mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
bbfc80a596
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11066-1.html)
|
||||
[#]: subject: (How To Find The Port Number Of A Service In Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-find-the-port-number-of-a-service-in-linux/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
@ -16,9 +16,9 @@
|
||||
|
||||
### 在 Linux 中查找服务的端口号
|
||||
|
||||
**方法1:使用 [grep][2] 命令**
|
||||
#### 方法1:使用 grep 命令
|
||||
|
||||
要使用 grep 命令在 Linux 中查找指定服务的默认端口号,只需运行:
|
||||
要使用 `grep` 命令在 Linux 中查找指定服务的默认端口号,只需运行:
|
||||
|
||||
```
|
||||
$ grep <port> /etc/services
|
||||
@ -84,11 +84,11 @@ tftp 69/tcp
|
||||
[...]
|
||||
```
|
||||
|
||||
**方法 2:使用 getent 命令**
|
||||
#### 方法 2:使用 getent 命令
|
||||
|
||||
如你所见,上面的命令显示指定搜索词 “ssh”、“http” 和 “ftp” 的所有端口名称和数字。这意味着,你将获得与给定搜索词匹配的所有端口名称的相当长的输出。
|
||||
|
||||
但是,你可以使用 “getent” 命令精确输出结果,如下所示:
|
||||
但是,你可以使用 `getent` 命令精确输出结果,如下所示:
|
||||
|
||||
```
|
||||
$ getent services ssh
|
||||
@ -114,17 +114,15 @@ http 80/tcp
|
||||
$ getent services
|
||||
```
|
||||
|
||||
**方法 3:使用 Whatportis 程序**
|
||||
#### 方法 3:使用 Whatportis 程序
|
||||
|
||||
**Whatportis** 是一个简单的 python 脚本,来用于查找端口名称和端口号。与上述命令不同,此程序以漂亮的表格形式输出。
|
||||
Whatportis 是一个简单的 Python 脚本,来用于查找端口名称和端口号。与上述命令不同,此程序以漂亮的表格形式输出。
|
||||
|
||||
确保已安装 PIP 包管理器。如果没有,请参考以下链接。
|
||||
确保已安装 pip 包管理器。如果没有,请参考以下链接。
|
||||
|
||||
* [**如何使用 Pip 管理 Python 包**][6]
|
||||
- [如何使用 pip 管理 Python 包][6]
|
||||
|
||||
|
||||
|
||||
安装 PIP 后,运行以下命令安装 Whatportis 程序。
|
||||
安装 pip 后,运行以下命令安装 Whatportis 程序。
|
||||
|
||||
```
|
||||
$ pip install whatportis
|
||||
@ -144,9 +142,9 @@ $ whatportis http
|
||||
|
||||
![][7]
|
||||
|
||||
在 Linux 中查找服务的端口号
|
||||
*在 Linux 中查找服务的端口号*
|
||||
|
||||
如果你不知道服务的确切名称,请使用 **–like** 标志来显示相关结果。
|
||||
如果你不知道服务的确切名称,请使用 `–like` 标志来显示相关结果。
|
||||
|
||||
```
|
||||
$ whatportis mysql --like
|
||||
@ -158,7 +156,7 @@ $ whatportis mysql --like
|
||||
$ whatportis 993
|
||||
```
|
||||
|
||||
你甚至可以以 **JSON** 格式显示结果。
|
||||
你甚至可以以 JSON 格式显示结果。
|
||||
|
||||
```
|
||||
$ whatportis 993 --json
|
||||
@ -168,9 +166,7 @@ $ whatportis 993 --json
|
||||
|
||||
有关更多详细信息,请参阅 GitHub 仓库。
|
||||
|
||||
* [**Whatportis GitHub 仓库**][9]
|
||||
|
||||
|
||||
* [Whatportis GitHub 仓库][9]
|
||||
|
||||
就是这些了。你现在知道了如何使用三种简单方法在 Linux 中查找端口名称和端口号。如果你知道任何其他方法/命令,请在下面的评论栏告诉我。我会查看并更相应地更新本指南。
|
||||
|
||||
@ -181,7 +177,7 @@ via: https://www.ostechnix.com/how-to-find-the-port-number-of-a-service-in-linux
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
1208
published/20180629 100 Best Ubuntu Apps.md
Normal file
1208
published/20180629 100 Best Ubuntu Apps.md
Normal file
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11061-1.html)
|
||||
[#]: subject: (Create a Custom System Tray Indicator For Your Tasks on Linux)
|
||||
[#]: via: (https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux)
|
||||
[#]: author: (M.Hanny Sabbagh https://fosspost.org/author/mhsabbagh)
|
||||
|
||||
在 Linux 上为你的任务创建一个自定义的系统托盘指示器
|
||||
======
|
||||
|
||||
系统托盘图标如今仍是一个很神奇的功能。只需要右击图标,然后选择想要的动作,你就可以大幅简化你的生活并且减少日常行为中的大量无用的点击。
|
||||
|
||||
一说到有用的系统托盘图标,我们很容易就想到 Skype、Dropbox 和 VLC:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux][1]
|
||||
|
||||
然而系统托盘图标实际上要更有用得多;你可以根据自己的需求创建自己的系统托盘图标。本指导将会教你通过简单的几个步骤来实现这一目的。
|
||||
|
||||
### 前置条件
|
||||
|
||||
我们将要用 Python 来实现一个自定义的系统托盘指示器。Python 可能已经默安装在所有主流的 Linux 发行版中了,因此你只需要确定一下它已经被安装好了(此处使用版本为 2.7)。另外,我们还需要安装好 `gir1.2-appindicator3` 包。该库能够让我们很容易就能创建系统图标指示器。
|
||||
|
||||
在 Ubuntu/Mint/Debian 上安装:
|
||||
|
||||
```
|
||||
sudo apt-get install gir1.2-appindicator3
|
||||
```
|
||||
|
||||
在 Fedora 上安装:
|
||||
|
||||
```
|
||||
sudo dnf install libappindicator-gtk3
|
||||
```
|
||||
|
||||
对于其他发行版,只需要搜索包含 “appindicator” 的包就行了。
|
||||
|
||||
在 GNOME Shell 3.26 开始,系统托盘图标被删除了。你需要安装 [这个扩展][2](或者其他扩展)来为桌面启用该功能。否则你无法看到我们创建的指示器。
|
||||
|
||||
### 基础代码
|
||||
|
||||
下面是该指示器的基础代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/python
|
||||
import os
|
||||
from gi.repository import Gtk as gtk, AppIndicator3 as appindicator
|
||||
def main():
|
||||
indicator = appindicator.Indicator.new("customtray", "semi-starred-symbolic", appindicator.IndicatorCategory.APPLICATION_STATUS)
|
||||
indicator.set_status(appindicator.IndicatorStatus.ACTIVE)
|
||||
indicator.set_menu(menu())
|
||||
gtk.main()
|
||||
def menu():
|
||||
menu = gtk.Menu()
|
||||
|
||||
command_one = gtk.MenuItem('My Notes')
|
||||
command_one.connect('activate', note)
|
||||
menu.append(command_one)
|
||||
exittray = gtk.MenuItem('Exit Tray')
|
||||
exittray.connect('activate', quit)
|
||||
menu.append(exittray)
|
||||
|
||||
menu.show_all()
|
||||
return menu
|
||||
|
||||
def note(_):
|
||||
os.system("gedit $HOME/Documents/notes.txt")
|
||||
def quit(_):
|
||||
gtk.main_quit()
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
我们待会会解释一下代码是怎么工作的。但是现在,让我们将该文本保存为 `tray.py`,然后使用 Python 运行之:
|
||||
|
||||
```
|
||||
python tray.py
|
||||
```
|
||||
|
||||
我们会看到指示器运行起来了,如下图所示:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 13][3]
|
||||
|
||||
现在,让我们解释一下这个魔法的原理:
|
||||
|
||||
* 前三行代码仅仅用来指明 Python 的路径并且导入需要的库。
|
||||
* `def main()` :此为指示器的主函数。该函数的代码用来初始化并创建指示器。
|
||||
* `indicator = appindicator.Indicator.new("customtray","semi-starred-symbolic",appindicator.IndicatorCategory.APPLICATION_STATUS)` :这里我们指明创建一个名为 `customtray` 的新指示器。这是指示器的唯一名称,这样系统就不会与其他运行中的指示器搞混了。同时我们使用名为 `semi-starred-symbolic` 的图标作为指示器的默认图标。你可以将之改成任何其他值;比如 `firefox` (如果你希望该指示器使用 FireFox 的图标),或任何其他你想用的图标名。最后与 `APPLICATION_STATUS` 相关的部分是指明指示器类别/范围的常规代码。
|
||||
* `indicator.set_status(appindicator.IndicatorStatus.ACTIVE)`:这一行激活指示器。
|
||||
* `indicator.set_menu(menu())`:这里说的是我们想使用 `menu()` 函数(我们会在后面定义) 来为我们的指示器创建菜单项。这很重要,可以让你右击指示器后看到一个可以实施行为的列表。
|
||||
* `gtk.main()`:运行 GTK 主循环。
|
||||
* 在 `menu()` 中我们定义了想要指示器提供的行为或项目。`command_one = gtk.MenuItem('My Notes')` 仅仅使用文本 “My notes” 来初始化第一个菜单项,接下来 `command_one.connect('activate',note)` 将菜单的 `activate` 信号与后面定义的 `note()` 函数相连接;换句话说,我们告诉我们的系统:“当该菜单项被点击,运行 `note()` 函数”。最后,`menu.append(command_one)` 将菜单项添加到列表中。
|
||||
* `exittray` 相关的行是为了创建一个退出的菜单项,以便让你在想要的时候关闭指示器。
|
||||
* `menu.show_all()` 以及 `return menu` 只是返回菜单项给指示器的常规代码。
|
||||
* 在 `note(_)` 下面是点击 “My Notes” 菜单项时需要执行的代码。这里只是 `os.system("gedit $HOME/Documents/notes.txt")` 这一句话;`os.system` 函数允许你在 Python 中运行 shell 命令,因此这里我们写了一行命令来使用 `gedit` 打开家目录下 `Documents` 目录中名为 `notes.txt` 的文件。例如,这个可以称为你今后的日常笔记程序了!
|
||||
|
||||
### 添加你所需要的任务
|
||||
|
||||
你只需要修改代码中的两块地方:
|
||||
|
||||
1. 在 `menu()` 中为你想要的任务定义新的菜单项。
|
||||
2. 创建一个新的函数让给该菜单项被点击时执行特定的行为。
|
||||
|
||||
所以,比如说你想要创建一个新菜单项,在点击后,会使用 VLC 播放硬盘中某个特定的视频/音频文件?要做到这一点,只需要在第 17 行处添加下面三行内容:
|
||||
|
||||
```
|
||||
command_two = gtk.MenuItem('Play video/audio')
|
||||
command_two.connect('activate', play)
|
||||
menu.append(command_two)
|
||||
```
|
||||
|
||||
然后在第 30 行添加下面内容:
|
||||
|
||||
```
|
||||
def play(_):
|
||||
os.system("vlc /home/<username>/Videos/somevideo.mp4")
|
||||
```
|
||||
|
||||
将` `/home/<username>/Videos/somevideo.mp4` 替换成你想要播放的视频/音频文件路径。现在保存该文件然后再次运行该指示器:
|
||||
|
||||
```
|
||||
python tray.py
|
||||
```
|
||||
|
||||
你将会看到:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 15][4]
|
||||
|
||||
而且当你点击新创建的菜单项时,VLC 会开始播放!
|
||||
|
||||
要创建其他项目/任务,只需要重复上面步骤即可。但是要小心,需要用其他命令来替换 `command_two`,比如 `command_three`,这样在变量之间才不会产生冲突。然后定义新函数,就像 `play(_)` 函数那样。
|
||||
|
||||
可能性是无穷的;比如我用这种方法来从网上获取数据(使用 urllib2 库)并显示出来。我也用它来在后台使用 `mpg123` 命令播放 mp3 文件,而且我还定义了另一个菜单项来 `killall mpg123` 以随时停止播放音频。比如 Steam 上的 CS:GO 退出很费时间(窗口并不会自动关闭),因此,作为一个变通的方法,我只是最小化窗口然后点击某个自建的菜单项,它会执行 `killall -9 csgo_linux64` 命令。
|
||||
|
||||
你可以使用这个指示器来做任何事情:升级系统包、运行其他脚本——字面上的任何事情。
|
||||
|
||||
### 自动启动
|
||||
|
||||
我们希望系统托盘指示器能在系统启动后自动启动,而不用每次都手工运行。要做到这一点,只需要在自启动应用程序中添加下面命令即可(但是你需要将 `tray.py` 的路径替换成你自己的路径):
|
||||
|
||||
```
|
||||
nohup python /home/<username>/tray.py &
|
||||
```
|
||||
|
||||
下次重启系统,指示器会在系统启动后自动开始工作了!
|
||||
|
||||
### 结论
|
||||
|
||||
你现在知道了如何为你想要的任务创建自己的系统托盘指示器了。根据每天需要运行的任务的性质和数量,此方法可以节省大量时间。有些人偏爱从命令行创建别名,但是这需要你每次都打开终端窗口或者需要有一个可用的下拉式终端仿真器,而这里,这个系统托盘指示器一直在工作,随时可用。
|
||||
|
||||
你以前用过这个方法来运行你的任务吗?很想听听你的想法。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux
|
||||
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fosspost.org/author/mhsabbagh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-28-0808.png?resize=407%2C345&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 12)
|
||||
[2]: https://extensions.gnome.org/extension/1031/topicons/
|
||||
[3]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1041.png?resize=434%2C140&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 14)
|
||||
[4]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1141.png?resize=440%2C149&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 16)
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11058-1.html)
|
||||
[#]: subject: (Zorin OS Becomes Even More Awesome With Zorin 15 Release)
|
||||
[#]: via: (https://itsfoss.com/zorin-os-15-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
随着 Zorin 15 的发布,Zorin OS 变得更为强大
|
||||
======
|
||||
|
||||

|
||||
|
||||
长久以来 Zorin OS 一直在 [初学者适用的Linux发行版排行][1] 中占有一席之地。的确,它可能不是最受欢迎的,但是对于从 Windows 阵营转向 Linux 的用户而言,它一定是最好的一个发行版。
|
||||
|
||||
我还记得,在几年前,我的一位朋友一直坚持让我安装 [Zorin OS][2]。就我个人而言,当时我并不喜欢它的 UI 风格。但是,现如今 Zorin OS 15 发布了,这也让我有了更多的理由安装并将它作为我日常的操作系统。
|
||||
|
||||
不要担心,在这篇文章里,我会向你介绍你所需要了解的一切。
|
||||
|
||||
### Zorin 15 中的新特性
|
||||
|
||||
让我们来看一下最新版本的 Zorin 有哪些主要的改变。Zorin 15 是基于 Ubuntu 18.04.2 的,因此带来了许多性能上的提升。除此之外,也有许多 UI(用户界面)的改进。
|
||||
|
||||
#### Zorin Connect
|
||||
|
||||
![Zorin Connect][3]
|
||||
|
||||
Zorin OS 15 最主要的一个亮点就是 —— Zorin Connect。如果你使用的是安卓设备,那你一定会喜欢这一功能。类似于 [PushBullet][4](LCTT 译注:PushBullet,子弹推送,一款跨平台推送工具), [Zorin Connect][5] 会提升你的手机和桌面一体化的体验。
|
||||
|
||||
你可以在桌面上同步智能手机的通知,同时还可以回复它。甚至,你可以回复短信并查看对话。
|
||||
|
||||
总的来说,你可以体验到以下功能:
|
||||
|
||||
* 在设备间分享文件或链接
|
||||
* 将你的手机作为电脑的遥控器
|
||||
* 使用手机控制电脑上媒体的播放,并且当有来电接入时自动停止播放
|
||||
|
||||
正如他们在[官方公告][6]中提到的, 数据的传输仅限于本地网络之间,并且不会有数据被上传到云端服务器。通过以下操作体验 Zorin Connect ,找到:Zorin menu (Zorin 菜单) > System Tools (系统工具) > Zorin Connect。
|
||||
|
||||
#### 新的桌面主题(包含夜间模式!)
|
||||
|
||||
![Zorin 夜间模式][7]
|
||||
|
||||
一提到 “夜间模式” 我就毫无抵抗力。对我而言,这是Zorin OS 15 自带的最好的功能。
|
||||
|
||||
当我启用了界面的深色模式时,我的眼睛感到如此舒适,你不想来试试么?
|
||||
|
||||
它不单单是一个深色的主题,而是 UI 更干净直观,并且带有恰到好处的新动画。你可以从 Zorin 内置的外观应用程序里找到所有的相关设置。
|
||||
|
||||
#### 自适应背景调整 & 深色浅色模式
|
||||
|
||||
你可以选择让桌面背景根据一天中每小时的环境亮度进行自动调整。此外,如果你想避免蓝光给眼睛带来伤害,你可以使用夜间模式。
|
||||
|
||||
#### 代办事项应用
|
||||
|
||||
![Todo][9]
|
||||
|
||||
我一直希望支持这个功能,这样我就不必使用其他 Linux 客户端程序来添加任务。很高兴看到内置的应用程序集成并支持谷歌任务和 Todoist。
|
||||
|
||||
#### 还有更多么?
|
||||
|
||||
是的!其他主要的变化包括对 Flatpak 的支持,支持平板笔记本二合一电脑的触摸布局,DND 模式,以及一些重新设计的应用程序(设置、Libre Office),以此来给你更好的用户体验。
|
||||
|
||||
如果你想要了解所有更新和改动的详细信息,你可以查看[官方公告][6]。如果你已经是 Zorin 的用户,你应该已经注意到他们的网站也已经启用了一个全新的外观。
|
||||
|
||||
### 下载 Zorin OS 15
|
||||
|
||||
**注释** : 今年的晚些时候将会推出从 Zorin OS 12 直升 15 版本而不需要重新安装的升级包。
|
||||
|
||||
提示一下,Zorin OS 有三个版本:旗舰版本、核心板和轻量版。
|
||||
|
||||
如果你想支持开发者和项目,同时解锁 Zorin OS 全部的功能,你可以花 39 美元购买旗舰版本。
|
||||
|
||||
如果你只是想要一些基本功能,核心版就可以了(你可以免费下载)。如果是这种情况,比如你有一台旧电脑,那么你可以使用轻量版。
|
||||
|
||||
- [下载 ZORIN OS 15][10]
|
||||
|
||||
你觉得 Zorin 15 怎么样?
|
||||
|
||||
我肯定会尝试一下,将 Zorin OS 作为我的主要操作系统 -(手动狗头)。你呢?你觉得最新的版本怎么样?欢迎在下面的评论中告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/zorin-os-15-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-beginners/
|
||||
[2]: https://zorinos.com/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-connect.jpg
|
||||
[4]: https://www.pushbullet.com/
|
||||
[5]: https://play.google.com/store/apps/details?id=com.zorinos.zorin_connect&hl=en_IN
|
||||
[6]: https://zoringroup.com/blog/2019/06/05/zorin-os-15-is-here-faster-easier-more-connected/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-dark-mode.jpg
|
||||
[8]: https://itsfoss.com/necunos-linux-smartphone/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/Todo.jpg
|
||||
[10]: https://zorinos.com/download/
|
||||
[11]: https://itsfoss.com/ubuntu-1404-codenamed-trusty-tahr/
|
||||
@ -1,36 +1,37 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11063-1.html)
|
||||
[#]: subject: (Free and Open Source Trello Alternative OpenProject 9 Released)
|
||||
[#]: via: (https://itsfoss.com/openproject-9-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
替代 Trello 的免费开源 OpenProject 9 发布了
|
||||
替代 Trello 的 OpenProject 9 发布了
|
||||
======
|
||||
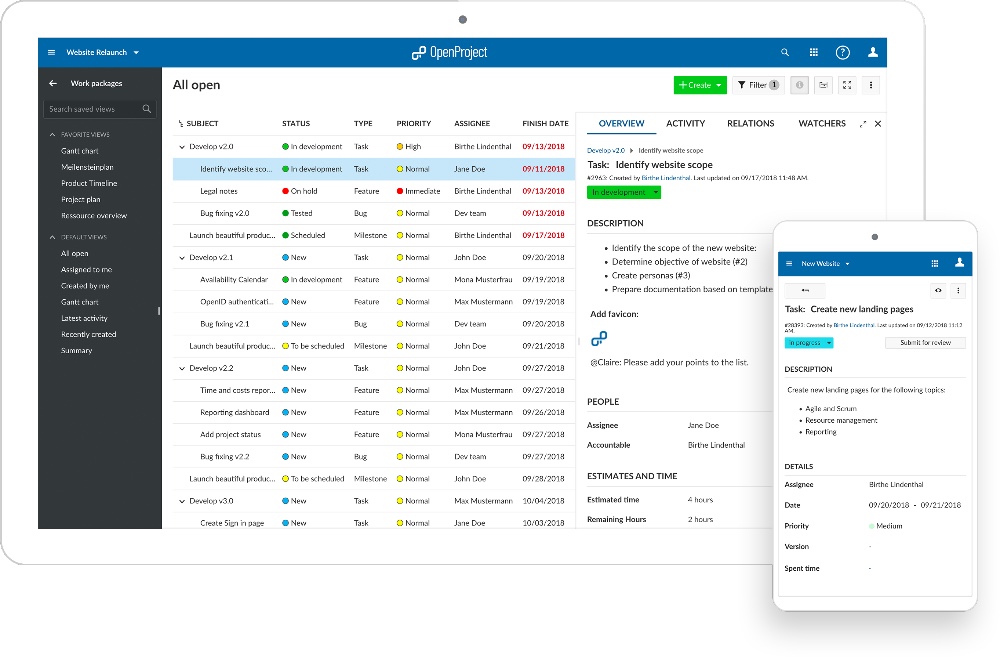
|
||||
|
||||
[OpenProject][1] 是一个开源项目协作管理软件。它是 [Trello][2] 和 [Jira][3] 等专有方案的替代品。
|
||||
|
||||
如果个人使用,你可以免费使用它,并在你自己的服务器上进行设置(并托管它)。这样,你就可以控制数据。
|
||||
|
||||
当然,如果你是[云或企业版用户][4],那么你可以使用高级功能和更优先的帮助。
|
||||
当然,如果你是[企业云版的用户][4],那么你可以使用高级功能和更优先的帮助。
|
||||
|
||||
OpenProject 9 的重点是新的看板试图,包列表视图和工作模板。
|
||||
OpenProject 9 的重点是新的面板视图,包列表视图和工作模板。
|
||||
|
||||
如果你对此不了解,可以尝试一下。但是,如果你是现有用户 - 在迁移到 OpenProject 9 之前,你应该知道这些新功能。
|
||||
如果你对此不了解,可以尝试一下。但是,如果你是已有用户 —— 在迁移到 OpenProject 9 之前,你应该知道这些新功能。
|
||||
|
||||
### OpenProject 9 有什么新功能?
|
||||
|
||||
以下是最新版 OpenProjec t的一些主要更改。
|
||||
以下是最新版 OpenProject 的一些主要更改。
|
||||
|
||||
#### Scrum 和敏捷看板
|
||||
#### Scrum 和敏捷面板
|
||||
|
||||
![][5]
|
||||
|
||||
对于云和企业版,有一个新的 [scrum][6] 和[敏捷][7]看板视图。你还可以 [kanban 风格][8]方式展示你的工作,从而更轻松地支持你的敏捷和 scrum 团队。
|
||||
对于企业云版,有了一个新的 [scrum][6] 和[敏捷][7]面板视图。你还可以[看板风格][8]方式展示你的工作,从而更轻松地支持你的敏捷和 scrum 团队。
|
||||
|
||||
新的看板视图使你可以轻松了解为该任务分配的人员并快速更新状态。你还有不同的看板视图选项,如基本看板、状态看板和版本看板。
|
||||
新的面板视图使你可以轻松了解为该任务分配的人员并快速更新状态。你还有不同的面板视图选项,如基本面板、状态面板和版本面板。
|
||||
|
||||
#### 工作包模板
|
||||
|
||||
@ -46,9 +47,9 @@ OpenProject 9 的重点是新的看板试图,包列表视图和工作模板。
|
||||
|
||||
#### “我的”页面的可自定义工作包视图
|
||||
|
||||
“我的”页面显示你正在处理的内容(以及进度),它不应该一直很无聊。因此,现在你可以自定义它,甚至可以添加甘特图来可视化你的工作。
|
||||
“我的”页面显示你正在处理的内容(以及进度),它不应该一直那么呆板。因此,现在你可以自定义它,甚至可以添加甘特图来可视化你的工作。
|
||||
|
||||
**总结**
|
||||
### 总结
|
||||
|
||||
有关迁移和安装的详细说明,请参阅[官方的公告帖][12],其中包含了必要的细节。
|
||||
|
||||
@ -61,7 +62,7 @@ via: https://itsfoss.com/openproject-9-release/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,18 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11064-1.html)
|
||||
[#]: subject: (IPython is still the heart of Jupyter Notebooks for Python developers)
|
||||
[#]: via: (https://opensource.com/article/19/6/ipython-still-heart-jupyterlab)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg/users/marcobravo)
|
||||
|
||||
对 Python 开发者而言,IPython 仍然是 Jupyter Notebook 的核心
|
||||
======
|
||||
Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IPython 基因。
|
||||
![I love Free Software FSFE celebration][1]
|
||||
|
||||
> Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IPython 基因。
|
||||
|
||||

|
||||
|
||||
最近刚刚写过我为什么觉得觉得 Jupyter 项目(特别是 JupyterLab)提供了一种 [魔法般的 Python 开发体验][2]。在研究这些不同项目之间的关联的时候,我回顾了一下 Jupyter 最初从 IPython 分支出来的这段历史。正如 Jupyter 项目的 [大拆分™ 声明][3] 所说:
|
||||
|
||||
@ -34,7 +36,7 @@ Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IP
|
||||
|
||||
### IPython 如今的作用
|
||||
|
||||
IPython 提供了一个强大的、交互性的 Python shell,以及 Jupyter 的内核。安装完成之后,我可以在任何命令行运行 **ipython** 本身,将它当作一个(比默认 Python shell 好太多的)Python shell 来使用:
|
||||
IPython 提供了一个强大的、交互性的 Python shell,以及 Jupyter 的内核。安装完成之后,我可以在任何命令行运行 `ipython` 本身,将它当作一个(比默认 Python shell 好太多的)Python shell 来使用:
|
||||
|
||||
|
||||
```
|
||||
@ -50,15 +52,15 @@ In [4]: print(average)
|
||||
6.571428571428571
|
||||
```
|
||||
|
||||
这就让我们发现了一个更为重要的问题:是IPython 让 JupyterLab 可以在项目中执行代码,并且支持了一系列被称为 *magic*的功能(感谢 Nicholas Reith 在我上一篇文章的评论里提到这点)。
|
||||
这就让我们发现了一个更为重要的问题:是 IPython 让 JupyterLab 可以在项目中执行代码,并且支持了一系列被称为 *Magic* 的功能(感谢 Nicholas Reith 在我上一篇文章的评论里提到这点)。
|
||||
|
||||
### IPython 让魔法成为现实
|
||||
|
||||
JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最喜欢的 IDE 或者是终端模拟器的环境下工作。我非常喜欢 [dotfiles][5] 快捷键功能,magic 也有类似 dotfile 的特征。比如说,可以试一下 **[%bookmark][6]** 这个命令。我把默认开发文件夹 **~/Develop** 关联到了一个可以在任何时候直接跳转的快捷方式上。
|
||||
JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最喜欢的 IDE 或者是终端模拟器的环境下工作。我非常喜欢 [点文件][5] 快捷键功能,Magic 也有类似点文件的特征。比如说,可以试一下 [%bookmark][6] 这个命令。我把默认开发文件夹 `~/Develop` 关联到了一个可以在任何时候直接跳转的快捷方式上。
|
||||
|
||||
![Screenshot of commands from JupyterLab][7]
|
||||
|
||||
**%bookmark**、**%cd**,以及我在前一篇文章里介绍过的 **!** 操作符,都是由 IPython 支持的。正如这篇 [文档][8] 所说:
|
||||
`%bookmark`、`%cd`,以及我在前一篇文章里介绍过的 `!` 操作符,都是由 IPython 支持的。正如这篇 [文档][8] 所说:
|
||||
|
||||
> Jupyter 用户你们好:Magic 功能是 IPython 内核提供的专属功能。一个内核是否支持 Magic 功能是由该内核的开发者针对该内核所决定的。
|
||||
|
||||
@ -66,7 +68,7 @@ JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最
|
||||
|
||||
作为一个好奇的新手,我之前并不是特别确定 IPython 是否仍然和 Jupyter 生态还有任何联系。现在我对 IPython 的持续开发有了新的认识和,并且意识到它正是 JupyterLab 强大的用户体验的来源。这也是相当有才华的一批贡献者进行最前沿研究的成果,所以如果你在学术论文中使用到了 Jupyter 项目的话别忘了引用他们。为了方便引用,他们还提供了一个 [现成的引文][9]。
|
||||
|
||||
如果你在考虑参与哪个开源项目的贡献的话,一定不要忘了 IPython 哦。记得看看 [最新发布说明][10],在这里可以找到 magic 功能的完整列表。
|
||||
如果你在考虑参与哪个开源项目的贡献的话,一定不要忘了 IPython 哦。记得看看 [最新发布说明][10],在这里可以找到 Magic 功能的完整列表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -74,8 +76,8 @@ via: https://opensource.com/article/19/6/ipython-still-heart-jupyterlab
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,24 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11056-1.html)
|
||||
[#]: subject: (A beginner's guide to Linux permissions)
|
||||
[#]: via: (https://opensource.com/article/19/6/understanding-linux-permissions)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brson/users/greg-p/users/tj)
|
||||
|
||||
Linux 权限入门指南
|
||||
======
|
||||
Linux安全权限能够指定谁可以对文件或目录执行什么操作。
|
||||
![Hand putting a Linux file folder into a drawer][1]
|
||||
|
||||
与其他系统相比而言 Linux 系统的众多优点中最为主要一个便是Linux 系统有着更少的安全漏洞和被攻击的隐患。Linux无疑为用户提供了更为灵活和精细化的文件系统安全权限控制。这可能意味着Linux用户理解安全权限是至关重要的。虽然这并不一定是必要的,但是对于初学者来说,理解Linux权限的基本知识仍是一个明智之选。
|
||||
> Linux 安全权限能够指定谁可以对文件或目录执行什么操作。
|
||||
|
||||

|
||||
|
||||
与其他系统相比而言 Linux 系统的众多优点中最为主要一个便是 Linux 系统有着更少的安全漏洞和被攻击的隐患。Linux 无疑为用户提供了更为灵活和精细化的文件系统安全权限控制。这可能意味着 Linux 用户理解安全权限是至关重要的。虽然这并不一定是必要的,但是对于初学者来说,理解 Linux 权限的基本知识仍是一个明智之选。
|
||||
|
||||
### 查看 Linux 安全权限
|
||||
|
||||
在开始 Linux 权限的相关学习之前,假设我们新建了一个名为 **PermissionDemo**的目录。使用 **cd** 命令进入这个目录,然后使用 **ls -l** 命令查看 Linux 安全管理权限信息。如果你想以时间为序排列,加上 **-t** 选项
|
||||
在开始 Linux 权限的相关学习之前,假设我们新建了一个名为 `PermissionDemo` 的目录。使用 `cd` 命令进入这个目录,然后使用 `ls -l` 命令查看 Linux 安全管理权限信息。如果你想以时间为序排列,加上 `-t` 选项
|
||||
|
||||
|
||||
```
|
||||
@ -27,11 +29,11 @@ Linux安全权限能够指定谁可以对文件或目录执行什么操作。
|
||||
|
||||
![No output from ls -l command][2]
|
||||
|
||||
要了解关于 **ls** 命令的更多信息,请通过在命令行中输入 **man ls** 来查看命令手册。
|
||||
要了解关于 `ls` 命令的更多信息,请通过在命令行中输入 `man ls` 来查看命令手册。
|
||||
|
||||
![ls man page][3]
|
||||
|
||||
现在,让我们创建两个名为 **cat.txt** 和 **dog.txt** 的空白文件;这一步使用 **touch** 命令将更为简便。然后继续使用 **mkdir** 命令创建一个名为 **Pets** 的空目录。我们可以再次使用**ls -l**命令查看这些新文件的权限。
|
||||
现在,让我们创建两个名为 `cat.txt` 和 `dog.txt` 的空白文件;这一步使用 `touch` 命令将更为简便。然后继续使用 `mkdir` 命令创建一个名为 `Pets` 的空目录。我们可以再次使用`ls -l`命令查看这些新文件的权限。
|
||||
|
||||
![Creating new files and directory][4]
|
||||
|
||||
@ -39,42 +41,43 @@ Linux安全权限能够指定谁可以对文件或目录执行什么操作。
|
||||
|
||||
### 谁拥有权限?
|
||||
|
||||
首先要注意的是 _who_ 具有访问文件/目录的权限。请注意下面红色框中突出显示的部分。第一列是指具有访问权限的 _user(用户)_ ,而第二列是指具有访问权限的 _group(组)_ 。
|
||||
首先要注意的是*谁*具有访问文件/目录的权限。请注意下面红色框中突出显示的部分。第一列是指具有访问权限的*用户*,而第二列是指具有访问权限的*组*。
|
||||
|
||||
![Output from -ls command][5]
|
||||
|
||||
用户的类型主要有三种:**user**、**group**;和**other**(本质上既不是用户也不是组)。还有一个**all**,意思是几乎所有人。
|
||||
用户的类型主要有三种:用户、组和其他人(本质上既不是用户也不是组)。还有一个*全部*,意思是几乎所有人。
|
||||
|
||||
![User types][6]
|
||||
|
||||
由于我们使用 **root** 作为当前用户,所以我们可以访问任何文件或目录,因为 **root** 是超级用户。然而,通常情况并非如此,您可能会被限定使用您的普通用户登录。所有的用户都存储在 **/etc/passwd** 文件中。
|
||||
由于我们使用 `root` 作为当前用户,所以我们可以访问任何文件或目录,因为 `root` 是超级用户。然而,通常情况并非如此,你可能会被限定使用你的普通用户登录。所有的用户都存储在 `/etc/passwd` 文件中。
|
||||
|
||||
![/etc/passwd file][7]
|
||||
|
||||
“组“的相关信息保存在 **/etc/group** 文件中。
|
||||
“组“的相关信息保存在 `/etc/group` 文件中。
|
||||
|
||||
![/etc/passwd file][8]
|
||||
|
||||
### 他们有什么权限?
|
||||
|
||||
我们需要注意的是 **ls -l** 命令输出结果的另一部分与执行权限有关。以上,我们查看了创建的dog.txt 和 cat.txt文件以及Pets目录的所有者和组权限都属于 **root** 用户。我们可以通过这一信息了解到不同用户组所拥有的相应权限,如下面的红色框中的标示。
|
||||
我们需要注意的是 `ls -l` 命令输出结果的另一部分与执行权限有关。以上,我们查看了创建的 `dog.txt` 和 `cat.txt` 文件以及 `Pets` 目录的所有者和组权限都属于 `root` 用户。我们可以通过这一信息了解到不同用户组所拥有的相应权限,如下面的红色框中的标示。
|
||||
|
||||
![Enforcing permissions for different user ownership types][9]
|
||||
|
||||
我们可以把每一行分解成五部分。第一部分标志着它是文件还是目录;文件用 **-** (连字符)标记,目录用 **d** 来标记。接下来的三个部分分别是**user**、**group**和**other**的对应权限。最后一部分是[**access-control list**][10] (ACL)(访问控制列表)的标志,是记录着特定用户或者用户组对该文件的操作权限的列表。
|
||||
我们可以把每一行分解成五部分。第一部分标志着它是文件还是目录:文件用 `-`(连字符)标记,目录用 `d` 来标记。接下来的三个部分分别是用户、组和其他人的对应权限。最后一部分是[访问控制列表][10] (ACL)的标志,是记录着特定用户或者用户组对该文件的操作权限的列表。
|
||||
|
||||
![Different Linux permissions][11]
|
||||
|
||||
Linux 的权限级别可以用字母或数字标识。有三种权限类型:
|
||||
|
||||
* **read(读):** r or 4
|
||||
* **write(写):** w or 2
|
||||
* **executable(可执行):** x or 1
|
||||
(LCTT译注:原文此处对应的字母标示 **x** 误写为 **e** 已更正)
|
||||
* 可读取:`r` 或 `4`
|
||||
* 可写入:`w` 或 `2`
|
||||
* 可执行:`x` 或 `1`
|
||||
|
||||
(LCTT 译注:原文此处对应的字母标示 `x` 误写为 `e`,已更正)
|
||||
|
||||
![Privilege types][12]
|
||||
|
||||
每个字母符号(**r**、**w**或**x**)表示有该项权限,而 **-** 表示无该项权限。在下面的示例中,文件的所有者可读可写,用户组成员仅可读,其他人可读可执行。转换成数字表示法,对应的是645(如何计算,请参见下图的图示)。
|
||||
每个字母符号(`r`、`w` 或 `x`)表示有该项权限,而 `-` 表示无该项权限。在下面的示例中,文件的所有者可读可写,用户组成员仅可读,其他人可读可执行。转换成数字表示法,对应的是 `645`(如何计算,请参见下图的图示)。
|
||||
|
||||
![Permission type example][13]
|
||||
|
||||
@ -93,7 +96,7 @@ via: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11059-1.html)
|
||||
[#]: subject: (Ubuntu or Fedora: Which One Should You Use and Why)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-vs-fedora/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -10,9 +10,9 @@
|
||||
你应该选择 Ubuntu 还是 Fedora?
|
||||
======
|
||||
|
||||
_**摘要:选择 Ubuntu 还是 Fedora?它们的区别是什么?哪一个更好?你应该使用哪一个?看看这篇对比 Ubuntu 和 Fedora 的文章吧。**_
|
||||
> 选择 Ubuntu 还是 Fedora?它们的区别是什么?哪一个更好?你应该使用哪一个?看看这篇对比 Ubuntu 和 Fedora 的文章吧。
|
||||
|
||||
Ubuntu 和 Fedora 都是最流行的 Linux 发行版之一,在两者之间做出选择实非易事。在这篇文章里,我会对比一下 Ubuntu 和 Fedora 的不同特点,帮助你进行决策。
|
||||
[Ubuntu][1] 和 [Fedora][2] 都是最流行的 Linux 发行版之一,在两者之间做出选择实非易事。在这篇文章里,我会对比一下 Ubuntu 和 Fedora 的不同特点,帮助你进行决策。
|
||||
|
||||
请注意,这篇文章主要是从桌面版的角度进行对比的。Fedora 或者 Ubuntu 针对容器的特殊版本不会被考虑在内。
|
||||
|
||||
@ -57,7 +57,7 @@ Ubuntu 和 Fedora 默认都使用 GNOME 桌面环境。
|
||||
|
||||
![GNOME Desktop in Fedora][6]
|
||||
|
||||
Fedora 使用的是 stock GNOME 桌面,而 Ubuntu 则在此基础上做了个性化调整,让它看起来就像 Ubuntu 之前使用的 Unity 桌面环境。
|
||||
Fedora 使用的是原装的 GNOME 桌面,而 Ubuntu 则在此基础上做了个性化调整,让它看起来就像 Ubuntu 之前使用的 Unity 桌面环境。
|
||||
|
||||
![GNOME desktop customized by Ubuntu][7]
|
||||
|
||||
@ -69,15 +69,13 @@ Fedora 通过 [Fedora Spins][8] 的方式提供了一些不同桌面环境的版
|
||||
|
||||
#### 软件包管理和可用软件数量
|
||||
|
||||
Ubuntu 使用 APT 软件包管理器提供软件并进行管理(包括应用程序、库,以及其它所需代码),而 Fedora 使用 DNF 软件包管理器。
|
||||
|
||||
[][9]
|
||||
Ubuntu 使用 APT 软件包管理器提供软件并进行管理(包括应用程序、库,以及其它所需编解码器),而 Fedora 使用 DNF 软件包管理器。
|
||||
|
||||
[Ubuntu 拥有庞大的软件仓库][10],能够让你轻松安装数以千计的程序,包括 FOSS(LCTT 译注:Free and Open-Source Software 的缩写,自由开源软件)和非 FOSS 的软件。Fedora 则只专注于提供开源软件。虽然这一点在最近的版本里有所转变,但是 Fedora 的软件仓库在规模上仍然比 Ubuntu 的要逊色一些。
|
||||
|
||||
一些第三方软件开发者为 Linux 提供像 .exe 文件一样可以点击安装的软件包。在 Ubuntu 里这些软件包是 .deb 格式的,在 Fedora 里是 .rpm 格式的。
|
||||
|
||||
大多数软件供应商都为 Linux 用户提供 DEM 和 RPM 文件,但是我也经历过供应商只提供 DEB 文件的情况。比如说 SEO 工具 [Screaming Frog][11] 就只提供 DEB 软件包。反过来,一个软件只有 RPM 格式但是没有 DEB 格式这种情况就极其罕见了。
|
||||
大多数软件供应商都为 Linux 用户提供 DEB 和 RPM 文件,但是我也经历过供应商只提供 DEB 文件的情况。比如说 SEO 工具 [Screaming Frog][11] 就只提供 DEB 软件包。反过来,一个软件只有 RPM 格式但是没有 DEB 格式这种情况就极其罕见了。
|
||||
|
||||
#### 硬件支持
|
||||
|
||||
@ -113,9 +111,9 @@ Fedora 则是红帽公司的一个社区项目。红帽公司是一个专注于
|
||||
|
||||
#### 在背后支持的企业
|
||||
|
||||
Ubuntu 和 Fedora 都有来自母公司的支持。Ubuntu 源自 [Canonical][21] 公司,而 Fedora 源自 [红帽公司][22](现在是 [IBM 的一部分][23])。背后企业的支持非常重要,因为可以确保 Linux 发行版良好的维护。
|
||||
Ubuntu 和 Fedora 都有来自母公司的支持。Ubuntu 源自 [Canonical][21] 公司,而 Fedora 源自 [红帽公司][22](现在是 [IBM 的一部分][23])。背后企业的支持非常重要,因为可以确保 Linux 发行版良好的维护。
|
||||
|
||||
有一些发行版是由一群独立的业余爱好者们共同创建的,但是在工作负荷之下经常会崩溃。你也许见过一些还算比较流行的发行版项目仅仅是因为这个原因而终止了。很多这样的发行版由于开发者没有足够的业余时间可以投入到项目上而不得不终止,比如 [Antergos][24] 和 Korora。
|
||||
有一些发行版是由一群独立的业余爱好者们共同创建的,但是在工作压力之下经常会结束。你也许见过一些还算比较流行的发行版项目仅仅是因为这个原因而终止了。很多这样的发行版由于开发者没有足够的业余时间可以投入到项目上而不得不终止,比如 [Antergos][24] 和 Korora。
|
||||
|
||||
Ubuntu 和 Fedora 的背后都有基于 Linux 的企业的支持,这让它们比其它独立的发行版更胜一筹。
|
||||
|
||||
@ -131,7 +129,7 @@ Fedora 同样有服务端版本,并且也有人在使用。但是大多数系
|
||||
|
||||
学习 Fedora 可以更好地帮助你使用红帽企业级 Linux(RHEL)。RHEL 是一个付费产品,你需要购买订阅才可以使用。如果你希望在服务器上运行一个和 Fedora 或者红帽类似的操作系统,我推荐使用 CentOS。[CentOS][26] 同样是红帽公司附属的一个社区项目,但是专注于服务端。
|
||||
|
||||
#### 结论
|
||||
### 结论
|
||||
|
||||
你可以看到,Ubuntu 和 Fedora 有很多相似之处。不过就可用软件数量、驱动安装和线上支持来说,Ubuntu 的确更有优势。**Ubuntu 也因此成为了一个更好的选择,尤其是对于没有经验的 Linux 新手而言。**
|
||||
|
||||
@ -147,8 +145,8 @@ via: https://itsfoss.com/ubuntu-vs-fedora/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,116 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Zorin OS Becomes Even More Awesome With Zorin 15 Release)
|
||||
[#]: via: (https://itsfoss.com/zorin-os-15-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Zorin OS Becomes Even More Awesome With Zorin 15 Release
|
||||
======
|
||||
|
||||
Zorin OS has always been known as one of the [beginner-focused Linux distros][1] out there. Yes, it may not be the most popular – but it sure is a good distribution specially for Windows migrants.
|
||||
|
||||
A few years back, I remember, a friend of mine always insisted me to install [Zorin OS][2]. Personally, I didn’t like the UI back then. But, now that Zorin OS 15 is here – I have more reasons to get it installed as my primary OS.
|
||||
|
||||
Fret not, in this article, we’ll talk about everything that you need to know.
|
||||
|
||||
### New Features in Zorin 15
|
||||
|
||||
Let’s see the major changes in the latest release of Zorin. Zorin 15 is based on Ubuntu 18.04.2 and thus it brings the performance improvement under the hood. Other than that, there are several UI (User Interface) improvements.
|
||||
|
||||
#### Zorin Connect
|
||||
|
||||
![Zorin Connect][3]
|
||||
|
||||
Zorin OS 15’s main highlight is – Zorin Connect. If you have an Android device, you are in for a treat. Similar to [PushBullet][4], [Zorin Connect][5] integrates your phone with the desktop experience.
|
||||
|
||||
You get to sync your smartphone’s notifications on your desktop while also being able to reply to it. Heck, you can also reply to the SMS messages and view those conversations.
|
||||
|
||||
In addition to these, you get the following abilities:
|
||||
|
||||
* Share files and web links between devices
|
||||
* Use your phone as a remote control for your computer
|
||||
* Control media playback on your computer from your phone, and pause playback automatically when a phone call arrives
|
||||
|
||||
|
||||
|
||||
As mentioned in their [official announcement post][6], the data transmission will be on your local network and no data will be transmitted to the cloud. To access Zorin Connect, navigate your way through – Zorin menu > System Tools > Zorin Connect.
|
||||
|
||||
[Get ZORIN CONNECT ON PLAY STORE][5]
|
||||
|
||||
#### New Desktop Theme (with dark mode!)
|
||||
|
||||
![Zorin Dark Mode][7]
|
||||
|
||||
I’m all in when someone mentions “Dark Mode” or “Dark Theme”. For me, this is the best thing that comes baked in with Zorin OS 15.
|
||||
|
||||
[][8]
|
||||
|
||||
Suggested read Necuno is a New Open Source Smartphone Running KDE
|
||||
|
||||
It’s so pleasing to my eyes when I enable the dark mode on anything, you with me?
|
||||
|
||||
Not just a dark theme, the UI is a lot cleaner and intuitive with subtle new animations. You can find all the settings from the Zorin Appearance app built-in.
|
||||
|
||||
#### Adaptive Background & Night Light
|
||||
|
||||
You get an option to let the background adapt according to the brightness of the environment every hour of the day. Also, you can find the night mode if you don’t want the blue light to stress your eyes.
|
||||
|
||||
#### To do app
|
||||
|
||||
![Todo][9]
|
||||
|
||||
I always wanted this to happen so that I don’t have to use a separate service that offers a Linux client to add my tasks. It’s good to see a built-in app with integration support for Google Tasks and Todoist.
|
||||
|
||||
#### There’s More?
|
||||
|
||||
Yes! Other major changes include the support for Flatpak, a touch layout for convertible laptops, a DND mode, and some redesigned apps (Settings, Libre Office) to give you better user experience.
|
||||
|
||||
If you want the detailed list of changes along with the minor improvements, you can follow the [announcement post][6]. If you are already a Zorin user, you would notice that they have refreshed their website with a new look as well.
|
||||
|
||||
### Download Zorin OS 15
|
||||
|
||||
**Note** : _Direct upgrades from Zorin OS 12 to 15 – without needing to re-install the operating system – will be available later this year._
|
||||
|
||||
In case you didn’t know, there are three versions of Zorin OS – Ultimate, Core, and the Lite version.
|
||||
|
||||
If you want to support the devs and the project while unlocking the full potential of Zorin OS, you should get the ultimate edition for $39.
|
||||
|
||||
If you just want the essentials, the core edition will do just fine (which you can download for free). In either case, if you have an old computer, the lite version is the one to go with.
|
||||
|
||||
[DOWNLOAD ZORIN OS 15][10]
|
||||
|
||||
**What do you think of Zorin 15?**
|
||||
|
||||
[][11]
|
||||
|
||||
Suggested read Ubuntu 14.04 Codenamed Trusty Tahr
|
||||
|
||||
I’m definitely going to give it a try as my primary OS – fingers crossed. What about you? What do you think about the latest release? Feel free to let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/zorin-os-15-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-beginners/
|
||||
[2]: https://zorinos.com/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-connect.jpg?fit=800%2C473&ssl=1
|
||||
[4]: https://www.pushbullet.com/
|
||||
[5]: https://play.google.com/store/apps/details?id=com.zorinos.zorin_connect&hl=en_IN
|
||||
[6]: https://zoringroup.com/blog/2019/06/05/zorin-os-15-is-here-faster-easier-more-connected/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-dark-mode.jpg?fit=722%2C800&ssl=1
|
||||
[8]: https://itsfoss.com/necunos-linux-smartphone/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/Todo.jpg?fit=800%2C652&ssl=1
|
||||
[10]: https://zorinos.com/download/
|
||||
[11]: https://itsfoss.com/ubuntu-1404-codenamed-trusty-tahr/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,85 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is DevSecOps?)
|
||||
[#]: via: (https://opensource.com/article/19/1/what-devsecops)
|
||||
[#]: author: (Brett Hunoldt https://opensource.com/users/bretthunoldtcom)
|
||||
|
||||
What is DevSecOps?
|
||||
======
|
||||
The journey to DevSecOps begins with empowerment, enablement, and education. Here's how to get started.
|
||||

|
||||
|
||||
> “DevSecOps enables organizations to deliver inherently secure software at DevOps speed.” -Stefan Streichsbier
|
||||
|
||||
DevSecOps as a practice or an art form is an evolution on the concept of DevOps. To better understand DevSecOps, you should first have an understanding of what DevOps means.
|
||||
|
||||
DevOps was born from merging the practices of development and operations, removing the silos, aligning the focus, and improving efficiency and performance of both the teams and the product. A new synergy was formed, with DevOps focused on building products and services that are easy to maintain and that automate typical operations functions.
|
||||
|
||||
Security is a common silo in many organizations. Security’s core focus is protecting the organization, and sometimes this means creating barriers or policies that slow down the execution of new services or products to ensure that everything is well understood and done safely and that nothing introduces unnecessary risk to the organization.
|
||||
|
||||
**[[Download the Getting started with DevSecOps guide]][1]**
|
||||
|
||||
Because of the distinct nature of the security silo and the friction it can introduce, development and operations sometimes bypass or work around security to meet their objectives. At some firms, the silo creates an expectation that security is entirely the responsibility of the security team and it is up to them to figure out what security defects or issues may be introduced as a result of a product.
|
||||
|
||||
DevSecOps looks at merging the security discipline within DevOps. By enhancing or building security into the developer and/or operational role, or including a security role within the product engineering team, security naturally finds itself in the product by design.
|
||||
|
||||
This allows companies to release new products and updates more quickly and with full confidence that security is embedded into the product.
|
||||
|
||||
### Where does rugged software fit into DevSecOps?
|
||||
|
||||
Building rugged software is more an aspect of the DevOps culture than a distinct practice, and it complements and enhances a DevSecOps practice. Think of a rugged product as something that has been battle-hardened through experimentation or experience.
|
||||
|
||||
It’s important to note that rugged software is not necessarily 100% secure (although it may have been at some point in time). However, it has been designed to handle most of what is thrown at it.
|
||||
|
||||
The key tenets of a rugged software practice are fostering competition, experimentation, controlled failure, and cooperation.
|
||||
|
||||
### How do you get started in DevSecOps?
|
||||
|
||||
Gettings started with DevSecOps involves shifting security requirements and execution to the earliest possible stage in the development process. It ultimately creates a shift in culture where security becomes everyone’s responsibility, not only the security team’s.
|
||||
|
||||
You may have heard teams talking about a "shift left." If you flatten the development pipeline into a horizontal line to include the key stages of the product evolution—from initiation to design, building, testing, and finally to operating—the goal of a security is to be involved as early as possible. This allows the risks to be better evaluated, socialized, and mitigated by design. The "shift-left" mentality is about moving this engagement far left in this pipeline.
|
||||
|
||||
This journey begins with three key elements:
|
||||
|
||||
* empowerment
|
||||
* enablement
|
||||
* education
|
||||
|
||||
|
||||
|
||||
Empowerment, in my view, is about releasing control and allowing teams to make independent decisions without fear of failure or repercussion (within reason). The only caveat in this process is that information is critical to making informed decisions (more on that below).
|
||||
|
||||
To achieve empowerment, business and executive support (which can be created through internal sales, presentations, and establishing metrics to show the return on this investment) is critical to break down the historic barriers and siloed teams. Integrating security into the development and operations teams and increasing both communication and transparency can help you begin the journey to DevSecOps.
|
||||
|
||||
This integration and mobilization allows teams to focus on a single outcome: Building a product for which they share responsibility and collaborate on development and security in a reliable way. This will take you most of the way towards empowerment. It places the shared responsibility for the product with the teams building it and ensures that any part of the product can be taken apart and maintain its security.
|
||||
|
||||
Enablement involves placing the right tools and resources in the hands of the teams. It’s about creating a culture of knowledge-sharing through forums, wikis, and informal gatherings.
|
||||
|
||||
Creating a culture that focuses on automation and the concept that repetitive tasks should be coded will likely reduce operational overhead and strengthen security. This scenario is about more than providing knowledge; it is about making this knowledge highly accessible through multiple channels and mediums (which are enabled through tools) so that it can be consumed and shared in whatever way teams or individuals prefer. One medium might work best when team members are coding and another when they are on the road. Make the tools accessible and simple and let the team play with them.
|
||||
|
||||
Different DevSecOp teams will have different preferences, so allow them to be independent whenever possible. This is a delicate balancing exercise because you do want economies of scale and the ability to share among products. Collaboration and involvement in the selection and renewal of these tools will help lower the barriers of adoption.
|
||||
|
||||
Finally, and perhaps most importantly, DevSecOps is about training and awareness building. Meetups, social gatherings, or formal presentations within the organization are great ways for peers to teach and share their learnings. Sometimes these highlight shared challenges, concerns, or risks others may not have considered. Sharing and teaching are also effective ways to learn and to mentor teams.
|
||||
|
||||
In my experience, each organization's culture is unique, so you can’t take a “one-size-fits-all” approach. Reach out to your teams and find out what tools they want to use. Test different forums and gatherings and see what works best for your culture. Seek feedback and ask the teams what is working, what they like, and why. Adapt and learn, be positive, and never stop trying, and you’ll almost always succeed.
|
||||
|
||||
[Download the Getting started with DevSecOps guide][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/what-devsecops
|
||||
|
||||
作者:[Brett Hunoldt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bretthunoldtcom
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/downloads/devsecops
|
||||
@ -1,3 +1,5 @@
|
||||
translating by qfzy1233
|
||||
|
||||
MX Linux: A Mid-Weight Distro Focused on Simplicity
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhang5788)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (QiaoN)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -213,7 +213,7 @@ via: https://opensource.com/article/19/5/run-your-blog-github-pages-python
|
||||
|
||||
作者:[Erik O'Shaughnessy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[QiaoN](https://github.com/QiaoN)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,215 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to use Tig to browse Git logs)
|
||||
[#]: via: (https://opensource.com/article/19/6/what-tig)
|
||||
[#]: author: (Olaf Alders https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo)
|
||||
|
||||
How to use Tig to browse Git logs
|
||||
======
|
||||
Tig is more than just a text-mode interface for Git. Here's how it can enhance your daily workflow.
|
||||
![A person programming][1]
|
||||
|
||||
If you work with Git as your version control system, you've likely already resigned yourself to the fact that Git is a complicated beast. It is a fantastic tool, but it can be cumbersome to navigate Git repositories. That's where a tool like [Tig][2] comes in.
|
||||
|
||||
From the [Tig man page][3]:
|
||||
|
||||
> Tig is an ncurses-based text-mode interface for git(1). It functions mainly as a Git repository browser, but can also assist in staging changes for commit at chunk level and act as a pager for output from various Git commands.
|
||||
|
||||
This basically means that Tig provides a text-based user interface you can run in your terminal. Tig makes it easy to browse your Git logs, but it can do much more than just bounce you around from your last commit to a previous one.
|
||||
|
||||
![Tig screenshot][4]
|
||||
|
||||
Many of the examples in this quick introduction to Tig have been poached directly from its excellent man page. I highly recommend reading it to learn more.
|
||||
|
||||
### Install Tig
|
||||
|
||||
* Fedora and RHEL: **sudo dnf install tig**
|
||||
* Ubuntu and Debian: **sudo apt install tig**
|
||||
* MacOS: **brew install tig**
|
||||
|
||||
|
||||
|
||||
See the official [installation instructions][5] for even more options.
|
||||
|
||||
### Browse commits in your current branch
|
||||
|
||||
If you want to browse the latest commits in your branch, enter:
|
||||
|
||||
|
||||
```
|
||||
`tig`
|
||||
```
|
||||
|
||||
That's it. This three-character command will launch a browser where you can navigate the commits in your current branch. You can think of it as a wrapper around **git log**.
|
||||
|
||||
To navigate the output, you can use the Up and Down arrow keys to move from one commit to another. Pressing the Return/Enter key will open a vertical split with the contents of the chosen commit on the right-hand side. You can continue to browse up and down in your commit history on the left-hand side, and your changes will appear on the right. Use **k** and **j** to navigate up and down by line and **-** and the Space Bar to page up and down on the right-hand side. Use **q** to exit the right-hand pane.
|
||||
|
||||
Searching on **tig** output is simple as well. Use **/** to search forward and **?** to search backward on both the left and right panes.
|
||||
|
||||
![Searching Tig][6]
|
||||
|
||||
That's enough to get you started navigating your commits. There are too many key bindings to cover here, but clicking **h** will display a Help menu where you can discover its navigation and command options. You can also use **/** and **?** to search the Help menu. Use **q** to exit Help.
|
||||
|
||||
![Tig Help][7]
|
||||
|
||||
### Browse revisions for a single file
|
||||
|
||||
Since Tig is a wrapper around **git log**, it conveniently accepts the same arguments that can be passed to **git log**. For instance, to browse the commit history for a single file, enter:
|
||||
|
||||
|
||||
```
|
||||
`tig README.md`
|
||||
```
|
||||
|
||||
Compare this with the output of the Git command being wrapped to get a clearer view of how Tig enhances the output.
|
||||
|
||||
|
||||
```
|
||||
`git log README.md`
|
||||
```
|
||||
|
||||
To include the patches in the raw Git output, you can add a **-p** option:
|
||||
|
||||
|
||||
```
|
||||
`git log -p README.md`
|
||||
```
|
||||
|
||||
If you want to narrow the commits down to a specific date range, try something like this:
|
||||
|
||||
|
||||
```
|
||||
`tig --after="2017-01-01" --before="2018-05-16" -- README.md`
|
||||
```
|
||||
|
||||
Again, you can compare this with the raw Git version:
|
||||
|
||||
|
||||
```
|
||||
`git log --after="2017-01-01" --before="2018-05-16" -- README.md`
|
||||
```
|
||||
|
||||
### Browse who changed a file
|
||||
|
||||
Sometimes you want to find out who made a change to a file and why. The command:
|
||||
|
||||
|
||||
```
|
||||
`tig blame README.md`
|
||||
```
|
||||
|
||||
is essentially a wrapper around **git blame**. As you would expect, it allows you to see who the last person was to edit a given line, and it also allows you to navigate to the commit that introduced the line. This is somewhat like the **:Gblame** command Vim's **vim-fugitive** plugin provides.
|
||||
|
||||
### Browse your stash
|
||||
|
||||
If you're like me, you may have a pile of edits in your stash. It's easy to lose track of them. You can view the latest item in your stash via:
|
||||
|
||||
|
||||
```
|
||||
`git stash show -p stash@{0}`
|
||||
```
|
||||
|
||||
You can find the second most recent item via:
|
||||
|
||||
|
||||
```
|
||||
`git stash show -p stash@{1}`
|
||||
```
|
||||
|
||||
and so on. If you can recall these commands whenever you need them, you have a much sharper memory than I do.
|
||||
|
||||
As with the Git commands above, Tig makes it easy to enhance your Git output with a simple invocation:
|
||||
|
||||
|
||||
```
|
||||
`tig stash`
|
||||
```
|
||||
|
||||
Try issuing this command in a repository with a populated stash. You'll be able to browse _and search_ your stash items, giving you a quick overview of everything you saved for a rainy day.
|
||||
|
||||
### Browse your refs
|
||||
|
||||
A Git ref is the hash of something you have committed. This includes files as well as branches. Using the **tig refs** command allows you to browse all of your refs and drill down to specific commits.
|
||||
|
||||
|
||||
```
|
||||
`tig refs`
|
||||
```
|
||||
|
||||
When you're finished, use **q** to return to a previous menu.
|
||||
|
||||
### Browse git status
|
||||
|
||||
If you want to view which files have been staged and which are untracked, use **tig status**, a wrapper around **git status**.
|
||||
|
||||
![Tig status][8]
|
||||
|
||||
### Browse git grep
|
||||
|
||||
You can use the **grep** command to search for expressions in text files. The command **tig grep** allows you to navigate the output of **git grep**. For example:
|
||||
|
||||
|
||||
```
|
||||
`tig grep -i foo lib/Bar`
|
||||
```
|
||||
|
||||
will navigate the output of a case-insensitive search for **foo** in the **lib/Bar** directory.
|
||||
|
||||
### Pipe output to Tig via STDIN
|
||||
|
||||
If you are piping a list of commit IDs to Tig, you must use the **\--stdin** flag so that **tig show** reads from stdin. Otherwise, **tig show** launches without input (rendering an empty screen).
|
||||
|
||||
|
||||
```
|
||||
`git rev-list --author=olaf HEAD | tig show --stdin`
|
||||
```
|
||||
|
||||
### Add custom bindings
|
||||
|
||||
You can customize Tig with an [rc][9] file. Here's how you can configure Tig to your liking, using the example of adding some helpful custom key bindings.
|
||||
|
||||
Create a file in your home directory called **.tigrc**. Open **~/.tigrc** in your favorite editor and add:
|
||||
|
||||
|
||||
```
|
||||
# Apply the selected stash
|
||||
bind stash a !?git stash apply %(stash)
|
||||
|
||||
# Drop the selected stash item
|
||||
bind stash x !?git stash drop %(stash)
|
||||
```
|
||||
|
||||
Run **tig stash** to browse your stash, as above. However, with these bindings in place, you can press **a** to apply an item from the stash to your repository and **x** to drop an item from the stash. Keep in mind that you'll need to perform these commands when browsing the stash _list_. If you're browsing a stash _item_, enter **q** to exit that view and press **a** or **x** to get the effect you want.
|
||||
|
||||
For more information, you can read more about [Tig key bindings][10].
|
||||
|
||||
### Wrapping up
|
||||
|
||||
I hope this has been a helpful demonstration of how Tig can enhance your daily workflow. Tig can do even more powerful things (such as staging lines of code), but that's outside the scope of this introductory article. There's enough information here to make you dangerous, but there's still more to explore.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-tig
|
||||
|
||||
作者:[Olaf Alders][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
|
||||
[2]: https://jonas.github.io/tig/
|
||||
[3]: http://manpages.ubuntu.com/manpages/bionic/man1/tig.1.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/tig.jpg (Tig screenshot)
|
||||
[5]: https://jonas.github.io/tig/INSTALL.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/tig-search.png (Searching Tig)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/tig-help.png (Tig Help)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/tig-status.png (Tig status)
|
||||
[9]: https://en.wikipedia.org/wiki/Run_commands
|
||||
[10]: https://github.com/jonas/tig/wiki/Bindings
|
||||
@ -1,246 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Jupyter and data science in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/jupyter-and-data-science-in-fedora/)
|
||||
[#]: author: (Avi Alkalay https://fedoramagazine.org/author/aviram/)
|
||||
|
||||
Jupyter and data science in Fedora
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
In the past, kings and leaders used oracles and magicians to help them predict the future — or at least get some good advice due to their supposed power to perceive hidden information. Nowadays, we live in a society obsessed with quantifying everything. So we have data scientists to do this job.
|
||||
|
||||
Data scientists use statistical models, numerical techniques and advanced algorithms that didn’t come from statistical disciplines, along with the data that exist on databases, to find, to infer, to predict data that doesn’t exist yet. Sometimes this data is about the future. That is why we do a lot of predictive analytics and prescriptive analytics.
|
||||
|
||||
Here are some questions to which data scientists help find answers:
|
||||
|
||||
1. Who are the students with high propensity to abandon the class? For each one, what are the reasons for leaving?
|
||||
2. Which house has a price above or below the fair price? What is the fair price for a certain house?
|
||||
3. What are the hidden groups that my clients classify themselves?
|
||||
4. Which future problems this premature child will develop?
|
||||
5. How many calls will I get in my call center tomorrow 11:43 AM?
|
||||
6. My bank should or should not lend money to this customer?
|
||||
|
||||
|
||||
|
||||
Note how the answer to all these question is not sitting in any database waiting to be queried. These are all data that still doesn’t exist and has to be calculated. That is part of the job we data scientists do.
|
||||
|
||||
Throughout this article you’ll learn how to prepare a Fedora system as a Data Scientist’s development environment and also a production system. Most of the basic software is RPM-packaged, but the most advanced parts can only be installed, nowadays, with Python’s _pip_ tool.
|
||||
|
||||
### Jupyter — the IDE
|
||||
|
||||
Most modern data scientists use Python. And an important part of their work is EDA (exploratory data analysis). EDA is a manual and interactive process that retrieves data, explores its features, searches for correlations, and uses plotted graphics to visualize and understand how data is shaped and prototypes predictive models.
|
||||
|
||||
Jupyter is a web application perfect for this task. Jupyter works with Notebooks, documents that mix rich text including beautifully rendered math formulas (thanks to [mathjax][2]), blocks of code and code output, including graphics.
|
||||
|
||||
Notebook files have extension _.ipynb_, which means Interactive Python Notebook.
|
||||
|
||||
#### Setting up and running Jupyter
|
||||
|
||||
First, install essential packages for Jupyter ([using][3] _[sudo][3]_):
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-notebook mathjax sscg
|
||||
```
|
||||
|
||||
You might want to install additional and optional Python modules commonly used by data scientists:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
|
||||
```
|
||||
|
||||
Set a password to log into Notebook web interface and avoid those long tokens. Run the following command anywhere on your terminal:
|
||||
|
||||
```
|
||||
$ mkdir -p $HOME/.jupyter
|
||||
$ jupyter notebook password
|
||||
```
|
||||
|
||||
Now, type a password for yourself. This will create the file _$HOME/.jupyter/jupyter_notebook_config.json_ with your encrypted password.
|
||||
|
||||
Next, prepare for SSLby generating a self-signed HTTPS certificate for Jupyter’s web server:
|
||||
|
||||
```
|
||||
$ cd $HOME/.jupyter; sscg
|
||||
```
|
||||
|
||||
Finish configuring Jupyter by editing your _$HOME/.jupyter/jupyter_notebook_config.json_ file. Make it look like this:
|
||||
|
||||
```
|
||||
{
|
||||
"NotebookApp": {
|
||||
"password": "sha1:abf58...87b",
|
||||
"ip": "*",
|
||||
"allow_origin": "*",
|
||||
"allow_remote_access": true,
|
||||
"open_browser": false,
|
||||
"websocket_compression_options": {},
|
||||
"certfile": "/home/aviram/.jupyter/service.pem",
|
||||
"keyfile": "/home/aviram/.jupyter/service-key.pem",
|
||||
"notebook_dir": "/home/aviram/Notebooks"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The parts in red must be changed to match your folders. Parts in blue were already there after you created your password. Parts in green are the crypto-related files generated by _sscg_.
|
||||
|
||||
Create a folder for your notebook files, as configured in the _notebook_dir_ setting above:
|
||||
|
||||
```
|
||||
$ mkdir $HOME/Notebooks
|
||||
```
|
||||
|
||||
Now you are all set. Just run Jupyter Notebook from anywhere on your system by typing:
|
||||
|
||||
```
|
||||
$ jupyter notebook
|
||||
```
|
||||
|
||||
Or add this line to your _$HOME/.bashrc_ file to create a shortcut command called _jn_:
|
||||
|
||||
```
|
||||
alias jn='jupyter notebook'
|
||||
```
|
||||
|
||||
After running the command _jn_, access _<https://your-fedora-host.com:8888>_ from any browser on the network to see the Jupyter user interface. You’ll need to use the password you set up earlier. Start typing some Python code and markup text. This is how it looks:
|
||||
|
||||
![Jupyter with a simple notebook][4]
|
||||
|
||||
In addition to the IPython environment, you’ll also get a web-based Unix terminal provided by _terminado_. Some people might find this useful, while others find this insecure. You can disable this feature in the config file.
|
||||
|
||||
### JupyterLab — the next generation of Jupyter
|
||||
|
||||
JupyterLab is the next generation of Jupyter, with a better interface and more control over your workspace. It’s currently not RPM-packaged for Fedora at the time of writing, but you can use _pip_ to get it installed easily:
|
||||
|
||||
```
|
||||
$ pip3 install jupyterlab --user
|
||||
$ jupyter serverextension enable --py jupyterlab
|
||||
```
|
||||
|
||||
Then run your regular _jupiter notebook_ command or _jn_ alias. JupyterLab will be accessible from _<http://your-linux-host.com:8888/**lab>_**.
|
||||
|
||||
### Tools used by data scientists
|
||||
|
||||
In this section you can get to know some of these tools, and how to install them. Unless noted otherwise, the module is already packaged for Fedora and was installed as prerequisites for previous components.
|
||||
|
||||
#### **Numpy**
|
||||
|
||||
_Numpy_ is an advanced and C-optimized math library designed to work with large in-memory datasets. It provides advanced multidimensional matrix support and operations, including math functions as log(), exp(), trigonometry etc.
|
||||
|
||||
#### Pandas
|
||||
|
||||
In this author’s opinion, Python is THE platform for data science mostly because of Pandas. Built on top of numpy, Pandas makes easy the work of preparing and displaying data. You can think of it as a no-UI spreadsheet, but ready to work with much larger datasets. Pandas helps with data retrieval from a SQL database, CSV or other types of files, columns and rows manipulation, data filtering and, to some extent, data visualization with matplotlib.
|
||||
|
||||
#### Matplotlib
|
||||
|
||||
Matplotlib is a library to plot 2D and 3D data. It has great support for notations in graphics, labels and overlays
|
||||
|
||||
![matplotlib pair of graphics showing a cost function searching its optimal value through a gradient descent algorithm][5]
|
||||
|
||||
#### Seaborn
|
||||
|
||||
Built on top of matplotlib, Seaborn’s graphics are optimized for a more statistical comprehension of data. It automatically displays regression lines or Gauss curve approximations of plotted data.
|
||||
|
||||
![Linear regression visualised with SeaBorn][6]
|
||||
|
||||
#### [StatsModels][7]
|
||||
|
||||
StatsModels provides algorithms for statistical and econometrics data analysis such as linear and logistic regressions. Statsmodel is also home for the classical family of [time series algorithms][8] known as ARIMA.
|
||||
|
||||
![Normalized number of passengers across time \(blue\) and ARIMA-predicted number of passengers \(red\)][9]
|
||||
|
||||
#### Scikit-learn
|
||||
|
||||
The central piece of the machine-learning ecosystem, [scikit][10] provides predictor algorithms for [regression][11] (Elasticnet, Gradient Boosting, Random Forest etc) and [classification][11] and clustering (K-means, DBSCAN etc). It features a very well designed API. Scikit also has classes for advanced data manipulation, dataset split into train and test parts, dimensionality reduction and data pipeline preparation.
|
||||
|
||||
#### XGBoost
|
||||
|
||||
XGBoost is the most advanced regressor and classifier used nowadays. It’s not part of scikit-learn, but it adheres to scikit’s API. [XGBoost][12] is not packaged for Fedora and should be installed with pip. [XGBoost can be accelerated with your nVidia GPU][13], but not through its _pip_ package. You can get this if you compile it yourself against CUDA. Get it with:
|
||||
|
||||
```
|
||||
$ pip3 install xgboost --user
|
||||
```
|
||||
|
||||
#### Imbalanced Learn
|
||||
|
||||
[imbalanced-learn][14] provides ways for under-sampling and over-sampling data. It is useful in fraud detection scenarios where known fraud data is very small when compared to non-fraud data. In these cases data augmentation is needed for the known fraud data, to make it more relevant to train predictors. Install it with _pip_:
|
||||
|
||||
```
|
||||
$ pip3 install imblearn --user
|
||||
```
|
||||
|
||||
#### NLTK
|
||||
|
||||
The [Natural Language toolkit][15], or NLTK, helps you work with human language data for the purpose of building chatbots (just to cite an example).
|
||||
|
||||
#### SHAP
|
||||
|
||||
Machine learning algorithms are very good on predicting, but aren’t good at explaining why they made a prediction. [SHAP][16] solves that, by analyzing trained models.
|
||||
|
||||
![Where SHAP fits into the data analysis process][17]
|
||||
|
||||
Install it with _pip_:
|
||||
|
||||
```
|
||||
$ pip3 install shap --user
|
||||
```
|
||||
|
||||
#### [Keras][18]
|
||||
|
||||
Keras is a library for deep learning and neural networks. Install it with _pip_:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-h5py
|
||||
$ pip3 install keras --user
|
||||
```
|
||||
|
||||
#### [TensorFlow][19]
|
||||
|
||||
TensorFlow is a popular neural networks builder. Install it with _pip_:
|
||||
|
||||
```
|
||||
$ pip3 install tensorflow --user
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
_Photo courtesy of [FolsomNatural][20] on [Flickr][21] (CC BY-SA 2.0)._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/jupyter-and-data-science-in-fedora/
|
||||
|
||||
作者:[Avi Alkalay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/aviram/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/jupyter-816x345.jpg
|
||||
[2]: http://mathjax.org
|
||||
[3]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]: https://avi.alkalay.net/articlefiles/2018/07/jupyter-fedora.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/06/gradient-descent-cost-function-optimization.png
|
||||
[6]: https://seaborn.pydata.org/_images/regression_marginals.png
|
||||
[7]: https://www.statsmodels.org/
|
||||
[8]: https://www.statsmodels.org/stable/examples/index.html#stats
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/06/time-series.png
|
||||
[10]: https://scikit-learn.org/stable/
|
||||
[11]: https://scikit-learn.org/stable/supervised_learning.html#supervised-learning
|
||||
[12]: https://xgboost.ai
|
||||
[13]: https://xgboost.readthedocs.io/en/latest/gpu/index.html
|
||||
[14]: https://imbalanced-learn.readthedocs.io
|
||||
[15]: https://www.nltk.org
|
||||
[16]: https://github.com/slundberg/shap
|
||||
[17]: https://raw.githubusercontent.com/slundberg/shap/master/docs/artwork/shap_diagram.png
|
||||
[18]: https://keras.io
|
||||
[19]: https://www.tensorflow.org
|
||||
[20]: https://www.flickr.com/photos/87249144@N08/
|
||||
[21]: https://www.flickr.com/photos/87249144@N08/45871861611/
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to be good at creating and maintaining systems at-large)
|
||||
[#]: via: (https://opensource.com/article/19/7/book-review-building-evolutionary-architectures)
|
||||
[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
|
||||
|
||||
How to be good at creating and maintaining systems at-large
|
||||
======
|
||||
A book review of "Building Evolutionary Architectures: Support Constant
|
||||
Change" for open source and security folks
|
||||
![An open book][1]
|
||||
|
||||
Initially, this article was simply a review of the book, but as I got into it, I realised that I wanted to talk about how the approach it describes is applicable to a couple of different groups (security folks and open source projects), and so I’ve gone with it.
|
||||
|
||||
How, then, did I come across the book? I was attending a conference a few months ago (DeveloperWeek San Diego), and decided to go to one of the sessions because it looked interesting. The speaker was Dr. Rebecca Parsons, and I liked what she was talking about so much that I ordered this book, whose subject was the topic of her talk, to arrive at home by the time I would return a couple of days later.
|
||||
|
||||
![Building Evolutionary Architectures: Support Constant Change][2]
|
||||
|
||||
[_Building Evolutionary Architectures: Support Constant Change_][3] is not a book about securitym, and I'm a security guy, but it deals with security as one application of its approach, and very convincingly. The central issue that the authors—all employees of ThoughtWorks—identify is, simplified, that although we’re good at creating features for applications, we’re less good at creating, and then maintaining, broader properties of systems. This problem is compounded, they suggest, by the fast and ever-changing nature of modern development practices, where "enterprise architects can no longer rely on static planning".
|
||||
|
||||
The alternative that they propose is to consider "fitness functions", "objectives you want your architecture to exhibit or move towards". Crucially, these are properties of the architecture—or system—rather than features or specific functionality. Tests should be created to monitor the specific functions, but they won’t be your standard unit tests, nor will they necessarily be "point in time" tests. Instead, they will measure a variety of issues, possibly over a period of time, to let you know whether your system is meeting the particular fitness functions you are measuring. There’s a lot of discussion of how to measure these fitness functions, but I would have liked even more. From my point of view, it was one of the most valuable topics covered.
|
||||
|
||||
Frankly, the above might be enough to recommend the book, but there’s more. They advocate strongly for creating incremental change to meet your requirements (gradual, rather than major changes) and "evolvable architectures", encouraging you to realise that:
|
||||
|
||||
1. you may not meet all your fitness functions at the beginning;
|
||||
2. applications which may have met the fitness functions at one point may _cease_ to meet them later on, for various reasons;
|
||||
3. your architecture is likely to change over time;
|
||||
4. your requirements, and therefore the priority that you give to each fitness function, will change over time;
|
||||
5. even if your fitness functions remain the same, the ways in which you need to monitor them may change.
|
||||
|
||||
|
||||
|
||||
All of these are, in my view, extremely useful insights for anybody designing and building a system. Combining them with architectural thinking is even more valuable.
|
||||
|
||||
As is standard for modern O’Reilly books, there are examples throughout, including a worked fake consultancy journey of a particular company with specific needs, leading you through some of the practices in the book. At times, this felt a little contrived, but the mechanism is generally helpful. There were times when the book seemed to stray from its core approach—which is architectural, as per the title—into explanations through pseudo code, but these support one of the useful aspects of the book, which is giving examples of what architectures are more or less suited to the principles expounded in the more theoretical parts. Some readers may feel more at home with the theoretical, others with the more example-based approach (I lean towards the former), but all in all, it seems like an appropriate balance. Relating these to the impact of "architectural coupling" was particularly helpful, in my view.
|
||||
|
||||
There is a useful grounding in some of the advice in Conway’s Law ("Organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations.") which led me to wonder how we could model open source projects—and their architectures—based on this perspective. There are also (as is also standard these days) patterns and anti-patterns: I would generally consider these a useful part of any book on design and architecture.
|
||||
|
||||
### Why is this a book for security folks?
|
||||
|
||||
The most important thing about this book, from my point of view as a security systems architect, is that it _isn’t_ about security. Security is mentioned, but is not considered core enough to the book to merit a mention in the appendix. The point, though, is that the security of a system—an embodiment of an architecture—is a perfect example of a fitness function. Taking this as a starting point for a project will help you do two things.
|
||||
|
||||
First, you will avoid focussing on features and functionality, and look at the bigger picture. Second, you will consider what you _really_ need from security in the system, and how that translates into issues such as the security posture to be adopted, and the measurements you will take to validate it through the lifecycle.
|
||||
|
||||
Possibly even more important than those two points is that it will force you to consider the priority of security in relation to other fitness functions (resilience, maybe, or ease of use?) and how the relative priorities will—and should—change over time. A realisation that we don’t live in a bubble, and that our priorities are not always that same as those of other stakeholders in a project, is always useful.
|
||||
|
||||
### Why is this a book for open source folks?
|
||||
|
||||
Very often—and for quite understandable and forgiveable reasons—the architectures of open source projects grow organically at first, needing major overhauls and refactoring at various stages of their lifecycles. This is not to say that this doesn’t happen in proprietary software projects as well, of course, but the sometimes frequent changes in open source projects' emphasis and requirements, the ebb and flow of contributors and contributions and the sometimes, um, reduced levels of documentation aimed at end users can mean that features are significantly prioritised over what we could think of as the core vision of the project. One way to remedy this would be to consider the appropriate fitness functions of the project, to state them upfront, and to have a regular cadence of review by the community, to ensure that they are:
|
||||
|
||||
* still relevant;
|
||||
* correctly prioritised at this stage in the project;
|
||||
* actually being met.
|
||||
|
||||
|
||||
|
||||
If any of the above come into question, it’s a good time to consider a wider review by the community, and maybe a refactoring or partial redesign of the project.
|
||||
|
||||
Open source projects have—quite rightly—various different models of use and intended users. One of the happenstances that can negatively affect a project is when it is identified as a possible fit for a use case for which it was not originally intended. Academic software which is designed for accuracy over performance might not be a good fit for corporate research, for instance, in the same way that a project aimed at home users which prioritises minimal computing resources might not be appropriate for a high-availability enterprise roll-out. One of the ways of making this clear is by being very clear up-front about the fitness functions that you expect your project to meet—and, vice versa, about the fitness functions you are looking to fulfil when you are looking to select a project. It is easy to focus on features and functionality, and to overlook the more non-functional aspects of a system, and fitness functions allow us to make some informed choices about how to balance these decisions.
|
||||
|
||||
_This article was originally posted on [Alice, Eve and Bob - a security blog][4]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/book-review-building-evolutionary-architectures
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mikecamel
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/open_book_color.jpg?itok=I-8tNQOP (An open book)
|
||||
[2]: https://opensource.com/sites/default/files/styles/medium/public/uploads/building-evolutionary-architectures.jpg?itok=UlyKLSxV (Building Evolutionary Architectures: Support Constant Change)
|
||||
[3]: https://www.oreilly.com/library/view/building-evolutionary-architectures/9781491986356/
|
||||
[4]: https://aliceevebob.com/2019/06/25/building-evolutionary-architectures-for-security-and-for-open-source/
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux
|
||||
======
|
||||
|
||||
There are many open source monitoring tools are currently available in market to monitor Linux systems performance.
|
||||
|
||||
It will send an email alert when the system reaches the specified threshold limit.
|
||||
|
||||
It monitors everything such as CPU utilization, Memory utilization, swap utilization, disk space utilization and much more.
|
||||
|
||||
If you only have few systems and want to monitor them then writing a small shell script can make your task very easy.
|
||||
|
||||
In this tutorial we have added a shell script to monitor Messages Log on Linux system.
|
||||
|
||||
We had added many useful shell scripts in the past. If you want to check those, navigate to the below link.
|
||||
|
||||
* **[How to automate day to day activities using shell scripts?][1]**
|
||||
|
||||
|
||||
|
||||
This script will check **“warning, error and critical”** in the `/var/log/messages` file and trigger a mail to given email id, if it’s found anything related it.
|
||||
|
||||
We can’t run this script frequently that may fill up your inbox if the server has many matching strings, instead we can run once in a day.
|
||||
|
||||
To overcome this issue, i made the script to trigger an email in a different manner.
|
||||
|
||||
If any given strings are found in the **“/var/log/messages”** file for yesterday’s date then the script will send an email alert to given email id.
|
||||
|
||||
**Note:** You need to change the email id instead of ours. Also, you can change the Memory utilization threshold value as per your requirement.
|
||||
|
||||
```
|
||||
# vi /opt/scripts/os-log-alert.sh
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#Set the variable which equal to zero
|
||||
|
||||
prev_count=0
|
||||
|
||||
count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | egrep -wi 'warning|error|critical' | wc -l)
|
||||
|
||||
if [ "$prev_count" -lt "$count" ] ; then
|
||||
|
||||
# Send a mail to given email id when errors found in log
|
||||
|
||||
SUBJECT="WARNING: Errors found in log on "`date --date='yesterday' '+%b %e'`""
|
||||
|
||||
# This is a temp file, which is created to store the email message.
|
||||
|
||||
MESSAGE="/tmp/logs.txt"
|
||||
|
||||
TO="[email protected]"
|
||||
|
||||
echo "ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin." >> $MESSAGE
|
||||
|
||||
echo "Hostname: `hostname`" >> $MESSAGE
|
||||
|
||||
echo -e "\n" >> $MESSAGE
|
||||
|
||||
echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
|
||||
|
||||
echo "Error messages in the log file as below" >> $MESSAGE
|
||||
|
||||
echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
|
||||
|
||||
grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | awk '{ $3=""; print}' | egrep -wi 'warning|error|critical' >> $MESSAGE
|
||||
|
||||
mail -s "$SUBJECT" "$TO" < $MESSAGE
|
||||
|
||||
#rm $MESSAGE
|
||||
|
||||
fi
|
||||
```
|
||||
|
||||
Set an executable permission to `os-log-alert.sh` file.
|
||||
|
||||
```
|
||||
$ chmod +x /opt/scripts/os-log-alert.sh
|
||||
```
|
||||
|
||||
Finally add a cronjob to automate this. It will run everyday at 7'o clock.
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
0 7 * * * /bin/bash /opt/scripts/os-log-alert.sh
|
||||
```
|
||||
|
||||
**Note:** You will be getting an email alert everyday at 7 o'clock, which is for yesterday's log.
|
||||
|
||||
**Output:** You will be getting an email alert similar to below.
|
||||
|
||||
```
|
||||
ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin.
|
||||
|
||||
+-----------------------------------------------------+
|
||||
Error messages in the log file as below
|
||||
+-----------------------------------------------------+
|
||||
Jul 3 02:40:11 ns1 kernel: php-fpm[3175]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
Jul 3 02:50:14 ns1 kernel: lmtp[8249]: segfault at 20 ip 00007f9cc05295e4 sp 00007ffc57bca1a0 error 4 in libdovecot-storage.so.0.0.0[7f9cc04df000+148000]
|
||||
Jul 3 15:36:09 ns1 kernel: php-fpm[17846]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
Jul 3 15:45:54 ns1 pure-ftpd: ([email protected]) [WARNING] Authentication failed for user [daygeek]
|
||||
Jul 3 16:25:36 ns1 pure-ftpd: ([email protected]) [WARNING] Sorry, cleartext sessions and weak ciphers are not accepted on this server.#012Please reconnect using TLS security mechanisms.
|
||||
Jul 3 16:44:20 ns1 kernel: php-fpm[8979]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/shell-script/
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Copy and paste at the Linux command line with xclip)
|
||||
[#]: via: (https://opensource.com/article/19/7/xclip)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
Copy and paste at the Linux command line with xclip
|
||||
======
|
||||
Learn how to get started with the Linux xclip utility.
|
||||
![Green paperclips][1]
|
||||
|
||||
How do you usually copy all or part of a text file when working on the Linux desktop? Chances are you open the file in a text editor, select all or just the text you want to copy, and paste it somewhere else.
|
||||
|
||||
That works. But you can do the job a bit more efficiently at the command line using the [xclip][2] utility. xclip provides a conduit between commands you run in a terminal window and the clipboard in a Linux graphical desktop environment.
|
||||
|
||||
### Installing xclip
|
||||
|
||||
xclip isn't standard kit with many Linux distributions. To see if it's installed on your computer, open a terminal window and type **which xclip**. If that command returns output like _/usr/bin/xclip_, then you're ready to go. Otherwise, you need to install xclip.
|
||||
|
||||
To do that, use your distribution's package manager. Or, if you're adventurous, [grab the source code][2] from GitHub and compile it yourself.
|
||||
|
||||
### Doing the basics
|
||||
|
||||
Let's say you want to copy the contents of a file to the clipboard. There are two ways to do that with xclip. Type either:
|
||||
|
||||
|
||||
```
|
||||
`xclip file_name`
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
|
||||
```
|
||||
`xclip -sel clip file_name`
|
||||
```
|
||||
|
||||
What's the difference between the two commands (aside from the second one being longer)? The first command works if you use the middle button on the mouse to paste text. However, not everyone does. Many people are conditioned to use a right-click menu or to press Ctrl+V to paste text. If you're one of those people (I am!), using the **-sel clip** option ensures you can paste what you want to paste.
|
||||
|
||||
### Using xclip with other applications
|
||||
|
||||
Copying the contents of a file directly to the clipboard is a neat parlor trick. Chances are, you won't be doing that very often. There are other ways you can use xclip, and those involve pairing it with another command-line application.
|
||||
|
||||
That pairing is done with a _pipe_ (|). The pipe redirects the output of one command line application to another. Doing that opens several possibilities. Let's take a look at three of them.
|
||||
|
||||
Say you're a system administrator and you need to copy the last 30 lines of a log file into a bug report. Opening the file in a text editor, scrolling down to the end, and copying and pasting is a bit of work. Why not use xclip and the [tail][3] utility to quickly and easily do the deed? Run this command to copy those last 30 lines:
|
||||
|
||||
|
||||
```
|
||||
`tail -n 30 logfile.log | xclip -sel clip`
|
||||
```
|
||||
|
||||
Quite a bit of my writing goes into some content management system (CMS) or another for publishing on the web. However, I never use a CMS's WYSIWYG editor to write—I write offline in [plain text][4] formatted with [Markdown][5]. That said, many of those editors have an HTML mode. By using this command, I can convert a Markdown-formatted file to HTML using [Pandoc][6] and copy it to the clipboard in one fell swoop:
|
||||
|
||||
|
||||
```
|
||||
`pandoc -t html file.md | xclip -sel clip`
|
||||
```
|
||||
|
||||
From there, I paste away.
|
||||
|
||||
Two of my websites are hosted using [GitLab Pages][7]. I generate the HTTPS certificates for those sites using a tool called [Certbot][8], and I need to copy the certificate for each site to GitLab whenever I renew it. Combining the [cat][9] command and xclip is faster and more efficient than using an editor. For example:
|
||||
|
||||
|
||||
```
|
||||
`cat /etc/letsencrypt/live/website/fullchain.pem | xclip -sel clip`
|
||||
```
|
||||
|
||||
Is that all you can do with xclip? Definitely not. I'm sure you can find more uses to fit your needs.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Not everyone will use xclip. That's fine. It is, however, one of those little utilities that really comes in handy when you need it. And, as I've discovered on a few occasions, you don't know when you'll need it. When that time comes, you'll be glad xclip is there.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/xclip
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life_paperclips.png?itok=j48op49T (Green paperclips)
|
||||
[2]: https://github.com/astrand/xclip
|
||||
[3]: https://en.wikipedia.org/wiki/Tail_(Unix)
|
||||
[4]: https://plaintextproject.online
|
||||
[5]: https://gumroad.com/l/learnmarkdown
|
||||
[6]: https://pandoc.org
|
||||
[7]: https://docs.gitlab.com/ee/user/project/pages/
|
||||
[8]: https://certbot.eff.org/
|
||||
[9]: https://en.wikipedia.org/wiki/Cat_(Unix)
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Enable ‘Tap to click’ on Ubuntu Login Screen [Quick Tip])
|
||||
[#]: via: (https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Enable ‘Tap to click’ on Ubuntu Login Screen [Quick Tip]
|
||||
======
|
||||
|
||||
_**Brief: The tap to click option doesn’t work on the login screen in Ubuntu 18.04 GNOME desktop. In this tutorial, you’ll learn to enable the ‘tap to click’ on the Ubuntu login screen.**_
|
||||
|
||||
One of the first few things I do after installing Ubuntu is to make sure that tap to click has been enabled. As a laptop user, I prefer to tap the touchpad for making a left click. This is more convenient than using the left click button on the touchpad all the time.
|
||||
|
||||
This is what happens when I have logged in and using the operating system. But if you are at the login screen, the tap to click doesn’t work and that’s an annoyance.
|
||||
|
||||
On the [GDM login screen][1] in Ubuntu (or other distributions using GNOME desktop), you have to click the username in order to bring the password field. Now if you are habitual of tap to click, it doesn’t work on the login screen even if you have it enabled and use it after logging into the system.
|
||||
|
||||
This is a minor annoyance but an annoyance nonetheless. The good news is that you can fix this annoyance.Let me show you how to do that in this quick tip.
|
||||
|
||||
### Enabling tap to click on Ubuntu login screen
|
||||
|
||||
![][2]
|
||||
|
||||
You’ll have to use the terminal and a few commands here. I hope you are comfortable with it.
|
||||
|
||||
[Open a terminal using Ctrl+Alt+T shortcut in Ubuntu][3]. Since Ubuntu 18.04 is still using X server, you need to enable it to connect to the [x server][4]. For that, you can add gdm to access control list.
|
||||
|
||||
Switch to root user first. It’s required because you have to switch as gdm user later and you cannot do that as a non-root user.
|
||||
|
||||
```
|
||||
sudo -i
|
||||
```
|
||||
|
||||
[There is no password set for root user in Ubuntu][5]. You access it with your admin user account. So when asked for password, use your own password. You won’t see anything being typed on the screen when you type in your password.
|
||||
|
||||
```
|
||||
xhost +SI:localuser:gdm
|
||||
```
|
||||
|
||||
Here’s the output for me:
|
||||
|
||||
```
|
||||
xhost +SI:localuser:gdm
|
||||
localuser:gdm being added to access control list
|
||||
```
|
||||
|
||||
Now run this command so that the the ‘user gdm’ has the correct tap to click setting.
|
||||
|
||||
```
|
||||
gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click true
|
||||
```
|
||||
|
||||
If you see a warning like this: (process:6339): dconf-WARNING **: 19:52:21.217: Unable to open /root/.local/share/flatpak/exports/share/dconf/profile/user: Permission denied . Don’t worry. Just ignore it.
|
||||
|
||||
[][6]
|
||||
|
||||
Suggested read How To Change Hostname on Ubuntu & Other Linux Distributions
|
||||
|
||||
This will enable you to perform a tap to click on the login screen. Why were you not able to use tap to click when you made the changes in the system settings before? It’s because at the login screen, you haven’t selected your username yet. You get to use your account only when you select the user on the screen. This is why you had to use the user gdm and add the correct settings with it.
|
||||
|
||||
Restart Ubuntu and you’ll see that you can now use the tap to select your user account now.
|
||||
|
||||
#### Revert the changes
|
||||
|
||||
If you are not happy with the tap to click on the Ubuntu login screen for some reason, you can revert the changes.
|
||||
|
||||
You’ll have to perform all the steps you did in the previous section: switch to root, connect gdm with x server, switch to gdm user. But instead of the last command, you need to run this command:
|
||||
|
||||
```
|
||||
gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click false
|
||||
```
|
||||
|
||||
That’s it.
|
||||
|
||||
As I said, it’s a tiny thing. I mean you can easily do a left click instead of the tap to click. It’s just a matter of one single click.However, it breaks the ‘continuity’ when you are forced to use the left click after a few taps.
|
||||
|
||||
I hope you liked this quick little tweak. If you know some other cool tweaks, do share it with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://wiki.archlinux.org/index.php/GDM
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/tap-to-click-on-ubuntu-login.jpg?ssl=1
|
||||
[3]: https://itsfoss.com/ubuntu-shortcuts/
|
||||
[4]: https://en.wikipedia.org/wiki/X.Org_Server
|
||||
[5]: https://itsfoss.com/change-password-ubuntu/
|
||||
[6]: https://itsfoss.com/change-hostname-ubuntu/
|
||||
@ -0,0 +1,311 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Learn object-oriented programming with Python)
|
||||
[#]: via: (https://opensource.com/article/19/7/get-modular-python-classes)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Learn object-oriented programming with Python
|
||||
======
|
||||
Make your code more modular with Python classes.
|
||||
![Developing code.][1]
|
||||
|
||||
In my previous article, I explained how to [make Python modular][2] by using functions, creating modules, or both. Functions are invaluable to avoid repeating code you intend to use several times, and modules ensure that you can use your code across different projects. But there's another component to modularity: the class.
|
||||
|
||||
If you've heard the term _object-oriented programming_, then you may have some notion of the purpose classes serve. Programmers tend to consider a class as a virtual object, sometimes with a direct correlation to something in the physical world, and other times as a manifestation of some programming concept. Either way, the idea is that you can create a class when you want to create "objects" within a program for you or other parts of the program to interact with.
|
||||
|
||||
### Templates without classes
|
||||
|
||||
Assume you're writing a game set in a fantasy world, and you need this application to be able to drum up a variety of baddies to bring some excitement into your players' lives. Knowing quite a lot about functions, you might think this sounds like a textbook case for functions: code that needs to be repeated often but is written once with allowance for variations when called.
|
||||
|
||||
Here's an example of a purely function-based implementation of an enemy generator:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
def enemy(ancestry,gear):
|
||||
enemy=ancestry
|
||||
weapon=gear
|
||||
hp=random.randrange(0,20)
|
||||
ac=random.randrange(0,20)
|
||||
return [enemy,weapon,hp,ac]
|
||||
|
||||
def fight(tgt):
|
||||
print("You take a swing at the " + tgt[0] + ".")
|
||||
hit=random.randrange(0,20)
|
||||
if hit > tgt[3]:
|
||||
print("You hit the " + tgt[0] + " for " + str(hit) + " damage!")
|
||||
tgt[2] = tgt[2] - hit
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
foe=enemy("troll","great axe")
|
||||
print("You meet a " + foe[0] + " wielding a " + foe[1])
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
while True:
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
fight(foe)
|
||||
|
||||
if foe[2] < 1:
|
||||
print("You killed your foe!")
|
||||
else:
|
||||
print("The " + foe[0] + " has " + str(foe[2]) + " HP remaining")
|
||||
```
|
||||
|
||||
The **enemy** function creates an enemy with several attributes, such as ancestry, a weapon, health points, and a defense rating. It returns a list of each attribute, representing the sum total of the enemy.
|
||||
|
||||
In a sense, this code has created an object, even though it's not using a class yet. Programmers call this "enemy" an _object_ because the result (a list of strings and integers, in this case) of the function represents a singular but complex _thing_ in the game. That is, the strings and integers in the list aren't arbitrary: together, they describe a virtual object.
|
||||
|
||||
When writing a collection of descriptors, you use variables so you can use them any time you want to generate an enemy. It's a little like a template.
|
||||
|
||||
In the example code, when an attribute of the object is needed, the corresponding list item is retrieved. For instance, to get the ancestry of an enemy, the code looks at **foe[0]**, for health points, it looks at **foe[2]** for health points, and so on.
|
||||
|
||||
There's nothing necessarily wrong with this approach. The code runs as expected. You could add more enemies of different types, you could create a list of enemy types and randomly select from the list during enemy creation, and so on. It works well enough, and in fact [Lua][3] uses this principle very effectively to approximate an object-oriented model.
|
||||
|
||||
However, there's sometimes more to an object than just a list of attributes.
|
||||
|
||||
### The way of the object
|
||||
|
||||
In Python, everything is an object. Anything you create in Python is an _instance_ of some predefined template. Even basic strings and integers are derivatives of the Python **type** class. You can witness this for yourself an interactive Python shell:
|
||||
|
||||
|
||||
```
|
||||
>>> foo=3
|
||||
>>> type(foo)
|
||||
<class 'int'>
|
||||
>>> foo="bar"
|
||||
>>> type(foo)
|
||||
<class 'str'>
|
||||
```
|
||||
|
||||
When an object is defined by a class, it is more than just a collection of attributes. Python classes have functions all their own. This is convenient, logically, because actions that pertain only to a certain class of objects are contained within that object's class.
|
||||
|
||||
In the example code, the fight code is a function of the main application. That works fine for a simple game, but in a complex one, there would be more than just players and enemies in the game world. There might be townsfolk, livestock, buildings, forests, and so on, and none of them ever need access to a fight function. Placing code for combat in an enemy class means your code is better organized; and in a complex application, that's a significant advantage.
|
||||
|
||||
Furthermore, each class has privileged access to its own local variables. An enemy's health points, for instance, isn't data that should ever change except by some function of the enemy class. A random butterfly in the game should not accidentally reduce an enemy's health to 0. Ideally, even without classes, that would never happen, but in a complex application with lots of moving parts, it's a powerful trick of the trade to ensure that parts that don't need to interact with one another never do.
|
||||
|
||||
Python classes are also subject to garbage collection. When an instance of a class is no longer used, it is moved out of memory. You may never know when this happens, but you tend to notice when it doesn't happen because your application takes up more memory and runs slower than it should. Isolating data sets into classes helps Python track what is in use and what is no longer needed.
|
||||
|
||||
### Classy Python
|
||||
|
||||
Here's the same simple combat game using a class for the enemy:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.ac=random.randrange(12,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
|
||||
# game start
|
||||
foe=Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
This version of the game handles the enemy as an object containing the same attributes (ancestry, weapon, health, and defense), plus a new attribute measuring whether the enemy has been vanquished yet, as well as a function for combat.
|
||||
|
||||
The first function of a class is a special function called (in Python) an _init_, or initialization, function. This is similar to a [constructor][4] in other languages; it creates an instance of the class, which is identifiable to you by its attributes and to whatever variable you use when invoking the class (**foe** in the example code).
|
||||
|
||||
### Self and class instances
|
||||
|
||||
The class' functions accept a new form of input you don't see outside of classes: **self**. If you don't include **self**, then Python has no way of knowing _which_ instance of the class to use when you call a class function. It's like challenging a single orc to a duel by saying "I'll fight the orc" in a room full of orcs; nobody knows which one you're referring to, and so bad things happen.
|
||||
|
||||
![Image of an Orc, CC-BY-SA by Buch on opengameart.org][5]
|
||||
|
||||
CC-BY-SA by Buch on opengameart.org
|
||||
|
||||
Each attribute created within a class is prepended with the **self** notation, which identifies that variable as an attribute of the class. Once an instance of a class is spawned, you swap out the **self** prefix with the variable representing that instance. Using this technique, you could challenge just one orc to a duel in a room full of orcs by saying "I'll fight the gorblar.orc"; when Gorblar the Orc hears **gorblar.orc**, he knows which orc you're referring to (him_self_), and so you get a fair fight instead of a brawl. In Python:
|
||||
|
||||
|
||||
```
|
||||
gorblar=Enemy("orc","sword")
|
||||
print("The " + gorblar.enemy + " has " + str(gorblar.hp) + " remaining.")
|
||||
```
|
||||
|
||||
Instead of looking to **foe[0]** (as in the functional example) or **gorblar[0]** for the enemy type, you retrieve the class attribute (**gorblar.enemy** or **gorblar.hp** or whatever value for whatever object you need).
|
||||
|
||||
### Local variables
|
||||
|
||||
If a variable in a class is not prepended with the **self** keyword, then it is a local variable, just as in any function. For instance, no matter what you do, you cannot access the **hit** variable outside the **Enemy.fight** class:
|
||||
|
||||
|
||||
```
|
||||
>>> print(foe.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.hit)
|
||||
AttributeError: 'Enemy' object has no attribute 'hit'
|
||||
|
||||
>>> print(foe.fight.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.fight.hit)
|
||||
AttributeError: 'function' object has no attribute 'hit'
|
||||
```
|
||||
|
||||
The **hit** variable is contained within the Enemy class, and only "lives" long enough to serve its purpose in combat.
|
||||
|
||||
### More modularity
|
||||
|
||||
This example uses a class in the same text document as your main application. In a complex game, it's easier to treat each class almost as if it were its own self-standing application. You see this when multiple developers work on the same application: one developer works on a class, and the other works on the main program, and as long as they communicate with one another about what attributes the class must have, the two code bases can be developed in parallel.
|
||||
|
||||
To make this example game modular, split it into two files: one for the main application and one for the class. Were it a more complex application, you might have one file per class, or one file per logical groups of classes (for instance, a file for buildings, a file for natural surroundings, a file for enemies and NPCs, and so on).
|
||||
|
||||
Save one file containing just the Enemy class as **enemy.py** and another file containing everything else as **main.py**.
|
||||
|
||||
Here's **enemy.py**:
|
||||
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.stg=random.randrange(0,20)
|
||||
self.ac=random.randrange(0,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
```
|
||||
|
||||
Here's **main.py**:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import enemy as en
|
||||
|
||||
# game start
|
||||
foe=en.Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
Importing the module **enemy.py** is done very specifically with a statement that refers to the file of classes as its name without the **.py** extension, followed by a namespace designator of your choosing (for example, **import enemy as en**). This designator is what you use in the code when invoking a class. Instead of just using **Enemy()**, you preface the class with the designator of what you imported, such as **en.Enemy**.
|
||||
|
||||
All of these file names are entirely arbitrary, although not uncommon in principle. It's a common convention to name the part of the application that serves as the central hub **main.py**, and a file full of classes is often named in lowercase with the classes inside it, each beginning with a capital letter. Whether you follow these conventions doesn't affect how the application runs, but it does make it easier for experienced Python programmers to quickly decipher how your application works.
|
||||
|
||||
There's some flexibility in how you structure your code. For instance, using the code sample, both files must be in the same directory. If you want to package just your classes as a module, then you must create a directory called, for instance, **mybad** and move your classes into it. In **main.py**, your import statement changes a little:
|
||||
|
||||
|
||||
```
|
||||
`from mybad import enemy as en`
|
||||
```
|
||||
|
||||
Both systems produce the same results, but the latter is best if the classes you have created are generic enough that you think other developers could use them in their projects.
|
||||
|
||||
Regardless of which you choose, launch the modular version of the game:
|
||||
|
||||
|
||||
```
|
||||
$ python3 ./main.py
|
||||
You meet a troll wielding a great axe
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You missed.
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 8 damage!
|
||||
The troll has 4 HP remaining
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 11 damage!
|
||||
The troll has -7 HP remaining
|
||||
You have won...this time.
|
||||
```
|
||||
|
||||
The game works. It's modular. And now you know what it means for an application to be object-oriented. But most importantly, you know to be specific when challenging an orc to a duel.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: https://opensource.com/article/19/6/get-modular-python-functions
|
||||
[3]: https://opensource.com/article/17/4/how-program-games-raspberry-pi
|
||||
[4]: https://opensource.com/article/19/6/what-java-constructor
|
||||
[5]: https://opensource.com/sites/default/files/images/orc-buch-opengameart_cc-by-sa.jpg (CC-BY-SA by Buch on opengameart.org)
|
||||
121
sources/tech/20190705 Manage your shell environment.md
Normal file
121
sources/tech/20190705 Manage your shell environment.md
Normal file
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Manage your shell environment)
|
||||
[#]: via: (https://fedoramagazine.org/manage-your-shell-environment/)
|
||||
[#]: author: (Eduard Lucena https://fedoramagazine.org/author/x3mboy/)
|
||||
|
||||
Manage your shell environment
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Some time ago, the Fedora Magazine has published an [article introducing ZSH][2] — an alternative shell to Fedora’s default, bash. This time, we’re going to look into customizing it to use it in a more effective way. All of the concepts shown in this article also work in other shells such as bash.
|
||||
|
||||
### Alias
|
||||
|
||||
Aliases are shortcuts for commands. This is useful for creating short commands for actions that are performed often, but require a long command that would take too much time to type. The syntax is:
|
||||
|
||||
```
|
||||
$ alias yourAlias='complex command with arguments'
|
||||
```
|
||||
|
||||
They don’t always need to be used for shortening long commands. Important is that you use them for tasks that you do often. An example could be:
|
||||
|
||||
```
|
||||
$ alias dnfUpgrade='dnf -y upgrade'
|
||||
```
|
||||
|
||||
That way, to do a system upgrade, I just type dnfUpgrade instead of the whole dnf command.
|
||||
|
||||
The problem of setting aliases right in the console is that once the terminal session is closed, the alias would be lost. To set them permanently, resource files are used.
|
||||
|
||||
### Resource Files
|
||||
|
||||
Resource files (or rc files) are configuration files that are loaded per user in the beginning of a session or a process (when a new terminal window is opened, or a new program like vim is started). In the case of ZSH, the resource file is _.zshrc_, and for bash it’s _.bashrc_.
|
||||
|
||||
To make the aliases permanent, you can either put them in your resource. You can edit your resource file with a text editor of your choice. This example uses vim:
|
||||
|
||||
```
|
||||
$ vim $HOME/.zshrc
|
||||
```
|
||||
|
||||
Or for bash:
|
||||
|
||||
```
|
||||
$ vim $HOME/.bashrc
|
||||
```
|
||||
|
||||
Note that the location of the resource file is specified relatively to a home directory — and that’s where ZSH (or bash) are going to look for the file by default for each user.
|
||||
|
||||
Other option is to put your configuration in any other file, and then source it:
|
||||
|
||||
```
|
||||
$ source /path/to/your/rc/file
|
||||
```
|
||||
|
||||
Again, sourcing it right in your session will only apply it to the session, so to make it permanent, add the source command to your resource file. The advantage of having your source file in a different location is that you can source it any time. Or anywhere which is especially useful in shared environments.
|
||||
|
||||
### Environment Variables
|
||||
|
||||
Environment variables are values assigned to a specific name which can be then called in scripts and commands. They start with the $ dollar sign. One of the most common is $HOME that references the home directory.
|
||||
|
||||
As the name suggests, environment variables are a part of your environment. Set a variable using the following syntax:
|
||||
|
||||
```
|
||||
$ http_proxy="http://your.proxy"
|
||||
```
|
||||
|
||||
And to make it an environment variable, export it with the following command:
|
||||
|
||||
```
|
||||
$ export $http_proxy
|
||||
```
|
||||
|
||||
To see all the environment variables that are currently set, use the _env_ command:
|
||||
|
||||
```
|
||||
$ env
|
||||
```
|
||||
|
||||
The command outputs all the variables available in your session. To demonstrate how to use them in a command, try running the following echo commands:
|
||||
|
||||
```
|
||||
$ echo $PWD
|
||||
/home/fedora
|
||||
$ echo $USER
|
||||
fedora
|
||||
```
|
||||
|
||||
What happens here is variable expansion — the value stored in the variable is used in your command.
|
||||
|
||||
Another useful variable is _$PATH_, that defines directories that your shell uses to look for binaries.
|
||||
|
||||
### The $PATH variable
|
||||
|
||||
There are many directories, or folders (the way they are called in graphical environments) that are important to the OS. Some directories are set to hold binaries you can use directly in your shell. And these directories are defined in the $PATH variable.
|
||||
|
||||
```
|
||||
$ echo $PATH
|
||||
/usr/lib64/qt-3.3/bin:/usr/share/Modules/bin:/usr/lib64/ccache:/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/usr/libexec/sdcc:/usr/libexec/sdcc:/usr/bin:/bin:/sbin:/usr/sbin:/opt/FortiClient
|
||||
```
|
||||
|
||||
This will help you when you want to have your own binaries (or scripts) accessible in the shell.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/manage-your-shell-environment/
|
||||
|
||||
作者:[Eduard Lucena][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/x3mboy/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2018/05/manage-shell-env-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/set-zsh-fedora-system/
|
||||
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Say WHAAAT? Mozilla has Been Nominated for the “Internet Villain” Award in the UK)
|
||||
[#]: via: (https://itsfoss.com/mozilla-internet-villain/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Say WHAAAT? Mozilla has Been Nominated for the “Internet Villain” Award in the UK
|
||||
======
|
||||
|
||||
Mozilla Firefox is one of the most popular browsers available out there. A lot of users prefer it over Chrome just because it encourages privacy protection and features options to keep your Internet activity as private as possible.
|
||||
|
||||
But, one of the recently proposed features – **[DoH (DNS-over-HTTPS)][1]** which is still in the testing phase didn’t receive a good response from the UK’s ISPs trade association.
|
||||
|
||||
So, the ISPA (Internet Services Providers Association) of UK decided to [nominate][2] Mozilla as one of the “Internet Villains” among the nominees for 2019. This is for an award ceremony to be held on 11th July in London by the ISP trade association of the UK.
|
||||
|
||||
![][3]
|
||||
|
||||
### Why “Mozilla” is the “Internet Villain” here?
|
||||
|
||||
In their announcement, the ISPA mentioned that Mozilla is one of the Internet Villains for supporting **DoH** (DNS-over-HTTPS).
|
||||
|
||||
> [@mozilla][4] is nominated for the [#ISPAs][5] [#InternetVillain][6] for their proposed approach to introduce DNS-over-HTTPS in such a way as to bypass UK filtering obligations and parental controls, undermining [#internet][7] safety standards in the UK. <https://t.co/d9NaiaJYnk> [pic.twitter.com/WeZhLq2uvi][8]
|
||||
>
|
||||
> — Internet Services Providers Association (ISPAUK) (@ISPAUK) [July 4, 2019][9]
|
||||
|
||||
Along with Mozilla, Article 13 Copyright Directive and President Donald Trump also appear in the list. Here’s how ISPA explained in their announcement:
|
||||
|
||||
_**Mozilla**_ _– for their proposed approach to introduce DNS-over-HTTPS in such a way as to bypass UK filtering obligations and parental controls, undermining internet safety standards in the UK_.
|
||||
|
||||
**_Article_ _13 Copyright Directive_** _– for threatening freedom of expression online by requiring ‘content recognition technologies’ across platforms_
|
||||
|
||||
_**President Donald Trump**_ _– for causing a huge amount of uncertainty across the complex, global telecommunications supply chain in the course of trying to protect national security_
|
||||
|
||||
### What is DNS-over-HTTPS?
|
||||
|
||||
DoH basically means that your DNS requests will be encrypted over an HTTPS connection.
|
||||
|
||||
Traditionally, the DNS requests are unencrypted and your DNS provider or the ISP can monitor/control your browsing activity. Without DoH, you can easily enforce blocking/content filtering through your DNS provider or the ISP can do that when they want.
|
||||
|
||||
[][10]
|
||||
|
||||
Suggested read Firefox: The Internet's Knight in Shining Armor
|
||||
|
||||
However, DoH completely takes that out of the equation and hence, you get a private browsing experience.
|
||||
|
||||
You can explore [how Mozilla implements this partnering with Cloudflare][11] and set it up for yourself if you want.
|
||||
|
||||
### Is DoH helpful?
|
||||
|
||||
Yes and no.
|
||||
|
||||
Of course, on one side of the coin, it lets user bypass any content filters enforced by the DNS or the ISPs. So, it is a good thing that we want to put a stop to Internet censorship and DoH helps us with that.
|
||||
|
||||
But, on the other side, if you are a parent, you can no longer [set content filters][12] if your kid utilizes DoH on Mozilla Firefox. It depends on how good/bad the [firewall is configured][13].
|
||||
|
||||
But potentially DoH is a solution for some to bypass parental controls, which could be a bad thing.
|
||||
|
||||
Correct me if I’m wrong here – in the comments below.
|
||||
|
||||
Also, using DoH means that you can no longer use the local host file (in case you are using it for ad blocking or something else)
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
What do you think about DoH in general? Is it good enough?
|
||||
|
||||
And, what’s your take on ISPA’s decision? Do you think that they are encouraging Internet censorship and government monitoring on netizens with this kind of announcement?
|
||||
|
||||
Personally, I find it hilarious. Even if DoH isn’t the ultimate feature that everyone wants, it is always good to have an option to protect your privacy in some way.
|
||||
|
||||
Let us know your thoughts in the comments below. Meanwhile, I’ll just put this quote here:
|
||||
|
||||
> In a time of universal deceit, telling the truth is a revolutionary act
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mozilla-internet-villain/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/DNS_over_HTTPS
|
||||
[2]: https://www.ispa.org.uk/ispa-announces-finalists-for-2019-internet-heroes-and-villains-trump-and-mozilla-lead-the-way-as-villain-nominees/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/mozilla-internet-villain.jpg?resize=800%2C450&ssl=1
|
||||
[4]: https://twitter.com/mozilla?ref_src=twsrc%5Etfw
|
||||
[5]: https://twitter.com/hashtag/ISPAs?src=hash&ref_src=twsrc%5Etfw
|
||||
[6]: https://twitter.com/hashtag/InternetVillain?src=hash&ref_src=twsrc%5Etfw
|
||||
[7]: https://twitter.com/hashtag/internet?src=hash&ref_src=twsrc%5Etfw
|
||||
[8]: https://t.co/WeZhLq2uvi
|
||||
[9]: https://twitter.com/ISPAUK/status/1146725374455373824?ref_src=twsrc%5Etfw
|
||||
[10]: https://itsfoss.com/why-firefox/
|
||||
[11]: https://blog.nightly.mozilla.org/2018/06/01/improving-dns-privacy-in-firefox/
|
||||
[12]: https://itsfoss.com/how-to-block-porn-by-content-filtering-on-ubuntu/
|
||||
[13]: https://itsfoss.com/set-up-firewall-gufw/
|
||||
85
translated/talk/20191110 What is DevSecOps.md
Normal file
85
translated/talk/20191110 What is DevSecOps.md
Normal file
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (PandaWizard)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is DevSecOps?)
|
||||
[#]: via: (https://opensource.com/article/19/1/what-devsecops)
|
||||
[#]: author: (Brett Hunoldt https://opensource.com/users/bretthunoldtcom)
|
||||
|
||||
什么是 DevSecOps?
|
||||
======
|
||||
DevSecOps 的实践之旅开始于 DevSecOps 授权,启用和培养。下面就介绍如何开始学习使用 DevSecOps。
|
||||

|
||||
|
||||
> Stephen Streichsbier 说过: DevSecOps 使得组织可以用 DevOps 的速度发布内在安全的软件。
|
||||
|
||||
DevSecOps 是一场关于 DevOps 概念实践或艺术形式的变革。为了更好理解 DevSecOps,你应该首先理解 DevOps 的含义。
|
||||
|
||||
DevOps 起源于通过合并开发和运维实践,消除隔离,统一关注点,提升团队和产品的效率和性能。它是一种注重构建容易维持和易于平常自动运营维护产品和服务的新型协作方式。
|
||||
|
||||
安全在很多团队中都是常见的隔离点。安全的核心关注点是保护团队,而有时这也意味着生成延缓新服务或是新产品发布的障碍或是策略,用于保障任何事都能被很好的理解和安全的执行,并且没有给团队带来不必要的风险。
|
||||
|
||||
**[[点击下载 DevSecOps 的引导手册]][1]**
|
||||
|
||||
因为安全方面的明显特征和它可能带来的摩擦,开发和运维有时会避开或是满足客观的安全要求。在一些公司,这种隔离形成了一种产品安全完全是安全团队责任的期望,并取决于安全团队去寻找产品的安全缺陷或是可能带来的问题。
|
||||
|
||||
DevSecOps 看起来是通过给开发或是运维角色加强或是建立安全意识,或是在产品团队中引入一个安全工程师角色,在产品设计中找到安全问题,从而把安全要求汇聚在 Devops 中。
|
||||
|
||||
这样使得公司能更快发布和更新产品,并且充分相信安全已经嵌入产品中。
|
||||
|
||||
### 坚固的软件哪里适用 DevSecOps?
|
||||
|
||||
建造坚固的软件是 DevOps 文化的一个层面而不是一个特别的实践,它完善和增强了 DevSecops 的实践。想想一款坚固的软件就像是某些经历过残酷战斗过程的事物。
|
||||
|
||||
有必要指出坚固的软件并不是 100% 安全可靠的(虽然它可能最终是在某些方面)。然而,它被设计成可以处理大部分被抛过来的问题。
|
||||
|
||||
践行坚固软件最重要的原则是促进竞争,实践,可控的失败与合作。
|
||||
|
||||
### 你如何开始学习 DevSecOps ?
|
||||
|
||||
开始实践 DevSecOps 涉及提升安全需求和在开发过程中最早期可能的阶段实践。它最终在公司文化上提升了安全的重要性,使得安全成为所有人的责任,而并不只是安全团队的责任。
|
||||
|
||||
你可能在团队中听说过“左上升”这个词,如果你把开发周期包括产品变革的的关键时期线放平在一条横线上,从初始化到设计,建造,测试以及最终的运行。安全的目的就是今早的参与进来。这使得风险可以在设计中能更好的评估、交流和减轻。“左提升”的含义是指促使安全能在开发周期线上更往左走。
|
||||
|
||||
这篇入门文章有三个关键要素:
|
||||
|
||||
* 授权
|
||||
* 启用
|
||||
* 培养
|
||||
|
||||
|
||||
|
||||
授权,在我看来,是关于释放控制权以及使得团队做出独立决定而不用害怕失败或影响(理性分析)。这个过程的唯一告诫信息就是要严格的做出明智的决定(不要比这更低要求)。
|
||||
|
||||
为了实现授权,商务和行政支持(通过内部销售,展示来建立,通过建立矩阵来 展示这项投资的回报)是打破历史障碍和分割的团队的关键。合并安全人员到开发和运维团队中,提升交流和透明度透明度有助于 DevSecOps 的开始之旅。
|
||||
|
||||
这次整合和移动使得团队只关注单一的结果:打造一个他们共同负责的产品,让开发和安全人员相互依赖合作。这将引领你们共同走向授权。这是产品研发团队的共同责任,并保证每个可分割的产品都保持其安全性。
|
||||
|
||||
启用涉及正确的使用掌握在团队手中的工具和资源。这是准备建立一种通过论坛、维基、信息聚合的知识分享文化。
|
||||
|
||||
打造一种注重自动化、重复任务应该编码来尽可能减少以后的操作并增强安全性。这种场景不仅仅是提供知识,而是让这种知识能够通过多种渠道和媒介(通过某些工具)可获取,以便它可以被团队或是个人以他喜欢的方式去消化和分享。一种工具可以更好的实现当团队成员正在编码而另一组成员正在来的路上。让工具简单可用和让团队可以使用它们。
|
||||
|
||||
不同的 DevSecOps 团队有不同的喜好,因此允许它们尽可能的保持独立。这是一种微笑平衡的练习,因为你真的很想在经济规模和能力中分享产品。在选择中协作参与并更新工具方法有助于减少使用中的障碍。
|
||||
|
||||
最后,也可能是最重要的, DevSecOps 是有关训练和兴趣打造。聚会、社交或是组织中通常的报告会都是很棒的方式让同事们教学和分享他们的知识。有时,这些高光的被分享的挑战、关注点或是一些其他人没有关注到的风险。分享和教学也是一种高效的学习和指导团队的方法。
|
||||
|
||||
在我个人经验中,每个团队的文化都是独一无二的,因此你不能用“一种尺寸适合所有”的方法。走进你的团队并找到他们想要使用的工具方法。尝试不同的论坛和聚会并找出最适用于你们文化的方式。寻找反馈并询问团队如何工作,他们喜欢什么以及对应的原因。适应和学习,保持乐观,不要停止尝试,你们将会有所收获。
|
||||
|
||||
[下载 DevSecOps 的入门手册][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/what-devsecops
|
||||
|
||||
作者:[Brett Hunoldt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[PandaWizard](https://github.com/PandaWizard)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bretthunoldtcom
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/downloads/devsecops
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,187 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create a Custom System Tray Indicator For Your Tasks on Linux)
|
||||
[#]: via: (https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux)
|
||||
[#]: author: (M.Hanny Sabbagh https://fosspost.org/author/mhsabbagh)
|
||||
|
||||
在 Linux 上为你的任务创建一个自定义的系统托盘指示器
|
||||
======
|
||||
|
||||
时至今日系统托盘图标依然很有用。只需要右击图标,然后选择想要的动作即可,你可以大幅简化你的生活并且减少日常行为中的大量无用的点击。
|
||||
|
||||
一说到有用的系统托盘图标,我们很容易就想到 Skype,Dropbox 和 VLC:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 11][1]
|
||||
|
||||
然而系统托盘图标实际上要更有用得多; 你可以根据自己的需求创建自己的系统托盘图标。本指导将会教你通过简单的几个步骤来实现这一目的。
|
||||
|
||||
### 前置条件
|
||||
|
||||
我们将要用 Python 来实现一个自定义的系统托盘指示器。Python 默认在所有主流的 Linux 发行版中都有安装,因此你只需要确定一下它已经确实被安装好了(版本为 2.7)。另外,我们还需要安装好 gir1.2-appindicator3 包。该库能够让我们很容易就能创建系统图标指示器。
|
||||
|
||||
在 Ubuntu/Mint/Debian 上安装:
|
||||
|
||||
```
|
||||
sudo apt-get install gir1.2-appindicator3
|
||||
```
|
||||
|
||||
在 Fedora 上安装:
|
||||
|
||||
```
|
||||
sudo dnf install libappindicator-gtk3
|
||||
```
|
||||
|
||||
对于其他发行版,只需要搜索包含 appindicator 的包就行了。
|
||||
|
||||
在 GNOME Shell 3.26 开始,系统托盘图标被删除了。你需要安装 [这个扩展 ][2] (或者其他扩展) 来为桌面启用该功能。否则你无法看到我们创建的指示器。
|
||||
|
||||
### 基础代码
|
||||
|
||||
下面是指示器的基础代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/python
|
||||
import os
|
||||
from gi.repository import Gtk as gtk, AppIndicator3 as appindicator
|
||||
|
||||
def main():
|
||||
indicator = appindicator.Indicator.new("customtray", "semi-starred-symbolic", appindicator.IndicatorCategory.APPLICATION_STATUS)
|
||||
indicator.set_status(appindicator.IndicatorStatus.ACTIVE)
|
||||
indicator.set_menu(menu())
|
||||
gtk.main()
|
||||
|
||||
def menu():
|
||||
menu = gtk.Menu()
|
||||
|
||||
command_one = gtk.MenuItem('My Notes')
|
||||
command_one.connect('activate', note)
|
||||
menu.append(command_one)
|
||||
|
||||
exittray = gtk.MenuItem('Exit Tray')
|
||||
exittray.connect('activate', quit)
|
||||
menu.append(exittray)
|
||||
|
||||
menu.show_all()
|
||||
return menu
|
||||
|
||||
def note(_):
|
||||
os.system("gedit $HOME/Documents/notes.txt")
|
||||
|
||||
def quit(_):
|
||||
gtk.main_quit()
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
我们待会会解释一下代码是怎么工作的。但是现在,让我们将该文本保存为 tray.py,然后使用 Python 运行之:
|
||||
|
||||
```
|
||||
python tray.py
|
||||
```
|
||||
|
||||
我们会看到指示器运行起来了,如下图所示:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 13][3]
|
||||
|
||||
现在,让我们解释一下魔术的原理:
|
||||
|
||||
* 前三行代码仅仅用来指明 Python 的路径并且导入需要的库。
|
||||
|
||||
* def main() : 此为指示器的主函数。该函数的代码用来初始化并创建指示器。
|
||||
|
||||
* indicator = appindicator.Indicator.new(“customtray”,“semi-starred-symbolic”,appindicator.IndicatorCategory.APPLICATION_STATUS) : 这里我们指明创建一个名为 `customtray` 的指示器。这是指示器的唯一名称这样系统就不会与其他运行中的指示器搞混了。同时我们使用名为 `semi-starred-symbolic` 的图标作为指示器的默认图标。你可以将之改成任何其他值; 比如 `firefox` (如果你希望该指示器使用 FireFox 的图标),或任何其他希望的图标名。最后与 `APPLICATION_STATUS` 相关的部分是指明指示器类别/范围的常规代码。
|
||||
|
||||
* `indicator.set_status(appindicator.IndicatorStatus.ACTIVE)` : 这一行激活指示器。
|
||||
|
||||
* `indicator.set_menu(menu())` : 这里我的是我们想使用 `menu()` 函数 (我们会在后面定义) 来为我们的指示器创建菜单项。这很重要,可以让你右击指示器后看到一个可以实施行为的列别。
|
||||
|
||||
* `gtk.main()` : 运行 GTK 主循环。
|
||||
|
||||
* 在 `menu()` 中我们定义了想要指示器提供的行为或项目。`command_one = gtk.MenuItem(‘My Notes’)` 仅仅使用文本 “My notes” 来初始化第一个菜单项,接下来 `command_one.connect(‘activate’,note)` 将菜单的 `activate` 信号与后面定义的 `note()` 函数相连接; 换句话说,我们告诉我们的系统:“当该菜单项被点击,运行 note() 函数”。最后,`menu.append(command_one)` 将菜单项添加到列表中。
|
||||
|
||||
* `exittray` 相关的行是为了创建一个退出的菜单项让你在想要的时候关闭指示器。
|
||||
|
||||
* `menu.show_all()` 以及 `return menu` 只是返回菜单项给指示器的常规代码。
|
||||
|
||||
* 在 `note(_)` 下面是点击 “My Notes” 菜单项时需要执行的代码。这里只是 `os.system(“gedit $HOME/Documents/notes.txt”)` 这一句话; `os.system` 函数允许你在 Python 中运行 shell 命令,因此这里我们写了一行命令来使用 `gedit` 打开 home 目录下 `Documents` 目录中名为 `notes.txt` 的文件。例如,这个可以称为你今后的日常笔记程序了!
|
||||
|
||||
### 添加你所需要的任务
|
||||
|
||||
你只需要修改代码中的两块地方:
|
||||
|
||||
1。在 `menu()` 中为你想要的任务定义新的菜单项。
|
||||
|
||||
2。创建一个新的函数让给该菜单项被点击时执行特定的行为。
|
||||
|
||||
|
||||
所以,比如说你想要创建一个新菜单项,在点击后,会使用 VLC 播放硬盘中某个特定的视频/音频文件?要做到这一点,只需要在地 17 行处添加下面三行内容:
|
||||
|
||||
```
|
||||
command_two = gtk.MenuItem('Play video/audio')
|
||||
command_two.connect('activate', play)
|
||||
menu.append(command_two)
|
||||
```
|
||||
|
||||
然后在地 30 行添加下面内容:
|
||||
|
||||
```
|
||||
def play(_):
|
||||
os.system("vlc /home/<username>/Videos/somevideo.mp4")
|
||||
```
|
||||
|
||||
将 /home/<username>/Videos/somevideo.mp4 替换成你想要播放的视频/音频文件路径。现在保存该文件然后再次运行该指示器:
|
||||
|
||||
```
|
||||
python tray.py
|
||||
```
|
||||
|
||||
你将会看到:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 15][4]
|
||||
|
||||
而且当你点击新创建的菜单项时,VLC 会开始播放!
|
||||
|
||||
要创建其他项目/任务,只需要重复上面步骤即可。但是要小心,需要用其他命令来为 command_two 改名,比如 command_three,这样在变量之间才不会产生冲突。然后定义新函数,就像 play(_) 函数那样。
|
||||
|
||||
从这里开始的可能性是无穷的; 比如我用这种方法来从网上获取数据(使用 urllib2 库) 并显示出来。我也用它来在后台使用 mpg123 命令播放 mp3 文件,而且我还定义了另一个菜单项来杀掉所有的 mpg123 来随时停止播放音频。比如 Steam 上的 CS:GO 退出很费时间(窗口并不会自动关闭),因此,作为一个变通的方法,我只是最小化窗口然后点击某个自建的菜单项,它会执行 killall -9 csgo_linux64 命令。
|
||||
|
||||
你可以使用这个指示器来做任何事情:升级系统包,运行其他脚本。字面上的任何事情。
|
||||
|
||||
### 自动启动
|
||||
|
||||
我们希望系统托盘指示器能在系统启动后自动启动,而不用每次都手工运行。要做到这一点,只需要在自启动应用程序中添加下面命令即可(但是你需要将 tray.py 的路径替换成你自己的路径):
|
||||
|
||||
```
|
||||
nohup python /home/<username>/tray.py &
|
||||
```
|
||||
|
||||
下次重启系统,指示器会在系统启动后自动开始工作了!
|
||||
|
||||
### 结论
|
||||
|
||||
你现在知道了如何为你想要的任务创建自己的系统托盘指示器了。根据每天需要运行的任务的性质和数量,此方法可以节省大量时间。有些人偏爱从命令行创建别名,但是这需要你每次都打开终端窗口或者需要有一个可用的下拉式终端仿真器,而这里,这个系统托盘指示器一直在工作,随时可用。
|
||||
|
||||
你以前用过这个方法来运行你的任务吗?很想听听你的想法。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux
|
||||
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fosspost.org/author/mhsabbagh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-28-0808.png?resize=407%2C345&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 12)
|
||||
[2]: https://extensions.gnome.org/extension/1031/topicons/
|
||||
[3]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1041.png?resize=434%2C140&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 14)
|
||||
[4]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1141.png?resize=440%2C149&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 16)
|
||||
216
translated/tech/20190627 How to use Tig to browse Git logs.md
Normal file
216
translated/tech/20190627 How to use Tig to browse Git logs.md
Normal file
@ -0,0 +1,216 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to use Tig to browse Git logs)
|
||||
[#]: via: (https://opensource.com/article/19/6/what-tig)
|
||||
[#]: author: (Olaf Alders https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo)
|
||||
|
||||
如何使用 Tig 浏览 Git 日志
|
||||
======
|
||||
Tig不仅仅是 Git 的文本界面。以下是它如何增强你的日常工作流程。
|
||||
![A person programming][1]
|
||||
|
||||
如果你使用 Git 作为你的版本控制系统,你可能已经让自己接受 Git 是一个复杂的野兽。它是一个很棒的工具,但在 Git 仓库查找可能很麻烦。因此像 [Tig][2] 这样的工具出现了。
|
||||
|
||||
来自 [Tig 手册页][3]:
|
||||
|
||||
> Tig 是 git(1) 的基于 ncurses 的文本界面。它主要用作 Git 仓库浏览器,但也有助于在块级别暂存提交更改,并显示各种 Git 命令的输出。
|
||||
|
||||
这基本上意味着 Tig 提供了一个可以在终端中运行的基于文本的用户界面。Tig 可以让你轻松浏览你的 Git 日志,但它可以做的远不止让你从最后的提交跳到前一个提交。
|
||||
|
||||
![Tig screenshot][4]
|
||||
|
||||
这篇快速入门的 Tig 中的许多例子都是直接从其出色的手册页中拿出来的。我强烈建议你阅读它以了解更多信息。
|
||||
|
||||
### 安装 Tig
|
||||
|
||||
* Fedora 和 RHEL: **sudo dnf install tig**
|
||||
* Ubuntu 和 Debian: **sudo apt install tig**
|
||||
* MacOS:**:brew install tig**
|
||||
|
||||
|
||||
|
||||
有关更多选项,请参阅官方[安装说明][5]。
|
||||
|
||||
### 浏览当前分支中的提交
|
||||
|
||||
如果要浏览分支中的最新提交,请输入:
|
||||
|
||||
|
||||
```
|
||||
`tig`
|
||||
```
|
||||
|
||||
这是这样。这个三字符命令将启动一个浏览器,你可以在其中导航当前分支中的提交。你可以将其视为 **git log** 的封装器。
|
||||
|
||||
要浏览输出,可以使用向上和向下箭头键从一个提交移动到另一个提交。按回车键将会垂直分割窗口,右侧包含所选提交的内容。你可以继续在左侧的提交历史记录中上下浏览,你的更改将显示在右侧。使用 **k** 和 **j** 逐行上下浏览,**-** 和空格键在右侧上下翻页。使用 **q** 退出右侧窗格。
|
||||
|
||||
搜索 **tig** 输出也很简单。使用 **/** 向前搜索,使用 **?** 在左右窗格中向后搜索。
|
||||
|
||||
![Searching Tig][6]
|
||||
|
||||
这足以让你开始浏览你的提交。这里有很多的键绑定,但单击 **h** 将显示“帮助”菜单,你可以在其中发现其导航和命令选项。你还可以使用 **/** 和 **?** 来搜索“帮助”菜单。使用 **q** 退出帮助。
|
||||
|
||||
![Tig Help][7]
|
||||
|
||||
### 浏览单个文件的修改
|
||||
|
||||
由于 Tig 是 **git log** 的封装器,它可以方便地接受可以传递给 **git log** 的相同参数。例如,要浏览单个文件的提交历史记录,请输入:
|
||||
|
||||
|
||||
```
|
||||
`tig README.md`
|
||||
```
|
||||
|
||||
将其与被封装的 Git 命令的输出进行比较,以便更清楚地了解 Tig 如何增强输出。
|
||||
|
||||
|
||||
```
|
||||
`git log README.md`
|
||||
```
|
||||
|
||||
要在原始 Git 输出中包含补丁,你可以添加 **-p** 选项:
|
||||
|
||||
|
||||
```
|
||||
`git log -p README.md`
|
||||
```
|
||||
|
||||
如果要将提交范围缩小到特定日期范围,请尝试以下操作:
|
||||
|
||||
|
||||
```
|
||||
`tig --after="2017-01-01" --before="2018-05-16" -- README.md`
|
||||
```
|
||||
|
||||
再一次,你可以将其与原始的 Git 版本进行比较:
|
||||
|
||||
|
||||
```
|
||||
`git log --after="2017-01-01" --before="2018-05-16" -- README.md`
|
||||
```
|
||||
|
||||
### 浏览谁更改了文件
|
||||
|
||||
有时你想知道谁对文件进行了更改以及原因。命令:
|
||||
|
||||
|
||||
```
|
||||
`tig blame README.md`
|
||||
```
|
||||
|
||||
本质上是 **git blame** 的封装。正如你 所期望的那样,它允许你查看谁是编辑指定行的最后一人,它还允许你查看到引入该行的提交。这有点像 vim 的 **vim-fugitive**插件提供的**:Gblame**命令。
|
||||
|
||||
### 浏览你的暂存
|
||||
|
||||
如果你像我一样,你可能会在你的暂存处有许多编辑。你很容易忘记它们。你可以通过以下方式查看暂存处中的最新项目:
|
||||
|
||||
|
||||
```
|
||||
`git stash show -p stash@{0}`
|
||||
```
|
||||
|
||||
你可以通过以下方式找到第二个最新项目:
|
||||
|
||||
|
||||
```
|
||||
`git stash show -p stash@{1}`
|
||||
```
|
||||
|
||||
以此类推。如果你在需要它们时调用这些命令,那么你会有比我更清晰的内存。
|
||||
|
||||
|
||||
与上面的 Git 命令一样,Tig 可以通过简单的调用轻松增强你的 Git 输出:
|
||||
|
||||
|
||||
```
|
||||
`tig stash`
|
||||
```
|
||||
|
||||
尝试在有暂存的仓库中执行此命令。你将能够浏览_并搜索_你的暂存项,快速浏览你的那些修改。
|
||||
|
||||
### 浏览你的引用
|
||||
|
||||
git ref 是你提交的东西的哈希值。这包括文件和分支。使用 **tig refs** 命令可以浏览所有引用并深入查看特定提交。
|
||||
|
||||
|
||||
```
|
||||
`tig refs`
|
||||
```
|
||||
|
||||
完成后,使用 **q** 回到前面的菜单。
|
||||
|
||||
### 浏览 git 状态
|
||||
|
||||
如果要查看哪些文件已被暂存,哪些文件未被跟踪,请使用 **tig status**,它是 **git status** 的封装。
|
||||
|
||||
![Tig status][8]
|
||||
|
||||
### 浏览 git grep
|
||||
|
||||
你可以使用 **grep** 命令在文本文件中搜索表达式。命令 **tig grep** 允许你导览 **git grep** 的输出。例如:
|
||||
|
||||
|
||||
```
|
||||
`tig grep -i foo lib/Bar`
|
||||
```
|
||||
|
||||
它会导览 **lib/Bar** 目录中以大小写敏感的方式搜索 **foo** 的输出。
|
||||
|
||||
### 通过标准输入管道输出给 Tig
|
||||
|
||||
如果要将提交 ID 列表传递给 Tig,那么必须使用 **\--stdin** 标志,以便 **tig show** 从标准输入读取。否则,**tig show** 会在没有输入的情况下启动(出现空白屏幕)。
|
||||
|
||||
|
||||
```
|
||||
`git rev-list --author=olaf HEAD | tig show --stdin`
|
||||
```
|
||||
|
||||
### 添加自定义绑定
|
||||
|
||||
你可以使用 [rc][9] 文件自定义 Tig。以下是如何根据自己的喜好添加一些有用的自定义键绑定的示例。
|
||||
|
||||
在主目录中创建一个名为 **.tigrc** 的文件。在你喜欢的编辑器中打开 **~/.tigrc** 并添加:
|
||||
|
||||
|
||||
```
|
||||
# Apply the selected stash
|
||||
bind stash a !?git stash apply %(stash)
|
||||
|
||||
# Drop the selected stash item
|
||||
bind stash x !?git stash drop %(stash)
|
||||
```
|
||||
|
||||
如上所述,运行 **tig stash** 以浏览你的暂存。但是,通过这些绑定,你可以按 **a**将暂存中的项目应用到仓库,并按 **x** 从暂存中删除项目。请记住,你要在浏览暂存_列表_时,才能执行这些命令。如果你正在浏览暂存_项_,请输入 **q** 退出该视图,然后按 **a** 或 **x** 以获得所需效果。
|
||||
|
||||
有关更多信息,你可以阅读有关 [Tig 键绑定][10]。
|
||||
|
||||
### 总结
|
||||
|
||||
我希望这有助于演示 Tig 如何增强你的日常工作流程。Tig 可以做更强大的事情(比如暂存代码行),但这超出了这篇介绍性文章的范围。这里有足够的让你危险的信息,但还有更多值得探索的地方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-tig
|
||||
|
||||
作者:[Olaf Alders][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
|
||||
[2]: https://jonas.github.io/tig/
|
||||
[3]: http://manpages.ubuntu.com/manpages/bionic/man1/tig.1.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/tig.jpg (Tig screenshot)
|
||||
[5]: https://jonas.github.io/tig/INSTALL.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/tig-search.png (Searching Tig)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/tig-help.png (Tig Help)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/tig-status.png (Tig status)
|
||||
[9]: https://en.wikipedia.org/wiki/Run_commands
|
||||
[10]: https://github.com/jonas/tig/wiki/Bindings
|
||||
244
translated/tech/20190702 Jupyter and data science in Fedora.md
Normal file
244
translated/tech/20190702 Jupyter and data science in Fedora.md
Normal file
@ -0,0 +1,244 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Jupyter and data science in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/jupyter-and-data-science-in-fedora/)
|
||||
[#]: author: (Avi Alkalay https://fedoramagazine.org/author/aviram/)
|
||||
|
||||
在 Fedora 上搭建 Jupyter 和数据科学环境
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
在过去,神谕和魔法师被认为拥有发现奥秘的力量,国王和统治者们会借助他们预测未来,或者至少是听取一些建议。如今我们生活在一个痴迷于将一切事情量化的社会里,这份工作就交给数据科学家了。
|
||||
|
||||
数据科学家通过使用统计模型、数值分析,以及统计学之外的高级算法,结合数据库里已经存在的数据,去发掘、推断和预测尚不存在的数据(有时是关于未来的数据)。这就是为什么我们要做这么多的预测分析和规划分析。
|
||||
|
||||
下面是一些可以借助数据科学家回答的问题:
|
||||
|
||||
1. 哪些学生有旷课倾向?每个人旷课的原因分别是什么?
|
||||
2. 哪栋房子的售价比合理价格要高或者低?一栋房子的合理价格是多少?
|
||||
3. 如何将我们的客户按照潜在的特质进行分组?
|
||||
4. 这个孩子的早熟可能会在未来引发什么问题?
|
||||
5. 我们的呼叫中心在明天早上 11 点 43 分会接收到多少次呼叫?
|
||||
6. 我们的银行是否应该向这位客户发放贷款?
|
||||
|
||||
请注意,这些问题的答案是在任何数据库里都查询不到的,因为它们尚不存在,需要被计算出来才行。这就是我们数据科学家从事的工作。
|
||||
|
||||
在这篇文章中你会学习如何将 Fedora 系统打造成数据科学家的开发环境和生产系统。其中大多数基本软件都有 RPM 软件包,但是最先进的组件目前只能通过 Python 的 **pip** 工具安装。
|
||||
|
||||
### Jupyter IDE
|
||||
|
||||
大多数现代数据科学家使用 Python 工作。他们工作中很重要的一部分是 <ruby>探索性数据分析<rt>Exploratory Data Analysis<rt></ruby>(EDA)。EDA 是一种手动进行的、交互性的过程,包括提取数据、探索数据特征、寻找相关性、通过绘制图形进行数据可视化并理解数据的分布特征,以及实现简易的预测模型。
|
||||
|
||||
Jupyter 是能够完美胜任该工作的一个 web 应用。Jupyter 使用的 Notebook 文件支持丰富的文本,包括渲染精美的数学公式(得益于 [mathjax][2])、代码块和代码输出(包括图形输出)。
|
||||
|
||||
Notebook 文件的后缀是 **.ipynb**,意思是“交互式 Python Notebook”。
|
||||
|
||||
#### 搭建并运行 Jupyter
|
||||
|
||||
首先,[使用 sudo][3] 安装 Jupyter 核心软件包:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-notebook mathjax sscg
|
||||
```
|
||||
你或许需要安装数据科学家常用的一些附加可选模块:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
|
||||
```
|
||||
|
||||
设置一个用来登陆 Notebook 的 web 界面的密码,从而避免使用冗长的令牌。你可以在终端里任何一个位置运行下面的命令:
|
||||
|
||||
```
|
||||
$ mkdir -p $HOME/.jupyter
|
||||
$ jupyter notebook password
|
||||
```
|
||||
|
||||
然后输入你的密码,这时会自动创建 ** $HOME/.jupyter/jupyter_notebook_config.json ** 这个文件,包含了你的密码的加密后版本。
|
||||
|
||||
接下来,通过使用 SSLby 为 Jupyter 的 web 服务器生成一个自签名的 HTTPS 证书:
|
||||
|
||||
```
|
||||
$ cd $HOME/.jupyter; sscg
|
||||
```
|
||||
|
||||
配置 Jupyter 的最后一步是编辑 **$HOME/.jupyter/jupyter_notebook_config.json** 这个文件。按照下面的模版编辑该文件:
|
||||
|
||||
```
|
||||
{
|
||||
"NotebookApp": {
|
||||
"password": "sha1:abf58...87b",
|
||||
"ip": "*",
|
||||
"allow_origin": "*",
|
||||
"allow_remote_access": true,
|
||||
"open_browser": false,
|
||||
"websocket_compression_options": {},
|
||||
"certfile": "/home/aviram/.jupyter/service.pem",
|
||||
"keyfile": "/home/aviram/.jupyter/service-key.pem",
|
||||
"notebook_dir": "/home/aviram/Notebooks"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
红色的部分应该替换为你的文件夹。蓝色的部分在你创建完密码之后就已经自动生成了。绿色的部分是 **sscg** 生成的和加密相关的文件。
|
||||
|
||||
接下来创建一个用来存放 notebook 文件的文件夹,应该和上面配置里 **notebook_dir** 一致:
|
||||
|
||||
```
|
||||
$ mkdir $HOME/Notebooks
|
||||
```
|
||||
|
||||
你已经完成了配置。现在可以在系统里的任何一个地方通过以下命令启动 Jupyter Notebook:
|
||||
|
||||
```
|
||||
$ jupyter notebook
|
||||
```
|
||||
|
||||
或者是将下面这行代码添加到 **$HOME/.bashrc** 文件,创建一个叫做 **jn** 的快捷命令:
|
||||
|
||||
```
|
||||
alias jn='jupyter notebook'
|
||||
```
|
||||
|
||||
运行 **jn** 命令之后,你可以通过网络内部的任何一个浏览器访问 **<https://your-fedora-host.com:8888>** (LCTT 译注:将域名替换为服务器的域名),就可以看到 Jupyter 的用户界面了,需要使用前面设置的密码登录。你可以尝试键入一些 Python 代码和标记文本,看起来会像下面这样:
|
||||
|
||||
![Jupyter with a simple notebook][4]
|
||||
|
||||
除了 IPython 环境,安装过程还会生成一个由 **terminado** 提供的基于 web 的 Unix 终端。有人觉得这很实用,也有人觉得这样不是很安全。你可以在配置文件里禁用这个功能。
|
||||
|
||||
### JupyterLab — 下一代 Jupyter
|
||||
|
||||
JupyterLab 是下一代的 Jupyter,拥有更好的用户界面和对工作空间更强的操控性。在写这篇文章的时候 JupyterLab 还没有可用的 RPM 软件包,但是你可以使用 **pip** 轻松完成安装:
|
||||
|
||||
```
|
||||
$ pip3 install jupyterlab --user
|
||||
$ jupyter serverextension enable --py jupyterlab
|
||||
```
|
||||
|
||||
然后运行 **jupiter notebook** 命令或者 **jn** 快捷命令。访问 **<http://your-linux-host.com:8888/**lab**>** LCTT 译注:将域名替换为服务器的域名)就可以使用 JupyterLab 了。
|
||||
|
||||
### 数据科学家使用的工具
|
||||
|
||||
在下面这一节里,你将会了解到数据科学家使用的一些工具及其安装方法。除非另作说明,这些工具应该已经有 Fedora 软件包版本,并且已经作为前面组件所需要的软件包而被安装了。
|
||||
|
||||
#### **Numpy**
|
||||
|
||||
**Numpy** 是一个针对 C 语言优化过的高级库,用来处理内存里的大型数据集。它支持高级多维矩阵及其运算,并且包含了 log()、exp()、三角函数等数学函数。
|
||||
|
||||
#### Pandas
|
||||
|
||||
在我看来,正是 Pandas 成就了 Python 作为数据科学首选平台的地位。Pandas 构建在 numpy 之上,可以让数据准备和数据呈现工作变得简单很多。你可以把它想象成一个没有用户界面的电子表格程序,但是能够处理的数据集要大得多。Pandas 支持从 SQL 数据库或者 CSV 等格式的文件中提取数据、按列或者按行进行操作、数据筛选,以及通过 matplotlib 实现数据可视化的一部分功能。
|
||||
|
||||
#### Matplotlib
|
||||
|
||||
Matplotlib 是一个用来绘制 2D 和 3D 数据图像的库,在图象注解、标签和叠加层方面都提供了相当不错的支持。
|
||||
|
||||
![matplotlib pair of graphics showing a cost function searching its optimal value through a gradient descent algorithm][5]
|
||||
|
||||
#### Seaborn
|
||||
|
||||
Seaborn 构建在 matplotlib 之上,它的绘图功能经过了优化,更加适合数据的统计学研究,比如说可以自动显示所绘制数据的近似回归线或者正态分布曲线。
|
||||
|
||||
![Linear regression visualised with SeaBorn][6]
|
||||
|
||||
#### [StatsModels][7]
|
||||
|
||||
StatsModels 为统计学和经济计量学的数据分析问题(例如线形回归和逻辑回归)提供算法支持,同时提供经典的 [时间序列算法][8] 家族:ARIMA。
|
||||
|
||||
![Normalized number of passengers across time \(blue\) and ARIMA-predicted number of passengers \(red\)][9]
|
||||
|
||||
#### Scikit-learn
|
||||
|
||||
作为机器学习生态系统的核心部件,[scikit][10] 为不同类型的问题提供预测算法,包括 [回归问题][11](算法包括 Elasticnet、Gradient Boosting、随机森林等等)、[分类问题][11] 和聚类问题(算法包括 K-means 和 DBSCAN 等等),并且拥有设计精良的 API。Scikit 还定义了一些专门的 Python 类,用来支持数据操作的高级技巧,比如将数据集拆分为训练集和测试集、降维算法、数据准备管道流程等等。
|
||||
|
||||
#### XGBoost
|
||||
|
||||
XGBoost 是目前可以使用的最先进的回归器和分类器。它并不是 scikit-learn 的一部分,但是却遵循了 scikit 的 API。[XGBoost][12] 并没有针对 Fedora 的软件包,但可以使用 pip 安装。[使用英伟达显卡可以提升 XGBoost 算法的性能][13],但是这并不能通过 **pip** 软件包来实现。如果你希望使用这个功能,可以针对 CUDA (LCTT 译注:英伟达开发的并行计算平台)自己进行编译。使用下面这个命令安装 XGBoost:
|
||||
|
||||
```
|
||||
$ pip3 install xgboost --user
|
||||
```
|
||||
|
||||
#### Imbalanced Learn
|
||||
|
||||
[imbalanced-learn][14] 是一个解决数据欠采样和过采样问题的工具。比如在反欺诈问题中,欺诈数据相对于正常数据来说数量非常小,这个时候就需要对欺诈数据进行数据增强,从而让预测器能够更好地适应数据集。使用 **pip** 安装:
|
||||
|
||||
```
|
||||
$ pip3 install imblearn --user
|
||||
```
|
||||
|
||||
#### NLTK
|
||||
|
||||
[Natural Language toolkit][15](简称 NLTK)是一个处理人类语言数据的工具,举例来说,它可以被用来开发一个聊天机器人。
|
||||
|
||||
|
||||
#### SHAP
|
||||
|
||||
机器学习算法拥有强大的预测能力,但并不能够很好地解释为什么做出这样或那样的预测。[SHAP][16] 可以通过分析训练后的模型来解决这个问题。
|
||||
|
||||
![Where SHAP fits into the data analysis process][17]
|
||||
|
||||
使用 **pip** 安装:
|
||||
|
||||
```
|
||||
$ pip3 install shap --user
|
||||
```
|
||||
|
||||
#### [Keras][18]
|
||||
|
||||
Keras 是一个深度学习和神经网络模型的库,使用 **pip** 安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-h5py
|
||||
$ pip3 install keras --user
|
||||
```
|
||||
|
||||
#### [TensorFlow][19]
|
||||
|
||||
TensorFlow 是一个非常流行的神经网络模型搭建工具,使用 **pip** 安装:
|
||||
|
||||
```
|
||||
$ pip3 install tensorflow --user
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
_Photo courtesy of [FolsomNatural][20] on [Flickr][21] (CC BY-SA 2.0)._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/jupyter-and-data-science-in-fedora/
|
||||
|
||||
作者:[Avi Alkalay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/aviram/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/jupyter-816x345.jpg
|
||||
[2]: http://mathjax.org
|
||||
[3]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]: https://avi.alkalay.net/articlefiles/2018/07/jupyter-fedora.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/06/gradient-descent-cost-function-optimization.png
|
||||
[6]: https://seaborn.pydata.org/_images/regression_marginals.png
|
||||
[7]: https://www.statsmodels.org/
|
||||
[8]: https://www.statsmodels.org/stable/examples/index.html#stats
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/06/time-series.png
|
||||
[10]: https://scikit-learn.org/stable/
|
||||
[11]: https://scikit-learn.org/stable/supervised_learning.html#supervised-learning
|
||||
[12]: https://xgboost.ai
|
||||
[13]: https://xgboost.readthedocs.io/en/latest/gpu/index.html
|
||||
[14]: https://imbalanced-learn.readthedocs.io
|
||||
[15]: https://www.nltk.org
|
||||
[16]: https://github.com/slundberg/shap
|
||||
[17]: https://raw.githubusercontent.com/slundberg/shap/master/docs/artwork/shap_diagram.png
|
||||
[18]: https://keras.io
|
||||
[19]: https://www.tensorflow.org
|
||||
[20]: https://www.flickr.com/photos/87249144@N08/
|
||||
[21]: https://www.flickr.com/photos/87249144@N08/45871861611/
|
||||
Loading…
Reference in New Issue
Block a user