNSCrypt使用127.0.0.2了, 所以按照上面的教程,应该把127.0.0.1换成127.0.0.2了。
|
||||
|
||||
要安装此脚本请使用以下的指令(要首先解压下下来的压缩文件):
|
||||
|
||||
sudo cp dnscrypt.conf /etc/init/
|
||||
sudo ln -s /lib/init/upstart-job /etc/init.d/dnscrypt
|
||||
|
||||
然后用这个指令来启动:
|
||||
|
||||
sudo start dnscrypt
|
||||
|
||||
现在DNSCrypt就应该是开机自启了,如果您想停止的话,可以使用:
|
||||
|
||||
sudo stop dnscrypt
|
||||
|
||||
[下载DNSCrypt][8] (.deb、 .rpm以及源码都可供下载哦!)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2012/02/encrypt-dns-traffic-in-linux-with.html
|
||||
|
||||
译者:[213edu](https://github.com/213edu) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://blog.opendns.com/2012/02/16/tales-from-the-dnscrypt-linux-rising/
|
||||
[2]:http://www.opendns.com/technology/dnscrypt/
|
||||
[3]:https://github.com/opendns/dnscrypt-proxy
|
||||
[4]:http://download.dnscrypt.org/dnscrypt-proxy/
|
||||
[5]:http://www.opendns.com/welcome
|
||||
[6]:http://aur.archlinux.org/packages.php?ID=54702
|
||||
[7]:http://webupd8.googlecode.com/files/dnscrypt-0.2.tar.gz
|
||||
[8]:https://github.com/opendns/dnscrypt-proxy/downloads
|
||||
@ -0,0 +1,41 @@
|
||||
Red Hat Revenues Power Forward in 2015
|
||||
================================================================================
|
||||
Red Hat reported its first quarter fiscal 2015 revenues on June 18, showing continued demand and momentum for its Linux and open-source technologies. Red Hat has been particularly busy of late, acquiring a pair of companies and launching its Red Hat Enterprise Linux 7 (RHEL) flagship platform.
|
||||
|
||||
For the quarter, Red Hat reported revenue of $424 million, which is a 17 percent year-over-year gain.
|
||||
|
||||

|
||||
|
||||
"The main driver of our total revenue growth was subscription revenue of $372 million," Red Hat CFO Charlie Peters said during his company's earnings call. "Subscription revenue was up 18 percent year-over-year and it's important to point out that this renewable revenue stream now constitutes 88 percent of total revenue."
|
||||
|
||||
Looking forward, Red Hat provided second quarter guidance for approximately $432 million to $436 million in revenue.
|
||||
|
||||
One of the key metrics for growth that Red Hat provides is its top 30 deals during a given quarter. Peters noted that for the first time, all of the top 30 deals were valued at over $1 million.
|
||||
|
||||
"We also had a Q1 record with four deals that were in excess of $5 million and one that was greater than $10 million," Peters said. "Cross-selling was strong with 65 percent of these deals including one or more components from our group of applications development and emerging technologies offerings."
|
||||
|
||||
At the core of Red Hat's product portfolio is the Red Hat Enterprise Linux platform, which hit a major milestone last week with the debut of RHEL 7.
|
||||
|
||||
"RHEL 7 is significant because it was designed to meet both modern data center and next generation IT requirements for cloud, Linux containers and Big Data," Red Hat CEO Jim Whitehurst said during the earnings call. "As the worlds of physical, virtual and cloud systems converge Red Hat Enterprise Linux 7 delivers a true foundation for open hybrid cloud that will serve as the backbone for future application architectures."
|
||||
|
||||
### Acquisitions and Cloud Provide Opportunities for Further Growth ###
|
||||
|
||||
Red Hat has also been busy acquiring a pair of companies that further expand the company's ability to grow. In April, Red Hat acquired Inktank, the lead commercial sponsor behind the Ceph open-source storage filesystem. And on June 18, Red Hat announced the acquisition of OpenStack services vendor eNovance.
|
||||
|
||||
"With eNovance as a part of the Red Hat consulting team, we can enhance our consulting resources to be able to reach more customers with world-class OpenStack technologies and implementation services," Whitehurst said.
|
||||
|
||||
While cloud remains a growth opportunity for Red Hat, Whitehurst sees growth also coming from continuing to take market share away from other server operating system platforms. In particular, Whitehurst noted that there is still a continued move from mainframe and Unix to Linux.
|
||||
|
||||
"I was just on the phone today with a massive European customer that is literally just ready to start on the journey right now," Whitehurst said. "We continue to believe we're taking share from Windows especially with net new workloads."
|
||||
|
||||
Another driver of growth for Red Hat is the maturity and expansion of its sales force.
|
||||
|
||||
"We definitely have more boots on the street because we have been hiring consistently," Whitehurst said. "But I think our sales guys are more experienced, they are better trained, their confidence level is high and their enthusiasm is high."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.serverwatch.com/server-news/red-hat-revenues-power-forward-in-2015.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,82 +0,0 @@
|
||||
jiajia translating...
|
||||
Has Microsoft really changed its attitude toward open source?
|
||||
================================================================================
|
||||
> **In today's open source roundup: Microsoft may or may not have a new attitude toward open source. Plus: Android versus Windows, and Cinnamon versus Unity in Ubuntu 14.04**
|
||||
|
||||
Microsoft became infamous for its very negative early remarks about open source software. But restructuring at the company may be giving it a more positive attitude toward open source. CNet reports on changes in Microsoft's perceptions and behavior when it comes to open source software.
|
||||
|
||||
> According to [CNet][1]:
|
||||
>
|
||||
> But Microsoft's feud with open source has been sputtering for quite some time, and the senior managers who led the anti-open source charge are gone from the scene -- or at least no longer in positions of authority. Open source is now routinely used by corporations around the world, and the company's sniffy put-downs only fed into the perception of Microsoft as out of touch.
|
||||
>
|
||||
> Some of that new thinking reflects the change at the top of the corporate pyramid, with Satya Nadella replacing Ballmer as CEO in early February. Since taking over, Nadella has talked up his vision of a Microsoft whose future isn't shackled to its Windows past.
|
||||
>
|
||||
> [More at CNet][2]
|
||||
>
|
||||
> 
|
||||
>
|
||||
> Microsoft and Communist Open Source
|
||||
> Image credit: [Curako's Blog][3]
|
||||
|
||||
Okay, I hate to be a Negative Ned here, but I'm firmly in the "trust but verify" camp when it comes to Microsoft and open source. Yes, a new CEO and other changes may be helping Microsoft to adjust to living in an open source world. But change never comes easy or fast in such a large organization, so I think the jury is still out on whether or not Microsoft has really changed for the better when it comes to open source software.
|
||||
|
||||
Also, I've never forgotten the company's "embrace, extend, extinguish" strategy that they used in the past to destroy competitive software products. That alone is reason enough to keep a wary eye on Microsoft's involvement with any open source project. Perhaps the company really has changed, but maybe it hasn't. I think it bears watching for at least another few years to see if enduring change has really set in or not.
|
||||
|
||||
### Android versus Windows ###
|
||||
|
||||
ZDNet has an article that covers the top end-user Linux distributions. It notes that Windows still rules the desktop for now, but Android may eventually be the big kahuna among end-user operating systems by the end of this year.
|
||||
|
||||
> According to [ZDNet][4]:
|
||||
>
|
||||
> If smartphones and tablet sales continue to grow as expected, Android tablet vendors continue to erode Apple's market share, and PCs continue their decline, Android may end up being the top end-user operating system by the end of 2014—regardless of what happens with the proposed Android PCs.
|
||||
>
|
||||
> Taken as a whole, Android clearly rules the Linux end-user space. No, you may not think of it as a desktop yet —although AMD and Intel would both like you to change your mind about that — but Android is on its way to being the top end-user operating system of all.
|
||||
>
|
||||
> [More at ZDNet][4]
|
||||
>
|
||||
> 
|
||||
> Image credit: [ZDNet][4]
|
||||
|
||||
The numbers mentioned in the article aren't really a surprise, given the mobile revolution that's happened over the last ten years. The desktop just isn't as important as it used to be, and Microsoft just never really mattered in mobile devices. Even now, as they struggle desperately for traction in tablets and phones, Microsoft is still mostly irrelevant in the mobile devices market.
|
||||
|
||||
Google has wreaked absolute havoc on Microsoft's efforts in mobile and is now beginning to be a threat to Microsoft in the desktop market. Between Chrome OS and Android, Google has been battering Microsoft on a number of fronts. If you look at Amazon's list of [top selling desktops][5] and [top selling laptops][6], you see plenty of Chrome OS computers and even some Android PCs. So people are actually buying alternatives to Windows computers and aren't bothered in the least by it.
|
||||
|
||||
### Cinnamon versus Unity in Ubuntu 14.04 ###
|
||||
|
||||
Tech Republic takes a look at whether or not Cinnamon is a viable replacement for Unity in Ubuntu 14.04. The article includes instructions on how to install Cinnamon in Ubuntu 14.04.
|
||||
|
||||
> According to [Tech Republic][7]:
|
||||
>
|
||||
> If you want a performance-centric desktop that doesn't toss aside feature and customization, Cinnamon is for you. Cinnamon is a straight-forward desktop interface that pretty much anyone can use -- from your IT staff to your grandmother. It really is that easy to use. Cinnamon doesn't surprise you, it doesn't trick you, but it also (in my opinion) doesn't wow you. But that's not what Cinnamon is about. This take on the desktop is all about functionality -- on a standard level. It doesn't break rules, push envelopes, or have new tricks up its sleeve.
|
||||
>
|
||||
> Cinnamon is a fairly pedestrian desktop that takes the bits and pieces of what's worked well over the years and cobbles them together into one, well-designed piece. So, if you're okay with using a desktop that looks and feels a bit long in the tooth (but one that functions very, very well), Cinnamon is for you. If you lean towards the bleeding edge of design and prefer a more modern look and feel, Cinnamon will most likely disappoint.
|
||||
>
|
||||
> [More at Tech Republic][7]
|
||||
>
|
||||
> 
|
||||
>
|
||||
> Image credit: [Tech Republic][7]
|
||||
|
||||
I'll have to weigh in on the side of Cinnamon here. While Unity has its pluses, I have never really been able to warm up to it. Cinnamon is closer to a more traditional desktop interface and that seems to work the best for me.
|
||||
|
||||
But as always, beauty is in the eye of the beholder. The great thing about Linux is that it offers so many different choices. So you really can't go wrong with Unity or Cinnamon, just use whichever one you like best.
|
||||
|
||||
What's your take on all this? Tell me in the comments below.
|
||||
|
||||
The opinions expressed by the author do not necessarily reflect the views of ITworld.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/open-source/421894/has-microsoft-really-changed-its-attitude-toward-open-source
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cnet.com/news/dead-and-buried-microsofts-holy-war-on-open-source-software/
|
||||
[2]:http://www.cnet.com/news/dead-and-buried-microsofts-holy-war-on-open-source-software/
|
||||
[3]:http://curako.wordpress.com/2010/12/06/the-uneasy-alliance-free-software-vs-open-source/
|
||||
[4]:http://www.zdnet.com/the-five-most-popular-end-user-linux-distributions-7000030058/http://www.zdnet.com/the-five-most-popular-end-user-linux-distributions-7000030058/
|
||||
[5]:http://www.amazon.com/Best-Sellers-Electronics-Desktop-Computers/zgbs/electronics/565098/?_encoding=UTF8&camp=1789&creative=390957&linkCode=ur2&tag=fnh-20&linkId=REWXUPB7SQXPDSOL
|
||||
[6]:http://www.amazon.com/Best-Sellers-Computers-Accessories-Laptop/zgbs/pc/565108/?_encoding=UTF8&camp=1789&creative=390957&linkCode=ur2&tag=fnh-20&linkId=POG3J2CFBHDWBAVL
|
||||
[7]:http://www.techrepublic.com/article/is-cinnamon-a-worthy-replacement-for-ubuntu-unity/
|
||||
@ -0,0 +1,86 @@
|
||||
How Many Languages Do Developers Need To Know?
|
||||
================================================================================
|
||||

|
||||
|
||||
> Big companies like Apple, Facebook and Google are developing their own programming languages, forcing developers to adapt.
|
||||
|
||||
At its Worldwide Developer Conference last week, Apple announced its new programming language [Swift][1]. It’s the latest in a rash of new languages developed by big tech companies, in some cases for specific use with their own platforms.
|
||||
|
||||
Apple has Swift for iOS developers; [Facebook has Hack][2], a language for back-end development. Google, meanwhile, has its own entries—the would-be Javascript replacement Dart and a new general programming language called Go.
|
||||
|
||||
This rash of new languages raises a number of issues for developers. Perhaps the most significant is one my colleague [Adriana Lee][3] raised after Apple's Swift announcement:
|
||||
|
||||
> (How many languages are devs supposed to learn?)
|
||||
> — Adriana Lee (@adra_la) [June 2, 2014][4]
|
||||
|
||||
### A Computer-Language Babel ###
|
||||
|
||||
There are already [hundreds of programming languages][5] in existence, and more are popping into existence all the time. Many are designed for use in a relatively narrow range of applications, and large numbers never catch on beyond small groups of coders.
|
||||
|
||||
Similarly, big tech companies have been developing new languages for about as long as there have been big tech companies. The [seminal general-purpose language C][6] originated at AT&T Bell Labs in the early 1970s. Java, now the primary language for development of Android apps, was [born at Sun Microsystems][7] in the 1990s.
|
||||
|
||||
What's different these days is the extent to which companies embrace new languages to further their specific business objectives—a process that also has the effect of creating a dedicated base of developers who are effectively "locked in" to a company's particular platform. That sort of dual strategy dates back at least to Sun's introduction of Java, which the company promoted as a way to challenge Microsoft's dominance on the PC desktop. (Things didn't work out the way Sun planned, although Java eventually found a home in enterprise middleware systems before Google adopted it for Android.)
|
||||
|
||||
It's also clearly Apple's goal with Swift. Should it live up to the company's early hype, Swift seems likely to simplify iOS app development by filing the rough edges off Objective-C, the current lingua franca of iOS and Mac OS X developers. But it will also require those same developers to learn the ins and outs of a new language that they're unlikely to use anywhere else.
|
||||
|
||||
### Why Companies Roll Their Own ###
|
||||
|
||||
Which cuts against the ingrained "don’t reinvent the wheel” philosophy that animates most developers. So why don't more companies just adopt already existing languages to new uses?
|
||||
|
||||
One answer is simply that companies build their own languages because they can. Designing a new language can be complex, but it's not particularly resource-intensive. What's hard is building support for it, both in terms of providing software resources (shared code libraries, APIs, compilers, documentation and so forth) and winning the hearts and minds of developers. Companies are uniquely positioned to do both.
|
||||
|
||||
There's also the fact that existing languages are often difficult to shoehorn into today's complex code frameworks. Take, for instance, [Facebook's decision to create Hack][8], a superset of the [scripting language PHP][9] that's commonly used in Web development.
|
||||
|
||||
Facebook's main goal with Hack—a common one these days—was to improve code reliability, in this case by enforcing data-type checking before a program is executed. Such checks ensure that a program won't, say, try to interpret an integer as a string of characters, an error that could yield unpredictable results if not caught. In Hack, those checks take place in advance so that programmers can identify such errors long before their code goes live.
|
||||
|
||||
According to Julien Verlaguet, a core developer on Facebook’s Hack team, the company first looked for an an existing language that might allow for more efficient programming. But much of Facebook was already built on PHP, and the company has built up a substantial software infrastructure to support PHP and its offshoots. While it's possible to make PHP work with code written in a different language, it's not easy—nor is it fast.
|
||||
|
||||
“Let’s say I try to rewrite our PHP codebase in Scala,” Verlaguet said. “It’s a well designed, beautiful language, but it’s not at all compatible with PHP. Everytime I need to call to PHP from the Scala part of the code base, I’ll lose performance speed. We would have liked to use an existing language but for us, it just wasn’t an option.”
|
||||
|
||||
Instead, Facebook invented Hack, which has enough in common with PHP that it can share the company's existing infrastructure. The vast majority of the Facebook codebase has been migrated from PHP to Hack, said Verlaguet, but the company has open sourced the language in hopes that independent developers will find uses for it outside of Facebook.
|
||||
|
||||
“You can still use PHP,” he said. “But we’re hoping you’ll want to use Hack.”
|
||||
|
||||
### Who Holds The Power ###
|
||||
|
||||
Therein lies the balance of power between companies and developers. Companies can make their languages as specific as they like. But if developers don’t want to use them, nobody is going to—outside, that is, of anyone who might harbor hopes of one day working at the company that invented the language.
|
||||
|
||||
It’s not unusual for companies to make it easiest to develop in one language over another. For example, you would use Objective-C to develop iOS apps, but Java to develop Android apps. This has never been a major sticking point with developers because both Objective-C and Java are general purpose object-oriented languages. They’re useful for a number of purposes.
|
||||
|
||||
Hack, Dart, Go, and Swift, however, so far have only proven useful for particular company-designated programming solutions, usually in tandem with that company’s programming environment of choice. Granted, it may be too soon to judge. Hack, for example, can be used in several back-end implementations; it’s just so new that Facebook doesn’t yet have any data that people want to use it that way.
|
||||
|
||||
It’s not that developers aren’t capable of learning multiple languages. Most already do. Think of them like the Romance languages—if you know Spanish, it’ll be easier to learn French and so on than if you didn’t already know one. Likewise, if you already know Java, it’ll be easier to learn Ruby or Perl. And if you know PHP, you basically already know Hack.
|
||||
|
||||
On the contrary, it’s more of a question of habit. If Java already solves your specific problems, you don’t have any incentive to learn Ruby. And if you are happy coding iOS apps in Objective-C, you’re not going to feel very tempted to pick up Swift.
|
||||
|
||||
To some developers, though, ecosystem-specific languages just make life harder for everybody. Freelance designer Jack Watson-Hamblin, for instance, told me that initiatives like Apple's Swift risk overburdening programmers and fragmenting the developer community:
|
||||
|
||||
> It's important for programmers to know multiple languages, but forcing them to keep up with new languages all the time doesn't make sense. If I'm making a simple cross-platform app, I don't want to have to know four languages to do it. I only want to use the single-purpose language if I really need to.
|
||||
|
||||
Watson-Hamblin argues that when companies each build their own language for their own needs, it slows down overall progress both by dividing the attention of coders and by enforcing a monolithic perspective on development within that language. "When companies are in charge of a language vs. an open-source community, it's like the difference between a corporation and a start-up," he said. Communities are more flexible and adaptive by definition.
|
||||
|
||||
Of course, Apple had [a lot of very good reasons to start from scratch][10] with Swift, just as Facebook did when it invented Hack. That doesn't mean it's not going to force change on developers—some of it doubtless unwelcome.
|
||||
|
||||
“As new languages are invented, it gets more hegemonic,” said Verlaguet. “It can be frustrating to have to keep up. But on the other hand, you’re more likely to have a new language to fit your exact problem. Imagine the reverse—a world where programmers used the same language for everything. It’d be a language that could do everything poorly but nothing well.”
|
||||
|
||||
Lead image by [Flickr user Ruiwen Chua][11], CC 2.0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://readwrite.com/2014/06/17/apple-swift-facebook-hack-google-dart
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://developer.apple.com/swift/
|
||||
[2]:http://readwrite.com/2014/03/20/facebook-new-programming-language-hack
|
||||
[3]:http://readwrite.com/author/adriana-lee#awesm=~oGfPbJlSrFBamJ
|
||||
[4]:https://twitter.com/adra_la/statuses/473537386266112000
|
||||
[5]:http://en.wikipedia.org/wiki/List_of_programming_languages
|
||||
[6]:http://en.wikipedia.org/wiki/C_(programming_language)
|
||||
[7]:http://en.wikipedia.org/wiki/Java_(programming_language)
|
||||
[8]:http://readwrite.com/2014/03/20/facebook-new-programming-language-hack
|
||||
[9]:http://en.wikipedia.org/wiki/PHP
|
||||
[10]:http://blog.erratasec.com/2014/06/why-it-had-to-be-swift.html#.U58BJI1dXtA
|
||||
[11]:https://www.flickr.com/photos/ruiwen/3260095534
|
||||
@ -0,0 +1,120 @@
|
||||
Linux Poetry Explains the Kernel, Line By Line
|
||||
================================================================================
|
||||
> Editor's Note: Feeling inspired? Send your Linux poem to [editors@linux.com][1] for your chance to win a free pass to [LinuxCon North America][2] in Chicago, Aug. 20-22. Be sure to include your name, contact information and a brief explanation of your poem. We'll draw one winner at random from all eligible entries each week through Aug. 1, 2014.
|
||||
|
||||

|
||||
|
||||
Software developer Morgan Phillips is teaching herself how the Linux kernel works by writing poetry.
|
||||
|
||||
Writing poems about the Linux kernel has been enlightening in more ways than one for software developer Morgan Phillips.
|
||||
|
||||
Over the past few months she's begun to teach herself how the Linux kernel works by studying text books, including [Understanding the Linux Kernel][3], Unix Network Programming, and The Unix Programming Environment. But instead of taking notes, she weaves the new terminology and ideas she learns into poetry about system architecture and programming concepts. (See some examples, below, and on her [Linux Poetry blog][4].)
|
||||
|
||||
It's a “pedagogical hack” she adopted in college and took up again a few years ago when she first landed a job as a data warehouse engineer at Facebook and needed to quickly learn Hadoop.
|
||||
|
||||
“I could remember bits and pieces of information but it was too rote, too rigid in my mind, so I started writing poems,” she said. “It forced me to wrap all of these bits of information into context and helped me learn things much more effectively.”
|
||||
|
||||
The Linux kernel's history, architecture, abundant terminology and complex concepts, are rich fodder for her poetry.
|
||||
|
||||
“I could probably write thousands of poems about just one subsystem in the kernel,” she said.
|
||||
|
||||
### Why learn Linux? ###
|
||||
|
||||

|
||||
Phillips publishes on her Linux Poetry blog.
|
||||
|
||||
Phillips started her software career through a somewhat unconventional route as a physics major in a research laboratory. Instead of writing journal articles she was writing Python scripts to parse research project data on active galactic nuclei. She never learned the fundamentals of computer science (CS), but picked up the information on the job, as the need arose.
|
||||
|
||||
She soon got a job doing network security research for the Army Research Laboratory in Adelphi, Maryland, working with Linux. That was her first foray into the networking stack and the lower levels of the operating system.
|
||||
|
||||
Most recently she worked at Facebook until about six months ago when she moved from the Silicon Valley back to Nashville, near her home state of Kentucky, to work for a software startup that helps major record labels manage their business.
|
||||
|
||||
“I have all this experience but I suffer from a thing that almost every person who doesn’t have an actual background in CS does: I have islands of knowledge with big gaps in between,” she said. “Every time I'd come across some concept, some data structure in the kernel, I'd have to go educate myself on it.”
|
||||
|
||||
A few weeks ago her frustration peaked. She was trying to do a form of message passing between web application processes and a web socket server she had written and found herself having to brush up on all the ways she could do interprocess communication.
|
||||
|
||||
“I was like, that's it. I'm going to start really learning everything I should have known starting at the bottom up with the Linux kernel,” she said. “So I bought some textbooks and started reading.”
|
||||
|
||||

|
||||
|
||||
### What she's learned ###
|
||||
|
||||
Over the course of a few months of reading books and writing poems she's learned about how the virtual memory subsystem works. She's learned about the data structures that hold process information, about the virtual memory layout and how pages are mapped into memory, and about memory management.
|
||||
|
||||
“I hadn't thought about a lot of things, like that a system that's multiprocessing shouldn’t bother with semaphores,” she said. “Spin locks are often more efficient.”
|
||||
|
||||
Writing poems has also given her insight into her own way of thinking about the world. In some small way she is communicating not just her knowledge of Linux systems, but also the way that she conceptualizes them.
|
||||
|
||||
“It's a deep look into my mind,” she said. “Poetry is the best way to share these abstract ideas and things that we can't possibly truly share with other people.”
|
||||
|
||||
Writing a Linux poem
|
||||
|
||||
The inspiration for her Linux poems starts with reading a textbook chapter. She hones the topics down to the key concepts that she wants to remember and what others might find interesting, as well as things she can “wrap a conceptual bubble around.”
|
||||
|
||||
A concept like demand paging is too broad to fit into a single poem, for example. “So I'm working my way down deeper in it,” she said. “Instead I'm looking at writing a poem about the actual data structure where process memory is laid out and then mapped into a page map.”
|
||||
|
||||
She hasn't had any formal training writing poetry, but writes the lines so that they are visually appealing and have a nice rhythm when they're read aloud.
|
||||
|
||||
In her poem, “The Reentrant Kernel,” Phillips writes about an important property in software that allows a function to be paused and restarted later with the same result. System calls need to have this reentrant property in order to make the scheduler run as efficiently as possible, Phillips explains. The poem also includes a program, written in C style pseudocode, to help illustrate the concept.
|
||||
|
||||
Phillips hopes her Linux poetry helps her increase her understanding enough to start contributing to the Linux kernel.
|
||||
|
||||
“I've been very intimidated for a long time by the idea of submitting a patch to the kernel, being a kernel hacker,” she said. “To me that's the pinnacle of success.
|
||||
|
||||
“My ultimate dream is that I can gain a good enough understanding of the kernel and C to submit a patch and have it accepted.”
|
||||
|
||||
The Reentrant Kernel
|
||||
|
||||
A reentrant function,
|
||||
if interrupted,
|
||||
will return a result,
|
||||
which is not perturbed.
|
||||
|
||||
int global_int;
|
||||
int is_not_reentrant(int x) {
|
||||
int x = x;
|
||||
return global_int + x; },
|
||||
depends on a global variable,
|
||||
which may change during execution.
|
||||
|
||||
int global_int;
|
||||
int is_reentrant(int x) {
|
||||
int saved = global_int;
|
||||
return saved + x; },
|
||||
mitigates external dependency,
|
||||
it is reentrant, though not thread safe.
|
||||
|
||||
UNIX kernels are reentrant,
|
||||
a process may be interrupted while in kernel mode,
|
||||
so that, for instance, time is not wasted,
|
||||
waiting on devices.
|
||||
|
||||
Process alpha requests to read from a device,
|
||||
the kernel obliges,
|
||||
CPU switches into kernel mode,
|
||||
system call begins execution.
|
||||
|
||||
Process alpha is waiting for data,
|
||||
it yields to the scheduler,
|
||||
process beta writes to a file,
|
||||
the device signals that data is available.
|
||||
|
||||
Context switches,
|
||||
process alpha continues execution,
|
||||
data is fetched,
|
||||
CPU enters user mode.
|
||||
|
||||
注:上面代码内文本发布时请参考原文排版(第一行着重,全部居中)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/featured-blogs/200-libby-clark/777473-linux-poetry-explains-the-kernel-line-by-line/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:editors@linux.com
|
||||
[2]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[3]:http://shop.oreilly.com/product/9780596005658.do
|
||||
[4]:http://www.linux-poetry.com/
|
||||
@ -0,0 +1,190 @@
|
||||
9 ASCII Games You'll Want to Play Again and Again
|
||||
================================================================================
|
||||
Modern Graphics Processing Units (GPUs) offer exceptional gaming capabilities, and have contributed to the trend of astonishing leaps in graphics fidelity. There is not a year that has gone by without a game being released that makes significant advances in technical graphics wizardry. Computer graphics have been advancing at a staggering pace. At the current rate of progress, in the next 10 years it may not be possible to distinguish computer graphics from reality.
|
||||
|
||||
Personally, these developments do not overly interest me. I find little fascination playing games that focus so much on the visuals they neglect the essential elements. Too often the storyline and game play has been compromised for visual quality. Most of my favourite games are somewhat deficient in the graphics department. Gameplay is always king in my eyes.
|
||||
|
||||
Linux has an excellent library of free games many of which are released under an open source license. The vast majority of these games are aesthetically pleasing. Popular games often have full motion video, vector graphics, 3D graphics, realistic 3D rendering, animation, texturing, a physics engine, and much more. Early computer games did not have these graphic techniques. The earliest video games were text games or text-based games that used text characters rather than vector or bitmapped graphics.
|
||||
|
||||
Text-based games often receive little coverage in the Linux press. However, there are some real ASCII gems out there waiting to be explored which are immensely addictive and great fun to play.
|
||||
|
||||
The idiom 'don't judge a book by its cover' can be extended to 'don't judge a computer game by its graphics'. Whilst the games featured in this article have extremely basic graphics, they have many redeeming qualities beyond evoking fond memories of the early days of computer gaming.
|
||||
|
||||
There are no fancy graphics here, just great gameplay coupled with the urge of always having just one more play.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
The first game in this roundup is UnNetHack, a fork of NetHack, originally based on the hugely popular roguelike game NetHack. NetHack was first released in 1987, and is considered by many gamers to be one of the best gaming experiences the computing world offers.
|
||||
|
||||
UnNetHack adds a number of enhancements to NetHack, such as additional monsters, more levels, a few new objects, additional dangers, more challenging gameplay, and most importantly more entertainment than vanilla NetHack. It offers a tutorial to help new players get started.
|
||||
|
||||
Be warned, UnNetHack is fiendishly addictive.
|
||||
|
||||
- Website: [sourceforge.net/apps/trac/unnethack][1]
|
||||
- Authors: Patric Mueller
|
||||
- License: Nethack General Public License
|
||||
- Version Number: 5.1.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Empire is a simulation of a full-scale war between two emperors, the computer and you. Naturally, there is only room for one, so the object of the game is to destroy the other. The computer plays by the same rules that you do.
|
||||
|
||||
This game is the ancestor of all the multiplayer 4X simulations out there, including Civilization and Master of Orion. The classic game from the 1980s uses text mode graphical output, drawing your units, cities and the world in color. Commands are issued using the keyboard.
|
||||
|
||||
The world on which the game takes place is a square rectangle containing cities, land, and water. Cities are used to build armies, planes, and ships which can move across the world destroying enemy pieces, exploring, and capturing more cities. The objective of the game is to destroy all the enemy pieces, and capture all the cities.
|
||||
|
||||
The game starts by assigning you one city and the computer one city. Cities can produce new pieces. Every city that you own produces more pieces for you according to the cost of the desired piece. The typical play of the game is to issue the Automove command until you decide to do something special. During movement in each round, the player is prompted to move each piece that does not otherwise have an assigned function.
|
||||
|
||||
- Website: [www.catb.org/~esr/vms-empire][2]
|
||||
- Authors: Chuck Simmons, Eric S. Raymond
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.12
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Intricacy is an addictive, open source, networked, video puzzle game. It is written in Haskell, using the Curses and SDL libraries.
|
||||
|
||||
Intricacy runs directly from the command-line, and provides a turn-based, abstract puzzle game where the players need to pick locks, simply by coordinating a couple of tools in order to manipulate the lock’s mechanism. Constructing and solving difficult puzzles within certain strict design constraints is both challenging and good fun.
|
||||
|
||||
The catch is that you will be able to pick locks that are designed by other players. It has multi-platform support, with binaries for both Linux and Windows.
|
||||
|
||||
- Website: [mbays.freeshell.org/intricacy][3]
|
||||
- Authors: Chuck Simmons, Eric S. Raymond
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 0.2.6.3
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
XorCurses is a puzzle game set inside a series of mazes. It is a remake of XOR by Astral Software, a game published in 1987 and released on the popular home computers of the day including the Commodore 64, ZX Spectrum, Atari ST, and Amiga. XOR is a pure puzzle game with no random or arcade elements.
|
||||
|
||||
In some respects, XorCurses is a regression from the graphics of the old 8 bit computers as it uses even more simplistic graphics, with coloured ASCII characters instead of pixel based graphics.
|
||||
|
||||
XorCurses attempts to faithfully recreate that game for Linux, with particular attention placed on the behaviour of the objects within the original game.
|
||||
|
||||
The basic premise of Xor is to roam around a series of mazes collecting all of the blue masks and then finding the exit. You have two player-shields to aid you and you can use either one at any time and switch between them. The first few levels are easy to progress, but the rest are progressively harder to solve. A particularly challenging and difficult puzzle game that will keep you engaged for hours.
|
||||
|
||||
- Website: [www.jwm-art.net/dark.php?p=XorCurses][4]
|
||||
- Authors: James W. Morris
|
||||
- License: GNU GPL
|
||||
- Version Number: 0.2.2
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Goblin Hack is an open source roguelike OpenGL-based smooth-scrolling ASCII graphics game. The game is inspired by the likes of NetHack, but faster with fewer keys.
|
||||
|
||||
Goblin Hack has a simple interface that appears to appeal to players of all ages, and fires their imagination in today's world of over-rendered games.
|
||||
|
||||
Players can choose one of several classes before being thrown into the first floor of a randomized, ongoing dungeon.
|
||||
|
||||
- Website: [goblinhack.sourceforge.net][5]
|
||||
- Authors: Neil McGill
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.18
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Curse of War is a fast-paced real time strategy game released under an open source license. It is implemented using C and ncurses. There is also an SDL version available.
|
||||
|
||||
The core game mechanics turns out to be quite close to WWI-WWII type of warfare, however, there is no explicit reference to any historical period.
|
||||
|
||||
Unlike most real time strategy games, in Curse of War players do not control units, but instead they concentrate on high-level strategic planning: Building infrastructure, securing resources, and moving armies.
|
||||
|
||||
A multiplayer mode is available. Computer opponents differ in personality, and it affects the way they fight.
|
||||
|
||||
- Website: [a-nikolaev.github.io/curseofwar][6]
|
||||
- Authors: Alexey Nikolaev
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 1.2.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Brogue is an open source Roguelike game for Mac OS X, Windows, Linux, iOS and Android.
|
||||
|
||||
Brogue is a direct descendant of Rogue, a dungeon crawling video game first developed by Michael Toy and Glenn Wichman around 1980. Unlike other popular modern roguelikes, Brogue favors simplicity over complexity, while trying to ensure that the interactions between components are interesting and varied.
|
||||
|
||||
Your goal is to travel to the 26th subterranean floor of the dungeon, retrieve the Amulet of Yendor and return with it to the surface. For the truly skillful who desire further challenge, depths below 26 contain three lumenstones each, items which confer an increased score upon victory.
|
||||
|
||||
Brogue is a challenging game, but still great fun to play. Try not to be disheartened by the difficulty of the game; with some application, Brogue will become very addictive.
|
||||
|
||||
- Website: [sites.google.com/site/broguegame][7]
|
||||
- Authors: Brian Walker
|
||||
- License: GNU Affero GPL
|
||||
- Version Number: 1.7.3
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
DiabloRL is a roguelike "unmake" of the popular Blizzard game Diablo 1 classic RPG to a turn-based ASCII roguelike.
|
||||
|
||||
The game was created for the 7 Day Roguelike Competition, but has since been expanded with magic items, spells, more classes and levels, as well as fast travelling to known locations, and high scores.
|
||||
|
||||
DiabloRL gives you a choice of classes, the Warrior, Rogue, or Sorcerer. Each of these has different starting and maximum stats, as well as completely different play styles.
|
||||
|
||||
- Website: [diablo.chaosforge.org][8]
|
||||
- Authors: Kornel Kisielewicz, Chris Johnson and Mel'nikova Anastasia
|
||||
- License: GNU GPL
|
||||
- Version Number: 0.5.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Cataclysm is an open source post-apocalyptic roguelike, set in the countryside of fictional New England after a devastating plague of monsters and zombies. It is a continuation of Whale's original Cataclysm, which expands it with numerous new creatures, buildings, gameplay mechanics and many other features.
|
||||
|
||||
While some have described it as a "zombie game", there's far more to Cataclysm than that. Struggle to survive in a harsh, persistent, procedurally generated world. Scavenge the remnants of a dead civilization for for food, equipment, or, if you're lucky, a vehicle with a full tank of gas to get you the hell out of Dodge. Fight to defeat or escape from a wide variety of powerful monstrosities, from zombies to giant insects to killer robots and things far stranger and deadlier, and against the others like yourself, that want what you have...
|
||||
|
||||
Cataclysm is very different from most roguelikes in many ways. Rather than being set in a vertical, linear dungeon, it is set in an unbounded, 3D world. This means that exploration plays a much bigger role than in most roguelikes, and the game is much less linear. As the map is so huge, it is actually completely persistant between games. If you die, and start a new character, your new game will be set in the same game world as your last. Like in many roguelikes, you will be able to loot the dead bodies of previous characters; unlike most roguelikes, you will also be able to retrace their steps completely, and any dramatic changes made to the world will persist into your next game.
|
||||
|
||||
- Website: [en.cataclysmdda.com][9]
|
||||
- Authors: Kevin Granade
|
||||
- License: Creative Commons Attribution-ShareAlike 3.0 Unported License
|
||||
- Version Number: 0.A
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20140621060017503/9ASCIIGames.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://sourceforge.net/apps/trac/unnethack/
|
||||
[2]:http://www.catb.org/~esr/vms-empire/
|
||||
[3]:http://mbays.freeshell.org/intricacy/
|
||||
[4]:http://www.jwm-art.net/dark.php?p=XorCurses
|
||||
[5]:http://goblinhack.sourceforge.net/
|
||||
[6]:http://a-nikolaev.github.io/curseofwar/
|
||||
[7]:https://sites.google.com/site/broguegame/
|
||||
[8]:http://diablo.chaosforge.org/
|
||||
[9]:http://en.cataclysmdda.com/
|
||||
@ -1,142 +0,0 @@
|
||||
How To Install Linux On A MacBook Pro Retina
|
||||
================================================================================
|
||||

|
||||
|
||||
MacBook Pros come with some very nice hardware, but some people want more. Some people want Linux.
|
||||
|
||||
Whether you’d like a more open and customizable operating system or simply need to dual-boot in order to access certain software, you might want Linux on your MacBook. The thing is, MacBook Pros are also pretty closed-down pieces of hardware that make installing other operating systems difficult – Linux more so than Windows. Boot Camp won’t help you with Linux, even though it doesn’t mean it’s impossible. Here’s how to do it.
|
||||
|
||||
### Why Install Linux On A MacBook Pro Retina? ###
|
||||
|
||||
The reasoning for installing Linux on a MacBook Pro might seem a bit strange at first – isn’t OS X one of the main reasons to get a Mac? That might be true, but another great reason to get a Mac is the hardware. They offer excellent performance, superb battery life, and long durability. For the ones with a Retina display, you’re also wanting a HiDPI experience for ultra-crisp photos and text.
|
||||
|
||||
But if you don’t like Mac OS X, or simply need to use Linux, you may want to put another operating system on that Mac hardware. Linux is lean, open, and highly customizable. Who says that you can’t bring the two together in a happy marriage? Well, Apple might have a word to say about that, but you probably don’t care anyways.
|
||||
|
||||
Note: For the purposes of this tutorial, we’ll be using Ubuntu, the [most popular Linux distribution][1], as our preferred choice. You’re free to choose a different distribution, but you can then only follow these steps are generic guidelines and not exact instructions. We claim no responsibility for any damage that is done to your system. Additionally, this tutorial assumes that you want to dual-boot between Linux and Mac OS X. It’s recommended to keep Mac OS X on the hard drive so that you can update the firmware if needed — something you cannot do in Linux.
|
||||
|
||||
Before we even start with the first step, make sure that your computer is backed up in case anything goes wrong. How you do this is up to you, so feel free to use Time Machine, CrashPlan, or whatever else you might prefer.
|
||||
|
||||
### Download Ubuntu ###
|
||||
|
||||
First, you’ll want to get a [copy of the Ubuntu desktop ISO image][2]. Be sure to choose the 64-bit desktop flavor, and not the image made for Macs. The regular image can boot up in BIOS and EFI modes, while the Mac image can only boot up in BIOS mode. This was done on purpose for some Macs, but we want to be able to boot it up in EFI mode.
|
||||
|
||||
### Write to USB Drive ###
|
||||
|
||||
Next, grab a USB flash drive that is at least 2GB large – we’ll use this to boot up the Ubuntu installer on. To make this drive you can follow [the official Ubuntu steps][3], or [use the dedicated GUI tool for the job][4].
|
||||
|
||||
### Resize Partitions ###
|
||||
|
||||

|
||||
|
||||
nce you’ve done that, you can get your MacBook Pro ready for the installation. Open up the Disk Utility, click on your hard drive on the left side, and then choose the Partitions tab. Resize the Mac partition to whatever size you’d like it to be — we’ll use the newly created free space to install Ubuntu.
|
||||
|
||||
### Boot Up Ubuntu Image ###
|
||||
|
||||

|
||||
|
||||
After that’s completed, plug in the USB flash drive you prepared and restart your MacBook Pro. Be sure to hold down the Options button from when the screen blanks out for a second to when you see a screen with various boot options. Choose the EFI option (the left one in case you see two of them) to boot up your Ubuntu USB flash drive.
|
||||
|
||||
When prompted to choose between “Try Ubuntu” and “Install Ubuntu”, choose “Try Ubuntu” because we’ll need to perform a step after the installer completes but before you restart the system.
|
||||
|
||||
### Installer ###
|
||||
|
||||
Once the Ubuntu desktop loads, start the installer and go through it normally until you reach the partitioning step. If you cannot access WiFi, it’s because Ubuntu currently doesn’t recognize your WiFi chipset. Don’t worry – we don’t need to have Internet access right now, and it’ll detect the right driver to use whenever you boot up into your new installation later on.
|
||||
|
||||

|
||||
|
||||
Once you come to the partitioning step, choose to “Do something else”. Then, make sure that the small partition that’s ~128MB large is recognized as an EFI boot partition (you can check by clicking on it and choosing Options; additionally, that should be /dev/sda1). Next, you can create an ext4 partition in the new space and have the path “/” be mounted to it. You can also create multiple partitions here if you prefer that and know what you’re doing.
|
||||
|
||||
Before you continue to the next step, make sure that the bootloader installation location says /dev/sda1, as you want GRUB to be installed into that partition. Then, finish off the installation like normal.
|
||||
|
||||
### EFI Boot Fix ###
|
||||
|
||||

|
||||
|
||||
When the installer completes, don’t restart just yet! We still need to do one more thing so that we’ll be able to use GRUB. Run the following command:
|
||||
|
||||
sudo apt-get install efibootmgr
|
||||
|
||||
This will temporarily install a configuration tool for EFI boot setups. Next, run
|
||||
|
||||
sudo efibootmgr
|
||||
|
||||
This will print out the current boot configuration to your screen. In this, you should be able to see “ubuntu” and “Boot0000*”. Currently, the EFI system will point to Boot0080*, which skips GRUB and goes directly to Mac OS X. To fix this, run the command
|
||||
|
||||
sudo efibootmgr -o 0,80`
|
||||
|
||||
Now you can restart!
|
||||
|
||||
Congratulations! Your Ubuntu installation should now be working! However, there are a few tweaks that you can perform to have a better experience.
|
||||
|
||||
### Various Tweaks ###
|
||||
|
||||
First, you’ll need to make a quick change to a GRUB setting so that the SSD won’t occasionally freeze. Type
|
||||
|
||||
sudo nano /etc/default/grub
|
||||
|
||||
in a terminal, and then find the line with **GRUB_CMDLINE_LINUX** and change it to **GRUB_CMDLINE_LINUX="libata.force=noncq"**. Hit CTRL+X to save, and Y then Enter to confirm. Then, you’ll want to type
|
||||
|
||||
sudo nano /etc/grub.d/40_custom
|
||||
|
||||
into the terminal, which will open up a new file. In it, type this exactly:
|
||||
|
||||
menuentry "Mac OS X" {
|
||||
exit
|
||||
}
|
||||
|
||||
This will allow you to boot into your Mac OS X installation (the 32-bit and 64-bit entries in GRUB do not work). Do the same thing to save and exit, then type in
|
||||
|
||||
sudo update-grub
|
||||
|
||||
for the changes to go into effect. Finally, restart your system for good measure.
|
||||
|
||||

|
||||
|
||||
As you can see, everything is ridiculously small on the Retina display. To fix this, System Settings –> Display and change the scaling factor to something larger. On the Retina screen, everything will look extremely tiny and it will make your life much more difficult if you don’t change it to something you like.
|
||||
|
||||
You may also find that it’s difficult to grab the edges of a window for resizing. This can also be changed. Type
|
||||
|
||||
sudo nano /usr/share/themes/Ambiance/metacity-1/metacity-theme-1.xml
|
||||
|
||||
into a terminal, and then change these values appropriately:
|
||||
|
||||
<distance name="left_width" value="4"/>
|
||||
<distance name="right_width" value="4"/>
|
||||
<distance name="bottom_height" value="4"/>
|
||||
|
||||
If that’s not big enough, you can also change those values to “6″ instead.
|
||||
|
||||
Finally, if you experience any washed out colors, you can grab the display color profile from Mac OS X and use it in Ubuntu. Mount your Mac OS X drive and navigate to
|
||||
|
||||
/Library/ColorSync/Profiles/Displays/Color LCD-xxxxxx.icc
|
||||
|
||||
where xxxxxx is some random string (there should only be one file anyways, but this string gets randomized). Copy it into your Ubuntu home folder, and then go to System Settings –> Color and choose Add New Profile and choose the profile you saved in your home folder.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||

|
||||
|
||||
Congratulations! You now have a great working Linux installation on your MacBook Pro Retina! Feel free to make additional tweaks to [make Ubuntu feel more like home][5]. I’m sure that these instructions can be applied to other Mac systems, but each new release has its own pitfalls and advantages. If you use a different machine, it’s a good idea to look up some documentation first, such as [this][6] for Ubuntu.
|
||||
|
||||
Additionally, feel free to check out [other great Linux distros][7] that you can install to your Mac!
|
||||
|
||||
Have you installed Linux on a Mac? What problems did you encounter and how did you solve it? Let us know in the comments!
|
||||
|
||||
Image Credits: [K?rlis Dambr?ns][8] Via Flickr
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/install-linux-macbook-pro/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.makeuseof.com/tag/windows-xp-users-switch-ubuntu-14-04-lts-trusty-tahr/
|
||||
[2]:http://www.ubuntu.com/download/desktop/
|
||||
[3]:http://www.ubuntu.com/download/desktop/create-a-usb-stick-on-mac-osx
|
||||
[4]:http://www.makeuseof.com/tag/how-to-boot-a-linux-live-usb-stick-on-your-mac/
|
||||
[5]:http://www.makeuseof.com/tag/11-tweaks-perform-ubuntu-installation/
|
||||
[6]:https://help.ubuntu.com/community/MacBookPro
|
||||
[7]:http://www.makeuseof.com/pages/best-linux-distributions
|
||||
[8]:https://www.flickr.com/photos/janitors/10037346335
|
||||
@ -1,127 +0,0 @@
|
||||
jiajia translating...
|
||||
|
||||
Cup 2014 Brazil: Watch FIFA World Cup 2014 Competition in Your Linux Desktop
|
||||
================================================================================
|
||||
Football is the most played and most watched sports on Earth. The present form of football originated in Britain. Football players run an average of more than six miles during a single match. Over one billion fans watched last world cup football matches on Television. This figure is estimated to rise on an above note, this year.
|
||||
|
||||
Yeah! 2014 FIFA World Cup is going to start from 12th of June and will last on 13th of July. This will be the 20th FIFA World Cup, which is scheduled to be played in Brazil. A total of 32 countries are participating in this event.
|
||||
|
||||
For the fan-boys of football, here we are going to throw light on an application software called “icup 2014 Brazil”, which will update you with latest scores, keep tracks of the match score of your favourite team. Here in this article we will be discussing its features, usages, installation, etc.
|
||||
|
||||

|
||||
iCup 2014 Brazil
|
||||
|
||||
### What is icup 2014 Brazil? ###
|
||||
|
||||
icup 2014 Brazil is an application which is capable of keeping a track of match results of the FIFA world cup 2014 into your Linux desktop, starting shortly.
|
||||
|
||||
### Features of icup 2014 Brazil ###
|
||||
|
||||
- Adaptive User Interface, i.e., auto-resize of user interface.
|
||||
- Fast Access to Statistics.
|
||||
- Social Network Sharing Enabled, which extends to Facebook, Twitter and Google+.
|
||||
- Latest one is – Retina display Support.
|
||||
- Detailed data with time events and Statistics related to match and Team.
|
||||
- Audio Kit which comprise of the ‘National-Anthem’ of all the participating countries (32) in high quality effect along with the stadium background sound which makes the whole thing real.
|
||||
- An inbuilt calendar with the support of time zone for better understanding of events in local time zone, grouping of data and statistics for real time comparison groupable by day or stage, Graphical 2nd stage table, Result and Scores of Teams in real time.
|
||||
- Proxy support.
|
||||
|
||||
### Platforms and Architecture Supported ###
|
||||
|
||||
The application is designed to run on all major platforms including **Mac**, **Windows** and **Linux**. For the point of Linux, it is important to mention that the application is designed for **x86** processor only. However installing an **x86** application on **x86_64** architecture is possible. We have to tweak a little to make it work **x86_64** systems.
|
||||
|
||||
#### An insight of the Technical Specification on different Platforms ####
|
||||
|
||||
- Live Result, Calendar, Grouping of Data, 2nd stage Table, Social Network Linking and Multi-language support – Available for all supported platform.
|
||||
- Retina Display – No support in Windows and Linux, however supported in Mac OS.
|
||||
- Detailed Statistics – Supported in Linux. Donation-ware for Windows and Mac.
|
||||
- Audio Kit – Supported in Mac and Linux. Unknown for Windows.
|
||||
|
||||
**Important**: As visible in the above specification, some of the features like detailed specification are not available on platform other than Linux, for free. It is just to support Server and Bandwidth cost. For a Linux user, nothing needs to be cared about as far as detailed statistics are concerned, a proud moment.
|
||||
|
||||
### Installing iCup 2014 Brazil in Linux ###
|
||||
|
||||
First go to official [iCup 2014 Brazil download][1] page and download application according to your platform and architecture.
|
||||
|
||||
#### On 32-Bit System ####
|
||||
|
||||
# cd Downloads/
|
||||
# tar xvf iCup_2014_FREE-Brazil_1.1_linux.tar.bz2
|
||||
# cd iCup\ 2014\ FREE\ -\ Brazil\ 1.1/
|
||||
# chmod 755 iCup\ 2014\ FREE\ -\ Brazil
|
||||
|
||||
As I said above, this application is designed for x86 systems only. In order to Install a 32 bit application on 64 bit architecture, we need to prepare our system by installing some packages – **GTK+2** and **libstdc++.so.6**.
|
||||
|
||||
Well not for this Application only, but there are a whole lot of application in Linux which is not supported in 64-bit e.g., **Skype**. We need to build our System to install those applications.
|
||||
|
||||
#### On 64-Bit Systems ####
|
||||
|
||||
Install **GTK+2** and **libstdc++so.6**, using apt or yum command as shown below.
|
||||
|
||||
$ sudo apt-get install libgtk2.0-0 libstdc++6 [on Debian based systems]
|
||||
|
||||
If you get any dependency error, run the following command to resolve those dependencies
|
||||
|
||||
$ sudo apt-get -f install
|
||||
|
||||
----------
|
||||
|
||||
# yum install gtk2 libstdc++ [on RedHat based systems]
|
||||
|
||||
Once all the required packages are installed. Now the System is capable of running 32 bit applications on 64-bit systems, now go the directory where you’ve downloaded ‘**iCup 2014 Brazil**‘ package and run the following commands to install it.
|
||||
|
||||
# cd Downloads/
|
||||
# tar xvf iCup_2014_FREE-Brazil_1.1_linux.tar.bz2
|
||||
# cd iCup\ 2014\ FREE\ -\ Brazil\ 1.1/
|
||||
# chmod 755 iCup\ 2014\ FREE\ -\ Brazil
|
||||
|
||||
Next, move to the directory and double click the executable to start the application. In the below screen-shot you may not get the full information since the FIFA 2014 has not started till now. Although the glimpse of what we can get once the event starts.
|
||||
|
||||

|
||||
iCup Brazil 2014
|
||||
|
||||
No detailed Information : World cup hasn’t started Yet.
|
||||
|
||||

|
||||
Match Detailed Information
|
||||
|
||||
Groups and Teams
|
||||
|
||||

|
||||
Groups and Teams
|
||||
|
||||
2nd stage Detailed Information
|
||||
|
||||

|
||||
2nd stage Detailed Information
|
||||
|
||||
Match Details. Seems incomplete now.
|
||||
|
||||

|
||||
Match Summary
|
||||
|
||||
Language Change window and Social share button Integrated.
|
||||
|
||||

|
||||
Language Change
|
||||
|
||||
Donation is optional for Linux. You can always contribute.
|
||||
|
||||

|
||||
Donation
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The above Application seems promising and may prove to be a boon for those Football fan-wall who can now remain connected.
|
||||
|
||||
That’s all for now. I’ll be here again with another interesting article soon. In that mean keep connected to Tecmint.com. Don’t forget to provide us with your valuable feedback in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/view-fifa-world-cup-matche-results/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.e-link.it/icup/brazil2014/icup-brazil-2014-desktop-app.php
|
||||
@ -0,0 +1,203 @@
|
||||
translating by johnhoow...
|
||||
给linux用户的11个高级MySQL数据库面试问题和答案
|
||||
================================================================================
|
||||
我们已经发表了两篇MySQL的文章,非常感谢Tecmint社区的大力支持.这是MySQL面试系列的第三篇文章,并且在面试专栏中排第16.
|
||||
- [15个基本的MySQL面试问题][1]
|
||||
- [给中级人员的10个MySQL面试问题][1]
|
||||
|
||||

|
||||
|
||||
感谢你们这一路上对我们的支持.这篇文章主要针对MySQL的实用性,讲面试方面的问题.
|
||||
|
||||
### 1. 如何使用SELECT语句找到你正在运行的服务器的版本并打印出当前数据库的名称? ###
|
||||
**答案**:下面的语句的结果会显示服务器的版本和当前的数据库名称
|
||||
|
||||
mysql> SELECT VERSION(), DATABASE();
|
||||
|
||||
+-------------------------+------------+
|
||||
| VERSION() | DATABASE() |
|
||||
+-------------------------+------------+
|
||||
| 5.5.34-0ubuntu0.13.10.1 | NULL |
|
||||
+-------------------------+------------+
|
||||
1 row in set (0.06 sec)
|
||||
|
||||
在Database一栏中显示**NULL**是因为我们当前没有选择任何数据库.因此,使用下面的语句先选择一个数据库,就能看到相应的结果.
|
||||
|
||||
mysql> use Tecmint;
|
||||
|
||||
Reading table information for completion of table and column names
|
||||
You can turn off this feature to get a quicker startup with -A
|
||||
|
||||
Database changed
|
||||
|
||||
----------
|
||||
|
||||
mysql> select VERSION(), DATABASE();
|
||||
|
||||
+-------------------------+------------+
|
||||
| VERSION() | DATABASE() |
|
||||
+-------------------------+------------+
|
||||
| 5.5.34-0ubuntu0.13.10.1 | tecmint |
|
||||
+-------------------------+------------+
|
||||
1 row in set (0.00 sec)
|
||||
|
||||
### 2. 使用非运算符(!)从表"Tecmint"中列出除了user等于"SAM"的所有记录
|
||||
|
||||
**答案**:使用下面的语句
|
||||
|
||||
mysql> SELECT * FROM Tecmint WHERE user !=SAM;
|
||||
|
||||
+---------------------+---------+---------+---------+---------+-------+
|
||||
| date | user | host | root | local | size |
|
||||
+---------------------+---------+---------+---------+---------+-------+
|
||||
| 2001-05-14 14:42:21 | Anthony | venus | barb | venus | 98151 |
|
||||
| 2001-05-15 08:50:57 | TIM | venus | phil | venus | 978 |
|
||||
+---------------------+---------+---------+---------+---------+-------+
|
||||
|
||||
### 3. 是否能够使用非运算符(!)来实现'AND'运算
|
||||
|
||||
**答案**: The AND operator is used when we use (=) and the operator OR is used when we use (!=). An example of (=) with AND Operator.
|
||||
**答案**:
|
||||
|
||||
mysql> SELECT * FROM mail WHERE user = SAM AND root = phil
|
||||
|
||||
An Example of (!=) with OR Operator.
|
||||
|
||||
mysql> SELECT * FROM mail WHERE user != SAM OR root != phil
|
||||
|
||||
+---------------------+---------+---------+---------+---------+-------+
|
||||
| date | user | host | root | local | size |
|
||||
+---------------------+---------+---------+---------+---------+-------+
|
||||
| 2001-05-14 14:42:21 | Anthony | venus | barb | venus | 98151 |
|
||||
+---------------------+---------+---------+---------+---------+-------+
|
||||
|
||||
- = : means Equal to
|
||||
- != : Not Equal to
|
||||
- ! : represents NOT Operator
|
||||
|
||||
The AND & OR are treated as joining operators in MySQL.
|
||||
|
||||
### 4. What IFNULL() statement is used for in MySQL? ###
|
||||
|
||||
**Ans**: The Query in MySQL can be written precisely using **IFNULL()** statement. The IFNULL() statement test its first argument and returns if it’s not NULL, or returns its second argument, otherwise.
|
||||
|
||||
mysql> SELECT name, IFNULL(id,'Unknown') AS 'id' FROM taxpayer;
|
||||
|
||||
+---------+---------+
|
||||
| name | id |
|
||||
+---------+---------+
|
||||
| bernina | 198-48 |
|
||||
| bertha | Unknown |
|
||||
| ben | Unknown |
|
||||
| bill | 475-83 |
|
||||
+---------+---------+
|
||||
|
||||
### 5. You want to see only certain rows from a result set from the beginning or end of a result set. How will you do it? ###
|
||||
|
||||
**Ans**: We need to use **LIMIT** clause along with ORDER BY to achieve the above described scenario.
|
||||
|
||||
#### Show 1 Record ####
|
||||
|
||||
mysql> SELECT * FROM name LIMIT 1;
|
||||
|
||||
+----+------+------------+-------+----------------------+------+
|
||||
| id | name | birth | color | foods | cats |
|
||||
+----+------+------------+-------+----------------------+------+
|
||||
| 1 | Fred | 1970-04-13 | black | lutefisk,fadge,pizza | 0 |
|
||||
+----+------+------------+-------+----------------------+------+
|
||||
|
||||
#### Show 5 Record ####
|
||||
|
||||
mysql> SELECT * FROM profile LIMIT 5;
|
||||
|
||||
+----+------+------------+-------+-----------------------+------+
|
||||
| id | name | birth | color | foods | cats |
|
||||
+----+------+------------+-------+-----------------------+------+
|
||||
| 1 | Fred | 1970-04-13 | black | lutefisk,fadge,pizza | 0 |
|
||||
| 2 | Mort | 1969-09-30 | white | burrito,curry,eggroll | 3 |
|
||||
| 3 | Brit | 1957-12-01 | red | burrito,curry,pizza | 1 |
|
||||
| 4 | Carl | 1973-11-02 | red | eggroll,pizza | 4 |
|
||||
| 5 | Sean | 1963-07-04 | blue | burrito,curry | 5 |
|
||||
+----+------+------------+-------+-----------------------+------+
|
||||
|
||||
----------
|
||||
|
||||
mysql> SELECT * FROM profile ORDER BY birth LIMIT 1;
|
||||
|
||||
+----+------+------------+-------+----------------+------+
|
||||
| id | name | birth | color | foods | cats |
|
||||
+----+------+------------+-------+----------------+------+
|
||||
| 9 | Dick | 1952-08-20 | green | lutefisk,fadge | 0 |
|
||||
+----+------+------------+-------+----------------+------+
|
||||
|
||||
### 6. Oracle Vs MySQL. Which one and Why? ###
|
||||
|
||||
**Ans**: Well both has its advantages and disadvantages. As a matter of time I prefer MySQL.
|
||||
|
||||
#### Reason for Selection MySQL Over oracle ####
|
||||
|
||||
- Mysql is FOSS.
|
||||
- MySQL is portable.
|
||||
- MYSQL supports both GUI as well as Command Prompt.
|
||||
- MySQL Administration is supported over Query Browser.
|
||||
|
||||
### 7. How will you get current date in MySQL? ###
|
||||
|
||||
**Ans**: Getting current date in MySQL is as simple as executing the below SELECT Statement.
|
||||
|
||||
mysql> SELECT CURRENT_DATE();
|
||||
|
||||
+----------------+
|
||||
| CURRENT_DATE() |
|
||||
+----------------+
|
||||
| 2014-06-17 |
|
||||
+----------------+
|
||||
|
||||
### 8. How will you export tables as an XML file in MySQL? ###
|
||||
|
||||
**Ans**: We use ‘-e‘ (export) option to export MySQL table or the whole database into an XML file. With large tables we may need to implement it manually but for small tables, applications like phpMyAdmin can do the job.
|
||||
A native command of MySQL can do it.
|
||||
|
||||
mysql -u USER_NAME –xml -e 'SELECT * FROM table_name' > table_name.xml
|
||||
|
||||
Where USER_NAME is username of Database, table_name is the table we are exporting to XML and table_name.xml is the xml file where data is stored.
|
||||
|
||||
### 9. What is MySQL_pconnect? And how it differs from MySQL_connect? ###
|
||||
|
||||
**Ans**: MySQL_pconnect() opens a connection that is persistent to the MySQL Database which simply means that the database is not opened every-time the page loads and hence we can not use MySQL_close() to close a persistent connection.
|
||||
|
||||
A brief difference between MySQL_pconnect and MySQL_connect are.
|
||||
|
||||
Unlike MySQL_pconnect, MySQL_connect – Opens the Database every-time the page is loaded which can be closed any-time using statement MySQL_close().
|
||||
|
||||
### 10. You need to show all the indexes defined in a table say ‘user’ of Database say ‘mysql’. How will you achieve this? ###
|
||||
|
||||
**Ans**: The following command will show all the indexes of a table ‘user’.
|
||||
|
||||
mysql> show index from user;
|
||||
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
|
||||
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
|
||||
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
|
||||
| user | 0 | PRIMARY | 1 | Host | A | NULL | NULL | NULL | | BTREE | | |
|
||||
| user | 0 | PRIMARY | 2 | User | A | 4 | NULL | NULL | | BTREE | | |
|
||||
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
|
||||
2 rows in set (0.00 sec)
|
||||
|
||||
### 11. What are CSV tables? ###
|
||||
|
||||
**Ans**: CSV stands for Comma-Separated Values aka Character-Separated Values. CSV table stores data in plain text and tabular format. It typically contains one record per line.
|
||||
|
||||
Each record is separated by specific delimiters (Comma, Semi-colon, …) where each record has same sequence of field. CSV tables are most widely used to store phone contacts to Import and Export and can be used to store any sort of plain text data.
|
||||
|
||||
That’s all for now. I’ll be here again with another Interesting article, you people will love to read. Till then stay tuned and connected to Tecmint and Don’t forget to provide us with your valuable feedback in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mysql-advance-interview-questions/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.tecmint.com/basic-mysql-interview-questions-for-database-administrators/
|
||||
[2]:http://www.tecmint.com/10-mysql-database-interview-questions-for-beginners-and-intermediates/
|
||||
@ -0,0 +1,159 @@
|
||||
[Translating] --213edu
|
||||
|
||||
How to enable testing and unstable repository on Debian
|
||||
================================================================================
|
||||
Testing/Unstable sources
|
||||
|
||||
The testing and unstable repositories of Debian provide with a higher version of software applications than what is present in the stable repository. Note that these names are actually aliases such that the stable repository points to the current Debian stable release and the Testing repository is what is going to be part of the next Debian stable release. So at the time of this post, Wheezy 7.x is the Stable release and Jessie is the Testing source which is going to be the next stable release.
|
||||
|
||||
At times, when you need to get a more recent version of a particular application, then the testing/unstable repository is a good option. I had the task of installing Apache 2.4.x onto a Debian wheezy system. But the repo had only 2.2.x and the testing repo had the required 2.4.x version. So the solution is to grab it from the testing repo.
|
||||
|
||||
Most of the time, when looking for newer versions of software applications, we would fiddle with the "Testing" repository only.
|
||||
|
||||
This post is going to show you how to setup the Testing and Unstable sources on a Debian system and how to install software from them, without breaking your existing system.
|
||||
|
||||
> Stable < Testing < Unstable
|
||||
> Wheezy < Jessie < Sid
|
||||
|
||||
### 1. Setup the apt sources for testing/unstable repo ###
|
||||
|
||||
The first step is to add the testing/unstable sources to your sources.list file. The /etc/apt/sources.list file on a Debian wheezy system looks something like this by default.
|
||||
|
||||
$ cat /etc/apt/sources.list
|
||||
|
||||
----------
|
||||
|
||||
...
|
||||
deb http://security.debian.org/ wheezy/updates main
|
||||
deb http://http.us.debian.org/debian/ wheezy main
|
||||
deb-src http://security.debian.org/ wheezy/updates main
|
||||
...
|
||||
|
||||
Note down the url of the repository server - http://http.us.debian.org/debian/
|
||||
This repository server is a mirror that is located nearest to you. It shall be different in your sources.list file. The same shall be used in the next steps
|
||||
|
||||
To add the testing and unstable sources you need to add something like this to your sources.list file
|
||||
|
||||
# Testing repository - main, contrib and non-free branches
|
||||
deb http://http.us.debian.org/debian testing main non-free contrib
|
||||
deb-src http://http.us.debian.org/debian testing main non-free contrib
|
||||
|
||||
|
||||
# Testing security updates repository
|
||||
deb http://security.debian.org/ testing/updates main contrib non-free
|
||||
deb-src http://security.debian.org/ testing/updates main contrib non-free
|
||||
|
||||
|
||||
# Unstable repo main, contrib and non-free branches, no security updates here
|
||||
deb http://http.us.debian.org/debian unstable main non-free contrib
|
||||
deb-src http://http.us.debian.org/debian unstable main non-free contrib
|
||||
|
||||
The format is
|
||||
|
||||
deb <respository server/mirror> <repository name> <sub branches of the repo>
|
||||
|
||||
Instead of testing/unstable the corresponding codenames jessie and sid can also be used
|
||||
|
||||
deb http://http.us.debian.org/debian jessie main non-free contrib
|
||||
deb http://security.debian.org/ jessie/updates main contrib non-free
|
||||
deb http://http.us.debian.org/debian sid main non-free contrib
|
||||
|
||||
### 2. Do some apt pinning - Important ! ###
|
||||
|
||||
> After adding the testing and unstable repos, if you update the system then all available updates for all installed applications would be installed right away, leading the system to an unpredictable state.
|
||||
|
||||
Therefore some rules have to be setup in order to restrict the package selection during regular updates/upgrades.
|
||||
|
||||
This is done through "apt pinning" where we tell the apt system to use only the stable system as always, but we may select to install a particular package from the testing or unstable repository if we wish to.
|
||||
|
||||
The apt pinning preferences can be configured into either of the following 2 files.
|
||||
|
||||
/etc/apt/preferences
|
||||
OR
|
||||
/etc/apt/preferences.d/my_preferences
|
||||
|
||||
Open either of the 2 locations (create one if it does not exist) and fill the following into the file
|
||||
|
||||
Package: *
|
||||
Pin: release a=stable
|
||||
Pin-Priority: 700
|
||||
|
||||
Package: *
|
||||
Pin: release a=testing
|
||||
Pin-Priority: 650
|
||||
|
||||
Package: *
|
||||
Pin: release a=unstable
|
||||
Pin-Priority: 600
|
||||
|
||||
Mentioned earlier, stable will point to your current debian version, testing to the next, and unstable would be further away in future. Main thing to note is the priority. The stable/current version has been given the highest priority which means that for regular tasks apt-get will install packages only from the current stable repository (wheezy in this case).
|
||||
|
||||
#### Update the package cache ####
|
||||
|
||||
After adding the new repository and specify the pinning rules, update the package cache.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
#### Confirm the apt policy ####
|
||||
|
||||
We must ensure that the pinning configuration is correct and that the priorities are met correctly. Check the effective apt policy with the apt-cache command
|
||||
|
||||
$ apt-cache policy apache2
|
||||
apache2:
|
||||
Installed: (none)
|
||||
Candidate: 2.2.22-13
|
||||
Version table:
|
||||
2.4.7-1 0
|
||||
600 http://http.us.debian.org/debian/ unstable/main amd64 Packages
|
||||
2.4.6-3 0
|
||||
650 http://http.us.debian.org/debian/ testing/main amd64 Packages
|
||||
2.2.22-13 0
|
||||
700 http://http.us.debian.org/debian/ wheezy/main amd64 Packages
|
||||
|
||||
The above output confirms that version 2.2.22 ( the wheezy main/stable ) repository is selected, its on highest priority.
|
||||
|
||||
### 3. Install apps from testing/unstable source ###
|
||||
|
||||
Now its time to pick a particular package out from the testing or unstable repo and install it. So lets say we want to install apache2 from testing source.
|
||||
|
||||
There are 2 ways to do it and each has a different effect.
|
||||
|
||||
#### Method 1 ####
|
||||
|
||||
# apt-get install apache2/testing
|
||||
|
||||
The above command will install the apache2 package from the testing source and install dependencies from stable source (or whatever the apt policy holds). This command fail in situations where the dependencies are outdated compared to what the installation package (apache2) needs.
|
||||
|
||||
#### Method 2 ####
|
||||
|
||||
# apt-get -t testing install apache2
|
||||
|
||||
The above command will install apache2 from testing source and install all dependencies from testing source as well. This should work better than the above command.
|
||||
|
||||
So to install newer version of any package, simply head towards the testing/unstable sources and enjoy. Note that the priority numbers are not just plain numbers, but have special meanings. Check the man page on apt preferences to learn more about them
|
||||
|
||||
$ man 5 apt_preferences
|
||||
|
||||
### Summary ###
|
||||
|
||||
Using the testing/unstable repository with pinning is an easy way to get newer versions of packages, but it is not recommended. If done wrong, it can mess up the system by pulling packages from different branches that may not be compatible.
|
||||
|
||||
A more recommended method to install updated packages is using the backports repository. It provides newer versions of selected packages from testing/unstable repo, but compiled for the current stable version. So on debian wheezy you can use wheezy-backports repository. Check out http://backports.debian.org/ for more information.
|
||||
|
||||
### Resources ###
|
||||
|
||||
- [https://wiki.debian.org/AptPreferences][1]
|
||||
- [https://wiki.debian.org/DebianTesting][2]
|
||||
- [https://www.debian.org/security/][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.binarytides.com/enable-testing-repo-debian/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://wiki.debian.org/AptPreferences
|
||||
[2]:http://wiki.debian.org/DebianTesting
|
||||
[3]:http://www.debian.org/security/
|
||||
@ -0,0 +1,190 @@
|
||||
hyaocuk is translating
|
||||
|
||||
10 Tips to Push Your Git Skills to the Next Level
|
||||
================================================================================
|
||||
Recently we published a couple of tutorials to get you familiar with [Git basics][1] and [using Git in a team environment][2]. The commands that we discussed were about enough to help a developer survive in the Git world. In this post, we will try to explore how to manage your time effectively and make full use of the features that Git provides.
|
||||
|
||||
> Note: Some commands in this article include part of the command in square brackets (e.g. `git add -p [file_name]`). In those examples, you would insert the necessary number, identifier, etc. without the square brackets.
|
||||
|
||||
### 1. Git Auto Completion ###
|
||||
|
||||
If you run Git commands through the command line, it’s a tiresome task to type in the commands manually every single time. To help with this, you can enable auto completion of Git commands within a few minutes.
|
||||
|
||||
To get the script, run the following in a Unix system:
|
||||
|
||||
cd ~
|
||||
curl https://raw.github.com/git/git/master/contrib/completion/git-completion.bash -o ~/.git-completion.bash
|
||||
|
||||
Next, add the following lines to your ~/.bash_profile file:
|
||||
|
||||
if [ -f ~/.git-completion.bash ]; then
|
||||
. ~/.git-completion.bash
|
||||
fi
|
||||
|
||||
Although I have mentioned this earlier, I can not stress it enough: If you want to use the features of Git fully, you should definitely shift to the command line interface!
|
||||
|
||||
### 2. Ignoring Files in Git ###
|
||||
|
||||
Are you tired of compiled files (like `.pyc`) appearing in your Git repository? Or are you so fed up that you have added them to Git? Look no further, there is a way through which you can tell Git to ignore certain files and directories altogether. Simply create a file with the name `.gitignore` and list the files and directories that you don’t want Git to track. You can make exceptions using the exclamation mark(!).
|
||||
|
||||
*.pyc
|
||||
*.exe
|
||||
my_db_config/
|
||||
|
||||
!main.pyc
|
||||
|
||||
### 3. Who Messed With My Code? ###
|
||||
|
||||
It’s the natural instinct of human beings to blame others when something goes wrong. If your production server is broke, it’s very easy to find out the culprit — just do a `git blame`. This command shows you the author of every line in a file, the commit that saw the last change in that line, and the timestamp of the commit.
|
||||
|
||||
git blame [file_name]
|
||||
|
||||
|
||||
|
||||
And in the screenshot below, you can see how this command would look on a bigger repository:
|
||||
|
||||
|
||||
|
||||
### 4. Review History of the Repository ###
|
||||
|
||||
We had a look at the use of `git log` in a previous tutorial, however, there are three options that you should know about.
|
||||
|
||||
|
||||
- **--oneline** – Compresses the information shown beside each commit to a reduced commit hash and the commit message, all shown in a single line.
|
||||
- **--graph** – This option draws a text-based graphical representation of the history on the left hand side of the output. It’s of no use if you are viewing the history for a single branch.
|
||||
- **--all** – Shows the history of all branches.
|
||||
|
||||
Here’s what a combination of the options looks like:
|
||||
|
||||
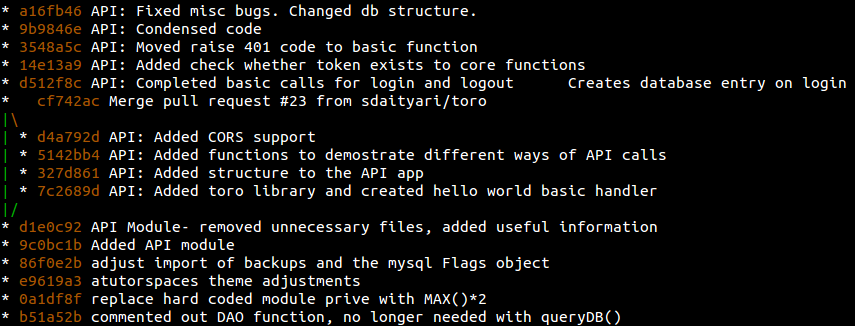
|
||||
|
||||
### 5. Never Lose Track of a Commit ###
|
||||
|
||||
Let’s say you committed something you didn’t want to and ended up doing a hard reset to come back to your previous state. Later, you realize you lost some other information in the process and want to get it back, or at least view it. This is where `git reflog` can help.
|
||||
|
||||
A simple `git log` shows you the latest commit, its parent, its parent’s parent, and so on. However, `git reflog` is a list of commits that the head was pointed to. Remember that it’s local to your system; it’s not a part of your repository and not included in pushes or merges.
|
||||
|
||||
If I run `git log`, I get the commits that are a part of my repository:
|
||||
|
||||
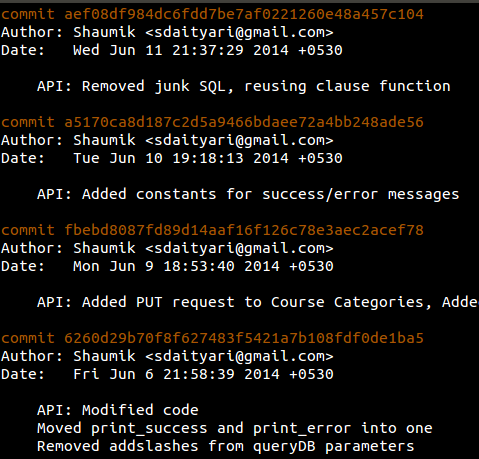
|
||||
|
||||
However, a `git reflog` shows a commit (`b1b0ee9` – `HEAD@{4}`) that was lost when I did a hard reset:
|
||||
|
||||
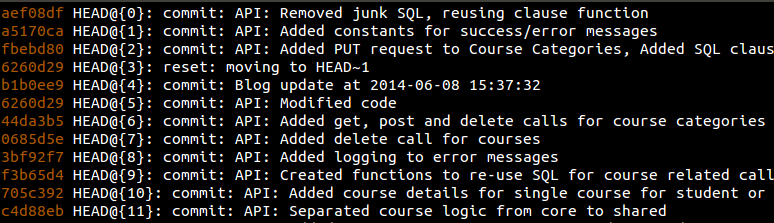
|
||||
|
||||
### 6. Staging Parts of a Changed File for a Commit ###
|
||||
|
||||
It is generally a good practice to make feature-based commits, that is, each commit must represent a feature or a bug fix. Consider what would happen if you fixed two bugs, or added multiple features without committing the changes. In such a situation situation, you could put the changes in a single commit. But there is a better way: Stage the files individually and commit them separately.
|
||||
|
||||
Let’s say you’ve made multiple changes to a single file and want them to appear in separate commits. In that case, we add files by prefixing `-p` to our add commands.
|
||||
|
||||
git add -p [file_name]
|
||||
|
||||
Let’s try to demonstrate the same. I have added three new lines to `file_name` and I want only the first and third lines to appear in my commit. Let’s see what a `git diff` shows us.
|
||||
|
||||
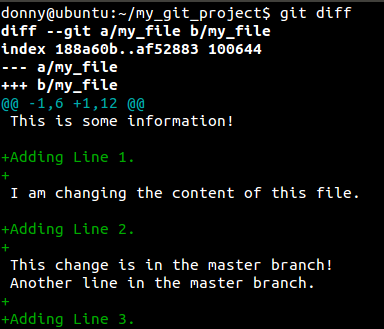
|
||||
|
||||
And let’s see what happes when we prefix a `-p` to our `add` command.
|
||||
|
||||
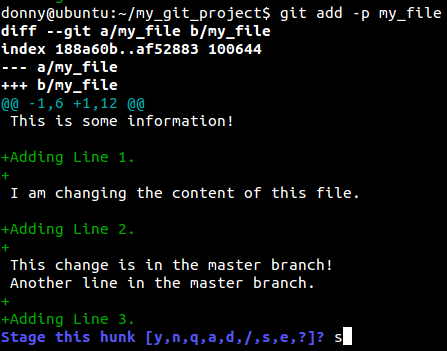
|
||||
|
||||
It seems that Git assumed that all the changes were a part of the same idea, thereby grouping it into a single hunk. You have the following options:
|
||||
|
||||
- Enter y to stage that hunk
|
||||
- Enter n to not stage that hunk
|
||||
- Enter e to manually edit the hunk
|
||||
- Enter d to exit or go to the next file.
|
||||
- Enter s to split the hunk.
|
||||
|
||||
In our case, we definitely want to split it into smaller parts to selectively add some and ignore the rest.
|
||||
|
||||
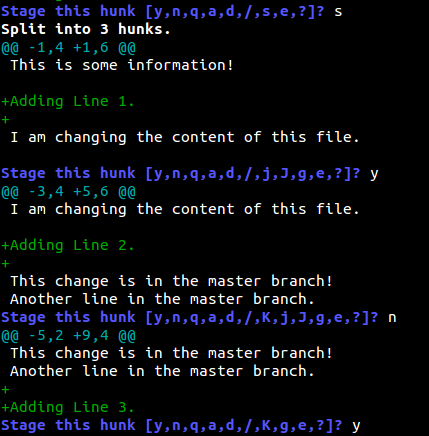
|
||||
|
||||
As you can see, we have added the first and third lines and ignored the second. You can then view the status of the repository and make a commit.
|
||||
|
||||
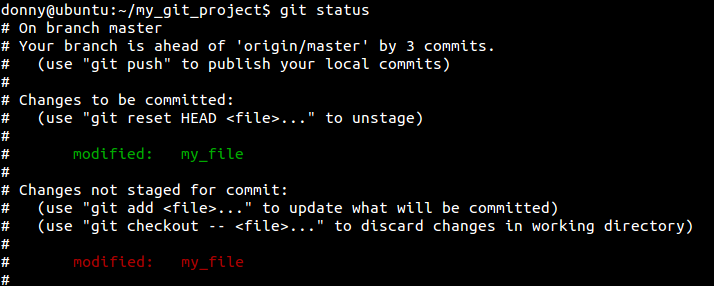
|
||||
|
||||
### 7. Squash Multiple Commits ###
|
||||
|
||||
When you submit your code for review and create a pull request (which happens often in open source projects), you might be asked to make a change to your code before it’s accepted. You make the change, only to be asked to change it yet again in the next review. Before you know it, you have a few extra commits. Ideally, you could squash them into one using the rebase command.
|
||||
|
||||
git rebase -i HEAD~[number_of_commits]
|
||||
|
||||
If you want to squash the last two commits, the command that you run is the following.
|
||||
|
||||
git rebase -i HEAD~2
|
||||
|
||||
On running this command, you are taken to an interactive interface listing the commits and asking you which ones to squash. Ideally, you `pick` the latest commit and `squash` the old ones.
|
||||
|
||||
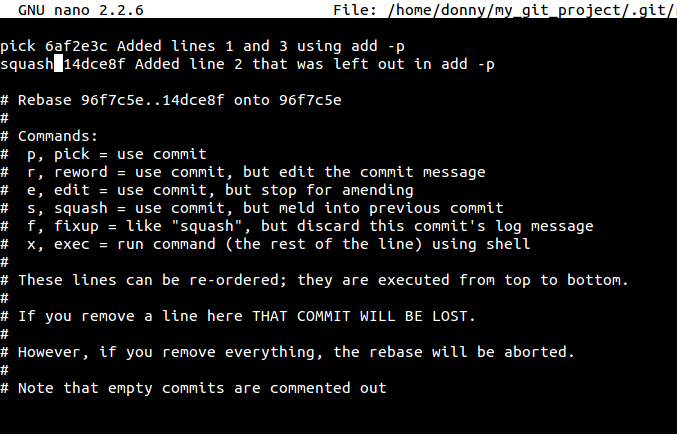
|
||||
|
||||
You are then asked to provide a commit message to the new commit. This process essentially re-writes your commit history.
|
||||
|
||||
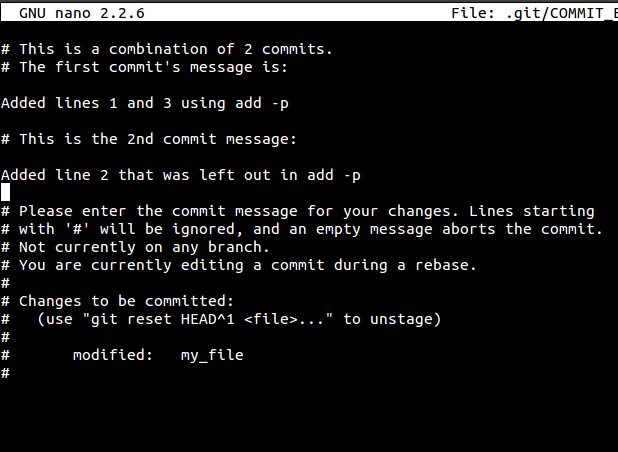
|
||||
|
||||
### 8. Stash Uncommitted Changes ###
|
||||
|
||||
Let’s say you are working on a certain bug or a feature, and you are suddenly asked to demonstrate your work. Your current work is not complete enough to be committed, and you can’t give a demonstration at this stage (without reverting the changes). In such a situation, `git stash` comes to the rescue. Stash essentially takes all your changes and stores them for further use. To stash your changes, you simply run the following-
|
||||
|
||||
git stash
|
||||
|
||||
To check the list of stashes, you can run the following:
|
||||
|
||||
git stash list
|
||||
|
||||

|
||||
|
||||
If you want to un-stash and recover the uncommitted changes, you apply the stash:
|
||||
|
||||
git stash apply
|
||||
|
||||
In the last screenshot, you can see that each stash has an indentifier, a unique number (although we have only one stash in this case). In case you want to apply only selective stashes, you add the specific identifier to the apply command:
|
||||
|
||||
git stash apply stash@{2}
|
||||
|
||||
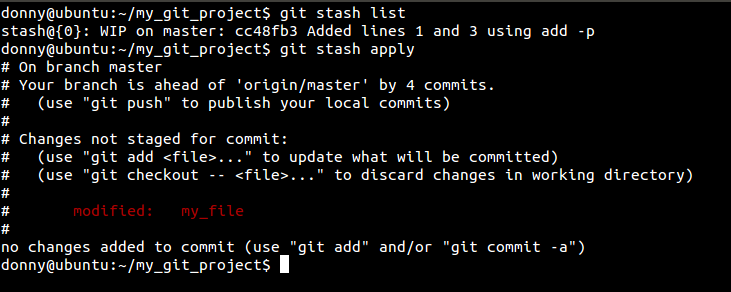
|
||||
|
||||
### 9. Check for Lost Commits ###
|
||||
|
||||
Although `reflog` is one way of checking for lost commits, it’s not feasible in large repositories. That is when the `fsck` (file system check) command comes into play.
|
||||
|
||||
git fsck --lost-found
|
||||
|
||||
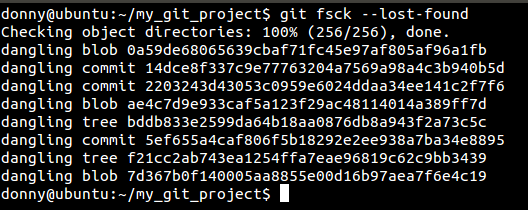
|
||||
|
||||
Here you can see a lost commit. You can check the changes in the commit by running git show [commit_hash] or recover it by running `git merge [commit_hash]`.
|
||||
|
||||
`git fsck` has an advantage over `reflog`. Let’s say you deleted a remote branch and then cloned the repository. With `fsck` you can search for and recover the deleted remote branch.
|
||||
|
||||
### 10. Cherry Pick ###
|
||||
|
||||
I have saved the most elegant Git command for the last. The `cherry-pick` command is by far my favorite Git command, because of its literal meaning as well as its utility!
|
||||
|
||||
In the simplest of terms, `cherry-pick` is picking a single commit from a different branch and merging it with your current one. If you are working in a parallel fashion on two or more branches, you might notice a bug that is present in all branches. If you solve it in one, you can cherry pick the commit into the other branches, without messing with other files or commits.
|
||||
|
||||
Let’s consider a scenario where we can apply this. I have two branches and I want to cherry-pick the commit `b20fd14: Cleaned junk` into another one.
|
||||
|
||||
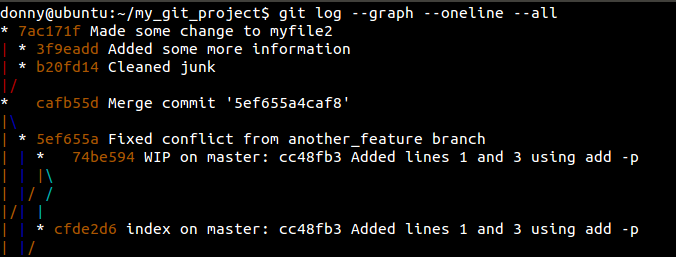
|
||||
|
||||
I switch to the branch into which I want to cherry-pick the commit, and run the following:
|
||||
|
||||
git cherry-pick [commit_hash]
|
||||
|
||||
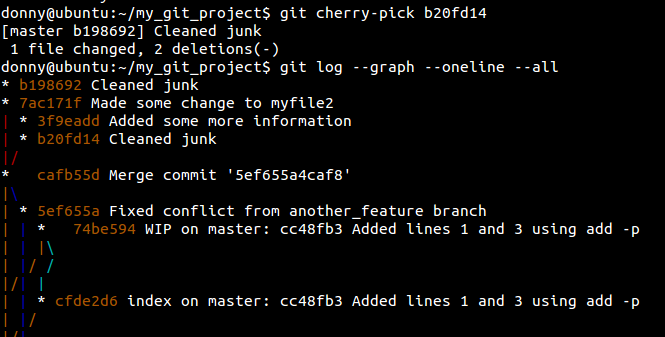
|
||||
|
||||
Although we had a clean `cherry-pick` this time, you should know that this command can often lead to conflicts, so use it with care.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
With this, we come to the end of our list of tips that I think can help you take your Git skills to a new level. Git is the best out there and it can accomplish anything you can imagine. Therefore, always try to challenge yourself with Git. Chances are, you will end up learning something new!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.sitepoint.com/10-tips-git-next-level/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.sitepoint.com/git-for-beginners/
|
||||
[2]:http://www.sitepoint.com/getting-started-git-team-environment/
|
||||
@ -0,0 +1,91 @@
|
||||
Advanced Directory Navigations Tips and Tricks in Linux
|
||||
================================================================================
|
||||
Directory navigation is one of the most basic concepts when it comes to understanding any command line system. Although it’s not a very difficult thing to understand when it comes to Linux, there are certain tips and tricks that can enhance your experience, and help you do things faster. In this article, we will discuss some advanced directory navigation tips.
|
||||
|
||||
### The Stuff We Already Know ###
|
||||
|
||||
Before jumping on to the advanced concepts, here is the basics of directory navigation that the article expects its readers to know:
|
||||
|
||||
- ‘pwd’ command is used to display the current working directory.
|
||||
- ‘cd’ command is used to change the current working directory.
|
||||
- ‘cd’ followed by space and followed by a couple of periods (cd ..) brings the control back to the parent directory
|
||||
- ‘cd’ followed by just the name of a subdirectory changes to that subdirectory
|
||||
- ‘cd’ followed by a complete path changes to that directory
|
||||
|
||||
### Advanced Tips ###
|
||||
|
||||
In this section we will discuss some directory navigation tips and tricks that will help you easily switch between directories.
|
||||
|
||||
### Change to the home directory from anywhere ###
|
||||
|
||||
Your home directory is an important directory, and everyone switches back and forth quite frequently. While typing ‘cd /home/<your-home-directory-name>’, isn’t a big deal, there is another way out which is not only easier but faster too. And that alternative is typing only ‘cd’.
|
||||
|
||||
Here is an example :
|
||||
|
||||
$ pwd
|
||||
/usr/include/netipx
|
||||
$ cd
|
||||
$ pwd
|
||||
/home/himanshu
|
||||
|
||||
So you can see, no matter where the current control is, just type ‘cd’ command and you can immediately change to your home directory.
|
||||
|
||||
**NOTE**- To change to the home directory of a particular user, just type ‘cd ~user_name'
|
||||
|
||||
### Switch between directories using cd - ###
|
||||
|
||||
Suppose your current working directory is this:
|
||||
|
||||
$ pwd
|
||||
/home/himanshu/practice
|
||||
|
||||
and you want to switch to the directory **/usr/bin/X11**, and then switch back to the directory mentioned above. So what will you do? The most straight forward way is :
|
||||
|
||||
$ cd /usr/bin/X11
|
||||
$ cd /home/himanshu/practice/
|
||||
|
||||
Although it seems a good way out, it really becomes tiring when the path to the directories is very long and complicated. In those cases, you can use the ‘cd -’ command.
|
||||
|
||||
While using ‘cd -’ command, the first step will remain the same, i.e., you have to do a cd <path> to the directory to you want to change to, but for coming back to the previous directory, just do a ‘cd -’, and that’s it.
|
||||
|
||||
$ cd /usr/bin/X11
|
||||
$ cd -
|
||||
/home/himanshu/practice
|
||||
$ pwd
|
||||
/home/himanshu/practice
|
||||
|
||||
And if you want to again go back to the last directory, which in this case is /usr/bin/X11, run the ‘cd -’ command again. So you can see that using ‘cd -’ you can switch between directories easily. The only limitation is that it works with the last switched directories only.
|
||||
|
||||
### Switch between directories using pushd and popd ###
|
||||
|
||||

|
||||
|
||||
If you closely analyse the ‘cd -’ trick, you’ll find that it helps switching between only the last two directories, but what if there is a situation in which you switch multiple directories, and then want to switch back to the first one. For example, if you switch from directory A to directory B, and then to directory C and directory D. Now, you want to change back to Directory A.
|
||||
|
||||
As a general solution, you can type ‘cd’ followed by the path to directory A. But then again, if the path is long or complicated, the process can be time-consuming, especially when you have to switch between them frequently.
|
||||
|
||||
In these kind of situations, you can use the ‘pushd’ and ‘popd’ commands. The ‘pushd’ command saves the path to a directory in memory, and the ‘popd’ command removes it, and switches back to it too.
|
||||
|
||||
For example :
|
||||
|
||||
$ pushd .
|
||||
/usr/include/netipx /usr/include/netipx
|
||||
$ cd /etc/hp/
|
||||
$ cd /home/himanshu/practice/
|
||||
$ cd /media/
|
||||
$ popd
|
||||
/usr/include/netipx
|
||||
$ pwd
|
||||
/usr/include/netipx
|
||||
|
||||
So you can see that I used ‘pushd’ command to save the path to current working directory (represented by .), and then changed multiple directories. To come back to the saved directory, I just executed the ‘popd’ command.
|
||||
|
||||
**NOTE**- You can also use ‘pushd’ command to switch back to the saved directory, but that doesn’t remove it from the memory, like ‘popd’ does.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/directory-navigations-tips-tricks/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,87 @@
|
||||
How to speed up directory navigation in a Linux terminal
|
||||
================================================================================
|
||||
As useful as navigating through directories from the command line is, rarely anything has become as frustrating as repeating over and over "cd ls cd ls cd ls ..." If you are not a hundred percent sure of the name of the directory you want to go to next, you have to use ls. Then use cd to go where you want to. Hopefully, a lot of terminals and shell languages now propose a powerful auto-completion feature to cope with that problem. But it remains that you have to hit the tabulation key frenetically all the time. If you are as lazy as I am, you will be very interested in autojump. autojump is a command line utility that allows you to jump straight to your favorite directory, regardless of where you currently are.
|
||||
|
||||
### Install autojump on Linux ###
|
||||
|
||||
To install autojump on Ubuntu or Debian:
|
||||
|
||||
$ sudo apt-get install autojump
|
||||
|
||||
To install autojump on CentOS or Fedora, use yum command. On CentOS, you need to [enable EPEL repository][1] first.
|
||||
|
||||
$ sudo yum install autojump
|
||||
|
||||
To install autojump on Archlinux:
|
||||
|
||||
$ sudo pacman -S autojump
|
||||
|
||||
If you cannot find a package for your distribution, you can always compile from the sources on [GitHub][2].
|
||||
|
||||
### Basic Usage of autojump ###
|
||||
|
||||
The way autojump works is simple: it records your current location every time you launch a command, and adds it in its database. That way, some directories will be added more than others, typically your most important ones, and their "weight" will then be greater.
|
||||
|
||||
From there you can jump straight to them using the syntax:
|
||||
|
||||
autojump [name or partial name of the directory]
|
||||
|
||||
Notice that you do not need a full name as autojump will go through its database and return its most probable result.
|
||||
|
||||
For example, assume that we are working in a directory structure such as the following.
|
||||
|
||||

|
||||
|
||||
Then the command below will take you straight to /root/home/doc regardless of where you were.
|
||||
|
||||
$ autojump do
|
||||
|
||||
If you hate typing too, I recommend making an alias for autojump or using the default one.
|
||||
|
||||
$ j [name or partial name of the directory]
|
||||
|
||||
Another notable feature is that autojump supports both zsh shell and auto-completion. If you are not sure of where you are about to jump, just hit the tabulation key and you will see the full path.
|
||||
|
||||
So keeping the same example, typing:
|
||||
|
||||
$ autojump d
|
||||
|
||||
and then hitting tab will return either /root/home/doc or /root/home/ddl.
|
||||
|
||||
Finally for the advanced user, you can access the directory database and modify its content. It then becomes possible to manually add a directory to it via:
|
||||
|
||||
$ autojump -a [directory]
|
||||
|
||||
If you suddenly want to make it your favorite and most frequently used folder, you can artificially increase its weight by launching from within it the command
|
||||
|
||||
$ autojump -i [weight]
|
||||
|
||||
This will result in this directory being more likely to be selected to jump to. The opposite would be to decrease its weight with:
|
||||
|
||||
$ autojump -d [weight]
|
||||
|
||||
To keep track of all these changes, typing:
|
||||
|
||||
$ autojump -s
|
||||
|
||||
will display the statistics in the database, while:
|
||||
|
||||
$ autojump --purge
|
||||
|
||||
will remove from the database any directory that does not exist anymore.
|
||||
|
||||
To conclude, autojump will be appreciated by all the command line power users. Whether you are ssh-ing into a server, or just like to do things the old fashion way, reducing your navigation time with fewer keystrokes is always a plus. If you are really into that kind of utilities, you should definitely look into [Fasd][3] too, which deserves a post in itself.
|
||||
|
||||
What do you think of autojump? Do you use it regularly? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/06/speed-up-directory-navigation-linux-terminal.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
[2]:https://github.com/joelthelion/autojump
|
||||
[3]:https://github.com/clvv/fasd
|
||||
@ -0,0 +1,82 @@
|
||||
微软真的改变对开源软件的态度了吗?
|
||||
================================================================================
|
||||
> **在今天的开源软件摘要中:微软或许没有对开源软件有一个新的态度,就像安卓和windows的对抗,Cinnamon和Unity在Ubuntu14.04的对抗。**
|
||||
|
||||
微软因为以前对开源软件的态度而臭名昭著,但是公司改建后对开源软件发出了积极的信号。CNet报道了微软对开源软件认知的行为的改变。
|
||||
|
||||
> [CNet][1]消息:
|
||||
> 微软自助开源软件有一些时间了,那些曾经反对开源软件的领导者们已经退出了或者不在位了。开软软件现在用在遍布全世界的公司当中,这些公司有些自命不凡但这只是在认识到微软帝国之外的事。
|
||||
> 一些新的想法反映了企业顶层的一些变化,今年二月初Satya Nadella代替鲍尔默成为了微软CEO,Nadella已经给微软带来了一些新的东西改变了微软以前的一些束缚。
|
||||
>
|
||||
> [更多报道][2]
|
||||
>
|
||||
> 
|
||||
>
|
||||
> 微软和开源社区
|
||||
> Image credit: [Curako's Blog][3]
|
||||
|
||||
我是一个持悲观态度的人,但是我认为微软和开源软件之间的信任关系是有待确定的。一个新的CEO和些许改变或许会改变微软在开源世界中的存在状态,但是对于微软这么大的企业来说改变并不容易,所以对于开源的世界来说微软是否真的改变还有待确定。
|
||||
|
||||
我也从来不会忘记微软“欢迎,扩大,压死”的策略来打翻其他的竞争软件,光这一条凡是微软参合的开源项目就必须多一只谨慎的眼,或许这家公司真的改了,但如果没有呢!我们还是用几年时间来观察下吧。
|
||||
|
||||
### 安卓对抗windows ###
|
||||
|
||||
ZDNet曾经报道过使用数量最多的Linux发行版本,但是现在桌面环境仍然是windows的天下,但是安卓今年很可能会是用户数量最大的用户终端操作系统。
|
||||
|
||||
> [ZDNet][4]报道:
|
||||
>
|
||||
> 如果桌面和平板依旧像预期增长的销量,安卓平板渐渐蚕食苹果的市场,PC市场继续萎缩,安卓在2014年末很有可能成为终端用户数量最多的操作系统而且不算安卓PC。
|
||||
>
|
||||
> 总而言之,安卓几乎统治了Linux终端用户。你可能不会想到它作为桌面使用,尽管Intel和AMD努力在让它变成现实,但是安卓正在变成使用量第一的终端操作系统。
|
||||
|
||||
>
|
||||
> [更多消息][4]
|
||||
>
|
||||
> 
|
||||
> Image credit: [ZDNet][4]
|
||||
|
||||
上面提到的并不算真的惊喜,移动终端的革命发展了接近10年了。桌面依然还像原来那样重要,微软也确实没有真正的在乎过移动设备。即使现在,微软在艰难的推他的手机和平板,他仍旧认为移动终端市场并不重要。
|
||||
|
||||
|
||||
谷歌严重的破坏了微软在移动领域的努力,而现在他在桌面市场又对微软发起了挑战。从chrome OS到安卓,谷歌给微软一连串的打击,如果你查看下Amazon最受欢迎的[台式机][5]和[笔记本][6]的话,你会看到很多chrome OS的电脑甚至是装有安卓的PC。所以人们的购买需求在变得多样化,并不局限在windows一家了。
|
||||
|
||||
### Cinnamon和Unity在Ubuntu14.04上的对抗 ###
|
||||
|
||||
Tech Republic发表了一篇文章介绍了如何在Ubuntu14.04上安装cinnamon,研究了一下Ubuntu14.04上用cinnamon替换unity的可行性。
|
||||
|
||||
> [Tech Republic][7]报道:
|
||||
>
|
||||
> 如果你寻求性能为主不需要其他有特色的可自定义的桌面,cinnamon适合你。Cinnamon是一个直观简洁的桌面,任何人都可以使用,不论你是IT工作者还是你的老妈妈。它非常的简单易用。Cinnamon很平淡,不会和你开什么玩笑,也不会让你感到有惊奇的感觉,但这就是它所注重的。它只会给桌面带来在标准层面上带来实用性,它不求突破,不耍花招,不加条条框框。
|
||||
>
|
||||
> Cinnamon是一个很平凡的桌面它只集成了最好的功能并且把它们集成到一起,完美整合到一块。如果你可以用一个看起来和用起来都点老掉牙但是性能很好的桌面的话,cinnamon完全适合你。如果你喜欢各种花哨的界面和看起来很现代的感觉,cinnamon可能就不适合你了。
|
||||
|
||||
> [ 更多消息][7]
|
||||
>
|
||||
> 
|
||||
>
|
||||
> Image credit: [Tech Republic][7]
|
||||
|
||||
我是站在cinnamon这边的,unity有自己的长处,但是我从来没用习惯过。Cinnamon更接近传统桌面,我用起来不错!
|
||||
|
||||
但是在别人眼里,漂亮的桌面总是很受欢迎。Linux最大的特色就是提供很多很多不同的选择,如果你真不知道unity和cinnamon该选择谁,你就用自己最喜欢的就行了。
|
||||
|
||||
你赞成那些呢?请在下方留下你的评论吧
|
||||
|
||||
作者的观点和ITworld无关!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/open-source/421894/has-microsoft-really-changed-its-attitude-toward-open-source
|
||||
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cnet.com/news/dead-and-buried-microsofts-holy-war-on-open-source-software/
|
||||
[2]:http://www.cnet.com/news/dead-and-buried-microsofts-holy-war-on-open-source-software/
|
||||
[3]:http://curako.wordpress.com/2010/12/06/the-uneasy-alliance-free-software-vs-open-source/
|
||||
[4]:http://www.zdnet.com/the-five-most-popular-end-user-linux-distributions-7000030058/http://www.zdnet.com/the-five-most-popular-end-user-linux-distributions-7000030058/
|
||||
[5]:http://www.amazon.com/Best-Sellers-Electronics-Desktop-Computers/zgbs/electronics/565098/?_encoding=UTF8&camp=1789&creative=390957&linkCode=ur2&tag=fnh-20&linkId=REWXUPB7SQXPDSOL
|
||||
[6]:http://www.amazon.com/Best-Sellers-Computers-Accessories-Laptop/zgbs/pc/565108/?_encoding=UTF8&camp=1789&creative=390957&linkCode=ur2&tag=fnh-20&linkId=POG3J2CFBHDWBAVL
|
||||
[7]:http://www.techrepublic.com/article/is-cinnamon-a-worthy-replacement-for-ubuntu-unity/
|
||||
@ -1,14 +1,14 @@
|
||||
Linux 平台七大桌面环境
|
||||
================================================================================
|
||||
通常的 Linux 发行版上都使用 KDE 或者 GNOME 作为默认的桌面环境。它们都给用户提供了一个易用的并且有吸引力的桌面,并且内置了各式各样的多媒体软件、系统程序、游戏、实用程序、网页开发工具、编程工具等等。这两个桌面致力于提供给用户一个拥有类似于 Windows 操作系统体验的尖端的计算环境,而忽略了最小化它们所占用的系统资源。
|
||||
通常的 Linux 发行版都使用 KDE 或者 GNOME 作为默认的桌面环境。它们都给用户提供了一个原始的并且有吸引力的桌面,并且内置了各式各样的多媒体软件、系统程序、游戏、实用程序、网页开发工具、编程工具等等。这两个桌面致力于提供给用户一个拥有类似于 Windows 操作系统体验的尖端计算环境,而忽略了最小化它们所占用的系统资源。
|
||||
|
||||
如果你正在使用 Ubuntu (或者其他Linux发行版) 并且疲于始终使用 Unity 桌面,那么你应该看看这些可以替代 Unity 的选择。我收集了 7 种桌面环境。它们都很棒。在你读完这篇文章之后,请试着使用它们吧。
|
||||
如果你正在使用 Ubuntu (或者其他Linux发行版) 并且厌倦始终使用 Unity 桌面,那么你应该看看这些可以替代 Unity 的选择。我收集了 7 种桌面环境。它们都很棒。在你读完这篇文章之后,请试着使用它们吧。
|
||||
|
||||
### [Mate][1] ###
|
||||
|
||||

|
||||
|
||||
MATE 是 GNOME2 的一个分支。它提供了一个自然且吸引人的桌面环境。它是 Linux 和其他 Unix-like 工作环境中的传统工作框架的代表。MATE 正在改善以使用新的技术来保留传统的桌面体验。
|
||||
MATE 是 GNOME2 的一个分支。它提供了一个自然且吸引人的桌面环境。它是 Linux 和其它类 Unix 工作环境中的传统工作框架的代表。MATE 正在改善以使用新的技术来保留传统的桌面体验。
|
||||
|
||||
在 Ubuntu 14.04 中,可以直接从 Ubuntu 软件中心获取 MATE 桌面。
|
||||
|
||||
@ -16,19 +16,19 @@ MATE 是 GNOME2 的一个分支。它提供了一个自然且吸引人的桌面
|
||||
|
||||

|
||||
|
||||
KDE 是一个类似于 GNOME 一样的重量级桌面环境。它在本文章所提及的7种桌面环境中被认为是最华丽最重量级的一个。它同样是一个类似于 Windows 的桌面,在这一点上没有什么特殊的变化。不过 KDE 非常有特点,但是随之而来的是大量的设置来提升你的桌面体验。同样的,有很多关于 KDE 的话题。所以真的可以从 KDE 的特点中获益,并且保持你所想的外观。
|
||||
KDE 是另一个类似于 GNOME 一样的重量级桌面环境。它在本文章所提及的7种桌面环境中被认为是最华丽最重量级的一个。它同样是一个类似于 Windows 的桌面,在这一点上没有什么特殊的变化。不过 KDE 非常有特点,但是随之而来的是大量的设置来提升你的桌面体验。同样的,有很多关于 KDE 的话题。所以真的可以从 KDE 的特点中获益,并且保持你所想的外观。
|
||||
|
||||
### [Cinnamon][3] ###
|
||||
|
||||

|
||||
|
||||
Cinnamon 是一个基于 Gtk+ 的环境。它最初作为 GNOME Shell 的一个用户界面分支,由 Linux Mint 创造。 Cinnamon 本质上是为了推行使用终端和定点装置。无论是使用鼠标,还是使用触摸屏都可以获得同样便捷的操作。不像 KDE Plasma 工作空间, 只有一种 GUI。 当前版本—— Cinnamon 2.0 展示于2013年10月10日。
|
||||
Cinnamon 是一个基于 Gtk+ 的环境。它最初作为 GNOME Shell 的一个用户界面分支,由 Linux Mint 创造。 Cinnamon 本质上是为了推行使用终端和定点装置。无论是使用鼠标,还是使用触摸屏都可以获得同样便捷的操作。不像 KDE Plasma 工作空间,只有一种 GUI。 当前版本—— Cinnamon 2.0 于2013年10月10日发布。
|
||||
|
||||
### [Unity][4] ###
|
||||
|
||||

|
||||
|
||||
Unity 是 GNOME 桌面环境的一个界面,由 Canonical 公司创建,使用于 Ubuntu 系统中。Unity 最初现身于 Ubuntu 10.10 的上网本版本中。它起初打算充分利用上网本的屏幕空间,例如一个被称为启动器的垂直应用切换器(a vertical app switcher called launcher)和一个节省垂直空间的多功能顶部菜单栏。Unity 不像 GNOME , KDE, Xfce 或者 LXDE 是许多软件的合集,它是作为使用实用程序而开发的(it is developed to use available utilities)。
|
||||
Unity 是 GNOME 桌面环境的一个界面,由 Canonical 公司创建,使用于 Ubuntu 系统中。Unity 最初现身于 Ubuntu 10.10 的上网本版本中。它起初打算充分利用上网本的屏幕空间,例如一个被称为启动器的垂直应用切换器(a vertical app switcher called launcher)和一个节省垂直空间的多功能顶部菜单栏。Unity 不像 GNOME、KDE、 Xfce 或者 LXDE 是许多软件的合集,它是作为使用实用功能而开发的。
|
||||
|
||||
### [GNOME Shell][5] ###
|
||||
|
||||
@ -36,25 +36,25 @@ Unity 是 GNOME 桌面环境的一个界面,由 Canonical 公司创建,使
|
||||
|
||||
GNOME 提供了桌面核心接口例如交换窗口,启动应用程序以及显示提示。它利用先进图形硬件来实现吸引人的,创新的界面思想,提供了愉悦简单的用户体验。GNOME Shell 定义了 GNOME 3 的客户体验。
|
||||
|
||||
作为 GNOME 的一个重要组成部分, GNOME Shell 的稳定版本首次发布于 2011年3月3日。
|
||||
作为 GNOME 的一个重要组成部分, GNOME Shell 的稳定版本首次发布于2011年3月3日。
|
||||
|
||||
### [Xfce][6] ###
|
||||
|
||||

|
||||
|
||||
Xfce 是一个轻量级的桌面环境,围绕 GTK 框架实现。他看起来很像 Gnome 2 或者 MATE,然而 Xfce 是它们的轻量级替代品。相较于 KDE 和 GNOME 3 而言,Xfce 非常轻量级,所以它是运行小工具或者那些希望实现最大执行效率的框架的理想环境。它还不是可以获得的最轻量级的选择 - 请继续往下看 - 然而,Xfce 的确完成了执行效率和功能的平衡。
|
||||
Xfce 是一个轻量级的桌面环境,围绕 GTK 框架实现。它看起来很像 Gnome 2 和 MATE,然而 Xfce 是它们的轻量级替代品。相较于 KDE 和 GNOME 3 而言,Xfce 非常轻量级,所以它对于运行轻量级的工具或者那些希望实现最大执行效率的框架使用者来说是理想的环境。它还不是可以获得的最轻量级的选择 - 请继续往下看 - 然而,Xfce 的确完成了执行效率和功能的平衡。
|
||||
|
||||
### [LXDE][7] ###
|
||||
|
||||

|
||||
|
||||
LXDE 显然是桌面环境中最轻量级的选择,至少在消费级的桌面标准中是这样。这个基于 GTK 的桌面环境使用了很多轻量级的选择替代了默认的应用(例如 Abiword, Gnumeric, 而不是 LibreOffice)。它提供了无闪烁的视觉冲击 - 总体感觉也没有很不错,没有复杂的设置。但是,LXDE 仍然提供了漂亮的桌面和完整的功能。当你需要快速简洁时,它就是你需要的选择。
|
||||
LXDE 显然是桌面环境中最轻量级的选择,至少在传统的桌面标准中是这样。这个基于 GTK 的桌面环境使用了很多轻量级的选择替代了默认的应用(例如 Abiword, Gnumeric, 而不是 LibreOffice)。它没有提供 flash 视觉冲击 ,总体感觉也不是特别的棒,没有高级的设置。但是,LXDE 仍然提供了漂亮的桌面和完整的功能。当你需要快速简洁时,它就是你的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://pulpybucket.com/top-7-desktop-environment-linux/
|
||||
|
||||
译者:[wwhio](https://github.com/wwhio) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[wwhio](https://github.com/wwhio) 校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -65,3 +65,4 @@ via: http://pulpybucket.com/top-7-desktop-environment-linux/
|
||||
[5]:http://www.gnome.org/
|
||||
[6]:http://xfce.org/
|
||||
[7]:http://lxde.org/
|
||||
|
||||
|
||||
@ -1,369 +0,0 @@
|
||||
编写属于你的第一个Linux内核模块
|
||||
================================================================================
|
||||
> 曾经多少次想要在内核游荡?曾经多少次茫然不知方向?你不要再对着它迷惘,让我们指引你走向前方……
|
||||
内核编程常常看起来像是黑魔法,而在亚瑟 C 克拉克的眼中,它八成就是了。Linux内核和它的用户空间是大不相同的:抛开漫不经心,你必须小心翼翼,因为你编程中的一个bug就会影响到整个系统。浮点数学做起来可不容易,堆栈固定而渺小,而你写的代码总是异步的,因此你需要想想怎样让它并发。而除了所有这一切之外,Linux内核只是一个很大的、很复杂的C程序,它对每个人开放,任何人都去读它、学习它并改进它,而你也可以是其中之一。
|
||||
|
||||
> “开始内核编程的最简单的方式
|
||||
> 是写模块——一段代码
|
||||
> 可以用来动态加载进内核。”
|
||||
|
||||
可能,开始内核编程的最简单的方式,就是写模块——一段可以动态加载进内核并从内核移除的代码。模块所能做的事是有限的——例如,他们不能添加或移除像进程描述符这样的常规数据结构域。但是,在其它方面,他们是成熟的内核级的代码,可以在需要时随时编译进内核(这样就可以摒弃所有的限制了)。完全可以在Linux源代码树以外来开发并编译一个模块(这并不奇怪,它称为树外开发),如果你只是想稍微玩玩,而并不想提交修改以包含到主线内核中去,这样的方式是很方便的。
|
||||
|
||||
在本教程中,我们将开发一个简单的内核模块用以创建一个**/dev/reverse**设备。写入该设备的字符串将以逆序的方式读回(“Hello World”读成“World Hello”)。这是一个流行的节目采访智力游戏,而当你展示能力来实施时,你也可能获得一些奖励分。在开始前,有一句忠告:你的模块中的一个bug会导致系统崩溃(虽然可能性不大,但还是有可能的)和数据丢失。在开始前,请确保你已经将重要数据备份,或者,采用一种更好的方式,在虚拟机中进行试验。
|
||||
### 尽可能避免root身份 ###
|
||||
|
||||
> 默认情况下,**/dev/reverse**只有root可以使用,因此你不得不使用**sudo**来测试该程序。要解决该问题,可以创建一个包含以下内容的**/lib/udev/rules.d/99-reverse.rules**文件:
|
||||
>
|
||||
> SUBSYSTEM=="misc", KERNEL=="reverse", MODE="0666"
|
||||
>
|
||||
> 别忘了重新插入模块。让设备节点让非root用户访问这往往不是一个好主意,但是在开发其间却是十分有用的,这不是说以root身份运行二进制测试文件也不是个好主意。
|
||||
|
||||
#### 模块的构造 ####
|
||||
|
||||
由于大多数的Linux内核模块是用C写的(除了低级别特定架构部分),所以推荐你将模块以单一文件形式保存(例如,reverse.c)。我们已经把完整的源代码放在GitHub上——这里我们将看其中的一些片段。开始时,我们先要包含一些常见的文件头,并用预定义的宏来描述模块:
|
||||
|
||||
#include <linux/init.h>
|
||||
#include <linux/kernel.h>
|
||||
#include <linux/module.h>
|
||||
|
||||
MODULE_LICENSE("GPL");
|
||||
MODULE_AUTHOR("Valentine Sinitsyn <valentine.sinitsyn@gmail.com>");
|
||||
MODULE_DESCRIPTION("In-kernel phrase reverser");
|
||||
|
||||
这里一切都直接明了,除了**MODULE_LICENSE()**:它不仅仅是一个标记。内核坚定地支持GPL兼容代码,因此如果你把许可证设置为其它非GPL兼容的(如,“专利”),特定的内核功能将在你的模块中不可用。
|
||||
|
||||
### 什么时候不该写内核模块 ###
|
||||
|
||||
> 内核编程很有趣,但是在现实项目中写(尤其是调试)内核代码要求特定的技巧。通常来讲,在没有其它方式解决你的问题时,你才应该沉入内核级别。可能你可以待在用户空间中,如果:
|
||||
|
||||
> - 你开发一个USB驱动 —— 请查看[libusb][1]。
|
||||
> - 你开发一个文件系统 —— 试试[FUSE][2]。
|
||||
> - 你在扩展Netfilter —— 那么[libnetfilter_queue][3]对你有所帮助。
|
||||
>
|
||||
> 通常,本地内核代码会干得更好,但是对于许多项目而言,这点性能丢失并不严重。
|
||||
由于内核编程总是异步的,没有Linux顺序执行得**main()**函数来运行你的模块。取而代之的是,你为各种事件提供了回调函数,像这个:
|
||||
|
||||
static int __init reverse_init(void)
|
||||
{
|
||||
printk(KERN_INFO "reverse device has been registered\n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
static void __exit reverse_exit(void)
|
||||
{
|
||||
printk(KERN_INFO "reverse device has been unregistered\n");
|
||||
}
|
||||
|
||||
module_init(reverse_init);
|
||||
module_exit(reverse_exit);
|
||||
|
||||
这儿,我们定义了函数,用来访问模块的插入和移除功能,只有第一个是必要的。目前,它们只是打印消息到内核环缓冲区(可以通过**dmesg**命令从用户空间访问);**KERN_INFO**是日志等级(注意,没有逗号)。**_init**和**_exit**是属性 —— 联结到函数的元数据片(或者变量)。属性在用户空间的C代码中是很罕见的,但是内核中却很普遍。所有标记为**_init**的,会在初始化后再生(还记得那条老旧的“释放未使用的内核内存……”信息?)。**__exit**表明,当代码被静态构建进内核时,该函数可以安全地优化。最后,**module_init()**和**module_exit()**这两个宏将**reverse_init()**和**reverse_exit()**函数设置成为我们模块的生命周期回调函数。实际的函数名称并不重要,你可以称它们为**init()**和**exit()**,或者**start()**和**stop()**,你想叫什么就叫什么吧。在你的模块外,它们被申明成为静态的和不可见的。事实上,内核中的任何函数都是不可见的,除非明确地被导出。然而,在内核程序员中,给你的函数加上模块名前缀是约定俗成的。
|
||||
|
||||
这些是基本要素 —— 让我们把事情变得更有趣些。模块可以接收参数,就像这样:
|
||||
|
||||
# modprobe foo bar=1
|
||||
|
||||
**modinfo**命令显示了所有模块接受的参数,而这些也可以在**/sys/module//parameters**下作为文件使用。我们的模块需要一个缓冲区来存储短语 —— 让我们把这大小设置为用户可配置。添加**MODULE_DESCRIPTION()**以下的三行:
|
||||
|
||||
static unsigned long buffer_size = 8192;
|
||||
module_param(buffer_size, ulong, (S_IRUSR | S_IRGRP | S_IROTH));
|
||||
MODULE_PARM_DESC(buffer_size, "Internal buffer size");
|
||||
|
||||
这儿,我们定义了一个变量来存储该值,将其包裹到一个参数中,并通过sysfs来让所有人可读。参数的描述(最后一行)会出现在modinfo的输出中。
|
||||
|
||||
由于用户可以直接设置**buffer_size**,我们需要在**reverseinit()**来清除它。你总该检查来自内核外的数据 —— 如果你不这么做,你就是会将你自身置于内核异常之中,设置造成安全漏洞。
|
||||
|
||||
static int __init reverse_init()
|
||||
{
|
||||
if (!buffer_size)
|
||||
return -1;
|
||||
printk(KERN_INFO
|
||||
"reverse device has been registered, buffer size is %lu bytes\n",
|
||||
buffer_size);
|
||||
return 0;
|
||||
}
|
||||
|
||||
来自模块初始化函数的非0返回值意味着模块执行失败。
|
||||
|
||||
### 导航 ###
|
||||
|
||||
> 但你开发模块时,Linux内核就是你所需一切的源头。然而,它相当大,你可能在查找你所要的内容时会有困难。幸运的是,在浏览庞大的代码库时,有工具可以帮助你干得轻松一点。首先,是Cscope —— 在终端中运行的一个令人肃然起敬的工具。你所要做的,就是在内核源代码的顶级目录中运行**make cscope && cscope**。Cscope和Vim以及Emacs整合得很好,因此你可以在使用你最喜爱的编辑器舒适地工作时来使用它。
|
||||
|
||||
> 如果基于终端的工具不是你的最爱,那么就访问[http://lxr.free-electrons.com][4]吧。它是一个基于web的内核导航工具,即使它的功能没有Cscope来得多(例如,你不能方便地找到函数的用法),但它仍然提供了足够多的快速查询功能。
|
||||
现在是时候来编译模块了。你将需要用于正在运行的内核版本的头文件(**linux-headers**,或者同等软件包)和**build-essential**(或者类似的包)。接下来,该创建一个标准的Makefile模板:
|
||||
|
||||
obj-m += reverse.o
|
||||
all:
|
||||
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
|
||||
clean:
|
||||
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
|
||||
|
||||
现在,调用**make**来构建你的第一个模块。如果你输入的都正确,在当前目录内会发现reverse.ko文件。使用**sudo insmod reverse.ko**插入,然后运行:
|
||||
|
||||
$ dmesg | tail -1
|
||||
[ 5905.042081] reverse device has been registered, buffer size is 8192 bytes
|
||||
|
||||
恭喜了!然而,目前这一行还只是在逗你玩而已 —— 还没有设备节点呢。让我们来修复它。
|
||||
|
||||
#### 混杂设备 ####
|
||||
|
||||
在Linux中,有一种特殊的字符设备类型,叫做“混杂设备”(或者简称为“misc”)。它设计用于只有一个单一接入点的小型设备驱动,而这正是我们所需要的。所有混杂设备共享同一个主设备号(10),因此一个驱动(**drivers/char/misc.c**)就可以查看它们所有设备了,而这些设备用次设备号来区分。在所有其它意义上,它们只是普通字符设备。
|
||||
|
||||
要为该设备注册一个次设备号(以及一个接入点),你需要声明**struct misc_device**,填上所有字段(注意语法),然后使用指针指向该结构函数来调用**misc_register()**。为了这个能工作,你也需要包含**linux/miscdevice.h**头文件:
|
||||
|
||||
static struct miscdevice reverse_misc_device = {
|
||||
.minor = MISC_DYNAMIC_MINOR,
|
||||
.name = "reverse",
|
||||
.fops = &reverse_fops
|
||||
};
|
||||
static int __init reverse_init()
|
||||
{
|
||||
...
|
||||
misc_register(&reverse_misc_device);
|
||||
printk(KERN_INFO ...
|
||||
}
|
||||
|
||||
这儿,我们为名为“reverse”的设备请求一个第一个可用的(动态的)次设备号;省略号表明我们已经见过的省略的代码。别忘了在模块卸下后注销掉该设备。
|
||||
|
||||
static void __exit reverse_exit(void)
|
||||
{
|
||||
misc_deregister(&reverse_misc_device);
|
||||
...
|
||||
}
|
||||
|
||||
‘fops’字段存储了一个指针,指向结构函数**file_operations**(在Linux/fs.h中已声明),而这真是我们模块的接入点。**reverse_fops**定义如下:
|
||||
|
||||
static struct file_operations reverse_fops = {
|
||||
.owner = THIS_MODULE,
|
||||
.open = reverse_open,
|
||||
...
|
||||
.llseek = noop_llseek
|
||||
};
|
||||
|
||||
再者,**reverse_fops**包含了一系列回调函数(也称之为方法),当用户空间代码打开一个设备时,就会执行。从该设备读取,向该设备写入,或者关闭文件描述符。如果你忽略了所有这些,就会使用一个灵敏的回调函数来替代。这就是为什么我们明确给**noop_llseek()**设置了**llseek**方法,而它却什么也不干(就像名称中暗指的)。默认部署改变了文件指针,我们现在也不想我们的设备被找到(这是你们的今天的回家作业)。
|
||||
|
||||
#### 我在关闭时打开 ####
|
||||
|
||||
让我们实施该方法。我们将分配一个新的缓冲区给每个打开的文件描述符,并在它关闭时释放。这事实上并不安全:如果一个用户空间应用程序泄漏了描述符(也许是故意的),它就会霸占RAM,并使系统不可用。在现实世界中,你总得考虑到这些可能性。但在本教程中,这种方法可以接受。
|
||||
|
||||
我们需要一个结构函数来描述缓冲区。内核提供了许多常规的数据结构:链接列表(双联的),哈希表,树等等之类。然而,缓冲区常常从零开始实施。我们将调用我们的“struct buffer”:
|
||||
|
||||
struct buffer {
|
||||
char *data, *end, *read_ptr;
|
||||
unsigned long size;
|
||||
};
|
||||
|
||||
**data**是该缓冲区存储的一个指向字符串的指针,而最后部分是字符串结尾后的第一个字节。**read_ptr**是**read()**开始读取数据的地方。缓冲区大小为了完整性而存储 —— 目前,我们还没有使用该区域。你不能假设使用你结构体的用户会正确地初始化所有这些东西,所以最好在函数中封装缓冲区分配和解除。它们通常命名为**buffer_alloc()**和**buffer_free()**。
|
||||
|
||||
static struct buffer *buffer_alloc(unsigned long size)
|
||||
{
|
||||
struct buffer *buf;
|
||||
buf = kzalloc(sizeof(*buf), GFP_KERNEL);
|
||||
if (unlikely(!buf))
|
||||
goto out;
|
||||
...
|
||||
out:
|
||||
return buf;
|
||||
}
|
||||
|
||||
内核内存使用**kmalloc()**来分配,并使用**kfree()**来释放;**kzalloc()**的风格是将内存设置为全零。不同于标准的**malloc()**,它的内核对应部分收到的标志指定了第二个参数中请求的内存类型。这里,**GFP_KERNEL**是说我们需要一个普通的内核内存(不是在DMA或高内存中)以及函数可以按需睡眠(重新编排进程)。**sizeof(*buf)**是一种常见的方式,它用来获取可通过指针访问的结构体的大小。
|
||||
|
||||
你应该随时检查**kmalloc()**的返回值:解应用NULL指针将导致内核异常。同时也需要注意**unlikely()**宏的使用。它(及其相对宏**likely()**)被广泛用于内核中,用于表明条件几乎总是真的(或假的)。它不会影响到控制流,但是能帮助现代处理器通过分支预测技术来提升性能。
|
||||
|
||||
最后,注意**gotos**。它们常常为认为是邪恶的,但是,Linux内核(以及一些其它系统软件)采用它们来实施集中式的函数退出。这样的结果是减少嵌套深度,使代码更具可读性,而且非常像更高级语言中的**try-catch**区块。
|
||||
|
||||
有了**buffer_alloc()**和**buffer_free()**,**open**和**close**方法就变得很简单了。
|
||||
|
||||
static int reverse_open(struct inode *inode, struct file *file)
|
||||
{
|
||||
int err = 0;
|
||||
file->private_data = buffer_alloc(buffer_size);
|
||||
...
|
||||
return err;
|
||||
}
|
||||
|
||||
**struct file**是一个标准的内核数据结构,用以存储打开的文件的信息,如当前文件位置(**file->fpos**),标志(**file->flags**),或者打开模式(**file->fmode**)。另外一个字段**file->privatedata**用于关联文件到一些专有数据,它的类型是void *,而且它在文件拥有者以外对内核不透明。我们将一个缓冲区存储在那里。
|
||||
|
||||
如果缓冲区分配失败,我们通过返回否定值(**-ENOMEM**)来为调用的用户空间代码标明。
|
||||
|
||||
#### 学会读写 ####
|
||||
|
||||
“read”和“write”方法是真正完成工作的地方。当数据写入到缓冲区时,我们就丢弃它里头先前的内容,并在没有任何临时存储时将短语恢复原状。**read**方法仅仅是从内核缓冲区复制数据到用户空间。但是如果缓冲区还没有数据,**reverseread()**会做什么呢?在用户空间中,**read()**调用会在有可用数据前阻塞它。在内核中,你必须等待。幸运的是,有一项机制用于处理这种情况,就是‘wait queues’。
|
||||
|
||||
想法很简单。如果当前进程需要等待某个事件,它的描述符(**struct task_struct**存储为‘current’)被放进非可运行(睡眠中)状态,并添加到一个队列中。然后**schedule()**就被调用来选择另一个进程运行。生成事件的代码通过使用队列将等待进程放回**TASKRUNNING**状态来唤醒它们。调度程序将在以后在某个地方选择它们之一。Linux有多种非可运行状态,最值得注意的是**TASKINTERRUPTIBLE**(一个可以通过信号中断的睡眠)和**TASKKILLABLE**(一个可被杀死的睡眠中的进程)。所有这些都应该正确处理,并等待队列为你做这些事。
|
||||
|
||||
一个用以存储读取等待队列头的天然场所就是结构缓冲区,所以从为它添加**wait_queue_head_t read_queue**字段开始。你也应该包含**linux/sched.h**。可以使用DECLARE_WAITQUEUE()宏来静态声明一个等待队列。在我们这种情况下,需要动态初始化,因此添加下面这行到**buffer_alloc()**:
|
||||
|
||||
init_waitqueue_head(&buf->read_queue);
|
||||
|
||||
我们等待可用数据;或者等待**read_ptr != end**条件成立。我们也想要让等待操作可以被中断(如,通过Ctrl+C)。因此,“read”方法应该像这样开始:
|
||||
|
||||
static ssize_t reverse_read(struct file *file, char __user * out,
|
||||
size_t size, loff_t * off)
|
||||
{
|
||||
struct buffer *buf = file->private_data;
|
||||
ssize_t result;
|
||||
while (buf->read_ptr == buf->end) {
|
||||
if (file->f_flags & O_NONBLOCK) {
|
||||
result = -EAGAIN;
|
||||
goto out;
|
||||
}
|
||||
if (wait_event_interruptible
|
||||
(buf->read_queue, buf->read_ptr != buf->end)) {
|
||||
result = -ERESTARTSYS;
|
||||
goto out;
|
||||
}
|
||||
}
|
||||
...
|
||||
|
||||
我们让它循环,直到有可用数据,如果没有则使用**wait_event_interruptible()**(它是一个宏,不是函数,这就是为什么要给队列传递值)来等待。好吧,如果**wait_event_interruptible()**被中断,它返回一个非0值,这个值代表**-ERESTARTSYS**。这段代码意味着系统调用应该重新启动。**file->f_flags**检查以非阻塞模式打开的文件数:如果没有数据,返回**-EAGAIN**。
|
||||
|
||||
我们不能使用**if()**来替代**while()**,因为可能有许多进程正等待数据。当**write**方法唤醒它们时,调度程序选择一个来以不可预知的方式运行,因此,在这段代码有机会执行的时候,缓冲区可能再次空出。现在,我们需要将数据从**buf->data** 复制到用户空间。**copytouser()**内核函数就干了此事:
|
||||
|
||||
size = min(size, (size_t) (buf->end - buf->read_ptr));
|
||||
if (copy_to_user(out, buf->read_ptr, size)) {
|
||||
result = -EFAULT;
|
||||
goto out;
|
||||
}
|
||||
|
||||
如果用户空间指针错误,那么调用可能会失败;如果发生了此事,我们就返回**-EFAULT**。记住,不要相信任何来自内核外的事物!
|
||||
|
||||
buf->read_ptr += size;
|
||||
result = size;
|
||||
out:
|
||||
return result;
|
||||
}
|
||||
|
||||
为了让数据能读入到专有组块中,需要进行简单运算。该方法返回读入的字节数,或者一个错误代码。
|
||||
|
||||
写方法更简短。首先,我们检查缓冲区是否有足够的空间,然后我们使用**copy_from_userspace()**函数来获取数据。再然后**read_ptr**和结束指针会被重置,缓冲区内容会被撤销掉:
|
||||
|
||||
buf->end = buf->data + size;
|
||||
buf->read_ptr = buf->data;
|
||||
if (buf->end > buf->data)
|
||||
reverse_phrase(buf->data, buf->end - 1);
|
||||
|
||||
这里, **reverse_phrase()**干了所有吃力的工作。它依赖于**reverse_word()**函数,该函数相当简短并且标记为内联。这是另外一个常见的优化;但是,你不能过度使用。因为积极的内联会导致内核映像徒然增大。
|
||||
|
||||
最后,我们需要唤醒**read_queue**中等待数据的进程,就跟先前讲过的那样。**wake_up_interruptible()**就是用来干此事的:
|
||||
|
||||
wake_up_interruptible(&buf->read_queue);
|
||||
|
||||
唷!你现在已经有了一个内核模块,它至少已经编译成功了。现在,是时候来测试了。
|
||||
|
||||
### 调试内核代码 ###
|
||||
|
||||
> 或许,内核中最常见的调试方法就是打印。如果你愿意,你可以使用普通的**printk()** (假定使用**KERN_DEBUG**日志等级)。然而,那儿还有更好的办法。如果你正在写一个设备驱动,这个设备驱动有它自己的“struct device”,可以使用**pr_debug()**或者**dev_dbg()**:它们支持动态调试(**dyndbg**)特性,并可以根据需要启用或者禁用(请查阅**Documentation/dynamic-debug-howto.txt**)。对于单纯的开发消息,使用**prdevel()**,该函数没有操作符,除非设置了DEBUG。要为我们的模块启用DEBUG,请添加以下行到Makefile中:
|
||||
|
||||
> CFLAGS_reverse.o := -DDEBUG
|
||||
>
|
||||
> 完了之后,使用**dmesg**来查看**pr_debug()**或**pr_devel()**生成的调试信息。
|
||||
> 或者,你可以直接发送调试信息到控制台。要想这么干,你可以设置**console_loglevel**内核变量为8或者更大的值(**echo 8 /proc/sys/kernel/printk**),或者在高日志等级,如**KERN_ERR**,来临时打印要查询的调试信息。很自然,在发布代码前,你应该移除这样的调试声明。
|
||||
|
||||
> 注意出现在控制台的内核消息,而不要在Xterm这样的终端模拟器窗口中去查看;那也是你在内核开发时,经常会建议你不要再X环境下进行的原因。
|
||||
|
||||
### 惊喜,惊喜! ###
|
||||
|
||||
编译模块,然后加载进内核:
|
||||
|
||||
$ make
|
||||
$ sudo insmod reverse.ko buffer_size=2048
|
||||
$ lsmod
|
||||
reverse 2419 0
|
||||
$ ls -l /dev/reverse
|
||||
crw-rw-rw- 1 root root 10, 58 Feb 22 15:53 /dev/reverse
|
||||
|
||||
一切似乎就位。现在,要测试模块是否正常工作,我们将写一段小程序来翻转它的第一个命令行参数。**main()**(没有错误检查)可能看上去像这样:
|
||||
|
||||
int fd = open("/dev/reverse", O_RDWR);
|
||||
write(fd, argv[1], strlen(argv[1]));
|
||||
read(fd, argv[1], strlen(argv[1]));
|
||||
printf("Read: %s\n", argv[1]);
|
||||
|
||||
像这样运行:
|
||||
|
||||
$ ./test 'A quick brown fox jumped over the lazy dog'
|
||||
Read: dog lazy the over jumped fox brown quick A
|
||||
|
||||
它工作正常!玩得更逗一点:试试传递单个单词或者单个字母的短语,空的字符串或者是非英语字符串(如果你有这样的键盘布局设置),以及其它任何东西。
|
||||
|
||||
现在,让我们让事情变得更好玩一点。我们将创建两个进程,它们共享一个文件描述符(因而还有内核缓冲区)。其中一个会持续写入字符串到设备,而另一个将读取这些字符串。在下例中,我们使用了**fork(2)**系统调用,而pthreads也很好用。我也忽略了打开和关闭设备,以及错误检查部分的代码(又来了):
|
||||
|
||||
char *phrase = "A quick brown fox jumped over the lazy dog";
|
||||
if (fork())
|
||||
/* Parent is the writer */
|
||||
while (1)
|
||||
write(fd, phrase, len);
|
||||
else
|
||||
/* child is the reader */
|
||||
while (1) {
|
||||
read(fd, buf, len);
|
||||
printf("Read: %s\n", buf);
|
||||
}
|
||||
|
||||
你希望这个程序会输出什么呢?下面就是在我的笔记本上得到的东西:
|
||||
|
||||
Read: dog lazy the over jumped fox brown quick A
|
||||
Read: A kcicq brown fox jumped over the lazy dog
|
||||
Read: A kciuq nworb xor jumped fox brown quick A
|
||||
Read: A kciuq nworb xor jumped fox brown quick A
|
||||
...
|
||||
|
||||
这里发生了什么呢?举行了一场比赛。我们认为**read**和**write**是很小的,或者从头到尾一次执行一个指令。然而,内核是并发的野兽,它可以很容易地重排**reverse_phrase()**函数内部某个地方运行着的内核模式部分的写入操作。如果进行**read()**操作的进程在写入操作结束前就被编排进去,就会产生数据不连续状态。这些bug非常难以排除。但是,怎样来处理这个问题呢?
|
||||
|
||||
基本上,我们需要确保在写方法返回前没有**read**方法能被执行。如果你曾经编写过一个多线程的应用程序,你可能见过同步原语(锁),如互斥锁或者信号。Linux也有这些,但有些细微的差别。内核代码可以运行在进程条件中(“代表”用户空间代码工作,就像我们的方法那样)以及运行在中断条件中(例如,在IRQ处理器中)。如果你的程序处于进程条件中,并且你需要的锁已经被拿走,你的程序就会睡眠并重试直至成功。在中断条件中是无法睡眠的,因此代码在循环中流转,直到有可用的锁为止。关联原语被称为自旋锁,但在我们的环境中,一个简单的互斥锁 —— 在特定时间内只有唯一一个进程能“占有”的对象 —— 就足够了。处于性能方面的考虑,现实的代码可能也会使用读-写信号。
|
||||
|
||||
锁总是保护某些数据(在我们的环境中,是一个“struct buffer”实例),而且也常常会把它们嵌入到它们所保护的结构体中。因此,我们添加一个互斥锁(‘struct mutex lock’)到“struct buffer”中。我们也必须用**mutex_init()**来初始化互斥锁;**buffer_alloc**是用来处理这件事的好地方。使用互斥锁的代码也必须包含**linux/mutex.h**。
|
||||
|
||||
互斥锁很像交通信号灯 —— 除非驱动查看并跟踪信号,否则它没什么用。因此,在对缓冲区做操作并在操作完成时释放它之前,我们需要更新**reverse_read()**和**reverse_write()**来获取互斥锁。让我们来看看**read**方法 —— **write**的工作原理相同:
|
||||
|
||||
static ssize_t reverse_read(struct file *file, char __user * out,
|
||||
size_t size, loff_t * off)
|
||||
{
|
||||
struct buffer *buf = file->private_data;
|
||||
ssize_t result;
|
||||
if (mutex_lock_interruptible(&buf->lock)) {
|
||||
result = -ERESTARTSYS;
|
||||
goto out;
|
||||
}
|
||||
|
||||
我们在函数一开始就获取锁。**mutex_lock_interruptible()**要么抓取互斥锁然后返回,要么让进程睡眠,直到有可用的互斥锁。就像前面一样,**_interruptible**后缀意味着睡眠可以由信号来中断。
|
||||
|
||||
while (buf->read_ptr == buf->end) {
|
||||
mutex_unlock(&buf->lock);
|
||||
/* ... wait_event_interruptible() here ... */
|
||||
if (mutex_lock_interruptible(&buf->lock)) {
|
||||
result = -ERESTARTSYS;
|
||||
goto out;
|
||||
}
|
||||
}
|
||||
|
||||
下面是我们的“等待数据”循环。当持有互斥锁,或者发生称之为“死锁”的情境时,不应该让进程睡眠。因此,如果没有数据,我们释放互斥锁并调用**wait_event_interruptible()**。当它返回时,我们重新获取互斥锁并像往常一样继续:
|
||||
|
||||
if (copy_to_user(out, buf->read_ptr, size)) {
|
||||
result = -EFAULT;
|
||||
goto out_unlock;
|
||||
}
|
||||
...
|
||||
out_unlock:
|
||||
mutex_unlock(&buf->lock);
|
||||
out:
|
||||
return result;
|
||||
|
||||
最后,当函数结束,或者在互斥锁被占有过程中发生错误时,互斥锁被解锁。重新编译模块(别忘了重新加载),然后再次进行测试。现在你应该没发现毁坏的数据了。
|
||||
|
||||
### 接下来是什么? ###
|
||||
现在,你体验了一把内核侵入。我们刚刚为你揭开了今天话题的外衣,里面还有更多东西供你探索。我们的第一个模块是有意识地写得简单一点,在从中学到的概念在更复杂的环境中也一样。并发、方法表、注册回调函数、使进程睡眠以及唤醒进程,这些都是内核黑客们耳熟能详的东西,而现在你已经看过了它们的运作。或许某天,你的内核代码也将被加入到主线Linux源代码树中 —— 如果真这样,请联系我们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/be-a-kernel-hacker/
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.libusb.org/
|
||||
[2]:http://fuse.sf.net/
|
||||
[3]:http://www.linuxvoice.com/be-a-kernel-hacker/www.netfilter.org/projects/libnetfilter_queue
|
||||
[4]:http://lxr.free-electrons.com/
|
||||
@ -1,33 +0,0 @@
|
||||
用iCup在linux追世界杯
|
||||
================================================================================
|
||||

|
||||
|
||||
嗨,Linux 极客们,
|
||||
|
||||
在本文简短的叙述中,我将教你如何在Linux中安装一个非常棒的2014FIFA世界杯APP。这个应用叫iCup,支持Windows,Mac以及伟大的Linux。
|
||||
|
||||
我看足球比赛已经有很长的时间了,所以我得我的电脑上安装这样的应用来保持更新2014世界杯的最新情况。我不想在我朋友们面前看起来一无所知。iCup应用正好提供了每一场赛程、比分、球队教练组等信息。更有提供实时比赛更新,给你正在进行的比赛的最新数据。
|
||||
|
||||
### 支持一下功能: ###
|
||||
|
||||
- 30种语言支持,完全本地化(使用语言菜单选择)
|
||||
- 可以随意调整窗口大小的独家灵活的界面
|
||||
- 可按天、阶段检索的比赛日历
|
||||
- 可视化分组
|
||||
- 支持自动转变比赛时间来适应本地时间和格式
|
||||
- 一键化社交网络发表比赛评论(支持Facebook,Google+和Twitter)
|
||||
- 支持代理(支持基本认证和摘要认证方法)
|
||||
|
||||
我已经在Ubuntu12.04LTS上测试并且运很好!目前为止,我没有经历过任何错误或崩溃。你可以十分轻松地安装这个很棒的应用,通过[官方网站][1]你可以得到压缩包,然后你可以解压到任何你喜欢的地方。解压完成后,双击iCup 2014 FREE- Brazil运行。
|
||||
|
||||
iCup 对我非常有用,我希你也能享受到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-icup-2014-linux/
|
||||
|
||||
译者:[Vic020](http://www.vicyu.net) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.e-link.it/icup/brazil2014/icup-brazil-2014-desktop-app.php
|
||||
@ -2,11 +2,12 @@ Linux:使用bash删除目录中的特定文件
|
||||
================================================================================
|
||||

|
||||
|
||||
我是一个Linux新手用户。现在我需要清理一个下载目录中的文件,其实我就是想删除~/Download/文件夹下面除了以下格式的文件外所以其它文件:
|
||||
我是一名Linux新用户。现在我需要清理一个下载目录中的文件,其实我就是想从~/Download/文件夹删去除了以下格式的文件外所以其它文件:
|
||||
|
||||
*.iso - 所有的iso格式的文件。
|
||||
*.zip - 所有zip格式的文件。
|
||||
|
||||
我如何在一个基于Linux,OS X 或者Unix-like系统上的bash shell中删除特定的文件呢?
|
||||
我如何在一个基于Linux,OS X 或者 Unix-like 系统上的bash shell中删除特定的文件呢?
|
||||
|
||||
Bash shell 支持丰富的文件模式匹配符例如:
|
||||
|
||||
@ -19,7 +20,7 @@ Bash shell 支持丰富的文件模式匹配符例如:
|
||||
这里你需要用系统内置的shopt命令来开启shell中的extglob选项,然后你就可以使用扩展的模式符了,这些模式匹配符如下:
|
||||
|
||||
1. ?(pattern-list) - 匹配零次或一次给定的模式。
|
||||
1. *(pattern-list) -至少匹配零次给定的模式。
|
||||
1. *(pattern-list) - 至少匹配零次给定的模式。
|
||||
1. +(pattern-list) - 至少匹配一次给定的模式。
|
||||
1. @(pattern-list) - 匹配一次给定的模式。
|
||||
1. !(pattern-list) - 匹配所有除给定模式以外的模式。
|
||||
@ -60,6 +61,7 @@ rm 命令的语法格式为:
|
||||
### 策略 #2: 使用bash的 GLOBIGNORE 变量删除指定文件以外的所有文件 ###
|
||||
|
||||
摘自 [bash(1)][1] 手册页:
|
||||
|
||||
> 一个用冒号分开的模式列表定义了被路径扩展忽略的文件的集合。如果一个文件同时与路径扩展模式和GLOBIGNORE中的模式匹配,那么它就从匹配列表中移除了。
|
||||
|
||||
要删除所有文件只保留 zip 和 iso 文件,应如下设置 GLOBIGNORE:
|
||||
@ -84,7 +86,7 @@ rm 命令的语法格式为:
|
||||
find /dir/ -type f -not -name 'PATTERN' -print0 | xargs -0 -I {} rm [options] {}
|
||||
|
||||
|
||||
为了删除 ~/source 目录下除 php 以外的文件,键入:
|
||||
想要删除 ~/source 目录下除 php 以外的文件,键入:
|
||||
|
||||
find ~/sources/ -type f -not -name '*.php' -delete
|
||||
|
||||
@ -103,9 +105,9 @@ rm 命令的语法格式为:
|
||||
|
||||
via: http://www.cyberciti.biz/faq/linux-bash-delete-all-files-in-directory-except-few/
|
||||
|
||||
译者:[Linchenguang](https://github.com/Linchenguang) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Linchenguang](https://github.com/Linchenguang) 校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.manpager.com/linux/man1/bash.1.html
|
||||
[2]:http://www.manpager.com/linux/man1/find.1.html
|
||||
[2]:http://www.manpager.com/linux/man1/find.1.html
|
||||
|
||||
@ -1,13 +1,12 @@
|
||||
-------------translating by tenght~
|
||||
9 commands to check hard disk partitions and disk space on Linux
|
||||
查看Linux硬盘分区和磁盘空间的9个命令
|
||||
================================================================================
|
||||
In this post we are taking a look at some commands that can be used to check up the partitions on your system. The commands would check what partitions there are on each disk and other details like the total size, used up space and file system etc.
|
||||
|
||||
Commands like fdisk, sfdisk and cfdisk are general partitioning tools that can not only display the partition information, but also modify them.
|
||||
在这篇文章中,我们将看看用来检查你的系统分区的一些命令,这些命令将检查每个磁盘的分区情况和其他细节,例如总大小,用完的空间和文件系统等。
|
||||
|
||||
像fdisk,sfdisk和cfdisk命令是一般分区工具,不仅可以显示分区信息,还可以修改。
|
||||
### 1. fdisk ###
|
||||
|
||||
Fdisk is the most commonly used command to check the partitions on a disk. The fdisk command can display the partitions and details like file system type. However it does not report the size of each partitions.
|
||||
Fdisk是检查磁盘上分区的最常用命令,fdisk命令可以显示分区和细节,如文件系统类型,但是它并不报告每个分区的大小。
|
||||
|
||||
$ sudo fdisk -l
|
||||
|
||||
@ -36,11 +35,10 @@ Fdisk is the most commonly used command to check the partitions on a disk. The f
|
||||
Device Boot Start End Blocks Id System
|
||||
/dev/sdb1 * 2048 7907327 3952640 b W95 FAT32
|
||||
|
||||
Each device is reported separately with details about size, seconds, id and individual partitions.
|
||||
|
||||
单独显示了每个设备的详细信息:大小,秒,ID和单个分区。
|
||||
### 2. sfdisk ###
|
||||
|
||||
Sfdisk is another utility with a purpose similar to fdisk, but with more features. It can display the size of each partition in MB.
|
||||
Sfdisk是另一种跟fdisk目的相似的实用工具,但具有更多的功能。它可以以MB为单位显示每个分区的大小。
|
||||
|
||||
$ sudo sfdisk -l -uM
|
||||
|
||||
@ -75,20 +73,20 @@ Sfdisk is another utility with a purpose similar to fdisk, but with more feature
|
||||
|
||||
### 3. cfdisk ###
|
||||
|
||||
Cfdisk is a linux partition editor with an interactive user interface based on ncurses. It can be used to list out the existing partitions as well as create or modify them.
|
||||
Cfdisk是一个基于ncurses(提供字符终端处理库,包括面板和菜单)的带有交互式用户界面的Linux分区编辑器,它可以用来列出现有分区以及创建或修改这些分区。
|
||||
|
||||
Here is an example of how to use cfdisk to list the partitions.
|
||||
下面是一个如何使用Cfdisk来列出分区的例子。
|
||||
|
||||
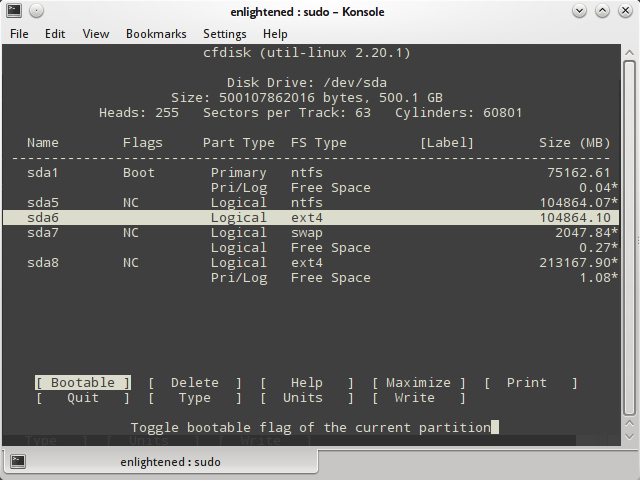
|
||||
|
||||
Cfdisk works with one partition at a time. So if you need to see the details of a particular disk, then pass the device name to cfdisk.
|
||||
Cfdisk工作在同一个分区,所以如果你需要看某一磁盘的细节,可以把设备名传给Cfdisk。
|
||||
|
||||
$ sudo cfdisk /dev/sdb
|
||||
|
||||
### 4. parted ###
|
||||
|
||||
Parted is yet another command line utility to list out partitions and modify them if needed.
|
||||
Here is an example that lists out the partition details.
|
||||
Parted是另一个命令行实用程序用来列出分区,如果需要的话,也可进行修改。
|
||||
下面是一个例子,列出了详细的分区信息。
|
||||
|
||||
$ sudo parted -l
|
||||
Model: ATA ST3500418AS (scsi)
|
||||
@ -115,9 +113,9 @@ Here is an example that lists out the partition details.
|
||||
|
||||
### 5. df ###
|
||||
|
||||
Df is not a partitioning utility, but prints out details about only mounted file systems. The list generated by df even includes file systems that are not real disk partitions.
|
||||
Df是不是一个分区工具,但它打印出挂装文件系统的细节,Df可以列出甚至不是真实的磁盘分区的文件系统。
|
||||
|
||||
Here is a simple example
|
||||
这里是个简单的例子:
|
||||
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
@ -131,16 +129,16 @@ Here is a simple example
|
||||
/dev/sda8 196G 154G 33G 83% /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1
|
||||
/dev/sda5 98G 37G 62G 38% /media/4668484A68483B47
|
||||
|
||||
Only the file systems that start with a /dev are actual devices or partitions.
|
||||
文件系统只有以 /dev 开始的,是实际设备或分区。
|
||||
|
||||
Use grep to filter out real hard disk partitions/file systems.
|
||||
使用grep命令来筛选出实际的硬盘分区或文件系统。
|
||||
|
||||
$ df -h | grep ^/dev
|
||||
/dev/sda6 97G 43G 49G 48% /
|
||||
/dev/sda8 196G 154G 33G 83% /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1
|
||||
/dev/sda5 98G 37G 62G 38% /media/4668484A68483B47
|
||||
|
||||
To display only real disk partitions along with partition type, use df like this
|
||||
为了只显示真正的磁盘分区与分区类型,可以这样使用Df:
|
||||
|
||||
$ df -h --output=source,fstype,size,used,avail,pcent,target -x tmpfs -x devtmpfs
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
@ -148,11 +146,11 @@ To display only real disk partitions along with partition type, use df like this
|
||||
/dev/sda8 ext4 196G 154G 33G 83% /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1
|
||||
/dev/sda5 fuseblk 98G 37G 62G 38% /media/4668484A68483B47
|
||||
|
||||
Note that df shows only the mounted file systems or partitions and not all.
|
||||
请注意,Df只显示已挂载的文件系统或分区,并不是所有。
|
||||
|
||||
### 6. pydf ###
|
||||
|
||||
Improved version of df, written in python. Prints out all the hard disk partitions in a easy to read manner.
|
||||
用Python写的Df的改进版本,以一个易于阅读的方式打印出所有磁盘分区。
|
||||
|
||||
$ pydf
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
@ -160,12 +158,13 @@ Improved version of df, written in python. Prints out all the hard disk partitio
|
||||
/dev/sda8 195G 153G 32G 78.4 [#######..] /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1
|
||||
/dev/sda5 98G 36G 61G 37.1 [###......] /media/4668484A68483B47
|
||||
|
||||
Again, pydf is limited to showing only the mounted file systems.
|
||||
另外,pydf限制为仅显示已挂载的文件系统
|
||||
|
||||
### 7. lsblk ###
|
||||
|
||||
Lists out all the storage blocks, which includes disk partitions and optical drives. Details include the total size of the partition/block and the mount point if any.
|
||||
Does not report the used/free disk space on the partitions.
|
||||
列出了所有的存储块,包括磁盘分区和光盘驱动器。细节包括所有分区/块总大小和挂载点。
|
||||
|
||||
不报告分区上的已使用和空闲磁盘空间。
|
||||
|
||||
$ lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
@ -180,13 +179,14 @@ Does not report the used/free disk space on the partitions.
|
||||
└─sdb1 8:17 1 3.8G 0 part
|
||||
sr0 11:0 1 1024M 0 rom
|
||||
|
||||
If there is no MOUNTPOINT, then it means that the file system is not yet mounted. For cd/dvd this means that there is no disk.
|
||||
|
||||
Lsblk is capbale of displaying more information about each device like the label and model. Check out the man page for more information
|
||||
如果没有挂载点,这就意味着文件系统未安装,对于cd/dvd这意味着没有磁盘。
|
||||
|
||||
lsblk能够显示每个设备的更多信息,如标签和模型,更多请查看信息手册。
|
||||
|
||||
### 8. blkid ###
|
||||
|
||||
Prints the block device (partitions and storage media) attributes like uuid and file system type. Does not report the space on the partitions.
|
||||
打印块设备(分区和存储介质)属性,例如UUID和文件系统类型,不报告分区空间。
|
||||
|
||||
$ sudo blkid
|
||||
/dev/sda1: UUID="5E38BE8B38BE6227" TYPE="ntfs"
|
||||
@ -198,7 +198,7 @@ Prints the block device (partitions and storage media) attributes like uuid and
|
||||
|
||||
### 9. hwinfo ###
|
||||
|
||||
The hwinfo is a general purpose hardware information tool and can be used to print out the disk and partition list. The output however does not print details about each partition like the above commands.
|
||||
hwinfo是一个通用的硬件信息的工具,可以用来打印出磁盘和分区表,输出不再像上面的命令那样打印每个分区的详细信息。
|
||||
|
||||
$ hwinfo --block --short
|
||||
disk:
|
||||
@ -216,17 +216,18 @@ The hwinfo is a general purpose hardware information tool and can be used to pri
|
||||
/dev/sr0 SONY DVD RW DRU-190A
|
||||
|
||||
### Summary ###
|
||||
### 总结 ###
|
||||
|
||||
The output of parted is concise and complete to get an overview of different partitions, file system on them and the total space. Pydf and df are limited to showing only mounted file systems and the same on them.
|
||||
parted的输出简洁而完整的得到不同分区的概述、上面的文件系统以及总空间。pydf和df被限制为只显示和他们一样的已挂载的文件系统。
|
||||
|
||||
Fdisk and Sfdisk show a whole lot of information that can take sometime to interpret whereas, Cfdisk is an interactive partitioning tool that display a single device at a time.
|
||||
fdisk和sfdisk显示完整的大量的可以花些时间来解释的信息,,cfdisk是一个互动的分区工具,每次显示一个单一的设备。
|
||||
|
||||
So try them out, and do not forget to comment below.
|
||||
来尝试下吧,别忘了在下面评论哟!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.binarytides.com/linux-command-check-disk-partitions/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[tenght](https://github.com/tenght) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,138 @@
|
||||
如何在Ubuntu,Linux Mint,Debian上禁用Ipv6
|
||||
================================================================================
|
||||
### Ipv6 ###
|
||||
|
||||
IPv6是寻址方案Ipv4的下一个版本,被用来给如google.com这样的域名分配数字地址。
|
||||
|
||||
Ipv6比Ipv4支持更多的地址。然而,它还没有被广泛支持,还在被接受的过程中。
|
||||
|
||||
### 你的系统支持Ipv6么? ###
|
||||
|
||||
为了支持Ipv6,需要很多事情。首先你需要系统/操作系统支持Ipv6。Ubuntu,Linux Mint,和大多是现代发行版都支持它。如果你看一下ifconfig指令的输出,你就会看见你的网络接口被分配了ipv6地址。
|
||||
|
||||
$ ifconfig
|
||||
eth0 Link encap:Ethernet HWaddr 00:1c:c0:f8:79:ee
|
||||
inet addr:192.168.1.2 Bcast:192.168.1.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::21c:c0ff:fef8:79ee/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:110880 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:111960 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:62289395 (62.2 MB) TX bytes:25169458 (25.1 MB)
|
||||
Interrupt:20 Memory:e3200000-e3220000
|
||||
|
||||
lo Link encap:Local Loopback
|
||||
inet addr:127.0.0.1 Mask:255.0.0.0
|
||||
inet6 addr: ::1/128 Scope:Host
|
||||
UP LOOPBACK RUNNING MTU:65536 Metric:1
|
||||
RX packets:45258 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:45258 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:0
|
||||
RX bytes:4900560 (4.9 MB) TX bytes:4900560 (4.9 MB)
|
||||
|
||||
看一下行“inet6 addr”。
|
||||
|
||||
接下来你需要一个支持ipv6的路由器/调制解调器。额外地,你的ISP也必须支持ipv6。
|
||||
|
||||
除了检查网络设备的每一部分,最好查出你是否可以通过ipv6访问网站。
|
||||
|
||||
有很多网站可以检测你的连接是否支持ipv6. 这里就是个例子:[http://testmyipv6.com/][1]
|
||||
|
||||
下面是在内核中启用ipv6的参数:
|
||||
|
||||
$ sysctl net.ipv6.conf.all.disable_ipv6
|
||||
net.ipv6.conf.all.disable_ipv6 = 0
|
||||
|
||||
$ sysctl net.ipv6.conf.default.disable_ipv6
|
||||
net.ipv6.conf.default.disable_ipv6 = 0
|
||||
|
||||
$ sysctl net.ipv6.conf.lo.disable_ipv6
|
||||
net.ipv6.conf.lo.disable_ipv6 = 0
|
||||
|
||||
同样可以在proc文件中检查
|
||||
|
||||
$ cat /proc/sys/net/ipv6/conf/all/disable_ipv6
|
||||
0
|
||||
|
||||
注意这里的变量是控制ipv6的“禁用”。所以设置1就会禁用ipv6。
|
||||
|
||||
### 如果它不支持就禁用ipv6 ###
|
||||
|
||||
如果你的网络设备中不支持ipv6,那最好就全部禁用它们。为什么?因为这回引起延迟域查询,在网络连接中不必要地尝试连接到ipv6地址导致延迟等等问题。
|
||||
|
||||
我也遇到过像这样的问题,apt-get命令偶尔会尝试连接到ipv6地址失败接着检索ipv4地址。看一下下面的输出。
|
||||
|
||||
$ sudo apt-get update
|
||||
Ign http://archive.canonical.com trusty InRelease
|
||||
Ign http://archive.canonical.com raring InRelease
|
||||
Err http://archive.canonical.com trusty Release.gpg
|
||||
Cannot initiate the connection to archive.canonical.com:80 (2001:67c:1360:8c01::1b). - connect (101: Network is unreachable) [IP: 2001:67c:1360:8c01::1b 80]
|
||||
Err http://archive.canonical.com raring Release.gpg
|
||||
Cannot initiate the connection to archive.canonical.com:80 (2001:67c:1360:8c01::1b). - connect (101: Network is unreachable) [IP: 2001:67c:1360:8c01::1b 80]
|
||||
|
||||
.....
|
||||
|
||||
像这样的错误在最近的Ubuntu中更频繁了,或许它比以前更频繁地尝试使用IPv6地址。
|
||||
|
||||
我在其他的应用上也注意到了相似的问题,如Hexchat,同样Google Chrome也会有时会在查询域名的时候花费更长的时间。
|
||||
|
||||
所以最好的方案是完全禁用Ipv6来摆脱这些事情。这只需要一点点配置但可以帮助你解决很多你系统上的很多问题。用户甚至反应这可以加速网络。
|
||||
|
||||
#### 禁用 Ipv6 - 方案1 ####
|
||||
|
||||
编辑文件 - /etc/sysctl.conf
|
||||
|
||||
$ sudo gedit /etc/sysctl.conf
|
||||
|
||||
在文件的最后加入下面的行。
|
||||
|
||||
# IPv6 disabled
|
||||
net.ipv6.conf.all.disable_ipv6 = 1
|
||||
net.ipv6.conf.default.disable_ipv6 = 1
|
||||
net.ipv6.conf.lo.disable_ipv6 = 1
|
||||
|
||||
保存并关闭
|
||||
|
||||
重启sysctl
|
||||
|
||||
$ sudo sysctl -p
|
||||
|
||||
再次检查ifconfig的输出,这里应该没有ipv6地址了。
|
||||
|
||||
$ ifconfig
|
||||
eth0 Link encap:Ethernet HWaddr 08:00:27:5f:28:8b
|
||||
inet addr:192.168.1.3 Bcast:192.168.1.255 Mask:255.255.255.0
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:1346 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:965 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:1501691 (1.5 MB) TX bytes:104883 (104.8 KB)
|
||||
|
||||
If it does not work, then try rebooting the system and check ifconfig again.
|
||||
如果不行,尝试重启系统并再次检查ifconfig
|
||||
|
||||
#### 禁用 ipv6 - GRUB 方案 ####
|
||||
|
||||
Ipv6同样可以通过编辑grub配置文件禁用。
|
||||
|
||||
$ sudo gedit /etc/default/grub
|
||||
|
||||
查找包含"GRUB_CMDLINE_LINUX"的行,并如下编辑:
|
||||
|
||||
GRUB_CMDLINE_LINUX="ipv6.disable=1"
|
||||
|
||||
同样可以加入名为"GRUB_CMDLINE_LINUX_DEFAULT"的变量,这同样有用。保存并关闭文件,重新生成grub配置。
|
||||
|
||||
$ sudo update-grub2
|
||||
|
||||
重启,现在ipv应该就已经禁用了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.binarytides.com/disable-ipv6-ubuntu/
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://testmyipv6.com/
|
||||
Loading…
Reference in New Issue
Block a user