mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
This commit is contained in:
commit
bcc496c1ce
80
published/20151117 How bad a boss is Linus Torvalds.md
Normal file
80
published/20151117 How bad a boss is Linus Torvalds.md
Normal file
@ -0,0 +1,80 @@
|
||||
Linus Torvalds 是一个糟糕的老板吗?
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
*1999 年 8 月 10 日,加利福尼亚州圣何塞市,在 LinuxWorld Show 上 Linus Torvalds 在一个坐满 Linux 爱好者的礼堂中发表了一篇演讲。图片来自:James Niccolai*
|
||||
|
||||
**这取决于所处的领域。在软件开发的世界中,他也是个普通人。问题是,这种情况是否应该继续下去?**
|
||||
|
||||
Linus Torvalds 是 Linux 的发明者,我认识他超过 20 年了。我们不是密友,但是我们欣赏彼此。
|
||||
|
||||
最近,因为 Linus Torvalds 的管理风格,他正遭到严厉的炮轰。Linus 无法忍受胡来的人。“代码的质量有多好?”是他在 Linux 内核的开发过程中评判人的一种方式。
|
||||
|
||||
没有什么比这个更重要了。正如 Linus 今年(2015年)早些时候在 Linux.conf.au 会议上说的那样,“我不是一个友好的人,我也不在意你。对我重要的是『[我所关心的技术和内核][1]』。”
|
||||
|
||||
现在我也可以和这种只关心技术的人打交道了。如果你不能,你应当避免参加 Linux 内核会议,因为在那里你会遇到许多有这种精英思想的人。这不代表我认为在 Linux 领域所有东西都是极好的,并且不应该受到其他影响而带来改变。我能够和一个精英待在一起;而在一个男性做主导的大城堡中遇到的问题是,女性经常受到蔑视和无礼的对待。
|
||||
|
||||
这就是我看到的最近关于 Linus 管理风格所引发争论的原因 -- 或者更准确的说,他对于个人管理方面是完全冷漠的 -- 就像是在软件开发世界的标准操作流程一样。与此同时,我看到了揭示了这个事情需要改变的另外一个证据。
|
||||
|
||||
第一次是在 [Linux 4.3 发布][2]的时候出现的这个情况,Linus 使用 Linux 内核邮件列表来狠狠的数落了一个插入了一些网络方面的代码的开发者——这些代码很“烂”,“[生成了如此烂的代码][3]。这看起来太糟糕了,并且完全没有理由这样做。”他继续咆哮了半天。这里使用“烂”这个词,相对他早期使用的“愚蠢的”这个同义词来说还算好的。
|
||||
|
||||
但是,事情就是这样。Linus 是对的。我读了代码后,发现代码确实很烂,并且开发者只是为了用新的“overflow_usub()” 函数而用的。
|
||||
|
||||
现在,一些人把 Linus 的这种谩骂的行为看作他脾气不好而且恃强凌弱的证据。我见过一个完美主义者,在他的领域中,他无法忍受这种糟糕。
|
||||
|
||||
许多人告诉我,这不是一个专业的程序员应当有的行为。群众们,你曾经和最优秀的开发者一起工作过吗?据我所知道的,在 Apple,Microsoft,Oracle 这就是他们的行为。
|
||||
|
||||
我曾经听过 Steve Jobs 攻击一个开发者,就像要把他撕成碎片那样。我也被一个 Oracle 的高级开发者攻击一屋子的新开发者吓到过,就像食人鱼穿过一群金鱼那样。
|
||||
|
||||
在 Robert X. Cringely 关于 PC 崛起的经典书籍《[意外帝国(Accidental Empires)][5]》,中,他这样描述了微软的软件管理风格,比尔·盖茨像计算机系统一样管理他们,“比尔·盖茨的是最高等级,从他开始每一个等级依次递减,上级会向下级叫嚷,刺激他们,甚至羞辱他们。”
|
||||
|
||||
Linus 和所有大型的商业软件公司的领导人不同的是,Linus 说在这里所有的东西是向全世界公开的。而其他人是在自己的会议室中做东西的。我听有人说 Linus 在那种公司中可能会被开除。这是不可能的。他会处于他现在所处的地位,他在编程世界的最顶端。
|
||||
|
||||
但是,这里有另外一个不同。如果 Larry Ellison (Oracle 的首席执行官)向你发火,你就别想在这里干了。如果 Linus 向你发火,你会在邮件中收到他的责骂。这就是差别。
|
||||
|
||||
你知道的,Linus 不是任何人的老板。他完全没有雇佣和解聘的权利,他只是负责着有 10000 个贡献者的一个项目而已。他仅仅能做的就是从心理上伤害你。
|
||||
|
||||
这说明,在开源软件开发圈和商业软件开发圈中同时存在一个非常严重的问题。不管你是一个多么好的编程者,如果你是一个女性,你的这个身份就是对你不利的。
|
||||
|
||||
这种情况并没有在 Sarah Sharp 的身上有任何好转,她现在是一个 Intel 的开发者,以前是一个顶尖的 Linux 程序员。[在她博客上10月份的一个帖子中][4],她解释道:“我最终发现,我不能够再为 Linux 社区做出贡献了。因为在那里,我虽然能够得到技术上的尊重,却得不到个人的尊重……我不想专职于同那些有着轻微的性别歧视或开同性恋玩笑的人一起工作。”
|
||||
|
||||
谁会责怪她呢?我不会。很抱歉,我必须说,Linus 就像所有我见过的软件经理一样,是他造成了这种不利的工作环境。
|
||||
|
||||
他可能会说,确保 Linux 的贡献者都表现出专业精神和相互尊重不应该是他的工作。除了代码以外,他不关心任何其他事情。
|
||||
|
||||
就像 Sarah Sharp 写的那样:
|
||||
|
||||
|
||||
> 我对于 Linux 内核社区做出的技术努力表示最大尊重。他们在那维护一些最高标准的代码,以此来平衡并且发展一个项目。他们专注于优秀的技术,以及超过负荷的维护人员,他们有不同的文化背景和社会规范,这些意味着这些 Linux 内核维护者说话非常直率、粗鲁,或者为了完成他们的任务而不讲道理。顶尖的 Linux 内核开发者经常为了使别人改正行为而向他们大喊大叫。
|
||||
>
|
||||
> 这种事情发生在我身上,但它不是一种有效的沟通方式。
|
||||
>
|
||||
> 许多高级的 Linux 内核开发者支持那些技术上和人性上不讲道理的维护者的权利。即使他们自己是非常友好的人,他们不想看到 Linux 内核交流方式改变。
|
||||
|
||||
她是对的。
|
||||
|
||||
我和其他观察者不同的是,我不认为这个问题对于 Linux 或开源社区在任何方面有特殊之处。作为一个从事技术商业工作超过五年和有着 25 年技术工作经历的记者,我见多了这种不成熟的小孩子行为。
|
||||
|
||||
这不是 Linus 的错误。他不是一个经理,他是一个有想象力的技术领导者。看起来真正的问题是,在软件开发领域没有人能够用一种支持的语气来对待团队和社区。
|
||||
|
||||
展望未来,我希望像 Linux 基金会这样的公司和组织,能够找到一种方式去授权社区经理或其他经理来鼓励并且强制实施民主的行为。
|
||||
|
||||
非常遗憾的是,我们不能够在我们这种纯技术或纯商业的领导人中找到这种管理策略。它不存在于这些人的基因中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[FrankXinqi](https://github.com/FrankXinqi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
[5]:https://www.amazon.cn/Accidental-Empires-Cringely-Robert-X/dp/0887308554/479-5308016-9671450?ie=UTF8&qid=1447101469&ref_=sr_1_1&tag=geo-23
|
||||
@ -0,0 +1,110 @@
|
||||
Linux 开发者如何看待 Git 和 Github?
|
||||
=====================================================
|
||||
|
||||
### Linux 开发者如何看待 Git 和 Github?
|
||||
|
||||
Git 和 Github 在 Linux 开发者中有很高的知名度。但是开发者如何看待它们呢?另外,Github 是不是真的和 Git 是一个意思?一个 Linux reddit 用户最近问到了这个问题,并且得到了很有意思的答案。
|
||||
|
||||
Dontwakemeup46 提问:
|
||||
|
||||
> 我正在学习 Git 和 Github。我感兴趣社区如何看待两者?据我所知,Git 和 Github 应用十分广泛。但是 Git 或 Github 有没有严重的不足?社区喜欢去改变些什么呢?
|
||||
|
||||
[更多见 Reddit](https://www.reddit.com/r/linux/comments/45jy59/the_popularity_of_git_and_github/)
|
||||
|
||||
与他志同道合的 Linux reddit 用户回答了他们对于 Git 和 Github的观点:
|
||||
|
||||
>**Derenir**: “Github 并不附属于 Git。
|
||||
|
||||
> Git 是由 Linus Torvalds 开发的。
|
||||
|
||||
> Github 几乎不支持 Linux。
|
||||
|
||||
> Github 是一家企图借助 Git 赚钱的公司。
|
||||
|
||||
> https://desktop.github.com/ 并没有支持 Linux。”
|
||||
|
||||
---
|
||||
>**Bilog78**: “一个小的补充: Linus Torvalds 已经不再维护 Git了。维护者是 Junio C Hamano,以及 在他之后的主要贡献者是 Jeff King 和 Shawn O. Pearce。”
|
||||
|
||||
---
|
||||
|
||||
>**Fearthefuture**: “我喜欢 Git,但是不明白人们为什么还要使用 Github。从我的角度,Github 比 Bitbucket 好的一点是用户统计和更大的用户基础。Bitbucket 有无限的免费私有库,更好的 UI,以及更好地集成了其他服务,比如说 Jenkins。”
|
||||
|
||||
---
|
||||
|
||||
>**Thunger**: “Gitlab.com 也很不错,特别是你可以在自己的服务器上架设自己的实例。”
|
||||
|
||||
---
|
||||
|
||||
>**Takluyver**: “很多人熟悉 Github 的 UI 以及相关联的服务,比如说 Travis 。并且很多人都有 Github 账号,所以它是存储项目的一个很好的地方。人们也使用他们的 Github 个人信息页作为一种求职用的作品选辑,所以他们很积极地将更多的项目放在这里。Github 是一个存放开源项目的事实标准。”
|
||||
|
||||
---
|
||||
|
||||
>**Tdammers**: “Git 严重问题在于 UI,它有些违反直觉,以至于很多用户只能达到使用一些容易记住的咒语的程度。”
|
||||
|
||||
> Github:最严重的问题在于它是商业托管的解决方案;你买了方便,但是代价是你的代码在别人的服务器上面,已经不在你的掌控范围之内了。另一个对于 Github 的普遍批判是它的工作流和 Git 本身的精神不符,特别是 pull requests 工作的方式。最后, Github 垄断了代码的托管环境,同时对于多样性是很不好的,这反过来对于旺盛的免费软件社区很重要。”
|
||||
|
||||
---
|
||||
|
||||
>**Dies**: “更重要的是,如果一旦是这样,按照现状来说,我猜我们会被 Github 所困,因为它们控制如此多的项目。”
|
||||
|
||||
---
|
||||
|
||||
>**Tdammers**: “代码托管在别人的服务器上,这里"别人"指的是 Github。这对于开源项目来说,并不是什么太大的问题,但是尽管如此,你无法控制它。如果你在 Github 上有私有项目,“它将保持私有”的唯一的保险只是 Github 的承诺而已。如果你决定删除东西,你不能确定东西是否被删除了,或者只是隐藏了。
|
||||
|
||||
Github 并不自己控制这些项目(你总是可以拿走你的代码,然后托管到别的地方,声明新位置是“官方”的),它只是有比开发者本身有更深的使用权。”
|
||||
|
||||
---
|
||||
|
||||
>**Drelos**: “我已经读了大量的关于 Github 的赞美与批评。(这里有一个[例子](http://www.wired.com/2015/06/problem-putting-worlds-code-github/)),但是我的幼稚问题是为什么不向一个免费开源的版本努力呢?”
|
||||
|
||||
---
|
||||
|
||||
>**Twizmwazin**: “Gitlab 的源码就存在这里”
|
||||
|
||||
---
|
||||
|
||||
[更多见 Reddit](https://www.reddit.com/r/linux/comments/45jy59/the_popularity_of_git_and_github/)
|
||||
|
||||
### DistroWatch 评估 XStream 桌面 153 版本
|
||||
|
||||
XStreamOS 是一个由 Sonicle 创建的 Solaris 的一个版本。XStream 桌面将 Solaris 的强大带给了桌面用户,同时新手用户很可能有兴趣体验一下。DistroWatch 对于 XStream 桌面 153 版本做了一个很全面的评估,并且发现它运行相当好。
|
||||
|
||||
Jesse Smith 为 DistroWatch 报道:
|
||||
|
||||
> 我认为 XStream 桌面做好了很多事情。诚然,当操作系统无法在我的硬件上启动,同时当运行在 VirtualBox 中时我无法使得桌面使用我显示器的完整分辨率,我的开端并不很成功。不过,除此之外,XStream 表现的很好。安装器工作的很好,该系统自动设置和使用了引导环境(boot environments),这让我们可以在发生错误时恢复该系统。包管理器有工作的不错, XStream 带了一套有用的软件。
|
||||
|
||||
> 我确实在播放多媒体文件时遇见一些问题,特别是使声卡工作。我不确定这是不是又一个硬件兼容问题,或者是该操作系统自带的多媒体软件的问题。另一方面,像 Web 浏览器,电子邮件,生产工具套件以及配置工具这样的工作的很好。
|
||||
|
||||
> 我最欣赏 XStream 的地方是这个操作系统是 OpenSolaris 家族的一个使用保持最新的分支。OpenSolaris 的其他衍生系统有落后的倾向,但是至少在桌面软件上,XStream 搭载最新版本的火狐和 LibreOffice。
|
||||
|
||||
> 对我个人来说,XStream 缺少一些组件,比如打印机管理器,多媒体支持和我的特定硬件的驱动。这个操作系统的其他方面也是相当吸引人的。我喜欢开发者搭配了 LXDE,也喜欢它的默认软件集,以及我最喜欢文件系统快照和启动环境开箱即用的方式。大多数的 Linux 发行版,openSUSE 除外,并没有利用好引导环境(boot environments)的用途。我希望它是一个被更多项目采用的技术。
|
||||
|
||||
[更多见 DistroWatch](http://distrowatch.com/weekly.php?issue=20160215#xstreamos)
|
||||
|
||||
### 街头霸王 V 和 SteamOS
|
||||
|
||||
街头霸王是最出名的游戏之一,并且 [Capcom 已经宣布](http://steamcommunity.com/games/310950/announcements/detail/857177755595160250) 街头霸王 V 将会在这个春天进入 Linux 和 StreamOS。这对于 Linux 游戏者是非常好的消息。
|
||||
|
||||
Joe Parlock 为 Destructoid 报道:
|
||||
|
||||
> 你是不足 1% 的那些在 Linux 系统上玩游戏的 Stream 用户吗?你是更少数的那些在 Linux 平台上玩游戏,同时也很喜欢街头霸王 V 的人之一吗?是的话,我有一些好消息要告诉你。
|
||||
|
||||
> Capcom 已经宣布,这个春天街头霸王 V 通过 Stream 进入 StreamOS 以及其他 Linux 发行版。它无需任何额外的花费,所以那些已经在自己的个人电脑上安装了该游戏的人可以很容易在 Linux 上安装它并玩了。
|
||||
|
||||
[更多 Destructoid](https://www.destructoid.com/street-fighter-v-is-coming-to-linux-and-steamos-this-spring-341531.phtml)
|
||||
|
||||
你是否错过了摘要?检查 [开源之眼的主页](http://www.infoworld.com/blog/eye-on-open/) 来获得关于 Linux 和开源的最新的新闻。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3033059/linux/what-do-linux-developers-think-of-git-and-github.html
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Jim-Lynch/
|
||||
|
||||
@ -3,9 +3,9 @@
|
||||
|
||||

|
||||
|
||||
云存储服务 Copy 即将关闭,我们 Linux 用户是时候该寻找其他优秀的** Copy 之外的 Linux 云存储服务**。
|
||||
云存储服务 Copy 已经关闭,我们 Linux 用户是时候该寻找其他优秀的** Copy 之外的 Linux 云存储服务**。
|
||||
|
||||
全部文件将会在 2016年5月1号 被删除。如果你是 Copy 的用户,你应该保存你的文件并将它们移至其他地方。
|
||||
全部文件会在 2016年5月1号 被删除。如果你是 Copy 的用户,你应该保存你的文件并将它们移至其他地方。
|
||||
|
||||
在过去的两年里,Copy 已经成为了我最喜爱的云存储。它为我提供了大量的免费空间并且带有桌面平台的原生应用程序,包括 Linux 和移动平台如 iOS 和 Android。
|
||||
|
||||
@ -13,16 +13,16 @@
|
||||
|
||||
当我从 Copy.com 看到它即将关闭的消息,我的担忧成真了。事实上,Copy 并不孤独。它的母公司 [Barracuda Networks](https://www.barracuda.com/)正经历一段困难时期并且已经[雇佣 Morgan Stanely 寻找 合适的卖家](http://www.bloomberg.com/news/articles/2016-02-01/barracuda-networks-said-to-work-with-morgan-stanley-to-seek-sale)(s)
|
||||
|
||||
无论什么理由,我们所知道的是 Copy 将会成为历史,我们需要寻找相似的**优秀的 Linux 云服务**。我之所以强调 Linux 是因为其他流行的云存储服务,如[微软的OneDrive](https://onedrive.live.com/about/en-us/) 和 [Google Drive](https://www.google.com/drive/) 都没有提供本地 Linux 客户端。这是微软预计的事情,但是谷歌对 Linux 的冷漠令人震惊。
|
||||
无论什么理由,我们所知道的是 Copy 将会成为历史,我们需要寻找相似的**优秀的 Linux 云服务**。我之所以强调 Linux 是因为其他流行的云存储服务,如[微软的 OneDrive](https://onedrive.live.com/about/en-us/) 和 [Google Drive](https://www.google.com/drive/) 都没有提供本地 Linux 客户端。微软并没有出乎我们的预料,但是[谷歌对 Linux 的冷漠][1]令人震惊。
|
||||
|
||||
## Linux 下 Copy 的最佳替代者
|
||||
|
||||
现在,作为一个 Linux 存储,在云存储中你需要什么?让我们猜猜:
|
||||
什么样的云服务才适合作为 Linux 下的存储服务?让我们猜猜:
|
||||
|
||||
- 大量的免费空间。毕竟,个人用户无法每月支付巨额款项。
|
||||
- 原生的 Linux 客户端。因此你能够使用提供的服务,方便地同步文件,而不用做一些特殊的调整或者定时执行脚本。
|
||||
- 其他桌面系统的客户端,比如 Windows 和 OS X。便携性是必要的,并且同步设备间的文件是一种很好的缓解。
|
||||
- Android 和 iOS 的移动应用程序。在今天的现代世界里,你需要连接所有设备。
|
||||
- 大量的免费空间。毕竟,个人用户无法支付每月的巨额款项。
|
||||
- 原生的 Linux 客户端。以便你能够方便的在服务器之间同步文件,而不用做一些特殊的调整或者定时执行脚本。
|
||||
- 其他桌面系统的客户端,比如 Windows 和 OS X。移动性是必要的,并且同步设备间的文件也很有必要。
|
||||
- 基于 Android 和 iOS 的移动应用程序。在今天的现代世界里,你需要连接所有设备。
|
||||
|
||||
我不将自托管的云服务计算在内,比如 OwnCloud 或 [Seafile](https://www.seafile.com/en/home/) ,因为它们需要自己建立和运行一个服务器。这不适合所有想要类似 Copy 的云服务的家庭用户。
|
||||
|
||||
@ -32,7 +32,7 @@
|
||||
|
||||

|
||||
|
||||
如果你是一个 It’s FOSS 的普通读者,你可能已经看过我之前的一篇有关[Mega on Linux](http://itsfoss.com/install-mega-cloud-storage-linux/)的文章。这种云服务由[Megaupload scandal](https://en.wikipedia.org/wiki/Megaupload) 公司下臭名昭著的[Kim Dotcom](https://en.wikipedia.org/wiki/Kim_Dotcom)提供。这也使一些用户怀疑它,因为 Kim Dotcom 已经很长一段时间成为美国当局的目标。
|
||||
如果你是一个 It’s FOSS 的普通读者,你可能已经看过我之前的一篇有关 [Mega on Linux](http://itsfoss.com/install-mega-cloud-storage-linux/)的文章。这种云服务由 [Megaupload scandal](https://en.wikipedia.org/wiki/Megaupload) 公司下臭名昭著的 [Kim Dotcom](https://en.wikipedia.org/wiki/Kim_Dotcom) 提供。这也使一些用户怀疑它,因为 Kim Dotcom 已经很长一段时间成为美国当局的目标。
|
||||
|
||||
Mega 拥有方便免费云服务下你所期望的一切。它给每个个人用户提供 50 GB 的免费存储空间。提供Linux 和其他平台下的原生客户端,并带有端到端的加密。原生的 Linux 客户端运行良好,可以无缝地跨平台同步。你也能在浏览器上查看操作你的文件。
|
||||
|
||||
@ -74,7 +74,7 @@ Hubic 拥有一些不错的功能。除了简单的用户界面、文件共享
|
||||
|
||||

|
||||
|
||||
pCloud 是另一款欧洲的发行软件,但这一次从瑞士横跨法国边境。专注于加密和安全,pCloud 为每一个注册者提供 10 GB 的免费存储空间。你可以通过邀请好友、在社交媒体上分享链接等方式将空间增加至 20 GB。
|
||||
pCloud 是另一款欧洲的发行软件,但这一次跨过了法国边境,它来自瑞士。专注于加密和安全,pCloud 为每一个注册者提供 10 GB 的免费存储空间。你可以通过邀请好友、在社交媒体上分享链接等方式将空间增加至 20 GB。
|
||||
|
||||
它拥有云服务的所有标准特性,例如文件共享、同步、选择性同步等等。pCloud 也有跨平台原生客户端,当然包括 Linux。
|
||||
|
||||
@ -128,8 +128,9 @@ via: http://itsfoss.com/cloud-services-linux/
|
||||
|
||||
作者:[ABHISHEK][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/google-hates-desktop-linux/
|
||||
@ -1,4 +1,4 @@
|
||||
基于 Python、 RabbitMQ 和 Nameko 的微服务
|
||||
用 Python、 RabbitMQ 和 Nameko 实现微服务
|
||||
==============================================
|
||||
|
||||
>"微服务是一股新浪潮" - 现如今,将项目拆分成多个独立的、可扩展的服务是保障代码演变的最好选择。在 Python 的世界里,有个叫做 “Nameko” 的框架,它将微服务的实现变得简单并且强大。
|
||||
@ -8,19 +8,17 @@
|
||||
|
||||
> 在最近的几年里,“微服务架构”如雨后春笋般涌现。它用于描述一种特定的软件应用设计方式,这种方式使得应用可以由多个独立部署的服务以服务套件的形式组成。 - M. Fowler
|
||||
|
||||
推荐各位读一下 [Fowler's posts][1] 以理解它背后的原理。
|
||||
|
||||
推荐各位读一下 [Fowler 的文章][1] 以理解它背后的原理。
|
||||
|
||||
#### 好吧,那它究竟意味着什么呢?
|
||||
|
||||
简单来说,**微服务架构**可以将你的系统拆分成多个负责不同任务的小块儿,它们之间互不依赖,各自只提供用于通讯的通用指向。这个指向通常是已经将通讯协议和接口定义好的消息队列。
|
||||
|
||||
简单来说,**微服务架构**可以将你的系统拆分成多个负责不同任务的小的(单一上下文内)功能块(responsibilities blocks),它们彼此互无感知,各自只提供用于通讯的通用指向(common point)。这个指向通常是已经将通讯协议和接口定义好的消息队列。
|
||||
|
||||
#### 这里给大家提供一个真实案例
|
||||
|
||||
>案例的代码可以通过github: <http://github.com/rochacbruno/nameko-example> 访问,查看 service 和 api 文件夹可以获取更多信息。
|
||||
> 案例的代码可以通过 github: <http://github.com/rochacbruno/nameko-example> 访问,查看 service 和 api 文件夹可以获取更多信息。
|
||||
|
||||
想象一下,你有一个 REST API ,这个 API 有一个端点(译者注:REST 风格的 API 可以有多个端点用于处理对同一资源的不同类型的请求)用来接受数据,并且你需要将接收到的数据进行一些运算。那么相比阻塞接口调用者的请求来说,异步实现此接口是一个更好的选择。你可以先给用户返回一个 "OK - 你的请求稍后会处理" 的状态,然后在后台任务中完成运算。
|
||||
想象一下,你有一个 REST API ,这个 API 有一个端点(LCTT 译注:REST 风格的 API 可以有多个端点用于处理对同一资源的不同类型的请求)用来接受数据,并且你需要将接收到的数据进行一些运算工作。那么相比阻塞接口调用者的请求来说,异步实现此接口是一个更好的选择。你可以先给用户返回一个 "OK - 你的请求稍后会处理" 的状态,然后在后台任务中完成运算。
|
||||
|
||||
同样,如果你想要在不阻塞主进程的前提下,在计算完成后发送一封提醒邮件,那么将“邮件发送”委托给其他服务去做会更好一些。
|
||||
|
||||
@ -30,20 +28,18 @@
|
||||

|
||||
|
||||
|
||||
### 用代码说话:
|
||||
### 用代码说话
|
||||
|
||||
让我们将系统创建起来,在实践中理解它:
|
||||
|
||||
|
||||
#### 环境
|
||||
|
||||
我们需要的环境:
|
||||
|
||||
- 运行良好的 RabbitMQ(译者注:[RabbitMQ][2]是一个流行的消息队列实现)
|
||||
- 运行良好的 RabbitMQ(LCTT 译注:[RabbitMQ][2] 是一个流行的消息队列实现)
|
||||
- 由 VirtualEnv 提供的 Services 虚拟环境
|
||||
- 由 VirtualEnv 提供的 API 虚拟环境
|
||||
|
||||
|
||||
#### Rabbit
|
||||
|
||||
在开发环境中使用 RabbitMQ 最简单的方式就是运行其官方的 docker 容器。在你已经拥有 Docker 的情况下,运行:
|
||||
@ -56,10 +52,9 @@ docker run -d --hostname my-rabbit --name some-rabbit -p 15672:15672 -p 5672:567
|
||||
|
||||

|
||||
|
||||
|
||||
#### 服务环境
|
||||
|
||||
现在让我们创建微服务来消费我们的任务。其中一个服务用来执行计算任务,另一个用来发送邮件。按以下步骤执行:
|
||||
现在让我们创建微服务来满足我们的任务需要。其中一个服务用来执行计算任务,另一个用来发送邮件。按以下步骤执行:
|
||||
|
||||
在 Shell 中创建项目的根目录
|
||||
|
||||
@ -82,7 +77,6 @@ $ source service_env/bin/activate
|
||||
(service_env)$ pip install yagmail
|
||||
```
|
||||
|
||||
|
||||
#### 服务的代码
|
||||
|
||||
现在我们已经准备好了 virtualenv 所提供的虚拟环境(可以想象成我们的服务是运行在一个独立服务器上的,而我们的 API 运行在另一个服务器上),接下来让我们编码,实现 nameko 的 RPC 服务。
|
||||
@ -135,7 +129,7 @@ class Compute(object):
|
||||
|
||||
现在我们已经用以上代码定义好了两个服务,下面让我们将 Nameko RPC service 运行起来。
|
||||
|
||||
>注意:我们会在控制台中启动并运行它。但在生产环境中,建议大家使用 supervisord 替代控制台命令。
|
||||
> 注意:我们会在控制台中启动并运行它。但在生产环境中,建议大家使用 supervisord 替代控制台命令。
|
||||
|
||||
在 Shell 中启动并运行服务
|
||||
|
||||
@ -149,7 +143,7 @@ Connected to amqp://guest:**@127.0.0.1:5672//
|
||||
|
||||
#### 测试
|
||||
|
||||
在另外一个 Shell 中(使用相同的虚拟环境),用 nameko shell 进行测试:
|
||||
在另外一个 Shell 中(使用相同的虚拟环境),用 nameko shell 进行测试:
|
||||
|
||||
```
|
||||
(service_env)$ nameko shell --broker amqp://guest:guest@localhost
|
||||
@ -178,19 +172,18 @@ Broker: amqp://guest:guest@localhost
|
||||
3
|
||||
```
|
||||
|
||||
|
||||
### 在 API 中调用微服务
|
||||
|
||||
在另外一个 Shell 中(甚至可以是另外一台服务器上),准备好 API 环境。
|
||||
|
||||
用 virtualenv 工具创建并且激活一个虚拟环境(你也可以使用virtualenv-wrapper)
|
||||
用 virtualenv 工具创建并且激活一个虚拟环境(你也可以使用 virtualenv-wrapper)
|
||||
|
||||
```
|
||||
$ virtualenv api_env
|
||||
$ source api_env/bin/activate
|
||||
```
|
||||
|
||||
安装 Nameko, Flask 和 Flasgger
|
||||
安装 Nameko、 Flask 和 Flasgger
|
||||
|
||||
```
|
||||
(api_env)$ pip install nameko
|
||||
@ -269,7 +262,7 @@ app.run(debug=True)
|
||||
|
||||

|
||||
|
||||
>注意: 你可以在 shell 中查看到服务的运行日志,打印信息和错误信息。也可以访问 RabbitMQ 控制面板来查看消息在队列中的处理情况。
|
||||
> 注意: 你可以在 shell 中查看到服务的运行日志,打印信息和错误信息。也可以访问 RabbitMQ 控制面板来查看消息在队列中的处理情况。
|
||||
|
||||
Nameko 框架还为我们提供了很多高级特性,你可以从 <https://nameko.readthedocs.org/en/stable/> 获取更多的信息。
|
||||
|
||||
@ -282,7 +275,7 @@ via: http://brunorocha.org/python/microservices-with-python-rabbitmq-and-nameko.
|
||||
|
||||
作者: [Bruno Rocha][a]
|
||||
译者: [mr-ping](http://www.mr-ping.com)
|
||||
校对: [校对者ID](https://github.com/校对者ID)
|
||||
校对: [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,45 @@
|
||||
Cassandra 和 Spark 数据处理一窥
|
||||
==============================================================
|
||||
|
||||

|
||||
|
||||
Apache Cassandra 数据库近来引起了很多的兴趣,这主要源于现代云端软件对于可用性及性能方面的要求。
|
||||
|
||||
那么,Apache Cassandra 是什么?它是一种为高可用性及线性可扩展性优化的分布式的联机交易处理 (OLTP) 数据库。具体说到 Cassandra 的用途时,可以想想你希望贴近用户的系统,比如说让我们的用户进行交互的系统、需要保证实时可用的程序等等,如:产品目录,物联网,医疗系统,以及移动应用。对这些程序而言,下线时间意味着利润降低甚至导致其他更坏的结果。Netfilix 是这个在 2008 年开源的项目的早期使用者,他们对此项目的贡献以及带来的成功让这个项目名声大噪。
|
||||
|
||||
Cassandra 于2010年成为了 Apache 软件基金会的顶级项目,并从此之后就流行起来。现在,只要你有 Cassadra 的相关知识,找工作时就能轻松不少。想想看,NoSQL 语言和开源技术能达到企业级 SQL 技术的高度,真让人觉得十分疯狂而又不可思议的。这引出了一个问题。是什么让它如此的流行?
|
||||
|
||||
因为采用了[亚马逊发表的 Dynamo 论文][1]中率先提出的设计,Cassandra 有能力在大规模的硬件及网络故障时保持实时在线。由于采用了点对点模式,在没有单点故障的情况下,我们能幸免于机架故障甚至全网中断。我们能在不影响用户体验的前提下处理数据中心故障。一个能考虑到故障的分布式系统才是一个没有后顾之忧的分布式系统,因为老实说,故障是迟早会发生的。有了 Cassandra, 我们可以直面残酷的生活并将之融入数据库的结构和功能中。
|
||||
|
||||
我们能猜到你现在在想什么,“但我只有关系数据库相关背景,难道这样的转变不会很困难吗?”这问题的答案介于是和不是之间。使用 Cassandra 建立数据模型对有关系数据库背景的开发者而言是轻车熟路。我们使用表格来建立数据模型,并使用 CQL ( Cassandra 查询语言)来查询数据库。然而,与 SQL 不同的是,Cassandra 支持更加复杂的数据结构,例如嵌套和用户自定义类型。举个例子,当要储存对一个小猫照片的点赞数目时,我们可以将整个数据储存在一个包含照片本身的集合之中从而获得更快的顺序查找而不是建立一个独立的表。这样的表述在 CQL 中十分的自然。在我们照片表中,我们需要记录名字,URL以及给此照片点赞过的人。
|
||||
|
||||

|
||||
|
||||
在一个高性能系统中,毫秒级处理都能对用户体验和客户维系产生影响。昂贵的 JOIN 操作制约了我们通过增加不可预见的网络调用而扩容的能力。当我们将数据反范式化使其能通过尽可能少的请求就可获取时,我们即可从磁盘空间成本的降低中获益并获得可预期的、高性能应用。我们将反范式化同 Cassandra 一同介绍是因为它提供了很有吸引力的的折衷方案。
|
||||
|
||||
很明显,我们不会局限于对于小猫照片的点赞数量。Canssandra 是一款为高并发写入优化的方案。这使其成为需要时常吞吐数据的大数据应用的理想解决方案。实时应用和物联网方面的应用正在稳步增长,无论是需求还是市场表现,我们也会不断的利用我们收集到的数据来寻求改进技术应用的方式。
|
||||
|
||||
这就引出了我们的下一步,我们已经提到了如何以一种现代的、性价比高的方式储存数据,但我们应该如何获得更多的动力呢?具体而言,当我们收集到了所需的数据,我们应该怎样处理呢?如何才能有效的分析几百 TB 的数据呢?如何才能实时的对我们所收集到的信息进行反馈,并在几秒而不是几小时的时间利作出决策呢?Apache Spark 将给我们答案。
|
||||
|
||||
Spark 是大数据变革中的下一步。 Hadoop 和 MapReduce 都是革命性的产品,它们让大数据界获得了分析所有我们所取得的数据的机会。Spark 对性能的大幅提升及对代码复杂度的大幅降低则将大数据分析提升到了另一个高度。通过 Spark,我们能大批量的处理计算,对流处理进行快速反应,通过机器学习作出决策,并通过图遍历来理解复杂的递归关系。这并非只是为你的客户提供与快捷可靠的应用程序连接(Cassandra 已经提供了这样的功能),这更是能洞悉 Canssandra 所储存的数据,作出更加合理的商业决策并同时更好地满足客户需求。
|
||||
|
||||
你可以看看 [Spark-Cassandra Connector][2] (开源) 并动手试试。若想了解更多关于这两种技术的信息,我们强烈推荐名为 [DataStax Academy][3] 的自学课程
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/basics-cassandra-and-spark-data-processing
|
||||
|
||||
作者:[Jon Haddad][a],[Dani Traphagen][b]
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/rustyrazorblade
|
||||
[b]: https://opensource.com/users/dtrapezoid
|
||||
[1]: http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
|
||||
[2]: https://github.com/datastax/spark-cassandra-connector
|
||||
[3]: https://academy.datastax.com/
|
||||
[4]: http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/49162
|
||||
[5]: https://twitter.com/dtrapezoid
|
||||
[6]: https://twitter.com/rustyrazorblade
|
||||
@ -1,17 +1,17 @@
|
||||
在 Ubuntu 16.04 上安装使用 VBoxManage 以及 VBoxManage 命令行选项的用法
|
||||
在 Linux 上安装使用 VirtualBox 的命令行管理界面 VBoxManage
|
||||
=================
|
||||
|
||||
VirtualBox 拥有一套命令行工具,然后你可以使用 VirtualBox 的命令行界面 (CLI) 对远端无界面的服务器上的虚拟机进行管理操作。在这篇教程中,你将会学到如何在没有 GUI 的情况下使用 VBoxManage 创建、启动一个虚拟机。VBoxManage 是 VirtualBox 的命令行界面,你可以在你的主机操作系统的命令行中来用它实现对 VirtualBox 的所有操作。VBoxManage 拥有图形化用户界面所支持的全部功能,而且它支持的功能远不止这些。它提供虚拟引擎的所有功能,甚至包含 GUI 还不能实现的那些功能。如果你想尝试不同的用户界面而不仅仅是 GUI,或者更改虚拟机更多高级和实验性的配置,那么你就需要用到命令行。
|
||||
VirtualBox 拥有一套命令行工具,你可以使用 VirtualBox 的命令行界面 (CLI) 对远程无界面的服务器上的虚拟机进行管理操作。在这篇教程中,你将会学到如何在没有 GUI 的情况下使用 VBoxManage 创建、启动一个虚拟机。VBoxManage 是 VirtualBox 的命令行界面,你可以在你的主机操作系统的命令行中用它来实现对 VirtualBox 的所有操作。VBoxManage 拥有图形化用户界面所支持的全部功能,而且它支持的功能远不止这些。它提供虚拟引擎的所有功能,甚至包含 GUI 还不能实现的那些功能。如果你想尝试下不同的用户界面而不仅仅是 GUI,或者更改虚拟机更多高级和实验性的配置,那么你就需要用到命令行。
|
||||
|
||||
当你想要在 VirtualBox 上创建或运行虚拟机时,你会发现 VBoxManage 非常有用,你只需要使用远程主机的终端就够了。这对于服务器来说是一种常见的情形,因为在服务器上需要进行虚拟机的远程操作。
|
||||
当你想要在 VirtualBox 上创建或运行虚拟机时,你会发现 VBoxManage 非常有用,你只需要使用远程主机的终端就够了。这对于需要远程管理虚拟机的服务器来说是一种常见的情形。
|
||||
|
||||
### 准备工作
|
||||
|
||||
在开始使用 VBoxManage 的命令行工具前,确保在运行着 Ubuntu 16.04 的服务器上,你拥有超级用户的权限或者你能够使用 sudo 命令,而且你已经在服务器上安装了 Oracle Virtual Box。 然后你需要安装 VirtualBox 扩展包,这是运行远程桌面环境,访问无界面启动虚拟机所必须的。(headless的翻译拿不准,翻译为无界面启动)
|
||||
在开始使用 VBoxManage 的命令行工具前,确保在运行着 Ubuntu 16.04 的服务器上,你拥有超级用户的权限或者你能够使用 sudo 命令,而且你已经在服务器上安装了 Oracle Virtual Box。 然后你需要安装 VirtualBox 扩展包,这是运行 VRDE 远程桌面环境,访问无界面虚拟机所必须的。
|
||||
|
||||
### 安装 VBoxManage
|
||||
|
||||
通过 [Virtual Box Download Page][1] 这个链接,你能够获取你所需要的软件扩展包的最新版本,扩展包的版本和你安装的 VirtualBox 版本需要一致!
|
||||
通过 [Virtual Box 下载页][1] 这个链接,你能够获取你所需要的软件扩展包的最新版本,扩展包的版本和你安装的 VirtualBox 版本需要一致!
|
||||
|
||||

|
||||
|
||||
@ -71,11 +71,11 @@ $ VBoxManage modifyvm Ubuntu10.10 --memory 512
|
||||
$ VBoxManage storagectl Ubuntu16.04 --name IDE --add ide --controller PIIX4 --bootable on
|
||||
```
|
||||
|
||||
这里的 “storagect1” 是给虚拟机创建存储控制器的,“--name” 指定了虚拟机里需要创建、更改或者移除的存储控制器的名称。“--add” 选项指明系统总线类型,可选的选项有 ide / sata / scsi / floppy,存储控制器必须要连接到系统总线。“--controller” 选择主板的类型,主板需要根据需要的存储控制器选择,可选的选项有 LsiLogic / LSILogicSAS / BusLogic / IntelAhci / PIIX3 / PIIX4 / ICH6 / I82078。最后的 “--bootable” 表示控制器是否可以引导。
|
||||
这里的 “storagect1” 是给虚拟机创建存储控制器的,“--name” 指定了虚拟机里需要创建、更改或者移除的存储控制器的名称。“--add” 选项指明存储控制器所需要连接到的系统总线类型,可选的选项有 ide / sata / scsi / floppy。“--controller” 选择主板的类型,主板需要根据需要的存储控制器选择,可选的选项有 LsiLogic / LSILogicSAS / BusLogic / IntelAhci / PIIX3 / PIIX4 / ICH6 / I82078。最后的 “--bootable” 表示控制器是否可以引导系统。
|
||||
|
||||
上面的命令创建了叫做 IDE 的存储控制器。然后虚拟设备就能通过 “storageattach” 命令连接到控制器。
|
||||
上面的命令创建了叫做 IDE 的存储控制器。之后虚拟介质就能通过 “storageattach” 命令连接到该控制器。
|
||||
|
||||
然后运行下面这个命令来创建一个叫做 SATA 的存储控制器,它将会连接到硬盘镜像上。
|
||||
然后运行下面这个命令来创建一个叫做 SATA 的存储控制器,它将会连接到之后的硬盘镜像上。
|
||||
|
||||
```
|
||||
$ VBoxManage storagectl Ubuntu16.04 --name SATA --add sata --controller IntelAhci --bootable on
|
||||
@ -87,7 +87,7 @@ $ VBoxManage storagectl Ubuntu16.04 --name SATA --add sata --controller IntelAhc
|
||||
$ VBoxManage storageattach Ubuntu16.04 --storagectl SATA --port 0 --device 0 --type hdd --medium "your_iso_filepath"
|
||||
```
|
||||
|
||||
用媒体把 SATA 存储控制器连接到 Ubuntu16.04 虚拟机中,也就是之前创建的虚拟硬盘镜像里。
|
||||
这将把 SATA 存储控制器及介质(比如之前创建的虚拟磁盘镜像)连接到 Ubuntu16.04 虚拟机中。
|
||||
|
||||
运行下面的命令添加像网络连接,音频之类的功能。
|
||||
|
||||
@ -120,9 +120,9 @@ $VBoxManage controlvm
|
||||
|
||||

|
||||
|
||||
完结!
|
||||
###完结
|
||||
|
||||
从这篇文章中,我们了解了 Oracle Virtual Box 中一个十分实用的工具,就是 VBoxManage,包含了 VBoxManage 的安装和在 Ubuntu 16.04 系统上的使用。文章包含详细的教程, 通过 VBoxManage 中实用的命令来创建和管理虚拟机。希望这篇文章对你有帮助,另外别忘了分享你的评论或者建议。
|
||||
从这篇文章中,我们了解了 Oracle Virtual Box 中一个十分实用的工具 VBoxManage,文章包含了 VBoxManage 的安装和在 Ubuntu 16.04 系统上的使用,包括通过 VBoxManage 中实用的命令来创建和管理虚拟机。希望这篇文章对你有帮助,另外别忘了分享你的评论或者建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -130,7 +130,7 @@ via: http://linuxpitstop.com/install-and-use-command-line-tool-vboxmanage-on-ubu
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
如何在 Linux 上录制你的终端操作
|
||||
=================================================
|
||||
|
||||
录制一个终端操作可能是一个帮助他人学习 Linux 、展示一系列正确命令行操作的和分享知识的通俗易懂方法。不管是出于什么目的,从终端复制粘贴文本需要重复很多次,而录制视频的过程也是相当麻烦,有时候还不能录制。在这次的文章中,我们将简单的了解一下以 gif 格式记录和分享终端会话的方法。
|
||||
|
||||
### 预先要求
|
||||
|
||||
如果你只是希望能记录你的终端会话,并且能在终端进行回放或者和他人分享,那么你只需要一个叫做:ttyrec 的软件。Ubuntu 用户可以通过运行这行代码进行安装:
|
||||
|
||||
```
|
||||
sudo apt-get install ttyrec
|
||||
```
|
||||
|
||||
如果你想将生成的视频转换成一个 gif 文件,这样能够和那些不使用终端的人分享,就可以发布到网站上去,或者你只是想做一个 gif 方便使用而不想写命令。那么你需要安装额外的两个软件包。第一个就是 imagemagick , 你可以通过以下的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
第二个软件包就是:tty2gif.py,访问其[项目网站][1]下载。这个软件包需要安装如下依赖:
|
||||
|
||||
```
|
||||
sudo apt-get install python-opster
|
||||
```
|
||||
|
||||
### 录制
|
||||
|
||||
开始录制终端操作,你需要的仅仅是键入 `ttyprec` ,然后回车。这个命令将会在后台运行一个实时的记录工具。我们可以通过键入`exit`或者`ctrl+d`来停止。ttyrec 默认会在主目录下创建一个`ttyrecord`的文件。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 回放
|
||||
|
||||
回放这个文件非常简单。你只需要打开终端并且使用 `ttyplay` 命令打开 `ttyrecord` 文件即可。(在这个例子里,我们使用 ttyrecord 作为文件名,当然,你也可以改成你用的文件名)
|
||||
|
||||
|
||||
|
||||
然后就可以开始播放这个文件。这个视频记录了所有的操作,包括你的删除,修改。这看起来像一个拥有自我意识的终端,但是这个命令执行的过程并不是只是为了给系统看,而是为了更好的展现给人。
|
||||
|
||||
注意一点,播放这个记录是完全可控的,你可以通过点击 `+` 或者 `-` 进行加速减速,或者 `0`和 `1` 暂停和恢复播放。
|
||||
|
||||
### 导出成 GIF
|
||||
|
||||
为了方便,我们通常会将视频记录转换为 gif 格式,并且,这个非常容易做到。以下是方法:
|
||||
|
||||
将之前下载的 tty2gif.py 这个文件拷贝到 ttyprecord 文件(或者你命名的那个视频文件)相同的目录,然后在这个目录下打开终端,输入命令:
|
||||
|
||||
```
|
||||
python tty2gif.py typing ttyrecord
|
||||
```
|
||||
|
||||
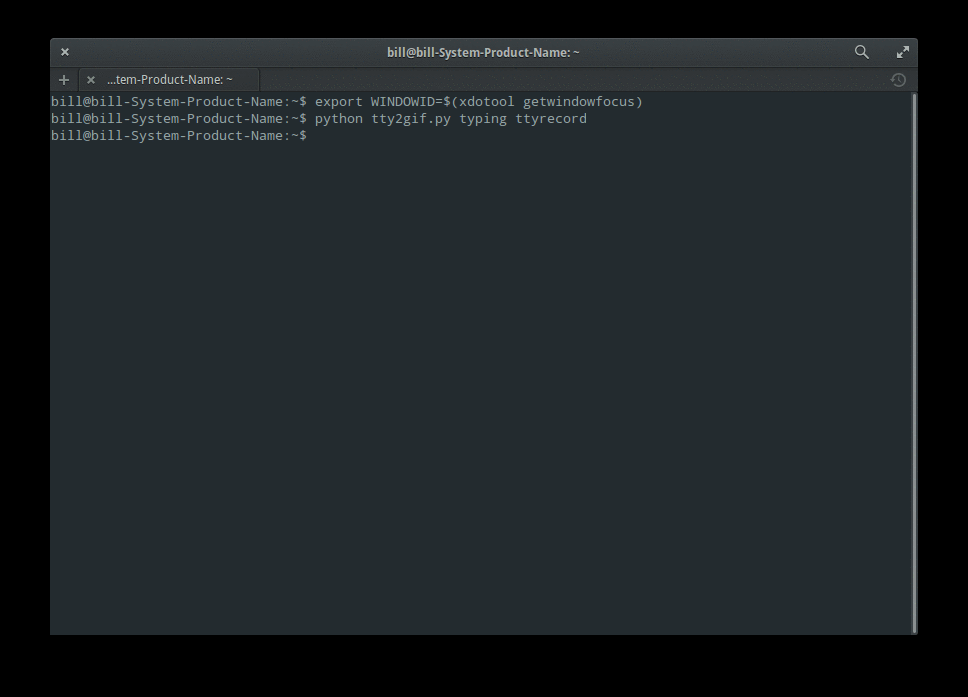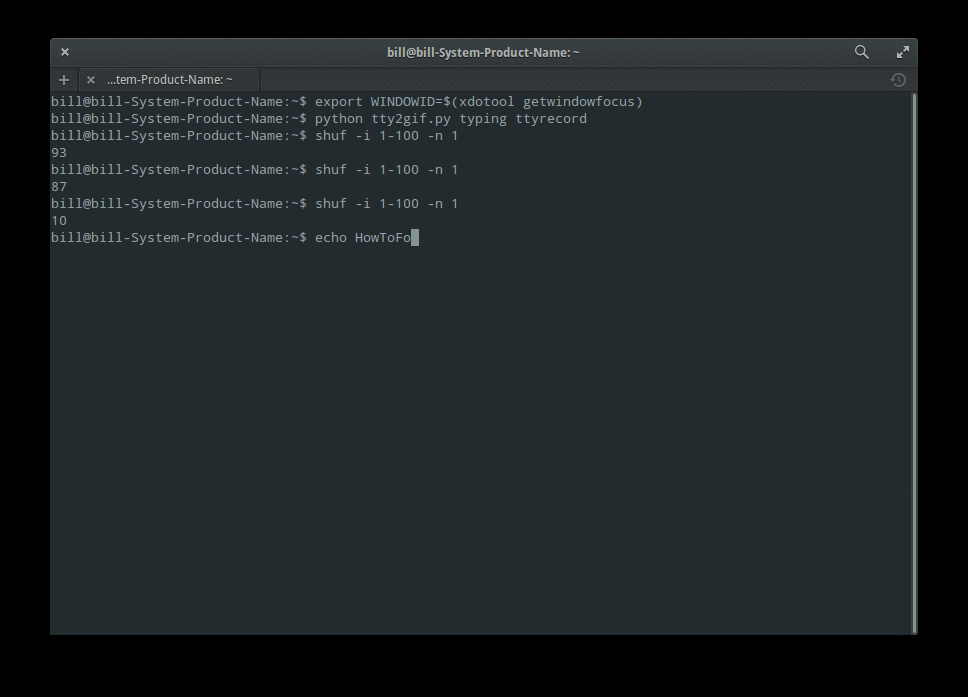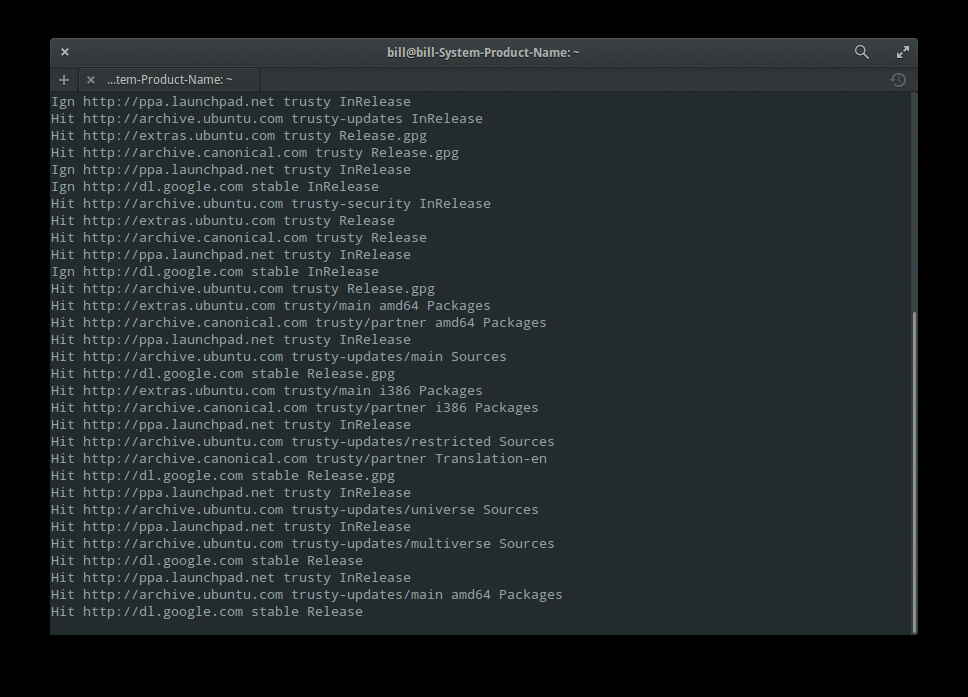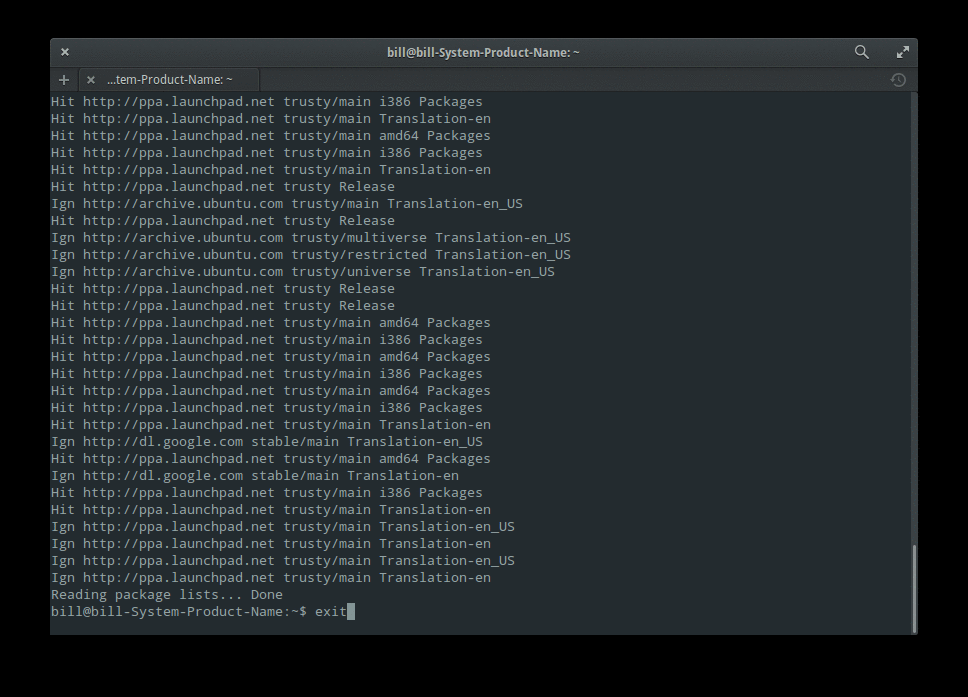
如果出现了错误,检查一下你是否有安装 python-opster 包。如果还是有错误,使用如下命令进行排除。
|
||||
|
||||
```
|
||||
sudo apt-get install xdotool
|
||||
export WINDOWID=$(xdotool getwindowfocus)
|
||||
```
|
||||
|
||||
然后重复这个命令 `python tty2gif.py` 并且你将会看到在 ttyrecord 目录下多了一些 gif 文件。
|
||||
|
||||
|
||||
|
||||
接下来的一步就是整合所有的 gif 文件,将他打包成一个 gif 文件。我们通过使用 imagemagick 工具。输入下列命令:
|
||||
|
||||
```
|
||||
convert -delay 25 -loop 0 *.gif example.gif
|
||||
```
|
||||
|
||||
|
||||
|
||||
你可以使用任意的文件名,我用的是 example.gif。 并且,你可以改变这个延时和循环时间。 Enjoy。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-record-your-terminal-session-on-linux/
|
||||
|
||||
作者:[Bill Toulas][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/howtoforgecom
|
||||
[1]: https://bitbucket.org/antocuni/tty2gif/raw/61d5596c916512ce5f60fcc34f02c686981e6ac6/tty2gif.py
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,23 +1,23 @@
|
||||
在 Ubuntu Mate 16.04("Xenial Xerus") 上通过 PPA 安装 Mate 1.14
|
||||
在 Ubuntu Mate 16.04 上通过 PPA 升级 Mate 1.14
|
||||
=================================================================
|
||||
|
||||
Mate 桌面环境 1.14 现在可以在 Ubuntu Mate 16.04("Xenial Xerus") 上使用了。根据这个[发布版本][1]的描述, 为了全面测试 Mate 1.14,所以在 PPA 上发布 Mate 桌面环境 1.14大概了用2个月的时间。因此,你不太可能遇到安装的问题。
|
||||
Mate 桌面环境 1.14 现在可以在 Ubuntu Mate 16.04 ("Xenial Xerus") 上使用了。根据这个[发布版本][1]的描述,为了全面测试 Mate 1.14,所以 Mate 桌面环境 1.14 已经在 PPA 上发布 2 个月了。因此,你不太可能遇到安装的问题。
|
||||
|
||||

|
||||
|
||||
**现在 PPA 提供 Mate 1.14.1 包含如下改变(Ubuntu Mate 16.04 默认安装的是 Mate 1.12.x):**
|
||||
**现在 PPA 提供 Mate 1.14.1 包含如下改变(Ubuntu Mate 16.04 默认安装的是 Mate 1.12.x):**
|
||||
|
||||
- 客户端的装饰应用现在可以正确的在所有主题中渲染;
|
||||
- 触摸板配置现在支持边缘操作和双指的滚动;
|
||||
- 在 Caja 中的 Python 扩展可以被单独管理;
|
||||
- 所有三个窗口焦点模式都是是可选的;
|
||||
- Mate Panel 中的所有菜单栏图标和菜单图标可以改变大小;
|
||||
- 音量和亮度 OSD 目前可以启用和禁用;
|
||||
- 更多的改进和 bug 修改;
|
||||
- 客户端的装饰应用现在可以正确的在所有主题中渲染;
|
||||
- 触摸板配置现在支持边缘操作和双指滚动;
|
||||
- 在 Caja 中的 Python 扩展可以被单独管理;
|
||||
- 所有三个窗口焦点模式都是可选的;
|
||||
- Mate Panel 中的所有菜单栏图标和菜单图标可以改变大小;
|
||||
- 音量和亮度 OSD 目前可以启用和禁用;
|
||||
- 更多的改进和 bug 修改;
|
||||
|
||||
Mate 1.14 同时改进了整个桌面环境中对 GTK+3 的支持,包括各种各项的 GTK+3 小应用。但是,Ubuntu MATE 的博客中提到:PPA 的发行包使用 GTK+2编译"为了确保对 Ubuntu MATE 16.05还有各种各样的第三方 MATE 应用,插件,扩展的支持"。
|
||||
Mate 1.14 同时改进了整个桌面环境中对 GTK+ 3 的支持,包括各种 GTK+3 小应用。但是,Ubuntu MATE 的博客中提到:PPA 的发行包使用 GTK+ 2 编译是“为了确保对 Ubuntu MATE 16.04 还有各种各样的第三方 MATE 应用、插件、扩展的支持"。
|
||||
|
||||
MATE 1.14 的完成修改列表[点击此处][2]阅读。
|
||||
MATE 1.14 的完整修改列表[点击此处][2]阅读。
|
||||
|
||||
### 在 Ubuntu MATE 16.04 中升级 MATE 1.14.x
|
||||
|
||||
@ -29,7 +29,7 @@ sudo apt update
|
||||
sudo apt dist-upgrade
|
||||
```
|
||||
|
||||
**注意**: mate-netspeed 应用将会在升级中删除。因为该应用现在已经是 mate-applets 应用报的一部分,所以他依旧是可以获得的。
|
||||
**注意**: mate-netspeed 应用将会在升级中删除。因为该应用现在已经是 mate-applets 应用报的一部分,所以它依旧是可以使用的。
|
||||
|
||||
一旦升级完成,请重启你的系统,享受全新的 MATE!
|
||||
|
||||
@ -51,8 +51,8 @@ via [Ubuntu MATE blog][3]
|
||||
via: http://www.webupd8.org/2016/06/install-mate-114-in-ubuntu-mate-1604.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[译者ID](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,28 +1,26 @@
|
||||
[Translated by HaohongWANG]
|
||||
//校对爸爸辛苦了!>_<
|
||||
惊艳!6款面向儿童的 Linux 发行版
|
||||
======================================
|
||||
|
||||
毫无疑问未来是属于 Linux 和开源的。为了实现这样的未来、使Linux占据一席之地,人们已经着手从尽可能低的水平开始开发面向儿童的Linux发行版,并尝试教授他们如何使用Linux操作系统。
|
||||
毫无疑问未来是属于 Linux 和开源的。为了实现这样的未来、使 Linux 占据一席之地,人们已经着手开发尽可能简单的、面向儿童的 Linux 发行版,并尝试教导他们如何使用 Linux 操作系统。
|
||||
|
||||

|
||||
>面向儿童的 Linux 发行版
|
||||
|
||||
Linux 是一款非常强大的操作系统,原因之一便是它驱动了互联网上绝大多数的服务器。但出于对其用户友好性的担忧,坊间时常展开有关于 Linux 应如何取代 Mac OS X 或 Windows 的辩论。而我认为用户应该接受 Linux 来见识它真正的威力。
|
||||
Linux 是一款非常强大的操作系统,原因之一便是它支撑了互联网上绝大多数的服务器。但出于对其用户友好性的担忧,坊间时常展开有关于 Linux 应如何取代 Mac OS X 或 Windows 的争论。而我认为用户应该接受 Linux 来见识它真正的威力。
|
||||
|
||||
如今,Linux 运行在绝大多数设备上,从智能手机到平板电脑,笔记本电脑,工作站,服务器,超级计算机,再到汽车,航空管制系统,甚至电冰箱,都有 Linux 的身影。正如我在开篇所说,有了这一切, Linux 是未来的操作系统。
|
||||
如今,Linux 运行在绝大多数设备上,从智能手机到平板电脑,笔记本电脑,工作站,服务器,超级计算机,再到汽车,航空管制系统,电冰箱,到处都有 Linux 的身影。正如我在开篇所说,有了这一切, Linux 是未来的操作系统。
|
||||
|
||||
>参考阅读: [30 Big Companies and Devices Running on Linux][1]
|
||||
|
||||
未来是属于孩子们的,教育要从娃娃抓起。所以,要让小孩子尽早地学习计算机、了解 Linux 、接触科学技术。这是改变未来图景的最好方法。
|
||||
未来是属于孩子们的,教育要从娃娃抓起。所以,要让小孩子尽早地学习计算机,而 Linux 就是其中一个重要的部分。
|
||||
|
||||
一个常见的现象是,当儿童在一个适合他的环境中学习时,好奇心和早期学习的能力会使他自己养成喜好探索的性格。
|
||||
对小孩来说,一个常见的现象是,当他们在一个适合他的环境中学习时,好奇心和早期学习的能力会使他自己养成喜好探索的性格。
|
||||
|
||||
说了这么多儿童应该学习 Linux 的原因,接下来我就列出这些令人激动的发行版。你可以把它们推荐给小孩子来帮助他们开始学习使用 Linux 。
|
||||
|
||||
### Sugar on a Stick
|
||||
|
||||
Sugar on a Stick (译注:“糖在棒上”)是 Sugar Labs 旗下的工程,Sugar Labs 是一个由志愿者领导的非盈利组织。这一发行版旨在设计大量的免费工具来使儿童在探索、发现、创造中认知自己的思想。
|
||||
Sugar on a Stick (译注:“糖棒”)是 Sugar 实验室旗下的工程,Sugar 实验室是一个由志愿者领导的非盈利组织。这一发行版旨在设计大量的免费工具来促进儿童在探索中学会技能,发现、创造,并将这些反映到自己的思想上。
|
||||
|
||||

|
||||
>Sugar Neighborhood 界面
|
||||
@ -36,31 +34,31 @@ Sugar on a Stick (译注:“糖在棒上”)是 Sugar Labs 旗下的工程,S
|
||||
|
||||
### Edubuntu
|
||||
|
||||
Edubuntu 是基于当下最流行的发行版 Ubuntu 而开发的一款草根发行版。主要致力于降低学校、家庭和社区安装、使用 Ubuntu 自由软件的难度。
|
||||
Edubuntu 是基于当下最流行的发行版 Ubuntu 而开发的一款非官方发行版。主要致力于降低学校、家庭和社区安装、使用 Ubuntu 自由软件的难度。
|
||||
|
||||

|
||||
>Edubuntu 桌面应用
|
||||
|
||||
它的桌面应用由来自不同组织的学生、教师、家长、一些利益相关者甚至黑客来提供。他们都笃信社区的发展和知识的共享是自由学习和自由分享的基石。
|
||||
它是由来自不同组织的学生、教师、家长、一些利益相关者甚至黑客支持的,这些人都坚信自由的学习和共享知识能够提高自己和社区的发展。
|
||||
|
||||
该项目的主要目标是组建一款安装、管理软件难度低的操作系统以增长使用 Linux 学习和教育的用户数量。
|
||||
该项目的主要目标是通过组建一款能够降低安装、管理软件难度的操作系统来增强学习和教育水平。
|
||||
|
||||
访问主页: <http://www.edubuntu.org/>
|
||||
|
||||
### Doudou Linux
|
||||
|
||||
Doudou Linux 是专为方便儿童使用而设计的发行版,能在构建中激发儿童的创造性思维。它提供了简单但是颇具教育意义的应用来使儿童在应用过程中学习发现新的知识。
|
||||
Doudou Linux 是专为方便孩子们在建设创新思维时使用计算机而设计的发行版。它提供了简单但是颇具教育意义的应用来使儿童在应用过程中学习发现新的知识。
|
||||
|
||||

|
||||
>Doudou Linux
|
||||
|
||||
其最引人注目的一点便是内容过滤功能,顾名思义,它能够阻止孩童访问网络上的禁止内容。如果想要更进一步的儿童保护功能,Doudou Linux 还提供了互联网用户隐私功能,能够去除网页中的特定加载内容。
|
||||
其最引人注目的一点便是内容过滤功能,顾名思义,它能够阻止孩童访问网络上的限制性内容。如果想要更进一步的儿童保护功能,Doudou Linux 还提供了互联网用户隐私功能,能够去除网页中的特定加载内容。
|
||||
|
||||
访问主页: <http://www.doudoulinux.org/>
|
||||
|
||||
### LinuxKidX
|
||||
|
||||
这是一款整合了许多专为儿童的教育类软件的 Slackware Linux 的 LiveCD。它使用 KDE 作为默认桌面环境并配置了诸如 Ktouch 打字指导,Kstars 虚拟天文台,Kalzium 元素周期表和 KwordQuiz 单词测试等应用。
|
||||
这是一款整合了许多专为儿童设计的教育软件的基于 Slackware Linux 发行版的 LiveCD。它使用 KDE 作为默认桌面环境并配置了诸如 Ktouch 打字指导,Kstars 虚拟天文台,Kalzium 元素周期表和 KwordQuiz 单词测试等应用。
|
||||
|
||||

|
||||
>LinuxKidX
|
||||
@ -85,7 +83,7 @@ Ubermix 还具有5分钟快速安装和快速恢复等功能,可以给小孩
|
||||

|
||||
>Qimo Linux
|
||||
|
||||
你仍然可以在 Ubuntu 或者其他的 Linux 发行版中找到大多数儿童游戏。正如这些开发商所说,他们不仅在为儿童制作教育软件,同时也在开发增长儿童文化水平的安卓应用。
|
||||
你仍然可以在 Ubuntu 或者其他的 Linux 发行版中找到大多数儿童游戏。正如这些开发商所说,他们并不是要终止为孩子们开发教育软件,而是在开发能够提高儿童读写能力的 android 应用。
|
||||
|
||||
如果你想进一步了解,可以移步他们的官方网站。
|
||||
|
||||
@ -93,7 +91,7 @@ Ubermix 还具有5分钟快速安装和快速恢复等功能,可以给小孩
|
||||
|
||||
以上这些便是我所知道的面向儿童的Linux发行版,或有缺漏,欢迎评论补充。
|
||||
|
||||
如果你想探讨桌面 Linux 的发展前景或是如何引导儿童接触 Linux ,欢迎与我联系。
|
||||
如果你想让我们知道你对如何想儿童介绍 Linux 或者你对未来的 Linux ,特别是桌面计算机上的 Linux,欢迎与我联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -102,12 +100,11 @@ via: http://www.tecmint.com/best-linux-distributions-for-kids/?utm_source=feedbu
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[HaohongWANG](https://github.com/HaohongWANG)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]: http://www.tecmint.com/big-companies-and-devices-running-on-gnulinux/
|
||||
|
||||
|
||||
@ -1,29 +1,33 @@
|
||||
用 Netdata 监控 Linux
|
||||
=======
|
||||
|
||||
Netdata 是一个实时的资源监控工具,它拥有基于 web 的友好界面,由 [FireHQL][1] 开发和维护。通过这个工具,你可以通过图表来了解 CPU,RAM,硬盘,网络,Apache, Postfix等软硬件的资源使用情况。它很像 Nagios 等别的监控软件;但是,Netdata 仅仅支持通过网络接口进行实时监控。
|
||||

|
||||
|
||||
Netdata 是一个实时的资源监控工具,它拥有基于 web 的友好界面,由 [FireHQL][1] 开发和维护。通过这个工具,你可以通过图表来了解 CPU,RAM,硬盘,网络,Apache, Postfix 等软硬件的资源使用情况。它很像 Nagios 等别的监控软件;但是,Netdata 仅仅支持通过 Web 界面进行实时监控。
|
||||
|
||||
### 了解 Netdata
|
||||
|
||||
目前 Netdata 还没有验证机制,如果你担心别人能从你的电脑上获取相关信息的话,你应该设置防火墙规则来限制访问。UI 是简化版的,以便用户查看和理解他们看到的表格数据,至少你能够记住它的快速安装。
|
||||
目前 Netdata 还没有验证机制,如果你担心别人能从你的电脑上获取相关信息的话,你应该设置防火墙规则来限制访问。UI 很简单,所以任何人看懂图形并理解他们看到的结果,至少你会对它的快速安装印象深刻。
|
||||
|
||||
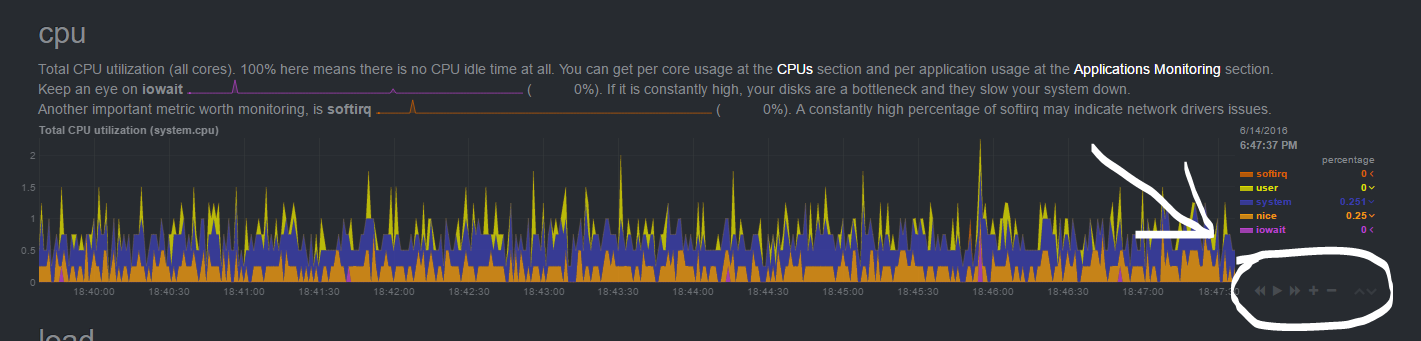
它的 web 前端响应很快,而且不需要 Flash 插件。 UI 很整洁,保持着 Netdata 应有的特性。粗略的看,你能够看到很多图表,幸运的是绝大多数常用的图表数据(像 CPU,RAM,网络和硬盘)都在顶部。如果你想深入了解图形化数据,你只需要下滑滚动条,或者点击在右边菜单的项目。通过每个图表的右下方的按钮, Netdata 还能让你控制图表的显示,重置,缩放。
|
||||
它的 web 前端响应很快,而且不需要 Flash 插件。 UI 很整洁,保持着 Netdata 应有的特性。第一眼看上去,你能够看到很多图表,幸运的是绝大多数常用的图表数据(像 CPU,RAM,网络和硬盘)都在顶部。如果你想深入了解图形化数据,你只需要下滑滚动条,或者点击在右边菜单的项目。通过每个图表的右下方的按钮, Netdata 还能让你控制图表的显示,重置,缩放。
|
||||
|
||||
|
||||
>Netdata 图表控制
|
||||
|
||||
*Netdata 图表控制*
|
||||
|
||||
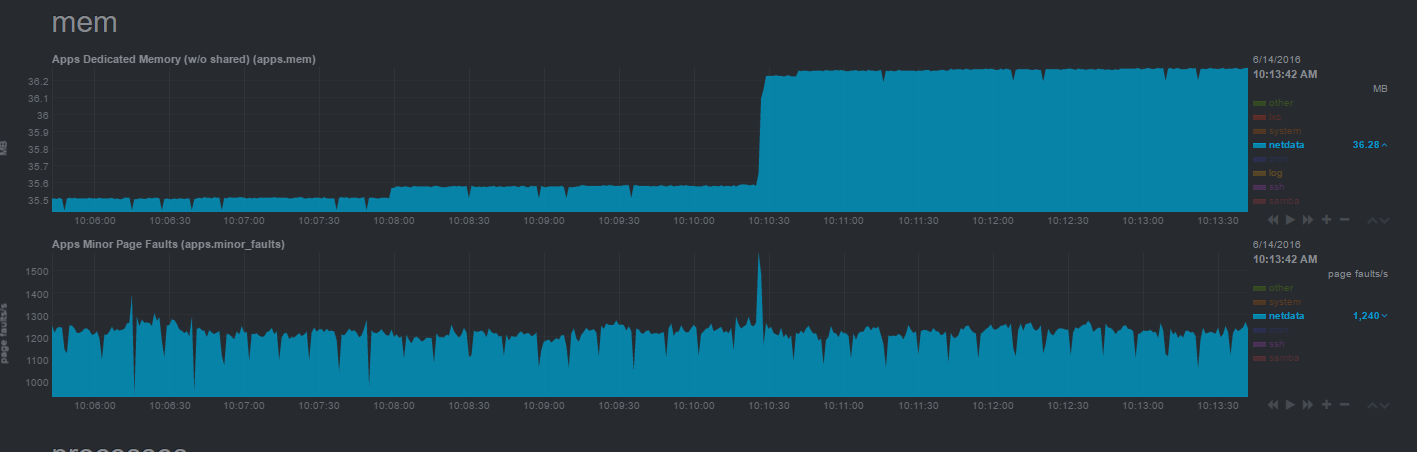
Netdata 并不会占用多少系统资源,它占用的内存不会超过 40MB。因为这个软件是作者用 C 语言写的。
|
||||
|
||||
|
||||
>Netdata 显示的内存使用情况
|
||||
|
||||
*Netdata 显示的内存使用情况*
|
||||
|
||||
### 下载 Netdata
|
||||
|
||||
要下载这个软件,你可以从访问 [Netdata GitHub page][2]。然后点击页面左边绿色的 "Clone or download" 按钮 。你应该能看到两个选项。
|
||||
要下载这个软件,你可以访问 [Netdata 的 GitHub 页面][2],然后点击页面左边绿色的 "Clone or download" 按钮 。你应该能看到以下两个选项:
|
||||
|
||||
#### 通过 ZIP 文件下载
|
||||
|
||||
另一种方法是下载 ZIP 文件。它包含在仓库的所有东西。但是如果仓库更新了,你需要重新下载 ZIP 文件。下载完 ZIP 文件后,你要用 `unzip` 命令行工具来解压文件。运行下面的命令能把 ZIP 文件的内容解压到 `netdata` 文件夹。
|
||||
一种方法是下载 ZIP 文件。它包含仓库里的所有东西。但是如果仓库更新了,你需要重新下载 ZIP 文件。下载完 ZIP 文件后,你要用 `unzip` 命令行工具来解压文件。运行下面的命令能把 ZIP 文件的内容解压到 `netdata` 文件夹。
|
||||
|
||||
```
|
||||
$ cd ~/Downloads
|
||||
@ -31,9 +35,10 @@ $ unzip netdata-master.zip
|
||||
```
|
||||
|
||||
|
||||
>解压 Netdata
|
||||
|
||||
没必要在 unzip 命令后加上 `-d` 选项,因为文件都是是放在 ZIP 文件里的一个文件夹里面。如果没有那个文件夹, unzip 会把所有东西都解压到当前目录下面(这会让文件非常混乱)。
|
||||
*解压 Netdata*
|
||||
|
||||
没必要在 unzip 命令后加上 `-d` 选项,因为文件都是是放在 ZIP 文件的根文件夹里面。如果没有那个文件夹, unzip 会把所有东西都解压到当前目录下面(这会让文件非常混乱)。
|
||||
|
||||
#### 通过 Git 下载
|
||||
|
||||
@ -53,7 +58,7 @@ $ git clone https://github.com/firehol/netdata.git
|
||||
|
||||
### 安装 Netdata
|
||||
|
||||
有些软件包是你成功构造 Netdata 时候需要的。 还好,一行命令就可以安装你所需要的东西([as stated in their installation guide][3])。在命令行运行下面的命令就能满足安装 Netdata 需要的所有依赖关系。
|
||||
有些软件包是你成功构造 Netdata 时候需要的。 还好,一行命令就可以安装你所需要的东西([这写在它的安装文档中][3])。在命令行运行下面的命令就能满足安装 Netdata 需要的所有依赖关系。
|
||||
|
||||
```
|
||||
$ dnf install zlib-devel libuuid-devel libmnl-devel gcc make git autoconf autogen automake pkgconfig
|
||||
@ -68,7 +73,8 @@ $ sudo ./netdata-installer.sh
|
||||
然后就会提示你按回车键,开始安装程序。如果要继续的话,就按下回车吧。
|
||||
|
||||
|
||||
>Netdata 的安装。
|
||||
|
||||
*Netdata 的安装*
|
||||
|
||||
如果一切顺利,你的系统上就已经安装并且运行了 Netdata。安装脚本还会在相应的文件夹里添加一个卸载脚本,叫做 `netdata-uninstaller.sh`。如果你以后不想使用 Netdata,运行这个脚本可以从你的系统里面卸载掉 Netdata。
|
||||
|
||||
@ -83,10 +89,10 @@ $ sudo systemctl status netdata
|
||||
既然我们已经安装并且运行了 Netdata,你就能够通过 19999 端口来访问 web 界面。下面的截图是我在一个测试机器上运行的 Netdata。
|
||||
|
||||
|
||||
>关于 Netdata 运行时的概览
|
||||
|
||||
恭喜!你已经成功安装并且能够看到关于你的机器性能的完美显示,图形和高级的统计数据。无论是否是你个人的机器,你都可以向你的朋友们炫耀,因为你能够深入的了解你的服务器性能,Netdata 在任何机器上的性能报告都非常出色。
|
||||
*关于 Netdata 运行时的概览*
|
||||
|
||||
恭喜!你已经成功安装并且能够看到漂亮的外观和图形,以及你的机器性能的高级统计数据。无论是否是你个人的机器,你都可以向你的朋友们炫耀,因为你能够深入的了解你的服务器性能,Netdata 在任何机器上的性能报告都非常出色。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -94,7 +100,7 @@ via: https://fedoramagazine.org/monitor-linux-netdata/
|
||||
|
||||
作者:[Martino Jones][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -4,13 +4,14 @@
|
||||
> 如果你已经厌倦了每次重启 Linux 就得重新挂载 Windows 共享,读读这个让共享永久挂载的简单方法。
|
||||
|
||||

|
||||
>图片: Jack Wallen
|
||||
|
||||
在 Linux 上和一个 Windows 网络进行交互从来就不是件轻松的事情。想想多少企业正在采用 Linux,这两个平台不得不一起好好协作。幸运的是,有了一些工具的帮助,你可以轻松地将 Windows 网络驱动器映射到一台 Linux 机器上,甚至可以确保在重启 Linux 机器之后共享还在。
|
||||
*图片: Jack Wallen*
|
||||
|
||||
在 Linux 上和一个 Windows 网络进行交互从来就不是件轻松的事情。想想多少企业正在采用 Linux,需要在这两个平台上彼此协作。幸运的是,有了一些工具的帮助,你可以轻松地将 Windows 网络驱动器映射到一台 Linux 机器上,甚至可以确保在重启 Linux 机器之后共享还在。
|
||||
|
||||
### 在我们开始之前
|
||||
|
||||
要实现这个,你需要用到命令行。过程十分简单,但你需要编辑 /etc/fstab 文件,所以小心操作。还有,我假设你已经有正常工作的 Samba 了,可以手动从 Windows 网络挂载共享到你的 Linux 机器,还知道这个共享的主机 IP 地址。
|
||||
要实现这个,你需要用到命令行。过程十分简单,但你需要编辑 /etc/fstab 文件,所以小心操作。还有,我假设你已经让 Samba 正常工作了,可以手动从 Windows 网络挂载共享到你的 Linux 机器,还知道这个共享的主机 IP 地址。
|
||||
|
||||
准备好了吗?那就开始吧。
|
||||
|
||||
@ -22,7 +23,7 @@
|
||||
sudo mkdir /media/share
|
||||
```
|
||||
|
||||
### 一些安装
|
||||
### 安装一些软件
|
||||
|
||||
现在我们得安装允许跨平台文件共享的系统;这个系统是 cifs-utils。在终端窗口输入:
|
||||
|
||||
@ -44,7 +45,7 @@ hosts: files mdns4_minimal [NOTFOUND=return] dns
|
||||
hosts: files mdns4_minimal [NOTFOUND=return] wins dns
|
||||
```
|
||||
|
||||
现在你必须安装 windbind 让你的 Linux 机器可以在 DHCP 网络中解析 Windows 机器名。在终端里执行:
|
||||
现在你需要安装 windbind 让你的 Linux 机器可以在 DHCP 网络中解析 Windows 机器名。在终端里执行:
|
||||
|
||||
```
|
||||
sudo apt-get install libnss-windbind windbind
|
||||
@ -70,7 +71,7 @@ sudo cp /etc/fstab /etc/fstab.old
|
||||
sudo mv /etc/fstab.old /etc/fstab
|
||||
```
|
||||
|
||||
在你的主目录创建一个认证信息文件 .smbcredentials。在这个文件里添加你的用户名和密码,就像这样(USER 和 PASSWORD 是实际的用户名和密码):
|
||||
在你的主目录创建一个认证信息文件 .smbcredentials。在这个文件里添加你的用户名和密码,就像这样(USER 和 PASSWORD 替换为实际的用户名和密码):
|
||||
|
||||
```
|
||||
username=USER
|
||||
@ -84,7 +85,7 @@ password=PASSWORD
|
||||
id USER
|
||||
```
|
||||
|
||||
USER 是实际的用户名,你应该会看到类似这样的信息:
|
||||
USER 是你的实际用户名,你应该会看到类似这样的信息:
|
||||
|
||||
```
|
||||
uid=1000(USER) gid=1000(GROUP)
|
||||
@ -115,7 +116,7 @@ via: http://www.techrepublic.com/article/how-to-permanently-mount-a-windows-shar
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,63 @@
|
||||
IT 运行在云端,而云运行在 Linux 上。你怎么看?
|
||||
===================================================================
|
||||
|
||||
> IT 正在逐渐迁移到云端。那又是什么驱动了云呢?答案是 Linux。 当连微软的 Azure 都开始拥抱 Linux 时,你就应该知道这一切都已经改变了。
|
||||
|
||||

|
||||
|
||||
*图片: ZDNet*
|
||||
|
||||
不管你接不接受, 云正在接管 IT 已经成为现实。 我们这几年见证了 [ 云在内部 IT 的崛起 ][1] 。 那又是什么驱动了云呢? 答案是 Linux 。
|
||||
|
||||
[Uptime Institute][2] 最近对 1000 个 IT 决策者进行了调查,发现约 50% 左右的资深企业 IT 决策者认为在将来[大部分的 IT 工作应该放在云上 ][3] 或托管网站上。在这个调查中,23% 的人认为这种改变即将发生在明年,有 70% 的人则认为这种情况会在四年内出现。
|
||||
|
||||
这一点都不奇怪。 我们中的许多人仍热衷于我们的物理服务器和机架, 但一般运营一个自己的数据中心并不会产生任何的经济效益。
|
||||
|
||||
很简单, 只需要对比你[运行在你自己的硬件上的资本费用(CAPEX)和使用云的业务费用(OPEX)][4]即可。 但这并不是说你应该把所有的东西都一股脑外包出去,而是说在大多数情况下你应该把许多工作都迁移到云端。
|
||||
|
||||
相应地,如果你想充分地利用云,你就得了解 Linux 。
|
||||
|
||||
[亚马逊的 AWS][5]、 [Apache CloudStack][6]、 [Rackspace][7]、[谷歌的 GCP][8] 以及 [ OpenStack ][9] 的核心都是运行在 Linux 上的。那么结果如何?截至到 2014 年, [在 Linux 服务器上部署的应用达到所有企业的 79% ][10],而 在 Windows 服务器上部署的则跌到 36%。从那时起, Linux 就获得了更多的发展动力。
|
||||
|
||||
即便是微软自身也明白这一点。
|
||||
|
||||
Azure 的技术主管 Mark Russinovich 曾说,仅仅在过去的几年内微软就从[四分之一的 Azure 虚拟机运行在 Linux 上][11] 变为[将近三分之一的 Azure 虚拟机运行在 Linux 上][12]。
|
||||
|
||||
试想一下。微软,一家正逐渐将[云变为自身财政收入的主要来源][13] 的公司,其三分之一的云产业依靠于 Linux 。
|
||||
|
||||
即使是到目前为止, 这些不论喜欢或者不喜欢微软的人都很难想象得到[微软会从一家以商业软件为基础的软件公司转变为一家开源的、基于云服务的企业][14] 。
|
||||
|
||||
Linux 对于这些专用服务器机房的渗透甚至比它刚开始的时候更深了。 举个例子, [Docker 最近发行了其在 Windows 10 和 Mac OS X 上的公测版本 ][15] 。 这难道是意味着 [Docker][16] 将会把其同名的容器服务移植到 Windows 10 和 Mac 上吗? 并不是的。
|
||||
|
||||
在这两个平台上, Docker 只是运行在一个 Linux 虚拟机内部。 在 Mac OS 上是 HyperKit ,在 Windows 上则是 Hyper-V 。 在图形界面上可能看起来就像另一个 Mac 或 Windows 上的应用, 但在其内部的容器仍然是运行在 Linux 上的。
|
||||
|
||||
所以,就像大量的安卓手机和 Chromebook 的用户压根就不知道他们所运行的是 Linux 系统一样。这些 IT 用户也会随之悄然地迁移到 Linux 和云上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/it-runs-on-the-cloud-and-the-cloud-runs-on-linux-any-questions/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[chenxinlong](https://github.com/chenxinlong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]: http://www.zdnet.com/article/2014-the-year-the-cloud-killed-the-datacenter/
|
||||
[2]: https://uptimeinstitute.com/
|
||||
[3]: http://www.zdnet.com/article/move-to-cloud-accelerating-faster-than-thought-survey-finds/
|
||||
[4]: http://www.zdnet.com/article/rethinking-capex-and-opex-in-a-cloud-centric-world/
|
||||
[5]: https://aws.amazon.com/
|
||||
[6]: https://cloudstack.apache.org/
|
||||
[7]: https://www.rackspace.com/en-us
|
||||
[8]: https://cloud.google.com/
|
||||
[9]: http://www.openstack.org/
|
||||
[10]: http://www.zdnet.com/article/linux-foundation-finds-enterprise-linux-growing-at-windows-expense/
|
||||
[11]: http://news.microsoft.com/bythenumbers/azure-virtual
|
||||
[12]: http://www.zdnet.com/article/microsoft-nearly-one-in-three-azure-virtual-machines-now-are-running-linux/
|
||||
[13]: http://www.zdnet.com/article/microsofts-q3-azure-commercial-cloud-strong-but-earnings-revenue-light/
|
||||
[14]: http://www.zdnet.com/article/why-microsoft-is-turning-into-an-open-source-company/
|
||||
[15]: http://www.zdnet.com/article/new-docker-betas-for-azure-windows-10-now-available/
|
||||
[16]: http://www.docker.com/
|
||||
|
||||
@ -3,17 +3,19 @@
|
||||
|
||||

|
||||
|
||||
在 Kickstarter 众筹网站上,一个叫“MyPi”的项目用 RPi 计算模块制作了一款 SBC(Single Board Computer 单板计算机),提供 mini-PCIe 插槽,串口,宽范围输入电源,以及模块扩展等功能。
|
||||
在 Kickstarter 众筹网站上,一个叫 “MyPi” 的项目用树莓派计算模块制作了一款 SBC(LCTT 译注: Single Board Computer 单板计算机),提供一个 mini-PCIe 插槽,串口,宽范围输入电源,以及模块扩展等功能。
|
||||
|
||||
你也许觉得奇怪,都 2016 年了,为什么还会有人发布这样一款长得有点像三明治,用过时的基于 ARM11 的原版树莓派 COM(Compuer on Module,模块化计算机)版本,[树莓派计算模块][1],构建的单板计算机。首先,目前仍然有大量工业应用不需要太多 CPU 处理能力,第二,树莓派计算模块仍是目前仅有的基于树莓派硬件的 COM,虽然更便宜,有点像 COM 并采用 700MHz 处理器的 [零号树莓派][2],快要发布了。
|
||||
你也许觉得奇怪,都 2016 年了,为什么还会有人发布这样一款长得有点像三明治,用过时的 ARM11 构建的 COM (LCTT 译注: Compuer on Module,模块化计算机)版本的树莓派单板计算机:[树莓派计算模块][1]。原因是这样的,首先,目前仍然有大量工业应用不需要太多 CPU 处理能力,第二,树莓派计算模块仍是目前仅有的基于树莓派硬件的 COM,虽然更便宜、有点像 COM 并采用同样的 700MHz 处理器的 [零号树莓派][2] 也很类似。
|
||||
|
||||

|
||||
|
||||
*安装了 COM 和 I/O 组件的 MyPi*
|
||||
|
||||

|
||||
|
||||
>安装了 COM 和 I/O 组件的 MyPi(左),装入了可选的工业外壳中
|
||||
*装入了可选的工业外壳中*
|
||||
|
||||
另外,Embedded Micro Technology 还表示它的 SBC 还设计成支持和承诺的树莓派计算模块升级版互换,采用树莓派 3 的四核,Cortex-A53 博通 BCM2837 SoC。因为这个产品最近很快就会到货,不确定他们怎么能及时为 Kickstarter 赞助者处理好这一切。不过,以后能支持也挺不错,就算要为这个升级付费也可以接受。
|
||||
另外,Embedded Micro Technology 还表示它的 SBC 还设计成可升级替换为支持的树莓派计算模块 —— 采用了树莓派 3 的四核、Cortex-A53 博通 BCM2837处理器的 SoC。因为这个产品最近很快就会到货,不确定他们怎么能及时为 Kickstarter 赞助者处理好这一切。不过,以后能支持也挺不错,就算要为这个升级付费也可以接受。
|
||||
|
||||
MyPi 并不是唯一一款新的基于树莓派计算模块的商业嵌入式设备。Pigeon Computers 在五月份启动了 [Pigeon RB100][3] 的项目,是一个基于 COM 的工业自动化控制器。不过,包括 [Techbase Modberry][4] 在内的这一类设备大都出现在 2014 年 COM 发布之后的一小段时间内。
|
||||
|
||||
@ -21,44 +23,49 @@ MyPi 的目标是 30 天内筹集 $21,696,目前已经实现了三分之一。
|
||||
|
||||

|
||||
|
||||
*不带 COM 和插件板的 MyPi 主板*
|
||||
|
||||

|
||||
|
||||
>不带 COM 和插件板的 MyPi 主板(左)以及它的接口定义
|
||||
*以及它的接口定义*
|
||||
|
||||
树莓派计算模块能给 MyPi 带来博通 BCM2835 Soc,512MB 内存,以及 4GB eMMC 存储空间。MyPi 主板扩展了一个 microSD 卡槽,一个 HDMI 接口,两个 USB 2.0 接口,一个 10/100 以太网口,还有一个类似网口的 RS232 端口(通过 USB)。
|
||||
树莓派计算模块能给 MyPi 带来博通 BCM2835 Soc,512MB 内存,以及 4GB eMMC 存储空间。MyPi 主板扩展了一个 microSD 卡槽,一个 HDMI 接口,两个 USB 2.0 接口,一个 10/100M 以太网口,还有一个像网口的 RS232 端口(通过 USB 连接)。
|
||||
|
||||

|
||||
|
||||
*插上树莓派计算模块和 mini-PCIe 模块的 MyPi 的两个视角*
|
||||
|
||||

|
||||
|
||||
>插上树莓派计算模块和 mini-PCIe 模块的 MyPi 的两个视角
|
||||
*插上树莓派计算模块和 mini-PCIe 模块的 MyPi 的两个视角*
|
||||
|
||||
MyPi 还将配备一个 mini-PCIe 插槽,据说“只支持 USB,以及只适用 mPCIe 形式的调制解调器”。还带有一个 SIM 卡插槽。板上还有双标准的树莓派摄像头接口,一个音频输出接口,自带备用电池的 RTC,LED 灯。还支持宽范围的 9-23V 直流输入。
|
||||
|
||||
Embedded Micro 表示,MyPi 是为那些树莓派爱好者们设计的,他们堆积了太多 HAT 外接板,已经不能有效地工作了,或者不能很好地装入工业外壳里。MyPi 支持 HAT,另外还提供了公司自己定义的“ASIO”(特定应用接口)插件模块,它会将自己的 I/O 扩展到主板上,主板再将它们连到主板边上的 8 脚,绿色,工业 I/O 连接器(标记了“ASIO Out”)上,在下面图片里有描述。
|
||||
Embedded Micro 表示,MyPi 是为那些树莓派爱好者们设计的,他们拼接了太多 HAT 外接板,已经不能有效地工作了,或者不能很好地装入工业外壳里。MyPi 支持 HAT,另外还提供了公司自己定义的 “ASIO” (特定应用接口)插件模块,它会将自己的 I/O 扩展到载板上,载板再将它们连到载板边上的 8针的绿色凤凰式工业 I/O 连接器(标记了“ASIO Out”)上,在下面图片里有描述。
|
||||
|
||||

|
||||
>MyPi 的模块扩展接口
|
||||
|
||||
就像 Kickstarter 页面里描述的:“比起在板边插满带 IO 信号接头的 HAT 板,我们有意将同样的 IO 信号接到另一个接头,它直接接到绿色的工业接头上。”另外,“通过简单地延长卡上的插脚长度(抬高),你将来可以直接扩展 IO 集 - 这些都不需要任何排线!”Embedded Micro 表示。
|
||||
*MyPi 的模块扩展接口*
|
||||
|
||||
就像 Kickstarter 页面里描述的:“比起在板边插满带 IO 信号接头的 HAT 板,我们更愿意把同样的 IO 信号接到另一个接头,它直接接到绿色的工业接头上。” 另外,“通过简单地延长卡上的插脚长度(抬高),你将来可以直接扩展 IO 集 - 这些都不需要任何排线!”Embedded Micro 表示。
|
||||
|
||||

|
||||
>MyPi 和它的可选 I/O 插件板卡
|
||||
|
||||
公司为 MyPi 提供了一系列可靠的 ASIO 插件板,像上面展示的。这些一开始会包括 CAN 总线,4-20mA 传感器信号,RS485,窄带 RF,等等。
|
||||
*MyPi 和它的可选 I/O 插件板卡*
|
||||
|
||||
像上面展示的,这家公司为 MyPi 提供了一系列可靠的 ASIO 插卡,。一开始这些会包括 CAN 总线,4-20mA 传感器信号,RS485,窄带 RF,等等。
|
||||
|
||||
### 更多信息
|
||||
|
||||
MyPi 在 Kickstarter 上提供了 7 月 23 日到期的 79 英镑($119)早期参与包(不包括树莓派计算模块),预计九月份发货。更多信息请查看 [Kickstarter 上 MyPi 的页面][5] 以及 [Embedded Micro Technology 官网][6]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/industrial-sbc-builds-on-rpi-compute-module/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
如何进入无痕模式进而隐藏 Linux 的命令行历史
|
||||
如何隐藏你的 Linux 的命令行历史
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
如果你是 Linux 命令行的用户,你会同意有的时候你不希望某些命令记录在你的命令行历史中。其中原因可能很多。例如,你在公司处于某个职位,你有一些不希望被其它人滥用的特权。亦或者有些特别重要的命令,你不希望在你浏览历史列表时误执行。
|
||||
如果你是 Linux 命令行的用户,有的时候你可能不希望某些命令记录在你的命令行历史中。原因可能很多,例如,你在公司担任某个职位,你有一些不希望被其它人滥用的特权。亦或者有些特别重要的命令,你不希望在你浏览历史列表时误执行。
|
||||
|
||||
然而,有方法可以控制哪些命令进入历史列表,哪些不进入吗?或者换句话说,我们在 Linux 终端中可以开启像浏览器一样的无痕模式吗?答案是肯定的,而且根据你想要的具体目标,有很多实现方法。在这篇文章中,我们将讨论一些行之有效的方法。
|
||||
|
||||
@ -15,15 +15,15 @@
|
||||
|
||||
#### 1. 在命令前插入空格
|
||||
|
||||
是的,没看错。在命令前面插入空格,这条命令会被终端忽略,也就意味着它不会出现在历史记录中。但是这种方法有个前提,只有在你的环境变量 HISTCONTROL 设置为 "ignorespace" 或者 "ignoreboth" 才会起作用。在大多数情况下,这个是默认值。
|
||||
是的,没看错。在命令前面插入空格,这条命令会被 shell 忽略,也就意味着它不会出现在历史记录中。但是这种方法有个前提,只有在你的环境变量 `HISTCONTROL` 设置为 "ignorespace" 或者 "ignoreboth" 才会起作用。在大多数情况下,这个是默认值。
|
||||
|
||||
所以,像下面的命令:
|
||||
所以,像下面的命令(LCTT 译注:这里`[space]`表示输入一个空格):
|
||||
|
||||
```
|
||||
[space]echo "this is a top secret"
|
||||
```
|
||||
|
||||
你执行后,它不会出现在历史记录中。
|
||||
如果你之前执行过如下设置环境变量的命令,那么上述命令不会出现在历史记录中。
|
||||
|
||||
```
|
||||
export HISTCONTROL = ignorespace
|
||||
@ -37,35 +37,35 @@ export HISTCONTROL = ignorespace
|
||||
|
||||
#### 2. 禁用当前会话的所有历史记录
|
||||
|
||||
如果你想禁用某个会话所有历史,你可以简单地在开始命令行工作前清除环境变量 HISTSIZE 的值。执行下面的命令来清除其值:
|
||||
如果你想禁用某个会话所有历史,你可以在开始命令行工作前简单地清除环境变量 HISTFILESIZE 的值即可。执行下面的命令来清除其值:
|
||||
|
||||
```
|
||||
export HISTFILE=0
|
||||
export HISTFILESIZE=0
|
||||
```
|
||||
|
||||
HISTFILE 表示对于 bash 会话其历史中可以保存命令的个数。默认情况,它设置了一个非零值,例如 在我的电脑上,它的值为 1000。
|
||||
HISTFILESIZE 表示对于 bash 会话其历史文件中可以保存命令的个数(行数)。默认情况,它设置了一个非零值,例如在我的电脑上,它的值为 1000。
|
||||
|
||||
所以上面所提到的命令将其值设置为 0,结果就是直到你关闭终端,没有东西会存储在历史记录中。记住同样你也不能通过按向上的箭头按键来执行之前的命令,也不能运行 history 命令。
|
||||
所以上面所提到的命令将其值设置为 0,结果就是直到你关闭终端,没有东西会存储在历史记录中。记住同样你也不能通过按向上的箭头按键或运行 history 命令来看到之前执行的命令。
|
||||
|
||||
#### 3. 工作结束后清除整个历史
|
||||
|
||||
这可以看作是前一部分所提方案的另外一种实现。唯一的区别是在你完成所有工作之后执行这个命令。下面是刚讨论的命令:
|
||||
这可以看作是前一部分所提方案的另外一种实现。唯一的区别是在你完成所有工作之后执行这个命令。下面是刚说到的命令:
|
||||
|
||||
```
|
||||
history -cw
|
||||
```
|
||||
|
||||
刚才已经提到,这个和 HISTFILE 方法有相同效果。
|
||||
刚才已经提到,这个和 HISTFILESIZE 方法有相同效果。
|
||||
|
||||
#### 4. 只针对你的工作关闭历史记录
|
||||
|
||||
虽然前面描述的方法(2 和 3)可以实现目的,它们清除整个历史,在很多情况下,有些可能不是我们所期望的。有时候你可能想保存直到你开始命令行工作之间的历史记录。类似的需求需要在你开始工作前执行下述命令:
|
||||
虽然前面描述的方法(2 和 3)可以实现目的,它们可以清除整个历史,在很多情况下,有些可能不是我们所期望的。有时候你可能想保存直到你开始命令行工作之间的历史记录。对于这样的需求,你开始在工作前执行下述命令:
|
||||
|
||||
```
|
||||
[space]set +o history
|
||||
```
|
||||
|
||||
备注:[space] 表示空格。
|
||||
备注:[space] 表示空格。并且由于空格的缘故,该命令本身也不会被记录。
|
||||
|
||||
上面的命令会临时禁用历史功能,这意味着在这命令之后你执行的所有操作都不会记录到历史中,然而这个命令之前的所有东西都会原样记录在历史列表中。
|
||||
|
||||
@ -75,14 +75,14 @@ history -cw
|
||||
[Space]set -o history
|
||||
```
|
||||
|
||||
它将环境恢复原状,也就是你完成你的工作,执行上述命令之后的命令都会出现在历史中。
|
||||
它将环境恢复原状,也就是你完成了你的工作,执行上述命令之后的命令都会出现在历史中。
|
||||
|
||||
#### 5. 从历史记录中删除指定的命令
|
||||
|
||||
现在假设历史记录中有一些命令你不希望被记录。这种情况下我们怎么办?很简单。直接动手删除它们。通过下面的命令来删除:
|
||||
现在假设历史记录中已经包含了一些你不希望记录的命令。这种情况下我们怎么办?很简单。直接动手删除它们。通过下面的命令来删除:
|
||||
|
||||
```
|
||||
[space]history | grep "part of command you want to remove"
|
||||
history | grep "part of command you want to remove"
|
||||
```
|
||||
|
||||
上面的命令会输出历史记录中匹配的命令,每一条前面会有个数字。
|
||||
@ -99,6 +99,8 @@ history -d [num]
|
||||
|
||||
第二个 ‘echo’命令被成功的删除了。
|
||||
|
||||
(LCTT 译注:如果你不希望上述命令本身也被记录进历史中,你可以在上述命令前加个空格)
|
||||
|
||||
同样的,你可以使用向上的箭头一直往回翻看历史记录。当你发现你感兴趣的命令出现在终端上时,按下 “Ctrl + U”清除整行,也会从历史记录中删除它。
|
||||
|
||||
### 总结
|
||||
@ -107,11 +109,11 @@ history -d [num]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-command-line-history-incognito/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
via: https://www.maketecheasier.com/linux-command-line-history-incognito/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
Using Vagrant to control your DigitalOcean cloud instances
|
||||
使用 Vagrant 控制你的 DigitalOcean 云主机
|
||||
=========================================================
|
||||
|
||||

|
||||
|
||||
[Vagrant][1] is an application to create and support virtual development environments using virtual machines. Fedora has [official support for Vagrant][2] with libvirt on your local system. [DigitalOcean][3] is a cloud provider that provides a one-click deployment of a Fedora Cloud instance to an all-SSD server in under a minute. During the [recent Cloud FAD][4] in Raleigh, the Fedora Cloud team packaged a new plugin for Vagrant which enables Fedora users to keep up cloud instances in DigitalOcean using local Vagrantfiles.
|
||||
[Vagrant][1] 是一个使用虚拟机创建和支持虚拟开发环境的应用。Fedora 官方已经在本地系统上通过库 `libvirt` [支持 Vagrant][2]。[DigitalOcean][3] 是一个提供一键部署 Fedora 云服务实例到全 SSD 服务器的云计算服务提供商。在[最近的 Raleigh 举办的 FAD 大会][4]中,Fedora 云计算队伍为 Vagrant 打包了一个新的插件,它能够帮助 Fedora 用户通过使用本地的 Vagrantfile 文件来管理 DigitalOcean 上的云服务实例。
|
||||
|
||||
### How to use this plugin
|
||||
### 如何使用这个插件
|
||||
|
||||
First step is to install the package in the command line.
|
||||
第一步在命令行下是安装软件。
|
||||
|
||||
```
|
||||
$ sudo dnf install -y vagrant-digitalocean
|
||||
```
|
||||
|
||||
After installing the plugin, the next task is to create the local Vagrantfile. An example is provided below.
|
||||
安装 结束之后,下一步是创建本地的 Vagrantfile 文件。下面是一个例子。
|
||||
|
||||
```
|
||||
$ mkdir digitalocean
|
||||
@ -37,28 +37,25 @@ Vagrant.configure('2') do |config|
|
||||
end
|
||||
```
|
||||
|
||||
### Notes about Vagrant DigitalOcean plugin
|
||||
### Vagrant DigitalOcean 插件的注意事项
|
||||
|
||||
A few points to remember about the SSH key naming scheme: if you already have the key uploaded to DigitalOcean, make sure that the provider.ssh_key_name matches the name of the existing key in their server. The provider.image details are found at the [DigitalOcean documentation][5]. The AUTH token is created on the control panel within the Apps & API section.
|
||||
一定要记住的几个关于 SSH 的关键命名规范 : 如果你已经在 DigitalOcean 上传了秘钥,请确保 `provider.ssh_key_name` 和已经在服务器中的名字吻合。 `provider.image` 具体的文档可以在[DigitalOcean documentation][5]找到。在控制面板上的 `App & API` 部分可以创建 AUTH 令牌。
|
||||
|
||||
You can then get the instance up with the following command.
|
||||
你可以使用下面的命令启动一个实例。
|
||||
|
||||
```
|
||||
$ vagrant up --provider=digital_ocean
|
||||
```
|
||||
|
||||
This command will fire up the instance in the DigitalOcean server. You can then SSH into the box by using vagrant ssh command. Run vagrant destroy to destroy the instance.
|
||||
|
||||
|
||||
|
||||
这个命令会在 DigitalOcean 的启动一个服务器实例。然后你就可以使用 `vagrant ssh` 命令来 `ssh` 登录进入这个实例。可以执行 `vagrant destroy` 来删除这个实例。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-vagrant-digitalocean-cloud/
|
||||
|
||||
作者:[Kushal Das][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,28 +1,28 @@
|
||||
如何使用Awk和正则表达式过滤文本或文件中的字符串
|
||||
awk 系列:如何使用 awk 和正则表达式过滤文本或文件中的字符串
|
||||
=============================================================================
|
||||
|
||||

|
||||
|
||||
当我们在 Unix/Linux 下使用特定的命令从字符串或文件中读取或编辑文本时,我们经常会尝试过滤输出以得到感兴趣的部分。这时正则表达式就派上用场了。
|
||||
当我们在 Unix/Linux 下使用特定的命令从字符串或文件中读取或编辑文本时,我们经常需要过滤输出以得到感兴趣的部分。这时正则表达式就派上用场了。
|
||||
|
||||
### 什么是正则表达式?
|
||||
|
||||
正则表达式可以定义为代表若干个字符序列的字符串。它最重要的功能就是它允许你过滤一条命令或一个文件的输出,编辑文本或配置等文件的一部分。
|
||||
正则表达式可以定义为代表若干个字符序列的字符串。它最重要的功能之一就是它允许你过滤一条命令或一个文件的输出、编辑文本或配置文件的一部分等等。
|
||||
|
||||
### 正则表达式的特点
|
||||
|
||||
正则表达式由以下内容组合而成:
|
||||
|
||||
- 普通的字符,例如空格、下划线、A-Z、a-z、0-9。
|
||||
- 可以扩展为普通字符的元字符,它们包括:
|
||||
- **普通字符**,例如空格、下划线、A-Z、a-z、0-9。
|
||||
- 可以扩展为普通字符的**元字符**,它们包括:
|
||||
- `(.)` 它匹配除了换行符外的任何单个字符。
|
||||
- `(*)` 它匹配零个或多个在其之前的立即字符。
|
||||
- `[ character(s) ]` 它匹配任何由 character(s) 指定的一个字符,你可以使用连字符(-)代表字符区间,例如 [a-f]、[1-5]等。
|
||||
- `(*)` 它匹配零个或多个在其之前紧挨着的字符。
|
||||
- `[ character(s) ]` 它匹配任何由其中的字符/字符集指定的字符,你可以使用连字符(-)代表字符区间,例如 [a-f]、[1-5]等。
|
||||
- `^` 它匹配文件中一行的开头。
|
||||
- `$` 它匹配文件中一行的结尾。
|
||||
- `\` 这是一个转义字符。
|
||||
|
||||
你必须使用类似 awk 这样的文本过滤工具来过滤文本。你还可以把 awk 当作一个用于自身的编程语言。但由于这个指南的适用范围是关于使用 awk 的,我会按照一个简单的命令行过滤工具来介绍它。
|
||||
你必须使用类似 awk 这样的文本过滤工具来过滤文本。你还可以把 awk 自身当作一个编程语言。但由于这个指南的适用范围是关于使用 awk 的,我会按照一个简单的命令行过滤工具来介绍它。
|
||||
|
||||
awk 的一般语法如下:
|
||||
|
||||
@ -30,13 +30,13 @@ awk 的一般语法如下:
|
||||
# awk 'script' filename
|
||||
```
|
||||
|
||||
此处 `'script'` 是一个由 awk 使用并应用于 filename 的命令集合。
|
||||
此处 `'script'` 是一个由 awk 可以理解并应用于 filename 的命令集合。
|
||||
|
||||
它通过读取文件中的给定的一行,复制该行的内容并在该行上执行脚本的方式工作。这个过程会在该文件中的所有行上重复。
|
||||
它通过读取文件中的给定行,复制该行的内容并在该行上执行脚本的方式工作。这个过程会在该文件中的所有行上重复。
|
||||
|
||||
该脚本 `'script'` 中内容的格式是 `'/pattern/ action'`,其中 `pattern` 是一个正则表达式,而 `action` 是当 awk 在该行中找到此模式时应当执行的动作。
|
||||
|
||||
### 如何在 Linux 中使用 Awk 过滤工具
|
||||
### 如何在 Linux 中使用 awk 过滤工具
|
||||
|
||||
在下面的例子中,我们将聚焦于之前讨论过的元字符。
|
||||
|
||||
@ -45,13 +45,14 @@ awk 的一般语法如下:
|
||||
下面的例子打印文件 /etc/hosts 中的所有行,因为没有指定任何的模式。
|
||||
|
||||
```
|
||||
# awk '//{print}'/etc/hosts
|
||||
# awk '//{print}' /etc/hosts
|
||||
```
|
||||
|
||||
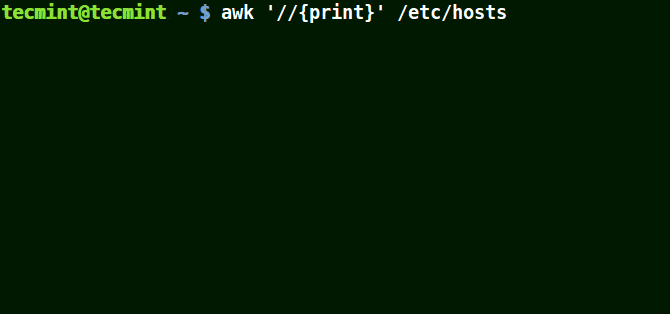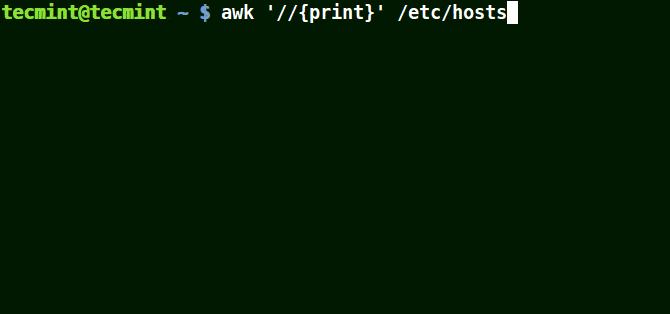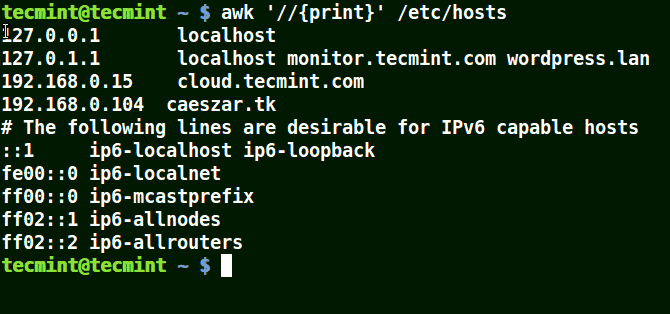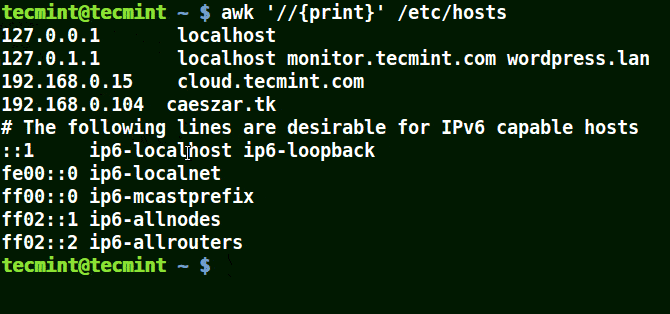
|
||||
>Awk 打印文件中的所有行
|
||||
|
||||
#### 结合模式使用 Awk
|
||||
*awk 打印文件中的所有行*
|
||||
|
||||
#### 结合模式使用 awk
|
||||
|
||||
在下面的示例中,指定了模式 `localhost`,因此 awk 将匹配文件 `/etc/hosts` 中有 `localhost` 的那些行。
|
||||
|
||||
@ -60,22 +61,24 @@ awk 的一般语法如下:
|
||||
```
|
||||
|
||||

|
||||
>Awk 打印文件中匹配模式的行
|
||||
|
||||
#### 在 Awk 模式中使用通配符 (.)
|
||||
*awk 打印文件中匹配模式的行*
|
||||
|
||||
#### 在 awk 模式中使用通配符 (.)
|
||||
|
||||
在下面的例子中,符号 `(.)` 将匹配包含 loc、localhost、localnet 的字符串。
|
||||
|
||||
这里的意思是匹配 *** l 一些单个字符 c ***。
|
||||
这里的正则表达式的意思是匹配 **l一个字符c**。
|
||||
|
||||
```
|
||||
# awk '/l.c/{print}' /etc/hosts
|
||||
```
|
||||
|
||||
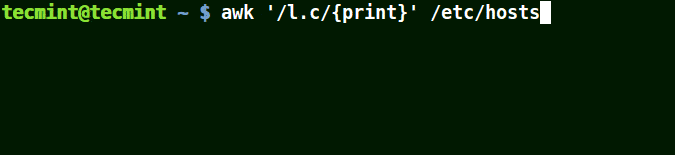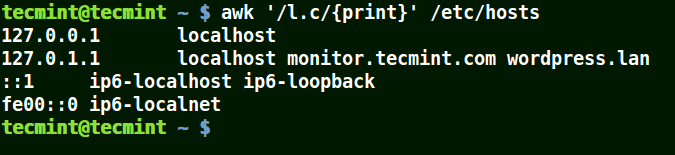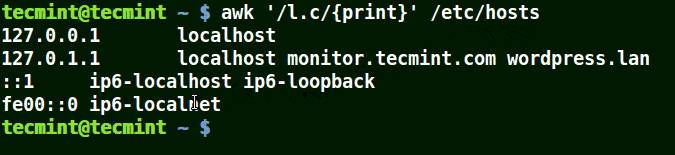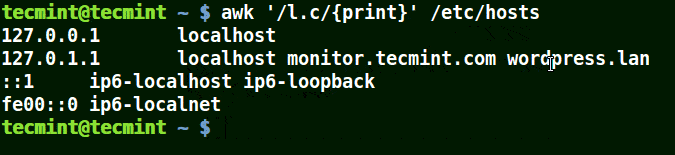
|
||||
>使用 Awk 打印文件中匹配模式的字符串
|
||||
|
||||
#### 在 Awk 模式中使用字符 (*)
|
||||
*使用 awk 打印文件中匹配模式的字符串*
|
||||
|
||||
#### 在 awk 模式中使用字符 (*)
|
||||
|
||||
在下面的例子中,将匹配包含 localhost、localnet、lines, capable 的字符串。
|
||||
|
||||
@ -84,7 +87,8 @@ awk 的一般语法如下:
|
||||
```
|
||||
|
||||
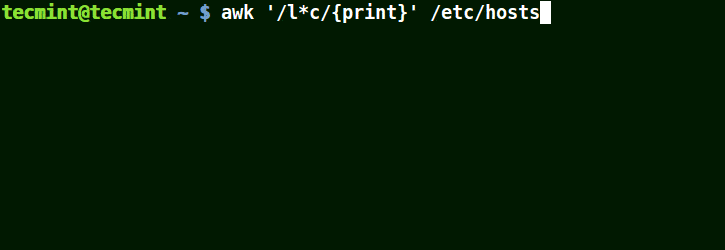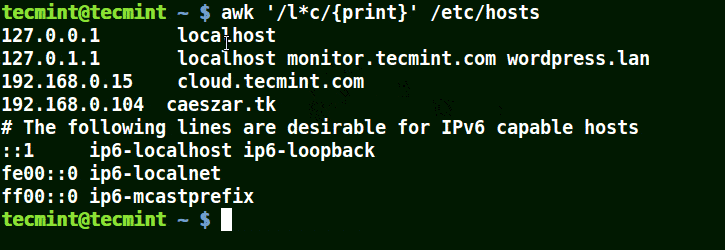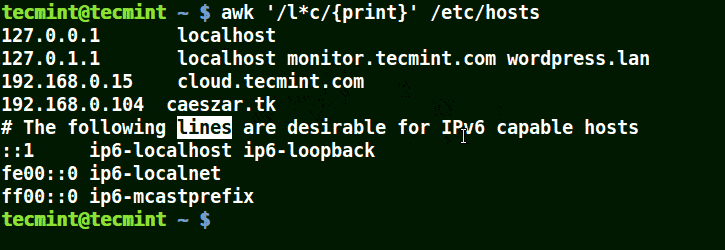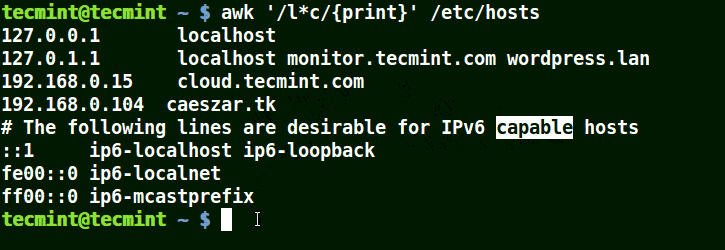
|
||||
>使用 Awk 匹配文件中的字符串
|
||||
|
||||
*使用 awk 匹配文件中的字符串*
|
||||
|
||||
你可能也意识到 `(*)` 将会尝试匹配它可能检测到的最长的匹配。
|
||||
|
||||
@ -112,7 +116,7 @@ this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
|
||||
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
|
||||
```
|
||||
|
||||
#### 结合集合 [ character(s) ] 使用 Awk
|
||||
#### 结合集合 [ character(s) ] 使用 awk
|
||||
|
||||
以集合 [al1] 为例,awk 将匹配文件 /etc/hosts 中所有包含字符 a 或 l 或 1 的字符串。
|
||||
|
||||
@ -121,7 +125,8 @@ this is tecmint, where you get the best good tutorials, how to's, guides, tecmin
|
||||
```
|
||||
|
||||
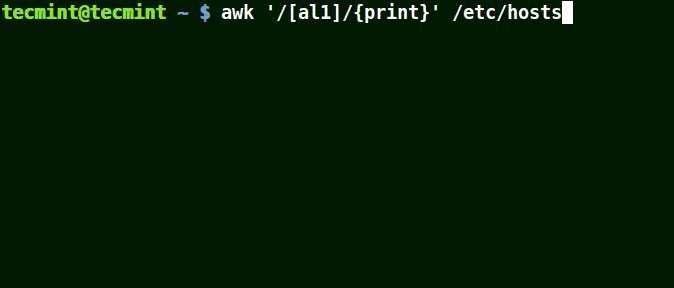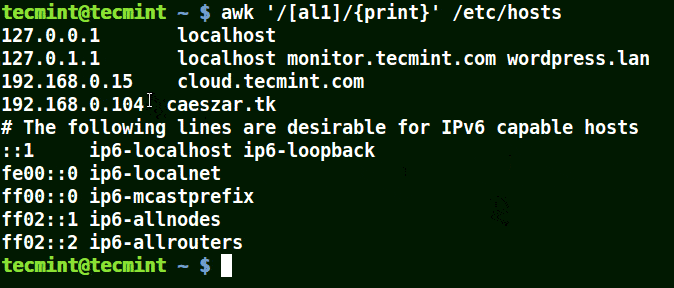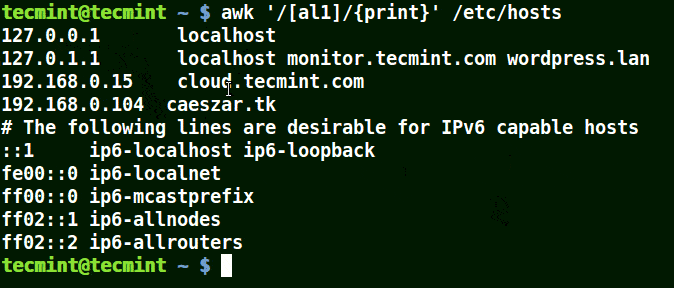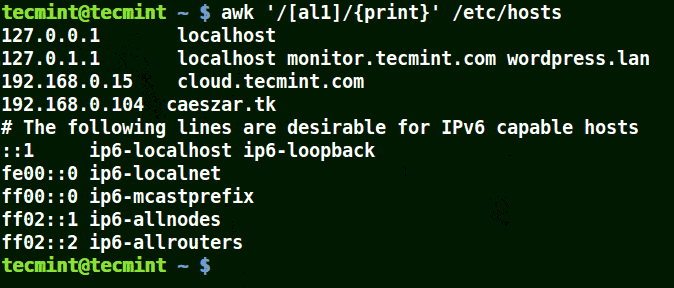
|
||||
>使用 Awk 打印文件中匹配的字符
|
||||
|
||||
*使用 awk 打印文件中匹配的字符*
|
||||
|
||||
下一个例子匹配以 `K` 或 `k` 开始头,后面跟着一个 `T` 的字符串:
|
||||
|
||||
@ -130,7 +135,8 @@ this is tecmint, where you get the best good tutorials, how to's, guides, tecmin
|
||||
```
|
||||
|
||||

|
||||
>使用 Awk 打印文件中匹配的字符
|
||||
|
||||
*使用 awk 打印文件中匹配的字符*
|
||||
|
||||
#### 以范围的方式指定字符
|
||||
|
||||
@ -149,11 +155,12 @@ awk 所能理解的字符:
|
||||
```
|
||||
|
||||
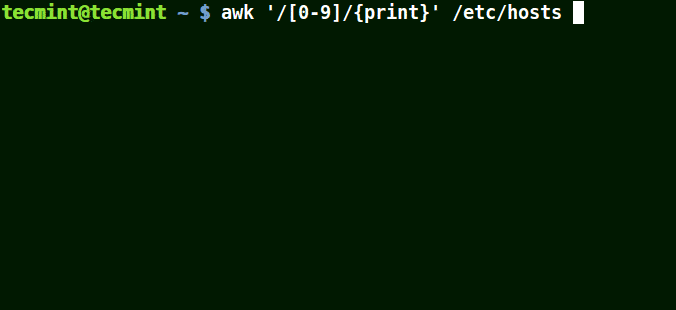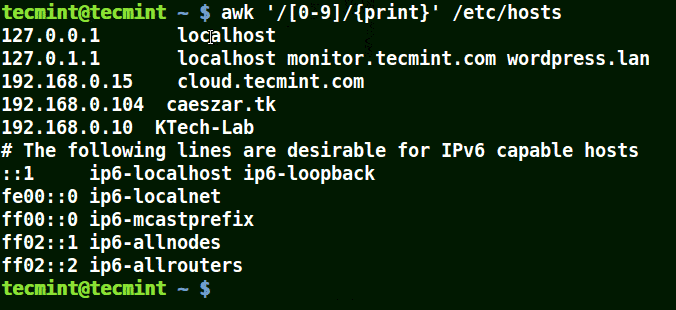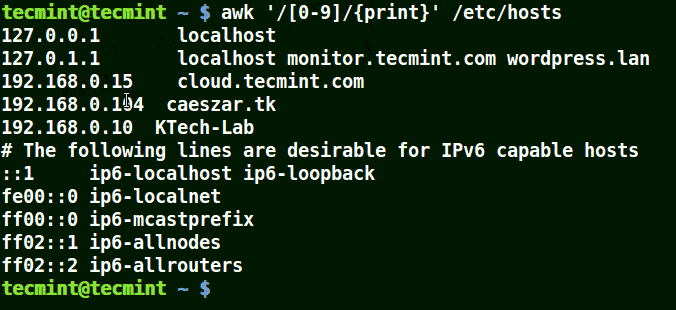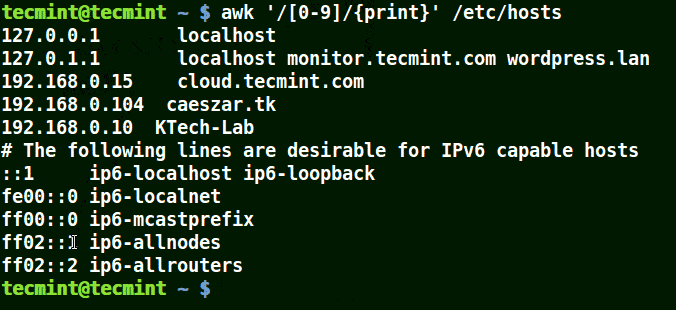
|
||||
>使用 Awk 打印文件中匹配的数字
|
||||
|
||||
*使用 awk 打印文件中匹配的数字*
|
||||
|
||||
在上面的例子中,文件 /etc/hosts 中的所有行都至少包含一个单独的数字 [0-9]。
|
||||
|
||||
#### 结合元字符 (\^) 使用 Awk
|
||||
#### 结合元字符 (\^) 使用 awk
|
||||
|
||||
在下面的例子中,它匹配所有以给定模式开头的行:
|
||||
|
||||
@ -163,9 +170,10 @@ awk 所能理解的字符:
|
||||
```
|
||||
|
||||
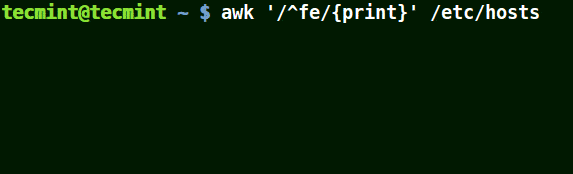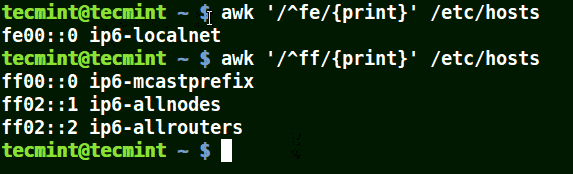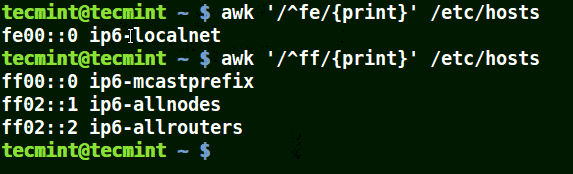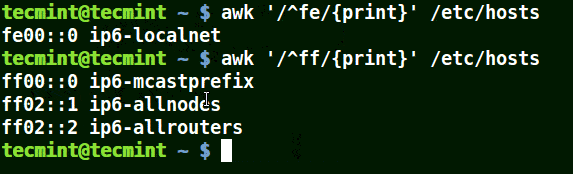
|
||||
>使用 Awk 打印与模式匹配的行
|
||||
|
||||
#### 结合元字符 ($) 使用 Awk
|
||||
*使用 awk 打印与模式匹配的行*
|
||||
|
||||
#### 结合元字符 ($) 使用 awk
|
||||
|
||||
它将匹配所有以给定模式结尾的行:
|
||||
|
||||
@ -176,9 +184,10 @@ awk 所能理解的字符:
|
||||
```
|
||||
|
||||
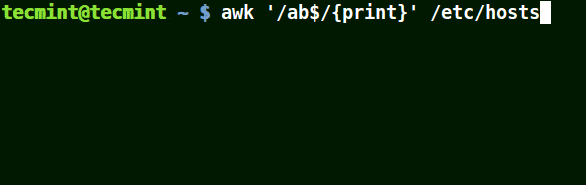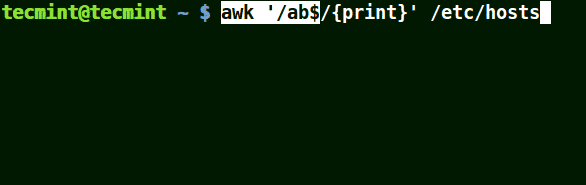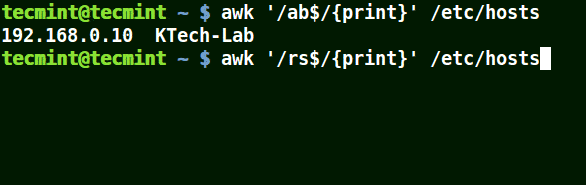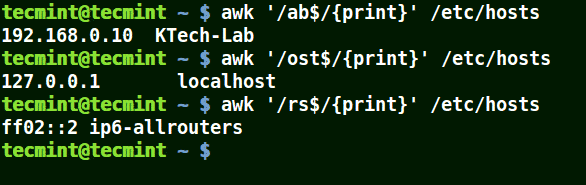
|
||||
>使用 Awk 打印与模式匹配的字符串
|
||||
|
||||
#### 结合转义字符 (\\) 使用 Awk
|
||||
*使用 awk 打印与模式匹配的字符串*
|
||||
|
||||
#### 结合转义字符 (\\) 使用 awk
|
||||
|
||||
它允许你将该转义字符后面的字符作为文字,即理解为其字面的意思。
|
||||
|
||||
@ -193,11 +202,12 @@ awk 所能理解的字符:
|
||||
```
|
||||
|
||||
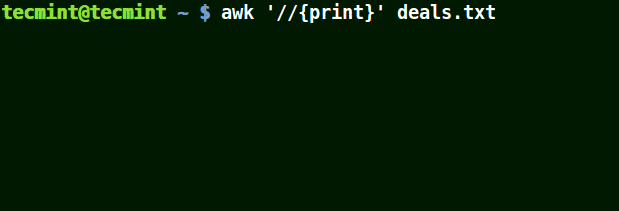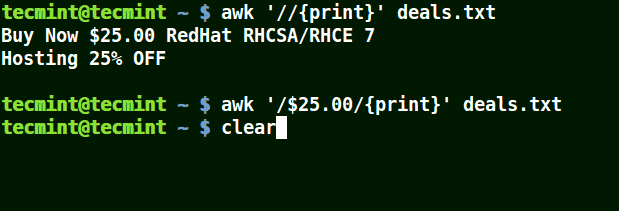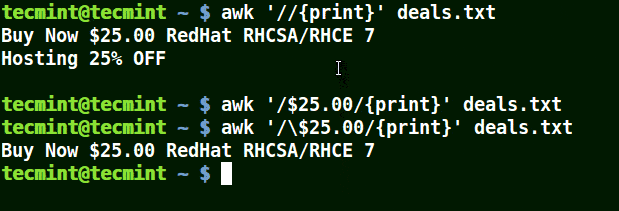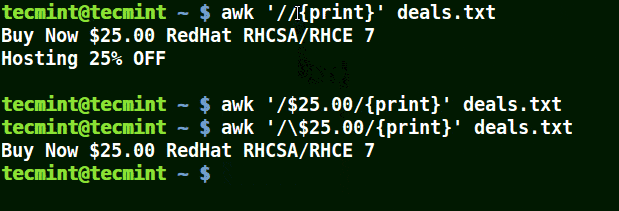
|
||||
>结合转义字符使用 Awk
|
||||
|
||||
*结合转义字符使用 awk*
|
||||
|
||||
### 总结
|
||||
|
||||
以上内容并不是 Awk 命令用做过滤工具的全部,上述的示例均是 awk 的基础操作。在下面的章节中,我将进一步介绍如何使用 awk 的高级功能。感谢您的阅读,请在评论区贴出您的评论。
|
||||
以上内容并不是 awk 命令用做过滤工具的全部,上述的示例均是 awk 的基础操作。在下面的章节中,我将进一步介绍如何使用 awk 的高级功能。感谢您的阅读,请在评论区贴出您的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -205,7 +215,7 @@ via: http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,19 @@
|
||||
如何使用 Awk 输出文本中的字段和列
|
||||
awk 系列:如何使用 awk 输出文本中的字段和列
|
||||
======================================================
|
||||
|
||||
在 Awk 系列的这一节中,我们将看到 Awk 最重要的特性之一,字段编辑。
|
||||
在 Awk 系列的这一节中,我们将看到 awk 最重要的特性之一,字段编辑。
|
||||
|
||||
需要知道的是,Awk 能够自动将输入的行,分隔为若干字段。每一个字段就是一组字符,它们和其他的字段由一个内部字段分隔符分隔开来。
|
||||
首先我们要知道,Awk 能够自动将输入的行,分隔为若干字段。每一个字段就是一组字符,它们和其他的字段由一个内部字段分隔符分隔开来。
|
||||
|
||||

|
||||
>Awk Print Fields and Columns
|
||||
|
||||
如果你熟悉 Unix/Linux 或者使用 [bash 脚本][1]编过程,那么你应该知道什么是内部字段分隔符(IFS)变量。Awk 中默认的 IFS 是制表符和空格。
|
||||
*Awk 输出字段和列*
|
||||
|
||||
Awk 中的字段分隔符的工作流程如下:当读到一行输入时,将它按照指定的 IFS 分割为不同字段,第一组字符就是字段一,可以通过 $1 来访问,第二组字符就是字段二,可以通过 $2 来访问,第三组字符就是字段三,可以通过 $3 来访问,以此类推,直到最后一组字符。
|
||||
如果你熟悉 Unix/Linux 或者懂得 [bash shell 编程][1],那么你应该知道什么是内部字段分隔符(IFS)变量。awk 中默认的 IFS 是制表符和空格。
|
||||
|
||||
为了更好地理解 Awk 的字段编辑,让我们看一个下面的例子:
|
||||
awk 中的字段分隔符的工作原理如下:当读到一行输入时,将它按照指定的 IFS 分割为不同字段,第一组字符就是字段一,可以通过 $1 来访问,第二组字符就是字段二,可以通过 $2 来访问,第三组字符就是字段三,可以通过 $3 来访问,以此类推,直到最后一组字符。
|
||||
|
||||
为了更好地理解 awk 的字段编辑,让我们看一个下面的例子:
|
||||
|
||||
**例 1**:我创建了一个名为 tecmintinfo.txt 的文本文件。
|
||||
|
||||
@ -22,7 +23,8 @@ Awk 中的字段分隔符的工作流程如下:当读到一行输入时,将
|
||||
```
|
||||
|
||||

|
||||
>在 Linux 上创建一个文件
|
||||
|
||||
*在 Linux 上创建一个文件*
|
||||
|
||||
然后在命令行中,我试着使用下面的命令从文本 tecmintinfo.txt 中输出第一个,第二个,以及第三个字段。
|
||||
|
||||
@ -47,15 +49,16 @@ $ awk '//{print $1, $2, $3; }' tecmintinfo.txt
|
||||
TecMint.com is the
|
||||
```
|
||||
|
||||
需要记住而且非常重要的是,`($)` 在 Awk 和在 shell 脚本中的使用是截然不同的!
|
||||
需要记住而且非常重要的是,`($)` 在 awk 和在 shell 脚本中的使用是截然不同的!
|
||||
|
||||
在 shell 脚本中,`($)` 被用来获取变量的值。而在 Awk 中,`($)` 只有在获取字段的值时才会用到,不能用于获取变量的值。
|
||||
在 shell 脚本中,`($)` 被用来获取变量的值。而在 awk 中,`($)` 只有在获取字段的值时才会用到,不能用于获取变量的值。
|
||||
|
||||
**例 2**:让我们再看一个例子,用到了一个名为 my_shoping.list 的包含多行的文件。
|
||||
|
||||
```
|
||||
No Item_Name Unit_Price Quantity Price
|
||||
1 Mouse #20,000 1 #20,000
|
||||
2 Monitor #500,000 1 #500,000
|
||||
2 Monitor #500,000 1 #500,000
|
||||
3 RAM_Chips #150,000 2 #300,000
|
||||
4 Ethernet_Cables #30,000 4 #120,000
|
||||
```
|
||||
@ -72,7 +75,7 @@ RAM_Chips #150,000
|
||||
Ethernet_Cables #30,000
|
||||
```
|
||||
|
||||
可以看到上面的输出不够清晰,Awk 还有一个 `printf` 的命令,可以帮助你将输出格式化。
|
||||
可以看到上面的输出不够清晰,awk 还有一个 `printf` 的命令,可以帮助你将输出格式化。
|
||||
|
||||
使用 `printf` 来格式化 Item_Name 和 Unit_Price 的输出:
|
||||
|
||||
@ -88,7 +91,7 @@ Ethernet_Cables #30,000
|
||||
|
||||
### 总结
|
||||
|
||||
使用 Awk 过滤文本或字符串时,字段编辑的功能是非常重要的。它能够帮助你从一个表的数据中得到特定的列。一定要记住的是,Awk 中 `($)` 操作符的用法与其在 shell 脚本中的用法是不同的!
|
||||
使用 awk 过滤文本或字符串时,字段编辑的功能是非常重要的。它能够帮助你从一个表的数据中得到特定的列。一定要记住的是,awk 中 `($)` 操作符的用法与其在 shell 脚本中的用法是不同的!
|
||||
|
||||
希望这篇文章对您有所帮助。如有任何疑问,可以在评论区域发表评论。
|
||||
|
||||
@ -97,8 +100,8 @@ Ethernet_Cables #30,000
|
||||
via: http://www.tecmint.com/awk-print-fields-columns-with-space-separator/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Cathon](https://github.com/Cathon),[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,47 +0,0 @@
|
||||
Linus Torvalds Talks IoT, Smart Devices, Security Concerns, and More[video]
|
||||
===========================================================================
|
||||
|
||||

|
||||
>Dirk Hohndel interviews Linus Torvalds at ELC.
|
||||
|
||||
For the first time in the 11-year history of the [Embedded Linux Conference (ELC)][0], held in San Diego, April 4-6, the keynotes included a discussion with Linus Torvalds. The creator and lead overseer of the Linux kernel, and “the reason we are all here,” in the words of his interviewer, Intel Chief Linux and Open Source Technologist Dirk Hohndel, seemed upbeat about the state of Linux in embedded and Internet of Things applications. Torvalds very presence signaled that embedded Linux, which has often been overshadowed by Linux desktop, server, and cloud technologies, had come of age.
|
||||
|
||||

|
||||
>Linus Torvalds speaking at Embedded Linux Conference.
|
||||
|
||||
IoT was the main topic at ELC, which included an OpenIoT Summit track, and the chief topic in the Torvalds interview.
|
||||
|
||||
“Maybe you won’t see Linux at the IoT leaf nodes, but anytime you have a hub, you will need it,” Torvalds told Hohndel. “You need smart devices especially if you have 23 [IoT standards]. If you have all these stupid devices that don’t necessarily run Linux, and they all talk with slightly different standards, you will need a lot of smart devices. We will never have one completely open standard, one ring to rule them all, but you will have three of four major protocols, and then all these smart hubs that translate.”
|
||||
|
||||
Torvalds remained customarily philosophical when Hohndel asked about the gaping security holes in IoT. “I don’t worry about security because there’s not a lot we can do,” he said. “IoT is unpatchable -- it’s a fact of life.”
|
||||
|
||||
The Linux creator seemed more concerned about the lack of timely upstream contributions from one-off embedded projects, although he noted there have been significant improvements in recent years, partially due to consolidation on hardware.
|
||||
|
||||
“The embedded world has traditionally been hard to interact with as an open source developer, but I think that’s improving,” Torvalds said. “The ARM community has become so much better. Kernel people can now actually keep up with some of the hardware improvements. It’s improving, but we’re not nearly there yet.”
|
||||
|
||||
Torvalds admitted to being more at home on the desktop than in embedded and to having “two left hands” when it comes to hardware.
|
||||
|
||||
“I’ve destroyed things with a soldering iron many times,” he said. “I’m not really set up to do hardware.” On the other hand, Torvalds guessed that if he were a teenager today, he would be fiddling around with a Raspberry Pi or BeagleBone. “The great part is if you’re not great at soldering, you can just buy a new one.”
|
||||
|
||||
Meanwhile, Torvalds vowed to continue fighting for desktop Linux for another 25 years. “I’ll wear them down,” he said with a smile.
|
||||
|
||||
Watch the full video, below.
|
||||
|
||||
Get the Latest on Embedded Linux and IoT. Access 150+ recorded sessions from Embedded Linux Conference 2016. [Watch Now][1].
|
||||
|
||||
[video](https://youtu.be/tQKUWkR-wtM)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[0]: http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[1]: http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom
|
||||
|
||||
@ -1,57 +0,0 @@
|
||||
vim-kakali translating
|
||||
|
||||
The Anatomy of a Linux User
|
||||
================================
|
||||
|
||||
|
||||
**Some new GNU/Linux users understand right away that Linux isn’t Windows. Others never quite get it. The best distro designers strive to keep both in mind.**
|
||||
|
||||
### The Heart of Linux
|
||||
|
||||
Nicky isn’t outwardly remarkable in any way. She’s a thirtysomething who decided to go back to school later in life than most. She spent six years in the Navy until she decided a job offer from an old friend would be a better bet than a career in the armed forces. That happens a lot in any of the post-war military service branches. It was at that job where I met her. She was the regional manager for an eight state trucking broker and I was driving for a meat packing outfit in Dallas.
|
||||
|
||||

|
||||
|
||||
We became good friends in 2006, Nicky and me. She’s an outgoing spirit, curious about almost anyone whose path she crosses. We had an ongoing Friday night date to go fight in an indoor laser combat arena. It wasn’t rare for us to burn through three 30 minute sessions in a row. Maybe it wasn’t as cheap as a paint ball arena, but it was climate controlled and had a horror game feel to it. It was during one of those outings that she asked me if I could fix her computer.
|
||||
|
||||
She knew about my efforts to get computers into the homes of disadvantaged kids and I kidded her about paying into Bill Gates’ 401K plan when she complained about her computer becoming too slow. Nicky figured this was as good a time as any to see what Linux was all about.
|
||||
|
||||
Her computer was a decent machine, a mid 2005 Asus desktop with a Dell 19″ monitor. Unfortunately, it had all the obligatory toolbars and popups that a Windows computer can collect when not properly tended. After getting all of the files from the computer, we began the process of installing Linux. We sat together during the install process and I made sure she understood the partitioning process. Inside of an hour, she had a bright new and shiny PCLinuxOS desktop.
|
||||
|
||||
She remarked often, as she navigated her way through her new system, at how beautiful the system looked. She wasn’t mentioning this as an aside; she was almost hypnotized by the sleek beauty in front of her. She remarked that her screen “shimmered” with beauty. That’s something I took away from our install session and have made sure to deploy on every Linux computer I’ve installed since. I want the screen to shimmer for everyone.
|
||||
|
||||
The first week or so, she called or emailed me with the usual questions, but the one that was probably the most important was wanting to know how to save her OpenOffice documents so colleagues could read them. This is key when teaching anyone Linux or Open/LibreOffice. Most people just obey the first popup, allow the document to be saved in Open Document Format and get their fingers bit in the process.
|
||||
|
||||
There was a story going around a year or so ago about a high school kid who claimed he flunked an exam when his professor couldn’t open the file containing his paper. It made for some blustery comments from readers who couldn’t decide who was more of a moron, the kid for not having a clue or his professor for not having a ummm… clue of his own.
|
||||
|
||||
I know some college professors and each and every one of them could figure out how to open an ODF file. Heck, even as much as Microsoft can be grade A, blue-ribbon proprietary jerks, I think Microsoft Office has been able to open an ODT or ODF file for a while now. I can’t say for sure since I haven’t used Microsoft Office much since 2005.
|
||||
|
||||
Even in the bad ol’ days, when Microsoft was openly and flagrantly shoving their way onto enterprise desktops via their vendor lock-in, I never had a problem when conducting business or collaborating with users of Microsoft Office, because I became pro-active and never assumed. I would email the person or people I was to work with and ask what version of Office they were using. From that information, I could make sure to save my documents in a format they could readily open and read.
|
||||
|
||||
But back to Nicky, who put a lot of time into learning about her Linux computer. I was surprised by her enthusiasm.
|
||||
|
||||
Learning how to use Linux on the desktop is made much simpler when the person doing the learning realizes that all habits and tools for using Windows are to be left at the door. Even after telling our Reglue kids this, more often than not when I come back to do a check-up with them there is some_dodgy_file.exe on the desktop or in the download folder.
|
||||
|
||||
While we are in the general vicinity of discussing files, let’s talk about doing updates. For a long time I was dead set against having multiple program installers or updaters on the same computer. In the case of Mint, it was decided to disable the update ability completely within Synaptic and that frosted my flakes. But while for us older folks dpkg and apt are our friends, wise heads have prevailed and have come to understand that the command line doesn’t often seem warm and welcoming to new users.
|
||||
|
||||
I frothed at the mouth and raged against the machine over the crippling of Synaptic until it was ‘splained to me. Do you remember when you were just starting out and had full admin rights to your brand new Linux install? Remember when you combed through the massive amounts of software listed in Synaptic? Remember how you began check marking every cool program you found? Do you remember how many of those cool programs started with the letters “lib”?
|
||||
|
||||
Yeah, me too. I installed and broke a few brand new installations until I found out that those LIB files were the nuts and bolts of the application and not the application itself. That’s why the genius’ behind Linux Mint and Ubuntu have created smart, pretty-to-look-at and easy-to-use application installers. Synaptic is still there for us old heads, but for the people coming up behind us, there are just too many ways to leave a system open to major borks by installing lib files and the like. In the new installers, those files are tucked away and not even shown to the user. And really, that’s the way it should be.
|
||||
|
||||
Unless you are charging for support calls that is.
|
||||
|
||||
There are a lot of smarts built into today’s Linux distros and I applaud those folks because they make my job easier. Not every new user is a Nicky. She was pretty much an install and forget project for me, and she is in the minority. The majority of new Linux users can be needy at times.
|
||||
|
||||
That’s okay. They are the ones who will be teaching their kids how to use Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2016/05/anatomy-linux-user/
|
||||
|
||||
作者:[Ken Starks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxlock.blogspot.com/
|
||||
@ -1,3 +1,6 @@
|
||||
vim-kakali translating
|
||||
|
||||
|
||||
Ubuntu Snap takes charge of Linux desktop and IoT software distribution
|
||||
===========================================================================
|
||||
|
||||
|
||||
@ -1,63 +0,0 @@
|
||||
[Cathon is translating]
|
||||
Training vs. hiring to meet the IT needs of today and tomorrow
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
In the digital era, IT skills requirements are in a constant state of flux thanks to the constant change of the tools and technologies companies need to keep pace. It’s not easy for companies to find and hire talent with coveted skills that will enable them to innovate. Meanwhile, training internal staff to take on new skills and challenges takes time that is often in short supply.
|
||||
|
||||
[Sandy Hill][1] is quite familiar with the various skills required across a variety of IT disciplines. As the director of IT for [Pegasystems][2], she is responsible for IT teams involved in areas ranging from application development to data center operations. What’s more, Pegasystems develops applications to help sales, marketing, service and operations teams streamline operations and connect with customers, which means she has to grasp the best way to use IT resources internally, and the IT challenges the company’s customers face.
|
||||
|
||||

|
||||
|
||||
**The Enterprisers Project (TEP): How has the emphasis you put on training changed in recent years?**
|
||||
|
||||
**Hill**: We’ve been growing exponentially over the past couple of years so now we’re implementing more global processes and procedures. With that comes the training aspect of making sure everybody is on the same page.
|
||||
|
||||
Most of our focus has shifted to training staff on new products and tools that get implemented to drive innovation and enhance end user productivity. For example, we’ve implemented an asset management system; we didn’t have one before. So we had to do training globally instead of hiring someone who already knew the product. As we’re growing, we’re also trying to maintain a tight budget and flat headcount. So we’d rather internally train than try to hire new people.
|
||||
|
||||
**TEP: Describe your approach to training. What are some of the ways you help employees evolve their skills?**
|
||||
|
||||
**Hill**: I require each staff member to have a technical and non-technical training goal, which are tracked and reported on as part of their performance review. Their technical goal needs to align within their job function, and the non-technical goal can be anything from focusing on sharpening one of their soft skills to learning something outside of their area of expertise. I perform yearly staff evaluations to see where the gaps and shortages are so that teams remain well-rounded.
|
||||
|
||||
**TEP: To what extent have your training initiatives helped quell recruitment and retention issues?**
|
||||
|
||||
**Hill**: Keeping our staff excited about learning new technologies keeps their skill sets sharp. Having the staff know that we value them, and we are vested in their professional growth and development motivates them.
|
||||
|
||||
**TEP: What sorts of training have you found to be most effective?**
|
||||
|
||||
**Hill**: We use several different training methods that we’ve found to be effective. With new or special projects, we try to incorporate a training curriculum led by the vendor as part of the project rollout. If that’s not an option, we use off-site training. We also purchase on-line training packages, and I encourage my staff to attend at least one conference per year to keep up with what’s new in the industry.
|
||||
|
||||
**TEP**: For what sorts of skills have you found it’s better to hire new people than train existing staff?
|
||||
|
||||
**Hill**: It depends on the project. In one recent initiative, trying to implement OpenStack, we didn’t have internal expertise at all. So we aligned with a consulting firm that specialized in that area. We utilized their expertise on-site to help run the project and train internal team members. It was a massive undertaking to get internal people to learn the skills they needed while also doing their day-to-day jobs.
|
||||
|
||||
The consultant helped us determine the headcount we needed to be proficient. This allowed us to assess our staff to see if gaps remained, which would require additional training or hiring. And we did end up hiring some of the contractors. But the alternative was to send some number of FTEs (full-time employees) for 6 to 8 weeks of training, and our pipeline of projects wouldn’t allow that.
|
||||
|
||||
**TEP: In thinking about some of your most recent hires, what skills did they have that are especially attractive to you?**
|
||||
|
||||
**Hill**: In recent hires, I’ve focused on soft skills. In addition to having solid technical skills, they need to be able to communicate effectively, work in teams and have the ability to persuade, negotiate and resolve conflicts.
|
||||
|
||||
IT people in general kind of keep to themselves; they’re often not the most social people. Now, where IT is more integrated throughout the organization, the ability to give useful updates and status reports to other business units is critical to show that IT is an active presence and to be successful.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
|
||||
作者:[ Paul Desmond][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://enterprisersproject.com/user/paul-desmond
|
||||
[1]: https://enterprisersproject.com/user/sandy-hill
|
||||
[2]: https://www.pega.com/pega-can?&utm_source=google&utm_medium=cpc&utm_campaign=900.US.Evaluate&utm_term=pegasystems&gloc=9009726&utm_content=smAXuLA4U|pcrid|102822102849|pkw|pegasystems|pmt|e|pdv|c|
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
72
sources/talk/20160627 Linux Practicality vs Activism.md
Normal file
72
sources/talk/20160627 Linux Practicality vs Activism.md
Normal file
@ -0,0 +1,72 @@
|
||||
Linux Practicality vs Activism
|
||||
==================================
|
||||
|
||||
>Is Linux actually more practical than other OSes, or is there some higher minded reason to use it?
|
||||
|
||||
One of the greatest things about running Linux is the freedom it provides. Where the division among the Linux community appears is in how we value this freedom.
|
||||
|
||||
For some, the freedom enjoyed by using Linux is the freedom from vendor lock-in or high software costs. Most would call this a practical consideration. Others users would tell you the freedom they enjoy is software freedom. This means embracing Linux distributions that support the [Free Software Movement][1], avoiding proprietary software completely and all things related.
|
||||
|
||||
In this article, I'll walk you through some of the differences between these two freedoms and how they affect Linux usage.
|
||||
|
||||
### The problem with proprietary
|
||||
|
||||
One thing most Linux users have in common is their preference for avoiding proprietary software. For practical enthusiasts like myself, it's a matter of how I spend my money, the ability to control my software and avoiding vendor lock-in. Granted, I'm not a coder...so my tweaks to my installed software are pretty mild. But there are instances where a minor tweak to an application can mean the difference between it working and it not working.
|
||||
|
||||
Then there are Linux enthusiasts who opt to avoid proprietary software because they feel it's unethical to use it. Usually the main concern here is that using proprietary software takes away or simply obstructs your personal freedom. Users in this corner prefer to use Linux distributions and software that support the [Free Software philosophy][2]. While it's similar to and often directly confused with Open Source concepts, [there are differences][3].
|
||||
|
||||
So here's the issue: Users such as myself tend to put convenience over the ideals of pure software freedom. Don't get me wrong, folks like me prefer to use software that meets the ideals behind Free Software, but we also are more likely to make concessions in order to accomplish specific tasks.
|
||||
|
||||
Both types of Linux enthusiasts prefer using non-proprietary solutions. But Free Software advocates won't use proprietary at all, where as the practical user will rely on the best tool with the best performance. This means there are instances where the practical user is willing to run a proprietary application or code on their non-proprietary operating system.
|
||||
|
||||
In the end, both user types enjoy using what Linux has to offer. But our reasons for doing so tend to vary. Some have argued that this is a matter of ignorance with those who don't support Free Software. I disagree and believe it's a matter of practical convenience. Users who prefer practical convenience simply aren't concerned about the politics of their software.
|
||||
|
||||
### Practical Convenience
|
||||
|
||||
When you ask most people why they use the operating system they use, it's usually tied in with practical convenience. Examples of this convenience might include "it's what I've always used" down to "it runs the software I need." Other folks might take this a step further and explain it's not so much the software that drives their OS preference, as the familiarity of the OS in question. And finally, there are specialty "niche tasks" or hardware compatibility issues that also provide good reasons for using one OS over another.
|
||||
|
||||
This might surprise many of you, but the single biggest reason I run desktop Linux today is due to familiarity. Even though I provide support for Windows and OS X for others, it's actually quite frustrating to use these operating systems as they're simply not what my muscle memory is used to. I like to believe this allows me to empathize with Linux newcomers, as I too know how off-putting it can be to step into the realm of the unfamiliar. My point here is this – familiarity has value. And familiarity also powers practical convenience as well.
|
||||
|
||||
Now if we compare this to the needs of a Free Software advocate, you'll find those folks are willing to learn something new and perhaps even more challenging if it translates into them avoiding using non-free software. It's actually something I've always admired about this type of user. Their willingness to take the path less followed to stick to their principles is, in my opinion, admirable.
|
||||
|
||||
### The price of freedom
|
||||
|
||||
One area I don't envy is the extra work involved in making sure a Free Software advocate is always using Linux distros and hardware that respect their digital freedom according to the standards set forth by the [Free Software Foundation][4]. This means the Linux kernel needs to be free from proprietary blobs for driver support and the hardware in question doesn't require any proprietary code whatsoever. Certainly not impossible, but it's pretty close.
|
||||
|
||||
The absolute best scenario a Free Software advocate can shoot for is hardware that is "freedom-compatible." There are vendors out there that can meet this need, however most of them are offering hardware that relies on Linux compatible proprietary firmware. Great for the practical user, a show-stopper for the Free Software advocate.
|
||||
|
||||
What all of this translates into is that the advocate must be far more vigilant than the practical Linux enthusiast. This isn't necessarily a negative thing per se, however it's a consideration if one is planning on jumping onto the Free Software approach to computing. Practical users, by contrast, can use any software or hardware that happens to be Linux compatible without a second thought. I don't know about you, but in my eyes this seems a bit easier to me.
|
||||
|
||||
### Defining software freedom
|
||||
|
||||
This part is going to get some folks upset as I personally don't subscribe to the belief that there's only one flavor of software freedom. From where I stand, I think true freedom is being able to soak in all the available data on a given issue and then come to terms with the approach that best suits that person's lifestyle.
|
||||
|
||||
So for me, I prefer using Linux distributions that provide me with the desktop that meets all of my needs. This includes the use of non-proprietary software and proprietary software. Even though it's fair to suggest that the proprietary software restricts my personal freedom, I must counter this by pointing out that I had the freedom to use it in the first place. One might even call this freedom of choice.
|
||||
|
||||
Perhaps this too, is why I find myself identifying more with the ideals of Open Source Software instead of sticking with the ideals behind the Free Software movement. I prefer to stand with the group that doesn't spend their time telling me how I'm wrong for using what works best for me. It's been my experience that the Open Source crowd is merely interested in sharing the merits of software freedom without the passion for Free Software idealism.
|
||||
|
||||
I think the concept of Free Software is great. And to those who need to be active in software politics and point out the flaws of using proprietary software to folks, then I think Linux ([GNU/Linux][5]) activism is a good fit. Where practical users such as myself tend to change course from Free Software Linux advocates is in our presentation.
|
||||
|
||||
When I present Linux on the desktop, I share my passion for its practical merits. And if I'm successful and they enjoy the experience, I allow the user to discover the Free Software perspective on their own. I've found most people use Linux on their computers not because they want to embrace software freedom, rather because they simply want the best user experience possible. Perhaps I'm alone in this, it's hard to say.
|
||||
|
||||
What say you? Are you a Free Software Advocate? Perhaps you're a fan of using proprietary software/code on your desktop Linux distribution? Hit the Comments and share your Linux desktop experiences.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/linux-practicality-vs-activism.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]: https://en.wikipedia.org/wiki/Free_software_movement
|
||||
[2]: https://www.gnu.org/philosophy/free-sw.en.html
|
||||
[3]: https://www.gnu.org/philosophy/free-software-for-freedom.en.html
|
||||
[4]: https://en.wikipedia.org/wiki/Free_Software_Foundation
|
||||
[5]: https://en.wikipedia.org/wiki/GNU/Linux_naming_controversy
|
||||
|
||||
|
||||
@ -1,110 +0,0 @@
|
||||
Translating by ivo-wang
|
||||
What is good stock portfolio management software on Linux
|
||||
================================================================================
|
||||
If you are investing in the stock market, you probably understand the importance of a sound portfolio management plan. The goal of portfolio management is to come up with the best investment plan tailored for you, considering your risk tolerance, time horizon and financial goals. Given its importance, no wonder there are no shortage of commercial portfolio management apps and stock market monitoring software, each touting various sophisticated portfolio performance tracking and reporting capabilities.
|
||||
|
||||
For those of you Linux aficionados who are looking for a **good open-source portfolio management tool** to manage and track your stock portfolio on Linux, I would highly recommend a Java-based portfolio manager called [JStock][1]. If you are not a big Java fan, you might be turned off by the fact that JStock runs on a heavyweight JVM. At the same time I am sure many people will appreciate the fact that JStock is instantly accessible on every Linux platform with JRE installed. No hoops to jump through to make it work on your Linux environment.
|
||||
|
||||
The day is gone when "open-source" means "cheap" or "subpar". Considering that JStock is just a one-man job, JStock is impressively packed with many useful features as a portfolio management tool, and all that credit goes to Yan Cheng Cheok! For example, JStock supports price monitoring via watchlists, multiple portfolios, custom/built-in stock indicators and scanners, support for 27 different stock markets and cross-platform cloud backup/restore. JStock is available on multiple platforms (Linux, OS X, Android and Windows), and you can save and restore your JStock portfolios seamlessly across different platforms via cloud backup/restore.
|
||||
|
||||
Sounds pretty neat, huh? Now I am going to show you how to install and use JStock in more detail.
|
||||
|
||||
### Install JStock on Linux ###
|
||||
|
||||
Since JStock is written in Java, you must [install JRE][2] to run it. Note that JStock requires JRE 1.7 or higher. If your JRE version does not meet this requirement, JStock will fail with the following error.
|
||||
|
||||
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/yccheok/jstock/gui/JStock : Unsupported major.minor version 51.0
|
||||
|
||||
Once you install JRE on your Linux, download the latest JStock release from the official website, and launch it as follows.
|
||||
|
||||
$ wget https://github.com/yccheok/jstock/releases/download/release_1-0-7-13/jstock-1.0.7.13-bin.zip
|
||||
$ unzip jstock-1.0.7.13-bin.zip
|
||||
$ cd jstock
|
||||
$ chmod +x jstock.sh
|
||||
$ ./jstock.sh
|
||||
|
||||
In the rest of the tutorial, let me demonstrate several useful features of JStock.
|
||||
|
||||
### Monitor Stock Price Movements via Watchlist ###
|
||||
|
||||
On JStock you can monitor stock price movement and automatically get notified by creating one or more watchlists. In each watchlist, you can add multiple stocks you are interested in. Then add your alert thresholds under "Fall Below" and "Rise Above" columns, which correspond to minimum and maximum stock prices you want to set, respectively.
|
||||
|
||||
|
||||
|
||||
For example, if you set minimum/maximum prices of AAPL stock to $102 and $115.50, you will be alerted via desktop notifications if the stock price goes below $102 or moves higher than $115.50 at any time.
|
||||
|
||||
You can also enable email alert option, so that you will instead receive email notifications for such price events. To enable email alerts, go to "Options" menu. Under "Alert" tab, turn on "Send message to email(s)" box, and enter your Gmail account. Once you go through Gmail authorization steps, JStock will start sending email alerts to that Gmail account (and optionally CC to any third-party email address).
|
||||
|
||||
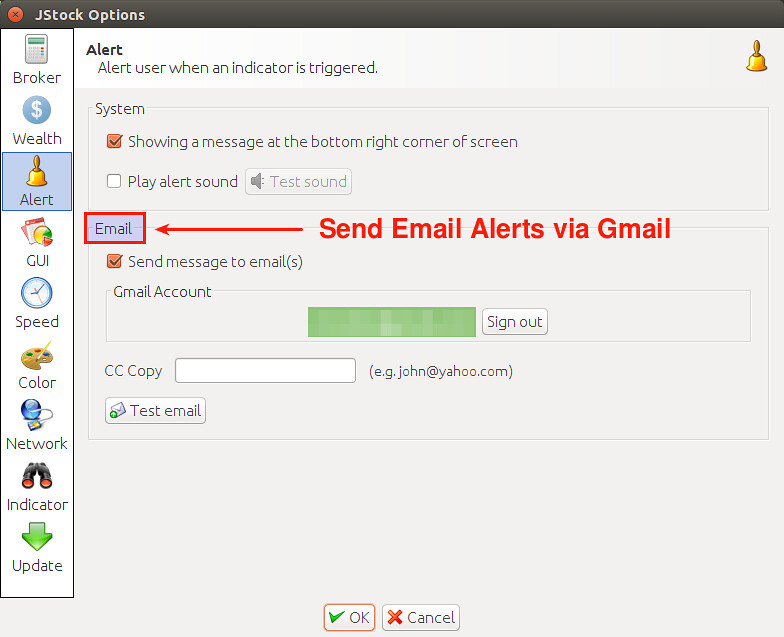
|
||||
|
||||
### Manage Multiple Portfolios ###
|
||||
|
||||
JStock allows you to manage multiple portfolios. This feature is useful if you are using multiple stock brokers. You can create a separate portfolio for each broker and manage your buy/sell/dividend transactions on a per-broker basis. You can switch different portfolios by choosing a particular portfolio under "Portfolio" menu. The following screenshot shows a hypothetical portfolio.
|
||||
|
||||
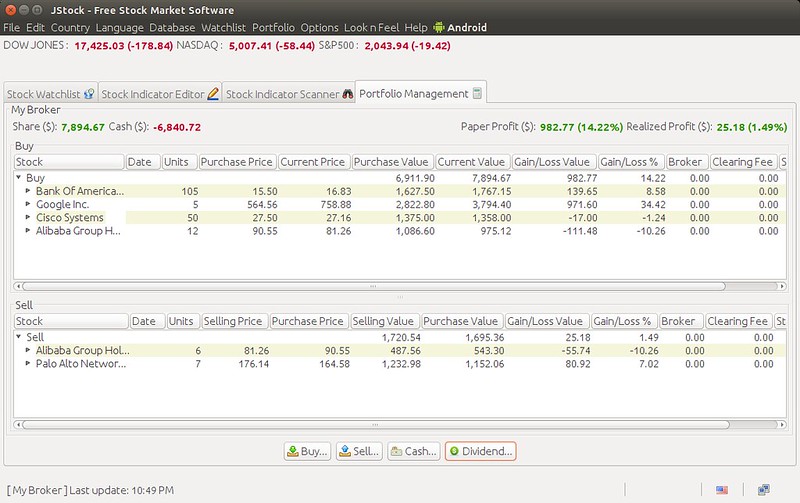
|
||||
|
||||
Optionally you can enable broker fee option, so that you can enter any broker fees, stamp duty and clearing fees for each buy/sell transaction. If you are lazy, you can enable fee auto-calculation and enter fee schedules for each brokering firm from the option menu beforehand. Then JStock will automatically calculate and enter fees when you add transactions to your portfolio.
|
||||
|
||||
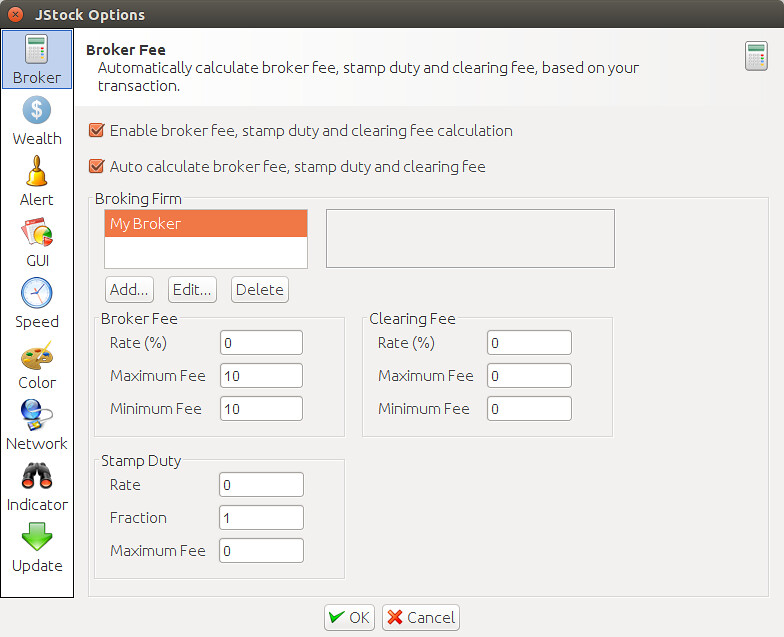
|
||||
|
||||
### Screen Stocks with Built-in/Custom Indicators ###
|
||||
|
||||
If you are doing any technical analysis on stocks, you may want to screen stocks based on various criteria (so-called "stock indicators"). For stock screening, JStock offers several [pre-built technical indicators][3] that capture upward/downward/reversal trends of individual stocks. The following is a list of available indicators.
|
||||
|
||||
- Moving Average Convergence Divergence (MACD)
|
||||
- Relative Strength Index (RSI)
|
||||
- Money Flow Index (MFI)
|
||||
- Commodity Channel Index (CCI)
|
||||
- Doji
|
||||
- Golden Cross, Death Cross
|
||||
- Top Gainers/Losers
|
||||
|
||||
To install any pre-built indicator, go to "Stock Indicator Editor" tab on JStock. Then click on "Install" button in the right-side panel. Choose "Install from JStock server" option, and then install any indicator(s) you want.
|
||||
|
||||

|
||||
|
||||
Once one or more indicators are installed, you can scan stocks using them. Go to "Stock Indicator Scanner" tab, click on "Scan" button at the bottom, and choose any indicator.
|
||||
|
||||

|
||||
|
||||
Once you select the stocks to scan (e.g., NYSE, NASDAQ), JStock will perform scan, and show a list of stocks captured by the indicator.
|
||||
|
||||

|
||||
|
||||
Besides pre-built indicators, you can also define custom indicator(s) on your own with a GUI-based indicator editor. The following example screens for stocks whose current price is less than or equal to its 60-day average price.
|
||||
|
||||

|
||||
|
||||
### Cloud Backup and Restore between Linux and Android JStock ###
|
||||
|
||||
Another nice feature of JStock is cloud backup and restore. JStock allows you to save and restore your portfolios/watchlists via Google Drive, and this features works seamlessly across different platforms (e.g., Linux and Android). For example, if you saved your JStock portfolios to Google Drive on Android, you can restore them on Linux version of JStock.
|
||||
|
||||

|
||||
|
||||
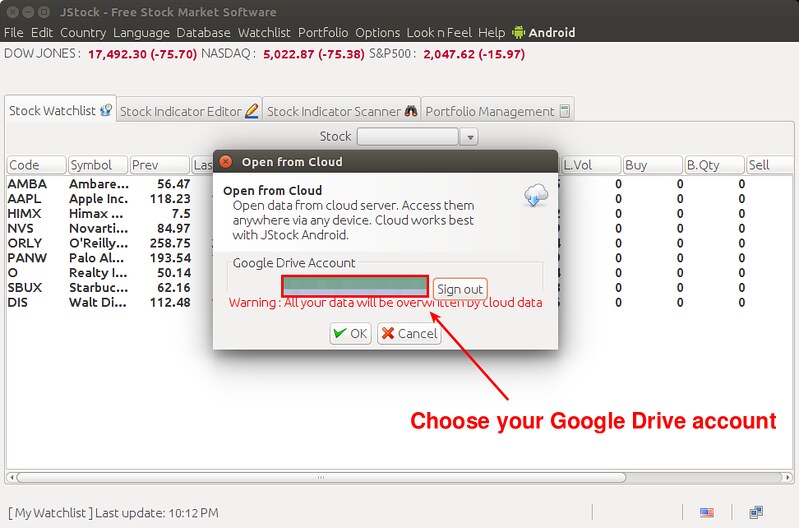
|
||||
|
||||
If you don't see your portfolios/watchlists after restoring from Google Drive, make sure that your country is correctly set under "Country" menu.
|
||||
|
||||
JStock Android free version is available from [Google Play store][4]. You will need to upgrade to premium version for one-time payment if you want to use its full features (e.g., cloud backup, alerts, charts). I think the premium version is definitely worth it.
|
||||
|
||||
|
||||
|
||||
As a final note, I should mention that its creator, Yan Cheng Cheok, is pretty active in JStock development, and quite responsive in addressing any bugs. Kudos to him!
|
||||
|
||||
What do you think of JStock as portfolio tracking software?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/stock-portfolio-management-software-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://jstock.org/
|
||||
[2]:http://ask.xmodulo.com/install-java-runtime-linux.html
|
||||
[3]:http://jstock.org/ma_indicator.html
|
||||
[4]:https://play.google.com/store/apps/details?id=org.yccheok.jstock.gui
|
||||
@ -1,80 +0,0 @@
|
||||
Achieving Enterprise-Ready Container Tools With Wercker’s Open Source CLI
|
||||
===========================================
|
||||
|
||||
For enterprises, containers offer more efficient build environments, cloud-native applications and migration from legacy systems to the cloud. But enterprise adoption of the technology -- Docker specifically -- has been hampered by, among other issues, [a lack of mature developer tools][1].
|
||||
|
||||
Amsterdam-based [Wercker][2] is one of many early-stage companies looking to meet the need for better tools with its cloud platform for automating microservices and application development, based on Docker.
|
||||
|
||||
The company [announced a $4.5 million Series A][3] funding round this month, which will help it ramp up development on an upcoming on-premise enterprise product. Key to its success, however, will be building a community around its newly [open-sourced CLI][4] tool. Wercker must quickly integrate with myriad other container technologies -- open source Kubernetes and Mesos among them -- to remain competitive in the evolving container space.
|
||||
|
||||
“By open sourcing our CLI technology, we hope to get to dev-prod parity faster and turn “build once, ship anywhere” into an automated reality,” said Wercker CEO and founder Micha Hernández van Leuffen.
|
||||
|
||||
I reached out to van Leuffen to learn more about the company, its CLI tool, and how it’s planning to help grow the pool of enterprise customers actually using containers in production. Below is an edited version of the interview.
|
||||
|
||||
### Linux.com: Can you briefly tell us about Wercker?
|
||||
|
||||
van Leuffen: Wercker is a container-centric platform for automating the development of microservices and applications.
|
||||
|
||||
With Wercker’s Docker-based infrastructure, teams can increase developer velocity with custom automation pipelines using steps that produce containers as artifacts. Once the build passes, users can continue to deploy the steps as specified in the wercker.yml. Continuously repeating these steps allows teams to work in small increments, making it easy to debug and ship faster.
|
||||
|
||||
|
||||
|
||||
### Linux.com: How does it help developers?
|
||||
|
||||
van Leuffen: The Wercker CLI helps developers attain greater dev-prod parity. They’re able to release faster and more often because they are developing, building and testing in an environment very similar to that in production. We’ve open sourced the exact same program that we execute in the Wercker cloud platform to run your pipelines.
|
||||
|
||||
### Linux.com: Can you point out some of the features and advantages of your tool as compared to competitors?
|
||||
|
||||
van Leuffen: Unlike some of our competitors, we’re not just offering Docker support. With Wercker, the Docker container is the unit of work. All jobs run inside containers, and each build artifact can be a Docker container.
|
||||
|
||||
Wercker’s Docker container pipeline is completely customizable. A ‘pipeline’ refers to any automated workflow, for instance, a build or deploy pipeline. In those workflows, you want to execute tasks: install dependencies, test your code, push your container, or create a slack notification when something fails, for example. We call these tasks ‘steps,’ and there is no limit to the types of steps created. In fact, we have a marketplace of steps built by the Wercker community. So if you’ve built a step that fits my workflow, I can use that in my pipeline.
|
||||
|
||||
Our Docker container pipelines adapt to any developer workflow. Users can use any Docker container out there — not just those made by or for Wercker. Whether the container is on Docker Hub or a private registry such as CoreOS’s Quay, it works with Wercker.
|
||||
|
||||
Our competitors range from the classic CI/CD tools to larger-scale DevOps solutions like CloudBees.
|
||||
|
||||
### Linux.com: How does it integrate with other cloud technologies?
|
||||
|
||||
van Leuffen: Wercker is vendor-agnostic and can automate development with any cloud platform or service. We work closely with ecosystem partners like Mesosphere, Kubernetes and CoreOS to make integrations as seamless as possible. We also recently partnered with Atlassian to integrate the Wercker platform with Bitbucket. More than 3 million Bitbucket users can install the Wercker Pipeline Viewer and view build status directly from their dashboard.
|
||||
|
||||
### Linux.com: Why did you open source the Wercker CLI tool?
|
||||
|
||||
van Leuffen: Open sourcing the Wercker CLI will help us stay ahead of the curve and strengthen the developer community. The market landscape is changing fast; developers are expected to release more frequently, using infrastructure of increasing complexity. While Docker has solved a lot of infrastructure problems, developer teams are still looking for the perfect tools to test, build and deploy rapidly.
|
||||
|
||||
The Wercker community is already experimenting with these new tools: Kubernetes, Mesosphere, CoreOS. It makes sense to tap that community to create integrations that work with our technology – and make that process as frictionless as possible. By open sourcing our CLI technology, we hope to get to dev-prod parity faster and turn “build once, ship anywhere” into an automated reality.
|
||||
|
||||
### Linux.com: You recently raised over $4.5 million, so how is this fund being used for product development?
|
||||
|
||||
van Leuffen: We’re focused on building out our commercial team and bringing an enterprise product to market. We’ve had a lot of inbound interest from the enterprise looking for VPC and on-premise solutions. While the enterprise is still largely in the discovery stage, we can see the market shifting toward containers. Enterprise software devs need to release often, just like the small, agile teams with whom they are increasingly competing. We need to prove containers can scale, and that Wercker has the organizational permissions and the automation suite to make that process as efficient as possible.
|
||||
|
||||
In addition to continuing to invest in our product, we’ll be focusing our resources on market education and developer evangelism. Developer teams are still looking for the right mix of tools to test, build and deploy rapidly (including Kubernetes, Mesosphere, CoreOS, etc.). As an ecosystem, we need to do more to educate and provide the tutorials and resources to help developers succeed in this changing landscape.
|
||||
|
||||
### Linux.com: What products do you offer and who is your target audience?
|
||||
|
||||
van Leuffen: We currently offer one service level of our product Wercker; however, we’re developing an enterprise offering. Current organizations using Wercker range from startups, such as Open Listings, to larger companies and big agencies, like Pivotal Labs.
|
||||
|
||||
|
||||
### Linux.com: What does this recently open-sourced CLI do?
|
||||
|
||||
van Leuffen: Using the Wercker Command Line Interface (CLI), developers can spin up Docker containers on their desktop, automate their build and deploy processes and then deploy them to various cloud providers, like AWS, and scheduler and orchestration platforms, such as Mesosphere and Kubernetes.
|
||||
|
||||
The Wercker Command Line Interface is available as an open source project on GitHub and runs on both OSX and Linux machines.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/enterprise/systems-management/887177-achieving-enterprise-ready-container-tools-with-werckers-open-source-cli
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/community/forums/person/61003
|
||||
[1]:http://thenewstack.io/adopting-containers-enterprise/
|
||||
[2]:http://wercker.com/
|
||||
[3]:http://venturebeat.com/2016/01/28/wercker-raises-4-5-million-open-sources-its-command-line-tool/
|
||||
[4]:https://github.com/wercker/wercker
|
||||
|
||||
|
||||
@ -1,79 +0,0 @@
|
||||
15 podcasts for FOSS fans
|
||||
=============================
|
||||
|
||||
keyword : FOSS , podcast
|
||||
|
||||

|
||||
|
||||
I listen to a lot of podcasts. A lot. On my phone's podcatcher, I am subscribed to around 60 podcasts... and I think that only eight of those have podfaded (died). Unsurprisingly, a fairly sizeable proportion of those remaining alive-and-well subscriptions are shows with a specific interest or relevance to open source software. As I seek to resurrect my own comatose podcast from the nebulous realm of podfadery, I thought it would be great for us as a community to share what we're listening to.
|
||||
|
||||
>Quick digression: I understand that there are a lot of "pod"-prefixed words in that first paragraph. Furthermore, I also know that the term itself is related to a proprietary device that, by most accounts, isn't even used for listening to these web-based audio broadcasts. However, the term 'webcast' died in the nineties and 'oggcast' never gathered a substantial foothold among the listening public. As such, in order to ensure that the most people actually know what I'm referring to, I'm essentially forced to use the web-anachronistic, but publicly recognized term, podcast.
|
||||
|
||||
I should also mention that a number of these shows involve grown-ups using grown-up language (i.e. swearing). I've tried to indicate which shows these are by putting a red E next to their names, but please do your own due diligence if you're concerned about listening to these shows at work or with children around.
|
||||
|
||||
The following lists are podcasts that I keep in heavy rotation (each sublist is listed in alphabetical order). In the first list are the ones I think of as my "general coverage" shows. They tend to either discuss general topics related to free and open source software, or they give a survey of multiple open source projects from one episode to the next.
|
||||
|
||||
- [Bad Voltage][1] E — Regular contributor and community moderator here on Opensource.com, Jono Bacon, shares hosting dutes on this podcast with Jeremy Garcia, Stuart Langridge, and Bryan Lunduke, four friends with a variety of digressing and intersecting opinions. That's the most interesting part of the show for me. Of course, they also do product reviews and cover timely news relevant to free and open source software, but it's the banter that I stick around for.
|
||||
|
||||
- [FLOSS Weekly][2] — The Twit network of podcasts is a long-time standby in technology broadcasts. Hosted by Randal Schwartz, FLOSS Weekly focuses on covering one open source project each week, typically by interviewing someone relevant in the development of that project. It's a really good show for getting exposed to new open source tools... or learning more about the programs you're already familiar with.
|
||||
|
||||
- [Free as in Freedom][3] — Hosted by Bradley Kuhn and Karen Sandler, this show has a specific focus on legal and policy matters as it relates to both specific free and open source projects, as well as open culture in general. The show seems to have gone on a bit of a hiatus since its last episode in November of 2015, but I for one am immensely hopeful that Free as in Freedom emerges victoriously from its battle with being podfaded and returns to its regular bi-weekly schedule.
|
||||
|
||||
- [GNU World Order][4] — I think that this show can be best descrbed as a free and open source variety show. Solo host, Klaatu, spends the majority of each show going in-depth at nearly tutorial level with a whole range of specific software tools and workflows. It's a really friendly way to get an open source neophyte up to speed with everything from understanding SSH to playing with digital painting and video. And there's a video component to the show, too, which certainly helps make some of these topics easier to follow.
|
||||
|
||||
- [Hacker Public Radio][5] — This is just a well-executed version of a fantastic concept. Hacker Public Radio (HPR) is a community-run daily (well, working-week daily) podcast with a focus on "anything of interest to hackers." Sure there are wide swings in audio quality from show to show, but it's an open platform where anyone can share what they know (or what they think) in that topic space. Show topics include 3D printing, hardware hacking, conference interviews, and more. There are even long-running tutorial series and an audio book club. The monthly recap episodes are particularly useful if you're having trouble picking a place to start. And best of all, you can record your own episode and add it to the schedule. In fact, they actively encourage it.
|
||||
|
||||
My next list of open source podcasts are a bit more specific to particular topics or software packages in the free and open source ecosystem.
|
||||
|
||||
- [Blender Podcast][6] — Although this podcast is very specific to one particular application—Blender, in case you couldn't guess—many of the topics are relevant to issues faced by users and developers of open source other softrware programs. Hosts Thomas Dinges and Campbell Barton—both on the core development team for Blender—discuss the latest happenings in the Blender community, sometimes with a guest. The release schedule is a bit sporadic, but one of the things I really like about this particular show is the fact that they talk about both user issues and developer issues... and the various intersections of the two. It's a great way for each part of the community to gain insight from the other.
|
||||
|
||||
- [Sunday Morning Linux Review][7] — As it's name indicates, SMLR offers a weekly review of topics relevant to Linux. Since around the end of last year, the show has seen a bit of a restructuring. However, that has not detracted from its quality. Tony Bemus, Mary Tomich, and Tom Lawrence deliver a lot of good information, and you can catch them recording their shows live through their website (if you happen to have free time on your Sundays).
|
||||
|
||||
- [LinuxLUGcast][8] — The LinuxLUGcast is a community podcast that's really a recording of an online Linux Users Group (LUG) that meets on the first and third Friday of each month. The group meets (and records) via Mumble and discussions range from home builds with single-board computers like the Raspberry Pi to getting help with trying out a new distro. The LUG is open to everyone, but there is a rotating cast of regulars who've made themselves (and their IRC handles) recognizable fixtures on the show. (Full disclosure: I'm a regular on this one)
|
||||
|
||||
- [The Open EdTech Podcast][9] — Thaj Sara's Open EdTech Podcast is a fairly new show that so far only has three episodes. However, since there's a really sizeable community of open source users in the field of education (both in teaching and in IT), this show serves an important and underserved segment of our community. I've spoken with Thaj via email and he assures me that new episodes are in the pipe. He just needs to set aside the time to edit them.
|
||||
|
||||
- [The Linux Action Show][10] — It would be remiss of me to make a list of open source podcasts and not mention one of the stallwart fixtures in the space: The Linux Action Show. Chris Fisher and Noah Chelliah discuss current news as it pertains to Linux and open source topics while at the same time giving feature attention to specific projects or their own experiences using various open source tools.
|
||||
|
||||
This next section is what I'm going to term my "honorable mention" section. These shows are either new or have a more tangential focus on open source software and culture. In any case, I still think readers of Opensource.com would enjoy listening to these shows.
|
||||
|
||||
- [Blender Institute Podcast][11] — The Blender Institute—the more commercial creative production spin-off from the Blender Foundation—started hosting their own weekly podcast a few months ago. In the show, artists (and now a developer!) working at the Institute discuss the open content projects they're working on, answer questions about using Blender, and give great insight into how things go (or occasionally don't go) in their day-to-day work.
|
||||
|
||||
- [Geek News Radio][12] E — There was a tangible sense of loss about a year ago when the hosts of Linux Outlaws hung up their mics. Well good news! A new show has sprung from its ashes. In episodes of Geek News Radio, Fab Scherschel and Dave Nicholas have a wider focus than Linux Outlaws did. Rather than being an actual news podcast, it's more akin to an informal discussion among friends about video games, movies, technology, and open source (of course).
|
||||
|
||||
- [Geekrant][13] — Formerly known as the Everyday Linux Podcast, this show was rebranded at the start of the year to reflect kind of content that the hosts Mark Cockrell, Seth Anderson, and Chris Neves were already discussing. They do discuss open source software and culture, but they also give their own spin and opinions on topics of interest in general geek culture. Topics have a range that includes everything from popular media to network security. (P.S. Opensource.com content manager Jen Wike Huger was a guest on Episode 164.)
|
||||
|
||||
- [Open Source Creative][14] E — In case you haven't read my little bio blurb, I also have my own podcast. In this show, I talk about news and topics that are [hopefully] of interest to artists and creatives who use free and open source tools. I record it during my work commute so episode length varies with traffic, and I haven't quite figured out a good way to do interviews safely, but if you listen while you're on your way to work, it'll be like we're carpooling. The show has been on a bit of hiatus for almost a year, but I've commited to making sure it comes back... and soon.
|
||||
|
||||
- [Still Untitled][15] E — As you may have noticed from most of the selections on this list, I tend to lean toward the indie side of the spectrum, preferring to listen to shows by people with less of a "name." That said, this show really hits a good place for me. Hosts Adam Savage, Norman Chan, and Will Smith talk about all manner of interesting and geeky things. From Adam's adventures with Mythbusters to maker builds and book reviews, there's rarely ever a show that hasn't been fun for me to listen to.
|
||||
|
||||
So there you go! I'm always looking for more interesting shows to listen to on my commute (as I'm sure many others are). What suggestions or recommendations do you have?
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/open-source-podcasts
|
||||
|
||||
作者:[Jason van Gumster][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-van-gumster
|
||||
[1]: http://badvoltage.org/
|
||||
[2]: https://twit.tv/shows/floss-weekly
|
||||
[3]: http://faif.us/
|
||||
[4]: http://gnuworldorder.info/
|
||||
[5]: http://hackerpublicradio.org/
|
||||
[6]: https://blender-podcast.org/
|
||||
[7]: http://smlr.us/
|
||||
[8]: http://linuxlugcast.com/
|
||||
[9]: http://openedtechpodcast.com/
|
||||
[10]: http://www.jupiterbroadcasting.com/tag/linux-action-show/
|
||||
[11]: http://podcast.blender.institute/
|
||||
[12]: http://sixgun.org/geeknewsradio
|
||||
[13]: http://elementopie.com/geekrant-episodes
|
||||
[14]: http://monsterjavaguns.com/podcast
|
||||
[15]: http://www.tested.com/still-untitled-the-adam-savage-project/
|
||||
@ -1,212 +0,0 @@
|
||||
Healthy Open Source
|
||||
============================
|
||||
|
||||
keyword: Node.js , opensource , project management , software
|
||||
|
||||
*A walkthrough of the Node.js Foundation’s base contribution policy*.
|
||||
|
||||
A lot has changed since io.js and Node.js merged under the Node.js Foundation. The most impressive change, and probably the change that is most relevant to the rest of the community and to open source in general, is the growth in contributors and committers to the project.
|
||||
|
||||
A few years ago, Node.js had just a few committers (contributors with write access to the repository in order to merge code and triage bugs). The maintenance overhead for the few committers on Node.js Core was overwhelming and the project began to see a decline in both committers and outside contribution. This resulted in a corresponding decline in releases.
|
||||
|
||||
Today, the Node.js project is divided into many components with a full org size of well over 400 members. Node.js Core now has over 50 committers and over 100 contributors per month.
|
||||
|
||||
Through this growth we’ve found many tools that help scale the human infrastructure around an Open Source project. We also identified a few core values we believe are fundamental to modern Open Source: transparency, participation, and efficacy. As we continue to scale the way we do Open Source we try to find a balance of these values and adapt the practices we find help to fit the needs of each component of the Node.js project.
|
||||
|
||||
Now that Node.js is in a good place, the foundation is looking to promote this kind of sustainability in the ecosystem. Part of this is a new umbrella for additional projects to enter the foundation, of which [Express was recently admitted][1], and the creation of this new contribution policy.
|
||||
|
||||
This contribution policy is not universal. It’s meant as a starting point. Additions and alterations to this policy are encouraged so that the process used by each project fits its needs and can continue to change shape as the project grows and faces new challenges.
|
||||
|
||||
The [current version][2] is hosted in the Node.js Foundation. We expect to iterate on this over time and encourage people to [log issues][3] with questions and feedback regarding the policy for future iterations.
|
||||
|
||||
This document describes a very simple process suitable for most projects in the Node.js ecosystem. Projects are encouraged to adopt this whether they are hosted in the Node.js Foundation or not.
|
||||
|
||||
The Node.js project is organized into over a hundred repositories and a few dozen Working Groups. There are large variations in contribution policy between many of these components because each one has different constraints. This document is a minimalist version of the processes and philosophy we’ve found works best everywhere.
|
||||
|
||||
We believe that contributors should own their projects, and that includes contribution policies like this. While new foundation projects start with this policy we expect many of them to alter it or possibly diverge from it entirely to suite their own specific needs.
|
||||
|
||||
The goal of this document is to create a contribution process that:
|
||||
|
||||
* Encourages new contributions.
|
||||
|
||||
* Encourages contributors to remain involved.
|
||||
|
||||
* Avoids unnecessary processes and bureaucracy whenever possible.
|
||||
|
||||
* Creates a transparent decision making process which makes it clear how contributors can be involved in decision making.
|
||||
|
||||
Most contribution processes are created by maintainers who feel overwhelmed by outside contributions. These documents have traditionally been about processes that make life easier for a small group of maintainers, often at the cost of attracting new contributors.
|
||||
|
||||
We’ve gone the opposite direction. The purpose of this policy is to gain contributors, to retain them as much as possible, and to use a much larger and growing contributor base to manage the corresponding influx of contributions.
|
||||
|
||||
As projects mature, there’s a tendency to become top heavy and overly hierarchical as a means of quality control and this is enforced through process. We use process to add transparency that encourages participation which grows the code review pool which leads to better quality control.
|
||||
|
||||
This document is based on much prior art in the Node.js community, io.js, and the Node.js project.
|
||||
|
||||
This document is based on what we’ve learned growing the Node.js project. Not just the core project, which has been a massive undertaking, but also much smaller sub-projects like the website which have very different needs and, as a result, very different processes.
|
||||
|
||||
When we began these reforms in the Node.js project, we were taking a lot of inspiration from the broader Node.js ecosystem. In particular, Rod Vagg’s [OPEN Open Source policy][4]. Rod’s work in levelup and nan is the basis for what we now call “liberal contribution policies.”
|
||||
|
||||
### Vocabulary
|
||||
|
||||
* A **Contributor** is any individual creating or commenting on an issue or pull request.
|
||||
|
||||
* A **Committer** is a subset of contributors who have been given write access to the repository.
|
||||
|
||||
* A **TC (Technical Committee)** is a group of committers representing the required technical expertise to resolve rare disputes.
|
||||
|
||||
Every person who shows up to comment on an issue or submit code is a member of a project’s community. Just being able to see them means that they have crossed the line from being a user to being a contributor.
|
||||
|
||||
Typically open source projects have had a single distinction for those that have write access to the repository and those empowered with decision making. We’ve found this to be inadequate and have separated this into two distinctions which we’ll dive into more a bit later.
|
||||
|
||||
|
||||
|
||||
healthy 1Looking at the community in and around a project as a bunch of concentric circles helps to visualize this.
|
||||
|
||||
In the outermost circle are users, a subset of those users are contributors, a subset of contributors become committers who can merge code and triage issues. Finally, a smaller group of trusted experts who only get pulled in to the hard problems and can act as a tie-breaker in disputes.
|
||||
|
||||
This is what a healthy project should look like. As the demands on the project from increased users rise, so do the contributors, and as contributors increase more are converted into committers. As the committer base grows, more of them rise to the level of expertise where they should be involved in higher level decision making.
|
||||
|
||||
|
||||
|
||||
If these groups don’t grow in proportion to each other they can’t carry the load imposed on them by outward growth. A project’s ability to convert people from each of these groups is the only way it can stay healthy if its user base is growing.
|
||||
|
||||
This is what unhealthy projects look like in their earliest stages of dysfunction, but imagine that the committers bubble is so small you can’t actually read the word “committers” in it, and imagine this is a logarithmic scale.
|
||||
|
||||
healthy-2A massive user base is pushing a lot of contributions onto a very small number of maintainers.
|
||||
|
||||
This is when maintainers build processes and barriers to new contributions as a means to manage the workload. Often the problems the project is facing will be attributed to the tools the project is using, especially GitHub.
|
||||
|
||||
In Node.js we had all the same problems, resolved them without a change in tooling, and today manage a growing workload much larger than most projects, and GitHub has not been a bottleneck.
|
||||
|
||||
We know what happens to unhealthy projects over a long enough time period, more maintainers leave, contributions eventually fall, and **if we’re lucky** users leave it. When we aren’t so lucky adoption continues and years later we’re plagued with security and stability issues in widely adopt software that can’t be effectively maintained.
|
||||
|
||||
The number of users a project has is a poor indicator of the health of the project, often it is the most used software that suffers the biggest contribution crisis.
|
||||
|
||||
### Logging
|
||||
|
||||
Log an issue for any question or problem you might have. When in doubt, log an issue, any additional policies about what to include will be provided in the responses. The only exception is security disclosures which should be sent privately.
|
||||
|
||||
The first sentence is surprisingly controversial. A lot of maintainers complain that there isn’t a more heavy handed way of forcing people to read a document before they log an issue on GitHub. We have documents all over projects in the Node.js Foundation about writing good bug reports but, first and foremost, we encourage people to log something and try to avoid putting barriers in the way of that.
|
||||
|
||||
Sure, we get bad bugs, but we have a ton of contributors who can immediately work with people who log them to educate them on better practices and treat it as an opportunity to educate. This is why we have documentation on writing good bugs, in order to educate contributors, not as a barrier to entry.
|
||||
|
||||
Creating barriers to entry just reduces the number of people there’s a chance to identify, educate and potentially grow into greater contributors.
|
||||
|
||||
Of course, never log a public issue about a security disclosure, ever. This is a bit vague about the best private venue because we can’t determine that for every project that adopts this policy, but we’re working on a responsible disclosure mechanism for the broader community (stay tuned).
|
||||
|
||||
Committers may direct you to another repository, ask for additional clarifications, and add appropriate metadata before the issue is addressed.
|
||||
|
||||
For smaller projects this isn’t a big deal but in Node.js we’ve had to continually break off work into other, more specific, repositories just to keep the volume on a single repo manageable. But all anyone has to do when someone puts something in the wrong place is direct them to the right one.
|
||||
|
||||
Another benefit of growing the committer base is that there’s more people to deal with little things, like redirecting issues to other repos, or adding metadata to issues and PRs. This allows developers who are more specialized to focus on just a narrow subset of work rather than triaging issues.
|
||||
|
||||
Please be courteous, respectful, and every participant is expected to follow the project’s Code of Conduct.
|
||||
|
||||
One thing that can burn out a project is when people show up with a lot of hostility and entitlement. Most of the time this sentiment comes from a feeling that their input isn’t valued. No matter what, a few people will show up who are used to more hostile environments and it’s good to have these kinds of expectations explicit and written down.
|
||||
|
||||
And each project should have a Code of Conduct, which is an extension of these expectations that makes people feel safe and respected.
|
||||
|
||||
### Contributions
|
||||
|
||||
Any change to resources in this repository must be through pull requests. This applies to all changes to documentation, code, binary files, etc. Even long term committers and TC members must use pull requests.
|
||||
|
||||
No pull request can be merged without being reviewed.
|
||||
|
||||
Every change needs to be a pull request.
|
||||
|
||||
A Pull Request captures the entire discussion and review of a change. Allowing some subset of committers to slip things in without a Pull Request gives the impression to potential contributors that they they can’t be involved in the project because they don’t have access to a behind the scenes process or culture.
|
||||
|
||||
This isn’t just a good practice, it’s a necessity in order to be transparent enough to attract new contributors.
|
||||
|
||||
For non-trivial contributions, pull requests should sit for at least 36 hours to ensure that contributors in other timezones have time to review. Consideration should also be given to weekends and other holiday periods to ensure active committers all have reasonable time to become involved in the discussion and review process if they wish.
|
||||
|
||||
Part of being open and inviting to more contributors is making the process accessible to people in timezones all over the world. We don’t want to add an artificial delay in small doc changes but for any change that needs a bit of consideration needs to give people in different parts of the world time to consider it.
|
||||
|
||||
In Node.js we actually have an even longer timeline than this, 48 hours on weekdays and 72 on weekends. That might be too much for smaller projects so it is shorter in this base policy but as a project grows it may want to increase this as well.
|
||||
|
||||
The default for each contribution is that it is accepted once no committer has an objection. During review committers may also request that a specific contributor who is most versed in a particular area gives a “LGTM” before the PR can be merged. There is no additional “sign off” process for contributions to land. Once all issues brought by committers are addressed it can be landed by any committer.
|
||||
|
||||
A key part of the liberal contribution policies we’ve been building is an inversion of the typical code review process. Rather than the default mode for a change to be rejected until enough people sign off, we make the default for every change to land. This puts the onus on reviewers to note exactly what adjustments need to be made in order for it to land.
|
||||
|
||||
For new contributors it’s a big leap just to get that initial code up and sent. Viewing the code review process as a series of small adjustments and education, rather than a quality control hierarchy, does a lot to encourage and retain these new contributors.
|
||||
|
||||
It’s important not to build processes that encourage a project to be too top heavy, with a few people needing to sign off on every change. Instead, we just mention any committer than we think should weigh in on a specific review. In Node.js we have people who are the experts on OpenSSL, any change to crypto is going to need a LGTM from them. This kind of expertise forms naturally as a project grows and this is a good way to work with it without burning people out.
|
||||
|
||||
In the case of an objection being raised in a pull request by another committer, all involved committers should seek to arrive at a consensus by way of addressing concerns being expressed by discussion, compromise on the proposed change, or withdrawal of the proposed change.
|
||||
|
||||
This is what we call a lazy consensus seeking process. Most review comments and adjustments are uncontroversial and the process should optimize for getting them in without unnecessary process. When there is disagreement, try to reach an easy consensus among the committers. More than 90% of the time this is simple, easy and obvious.
|
||||
|
||||
If a contribution is controversial and committers cannot agree about how to get it to land or if it should land then it should be escalated to the TC. TC members should regularly discuss pending contributions in order to find a resolution. It is expected that only a small minority of issues be brought to the TC for resolution and that discussion and compromise among committers be the default resolution mechanism.
|
||||
|
||||
For the minority of changes that are controversial and don’t reach an easy consensus we escalate that to the TC. These are rare but when they do happen it’s good to reach a resolution quickly rather than letting things fester. Contentious issues tend to get a lot of attention, especially by those more casually involved in the project or even entirely outside of it, but they account for a relatively small amount of what the project does every day.
|
||||
|
||||
### Becoming a Committer
|
||||
|
||||
All contributors who land a non-trivial contribution should be on-boarded in a timely manner, and added as a committer, and be given write access to the repository.
|
||||
|
||||
This is where we diverge sharply from open source tradition.
|
||||
|
||||
Projects have historically guarded commit rights to their version control system. This made a lot of sense when we were using version control systems like subversion. A single contributor can inadvertently mess up a project pretty badly in older version control systems, but not so much in git. In git, there isn’t a lot that can’t be fixed and so most of the quality controls we put on guarding access are no longer necessary.
|
||||
|
||||
Not every committer has the rights to release or make high level decisions, so we can be much more liberal about giving out commit rights. That increases the committer base for code review and bug triage. As a wider range of expertise in the committer pool smaller changes are reviewed and adjusted without the intervention of the more technical contributors, who can spend their time on reviews only they can do.
|
||||
|
||||
This is they key to scaling contribution growth: committer growth.
|
||||
|
||||
Committers are expected to follow this policy and continue to send pull requests, go through proper review, and have other committers merge their pull requests.
|
||||
|
||||
This part is entirely redundant, but on purpose. Just a reminder even once someone is a committer their changes still flow through the same process they followed before.
|
||||
|
||||
### TC Process
|
||||
|
||||
The TC uses a “consensus seeking” process for issues that are escalated to the TC. The group tries to find a resolution that has no open objections among TC members. If a consensus cannot be reached that has no objections then a majority wins vote is called. It is also expected that the majority of decisions made by the TC are via a consensus seeking process and that voting is only used as a last-resort.
|
||||
|
||||
The best solution tends to be the one everyone can agree to so you would think that consensus systems would be the norm. However, **pure consensus** systems incentivize obstructionism which we need to avoid.
|
||||
|
||||
In pure consensus everyone essentially has a veto. So, if I don’t want something to happen I’m in a strong position of power over everyone that wants something to happen. They have to convince me, and I don’t have to convince anyone else of anything.
|
||||
|
||||
To avoid this we use a system called “consensus seeking” which has a long history outside of open source. It’s quite simple, just attempt to reach a consensus, if a consensus can’t be reached then call for a majority wins vote.
|
||||
|
||||
Just the fact that a vote **is a possibility** means that people can’t be obstructionists, whether someone favor a change or not, they have to convince their peers and if they aren’t willing to put in the work to convince their peers then they probably don’t involve themselves in that decision at all.
|
||||
|
||||
The way these incentives play out is pretty impressive. We started using this process in io.js and adopted it in Node.js when we merged into the foundation. In that entire time we’ve never actually had to call for a vote, just the fact that we could is enough to keep everyone working together to find a solution and move forward.
|
||||
|
||||
Resolution may involve returning the issue to committers with suggestions on how to move forward towards a consensus. It is not expected that a meeting of the TC will resolve all issues on its agenda during that meeting and may prefer to continue the discussion happening among the committers.
|
||||
|
||||
A TC tries to resolve things in a timely manner so that people can make progress but often it’s better to provide some additional guidance that pushes the greater contributorship towards resolution without being heavy handed.
|
||||
|
||||
Avoid creating big decision hierarchies. Instead, invest in a broad, growing and empowered contributorship that can make progress without intervention. We need to view a constant need for intervention by a few people to make any and every tough decision as the biggest obstacle to healthy Open Source.
|
||||
|
||||
Members can be added to the TC at any time. Any committer can nominate another committer to the TC and the TC uses its standard consensus seeking process to evaluate whether or not to add this new member. Members who do not participate consistently at the level of a majority of the other members are expected to resign.
|
||||
|
||||
The TC just uses the same consensus seeking process for adding new members as it uses for everything else.
|
||||
|
||||
It’s a good idea to encourage committers to nominate people to the TC and not just wait around for TC members to notice the impact some people are having. Listening to the broader committers about who they see as having a big impact keeps the TC’s perspective inline with the rest of the project.
|
||||
|
||||
As a project grows it’s important to add people from a variety of skill sets. If people are doing a lot of docs work, or test work, treat the investment they are making as equally valuable as the hard technical stuff.
|
||||
|
||||
Projects should have the same ladder, user -> contributor -> commiters -> TC member, for every skill set they want to build into the project to keep it healthy.
|
||||
|
||||
I often see long time maintainers worry about adding people who don’t understand every part of the project, as if they have to be involved in every decision. The reality is that people do know their limitations and want to defer hard decisions to people they know have more experience.
|
||||
|
||||
Thanks to Greg [Wallace][5] and ashley [williams][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/biz-os/governance/892141-healthy-open-source
|
||||
|
||||
作者:[Mikeal Rogers][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/community/forums/person/66928
|
||||
|
||||
|
||||
[1]: https://medium.com/@nodejs/node-js-foundation-to-add-express-as-an-incubator-project-225fa3008f70#.mc30mvj4m
|
||||
[2]: https://github.com/nodejs/TSC/blob/master/BasePolicies/CONTRIBUTING.md
|
||||
[3]: https://github.com/nodejs/TSC/issues
|
||||
[4]: https://github.com/Level/community/blob/master/CONTRIBUTING.md
|
||||
[5]: https://medium.com/@gtewallaceLF
|
||||
[6]: https://medium.com/@ag_dubs
|
||||
@ -1,73 +0,0 @@
|
||||
xinglianfly translate
|
||||
Writing online multiplayer game with python and asyncio - part 1
|
||||
===================================================================
|
||||
|
||||
Have you ever combined async with Python? Here I’ll tell you how to do it and show it on a [working example][1] - a popular Snake game, designed for multiple players.
|
||||
|
||||
[Play gmae][2]
|
||||
|
||||
### 1. Introduction
|
||||
|
||||
Massive multiplayer online games are undoubtedly one of the main trends of our century, in both tech and cultural domains. And while for a long time writing a server for a MMO game was associated with massive budgets and complex low-level programming techniques, things are rapidly changing in the recent years. Modern frameworks based on dynamic languages allow handling thousands of parallel user connections on moderate hardware. At the same time, HTML 5 and WebSockets standards enabled the creation of real-time graphics-based game clients that run directly in web browser, without any extensions.
|
||||
|
||||
Python may be not the most popular tool for creating scalable non-blocking servers, especially comparing to node.js popularity in this area. But the latest versions of Python are aimed to change this. The introduction of [asyncio][3] library and a special [async/await][4] syntax makes asynchronous code look as straightforward as regular blocking code, which now makes Python a worthy choice for asynchronous programming. So I will try to utilize these new features to demonstrate a way to create an online multiplayer game.
|
||||
|
||||
### 2. Getting asynchronous
|
||||
|
||||
A game server should handle a maximum possible number of parallel users' connections and process them all in real time. And a typical solution - creating threads, doesn't solve a problem in this case. Running thousands of threads requires CPU to switch between them all the time (it is called context switching), which creates big overhead, making it very ineffective. Even worse with processes, because, in addition, they do occupy too much memory. In Python there is even one more problem - regular Python interpreter (CPython) is not designed to be multithreaded, it aims to achieve maximum performance for single-threaded apps instead. That's why it uses GIL (global interpreter lock), a mechanism which doesn't allow multiple threads to run Python code at the same time, to prevent uncontrolled usage of the same shared objects. Normally the interpreter switches to another thread when currently running thread is waiting for something, usually a response from I/O (like a response from web server for example). This allows having non-blocking I/O operations in your app, because every operation blocks only one thread instead of blocking the whole server. However, it also makes general multithreading idea nearly useless, because it doesn't allow you to execute python code in parallel, even on multi-core CPU. While at the same time it is completely possible to have non-blocking I/O in one single thread, thus eliminating the need of heavy context-switching.
|
||||
|
||||
Actually, a single-threaded non-blocking I/O is a thing you can do in pure python. All you need is a standard [select][5] module which allows you to write an event loop waiting for I/O from non-blocking sockets. However, this approach requires you to define all the app logic in one place, and soon your app becomes a very complex state-machine. There are frameworks that simplify this task, most popular are [tornado][6] and [twisted][7]. They are utilized to implement complex protocols using callback methods (and this is similar to node.js). The framework runs its own event loop invoking your callbacks on the defined events. And while this may be a way to go for some, it still requires programming in callback style, what makes your code fragmented. Compare this to just writing synchronous code and running multiple copies concurrently, like we would do with normal threads. Why wouldn't this be possible in one thread?
|
||||
|
||||
And this is where the concept of microthreads come in. The idea is to have concurrently running tasks in one thread. When you call a blocking function in one task, behind the scenes it calls a "manager" (or "scheduler") that runs an event loop. And when there is some event ready to process, a manager passes execution to a task waiting for it. That task will also run until it reaches a blocking call, and then it will return execution to a manager again.
|
||||
|
||||
>Microthreads are also called lightweight threads or green threads (a term which came from Java world). Tasks which are running concurrently in pseudo-threads are called tasklets, greenlets or coroutines.
|
||||
|
||||
One of the first implementations of microthreads in Python was [Stackless Python][8]. It got famous because it is used in a very successful online game [EVE online][9]. This MMO game boasts about a persistent universe, where thousands of players are involved in different activities, all happening in the real time. Stackless is a standalone Python interpreter which replaces standard function calling stack and controls the flow directly to allow minimum possible context-switching expenses. Though very effective, this solution remained less popular than "soft" libraries that work with a standard interpreter. Packages like [eventlet][10] and [gevent][11] come with patching of a standard I/O library in the way that I/O function pass execution to their internal event loop. This allows turning normal blocking code into non-blocking in a very simple way. The downside of this approach is that it is not obvious from the code, which calls are non-blocking. A newer version of Python introduced native coroutines as an advanced form of generators. Later in Python 3.4 they included asyncio library which relies on native coroutines to provide single-thread concurrency. But only in python 3.5 coroutines became an integral part of python language, described with the new keywords async and await. Here is a simple example, which illustrates using asyncio to run concurrent tasks:
|
||||
|
||||
```
|
||||
import asyncio
|
||||
|
||||
async def my_task(seconds):
|
||||
print("start sleeping for {} seconds".format(seconds))
|
||||
await asyncio.sleep(seconds)
|
||||
print("end sleeping for {} seconds".format(seconds))
|
||||
|
||||
all_tasks = asyncio.gather(my_task(1), my_task(2))
|
||||
loop = asyncio.get_event_loop()
|
||||
loop.run_until_complete(all_tasks)
|
||||
loop.close()
|
||||
```
|
||||
|
||||
We launch two tasks, one sleeps for 1 second, the other - for 2 seconds. The output is:
|
||||
|
||||
```
|
||||
start sleeping for 1 seconds
|
||||
start sleeping for 2 seconds
|
||||
end sleeping for 1 seconds
|
||||
end sleeping for 2 seconds
|
||||
```
|
||||
|
||||
As you can see, coroutines do not block each other - the second task starts before the first is finished. This is happening because asyncio.sleep is a coroutine which returns execution to a scheduler until the time will pass. In the next section, we will use coroutine-based tasks to create a game loop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: http://snakepit-game.com/
|
||||
[3]: https://docs.python.org/3/library/asyncio.html
|
||||
[4]: https://docs.python.org/3/whatsnew/3.5.html#whatsnew-pep-492
|
||||
[5]: https://docs.python.org/2/library/select.html
|
||||
[6]: http://www.tornadoweb.org/
|
||||
[7]: http://twistedmatrix.com/
|
||||
[8]: http://www.stackless.com/
|
||||
[9]: http://www.eveonline.com/
|
||||
[10]: http://eventlet.net/
|
||||
[11]: http://www.gevent.org/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by ivo-wang
|
||||
Microfluidic cooling may prevent the demise of Moore's Law
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,124 +0,0 @@
|
||||
Johnny-Liao translating...
|
||||
|
||||
Advanced Image Processing with Python
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
Building an image processing search engine is no easy task. There are several concepts, tools, ideas and technologies that go into it. One of the major image-processing concepts is reverse image querying (RIQ) or reverse image search. Google, Cloudera, Sumo Logic and Birst are among the top organizations to use reverse image search. Great for analyzing images and making use of mined data, RIQ provides a very good insight into analytics.
|
||||
|
||||
### Top Companies and Reverse Image Search
|
||||
|
||||
There are many top tech companies that are using RIQ to best effect. For example, Pinterest first brought in visual search in 2014. It subsequently released a white paper in 2015, revealing the architecture. Reverse image search enabled Pinterest to obtain visual features from fashion objects and display similar product recommendations.
|
||||
|
||||
As is generally known, Google images uses reverse image search allowing users to upload an image and then search for connected images. The submitted image is analyzed and a mathematical model made out of it, by advanced algorithm use. The image is then compared with innumerable others in the Google databases before results are matched and similar results obtained.
|
||||
|
||||
**Here is a graph representation from the OpenCV 2.4.9 Features Comparison Report:**
|
||||
|
||||

|
||||
|
||||
### Algorithms & Python Libraries
|
||||
|
||||
Before we get down to the workings of it, let us rush through the main elements that make building an image processing search engine with Python possible:
|
||||
|
||||
### Patented Algorithms
|
||||
|
||||
#### SIFT (Scale-Invariant Feature Transform) Algorithm
|
||||
|
||||
1. A patented technology with nonfree functionality that uses image identifiers in order to identify a similar image, even those clicked from different angles, sizes, depths and scale, that they are included in the search results. Check the detailed video on SIFT here.
|
||||
2. SIFT correctly matches the search criteria with a large database of features from many images.
|
||||
3. Matching same images with different viewpoints and matching invariant features to obtain search results is another SIFT feature. Read more about scale-invariant keypoints here.
|
||||
|
||||
#### SURF (Speeded Up Robust Features) Algorithm
|
||||
|
||||
1. [SURF][1] is also patented with nonfree functionality and a more ‘speeded’ up version of SIFT. Unlike SIFT, SURF approximates Laplacian of Gaussian (unlike SIFT) with Box Filter.
|
||||
|
||||
2. SURF relies on the determinant of Hessian Matrix for both its location and scale.
|
||||
|
||||
3. Rotation invariance is not a requisite in many applications. So not finding this orientation speeds up the process.
|
||||
|
||||
4. SURF includes several features that the speed improved in each step. Three times faster than SIFT, SURF is great with rotation and blurring. It is not as great in illumination and viewpoint change though.
|
||||
|
||||
5. Open CV, a programming function library provides SURF functionalities. SURF.compute() and SURF. Detect() can be used to find descriptors and keypoints. Read more about SURF [here][2].
|
||||
|
||||
### Open Source Algorithms
|
||||
|
||||
#### KAZE Algorithm
|
||||
|
||||
1.KAZE is a open source 2D multiscale and novel feature detection and description algorithm in nonlinear scale spaces. Efficient techniques in Additive Operator Splitting (AOS) and variable conductance diffusion is used to build the nonlinear scale space.
|
||||
|
||||
2. Multiscale image processing basics are simple – Creating an image’s scale space while filtering original image with right function over enhancing time or scale.
|
||||
|
||||
#### AKAZE (Accelerated-KAZE) Algorithm
|
||||
|
||||
1. As the name suggests, this is a faster mode to image search, finding matching keypoints between two images. AKAZE uses a binary descriptor and nonlinear scale space that balances accuracy and speed.
|
||||
|
||||
#### BRISK (Binary Robust Invariant Scalable Keypoints) Algorithm
|
||||
|
||||
1. BRISK is great for description, keypoint detection and matching.
|
||||
|
||||
2. An algorithm that is highly adaptive, scale-space FAST-based detector along with a bit-string descriptor, helps speed up the search significantly.
|
||||
|
||||
3. Scale-space keypoint detection and keypoint description helps optimize the performance with relation to the task at hand.
|
||||
|
||||
#### FREAK (Fast Retina Keypoint)
|
||||
|
||||
1. This is a novel keypoint descriptor inspired by the human eye.A binary strings cascade is efficiently computed by an image intensity comparison. The FREAK algorithm allows faster computing with lower memory load as compared to BRISK, SURF and SIFT.
|
||||
|
||||
#### ORB (Oriented FAST and Rotated BRIEF)
|
||||
|
||||
1.A fast binary descriptor, ORB is resistant to noise and rotation invariant. ORB builds on the FAST keypoint detector and the BRIEF descriptor, elements attributed to its low cost and good performance.
|
||||
|
||||
2. Apart from the fast and precise orientation component, efficiently computing the oriented BRIEF, analyzing variance and co-relation of oriented BRIEF features, is another ORB feature.
|
||||
|
||||
### Python Libraries
|
||||
|
||||
#### Open CV
|
||||
|
||||
1. OpenCV is available for both academic and commercial use. A open source machine learning and computer vision library, OpenCV makes it easy for organizations to utilize and modify code.
|
||||
|
||||
2. Over 2500 optimized algorithms, including state-of-the-art machine learning and computer vision algorithms serve various image search purposes – face detection, object identification, camera movement tracking, finding similar images from image database, following eye movements, scenery recognition, etc.
|
||||
|
||||
3. Top companies like Google, IBM, Yahoo, IBM, Sony, Honda, Microsoft and Intel make wide use of OpenCV.
|
||||
|
||||
4. OpenCV uses Python, Java, C, C++ and MATLAB interfaces while supporting Windows, Linux, Mac OS and Android.
|
||||
|
||||
#### Python Imaging Library (PIL)
|
||||
|
||||
1. The Python Imaging Library (PIL) supports several file formats while providing image processing and graphics solutions.The open source PIL adds image processing capabilities to your Python interpreter.
|
||||
2. The standard procedure for image manipulation include image enhancing, transparency and masking handling, image filtering, per-pixel manipulation, etc.
|
||||
|
||||
For detailed statistics and graphs, view the OpenCV 2.4.9 Features Comparison Report [here][3].
|
||||
|
||||
### Building an Image Search Engine
|
||||
|
||||
An image search engine helps pick similar images from a prepopulated set of image base. The most popular among these is Google’s well known image search engine. For starters, there are various approaches to build a system like this. To mention a few:
|
||||
|
||||
1.Using image extraction, image description extraction, meta data extraction and search result extraction to build an image search engine.
|
||||
2. Define your image descriptor, dataset indexing, define your similarity metric and then search and rank.
|
||||
3. Select image to be searched, select directory for carrying out search, search directory for all pictures, create picture feature index, evaluate same feature for search picture, match pictures in search and obtain matched pictures.
|
||||
|
||||
Our approach basically began with comparing grayscaled versions of the images, gradually moving on to complex feature matching algorithms like SIFT and SURF, and then finally settling down to am open source solution called BRISK. All these algorithms give efficient results with minor changes in performance and latency. An engine built on these algorithms have numerous applications like analyzing graphic data for popularity statistics, identification of objects in graphic contents, and many more.
|
||||
|
||||
**Example**: An image search engine needs to be build by an IT company for a client. So if a brand logo image is submitted in the search, all related brand image searches show up as results. The obtained results can also be used for analytics by the client, allowing them to estimate the brand popularity as per the geographic location. Its still early days though, RIQ or reverse image search has not been exploited to its full extent yet.
|
||||
|
||||
This concludes our article on building an image search engine using Python. Check our blog section out for the latest on technology and programming.
|
||||
|
||||
Statistics Source: OpenCV 2.4.9 Features Comparison Report (computer-vision-talks.com)
|
||||
|
||||
(Guidance and additional inputs by Ananthu Nair.)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cuelogic.com/blog/advanced-image-processing-with-python/
|
||||
|
||||
作者:[Snehith Kumbla][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cuelogic.com/blog/author/snehith-kumbla/
|
||||
[1]: http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html
|
||||
[2]: http://www.vision.ee.ethz.ch/~surf/eccv06.pdf
|
||||
[3]: https://docs.google.com/spreadsheets/d/1gYJsy2ROtqvIVvOKretfxQG_0OsaiFvb7uFRDu5P8hw/edit#gid=10
|
||||
@ -0,0 +1,101 @@
|
||||
How To Setup Open Source Discussion Platform Discourse On Ubuntu Linux 16.04
|
||||
===============================================================================
|
||||
|
||||
Discourse is an open source discussion platform, that can work as a mailing list, a chat room and a forum as well. It is a popular tool and modern day implementation of a successful discussion platform. On server side, it is built using Ruby on Rails and uses Postgres on the backend, it also makes use of Redis caching to reduce the loading times, while on client’s side end, it runs in browser using Java Script. It is a pretty well optimized and well structured tool. It also offers converter plugins to migrate your existing discussion boards / forums like vBulletin, phpBB, Drupal, SMF etc to Discourse. In this article, we will be learning how to install Discourse on Ubuntu operating system.
|
||||
|
||||
It is developed by keeping security in mind, so spammers and hackers might not be lucky with this application. It works well with all modern devices, and adjusts its display setting accordingly for mobile devices and tablets.
|
||||
|
||||
### Installing Discourse on Ubuntu 16.04
|
||||
|
||||
Let’s get started ! the minimum system RAM to run Discourse is 1 GB and the officially supported installation process for Discourse requires dockers to be installed on our Linux system. Besides dockers, it also requires Git. We can fulfill these two requirements by simply running the following command on our system’s terminal.
|
||||
|
||||
```
|
||||
wget -qO- https://get.docker.com/ | sh
|
||||
```
|
||||
|
||||

|
||||
|
||||
It shouldn’t take longer to complete the installation for Docker and Git, as soon its installation process is complete, create a directory for Discourse inside /var partition of your system (You can choose any other partition here too).
|
||||
|
||||
```
|
||||
mkdir /var/discourse
|
||||
```
|
||||
|
||||
Now clone the Discourse’s Github repository to this newly created directory.
|
||||
|
||||
```
|
||||
git clone https://github.com/discourse/discourse_docker.git /var/discourse
|
||||
```
|
||||
|
||||
Go into the cloned directory.
|
||||
|
||||
```
|
||||
cd /var/discourse
|
||||
```
|
||||
|
||||

|
||||
|
||||
You should be able to locate “discourse-setup” script file here, simply run this script to initiate the installation wizard for Discourse.
|
||||
|
||||
```
|
||||
./discourse-setup
|
||||
```
|
||||
|
||||
**Side note: Please make sure you have a ready email server setup before attempting install for discourse.**
|
||||
|
||||
Installation wizard will ask you following six questions.
|
||||
|
||||
```
|
||||
Hostname for your Discourse?
|
||||
Email address for admin account?
|
||||
SMTP server address?
|
||||
SMTP user name?
|
||||
SMTP port [587]:
|
||||
SMTP password? []:
|
||||
```
|
||||
|
||||

|
||||
|
||||
Once you supply these information, it will ask for the confirmation, if everything is fine, hit “Enter” and installation process will take off.
|
||||
|
||||

|
||||
|
||||
Sit back and relax! it will take sweet amount of time to complete the installation, grab a cup of coffee, and keep an eye for any error messages.
|
||||
|
||||

|
||||
|
||||
Here is how the successful completion of the installation process should look alike.
|
||||
|
||||

|
||||
|
||||
Now launch your web browser, if the hostname for discourse installation resolves properly to IP, then you can use your hostname in browser , otherwise use your IP address to launch the Discourse page. Here is what you should see:
|
||||
|
||||

|
||||
|
||||
That’s it, create new account by using “Sign Up” option and you should be good to go with your Discourse setup.
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
It is an easy to setup application and works flawlessly. It is equipped with all required features of modern day discussion board. It is available under General Public License and is 100% open source product. The simplicity, easy of use, powerful and long feature list are the most important feathers of this tool. Hope you enjoyed this article, Question? do let us know in comments please.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/aun/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,227 +0,0 @@
|
||||
Translating by cposture 2016.07.09
|
||||
Create Your Own Shell in Python : Part I
|
||||
|
||||
I’m curious to know how a shell (like bash, csh, etc.) works internally. So, I implemented one called yosh (Your Own SHell) in Python to answer my own curiosity. The concept I explain in this article can be applied to other languages as well.
|
||||
|
||||
(Note: You can find source code used in this blog post here. I distribute it with MIT license.)
|
||||
|
||||
Let’s start.
|
||||
|
||||
### Step 0: Project Structure
|
||||
|
||||
For this project, I use the following project structure.
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- __init__.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
`yosh_project` is the root project folder (you can also name it just `yosh`).
|
||||
|
||||
`yosh` is the package folder and `__init__.py` will make it a package named the same as the package folder name. (If you don’t write Python, just ignore it.)
|
||||
|
||||
`shell.py` is our main shell file.
|
||||
|
||||
### Step 1: Shell Loop
|
||||
|
||||
When you start a shell, it will show a command prompt and wait for your command input. After it receives the command and executes it (the detail will be explained later), your shell will be back to the wait loop for your next command.
|
||||
|
||||
In `shell.py`, we start by a simple main function calling the shell_loop() function as follows:
|
||||
|
||||
```
|
||||
def shell_loop():
|
||||
# Start the loop here
|
||||
|
||||
|
||||
def main():
|
||||
shell_loop()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
Then, in our `shell_loop()`, we use a status flag to indicate whether the loop should continue or stop. In the beginning of the loop, our shell will show a command prompt and wait to read command input.
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
SHELL_STATUS_RUN = 1
|
||||
SHELL_STATUS_STOP = 0
|
||||
|
||||
|
||||
def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
# Display a command prompt
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
# Read command input
|
||||
cmd = sys.stdin.readline()
|
||||
```
|
||||
|
||||
After that, we tokenize the command input and execute it (we’ll implement the tokenize and execute functions soon).
|
||||
|
||||
Therefore, our shell_loop() will be the following.
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
SHELL_STATUS_RUN = 1
|
||||
SHELL_STATUS_STOP = 0
|
||||
|
||||
|
||||
def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
# Display a command prompt
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
# Read command input
|
||||
cmd = sys.stdin.readline()
|
||||
|
||||
# Tokenize the command input
|
||||
cmd_tokens = tokenize(cmd)
|
||||
|
||||
# Execute the command and retrieve new status
|
||||
status = execute(cmd_tokens)
|
||||
```
|
||||
|
||||
That’s all of our shell loop. If we start our shell with python shell.py, it will show the command prompt. However, it will throw an error if we type a command and hit enter because we don’t define tokenize function yet.
|
||||
|
||||
To exit the shell, try ctrl-c. I will tell how to exit gracefully later.
|
||||
|
||||
### Step 2: Tokenization
|
||||
|
||||
When a user types a command in our shell and hits enter. The command input will be a long string containing both a command name and its arguments. Therefore, we have to tokenize it (split a string into several tokens).
|
||||
|
||||
It seems simple at first glance. We might use cmd.split() to separate the input by spaces. It works well for a command like `ls -a my_folder` because it splits the command into a list `['ls', '-a', 'my_folder']` which we can use them easily.
|
||||
|
||||
However, there are some cases that some arguments are quoted with single or double quotes like `echo "Hello World"` or `echo 'Hello World'`. If we use cmd.split(), we will get a list of 3 tokens `['echo', '"Hello', 'World"']` instead of 2 tokens `['echo', 'Hello World']`.
|
||||
|
||||
Fortunately, Python provides a library called shlex that helps us split like a charm. (Note: we can also use regular expression but it’s not the main point of this article.)
|
||||
|
||||
```
|
||||
import sys
|
||||
import shlex
|
||||
|
||||
...
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
Then, we will send these tokens to the execution process.
|
||||
|
||||
### Step 3: Execution
|
||||
|
||||
This is the core and fun part of a shell. What happened when a shell executes mkdir test_dir? (Note: mkdir is a program to be executed with arguments test_dir for creating a directory named test_dir.)
|
||||
|
||||
The first function involved in this step is execvp. Before I explain what execvp does, let’s see it in action.
|
||||
|
||||
```
|
||||
import os
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Execute command
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
|
||||
# Return status indicating to wait for next command in shell_loop
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
Try running our shell again and input a command `mkdir test_dir`, then, hit enter.
|
||||
|
||||
The problem is, after we hit enter, our shell exits instead of waiting for the next command. However, the directory is correctly created.
|
||||
|
||||
So, what execvp really does?
|
||||
|
||||
execvp is a variant of a system call exec. The first argument is the program name. The v indicates the second argument is a list of program arguments (variable number of arguments). The p indicates the PATH environment will be used for searching for the given program name. In our previous attempt, the mkdir program was found based on your PATH environment variable.
|
||||
|
||||
(There are other variants of exec such as execv, execvpe, execl, execlp, execlpe; you can google them for more information.)
|
||||
|
||||
exec replaces the current memory of a calling process with a new process to be executed. In our case, our shell process memory was replaced by `mkdir` program. Then, mkdir became the main process and created the test_dir directory. Finally, its process exited.
|
||||
|
||||
The main point here is that our shell process was replaced by mkdir process already. That’s the reason why our shell disappeared and did not wait for the next command.
|
||||
|
||||
Therefore, we need another system call to rescue: fork.
|
||||
|
||||
fork will allocate new memory and copy the current process into a new process. We called this new process as child process and the caller process as parent process. Then, the child process memory will be replaced by a execed program. Therefore, our shell, which is a parent process, is safe from memory replacement.
|
||||
|
||||
Let’s see our modified code.
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Fork a child shell process
|
||||
# If the current process is a child process, its `pid` is set to `0`
|
||||
# else the current process is a parent process and the value of `pid`
|
||||
# is the process id of its child process.
|
||||
pid = os.fork()
|
||||
|
||||
if pid == 0:
|
||||
# Child process
|
||||
# Replace the child shell process with the program called with exec
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
elif pid > 0:
|
||||
# Parent process
|
||||
while True:
|
||||
# Wait response status from its child process (identified with pid)
|
||||
wpid, status = os.waitpid(pid, 0)
|
||||
|
||||
# Finish waiting if its child process exits normally
|
||||
# or is terminated by a signal
|
||||
if os.WIFEXITED(status) or os.WIFSIGNALED(status):
|
||||
break
|
||||
|
||||
# Return status indicating to wait for next command in shell_loop
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
When the parent process call `os.fork()`, you can imagine that all source code is copied into a new child process. At this point, the parent and child process see the same code and run in parallel.
|
||||
|
||||
If the running code is belong to the child process, pid will be 0. Else, the running code is belong to the parent process, pid will be the process id of the child process.
|
||||
|
||||
When os.execvp is invoked in the child process, you can imagine like all the source code of the child process is replaced by the code of a program that is being called. However, the code of the parent process is not changed.
|
||||
|
||||
When the parent process finishes waiting its child process to exit or be terminated, it returns the status indicating to continue the shell loop.
|
||||
|
||||
### Run
|
||||
|
||||
Now, you can try running our shell and enter mkdir test_dir2. It should work properly. Our main shell process is still there and waits for the next command. Try ls and you will see the created directories.
|
||||
|
||||
However, there are some problems here.
|
||||
|
||||
First, try cd test_dir2 and then ls. It’s supposed to enter the directory test_dir2 which is an empty directory. However, you will see that the directory was not changed into test_dir2.
|
||||
|
||||
Second, we still have no way to exit from our shell gracefully.
|
||||
|
||||
We will continue to solve such problems in [Part 2][1].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/
|
||||
@ -1,216 +0,0 @@
|
||||
Translating by cposture 2016.07.09
|
||||
Create Your Own Shell in Python - Part II
|
||||
===========================================
|
||||
|
||||
In [part 1][1], we already created a main shell loop, tokenized command input, and executed a command by fork and exec. In this part, we will solve the remaining problmes. First, `cd test_dir2` does not change our current directory. Second, we still have no way to exit from our shell gracefully.
|
||||
|
||||
### Step 4: Built-in Commands
|
||||
|
||||
The statement “cd test_dir2 does not change our current directory” is true and false in some senses. It’s true in the sense that after executing the command, we are still at the same directory. However, the directory is actullay changed, but, it’s changed in the child process.
|
||||
|
||||
Remember that we fork a child process, then, exec the command which does not happen on a parent process. The result is we just change the current directory of a child process, not the directory of a parent process.
|
||||
|
||||
Then, the child process exits, and the parent process continues with the same intact directory.
|
||||
|
||||
Therefore, this kind of commands must be built-in with the shell itself. It must be executed in the shell process without forking.
|
||||
|
||||
#### cd
|
||||
|
||||
Let’s start with cd command.
|
||||
|
||||
We first create a builtins directory. Each built-in command will be put inside this directory.
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
|-- __init__.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
In cd.py, we implement our own cd command by using a system call os.chdir.
|
||||
|
||||
```
|
||||
import os
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def cd(args):
|
||||
os.chdir(args[0])
|
||||
|
||||
return SHELL_STATUS_RUN
|
||||
```
|
||||
|
||||
Notice that we return shell running status from a built-in function. Therefore, we move constants into yosh/constants.py to be used across the project.
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
|-- __init__.py
|
||||
|-- constants.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
In constants.py, we put shell status constants here.
|
||||
|
||||
```
|
||||
SHELL_STATUS_STOP = 0
|
||||
SHELL_STATUS_RUN = 1
|
||||
```
|
||||
|
||||
Now, our built-in cd is ready. Let’s modify our shell.py to handle built-in functions.
|
||||
|
||||
```
|
||||
...
|
||||
# Import constants
|
||||
from yosh.constants import *
|
||||
|
||||
# Hash map to store built-in function name and reference as key and value
|
||||
built_in_cmds = {}
|
||||
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Extract command name and arguments from tokens
|
||||
cmd_name = cmd_tokens[0]
|
||||
cmd_args = cmd_tokens[1:]
|
||||
|
||||
# If the command is a built-in command, invoke its function with arguments
|
||||
if cmd_name in built_in_cmds:
|
||||
return built_in_cmds[cmd_name](cmd_args)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
We use a Python dictionary built_in_cmds as a hash map to store our built-in functions. In execute function, we extract command name and arguments. If the command name is in our hash map, we call that built-in function.
|
||||
|
||||
(Note: built_in_cmds[cmd_name] returns the function reference that can be invoked with arguments immediately.)
|
||||
|
||||
We are almost ready to use the built-in cd function. The last thing is to add cd function into the built_in_cmds map.
|
||||
|
||||
```
|
||||
...
|
||||
# Import all built-in function references
|
||||
from yosh.builtins import *
|
||||
|
||||
...
|
||||
|
||||
# Register a built-in function to built-in command hash map
|
||||
def register_command(name, func):
|
||||
built_in_cmds[name] = func
|
||||
|
||||
|
||||
# Register all built-in commands here
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
|
||||
|
||||
def main():
|
||||
# Init shell before starting the main loop
|
||||
init()
|
||||
shell_loop()
|
||||
```
|
||||
|
||||
We define register_command function for adding a built-in function to our built-in commmand hash map. Then, we define init function and register the built-in cd function there.
|
||||
|
||||
Notice the line register_command("cd", cd). The first argument is a command name. The second argument is a reference to a function. In order to let cd, in the second argument, refer to the cd function reference in yosh/builtins/cd.py, we have to put the following line in yosh/builtins/__init__.py.
|
||||
|
||||
```
|
||||
from yosh.builtins.cd import *
|
||||
```
|
||||
Therefore, in yosh/shell.py, when we import * from yosh.builtins, we get cd function reference that is already imported by yosh.builtins.
|
||||
|
||||
We’ve done preparing our code. Let’s try by running our shell as a module python -m yosh.shell at the same level as the yosh directory.
|
||||
|
||||
Now, our cd command should change our shell directory correctly while non-built-in commands still work too. Cool.
|
||||
|
||||
#### exit
|
||||
|
||||
Here comes the last piece: to exit gracefully.
|
||||
|
||||
We need a function that changes the shell status to be SHELL_STATUS_STOP. So, the shell loop will naturally break and the shell program will end and exit.
|
||||
|
||||
As same as cd, if we fork and exec exit in a child process, the parent process will still remain inact. Therefore, the exit function is needed to be a shell built-in function.
|
||||
|
||||
Let’s start by creating a new file called exit.py in the builtins folder.
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
| |-- exit.py
|
||||
|-- __init__.py
|
||||
|-- constants.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
The exit.py defines the exit function that just returns the status to break the main loop.
|
||||
|
||||
```
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def exit(args):
|
||||
return SHELL_STATUS_STOP
|
||||
```
|
||||
|
||||
Then, we import the exit function reference in `yosh/builtins/__init__.py`.
|
||||
|
||||
```
|
||||
from yosh.builtins.cd import *
|
||||
from yosh.builtins.exit import *
|
||||
```
|
||||
|
||||
Finally, in shell.py, we register the exit command in `init()` function.
|
||||
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
# Register all built-in commands here
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
register_command("exit", exit)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
That’s all!
|
||||
|
||||
Try running python -m yosh.shell. Now you can enter exit to quit the program gracefully.
|
||||
|
||||
### Final Thought
|
||||
|
||||
I hope you enjoy creating yosh (your own shell) like I do. However, my version of yosh is still in an early stage. I don’t handle several corner cases that can corrupt the shell. There are a lot of built-in commands that I don’t cover. Some non-built-in commands can also be implemented as built-in commands to improve performance (avoid new process creation time). And, a ton of features are not yet implemented (see Common features and Differing features).
|
||||
|
||||
I’ve provided the source code at github.com/supasate/yosh. Feel free to fork and play around.
|
||||
|
||||
Now, it’s your turn to make it real Your Own SHell.
|
||||
|
||||
Happy Coding!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
[2]: http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html
|
||||
[3]: http://www.tldp.org/LDP/intro-linux/html/x12249.html
|
||||
[4]: https://github.com/supasate/yosh
|
||||
123
sources/tech/20160706 What is Git.md
Normal file
123
sources/tech/20160706 What is Git.md
Normal file
@ -0,0 +1,123 @@
|
||||
translating by cvsher
|
||||
What is Git
|
||||
===========
|
||||
|
||||
Welcome to my series on learning how to use the Git version control system! In this introduction to the series, you will learn what Git is for and who should use it.
|
||||
|
||||
If you're just starting out in the open source world, you're likely to come across a software project that keeps its code in, and possibly releases it for use, by way of Git. In fact, whether you know it or not, you're certainly using software right now that is developed using Git: the Linux kernel (which drives the website you're on right now, if not the desktop or mobile phone you're accessing it on), Firefox, Chrome, and many more projects share their codebase with the world in a Git repository.
|
||||
|
||||
On the other hand, all the excitement and hype over Git tends to make things a little muddy. Can you only use Git to share your code with others, or can you use Git in the privacy of your own home or business? Do you have to have a GitHub account to use Git? Why use Git at all? What are the benefits of Git? Is Git the only option?
|
||||
|
||||
So forget what you know or what you think you know about Git, and let's take it from the beginning.
|
||||
|
||||
### What is version control?
|
||||
|
||||
Git is, first and foremost, a version control system (VCS). There are many version control systems out there: CVS, SVN, Mercurial, Fossil, and, of course, Git.
|
||||
|
||||
Git serves as the foundation for many services, like GitHub and GitLab, but you can use Git without using any other service. This means that you can use Git privately or publicly.
|
||||
|
||||
If you have ever collaborated on anything digital with anyone, then you know how it goes. It starts out simple: you have your version, and you send it to your partner. They make some changes, so now there are two versions, and send the suggestions back to you. You integrate their changes into your version, and now there is one version again.
|
||||
|
||||
Then it gets worse: while you change your version further, your partner makes more changes to their version. Now you have three versions; the merged copy that you both worked on, the version you changed, and the version your partner has changed.
|
||||
|
||||
As Jason van Gumster points out in his article, 【Even artists need version control][1], this syndrome tends to happen in individual settings as well. In both art and science, it's not uncommon to develop a trial version of something; a version of your project that might make it a lot better, or that might fail miserably. So you create file names like project_justTesting.kdenlive and project_betterVersion.kdenlive, and then project_best_FINAL.kdenlive, but with the inevitable allowance for project_FINAL-alternateVersion.kdenlive, and so on.
|
||||
|
||||
Whether it's a change to a for loop or an editing change, it happens to the best of us. That is where a good version control system makes life easier.
|
||||
|
||||
### Git snapshots
|
||||
|
||||
Git takes snapshots of a project, and stores those snapshots as unique versions.
|
||||
|
||||
If you go off in a direction with your project that you decide was the wrong direction, you can just roll back to the last good version and continue along an alternate path.
|
||||
|
||||
If you're collaborating, then when someone sends you changes, you can merge those changes into your working branch, and then your collaborator can grab the merged version of the project and continue working from the new current version.
|
||||
|
||||
Git isn't magic, so conflicts do occur ("You changed the last line of the book, but I deleted that line entirely; how do we resolve that?"), but on the whole, Git enables you to manage the many potential variants of a single work, retaining the history of all the changes, and even allows for parallel versions.
|
||||
|
||||
### Git distributes
|
||||
|
||||
Working on a project on separate machines is complex, because you want to have the latest version of a project while you work, makes your own changes, and share your changes with your collaborators. The default method of doing this tends to be clunky online file sharing services, or old school email attachments, both of which are inefficient and error-prone.
|
||||
|
||||
Git is designed for distributed development. If you're involved with a project you can clone the project's Git repository, and then work on it as if it was the only copy in existence. Then, with a few simple commands, you can pull in any changes from other contributors, and you can also push your changes over to someone else. Now there is no confusion about who has what version of a project, or whose changes exist where. It is all locally developed, and pushed and pulled toward a common target (or not, depending on how the project chooses to develop).
|
||||
|
||||
### Git interfaces
|
||||
|
||||
In its natural state, Git is an application that runs in the Linux terminal. However, as it is well-designed and open source, developers all over the world have designed other ways to access it.
|
||||
|
||||
It is free, available to anyone for $0, and comes in packages on Linux, BSD, Illumos, and other Unix-like operating systems. It looks like this:
|
||||
|
||||
```
|
||||
$ git --version
|
||||
git version 2.5.3
|
||||
```
|
||||
|
||||
Probably the most well-known Git interfaces are web-based: sites like GitHub, the open source GitLab, Savannah, BitBucket, and SourceForge all offer online code hosting to maximise the public and social aspect of open source along with, in varying degrees, browser-based GUIs to minimise the learning curve of using Git. This is what the GitLab interface looks like:
|
||||
|
||||
|
||||
|
||||
Additionally, it is possible that a Git service or independent developer may even have a custom Git frontend that is not HTML-based, which is particularly handy if you don't live with a browser eternally open. The most transparent integration comes in the form of file manager support. The KDE file manager, Dolphin, can show the Git status of a directory, and even generate commits, pushes, and pulls.
|
||||
|
||||
|
||||
|
||||
[Sparkleshare][2] uses Git as a foundation for its own Dropbox-style file sharing interface.
|
||||
|
||||
|
||||
|
||||
For more, see the (long) page on the official [Git wiki][3] listing projects with graphical interfaces to Git.
|
||||
|
||||
### Who should use Git?
|
||||
|
||||
You should! The real question is when? And what for?
|
||||
|
||||
### When should I use Git, and what should I use it for?
|
||||
|
||||
To get the most out of Git, you need to think a little bit more than usual about file formats.
|
||||
|
||||
Git is designed to manage source code, which in most languages consists of lines of text. Of course, Git doesn't know if you're feeding it source code or the next Great American Novel, so as long as it breaks down to text, Git is a great option for managing and tracking versions.
|
||||
|
||||
But what is text? If you write something in an office application like Libre Office, then you're probably not generating raw text. There is usually a wrapper around complex applications like that which encapsulate the raw text in XML markup and then in a zip container, as a way to ensure that all of the assets for your office file are available when you send that file to someone else. Strangely, though, something that you might expect to be very complex, like the save files for a [Kdenlive][4] project, or an SVG from [Inkscape][5], are actually raw XML files that can easily be managed by Git.
|
||||
|
||||
If you use Unix, you can check to see what a file is made of with the file command:
|
||||
|
||||
```
|
||||
$ file ~/path/to/my-file.blah
|
||||
my-file.blah: ASCII text
|
||||
$ file ~/path/to/different-file.kra: Zip data (MIME type "application/x-krita")
|
||||
```
|
||||
|
||||
If unsure, you can view the contents of a file with the head command:
|
||||
|
||||
```
|
||||
$ head ~/path/to/my-file.blah
|
||||
```
|
||||
|
||||
If you see text that is mostly readable by you, then it is probably a file made of text. If you see garbage with some familiar text characters here and there, it is probably not made of text.
|
||||
|
||||
Make no mistake: Git can manage other formats of files, but it treats them as blobs. The difference is that in a text file, two Git snapshots (or commits, as we call them) might be, say, three lines different from each other. If you have a photo that has been altered between two different commits, how can Git express that change? It can't, really, because photographs are not made of any kind of sensible text that can just be inserted or removed. I wish photo editing were as easy as just changing some text from "<sky>ugly greenish-blue</sky>" to "<sky>blue-with-fluffy-clouds</sky>" but it truly is not.
|
||||
|
||||
People check in blobs, like PNG icons or a speadsheet or a flowchart, to Git all the time, so if you're working in Git then don't be afraid to do that. Know that it's not sensible to do that with huge files, though. If you are working on a project that does generate both text files and large blobs (a common scenario with video games, which have equal parts source code to graphical and audio assets), then you can do one of two things: either invent your own solution, such as pointers to a shared network drive, or use a Git add-on like Joey Hess's excellent [git annex][6], or the [Git-Media][7] project.
|
||||
|
||||
So you see, Git really is for everyone. It is a great way to manage versions of your files, it is a powerful tool, and it is not as scary as it first seems.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/resources/what-is-git
|
||||
|
||||
作者:[Seth Kenlon ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://opensource.com/life/16/2/version-control-isnt-just-programmers
|
||||
[2]: http://sparkleshare.org/
|
||||
[3]: https://git.wiki.kernel.org/index.php/InterfacesFrontendsAndTools#Graphical_Interfaces
|
||||
[4]: https://opensource.com/life/11/11/introduction-kdenlive
|
||||
[5]: http://inkscape.org/
|
||||
[6]: https://git-annex.branchable.com/
|
||||
[7]: https://github.com/alebedev/git-media
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
Translated by FrankXinqi
|
||||
|
||||
Linus Torvalds作为一个老板有多么糟糕?
|
||||
================================================================================
|
||||

|
||||
|
||||
*1999 年 8 月 10 日,加利福尼亚州圣何塞市,在 LinuxWorld Show 上 Linus Torvalds 在一个坐满 Linux 爱好者的礼堂中发表了一篇演讲。作者:James Niccolai*
|
||||
|
||||
**这取决于所处的领域。在软件开发的世界中,他变得更加平庸。问题是,这种情况是否应该被允许继续?**
|
||||
|
||||
Linus Torvalds 是 Linux 的发明者,我认识他超过 20 年了。我们不是密友,但是我们欣赏彼此。
|
||||
|
||||
最近,因为 Linus Torvalds 的管理风格,他正遭到严厉的炮轰。Linus 无法忍受胡来的人。「代码的质量有多好?」是他在 Linux 内核的开发过程中评判人的一种方式。
|
||||
|
||||
没有什么比这个更重要了。正如 Linus 今年(1999年)早些时候在 Linux.conf.au 会议上说的那样,「我不是一个友好的人,并且我不关心你。对我重要的是『[我所关心的技术和内核][1]』。」
|
||||
|
||||
现在我也可以和这只关心技术的这一类人打交道了。如果你不能,你应当避免参加 Linux 内核会议,因为在那里你会遇到许多有这种精英思想的人。这不代表我认为在 Linux 领域所有东西都是极好的,并且应该不受其他影响的来激起改变。我能够一起生活的一个精英;在一个男性做主导的大城堡中遇到的问题是,女性经常受到蔑视和无礼的对待。
|
||||
|
||||
这就是我看到的最近关于 Linus 管理风格所引发社会争吵的原因 -- 或者更准确的说,他对于个人管理方面是完全冷漠的 -- 就像不过是在软件开发世界的标准操作流程一样。与此同时,我看到了另外一个非常需要被改变的事实,它必须作为证据公开。
|
||||
|
||||
第一次是在 [Linux 4.3 发布][2]的时候出现的这个情况,Linus 使用 Linux 内核邮件列表来狠狠的攻击一个插入了非常糟糕并且没有价值的网络代码的开发者。「[这段代码导致了非常糟糕并且没有价值的代码。][3]这看起来太糟糕了,并且完全没有理由这样做。」当他说到这里的时候,他沉默了很长时间。除了使用「非常糟糕并且没有价值」这个词,他在早期使用「愚蠢的」这个同义词是相对较好的。
|
||||
|
||||
但是,事情就是这样。Linus 是对的。我读了代码后,发现代码确实很烂并且开发者是为了使用新的「overflow_usub()」 函数而使用的。
|
||||
|
||||
现在,一些人把 Linus 的这种谩骂的行为看作他脾气不好而且恃强凌弱的证据。我见过一个完美主义者,在他的领域中,他无法忍受这种糟糕。
|
||||
|
||||
许多人告诉我,这不是一个专业的程序员应当有的行为。人们,你曾经和最优秀的开发者一起工作过吗?据我所知道的,在 Apple,Microsoft,Oracle 这就是他们的行为。
|
||||
|
||||
我曾经听过 Steve Jobs 攻击一个开发者,像把他撕成碎片那样。我大为不快,当一个 Oracle 的高级开发者攻击一屋子的新开发者的时候就像食人鱼穿过一群金鱼那样。
|
||||
|
||||
在意外的电脑帝国,在 Robert X. Cringely 关于 PCs 崛起的经典书籍中,他这样描述 Bill Gates 的微软软件管理风格,Bill Gates 像计算机系统一样管理他们,『比尔盖茨是最高等级,从他开始每一个等级依次递减,上级会向下级叫嚷,刺激他们,甚至羞辱他们。』
|
||||
|
||||
Linus 和所有大型的私有软件公司的领导人不同的是,Linus 说在这里所有的东西是向全世界公开的。而其他人是在私有的会议室中做东西的。我听有人说 Linus 在那种公司中可能会被开除。这是不可能的。他会在正确的地方就像现在这样,他在编程世界的最顶端。
|
||||
|
||||
但是,这里有另外一个不同。如果 Larry Ellison (Oracle的首席执行官)向你发火,你就别想在这里干了。如果 Linus 向你发火,你会在邮件中收到他的责骂。这就是差别。
|
||||
|
||||
你知道的,Linus 不是任何人的老板。他完全没有雇佣和解聘的权利,他只是负责着有 10,000 个贡献者的一个项目而已。他仅仅能做的就是从心理上伤害你。
|
||||
|
||||
这说明,在开源软件开发圈和私有软件开发圈中同时存在一个非常严重的问题。不管你是一个多么好的编程者,如果你是一个女性,你的这个身份就是对你不利的。
|
||||
|
||||
这种情况并没有在 Sarah Sharp 的身上有任何好转,她现在是一个Intel的开发者,以前是一个顶尖的Linux程序员。[在她博客10月份的一个帖子中][4],她解释道:『我最终发现,我不能够再为Linux社区做出贡献了。因为在在那里,我虽然能够得到技术上的尊重,却得不到个人的尊重……我不想专职于同那些轻微的性别歧视者或开同性恋玩笑的人一起工作。』
|
||||
|
||||
谁能责怪她呢?我不能。我非常伤心的说,Linus 就像所有我见过的软件经理一样,是他造成了这种不利的工作环境。
|
||||
|
||||
他可能会说,确保 Linux 的贡献者都表现出专业精神和相互尊重不应该是他的工作。除了代码以外,他不关系任何其他事情。
|
||||
|
||||
就像Sarah Sharp写的那样:
|
||||
|
||||
|
||||
> 我对于 Linux 内核社区做出的技术努力表现出非常的尊重。他们在那维护一些最高标准的代码,以此来平衡并且发展一个项目。他们专注于优秀的技术,却带有过量的维护人员,他们有不同的文化背景和社会规范,这些意味着这些 Linux 内核维护者说话非常直率,粗鲁或者为了完成他们的任务而不讲道理。顶尖的 Linux 内核开发者经常为了使别人改正行为而向他们大喊大叫。
|
||||
>
|
||||
> 这种事情发生在我身上,但它不是一种有效的沟通方式。
|
||||
>
|
||||
> 许多高级的 Linux 内核开发者支持那些技术上和人性上不讲道理的维护者的权利。即使他们是非常友好的人,他们不想看到 Linux 内核交流方式改变。
|
||||
|
||||
她是对的。
|
||||
|
||||
我和其他调查者不同的是,我不认为这个问题对于 Linux 或开源社区在任何方面有特殊之处。作为一个从事技术商业工作超过五年和有着 25 年技术工作经历的记者,我随处可见这种不成熟的男孩的行为。
|
||||
|
||||
这不是 Linus 的错误。他不是一个经理,他是一个有想象力的技术领导者。看起来真正的问题是,在软件开发领域没有人能够用一种支持的语气来对待团队和社区。
|
||||
|
||||
展望未来,我希望像 Linux Foundation 这样的公司和组织,能够找到一种方式去授权社区经理或其他经理来鼓励并且强制实施民主的行为。
|
||||
|
||||
非常遗憾的是,我们不能够在我们这种纯技术或纯商业的领导人中找到这种管理策略。它不存在于这些人的基因中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[FrankXinqi](https://github.com/FrankXinqi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
@ -0,0 +1,48 @@
|
||||
|
||||
Linus Torvalds 谈及物联网,智能设备,安全连接等问题[video]
|
||||
===========================================================================
|
||||
|
||||

|
||||
>Dirk Hohndel 在嵌入式大会上采访 Linus Torvalds 。
|
||||
|
||||
|
||||
[嵌入式大会(Embedded Linux Conference)][0] 从在 San Diego 【译注:圣迭戈,美国加利福尼亚州的一个太平洋沿岸城市。】开始举办到现在已经有 11 年了,在 4 月 4 日到 6 日,Linus Torvalds 加入了会议的主题讨论。他是 Linux 内核的缔造者和最高决策者,也是“我们都在这里的原因”,在采访他的对话中,英特尔的 Linux 和开源技术总监 Dirk Hohndel 谈到了 Linux 在嵌入式和物联网应用程序领域的快速发展前景。Torvalds 很少出席嵌入式 Linux 大会,这些大会经常被 Linux 桌面、服务器和云技术夺去光芒。
|
||||

|
||||
>Linus Torvalds 在嵌入式 Linux 大会上的演讲。
|
||||
|
||||
|
||||
物联网是嵌入式大会的主题,也包括未来开放物联网的最高发展方向(OpenIoT Summit),这是采访 Torvalds 的主要话题。
|
||||
|
||||
Torvalds 对 Hohndel 说到,“或许你不会在物联网设备上看到 Linux 的影子,但是在你有一个核心设备的时候,你就会需要它。你需要智能设备尤其在你有 23 [物联网标准]的时候。如果你全部使用低级设备,它们没必要一定运行 Linux ,它们采用的标准稍微有点不同,所以你需要很多智能设备。我们将来也不会有一个完全开放的标准,只是给它一个统一的标准,但是你将会需要 4 分之 3 的主要协议,它们都是这些智能核心的转化形式。”
|
||||
|
||||
当 Hohndel 问及在物联网的巨大安全漏洞的时候, Torvalds 神情如常。他说:“我不担心安全问题因为我们能做的不是很多,物联网如果遭受攻击是无法挽回的-这是事实。"
|
||||
|
||||
Linux 缔造者看起来更关心的是一次性的嵌入式项目缺少及时的上游贡献,尽管他注意到近年来这些都有一些本质上的提升,特别是在硬件上的发展。
|
||||
|
||||
Torvalds 说:”嵌入式领域历来就很难与开源开发者有所联系,但是我认为这些都在发生改变,ARM 团队也已经很优秀了。内核维护者事实上也看到了硬件性能的提升。一切都在变好,但是昨天却不是这样的。”
|
||||
|
||||
Torvalds 承认他在家经常使用桌面系统而不是嵌入式系统,并且在使用硬件的时候他有“两只左手”。
|
||||
|
||||
“我已经用电烙铁弄坏了很多东西。”他说到。“我真的不适合搞硬件开发。”;另一方面,Torvalds 设想如果他现在是个年轻人,他可能被 Raspberry Pi(树莓派) 和 BeagleBone(猎兔犬板)【译注:Beagle板实际是由TI支持的一个以教育(STEP)为目的的开源项目】欺骗。“最主要是原因是如果你善于焊接,那么你就仅仅是买到了一个新的板子。”
|
||||
|
||||
同时,Torvalds 也承诺他要为 Linux 桌面再奋斗一个 25 年。他笑着说:“我要为它工作一生。”
|
||||
|
||||
下面,请看完整视频。
|
||||
|
||||
获取关于嵌入式 Linux 和物联网的最新信息。进入 2016 年嵌入式 Linux 大会 150+ 分钟的会议全程。[现在观看][1].
|
||||
[video](https://youtu.be/tQKUWkR-wtM)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[0]: http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[1]: http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom
|
||||
|
||||
58
translated/talk/20160531 The Anatomy of a Linux User.md
Normal file
58
translated/talk/20160531 The Anatomy of a Linux User.md
Normal file
@ -0,0 +1,58 @@
|
||||
|
||||
|
||||
一个 Linux 用户的故事
|
||||
================================
|
||||
|
||||
|
||||
|
||||
**一些新的 GNU/Linux 用户都很清楚的知道 Linux 不是 Windows .其他很多人都不是很清楚的知道.最好的发行版设计者努力保持新的思想**
|
||||
|
||||
### Linux 的核心
|
||||
|
||||
不管怎么说,Nicky 都不是那种表面上看起来很值得注意的人.她已经三十岁了,却决定回到学校学习.她在海军待了6年时间直到她的老友给她一份新的工作,而且这份工作比她在军队的工作还好.在过去的军事分支服务期间发生了很多事情.我认识她还是她在军队工作的时候.她是8个州的货车运输业协商区域的管理者.那会我在达拉斯跑肉品包装工具的运输.
|
||||

|
||||
|
||||
|
||||
Nicky 和我在 2006 年成为了好朋友.她很外向,并且有很强的好奇心,她几乎走过每个运输商走的路线.一个星期五晚上我们在灯光下有一场很激烈的争论,像这样的 达 30 分钟的争论在我们之间并不少见.或许这并不比油漆一个球场省事,但是气氛还是可以控制的住的,感觉就像是一个很恐怖的游戏.在这次争论的时候她问到我是否可以修复她的电脑.
|
||||
|
||||
她知道我为了一些贫穷的孩子能拥有他们自己的电脑做出的努力,当她抱怨她的电脑很慢的时候,我提到了参加 Bill Gate 的 401k 计划[译注:这个计划是为那些为内部收益代码做过贡献的人们提供由税收定义的养老金账户.].Nicky 说这是了解 Linux 的最佳时间.
|
||||
|
||||
她的电脑相当好,它是一个带有 Dell 19 显示器的华硕电脑.不好的是,当不需要一些东西的时候,这个 Windows 电脑会强制性的显示所有的工具条和文本菜单.我们把电脑上的文件都做了备份之后就开始安装 Linux 了.我们一起完成了安装,并且我确信她知道了如何分区.不到一个小时,她的电脑上就有了一个漂亮的 PCLinuxOS 桌面.
|
||||
|
||||
她会经常谈论她使用新系统的方法,系统看起来多么漂亮.她不曾提及的是,她几乎被她面前的井然有序的漂亮桌面吸引.她说她的桌面带有漂亮的"微光".这是我在安装系统期间特意设置的.我每次在安装 Linux 的时候都会进行这样的配置.我想让每个 Linux 用户的桌面都配置这个漂亮的微光.
|
||||
|
||||
大概第一周左右,她给我打电话或者发邮件问了一些常规的问题,但是最主要的问题还是她想知道怎样保存她打开的 Office 文件(OpenOffice)以至于她的同事也可以读这些文件.教一个人使用 Linux 或者 Open/LibreOffice 的时候最重要的就是教她保存文件.大多数用户仅仅看到第一个提示,只需要手指轻轻一点就可以以打开文件模式( Open Document Format )保存.
|
||||
|
||||
|
||||
大约一年前或者更久,一个高中生说他没有通过期末考试,因为教授不能打开他写着论文的文件.这引来不能决定谁对谁错的读者的激烈评论.这个高中生和教授都不知道这件事该怪谁.
|
||||
|
||||
我知道一些大学教授甚至每个人都能够打开一个 ODF 文件.见鬼,很少有像微软这样优秀的公司,我想 Microsoft Office 现在已经能打开 ODT 或者 ODF 文件了.我也不能确保,毕竟我最近一次用 Microsoft Office 是在 2005 年.
|
||||
|
||||
甚至在困难时期,当 Microsoft 很受欢迎并且很热衷于为使用他们系统的厂商的企业桌面上安装他们自己的软件的时候,我和一些使用 Microsoft Office 的用户的产品生意和合作从来没有出现过问题,因为我会提前想到可能出现的问题并且不会有侥幸心理.我会发邮件给他们询问他们正在使用的 Office 版本.这样,我就可以确保以他们能够读写的格式保存文件.
|
||||
|
||||
说到 Nicky ,她花了很多时间学习她的 Linux 系统.我很惊奇于她的热情.
|
||||
|
||||
当人们意识到所有的使用 Windows 的习惯和工具都要被抛弃的时候,学习 Linux 系统也会很容易.甚至在我们谈论第一次用的系统时,我查看这些系统的桌面或者下载文件夹大多都找不到 some_dodgy_file.exe 这样的文件.
|
||||
|
||||
在我们通常讨论这些文件的时候,我们也会提及关于更新的问题.很长时间我都不会在一台电脑上反复设置去完成多种程序的更新和安装.比如 Mint ,它没有带有 Synaptic [译注:一个 Linux 管理图像程序包]的完整更新方法,这让我失去兴趣.但是我们的老成员 dpkg 和 apt 是我们的好朋友,聪明的领导者已经得到肯定并且认识到命令行看起来不是那么舒服,同时欢迎新的用户加入.
|
||||
|
||||
我很生气,强烈反对机器对 Synaptic 的削弱,最后我放弃使用它.你记得你第一次使用的 Linux 发行版吗?记得你什么时候在 Synaptic 中详细查看大量的软件列表吗?记得你怎样开始检查并标记每个你发现的很酷的程序吗?你记得有多少这样的程序开始都是使用"lib"这样的文件吗?
|
||||
|
||||
是的,我也是。我安装并且查看了一些新的安装程序,直到我发现那些库文件是应用程序的螺母和螺栓,而不是应用程序本身.这就是为什么这些聪明的开发者在 Linux Mint 和 Ubuntu 之后创造了聪明、漂亮和易于使用的应用程序的安装程序.Synaptic 仍然是我们的老大,但是对于一些后来者,安装像 lib 文件这样的方式需要打开大量的文件夹,很多这样的事情都会导致他们放弃使用这个系统.在新的安装程序中,这些文件会被放在一个文件夹中甚至不会展示给用户.总之,这也是该有的解决方法.
|
||||
|
||||
除非你要改变应该支持的需求.
|
||||
|
||||
现在的 Linux 发行版中有很多有用的软件,我也很感谢这些开发者,因为他们,我的工作变得容易.不是每一个 Linux 新用户都像 Nicky 这样富有热情.她相当不错的完成了安装过程并且达到了忘我的状态.像她这样极具热情的毕竟是少数.大多数新的 Linux 用户也就是在需要的时候才这样用心.
|
||||
|
||||
很不错,他们都是要教自己的孩子使用 Linux 的人.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2016/05/anatomy-linux-user/
|
||||
|
||||
作者:[Ken Starks][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxlock.blogspot.com/
|
||||
@ -0,0 +1,59 @@
|
||||
Training vs. hiring to meet the IT needs of today and tomorrow
|
||||
培训还是雇人,来满足当今和未来的 IT 需求
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
在数字化时代,由于企业需要不断跟上工具和技术更新换代的步伐,对 IT 技能的需求也稳定增长。对于企业来说,寻找和雇佣那些拥有令人垂涎能力的创新人才,是非常不容易的。同时,培训内部员工来使他们接受新的技能和挑战,需要一定的时间。而且,这也往往满足不了需求。
|
||||
|
||||
[Sandy Hill][1] 对多种 IT 学科涉及到的多项技术都很熟悉。她作为 [Pegasystems][2] 项目的 IT 主管,负责的 IT 团队涉及的领域从应用的部署到数据中心的运营。更重要的是,Pegasystems 开发应用来帮助销售,市场,服务以及运行团队简化操作,联系客户。这意味着她需要掌握和利用 IT 内部资源的最佳方法,面对公司客户遇到的 IT 挑战。
|
||||
|
||||

|
||||
|
||||
**企业家项目(TEP):这些年你是如何调整培训重心的?**
|
||||
|
||||
**Hill**:在过去的几十年中,我们经历了爆炸式的发展,所以现在我们要实现更多的全球化进程。随之而来的培训方面,将确保每个人都在同一起跑线上。
|
||||
|
||||
我们大多的关注点已经转移到培养员工使用新的产品和工具上,这些新产品和工具的实现,能够推动创新,并提高工作效率。例如,我们实现了资产管理系统; 以前我们是没有的。因此我们需要为全部员工做培训,而不是雇佣那些已经知道该产品的人。当我们正在发展的时候,我们也试图保持紧张的预算和稳定的职员总数。所以,我们更愿意在内部培训而不是雇佣新人。
|
||||
|
||||
**TEP:说说培训方法吧,你是怎样帮助你的员工发展他们的技能?**
|
||||
|
||||
**Hill**:我要求每一位员工制定一个技术性的和非技术性的训练目标。这作为他们绩效评估的一部分。他们的技术性目标需要与他们的工作职能相符,非技术行目标则着重发展一项软技能,或是学一些专业领域之外的东西。我每年对职员进行一次评估,看看差距和不足之处,以使团队保持全面发展。
|
||||
|
||||
**TEP:你的训练计划能够在多大程度上减轻招聘和保留职员的问题?**
|
||||
|
||||
**Hill**:使我们的职员对学习新的技术保持兴奋,让他们的技能更好。让职员知道我们重视他们并且让他们在擅长的领域成长和发展,以此激励他们。
|
||||
|
||||
**TEP:你有没有发现哪种培训是最有效的?**
|
||||
|
||||
**HILL**:我们使用几种不同的我们发现是有效的培训方法。当有新的或特殊的项目时,我们尝试加入一套由甲方(不会翻:乙方,卖方?)领导的培训课程,作为项目的一部分。要是这个方法不能实现,我们将进行异地培训。我们也会购买一些在线的培训课程。我也鼓励职员每年参加至少一次会议,以了解行业的动向。
|
||||
|
||||
**TEP:你有没有发现有哪些技能,雇佣新人要比培训现有员工要好?**
|
||||
|
||||
**Hill**:这和项目有关。有一个最近的计划,试图实现 OpenStack,而我们根本没有这方面的专家。所以我们与一家从事这一领域的咨询公司合作。我们利用他们的专业知识帮助我们运行项目,并现场培训我们的内部团队成员。让内部员工学习他们需要的技能,同时还要完成他们们天的工作,这是一项艰巨的任务。
|
||||
|
||||
顾问帮助我们确定我们需要的对某一技术熟练的的员工人数。这使我们能够对员工进行评估,看看是否存在缺口。如果存在人员上的缺口,我们还需要额外的培训或是员工招聘。我们也确实雇佣了一些承包商。另一个选择是让一些全职员工进行为期六至八周的培训,但我们的项目模式不容许这么做。
|
||||
|
||||
**TEP:想一下你最近雇佣的员工,他们的那些技能特别能够吸引到你?**
|
||||
|
||||
**Hill**:在最近的招聘中,我侧重于软技能。除了扎实的技术能力外,他们需要能够在团队中进行有效的沟通和工作,要有说服他人,谈判和解决冲突的能力。
|
||||
|
||||
IT 人一向独来独往。他们一般不是社交最多的人。现在,IT 越来越整合到组织中,它为其他业务部门提供有用的更新报告和状态报告的能力是至关重要的,这也表明 IT 是积极的存在,并将取得成功。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2016/6/training-vs-hiring-meet-it-needs-today-and-tomorrow
|
||||
|
||||
作者:[Paul Desmond][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://enterprisersproject.com/user/paul-desmond
|
||||
[1]: https://enterprisersproject.com/user/sandy-hill
|
||||
[2]: https://www.pega.com/pega-can?&utm_source=google&utm_medium=cpc&utm_campaign=900.US.Evaluate&utm_term=pegasystems&gloc=9009726&utm_content=smAXuLA4U|pcrid|102822102849|pkw|pegasystems|pmt|e|pdv|c|
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,62 +0,0 @@
|
||||
信息技术运行在云端,而云运行在 Linux 上。有什么问题吗?
|
||||
===================================================================
|
||||
|
||||
>信息技术正在逐渐被迁移到云端. 那又是什么驱动了云呢?答案是 Linux。 当连微软的 Azure 都开始拥抱 Linux 时,你就应该知道这一切都已经改变了。
|
||||
|
||||

|
||||
>图片: ZDNet
|
||||
|
||||
不管你接不接受, 云正在接管信息技术都已成现实。 我们这几年见证了 [ 云在信息技术产业内部的崛起 ][1] 。 那又是什么驱动了云呢? 答案是 Linux 。
|
||||
|
||||
[Uptime Institute][2] 最近对 1000 个 IT 执行部门进行调查并发现了约 50% 左右的高级企业的 IT 执行部门认为在将来 [ 大部分的 IT 工作内容应存储备份在云上 ][3] 或托管网站上。在这个调查中,23% 的人认为这种改变即将发生在明年,有 70% 的人则认为这种情况会在四年内出现。
|
||||
|
||||
这一点都不奇怪。 我们中的许多人仍热衷于我们的物理服务器和机架, 但一般运营一个自己的数据中心并不会产生任何的经济效益。
|
||||
|
||||
这真的非常简单。 只需要对比你 [ 运行在硬件上的个人资本费用 (CAPEX) 和使用云的操作费用 (OPEX)][4]。 但这并不是说你会想把所有的一切都外置,而是说在大部分时间内你会想把你的一些工作内容迁移到云端。
|
||||
|
||||
相应地,如果你想充分地利用云,你就得了解 Linux 。
|
||||
|
||||
[ 亚马逊 web 服务 ][5], [ Apache 的 CloudStack][6], [Rackspace][7], [ 谷歌云平台 ][8] 以及 [ OpenStack ][9] 的核心都是运行在 Linux 上的。那么结果如何?截至到 2014 年, [ 在 Linux 服务器上部署的应用达到所有企业的 79% ][10],而 Windows 服务器上部署的应用则跌到 36%。从那时起, Linux 就获得了更多的发展动力。
|
||||
|
||||
即便是微软自身也明白这一点。
|
||||
|
||||
Azure 的技术主管 Mark Russinovich 曾说,仅仅在过去的几年内微软就从 [ 四分之一的 Azure 虚拟机运行在 Linux 上 ][11] 变为 [ 将近三分之一的 Azure 虚拟机运行在 Linux 上][12].
|
||||
|
||||
试想一下。 微软, 一家正逐渐将 [ 云变为自身财政收入的主要来源 ][13] 的公司,其三分之一的云产业依靠于 Linux 。
|
||||
|
||||
即使是到目前为止, 这些不论喜欢或者不喜欢微软的人都很难想象得到 [ 微软会从一家以专利保护为基础的软件公司转变为一家开源,基于云服务的企业][14] 。
|
||||
|
||||
Linux 对于这些专用服务器机房的渗透甚至比它刚开始的时候更深了。 举个例子, [ Docker 最近发行了其在 Windows 10 和 Mac OS X 上的公测版本 ][15] 。 所以难道这意味着 [Docker][16] 将会把其同名的容器服务移植到 Windows 10 和 Mac 上吗? 并不是的。
|
||||
|
||||
在这两个平台上, Docker 只是运行在一个 Linux 虚拟机内部。 在 Mac OS 上是 HyperKit ,在 Windows 上则是 Hyper-V 。 你的图形界面可能看起来就像另一个 Mac 或 Windows 上的应用, 但在其内部核心的容器仍然是运行在 Linux 上的。
|
||||
|
||||
所以,就像大量的安卓手机和 Chromebook 的用户压根就不知道他们所运行的是 Linux 系统一样。这些信息技术的用户也会随之悄然地迁移到 Linux 和云上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/it-runs-on-the-cloud-and-the-cloud-runs-on-linux-any-questions/#ftag=RSSbaffb68
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[chenxinlong](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]: http://www.zdnet.com/article/2014-the-year-the-cloud-killed-the-datacenter/
|
||||
[2]: https://uptimeinstitute.com/
|
||||
[3]: http://www.zdnet.com/article/move-to-cloud-accelerating-faster-than-thought-survey-finds/
|
||||
[4]: http://www.zdnet.com/article/rethinking-capex-and-opex-in-a-cloud-centric-world/
|
||||
[5]: https://aws.amazon.com/
|
||||
[6]: https://cloudstack.apache.org/
|
||||
[7]: https://www.rackspace.com/en-us
|
||||
[8]: https://cloud.google.com/
|
||||
[9]: http://www.openstack.org/
|
||||
[10]: http://www.zdnet.com/article/linux-foundation-finds-enterprise-linux-growing-at-windows-expense/
|
||||
[11]: http://news.microsoft.com/bythenumbers/azure-virtual
|
||||
[12]: http://www.zdnet.com/article/microsoft-nearly-one-in-three-azure-virtual-machines-now-are-running-linux/
|
||||
[13]: http://www.zdnet.com/article/microsofts-q3-azure-commercial-cloud-strong-but-earnings-revenue-light/
|
||||
[14]: http://www.zdnet.com/article/why-microsoft-is-turning-into-an-open-source-company/
|
||||
[15]: http://www.zdnet.com/article/new-docker-betas-for-azure-windows-10-now-available/
|
||||
[16]: http://www.docker.com/
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
Translating by ivo-wang
|
||||
What is good stock portfolio management software on Linux
|
||||
linux上那些不错的管理股票组合投资软件
|
||||
================================================================================
|
||||
如果你在股票市场做投资,那么你可能非常清楚管理组合投资的计划有多重要。管理组合投资的目标是依据你能承受的风险,时间层面的长短和资金盈利的目标去为你量身打造的一种投资计划。鉴于这类软件的重要性,难怪从不缺乏商业性质的app和股票行情检测软件,每一个都可以兜售复杂的组合投资以及跟踪报告功能。
|
||||
|
||||
对于这些linux爱好者们,我们找到了一些 **好用的开源组合投资管理工具** 用来在linux上管理和跟踪股票的组合投资,这里高度推荐一个基于java编写的管理软件[JStock][1]。如果你不是一个java粉,你不得不面对这样一个事实JStock需要运行在重型的JVM环境上。同时我相信许多人非常欣赏JStock,安装JRE以后它可以非常迅速的安装在各个linux平台上。没有障碍能阻止你将它安装在你的linux环境中。
|
||||
|
||||
开源就意味着免费或标准低下的时代已经过去了。鉴于JStock只是一个个人完成的产物,作为一个组合投资管理软件它最令人印象深刻的是包含了非常多实用的功能,以上所有的荣誉属于它的作者Yan Cheng Cheok!例如,JStock 支持通过监视列表去监控价格,多种组合投资,按习惯/按固定 做股票指示与相关扫描,支持27个不同的股票市场和交易平台云端备份/还原。JStock支持多平台部署(Linux, OS X, Android 和 Windows),你可以通过云端保存你的JStock记录,它可以无缝的备份还原到其他的不同平台上面。
|
||||
|
||||
现在我将向你展示如何安装以及使用过程的一些具体细节。
|
||||
|
||||
### 在Linux上安装JStock ###
|
||||
|
||||
因为JStock使用Java编写,所以必须[安装 JRE][2]才能让它运行起来.小提示JStock 需要JRE1.7或更高版本。如你的JRE版本不能满足这个需求,JStock将会安装失败然后出现下面的报错。
|
||||
|
||||
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/yccheok/jstock/gui/JStock : Unsupported major.minor version 51.0
|
||||
|
||||
|
||||
一旦你安装了JRE在你的linux上,从官网下载最新的发布的JStock,然后加载启动它。
|
||||
|
||||
$ wget https://github.com/yccheok/jstock/releases/download/release_1-0-7-13/jstock-1.0.7.13-bin.zip
|
||||
$ unzip jstock-1.0.7.13-bin.zip
|
||||
$ cd jstock
|
||||
$ chmod +x jstock.sh
|
||||
$ ./jstock.sh
|
||||
|
||||
教程的其他部分,让我来给大家展示一些JStock的实用功能
|
||||
|
||||
### 监视监控列表股票价格的波动 ###
|
||||
|
||||
使用JStock你可以创建一个或多个监视列表,它可以自动的监视股票价格的波动并给你提供相应的通知。在每一个监视列表里面你可以添加多个感兴趣的股票进去。之后添加你的警戒值在"Fall Below"和"Rise Above"的表格里,分别是在设定最低价格和最高价格。
|
||||
|
||||

|
||||
|
||||
例如你设置了AAPL股票的最低/最高价格分别是$102 和 $115.50,你将在价格低于$102或高于$115.50的任意时间在桌面得到通知。
|
||||
|
||||
你也可以设置邮件通知,之后你将收到一些价格信息的邮件通知。设置邮件通知在栏的"Options"选项。在"Alert"标签,打开"Send message to email(s)",填入你的Gmail账户。一旦完成Gmail认证步骤,JStock将开始发送邮件通知到你的Gmail账户(也可以设置其他的第三方邮件地址)
|
||||

|
||||
|
||||
### 管理多个组合投资 ###
|
||||
|
||||
JStock能够允许你管理多个组合投资。这个功能对于股票经纪人是非常实用的。你可以为经纪人创建一个投资项去管理你的 买入/卖出/红利 用来了解每一个经纪人的业务情况。你也可以切换不同的组合项目通过选择一个特殊项目在"Portfolio"菜单里面。下面是一张截图用来展示一个意向投资
|
||||

|
||||
|
||||
因为能够设置付给经纪人小费的选项,所以你能付给经纪人任意的小费,印花税以及清空每一比交易的小费。如果你非常懒,你也可以在菜单里面设置自动计算小费和给每一个经纪人固定的小费。在完成交易之后JStock将自动的计算并发送小费。
|
||||
|
||||

|
||||
|
||||
### 显示固定/自选股票提示 ###
|
||||
|
||||
如果你要做一些股票的技术分析,你可能需要不同股票的指数(这里叫做“平均股指”),对于股票的跟踪,JStock提供多个[预设技术指示器][3] 去获得股票上涨/下跌/逆转指数的趋势。下面的列表里面是一些可用的指示。
|
||||
- 异同平均线(MACD)
|
||||
- 相对强弱指数 (RSI)
|
||||
- 货币流通指数 (MFI)
|
||||
- 顺势指标 (CCI)
|
||||
- 十字线
|
||||
- 黄金交叉线, 死亡交叉线
|
||||
- 涨幅/跌幅
|
||||
|
||||
开启预设指示器能需要在JStock中点击"Stock Indicator Editor"标签。之后点击右侧面板中的安装按钮。选择"Install from JStock server"选项,之后安装你想要的指示器。
|
||||
|
||||

|
||||
|
||||
一旦安装了一个或多个指示器,你可以用他们来扫描股票。选择"Stock Indicator Scanner"标签,点击底部的"Scan"按钮,选择需要的指示器。
|
||||
|
||||

|
||||
|
||||
当你选择完需要扫描的股票(例如e.g., NYSE, NASDAQ)以后,JStock将执行扫描,并将捕获的结果通过列表的形式展现在指示器上面。
|
||||
|
||||

|
||||
|
||||
除了预设指示器以外,你也可以使用一个图形化的工具来定义自己的指示器。下面这张图例中展示的是当前价格小于或等于60天平均价格
|
||||
|
||||

|
||||
|
||||
### 云备份还原Linux 和 Android JStock ###
|
||||
|
||||
另一个非常棒的功能是JStock可以支持云备份还原。Jstock也可以把你的组合投资/监视列表备份还原在 Google Drive,这个功能可以实现在不同平台(例如Linux和Android)上无缝穿梭。举个例子,如果你把Android Jstock组合投资的信息保存在Google Drive上,你可以在Linux班级本上还原他们。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
如果你在从Google Drive还原之后不能看到你的投资信息以及监视列表,请确认你的国家信息与“Country”菜单里面设置的保持一致。
|
||||
|
||||
JStock的安卓免费版可以从[Google Play Store][4]获取到。如果你需要完整的功能(比如云备份,通知,图表等),你需要一次性支付费用升级到高级版。我想高级版肯定有它的价值所在。
|
||||
|
||||

|
||||
|
||||
写在最后,我应该说一下它的作者,Yan Cheng Cheok,他是一个十分活跃的开发者,有bug及时反馈给他。最后多有的荣耀都属于他一个人!!!
|
||||
|
||||
关于JStock这个组合投资跟踪软件你有什么想法呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/stock-portfolio-management-software-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/ivo-wang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://jstock.org/
|
||||
[2]:http://ask.xmodulo.com/install-java-runtime-linux.html
|
||||
[3]:http://jstock.org/ma_indicator.html
|
||||
[4]:https://play.google.com/store/apps/details?id=org.yccheok.jstock.gui
|
||||
@ -1,93 +0,0 @@
|
||||
Linux 开发者如何看待 Git 和 Github?
|
||||
=====================================================
|
||||
|
||||
**同样在今日的开源摘要: DistroWatch 评估 XStream 桌面 153 版本,街头霸王 V 即将在这个春天进入 Linux 和 SteamOS**
|
||||
|
||||
## Linux 开发者如何看待 Git 和 Github?
|
||||
|
||||
Git 和 Github 在 Linux 开发者中有很高的知名度。但是开发者如何看待它们呢?另外,Github 是不是真的和 Git 是一个意思?一个 Linux reddit 用户最近问到了这个问题,并且得到了很有意思的答案。
|
||||
|
||||
Dontwakemeup46 提问:
|
||||
|
||||
> 我正在学习 Git 和 Github。我感兴趣的是社区如何看待两者?据我所知,Git 和 Github 应用十分广泛。但是 Git 或 Github 有没有严重的,社区喜欢去修改的问题呢?
|
||||
|
||||
[更多见 Reddit](http://api.viglink.com/api/click?format=go&jsonp=vglnk_145580413015211&key=0a7039c08493c7c51b759e3d13019dbe&libId=iksc5hc8010113at000DL3yrsuvp7&loc=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3033059%2Flinux%2Fwhat-do-linux-developers-think-of-git-and-github.html&v=1&out=https%3A%2F%2Fwww.reddit.com%2Fr%2Flinux%2Fcomments%2F45jy59%2Fthe_popularity_of_git_and_github%2F&ref=http%3A%2F%2Fwww.linux.com%2Fnews%2Fsoftware%2Fapplications%2F886008-what-do-linux-developers-think-of-git-and-github&title=What%20do%20Linux%20developers%20think%20of%20Git%20and%20GitHub%3F%20%7C%20InfoWorld&txt=More%20at%20Reddit)
|
||||
|
||||
与他志同道合的 Linux reddit 用户回答了他们对于 Git 和 Github的想法:
|
||||
|
||||
>Derenir: “Github 并不隶属于 Git。
|
||||
|
||||
>Git 是由 Linus Torvalds 开发的。
|
||||
|
||||
>Github 几乎不支持 Linux。
|
||||
|
||||
>Github 是一家唯利是图的,企图借助 Git 赚钱的公司。
|
||||
|
||||
>[https://desktop.github.com/](http://api.viglink.com/api/click?format=go&jsonp=vglnk_145580415025712&key=0a7039c08493c7c51b759e3d13019dbe&libId=iksc5hc8010113at000DL3yrsuvp7&loc=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3033059%2Flinux%2Fwhat-do-linux-developers-think-of-git-and-github.html&v=1&type=U&out=https%3A%2F%2Fdesktop.github.com%2F&ref=http%3A%2F%2Fwww.linux.com%2Fnews%2Fsoftware%2Fapplications%2F886008-what-do-linux-developers-think-of-git-and-github&title=What%20do%20Linux%20developers%20think%20of%20Git%20and%20GitHub%3F%20%7C%20InfoWorld&txt=https%3A%2F%2Fdesktop.github.com%2F) 并没有支持 Linux。”
|
||||
|
||||
>**Bilog78**: “一个简单的更新: Linus Torvalds 已经不再维护 Git了。维护者是 Junio C Hamano,以及 Linus 之后的主要贡献者是Jeff King 和 Shawn O. Pearce。”
|
||||
|
||||
>**Fearthefuture**: “我喜欢 Git,但是不明白人们为什么还要使用 Github。从我的角度,Github 比 Bitbucket 好的一点是用户统计和更大的用户基础。Bitbucket 有无限的免费私有库,更好的 UI,以及更好地继承其他服务,比如说 Jenkins。”
|
||||
|
||||
>**Thunger**: “Gitlab.com 也很不错,特别是你可以在自己的服务器上架设自己的实例。”
|
||||
|
||||
>**Takluyver**: “很多人熟悉 Github 的 UI 以及相关联的服务,像 Travis 。并且很多人都有 Github 账号,所以它是一个很好地存储项目的地方。人们也使用他们的 Github 简况作为一种求职用的作品选辑,所以他们很积极地将更多的项目放在这里。Github 是一个事实上的,存放开源项目的标准。”
|
||||
|
||||
>**Tdammers**: “Git 严重问题在于 UI,它有些违反直觉,到很多用户只使用一些容易记住的咒语程度。”
|
||||
|
||||
Github:最严重的问题在于它是私人拥有的解决方案;你买了方便,但是代价是你的代码在别人的服务器上面,已经不在你的掌控范围之内了。另一个对于 Github 的普遍批判是它的工作流和 Git 本身的精神不符,特别是 pull requests 工作的方式。最后, Github 垄断代码的托管环境,同时对于多样性是很不好的,这反过来对于旺盛的免费软件社区很重要。”
|
||||
|
||||
>**Dies**: “更重要的是,如果一旦是这样,做过的都做过了,并且我猜我们会被 Github 所困,因为它们控制如此多的项目。”
|
||||
|
||||
>**Tdammers**: “代码托管在别人的服务器上,别人指的是 Github。这对于开源项目来说,并不是什么太大的问题,但是仍然,你无法控制它。如果你在 Github 上有私有项目,唯一的保险在于它将保持私有是 Github 的承诺。如果你决定删除东西,你不能确定东西是否被删除了,或者只是隐藏了。
|
||||
|
||||
Github 并不自己控制这些项目(你总是可以拿走你的代码,然后托管到别的地方,声明新位置是“官方”的),它只是有比开发者本身有更深的使用权。”
|
||||
|
||||
>**Drelos**: “我已经读了大量的关于 Github 的赞美与批评。(这里有一个[例子](http://api.viglink.com/api/click?format=go&jsonp=vglnk_145580428524613&key=0a7039c08493c7c51b759e3d13019dbe&libId=iksc5hc8010113at000DL3yrsuvp7&loc=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3033059%2Flinux%2Fwhat-do-linux-developers-think-of-git-and-github.html&v=1&out=http%3A%2F%2Fwww.wired.com%2F2015%2F06%2Fproblem-putting-worlds-code-github%2F&ref=http%3A%2F%2Fwww.linux.com%2Fnews%2Fsoftware%2Fapplications%2F886008-what-do-linux-developers-think-of-git-and-github&title=What%20do%20Linux%20developers%20think%20of%20Git%20and%20GitHub%3F%20%7C%20InfoWorld&txt=here%27s%20an%20example)),但是我的新手问题是为什么不向一个免费开源的版本努力呢?”
|
||||
|
||||
>**Twizmwazin**: “Gitlab 的源码就存在这里”
|
||||
|
||||
[更多见 Reddit](http://api.viglink.com/api/click?format=go&jsonp=vglnk_145580429720714&key=0a7039c08493c7c51b759e3d13019dbe&libId=iksc5hc8010113at000DL3yrsuvp7&loc=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3033059%2Flinux%2Fwhat-do-linux-developers-think-of-git-and-github.html&v=1&out=https%3A%2F%2Fwww.reddit.com%2Fr%2Flinux%2Fcomments%2F45jy59%2Fthe_popularity_of_git_and_github%2F&ref=http%3A%2F%2Fwww.linux.com%2Fnews%2Fsoftware%2Fapplications%2F886008-what-do-linux-developers-think-of-git-and-github&title=What%20do%20Linux%20developers%20think%20of%20Git%20and%20GitHub%3F%20%7C%20InfoWorld&txt=More%20at%20Reddit)
|
||||
|
||||
## DistroWatch 评估 XStream 桌面 153 版本
|
||||
|
||||
XStreamOS 是一个由 Sonicle 创建的 Solaris 的一个版本。XStream 桌面将 Solaris 的强大带给了桌面用户,同时新手用户很可能有兴趣体验一下。DistroWatch 对于 XStream 桌面 153 版本做了一个很全面的评估,并且发现它运行相当好。
|
||||
|
||||
Jesse Smith 为 DistroWatch 报道:
|
||||
|
||||
> 我认为 XStream 桌面做好了很多事情。无可否认地,我的实验陷入了头晕目眩的状态当操作系统无法在我的硬件上启动。同时,当运行在 VirtualBox 中我无法使得桌面使用我显示器的完整分辨率。
|
||||
|
||||
> 我确实在播放多媒体文件时遇见一些问题,特别是使声卡工作。我不确定是不是另外一个硬件兼容问题,或者一个关于操作系统自带的多媒体软件的问题。另一方面,像 Web 浏览器,电子邮件,生产工具套件以及配置工具这样的工作都工作的很好。
|
||||
|
||||
> 我最欣赏 XStream 的地方是这个操作系统是 OpenSolaris 家族的一个使用保持最新的分支。OpenSolaris 的其他衍生系统有落后的倾向,至少在桌面软件上,但是 XStream 仍然搭载最新版本的火狐和 LibreOffice。
|
||||
|
||||
>对我个人来说,XStream 缺少一些组件,比如打印机管理器,多媒体支持和我特定硬件的驱动。这个操作系统的其他方面也是相当吸引人的。我喜欢开发者搭建 LXDE 的方式,软件的默认组合,以及我最喜欢文件系统快照和启动环境开箱即用的方式。大多数的 Linux 发行版,openSUSE 除外,并没有使得启动环境的有用性流行起来。我希望它是一个被更多项目采用的技术。
|
||||
|
||||
[更多见 DistroWatch](http://api.viglink.com/api/click?format=go&jsonp=vglnk_145580434172315&key=0a7039c08493c7c51b759e3d13019dbe&libId=iksc5hc8010113at000DL3yrsuvp7&loc=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3033059%2Flinux%2Fwhat-do-linux-developers-think-of-git-and-github.html&v=1&out=http%3A%2F%2Fdistrowatch.com%2Fweekly.php%3Fissue%3D20160215%23xstreamos&ref=http%3A%2F%2Fwww.linux.com%2Fnews%2Fsoftware%2Fapplications%2F886008-what-do-linux-developers-think-of-git-and-github&title=What%20do%20Linux%20developers%20think%20of%20Git%20and%20GitHub%3F%20%7C%20InfoWorld&txt=More%20at%20DistroWatch)
|
||||
|
||||
## 街头霸王 V 和 SteamOS
|
||||
|
||||
街头霸王是最出名的游戏之一,并且 [Capcom 已经宣布](http://api.viglink.com/api/click?format=go&jsonp=vglnk_145580435418216&key=0a7039c08493c7c51b759e3d13019dbe&libId=iksc5hc8010113at000DL3yrsuvp7&loc=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3033059%2Flinux%2Fwhat-do-linux-developers-think-of-git-and-github.html&v=1&out=http%3A%2F%2Fsteamcommunity.com%2Fgames%2F310950%2Fannouncements%2Fdetail%2F857177755595160250&ref=http%3A%2F%2Fwww.linux.com%2Fnews%2Fsoftware%2Fapplications%2F886008-what-do-linux-developers-think-of-git-and-github&title=What%20do%20Linux%20developers%20think%20of%20Git%20and%20GitHub%3F%20%7C%20InfoWorld&txt=Capcom%20has%20announced) 街头霸王 V 将会在这个春天进入 Linux 和 StreamOS。这对于 Linux 游戏者是非常好的消息。
|
||||
|
||||
Joe Parlock 为 Destructoid 报道:
|
||||
|
||||
>你是少于 1% 的,在 Linux 系统上玩游戏的 Stream 用户吗?你是更少百分比的,在 Linux 平台上玩游戏,同时很喜欢街头霸王 V 的人之一吗?是的话,我有一些好消息要告诉你。
|
||||
|
||||
>Capcom 已经宣布,这个春天街头霸王 V 通过 Stream 进入 StreamOS 以及其他 Linux 发行版。它无需任何额外的成本,所以那些已经个人电脑建立的游戏的人可以很容易在 Linux 上安装它,并且运行良好。
|
||||
|
||||
[更多 Destructoid](http://api.viglink.com/api/click?format=go&jsonp=vglnk_145580435418216&key=0a7039c08493c7c51b759e3d13019dbe&libId=iksc5hc8010113at000DL3yrsuvp7&loc=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3033059%2Flinux%2Fwhat-do-linux-developers-think-of-git-and-github.html&v=1&out=http%3A%2F%2Fsteamcommunity.com%2Fgames%2F310950%2Fannouncements%2Fdetail%2F857177755595160250&ref=http%3A%2F%2Fwww.linux.com%2Fnews%2Fsoftware%2Fapplications%2F886008-what-do-linux-developers-think-of-git-and-github&title=What%20do%20Linux%20developers%20think%20of%20Git%20and%20GitHub%3F%20%7C%20InfoWorld&txt=Capcom%20has%20announced)
|
||||
|
||||
你是否错过了摘要?检查 [Eye On Open home page](http://www.infoworld.com/blog/eye-on-open/) 来获得关于 Linux 和开源的最新的新闻。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3033059/linux/what-do-linux-developers-think-of-git-and-github.html
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Jim-Lynch/
|
||||
|
||||
@ -1,150 +0,0 @@
|
||||
Let’s Build A Web Server. Part 1.
|
||||
=====================================
|
||||
|
||||
Out for a walk one day, a woman came across a construction site and saw three men working. She asked the first man, “What are you doing?” Annoyed by the question, the first man barked, “Can’t you see that I’m laying bricks?” Not satisfied with the answer, she asked the second man what he was doing. The second man answered, “I’m building a brick wall.” Then, turning his attention to the first man, he said, “Hey, you just passed the end of the wall. You need to take off that last brick.” Again not satisfied with the answer, she asked the third man what he was doing. And the man said to her while looking up in the sky, “I am building the biggest cathedral this world has ever known.” While he was standing there and looking up in the sky the other two men started arguing about the errant brick. The man turned to the first two men and said, “Hey guys, don’t worry about that brick. It’s an inside wall, it will get plastered over and no one will ever see that brick. Just move on to another layer.”1
|
||||
|
||||
The moral of the story is that when you know the whole system and understand how different pieces fit together (bricks, walls, cathedral), you can identify and fix problems faster (errant brick).
|
||||
|
||||
What does it have to do with creating your own Web server from scratch?
|
||||
|
||||
I believe to become a better developer you MUST get a better understanding of the underlying software systems you use on a daily basis and that includes programming languages, compilers and interpreters, databases and operating systems, web servers and web frameworks. And, to get a better and deeper understanding of those systems you MUST re-build them from scratch, brick by brick, wall by wall.
|
||||
|
||||
Confucius put it this way:
|
||||
|
||||
>“I hear and I forget.”
|
||||
|
||||
|
||||
|
||||
>“I see and I remember.”
|
||||
|
||||
|
||||
|
||||
>“I do and I understand.”
|
||||
|
||||
|
||||
|
||||
I hope at this point you’re convinced that it’s a good idea to start re-building different software systems to learn how they work.
|
||||
|
||||
In this three-part series I will show you how to build your own basic Web server. Let’s get started.
|
||||
|
||||
First things first, what is a Web server?
|
||||
|
||||
|
||||
|
||||
In a nutshell it’s a networking server that sits on a physical server (oops, a server on a server) and waits for a client to send a request. When it receives a request, it generates a response and sends it back to the client. The communication between a client and a server happens using HTTP protocol. A client can be your browser or any other software that speaks HTTP.
|
||||
|
||||
What would a very simple implementation of a Web server look like? Here is my take on it. The example is in Python but even if you don’t know Python (it’s a very easy language to pick up, try it!) you still should be able to understand concepts from the code and explanations below:
|
||||
|
||||
```
|
||||
import socket
|
||||
|
||||
HOST, PORT = '', 8888
|
||||
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
listen_socket.bind((HOST, PORT))
|
||||
listen_socket.listen(1)
|
||||
print 'Serving HTTP on port %s ...' % PORT
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
request = client_connection.recv(1024)
|
||||
print request
|
||||
|
||||
http_response = """\
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
client_connection.close()
|
||||
```
|
||||
|
||||
Save the above code as webserver1.py or download it directly from GitHub and run it on the command line like this
|
||||
|
||||
```
|
||||
$ python webserver1.py
|
||||
Serving HTTP on port 8888 …
|
||||
```
|
||||
|
||||
Now type in the following URL in your Web browser’s address bar http://localhost:8888/hello, hit Enter, and see magic in action. You should see “Hello, World!” displayed in your browser like this:
|
||||
|
||||
|
||||
|
||||
Just do it, seriously. I will wait for you while you’re testing it.
|
||||
|
||||
Done? Great. Now let’s discuss how it all actually works.
|
||||
|
||||
First let’s start with the Web address you’ve entered. It’s called an URL and here is its basic structure:
|
||||
|
||||
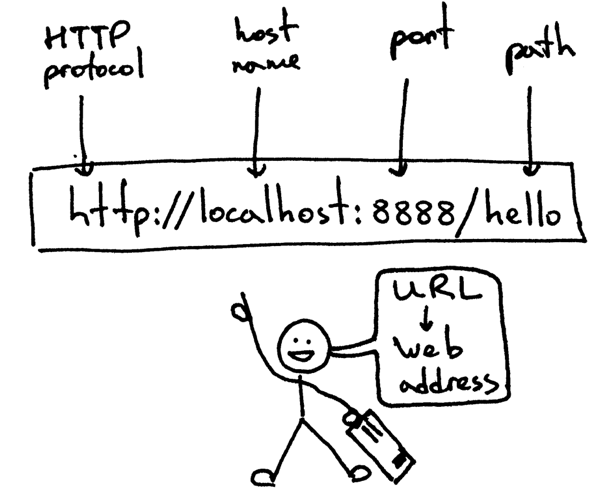
|
||||
|
||||
This is how you tell your browser the address of the Web server it needs to find and connect to and the page (path) on the server to fetch for you. Before your browser can send a HTTP request though, it first needs to establish a TCP connection with the Web server. Then it sends an HTTP request over the TCP connection to the server and waits for the server to send an HTTP response back. And when your browser receives the response it displays it, in this case it displays “Hello, World!”
|
||||
|
||||
Let’s explore in more detail how the client and the server establish a TCP connection before sending HTTP requests and responses. To do that they both use so-called sockets. Instead of using a browser directly you are going to simulate your browser manually by using telnet on the command line.
|
||||
|
||||
On the same computer you’re running the Web server fire up a telnet session on the command line specifying a host to connect to localhost and the port to connect to 8888 and then press Enter:
|
||||
|
||||
```
|
||||
$ telnet localhost 8888
|
||||
Trying 127.0.0.1 …
|
||||
Connected to localhost.
|
||||
```
|
||||
|
||||
At this point you’ve established a TCP connection with the server running on your local host and ready to send and receive HTTP messages. In the picture below you can see a standard procedure a server has to go through to be able to accept new TCP connections.
|
||||
|
||||
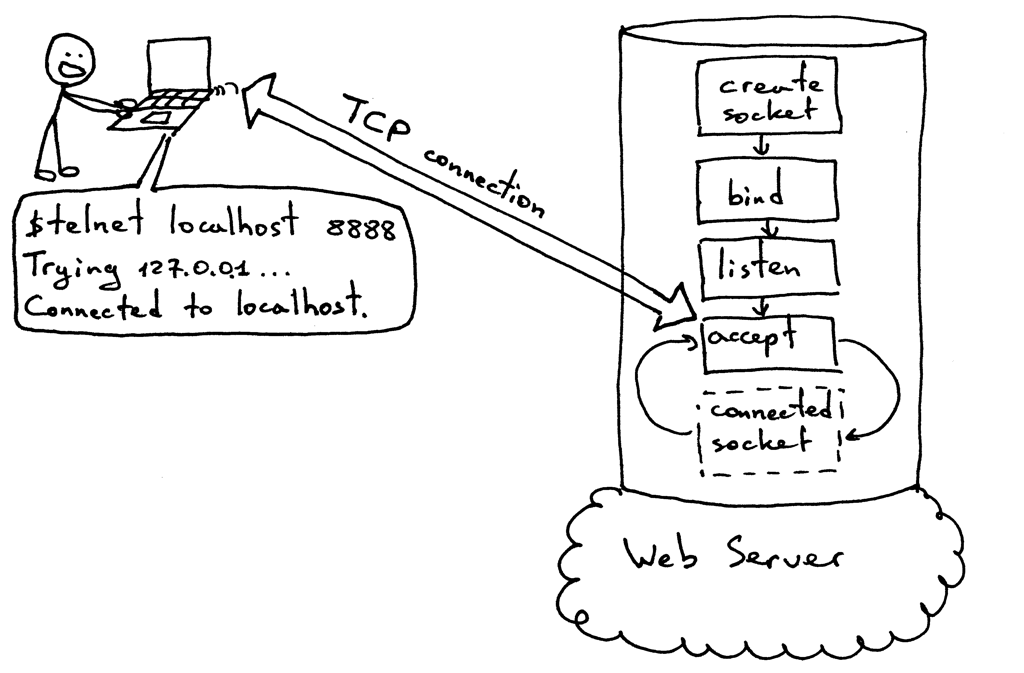
|
||||
|
||||
In the same telnet session type GET /hello HTTP/1.1 and hit Enter:
|
||||
|
||||
```
|
||||
$ telnet localhost 8888
|
||||
Trying 127.0.0.1 …
|
||||
Connected to localhost.
|
||||
GET /hello HTTP/1.1
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
```
|
||||
|
||||
You’ve just manually simulated your browser! You sent an HTTP request and got an HTTP response back. This is the basic structure of an HTTP request:
|
||||
|
||||
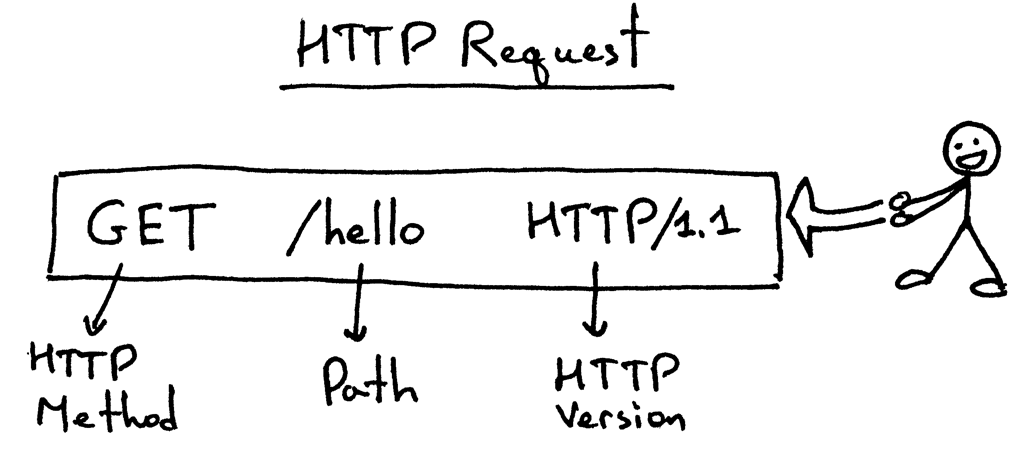
|
||||
|
||||
The HTTP request consists of the line indicating the HTTP method (GET, because we are asking our server to return us something), the path /hello that indicates a “page” on the server we want and the protocol version.
|
||||
|
||||
For simplicity’s sake our Web server at this point completely ignores the above request line. You could just as well type in any garbage instead of “GET /hello HTTP/1.1” and you would still get back a “Hello, World!” response.
|
||||
|
||||
Once you’ve typed the request line and hit Enter the client sends the request to the server, the server reads the request line, prints it and returns the proper HTTP response.
|
||||
|
||||
Here is the HTTP response that the server sends back to your client (telnet in this case):
|
||||
|
||||
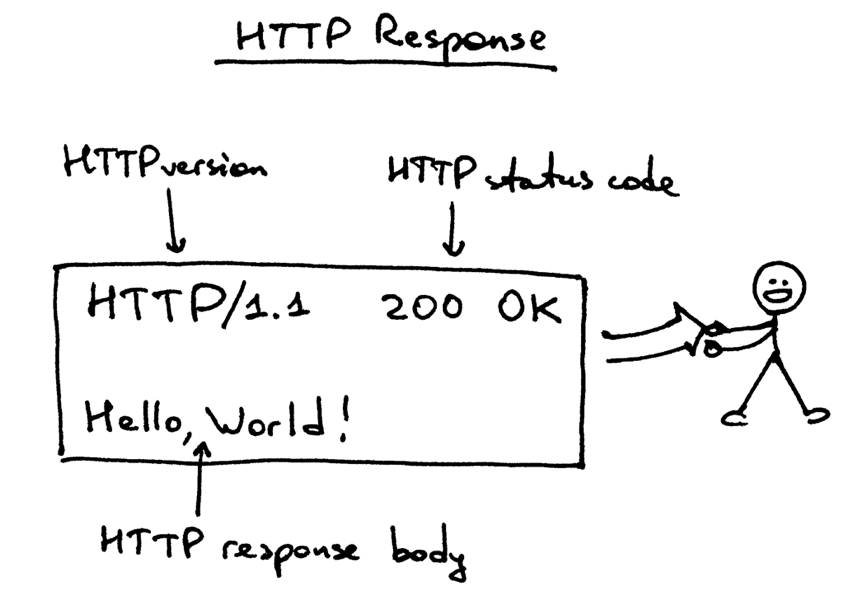
|
||||
|
||||
Let’s dissect it. The response consists of a status line HTTP/1.1 200 OK, followed by a required empty line, and then the HTTP response body.
|
||||
|
||||
The response status line HTTP/1.1 200 OK consists of the HTTP Version, the HTTP status code and the HTTP status code reason phrase OK. When the browser gets the response, it displays the body of the response and that’s why you see “Hello, World!” in your browser.
|
||||
|
||||
And that’s the basic model of how a Web server works. To sum it up: The Web server creates a listening socket and starts accepting new connections in a loop. The client initiates a TCP connection and, after successfully establishing it, the client sends an HTTP request to the server and the server responds with an HTTP response that gets displayed to the user. To establish a TCP connection both clients and servers use sockets.
|
||||
|
||||
Now you have a very basic working Web server that you can test with your browser or some other HTTP client. As you’ve seen and hopefully tried, you can also be a human HTTP client too, by using telnet and typing HTTP requests manually.
|
||||
|
||||
Here’s a question for you: “How do you run a Django application, Flask application, and Pyramid application under your freshly minted Web server without making a single change to the server to accommodate all those different Web frameworks?”
|
||||
|
||||
I will show you exactly how in Part 2 of the series. Stay tuned.
|
||||
|
||||
BTW, I’m writing a book “Let’s Build A Web Server: First Steps” that explains how to write a basic web server from scratch and goes into more detail on topics I just covered. Subscribe to the mailing list to get the latest updates about the book and the release date.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbaws-part1/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://linkedin.com/in/ruslanspivak/
|
||||
|
||||
|
||||
|
||||
@ -1,427 +0,0 @@
|
||||
Let’s Build A Web Server. Part 2.
|
||||
===================================
|
||||
|
||||
Remember, in Part 1 I asked you a question: “How do you run a Django application, Flask application, and Pyramid application under your freshly minted Web server without making a single change to the server to accommodate all those different Web frameworks?” Read on to find out the answer.
|
||||
|
||||
In the past, your choice of a Python Web framework would limit your choice of usable Web servers, and vice versa. If the framework and the server were designed to work together, then you were okay:
|
||||
|
||||
|
||||
|
||||
But you could have been faced (and maybe you were) with the following problem when trying to combine a server and a framework that weren’t designed to work together:
|
||||
|
||||
|
||||
|
||||
Basically you had to use what worked together and not what you might have wanted to use.
|
||||
|
||||
So, how do you then make sure that you can run your Web server with multiple Web frameworks without making code changes either to the Web server or to the Web frameworks? And the answer to that problem became the Python Web Server Gateway Interface (or WSGI for short, pronounced “wizgy”).
|
||||
|
||||

|
||||
|
||||
WSGI allowed developers to separate choice of a Web framework from choice of a Web server. Now you can actually mix and match Web servers and Web frameworks and choose a pairing that suits your needs. You can run Django, Flask, or Pyramid, for example, with Gunicorn or Nginx/uWSGI or Waitress. Real mix and match, thanks to the WSGI support in both servers and frameworks:
|
||||
|
||||
|
||||
|
||||
So, WSGI is the answer to the question I asked you in Part 1 and repeated at the beginning of this article. Your Web server must implement the server portion of a WSGI interface and all modern Python Web Frameworks already implement the framework side of the WSGI interface, which allows you to use them with your Web server without ever modifying your server’s code to accommodate a particular Web framework.
|
||||
|
||||
Now you know that WSGI support by Web servers and Web frameworks allows you to choose a pairing that suits you, but it is also beneficial to server and framework developers because they can focus on their preferred area of specialization and not step on each other’s toes. Other languages have similar interfaces too: Java, for example, has Servlet API and Ruby has Rack.
|
||||
|
||||
It’s all good, but I bet you are saying: “Show me the code!” Okay, take a look at this pretty minimalistic WSGI server implementation:
|
||||
|
||||
```
|
||||
# Tested with Python 2.7.9, Linux & Mac OS X
|
||||
import socket
|
||||
import StringIO
|
||||
import sys
|
||||
|
||||
|
||||
class WSGIServer(object):
|
||||
|
||||
address_family = socket.AF_INET
|
||||
socket_type = socket.SOCK_STREAM
|
||||
request_queue_size = 1
|
||||
|
||||
def __init__(self, server_address):
|
||||
# Create a listening socket
|
||||
self.listen_socket = listen_socket = socket.socket(
|
||||
self.address_family,
|
||||
self.socket_type
|
||||
)
|
||||
# Allow to reuse the same address
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
# Bind
|
||||
listen_socket.bind(server_address)
|
||||
# Activate
|
||||
listen_socket.listen(self.request_queue_size)
|
||||
# Get server host name and port
|
||||
host, port = self.listen_socket.getsockname()[:2]
|
||||
self.server_name = socket.getfqdn(host)
|
||||
self.server_port = port
|
||||
# Return headers set by Web framework/Web application
|
||||
self.headers_set = []
|
||||
|
||||
def set_app(self, application):
|
||||
self.application = application
|
||||
|
||||
def serve_forever(self):
|
||||
listen_socket = self.listen_socket
|
||||
while True:
|
||||
# New client connection
|
||||
self.client_connection, client_address = listen_socket.accept()
|
||||
# Handle one request and close the client connection. Then
|
||||
# loop over to wait for another client connection
|
||||
self.handle_one_request()
|
||||
|
||||
def handle_one_request(self):
|
||||
self.request_data = request_data = self.client_connection.recv(1024)
|
||||
# Print formatted request data a la 'curl -v'
|
||||
print(''.join(
|
||||
'< {line}\n'.format(line=line)
|
||||
for line in request_data.splitlines()
|
||||
))
|
||||
|
||||
self.parse_request(request_data)
|
||||
|
||||
# Construct environment dictionary using request data
|
||||
env = self.get_environ()
|
||||
|
||||
# It's time to call our application callable and get
|
||||
# back a result that will become HTTP response body
|
||||
result = self.application(env, self.start_response)
|
||||
|
||||
# Construct a response and send it back to the client
|
||||
self.finish_response(result)
|
||||
|
||||
def parse_request(self, text):
|
||||
request_line = text.splitlines()[0]
|
||||
request_line = request_line.rstrip('\r\n')
|
||||
# Break down the request line into components
|
||||
(self.request_method, # GET
|
||||
self.path, # /hello
|
||||
self.request_version # HTTP/1.1
|
||||
) = request_line.split()
|
||||
|
||||
def get_environ(self):
|
||||
env = {}
|
||||
# The following code snippet does not follow PEP8 conventions
|
||||
# but it's formatted the way it is for demonstration purposes
|
||||
# to emphasize the required variables and their values
|
||||
#
|
||||
# Required WSGI variables
|
||||
env['wsgi.version'] = (1, 0)
|
||||
env['wsgi.url_scheme'] = 'http'
|
||||
env['wsgi.input'] = StringIO.StringIO(self.request_data)
|
||||
env['wsgi.errors'] = sys.stderr
|
||||
env['wsgi.multithread'] = False
|
||||
env['wsgi.multiprocess'] = False
|
||||
env['wsgi.run_once'] = False
|
||||
# Required CGI variables
|
||||
env['REQUEST_METHOD'] = self.request_method # GET
|
||||
env['PATH_INFO'] = self.path # /hello
|
||||
env['SERVER_NAME'] = self.server_name # localhost
|
||||
env['SERVER_PORT'] = str(self.server_port) # 8888
|
||||
return env
|
||||
|
||||
def start_response(self, status, response_headers, exc_info=None):
|
||||
# Add necessary server headers
|
||||
server_headers = [
|
||||
('Date', 'Tue, 31 Mar 2015 12:54:48 GMT'),
|
||||
('Server', 'WSGIServer 0.2'),
|
||||
]
|
||||
self.headers_set = [status, response_headers + server_headers]
|
||||
# To adhere to WSGI specification the start_response must return
|
||||
# a 'write' callable. We simplicity's sake we'll ignore that detail
|
||||
# for now.
|
||||
# return self.finish_response
|
||||
|
||||
def finish_response(self, result):
|
||||
try:
|
||||
status, response_headers = self.headers_set
|
||||
response = 'HTTP/1.1 {status}\r\n'.format(status=status)
|
||||
for header in response_headers:
|
||||
response += '{0}: {1}\r\n'.format(*header)
|
||||
response += '\r\n'
|
||||
for data in result:
|
||||
response += data
|
||||
# Print formatted response data a la 'curl -v'
|
||||
print(''.join(
|
||||
'> {line}\n'.format(line=line)
|
||||
for line in response.splitlines()
|
||||
))
|
||||
self.client_connection.sendall(response)
|
||||
finally:
|
||||
self.client_connection.close()
|
||||
|
||||
|
||||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||||
|
||||
|
||||
def make_server(server_address, application):
|
||||
server = WSGIServer(server_address)
|
||||
server.set_app(application)
|
||||
return server
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if len(sys.argv) < 2:
|
||||
sys.exit('Provide a WSGI application object as module:callable')
|
||||
app_path = sys.argv[1]
|
||||
module, application = app_path.split(':')
|
||||
module = __import__(module)
|
||||
application = getattr(module, application)
|
||||
httpd = make_server(SERVER_ADDRESS, application)
|
||||
print('WSGIServer: Serving HTTP on port {port} ...\n'.format(port=PORT))
|
||||
httpd.serve_forever()
|
||||
```
|
||||
|
||||
It’s definitely bigger than the server code in Part 1, but it’s also small enough (just under 150 lines) for you to understand without getting bogged down in details. The above server also does more - it can run your basic Web application written with your beloved Web framework, be it Pyramid, Flask, Django, or some other Python WSGI framework.
|
||||
|
||||
Don’t believe me? Try it and see for yourself. Save the above code as webserver2.py or download it directly from GitHub. If you try to run it without any parameters it’s going to complain and exit.
|
||||
|
||||
```
|
||||
$ python webserver2.py
|
||||
Provide a WSGI application object as module:callable
|
||||
```
|
||||
|
||||
It really wants to serve your Web application and that’s where the fun begins. To run the server the only thing you need installed is Python. But to run applications written with Pyramid, Flask, and Django you need to install those frameworks first. Let’s install all three of them. My preferred method is by using virtualenv. Just follow the steps below to create and activate a virtual environment and then install all three Web frameworks.
|
||||
|
||||
```
|
||||
$ [sudo] pip install virtualenv
|
||||
$ mkdir ~/envs
|
||||
$ virtualenv ~/envs/lsbaws/
|
||||
$ cd ~/envs/lsbaws/
|
||||
$ ls
|
||||
bin include lib
|
||||
$ source bin/activate
|
||||
(lsbaws) $ pip install pyramid
|
||||
(lsbaws) $ pip install flask
|
||||
(lsbaws) $ pip install django
|
||||
```
|
||||
|
||||
At this point you need to create a Web application. Let’s start with Pyramid first. Save the following code as pyramidapp.py to the same directory where you saved webserver2.py or download the file directly from GitHub:
|
||||
|
||||
```
|
||||
from pyramid.config import Configurator
|
||||
from pyramid.response import Response
|
||||
|
||||
|
||||
def hello_world(request):
|
||||
return Response(
|
||||
'Hello world from Pyramid!\n',
|
||||
content_type='text/plain',
|
||||
)
|
||||
|
||||
config = Configurator()
|
||||
config.add_route('hello', '/hello')
|
||||
config.add_view(hello_world, route_name='hello')
|
||||
app = config.make_wsgi_app()
|
||||
```
|
||||
|
||||
Now you’re ready to serve your Pyramid application with your very own Web server:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py pyramidapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
You just told your server to load the ‘app’ callable from the python module ‘pyramidapp’ Your server is now ready to take requests and forward them to your Pyramid application. The application only handles one route now: the /hello route. Type http://localhost:8888/hello address into your browser, press Enter, and observe the result:
|
||||
|
||||
|
||||
|
||||
You can also test the server on the command line using the ‘curl’ utility:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Check what the server and curl prints to standard output.
|
||||
|
||||
Now onto Flask. Let’s follow the same steps.
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
from flask import Response
|
||||
flask_app = Flask('flaskapp')
|
||||
|
||||
|
||||
@flask_app.route('/hello')
|
||||
def hello_world():
|
||||
return Response(
|
||||
'Hello world from Flask!\n',
|
||||
mimetype='text/plain'
|
||||
)
|
||||
|
||||
app = flask_app.wsgi_app
|
||||
```
|
||||
|
||||
Save the above code as flaskapp.py or download it from GitHub and run the server as:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py flaskapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
Now type in the http://localhost:8888/hello into your browser and press Enter:
|
||||
|
||||
|
||||
|
||||
Again, try ‘curl’ and see for yourself that the server returns a message generated by the Flask application:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Can the server also handle a Django application? Try it out! It’s a little bit more involved, though, and I would recommend cloning the whole repo and use djangoapp.py, which is part of the GitHub repository. Here is the source code which basically adds the Django ‘helloworld’ project (pre-created using Django’s django-admin.py startproject command) to the current Python path and then imports the project’s WSGI application.
|
||||
|
||||
```
|
||||
import sys
|
||||
sys.path.insert(0, './helloworld')
|
||||
from helloworld import wsgi
|
||||
|
||||
|
||||
app = wsgi.application
|
||||
```
|
||||
|
||||
Save the above code as djangoapp.py and run the Django application with your Web server:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py djangoapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
Type in the following address and press Enter:
|
||||
|
||||
|
||||
|
||||
And as you’ve already done a couple of times before, you can test it on the command line, too, and confirm that it’s the Django application that handles your requests this time around:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Did you try it? Did you make sure the server works with those three frameworks? If not, then please do so. Reading is important, but this series is about rebuilding and that means you need to get your hands dirty. Go and try it. I will wait for you, don’t worry. No seriously, you must try it and, better yet, retype everything yourself and make sure that it works as expected.
|
||||
|
||||
Okay, you’ve experienced the power of WSGI: it allows you to mix and match your Web servers and Web frameworks. WSGI provides a minimal interface between Python Web servers and Python Web Frameworks. It’s very simple and it’s easy to implement on both the server and the framework side. The following code snippet shows the server and the framework side of the interface:
|
||||
|
||||
```
|
||||
def run_application(application):
|
||||
"""Server code."""
|
||||
# This is where an application/framework stores
|
||||
# an HTTP status and HTTP response headers for the server
|
||||
# to transmit to the client
|
||||
headers_set = []
|
||||
# Environment dictionary with WSGI/CGI variables
|
||||
environ = {}
|
||||
|
||||
def start_response(status, response_headers, exc_info=None):
|
||||
headers_set[:] = [status, response_headers]
|
||||
|
||||
# Server invokes the ‘application' callable and gets back the
|
||||
# response body
|
||||
result = application(environ, start_response)
|
||||
# Server builds an HTTP response and transmits it to the client
|
||||
…
|
||||
|
||||
def app(environ, start_response):
|
||||
"""A barebones WSGI app."""
|
||||
start_response('200 OK', [('Content-Type', 'text/plain')])
|
||||
return ['Hello world!']
|
||||
|
||||
run_application(app)
|
||||
```
|
||||
|
||||
Here is how it works:
|
||||
|
||||
1. The framework provides an ‘application’ callable (The WSGI specification doesn’t prescribe how that should be implemented)
|
||||
2. The server invokes the ‘application’ callable for each request it receives from an HTTP client. It passes a dictionary ‘environ’ containing WSGI/CGI variables and a ‘start_response’ callable as arguments to the ‘application’ callable.
|
||||
3. The framework/application generates an HTTP status and HTTP response headers and passes them to the ‘start_response’ callable for the server to store them. The framework/application also returns a response body.
|
||||
4. The server combines the status, the response headers, and the response body into an HTTP response and transmits it to the client (This step is not part of the specification but it’s the next logical step in the flow and I added it for clarity)
|
||||
|
||||
And here is a visual representation of the interface:
|
||||
|
||||
|
||||
|
||||
So far, you’ve seen the Pyramid, Flask, and Django Web applications and you’ve seen the server code that implements the server side of the WSGI specification. You’ve even seen the barebones WSGI application code snippet that doesn’t use any framework.
|
||||
|
||||
The thing is that when you write a Web application using one of those frameworks you work at a higher level and don’t work with WSGI directly, but I know you’re curious about the framework side of the WSGI interface, too because you’re reading this article. So, let’s create a minimalistic WSGI Web application/Web framework without using Pyramid, Flask, or Django and run it with your server:
|
||||
|
||||
```
|
||||
def app(environ, start_response):
|
||||
"""A barebones WSGI application.
|
||||
|
||||
This is a starting point for your own Web framework :)
|
||||
"""
|
||||
status = '200 OK'
|
||||
response_headers = [('Content-Type', 'text/plain')]
|
||||
start_response(status, response_headers)
|
||||
return ['Hello world from a simple WSGI application!\n']
|
||||
```
|
||||
|
||||
Again, save the above code in wsgiapp.py file or download it from GitHub directly and run the application under your Web server as:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py wsgiapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
Type in the following address and press Enter. This is the result you should see:
|
||||
|
||||
|
||||
|
||||
You just wrote your very own minimalistic WSGI Web framework while learning about how to create a Web server! Outrageous.
|
||||
|
||||
Now, let’s get back to what the server transmits to the client. Here is the HTTP response the server generates when you call your Pyramid application using an HTTP client:
|
||||
|
||||

|
||||
|
||||
The response has some familiar parts that you saw in Part 1 but it also has something new. It has, for example, four HTTP headers that you haven’t seen before: Content-Type, Content-Length, Date, and Server. Those are the headers that a response from a Web server generally should have. None of them are strictly required, though. The purpose of the headers is to transmit additional information about the HTTP request/response.
|
||||
|
||||
Now that you know more about the WSGI interface, here is the same HTTP response with some more information about what parts produced it:
|
||||
|
||||
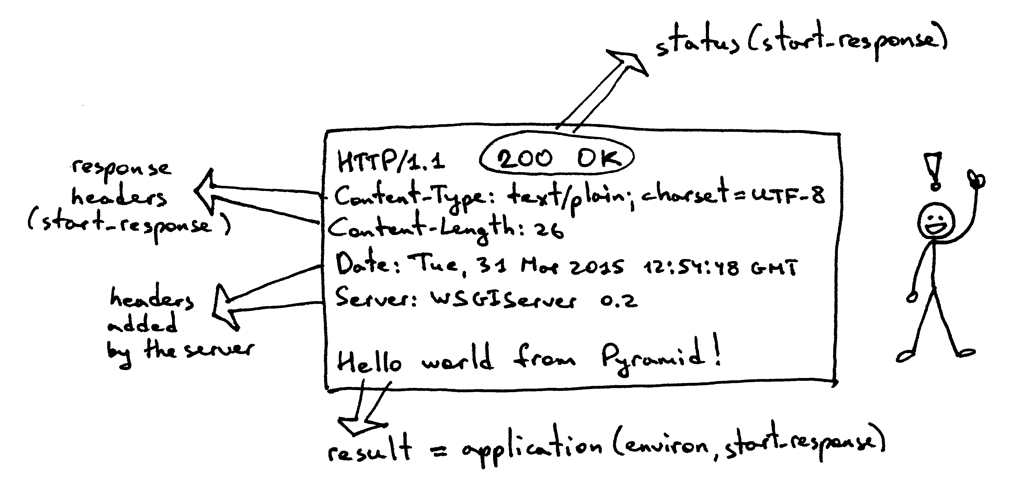
|
||||
|
||||
I haven’t said anything about the ‘environ’ dictionary yet, but basically it’s a Python dictionary that must contain certain WSGI and CGI variables prescribed by the WSGI specification. The server takes the values for the dictionary from the HTTP request after parsing the request. This is what the contents of the dictionary look like:
|
||||
|
||||
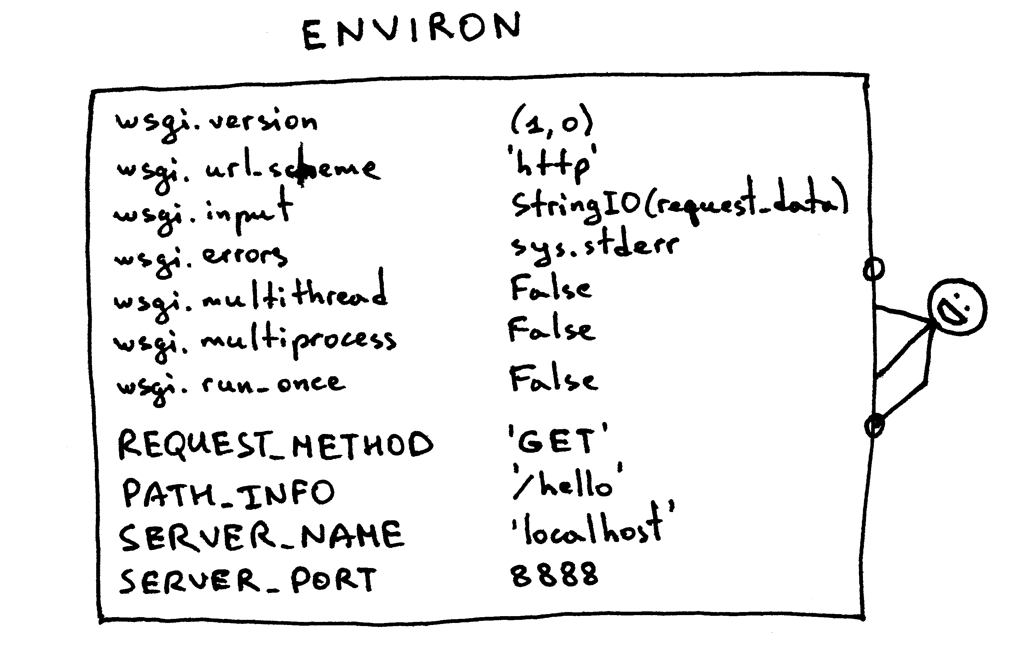
|
||||
|
||||
A Web framework uses the information from that dictionary to decide which view to use based on the specified route, request method etc., where to read the request body from and where to write errors, if any.
|
||||
|
||||
By now you’ve created your own WSGI Web server and you’ve made Web applications written with different Web frameworks. And, you’ve also created your barebones Web application/Web framework along the way. It’s been a heck of a journey. Let’s recap what your WSGI Web server has to do to serve requests aimed at a WSGI application:
|
||||
|
||||
- First, the server starts and loads an ‘application’ callable provided by your Web framework/application
|
||||
- Then, the server reads a request
|
||||
- Then, the server parses it
|
||||
- Then, it builds an ‘environ’ dictionary using the request data
|
||||
- Then, it calls the ‘application’ callable with the ‘environ’ dictionary and a ‘start_response’ callable as parameters and gets back a response body.
|
||||
- Then, the server constructs an HTTP response using the data returned by the call to the ‘application’ object and the status and response headers set by the ‘start_response’ callable.
|
||||
- And finally, the server transmits the HTTP response back to the client
|
||||
|
||||
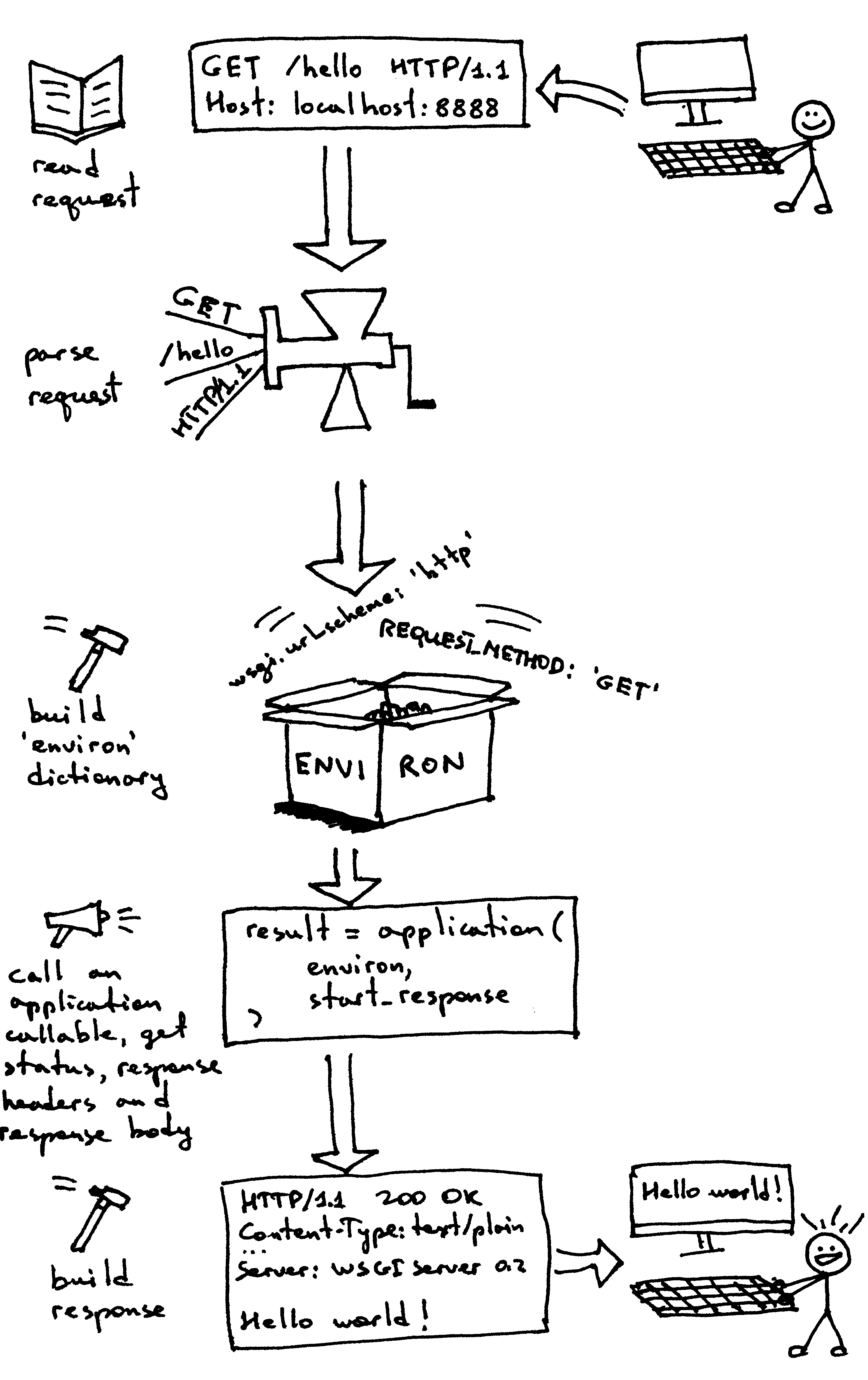
|
||||
|
||||
That’s about all there is to it. You now have a working WSGI server that can serve basic Web applications written with WSGI compliant Web frameworks like Django, Flask, Pyramid, or your very own WSGI framework. The best part is that the server can be used with multiple Web frameworks without any changes to the server code base. Not bad at all.
|
||||
|
||||
Before you go, here is another question for you to think about, “How do you make your server handle more than one request at a time?”
|
||||
|
||||
Stay tuned and I will show you a way to do that in Part 3. Cheers!
|
||||
|
||||
BTW, I’m writing a book “Let’s Build A Web Server: First Steps” that explains how to write a basic web server from scratch and goes into more detail on topics I just covered. Subscribe to the mailing list to get the latest updates about the book and the release date.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbaws-part2/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/rspivak/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by kylepeng93
|
||||
给学习OpenStack基础设施的新手的入门指南
|
||||
===========================================================
|
||||
|
||||
@ -39,7 +38,7 @@ translating by kylepeng93
|
||||
via: https://opensource.com/business/16/4/interview-openstack-infrastructure-beginners
|
||||
|
||||
作者:[linux.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[kylepeng93](https://github.com/kylepeng93)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,49 +0,0 @@
|
||||
Cassandra 和 Spark 数据处理入门
|
||||
==============================================================
|
||||
|
||||

|
||||
|
||||
Apache Cassandra 数据库近来引起了很多的兴趣,这主要源于现代云端软件对于可用性及性能方面的要求。
|
||||
|
||||
那么,Apache Cassandra 是什么?它是一种为高可用性及线性可扩展性优化的分布式的联机交易处理 (OLTP) 数据库。当人们想知道 Cassandra 的用途时,可以想想你想要的离客户近的系统。这j最终是我们的用户进行交互的系统。需要保证实时可用的程序:产品目录,IoT,医疗系统,以及移动应用。对这些程序而言,下线时间意味着利润降低甚至导致其他更坏的结果。Netfilix 是这个于2008年开源的项目的早期使用者,他们对此项目的贡献以及带来的成功让这个项目名声大噪。
|
||||
|
||||
Cassandra 于2010年成为了 Apache 软件基金会的顶级项目,在这之后就开始变得流行。现在,只要你有 Cassadra 的相关知识,找工作时就能轻松不少。光是想想一个 NoSQL 语言和开源技术能达到如此企业级 SQL 的高度就觉得这是十分疯狂而又不可思议的。这引出了一个问题。是什么让它如此的流行?
|
||||
|
||||
因为采用了首先在[亚马逊发表的 Dynamo 论文][1]提出的设计,Cassandra 有能力在大规模的硬件及网络故障时保持实时在线。由于采用了点对点模式,在没有单点故障的情况下,我们能幸免于机架故障甚至完全网络分区。我们能在不影响用户体验的前提下处理数据中心故障。一个能考虑到故障的分布式系统才是一个没有后顾之忧的分布式系统,因为老实说,故障是迟早会发生的。有了 Cassandra, 我们可疑直面残酷的生活并将之融入数据库的结构和功能中。
|
||||
|
||||
|
||||
|
||||
我们能猜到你现在在想什么,“但我只有关系数据库相关背景,难道这样的转变不会很困难吗?"这问题的答案介于是和不是之间。使用 Cassandra 建立数据模型对有关系数据库背景的开发者而言是轻车熟路。我们使用表格来建立数据模型,并使用 CQL 或者 Cassandra 查询语言来查询数据库。然而,与 SQL 不同的是,Cassandra 支持更加复杂的数据结构,例如多重和用户自定义类型。举个例子,当要储存对一个小猫照片的点赞数目时,我们可以将整个数据储存在一个包含照片本身的集合之中从而获得更快的顺序查找而不是建立一个独立的表。这样的表述在 CQL 中十分的自然。在我们照片表中,我们需要记录名字,URL以及给此照片点赞过的人。
|
||||
|
||||

|
||||
|
||||
在一个高性能系统中,毫秒对用户体验和客户保留都能产生影响。昂贵的 JOIN 制约了我们通过增加不可预见的网络调用而扩容的能力。当我们将数据反规范化使其能在尽可能少的请求中被获取到时,我们即可从磁盘空间花费的降低中获益并获得可预测的,高性能应用。我们将反规范化同 Cassandra 一同介绍是因为它提供了很有吸引力的的折衷方案。
|
||||
|
||||
很明显,我们不会局限于对于小猫照片的点赞数量。Canssandra 是一款个为并发高写入优化的方案。这使其成为需要时常吞吐数据的大数据应用的理想解决方案。市场上的时序和 IoT 的使用场景正在以稳定的速度在需求和亮相方面增加,我们也在不断探寻优化我们所收集到的数据以求提升我们的技术应用(注:这句翻的非常别扭,求校队)
|
||||
|
||||
|
||||
这就引出了我们的下一步,我们已经提到了如何以一种现代的,性价比高的方式储存数据,但我们应该如何获得更多的马力呢?具体而言,当我们收集到了所需的数据,我们应该怎样处理呢?如何才能有效的分析几百 TB 的数据呢?如何才能在实时的对我们所收集到的信息进行反馈并在几秒而不是几小时的时间利作出决策呢?Apache Spark 将给我们答案。
|
||||
|
||||
|
||||
Spark 是大数据变革中的下一步。 Hadoop 和 MapReduce 都是革命性的产品,他们让大数据界获得了分析所有我们所取得的数据的机会。Spark 对性能的大幅提升及对代码复杂度的大幅降低则将大数据分析提升到了另一个高度。通过 Spark,我们能大批量的处理计算,对流处理进行快速反映,通过机器学习作出决策并理解通过对图的遍历理解复杂的递归关系。这并非只是为你的客户提供与快捷可靠的应用程序连接(Cassandra 已经提供了这样的功能),这更是能一探 Canssandra 所储存的数据并作出更加合理的商业决策同时更好地满足客户需求。
|
||||
|
||||
你可以看看 [Spark-Cassandra Connector][2] (open source) 并动手试试。若想了解更多关于这两种技术的信息,我们强烈推荐名为 [DataStax Academy][3] 的自学课程
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/basics-cassandra-and-spark-data-processing
|
||||
|
||||
作者:[Jon Haddad][a],[Dani Traphagen][b]
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/rustyrazorblade
|
||||
[b]: https://opensource.com/users/dtrapezoid
|
||||
[1]: http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
|
||||
[2]: https://github.com/datastax/spark-cassandra-connector
|
||||
[3]: https://academy.datastax.com/
|
||||
[4]: http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/49162
|
||||
[5]: https://twitter.com/dtrapezoid
|
||||
[6]: https://twitter.com/rustyrazorblade
|
||||
@ -0,0 +1,71 @@
|
||||
使用python 和asyncio编写在线多人游戏 - 第1部分
|
||||
===================================================================
|
||||
|
||||
你曾经把async和python关联起来过吗?在这里我将告诉你怎样做,而且在[working example][1]这个例子里面展示-一个流行的贪吃蛇游戏,这是为多人游戏而设计的。
|
||||
[Play game][2]
|
||||
|
||||
###1.简介
|
||||
|
||||
在技术和文化领域,大量的多人在线游戏毋庸置疑是我们这个世界的主流之一。同时,为一个MMO游戏写一个服务器一般和大量的预算与低水平的编程技术相关,在最近这几年,事情发生了很大的变化。基于动态语言的现代框架允许在稳健的硬件上面处理大量并发的用户连接。同时,HTML5 和 WebSockets 标准允许基于实时的图形游戏直接在web浏览器上创建客户端,而不需要任何的扩展。
|
||||
|
||||
对于创建可扩展非堵塞的服务器,Python可能不是最受欢迎的工具,尤其是和在这个领域最受欢迎的node.js相比。但是最近版本的python打算改变这种现状。[asyncio][3]的介绍和一个特别的[async/await][4] 语法使得异步代码看起来像常规的阻塞代码,这使得python成为一个值得信赖的异步编程语言。所以我将尝试利用这些新特点来创建一个多人在线游戏。
|
||||
|
||||
###2.异步
|
||||
一个游戏服务器应该处理最大数量的用户的并发连接和实时处理这些连接。一个典型的解决方案----创建线程,然而在这种情况下并不能解决这个问题。运行上千的线程需要CPU在它们之间不停的切换(这叫做上下文切换),这将开销非常大,效率很低下。更糟糕的是,因为,此外,它们会占用大量的内存。在python中,还有一个问题,python的解释器(CPython)并不是针对多线程设计的,它主要针对于单线程实现最大数量的行为。这就是为什么它使用GIL(global interpreter lock),一个不允许同时运行多线程python代码的架构,来防止共享物体的不可控用法。正常情况下当当前线程正在等待的时候,解释器转换到另一个线程,通常是一个I/O的响应(像一个服务器的响应一样)。这允许在你的应用中有非阻塞I/O,因为每一个操作仅仅堵塞一个线程而不是堵塞整个服务器。然而,这也使得通常的多线程变得无用,因为它不允许你并发执行python代码,即使是在多核心的cpu上。同时在单线程中拥有非阻塞IO是完全有可能的,因而消除了经常切换上下文的需要。
|
||||
|
||||
实际上,你可以用纯python代码来实现一个单线程的非阻塞IO。你所需要的只是标准的[select][5]模块,这个模块可以让你写一个事件循环来等待未阻塞的socket的io。然而,这个方法需要你在一个地方定义所有app的逻辑,不久之后,你的app就会变成非常复杂的状态机。有一些框架可以简化这个任务,比较流行的是[tornade][6] 和 [twisted][7]。他们被用来使用回调方法实现复杂的协议(这和node.js比较相似)。这个框架运行在他自己的事件循环中,这个事件在定义的事件上调用你的回调。并且,这或许是一些情况的解决方案,但是它仍然需要使用回调的方式编程,这使你的代码碎片化。和写同步代码并且并发执行多个副本相比,就像我们会在普通的线程上做一样。这为什么在单个线程上是不可能的呢?
|
||||
|
||||
这就是为什么microthread出现的原因。这个想法是为了在一个线程上并发执行任务。当你在一个任务中调用阻塞的方法时,有一个叫做"manager" (或者“scheduler”)的东西在执行事件循环。当有一些事件准备处理的时候,一个manager会让等这个事件的“任务”单元去执行,直到自己停了下来。然后执行完之后就返回那个管理器(manager)。
|
||||
|
||||
>Microthreads are also called lightweight threads or green threads (a term which came from Java world). Tasks which are running concurrently in pseudo-threads are called tasklets, greenlets or coroutines.(Microthreads 也会被称为lightweight threads 或者 green threads(java中的一个术语)。在伪线程中并发执行的任务叫做tasklets,greenlets或者coroutines).
|
||||
|
||||
microthreads的其中一种实现在python中叫做[Stackless Python][8]。这个被用在了一个叫[EVE online][9]的非常有名的在线游戏中,所以它变得非常有名。这个MMO游戏自称说在一个持久的宇宙中,有上千个玩家在做不同的活动,这些都是实时发生的。Stackless 是一个单独的python解释器,它代替了标准的栈调用并且直接控制流来减少上下文切换的开销。尽管这非常有效,这个解决方案不如使用标准解释器的“soft”库有名。像[eventlet][10]和[gevent][11] 的方式配备了标准的I / O库的补丁的I / O功能在内部事件循环执行。这使得将正常的阻塞代码转变成非阻塞的代码变得简单。这种方法的一个缺点是从代码看这并不明显,这被称为非阻塞。Python的新的版本介绍了本地协同程序作为生成器的高级形式。在Python 的3.4版本中,引入了asyncio库,这个库依赖于本地协同程序来提供单线程并发。但是在Python 3.5 协同程序变成了Python语言的一部分,使用新的关键字 async 和 await 来描述。这是一个简单的例子,这表明了使用asyncio来运行 并发任务。
|
||||
|
||||
```
|
||||
import asyncio
|
||||
|
||||
async def my_task(seconds):
|
||||
print("start sleeping for {} seconds".format(seconds))
|
||||
await asyncio.sleep(seconds)
|
||||
print("end sleeping for {} seconds".format(seconds))
|
||||
|
||||
all_tasks = asyncio.gather(my_task(1), my_task(2))
|
||||
loop = asyncio.get_event_loop()
|
||||
loop.run_until_complete(all_tasks)
|
||||
loop.close()
|
||||
```
|
||||
|
||||
我们启动了两个任务,一个睡眠1秒钟,另一个睡眠2秒钟,输出如下:
|
||||
|
||||
```
|
||||
start sleeping for 1 seconds
|
||||
start sleeping for 2 seconds
|
||||
end sleeping for 1 seconds
|
||||
end sleeping for 2 seconds
|
||||
```
|
||||
|
||||
正如你所看到的,协同程序不会阻塞彼此-----第二个任务在第一个结束之前启动。这发生的原因是asyncio.sleep是协同程序,它会返回一个调度器的执行直到时间过去。在下一节中,
|
||||
我们将会使用coroutine-based的任务来创建一个游戏循环。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[xinglianfly](https://github.com/xinglianfly)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: http://snakepit-game.com/
|
||||
[3]: https://docs.python.org/3/library/asyncio.html
|
||||
[4]: https://docs.python.org/3/whatsnew/3.5.html#whatsnew-pep-492
|
||||
[5]: https://docs.python.org/2/library/select.html
|
||||
[6]: http://www.tornadoweb.org/
|
||||
[7]: http://twistedmatrix.com/
|
||||
[8]: http://www.stackless.com/
|
||||
[9]: http://www.eveonline.com/
|
||||
[10]: http://eventlet.net/
|
||||
[11]: http://www.gevent.org/
|
||||
@ -1,104 +0,0 @@
|
||||
如何在 Linux 上录制你的终端操作
|
||||
=================================================
|
||||
|
||||
录制一次终端操作可能是一个帮助他人学习 Linux 、展示一系列正确命令行操作的和分享知识的通俗易懂方法。不管是什么目的,大多数情况下从终端复制粘贴文本从终端不会是很有帮助而且录制视频的过程也是相当困难。在这次的文章中,我们将简单的了解一下在终端会话中用 GIF 格式录制视频的方法。
|
||||
|
||||
### 预先要求
|
||||
|
||||
如果你只是希望能记录你的终端会话,并且能在终端进行播放或者和他人分享,那么你只需要一个叫做:'ttyrec' 的软件。Ubuntu 使用者可以通过运行这行代码进行安装:
|
||||
|
||||
```
|
||||
sudo apt-get install ttyrec
|
||||
```
|
||||
|
||||
如果你想将生成的视频转换成一个 GIF 文件,并且能够和那些希望发布在网站上或者不使用终端或者只是简单的想保留一个 GIF 的用户分享。那么你需要安装额外的两个软件包。第一个就是'imagemagick', 你可以通过以下的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
第二个软件包就是:'tty2gif',你可以从这里下载。这个软件包需要安装如下依赖:
|
||||
|
||||
```
|
||||
sudo apt-get install python-opster
|
||||
```
|
||||
|
||||
### 录制
|
||||
|
||||
开始录制中毒啦操作,你需要的仅仅是键入'ttyprec' + 回车。这个命令将会在后台运行一个实时的记录工具。我们可以通过键入'exit'或者'ctrl+d'来停止。ttyrec 默认会在'Home'目录下创建一个'ttyrecord'的文件。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 播放
|
||||
|
||||
播放这个文件非常简单。你只需要打开终端并且使用 'ttyplay' 命令打开 'ttyrecord' 文件即可。(在这个例子里,我们使用 ttyrecord 作为文件名,当然,你也可以对这个文件进行重命名)
|
||||
|
||||

|
||||
|
||||
然后就可以开始播放这个文件。这个视频记录了所有的操作,包括你的删除,修改。这看起来想一个拥有自我意识的终端,但是这个命令执行的过程并不是只是为了给系统看,而是为了更好的展现给人。
|
||||
|
||||
注意的一点,播放这个记录是完全可控的,你可以通过点击 '+' 或者 '-' 或者 '0', 或者 '1' 按钮加速、减速、暂停、和恢复播放。
|
||||
|
||||
### 导出成 GIF
|
||||
|
||||
为了方便,我们通常会将视频记录转换为 GIF 格式,并且,这个也非常方便可以实现。以下是方法:
|
||||
|
||||
首先,解压这个文件 'tty2gif.tar.bz2':
|
||||
|
||||
```
|
||||
tar xvfj tty2gif.tar.bz2
|
||||
```
|
||||
|
||||
然后,将 'tty2gif.py' 这个文件拷贝到 'ttyprecord' 文件同目录(或者你命名的那个视频文件), 然后在这个目录下打开终端,输入命令:
|
||||
|
||||
```
|
||||
python tty2gif.py typing ttyrecord
|
||||
```
|
||||
|
||||
如果你出现了错误,检查一下你是否有安装 'python-opster' 包。如果还是有错误,使用如下命令进行排除。
|
||||
|
||||
```
|
||||
sudo apt-get install xdotool
|
||||
export WINDOWID=$(xdotool getwindowfocus)
|
||||
```
|
||||
|
||||
然后重复这个命令 'python tty2gif.py' 并且你将会看到在 ttyrecord 目录下多了一大串的 gif 文件。
|
||||
|
||||

|
||||
|
||||
接下来的一步就是整合所有的 gif 文件,将他打包成一个 GIF 文件。我们通过使用 imagemagick 工具。输入下列命令:
|
||||
|
||||
```
|
||||
convert -delay 25 -loop 0 *.gif example.gif
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以任意的文件名,我喜欢用 'example.gif'。 并且,你可以改变这个延时和循环时间。 Enjoy.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-record-your-terminal-session-on-linux/
|
||||
|
||||
作者:[Bill Toulas][a]
|
||||
译者:[译者ID](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/howtoforgecom
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,124 @@
|
||||
Python高级图像处理
|
||||
======================================
|
||||
|
||||

|
||||
|
||||
构建图像搜索引擎并不是一件容易的任务。这里有几个概念、工具、想法和技术需要实现。主要的图像处理概念之一是逆图像查询(RIQ)或者说逆图像搜索。Google、Cloudera、Sumo Logic 和 Birst等公司在使用逆图像搜索中名列前茅。通过分析图像和使用数据挖掘RIQ提供了很好的洞察分析能力。
|
||||
|
||||
### 顶级公司与逆图像搜索
|
||||
|
||||
有很多顶级的技术公司使用RIQ来产生最好的收益。例如:在2014年Pinterest第一次带来了视觉搜索。随后在2015年发布了一份白皮书,揭示了其架构。逆图像搜索让Pinterest获得对时尚对象的视觉特征和显示类似的产品建议的能力。
|
||||
|
||||
众所周知,谷歌图片使用逆图像搜索允许用户上传一张图片然后搜索相关联的图片。通过使用先进的算法对提交的图片进行分析和数学建模。然后和谷歌数据库中无数的其他图片进行比较得到相似的结果。
|
||||
|
||||
**这是opencv 2.4.9特征比较报告一个图表:**
|
||||
|
||||

|
||||
|
||||
### 算法 & Python库
|
||||
|
||||
在我们使用它工作之前,让我们过一遍构建图像搜索引擎的Python库的主要元素:
|
||||
|
||||
### 专利算法
|
||||
|
||||
#### 尺度不变特征变换算法(SIFT - Scale-Invariant Feature Transform)
|
||||
|
||||
1. 非自由功能的一个专利技术,利用图像识别符,以识别相似图像,甚至那些从不同的角度,大小,深度和规模点击,它们被包括在搜索结果中。[点击这里][4]查看SIFT详细视频。
|
||||
2. SIFT能与从许多图片中提取的特征的大型数据库正确的匹配搜索条件。
|
||||
3. 从不同的方面来匹配相同的图像和匹配不变特征来获得搜索结果是SIFT的另一个特征。了解更多关于尺度不变[关键点][5]
|
||||
|
||||
#### 加速鲁棒特征(SURF - Speeded Up Robust Features)算法
|
||||
|
||||
1. [SURF][1] 也是一种非自由功能的专利技术而且还是一种“加速”的SIFT版本。不像SIFT,
|
||||
|
||||
2. SURF依赖于Hessian矩阵行列式的位置和尺度。
|
||||
|
||||
3. 在许多应用中,旋转不变性是不是一个必要条件。所以找不到这个方向的速度加快了这个过程。
|
||||
|
||||
4. SURF包括几种特性,在每一步的速度提高。比SIFT快三倍的速度,SIFT擅长旋转和模糊化。然而它不擅长处理照明和变换视角。
|
||||
|
||||
5. Open CV,一个程序功能库提供SURF相似的功能,SURF.compute()和SURF.Detect()可以用来找到描述符和要点。阅读更多关于SURF[点击这里][2]
|
||||
|
||||
### 开源算法
|
||||
|
||||
#### KAZE 算法
|
||||
|
||||
1. KAZE是一个开源的非线性尺度空间的二维多尺度和新的特征检测和描述算法。在加性算子分裂的有效技术(AOS)和可变电导扩散是用来建立非线性尺度空间。
|
||||
|
||||
2. 多尺度图像处理基础是简单的创建一个图像的尺度空间,同时用正确的函数过滤原始图像,提高时间或规模。
|
||||
|
||||
#### AKAZE (Accelerated-KAZE) 算法
|
||||
|
||||
1. 顾名思义,这是一个更快的图像搜索方式,找到匹配的关键点在两幅图像之间。AKAZE 使用二进制描述符和非线性尺度空间来平衡精度和速度。
|
||||
|
||||
#### BRISK (Binary Robust Invariant Scalable Keypoints) 算法
|
||||
|
||||
1. BRISK 非常适合描述关键点的检测与匹配。
|
||||
|
||||
2. 是一种高度自适应的算法,基于尺度空间的快速检测器和一个位字符串描述符,有助于加快搜索显着。
|
||||
|
||||
3. 尺度空间关键点检测与关键点描述帮助优化手头相关任务的性能
|
||||
|
||||
#### FREAK (Fast Retina Keypoint)
|
||||
|
||||
1. 这个新的关键点描述的灵感来自人的眼睛。通过图像强度比能有效地计算一个二进制串级联。FREAK算法相比BRISK,SURF和SIFT算法有更快的计算与较低的内存负载。
|
||||
|
||||
#### ORB (Oriented FAST and Rotated BRIEF)
|
||||
|
||||
1. 快速的二进制描述符,ORB具有抗噪声和旋转不变性。ORB建立在FAST关键点检测器和BRIEF描述符之上,有成本低、性能好的元素属性。
|
||||
|
||||
2. 除了快速和精确的定位元件,有效地计算定向的BRIEF,分析变动和面向BRIEF特点相关,是另一个ORB的特征。
|
||||
|
||||
### Python库
|
||||
|
||||
#### Open CV
|
||||
|
||||
1. Open CV提供学术和商业用途。一个开源的机器学习和计算机视觉库,OpenCV便于组织利用和修改代码。
|
||||
|
||||
2. 超过2500个优化算法,包括国家最先进的机器学习和计算机视觉算法服务与各种图像搜索--人脸检测、目标识别、摄像机目标跟踪,从图像数据库中寻找类似图像、眼球运动跟随、风景识别等。
|
||||
|
||||
3. 像谷歌,IBM,雅虎,IBM,索尼,本田,微软和英特尔这样的大公司广泛的使用OpenCV。
|
||||
|
||||
4. OpenCV拥有python,java,C,C++和MATLAB接口,同时支持Windows,Linux,Mac OS和Android。
|
||||
|
||||
#### Python图像库 (PIL)
|
||||
|
||||
1. Python图像库(PIL)支持多种文件格式,同时提供图像处理和图形解决方案。开源的PIL为你的Python解释器添加图像处理能力。
|
||||
2. 标准的图像处理能力包括图像增强、透明和屏蔽作用、图像过滤、像素操作等。
|
||||
|
||||
详细的数据和图表,请看OpenCV 2.4.9 特征比较报告。[这里][3]
|
||||
|
||||
### 构建图像搜索引擎
|
||||
|
||||
图像搜索引擎可以从预置集图像库选择相似的图像。其中最受欢迎的是谷歌的著名的图像搜索引擎。对于初学者来说,有不同的方法来建立这样的系统。提几个如下:
|
||||
|
||||
1. 采用图像提取、图像描述提取、元数据提取和搜索结果提取,建立图像搜索引擎。
|
||||
2. 定义你的图像描述符,数据集索引,定义你的相似性度量,然后搜索和排名。
|
||||
3. 选择要搜索的图像,选择用于进行搜索的目录,所有图片的搜索目录,创建图片特征索引,评估相同的搜索图片的功能,在搜索中匹配图片,并获得匹配的图片。
|
||||
|
||||
我们的方法基本上就比较grayscaled版本的图像,逐渐移动到复杂的特征匹配算法如SIFT和SURF,最后沉淀下来的是开源的解决方案称为BRISK。所有这些算法提供了有效的结果,在性能和延迟的细微变化。建立在这些算法上的引擎有许多应用,如分析流行统计的图形数据,在图形内容中识别对象,以及更多。
|
||||
|
||||
**例如**:一个图像搜索引擎需要由一个IT公司作为客户机来建立。因此,如果一个品牌的标志图像被提交在搜索中,所有相关的品牌形象搜索显示结果。所得到的结果也可以通过客户端分析,使他们能够根据地理位置估计品牌知名度。但它还比较年轻,RIQ或反向图像搜索尚未被完全挖掘利用。
|
||||
|
||||
这就结束了我们的文章,使用Python构建图像搜索引擎。浏览我们的博客部分来查看最新的编程技术。
|
||||
|
||||
数据来源:OpenCV 2.4.9 特征比较报告(computer-vision-talks.com)
|
||||
|
||||
(Ananthu Nair 的指导与补充)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cuelogic.com/blog/advanced-image-processing-with-python/
|
||||
|
||||
作者:[Snehith Kumbla][a]
|
||||
译者:[Johnny-Liao](https://github.com/Johnny-Liao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cuelogic.com/blog/author/snehith-kumbla/
|
||||
[1]: http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html
|
||||
[2]: http://www.vision.ee.ethz.ch/~surf/eccv06.pdf
|
||||
[3]: https://docs.google.com/spreadsheets/d/1gYJsy2ROtqvIVvOKretfxQG_0OsaiFvb7uFRDu5P8hw/edit#gid=10
|
||||
[4]: https://www.youtube.com/watch?v=NPcMS49V5hg
|
||||
[5]: https://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
|
||||
@ -1,48 +1,49 @@
|
||||
How To Setup Bridge (br0) Network on Ubuntu Linux 14.04 and 16.04 LTS
|
||||
如何在 Ubuntu 14.04 和 16.04 上建立网桥(br0)
|
||||
=======================================================================
|
||||
|
||||
> am a new Ubuntu Linux 16.04 LTS user. How do I setup a network bridge on the host server powered by Ubuntu 14.04 LTS or 16.04 LTS operating system?
|
||||
> 作为一个 Ubuntu 16.04 LTS 的初学者。如何在 Ubuntu 14.04 和 16.04 的主机上建立网桥呢?
|
||||
|
||||

|
||||
|
||||
A Bridged networking is nothing but a simple technique to connect to the outside network through the physical interface. It is useful for LXC/KVM/Xen/Containers virtualization and other virtual interfaces. The virtual interfaces appear as regular hosts to the rest of the network. In this tutorial I will explain how to configure a Linux bridge with bridge-utils (brctl) command line utility on Ubuntu server.
|
||||
顾名思义,网桥的作用是通过物理接口连接内部和外部网络。对于虚拟端口或者 LXC/KVM/Xen/容器来说,这非常有用。通过网桥虚拟端口看起来是网络上的一个常规设备。在这个教程中,我将会介绍如何在 Ubuntu 服务器上通过 bridge-utils(brctl) 命令行来配置 Linux 网桥。
|
||||
|
||||
### Our sample bridged networking
|
||||
### 网桥网络示例
|
||||
|
||||
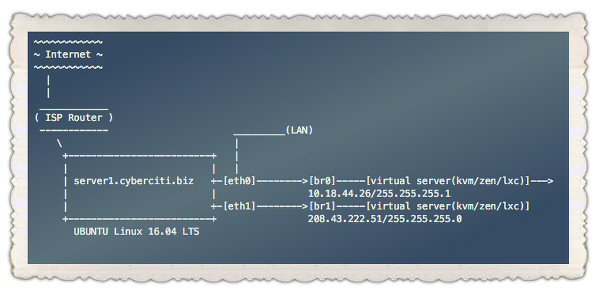
|
||||
>Fig.01: Sample Ubuntu Bridged Networking Setup For Kvm/Xen/LXC Containers (br0)
|
||||
>Fig.01: Kvm/Xen/LXC 容器网桥实例 (br0)
|
||||
|
||||
In this example eth0 and eth1 is the physical network interface. eth0 connected to the LAN and eth1 is attached to the upstream ISP router/Internet.
|
||||
在这个例子中,eth0 和 eth1 是物理网络接口。eth0 连接着局域网,eth1 连接着上游路由器/网络。
|
||||
|
||||
### Install bridge-utils
|
||||
### 安装 bridge-utils
|
||||
|
||||
Type the following [apt-get command][1] to install the bridge-utils:
|
||||
使用[apt-get 命令][1] 安装 bridge-utils:
|
||||
|
||||
```
|
||||
$ sudo apt-get install bridge-utils
|
||||
```
|
||||
|
||||
OR
|
||||
或者
|
||||
|
||||
````
|
||||
$ sudo apt install bridge-utils
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
样例输出:
|
||||
|
||||
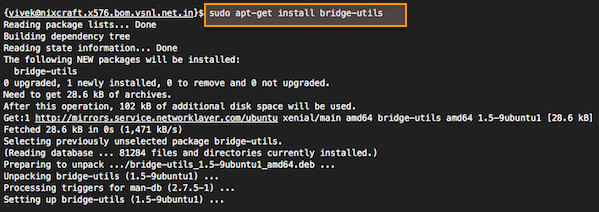
|
||||
>Fig.02: Ubuntu Linux install bridge-utils package
|
||||
>Fig.02: Ubuntu 安装 bridge-utils 包
|
||||
|
||||
### Creating a network bridge on the Ubuntu server
|
||||
### 在 Ubuntu 服务器上创建网桥
|
||||
|
||||
Edit `/etc/network/interfaces` using a text editor such as nano or vi, enter:
|
||||
使用你熟悉的文本编辑器修改 `/etc/network/interfaces` ,例如 vi 或者 nano :
|
||||
|
||||
```
|
||||
$ sudo cp /etc/network/interfaces /etc/network/interfaces.bakup-1-july-2016
|
||||
$ sudo vi /etc/network/interfaces
|
||||
```
|
||||
|
||||
Let us setup eth1 and map it to br1, enter (delete or comment out all eth1 entries):
|
||||
接下来设置 eth1 并且将他绑定到 br1 ,输入(删除或者注释所有 eth1 相关配置):
|
||||
|
||||
```
|
||||
# br1 setup with static wan IPv4 with ISP router as gateway
|
||||
@ -59,7 +60,7 @@ iface br1 inet static
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
To setup eth0 and map it to br0, enter (delete or comment out all eth1 entries):
|
||||
接下来设置 eth0 并将它绑定到 br0,输入(删除或者注释所有 eth1 相关配置):
|
||||
|
||||
```
|
||||
auto br0
|
||||
@ -77,9 +78,9 @@ iface br0 inet static
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
### A note about br0 and DHCP
|
||||
### 关于 br0 和 DHCP 的一点说明
|
||||
|
||||
DHCP config options:
|
||||
DHCP 的配置选项:
|
||||
|
||||
```
|
||||
auto br0
|
||||
@ -90,25 +91,25 @@ iface br0 inet dhcp
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
保存并且关闭文件。
|
||||
|
||||
### Restart the server or networking service
|
||||
### 重启服务器或者网络服务
|
||||
|
||||
You need to reboot the server or type the following command to restart the networking service (this may not work on SSH based session):
|
||||
你需要重启服务器或者输入下列命令来重启网络服务(在 SSH 登陆的会话中这可能不管用):
|
||||
|
||||
```
|
||||
$ sudo systemctl restart networking
|
||||
```
|
||||
|
||||
If you are using Ubuntu 14.04 LTS or older not systemd based system, enter:
|
||||
如果你证使用 Ubuntu 14.04 LTS 或者更老的没有 systemd 的系统,输入:
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/restart networking
|
||||
```
|
||||
|
||||
### Verify connectivity
|
||||
### 验证网络配置成功
|
||||
|
||||
Use the ping/ip commands to verify that both LAN and WAN interfaces are reachable:
|
||||
使用 ping/ip 命令来验证 LAN 和 WAN 网络接口运行正常:
|
||||
```
|
||||
# See br0 and br1
|
||||
ip a show
|
||||
@ -120,12 +121,12 @@ ping -c 2 cyberciti.biz
|
||||
ping -c 2 10.0.80.12
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
样例输出:
|
||||
|
||||
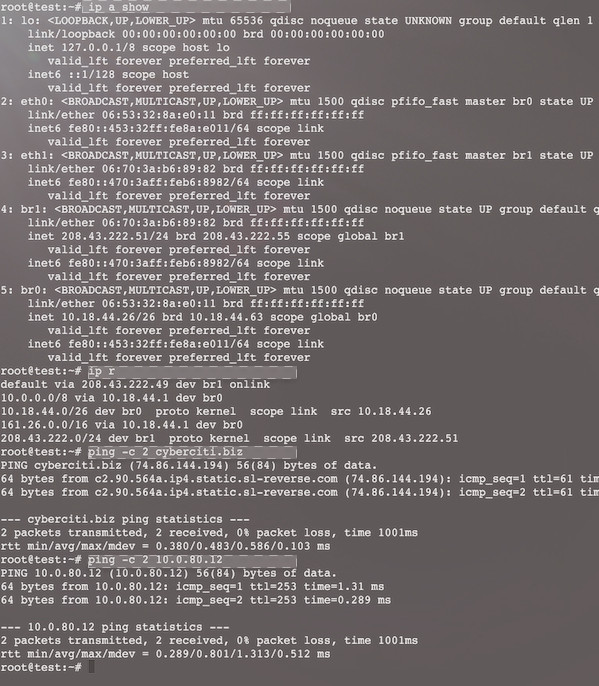
|
||||
>Fig.03: Verify Bridging Ethernet Connections
|
||||
>Fig.03: 验证网桥的以太网连接
|
||||
|
||||
Now, you can configure XEN/KVM/LXC containers to use br0 and br1 to reach directly to the internet or private lan. No need to setup special routing or iptables SNAT rules.
|
||||
现在,你就可以配置 br0 和 br1 来让 XEN/KVM/LXC 容器访问因特网或者私有局域网了。再也没有必要去设置特定路由或者 iptables 的 SNAT 规则了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -133,7 +134,7 @@ Now, you can configure XEN/KVM/LXC containers to use br0 and br1 to reach direct
|
||||
via: http://www.cyberciti.biz/faq/how-to-create-bridge-interface-ubuntu-linux/
|
||||
|
||||
作者:[VIVEK GITE][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[译者ID](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,228 @@
|
||||
使用 Python 创建你自己的 Shell:Part I
|
||||
==========================================
|
||||
|
||||
我很想知道一个 shell (像 bash,csh 等)内部是如何工作的。为了满足自己的好奇心,我使用 Python 实现了一个名为 **yosh** (Your Own Shell)的 Shell。本文章所介绍的概念也可以应用于其他编程语言。
|
||||
|
||||
(提示:你可以在[这里](https://github.com/supasate/yosh)查找本博文使用的源代码,代码以 MIT 许可证发布。在 Mac OS X 10.11.5 上,我使用 Python 2.7.10 和 3.4.3 进行了测试。它应该可以运行在其他类 Unix 环境,比如 Linux 和 Windows 上的 Cygwin。)
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
### 步骤 0:项目结构
|
||||
|
||||
对于此项目,我使用了以下的项目结构。
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- __init__.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
`yosh_project` 为项目根目录(你也可以把它简单命名为 `yosh`)。
|
||||
|
||||
`yosh` 为包目录,且 `__init__.py` 可以使它成为与包目录名字相同的包(如果你不写 Python,可以忽略它。)
|
||||
|
||||
`shell.py` 是我们主要的脚本文件。
|
||||
|
||||
### 步骤 1:Shell 循环
|
||||
|
||||
当启动一个 shell,它会显示一个命令提示符并等待你的命令输入。在接收了输入的命令并执行它之后(稍后文章会进行详细解释),你的 shell 会重新回到循环,等待下一条指令。
|
||||
|
||||
在 `shell.py`,我们会以一个简单的 mian 函数开始,该函数调用了 shell_loop() 函数,如下:
|
||||
|
||||
```
|
||||
def shell_loop():
|
||||
# Start the loop here
|
||||
|
||||
|
||||
def main():
|
||||
shell_loop()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
接着,在 `shell_loop()`,为了指示循环是否继续或停止,我们使用了一个状态标志。在循环的开始,我们的 shell 将显示一个命令提示符,并等待读取命令输入。
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
SHELL_STATUS_RUN = 1
|
||||
SHELL_STATUS_STOP = 0
|
||||
|
||||
|
||||
def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
# Display a command prompt
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
# Read command input
|
||||
cmd = sys.stdin.readline()
|
||||
```
|
||||
|
||||
之后,我们切分命令输入并进行执行(我们即将实现`命令切分`和`执行`函数)。
|
||||
|
||||
因此,我们的 shell_loop() 会是如下这样:
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
SHELL_STATUS_RUN = 1
|
||||
SHELL_STATUS_STOP = 0
|
||||
|
||||
|
||||
def shell_loop():
|
||||
status = SHELL_STATUS_RUN
|
||||
|
||||
while status == SHELL_STATUS_RUN:
|
||||
# Display a command prompt
|
||||
sys.stdout.write('> ')
|
||||
sys.stdout.flush()
|
||||
|
||||
# Read command input
|
||||
cmd = sys.stdin.readline()
|
||||
|
||||
# Tokenize the command input
|
||||
cmd_tokens = tokenize(cmd)
|
||||
|
||||
# Execute the command and retrieve new status
|
||||
status = execute(cmd_tokens)
|
||||
```
|
||||
|
||||
这就是我们整个 shell 循环。如果我们使用 `python shell.py` 启动我们的 shell,它会显示命令提示符。然而如果我们输入命令并按回车,它会抛出错误,因为我们还没定义`命令切分`函数。
|
||||
|
||||
为了退出 shell,可以尝试输入 ctrl-c。稍后我将解释如何以优雅的形式退出 shell。
|
||||
|
||||
### 步骤 2:命令切分
|
||||
|
||||
当用户在我们的 shell 中输入命令并按下回车键,该命令将会是一个包含命令名称及其参数的很长的字符串。因此,我们必须切分该字符串(分割一个字符串为多个标记)。
|
||||
|
||||
咋一看似乎很简单。我们或许可以使用 `cmd.split()`,以空格分割输入。它对类似 `ls -a my_folder` 的命令起作用,因为它能够将命令分割为一个列表 `['ls', '-a', 'my_folder']`,这样我们便能轻易处理它们了。
|
||||
|
||||
然而,也有一些类似 `echo "Hello World"` 或 `echo 'Hello World'` 以单引号或双引号引用参数的情况。如果我们使用 cmd.spilt,我们将会得到一个存有 3 个标记的列表 `['echo', '"Hello', 'World"']` 而不是 2 个标记的列表 `['echo', 'Hello World']`。
|
||||
|
||||
幸运的是,Python 提供了一个名为 `shlex` 的库,它能够帮助我们效验如神地分割命令。(提示:我们也可以使用正则表达式,但它不是本文的重点。)
|
||||
|
||||
|
||||
```
|
||||
import sys
|
||||
import shlex
|
||||
|
||||
...
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
然后我们将这些标记发送到执行进程。
|
||||
|
||||
### 步骤 3:执行
|
||||
|
||||
这是 shell 中核心和有趣的一部分。当 shell 执行 `mkdir test_dir` 时,到底发生了什么?(提示: `mkdir` 是一个带有 `test_dir` 参数的执行程序,用于创建一个名为 `test_dir` 的目录。)
|
||||
|
||||
`execvp` 是涉及这一步的首个函数。在我们解释 `execvp` 所做的事之前,让我们看看它的实际效果。
|
||||
|
||||
```
|
||||
import os
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Execute command
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
|
||||
# Return status indicating to wait for next command in shell_loop
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
再次尝试运行我们的 shell,并输入 `mkdir test_dir` 命令,接着按下回车键。
|
||||
|
||||
在我们敲下回车键之后,问题是我们的 shell 会直接退出而不是等待下一个命令。然而,目标正确地被创建。
|
||||
|
||||
因此,`execvp` 实际上做了什么?
|
||||
|
||||
`execvp` 是系统调用 `exec` 的一个变体。第一个参数是程序名字。`v` 表示第二个参数是一个程序参数列表(可变参数)。`p` 表示环境变量 `PATH` 会被用于搜索给定的程序名字。在我们上一次的尝试中,它将会基于我们的 `PATH` 环境变量查找`mkdir` 程序。
|
||||
|
||||
(还有其他 `exec` 变体,比如 execv、execvpe、execl、execlp、execlpe;你可以 google 它们获取更多的信息。)
|
||||
|
||||
`exec` 会用即将运行的新进程替换调用进程的当前内存。在我们的例子中,我们的 shell 进程内存会被替换为 `mkdir` 程序。接着,`mkdir` 成为主进程并创建 `test_dir` 目录。最后该进程退出。
|
||||
|
||||
这里的重点在于**我们的 shell 进程已经被 `mkdir` 进程所替换**。这就是我们的 shell 消失且不会等待下一条命令的原因。
|
||||
|
||||
因此,我们需要其他的系统调用来解决问题:`fork`。
|
||||
|
||||
`fork` 会开辟新的内存并拷贝当前进程到一个新的进程。我们称这个新的进程为**子进程**,调用者进程为**父进程**。然后,子进程内存会被替换为被执行的程序。因此,我们的 shell,也就是父进程,可以免受内存替换的危险。
|
||||
|
||||
让我们看看修改的代码。
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Fork a child shell process
|
||||
# If the current process is a child process, its `pid` is set to `0`
|
||||
# else the current process is a parent process and the value of `pid`
|
||||
# is the process id of its child process.
|
||||
pid = os.fork()
|
||||
|
||||
if pid == 0:
|
||||
# Child process
|
||||
# Replace the child shell process with the program called with exec
|
||||
os.execvp(cmd_tokens[0], cmd_tokens)
|
||||
elif pid > 0:
|
||||
# Parent process
|
||||
while True:
|
||||
# Wait response status from its child process (identified with pid)
|
||||
wpid, status = os.waitpid(pid, 0)
|
||||
|
||||
# Finish waiting if its child process exits normally
|
||||
# or is terminated by a signal
|
||||
if os.WIFEXITED(status) or os.WIFSIGNALED(status):
|
||||
break
|
||||
|
||||
# Return status indicating to wait for next command in shell_loop
|
||||
return SHELL_STATUS_RUN
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
当我们的父进程调用 `os.fork()`时,你可以想象所有的源代码被拷贝到了新的子进程。此时此刻,父进程和子进程看到的是相同的代码,且并行运行着。
|
||||
|
||||
如果运行的代码属于子进程,`pid` 将为 `0`。否则,如果运行的代码属于父进程,`pid` 将会是子进程的进程 id。
|
||||
|
||||
当 `os.execvp` 在子进程中被调用时,你可以想象子进程的所有源代码被替换为正被调用程序的代码。然而父进程的代码不会被改变。
|
||||
|
||||
当父进程完成等待子进程退出或终止时,它会返回一个状态,指示继续 shell 循环。
|
||||
|
||||
### 运行
|
||||
|
||||
现在,你可以尝试运行我们的 shell 并输入 `mkdir test_dir2`。它应该可以正确执行。我们的主 shell 进程仍然存在并等待下一条命令。尝试执行 `ls`,你可以看到已创建的目录。
|
||||
|
||||
但是,这里仍有许多问题。
|
||||
|
||||
第一,尝试执行 `cd test_dir2`,接着执行 `ls`。它应该会进入到一个空的 `test_dir2` 目录。然而,你将会看到目录并没有变为 `test_dir2`。
|
||||
|
||||
第二,我们仍然没有办法优雅地退出我们的 shell。
|
||||
|
||||
我们将会在 [Part 2][1] 解决诸如此类的问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/
|
||||
@ -0,0 +1,216 @@
|
||||
使用 Python 创建你自己的 Shell:Part II
|
||||
===========================================
|
||||
|
||||
在[part 1][1] 中,我们已经创建了一个主要的 shell 循环、切分了的命令输入,以及通过 `fork` 和 `exec` 执行命令。在这部分,我们将会解决剩下的问题。首先,`cd test_dir2` 命令无法修改我们的当前目录。其次,我们仍无法优雅地从 shell 中退出。
|
||||
|
||||
### 步骤 4:内置命令
|
||||
|
||||
“cd test_dir2 无法修改我们的当前目录” 这句话是对的,但在某种意义上也是错的。在执行完该命令之后,我们仍然处在同一目录,从这个意义上讲,它是对的。然而,目录实际上已经被修改,只不过它是在子进程中被修改。
|
||||
|
||||
还记得我们 fork 了一个子进程,然后执行命令,执行命令的过程没有发生在父进程上。结果是我们只是改变了子进程的当前目录,而不是父进程的目录。
|
||||
|
||||
然后子进程退出,而父进程在原封不动的目录下继续运行。
|
||||
|
||||
因此,这类与 shell 自己相关的命令必须是内置命令。它必须在 shell 进程中执行而没有分叉(forking)。
|
||||
|
||||
#### cd
|
||||
|
||||
让我们从 `cd` 命令开始。
|
||||
|
||||
我们首先创建一个 `builtins` 目录。每一个内置命令都会被放进这个目录中。
|
||||
|
||||
```shell
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
|-- __init__.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
在 `cd.py` 中,我们通过使用系统调用 `os.chdir` 实现自己的 `cd` 命令。
|
||||
|
||||
```python
|
||||
import os
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def cd(args):
|
||||
os.chdir(args[0])
|
||||
|
||||
return SHELL_STATUS_RUN
|
||||
```
|
||||
|
||||
注意,我们会从内置函数返回 shell 的运行状态。所以,为了能够在项目中继续使用常量,我们将它们移至 `yosh/constants.py`。
|
||||
|
||||
```shell
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
|-- __init__.py
|
||||
|-- constants.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
在 `constants.py` 中,我们将状态常量都放在这里。
|
||||
|
||||
```python
|
||||
SHELL_STATUS_STOP = 0
|
||||
SHELL_STATUS_RUN = 1
|
||||
```
|
||||
|
||||
现在,我们的内置 `cd` 已经准备好了。让我们修改 `shell.py` 来处理这些内置函数。
|
||||
|
||||
```python
|
||||
...
|
||||
# Import constants
|
||||
from yosh.constants import *
|
||||
|
||||
# Hash map to store built-in function name and reference as key and value
|
||||
built_in_cmds = {}
|
||||
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Extract command name and arguments from tokens
|
||||
cmd_name = cmd_tokens[0]
|
||||
cmd_args = cmd_tokens[1:]
|
||||
|
||||
# If the command is a built-in command, invoke its function with arguments
|
||||
if cmd_name in built_in_cmds:
|
||||
return built_in_cmds[cmd_name](cmd_args)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
我们使用一个 python 字典变量 `built_in_cmds` 作为哈希映射(hash map),以存储我们的内置函数。我们在 `execute` 函数中提取命令的名字和参数。如果该命令在我们的哈希映射中,则调用对应的内置函数。
|
||||
|
||||
(提示:`built_in_cmds[cmd_name]` 返回能直接使用参数调用的函数引用的。)
|
||||
|
||||
我们差不多准备好使用内置的 `cd` 函数了。最后一步是将 `cd` 函数添加到 `built_in_cmds` 映射中。
|
||||
|
||||
```
|
||||
...
|
||||
# Import all built-in function references
|
||||
from yosh.builtins import *
|
||||
|
||||
...
|
||||
|
||||
# Register a built-in function to built-in command hash map
|
||||
def register_command(name, func):
|
||||
built_in_cmds[name] = func
|
||||
|
||||
|
||||
# Register all built-in commands here
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
|
||||
|
||||
def main():
|
||||
# Init shell before starting the main loop
|
||||
init()
|
||||
shell_loop()
|
||||
```
|
||||
|
||||
我们定义了 `register_command` 函数,以添加一个内置函数到我们内置的命令哈希映射。接着,我们定义 `init` 函数并且在这里注册内置的 `cd` 函数。
|
||||
|
||||
注意这行 `register_command("cd", cd)` 。第一个参数为命令的名字。第二个参数为一个函数引用。为了能够让第二个参数 `cd` 引用到 `yosh/builtins/cd.py` 中的 `cd` 函数引用,我们必须将以下这行代码放在 `yosh/builtins/__init__.py` 文件中。
|
||||
|
||||
```
|
||||
from yosh.builtins.cd import *
|
||||
```
|
||||
|
||||
因此,在 `yosh/shell.py` 中,当我们从 `yosh.builtins` 导入 `*` 时,我们可以得到已经通过 `yosh.builtins` 导入的 `cd` 函数引用。
|
||||
|
||||
我们已经准备好了代码。让我们尝试在 `yosh` 同级目录下以模块形式运行我们的 shell,`python -m yosh.shell`。
|
||||
|
||||
现在,`cd` 命令可以正确修改我们的 shell 目录了,同时非内置命令仍然可以工作。非常好!
|
||||
|
||||
#### exit
|
||||
|
||||
最后一块终于来了:优雅地退出。
|
||||
|
||||
我们需要一个可以修改 shell 状态为 `SHELL_STATUS_STOP` 的函数。这样,shell 循环可以自然地结束,shell 将到达终点而退出。
|
||||
|
||||
和 `cd` 一样,如果我们在子进程中 fork 和执行 `exit` 函数,其对父进程是不起作用的。因此,`exit` 函数需要成为一个 shell 内置函数。
|
||||
|
||||
让我们从这开始:在 `builtins` 目录下创建一个名为 `exit.py` 的新文件。
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
| |-- exit.py
|
||||
|-- __init__.py
|
||||
|-- constants.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
`exit.py` 定义了一个 `exit` 函数,该函数仅仅返回一个可以退出主循环的状态。
|
||||
|
||||
```
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def exit(args):
|
||||
return SHELL_STATUS_STOP
|
||||
```
|
||||
|
||||
然后,我们导入位于 `yosh/builtins/__init__.py` 文件的 `exit` 函数引用。
|
||||
|
||||
```
|
||||
from yosh.builtins.cd import *
|
||||
from yosh.builtins.exit import *
|
||||
```
|
||||
|
||||
最后,我们在 `shell.py` 中的 `init()` 函数注册 `exit` 命令。
|
||||
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
# Register all built-in commands here
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
register_command("exit", exit)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
到此为止!
|
||||
|
||||
尝试执行 `python -m yosh.shell`。现在你可以输入 `exit` 优雅地退出程序了。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
我希望你能像我一样享受创建 `yosh` (**y**our **o**wn **sh**ell)的过程。但我的 `yosh` 版本仍处于早期阶段。我没有处理一些会使 shell 崩溃的极端状况。还有很多我没有覆盖的内置命令。为了提高性能,一些非内置命令也可以实现为内置命令(避免新进程创建时间)。同时,大量的功能还没有实现(请看 [公共特性](http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html) 和 [不同特性](http://www.tldp.org/LDP/intro-linux/html/x12249.html))
|
||||
|
||||
我已经在 github.com/supasate/yosh 中提供了源代码。请随意 fork 和尝试。
|
||||
|
||||
现在该是创建你真正自己拥有的 Shell 的时候了。
|
||||
|
||||
Happy Coding!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
[2]: http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html
|
||||
[3]: http://www.tldp.org/LDP/intro-linux/html/x12249.html
|
||||
[4]: https://github.com/supasate/yosh
|
||||
Loading…
Reference in New Issue
Block a user