mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
MonkeyEcho translate
This commit is contained in:
parent
80f01dc722
commit
bca118ba8d
@ -1,312 +0,0 @@
|
|||||||
MonkeyDEcho translated
|
|
||||||
|
|
||||||
[MySQL infrastructure testing automation at GitHub][31]
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
Our MySQL infrastructure is a critical component to GitHub. MySQL serves GitHub.com, GitHub’s API, authentication and more. Every `git` request touches MySQL in some way. We are tasked with keeping the data available, and maintaining its integrity. Even while our MySQL clusters serve traffic, we need to be able to perform tasks such as heavy duty cleanups, ad-hoc updates, online schema migrations, cluster topology refactoring, pooling and load balancing and more. We have the infrastructure to automate away such operations; in this post we share a few examples of how we build trust in our infrastructure through continuous testing. It is essentially how we sleep well at night.
|
|
||||||
|
|
||||||
### Backups[][36]
|
|
||||||
|
|
||||||
It is incredibly important to take backups of your data. If you are not taking backups of your database, it is likely a matter of time before this will become an issue. Percona [Xtrabackup][37]is the tool we have been using for issuing full backups for our MySQL databases. If there is data that we need to be certain is saved, we have a server that is backing up the data.
|
|
||||||
|
|
||||||
In addition to the full binary backups, we run logical backups several times a day. These backups allow our engineers to get a copy of recent data. There are times that they would like a complete set of data from a table so they can test an index change on a production sized table or see data from a certain point of time. Hubot allows us to restore a backed up table and will ping us when the table is ready to use.
|
|
||||||
|
|
||||||

|
|
||||||
**tomkrouper**.mysql backup-list locations
|
|
||||||

|
|
||||||
**Hubot**
|
|
||||||
```
|
|
||||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
|
||||||
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
|
|
||||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
|
||||||
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
|
|
||||||
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
|
|
||||||
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
|
|
||||||
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
|
|
||||||
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
|
|
||||||
| ...
|
|
||||||
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
|
|
||||||
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
|
|
||||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||

|
|
||||||
**tomkrouper**.mysql restore 1699133
|
|
||||||

|
|
||||||
**Hubot**A restore job has been created for the backup job 1699133\. You will be notified in #database-ops when the restore is complete.
|
|
||||||

|
|
||||||
**Hubot**[@tomkrouper][1]: the locations table has been restored as locations_2017_07_01_16_11 in the restores database on db-mysql-0482
|
|
||||||
|
|
||||||
The data is loaded onto a non-production database which is accessible to the engineer requesting the restore.
|
|
||||||
|
|
||||||
The last way we keep a “backup” of data around is we use [delayed replicas][38]. This is less of a backup and more of a safeguard. For each production cluster we have a host that has replication delayed by 4 hours. If a query is run that shouldn’t have, we can run `mysql panic` in chatops. This will cause all of our delayed replicas to stop replication immediately. This will also page the on-call DBA. From there we can use delayed replica to verify there is an issue, and then fast forward the binary logs to the point right before the error. We can then restore this data to the master, thus recovering data to that point.
|
|
||||||
|
|
||||||
Backups are great, however they are worthless if some unknown or uncaught error occurs corrupting the backup. A benefit of having a script to restore backups is it allows us to automate the verification of backups via cron. We have set up a dedicated host for each cluster that runs a restore of the latest backup. This ensures that the backup ran correctly and that we are able to retrieve the data from the backup.
|
|
||||||
|
|
||||||
Depending on dataset size, we run several restores per day. Restored servers are expected to join the replication stream and to be able to catch up with replication. This tests not only that we took a restorable backup, but also that we correctly identified the point in time at which it was taken and can further apply changes from that point in time. We are alerted if anything goes wrong in the restore process.
|
|
||||||
|
|
||||||
We furthermore track the time the restore takes, so we have a good idea of how long it will take to build a new replica or restore in cases of emergency.
|
|
||||||
|
|
||||||
The following is an output from an automated restore process, written by Hubot in our robots chat room.
|
|
||||||
|
|
||||||

|
|
||||||
**Hubot**gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Determining backup to restore for cluster 'prodcluster'.
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Enabling maintenance mode
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Disabling Puppet
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Removing MySQL files
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-restore
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Restore file: xtrabackup-notify-2017-07-02_0000.xbstream
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-prepare
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Update file ownership
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Upgrade MySQL
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Backup Host: db-mysql-0034
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Setting up replication
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Starting replication
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Replication catch-up
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Restore complete (replication running)
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Enabling Puppet
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Disabling maintenance mode
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
|
|
||||||
gh-mysql-backup-restore: db-mysql-0752: Restore process complete.
|
|
||||||
|
|
||||||
One thing we use backups for is adding a new replica to an existing set of MySQL servers. We will initiate the build of a new server, and once we are notified it is ready, we can start a restore of the latest backup for that particular cluster. We have a script in place that runs all of the restore commands that we would otherwise have to do by hand. Our automated restore system essentially uses the same script. This simplifies the system build process and allows us to have a host up and running with a handful of chat commands opposed to dozens of manual processes. Shown below is a restore kicked manually in chat:
|
|
||||||
|
|
||||||

|
|
||||||
**jessbreckenridge**.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
|
|
||||||

|
|
||||||
**Hubot**[@jessbreckenridge][2] gh-mysql-backup-restore: db-mysql-0007: Determining backup to restore for cluster 'mycluster'.
|
|
||||||
[@jessbreckenridge][3] gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
|
|
||||||
[@jessbreckenridge][4] gh-mysql-backup-restore: db-mysql-0007: Enabling maintenance mode
|
|
||||||
[@jessbreckenridge][5] gh-mysql-backup-restore: db-mysql-0007: Setting orchestrator downtime
|
|
||||||
[@jessbreckenridge][6] gh-mysql-backup-restore: db-mysql-0007: Disabling Puppet
|
|
||||||
[@jessbreckenridge][7] gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
|
|
||||||
[@jessbreckenridge][8] gh-mysql-backup-restore: db-mysql-0007: Removing MySQL files
|
|
||||||
[@jessbreckenridge][9] gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-restore
|
|
||||||
[@jessbreckenridge][10] gh-mysql-backup-restore: db-mysql-0007: Restore file: xtrabackup-mycluster-2017-07-02_0015.xbstream
|
|
||||||
[@jessbreckenridge][11] gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-prepare
|
|
||||||
[@jessbreckenridge][12] gh-mysql-backup-restore: db-mysql-0007: Update file ownership
|
|
||||||
[@jessbreckenridge][13] gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
|
|
||||||
[@jessbreckenridge][14] gh-mysql-backup-restore: db-mysql-0007: Upgrade MySQL
|
|
||||||
[@jessbreckenridge][15] gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
|
|
||||||
[@jessbreckenridge][16] gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
|
|
||||||
[@jessbreckenridge][17] gh-mysql-backup-restore: db-mysql-0007: Setting up replication
|
|
||||||
[@jessbreckenridge][18] gh-mysql-backup-restore: db-mysql-0007: Starting replication
|
|
||||||
[@jessbreckenridge][19] gh-mysql-backup-restore: db-mysql-0007: Backup Host: db-mysql-0201
|
|
||||||
[@jessbreckenridge][20] gh-mysql-backup-restore: db-mysql-0007: Replication catch-up
|
|
||||||
[@jessbreckenridge][21] gh-mysql-backup-restore: db-mysql-0007: Replication behind by 4589 seconds, waiting 1800 seconds before next check.
|
|
||||||
[@jessbreckenridge][22] gh-mysql-backup-restore: db-mysql-0007: Restore complete (replication running)
|
|
||||||
[@jessbreckenridge][23] gh-mysql-backup-restore: db-mysql-0007: Enabling puppet
|
|
||||||
[@jessbreckenridge][24] gh-mysql-backup-restore: db-mysql-0007: Disabling maintenance mode
|
|
||||||
|
|
||||||
### Failovers[][39]
|
|
||||||
|
|
||||||
[We use orchestrator][40] to perform automated failovers for masters and intermediate masters. We expect `orchestrator` to correctly detect master failure, designate a replica for promotion, heal the topology under said designated replica, make the promotion. We expect VIPs to change, pools to change, clients to reconnect, `puppet` to run essential components on promoted master, and more. A failover is a complex task that touches many aspects of our infrastructure.
|
|
||||||
|
|
||||||
To build trust in our failovers we set up a _production-like_ , test cluster, and we continuously crash it to observe failovers.
|
|
||||||
|
|
||||||
The _production-like_ cluster is a replication setup that is identical in all aspects to our production clusters: types of hardware, operating systems, MySQL versions, network environments, VIP, `puppet` configurations, [haproxy setup][41], etc. The only thing different to this cluster is that it doesn’t send/receive production traffic.
|
|
||||||
|
|
||||||
We emulate a write load on the test cluster, while avoiding replication lag. The write load is not too heavy, but has queries that are intentionally contending to write on same datasets. This isn’t too interesting in normal times, but proves to be useful upon failovers, as we will shortly describe.
|
|
||||||
|
|
||||||
Our test cluster has representative servers from three data centers. We would _like_ the failover to promote a replacement replica from within the same data center. We would _like_ to be able to salvage as many replicas as possible under such constraint. We _require_ that both apply whenever possible. `orchestrator` has no prior assumption on the topology; it must react on whatever the state was at time of the crash.
|
|
||||||
|
|
||||||
We, however, are interested in creating complex and varying scenarios for failovers. Our failover testing script prepares the grounds for the failover:
|
|
||||||
|
|
||||||
* It identifies existing master
|
|
||||||
|
|
||||||
* It refactors the topology to have representatives of all three data centers under the master. Different DCs have different network latencies and are expected to react in different timing to master’s crash.
|
|
||||||
|
|
||||||
* It chooses a crash method. We choose from shooting the master (`kill -9`) or network partitioning it: `iptables -j REJECT` (nice-ish) or `iptables -j DROP`(unresponsive).
|
|
||||||
|
|
||||||
The script proceeds to crash the master by chosen method, and waits for `orchestrator` to reliably detect the crash and to perform failover. While we expect detection and promotion to both complete within `30` seconds, the script relaxes this expectation a bit, and sleeps for a designated time before looking into failover results. It will then:
|
|
||||||
|
|
||||||
* Check that a new (different) master is in place
|
|
||||||
|
|
||||||
* There is a good number of replicas in the cluster
|
|
||||||
|
|
||||||
* The master is writable
|
|
||||||
|
|
||||||
* Writes to the master are visible on the replicas
|
|
||||||
|
|
||||||
* Internal service discovery entries are updated (identity of new master is as expected; old master removed)
|
|
||||||
|
|
||||||
* Other internal checks
|
|
||||||
|
|
||||||
These tests confirm that the failover was successful, not only MySQL-wise but also on our larger infrastructure scope. A VIP has been assumed; specific services have been started; information got to where it was supposed to go.
|
|
||||||
|
|
||||||
The script further proceeds to restore the failed server:
|
|
||||||
|
|
||||||
* Restoring it from backup, thereby implicitly testing our backup/restore procedure
|
|
||||||
|
|
||||||
* Verifying server configuration is as expected (the server no longer believes it’s the master)
|
|
||||||
|
|
||||||
* Returning it to the replication cluster, expecting to find data written on the master
|
|
||||||
|
|
||||||
Consider the following visualization of a scheduled failover test: from having a well-running cluster, to seeing problems on some replicas, to diagnosing the master (`7136`) is dead, to choosing a server to promote (`a79d`), refactoring the topology below that server, to promoting it (failover successful), to restoring the dead master and placing it back into the cluster.
|
|
||||||
|
|
||||||
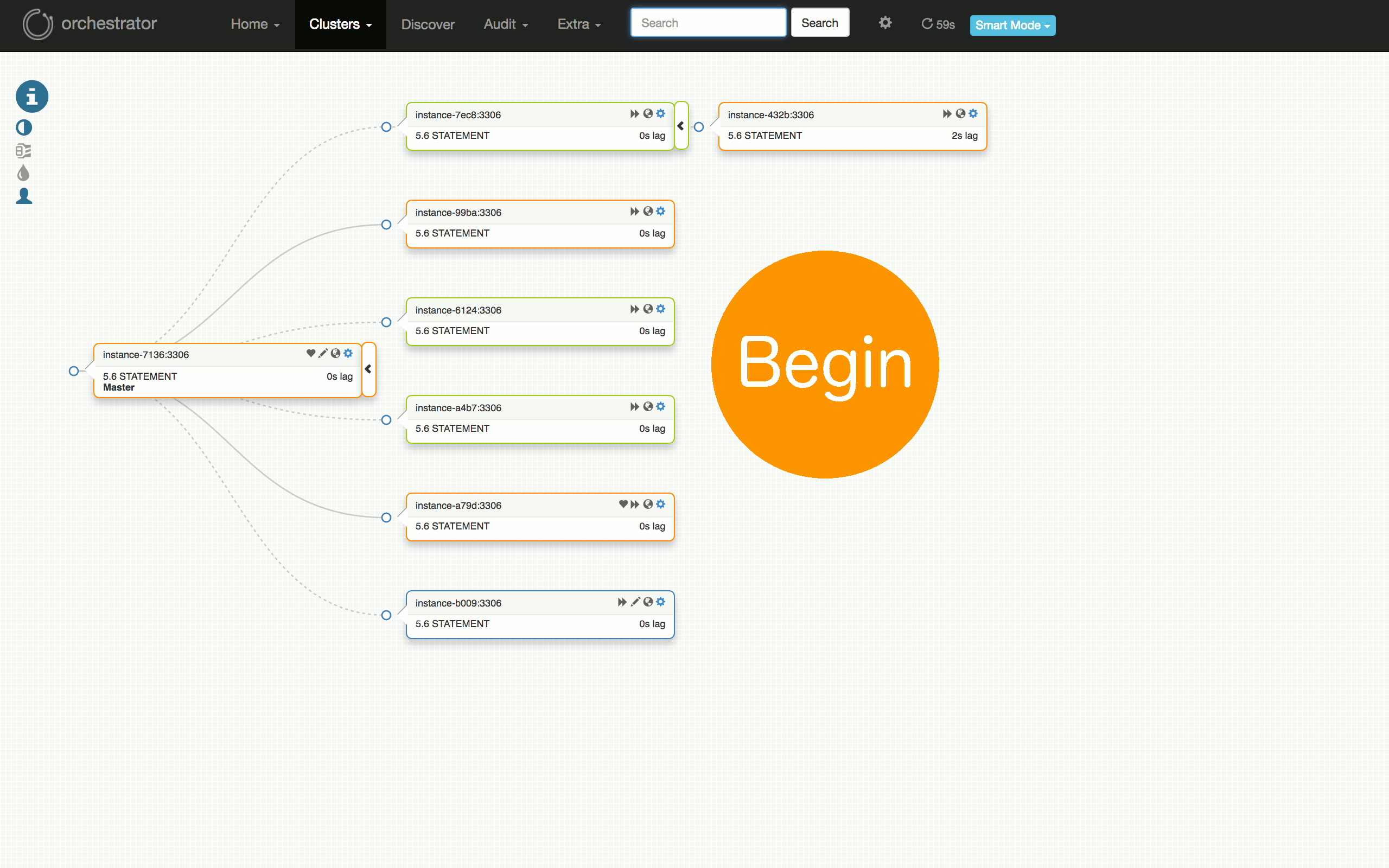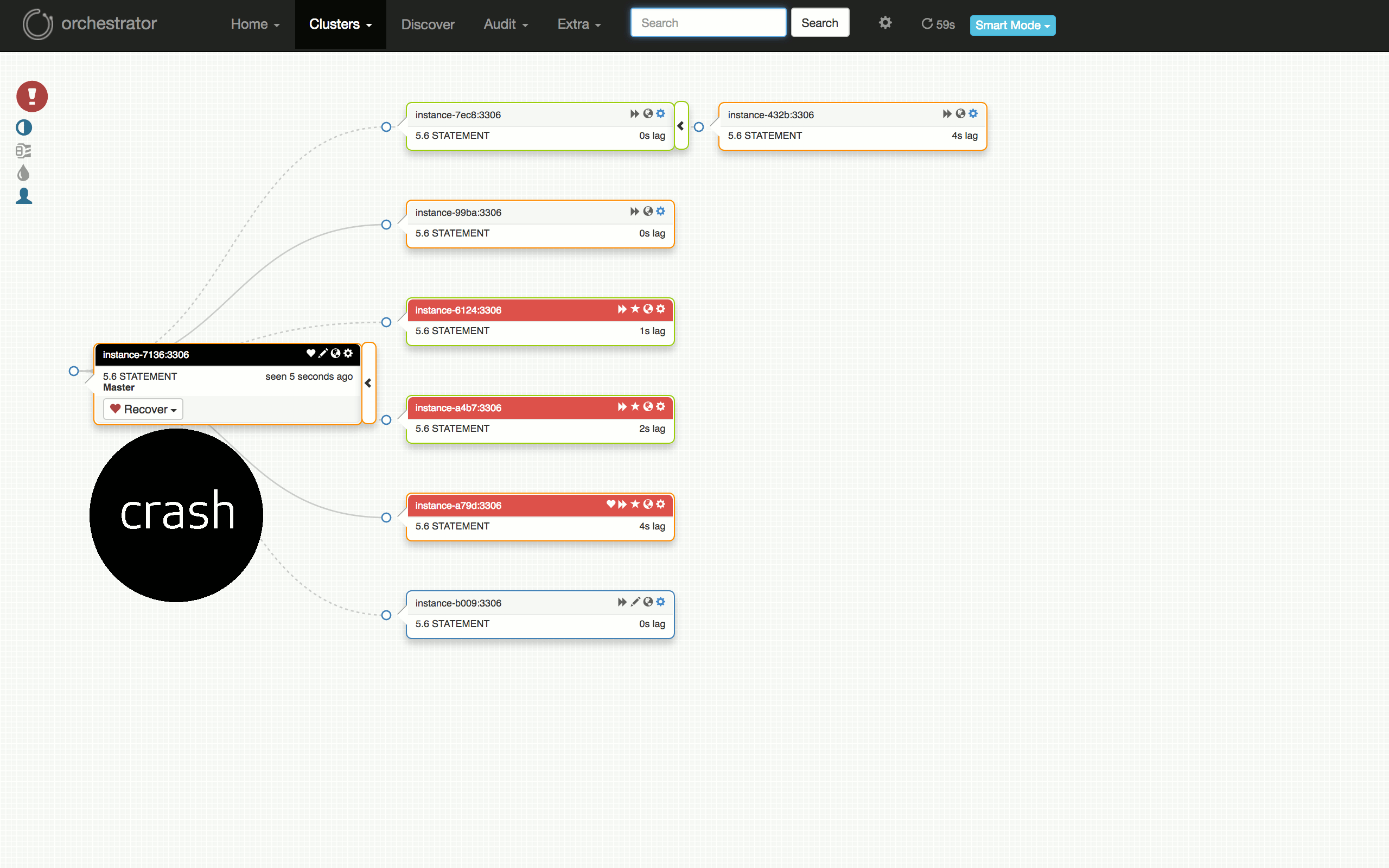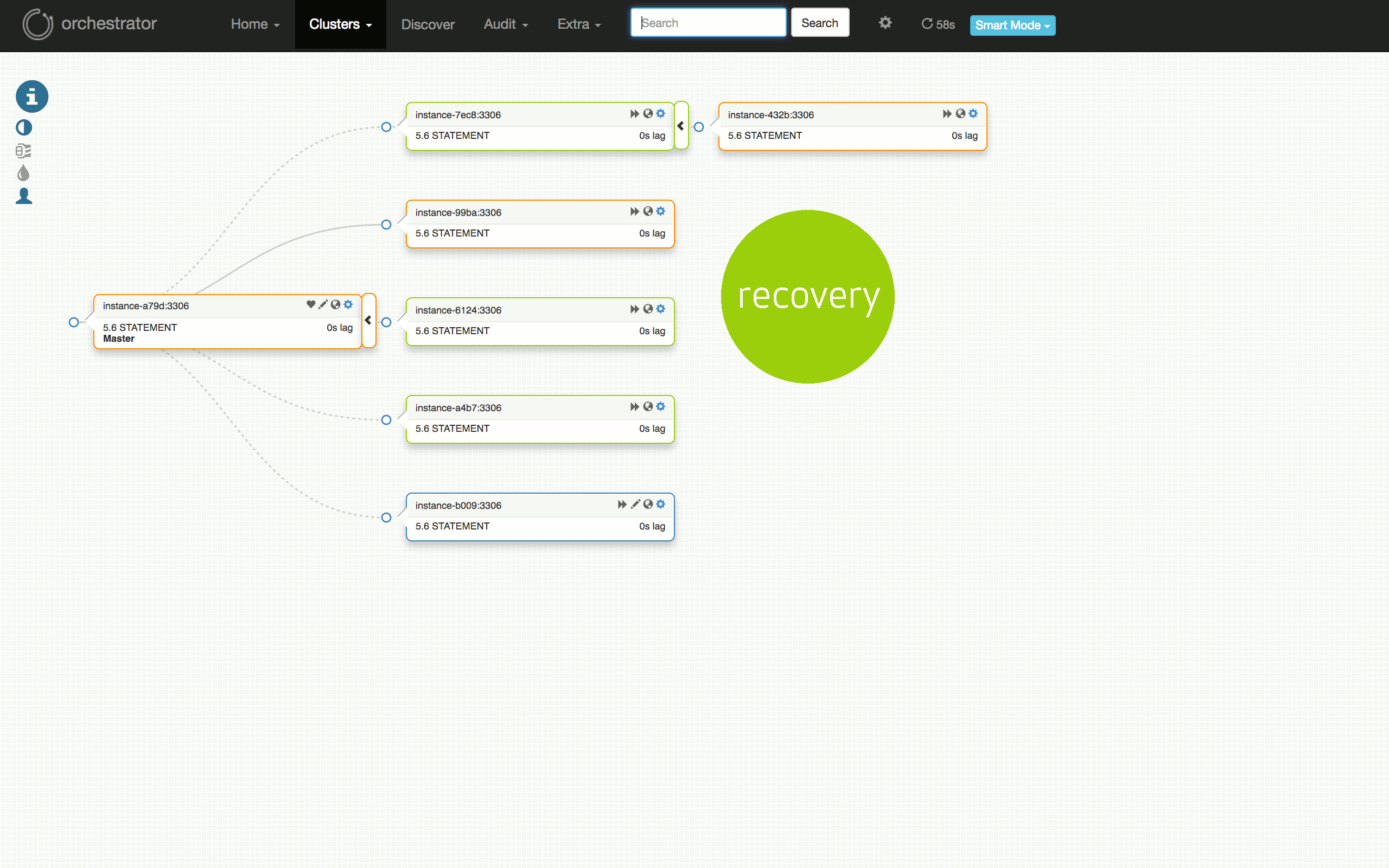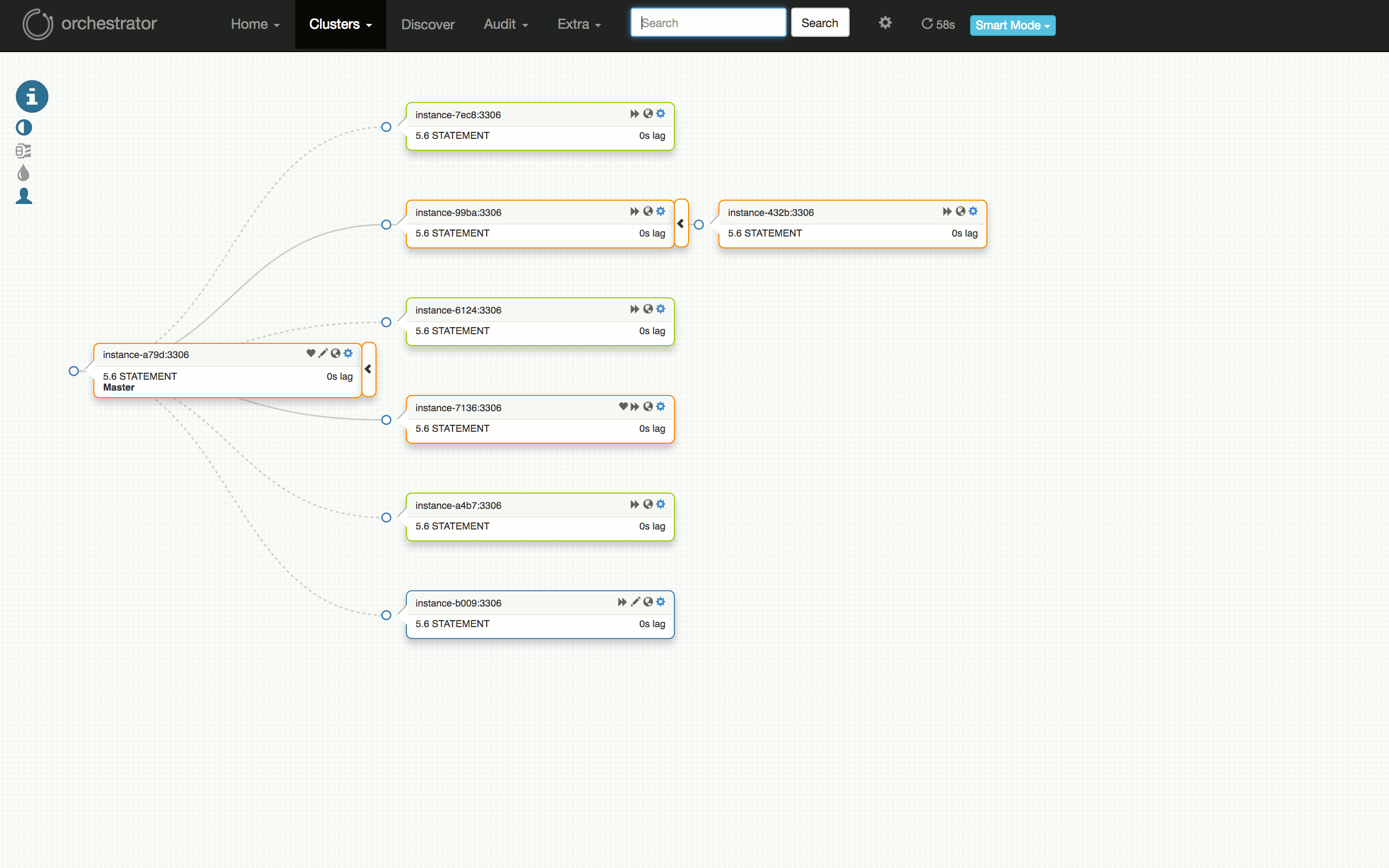
|
|
||||||
|
|
||||||
#### What would a test failure look like?
|
|
||||||
|
|
||||||
Our testing script uses a stop-the-world approach. A single failure in any of the failover components fails the entire test, disabling any future automated tests until a human resolves the matter. We get alerted and proceed to check the status and logs.
|
|
||||||
|
|
||||||
The script would fail on an unacceptable detection or failover time; on backup/restore issues; on losing too many servers; on unexpected configuration following the failover; etc.
|
|
||||||
|
|
||||||
We need to be certain `orchestrator` connects the servers correctly. This is where the contending write load comes useful: if set up incorrectly, replication is easily susceptible to break. We would get `DUPLICATE KEY` or other errors to suggest something went wrong.
|
|
||||||
|
|
||||||
This is particularly important as we make improvements and introduce new behavior to `orchestrator`, and allows us to test such changes in a safe environment.
|
|
||||||
|
|
||||||
#### Coming up: chaos testing
|
|
||||||
|
|
||||||
The testing procedure illustrated above will catch (and has caught) problems on many parts of our infrastructure. Is it enough?
|
|
||||||
|
|
||||||
In a production environment there’s always something else. Something about the particular test method that won’t apply to our production clusters. They don’t share the same traffic and traffic manipulation, nor the exact same set of servers. The types of failure can vary.
|
|
||||||
|
|
||||||
We are designing chaos testing for our production clusters. Chaos testing would literally destroy pieces in our production, but on expected schedule and under sufficiently controlled manner. Chaos testing introduces a higher level of trust in the recovery mechanism and affects (thus tests) larger parts of our infrastructure and application.
|
|
||||||
|
|
||||||
This is delicate work: while we acknowledge the need for chaos testing, we also wish to avoid unnecessary impact to our service. Different tests will differ in risk level and impact, and we will work to ensure availability of our service.
|
|
||||||
|
|
||||||
### Schema migrations[][42]
|
|
||||||
|
|
||||||
[We use gh-ost][43] to run live schema migrations. `gh-ost` is stable, but also under active developments, with major new features being added or planned.
|
|
||||||
|
|
||||||
`gh-ost` migrates tables by copying data onto a _ghost_ table, applying ongoing changes intercepted by the binary logs onto the _ghost_ table, even as the original table is being written to. It then swaps the _ghost_ table in place of the original table. At migration completion GitHub proceeds to work with a table generated and populated by `gh-ost`.
|
|
||||||
|
|
||||||
At this time almost all of GitHub’s MySQL data has been recreated by `gh-ost`, and most of it multiple times. We must have high trust in `gh-ost` to let it tamper with our data over and over again, even in face of active development. Here’s how we gain this trust.
|
|
||||||
|
|
||||||
`gh-ost` provides a testing-in-production capability. It supports running a migration on a replica, in much the same way as it would run on the master: `gh-ost` would connect to the replica and treat it as if it were the master. It would parse its binary logs the same way it would for a real master migration. However it would copy rows and apply binlog events to the replica, and avoid making writes onto the master.
|
|
||||||
|
|
||||||
We run `gh-ost`-dedicated replicas in production. These replicas do not serve production traffic. Each such replica retrieves the current list of production tables and iterates them in random order. One by one it picks a table and performs a replica-migration on that table. The migration doesn’t actually modify table structure, but instead runs a trivial `ENGINE=InnoDB`. The test runs the migration even as the table is being used in production, thus copying real production data and applying true production traffic off the binary logs.
|
|
||||||
|
|
||||||
These migrations can be audited. Here’s how we can inspect status of running tests from chat:
|
|
||||||
|
|
||||||

|
|
||||||
**ggunson**.migration test-status
|
|
||||||

|
|
||||||
**Hubot**
|
|
||||||
```
|
|
||||||
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
|
|
||||||
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
|
|
||||||
# Migration started at Mon Jan 30 02:13:39 -0800 2017
|
|
||||||
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
|
|
||||||
# throttle-additional-flag-file: /tmp/gh-ost.throttle
|
|
||||||
# panic-flag-file: /tmp/ghost-test-panic.flag
|
|
||||||
# Serving on unix socket: /tmp/gh-ost.test.sock
|
|
||||||
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
|
|
||||||
```
|
|
||||||
|
|
||||||
When a test migration completes copying of table data it stops replication and performs the cut-over, replacing the original table with the _ghost_ table, and then swaps back. We’re not interested in actually replacing the data. Instead we are left with both the original table and the _ghost_ table, which should both be identical. We verify that by checksumming the entire table data for both tables.
|
|
||||||
|
|
||||||
A test can complete with:
|
|
||||||
|
|
||||||
* _success_ : All went well and checksum is identical. We expect to see this.
|
|
||||||
|
|
||||||
* _failure_ : Execution problem. This can occasionally happen due to the migration process being killed, a replication issue etc., and is typically unrelated to `gh-ost` itself.
|
|
||||||
|
|
||||||
* _checksum failure_ : table data inconsistency. For a tested branch, this call for fixes. For an ongoing `master` branch test, this would imply immediate blocking of production migrations. We don’t get the latter.
|
|
||||||
|
|
||||||
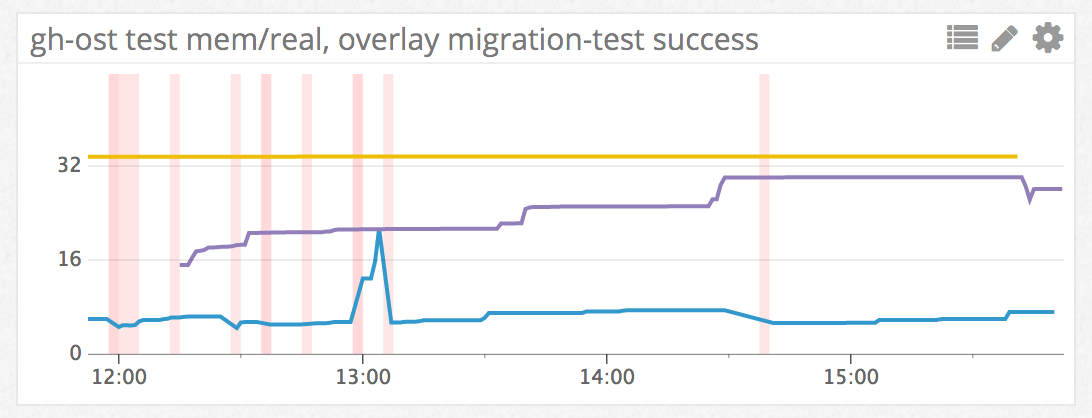
Test results are audited, sent to robot chatrooms, sent as events to our metrics systems. Each vertical line in the following graph represents a successful migration test:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
These tests run continuously. We are notified by alerts in case of failures. And of course we can always visit the robots chatroom to know what’s going on.
|
|
||||||
|
|
||||||
#### Testing new versions
|
|
||||||
|
|
||||||
We continuously improve `gh-ost`. Our development flow is based on `git` branches, which we then offer to merge via [pull requests][44].
|
|
||||||
|
|
||||||
A submitted `gh-ost` pull request goes through Continuous Integration (CI) which runs basic compilation and unit tests. Once past this, the PR is technically eligible for merging, but even more interestingly it is [eligible for deployment via Heaven][45]. Being the sensitive component in our infrastructure that it is, we take care to deploy `gh-ost` branches for intensive testing before merging into `master`.
|
|
||||||
|
|
||||||

|
|
||||||
**shlomi-noach**.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
|
|
||||||

|
|
||||||
**Hubot**[@shlomi-noach][25] is deploying gh-ost/fix-reappearing-throttled-reasons (baee4f6) to production (ghost-db-mysql-0007).
|
|
||||||
[@shlomi-noach][26]'s production deployment of gh-ost/fix-reappearing-throttled-reasons (baee4f6) is done! (2s)
|
|
||||||
[@shlomi-noach][27], make sure you watch for exceptions in haystack
|
|
||||||

|
|
||||||
**jonahberquist**.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
|
|
||||||

|
|
||||||
**Hubot**[@jonahberquist][28] is deploying gh-ost/interactive-command-question (be1ab17) to production (ghost-db-mysql-0012).
|
|
||||||
[@jonahberquist][29]'s production deployment of gh-ost/interactive-command-question (be1ab17) is done! (2s)
|
|
||||||
[@jonahberquist][30], make sure you watch for exceptions in haystack
|
|
||||||

|
|
||||||
**shlomi-noach**.wcid gh-ost
|
|
||||||

|
|
||||||
**Hubot**shlomi-noach testing fix-reappearing-throttled-reasons 41 seconds ago: ghost-db-mysql-0007
|
|
||||||
jonahberquist testing interactive-command-question 7 seconds ago: ghost-db-mysql-0012
|
|
||||||
|
|
||||||
Nobody is in the queue.
|
|
||||||
|
|
||||||
Some PRs are small and do not affect the data itself. Changes to status messages, interactive commands etc. are of lesser impact to the `gh-ost` app. Others pose significant changes to the migration logic and operation. We would tests these rigorously, running through our production tables fleet until satisfied these changes do not pose data corruption threat.
|
|
||||||
|
|
||||||
### Summary[][46]
|
|
||||||
|
|
||||||
Throughout testing we build trust in our systems. By automating these tests, in production, we get repetitive confirmation that everything is working as expected. As we continue to develop our infrastructure we also follow up by adapting tests to cover the newest changes.
|
|
||||||
|
|
||||||
Production always surprises with scenarios not covered by tests. The more we test on production environment, the more input we get on our app’s expectations and our infrastructure’s capabilities.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://githubengineering.com/mysql-testing-automation-at-github/
|
|
||||||
|
|
||||||
作者:[tomkrouper ][a], [Shlomi Noach][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://github.com/tomkrouper
|
|
||||||
[b]:https://github.com/shlomi-noach
|
|
||||||
[1]:https://github.com/tomkrouper
|
|
||||||
[2]:https://github.com/jessbreckenridge
|
|
||||||
[3]:https://github.com/jessbreckenridge
|
|
||||||
[4]:https://github.com/jessbreckenridge
|
|
||||||
[5]:https://github.com/jessbreckenridge
|
|
||||||
[6]:https://github.com/jessbreckenridge
|
|
||||||
[7]:https://github.com/jessbreckenridge
|
|
||||||
[8]:https://github.com/jessbreckenridge
|
|
||||||
[9]:https://github.com/jessbreckenridge
|
|
||||||
[10]:https://github.com/jessbreckenridge
|
|
||||||
[11]:https://github.com/jessbreckenridge
|
|
||||||
[12]:https://github.com/jessbreckenridge
|
|
||||||
[13]:https://github.com/jessbreckenridge
|
|
||||||
[14]:https://github.com/jessbreckenridge
|
|
||||||
[15]:https://github.com/jessbreckenridge
|
|
||||||
[16]:https://github.com/jessbreckenridge
|
|
||||||
[17]:https://github.com/jessbreckenridge
|
|
||||||
[18]:https://github.com/jessbreckenridge
|
|
||||||
[19]:https://github.com/jessbreckenridge
|
|
||||||
[20]:https://github.com/jessbreckenridge
|
|
||||||
[21]:https://github.com/jessbreckenridge
|
|
||||||
[22]:https://github.com/jessbreckenridge
|
|
||||||
[23]:https://github.com/jessbreckenridge
|
|
||||||
[24]:https://github.com/jessbreckenridge
|
|
||||||
[25]:https://github.com/shlomi-noach
|
|
||||||
[26]:https://github.com/shlomi-noach
|
|
||||||
[27]:https://github.com/shlomi-noach
|
|
||||||
[28]:https://github.com/jonahberquist
|
|
||||||
[29]:https://github.com/jonahberquist
|
|
||||||
[30]:https://github.com/jonahberquist
|
|
||||||
[31]:https://githubengineering.com/mysql-testing-automation-at-github/
|
|
||||||
[32]:https://github.com/tomkrouper
|
|
||||||
[33]:https://github.com/tomkrouper
|
|
||||||
[34]:https://github.com/shlomi-noach
|
|
||||||
[35]:https://github.com/shlomi-noach
|
|
||||||
[36]:https://githubengineering.com/mysql-testing-automation-at-github/#backups
|
|
||||||
[37]:https://www.percona.com/software/mysql-database/percona-xtrabackup
|
|
||||||
[38]:https://dev.mysql.com/doc/refman/5.6/en/replication-delayed.html
|
|
||||||
[39]:https://githubengineering.com/mysql-testing-automation-at-github/#failovers
|
|
||||||
[40]:http://githubengineering.com/orchestrator-github/
|
|
||||||
[41]:https://githubengineering.com/context-aware-mysql-pools-via-haproxy/
|
|
||||||
[42]:https://githubengineering.com/mysql-testing-automation-at-github/#schema-migrations
|
|
||||||
[43]:http://githubengineering.com/gh-ost-github-s-online-migration-tool-for-mysql/
|
|
||||||
[44]:https://github.com/github/gh-ost/pulls
|
|
||||||
[45]:https://githubengineering.com/deploying-branches-to-github-com/
|
|
||||||
[46]:https://githubengineering.com/mysql-testing-automation-at-github/#summary
|
|
||||||
@ -0,0 +1,315 @@
|
|||||||
|
[GitHub 的 MySql 基础架构自动化测试][31]
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
我们 MySQL 数据库基础架构是 Github 关键组件。 MySQL 提供 Github.com, GitHub 的 API 和验证等等的服务。每一次的 `git` 请求都以某种方式触及 MySQL。即使我们 MySQL 集群是按流量的,但是我们还是需要执行重型清理,即时更新,在线模式迁移,集群拓扑重构,池化和负载平衡等任务。 我们建有基础架构自动化测试这种方式,在这篇文章中,我们分享几个例子,说明我们如何通过连续不间断的来测试建立基础架构的。这样的方式是为了让我们晚上有一个好梦到早晨。
|
||||||
|
|
||||||
|
### 备份[][36]
|
||||||
|
|
||||||
|
备份数据是非常重要的,如果您没有备份数据库,虽然当时没有说明问题,在之后可能就是一个大问题。Percona [Xtrabackup][37] 是我们一直使用的 MySQL 数据库备份工具。如果有需要备份数据库我们就会备份到另一个专门备份数据的服务器上。
|
||||||
|
|
||||||
|
In addition to the full binary backups, we run logical backups several times a day. These backups allow our engineers to get a copy of recent data. There are times that they would like a complete set of data from a table so they can test an index change on a production sized table or see data from a certain point of time. Hubot allows us to restore a backed up table and will ping us when the table is ready to use.
|
||||||
|
|
||||||
|
除了完整的二进制备份外,我们每天还会多次运行逻辑备份。这些备份数据允许我们的工程师获取最新的副本。有时候,他们希望从表中获取一整套数据,以便他们可以测试表上的索引,更改或从特定时间点查看数据。Hubot 允许我们恢复备份的表,并且当表准备使用时会自动检测连接( ping )我们。
|
||||||
|
|
||||||
|

|
||||||
|
**tomkrouper**.mysql 备份列表的位置
|
||||||
|

|
||||||
|
**Hubot**
|
||||||
|
```
|
||||||
|
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||||
|
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
|
||||||
|
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||||
|
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
|
||||||
|
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
|
||||||
|
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
|
||||||
|
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
|
||||||
|
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
|
||||||
|
| ...
|
||||||
|
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
|
||||||
|
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
|
||||||
|
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
**tomkrouper**.mysql 恢复 1699133
|
||||||
|

|
||||||
|
**Hubot**已为备份作业 1699133 创建还原作业,还原完成后,将在 #database-ops 中收到通知。
|
||||||
|

|
||||||
|
**Hubot**[@tomkrouper][1]: 恢复 db-mysql-0482 上数据库中的 locations 表已恢复为 locations_2017_07_01_16_11
|
||||||
|
|
||||||
|
数据被加载到非生产环境的数据库,该数据库可供请求恢复的工程师访问。
|
||||||
|
|
||||||
|
我们保留数据的“备份”的最后一个方法是使用 [延迟的副本delayed replicas][38]。这不是一个备份,而是更多层次的保护。对于每个生产集群中,我们有一个主机延迟4个小时。如果运行一个不应该有的查询,我们可以在 chatops 中运行 `mysql panic` 。这将导致我们所有的延迟副本立即停止复制。这也将页面呼叫DBA。从那里我们可以使用延迟复制来验证是否有问题,然后将二进制日志快速转发到错误之前的位置。然后,我们可以将此数据恢复到主服务器,从而恢复数据到该点。
|
||||||
|
|
||||||
|
备份是很棒的,但如果一些未知或未捕获的错误发生破坏它们,它们就显得没有价值了。让脚本恢复备份的好处是它允许我们通过 cron 自动执行备份验证。我们为每个集群设置了一个专用的主机,用于运行最新备份的恢复。这样可以确保备份运行正常,并且我们能够从备份中检索数据。
|
||||||
|
|
||||||
|
根据数据集大小,我们每天运行多个恢复。预期恢复的服务器将加入复制流并能够赶上复制。这不仅测试了我们采取可恢复的备份,而且我们正确地确定采取的时间点,并且可以从该时间点进一步应用更改。如果恢复过程中出现问题,我们会收到通知。
|
||||||
|
|
||||||
|
我们还追踪恢复所需的时间,所以我们知道在紧急情况下建立新的副本或还原需要多长时间。
|
||||||
|
|
||||||
|
以下是由 Hubot 在我们的机器人聊天室中编写的自动恢复过程的输出。
|
||||||
|
|
||||||
|

|
||||||
|
**Hubot**
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 确定要为集群 “prodcluster” 还原备份。
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 启用维护模式
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 设置协调器停机时间
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 禁用 Puppet
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 停止 MySQL
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 删除 MySQL 文件
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 运行中 gh-xtrabackup-restore
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 恢复文件: xtrabackup-notify-2017-07-02_0000.xbstream
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 运行 gh-xtrabackup-prepare
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 启动 MySQL
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 更新文件权限
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 升级 MySQL
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 停止 MySQL
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 启动 MySQL
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 备份 Host: db-mysql-0034
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 设置开启复制
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 启动复制
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 响应缓存
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 还原完成 (响应运行中)
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 开启操作
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 关闭维护模式
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 设置协调器停机时间
|
||||||
|
gh-mysql-backup-restore: db-mysql-0752: 恢复过程完成
|
||||||
|
|
||||||
|
我们使用备份的一件事是向现有的一组 MySQL 服务器添加一个新的副本。我们将启动一个新的服务器的构建,一旦我们通知它已经准备就绪,我们可以开始恢复该特定集群的最新备份。我们有一个脚本,运行我们手动执行的所有恢复命令。我们的自动恢复系统基本上使用相同的脚本。这简化了系统构建过程,并允许我们使用少数几个手动进程的聊天命令来启动和运行主机。下面显示的是在聊天中手动恢复:
|
||||||
|
|
||||||
|

|
||||||
|
**jessbreckenridge**.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
|
||||||
|

|
||||||
|
**Hubot**
|
||||||
|
[@jessbreckenridge][2] gh-mysql-backup-restore: db-mysql-0007: 确定要还原群集'mycluster'的备份
|
||||||
|
[@jessbreckenridge][3] gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
|
||||||
|
[@jessbreckenridge][4] gh-mysql-backup-restore: db-mysql-0007: 启用维护模式
|
||||||
|
[@jessbreckenridge][5] gh-mysql-backup-restore: db-mysql-0007: 设置协调器停机时间
|
||||||
|
[@jessbreckenridge][6] gh-mysql-backup-restore: db-mysql-0007: 禁用操作
|
||||||
|
[@jessbreckenridge][7] gh-mysql-backup-restore: db-mysql-0007: 停止 MySQL
|
||||||
|
[@jessbreckenridge][8] gh-mysql-backup-restore: db-mysql-0007: 删除 MySQL 文件
|
||||||
|
[@jessbreckenridge][9] gh-mysql-backup-restore: db-mysql-0007: 运行 gh-xtrabackup-restore
|
||||||
|
[@jessbreckenridge][10] gh-mysql-backup-restore: db-mysql-0007: 恢复文件: xtrabackup-mycluster-2017-07-02_0015.xbstream
|
||||||
|
[@jessbreckenridge][11] gh-mysql-backup-restore: db-mysql-0007: 运行 gh-xtrabackup-prepare
|
||||||
|
[@jessbreckenridge][12] gh-mysql-backup-restore: db-mysql-0007: 更新文件权限
|
||||||
|
[@jessbreckenridge][13] gh-mysql-backup-restore: db-mysql-0007: 启用 MySQL
|
||||||
|
[@jessbreckenridge][14] gh-mysql-backup-restore: db-mysql-0007: 升级 MySQL
|
||||||
|
[@jessbreckenridge][15] gh-mysql-backup-restore: db-mysql-0007: 停止 MySQL
|
||||||
|
[@jessbreckenridge][16] gh-mysql-backup-restore: db-mysql-0007: 开启 MySQL
|
||||||
|
[@jessbreckenridge][17] gh-mysql-backup-restore: db-mysql-0007: 设置开启复制
|
||||||
|
[@jessbreckenridge][18] gh-mysql-backup-restore: db-mysql-0007: 启动复制
|
||||||
|
[@jessbreckenridge][19] gh-mysql-backup-restore: db-mysql-0007: 备份 Host: db-mysql-0201
|
||||||
|
[@jessbreckenridge][20] gh-mysql-backup-restore: db-mysql-0007: 复制缓存
|
||||||
|
[@jessbreckenridge][21] gh-mysql-backup-restore: db-mysql-0007: 复制后 4589 秒,下次检查之前等待 1800 秒
|
||||||
|
[@jessbreckenridge][22] gh-mysql-backup-restore: db-mysql-0007: 还原完成 (响应运行中)
|
||||||
|
[@jessbreckenridge][23] gh-mysql-backup-restore: db-mysql-0007: 禁用操作
|
||||||
|
[@jessbreckenridge][24] gh-mysql-backup-restore: db-mysql-0007: 禁用维护模式
|
||||||
|
|
||||||
|
### 故障转移[][39]
|
||||||
|
|
||||||
|
[我们使用协调器][40] 在主和从中执行自动化故障切换。我们期望 orchestrator 正确检测主故障,指定副本进行升级,在所指定的副本下修复拓扑,进行升级。我们期待 VIP 变化,池变化,客户端重连,`puppet` 运行的基本组件等等。故障转移是一项复杂的任务,涉及到我们基础架构的许多方面。
|
||||||
|
|
||||||
|
为了建立对我们的故障转移的信任,我们建立了一个 _类似生产的测试集群_ ,并且我们不断地崩溃它来观察故障转移。
|
||||||
|
|
||||||
|
_类似生产的测试集群_ 是一个复制设置,在所有方面与我们的生产集群相同:硬件类型,操作系统,MySQL版本,网络环境,VIP,`puppet` 配置,[haproxy 设置][41] 等。与此集群不同的是它不发送/接收生产流量。
|
||||||
|
|
||||||
|
我们在测试集群上模拟写入负载,同时避免复制滞后。写入负载不会太大,但是有一些有意争取写入相同数据集的查询。这在正常的时间并不是太有意思,但是证明在故障转移中是有用的,正如我们将会简要描述的那样。
|
||||||
|
|
||||||
|
我们的测试集群有三个数据中心的代表服务器。 我们希望故障转移能够在同一个数据中心内推广替代副本。 我们希望在这样的限制下尽可能多地复制副本。 我们要求尽可能适用。 协调者对拓扑结构没有先前的假设; 它必须对崩溃时的状态作出反应。
|
||||||
|
|
||||||
|
然而,我们有兴趣为故障切换创建复杂而多变的场景。我们的故障转移测试脚本为故障转移准备了理由:
|
||||||
|
|
||||||
|
* 它识别现有的主人
|
||||||
|
|
||||||
|
* 重构拓扑结构,使所有三个数据中心的代表成为主控。不同的 DC 具有不同的网络延迟,并且预期会在不同的时间对主机崩溃做出反应。
|
||||||
|
|
||||||
|
* 它选择一个崩溃方法。我们选择 master(`kill -9`)或网络划分它: `iptables -j REJECT` (nice-ish) 或 `iptables -j DROP`(unresponsive无响应)。
|
||||||
|
|
||||||
|
脚本继续通过选择的方法使主机崩溃,并等待 `orchestrator` 可靠地检测到崩溃并执行故障转移。虽然我们期望检测和升级在 `30` 几秒钟内 完成,但脚本会打破这一期望,并在查找故障转移结果之前睡觉一段指定的时间。然后:
|
||||||
|
|
||||||
|
* 检查一个新的(不同的)master 是否到位
|
||||||
|
|
||||||
|
* 集群中有很多副本
|
||||||
|
|
||||||
|
* master 是可写的
|
||||||
|
|
||||||
|
* 对 master 的写入在副本上可见
|
||||||
|
|
||||||
|
* 更新内部服务发现条目(新 master 的身份如预期;旧 master 已删除)
|
||||||
|
|
||||||
|
* 其他内部检查
|
||||||
|
|
||||||
|
这些测试证实故障转移是成功的,不仅是 MySQL 明智的,而且在更大的基础设施范围。VIP 被拒绝; 特别服务已经开始; 信息到达应该去的地方。
|
||||||
|
|
||||||
|
该脚本进一步继续恢复失败的服务器:
|
||||||
|
|
||||||
|
* 从备份恢复,从而隐含地测试我们的备份/恢复过程
|
||||||
|
|
||||||
|
* 验证服务器配置是否符合预期(服务器不再相信是主服务器)
|
||||||
|
|
||||||
|
* 返回到复制集群,期望找到在主机上写入的数据
|
||||||
|
|
||||||
|
考虑以下可视化的计划故障转移测试:从运行良好的群集到某些副本上的问题,诊断主机 (`7136`) 是否死机,选择一个服务器来促进 (`a79d`) ,重构该服务器下面的拓扑,推动它(故障切换成功),恢复死主机并将其放回群集。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 测试失败怎么样?
|
||||||
|
|
||||||
|
我们的测试脚本使用了一种停止世界的方法。任何故障切换组件中的单个故障都将失败,因此在人类解决问题之前,无法进行任何未来的自动化测试。我们得到警报,并继续检查状态和日志。
|
||||||
|
|
||||||
|
脚本将在不可接受的检测或故障转移时间失败; 备份/还原问题; 失去太多服务器; 在故障切换后的意外配置; 等等
|
||||||
|
|
||||||
|
我们需要确保 `orchestrator` 正确连接服务器。这是竞争性写入负载有用的地方:如果设置不正确,复制很容易中断。我们会得到 `DUPLICATE KEY` 或其他错误提示出错。
|
||||||
|
|
||||||
|
这是特别重要的,因为我们改进 `orchestrator` 并引入新的行为,允许我们在安全的环境中测试这些变化。
|
||||||
|
|
||||||
|
#### 来了:chaos 测试
|
||||||
|
|
||||||
|
上面所示的测试程序将捕获(并已经捕获)我们基础设施许多部分的问题。这些够了吗?
|
||||||
|
|
||||||
|
在生产环境中总是有其他的东西。关于不适用于我们的生产集群的特定测试方法。它们不具有相同的流量和流量操纵,也不具有完全相同的服务器集。故障类型可能有所不同。
|
||||||
|
|
||||||
|
我们正在为我们的生产集群设计 chaos 测试。 chaos 测试将会在我们的生产中,但是按照预期的时间表和充分控制的方式来破坏碎片。 chaos 测试在恢复机制中引入更高层次的信任,并影响(因此测试)我们的基础设施和应用程序的较大部分。
|
||||||
|
|
||||||
|
这是微妙的工作:当我们承认 chaos 测试的需要时,我们也希望避免对我们的服务造成不必要的影响。不同的测试将在风险级别和影响方面有所不同,我们将努力确保我们的服务的可用性。
|
||||||
|
|
||||||
|
### 模式迁移[][42]
|
||||||
|
|
||||||
|
[我们使用 gh-ost ][43]来运行实时模式迁移。 `gh-ost` 它是稳定的,但也在迅速的发展,增加或计划的主要新功能。
|
||||||
|
|
||||||
|
`gh-ost` 通过将数据复制到 _gh-ost_ 表来迁移,将进行的二进制日志拦截的更改应用到 _gh-ost_表,即使正在写入原始表。然后它将 _gh-ost_ 表交换代替原始表。迁移完成时,GitHub 继续使用生成和填充的 `gh-ost` 表。
|
||||||
|
|
||||||
|
在这个时候,几乎所有的 GitHub 的 MySQL 数据都被重新创建 `gh-ost`,其中大部分都是重新创建的。我们必须高度信任 `gh-ost`,即使面对快速的发展,也可以一再修改数据。这是我们如何获得这种信任。
|
||||||
|
|
||||||
|
`gh-ost` 提供生产测试能力。它支持在副本上运行迁移,其方式与在主服务器上运行的方式大致相同: `gh-ost` 将连接到副本,并将其视为主服务器。它将解析其二进制日志的方式与实际主机迁移相同。但是,它将复制行并将二进制日志事件应用于副本,并避免对主机进行写入。
|
||||||
|
|
||||||
|
我们经营的 `gh-ost` 复制品在生产中。这些副本不能提供生产流量。每个这样的副本将检索生产表的当前列表,并以随机顺序对其进行迭代。一个接一个地,它选择一个表并在该表上执行复制迁移。迁移实际上并不修改表结构,而是运行一个微不足道的 `ENGINE=InnoDB`。测试运行迁移,即使在生产中使用表,从而复制实际的生产数据,并将真正的生产流量从二进制日志中应用。
|
||||||
|
|
||||||
|
这些迁移可以被审计。以下是我们如何从聊天中检查运行测试的状态:
|
||||||
|
|
||||||
|

|
||||||
|
**ggunson**.migration test-status
|
||||||
|

|
||||||
|
**Hubot**
|
||||||
|
```
|
||||||
|
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
|
||||||
|
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
|
||||||
|
# Migration started at Mon Jan 30 02:13:39 -0800 2017
|
||||||
|
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
|
||||||
|
# throttle-additional-flag-file: /tmp/gh-ost.throttle
|
||||||
|
# panic-flag-file: /tmp/ghost-test-panic.flag
|
||||||
|
# Serving on unix socket: /tmp/gh-ost.test.sock
|
||||||
|
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
|
||||||
|
```
|
||||||
|
|
||||||
|
当测试迁移完成表数据的复制时,它将停止复制并执行切换,使用 _gh-ost_ 表替换原始表,然后交换回来。我们对实际更换数据并不感兴趣。相反,我们将留下原始的表和 _gh-ost_ 表,它们都应该是相同的。我们通过校验两个表的整个表数据来验证。
|
||||||
|
|
||||||
|
测试可以完成:
|
||||||
|
|
||||||
|
* _成功_ : 一切顺利,校验和相同。我们期待看到这一点。
|
||||||
|
|
||||||
|
* _失败_ : 执行问题。这可能偶尔发生,因为迁移过程被杀死,复制问题等,并且通常与 `gh-ost` 自身无关。
|
||||||
|
|
||||||
|
* _校验失败_ : 表数据不一致。对于被测试的分支,这个调用修复。对于正在进行的 `master` 分支测试,这意味着立即阻止生产迁移。我们不会得到后者。
|
||||||
|
|
||||||
|
测试结果经过审核,发送到机器人聊天室,作为事件发送到我们的度量系统。下图中的每条垂直线代表成功的迁移测试:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这些测试不断运行。如果发生故障,我们会收到通知。当然,我们可以随时访问机器人聊天室,了解发生了什么。
|
||||||
|
|
||||||
|
#### 测试新版本
|
||||||
|
|
||||||
|
我们不断提高 `gh-ost`。我们的开发流程基于 `git` 分支机构,然后我们提供通过[拉请求][44]进行合并。
|
||||||
|
|
||||||
|
提交的 `gh-ost` 拉请求通过持续集成(CI)进行基本的编译和单元测试。一旦过去,公关在技术上有资格合并,但更有趣的是它有 [eligible for deployment via Heaven][45] 。作为我们基础架构中的敏感组件,我们 `gh-ost` 在合并之前,要小心部署 master 分支机构,进行密集测试。
|
||||||
|
|
||||||
|

|
||||||
|
**shlomi-noach**.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
|
||||||
|

|
||||||
|
**Hubot**[@shlomi-noach][25] 正在部署 gh-ost/fix-reappearing-throttled-reasons (baee4f6) 到生产中 (ghost-db-mysql-0007).
|
||||||
|
[@shlomi-noach][26] gh-ost/fix-reappearing-throttled-reasons (baee4f6) 的生产部署已经完成了! (2s)
|
||||||
|
[@shlomi-noach][27] 确保你在 haystack 中看到异常
|
||||||
|

|
||||||
|
**jonahberquist**.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
|
||||||
|

|
||||||
|
**Hubot**[@jonahberquist][28] 正在部署 gh-ost/interactive-command-question (be1ab17) 到生产 (ghost-db-mysql-0012).
|
||||||
|
[@jonahberquist][29] gh-ost/interactive-command-question (be1ab17) 的生产部署已经完成了!(2s)
|
||||||
|
[@jonahberquist][30] 确保你在 haystack 中看到异常
|
||||||
|

|
||||||
|
**shlomi-noach**.wcid gh-ost
|
||||||
|

|
||||||
|
**Hubot**shlomi-noach 测试 fix-reappearing-throttled-reasons 41 秒前: ghost-db-mysql-0007
|
||||||
|
jonahberquist 测试 interactive-command-question 7 秒前: ghost-db-mysql-0012
|
||||||
|
|
||||||
|
没人在排队。
|
||||||
|
|
||||||
|
一些 PR 很小,不影响数据本身。对状态消息,交互式命令等的更改对 `gh-ost` 应用程序的影响较小 。其他对迁移逻辑和操作造成重大变化。我们将严格测试这些,通过我们的生产表车队,直到满足这些变化不会造成数据损坏的威胁。
|
||||||
|
|
||||||
|
### 总结[][46]
|
||||||
|
|
||||||
|
在整个测试过程中,我们建立对系统的信任。通过自动化这些测试,在生产中,我们得到重复的确认,一切都按预期工作。随着我们继续发展我们的基础设施,我们还通过调整测试来覆盖最新的变化。
|
||||||
|
|
||||||
|
生产总是令人惊奇的,不包括测试的场景。我们对生产环境的测试越多,我们对应用程序的期望越多,基础设施的能力就越强。
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://githubengineering.com/mysql-testing-automation-at-github/
|
||||||
|
|
||||||
|
作者:[tomkrouper ][a], [Shlomi Noach][b]
|
||||||
|
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://github.com/tomkrouper
|
||||||
|
[b]:https://github.com/shlomi-noach
|
||||||
|
[1]:https://github.com/tomkrouper
|
||||||
|
[2]:https://github.com/jessbreckenridge
|
||||||
|
[3]:https://github.com/jessbreckenridge
|
||||||
|
[4]:https://github.com/jessbreckenridge
|
||||||
|
[5]:https://github.com/jessbreckenridge
|
||||||
|
[6]:https://github.com/jessbreckenridge
|
||||||
|
[7]:https://github.com/jessbreckenridge
|
||||||
|
[8]:https://github.com/jessbreckenridge
|
||||||
|
[9]:https://github.com/jessbreckenridge
|
||||||
|
[10]:https://github.com/jessbreckenridge
|
||||||
|
[11]:https://github.com/jessbreckenridge
|
||||||
|
[12]:https://github.com/jessbreckenridge
|
||||||
|
[13]:https://github.com/jessbreckenridge
|
||||||
|
[14]:https://github.com/jessbreckenridge
|
||||||
|
[15]:https://github.com/jessbreckenridge
|
||||||
|
[16]:https://github.com/jessbreckenridge
|
||||||
|
[17]:https://github.com/jessbreckenridge
|
||||||
|
[18]:https://github.com/jessbreckenridge
|
||||||
|
[19]:https://github.com/jessbreckenridge
|
||||||
|
[20]:https://github.com/jessbreckenridge
|
||||||
|
[21]:https://github.com/jessbreckenridge
|
||||||
|
[22]:https://github.com/jessbreckenridge
|
||||||
|
[23]:https://github.com/jessbreckenridge
|
||||||
|
[24]:https://github.com/jessbreckenridge
|
||||||
|
[25]:https://github.com/shlomi-noach
|
||||||
|
[26]:https://github.com/shlomi-noach
|
||||||
|
[27]:https://github.com/shlomi-noach
|
||||||
|
[28]:https://github.com/jonahberquist
|
||||||
|
[29]:https://github.com/jonahberquist
|
||||||
|
[30]:https://github.com/jonahberquist
|
||||||
|
[31]:https://githubengineering.com/mysql-testing-automation-at-github/
|
||||||
|
[32]:https://github.com/tomkrouper
|
||||||
|
[33]:https://github.com/tomkrouper
|
||||||
|
[34]:https://github.com/shlomi-noach
|
||||||
|
[35]:https://github.com/shlomi-noach
|
||||||
|
[36]:https://githubengineering.com/mysql-testing-automation-at-github/#backups
|
||||||
|
[37]:https://www.percona.com/software/mysql-database/percona-xtrabackup
|
||||||
|
[38]:https://dev.mysql.com/doc/refman/5.6/en/replication-delayed.html
|
||||||
|
[39]:https://githubengineering.com/mysql-testing-automation-at-github/#failovers
|
||||||
|
[40]:http://githubengineering.com/orchestrator-github/
|
||||||
|
[41]:https://githubengineering.com/context-aware-mysql-pools-via-haproxy/
|
||||||
|
[42]:https://githubengineering.com/mysql-testing-automation-at-github/#schema-migrations
|
||||||
|
[43]:http://githubengineering.com/gh-ost-github-s-online-migration-tool-for-mysql/
|
||||||
|
[44]:https://github.com/github/gh-ost/pulls
|
||||||
|
[45]:https://githubengineering.com/deploying-branches-to-github-com/
|
||||||
|
[46]:https://githubengineering.com/mysql-testing-automation-at-github/#summary
|
||||||
Loading…
Reference in New Issue
Block a user