mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
bc5d3a4865
published
20151210 Getting started with Docker by Dockerizing this Blog.md.md20160217 How to Enable Multiple PHP-FPM Instances with Nginx or Apache.md20160218 7 Steps to Start Your Linux SysAdmin Career.md20160218 9 Key Trends in Hybrid Cloud Computing.md20160218 A Linux-powered microwave oven.md20160218 Top 4 open source issue tracking tools.md20160221 NXP unveils a tiny 64-bit ARM processor for the Internet of Things.md20160514 NODEOS - LINUX DISTRIBUTION FOR NODE LOVERS.md20160601 Apps to Snaps.md
LFCS
sources
talk
20160518 Android Use Apps Even Without Installing Them.md20160531 Linux vs. Windows device driver model.md20160605 Will Google Replace Passwords With A New Trust-Based Authentication Method.md
tech
20160519 The future of sharing: integrating Pydio and ownCloud.md20160529 LAMP Stack Installation Guide on Ubuntu Server 16.04 LTS.md20160601 scp command in Linux.md20160602 How to mount your Google Drive on Linux with google-drive-ocamlfuse.md20160603 How To Install And Use VBoxManage On Ubuntu 16.04 And Use Its Command line Options.md20160605 How to Add Cron Jobs in Linux and Unix.md
LFCS
translated
talk
20160518 Android Use Apps Even Without Installing Them.md20160605 Will Google Replace Passwords With A New Trust-Based Authentication Method.md
tech
20151210 Getting started with Docker by Dockerizing this Blog.md.md20160217 How to Enable Multiple PHP-FPM Instances with Nginx or Apache.md20160218 7 Steps to Start Your Linux SysAdmin Career.md20160218 9 Key Trends in Hybrid Cloud Computing.md20160514 NODEOS - LINUX DISTRIBUTION FOR NODE LOVERS.md20160529 LAMP Stack Installation Guide on Ubuntu Server 16.04 LTS.md20160601 Apps to Snaps.md20160601 scp command in Linux.md20160603 How To Install And Use VBoxManage On Ubuntu 16.04 And Use Its Command line Options.md20160606 Basic Git Commands You Must Know.md
LFCS
@ -0,0 +1,464 @@
|
||||
通过 Docker 化一个博客网站来开启我们的 Docker 之旅
|
||||
===
|
||||
|
||||

|
||||
|
||||
> 这篇文章包含 Docker 的基本概念,以及如何通过创建一个定制的 Dockerfile 来 Docker 化(Dockerize)一个应用。
|
||||
|
||||
Docker 是一个过去两年来从某个 idea 中孕育而生的有趣技术,公司组织们用它在世界上每个角落来部署应用。在今天的文章中,我将讲述如何通过“Docker 化(Dockerize)”一个现有的应用,来开始我们的 Docker 之旅。这里提到的应用指的就是这个博客!
|
||||
|
||||
## 什么是 Docker?
|
||||
|
||||
当我们开始学习 Docker 基本概念时,让我们先去搞清楚什么是 Docker 以及它为什么这么流行。Docker 是一个操作系统容器管理工具,它通过将应用打包在操作系统容器中,来方便我们管理和部署应用。
|
||||
|
||||
### 容器 vs. 虚拟机
|
||||
|
||||
容器和虚拟机并不完全相似,它是另外一种提供**操作系统虚拟化**的方式。它和标准的虚拟机还是有所不同。
|
||||
|
||||
标准的虚拟机一般会包括一个完整的操作系统、操作系统软件包、最后还有一至两个应用。这都得益于为虚拟机提供硬件虚拟化的管理程序。这样一来,一个单一的服务器就可以将许多独立的操作系统作为虚拟客户机运行了。
|
||||
|
||||
容器和虚拟机很相似,它们都支持在单一的服务器上运行多个操作环境,只是,在容器中,这些环境并不是一个个完整的操作系统。容器一般只包含必要的操作系统软件包和一些应用。它们通常不会包含一个完整的操作系统或者硬件的虚拟化。这也意味着容器比传统的虚拟机开销更少。
|
||||
|
||||
容器和虚拟机常被误认为是两种对立的技术。虚拟机采用一个物理服务器来提供全功能的操作环境,该环境会和其余虚拟机一起共享这些物理资源。容器一般用来隔离一个单一主机上运行的应用进程,以保证隔离后的进程之间不能相互影响。事实上,容器和 **BSD Jails** 以及 `chroot` 进程的相似度,超过了和完整虚拟机的相似度。
|
||||
|
||||
### Docker 在容器之上提供了什么
|
||||
|
||||
Docker 本身不是一个容器运行环境,事实上,只是一个与具体实现无关的容器技术,Docker 正在努力支持 [Solaris Zones](https://blog.docker.com/2015/08/docker-oracle-solaris-zones/) 和 [BSD Jails](https://wiki.freebsd.org/Docker)。Docker 提供了一种管理、打包和部署容器的方式。虽然一定程度上,虚拟机多多少少拥有这些类似的功能,但虚拟机并没有完整拥有绝大多数的容器功能,即使拥有,这些功能用起来都并没有 Docker 来的方便或那么完整。
|
||||
|
||||
现在,我们应该知道 Docker 是什么了,然后,我们将从安装 Docker,并部署一个公开的预构建好的容器开始,学习 Docker 是如何工作的。
|
||||
|
||||
## 从安装开始
|
||||
|
||||
默认情况下,Docker 并不会自动被安装在您的计算机中,所以,第一步就是安装 Docker 软件包;我们的教学机器系统是 Ubuntu 14.0.4,所以,我们将使用 Apt 软件包管理器,来执行安装操作。
|
||||
|
||||
```
|
||||
# apt-get install docker.io
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following extra packages will be installed:
|
||||
aufs-tools cgroup-lite git git-man liberror-perl
|
||||
Suggested packages:
|
||||
btrfs-tools debootstrap lxc rinse git-daemon-run git-daemon-sysvinit git-doc
|
||||
git-el git-email git-gui gitk gitweb git-arch git-bzr git-cvs git-mediawiki
|
||||
git-svn
|
||||
The following NEW packages will be installed:
|
||||
aufs-tools cgroup-lite docker.io git git-man liberror-perl
|
||||
0 upgraded, 6 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 7,553 kB of archives.
|
||||
After this operation, 46.6 MB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n] y
|
||||
```
|
||||
|
||||
为了检查当前是否有容器运行,我们可以执行`docker`命令,加上`ps`选项
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
`docker`命令中的`ps`功能类似于 Linux 的`ps`命令。它将显示可找到的 Docker 容器及其状态。由于我们并没有启动任何 Docker 容器,所以命令没有显示任何正在运行的容器。
|
||||
|
||||
## 部署一个预构建好的 nginx Docker 容器
|
||||
|
||||
我比较喜欢的 Docker 特性之一就是 Docker 部署预先构建好的容器的方式,就像`yum`和`apt-get`部署包一样。为了更好地解释,我们来部署一个运行着 nginx web 服务器的预构建容器。我们可以继续使用`docker`命令,这次选择`run`选项。
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
`docker`命令的`run`选项,用来通知 Docker 去寻找一个指定的 Docker 镜像,然后启动运行着该镜像的容器。默认情况下,Docker 容器运行在前台,这意味着当你运行`docker run`命令的时候,你的 shell 会被绑定到容器的控制台以及运行在容器中的进程。为了能在后台运行该 Docker 容器,我们使用了`-d` (**detach**)标志。
|
||||
|
||||
再次运行`docker ps`命令,可以看到 nginx 容器正在运行。
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 nginx:latest nginx -g 'daemon off 4 seconds ago Up 3 seconds 443/tcp, 80/tcp desperate_lalande
|
||||
```
|
||||
|
||||
从上面的输出信息中,我们可以看到正在运行的名为`desperate_lalande`的容器,它是由`nginx:latest image`(LCTT 译注: nginx 最新版本的镜像)构建而来得。
|
||||
|
||||
### Docker 镜像
|
||||
|
||||
镜像是 Docker 的核心特征之一,类似于虚拟机镜像。和虚拟机镜像一样,Docker 镜像是一个被保存并打包的容器。当然,Docker 不只是创建镜像,它还可以通过 Docker 仓库发布这些镜像,Docker 仓库和软件包仓库的概念差不多,它让 Docker 能够模仿`yum`部署软件包的方式来部署镜像。为了更好地理解这是怎么工作的,我们来回顾`docker run`执行后的输出。
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
```
|
||||
|
||||
我们可以看到第一条信息是,Docker 不能在本地找到名叫 nginx 的镜像。这是因为当我们执行`docker run`命令时,告诉 Docker 运行一个基于 nginx 镜像的容器。既然 Docker 要启动一个基于特定镜像的容器,那么 Docker 首先需要找到那个指定镜像。在检查远程仓库之前,Docker 首先检查本地是否存在指定名称的本地镜像。
|
||||
|
||||
因为系统是崭新的,不存在 nginx 镜像,Docker 将选择从 Docker 仓库下载之。
|
||||
|
||||
```
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
这就是第二部分输出信息显示给我们的内容。默认情况下,Docker 会使用 [Docker Hub](https://hub.docker.com/) 仓库,该仓库由 Docker 公司维护。
|
||||
|
||||
和 Github 一样,在 Docker Hub 创建公共仓库是免费的,私人仓库就需要缴纳费用了。当然,部署你自己的 Docker 仓库也是可以的,事实上只需要简单地运行`docker run registry`命令就行了。但在这篇文章中,我们的重点将不是讲解如何部署一个定制的注册服务。
|
||||
|
||||
### 关闭并移除容器
|
||||
|
||||
在我们继续构建定制容器之前,我们先清理一下 Docker 环境,我们将关闭先前的容器,并移除它。
|
||||
|
||||
我们利用`docker`命令和`run`选项运行一个容器,所以,为了停止同一个容器,我们简单地在执行`docker`命令时,使用`kill`选项,并指定容器名。
|
||||
|
||||
```
|
||||
# docker kill desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
当我们再次执行`docker ps`,就不再有容器运行了
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
但是,此时,我们这是停止了容器;虽然它不再运行,但仍然存在。默认情况下,`docker ps`只会显示正在运行的容器,如果我们附加`-a` (all) 标识,它会显示所有运行和未运行的容器。
|
||||
|
||||
```
|
||||
# docker ps -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 5c82215b03d1 nginx -g 'daemon off 4 weeks ago Exited (-1) About a minute ago desperate_lalande
|
||||
```
|
||||
|
||||
为了能完整地移除容器,我们在用`docker`命令时,附加`rm`选项。
|
||||
|
||||
```
|
||||
# docker rm desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
虽然容器被移除了;但是我们仍拥有可用的**nginx**镜像(LCTT 译注:镜像缓存)。如果我们重新运行`docker run -d nginx`,Docker 就无需再次拉取 nginx 镜像即可启动容器。这是因为我们本地系统中已经保存了一个副本。
|
||||
|
||||
为了列出系统中所有的本地镜像,我们运行`docker`命令,附加`images`选项。
|
||||
|
||||
```
|
||||
# docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
nginx latest 9fab4090484a 5 days ago 132.8 MB
|
||||
```
|
||||
|
||||
## 构建我们自己的镜像
|
||||
|
||||
截至目前,我们已经使用了一些基础的 Docker 命令来启动、停止和移除一个预构建好的普通镜像。为了“Docker 化(Dockerize)”这篇博客,我们需要构建我们自己的镜像,也就是创建一个 **Dockerfile**。
|
||||
|
||||
在大多数虚拟机环境中,如果你想创建一个机器镜像,首先,你需要建立一个新的虚拟机、安装操作系统、安装应用,最后将其转换为一个模板或者镜像。但在 Docker 中,所有这些步骤都可以通过 Dockerfile 实现全自动。Dockerfile 是向 Docker 提供构建指令去构建定制镜像的方式。在这一章节,我们将编写能用来部署这个博客的定制 Dockerfile。
|
||||
|
||||
### 理解应用
|
||||
|
||||
我们开始构建 Dockerfile 之前,第一步要搞明白,我们需要哪些东西来部署这个博客。
|
||||
|
||||
这个博客本质上是由一个静态站点生成器生成的静态 HTML 页面,这个生成器是我编写的,名为 **hamerkop**。这个生成器很简单,它所做的就是生成该博客站点。所有的代码和源文件都被我放在了一个公共的 [Github 仓库](https://github.com/madflojo/blog)。为了部署这篇博客,我们要先从 Github 仓库把这些内容拉取下来,然后安装 **Python** 和一些 **Python** 模块,最后执行`hamerkop`应用。我们还需要安装 **nginx**,来运行生成后的内容。
|
||||
|
||||
截止目前,这些还是一个简单的 Dockerfile,但它却给我们展示了相当多的 [Dockerfile 语法]((https://docs.docker.com/v1.8/reference/builder/))。我们需要克隆 Github 仓库,然后使用你最喜欢的编辑器编写 Dockerfile,我选择`vi`
|
||||
|
||||
```
|
||||
# git clone https://github.com/madflojo/blog.git
|
||||
Cloning into 'blog'...
|
||||
remote: Counting objects: 622, done.
|
||||
remote: Total 622 (delta 0), reused 0 (delta 0), pack-reused 622
|
||||
Receiving objects: 100% (622/622), 14.80 MiB | 1.06 MiB/s, done.
|
||||
Resolving deltas: 100% (242/242), done.
|
||||
Checking connectivity... done.
|
||||
# cd blog/
|
||||
# vi Dockerfile
|
||||
```
|
||||
|
||||
### FROM - 继承一个 Docker 镜像
|
||||
|
||||
第一条 Dockerfile 指令是`FROM`指令。这将指定一个现存的镜像作为我们的基础镜像。这也从根本上给我们提供了继承其他 Docker 镜像的途径。在本例中,我们还是从刚刚我们使用的 **nginx** 开始,如果我们想从头开始,我们可以通过指定`ubuntu:latest`来使用 **Ubuntu** Docker 镜像。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
```
|
||||
|
||||
除了`FROM`指令,我还使用了`MAINTAINER`,它用来显示 Dockerfile 的作者。
|
||||
|
||||
Docker 支持使用`#`作为注释,我将经常使用该语法,来解释 Dockerfile 的部分内容。
|
||||
|
||||
### 运行一次测试构建
|
||||
|
||||
因为我们继承了 **nginx** Docker镜像,我们现在的 Dockerfile 也就包括了用来构建 **nginx** 镜像的 [Dockerfile](https://github.com/nginxinc/docker-nginx/blob/08eeb0e3f0a5ee40cbc2bc01f0004c2aa5b78c15/Dockerfile) 中所有指令。这意味着,此时我们可以从该 Dockerfile 中构建出一个 Docker 镜像,然后以该镜像运行一个容器。虽然,最终的镜像和 **nginx** 镜像本质上是一样的,但是我们这次是通过构建 Dockerfile 的形式,然后我们将讲解 Docker 构建镜像的过程。
|
||||
|
||||
想要从 Dockerfile 构建镜像,我们只需要在运行 `docker` 命令的时候,加上 `build` 选项。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 23.6 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Running in c97f36450343
|
||||
---> 60a44f78d194
|
||||
Removing intermediate container c97f36450343
|
||||
Successfully built 60a44f78d194
|
||||
```
|
||||
|
||||
上面的例子,我们使用了`-t` (**tag**)标识给镜像添加“blog”的标签。实质上我们就是在给镜像命名,如果我们不指定标签,就只能通过 Docker 分配的 **Image ID** 来访问镜像了。本例中,从 Docker 构建成功的信息可以看出,**Image ID**值为 `60a44f78d194`。
|
||||
|
||||
除了`-t`标识外,我还指定了目录`/root/blog`。该目录被称作“构建目录”,它将包含 Dockerfile,以及其它需要构建该容器的文件。
|
||||
|
||||
现在我们构建成功了,下面我们开始定制该镜像。
|
||||
|
||||
### 使用 RUN 来执行 apt-get
|
||||
|
||||
用来生成 HTML 页面的静态站点生成器是用 **Python** 语言编写的,所以,在 Dockerfile 中需要做的第一件定制任务是安装 Python。我们将使用 Apt 软件包管理器来安装 Python 软件包,这意味着在 Dockerfile 中我们要指定运行`apt-get update`和`apt-get install python-dev`;为了完成这一点,我们可以使用`RUN`指令。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
```
|
||||
|
||||
如上所示,我们只是简单地告知 Docker 构建镜像的时候,要去执行指定的`apt-get`命令。比较有趣的是,这些命令只会在该容器的上下文中执行。这意味着,即使在容器中安装了`python-dev`和`python-pip`,但主机本身并没有安装这些。说的更简单点,`pip`命令将只在容器中执行,出了容器,`pip`命令不存在。
|
||||
|
||||
还有一点比较重要的是,Docker 构建过程中不接受用户输入。这说明任何被`RUN`指令执行的命令必须在没有用户输入的时候完成。由于很多应用在安装的过程中需要用户的输入信息,所以这增加了一点难度。不过我们例子中,`RUN`命令执行的命令都不需要用户输入。
|
||||
|
||||
### 安装 Python 模块
|
||||
|
||||
**Python** 安装完毕后,我们现在需要安装 Python 模块。如果在 Docker 外做这些事,我们通常使用`pip`命令,然后参考我的博客 Git 仓库中名叫`requirements.txt`的文件。在之前的步骤中,我们已经使用`git`命令成功地将 Github 仓库“克隆”到了`/root/blog`目录;这个目录碰巧也是我们创建`Dockerfile`的目录。这很重要,因为这意味着 Docker 在构建过程中可以访问这个 Git 仓库中的内容。
|
||||
|
||||
当我们执行构建后,Docker 将构建的上下文环境设置为指定的“构建目录”。这意味着目录中的所有文件都可以在构建过程中被使用,目录之外的文件(构建环境之外)是不能访问的。
|
||||
|
||||
为了能安装所需的 Python 模块,我们需要将`requirements.txt`从构建目录拷贝到容器中。我们可以在`Dockerfile`中使用`COPY`指令完成这一需求。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
```
|
||||
|
||||
在`Dockerfile`中,我们增加了3条指令。第一条指令使用`RUN`在容器中创建了`/build/`目录。该目录用来拷贝生成静态 HTML 页面所需的一切应用文件。第二条指令是`COPY`指令,它将`requirements.txt`从“构建目录”(`/root/blog`)拷贝到容器中的`/build/`目录。第三条使用`RUN`指令来执行`pip`命令;安装`requirements.txt`文件中指定的所有模块。
|
||||
|
||||
当构建定制镜像时,`COPY`是条重要的指令。如果在 Dockerfile 中不指定拷贝文件,Docker 镜像将不会包含requirements.txt 这个文件。在 Docker 容器中,所有东西都是隔离的,除非在 Dockerfile 中指定执行,否则容器中不会包括所需的依赖。
|
||||
|
||||
### 重新运行构建
|
||||
|
||||
现在,我们让 Docker 执行了一些定制任务,现在我们尝试另一次 blog 镜像的构建。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Running in bde05cf1e8fe
|
||||
---> f4b66e09fa61
|
||||
Removing intermediate container bde05cf1e8fe
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
Removing intermediate container 9aa8ff43f4b0
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Running in c50b15ddd8b1
|
||||
Downloading/unpacking jinja2 (from -r /build/requirements.txt (line 1))
|
||||
Downloading/unpacking PyYaml (from -r /build/requirements.txt (line 2))
|
||||
<truncated to reduce noise>
|
||||
Successfully installed jinja2 PyYaml mistune markdown MarkupSafe
|
||||
Cleaning up...
|
||||
---> abab55c20962
|
||||
Removing intermediate container c50b15ddd8b1
|
||||
Successfully built abab55c20962
|
||||
```
|
||||
|
||||
上述输出所示,我们可以看到构建成功了,我们还可以看到另外一个有趣的信息` ---> Using cache`。这条信息告诉我们,Docker 在构建该镜像时使用了它的构建缓存。
|
||||
|
||||
### Docker 构建缓存
|
||||
|
||||
当 Docker 构建镜像时,它不仅仅构建一个单独的镜像;事实上,在构建过程中,它会构建许多镜像。从上面的输出信息可以看出,在每一“步”执行后,Docker 都在创建新的镜像。
|
||||
|
||||
```
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
```
|
||||
|
||||
上面片段的最后一行可以看出,Docker 在告诉我们它在创建一个新镜像,因为它打印了**Image ID** : `cef11c3fb97c`。这种方式有用之处在于,Docker能在随后构建这个 **blog** 镜像时将这些镜像作为缓存使用。这很有用处,因为这样, Docker 就能加速同一个容器中新构建任务的构建流程。从上面的例子中,我们可以看出,Docker 没有重新安装`python-dev`和`python-pip`包,Docker 则使用了缓存镜像。但是由于 Docker 并没有找到执行`mkdir`命令的构建缓存,随后的步骤就被一一执行了。
|
||||
|
||||
Docker 构建缓存一定程度上是福音,但有时也是噩梦。这是因为决定使用缓存或者重新运行指令的因素很少。比如,如果`requirements.txt`文件发生了修改,Docker 会在构建时检测到该变化,然后 Docker 会重新执行该执行那个点往后的所有指令。这得益于 Docker 能查看`requirements.txt`的文件内容。但是,`apt-get`命令的执行就是另一回事了。如果提供 Python 软件包的 **Apt** 仓库包含了一个更新的 python-pip 包;Docker 不会检测到这个变化,转而去使用构建缓存。这会导致之前旧版本的包将被安装。虽然对`python-pip`来说,这不是主要的问题,但对使用了存在某个致命攻击缺陷的软件包缓存来说,这是个大问题。
|
||||
|
||||
出于这个原因,抛弃 Docker 缓存,定期地重新构建镜像是有好处的。这时,当我们执行 Docker 构建时,我简单地指定`--no-cache=True`即可。
|
||||
|
||||
## 部署博客的剩余部分
|
||||
|
||||
Python 软件包和模块安装后,接下来我们将拷贝需要用到的应用文件,然后运行`hamerkop`应用。我们只需要使用更多的`COPY` 和 `RUN`指令就可完成。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
|
||||
## Add blog code nd required files
|
||||
COPY static /build/static
|
||||
COPY templates /build/templates
|
||||
COPY hamerkop /build/
|
||||
COPY config.yml /build/
|
||||
COPY articles /build/articles
|
||||
|
||||
## Run Generator
|
||||
RUN /build/hamerkop -c /build/config.yml
|
||||
```
|
||||
|
||||
现在我们已经写出了剩余的构建指令,我们再次运行另一次构建,并确保镜像构建成功。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog/
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Using cache
|
||||
---> f4b66e09fa61
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> Using cache
|
||||
---> cef11c3fb97c
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Using cache
|
||||
---> abab55c20962
|
||||
Step 7 : COPY static /build/static
|
||||
---> 15cb91531038
|
||||
Removing intermediate container d478b42b7906
|
||||
Step 8 : COPY templates /build/templates
|
||||
---> ecded5d1a52e
|
||||
Removing intermediate container ac2390607e9f
|
||||
Step 9 : COPY hamerkop /build/
|
||||
---> 59efd1ca1771
|
||||
Removing intermediate container b5fbf7e817b7
|
||||
Step 10 : COPY config.yml /build/
|
||||
---> bfa3db6c05b7
|
||||
Removing intermediate container 1aebef300933
|
||||
Step 11 : COPY articles /build/articles
|
||||
---> 6b61cc9dde27
|
||||
Removing intermediate container be78d0eb1213
|
||||
Step 12 : RUN /build/hamerkop -c /build/config.yml
|
||||
---> Running in fbc0b5e574c5
|
||||
Successfully created file /usr/share/nginx/html//2011/06/25/checking-the-number-of-lwp-threads-in-linux
|
||||
Successfully created file /usr/share/nginx/html//2011/06/checking-the-number-of-lwp-threads-in-linux
|
||||
<truncated to reduce noise>
|
||||
Successfully created file /usr/share/nginx/html//archive.html
|
||||
Successfully created file /usr/share/nginx/html//sitemap.xml
|
||||
---> 3b25263113e1
|
||||
Removing intermediate container fbc0b5e574c5
|
||||
Successfully built 3b25263113e1
|
||||
```
|
||||
|
||||
### 运行定制的容器
|
||||
|
||||
成功的一次构建后,我们现在就可以通过运行`docker`命令和`run`选项来运行我们定制的容器,和之前我们启动 nginx 容器一样。
|
||||
|
||||
```
|
||||
# docker run -d -p 80:80 --name=blog blog
|
||||
5f6c7a2217dcdc0da8af05225c4d1294e3e6bb28a41ea898a1c63fb821989ba1
|
||||
```
|
||||
|
||||
我们这次又使用了`-d` (**detach**)标识来让Docker在后台运行。但是,我们也可以看到两个新标识。第一个新标识是`--name`,这用来给容器指定一个用户名称。之前的例子,我们没有指定名称,因为 Docker 随机帮我们生成了一个。第二个新标识是`-p`,这个标识允许用户从主机映射一个端口到容器中的一个端口。
|
||||
|
||||
之前我们使用的基础 **nginx** 镜像分配了80端口给 HTTP 服务。默认情况下,容器内的端口通道并没有绑定到主机系统。为了让外部系统能访问容器内部端口,我们必须使用`-p`标识将主机端口映射到容器内部端口。上面的命令,我们通过`-p 8080:80`语法将主机80端口映射到容器内部的80端口。
|
||||
|
||||
经过上面的命令,我们的容器看起来成功启动了,我们可以通过执行`docker ps`核实。
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
d264c7ef92bd blog:latest nginx -g 'daemon off 3 seconds ago Up 3 seconds 443/tcp, 0.0.0.0:80->80/tcp blog
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
截止目前,我们拥有了一个运行中的定制 Docker 容器。虽然在这篇文章中,我们只接触了一些 Dockerfile 指令用法,但是我们还是要学习所有的指令。我们可以检查 [Docker's reference page](https://docs.docker.com/v1.8/reference/builder/) 来获取所有的 Dockerfile 指令用法,那里对指令的用法说明得很详细。
|
||||
|
||||
另一个比较好的资源是 [Dockerfile Best Practices page](https://docs.docker.com/engine/articles/dockerfile_best-practices/),它有许多构建定制 Dockerfile 的最佳练习。有些技巧非常有用,比如战略性地组织好 Dockerfile 中的命令。上面的例子中,我们将`articles`目录的`COPY`指令作为 Dockerfile 中最后的`COPY`指令。这是因为`articles`目录会经常变动。所以,将那些经常变化的指令尽可能地放在最后面的位置,来最优化那些可以被缓存的步骤。
|
||||
|
||||
通过这篇文章,我们涉及了如何运行一个预构建的容器,以及如何构建,然后部署定制容器。虽然关于 Docker 你还有许多需要继续学习的地方,但我想这篇文章给了你如何继续开始的好建议。当然,如果你认为还有一些需要继续补充的内容,在下面评论即可。
|
||||
|
||||
--------------------------------------
|
||||
via: http://bencane.com/2015/12/01/getting-started-with-docker-by-dockerizing-this-blog/
|
||||
|
||||
作者:Benjamin Cane
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,121 @@
|
||||
如何启用 Nginx/Apache 的 PHP-FPM 多实例
|
||||
================================================================================
|
||||
|
||||
PHP-FPM 作为 FastCGI 进程管理器而广为熟知,它是 PHP FastCGI 实现的改进,带有更为有用的功能,用于处理高负载的服务器和网站。下面列出其中一些功能:
|
||||
|
||||
### 新功能 ###
|
||||
|
||||
- 拥有具有优雅(graceful)启动/停止选项的高级进程管理能力。
|
||||
- 可以通过不同的用户身份/组身份来以监听多个端口以及使用多个PHP配置。
|
||||
- 错误日志记录。
|
||||
- 支持上传加速。
|
||||
- 特别用于在处理一些耗时任务时结束请求和清空所有数据的功能。
|
||||
- 同时支持动态和静态的子进程重生。
|
||||
- 支持IP地址限制。
|
||||
|
||||
在本文中,我将要讨论的是,在运行 CPanel 11.52 及 EA3 (EasyApache)的 CentOS 7 服务器上,于 Nginx 和 Apache 之上安装 PHP-FPM,以及如何来通过 CPanel 管理这些安装好的多个 PHP-FPM 实例。
|
||||
|
||||
在我们开始安装前, 先看看安装的先决条件。
|
||||
|
||||
### 先决条件 ###
|
||||
|
||||
1. 启用 Mod_proxy_fcgi 模块
|
||||
2. 启用 MPM_Event
|
||||
|
||||
由于我们要将 PHP-FPM 安装到一台 EA3 服务器,我们需要运行 EasyApache 来编译 Apache 以启用这些模块。
|
||||
|
||||
你们可以参考我以前写的,关于如何在 Apache 服务器上安装 Nginx 作为反向代理的文档来了解 Nginx 的安装。
|
||||
|
||||
这里,我将再次简述那些安装步骤。具体细节,你可以参考我之前写的**(如何在 CentOS 7/CPanel 服务器上配置 Nginx 反向代理)**一文。
|
||||
|
||||
- 步骤 1:安装 Epel 仓库
|
||||
- 步骤 2:安装 nDeploy RPM 仓库,这是此次安装中最为**重要**的步骤。
|
||||
- 步骤 3:使用 yum 从 nDeploy 仓库安装 nDeploy 和 Nginx 插件。
|
||||
- 步骤 4:启用/配置 Nginx 为反向代理。
|
||||
|
||||
完成这些步骤后,下面为服务器中所有可用 PHP 版本安装 PHP-FPM 包,EA3 使用 remi 仓库来安装这些包。你可以运行这个 nDeploy 脚本来下载所有的包。
|
||||
|
||||
root@server1 [~]# /opt/nDeploy/scripts/easy_php_setup.sh
|
||||
Loaded plugins: fastestmirror, tsflags, universal-hooks
|
||||
EA4 | 2.9 kB 00:00:00
|
||||
base | 3.6 kB 00:00:00
|
||||
epel/x86_64/metalink | 9.7 kB 00:00:00
|
||||
epel | 4.3 kB 00:00:00
|
||||
extras | 3.4 kB 00:00:00
|
||||
updates | 3.4 kB 00:00:00
|
||||
(1/2): epel/x86_64/updateinfo | 460 kB 00:00:00
|
||||
(2/2): epel/x86_64/primary_db
|
||||
|
||||
运行该脚本将为 PHP 54,PHP 55,PHP 56 和 PHP 70 安装所有这些 FPM 包。
|
||||
|
||||
Installed Packages
|
||||
php54-php-fpm.x86_64 5.4.45-3.el7.remi @remi
|
||||
php55-php-fpm.x86_64 5.5.31-1.el7.remi @remi
|
||||
php56-php-fpm.x86_64 5.6.17-1.el7.remi @remi
|
||||
php70-php-fpm.x86_64 7.0.2-1.el7.remi @remi
|
||||
|
||||
在以上安装完成后,你需要为 Apache 启用 PHP-FPM SAPI。你可以运行下面这个脚本来启用 PHP-FPM 实例。
|
||||
|
||||
root@server1 [~]# /opt/nDeploy/scripts/apache_php-fpm_setup.sh enable
|
||||
mod_proxy_fcgi.c
|
||||
Please choose one default PHP version from the list below
|
||||
PHP70
|
||||
PHP56
|
||||
PHP54
|
||||
PHP55
|
||||
Provide the exact desired version string here and press ENTER: PHP54
|
||||
ConfGen:: lxblogger
|
||||
ConfGen:: blogr
|
||||
ConfGen:: saheetha
|
||||
ConfGen:: satest
|
||||
which: no cagefsctl in (/usr/local/jdk/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/local/bin:/usr/X11R6/bin:/root/bin)
|
||||
info [rebuildhttpdconf] Missing owner for domain server1.centos7-test.com, force lookup to root
|
||||
Built /usr/local/apache/conf/httpd.conf OK
|
||||
Waiting for “httpd” to restart gracefully …waiting for “httpd” to initialize ……
|
||||
…finished.
|
||||
|
||||
它会问你需要运行哪个 PHP 版本作为服务器默认版本,你可以输入那些细节内容,然后继续配置并为现存的域名生成虚拟主机文件。
|
||||
|
||||
我选择了 PHP 54 作为我服务器上的默认 PHP-FPM 版本。
|
||||
|
||||

|
||||
|
||||
虽然服务器配置了 PHP-FPM 54,但是我们可以通过 CPanel 为各个独立的域名修改 PHP-FPM 实例。
|
||||
|
||||
下面我将通过一些截图来为你们说明一下,怎样通过 CPanel 为各个独立域修改 PHP-FPM 实例。
|
||||
|
||||
安装了 Nginx 插件后,你的域名的 CPanel 就会有一个 Nginx Webstack 图标,你可以点击该图标来配置你的 Web 服务器。我已经登录进了我其中的一个 CPanel 来配置相应的 Web 服务器。
|
||||
|
||||
请看这些截图。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
现在,你可以根据需要为选中的主域配置 web 服务器(这里,我已经选择了主域 saheetha.com)。我已经继续通过自动化配置选项来进行了,因为我不需要添加任何手动设置。
|
||||
|
||||

|
||||
|
||||
当 Nginx 配置完后,你可以在这里为你的域名选择 PHP-FPM 实例。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
就像你在截图中所看到的,我服务器上的默认 PHP-FPM 是**PHP 54**,而我正要将我的域名的 PHP-FPM 实例单独修改成 **PHP 55**。当你为你的域修改 PHP-FPM 后,你可以通过访问 **phpinfo** 页面来确认。
|
||||
|
||||
谢谢你们参考本文,我相信这篇文章会给你提供不少信息和帮助。我会为你们推荐关于这个内容的有价值的评论 :)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/enable-multiple-php-fpm-instances-nginx-apache/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/saheethas/
|
||||
@ -0,0 +1,59 @@
|
||||
七步开始你的 Linux 系统管理员生涯
|
||||
===============================================
|
||||
|
||||
Linux 现在是个大热门。每个人都在寻求 Linux 才能。招聘人员对有 Linux 经验的人求贤若渴,还有无数的职位虚位以待。但是如果你是 Linux 新手,又想要赶上这波热潮,该从何开始下手呢?
|
||||
|
||||
###1、安装 Linux###
|
||||
|
||||
这应该是不言而喻的,但学习 Linux 的第一关键就是安装 Linux。LFS101x 和 LFS201 课程都包含第一次安装和配置 Linux 的详细内容。
|
||||
|
||||
###2、 完成 LFS101x 课程###
|
||||
|
||||
如果你是完完全全的 Linux 新手,最佳的起点是我们的免费 Linux 课程 [LFS101x Introduction to Linux](https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-2)。这个在线课程放在 edX.org,探索 Linux 系统管理员和终端用户常用的各种工具和技能以及日常的 Linux 工作环境。该课程是为有一定经验,但较少或没有接触过 Linux 的电脑用户设计的,不论他们是在个人还是企业环境中工作。这个课程会从图形界面和命令行两个方面教会你有用的 Linux 知识,让你能够了解主流的 Linux 发行版。
|
||||
|
||||
###3、 看看 LFS201 课程###
|
||||
|
||||
在你完成 LFS101x 之后,你就可以开始挑战 Linux 中更加复杂的任务了,这是成为一名专业的系统管理员所必须的。为了掌握这些技能,你应该看看 [LFS201 Essentials of Linux System Administration](http://training.linuxfoundation.org/linux-courses/system-administration-training/essentials-of-system-administration) 这个课程。该课程对每个话题进行了深度的解释和介绍,还有大量的练习和实验,帮助你获得相关主题实际的上手经验。
|
||||
|
||||
如果你更愿意有个教练,或者你的雇主想将你培养成 Linux 系统管理员的话,你可能会对 LFS220 Linux System Administration 感兴趣。这个课程有 LFS201 中所有的主题,但是它是由专家专人教授的,帮助你进行实验以及解答你在课程主题中的问题。
|
||||
|
||||
###4、 练习!###
|
||||
|
||||
熟能生巧,和对任何乐器或运动适用一样,这对 Linux 来说也一样适用。在你安装 Linux 之后,经常使用它。一遍遍地练习关键任务,直到你不需要参考材料也能轻而易举地完成。练习命令行的输入输出以及图形界面。这些练习能够保证你掌握成为成功的 Linux 系统管理员所必需的知识和技能。
|
||||
|
||||
###5、 获得认证###
|
||||
|
||||
在你完成 LFS201 或 LFS220 并且充分练习之后,你现在已经准备好获得系统管理员的认证了。你需要这个证书,因为你需要向雇主证明你拥有一名专业 Linux 系统管理员必需的技能。
|
||||
|
||||
现在有一些不同的 Linux 证书,它们每个都有其独到之处。但是,它们里大部分不是在特定发行版(如红帽)上认证,就是纯粹的知识测试,没有演示 Linux 的实际技能。Linux 基金会认证系统管理员(Linux Foundation Certified System Administrator)证书对想要一个灵活的,有意义的初级证书的人来说是个不错的选择。
|
||||
|
||||
###6、 参与进来###
|
||||
|
||||
如果你所在的地方有本地 Linux 用户组(Linux Users Group,LUG)的话,这时候你可以考虑加入他们。这些组织通常由各种年龄和经验水平的人组成,所以不管你的 Linux 经验水平如何,你都能找到和你类似技能水平的人互助,或是更高水平的 Linux 用户来解答你的问题以及介绍有用的资源。要想知道你附近有没有 LUG,上 meet.com 看看,或是附近的大学,又或是上网搜索一下。
|
||||
|
||||
还有不少在线社区可以在你学习 Linux 的时候帮助你。这些站点和社区向 Linux 新手和有经验的管理员都能够提供帮助和支持:
|
||||
|
||||
- [Linux Admin subreddit](https://www.reddit.com/r/linuxadmin)
|
||||
- [Linux.com](http://www.linux.com/)
|
||||
- [training.linuxfoundation.org](http://training.linuxfoundation.org/)
|
||||
- [http://community.ubuntu.com/help-information/](http://community.ubuntu.com/help-information/)
|
||||
- [https://forums.opensuse.org/forum.php](https://forums.opensuse.org/forum.php)
|
||||
- [http://wiki.centos.org/Documentation](http://wiki.centos.org/Documentation)
|
||||
|
||||
###7、 学会热爱文档###
|
||||
|
||||
最后但同样重要的是,如果你困在 Linux 的某些地方,别忘了 Linux 包含的文档。使用命令 man(manual,手册),info 和 help,你从系统内就可以找到 Linux 几乎所有方面的信息。这些内置资源的用处再夸大也不为过,你会发现你在生涯中始终会用到,所以你可能最好早点掌握使用它们。
|
||||
|
||||
想要了解更多开始你 Linux IT 生涯的信息?查看我们免费的电子书“[开始你 Linux IT 生涯的简短指南](http://training.linuxfoundation.org/sysadmin-it-career-guide)”。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/featured-blogs/191-linux-training/834644-7-steps-to-start-your-linux-sysadmin-career
|
||||
|
||||
作者:[linux.com][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:linux.com
|
||||
74
published/20160218 9 Key Trends in Hybrid Cloud Computing.md
Normal file
74
published/20160218 9 Key Trends in Hybrid Cloud Computing.md
Normal file
@ -0,0 +1,74 @@
|
||||
混合云计算的 9 大关键趋势
|
||||
========================================
|
||||
|
||||
自从几年前云计算的概念受到IT界的关注以来,公有云、私有云和混合云这三种云计算方式都有了可观的演进。其中混合云计算方式是最热门的云计算方式,在接受调查的公司中,有[88%的公司](https://www.greenhousedata.com/blog/hybrid-continues-to-be-most-popular-cloud-option-adoption-accelerating)将混合云计算摆在至关重要的地位。
|
||||
|
||||
混合云计算的疾速演进意味着一两年前的传统观念已经过时了。为此,我们询问了几个行业分析师,混合云在2016年的走势将会如何,我们得到了几个比较有意思的答案。
|
||||
|
||||
1. **2016年可能是我们将混合云投入使用的一年。**
|
||||
|
||||
混合云从本质上来说依赖于私有云,这对企业来说是比较难实现的。事实上,亚马逊,谷歌和微软的公有云已经进行了大量的投资,并且起步也比较早。私有云拖了混合云发展和使用的后腿。
|
||||
|
||||
私有云没有得到这么多的投资,这是有私有云的性质决定的。私有云意味着维护和投资你自己的数据中心。而许多公有云提供商正在推动企业减少或者消除他们的数据中心。
|
||||
|
||||
然而,得益于 OpenStack 的发展和微软的 Azure Stack ,这两者基本上就是封装在一个盒子里的私有云,我们将会看到私有云慢慢追上公有云的发展步伐。支持混合云的工具、基础设施和架构也变得更加健壮。
|
||||
|
||||
2. **容器,微服务和 unikernels 将会促进混合云的发展。**
|
||||
|
||||
分析师预言,到2016年底,这些原生云技术会或多或少成为主流的。这些云技术正在快速成熟,将会成为虚拟机的一个替代品,而虚拟机需要更多的资源。
|
||||
|
||||
更重要的是,他们既能工作在在线场景,也能工作在离线场景。容器化和编排允许快速的扩大规模,进行公有云和私有云之间的服务迁移,使你能够更容易移动你的服务。
|
||||
|
||||
3. **数据和相关性占据核心舞台。**
|
||||
|
||||
所有的云计算方式都处在发展模式。这使得云计算变成了一个技术类的故事。咨询公司 [Avoa](http://avoa.com/2016/01/01/2016-is-the-year-of-data-and-relevance/)称,随着云趋于成熟,数据和相关性变得越来越重要。起初,云计算和大数据都是关于怎么得到尽可能多的数据,然后他们担心如何处理这海量的数据。
|
||||
|
||||
2016年,相关组织将会继续锤炼如何进行数据收集和使用的相关技术。在必须处理的技术和文化方面仍然有待提高。但是2016年应该重新将关注点放在从各个方面考虑的数据重要性上,发现最相关的信息,而不只是数据的数量。
|
||||
|
||||
4. **云服务将超越按需工作负载。**
|
||||
|
||||
AWS(Amazon Web Services) 起初是提供给程序员或者是开发人员能够快速启动虚拟机、做一些工作然后离线的一个地方。本质上是按需使用,要花费更多的钱才能让这些服务持续运行、全天候工作。
|
||||
|
||||
然而,IT 公司正开始作为服务代理,为内部用户提供各种 IT 服务。可以是内部 IT 服务,公有云基础架构提供商,平台服务和软件服务。
|
||||
|
||||
他们将越来越多的认识到像云管理平台这样的工具的价值。云管理平台可以提供针对不同服务的基于策略的一致性管理。他们也将看到像提高可移植性的容器等技术的价值。然而,云服务代理,在不同云之间快速移动工作负载从而进行价格套利或者类似的原因,仍然是行不通的。
|
||||
|
||||
5. **服务提供商转变成了云服务提供商。**
|
||||
|
||||
到目前为止,购买云服务成了直销模式。AWS EC2 服务的使用者通常变成了购买者,要么通过官方认证渠道,要么通过影子 IT。但是随着云服务越来越全面,提供的服务菜单越来越复杂,越来越多的人转向了经销商,服务提供商转变成了他们 IT 服务的购买者。
|
||||
|
||||
2nd Watch (2nd Watch 是为企业提供云管理的 AWS 的首选合作伙伴)最近的一项调查发现,在美国将近85%的 IT 高管愿意支付一个小的溢价从渠道商那里购买公有云服务,如果购买过程变得不再那么复杂。根据调查,这85%的高管有五分之四的愿意支付额外的15%或者更多。三分之一的受访高管表示,这些有助于他们购买、使用和管理公有云服务。
|
||||
|
||||
6. **物联网和云对于2016年的意义好比移动和云对2012年的意义。**
|
||||
|
||||
物联网获得了广泛的关注,更重要的是,物联网已经从测试场景进行了实际应用。云的分布式特性使得云成为了物联网非常重要的一部分,对于工业物联网,与后端系统交互的机械和重型设备,混合云将会成为最自然的驱动者,连接,数据采集和处理将会发生在混合云环境中,这得益于私有云在安全和隐私方面的好处。
|
||||
|
||||
7. **NIST 对云的定义开始瓦解。**
|
||||
|
||||
2011年,美国国家标准与技术研究院发布了“[ NIST 对于云计算的定义](http://csrc.nist.gov/publications/nistpubs/800-145/SP800-145.pdf)”(PDF),这个定义成为了私有云、公有云、混合云和 aaS 模板的标准定义。
|
||||
|
||||
然而随着时间的推移,定义开始改变。IaaS 变得更加复杂,开始支持 OpenStack,[Swift](https://wiki.openstack.org/wiki/Swift) 对象存储和神经网络这样的项目。PaaS 似乎正在消退,因为 PaaS 和传统的中间件开发几乎无异。SaaS,只是通过浏览器进行访问的应用,也正在失去发展动力,因为许多 app 和服务提供了许多云接口,你可以通过各种手段调用接口,不仅仅通过浏览器。
|
||||
|
||||
8. **分析变得更加重要**
|
||||
|
||||
对于混合云计算来说,分析将会成为一个巨大的增长机遇,云计算具有规模大、灵活性高的优势,使得云计算非常适合需要海量数据的分析工作。对于某些分析方式,比如高度敏感的数据,私有云仍然是主导地位,但是私有云也是混合云的一部分。因此,无论如何,混合云计算胜出。
|
||||
|
||||
9. **安全仍然是一个非常紧迫的问题。**
|
||||
|
||||
随着混合云计算在2016年的发展,以及对物联网和容器等新技术的引进,这同时也增加了更多的脆弱可攻破的地方,从而导致数据泄露。先增加使用新技术的趋势,然后再去考虑安全性,这种问题经常发生,同时还有缺少经验的工程师不去考虑系统的安全问题,总有一天你会尝到灾难的后果的。
|
||||
|
||||
当一项新技术出来,管理规范总是落后于安全问题产生后,然后我们才考虑去保护技术。容器就是一个很鲜明的例子。你可以从 Docker 下载各种示例容器,但是你知道你下载的东西来自哪里么?在人们在对容器内容不知情的情况下下载并运行了容器之后,Docker 不得不重新加上安全验证。
|
||||
|
||||
像 Path 和 Snapchat 这样的移动技术在智能手机市场火起来之后也出现了重大的安全问题。一项新技术被恶意利用无可避免。所以安全研究人员需要通过各种手段来保证新技术的安全性,很有可能在部署之后才会发现安全问题。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/cloud-computing/9-key-trends-in-hybrid-cloud-computing.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
译者:[棣琦](https://github.com/sonofelice)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Andy-Patrizio-90720.html
|
||||
@ -1,9 +1,9 @@
|
||||
一个Linux驱动的微波炉
|
||||
一个 Linux 驱动的微波炉
|
||||
================================================================================
|
||||
|
||||
[linux.conf.au](http://linux.conf.au/)里的人们都有一种想到什么就动手去实现的想法。随着硬件开源运动不断地发展壮大,这种想法越来越多,与现实世界联系的越来越紧密,而不仅仅存在于数字世界中。David Tulloh用他制作的[Linux驱动的微波炉 [WebM]](http://mirror.linux.org.au/linux.conf.au/2016/04_Thursday/D4.303_Costa_Theatre/Linux_driven_microwave.webm)来展示一个差劲的微波炉会多么难用以及说明他的项目可以改造这些微波炉使得它们不那么讨人厌。
|
||||
[linux.conf.au](http://linux.conf.au/)里的人们都有一种想到什么就动手去实现的想法。随着硬件开源运动不断地发展壮大,这种想法越来越多,也与现实世界联系的越来越紧密,而不仅仅存在于数字世界中。David Tulloh用他制作的[Linux驱动的微波炉 [WebM]](http://mirror.linux.org.au/linux.conf.au/2016/04_Thursday/D4.303_Costa_Theatre/Linux_driven_microwave.webm)来展示一个差劲的微波炉会多么难用,以及说明他的项目可以改造这些微波炉使得它们不那么讨人厌。
|
||||
|
||||
Tulloh的故事要从他买到了一个公认很便宜的微波炉开始说起,它的用户界面比其它微波炉默认的还要糟糕。设定时间时必须使劲按按钮以至于把微波炉都向后推了一段距离——而事实上必须要用力拉仓门把手才能把微波炉拖回原来的位置,这形成了一个“优雅”的平衡。当然这只是极端情况。Tulloh很郁闷因为这个微波炉近十年来都没有一丁点明显的改善。他可能买到了一个又小又便宜的微波炉,而且特点是大部分人不研究使用手册就不会使用它——和智能手机的对比更加明显:智能手机只需知道一点点的操作指南并且被广泛使用。
|
||||
Tulloh的故事要从他买到了一个公认很便宜的微波炉开始说起,它的用户界面比其它微波炉默认的还要糟糕。设定时间时必须使劲按按钮以至于把微波炉都向后推了一段距离——而事实上必须要用力拉仓门把手才能把微波炉拖回原来的位置,这形成了一个“优雅”的平衡。当然这只是极端情况。Tulloh郁闷的是因为这个微波炉近十年来都没有一丁点明显的改善。他可能买到了一个又小又便宜的微波炉,而且特点是大部分人不研究使用手册就不会使用它——和智能手机的对比更加明显:智能手机只需知道一点点的操作指南并且被广泛使用。
|
||||
|
||||
改造这个微波炉不一定没有前途,“让微波炉重获新生”——这个想法成为了一个原型,如果Tulloh可以再平衡一下想做的功能和需求之间的关系的话他希望这变成一个众筹项目:一个Linux驱动的微波炉。
|
||||
|
||||
@ -11,35 +11,29 @@ Tulloh的故事要从他买到了一个公认很便宜的微波炉开始说起
|
||||
|
||||
## 加一点新奇的小玩意
|
||||
|
||||
如果把“Linux”和“微波炉”联系在一起的话,你可能会想到给微波炉加上一个智能手机式的触摸屏和网络链接,然后再通过社区做一款微波炉的“革命性”的手机应用,想到这些就像做菜想到分享食谱一样显而易见。但Tulloh的目标和他的原型远远超过这些,他做了两个新奇的功能——热感相机和称量物体质量的称重装置。
|
||||
|
||||
这个热感相机提供一个可以精确到两度的八乘八像素的图像,这足够发现一杯牛奶是否加热到沸腾或者牛排是否解冻到快不能用来烹饪。不论发生哪种情况,都可以减小功率或者关掉它。而且在必要的时候会发出警报。这可能不是第一个可以检测温度的微波炉——GE在十年前就开始卖带温度探针的微波炉了——但是一个一直工作的内置传感器比一个手工探针有用多了,尤其是有一个可用的API支持的时候。
|
||||
|
||||
如果你把“Linux”和“微波炉”联系在一起的话就可能想到给微波炉加上一个智能手机式的触摸屏和网络链接,然后再通过社区做一款微波炉的“革命性”的手机应用,想到这些就像做菜想到分享食谱一样显而易见。但Tulloh的目标和他的原型远远超过这些,他做了两个新奇的功能——热感相机和称量物体质量的称重装置。
|
||||
第二个新发明是一个嵌入的称重装置,它可以在加热之前称量食物(和容器)。很多食谱根据质量大小给出指导的烹饪时间,很多微波炉支持你手动输入质量以便它帮你计算。利用内置的称重装置,这一过程可以变成自动化的。在许多微波炉的转盘下面稳固地放置一个称重装置是一个机械方面的挑战,不过Tulloh觉得这个问题不难处理。相反,他对微波炉的设计是基于“平板”或者“平板挂车”的风格——在四角各放置一个传感器,这不仅在机械实现上很简单而且很好的达到了要求。
|
||||
|
||||
这个热感相机提供一个精确度两自由度的八乘八像素的图片,这足够发现一杯牛奶是否加热到沸腾或者牛排是否解冻到快不能用来烹饪。不论发生哪种情况,功率都可以减小或者关掉。而且在必要的时候会发出警报。这可能不是第一个可以检测温度的微波炉——GE在十年前就开始卖带温度探针的微波炉了——但是一个一直工作的内置传感器比一个手工探针有用多了尤其是有一个可用的API支持的时候。
|
||||
|
||||
第二个新发明是一个嵌入的称重装置,它可以在加热之前称量食物(和容器)。很多食谱根据质量给出指导的烹饪时间,很多微波炉支持你手动输入质量以便它帮你计算。利用内置的称重装置,这一过程可以变成自动化的。在许多微波炉的转盘下面稳固地放置一个称重装置是一个机械方面的挑战不过Tulloh觉得这个问题不难处理。反而他对微波炉的设计是基于“平板”或者“平板挂车”的风格——在四角各放置一个传感器,这不仅在机械实现上很简单而且很好的达到了要求。
|
||||
|
||||
|
||||
[用户界面]
|
||||
一旦你有了这些额外添加的并与逻辑引擎相连的质量温度传感器,你可以去尝试更多好玩的可能。一杯刚从冰箱里拿出来的冰牛奶的质量温度分布可能会有适度误差。Tulloh发现这种情况可以被检测到而且提供一些有关的像“煮沸”或者“加热”的选项也是容易做到的(下面有一个模拟的界面,可点击操作的版本请点击右边链接 [here](http://mwgui.tulloh.id.au/))
|
||||
一旦你有了这些额外添加的并与逻辑引擎相连的质量温度传感器,你可以去尝试更多好玩的可能。一杯刚从冰箱里拿出来的冰牛奶的质量温度分布可能会有适度误差。Tulloh发现可以监检测到这种情况,而且提供一些有关的像“煮沸”或者“加热”的选项也是容易做到的(下面有一个模拟的界面,可点击操作的版本请点击右边链接 [here](http://mwgui.tulloh.id.au/))
|
||||
|
||||
|
||||
|
||||
## 改造陈旧的东西
|
||||
|
||||
除了才开发出来的新功能,Tulloh还想要提升那些原本就提供的功能。可能不是所有微波炉的门把手都像Tulloh那个廉价的一样僵硬,但是很少有微波炉将把手设计的让残疾人也能轻松使用。这些缺陷都是可调整的,尤其是在美国,微波炉应该在仓门关闭的时候给出一个确定关闭的提示。这种确认必须是可靠的以预防那些伪劣产品,所以在仓门闭合时固定的槽位里添加一个短杆以确认仓门开闭状态,不误使微波炉在仓门开着的时候工作。事实上,必须要两个相互联系的机关,如果他们提供的结果不一致,
|
||||
保险丝必须断开以便启动一个呼叫服务。Tulloh认为提供一个磁力门闩有更大的灵活性(包含简单的软件控制)并且像磁控也同样用于[磁性钥匙锁](https://en.wikipedia.org/wiki/Magnetic_keyed_lock),它可以让磁力门闩确认微波炉门是否关闭。
|
||||
除了才开发出来的新功能,Tulloh还想要提升那些原本就提供的功能。可能不是所有微波炉的门把手都像Tulloh那个廉价的一样僵硬,但是很少有微波炉将把手设计的让残疾人也能轻松使用。这些缺陷都是可调整的,尤其是在美国,微波炉应该在仓门关闭的时候给出一个确定关闭的提示。这种确认必须是可靠的以预防那些伪劣产品,所以在仓门闭合时固定的槽位里添加一个短杆以确认仓门开闭状态,不至于误使微波炉在仓门开着的时候工作。事实上,必须要有两个相互联系的机关,如果他们提供的结果不一致,保险丝必须断开以便启动一个呼叫服务。Tulloh认为提供一个磁力门闩有更大的灵活性(包含简单的软件控制)并且像磁控也同样用于[磁性钥匙锁](https://en.wikipedia.org/wiki/Magnetic_keyed_lock),它可以让磁力门闩确认微波炉门是否关闭。
|
||||
|
||||
微波炉的另一个痛点是它会发出令人厌烦的声音。Tulloh去掉了蜂鸣器并且使用香蕉派(类似于树莓派的单片机开发板)控制他的微波炉。这可以通过一个把文本转换成语音的系统来用令人愉悦而且可配置的警报来提示和引导使用者。显然,下一步就是装上一个用来控制声音的扩音器。
|
||||
|
||||
|
||||
许多微波炉除了定时和设置功率档位之外还可以做更多的事情——它们为烹饪,加热,化冻等提供一系列的功率谱。加上一个精确的温度测量装置感觉会为这个图表大大扩展它们的序列。Andrew Tridgell对一个问题很好奇,加热巧克力——一个需要非常精确的温度控制的过程——是否是可能的。Tulloh没有过这方面的经验,他不敢保证这个一定可以,但是这个实验结果的确值得期待。即使没做成这件事,它也显出了潜在价值——社区接下来可以更进一步去做这件事。
|
||||
许多微波炉除了定时和设置功率档位之外还可以做更多的事情——它们为烹饪,加热,化冻等提供一系列的功率档位。加上一个精确的温度测量装置感觉会为这个图表大大扩展这个列表。Andrew Tridgell对一个问题很好奇,加热巧克力——一个需要非常精确的温度控制的过程——是否是可能的。Tulloh没有过这方面的经验,他不敢保证这个一定可以,但是这个实验结果的确值得期待。即使没做成这件事,它也显出了潜在价值——社区接下来可以更进一步去做这件事。
|
||||
|
||||
## 实用性怎么样?
|
||||
|
||||
Tulloh十分乐意向全世界分享这个linux驱动的微波炉,他希望看到(因为这件事)形成一个社区并且想看到它接下来的走势。买一个现成的微波炉并且替换掉里面的电子元件看起来不是一个可行的点子。最后的结果可能会很糟,而买一个小巧智能的微波炉必然要花掉(比自己改造)更多的钱,但是潜在的顾客不想在他们的厨房里看到乱七八糟又不协调的东西。
|
||||
|
||||
许多零件都是现成的可以买到的(磁电管,处理器板,热传感器等等),像USB接口的热传感器,而且都很容易安装。软件原型当然也开源在[GitHub](https://github.com/lod?tab=repositories)。这个样例和微波炉门有不小的挑战性并且很可能要定制。Tulloh想要通过提供左侧开仓门的微波炉和颜色多样化的选项来转逆境为机遇。
|
||||
许多零件都是现成的可以买到的(磁电管,处理器板,热传感器等等),像USB接口的热传感器,而且都很容易安装。软件原型当然也开源在[GitHub](https://github.com/lod?tab=repositories)。微波炉的舱室和门有不小的挑战性并且很可能要定制。Tulloh想要通过提供左侧开仓门的微波炉和颜色多样化的选项来转逆境为机遇。
|
||||
|
||||
一个对读者的快速调查:很少有人会贸然承诺他会为了一个全新的升级过的烤箱付出1000澳大利亚元。当然,很难知道是否会有充足的时间和足够多的读者来完成这个调查。这整个项目看起来很有趣。所以Tulloh的[博客](http://david.tulloh.id.au/category/microwave/) (点击这里)也很值得一看。
|
||||
|
||||
@ -48,8 +42,6 @@ Tulloh十分乐意向全世界分享这个linux驱动的微波炉,他希望看
|
||||
via: https://lwn.net/Articles/674877/
|
||||
|
||||
作者:Neil Brown
|
||||
译者:yuba0604(https://github.com/yuba0604)
|
||||
|
||||
译者水平有限,敬请指正。(lizhengyu@gmail.com)
|
||||
译者:[yuba0604](https://github.com/yuba0604)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,13 +1,13 @@
|
||||
开源问题跟踪管理工具Top4
|
||||
4 个顶级的开源问题跟踪管理工具
|
||||
========================================
|
||||
|
||||
生活充满了bug。
|
||||
|
||||
无论怎样小心计划,无论花多少时间去设计,在执行阶段当轮胎压在路上,任何工程都会有未知的问题。也无妨。也许对于任何一个组织的最佳弹性衡量不是他们如何一切都按计划运行地处理事情,而是,当出现磕磕碰碰时他们如何驾驭。
|
||||
无论怎样小心计划,无论花多少时间去设计,在执行阶段实际执行时,任何工程都会有未知的问题。也无妨。也许对于任何一个组织的最佳弹性衡量不是他们如何一切都按计划运行地处理事情,而是,当出现磕磕碰碰时他们如何驾驭。
|
||||
|
||||
对任何一个项目管理流程来说,特别是在软件开发领域,都需要一个关键工具——问题跟踪管理系统。其基本功能很简单:可以对bug进行查看、追踪,并以协作的方式解决bug,有了它,我们更容易跟随整个过程的进展。除了基本功能,还有很多专注于满足特定需求的选项及功能,使用场景不仅限于软件开发。你可能已经熟悉某些托管版本的工具,像 [GitHub Issues](https://guides.github.com/features/issues/)或者[Launchpad](https://launchpad.net/),其中一些工具已经有了自己的开源社区。
|
||||
|
||||
接下来,这四个bug问题跟踪管理软件的极佳备选,全部开源、易于下载,自己就可以部署。先说好,我们可能没有办法在这里列出每一个问题跟踪工具;相反,我们列出这四个,基于的是其丰富的功能和项目背后的社区规模。当然,肯定还有其他类似软件,如果你喜欢的没有列在这里,如果你有一个好的理由,一定要让我们知道,在下面的评论中使它脱颖而出吧。
|
||||
接下来,这四个bug问题跟踪管理软件的极佳备选,全部开源、易于下载,自己就可以部署。先说好,我们可能没有办法在这里列出每一个问题跟踪工具;相反,我们列出这四个,原因基于是其丰富的功能和项目背后的社区规模。当然,肯定还有其他类似软件,如果你喜欢的没有列在这里,如果你有一个好的理由,一定要让我们知道,在下面的评论中使它脱颖而出吧。
|
||||
|
||||
## Redmine
|
||||
|
||||
@ -15,7 +15,7 @@
|
||||
|
||||
Redmine的设置相当灵活,支持多种数据库后端和几十种语言,还是可定制的,可以向问题(issue)、用户、工程等添加自定义字段。通过社区创建的插件和主题它可以进一步定制。
|
||||
|
||||
如果你想试一试,一个[在线演示](http://demo.redmine.org/)可提供使用。Redmine在开源[GPL版本2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html)下许可;开源代码可以在工程的[svn仓库](https://svn.redmine.org/redmine)或在[GitHub](https://github.com/redmine/redmine)镜像上找到。
|
||||
如果你想试一试,一个[在线演示](http://demo.redmine.org/)可提供使用。Redmine采用[GPL版本2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html)许可证;开源代码可以在工程的[svn仓库](https://svn.redmine.org/redmine)或在[GitHub](https://github.com/redmine/redmine)镜像上找到。
|
||||
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ Redmine的设置相当灵活,支持多种数据库后端和几十种语言,
|
||||
|
||||
从通知到重复bug检测再到搜索共享,Bugzilla拥有许多高级工具,是一个功能更丰富的选项。Bugzilla拥有一套高级搜索系统以及全面的报表工具,具有生成图表和自动化按计划生成报告的能力。像Redmine一样,Bugzilla是可扩展和可定制的,除了字段本身,还能针对bug创建自定义工作流。它也支持多种后端数据库,和自带的多语言支持。
|
||||
|
||||
Bugzilla在[Mozilla公共许可证](https://en.wikipedia.org/wiki/Mozilla_Public_License)下许可,你可以读取他们的[未来路线图](https://www.bugzilla.org/status/roadmap.html)还有在官网尝试一个[示例服务](https://landfill.bugzilla.org/)
|
||||
Bugzilla采用[Mozilla公共许可证](https://en.wikipedia.org/wiki/Mozilla_Public_License),你可以读取他们的[未来路线图](https://www.bugzilla.org/status/roadmap.html)还有在官网尝试一个[示例服务](https://landfill.bugzilla.org/)
|
||||
|
||||
|
||||
|
||||
@ -35,7 +35,7 @@ Bugzilla在[Mozilla公共许可证](https://en.wikipedia.org/wiki/Mozilla_Public
|
||||
|
||||
由python编写的Trac,将其漏洞跟踪能力与它的wiki系统和版本控制系统轻度整合。项目管理能力突出,如生成里程碑和路线图,一个可定制的报表系统,大事记,支持多资源库,内置的垃圾邮件过滤,还可以使用很多通用语言。如其他我们已经看到的漏洞追踪软件,有很多插件可进一步扩展其基本特性。
|
||||
|
||||
Trac是在改进的[BSD许可](http://trac.edgewall.org/wiki/TracLicense)下获得开放源码许可,虽然更老的版本发布在GPL下。你可以在一个[自托管仓库](http://trac.edgewall.org/browser)预览Trac的源码或者查看他们的[路线图](http://trac.edgewall.org/wiki/TracRoadmap)对未来的规划。
|
||||
Trac以[改进的BSD许可协议](http://trac.edgewall.org/wiki/TracLicense)开源,虽然更老的版本发布在GPL下。你可以在一个[自托管仓库](http://trac.edgewall.org/browser)预览Trac的源码或者查看他们的[路线图](http://trac.edgewall.org/wiki/TracRoadmap)对未来的规划。
|
||||
|
||||
|
||||
|
||||
@ -43,11 +43,11 @@ Trac是在改进的[BSD许可](http://trac.edgewall.org/wiki/TracLicense)下获
|
||||
|
||||
[Mantis](https://www.mantisbt.org/)是这次合集中我们将看到的最后一个工具,基于PHP,且有16年历史。作为另一个支持多种不同版本控制系统和事件驱动通知系统的bug跟踪管理软件,Mantis有一个与其他工具类似的功能设置。虽然它不本身包含wiki,但它整合了很多流行的wiki平台且本地化到多种语言。
|
||||
|
||||
Mantis在[GPL版本2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html)下获得开源许可证书;你可以在[GitHub](https://github.com/mantisbt/mantisbt)浏览他的源代码或查看自托管[路线图](https://www.mantisbt.org/bugs/roadmap_page.php?project=mantisbt&version=1.3.x)对未来的规划。一个示例,你可以查看他们的内部[漏洞跟踪](https://www.mantisbt.org/bugs/my_view_page.php)。
|
||||
Mantis使用[GPL版本2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html)开源许可证书;你可以在[GitHub](https://github.com/mantisbt/mantisbt)浏览他的源代码或查看自托管[路线图](https://www.mantisbt.org/bugs/roadmap_page.php?project=mantisbt&version=1.3.x)对未来的规划。一个示例,你可以查看他们的内部[漏洞跟踪](https://www.mantisbt.org/bugs/my_view_page.php)。
|
||||
|
||||
|
||||
|
||||
正如我们指出的,这四个不是唯一的选项。想要探索更多?[Apache Bloodhound](https://issues.apache.org/bloodhound/),[Fossil](http://fossil-scm.org/index.html/doc/trunk/www/index.wiki),[The Bug Genie](http://www.thebuggenie.com/),还有很多可替换品都有专注的追随者,每个都有不同的优点和缺点。另外,一些工具在我们[项目管理](https://opensource.com/business/15/1/top-project-management-tools-2015)摘要有问题跟踪功能。所以,哪个是你首选的跟踪和碾压bug的工具?
|
||||
正如我们指出的,这四个不是唯一的选项。想要探索更多?[Apache Bloodhound](https://issues.apache.org/bloodhound/),[Fossil](http://fossil-scm.org/index.html/doc/trunk/www/index.wiki),[The Bug Genie](http://www.thebuggenie.com/),还有很多可替换品都有自己的忠实追随者,每个都有不同的优点和缺点。另外,一些工具在我们[项目管理](https://opensource.com/business/15/1/top-project-management-tools-2015)摘要有问题跟踪功能。所以,哪个是你首选的跟踪和碾压bug的工具?
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
@ -1,21 +1,20 @@
|
||||
NXP 揭幕了一块超小型物联网64位ARM处理器
|
||||
NXP 发布了一块超小型物联网64位 ARM 处理器
|
||||
=========================================================================
|
||||
|
||||
**标签**:[ARM][1], [物联网][2], [NXP][3], [NXP 半导体][4]
|
||||
|
||||

|
||||
|
||||
[NXP 半导体][5]揭幕了一块声称世界上最小的用于物联网(IoT)的低功耗64位ARM处理器。
|
||||
[NXP 半导体][5]发布了一块声称世界上最小的用于物联网(IoT)的低功耗64位ARM处理器。
|
||||
|
||||
这片小型的QorIQ LS1012A为电池供电,大小受限的应用提供了网络级的安全和性能加速。这包括了运行物联网应用,或者任何智能及可连接的设备。如果物联网能在2020达到1.7万亿美金的潜力(由IDC研究员估算市场得出),那么它将需要像NXP这样的处理器,该处理器在德国纽伦堡的Embedded World 2016 上揭开了什么的面纱。
|
||||
这片小型的QorIQ LS1012A为电池供电、大小受限的应用提供了网络级的安全和性能加速。这包括了运行物联网应用,或者任何智能及可连接的设备。如果物联网能在2020达到1.7万亿美金的潜力(由IDC研究员估算市场得出),那么它将需要像NXP这样的处理器,该处理器在德国纽伦堡的Embedded World 2016 上揭开了什么的面纱。
|
||||
|
||||
该芯片带有64位ARMv8芯片,拥有网络包加速及内置的安全。它占用9.6平方毫米的空间,并且大约消耗1瓦特的电力。潜在的应用包括下一代的物联网网关、可携带娱乐平台、高性能可携带存储应用、移动硬盘、相机的移动存储、平板及其他可充电的设备。
|
||||
|
||||
除此之外,LS1012A是第一款为新起的基于对象的存储方案设计的处理器,基于对象存储基于智能硬盘,它直接连接到以太网数据中心。处理器必须足够小才能直接集成在硬盘的集成电路上。
|
||||
除此之外,LS1012A是第一款为最新兴起的基于对象的存储方案设计的处理器,基于对象存储通过智能硬盘直接连接到以太网数据中心。处理器必须足够小才能直接集成在硬盘的集成电路上。
|
||||
|
||||
NXP的高级副总裁及数字网络部的经理Tareq Bustami说:“低功耗、占用空间小及网络级性能这些突破性组合的NXP LS1012处理器是消费者、物联网相关应用的理想选择。独有的混合能力解放了物联网设计者及开发者使得他们可以在这个高增长的市场中想象并创造更多创新产品。”
|
||||
NXP的高级副总裁及数字网络部的经理Tareq Bustami说:“突破性组合了低功耗、占用空间小及网络级性能的NXP LS1012处理器是消费者、物联网相关应用的理想选择。独有地将这些能力结合到一起解放了物联网设计者及开发者,使得他们可以在这个高增长的市场中设计并创造更多创新产品。”
|
||||
|
||||
NXP说这是唯一一个能够结合全面的高速外围在一个芯片中的1瓦特、64位处理器,这意味着低系统功耗。归功于创新的封装,该处理器可以在低成本的电路板中布线。
|
||||
NXP说这是唯一一个1瓦特功耗、64位的、并将这些高速外设综合到一个芯片中的处理器,这意味着更低的系统级功耗。归功于创新性的封装,该处理器可以运用在低成本的电路板中。
|
||||
|
||||
NXP的LS1012A可以在2016年4月开始发货,并且现在可以订货。NXP在全球35个国家拥有超过4,5000名员工。
|
||||
|
||||
@ -25,7 +24,7 @@ via: http://venturebeat.com/2016/02/21/nxp-unveils-a-small-and-tiny-64-bit-arm-p
|
||||
|
||||
作者:[DEAN TAKAHASHI][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,53 @@
|
||||
NodeOS:Node 爱好者的 Linux 发行版
|
||||
================================================
|
||||
|
||||

|
||||
|
||||
[NodeOS][1] 是一款基于 [Node.js][2] 的操作系统,自去年其首个[发布候选版][3]之后正朝着它的1.0版本进发。
|
||||
|
||||
如果你之前不知道的话,NodeOS 是首个架构在 [Linux][5] 内核之上的由 Node.js 和 [npm][4] 驱动的操作系统。[Jacob Groundwater][6] 在2013年中期介绍了这个项目。该操作系统中用到的主要技术是:
|
||||
|
||||
- **Linux 内核**: 这个系统建造在 Linux 内核上
|
||||
- **Node.js 运行时**: Node 作为主要的运行时环境
|
||||
- **npm 包管理**: npm 作为包管理
|
||||
|
||||
NodeOS 源码托管在 [Github][7] 上,因此,任何感兴趣的人都可以轻松贡献或者报告 bug。用户可以从源码构建或者使用[预编译镜像][8]。构建过程及快速起步指南可以在项目仓库中找到。
|
||||
|
||||
NodeOS 背后的思想是提供足够 npm 运行的环境,剩余的功能就可以让 npm 包管理来完成。因此,用户可以使用多达大约 250,000 个软件包,并且这个数目每天都还在增长。所有的都是开源的,你可以根据你的需要很容易地打补丁或者增加更多的包。
|
||||
|
||||
NodeOS 核心开发被分离成了不同的层面,基本的结构包含:
|
||||
|
||||
- **barebones** – 带有可以启动到 Node.js REPL 的 initramfs 的自定义内核
|
||||
- **initramfs** – 用于挂载用户分区以及启动系统的 initram 文件系统
|
||||
- **rootfs** – 存放 linux 内核及 initramfs 文件的只读分区
|
||||
- **usersfs** – 多用户文件系统(如传统系统一样)
|
||||
|
||||
NodeOS 的目标是可以在任何平台上运行,包括: **实际的硬件(用户计算机或者 SoC)**、**云平台、虚拟机、PaaS 提供商,容器**(Docker 和 Vagga)等等。如今看来,它做得似乎不错。在3.3号,NodeOS 的成员 [Jesús Leganés Combarro][9] 在 Github上[宣布][10]:
|
||||
|
||||
>**NodeOS 不再是一个玩具系统了**,它现在开始可以用在有实际需求的生产环境中了。
|
||||
|
||||
因此,如果你是 Node.js 的死忠或者乐于尝试新鲜事物,这或许值得你一试。在相关的文章中,你应该了解这些[Linux 发行版的具体用法][11]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/nodeos-operating-system/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/munif/
|
||||
[1]: http://node-os.com/
|
||||
[2]: https://nodejs.org/en/
|
||||
[3]: https://github.com/NodeOS/NodeOS/releases/tag/v1.0-RC1
|
||||
[4]: https://www.npmjs.com/
|
||||
[5]: http://itsfoss.com/tag/linux/
|
||||
[6]: https://github.com/groundwater
|
||||
[7]: https://github.com/nodeos/nodeos
|
||||
[8]: https://github.com/NodeOS/NodeOS/releases
|
||||
[9]: https://github.com/piranna
|
||||
[10]: https://github.com/NodeOS/NodeOS/issues/216
|
||||
[11]: http://itsfoss.com/weird-ubuntu-based-linux-distributions/
|
||||
61
published/20160601 Apps to Snaps.md
Normal file
61
published/20160601 Apps to Snaps.md
Normal file
@ -0,0 +1,61 @@
|
||||
将 Linux 软件打包成 Snap 软件包
|
||||
================
|
||||
|
||||

|
||||
|
||||
在 Linux 分发应用不总是那么容易。有各种不同的包格式、基础系统、可用库,随着发行版的一次次发布,所有的这些都让人头疼。然而,现在我们有了更简单的东西:Snap。
|
||||
|
||||
Snap 是开发者打包他们应用的新途径,它相对于传统包格式,如 .deb,.rpm 等带来了许多优点。Snap 安全,彼此隔离,宿主系统使用了类似 AppArmor 的技术,它们跨平台且自足的,让开发者可以准确地将应用所需要的依赖打包到一起。沙盒隔离也加强了安全,并允许应用和整个基于 snap 的系统,在出现问题的时候可以回滚。Snap 确实是 Linux 应用打包的未来。
|
||||
|
||||
创建一个 snap 包并不困难。首先,你需要一个 snap 基础运行环境,能够让你的桌面环境认识并运行 snap 软件包,这个工具叫做 snapd ,默认内置于所有 Ubuntu 16.04 系统中。接着你需要创建 snap 的工具 Snapcraft,它可以通过一个简单的命令安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install snapcraft
|
||||
```
|
||||
|
||||
这个环境安装好了之后就可以 snap 起来了。
|
||||
|
||||
Snap 使用一个特定的 YAML 格式的文件 snapcraft.yaml,它定义了应用是如何打包的以及它需要的依赖。用一个简单的应用来演示一下,下面的 YAML 文件是个如何 snap 一个 moon-buggy 游戏的实际例子,该游戏在 Ubuntu 源中提供。
|
||||
|
||||
```
|
||||
name: moon-buggy
|
||||
version: 1.0.51.11
|
||||
summary: Drive a car across the moon
|
||||
description: |
|
||||
A simple command-line game where you drive a buggy on the moon
|
||||
apps:
|
||||
play:
|
||||
command: usr/games/moon-buggy
|
||||
parts:
|
||||
moon-buggy:
|
||||
plugin: nil
|
||||
stage-packages: [moon-buggy]
|
||||
snap:
|
||||
– usr/games/moon-buggy
|
||||
```
|
||||
|
||||
上面的代码出现了几个新概念。第一部分是关于如何让你的应用可以在商店找到的信息,设置软件包的元数据名称、版本号、摘要、以及描述。apps 部分实现了 play 命令,指向了 moon-buggy 可执行文件位置。parts 部分告诉 snapcraft 用来构建应用所需要的插件以及依赖的包。在这个简单的例子中我们需要的所有东西就是来自 Ubuntu 源中的 moon-buggy 应用本身,snapcraft 负责剩下的工作。
|
||||
|
||||
在你的 snapcraft.yaml 所在目录下运行 snapcraft ,它会创建 moon-buggy_1.0.51.11_amd64.snap 包,可以通过以下命令来安装它:
|
||||
|
||||
```
|
||||
$ snap install moon-buggy_1.0.51.11_amd64.snap
|
||||
```
|
||||
|
||||
想了解更复杂一点的 snap 打包操作,比如基于 Electron 的 Simplenote 可以[看这里][1],在线教程在[这里][2],相应的代码在 [Github][3]。更多的例子可以在 Ubuntu 开发者[站点][4]找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2016/06/01/apps-to-snaps/
|
||||
|
||||
作者:[Jamie][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://insights.ubuntu.com/author/jamiebennett/
|
||||
[1]: http://www.simplenote.com/
|
||||
[2]: http://www.linuxuk.org/post/20160518_snapping_electron_based_applications_simplenote/
|
||||
[3]: https://github.com/jamiedbennett/snaps/tree/master/simplenote
|
||||
[4]: https://developer.ubuntu.com/en/desktop/get-started/
|
||||
@ -0,0 +1,205 @@
|
||||
LFCS 系列第九讲: 使用 Yum、RPM、Apt、Dpkg、Aptitude 进行 Linux 软件包管理
|
||||
================================================================================
|
||||
|
||||
去年八月, Linux基金会宣布了一个全新的LFCS(Linux Foundation Certified Sysadmin,Linux基金会认证系统管理员)认证计划,这对广大系统管理员来说是一个很好的机会,管理员们可以通过认证考试来表明自己可以成功支持Linux系统的整体运营。 一个Linux基金会认证的系统管理员能有足够的专业知识来确保系统高效运行,提供第一手的故障诊断和监视,并且在需要的情况下将问题提交给工程师支持团队。
|
||||
|
||||

|
||||
|
||||
*Linux基金会认证系统管理员 – 第九讲*
|
||||
|
||||
请观看下面关于Linux基金会认证计划的演示。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="http://www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
本文是本系列教程中的第九讲,今天在这篇文章中我们会引导你学习Linux软件包管理,这也是LFCS认证考试所需要的。
|
||||
|
||||
### 软件包管理 ###
|
||||
|
||||
简单的说,软件包管理是系统中安装和维护软件的一种方法,这里说的维护包含更新和卸载。
|
||||
|
||||
在Linux早期,程序只以源代码的方式发行,还带有所需的用户使用手册和必备的配置文件,甚至更多。现如今,大多数发行商一般使用预装程序或者被称为软件包的程序集合。用户可以使用这些预装程序或者软件包安装到该发行版中。然而,Linux最伟大的一点是我们仍然能够获得程序的源代码用来学习、改进和编译。
|
||||
|
||||
####软件包管理系统是如何工作的####
|
||||
|
||||
如果某一个软件包需要一定的资源,如共享库,或者需要另一个软件包,这就称之为依赖性。所有现在的包管理系统提供了一些解决依赖性的方法,以确保当安装一个软件包时,相关的依赖包也安装好了。
|
||||
|
||||
####打包系统####
|
||||
|
||||
几乎所有安装在现代Linux系统上的软件都会能互联网上找到。它要么由发行商通过中央仓库(中央仓库能包含几千个软件包,每个软件包都已经为发行版构建、测试并且维护好了)提供,要么能够直接得到可以下载和手动安装的源代码。
|
||||
|
||||
由于不同的发行版使用不同的打包系统(Debian的\*.deb文件/CentOS的\*.rpm文件/openSUSE的专门为openSUSE构建的*.rpm文件),因此为一个发行版开发的软件包会与其他发行版不兼容。然而,大多数发行版都属于LFCS认证所涉及的三个发行版家族之一。
|
||||
|
||||
####高级和低级打包工具####
|
||||
|
||||
为了有效地进行软件包管理的任务,你需要知道,有两种类型的实用工具:低级工具(能在后端实际安装、升级、卸载软件包文件),以及高级工具(负责确保能很好的执行依赖性解决和元数据检索的任务——元数据也称为数据的数据)。
|
||||
|
||||
|
||||
|发行版|低级工具|高级工具|
|
||||
|-----|-------|------|
|
||||
|Debian版及其衍生版|dpkg|apt-get / aptitude|
|
||||
|CentOS版|rpm|yum|
|
||||
|openSUSE版|rpm|zypper|
|
||||
|
||||
让我们来看下低级工具和高级工具的描述。
|
||||
|
||||
dpkg的是基于Debian的系统的一个低级包管理器。它可以安装,删除,提供有关资料,以及建立*.deb包,但它不能自动下载并安装它们相应的依赖包。
|
||||
|
||||
- 阅读更多: [15个dpkg命令实例][1]
|
||||
|
||||
apt-get是Debian及其衍生版的高级包管理器,并提供命令行方式来从多个来源检索和安装软件包,其中包括解决依赖性。和dpkg不同的是,apt-get不是直接基于.deb文件工作,而是基于软件包的正确名称。
|
||||
|
||||
- 阅读更多: [25个apt-get命令实力][2]
|
||||
|
||||
Aptitude是基于Debian的系统的另一个高级包管理器,它可用于快速简便的执行管理任务(安装,升级和删除软件包,还可以自动处理解决依赖性)。它在atp-get的基础上提供了更多功能,例如提供对软件包的几个版本的访问。
|
||||
|
||||
rpm是Linux标准基础(LSB)兼容发行版所使用的一种软件包管理器,用来对软件包进行低级处理。就像dpkg一样,rpm可以查询、安装、检验、升级和卸载软件包,它多数用于基于Fedora的系统,比如RHEL和CentOS。
|
||||
|
||||
- 阅读更多: [20个rpm命令实例][3]
|
||||
|
||||
相对于基于RPM的系统,yum增加了系统自动更新的功能和带依赖性管理的软件包管理功能。作为一个高级工具,和apt-get或者aptitude相似,yum需要配合仓库工作。
|
||||
|
||||
- 阅读更多: [20个yum命令实例][4]
|
||||
|
||||
### 低级工具的常见用法 ###
|
||||
|
||||
使用低级工具处理最常见的任务如下。
|
||||
|
||||
####1. 从已编译(*.deb或*.rpm)的文件安装一个软件包####
|
||||
|
||||
这种安装方法的缺点是没有提供解决依赖性的方案。当你在发行版本库中无法获得某个软件包并且又不能通过高级工具下载安装时,你很可能会从一个已编译文件安装该软件包。因为低级工具不会解决依赖性问题,所以当安装一个没有解决依赖性的软件包时会出现出错并且退出。
|
||||
|
||||
# dpkg -i file.deb [Debian版和衍生版]
|
||||
# rpm -i file.rpm [CentOS版 / openSUSE版]
|
||||
|
||||
**注意**:不要试图在CentOS中安装一个为openSUSE构建的.rpm文件,反之亦然!
|
||||
|
||||
####2. 从已编译文件中更新一个软件包####
|
||||
|
||||
同样,当某个安装的软件包不在中央仓库中时,你只能手动升级该软件包。
|
||||
|
||||
# dpkg -i file.deb [Debian版和衍生版]
|
||||
# rpm -U file.rpm [CentOS版 / openSUSE版]
|
||||
|
||||
####3. 列举安装的软件包####
|
||||
|
||||
当你第一次接触一个已经在工作中的系统时,很可能你会想知道安装了哪些软件包。
|
||||
|
||||
# dpkg -l [Debian版和衍生版]
|
||||
# rpm -qa [CentOS版 / openSUSE版]
|
||||
|
||||
如果你想知道一个特定的软件包安装在哪儿,你可以使用管道命令从以上命令的输出中去搜索,这在这个系列的[第一讲 操作Linux文件][5] 中有介绍。例如我们需要验证mysql-common这个软件包是否安装在Ubuntu系统中:
|
||||
|
||||
# dpkg -l | grep mysql-common
|
||||
|
||||

|
||||
|
||||
*检查安装的软件包*
|
||||
|
||||
另外一种方式来判断一个软件包是否已安装。
|
||||
|
||||
# dpkg --status package_name [Debian版和衍生版]
|
||||
# rpm -q package_name [CentOS版 / openSUSE版]
|
||||
|
||||
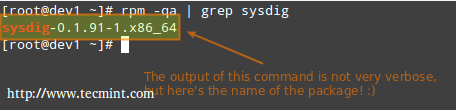
例如,让我们找出sysdig软件包是否安装在我们的系统。
|
||||
|
||||
# rpm -qa | grep sysdig
|
||||
|
||||
|
||||
|
||||
*检查sysdig软件包*
|
||||
|
||||
####4. 查询一个文件是由哪个软件包安装的####
|
||||
|
||||
# dpkg --search file_name
|
||||
# rpm -qf file_name
|
||||
|
||||
例如,pw_dict.hwm文件是由那个软件包安装的?
|
||||
|
||||
# rpm -qf /usr/share/cracklib/pw_dict.hwm
|
||||
|
||||

|
||||
|
||||
*Linux中查询文件*
|
||||
|
||||
### 高级工具的常见用法 ###
|
||||
|
||||
使用高级工具处理最常见的任务如下。
|
||||
|
||||
####1. 搜索软件包####
|
||||
|
||||
aptitude的更新操作将会更新可用的软件包列表,而aptitude的搜索操作会根据软件包名进行实际搜索。
|
||||
|
||||
# aptitude update && aptitude search package_name
|
||||
|
||||
在search all选项中,yum不仅可以通过软件包名还可以通过软件包的描述搜索。
|
||||
|
||||
# yum search package_name
|
||||
# yum search all package_name
|
||||
# yum whatprovides “*/package_name”
|
||||
|
||||
假定我们需要一个名为sysdig文件,想知道我们需要安装哪个软件包才行,那么运行。
|
||||
|
||||
# yum whatprovides “*/sysdig”
|
||||
|
||||

|
||||
|
||||
*检查软件包描述*
|
||||
|
||||
whatprovides告诉yum搜索一个含有能够匹配上述正则表达式的文件的软件包。
|
||||
|
||||
# zypper refresh && zypper search package_name [在openSUSE上]
|
||||
|
||||
####2. 从仓库安装一个软件包####
|
||||
|
||||
当安装一个软件包时,在软件包管理器解决了所有依赖性问题后,可能会提醒你确认安装。需要注意的是运行更新( update)或刷新(refresh)(根据所使用的软件包管理器)不是绝对必要,但是考虑到安全性和依赖性的原因,保持安装的软件包是最新的是系统管理员的一个好经验。
|
||||
|
||||
# aptitude update && aptitude install package_name [Debian版和衍生版]
|
||||
# yum update && yum install package_name [CentOS版]
|
||||
# zypper refresh && zypper install package_name [openSUSE版]
|
||||
|
||||
####3. 卸载软件包####
|
||||
|
||||
remove选项将会卸载软件包,但把配置文件保留完好,然而purge选项将从系统中完全删去该程序以及相关内容。
|
||||
|
||||
# aptitude remove / purge package_name
|
||||
# yum erase package_name
|
||||
|
||||
---注意要卸载的openSUSE包前面的减号 ---
|
||||
|
||||
# zypper remove -package_name
|
||||
|
||||
在默认情况下,大部分(如果不是全部的话)的软件包管理器会提示你,在你实际卸载之前你是否确定要继续卸载。所以,请仔细阅读屏幕上的信息,以避免陷入不必要的麻烦!
|
||||
|
||||
####4. 显示软件包的信息####
|
||||
|
||||
下面的命令将会显示birthday这个软件包的信息。
|
||||
|
||||
# aptitude show birthday
|
||||
# yum info birthday
|
||||
# zypper info birthday
|
||||
|
||||

|
||||
|
||||
*检查包信息*
|
||||
|
||||
### 总结 ###
|
||||
|
||||
作为一个系统管理员,软件包管理器是你不能回避的东西。你应该立即去使用本文中介绍的这些工具。希望你在准备LFCS考试和日常工作中会觉得这些工具好用。欢迎在下面留下您的意见或问题,我们将尽可能快的回复你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-package-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[2]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[3]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[4]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[5]:https://linux.cn/article-7161-1.html
|
||||
@ -1,67 +0,0 @@
|
||||
Android’s Next Revolution: Use Apps Even Without Installing Them!
|
||||
===================================================================
|
||||
|
||||
|
||||
A new innovation by Google’s Android will let you use apps even if they aren’t installed on your device. A few prototypes have already been made.
|
||||
|
||||
Remember that time when someone sent you a link that required you installing an app in order to view?
|
||||
|
||||
The dilemma of whether you should install the app just to view a one-time link may have frustrated you. Furthermore, the app installation itself may took some of your precious time as well.
|
||||
|
||||
The above scenario has probably been experienced by most, if not all, modern day technology users. Nonetheless, we’ve all came to accept that this is simply the correct and logical way by which things work.
|
||||
|
||||
Or is it?
|
||||
|
||||
To that question Google’s Android division came up with a new, out-of-the-box answer:
|
||||
|
||||
Android Instant Apps
|
||||
|
||||
Android Instant Apps purports to rid you of any such dilemmas in the first place by letting you simply click the link (see opening example) and start using the app straight away.
|
||||
|
||||
Another real life example of a scenario where Instant Apps might come handy, is the case you want to park your car but don’t have the parking meter matching app.
|
||||
|
||||
According to Google, you could simply tap your phone on the meter and the parking app will pop on your screen immediately, ready to be used.
|
||||
|
||||
How Does It Work?
|
||||
|
||||
Instant Apps are basically the same apps you’ve already familiarized yourself with, only with a twist – these apps have been trimmed and modularized in order to supply you only the essential parts required for you to complete a certain task.
|
||||
|
||||
For instance, expanding on the opening scenario as an example, in order to view a link, you don’t have to have a full featured app that can write, send, make coffee or whatever. All you need is the viewing feature – and that’s exactly what you’ll get.
|
||||
|
||||
That way the app could open up rapidly, allowing you to complete the task of which you came for.
|
||||
|
||||

|
||||
>AIA demo
|
||||
|
||||
|
||||
>B&H Photo (via Google Search)
|
||||
|
||||
|
||||
>BuzzFeedVideo (via a shared link)
|
||||
|
||||

|
||||
>Park and Pay (example) (via NFC)
|
||||
|
||||
|
||||
Sounds great, isn’t it? However, there are still many technical aspects need to be addressed.
|
||||
|
||||
For instance, from a security point of view: if any app can theoretically run on your device, even if you haven’t installed it – how will you keep your device safe from malaware attacks?
|
||||
|
||||
Therefore, in order to iron out such risks, Google is still working on the project, currently with a small set of partners which will gradually expand.
|
||||
|
||||
Eventually, Google plans to release AIA (Android Instant Apps) somewhere along next year.
|
||||
|
||||
relate: [Introducing Android Instant Apps][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.iwillfolo.com/androids-next-revolution-use-apps-even-without-installing-them/
|
||||
|
||||
作者:[iwillfolo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.iwillfolo.com
|
||||
[1]: http://android-developers.blogspot.co.il/2016/05/android-instant-apps-evolving-apps.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed:+blogspot/hsDu+%28Android+Developers+Blog%29
|
||||
@ -1,3 +1,5 @@
|
||||
GHLandy Translating
|
||||
|
||||
Linux vs. Windows device driver model : architecture, APIs and build environment comparison
|
||||
============================================================================================
|
||||
|
||||
@ -177,7 +179,7 @@ Download this article as ad-free PDF (made possible by [your kind donation][2]):
|
||||
via: http://xmodulo.com/linux-vs-windows-device-driver-model.html
|
||||
|
||||
作者:[Dennis Turpitka][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,39 +0,0 @@
|
||||
Will Google Replace Passwords With A New Trust-Based Authentication Method?
|
||||
===========================================================================
|
||||
|
||||

|
||||
|
||||
A newly developed authentication method by Google will rate how trustworthy is your login and will authenticate it based on a “Trust Score”.
|
||||
|
||||
|
||||
Abacus is the name of the Google project that aims to rid you off of the nuisance which is remembering and typing passwords.
|
||||
|
||||
In latest Google I/O developer conference, the company has introduced a new feature stemming from the ambitious project, called “**Trust API**“.
|
||||
|
||||
The API (Application Programming Interface) which will be available for Android developers by the year end “if all goes well”, is intended to make use of Android devices’ various types of sensors in order to profile a user and create what they refer to as Trust Score.
|
||||
|
||||
Based on that Trust Score, an application which requires login credentials will be able to verify that indeed you are authorized to login and thus will not prompt for a password.
|
||||
|
||||

|
||||
>Abacus to Trust API
|
||||
|
||||
### A Point To Consider
|
||||
|
||||
Although the idea, functionality-wise, sounds pretty great – mitigating the burden which is password authentication.
|
||||
|
||||
The other side of the coin tough, is that once again, by doing so Google pushes us (deliberately or not) to give up our privacy in favor of ease of use.
|
||||
|
||||
Is it worth it? it’s up to you to decide…
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.iwillfolo.com/will-google-replace-passwords-with-a-new-trust-based-authentication-method/
|
||||
|
||||
作者:[iWillFolo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.iwillfolo.com/
|
||||
@ -1,3 +1,5 @@
|
||||
martin
|
||||
|
||||
The future of sharing: integrating Pydio and ownCloud
|
||||
=========================================================
|
||||
|
||||
|
||||
@ -1,159 +0,0 @@
|
||||
LAMP Stack Installation Guide on Ubuntu Server 16.04 LTS
|
||||
=========================================================
|
||||
|
||||
LAMP stack is a collection of free and open source softwares like **Linux**, Web Server (**Apache**), Database server (**MySQL / MariaDB**) and **PHP** (Scripting Language). LAMP is the platform which is required to install and build dynamic web sites and application like WordPress, Joomla, OpenCart and Drupal.
|
||||
|
||||
In this article i will describe how to install LAMP on Ubuntu Server 16.04 LTS, As We know that Ubuntu is a Linux based Operating system, so it provides the first component of LAMP and i am assuming Ubuntu Server 16.04 is already installed on your system.
|
||||
|
||||
### Installation of Web Server (Apache2) :
|
||||
|
||||
In Ubuntu Linux Web server comes with the name Apache2, Use the beneath apt command to install it.
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt update
|
||||
linuxtechi@ubuntu:~$ sudo apt install apache2 -y
|
||||
```
|
||||
|
||||
When Apache2 package is installed then its service is automatically started and enabled across the reboot, In case it is not started and enabled, use the following command :
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo systemctl start apache2.service
|
||||
linuxtechi@ubuntu:~$ sudo systemctl enable apache2.service
|
||||
linuxtechi@ubuntu:~$ sudo systemctl status apache2.service
|
||||
```
|
||||
|
||||
If Ubuntu firewall (ufw) is active, then allow the Web Server ports (80 and 443) in firewall using below commands.
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo ufw status
|
||||
Status: active
|
||||
linuxtechi@ubuntu:~$ sudo ufw allow in 'Apache Full'
|
||||
Rule added
|
||||
Rule added (v6)
|
||||
linuxtechi@ubuntu:~$
|
||||
```
|
||||
|
||||
### Access Web Server now :
|
||||
|
||||
Open the Web browser and type the IP Address or Host name of your server (http://IP_Address_OR_Host_Name), In my Case my server IP is ‘192.168.1.13’
|
||||
|
||||

|
||||
|
||||
### Installation of Data Base Server (MySQL Server 5.7) :
|
||||
|
||||
MySQL and MariaDB are the database servers in Ubuntu 16.04. MySQL Server and MariaDB Server’s packages are available in the default repositories and we can install either of the database. Run the following apt command to install MySQL Server from terminal.
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt install mysql-server mysql-client
|
||||
```
|
||||
|
||||
During the installation, it will prompt us to set the root password of mysql server.
|
||||
|
||||

|
||||
|
||||
Confirm root password and click on ‘OK’
|
||||
|
||||
|
||||
|
||||
Installation of MySQL Server is completed Now. MySQL Service will be started and enabled automatically.We can verify the MySQL Server’s service using below systemcl command :
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo systemctl status mysql.service
|
||||
```
|
||||
|
||||
### Installation of MariaDB Server :
|
||||
|
||||
Use the beneath command to install MariaDB Server 10.0 from the terminal.
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt install mariadb-server
|
||||
```
|
||||
|
||||
Run the following command to set root password of mariadb and disable other options like disable remote login.
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
### Installation of PHP ( Scripting Language ) :
|
||||
|
||||
PHP 7.0 is available in the Ubuntu repositories. Execute the beneath command from the terminal to install PHP 7 :
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt install php7.0-mysql php7.0-curl php7.0-json php7.0-cgi php7.0 libapache2-mod-php7.0
|
||||
```
|
||||
|
||||
Create a sample php page and place it in apache document root (/var/ww/html)
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ vi samplepage.php
|
||||
<?php
|
||||
phpinfo();
|
||||
?>
|
||||
```
|
||||
|
||||
Save and exit the file.
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo mv samplepage.php /var/www/html/
|
||||
```
|
||||
|
||||
Now Access the sample PHP page from the Web Browser, type : “http://<Server_IP>/samplepage.php” , You should get the page like below.
|
||||
|
||||
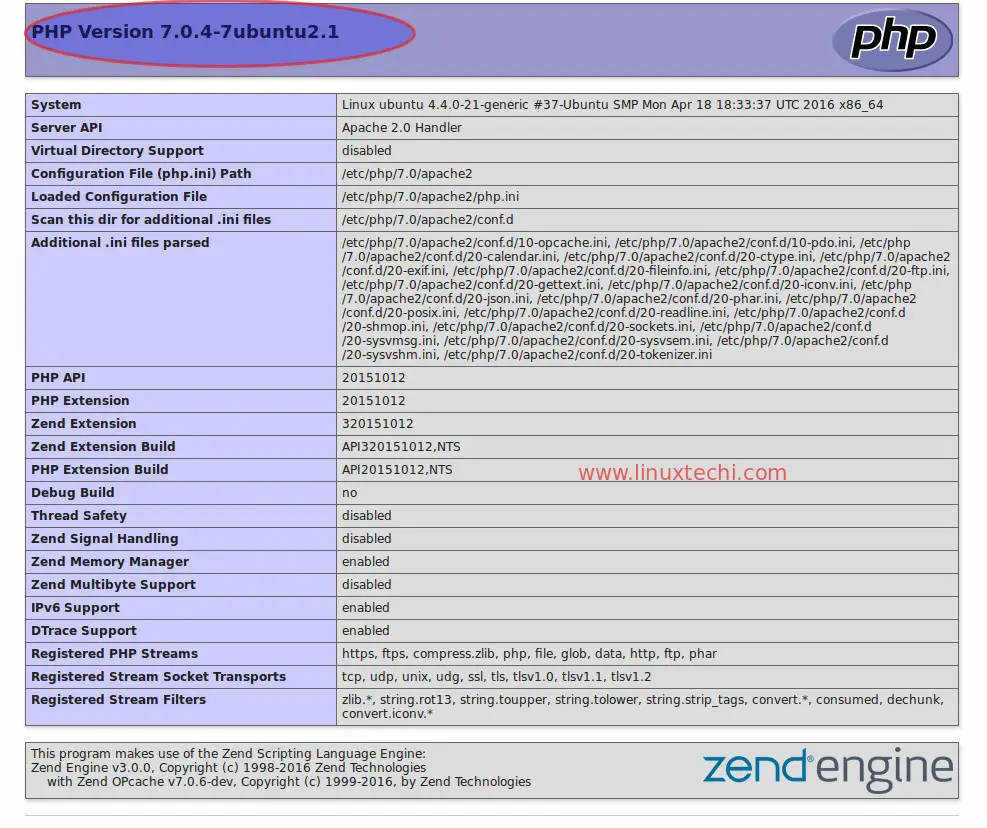
|
||||
|
||||
Above Page shows that our PHP installation is completed successfully.
|
||||
|
||||
### Installation of phpMyAdmin :
|
||||
|
||||
phpMyAdmin allows us to perform all the database related administrative and other DB operation task from its web interface. Its package is already listed in the Ubuntu server repositories.
|
||||
|
||||
Use the below commands to Install phpMyAdmin on Ubuntu server 16.04 LTS.
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt install php-mbstring php7.0-mbstring php-gettext
|
||||
linuxtechi@ubuntu:~$ sudo systemctl restart apache2.service
|
||||
linuxtechi@ubuntu:~$ sudo apt install phpmyadmin
|
||||
```
|
||||
|
||||
During its installation it will prompt us to choose the Web server to be configured for phpMyAdmin.
|
||||
|
||||
Select Apache2 and Click on OK.
|
||||
|
||||
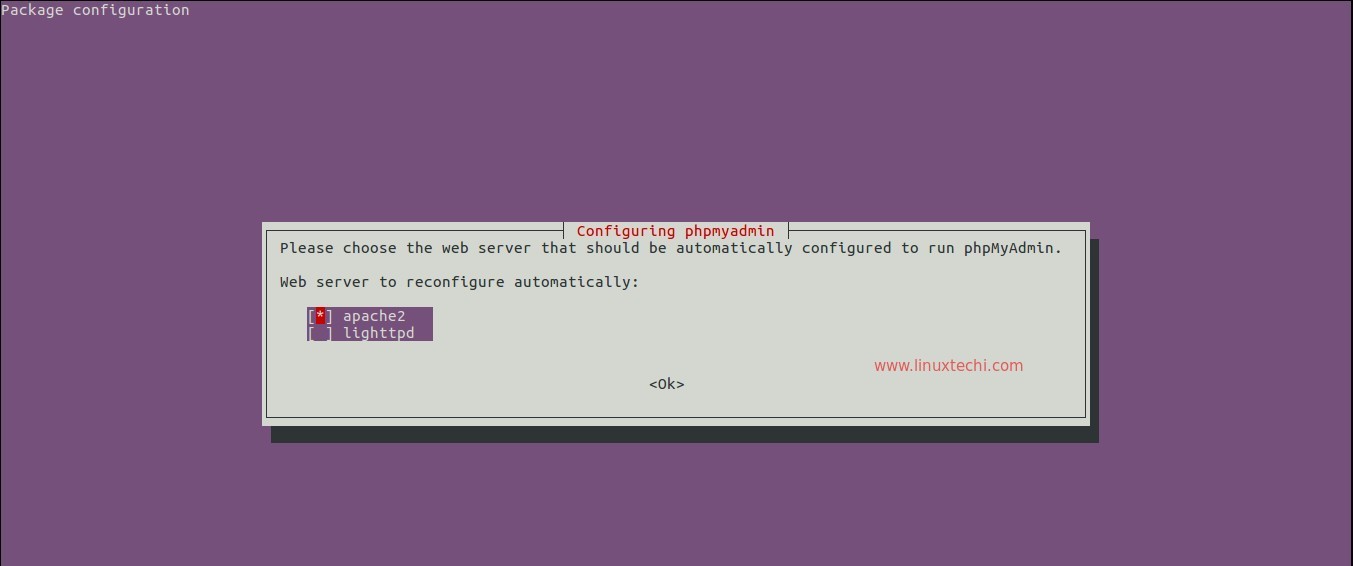
|
||||
|
||||
Click on ‘Yes’ to Configure database for phpMyAdmin.
|
||||
|
||||
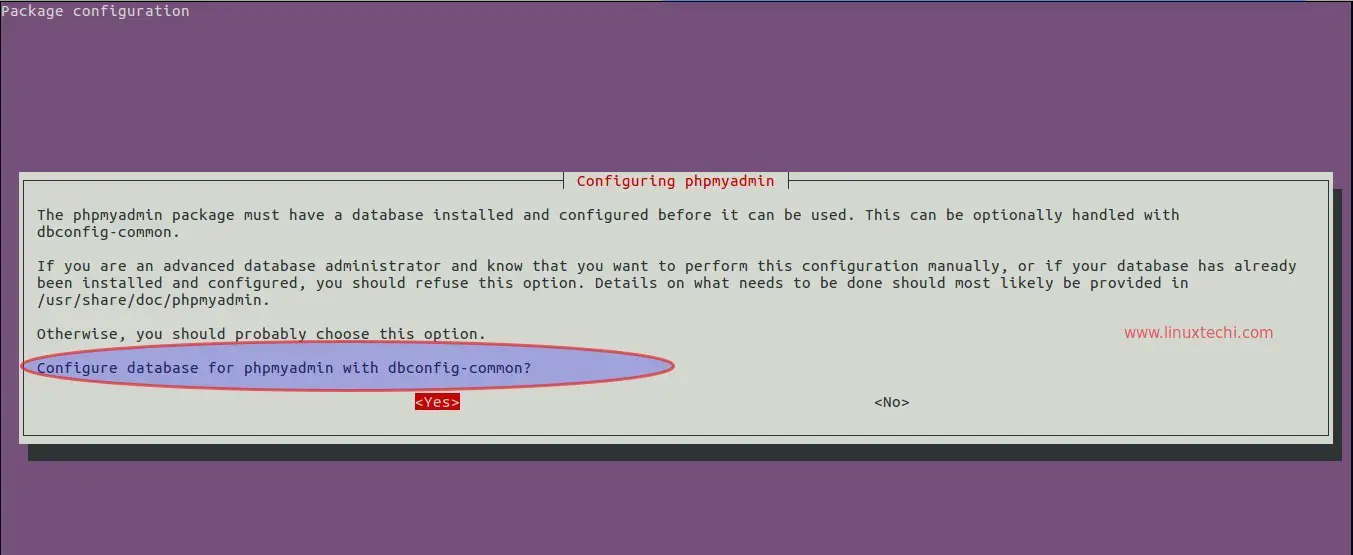
|
||||
|
||||
Specify the password for phpMyAdmin to register with Database Server.
|
||||
|
||||
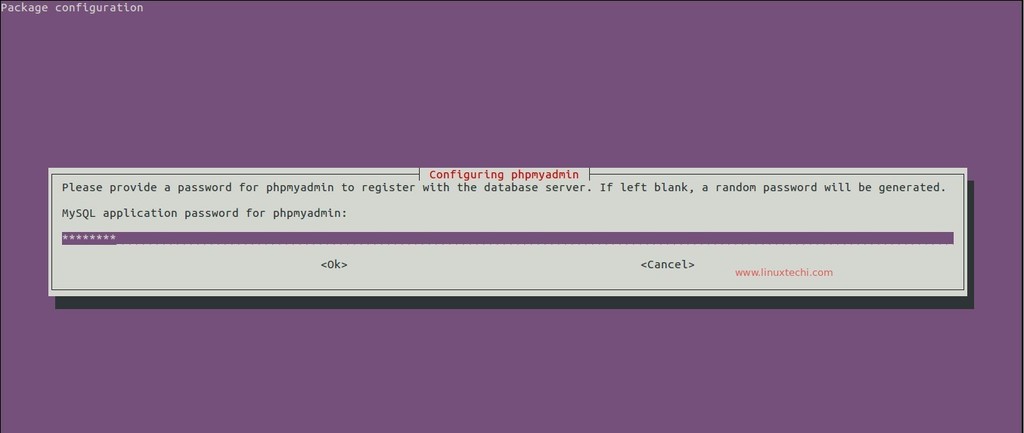
|
||||
|
||||
Confirm the password for phpMyAdmin and then click on ‘OK’
|
||||
|
||||
|
||||
|
||||
Now try to access the phpMyAdmin, open the browser type : “http://Server_IP_OR_Host_Name/phpmyadmin”
|
||||
|
||||
Use the user name as ‘root’ and password that we set during the installation.
|
||||
|
||||
|
||||
|
||||
When we click on ‘Go’, it will redirect the page to ‘phpMyAdmin’ Web interface as shown below.
|
||||
|
||||
|
||||
|
||||
That’s it, LAMP stack is successfully installed and is ready for use 🙂 . Please share your feedback and comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/lamp-stack-installation-on-ubuntu-server-16-04/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
@ -1,176 +0,0 @@
|
||||
scp command in Linux
|
||||
=======================
|
||||
|
||||

|
||||
|
||||
|
||||
scp means Secure Copy Protocol, already every Linux/Unix user known about cp command well. scp also works like cp command, cp command copies files or folders from one location i.e source to other location i.e target in local system, but scp copies the files from one host to another host in network.
|
||||
|
||||
The usage of the scp command is as follows, here i copy a file named importantfile from local system(10.10.16.147) to Remote system(10.0.0.6) here instead of ip address you can also use System name.
|
||||
|
||||
```
|
||||
[root@localhost ~]# scp importantfile admin@10.0.0.6:/home/admin/
|
||||
The authenticity of host '10.0.0.6 (10.0.0.6)' can't be established.
|
||||
RSA key fingerprint is SHA256:LqBzkeGa6K9BfWWKgcKlQoE0u+gjorX0lPLx5YftX1Y.
|
||||
RSA key fingerprint is MD5:ed:44:42:59:3e:dd:4c:12:43:4a:89:b1:5d:bd:9e:20.
|
||||
Are you sure you want to continue connecting (yes/no)? yes
|
||||
Warning: Permanently added '10.0.0.6' (RSA) to the list of known hosts.
|
||||
admin@10.0.0.6's password:
|
||||
importantfile 100% 0 0.0KB/s 00:00
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
Similarly if you want to get a file from remote system you can use scp command as follows
|
||||
|
||||
```
|
||||
[root@localhost ~]# scp root@10.10.16.137:/root/importantfile /home/admin/
|
||||
The authenticity of host '10.10.16.137 (10.10.16.137)' can't be established.
|
||||
RSA key fingerprint is b0:b0:a3:c3:2e:94:13:0c:29:2e:ba:0b:d3:d6:12:8f.
|
||||
Are you sure you want to continue connecting (yes/no)? yes
|
||||
Warning: Permanently added '10.10.16.137' (RSA) to the list of known hosts.
|
||||
root@10.10.16.137's password:
|
||||
importantfile 100% 0 0.0KB/s 00:00
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
You can also use various options along with scp command like cp command,The man page of the scp command clearly explain about the usage of various options and advantages of that.
|
||||
|
||||
**Sample Output.**
|
||||
|
||||
|
||||
|
||||
```
|
||||
The options are as follows:
|
||||
|
||||
-B Selects batch mode (prevents asking for passwords or passphrases).
|
||||
|
||||
-C Compression enable. Passes the -C to enable compression.
|
||||
|
||||
-c cipher
|
||||
Selects the cipher to use for encrypting the data transfer. This
|
||||
option is directly passed to ssh(1).
|
||||
|
||||
-F ssh_config
|
||||
Specifies an alternative per-user configuration file for ssh.
|
||||
This option is directly passed to ssh(1).
|
||||
|
||||
-l limit
|
||||
Limits the used bandwidth, specified in Kbit/s.
|
||||
|
||||
-P port
|
||||
Specifies the port to connect to on the remote host. Note that
|
||||
this option is written with a capital ‘P’, because -p is already
|
||||
reserved for preserving the times and modes of the file.
|
||||
|
||||
-p Preserves modification times, access times, and modes from the
|
||||
original file.
|
||||
|
||||
-q Quiet mode: disables the progress meter as well as warning and
|
||||
diagnostic messages from ssh(1).
|
||||
|
||||
-r Recursively copy entire directories. Note that scp follows sym‐
|
||||
bolic links encountered in the tree traversal.
|
||||
|
||||
-v Verbose mode. Causes scp and ssh(1) to print debugging messages
|
||||
about their progress. This is helpful in debugging connection,
|
||||
authentication, and configuration problems.
|
||||
|
||||
```
|
||||
|
||||
The scp command along with -v option you can get detailed information about authentication, debugging information etc.
|
||||
|
||||

|
||||
|
||||
Sample output is like when we pass the option `-v`
|
||||
|
||||
```
|
||||
[root@localhost ~]# scp -v abc.txt admin@10.0.0.6:/home/admin
|
||||
Executing: program /usr/bin/ssh host 10.0.0.6, user admin,
|
||||
command scp -v -t/home/admin
|
||||
OpenSSH_7.1p1, OpenSSL 1.0.2d-fips 9 Jul 2015
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config
|
||||
debug1: /etc/ssh/ssh_config line 56: Applying options for *
|
||||
debug1: Connecting to 10.0.0.6 [10.0.0.6] port 22.
|
||||
debug1: Connection established.
|
||||
debug1: Server host key: ssh-rsa SHA256:LqBzkeGa6K9BfWWKgcKlQoE0u+gjorX0lPLx5YftX1Y
|
||||
debug1: Next authentication method: publickey
|
||||
debug1: Trying private key: /root/.ssh/id_rsa
|
||||
debug1: Trying private key: /root/.ssh/id_dsa
|
||||
debug1: Trying private key: /root/.ssh/id_ecdsa
|
||||
debug1: Trying private key: /root/.ssh/id_ed25519
|
||||
debug1: Next authentication method: password
|
||||
admin@10.0.0.6's password:
|
||||
debug1: Authentication succeeded (password).
|
||||
Authenticated to 10.0.0.6 ([10.0.0.6]:22).
|
||||
debug1: channel 0: new [client-session]
|
||||
debug1: Requesting no-more-sessions@openssh.com
|
||||
debug1: Entering interactive session.
|
||||
debug1: Sending environment.
|
||||
debug1: Sending command: scp -v -t /home/admin
|
||||
Sending file modes: C0644 174 abc.txt
|
||||
Sink: C0644 174 abc.txt
|
||||
abc.txt 100% 174 0.2KB/s 00:00
|
||||
Transferred: sent 3024, received 2584 bytes, in 0.3 seconds
|
||||
Bytes per second: sent 9863.3, received 8428.1
|
||||
debug1: Exit status 0
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
If we need to copy the Directories or folders we can use the option –r. It Recursively copy entire directories
|
||||
|
||||

|
||||
|
||||
Quiet mode:
|
||||
|
||||
If you want disables the progress meter as well as warning and diagnostic messages pass the argument -q along with scp command.
|
||||
|
||||

|
||||
|
||||
last time we pass the argument -r only then it shows the information file by file, but when we pass the argument -q it disables the progress meter this time.
|
||||
|
||||
Preserves modification times, access times, and modes from the original file by passing the option -p along with scp.
|
||||
|
||||

|
||||
|
||||
Specifies the port to connect to on the remote host by using the option -P.
|
||||
scp uses the ssh to transfer the files between hosts, ssh uses the port number 22 so the scp also uses the same port number 22.
|
||||
|
||||
If we want to change the port number we can pass the particular port number along with -P(capital P because small p uses for preserving access time etc.)
|
||||
|
||||
for example if we want to use port number 2222 then the command is as follows
|
||||
|
||||
```
|
||||
[root@localhost ~]# scp -P 2222 abcd1 root@10.10.16.137:/root/
|
||||
```
|
||||
|
||||
**Limits the used bandwidth, specified in Kbit/s**
|
||||
|
||||
we can limit the bandwidth by using the argument -l option as follows. here i used the limit is 512kbit/s
|
||||
|
||||

|
||||
|
||||
**Compression enable**
|
||||
|
||||
we can enable the compression mode when we transfer the data through scp command to save tha bandwidth and time as follows
|
||||
|
||||
|
||||
|
||||
**Selects the cipher to use for encrypting the data**
|
||||
|
||||
By default scp uses AES-128, if we want to change the encryption then we can pass the argument -c(small c) along with scp.
|
||||
|
||||

|
||||
|
||||
Now you can transfer the files between different nodes in your network securely by using scp(Secure copy).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/scp-command-linuxunix/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+unixmenhowtos+%28Unixmen+Howtos+%26+Tutorials%29
|
||||
|
||||
作者:[Naga Ramesh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.unixmen.com/author/naga/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by GitFuture
|
||||
|
||||
How to mount your Google Drive on Linux with google-drive-ocamlfuse
|
||||
========================================================================
|
||||
|
||||
|
||||
@ -1,138 +0,0 @@
|
||||
How To Install And Use VBoxManage On Ubuntu 16.04 And Use Its Command line Options
|
||||
======================================================================================
|
||||
|
||||
VirtualBox comes with a suite of command line utilities, and you can use the VirtualBox command line interfaces (CLIs) to manage VMs on a remote headless server. In this tutorial, we will show you how to create and start a VM without VirtualBox GUI using VBoxManage. VBoxManage is the command-line interface to VirtualBox taht you can use to completely control VirtualBox from the command line of your host operating system. VBoxManage supports all the features that the graphical user interface gives you access to, but it supports a lot more than that. It exposes really all the features of the virtualization engine, even those that cannot (yet) be accessed from the GUI. You will need to use the command line if you want to use a different user interface than the main GUI and control some of the more advanced and experimental configuration settings for a VM.
|
||||
|
||||
You will find VBoxManage helpful when you want to create and run virtual machines (VMs) on VirtualBox, but you only have access to a terminal on a remote host machine. This can be a common situation for servers where VMs are managed from remotely.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Before we start using VBoxManage command line utility, make sure that you have root or sudo user access to your Ubuntu 16.04 server and the Oracle Virtual Box is already installed on it. Then you need to install VirtualBox Extension Pack which is needed to run a VRDE remote desktop server used to access headless VMs.
|
||||
|
||||
### Installing VBoxManage
|
||||
|
||||
You can get your required package by following the link to [Virtual Box Download Page][1] to get the latest extension pack, same version as your installed version of VirtualBox!.
|
||||
|
||||

|
||||
|
||||
You can also make use of below command to get the VBoxManage extension on your system
|
||||
|
||||
```
|
||||
$ wget http://download.virtualbox.org/virtualbox/5.0.20/Oracle_VM_VirtualBox_Extension_Pack-5.0.20-106931.vbox-extpack
|
||||
```
|
||||
|
||||

|
||||
|
||||
Run the below command to confirm that VBoxManage has been successfully installed.
|
||||
|
||||
```
|
||||
$ VBoxManage list extpacks
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Using VBoxManage on Ubuntu 16.04
|
||||
|
||||
Now we are going to use VBoxManage to show you that how easily you can create and manage your virtual machines by using this utility from command line terminal.
|
||||
|
||||
Let’s run the below command to create a virtual machine for Ubuntu OS.
|
||||
|
||||
```
|
||||
# VBoxManage createvm --name Ubuntu16.04 --register
|
||||
```
|
||||
|
||||
After executing this command it will create virtual machine called “Ubuntu16.vbox” in home folder under “VirtualBox VMs/Ubuntu16/Ubuntu16.04.vbox” . In the above command, “createvm” is used to create a virtual machine and “–name“ defines the name of the virtual machine while “registervm” command is used to register the virtual machine.
|
||||
|
||||
Now, create the hard disk image for the virtual machine using the below command.
|
||||
|
||||
```
|
||||
$ VBoxManage createhd --filename Ubuntu16.04 --size 5124
|
||||
```
|
||||
|
||||
Here “createhd” is used to create hard disk image and “–filename” is used to specify the virtual machine’s name, for which the hard disk image is created. Here, “–size” denotes the size of the hard disk image. The size is always given in MB. Here we have specified 5Gb that is 5124MB.
|
||||
|
||||
Next we will set the OS type, if the Linux OS has to be installed, then specify the OS type as Linux or Ubuntu Or Fedora etc using below command.
|
||||
|
||||
```
|
||||
$ VBoxManage modifyvm Ubuntu16.04 --ostype Ubuntu
|
||||
```
|
||||
|
||||
Use below command to set the memory size for the virtual OS, i.e. the ram size for the virtual OS from the host Machine.
|
||||
|
||||
```
|
||||
$ VBoxManage modifyvm Ubuntu10.10 --memory 512
|
||||
```
|
||||
|
||||

|
||||
|
||||
Now we are going to create a storage controller for the virtual machine by using below command.
|
||||
|
||||
```
|
||||
$ VBoxManage storagectl Ubuntu16.04 --name IDE --add ide --controller PIIX4 --bootable on
|
||||
```
|
||||
|
||||
Here in above command ‘storagectl’ is used to create a storage controller for virtual machine,’–name’ specifies the name of the storage controller that needs to be created, modified or removed from the virtual machine. Then ‘–add’ defines the type of system bus to which the storage controller must be connected. Its available options are ide/sata/scsi/floppy. The ‘–controller’ option allows to choose the type of chipset that is to be emulated for the given storage controller while its available options are LsiLogic / LSILogicSAS / BusLogic / IntelAhci / PIIX3 / PIIX4 / ICH6 / I82078. At the end ‘–bootable’ defines whether this controller is bootable or not.
|
||||
|
||||
The above command creates the storage controller called IDE. Later the virtual media can be attached to the controller using ‘storageattach’ command.
|
||||
|
||||
Now run below command to create a storage controller called SATA, that will be used to attach the hard disk image to this later.
|
||||
|
||||
```
|
||||
$ VBoxManage storagectl Ubuntu16.04 --name SATA --add sata --controller IntelAhci --bootable on
|
||||
```
|
||||
|
||||
Attach the previously created disk image as well as CD/DVD drive to the IDE controller. Ubuntu installation ISO image which is then inserted to the CD/DVD drive. Now, attach the storage controller to the virtual machine using ‘storageattach’ command.
|
||||
|
||||
```
|
||||
$ VBoxManage storageattach Ubuntu16.04 --storagectl SATA --port 0 --device 0 --type hdd --medium "your_iso_filepath"
|
||||
```
|
||||
|
||||
This will attach the storage controller SATA to virtual machine Ubuntu16.04 with the medium i.e., to the virtual disk image which is created.
|
||||
|
||||
Run below commands to add some features like networking setup, audio, etc.
|
||||
|
||||
```
|
||||
$ VBoxManage modifyvm Ubuntu10.10 --nic1 nat --nictype1 82540EM --cableconnected1 on
|
||||
$ VBoxManage modifyvm Ubuntu10.10 --vram 128 --accelerate3d on --audio alsa --audiocontroller ac97
|
||||
```
|
||||
|
||||
Now, start the VM by using the below command by specifying the name of the VM that you wish to start.
|
||||
|
||||
```
|
||||
$ VBoxManage startvm Ubuntu16.04
|
||||
```
|
||||
|
||||
A new window will be opened where you new VM be booted from your attached file.
|
||||
|
||||

|
||||
|
||||
To stop the virtual machine , you can make use of the following command.
|
||||
|
||||
```
|
||||
$ VBoxManage controlvm Ubuntu16.04 poweroff
|
||||
```
|
||||
|
||||
The ‘controlvm’ command is used to control the state of the virtual machine. Some of the available options are pause / resume / reset / poweroff / savestate / acpipowerbutton / acpisleepbutton. There are many options in controlvm to see all the options available in it, run below command.
|
||||
|
||||
```
|
||||
$VBoxManage controlvm
|
||||
```
|
||||
|
||||

|
||||
|
||||
Conclusion
|
||||
|
||||
In this article we have learned about an awesome tool of Oracle Virtual Box that is VBoxManage, that includes its installation and usage on Ubuntu 16.04 Operating system. The article includes a detailed instructions about its useful commands to create and manage your virtual machines using VBoxManage. Hope you find this much helpful, do not forget to share your comments or suggestions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-and-use-command-line-tool-vboxmanage-on-ubuntu-16-04/
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/kashif/
|
||||
[1]: https://www.virtualbox.org/wiki/Downloads
|
||||
@ -1,3 +1,5 @@
|
||||
Vic020
|
||||
|
||||
How to Add Cron Jobs in Linux and Unix
|
||||
======================================
|
||||
|
||||
|
||||
@ -1,319 +0,0 @@
|
||||
LFCS 第十讲:学习简单的 Shell 脚本编程和文件系统故障排除
|
||||
|
||||
================================================================================
|
||||
Linux 基金会发起了 LFCS 认证 (Linux Foundation Certified Sysadmin, Linux 基金会认证系统管理员),这是一个全新的认证体系,主要目标是让全世界任何人都有机会考取认证。认证内容为 Linux 中间系统的管理,主要包括:系统运行和服务的维护、全面监控和分析的能力以及问题来临时何时想上游团队请求帮助的决策能力
|
||||
|
||||

|
||||
|
||||
LFCS 系列第十讲
|
||||
|
||||
请看以下视频,这里边介绍了 Linux 基金会认证程序。
|
||||
|
||||
注:youtube 视频
|
||||
|
||||
<video src="https://dn-linuxcn.qbox.me/static%2Fvideo%2FIntroducing%20The%20Linux%20Foundation%20Certification%20Program-Y29qZ71Kicg.mp4" controls="controls" width="100%">
|
||||
</video>
|
||||
|
||||
本讲是系列教程中的第十讲,主要集中讲解简单的 Shell 脚本编程和文件系统故障排除。这两块内容都是 LFCS 认证中的必备考点。
|
||||
|
||||
### 理解终端 (Terminals) 和 Shell ###
|
||||
|
||||
首先要声明一些概念。
|
||||
|
||||
- Shell 是一个程序,它将命令传递给操作系统来执行。
|
||||
- Terminal 也是一个程序,作为最终用户,我们需要使用它与 Shell 来交互。比如,下边的图片是 GNOME Terminal。
|
||||
|
||||

|
||||
|
||||
Gnome Terminal
|
||||
|
||||
启动 Shell 之后,会呈现一个命令提示符 (也称为命令行) 提示我们 Shell 已经做好了准备,接受标准输入设备输入的命令,这个标准输入设备通常是键盘。
|
||||
|
||||
你可以参考该系列文章的 [第一讲 使用命令创建、编辑和操作文件][1] 来温习一些常用的命令。
|
||||
|
||||
Linux 为提供了许多可以选用的 Shell,下面列出一些常用的:
|
||||
|
||||
**bash Shell**
|
||||
|
||||
Bash 代表 Bourne Again Shell,它是 GNU 项目默认的 Shell。它借鉴了 Korn shell (ksh) 和 C shell (csh) 中有用的特性,并同时对性能进行了提升。它同时也是 LFCS 认证中所涵盖的风发行版中默认 Shell,也是本系列教程将使用的 Shell。
|
||||
|
||||
**sh Shell**
|
||||
|
||||
Bash Shell 是一个比较古老的 shell,一次多年来都是多数类 Unix 系统的默认 shell。
|
||||
|
||||
**ksh Shell**
|
||||
|
||||
Korn SHell (ksh shell) 也是一个 Unix shell,是贝尔实验室 (Bell Labs) 的 David Korn 在 19 世纪 80 年代初的时候开发的。它兼容 Bourne shell ,并同时包含了 C shell 中的多数特性。
|
||||
|
||||
|
||||
一个 shell 脚本仅仅只是一个可执行的文本文件,里边包含一条条可执行命令。
|
||||
|
||||
### 简单的 Shell 脚本编程 ###
|
||||
|
||||
As mentioned earlier, a shell script is born as a plain text file. Thus, can be created and edited using our preferred text editor. You may want to consider using vi/m (refer to [Usage of vi Editor – Part 2][2] of this series), which features syntax highlighting for your convenience.
|
||||
|
||||
Type the following command to create a file named myscript.sh and press Enter.
|
||||
|
||||
# vim myscript.sh
|
||||
|
||||
The very first line of a shell script must be as follows (also known as a shebang).
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
It “tells” the operating system the name of the interpreter that should be used to run the text that follows.
|
||||
|
||||
Now it’s time to add our commands. We can clarify the purpose of each command, or the entire script, by adding comments as well. Note that the shell ignores those lines beginning with a pound sign # (explanatory comments).
|
||||
|
||||
#!/bin/bash
|
||||
echo This is Part 10 of the 10-article series about the LFCS certification
|
||||
echo Today is $(date +%Y-%m-%d)
|
||||
|
||||
Once the script has been written and saved, we need to make it executable.
|
||||
|
||||
# chmod 755 myscript.sh
|
||||
|
||||
Before running our script, we need to say a few words about the $PATH environment variable. If we run,
|
||||
|
||||
echo $PATH
|
||||
|
||||
from the command line, we will see the contents of $PATH: a colon-separated list of directories that are searched when we enter the name of a executable program. It is called an environment variable because it is part of the shell environment – a set of information that becomes available for the shell and its child processes when the shell is first started.
|
||||
|
||||
When we type a command and press Enter, the shell searches in all the directories listed in the $PATH variable and executes the first instance that is found. Let’s see an example,
|
||||
|
||||

|
||||
|
||||
Environment Variables
|
||||
|
||||
If there are two executable files with the same name, one in /usr/local/bin and another in /usr/bin, the one in the first directory will be executed first, whereas the other will be disregarded.
|
||||
|
||||
If we haven’t saved our script inside one of the directories listed in the $PATH variable, we need to append ./ to the file name in order to execute it. Otherwise, we can run it just as we would do with a regular command.
|
||||
|
||||
# pwd
|
||||
# ./myscript.sh
|
||||
# cp myscript.sh ../bin
|
||||
# cd ../bin
|
||||
# pwd
|
||||
# myscript.sh
|
||||
|
||||

|
||||
|
||||
Execute Script
|
||||
|
||||
#### Conditionals ####
|
||||
|
||||
Whenever you need to specify different courses of action to be taken in a shell script, as result of the success or failure of a command, you will use the if construct to define such conditions. Its basic syntax is:
|
||||
|
||||
if CONDITION; then
|
||||
COMMANDS;
|
||||
else
|
||||
OTHER-COMMANDS
|
||||
fi
|
||||
|
||||
Where CONDITION can be one of the following (only the most frequent conditions are cited here) and evaluates to true when:
|
||||
|
||||
- [ -a file ] → file exists.
|
||||
- [ -d file ] → file exists and is a directory.
|
||||
- [ -f file ] →file exists and is a regular file.
|
||||
- [ -u file ] →file exists and its SUID (set user ID) bit is set.
|
||||
- [ -g file ] →file exists and its SGID bit is set.
|
||||
- [ -k file ] →file exists and its sticky bit is set.
|
||||
- [ -r file ] →file exists and is readable.
|
||||
- [ -s file ]→ file exists and is not empty.
|
||||
- [ -w file ]→file exists and is writable.
|
||||
- [ -x file ] is true if file exists and is executable.
|
||||
- [ string1 = string2 ] → the strings are equal.
|
||||
- [ string1 != string2 ] →the strings are not equal.
|
||||
|
||||
[ int1 op int2 ] should be part of the preceding list, while the items that follow (for example, -eq –> is true if int1 is equal to int2.) should be a “children” list of [ int1 op int2 ] where op is one of the following comparison operators.
|
||||
|
||||
- -eq –> is true if int1 is equal to int2.
|
||||
- -ne –> true if int1 is not equal to int2.
|
||||
- -lt –> true if int1 is less than int2.
|
||||
- -le –> true if int1 is less than or equal to int2.
|
||||
- -gt –> true if int1 is greater than int2.
|
||||
- -ge –> true if int1 is greater than or equal to int2.
|
||||
|
||||
#### For Loops ####
|
||||
|
||||
This loop allows to execute one or more commands for each value in a list of values. Its basic syntax is:
|
||||
|
||||
for item in SEQUENCE; do
|
||||
COMMANDS;
|
||||
done
|
||||
|
||||
Where item is a generic variable that represents each value in SEQUENCE during each iteration.
|
||||
|
||||
#### While Loops ####
|
||||
|
||||
This loop allows to execute a series of repetitive commands as long as the control command executes with an exit status equal to zero (successfully). Its basic syntax is:
|
||||
|
||||
while EVALUATION_COMMAND; do
|
||||
EXECUTE_COMMANDS;
|
||||
done
|
||||
|
||||
Where EVALUATION_COMMAND can be any command(s) that can exit with a success (0) or failure (other than 0) status, and EXECUTE_COMMANDS can be any program, script or shell construct, including other nested loops.
|
||||
|
||||
#### Putting It All Together ####
|
||||
|
||||
We will demonstrate the use of the if construct and the for loop with the following example.
|
||||
|
||||
**Determining if a service is running in a systemd-based distro**
|
||||
|
||||
Let’s create a file with a list of services that we want to monitor at a glance.
|
||||
|
||||
# cat myservices.txt
|
||||
|
||||
sshd
|
||||
mariadb
|
||||
httpd
|
||||
crond
|
||||
firewalld
|
||||
|
||||
|
||||
|
||||
Script to Monitor Linux Services
|
||||
|
||||
Our shell script should look like.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script iterates over a list of services and
|
||||
# is used to determine whether they are running or not.
|
||||
|
||||
for service in $(cat myservices.txt); do
|
||||
systemctl status $service | grep --quiet "running"
|
||||
if [ $? -eq 0 ]; then
|
||||
echo $service "is [ACTIVE]"
|
||||
else
|
||||
echo $service "is [INACTIVE or NOT INSTALLED]"
|
||||
fi
|
||||
done
|
||||
|
||||
|
||||
|
||||
Linux Service Monitoring Script
|
||||
|
||||
**Let’s explain how the script works.**
|
||||
|
||||
1). The for loop reads the myservices.txt file one element of LIST at a time. That single element is denoted by the generic variable named service. The LIST is populated with the output of,
|
||||
|
||||
# cat myservices.txt
|
||||
|
||||
2). The above command is enclosed in parentheses and preceded by a dollar sign to indicate that it should be evaluated to populate the LIST that we will iterate over.
|
||||
|
||||
3). For each element of LIST (meaning every instance of the service variable), the following command will be executed.
|
||||
|
||||
# systemctl status $service | grep --quiet "running"
|
||||
|
||||
This time we need to precede our generic variable (which represents each element in LIST) with a dollar sign to indicate it’s a variable and thus its value in each iteration should be used. The output is then piped to grep.
|
||||
|
||||
The –quiet flag is used to prevent grep from displaying to the screen the lines where the word running appears. When that happens, the above command returns an exit status of 0 (represented by $? in the if construct), thus verifying that the service is running.
|
||||
|
||||
An exit status different than 0 (meaning the word running was not found in the output of systemctl status $service) indicates that the service is not running.
|
||||
|
||||

|
||||
|
||||
Services Monitoring Script
|
||||
|
||||
We could go one step further and check for the existence of myservices.txt before even attempting to enter the for loop.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script iterates over a list of services and
|
||||
# is used to determine whether they are running or not.
|
||||
|
||||
if [ -f myservices.txt ]; then
|
||||
for service in $(cat myservices.txt); do
|
||||
systemctl status $service | grep --quiet "running"
|
||||
if [ $? -eq 0 ]; then
|
||||
echo $service "is [ACTIVE]"
|
||||
else
|
||||
echo $service "is [INACTIVE or NOT INSTALLED]"
|
||||
fi
|
||||
done
|
||||
else
|
||||
echo "myservices.txt is missing"
|
||||
fi
|
||||
|
||||
**Pinging a series of network or internet hosts for reply statistics**
|
||||
|
||||
You may want to maintain a list of hosts in a text file and use a script to determine every now and then whether they’re pingable or not (feel free to replace the contents of myhosts and try for yourself).
|
||||
|
||||
The read shell built-in command tells the while loop to read myhosts line by line and assigns the content of each line to variable host, which is then passed to the ping command.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script is used to demonstrate the use of a while loop
|
||||
|
||||
while read host; do
|
||||
ping -c 2 $host
|
||||
done < myhosts
|
||||
|
||||
|
||||
|
||||
Script to Ping Servers
|
||||
|
||||
Read Also:
|
||||
|
||||
- [Learn Shell Scripting: A Guide from Newbies to System Administrator][3]
|
||||
- [5 Shell Scripts to Learn Shell Programming][4]
|
||||
|
||||
### Filesystem Troubleshooting ###
|
||||
|
||||
Although Linux is a very stable operating system, if it crashes for some reason (for example, due to a power outage), one (or more) of your file systems will not be unmounted properly and thus will be automatically checked for errors when Linux is restarted.
|
||||
|
||||
In addition, each time the system boots during a normal boot, it always checks the integrity of the filesystems before mounting them. In both cases this is performed using a tool named fsck (“file system check”).
|
||||
|
||||
fsck will not only check the integrity of file systems, but also attempt to repair corrupt file systems if instructed to do so. Depending on the severity of damage, fsck may succeed or not; when it does, recovered portions of files are placed in the lost+found directory, located in the root of each file system.
|
||||
|
||||
Last but not least, we must note that inconsistencies may also happen if we try to remove an USB drive when the operating system is still writing to it, and may even result in hardware damage.
|
||||
|
||||
The basic syntax of fsck is as follows:
|
||||
|
||||
# fsck [options] filesystem
|
||||
|
||||
**Checking a filesystem for errors and attempting to repair automatically**
|
||||
|
||||
In order to check a filesystem with fsck, we must first unmount it.
|
||||
|
||||
# mount | grep sdg1
|
||||
# umount /mnt
|
||||
# fsck -y /dev/sdg1
|
||||
|
||||

|
||||
|
||||
Check Filesystem Errors
|
||||
|
||||
Besides the -y flag, we can use the -a option to automatically repair the file systems without asking any questions, and force the check even when the filesystem looks clean.
|
||||
|
||||
# fsck -af /dev/sdg1
|
||||
|
||||
If we’re only interested in finding out what’s wrong (without trying to fix anything for the time being) we can run fsck with the -n option, which will output the filesystem issues to standard output.
|
||||
|
||||
# fsck -n /dev/sdg1
|
||||
|
||||
Depending on the error messages in the output of fsck, we will know whether we can try to solve the issue ourselves or escalate it to engineering teams to perform further checks on the hardware.
|
||||
|
||||
### 总结 ###
|
||||
|
||||
We have arrived at the end of this 10-article series where have tried to cover the basic domain competencies required to pass the LFCS exam.
|
||||
|
||||
For obvious reasons, it is not possible to cover every single aspect of these topics in any single tutorial, and that’s why we hope that these articles have put you on the right track to try new stuff yourself and continue learning.
|
||||
|
||||
If you have any questions or comments, they are always welcome – so don’t hesitate to drop us a line via the form below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/learning-shell-scripting-language-a-guide-from-newbies-to-system-administrator/
|
||||
[4]:http://www.tecmint.com/basic-shell-programming-part-ii/
|
||||
@ -0,0 +1,180 @@
|
||||
Part 12 - LFCS: How to Explore Linux with Installed Help Documentations and Tools
|
||||
==================================================================================
|
||||
|
||||
Because of the changes in the LFCS exam requirements effective Feb. 2, 2016, we are adding the necessary topics to the [LFCS series][1] published here. To prepare for this exam, your are highly encouraged to use the [LFCE series][2] as well.
|
||||
|
||||

|
||||
>LFCS: Explore Linux with Installed Documentations and Tools – Part 12
|
||||
|
||||
Once you get used to working with the command line and feel comfortable doing so, you realize that a regular Linux installation includes all the documentation you need to use and configure the system.
|
||||
|
||||
Another good reason to become familiar with command line help tools is that in the [LFCS][3] and [LFCE][4] exams, those are the only sources of information you can use – no internet browsing and no googling. It’s just you and the command line.
|
||||
|
||||
For that reason, in this article we will give you some tips to effectively use the installed docs and tools in order to prepare to pass the **Linux Foundation Certification** exams.
|
||||
|
||||
### Linux Man Pages
|
||||
|
||||
A man page, short for manual page, is nothing less and nothing more than what the word suggests: a manual for a given tool. It contains the list of options (with explanation) that the command supports, and some man pages even include usage examples as well.
|
||||
|
||||
To open a man page, use the **man command** followed by the name of the tool you want to learn more about. For example:
|
||||
|
||||
```
|
||||
# man diff
|
||||
```
|
||||
|
||||
will open the manual page for `diff`, a tool used to compare text files line by line (to exit, simply hit the q key.).
|
||||
|
||||
Let’s say we want to compare two text files named `file1` and `file2` in Linux. These files contain the list of packages that are installed in two Linux boxes with the same distribution and version.
|
||||
|
||||
Doing a `diff` between `file1` and `file2` will tell us if there is a difference between those lists:
|
||||
|
||||
```
|
||||
# diff file1 file2
|
||||
```
|
||||
|
||||
|
||||
>Compare Two Text Files in Linux
|
||||
|
||||
where the `<` sign indicates lines missing in `file2`. If there were lines missing in `file1`, they would be indicated by the `>` sign instead.
|
||||
|
||||
On the other hand, **7d6** means line **#7** in file should be deleted in order to match `file2` (same with **24d22** and **41d38**), and 65,67d61 tells us we need to remove lines **65** through **67** in file one. If we make these corrections, both files will then be identical.
|
||||
|
||||
Alternatively, you can display both files side by side using the `-y` option, according to the man page. You may find this helpful to more easily identify missing lines in files:
|
||||
|
||||
```
|
||||
# diff -y file1 file2
|
||||
```
|
||||
|
||||

|
||||
>Compare and List Difference of Two Files
|
||||
|
||||
Also, you can use `diff` to compare two binary files. If they are identical, `diff` will exit silently without output. Otherwise, it will return the following message: “**Binary files X and Y differ**”.
|
||||
|
||||
### The –help Option
|
||||
|
||||
The `--help` option, available in many (if not all) commands, can be considered a short manual page for that specific command. Although it does not provide a comprehensive description of the tool, it is an easy way to obtain information on the usage of a program and a list of its available options at a quick glance.
|
||||
|
||||
For example,
|
||||
|
||||
```
|
||||
# sed --help
|
||||
```
|
||||
|
||||
shows the usage of each option available in sed (the stream editor).
|
||||
|
||||
One of the classic examples of using `sed` consists of replacing characters in files. Using the `-i` option (described as “**edit files in place**”), you can edit a file without opening it. If you want to make a backup of the original contents as well, use the `-i` option followed by a SUFFIX to create a separate file with the original contents.
|
||||
|
||||
For example, to replace each occurrence of the word `Lorem` with `Tecmint` (case insensitive) in `lorem.txt` and create a new file with the original contents of the file, do:
|
||||
|
||||
```
|
||||
# less lorem.txt | grep -i lorem
|
||||
# sed -i.orig 's/Lorem/Tecmint/gI' lorem.txt
|
||||
# less lorem.txt | grep -i lorem
|
||||
# less lorem.txt.orig | grep -i lorem
|
||||
```
|
||||
|
||||
Please note that every occurrence of `Lorem` has been replaced with `Tecmint` in `lorem.txt`, and the original contents of `lorem.txt` has been saved to `lorem.txt.orig`.
|
||||
|
||||

|
||||
>Replace A String in Files
|
||||
|
||||
### Installed Documentation in /usr/share/doc
|
||||
|
||||
This is probably my favorite pick. If you go to `/usr/share/doc` and do a directory listing, you will see lots of directories with the names of the installed tools in your Linux system.
|
||||
|
||||
According to the [Filesystem Hierarchy Standard][5], these directories contain useful information that might not be in the man pages, along with templates and configuration files to make configuration easier.
|
||||
|
||||
For example, let’s consider `squid-3.3.8` (version may vary from distribution to distribution) for the popular HTTP proxy and [squid cache server][6].
|
||||
|
||||
Let’s `cd` into that directory:
|
||||
|
||||
```
|
||||
# cd /usr/share/doc/squid-3.3.8
|
||||
```
|
||||
|
||||
and do a directory listing:
|
||||
|
||||
```
|
||||
# ls
|
||||
```
|
||||
|
||||

|
||||
>Linux Directory Listing with ls Command
|
||||
|
||||
You may want to pay special attention to `QUICKSTART` and `squid.conf.documented`. These files contain an extensive documentation about Squid and a heavily commented configuration file, respectively. For other packages, the exact names may differ (as **QuickRef** or **00QUICKSTART**, for example), but the principle is the same.
|
||||
|
||||
Other packages, such as the Apache web server, provide configuration file templates inside `/usr/share/doc`, that will be helpful when you have to configure a standalone server or a virtual host, to name a few cases.
|
||||
|
||||
### GNU info Documentation
|
||||
|
||||
You can think of info documents as man pages on steroids. As such, they not only provide help for a specific tool, but also they do so with hyperlinks (yes, hyperlinks in the command line!) that allow you to navigate from a section to another using the arrow keys and Enter to confirm.
|
||||
|
||||
Perhaps the most illustrative example is:
|
||||
|
||||
```
|
||||
# info coreutils
|
||||
```
|
||||
|
||||
Since coreutils contains the [basic file, shell and text manipulation utilities][7] which are expected to exist on every operating system, you can reasonably expect a detailed description for each one of those categories in info **coreutils**.
|
||||
|
||||
|
||||
>Info Coreutils
|
||||
|
||||
As it is the case with man pages, you can exit an info document by pressing the `q` key.
|
||||
|
||||
Additionally, GNU info can be used to display regular man pages as well when followed by the tool name. For example:
|
||||
|
||||
```
|
||||
# info tune2fs
|
||||
```
|
||||
|
||||
will return the man page of **tune2fs**, the ext2/3/4 filesystems management tool.
|
||||
|
||||
And now that we’re at it, let’s review some of the uses of **tune2fs**:
|
||||
|
||||
Display information about the filesystem on top of **/dev/mapper/vg00-vol_backups**:
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/mapper/vg00-vol_backups
|
||||
```
|
||||
|
||||
Set a filesystem volume name (Backups in this case):
|
||||
|
||||
```
|
||||
# tune2fs -L Backups /dev/mapper/vg00-vol_backups
|
||||
```
|
||||
|
||||
Change the check intervals and `/` or mount counts (use the `-c` option to set a number of mount counts and `/` or the `-i` option to set a check interval, where **d=days, w=weeks, and m=months**).
|
||||
|
||||
```
|
||||
# tune2fs -c 150 /dev/mapper/vg00-vol_backups # Check every 150 mounts
|
||||
# tune2fs -i 6w /dev/mapper/vg00-vol_backups # Check every 6 weeks
|
||||
```
|
||||
|
||||
All of the above options can be listed with the `--help` option, or viewed in the man page.
|
||||
|
||||
### Summary
|
||||
|
||||
Regardless of the method that you choose to invoke help for a given tool, knowing that they exist and how to use them will certainly come in handy in the exam. Do you know of any other tools that can be used to look up documentation? Feel free to share with the Tecmint community using the form below.
|
||||
|
||||
Questions and other comments are more than welcome as well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[4]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[5]: http://www.tecmint.com/linux-directory-structure-and-important-files-paths-explained/
|
||||
[6]: http://www.tecmint.com/configure-squid-server-in-linux/
|
||||
[7]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[8]:
|
||||
@ -0,0 +1,185 @@
|
||||
Part 13 - LFCS: How to Configure and Troubleshoot Grand Unified Bootloader (GRUB)
|
||||
=====================================================================================
|
||||
|
||||
Because of the changes in the LFCS exam requirements effective Feb. 2, 2016, we are adding the necessary topics to the [LFCS series][1] published here. To prepare for this exam, your are highly encouraged to use the [LFCE series][2] as well.
|
||||
|
||||

|
||||
>LFCS: Configure and Troubleshoot Grub Boot Loader – Part 13
|
||||
|
||||
In this article we will introduce you to GRUB and explain why a boot loader is necessary, and how it adds versatility to the system.
|
||||
|
||||
The [Linux boot process][3] from the time you press the power button of your computer until you get a fully-functional system follows this high-level sequence:
|
||||
|
||||
* 1. A process known as **POST** (**Power-On Self Test**) performs an overall check on the hardware components of your computer.
|
||||
* 2. When **POST** completes, it passes the control over to the boot loader, which in turn loads the Linux kernel in memory (along with **initramfs**) and executes it. The most used boot loader in Linux is the **GRand Unified Boot loader**, or **GRUB** for short.
|
||||
* 3. The kernel checks and accesses the hardware, and then runs the initial process (mostly known by its generic name “**init**”) which in turn completes the system boot by starting services.
|
||||
|
||||
In Part 7 of this series (“[SysVinit, Upstart, and Systemd][4]”) we introduced the [service management systems and tools][5] used by modern Linux distributions. You may want to review that article before proceeding further.
|
||||
|
||||
### Introducing GRUB Boot Loader
|
||||
|
||||
Two major **GRUB** versions (**v1** sometimes called **GRUB Legacy** and **v2**) can be found in modern systems, although most distributions use **v2** by default in their latest versions. Only **Red Hat Enterprise Linux 6** and its derivatives still use **v1** today.
|
||||
|
||||
Thus, we will focus primarily on the features of **v2** in this guide.
|
||||
|
||||
Regardless of the **GRUB** version, a boot loader allows the user to:
|
||||
|
||||
* 1). modify the way the system behaves by specifying different kernels to use,
|
||||
* 2). choose between alternate operating systems to boot, and
|
||||
* 3). add or edit configuration stanzas to change boot options, among other things.
|
||||
|
||||
Today, **GRUB** is maintained by the **GNU** project and is well documented in their website. You are encouraged to use the [GNU official documentation][6] while going through this guide.
|
||||
|
||||
When the system boots you are presented with the following **GRUB** screen in the main console. Initially, you are prompted to choose between alternate kernels (by default, the system will boot using the latest kernel) and are allowed to enter a **GRUB** command line (with `c`) or edit the boot options (by pressing the `e` key).
|
||||
|
||||

|
||||
>GRUB Boot Screen
|
||||
|
||||
One of the reasons why you would consider booting with an older kernel is a hardware device that used to work properly and has started “acting up” after an upgrade (refer to [this link][7] in the AskUbuntu forums for an example).
|
||||
|
||||
The **GRUB v2** configuration is read on boot from `/boot/grub/grub.cfg` or `/boot/grub2/grub.cfg`, whereas `/boot/grub/grub.conf` or `/boot/grub/menu.lst` are used in **v1**. These files are NOT to be edited by hand, but are modified based on the contents of `/etc/default/grub` and the files found inside `/etc/grub.d`.
|
||||
|
||||
In a **CentOS 7**, here’s the configuration file that is created when the system is first installed:
|
||||
|
||||
```
|
||||
GRUB_TIMEOUT=5
|
||||
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
|
||||
GRUB_DEFAULT=saved
|
||||
GRUB_DISABLE_SUBMENU=true
|
||||
GRUB_TERMINAL_OUTPUT="console"
|
||||
GRUB_CMDLINE_LINUX="vconsole.keymap=la-latin1 rd.lvm.lv=centos_centos7-2/swap crashkernel=auto vconsole.font=latarcyrheb-sun16 rd.lvm.lv=centos_centos7-2/root rhgb quiet"
|
||||
GRUB_DISABLE_RECOVERY="true"
|
||||
```
|
||||
|
||||
In addition to the online documentation, you can also find the GNU GRUB manual using info as follows:
|
||||
|
||||
```
|
||||
# info grub
|
||||
```
|
||||
|
||||
If you’re interested specifically in the options available for /etc/default/grub, you can invoke the configuration section directly:
|
||||
|
||||
```
|
||||
# info -f grub -n 'Simple configuration'
|
||||
```
|
||||
|
||||
Using the command above you will find out that `GRUB_TIMEOUT` sets the time between the moment when the initial screen appears and the system automatic booting begins unless interrupted by the user. When this variable is set to `-1`, boot will not be started until the user makes a selection.
|
||||
|
||||
When multiple operating systems or kernels are installed in the same machine, `GRUB_DEFAULT` requires an integer value that indicates which OS or kernel entry in the GRUB initial screen should be selected to boot by default. The list of entries can be viewed not only in the splash screen shown above, but also using the following command:
|
||||
|
||||
### In CentOS and openSUSE:
|
||||
|
||||
```
|
||||
# awk -F\' '$1=="menuentry " {print $2}' /boot/grub2/grub.cfg
|
||||
```
|
||||
|
||||
### In Ubuntu:
|
||||
|
||||
```
|
||||
# awk -F\' '$1=="menuentry " {print $2}' /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
In the example shown in the below image, if we wish to boot with the kernel version **3.10.0-123.el7.x86_64** (4th entry), we need to set `GRUB_DEFAULT` to `3` (entries are internally numbered beginning with zero) as follows:
|
||||
|
||||
```
|
||||
GRUB_DEFAULT=3
|
||||
```
|
||||
|
||||

|
||||
>Boot System with Old Kernel Version
|
||||
|
||||
One final GRUB configuration variable that is of special interest is `GRUB_CMDLINE_LINUX`, which is used to pass options to the kernel. The options that can be passed through GRUB to the kernel are well documented in the [Kernel Parameters file][8] and in [man 7 bootparam][9].
|
||||
|
||||
Current options in my **CentOS 7** server are:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX="vconsole.keymap=la-latin1 rd.lvm.lv=centos_centos7-2/swap crashkernel=auto vconsole.font=latarcyrheb-sun16 rd.lvm.lv=centos_centos7-2/root rhgb quiet"
|
||||
```
|
||||
|
||||
Why would you want to modify the default kernel parameters or pass extra options? In simple terms, there may be times when you need to tell the kernel certain hardware parameters that it may not be able to determine on its own, or to override the values that it would detect.
|
||||
|
||||
This happened to me not too long ago when I tried **Vector Linux**, a derivative of **Slackware**, on my 10-year old laptop. After installation it did not detect the right settings for my video card so I had to modify the kernel options passed through GRUB in order to make it work.
|
||||
|
||||
Another example is when you need to bring the system to single-user mode to perform maintenance tasks. You can do this by appending the word single to `GRUB_CMDLINE_LINUX` and rebooting:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX="vconsole.keymap=la-latin1 rd.lvm.lv=centos_centos7-2/swap crashkernel=auto vconsole.font=latarcyrheb-sun16 rd.lvm.lv=centos_centos7-2/root rhgb quiet single"
|
||||
```
|
||||
|
||||
After editing `/etc/defalt/grub`, you will need to run `update-grub` (Ubuntu) or `grub2-mkconfig -o /boot/grub2/grub.cfg` (**CentOS** and **openSUSE**) afterwards to update `grub.cfg` (otherwise, changes will be lost upon boot).
|
||||
|
||||
This command will process the boot configuration files mentioned earlier to update `grub.cfg`. This method ensures changes are permanent, while options passed through GRUB at boot time will only last during the current session.
|
||||
|
||||
### Fixing Linux GRUB Issues
|
||||
|
||||
If you install a second operating system or if your GRUB configuration file gets corrupted due to human error, there are ways you can get your system back on its feet and be able to boot again.
|
||||
|
||||
In the initial screen, press `c` to get a GRUB command line (remember that you can also press `e` to edit the default boot options), and use help to bring the available commands in the GRUB prompt:
|
||||
|
||||

|
||||
>Fix Grub Configuration Issues in Linux
|
||||
|
||||
We will focus on **ls**, which will list the installed devices and filesystems, and we will examine what it finds. In the image below we can see that there are 4 hard drives (`hd0` through `hd3`).
|
||||
|
||||
Only `hd0` seems to have been partitioned (as evidenced by msdos1 and msdos2, where 1 and 2 are the partition numbers and msdos is the partitioning scheme).
|
||||
|
||||
Let’s now examine the first partition on `hd0` (**msdos1**) to see if we can find GRUB there. This approach will allow us to boot Linux and there use other high level tools to repair the configuration file or reinstall GRUB altogether if it is needed:
|
||||
|
||||
```
|
||||
# ls (hd0,msdos1)/
|
||||
```
|
||||
|
||||
As we can see in the highlighted area, we found the `grub2` directory in this partition:
|
||||
|
||||

|
||||
>Find Grub Configuration
|
||||
|
||||
Once we are sure that GRUB resides in (**hd0,msdos1**), let’s tell GRUB where to find its configuration file and then instruct it to attempt to launch its menu:
|
||||
|
||||
```
|
||||
set prefix=(hd0,msdos1)/grub2
|
||||
set root=(hd0,msdos1)
|
||||
insmod normal
|
||||
normal
|
||||
```
|
||||
|
||||

|
||||
>Find and Launch Grub Menu
|
||||
|
||||
Then in the GRUB menu, choose an entry and press **Enter** to boot using it. Once the system has booted you can issue the `grub2-install /dev/sdX` command (change `sdX` with the device you want to install GRUB on). The boot information will then be updated and all related files be restored.
|
||||
|
||||
```
|
||||
# grub2-install /dev/sdX
|
||||
```
|
||||
|
||||
Other more complex scenarios are documented, along with their suggested fixes, in the [Ubuntu GRUB2 Troubleshooting guide][10]. The concepts explained there are valid for other distributions as well.
|
||||
|
||||
### Summary
|
||||
|
||||
In this article we have introduced you to GRUB, indicated where you can find documentation both online and offline, and explained how to approach an scenario where a system has stopped booting properly due to a bootloader-related issue.
|
||||
|
||||
Fortunately, GRUB is one of the tools that is best documented and you can easily find help either in the installed docs or online using the resources we have shared in this article.
|
||||
|
||||
Do you have questions or comments? Don’t hesitate to let us know using the comment form below. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/linux-boot-process/
|
||||
[4]: http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
[5]: http://www.tecmint.com/best-linux-log-monitoring-and-management-tools/
|
||||
[6]: http://www.gnu.org/software/grub/manual/
|
||||
[7]: http://askubuntu.com/questions/82140/how-can-i-boot-with-an-older-kernel-version
|
||||
[8]: https://www.kernel.org/doc/Documentation/kernel-parameters.txt
|
||||
[9]: http://man7.org/linux/man-pages/man7/bootparam.7.html
|
||||
[10]: https://help.ubuntu.com/community/Grub2/Troubleshooting
|
||||
@ -0,0 +1,67 @@
|
||||
安卓的下一场革命:不安装即可使用应用!
|
||||
===================================================================
|
||||
|
||||
|
||||
谷歌安卓的一项新创新将让你可以使用没有在你的设备上安装的应用。现在已经有了一些原型了。
|
||||
|
||||
还记得某人给你发了一个链接,要求你安装一个应用来查看的情形吗?
|
||||
|
||||
是否要安装这个应用来查看一个一次性的链接,这个困境一定让你感到很挫败。而且,应用安装本身也会消耗你不少宝贵的时间。
|
||||
|
||||
上述场景可能大多数人都经历过,或者说大多数现代科技用户都经历过。尽管如此,我们都接受这是正确且合理的过程。
|
||||
|
||||
真的吗?
|
||||
|
||||
针对这个问题谷歌的安卓部门给出了一个全新的,开箱即用的答案:
|
||||
|
||||
### Android Instant Apps
|
||||
|
||||
Android Instant Apps 声称第一时间帮你摆脱这样的两难境地,让你简单地点击链接(见打开链接的示例)然后直接开始使用这个应用。
|
||||
|
||||
另一个真实生活场景的例子,如果你想停车但是没有停车码表的配对应用,有了 Instant Apps 在这种情况下就方便多了。
|
||||
|
||||
根据谷歌的信息,你可以简单地将你的手机和码表触碰,停车应用就会直接显示在你的屏幕上,并且准备就绪可以使用。
|
||||
|
||||
#### 它是怎么工作的?
|
||||
|
||||
Instant Apps 和你已经熟悉的应用基本相同,只有一个不同——这些应用为了满足你完成某项任务的需要,只提供给你已经经过**裁剪和模块化**的应用关键部分。
|
||||
|
||||
例如,展开打开链接的场景作为例子,为了查看一个链接,你不需要拥有一个可以写,发送,做咖啡或其它特性的全功能应用。你所需要的全部就是查看功能——而这就是你所会获取到的部分。
|
||||
|
||||
这样应用就可以快速打开,让你可以完成你的目标任务。
|
||||
|
||||

|
||||
>AIA 示例
|
||||
|
||||

|
||||
>B&H 图片(通过谷歌搜索)
|
||||
|
||||

|
||||
>BuzzFeedVideo(通过一个共享链接)
|
||||
|
||||

|
||||
>停车与支付(例)(通过 NFC)
|
||||
|
||||
|
||||
听起来很棒,不是吗?但是其中还有很多技术方面的问题需要解决。
|
||||
|
||||
比如,从安全的观点来说:如果任何应用从理论上来说都能在你的设备上运行,甚至你都不用安装它——你要怎么保证设备远离恶意软件攻击?
|
||||
|
||||
因此,为了消除这类威胁,谷歌还在这个项目上努力,目前只有少数合作伙伴,未来将逐步扩展。
|
||||
|
||||
谷歌最终计划在明年发布 AIA(Android Instant Apps)。
|
||||
|
||||
相关:[介绍 Android Instant Apps][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.iwillfolo.com/androids-next-revolution-use-apps-even-without-installing-them/
|
||||
|
||||
作者:[iwillfolo][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.iwillfolo.com
|
||||
[1]: http://android-developers.blogspot.co.il/2016/05/android-instant-apps-evolving-apps.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed:+blogspot/hsDu+%28Android+Developers+Blog%29
|
||||
@ -0,0 +1,38 @@
|
||||
谷歌会用基于信任的认证措施取代密码吗?
|
||||
===========================================================================
|
||||
|
||||

|
||||
|
||||
一个谷歌新开发的认证措施会评估你的登录有多可靠,并且基于一个“信任分(Trust Score)”认证你的登录。
|
||||
|
||||
这个谷歌项目的名字是 Abacus,它的目标是让你摆脱讨厌的密码记忆和输入。
|
||||
|
||||
在最近的 Google I/O 开发者大会上,谷歌引入了自这个雄心勃勃的项目而来的新特性,称作“**Trust API**”。
|
||||
|
||||
“如果一切进展顺利”,这个 API(Application Programming Interface,应用程序编程接口)会在年底前供安卓开发者使用。API 会利用安卓设备上不同的传感器来识别用户,并创建一个他们称之为“信任分(Trust Score)”的结果。
|
||||
|
||||
基于这个信任分,一个需要登录认证的应用可以验证你确实可以授权登录,从而不会提示需要密码。
|
||||
|
||||

|
||||
>Abacus 到 Trust API
|
||||
|
||||
### 需要思考的地方
|
||||
|
||||
尽管这个想法,明智的功能,听起来很棒——减轻了密码认证的负担。
|
||||
|
||||
但从另一面来说,这是不是谷歌又一次逼迫我们(有意或无意)为了方便使用而放弃我们的隐私?
|
||||
|
||||
是否值得?这取决于你的决定...
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.iwillfolo.com/will-google-replace-passwords-with-a-new-trust-based-authentication-method/
|
||||
|
||||
作者:[iWillFolo][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.iwillfolo.com/
|
||||
@ -1,464 +0,0 @@
|
||||
通过Dockerize这篇博客来开启我们的Docker之旅
|
||||
===
|
||||
>这篇文章将包含Docker的基本概念,以及如何通过创建一个定制的Dockerfile来Dockerize一个应用
|
||||
>作者:Benjamin Cane,2015-12-01 10:00:00
|
||||
|
||||
Docker是2年前从某个idea中孕育而生的有趣技术,世界各地的公司组织都积极使用它来部署应用。在今天的文章中,我将教你如何通过"Dockerize"一个现有的应用,来开始我们的Docker运用。问题中的应用指的就是这篇博客!
|
||||
|
||||
## 什么是Docker?
|
||||
|
||||
当我们开始学习Docker基本概念时,让我们先去搞清楚什么是Docker以及它为什么这么流行。Docker是一个操作系统容器管理工具,它通过将应用打包在操作系统容器中,来方便我们管理和部署应用。
|
||||
|
||||
### 容器 vs. 虚拟机
|
||||
|
||||
容器虽和虚拟机并不完全相似,但它也是一种提供**操作系统虚拟化**的方式。但是,它和标准的虚拟机还是有不同之处的。
|
||||
|
||||
标准虚拟机一般会包括一个完整的操作系统,操作系统包,最后还有一至两个应用。这都得益于为虚拟机提供硬件虚拟化的管理程序。这样一来,一个单一的服务器就可以将许多独立的操作系统作为虚拟客户机运行了。
|
||||
|
||||
容器和虚拟机很相似,它们都支持在单一的服务器上运行多个操作环境,只是,在容器中,这些环境并不是一个个完整的操作系统。容器一般只包含必要的操作系统包和一些应用。它们通常不会包含一个完整的操作系统或者硬件虚拟化程序。这也意味着容器比传统的虚拟机开销更少。
|
||||
|
||||
容器和虚拟机常被误认为是两种抵触的技术。虚拟机采用同一个物理服务器,来提供全功能的操作环境,该环境会和其余虚拟机一起共享这些物理资源。容器一般用来隔离运行中的应用进程,运行进程将在单独的主机中运行,以保证隔离后的进程之间不能相互影响。事实上,容器和**BSD Jails**以及`chroot`进程的相似度,超过了和完整虚拟机的相似度。
|
||||
|
||||
### Docker在容器的上层提供了什么
|
||||
|
||||
Docker不是一个容器运行环境,事实上,只是一个容器技术,并不包含那些帮助Docker支持[Solaris Zones](https://blog.docker.com/2015/08/docker-oracle-solaris-zones/)和[BSD Jails](https://wiki.freebsd.org/Docker)的技术。Docker提供管理,打包和部署容器的方式。虽然一定程度上,虚拟机多多少少拥有这些类似的功能,但虚拟机并没有完整拥有绝大多数的容器功能,即使拥有,这些功能用起来都并没有Docker来的方便。
|
||||
|
||||
现在,我们应该知道Docker是什么了,然后,我们将从安装Docker,并部署一个公共的预构建好的容器开始,学习Docker是如何工作的。
|
||||
|
||||
## 从安装开始
|
||||
|
||||
默认情况下,Docker并不会自动被安装在您的计算机中,所以,第一步就是安装Docker包;我们的教学机器系统是Ubuntu 14.0.4,所以,我们将使用Apt包管理器,来执行安装操作。
|
||||
|
||||
```
|
||||
# apt-get install docker.io
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following extra packages will be installed:
|
||||
aufs-tools cgroup-lite git git-man liberror-perl
|
||||
Suggested packages:
|
||||
btrfs-tools debootstrap lxc rinse git-daemon-run git-daemon-sysvinit git-doc
|
||||
git-el git-email git-gui gitk gitweb git-arch git-bzr git-cvs git-mediawiki
|
||||
git-svn
|
||||
The following NEW packages will be installed:
|
||||
aufs-tools cgroup-lite docker.io git git-man liberror-perl
|
||||
0 upgraded, 6 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 7,553 kB of archives.
|
||||
After this operation, 46.6 MB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n] y
|
||||
```
|
||||
|
||||
为了检查当前是否有容器运行,我们可以执行`docker`命令,加上`ps`选项
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
`docker`命令中的`ps`功能类似于Linux的`ps`命令。它将显示可找到的Docker容器以及各自的状态。由于我们并没有开启任何Docker容器,所以命令没有显示任何正在运行的容器。
|
||||
|
||||
## 部署一个预构建好的nginx Docker容器
|
||||
|
||||
我比较喜欢的Docker特性之一就是Docker部署预先构建好的容器的方式,就像`yum`和`apt-get`部署包一样。为了更好地解释,我们来部署一个运行着nginx web服务器的预构建容器。我们可以继续使用`docker`命令,这次选择`run`选项。
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
`docker`命令的`run`选项,用来通知Docker去寻找一个指定的Docker镜像,然后开启运行着该镜像的容器。默认情况下,Docker容器在前台运行,这意味着当你运行`docker run`命令的时候,你的shell会被绑定到容器的控制台以及运行在容器中的进程。为了能在后台运行该Docker容器,我们可以使用`-d` (**detach**)标志。
|
||||
|
||||
再次运行`docker ps`命令,可以看到nginx容器正在运行。
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 nginx:latest nginx -g 'daemon off 4 seconds ago Up 3 seconds 443/tcp, 80/tcp desperate_lalande
|
||||
```
|
||||
|
||||
从上面的打印信息中,我们可以看到正在运行的名为`desperate_lalande`的容器,它是由`nginx:latest image`(译者注:nginx最新版本的镜像)构建而来得。
|
||||
|
||||
### Docker镜像
|
||||
|
||||
镜像是Docker的核心特征之一,类似于虚拟机镜像。和虚拟机镜像一样,Docker镜像是一个被保存并打包的容器。当然,Docker不只是创建镜像,它还可以通过Docker仓库发布这些镜像,Docker仓库和包仓库的概念差不多,它让Docker能够模仿`yum`部署包的方式来部署镜像。为了更好地理解这是怎么工作的,我们来回顾`docker run`执行后的输出。
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
```
|
||||
|
||||
我们可以看到第一条信息是,Docker不能在本地找到名叫nginx的镜像。这是因为当我们执行`docker run`命令时,告诉Docker运行一个基于nginx镜像的容器。既然Docker要启动一个基于特定镜像的容器,那么Docker首先需要知道那个指定镜像。在检查远程仓库之前,Docker首先检查本地是否存在指定名称的本地镜像。
|
||||
|
||||
因为系统是崭新的,不存在nginx镜像,Docker将选择从Docker仓库下载之。
|
||||
|
||||
```
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
这就是第二部分打印信息显示给我们的内容。默认,Docker会使用[Docker Hub](https://hub.docker.com/)仓库,该仓库由Docker公司维护。
|
||||
|
||||
和Github一样,在Docker Hub创建公共仓库是免费的,私人仓库就需要缴纳费用了。当然,部署你自己的Docker仓库也是可以实现的,事实上只需要简单地运行`docker run registry`命令就行了。但在这篇文章中,我们的重点将不是讲解如何部署一个定制的注册服务。
|
||||
|
||||
### 关闭并移除容器
|
||||
|
||||
在我们继续构建定制容器之前,我们先清理Docker环境,我们将关闭先前的容器,并移除它。
|
||||
|
||||
我们利用`docker`命令和`run`选项运行一个容器,所以,为了停止该相同的容器,我们简单地在执行`docker`命令时,使用`kill`选项,并指定容器名。
|
||||
|
||||
```
|
||||
# docker kill desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
当我们再次执行`docker ps`,就不再有容器运行了
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
但是,此时,我们这是停止了容器;虽然它不再运行,但仍然存在。默认情况下,`docker ps`只会显示正在运行的容器,如果我们附加`-a` (all) 标识,它会显示所有运行和未运行的容器。
|
||||
|
||||
```
|
||||
# docker ps -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 5c82215b03d1 nginx -g 'daemon off 4 weeks ago Exited (-1) About a minute ago desperate_lalande
|
||||
```
|
||||
|
||||
为了能完整地移除容器,我们在用`docker`命令时,附加`rm`选项。
|
||||
|
||||
```
|
||||
# docker rm desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
虽然容器被移除了;但是我们仍拥有可用的**nginx**镜像(译者注:镜像缓存)。如果我们重新运行`docker run -d nginx`,Docker就无需再次拉取nginx镜像,即可启动容器。这是因为我们本地系统中已经保存了一个副本。
|
||||
|
||||
为了列出系统中所有的本地镜像,我们运行`docker`命令,附加`images`选项。
|
||||
|
||||
```
|
||||
# docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
nginx latest 9fab4090484a 5 days ago 132.8 MB
|
||||
```
|
||||
|
||||
## 构建我们自己的镜像
|
||||
|
||||
截至目前,我们已经使用了一些基础的Docker命令来开启,停止和移除一个预构建好的普通镜像。为了"Dockerize"这篇博客,我们需要构建我们自己的镜像,也就是创建一个**Dockerfile**。
|
||||
|
||||
在大多数虚拟机环境中,如果你想创建一个机器镜像,首先,你需要建立一个新的虚拟机,安装操作系统,安装应用,最后将其转换为一个模板或者镜像。但在Docker中,所有这些步骤都可以通过Dockerfile实现全自动。Dockerfile是向Docker提供构建指令去构建定制镜像的方式。在这一章节,我们将编写能用来部署这篇博客的定制Dockerfile。
|
||||
|
||||
### 理解应用
|
||||
|
||||
我们开始构建Dockerfile之前,第一步要搞明白,我们需要哪些东西来部署这篇博客。
|
||||
|
||||
博客本质上是由静态站点生成器生成的静态HTML页面,这个静态站点是我编写的,名为**hamerkop**。这个生成器很简单,它所做的就是生成该博客站点。所有的博客源码都被我放在了一个公共的[Github仓库](https://github.com/madflojo/blog)。为了部署这篇博客,我们要先从Github仓库把博客内容拉取下来,然后安装**Python**和一些**Python**模块,最后执行`hamerkop`应用。我们还需要安装**nginx**,来运行生成后的内容。
|
||||
|
||||
截止目前,这些还是一个简单的Dockerfile,但它却给我们展示了相当多的[Dockerfile语法]((https://docs.docker.com/v1.8/reference/builder/))。我们需要克隆Github仓库,然后使用你最喜欢的编辑器编写Dockerfile;我选择`vi`
|
||||
|
||||
```
|
||||
# git clone https://github.com/madflojo/blog.git
|
||||
Cloning into 'blog'...
|
||||
remote: Counting objects: 622, done.
|
||||
remote: Total 622 (delta 0), reused 0 (delta 0), pack-reused 622
|
||||
Receiving objects: 100% (622/622), 14.80 MiB | 1.06 MiB/s, done.
|
||||
Resolving deltas: 100% (242/242), done.
|
||||
Checking connectivity... done.
|
||||
# cd blog/
|
||||
# vi Dockerfile
|
||||
```
|
||||
|
||||
### FROM - 继承一个Docker镜像
|
||||
|
||||
第一条Dockerfile指令是`FROM`指令。这将指定一个现存的镜像作为我们的基础镜像。这也从根本上给我们提供了继承其他Docker镜像的途径。在本例中,我们还是从刚刚我们使用的**nginx**开始,如果我们想重新开始,我们可以通过指定`ubuntu:latest`来使用**Ubuntu** Docker镜像。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
```
|
||||
|
||||
除了`FROM`指令,我还使用了`MAINTAINER`,它用来显示Dockerfile的作者。
|
||||
|
||||
Docker支持使用`#`作为注释,我将经常使用该语法,来解释Dockerfile的部分内容。
|
||||
|
||||
### 运行一次测试构建
|
||||
|
||||
因为我们继承了**nginx** Docker镜像,我们现在的Dockerfile也就包括了用来构建**nginx**镜像的[Dockerfile](https://github.com/nginxinc/docker-nginx/blob/08eeb0e3f0a5ee40cbc2bc01f0004c2aa5b78c15/Dockerfile)中所有指令。这意味着,此时我们可以从该Dockerfile中构建出一个Docker镜像,然后从该镜像中运行一个容器。虽然,最终的镜像和**nginx**镜像本质上是一样的,但是我们这次是通过构建Dockerfile的形式,然后我们将讲解Docker构建镜像的过程。
|
||||
|
||||
想要从Dockerfile构建镜像,我们只需要在运行`docker`命令的时候,加上**build**选项。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 23.6 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Running in c97f36450343
|
||||
---> 60a44f78d194
|
||||
Removing intermediate container c97f36450343
|
||||
Successfully built 60a44f78d194
|
||||
```
|
||||
|
||||
上面的例子,我们使用了`-t` (**tag**)标识给镜像添加"blog"的标签。本质上我们只是在给镜像命名,如果我们不指定标签,就只能通过Docker分配的**Image ID**来访问镜像了。本例中,从Docker构建成功的信息可以看出,**Image ID**值为`60a44f78d194`。
|
||||
|
||||
除了`-t`标识外,我还指定了目录`/root/blog`。该目录被称作"构建目录",它将包含Dockerfile,以及其他需要构建该容器的文件。
|
||||
|
||||
现在我们构建成功,下面我们开始定制该镜像。
|
||||
|
||||
### 使用RUN来执行apt-get
|
||||
|
||||
用来生成HTML页面的静态站点生成器是用**Python**语言编写的,所以,在Dockerfile中需要做的第一件定制任务是安装Python。我们将使用Apt包管理器来安装Python包,这意味着在Dockerfile中我们要指定运行`apt-get update`和`apt-get install python-dev`;为了完成这一点,我们可以使用`RUN`指令。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
```
|
||||
|
||||
如上所示,我们只是简单地告知Docker构建镜像的时候,要去执行指定的`apt-get`命令。比较有趣的是,这些命令只会在该容器的上下文中执行。这意味着,即使容器中安装了`python-dev`和`python-pip`,但主机本身并没有安装这些。说的更简单点,`pip`命令将只在容器中执行,出了容器,`pip`命令不存在。
|
||||
|
||||
还有一点比较重要的是,Docker构建过程中不接受用户输入。这说明任何被`RUN`指令执行的命令必须在没有用户输入的时候完成。由于很多应用在安装的过程中需要用户的输入信息,所以这增加了一点难度。我们例子,`RUN`命令执行的命令都不需要用户输入。
|
||||
|
||||
### 安装Python模块
|
||||
|
||||
**Python**安装完毕后,我们现在需要安装Python模块。如果在Docker外做这些事,我们通常使用`pip`命令,然后参考博客Git仓库中名叫`requirements.txt`的文件。在之前的步骤中,我们已经使用`git`命令成功地将Github仓库"克隆"到了`/root/blog`目录;这个目录碰巧也是我们创建`Dockerfile`的目录。这很重要,因为这意味着Dokcer在构建过程中可以访问Git仓库中的内容。
|
||||
|
||||
当我们执行构建后,Docker将构建的上下文环境设置为指定的"构建目录"。这意味着目录中的所有文件都可以在构建过程中被使用,目录之外的文件(构建环境之外)是不能访问的。
|
||||
|
||||
为了能安装需要的Python模块,我们需要将`requirements.txt`从构建目录拷贝到容器中。我们可以在`Dockerfile`中使用`COPY`指令完成这一需求。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
```
|
||||
|
||||
在`Dockerfile`中,我们增加了3条指令。第一条指令使用`RUN`在容器中创建了`/build/`目录。该目录用来拷贝生成静态HTML页面需要的一切应用文件。第二条指令是`COPY`指令,它将`requirements.txt`从"构建目录"(`/root/blog`)拷贝到容器中的`/build/`目录。第三条使用`RUN`指令来执行`pip`命令;安装`requirements.txt`文件中指定的所有模块。
|
||||
|
||||
当构建定制镜像时,`COPY`是条重要的指令。如果在Dockerfile中不指定拷贝文件,Docker镜像将不会包含requirements.txt文件。在Docker容器中,所有东西都是隔离的,除非在Dockerfile中指定执行,否则容器中不会包括需要的依赖。
|
||||
|
||||
### 重新运行构建
|
||||
|
||||
现在,我们让Docker执行了一些定制任务,现在我们尝试另一次blog镜像的构建。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Running in bde05cf1e8fe
|
||||
---> f4b66e09fa61
|
||||
Removing intermediate container bde05cf1e8fe
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
Removing intermediate container 9aa8ff43f4b0
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Running in c50b15ddd8b1
|
||||
Downloading/unpacking jinja2 (from -r /build/requirements.txt (line 1))
|
||||
Downloading/unpacking PyYaml (from -r /build/requirements.txt (line 2))
|
||||
<truncated to reduce noise>
|
||||
Successfully installed jinja2 PyYaml mistune markdown MarkupSafe
|
||||
Cleaning up...
|
||||
---> abab55c20962
|
||||
Removing intermediate container c50b15ddd8b1
|
||||
Successfully built abab55c20962
|
||||
```
|
||||
|
||||
上述输出所示,我们可以看到构建成功了,我们还可以看到另外一个有趣的信息` ---> Using cache`。这条信息告诉我们,Docker在构建该镜像时使用了它的构建缓存。
|
||||
|
||||
### Docker构建缓存
|
||||
|
||||
当Docker构建镜像时,它不仅仅构建一个单独的镜像;事实上,在构建过程中,它会构建许多镜像。从上面的输出信息可以看出,在每一"步"执行后,Docker都在创建新的镜像。
|
||||
|
||||
```
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
```
|
||||
|
||||
上面片段的最后一行可以看出,Docker在告诉我们它在创建一个新镜像,因为它打印了**Image ID**;`cef11c3fb97c`。这种方式有用之处在于,Docker能在随后构建**blog**镜像时将这些镜像作为缓存使用。这很有用处,因为这样,Docker就能加速同一个容器中新构建任务的构建流程。从上面的例子中,我们可以看出,Docker没有重新安装`python-dev`和`python-pip`包,Docker则使用了缓存镜像。但是由于Docker并没有找到执行`mkdir`命令的构建缓存,随后的步骤就被一一执行了。
|
||||
|
||||
Docker构建缓存一定程度上是福音,但有时也是噩梦。这是因为使用缓存或者重新运行指令的决定在一个很狭窄的范围内执行。比如,如果`requirements.txt`文件发生了修改,Docker会在构建时检测到该变化,然后Docker会重新执行该执行那个点往后的所有指令。这得益于Docker能查看`requirements.txt`的文件内容。但是,`apt-get`命令的执行就是另一回事了。如果提供Python包的**Apt** 仓库包含了一个更新的python-pip包;Docker不会检测到这个变化,转而去使用构建缓存。这会导致之前旧版本的包将被安装。虽然对`python-pip`来说,这不是主要的问题,但对使用了某个致命攻击缺陷的包缓存来说,这是个大问题。
|
||||
|
||||
出于这个原因,抛弃Docker缓存,定期地重新构建镜像是有好处的。这时,当我们执行Docker构建时,我简单地指定`--no-cache=True`即可。
|
||||
|
||||
## 部署博客的剩余部分
|
||||
|
||||
Python包和模块安装后,接下来我们将拷贝需要用到的应用文件,然后运行`hamerkop`应用。我们只需要使用更多的`COPY` and `RUN`指令就可完成。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
|
||||
## Add blog code nd required files
|
||||
COPY static /build/static
|
||||
COPY templates /build/templates
|
||||
COPY hamerkop /build/
|
||||
COPY config.yml /build/
|
||||
COPY articles /build/articles
|
||||
|
||||
## Run Generator
|
||||
RUN /build/hamerkop -c /build/config.yml
|
||||
```
|
||||
|
||||
现在我们已经写出了剩余的构建指令,我们再次运行另一次构建,并确保镜像构建成功。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog/
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Using cache
|
||||
---> f4b66e09fa61
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> Using cache
|
||||
---> cef11c3fb97c
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Using cache
|
||||
---> abab55c20962
|
||||
Step 7 : COPY static /build/static
|
||||
---> 15cb91531038
|
||||
Removing intermediate container d478b42b7906
|
||||
Step 8 : COPY templates /build/templates
|
||||
---> ecded5d1a52e
|
||||
Removing intermediate container ac2390607e9f
|
||||
Step 9 : COPY hamerkop /build/
|
||||
---> 59efd1ca1771
|
||||
Removing intermediate container b5fbf7e817b7
|
||||
Step 10 : COPY config.yml /build/
|
||||
---> bfa3db6c05b7
|
||||
Removing intermediate container 1aebef300933
|
||||
Step 11 : COPY articles /build/articles
|
||||
---> 6b61cc9dde27
|
||||
Removing intermediate container be78d0eb1213
|
||||
Step 12 : RUN /build/hamerkop -c /build/config.yml
|
||||
---> Running in fbc0b5e574c5
|
||||
Successfully created file /usr/share/nginx/html//2011/06/25/checking-the-number-of-lwp-threads-in-linux
|
||||
Successfully created file /usr/share/nginx/html//2011/06/checking-the-number-of-lwp-threads-in-linux
|
||||
<truncated to reduce noise>
|
||||
Successfully created file /usr/share/nginx/html//archive.html
|
||||
Successfully created file /usr/share/nginx/html//sitemap.xml
|
||||
---> 3b25263113e1
|
||||
Removing intermediate container fbc0b5e574c5
|
||||
Successfully built 3b25263113e1
|
||||
```
|
||||
|
||||
### 运行定制的容器
|
||||
|
||||
成功的一次构建后,我们现在就可以通过运行`docker`命令和`run`选项来运行我们定制的容器,和之前我们启动nginx容器一样。
|
||||
|
||||
```
|
||||
# docker run -d -p 80:80 --name=blog blog
|
||||
5f6c7a2217dcdc0da8af05225c4d1294e3e6bb28a41ea898a1c63fb821989ba1
|
||||
```
|
||||
|
||||
我们这次又使用了`-d` (**detach**)标识来让Docker在后台运行。但是,我们也可以看到两个新标识。第一个新标识是`--name`,这用来给容器指定一个用户名称。之前的例子,我们没有指定名称,因为Docker随机帮我们生成了一个。第二个新标识是`-p`,这个标识允许用户从主机映射一个端口到容器中的一个端口。
|
||||
|
||||
之前我们使用的基础**nginx**镜像分配了80端口给HTTP服务。默认情况下,容器内的端口通道并没有绑定到主机系统。为了让外部系统能访问容器内部端口,我们必须使用`-p`标识将主机端口映射到容器内部端口。上面的命令,我们通过`-p 8080:80`语法将主机80端口映射到容器内部的80端口。
|
||||
|
||||
经过上面的命令,我们的容器似乎成功启动了,我们可以通过执行`docker ps`核实。
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
d264c7ef92bd blog:latest nginx -g 'daemon off 3 seconds ago Up 3 seconds 443/tcp, 0.0.0.0:80->80/tcp blog
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
截止目前,我们拥有了正在运行的定制Docker容器。虽然在这篇文章中,我们只接触了一些Dockerfile指令用法,但是我们还是要讨论所有的指令。我们可以检查[Docker's reference page](https://docs.docker.com/v1.8/reference/builder/)来获取所有的Dockerfile指令用法,那里对指令的用法说明得很详细。
|
||||
|
||||
另一个比较好的资源是[Dockerfile Best Practices page](https://docs.docker.com/engine/articles/dockerfile_best-practices/),它有许多构建定制Dockerfile的最佳练习。有些技巧非常有用,比如战略性地组织好Dockerfile中的命令。上面的例子中,我们将`articles`目录的`COPY`指令作为Dockerfile中最后的`COPY`指令。这是因为`articles`目录会经常变动。所以,将那些经常变化的指令尽可能地放在最后面的位置,来最优化那些可以被缓存的步骤。
|
||||
|
||||
通过这篇文章,我们涉及了如何运行一个预构建的容器,以及如何构建,然后部署定制容器。虽然关于Docker你还有许多需要继续学习的地方,但我想这篇文章给了你如何继续开始的好建议。当然,如果你认为还有一些需要继续补充的内容,在下面评论即可。
|
||||
|
||||
--------------------------------------
|
||||
via:http://bencane.com/2015/12/01/getting-started-with-docker-by-dockerizing-this-blog/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+bencane%2FSAUo+%28Benjamin+Cane%29
|
||||
|
||||
作者:Benjamin Cane
|
||||
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,119 +0,0 @@
|
||||
启用Nginx/Apache的PHP-FPM多实例
|
||||
================================================================================
|
||||
|
||||
PHP-FPM作为FastCGI进程管理器而广为熟知,它是PHP FastCGI实现的改进,带有更为有用的功能,用于处理高负载的服务器和网站。下面列出其中一些功能:
|
||||
### 新功能 ###
|
||||
|
||||
- 拥有具有优雅启动/停止选项的高级进程管理能力。
|
||||
- 可以以监听不同端口以及使用不同PHP配置的不同用户身份/组身份来运行进程。
|
||||
- 错误日志记录。
|
||||
- 支持上传加速。
|
||||
- 用于在处理一些耗时任务时结束请求和清空所有数据的特别功能。
|
||||
- 同时支持动态和静态子进程重生。
|
||||
- 支持IP地址限制。
|
||||
|
||||
在本文中,我将要讨论的是,在运行EA3下CPanel 11.52的CentOS 7服务器上与Nginx和Apache一起安装PHP-FPM,以及如何来通过CPanel管理这些安装好的多个PHP-FPM实例。
|
||||
Before going to the installation procedures, let us take a look on the pre-requisites.
|
||||
|
||||
### 先决条件 ###
|
||||
|
||||
1. 启用 Mod_proxy_fcgi模块
|
||||
2. 启用 MPM_Event
|
||||
|
||||
由于我们要将PHP-FPM安装到一台EA3服务器,我们需要运行EasyApache来编译Apache以启用这些模块。
|
||||
|
||||
你们可以参考我以前写的,关于如何在Apache服务器上安装Nginx作为反向代理的文档来确认Nginx的安装。
|
||||
|
||||
这里,我将再次简述那些安装步骤。具体细节,你可以参考我之前写的**(如何在CentOS 7/CPanel服务器上配置Nginx反向代理)**一文。
|
||||
|
||||
步骤 1:安装Epel仓库
|
||||
步骤 2:安装nDeploy RPM仓库,这是此次安装中最为**重要**的步骤。
|
||||
步骤 3:使用yum从nDeploy仓库安装nDeploy和Nginx插件。
|
||||
步骤 4:启用/配置Nginx为反向代理。
|
||||
|
||||
完成这些步骤后,下面为服务器中所有可用PHP版本安装PHP-FPM包,EA3使用remi仓库来安装这些包。你可以运行这个nDeploy脚本来下载所有的包。
|
||||
|
||||
root@server1 [~]# /opt/nDeploy/scripts/easy_php_setup.sh
|
||||
Loaded plugins: fastestmirror, tsflags, universal-hooks
|
||||
EA4 | 2.9 kB 00:00:00
|
||||
base | 3.6 kB 00:00:00
|
||||
epel/x86_64/metalink | 9.7 kB 00:00:00
|
||||
epel | 4.3 kB 00:00:00
|
||||
extras | 3.4 kB 00:00:00
|
||||
updates | 3.4 kB 00:00:00
|
||||
(1/2): epel/x86_64/updateinfo | 460 kB 00:00:00
|
||||
(2/2): epel/x86_64/primary_db
|
||||
|
||||
运行该脚本将为PHP 54,PHP 55,PHP 56和PHP 70安装所有这些FPM包。
|
||||
|
||||
Installed Packages
|
||||
php54-php-fpm.x86_64 5.4.45-3.el7.remi @remi
|
||||
php55-php-fpm.x86_64 5.5.31-1.el7.remi @remi
|
||||
php56-php-fpm.x86_64 5.6.17-1.el7.remi @remi
|
||||
php70-php-fpm.x86_64 7.0.2-1.el7.remi @remi
|
||||
|
||||
在以上安装完成后,你需要为Apache启用PHP-FPM SAPI。你可以运行下面这个脚本来启用PHP-FPM实例。
|
||||
|
||||
root@server1 [~]# /opt/nDeploy/scripts/apache_php-fpm_setup.sh enable
|
||||
mod_proxy_fcgi.c
|
||||
Please choose one default PHP version from the list below
|
||||
PHP70
|
||||
PHP56
|
||||
PHP54
|
||||
PHP55
|
||||
Provide the exact desired version string here and press ENTER: PHP54
|
||||
ConfGen:: lxblogger
|
||||
ConfGen:: blogr
|
||||
ConfGen:: saheetha
|
||||
ConfGen:: satest
|
||||
which: no cagefsctl in (/usr/local/jdk/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/local/bin:/usr/X11R6/bin:/root/bin)
|
||||
info [rebuildhttpdconf] Missing owner for domain server1.centos7-test.com, force lookup to root
|
||||
Built /usr/local/apache/conf/httpd.conf OK
|
||||
Waiting for “httpd” to restart gracefully …waiting for “httpd” to initialize ……
|
||||
…finished.
|
||||
|
||||
它会问你需要运行哪个PHP版本作为服务器默认版本,你可以输入那些细节内容,然后继续配置并为现存的域生成虚拟主机文件。
|
||||
|
||||
我选择了PHP 54作为我服务器上的默认PHP-FPM版本。
|
||||
|
||||

|
||||
|
||||
虽然服务器配置了PHP-FPM 54,但是我们可以通过CPanel为各个独立的域修改PHP-FPM实例。
|
||||
|
||||
下面我将通过一些截图来为你们说明一下,怎样通过CPanel为各个独立域修改PHP-FPM实例。
|
||||
|
||||
Nginx插件的安装将为你的域的CPanel提供一个Nginx Webstack图标,你可以点击该图标来配置你的Web服务器。我已经登陆进了我其中的一个CPanel来配置相应的Web服务器。
|
||||
|
||||
请看这些截图。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
现在,你可以根据需要为选中的主域配置web服务器(这里,我已经选择了主域saheetha.com)。我已经继续通过自动化配置选项来进行了,因为我不需要添加任何手动设置。
|
||||
|
||||

|
||||
|
||||
当Nginx配置完后,你可以在这里为你的域选择PHP-FPM实例。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
就像你在截图中所看到的,我服务器上的默认PHP-FPM是**PHP 54**,而我正要将我的域的PHP-FPM实例单独修改成**PHP 55**。当你为你的域修改PHP-FPM后,你可以通过访问**phpinfo**页面来确认。
|
||||
|
||||
谢谢你们参考本文,我相信这篇文章会给你提供不少信息和帮助。我会为你们推荐关于这个内容的有价值的评论 :)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/enable-multiple-php-fpm-instances-nginx-apache/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/saheethas/
|
||||
@ -1,67 +0,0 @@
|
||||
七步开始你的 Linux 系统管理员生涯
|
||||
===============================================
|
||||
|
||||
|
||||
Linux 现在是个大热门。每个人都在寻求 Linux 才能。招聘人员对有 Linux 经验的人求贤若渴,还有无数的职位虚位以待。但是如果你是 Linux 新手,又想要赶上这波热潮,该从何开始下手呢?
|
||||
|
||||
1. 安装 Linux
|
||||
|
||||
这应该是不言而喻的,但学习 Linux 的第一关键就是安装 Linux。LFS101x 和 LFS201 课程都包含第一次安装和配置 Linux 的详细内容。
|
||||
|
||||
2. 完成 LFS101x 课程
|
||||
|
||||
如果你是 Linux 完完全全的新手,最佳的起点是免费的 Linux 课程 [LFS101x Introduction](https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-2)。这个在线课程在 edX.org,探索 Linux 系统管理员和终端用户常用的各种工具和技能以及日常 Linux 工作环境。该课程是为有一定经验但较少或没有接触过 Linux 的电脑用户设计的,不论他们是在个人还是企业环境中工作。这个课程会从图形界面和命令行教会你有用的 Linux 知识,让你能够了解主流的 Linux 发行版。
|
||||
|
||||
3. 看看 LFS201 课程
|
||||
|
||||
在你完成 LFS101x 之后,你就准备好开始进入 Linux 更加复杂的任务了,这是成为一名专业的系统管理员所必须的。为了掌握这些技能,你应该看看 [LFS201 Essentials of Linux System Administration](http://training.linuxfoundation.org/linux-courses/system-administration-training/essentials-of-system-administration) 这个课程。该课程对每个话题进行了深度的解释和介绍,还有大量的练习和实验,帮助你获得相关主题实际的上手经验。
|
||||
|
||||
如果你更愿意有个教练或者你的雇主对将你培养成 Linux 系统管理员有兴趣,你可能会对 LFS220 Linux System Administration 有兴趣。这个课程有 LFS201 中所有的主题,但是它是由专家专人教授的,帮助你进行实验以及解答你在课程主题中的问题。
|
||||
|
||||
4. 练习!
|
||||
|
||||
熟能生巧,和对任何乐器或运动适用一样,这对 Linux 来说也一样适用。在你安装 Linux 之后,经常使用它。一遍遍地练习关键任务,直到你不需要参考材料也能轻而易举地完成。练习命令行和图形界面的输入输出。这些练习能够保证你掌握成为成功的 Linux 系统管理员所必需的知识和技能。
|
||||
|
||||
5. 获得认证
|
||||
|
||||
在你完成 LFS201 或 LFS220 并且充分练习之后,你现在已经准备好获得系统管理员的认证了。你需要这个证书,因为你需要向雇主证明你拥有一名专业 Linux 系统管理员必需的技能。
|
||||
|
||||
现在有一些不同的 Linux 证书,它们有它们的独到之处。但是,它们里大部分不是在特定发行版(如红帽)上认证,就是纯粹的知识测试,没有演示 Linux 的实际技能。Linux 基金会认证系统管理员(Linux Foundation Certified System Administrator)证书对想要一个灵活的,有意义的初级证书的人来说是个优秀的替代。
|
||||
|
||||
6. 参与进来
|
||||
|
||||
如果你所在的地方有本地 Linux 用户组(Linux Users Group,LUG)的话,这时候你可能还想要考虑加入他们。这些组织通常由各种年龄和经验水平的人组成,所以不管你的 Linux 经验水平如何,你都能找到和你类似技能水平的人互助,或是更高水平的 Linux 用户来解答你的问题以及介绍有用的资源。要想知道你附近有没有 LUG,上 meet.com 看看,或是附近的大学,又或是上网搜索一下。
|
||||
|
||||
还有不少在线社区可以在你学习 Linux 的时候帮助你。这些站点和社区向 Linux 新手和有经验的管理员都能够提供帮助和支持:
|
||||
|
||||
- [Linux Admin subreddit](https://www.reddit.com/r/linuxadmin)
|
||||
|
||||
- [Linux.com](http://www.linux.com/)
|
||||
|
||||
- [training.linuxfoundation.org](http://training.linuxfoundation.org/)
|
||||
|
||||
- [http://community.ubuntu.com/help-information/](http://community.ubuntu.com/help-information/)
|
||||
|
||||
- [https://forums.opensuse.org/forum.php](https://forums.opensuse.org/forum.php)
|
||||
|
||||
- [http://wiki.centos.org/Documentation](http://wiki.centos.org/Documentation)
|
||||
|
||||
7. 学会热爱文档
|
||||
|
||||
最后但同样重要的是,如果你困在 Linux 的某些地方,别忘了 Linux 包含的文档。使用命令 man(manual,手册),info 和 help,你从系统内就可以找到 Linux 几乎所有方面的信息。这些内置资源的用处再夸大也不为过,你会发现你在生涯中始终会用到,所以你可能最好早点掌握使用它们。
|
||||
|
||||
想要了解更多开始你 Linux IT 生涯的信息?查看我们免费的电子书“[开始你 Linux IT 生涯的简短指南](http://training.linuxfoundation.org/sysadmin-it-career-guide)”。
|
||||
|
||||
[立刻下载](http://training.linuxfoundation.org/sysadmin-it-career-guide)
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/featured-blogs/191-linux-training/834644-7-steps-to-start-your-linux-sysadmin-career
|
||||
|
||||
作者:[linux.com][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:linux.com
|
||||
@ -1,76 +0,0 @@
|
||||
混合云计算的9大关键趋势
|
||||
========================================
|
||||
|
||||
自从几年前云计算的概念受到IT界的关注以来,公有云、私有云和混合云这三种云计算方式都有了可观的演进。其中混合云计算方式是最热门的云计算方式,在接受调查的公司中,有[88%的公司](https://www.greenhousedata.com/blog/hybrid-continues-to-be-most-popular-cloud-option-adoption-accelerating)将混合云计算摆在至关重要的地位。
|
||||
|
||||
混合云计算的疾速演进意味着一两年前的传统观念已经过时了。为此,我们询问了几个行业分析师,混合云在2016年的走势将会如何,我们得到了几个比较有意思的答案。
|
||||
|
||||
1. **2016年可能是我们将混合云投入使用的一年。**
|
||||
|
||||
混合云从本质上来说依赖于私有云,这对企业来说是比较难实现的。事实上,亚马逊,谷歌和微软的公有云已经进行了大量的投资,并且起步也比较早。私有云拖了混合云发展和使用的后腿。
|
||||
|
||||
私有云没有得到这么多的投资,这是有私有云的性质决定的。私有云意味着维护和投资你自己的数据中心。许多公有云提供商正在推动企业减少或者消除他们的数据中心。
|
||||
|
||||
然而,得益于OpenStack的发展和微软的 Azure Stack ,这两者基本上就是封装在一个盒子里的私有云,我们将会看到私有云慢慢追上公有云的发展步伐。支持混合云的工具、基础设施和架构也变得更加健壮。
|
||||
|
||||
|
||||
2. **容器,微服务和unikernels将会促进混合云的发展。**
|
||||
|
||||
分析师预言,到2016年底,这些原生云技术会或多或少成为主流的。这些云技术正在快速成熟,将会成为虚拟机的一个替代品,而虚拟机需要更多的资源。
|
||||
|
||||
更重要的是,他们既能工作在在线场景,也能工作在离线场景。容器化和编排允许快速的扩大规模,进行公有云和私有云之间的服务迁移,使你能够更容易移动你的服务。
|
||||
|
||||
3. **数据和相关性占据核心舞台。**
|
||||
|
||||
所有的云计算方式都处在发展模式。这使得云计算变成了一个技术类的故事。咨询公司[Avoa](http://avoa.com/2016/01/01/2016-is-the-year-of-data-and-relevance/)称,随着云趋于成熟,数据和相关性变得越来越重要。起初,云计算和大数据都是关于怎么吸收尽可能多的数据,然后他们担心如何处理这海量的数据。
|
||||
|
||||
2016年,相关组织将会继续锤炼如何进行数据收集和使用的相关技术。在必须处理的技术和文化方面仍然有待提高。但是2016年应该重新将关注点放在从各个方面考虑的数据重要性上,发现最相关的信息,而不只是数据的数量。
|
||||
|
||||
4. **云服务将超越按需工作负载。**
|
||||
|
||||
AWS(Amazon Web Services)起初是提供给程序员或者是开发人员能够快速启动虚拟机,做一些工作然后离线的一个地方。这就是按需使用的本质。要让这些服务持续运行,几乎需要全天候工作。
|
||||
|
||||
然而,IT组织正开始作为服务代理,为内部用户提供各种IT服务。可以是内部IT服务,公有云基础架构提供商,平台服务和软件服务。
|
||||
|
||||
他们将越来越多的认识到想云管理平台这样的工具的价值。云管理平台可以提供针对不同服务的基于策略的一致性管理。他们也将看到像提高可移植性的容器等技术的价值。然而,云服务代理,在不同云之间快速移动的工作负载进行价格套利或者相关原因的意义上来讲,仍然是行不通的。
|
||||
|
||||
5. **服务提供商转变成了云服务提供商。**
|
||||
|
||||
到目前为止,购买云服务成了直销模式。AWS EC2 服务的使用者通常变成了购买者,通过官方认证渠道或者通过影子IT。但是随着云服务越来越全面,提供的服务菜单越来越复杂,越来越多的人转向了经销商,服务提供商转变成了他们IT服务的购买者。
|
||||
|
||||
2nd Watch (2nd Watch是为企业提供云管理的 AWS 的首选合作伙伴)最近的一项调查发现,在美国将近85%的IT高管愿意支付一个小的溢价从渠道商那里购买公有云服务,如果购买过程变得不再那么复杂。根据调查,这85%的高管有五分之四的愿意支付额外的15%或者更多。三分之一的受访高管表示,他们可以使用帮助来购买、使用和管理公有云服务。
|
||||
|
||||
6. **物联网和云对于2016年的意义好比移动和云对2012年的意义。**
|
||||
|
||||
物联网获得了广泛的关注,更重要的是,物联网已经从测试场景进行了实际应用。云的分布式特性使得云成为了物联网非常重要的一部分,对于工业物联网,与后端系统交互的机械和重型设备,混合云将会成为最自然的驱动者,连接,数据采集和处理将会发生在混合云环境中,这得益于私有云在安全和隐私方面的好处。
|
||||
|
||||
7. **NIST 对云的定义开始瓦解。**
|
||||
|
||||
2011年,美国国家标准与技术研究院发布了“[ NIST 对于云计算的定义](http://csrc.nist.gov/publications/nistpubs/800-145/SP800-145.pdf)”(PDF),这个定义成为了私有云、公有云、混合云和 aas模板的标准定义。
|
||||
|
||||
然而随着时间的推移,定义开始改变。Iaas变得更加复杂,开始支持OpenStack,[Swift](https://wiki.openstack.org/wiki/Swift) 对象存储和神经网络这样的项目。Paas似乎正在消退,因为Paas和传统的中间件开发几乎无异。Saas,只是通过浏览器进行访问的应用,也正在失去发展动力,因为许多app和服务提供了许多云接口,你可以通过各种手段调用接口,不仅仅通过浏览器。
|
||||
|
||||
8. **分析变得更加重要**
|
||||
|
||||
对于混合云计算来说,分析将会成为一个巨大的增长机遇,云计算具有规模大、灵活性高的优势,使得云计算非常适合需要海量数据的分析工作。对于某些分析方式,比如高度敏感的数据,私有云仍然是主导地位但是私有云也是混合云的一部分。因此,无论如何,混合云计算胜出。
|
||||
|
||||
9. **安全仍然是一个非常紧迫的问题。**
|
||||
|
||||
随着混合云计算在2016年的发展,以及对物联网和容器等新技术的引进,这同时也增加了更多的脆弱可攻破的地方从而导致数据泄露。先增加使用新技术的趋势,然后再去考虑安全性,这种问题经常发生,同时还有缺少经验的工程师不去考虑系统的安全问题,总有一天你会尝到灾难的后果的。
|
||||
|
||||
当一项新技术出来,管理规范总是落后于安全问题产生后,然后我们才考虑去保护技术。容器就是一个很鲜明的例子。你可以从Docker下周各种示例容器,但是你知道你下载的东西来自哪里么?在人们在对容器内容不知情的情况下下载并运行了容器之后,Docker不得不重新加上安全验证。
|
||||
|
||||
像Path和Snapchat这样的移动技术在智能手机市场火起来之后也出现了重大的安全问题。一项新技术被恶意利用无可避免。所以安全研究人员需要通过各种手段来保证新技术的安全性。很有可能在部署之后才会发现安全问题。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/cloud-computing/9-key-trends-in-hybrid-cloud-computing.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
译者:[棣琦](https://github.com/sonofelice)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Andy-Patrizio-90720.html
|
||||
@ -1,53 +0,0 @@
|
||||
NODEOS: NODE爱好者的Linux发行版
|
||||
================================================
|
||||
|
||||

|
||||
|
||||
[NodeOS][1]是一个基于[Node.js][2]的操作系统,自去年的首个[发布候选版][3]之后正朝着它的1.0版本进发。
|
||||
|
||||
如果你是第一次听到它,NodeOS是首个在[Linux][5]内核之上由Node.js和[npm][4]驱动的操作系统。[Jacob Groundwater][6]仔2013年中介绍了这个项目。操作系统中用到的主要技术是:
|
||||
|
||||
- **Linux 内核**: 这个系统内置了Linux内核
|
||||
- **Node.js 运行时**: Node作为主要的运行时
|
||||
- **npm 包管理**: npm作为包管理
|
||||
|
||||
NodeOS源码托管在[Github][7]上,因此,任何感兴趣的人都可以轻松贡献或者报告bug。用户可以从源码构建或者使用[预编译镜像][8]。构建过程及使用可以在项目仓库中找到。
|
||||
|
||||
NodeOS背后的思想是提供足够npm运行的环境,剩余的功能就可以来自npm包管理。因此,用户可以使用大量的大约250,000的包,并且这个数目每天都还在增长。并且所有的都是开源的,你可以根据你的需要很容易地打补丁或者增加更多的包。
|
||||
|
||||
NodeOS核心开发被分离成了不同的层,基本的结构包含:
|
||||
|
||||
- **barebones** – 带有可以启动到Node.js REPL的initramfs的自定义内核
|
||||
- **initramfs** – =用于挂载用户分区以及启动系统的initram文件系统
|
||||
- **rootfs** – 托管linux内核及initramfs文件的只读分区
|
||||
- **usersfs** – 多用户文件系统(如传统系统一样)
|
||||
|
||||
NodeOS的目标是可以仔任何平台上运行,包括- **真实的硬件(用户计算机或者SoC)**、**云平台、虚拟机、PaaS提供商,容器**(Docker和Vagga)等等。如今看来,它做得似乎不错。在3.3号,NodeOS的成员[Jesús Leganés Combarro][9]在Github上[宣布][10]:
|
||||
|
||||
>**NodeOS不再是一个玩具系统了**,它现在开始可以用在有实际需求的生产环境中了。
|
||||
|
||||
因此,如果你是Node.js的死忠或者乐于尝试新鲜事物,这或许值得你一试。在相关的文章中,你应该了解这些[Linux发行版的具体用法][11]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/nodeos-operating-system/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/munif/
|
||||
[1]: http://node-os.com/
|
||||
[2]: https://nodejs.org/en/
|
||||
[3]: https://github.com/NodeOS/NodeOS/releases/tag/v1.0-RC1
|
||||
[4]: https://www.npmjs.com/
|
||||
[5]: http://itsfoss.com/tag/linux/
|
||||
[6]: https://github.com/groundwater
|
||||
[7]: https://github.com/nodeos/nodeos
|
||||
[8]: https://github.com/NodeOS/NodeOS/releases
|
||||
[9]: https://github.com/piranna
|
||||
[10]: https://github.com/NodeOS/NodeOS/issues/216
|
||||
[11]: http://itsfoss.com/weird-ubuntu-based-linux-distributions/
|
||||
@ -0,0 +1,162 @@
|
||||
在 Ubuntu Server 16.04 LTS 上安装 LAMP
|
||||
=========================================================
|
||||
|
||||
LAMP方案是一系列自由和开源软件的集合,包含了 **Linux**, web服务器 (**Apache**), 数据库服务器 (**MySQL / MariaDB**) 和 **PHP** (脚本语言). LAMP是那些需要安装和构建动态网页应用的基础平台,比如WordPress, Joomla, OpenCart and Drupal。
|
||||
|
||||
在这篇文章中,我将描述如何在Ubuntu Server 16.04 LTS 上安装LAMP,众所周知Ubuntu是一个基于linux的操作系统,因此它构成了LAMP的第一个部分,在接下来的操作中,我将默认你已经安装了 Ubuntu Server 16.04。
|
||||
|
||||
### Apache2 web服务器的安装 :
|
||||
|
||||
在Ubuntu linux中,web 服务器称之为 Apache2,我们可以利用下面的命令来安装它
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt update
|
||||
linuxtechi@ubuntu:~$ sudo apt install apache2 -y
|
||||
```
|
||||
|
||||
当安装Apache2包之后,Apache2相关的服务将会在重启后变成可用状态和自动运行,在某些情况下,如果你的Apache2服务并没有自动可用和启动,你可以利用如下命令来启用它。
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo systemctl start apache2.service
|
||||
linuxtechi@ubuntu:~$ sudo systemctl enable apache2.service
|
||||
linuxtechi@ubuntu:~$ sudo systemctl status apache2.service
|
||||
```
|
||||
|
||||
如果你开启了Ubuntu的防火墙(ufw),那么你可以使用如下的命令来解除web服务器的端口(80和443)限制
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo ufw status
|
||||
Status: active
|
||||
linuxtechi@ubuntu:~$ sudo ufw allow in 'Apache Full'
|
||||
Rule added
|
||||
Rule added (v6)
|
||||
linuxtechi@ubuntu:~$
|
||||
```
|
||||
|
||||
### 现在开始访问你的web服务器 :
|
||||
|
||||
打开浏览器并输入服务器的IP地址或者主机名
|
||||
(http://IP_Address_OR_Host_Name),在我的例子中我的服务器IP是‘192.168.1.13’
|
||||
|
||||

|
||||
|
||||
### 数据库服务器的安装r (MySQL Server 5.7) :
|
||||
|
||||
MySQL 和 MariaDB 都是 Ubuntu 16.04 中的数据库服务器. MySQL Server 和 MariaDB Server的安装包都可以在Ubuntu的默认软件源中找到,我们可以选择其中的一个来安装.通过下面的命令来在终端中安装mysql服务器
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt install mysql-server mysql-client
|
||||
```
|
||||
|
||||
在安装过程中,它会要求你设置mysql服务器root帐户的密码.
|
||||
|
||||

|
||||
|
||||
确认root帐户的密码,并点击确定
|
||||
|
||||

|
||||
|
||||
Mysql 服务器的安装到此已经结束了, MySQL 服务会自动变成可用状态和自动启动.我们可以通过如下的命令来校验Mysql服务的状态
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo systemctl status mysql.service
|
||||
```
|
||||
|
||||
### MariaDB Server的安装 :
|
||||
|
||||
在终端中利用如下的命令来安装 Mariadb 10.0 服务器。
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt install mariadb-server
|
||||
```
|
||||
|
||||
运行如下的命令来设置mariadb root帐户的密码,还可以用来关闭某些选项,比如关闭远程登录功能。
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
### PHP脚本语言的安装:
|
||||
|
||||
PHP 7 已经存在于Ubuntu的软件源中了,在终端中执行如下的命令来安装PHP 7:
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt install php7.0-mysql php7.0-curl php7.0-json php7.0-cgi php7.0 libapache2-mod-php7.0
|
||||
```
|
||||
|
||||
创建一个简单的php页面,并且将它移动到 apache的文档根目录下 (/var/ww/html)
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ vi samplepage.php
|
||||
<?php
|
||||
phpinfo();
|
||||
?>
|
||||
```
|
||||
|
||||
在vi中编辑之后,保存并退出该文件。
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo mv samplepage.php /var/www/html/
|
||||
```
|
||||
|
||||
现在你可以从web浏览器中访问这个页面,
|
||||
输入 : “http://<Server_IP>/samplepage.php” ,你可以看到如下页面.
|
||||
|
||||

|
||||
|
||||
以上的页面向我们展示了PHP已经完全安装成功了
|
||||
|
||||
### phpMyAdmin的安装:
|
||||
|
||||
phpMyAdmin可以让我们通过它的web界面来执行所有和数据库管理和其他数据库操作相关的任务,这个安装包已经存在于Ubuntu的软件源中
|
||||
|
||||
利用如下的命令来在Ubuntu server 16.04 LTS中安装phpMyAdmin
|
||||
|
||||
```
|
||||
linuxtechi@ubuntu:~$ sudo apt install php-mbstring php7.0-mbstring php-gettext
|
||||
linuxtechi@ubuntu:~$ sudo systemctl restart apache2.service
|
||||
linuxtechi@ubuntu:~$ sudo apt install phpmyadmin
|
||||
```
|
||||
|
||||
在以下的安装过程中,它会提示我们选择phpMyAdmin运行的目标服务器
|
||||
|
||||
|
||||
选择 Apache2 并点击确定
|
||||
|
||||

|
||||
|
||||
点击确定来配置phpMyAdmin管理的数据库
|
||||
|
||||

|
||||
|
||||
指定phpMyAdmin向数据库服务器注册时所用的密码
|
||||
|
||||

|
||||
|
||||
确认phpMyAdmin所需的密码,并点击确认
|
||||
|
||||

|
||||
|
||||
现在可以开始尝试访问phpMyAdmin, 打开浏览器并输入 : “http://Server_IP_OR_Host_Name/phpmyadmin”
|
||||
|
||||
利用我们安装时设置的 root帐户和密码
|
||||
|
||||

|
||||
|
||||
当我们点击“Go”的时候,将会重定向到如下所示的 ‘phpMyAdmin’web界面
|
||||
|
||||

|
||||
|
||||
到现在,LAMP方案已经被成功安装和使用了,欢迎分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/lamp-stack-installation-on-ubuntu-server-16-04/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[陆建波](https://github.com/lujianbo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
@ -1,61 +0,0 @@
|
||||
Apps to Snaps
|
||||
================
|
||||
|
||||

|
||||
|
||||
在 Linux 分发应用不总是那么容易。你有不同的包格式,基础系统,可用库,以及发行版发布周期,所有的这些都让人头疼。但现在我们有了更简单的东西:Snap。
|
||||
|
||||
Snap 是开发者打包他们应用的新途径,它相对于传统包格式,如 .deb,.rpm 等带来了许多优点。Snap 安全,互相独立,宿主系统使用类似 AppArmor 的技术,它们跨平台,而且是自足的,让开发者可以准确打包它们应用所需要的依赖。沙盒隔离也加强了安全,并允许应用和整个基于 snap 的系统,在出现问题的时候可以回滚。Snap 确实是 Linux 应用打包的未来。
|
||||
|
||||
创建一个 snap 包并不困难。首先,你需要一个 snap 基础运行环境,能够在你的桌面理解和运行 snap,这个工具叫做 snapd 并且默认内置于所有 Ubuntu 16.04 系统中。接着你需要创建 snap 的工具,Snapcraft,可以通过一个简单的命令安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install snapcraft
|
||||
```
|
||||
|
||||
这个环境安装好了之后就可以 snap 起来了。
|
||||
|
||||
Snap 使用一个特殊的 YAML 格式文件,称作 snapcraft.yaml,它定义了应用是如何打包的以及它需要的依赖。用一个简单的应用来演示一下,下面的 YAML 文件是个如何 snap 打包 moon-buggy 游戏的实际例子,该游戏在 Ubuntu 源中提供。
|
||||
|
||||
```
|
||||
name: moon-buggy
|
||||
version: 1.0.51.11
|
||||
summary: Drive a car across the moon
|
||||
description: |
|
||||
A simple command-line game where you drive a buggy on the moon
|
||||
apps:
|
||||
play:
|
||||
command: usr/games/moon-buggy
|
||||
parts:
|
||||
moon-buggy:
|
||||
plugin: nil
|
||||
stage-packages: [moon-buggy]
|
||||
snap:
|
||||
– usr/games/moon-buggy
|
||||
```
|
||||
|
||||
上面的代码演示了几个新概念。第一部分是关于让你的应用可以在商店找到的,设置包元数据名称,版本号,摘要,以及描述。Apps 部分实现了运行命令,指向 moon-buggy 可执行文件位置。Parts 部分告诉 snapcraft 用来构建应用所需要的插件以及依赖的包。在这个简单的例子中我们需要的所有东西就是 Ubuntu 源中的 moon-buggy 应用本身,snapcraft 负责剩下的工作。
|
||||
|
||||
在你的 snapcraft.yaml 所在目录下运行 snapcraft 会创建 moon-buggy_1.0.51.11_amd64.snap 包,可以通过以下命令来安装它:
|
||||
|
||||
```
|
||||
$ snap install moon-buggy_1.0.51.11_amd64.snap
|
||||
```
|
||||
|
||||
想了解更复杂一点的 snap 打包,比如基于 Electron 的 Simplenote [看这里][1],在线教程在[这里][2],相应的代码在[Github][3]。更多的例子可以在这里的 Ubuntu 开发者[站点][4]找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2016/06/01/apps-to-snaps/
|
||||
|
||||
作者:[Jamie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://insights.ubuntu.com/author/jamiebennett/
|
||||
[1]: http://www.simplenote.com/
|
||||
[2]: http://www.linuxuk.org/post/20160518_snapping_electron_based_applications_simplenote/
|
||||
[3]: https://github.com/jamiedbennett/snaps/tree/master/simplenote
|
||||
[4]: https://developer.ubuntu.com/en/desktop/get-started/
|
||||
171
translated/tech/20160601 scp command in Linux.md
Normal file
171
translated/tech/20160601 scp command in Linux.md
Normal file
@ -0,0 +1,171 @@
|
||||
Linux中的scp命令
|
||||
=======================
|
||||
|
||||

|
||||
|
||||
|
||||
scp 意味着安全拷贝协议 (Secure Copy Protocol), 和众多Linux/Unix使用者所了解的拷贝(cp)命令一样. scp 的使用方式跟 cp命令是很相似的, cp命令将一个文件或文件夹从本地操作系统的一个位置拷贝到目标位置上,而scp用来将一个文件或者文件夹通过网络传输从一个主机拷贝到另一个主机当中去。
|
||||
|
||||
scp命令的使用方法如下所示,在这个例子中,我将一个叫 “imporimposetantfile”的文件从本机(10.10.16.147)拷贝到远程主机(10.0.0.6)中。在这个命令里,你也可以使用主机名字来替代IP地址。
|
||||
|
||||
```
|
||||
[root@localhost ~]# scp importantfile admin@10.0.0.6:/home/admin/
|
||||
The authenticity of host '10.0.0.6 (10.0.0.6)' can't be established.
|
||||
RSA key fingerprint is SHA256:LqBzkeGa6K9BfWWKgcKlQoE0u+gjorX0lPLx5YftX1Y.
|
||||
RSA key fingerprint is MD5:ed:44:42:59:3e:dd:4c:12:43:4a:89:b1:5d:bd:9e:20.
|
||||
Are you sure you want to continue connecting (yes/no)? yes
|
||||
Warning: Permanently added '10.0.0.6' (RSA) to the list of known hosts.
|
||||
admin@10.0.0.6's password:
|
||||
importantfile 100% 0 0.0KB/s 00:00
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
同样的,如果你想从一个远程主机中获取文件,你可以利用如下的scp命令。
|
||||
|
||||
```
|
||||
[root@localhost ~]# scp root@10.10.16.137:/root/importantfile /home/admin/
|
||||
The authenticity of host '10.10.16.137 (10.10.16.137)' can't be established.
|
||||
RSA key fingerprint is b0:b0:a3:c3:2e:94:13:0c:29:2e:ba:0b:d3:d6:12:8f.
|
||||
Are you sure you want to continue connecting (yes/no)? yes
|
||||
Warning: Permanently added '10.10.16.137' (RSA) to the list of known hosts.
|
||||
root@10.10.16.137's password:
|
||||
importantfile 100% 0 0.0KB/s 00:00
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
你同样可以像cp命令一样,在scp命令中使用不同的选项,scp的man文件详细地阐述了不同选项的用法和优点。
|
||||
|
||||
**简单输出.**
|
||||
|
||||

|
||||
|
||||
```
|
||||
scp可选参数如下所示:
|
||||
|
||||
-B 采取批量模式 (prevents asking for passwords or passphrases).
|
||||
|
||||
-C 允许压缩. 通过指明-C来开启压缩模式.
|
||||
|
||||
-c 加密方式
|
||||
选择在传输过程中用来加密的加密方式
|
||||
这个选项会被直接传递到ssh(1).
|
||||
|
||||
-F ssh配置
|
||||
为ssh指定一个用来替代默认配置的文件.
|
||||
这个选项会被直接传递到ssh(1).
|
||||
|
||||
-l 限速
|
||||
限制命令使用的带宽, 默认单位是 Kbit/s.
|
||||
|
||||
-P 端口
|
||||
指定需要的连接的远程主机的端口.
|
||||
注意,这个选项使用的是一个大写的"P", 因为小写的 -p 已经用来保留目标文件的时间和模式相关信息。
|
||||
|
||||
-p 保留目标文件的修改时间,访问时间以及权限模式.
|
||||
|
||||
-q 静默模式: 不显示来自ssh(1)命令的进度信息,警告和诊断信息.
|
||||
|
||||
-r 递归拷贝整个目录.
|
||||
注意,scp命令在树形遍历的时候同样会对符号连接进行相同的处理。
|
||||
|
||||
-v 详细模式.scp和ssh(1)将会打印出处理过程中的调试信息.当你要调试连接,认证和配置问题的时候这将会帮助到你。
|
||||
|
||||
```
|
||||
|
||||
利用scp命令的-v选项,你可以获得认证,调试相关的处理信息.
|
||||
|
||||

|
||||
|
||||
当我们使用-v选项的时候,一个简单的输出如下所示
|
||||
|
||||
```
|
||||
[root@localhost ~]# scp -v abc.txt admin@10.0.0.6:/home/admin
|
||||
Executing: program /usr/bin/ssh host 10.0.0.6, user admin,
|
||||
command scp -v -t/home/admin
|
||||
OpenSSH_7.1p1, OpenSSL 1.0.2d-fips 9 Jul 2015
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config
|
||||
debug1: /etc/ssh/ssh_config line 56: Applying options for *
|
||||
debug1: Connecting to 10.0.0.6 [10.0.0.6] port 22.
|
||||
debug1: Connection established.
|
||||
debug1: Server host key: ssh-rsa SHA256:LqBzkeGa6K9BfWWKgcKlQoE0u+gjorX0lPLx5YftX1Y
|
||||
debug1: Next authentication method: publickey
|
||||
debug1: Trying private key: /root/.ssh/id_rsa
|
||||
debug1: Trying private key: /root/.ssh/id_dsa
|
||||
debug1: Trying private key: /root/.ssh/id_ecdsa
|
||||
debug1: Trying private key: /root/.ssh/id_ed25519
|
||||
debug1: Next authentication method: password
|
||||
admin@10.0.0.6's password:
|
||||
debug1: Authentication succeeded (password).
|
||||
Authenticated to 10.0.0.6 ([10.0.0.6]:22).
|
||||
debug1: channel 0: new [client-session]
|
||||
debug1: Requesting no-more-sessions@openssh.com
|
||||
debug1: Entering interactive session.
|
||||
debug1: Sending environment.
|
||||
debug1: Sending command: scp -v -t /home/admin
|
||||
Sending file modes: C0644 174 abc.txt
|
||||
Sink: C0644 174 abc.txt
|
||||
abc.txt 100% 174 0.2KB/s 00:00
|
||||
Transferred: sent 3024, received 2584 bytes, in 0.3 seconds
|
||||
Bytes per second: sent 9863.3, received 8428.1
|
||||
debug1: Exit status 0
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
当我们需要拷贝一个目录或者文件夹的时候,我们可以使用-r选项,它会递归拷贝整个目录。
|
||||
|
||||

|
||||
|
||||
静默模式:
|
||||
|
||||
如果你想要关闭进度信息以及警告和诊断信息,你可以通过使用scp命令中的-q选项.
|
||||
|
||||

|
||||
|
||||
上一次我们仅仅使用-r参数,它显示了逐个文件的信息,但这一次当我们使用了-q参数,它就不显示进度信息.
|
||||
|
||||
利用scp的-p选项来保留目标文件的更新时间,访问时间和权限模式.
|
||||
|
||||

|
||||
|
||||
通过 -P 选项来指定远程主机的连接端口。
|
||||
scp使用ssh命令来在两个主机之间传输文件,因为ssh使用的是22端口号,所以scp也使用相同的22端口号.
|
||||
|
||||
如果我们希望改变这个端口号,我们可以使用-P(大写的P,因为小写的p用来保存文件的访问时间等) 选项来指定所需的端口号
|
||||
|
||||
举个例子,如果我们想要使用2222端口号,我们可以使用如下的命令
|
||||
|
||||
```
|
||||
[root@localhost ~]# scp -P 2222 abcd1 root@10.10.16.137:/root/
|
||||
```
|
||||
|
||||
**限制命令使用的带宽, 指定的单位是 Kbit/s**
|
||||
|
||||
如下所示,我们可以使用-l参数来指定scp命令所使用的带宽,在此我们将速度限制为512kbit/s
|
||||
|
||||

|
||||
|
||||
**开启压缩**
|
||||
|
||||
如下所示,我们可以通过开启scp命令的压缩模式来节省传输过程中的带宽和时间
|
||||
|
||||

|
||||
|
||||
**选择加密数据的加密方式**
|
||||
|
||||
scp默认使用 AES-128的加密方式,如果我们想要改变这个加密方式,可以通过-c(小写的c) 参数来指定其他的加密方式
|
||||
|
||||

|
||||
|
||||
现在你可以利用scp(Secure copy)命令在你所属网络中的两个结点之间安全地拷贝文件了.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/scp-command-linuxunix/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+unixmenhowtos+%28Unixmen+Howtos+%26+Tutorials%29
|
||||
|
||||
作者:[Naga Ramesh][a]
|
||||
译者:[lujianbo](https://github.com/lujianbo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.unixmen.com/author/naga/
|
||||
@ -0,0 +1,138 @@
|
||||
在 Ubuntu 16.04 上安装使用 VBoxManage 以及 VBoxManage 命令行选项的用法
|
||||
=================
|
||||
|
||||
VirtualBox 拥有一套命令行工具,然后你可以使用 VirtualBox 的命令行界面 (CLI) 对远端无界面的服务器上的虚拟机进行管理操作。在这篇教程中,你将会学到如何在没有 GUI 的情况下使用 VBoxManage 创建、启动一个虚拟机。VBoxManage 是 VirtualBox 的命令行界面,你可以在你的主机操作系统的命令行中来用它实现对 VirtualBox 的所有操作。VBoxManage 拥有图形化用户界面所支持的全部功能,而且它支持的功能远不止这些。它提供虚拟引擎的所有功能,甚至包含 GUI 还不能实现的那些功能。如果你想尝试不同的用户界面而不仅仅是 GUI,或者更改虚拟机更多高级和实验性的配置,那么你就需要用到命令行。
|
||||
|
||||
当你想要在 VirtualBox 上创建或运行虚拟机时,你会发现 VBoxManage 非常有用,你只需要使用远程主机的终端就够了。这对于服务器来说是一种常见的情形,因为在服务器上需要进行虚拟机的远程操作。
|
||||
|
||||
### 准备工作
|
||||
|
||||
在开始使用 VBoxManage 的命令行工具前,确保在运行着 Ubuntu 16.04 的服务器上,你拥有超级用户的权限或者你能够使用 sudo 命令,而且你已经在服务器上安装了 Oracle Virtual Box。 然后你需要安装 VirtualBox 扩展包,这是运行远程桌面环境,访问无界面启动虚拟机所必须的。(headless的翻译拿不准,翻译为无界面启动)
|
||||
|
||||
### 安装 VBoxManage
|
||||
|
||||
通过 [Virtual Box Download Page][1] 这个链接,你能够获取你所需要的软件扩展包的最新版本,扩展包的版本和你安装的 VirtualBox 版本需要一致!
|
||||
|
||||

|
||||
|
||||
也可以用下面这条命令来获取 VBoxManage 扩展。
|
||||
|
||||
```
|
||||
$ wget http://download.virtualbox.org/virtualbox/5.0.20/Oracle_VM_VirtualBox_Extension_Pack-5.0.20-106931.vbox-extpack
|
||||
```
|
||||
|
||||

|
||||
|
||||
运行下面这条命令,确认 VBoxManage 已经成功安装在你的机器上。
|
||||
|
||||
```
|
||||
$ VBoxManage list extpacks
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 在 Ubuntu 16.04 上使用 VBoxManage
|
||||
|
||||
接下来我们将要使用 VBoxManage 向你展现通过命令行终端工具来新建和管理虚拟机是多么的简单。
|
||||
|
||||
运行下面的命令,新建一个将用来安装 Ubuntu 系统的虚拟机。
|
||||
|
||||
```
|
||||
# VBoxManage createvm --name Ubuntu16.04 --register
|
||||
```
|
||||
|
||||
在运行了这条命令之后,VBoxMnage 将会新建一个叫 做“Ubuntu16.vbox” 的虚拟机,这个虚拟机的位置是家目录路径下的 “VirtualBox VMs/Ubuntu16/Ubuntu16.04.vbox”。在上面这条命令中,“createvm” 是用来新建虚拟机,“--name” 定义了虚拟机的名字,而 “registervm” 命令是用来注册虚拟机的。
|
||||
|
||||
现在,使用下面这条命令为虚拟机创建一个硬盘镜像。
|
||||
|
||||
```
|
||||
$ VBoxManage createhd --filename Ubuntu16.04 --size 5124
|
||||
```
|
||||
|
||||
这里,“createhd” 用来创建硬盘镜像,“--filename” 用来指定虚拟机的名称,也就是创建的硬盘镜像名称。“--size” 表示硬盘镜像的空间容量,空间容量的单位总是 MB。我们指定了 5Gb,也就是 5124 MB。
|
||||
|
||||
接下来我们需要设置操作系统类型,如果要安装 Linux 系的系统,那么用下面这条命令指定系统类型为 Linux 或者 Ubuntu 或者 Fedora 之类的。
|
||||
|
||||
```
|
||||
$ VBoxManage modifyvm Ubuntu16.04 --ostype Ubuntu
|
||||
```
|
||||
|
||||
用下面这条命令来设置虚拟系统的内存大小,也就是从主机中分配到虚拟机系统的内存。
|
||||
|
||||
```
|
||||
$ VBoxManage modifyvm Ubuntu10.10 --memory 512
|
||||
```
|
||||
|
||||

|
||||
|
||||
现在用下面这个命令为虚拟机创建一个存储控制器。
|
||||
|
||||
```
|
||||
$ VBoxManage storagectl Ubuntu16.04 --name IDE --add ide --controller PIIX4 --bootable on
|
||||
```
|
||||
|
||||
这里的 “storagect1” 是给虚拟机创建存储控制器的,“--name” 指定了虚拟机里需要创建、更改或者移除的存储控制器的名称。“--add” 选项指明系统总线类型,可选的选项有 ide / sata / scsi / floppy,存储控制器必须要连接到系统总线。“--controller” 选择主板的类型,主板需要根据需要的存储控制器选择,可选的选项有 LsiLogic / LSILogicSAS / BusLogic / IntelAhci / PIIX3 / PIIX4 / ICH6 / I82078。最后的 “--bootable” 表示控制器是否可以引导。
|
||||
|
||||
上面的命令创建了叫做 IDE 的存储控制器。然后虚拟设备就能通过 “storageattach” 命令连接到控制器。
|
||||
|
||||
然后运行下面这个命令来创建一个叫做 SATA 的存储控制器,它将会连接到硬盘镜像上。
|
||||
|
||||
```
|
||||
$ VBoxManage storagectl Ubuntu16.04 --name SATA --add sata --controller IntelAhci --bootable on
|
||||
```
|
||||
|
||||
将之前创建的硬盘镜像和 CD/DVD 驱动器加载到 IDE 控制器。将 Ubuntu 的安装光盘插到 CD/DVD 驱动器上。然后用 “storageattach” 命令连接存储控制器和虚拟机。
|
||||
|
||||
```
|
||||
$ VBoxManage storageattach Ubuntu16.04 --storagectl SATA --port 0 --device 0 --type hdd --medium "your_iso_filepath"
|
||||
```
|
||||
|
||||
用媒体把 SATA 存储控制器连接到 Ubuntu16.04 虚拟机中,也就是之前创建的虚拟硬盘镜像里。
|
||||
|
||||
运行下面的命令添加像网络连接,音频之类的功能。
|
||||
|
||||
```
|
||||
$ VBoxManage modifyvm Ubuntu10.10 --nic1 nat --nictype1 82540EM --cableconnected1 on
|
||||
$ VBoxManage modifyvm Ubuntu10.10 --vram 128 --accelerate3d on --audio alsa --audiocontroller ac97
|
||||
```
|
||||
|
||||
通过指定你想要启动虚拟机的名称,用下面这个命令启动虚拟机。
|
||||
|
||||
```
|
||||
$ VBoxManage startvm Ubuntu16.04
|
||||
```
|
||||
|
||||
然后会打开一个新窗口,新窗口里虚拟机通过关联文件中引导。
|
||||
|
||||

|
||||
|
||||
你可以用接下来的命令来关掉虚拟机。
|
||||
|
||||
```
|
||||
$ VBoxManage controlvm Ubuntu16.04 poweroff
|
||||
```
|
||||
|
||||
“controlvm” 命令用来控制虚拟机的状态,可选的选项有 pause / resume / reset / poweroff / savestate / acpipowerbutton / acpisleepbutton。controlvm 有很多选项,用下面这个命令来查看它支持的所有选项。
|
||||
|
||||
```
|
||||
$VBoxManage controlvm
|
||||
```
|
||||
|
||||

|
||||
|
||||
完结!
|
||||
|
||||
从这篇文章中,我们了解了 Oracle Virtual Box 中一个十分实用的工具,就是 VBoxManage,包含了 VBoxManage 的安装和在 Ubuntu 16.04 系统上的使用。文章包含详细的教程, 通过 VBoxManage 中实用的命令来创建和管理虚拟机。希望这篇文章对你有帮助,另外别忘了分享你的评论或者建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-and-use-command-line-tool-vboxmanage-on-ubuntu-16-04/
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/kashif/
|
||||
[1]: https://www.virtualbox.org/wiki/Downloads
|
||||
218
translated/tech/20160606 Basic Git Commands You Must Know.md
Normal file
218
translated/tech/20160606 Basic Git Commands You Must Know.md
Normal file
@ -0,0 +1,218 @@
|
||||
你应该知道的基础 Git 命令
|
||||
=====================================
|
||||
|
||||

|
||||
|
||||
*简介:这个快速指南将向你展示所有的基础 Git 命令以及用法。你可以下载这些命令作为快速参考。*
|
||||
|
||||
我们在早先一篇文章中已经见过快速指南和 [Vi cheat sheet 下载][1]了。在这篇文章里,我们将会看到开始使用 Git 所需要的基础命令。
|
||||
|
||||
### GIT
|
||||
|
||||
[Git][2] 是一个分布式版本控制系统,它被用在大量开源项目中。它是在 2005 年由 Linux 创始人 [Linus Torvalds][3] 写就的。这个程序允许非线性的项目开发,并且能够通过存储在本地服务器高效处理大量数据。在这个教程里,我们将要和 Git 愉快玩耍并学习如何开始使用它。
|
||||
|
||||
我在这个教程里使用 Ubuntu,但你可以使用你选择的任何发行版。除了安装以外,剩下的所有命令在任何 Linux 发行版上都是一样的。
|
||||
|
||||
### 安装 GIT
|
||||
|
||||
要安装 git 执行以下命令:
|
||||
|
||||
```
|
||||
sudo apt-get install git-core
|
||||
```
|
||||
|
||||
在它完成下载之后,你就安装好了 Git 并且可以使用了。
|
||||
|
||||
### 设置 GIT:
|
||||
|
||||
在 Git 安装之后,不论是从 apt-get 还是从源码安装,你需要将你的用户名和邮箱地址复制到 gitconfig 文件。你可以访问 ~/.gitconfig 这个文件。
|
||||
|
||||
全新安装 Git 之后打开它会是完全空白的页面:
|
||||
|
||||
```
|
||||
sudo vim ~/.gitconfig
|
||||
```
|
||||
|
||||
你也可以使用以下命令添加所需的信息。将‘user’替换成你的用户名,‘user@example.com’替换成你的邮箱。
|
||||
|
||||
```
|
||||
git config --global user.name "User"
|
||||
git config --global user.email user@example.com
|
||||
```
|
||||
|
||||
然后你就完成设置了。现在让我们开始 Git。
|
||||
|
||||
### 仓库:
|
||||
|
||||
创建一个新目录,打开它并运行以下命令:
|
||||
|
||||
```
|
||||
git init
|
||||
```
|
||||
|
||||

|
||||
|
||||
这个命令会创建一个新的 git 仓库。你的本地仓库由三个 git 维护的“树”组成。
|
||||
|
||||
第一个是你的**工作目录**,保存实际的文件。第二个是索引,实际上扮演的是暂存区,最后一个是 HEAD,它指向你最后一个 commit 提交。
|
||||
|
||||
使用 git clone /path/to/repository 签出你的仓库(从你刚创建的仓库或服务器上已存在的仓库)。
|
||||
|
||||
### 添加文件并提交:
|
||||
|
||||
你可以用以下命令添加改动:
|
||||
|
||||
```
|
||||
git add <filename>
|
||||
```
|
||||
|
||||
这会添加一个新文件到暂存区以提交。如果你想添加每个新文件,输入:
|
||||
|
||||
```
|
||||
git add --all
|
||||
```
|
||||
|
||||
添加文件之后可以使用以下命令检查状态:
|
||||
|
||||
```
|
||||
git status
|
||||
```
|
||||
|
||||

|
||||
|
||||
正如你看到的,那里已经有一些变化但还没有提交。现在你需要提交这些变化,使用:
|
||||
|
||||
```
|
||||
git commit -m "提交信息"
|
||||
```
|
||||
|
||||

|
||||
|
||||
你也可以这么做(首选):
|
||||
|
||||
```
|
||||
git commit -a
|
||||
```
|
||||
|
||||
然后写下你的提交信息。现在你的文件提交到了 HEAD,但还不在你的远程仓库中。
|
||||
|
||||
### 推送你的改动
|
||||
|
||||
你的改动在你本地工作副本的 HEAD 中。如果你还没有从一个已存在的仓库克隆或想将你的仓库连接到远程服务器,你需要先添加它:
|
||||
|
||||
```
|
||||
git remote add origin <服务器地址>
|
||||
```
|
||||
|
||||
现在你可以将改动推送到指定的远程服务器。要将改动发送到远程服务器,运行:
|
||||
|
||||
```
|
||||
git push -u origin master
|
||||
```
|
||||
|
||||
### 分支:
|
||||
|
||||
分支用于开发特性,它们之间是互相独立的。主分支 master 是你创建一个仓库时的“默认”分支。使用其它分支用于开发,在完成时将它合并回主分支。
|
||||
|
||||
创建一个名为“mybranch”的分支并切换到它之上:
|
||||
|
||||
```
|
||||
git checkout -b mybranch
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以使用这个命令切换回主分支:
|
||||
|
||||
```
|
||||
git checkout master
|
||||
```
|
||||
|
||||
如果你想删除这个分支,执行:
|
||||
|
||||
```
|
||||
git branch -d mybranch
|
||||
```
|
||||
|
||||

|
||||
|
||||
除非你将分支推送到远程服务器上,否则该分支对其他人是不可用的,所以只需把它推送上去:
|
||||
|
||||
```
|
||||
git push origin <分支名>
|
||||
```
|
||||
|
||||
### 更新和合并
|
||||
|
||||
要将你本地仓库更新到最新提交,运行:
|
||||
|
||||
```
|
||||
git pull
|
||||
```
|
||||
|
||||
在你的工作目录获取和合并远程变动。要合并其它分支到你的活动分支(如 master),使用:
|
||||
|
||||
```
|
||||
git merge <分支>
|
||||
```
|
||||
|
||||
在这两种情况下,git 会尝试自动合并(auto-merge)改动。不幸的是,这不总是可能的,可能会导致冲突。你需要负责通过编辑 git 显示的文件,手动合并那些冲突。改动之后,你需要用以下命令将它们标记为已合并:
|
||||
|
||||
```
|
||||
git add <文件名>
|
||||
```
|
||||
|
||||
在合并改动之前,你也可以使用以下命令预览:
|
||||
|
||||
```
|
||||
git diff <源分支> <目标分支>
|
||||
```
|
||||
|
||||
### GIT 日志:
|
||||
|
||||
你可以这么查看仓库历史:
|
||||
|
||||
```
|
||||
git log
|
||||
```
|
||||
|
||||
要查看每个提交一行样式的日志你可以用:
|
||||
|
||||
```
|
||||
git log --pretty=oneline
|
||||
```
|
||||
|
||||
或者也许你想要看一个所有分支的 ASCII 艺术树,带有标签和分支名:
|
||||
|
||||
```
|
||||
git log --graph --oneline --decorate --all
|
||||
```
|
||||
|
||||
如果你只想看哪些文件改动过:
|
||||
|
||||
```
|
||||
git log --name-status
|
||||
```
|
||||
|
||||
在这整个过程中如果你需要任何帮助,你可以用 git --help。
|
||||
|
||||
Git 棒不棒!!!祝贺你你已经会 git 基础了。如果你愿意的话,你可以从下面这个链接下载这些基础 Git 命令作为快速参考:
|
||||
|
||||
[下载 Git Cheat Sheet][4]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/basic-git-commands-cheat-sheet/
|
||||
|
||||
作者:[Rakhi Sharma][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/rakhi/
|
||||
[1]: http://itsfoss.com/download-vi-cheat-sheet/
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://en.wikipedia.org/wiki/Linus_Torvalds
|
||||
[4]: https://drive.google.com/open?id=0By49_3Av9sT1bXpINjhvU29VNUU
|
||||
@ -0,0 +1,316 @@
|
||||
LFCS 第十讲:学习简单的 Shell 脚本编程和文件系统故障排除
|
||||
================================================================================
|
||||
Linux 基金会发起了 LFCS 认证 (Linux Foundation Certified Sysadmin, Linux 基金会认证系统管理员),这是一个全新的认证体系,主要目标是让全世界任何人都有机会考取认证。认证内容为 Linux 中间系统的管理,主要包括:系统运行和服务的维护、全面监控和分析的能力以及问题来临时何时想上游团队请求帮助的决策能力
|
||||
|
||||

|
||||
|
||||
LFCS 系列第十讲
|
||||
|
||||
请看以下视频,这里边介绍了 Linux 基金会认证程序。
|
||||
|
||||
<video src="https://dn-linuxcn.qbox.me/static%2Fvideo%2FIntroducing%20The%20Linux%20Foundation%20Certification%20Program-Y29qZ71Kicg.mp4" controls="controls" width="100%">
|
||||
</video>
|
||||
|
||||
本讲是系列教程中的第十讲,主要集中讲解简单的 Shell 脚本编程和文件系统故障排除。这两块内容都是 LFCS 认证中的必备考点。
|
||||
|
||||
### 理解终端 (Terminals) 和 Shell ###
|
||||
|
||||
首先要声明一些概念。
|
||||
|
||||
- Shell 是一个程序,它将命令传递给操作系统来执行。
|
||||
- Terminal 也是一个程序,作为最终用户,我们需要使用它与 Shell 来交互。比如,下边的图片是 GNOME Terminal。
|
||||
|
||||

|
||||
|
||||
Gnome Terminal
|
||||
|
||||
启动 Shell 之后,会呈现一个命令提示符 (也称为命令行) 提示我们 Shell 已经做好了准备,接受标准输入设备输入的命令,这个标准输入设备通常是键盘。
|
||||
|
||||
你可以参考该系列文章的 [第一讲 使用命令创建、编辑和操作文件][1] 来温习一些常用的命令。
|
||||
|
||||
Linux 为提供了许多可以选用的 Shell,下面列出一些常用的:
|
||||
|
||||
**bash Shell**
|
||||
|
||||
Bash 代表 Bourne Again Shell,它是 GNU 项目默认的 Shell。它借鉴了 Korn shell (ksh) 和 C shell (csh) 中有用的特性,并同时对性能进行了提升。它同时也是 LFCS 认证中所涵盖的风发行版中默认 Shell,也是本系列教程将使用的 Shell。
|
||||
|
||||
**sh Shell**
|
||||
|
||||
Bash Shell 是一个比较古老的 shell,一次多年来都是多数类 Unix 系统的默认 shell。
|
||||
|
||||
**ksh Shell**
|
||||
|
||||
Korn SHell (ksh shell) 也是一个 Unix shell,是贝尔实验室 (Bell Labs) 的 David Korn 在 19 世纪 80 年代初的时候开发的。它兼容 Bourne shell ,并同时包含了 C shell 中的多数特性。
|
||||
|
||||
|
||||
一个 shell 脚本仅仅只是一个可执行的文本文件,里边包含一条条可执行命令。
|
||||
|
||||
### 简单的 Shell 脚本编程 ###
|
||||
|
||||
如前所述,一个 shell 脚本就是一个纯文本文件,因此,可以使用自己喜欢的文本编辑器来创建和编辑。你可以考虑使用 vi/vim (参考本系列 [第二部分 - vi/vim 编辑器的使用][2]),它的语法高亮让我的编辑工作非常方便。
|
||||
|
||||
输入如下命令来创建一个名为 myscript.sh 的脚本文件:
|
||||
|
||||
# vim myscript.sh
|
||||
|
||||
shell 脚本的第一行 (著名的 [shebang 符](http://smilejay.com/2012/03/linux_shebang/)) 必须如下:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
这条语句“告诉”操作系统需要用那个解释器来运行这个脚本文件之后命令。
|
||||
|
||||
现在可以添加需要执行的命令了。通过注释,我们可以声明每一条命令或者整个脚本的具体含义。注意,shell 会忽略掉以井号 (#) 开始的语句。
|
||||
|
||||
#!/bin/bash
|
||||
echo 这是关于 LFCS 认证系列的第十部分
|
||||
echo 今天是 $(date +%Y-%m-%d)
|
||||
|
||||
编写并保存脚本之后,通过以下命令来是脚本文件称为可执行文件:
|
||||
|
||||
# chmod 755 myscript.sh
|
||||
|
||||
在执行脚本之前,我们需要说一下环境变量 ($PATH),运行:
|
||||
|
||||
echo $PATH
|
||||
|
||||
我们就会看到环境变量 ($PATH) 的具体内容:当输入命令是系统搜索可执行程序的目录,每一项之间使用冒号 (:) 隔开。称它为环境变量,是因为他本是就是 shell 环境的一部分 —— 当 shell 第每次启动时 shell 及其子进程可以获取的一系列信息。
|
||||
|
||||
当我们输入一个命令并按下回车时,shell 会搜索 $PATH 变量中列出的目录并执行第一个知道的实例。请看如下例子:
|
||||
|
||||

|
||||
|
||||
环境变量
|
||||
|
||||
假如存在两个同名的可执行程序,一个在 /usr/local/bin,另一个在 /usr/bin,则会执行环境变量中最先列出的那个,并忽略另外一个。
|
||||
|
||||
如果我们自己编写的脚本没有在 $PATH 变量列出目录的其中一个,则需要输入 ./filename 来执行它。而如果存储在 $PATH 变量中的任意一个目录,我们就可以像运行其他命令一样来运行之前编写的脚本了。
|
||||
|
||||
# pwd
|
||||
# ./myscript.sh
|
||||
# cp myscript.sh ../bin
|
||||
# cd ../bin
|
||||
# pwd
|
||||
# myscript.sh
|
||||
|
||||

|
||||
|
||||
执行脚本
|
||||
|
||||
#### if 条件语句 ####
|
||||
|
||||
无论何时,当你需要在脚本中根据某个命令的运行结果来采取相应动作时,你应该使用 if 结构来定义条件。基本语法如下:
|
||||
|
||||
if CONDITION; then
|
||||
COMMANDS;
|
||||
else
|
||||
OTHER-COMMANDS
|
||||
fi
|
||||
|
||||
其中,CONDITION 为如下情形的任意一项 (仅列出常用的),并且达到以下条件时返回 true:
|
||||
|
||||
- [ -a file ] → 指定文件存在。
|
||||
- [ -d file ] → 指定文件存在,并且是一个目录。
|
||||
- [ -f file ] → 指定文件存在,并且是一个普通文件。
|
||||
- [ -u file ] → 指定文件存在,并设置了 SUID。
|
||||
- [ -g file ] → 指定文件存在,并设置了 SGID。
|
||||
- [ -k file ] → 指定文件存在,并设置了“黏连 (Sticky)”位。
|
||||
- [ -r file ] → 指定文件存在,并且文件可读。
|
||||
- [ -s file ] → 指定文件存在,并且文件为空。
|
||||
- [ -w file ] → 指定文件存在,并且文件可写入·
|
||||
- [ -x file ] → 指定文件存在,并且可执行。
|
||||
- [ string1 = string2 ] → 字符串相同。
|
||||
- [ string1 != string2 ] → 字符串不相同。
|
||||
|
||||
[ int1 op int2 ] 为前述列表中的一部分,紧跟着的项 (例如: -eq –> int1 与 int2 相同时返回 true) 则是 [ int1 op int2 ] 的一个子项, 其中 op 为以下比较操作符。
|
||||
|
||||
- -eq –> int1 等于 int2 时返回 true。
|
||||
- -ne –> int1 不等于 int2 时返回 true。
|
||||
- -lt –> int1 小于 int2 时返回 true。
|
||||
- -le –> int1 小于或等于 int2 时返回 true。
|
||||
- -gt –> int1 大于 int2 时返回 true。
|
||||
- -ge –> int1 大于或等于 int2 时返回 true。
|
||||
|
||||
#### for 循环语句 ####
|
||||
|
||||
循环语句可以在某个条件下重复执行某个命令。基本语法如下:
|
||||
|
||||
for item in SEQUENCE; do
|
||||
COMMANDS;
|
||||
done
|
||||
|
||||
其中,item 为每次执行 COMMANDS 时,在 SEQUENCE 中匹配到的值。
|
||||
|
||||
#### While 循环语句 ####
|
||||
|
||||
该循环结构会一直执行重复的命令,直到控制命令执行的退出状态值等于 0 时 (即执行成功) 停止。基本语法如下:
|
||||
|
||||
while EVALUATION_COMMAND; do
|
||||
EXECUTE_COMMANDS;
|
||||
done
|
||||
|
||||
其中,EVALUATION_COMMAND 可以是任何能够返回成功 (0) 或失败 (0 以外的值) 的退出状态值的命令,EXECUTE_COMMANDS 则可以是任何的程序、脚本或者 shell 结构体,包括其他的嵌套循环。
|
||||
|
||||
#### 综合使用 ####
|
||||
|
||||
我们会通过以下例子来演示 if 条件语句和 for 循环语句。
|
||||
|
||||
**在基于 systemd 的发行版中探测某个服务是否在运行**
|
||||
|
||||
先建立一个文件,列出我们想要想要查看的服务名。
|
||||
|
||||
# cat myservices.txt
|
||||
|
||||
sshd
|
||||
mariadb
|
||||
httpd
|
||||
crond
|
||||
firewalld
|
||||
|
||||

|
||||
|
||||
使用脚本监控 Linux 服务
|
||||
|
||||
我们编写的脚本看起来应该是这样的:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script iterates over a list of services and
|
||||
# is used to determine whether they are running or not.
|
||||
|
||||
for service in $(cat myservices.txt); do
|
||||
systemctl status $service | grep --quiet "running"
|
||||
if [ $? -eq 0 ]; then
|
||||
echo $service "is [ACTIVE]"
|
||||
else
|
||||
echo $service "is [INACTIVE or NOT INSTALLED]"
|
||||
fi
|
||||
done
|
||||
|
||||

|
||||
|
||||
Linux 服务监控脚本
|
||||
|
||||
**我们来解释一下这个脚本的工作流程**
|
||||
|
||||
1). for 循环每次读取 myservices.txt 文件中的一项记录,每一项纪录表示一个服务的通用变量名。各项记录组成如下:
|
||||
|
||||
# cat myservices.txt
|
||||
|
||||
2). 以上命令由圆括号括着,并在前面添加美元符,表示它需要从 myservices.txt 的记录列表中取值作为变量传递给 for 循环。
|
||||
|
||||
3). 对于记录列表中的每一项纪录 (即每一项纪录的服务变量),都会这行以下动作:
|
||||
|
||||
# systemctl status $service | grep --quiet "running"
|
||||
|
||||
此时,需要在每个通用变量名 (即每一项纪录的服务变量) 的前面添加美元符,以表明它是作为变量来传递的。其输出则通过管道符传给 grep。
|
||||
|
||||
其中,-quiet 选项用于阻止 grep 命令将出现 "running" 的行回显到屏幕。当 grep 捕获到 "running" 时,则会返回一个退出状态码 "0" (在 if 结构体表示为 $?),由此确认某个服务正在运行中。
|
||||
|
||||
如果退出状态码是非零值 (即 systemctl status $service 命令中的回显中没有出现 "running"),则表明某个服务为运行。
|
||||
|
||||

|
||||
|
||||
服务监控脚本
|
||||
|
||||
我们可以增加一步,在开始循环之前,先确认 myservices.txt 是否存在。
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script iterates over a list of services and
|
||||
# is used to determine whether they are running or not.
|
||||
|
||||
if [ -f myservices.txt ]; then
|
||||
for service in $(cat myservices.txt); do
|
||||
systemctl status $service | grep --quiet "running"
|
||||
if [ $? -eq 0 ]; then
|
||||
echo $service "is [ACTIVE]"
|
||||
else
|
||||
echo $service "is [INACTIVE or NOT INSTALLED]"
|
||||
fi
|
||||
done
|
||||
else
|
||||
echo "myservices.txt is missing"
|
||||
fi
|
||||
|
||||
**Ping 一系列网络或者 Internet 主机名以获取应答数据**
|
||||
|
||||
你可能想把自己维护的主机写入一个文本文件,并使用脚本探测它们是否能够 ping 得通 (脚本中的 myhosts 可以随意替换为你想要的名称)。
|
||||
|
||||
内置的 read shell 命令将告诉 while 循环一行行的读取 myhosts,并将读取的每行内容传给 host 变量,随后 host 变量传递给 ping 命令。
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# This script is used to demonstrate the use of a while loop
|
||||
|
||||
while read host; do
|
||||
ping -c 2 $host
|
||||
done < myhosts
|
||||
|
||||

|
||||
|
||||
使用脚本 Ping 服务器
|
||||
|
||||
扩展阅读:
|
||||
|
||||
- [Learn Shell Scripting: A Guide from Newbies to System Administrator][3]
|
||||
- [5 Shell Scripts to Learn Shell Programming][4]
|
||||
|
||||
### 文件系统排除 ###
|
||||
|
||||
尽管 Linux 是一个很稳定的操作系统,但仍然会因为某些原因出现崩溃 (比如以外断电等),正好你有一个 (或者更多个) 文件系统未能正确卸载,Linux 重启的时候就会自动检测其中可能发生的错误。
|
||||
|
||||
此外,每次系统正常启动的时候,都会在文件系统挂载之前校验它们的完整度。而这些全部都依赖于 fsck 工具 ("文件系统校验")。
|
||||
|
||||
如果对 fsck 进行设定,它除了校验文件系统的完整性之外,还可以尝试修复错误。fsck 能否成功修复错误,取决于文件系统的损伤程度;如果可以修复,被损坏部分的文件会恢复到位于每个文件系统根目录的 lost+found。
|
||||
|
||||
最后但同样重要的是,我们必须注意,如果拔掉系统正在写入数据的 USB 设备同样会发生错误,甚至可能发生硬件损坏。
|
||||
|
||||
fsck 的基本用如下:
|
||||
|
||||
# fsck [options] filesystem
|
||||
|
||||
**检查文件系统错误并尝试自动修复**
|
||||
|
||||
想要使用 fsck 检查文件系统,我们需要首先卸载文件系统。
|
||||
|
||||
# mount | grep sdg1
|
||||
# umount /mnt
|
||||
# fsck -y /dev/sdg1
|
||||
|
||||

|
||||
|
||||
检查文件系统错误
|
||||
|
||||
除了 -y 选项,我们也可以使用 -a 选项来自动修复文件系统错误,而不必做出交互式应答,并在文件系统看起来 "干净" 的情况下强制校验。
|
||||
|
||||
# fsck -af /dev/sdg1
|
||||
|
||||
如果只是要找出什么地方发生了错误 (不用再检测到错误的时候修复),我们开使用 -n 选项,这样只会讲文集系统错误输出到标准输出设备。
|
||||
|
||||
# fsck -n /dev/sdg1
|
||||
|
||||
根据 fsck 输出的错误信息,我们可以知道是否可以自己修复或者需要将问题提交给工程师团队来做详细的硬件校验。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
至此,系列教程的十讲就全部结束了,全系列教程涵盖了通过 LFCS 测试所需的基础内容。
|
||||
|
||||
但显而易见的,本系列的十讲并不足以在单个主题方面做到全面描述,我们希望这一系列教程可以成为你学习的基础素材,并一直保持学习的热情。
|
||||
|
||||
我们欢迎你提出任何问题或者建议,所以你可以毫不犹豫的通过以下链接联系我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/learning-shell-scripting-language-a-guide-from-newbies-to-system-administrator/
|
||||
[4]:http://www.tecmint.com/basic-shell-programming-part-ii/
|
||||
@ -1,230 +0,0 @@
|
||||
Flowsnow translating...
|
||||
LFCS系列第九讲: 使用Yum, RPM, Apt, Dpkg, Aptitude, Zypper进行Linux包管理
|
||||
================================================================================
|
||||
去年八月, Linux基金会宣布了一个全新的LFCS(Linux Foundation Certified Sysadmin,Linux基金会认证系统管理员)认证计划,这对广大系统管理员来说是一个很好的机会,管理员们可以通过绩效考试来表明自己可以成功支持Linux系统的整体运营。 当需要的时候一个Linux基金会认证的系统管理员有足够的专业知识来确保系统高效运行,提供第一手的故障诊断和监视,并且为工程师团队在问题升级时提供智能决策。
|
||||
|
||||

|
||||
|
||||
Linux基金会认证系统管理员 – 第九讲
|
||||
|
||||
请观看下面关于Linux基金会认证计划的演示。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="http://www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
本文是本系列十套教程中的第九讲,今天在这篇文章中我们会引导你学习Linux包管理,这也是LFCS认证考试所需要的。
|
||||
|
||||
### 包管理 ###
|
||||
|
||||
简单的说,包管理是系统中安装和维护软件的一种方法,其中维护也包含更新和卸载。
|
||||
|
||||
在Linux早期,程序只以源代码的方式发行,还带有所需的用户使用手册和必备的配置文件,甚至更多。现如今,大多数发行商使用默认的预装程序或者被称为包的程序集合。用户使用这些预装程序或者包来安装该发行版本。然而,Linux最伟大的一点是我们仍然能够获得程序的源代码用来学习、改进和编译。
|
||||
|
||||
**包管理系统是如何工作的**
|
||||
|
||||
如果某一个包需要一定的资源,如共享库,或者需要另一个包,据说就会存在依赖性问题。所有现在的包管理系统提供了一些解决依赖性的方法,以确保当安装一个包时,相关的依赖包也安装好了
|
||||
|
||||
**打包系统**
|
||||
|
||||
几乎所有安装在现代Linux系统上的软件都会在互联网上找到。它要么能够通过中央库(中央库能包含几千个包,每个包都已经构建、测试并且维护好了)发行商得到,要么能够直接得到可以下载和手动安装的源代码。
|
||||
|
||||
由于不同的发行版使用不同的打包系统(Debian的*.deb文件/ CentOS的*.rpm文件/ openSUSE的专门为openSUSE构建的*.rpm文件),因此为一个发行版本开发的包会与其他发行版本不兼容。然而,大多数发行版本都可能是LFCS认证的三个发行版本之一。
|
||||
|
||||
**高级和低级打包工具**
|
||||
|
||||
为了有效地进行包管理的任务,你需要知道,你将有两种类型的实用工具:低级工具(能在后端实际安装,升级,卸载包文件),以及高级工具(负责确保能很好的执行依赖性解决和元数据检索的任务,元数据也称为关于数据的数据)。
|
||||
|
||||
注:表格
|
||||
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="200">
|
||||
</colgroup>
|
||||
<colgroup width="200">
|
||||
</colgroup>
|
||||
<colgroup width="200">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td bgcolor="#AEA79F" align="CENTER" height="18" style="border: 1px solid #000001;"><b><span style="color: black;">发行版</span></b></td>
|
||||
<td bgcolor="#AEA79F" align="CENTER" style="border: 1px solid #000001;"><b><span style="color: black;">低级工具</span></b></td>
|
||||
<td bgcolor="#AEA79F" align="CENTER" style="border: 1px solid #000001;"><b><span style="color: black;">高级工具</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td bgcolor="#FFFFFF" align="LEFT" height="18" style="border: 1px solid #000001;"><span style="color: black;"> Debian版及其衍生版</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> dpkg</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> apt-get / aptitude</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" height="18" style="border: 1px solid #000001;"><span style="color: black;"> CentOS版</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> rpm</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> yum</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td bgcolor="#FFFFFF" align="LEFT" height="18" style="border: 1px solid #000001;"><span style="color: black;"> openSUSE版</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> rpm</span></td>
|
||||
<td bgcolor="#FFFFFF" align="LEFT" style="border: 1px solid #000001;"><span style="color: black;"> zypper</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
让我们来看下低级工具和高级工具的描述。
|
||||
|
||||
dpkg的是基于Debian系统中的一个低级包管理器。它可以安装,删除,提供有关资料,并建立*.deb包,但它不能自动下载并安装它们相应的依赖包。
|
||||
|
||||
- 阅读更多: [15个dpkg命令实例][1]
|
||||
|
||||
apt-get是Debian和衍生版的高级包管理器,并提供命令行方式从多个来源检索和安装软件包,其中包括解决依赖性。和dpkg不同的是,apt-get不是直接基于.deb文件工作,而是基于包的正确名称。
|
||||
|
||||
- 阅读更多: [25个apt-get命令实力][2]
|
||||
|
||||
Aptitude是基于Debian的系统的另一个高级包管理器,它可用于快速简便的执行管理任务(安装,升级和删除软件包,还可以自动处理解决依赖性)。与atp-get和额外的包管理器相比,它提供了相同的功能,例如提供对包的几个版本的访问。
|
||||
|
||||
rpm是Linux标准基础(LSB)兼容发布版使用的一种包管理器,用来对包进行低级处理。就像dpkg,rpm可以查询,安装,检验,升级和卸载软件包,并能被基于Fedora的系统频繁地使用,比如RHEL和CentOS。
|
||||
|
||||
- 阅读更多: [20个rpm命令实例][3]
|
||||
|
||||
相对于基于RPM的系统,yum增加了系统自动更新的功能和带依赖性管理的包管理功能。作为一个高级工具,和apt-get或者aptitude相似,yum基于库工作。
|
||||
|
||||
- 阅读更多: [20个yum命令实例][4]
|
||||
-
|
||||
### 低级工具的常见用法 ###
|
||||
|
||||
你用低级工具处理最常见的任务如下。
|
||||
|
||||
**1. 从已编译(*.deb或*.rpm)的文件安装一个包**
|
||||
|
||||
这种安装方法的缺点是没有提供解决依赖性的方案。当你在发行版本库中无法获得某个包并且又不能通过高级工具下载安装时,你很可能会从一个已编译文件安装该包。因为低级工具不需要解决依赖性问题,所以当安装一个没有解决依赖性的包时会出现出错并且退出。
|
||||
|
||||
# dpkg -i file.deb [Debian版和衍生版]
|
||||
# rpm -i file.rpm [CentOS版 / openSUSE版]
|
||||
|
||||
**注意**: 不要试图在CentOS中安装一个为openSUSE构建的.rpm文件,反之亦然!
|
||||
|
||||
**2. 从已编译文件中更新一个包**
|
||||
|
||||
同样,当中央库中没有某安装包时,你只能手动升级该包。
|
||||
|
||||
# dpkg -i file.deb [Debian版和衍生版]
|
||||
# rpm -U file.rpm [CentOS版 / openSUSE版]
|
||||
|
||||
**3. 列举安装的包**
|
||||
|
||||
当你第一次接触一个已经在工作中的系统时,很可能你会想知道安装了哪些包。
|
||||
|
||||
# dpkg -l [Debian版和衍生版]
|
||||
# rpm -qa [CentOS版 / openSUSE版]
|
||||
|
||||
如果你想知道一个特定的包安装在哪儿, 你可以使用管道命令从以上命令的输出中去搜索,这在这个系列的[操作Linux文件 – 第一讲][5] 中有介绍。假定我们需要验证mysql-common这个包是否安装在Ubuntu系统中。
|
||||
|
||||
# dpkg -l | grep mysql-common
|
||||
|
||||

|
||||
|
||||
检查安装的包
|
||||
|
||||
另外一种方式来判断一个包是否已安装。
|
||||
|
||||
# dpkg --status package_name [Debian版和衍生版]
|
||||
# rpm -q package_name [CentOS版 / openSUSE版]
|
||||
|
||||
例如,让我们找出sysdig包是否安装在我们的系统。
|
||||
|
||||
# rpm -qa | grep sysdig
|
||||
|
||||

|
||||
|
||||
检查sysdig包
|
||||
|
||||
**4. 查询一个文件是由那个包安装的**
|
||||
|
||||
# dpkg --search file_name
|
||||
# rpm -qf file_name
|
||||
|
||||
例如,pw_dict.hwm文件是由那个包安装的?
|
||||
|
||||
# rpm -qf /usr/share/cracklib/pw_dict.hwm
|
||||
|
||||

|
||||
|
||||
Linux中查询文件
|
||||
|
||||
### 高级工具的常见用法 ###
|
||||
|
||||
你用高级工具处理最常见的任务如下。
|
||||
|
||||
**1. 搜索包**
|
||||
|
||||
aptitude更新将会更新可用的软件包列表,并且aptitude搜索会根据包名进行实际性的搜索。
|
||||
|
||||
# aptitude update && aptitude search package_name
|
||||
|
||||
在搜索所有选项中,yum不仅可以通过包名还可以通过包的描述搜索程序包。
|
||||
|
||||
# yum search package_name
|
||||
# yum search all package_name
|
||||
# yum whatprovides “*/package_name”
|
||||
|
||||
假定我们需要一个名为sysdig的包,要知道的是我们需要先安装然后才能运行。
|
||||
|
||||
# yum whatprovides “*/sysdig”
|
||||
|
||||

|
||||
|
||||
检查包描述
|
||||
|
||||
whatprovides告诉yum搜索一个含有能够匹配上述正则表达式的文件的包。
|
||||
|
||||
# zypper refresh && zypper search package_name [在openSUSE上]
|
||||
|
||||
**2. 从仓库安装一个包**
|
||||
|
||||
当安装一个包时,在包管理器解决了所有依赖性问题后,可能会提醒你确认安装。需要注意的是运行更新或刷新(根据所使用的软件包管理器)不是绝对必要,但是考虑到安全性和依赖性的原因,保持安装的软件包是最新的是一个好的系统管理员的做法。
|
||||
|
||||
# aptitude update && aptitude install package_name [Debian版和衍生版]
|
||||
# yum update && yum install package_name [CentOS版]
|
||||
# zypper refresh && zypper install package_name [openSUSE版]
|
||||
|
||||
**3. 卸载包**
|
||||
|
||||
按选项卸载将会卸载软件包,但把配置文件保留完好,然而清除包从系统中完全删去该程序。
|
||||
# aptitude remove / purge package_name
|
||||
# yum erase package_name
|
||||
|
||||
---注意要卸载的openSUSE包前面的减号 ---
|
||||
|
||||
# zypper remove -package_name
|
||||
|
||||
在默认情况下,大部分(如果不是全部)的包管理器会提示你,在你实际卸载之前你是否确定要继续卸载。所以,请仔细阅读屏幕上的信息,以避免陷入不必要的麻烦!
|
||||
|
||||
**4. 显示包的信息**
|
||||
|
||||
下面的命令将会显示birthday这个包的信息。
|
||||
|
||||
# aptitude show birthday
|
||||
# yum info birthday
|
||||
# zypper info birthday
|
||||
|
||||

|
||||
|
||||
检查包信息
|
||||
|
||||
### 总结 ###
|
||||
|
||||
作为一个系统管理员,包管理器是你不能回避的东西。你应该立即准备使用本文中介绍的这些工具。希望你在准备LFCS考试和日常工作中会觉得这些工具好用。欢迎在下面留下您的意见或问题,我们将尽可能快的回复你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-package-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[2]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[3]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[4]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[5]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user