mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-06 23:50:16 +08:00
commit
bd706636a9
2
.gitignore
vendored
2
.gitignore
vendored
@ -3,3 +3,5 @@ members.md
|
||||
*.html
|
||||
*.bak
|
||||
.DS_Store
|
||||
sources/*/.*
|
||||
translated/*/.*
|
||||
@ -104,10 +104,10 @@ Arch Linux 也因其丰富的 Wiki 帮助文档而大受推崇。该系统基于
|
||||
][23]
|
||||
|
||||
输入下面的命令来检查网络连接。
|
||||
|
||||
|
||||
```
|
||||
ping google.com
|
||||
```
|
||||
```
|
||||
|
||||
这个单词 ping 表示网路封包搜寻。你将会看到下面的返回信息,表明 Arch Linux 已经连接到外网了。这是执行安装过程中的很关键的一点。(LCTT 译注:或许你 ping 不到那个不存在的网站,你选个存在的吧。)
|
||||
|
||||
@ -117,8 +117,8 @@ ping google.com
|
||||
|
||||
输入如下命令清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
在开始安装之前,你得先为硬盘分区。输入 `fdisk -l` ,你将会看到当前系统的磁盘分区情况。注意一开始你给 Arch Linux 系统分配的 20 GB 存储空间。
|
||||
@ -137,8 +137,8 @@ clear
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
|
||||
你将看到 `gpt`、`dos`、`sgi` 和 `sun` 类型,选择 `dos` 选项,然后按回车。
|
||||
@ -185,8 +185,8 @@ cfdisk
|
||||
|
||||
以同样的方式创建逻辑分区。在“退出(quit)”选项按回车键,然后输入下面的命令来清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
[
|
||||
@ -195,21 +195,21 @@ clear
|
||||
|
||||
输入下面的命令来格式化新建的分区:
|
||||
|
||||
```
|
||||
```
|
||||
mkfs.ext4 /dev/sda1
|
||||
```
|
||||
```
|
||||
|
||||
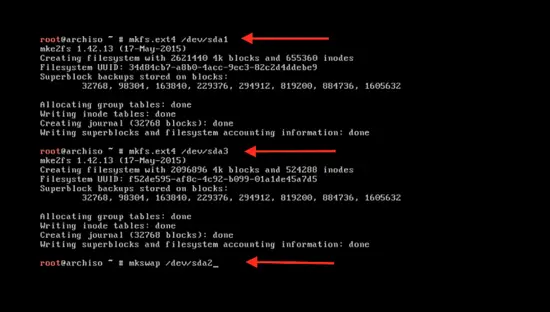
这里的 `sda1` 是分区名。使用同样的命令来格式化第二个分区 `sda3` :
|
||||
|
||||
```
|
||||
```
|
||||
mkfs.ext4 /dev/sda3
|
||||
```
|
||||
```
|
||||
|
||||
格式化 swap 分区:
|
||||
|
||||
```
|
||||
```
|
||||
mkswap /dev/sda2
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -217,14 +217,14 @@ mkswap /dev/sda2
|
||||
|
||||
使用下面的命令来激活 swap 分区:
|
||||
|
||||
```
|
||||
swapon /dev/sda2
|
||||
```
|
||||
swapon /dev/sda2
|
||||
```
|
||||
|
||||
输入 clear 命令清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
[
|
||||
@ -233,9 +233,9 @@ clear
|
||||
|
||||
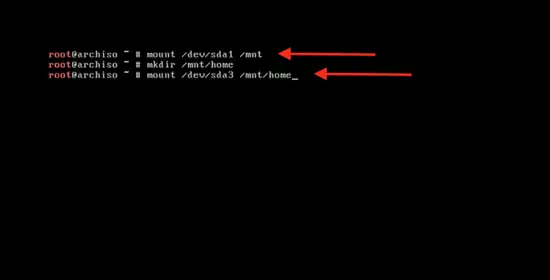
输入下面的命令来挂载主分区以开始系统安装:
|
||||
|
||||
```
|
||||
mount /dev/sda1 / mnt
|
||||
```
|
||||
```
|
||||
mount /dev/sda1 /mnt
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -245,9 +245,9 @@ mount /dev/sda1 / mnt
|
||||
|
||||
输入下面的命令来引导系统启动:
|
||||
|
||||
```
|
||||
```
|
||||
pacstrap /mnt base base-devel
|
||||
```
|
||||
```
|
||||
|
||||
可以看到系统正在同步数据包。
|
||||
|
||||
@ -263,9 +263,9 @@ pacstrap /mnt base base-devel
|
||||
|
||||
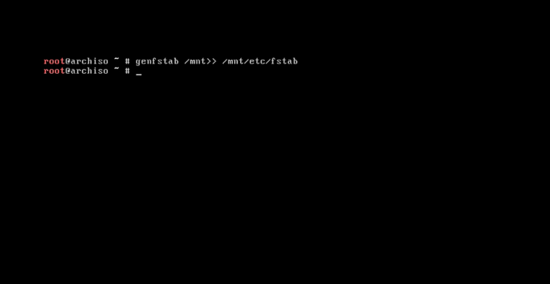
系统基本软件安装完成后,输入下面的命令来创建 fstab 文件:
|
||||
|
||||
```
|
||||
```
|
||||
genfstab /mnt>> /mnt/etc/fstab
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -275,14 +275,14 @@ genfstab /mnt>> /mnt/etc/fstab
|
||||
|
||||
输入下面的命令来更改系统的根目录为 Arch Linux 的安装目录:
|
||||
|
||||
```
|
||||
```
|
||||
arch-chroot /mnt /bin/bash
|
||||
```
|
||||
```
|
||||
|
||||
现在来更改语言配置:
|
||||
|
||||
```
|
||||
nano /etc/local.gen
|
||||
```
|
||||
nano /etc/locale.gen
|
||||
```
|
||||
|
||||
[
|
||||
@ -297,9 +297,9 @@ nano /etc/local.gen
|
||||
|
||||
输入下面的命令来激活它:
|
||||
|
||||
```
|
||||
```
|
||||
locale-gen
|
||||
```
|
||||
```
|
||||
|
||||
按回车。
|
||||
|
||||
@ -309,8 +309,8 @@ locale-gen
|
||||
|
||||
使用下面的命令来创建 `/etc/locale.conf` 配置文件:
|
||||
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
|
||||
然后按回车。现在你就可以在配置文件中输入下面一行内容来为系统添加语言:
|
||||
@ -326,9 +326,9 @@ LANG=en_US.UTF-8
|
||||
][44]
|
||||
|
||||
输入下面的命令来同步时区:
|
||||
|
||||
|
||||
```
|
||||
ls user/share/zoneinfo
|
||||
ls /usr/share/zoneinfo
|
||||
```
|
||||
|
||||
下面你将看到整个世界的时区列表。
|
||||
@ -339,9 +339,9 @@ ls user/share/zoneinfo
|
||||
|
||||
输入下面的命令来选择你所在的时区:
|
||||
|
||||
```
|
||||
```
|
||||
ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
```
|
||||
```
|
||||
|
||||
或者你可以从下面的列表中选择其它名称。
|
||||
|
||||
@ -351,8 +351,8 @@ ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
|
||||
使用下面的命令来设置标准时间:
|
||||
|
||||
```
|
||||
hwclock --systohc –utc
|
||||
```
|
||||
hwclock --systohc --utc
|
||||
```
|
||||
|
||||
硬件时钟已同步。
|
||||
@ -363,8 +363,8 @@ hwclock --systohc –utc
|
||||
|
||||
设置 root 帐号密码:
|
||||
|
||||
```
|
||||
passwd
|
||||
```
|
||||
passwd
|
||||
```
|
||||
|
||||
按回车。 然而输入你想设置的密码,按回车确认。
|
||||
@ -377,9 +377,9 @@ passwd
|
||||
|
||||
使用下面的命令来设置主机名:
|
||||
|
||||
```
|
||||
```
|
||||
nano /etc/hostname
|
||||
```
|
||||
```
|
||||
|
||||
然后按回车。输入你想设置的主机名称,按 `control + x` ,按 `y` ,再按回车 。
|
||||
|
||||
@ -389,9 +389,9 @@ nano /etc/hostname
|
||||
|
||||
启用 dhcpcd :
|
||||
|
||||
```
|
||||
```
|
||||
systemctl enable dhcpcd
|
||||
```
|
||||
```
|
||||
|
||||
这样在下一次系统启动时, dhcpcd 将会自动启动,并自动获取一个 IP 地址:
|
||||
|
||||
@ -403,9 +403,9 @@ systemctl enable dhcpcd
|
||||
|
||||
最后一步,输入以下命令来初始化 grub 安装。输入以下命令:
|
||||
|
||||
```
|
||||
```
|
||||
pacman –S grub os-rober
|
||||
```
|
||||
```
|
||||
|
||||
然后按 `y` ,将会下载相关程序。
|
||||
|
||||
@ -415,14 +415,14 @@ pacman –S grub os-rober
|
||||
|
||||
使用下面的命令来将启动加载程序安装到硬盘上:
|
||||
|
||||
```
|
||||
```
|
||||
grub-install /dev/sda
|
||||
```
|
||||
```
|
||||
|
||||
然后进行配置:
|
||||
|
||||
```
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
[
|
||||
@ -431,9 +431,9 @@ grub-mkconfig -o /boot/grub/grub.cfg
|
||||
|
||||
最后重启系统:
|
||||
|
||||
```
|
||||
```
|
||||
reboot
|
||||
```
|
||||
```
|
||||
|
||||
然后按回车 。
|
||||
|
||||
@ -459,7 +459,7 @@ reboot
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-arch-linux-on-virtualbox/
|
||||
|
||||
译者简介:
|
||||
译者简介:
|
||||
|
||||
rusking:春城初春/春水初生/春林初盛/春風十裏不如妳
|
||||
|
||||
|
||||
125
published/20180107 7 leadership rules for the DevOps age.md
Normal file
125
published/20180107 7 leadership rules for the DevOps age.md
Normal file
@ -0,0 +1,125 @@
|
||||
DevOps 时代的 7 个领导力准则
|
||||
======
|
||||
|
||||
> DevOps 是一种持续性的改变和提高:那么也准备改变你所珍视的领导力准则吧。
|
||||
|
||||

|
||||
|
||||
如果 [DevOps] 最终更多的是一种文化而非某种技术或者平台,那么请记住:它没有终点线。而是一种持续性的改变和提高——而且最高管理层并不及格。
|
||||
|
||||
然而,如果期望 DevOps 能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法][2]。让我们考虑 7 个在 DevOps 时代更有效的 IT 领导的想法。
|
||||
|
||||
### 1、 向失败说“是的”
|
||||
|
||||
“失败”这个词在 IT 领域中一直包含着非常具体的意义,而且通常是糟糕的意思:服务器失败、备份失败、硬盘驱动器失败——你的印象就是如此。
|
||||
|
||||
然而一个健康的 DevOps 文化取决于如何重新定义失败——IT 领导者应该在他们的字典里重新定义这个单词,使这个词的含义和“机会”对等起来。
|
||||
|
||||
“在 DevOps 之前,我们曾有一种惩罚失败者的文化,”[Datical][3] 的首席技术官兼联合创始人罗伯特·里夫斯说,“我们学到的仅仅是去避免错误。在 IT 领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
|
||||
|
||||
那是一个旧时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞实际上是失败。
|
||||
|
||||
“那些缓慢的发布周期并逃避云的公司被恐惧所麻痹——他们将会走向失败,”里夫斯说道。“IT 领导者必须拥抱失败,并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从别人的错误中学习。开放和[安全心理][4]的文化促进学习和提高。”
|
||||
|
||||
**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义][5]]**
|
||||
|
||||
### 2、 在管理层渗透开发运营的理念
|
||||
|
||||
尽管 DevOps 文化可以在各个方向有机的发展,那些正在从单体、孤立的 IT 实践中转变出来的公司,以及可能遭遇逆风的公司——需要高管层的全面支持。如果缺少了它,你就会传达模糊的信息,而且可能会鼓励那些宁愿被推着走的人,但这是我们一贯的做事方式。[改变文化是困难的][6];人们需要看到高管层完全投入进去并且知道改变已经实际发生了。
|
||||
|
||||
“高层管理必须全力支持 DevOps,才能成功的实现收益”,来自 [Rainforest QA][7] 的首席信息官德里克·蔡说道。
|
||||
|
||||
成为一个 DevOps 商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
|
||||
|
||||
“没有高层管理的统一赞助支持,DevOps 的实施将很难成功,”德里克说道,“因此,在转变到 DevOps 之前在高层中保持一致是很重要的。”
|
||||
|
||||
### 3、 不要只是声明 “DevOps”——要明确它
|
||||
|
||||
即使 IT 公司也已经开始张开双臂拥抱 DevOps,也可能不是每个人都在同一个步调上。
|
||||
|
||||
**[参考我们的相关文章,[3 阐明了DevOps和首席技术官们必须在同一进程上][8]]**
|
||||
|
||||
造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
|
||||
|
||||
“DevOps 对不同的人可能意味着不同的含义,”德里克解释道,“对高管层和副总裁层来说,要执行明确的 DevOps 的目标,清楚地声明期望的成果,充分理解带来的成果将如何使公司的商业受益,并且能够衡量和报告成功的过程。”
|
||||
|
||||
事实上,在基线定义和远景之外,DevOps 要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT 领导者必须将它设置为优先。
|
||||
|
||||
“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道,“领导者们需要清楚的将这个过程向公司的其他人阐述清楚,告诉他们他们作为这个过程的一份子能够期待的结果。”
|
||||
|
||||
### 4、 DevOps 对于商业和技术同样重要
|
||||
|
||||
IT 领导者们成功的将 DevOps 商店的这种文化和实践当做一项商业策略,以及构建和运营软件的方法。DevOps 是将 IT 从支持部门转向战略部门的推动力。
|
||||
|
||||
IT 领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且 DevOps 的文化能够通过自动化和强大的协作加速这些成果,来自 [CYBRIC][9] 的首席技术官和联合创始人迈克·凯尔说道。
|
||||
|
||||
事实上,这是一个强烈的趋势,贯穿这些新“规则”,在 DevOps 时代走在前沿。
|
||||
|
||||
“促进创新并且鼓励团队成员去聪明的冒险是 DevOps 文化的一个关键部分,IT 领导者们需要在一个持续的基础上清楚的和他们交流”,凯尔说道。
|
||||
|
||||
“一个高效的 IT 领导者需要比以往任何时候都要积极的参与到业务中去,”来自 [West Monroe Partners][10] 的性能服务部门的主任埃文说道,“每年或季度回顾的日子一去不复返了——[你需要欢迎每两周一次的挤压整理][11],你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
|
||||
|
||||
### 5、 改变妨碍 DevOps 目标的任何事情
|
||||
|
||||
虽然 DevOps 的老兵们普遍认为 DevOps 更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个 DevOps 商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用了 20 年的引擎,每次转动钥匙都会冒烟。
|
||||
|
||||
展览 A: [自动化][12]。这是 DevOps 成功的重要并行策略。
|
||||
|
||||
“IT 领导者需要重点强调自动化,”卡伦德说,“这将是 DevOps 的前期投资,但是如果没有它,DevOps 将会很容易被低效吞噬,而且将会无法完整交付。”
|
||||
|
||||
自动化是基石,但改变不止于此。
|
||||
|
||||
“领导者们需要推动自动化、监控和持续交付过程。这意着对现有的实践、过程、团队架构以及规则的很多改变,” 德里克说。“领导者们需要改变一切会阻碍团队去实现完全自动化的因素。”
|
||||
|
||||
### 6、 重新思考团队架构和能力指标
|
||||
|
||||
当你想改变时……如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
|
||||
|
||||
“在这个 DevOps 的新时代文化中,IT 执行者需要采取一个全新的方法来组织架构。”凯尔说,“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织、敏捷管理。”
|
||||
|
||||
凯尔告诉我们在 DevOps 时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
|
||||
|
||||
“根据业务成果和总体的积极影响来衡量主动性,”凯尔建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
|
||||
|
||||
注意很容易收集的到测量值不是 DevOps 真正的指标,[Red Hat] 的技术专家戈登·哈夫写到,“DevOps 应该把指标以某种形式和商业成果绑定在一起”,他指出,“你可能并不真正在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
|
||||
|
||||
### 7、 丢弃传统的智慧
|
||||
|
||||
如果 DevOps 时代要求关于 IT 领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
|
||||
|
||||
“说实话,是全部”,凯尔说道,“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到 DevOps 文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
|
||||
|
||||
事实上,IT 领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
|
||||
|
||||
West Monroe Partners 的卡伦德分享了一个阻碍 DevOps 的领导力的例子:未能拥抱 IT 混合模型和现代的基础架构比如说容器和微服务。
|
||||
|
||||
“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
|
||||
|
||||
**领导者们,想要更多像这样的智慧吗?[注册我们的每周邮件新闻报道][15]。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
|
||||
[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[7]:https://www.rainforestqa.com/
|
||||
[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
|
||||
[9]:https://www.cybric.io/
|
||||
[10]:http://www.westmonroepartners.com/
|
||||
[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
|
||||
[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
|
||||
[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,30 +1,32 @@
|
||||
如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习
|
||||
============================================================
|
||||
=============================
|
||||
|
||||

|
||||
|
||||
> 探索如何将 Android Things 与 Tensorflow 集成起来,以及如何应用机器学习到物联网系统上。学习如何在装有 Android Things 的树莓派上使用 Tensorflow 进行图片分类。
|
||||
|
||||
这个项目探索了如何将机器学习应用到物联网上。具体来说,物联网平台我们将使用 **Android Things**,而机器学习引擎我们将使用 **Google TensorFlow**。
|
||||
|
||||

|
||||
现如今,Android Things 处于名为 Android Things 1.0 的稳定版本,已经可以用在生产系统中了。如你可能已经知道的,树莓派是一个可以支持 Android Things 1.0 做开发和原型设计的平台。本教程将使用 Android Things 1.0 和树莓派,当然,你可以无需修改代码就能换到其它所支持的平台上。这个教程是关于如何将机器学习应用到物联网的,这个物联网平台就是 Android Things Raspberry Pi。
|
||||
|
||||
现如今,机器学习是物联网上使用的最热门的主题之一。给机器学习的最简单的定义,可能就是 [维基百科上的定义][13]:机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
|
||||
物联网上的机器学习是最热门的话题之一。要给机器学习一个最简单的定义,可能就是 [维基百科上的定义][13]:
|
||||
|
||||
换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中一个前景看好的领域就是如何在物联网上应用机器学习,构建专业的系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。
|
||||
> 机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
|
||||
|
||||
这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个感兴趣的领域,它们是:
|
||||
换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中前景最看好的领域之一就是如何在物联网上应用机器学习,构建专家系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。在深入了解 Android Things 的细节之前,你应该先将其安装在你的设备上。如果你是第一次使用 Android Things,你可以阅读一下这篇[如何在你的设备上安装 Android Things][14] 的教程。
|
||||
|
||||
这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个有趣的领域,它们是:
|
||||
|
||||
* 在工业物联网(IIoT)中的预见性维护
|
||||
|
||||
* 消费物联网中,机器学习可以让设备更智能,它通过调整使设备更适应我们的习惯
|
||||
|
||||
在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车][5],因此,在开始这个项目之前,我们建议你去阅读那个教程。
|
||||
在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)并控制其道路方向的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车][5],因此,在开始这个项目之前,我们建议你去阅读那个教程。
|
||||
|
||||
这个机器学习和物联网项目包含如下的主题:
|
||||
|
||||
* 如何使用 Docker 配置 TensorFlow 环境
|
||||
|
||||
* 如何训练 TensorFlow 系统
|
||||
|
||||
* 如何使用 Android Things 去集成 TensorFlow
|
||||
|
||||
* 如何使用 TensorFlow 的成果去控制无人驾驶汽车
|
||||
|
||||
这个项目起源于 [Android Things TensorFlow 图像分类器][6]。
|
||||
@ -33,59 +35,55 @@
|
||||
|
||||
### 如何使用 Tensorflow 图像识别
|
||||
|
||||
在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要快速找到并且准备去使用一些东西,因此,我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
|
||||
在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要找到一些快速而能用的东西,以便我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
|
||||
|
||||
1. 克隆 TensorFlow 仓库:
|
||||
```
|
||||
git clone https://github.com/tensorflow/tensorflow.git
|
||||
cd /tensorflow
|
||||
git checkout v1.5.0
|
||||
```
|
||||
1、 克隆 TensorFlow 仓库:
|
||||
|
||||
2. 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
|
||||
```
|
||||
git clone https://github.com/tensorflow/tensorflow.git
|
||||
cd /tensorflow
|
||||
git checkout v1.5.0
|
||||
```
|
||||
|
||||
3. 运行 Docker:
|
||||
```
|
||||
docker run -it \
|
||||
--volume /tf-data:/tf-data \
|
||||
--volume /tensorflow:/tensorflow \
|
||||
--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
|
||||
```
|
||||
2、 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
|
||||
|
||||
使用这个命令,我们运行一个交互式 TensorFlow 环境,可以在使用项目期间挂载一些目录。
|
||||
3、 运行 Docker:
|
||||
|
||||
```
|
||||
docker run -it \
|
||||
--volume /tf-data:/tf-data \
|
||||
--volume /tensorflow:/tensorflow \
|
||||
--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
|
||||
```
|
||||
|
||||
使用这个命令,我们运行一个交互式 TensorFlow 环境,可以挂载一些在使用项目期间使用的目录。
|
||||
|
||||
### 如何训练 TensorFlow 去识别图像
|
||||
|
||||
在 Android Things 系统能够识别图像之前,我们需要去训练 TensorFlow 引擎,以使它能够构建它的模型。为此,我们需要去收集一些图像。正如前面所言,我们需要使用箭头来控制 Android Things 无人驾驶汽车,因此,我们至少要收集四种类型的箭头:
|
||||
|
||||
* 向上的箭头
|
||||
|
||||
* 向下的箭头
|
||||
|
||||
* 向左的箭头
|
||||
|
||||
* 向右的箭头
|
||||
|
||||
为训练这个系统,需要使用这四类不同的图像去创建一个“知识库”。在 `/tf-data` 目录下创建一个名为 `images` 的目录,然后在它下面创建如下名字的四个子目录:
|
||||
|
||||
* up-arrow
|
||||
|
||||
* down-arrow
|
||||
|
||||
* left-arrow
|
||||
|
||||
* right-arrow
|
||||
* `up-arrow`
|
||||
* `down-arrow`
|
||||
* `left-arrow`
|
||||
* `right-arrow`
|
||||
|
||||
现在,我们去找图片。我使用的是 Google 图片搜索,你也可以使用其它的方法。为了简化图片下载过程,你可以安装一个 Chrome 下载插件,这样你只需要点击就可以下载选定的图片。别忘了多下载一些图片,这样训练效果更好,当然,这样创建模型的时间也会相应增加。
|
||||
|
||||
**扩展阅读**
|
||||
[如何使用 API 去集成 Android Things][2]
|
||||
[如何与 Firebase 一起使用 Android Things][3]
|
||||
|
||||
- [如何使用 API 去集成 Android Things][2]
|
||||
- [如何与 Firebase 一起使用 Android Things][3]
|
||||
|
||||
打开浏览器,开始去查找四种箭头的图片:
|
||||
|
||||

|
||||
[Save][7]
|
||||
|
||||
每个类别我下载了 80 张图片。不用管图片文件的扩展名。
|
||||
|
||||
@ -102,9 +100,8 @@ python /tensorflow/examples/image_retraining/retrain.py \
|
||||
|
||||
这个过程你需要耐心等待,它需要花费很长时间。结束之后,你将在 `/tf-data` 目录下发现如下的两个文件:
|
||||
|
||||
1. retrained_graph.pb
|
||||
|
||||
2. retrained_labels.txt
|
||||
1. `retrained_graph.pb`
|
||||
2. `retrained_labels.txt`
|
||||
|
||||
第一个文件包含了 TensorFlow 训练过程产生的结果模型,而第二个文件包含了我们的四个图片类相关的标签。
|
||||
|
||||
@ -139,7 +136,6 @@ python /tensorflow/python/tools/optimize_for_inference.py \
|
||||
TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将 Android Things 与 TensorFlow 集成到一起。为此,我们将这个任务分为两步来完成:
|
||||
|
||||
1. 硬件部分,我们将把电机和其它部件连接到 Android Things 开发板上
|
||||
|
||||
2. 实现这个应用程序
|
||||
|
||||
### Android Things 示意图
|
||||
@ -147,13 +143,9 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
在深入到如何连接外围部件之前,先列出在这个 Android Things 项目中使用到的组件清单:
|
||||
|
||||
1. Android Things 开发板(树莓派 3)
|
||||
|
||||
2. 树莓派摄像头
|
||||
|
||||
3. 一个 LED 灯
|
||||
|
||||
4. LN298N 双 H 桥电机驱动模块(连接控制电机)
|
||||
|
||||
5. 一个带两个轮子的无人驾驶汽车底盘
|
||||
|
||||
我不再重复 [如何使用 Android Things 去控制电机][9] 了,因为在以前的文章中已经讲过了。
|
||||
@ -161,12 +153,10 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
下面是示意图:
|
||||
|
||||

|
||||
[Save][10]
|
||||
|
||||
上图中没有展示摄像头。最终成果如下图:
|
||||
|
||||

|
||||
[Save][11]
|
||||
|
||||
### 使用 TensorFlow 实现 Android Things 应用程序
|
||||
|
||||
@ -175,11 +165,8 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
这个 Android Things 应用程序与原始的应用程序是不一样的,因为:
|
||||
|
||||
1. 它不使用按钮去开启摄像头图像捕获
|
||||
|
||||
2. 它使用了不同的模型
|
||||
|
||||
3. 它使用一个闪烁的 LED 灯来提示,摄像头将在 LED 停止闪烁后拍照
|
||||
|
||||
4. 当 TensorFlow 检测到图像时(箭头)它将控制电机。此外,在第 3 步的循环开始之前,它将打开电机 5 秒钟。
|
||||
|
||||
为了让 LED 闪烁,使用如下的代码:
|
||||
@ -264,7 +251,7 @@ public void onImageAvailable(ImageReader reader) {
|
||||
|
||||
在这个方法中,当 TensorFlow 返回捕获的图片匹配到的可能的标签之后,应用程序将比较这个结果与可能的方向,并因此来控制电机。
|
||||
|
||||
最后,将去使用前面创建的模型了。拷贝 _assets_ 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
|
||||
最后,将去使用前面创建的模型了。拷贝 `assets` 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
|
||||
|
||||
打开 `Helper.java` 并修改如下的行:
|
||||
|
||||
@ -289,9 +276,9 @@ public static final String OUTPUT_NAME = "final_result";
|
||||
|
||||
via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html
|
||||
|
||||
作者:[Francesco Azzola ][a]
|
||||
作者:[Francesco Azzola][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -309,3 +296,4 @@ via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-usi
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=&url=https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html&is_video=false&description=Integrating%20Android%20Things%20with%20TensorFlow
|
||||
[12]:https://github.com/androidthings/sample-tensorflow-imageclassifier
|
||||
[13]:https://en.wikipedia.org/wiki/Machine_learning
|
||||
[14]:https://www.survivingwithandroid.com/2017/01/android-things-android-internet-of-things.html
|
||||
@ -0,0 +1,113 @@
|
||||
如何在 Linux 中的特定时间运行命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
有一天,我使用 `rsync` 将大文件传输到局域网上的另一个系统。由于它是非常大的文件,大约需要 20 分钟才能完成。我不想再等了,我也不想按 `CTRL+C` 来终止这个过程。我只是想知道在类 Unix 操作系统中是否有简单的方法可以在特定的时间运行一个命令,并且一旦超时就自动杀死它 —— 因此有了这篇文章。请继续阅读。
|
||||
|
||||
### 在 Linux 中在特定时间运行命令
|
||||
|
||||
我们可以用两种方法做到这一点。
|
||||
|
||||
#### 方法 1 - 使用 timeout 命令
|
||||
|
||||
最常用的方法是使用 `timeout` 命令。对于那些不知道的人来说,`timeout` 命令会有效地限制一个进程的绝对执行时间。`timeout` 命令是 GNU coreutils 包的一部分,因此它预装在所有 GNU/Linux 系统中。
|
||||
|
||||
假设你只想运行一个命令 5 秒钟,然后杀死它。为此,我们使用:
|
||||
|
||||
```
|
||||
$ timeout <time-limit-interval> <command>
|
||||
```
|
||||
|
||||
例如,以下命令将在 10 秒后终止。
|
||||
|
||||
```
|
||||
$ timeout 10s tail -f /var/log/pacman.log
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
你也可以不用在秒数后加后缀 `s`。以下命令与上面的相同。
|
||||
|
||||
```
|
||||
$ timeout 10 tail -f /var/log/pacman.log
|
||||
```
|
||||
|
||||
其他可用的后缀有:
|
||||
|
||||
* `m` 代表分钟。
|
||||
* `h` 代表小时。
|
||||
* `d` 代表天。
|
||||
|
||||
|
||||
如果你运行这个 `tail -f /var/log/pacman.log` 命令,它将继续运行,直到你按 `CTRL+C` 手动结束它。但是,如果你使用 `timeout` 命令运行它,它将在给定的时间间隔后自动终止。如果该命令在超时后仍在运行,则可以发送 `kill` 信号,如下所示。
|
||||
|
||||
```
|
||||
$ timeout -k 20 10 tail -f /var/log/pacman.log
|
||||
```
|
||||
|
||||
在这种情况下,如果 `tail` 命令在 10 秒后仍然运行,`timeout` 命令将在 20 秒后发送一个 kill 信号并结束。
|
||||
|
||||
有关更多详细信息,请查看手册页。
|
||||
|
||||
```
|
||||
$ man timeout
|
||||
```
|
||||
|
||||
有时,某个特定程序可能需要很长时间才能完成并最终冻结你的系统。在这种情况下,你可以使用此技巧在特定时间后自动结束该进程。
|
||||
|
||||
另外,可以考虑使用 `cpulimit`,一个简单的限制进程的 CPU 使用率的程序。有关更多详细信息,请查看下面的链接。
|
||||
|
||||
- [如何在 Linux 中限制一个进程的使用的 CPU][8]
|
||||
|
||||
#### 方法 2 - 使用 timelimit 程序
|
||||
|
||||
`timelimit` 使用提供的参数执行给定的命令,并在给定的时间后使用给定的信号终止进程。首先,它会发送警告信号,然后在超时后发送 kill 信号。
|
||||
|
||||
与 `timeout` 不同,`timelimit` 有更多选项。你可以传递参数数量,如 `killsig`、`warnsig`、`killtime`、`warntime` 等。它存在于基于 Debian 的系统的默认仓库中。所以,你可以使用命令来安装它:
|
||||
|
||||
```
|
||||
$ sudo apt-get install timelimit
|
||||
```
|
||||
|
||||
对于基于 Arch 的系统,它在 AUR 中存在。因此,你可以使用任何 AUR 助手进行安装,例如 [Pacaur][3]、[Packer][4]、[Yay][5]、[Yaourt][6] 等。
|
||||
|
||||
对于其他发行版,请[在这里][7]下载源码并手动安装。安装 `timelimit` 后,运行下面的命令执行一段特定的时间,例如 10 秒钟:
|
||||
|
||||
```
|
||||
$ timelimit -t10 tail -f /var/log/pacman.log
|
||||
```
|
||||
|
||||
如果不带任何参数运行 `timelimit`,它将使用默认值:`warntime=3600` 秒、`warnsig=15` 秒、`killtime=120` 秒、`killsig=9`。有关更多详细信息,请参阅本指南最后给出的手册页和项目网站。
|
||||
|
||||
```
|
||||
$ man timelimit
|
||||
```
|
||||
|
||||
今天就是这些。我希望对你有用。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
### 资源
|
||||
|
||||
- [timelimit 网站][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/run-command-specific-time-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/Timeout.gif
|
||||
[3]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[4]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[5]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:http://devel.ringlet.net/sysutils/timelimit/#download
|
||||
[8]:https://www.ostechnix.com/how-to-limit-cpu-usage-of-a-process-in-linux/
|
||||
[9]:http://devel.ringlet.net/sysutils/timelimit/
|
||||
@ -1,64 +1,63 @@
|
||||
你的路由器有多不安全?
|
||||
======
|
||||
|
||||
> 你的路由器是你与互联网之间的第一个联系点。它给你带来了多少风险?
|
||||
|
||||

|
||||
|
||||
我一直对写在 T 恤上的“127.0.0.1 这个地方是独一无二的” 这句话持有异议。我知道你可能会认为应该将它读作是“家”,但是对于我来说,我认为应该是“本地主机是独一无二的地方”,就像世界上没有完全相同的二个戒指一样。在本文中,我想去讨论一些宽泛的问题:家庭网络的入口,对大多数人来说它是线缆或宽带路由器。英国和美国政府刚公布了“俄罗斯”攻击路由器的通告。我估计这次的攻击主要针对的是机构,而不是家庭,(看我以前的文章 "[国家行为者是什么,我们应该注意些什么?][1]"),但这对我们所有人都是一个警示。
|
||||
我一直对写在 T 恤上的“127.0.0.1 是独一无二的地方” 这句话持有异议。我知道你可能会认为应该将它看作是“家”,但是对于我来说,我认为应该是“本地主机是独一无二的地方”,就像世界上没有完全相同的二个戒指一样。在本文中,我想去讨论一些宽泛的问题:家庭网络的入口,对大多数人来说它是线缆或宽带路由器。^1 英国和美国政府刚公布了“俄罗斯” ^2 攻击路由器的通告。我估计这次的攻击主要针对的是机构,而不是家庭,(看我以前的文章 “[国家行为者是什么,我们应该注意些什么?][1]”),但这对我们所有人都是一个警示。
|
||||
|
||||
### 路由器有什么用?
|
||||
|
||||
路由器很重要。它用于将一个网络(在本文中,是我们的家庭网络)与另外一个网络(在本文中,是指因特网,通过我们的因特网服务提供商的网络)连接。事实上,对于大多数人来说,我们所谓的”路由器“这个小盒子能够做的事情远比我们想到的要多。"routing" 比特就像它的发音一样;它让网络中的计算机能够找到一条向外部网络中计算机发送数据的路径 —— 当你接收数据时,正好是相反的方式。
|
||||
路由器很重要。它用于将一个网络(在本文中,是我们的家庭网络)与另外一个网络(在本文中,是指互联网,通过我们的互联网服务提供商的网络)连接。事实上,对于大多数人来说,我们所谓的“路由器” ^3 这个小盒子能够做的事情远比我们想到的要多。“路由” 一个比特就就如其听起来的意思一样:它让网络中的计算机能够找到一条向外部网络中计算机发送数据的路径 —— 当你接收数据时,反之。
|
||||
|
||||
在路由器的其它功能中,大多数时候也作为一台调制解调器来使用。在英国大部分到因特网的连接是通过电话线来实现的 —— 无论是电缆还是标准电话线 —— 尽管现在的最新趋势是通过移动互联网连接到家庭中。当你通过电话线连接时,我们所使用的因特网信号必须转换成其它的一些东西,(从另一端来的)返回信号也是如此。对于那些还记得过去的”拨号上网“时代的人来说,它就是你的电脑边上那个用于上网的发出刺耳声音的小盒子。
|
||||
在路由器的其它功能中,大多数时候也作为一台调制解调器来使用。我们中的大部分人 ^4 到互联网的连接是通过电话线来实现的 —— 无论是电缆还是标准电话线 —— 尽管现在的最新趋势是通过移动互联网连接到家庭中。当你通过电话线连接时,我们所使用的互联网信号必须转换成其它的一些东西,(从另一端来的)返回信号也是如此。对于那些还记得过去的“拨号上网”时代的人来说,它就是你的电脑边上那个用于上网的发出刺耳声音的小盒子。
|
||||
|
||||
但是路由器能做的事情很多,有时候很多的事情,包括流量记录、作为一个无线接入点、提供 VPN 功能以便于从外部访问你的内网、儿童上网控制、防火墙等等。
|
||||
|
||||
现在的家用路由器越来越复杂;虽然国家行为者并不想参与其中,但是其它人可以。
|
||||
现在的家用路由器越来越复杂;虽然国家行为者也行不会想着攻破它,但是其它人也许会。
|
||||
|
||||
你会问,这很重要吗?如果其它人可以进入你的系统,他们可以很容易地攻击你的笔记本电脑、电话、网络设备等等。他们可以访问和删除未被保护的个人数据。他们可以假装是你。他们使用你的网络去寄存非法数据或者用于攻击其它人。基本上所有的坏事都可以做。
|
||||
|
||||
幸运的是,现在的路由器趋向于因特网提供商来做设置,言外之意是你可以忘了它的存在,他们将保证它是运行良好和安全的。
|
||||
幸运的是,现在的路由器趋向于由互联网提供商来做设置,言外之意是你可以忘了它的存在,他们将保证它是运行良好和安全的。
|
||||
|
||||
### 因此,我们是安全的吗?
|
||||
|
||||
不幸的是,事实并非如此。
|
||||
|
||||
第一个问题是,因特网提供商是在有限的预算范围内做这些事情,而使用便宜的设备来做这些事可以让他们的利益最大化。因特网提供商的路由器质量越来越差。它是恶意攻击者的首选目标:如果他们知道特定型号的路由器被安装在几百万个家庭使用,那么很容易找到攻击的动机,因为攻击那个型号的路由器对他们来说是非常有价值的。
|
||||
第一个问题是,互联网提供商是在有限的预算范围内做这些事情,而使用便宜的设备来做这些事可以让他们的利益最大化。互联网提供商的路由器质量越来越差。它是恶意攻击者的首选目标:如果他们知道特定型号的路由器被安装在几百万个家庭使用,那么很容易找到攻击的动机,因为攻击那个型号的路由器对他们来说是非常有价值的。
|
||||
|
||||
产生的其它问题还包括:
|
||||
|
||||
* 修复 bug 或者漏洞的过程很缓慢。升级固件可能会让因特网提供商产生较高的成本,因此,修复过程可能非常缓慢(如果他们打算修复的话)。
|
||||
* 修复 bug 或者漏洞的过程很缓慢。升级固件可能会让互联网提供商产生较高的成本,因此,修复过程可能非常缓慢(如果他们打算修复的话)。
|
||||
* 非常容易获得或者默认的管理员密码,这意味着攻击者甚至都不需要去找到真实的漏洞 —— 他们就可以登入到路由器中。
|
||||
|
||||
|
||||
|
||||
### 对策
|
||||
|
||||
对于进入因特网第一跳的路由器,如何才能提升它的安全性,这里给你提供一个快速应对的清单。我是按从简单到复杂的顺序来列出它们的。在你对路由器做任何改变之前,需要先保存配置数据,以便于你需要的时候回滚它们。
|
||||
|
||||
1. **密码:** 一定,一定,一定要改变你的路由器的管理员密码。你可能很少会用到它,所以你一定要把密码记录在某个地方。它用的次数很少,你可以考虑将密码粘贴到路由器上,因为路由器一般都放置在仅授权的人(你和你的家人)才可以接触到的地方。
|
||||
2. **仅允许管理员从内部进行访问:** 除非你有足够好的理由和你知道如何去做,否则不要允许任何机器从外部的因特网上管理你的路由器。在你的路由器上有一个这样的设置。
|
||||
3. **WiFi 密码:** 一旦你做到了第 2 点,也要确保在你的网络上的那个 WiFi 密码 —— 无论是设置为你的路由器管理密码还是别的 —— 一定要是强密码。为了简单,为连接你的网络的访客设置一个”友好的“简单密码,但是,如果附近一个恶意的人猜到了密码,他做的第一件事情就是查找网络中的路由器。由于他在内部网络,他是可以访问路由器的(因此,第 1 点很重要)。
|
||||
4. **仅打开你知道的并且是你需要的功能:** 正如我在上面所提到的,现代的路由器有各种很酷的选项。不要使用它们。除非你真的需要它们,并且你真正理解了它们是做什么的,并且打开它们后有什么危险。否则,将增加你的路由器被攻击的风险。
|
||||
5. **购买你自己的路由器:** 用一个更好的路由器替换掉因特网提供商给你的路由器。去到你本地的电脑商店,让他们给你一些建议。你可能会花很多钱,但是也可能会遇到一些非常便宜的设备,而且比你现在拥有的更好、性能更强、更安全。你也可以只买一个调制解调器。一般设置调制解调器和路由器都很简单,并且,你可以从你的因特网提供商给你的设备中复制配置,它一般就能”正常工作“。
|
||||
6. **更新固件:** 我喜欢使用最新的功能,但是通常这并不容易。有时,你的路由器上会出现固件更新的提示。大多数的路由器会自动检查并且提示你在下次登入的时候去更新它。问题是如果更新失败则会产生灾难性后果或者丢失配置数据,那就需要你重新输入。但是你真的需要考虑去持续关注修复安全问题的固件更新,并更新它们。
|
||||
7. **转向开源:** 有一些非常好的开源路由器项目,可以让你用在现有的路由器上,用开源的软件去替换它的固件/软件。你可以在 [Wikipedia][2] 上找到许多这样的项目,以及在 [Opensource.com 上搜索 "router"][3],你将看到很多非常好的东西。对于谨慎的人来说要小心,这将会让你的路由器失去保修,但是如果你想真正控制你的路由器,开源永远是最好的选择。
|
||||
|
||||
对于进入互联网第一跳的路由器,如何才能提升它的安全性,这里给你提供一个快速应对的清单。我是按从简单到复杂的顺序来列出它们的。在你对路由器做任何改变之前,需要先保存配置数据,以便于你需要的时候回滚它们。
|
||||
|
||||
1. **密码:** 一定,一定,一定要改变你的路由器的管理员密码。你可能很少会用到它,所以你一定要把密码记录在某个地方。它用的次数很少,你可以考虑将密码粘贴到路由器上,因为路由器一般都放置在仅供授权的人(你和你的家人 ^5 )才可以接触到的地方。
|
||||
2. **仅允许管理员从内部进行访问:** 除非你有足够好的理由和你知道如何去做,否则不要允许任何机器从外部的互联网上管理你的路由器。在你的路由器上有一个这样的设置。
|
||||
3. **WiFi 密码:** 一旦你做到了第 2 点,也要确保在你的网络上的那个 WiFi 密码 —— 无论是设置为你的路由器管理密码还是别的 —— 一定要是强密码。为了简单,为连接你的网络的访客设置一个“友好的”简单密码,但是,如果附近一个恶意的人猜到了密码,他做的第一件事情就是查找网络中的路由器。由于他在内部网络,他是可以访问路由器的(因此,第 1 点很重要)。
|
||||
4. **仅打开你知道的并且是你需要的功能:** 正如我在上面所提到的,现代的路由器有各种很酷的选项。不要使用它们。除非你真的需要它们,并且你真正理解了它们是做什么的,以及打开它们后有什么危险。否则,将增加你的路由器被攻击的风险。
|
||||
5. **购买你自己的路由器:** 用一个更好的路由器替换掉互联网提供商给你的路由器。去到你本地的电脑商店,让他们给你一些建议。你可能会花很多钱,但是也可能会遇到一些非常便宜的设备,而且比你现在拥有的更好、性能更强、更安全。你也可以只买一个调制解调器。一般设置调制解调器和路由器都很简单,并且,你可以从你的互联网提供商给你的设备中复制配置,它一般就能“正常工作”。
|
||||
6. **更新固件:** 我喜欢使用最新的功能,但是通常这并不容易。有时,你的路由器上会出现固件更新的提示。大多数的路由器会自动检查并且提示你在下次登入的时候去更新它。问题是如果更新失败则会产生灾难性后果 ^6 或者丢失配置数据,那就需要你重新输入。但是你真的需要考虑去持续关注修复安全问题的固件更新,并更新它们。
|
||||
7. **转向开源:** 有一些非常好的开源路由器项目,可以让你用在现有的路由器上,用开源的软件去替换它的固件/软件。你可以在 [Wikipedia][2] 上找到许多这样的项目,以及在 [Opensource.com 上搜索 “router”][3],你将看到很多非常好的东西。对于谨慎的人来说要小心,这将会让你的路由器失去保修,但是如果你想真正控制你的路由器,开源永远是最好的选择。
|
||||
|
||||
### 其它问题
|
||||
|
||||
一旦你提升了你的路由器的安全性,你的家庭网络将变的很好,这是假像,事实并不是如此。你家里的物联网设备(Alexa、Nest、门铃、智能灯泡、等等)安全性如何?连接到其它网络的 VPN 安全性如何?通过 WiFi 的恶意主机、你的孩子手机上的恶意应用程序 …?
|
||||
一旦你提升了你的路由器的安全性,你的家庭网络将变的很好——这是假像,事实并不是如此。你家里的物联网设备(Alexa、Nest、门铃、智能灯泡、等等)安全性如何?连接到其它网络的 VPN 安全性如何?通过 WiFi 的恶意主机、你的孩子手机上的恶意应用程序 …?
|
||||
|
||||
不,你永远不会有绝对的安全。但是正如我们前面讨论的,虽然没有绝对的”安全“这种事情,但是并不意味着我们不需要去提升安全标准,以让坏人干坏事更困难。
|
||||
不,你永远不会有绝对的安全。但是正如我们前面讨论的,虽然没有绝对的“安全”这种事情,但是并不意味着我们不需要去提升安全标准,以让坏人干坏事更困难。
|
||||
|
||||
### 脚注
|
||||
|
||||
1. 我写的很简单 — 但请继续读下去,我们将达到目的。
|
||||
2. "俄罗斯政府赞助的信息技术国家行为者"
|
||||
3. 或者,以我父母的例子来说,我不相信 ”这个路由器“。
|
||||
2. “俄罗斯政府赞助的信息技术国家行为者”
|
||||
3. 或者,以我父母的例子来说,我猜叫做 “互联网盒子”。
|
||||
4. 这里还有一种这样的情况,我不希望在评论区告诉我,你是直接以 1TB/s 的带宽连接到本地骨干网络的。非常感谢!
|
||||
5. 或许并没有包含全部的家庭。
|
||||
6. 你的路由器现在是一块”砖“,并且你不想访问因特网。
|
||||
|
||||
|
||||
5. 或许并没有包含整个家庭。
|
||||
6. 你的路由器现在是一块“砖”,并且你不能访问互联网了。
|
||||
|
||||
这篇文章最初发表在 [Alice, Eve, 和 Bob – 安全博客][4] 并授权重发布。
|
||||
|
||||
@ -69,7 +68,7 @@ via: https://opensource.com/article/18/5/how-insecure-your-router
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
让我们从 GitHub 中迁移出来
|
||||
======
|
||||
正如你们今天听到的那样,[微软正在收购 GitHub][1]。这对 GitHub 的未来意味着什么尚不清楚,但[ Gitlab 的人][2]认为微软的最终目标是将 GitHub 整合到他们的 Azure 帝国。对我来说,这很有道理。
|
||||
|
||||
正如你们之前听到的那样,[微软收购了 GitHub][1]。这对 GitHub 的未来意味着什么尚不清楚,但 [Gitlab 的人][2]认为微软的最终目标是将 GitHub 整合到他们的 Azure 帝国。对我来说,这很有道理。
|
||||
|
||||
尽管我仍然不情愿地将 GitHub 用于某些项目,但我前一段时间将所有个人仓库迁移到了 Gitlab 中。现在是时候让你做同样的事情,并抛弃 GitHub。
|
||||
|
||||
@ -10,20 +11,17 @@
|
||||
|
||||
让我们花点时间提醒自己:
|
||||
|
||||
* Windows 仍然是一个巨大的专有怪物,每天都会将数十亿人从隐私和权利中剥离出来。
|
||||
* 微软公司以传播自由软件的“危害”闻名,以防止政府和学校放弃 Windows,转而支持 FOSS。
|
||||
* 为了确保他们的垄断地位,微软通过向全世界的小学颁发“免费”许可证来吸引孩子使用 Windows。毒品经销商使用相同的策略并提供免费样品来获取新客户。
|
||||
* 微软的 Azure 平台 - 即使它可以运行 Linux 虚拟机 - 它仍然是一个巨大的专有管理程序。
|
||||
* Windows 仍然是一个巨大的专有怪物,数十亿人每天都丧失了他们的隐私和权利中。
|
||||
* 微软公司(曾经)以传播自由软件的“危害”闻名,以防止政府和学校放弃 Windows,转而支持 FOSS。
|
||||
* 为了确保他们的垄断地位,微软通过向全世界的小学颁发“免费”许可证来吸引孩子使用 Windows。毒品经销商使用相同的策略并提供免费样品来获取新客户。
|
||||
* 微软的 Azure 平台 - 即使它可以运行 Linux 虚拟机 - 它仍然是一个巨大的专有管理程序。
|
||||
|
||||
|
||||
|
||||
我知道移动 git 仓库看起来像是一件痛苦的事情,但是 Gitlab 的员工正在乘着离开 GitHub 的人们的浪潮,并通过[提供 GitHub 导入器][4]使迁移变得容易。
|
||||
我知道移动 git 仓库看起来像是一件痛苦的事情,但是 Gitlab 的员工正在乘着人们离开 GitHub 的浪潮,并通过[提供 GitHub 导入器][4]使迁移变得容易。
|
||||
|
||||
如果你不想使用 Gitlab 的主实例([gitlab.org][5]),下面是另外两个你可以用于自由软件项目的备选实例:
|
||||
|
||||
* [Debian Gitlab 实例][6]适用于每个 FOSS 项目,它不仅适用于与 Debian 相关的项目。只要项目符合[ Debian 自由软件指南][7],你就可以使用该实例及其 CI。
|
||||
* Riseup 为名为 [0xacab][8] 的激进项目维护了一个 Gitlab 实例。如果你的[理念与 Riseup 的一致][9],他们很乐意在那里托管你的项目。
|
||||
|
||||
* [Debian Gitlab 实例][6]适用于每个 FOSS 项目,它不仅适用于与 Debian 相关的项目。只要项目符合 [Debian 自由软件指南][7],你就可以使用该实例及其 CI。
|
||||
* Riseup 为名为 [0xacab][8] 的激进项目维护了一个 Gitlab 实例。如果你的[理念与 Riseup 的一致][9],他们很乐意在那里托管你的项目。
|
||||
|
||||
朋友不要再让人使用 Github 了。
|
||||
|
||||
@ -34,7 +32,7 @@ via: https://veronneau.org/lets-migrate-away-from-github.html
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
55
published/20180627 CIP- Keeping the Lights On with Linux.md
Normal file
55
published/20180627 CIP- Keeping the Lights On with Linux.md
Normal file
@ -0,0 +1,55 @@
|
||||
CIP:延续 Linux 之光
|
||||
======
|
||||
|
||||
> CIP 的目标是创建一个基本的系统,使用开源软件来为我们现代社会的基础设施提供动力。
|
||||
|
||||

|
||||
|
||||
|
||||
现如今,现代民用基础设施遍及各处 —— 发电厂、雷达系统、交通信号灯、水坝和天气系统等。这些基础设施项目已然存在数十年,这些设施还将继续提供更长时间的服务,所以安全性和使用寿命是至关重要的。
|
||||
|
||||
并且,其中许多系统都是由 Linux 提供支持,它为技术提供商提供了对这些问题的更多控制。然而,如果每个提供商都在构建自己的解决方案,这可能会导致分散和重复工作。因此,<ruby>[民用基础设施平台][1]<rt>Civil Infrastructure Platform</rt></ruby>(CIP)最首要的目标是创造一个开源基础层,提供给工业设施,例如嵌入式控制器或是网关设备。
|
||||
|
||||
担任 CIP 的技术指导委员会主席的 Yoshitake Kobayashi 说过,“我们在这个领域有一种非常保守的文化,因为一旦我们建立了一个系统,它必须得到长达十多年的支持,在某些情况下超过 60 年。这就是为什么这个项目被创建的原因,因为这个行业的每个使用者都面临同样的问题,即能够长时间地使用 Linux。”
|
||||
|
||||
CIP 的架构是创建一个非常基础的系统,以在控制器上使用开源软件。其中,该基础层包括 Linux 内核和一系列常见的开源软件如 libc、busybox 等。由于软件的使用寿命是一个最主要的问题,CIP 选择使用 Linux 4.4 版本的内核,这是一个由 Greg Kroah-Hartman 维护的长期支持版本。
|
||||
|
||||
### 合作
|
||||
|
||||
由于 CIP 有上游优先政策,因此他们在项目中需要的代码必须位于上游内核中。为了与内核社区建立积极的反馈循环,CIP 聘请 Ben Hutchings 作为 CIP 的官方维护者。Hutchings 以他在 Debian LTS 版本上所做的工作而闻名,这也促成了 CIP 与 Debian 项目之间的官方合作。
|
||||
|
||||
在新的合作下,CIP 将使用 Debian LTS 版本作为构建平台。 CIP 还将支持 Debian 长期支持版本(LTS),延长所有 Debian 稳定版的生命周期。CIP 还将与 Freexian 进行密切合作,后者是一家围绕 Debian LTS 版本提供商业服务的公司。这两个组织将专注于嵌入式系统的开源软件的互操作性、安全性和维护。CIP 还会为一些 Debian LTS 版本提供资金支持。
|
||||
|
||||
Debian 项目负责人 Chris Lamb 表示,“我们对此次合作以及 CIP 对 Debian LTS 项目的支持感到非常兴奋,这样将使支持周期延长至五年以上。我们将一起致力于为用户提供长期支持,并为未来的城市奠定基础。”
|
||||
|
||||
### 安全性
|
||||
|
||||
Kobayashi 说过,其中最需要担心的是安全性。虽然出于明显的安全原因,大部分民用基础设施没有接入互联网(你肯定不想让一座核电站连接到互联网),但也存在其他风险。
|
||||
|
||||
仅仅是系统本身没有连接到互联网,这并不意味着能避开所有危险。其他系统,比如个人移动电脑也能够通过接入互联网而间接入侵到本地系统中。如若有人收到一封带有恶意文件作为电子邮件的附件,这将会“污染”系统内部的基础设备。
|
||||
|
||||
因此,至关重要的是保持运行在这些控制器上的所有软件是最新的并且完全修补的。为了确保安全性,CIP 还向后移植了<ruby>内核自我保护<rt>Kernel Self Protection</rt></ruby>(KSP)项目的许多组件。CIP 还遵循最严格的网络安全标准之一 —— IEC 62443,该标准定义了软件的流程和相应的测试,以确保系统更安全。
|
||||
|
||||
### 展望未来
|
||||
|
||||
随着 CIP 日趋成熟,官方正在加大与各个 Linux 提供商的合作力度。除了与 Debian 和 freexian 的合作外,CIP 最近还邀请了企业 Linux 操作系统供应商 Cybertrust Japan Co., Ltd. 作为新的银牌成员。
|
||||
|
||||
Cybertrust 与其他行业领军者合作,如西门子、东芝、Codethink、日立、Moxa、Plat'Home 和瑞萨,致力于为未来数十年打造一个可靠、安全的基于 Linux 的嵌入式软件平台。
|
||||
|
||||
这些公司在 CIP 的保护下所进行的工作,将确保管理我们现代社会中的民用基础设施的完整性。
|
||||
|
||||
想要了解更多信息,请访问 [民用基础设施官网][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cip-project.org/
|
||||
@ -0,0 +1,75 @@
|
||||
使用 Ledger 记录(财务)情况
|
||||
======
|
||||
|
||||
自 2005 年搬到加拿大以来,我使用 [Ledger CLI][1] 来跟踪我的财务状况。我喜欢纯文本的方式,它支持虚拟信封意味着我可以同时将我的银行帐户余额和我的虚拟分配到不同的目录下。以下是我们如何使用这些虚拟信封分别管理我们的财务状况。
|
||||
|
||||
每个月,我都有一个条目将我生活开支分配到不同的目录中,包括家庭开支的分配。W- 不要求太多, 所以我要谨慎地处理这两者之间的差别和我自己的生活费用。我们处理它的方式是我支付固定金额,这是贷记我支付的杂货。由于我们的杂货总额通常低于我预算的家庭开支,因此任何差异都会留在标签上。我过去常常给他写支票,但最近我只是支付偶尔额外的大笔费用。
|
||||
|
||||
这是个示例信封分配:
|
||||
|
||||
```
|
||||
2014.10.01 * Budget
|
||||
[Envelopes:Living]
|
||||
[Envelopes:Household] $500
|
||||
;; More lines go here
|
||||
```
|
||||
|
||||
这是设置的信封规则之一。它鼓励我正确地分类支出。所有支出都从我的 “Play” 信封中取出。
|
||||
|
||||
```
|
||||
= /^Expenses/
|
||||
(Envelopes:Play) -1.0
|
||||
```
|
||||
|
||||
这个为家庭支出报销 “Play” 信封,将金额从 “Household” 信封转移到 “Play” 信封。
|
||||
|
||||
```
|
||||
= /^Expenses:House$/
|
||||
(Envelopes:Play) 1.0
|
||||
(Envelopes:Household) -1.0
|
||||
```
|
||||
|
||||
我有一套定期的支出来模拟我的预算中的家庭开支。例如,这是 10 月份的。
|
||||
|
||||
```
|
||||
2014.10.1 * House
|
||||
Expenses:House
|
||||
Assets:Household $-500
|
||||
```
|
||||
|
||||
这是杂货交易的形式:
|
||||
|
||||
```
|
||||
2014.09.28 * No Frills
|
||||
Assets:Household:Groceries $70.45
|
||||
Liabilities:MBNA:September $-70.45
|
||||
|
||||
```
|
||||
|
||||
接着 `ledger bal Assets:Household` 就会告诉我是否欠他钱(负余额)。如果我支付大笔费用(例如:机票、通管道),那么正常家庭开支预算会逐渐减少余额。
|
||||
|
||||
我从 W- 那找到了一个为我的信用卡交易添加一个月标签的技巧,他还使用 Ledger 跟踪他的交易。它允许我再次检查条目的余额,看看前一个条目是否已被正确清除。
|
||||
|
||||
这个资产分类使用有点奇怪,但它在精神上对我有用。
|
||||
|
||||
使用 Ledger 以这种方式跟踪它可以让我跟踪我们的杂货费用以及我实际支付费用和我预算费用之间的差额。如果我最终支出超出预期,我可以从更多可自由支配的信封中移动虚拟货币,因此我的预算始终保持平衡。
|
||||
|
||||
Ledger 是一个强大的工具。相当极客,但也许更多的工作流描述可能会帮助那些正在搞清楚它的人!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
|
||||
|
||||
作者:[Sacha Chua][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://sachachua.com
|
||||
[1]:http://www.ledger-cli.org/
|
||||
[2]:http://sachachua.com/blog/category/finance/
|
||||
[3]:http://sachachua.com/blog/tag/ledger/
|
||||
[4]:http://pages.sachachua.com/sharing/blog.html?url=http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
|
||||
[5]:http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/#comments
|
||||
@ -0,0 +1,99 @@
|
||||
如何记录你在终端中执行的所有操作
|
||||
======
|
||||
|
||||

|
||||
|
||||
几天前,我们发布了一个解释如何[保存终端中的命令并按需使用][1]的指南。对于那些不想记忆冗长的 Linux 命令的人来说,这非常有用。今天,在本指南中,我们将看到如何使用 `script` 命令记录你在终端中执行的所有操作。你可能已经在终端中运行了一个命令,或创建了一个目录,或者安装了一个程序。`script` 命令会保存你在终端中执行的任何操作。如果你想知道你几小时或几天前做了什么,那么你可以查看它们。我知道我知道,我们可以使用上/下箭头或 `history` 命令查看以前运行的命令。但是,你无法查看这些命令的输出。而 `script` 命令记录并显示完整的终端会话活动。
|
||||
|
||||
`script` 命令会在终端中创建你所做的所有事件的记录。无论你是安装程序,创建目录/文件还是删除文件夹,一切都会被记录下来,包括命令和相应的输出。这个命令对那些想要一份交互式会话拷贝作为作业证明的人有用。无论是学生还是导师,你都可以将所有在终端中执行的操作和所有输出复制一份。
|
||||
|
||||
### 在 Linux 中使用 script 命令记录终端中的所有内容
|
||||
|
||||
`script` 命令预先安装在大多数现代 Linux 操作系统上。所以,我们不用担心安装。
|
||||
|
||||
让我们继续看看如何实时使用它。
|
||||
|
||||
运行以下命令启动终端会话记录。
|
||||
|
||||
```
|
||||
$ script -a my_terminal_activities
|
||||
```
|
||||
|
||||
其中,`-a` 标志用于将输出追加到文件(记录)中,并保留以前的内容。上述命令会记录你在终端中执行的所有操作,并将输出追加到名为 `my_terminal_activities` 的文件中,并将其保存在当前工作目录中。
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Script started, file is my_terminal_activities
|
||||
```
|
||||
|
||||
现在,在终端中运行一些随机的 Linux 命令。
|
||||
|
||||
```
|
||||
$ mkdir ostechnix
|
||||
$ cd ostechnix/
|
||||
$ touch hello_world.txt
|
||||
$ cd ..
|
||||
$ uname -r
|
||||
```
|
||||
|
||||
运行所有命令后,使用以下命令结束 `script` 命令的会话:
|
||||
|
||||
```
|
||||
$ exit
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
exit
|
||||
Script done, file is my_terminal_activities
|
||||
```
|
||||
|
||||
如你所见,终端活动已存储在名为 `my_terminal_activities` 的文件中,并将其保存在当前工作目录中。
|
||||
|
||||
要查看你的终端活动,只需在任何编辑器中打开此文件,或者使用 `cat` 命令直接显示它。
|
||||
|
||||
```
|
||||
$ cat my_terminal_activities
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Script started on Thu 09 Mar 2017 03:33:44 PM IST
|
||||
[sk@sk]: ~>$ mkdir ostechnix
|
||||
[sk@sk]: ~>$ cd ostechnix/
|
||||
[sk@sk]: ~/ostechnix>$ touch hello_world.txt
|
||||
[sk@sk]: ~/ostechnix>$ cd ..
|
||||
[sk@sk]: ~>$ uname -r
|
||||
4.9.11-1-ARCH
|
||||
[sk@sk]: ~>$ exit
|
||||
exit
|
||||
|
||||
Script done on Thu 09 Mar 2017 03:37:49 PM IST
|
||||
```
|
||||
|
||||
正如你在上面的输出中看到的,`script` 命令记录了我所有的终端活动,包括 `script` 命令的开始和结束时间。真棒,不是吗?使用 `script` 命令的原因不仅仅是记录命令,还有命令的输出。简单地说,脚本命令将记录你在终端上执行的所有操作。
|
||||
|
||||
### 结论
|
||||
|
||||
就像我说的那样,脚本命令对于想要保留其终端活动记录的学生,教师和 Linux 用户非常有用。尽管有很多 CLI 和 GUI 可用来执行此操作,但 `script` 命令是记录终端会话活动的最简单快捷的方式。
|
||||
|
||||
就是这些。希望这有帮助。如果你发现本指南有用,请在你的社交,专业网络上分享,并支持我们。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/record-everything-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
@ -1,49 +1,45 @@
|
||||
使用 Ftrace 跟踪内核
|
||||
使用 ftrace 跟踪内核
|
||||
============================================================
|
||||
|
||||
标签: [ftrace][8],[kernel][9],[kernel profiling][10],[kernel tracing][11],[linux][12],[tracepoints][13]
|
||||
|
||||

|
||||
|
||||
在内核级别上分析事件有很多的工具:[SystemTap][14],[ktap][15],[Sysdig][16],[LTTNG][17]等等,并且你也可以在网络上找到关于这些工具的大量介绍文章和资料。
|
||||
在内核层面上分析事件有很多的工具:[SystemTap][14]、[ktap][15]、[Sysdig][16]、[LTTNG][17] 等等,你也可以在网络上找到关于这些工具的大量介绍文章和资料。
|
||||
|
||||
而对于使用 Linux 原生机制去跟踪系统事件以及检索/分析故障信息的方面的资料却很少找的到。这就是 [ftrace][18],它是添加到内核中的第一款跟踪工具,今天我们来看一下它都能做什么,让我们从它的一些重要术语开始吧。
|
||||
|
||||
### 内核跟踪和分析
|
||||
|
||||
内核分析可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个概述 — 一个事件的总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
|
||||
<ruby>内核分析<rt>Kernel profiling</rt></ruby>可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个<ruby>概述<rt>profile</rt></ruby> — 这是一个事件总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
|
||||
|
||||
瓶颈经常发生在无法通过分析来识别的情况下。去推断出为什么会发生事件,去保存发生事件时的相关上下文,这就需要去跟踪。
|
||||
瓶颈经常发生在无法通过分析来识别的情况下。要推断出为什么会发生事件,就必须保存发生事件时的相关上下文,这就需要去<ruby>跟踪<rt>tracing</rt></ruby>。
|
||||
|
||||
跟踪可以理解为在一个正常工作的系统上活动的信息收集进程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种注册的系统事件。
|
||||
跟踪可以理解为在一个正常工作的系统上活动的信息收集过程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种系统事件。
|
||||
|
||||
跟踪程序能够同时跟踪应用级和操作系统级的事件。它们收集的信息能够用于诊断多种系统问题。
|
||||
|
||||
有时候会将跟踪与日志比较。它们两者确时很相似,但是也有不同的地方。
|
||||
|
||||
对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登陆系统、应用程序错误、数据库事务等等。
|
||||
对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登录系统、应用程序错误、数据库事务等等。
|
||||
|
||||
就像日志一样,跟踪数据可以被原样读取,但是用特定的应用程序提取的信息更有用。所有的跟踪程序都能这样做。
|
||||
|
||||
在内核跟踪和分析方面,Linux 内核有三个主要的机制:
|
||||
|
||||
* 跟踪点 —— 一种基于静态测试代码的工作机制
|
||||
|
||||
* 探针 —— 一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回。
|
||||
|
||||
* perf_events —— 一个访问 PMU(性能监视单元)的接口
|
||||
* <ruby>跟踪点<rt>tracepoint</rt></ruby>:一种基于静态测试代码的工作机制
|
||||
* <ruby>探针<rt>kprobe</rt></ruby>:一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回
|
||||
* perf_events —— 一个访问 PMU(<ruby>性能监视单元<rt>Performance Monitoring Unit</rt></ruby>)的接口
|
||||
|
||||
我并不想在这里写关于这些机制方面的内容,任何对它们感兴趣的人可以去访问 [Brendan Gregg 的博客][19]。
|
||||
|
||||
使用 ftrace,我们可以与这些机制进行交互,并可以从用户空间直接得到调试信息。下面我们将讨论这方面的详细内容。示例中的所有命令行都是在内核版本为 3.13.0-24 的 Ubuntu 14.04 中运行的。
|
||||
|
||||
### Ftrace:常用信息
|
||||
### ftrace:常用信息
|
||||
|
||||
Ftrace 是函数 Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
|
||||
ftrace 是 Function Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
|
||||
|
||||
Ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 `Ring` 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
|
||||
ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 Ring 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
|
||||
|
||||
Ftrace 工作在 debugfs 文件系统上,这是在大多数现代 Linux 分发版中默认挂载的文件系统。为开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
|
||||
ftrace 工作在 debugfs 文件系统上,在大多数现代 Linux 发行版中都默认挂载了。要开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
|
||||
|
||||
```
|
||||
# cd /sys/kernel/debug/tracing
|
||||
@ -70,16 +66,13 @@ kprobe_profile stack_max_size uprobe_profile
|
||||
我不想去描述这些文件和子目录;它们的描述在 [官方文档][20] 中已经写的很详细了。我只想去详细介绍与我们这篇文章相关的这几个文件:
|
||||
|
||||
* available_tracers —— 可用的跟踪程序
|
||||
|
||||
* current_tracer —— 正在运行的跟踪程序
|
||||
|
||||
* tracing_on —— 负责启用或禁用数据写入到 `Ring` 缓冲区的系统文件(如果启用它,在文件中添加数字 1,禁用它,添加数字 0)
|
||||
|
||||
* tracing_on —— 负责启用或禁用数据写入到 Ring 缓冲区的系统文件(如果启用它,数字 1 被添加到文件中,禁用它,数字 0 被添加)
|
||||
* trace —— 以人类友好格式保存跟踪数据的文件
|
||||
|
||||
### 可用的跟踪程序
|
||||
|
||||
我们可以使用如下的命令去查看可用的跟踪程序的一个列表
|
||||
我们可以使用如下的命令去查看可用的跟踪程序的一个列表:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing#: cat available_tracers
|
||||
@ -89,18 +82,14 @@ blk mmiotrace function_graph wakeup_rt wakeup function nop
|
||||
我们来快速浏览一下每个跟踪程序的特性:
|
||||
|
||||
* function —— 一个无需参数的函数调用跟踪程序
|
||||
|
||||
* function_graph —— 一个使用子调用的函数调用跟踪程序
|
||||
|
||||
* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 的用途)
|
||||
|
||||
* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 使用的)
|
||||
* mmiotrace —— 一个内存映射 I/O 操作跟踪程序
|
||||
|
||||
* nop —— 简化的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
|
||||
* nop —— 最简单的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
|
||||
|
||||
### 函数跟踪程序
|
||||
|
||||
在开始介绍函数跟踪程序 ftrace 之前,我们先看一下测试脚本:
|
||||
在开始介绍函数跟踪程序 ftrace 之前,我们先看一个测试脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
@ -117,7 +106,7 @@ less ${dir}/trace
|
||||
|
||||
这个脚本是非常简单的,但是还有几个需要注意的地方。命令 `sysctl ftrace.enabled=1` 启用了函数跟踪程序。然后我们通过写它的名字到 `current_tracer` 文件来启用 `current tracer`。
|
||||
|
||||
接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 `Ring` 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
|
||||
接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 Ring 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo 1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
|
||||
|
||||
我们为什么这样做呢?在两个 `echo` 命令之间,我们看到了命令 `sleep 1`。我们启用了缓冲区,运行了这个命令,然后禁用它。这将使跟踪程序采集了这个命令运行期间发生的所有系统调用的信息。
|
||||
|
||||
@ -156,21 +145,18 @@ less ${dir}/trace
|
||||
trace.sh-1295 [000] d... 90.502879: __acct_update_integrals <-acct_account_cputime
|
||||
```
|
||||
|
||||
这个输出以缓冲区中的信息条目数量和写入的条目数量开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
|
||||
这个输出以“缓冲区中的信息条目数量”和“写入的全部条目数量”开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
|
||||
|
||||
在这里有一个包含下列信息的函数列表:
|
||||
|
||||
* 进程标识符(PID)
|
||||
|
||||
* 运行这个进程的 CPU(CPU#)
|
||||
|
||||
* 进程开始时间(TIMESTAMP)
|
||||
|
||||
* 被跟踪函数的名字以及调用它的父级函数;例如,在我们输出的第一行,`rb_simple_write` 调用了 `mutex-unlock` 函数。
|
||||
|
||||
### Function_graph 跟踪程序
|
||||
### function_graph 跟踪程序
|
||||
|
||||
`function_graph` 跟踪程序的工作和函数一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
|
||||
function_graph 跟踪程序的工作和函数跟踪程序一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
|
||||
|
||||
我们来编辑一下最后一个示例的脚本:
|
||||
|
||||
@ -215,11 +201,11 @@ less ${dir}/trace
|
||||
0) ! 208.154 us | } /* ip_local_deliver_finish */
|
||||
```
|
||||
|
||||
在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(+)意思是这个函数花费的时间超过 10 毫秒;而感叹号(!)意思是这个函数花费的时间超过了 100 毫秒。
|
||||
在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(`+`)意思是这个函数花费的时间超过 10 毫秒;而感叹号(`!`)意思是这个函数花费的时间超过了 100 毫秒。
|
||||
|
||||
在 `FUNCTION_CALLS` 下面,我们可以看到每个函数调用的信息。
|
||||
|
||||
和 C 语言一样使用了花括号({)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(;)标记。
|
||||
和 C 语言一样使用了花括号(`{`)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(`;`)标记。
|
||||
|
||||
### 函数过滤器
|
||||
|
||||
@ -249,13 +235,13 @@ ftrace 还有很多过滤选项。对于它们更详细的介绍,你可以去
|
||||
|
||||
### 跟踪事件
|
||||
|
||||
我们在上面提到到跟踪点机制。跟踪点是插入的由系统事件触发的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
|
||||
我们在上面提到到跟踪点机制。跟踪点是插入的触发系统事件的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
|
||||
|
||||
静态跟踪点不会对系统有任何影响;它们只是增加几个字节用于调用测试函数以及在一个独立的节上增加一个数据结构。
|
||||
静态跟踪点不会对系统有任何影响;它们只是在测试的函数末尾增加几个字节的函数调用以及在一个独立的节上增加一个数据结构。
|
||||
|
||||
当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 `Ring` 缓冲区。
|
||||
当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 Ring 缓冲区。
|
||||
|
||||
跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(它在 [这里][22]):
|
||||
跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(取自 [这里][22]):
|
||||
|
||||
```
|
||||
{
|
||||
@ -294,7 +280,7 @@ fs kvm power scsi vfs
|
||||
ftrace kvmmmu printk signal vmscan
|
||||
```
|
||||
|
||||
所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 `Ring` 缓冲区写入:
|
||||
所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 Ring 缓冲区写入:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# cat tracing_on
|
||||
@ -306,25 +292,25 @@ root@andrei:/sys/kernel/debug/tracing# cat tracing_on
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 1 > tracing_on
|
||||
```
|
||||
|
||||
在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。为了跟踪,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
|
||||
在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。对于我们的跟踪程序,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo nop > current_tracer
|
||||
```
|
||||
|
||||
所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出多个系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
|
||||
所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出各种系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 1 > events/syscalls/sys_enter_chroot/enable
|
||||
```
|
||||
|
||||
然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息出现在输出中:
|
||||
然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [之前这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息不会出现在输出中:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 0 > tracing_on
|
||||
```
|
||||
|
||||
然后,我们去查看 `Ring` 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
|
||||
然后,我们去查看 Ring 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# сat trace
|
||||
@ -343,15 +329,10 @@ root@andrei:/sys/kernel/debug/tracing# сat trace
|
||||
在这篇文篇中,我们做了一个 ftrace 的功能概述。我们非常感谢你的任何意见或者补充。如果你想深入研究这个主题,我们为你推荐下列的资源:
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/tracepoints.txt][1] — 一个跟踪点机制的详细描述
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/events.txt][2] — 在 Linux 中跟踪系统事件的指南
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/ftrace.txt][3] — ftrace 的官方文档
|
||||
|
||||
* [https://lttng.org/files/thesis/desnoyers-dissertation-2009-12-v27.pdf][4] — Mathieu Desnoyers(作者是跟踪点和 LTTNG 的创建者)的关于内核跟踪和分析的学术论文。
|
||||
|
||||
* [https://lwn.net/Articles/370423/][5] — Steven Rostedt 的关于 ftrace 功能的文章
|
||||
|
||||
* [http://alex.dzyoba.com/linux/profiling-ftrace.html][6] — 用 ftrace 分析实际案例的一个概述
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -360,7 +341,7 @@ via:https://blog.selectel.com/kernel-tracing-ftrace/
|
||||
|
||||
作者:[Andrej Yemelianov][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,129 @@
|
||||
Ubunsys:面向 Ubuntu 资深用户的一个高级系统配置工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
**Ubunsys** 是一个面向 Ubuntu 及其衍生版的基于 Qt 的高级系统工具。高级用户可以使用命令行轻松完成大多数配置。不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如 Linux Mint、Elementary OS 等。Ubunsys 可用来修改系统配置,安装、删除、更新包和旧内核,启用或禁用 `sudo` 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的 Ubuntu 系统升级到最新版本等等。以上提到的所有功能都可以通过鼠标点击完成。你不需要再依赖于命令行模式,下面是你能用 Ubunsys 做到的事:
|
||||
|
||||
* 安装、删除、更新包
|
||||
* 更新和升级软件源
|
||||
* 安装主线内核
|
||||
* 删除旧的和不再使用的内核
|
||||
* 系统整体更新
|
||||
* 将系统升级到下一个可用的版本
|
||||
* 将系统升级到最新的开发版本
|
||||
* 清理系统垃圾文件
|
||||
* 在不输入密码的情况下启用或者禁用 `sudo` 权限
|
||||
* 当你在终端输入密码时使 `sudo` 密码可见
|
||||
* 启用或禁用系统休眠
|
||||
* 启用或禁用防火墙
|
||||
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件
|
||||
* 显示或者隐藏启动项
|
||||
* 启用或禁用登录音效
|
||||
* 配置双启动
|
||||
* 启用或禁用锁屏
|
||||
* 智能系统更新
|
||||
* 使用脚本管理器更新/一次性执行脚本
|
||||
* 从 `git` 执行常规用户安装脚本
|
||||
* 检查系统完整性和缺失的 GPG 密钥
|
||||
* 修复网络
|
||||
* 修复已破损的包
|
||||
* 还有更多功能在开发中
|
||||
|
||||
**重要提示:** Ubunsys 不适用于 Ubuntu 新手。它很危险并且仍然不是稳定版。它可能会使你的系统崩溃。如果你刚接触 Ubuntu 不久,不要使用。但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险。在使用这一应用之前记着备份你自己的重要数据。
|
||||
|
||||
### 安装 Ubunsys
|
||||
|
||||
Ubunsys 开发者制作了一个 PPA 来简化安装过程,Ubunsys 现在可以在 Ubuntu 16.04 LTS、 Ubuntu 17.04 64 位版本上使用。
|
||||
|
||||
逐条执行下面的命令,将 Ubunsys 的 PPA 添加进去,并安装它。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:adgellida/ubunsys
|
||||
sudo apt-get update
|
||||
sudo apt-get install ubunsys
|
||||
```
|
||||
|
||||
如果 PPA 无法使用,你可以在[发布页面][1]根据你自己当前系统,选择正确的安装包,直接下载并安装 Ubunsys。
|
||||
|
||||
### 用途
|
||||
|
||||
一旦安装完成,从菜单栏启动 Ubunsys。下图是 Ubunsys 主界面。
|
||||
|
||||
![][3]
|
||||
|
||||
你可以看到,Ubunsys 有四个主要部分,分别是 Packages、Tweaks、System 和 Repair。在每一个标签项下面都有一个或多个子标签项以对应不同的操作。
|
||||
|
||||
**Packages**
|
||||
|
||||
这一部分允许你安装、删除和更新包。
|
||||
|
||||
![][4]
|
||||
|
||||
**Tweaks**
|
||||
|
||||
在这一部分,我们可以对系统进行多种调整,例如:
|
||||
|
||||
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件;
|
||||
* 配置双启动;
|
||||
* 启用或禁用登录音效、防火墙、锁屏、系统休眠、`sudo` 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用 `sudo` 权限(在不需要密码的情况下);
|
||||
* 在终端中输入密码时可见(禁用星号)。
|
||||
|
||||
![][5]
|
||||
|
||||
**System**
|
||||
|
||||
这一部分被进一步分成 3 个部分,每个都是针对某一特定用户类型。
|
||||
|
||||
**Normal user** 这一标签下的选项可以:
|
||||
|
||||
* 更新、升级包和软件源
|
||||
* 清理系统
|
||||
* 执行常规用户安装脚本
|
||||
|
||||
**Advanced user** 这一标签下的选项可以:
|
||||
|
||||
* 清理旧的/无用的内核
|
||||
* 安装主线内核
|
||||
* 智能包更新
|
||||
* 升级系统
|
||||
|
||||
**Developer** 这一部分可以将系统升级到最新的开发版本。
|
||||
|
||||
![][6]
|
||||
|
||||
**Repair**
|
||||
|
||||
这是 Ubunsys 的第四个也是最后一个部分。正如名字所示,这一部分能让我们修复我们的系统、网络、缺失的 GPG 密钥,和已经缺失的包。
|
||||
|
||||
![][7]
|
||||
|
||||
正如你所见,Ubunsys 可以在几次点击下就能完成诸如系统配置、系统维护和软件维护之类的任务。你不需要一直依赖于终端。Ubunsys 能帮你完成任何高级任务。再次声明,我警告你,这个应用不适合新手,而且它并不稳定。所以当你使用的时候,能会出现 bug 或者系统崩溃。在仔细研究过每一个选项的影响之后再使用它。
|
||||
|
||||
谢谢阅读!
|
||||
|
||||
### 参考资源
|
||||
|
||||
- [Ubunsys GitHub Repository][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wenwensnow](https://github.com/wenwensnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/adgellida/ubunsys/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
|
||||
[8]:https://github.com/adgellida/ubunsys
|
||||
@ -0,0 +1,183 @@
|
||||
Streams:一个新的 Redis 通用数据结构
|
||||
======
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,<ruby>流<rt>streams</rt></ruby>只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息(LCTT 译注:参见 [CAP 定理][1]) ,也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
|
||||
|
||||
然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis <ruby>列表<rt>list</rt></ruby>、<ruby>有序集<rt>sorted list</rt></ruby>、<ruby>发布/订阅<rt>Pub/Sub</rt></ruby>功能之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件建模。
|
||||
|
||||
有序集是内存消耗大户,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
|
||||
|
||||
列表有另外的问题,它在某些特定的用例中会产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
|
||||
对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想<ruby>“即发即弃”<rt>fire-and-forget</rt></ruby>的东西:保留一个历史是很重要的,不只是因为是断开之后会重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:比如在这 10 秒范围内温度读数是多少?
|
||||
|
||||
我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
|
||||
|
||||
### 起源
|
||||
|
||||
在 Redis 4.0 中引入模块之后,用户开始考虑他们自己怎么去修复这些问题。其中一个用户 Timothy Downs 通过 IRC 和我说道:
|
||||
|
||||
\<forkfork> 我计划给这个模块增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不导致 redis 内存激增的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
|
||||
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在<ruby>对数时间<rt>logarithmic time</rt></ruby>内访问范围。同时,我开始去读关于 Kafka 的流相关的内容以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka <ruby>消费组<rt>consumer groups</rt></ruby>的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
|
||||
|
||||
### 让我们写一些代码吧
|
||||
|
||||
从 Redis 大会回来后,整个夏天我都在实现一个叫 listpack 的库。这个库是 `ziplist.c` 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:以便在各种用例中替代 ziplists。
|
||||
|
||||
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是可索引的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我还在完成这个实现,不管怎样,现在在 Github 上的 Redis 的 streams 分支里它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有意思的事实:一,在那时只有消费群组是缺失的,加上一些不太重要的操作流的命令,但是,所有的大的方面都已经实现了。二,一旦各个方面比较稳定了之后,我决定大概用两个月的时间将所有的流的特性<ruby>向后移植<rt>backport</rt></ruby>到 4.0 分支。这意味着 Redis 用户想要使用流,不用等待 Redis 4.2 发布,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部实现。
|
||||
|
||||
### 教程:欢迎使用 Redis 的 streams
|
||||
|
||||
在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,而是一个<ruby>字段<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询更适用而且更快。在流中,每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 流的一个基本的命令是 `XADD`。是的,所有的 Redis 流命令都是以一个 `X` 为前缀的。
|
||||
|
||||
```
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
```
|
||||
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。上面示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名可以更好地利用内存。有意思的是,字段的排序是可以保证顺序的。`XADD` 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示由命令自动生成 ID。通常这样做就够了,但是也可以去强制指定一个 ID,这种情况用于复制这个命令到<ruby>从服务器<rt>slave server</rt></ruby>和 <ruby>AOF<rt>append-only file</rt></ruby> 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它只是一个毫秒级的 UNIX 时间戳。圆点(`.`)后面的数字 `0` 是一个序号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着,我们可以在流中增加所有想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实上它们与被添加到的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
|
||||
|
||||
正如你想的那样,快速添加两个条目后,结果是仅一个序号递增了。我们可以用一个 `MULTI`/`EXEC` 块来简单模拟“快速插入”:
|
||||
|
||||
```
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
```
|
||||
|
||||
在上面的示例中,也展示了无需指定任何初始<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50-150 个消息内容)的第一个消息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,使用相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;<ruby>流播<rt>streaming</rt></ruby>,它是通过 `XREAD` 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
|
||||
|
||||
```
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
```
|
||||
|
||||
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
|
||||
```
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
```
|
||||
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为 ID 的“序号” 部分可以省略。因此,你可以只指定“毫秒”时间即可,下面的命令的意思是:“从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
```
|
||||
|
||||
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,随后连续的 ID 只是增加了序号部分,所以可以使用 `XRANGE` 遍历整个流,接收每个调用的指定个数的元素。Redis 中的`*SCAN` 系列命令允许迭代 Redis 数据结构,尽管事实上它们不是为迭代设计的,但这样可以避免再犯相同的错误。
|
||||
|
||||
### 使用 XREAD 处理流播:阻塞新的数据
|
||||
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 `XRANGE` 是非常完美的。然而,在使用流的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的<ruby>汇聚池<rt>pooling</rt></ruby>。(对于 *某些* 应用程序来说,这可能是个好主意,因为它们仅是偶尔连接查询的)
|
||||
|
||||
`XREAD` 命令是为读取设计的,在同一个时间,从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,就解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据,并且多个客户端可以同时访问同一份数据。
|
||||
|
||||
这里有一个典型的 `XREAD` 调用示例:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
```
|
||||
|
||||
它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
|
||||
|
||||
如果我从另一个客户端发送这样的命令:
|
||||
|
||||
```
|
||||
> XADD otherstream * message “Hi There”
|
||||
```
|
||||
|
||||
在 `XREAD` 侧会出现什么情况呢?
|
||||
|
||||
```
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
```
|
||||
|
||||
与收到的数据一起,我们也得到了数据的关键字。在下次调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
```
|
||||
|
||||
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟之后再次连接(因为它处理消息需要时间,或者其它什么原因)。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
|
||||
|
||||
### 流封顶
|
||||
|
||||
目前看起来还不错……然而,有些时候,流需要删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
```
|
||||
|
||||
它是基本意思是,如果在流中添加新元素后发现消息数量超过了 `1000000` 个,那么就删除旧的消息,以便于元素总量重新回到 `1000000` 以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将消耗一些 CPU 资源,所以在计算 `MAXLEN` 之前,尽可能使用 `~` 符号,以表明我们不要求非常 *精确* 的 1000000 个消息,就是稍微多一些也不是大问题:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
```
|
||||
|
||||
这种方式的 XADD 仅当它可以删除整个节点的时候才会删除消息。相比普通的 `XADD`,这种方式几乎可以自由地对流进行封顶。
|
||||
|
||||
### 消费组(开发中)
|
||||
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。灵感也是来自 Kafka,尽管在这里是以不同的方式实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。相同组的所有客户端将自动得到 *不同的* 消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
|
||||
当指定组时,能够指定一个 `RETRY <milliseconds>` 选项去扩展组:在这种情况下,如果消息没有通过 `XACK` 进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
|
||||
|
||||
### 内存使用和节省加载时间
|
||||
|
||||
因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,该格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
|
||||
|
||||
我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
### 关于最终发布时间的结论
|
||||
|
||||
Redis 的流特性将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难以解决的情况:那意味着你(之前)需要创造性地“滥用”当前提供的数据结构去解决那些问题。一个非常重要的使用场景是时间序列,但是,我觉得对于其它场景来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用场景。现在,如果你想在有问题环境中评估这个新数据结构,可以更新 GitHub 上的 streams 分支开始试用。欢迎向我们报告所有的 bug。:-)
|
||||
|
||||
如果你喜欢观看视频的方式,这里有一个现场演示:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
---
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://antirez.com/
|
||||
[1]: https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
|
||||
@ -1,40 +1,41 @@
|
||||
通过构建一个区块链来学习区块链技术
|
||||
想学习区块链?那就用 Python 构建一个
|
||||
======
|
||||
|
||||
> 了解区块链是如何工作的最快的方法是构建一个。
|
||||
|
||||

|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术是什么。
|
||||
|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术基础是什么。
|
||||
|
||||
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
|
||||
|
||||
我喜欢在实践中学习。这迫使我去处理被卡在代码级别上的难题。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
我喜欢在实践中学习。这会使得我在代码层面上处理主要问题,从而可以让我坚持到底。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
|
||||
### 开始之前 …
|
||||
|
||||
记住,区块链是一个 _不可更改的、有序的_ 被称为区块的记录链。它们可以包括事务~~(交易???校对确认一下,下同)~~、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
记住,区块链是一个 _不可更改的、有序的_ 记录(被称为区块)的链。它们可以包括<ruby>交易<rt>transaction</rt></ruby>、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
|
||||
如果你不知道哈希是什么,[这里有解释][1]。
|
||||
|
||||
**_本指南的目标读者是谁?_** 你应该能很容易地读和写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
**_本指南的目标读者是谁?_** 你应该能轻松地读、写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
|
||||
**_我需要做什么?_** 确保安装了 [Python 3.6][2]+(以及 `pip`),还需要去安装 Flask 和非常好用的 Requests 库:
|
||||
|
||||
```
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
```
|
||||
|
||||
当然,你也需要一个 HTTP 客户端,像 [Postman][3] 或者 cURL。哪个都行。
|
||||
|
||||
**_最终的代码在哪里可以找到?_** 源代码在 [这里][4]。
|
||||
|
||||
* * *
|
||||
|
||||
### 第 1 步:构建一个区块链
|
||||
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人 ❤️ [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将使用一个单个的文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人喜欢 [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将仅使用一个文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
|
||||
#### 描述一个区块链
|
||||
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存事务。下面是我们的类规划:
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存交易。下面是我们的类规划:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -58,15 +59,16 @@ class Blockchain(object):
|
||||
@property
|
||||
def last_block(self):
|
||||
# Returns the last Block in the chain
|
||||
pass
|
||||
pass
|
||||
```
|
||||
|
||||
*我们的 Blockchain 类的原型*
|
||||
|
||||
我们的区块链类负责管理链。它将存储事务并且有一些为链中增加新区块的助理性质的方法。现在我们开始去充实一些类的方法。
|
||||
我们的 `Blockchain` 类负责管理链。它将存储交易并且有一些为链中增加新区块的辅助性质的方法。现在我们开始去充实一些类的方法。
|
||||
|
||||
#### 一个区块是什么样子的?
|
||||
#### 区块是什么样子的?
|
||||
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个事务的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个交易的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
|
||||
单个区块的示例应该是下面的样子:
|
||||
|
||||
@ -86,13 +88,15 @@ block = {
|
||||
}
|
||||
```
|
||||
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。这一点非常重要,因为这就是区块链不可更改的原因:如果攻击者修改了一个早期的区块,那么所有的后续区块将包含错误的哈希。
|
||||
*我们的区块链中的块示例*
|
||||
|
||||
这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。**这一点非常重要,因为这就是区块链不可更改的原因**:如果攻击者修改了一个早期的区块,那么**所有**的后续区块将包含错误的哈希。
|
||||
|
||||
#### 添加事务到一个区块
|
||||
*这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。*
|
||||
|
||||
我们将需要一种区块中添加事务的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
#### 添加交易到一个区块
|
||||
|
||||
我们将需要一种区块中添加交易的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -113,14 +117,14 @@ class Blockchain(object):
|
||||
'amount': amount,
|
||||
})
|
||||
|
||||
return self.last_block['index'] + 1
|
||||
return self.last_block['index'] + 1
|
||||
```
|
||||
|
||||
在 `new_transaction()` 运行后将在列表中添加一个事务,它返回添加事务后的那个区块的索引 —— 那个区块接下来将被挖矿。提交事务的用户后面会用到这些。
|
||||
在 `new_transaction()` 运行后将在列表中添加一个交易,它返回添加交易后的那个区块的索引 —— 那个区块接下来将被挖矿。提交交易的用户后面会用到这些。
|
||||
|
||||
#### 创建新区块
|
||||
|
||||
当我们的区块链被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
当我们的 `Blockchain` 被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
|
||||
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 `new_block()`、`new_transaction()` 以及 `hash()`:
|
||||
|
||||
@ -190,18 +194,18 @@ class Blockchain(object):
|
||||
|
||||
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
|
||||
block_string = json.dumps(block, sort_keys=True).encode()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
```
|
||||
|
||||
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
|
||||
|
||||
#### 理解工作量证明
|
||||
|
||||
一个工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
<ruby>工作量证明<rt>Proof of Work</rt></ruby>(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
|
||||
我们来看一个非常简单的示例来帮助你了解它。
|
||||
|
||||
我们来解决一个问题,一些整数 x 乘以另外一个整数 y 的结果的哈希值必须以 0 结束。因此,hash(x * y) = ac23dc…0。为简单起见,我们先把 x = 5 固定下来。在 Python 中的实现如下:
|
||||
我们来解决一个问题,一些整数 `x` 乘以另外一个整数 `y` 的结果的哈希值必须以 `0` 结束。因此,`hash(x * y) = ac23dc…0`。为简单起见,我们先把 `x = 5` 固定下来。在 Python 中的实现如下:
|
||||
|
||||
```
|
||||
from hashlib import sha256
|
||||
@ -215,19 +219,21 @@ while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
|
||||
print(f'The solution is y = {y}')
|
||||
```
|
||||
|
||||
在这里的答案是 y = 21。因为它产生的哈希值是以 0 结尾的:
|
||||
在这里的答案是 `y = 21`。因为它产生的哈希值是以 0 结尾的:
|
||||
|
||||
```
|
||||
hash(5 * 21) = 1253e9373e...5e3600155e860
|
||||
```
|
||||
|
||||
在比特币中,工作量证明算法被称之为 [Hashcash][10]。与我们上面的例子没有太大的差别。这就是矿工们进行竞赛以决定谁来创建新块的算法。一般来说,其难度取决于在一个字符串中所查找的字符数量。然后矿工会因其做出的求解而得到奖励的币——在一个交易当中。
|
||||
|
||||
网络上的任何人都可以很容易地去核验它的答案。
|
||||
|
||||
#### 实现基本的 PoW
|
||||
|
||||
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
|
||||
|
||||
> 找出一个数字 p,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 0 组成。
|
||||
> 找出一个数字 `p`,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 `0` 组成。
|
||||
|
||||
```
|
||||
import hashlib
|
||||
@ -266,25 +272,21 @@ class Blockchain(object):
|
||||
|
||||
guess = f'{last_proof}{proof}'.encode()
|
||||
guess_hash = hashlib.sha256(guess).hexdigest()
|
||||
return guess_hash[:4] == "0000"
|
||||
return guess_hash[:4] == "0000"
|
||||
```
|
||||
|
||||
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
|
||||
|
||||
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
|
||||
|
||||
* * *
|
||||
|
||||
### 第 2 步:以 API 方式去访问我们的区块链
|
||||
|
||||
我们将去使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
我们将使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
|
||||
我们将创建三个方法:
|
||||
|
||||
* `/transactions/new` 在一个区块上创建一个新事务
|
||||
|
||||
* `/transactions/new` 在一个区块上创建一个新交易
|
||||
* `/mine` 告诉我们的服务器去挖矿一个新区块
|
||||
|
||||
* `/chain` 返回完整的区块链
|
||||
|
||||
#### 配置 Flask
|
||||
@ -332,33 +334,33 @@ def full_chain():
|
||||
return jsonify(response), 200
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
```
|
||||
|
||||
对上面的代码,我们做添加一些详细的解释:
|
||||
|
||||
* Line 15:实例化我们的节点。更多关于 Flask 的知识读 [这里][7]。
|
||||
|
||||
* Line 18:为我们的节点创建一个随机的名字。
|
||||
|
||||
* Line 21:实例化我们的区块链类。
|
||||
|
||||
* Line 24–26:创建 /mine 端点,这是一个 GET 请求。
|
||||
|
||||
* Line 28–30:创建 /transactions/new 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
|
||||
* Line 32–38:创建 /chain 端点,它返回全部区块链。
|
||||
|
||||
* Line 24–26:创建 `/mine` 端点,这是一个 GET 请求。
|
||||
* Line 28–30:创建 `/transactions/new` 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
* Line 32–38:创建 `/chain` 端点,它返回全部区块链。
|
||||
* Line 40–41:在 5000 端口上运行服务器。
|
||||
|
||||
#### 事务端点
|
||||
#### 交易端点
|
||||
|
||||
这就是对一个事务的请求,它是用户发送给服务器的:
|
||||
这就是对一个交易的请求,它是用户发送给服务器的:
|
||||
|
||||
```
|
||||
{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
|
||||
{
|
||||
"sender": "my address",
|
||||
"recipient": "someone else's address",
|
||||
"amount": 5
|
||||
}
|
||||
```
|
||||
|
||||
因为我们已经有了添加交易到块中的类方法,剩下的就很容易了。让我们写个函数来添加交易:
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
@ -383,18 +385,17 @@ def new_transaction():
|
||||
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
|
||||
|
||||
response = {'message': f'Transaction will be added to Block {index}'}
|
||||
return jsonify(response), 201
|
||||
return jsonify(response), 201
|
||||
```
|
||||
创建事务的方法
|
||||
|
||||
*创建交易的方法*
|
||||
|
||||
#### 挖矿端点
|
||||
|
||||
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
|
||||
|
||||
1. 计算工作量证明
|
||||
|
||||
2. 因为矿工(我们)添加一个事务而获得报酬,奖励矿工(我们) 1 个硬币
|
||||
|
||||
2. 因为矿工(我们)添加一个交易而获得报酬,奖励矿工(我们) 1 个币
|
||||
3. 通过将它添加到链上而打造一个新区块
|
||||
|
||||
```
|
||||
@ -434,10 +435,10 @@ def mine():
|
||||
'proof': block['proof'],
|
||||
'previous_hash': block['previous_hash'],
|
||||
}
|
||||
return jsonify(response), 200
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的区块链类的方法进行交互的。到目前为止,我们已经做到了,现在开始与我们的区块链去交互。
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的 `Blockchain` 类的方法进行交互的。到目前为止,我们已经做完了,现在开始与我们的区块链去交互。
|
||||
|
||||
### 第 3 步:与我们的区块链去交互
|
||||
|
||||
@ -447,24 +448,33 @@ return jsonify(response), 200
|
||||
|
||||
```
|
||||
$ python blockchain.py
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
我们通过生成一个 GET 请求到 http://localhost:5000/mine 去尝试挖一个区块:
|
||||
我们通过生成一个 `GET` 请求到 `http://localhost:5000/mine` 去尝试挖一个区块:
|
||||
|
||||
|
||||
使用 Postman 去生成一个 GET 请求
|
||||
|
||||
我们通过生成一个 POST 请求到 http://localhost:5000/transactions/new 去创建一个区块,它带有一个包含我们的事务结构的 `Body`:
|
||||
*使用 Postman 去生成一个 GET 请求*
|
||||
|
||||
我们通过生成一个 `POST` 请求到 `http://localhost:5000/transactions/new` 去创建一个区块,请求数据包含我们的交易结构:
|
||||
|
||||
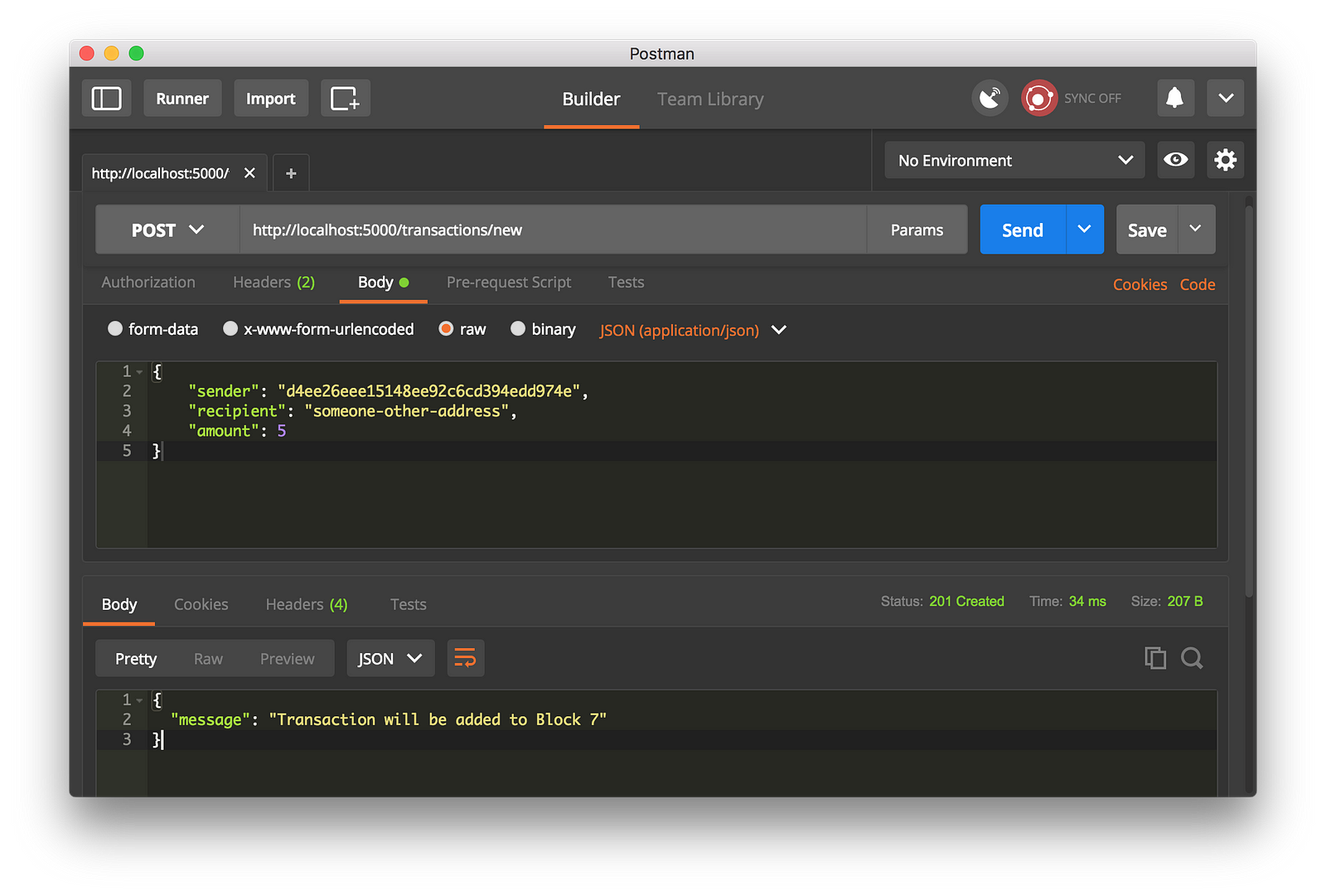
|
||||
使用 Postman 去生成一个 POST 请求
|
||||
|
||||
*使用 Postman 去生成一个 POST 请求*
|
||||
|
||||
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
|
||||
|
||||
```
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{
|
||||
"sender": "d4ee26eee15148ee92c6cd394edd974e",
|
||||
"recipient": "someone-other-address",
|
||||
"amount": 5
|
||||
}' "http://localhost:5000/transactions/new"
|
||||
```
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了3 个区块。我们通过请求 http://localhost:5000/chain 来检查整个区块链:
|
||||
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了 3 个区块。我们通过请求 `http://localhost:5000/chain` 来检查整个区块链:
|
||||
|
||||
```
|
||||
{
|
||||
"chain": [
|
||||
@ -503,18 +513,18 @@ $ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee151
|
||||
}
|
||||
],
|
||||
"length": 3
|
||||
}
|
||||
```
|
||||
### 第 4 步:共识
|
||||
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收事务并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收交易并允许我们去挖掘出新区块。但是区块链的整个重点在于它是<ruby>去中心化的<rt>decentralized</rt></ruby>。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是<ruby>共识<rt>Consensus</rt></ruby>问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
|
||||
#### 注册新节点
|
||||
|
||||
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
|
||||
|
||||
1. /nodes/register 以 URLs 的形式去接受一个新节点列表
|
||||
|
||||
2. /nodes/resolve 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
1. `/nodes/register` 以 URL 的形式去接受一个新节点列表
|
||||
2. `/nodes/resolve` 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
|
||||
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
|
||||
|
||||
@ -538,11 +548,12 @@ class Blockchain(object):
|
||||
"""
|
||||
|
||||
parsed_url = urlparse(address)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
```
|
||||
一个添加邻居节点到我们的网络的方法
|
||||
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的内容是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
*一个添加邻居节点到我们的网络的方法*
|
||||
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的节点是<ruby>幂等<rt>idempotent</rt></ruby>的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
|
||||
#### 实现共识算法
|
||||
|
||||
@ -615,12 +626,12 @@ class Blockchain(object)
|
||||
self.chain = new_chain
|
||||
return True
|
||||
|
||||
return False
|
||||
return False
|
||||
```
|
||||
|
||||
第一个方法 `valid_chain()` 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
|
||||
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。**如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。**
|
||||
|
||||
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
|
||||
|
||||
@ -658,18 +669,20 @@ def consensus():
|
||||
'chain': blockchain.chain
|
||||
}
|
||||
|
||||
return jsonify(response), 200
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
这种情况下,如果你愿意可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:[http://localhost:5000][9] 和 http://localhost:5001。
|
||||
这种情况下,如果你愿意,可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:`http://localhost:5000` 和 `http://localhost:5001`。
|
||||
|
||||
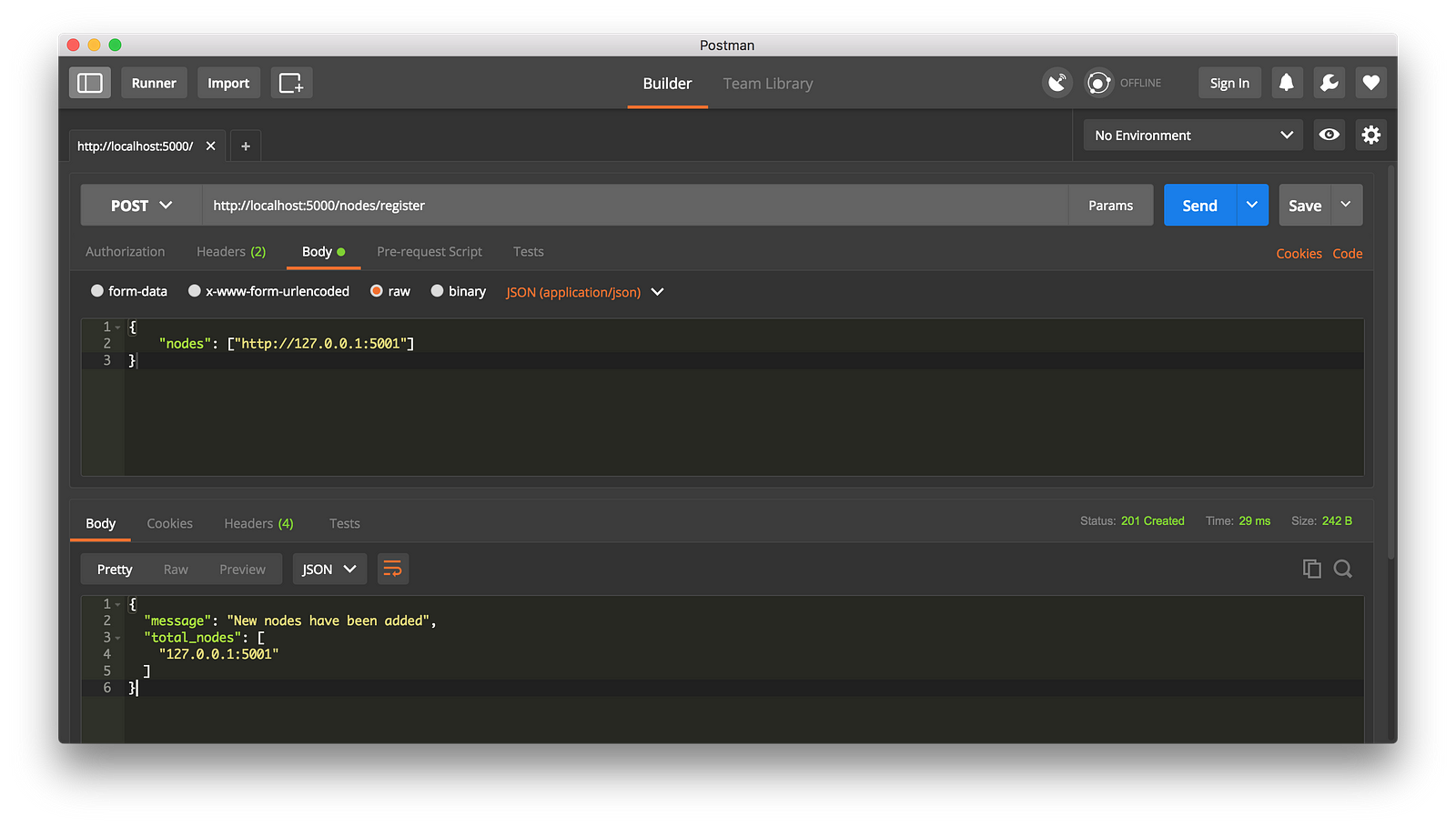
|
||||
注册一个新节点
|
||||
|
||||
*注册一个新节点*
|
||||
|
||||
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 `GET` 方式调用了 `/nodes/resolve`,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:
|
||||
|
||||
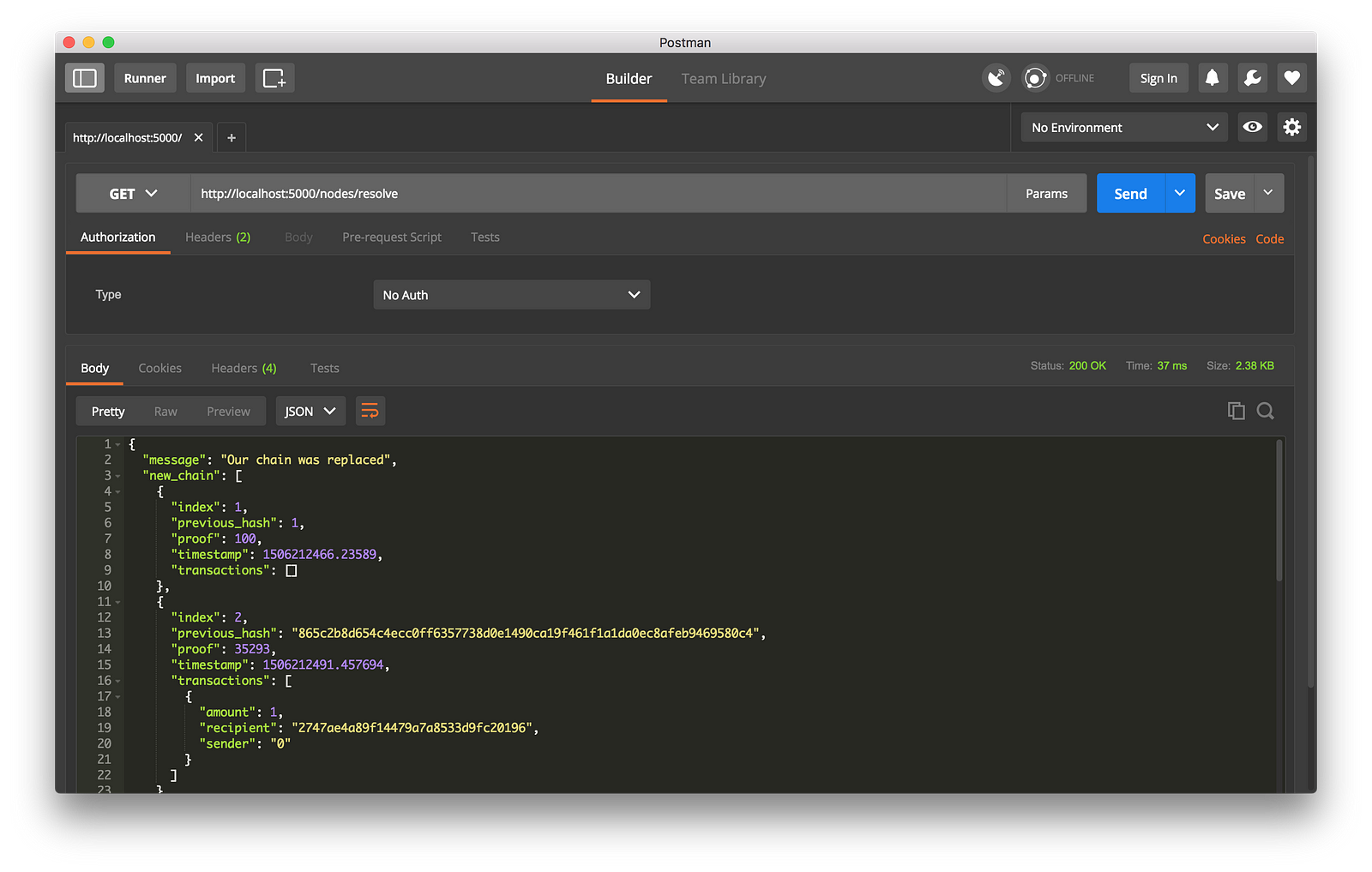
|
||||
工作中的共识算法
|
||||
|
||||
*工作中的共识算法*
|
||||
|
||||
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
|
||||
|
||||
@ -677,7 +690,7 @@ return jsonify(response), 200
|
||||
|
||||
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
|
||||
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备事务验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备交易验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。(LCTT 译注:第二篇并没有~!)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -685,7 +698,7 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
|
||||
作者:[Daniel van Flymen][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -699,3 +712,4 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
[7]:http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application
|
||||
[8]:http://localhost:5000/transactions/new
|
||||
[9]:http://localhost:5000
|
||||
[10]:https://en.wikipedia.org/wiki/Hashcash
|
||||
@ -1,12 +1,15 @@
|
||||
如何提升自动化的 ROI:4 个小提示
|
||||
======
|
||||
|
||||
> 想要在你的自动化项目上达成强 RIO?采取如下步骤来规避失败。
|
||||
|
||||

|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对成本随着工作量的增加而增加的这一事实可以重新定义而感到震惊。
|
||||
|
||||
机器人流程自动化(RPA)似乎预示着运营的圣杯(Holy Grail):“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对于可以重新定义成本随着工作量的增加而增加的这一事实而感到震惊。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处即实用可行度又高。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
<ruby>机器人流程自动化<rt>Robotic Process Automation</rt></ruby>(RPA)似乎预示着运营的<ruby>圣杯<rt>Holy Grail</rt></ruby>:“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处真实可及。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
|
||||
自动化的谈论都趋向于类似的话题:COO 们和他们的团队想知道,自动化操作能够给他们带来什么好处。他们想知道 RPA 平台特性和功能,以及自动化在现实中的真实案例。从这一点到概念验证的实现过程通常很短暂。
|
||||
|
||||
@ -14,7 +17,7 @@
|
||||
|
||||
但是自动化带来的现实好处有时候可能比你所预期的时间要晚。采用 RPA 的公司在其实施后可能会对它们自身的 ROI 提出一些质疑。一些人没有看到预期之中的成本节省,并对其中的原因感到疑惑。
|
||||
|
||||
## 你是不是自动化了错误的东西?
|
||||
### 你是不是自动化了错误的东西?
|
||||
|
||||
在这些情况下,自动化的愿景和现实之间的差距是什么呢?我们来分析一下它,在决定去继续进行一个自动化验证项目(甚至是一个成熟的实践)之后,我们来看一下通常会发生什么。
|
||||
|
||||
@ -26,7 +29,7 @@
|
||||
|
||||
那么,对于领导们来说,怎么才能确保实施自动化能够带来他们想要的 ROI 呢?实现这个目标有四步:
|
||||
|
||||
## 1. 教育团队
|
||||
### 1. 教育团队
|
||||
|
||||
在你的团队中,从 COO 职位以下的人中,很有可能都听说过 RPA 和运营自动化。同样很有可能他们都有许多的问题和担心。在你开始启动实施之前解决这些问题和担心是非常重要的。
|
||||
|
||||
@ -36,23 +39,23 @@
|
||||
|
||||
“实施自动化的第一步是更好地理解你的流程。”
|
||||
|
||||
## 2. 审查内部流程
|
||||
### 2. 审查内部流程
|
||||
|
||||
实施自动化的第一步是更好地理解你的流程。每个 RPA 实施之前都应该进行流程清单、动作分析、以及成本/价值的绘制练习。
|
||||
|
||||
这些练习对于理解流程中何处价值产生(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
这些练习对于理解流程中何处产生价值(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
|
||||
这将有助你去识别和优先考虑最合适的自动化候选者。由于能够或者可能需要自动化的任务数量较多,流程一般需要分段实施自动化,因此优先级很重要。
|
||||
|
||||
**建议**:设置一个小的工作团队,每个运营团队都参与其中。从每个运营团队中提名一个协调人 —— 一般是运营团队的领导或者团队管理者。在团队级别上组织一次研讨会,去构建流程清单、识别候选流程、以及推动购买。你的自动化合作伙伴很可能有“加速器” —— 调查问卷、计分卡等等 —— 这些将帮助你加速完成这项活动。
|
||||
|
||||
## 3. 为优先业务提供强有力的指导
|
||||
### 3. 为优先业务提供强有力的指导
|
||||
|
||||
实施自动化经常会涉及到在运营团队之间,基于业务价值对流程选择和自动化优先级上要达成共识(有时候是打破平衡)虽然团队的参与仍然是分析和实施的关键部分,但是领导仍然应该是最终的决策者。
|
||||
|
||||
**建议**:安排定期会议从工作团队中获取最新信息。除了像推动达成共识和购买之外,工作团队还应该在团队层面上去查看领导们关于 ROI、平台选择、以及自动化优先级上的指导性决定。
|
||||
|
||||
## 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
### 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
|
||||
当运营团队和技术团队紧密合作时,自动化的实施将异常顺利。COO 需要去帮助推动与 CIO 团队的合作。
|
||||
|
||||
@ -68,7 +71,7 @@ via: https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-
|
||||
|
||||
作者:[Rajesh Kamath][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user