mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
20150610-1 选题
This commit is contained in:
parent
71fcc1f770
commit
bbf84f32ce
@ -0,0 +1,95 @@
|
||||
Tickr Is An Open-Source RSS News Ticker for Linux Desktops
|
||||
================================================================================
|
||||

|
||||
|
||||
**Latest! Latest! Read all about it!**
|
||||
|
||||
Alright, so the app we’re highlighting today isn’t quite the binary version of an old newspaper seller — but it is a great way to have the latest news brought to you, on your desktop.
|
||||
|
||||
Tick is a GTK-based news ticker for the Linux desktop that scrolls the latest headlines and article titles from your favourite RSS feeds in horizontal strip that you can place anywhere on your desktop.
|
||||
|
||||
Call me Joey Calamezzo; I put mine on the bottom TV news station style.
|
||||
|
||||
“Over to you, sub-heading.”
|
||||
|
||||
### RSS — Remember That? ###
|
||||
|
||||
“Thanks paragraph ending.”
|
||||
|
||||
In an era of push notifications, social media, and clickbait, cajoling us into reading the latest mind-blowing, humanity saving listicle ASAP, RSS can seem a bit old hat.
|
||||
|
||||
For me? Well, RSS lives up to its name of Really Simple Syndication. It’s the easiest, most manageable way to have news come to me. I can manage and read stuff when I want; there’s no urgency to view lest the tweet vanish into the stream or the push notification vanish.
|
||||
|
||||
The beauty of Tickr is in its utility. You can have a constant stream of news trundling along the bottom of your screen, which you can passively glance at from time to time.
|
||||
|
||||

|
||||
|
||||
There’s no pressure to ‘read’ or ‘mark all read’ or any of that. When you see something you want to read you just click it to open it in a web browser.
|
||||
|
||||
### Setting it Up ###
|
||||
|
||||

|
||||
|
||||
Although Tickr is available to install from the Ubuntu Software Centre it hasn’t been updated for a long time. Nowhere is this sense of abandonment more keenly felt than when opening the unwieldy and unintuitive configuration panel.
|
||||
|
||||
To open it:
|
||||
|
||||
1. Right click on the Tickr bar
|
||||
1. Go to Edit > Preferences
|
||||
1. Adjust the various settings
|
||||
|
||||
Row after row of options and settings, few of which seem to make sense at first. But poke and prod around and you’ll controls for pretty much everything, including:
|
||||
|
||||
- Set scrolling speed
|
||||
- Choose behaviour when mousing over
|
||||
- Feed update frequency
|
||||
- Font, including font sizes and color
|
||||
- Separator character (‘delineator’)
|
||||
- Position of Tickr on screen
|
||||
- Color and opacity of Tickr bar
|
||||
- Choose how many articles each feed displays
|
||||
|
||||
One ‘quirk’ worth mentioning is that pressing the ‘Apply’ only updates the on-screen Tickr to preview changes. For changes to take effect when you exit the Preferences window you need to click ‘OK’.
|
||||
|
||||
Getting the bar to sit flush on your display can also take a fair bit of tweaking, especially on Unity.
|
||||
|
||||
Press the “full width button” to have the app auto-detect your screen width. By default when placed at the top or bottom it leaves a 25px gap (the app was created back in the days of GNOME 2.x desktops). After hitting the top or bottom buttons just add an extra 25 pixels to the input box compensate for this.
|
||||
|
||||
Other options available include: choose which browser articles open in; whether Tickr appears within a regular window frame; whether a clock is shown; and how often the app checks feed for articles.
|
||||
|
||||
#### Adding Feeds ####
|
||||
|
||||
Tickr comes with a built-in list of over 30 different feeds, ranging from technology blogs to mainstream news services.
|
||||
|
||||

|
||||
|
||||
You can select as many of these as you like to show headlines in the on screen ticker. If you want to add your own feeds you can: –
|
||||
|
||||
1. Right click on the Tickr bar
|
||||
1. Go to File > Open Feed
|
||||
1. Enter Feed URL
|
||||
1. Click ‘Add/Upd’ button
|
||||
1. Click ‘OK (select)’
|
||||
|
||||
To set how many items from each feed shows in the ticker change the “Read N items max per feed” in the other preferences window.
|
||||
|
||||
### Install Tickr in Ubuntu 14.04 LTS and Up ###
|
||||
|
||||
So that’s Tickr. It’s not going to change the world but it will keep you abreast of what’s happening in it.
|
||||
|
||||
To install it in Ubuntu 14.04 LTS or later head to the Ubuntu Software Centre but clicking the button below.
|
||||
|
||||
- [Click to install Tickr form the Ubuntu Software Center][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticker
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://tickr
|
||||
@ -0,0 +1,99 @@
|
||||
How to Clear RAM Memory Cache, Buffer and Swap Space on Linux
|
||||
================================================================================
|
||||
Like any other operating system, GNU/Linux has implemented a memory management efficiently and even more than that. But if any process is eating away your memory and you want to clear it, Linux provides a way to flush or clear ram cache.
|
||||
|
||||

|
||||
|
||||
### How to Clear Cache in Linux? ###
|
||||
|
||||
Every Linux System has three options to clear cache without interrupting any processes or services.
|
||||
|
||||
1. Clear PageCache only.
|
||||
|
||||
# sync; echo 1 > /proc/sys/vm/drop_caches
|
||||
|
||||
2. Clear dentries and inodes.
|
||||
|
||||
# sync; echo 2 > /proc/sys/vm/drop_caches
|
||||
|
||||
3. Clear PageCache, dentries and inodes.
|
||||
|
||||
# sync; echo 3 > /proc/sys/vm/drop_caches
|
||||
|
||||
Explanation of above command.
|
||||
|
||||
sync will flush the file system buffer. Command Separated by `“;”` run sequentially. The shell wait for each command to terminate before executing the next command in the sequence. As mentioned in kernel documentation, writing to drop_cache will clean cache without killing any application/service, [command echo][1] is doing the job of writing to file.
|
||||
|
||||
If you have to clear the disk cache, the first command is safest in enterprise and production as `“...echo 1 > ….”` will clear the PageCache only. It is not recommended to use third option above `“...echo 3 >”` in production until you know what you are doing, as it will clear PageCache, dentries and inodes.
|
||||
|
||||
**Is it a good idea to free Buffer and Cache in Linux that might be used by Linux Kernel?**
|
||||
|
||||
When you are applying various settings and want to check, if it is actually implemented specially on I/O-extensive benchmark, then you may need to clear buffer cache. You can drop cache as explained above without rebooting the System i.e., no downtime required.
|
||||
|
||||
Linux is designed in such a way that it looks into disk cache before looking onto the disk. If it finds the resource in the cache, then the request doesn’t reach the disk. If we clean the cache, the disk cache will be less useful as the OS will look for the resource on the disk.
|
||||
|
||||
Moreover it will also slow the system for a few seconds while the cache is cleaned and every resource required by OS is loaded again in the disk-cache.
|
||||
|
||||
Now we will be creating a shell script to auto clear RAM cache daily at 2PM via a cron scheduler task. Create a shell script clearcache.sh and add the following lines.
|
||||
|
||||
#!/bin/bash
|
||||
# Note, we are using "echo 3", but it is not recommended in production instead use "echo 1"
|
||||
echo "echo 3 > /proc/sys/vm/drop_caches"
|
||||
|
||||
Set execute permission on the clearcache.sh file.
|
||||
|
||||
# chmod 755 clearcache.sh
|
||||
|
||||
Now you may call the script whenever you required to clear ram cache.
|
||||
|
||||
Now set a cron to clear RAM cache everyday at 2PM. Open crontab for editing.
|
||||
|
||||
# crontab -e
|
||||
|
||||
Append the below line, save and exit to run it at 2PM daily.
|
||||
|
||||
0 3 * * * /path/to/clearcache.sh
|
||||
|
||||
For more details on how to cron a job you may like to check our article on [11 Cron Scheduling Jobs][2].
|
||||
|
||||
**Is it good idea to auto clear RAM cache on production server?**
|
||||
|
||||
No! it is not. Think of a situation when you have scheduled the script to clear ram cache everyday at 2PM. Everyday at 2PM the script is executed and it flushes your RAM cache. One day for whatsoever reason, may be more than expected users are online on your website and seeking resource from your server.
|
||||
|
||||
At the same time scheduled script run and clears everything in cache. Now all the user are fetching data from disk. It will result in server crash and corrupt the database. So clear ram-cache only when required,and known your foot steps, else you are a Cargo Cult System Administrator.
|
||||
|
||||
#### How to Clear Swap Space in Linux? ####
|
||||
|
||||
If you want to clear Swap space, you may like to run the below command.
|
||||
|
||||
# swapoff -a && swapon -a
|
||||
|
||||
Also you may add above command to a cron script above, after understanding all the associated risk.
|
||||
|
||||
Now we will be combining both above commands into one single command to make a proper script to clear RAM Cache and Swap Space.
|
||||
|
||||
# echo 3 > /proc/sys/vm/drop_caches && swapoff -a && swapon -a && printf '\n%s\n' 'Ram-cache and Swap Cleared'
|
||||
|
||||
OR
|
||||
|
||||
su -c 'echo 3 >/proc/sys/vm/drop_caches' && swapoff -a && swapon -a && printf '\n%s\n' 'Ram-cache and Swap Cleared'
|
||||
|
||||
After testing both above command, we will run command “free -h” before and after running the script and will check cache.
|
||||
|
||||
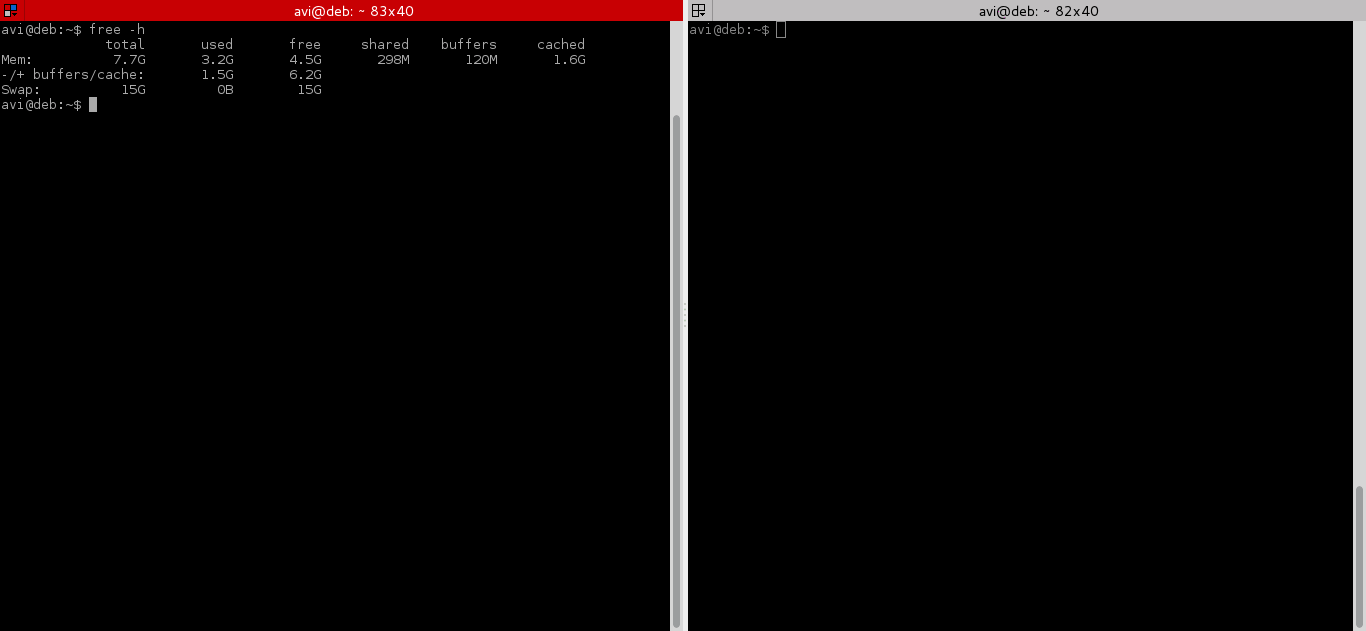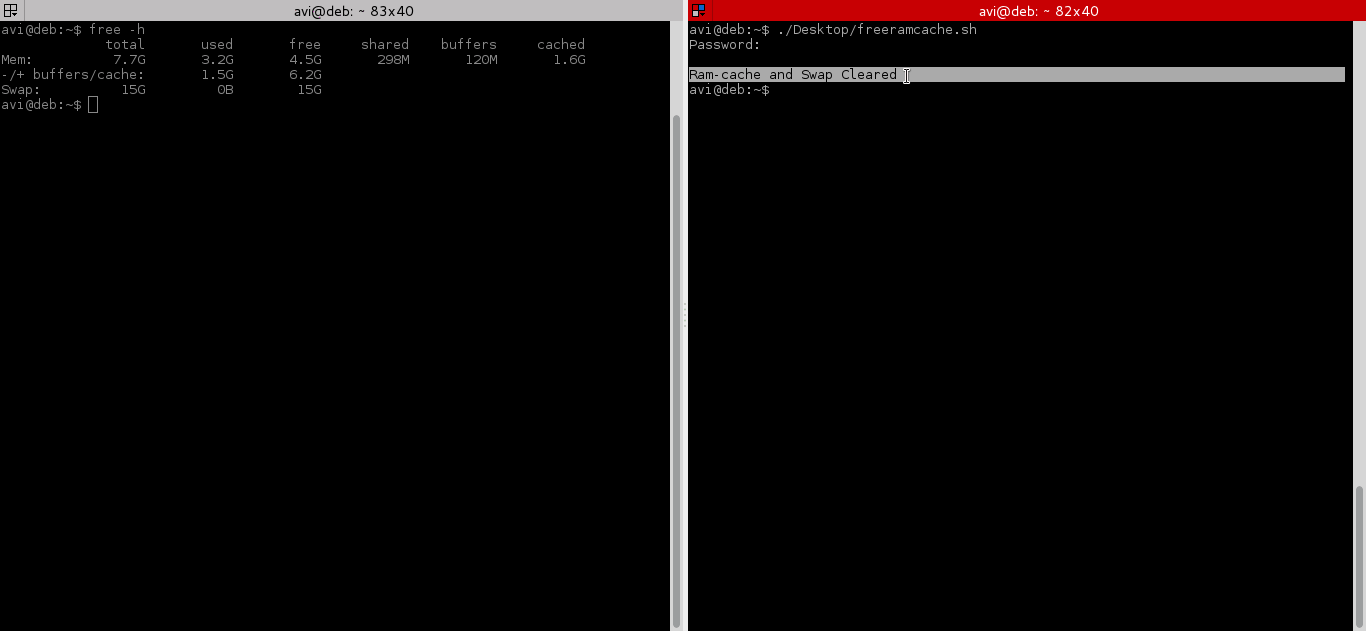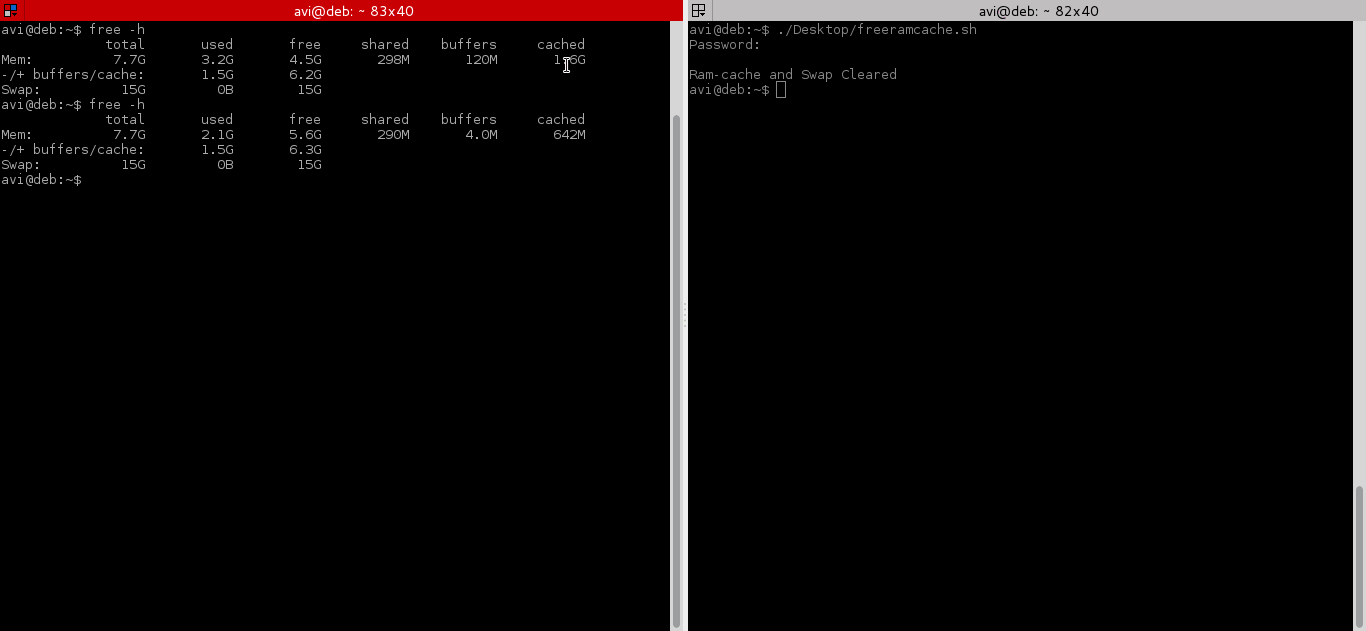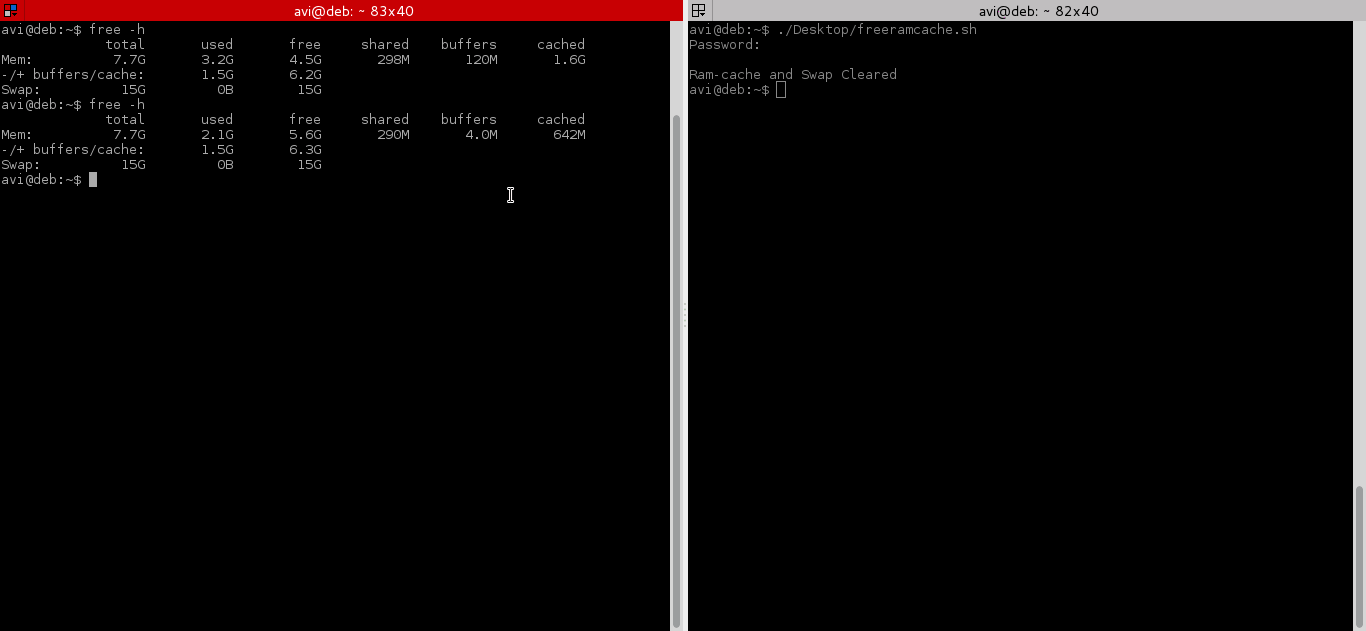
|
||||
|
||||
That’s all for now, if you liked the article, don’t forget to provide us with your valuable feedback in the comments to let us know, what you think is it a good idea to clear ram cache and buffer in production and Enterprise?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/clear-ram-memory-cache-buffer-and-swap-space-on-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
@ -0,0 +1,435 @@
|
||||
How to Manipulate Filenames Having Spaces and Special Characters in Linux
|
||||
================================================================================
|
||||
We come across files and folders name very regularly. In most of the cases file/folder name are related to the content of the file/folder and starts with number and characters. Alpha-Numeric file name are pretty common and very widely used, but this is not the case when we have to deal with file/folder name that has special characters in them.
|
||||
|
||||
**Note**: We can have files of any type but for simplicity and easy implementation we will be dealing with Text file (.txt), throughout the article.
|
||||
|
||||
Example of most common file names are:
|
||||
|
||||
abc.txt
|
||||
avi.txt
|
||||
debian.txt
|
||||
...
|
||||
|
||||
Example of numeric file names are:
|
||||
|
||||
121.txt
|
||||
3221.txt
|
||||
674659.txt
|
||||
...
|
||||
|
||||
Example of Alpha-Numeric file names are:
|
||||
|
||||
eg84235.txt
|
||||
3kf43nl2.txt
|
||||
2323ddw.txt
|
||||
...
|
||||
|
||||
Examples of file names that has special character and is not very common:
|
||||
|
||||
#232.txt
|
||||
#bkf.txt
|
||||
#bjsd3469.txt
|
||||
#121nkfd.txt
|
||||
-2232.txt
|
||||
-fbjdew.txt
|
||||
-gi32kj.txt
|
||||
--321.txt
|
||||
--bk34.txt
|
||||
...
|
||||
|
||||
One of the most obvious question here is – who on earth create/deal with files/folders name having a Hash `(#)`, a semi-colon `(;)`, a dash `(-)` or any other special character.
|
||||
|
||||
I Agree to you, that such file names are not common still your shell should not break/give up when you have to deal with any such file names. Also speaking technically every thing be it folder, driver or anything else is treated as file in Linux.
|
||||
|
||||
### Dealing with file that has dash (-) in it’s name ###
|
||||
|
||||
Create a file that starts with a dash `(-)`, say -abx.txt.
|
||||
|
||||
$ touch -abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: invalid option -- 'b'
|
||||
Try 'touch --help' for more information.
|
||||
|
||||
The reason for above error, that shell interprets anything after a dash `(-)`, as option, and obviously there is no such option, hence is the error.
|
||||
|
||||
To resolve such error, we have to tell the Bash shell (yup this and most of the other examples in the article is for BASH) not to interpret anything after special character (here dash), as option.
|
||||
|
||||
There are two ways to resolve this error as:
|
||||
|
||||
$ touch -- -abc.txt [Option #1]
|
||||
$ touch ./-abc.txt [Option #2]
|
||||
|
||||
You may verify the file thus created by both the above ways by running commands ls or [ls -l][1] for long listing.
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 11:05 -abc.txt
|
||||
|
||||
To edit the above file you may do:
|
||||
|
||||
$ nano -- -abc.txt
|
||||
or
|
||||
$ nano ./-abc.txt
|
||||
|
||||
**Note**: You may replace nano with any other editor of your choice say vim as:
|
||||
|
||||
$ vim -- -abc.txt
|
||||
or
|
||||
$ vim ./-abc.txt
|
||||
|
||||
Similarly to move such file you have to do:
|
||||
|
||||
$ mv -- -abc.txt -a.txt
|
||||
or
|
||||
$ mv -- -a.txt -abc.txt
|
||||
|
||||
and to Delete this file, you have to do:
|
||||
|
||||
$ rm -- -abc.txt
|
||||
or
|
||||
$ rm ./-abc.txt
|
||||
|
||||
If you have lots of files in a folder the name of which contains dash, and you want to delete all of them at once, do as:
|
||||
|
||||
$ rm ./-*
|
||||
|
||||
**Important to Note:**
|
||||
|
||||
1. The same rule as discussed above follows for any number of hypen in the name of the file and their occurrence. Viz., -a-b-c.txt, ab-c.txt, abc-.txt, etc.
|
||||
|
||||
2. The same rule as discussed above follows for the name of the folder having any number of hypen and their occurrence, except the fact that for deleting the folder you have to use ‘rm -rf‘ as:
|
||||
|
||||
$ rm -rf -- -abc
|
||||
or
|
||||
$ rm -rf ./-abc
|
||||
|
||||
### Dealing with files having HASH (#) in the name ###
|
||||
|
||||
The symbol `#` has a very different meaning in BASH. Anything after a `#` is interpreted as comment and hence neglected by BASH.
|
||||
|
||||
**Understand it using examples:**
|
||||
|
||||
create a file #abc.txt.
|
||||
|
||||
$ touch #abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: missing file operand
|
||||
Try 'touch --help' for more information.
|
||||
|
||||
The reason for above error, that Bash is interpreting #abc.txt a comment and hence ignoring. So the [command touch][2] has been passed without any file Operand, and hence is the error.
|
||||
|
||||
To resolve such error, you may ask BASH not to interpret # as comment.
|
||||
|
||||
$ touch ./#abc.txt
|
||||
or
|
||||
$ touch '#abc.txt'
|
||||
|
||||
and verify the file just created as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:14 #abc.txt
|
||||
|
||||
Now create a file the name of which contains # anywhere except at the begging.
|
||||
|
||||
$ touch ./a#bc.txt
|
||||
$ touch ./abc#.txt
|
||||
|
||||
or
|
||||
$ touch 'a#bc.txt'
|
||||
$ touch 'abc#.txt'
|
||||
|
||||
Run ‘ls -l‘ to verify it:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:16 a#bc.txt
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:16 abc#.txt
|
||||
|
||||
What happens when you create two files (say a and #bc) at once:
|
||||
|
||||
$ touch a.txt #bc.txt
|
||||
|
||||
Verify the file just created:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:18 a.txt
|
||||
|
||||
Obvious from the above example it only created file ‘a‘ and file ‘#bc‘ has been ignored. To execute the above situation successfully we can do,
|
||||
|
||||
$ touch a.txt ./#bc.txt
|
||||
or
|
||||
$ touch a.txt '#bc.txt'
|
||||
|
||||
and verify it as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:20 a.txt
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:20 #bc.txt
|
||||
|
||||
You can move the file as:
|
||||
|
||||
$ mv ./#bc.txt ./#cd.txt
|
||||
or
|
||||
$ mv '#bc.txt' '#cd.txt'
|
||||
|
||||
Copy it as:
|
||||
|
||||
$ cp ./#cd.txt ./#de.txt
|
||||
or
|
||||
$ cp '#cd.txt' '#de.txt'
|
||||
|
||||
You may edit it as using your choice of editor as:
|
||||
|
||||
$ vi ./#cd.txt
|
||||
or
|
||||
$ vi '#cd.txt'
|
||||
|
||||
----------
|
||||
|
||||
$ nano ./#cd.txt
|
||||
or
|
||||
$ nano '#cd.txt'
|
||||
|
||||
And Delete it as:
|
||||
|
||||
$ rm ./#bc.txt
|
||||
or
|
||||
$ rm '#bc.txt'
|
||||
|
||||
To delete all the files that has hash (#) in the file name, you may use:
|
||||
|
||||
# rm ./#*
|
||||
|
||||
### Dealing with files having semicolon (;) in its name ###
|
||||
|
||||
In case you are not aware, semicolon acts as a command separator in BASH and perhaps other shell as well. Semicolon lets you execute several command in one go and acts as separator. Have you ever deal with any file name having semicolon in it? If not here you will.
|
||||
|
||||
Create a file having semi-colon in it.
|
||||
|
||||
$ touch ;abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: missing file operand
|
||||
Try 'touch --help' for more information.
|
||||
bash: abc.txt: command not found
|
||||
|
||||
The reason for above error, that when you run the above command BASH interpret touch as a command but could not find any file operand before semicolon and hence it reports error. It also reports another error that ‘abc.txt‘ command not found, only because after semicolon BASH was expecting another command and ‘abc.txt‘, is not a command.
|
||||
|
||||
To resolve such error, tell BASH not to interpret semicolon as command separator, as:
|
||||
|
||||
$ touch ./';abc.txt'
|
||||
or
|
||||
$ touch ';abc.txt'
|
||||
|
||||
**Note**: We have enclosed the file name with single quote ''. It tells BASH that ; is a part of file name and not command separator.
|
||||
|
||||
Rest of the action (viz., copy, move, delete) on the file and folder having semicolon in its name can be carried out straight forward by enclosing the name in single quote.
|
||||
|
||||
### Dealing with other special characters in file/folder name ###
|
||||
|
||||
#### Plus Sign (+) in file name ####
|
||||
|
||||
Don’t requires anything extra, just do it normal way, as simple file name as shown below.
|
||||
|
||||
$ touch +12.txt
|
||||
|
||||
#### Dollar sign ($) in file name ####
|
||||
|
||||
You have to enclose file name in single quote, as we did in the case of semicolon. Rest of the things are straight forward..
|
||||
|
||||
$ touch '$12.txt'
|
||||
|
||||
#### Percent (%) in file name ####
|
||||
|
||||
You don’t need to do anything differently, treat it as normal file.
|
||||
|
||||
$ touch %12.txt
|
||||
|
||||
#### Asterisk (*) in file name ####
|
||||
|
||||
Having Asterisk in file name don’t change anything and you can continue using it as normal file.
|
||||
|
||||
$ touch *12.txt
|
||||
|
||||
Note: When you have to delete a file that starts with *, Never use following commands to delete such files.
|
||||
|
||||
$ rm *
|
||||
or
|
||||
$ rm -rf *
|
||||
|
||||
Instead use,
|
||||
|
||||
$ rm ./*.txt
|
||||
|
||||
#### Exclamation mark (!) in file name ####
|
||||
|
||||
Just Enclose the file name in single quote and rest of the things are same.
|
||||
|
||||
$ touch '!12.txt'
|
||||
|
||||
#### At Sign (@) in file name ####
|
||||
|
||||
Nothing extra, treat a filename having At Sign as nonrmal file.
|
||||
|
||||
$ touch '@12.txt'
|
||||
|
||||
#### ^ in file name ####
|
||||
|
||||
No extra attention required. Use a file having ^ in filename as normal file.
|
||||
|
||||
$ touch ^12.txt
|
||||
|
||||
#### Ampersand (&) in file name ####
|
||||
|
||||
Filename should be enclosed in single quotes and you are ready to go.
|
||||
|
||||
$ touch '&12.txt'
|
||||
|
||||
#### Parentheses () in file name ####
|
||||
|
||||
If the file name has Parenthesis, you need to enclose filename with single quotes.
|
||||
|
||||
$ touch '(12.txt)'
|
||||
|
||||
#### Braces {} in file name ####
|
||||
|
||||
No Extra Care needed. Just treat it as just another file.
|
||||
|
||||
$ touch {12.txt}
|
||||
|
||||
#### Chevrons <> in file name ####
|
||||
|
||||
A file name having Chevrons must be enclosed in single quotes.
|
||||
|
||||
$ touch '<12.txt>'
|
||||
|
||||
#### Square Brackets [ ] in file name ####
|
||||
|
||||
Treat file name having Square Brackets as normal files and you need not take extra care of it.
|
||||
|
||||
$ touch [12.txt]
|
||||
|
||||
#### Under score (_) in file name ####
|
||||
|
||||
They are very common and don’t require anything extra. Just do what you would have done with a normal file.
|
||||
|
||||
$ touch _12.txt
|
||||
|
||||
#### Equal-to (=) in File name ####
|
||||
|
||||
Having an Equal-to sign do not change anything, you can use it as normal file.
|
||||
|
||||
$ touch =12.txt
|
||||
|
||||
#### Dealing with back slash (\) ####
|
||||
|
||||
Backslash tells shell to ignore the next character. You have to enclose file name in single quote, as we did in the case of semicolon. Rest of the things are straight forward.
|
||||
|
||||
$ touch '\12.txt'
|
||||
|
||||
#### The Special Case of Forward Slash ####
|
||||
|
||||
You cannot create a file the name of which includes a forward slash (/), until your file system has bug. There is no way to escape a forward slash.
|
||||
|
||||
So if you can create a file such as ‘/12.txt’ or ‘b/c.txt’ then either your File System has bug or you have Unicode support, which lets you create a file with forward slash. In this case the forward slash is not a real forward slash but a Unicode character that looks alike a forward slash.
|
||||
|
||||
#### Question Mark (?) in file name ####
|
||||
|
||||
Again, an example where you don’t need to put any special attempt. A file name having Question mark can be treated in the most general way.
|
||||
|
||||
$ touch ?12.txt
|
||||
|
||||
#### Dot Mark (.) in file name ####
|
||||
|
||||
The files starting with dot `(.)` are very special in Linux and are called dot files. They are hidden files generally a configuration or system files. You have to use switch ‘-a‘ or ‘-A‘ with ls command to view such files.
|
||||
|
||||
Creating, editing, renaming and deleting of such files are straight forward.
|
||||
|
||||
$ touch .12.txt
|
||||
|
||||
Note: In Linux you may have as many dots `(.)` as you need in a file name. Unlike other system dots in file name don’t means to separate name and extension. You can create a file having multiple dots as:
|
||||
|
||||
$ touch 1.2.3.4.5.6.7.8.9.10.txt
|
||||
|
||||
and check it as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 14:32 1.2.3.4.5.6.7.8.9.10.txt
|
||||
|
||||
#### Comma (,) in file name ####
|
||||
|
||||
You can have comma in a file name, as many as you want and you Don’t requires anything extra. Just do it normal way, as simple file name.
|
||||
|
||||
$ touch ,12.txt
|
||||
or
|
||||
$ touch ,12,.txt
|
||||
|
||||
#### Colon (:) in File name ####
|
||||
|
||||
You can have colon in a file name, as many as you want and you Don’t requires anything extra. Just do it normal way, as simple file name.
|
||||
|
||||
$ touch :12.txt
|
||||
or
|
||||
$ touch :12:.txt
|
||||
|
||||
#### Having Quotes (single and Double) in file name ####
|
||||
|
||||
To have quotes in file name, we have to use the rule of exchange. I.e, if you need to have single quote in file name, enclose the file name with double quotes and if you need to have double quote in file name, enclose it with single quote.
|
||||
|
||||
$ touch "15'.txt"
|
||||
|
||||
and
|
||||
|
||||
$ touch '15”.txt'
|
||||
|
||||
#### Tilde (~) in file name ####
|
||||
|
||||
Some Editors in Linux like emacs create a backup file of the file being edited. The backup file has the name of the original file plus a tilde at the end of the file name. You can have a file that name of which includes tilde, at any location simply as:
|
||||
|
||||
$ touch ~1a.txt
|
||||
or
|
||||
$touch 2b~.txt
|
||||
|
||||
#### White Space in file name ####
|
||||
|
||||
Create a file the name of which has space between character/word, say “hi my name is avishek.txt”.
|
||||
|
||||
It is not a good idea to have file name with spaces and if you have to distinct readable name, you should use, underscore or dash. However if you have to create such a file, you have to use backward slash which ignores the next character to it. To create above file we have to do it this way..
|
||||
|
||||
$ touch hi\ my\ name\ is\ avishek.txt
|
||||
|
||||
hi my name is avishek.txt
|
||||
|
||||
I have tried covering all the scenario you may come across. Most of the above implementation are explicitly for BASH Shell and may not work in other shell.
|
||||
|
||||
If you feel that I missed something (that is very common and human nature), you may include your suggestion in the comments below. Keep Connected, Keep Commenting. Stay Tuned and connected! Like and share us and help us get spread!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
@ -0,0 +1,212 @@
|
||||
Nishita Agarwal Shares Her Interview Experience on Linux ‘iptables’ Firewall
|
||||
================================================================================
|
||||
Nishita Agarwal, a frequent Tecmint Visitor shared her experience (Question and Answer) with us regarding the job interview she had just given in a privately owned hosting company in Pune, India. She was asked a lot of questions on a variety of topics however she is an expert in iptables and she wanted to share those questions and their answer (she gave) related to iptables to others who may be going to give interview in near future.
|
||||
|
||||

|
||||
|
||||
All the questions and their Answer are rewritten based upon the memory of Nishita Agarwal.
|
||||
|
||||
> “Hello Friends! My name is **Nishita Agarwal**. I have Pursued Bachelor Degree in Technology. My area of Specialization is UNIX and Variants of UNIX (BSD, Linux) fascinates me since the time I heard it. I have 1+ years of experience in storage. I was looking for a job change which ended with a hosting company in Pune, India.”
|
||||
|
||||
Here is the collection of what I was asked during the Interview. I’ve documented only those questions and their answer that were related to iptables based upon my memory. Hope this will help you in cracking your Interview.
|
||||
|
||||
**1. Have you heard of iptables and firewall in Linux? Any idea of what they are and for what it is used?**
|
||||
|
||||
> **Answer** : I’ve been using iptables for quite long time and I am aware of both iptables and firewall. Iptables is an application program mostly written in C Programming Language and is released under GNU General Public License. Written for System administration point of view, the latest stable release if iptables 1.4.21.iptables may be considered as firewall for UNIX like operating system which can be called as iptables/netfilter, more accurately. The Administrator interact with iptables via console/GUI front end tools to add and define firewall rules into predefined tables. Netfilter is a module built inside of kernel that do the job of filtering.
|
||||
>
|
||||
> Firewalld is the latest implementation of filtering rules in RHEL/CentOS 7 (may be implemented in other distributions which I may not be aware of). It has replaced iptables interface and connects to netfilter.
|
||||
|
||||
**2. Have you used some kind of GUI based front end tool for iptables or the Linux Command Line?**
|
||||
|
||||
> **Answer** : Though I have used both the GUI based front end tools for iptables like Shorewall in conjugation of [Webmin][1] in GUI and Direct access to iptables via console.And I must admit that direct access to iptables via Linux console gives a user immense power in the form of higher degree of flexibility and better understanding of what is going on in the background, if not anything other. GUI is for novice administrator while console is for experienced.
|
||||
|
||||
**3. What are the basic differences between between iptables and firewalld?**
|
||||
|
||||
> **Answer** : iptables and firewalld serves the same purpose (Packet Filtering) but with different approach. iptables flush the entire rules set each time a change is made unlike firewalld. Typically the location of iptables configuration lies at ‘/etc/sysconfig/iptables‘ whereas firewalld configuration lies at ‘/etc/firewalld/‘, which is a set of XML files.Configuring a XML based firewalld is easier as compared to configuration of iptables, however same task can be achieved using both the packet filtering application ie., iptables and firewalld. Firewalld runs iptables under its hood along with it’s own command line interface and configuration file that is XML based and said above.
|
||||
|
||||
**4. Would you replace iptables with firewalld on all your servers, if given a chance?**
|
||||
|
||||
> **Answer** : I am familiar with iptables and it’s working and if there is nothing that requires dynamic aspect of firewalld, there seems no reason to migrate all my configuration from iptables to firewalld.In most of the cases, so far I have never seen iptables creating an issue. Also the general rule of Information technology says “why fix if it is not broken”. However this is my personal thought and I would never mind implementing firewalld if the Organization is going to replace iptables with firewalld.
|
||||
|
||||
**5. You seems confident with iptables and the plus point is even we are using iptables on our server.**
|
||||
|
||||
What are the tables used in iptables? Give a brief description of the tables used in iptables and the chains they support.
|
||||
|
||||
> **Answer** : Thanks for the recognition. Moving to question part, There are four tables used in iptables, namely they are:
|
||||
>
|
||||
> - Nat Table
|
||||
> - Mangle Table
|
||||
> - Filter Table
|
||||
> - Raw Table
|
||||
>
|
||||
> Nat Table : Nat table is primarily used for Network Address Translation. Masqueraded packets get their IP address altered as per the rules in the table. Packets in the stream traverse Nat Table only once. ie., If a packet from a jet of Packets is masqueraded they rest of the packages in the stream will not traverse through this table again. It is recommended not to filter in this table. Chains Supported by NAT Table are PREROUTING Chain, POSTROUTING Chain and OUTPUT Chain.
|
||||
>
|
||||
> Mangle Table : As the name suggests, this table serves for mangling the packets. It is used for Special package alteration. It can be used to alter the content of different packets and their headers. Mangle table can’t be used for Masquerading. Supported chains are PREROUTING Chain, OUTPUT Chain, Forward Chain, INPUT Chain, POSTROUTING Chain.
|
||||
>
|
||||
> Filter Table : Filter Table is the default table used in iptables. It is used for filtering Packets. If no rules are defined, Filter Table is taken as default table and filtering is done on the basis of this table. Supported Chains are INPUT Chain, OUTPUT Chain, FORWARD Chain.
|
||||
>
|
||||
> Raw Table : Raw table comes into action when we want to configure packages that were exempted earlier. It supports PREROUTING Chain and OUTPUT Chain.
|
||||
|
||||
**6. What are the target values (that can be specified in target) in iptables and what they do, be brief!**
|
||||
|
||||
> **Answer** : Following are the target values that we can specify in target in iptables:
|
||||
>
|
||||
> - ACCEPT : Accept Packets
|
||||
> - QUEUE : Paas Package to user space (place where application and drivers reside)
|
||||
> - DROP : Drop Packets
|
||||
> - RETURN : Return Control to calling chain and stop executing next set of rules for the current Packets in the chain.
|
||||
|
||||
|
||||
**7. Lets move to the technical aspects of iptables, by technical I means practical.**
|
||||
|
||||
How will you Check iptables rpm that is required to install iptables in CentOS?.
|
||||
|
||||
> **Answer** : iptables rpm are included in standard CentOS installation and we do not need to install it separately. We can check the rpm as:
|
||||
>
|
||||
> # rpm -qa iptables
|
||||
>
|
||||
> iptables-1.4.21-13.el7.x86_64
|
||||
>
|
||||
> If you need to install it, you may do yum to get it.
|
||||
>
|
||||
> # yum install iptables-services
|
||||
|
||||
**8. How to Check and ensure if iptables service is running?**
|
||||
|
||||
> **Answer** : To check the status of iptables, you may run the following command on the terminal.
|
||||
>
|
||||
> # service status iptables [On CentOS 6/5]
|
||||
> # systemctl status iptables [On CentOS 7]
|
||||
>
|
||||
> If it is not running, the below command may be executed.
|
||||
>
|
||||
> ---------------- On CentOS 6/5 ----------------
|
||||
> # chkconfig --level 35 iptables on
|
||||
> # service iptables start
|
||||
>
|
||||
> ---------------- On CentOS 7 ----------------
|
||||
> # systemctl enable iptables
|
||||
> # systemctl start iptables
|
||||
>
|
||||
> We may also check if the iptables module is loaded or not, as:
|
||||
>
|
||||
> # lsmod | grep ip_tables
|
||||
|
||||
**9. How will you review the current Rules defined in iptables?**
|
||||
|
||||
> **Answer** : The current rules in iptables can be review as simple as:
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Sample Output
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**10. How will you flush all iptables rules or a particular chain?**
|
||||
|
||||
> **Answer** : To flush a particular iptables chain, you may use following commands.
|
||||
>
|
||||
>
|
||||
> # iptables --flush OUTPUT
|
||||
>
|
||||
> To Flush all the iptables rules.
|
||||
>
|
||||
> # iptables --flush
|
||||
|
||||
**11. Add a rule in iptables to accept packets from a trusted IP Address (say 192.168.0.7)**
|
||||
|
||||
> **Answer** : The above scenario can be achieved simply by running the below command.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
>
|
||||
> We may include standard slash or subnet mask in the source as:
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
**12. How to add rules to ACCEPT, REJECT, DENY and DROP ssh service in iptables.**
|
||||
|
||||
> **Answer** : Hoping ssh is running on port 22, which is also the default port for ssh, we can add rule to iptables as:
|
||||
>
|
||||
> To ACCEPT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j ACCEPT
|
||||
>
|
||||
> To REJECT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j REJECT
|
||||
>
|
||||
> To DENY tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j DENY
|
||||
>
|
||||
> To DROP tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j DROP
|
||||
|
||||
**13. Let me give you a scenario. Say there is a machine the local ip address of which is 192.168.0.6. You need to block connections on port 21, 22, 23, and 80 to your machine. What will you do?**
|
||||
|
||||
> **Answer** : Well all I need to use is the ‘multiport‘ option with iptables followed by port numbers to be blocked and the above scenario can be achieved in a single go as.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 21,22,23,80 -j DROP
|
||||
>
|
||||
> The written rules can be checked using the below command.
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**Interviewer** : That’s all I wanted to ask. You are a valuable employee we won’t like to miss. I will recommend your name to the HR. If you have any question you may ask me.
|
||||
|
||||
As a candidate I don’t wanted to kill the conversation hence keep asking about the projects I would be handling if selected and what are the other openings in the company. Not to mention HR round was not difficult to crack and I got the opportunity.
|
||||
|
||||
Also I would like to thank Avishek and Ravi (whom I am a friend since long) for taking the time to document my interview.
|
||||
|
||||
Friends! If you had given any such interview and you would like to share your interview experience to millions of Tecmint readers around the globe? then send your questions and answers to admin@tecmint.com or you may submit your interview experience using following form.
|
||||
|
||||
- [Share Your Interview Experience][2]
|
||||
|
||||
Thank you! Keep Connected. Also let me know if I could have answered a question more correctly than what I did.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
[2]:https://docs.google.com/a/tecmint.com/forms/d/1jfu1Kg8_qToqvyi6pOT1HQb0dAFvRE-Yc_aOkj0RoSg/viewform
|
||||
@ -0,0 +1,133 @@
|
||||
watch - Repeat Linux / Unix Commands Regular Intervals
|
||||
================================================================================
|
||||
A server administrator needs to maintain the system and keep it updated and safe. A number of intrusion attempts may happen every day. There are some other activities that maintain their log. These logs are updated regularly. In order to check these updates, the commands are executed repeatedly. For example, for simply reading a file, commands like head, tail, cat etc are used. These commands need to be executed repeatedly. The watch command can be used to repeat a command at regular intervals.
|
||||
|
||||
### Watch Command ###
|
||||
|
||||
Watch is a simple command, with a few options. The basic syntax of watch command is:
|
||||
|
||||
watch [-dhvt] [-n <seconds>] [--differences[=cumulative]] [--help] [--interval=<seconds>] [--no-title] [--version] <command>
|
||||
|
||||
Watch command runs the command specified to it after every 2 seconds by default. This time is counted between the completion of command and beginning of next execution. As a simple example, watch command can be used to watch the log updates, The updates are appended at the end of the file, so tail command can be used with watch to see the updates to the file. This command continues to run until you hit CTRL + C to return to the prompt.
|
||||
|
||||
### Examples ###
|
||||
|
||||
> Keep an eye on errors/notices/warning being generated at run time every couple of seconds.
|
||||
|
||||
watch tail /var/log/messages
|
||||
|
||||

|
||||
|
||||
> Keep an eye on disk usage after specified time interval.
|
||||
|
||||
watch df -h
|
||||
|
||||

|
||||
|
||||
> It is very important for administrators to keep an eye on high I/O wait causing disk operations especially the Mysql transactions.
|
||||
|
||||
watch mysqladmin processlist
|
||||
|
||||

|
||||
|
||||
> Keep an eye on server load and uptime at runtime.
|
||||
|
||||
watch uptime
|
||||
|
||||

|
||||
|
||||
> Keep an eye on queue size for Exim at the time a cron is run to send notices to subscribers.
|
||||
|
||||
watch exim -bpc
|
||||
|
||||

|
||||
|
||||
### 1) Iteration delay ###
|
||||
|
||||
watch [-n <seconds>] <command>
|
||||
|
||||
The default interval between the commands can be changed with -n switch. The following command will run the tail command after 5 seconds:
|
||||
|
||||
watch -n 5 date
|
||||
|
||||

|
||||
|
||||
### 2) Successive output comparison ###
|
||||
|
||||
If you use -d option with watch command, it will highlight the differences between the first command output to every next command output cumulatively.
|
||||
|
||||
watch [-d or --differences[=cumulative]] <command>
|
||||
|
||||
#### Example1 ####
|
||||
|
||||
Let’s see the successive time outputs extracted using following watch command and observe how the difference is highlighted.
|
||||
|
||||
watch -n 15 -d date
|
||||
|
||||
First time date is capture when command is executed, the next iteration will be repeated after 15 seconds.
|
||||
|
||||

|
||||
|
||||
Upon the execution of next iteration, it can be seen that all output is exactly same except the seconds have increased from 14 to 29 which is highlighted.
|
||||
|
||||

|
||||
|
||||
#### Example 2 ####
|
||||
|
||||
Let’s experience in difference between two successive outputs of “uptime” command repeated by watch.
|
||||
|
||||
watch -n 20 -d uptime
|
||||
|
||||

|
||||
|
||||
Now the difference between the time is highlighted as well as the three load snapshots as well.
|
||||
|
||||

|
||||
|
||||
### 3) Output without title ###
|
||||
|
||||
If you don’t want to display extra details about the iteration delay and actual command run by watch then –t switch can be used.
|
||||
|
||||
watch [-t or --no-title] <command>
|
||||
|
||||
Let’s see the output of following command as an example.
|
||||
|
||||
watch -t date
|
||||
|
||||

|
||||
|
||||
### Watch help ###
|
||||
|
||||
Brief details of the watch command can be found by typing the following command in SSH.
|
||||
|
||||
watch -h [or --help]
|
||||
|
||||

|
||||
|
||||
### Watch version ###
|
||||
|
||||
Run the following command in SSH terminal to check the version of watch.
|
||||
|
||||
watch -v [--version]
|
||||
|
||||

|
||||
|
||||
**BUGS**
|
||||
|
||||
Unfortunately, upon terminal resize, the screen will not be correctly repainted until the next scheduled update. All --differences highlight-ing is lost on that update as well.
|
||||
|
||||
### Summary ###
|
||||
|
||||
Watch is a very powerful utility for system administrators because it can be used to monitor, logs, operations, performance and throughput of the system at run time. One can easily format and delay the output of watch utility. Any Linux command / utility or script and be supplied to watch for desired and continuous output.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/linux-watch-command/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
Loading…
Reference in New Issue
Block a user