mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge branch 'master' of github.com:LCTT/TranslateProject into newbranch
This commit is contained in:
commit
bd1d995216
@ -0,0 +1,82 @@
|
||||
ChromeOS 对战 Linux : 孰优孰劣,仁者见仁,智者见智
|
||||
================================================================================
|
||||
> 在 ChromeOS 和 Linux 的斗争过程中,两个桌面环境都有强有弱,这两者到底怎样呢?
|
||||
|
||||
只要稍加留意,任何人都会相信,Google 在桌面领域绝不是“玩玩而已”。在近几年,我们见到的 [ChromeOS][1] 制造的 [Google Chromebook][2] 相当的轰动。和同期人气火爆的 Amazon 一样,ChromeOS 似乎势不可挡。
|
||||
|
||||
在本文中,我们要了解的是 ChromeOS 的概念市场,ChromeOS 怎么影响着Linux 的份额,整个 ChromeOS 对于Linux 社区来说,是好事还是坏事。另外,我将会谈到一些重大问题,以及为什么没人针对这些问题做点什么。
|
||||
|
||||
### ChromeOS 并非真正的Linux ###
|
||||
|
||||
每当有朋友问我说 ChromeOS 是否是 Linux 的一个发行版时,我都会这样回答:ChromeOS 之于 Linux 就如同 OS X 之于 BSD。换句话说,我认为,ChromeOS 是 Linux 的一个派生操作系统,运行于 Linux 内核的引擎之下。而这个操作系统的大部分由 Google 的专利代码及软件组成。
|
||||
|
||||
尽管 ChromeOS 是利用了 Linux 的内核引擎,但是和现在流行的 Linux 分支版本相比,它仍然有很大的不同。
|
||||
|
||||
其实,ChromeOS 的差异化越来越明显的原因,是在于它给终端用户提供的包括 Web 应用在内的 app。因为ChromeOS 的每一个操作都是开始于浏览器窗口,这对于 Linux 用户来说,可能会有很多不一样的感受,但是,对于没有 Linux 经验的用户来说,这与他们使用的旧电脑并没有什么不同。
|
||||
|
||||
比方说,每一个以“依赖 Google 产品”为生活方式的人来说,在 ChromeOS 上的感觉将会非常良好,就好像是回家一样,特别是这个人已经接受了 Chrome 浏览器、Google Drive 云存储和Gmail 的话。久而久之,他们使用ChromeOS 也就是很自然的事情了,因为他们很容易接受使用早已习惯的 Chrome 浏览器。
|
||||
|
||||
然而,对于 Linux 爱好者来说,这样的约束就立即带来了不适应。因为软件的选择是被限制、被禁锢的,再加上要想玩游戏和 VoIP 是完全不可能的。对不起,因为 [GooglePlus Hangouts][3] 是代替不了VoIP 软件的。甚至这种情况将持续很长一段时间。
|
||||
|
||||
### ChromeOS 还是 Linux 桌面 ###
|
||||
|
||||
有人断言,ChromeOS 要是想在桌面系统的浪潮中对 Linux 产生影响,只有在 Linux 停下来浮出水面喘气的时候,或者是满足某个非技术用户的时候。
|
||||
|
||||
是的,桌面 Linux 对于大多数休闲型的用户来说绝对是一个好东西。然而,它必须有专人帮助你安装操作系统,并且提供“维修”服务,就如同我们在 Windows 和 OS X 阵营看到的一样。但是,令人失望的是,在美国, Linux 恰恰在这个方面很缺乏。所以,我们看到,ChromeOS 正慢慢的走入我们的视线。
|
||||
|
||||
我发现 Linux 桌面系统最适合那些能够提供在线技术支持的环境中。比如说:可以在家里操作和处理更新的高级用户、政府和学校的 IT 部门等等。这些环境中,Linux 桌面系统可以被配置给任何技能水平和背景的人使用。
|
||||
|
||||
相比之下,ChromeOS 是建立在完全免维护的初衷之下的,因此,不需要第三者的帮忙,你只需要允许更新,然后让他静默完成即可。这在一定程度上可能是由于 ChromeOS 是为某些特定的硬件结构设计的,这与苹果开发自己的PC 电脑也有异曲同工之妙。因为 Google 的 ChromeOS 伴随着其硬件一起提供,大部分情况下都无需担心错误的驱动、适配什么的问题。对于某些人来说,这太好了。
|
||||
|
||||
然而有些人则认为这是一个很严重的问题,不过滑稽的是,对 ChomeOS 来说,这些人压根就不在它的目标市场里。简言之,这只是一些狂热的 Linux 爱好者在对 ChomeOS 鸡蛋里挑骨头罢了。要我说,还是停止这些没必要的批评吧。
|
||||
|
||||
问题的关键在于:ChromeOS 的市场份额和 Linux 桌面系统在很长的一段时间内是不同的。这个局面可能会在将来被打破,然而在现在,仍然会是两军对峙的局面。
|
||||
|
||||
### ChromeOS 的使用率正在增长 ###
|
||||
|
||||
不管你对ChromeOS 有怎么样的看法,事实是,ChromeOS 的使用率正在增长。专门针对 ChromeOS 的电脑也一直有发布。最近,戴尔(Dell)也发布了一款针对 ChromeOS 的电脑。命名为 [Dell Chromebox][5],这款 ChromeOS 设备将会是对传统设备的又一次冲击。它没有软件光驱,没有反病毒软件,能够提供无缝的幕后自动更新。对于一般的用户,Chromebox 和 Chromebook 正逐渐成为那些工作在 Web 浏览器上的人们的一个可靠选择。
|
||||
|
||||
尽管增长速度很快,ChromeOS 设备仍然面临着一个很严峻的问题 - 存储。受限于有限的硬盘大小和严重依赖于云存储,ChromeOS 对于那些需要使用基本的浏览器功能之外的人们来说还不够用。
|
||||
|
||||
### ChromeOS 和 Linux 的异同点 ###
|
||||
|
||||
以前,我注意到 ChromeOS 和 Linux 桌面系统分别占有着两个完全不同的市场。出现这样的情况是源于 Linux 社区在线下的桌面支持上一直都有着极其糟糕的表现。
|
||||
|
||||
是的,偶然的,有些人可能会第一时间发现这个“Linux特点”。但是,并没有一个人接着跟进这些问题,确保得到问题的答案,以让他们得到 Linux 方面更多的帮助。
|
||||
|
||||
事实上,线下问题的出现可能是这样的:
|
||||
|
||||
- 有些用户偶然的在当地的 Linux 活动中发现了 Linux。
|
||||
- 他们带回了 DVD/USB 设备,并尝试安装这个操作系统。
|
||||
- 当然,有些人很幸运的成功完成了安装过程,但是,据我所知大多数的人并没有那么幸运。
|
||||
- 令人失望的是,这些人只能寄希望于在网上论坛里搜索帮助。他们很难通过主流的计算机网络经验或视频教程解决这些问题。
|
||||
-于是这些人受够了。后来有很多失望的用户拿着他们的电脑到 Windows 商店来“维修”。除了重装一个 Windows 操作系统,他们很多时候都会听到一句话,“Linux 并不适合你们”,应该尽量避免。
|
||||
|
||||
有些人肯定会说,上面的举例肯定夸大其词了。让我来告诉你:这是发生在我身边的真事,而且是经常发生。醒醒吧,Linux 社区的人们,我们的推广模式早已过期无力了。
|
||||
|
||||
### 伟大的平台,糟糕的营销和最终结论 ###
|
||||
|
||||
如果非要找一个 ChromeOS 和 Linux 桌面系统的共同点,除了它们都使用了 Linux 内核,那就是它们都是伟大的产品却拥有极其差劲的市场营销。对此,Google 认为自己的优势是,它能投入大量的资金在网上构建大面积存储空间。
|
||||
|
||||
Google 相信他们拥有“网上的优势”,而线下的问题不是很重要。这真是一个让人难以置信的目光短浅,这也成了Google 最严重的失误之一。而当地的 Linux 零售商则坚信,对于不怎么上网的人,自然不必担心他们会受到 Google巨大的在线存储的诱惑。
|
||||
|
||||
我的建议是:Linux 可以通过线下的努力,提供桌面系统,渗透 ChromeOS 市场。这就意味着 Linux 社区需要在节假日筹集资金来出席博览会、商场展览,并且在社区中进行免费的教学课程。这会立即使 Linux 桌面系统走入人们的视线,否则,最终将会是一个 ChromeOS 设备出现在人们的面前。
|
||||
|
||||
如果说本地的线下市场并没有像我说的这样,别担心。Linux 桌面系统的市场仍然会像 ChromeOS 一样增长。最坏也能保持现在这种两军对峙的市场局面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -0,0 +1,64 @@
|
||||
Linux上几款好用的字幕编辑器
|
||||
================================================================================
|
||||
如果你经常看国外的大片,你应该会喜欢带字幕版本而不是有国语配音的版本。我在法国长大,童年的记忆里充满了迪斯尼电影。但是这些电影因为有了法语的配音而听起来很怪。如果现在有机会能看原始的版本,我想,对于大多数的人来说,字幕还是必须的。我很高兴能为家人制作字幕。给我带来希望的是,Linux 也不乏有很多花哨、开源的字幕编辑器。总之一句话,文中Linux上字幕编辑器的列表并不详尽,你可以告诉我哪一款是你认为最好的字幕编辑器。
|
||||
|
||||
### 1. Gnome Subtitles ###
|
||||
|
||||
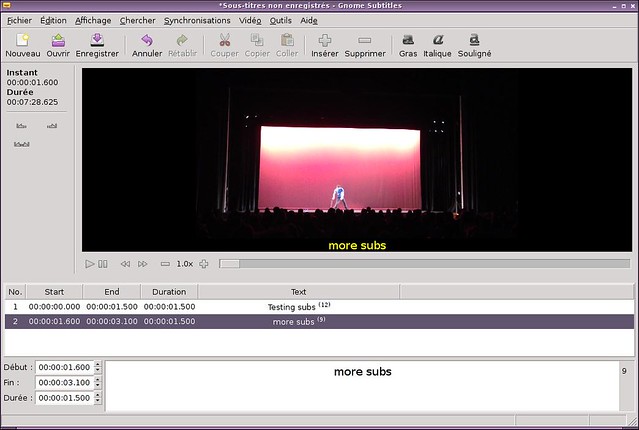
|
||||
|
||||
当有现有字幕需要快速编辑时,[Gnome Subtitles][1] 是我的一个选择。你可以载入视频,载入字幕文本,然后就可以即刻开始了。我很欣赏其对于易用性和高级特性之间的平衡。它带有一个同步工具以及一个拼写检查工具。最后但同样重要的的一点,这么好用最主要的是因为它的快捷键:当你编辑很多的台词的时候,你最好把你的手放在键盘上,使用其内置的快捷键来移动。
|
||||
|
||||
### 2. Aegisub ###
|
||||
|
||||
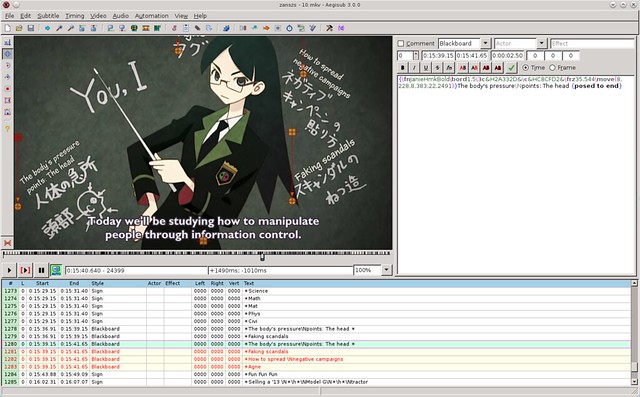
|
||||
|
||||
[Aegisub][2] 已经是一款高级别的复杂字幕编辑器。仅仅是界面就反映出了一定的学习曲线。但是,除了它吓人的样子以外,Aegisub 是一个非常完整的软件,提供的工具远远超出你能想象的。和Gnome Subtitles 一样,Aegisub也采用了所见即所得(WYSIWYG:what you see is what you get)的处理方式。但是是一个全新的高度:可以再屏幕上任意拖动字幕,也可以在另一边查看音频的频谱,并且可以利用快捷键做任何的事情。除此以外,它还带有一个汉字工具,有一个kalaok模式,并且你可以导入lua 脚本让它自动完成一些任务。我希望你在用之前,先去阅读下它的[指南][3]。
|
||||
|
||||
### 3. Gaupol ###
|
||||
|
||||

|
||||
|
||||
另一个操作复杂的软件是[Gaupol][4],不像Aegisub ,Gaupol 很容易上手而且采用了一个和Gnome Subtitles 很像的界面。但是在这些相对简单背后,它拥有很多很必要的工具:快捷键、第三方扩展、拼写检查,甚至是语音识别(由[CMU Sphinx][5]提供)。这里也提一个缺点,我注意到有时候在测试的时候也,软件会有消极怠工的表现,不是很严重,但是也足以让我更有理由喜欢Gnome Subtitles了。
|
||||
|
||||
### 4. Subtitle Editor ###
|
||||
|
||||
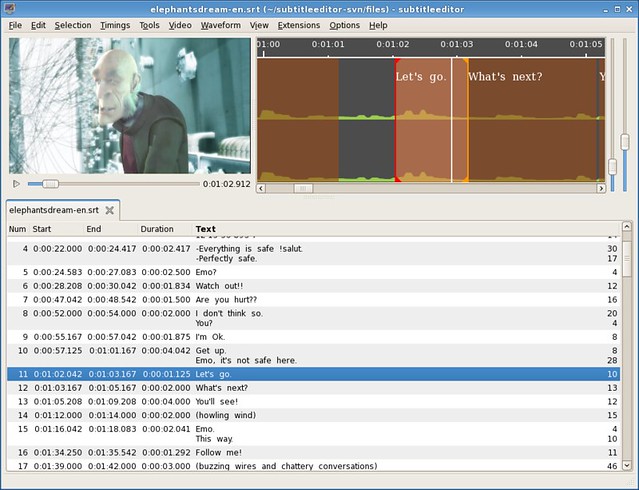
|
||||
|
||||
[Subtitle Editor][6]和 Gaupol 很像,但是它的界面有点不太直观,特性也只是稍微的高级一点点。我很欣赏的一点是,它可以定义“关键帧”,而且提供所有的同步选项。然而,多一点的图标,或者是少一点的文字都能提供界面的特性。作为一个值得称赞的字幕编辑器,Subtitle Editor 可以模仿“作家”打字的效果,虽然我不确定它是否特别有用。最后但同样重要的一点,重定义快捷键的功能很实用。
|
||||
|
||||
### 5. Jubler ###
|
||||
|
||||

|
||||
|
||||
[Jubler][7]是一个用Java编写并有多平台支持的字幕编辑器。我对它的界面印象特别深刻。在上面我确实看出了Java特点的东西,但是,它仍然是经过精心的构造和构思的。像Aegisub 一样,你可以再屏幕上任意的拖动字幕,让你有愉快的体验而不单单是打字。它也可以为字幕自定义一个风格,在另外的一个轨道播放音频,翻译字幕,或者是是做拼写检查。不过,要注意的是,你需要事先安装好媒体播放器并且正确的配置,如果你想完整的使用Jubler。我把这些归功于在[官方页面][8]下载了脚本以后其简便的安装方式。
|
||||
|
||||
### 6. Subtitle Composer ###
|
||||
|
||||

|
||||
|
||||
[Subtitle Composer][9]被视为“KDE里的字幕作曲家”,它能够唤起对很多传统功能的回忆。伴随着KDE界面,我们充满了期待。我们自然会说到快捷键,我特别喜欢这个功能。除此之外,Subtitle Composer 与上面提到的编辑器最大的不同地方就在于,它可以执行用JavaScript,Python,甚至是Ruby写成的脚本。软件带有几个例子,肯定能够帮助你很好的学习使用这些特性的语法。
|
||||
|
||||
最后,不管你是否喜欢,都来为你的家庭编辑几个字幕吧,重新同步整个轨道,或者是一切从头开始,那么Linux 有很好的工具给你。对我来说,快捷键和易用性使得各个工具有差异,想要更高级别的使用体验,脚本和语音识别就成了很便利的一个功能。
|
||||
|
||||
你会使用哪个字幕编辑器,为什么?你认为还有没有更好用的字幕编辑器这里没有提到的?在评论里告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://gnomesubtitles.org/
|
||||
[2]:http://www.aegisub.org/
|
||||
[3]:http://docs.aegisub.org/3.2/Main_Page/
|
||||
[4]:http://home.gna.org/gaupol/
|
||||
[5]:http://cmusphinx.sourceforge.net/
|
||||
[6]:http://home.gna.org/subtitleeditor/
|
||||
[7]:http://www.jubler.org/
|
||||
[8]:http://www.jubler.org/download.html
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
@ -1,22 +1,22 @@
|
||||
Linux用户应该了解一下开源硬件
|
||||
Linux用户,你们真的了解开源硬件吗?
|
||||
================================================================================
|
||||
> Linux用户不了解一点开源硬件制造相关的事情,他们将会很失望。
|
||||
> Linux用户不了解一点开源硬件制造相关的事情,他们就会经常陷入失望的情绪中。
|
||||
|
||||
商业软件和免费软件已经互相纠缠很多年了,但是这俩经常误解对方。这并不奇怪 -- 对一方来说是生意,而另一方只是一种生活方式。但是,这种误解会给人带来痛苦,这也是为什么值得花精力去揭露这里面的内幕。
|
||||
|
||||
一个逐渐普遍的现象:对开源硬件的不断尝试,不管是Canonical,Jolla,MakePlayLive,或者其他几个。不管是评论员或终端用户,一般的免费软件用户会为新的硬件平台发布表现出过分的狂热,然后因为不断延期有所醒悟,最终放弃整个产品。
|
||||
一个逐渐普遍的现象:对开源硬件的不断尝试,不管是Canonical,Jolla,MakePlayLive,或者其他公司。无论是评论员或是终端用户,通常免费软件用户都会为新的硬件平台发布表现出过分的狂热,然后因为不断延期有所醒悟,直到最终放弃整个产品。
|
||||
|
||||
这是一个没有人获益的怪圈,而且滋生出不信任 - 都是因为一般的Linux用户根本不知道这些新闻背后发生的事情。
|
||||
这是一个没有人获益的怪圈,而且常常滋生出不信任 - 都是因为一般的Linux用户根本不知道这些新闻背后发生的事情。
|
||||
|
||||
我个人对于把产品推向市场的经验很有限。但是,我还不知道谁能有所突破。推出一个开源硬件或其他产品到市场仍然不仅仅是个残酷的生意,而且严重不利于新加入的厂商。
|
||||
我个人对于把产品推向市场的经验很有限。但是,我还没听说谁能有所突破。推出一个开源硬件或其他产品到市场仍然不仅仅是个残酷的生意,而且严重不利于新进厂商。
|
||||
|
||||
### 寻找合作伙伴 ###
|
||||
|
||||
不管是数码产品的生产还是分销都被相对较少的一些公司控制着,有时需要数月的预订。利润率也会很低,所以就像那些购买古老情景喜剧的电影工作室一样,生成商一般也希望复制当前热销产品的成功。像Aaron Seigo在谈到他花精力开发Vivaldi平板时告诉我的,生产商更希望能由其他人去承担开发新产品的风险。
|
||||
不管是数码产品的生产还是分销都被相对较少的一些公司控制着,有时需要数月的预订。利润率也会很低,所以就像那些购买古老情景喜剧的电影工作室一样,生产商一般也希望复制当前热销产品的成功。像Aaron Seigo在谈到他花精力开发Vivaldi平板时告诉我的,生产商更希望能由其他人去承担开发新产品的风险。
|
||||
|
||||
不仅如此,他们更希望和那些有现成销售记录的有可能带来可复制生意的人合作。
|
||||
不仅如此,他们更希望和那些有现成销售记录的有可能带来长期客户生意的人合作。
|
||||
|
||||
而且,一般新加入的厂商所关心的产品只有几千的量。芯片制造商更愿意和苹果或三星合作,因为它们的订单很可能是几百K。
|
||||
而且,一般新加入的厂商所关心的产品只有几千的量。芯片制造商更愿意和苹果或三星这样的公司合作,因为它们的订单很可能是几十上百万的量。
|
||||
|
||||
面对这种情形,开源硬件制造者们可能会发现他们在工厂的列表中被淹没了,除非能找到二线或三线厂愿意尝试一下小批量生产新产品。
|
||||
|
||||
@ -28,9 +28,9 @@ Linux用户应该了解一下开源硬件
|
||||
|
||||
这样必然会引起潜在用户的批评,但是开源硬件制造者没得选,只能折中他们的愿景。寻找其他生产商也不能解决问题,有一个原因是这样做意味着更多延迟,但是更多的是因为完全免授权费的硬件是不存在的。像三星这样的业内巨头对免费硬件没有任何兴趣,而作为新人,开源硬件制造者也没有影响力去要求什么。
|
||||
|
||||
更何况,就算有免费硬件,生产商也不能保证会用在下一批生产中。制造者们会轻易地发现他们每次需要生产的时候都要重打一样的仗。
|
||||
更何况,就算有免费硬件,生产商也不能保证会用在下一批生产中。制造者们会轻易地发现他们每次需要生产的时候都要重打一次一模一样的仗。
|
||||
|
||||
这些都还不够,这个时候开源硬件制造者们也许已经花了6-12个月时间来讨价还价。机会来了,产业标准已经变更,他们也许为了升级产品规格又要从头来过。
|
||||
这些都还不够,这个时候开源硬件制造者们也许已经花了6-12个月时间来讨价还价。等机会终于来了,产业标准却已经变更,于是他们可能为了升级产品规格又要从头来过。
|
||||
|
||||
### 短暂而且残忍的货架期 ###
|
||||
|
||||
@ -42,15 +42,15 @@ Linux用户应该了解一下开源硬件
|
||||
|
||||
### 衡量整件怪事 ###
|
||||
|
||||
在这里我只是粗略地概括了一下,但是任何涉足过制造的人会认出我形容成标准的东西。而更糟糕的是,开源硬件制造者们通常在这个过程中才会有所觉悟。不可避免,他们也会犯错,从而带来更多的延迟。
|
||||
在这里我只是粗略地概括了一下,但是任何涉足过制造的人会认同我形容为行业标准的东西。而更糟糕的是,开源硬件制造者们通常只有在亲身经历过后才会有所觉悟。不可避免,他们也会犯错,从而带来更多的延迟。
|
||||
|
||||
但重点是,一旦你对整个过程有所了解,你对另一个开源硬件进行尝试的消息的反应就会改变。这个过程意味着,除非哪家公司处于严格的保密模式,对于产品将于六个月内发布的声明会很快会被证实是过期的推测。很可能是12-18个月,而且面对之前提过的那些困难很可能意味着这个产品永远不会真正发布。
|
||||
但重点是,一旦你对整个过程有所了解,你对另一个开源硬件进行尝试的新闻的反应就会改变。这个过程意味着,除非哪家公司处于严格的保密模式,对于产品将于六个月内发布的声明会很快会被证实是过期的推测。很可能是12-18个月,而且面对之前提过的那些困难很可能意味着这个产品永远都不会真正发布。
|
||||
|
||||
举个例子,就像我写的,人们等待第一代Steam Machines面世,它是一台基于Linux的游戏主机。他们相信Steam Machines能彻底改变Linux和游戏。
|
||||
|
||||
作为一个市场分类,Steam Machines也许比其他新产品更有优势,因为参与开发的人员至少有开发软件产品的经验。然而,整整一年过去了Steam Machines的开发成果都还只有原型机,而且直到2015年中都不一定能买到。面对硬件生产的实际情况,就算有一半能见到阳光都是很幸运了。而实际上,能发布2-4台也许更实际。
|
||||
|
||||
我做出这个预测并没有考虑个体努力。但是,对硬件生产的理解,比起那些Linux和游戏的黄金年代之类的预言,我估计这个更靠谱。如果我错了也会很开心,但是事实不会改变:让人吃惊的不是如此多的Linux相关硬件产品失败了,而是那些即使是短暂的成功的产品。
|
||||
我做出这个预测并没有考虑个体努力。但是,对硬件生产的理解,比起那些Linux和游戏的黄金年代之类的预言,我估计这个更靠谱。如果我错了也会很开心,但是事实不会改变:让人吃惊的不是如此多的Linux相关硬件产品失败了,而是那些虽然短暂但却成功的产品。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -58,7 +58,7 @@ via: http://www.datamation.com/open-source/what-linux-users-should-know-about-op
|
||||
|
||||
作者:[Bruce Byfield][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
66
published/20141108 When hackers grow old.md
Normal file
66
published/20141108 When hackers grow old.md
Normal file
@ -0,0 +1,66 @@
|
||||
ESR:黑客年暮
|
||||
================================================================================
|
||||
近来我一直在与某资深开源开发团队中的多个成员缠斗,尽管密切关注我的人们会在读完本文后猜到是哪个组织,但我不会在这里说出这个组织的名字。
|
||||
|
||||
怎么让某些人进入 21 世纪就这么难呢?真是的...
|
||||
|
||||
我快 56 岁了,也就是大部分年轻人会以为的我将时不时朝他们发出诸如“滚出我的草坪”之类歇斯底里咆哮的年龄。但事实并非如此 —— 我发现,尤其是在技术背景之下,我变得与我的年龄非常不相称。
|
||||
|
||||
在我这个年龄的大部分人确实变成了爱发牢骚、墨守成规的老顽固。并且,尴尬的是,偶尔我会成为那个打断谈话的人,我会指出他们某个在 1995 年(或者在某些特殊情况下,1985 年)时很适合的方法... 几十年后的今天就不再是好方法了。
|
||||
|
||||
为什么是我?因为年轻人在我的同龄人中很难有什么说服力。如果有人想让那帮老头改变主意,首先他得是自己同龄人中具有较高思想觉悟的佼佼者。即便如此,在与习惯做斗争的过程中,我也比看起来花费了更多的时间。
|
||||
|
||||
年轻人犯下无知的错误是可以被原谅的。他们还年轻。年轻意味着缺乏经验,缺乏经验通常会导致片面的判断。我很难原谅那些经历了足够多本该有经验的人,却被*长期的固化思维*蒙蔽,无法发觉近在咫尺的东西。
|
||||
|
||||
(补充一下:我真的不是保守党拥护者。那些和我争论政治的,无论保守党还是非保守党都没有注意到这点,我觉得这颇有点嘲讽的意味。)
|
||||
|
||||
那么,现在我们来讨论下 GNU 更新日志文件(ChangeLog)这件事。在 1985 年的时候,这是一个不错的主意,甚至可以说是必须的。当时的想法是用单独的更新日志条目来记录多个相关文件的变更情况。用这种方式来对那些存在版本缺失或者非常原始的版本进行版本控制确实不错。当时我也*在场*,所以我知道这些。
|
||||
|
||||
不过即使到了 1995 年,甚至 21 世纪早期,许多版本控制系统仍然没有太大改进。也就是说,这些版本控制系统并非对批量文件的变化进行分组再保存到一条记录上,而是对每个变化的文件分别进行记录并保存到不同的地方。CVS,当时被广泛使用的版本控制系统,仅仅是模拟日志变更 —— 并且在这方面表现得很糟糕,导致大多数人不再依赖这个功能。即便如此,更新日志文件的出现依然是必要的。
|
||||
|
||||
但随后,版本控制系统 Subversion 于 2003 年发布 beta 版,并于 2004 年发布 1.0 正式版,Subversion 真正实现了更新日志记录功能,得到了人们的广泛认可。它与一年后兴起的分布式版本控制系统(Distributed Version Control System,DVCS)共同引发了主流世界的激烈争论。因为如果你在项目上同时使用了分布式版本控制与更新日志文件记录的功能,它们将会因为争夺相同元数据的控制权而产生不可预料的冲突。
|
||||
|
||||
有几种不同的方法可以折衷解决这个问题。一种是继续将更新日志作为代码变更的授权记录。这样一来,你基本上只能得到简陋的、形式上的提交评论数据。
|
||||
|
||||
另一种方法是对提交的评论日志进行授权。如果你这样做了,不久后你就会开始思忖为什么自己仍然对所有的日志更新条目进行记录。提交元数据与变化的代码具有更好的相容性,毕竟这才是当初设计它的目的。
|
||||
|
||||
(现在,试想有这样一个项目,同样本着把项目做得最好的想法,但两拨人却做出了完全不同的选择。因此你必须同时阅读更新日志和评论日志以了解到底发生了什么。最好在矛盾激化前把问题解决....)
|
||||
|
||||
第三种办法是尝试同时使用以上两种方法 —— 在更新日志条目中,以稍微变化后的的格式复制一份评论数据,将其作为评论提交的一部分。这会导致各种你意想不到的问题,最具代表性的就是它不符合“真理的单点性(single point of truth)”原理;只要其中有拷贝文件损坏,或者日志文件条目被修改,这就不再是同步时数据匹配的问题,它将导致在其后参与进来的人试图搞清人们是怎么想的时候变得非常困惑。(LCTT 译注:《[程序员修炼之道][1]》(The Pragmatic Programmer):任何一个知识点在系统内都应当有一个唯一、明确、权威的表述。根据Brian Kernighan的建议,把这个原则称为“真理的单点性(Single Point of Truth)”或者SPOT原则。)
|
||||
|
||||
或者,正如这个*我就不说出具体名字的特定项目*所做的,它的高层开发人员在电子邮件中最近声明说,提交可以包含多个更新日志条目,并且提交的元数据与更新日志是无关的。这导致我们直到现在还得不断进行记录。
|
||||
|
||||
当时我读到邮件的时候都要吐了。什么样的傻瓜才会意识不到这是自找麻烦 —— 事实上,在 DVCS 中针对可靠的提交日志有很好的浏览工具,围绕更新日志文件的整个定制措施只会成为负担和拖累。
|
||||
|
||||
唉,这是比较特殊的笨蛋:变老的并且思维僵化了的黑客。所有的合理化改革他都会极力反对。他所遵循的行事方法在几十年前是有效的,但现在只能适得其反。如果你试图向他解释这些不仅仅和 git 的摘要信息有关,同时还为了正确适应当前的工具集,以便实现更新日志的去条目化... 呵呵,那你就准备好迎接无法忍受、无法想象的疯狂对话吧。
|
||||
|
||||
的确,它成功激怒了我。这样那样的胡言乱语使这个项目变成了很难完成的工作。而且,同样的糟糕还体现在他们吸引年轻开发者的过程中,我认为这是真正的问题。相关 Google+ 社区的人员数量已经达到了 4 位数,他们大部分都是孩子,还没有成长起来。显然外界已经接受了这样的信息:这个项目的开发者都是部落中地位根深蒂固的崇高首领,最好的崇拜方式就是远远的景仰着他们。
|
||||
|
||||
这件事给我的最大触动就是每当我要和这些部落首领较量时,我都会想:有一天我也会这样吗?或者更糟的是,我看到的只是如同镜子一般对我自己的真实写照,而我自己却浑然不觉?我的意思是,我所得到的印象来自于他的网站,这个特殊的笨蛋要比我年轻。年轻至少 15 岁呢。
|
||||
|
||||
我总是认为自己的思路很清晰。当我和那些比我聪明的人打交道时我不会受挫,我只会因为那些思路跟不上我、看不清事实的人而沮丧。但这种自信也许只是邓宁·克鲁格效应(Dunning-Krueger effect)在我身上的消极影响,我并不确定这意味着什么。很少有什么事情会让我感到害怕;而这件事在让我害怕的事情名单上是名列前茅的。
|
||||
|
||||
另一件让人不安的事是当我逐渐变老的时候,这样的矛盾发生得越来越频繁。不知怎的,我希望我的黑客同行们能以更加优雅的姿态老去,即使身体老去也应该保持一颗年轻的心灵。有些人确实是这样;但可惜绝大多数人都不是。真令人悲哀。
|
||||
|
||||
我不确定我的职业生涯会不会完美收场。假如我最后成功避免了思维僵化(注意我说的是假如),我想我一定知道其中的部分原因,但我不确定这种模式是否可以被复制 —— 为了达成目的也许得在你的头脑中发生一些复杂的化学反应。尽管如此,无论对错,请听听我给年轻黑客以及其他有志青年的建议。
|
||||
|
||||
你们——对的,也包括你——一定无法在你中年老年的时候保持不错的心灵,除非你能很好的控制这点。你必须不断地去磨练你的内心、在你还年轻的时候完成自己的种种心愿,你必须把这些行为养成一种习惯直到你老去。
|
||||
|
||||
有种说法是中年人锻炼身体的最佳时机是 30 岁以前。我以为同样的方法,坚持我以上所说的习惯能让你在 56 岁,甚至 65 岁的时候仍然保持灵活的头脑。挑战你的极限,使不断地挑战自己成为一种习惯。立刻离开安乐窝,由此当你以后真正需要它的时候你可以建立起自己的安乐窝。
|
||||
|
||||
你必须要清楚的了解这点;还有一个可选择的挑战是你选择一个可以实现的目标并且为了这个目标不断努力。这个月我要学习 Go 语言。不是指游戏,我早就玩儿过了(虽然玩儿的不是太好)。并不是因为工作需要,而是因为我觉得是时候来扩展下我自己了。
|
||||
|
||||
保持这个习惯。永远不要放弃。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=6485
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://book.51cto.com/art/200809/88490.htm
|
||||
@ -1,37 +1,40 @@
|
||||
四招搞定Linux内核热补丁
|
||||
不重启不当机!Linux内核热补丁的四种技术
|
||||
================================================================================
|
||||

|
||||
Credit: Shutterstock
|
||||
|
||||
多种技术在竞争成为实现inux内核热补丁的最优方案。
|
||||
供图: Shutterstock
|
||||
|
||||
有多种技术在竞争成为实现Linux内核热补丁的最优方案。
|
||||
|
||||
没人喜欢重启机器,尤其是涉及到一个内核问题的最新补丁程序。
|
||||
为达到不重启的目的,目前有3个项目在朝这方面努力,将为大家提供对内核进行运行时打热补丁的机制,这样就可以做到完全不重启机器。
|
||||
|
||||
为达到不重启的目的,目前有3个项目在朝这方面努力,将为大家提供内核升级时打热补丁的机制,这样就可以做到完全不重启机器。
|
||||
|
||||
### Ksplice项目 ###
|
||||
|
||||
首先要介绍的项目是Ksplice,它是热补丁技术的创始者,并于2008年建立了与项目同名的公司。Ksplice在替换新内核时,不需要预先修改;只需要一个diff文件,将内核的修改点列全即可。Ksplice公司免费提供软件,但技术支持是需要收费的,目前能够支持大部分常用的Linux发行版本。
|
||||
首先要介绍的项目是Ksplice,它是热补丁技术的创始者,并于2008年建立了与项目同名的公司。Ksplice在替换新内核时,不需要预先修改;只需要一个diff文件,列出内核即将接受的修改即可。Ksplice公司免费提供软件,但技术支持是需要收费的,目前能够支持大部分常用的Linux发行版本。
|
||||
|
||||
但在2011年[Oracle收购了这家公司][1]后,情况发生了变化。 这项功能被合入到Oracle的Linux发行版本中,且只对Oralcle的版本提供技术更新。 这就导致,其他内核hacker们开始寻找替代Ksplice的方法,以避免缴纳Oracle税。
|
||||
但在2011年[Oracle收购了这家公司][1]后,情况发生了变化。 这项功能被合入到Oracle自己的Linux发行版本中,只对Oralcle自己提供技术更新。 这就导致,其他内核hacker们开始寻找替代Ksplice的方法,以避免缴纳Oracle税。
|
||||
|
||||
### Kgraft项目 ###
|
||||
|
||||
2014年2月,Suse提供了一个很好的解决方案:[Kgraft][2],该技术以GPLv2/GPLv3混合许可证发布,且Suse不会将其作为一个专有的实现。Kgraft被[提交][3]到Linux内核主线,很有可能被内核主线采用。目前Suse已经把此技术集成到[Suse Linux Enterprise Server 12][4]。
|
||||
2014年2月,Suse提供了一个很好的解决方案:[Kgraft][2],该内核更新技术以GPLv2/GPLv3混合许可证发布,且Suse不会将其作为一个专有发明封闭起来。Kgraft被[提交][3]到Linux内核主线,很有可能被内核主线采用。目前Suse已经把此技术集成到[Suse Linux Enterprise Server 12][4]。
|
||||
|
||||
Kgraft和Ksplice在工作原理上很相似,都是使用一组diff文件来计算内核中需要修改的部分。但与Ksplice不同的是,Kgraft在做替换时,不需要完全停止内核。 在打补丁时,正在运行的函数可以先使用老版本中对应的部分,当补丁打完后就可以切换新的版本。
|
||||
Kgraft和Ksplice在工作原理上很相似,都是使用一组diff文件来计算内核中需要修改的部分。但与Ksplice不同的是,Kgraft在做替换时,不需要完全停止内核。 在打补丁时,正在运行的函数可以先使用老版本或新内核中对应的部分,当补丁打完后就可以完全切换新的版本。
|
||||
|
||||
### Kpatch项目 ###
|
||||
|
||||
Red Hat也提出了他们的内核热补丁技术。同样是在今年年初 -- 与Suse在这方面的工作差不多 -- [Kpatch][5]的工作原理也和Kgraft相似。
|
||||
Red Hat也提出了他们的内核热补丁技术。同样是在2014年初 -- 与Suse在这方面的工作差不多 -- [Kpatch][5]的工作原理也和Kgraft相似。
|
||||
|
||||
主要的区别点在于,正如Red Hat的Josh Poimboeuf[总结][6]的那样,Kpatch不能将内核调用重定向到老版本。相反,它会等待所有函数调用都停止时,再切换到新内核。Red Hat的工程师认为这种方法更为安全,且更容易维护,缺点就是在打补丁的过程中会带来更大的延迟。
|
||||
主要的区别点在于,正如Red Hat的Josh Poimboeuf[总结][6]的那样,Kpatch并不将内核调用重定向到老版本。相反,它会等待所有函数调用都停止时,再切换到新内核。Red Hat的工程师认为这种方法更为安全,且更容易维护,缺点就是在打补丁的过程中会带来更大的延迟。
|
||||
|
||||
和Kgraft一样,Kpatch不仅仅能在Red Hat的发行版本上可以使用,同时也被提交到了内核主线,作为一个可能的候选。 坏消息是Red Hat还未将此技术集成到产品中。 它只是被合入到了Red Hat Enterprise Linux 7的技术预览版中。
|
||||
和Kgraft一样,Kpatch不仅仅可以在Red Hat的发行版本上使用,同时也被提交到了内核主线,作为一个可能的候选。 坏消息是Red Hat还未将此技术集成到产品中。 它只是被合入到了Red Hat Enterprise Linux 7的技术预览版中。
|
||||
|
||||
### ...也许 Kgraft + Kpatch更合适? ###
|
||||
|
||||
Red Hat的工程师Seth Jennings在2014年11月初,提出了[第四种解决方案][7]。将Kgraft和Kpatch结合起来, 补丁包用这两种方式都可以。在新的方法中,Jennings提出,“热补丁核心为其他内核模块提供了热补丁的注册机制”, 通过这种方法,打补丁的过程 -- 更准确的说,如何处理运行时内核调用 --可以被更加有序的进行。
|
||||
Red Hat的工程师Seth Jennings在2014年11月初,提出了[第四种解决方案][7]。将Kgraft和Kpatch结合起来, 补丁包用这两种方式都可以。在新的方法中,Jennings提出,“热补丁核心为其他内核模块提供了一个热补丁的注册接口”, 通过这种方法,打补丁的过程 -- 更准确的说,如何处理运行时内核调用 --可以被更加有序的组织起来。
|
||||
|
||||
这项新建议也意味着两个方案都还需要更长的时间,才能被linux内核正式采纳。尽管Suse步子迈得更快,并把Kgraft应用到了最新的enterprise版本中。让我们也关注一下Red Hat和Linux官方近期的动态。
|
||||
这项新建议也意味着两个方案都还需要更长的时间,才能被linux内核正式采纳。尽管Suse步子迈得更快,并把Kgraft应用到了最新的enterprise版本中。让我们也关注一下Red Hat和Canonical近期是否会跟进。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -40,7 +43,7 @@ via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-fo
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[tinyeyeser](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -51,4 +54,4 @@ via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-fo
|
||||
[4]:http://www.infoworld.com/article/2838421/linux/suse-linux-enterprise-12-goes-light-on-docker-heavy-on-reliability.html
|
||||
[5]:https://github.com/dynup/kpatch
|
||||
[6]:https://lwn.net/Articles/597123/
|
||||
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||
@ -1,10 +1,8 @@
|
||||
Translated by H-mudcup
|
||||
|
||||
2014年Linux界发生的好事,坏事和丑事
|
||||
================================================================================
|
||||

|
||||
|
||||
2014年已经接近尾声,现在正是盘点**2014年Linux大事件**的时候。整整一年,我们关注了有关Linux和开源的一些好事,坏事和丑事。让我们来快速回顾一下2014对于Linux是怎样的一年。
|
||||
2014年已经过去,现在正是盘点**2014年Linux大事件**的时候。整整一年,我们关注了有关Linux和开源的一些好事,坏事和丑事。让我们来快速回顾一下2014对于Linux是怎样的一年。
|
||||
|
||||
### 好事 ###
|
||||
|
||||
@ -14,7 +12,7 @@ Translated by H-mudcup
|
||||
|
||||

|
||||
|
||||
从使用Wine到[使用Chrome的测试功能][1],为了能让Netflix能在Linux上工作,Linux用户曾尝试了各种方法。好消息是Netflix终于在2014年带来了Linux的本地支持。这让所有能使用Netflix的地区的Linux用户的脸上浮现出了微笑。想在[美国以外的地区使用Netflix][2](或其他官方授权使用Netflix的国家之外)的人还是得靠其他的方法。
|
||||
从使用Wine到[使用Chrome的测试功能][1],为了能让Netflix能在Linux上工作,Linux用户曾尝试了各种方法。好消息是Netflix终于在2014年带来了Linux的本地支持。这让所有能使用Netflix的地区的Linux用户的脸上浮现出了微笑。不过,想在[美国以外的地区使用Netflix][2](或其他官方授权使用Netflix的国家之外)的人还是得靠其他的方法。
|
||||
|
||||
#### 欧洲国家采用开源/Linux ####
|
||||
|
||||
@ -30,19 +28,19 @@ Translated by H-mudcup
|
||||
|
||||
### 坏事 ###
|
||||
|
||||
Linux在2014年并不是一帆风顺。某些事件的发生损坏了Linux/开源的形象。
|
||||
Linux在2014年并不是一帆风顺。某些事件的发生败坏了Linux/开源的形象。
|
||||
|
||||
#### Heartbleed心血 ####
|
||||
#### Heartbleed 心血漏洞 ####
|
||||
|
||||

|
||||
|
||||
在今年的四月份,检测到[OpenSSL][8]有一个缺陷。这个漏洞被命名为[Heartbleed心血][9]。他影响了包括Facebook和Google在内的50多万个“安全”网站。这项漏洞可以真正的允许任何人读取系统的内存,并能因此给予用于加密数据流的密匙的访问权限。[xkcd上的漫画以更简单的方式解释了心血][10]。不必说,这个漏洞在OpenSSL的更新中被修复了。
|
||||
在今年的四月份,检测到[OpenSSL][8]有一个缺陷。这个漏洞被命名为[Heartbleed心血漏洞][9]。他影响了包括Facebook和Google在内的50多万个“安全”网站。这项漏洞可以真正的允许任何人读取系统的内存,并能因此给予用于加密数据流的密匙的访问权限。[xkcd上的漫画以更简单的方式解释了心血漏洞][10]。自然,这个漏洞在OpenSSL的更新中被修复了。
|
||||
|
||||
#### Shellshock ####
|
||||
#### Shellshock 破壳漏洞 ####
|
||||
|
||||

|
||||
|
||||
好像有个心血还不够似的,在Bash里的一个缺陷更严重的震撼了Linux世界。这个漏洞被命名为[Shellshock][11]。这个漏洞把Linux往远程攻击的危险深渊又推了一把。这项漏洞是通过黑客的DDoS攻击暴露出来的。升级一下Bash版本应该能修复这个问题。
|
||||
好像有个心血漏洞还不够似的,在Bash里的一个缺陷更严重的震撼了Linux世界。这个漏洞被命名为[Shellshock 破壳漏洞][11]。这个漏洞把Linux往远程攻击的危险深渊又推了一把。这项漏洞是通过黑客的DDoS攻击暴露出来的。升级一下Bash版本应该能修复这个问题。
|
||||
|
||||
#### Ubuntu Phone和Steam控制台 ####
|
||||
|
||||
@ -52,13 +50,13 @@ Linux在2014年并不是一帆风顺。某些事件的发生损坏了Linux/开
|
||||
|
||||
### 丑事 ###
|
||||
|
||||
systemd的归属战变得不知廉耻。
|
||||
是否采用 systemd 的争论变得让人羞耻。
|
||||
|
||||
### systemd大论战 ###
|
||||
|
||||

|
||||
|
||||
用init还是systemd的争吵已经进行了一段时间了。但是在2014年当systemd准备在包括Debian, Ubuntu, OpenSUSE, Arch Linux and Fedora几个主流Linux分布中替代init时,事情变得不知廉耻了起来。它是如此的一发不可收拾,以至于它已经不限于boycottsystemd.org这类网站了。Lennart Poettering(systemd的首席开发人员及作者)在一条Google Plus状态上声明,说那些反对systemd的人在“收集比特币来雇杀手杀他”。Lennart还声称开源社区“是个恶心得不能待的地方”。人们吵得越来越离谱以至于把Debian分裂成了一个新的操作系统,称为[Devuan][15]。
|
||||
用init还是systemd的争吵已经进行了一段时间了。但是在2014年当systemd准备在包括Debian, Ubuntu, OpenSUSE, Arch Linux 和 Fedora几个主流Linux分布中替代init时,事情变得不知廉耻了起来。它是如此的一发不可收拾,以至于它已经不限于boycottsystemd.org这类网站了。Lennart Poettering(systemd的首席开发人员及作者)在一条Google Plus状态上声明,说那些反对systemd的人在“收集比特币来雇杀手杀他”。Lennart还声称开源社区“是个恶心得不能待的地方”。人们吵得越来越离谱以至于把Debian分裂成了一个新的操作系统,称为[Devuan][15]。
|
||||
|
||||
### 还有诡异的事 ###
|
||||
|
||||
@ -81,10 +79,10 @@ via: http://itsfoss.com/biggest-linux-stories-2014/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/watch-netflix-in-ubuntu-14-04/
|
||||
[1]:http://linux.cn/article-3024-1.html
|
||||
[2]:http://itsfoss.com/easiest-watch-netflix-hulu-usa/
|
||||
[3]:http://itsfoss.com/french-city-toulouse-saved-1-million-euro-libreoffice/
|
||||
[4]:http://itsfoss.com/italian-city-turin-open-source/
|
||||
[3]:http://linux.cn/article-3575-1.html
|
||||
[4]:http://linux.cn/article-3602-1.html
|
||||
[5]:http://itsfoss.com/170-primary-public-schools-geneva-switch-ubuntu/
|
||||
[6]:http://itsfoss.com/german-town-gummersbach-completes-switch-open-source/
|
||||
[7]:http://itsfoss.com/windows-10-inspired-linux/
|
||||
@ -95,8 +93,8 @@ via: http://itsfoss.com/biggest-linux-stories-2014/
|
||||
[12]:http://itsfoss.com/ubuntu-phone-specification-release-date-pricing/
|
||||
[13]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[14]:https://plus.google.com/+LennartPoetteringTheOneAndOnly/posts/J2TZrTvu7vd
|
||||
[15]:http://debianfork.org/
|
||||
[16]:http://thenewstack.io/microsoft-professes-love-for-linux-adds-support-for-coreos-cloudera-and-host-of-new-features/
|
||||
[15]:http://linux.cn/article-4512-1.html
|
||||
[16]:http://linux.cn/article-4056-1.html
|
||||
[17]:http://www.theregister.co.uk/2001/06/02/ballmer_linux_is_a_cancer/
|
||||
[18]:http://azure.microsoft.com/en-us/
|
||||
[19]:http://www.zdnet.com/article/top-five-linux-contributor-microsoft/
|
||||
@ -1,25 +0,0 @@
|
||||
Git 2.2.1 Released To Fix Critical Security Issue
|
||||
================================================================================
|
||||
|
||||
|
||||
Git 2.2.1 was released this afternoon to fix a critical security vulnerability in Git clients. Fortunately, the vulnerability doesn't plague Unix/Linux users but rather OS X and Windows.
|
||||
|
||||
Today's Git vulnerability affects those using the Git client on case-insensitive file-systems. On case-insensitive platforms like Windows and OS X, committing to .Git/config could overwrite the user's .git/config and could lead to arbitrary code execution. Fortunately with most Phoronix readers out there running Linux, this isn't an issue thanks to case-sensitive file-systems.
|
||||
|
||||
Besides the attack vector from case insensitive file-systems, Windows and OS X's HFS+ would map some strings back to .git too if certain characters are present, which could lead to overwriting the Git config file. Git 2.2.1 addresses these issues.
|
||||
|
||||
More details via the [Git 2.2.1 release announcement][1] and [GitHub has additional details][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=MTg2ODA
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://article.gmane.org/gmane.linux.kernel/1853266
|
||||
[2]:https://github.com/blog/1938-git-client-vulnerability-announced
|
||||
@ -1,168 +0,0 @@
|
||||
Translating By H-mudcup
|
||||
|
||||
Easy File Comparisons With These Great Free Diff Tools
|
||||
================================================================================
|
||||
by Frazer Kline
|
||||
|
||||
File comparison compares the contents of computer files, finding their common contents and their differences. The result of the comparison is often known as a diff.
|
||||
|
||||
diff is also the name of a famous console based file comparison utility that outputs the differences between two files. The diff utility was developed in the early 1970s on the Unix operating system. diff will output the parts of the files where they are different.
|
||||
|
||||
Linux has many good GUI tools that enable you to clearly see the difference between two files or two versions of the same file. This roundup selects 5 of my favourite GUI diff tools, with all but one released under an open source license.
|
||||
|
||||
These utilities are an essential software development tool, as they visualize the differences between files or directories, merge files with differences, resolve conflicts and save output to a new file or patch, and assist file changes reviewing and comment production (e.g. approving source code changes before they get merged into a source tree). They help developers work on a file, passing it back and forth between each other. The diff tools are not only useful for showing differences in source code files; they can be used on many text-based file types as well. The visualisations make it easier to compare files.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Meld is an open source graphical diff viewer and merge application for the Gnome desktop. It supports 2 and 3-file diffs, recursive directory diffs, diffing of directories under version control (Bazaar, Codeville, CVS, Darcs, Fossil SCM, Git, Mercurial, Monotone, Subversion), as well as the ability to manually and automatically merge file differences.
|
||||
|
||||
Meld's focus is on helping developers compare and merge source files, and get a visual overview of changes in their favourite version control system.
|
||||
|
||||
Features include
|
||||
|
||||
- Edit files in-place, and your comparison updates on-the-fly
|
||||
- Perform twoand three-way diffs and merges
|
||||
- Easily navigate between differences and conflicts
|
||||
- Visualise global and local differences with insertions, changes and conflicts marked
|
||||
- Built-in regex text filtering to ignore uninteresting differences
|
||||
- Syntax highlighting (with optional gtksourceview)
|
||||
- Compare two or three directories file-by-file, showing new, missing, and altered files
|
||||
- Directly open file comparisons of any conflicting or differing files
|
||||
- Filter out files or directories to avoid seeing spurious differences
|
||||
- Auto-merge mode and actions on change blocks help make merges easier
|
||||
- Simple file management is also available
|
||||
- Supports many version control systems, including Git, Mercurial, Bazaar and SVN
|
||||
- Launch file comparisons to check what changes were made, before you commit
|
||||
- View file versioning statuses
|
||||
- Simple version control actions are also available (i.e., commit/update/add/remove/delete files)
|
||||
- Automatically merge two files using a common ancestor
|
||||
- Mark and display the base version of all conflicting changes in the middle pane
|
||||
- Visualise and merge independent modifications of the same file
|
||||
- Lock down read-only merge bases to avoid mistakes
|
||||
- Command line interface for easy integration with existing tools, including git mergetool
|
||||
- Internationalization support
|
||||
- Visualisations make it easier to compare your files
|
||||
|
||||
- Website: [meldmerge.org][1]
|
||||
- Developer: Kai Willadsen
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.8.5
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
注:上面这个图访问不到,图的地址是原文地址的小图的链接地址,发布的时候在验证一下,如果还访问不到,不行先采用小图或者网上搜一下看有没有大图
|
||||
|
||||
DiffMerge is an application to visually compare and merge files on Linux, Windows, and OS X.
|
||||
|
||||
Features include:
|
||||
|
||||
- Graphically shows the changes between two files. Includes intra-line highlighting and full support for editing
|
||||
- Graphically shows the changes between 3 files. Allows automatic merging (when safe to do so) and full control over editing the resulting file
|
||||
- Performs a side-by-side comparison of 2 folders, showing which files are only present in one file or the other, as well as file pairs which are identical, equivalent or different
|
||||
- Rulesets and options provide for customized appearance and behavior
|
||||
- Unicode-based application and can import files in a wide range of character encodings
|
||||
- Cross-platform tool
|
||||
|
||||
- Website: [sourcegear.com/diffmerge][2]
|
||||
- Developer: SourceGear LLC
|
||||
- License: Licensed for use free of charge (not open source)
|
||||
- Version Number: 4.2
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
xxdiff is an open source graphical file and directories comparator and merge tool.
|
||||
|
||||
xxdiff can be used for viewing the differences between two or three files, or two directories, and can be used to produce a merged version. The texts of the two or three files are presented side by side with their differences highlighted with colors for easy identification.
|
||||
|
||||
This program is an essential software development tool that can be used to visualize the differences between files or directories, merge files with differences, resolving conflicts and saving output to a new file or patch, and assist file changes reviewing and comment production (e.g. approving source code changes before they get merged into a source tree).
|
||||
|
||||
Features include:
|
||||
|
||||
- Compare two files, three files, or two directories (shallow and recursive)
|
||||
- Horizontal diffs highlighting
|
||||
- Files can be merged interactively and resulting output visualized and saved
|
||||
- Features to assist in performing merge reviews/policing
|
||||
- Unmerge CVS conflicts in automatically merged file and display them as two files, to help resolve conflicts
|
||||
- Uses external diff program to compute differences: works with GNU diff, SGI diff and ClearCase's cleardiff, and any other diff whose output is similar to those
|
||||
- Fully customizable with a resource file
|
||||
- Look-and-feel similar to Rudy Wortel's/SGI xdiff, it is desktop agnostic
|
||||
- Features and output that ease integration with scripts
|
||||
|
||||
- Website: [furius.ca/xxdiff][3]
|
||||
- Developer: Martin Blais
|
||||
- License: GNU GPL
|
||||
- Version Number: 4.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Diffuse is an open source graphical tool for merging and comparing text files. Diffuse is able to compare an arbitrary number of files side-by-side and offers the ability to manually adjust line-matching and directly edit files. Diffuse can also retrieve revisions of files from bazaar, CVS, darcs, git, mercurial, monotone, Subversion and GNU Revision Control System (RCS) repositories for comparison and merging.
|
||||
|
||||
Features include:
|
||||
|
||||
- Compare and merge an arbitrary number of files side-by-side (n-way merges)
|
||||
- Line matching can be manually corrected by the user
|
||||
- Directly edit files
|
||||
- Syntax highlighting
|
||||
- Bazaar, CVS, Darcs, Git, Mercurial, Monotone, RCS, Subversion, and SVK support
|
||||
- Unicode support
|
||||
- Unlimited undo
|
||||
- Easy keyboard navigation
|
||||
|
||||
- Website: [diffuse.sourceforge.net][]
|
||||
- Developer: Derrick Moser
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 0.4.7
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Kompare is an open source GUI front-end program that enables differences between source files to be viewed and merged. Kompare can be used to compare differences on files or the contents of folders. Kompare supports a variety of diff formats and provide many options to customize the information level displayed.
|
||||
|
||||
Whether you are a developer comparing source code, or you just want to see the difference between that research paper draft and the final document, Kompare is a useful tool.
|
||||
|
||||
Kompare is part of the KDE desktop environment.
|
||||
|
||||
Features include:
|
||||
|
||||
- Compare two text files
|
||||
- Recursively compare directories
|
||||
- View patches generated by diff
|
||||
- Merge a patch into an existing directory
|
||||
- Entertain you during that boring compile
|
||||
|
||||
- Website: [www.caffeinated.me.uk/kompare/][5]
|
||||
- Developer: The Kompare Team
|
||||
- License: GNU GPL
|
||||
- Version Number: Part of KDE
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/2014062814400262/FileComparisons.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://meldmerge.org/
|
||||
[2]:https://sourcegear.com/diffmerge/
|
||||
[3]:http://furius.ca/xxdiff/
|
||||
[4]:http://diffuse.sourceforge.net/
|
||||
[5]:http://www.caffeinated.me.uk/kompare/
|
||||
@ -0,0 +1,111 @@
|
||||
Best GNOME Shell Themes For Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
Themes are the best way to customize your Linux desktop. If you [install GNOME on Ubuntu 14.04][1] or 14.10, you might want to change the default theme and give it a different look. To help you in this task, I have compiled here a **list of best GNOME shell themes for Ubuntu** or any other Linux OS that has GNOME shell installed on it. But before we see the list, let’s first see how to change install new themes in GNOME Shell.
|
||||
|
||||
### Install themes in GNOME Shell ###
|
||||
|
||||
To install new themes in GNOME with Ubuntu, you can use Gnome Tweak Tool which is available in software repository in Ubuntu. Open a terminal and use the following command:
|
||||
|
||||
sudo apt-get install gnome-tweak-tool
|
||||
|
||||
Alternatively, you can use themes by putting them in ~/.themes directory. I have written a detailed tutorial on [how to install and use themes in GNOME Shell][2], in case you need it.
|
||||
|
||||
### Best GNOME Shell themes ###
|
||||
|
||||
The themes listed here are tested on GNOME Shell 3.10.4 but it should work for all version of GNOME 3 and higher. For the sake of mentioning, the themes are not in any kind of priority order. Let’s have a look at the best GNOME themes:
|
||||
|
||||
#### Numix ####
|
||||
|
||||

|
||||
|
||||
No list can be completed without the mention of [Numix themes][3]. These themes got so popular that it encouraged [Numix team to work on a new Linux OS, Ozon][4]. Considering their design work with Numix theme, it won’t be exaggeration to call it one of the [most beautiful Linux OS][5] releasing in near future.
|
||||
|
||||
To install Numix theme in Ubuntu based distributions, use the following commands:
|
||||
|
||||
sudo apt-add-repository ppa:numix/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install numix-icon-theme-circle
|
||||
|
||||
#### Elegance Colors ####
|
||||
|
||||

|
||||
|
||||
Another beautiful theme from Satyajit Sahoo, who is also a member of Numix team. [Elegance Colors][6] has its own PPA so that you can easily install it:
|
||||
|
||||
sudo add-apt-repository ppa:satyajit-happy/themes
|
||||
sudo apt-get update
|
||||
sudo apt-get install gnome-shell-theme-elegance-colors
|
||||
|
||||
#### Moka ####
|
||||
|
||||

|
||||
|
||||
[Moka][7] is another mesmerizing theme that is always included in the list of beautiful themes. Designed by the same developer who gave us Unity Tweak Tool, Moka is a must try:
|
||||
|
||||
sudo add-apt-repository ppa:moka/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install moka-gnome-shell-theme
|
||||
|
||||
#### Viva ####
|
||||
|
||||

|
||||
|
||||
Based on Gnome’s default Adwaita theme, Viva is a nice theme with shades of black and oranges. You can download Viva from the link below.
|
||||
|
||||
- [Download Viva GNOME Shell Theme][8]
|
||||
|
||||
#### Ciliora-Prima ####
|
||||
|
||||

|
||||
|
||||
Previously known as Zukitwo Dark, Ciliora-Prima has square icons theme. Theme is available in three versions that are slightly different from each other. You can download it from the link below.
|
||||
|
||||
- [Download Ciliora-Prima GNOME Shell Theme][9]
|
||||
|
||||
#### Faience ####
|
||||
|
||||

|
||||
|
||||
Faience has been a popular theme for quite some time and rightly so. You can install Faience using the PPA below for GNOME 3.10 and higher.
|
||||
|
||||
sudo add-apt-repository ppa:tiheum/equinox
|
||||
sudo apt-get update
|
||||
sudo apt-get install faience-theme
|
||||
|
||||
#### Paper [Incomplete] ####
|
||||
|
||||

|
||||
|
||||
Ever since Google talked about Material Design, people have been going gaga over it. Paper GTK theme, by Sam Hewitt (of Moka Project), is inspired by Google Material design and currently under development. Which means you will not have the best experience with Paper at the moment. But if your a bit experimental, like me, you can definitely give it a try.
|
||||
|
||||
sudo add-apt-repository ppa:snwh/pulp
|
||||
sudo apt-get update
|
||||
sudo apt-get install paper-gtk-theme
|
||||
|
||||
That concludes my list. If you are trying to give a different look to your Ubuntu, you should also try the list of [best icon themes for Ubuntu 14.04][10].
|
||||
|
||||
How do you find this list of **best GNOME Shell themes**? Which one is your favorite among the one listed here? And if it’s not listed here, do let us know which theme you think is the best GNOME Shell theme.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/gnome-shell-themes-ubuntu-1404/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/how-to-install-gnome-in-ubuntu-14-04/
|
||||
[2]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[3]:https://numixproject.org/
|
||||
[4]:http://itsfoss.com/numix-linux-distribution/
|
||||
[5]:http://itsfoss.com/new-beautiful-linux-2015/
|
||||
[6]:http://satya164.deviantart.com/art/Gnome-Shell-Elegance-Colors-305966388
|
||||
[7]:http://mokaproject.com/
|
||||
[8]:https://github.com/vivaeltopo/gnome-shell-theme-viva
|
||||
[9]:http://zagortenay333.deviantart.com/art/Ciliora-Prima-Shell-451947568
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by ZTinoZ
|
||||
20 Linux Commands Interview Questions & Answers
|
||||
================================================================================
|
||||
**Q:1 How to check current run level of a linux server ?**
|
||||
@ -140,4 +141,4 @@ via: http://www.linuxtechi.com/20-linux-commands-interview-questions-answers/
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
[20]:
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
(translating by runningwater)
|
||||
2015: Open Source Has Won, But It Isn't Finished
|
||||
================================================================================
|
||||
> After the wins of 2014, what's next?
|
||||
@ -31,7 +32,7 @@ In other words, whatever amazing free software 2014 has already brought us, we c
|
||||
via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-3592314/
|
||||
|
||||
作者:[lyn Moody][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -44,4 +45,4 @@ via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-35
|
||||
[5]:http://timesofindia.indiatimes.com/tech/tech-news/Android-tablet-market-share-hits-70-in-Q2-iPads-slip-to-25-Survey/articleshow/38966512.cms
|
||||
[6]:http://linuxgizmos.com/embedded-developers-prefer-linux-love-android/
|
||||
[7]:http://www.computerworlduk.com/blogs/open-enterprise/allseen-3591023/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
|
||||
@ -0,0 +1,29 @@
|
||||
Linus Tells Wired Leap Second Irrelevant
|
||||
================================================================================
|
||||

|
||||
|
||||
Two larger publications today featured Linux and the effect of the upcoming leap second. The Register today said that the leap second effects of the past are no longer an issue. Coincidentally, Wired talked to Linus Torvalds about the same issue today as well.
|
||||
|
||||
**Linus Torvalds** spoke with Wired's Robert McMillan about the approaching leap second due to be added in June. The Register said the last leap second in 2012 took out Mozilla, StumbleUpon, Yelp, FourSquare, Reddit and LinkedIn as well as several major airlines and travel reservation services that ran Linux. Torvalds told Wired today that the kernel is patched and he doesn't expect too many issues this time around. [He said][1], "Just take the leap second as an excuse to have a small nonsensical party for your closest friends. Wear silly hats, get a banner printed, and get silly drunk. That’s exactly how relevant it should be to most people."
|
||||
|
||||
**However**, The Register said not everyone agrees with Torvalds' sentiments. They quote Daily Mail saying, "The year 2015 will have an extra second — which could wreak havoc on the infrastructure powering the Internet," then remind us of the Y2K scare that ended up being a non-event. The Register's Gavin [Clarke concluded][2]:
|
||||
|
||||
> No reason the Penguins were caught sans pants.
|
||||
|
||||
> Now they've gone belt and braces.
|
||||
|
||||
The take-away is: move along, nothing to see here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/linus-tells-wired-leap-second-irrelevant
|
||||
|
||||
作者:[Susan Linton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/susan-linton
|
||||
[1]:http://www.wired.com/2015/01/torvalds_leapsecond/
|
||||
[2]:http://www.theregister.co.uk/2015/01/09/leap_second_bug_linux_hysteria/
|
||||
@ -0,0 +1,36 @@
|
||||
diff -u: What's New in Kernel Development
|
||||
================================================================================
|
||||
**David Drysdale** wanted to add Capsicum security features to Linux after he noticed that FreeBSD already had Capsicum support. Capsicum defines fine-grained security privileges, not unlike filesystem capabilities. But as David discovered, Capsicum also has some controversy surrounding it.
|
||||
|
||||
Capsicum has been around for a while and was described in a USENIX paper in 2010: [http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf][1].
|
||||
|
||||
Part of the controversy is just because of the similarity with capabilities. As Eric Biderman pointed out during the discussion, it would be possible to implement features approaching Capsicum's as an extension of capabilities, but implementing Capsicum directly would involve creating a whole new (and extensive) abstraction layer in the kernel. Although David argued that capabilities couldn't actually be extended far enough to match Capsicum's fine-grained security controls.
|
||||
|
||||
Capsicum also was controversial within its own developer community. For example, as Eric described, it lacked a specification for how to revoke privileges. And, David pointed out that this was because the community couldn't agree on how that could best be done. David quoted an e-mail sent by Ben Laurie to the cl-capsicum-discuss mailing list in 2011, where Ben said, "It would require additional book-keeping to find and revoke outstanding capabilities, which requires knowing how to reach capabilities, and then whether they are derived from the capability being revoked. It also requires an authorization model for revocation. The former two points mean additional overhead in terms of data structure operations and synchronisation."
|
||||
|
||||
Given the ongoing controversy within the Capsicum developer community and the corresponding lack of specification of key features, and given the existence of capabilities that already perform a similar function in the kernel and the invasiveness of Capsicum patches, Eric was opposed to David implementing Capsicum in Linux.
|
||||
|
||||
But, given the fact that capabilities are much coarser-grained than Capsicum's security features, to the point that capabilities can't really be extended far enough to mimic Capsicum's features, and given that FreeBSD already has Capsicum implemented in its kernel, showing that it can be done and that people might want it, it seems there will remain a lot of folks interested in getting Capsicum into the Linux kernel.
|
||||
|
||||
Sometimes it's unclear whether there's a bug in the code or just a bug in the written specification. Henrique de Moraes Holschuh noticed that the Intel Software Developer Manual (vol. 3A, section 9.11.6) said quite clearly that microcode updates required 16-byte alignment for the P6 family of CPUs, the Pentium 4 and the Xeon. But, the code in the kernel's microcode driver didn't enforce that alignment.
|
||||
|
||||
In fact, Henrique's investigation uncovered the fact that some Intel chips, like the Xeon X5550 and the second-generation i5 chips, needed only 4-byte alignment in practice, and not 16. However, to conform to the documented specification, he suggested fixing the kernel code to match the spec.
|
||||
|
||||
Borislav Petkov objected to this. He said Henrique was looking for problems where there weren't any. He said that Henrique simply had discovered a bug in Intel's documentation, because the alignment issue clearly wasn't a problem in the real world. He suggested alerting the Intel folks to the documentation problem and moving on. As he put it, "If the processor accepts the non-16-byte-aligned update, why do you care?"
|
||||
|
||||
But, as H. Peter Anvin remarked, the written spec was Intel's guarantee that certain behaviors would work. If the kernel ignored the spec, it could lead to subtle bugs later on. And, Bill Davidsen said that if the kernel ignored the alignment requirement, and "if the requirement is enforced in some future revision, and updates then fail in some insane way, the vendor is justified in claiming 'I told you so'."
|
||||
|
||||
The end result was that Henrique sent in some patches to make the microcode driver enforce the 16-byte alignment requirement.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/diff-u-whats-new-kernel-development-6
|
||||
|
||||
作者:[Zack Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/801501
|
||||
[1]:http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf
|
||||
@ -1,75 +0,0 @@
|
||||
(translating by runningwater)
|
||||
Linux FAQs with Answers--How to install 7zip on Linux
|
||||
================================================================================
|
||||
> **Question**: I need to extract files from an ISO image, and for that I want to use 7zip program. How can I install 7zip on [insert your Linux distro]?
|
||||
|
||||
7zip is an open-source archive program originally developed for Windows, which can pack or unpack a variety of archive formats including its native format 7z as well as XZ, GZIP, TAR, ZIP and BZIP2. 7zip is also popularly used to extract RAR, DEB, RPM and ISO files. Besides simple archiving, 7zip can support AES-256 encryption as well as self-extracting and multi-volume archiving. For POSIX systems (Linux, Unix, BSD), the original 7zip program has been ported as p7zip (short for "POSIX 7zip").
|
||||
|
||||
Here is how to install 7zip (or p7zip) on Linux.
|
||||
|
||||
### Install 7zip on Debian, Ubuntu or Linux Mint ###
|
||||
|
||||
Debian-based distributions come with three packages related to 7zip.
|
||||
|
||||
- **p7zip**: contains 7zr (a minimal 7zip archive tool) which can handle its native 7z format only.
|
||||
- **p7zip-full**: contains 7z which can support 7z, LZMA2, XZ, ZIP, CAB, GZIP, BZIP2, ARJ, TAR, CPIO, RPM, ISO and DEB.
|
||||
- **p7zip-rar**: contains a plugin for extracting RAR files.
|
||||
|
||||
It is recommended to install p7zip-full package (not p7zip) since this is the most complete 7zip package which supports many archive formats. In addition, if you want to extract RAR files, you also need to install p7zip-rar package as well. The reason for having a separate plugin package is because RAR is a proprietary format.
|
||||
|
||||
$ sudo apt-get install p7zip-full p7zip-rar
|
||||
|
||||
### Install 7zip on Fedora or CentOS/RHEL ###
|
||||
|
||||
Red Hat-based distributions offer two packages related to 7zip.
|
||||
|
||||
- **p7zip**: contains 7za command which can support 7z, ZIP, GZIP, CAB, ARJ, BZIP2, TAR, CPIO, RPM and DEB.
|
||||
- **p7zip-plugins**: contains 7z command and additional plugins to extend 7za command (e.g., ISO extraction).
|
||||
|
||||
On CentOS/RHEL, you need to enable [EPEL repository][1] before running yum command below. On Fedora, there is not need to set up additional repository.
|
||||
|
||||
$ sudo yum install p7zip p7zip-plugins
|
||||
|
||||
Note that unlike Debian based distributions, Red Hat based distributions do not offer a RAR plugin. Therefore you will not be able to extract RAR files using 7z command.
|
||||
|
||||
### Create or Extract an Archive with 7z ###
|
||||
|
||||
Once you installed 7zip, you can use 7z command to pack or unpack various types of archives. The 7z command uses other plugins to handle the archives.
|
||||
|
||||
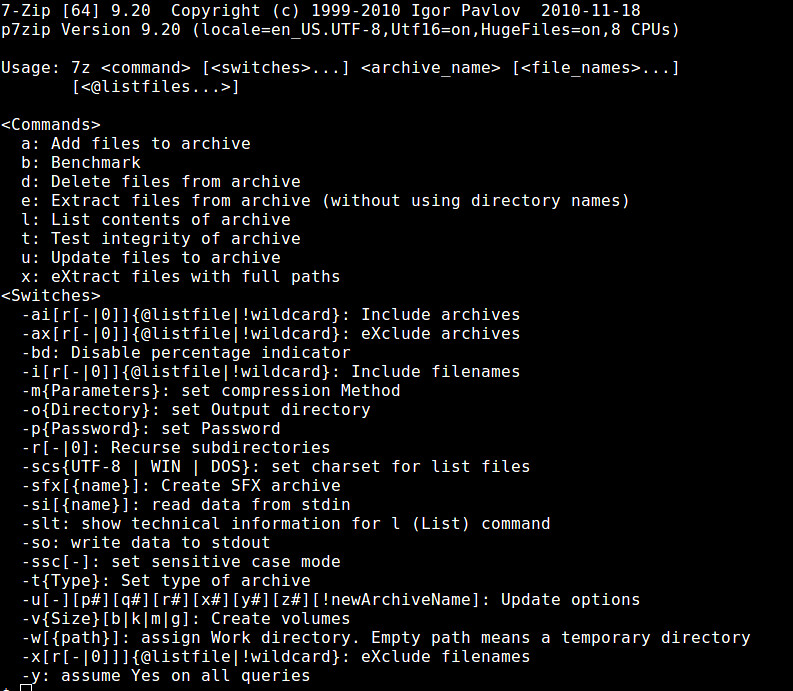
|
||||
|
||||
To create an archive, use "a" option. Supported archive types for creation are 7z, XZ, GZIP, TAR, ZIP and BZIP2. If the specified archive file already exists, it will "add" the files to the existing archive, instead of overwriting it.
|
||||
|
||||
$ 7z a <archive-filename> <list-of-files>
|
||||
|
||||
To extract an archive, use "e" option. It will extract the archive in the current directory. Supported archive types for extraction are a lot more than those for creation. The list includes 7z, XZ, GZIP, TAR, ZIP, BZIP2, LZMA2, CAB, ARJ, CPIO, RPM, ISO and DEB.
|
||||
|
||||
$ 7z e <archive-filename>
|
||||
|
||||
Another way to unpack an archive is to use "x" option. Unlike "e" option, it will extract the content with full paths.
|
||||
|
||||
$ 7z x <archive-filename>
|
||||
|
||||
To see a list of files in an archive, use "l" option.
|
||||
|
||||
$ 7z l <archive-filename>
|
||||
|
||||
You can update or remove file(s) in an archive with "u" and "d" options, respectively.
|
||||
|
||||
$ 7z u <archive-filename> <list-of-files-to-update>
|
||||
$ 7z d <archive-filename> <list-of-files-to-delete>
|
||||
|
||||
To test the integrity of an archive:
|
||||
|
||||
$ 7z t <archive-filename>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://ask.xmodulo.com/install-7zip-linux.html
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -1,207 +0,0 @@
|
||||
How to configure fail2ban to protect Apache HTTP server
|
||||
================================================================================
|
||||
An Apache HTTP server in production environments can be under attack in various different ways. Attackers may attempt to gain access to unauthorized or forbidden directories by using brute-force attacks or executing evil scripts. Some malicious bots may scan your websites for any security vulnerability, or collect email addresses or web forms to send spams to.
|
||||
|
||||
Apache HTTP server comes with comprehensive logging capabilities capturing various abnormal events indicative of such attacks. However, it is still non-trivial to systematically parse detailed Apache logs and react to potential attacks quickly (e.g., ban/unban offending IP addresses) as they are perpetrated in the wild. That is when `fail2ban` comes to the rescue, making a sysadmin's life easier.
|
||||
|
||||
`fail2ban` is an open-source intrusion prevention tool which detects various attacks based on system logs and automatically initiates prevention actions e.g., banning IP addresses with `iptables`, blocking connections via /etc/hosts.deny, or notifying the events via emails. fail2ban comes with a set of predefined "jails" which use application-specific log filters to detect common attacks. You can also write custom jails to deter any specific attack on an arbitrary application.
|
||||
|
||||
In this tutorial, I am going to demonstrate how you can configure fail2ban to protect your Apache HTTP server. I assume that you have Apache HTTP server and fail2ban already installed. Refer to [another tutorial][1] for fail2ban installation.
|
||||
|
||||
### What is a Fail2ban Jail ###
|
||||
|
||||
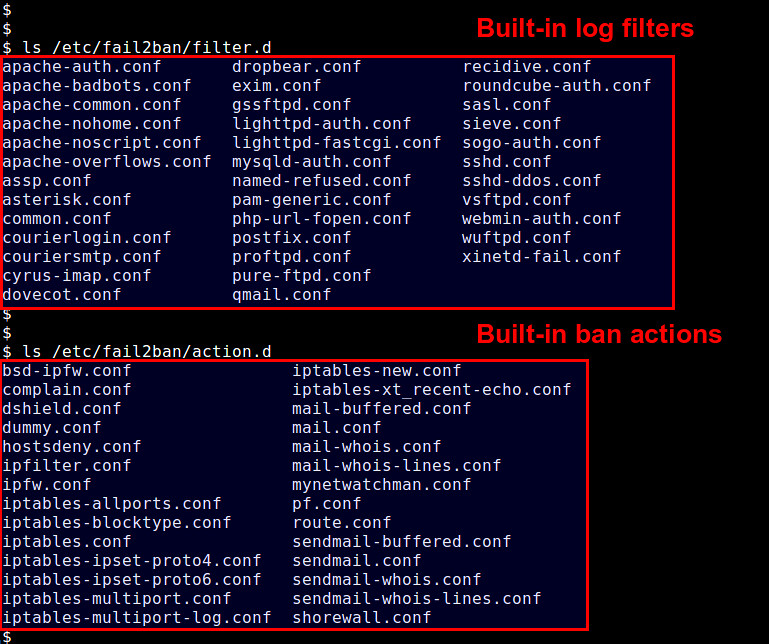
Let me go over more detail on fail2ban jails. A jail defines an application-specific policy under which fail2ban triggers an action to protect a given application. fail2ban comes with several jails pre-defined in /etc/fail2ban/jail.conf, for popular applications such as Apache, Dovecot, Lighttpd, MySQL, Postfix, [SSH][2], etc. Each jail relies on application-specific log filters (found in /etc/fail2ban/fileter.d) to detect common attacks. Let's check out one example jail: SSH jail.
|
||||
|
||||
[ssh]
|
||||
enabled = true
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry = 6
|
||||
banaction = iptables-multiport
|
||||
|
||||
This SSH jail configuration is defined with several parameters:
|
||||
|
||||
- **[ssh]**: the name of a jail with square brackets.
|
||||
- **enabled**: whether the jail is activated or not.
|
||||
- **port**: a port number to protect (either numeric number of well-known name).
|
||||
- **filter**: a log parsing rule to detect attacks with.
|
||||
- **logpath**: a log file to examine.
|
||||
- **maxretry**: maximum number of failures before banning.
|
||||
- **banaction**: a banning action.
|
||||
|
||||
Any parameter defined in a jail configuration will override a corresponding `fail2ban-wide` default parameter. Conversely, any parameter missing will be assgined a default value defined in [DEFAULT] section.
|
||||
|
||||
Predefined log filters are found in /etc/fail2ban/filter.d, and available actions are in /etc/fail2ban/action.d.
|
||||
|
||||
|
||||
|
||||
If you want to overwrite `fail2ban` defaults or define any custom jail, you can do so by creating **/etc/fail2ban/jail.local** file. In this tutorial, I am going to use /etc/fail2ban/jail.local.
|
||||
|
||||
### Enable Predefined Apache Jails ###
|
||||
|
||||
Default installation of `fail2ban` offers several predefined jails and filters for Apache HTTP server. I am going to enable those built-in Apache jails. Due to slight differences between Debian and Red Hat configurations, let me provide fail2ban jail configurations for them separately.
|
||||
|
||||
#### Enable Apache Jails on Debian or Ubuntu ####
|
||||
|
||||
To enable predefined Apache jails on a Debian-based system, create /etc/fail2ban/jail.local as follows.
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect potential search for exploits and php vulnerabilities
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
Since none of the jails above specifies an action, all of these jails will perform a default action when triggered. To find out the default action, look for "banaction" under [DEFAULT] section in /etc/fail2ban/jail.conf.
|
||||
|
||||
banaction = iptables-multiport
|
||||
|
||||
In this case, the default action is iptables-multiport (defined in /etc/fail2ban/action.d/iptables-multiport.conf). This action bans an IP address using iptables with multiport module.
|
||||
|
||||
After enabling jails, you must restart fail2ban to load the jails.
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
#### Enable Apache Jails on CentOS/RHEL or Fedora ####
|
||||
|
||||
To enable predefined Apache jails on a Red Hat based system, create /etc/fail2ban/jail.local as follows.
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect spammer robots crawling email addresses
|
||||
[apache-badbots]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-badbots
|
||||
logpath = /var/log/httpd/*access_log
|
||||
bantime = 172800
|
||||
maxretry = 1
|
||||
|
||||
# detect potential search for exploits and php <a href="http://xmodulo.com/recommend/penetrationbook" style="" target="_blank" rel="nofollow" >vulnerabilities</a>
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to execute non-existing scripts that
|
||||
# are associated with several popular web services
|
||||
# e.g. webmail, phpMyAdmin, WordPress
|
||||
port = http,https
|
||||
filter = apache-botsearch
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
Note that the default action for all these jails is iptables-multiport (defined as "banaction" under [DEFAULT] in /etc/fail2ban/jail.conf). This action bans an IP address using iptables with multiport module.
|
||||
|
||||
After enabling jails, you must restart fail2ban to load the jails in fail2ban.
|
||||
|
||||
On Fedora or CentOS/RHEL 7:
|
||||
|
||||
$ sudo systemctl restart fail2ban
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
### Check and Manage Fail2ban Banning Status ###
|
||||
|
||||
Once jails are activated, you can monitor current banning status with fail2ban-client command-line tool.
|
||||
|
||||
To see a list of active jails:
|
||||
|
||||
$ sudo fail2ban-client status
|
||||
|
||||
To see the status of a particular jail (including banned IP list):
|
||||
|
||||
$ sudo fail2ban-client status [name-of-jail]
|
||||
|
||||
|
||||
|
||||
You can also manually ban or unban IP addresses.
|
||||
|
||||
To ban an IP address with a particular jail:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] banip [ip-address]
|
||||
|
||||
To unban an IP address blocked by a particular jail:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] unbanip [ip-address]
|
||||
|
||||
### Summary ###
|
||||
|
||||
This tutorial explains how a fail2ban jail works and how to protect an Apache HTTP server using built-in Apache jails. Depending on your environments and types of web services you need to protect, you may need to adapt existing jails, or write custom jails and log filters. Check outfail2ban's [official Github page][3] for more up-to-date examples of jails and filters.
|
||||
|
||||
Are you using fail2ban in any production environment? Share your experience.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-fail2ban-apache-http-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[2]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[3]:https://github.com/fail2ban/fail2ban
|
||||
@ -1,3 +1,5 @@
|
||||
hi ! 让我来翻译
|
||||
|
||||
How to debug a C/C++ program with Nemiver debugger
|
||||
================================================================================
|
||||
If you read [my post on GDB][1], you know how important and useful a debugger I think can be for a C/C++ program. However, if a command line debugger like GDB sounds more like a problem than a solution to you, you might be more interested in Nemiver. [Nemiver][2] is a GTK+-based standalone graphical debugger for C/C++ programs, using GDB as its back-end. Admirable for its speed and stability, Nemiver is a very reliable debugger filled with goodies.
|
||||
@ -106,4 +108,4 @@ via: http://xmodulo.com/debug-program-nemiver-debugger.html
|
||||
[1]:http://xmodulo.com/gdb-command-line-debugger.html
|
||||
[2]:https://wiki.gnome.org/Apps/Nemiver
|
||||
[3]:https://download.gnome.org/sources/nemiver/0.9/
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
|
||||
@ -1,76 +0,0 @@
|
||||
How to deduplicate files on Linux with dupeGuru
|
||||
================================================================================
|
||||
Recently, I was given the task to clean up my father's files and folders. What made it difficult was the abnormal amount of duplicate files with incorrect names. By keeping a backup on an external drive, simultaneously editing multiple versions of the same file, or even changing the directory structure, the same file can get copied many times, change names, change locations, and just clog disk space. Hunting down every single one of them can become a problem of gigantic proportions. Hopefully, there exists nice little software that can save your precious hours by finding and removing duplicate files on your system: [dupeGuru][1]. Written in Python, this file deduplication software switched to a GPLv3 license a few hours ago. So time to apply your new year's resolutions and clean up your stuff!
|
||||
|
||||
### Installation of dupeGuru ###
|
||||
|
||||
On Ubuntu, you can add the Hardcoded Software PPA:
|
||||
|
||||
$ sudo apt-add-repository ppa:hsoft/ppa
|
||||
$ sudo apt-get update
|
||||
|
||||
And then install with:
|
||||
|
||||
$ sudo apt-get install dupeguru-se
|
||||
|
||||
On Arch Linux, the package is present in the [AUR][2].
|
||||
|
||||
If you prefer compiling it yourself, the sources are on [GitHub][3].
|
||||
|
||||
### Basic Usage of dupeGuru ###
|
||||
|
||||
DupeGuru is conceived to be fast and safe. Which means that the program is not going to run berserk on your system. It has a very low risk of deleting stuff that you did not intend to delete. However, as we are still talking about file deletion, it is always a good idea to stay vigilant and cautious: a good backup is always necessary.
|
||||
|
||||
Once you took your precautions, you can launch dupeGuru via the command:
|
||||
|
||||
$ dupeguru_se
|
||||
|
||||
You should be greeted by the folder selection screen, where you can add folders to scan for deduplication.
|
||||
|
||||

|
||||
|
||||
Once you selected your directories and launched the scan, dupeGuru will show its results by grouping duplicate files together in a list.
|
||||
|
||||

|
||||
|
||||
Note that by default dupeGuru matches files based on their content, and not their name. To be sure that you do not accidentally delete something important, the match column shows you the accuracy of the matching algorithm. From there, you can select the duplicate files that you want to take action on, and click on "Actions" button to see available actions.
|
||||
|
||||

|
||||
|
||||
The choice of actions is quite extensive. In short, you can delete the duplicates, move them to another location, ignore them, open them, rename them, or even invoke a custom command on them. If you choose to delete a duplicate, you might get as pleasantly surprised as I was by available deletion options.
|
||||
|
||||

|
||||
|
||||
You can not only send the duplicate files to the trash or delete them permanently, but you can also choose to leave a link to the original file (either using a symlink or a hardlink). In oher words, the duplicates will be erased, and a link to the original will be left instead, saving a lot of disk space. This can be particularly useful if you imported those files into a workspace, or have dependencies based on them.
|
||||
|
||||
Another fancy option: you can export the results to a HTML or CSV file. Not really sure why you would do that, but I suppose that it can be useful if you prefer keeping track of duplicates rather than use any of dupeGuru's actions on them.
|
||||
|
||||
Finally, last but not least, the preferences menu will make all your dream about duplicate busting come true.
|
||||
|
||||

|
||||
|
||||
There you can select the criterion for the scan, either content based or name based, and a threshold for duplicates to control the number of results. It is also possible to define the custom command that you can select in the actions. Among the myriad of other little options, it is good to notice that by default, dupeGuru ignores files less than 10KB.
|
||||
|
||||
For more information, I suggest that you go check out the [official website][4], which is filled with documention, support forums, and other goodies.
|
||||
|
||||
To conclude, dupeGuru is my go-to software whenever I have to prepare a backup or to free some space. I find it powerful enough for advanced users, and yet intuitive to use for newcomers. Cherry on the cake: dupeGuru is cross platform, which means that you can also use it for your Mac or Windows PC. If you have specific needs, and want to clean up music or image files, there exists two variations: [dupeguru-me][5] and [dupeguru-pe][6], which respectively find duplicate audio tracks and pictures. The main difference from the regular version is that it compares beyond file formats and takes into account specific media meta-data like quality and bit-rate.
|
||||
|
||||
What do you think of dupeGuru? Would you consider using it? Or do you have any alternative deduplication software to suggest? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/dupeguru-deduplicate-files-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://www.hardcoded.net/dupeguru/
|
||||
[2]:https://aur.archlinux.org/packages/dupeguru-se/
|
||||
[3]:https://github.com/hsoft/dupeguru
|
||||
[4]:http://www.hardcoded.net/dupeguru/
|
||||
[5]:http://www.hardcoded.net/dupeguru_me/
|
||||
[6]:http://www.hardcoded.net/dupeguru_pe/
|
||||
@ -1,71 +0,0 @@
|
||||
How to Install SSL on Apache 2.4 in Ubuntu 14.0.4
|
||||
================================================================================
|
||||
Today I will show you how to install a **SSL certificate** on your personal website or blog, to help secure the communications between your visitors and your website.
|
||||
|
||||
Secure Sockets Layer or SSL, is the standard security technology for creating an encrypted connection between a web server and a web browser. This ensures that all data passed between the web server and the web browser remain private and secure. It is used by millions of websites in the protection of their online communications with their customers. In order to be able to generate an SSL link, a web server requires a SSL Certificate.
|
||||
|
||||
You can create your own SSL Certificate, but it will not be trusted by default in web browsers, to fix this you will have to buy a digital certificate from a trusted Certification Authority (CA), we will show you below how to get the certificate and install it in apache.
|
||||
|
||||
### Generating a Certificate Signing Request ###
|
||||
|
||||
The Certification Authority (CA) will ask you for a Certificate Signing Request (CSR) generated on your web server. This is a simple step and only takes a minute, you will have to run the following command and input the requested information:
|
||||
|
||||
# openssl req -new -newkey rsa:2048 -nodes -keyout yourdomainname.key -out yourdomainname.csr
|
||||
|
||||
The output should look something like this:
|
||||
|
||||

|
||||
|
||||
This begins the process of generating two files: the Private-Key file for the decryption of your SSL Certificate, and a certificate signing request (CSR) file (used to apply for your SSL Certificate) with apache openssl.
|
||||
|
||||
Depending on the authority you apply to, you will either have to upload your csr file or paste it's content in a web form.
|
||||
|
||||
### Installing the actual certificate in Apache ###
|
||||
|
||||
After the generation process is finished you will receive your new digital certificate, for this article we have used [Comodo SSL][1] and received the certificate in a zip file. To use it in apache you will first have to create a bundle of the certificates you received in the zip file with the following command:
|
||||
|
||||
# cat COMODORSADomainValidationSecureServerCA.crt COMODORSAAddTrustCA.crt AddTrustExternalCARoot.crt > bundle.crt
|
||||
|
||||

|
||||
|
||||
Now make sure that the ssl module is loaded in apache by running the following command:
|
||||
|
||||
# a2enmod ssl
|
||||
|
||||
If you get the message "Module ssl already enabled" you are ok, if you get the message "Enabling module ssl." you will also have to run the following command to restart apache:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
Finally modify your virtual host file (generally found in /etc/apache2/sites-enabled) to look something like this:
|
||||
|
||||
DocumentRoot /var/www/html/
|
||||
ServerName linoxide.com
|
||||
SSLEngine on
|
||||
SSLCertificateFile /usr/local/ssl/crt/yourdomainname.crt
|
||||
SSLCertificateKeyFile /usr/local/ssl/yourdomainname.key
|
||||
SSLCACertificateFile /usr/local/ssl/bundle.crt
|
||||
|
||||
You should now access your website using https://YOURDOMAIN/ (be careful to use 'https' not http) and see the SSL in progress (generally indicated by a lock in your web browser).
|
||||
|
||||
**NOTE:** All the links must now point to https, if some of the content on the website (like images or css files) still point to http links you will get a warning in the browser, to fix this you have to make sure that every link points to https.
|
||||
|
||||
### Redirect HTTP requests to HTTPS version of your website ###
|
||||
|
||||
If you wish to redirect the normal HTTP requests to HTTPS version of your website, add the following text to either the virtual host you wish to apply it to or to the apache.conf if you wish to apply it for all websites hosted on the server:
|
||||
|
||||
RewriteEngine On
|
||||
RewriteCond %{HTTPS} off
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-ssl-apache-2-4-in-ubuntu/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:https://ssl.comodo.com/
|
||||
@ -1,129 +0,0 @@
|
||||
How to Install Scrapy a Web Crawling Tool in Ubuntu 14.04 LTS
|
||||
================================================================================
|
||||
It is an open source software which is used for extracting the data from websites. Scrapy framework is developed in Python and it perform the crawling job in fast, simple and extensible way. We have created a Virtual Machine (VM) in virtual box and Ubuntu 14.04 LTS is installed on it.
|
||||
|
||||
### Install Scrapy ###
|
||||
|
||||
Scrapy is dependent on Python, development libraries and pip software. Python latest version is pre-installed on Ubuntu. So we have to install pip and python developer libraries before installation of Scrapy.
|
||||
|
||||
Pip is the replacement for easy_install for python package indexer. It is used for installation and management of Python packages. Installation of pip package is shown in Figure 1.
|
||||
|
||||
sudo apt-get install python-pip
|
||||
|
||||

|
||||
|
||||
Fig:1 Pip installation
|
||||
|
||||
We have to install python development libraries by using following command. If this package is not installed then installation of scrapy framework generates error about python.h header file.
|
||||
|
||||
sudo apt-get install python-dev
|
||||
|
||||

|
||||
|
||||
Fig:2 Python Developer Libraries
|
||||
|
||||
Scrapy framework can be installed either from deb package or source code. However we have installed deb package using pip (Python package manager) which is shown in Figure 3.
|
||||
|
||||
sudo pip install scrapy
|
||||
|
||||

|
||||
|
||||
Fig:3 Scrapy Installation
|
||||
|
||||
Scrapy successful installation takes some time which is shown in Figure 4.
|
||||
|
||||

|
||||
|
||||
Fig:4 Successful installation of Scrapy Framework
|
||||
|
||||
### Data extraction using Scrapy framework ###
|
||||
|
||||
**(Basic Tutorial)**
|
||||
|
||||
We will use Scrapy for the extraction of store names (which are providing Cards) item from fatwallet.com web site. First of all, we created new scrapy project “store_name” using below given command and shown in Figure 5.
|
||||
|
||||
$sudo scrapy startproject store_name
|
||||
|
||||

|
||||
|
||||
Fig:5 Creation of new project in Scrapy Framework
|
||||
|
||||
Above command creates a directory with title “store_name” at current path. This main directory of the project contains files/folders which are shown in the following Figure 6.
|
||||
|
||||
$sudo ls –lR store_name
|
||||
|
||||

|
||||
|
||||
Fig:6 Contents of store_name project.
|
||||
|
||||
A brief description of each file/folder is given below;
|
||||
|
||||
- scrapy.cfg is the project configuration file
|
||||
- store_name/ is another directory inside the main directory. This directory contains python code of the project.
|
||||
- store_name/items.py contains those items which will be extracted by the spider.
|
||||
- store_name/pipelines.py is the pipelines file.
|
||||
- Setting of store_name project is in store_name/settings.py file.
|
||||
- and the store_name/spiders/ directory, contains spider for the crawling
|
||||
|
||||
As we are interested to extract the store names of the Cards from fatwallet.com site, so we updated the contents of the file as shown below.
|
||||
|
||||
import scrapy
|
||||
|
||||
class StoreNameItem(scrapy.Item):
|
||||
|
||||
name = scrapy.Field() # extract the names of Cards store
|
||||
|
||||
After this, we have to write new spider under store_name/spiders/ directory of the project. Spider is python class which consist of following mandatory attributes :
|
||||
|
||||
1. Name of the spider (name )
|
||||
1. Starting url of spider for crawling (start_urls)
|
||||
1. And parse method which consist of regex for the extraction of desired items from the page response. Parse method is the important part of spider.
|
||||
|
||||
We created spider “store_name.py” under store_name/spiders/ directory and added following python code for the extraction of store name from fatwallet.com site. The output of the spider is written in the file (**StoreName.txt**) which is shown in Figure 7.
|
||||
|
||||
from scrapy.selector import Selector
|
||||
from scrapy.spider import BaseSpider
|
||||
from scrapy.http import Request
|
||||
from scrapy.http import FormRequest
|
||||
import re
|
||||
class StoreNameItem(BaseSpider):
|
||||
name = "storename"
|
||||
allowed_domains = ["fatwallet.com"]
|
||||
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
|
||||
|
||||
def parse(self,response):
|
||||
output = open('StoreName.txt','w')
|
||||
resp = Selector(response)
|
||||
|
||||
tags = resp.xpath('//tr[@class="storeListRow"]|\
|
||||
//tr[@class="storeListRow even"]|\
|
||||
//tr[@class="storeListRow even last"]|\
|
||||
//tr[@class="storeListRow last"]').extract()
|
||||
for i in tags:
|
||||
i = i.encode('utf-8', 'ignore').strip()
|
||||
store_name = ''
|
||||
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
|
||||
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
|
||||
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
|
||||
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
|
||||
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
|
||||
#print store_name
|
||||
output.write(store_name+""+"\n")
|
||||
|
||||

|
||||
|
||||
Fig:7 Output of the Spider code .
|
||||
|
||||
*NOTE: The purpose of this tutorial is only the understanding of Scrapy Framework*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/scrapy-install-ubuntu/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
@ -0,0 +1,135 @@
|
||||
What are useful command-line network monitors on Linux
|
||||
================================================================================
|
||||
Network monitoring is a critical IT function for businesses of all sizes. The goal of network monitoring can vary. For example, the monitoring activity can be part of long-term network provisioning, security protection, performance troubleshooting, network usage accounting, and so on. Depending on its goal, network monitoring is done in many different ways, such as performing packet-level sniffing, collecting flow-level statistics, actively injecting probes into the network, parsing server logs, etc.
|
||||
|
||||
While there are many dedicated network monitoring systems capable of 24/7/365 monitoring, you can also leverage command-line network monitors in certain situations, where a dedicated monitor is an overkill. If you are a system admin, you are expected to have hands-on experience with some of well known CLI network monitors. Here is a list of **popular and useful command-line network monitors on Linux**.
|
||||
|
||||
### Packet-Level Sniffing ###
|
||||
|
||||
In this category, monitoring tools capture individual packets on the wire, dissect their content, and display decoded packet content or packet-level statistics. These tools conduct network monitoring from the lowest level, and as such, can possibly do the most fine-grained monitoring at the cost of network I/O and analysis efforts.
|
||||
|
||||
1. **dhcpdump**: a comman-line DHCP traffic sniffer capturing DHCP request/response traffic, and displays dissected DHCP protocol messages in a human-friendly format. It is useful when you are troubleshooting DHCP related issues.
|
||||
|
||||
2. **[dsniff][1]**: a collection of command-line based sniffing, spoofing and hijacking tools designed for network auditing and penetration testing. They can sniff various information such as passwords, NSF traffic, email messages, website URLs, and so on.
|
||||
|
||||
3. **[httpry][2]**: an HTTP packet sniffer which captures and decode HTTP requests and response packets, and display them in a human-readable format.
|
||||
|
||||
4. **IPTraf**: a console-based network statistics viewer. It displays packet-level, connection-level, interface-level, protocol-level packet/byte counters in real-time. Packet capturing can be controlled by protocol filters, and its operation is full menu-driven.
|
||||
|
||||
|
||||
|
||||
5. **[mysql-sniffer][3]**: a packet sniffer which captures and decodes packets associated with MySQL queries. It displays the most frequent or all queries in a human-readable format.
|
||||
|
||||
6. **[ngrep][4]**: grep over network packets. It can capture live packets, and match (filtered) packets against regular expressions or hexadecimal expressions. It is useful for detecting and storing any anomalous traffic, or for sniffing particular patterns of information from live traffic.
|
||||
|
||||
7. **[p0f][5]**: a passive fingerprinting tool which, based on packet sniffing, reliably identifies operating systems, NAT or proxy settings, network link types and various other properites associated with an active TCP connection.
|
||||
|
||||
8. **pktstat**: a command-line tool which analyzes live packets to display connection-level bandwidth usages as well as descriptive information of protocols involved (e.g., HTTP GET/POST, FTP, X11).
|
||||
|
||||
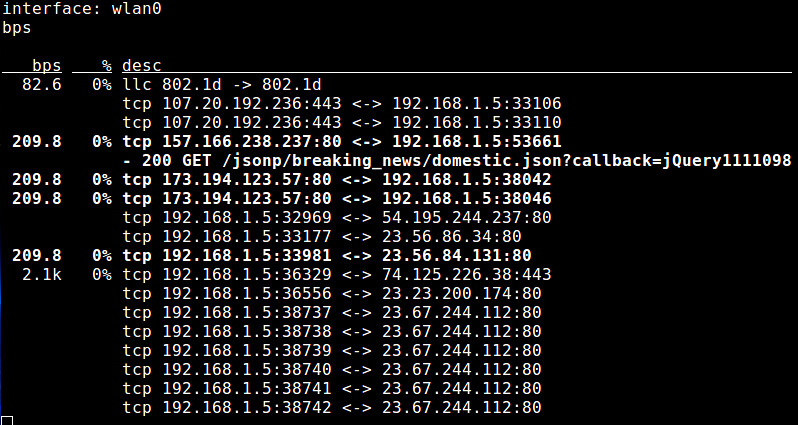
|
||||
|
||||
9. **Snort**: an intrusion detection and prevention tool which can detect/prevent a variety of backdoor, botnets, phishing, spyware attacks from live traffic based on rule-driven protocol analysis and content matching.
|
||||
|
||||
10. **tcpdump**: a command-line packet sniffer which is capable of capturing nework packets on the wire based on filter expressions, dissect the packets, and dump the packet content for packet-level analysis. It is widely used for any kinds of networking related troubleshooting, network application debugging, or [security][6] monitoring.
|
||||
|
||||
11. **tshark**: a command-line packet sniffing tool that comes with Wireshark GUI program. It can capture and decode live packets on the wire, and show decoded packet content in a human-friendly fashion.
|
||||
|
||||
### Flow-/Process-/Interface-Level Monitoring ###
|
||||
|
||||
In this category, network monitoring is done by classifying network traffic into flows, associated processes or interfaces, and collecting per-flow, per-process or per-interface statistics. Source of information can be libpcap packet capture library or sysfs kernel virtual filesystem. Monitoring overhead of these tools is low, but packet-level inspection capabilities are missing.
|
||||
|
||||
12. **bmon**: a console-based bandwidth monitoring tool which shows various per-interface information, including not-only aggregate/average RX/TX statistics, but also a historical view of bandwidth usage.
|
||||
|
||||
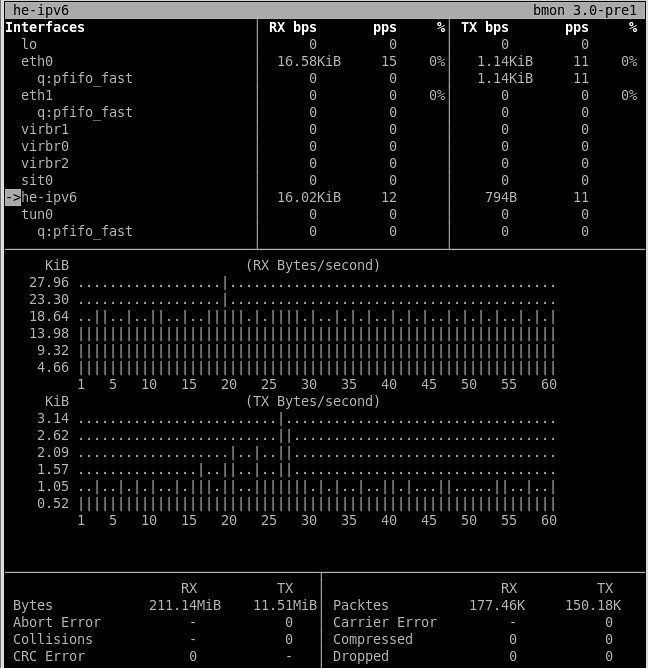
|
||||
|
||||
13. **[iftop][7]**: a bandwidth usage monitoring tool that can shows bandwidth usage for individual network connections in real time. It comes with ncurses-based interface to visualize bandwidth usage of all connections in a sorted order. It is useful for monitoring which connections are consuming the most bandwidth.
|
||||
|
||||
14. **nethogs**: a process monitoring tool which offers a real-time view of upload/download bandwidth usage of individual processes or programs in an ncurses-based interface. This is useful for detecting bandwidth hogging processes.
|
||||
|
||||
15. **netstat**: a command-line tool that shows various statistics and properties of the networking stack, such as open TCP/UDP connections, network interface RX/TX statistics, routing tables, protocol/socket statistics. It is useful when you diagnose performance and resource usage related problems of the networking stack.
|
||||
|
||||
16. **[speedometer][8]**: a console-based traffic monitor which visualizes the historical trend of an interface's RX/TX bandwidth usage with ncurses-drawn bar charts.
|
||||
|
||||
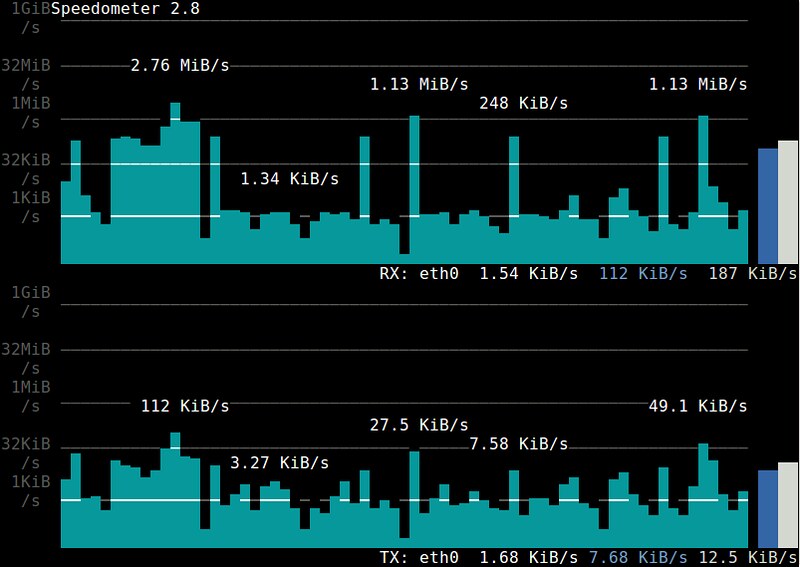
|
||||
|
||||
17. **[sysdig][9]**: a comprehensive system-level debugging tool with a unified interface for investigating different Linux subsystems. Its network monitoring module is capable of monitoring, either online or offline, various per-process/per-host networking statistics such as bandwidth usage, number of connections/requests, etc.
|
||||
|
||||
18. **tcptrack**: a TCP connection monitoring tool which displays information of active TCP connections, including source/destination IP addresses/ports, TCP state, and bandwidth usage.
|
||||
|
||||
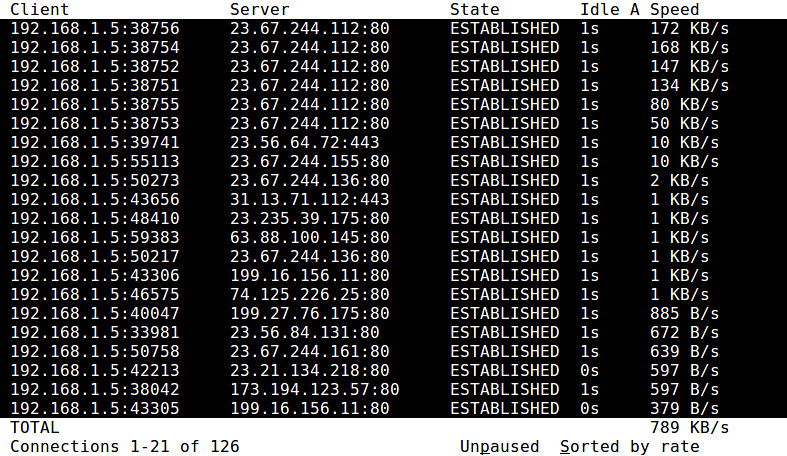
|
||||
|
||||
19. **vnStat**: a command-line traffic monitor which maintains a historical view of RX/TX bandwidh usage (e.g., current, daily, monthly) on a per-interface basis. Running as a background daemon, it collects and stores interface statistics on bandwidth rate and total bytes transferred.
|
||||
|
||||
### Active Network Monitoring ###
|
||||
|
||||
Unlike passive monitoring tools presented so far, tools in this category perform network monitoring by actively "injecting" probes into the network and collecting corresponding responses. Monitoring targets include routing path, available bandwidth, loss rates, delay, jitter, system settings or vulnerabilities, and so on.
|
||||
|
||||
20. **[dnsyo][10]**: a DNS monitoring tool which can conduct DNS lookup from open resolvers scattered across more than 1,500 different networks. It is useful when you check DNS propagation or troubleshoot DNS configuration.
|
||||
|
||||
21. **[iperf][11]**: a TCP/UDP bandwidth measurement utility which can measure maximum available bandwidth between two end points. It measures available bandwidth by having two hosts pump out TCP/UDP probe traffic between them either unidirectionally or bi-directionally. It is useful when you test the network capacity, or tune the parameters of network stack. A variant called [netperf][12] exists with more features and better statistics.
|
||||
|
||||
22. **[netcat][13]/socat**: versatile network debugging tools capable of reading from, writing to, or listen on TCP/UDP sockets. They are often used alongside with other programs or scripts for backend network transfer or port listening.
|
||||
|
||||
23. **nmap**: a command-line port scanning and network discovery utility. It relies on a number of TCP/UDP based scanning techniques to detect open ports, live hosts, or existing operating systems on the local network. It is useful when you audit local hosts for vulnerabilities or build a host map for maintenance purpose. [zmap][14] is an alernative scanning tool with Internet-wide scanning capability.
|
||||
|
||||
24. ping: a network testing tool which works by exchaning ICMP echo and reply packets with a remote host. It is useful when you measure round-trip-time (RTT) delay and loss rate of a routing path, as well as test the status or firewall rules of a remote system. Variations of ping exist with fancier interface (e.g., [noping][15]), multi-protocol support (e.g., [hping][16]) or parallel probing capability (e.g., [fping][17]).
|
||||
|
||||
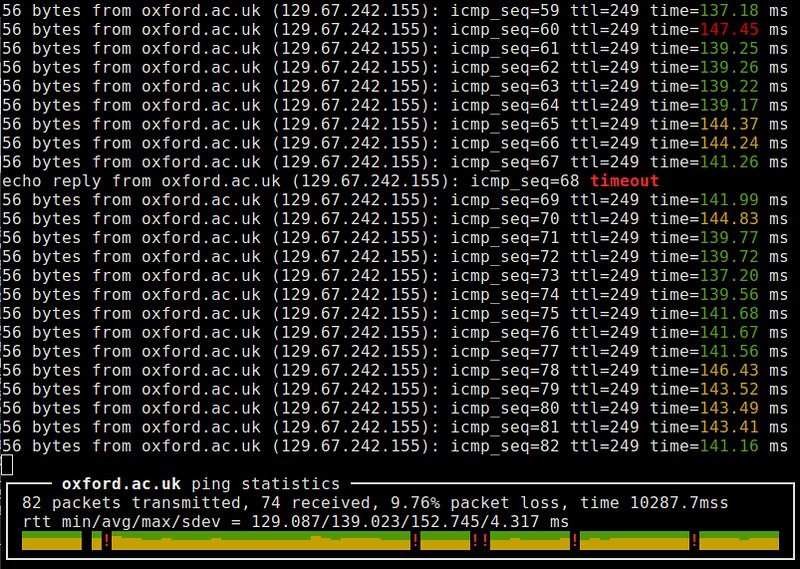
|
||||
|
||||
25. **[sprobe][18]**: a command-line tool that heuristically infers the bottleneck bandwidth between a local host and any arbitrary remote IP address. It uses TCP three-way handshake tricks to estimate the bottleneck bandwidth. It is useful when troubleshooting wide-area network performance and routing related problems.
|
||||
|
||||
26. **traceroute**: a network discovery tool which reveals a layer-3 routing/forwarding path from a local host to a remote host. It works by sending TTL-limited probe packets and collecting ICMP responses from intermediate routers. It is useful when troubleshooting slow network connections or routing related problems. Variations of traceroute exist with better RTT statistics (e.g., [mtr][19]).
|
||||
|
||||
### Application Log Parsing ###
|
||||
|
||||
In this category, network monitoring is targeted at a specific server application (e.g., web server or database server). Network traffic generated or consumed by a server application is monitored by analyzing its log file. Unlike network-level monitors presented in earlier categories, tools in this category can analyze and monitor network traffic from application-level.
|
||||
|
||||
27. **[GoAccess][20]**: a console-based interactive viewer for Apache and Nginx web server traffic. Based on access log analysis, it presents a real-time statistics of a number of metrics including daily visits, top requests, client operating systems, client locations, client browsers, in a scrollable view.
|
||||
|
||||
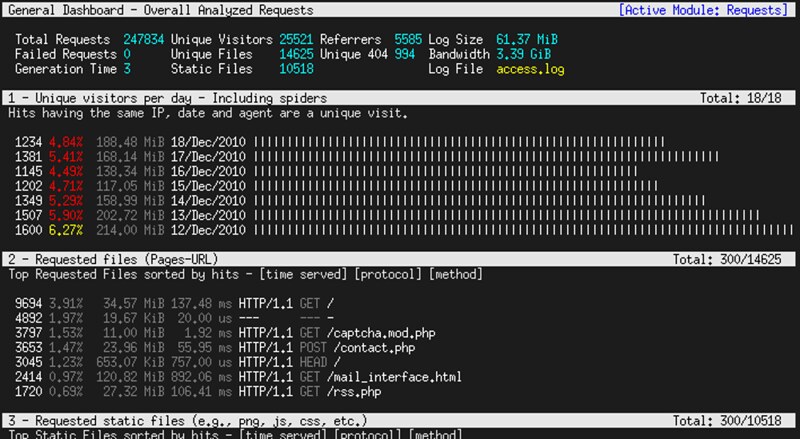
|
||||
|
||||
28. **[mtop][21]**: a command-line MySQL/MariaDB server moniter which visualizes the most expensive queries and current database server load. It is useful when you optimize MySQL server performance and tune server configurations.
|
||||
|
||||
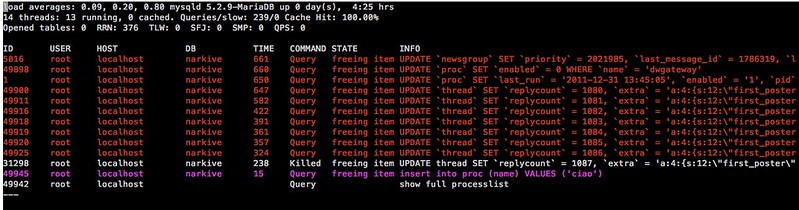
|
||||
|
||||
29. **[ngxtop][22]**: a traffic monitoring tool for Nginx and Apache web server, which visualizes web server traffic in a top-like interface. It works by parsing a web server's access log file and collecting traffic statistics for individual destinations or requests.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, I presented a wide variety of command-line network monitoring tools, ranging from the lowest packet-level monitors to the highest application-level network monitors. Knowing which tool does what is one thing, and choosing which tool to use is another, as any single tool cannot be a universal solution for your every need. A good system admin should be able to decide which tool is right for the circumstance at hand. Hopefully the list helps with that.
|
||||
|
||||
You are always welcome to improve the list with your comment!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/useful-command-line-network-monitors-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.monkey.org/~dugsong/dsniff/
|
||||
[2]:http://xmodulo.com/monitor-http-traffic-command-line-linux.html
|
||||
[3]:https://github.com/zorkian/mysql-sniffer
|
||||
[4]:http://ngrep.sourceforge.net/
|
||||
[5]:http://lcamtuf.coredump.cx/p0f3/
|
||||
[6]:http://xmodulo.com/recommend/firewallbook
|
||||
[7]:http://xmodulo.com/how-to-install-iftop-on-linux.html
|
||||
[8]:https://excess.org/speedometer/
|
||||
[9]:http://xmodulo.com/monitor-troubleshoot-linux-server-sysdig.html
|
||||
[10]:http://xmodulo.com/check-dns-propagation-linux.html
|
||||
[11]:https://iperf.fr/
|
||||
[12]:http://www.netperf.org/netperf/
|
||||
[13]:http://xmodulo.com/useful-netcat-examples-linux.html
|
||||
[14]:https://zmap.io/
|
||||
[15]:http://noping.cc/
|
||||
[16]:http://www.hping.org/
|
||||
[17]:http://fping.org/
|
||||
[18]:http://sprobe.cs.washington.edu/
|
||||
[19]:http://xmodulo.com/better-alternatives-basic-command-line-utilities.html#mtr_link
|
||||
[20]:http://goaccess.io/
|
||||
[21]:http://mtop.sourceforge.net/
|
||||
[22]:http://xmodulo.com/monitor-nginx-web-server-command-line-real-time.html
|
||||
@ -0,0 +1,168 @@
|
||||
Translated By H-mudcup
|
||||
|
||||
文件轻松比对,伟大而自由的比较软件们
|
||||
================================================================================
|
||||
作者 Frazer Kline
|
||||
|
||||
文件比较工具用于比较电脑文件的内容,找到他们之间相同与不同之处。比较的结果通常被称为diff。
|
||||
|
||||
diff同时也是一个著名的,基于控制台的,能输出两个文件之间不同之处的,文件比较程序的名字。diff是二十世纪70年代早期,在Unix操作系统上被开发出来的。diff将会把两个文件之间不同之处的部分进行输出。
|
||||
|
||||
Linux拥有很多不错的,能使你能清楚的看到两个文件或同一文件不同版本之间的不同之处的,很棒的GUI工具。这次我从自己最喜欢的GUI比较工具中选出了五个推荐给大家。除了其中的一个,其他的都有开源许可证。
|
||||
|
||||
这些应用程序可以让文件或目录的差别变得可见,能合并有差异的文件,可以解决冲突并将其输出成一个新的文件或补丁,还能帮助回顾文件被改动过的地方并评论最终产品(比如,在源代码合并到源文件树之前,要先批准源代码的改变)。因此它们是非常重要的软件开发工具。它们不停的把文件传来传,帮助开发人员们在同一个文件上工作。这些比较工具不仅仅能用于显示源代码文件中的不同之处;他们还适用于很多种文本类文件。可视化的特性使文件比较变得容易、简单。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Meld是一个适用于Gnome桌面的,开源的,图形化的文件差异查看和合并的应用程序。它支持2到3个文件的同时比较,递归式的目录比较,版本控制(Bazaar, Codeville, CVS, Darcs, Fossil SCM, Git, Mercurial, Monotone, Subversion)之下的目录比较。还能够手动或自动合并文件差异。
|
||||
|
||||
eld的重点在于帮助开发人员比较和合并多个源文件,并在他们最喜欢的版本控制系统下能直观的浏览改动过的地方。
|
||||
|
||||
功能包括
|
||||
|
||||
- 原地编辑文件,即时更新
|
||||
- 进行两到三个文件的比较及合并
|
||||
- 差异和冲突之间的导航
|
||||
- 可视化本地和总体间的插入、改变和冲突这几种不同之处。
|
||||
- 内置正则表达式文本过滤器,可以忽略不重要的差异
|
||||
- 语法高亮度显示(可选择gtksourceview)
|
||||
- 将两到三个目录一个文件一个文件的进行比较,显示新建,缺失和替换过的文件。
|
||||
- 可直接开启任何有冲突或差异的文件的比较
|
||||
- 可以过滤文件或目录以避免出现假差异
|
||||
- 被改动区域的自动合并模式使合并更容易
|
||||
- 简单的文件管理
|
||||
- 支持多种版本控制系统,包括Git, Mercurial, Bazaar and SVN
|
||||
- 在提交前开启文件比较来检查改动的地方和内容
|
||||
- 查看文件版本状态
|
||||
- 还能进行简单的版本控制操作(例如,提交、更新、添加、移动或删除文件)
|
||||
- 继承自同一文件的两个文件进行自动合并
|
||||
- 标注并在中间的窗格显示所有有冲突的变更的基础版本
|
||||
- 显示并合并同一文件的各自独立的修改
|
||||
- 锁定只读性质的基础文件以避免出错
|
||||
- 可以整合到已有的命令行界面中,包括gitmergetool
|
||||
- 国际化支持
|
||||
- 可视化使文件比较更简单
|
||||
|
||||
- 网址: [meldmerge.org][1]
|
||||
- 开发人员: Kai Willadsen
|
||||
- 证书: GNU GPL v2
|
||||
- 版本号: 1.8.5
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
注:上面这个图访问不到,图的地址是原文地址的小图的链接地址,发布的时候在验证一下,如果还访问不到,不行先采用小图或者网上搜一下看有没有大图
|
||||
|
||||
DiffMerge是一个可以在Linux、Windows和OS X上运行的,可以可视化文件的比较和合并的应用软件。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 图形化的显示两个文件之间的差别。包括插入行,高亮标注以及对编辑的全面支持。
|
||||
- 图形化的显示三个文件之间的差别。(安全的前提下)允许自动合并还完全拥有最终文件的编辑权。
|
||||
- 并排显示两个文件夹的比较,显示哪一个文件只存在于其中一个文件夹而不存在于与之相比较的那个文件夹,还能一对一的将完全相同的、等价的或不同的文件配对。
|
||||
- 规则设置和选项让你可以个性化它的外观和行为
|
||||
- 基于Unicode,可以导入多种编码的字符
|
||||
- 跨平台工具
|
||||
|
||||
- 网址: [sourcegear.com/diffmerge][2]
|
||||
- 开发人员: SourceGear LLC
|
||||
- 证书: Licensed for use free of charge (not open source)
|
||||
- 版本号: 4.2
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
xxdiff是个开源的图形化的,可进行文件、目录比较及合并的工具。
|
||||
|
||||
xxdiff可以用于显示两到三个文件或两个目录的差别,还能产生一个合并后的版本。被比较的两到三个文件会并排显示,并将有区别的文字内容用不同颜色高亮显示以便于识别。
|
||||
|
||||
这个程序是个非常重要的软件开发工具。他可以图形化的显示两个文件或目录之间的差别,合并有差异的文件,解决冲突并评论结果(例如在源代码合并到一个源文件树里之前必须先允许其改变)
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较两到三个文件,或是两个目录(浅层或递归)
|
||||
- 水平差别高亮显示
|
||||
- 文件可以被交互式的合并,可视化的输出和保存
|
||||
- 可以可视化合并的评论/监管
|
||||
- 保留自动合并文件中的冲突,并以两个文件显示以便于解决冲突
|
||||
- 用额外的比较程序估算差异:适用于GNU diff、SGI diff和ClearCase的cleardiff,以及所有与这些程序输出相似的文件比较程序。
|
||||
- 可以在源文件上实现完全的个性化设置
|
||||
- 用起来感觉和Rudy Wortel或SGI的xdiff差不多, it is desktop agnostic
|
||||
- 功能和输出可以和脚本轻松集成
|
||||
|
||||
- 网址: [furius.ca/xxdiff][3]
|
||||
- 开发人员: Martin Blais
|
||||
- 证书: GNU GPL
|
||||
- 版本号: 4.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Diffuse是个开源的图形化工具,可用于合并和比较文本文件。Diffuse能够比较任意数量的文件,并排显示,并提供手动行匹配调整,能直接编辑文件。Diffuse还能从bazaar、CVS、darcs, git, mercurial, monotone, Subversion和GNU矫正控制系统(GNU Revision Control System ,RCS)这些关于比较及合并的资源中对文件进行恢复和矫正。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较任意数量的文件,并排显示(多方合并)
|
||||
- 行匹配可以被用户人工矫正
|
||||
- 直接编辑文件
|
||||
- 语法高亮
|
||||
- 支持Bazaar, CVS, Darcs, Git, Mercurial, Monotone, RCS, Subversion和SVK
|
||||
- 支持Unicode
|
||||
- 可无限撤销
|
||||
- 简易键盘导航
|
||||
|
||||
- 网址: [diffuse.sourceforge.net][]
|
||||
- 开发人员: Derrick Moser
|
||||
- 证书: GNU GPL v2
|
||||
- 版本号: 0.4.7
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Kompare是个开源的GUI前端程序,可以开启不同源文件之间差异的可视化和合并。Kompare可以比较文件或文件夹内容的差异。Kompare支持很多种diff格式,并提供各种选项来设置显示的信息级别。
|
||||
|
||||
不论你是个想比较源代码的开发人员,还是只想比较一下研究论文手稿与最终文档的差异,Kompare都是个有用的工具。
|
||||
|
||||
Kompare是KDE桌面环境的一部分。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较两个文本文件
|
||||
- 递归式比较目录
|
||||
- 显示diff产生的补丁
|
||||
- 将补丁合并到一个已存在的目录
|
||||
- 在无聊的编译时刻,逗你玩
|
||||
|
||||
- 网址: [www.caffeinated.me.uk/kompare/][5]
|
||||
- 开发者: The Kompare Team
|
||||
- 证书: GNU GPL
|
||||
- 版本号: Part of KDE
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/2014062814400262/FileComparisons.html
|
||||
|
||||
译者:[H-mudcup](https://github.com/H-mudcup) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://meldmerge.org/
|
||||
[2]:https://sourcegear.com/diffmerge/
|
||||
[3]:http://furius.ca/xxdiff/
|
||||
[4]:http://diffuse.sourceforge.net/
|
||||
[5]:http://www.caffeinated.me.uk/kompare/
|
||||
@ -1,82 +0,0 @@
|
||||
ChromeOS 对战 Linux : 孰优孰劣,仁者见仁,智者见智
|
||||
================================================================================
|
||||
> 在 ChromeOS 和 Linux 的斗争过程中,不管是哪一家的操作系统都是有优有劣。
|
||||
|
||||
任何不关注Google 的人都不会相信Google在桌面用户当中扮演着一个很重要的角色。在近几年,我们见到的[ChromeOS][1]制造的[Google Chromebook][2]相当的轰动。和同期的人气火爆的Amazon 一样,似乎ChromeOS 势不可挡。
|
||||
|
||||
在本文中,我们要了解的是ChromeOS 的概念市场,ChromeOS 怎么影响着Linux 的份额,和整个 ChromeOS 对于linux 社区来说,是好事还是坏事。另外,我将会谈到一些重大的事情,和为什么没人去为他做点什么事情。
|
||||
|
||||
### ChromeOS 并非真正的Linux ###
|
||||
|
||||
每当有朋友问我说是否ChromeOS 是否是Linux 的一个版本时,我都会这样回答:ChromeOS 对于Linux 就好像是 OS X 对于BSD 。换句话说,我认为,ChromeOS 是linux 的一个派生操作系统,运行于Linux 内核的引擎之下。而很多操作系统就组成了Google 的专利代码和软件。
|
||||
|
||||
尽管ChromeOS 是利用了Linux 内核引擎,但是它仍然有很大的不同和现在流行的Linux 分支版本。
|
||||
|
||||
尽管ChromeOS 的差异化越来越明显,是在于它给终端用户提供的app,包括Web 应用。因为ChromeOS 的每一个操作都是开始于浏览器窗口,这对于Linux 用户来说,可能会有很多不一样的感受,但是,对于没有Linux 经验的用户来说,这与他们使用的旧电脑并没有什么不同。
|
||||
|
||||
就是说,每一个以Google-centric 为生活方式的人来说,在ChromeOS上的感觉将会非常良好,就好像是回家一样。这样的优势就是这个人已经接受了Chrome 浏览器,Google 驱动器和Gmail 。久而久之,他们的亲朋好友使用ChromeOs 也就是很自然的事情了,就好像是他们很容易接受Chrome 浏览器,因为他们觉得早已经用过。
|
||||
|
||||
然而,对于Linux 爱好者来说,这样的约束就立即带来了不适应。因为软件的选择被限制,有范围的,在加上要想玩游戏和VoIP 是完全不可能的。那么对不起,因为[GooglePlus Hangouts][3]是代替不了VoIP 软件的。甚至在很长的一段时间里。
|
||||
|
||||
### ChromeOS 还是Linux 桌面 ###
|
||||
|
||||
有人断言,ChromeOS 要是想在桌面系统的浪潮中对Linux 产生影响,只有在Linux 停下来浮出水面栖息的时候或者是满足某个非技术用户的时候。
|
||||
|
||||
是的,桌面Linux 对于大多数休闲型的用户来说绝对是一个好东西。然而,它必须有专人帮助你安装操作系统,并且提供“维修”服务,从windows 和 OS X 的阵营来看。但是,令人失望的是,在美国Linux 正好在这个方面很缺乏。所以,我们看到,ChromeOS 正慢慢的走入我们的视线。
|
||||
|
||||
我发现Linux 桌面系统最适合做网上技术支持来管理。比如说:家里的高级用户可以操作和处理更新政府和学校的IT 部门。Linux 还可以应用于这样的环境,Linux桌面系统可以被配置给任何技能水平和背景的人使用。
|
||||
|
||||
相比之下,ChromeOS 是建立在完全免维护的初衷之下的,因此,不需要第三者的帮忙,你只需要允许更新,然后让他静默完成即可。这在一定程度上可能是由于ChromeOS 是为某些特定的硬件结构设计的,这与苹果开发自己的PC 电脑也有异曲同工之妙。因为Google 的ChromeOS 附带一个硬件脉冲,它允许“犯错误”。对于某些人来说,这是一个很奇妙的地方。
|
||||
|
||||
滑稽的是,有些人却宣称,ChomeOs 的远期的市场存在很多问题。简言之,这只是一些Linux 激情的爱好者在找对于ChomeOS 的抱怨罢了。在我看来,停止造谣这些子虚乌有的事情才是关键。
|
||||
|
||||
问题是:ChromeOS 的市场份额和Linux 桌面系统在很长的一段时间内是不同的。这个存在可能会在将来被打破,然而在现在,仍然会是两军对峙的局面。
|
||||
|
||||
### ChromeOS 的使用率正在增长 ###
|
||||
|
||||
不管你对ChromeOS 有怎么样的看法,事实是,ChromeOS 的使用率正在增长。专门针对ChromeOS 的电脑也一直有发布。最近,戴尔(Dell)也发布了一款针对ChromeOS 的电脑。命名为[Dell Chromebox][5],这款ChromeOS 设备将会是另一些传统设备的终结者。它没有软件光驱,没有反病毒软件,offers 能够无缝的在屏幕后面自动更新。对于一般的用户,Chromebox 和Chromebook 正逐渐成为那些工作在web 浏览器上的人的一个选择。
|
||||
|
||||
尽管增长速度很快,ChromeOS 设备仍然面临着一个很严峻的问题 - 存储。受限于有限的硬盘的大小和严重依赖于云存储,并且ChromeOS 不会为了任何使用它们电脑的人消减基本的web 浏览器的功能。
|
||||
|
||||
### ChromeOS 和Linux 的异同点 ###
|
||||
|
||||
以前,我注意到ChromeOS 和Linux 桌面系统分别占有着两个完全不同的市场。出现这样的情况是源于,Linux 社区的致力于提升Linux 桌面系统的脱机性能。
|
||||
|
||||
是的,偶然的,有些人可能会第一时间发现这个“Linux 的问题”。但是,并没有一个人接着跟进这些问题,确保得到问题的答案,确保他们得到Linux 最多的帮助。
|
||||
|
||||
事实上,脱机故障可能是这样发现的:
|
||||
|
||||
- 有些用户偶然的在Linux 本地事件发现了Linux 的问题。
|
||||
- 他们带回了DVD/USB 设备,并尝试安装这个操作系统。
|
||||
- 当然,有些人很幸运的成功的安装成功了这个进程,但是,据我所知大多数的人并没有那么幸运。
|
||||
- 令人失望的是,这些人希望在网上论坛里搜索帮助。很难做一个主计算机,没有网络和视频的问题。
|
||||
- 我真的是受够了,后来有很多失望的用户拿着他们的电脑到windows 商店来“维修”。除了重装一个windows 操作系统,他们很多时候都会听到一句话,“Linux 并不适合你们”,应该尽量避免。
|
||||
|
||||
有些人肯定会说,上面的举例肯定夸大其词了。让我来告诉你:这是发生在我身边真实的事的,而且是经常发生。醒醒吧,Linux 社区的人们,我们的这种模式已经过时了。
|
||||
|
||||
### 伟大的平台,强大的营销和结论 ###
|
||||
|
||||
如果非要说ChromeOS 和Linux 桌面系统相同的地方,除了它们都使用了Linux 内核,就是它们都伟大的产品却拥有极其差劲的市场营销。而Google 的好处就是,他们投入大量的资金在网上构建大面积存储空间。
|
||||
|
||||
Google 相信他们拥有“网上的优势”,而线下的影响不是很重要。这真是一个让人难以置信的目光短浅,这也成了Google 历史上最大的一个失误之一。相信,如果你没有接触到他们在线的努力,你不值得困扰,仅仅就当是他们在是在选择网上存储空间上做出反击。
|
||||
|
||||
我的建议是:通过Google 的线下影响,提供Linux 桌面系统给ChromeOS 的市场。这就意味着Linux 社区的人需要筹集资金来出席县博览会、商场展览,在节日季节,和在社区中进行免费的教学课程。这会立即使Linux 桌面系统走入人们的视线,否则,最终将会是一个ChromeOS 设备出现在人们的面前。
|
||||
|
||||
如果说本地的线下市场并没有想我说的这样,别担心。Linux 桌面系统的市场仍然会像ChromeOS 一样增长。最坏也能保持现在这种两军对峙的市场局面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -1,64 +0,0 @@
|
||||
Linux 上好用的几款字幕编辑器介绍
|
||||
================================================================================
|
||||
如果你经常看国外的大片,你应该会喜欢带字幕版本而不是有国语配音的版本。在法国长大,我的童年记忆里充满了迪斯尼电影。但是这些电影因为有了法语的配音而听起来很怪。如果现在有机会能看原始的版本,我知道,对于大多数的人来说,字幕还是必须的。我很高兴能为家人制作字幕。最让我感到希望的是,Linux 也不无花哨,而且有很多开源的字幕编辑器。总之一句话,这篇文章并不是一个详尽的Linux上字幕编辑器的列表。你可以告诉我那一款是你认为最好的字幕编辑器。
|
||||
|
||||
### 1. Gnome Subtitles ###
|
||||
|
||||

|
||||
|
||||
[Gnome Subtitles][1] 我的一个选择,当有字幕需要快速编辑时。你可以载入视频,载入字幕文本,然后就可以即刻开始了。我很欣赏其对于易用性和高级特性之间的平衡性。它带有一个同步工具以及一个拼写检查工具。最后,虽然最后,但并不是不重要,这么好用最主要的是因为它的快捷键:当你编辑很多的台词的时候,你最好把你的手放在键盘上,使用其内置的快捷键来移动。
|
||||
|
||||
### 2. Aegisub ###
|
||||
|
||||

|
||||
|
||||
[Aegisub][2] 有更高级别的复杂性。接口仅仅反映了学习曲线。但是,除了它吓人的样子以外,Aegisub 是一个非常完整的软件,提供的工具远远超出你能想象的。和Gnome Subtitles 一样,Aegisub也采用了所见即所得(WYSIWYG:what you see is what you get)的处理方式。但是是一个全新的高度:可以再屏幕上任意拖动字幕,也可以在另一边查看音频的频谱,并且可以利用快捷键做任何的事情。除此以外,它还带有一个汉字工具,有一个kalaok模式,并且你可以导入lua 脚本让它自动完成一些任务。我希望你在用之前,先去阅读下它的[指南][3]。
|
||||
|
||||
### 3. Gaupol ###
|
||||
|
||||

|
||||
|
||||
另一个操作复杂的软件是[Gaupol][4],不像Aegisub ,Gaupol 很容易上手而且采用了一个和Gnome Subtitles 很像的界面。但是在这些相对简单背后,它拥有很多很必要的工具:快捷键、第三方扩展、拼写检查,甚至是语音识别(由[CMU Sphinx][5]提供)。这里也提一个缺点,我注意到有时候在测试的时候也,软件会有消极怠工的表现,不是很严重,但是也足以让我更有理由喜欢Gnome Subtitles了。
|
||||
|
||||
### 4. Subtitle Editor ###
|
||||
|
||||

|
||||
|
||||
[Subtitle Editor][6]和Gaupol 很像。但是,它的界面有点不太直观,特性也只是稍微的高级一点点。我很欣赏的一点是,它可以定义“关键帧”,而且提供所有的同步选项。然而,多一点的图标,或者是少一点的文字都能提供界面的特性。作为一个好人,我认为,Subtitle Editor 可以模仿“作家”打字的效果,虽然我不知道它是否有用。最后但并非不重要。重定义快捷键的功能很实用。
|
||||
|
||||
### 5. Jubler ###
|
||||
|
||||

|
||||
|
||||
用Java 写的,[Jubler][7]是一个多平台支持的字幕编辑器。我对它的界面印象特别深刻。在上面我确实看出了Java-ish 方面的东西,但是,它仍然是经过精心的构造和构思的。像Aegisub 一样,你可以再屏幕上任意的拖动字幕,让你有愉快的体验而不单单是打字。它也可以为字幕自定义一个风格,在另外的一个轨道播放音频,翻译字幕,或者是是做拼写检查,然而,你必须要注意的是,你必须事先安装好媒体播放器并且正确的配置,如果你想完整的使用Jubler。我把这些归功于在[官方页面][8]下载了脚本以后其简便的安装方式。
|
||||
|
||||
### 6. Subtitle Composer ###
|
||||
|
||||

|
||||
|
||||
被视为“KDE里的字幕作曲家”,[Subtitle Composer][9]能够唤起对很多传统功能的回忆。伴随着KDE界面,我们很期望。很自然的我们就会说到快捷键,我特别喜欢这个功能。除此之外,Subtitle Composer 与上面提到的编辑器最大的不同地方就在于,它可以执行用JavaScript,Python,甚至是Ruby写成的脚本。软件带有几个例子,肯定能够帮助你很好的学习使用这些特性的语法。
|
||||
|
||||
最后,不管你喜不喜欢我,都要为你的家庭编辑几个字幕,重新同步整个轨道,或者是一切从头开始,那么Linux 有很好的工具给你。对我来说,快捷键和易用性使得各个工具有差异,想要更高级别的使用体验,脚本和语音识别就成了很便利的一个功能。
|
||||
|
||||
你会使用哪个字幕编辑器,为什么?你认为还有没有更好用的字幕编辑器这里没有提到的?在评论里告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://gnomesubtitles.org/
|
||||
[2]:http://www.aegisub.org/
|
||||
[3]:http://docs.aegisub.org/3.2/Main_Page/
|
||||
[4]:http://home.gna.org/gaupol/
|
||||
[5]:http://cmusphinx.sourceforge.net/
|
||||
[6]:http://home.gna.org/subtitleeditor/
|
||||
[7]:http://www.jubler.org/
|
||||
[8]:http://www.jubler.org/download.html
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
@ -1,65 +0,0 @@
|
||||
黑客年暮
|
||||
================================================================================
|
||||
近来我一直在与某资深开源组织的各成员进行争斗,尽管密切关注我的人们会在读完本文后猜到是哪个组织,但我不会在这里说出这个组织的名字。
|
||||
|
||||
怎么让某些人进入 21 世纪就这么难呢?真是的...
|
||||
|
||||
我快56 岁了,也就是大部分年轻人会以为的我将时不时朝他们发出诸如“滚出我的草坪”之类歇斯底里咆哮的年龄。但事实并非如此 —— 我发现,尤其是在技术背景之下,我变得与我的年龄非常不相称。
|
||||
|
||||
在我这个年龄的大部分人确实变成了爱发牢骚、墨守成规的老顽固。并且,尴尬的是,偶尔我会成为那个打断谈话的人,然后提出在 1995 年(或者在某些特殊情况下,1985 年)时很适合的方法... 但十年后就不是个好方法了。
|
||||
|
||||
为什么是我?因为我的同龄人里大部分人在孩童时期都没有什么名气。任何想要改变自己的人,就必须成为他们中具有较高思想觉悟的佼佼者。即便如此,在与习惯做斗争的过程中,我也比实际上花费了更多的时间。
|
||||
|
||||
年轻人犯下无知的错误是可以被原谅的。他们还年轻。年轻意味着缺乏经验,缺乏经验通常会导致片面的判断。我很难原谅那些经历了足够多本该有经验的人,却被<em>长期的固化思维</em>蒙蔽,无法发觉近在咫尺的东西。
|
||||
|
||||
(补充一下:我真的不是老顽固。那些和我争论政治的,无论保守派还是非保守派都没有注意到这点,我觉得这颇有点嘲讽的意味。)
|
||||
|
||||
那么,现在我们来讨论下 GNU 更新日志文件这件事。在 1985 年的时候,这是一个不错的主意,甚至可以说是必须的。当时的想法是用单独的更新日志文件来记录相关文件的变更情况。用这种方式来对那些存在版本缺失或者非常原始的版本进行版本控制确实不错。当时我也在场,所以我知道这些。
|
||||
|
||||
不过即使到了 1995 年,甚至 21 世纪早期,许多版本控制系统仍然没有太大改进。也就是说,这些版本控制系统并非对批量文件的变化进行分组再保存到一条记录上,而是对每个变化的文件分别进行记录并保存到不同的地方。CVS,当时被广泛使用的版本控制系统,仅仅是模拟日志变更 —— 并且在这方面表现得很糟糕,导致大多数人不再依赖这个功能。即便如此,更新日志文件的出现依然是必要的。
|
||||
|
||||
但随后,版本控制系统 Subversion 于 2003 年发布 beta 版,并于 2004 年发布 1.0 正式版,Subversion 真正实现了更新日志记录功能,得到了人们的广泛认可。它与一年后兴起的分散式版本控制系统(Distributed Version Control System,DVCS)共同引发了主流世界的激烈争论。因为如果你在项目上同时使用了分散式版本控制与更新日志文件记录的功能,它们将会因为争夺相同元数据的控制权而产生不可预料的冲突。
|
||||
|
||||
另一种方法是对提交的评论日志进行授权。如果你这样做了,不久后你就会开始思忖为什么自己仍然对所有的日志更新条目进行记录。提交的元数据与变化的代码具有更好的相容性,毕竟这就是它当初设计的目的。
|
||||
|
||||
(现在,试想有这样一个项目,同样本着把项目做得最好的想法,但两拨人却做出了完全不同的选择。因此你必须同时阅读更新日志和评论日志以了解到底发生了什么。最好在矛盾激化前把问题解决....)
|
||||
|
||||
第三种办法是尝试同时使用两种方法 —— 以另一种格式再次提交评论数据,作为更新日志提交的一部分。这解决了所有你期待的有代表性的问题,并且没有任何缺陷遗留下来;只要其中有拷贝文件损坏,日志文件就会修改,因此这不再是同步时数据匹配的问题,而且导致在其后参与进来的人试图搞清人们是怎么想的时候将会变得非常困惑。
|
||||
|
||||
或者,如某个<em>我就不说出具体名字的特定项目</em>的高层开发只是通过电子邮件来完成这些,声明提交可以包含多个更新日志,以及提交的元数据与更新日志是无关的。这导致我们直到现在还得不断进行记录。
|
||||
|
||||
当我读到那条的时候我的眼光停在了那个地方。什么样的傻瓜才会没有意识到这是在自找麻烦 —— 事实上,针对更新日志文件采取的定制措施完全是不必要的,尤其是在分散式版本控制系统中
|
||||
有很好的浏览工具来阅读可靠的提交日志的时候。
|
||||
|
||||
唉,这是比较特殊的笨蛋:变老的并且思维僵化了的黑客。所有的合理化改革他都会极力反对。他所遵循的行事方法在十年前是有效的,但现在只能使得其反了。如果你试图解释不只是git的总摘要,还得正确掌握当前的各种工具才能完全弃用更新日志... 呵呵,准备好迎接无法忍受、无法想象的疯狂对话吧。
|
||||
|
||||
幸运的是这激怒了我。因为这点还有其他相关的胡言乱语使这个项目变成了很难完成的工作。而且,这类糟糕的事时常发生在年轻的开发者身上,这才是问题所在。相关 G+ 社群的数量已经达到了 4 位数,他们大部分都是孩子,他们也没有紧张起来。显然消息已经传到了外面;这个项目的开发者都是被莫名关注者的老牌黑客,同时还有很多对他们崇拜的人。
|
||||
|
||||
这件事给我的最大触动就是每当我要和这些老牌黑客较量时,我都会想:有一天我也会这样吗?或者更糟的是,我看到的只是如同镜子一般对我自己的真实写照,而我自己却浑然不觉吗?我的意思是,我的印象来自于他的网站,这个特殊的样本要比我年轻。通过十五年的仔细观察得出的结论。
|
||||
|
||||
我觉得思路很清晰。当我和那些比我聪明的人打交道时我不会受挫,我只会因为那些不能跟上我的人而
|
||||
沮丧,这些人也不能看见事实。但这种自信也许只是邓宁·克鲁格效应的消极影响,至少我明白这点。很少有什么事情会让我感到害怕;而这件事在让我害怕的事情名单上是名列前茅的。
|
||||
|
||||
另一件让人不安的事是当我逐渐变老的时候,这样的矛盾发生得越来越频繁。不知怎的,我希望我的黑客同行们能以更加优雅的姿态老去,即使身体老去也应该保持一颗年轻的心灵。有些人确实是这样;但可是绝大多数人都不是。真令人悲哀。
|
||||
|
||||
我不确定我的职业生涯会不会完美收场。假如我最后成功避免了思维僵化(注意我说的是假如),我想我一定知道其中的部分原因,但我不确定这种模式是否可以被复制 —— 为了达成目的也许得在你的头脑中发生一些复杂的化学反应。尽管如此,无论对错,请听听我给年轻黑客以及其他有志青年的建议。
|
||||
|
||||
你们 —— 对的,也包括你 —— 一定无法在你中年老年的时候保持不错的心灵,除非你能很好的控制这点。你必须不断地去磨练你的内心、在你还年轻的时候完成自己的种种心愿,你必须把这些行为养成一种习惯直到你老去。
|
||||
|
||||
有种说法是中年人锻炼身体的最佳时机是他进入中年的 30 年前。我以为同样的方法,坚持我以上所说的习惯能让你在 56 岁,甚至 65 岁的时候仍然保持灵活的头脑。挑战你的极限,使不断地挑战自己成为一种习惯。立刻离开安乐窝,由此当你以后真正需要它的时候你可以建立起自己的安乐窝。
|
||||
|
||||
你必须要清楚的了解这点;还有一个可选择的挑战是你选择一个可以实现的目标并且为了这个目标不断努力。这个月我要学习 Go 语言。不是指游戏,我早就玩儿过了(虽然玩儿的不是太好)。并不是因为工作需要,而是因为我觉得是时候来扩展下我自己了。
|
||||
|
||||
保持这个习惯。永远不要放弃。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=6485
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
@ -0,0 +1,74 @@
|
||||
Linux 有问必答--Linux 中如何安装 7zip
|
||||
================================================================================
|
||||
> **问题**: 我需要要从 ISO 映像中获取某些文件,为此我想要使用 7zip 程序。那么我应该如何安装 7zip 软件呢,[在 Linux 发布版本上完全安装]?
|
||||
|
||||
7zip 是一款开源的归档应用程序,开始是为 Windows 系统而开发的。它能对多种格式的档案文件进行打包或解包处理,除了支持原生的 7z 格式的文档外,还支持包括 XZ、GZIP、TAR、ZIP 和 BZIP2 等这些格式。 一般地,7zip 也常用来解压 RAR、DEB、RPM 和 ISO 等格式的文件。除了简单的归档功能,7zip 还具有支持 AES-256 算法加密以及自解压和建立多卷存档功能。在以 POSIX 协议为标准的系统上(Linux、Unix、BSD),原生的 7zip 程序被移植过来并被命名为 p7zip(“POSIX 7zip” 的简称)。
|
||||
|
||||
下面介绍如何在 Linux 中安装 7zip (或 p7zip)。
|
||||
|
||||
### 在 Debian、Ubuntu 或 Linux Mint 系统中安装 7zip ###
|
||||
|
||||
在基于的 Debian 的发布系统中存在有三种 7zip 的软件包。
|
||||
|
||||
- **p7zip**: 包含 7zr(最小的 7zip 归档工具),仅仅只能处理原生的 7z 格式。
|
||||
- **p7zip-full**: 包含 7z ,支持 7z、LZMA2、XZ、ZIP、CAB、GZIP、BZIP2、ARJ、TAR、CPIO、RPM、ISO 和 DEB 格式。
|
||||
- **p7zip-rar**: 包含一个能解压 RAR 文件的插件。
|
||||
|
||||
建议安装 p7zip-full 包(不是 p7zip),因为这是最完全的 7zip 程序包,它支持很多归档格式。此外,如果您想处理 RAR 文件话,还需要安装 p7zip-rar 包,做成一个独立的插件包的原因是因为 RAR 是一种专有格式。
|
||||
|
||||
$ sudo apt-get install p7zip-full p7zip-rar
|
||||
|
||||
### 在 Fedora 或 CentOS/RHEL 系统中安装 7zip ###
|
||||
|
||||
基于红帽的发布系统上提供了两个 7zip 的软件包。
|
||||
|
||||
- **p7zip**: 包含 7za 命令,支持 7z、ZIP、GZIP、CAB、ARJ、BZIP2、TAR、CPIO、RPM 和 DEB 格式。
|
||||
- **p7zip-plugins**: 包含 7z 命令,额外的插件,它扩展了 7za 命令(例如 支持 ISO 格式的抽取)。
|
||||
|
||||
在 CentOS/RHEL 系统中,在运行下面命令前您需要确保 [EPEL 资源库][1] 可用,但在 Fedora 系统中就不需要额外的资源库了。
|
||||
|
||||
$ sudo yum install p7zip p7zip-plugins
|
||||
|
||||
注意,跟基于 Debian 的发布系统不同的是,基于红帽的发布系统没有提供 RAR 插件,所以您不能使用 7z 命令来抽取解压 RAR 文件。
|
||||
|
||||
### 使用 7z 创建或提取归档文件 ###
|
||||
|
||||
一旦安装好 7zip 软件后,就可以使用 7z 命令来打包解包各式各样的归档文件了。7z 命令会使用不同的插件来辅助处理对应格式的归档文件。
|
||||
|
||||

|
||||
|
||||
使用 “a” 选项就可以创建一个归档文件,它可以创建 7z、XZ、GZIP、TAR、 ZIP 和 BZIP2 这几种格式的文件。如果指定的归档文件已经存在的话,它会把文件“添加”到存在的归档中,而不是覆盖原有归档文件。
|
||||
|
||||
$ 7z a <archive-filename> <list-of-files>
|
||||
|
||||
使用 “e” 选项可以抽取出一个归档文件,抽取出的文件会放在当前目录。抽取支持的格式比创建时支持的格式要多的多,包括 7z、XZ、GZIP、TAR、ZIP、BZIP2、LZMA2、CAB、ARJ、CPIO、RPM、ISO 和 DEB 这些格式。
|
||||
|
||||
$ 7z e <archive-filename>
|
||||
|
||||
解包的另外一种方式是使用 “x” 选项。和 “e” 选项不同的是,它使用的是全路径来抽取归档的内容。
|
||||
|
||||
$ 7z x <archive-filename>
|
||||
|
||||
要查看归档的文件列表,使用 “l” 选项。
|
||||
|
||||
$ 7z l <archive-filename>
|
||||
|
||||
要更新或删除归档文件,分别使用 “u” 和 “d” 选项。
|
||||
|
||||
$ 7z u <archive-filename> <list-of-files-to-update>
|
||||
$ 7z d <archive-filename> <list-of-files-to-delete>
|
||||
|
||||
要测试归档的完整性,使用:
|
||||
|
||||
$ 7z t <archive-filename>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://ask.xmodulo.com/install-7zip-linux.html
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -0,0 +1,207 @@
|
||||
如何配置fail2ban来保护Apache服务器
|
||||
================================================================================
|
||||
生产环境中的Apache服务器可能会受到不同的攻击。攻击者或许试图通过暴力攻击或者执行恶意脚本来获取未经授权或者禁止访问的目录。一些恶意爬虫或许会扫描你网站下的任意安全漏洞,或者手机email地址或者web表格来发送垃圾邮件。
|
||||
|
||||
Apache服务器具有综合的日志功能来捕捉不同表明是攻击的异常事件。然而,它还不能系统地解析具体的apache日志并迅速地反应到潜在的攻击(比如,禁止/解禁IP地址)。这时候`fail2ban`可以解救这一切,解放了系统管理员的工作。
|
||||
|
||||
`fail2ban`是一款入侵防御工具,可以基于系统日志检测不同的工具并且可以自动采取保护措施比如:通过`iptables`禁止ip、阻止/etc/hosts.deny中的连接、或者通过邮件通知事件。fail2ban具有一系列预定义的“监狱”,它使用特定程序日志过滤器来检测通常的攻击。你也可以编写自定义的规则来检测来自任意程序的攻击。
|
||||
|
||||
在本教程中,我会演示如何配置fail2ban来保护你的apache服务器。我假设你已经安装了apache和fail2ban。对于安装,请参考[另外一篇教程][1]。
|
||||
|
||||
### 什么是 Fail2ban 监狱 ###
|
||||
|
||||
让我们更深入地了解fail2ban监狱。监狱定义了具体的应用策略,它会为指定的程序触发一个保护措施。fail2ban在/etc/fail2ban/jail.conf 下为一些流行程序如Apache、Dovecot、Lighttpd、MySQL、Postfix、[SSH][2]等预定义了一些监狱。每个依赖于特定的程序日志过滤器(在/etc/fail2ban/fileter.d 下面)来检测通常的攻击。让我看一个例子监狱:SSH监狱。
|
||||
|
||||
[ssh]
|
||||
enabled = true
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry = 6
|
||||
banaction = iptables-multiport
|
||||
|
||||
SSH监狱的配置定义了这些参数:
|
||||
|
||||
- **[ssh]**: 方括号内是监狱的名字。
|
||||
- **enabled**:是否启用监狱
|
||||
- **port**: 端口的数字 (或者数字对应的名称).
|
||||
- **filter**: 检测攻击的检测规则
|
||||
- **logpath**: 检测的日志文件
|
||||
- **maxretry**: 禁止前失败的最大数字
|
||||
- **banaction**: 禁止操作
|
||||
|
||||
定义配置文件中的任意参数都会覆盖相应的默认配置`fail2ban-wide` 中的参数。相反,任意缺少的参数都会使用定义在[DEFAULT]字段的值。
|
||||
|
||||
预定义日志过滤器都必须在/etc/fail2ban/filter.d,可以采取的操作在/etc/fail2ban/action.d。
|
||||
|
||||

|
||||
|
||||
如果你想要覆盖`fail2ban`的默认操作或者定义任何自定义监狱,你可以创建*/etc/fail2ban/jail.local**文件。本篇教程中,我会使用/etc/fail2ban/jail.local。
|
||||
|
||||
### 启用预定义的apache监狱 ###
|
||||
|
||||
`fail2ban`的默认安装为Apache服务提供了一些预定义监狱以及过滤器。我要启用这些内建的Apache监狱。由于Debian和红买配置的稍微不同,我会分别它们的配置文件。
|
||||
|
||||
#### 在Debian 或者 Ubuntu启用Apache监狱 ####
|
||||
|
||||
要在基于Debian的系统上启用预定义的apache监狱,如下创建/etc/fail2ban/jail.local。
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect potential search for exploits and php vulnerabilities
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
由于上面的监狱没有指定措施,这些监狱都将会触发默认的措施。要查看默认的措施,在/etc/fail2ban/jail.conf中的[DEFAULT]下找到“banaction”。
|
||||
|
||||
banaction = iptables-multiport
|
||||
|
||||
本例中,默认的操作是iptables-multiport(定义在/etc/fail2ban/action.d/iptables-multiport.conf)。这个措施使用iptable的多端口模块禁止一个IP地址。
|
||||
|
||||
在启用监狱后,你必须重启fail2ban来加载监狱。
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
#### 在CentOS/RHEL 或者 Fedora中启用Apache监狱 ####
|
||||
|
||||
要在基于红帽的系统中启用预定义的监狱,如下创建/etc/fail2ban/jail.local。
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect spammer robots crawling email addresses
|
||||
[apache-badbots]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-badbots
|
||||
logpath = /var/log/httpd/*access_log
|
||||
bantime = 172800
|
||||
maxretry = 1
|
||||
|
||||
# detect potential search for exploits and php <a href="http://xmodulo.com/recommend/penetrationbook" style="" target="_blank" rel="nofollow" >vulnerabilities</a>
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to execute non-existing scripts that
|
||||
# are associated with several popular web services
|
||||
# e.g. webmail, phpMyAdmin, WordPress
|
||||
port = http,https
|
||||
filter = apache-botsearch
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
注意这些监狱文件默认的操作是iptables-multiport(定义在/etc/fail2ban/jail.conf中[DEFAULT]字段下的“banaction”中)。这个措施使用iptable的多端口模块禁止一个IP地址。
|
||||
|
||||
启用监狱后,你必须重启fail2ban来加载监狱。
|
||||
|
||||
在 Fedora 或者 CentOS/RHEL 7中:
|
||||
|
||||
$ sudo systemctl restart fail2ban
|
||||
|
||||
在 CentOS/RHEL 6中:
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
### 检查和管理fail2ban禁止状态 ###
|
||||
|
||||
监狱一旦激活后,你可以用fail2ban的客户端命令行工具来监测当前的禁止状态。
|
||||
|
||||
查看激活的监狱列表:
|
||||
|
||||
$ sudo fail2ban-client status
|
||||
|
||||
查看特定监狱的状态(包含禁止的IP列表):
|
||||
|
||||
$ sudo fail2ban-client status [监狱名]
|
||||
|
||||

|
||||
|
||||
你也可以手动禁止或者解禁IP地址
|
||||
|
||||
要用制定监狱禁止IP:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] banip [ip-address]
|
||||
|
||||
要解禁指定监狱屏蔽的IP:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] unbanip [ip-address]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇教程解释了fail2ban监狱如何工作以及如何使用内置的监狱来保护Apache服务器。依赖于你的环境以及要保护的web服务器类型,你或许要适配已存在的监狱或者编写自定义监狱和日志过滤器。查看outfail2ban的[官方Github页面][3]来获取最新的监狱和过滤器示例。
|
||||
|
||||
你有在生产环境中使用fail2ban么?分享一下你的经验吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-fail2ban-apache-http-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[2]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[3]:https://github.com/fail2ban/fail2ban
|
||||
@ -0,0 +1,76 @@
|
||||
如何在Linux上使用dupeGuru删除重复文件
|
||||
================================================================================
|
||||
最近,我被要求清理我父亲的文件和文件夹。有一个难题是,里面存在很多不正确的名字的重复文件。有移动硬盘的备份,同时还为同一个文件编辑了多个版本,甚至改变的目录结构,同一个文件被复制了好几次,改变名字,改变位置等,这些挤满了磁盘空间。追踪每一个文件成了一个最大的问题。万幸的是,有一个小巧的软件可以帮助你省下很多时间来找到删除你系统中重复的文件:[dupeGuru][1]。它用Python写成,这个去重软件几个小时钱前切换到了GPLv3许可证。因此是时候用它来清理你的文件了!
|
||||
|
||||
### dupeGuru的安装 ###
|
||||
|
||||
在Ubuntu上, 你可以加入Hardcoded的软件PPA:
|
||||
|
||||
$ sudo apt-add-repository ppa:hsoft/ppa
|
||||
$ sudo apt-get update
|
||||
|
||||
接着用下面的命令安装:
|
||||
|
||||
$ sudo apt-get install dupeguru-se
|
||||
|
||||
在ArchLinux中,这个包在[AUR][2]中。
|
||||
|
||||
如果你想自己编译,源码在[GitHub][3]上。
|
||||
|
||||
### dupeGuru的基本使用 ###
|
||||
|
||||
DupeGuru的构想是既快又安全。这意味着程序不会在你的系统上疯狂地运行。它很少会删除你不想要删除的文件。然而,既然在讨论文件删除,保持谨慎和小心总是好的:备份总是需要的。
|
||||
|
||||
你看完注意事项后,你可以用下面的命令运行duprGuru了:
|
||||
|
||||
$ dupeguru_se
|
||||
|
||||
你应该看到要你选择文件夹的欢迎界面,在这里加入你你想要扫描的重复文件夹。
|
||||
|
||||

|
||||
|
||||
一旦你选择完文件夹并启动扫描后,dupeFuru会以列表的形式显示重复文件的组:
|
||||
|
||||

|
||||
|
||||
注意的是默认上dupeGuru基于文件的内容匹配,而不是他们的名字。为了防止意外地删除了重要的文件,匹配那列列出了使用的匹配算法。在这里,你可以选择你想要删除的匹配文件,并按下“Action” 按钮来看到可用的操作。
|
||||
|
||||

|
||||
|
||||
可用的选项是相当广泛的。简而言之,你可以删除重复、移动到另外的位置、忽略它们、打开它们、重命名它们甚至用自定义命令运行它们。如果你选择删除重复文件,你可能会像我一样非常意外竟然还有删除选项。
|
||||
|
||||

|
||||
|
||||
你不及可以将删除文件移到垃圾箱或者永久删除,还可以选择留下指向原文件的链接(软链接或者硬链接)。也就是说,重复文件按将会删除但是会保留下指向原文件的链接。这将会省下大量的磁盘空间。如果你将这些文件导入到工作空间或者它们有一些依赖时很有用。
|
||||
|
||||
还有一个奇特的选项:你可以用HTML或者CSV文件导出结果。不确定你会不会这么做,但是我假设你想追踪重复文件而不是想让dupeGuru处理它们时会有用。
|
||||
|
||||
最后但并不是最不重要的是,偏好菜单可以让你对去重的想法成真。
|
||||
|
||||

|
||||
|
||||
这里你可以选择扫描的标准,基于内容还是基于文字,并且有一个阈值来控制结果的数量。这里同样可以定义自定义在执行中可以选择的命令。在无数其他小的选项中,要注意的是dupeGuru默认忽略小于10KB的文件。
|
||||
|
||||
要了解更多的信息,我建议你到[official website][4]官方网站看下,这里有很多文档、论坛支持和其他好东西。
|
||||
|
||||
总结一下,dupeGuru是我无论何时准备备份或者释放空间时想到的软件。我发现这对高级用户而言也足够强大了,对新人而言也很直观。锦上添花的是:dupeGuru是跨平台的额,这意味着你可以在Mac或者在Windows PC上都可以使用。如果你有特定的需求,想要清理音乐或者图片。这里有两个变种:[dupeguru-me][5]和 [dupeguru-pe][6], 相应地可以清理音频和图片文件。与常规版本的不同是它不仅比较文件格式还比较特定的媒体数据像质量和码率。
|
||||
|
||||
你dupeGuru怎么样?你会考虑使用它么?或者你有任何可以替代的软件的建议么?让我在评论区知道你们的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/dupeguru-deduplicate-files-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://www.hardcoded.net/dupeguru/
|
||||
[2]:https://aur.archlinux.org/packages/dupeguru-se/
|
||||
[3]:https://github.com/hsoft/dupeguru
|
||||
[4]:http://www.hardcoded.net/dupeguru/
|
||||
[5]:http://www.hardcoded.net/dupeguru_me/
|
||||
[6]:http://www.hardcoded.net/dupeguru_pe/
|
||||
@ -0,0 +1,73 @@
|
||||
如何在Ubuntu 14.04 上为Apache 2.4 安装SSL
|
||||
================================================================================
|
||||
今天我会站如如何为你的个人网站或者博客安装**SSL 证书**,来保护你的访问者和网站之间通信的安全。
|
||||
|
||||
安全套接字层或称SSL,是一种加密网站和浏览器之间连接的标准安全技术。这确保服务器和浏览器之间传输的数据保持隐私和安全。这被成千上万的人使用来保护他们与客户的通信。要启用SSL链接,web服务器需要安装SSL证书。
|
||||
|
||||
你可以创建你自己的SSL证书,但是这默认不会被浏览器信任,要修复这个问题,你需要从受信任的证书机构(CA)处购买证书,我们会向你展示如何
|
||||
或者证书并在apache中安装。
|
||||
|
||||
### 生成一个证书签名请求 ###
|
||||
|
||||
证书机构(CA)会要求你在你的服务器上生成一个证书签名请求(CSR)。这是一个很简单的过程,只需要一会就行,你需要运行下面的命令并输入需要的信息:
|
||||
|
||||
# openssl req -new -newkey rsa:2048 -nodes -keyout yourdomainname.key -out yourdomainname.csr
|
||||
|
||||
输出看上去会像这样:
|
||||
|
||||

|
||||
|
||||
这一步会生成两个文件按:一个用于解密SSL证书的私钥文件,一个证书签名请求(CSR)文件(用于申请你的SSL证书)。
|
||||
|
||||
根据你申请的机构,你会需要上传csr文件或者在网站表格中粘帖他的内容。
|
||||
|
||||
### 在Apache中安装实际的证书 ###
|
||||
|
||||
生成步骤完成之后,你会收到新的数字证书,本篇教程中我们使用[Comodo SSL][1]并在一个zip文件中收到了证书。要在apache中使用它,你首先需要用下面的命令为收到的证书创建一个组合的证书:
|
||||
|
||||
# cat COMODORSADomainValidationSecureServerCA.crt COMODORSAAddTrustCA.crt AddTrustExternalCARoot.crt > bundle.crt
|
||||
|
||||

|
||||
|
||||
用下面的命令确保ssl模块已经加载进apache了:
|
||||
|
||||
# a2enmod ssl
|
||||
|
||||
如果你看到了“Module ssl already enabled”这样的信息就说明你成功了,如果你看到了“Enabling module ssl”,那么你还需要用下面的命令重启apache:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
最后像下面这样修改你的虚拟主机文件(通常在/etc/apache2/sites-enabled 下):
|
||||
|
||||
DocumentRoot /var/www/html/
|
||||
ServerName linoxide.com
|
||||
SSLEngine on
|
||||
SSLCertificateFile /usr/local/ssl/crt/yourdomainname.crt
|
||||
SSLCertificateKeyFile /usr/local/ssl/yourdomainname.key
|
||||
SSLCACertificateFile /usr/local/ssl/bundle.crt
|
||||
|
||||
你现在应该可以用https://YOURDOMAIN/(注意使用‘https’而不是‘http’)来访问你的网站了,并可以看到SSL的进度条了(通常在你浏览器中用一把锁来表示)。
|
||||
|
||||
**NOTE:** All the links must now point to https, if some of the content on the website (like images or css files) still point to http links you will get a warning in the browser, to fix this you have to make sure that every link points to https.
|
||||
**注意:** 现在所有的链接都必须指向https,如果网站上的一些内容(像图片或者css文件等)仍旧指向http链接的话,你会在浏览器中得到一个警告,要修复这个问题,请确保每个链接都指向了https。
|
||||
|
||||
### 在你的网站上重定向HTTP请求到HTTPS中 ###
|
||||
|
||||
如果你希望重定向常规的HTTP请求到HTTPS,添加下面的文本到你希望的虚拟主机或者如果希望给服务器上所有网站都添加的话就加入到apache.conf中:
|
||||
|
||||
RewriteEngine On
|
||||
RewriteCond %{HTTPS} off
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-ssl-apache-2-4-in-ubuntu/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:https://ssl.comodo.com/
|
||||
@ -0,0 +1,130 @@
|
||||
如何在Ubuntu 14.04 LTS安装网络爬虫工具
|
||||
================================================================================
|
||||
这是一款提取网站数据的开源工具。Scrapy框架用Python开发而成,它使抓取工作又快又简单,且可扩展。我们已经在virtual box中创建一台虚拟机(VM)并且在上面安装了Ubuntu 14.04 LTS。
|
||||
|
||||
### 安装 Scrapy ###
|
||||
|
||||
Scrapy依赖于Python、开发库和pip。Python最新的版本已经在Ubuntu上预装了。因此我们在安装Scrapy之前只需安装pip和python开发库就可以了。
|
||||
|
||||
pip是作为python包索引器easy_install的替代品。用于安装和管理Python包。pip包的安装可见图 1。
|
||||
|
||||
sudo apt-get install python-pip
|
||||
|
||||

|
||||
|
||||
图:1 pip安装
|
||||
|
||||
我们必须要用下面的命令安装python开发库。如果包没有安装那么就会在安装scrapy框架的时候报关于python.h头文件的错误。
|
||||
|
||||
sudo apt-get install python-dev
|
||||
|
||||

|
||||
|
||||
图:2 Python 开发库
|
||||
|
||||
scrapy框架即可从deb包安装也可以从源码安装。然而在图3中我们已经用pip(Python 包管理器)安装了deb包了。
|
||||
|
||||
sudo pip install scrapy
|
||||
|
||||

|
||||
|
||||
图:3 Scrapy 安装
|
||||
|
||||
图4中scrapy的成功安装需要一些时间。
|
||||
|
||||

|
||||
|
||||
图:4 成功安装Scrapy框架
|
||||
|
||||
### 使用scrapy框架提取数据 ###
|
||||
|
||||
**(基础教程)**
|
||||
|
||||
我们将用scrapy从fatwallet.com上提取店名(提供卡的店)。首先,我们使用下面的命令新建一个scrapy项目“store name”, 见图5。
|
||||
|
||||
$sudo scrapy startproject store_name
|
||||
|
||||

|
||||
|
||||
图:5 Scrapy框架新建项目
|
||||
|
||||
Above command creates a directory with title “store_name” at current path. This main directory of the project contains files/folders which are shown in the following Figure 6.
|
||||
上面的命令在当前路径创建了一个“store_name”的目录。项目主目录下包含的文件/文件夹见图6。
|
||||
|
||||
$sudo ls –lR store_name
|
||||
|
||||

|
||||
|
||||
图:6 store_name项目的内容
|
||||
|
||||
每个文件/文件夹的概要如下:
|
||||
|
||||
- scrapy.cfg 是项目配置文件
|
||||
- store_name/ 主目录下的另一个文件夹。 这个目录包含了项目的python代码
|
||||
- store_name/items.py 包含了将由蜘蛛爬取的项目
|
||||
- store_name/pipelines.py 是管道文件
|
||||
- store_name/settings.py 是项目的配置文件
|
||||
- store_name/spiders/, 包含了用于爬取的蜘蛛
|
||||
|
||||
由于我们要从fatwallet.com上如提取店名,因此我们如下修改文件。
|
||||
|
||||
import scrapy
|
||||
|
||||
class StoreNameItem(scrapy.Item):
|
||||
|
||||
name = scrapy.Field() # extract the names of Cards store
|
||||
|
||||
之后我们要在项目的store_name/spiders/文件夹下写一个新的蜘蛛。蜘蛛是一个python类,它包含了下面几个必须的属性:
|
||||
|
||||
1. 蜘蛛名 (name )
|
||||
2. 爬取起点url (start_urls)
|
||||
3. 包含了从响应中提取需要内容相应的正则表达式的解析方法。解析方法对爬虫而言很重要。
|
||||
|
||||
我们在store_name/spiders/目录下创建了“store_name.py”爬虫,并添加如下的代码来从fatwallet.com上提取点名。爬虫的输出到文件(**StoreName.txt**)中,见图7。
|
||||
|
||||
from scrapy.selector import Selector
|
||||
from scrapy.spider import BaseSpider
|
||||
from scrapy.http import Request
|
||||
from scrapy.http import FormRequest
|
||||
import re
|
||||
class StoreNameItem(BaseSpider):
|
||||
name = "storename"
|
||||
allowed_domains = ["fatwallet.com"]
|
||||
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
|
||||
|
||||
def parse(self,response):
|
||||
output = open('StoreName.txt','w')
|
||||
resp = Selector(response)
|
||||
|
||||
tags = resp.xpath('//tr[@class="storeListRow"]|\
|
||||
//tr[@class="storeListRow even"]|\
|
||||
//tr[@class="storeListRow even last"]|\
|
||||
//tr[@class="storeListRow last"]').extract()
|
||||
for i in tags:
|
||||
i = i.encode('utf-8', 'ignore').strip()
|
||||
store_name = ''
|
||||
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
|
||||
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
|
||||
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
|
||||
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
|
||||
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
|
||||
#print store_name
|
||||
output.write(store_name+""+"\n")
|
||||
|
||||

|
||||
|
||||
图:7 爬虫的输出
|
||||
|
||||
*注意: 本教程的目的仅用于理解scrapy框架*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/scrapy-install-ubuntu/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
@ -0,0 +1,93 @@
|
||||
如何在Linux上找出并删除重复的文件
|
||||
================================================================================
|
||||
大家好,今天我们会学习如何在Linux PC或者服务器上找出和删除重复文件。这里有一款工具你可以工具自己的需要使用。
|
||||
|
||||
无论你是否正在使用Linux桌面或者服务器,有一些很好的工具能一帮你扫描系统中的重复文件并删除它们来释放空间。图形界面和命令行界面的都有。重复文件是磁盘空间不必要的浪费。毕竟,如果你的确需要在不同的位置享有同一个文件,你可以使用软链接或者硬链接,这样就可以这样就可以在磁盘的一处地方存储数据了。
|
||||
|
||||
### FSlint ###
|
||||
|
||||
[FSlint][1] 在不同的Linux发行办二进制仓库中都有,包括Ubuntu、Debian、Fedora和Red Hat。只需你运行你的包管理器并安装“fslint”包就行。这个工具默认提供了一个简单的图形化界面,同样也有包含各种功能的命令行版本。
|
||||
|
||||
不要让它让你害怕使用FSlint的图形化界面。默认情况下,它会自动选中Duplicate窗格,并以你的家目录作为搜索路径。
|
||||
|
||||
要安装fslint,若像我这样运行的是Ubuntu,这里是默认的命令:
|
||||
|
||||
$ sudo apt-get install fslint
|
||||
|
||||
这里还有针对其他发行版的安装命令:
|
||||
|
||||
Debian:
|
||||
|
||||
svn checkout http://fslint.googlecode.com/svn/trunk/ fslint-2.45
|
||||
cd fslint-2.45
|
||||
dpkg-buildpackage -I.svn -rfakeroot -tc
|
||||
sudo dpkg -i ../fslint_2.45-1_all.deb
|
||||
|
||||
Fedora:
|
||||
|
||||
sudo yum install fslint
|
||||
|
||||
For OpenSuse:
|
||||
|
||||
[ -f /etc/mandrake-release ] && pkg=rpm
|
||||
[ -f /etc/SuSE-release ] && pkg=packages
|
||||
wget http://www.pixelbeat.org/fslint/fslint-2.42.tar.gz
|
||||
sudo rpmbuild -ta fslint-2.42.tar.gz
|
||||
sudo rpm -Uvh /usr/src/$pkg/RPMS/noarch/fslint-2.42-1.*.noarch.rpm
|
||||
|
||||
对于其他发行版:
|
||||
|
||||
wget http://www.pixelbeat.org/fslint/fslint-2.44.tar.gz
|
||||
tar -xzf fslint-2.44.tar.gz
|
||||
cd fslint-2.44
|
||||
(cd po && make)
|
||||
./fslint-gui
|
||||
|
||||
要在Ubuntu中运行fslint的GUI版本fslint-gui, 使用Alt+F2运行命令或者在终端输入:
|
||||
|
||||
$ fslint-gui
|
||||
|
||||
默认情况下,它会自动选中Duplicate窗格,并以你的家目录作为搜索路径。你要做的就是点击Find按钮,FSlint会自动在你的家目录下找出重复文件列表。
|
||||
|
||||

|
||||
|
||||
使用按钮来删除任何你要删除的文件,并且可以双击预览。
|
||||
|
||||
完成这一切后,我们就成功地删除你系统中的重复文件了。
|
||||
|
||||
**注意** 的是命令行工具默认不在环境的路径中,你不能像典型的命令那样运行它。在Ubuntu中,你可以在/usr/share/fslint/fslint下找到它。因此,如果你要在一个单独的目录运行fslint完整扫描,下面是Ubuntu中的运行命令:
|
||||
|
||||
cd /usr/share/fslint/fslint
|
||||
|
||||
./fslint /path/to/directory
|
||||
|
||||
**这个命令实际上并不会删除任何文件。它只会打印出重复文件的列表-你需要自己做接下来的事。**
|
||||
|
||||
$ /usr/share/fslint/fslint/findup --help
|
||||
find dUPlicate files.
|
||||
Usage: findup [[[-t [-m|-d]] | [--summary]] [-r] [-f] paths(s) ...]
|
||||
|
||||
If no path(s) specified then the current directory is assumed.
|
||||
|
||||
When -m is specified any found duplicates will be merged (using hardlinks).
|
||||
When -d is specified any found duplicates will be deleted (leaving just 1).
|
||||
When -t is specfied, only report what -m or -d would do.
|
||||
When --summary is specified change output format to include file sizes.
|
||||
You can also pipe this summary format to /usr/share/fslint/fslint/fstool/dupwaste
|
||||
to get a total of the wastage due to duplicates.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/file-system/find-remove-duplicate-files-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.pixelbeat.org/fslint/
|
||||
[2]:http://www.pixelbeat.org/fslint/fslint-2.42.tar.gz
|
||||
Loading…
Reference in New Issue
Block a user