mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
OneNewLife translating
This commit is contained in:
parent
c0868cda9e
commit
bacd276816
@ -1,3 +1,5 @@
|
||||
OneNewLife translating
|
||||
|
||||
The truth about traditional JavaScript benchmarks
|
||||
============================================================
|
||||
|
||||
@ -9,7 +11,7 @@ That raises the question, why is JavaScript so popular/successful? There is no o
|
||||
Back in the days, these speed-ups were measured with what is now called _traditional JavaScript benchmarks_, starting with Apple’s [SunSpider benchmark][24], the mother of all JavaScript micro-benchmarks, followed by Mozilla’s [Kraken benchmark][25] and Google’s V8 benchmark. Later the V8 benchmark was superseded by the[Octane benchmark][26] and Apple released its new [JetStream benchmark][27]. These traditional JavaScript benchmarks drove amazing efforts to bring a level of performance to JavaScript that noone would have expected at the beginning of the century. Speed-ups up to a factor of 1000 were reported, and all of a sudden using `<script>` within a website was no longer a dance with the devil, and doing work client-side was not only possible, but even encouraged.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][28]
|
||||
|
||||
|
||||
@ -18,20 +20,20 @@ Now in 2016, all (relevant) JavaScript engines reached a level of performance th
|
||||
The vast majority of these accomplishments were due to the presence of these micro-benchmarks and static performance test suites, and the vital competition that resulted from having these traditional JavaScript benchmarks. You can say what you want about SunSpider, but it’s clear that without SunSpider, JavaScript performance would likely not be where it is today. Okay, so much for the praise… now on to the flip side of the coin: Any kind of static performance test - be it a micro-benchmark or a large application macro-benchmark - is doomed to become irrelevant over time! Why? Because the benchmark can only teach you so much before you start gaming it. Once you get above (or below) a certain threshold, the general applicability of optimizations that benefit a particular benchmark will decrease exponentially. For example we built Octane as a proxy for performance of real world web applications, and it probably did a fairly good job at that for quite some time, but nowadays the distribution of time in Octane vs. real world is quite different, so optimizing for Octane beyond where it is currently, is likely not going to yield any significant improvements in the real world (neither general web nor Node.js workloads).
|
||||
|
||||
[
|
||||

|
||||

|
||||
][32]
|
||||
|
||||
|
||||
Since it became more and more obvious that all the traditional benchmarks for measuring JavaScript performance, including the most recent versions of JetStream and Octane, might have outlived their usefulness, we started investigating new ways to measure real-world performance beginning of the year, and added a lot of new profiling and tracing hooks to V8 and Chrome. We especially added mechanisms to see where exactly we spend time when browsing the web, i.e. whether it’s script execution, garbage collection, compilation, etc., and the results of these investigations were highly interesting and surprising. As you can see from the slide above, running Octane spends more than 70% of the time executing JavaScript and collecting garbage, while browsing the web you always spend less than 30% of the time actually executing JavaScript, and never more than 5% collecting garbage. Instead a significant amount of time goes to parsing and compiling, which is not reflected in Octane. So spending a lot of time to optimize JavaScript execution will boost your score on Octane, but won’t have any positive impact on loading [youtube.com][33]. In fact, spending more time on optimizing JavaScript execution might even hurt your real-world performance since the compiler takes more time, or you need to track additional feedback, thus eventually adding more time to the Compile, IC and Runtime buckets.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][34]
|
||||
|
||||
There’s another set of benchmarks, which try to measure overall browser performance, including JavaScript **and** DOM performance, with the most recent addition being the [Speedometer benchmark][35]. The benchmark tries to capture real world performance more realistically by running a simple [TodoMVC][36] application implemented with different popular web frameworks (it’s a bit outdated now, but a new version is in the makings). The various tests are included in the slide above next to octane (angular, ember, react, vanilla, flight and backbone), and as you can see these seem to be a better proxy for real world performance at this point in time. Note however that this data is already six months old at the time of this writing and things might have changed as we optimized more real world patterns (for example we are refactoring the IC system to reduce overhead significantly, and the [parser is being redesigned][37]). Also note that while this looks like it’s only relevant in the browser space, we have very strong evidence that traditional peak performance benchmarks are also not a good proxy for real world Node.js application performance.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][38]
|
||||
|
||||
|
||||
@ -42,7 +44,7 @@ All of this is probably already known to a wider audience, so I’ll use the res
|
||||
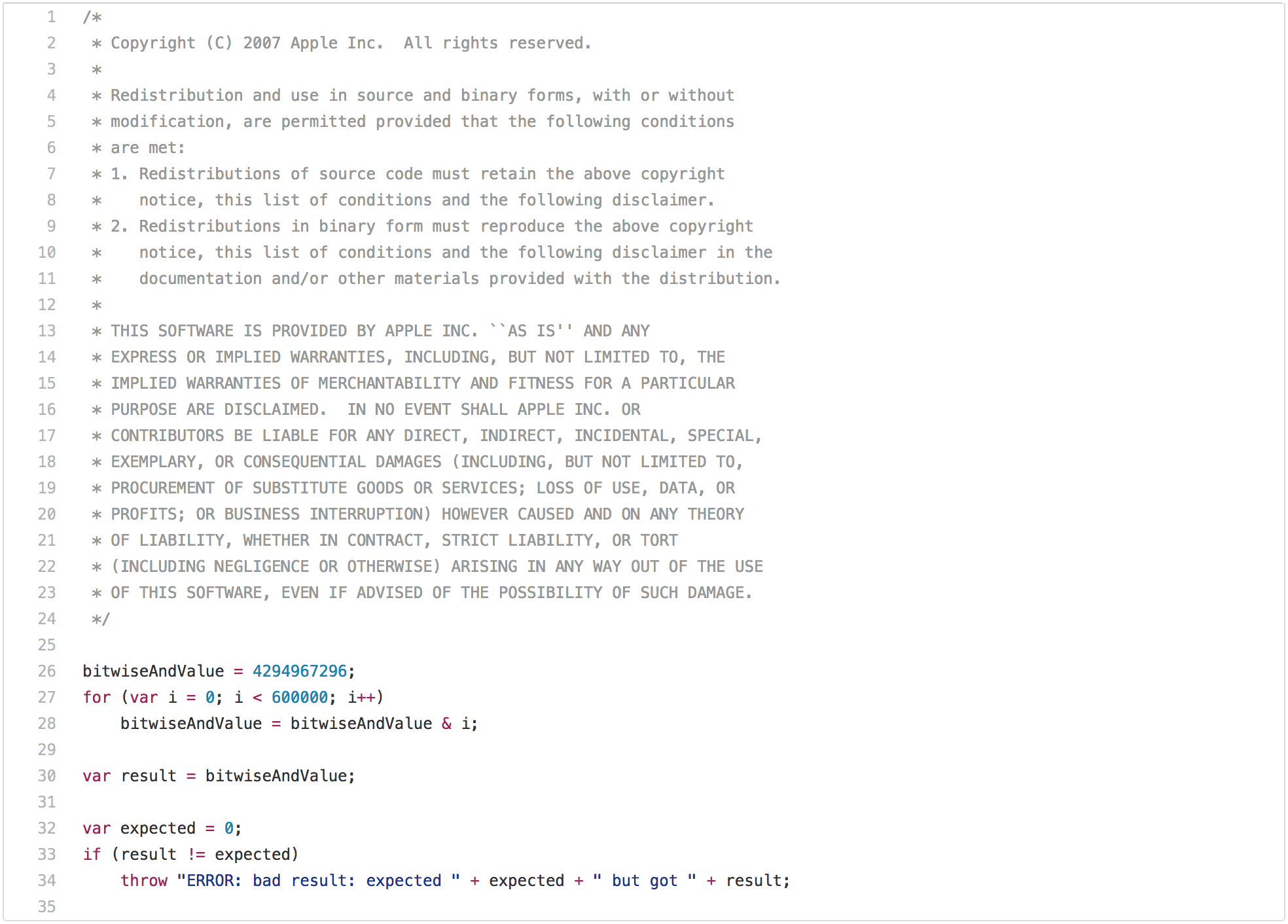
A blog post on traditional JavaScript benchmarks wouldn’t be complete without pointing out the obvious SunSpider problems. So let’s start with the prime example of performance test that has limited applicability in real world: The [`bitops-bitwise-and.js`][39] performance test.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][40]
|
||||
|
||||
There are a couple of algorithms that need fast bitwise and, especially in the area of code transpiled from C/C++ to JavaScript, so it does indeed make some sense to be able to perform this operation quickly. However real world web pages will probably not care whether an engine can execute bitwise and in a loop 2x faster than another engine. But staring at this code for another couple of seconds, you’ll probably notice that `bitwiseAndValue` will be `0` after the first loop iteration and will remain `0` for the next 599999 iterations. So once you get this to good performance, i.e. anything below 5ms on decent hardware, you can start gaming this benchmark by trying to recognize that only the first iteration of the loop is necessary, while the remaining iterations are a waste of time (i.e. dead code after [loop peeling][41]). This needs some machinery in JavaScript to perform this transformation, i.e. you need to check that `bitwiseAndValue` is either a regular property of the global object or not present before you execute the script, there must be no interceptor on the global object or it’s prototypes, etc., but if you really want to win this benchmark, and you are willing to go all in, then you can execute this test in less than 1ms. However this optimization would be limited to this special case, and slight modifications of the test would probably no longer trigger it.
|
||||
@ -50,7 +52,7 @@ There are a couple of algorithms that need fast bitwise and, especially in the a
|
||||
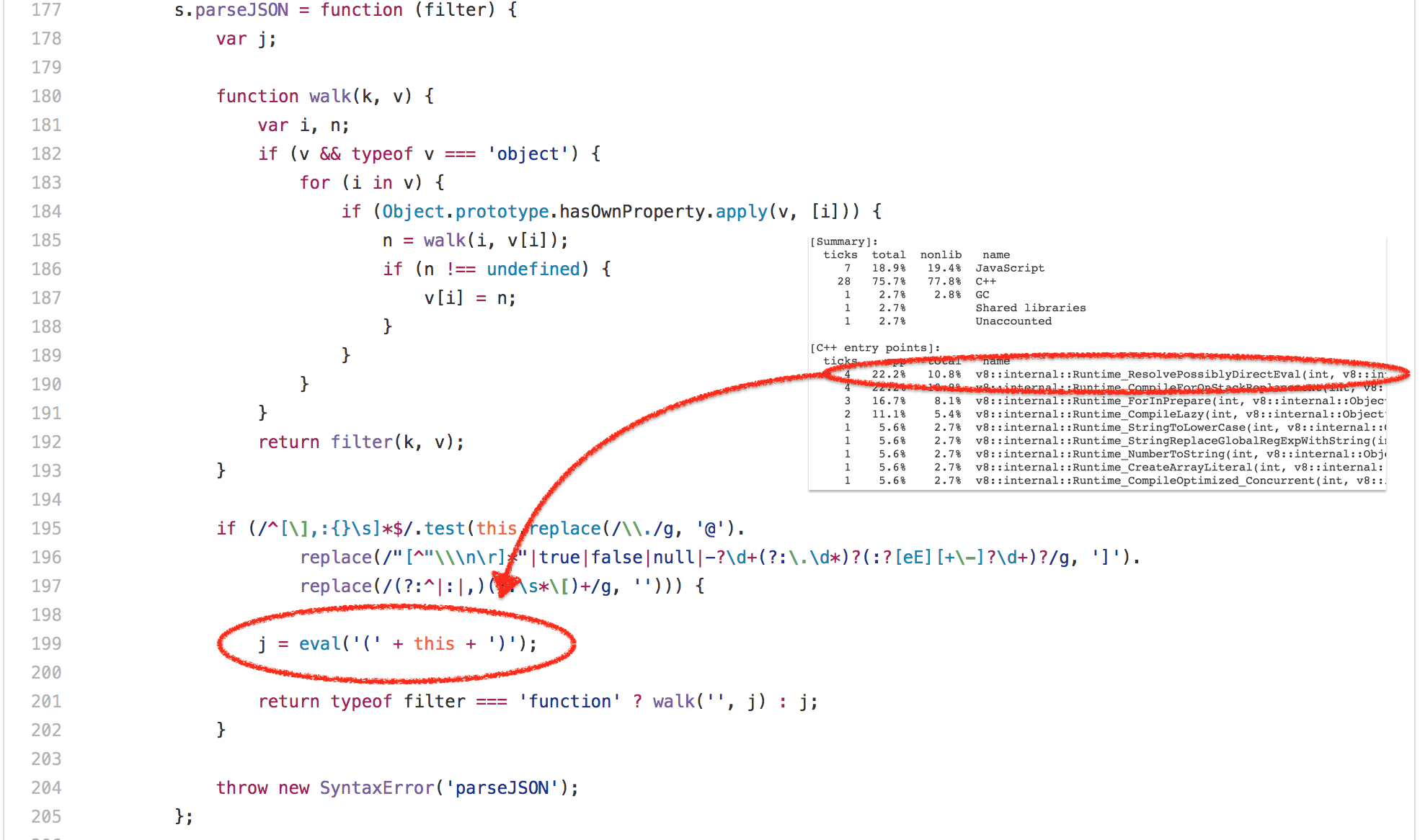
Ok, so that [`bitops-bitwise-and.js`][42] test was definitely the worst example of a micro-benchmark. Let’s move on to something more real worldish in SunSpider, the [`string-tagcloud.js`][43] test, which essentially runs a very early version of the `json.js` polyfill. The test arguably looks a lot more reasonable that the bitwise and test, but looking at the profile of the benchmark for some time immediately reveals that a lot of time is spent on a single `eval` expression (up to 20% of the overall execution time for parsing and compiling plus up to 10% for actually executing the compiled code):
|
||||
|
||||
[
|
||||
|
||||

|
||||
][44]
|
||||
|
||||
Looking closer reveals that this `eval` is executed exactly once, and is passed a JSONish string, that contains an array of 2501 objects with `tag` and `popularity` fields:
|
||||
@ -118,7 +120,7 @@ $ node string-tagcloud.js
|
||||
Time (string-tagcloud): 26 ms.
|
||||
$ node -v
|
||||
v8.0.0-pre
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
This is a common problem with static benchmarks and performance test suites. Today noone would seriously use `eval` to parse JSON data (also for obvious security reaons, not only for the performance issues), but rather stick to [`JSON.parse`][46] for all code written in the last five years. In fact using `eval` to parse JSON would probably be considered a bug in production code today! So the engine writers effort of focusing on performance of newly written code is not reflected in this ancient benchmark, instead it would be beneficial to make `eval`unnecessarily ~~smart~~complex to win on `string-tagcloud.js`.
|
||||
@ -126,13 +128,13 @@ This is a common problem with static benchmarks and performance test suites. Tod
|
||||
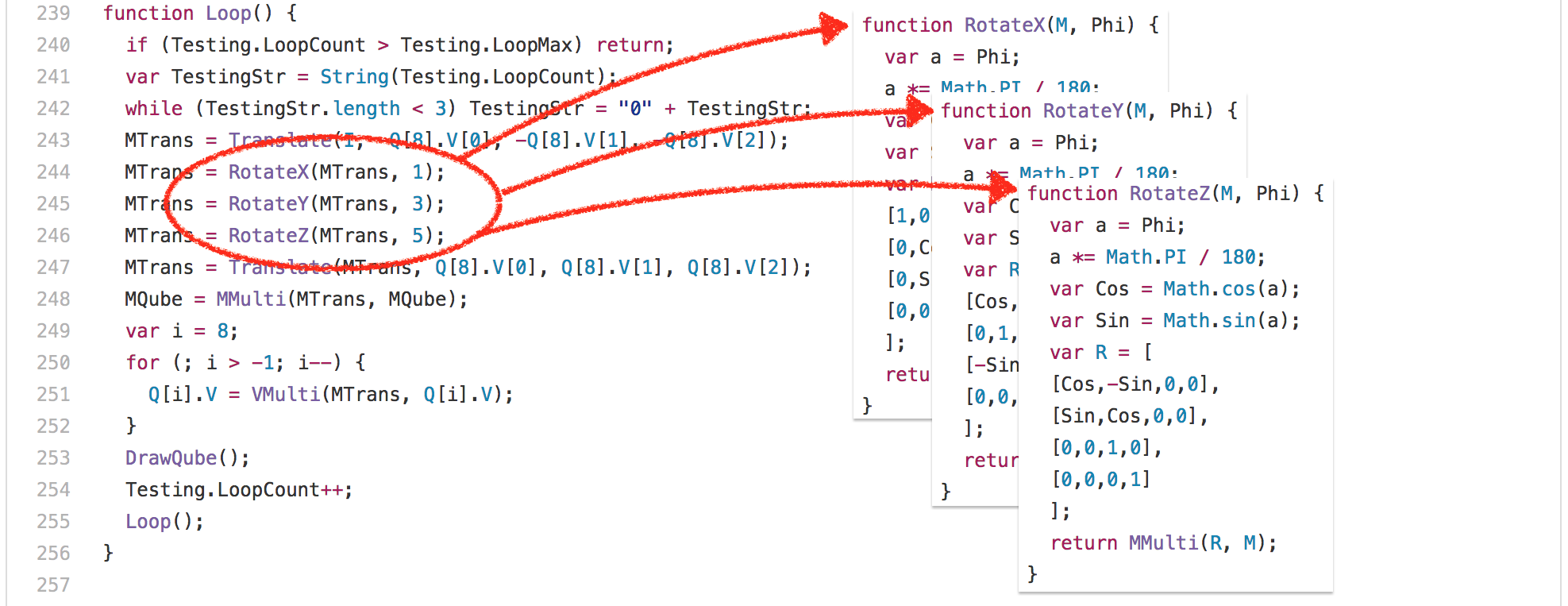
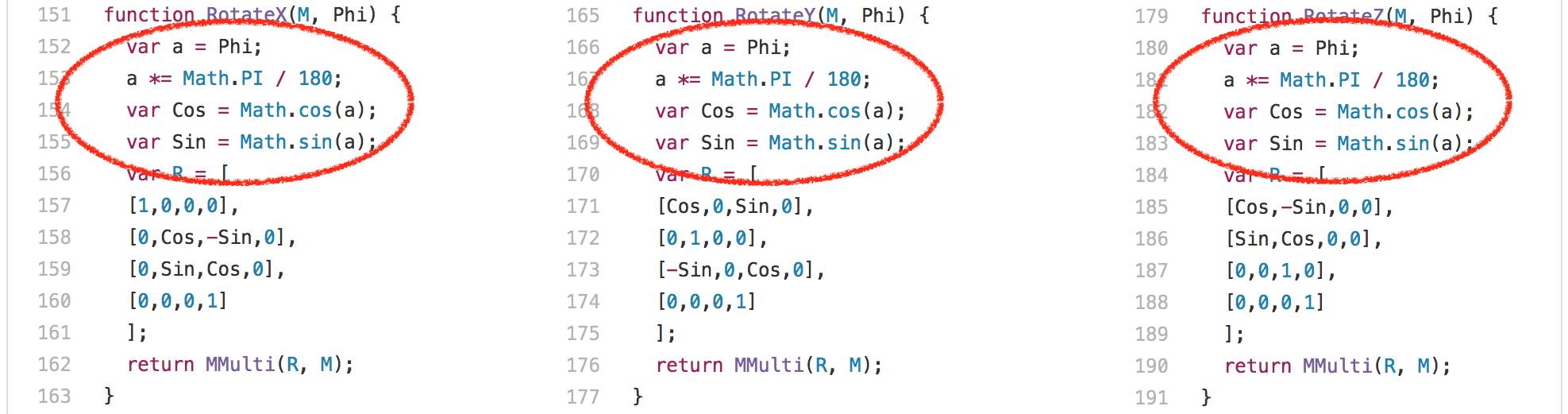
Ok, so let’s look at yet another example: the [`3d-cube.js`][47]. This benchmark does a lot of matrix operations, where even the smartest compiler can’t do a lot about it, but just has to execute it. Essentially the benchmark spends a lot of time executing the `Loop` function and functions called by it.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][48]
|
||||
|
||||
One interesting observation here is that the `RotateX`, `RotateY` and `RotateZ` functions are always called with the same constant parameter `Phi`.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][49]
|
||||
|
||||
This means that we basically always compute the same values for [`Math.sin`][50] and [`Math.cos`][51], 204 times each. There are only three different inputs,
|
||||
@ -144,7 +146,7 @@ This means that we basically always compute the same values for [`Math.sin`][50
|
||||
obviously. So, one thing you could do here to avoid recomputing the same sine and cosine values all the time is to cache the previously computed values, and in fact, that’s what V8 used to do in the past, and other engines like SpiderMonkey still do. We removed the so-called _transcendental cache_ from V8 because the overhead of the cache was noticable in actual workloads where you don’t always compute the same values in a row, which is unsurprisingly very common in the wild. We took serious hits on the SunSpider benchmark when we removed this benchmark specific optimizations back in 2013 and 2014, but we totally believe that it doesn’t make sense to optimize for a benchmark while at the same time penalizing the real world use case in such a way.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][52]
|
||||
|
||||
|
||||
@ -155,7 +157,7 @@ Obviously a better way to deal with the constant sine/cosine inputs is a sane in
|
||||
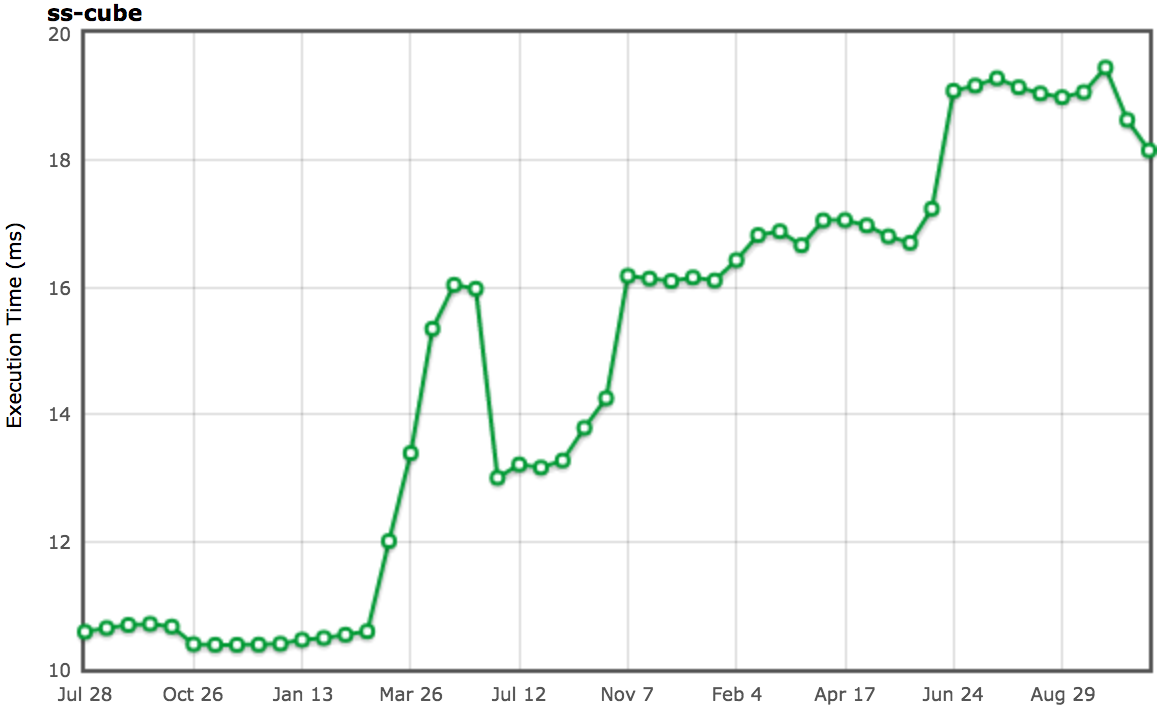
Besides these very test specific issues, there’s another fundamental problem with the SunSpider benchmark: The overall execution time. V8 on decent Intel hardware runs the whole benchmark in roughly 200ms currently (with the default configuration). A minor GC can take anything between 1ms and 25ms currently (depending on live objects in new space and old space fragmentation), while a major GC pause can easily take 30ms (not even taking into account the overhead from incremental marking), that’s more than 10% of the overall execution time of the whole SunSpider suite! So any engine that doesn’t want to risk a 10-20% slowdown due to a GC cycle has to somehow ensure it doesn’t trigger GC while running SunSpider.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][54]
|
||||
|
||||
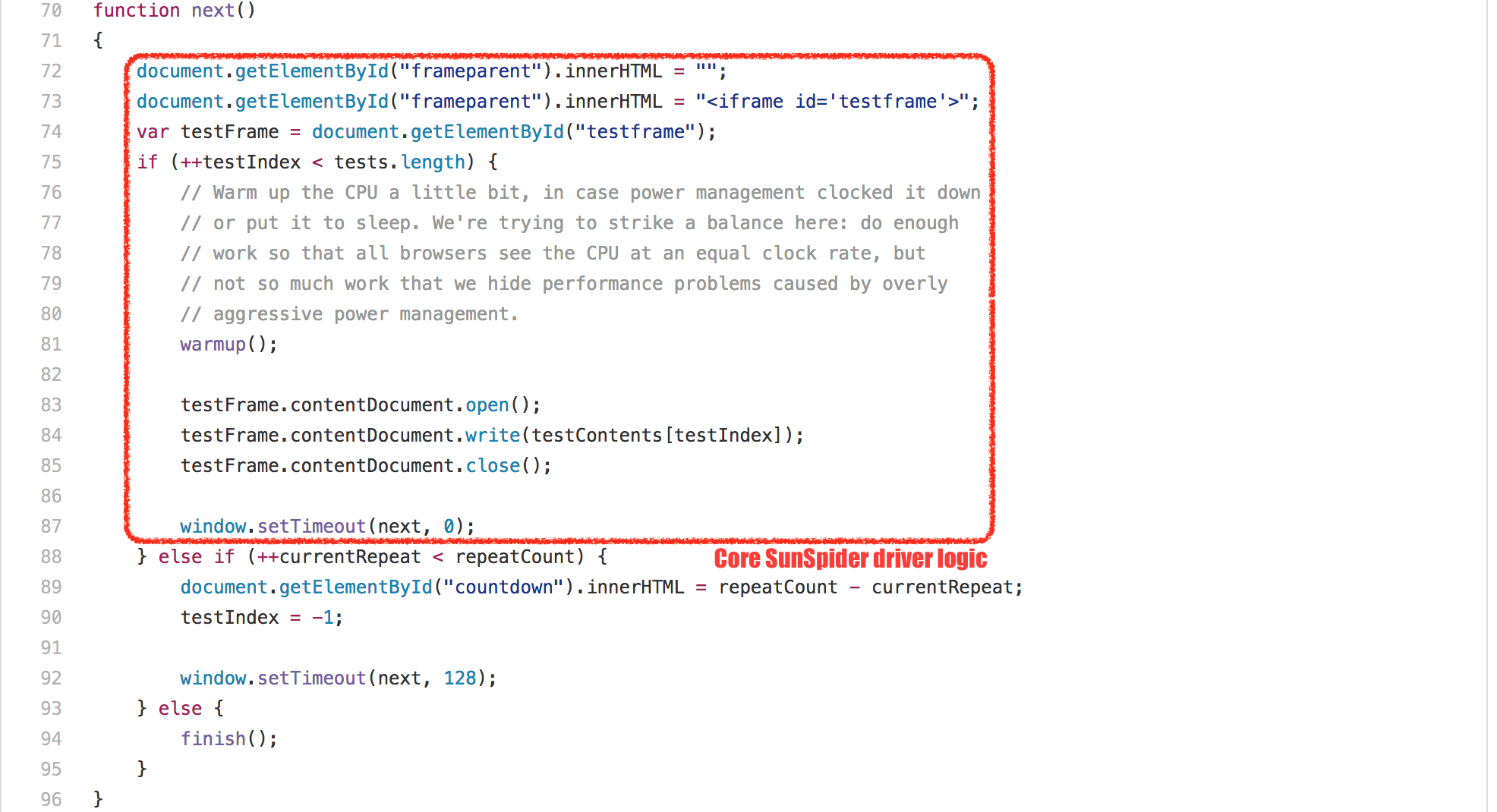
There are different tricks to accomplish this, none of which has any positive impact in real world as far as I can tell. V8 uses a rather simple trick: Since every SunSpider test is run in a new `<iframe>`, which corresponds to a new _native context_ in V8 speak, we just detect rapid `<iframe>` creation and disposal (all SunSpider tests take less than 50ms each), and in that case perform a garbage collection between the disposal and creation, to ensure that we never trigger a GC while actually running a test. This trick works pretty well, and in 99.9% of the cases doesn’t clash with real uses; except every now and then, it can hit you hard if for whatever reason you do something that makes you look like you are the SunSpider test driver to V8, then you can get hit hard by forced GCs, and that can have a negative effect on your application. So rule of thumb: **Don’t let your application look like SunSpider!**
|
||||
@ -163,7 +165,7 @@ There are different tricks to accomplish this, none of which has any positive im
|
||||
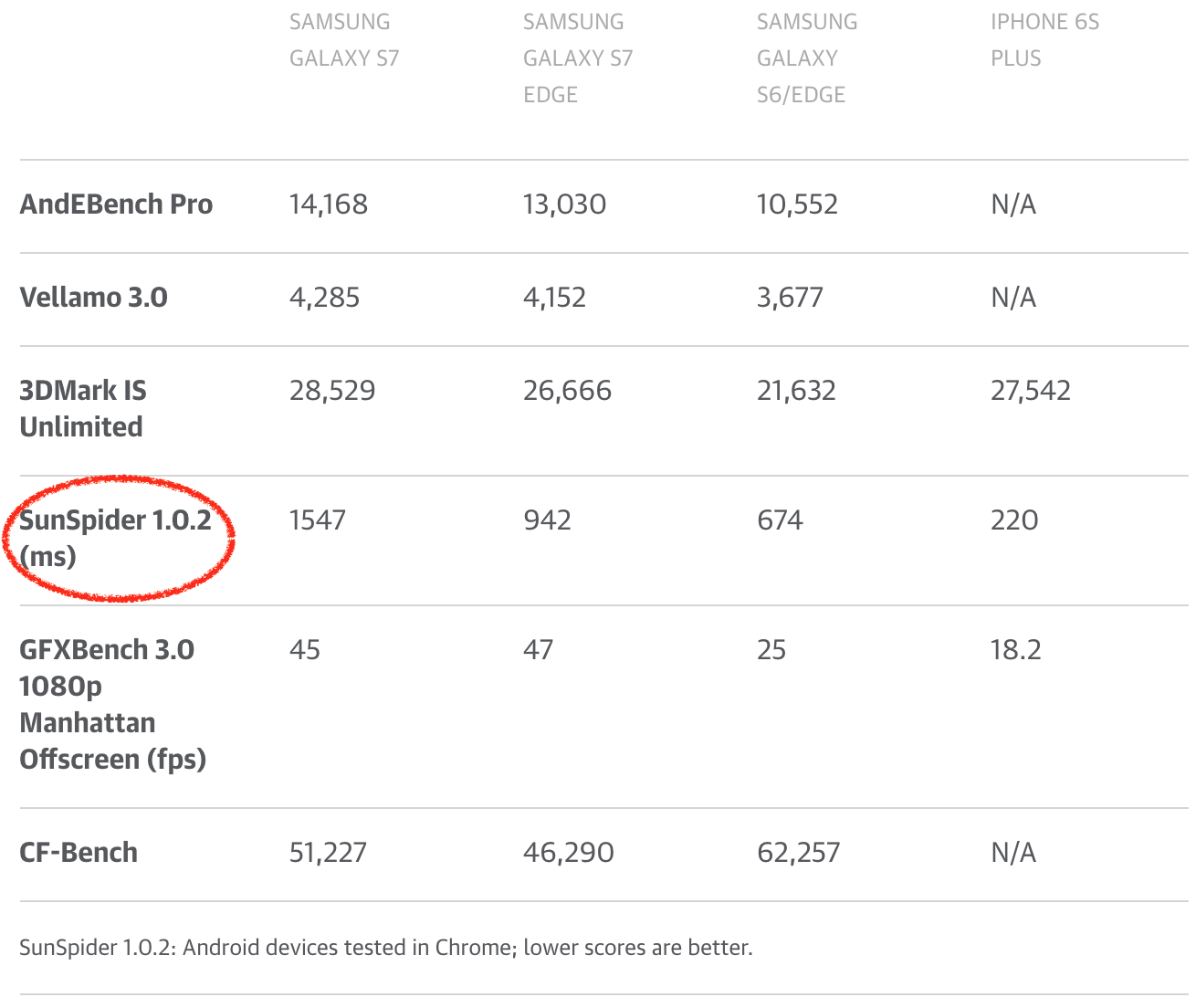
I could go on with more SunSpider examples here, but I don’t think that’d be very useful. By now it should be clear that optimizing further for SunSpider above the threshold of good performance will not reflect any benefits in real world. In fact the world would probably benefit a lot from not having SunSpider any more, as engines could drop weird hacks that are only useful for SunSpider and can even hurt real world use cases. Unfortunately SunSpider is still being used heavily by the (tech) press to compare what they think is browser performance, or even worse compare phones! So there’s a certain natural interest from phone makers and also from Android in general to have Chrome look somewhat decent on SunSpider (and other nowadays meaningless benchmarks FWIW). The phone makers generate money by selling phones, so getting good reviews is crucial for the success of the phone division or even the whole company, and some of them even went as far as shipping old versions of V8 in their phones that had a higher score on SunSpider, exposing their users to all kinds of unpatched security holes that had long been fixed, and shielding their users from any real world performance benefits that come with more recent V8 versions!
|
||||
|
||||
[
|
||||
|
||||

|
||||
][55]
|
||||
|
||||
|
||||
@ -172,7 +174,7 @@ If we as the JavaScript community really want to be serious about real world per
|
||||
### Cuteness break!
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
I always loved this in [Myles Borins][57]’ talks, so I had to shamelessly steal his idea. So now that we recovered from the SunSpider rant, let’s go on to check the other classic benchmarks…
|
||||
@ -182,19 +184,19 @@ I always loved this in [Myles Borins][57]’ talks, so I had to shamelessly ste
|
||||
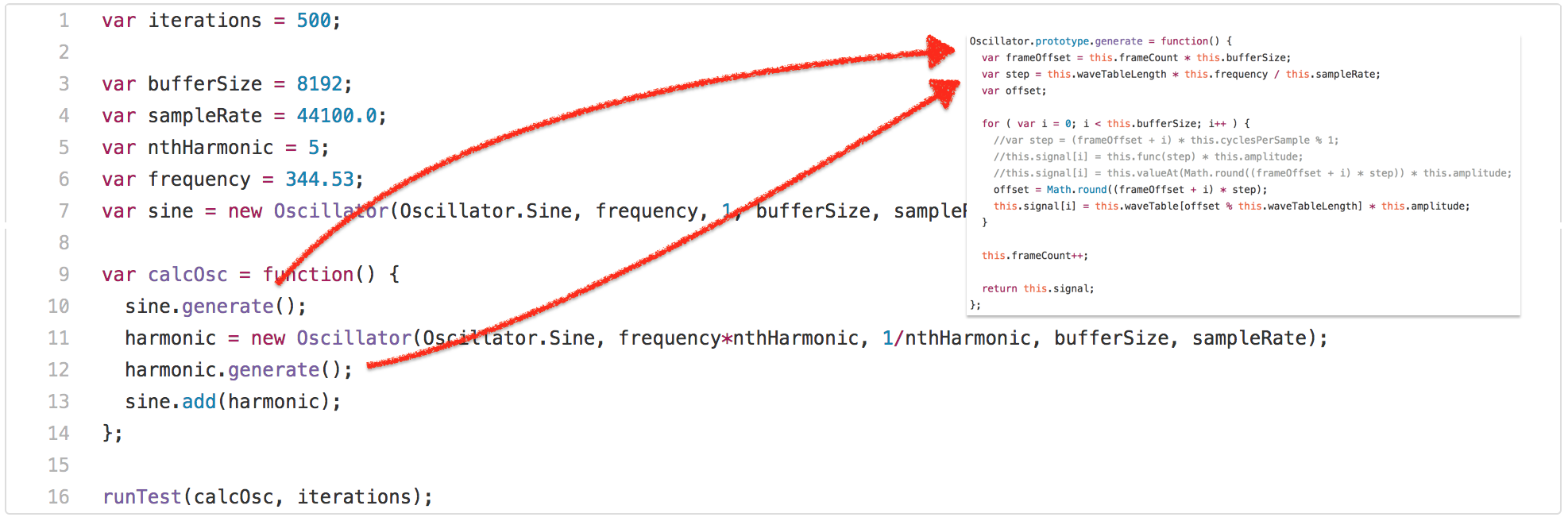
The Kraken benchmark was [released by Mozilla in September 2010][58], and it was said to contain snippets/kernels of real world applications, and be less of a micro-benchmark compared to SunSpider. I don’t want to spend too much time on Kraken, because I think it wasn’t as influential on JavaScript performance as SunSpider and Octane, so I’ll highlight one particular example from the [`audio-oscillator.js`][59] test.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][60]
|
||||
|
||||
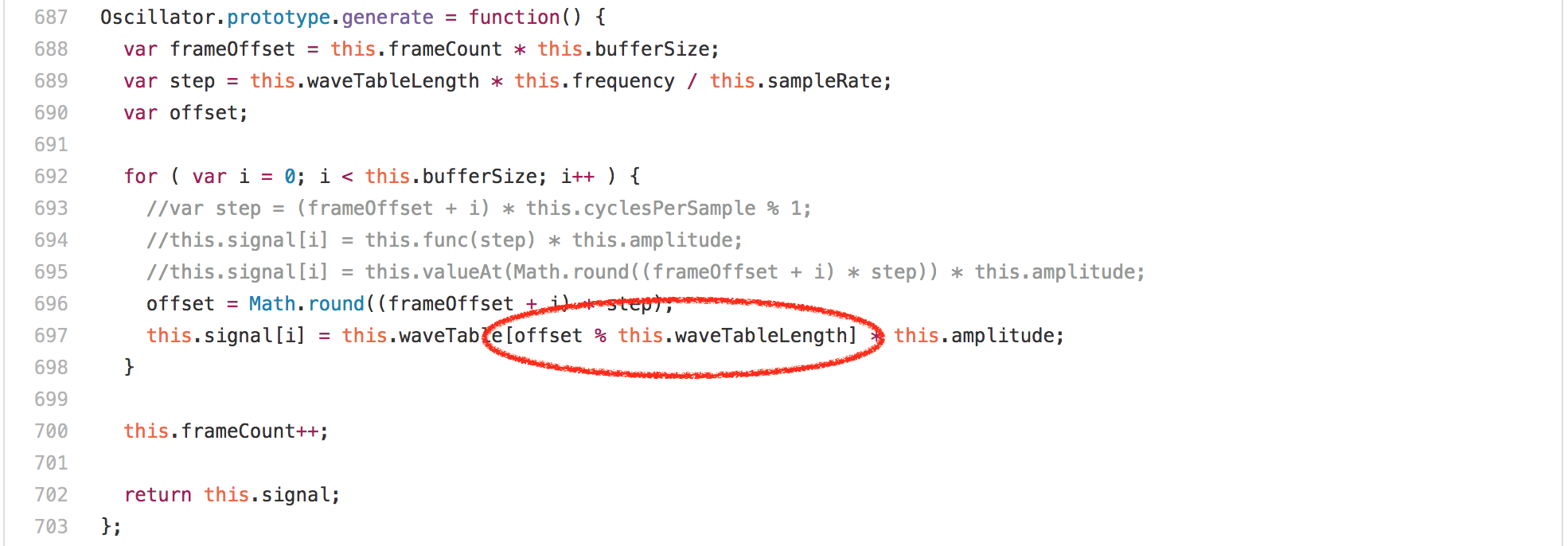
So the test invokes the `calcOsc` function 500 times. `calcOsc` first calls `generate` on the global `sine``Oscillator`, then creates a new `Oscillator`, calls `generate` on that and adds it to the global `sine` oscillator. Without going into detail why the test is doing this, let’s have a look at the `generate` method on the `Oscillator` prototype.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][61]
|
||||
|
||||
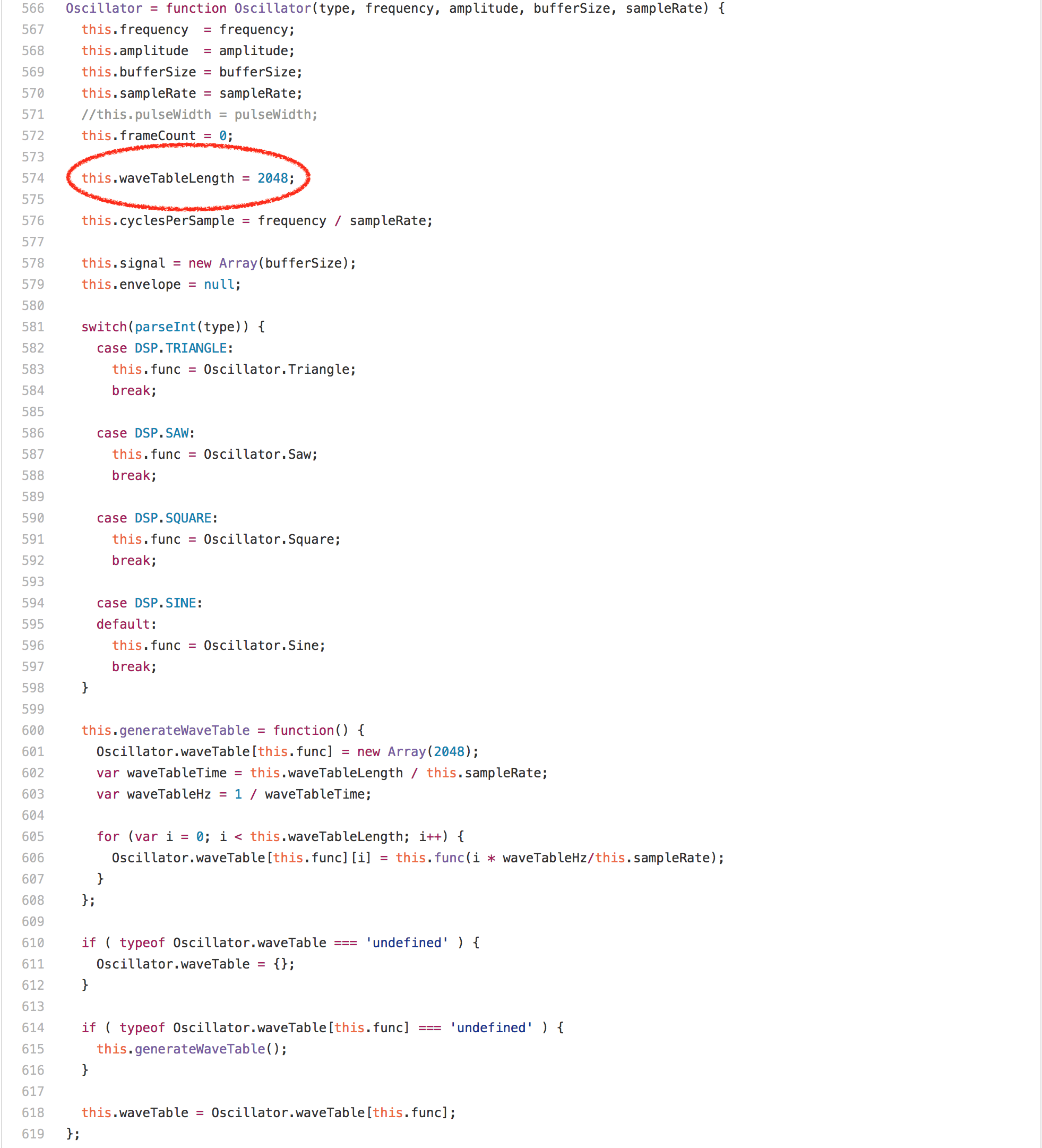
Looking at the code, you’d expect this to be dominated by the array accesses or the multiplications or the[`Math.round`][62] calls in the loop, but surprisingly what’s completely dominating the runtime of `Oscillator.prototype.generate` is the `offset % this.waveTableLength` expression. Running this benchmark in a profiler on any Intel machine reveals that more than 20% of the ticks are attributed to the `idiv`instruction that we generate for the modulus. One interesting observation however is that the `waveTableLength` field of the `Oscillator` instances always contains the same value 2048, as it’s only assigned once in the `Oscillator` constructor.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][63]
|
||||
|
||||
If we know that the right hand side of an integer modulus operation is a power of two, we can generate [way better code][64] obviously and completely avoid the `idiv` instruction on Intel. So what we needed was a way to get the information that `this.waveTableLength` is always 2048 from the `Oscillator` constructor to the modulus operation in `Oscillator.prototype.generate`. One obvious way would be to try to rely on inlining of everything into the `calcOsc` function and let load/store elimination do the constant propagation for us, but this would not work for the `sine` oscillator, which is allocated outside the `calcOsc` function.
|
||||
@ -206,7 +208,7 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
[...SNIP...]
|
||||
[BinaryOpIC(MOD:None*None->None) => (MOD:Smi*2048->Smi) @ ~Oscillator.generate+598 at audio-oscillator.js:697]
|
||||
[...SNIP...]
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
shows that the `BinaryOpIC` is picking up the proper constant feedback for the right hand side of the modulus, and properly tracks that the left hand side was always a small integer (a `Smi` in V8 speak), and we also always produced a small integer result. Looking at the generated code using `--print-opt-code --code-comments` quickly reveals that Crankshaft utilizes the feedback to generate an efficient code sequence for the integer modulus in `Oscillator.prototype.generate`:
|
||||
@ -261,7 +263,7 @@ $ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
|
||||
Time (audio-oscillator-once): 64 ms.
|
||||
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js
|
||||
Time (audio-oscillator-once): 81 ms.
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
This is an example for a pretty terrible performance cliff: Let’s say a developer writes code for a library and does careful tweaking and optimizations using certain sample input values, and the performance is decent. Now a user starts using that library reading through the performance notes, but somehow falls off the performance cliff, because she/he is using the library in a slightly different way, i.e. somehow polluting type feedback for a certain `BinaryOpIC`, and is hit by a 20% slowdown (compared to the measurements of the library author) that neither the library author nor the user can explain, and that seems rather arbitrary.
|
||||
@ -292,7 +294,7 @@ $ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
|
||||
Time (audio-oscillator-once): 69 ms.
|
||||
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js
|
||||
Time (audio-oscillator-once): 69 ms.
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
The problem with benchmarks and over-specialization is that the benchmark can give you hints where to look and what to do, but it doesn’t tell you how far you have to go and doesn’t protect the optimization properly. For example, all JavaScript engines use benchmarks as a way to guard against performance regressions, but running Kraken for example wouldn’t protect the general approach that we have in TurboFan, i.e. we could _degrade_ the modulus optimization in TurboFan to the over-specialized version of Crankshaft and the benchmark wouldn’t tell us that we regressed, because from the point of view of the benchmark it’s fine! Now you could extend the benchmark, maybe in the same way that I did above, and try to cover everything with benchmarks, which is what engine implementors do to a certain extent, but that approach doesn’t scale arbitrarily. Even though benchmarks are convenient and easy to use for communication and competition, you’ll also need to leave space for common sense, otherwise over-specialization will dominate everything and you’ll have a really, really fine line of acceptable performance and big performance cliffs.
|
||||
@ -361,7 +363,7 @@ function(t) {
|
||||
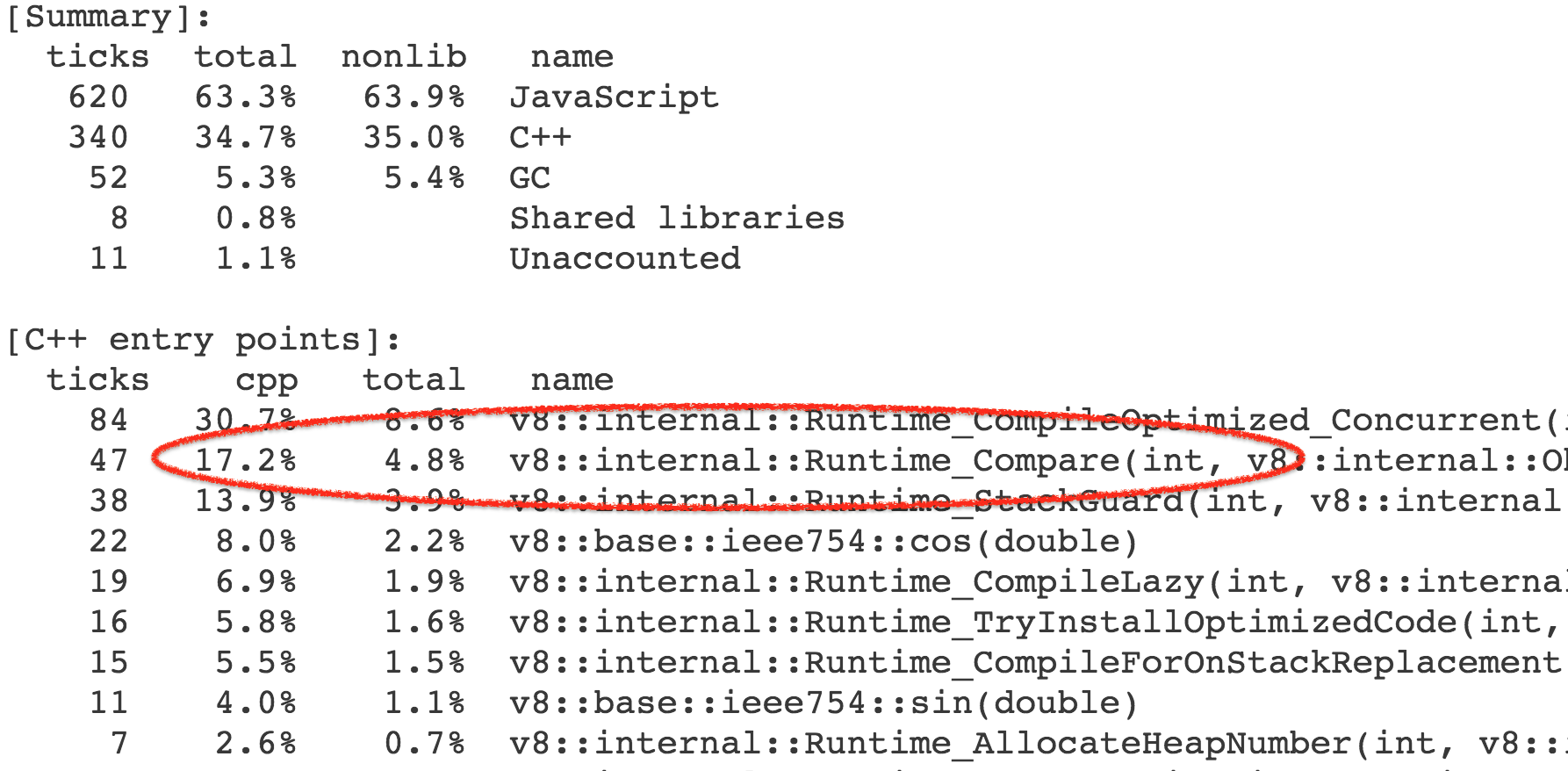
More precisely the time is not spent in this function itself, but rather operations and builtin library functions triggered by this. As it turned out we spent 4-7% of the overall execution time of the benchmark calling into the [`Compare` runtime function][76], which implements the general case for the [abstract relational comparison][77].
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Almost all the calls to the runtime function came from the [`CompareICStub`][78], which is used for the two relational comparisons in the inner function:
|
||||
@ -408,7 +410,7 @@ $ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
|
||||
Score (Box2D): 48063
|
||||
$ ~/Projects/v8/out/Release/d8 octane-box2d.js
|
||||
Score (Box2D): 55359
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
So how did we do that? As it turned out we already had a mechanism for tracking the shape of objects that are being compared in the `CompareIC`, the so-called _known receiver_ map tracking (where _map_ is V8 speak for object shape+prototype), but that was limited to abstract and strict equality comparisons. But I could easily extend the tracking to also collect the feedback for abstract relational comparison:
|
||||
@ -419,18 +421,18 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
[CompareIC in ~+557 at octane-box2d.js:2024 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#LT @ 0x1d5a860493a1]
|
||||
[CompareIC in ~+649 at octane-box2d.js:2025 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#GTE @ 0x1d5a860496e1]
|
||||
[...SNIP...]
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
Here the `CompareIC` used in the baseline code tells us that for the LT (less than) and the GTE (greather than or equal) comparisons in the function we’re looking at, it had only seen `RECEIVER`s so far (which is V8 speak for JavaScript objects), and all these receivers had the same map `0x1d5a860493a1`, which corresponds to the map of `L` instances. So in optimized code, we can constant-fold these operations to `false` and `true`respectively as long as we know that both sides of the comparison are instances with the map `0x1d5a860493a1` and noone messed with `L`s prototype chain, i.e. the `Symbol.toPrimitive`, `"valueOf"` and `"toString"` methods are the default ones, and noone installed a `Symbol.toStringTag` accessor property. The rest of the story is _black voodoo magic_ in Crankshaft, with a lot of cursing and initially forgetting to check `Symbol.toStringTag` properly:
|
||||
|
||||
[
|
||||
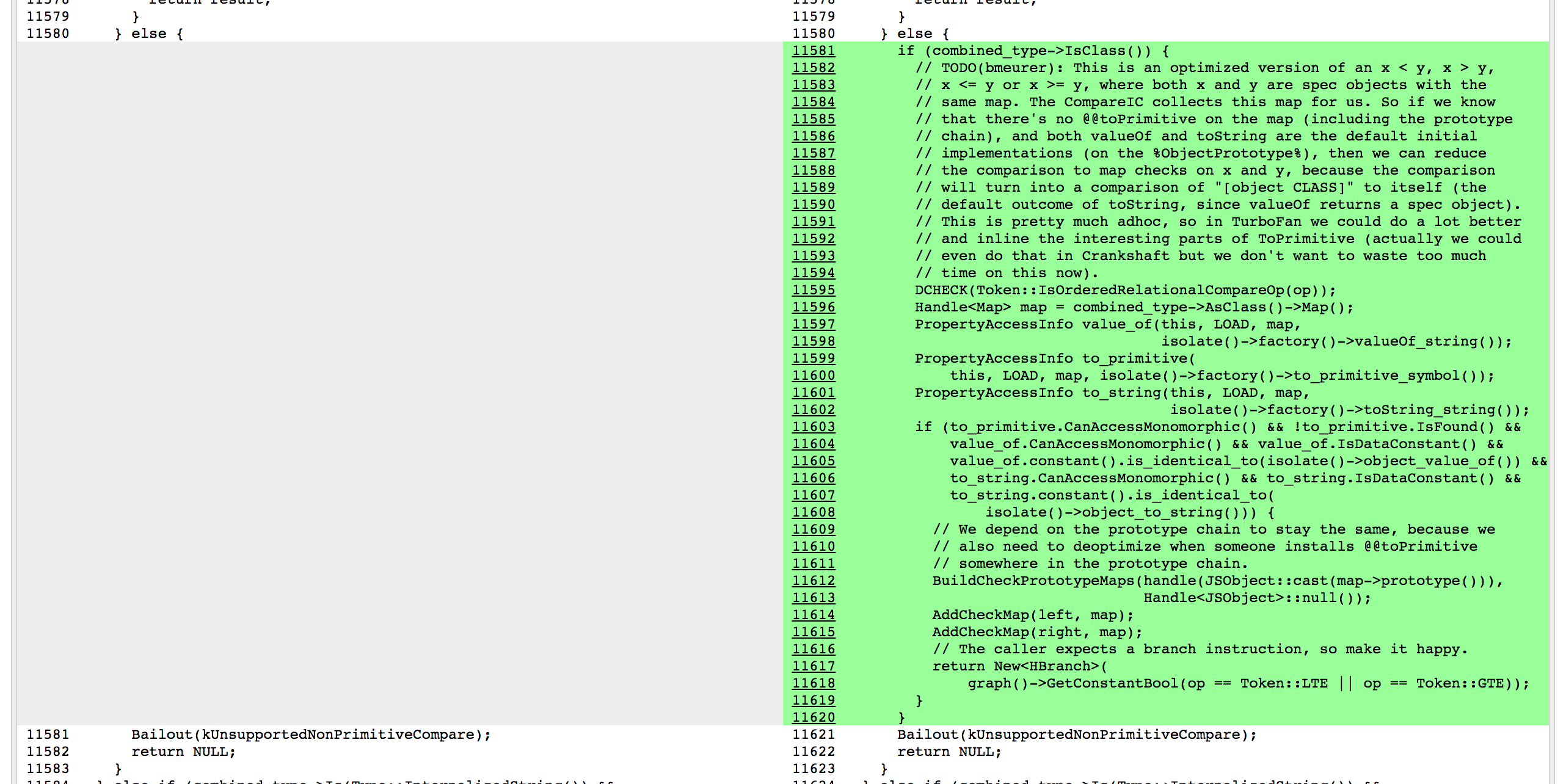
|
||||

|
||||
][80]
|
||||
|
||||
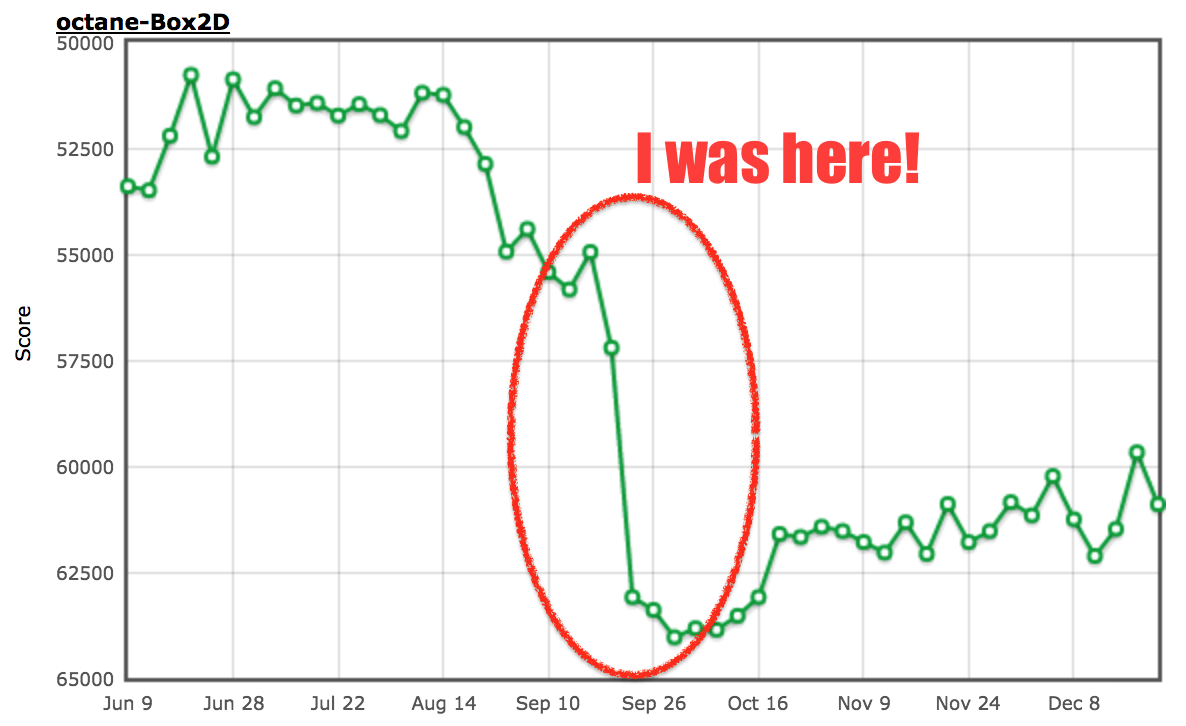
And in the end there was a rather huge performance boost on this particular benchmark:
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
To my defense, back then I was not convinced that this particular behavior would always point to a bug in the original code, so I was even expecting that code in the wild might hit this case fairly often, also because I was assuming that JavaScript developers wouldn’t always care about these kinds of potential bugs. However, I was so wrong, and here I stand corrected! I have to admit that this particular optimization is purely a benchmark thing, and will not help any real code (unless the code is written to benefit from this optimization, but then you could as well write `true` or `false` directly in your code instead of using an always-constant relational comparison). You might wonder why we slightly regressed soon after my patch. That was the period where we threw the whole team at implementing ES2015, which was really a dance with the devil to get all the new stuff in (ES2015 is a monster!) without seriously regressing the traditional benchmarks.
|
||||
@ -438,13 +440,13 @@ To my defense, back then I was not convinced that this particular behavior would
|
||||
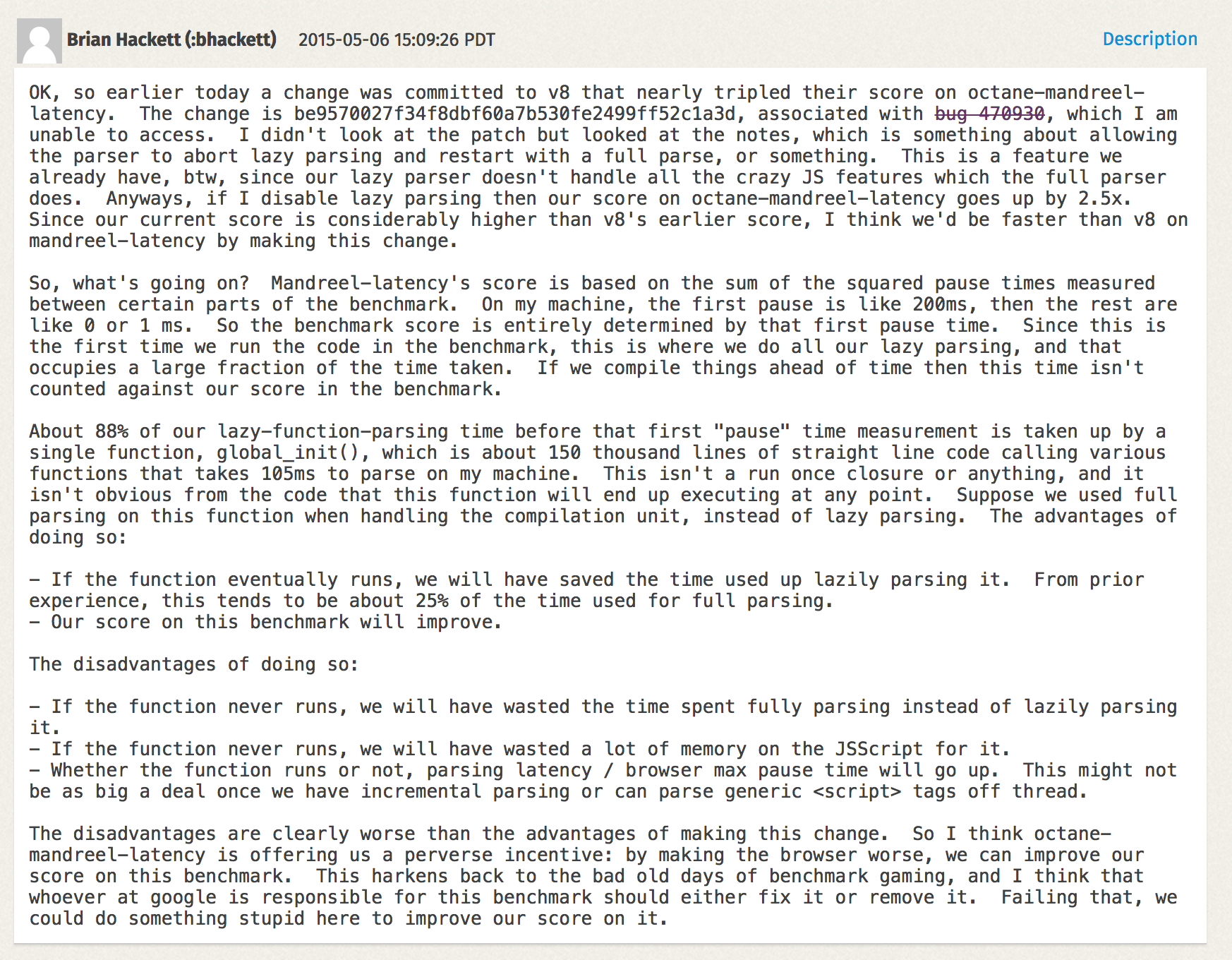
Enough said about Box2D, let’s have a look at the Mandreel benchmark. Mandreel was a compiler for compiling C/C++ code to JavaScript, it didn’t use the [asm.js][81] subset of JavaScript that is being used by the more recent [Emscripten][82] compiler, and has been deprecated (and more or less disappeared from the internet) since roughly three years now. Nevertheless, Octane still has a version of the [Bullet physics engine][83] compiled via [Mandreel][84]. An interesting test here is the MandreelLatency test, which instruments the Mandreel benchmark with frequent time measurement checkpoints. The idea here was that since Mandreel stresses the VM’s compiler, this test provides an indication of the latency introduced by the compiler, and long pauses between measurement checkpoints lower the final score. In theory that sounds very reasonable, and it does indeed make some sense. However as usual vendors figured out ways to cheat on this benchmark.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][85]
|
||||
|
||||
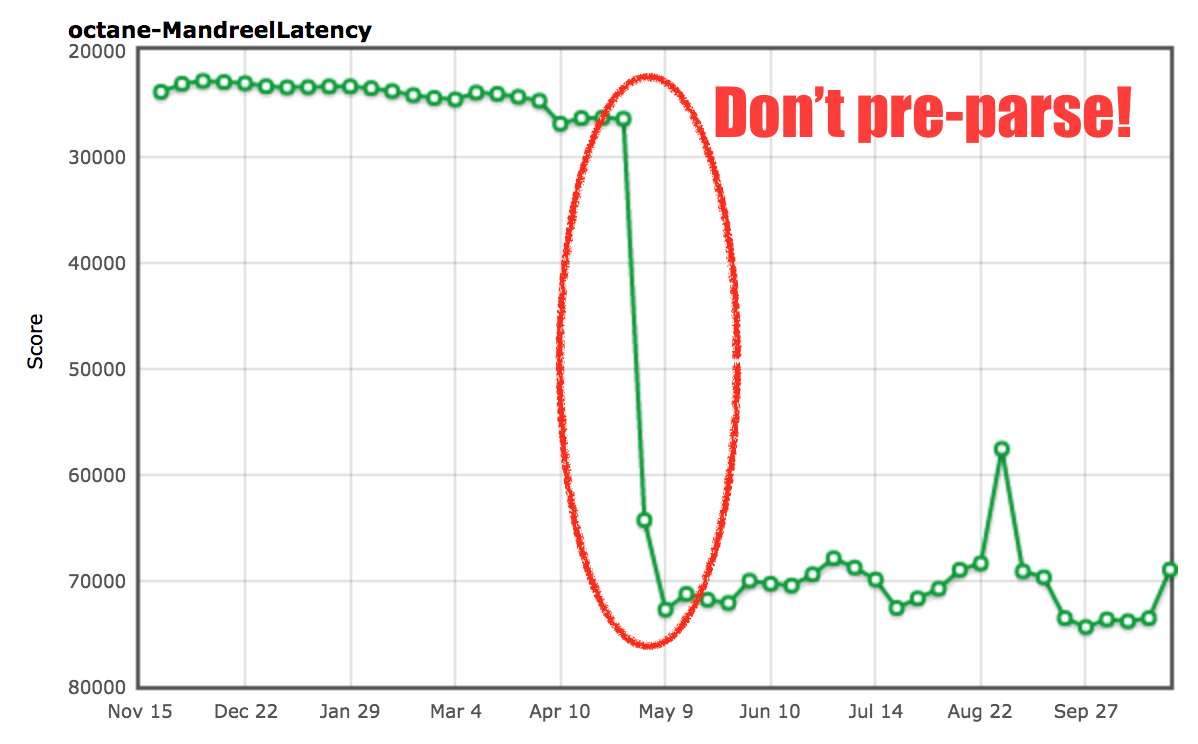
Mandreel contains a huge initialization function `global_init` that takes an incredible amount of time just parsing this function, and generating baseline code for it. Since engines usually parse various functions in scripts multiple times, one so-called pre-parse step to discover functions inside the script, and then as the function is invoked for the first time a full parse step to actually generate baseline code (or bytecode) for the function. This is called [_lazy parsing_][86] in V8 speak. V8 has some heuristics in place to detect functions that are invoked immediately where pre-parsing is actually a waste of time, but that’s not clear for the `global_init`function in the Mandreel benchmark, thus we’d would have an incredible long pause for pre-parsing + parsing + compiling the big function. So we [added an additional heuristic][87] that would also avoids the pre-parsing for this `global_init` function.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][88]
|
||||
|
||||
So we saw an almost 200% improvement just by detecting `global_init` and avoiding the expensive pre-parse step. We are somewhat certain that this should not negatively impact real world use cases, but there’s no guarantee that this won’t bite you on large functions where pre-parsing would be beneficial (because they aren’t immediately executed).
|
||||
@ -452,7 +454,7 @@ So we saw an almost 200% improvement just by detecting `global_init` and avoid
|
||||
So let’s look into another slightly less controversial benchmark: the [`splay.js`][89] test, which is meant to be a data manipulation benchmark that deals with splay trees and exercises the automatic memory management subsystem (aka the garbage collector). It comes bundled with a latency test that instruments the Splay code with frequent measurement checkpoints, where a long pause between checkpoints is an indication of high latency in the garbage collector. This test measures the frequency of latency pauses, classifies them into buckets and penalizes frequent long pauses with a low score. Sounds great! No GC pauses, no jank. So much for the theory. Let’s have a look at the benchmark, here’s what’s at the core of the whole splay tree business:
|
||||
|
||||
[
|
||||

|
||||

|
||||
][90]
|
||||
|
||||
This is the core of the splay tree construction, and despite what you might think looking at the full benchmark, this is more or less all that matters for the SplayLatency score. How come? Actually what the benchmark does is to construct huge splay trees, so that the majority of nodes survive, thus making it to old space. With a generational garbage collector like the one in V8 this is super expensive if a program violates the [generational hypothesis][91] leading to extreme pause times for essentially evacuating everything from new space to old space. Running V8 in the old configuration clearly shows this problem:
|
||||
@ -535,7 +537,7 @@ $ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||
[20872:0x7f26f24c70d0] 2105 ms: Scavenge 225.8 (305.0) -> 225.4 (305.0) MB, 24.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 2138 ms: Scavenge 234.8 (305.0) -> 234.4 (305.0) MB, 23.1 / 0.0 ms allocation failure
|
||||
[...SNIP...]
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
So the key observation here is that allocating the splay tree nodes in old space directly would avoid essentially all the overhead of copying objects around and reduce the number of minor GC cycles to the bare minimum (thereby reducing the pauses caused by the GC). So we came up with a mechanism called [_Allocation Site Pretenuring_][92] that would try to dynamically gather feedback at allocation sites when run in baseline code to decide whether a certain percent of the objects allocated here survives, and if so instrument the optimized code to allocate objects in old space directly - i.e. _pretenure the objects_.
|
||||
@ -562,13 +564,13 @@ $ out/Release/d8 --trace-gc octane-splay.js
|
||||
[20885:0x7ff4d7c220a0] 1828 ms: Mark-sweep 485.2 (520.0) -> 101.5 (519.5) MB, 3.4 / 0.0 ms (+ 102.8 ms in 58 steps since start of marking, biggest step 4.5 ms, walltime since start of marking 183 ms) finalize incremental marking via stack guard GC in old space requested
|
||||
[20885:0x7ff4d7c220a0] 2028 ms: Scavenge 371.4 (519.5) -> 358.5 (519.5) MB, 12.1 / 0.0 ms allocation failure
|
||||
[...SNIP...]
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
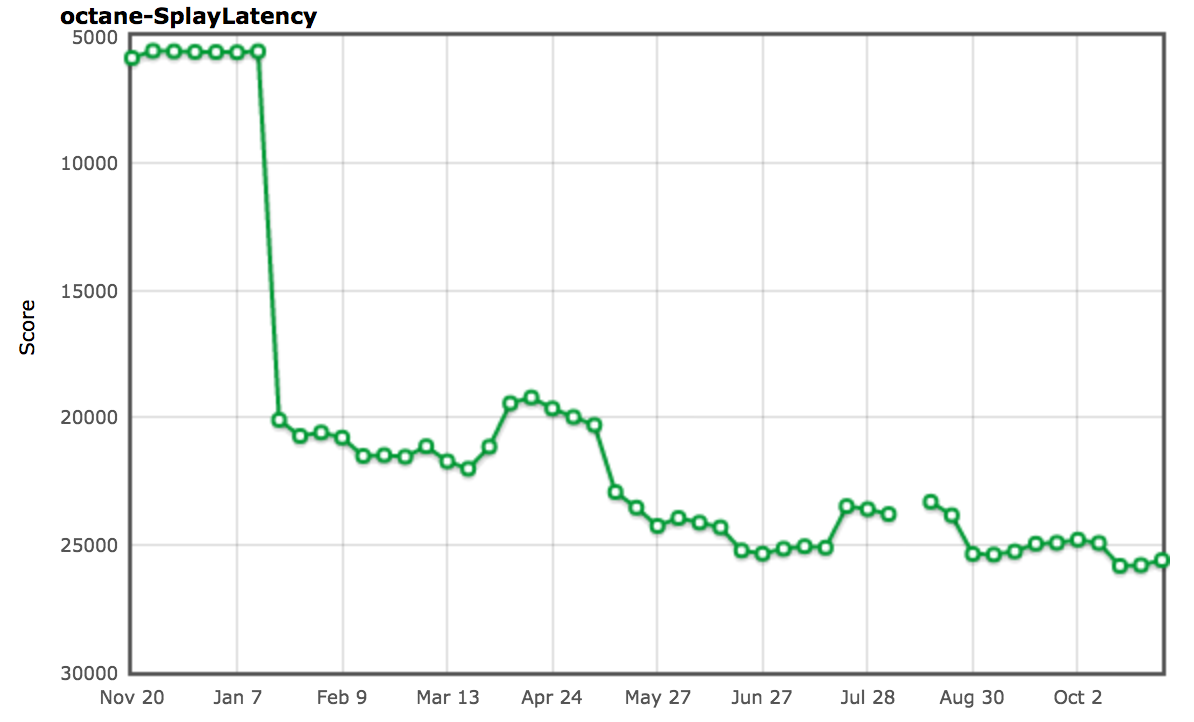
And indeed that essentially fixed the problem for the SplayLatency benchmark completely and boosted our score by over 250%!
|
||||
|
||||
[
|
||||
|
||||

|
||||
][93]
|
||||
|
||||
As mentioned in the [SIGPLAN paper][94] we had good reasons to believe that allocation site pretenuring might be a win for real world applications, and were really looking forward to seeing improvements and extending the mechanism to cover more than just object and array literals. But it didn’t take [long][95] [to][96] [realize][97] that allocation site pretenuring can have a pretty serious negative impact on real world application performance. We actually got a lot of negative press, including a shit storm from Ember.js developers and users, not only because of allocation site pretenuring, but that was big part of the story.
|
||||
@ -590,13 +592,13 @@ Ok, I think that should be sufficient to underline the point. I could go on poin
|
||||
I hope it should be clear by now why benchmarks are generally a good idea, but are only useful to a certain level, and once you cross the line of _useful competition_, you’ll start wasting the time of your engineers or even start hurting your real world performance! If we are serious about performance for the web, we need to start judging browser by real world performance and not their ability to game four year old benchmarks. We need to start educating the (tech) press, or failing that, at least ignore them.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][99]
|
||||
|
||||
Noone is afraid of competition, but gaming potentially broken benchmarks is not really useful investment of engineering time. We can do a lot more, and take JavaScript to the next level. Let’s work on meaningful performance tests that can drive competition on areas of interest for the end user and the developer. Additionally let’s also drive meaningful improvements for server and tooling side code running in Node.js (either on V8 or ChakraCore)!
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
One closing comment: Don’t use traditional JavaScript benchmarks to compare phones. It’s really the most useless thing you can do, as the JavaScript performance often depends a lot on the software and not necessarily on the hardware, and Chrome ships a new version every six weeks, so whatever you measure in March maybe irrelevant already in April. And if there’s no way to avoid running something in a browser that assigns a number to a phone, then at least use a recent full browser benchmark that has at least something to do with what people will do with their browsers, i.e. consider [Speedometer benchmark][100].
|
||||
|
||||
Loading…
Reference in New Issue
Block a user