mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-04-02 02:50:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
bb43cd5d9b
published
20140624 Performance benchmarks--KVM vs. Xen.md20140714 Fix No Sound In Ubuntu 14.04 As HDMI Enabled BY Default.md20140724 How to Merge Directory Trees in Linux using cp Command.md20140728 CoreOS Stable Release.md
sources
news
talk
tech
20140701 Get OpenVPN up and running, enjoy your privacy.md20140729 10 Useful 'Squid Proxy Server' Interview Questions and Answers in Linux.md20140729 How to access Linux command cheat sheets from the command line.md20140729 How to use awk command in Linux.md20140729 Linux FAQs with Answers--How to check which fonts are used in a PDF document.md20140729 Use Pushbullet Indicator In Ubuntu To Send Files To Android Or iOS Devices.md20140730 How to use variables in shell Scripting.md
translated
@ -1,26 +1,26 @@
|
||||
KVM和Xen的性能基准测试
|
||||
性能基准测试:KVM大战Xen
|
||||
================================================================================
|
||||
在上周,我们讨论了 KVM 和 Xen 的性能上一些令人感兴趣的话题后,我打算自己做一些这方面的研究。我能找到的最新的资料,是来自[2013年 Phoronix Haswell 性能评测][1]上的基准测试。当然,还有[2011年的评测][2],由于 Xen 已经被收录进 Kernel 3.0,这些曾经都是热门话题。
|
||||
在上周,我们对 KVM 和 Xen 近几年里在性能上的改进进行了一些有趣的探讨后,我打算自己做一些这方面的小研究。我能找到的最新的资料,是来自[2013年 Phoronix Haswell 性能评测][1]上的基准测试。当然,还有[其它一些2011年的评测][2],不过由于 Xen 被收录进 Kernel 3.0,它们都已被热烈地讨论过。
|
||||
|
||||
2011年的测试提供了[许多很好的基准报表][3],我尽最大努力把它们列出的属性重新测试一遍,但少测了两三个基准测试,原因是它们在未经特定优化的配置后跑出来的数据不是很好,或者它们需要跑很长时间才能得到结果。
|
||||
2011年的测试提供了[许多很好的基准报表][3],在三年后的现在,我尽最大努力把它们列出的属性重新测试一遍。但我删减了其中两三个基准测试,原因是它们在未经特定优化的配置后跑出来的数据不是很好,或者它们需要跑很长时间才能得到结果。
|
||||
|
||||
### 测试环境 ###
|
||||
|
||||
测试环境由两台一模一样的超微服务器组成,都配备一颗[Intel 至强 E3-1220][4](4核,3.10GHz),24G 金士顿 DDR3 内存,4块西数 RE-3 160G 磁盘(组成 RAID10 阵列)。另外 BIOS 也是一模一样。
|
||||
测试环境由两台一模一样的超微服务器组成,分别都配备一颗[Intel 至强 E3-1220][4](4核,3.10GHz),24G 金士顿 DDR3 内存,4块西数 RE-3 160G 磁盘(组成 RAID10 阵列)。另外 BIOS 也是一模一样。
|
||||
|
||||
所有测试项目(即实体机和虚拟机)都在 Fedora 20 (开 SELinux)上进行,并且测试过程中没有跑很多的不相关的服务。这里列一下相关服务的版本:
|
||||
所有测试项目(即实体机和虚拟机)都在 Fedora 20 (开 SELinux)上进行,并且测试过程中几乎没有运行的不相关的服务。这里列一下相关服务的版本:
|
||||
|
||||
- Kernel: 3.14.8
|
||||
- For KVM: qemu-kvm 1.6.2
|
||||
- For Xen: xen 4.3.2
|
||||
|
||||
根文件系统是 XFS,使用默认配置。虚拟机使用 virt-manager 来创建(virt-mamager 也使用默认配置)。虚拟磁盘使用 raw 镜像,容量为 8GB,虚拟4颗 CPU。Xen 虚拟机使用 [PVHVM][5] 建立虚拟磁盘。
|
||||
根文件系统都是使用默认配置的 XFS。虚拟机使用 virt-manager 来创建(virt-mamager 也使用默认配置)。虚拟磁盘使用 raw 镜像,容量为 8GB,虚拟4颗 CPU。Xen 虚拟机使用 [PVHVM][5] 建立虚拟磁盘。
|
||||
|
||||
### 警告 ###
|
||||
### 附加说明 ###
|
||||
|
||||
也许有人会考虑到 Fedora 是红帽公司所有,红帽一直在维护 KVM,而 Xen 则自从[在2009年红帽重新选择 KVM 作为虚拟化产品][6]后,再没得到这个公司的维护。在本测试中这个因素不会对结果产生任何影响,不过可以在心里稍微注意一下。
|
||||
也许有人会考虑到 Fedora 是红帽公司所有,红帽一直在维护 KVM,而 Xen 则自从[在2009年红帽重新选择 KVM 作为虚拟化产品][6]后,再没得到这个公司的重要改进。我将这个因素排除在了测试所考虑的范围之外,不过仍然可以在心里稍微注意一下。
|
||||
|
||||
不考虑资源竞争产生的影响。在大多数虚拟服务器上,你可以跑多个虚拟机,而这些虚拟机会争用 CPU 时间片、磁盘 IO、网络带宽等等资源。在本测试中也不考虑这些因素。一台虚拟机抢到资源少,性能就差,而另一台抢得多,性能就好(LCTT:它们的性能总和,就可以大致当作是 KVM 或 Xen 的性能了)。
|
||||
并且,资源竞争产生的影响也有被严格控制并最小化。在大多数虚拟服务器上,你可以跑多个虚拟机,而这些虚拟机会争用 CPU 时间片、磁盘 IO、网络带宽等等资源。在本测试中也不考虑这些因素。一台虚拟机抢到资源少,性能就差,而另一台抢得多,性能就好(LCTT译注:它们的性能总和,就可以大致当作是 KVM 或 Xen 的性能了)。
|
||||
|
||||
本测试运行在 Intel 的 CPU 上。如果使用的是 AMD 或 ARM,可能有些数据会不一样。
|
||||
|
||||
@ -28,11 +28,11 @@ KVM和Xen的性能基准测试
|
||||
|
||||
本测试使用裸机作为虚拟服务测试的基准设备。在不跑虚拟机的情况下,两台裸机的性能偏差不会大于0.51%
|
||||
|
||||
在所有测试中,KVM 的性能相比宿主机而言下降了1.5%以内,除了两个测试。第一个是 7-zip 压缩,比宿主机慢了 2.79%。第二个就奇怪了,我们搭了一个邮件服务器,用 PostMark 测试其性能,结果表明 KVM 竟比宿主机快了4.11%。然后我在两台服务器中重新跑了几遍 PostMark 测试,结果性能差异基本不变,浮动在1%以内。由于我对 virtio 的内部机制没有很深的理解,我只能在以后再对这个怪现象进行进一步了解。
|
||||
在几乎所有测试中,KVM 的性能相比宿主机而言下降了1.5%以内,只有两项测试例外。第一个是 7-zip 压缩,比宿主机慢了 2.79%。第二个就奇怪了,我们搭了一个邮件服务器,用 PostMark 测试其性能,结果表明 KVM 竟比宿主机快了4.11%。然后我在两台服务器中重新跑了几遍 PostMark 测试,结果性能差异基本不变,浮动都在最初测试结果的1%以内。由于我对 virtio 的内部机制没有很深的理解,我只能在以后再对这个怪现象进行进一步了解。
|
||||
|
||||
Xen 的性能相对宿主机而言差异就比较大了。有3个测试性能下降在2.5%以内,剩下的性能下降率都是 KVM 的2~4倍。PostMark 测试的性能比 KVM 慢了14.41%,这结果令我大吃一惊。重新跑了下测试,性能差还是在14%左右。KVM 表现最好的两个测试:CPU 测试和 MAFFT 对齐测试,是 Xen 表现最差的。
|
||||
Xen 的性能相对宿主机而言差异就比较大了。有3项测试性能下降在2.5%以内,剩下的性能下降率都是 KVM 的2~4倍。PostMark 测试的性能比 KVM 慢了14.41%,这结果令我大吃一惊。重新跑了下测试,性能差还是几乎不变,浮动都在最初结果的2%以内。KVM 表现最好的 CPU 测试:MAFFT 对齐测试,是 Xen 表现倒数第二差的。
|
||||
|
||||
现在奉上一个总结表:
|
||||
现在奉上一个简短得总结表:
|
||||
|
||||
<table id="tablepress-3" class="tablepress tablepress-id-3 dataTable">
|
||||
<thead>
|
||||
@ -67,19 +67,19 @@ Xen 的性能相对宿主机而言差异就比较大了。有3个测试性能下
|
||||
|
||||
### 结论 ###
|
||||
|
||||
基于上面的测试环境,KVM 的性能损耗在2%以内,Xen 则只有3项损耗在2.5%以内,其他几项损耗都在5~7%之间。虽然 KVM 在 PostMark 测试中性能表现优异,但这个测试只是众多测试中的一项,如果想证明 KVM 确实在 I/O 处理方面很强悍,就需要更多测试。
|
||||
基于上面的测试环境,KVM 的性能损耗几乎都在2%以内,Xen 则在十多项测试中有3项损耗在2.5%以内,而其他几项损耗都在5~7%之间。虽然 KVM 在 PostMark 测试中性能表现优异,但这是众多测试中仅有的一项 I/O 测试,如果想证明 KVM 确实在 I/O 处理方面很强悍,就需要更多测试。
|
||||
|
||||
对我来说,我需要深入理解 KVM 和 Xen 在 I/O 处理上为什么会有这么大的差别。并且还需要跑一些压力测试,来证明虚拟机是否真的比宿主机表现得更出色。
|
||||
对我来说,我想要深入了解一下 KVM 和 Xen 在 I/O 方面的处理,以及它们之间为什么会有这么大的差别。我也许还会跑一些有竞争的测试,来看看虚拟机在有压力的条件下是否真的能比宿主机表现得更出色。
|
||||
|
||||
我鼓励读者通过使用[Phoronix 测试套件][8]来进行一些基准测试,你们可以找到一些能模仿你们工作环境的用例。如果你的工作环境是低 CPU 高 I/O,你可以找找套件里面的 I/O 压力测试。另一方面,如果你的工作是音频、视频转码,你可以试试套件里面的 x264 或 mp3 测试。
|
||||
|
||||
更新:[Chris Behrens 指出][9],我忘了提到 Xen 虚拟机类型了。这里补充下,我使用的是 PVHVM 模型(LCTT:目前支持的模型包括 PV、HVM 和 PVHVM),因为在 Xen 4.3 中这个选拥有最好的性能。另外需要注意的是在 Xen 4.4 中可以使用 PVH,但是在 Fedora 20 中还没有使用 Xen 4.4。
|
||||
更新:[Chris Behrens 指出][9],我忘了提到 Xen 虚拟机类型了。这里补充下,我使用的是 PVHVM 模型(LCTT译注:目前支持的模型包括 PV、HVM 和 PVHVM),因为在 Xen 4.3 中这个选拥有最好的性能。另外需要注意的是在 Xen 4.4 中可以使用 PVH,但是在 Fedora 20 中还没有使用 Xen 4.4。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://major.io/2014/06/22/performance-benchmarks-kvm-vs-xen/
|
||||
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[bazz2](https://github.com/bazz2) 校对:[ReiNoir](https://github.com/reinoir)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
在linux中怎样使用cp命令合并目录树
|
||||
在 Linux 中怎样使用cp命令合并目录树
|
||||
================================================================================
|
||||
怎样将布局相似的两个目录树合并成新的目录树? 为理解该问题让我们思考下面的例子.
|
||||
|
||||
假设dir1和dir2目录中分别有3个子目录a,b和c.目录布局如下所示:
|
||||
怎样将两个布局相似的目录树合并成一个新的目录树?为理解该问题让我们思考下面的例子.
|
||||
|
||||
假设 dir1 和 dir2 目录中分别有3个子目录a,b和c.目录布局如下所示:
|
||||
|
||||

|
||||
输入目录布局
|
||||
@ -14,16 +15,14 @@
|
||||
|
||||
### 1. 使用cp命令创建合并: ###
|
||||
|
||||
现在我们将这两个目录合并成一个新的目录,如"merged".完成上述操作最简单的方式就是递归
|
||||
复制目录,如下图所示:
|
||||
现在我们将这两个目录合并成一个名为"merged"新的目录中.完成上述操作最简单的方式就是递归复制目录,如下图所示:
|
||||
|
||||

|
||||
递归复制完成新的合并
|
||||
|
||||
#### 1.1 cp命令和替换带来的问题: ####
|
||||
|
||||
这种方式所带来的问题是该合并目录中所创建的文件为原文件的副本,并非原文件本身. 别急, (你可能正在问自己) 如果不是原文件又有什么问题? 为了回答你的问题,考虑下你有很多大文件的情况
|
||||
.那种情形下,复制所有的文件可能消耗数小时.
|
||||
这种方式所带来的问题是该合并目录中所创建的文件为原文件的副本,并非原文件本身.别急, (你可能正在问自己) 如果不是原文件又有什么问题? 要回答你的问题,考虑下你有很多大文件的情况.那种情形下,复制所有的文件可能花费数小时.
|
||||
|
||||
现在让我们回到刚那问题上,且尝试使用mv命令而不是cp命令.
|
||||
|
||||
@ -33,7 +32,7 @@
|
||||
这些目录不能被合并.因此我们不能像这样使用mv命令去合并目录.
|
||||
现在你该怎样将原文件保存到"merged"目录中?
|
||||
|
||||
### 2. 方法: ###
|
||||
### 2. 解决方法: ###
|
||||
|
||||
cp命令有一个非常有用的选项来帮助我们摆脱这种状况.
|
||||
cp命令的-l 或 --link选项能够创建硬链接而非原文件副本.让我们尝试一下.
|
||||
@ -59,7 +58,7 @@ Verify Inodes
|
||||
#### 2.2 清除: ####
|
||||
|
||||
|
||||
正如你所看到的,这些文件的inodes和原文件的一样.现在 那问题已经被解决,且
|
||||
正如你所看到的,这些文件的inodes和原文件的一样.现在问题已经被解决,且
|
||||
原文件已被复制到合并目录中.现在我们能够移除dir1和dir2目录.
|
||||
|
||||

|
||||
@ -71,8 +70,8 @@ via: http://linoxide.com/linux-command/merge-directory-trees-linux/
|
||||
|
||||
原文作者:[Raghu][a]
|
||||
|
||||
译者:[hunanchenxingyu](https://github.com/hunanchenxingyu) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[hunanchenxingyu](https://github.com/hunanchenxingyu) 校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/raghu/
|
||||
[a]:http://linoxide.com/author/raghu/
|
||||
44
published/20140728 CoreOS Stable Release.md
Normal file
44
published/20140728 CoreOS Stable Release.md
Normal file
@ -0,0 +1,44 @@
|
||||
CoreOS 稳定版发布
|
||||
================================================================================
|
||||
|
||||
随着CoreOS稳定版的发布,我们相信我们已经为SysAdmin节准备好了一个不错的惊喜。从现在起,用户可以在产品环境中运行CoreOS了。这个版本对于想运行CoreOS的用户来说,是最经考验的、最安全的、最可靠的CoreOS版本。这对我们来说,是一个重大的里程碑。自从2013年八月我们第一个alpha版本发布以来,我们做了:
|
||||
|
||||
- 191个发布版本
|
||||
- 通过alpha和beta频道测试了成千上万的服务器
|
||||
- 支持10个以上平台,从裸机到Rackspace和Google云平台的主要镜像
|
||||
|
||||
对我们来说这是一个极为重要的日子,因为我们为了稳定版的发布付出了努力的工作。当然,如果没有社区的帮助,我们完成不了这些工作,感谢你们所有对项目的支持和贡献。
|
||||
|
||||
[CoreOS 367.1.0][2], 这是我们在稳定频道上的第一个版本, 包括以下内容:
|
||||
|
||||
- Linux 3.15.2
|
||||
- Docker 1.0.1
|
||||
- 所有主流的云服务商的支持, 包括 Rackspace Cloud, Amazon EC2 (包括 HVM) 和 Google Compute Engine
|
||||
- 通过 [CoreOS Managed Linux][3] 的商业支持
|
||||
|
||||
如果你还没有阅读我们的[Update Philosophy][4],我们建议您先看看。
|
||||
|
||||
请注意:稳定发布版本为了保持稳定性而不包括etcd和fleet ,此发布版仅针对基本的操作系统和Docker1.0。etcd和fleet的稳定版本支持会在随后的发布版本中。
|
||||
|
||||
如果想开始在产品中运行CoreOS,请确保阅读我们的快速指南“[切换到发布频道][5]”。如果你正在装新的机器,请确保在一开始就把他们建立在你想要的更新频道上。
|
||||
|
||||
最后,感谢社区的支持,我们迫不及待地想听到你们的反馈。对那些在产品环境中运行CoreOS上,希望得到额外支持的用户,请确保查看我们的[Managed Linux][6] 建议,因为我们已经有了一个完整的支持团队,他们正在准备回答你遇到的任何问题。
|
||||
|
||||
SysAdmin节快乐,感谢你们让互联网变得如此令人惊叹。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://coreos.com/blog/stable-release/
|
||||
|
||||
作者:Alex Polvi
|
||||
译者:[lfzark](https://github.com/lfzark)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://sysadminday.com/
|
||||
[2]:https://coreos.com/releases/#367.1.0
|
||||
[3]:https://coreos.com/products/managed-linux/
|
||||
[4]:https://coreos.com/using-coreos/updates/
|
||||
[5]:https://coreos.com/docs/cluster-management/setup/switching-channels/
|
||||
[6]:https://coreos.com/products/managed-linux/
|
||||
@ -1,38 +0,0 @@
|
||||
nd0104 is translate
|
||||
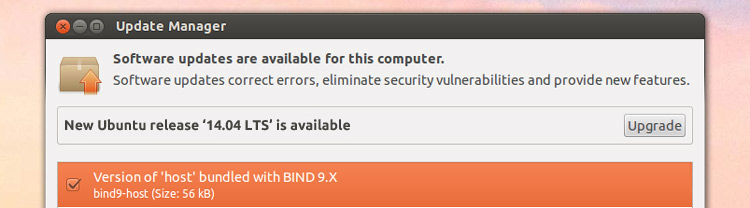
Time to Upgrade: Ubuntu 13.10 Support Ends Today
|
||||
================================================================================
|
||||
|
||||
|
||||
**It’s had a fair old run, but after 9 months basking in the sun today marks the end of official support for Ubuntu 13.10 ‘Saucy Salamander’.**
|
||||
|
||||
> Despite the name ‘Saucy’, the changes on offer were rather bland
|
||||
|
||||
Those still running it should look at upgrading to the most recent stable release, Ubuntu 14.04 LTS. Launched back in April, it will be supported with updates on the desktop all the way until mid-April 2019.
|
||||
|
||||
Support for the server version of Ubuntu 13.10 also formally ends today.
|
||||
|
||||
### Saucy Loses Flavour ###
|
||||
|
||||
Ubuntu 13.10 came out last October with Canonical pledging to provide a full 9 months of ongoing security and bug fixes on the desktop. As of July 17 these updates will cease and no further updates or backported packages will be provided.
|
||||
|
||||
Canonical’s [recommended upgrade path][1] is to 14.04, a transition that can be handled directly on the desktop itself through the Software Updater application or via the command line through the ‘`do-release-upgrade`‘ command.
|
||||
|
||||
Saucy in name, but bland in nature, 13.10 is far from being one of Ubuntu’s more remarkable releases — [as evidenced by many of the online reviews at the time][2].
|
||||
|
||||
It was, however, notable for inflicting(注:这个单词原文有删除线) introducing Smart Scopes to the Unity Dash, adding a keyboard indicator for faster language layout switching, and being the first release to integrate `Ubuntu One Single Sign-on` into the installation experience.
|
||||
|
||||
For a natty visual rundown of all that debuted with it you can watch the compilation video below.
|
||||
|
||||
Youtobe 视频地址:[http://www.youtube.com/embed/1EiRQ-znEcI?feature=oembed][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/07/ubuntu-13-10-support-ends-today
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://help.ubuntu.com/community/TrustyUpgrades
|
||||
[2]:http://www.omgubuntu.co.uk/2013/10/ubuntu-13-10-press-reaction
|
||||
[3]:http://www.youtube.com/embed/1EiRQ-znEcI?feature=oembed
|
||||
@ -1,44 +0,0 @@
|
||||
Translating by lfzark
|
||||
CoreOS Stable Release
|
||||
================================================================================
|
||||
First off, [Happy SysAdmin Day][1]. We think we have a pretty good SysAdmin surprise in store for you today as we are announcing the CoreOS stable release channel. Starting today, you can begin running CoreOS in production. This version is the most tested, secure and reliable version available for users wanting to run CoreOS. This is a huge milestone for us. Since our first alpha release in August 2013:
|
||||
|
||||
- 191 releases have been tagged
|
||||
- Tested on hundreds of thousands of servers on the alpha and beta channels
|
||||
- Supported on 10+ platforms, ranging from bare metal to being primary images on Rackspace and Google
|
||||
|
||||
It is a big day for us here at CoreOS, as we have been working hard to deliver the stable release. Of course, we couldn’t do this without the community so thank you for all of your support and contributions to the project.
|
||||
|
||||
[CoreOS 367.1.0][2], our first version on the stable channel, includes the following:
|
||||
|
||||
- Linux 3.15.2
|
||||
- Docker 1.0.1
|
||||
- Support on all major cloud providers, including Rackspace Cloud, Amazon EC2 (including HVM), and Google Compute Engine
|
||||
- Commercial support via [CoreOS Managed Linux][3]
|
||||
|
||||
This is a great opportunity to read about our [Update Philosophy][4] if you haven't already done so.
|
||||
|
||||
Please note: The stable release is not including etcd and fleet as stable, this release is only targeted at the base OS and Docker 1.0. etcd/fleet stable support will be in subsequent releases.
|
||||
|
||||
For those of you who want to start running CoreOS in production be sure to review our quick [Switching Release Channels][5] guide. As you're booting new machines, be sure to base them off your desired channel from the beginning.
|
||||
|
||||
Finally, thanks to the community for your support. We can’t wait to hear your feedback. For those looking for additional support of running CoreOS in production, be sure to check out our [Managed Linux][6] offerings, as we have a full support team in place ready to answer any questions you may have.
|
||||
|
||||
Happy SysAdmin Day, and thank you for making the web awesome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://coreos.com/blog/stable-release/
|
||||
|
||||
作者:Alex Polvi
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://sysadminday.com/
|
||||
[2]:https://coreos.com/releases/#367.1.0
|
||||
[3]:https://coreos.com/products/managed-linux/
|
||||
[4]:https://coreos.com/using-coreos/updates/
|
||||
[5]:https://coreos.com/docs/cluster-management/setup/switching-channels/
|
||||
[6]:https://coreos.com/products/managed-linux/
|
||||
@ -1,82 +0,0 @@
|
||||
Love-xuan翻译中
|
||||
Best Linux Browsers
|
||||
================================================================================
|
||||
> Pros and cons of the best browsers for the Linux desktop, including Firefox, Chrome and other browsers.
|
||||
|
||||
Choosing the best Linux browser for your needs requires just a bit of homework: Web browsers for the Linux desktop have evolved over the years, just as they have for other popular desktop platforms. With this evolution, both good and bad revelations have been discovered. Revelations from new functionality, to broken extensions, and so forth. In this article, I'll serve as your guide through these murky waters to help you discover the best in Linux browsers.
|
||||
|
||||
### **Firefox** ###
|
||||
|
||||
– [Firefox][1] has long been a friendly browser for Linux users. Accessible on both 32bit and 64bit Linux installs, Firefox also offers extensive extensions to choose from. It's a fast loading, easy to navigate Web browser that has found itself in a popular place with Linux users.
|
||||
|
||||
**The good**: It's easily installed from most common Linux software repositories, if not already installed on the distro by default. Thousands of extensions to choose from to make your Firefox browser more fully featured. Nearly every website on the Web (including government and banking sites) render properly.
|
||||
|
||||
Also important: Firefox respects your privacy. In addition to a straight forward privacy policy, they're not in the "same business" as Google. Therefore, most users feel more comfortable allowing Firefox to see their daily browsing activities whereas other browsers, might have more profit-driven interests. Firefox is also great for web developers, thanks to its element inspection tool, built right into the browser.
|
||||
|
||||
**The bad**: Not too long ago, I was finding that Firefox's frequent updates were breaking my extensions. This meant I needed to verify that my favorite extensions were compatible with new Firefox updates BEFORE I updated my browser.
|
||||
|
||||
To be blunt, this caused me to rethink which browser would be my default tool to browse the Internet. In fairness, Mozilla does post a blog post with each browser update for extension developers. In these posts, developers are told what has changed and what needs to be done to keep things working smoothly.
|
||||
|
||||
### **Chrome/Chromium** ###
|
||||
|
||||
– Google promotes its browser named [Chrome][2], however I tend to put [Chromium][3] into the same group as Chrome since Chromium is used as its base for development. Unlike Firefox, Chrome/Chromium was late to the game for Linux. Linux users only considered it worth trying at the time due to the fact that Chrome/Chromium was perceived by many as being the fastest browser.
|
||||
|
||||
**The good**: Even today, Chrome/Chromium is considered pretty fast. Even with the recent updates made to other competing browsers, Chrome/Chromium hasn't lost its speed. Extensions for Chrome/Chromium are plentiful and even better, updates to the browser have no affect on said extensions. This means that, unlike Firefox, I haven't dealt with extension incompatibilities. Like Firefox, Chrome/Chromium also has an element inspection tool, built right into the browser. After trying syncing options with other browsers, only Chrome/Chromium has proven itself to be truly idiot-proof. Without question, Chrome/Chromium syncing is the best in the browser space, from my perspective.
|
||||
|
||||
**The bad**: Chrome/Chromium doesn't always render pages correctly. Be it rare, some sites like Ebay don't always render correctly. Case in point, if I create a new Ebay submission, I find there are buttons missing in some cases. I've also found that sometimes Chrome/Chromium can lockup completely if an open tab is rendering heavy script. Sites like Google Plus and Facebook are the most common offenders.
|
||||
|
||||
### **Qupzilla** ###
|
||||
|
||||
– When it comes to lightweight browsers, I've found [Qupzilla][4] to be among the most awesome. Based on Webkit, it provides decent rendering support while maintaining a very small resource footprint.
|
||||
|
||||
**The good**: Qupzilla is ideal for lightweight desktop environments where you need a modern browser capable of rendering pages correctly and generally providing a solid web browser experience. It's extremely lightweight and will run on older PCs without missing a beat. Access Keys and [GreaseMonkey][5] extensions are installed (but disabled) by default.
|
||||
|
||||
Like Firefox and Chrome/Chromium, Qupzilla provides access to an element inspection tool as well. And finally, having [Adblock][6] installed by default makes this a clear lightweight winner for me.
|
||||
|
||||
**The bad**: HTML5 video doesn't seem to work reliably. Also, in order to watch Flash videos, you must visit the preferences and uncheck Click to Flash in the Extensions, Webkit plugins area. This is a poorly thought out decision to essentially disable Flash out of the box, while HTML5 video remains completely broken.
|
||||
|
||||
### **Midori** ###
|
||||
|
||||
– I like to call [Midori][7] the lightweight Chrome alternative. Like Google's browser(s), Midori offers a minimalist experience with its "hamburger menu," which is nice as it takes up less browser space. Not only do you get a solid browsing experience without the usual browser politics found elsewhere, Midori is also quite fast.
|
||||
|
||||
**The good**: Midori is fast, lightweight and feels familiar out of the box. I'm also happy to report that it renders pages correctly and works great with sites like YouTube. The best part, in my opinion, is the built-in functionality for creating browser profiles and actual launchable links for Web apps. For example, you can easily create a web app on your desktop for Gmail or Facebook. You can also setup user specific browser profiles as well, without creating new Linux user accounts.
|
||||
|
||||
**The bad**: Despite mentioning user extensions for this browser, the selection available is less than impressive. Also, the browser layout takes a bit of getting used to. A trash can for previously visited websites – seriously?
|
||||
|
||||
### **Opera** ###
|
||||
|
||||
– [Opera][8] has long been one of the misunderstood browsers out there. Very early on, Opera provided Linux support despite being dismissed by the overall Linux community. In addition to being a compatible, fast web browser that has been nothing but good to Linux users, it's also a full of configurable options.
|
||||
|
||||
**The good**: It's fast and it's full of user controllable settings. You can import and export everything from RSS feeds to email, and skin Opera with easy access to breathtaking themes. Plus, Opera offers an extensive library of extensions to choose from. Not to mention the ability to read RSS feeds and email, from your browser! Relive the days of the Mozilla Suite by using Opera's extended suite functionality. And perhaps best of all, Opera Turbo – super-charge your browser speed with selective compression to provide a faster experience.
|
||||
|
||||
**The bad**: A nag for the Terms of Service on its first run. Also, Opera Turbo can slightly alter your browsing experience – YouTube for example, may not show a video's thumbnail. Opera also provides so many options that it can feel a bit overwhelming to the casual user. And lastly, it's a closed source browser that hasn't been well recognized for desktop use. Most folks think of Opera as a mobile browser only these days.
|
||||
|
||||
### Which browser is right for you? ###
|
||||
|
||||
With so many great choices, it can be a tough call to say which browser is right for you. Speaking for myself, I've found that I rely heavily on Firefox and Chromium due to specific extensions I put to work each day. For someone with a lower end system or netbook, my suggestion is to try Midori first and if that's not a fit, fallback to Qupzilla.
|
||||
|
||||
So what about other web browsers for Linux? Such as the [Epiphany][9] browser or [Konqueror][10]? Browsers like these are great, but I feel strongly about the browsers I've shared above specifically. Each of the options listed above are browsers I use often and have found to be something I feel good about recommending to friends and family.
|
||||
|
||||
That said, by all means, share any browsers you're passionate about in the Comments below so others can benefit from your preferred method of browsing the Web.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/best-linux-browsers-1.html
|
||||
|
||||
原文作者:[Matt Hartley][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[2]:https://www.google.com/intl/en_us/chrome/browser/
|
||||
[3]:http://www.chromium.org/
|
||||
[4]:http://www.qupzilla.com/
|
||||
[5]:https://addons.mozilla.org/en-US/firefox/addon/greasemonkey/
|
||||
[6]:https://adblockplus.org/
|
||||
[7]:http://midori-browser.org/
|
||||
[8]:http://www.opera.com/
|
||||
[9]:https://wiki.gnome.org/Apps/Web
|
||||
[10]:http://www.konqueror.org/
|
||||
137
sources/talk/20140729 Don't Fear The Command Line.md
Normal file
137
sources/talk/20140729 Don't Fear The Command Line.md
Normal file
@ -0,0 +1,137 @@
|
||||
Don't Fear The Command Line
|
||||
================================================================================
|
||||

|
||||
|
||||
> Embrace your computer's most useful tool.
|
||||
|
||||
You've probably seen it in movies, even if you haven't ever called it up on your own computer: a blank screen with a simple text prompt and a cursor, just waiting for you to enter the appropriate arcane commands to do your bidding.
|
||||
|
||||
This is the command line. It's a text-based interface that predates the far more familiar windows, icons and tiles of today's major computer operating systems, from Windows to Mac OS X to Linux.
|
||||
|
||||
The command line is an extremely powerful tool for accessing basic functions of your computer. For most people, it's also a confusing, complicated and seemingly irrelevant distraction. It doesn't have to be.
|
||||
|
||||
### Computers Under Your Command ###
|
||||
|
||||
Typing text instructions and hitting Return to get a computer to do something sounds like a major step back compared to the swipe-and-tap touch-sensitive interfaces of mobile devices. Even a toddler can use an iPad, right? Yet the command line can save you time and aggravation, if you know when to use it.
|
||||
|
||||
If you're serious about learning to code—or just understanding computer technology—you absolutely need to get to know your command line.
|
||||
|
||||
Diving into the command line will teach you a lot about how your computer works and organizes information. You might find that some tasks you perform every day with a mouse are actually faster when you type a command or two instead.
|
||||
|
||||
Most important, you’ll be better prepared to learn [languages like Python][1] and [programs like Git][2] that require some command-line setup. By getting familiar with the command line, you’ll break down barriers that may have kept you from learning to program in the past.
|
||||
|
||||
So here's a quick, basic guide to getting around on the command line. It's focused on Mac OS X's Unix-based environment, simply because that's what I'm familiar with. Linux users probably know the command line well already, although newcomers might also find these tips useful. If you're running a Chromebook, Google has some helpful instructions for getting to its [version of the command line][3], which is similar to Mac and Linux systems. Windows users, unfortunately, are stuck with a command language derived from MS-DOS that just barely overlaps with Unix, so this guide isn't going to be much use to you; you might check out [this dosprompt.info tutorial][4].
|
||||
|
||||
### How To Find Your Way Around ###
|
||||
|
||||
The very first thing you’ll need to do is figure out how to access the command line, which is typically done through a program called a "shell." On any Mac running OS X, you'll need to start the Terminal application. You can do this through the Finder (it's in the Utilities folder under Applications), or just click the magnifying glass in the upper right hand corner of your screen and type “terminal,” then select it from the drop-down.
|
||||
|
||||

|
||||
|
||||
You’re in, but all you see is a blank box with a space to type prompts. This is the command line! Let’s get to know this window a little bit better.
|
||||
|
||||
Type pwd, which stands for Print Working Directory. In computer parlance, “printing” something has nothing to do with paper. It really just means spitting it out on the screen. The command should result in the computer returning the directory you are currently working in.
|
||||
|
||||

|
||||
|
||||
And indeed, /Users/laurenorsini is my home directory. Advanced tip: You can use the tilde symbol (~) as a shortcut for your home directory—it means the same thing as /Users/yourusername. So you can reference your Downloads subdirectory, for instance, as ~/Downloads. (If you look closely at the command prompt above, you'll see a tilde there. That indicates that I'm in my home directory.)
|
||||
|
||||
We don’t want to muddy up our main directory with all our command-line experimenting, so let’s make a new directory with the mkdir command. This is the same as creating a new folder on your desktop operating system. Let's call it "experiments":
|
||||
|
||||

|
||||
|
||||
Now we have a new directory. Using the graphic interface, we can visually verify that we actually created a new one. Sure enough, if I open the Finder and go into my home directory—here marked with a little house icon—I now see a folder named “experiments.” I made that on the command line! (The reverse works, too: You can create a folder on your desktop, and see it in the command line. They're just two different ways of looking at the same system.)
|
||||
|
||||

|
||||
|
||||
Now I need to change directories and enter the ~/experiments directory with the **cd** (change directory) command.
|
||||
|
||||

|
||||
|
||||
I have my command prompt on the default setting, so it automatically shows where my working directory is. But if yours looks different, here's how to make sure “experiments” is truly your working directory: type **pwd** again. It should tell you that your working directory is “experiments.”
|
||||
|
||||
### Getting Filed Away ###
|
||||
|
||||
I create and edit files on the command line every day that I code. It's faster than using the graphical user interface because I can test out my programs on the command line as soon as I finish editing them. And if I also happen to be pushing things to [GitHub][5] at the same time, well, it's even more convenient.
|
||||
|
||||
Now you have a new directory (also called a repository or folder) on your computer to mess around with. Let's start by creating a new file that contains only the words, "Hello World." There are a lot of ways to do this; here I'm using the echo command.
|
||||
|
||||
Now you have a new directory (also called a repository or folder) on your computer to mess around with. Let's start by creating a new file that contains only the words, "Hello World." There are a [lot of ways][6] to do this; here I'm using the **echo** command.
|
||||
|
||||

|
||||
|
||||
Oh no! I spelled "newfile" incorrectly. That happens. Let's fix it in two steps. First, I'll create a new file with the correct spelling...
|
||||
|
||||

|
||||
|
||||
And then, I'll use the **mv** (move) command to replace my old, misspelled file with my new file. This always takes the form "**mv oldfile newfile**."
|
||||
|
||||

|
||||
|
||||
A note about **mv**: like many commands, it's a deceptively powerful one. When we're "moving" newfil.txt into newfile.txt, what we're actually doing is completely overwriting the first file and replacing it with the second. So the text I wrote into newfil.txt is gone forever, replaced by what I wrote into newfile.txt.
|
||||
|
||||
To prove that I only have one file in my directory, I can use **ls** , the list command, to get a list of all the files in this directory.
|
||||
|
||||

|
||||
|
||||
See? Just the one. And if I look inside the folder using my computer's graphical user interface, I can see the file there, too.
|
||||
|
||||

|
||||
|
||||
But it's just a blank text file. Let's put something inside it using a text editor. On the command line, I tend to use the nano editor since it's simple and it works on just about every type of computer.
|
||||
|
||||
This should immediately bring up a new editing screen right inside your command line window. The basic commands are all laid out for you.
|
||||
|
||||

|
||||
|
||||
Write what you want, and then exit with CTRL + X. If it asks you to save and you'd like to, type "Y."
|
||||
|
||||

|
||||
|
||||
As you've probably guessed by now, it's possible to also see these changes by using the operating system and navigating to newfile.txt with your mouse. Here you can open and edit the file you've created in any text editor of your choice.
|
||||
|
||||
If you want to delete the file forever, do that with the **rm** (remove) command:
|
||||
|
||||

|
||||
|
||||
Keep in mind that the **rm** command is very powerful! A [common trick][7] on hacker forums is to convince a command-line newbie to type **rm -rf** / so she ends up deleting her whole computer. The "/" means the very top-level directory of your computer—and everything underneath it. NEVER type that command!
|
||||
|
||||
### Further Reading ###
|
||||
|
||||
This is just the beginning of the endless possibilities of the command line. You can use this tool to control every aspect of your computer, which is what makes it as dangerous as it is powerful. Make sure to always read up on new command-line prompts before you use them, and never blindly input a prompt that a stranger suggests to you online.
|
||||
|
||||
I've outlined the commands I use every day so I can code, but there are a lot more reasons to master the command line than that. If you're looking for a more thorough overview, you might want to try:
|
||||
|
||||
[The Command Line Crash Course][8]. A free, extended course that covers the basics of command line usage.
|
||||
|
||||
[A Command Line Primer For Beginners][9]. Lifehacker’s collection of helpful commands for first time users.
|
||||
|
||||
[Introduction to the Mac OS X Command Line][10]. Online-education site Treehouse covers the very basics in extreme detail.
|
||||
|
||||
Now that you've finished reading, you're better prepared for any code tutorial I've written in the past, since it's impossible to do any of them without typing in some commands. If you're ready to go, I suggest you check out ReadWrite's [Git tutorial][11], which utilizes the command line to introduce you to collaborative coding. Happy computing!
|
||||
|
||||
*Lead photo by [Jason Scott][12]; all other screenshots by Lauren Orsini for ReadWrite*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://readwrite.com/2014/07/18/command-line-tutorial-intro
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://readwrite.com/author/lauren-orsini
|
||||
[1]:http://readwrite.com/2014/07/08/what-makes-python-easy-to-learn
|
||||
[2]:http://readwrite.com/2013/09/30/understanding-github-a-journey-for-beginners-part-1
|
||||
[3]:http://www.chromium.org/chromium-os/poking-around-your-chrome-os-device
|
||||
[4]:http://dosprompt.info/
|
||||
[5]:http://www.github.com/
|
||||
[6]:http://www.cyberciti.biz/faq/unix-create-file-from-terminal-window-shell-prompt/
|
||||
[7]:http://www.urbandictionary.com/define.php?term=rm+-rf+%2F
|
||||
[8]:http://cli.learncodethehardway.org/book/
|
||||
[9]:http://lifehacker.com/5633909/who-needs-a-mouse-learn-to-use-the-command-line-for-almost-anything
|
||||
[10]:http://blog.teamtreehouse.com/introduction-to-the-mac-os-x-command-line
|
||||
[11]:http://readwrite.com/2013/09/30/understanding-github-a-journey-for-beginners-part-1
|
||||
[12]:http://en.wikipedia.org/wiki/Computer_terminal#mediaviewer/File:DEC_VT100_terminal.jpg
|
||||
@ -1,8 +1,9 @@
|
||||
Get OpenVPN up and running, enjoy your privacy
|
||||
2q1w2007翻译中
|
||||
搭建并运行OpenVPN,享受你的隐私生活
|
||||
================================================================================
|
||||

|
||||
|
||||
> We are fanatic supporters of privacy. Not so much because we have super secrets to hide, but because we consider privacy as a basic human right. So we believe that anytime anyone chooses to exercise that right on the net, then they should have unencumbered access to all the necessary tools and services. OpenVPN is such a service and there are also many tools (clients) which allow us to utilize and enjoy that service.
|
||||
> 我们支持保护隐私,不为我们有自己的秘密需要保护,只是我们认为保护隐私应该成为一项基本人权。所以我们坚信无论谁在什么时候行使这项权利,都应该不受拘束的获取必须的工具和服务。OpenVPN就是这样一种服务并且有多种工具(客户端) 来让我们利用并享受这种服务。
|
||||
|
||||
By establishing a connection to an [OpenVPN][1] server, we basically create a secure communications channel between our device and the remote host OpenVPN runs on. Although traffic flowing between these two end-points can be intercepted, it is strongly encrypted and thus practically useless to the interceptor. In addition to the OpenVPN acting as the facilitator of this encrypted channel (or tunnel), we may configure the server to also play the role of our Internet gateway. By doing so, we can for example hook up to any open, inherently insecure WiFi network, then immediately connect to the remote OpenVPN server and start using any Internet-enabled application without worrying of prying eyes or bored administrators. (Note though that we still need to trust any administrator in the vicinity of the OpenVPN server. But more on that towards the end of the post.)
|
||||
|
||||
@ -496,4 +497,4 @@ via: http://parabing.com/2014/06/openvpn-on-ubuntu/
|
||||
[6]:https://itunes.apple.com/us/app/openvpn-connect/id590379981?mt=8
|
||||
[7]:https://play.google.com/store/apps/details?id=net.openvpn.openvpn
|
||||
[8]:http://www.whatip.com/
|
||||
[9]:https://dnsleaktest.com/
|
||||
[9]:https://dnsleaktest.com/
|
||||
|
||||
@ -0,0 +1,131 @@
|
||||
10 Useful “Squid Proxy Server” Interview Questions and Answers in Linux
|
||||
================================================================================
|
||||
It’s not only to System Administrator and Network Administrator, who listens the phrase Proxy Server every now and then but we too. Proxy Server is now a corporate culture and is the need of the hour. Proxy server now a days is implemented from small schools, cafeteria to large MNCs. Squid (also known as proxy) is such an application which acts as proxy server and one of the most widely used tool of its kind.
|
||||
|
||||
This Interview article aims at strengthening your base from Interview point on the ground of proxy server and squid.
|
||||
|
||||

|
||||
Squid Interview Questions
|
||||
|
||||
### 1. What do you mean by Proxy Server? What is the use of Proxy Server in Computer Networks? ###
|
||||
|
||||
> **Answer** : A Proxy Server refers to physical machine or Application which acts intermediate between client and resource provider or server. A client seeks for file, page or data from the the proxy server and proxy server manages to get the requested demand of client fulfilled by handling all the complexities in between.
|
||||
|
||||
Proxy servers are the backbone of WWW (World Wide Web). Most of the proxies of today are web proxies. A proxy server handles the complexity in between the Communication of client and Server. Moreover it provides anonymity on the web which simply means your identity and digital footprints are safe. Proxies can be configured to allow which sites client can see and which sites are blocked.
|
||||
|
||||
### 2. What is Squid? ###
|
||||
|
||||
> **Answer** : Squid is an Application software released under GNU/GPL which acts as a proxy server as well as web cache Daemon. Squid primarily supports Protocol like HTTP and FTP however other protocols like HTTPS, SSL,TLS, etc are well supported. The feature web cache Daemon makes web surfing faster by caching web and DNS for frequently visited websites. Squid is known to support all major platforms including Linux, UNIX, Microsoft Windows and Mac.
|
||||
|
||||
### 3. What is the default port of squid and how to change its operating port? ###
|
||||
|
||||
> **Answer** : The default port on which squid runs is 3128. We can change the operating port of squid from default to any custom unused port by editing its configuration file which is located at /etc/squid/squid.conf as suggested below.
|
||||
|
||||
Open ‘/etc/squid/squid.conf’ file and with your choice of editor.
|
||||
|
||||
# nano /etc/squid/squid.conf
|
||||
|
||||
Now change this port to any other unused port. Save the editor and exit.
|
||||
|
||||
http_port 3128
|
||||
|
||||
Restart the squid service as shown below.
|
||||
|
||||
# service squid restart
|
||||
|
||||
### 4. You works for a company the management of which ask you to block certain domains through squid proxy server. What are you going to do? ###
|
||||
|
||||
> **Answer** : Blocking domain is a module which is implemented well in the configuration file. We just need to perform a little manual configuration as suggested below.
|
||||
|
||||
a. Create a file say ‘blacklist’ under directory ‘/etc/squid’.
|
||||
|
||||
# touch /etc/squid/blacklist
|
||||
|
||||
b. Open the file ‘/etc/squid/blacklist’ with nano editor.
|
||||
|
||||
# nano /etc/squid/blacklist
|
||||
|
||||
c. Add all the domains to the file blacklist with one domain per line.
|
||||
|
||||
.facebook.com
|
||||
.twitter.com
|
||||
.gmail.com
|
||||
.yahoo.com
|
||||
...
|
||||
|
||||
d. Save the file and exit. Now open the Squid configuration file from location ‘/etc/squid/squid.conf’.
|
||||
|
||||
# nano /etc/squid/squid.conf
|
||||
|
||||
e. Add the lines below to the Squid configuration file.
|
||||
|
||||
acl BLACKLIST dstdom_regex -i “/etc/squid/blacklist”
|
||||
http_access deny blacklist
|
||||
|
||||
f. Save the configuration file and exit. Restart Squid service to make the changes effective.
|
||||
|
||||
# service squid restart
|
||||
|
||||
### 5. What is Media Range Limitation and partial download in Squid? ###
|
||||
|
||||
> **Answer** : Media Range Limitation is a special feature of squid in which just the required data is requested from the server and not the whole file. This feature is very well implemented in various videos streaming websites like Youtube and Metacafe where a user can click on the middle of progress bar hence whole video need not be fetched except for the requested part.
|
||||
|
||||
The squid’s feature of partial download is implemented well within windows update where downloads are requested in the form of small packets which can be paused. Because of this feature a update downloading windows machine can be restarted without any fear of data loss. Squid makes the Media Range Limitation and Partial Download possible only after storing a copy of whole data in it. Moreover the partial download gets deleted and not cached when user points to another page until Squid is specially configured somehow.
|
||||
|
||||
### 6. What is reverse proxy in squid? ###
|
||||
|
||||
> **Answer** : Reverse proxy is a feature of Squid which is used to accelerate the web surfing for end user. Say the Real server ‘RS’ contains the resource and ‘PS’ is the proxy Server. The client seek some data which is available at RS. It will rely on RS for the specified data for the first time and the copy of that specified data gets stored on PS for configurable amount of time. For every request for that data from now PS becomes the real source. This results in Less traffic, Lesser CPU usages, Lesser web resource utilization and hence lesser load to actual server RS. But RS has no statistics for the total traffic since PS acted as actual server and no Client reached RS. ‘X-Forwarded-For HTTP’ can be used to log the client IP although on RS.
|
||||
|
||||
Technically it is feasible to use single squid server to act both as normal proxy server and reverse proxy server at the same point of time.
|
||||
|
||||
### 7. Since Squid can be used as web-cache Daemon, is it possible to Clear its Cache? How? ###
|
||||
|
||||
> **Answer** : No Doubt! Squid acts as web-cache Daemon which is used to accelerate web surfing still it is possible to clear its cache and that too very easily.
|
||||
|
||||
a. First stop Squid proxy server and delete cache from the location ‘/var/lib/squid/cache’ directory.
|
||||
|
||||
# service squid stop
|
||||
# rm -rf /var/lib/squid/cache/*<
|
||||
|
||||
b. Create Swap directories.
|
||||
|
||||
# squid -z
|
||||
|
||||
### 8. A client approaches you, who is working. They want the web access time be restricted for their children. How will you achieve this scenario? ###
|
||||
|
||||
Say the web access allow time be 4′o clock to 7′o clock in the evening for three hours, sharply form Monday to Friday.
|
||||
|
||||
a. To restrict web access between 4 to 7 from Monday to Friday, open the Squid configuration file.
|
||||
|
||||
# nano /etc/squid/squid.conf
|
||||
|
||||
b. Add the following lines and save the file and exit.
|
||||
|
||||
acl ALLOW_TIME time M T W H F 16:00-19:00
|
||||
shttp_access allow ALLOW_TIME
|
||||
|
||||
c. Restart the Squid Service.
|
||||
|
||||
# service squid restart
|
||||
|
||||
### 9. Squid stores data in which file format? ###
|
||||
|
||||
> **Answer** : Data stored by Squid is in ufs format. Ufs is the old well-known Squid storage format.
|
||||
|
||||
### 10. Where do cache gets stored by squid? ###
|
||||
|
||||
> **Answer** : A squid stores cache in special folder at the location ‘/var/spool/squid’.
|
||||
|
||||
That’s all for now. I’ll be here again with another interesting article soon. Till then stay tuned and connected to Tecmint. Don’t forget to provide us with your valuable feedback the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/squid-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
@ -0,0 +1,96 @@
|
||||
How to access Linux command cheat sheets from the command line
|
||||
================================================================================
|
||||
The power of Linux command line is its flexibility and versatility. Each Linux command comes with its share of command line options and parameters. Mix and match them, and even chain different commands with pipes and redirects. You get yourself literally hundreds of use cases even with a few basic commands, and it's hard even for seasoned system admins to get used to them all. That's when command line cheat sheets come to our rescue.
|
||||
|
||||
[][1]
|
||||
|
||||
I know man pages are still our best friend, but we want to be efficient and strategic by having quick reference cards at our disposal. Your ultimate cheet sheets could be hanging on your office wall with pride, or secretly stored in your hard drive as PDF files, or even be the background image on your desktop.
|
||||
|
||||
Alternatively, use yet(!) another command to access your favorite command line cheat sheets. That is, use [cheat][2]. Which is a command line tool allowing you to access, create or update cheat sheets from the command line. The concept is really simple, yet cheat turns out to be quite useful. This tutorial is about how to use cheat command on Linux. You don't need a cheat sheet for using cheat command. It's that simple.
|
||||
|
||||
### Installing Cheat on Linux ###
|
||||
|
||||
First install Git if you haven't:
|
||||
|
||||
$ sudo apt-get install git (Debian-based system)
|
||||
$ sudo yum install git (RedHat-based system)
|
||||
|
||||
Also install [Python package installer pip[3].
|
||||
|
||||
Finally, install cheat using the following commands.
|
||||
|
||||
$ sudo pip install docopt pygments
|
||||
$ git clone https://github.com/chrisallenlane/cheat.git
|
||||
$ cd cheat
|
||||
$ sudo python setup.py install
|
||||
|
||||
### Configuring Cheat ###
|
||||
|
||||
There is not much to configure for cheat command.
|
||||
|
||||
One thing to recommend is to enable command-line autocompletion. That way, when you look up a cheat sheet, you can use [TAB] key to auto-complete the name of the command you want to check. Here is how to enable autocompletion for bash.
|
||||
|
||||
$ wget https://github.com/chrisallenlane/cheat/raw/master/cheat/autocompletion/cheat.bash
|
||||
$ sudo cp cheat.bash /etc/bash_completion.d/
|
||||
|
||||
They provide autocompletion scripts for other shells such as zsh and fish as well.
|
||||
|
||||
Another thing is to define an EDITOR environment variable. This variable should point to a text editor that you want to use when creating or updating a cheat sheet. For example, if you want to use Vim editor, put the following in ~/.bashrc.
|
||||
|
||||
export EDITOR=/usr/bin/vim
|
||||
|
||||
Log out and log back in to activate autocompletion and updated .bashrc.
|
||||
|
||||
### Basic Usage of Cheat ###
|
||||
|
||||
One cool thing about the cheat command is that it comes with pre-built cheat sheets for more than 90 popular Linux commands. To get a list of available cheat sheets:
|
||||
|
||||
$ cheat -l
|
||||
|
||||

|
||||
|
||||
To access a cheat sheet of a specific command, simply run cheat with the name of the command:
|
||||
|
||||
$ cheat <command-name>
|
||||
|
||||

|
||||
|
||||
You can search all the cheat sheets that contain a specific keyword by using "-s" option:
|
||||
|
||||
$ cheat -s <keyword>
|
||||
|
||||
In many cases, cheat sheets that are useful to some folks may not that helpful to others. To personalize pre-built cheat sheets, cheat command allows you to create a new cheat sheet or update existing ones. To do so, cheat command can keep local copies of cheat sheets in ~/.cheat directory.
|
||||
|
||||
To take advantage of cheat's editing feature, first make sure that the EDITOR environment variable is set to the full path of your default text editor. Then copy (non-editable) built-in cheat sheets to ~/.cheat directory. You can find where the built-in cheat sheets are by running the following command. Once you know where they are, simply copy them over to ~/.cheat directory.
|
||||
|
||||
$ cheat -d
|
||||
|
||||
----------
|
||||
|
||||
/usr/lib/python2.6/site-packages/cheat/cheatsheets
|
||||
|
||||
----------
|
||||
|
||||
$ cp /usr/lib/python2.6/site-packages/cheat/cheatsheets/* ~/.cheat
|
||||
|
||||
Now you can create or update a cheat sheet by using "-e" option:
|
||||
|
||||
$ cheat -e openssl
|
||||
|
||||
As you can imagine, the cheat's editing feature is very useful to tailor a local cheat sheet repository to meet your needs. If you believe in sharing knowledge, you are more than welcome to contribute your cheat sheets to the cheat command's [official Git repository][4], so everyone can benefit from them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/access-linux-command-cheat-sheets-command-line.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xkcd.com/1168/
|
||||
[2]:https://github.com/chrisallenlane/cheat
|
||||
[3]:http://ask.xmodulo.com/install-pip-linux.html
|
||||
[4]:https://github.com/chrisallenlane/cheat
|
||||
131
sources/tech/20140729 How to use awk command in Linux.md
Normal file
131
sources/tech/20140729 How to use awk command in Linux.md
Normal file
@ -0,0 +1,131 @@
|
||||
How to use awk command in Linux
|
||||
================================================================================
|
||||
Text processing is at the heart of Unix. From pipes to the /proc subsystem, the "everything is a file" philosophy pervades the operating system and all of the tools built for it. Because of this, getting comfortable with text-processing is one of the most important skills for an aspiring Linux system administrator, or even any power user, and awk is one of the most powerful text-processing tools available outside general-purpose programming languages.
|
||||
|
||||
The simplest awk task is selecting fields from stdin; if you never learn any more about awk than this, you'll still have at your disposal an extremely useful tool.
|
||||
|
||||
By default, awk separates input lines by whitespace. If you'd like to select the first field from input, you just need to tell awk to print out $1:
|
||||
|
||||
$ echo 'one two three four' | awk '{print $1}'
|
||||
|
||||
> one
|
||||
|
||||
(Yes, the curly-brace syntax is a little weird, but I promise that's about as weird as it gets in this lesson.)
|
||||
|
||||
Can you guess how you'd select the second, third, or fourth fields? That's right, with $2, $3, and $4, respectively.
|
||||
|
||||
$ echo 'one two three four' | awk '{print $3}'
|
||||
|
||||
(Yes, the curly-brace syntax is a little weird, but I promise that's about as weird as it gets in this lesson.)
|
||||
|
||||
Can you guess how you'd select the second, third, or fourth fields? That's right, with $2, $3, and $4, respectively.
|
||||
|
||||
$ echo 'one two three four' | awk '{print $3}'
|
||||
|
||||
> three
|
||||
|
||||
Often when text munging, you need to create a specific format of data, and that covers more than just a single word. The good news is that awk makes it easy to print multiple fields, or even include static strings:
|
||||
|
||||
$ echo 'one two three four' | awk '{print $3,$1}'
|
||||
|
||||
> three one
|
||||
|
||||
----------
|
||||
|
||||
$ echo 'one two three four' | awk '{print "foo:",$3,"| bar:",$1}'
|
||||
|
||||
> foo: three | bar: one
|
||||
|
||||
Ok, but what if your input isn't separated by whitespace? Just pass awk the '-F' flag with your separator:
|
||||
|
||||
$ echo 'one mississippi,two mississippi,three mississippi,four mississippi' | awk -F , '{print $4}'
|
||||
|
||||
> four mississippi
|
||||
|
||||
Occasionally, you may find yourself working with data with a varied number of fields, and you just know you want the *last* one. awk prepopulates the $NF variable with the *number of fields*, so you can use it to grab the last element:
|
||||
|
||||
$ echo 'one two three four' | awk '{print $NF}'
|
||||
|
||||
> four
|
||||
|
||||
You can also do simple math on $NF, in case you need the next-to-last field:
|
||||
|
||||
$ echo 'one two three four' | awk '{print $(NF-1)}'
|
||||
|
||||
> three
|
||||
|
||||
Or even the middle field:
|
||||
|
||||
$ echo 'one two three four' | awk '{print $((NF/2)+1)}'
|
||||
|
||||
> three
|
||||
|
||||
$ echo 'one two three four five' | awk '{print $((NF/2)+1)}'
|
||||
|
||||
> three
|
||||
|
||||
While this is all very useful, you can get away with forcing sed, cut, and grep into a form to get these results, as well (albeit with a lot more work).
|
||||
|
||||
So, I'll leave you with one last introductory feature of awk, maintaining state across lines.
|
||||
|
||||
$ echo -e 'one 1\ntwo 2' | awk '{print $2}'
|
||||
|
||||
> 1
|
||||
>
|
||||
> 2
|
||||
|
||||
$ echo -e 'one 1\ntwo 2' | awk '{sum+=$2} END {print sum}'
|
||||
|
||||
> 3
|
||||
|
||||
(The END indicates that we should only perform the following block **after** we finish processing every line.)
|
||||
|
||||
The case where I've used this is to sum up bytes from web server request logs. Imagine we have an access log that looks like this:
|
||||
|
||||
$ cat requests.log
|
||||
|
||||
> Jul 23 18:57:12 httpd[31950]: "GET /foo/bar HTTP/1.1" 200 344
|
||||
>
|
||||
> Jul 23 18:57:13 httpd[31950]: "GET / HTTP/1.1" 200 9300
|
||||
>
|
||||
> Jul 23 19:01:27 httpd[31950]: "GET / HTTP/1.1" 200 9300
|
||||
>
|
||||
> Jul 23 19:01:55 httpd[31950]: "GET /foo/baz HTTP/1.1" 200 6401
|
||||
>
|
||||
> Jul 23 19:02:31 httpd[31950]: "GET /foo/baz?page=2 HTTP/1.1" 200 6312
|
||||
|
||||
We know the last field is the number of bytes of the response. We've already learned how to extract them using print and $NF:
|
||||
|
||||
$ < requests.log awk '{print $NF}'
|
||||
|
||||
> 344
|
||||
>
|
||||
> 9300
|
||||
>
|
||||
> 9300
|
||||
>
|
||||
> 6401
|
||||
>
|
||||
> 6312
|
||||
|
||||
And so we can sum into a variable to gather the total number of bytes our webserver has served to clients during the timespan of our log:
|
||||
|
||||
$ < requests.log awk '{totalBytes+=$NF} END {print totalBytes}'
|
||||
|
||||
> 31657
|
||||
|
||||
If you're looking for more to do with awk, you can find used copies of [the original awk book][1] for under 15 USD on Amazon. You may also enjoy Eric Pement's [collection of awk one-liners][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/use-awk-command-linux.html
|
||||
|
||||
作者:[James Pearson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/james
|
||||
[1]:http://www.amazon.com/gp/product/020107981X/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=020107981X&linkCode=as2&tag=xmodulo-20&linkId=6NW62B2WBRBXRFJB
|
||||
[2]:http://www.pement.org/awk/awk1line.txt
|
||||
@ -0,0 +1,39 @@
|
||||
Translating by GoLinux ...
|
||||
Linux FAQs with Answers--How to check which fonts are used in a PDF document
|
||||
================================================================================
|
||||
> **Question**: I would like to know what fonts are used or embedded in a PDF file. Is there a Linux tool which can check which fonts are used in a PDF document?
|
||||
|
||||
To check what fonts are included or used in a PDF file, you can use a command-line utility called pdffonts, which is a PDF font analyzer tool. pdffonts is a part of Poppler PDF utilities package.
|
||||
|
||||
### Install PDF Utilities on Linux ###
|
||||
|
||||
To install Poppler on Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo apt-get install poppler-utils
|
||||
|
||||
To install PDF Utilities on Fedora, CentOS or RHEL:
|
||||
|
||||
$ sudo yum install poppler-utils
|
||||
|
||||
### Check PDF Fonts ###
|
||||
|
||||
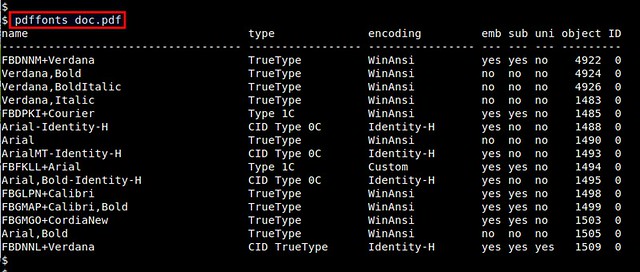
**pdffonts** can list all the fonts used in a PDF document. The basic usage of pdffonts is as follows.
|
||||
|
||||
$ pdffonts doc.pdf
|
||||
|
||||
|
||||
|
||||
The **pdffonts** tool shows various information about each font used, such as font name/type, or whether or not a font is embedded, etc.
|
||||
|
||||
In case of a multi-page PDF document, you can limit font scanning for a range of pages with "-f" (first page), and "-l" (last page) options. For example, if you want to find out which fonts are used in pages 5-10 of a document, run this:
|
||||
|
||||
$ pdffonts -f 5 -l 10 doc.pdf
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-which-fonts-are-used-pdf-document.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,67 @@
|
||||
Use Pushbullet Indicator In Ubuntu To Send Files To Android Or iOS Devices
|
||||
================================================================================
|
||||

|
||||
|
||||
[Pushbullet][1] is an app available for iOS and Android devices that lets you send files, links, images from your desktop to your mobile device and vice versa. Pushbullet can be used in any OS by installing extensions in Firefox or Chrome.
|
||||
|
||||
If you are not fan of browser extensions and want to use something more of a desktop app for **Pushbullet in Ubuntu 14.04**, you can use **Pushbullet Indicator** developed by [Atareao][2]. Pushbullet Indicator is in development stage at the moment and doesn’t have all the functionality of the official Windows desktop app but it still has enough to get you started.
|
||||
|
||||
### Install Pushbullet Indicator in Ubuntu 14.04 and Linux Mint 17 ###
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
|
||||
sudo add-apt-repository ppa:atareao/atareao
|
||||
sudo apt-get update
|
||||
sudo apt-get install pushbullet-indicator
|
||||
|
||||
The above PPA won’t work on Ubuntu 13.10.
|
||||
|
||||
### Using Pushbullet Indicator in Ubuntu 14.04 and Linux Mint 17 ###
|
||||
|
||||
- Create an account on [Pushbullet][3].
|
||||
- Install the Pushbullet app on your Android or iOS device.
|
||||
- After installing Pushbullet Indicator in Ubuntu or Linux Mint, start it. On the first launch, it will give the option to connect to your Pushbullet account:
|
||||
|
||||

|
||||
|
||||
- Once connected, you should also name your device, from the device tab in the above picture. If you want Pushbullet to autostart at each boot, you can choose it do so by going in preference and turn on the Autostart button (shown in the picture above).
|
||||
- Once you are done with this, you will see the Pushbullet indicator in Unity panel.
|
||||
|
||||

|
||||
|
||||
- To send something to your smartphone, click on the indicator and select the device (linked to your Pushbullet account). It’s as simple as that.
|
||||
|
||||

|
||||
|
||||
- You’ll get a notification on the other device of receiving a file. You can access them all from the Pushbullet app.
|
||||
- Android devices can also get notifications for phone calls, text messages and other notifications.
|
||||
- If you send a file from your mobile device to your desktop, you will be notified about it:
|
||||
|
||||

|
||||
|
||||
- The files are not automatically saved to a certain directory. To get the file sent from other device, go to Show last push from the indicator menu, it will show you the last push available. Click on it to download the file to a directory of your choice.
|
||||
|
||||
### Install Nautilus extension for Pushbullet: ###
|
||||
|
||||
Alternatively, you can also install Nautilus extension for Pushbullet to send files directly from right click menu. Use the following command:
|
||||
|
||||
sudo apt-get install nautilus-pushbullet
|
||||
|
||||
You’ll have to authenticate it again after restarting.
|
||||
|
||||
Do share your experience with Pushbullet Indicator in comment section. Ciao 
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/pushbullet-indicator-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:https://www.pushbullet.com/
|
||||
[2]:http://www.atareao.es/
|
||||
[3]:https://www.pushbullet.com/
|
||||
199
sources/tech/20140730 How to use variables in shell Scripting.md
Normal file
199
sources/tech/20140730 How to use variables in shell Scripting.md
Normal file
@ -0,0 +1,199 @@
|
||||
How to use variables in shell Scripting
|
||||
================================================================================
|
||||
In every **programming** language **variables** plays an important role , in Linux shell scripting we are using two types of variables : **System Defined Variables** & **User Defined Variables**.
|
||||
|
||||
A variable in a shell script is a means of **referencing** a **numeric** or **character value**. And unlike formal programming languages, a shell script doesn't require you to **declare a type** for your variables
|
||||
|
||||
In this article we will discuss variables, its types and how to set & use variables in shell scripting.
|
||||
|
||||
### System Defined Variables : ###
|
||||
|
||||
These are the variables which are created and maintained by **Operating System(Linux) itself**. Generally these variables are defined in **CAPITAL LETTERS**. We can see these variables by using the command "**$ set**". Some of the system defined variables are given below :
|
||||
|
||||
<table width="100%" cellspacing="1" cellpadding="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><strong> System Defined Variables </strong></td>
|
||||
<td><strong> Meaning </strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> BASH=/bin/bash </td>
|
||||
<td> Shell Name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> BASH_VERSION=4.1.2(1) </td>
|
||||
<td> Bash Version </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> COLUMNS=80 </td>
|
||||
<td> No. of columns for our screen </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> HOME=/home/linuxtechi </td>
|
||||
<td> Home Directory of the User </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> LINES=25 </td>
|
||||
<td> No. of columns for our screen </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> LOGNAME=LinuxTechi </td>
|
||||
<td> LinuxTechi Our logging name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> OSTYPE=Linux </td>
|
||||
<td> OS type </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PATH=/usr/bin:/sbin:/bin:/usr/sbin </td>
|
||||
<td> Path Settings </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PS1=[\u@\h \W]\$ </td>
|
||||
<td> Prompt Settings </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PWD=/home/linuxtechi </td>
|
||||
<td> Current Working Directory </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> SHELL=/bin/bash </td>
|
||||
<td> Shell Name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> USERNAME=linuxtechi </td>
|
||||
<td> User name who is currently login to system </td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
To Print the value of above variables, use **echo command** as shown below :
|
||||
|
||||
# echo $HOME
|
||||
# echo $USERNAME
|
||||
|
||||
We can tap into these environment variables from within your scripts by using the environment variable's name preceded by a dollar sign. This is demonstrated in the following script:
|
||||
|
||||
$ cat myscript
|
||||
|
||||
#!/bin/bash
|
||||
# display user information from the system.
|
||||
echo “User info for userid: $USER”
|
||||
echo UID: $UID
|
||||
echo HOME: $HOME
|
||||
|
||||
Notice that the **environment variables** in the echo commands are replaced by their current values when the script is run. Also notice that we were able to place the **$USER** system variable within the double quotation marks in the first string, and the shell script was still able to figure out what we meant. There is a **drawback** to using this method, however. Look at what happens in this example:
|
||||
|
||||
$ echo “The cost of the item is $15”
|
||||
The cost of the item is 5
|
||||
|
||||
That is obviously not what was intended. Whenever the script sees a dollar sign within quotes, it assumes you're referencing a variable. In this example the script attempted to display the **variable $1** (which was not defined), and then the number 5. To display an actual dollar sign, you **must precede** it with a **backslash character**:
|
||||
|
||||
$ echo “The cost of the item is \$15”
|
||||
The cost of the item is $15
|
||||
|
||||
That's better. The backslash allowed the shell script to interpret the **dollar sign** as an actual dollar sign, and not a variable.
|
||||
|
||||
### User Defined Variables: ###
|
||||
|
||||
These variables are defined by **users**. A shell script allows us to set and use our **own variables** within the script. Setting variables allows you to **temporarily store data** and use it throughout the script, making the shell script more like a real computer program.
|
||||
|
||||
**User variables** can be any text string of up to **20 letters, digits**, or **an underscore character**. User variables are case sensitive, so the variable Var1 is different from the variable var1. This little rule often gets novice script programmers in trouble.
|
||||
|
||||
Values are assigned to user variables using an **equal sign**. No spaces can appear between the variable, the equal sign, and the value (another trouble spot for novices). Here are a few examples of assigning values to user variables:
|
||||
|
||||
var1=10
|
||||
var2=-57
|
||||
var3=testing
|
||||
var4=“still more testing”
|
||||
|
||||
The shell script **automatically determines the data type** used for the variable value. Variables defined within the shell script maintain their values throughout the life of the shell script but are deleted when the shell script completes.
|
||||
|
||||
Just like system variables, user variables can be referenced using the dollar sign:
|
||||
|
||||
$ cat test3
|
||||
#!/bin/bash
|
||||
# testing variables
|
||||
days=10
|
||||
guest="Katie"
|
||||
echo "$guest checked in $days days ago"
|
||||
days=5
|
||||
guest="Jessica"
|
||||
echo "$guest checked in $days days ago"
|
||||
$
|
||||
|
||||
Running the script produces the following output:
|
||||
|
||||
$ chmod u+x test3
|
||||
$ ./test3
|
||||
Katie checked in 10 days ago
|
||||
Jessica checked in 5 days ago
|
||||
$
|
||||
|
||||
Each time the variable is **referenced**, it produces the value currently assigned to it. It's important to remember that when referencing a variable value you use the **dollar sign**, but when referencing the variable to assign a value to it, you do not use the dollar sign. Here's an example of what I mean:
|
||||
|
||||
$ cat test4
|
||||
#!/bin/bash
|
||||
# assigning a variable value to another variable
|
||||
value1=10
|
||||
value2=$value1
|
||||
echo The resulting value is $value2
|
||||
$
|
||||
|
||||
When you use the **value** of the **value1** variable in the assignment statement, you must still use the dollar sign. This code produces the following output:
|
||||
|
||||
$ chmod u+x test4
|
||||
$ ./test4
|
||||
The resulting value is 10
|
||||
$
|
||||
|
||||
If you forget the dollar sign, and make the value2 assignment line look like:
|
||||
|
||||
value2=value1
|
||||
you get the following output:
|
||||
|
||||
$ ./test4
|
||||
The resulting value is value1
|
||||
$
|
||||
|
||||
Without the dollar sign the **shell interprets** the variable name as a **normal text string**, which is most likely not what you wanted.
|
||||
|
||||
### Use of Backtick symbol (`) in shell variables : ###
|
||||
|
||||
The **backtick allows** you to assign the output of a shell command to a variable. While this doesn't seem like much, it is a major building block in **script programming**.You must surround the entire command line command with backtick characters:
|
||||
|
||||
**testing=`date`**
|
||||
|
||||
The shell runs the command within the **backticks** and assigns the output to the variable testing. Here's an example of creating a variable using the output from a normal shell command:
|
||||
|
||||
$ cat test5
|
||||
#!/bin/bash
|
||||
# using the backtick character
|
||||
testing=`date`
|
||||
echo "The date and time are: " $testing
|
||||
$
|
||||
|
||||
The variable testing receives the output from the date command, and it is used in the echo statement to display it. Running the shell script produces the following output:
|
||||
|
||||
$ chmod u+x test5
|
||||
$ ./test5
|
||||
The date and time are: Mon Jan 31 20:23:25 EDT 2011
|
||||
|
||||
**Note** : In bash you can also use the alternative $(…) syntax in place of backtick (`),which has the advantage of being re-entrant.
|
||||
|
||||
Example :
|
||||
|
||||
$ echo " Today’s date & time is :" $(date)
|
||||
Today’s date & time is : Sun Jul 27 16:26:56 IST 2014
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/variables-in-shell-scripting/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,31 @@
|
||||
小伙伴们,该更新系统啦:Ubuntu 13.10的支持到今天结束
|
||||
================================================================================
|
||||

|
||||
|
||||
|
||||
**尽管目前运行良好,在经历了9个月的折腾,今天官方对Ubuntu 13.10(俏皮蝾螈)的支持正式寿终正寝。**
|
||||
|
||||
> 尽管它的名字叫'俏皮蝾螈',但它所以提供的新功能却无比的乏味。
|
||||
那些仍然在使用的用户应该好好看看最新的发行的稳定版,Ubuntu 14.04 LTS,在四月推出的,提供良好的图形化支持,支持期限是到2019年的4月中旬。
|
||||
对于Ubuntu 13.10的服务器版本到今天正式的停止支持。
|
||||
### 俏皮蝾螈已然失宠 ###
|
||||
|
||||
Ubuntu 13.10在去年10月开始对桌面版本提供时常9个月的安全和Bug修复更新。截至到今年7月17日,所有更新将停止,未来也不再提供。
|
||||
[推荐的做法][1]是升级到14.04版本,目前可以直接通过图形化工具去升级,包括使用升级程序,或者在命令行运行‘`do-release-upgrade`‘命令。
|
||||
俏皮蝾螈,它的名字非常的好听,但其表现并不如人意,13.10在Ubuntu所有的发行版中也不是一个取得卓越成功的版本,[这一点已经被很多网络评论预言到了][2]。
|
||||
It was, however, notable for inflicting(注:这个单词原文有删除线) introducing Smart Scopes to the Unity Dash,
|
||||
然而,依然让人眼前一亮的是,它添加了键盘指示符来快速的选择安装语言,这可以让用户简便的在该智能域操作,这也是第一个在安装程序中整合了`Ubuntu One Single Sign-on`的发行版。
|
||||
查看13.10版本的所有新功能,请查看完整视频:
|
||||
Youtobe 视频地址:[http://www.youtube.com/embed/1EiRQ-znEcI?feature=oembed][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/07/ubuntu-13-10-support-ends-today
|
||||
|
||||
译者:[nd0104](https://github.com/nd0104) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://help.ubuntu.com/community/TrustyUpgrades
|
||||
[2]:http://www.omgubuntu.co.uk/2013/10/ubuntu-13-10-press-reaction
|
||||
[3]:http://www.youtube.com/embed/1EiRQ-znEcI?feature=oembed
|
||||
@ -1,58 +0,0 @@
|
||||
需要在Ubuntu上安装微软办公软件?去安装官方的网络应用程序
|
||||
================================================== ==============================
|
||||
|
||||
|
||||
**这是微软办公软件及其一贯繁琐的文件指令,而不是每个人的一杯咖啡。同时这是许多工作和教育环境的主要依靠——无论是好还是坏**
|
||||
|
||||
通过使用[LibreOffice的应用程序套件][1],阅读、编辑和保存这些专有指令出现在Ubuntu上是有着某种程度的可能。在作家中,Calc和Impress都不同程度的夸耀微软办公软件文件的协作性,但在我自己的实际操作经验中(谢天谢地,它很简洁!)它并不完美。
|
||||
|
||||
时不时的,你会不得不使用微软办公软件,(虽然我们大多数人都心里向着开放标准,但是我们不应该无视实际问题)但你已经没有意愿去购买一个完整的微软办公软件许可证来运行这个窗口模拟器,那么微软的在线网络应用程序是完美的解决方法。
|
||||
|
||||
###安装微软在线办公软件上的应用程序在Ubuntu###
|
||||
|
||||
为了使从Ubuntu的桌面访问这些在线版本更容易,“Linux的网络应用程序项目”创造了一个小的、非官方的安装程序。它可以添加网络应用程序的快捷方式(“荣耀书签”)到您的应用程序启动器。
|
||||
|
||||
|
||||
|
||||
通过快捷方式,相应的Microsoft Web应用程序在你默认的系统浏览器中打开,不可能有比这更精美的了。听起来漂亮吗?下面是你的应用程序的快捷方式:
|
||||
|
||||
- 文档
|
||||
- 表格
|
||||
- 幻灯片
|
||||
- Outlook
|
||||
- OneDrive
|
||||
- 日历
|
||||
- OneNote
|
||||
- 通讯录
|
||||
|
||||
该软件包还创建了一个新的应用程序类别来容纳这些链接,不但可以让您把这些快捷方式从其他应用程序单独分开来,而且是直接位于常见的“办公软件”应用程序下。
|
||||
|
||||
这些都是必不可少的吗?不见得。他们有用吗?这取决于你的工作流程。但它是不错的选择吗?一定是的。
|
||||
|
||||
你可以从下面的链接保存含有.deb文件安装程序,其中有安装链接。适用于Ubuntu14.04 LTS和更高版本。
|
||||
|
||||
- [下载微软的在线办公应用(.deb)][2]
|
||||
|
||||
###其他可选项###
|
||||
|
||||

|
||||
|
||||
类似的替代方案是[安装Chrome官方网上应用商店的在线办公应用程序][3],然后添加应用程序启动器到Linux。这次短跑中仍然会为它们创建可启动的快捷方式,但那些可以被设置为打开自己的窗框,而且不需要安装任何第三方软件包。
|
||||
|
||||
同时,谷歌最近在整合完整的Office功能(由于其购买了QuickOffice)[到自己的文档,幻灯片和床单应用][4]。Android应用程序Quickoffice退出了舞台,同时Chrome也实现了扩展。
|
||||
|
||||
如果你是一个深度的谷歌网络硬盘/文档的用户,那么这个解决方案可能对你是更加好了。
|
||||
|
||||
-------------------------------------------------- ------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/07/run-microsoft-office-web-apps-ubuntu-desktop
|
||||
|
||||
译者:[cereuz](https://github.com/cereuz)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.libreoffice.org/
|
||||
[2]:https://docs.google.com/file/d/0ByQnaVw7riBQMjNCUFh4ZlM4Y0E/edit?usp=sharing
|
||||
[3]:http://www.omgchrome.com/microsoft-brings-office-online-chrome-web-store/
|
||||
[4]:http://www.omgchrome.com/quickoffice-chrome-extension-gets-name-change/
|
||||
@ -0,0 +1,44 @@
|
||||
简捷安装Tor浏览器到Ubuntu 14.04和Linux Mint 17中
|
||||
================================================================================
|
||||

|
||||
|
||||
牢记[美国国家安全局对全世界政府和国民的窥视][1]的尴尬结局吧,隐私日益成为许多人关心的焦点。如果你也关注在线安全性并想要保护自己不受网络监视,[Tor项目][2]是当前可用的最佳选择。
|
||||
|
||||
Tor项目有它自己的[Tor浏览器][3],该浏览器基于Firefox并开启了用户隐私保护配置,并通过捆绑Tor和[Vidalia][4]工具进行匿名访问。虽然你可以[下载Tor浏览器并使用源码安装][5],但是我们将介绍一种更为便捷的方式,来将它安装到Ubuntu 14.04和Linux Mint 17中。
|
||||
|
||||
### 如何在Ubuntu 14.04和Linux Mint 17中安装Tor浏览器 ###
|
||||
|
||||
多亏了[Webupd8][6],我们可以方便地通过PPA将Tor浏览器到Ubuntu和其它基于Ubuntu的OS中(如果你对源代码安装很感冒)。打开终端(Ctrl+Alt+T)并使用以下命令进行安装:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/tor-browser
|
||||
sudo apt-get update
|
||||
sudo apt-get install tor-browser
|
||||
|
||||
以上PPA在Ubuntu 12.04和其它基于该版本的Linux发行版中可合法使用。
|
||||
|
||||
#### 卸载Tor浏览器 ####
|
||||
|
||||
如果你想要卸载Tor浏览器,使用下面的命令即可:
|
||||
|
||||
sudo apt-get remove tor-browser
|
||||
rm -r ~/.tor-browser-en
|
||||
|
||||
我希望这个快速测试对你**在Ubuntu 14.04和Linux Mint 17中便捷安装Tor浏览器**有所帮助。欢迎您在提问或者提供建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-tar-browser-ubuntu-linux-mint-17/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://projects.propublica.org/nsa-grid/
|
||||
[2]:https://www.torproject.org/
|
||||
[3]:https://www.torproject.org/projects/torbrowser.html.en
|
||||
[4]:https://www.torproject.org/projects/vidalia.html.en
|
||||
[5]:https://www.torproject.org/projects/torbrowser.html.en#linux
|
||||
[6]:http://www.webupd8.org/
|
||||
Loading…
Reference in New Issue
Block a user