mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-22 00:40:10 +08:00
commit
ba4579d347
65
README.md
65
README.md
@ -59,41 +59,42 @@ LCTT 的组成
|
||||
* 2016/12/24 拟定 LCTT [Core 规则](core.md),并增加新的 Core 成员: ucasFL、martin2011qi,及调整一些组。
|
||||
* 2017/03/13 制作了 LCTT 主页、成员列表和成员主页,LCTT 主页将移动至 https://linux.cn/lctt 。
|
||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
||||
|
||||
活跃成员
|
||||
核心成员
|
||||
-------------------------------
|
||||
|
||||
目前 TP 活跃成员有:
|
||||
- Leader @wxy,
|
||||
- Source @oska874,
|
||||
- Proofreaders @jasminepeng,
|
||||
- CORE @geekpi,
|
||||
- CORE @GOLinux,
|
||||
- CORE @ictlyh,
|
||||
- CORE @strugglingyouth,
|
||||
- CORE @FSSlc,
|
||||
- CORE @zpl1025,
|
||||
- CORE @runningwater,
|
||||
- CORE @bazz2,
|
||||
- CORE @Vic020,
|
||||
- CORE @alim0x,
|
||||
- CORE @tinyeyeser,
|
||||
- CORE @Locez,
|
||||
- CORE @ucasFL,
|
||||
- CORE @martin2011qi,
|
||||
- CORE @GHLandy,
|
||||
- CORE @bestony,
|
||||
- CORE @rusking,
|
||||
- Senior @DeadFire,
|
||||
- Senior @reinoir222,
|
||||
- Senior @vito-L,
|
||||
- Senior @willqian,
|
||||
- Senior @vizv,
|
||||
- Senior @dongfengweixiao,
|
||||
- Senior @PurlingNayuki,
|
||||
- Senior @carolinewuyan,
|
||||
目前 LCTT 核心成员有:
|
||||
|
||||
- 组长 @wxy,
|
||||
- 选题 @oska874,
|
||||
- 校对 @jasminepeng,
|
||||
- 钻石译者 @geekpi,
|
||||
- 钻石译者 @GOLinux,
|
||||
- 钻石译者 @ictlyh,
|
||||
- 技术组长 @bestony,
|
||||
- 漫画组长 @GHLandy,
|
||||
- LFS 组长 @martin2011qi,
|
||||
- 核心成员 @strugglingyouth,
|
||||
- 核心成员 @FSSlc,
|
||||
- 核心成员 @zpl1025,
|
||||
- 核心成员 @runningwater,
|
||||
- 核心成员 @bazz2,
|
||||
- 核心成员 @Vic020,
|
||||
- 核心成员 @alim0x,
|
||||
- 核心成员 @tinyeyeser,
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
- 前任校对 @carolinewuyan,
|
||||
- 功勋成员 @vito-L,
|
||||
- 功勋成员 @willqian,
|
||||
- 功勋成员 @vizv,
|
||||
- 功勋成员 @dongfengweixiao,
|
||||
|
||||
全部成员列表请参见: https://linux.cn/lctt-list/ 。
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
谢谢大家的支持!
|
||||
@ -1,13 +1,7 @@
|
||||
Linux Shell 中的命令行别名
|
||||
Linux 命令行工具使用小贴士及技巧(四)
|
||||
============================================================
|
||||
|
||||
### 本文包括
|
||||
|
||||
1. [Linux 中的命令行别名][1]
|
||||
2. [相关细节][2]
|
||||
3. [总结][3]
|
||||
|
||||
到目前为止,在该系列指南中,我们已经讨论了 [cd -][5] 和 **pushd**/**popd** 命令的基本使用方法和相关细节,以及 **CDPATH** 环境变量。在这第四期、也是最后一期文章中,我们会讨论别名的概念以及你可以如何使用它们使你的命令行导航更加轻松和平稳。
|
||||
|
||||
到目前为止,在该系列指南中,我们已经讨论了 [cd -](https://linux.cn/article-8335-1.html) 和 [pushd/popd 命令](https://linux.cn/article-8371-1.html)的基本使用方法和相关细节,以及 [CDPATH 环境变量](https://linux.cn/article-8387-1.html)。在这第四期、也是最后一期文章中,我们会讨论别名的概念以及你可以如何使用它们使你的命令行导航更加轻松和平稳。
|
||||
|
||||
一如往常,在进入该指南的核心之前,值得指出本文中的所有命令以及展示的例子都在 Ubuntu 14.04LTS 中进行了测试。我们使用的命令行 shell 是 bash(4.3.11 版本)。
|
||||
|
||||
@ -15,49 +9,55 @@ Linux Shell 中的命令行别名
|
||||
|
||||
按照外行人的定义,别名可以被认为是一个复杂命令或者一组命令(包括它们的参数和选项)的简称或缩写。所以基本上,使用别名,你可以为那些不那么容易书写/记忆的命令创建易于记忆的名称。
|
||||
|
||||
例如,下面的命令为 'cd ~' 命令创建别名 ‘home’:
|
||||
例如,下面的命令为 `cd ~` 命令创建别名 `home`:
|
||||
|
||||
```
|
||||
alias home="cd ~"
|
||||
|
||||
这意味着现在在你的系统中无论何地,无论何时你想要回到你的主目录时,你可以很快地输入 ‘home’ 然后按回车键实现。
|
||||
|
||||
关于 alias 命令,man 手册是这么描述的:
|
||||
|
||||
```
|
||||
alias 工具可以创建或者重定义别名定义,或者把现有别名定义输出到标准输出。别名定义提供了输入一个命令时应该被替换的字符串值
|
||||
|
||||
一个别名定义会影响当前 shell 的执行环境以及当前 shell 所有子 shell 的执行环境。按照 IEEE Std 1003.1-2001 规定,别名定义不应该影响当前 shell 的父进程以及任何 shell 调用的程序环境。
|
||||
```
|
||||
这意味着现在在你的系统中无论何地,无论何时你想要回到你的主目录时,你可以很快地输入 `home` 然后按回车键实现。
|
||||
|
||||
关于 `alias` 命令,man 手册是这么描述的:
|
||||
|
||||
> alias 工具可以创建或者重定义别名定义,或者把现有别名定义输出到标准输出。别名定义提供了输入一个命令时应该被替换的字符串值
|
||||
|
||||
> 一个别名定义会影响当前 shell 的执行环境以及当前 shell 的所有子 shell 的执行环境。按照 IEEE Std 1003.1-2001 规定,别名定义不应该影响当前 shell 的父进程以及任何 shell 调用的程序环境。
|
||||
|
||||
那么,别名到底如何帮助命令行导航呢?这是一个简单的例子:
|
||||
|
||||
假设你正在 _/home/himanshu/projects/howtoforge_ 目录工作,它包括很多子目录以及子子目录。例如下面就是一个完整的目录分支:
|
||||
假设你正在 `/home/himanshu/projects/howtoforge` 目录工作,它包括很多子目录以及子子目录。例如下面就是一个完整的目录分支:
|
||||
|
||||
```
|
||||
/home/himanshu/projects/howtoforge/command-line/navigation/tips-tricks/part4/final
|
||||
```
|
||||
|
||||
现在想象你在 ‘final’ 目录,然后你想回到 ‘tips-tricks’ 目录,然后再从那里,回到 ‘howtoforge’ 目录。你会怎么做呢?
|
||||
现在想象你在 `final` 目录,然后你想回到 `tips-tricks` 目录,然后再从那里,回到 `howtoforge` 目录。你会怎么做呢?
|
||||
|
||||
是的,一般情况下,你会运行下面的一组命令:
|
||||
|
||||
```
|
||||
cd ../..
|
||||
|
||||
cd ../../..
|
||||
```
|
||||
|
||||
虽然这种方法并没有错误,但它绝对不方便,尤其是当你在一个很长的路径中想往回走例如说 5 个目录时。那么,有什么解决办法吗?答案就是:别名。
|
||||
|
||||
你可以做的是,为每个 _cd .._ 命令创建容易记忆(和书写)的别名。例如:
|
||||
你可以做的是,为每个 `cd ..` 命令创建容易记忆(和书写)的别名。例如:
|
||||
|
||||
```
|
||||
alias bk1="cd .."
|
||||
alias bk2="cd ../.."
|
||||
alias bk3="cd ../../.."
|
||||
alias bk4="cd ../../../.."
|
||||
alias bk5="cd ../../../../.."
|
||||
```
|
||||
|
||||
现在无论你什么时候想从当前工作目录往回走,例如说 5 个目录,你只需要运行下面的命令:
|
||||
|
||||
```
|
||||
bk5
|
||||
```
|
||||
|
||||
现在这不是很简单吗?
|
||||
|
||||
@ -65,9 +65,9 @@ bk5
|
||||
|
||||
尽管当前我们在 shell 中用于定义别名的技术(通过使用 alias 命令)实现了效果,别名只存在于当前终端会话。很有可能你会希望你定义的别名能保存下来,使得此后你可以在任何新启动的命令行窗口/标签页中使用它们。
|
||||
|
||||
为此,你需要在 _~/.bash\_aliases_ 文件中定义你的别名,你的 _~/.bashrc_ 文件默认会加载该文件(如果你使用更早版本的 Ubuntu,请验证这点)。
|
||||
为此,你需要在 `~/.bash_aliases` 文件中定义你的别名,你的 `~/.bashrc` 文件默认会加载该文件(如果你使用更早版本的 Ubuntu,我没有验证过是否有效)。
|
||||
|
||||
下面是我的 .bashrc 文件中关于 .bash\_aliases 文件的部分:
|
||||
下面是我的 `.bashrc` 文件中关于 `.bash_aliases` 文件的部分:
|
||||
|
||||
```
|
||||
# Alias definitions.
|
||||
@ -80,43 +80,55 @@ if [ -f ~/.bash_aliases ]; then
|
||||
fi
|
||||
```
|
||||
|
||||
一旦你把别名定义添加到你的 .bash\_aliases 文件,该别名在任何新终端中都可用。但是,在任何其它你定义别名时已经启动的终端中,你还不能使用它们 - 解决办法是在这些终端中重新加载 .bashrc。下面就是你需要执行的具体命令:
|
||||
一旦你把别名定义添加到你的 `.bash_aliases` 文件,该别名在任何新终端中都可用。但是,在任何其它你定义别名时已经启动的终端中,你还不能使用它们 - 解决办法是在这些终端中重新加载 `.bashrc`。下面就是你需要执行的具体命令:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
如果你觉得这要做的也太多了(是的,我期待你更懒惰的办法),那么这里有一个快捷方式来做到这一切:
|
||||
如果你觉得这要做的也太多了(是的,我期待你有更懒惰的办法),那么这里有一个快捷方式来做到这一切:
|
||||
|
||||
"alias [the-alias]" >> ~/.bash\_aliases && source ~/.bash\_aliases
|
||||
```
|
||||
"alias [the-alias]" >> ~/.bash_aliases && source ~/.bash_aliases
|
||||
```
|
||||
|
||||
毫无疑问,你需要用实际的命令替换 [the-alias]。例如:
|
||||
毫无疑问,你需要用实际的命令替换 `[the-alias]`。例如:
|
||||
|
||||
"alias bk5='cd ../../../../..'" >> ~/.bash\_aliases && source ~/.bash\_aliases
|
||||
```
|
||||
"alias bk5='cd ../../../../..'" >> ~/.bash_aliases && source ~/.bash_aliases
|
||||
```
|
||||
|
||||
接下来,假设你已经创建了一些别名,并时不时使用它们有一段时间了。突然有一天,你发现它们其中的一个并不像期望的那样。因此你觉得需要查看被赋予该别名的真正命令。你会怎么做呢?
|
||||
|
||||
当然,你可以打开你的 .bash\_aliases 文件在那里看看,但这种方式可能有点费时,尤其是当文件中包括很多别名的时候。因此,如果你正在查找一种更简单的方式,这就有一个:你需要做的只是运行 _alias_ 命令并把别名名称作为参数。
|
||||
当然,你可以打开你的 `.bash_aliases` 文件在那里看看,但这种方式可能有点费时,尤其是当文件中包括很多别名的时候。因此,如果你正在查找一种更简单的方式,这就有一个:你需要做的只是运行 `alias` 命令并把别名名称作为参数。
|
||||
|
||||
这里有个例子:
|
||||
|
||||
```
|
||||
$ alias bk6
|
||||
alias bk6='cd ../../../../../..'
|
||||
```
|
||||
|
||||
你可以看到,上面提到的命令显示了被赋值给别名 bk6 的实际命令。这里还有另一种办法:使用 _type_ 命令。下面是一个例子:
|
||||
你可以看到,上面提到的命令显示了被赋值给别名 `bk6` 的实际命令。这里还有另一种办法:使用 `type` 命令。下面是一个例子:
|
||||
|
||||
```
|
||||
$ type bk6
|
||||
bk6 is aliased to `cd ../../../../../..'
|
||||
```
|
||||
|
||||
type 命令产生了一个易于人类理解的输出。
|
||||
`type` 命令产生了一个易于人类理解的输出。
|
||||
|
||||
另一个值得分享的是你可以将别名用于常见的输入错误。例如:
|
||||
|
||||
```
|
||||
alias mroe='more'
|
||||
```
|
||||
|
||||
_最后,还值得注意的是并非每个人都喜欢使用别名。他们中的大部分人认为一旦你习惯了你为了简便而定义的别名,当你在其它相同而不存在别名(而且不允许你创建)的系统中工作时就会变得非常困难。更多(也是更准确的)为什么一些专家不推荐使用别名的原因,你到[这里][4]查看。_
|
||||
|
||||
### 总结
|
||||
|
||||
就像我们之前文章讨论过的 CDPATH 环境变量,别名也是一把应该谨慎使用的双刃剑。尽管如此也别太丧气,因为每个东西都有它自己的好处和劣势。遇到类似别名的概念时,更多的练习和完备的知识才是重点。
|
||||
就像我们之前文章讨论过的 `CDPATH` 环境变量,别名也是一把应该谨慎使用的双刃剑。尽管如此也别太丧气,因为每个东西都有它自己的好处和劣势。遇到类似别名的概念时,更多的练习和完备的知识才是重点。
|
||||
|
||||
那么这就是该系列指南的最后章节。希望你喜欢它并能从中学到新的东西/概念。如果你有任何疑问或者问题,请在下面的评论框中和我们(以及其他人)分享。
|
||||
|
||||
@ -126,7 +138,7 @@ via: https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,11 @@
|
||||
bmon - Linux 下一个强大的网络带宽监视和调试工具
|
||||
bmon:Linux 下一个强大的网络带宽监视和调试工具
|
||||
============================================================
|
||||
|
||||
bmon 是类 Unix 系统中一个基于文本,简单但非常强大的 [网络监视和调试工具][1],它能抓取网络相关统计信息并把它们以用户友好的格式展现出来。它是一个可靠高效的带宽监视和网速预估器。
|
||||
bmon 是类 Unix 系统中一个基于文本,简单但非常强大的 [网络监视和调试工具][1],它能抓取网络相关统计信息并把它们以用户友好的格式展现出来。它是一个可靠高效的带宽监视和网速估测工具。
|
||||
|
||||
它能使用各种输入模块读取输入,并以各种输出模式显示输出,包括交互式用户界面和用于脚本编写的可编程文本输出。
|
||||
它能使用各种输入模块读取输入,并以各种输出模式显示输出,包括交互式文本用户界面和用于脚本编写的可编程文本输出。
|
||||
|
||||
**推荐阅读:** [监控 Linux 性能的20个命令行工具][2]
|
||||
**推荐阅读:** [监控 Linux 性能的 20 个命令行工具][2]
|
||||
|
||||
### 在 Linux 上安装 bmon 带宽监视工具
|
||||
|
||||
@ -19,9 +19,9 @@ $ sudo apt-get install bmon [On Debian/Ubuntu/Mint]
|
||||
|
||||
另外,你也可以从 [https://pkgs.org/download/bmon][3] 获取对应你 Linux 发行版的 `.rpm` 和 `.deb` 软件包。
|
||||
|
||||
如果你想要最新版本(例如版本4.0)的 bmon,你需要通过下面的命令从源码构建。
|
||||
如果你想要最新版本(例如版本 4.0)的 bmon,你需要通过下面的命令从源码构建。
|
||||
|
||||
#### 在 CentOS、RHEL 和 Fedora 中
|
||||
**在 CentOS、RHEL 和 Fedora 中**
|
||||
|
||||
```
|
||||
$ git clone https://github.com/tgraf/bmon.git
|
||||
@ -33,7 +33,7 @@ $ sudo make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
#### 在 Debian、Ubuntu 和 Linux Mint 中
|
||||
**在 Debian、Ubuntu 和 Linux Mint 中**
|
||||
|
||||
```
|
||||
$ git clone https://github.com/tgraf/bmon.git
|
||||
@ -47,7 +47,7 @@ $ sudo make install
|
||||
|
||||
### 如何在 Linux 中使用 bmon 带宽监视工具
|
||||
|
||||
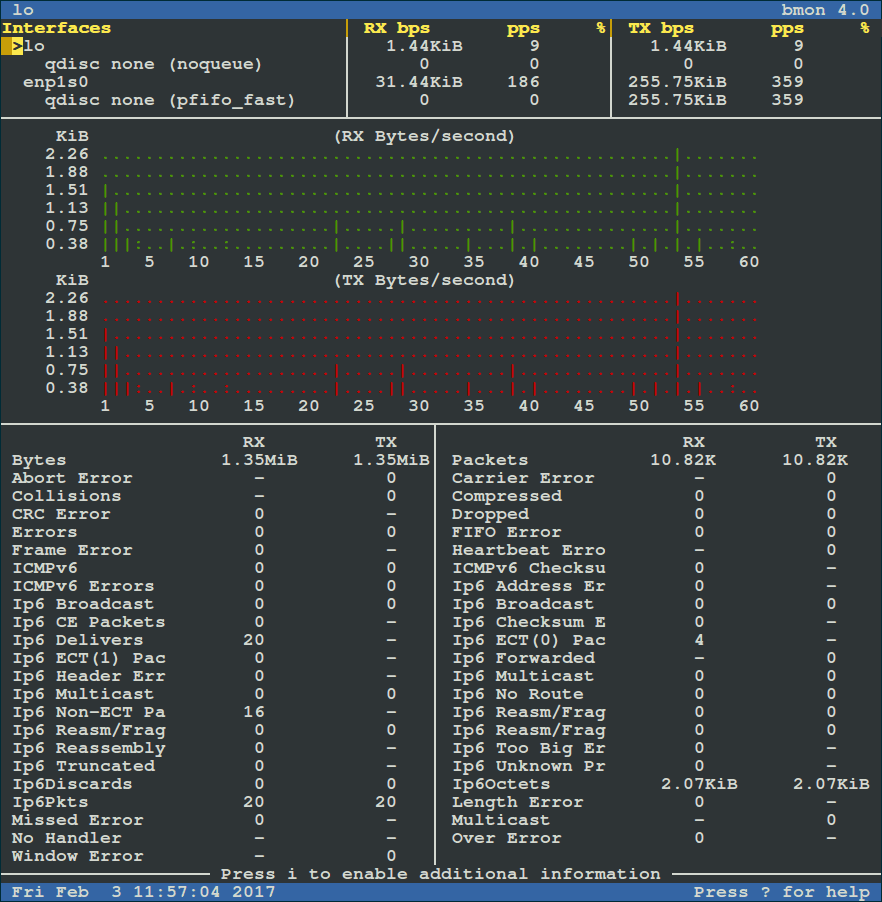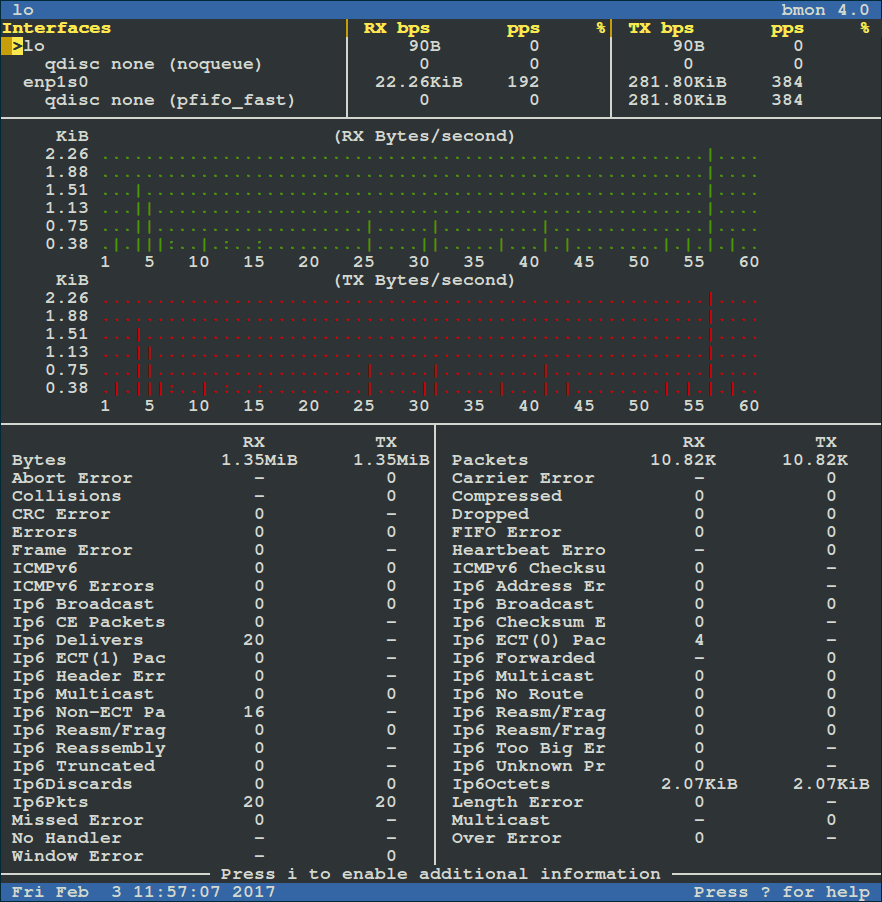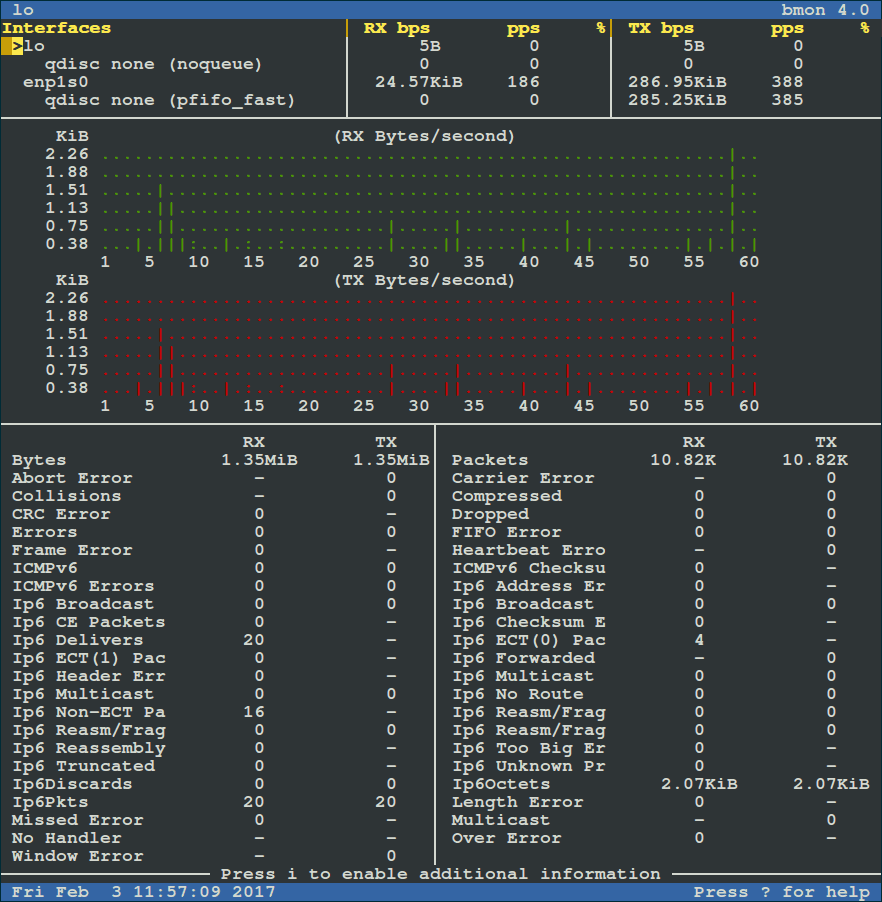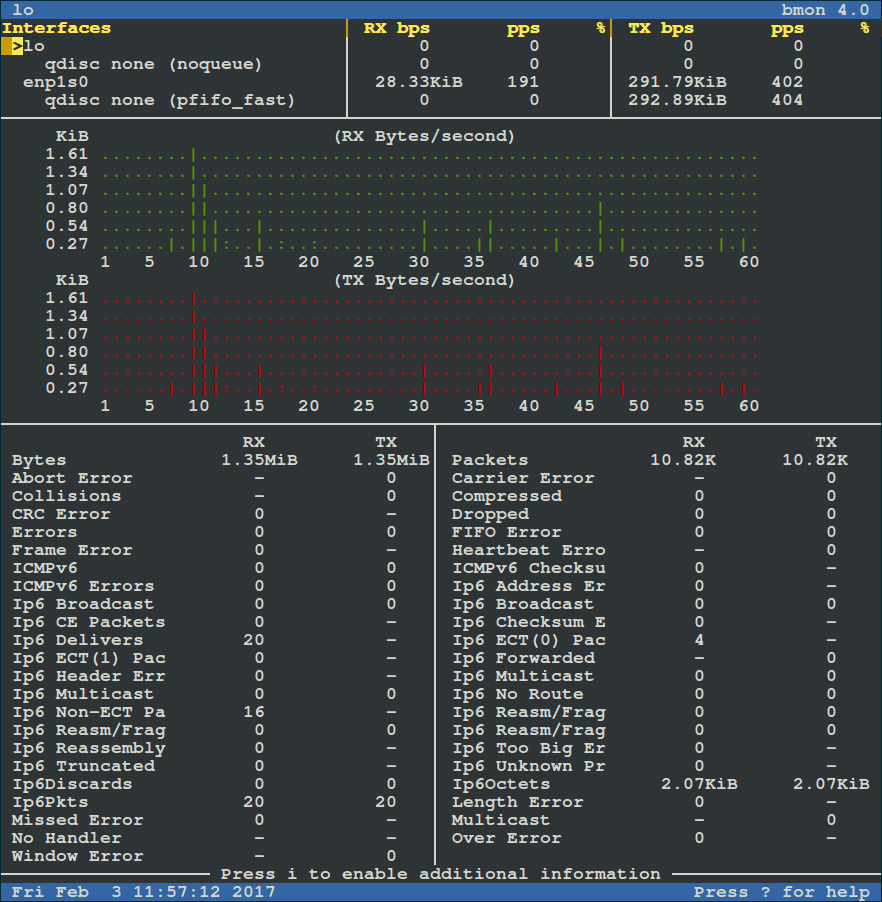
通过以下命令运行它(给初学者:RX 表示每秒接收数据,TX 表示每秒发送数据):
|
||||
通过以下命令运行它(初学者说明:RX 表示每秒接收数据,TX 表示每秒发送数据):
|
||||
|
||||
```
|
||||
$ bmon
|
||||
@ -63,19 +63,19 @@ $ bmon
|
||||
|
||||
][5]
|
||||
|
||||
按 `[Shift + ?]` 可以查看快速指南。再次按 `[Shift + ?]` 可以退出(指南)界面。
|
||||
按 `Shift + ?` 可以查看快速指南。再次按 `Shift + ?` 可以退出(指南)界面。
|
||||
|
||||
[
|
||||
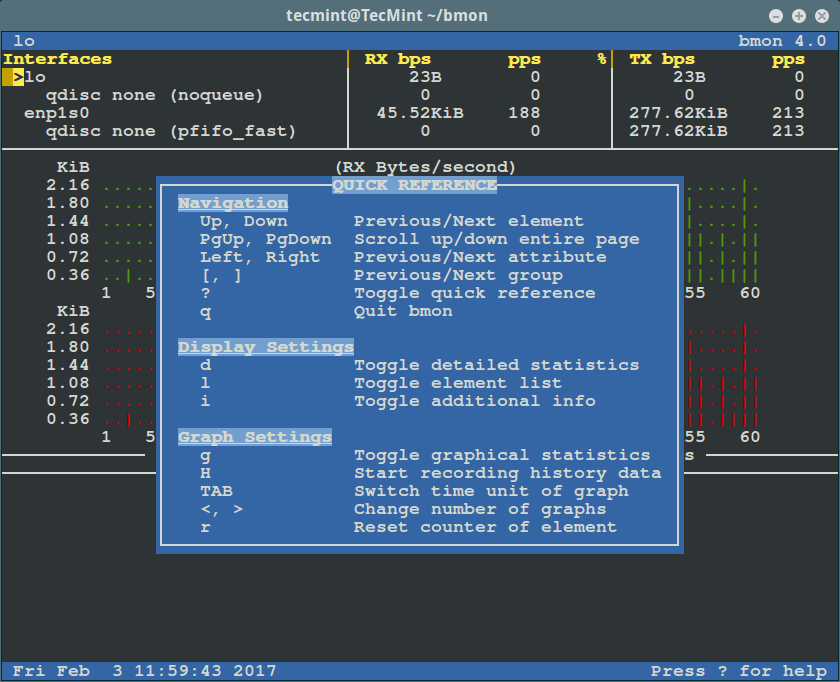
|
||||
][6]
|
||||
|
||||
bmon – 快速指南
|
||||
*bmon – 快速指南*
|
||||
|
||||
通过 `Up` 和 `Down` 箭头键可以查看特定网卡的统计信息。但是,要监视一个特定的网卡,你也可以像下面这样作为命令行参数指定。
|
||||
|
||||
**推荐阅读:** [监控 Linux 性能的13个工具][7]
|
||||
**推荐阅读:** [监控 Linux 性能的 13 个工具][7]
|
||||
|
||||
标签 `-p` 指定了要显示的网卡,在下面的例子中,我们会监视网卡 `enp1s0`:
|
||||
选项 `-p` 指定了要显示的网卡,在下面的例子中,我们会监视网卡 `enp1s0`:
|
||||
|
||||
```
|
||||
$ bmon -p enp1s0
|
||||
@ -84,31 +84,30 @@ $ bmon -p enp1s0
|
||||
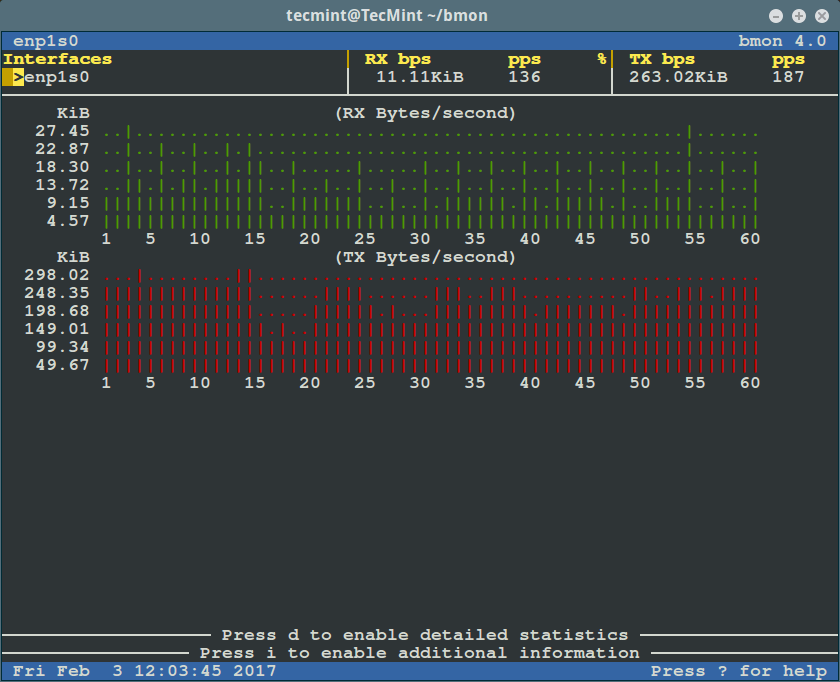
|
||||
][8]
|
||||
|
||||
bmon – 监控以太网带宽
|
||||
*bmon – 监控以太网带宽*
|
||||
|
||||
要查看每秒位数而不是字节数,可以像下面这样使用 `-b` 标签:
|
||||
要查看每秒位数而不是每秒字节数,可以像下面这样使用 `-b` 选项:
|
||||
|
||||
```
|
||||
$ bmon -bp enp1s0
|
||||
```
|
||||
|
||||
我们也可以像下面这样指定每秒的间隔数:
|
||||
我们也可以像下面这样按秒指定刷新间隔时间:
|
||||
|
||||
```
|
||||
$ bmon -r 5 -p enp1s0
|
||||
```
|
||||
|
||||
### 如何使用 bmon 的输入模块
|
||||
### How to Use bmon Input Modules
|
||||
|
||||
bmon 有很多能提供网卡统计数据的输入模块,其中包括:
|
||||
|
||||
1. netlink - 使用 Netlink 协议从内核中收集网卡和流量控制统计信息。这是默认的输入模块。
|
||||
2. proc - 从 /proc/net/dev 文件读取网卡统计信息。它被认为是传统界面,且提供了向后兼容性。它是 Netlink 接口不可用时的备用模块。
|
||||
2. proc - 从 `/proc/net/dev` 文件读取网卡统计信息。它被认为是传统界面,且提供了向后兼容性。它是 Netlink 接口不可用时的备用模块。
|
||||
3. dummy - 这是用于调试和测试的可编程输入模块。
|
||||
4. null - 停用数据收集。
|
||||
|
||||
要查看关于某个模块的其余信息,可以像下面这样使用 “help” 选项调用它:
|
||||
要查看关于某个模块的其余信息,可以像下面这样使用 `help` 选项调用它:
|
||||
|
||||
```
|
||||
$ bmon -i netlink:help
|
||||
@ -125,12 +124,11 @@ $ bmon -i proc -p enp1s0
|
||||
bmon 也使用输出模块显示或者导出上面输入模块收集的统计数据,输出模块包括:
|
||||
|
||||
1. curses - 这是一个交互式的文本用户界面,它提供实时的网上估计以及每个属性的图形化表示。这是默认的输出模块。
|
||||
2. ascii - 这是用于用户查看的简单可编程文本输出。它能显示网卡列表、详细计数以及图形到控制台。当 curses 不可用时这是默认的备选输出模块。
|
||||
2. ascii - 这是用于用户查看的简单可编程文本输出。它能显示网卡列表、详细计数以及图形到控制台。当 curses 库不可用时这是默认的备选输出模块。
|
||||
3. format - 这是完全脚本化的输出模式,供其它程序使用 - 意味着我们可以在后面的脚本和程序中使用它的输出值进行分析。
|
||||
4. null - 停用输出。
|
||||
|
||||
像下面这样通过 “help” 标签获取更多的模块信息。
|
||||
To get more info concerning a module, run the it with the “help” flag set like so:
|
||||
像下面这样通过 `help` 选项获取更多的模块信息。
|
||||
|
||||
```
|
||||
$ bmon -o curses:help
|
||||
@ -144,7 +142,7 @@ $ bmon -p enp1s0 -o ascii
|
||||
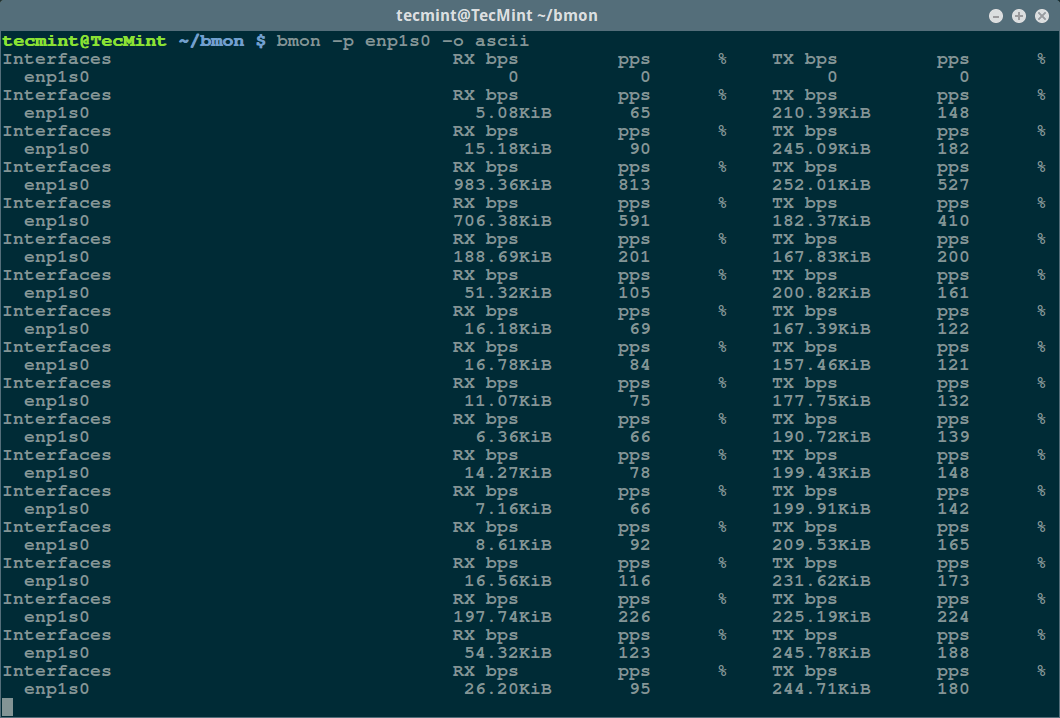
|
||||
][9]
|
||||
|
||||
bmon – Ascii 输出模式
|
||||
*bmon – Ascii 输出模式*
|
||||
|
||||
我们也可以用 format 输出模式,然后在脚本或者其它程序中使用获取的值:
|
||||
|
||||
@ -155,7 +153,7 @@ $ bmon -p enp1s0 -o format
|
||||

|
||||
][10]
|
||||
|
||||
bmon – Format 输出模式
|
||||
*bmon – Format 输出模式*
|
||||
|
||||
想要其它的使用信息、选项和事例,可以阅读 bmon 的 man 手册:
|
||||
|
||||
@ -163,7 +161,7 @@ bmon – Format 输出模式
|
||||
$ man bmon
|
||||
```
|
||||
|
||||
访问 bmon 的Github 仓库:[https://github.com/tgraf/bmon][11].
|
||||
访问 bmon 的 Github 仓库:[https://github.com/tgraf/bmon][11]。
|
||||
|
||||
就是这些,在不同场景下尝试 bmon 的多个功能吧,别忘了在下面的评论部分和我们分享你的想法。
|
||||
|
||||
@ -171,7 +169,7 @@ $ man bmon
|
||||
|
||||
译者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者、Linux 系统管理员、网络开发人员,现在也是 TecMint 的内容创作者,她喜欢和电脑一起工作,坚信共享知识。
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者、Linux 系统管理员、网络开发人员,现在也是 TecMint 的内容创作者,他喜欢和电脑一起工作,坚信共享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -179,7 +177,7 @@ via: http://www.tecmint.com/bmon-network-bandwidth-monitoring-debugging-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,137 @@
|
||||
微软 Office 在线版变得更好 - 在 Linux 上亦然
|
||||
=============
|
||||
|
||||
对于 linux 用户,影响 linux 使用体验的主要因素之一便是缺少微软 Office 套装。如果你非得靠 Office 谋生,而它被绝大多数人使用,你可能不能承受使用开源产品的代价。理解矛盾之所在了吗?
|
||||
|
||||
的确, LibreOffice 是一个 [很棒的][1] 自由程序,但如果你的客户、顾客或老板需要 Word 和 Excel 文件呢? 你确定能 [承担任何][2] 将这些文件从 ODT 或别的格式转换到 DOCX 之类时的失误、错误或小问题吗, 反之亦然。这是一系列难办的问题。 不幸的是,在技术在层面上对大多数人而言,Linux 超出了能力范围。当然,这不是绝对。
|
||||
|
||||

|
||||
|
||||
### 加入微软 Office 在线, 加入 Linux
|
||||
|
||||
众所周知,微软拥有自己的 Office 云服务多年。通过任何现代浏览器都可以使用使得它很棒且具有意义,并且这意味着在 Linux 上也能使用!我前阵子刚测试了这个[方法][3]并且它表现出色。我能够轻松使用这个产品,以原本的格式保存文件,或是转换为我的 ODF 格式,这真的很棒。
|
||||
|
||||
我决定再次使用这个套装看看它在过去几年的进步以及是否依旧对 Linux 友好。我使用 [Fedora 25][4] 作为例子。我同时也去测试了 [SoftMaker Office 2016][5]。 听起来有趣,也确实如此。
|
||||
|
||||
### 第一印象
|
||||
|
||||
我得说,我感到很高兴。Office 不需要任何特别的插件。没有 Silverlight 或 Flash 之类的东西。 单纯而大量的 HTML 和 Javascript 。 同时,交互界面反应极其迅速。唯一我不喜欢的就是 Word 文档的灰色背景,它让人很快感到疲劳。除了这个,整个套装工作流畅,没有延迟、行为古怪之处及意料之外的错误。接下来让我们放慢脚步。
|
||||
|
||||
这个套装需要你用在线账户或者手机号登录——不必是 Live 或 Hotmail 邮箱。任何邮箱都可以。如果你有微软 [手机][6], 那么你可以用相同的账户并且可以同步你的数据。账户也会免费分配 5GB OneDrive 的储存空间。这很有条理,不是优秀或令人超级兴奋而是非常得当。
|
||||
|
||||

|
||||
|
||||
你可以使用各种各样的程序,包括必需的三件套 - Word、Excel 和 Powerpoint,并且其它的东西也可使用,包括一些新奇事物。文档会自动保存,但你也可以下载副本并转换成其它格式,比如 PDF 和 ODF。
|
||||
|
||||
对我来说这简直完美。分享一个自己的小故事。我用 LibreOffice 写一本 [奇幻类的][7]书,之后当我需要将它们送去出版社编辑或者校对,我需要把它们转换成 DOCX 格式。唉,这需要微软 office。从我的 [Linux 问题解决大全][8]得知,我得一开始就使用 Word,因为有一堆工作要与我的编辑合作完成,而他们使用专有软件。没有任何情面可讲,只有出于对冷酷的金钱和商业的考量。错误是不容许接受的。
|
||||
|
||||

|
||||
|
||||
使用 Office 在线版能给很多偶尔需要使用的人以自由空间。偶尔使用 Word、Excel 等,不需要购买整个完整的套装。如果你表面上是 LibreOffice 的忠实粉丝,你也可以暗地里“加入微软 Office 负心者俱乐部”而不必感到愧疚。有人传给你一个 Word 或 PPT 文件,你可以上传然后在线操作它们,然后转换成所需要的。这样的话你就可以在线生成你的工作,发送给那些严格要求的人,同时自己留一个 ODF 格式的备份,有需要的话就用 LibreOffice 操作。虽然这种方法的灵活性很是实用,但这不应该成为你的主要手段。对于 Linux 用户,这给予了很多他们平时所没有的自由,毕竟即使你想用微软 Office 也不好安装。
|
||||
|
||||

|
||||
|
||||
### 特性、选项、工具
|
||||
|
||||
我开始琢磨一个文档——考虑到这其中各种细枝末节。写点文本,用一种或三种风格,链接某些文本,嵌入图片,加上脚注,评论自己的文章甚至作为一个多重人格的极客巧妙地回复自己的评论。
|
||||
|
||||
除了灰色背景——我们得学会很好地完成一项无趣工作,即便是像臭鼬工厂那样的工作方式,因为浏览器里没有选项调整背景颜色——其实也还好啦。
|
||||
|
||||
Skype 甚至也整合到了其中,你可以边沟通边协作,或者在协作中倾听。其色调相当一致。鼠标右键可以选择一些快捷操作,包括链接、评论和翻译。不过需要改进的地方还有不少,它并没有给我想要的,翻译有差错。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
你也可以加入图片——包括默认嵌入的必应搜索可以基于它们的许可证和分发权来筛选图片。这很棒,特别是当你想要创作文档而又想避免版权纷争时。
|
||||
|
||||

|
||||
|
||||
### 关于追踪多说几句
|
||||
|
||||
说老实话,很实用。这个产品基于在线使用使得默认情况下可以跟踪更改和编辑,所以你就有了基本的版本控制功能。不过如果直接关闭而不保存的话,阶段性的编辑会遗失。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
看到一个错误——如果你试着在 Linux 上(本地)编辑 Word 或 Excel 文件,会被提示你很调皮,因为这明显是个不支持的操作。
|
||||
|
||||

|
||||
|
||||
### Excel
|
||||
|
||||
实际工作流程不止使用 Word。我也使用 Excel,众所周知,它包含了很多整齐有效的模板之类的。好用而且在更新单元格和公式时没有任何延迟,它涵盖了你所需要的大多数功能。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### OneDrive
|
||||
|
||||
在这里你可以新建文件夹和文件、移动文件、给你的朋友(如果你需要的话)和同事们分享文件。5 GB 免费,当然,收费增容。总的来说,做的不错。在更新和展示内容上会花费一定时间。打开了的文档不能被删除,这可能看起来像一个漏洞,但从计算机角度来看是完美的体验。
|
||||
|
||||

|
||||
|
||||
### 帮助
|
||||
|
||||
如果你感到疑惑——比如被人工智能戏耍,可以向微软的云智囊团寻求帮助。 虽然这种方式不那么直接,但至少好用,结果往往也能令人满意。
|
||||
|
||||

|
||||
|
||||
### 问题
|
||||
|
||||
在我三个小时的摸索中,我只遇到了两个小问题。一是文件编辑的时候浏览器会有警告(黄色三角),提醒我在 HTTPS 会话中加载了不安全的元素。二是创建 Excel 文件失败,只出现过一次。
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
微软 Office 在线版是一个优秀的产品,与我两年前测试相比较,它变得更好了。外观出色,表现良好,使用期间错误很少,完美兼容,甚至对于 Linux 用户,使之具有个人意义和商业价值。我不能说它是自 VHS (Video Home System,家用录像系统)出现以来最好的东西,但一定是很棒的,它架起了 Linux 用户与微软 Office 之间的桥梁,解决了 Linux 用户长期以来的问题,方便且很好的支持 ODF 。
|
||||
|
||||
现在我们来让事情变得更有趣些,如果你喜欢云概念的事物,那你可能对 [Open365][9] 感兴趣,这是一个基于 LibreOfiice 的办公软件,加上额外的邮件客户端和图像处理软件,还有 20 GB 的免费存储空间。最重要的是,你可以用浏览器同时完成这一切,只需要多开几个窗口。
|
||||
|
||||
回到微软,如果你是 Linux 用户,如今可能确实需要微软 Office 产品。在线 Office 套装无疑是更方便的使用方法——或者至少不需要更改操作系统。它免费、优雅、透明度高。值得一提的是,你可以把思维游戏放在一边,享受你的云端生活。
|
||||
|
||||
干杯~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我的名字是 Igor Ljubuncic. 38 岁左右,已婚未育。现在是一家云技术公司的首席工程师,这是一个新的领域。到 2015 年初之前,我作为团队中的一名系统工程师就职于世界上最大的信息技术公司之一,开发新的 Linux 解决方案、完善内核、研究 linux。在这之前,我是创新设计团队的技术指导,致力于高性能计算环境的创新解决方案。还有一些像系统专家、系统程序员之类的新奇的名字。这些全是我的爱好,直到 2008 年,变成了工作,还有什么能比这更令人满意呢?
|
||||
|
||||
从 2004 到 2008,我作为物理学家在医学影像行业谋生。我专攻解决问题和发展算法,后来大量使用 Matlab 处理信号和图像。另外我考了很多工程计算方法的认证,包括 MEDIC Six Sigma Green Belt,实验设计和数据化工程。
|
||||
|
||||
我也开始写书,包括奇幻类和 Linux 上的技术性工作。彼此交融。
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/office-online-linux-better.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.ocsmag.com/2015/02/16/libreoffice-4-4-review-finally-it-rocks/
|
||||
[2]:http://www.ocsmag.com/2014/03/14/libreoffice-vs-microsoft-office-part-deux/
|
||||
[3]:http://www.dedoimedo.com/computers/office-online-linux.html
|
||||
[4]:http://www.dedoimedo.com/computers/fedora-25-gnome.html
|
||||
[5]:http://www.ocsmag.com/2017/01/18/softmaker-office-2016-your-alternative-to-libreoffice/
|
||||
[6]:http://www.dedoimedo.com/computers/microsoft-lumia-640.html
|
||||
[7]:http://www.thelostwordsbooks.com/
|
||||
[8]:http://www.dedoimedo.com/computers/linux-problem-solving-book.html
|
||||
[9]:http://www.ocsmag.com/2016/08/17/open365/
|
||||
84
published/20170316 What is Linux VPS Hosting.md
Normal file
84
published/20170316 What is Linux VPS Hosting.md
Normal file
@ -0,0 +1,84 @@
|
||||
什么是 Linux VPS 托管?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
如果你有一个吞吐量很大的网站,或者至少,预期网站吞吐量很大,那么你可以考虑使用 [Linux VPS 托管][6] 。如果你想对网站托管的服务器上安装的东西有更多控制,那么 Linux VPS 托管就是最好的选择之一。这里我会回答一些频繁被提及的关于 Linux VPS 托管的问题。
|
||||
|
||||
### Linux VPS 意味着什么?
|
||||
|
||||
基本上, **Linux VPS 就是一个运行在 Linux 系统上的虚拟专属服务器(virtual private server)**。虚拟专属服务器是一个在物理服务器上的虚拟服务主机。运行在物理主机的内存里的服务器就称之为虚拟服务器。物理主机可以轮流运行很多其他的虚拟专属服务器。
|
||||
|
||||
### 我必须和其他用户共享服务器吗?
|
||||
|
||||
一般是这样的。但这并不意味着下载时间变长或者服务器性能降低。每个虚拟服务器可以运行它自己的操作系统,这些系统之间可以相互独立的进行管理。一个虚拟专属服务器有它自己的操作系统、数据、应用程序;它们都与物理主机和其他虚拟服务器中的操作系统、应用程序、数据相互分离。
|
||||
|
||||
尽管必须和其他虚拟专属服务器共享物理主机,但是你却可以不需花费大价钱就可以得到一个昂贵专用服务器的诸多好处。
|
||||
|
||||
### Linux VPS 托管的优势是什么?
|
||||
|
||||
使用 Linux VPS 托管服务会有很多的优势,包括容易使用、安全性增加以及在更低的总体成本上提高可靠性。然而,对于大多数网站管理者、程序员、设计者和开发者来说,使用 Linux VPS 托管服务的最大的优势是它的灵活性。每个虚拟专属服务器都和它所在的操作环境相互隔离,这意味着你可以容易且安全的安装一个你喜欢或者需要的操作系统 — 本例中是 Linux — 任何想要做的时候,你还可以很容易的卸载或者安装软件及应用程序。
|
||||
|
||||
你也可以更改你的 VPS 环境以适应你的性能需求,同样也可以提高你的网站用户或访客的体验。灵活性会是你超越对手的主要优势。
|
||||
|
||||
记住,一些 Linux VPS 提供商可能不会给你对你的 Linux VPS 完全的 root 访问权限。这样你的功能就会受到限制。要确定你得到的是 [拥有 root 权限的 Linux VPS][7] ,这样你就可以做任何你想做的修改。
|
||||
|
||||
|
||||
### 任何人都可以使用 Linux VPS 托管吗?
|
||||
|
||||
当然,即使你运行一个专门的个人兴趣博客,你也可以从 Linux VPS 托管中受益。如果你为公司搭建、开发一个网站,你也会获益匪浅。基本上,如果你想使你的网站更健壮并且增加它的网络吞吐量,那么 Linux VPS 就是为你而生。
|
||||
|
||||
在定制和开发中需要很大的灵活性的个人和企业,特别是那些正在寻找不使用专用服务器就能得到高性能和服务的人们,绝对应该选择 Linux VPS,因为专用服务器会消耗大量的网站运营成本。
|
||||
|
||||
### 不会使用 Linux 也可以使用 Linux VPS 吗?
|
||||
|
||||
当然,如果 Linux VPS 由你管理,你的 VPS 提供商会为你管理整个服务器。更有可能,他们将会为你安装、配置一切你想要运行在 Linux VPS 上的服务。如果你使用我们的 VPS,我们会 24/7 全天候看护,也会安装、配置、优化一切服务。
|
||||
|
||||
如果你使用我们的主机服务,你会从 Linux VPS 中获益匪浅,并且不需要任何 Linux 知识。
|
||||
|
||||
对于新手来说,另一个简化 Linux VPS 使用的方式是得到一个带有 [cPanel][9]、[DirectAdmin][10] 或者任何 [其他托管控制面板][11]的 VPS。如果你使用控制面板,就可以通过一个图形界面管理你的服务器,尤其对于新手,它是很容易使用的。虽然[使用命令行管理 Linux VPS][12] 很有趣,而且那样做可以学到很多。
|
||||
|
||||
### Linux VPS 和专用服务器有什么不同?
|
||||
|
||||
如前所述,一个虚拟专属服务器仅仅是在物理主机上的一个虚拟分区。物理服务器被分为多个虚拟服务器,这些虚拟服务器用户可以分担降低成本和开销。这就是 Linux VPS 相比一个 [专用服务器][13] 更加便宜的原因,专用服务器的字面意思就是指只有一个用户专用。想要知道关于更多不同点的细节,可以查看 [物理服务器(专用)与 虚拟服务器(VPS) 比较][14]。
|
||||
|
||||
除了比专用服务器有更好的成本效益,Linux 虚拟专属服务器经常运行在比专用服务器的性能更强大的主机上,因此其性能和容量常常比专用服务器更大。
|
||||
|
||||
### 我可以把网站从共享托管环境迁移到到 Linux VPS 上吗?
|
||||
|
||||
如果你当前使用 [<ruby>**共享托管服务**<rt>shared hosting</rt></ruby>][15],你可以很容易的迁移到 Linux VPS 上。一种做法就是 [**您自己做**][16],但是迁移过程有点复杂,不建议新手使用。最好的方法是找到一个提供 [免费网站迁移][17] 的主机,然后让他们帮你完成迁移。你还可以从一个带有控制面板的共享主机迁移到一个不带有控制面板的 Linux VPS 。
|
||||
|
||||
### 更多问题?
|
||||
|
||||
欢迎随时在下面留下评论。
|
||||
|
||||
PS. 如果你喜欢这个专栏,请把它分享给你的彭友,或者你也可以在下面的评论区写下你的答复。谢谢。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||
|
||||
作者:[https://www.rosehosting.com][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||
[1]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||
[2]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/#comments
|
||||
[3]:https://www.rosehosting.com/blog/category/guides/
|
||||
[4]:https://plus.google.com/share?url=https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||
[5]:http://www.linkedin.com/shareArticle?mini=true&url=https://www.rosehosting.com/blog/what-is-linux-vps-hosting/&title=What%20is%20Linux%20VPS%20Hosting%3F&summary=If%20you%20have%20a%20site%20that%20gets%20a%20lot%20of%20traffic,%20or%20at%20least,%20is%20expected%20to%20generate%20a%20lot%20of%20traffic,%20then%20you%20might%20want%20to%20consider%20getting%20a%20Linux%20VPS%20hosting%20package.%20A%20Linux%20VPS%20hosting%20package%20is%20also%20one%20of%20your%20best%20options%20if%20you%20want%20more%20...
|
||||
[6]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
[7]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
[9]:https://www.rosehosting.com/cpanel-hosting.html
|
||||
[10]:https://www.rosehosting.com/directadmin-hosting.html
|
||||
[11]:https://www.rosehosting.com/control-panel-hosting.html
|
||||
[12]:https://www.rosehosting.com/blog/basic-shell-commands-after-putty-ssh-logon/
|
||||
[13]:https://www.rosehosting.com/dedicated-servers.html
|
||||
[14]:https://www.rosehosting.com/blog/physical-server-vs-virtual-server-all-you-need-to-know/
|
||||
[15]:https://www.rosehosting.com/linux-shared-hosting.html
|
||||
[16]:https://www.rosehosting.com/blog/from-shared-to-vps-hosting/
|
||||
[17]:https://www.rosehosting.com/website-migration.html
|
||||
@ -7,27 +7,25 @@ DHCP(Dynamic Host Configuration Protocol)是一个网络协议,它使得
|
||||
|
||||
在这篇指南中,我们会介绍如何在 CentOS/RHEL 和 Fedora 发行版中安装和配置 DHCP 服务。
|
||||
|
||||
#### 设置测试环境
|
||||
### 设置测试环境
|
||||
|
||||
本次安装中我们使用如下的测试环境。
|
||||
本次安装中我们使用如下的测试环境:
|
||||
|
||||
```
|
||||
DHCP 服务器 - CentOS 7
|
||||
DHCP 客户端 - Fedora 25 和 Ubuntu 16.04
|
||||
```
|
||||
- DHCP 服务器 - CentOS 7
|
||||
- DHCP 客户端 - Fedora 25 和 Ubuntu 16.04
|
||||
|
||||
#### DHCP 如何工作?
|
||||
### DHCP 如何工作?
|
||||
|
||||
在进入下一步之前,让我们首先了解一下 DHCP 的工作流程:
|
||||
|
||||
* 当已连接到网络的客户端计算机(配置为使用 DHCP)启动时,它会发送一个 DHCPDISCOVER 消息到 DHCP 服务器。
|
||||
* 当 DHCP 服务器接收到 DHCPDISCOVER 请求消息时,它会回复一个 DHCPOFFER 消息。
|
||||
* 客户端收到 DHCPOFFER 消息后,它再发送给服务器一个 DHCPREQUEST 消息,表示客户端已准备好获取 DHCPOFFER 消息中提供的网络配置。
|
||||
* 最后,DHCP 服务器收到客户端的 DHCPREQUEST 消息,并回复 DHCPACK 消息,表示允许客户端使用分配给它的 IP 地址。
|
||||
* 当已连接到网络的客户端计算机(配置为使用 DHCP)启动时,它会发送一个 `DHCPDISCOVER` 消息到 DHCP 服务器。
|
||||
* 当 DHCP 服务器接收到 `DHCPDISCOVER` 请求消息时,它会回复一个 `DHCPOFFER` 消息。
|
||||
* 客户端收到 `DHCPOFFER` 消息后,它再发送给服务器一个 `DHCPREQUEST` 消息,表示客户端已准备好获取 `DHCPOFFER` 消息中提供的网络配置。
|
||||
* 最后,DHCP 服务器收到客户端的 `DHCPREQUEST` 消息,并回复 `DHCPACK` 消息,表示允许客户端使用分配给它的 IP 地址。
|
||||
|
||||
### 第一步:在 CentOS 上安装 DHCP 服务
|
||||
|
||||
1. 安装 DHCP 服务非常简单,只需要运行下面的命令即可。
|
||||
1、安装 DHCP 服务非常简单,只需要运行下面的命令即可。
|
||||
|
||||
```
|
||||
$ yum -y install dhcp
|
||||
@ -35,7 +33,7 @@ $ yum -y install dhcp
|
||||
|
||||
重要:假如系统中有多个网卡,但你想只在其中一个网卡上启用 DHCP 服务,可以按照下面的步骤在该网卡上启用 DHCP 服务。
|
||||
|
||||
2. 打开文件 /etc/sysconfig/dhcpd,将指定网卡的名称添加到 DHCPDARGS 列表,假如网卡名称为 `eth0`,则添加:
|
||||
2、 打开文件 `/etc/sysconfig/dhcpd`,将指定网卡的名称添加到 `DHCPDARGS` 列表,假如网卡名称为 `eth0`,则添加:
|
||||
|
||||
```
|
||||
DHCPDARGS=eth0
|
||||
@ -45,9 +43,9 @@ DHCPDARGS=eth0
|
||||
|
||||
### 第二步:在 CentOS 上配置 DHCP 服务
|
||||
|
||||
3. 对于初学者来说,配置 DHCP 服务的第一步是创建 `dhcpd.conf` 配置文件,DHCP 主要配置文件一般是 /etc/dhcp/dhcpd.conf(默认情况下该文件为空),该文件保存了发送给客户端的所有网络信息。
|
||||
3、 对于初学者来说,配置 DHCP 服务的第一步是创建 `dhcpd.conf` 配置文件,DHCP 主要配置文件一般是 `/etc/dhcp/dhcpd.conf`(默认情况下该文件为空),该文件保存了发送给客户端的所有网络信息。
|
||||
|
||||
但是,有一个样例配置文件 /usr/share/doc/dhcp*/dhcpd.conf.sample,这是配置 DHCP 服务的良好开始。
|
||||
但是,有一个样例配置文件 `/usr/share/doc/dhcp*/dhcpd.conf.sample`,这是配置 DHCP 服务的良好开始。
|
||||
|
||||
DHCP 配置文件中定义了两种类型的语句:
|
||||
|
||||
@ -60,7 +58,7 @@ DHCP 配置文件中定义了两种类型的语句:
|
||||
$ cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
4. 然后,打开主配置文件并定义你的 DHCP 服务选项:
|
||||
4、 然后,打开主配置文件并定义你的 DHCP 服务选项:
|
||||
|
||||
```
|
||||
$ vi /etc/dhcp/dhcpd.conf
|
||||
@ -76,7 +74,7 @@ max-lease-time 7200;
|
||||
authoritative;
|
||||
```
|
||||
|
||||
5. 然后,定义一个子网;在这个事例中,我们会为 192.168.56.0/24 局域网配置 DHCP(注意使用你实际场景中的值):
|
||||
5、 然后,定义一个子网;在这个事例中,我们会为 `192.168.56.0/24` 局域网配置 DHCP(注意使用你实际场景中的值):
|
||||
|
||||
```
|
||||
subnet 192.168.56.0 netmask 255.255.255.0 {
|
||||
@ -91,7 +89,7 @@ range 192.168.56.120 192.168.56.200;
|
||||
|
||||
### 第三步:为 DHCP 客户端分配静态 IP
|
||||
|
||||
只需要在 /etc/dhcp/dhcpd.conf 文件中定义下面的部分,其中你必须显式指定它的 MAC 地址和打算分配的 IP,你就可以为网络中指定的客户端计算机分配一个静态 IP 地址:
|
||||
只需要在 `/etc/dhcp/dhcpd.conf` 文件中定义下面的部分,其中你必须显式指定它的 MAC 地址和打算分配的 IP,你就可以为网络中指定的客户端计算机分配一个静态 IP 地址:
|
||||
|
||||
```
|
||||
host ubuntu-node {
|
||||
@ -112,7 +110,7 @@ fixed-address 192.168.56.110;
|
||||
$ ifconfig -a eth0 | grep HWaddr
|
||||
```
|
||||
|
||||
6. 现在,使用下面的命令启动 DHCP 服务,并使在下次系统启动时自动启动:
|
||||
6、 现在,使用下面的命令启动 DHCP 服务,并使在下次系统启动时自动启动:
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
@ -120,9 +118,10 @@ $ systemctl start dhcpd
|
||||
$ systemctl enable dhcpd
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
$ service dhcpd start
|
||||
$ chkconfig dhcpd on```
|
||||
$ chkconfig dhcpd on
|
||||
```
|
||||
|
||||
7. 另外,别忘了使用下面的命令允许 DHCP 服务通过防火墙(DHCPD 守护进程通过 UDP 监听67号端口):
|
||||
7、 另外,别忘了使用下面的命令允许 DHCP 服务通过防火墙(DHCPD 守护进程通过 UDP 监听67号端口):
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
@ -135,7 +134,7 @@ $ service iptables save
|
||||
|
||||
### 第四步:配置 DHCP 客户端
|
||||
|
||||
8. 现在,你可以为网络中的客户端配置自动从 DHCP 服务器中获取 IP 地址。登录到客户端机器并按照下面的方式修改以太网接口的配置文件(注意网卡的名称和编号):
|
||||
8、 现在,你可以为网络中的客户端配置自动从 DHCP 服务器中获取 IP 地址。登录到客户端机器并按照下面的方式修改以太网接口的配置文件(注意网卡的名称和编号):
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
|
||||
@ -152,15 +151,15 @@ ONBOOT=yes
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
9. 你也可以在桌面服务器中按照下面的截图(Ubuntu 16.04桌面版)通过 GUI 设置 Method 为 Automatic (DHCP)。
|
||||
9、 你也可以在桌面服务器中按照下面的截图(Ubuntu 16.04桌面版)通过 GUI 设置 `Method` 为 `Automatic (DHCP)`。
|
||||
|
||||
[
|
||||
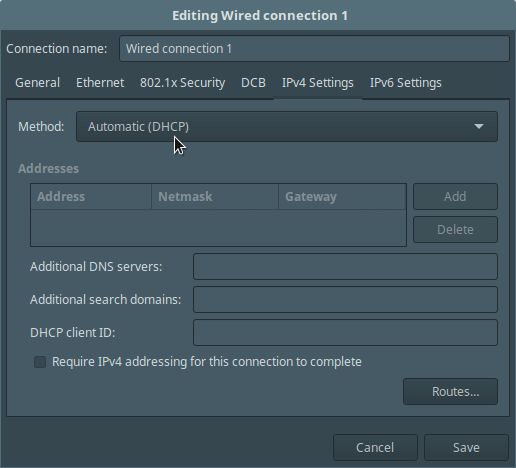
|
||||
][3]
|
||||
|
||||
在客户端网络中设置 DHCP
|
||||
*在客户端网络中设置 DHCP*
|
||||
|
||||
10. 按照下面的命令重启网络服务(你也可以通过重启系统):
|
||||
10、 按照下面的命令重启网络服务(你也可以通过重启系统):
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
@ -190,7 +189,7 @@ via: http://www.tecmint.com/install-dhcp-server-in-centos-rhel-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
101
published/20170330 5 open source RSS feed readers.md
Normal file
101
published/20170330 5 open source RSS feed readers.md
Normal file
@ -0,0 +1,101 @@
|
||||
5 个开源 RSS 订阅阅读器
|
||||
============================================================
|
||||
|
||||

|
||||
>Image by : [Rob McDonald][2] on Flickr. Modified by Opensource.com. [CC BY-SA 2.0][3].
|
||||
|
||||
### 你平时使用 RSS 阅读器么?
|
||||
|
||||
<form class="pollanon" action="https://opensource.com/article/17/3/rss-feed-readers" method="post" id="poll-view-voting" accept-charset="UTF-8"><label class="element-invisible" for="edit-choice" style="display: block; clip: rect(1px 1px 1px 1px); overflow: hidden; height: 1px; width: 1px; color: rgb(67, 81, 86); position: absolute !important;">选择</label><input type="radio" id="edit-choice-7621" name="choice" value="7621" class="form-radio" style="font-size: 16px; margin-top: 0px; max-width: 100%; -webkit-appearance: none; width: 0.8em; height: 0.8em; border-width: 1px; border-style: solid; border-color: rgb(51, 51, 51); border-radius: 50%; vertical-align: middle;"> <label class="option" for="edit-choice-7621" style="display: inline; font-weight: normal; color: rgb(67, 81, 86); margin-left: 0.2em; vertical-align: middle;">是</label><input type="radio" id="edit-choice-7626" name="choice" value="7626" class="form-radio" style="font-size: 16px; margin-top: 0px; max-width: 100%; -webkit-appearance: none; width: 0.8em; height: 0.8em; border-width: 1px; border-style: solid; border-color: rgb(51, 51, 51); border-radius: 50%; vertical-align: middle;"> <label class="option" for="edit-choice-7626" style="display: inline; font-weight: normal; color: rgb(67, 81, 86); margin-left: 0.2em; vertical-align: middle;">不,但是我过去使用</label><input type="radio" id="edit-choice-7631" name="choice" value="7631" class="form-radio" style="font-size: 16px; margin-top: 0px; max-width: 100%; -webkit-appearance: none; width: 0.8em; height: 0.8em; border-width: 1px; border-style: solid; border-color: rgb(51, 51, 51); border-radius: 50%; vertical-align: middle;"> <label class="option" for="edit-choice-7631" style="display: inline; font-weight: normal; color: rgb(67, 81, 86); margin-left: 0.2em; vertical-align: middle;">不,我从没使用过</label><input type="submit" id="edit-vote" name="op" value="投票" class="form-submit" style="font-family: "Swiss 721 SWA", "Helvetica Neue", Helvetica, Arial, "Nimbus Sans L", sans-serif; font-size: 1em; max-width: 100%; line-height: normal; font-style: normal; border-width: 1px; border-style: solid; border-color: rgb(119, 186, 77); color: rgb(255, 255, 255); background: rgb(119, 186, 77); padding: 0.6em 1.9em;"></form>
|
||||
|
||||
四年前当 Google Reader 宣布停止的时候,许多“技术专家”声称 RSS 订阅将会结束。
|
||||
|
||||
对于某些人而言,社交媒体和其他聚合工具满足了 RSS、Atom 以及其它格式的阅读器的需求。但是老技术绝对不会因为新技术而死,特别是如果新技术不能完全覆盖旧技术的所有使用情况时。技术的目标受众可能会有所改变,人们使用这个技术的工具也可能会改变。
|
||||
|
||||
但是,RSS 并不比像 email、JavaScript、SQL 数据库、命令行或者十几年前告诉我的其它时日无多的技术消失的更快。(黑胶专辑的销售额去年刚刚达到了其 [25 年的顶峰][4],这不是个奇迹么?)只要看看在线 Feed 阅读器网站 Feedly 的成功,就能了解 RSS 阅读器仍然有市场。
|
||||
|
||||
事实是,RSS 和相关的 Feed 格式比任何广泛使用的尝试替换它的东西还要多才多艺。作为一名阅读消费者,对于我来说没有比它更简单的方法了,我可以阅读大量的出版信息,并且是用我选择的客户端格式化的,我可以确认看到发布的每一条内容,同时不会显示我已经阅读过的文章。而作为发布者,这是一种比我使用过的大多数发布软件都简单的格式,开箱即用,它可以让我的信息递交给更多的人,并且可以很容易地分发多种不同类型的文档格式。
|
||||
|
||||
所以 RSS 没有死。RSS 长存!我们最后一次是在 2013 年回顾了[开源 RSS 阅读器][5]选择,现在是更新的时候了。这里是我关于 2017 年开源 RSS 订阅阅读器的一些最佳选择,每个在使用上稍微不同。
|
||||
|
||||
### Miniflux
|
||||
|
||||
[Miniflux][6] 是一个极度简约的基于 Web 的 RSS 阅读器,但不要将其特意的轻设计与开发人员的懒惰混淆。它目的是构建一个简单而有效的设计。Miniflux 的思想似乎是将程序弱化,以便让读者可以专注于内容,在大量臃肿的 web 程序中我们会特别欣赏这一点。
|
||||
|
||||
但轻便并不意味着缺乏功能。其响应式设计在任何设备上看起来都很好,并可以使用主题、API 接口、多语言、固定书签等等。
|
||||
|
||||
Miniflux 的 [源代码][7]以 [GPLv3 Affero][8] 许可证在 GitHub 中发布。如果你不想自行托管,则可以支付每年 15 美元的托管计划。
|
||||
|
||||
### RSSOwl
|
||||
|
||||
[RSSOwl][9] 是一个跨平台的桌面 Feed 阅读器。它用 Java 编写,在风格和感觉上它像很多流行的桌面邮件客户端。它具有强大的过滤和搜索功能、可定制的通知,以及用于排序 Feed 的标签。 如果你习惯使用 Thunderbird 或其他桌面阅读器进行电子邮件发送,那么在 RSSOwl 中你会感到宾至如归。
|
||||
|
||||
可以在 GitHub 中找到 [Eclipse Public 许可证][11]下发布的 [RSSOwl][10] 的源代码。
|
||||
|
||||
### Tickr
|
||||
|
||||
[Tickr][12] 在这个系列中有点不同。它是一个 Linux 桌面客户端,但它不是传统的浏览-阅读形式。相反,它会将你的 Feed 标题如滚动新闻那样在桌面横栏上滚动显示。对于想要从各种来源获得最新消息的新闻界来说,这是一个不错的选择。点击标题将在你选择的浏览器中打开它。它不像这个列表中的其他程序那样是专门的阅读客户端,但是如果比起阅读每篇文章,你对阅读标题更感兴趣,这是一个很好的选择。
|
||||
|
||||
Tickr 的源代码和二进制文件以 GPL 许可证的形式在这个[网站][13]上可以找到。
|
||||
|
||||
### Tiny Tiny RSS
|
||||
|
||||
如果缺少了 [Tiny Tiny RSS][14],那么很难称之为这是一个现代化的 RSS 阅读器列表。它是最受欢迎的自主托管的基于 Web 的阅读器,它功能丰富:支持OPML 导入和导出、键盘快捷键、共享功能、主题界面、插件支持、过滤功能等等。
|
||||
|
||||
Tiny Tiny RSS 还有官方的 [Android客户端][15],让你可以随时随地阅读。
|
||||
|
||||
Tiny Tiny RSS 的 [Web][16] 版本和 [Android][17] 源代码以 [GPLv3 许可][18] 在 GitLab 上发布。
|
||||
|
||||
### Winds
|
||||
|
||||
[Winds][19] 是一个建立在 React 之上的看起来很现代化的自托管的 web 订阅阅读器。它利用称为 Stream 的机器学习个性化 API,帮助你根据当前的兴趣找到可能感兴趣的更多内容。这有一个在线显示版本,因此你可以在下载之前先[尝试][20]。这是一个只有几个月的新项目,也许评估它是否能取代我日常的 Feed 阅读器还太早,但这当然是一个我感兴趣关注的项目。
|
||||
|
||||
Winds 的[源代码][21] 以 [MIT][22] 许可证在 GitHub 上发布。
|
||||
|
||||
* * *
|
||||
|
||||
这些当然不是仅有的选择。RSS 是一个相对易于解析、文档格式良好的格式,因此有许许多多因为不同的需求而建立的各种 Feed 阅读器。这有一个很长的自托管的开源 Feed 阅读器[列表][23],除了我们列出的之外你还可能会考虑使用它们。我们希望你能在下面的评论栏与我们分享你最喜欢的 RSS 阅读器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Baker - Jason 热衷于使用技术使世界更加开放,从软件开发到阳光政府行动。Linux 桌面爱好者、地图/地理空间爱好者、树莓派工匠、数据分析和可视化极客、偶尔的码农、云本土主义者。在 Twitter 上关注他 @jehb。
|
||||
|
||||
--------------
|
||||
|
||||
via: https://opensource.com/article/17/3/rss-feed-readers
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://opensource.com/article/17/3/rss-feed-readers?rate=2sJrLq0K3QPQCznBId7K1Qrt3QAkwhQ435UyP77B5rs
|
||||
[2]:https://www.flickr.com/photos/evokeartdesign/6002000807
|
||||
[3]:https://creativecommons.org/licenses/by/2.0/
|
||||
[4]:https://www.theguardian.com/music/2017/jan/03/record-sales-vinyl-hits-25-year-high-and-outstrips-streaming
|
||||
[5]:https://opensource.com/life/13/6/open-source-rss
|
||||
[6]:https://miniflux.net/
|
||||
[7]:https://github.com/miniflux/miniflux
|
||||
[8]:https://github.com/miniflux/miniflux/blob/master/LICENSE
|
||||
[9]:http://www.rssowl.org/
|
||||
[10]:https://github.com/rssowl/RSSOwl
|
||||
[11]:https://github.com/rssowl/RSSOwl/blob/master/LICENSE
|
||||
[12]:https://www.open-tickr.net/
|
||||
[13]:https://www.open-tickr.net/download.php
|
||||
[14]:https://tt-rss.org/gitlab/fox/tt-rss/wikis/home
|
||||
[15]:https://tt-rss.org/gitlab/fox/tt-rss-android
|
||||
[16]:https://tt-rss.org/gitlab/fox/tt-rss/tree/master
|
||||
[17]:https://tt-rss.org/gitlab/fox/tt-rss-android/tree/master
|
||||
[18]:https://tt-rss.org/gitlab/fox/tt-rss-android/blob/master/COPYING
|
||||
[19]:https://winds.getstream.io/
|
||||
[20]:https://winds.getstream.io/app/getting-started
|
||||
[21]:https://github.com/GetStream/Winds
|
||||
[22]:https://github.com/GetStream/Winds/blob/master/LICENSE.md
|
||||
[23]:https://github.com/Kickball/awesome-selfhosted#feed-readers
|
||||
[24]:https://opensource.com/user/19894/feed
|
||||
[25]:https://opensource.com/article/17/3/rss-feed-readers#comments
|
||||
[26]:https://opensource.com/users/jason-baker
|
||||
@ -1,324 +0,0 @@
|
||||
Translating by YYforymj
|
||||
|
||||
|
||||
[How debuggers work: Part 1 - Basics][21]
|
||||
============================================================
|
||||
|
||||
This is the first part in a series of articles on how debuggers work. I'm still not sure how many articles the series will contain and what topics it will cover, but I'm going to start with the basics.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to present the main building block of a debugger's implementation on Linux - the ptrace system call. All the code in this article is developed on a 32-bit Ubuntu machine. Note that the code is very much platform specific, although porting it to other platforms shouldn't be too difficult.
|
||||
|
||||
### Motivation
|
||||
|
||||
To understand where we're going, try to imagine what it takes for a debugger to do its work. A debugger can start some process and debug it, or attach itself to an existing process. It can single-step through the code, set breakpoints and run to them, examine variable values and stack traces. Many debuggers have advanced features such as executing expressions and calling functions in the debbugged process's address space, and even changing the process's code on-the-fly and watching the effects.
|
||||
|
||||
Although modern debuggers are complex beasts [[1]][13], it's surprising how simple is the foundation on which they are built. Debuggers start with only a few basic services provided by the operating system and the compiler/linker, all the rest is just [a simple matter of programming][14].
|
||||
|
||||
### Linux debugging - <tt class="docutils literal" style="font-family: Consolas, monaco, monospace; color: rgb(0, 0, 0); background-color: rgb(247, 247, 247); white-space: nowrap; border-radius: 2px; font-size: 21.6px; padding: 2px;">ptrace
|
||||
|
||||
The Swiss army knife of Linux debuggers is the ptrace system call [[2]][15]. It's a versatile and rather complex tool that allows one process to control the execution of another and to peek and poke at its innards [[3]][16]. ptrace can take a mid-sized book to explain fully, which is why I'm just going to focus on some of its practical uses in examples.
|
||||
|
||||
Let's dive right in.
|
||||
|
||||
### Stepping through the code of a process
|
||||
|
||||
I'm now going to develop an example of running a process in "traced" mode in which we're going to single-step through its code - the machine code (assembly instructions) that's executed by the CPU. I'll show the example code in parts, explaining each, and in the end of the article you will find a link to download a complete C file that you can compile, execute and play with.
|
||||
|
||||
The high-level plan is to write code that splits into a child process that will execute a user-supplied command, and a parent process that traces the child. First, the main function:
|
||||
|
||||
```
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
pid_t child_pid;
|
||||
|
||||
if (argc < 2) {
|
||||
fprintf(stderr, "Expected a program name as argument\n");
|
||||
return -1;
|
||||
}
|
||||
|
||||
child_pid = fork();
|
||||
if (child_pid == 0)
|
||||
run_target(argv[1]);
|
||||
else if (child_pid > 0)
|
||||
run_debugger(child_pid);
|
||||
else {
|
||||
perror("fork");
|
||||
return -1;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Pretty simple: we start a new child process with fork [[4]][17]. The if branch of the subsequent condition runs the child process (called "target" here), and the else if branch runs the parent process (called "debugger" here).
|
||||
|
||||
Here's the target process:
|
||||
|
||||
```
|
||||
void run_target(const char* programname)
|
||||
{
|
||||
procmsg("target started. will run '%s'\n", programname);
|
||||
|
||||
/* Allow tracing of this process */
|
||||
if (ptrace(PTRACE_TRACEME, 0, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Replace this process's image with the given program */
|
||||
execl(programname, programname, 0);
|
||||
}
|
||||
```
|
||||
|
||||
The most interesting line here is the ptrace call. ptrace is declared thus (in sys/ptrace.h):
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
The first argument is a _request_ , which may be one of many predefined PTRACE_* constants. The second argument specifies a process ID for some requests. The third and fourth arguments are address and data pointers, for memory manipulation. The ptrace call in the code snippet above makes the PTRACE_TRACEMErequest, which means that this child process asks the OS kernel to let its parent trace it. The request description from the man-page is quite clear:
|
||||
|
||||
> Indicates that this process is to be traced by its parent. Any signal (except SIGKILL) delivered to this process will cause it to stop and its parent to be notified via wait(). **Also, all subsequent calls to exec() by this process will cause a SIGTRAP to be sent to it, giving the parent a chance to gain control before the new program begins execution**. A process probably shouldn't make this request if its parent isn't expecting to trace it. (pid, addr, and data are ignored.)
|
||||
|
||||
I've highlighted the part that interests us in this example. Note that the very next thing run_targetdoes after ptrace is invoke the program given to it as an argument with execl. This, as the highlighted part explains, causes the OS kernel to stop the process just before it begins executing the program in execl and send a signal to the parent.
|
||||
|
||||
Thus, time is ripe to see what the parent does:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
Recall from above that once the child starts executing the exec call, it will stop and be sent the SIGTRAP signal. The parent here waits for this to happen with the first wait call. wait will return once something interesting happens, and the parent checks that it was because the child was stopped (WIFSTOPPED returns true if the child process was stopped by delivery of a signal).
|
||||
|
||||
What the parent does next is the most interesting part of this article. It invokes ptrace with the PTRACE_SINGLESTEP request giving it the child process ID. What this does is tell the OS - _please restart the child process, but stop it after it executes the next instruction_ . Again, the parent waits for the child to stop and the loop continues. The loop will terminate when the signal that came out of the wait call wasn't about the child stopping. During a normal run of the tracer, this will be the signal that tells the parent that the child process exited (WIFEXITED would return true on it).
|
||||
|
||||
Note that icounter counts the amount of instructions executed by the child process. So our simple example actually does something useful - given a program name on the command line, it executes the program and reports the amount of CPU instructions it took to run from start to finish. Let's see it in action.
|
||||
|
||||
### A test run
|
||||
|
||||
I compiled the following simple program and ran it under the tracer:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
printf("Hello, world!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
To my surprise, the tracer took quite long to run and reported that there were more than 100,000 instructions executed. For a simple printf call? What gives? The answer is very interesting [[5]][18]. By default, gcc on Linux links programs to the C runtime libraries dynamically. What this means is that one of the first things that runs when any program is executed is the dynamic library loader that looks for the required shared libraries. This is quite a lot of code - and remember that our basic tracer here looks at each and every instruction, not of just the main function, but _of the whole process_ .
|
||||
|
||||
So, when I linked the test program with the -static flag (and verified that the executable gained some 500KB in weight, as is logical for a static link of the C runtime), the tracing reported only 7,000 instructions or so. This is still a lot, but makes perfect sense if you recall that libc initialization still has to run before main, and cleanup has to run after main. Besides, printf is a complex function.
|
||||
|
||||
Still not satisfied, I wanted to see something _testable_ - i.e. a whole run in which I could account for every instruction executed. This, of course, can be done with assembly code. So I took this version of "Hello, world!" and assembled it:
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len
|
||||
mov ecx, msg
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
msg db 'Hello, world!', 0xa
|
||||
len equ $ - msg
|
||||
```
|
||||
|
||||
Sure enough. Now the tracer reported that 7 instructions were executed, which is something I can easily verify.
|
||||
|
||||
### Deep into the instruction stream
|
||||
|
||||
The assembly-written program allows me to introduce you to another powerful use of ptrace - closely examining the state of the traced process. Here's another version of the run_debugger function:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
unsigned instr = ptrace(PTRACE_PEEKTEXT, child_pid, regs.eip, 0);
|
||||
|
||||
procmsg("icounter = %u. EIP = 0x%08x. instr = 0x%08x\n",
|
||||
icounter, regs.eip, instr);
|
||||
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
The only difference is in the first few lines of the while loop. There are two new ptrace calls. The first one reads the value of the process's registers into a structure. user_regs_struct is defined in sys/user.h. Now here's the fun part - if you look at this header file, a comment close to the top says:
|
||||
|
||||
```
|
||||
/* The whole purpose of this file is for GDB and GDB only.
|
||||
Don't read too much into it. Don't use it for
|
||||
anything other than GDB unless know what you are
|
||||
doing. */
|
||||
```
|
||||
|
||||
Now, I don't know about you, but it makes _me_ feel we're on the right track :-) Anyway, back to the example. Once we have all the registers in regs, we can peek at the current instruction of the process by calling ptrace with PTRACE_PEEKTEXT, passing it regs.eip (the extended instruction pointer on x86) as the address. What we get back is the instruction [[6]][19]. Let's see this new tracer run on our assembly-coded snippet:
|
||||
|
||||
```
|
||||
$ simple_tracer traced_helloworld
|
||||
[5700] debugger started
|
||||
[5701] target started. will run 'traced_helloworld'
|
||||
[5700] icounter = 1\. EIP = 0x08048080\. instr = 0x00000eba
|
||||
[5700] icounter = 2\. EIP = 0x08048085\. instr = 0x0490a0b9
|
||||
[5700] icounter = 3\. EIP = 0x0804808a. instr = 0x000001bb
|
||||
[5700] icounter = 4\. EIP = 0x0804808f. instr = 0x000004b8
|
||||
[5700] icounter = 5\. EIP = 0x08048094\. instr = 0x01b880cd
|
||||
Hello, world!
|
||||
[5700] icounter = 6\. EIP = 0x08048096\. instr = 0x000001b8
|
||||
[5700] icounter = 7\. EIP = 0x0804809b. instr = 0x000080cd
|
||||
[5700] the child executed 7 instructions
|
||||
```
|
||||
|
||||
OK, so now in addition to icounter we also see the instruction pointer and the instruction it points to at each step. How to verify this is correct? By using objdump -d on the executable:
|
||||
|
||||
```
|
||||
$ objdump -d traced_helloworld
|
||||
|
||||
traced_helloworld: file format elf32-i386
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 0e 00 00 00 mov $0xe,%edx
|
||||
8048085: b9 a0 90 04 08 mov $0x80490a0,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: b8 01 00 00 00 mov $0x1,%eax
|
||||
804809b: cd 80 int $0x80
|
||||
```
|
||||
|
||||
The correspondence between this and our tracing output is easily observed.
|
||||
|
||||
### Attaching to a running process
|
||||
|
||||
As you know, debuggers can also attach to an already-running process. By now you won't be surprised to find out that this is also done with ptrace, which can get the PTRACE_ATTACH request. I won't show a code sample here since it should be very easy to implement given the code we've already gone through. For educational purposes, the approach taken here is more convenient (since we can stop the child process right at its start).
|
||||
|
||||
### The code
|
||||
|
||||
The complete C source-code of the simple tracer presented in this article (the more advanced, instruction-printing version) is available [here][20]. It compiles cleanly with -Wall -pedantic --std=c99 on version 4.4 of gcc.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
Admittedly, this part didn't cover much - we're still far from having a real debugger in our hands. However, I hope it has already made the process of debugging at least a little less mysterious. ptrace is truly a versatile system call with many abilities, of which we've sampled only a few so far.
|
||||
|
||||
Single-stepping through the code is useful, but only to a certain degree. Take the C "Hello, world!" sample I demonstrated above. To get to main it would probably take a couple of thousands of instructions of C runtime initialization code to step through. This isn't very convenient. What we'd ideally want to have is the ability to place a breakpoint at the entry to main and step from there. Fair enough, and in the next part of the series I intend to show how breakpoints are implemented.
|
||||
|
||||
### References
|
||||
|
||||
I've found the following resources and articles useful in the preparation of this article:
|
||||
|
||||
* [Playing with ptrace, Part I][11]
|
||||
* [How debugger works][12]
|
||||
|
||||
|
||||
|
||||
[1] I didn't check but I'm sure the LOC count of gdb is at least in the six-figures range.
|
||||
|
||||
[2] Run man 2 ptrace for complete enlightment.
|
||||
|
||||
[3] Peek and poke are well-known system programming jargon for directly reading and writing memory contents.
|
||||
|
||||
[4] This article assumes some basic level of Unix/Linux programming experience. I assume you know (at least conceptually) about fork, the exec family of functions and Unix signals.
|
||||
|
||||
[5] At least if you're as obsessed with low-level details as I am :-)
|
||||
|
||||
[6] A word of warning here: as I noted above, a lot of this is highly platform specific. I'm making some simplifying assumptions - for example, x86 instructions don't have to fit into 4 bytes (the size of unsigned on my 32-bit Ubuntu machine). In fact, many won't. Peeking at instructions meaningfully requires us to have a complete disassembler at hand. We don't have one here, but real debuggers do.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id1
|
||||
[2]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id2
|
||||
[3]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id3
|
||||
[4]:http://www.jargon.net/jargonfile/p/peek.html
|
||||
[5]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.linuxjournal.com/article/6100?page=0,1
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id7
|
||||
[14]:http://en.wikipedia.org/wiki/Small_matter_of_programming
|
||||
[15]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id8
|
||||
[16]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id9
|
||||
[17]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id10
|
||||
[18]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id11
|
||||
[19]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id12
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2011/simple_tracer.c
|
||||
[21]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
@ -1,3 +1,5 @@
|
||||
Firstadream translating
|
||||
|
||||
[How debuggers work: Part 2 - Breakpoints][26]
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,140 +0,0 @@
|
||||
|
||||
Translating by fristadream
|
||||
|
||||
Will Android do for the IoT what it did for mobile?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Android Things gives the IoT Wings
|
||||
|
||||
### My first 24 hours with Android Things
|
||||
|
||||
Just when I was in the middle of an Android based IoT commercial project running on a Raspberry Pi 3, something awesome happened. Google released the first preview of [Android Things][1], their SDK targeted specifically at (initially) 3 SBC’s (Single Board Computers) — the Pi 3, the Intel Edison and the NXP Pico. To say I was struggling is a bit of an understatement — without even an established port of Android to the Pi, we were at the mercy of the various quirks and omissions of the well-meaning but problematic homebrew distro brigade. One of these problems was a deal breaker too — no touchscreen support, not even for the official one sold by [Element14][2]. I had an idea Android was heading for the Pi already, and earlier a mention in a [commit to the AOSP project from Google][3] got everyone excited for a while. So when, on 12th Dec 2016, without much fanfare I might add, Google announced “Android Things” plus a downloadable SDK, I dived in with both hands, a map and a flashlight, and hung a “do not disturb” sign on my door…
|
||||
|
||||
### Questions?
|
||||
|
||||
I had many questions regarding Googles Android on the Pi, having done extensive work with Android previously and a few Pi projects, including being involved right now in the one mentioned. I’ll try to address these as I proceed, but the first and biggest was answered right away — there is full Android Studio support and the Pi becomes just another regular ADB-addressable device on your list. Yay! The power, convenience and sheer ease of use we get within Android Studio is available at last to real IoT hardware, so we get all the layout previews, debug system, source checkers, automated tests etc. I can’t stress this enough. Up until now, most of my work onboard the Pi had been in Python having SSH’d in using some editor running on the Pi (MC if you really want to know). This worked, and no doubt hardcore Pi/Python heads could point out far better ways of working, but it really felt like I’d timewarped back to the 80’s in terms of software development. My projects involved writing Android software on handsets which controlled the Pi, so this rubbed salt in the wound — I was using Android Studio for “real” Android work, and SSH for the rest. That’s all over now.
|
||||
|
||||
All samples are for the 3 SBC’s, of which the the Pi 3 is just one. The Build.DEVICE constant lets you determine this at runtime, so you see lots of code like:
|
||||
|
||||
```
|
||||
public static String getGPIOForButton() {
|
||||
switch (Build.DEVICE) {
|
||||
case DEVICE_EDISON_ARDUINO:
|
||||
return "IO12";
|
||||
case DEVICE_EDISON:
|
||||
return "GP44";
|
||||
case DEVICE_RPI3:
|
||||
return "BCM21";
|
||||
case DEVICE_NXP:
|
||||
return "GPIO4_IO20";
|
||||
default:
|
||||
throw new IllegalStateException(“Unknown Build.DEVICE “ + Build.DEVICE);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Of keen interest is the GPIO handling. Since I’m only familiar with the Pi, I can only assume the other SBCs work the same way, but this is the set of pins which can be defined as inputs/outputs and is the main interface to the physical outside world. The Pi Linux based OS distros have full and easy support via read and write methods in Python, but for Android you’d have to use the NDK to write C++ drivers, and talk to these via JNI in Java. Not that difficult, but something else to maintain in your build chain. The Pi also designates 2 pins for I2C, the clock and the data, so extra work would be needed handling those. I2C is the really cool bus-addressable system which turns many separate pins of data into one by serialising it. So here’s the kicker — all that’s done directly in Android Things for you. You just _read()_and _write() _to/from whatever GPIO pin you need, and I2C is as easy as this:
|
||||
|
||||
```
|
||||
public class HomeActivity extends Activity {
|
||||
// I2C Device Name
|
||||
private static final String I2C_DEVICE_NAME = ...;
|
||||
// I2C Slave Address
|
||||
private static final int I2C_ADDRESS = ...;
|
||||
|
||||
private I2cDevice mDevice;
|
||||
|
||||
@Override
|
||||
protected void onCreate(Bundle savedInstanceState) {
|
||||
super.onCreate(savedInstanceState);
|
||||
// Attempt to access the I2C device
|
||||
try {
|
||||
PeripheralManagerService manager = new PeripheralManagerService();
|
||||
mDevice = manager.openI2cDevice(I2C_DEVICE_NAME, I2C_ADDRESS)
|
||||
} catch (IOException e) {
|
||||
Log.w(TAG, "Unable to access I2C device", e);
|
||||
}
|
||||
}
|
||||
|
||||
@Override
|
||||
protected void onDestroy() {
|
||||
super.onDestroy();
|
||||
|
||||
if (mDevice != null) {
|
||||
try {
|
||||
mDevice.close();
|
||||
mDevice = null;
|
||||
} catch (IOException e) {
|
||||
Log.w(TAG, "Unable to close I2C device", e);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### What version of Android is Android Things based on?
|
||||
|
||||
This looks to be Android 7.0, which is fantastic because we get all the material design UI, the optimisations, the security hardening and so on from all the previous versions of Android. It also raises an interesting question — how are future platform updates rolled out, as opposed to your app which you have to manage separately? Remember, these devices may not be connected to the internet. We are no longer in the comfortable space of cellular/WiFi connections being assumed to at least be available, even if sometimes unreliable.
|
||||
|
||||
The other worry was this being an offshoot version of Android in name only, where to accommodate the lowest common denominator, something so simple it could power an Arduino has been released — more of a marketing exercise than a rich OS. That’s quickly put to bed by looking at the [samples][4], actually — some even use SVG graphics as resources, a very recent Android innovation, rather than the traditional bitmap-based graphics, which of course it also handles with ease.
|
||||
|
||||
Inevitably, regular Android will throw up issues when compared with Android Things. For example, there is the permissions conundrum. Mitigated somewhat by the fact Android Things is designed to power fixed hardware devices, so the user wouldn’t normally install apps after it’s been built, it’s nevertheless a problem asking them for permissions on a device which might not have a UI! The solution is to grant all the permissions an app might need at install time. Normally, these devices are one app only, and that app is the one which runs when it powers up.
|
||||
|
||||

|
||||
|
||||
### What happened to Brillo?
|
||||
|
||||
Brillo was the codename given to Googles previous IoT OS, which sounds a lot like what Android Things used to be called. In fact you see many references to Brillo still, especially in the source code folder names in the GitHub Android Things examples. However, it has ceased to be. All hail the new king!
|
||||
|
||||
### UI Guidelines?
|
||||
|
||||
Google issues extensive guidelines regarding Android smartphone and tablet apps, such as how far apart on screen buttons should be and so on. Sure, its best to follow these where practical, but we’re not in Kansas any more. There is nothing there by default — it’s up the the app author to manage _everything_. This includes the top status bar, the bottom navigation bar — absolutely everything. Years of Google telling Android app authors never to render an onscreen BACK button because the platform will supply one is thrown out, because for Android Things there [might not even be a UI at all!][5]
|
||||
|
||||
### How much support of the Google services we’re used to from smartphones can we expect?
|
||||
|
||||
Quite a bit actually, but not everything. The first preview has no bluetooth support. No NFC, either — both of which are heavily contributing to the IoT revolution. The SBC’s support them, so I can’t see them not being available for too long. Since there’s no notification bar, there can’t be any notifications. No Maps. There’s no default soft keyboard, you have to install one yourself. And since there is no Play Store, you have to get down and dirty with ADB to do this, and many other operations.
|
||||
|
||||
When developing for Android Things I tried to make the same APK I was targeting for the Pi run on a regular handset. This threw up an error preventing it from being installed on anything other than an Android Things device: library “_com.google.android.things_” not present. Kinda makes sense, because only Android Things devices would need this, but it seemed limiting because not only would no smartphones or tablets have it present, but neither would any emulators. It looked like you could only run and test your Android Things apps on physical Android Things devices … until Google helpfully replied to my query on this in the [G+ Google’s IoT Developers Community][6] group with a workaround. Bullet dodged there, then.
|
||||
|
||||
### How can we expect the Android Things ecosystem to evolve now?
|
||||
|
||||
I’d expect to see a lot more porting of traditional Linux server based apps which didn’t really make sense to an Android restricted to smartphones and tablets. For example, a web server suddenly becomes very useful. Some exist already, but nothing like the heavyweights such as Apache or Nginx. IoT devices might not have a local UI, but administering them via a browser is certainly viable, so something to present a web panel this way is needed. Similarly comms apps from the big names — all it needs is a mike and speaker and in theory it’s good to go for any video calling app, like Duo, Skype, FB etc. How far this evolution goes is anyone’s guess. Will there be a Play Store? Will they show ads? Can we be sure they won’t spy on us, or let hackers control them? The IoT from a consumer point of view always was net-connected devices with touchscreens, and everyone’s already used to that way of working from their smartphones.
|
||||
|
||||
I’d also expect to see rapid progress regarding hardware — in particular many more SBC’s at even lower costs. Look at the amazing $5 Raspberry Pi Zero, which unfortunately almost certainly can’t run Android Things due to its limited CPU and RAM. How long until one like this can? It’s pretty obvious, now the bar has been set, any self respecting SBC manufacturer will be aiming for Android Things compatibility, and probably the economies of scale will apply to the peripherals too such as a $2 3" touchscreen. Microwave ovens just won’t sell unless you can watch YouTube on them, and your dishwasher just put in a bid for more powder on eBay since it noticed you’re running low…
|
||||
|
||||
However, I don’t think we can get too carried away here. Knowing a little about Android architecture helps when thinking of it as an all-encompassing IoT OS. It still uses Java, which has been hammered to death in the past with all its garbage-collection induced timing issues. That’s the least of it though. A genuine realtime OS relies on predictable, accurate and rock-solid timing or it can’t be described as “mission critical”. Think about medical applications, safety monitors, industrial controllers etc. With Android, your Activity/Service can, in theory, be killed at any time if the host OS thinks it needs to. Not so bad on a phone — the user restarts the app, kills other apps, or reboots the handset. A heart monitor is a different kettle all together though. If that foreground Activity/Service is watching a GPIO pin, and the signal isn’t dealt with exactly when it is supposed to, we have failed. Some pretty fundamental changes would have to be made to Android to support this, and so far there’s no indication it’s even planned.
|
||||
|
||||
### Those 24 hours
|
||||
|
||||
So, back to my project. I thought I’d take the work I’d done already and just port as much as I could over, waiting for the inevitable roadblock where I had to head over to the G+ group, cap in hand for help. Which, apart from the query about running on non-AT devices, never happened. And it ran great! This project uses some oddball stuff too, custom fonts, prescise timers — all of which appeared perfectly laid out in Android Studio. So its top marks from me, Google — at last I can start giving actual prototypes out rather than just videos and screenshots.
|
||||
|
||||
### The big picture
|
||||
|
||||
The IoT OS landscape today looks very fragmented. There is clearly no market leader and despite all the hype and buzz we hear, it’s still incredibly early days. Can Google do to the IoT with Android Things what it did to mobile, where it’s dominance is now very close to 90%? I believe so, and if that is to happen, this launch of Android Things is exactly how they would go about it.
|
||||
|
||||
Remember all the open vs closed software wars, mainly between Apple who never licence theirs, and Google who can’t give it away for free to enough people? That policy now comes back once more, because the idea of Apple launching a free IoT OS is as far fetched as them giving away their next iPhone for nothing.
|
||||
|
||||
The IoT OS game is wide open for someone to grab, and the opposition won’t even be putting their kit on this time…
|
||||
|
||||
Head over to the [Developer Preview][7] site to get your copy of the Android Things SDK now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@carl.whalley/will-android-do-for-iot-what-it-did-for-mobile-c9ac79d06c#.hxva5aqi2
|
||||
|
||||
作者:[Carl Whalley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@carl.whalley
|
||||
[1]:https://developer.android.com/things/index.html
|
||||
[2]:https://www.element14.com/community/docs/DOC-78156/l/raspberry-pi-7-touchscreen-display
|
||||
[3]:http://www.androidpolice.com/2016/05/24/google-is-preparing-to-add-the-raspberry-pi-3-to-aosp-it-will-apparently-become-an-officially-supported-device/
|
||||
[4]:https://github.com/androidthings/sample-simpleui/blob/master/app/src/main/res/drawable/pinout_board_vert.xml
|
||||
[5]:https://developer.android.com/things/sdk/index.html
|
||||
[6]:https://plus.google.com/+CarlWhalley/posts/4tF76pWEs1D
|
||||
[7]:https://developer.android.com/things/preview/index.html
|
||||
@ -1,268 +0,0 @@
|
||||
**translating by [erlinux](https://github.com/erlinux)**
|
||||
inxi – A Great Tool to Check Hardware Information on Linux
|
||||
============================================================
|
||||
|
||||
One of the big challenge for Linux administrator to find, all the hardware information on the system. There are many command line utility is are available in Linux to get the hardware information but there will be a lack to get some of the information.
|
||||
|
||||
[inxi][1] is a nifty tool to check hardware information on Linux and offers wide range of option to get all the hardware information on Linux system that i never found in any other utility which are available in Linux. It was forked from the ancient and mindbendingly perverse yet ingenius infobash, by locsmif.
|
||||
|
||||
inxi is a script that quickly shows system hardware, CPU, drivers, Xorg, Desktop, Kernel, GCC version(s), Processes, RAM usage, and a wide variety of other useful information, also used for forum technical support & debugging tool.
|
||||
|
||||
#### Install inix on Linux
|
||||
|
||||
inxi is support all Linux distributions and never require latest dependencies, so no need to think about manual installation. Simply install inix from distribution official repository by using below commands.
|
||||
|
||||
```
|
||||
[Install inxi on CentOS/RHEL]
|
||||
$ sudo yum install inxi
|
||||
|
||||
[Install inix on Fedora]
|
||||
$ sudo dnf install inxi
|
||||
|
||||
[Install inxi on Debian/Linux Mint/Ubuntu]
|
||||
$ sudo apt-get install inxi
|
||||
|
||||
[Install inxi on openSUSE]
|
||||
$ sudo zypper in inxi
|
||||
|
||||
[Install inxi on Mageia]
|
||||
$ sudo urpmi inxi
|
||||
|
||||
[Install inxi on Arch based system]
|
||||
$ yaourt -S inxi
|
||||
```
|
||||
|
||||
By default inxi output comes with colors which can be turned off by using `-c` followed by `0` (you can use 0-32) to get better visibility.
|
||||
|
||||
#### Print one line output with inix
|
||||
|
||||
Issue inxi command without any option to print the hardware information in one line like, CPU, kernel, architecture, uptime, memory, HDD, process & inxi version.
|
||||
|
||||
```
|
||||
$ inxi -c 0
|
||||
CPU~Dual core Intel Core i7-6700HQ (-MCP-) speed~2591 MHz (max) Kernel~4.8.0-32-generic x86_64 Up~50 min Mem~1609.9/1999.8MB HDD~42.9GB(17.6% used) Procs~197 Client~Shell inxi~2.3.1
|
||||
```
|
||||
|
||||
#### Print basic system hardware
|
||||
|
||||
Issue inxi command with `-b` option wich will print basic system hardware information. I mean, it shows about System, Machine, CPU, Graphics, Network, Drives & Info.
|
||||
|
||||
```
|
||||
$ inxi -b
|
||||
System: Host: daygeek Kernel: 4.8.0-32-generic x86_64 (64 bit) Desktop: Unity 7.5.0 Distro: Ubuntu 16.10
|
||||
Machine: System: innotek (portable) product: VirtualBox v: 1.2
|
||||
Mobo: Oracle model: VirtualBox v: 1.2 BIOS: innotek v: VirtualBox date: 12/01/2006
|
||||
Battery BAT0: charge: 31.5 Wh 63.0% condition: 50.0/50.0 Wh (100%)
|
||||
CPU: Dual core Intel Core i7-6700HQ (-MCP-) speed: 2591 MHz (max)
|
||||
Graphics: Card: InnoTek Systemberatung VirtualBox Graphics Adapter
|
||||
Display Server: X.Org 1.18.4 drivers: (unloaded: fbdev,vesa) Resolution: 1920x955@59.89hz
|
||||
GLX Renderer: Gallium 0.4 on llvmpipe (LLVM 3.8, 256 bits) GLX Version: 3.0 Mesa 12.0.3
|
||||
Network: Card: Intel 82540EM Gigabit Ethernet Controller driver: e1000
|
||||
Drives: HDD Total Size: 42.9GB (17.6% used)
|
||||
Info: Processes: 197 Uptime: 50 min Memory: 1586.2/1999.8MB Client: Shell (bash) inxi: 2.3.1
|
||||
```
|
||||
|
||||
* System : Host Name, Kernel version, Architecture, Desktop & Distribution
|
||||
* Machine : Motherboard & Bios information
|
||||
* CPU : Processor Name and core
|
||||
* Graphics : Graphics card info
|
||||
* Network : Network card info
|
||||
* Drives : HDD size and used percent
|
||||
* Info : Total process count, Server Uptime, Memory total and used, inxi version
|
||||
|
||||
#### Show Audio/sound card information
|
||||
|
||||
Issue inxi command with `-A` which will show Audio/sound card information.
|
||||
|
||||
```
|
||||
$ inxi -A
|
||||
Audio: Card Intel 82801AA AC'97 Audio Controller driver: snd_intel8x0 Sound: ALSA v: k4.8.0-32-generic
|
||||
```
|
||||
|
||||
#### Show full CPU info
|
||||
|
||||
Issue inxi command with `-C` which will show full CPU information, including per CPU clock speed and CPU max speed (if available).
|
||||
|
||||
```
|
||||
$ inxi -C
|
||||
CPU: Dual core Intel Core i7-6700HQ (-MCP-) cache: 6144 KB
|
||||
clock speeds: max: 2591 MHz 1: 2591 MHz 2: 2591 MHz
|
||||
```
|
||||
|
||||
#### Show optical drive information
|
||||
|
||||
Issue inxi command with `-d` which will show optical drive data information, including all storage.
|
||||
|
||||
```
|
||||
$ inxi -d
|
||||
Drives: HDD Total Size: 42.9GB (17.6% used) ID-1: /dev/sda model: VBOX_HARDDISK size: 42.9GB
|
||||
Optical: /dev/sr0 model: VBOX CD-ROM dev-links: cdrom,dvd
|
||||
Features: speed: 32x multisession: yes audio: yes dvd: yes rw: none
|
||||
```
|
||||
#### Show full hard Disk information
|
||||
|
||||
Issue inxi command with `-D` which will show full hard Disk information, including HDD total size, used size and percentage, file system type & mount point.
|
||||
|
||||
```
|
||||
$ inxi -D
|
||||
Drives: HDD Total Size: 42.9GB (17.6% used) ID-1: /dev/sda model: VBOX_HARDDISK size: 42.9GB
|
||||
```
|
||||
|
||||
Issue inxi command with `-p` which will show full partition information.
|
||||
|
||||
```
|
||||
$ inxi -p
|
||||
Partition: ID-1: / size: 38G used: 5.2G (15%) fs: ext4 dev: /dev/sda1
|
||||
ID-2: swap-1 size: 2.15GB used: 0.20GB (9%) fs: swap dev: /dev/sda5
|
||||
```
|
||||
|
||||
Issue inxi command with `-0` which will show unmounted partition information.
|
||||
|
||||
```
|
||||
$ inxi -o
|
||||
Unmounted: No unmounted partitions detected
|
||||
```
|
||||
|
||||
#### Show Graphic card information
|
||||
|
||||
Issue inxi command with `-G` which will show Graphic card information.
|
||||
|
||||
```
|
||||
$ inxi -G
|
||||
Graphics: Card: InnoTek Systemberatung VirtualBox Graphics Adapter
|
||||
Display Server: X.Org 1.18.4 drivers: (unloaded: fbdev,vesa) Resolution: 1920x955@59.89hz
|
||||
GLX Renderer: Gallium 0.4 on llvmpipe (LLVM 3.8, 256 bits) GLX Version: 3.0 Mesa 12.0.3
|
||||
```
|
||||
|
||||
#### Show server public IP address
|
||||
|
||||
Issue inxi command with `-i` (requires ifconfig network tool) which will show server public IP address.
|
||||
|
||||
```
|
||||
$ inxi -i
|
||||
Network: Card: Intel 82540EM Gigabit Ethernet Controller driver: e1000
|
||||
IF: enp0s3 state: up speed: 1000 Mbps duplex: full mac: 08:00:27:ae:1d:fe
|
||||
WAN IP: 103.5.134.167 IF: enp0s3 ip-v4: 10.0.2.15
|
||||
```
|
||||
|
||||
#### Show machine data information
|
||||
|
||||
Issue inxi command with `-M` which will show machine data information, including Device, Motherboard, Bios, and if percentage, System Builder (Like Lenovo).
|
||||
|
||||
```
|
||||
$ inxi -M
|
||||
Machine: System: innotek (portable) product: VirtualBox v: 1.2
|
||||
Mobo: Oracle model: VirtualBox v: 1.2 BIOS: innotek v: VirtualBox date: 12/01/2006
|
||||
Battery BAT0: charge: 32.5 Wh 65.0% condition: 50.0/50.0 Wh (100%)
|
||||
```
|
||||
|
||||
#### Show Show Network card information
|
||||
|
||||
Issue inxi command with `-N` which will show Show Network card information.
|
||||
|
||||
```
|
||||
$ inxi -N
|
||||
Network: Card: Intel 82540EM Gigabit Ethernet Controller driver: e1000
|
||||
```
|
||||
|
||||
Issue inxi command with `-n` which will show Show Advanced Network card information, including interface, speed, mac id, state, etc.
|
||||
|
||||
```
|
||||
$ inxi -n
|
||||
Network: Card: Intel 82540EM Gigabit Ethernet Controller driver: e1000
|
||||
IF: enp0s3 state: up speed: 1000 Mbps duplex: full mac: 08:00:27:ae:1d:fe
|
||||
```
|
||||
|
||||
#### Show distro repository data information
|
||||
|
||||
Issue inxi command with `-r` which will show distro repository data information.
|
||||
|
||||
```
|
||||
$ inxi -r
|
||||
Repos: Active apt sources in file: /etc/apt/sources.list
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety main restricted
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates main restricted
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety universe
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates universe
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety multiverse
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-updates multiverse
|
||||
deb http://in.archive.ubuntu.com/ubuntu/ yakkety-backports main restricted universe multiverse
|
||||
deb http://security.ubuntu.com/ubuntu yakkety-security main restricted
|
||||
deb http://security.ubuntu.com/ubuntu yakkety-security universe
|
||||
deb http://security.ubuntu.com/ubuntu yakkety-security multiverse
|
||||
Active apt sources in file: /etc/apt/sources.list.d/arc-theme.list
|
||||
deb http://download.opensuse.org/repositories/home:/Horst3180/xUbuntu_16.04/ /
|
||||
Active apt sources in file: /etc/apt/sources.list.d/snwh-ubuntu-pulp-yakkety.list
|
||||
deb http://ppa.launchpad.net/snwh/pulp/ubuntu yakkety main
|
||||
```
|
||||
|
||||
#### Show possible system hardware information
|
||||
|
||||
Issue inxi command with `-F` which will show possible system hardware information.
|
||||
|
||||
```
|
||||
$ inxi -F
|
||||
System: Host: daygeek Kernel: 4.8.0-32-generic x86_64 (64 bit) Desktop: Unity 7.5.0 Distro: Ubuntu 16.10
|
||||
Machine: System: innotek (portable) product: VirtualBox v: 1.2
|
||||
Mobo: Oracle model: VirtualBox v: 1.2 BIOS: innotek v: VirtualBox date: 12/01/2006
|
||||
Battery BAT0: charge: 33.0 Wh 66.0% condition: 50.0/50.0 Wh (100%)
|
||||
CPU: Dual core Intel Core i7-6700HQ (-MCP-) cache: 6144 KB
|
||||
clock speeds: max: 2591 MHz 1: 2591 MHz 2: 2591 MHz
|
||||
Graphics: Card: InnoTek Systemberatung VirtualBox Graphics Adapter
|
||||
Display Server: X.Org 1.18.4 drivers: (unloaded: fbdev,vesa) Resolution: 1920x955@59.89hz
|
||||
GLX Renderer: Gallium 0.4 on llvmpipe (LLVM 3.8, 256 bits) GLX Version: 3.0 Mesa 12.0.3
|
||||
Audio: Card Intel 82801AA AC'97 Audio Controller driver: snd_intel8x0 Sound: ALSA v: k4.8.0-32-generic
|
||||
Network: Card: Intel 82540EM Gigabit Ethernet Controller driver: e1000
|
||||
IF: enp0s3 state: up speed: 1000 Mbps duplex: full mac: 08:00:27:ae:1d:fe
|
||||
Drives: HDD Total Size: 42.9GB (17.6% used) ID-1: /dev/sda model: VBOX_HARDDISK size: 42.9GB
|
||||
Partition: ID-1: / size: 38G used: 5.2G (15%) fs: ext4 dev: /dev/sda1
|
||||
ID-2: swap-1 size: 2.15GB used: 0.20GB (9%) fs: swap dev: /dev/sda5
|
||||
RAID: No RAID devices: /proc/mdstat, md_mod kernel module present
|
||||
Sensors: None detected - is lm-sensors installed and configured?
|
||||
Info: Processes: 198 Uptime: 53 min Memory: 1587.5/1999.8MB Client: Shell (bash) inxi: 2.3.1
|
||||
```
|
||||
|
||||
#### Get extra information about the device
|
||||
|
||||
Add `-x` with any above individual output which will show extra information about the device.
|
||||
|
||||
```
|
||||
$ inxi -F -x
|
||||
System: Host: daygeek Kernel: 4.8.0-32-generic x86_64 (64 bit gcc: 6.2.0)
|
||||
Desktop: Unity 7.5.0 (Gtk 3.20.9-1ubuntu2) Distro: Ubuntu 16.10
|
||||
Machine: System: innotek (portable) product: VirtualBox v: 1.2
|
||||
Mobo: Oracle model: VirtualBox v: 1.2 BIOS: innotek v: VirtualBox date: 12/01/2006
|
||||
Battery BAT0: charge: 33.0 Wh 66.0% condition: 50.0/50.0 Wh (100%) model: innotek 1 status: Charging
|
||||
CPU: Dual core Intel Core i7-6700HQ (-MCP-) cache: 6144 KB
|
||||
flags: (lm nx sse sse2 sse3 sse4_1 sse4_2 ssse3) bmips: 10368
|
||||
clock speeds: max: 2591 MHz 1: 2591 MHz 2: 2591 MHz
|
||||
Graphics: Card: InnoTek Systemberatung VirtualBox Graphics Adapter bus-ID: 00:02.0
|
||||
Display Server: X.Org 1.18.4 drivers: (unloaded: fbdev,vesa) Resolution: 1920x955@59.89hz
|
||||
GLX Renderer: Gallium 0.4 on llvmpipe (LLVM 3.8, 256 bits)
|
||||
GLX Version: 3.0 Mesa 12.0.3 Direct Rendering: Yes
|
||||
Audio: Card Intel 82801AA AC'97 Audio Controller driver: snd_intel8x0 ports: d100 d200 bus-ID: 00:05.0
|
||||
Sound: Advanced Linux Sound Architecture v: k4.8.0-32-generic
|
||||
Network: Card: Intel 82540EM Gigabit Ethernet Controller
|
||||
driver: e1000 v: 7.3.21-k8-NAPI port: d010 bus-ID: 00:03.0
|
||||
IF: enp0s3 state: up speed: 1000 Mbps duplex: full mac: 08:00:27:ae:1d:fe
|
||||
Drives: HDD Total Size: 42.9GB (17.6% used) ID-1: /dev/sda model: VBOX_HARDDISK size: 42.9GB
|
||||
Partition: ID-1: / size: 38G used: 5.2G (15%) fs: ext4 dev: /dev/sda1
|
||||
ID-2: swap-1 size: 2.15GB used: 0.20GB (9%) fs: swap dev: /dev/sda5
|
||||
RAID: No RAID devices: /proc/mdstat, md_mod kernel module present
|
||||
Sensors: None detected - is lm-sensors installed and configured?
|
||||
Info: Processes: 198 Uptime: 54 min Memory: 1592.5/1999.8MB Init: systemd runlevel: 5 Gcc sys: 6.2.0
|
||||
Client: Shell (bash 4.3.461) inxi: 2.3.1
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/inxi-system-hardware-information-on-linux/2/
|
||||
|
||||
作者:[ MAGESH MARUTHAMUTHU ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://smxi.org/docs/inxi.htm
|
||||
@ -1,97 +0,0 @@
|
||||
Building your own personal cloud with Cozy
|
||||
============================================================
|
||||
|
||||

|
||||
>Image by : [Pixabay][2]. Modified by Opensource.com. [CC BY-SA 4.0][3]
|
||||
|
||||
Most everyone I know uses some sort of web-based application for their calendar, emails, file storage, and much more. But what if, like me, you've got concerns about privacy, or just want to simplify your digital life into a place you control? [Cozy][4] is a project that is moving in the right direction—toward a robust self-hosted cloud platform. Cozy's source code is available on [GitHub][5], and it is licensed under the AGPL 3.0 license.
|
||||
|
||||
### Installation
|
||||
|
||||
Installing Cozy is snap-easy, with [easy-to-follow instructions][6] for a variety of platforms. For my testing, I'm using Debian 8, 64-bit. The installation takes a few minutes, but then you just go to the server's IP, register an account, and a default set of applications is loaded up and ready to roll.
|
||||
|
||||
One note on this—the installation assumes no other web server is running, and it will want to install [Nginx web server][7]. If your server already has websites running, configuration may be a bit more challenging. My install was on a brand new Virtual Private Server (VPS), so this was a snap. Run the installer, start Nginx, and you're ready to hit the cloud.
|
||||
|
||||
Cozy has [an App Store][8] where you can download additional applications. Some look pretty interesting, like the [Ghost blogging platform][9] and [TiddlyWiki][10] open source wiki. The intent here, clearly, is to allow integration in the platform with lots of other goodies. I think it's just a matter of time before you'll see this start to take off, with many other popular open source applications offering integration abilities. Right now, [Node.js][11] applications are supported, but if other application layers were possible, you'd see that many other good things could happen.
|
||||
|
||||
One capability that is possible is using the free Android application to access your information from Android devices. No iOS app exists, but there is a plan to solve that problem.
|
||||
|
||||
Currently, Cozy comes with a nice set of core applications.
|
||||
|
||||

|
||||
|
||||
Main Cozy interface
|
||||
|
||||
### Files
|
||||
|
||||
Like a lot of folks, I use [Dropbox][12] for file storage. In fact, I pay for Dropbox Pro because I use _so much_ storage. For me, then, moving my files to Cozy would be a money-saver—if it has the features I want.
|
||||
|
||||
I wish I could say it does, truly I do. I was very impressed with the web-based file upload and file-management tool built into the Cozy web application. Drag-and-drop works like you'd expect, and the interface is clean and uncluttered. I had no trouble at all uploading some sample files and folders, navigating around, and moving, deleting, and renaming files.
|
||||
|
||||
If what you want is a web-based cloud file storage, you're set. What's missing, for me, is the selective synchronization of files and folders, which Dropbox has. With Dropbox, if you drop a file in a folder, it's copied out to the cloud and made available to all your synced devices in a matter of minutes. To be fair, [Cozy is working on it][13], but it's in beta and only for Linux clients at the moment. Also, I have a [Chrome][14] extension called [Download to Dropbox][15] that I use to capture images and other content from time to time, and no such tool exists yet for Cozy.
|
||||
|
||||

|
||||
|
||||
File Manager interface
|
||||
|
||||
### Importing data from Google
|
||||
|
||||
If you currently use Google Calendar or Contacts, importing these is very easy with the app installed in Cozy. When you authorize access to Google, you're given an API key, which you paste in Cozy, and it performs the copy quickly and efficiently. In both cases, the contents were tagged as having been imported from Google. Given the clutter in my contacts, this is probably a good thing, as it gives you the opportunity to tidy up as you relabel them into more meaningful categories. Calendar events imported all on the "Google Calendar," but I noticed that _some_ of my events had the times incorrect, possibly an artifact of time zone settings on one end or the other.
|
||||
|
||||
### Contacts
|
||||
|
||||
Contacts works like you'd expect, and the interface looks a _lot_ like Google Contacts. There are a few sticky areas, though. Synchronization with (for instance) your smart phone happens via [CardDAV][16], a standard protocol for sharing contacts data—and a technology that Android phones _do not speak natively_. To sync your contacts to an Android device, you're going to have to load an app on your phone for that. For me, that's a _huge_ strike against it, as I have enough odd apps like that already (work mail versus Gmail versus other mail, oh my!), and I do not want to install another that won't sync up with my smartphone's native contacts application. If you're using an iPhone, you can do CardDAV right out of the box.
|
||||
|
||||
### Calendar
|
||||
|
||||
The good news for Calendar users is that an Android device _can_ speak [CalDAV][17], the interchange format for this type of data. As I noted with the import app, some of my calendar items came over with the wrong times. I've seen this before with other calendar system moves, so that really didn't bother me much. The interface lets you create and manage multiple calendars, just like with Google, but you can't subscribe to other calendars outside of this Cozy instance. One other quirk is of the app is starting of the week on Monday, which you can't change. Normally, I start my week on Sunday, so changing from Monday would be a useful feature for me. The Settings dialog didn't actually have any settings; it merely gave instructions on how to connect via CalDAV. Again, this application is close to what I need, but Cozy is not quite there.
|
||||
|
||||
### Photos
|
||||
|
||||
The Photos app is pretty impressive, borrowing a lot from the Files application. You can even add photos to an album that are in files in the other app, or upload directly with drag and drop. Unfortunately, I don't see any way to reorder or edit pictures once you've uploaded them. You can only delete them from the album. The app does have a tool for sharing via a token link, and you can specify one or more contact. The system will send those contacts an email inviting them to view the album. There are more feature-rich album applications than this, to be sure, but this is a good start for the Cozy platform.
|
||||
|
||||

|
||||
|
||||
Photos interface
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Cozy has some really big goals. They're trying to build a platform where you can deploy _any_ cloud-based service you like. Is it ready for prime time? Not quite. Some of the shortcomings I've mentioned are problematic for power users, and there is no iOS application yet, which may hamper adoption for those users. However, keep an eye on this one—Cozy has the potential, as development continues, to become a one-stop replacement for a great many applications.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
D Ruth Bavousett - D Ruth Bavousett has been a system administrator and software developer for a long, long time, getting her professional start on a VAX 11/780, way back when. She spent a lot of her career (so far) serving the technology needs of libraries, and has been a contributor since 2008 to the Koha open source library automation suite.Ruth is currently a Perl Developer at cPanel in Houston, and also serves as chief of staff for two cats.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/cozy-personal-cloud
|
||||
|
||||
作者:[D Ruth Bavousett][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/druthb
|
||||
[1]:https://opensource.com/article/17/2/cozy-personal-cloud?rate=FEMc3av4LgYK-jeEscdiqPhSgHZkYNsNCINhOoVR9N8
|
||||
[2]:https://pixabay.com/en/tree-field-cornfield-nature-247122/
|
||||
[3]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[4]:https://cozy.io/
|
||||
[5]:https://github.com/cozy/cozy
|
||||
[6]:https://docs.cozy.io/en/host/install/
|
||||
[7]:https://www.nginx.com/
|
||||
[8]:https://cozy.io/en/apps/
|
||||
[9]:https://ghost.org/
|
||||
[10]:http://tiddlywiki.com/
|
||||
[11]:http://nodejs.org/
|
||||
[12]:https://www.dropbox.com/
|
||||
[13]:https://github.com/cozy-labs/cozy-desktop
|
||||
[14]:https://www.google.com/chrome/
|
||||
[15]:https://github.com/pwnall/dropship-chrome
|
||||
[16]:https://en.wikipedia.org/wiki/CardDAV
|
||||
[17]:https://en.wikipedia.org/wiki/CalDAV
|
||||
[18]:https://opensource.com/user/36051/feed
|
||||
[19]:https://opensource.com/article/17/2/cozy-personal-cloud#comments
|
||||
[20]:https://opensource.com/users/druthb
|
||||
@ -1,297 +0,0 @@
|
||||
ictlyh Translating
|
||||
How to Make ‘Vim Editor’ as Bash-IDE Using ‘bash-support’ Plugin in Linux
|
||||
============================================================
|
||||
|
||||
An IDE ([Integrated Development Environment][1]) is simply a software that offers much needed programming facilities and components in a single program, to maximize programmer productivity. IDEs put forward a single program in which all development can be done, enabling a programmer to write, modify, compile, deploy and debug programs.
|
||||
|
||||
In this article, we will describe how to [install and configure Vim editor][2] as a Bash-IDE using bash-support vim plug-in.
|
||||
|
||||
#### What is bash-support.vim plug-in?
|
||||
|
||||
bash-support is a highly-customizable vim plug-in, which allows you to insert: file headers, complete statements, comments, functions, and code snippets. It also enables you to perform syntax checking, make a script executable, start a debugger simply with a keystroke; do all this without closing the editor.
|
||||
|
||||
It generally makes bash scripting fun and enjoyable through organized and consistent writing/insertion of file content using shortcut keys (mappings).
|
||||
|
||||
The current version plug-in is 4.3, version 4.0 was a rewriting of version 3.12.1; versions 4.0 or better, are based on a comprehensively new and more powerful template system, with changed template syntax unlike previous versions.
|
||||
|
||||
### How To Install Bash-support Plug-in in Linux
|
||||
|
||||
Start by downloading the latest version of <a target="_blank" rel="nofollow" style="border: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline; color: rgb(187, 14, 48); text-decoration: underline; outline: none 0px; transition-duration: 0.2s; transition-timing-function: ease;">bash-support plug-in</a> using the command below:
|
||||
|
||||
```
|
||||
$ cd Downloads
|
||||
$ curl http://www.vim.org/scripts/download_script.php?src_id=24452 >bash-support.zip
|
||||
```
|
||||
|
||||
Then install it as follows; create the `.vim` directory in your home folder (in case it doesn’t exist), move into it and extract the contents of bash-support.zip there:
|
||||
|
||||
```
|
||||
$ mkdir ~/.vim
|
||||
$ cd .vim
|
||||
$ unzip ~/Downloads/bash-support.zip
|
||||
```
|
||||
|
||||
Next, activate it from the `.vimrc` file:
|
||||
|
||||
```
|
||||
$ vi ~/.vimrc
|
||||
```
|
||||
|
||||
By inserting the line below:
|
||||
|
||||
```
|
||||
filetype plug-in on
|
||||
set number #optionally add this to show line numbers in vim
|
||||
```
|
||||
|
||||
### How To Use Bash-support plug-in with Vim Editor
|
||||
|
||||
To simplify its usage, the frequently used constructs as well as certain operations can be inserted/performed with key mappings respectively. The mappings are described in ~/.vim/doc/bashsupport.txt and ~/.vim/bash-support/doc/bash-hotkeys.pdf or ~/.vim/bash-support/doc/bash-hotkeys.tex files.
|
||||
|
||||
##### Important:
|
||||
|
||||
1. All mappings (`(\)+charater(s)` combination) are filetype specific: they are only work with ‘sh’ files, in order to avoid conflicts with mappings from other plug-ins.
|
||||
2. Typing speed matters-when using key mapping, the combination of a leader `('\')` and the following character(s) will only be recognized for a short time (possibly less than 3 seconds – based on assumption).
|
||||
|
||||
Below are certain remarkable features of this plug-in that we will explain and learn how to use:
|
||||
|
||||
#### How To Generate an Automatic Header for New Scripts
|
||||
|
||||
Look at the sample header below, to have this header created automatically in all your new bash scripts, follow the steps below.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Script Sample Header Options
|
||||
|
||||
Start by setting your personal details (author name, author reference, organization, company etc). Use the map `\ntw` inside a Bash buffer (open a test script as the one below) to start the template setup wizard.
|
||||
|
||||
Select option (1) to setup the personalization file, then press [Enter].
|
||||
|
||||
```
|
||||
$ vi test.sh
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Set Personalizations in Scripts File
|
||||
|
||||
Afterwards, hit [Enter] again. Then select the option (1) one more time to set the location of the personalization file and hit [Enter].
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Set Personalization File Location
|
||||
|
||||
The wizard will copy the template file .vim/bash-support/rc/personal.templates to .vim/templates/personal.templates and open it for editing, where you can insert your details.
|
||||
|
||||
Press `i` to insert the appropriate values within the single quotes as shown in the screenshot.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Add Info in Script Header
|
||||
|
||||
Once you have set the correct values, type `:wq` to save and exit the file. Close the Bash test script, open another script to check the new configuration. The file header should now have your personal details similar to that in the screen shot below:
|
||||
|
||||
```
|
||||
$ test2.sh
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Auto Adds Header to Script
|
||||
|
||||
#### Make Bash-support Plug-in Help Accessible
|
||||
|
||||
To do this, type the command below on the Vim command line and press [Enter], it will create a file .vim/doc/tags:
|
||||
|
||||
```
|
||||
:helptags $HOME/.vim/doc/
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Add Plugin Help in Vi Editor
|
||||
|
||||
#### How To Insert Comments in Shell Scripts
|
||||
|
||||
To insert a framed comment, type `\cfr` in normal mode:
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Add Comments to Scripts
|
||||
|
||||
#### How To Insert Statements in a Shell Script
|
||||
|
||||
The following are key mappings for inserting statements (`n` – normal mode, `i` – insert mode):
|
||||
|
||||
1. `\sc` – case in … esac (n, I)
|
||||
2. `\sei` – elif then (n, I)
|
||||
3. `\sf` – for in do done (n, i, v)
|
||||
4. `\sfo` – for ((…)) do done (n, i, v)
|
||||
5. `\si` – if then fi (n, i, v)
|
||||
6. `\sie` – if then else fi (n, i, v)
|
||||
7. `\ss` – select in do done (n, i, v)
|
||||
8. `\su` – until do done (n, i, v)
|
||||
9. `\sw` – while do done (n, i, v)
|
||||
10. `\sfu` – function (n, i, v)
|
||||
11. `\se` – echo -e “…” (n, i, v)
|
||||
12. `\sp` – printf “…” (n, i, v)
|
||||
13. `\sa` – array element, ${.[.]} (n, i, v) and many more array features.
|
||||
|
||||
#### Insert a Function and Function Header
|
||||
|
||||
Type `\sfu` to add a new empty function, then add the function name and press [Enter] to create it. Afterwards, add your function code.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Insert New Function in Script
|
||||
|
||||
To create a header for the function above, type `\cfu`, enter name of the function, click [Enter] and fill in the appropriate values (name, description, parameters and returns):
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Create Header Function in Script
|
||||
|
||||
#### More Examples of Adding Bash Statements
|
||||
|
||||
Below is an example showing insertion of an if statement using `\si`:
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Add Insert Statement to Script
|
||||
|
||||
Next example showing addition of an echo statement using `\se`:
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Add echo Statement to Script
|
||||
|
||||
#### How To Use Run Operation in Vi Editor
|
||||
|
||||
The following is a list of some run operations key mappings:
|
||||
|
||||
1. `\rr` – update file, run script (n, I)
|
||||
2. `\ra` – set script cmd line arguments (n, I)
|
||||
3. `\rc` – update file, check syntax (n, I)
|
||||
4. `\rco` – syntax check options (n, I)
|
||||
5. `\rd` – start debugger (n, I)
|
||||
6. `\re` – make script executable/not exec.(*) (in)
|
||||
|
||||
#### Make Script Executable
|
||||
|
||||
After writing script, save it and type `\re` to make it executable by pressing [Enter].
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Make Script Executable
|
||||
|
||||
#### How To Use Predefined Code Snippets To a Bash Script
|
||||
|
||||
Predefined code snippets are files that contain already written code meant for a specific purpose. To add code snippets, type `\nr` and `\nw` to read/write predefined code snippets. Issue the command that follows to list default code snippets:
|
||||
|
||||
```
|
||||
$ .vim/bash-support/codesnippets/
|
||||
```
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
List of Code Snippets
|
||||
|
||||
To use a code snippet such as free-software-comment, type `\nr` and use auto-completion feature to select its name, and press [Enter]:
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Add Code Snippet to Script
|
||||
|
||||
#### Create Custom Predefined Code Snippets
|
||||
|
||||
It is possible to write your own code snippets under ~/.vim/bash-support/codesnippets/. Importantly, you can also create your own code snippets from normal script code:
|
||||
|
||||
1. choose the section of code that you want to use as a code snippet, then press `\nw`, and closely give it a filename.
|
||||
2. to read it, type `\nr` and use the filename to add your custom code snippet.
|
||||
|
||||
#### View Help For the Built-in and Command Under the Cursor
|
||||
|
||||
To display help, in normal mode, type:
|
||||
|
||||
1. `\hh` – for built-in help
|
||||
2. `\hm` – for a command help
|
||||
|
||||
[
|
||||
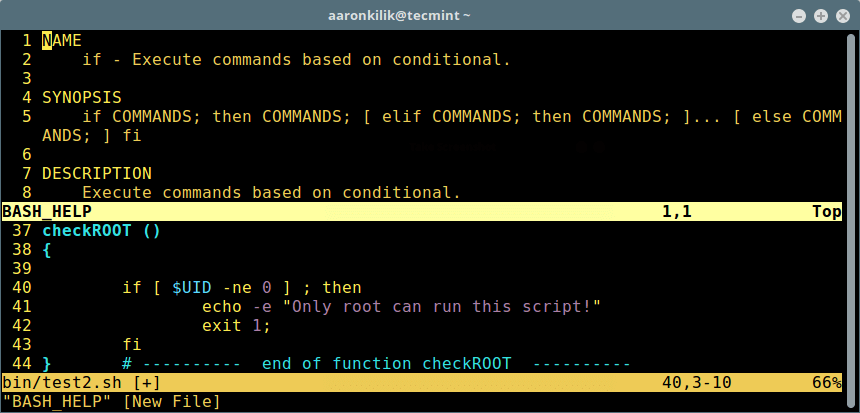
|
||||
][17]
|
||||
|
||||
View Built-in Command Help
|
||||
|
||||
For more reference, read through the file :
|
||||
|
||||
```
|
||||
~/.vim/doc/bashsupport.txt #copy of online documentation
|
||||
~/.vim/doc/tags
|
||||
```
|
||||
|
||||
Visit the Bash-support plug-in Github repository: [https://github.com/WolfgangMehner/bash-support][18]
|
||||
Visit Bash-support plug-in on the Vim Website: [http://www.vim.org/scripts/script.php?script_id=365][19]
|
||||
|
||||
That’s all for now, in this article, we described the steps of installing and configuring Vim as a Bash-IDE in Linux using bash-support plug-in. Check out the other exciting features of this plug-in, and do share them with us in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/best-linux-ide-editors-source-code-editors/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/02/Script-Header-Options.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Personalization-in-Scripts.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Personalization-File-Location.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Info-in-Script-Header.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Auto-Adds-Header-to-Script.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Plugin-Help-in-Vi-Editor.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Comments-to-Scripts.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/02/Insert-New-Function-in-Script.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/02/Create-Header-Function-in-Script.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Insert-Statement-to-Script.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-echo-Statement-to-Script.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/02/make-script-executable.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/02/list-of-code-snippets.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Code-Snippet-to-Script.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/02/View-Built-in-Command-Help.png
|
||||
[18]:https://github.com/WolfgangMehner/bash-support
|
||||
[19]:http://www.vim.org/scripts/script.php?script_id=365
|
||||
@ -1,235 +0,0 @@
|
||||
How to Secure a FTP Server Using SSL/TLS for Secure File Transfer in CentOS 7
|
||||
============================================================
|
||||
|
||||
By its original design, FTP (File Transfer Protocol) is not secure, meaning it doesn’t encrypt data being transmitted between two machines, along with user’s credentials. This poses a massive threat to data as well as server security.
|
||||
|
||||
In this tutorial, we will explain how to manually enable data encryption services in a FTP server in CentOS/RHEL 7 and Fedora; we will go through various steps of securing VSFTPD (Very Secure FTP Daemon) services using SSL/TLS certificates.
|
||||
|
||||
#### Prerequisites:
|
||||
|
||||
1. You must have [installed and configured a FTP server in CentOS 7][1]
|
||||
|
||||
Before we start, note that all the commands in this tutorial will be run as root, otherwise, use the [sudo command][2] to gain root privileges if you are not controlling the server using the root account.
|
||||
|
||||
### Step 1\. Generating SSL/TLS Certificate and Private Key
|
||||
|
||||
1. We need to start by creating a subdirectory under: `/etc/ssl/` where we will store the SSL/TLS certificate and key files:
|
||||
|
||||
```
|
||||
# mkdir /etc/ssl/private
|
||||
```
|
||||
|
||||
2. Then run the command below to create the certificate and key for vsftpd in a single file, here is the explanation of each flag used.
|
||||
|
||||
1. req – is a command for X.509 Certificate Signing Request (CSR) management.
|
||||
2. x509 – means X.509 certificate data management.
|
||||
3. days – defines number of days certificate is valid for.
|
||||
4. newkey – specifies certificate key processor.
|
||||
5. rsa:2048 – RSA key processor, will generate a 2048 bit private key.
|
||||
6. keyout – sets the key storage file.
|
||||
7. out – sets the certificate storage file, note that both certificate and key are stored in the same file: /etc/ssl/private/vsftpd.pem.
|
||||
|
||||
```
|
||||
# openssl req -x509 -nodes -keyout /etc/ssl/private/vsftpd.pem -out /etc/ssl/private/vsftpd.pem -days 365 -newkey rsa:2048
|
||||
```
|
||||
|
||||
The above command will ask you to answer the questions below, remember to use values that apply to your scenario.
|
||||
|
||||
```
|
||||
Country Name (2 letter code) [XX]:IN
|
||||
State or Province Name (full name) []:Lower Parel
|
||||
Locality Name (eg, city) [Default City]:Mumbai
|
||||
Organization Name (eg, company) [Default Company Ltd]:TecMint.com
|
||||
Organizational Unit Name (eg, section) []:Linux and Open Source
|
||||
Common Name (eg, your name or your server's hostname) []:tecmint
|
||||
Email Address []:admin@tecmint.com
|
||||
```
|
||||
|
||||
### Step 2\. Configuring VSFTPD To Use SSL/TLS
|
||||
|
||||
3. Before we perform any VSFTPD configurations, let’s open the ports 990 and 40000-50000 to allow TLS connections and the port range of passive ports to define in the VSFTPD configuration file respectively:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=public --permanent --add-port=990/tcp
|
||||
# firewall-cmd --zone=public --permanent --add-port=40000-50000/tcp
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
4. Now, open the VSFTPD config file and specify the SSL details in it:
|
||||
|
||||
```
|
||||
# vi /etc/vsftpd/vsftpd.conf
|
||||
```
|
||||
|
||||
Look for the option ssl_enable and set its value to `YES` to activate the use of SSL, in addition, since TSL is more secure than SSL, we will restrict VSFTPD to employ TLS instead, using the ssl_tlsv1_2 option:
|
||||
|
||||
```
|
||||
ssl_enable=YES
|
||||
ssl_tlsv1_2=YES
|
||||
ssl_sslv2=NO
|
||||
ssl_sslv3=NO
|
||||
```
|
||||
|
||||
5. Then, add the lines below to define the location of the SSL certificate and key file:
|
||||
|
||||
```
|
||||
rsa_cert_file=/etc/ssl/private/vsftpd.pem
|
||||
rsa_private_key_file=/etc/ssl/private/vsftpd.pem
|
||||
```
|
||||
|
||||
6. Next, we have to prevent anonymous users from using SSL, then force all non-anonymous logins to use a secure SSL connection for data transfer and to send the password during login:
|
||||
|
||||
```
|
||||
allow_anon_ssl=NO
|
||||
force_local_data_ssl=YES
|
||||
force_local_logins_ssl=YES
|
||||
```
|
||||
|
||||
7. In addition, we can add the options below to boost up FTP server security. When option require_ssl_reuse is set to `YES`, then, all SSL data connections are required to exhibit SSL session reuse; proving that they know the same master secret as the control channel.
|
||||
|
||||
Therefore, we have to turn it off.
|
||||
|
||||
```
|
||||
require_ssl_reuse=NO
|
||||
```
|
||||
|
||||
Again, we need to select which SSL ciphers VSFTPD will permit for encrypted SSL connections with the ssl_ciphers option. This can greatly limit efforts of attackers who try to force a particular cipher which they probably discovered vulnerabilities in:
|
||||
|
||||
```
|
||||
ssl_ciphers=HIGH
|
||||
```
|
||||
|
||||
8. Now, set the port range (min and max port) of passive ports.
|
||||
|
||||
```
|
||||
pasv_min_port=40000
|
||||
pasv_max_port=50000
|
||||
```
|
||||
|
||||
9. Optionally, allow SSL debugging, meaning openSSL connection diagnostics are recorded to the VSFTPD log file with the debug_ssl option:
|
||||
|
||||
```
|
||||
debug_ssl=YES
|
||||
```
|
||||
|
||||
Save all the changes and close the file. Then let’s restart VSFTPD service:
|
||||
|
||||
```
|
||||
# systemctl restart vsftpd
|
||||
```
|
||||
|
||||
### Step 3: Testing FTP server With SSL/TLS Connections
|
||||
|
||||
10. After doing all the above configurations, test if VSFTPD is using SSL/TLS connections by attempting to use FTP from the command line as follows:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.10
|
||||
Connected to 192.168.56.10 (192.168.56.10).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.10:root) : ravi
|
||||
530 Non-anonymous sessions must use encryption.
|
||||
Login failed.
|
||||
421 Service not available, remote server has closed connection
|
||||
ftp>
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Verify FTP SSL Secure Connection
|
||||
|
||||
From the screen shot above, we can see that there is an error informing us that VSFTPD can only allow user to login from clients that support encryption services.
|
||||
|
||||
The command line does not offer encryption services thus producing the error. So, to securely connect to the server, we need a FTP client that supports SSL/TLS connections such as FileZilla.
|
||||
|
||||
### Step 4: Install FileZilla to Securely Connect to a FTP Server
|
||||
|
||||
11. FileZilla is a modern, popular and importantly cross-platform FTP client that supports SSL/TLS connections by default.
|
||||
|
||||
To install FileZilla in Linux, run the command below:
|
||||
|
||||
```
|
||||
--------- On CentOS/RHEL/Fedora ---------
|
||||
# yum install epel-release filezilla
|
||||
--------- On Debian/Ubuntu ---------
|
||||
$ sudo apt-get install filezilla
|
||||
```
|
||||
|
||||
12. When the installation completes (or else if you already have it installed), open it and go to File=>Sites Manager or (press `Ctrl+S`) to get the Site Manager interface below.
|
||||
|
||||
Click on New Site button to add a new site/host connection details.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Add New FTP Site in Filezilla
|
||||
|
||||
13. Next, set the host/site name, add the IP address, define the protocol to use, encryption and logon type as in the screen shot below (use values that apply to your scenario):
|
||||
|
||||
```
|
||||
Host: 192.168.56.10
|
||||
Protocol: FTP – File Transfer Protocol
|
||||
Encryption: Require explicit FTP over #recommended
|
||||
Logon Type: Ask for password #recommended
|
||||
User: username
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Add FTP Server Details in Filezilla
|
||||
|
||||
14. Then click on Connect to enter the password again, and then verify the certificate being used for the SSL/TLS connection and click `OK` once more to connect to the FTP server:
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Verify FTP SSL Certificate
|
||||
|
||||
At this stage, we should have logged successfully into the FTP server over a TLS connection, check the connection status section for more information from the interface below.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Connected to FTP Server Over TLS/SSL
|
||||
|
||||
15. Last but not least, try [transferring files from the local machine to the FTP sever][8] in the files folder, take a look at the lower end of the FileZilla interface to view reports concerning file transfers.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Transfer Files Securely Using FTP
|
||||
|
||||
That’s all! Always keep in mind that FTP is not secure by default, unless we configure it to use SSL/TLS connections as we showed you in this tutorial. Do share your thoughts about this tutorial/topic via the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/secure-vsftpd-using-ssl-tls-on-centos/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/install-ftp-server-in-centos-7/
|
||||
[2]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/02/Verify-FTP-Secure-Connection.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-New-FTP-Site-in-Filezilla.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-FTP-Server-Details-in-Filezilla.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/Verify-FTP-SSL-Certificate.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/connected-to-ftp-server-with-tls.png
|
||||
[8]:http://www.tecmint.com/sftp-command-examples/
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/Transfer-Files-Securely-Using-FTP.png
|
||||
@ -0,0 +1,180 @@
|
||||
【翻译中】
|
||||
Getting started with Perl on the Raspberry Pi
|
||||
============================================================
|
||||
|
||||
> We're all free to pick what we want to run on our Raspberry Pi.
|
||||
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
When I spoke recently at SVPerl (Silicon Valley Perl) about Perl on the Raspberry Pi, someone asked, "I heard the Raspberry Pi is supposed to use Python. Is that right?" I was glad he asked because it's a common misconception. The Raspberry Pi can run any language. Perl, Python, and others are part of the initial installation of Raspbian Linux, the official software for the board.
|
||||
|
||||
The origin of the myth is simple. The Raspberry Pi's creator, UK Computer Science professor Eben Upton, has told the story that the "Pi" part of the name was intended to sound like Python because he likes the language. He chose it as his emphasis for kids to learn coding. But he and his team made a general-purpose computer. The open source software on the Raspberry Pi places no restrictions on us. We're all free to pick what we want to run and make each Raspberry Pi our own.
|
||||
|
||||
More on Raspberry Pi
|
||||
|
||||
* [Our latest on Raspberry Pi][1]
|
||||
* [What is Raspberry Pi?][2]
|
||||
* [Getting started with Raspberry Pi][3]
|
||||
* [Send us your Raspberry Pi projects and tutorials][4]
|
||||
|
||||
The second point to my presentation at SVPerl and this article is to introduce my "PiFlash" script. It was written in Perl, but it doesn't require any knowledge of Perl to automate your task of flashing SD cards for a Raspberry Pi from a Linux system. It provides safety for beginners, so they won't accidentally erase a hard drive while trying to flash an SD card. It offers automation and convenience for power users, which includes me and is why I wrote it. Similar tools already existed for Windows and Macs, but the instructions on the Raspberry Pi website oddly have no automated tools for Linux users. Now one exists.
|
||||
|
||||
Open source software has a long tradition of new projects starting because an author wanted to "scratch their own itch," or to solve their own problems. That's the way Eric S. Raymond described it in his 1997 paper and 1999 book "[The Cathedral and the Bazaar][8]," which defined the open source software development methodology. I wrote PiFlash to fill a need for Linux users like myself.
|
||||
|
||||
### Downloadable system images
|
||||
|
||||
When setting up a Raspberry Pi, you first need to download an operating system for it. We call it a "system image" file. Once you download it to your desktop, laptop, or even another Raspberry Pi, you have to write or "flash" it to an SD card. The details are covered online already. It can be a bit tricky to do manually because getting the system image on the whole SD card and not on a partition matters. The system image will actually contain at least one partition of its own because the Raspberry Pi's boot procedure needs a FAT32 filesystem partition from which to start. Other partitions after the boot partition can be any filesystem type supported by the OS kernel.
|
||||
|
||||
In most cases on the Raspberry Pi, we're running some distribution with a Linux kernel. Here's a list of common system images that you can download for the Raspberry Pi (but there's nothing to stop you from building your own from scratch).
|
||||
|
||||
The ["NOOBS"][9] system from the Raspberry Pi Foundation is their recommended system for new users. It stands for "New Out of the Box System." It's obviously intended to sound like the term "noob," short for "newbie." NOOBS starts a Raspbian-based Linux system, which presents a menu that you can use to automatically download and install several other system images on your Raspberry Pi.
|
||||
|
||||
[Raspbian ][10][Linux][11] is Debian Linux specialized for the Raspberry Pi. It's the official Linux distribution for the Raspberry Pi and is maintained by the Raspberry Pi Foundation. Nearly all Raspberry Pi software and drivers start with Raspbian before going to other Linux distributions. It runs on all models of the Raspberry Pi. The default installation includes Perl.
|
||||
|
||||
Ubuntu Linux (and the community edition Ubuntu MATE) includes the Raspberry Pi as one of its supported platforms for the ARM (Advanced RISC Machines) processor. [RISC (Reduced Instruction Set Computer) architecture] Ubuntu is a commercially supported open source variant of Debian Linux, so its software comes as DEB packages. Perl is included. It only works on the Raspberry Pi 2 and 3 models with their 32-bit ARM7 and 64-bit ARM8 processors. The ARM6 processor of the Raspberry Pi 1 and Zero was never supported by Ubuntu's build process.
|
||||
|
||||
[Fedora Linux][12] supports the Raspberry Pi 2 and 3 as of Fedora 25\. Fedora is the open source project affiliated with Red Hat. Fedora serves as the base that the commercial RHEL (Red Hat Enterprise Linux) adds commercial packages and support to, so its software comes as RPM (Red Hat Package Manager) packages like all Red Hat-compatible Linux distributions. Like the others, it includes Perl.
|
||||
|
||||
[RISC OS][13] is a single-user operating system made specifically for the ARM processor. If you want to experiment with a small desktop that is more compact than Linux (due to fewer features), it's an option. Perl runs on RISC OS.
|
||||
|
||||
[RaspBSD][14] is the Raspberry Pi distribution of FreeBSD. It's a Unix-based system, but isn't Linux. As an open source Unix, form follows function and it has many similarities to Linux, including that the operating system environment is made from a similar set of open source packages, including Perl.
|
||||
|
||||
[OSMC][15], the Open Source Media Center, and [LibreElec][16] are TV entertainment center systems. They are both based on the Kodi entertainment center, which runs on a Linux kernel. It's a really compact and specialized Linux system, so don't expect to find Perl on it.
|
||||
|
||||
[Microsoft ][17][Windows IoT Core][18] is a new entrant that runs only on the Raspberry Pi 3\. You need Microsoft developer access to download it, so as a Linux geek, that deterred me from looking at it. My PiFlash script doesn't support it, but if that's what you're looking for, it's there.
|
||||
|
||||
### The PiFlash script
|
||||
|
||||
If you look at the Raspberry Pi 's [SD card flashing][19][ instructions][20], you'll see the instructions to do that from Windows or Mac involve downloading a tool to write to the SD card. But for Linux systems, it's a set of instructions to do manually. I've done that manual procedure so many times that it triggered my software-developer instinct to automate the process, and that's where the PiFlash script came from. It's tricky because there are many ways a Linux system can be set up, but they are all based on the Linux kernel.
|
||||
|
||||
I always imagined one of the biggest potential errors of the manual procedure is accidentally erasing the wrong device, instead of the SD card, and destroying the data on a hard drive that I wanted to keep. In my presentation at SVPerl, I was surprised to find someone in the audience who has made that mistake (and wasn't afraid to admit it). Therefore, one of the purposes of the PiFlash script, to provide safety for new users by refusing to erase a device that isn't an SD card, is even more needed than I expected. PiFlash will also refuse to overwrite a device that contains a mounted filesystem.
|
||||
|
||||
For experienced users, including me, the PiFlash script offers the convenience of automation. After downloading the system image, I don't have to uncompress it or extract the system image from a zip archive. PiFlash will extract it from whichever format it's in and directly flash the SD card.
|
||||
|
||||
I posted [PiFlash and its instructions][21] on GitHub.
|
||||
|
||||
It's a command-line tool with the following usages:
|
||||
|
||||
**piflash [--verbose] input-file output-device**
|
||||
|
||||
**piflash [--verbose] --SDsearch**
|
||||
|
||||
The **input-file** parameter is the system image file, whatever you downloaded from the Raspberry Pi software distribution sites. The **output-device** parameter is the path of the block device for the SD card you want to write to.
|
||||
|
||||
Alternatively, use **--SDsearch** to print a list of the device names of SD cards on the system.
|
||||
|
||||
The optional **--verbose** parameter is useful for printing out all of the program's state data in case you need to ask for help, submit a bug report, or troubleshoot a problem yourself. That's what I used for developing it.
|
||||
|
||||
This example of using the script writes a Raspbian image, still in its zip archive, to the SD card at **/dev/mmcblk0**:
|
||||
|
||||
**piflash 2016-11-25-raspbian-jessie.img.zip /dev/mmcblk0**
|
||||
|
||||
If you had specified **/dev/mmcblk0p1** (the first partition on the SD card), it would have recognized that a partition is not the correct location and refused to write to it.
|
||||
|
||||
One tricky aspect is recognizing which devices are SD cards on various Linux systems. The example with **mmcblk0** is from the PCI-based SD card interface on my laptop. If I used a USB SD card interface, it would be **/dev/sdb**, which is harder to distinguish from hard drives present on many systems. However, there are only a few Linux block drivers that support SD cards. PiFlash checks the parameters of the block devices in both those cases. If all else fails, it will accept USB drives which are writable, removable and have the right physical sector count for an SD card.
|
||||
|
||||
I think that covers most cases. However, what if you have another SD card interface I haven't seen? I'd like to hear from you. Please include the **--verbose**** --SDsearch** output, so I can see what environment was present on your system when it tried. Ideally, if the PiFlash script becomes widely used, we should build up an open source community around maintaining it for as many Raspberry Pi users as we can.
|
||||
|
||||
### CPAN modules for Raspberry Pi
|
||||
|
||||
CPAN is the [Comprehensive Perl Archive Network][22], a worldwide network of download mirrors containing a wealth of Perl modules. All of them are open source. The vast quantity of modules on CPAN has been a huge strength of Perl over the years. For many thousands of tasks, there is no need to re-invent the wheel, you can just use the code someone else already posted, then submit your own once you have something new.
|
||||
|
||||
As Raspberry Pi is a full-fledged Linux system, most CPAN modules will run normally on it, but I'll focus on some that are specifically for the Raspberry Pi's hardware. These would usually be for embedded systems projects like measurement, control, or robotics. You can connect your Raspberry Pi to external electronics via its GPIO (General-Purpose Input/Output) pins.
|
||||
|
||||
Modules specifically for accessing the Raspberry Pi's GPIO pins include [Device::SMBus][23], [Device::I2C][24], [Rpi::PIGPIO][25], [Rpi::SPI][26], [Rpi::WiringPi][27], [Device::WebIO::RaspberryPi][28] and [Device::PiGlow][29]. Modules for other embedded systems with Raspberry Pi support include [UAV::Pilot::Wumpus::Server::Backend::RaspberryPiI2C][30], [RPi::DHT11][31] (temperature/humidity), [RPi::HCSR04][32] (ultrasonic), [App::RPi::EnvUI][33] (lights for growing plants), [RPi::DigiPot::MCP4XXXX][34] (potentiometer), [RPi::ADC::ADS][35] (A/D conversion), [Device::PaPiRus][36] and [Device::BCM2835::Timer][37] (the on-board timer chip).
|
||||
|
||||
### Examples
|
||||
|
||||
Here are some examples of what you can do with Perl on a Raspberry Pi.
|
||||
|
||||
### Example 1: Flash OSMC with PiFlash and play a video
|
||||
|
||||
For this example, you'll practice setting up and running a Raspberry Pi using the OSMC (Open Source Media Center).
|
||||
|
||||
* Go to [RaspberryPi.Org][5]. In the downloads area, get the latest version of OSMC.
|
||||
* Insert a blank SD card in your Linux desktop or laptop. The Raspberry Pi 1 uses a full-size SD card. Everything else uses a microSD, which may require a common adapter to insert it.
|
||||
* Check "cat /proc/partitions" before and after inserting the SD card to see which device name it was assigned by the system. It could be something like **/dev/mmcblk0** or **/dev/sdb**. Substitute your correct system image file and output device in a command that looks like this:
|
||||
|
||||
** piflash OSMC_TGT_rbp2_20170210.img.gz /dev/mmcblk0**
|
||||
|
||||
* Eject the SD card. Put it in the Raspberry Pi and boot it connected to an HDMI monitor.
|
||||
* While OSMC is setting up, get a USB stick and put some videos on it. For purposes of the demonstration, I suggest using the "youtube-dl" program to download two videos. Run "youtube-dl OHF2xDrq8dY" (The Bloomberg "Hello World" episode about UK tech including Raspberry Pi) and "youtube-dl nAvZMgXbE9c" (CNet's Top 5 Raspberry Pi projects). Move them to the USB stick, then unmount and remove it.
|
||||
* Insert the USB stick in the OSMC Raspberry Pi. Follow the Videos menu to the external device.
|
||||
* When you can play the videos on the Raspberry Pi, you have completed the exercise. Have fun.
|
||||
|
||||
### Example 2: A script to play random videos from a directory
|
||||
|
||||
This example uses a script to shuffle-play videos from a directory on the Raspberry Pi. Depending on the videos and where it's installed, this could be a kiosk display. I wrote it to display videos while using indoor exercise equipment.
|
||||
|
||||
* Set up a Raspberry Pi to boot Raspbian Linux. Connect it to an HDMI monitor.
|
||||
* Download my ["do-video" script][6] from GitHub and put it on the Raspberry Pi.
|
||||
* Follow the installation instructions on the page. The main thing is to install the **omxplayer** package, which plays videos smoothly using the Raspberry Pi's hardware video acceleration.
|
||||
* Put some videos in a directory called Videos under the home directory.
|
||||
* Run "do-video" and videos should start playing.
|
||||
|
||||
### Example 3: A script to read GPS data
|
||||
|
||||
This example is more advanced and optional, but it shows how Perl can read from external devices. At my "Perl on Pi" page on GitHub from the previous example, there is also a **gps-read.pl** script. It reads NMEA (National Marine Electronics Association) data from a GPS via the serial port. Instructions are on the page, including parts I used from AdaFruit Industries to build it, but any GPS that outputs NMEA data could be used.
|
||||
|
||||
With these tasks, I've made the case that you really can use Perl as well as any other language on a Raspberry Pi. I hope you enjoy it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ian Kluft - Ian has had parallel interests since grade school in computing and flight. He was coding on Unix before there was Linux, and started on Linux 6 months after the kernel was posted. He has a masters degree in Computer Science and is a CSSLP (Certified Secure Software Lifecycle Professional). On the side he's a pilot and a certified flight instructor. As a licensed Ham Radio operator for over 25 years, experimentation with electronics has evolved in recent years to include the Raspberry Pi
|
||||
|
||||
------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/perl-raspberry-pi
|
||||
|
||||
作者:[Ian Kluft ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ikluft
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:http://raspberrypi.org/
|
||||
[6]:https://github.com/ikluft/ikluft-tools/tree/master/perl-on-pi
|
||||
[7]:https://opensource.com/article/17/3/perl-raspberry-pi?rate=OsZH1-H_xMfLtSFqZw4SC-_nyV4yo_sgKKBJGjUsbfM
|
||||
[8]:http://www.catb.org/~esr/writings/cathedral-bazaar/
|
||||
[9]:https://www.raspberrypi.org/downloads/noobs/
|
||||
[10]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[11]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[12]:https://fedoraproject.org/wiki/Raspberry_Pi#Downloading_the_Fedora_ARM_image
|
||||
[13]:https://www.riscosopen.org/content/downloads/raspberry-pi
|
||||
[14]:http://www.raspbsd.org/raspberrypi.html
|
||||
[15]:https://osmc.tv/
|
||||
[16]:https://libreelec.tv/
|
||||
[17]:http://ms-iot.github.io/content/en-US/Downloads.htm
|
||||
[18]:http://ms-iot.github.io/content/en-US/Downloads.htm
|
||||
[19]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[20]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[21]:https://github.com/ikluft/ikluft-tools/tree/master/piflash
|
||||
[22]:http://www.cpan.org/
|
||||
[23]:https://metacpan.org/pod/Device::SMBus
|
||||
[24]:https://metacpan.org/pod/Device::I2C
|
||||
[25]:https://metacpan.org/pod/RPi::PIGPIO
|
||||
[26]:https://metacpan.org/pod/RPi::SPI
|
||||
[27]:https://metacpan.org/pod/RPi::WiringPi
|
||||
[28]:https://metacpan.org/pod/Device::WebIO::RaspberryPi
|
||||
[29]:https://metacpan.org/pod/Device::PiGlow
|
||||
[30]:https://metacpan.org/pod/UAV::Pilot::Wumpus::Server::Backend::RaspberryPiI2C
|
||||
[31]:https://metacpan.org/pod/RPi::DHT11
|
||||
[32]:https://metacpan.org/pod/RPi::HCSR04
|
||||
[33]:https://metacpan.org/pod/App::RPi::EnvUI
|
||||
[34]:https://metacpan.org/pod/RPi::DigiPot::MCP4XXXX
|
||||
[35]:https://metacpan.org/pod/RPi::ADC::ADS
|
||||
[36]:https://metacpan.org/pod/Device::PaPiRus
|
||||
[37]:https://metacpan.org/pod/Device::BCM2835::Timer
|
||||
[38]:https://opensource.com/user/120171/feed
|
||||
[39]:https://opensource.com/article/17/3/perl-raspberry-pi#comments
|
||||
[40]:https://opensource.com/users/ikluft
|
||||
@ -0,0 +1,166 @@
|
||||
How to Add a New Disk to an Existing Linux Server
|
||||
============================================================
|
||||
|
||||
|
||||
As system administrators, we would have got requirements wherein we need to configure raw hard disks to the existing servers as part of upgrading server capacity or sometimes disk replacement in case of disk failure.
|
||||
|
||||
In this article, I will take you through the steps by which we can add the new raw hard disk to an existing Linux server such as RHEL/CentOS or Debian/Ubuntu.
|
||||
|
||||
**Suggested Read:** [How to Add a New Disk Larger Than 2TB to An Existing Linux][1]
|
||||
|
||||
Important: Please note that the purpose of this article is to show only how to create a new partition and doesn’t include partition extension or any other switches.
|
||||
|
||||
I am using [fdisk utility][2] to do this configuration.
|
||||
|
||||
I have added a hard disk of 20GB capacity to be mounted as a `/data` partition.
|
||||
|
||||
fdisk is a command line utility to view and manage hard disks and partitions on Linux systems.
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
|
||||
This will list the current partitions and configurations.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Find Linux Partition Details
|
||||
|
||||
After attaching the hard disk of 20GB capacity, the `fdisk -l` will give the below output.
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
[
|
||||
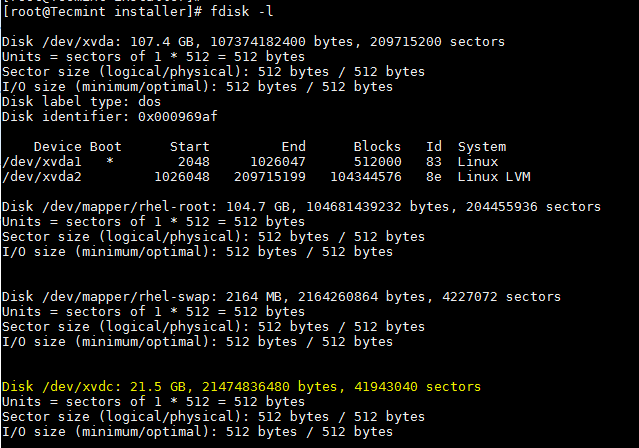
|
||||
][4]
|
||||
|
||||
Find New Partition Details
|
||||
|
||||
New disk added is shown as `/dev/xvdc`. If we are adding physical disk it will show as `/dev/sda` based of the disk type. Here I used a virtual disk.
|
||||
|
||||
To partition a particular hard disk, for example /dev/xvdc.
|
||||
|
||||
```
|
||||
# fdisk /dev/xvdc
|
||||
```
|
||||
|
||||
Commonly used fdisk commands.
|
||||
|
||||
* `n` – Create partition
|
||||
* `p` – print partition table
|
||||
* `d` – delete a partition
|
||||
* `q` – exit without saving the changes
|
||||
* `w` – write the changes and exit.
|
||||
|
||||
Here since we are creating a partition use `n` option.
|
||||
|
||||
[
|
||||
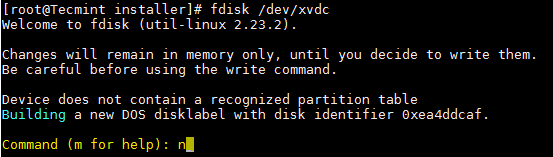
|
||||
][5]
|
||||
|
||||
Create New Partition in Linux
|
||||
|
||||
Create either primary/extended partitions. By default we can have upto 4 primary partitions.
|
||||
|
||||
[
|
||||
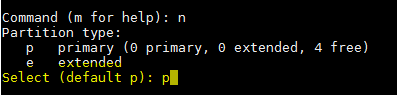
|
||||
][6]
|
||||
|
||||
Create Primary Partition
|
||||
|
||||
Give the partition number as desired. Recommended to go for the default value `1`.
|
||||
|
||||
[
|
||||
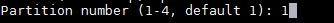
|
||||
][7]
|
||||
|
||||
Assign a Partition Number
|
||||
|
||||
Give the value of the first sector. If it is a new disk, always select default value. If you are creating a second partition on the same disk, we need to add `1` to the last sector of the previous partition.
|
||||
|
||||
[
|
||||
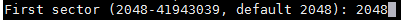
|
||||
][8]
|
||||
|
||||
Assign Sector to Partition
|
||||
|
||||
Give the value of the last sector or the partition size. Always recommended to give the size of the partition. Always prefix `+` to avoid value out of range error.
|
||||
|
||||
[
|
||||
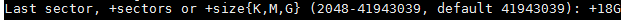
|
||||
][9]
|
||||
|
||||
Assign Partition Size
|
||||
|
||||
Save the changes and exit.
|
||||
|
||||
[
|
||||
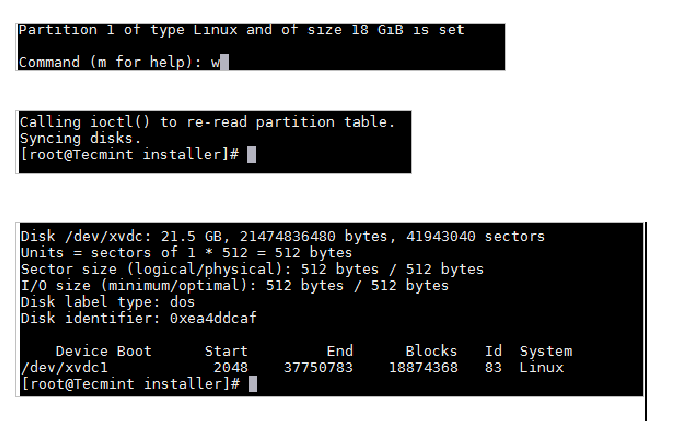
|
||||
][10]
|
||||
|
||||
Save Partition Changes
|
||||
|
||||
Now format the disk with mkfs command.
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/xvdc1
|
||||
```
|
||||
[
|
||||
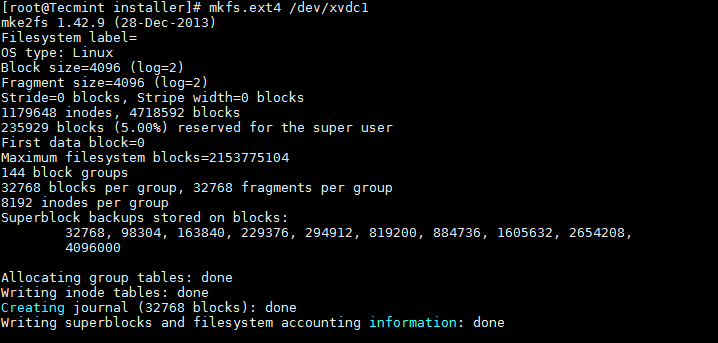
|
||||
][11]
|
||||
|
||||
Format New Partition
|
||||
|
||||
Once formatting has been completed, now mount the partition as shown below.
|
||||
|
||||
```
|
||||
# mount /dev/xvdc1 /data
|
||||
```
|
||||
|
||||
Make an entry in /etc/fstab file for permanent mount at boot time.
|
||||
|
||||
```
|
||||
/dev/xvdc1 /data ext4 defaults 0 0
|
||||
```
|
||||
|
||||
##### Conclusion
|
||||
|
||||
Now you know how to partition a raw disk using [fdisk command][12] and mount the same.
|
||||
|
||||
We need to be extra cautious while working with the partitions especially when you are editing the configured disks. Please share your feedback and suggestions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I work on various platforms including IBM-AIX, Solaris, HP-UX, and storage technologies ONTAP and OneFS and have hands on experience on Oracle Database.
|
||||
|
||||
-----------------------
|
||||
|
||||
via: http://www.tecmint.com/add-new-disk-to-an-existing-linux/
|
||||
|
||||
作者:[Lakshmi Dhandapani][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/lakshmi/
|
||||
[1]:http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
||||
[2]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Partition-Details.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-New-Partition-Details.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-New-Partition-in-Linux.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-Primary-Partition.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-a-Partition-Number.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-Sector-to-Partition.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-Partition-Size.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Save-Partition-Changes.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Format-New-Partition.png
|
||||
[12]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[13]:http://www.tecmint.com/author/lakshmi/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
Writing a Linux Debugger Part 1: Setup
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
icltyh Translating
|
||||
Writing a Linux Debugger Part 2: Breakpoints
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,102 +0,0 @@
|
||||
5 open source RSS feed readers
|
||||
============================================================
|
||||
|
||||

|
||||
>Image by : [Rob McDonald][2] on Flickr. Modified by Opensource.com. [CC BY-SA 2.0][3].
|
||||
|
||||
### Do you use an RSS reader regularly?
|
||||
|
||||
<form class="pollanon" action="https://opensource.com/article/17/3/rss-feed-readers" method="post" id="poll-view-voting" accept-charset="UTF-8"><label class="element-invisible" for="edit-choice" style="display: block; clip: rect(1px 1px 1px 1px); overflow: hidden; height: 1px; width: 1px; color: rgb(67, 81, 86); position: absolute !important;">Choices</label><input type="radio" id="edit-choice-7621" name="choice" value="7621" class="form-radio" style="font-size: 16px; margin-top: 0px; max-width: 100%; -webkit-appearance: none; width: 0.8em; height: 0.8em; border-width: 1px; border-style: solid; border-color: rgb(51, 51, 51); border-radius: 50%; vertical-align: middle;"> <label class="option" for="edit-choice-7621" style="display: inline; font-weight: normal; color: rgb(67, 81, 86); margin-left: 0.2em; vertical-align: middle;">Yes.</label><input type="radio" id="edit-choice-7626" name="choice" value="7626" class="form-radio" style="font-size: 16px; margin-top: 0px; max-width: 100%; -webkit-appearance: none; width: 0.8em; height: 0.8em; border-width: 1px; border-style: solid; border-color: rgb(51, 51, 51); border-radius: 50%; vertical-align: middle;"> <label class="option" for="edit-choice-7626" style="display: inline; font-weight: normal; color: rgb(67, 81, 86); margin-left: 0.2em; vertical-align: middle;">No, but I used to.</label><input type="radio" id="edit-choice-7631" name="choice" value="7631" class="form-radio" style="font-size: 16px; margin-top: 0px; max-width: 100%; -webkit-appearance: none; width: 0.8em; height: 0.8em; border-width: 1px; border-style: solid; border-color: rgb(51, 51, 51); border-radius: 50%; vertical-align: middle;"> <label class="option" for="edit-choice-7631" style="display: inline; font-weight: normal; color: rgb(67, 81, 86); margin-left: 0.2em; vertical-align: middle;">No, I never did.</label><input type="submit" id="edit-vote" name="op" value="Vote" class="form-submit" style="font-family: "Swiss 721 SWA", "Helvetica Neue", Helvetica, Arial, "Nimbus Sans L", sans-serif; font-size: 1em; max-width: 100%; line-height: normal; font-style: normal; border-width: 1px; border-style: solid; border-color: rgb(119, 186, 77); color: rgb(255, 255, 255); background: rgb(119, 186, 77); padding: 0.6em 1.9em;"></form>
|
||||
|
||||
When Google Reader was discontinued four years ago, many "technology experts" called it the end of RSS feeds.
|
||||
|
||||
And it's true that for some people, social media and other aggregation tools are filling a need that feed readers for RSS, Atom, and other syndication formats once served. But old technologies never really die just because new technologies come along, particularly if the new technology does not perfectly replicate all of the use cases of the old one. The target audience for a technology might change a bit, and the tools people use to consume the technology might change, too.
|
||||
|
||||
But RSS is no more gone than email, JavaScript, SQL databases, the command line, or any number of other technologies that various people told me more than a decade ago had numbered days. (Is it any wonder that vinyl album sales just hit a [25-year peak][4] last year?) One only has to look at the success of online feed reader site Feedly to understand that there's still definitely a market for RSS readers.
|
||||
|
||||
The truth is, RSS and related feed formats are just more versatile than anything in wide usage that has attempted to replace it. There is no other easy was for me as a consumer to read a wide variety of publications, formatted in a client of my choosing, where I am virtually guaranteed to see every item that is published, while simultaneously not being shown a bunch of articles I have already read. And as a publisher, it's a simple format that most any publishing software I already use will support out of the box, letting me reach more people and easily distribute many types of documents.
|
||||
|
||||
So no, RSS is not dead. Long live RSS! We last looked at [open source RSS reader][5] options in 2013, and it's time for an update. Here are some of my top choices for open source RSS feed readers in 2017, each a little different in its approach.
|
||||
|
||||
### Miniflux
|
||||
|
||||
[Miniflux][6] is an absolutely minimalist web-based RSS reader, but don't confuse its intentionally light approach with laziness on the part of the developers; it is purposefully built to be a simple and efficient design. The philosophy of Miniflux seems to be to keep the application out of the way so that the reader can focus on the content, something many of us can appreciate in a world of bloated web applications.
|
||||
|
||||
But lightweight doesn't mean void of features; its responsive design looks good across any device, and allows for theming, an API interface, multiple languages, bookmark pinning, and more.
|
||||
|
||||
Miniflux's [source code][7] can be found on GitHub under the [GPLv3 Affero][8] license. If you don't want to set up your own self-hosted version, a paid hosting plan is available for $15/year.
|
||||
|
||||
### RSSOwl
|
||||
|
||||
[RSSOwl][9] is a cross-platform desktop feed reader. Written in Java, it is reminiscent of many popular desktop email clients in style and feel. It features powerful filtering and search capabilities, customizable notifications, and labels and bins for sorting your feeds. If you're used to using Thunderbird or other desktop readers for email, you'll feel right at home in RSSOwl.
|
||||
|
||||
You can find the source code for [RSSOwl][10] on GitHub under the [Eclipse Public License][11].
|
||||
|
||||
### Tickr
|
||||
|
||||
[Tickr][12] is a slightly different entry in this mix. It's a Linux desktop client, but it's not your traditional browse-and-read format. Instead, it slides your feed's headlines across a bar on your desktop like a news ticker; it's a great choice for news junkies who want to get the latest from a variety of sources. Clicking on a headline will open it in your browser of choice. It's not a dedicated reading client like the rest of the applications on this list, but if you're more interested in skimming headlines than reading every article, it's a good pick.
|
||||
|
||||
Tickr's source code and binaries can be found on the project's [website][13] under a GPL license.
|
||||
|
||||
### Tiny Tiny RSS
|
||||
|
||||
It would be difficult to build a list of modern RSS readers without including [Tiny Tiny RSS][14]. It's among the most popular self-hosted web-based readers, and it's chocked full of features: OPML import and export, keyboard shortcuts, sharing features, a themeable interface, an infrastructure for plug-ins, filtering capabilities, and lots more.
|
||||
|
||||
Tiny Tiny RSS also hosts an official [Android client][15], for those hoping to read on the go.
|
||||
|
||||
Both the [web][16] and [Android][17] source code for Tiny Tiny RSS can be found on GitLab under a [GPLv3 license][18].
|
||||
|
||||
### Winds
|
||||
|
||||
[Winds][19] is a modern looking self-hosted web feed reader, built on React. It makes use of a hosted machine learning personalization API called Stream, with the intent of helping you find more content that might be of interest to you based on your current interests. An online demo is available so you can [try it out][20] before you download. It's a new project, just a few months old, and so perhaps too soon to evaluate whether it's up to replace my daily feed reader yet, but it's certainly a project I'm watching with interest.
|
||||
|
||||
You can find the [source code][21] for Winds on GitHub under an [MIT][22] license.
|
||||
|
||||
* * *
|
||||
|
||||
These are most definitely not the only options out there. RSS is a relatively easy-to-parse, well-documented format, and so there are many, many different feed readers out there built to suit just about every taste. Here's a [big list][23] of self-hosted open source feed readers you might consider in addition to the ones we listed. We hope you'll share with us what your favorite RSS reader is in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Baker - Jason is passionate about using technology to make the world more open, from software development to bringing sunlight to local governments. Linux desktop enthusiast. Map/geospatial nerd. Raspberry Pi tinkerer. Data analysis and visualization geek. Occasional coder. Cloud nativist. Follow him on Twitter.
|
||||
|
||||
|
||||
--------------
|
||||
|
||||
via: https://opensource.com/article/17/3/rss-feed-readers
|
||||
|
||||
作者:[ Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://opensource.com/article/17/3/rss-feed-readers?rate=2sJrLq0K3QPQCznBId7K1Qrt3QAkwhQ435UyP77B5rs
|
||||
[2]:https://www.flickr.com/photos/evokeartdesign/6002000807
|
||||
[3]:https://creativecommons.org/licenses/by/2.0/
|
||||
[4]:https://www.theguardian.com/music/2017/jan/03/record-sales-vinyl-hits-25-year-high-and-outstrips-streaming
|
||||
[5]:https://opensource.com/life/13/6/open-source-rss
|
||||
[6]:https://miniflux.net/
|
||||
[7]:https://github.com/miniflux/miniflux
|
||||
[8]:https://github.com/miniflux/miniflux/blob/master/LICENSE
|
||||
[9]:http://www.rssowl.org/
|
||||
[10]:https://github.com/rssowl/RSSOwl
|
||||
[11]:https://github.com/rssowl/RSSOwl/blob/master/LICENSE
|
||||
[12]:https://www.open-tickr.net/
|
||||
[13]:https://www.open-tickr.net/download.php
|
||||
[14]:https://tt-rss.org/gitlab/fox/tt-rss/wikis/home
|
||||
[15]:https://tt-rss.org/gitlab/fox/tt-rss-android
|
||||
[16]:https://tt-rss.org/gitlab/fox/tt-rss/tree/master
|
||||
[17]:https://tt-rss.org/gitlab/fox/tt-rss-android/tree/master
|
||||
[18]:https://tt-rss.org/gitlab/fox/tt-rss-android/blob/master/COPYING
|
||||
[19]:https://winds.getstream.io/
|
||||
[20]:https://winds.getstream.io/app/getting-started
|
||||
[21]:https://github.com/GetStream/Winds
|
||||
[22]:https://github.com/GetStream/Winds/blob/master/LICENSE.md
|
||||
[23]:https://github.com/Kickball/awesome-selfhosted#feed-readers
|
||||
[24]:https://opensource.com/user/19894/feed
|
||||
[25]:https://opensource.com/article/17/3/rss-feed-readers#comments
|
||||
[26]:https://opensource.com/users/jason-baker
|
||||
@ -0,0 +1,344 @@
|
||||
All You Need To Know About Processes in Linux [Comprehensive Guide]
|
||||
============================================================
|
||||
|
||||
In this article, we will walk through a basic understanding of processes and briefly look at [how to manage processes in Linux][9] using certain commands.
|
||||
|
||||
A process refers to a program in execution; it’s a running instance of a program. It is made up of the program instruction, data read from files, other programs or input from a system user.
|
||||
|
||||
#### Types of Processes
|
||||
|
||||
There are fundamentally two types of processes in Linux:
|
||||
|
||||
* Foreground processes (also referred to as interactive processes) – these are initialized and controlled through a terminal session. In other words, there has to be a user connected to the system to start such processes; they haven’t started automatically as part of the system functions/services.
|
||||
* Background processes (also referred to as non-interactive/automatic processes) – are processes not connected to a terminal; they don’t expect any user input.
|
||||
|
||||
#### What is Daemons
|
||||
|
||||
These are special types of background processes that start at system startup and keep running forever as a service; they don’t die. They are started as system tasks (run as services), spontaneously. However, they can be controlled by a user via the init process.
|
||||
|
||||
[
|
||||
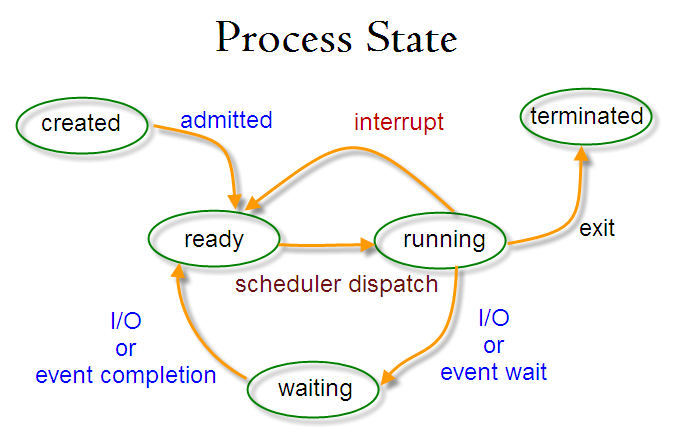
|
||||
][10]
|
||||
|
||||
Linux Process State
|
||||
|
||||
### Creation of a Processes in Linux
|
||||
|
||||
A new process is normally created when an existing process makes an exact copy of itself in memory. The child process will have the same environment as its parent, but only the process ID number is different.
|
||||
|
||||
There are two conventional ways used for creating a new process in Linux:
|
||||
|
||||
* Using The System() Function – this method is relatively simple, however, it’s inefficient and has significantly certain security risks.
|
||||
* Using fork() and exec() Function – this technique is a little advanced but offers greater flexibility, speed, together with security.
|
||||
|
||||
### How Does Linux Identify Processes?
|
||||
|
||||
Because Linux is a multi-user system, meaning different users can be running various programs on the system, each running instance of a program must be identified uniquely by the kernel.
|
||||
|
||||
And a program is identified by its process ID (PID) as well as it’s parent processes ID (PPID), therefore processes can further be categorized into:
|
||||
|
||||
* Parent processes – these are processes that create other processes during run-time.
|
||||
* Child processes – these processes are created by other processes during run-time.
|
||||
|
||||
#### The Init Process
|
||||
|
||||
Init process is the mother (parent) of all processes on the system, it’s the first program that is executed when the [Linux system boots up][11]; it manages all other processes on the system. It is started by the kernel itself, so in principle it does not have a parent process.
|
||||
|
||||
The init process always has process ID of 1. It functions as an adoptive parent for all orphaned processes.
|
||||
|
||||
You can use the pidof command to find the ID of a process:
|
||||
|
||||
```
|
||||
# pidof systemd
|
||||
# pidof top
|
||||
# pidof httpd
|
||||
```
|
||||
[
|
||||
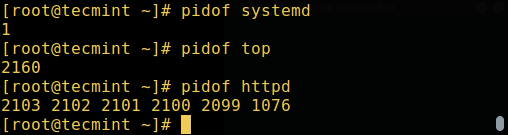
|
||||
][12]
|
||||
|
||||
Find Linux Process ID
|
||||
|
||||
To find the process ID and parent process ID of the current shell, run:
|
||||
|
||||
```
|
||||
$ echo $$
|
||||
$ echo $PPID
|
||||
```
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Find Linux Parent Process ID
|
||||
|
||||
#### Starting a Process in Linux
|
||||
|
||||
Once you run a command or program (for example cloudcmd – CloudCommander), it will start a process in the system. You can start a foreground (interactive) process as follows, it will be connected to the terminal and a user can send input it:
|
||||
|
||||
```
|
||||
# cloudcmd
|
||||
```
|
||||
[
|
||||
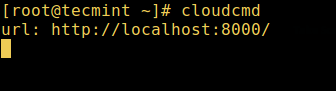
|
||||
][14]
|
||||
|
||||
Start Linux Interactive Process
|
||||
|
||||
#### Linux Background Jobs
|
||||
|
||||
To start a process in the background (non-interactive), use the `&` symbol, here, the process doesn’t read input from a user until it’s moved to the foreground.
|
||||
|
||||
```
|
||||
# cloudcmd &
|
||||
# jobs
|
||||
```
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Start Linux Process in Background
|
||||
|
||||
You can also send a process to the background by suspending it using `[Ctrl + Z]`, this will send the SIGSTOP signal to the process, thus stopping its operations; it becomes idle:
|
||||
|
||||
```
|
||||
# tar -cf backup.tar /backups/* #press Ctrl+Z
|
||||
# jobs
|
||||
```
|
||||
|
||||
To continue running the above-suspended command in the background, use the bg command:
|
||||
|
||||
```
|
||||
# bg
|
||||
```
|
||||
|
||||
To send a background process to the foreground, use the fg command together with the job ID like so:
|
||||
|
||||
```
|
||||
# jobs
|
||||
# fg %1
|
||||
```
|
||||
[
|
||||
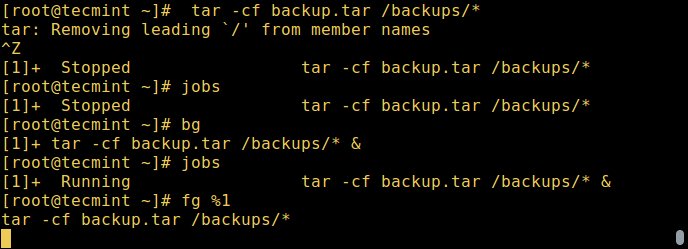
|
||||
][16]
|
||||
|
||||
Linux Background Process Jobs
|
||||
|
||||
You may also like: [How to Start Linux Command in Background and Detach Process in Terminal][17]
|
||||
|
||||
#### States of a Process in Linux
|
||||
|
||||
During execution, a process changes from one state to another depending on its environment/circumstances. In Linux, a process has the following possible states:
|
||||
|
||||
* Running – here it’s either running (it is the current process in the system) or it’s ready to run (it’s waiting to be assigned to one of the CPUs).
|
||||
* Waiting – in this state, a process is waiting for an event to occur or for a system resource. Additionally, the kernel also differentiates between two types of waiting processes; interruptible waiting processes – can be interrupted by signals and uninterruptible waiting processes – are waiting directly on hardware conditions and cannot be interrupted by any event/signal.
|
||||
* Stopped – in this state, a process has been stopped, usually by receiving a signal. For instance, a process that is being debugged.
|
||||
* Zombie – here, a process is dead, it has been halted but it’s still has an entry in the process table.
|
||||
|
||||
#### How to View Active Processes in Linux
|
||||
|
||||
There are several Linux tools for viewing/listing running processes on the system, the two traditional and well known are [ps][18] and [top][19] commands:
|
||||
|
||||
#### 1\. ps Command
|
||||
|
||||
It displays information about a selection of the active processes on the system as shown below:
|
||||
|
||||
```
|
||||
# ps
|
||||
# ps -e | head
|
||||
```
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
List Linux Active Processes
|
||||
|
||||
#### 2\. top – System Monitoring Tool
|
||||
|
||||
[top is a powerful tool][21] that offers you a [dynamic real-time view of a running system][22] as shown in the screenshot below:
|
||||
|
||||
```
|
||||
# top
|
||||
```
|
||||
[
|
||||
|
||||
][23]
|
||||
|
||||
List Linux Running Processes
|
||||
|
||||
Read this for more top usage examples: [12 TOP Command Examples in Linux][24]
|
||||
|
||||
#### 3\. glances – System Monitoring Tool
|
||||
|
||||
glances is a relatively new system monitoring tool with advanced features:
|
||||
|
||||
```
|
||||
# glances
|
||||
```
|
||||
[
|
||||
|
||||
][25]
|
||||
|
||||
Glances – Linux Process Monitoring
|
||||
|
||||
For a comprehensive usage guide, read through: [Glances – An Advanced Real Time System Monitoring Tool for Linux][26]
|
||||
|
||||
There are several other useful Linux system monitoring tools you can use to list active processes, open the link below to read more about them:
|
||||
|
||||
1. [20 Command Line Tools to Monitor Linux Performance][1]
|
||||
2. [13 More Useful Linux Monitoring Tools][2]
|
||||
|
||||
### How to Control Processes in Linux
|
||||
|
||||
Linux also has some commands for controlling processes such as kill, pkill, pgrep and killall, below are a few basic examples of how to use them:
|
||||
|
||||
```
|
||||
$ pgrep -u tecmint top
|
||||
$ kill 2308
|
||||
$ pgrep -u tecmint top
|
||||
$ pgrep -u tecmint glances
|
||||
$ pkill glances
|
||||
$ pgrep -u tecmint glances
|
||||
```
|
||||
[
|
||||
|
||||
][27]
|
||||
|
||||
Control Linux Processes
|
||||
|
||||
To learn how to use these commands in-depth, to kill/terminate active processes in Linux, open the links below:
|
||||
|
||||
1. [A Guide to Kill, Pkill and Killall Commands to Terminate Linux Processess][3]
|
||||
2. [How to Find and Kill Running Processes in Linux][4]
|
||||
|
||||
Note that you can use them to kill [unresponsive applications in Linux][28] when your system freezes.
|
||||
|
||||
#### Sending Signals To Processes
|
||||
|
||||
The fundamental way of controlling processes in Linux is by sending signals to them. There are multiple signals that you can send to a process, to view all the signals run:
|
||||
|
||||
```
|
||||
$ kill -l
|
||||
```
|
||||
[
|
||||

|
||||
][29]
|
||||
|
||||
List All Linux Signals
|
||||
|
||||
To send a signal to a process, use the kill, pkill or pgrep commands we mentioned earlier on. But programs can only respond to signals if they are programmed to recognize those signals.
|
||||
|
||||
And most signals are for internal use by the system, or for programmers when they write code. The following are signals which are useful to a system user:
|
||||
|
||||
* SIGHUP 1 – sent to a process when its controlling terminal is closed.
|
||||
* SIGINT 2 – sent to a process by its controlling terminal when a user interrupts the process by pressing `[Ctrl+C]`.
|
||||
* SIGQUIT 3 – sent to a process if the user sends a quit signal `[Ctrl+D]`.
|
||||
* SIGKILL 9 – this signal immediately terminates (kills) a process and the process will not perform any clean-up operations.
|
||||
* SIGTERM 15 – this a program termination signal (kill will send this by default).
|
||||
* SIGTSTP 20 – sent to a process by its controlling terminal to request it to stop (terminal stop); initiated by the user pressing `[Ctrl+Z]`.
|
||||
|
||||
The following are kill commands examples to kill the Firefox application using its PID once it freezes:
|
||||
|
||||
```
|
||||
$ pidof firefox
|
||||
$ kill 9 2687
|
||||
OR
|
||||
$ kill -KILL 2687
|
||||
OR
|
||||
$ kill -SIGKILL 2687
|
||||
```
|
||||
|
||||
To kill an application using its name, use pkill or killall like so:
|
||||
|
||||
```
|
||||
$ pkill firefox
|
||||
$ killall firefox
|
||||
```
|
||||
|
||||
#### Changing Linux Process Priority
|
||||
|
||||
On the Linux system, all active processes have a priority and certain nice value. Processes with higher priority will normally get more CPU time than lower priority processes.
|
||||
|
||||
However, a system user with root privileges can influence this with the nice and renice commands.
|
||||
|
||||
From the output of the top command, the NI shows the process nice value:
|
||||
|
||||
```
|
||||
$ top
|
||||
```
|
||||
[
|
||||

|
||||
][30]
|
||||
|
||||
List Linux Running Processes
|
||||
|
||||
Use the nice command to set a nice value for a process. Keep in mind that normal users can attribute a nice value from zero to 20 to processes they own.
|
||||
Only the root user can use negative nice values.
|
||||
|
||||
To renice the priority of a process, use the renice command as follows:
|
||||
|
||||
```
|
||||
$ renice +8 2687
|
||||
$ renice +8 2103
|
||||
```
|
||||
|
||||
Check out our some useful articles on how to manage and control Linux processes.
|
||||
|
||||
1. [Linux Process Management: Boot, Shutdown, and Everything in Between][5]
|
||||
2. [Find Top 15 Processes by Memory Usage with ‘top’ in Batch Mode][6]
|
||||
3. [Find Top Running Processes by Highest Memory and CPU Usage in Linux][7]
|
||||
4. [How to Find a Process Name Using PID Number in Linux][8]
|
||||
|
||||
That’s all for now! Do you have any questions or additional ideas, share them with us via the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-process-management/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[2]:http://www.tecmint.com/linux-performance-monitoring-tools/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
[4]:http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
[6]:http://www.tecmint.com/find-processes-by-memory-usage-top-batch-mode/
|
||||
[7]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[8]:http://www.tecmint.com/find-process-name-pid-number-linux/
|
||||
[9]:http://www.tecmint.com/dstat-monitor-linux-server-performance-process-memory-network/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/ProcessState.png
|
||||
[11]:http://www.tecmint.com/linux-boot-process/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Process-ID.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Parent-Process-ID.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Start-Linux-Interactive-Process.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Start-Linux-Process-in-Background.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Linux-Background-Process-Jobs.png
|
||||
[17]:http://www.tecmint.com/run-linux-command-process-in-background-detach-process/
|
||||
[18]:http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
[19]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2017/03/ps-command.png
|
||||
[21]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[22]:http://www.tecmint.com/bcc-best-linux-performance-monitoring-tools/
|
||||
[23]:http://www.tecmint.com/wp-content/uploads/2017/03/top-command.png
|
||||
[24]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[25]:http://www.tecmint.com/wp-content/uploads/2017/03/glances.png
|
||||
[26]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[27]:http://www.tecmint.com/wp-content/uploads/2017/03/Control-Linux-Processes.png
|
||||
[28]:http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
[29]:http://www.tecmint.com/wp-content/uploads/2017/03/list-all-signals.png
|
||||
[30]:http://www.tecmint.com/wp-content/uploads/2017/03/top-command.png
|
||||
[31]:http://www.tecmint.com/author/aaronkili/
|
||||
[32]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[33]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,188 @@
|
||||
pyDash – A Web Based Linux Performance Monitoring Tool
|
||||
============================================================
|
||||
|
||||
|
||||
pydash is a lightweight [web-based monitoring tool for Linux][1] written in Python and [Django][2] plus Chart.js. It has been tested and can run on the following mainstream Linux distributions: CentOS, Fedora, Ubuntu, Debian, Arch Linux, Raspbian as well as Pidora.
|
||||
|
||||
You can use it to keep an eye on your Linux PC/server resources such as CPUs, RAM, network stats, processes including online users and more. The dashboard is developed entirely using Python libraries provided in the main Python distribution, therefore it has a few dependencies; you don’t need to install many packages or libraries to run it.
|
||||
|
||||
In this article, we will show you how to install pydash to monitor Linux server performance.
|
||||
|
||||
### How to Install pyDash in Linux System
|
||||
|
||||
1. First install required packages: git and Python pip as follows:
|
||||
|
||||
```
|
||||
-------------- On Debian/Ubuntu --------------
|
||||
$ sudo apt-get install git python-pip
|
||||
-------------- On CentOS/RHEL --------------
|
||||
# yum install epel-release
|
||||
# yum install git python-pip
|
||||
-------------- On Fedora 22+ --------------
|
||||
# dnf install git python-pip
|
||||
```
|
||||
|
||||
2. If you have git and Python pip installed, next, install virtualenv which helps to deal with dependency issues for Python projects, as below:
|
||||
|
||||
```
|
||||
# pip install virtualenv
|
||||
OR
|
||||
$ sudo pip install virtualenv
|
||||
```
|
||||
|
||||
3. Now using git command, clone the pydash directory into your home directory like so:
|
||||
|
||||
```
|
||||
# git clone https://github.com/k3oni/pydash.git
|
||||
# cd pydash
|
||||
```
|
||||
|
||||
4. Next, create a virtual environment for your project called pydashtest using the virtualenv command below.
|
||||
|
||||
```
|
||||
$ virtualenv pydashtest #give a name for your virtual environment like pydashtest
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Create Virtual Environment
|
||||
|
||||
Important: Take note the virtual environment’s bin directory path highlighted in the screenshot above, yours could be different depending on where you cloned the pydash folder.
|
||||
|
||||
5. Once you have created the virtual environment (pydashtest), you must activate it before using it as follows.
|
||||
|
||||
```
|
||||
$ source /home/aaronkilik/pydash/pydashtest/bin/activate
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Active Virtual Environment
|
||||
|
||||
From the screenshot above, you’ll note that the PS1 prompt changes indicating that your virtual environment has been activated and is ready for use.
|
||||
|
||||
6. Now install the pydash project requirements; if you are curious enough, view the contents of requirements.txt using the [cat command][5] and the install them using as shown below.
|
||||
|
||||
```
|
||||
$ cat requirements.txt
|
||||
$ pip install -r requirements.txt
|
||||
```
|
||||
|
||||
7. Now move into the pydash directory containing settings.py or simple run the command below to open this file to change the SECRET_KEY to a custom value.
|
||||
|
||||
```
|
||||
$ vi pydash/settings.py
|
||||
```
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Set Secret Key
|
||||
|
||||
Save the file and exit.
|
||||
|
||||
8. Afterward, run the django command below to create the project database and install Django’s auth system and create a project super user.
|
||||
|
||||
```
|
||||
$ python manage.py syncdb
|
||||
```
|
||||
|
||||
Answer the questions below according to your scenario:
|
||||
|
||||
```
|
||||
Would you like to create one now? (yes/no): yes
|
||||
Username (leave blank to use 'root'): admin
|
||||
Email address: aaronkilik@gmail.com
|
||||
Password: ###########
|
||||
Password (again): ############
|
||||
```
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
Create Project Database
|
||||
|
||||
9. At this point, all should be set, now run the following command to start the Django development server.
|
||||
|
||||
```
|
||||
$ python manage.py runserver
|
||||
```
|
||||
|
||||
10. Next, open your web browser and type the URL: http://127.0.0.1:8000/ to get the web dashboard login interface. Enter the super user name and password you created while creating the database and installing Django’s auth system in step 8 and click Sign In.
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
pyDash Login Interface
|
||||
|
||||
11. Once you login into pydash main interface, you will get a section for monitoring general system info, CPU, memory and disk usage together with system load average.
|
||||
|
||||
Simply scroll down to view more sections.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
pyDash Server Performance Overview
|
||||
|
||||
12. Next, screenshot of the pydash showing a section for keeping track of interfaces, IP addresses, Internet traffic, disk read/writes, online users and netstats.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
pyDash Network Overview
|
||||
|
||||
13. Next is a screenshot of the pydash main interface showing a section to keep an eye on active processes on the system.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
pyDash Active Linux Processes
|
||||
|
||||
For more information, check out pydash on Github: [https://github.com/k3oni/pydash][12].
|
||||
|
||||
That’s it for now! In this article, we showed you how to setup and test the main features of pydash in Linux. Share any thoughts with us via the feedback section below and in case you know of any useful and similar tools out there, let us know as well in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
I am Ravi Saive, creator of TecMint. A Computer Geek and Linux Guru who loves to share tricks and tips on Internet. Most Of My Servers runs on Open Source Platform called Linux. Follow Me: [Twitter][00], [Facebook][01] and [Google+][02]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/pydash-a-web-based-linux-performance-monitoring-tool/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[00]:https://twitter.com/ravisaive
|
||||
[01]:https://www.facebook.com/ravi.saive
|
||||
[02]:https://plus.google.com/u/0/+RaviSaive
|
||||
|
||||
[1]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[2]:http://www.tecmint.com/install-and-configure-django-web-framework-in-centos-debian-ubuntu/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/create-virtual-environment.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/after-activating-virtualenv.png
|
||||
[5]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/change-secret-key.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/python-manage.py-syncdb.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-web-login-interface.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Server-Performance-Overview.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Network-Overview.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Active-Linux-Processes.png
|
||||
[12]:https://github.com/k3oni/pydash
|
||||
[13]:http://www.tecmint.com/author/admin/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,128 @@
|
||||
How To Enable Desktop Sharing In Ubuntu and Linux Mint
|
||||
============================================================
|
||||
|
||||
|
||||
Desktop sharing refers to technologies that enable remote access and remote collaboration on a computer desktop via a graphical terminal emulator. Desktop sharing allows two or more Internet-enabled computer users to work on the same files from different locations.
|
||||
|
||||
In this article, we will show you how to enable desktop sharing in Ubuntu and Linux Mint, with a few vital security features.
|
||||
|
||||
### Enabling Desktop Sharing in Ubuntu and Linux Mint
|
||||
|
||||
1. In the Ubuntu Dash or Linux Mint Menu, search for “desktop sharing” as shown in the following screenshot, once you get it, launch it.
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
Search for Desktop Sharing in Ubuntu
|
||||
|
||||
2. Once you launch Desktop sharing, there are three categories of desktop sharing settings: sharing, security and notification settings.
|
||||
|
||||
Under sharing, check the option “Allow others users to view your desktop” to enable desktop sharing. Optionally, you can also permit other users to remotely control your desktops by checking the option “Allow others users to control your desktop”.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Desktop Sharing Preferences
|
||||
|
||||
3. Next in security section, you can choose to manually confirm each remote connection by checking the option “You must confirm each access to this computer”.
|
||||
|
||||
Again, another useful security feature is creating a certain shared password using the option “Require user to enter this password”, that remote users must know and enter each time they want to access your desktop.
|
||||
|
||||
4. Concerning notifications, you can keep an eye on remote connections by choosing to show the notification area icon each time there is a remote connection to your desktops by selecting “Only when someone is connected”.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Configure Desktop Sharing Set
|
||||
|
||||
When you have set all the desktop sharing options, click Close. Now you have successfully permitted desktop sharing on your Ubuntu or Linux Mint desktop.
|
||||
|
||||
### Testing Desktop Sharing in Ubuntu Remotely
|
||||
|
||||
You can test to ensure that it’s working using a remote connection application. In this example, I will show you how some of the options we set above work.
|
||||
|
||||
5. I will connect to my Ubuntu PC using VNC (Virtual Network Computing) protocol via [remmina remote connection application][4].
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Remmina Desktop Sharing Tool
|
||||
|
||||
6. After clicking on Ubuntu PC item, I get the interface below to configure my connection settings.
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
Remmina Desktop Sharing Preferences
|
||||
|
||||
7. After performing all the settings, I will click Connect. Then provide the SSH password for the username and click OK.
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
Enter SSH User Password
|
||||
|
||||
I have got this black screen after clicking OK because, on the remote machine, the connection has not been confirmed yet.
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
Black Screen Before Confirmation
|
||||
|
||||
8. Now on the remote machine, I have to accept the remote access request by clicking on “Allow” as shown in the next screenshot.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Allow Remote Desktop Sharing
|
||||
|
||||
9. After accepting the request, I have successfully connected, remotely to my Ubuntu desktop machine.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Remote Ubuntu Desktop
|
||||
|
||||
That’s it! In this article, we described how to enable desktop sharing in Ubuntu and Linux Mint. Use the comment section below to write back to us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/enable-desktop-sharing-in-ubuntu-linux-mint/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/03/search-for-desktop-sharing.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/desktop-sharing-settings-inte.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Desktop-Sharing-Set.png
|
||||
[4]:http://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Desktop-Sharing-Tool.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Configure-Remote-Desk.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/shared-pass.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/black-screen-before-confirmat.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/accept-remote-access-request.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/successfully-connected-to-rem.png
|
||||
[11]:http://www.tecmint.com/author/aaronkili/
|
||||
[12]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[13]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,141 @@
|
||||
How to Add a New Disk Larger Than 2TB to An Existing Linux
|
||||
============================================================
|
||||
|
||||
|
||||
Have you ever tried to do the partitioning of hard disk larger than 2TB using [fdisk utility][1] and wondered why you end up getting a warning to use GPT? Yes, you got that right. We cannot partition a hard disk larger than 2TB using fdisk tool.
|
||||
|
||||
In such cases, we can use parted command. The major difference lies in the partitioning formats that fdisk uses DOS partitioning table format and parted uses GPT format.
|
||||
|
||||
TIP: You can use gdisk as well instead of parted tool.
|
||||
|
||||
In this article, we will show you to add a new disk larger than 2TB to an existing Linux server such as RHEL/CentOS or Debian/Ubuntu.
|
||||
|
||||
I am using fdisk and parted utilities to do this configuration.
|
||||
|
||||
First list the current partition details using fdisk command as shown.
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
[
|
||||
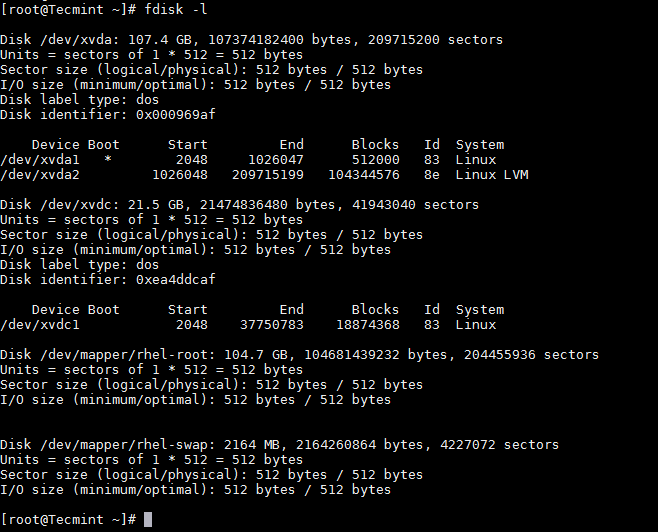
|
||||
][2]
|
||||
|
||||
List Linux Partition Table
|
||||
|
||||
For the purpose of this article, I am attaching a hard disk of 20GB capacity, which can be followed for disk larger than 2TB as well. Once you added a disk, verify the partition table using same fdisk command as shown.
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
List New Partition Table
|
||||
|
||||
Tip: If you are adding a physical hard disk, you may find that partitions already created. In such cases, you can use fdsik to delete the same before using parted.
|
||||
|
||||
```
|
||||
# fdisk /dev/xvdd
|
||||
```
|
||||
|
||||
Use `d` switch for the command to delete the partition and `w` to write the changes and quit.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Delete Linux Partition
|
||||
|
||||
Important: You need to be careful while deleting the partition. This will erase the data on the disk.
|
||||
|
||||
Now its time to partition a new hard disk using parted command.
|
||||
|
||||
```
|
||||
# parted /dev/xvdd
|
||||
```
|
||||
|
||||
Set the partition table format to GPT
|
||||
|
||||
```
|
||||
(parted) mklabel gpt
|
||||
```
|
||||
|
||||
Create the Primary partition and assign the disk capacity, here I am using 20GB (in your case it would be 2TB).
|
||||
|
||||
```
|
||||
(parted) mkpart primary 0GB 20GB
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Create Partition using Parted
|
||||
|
||||
Just for curiosity, let’s see how this new partition is listed in fdisk.
|
||||
|
||||
```
|
||||
# fdisk /dev/xvdd
|
||||
```
|
||||
[
|
||||
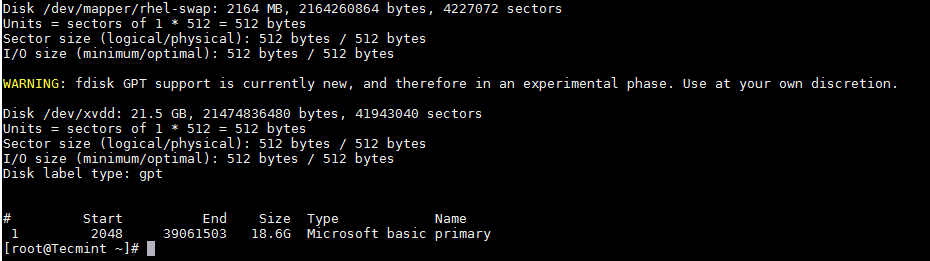
|
||||
][6]
|
||||
|
||||
Verify Partition Details
|
||||
|
||||
Now format and then mount the partition and add the same in /etc/fstab which controls the file systems to be mounted when the system boots.
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/xvdd1
|
||||
```
|
||||
[
|
||||
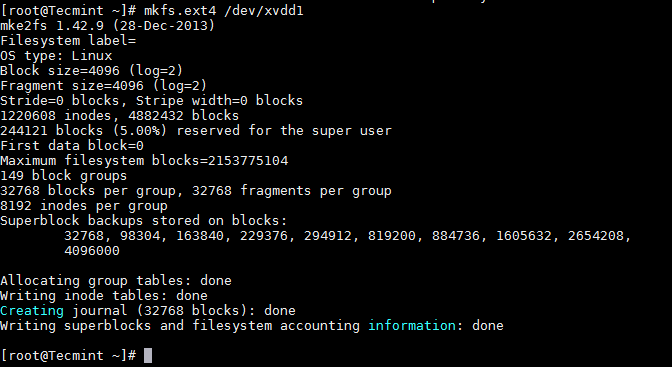
|
||||
][7]
|
||||
|
||||
Format Linux Partition
|
||||
|
||||
Once partition has been formatted, now it’s time mount the partition under /data1.
|
||||
|
||||
```
|
||||
# mount /dev/xvdd1 /data1
|
||||
```
|
||||
|
||||
For permanent mounting add the entry in /etc/fstab file.
|
||||
|
||||
```
|
||||
/dev/xvdd1 /data1 ext4 defaults 0 0
|
||||
```
|
||||
|
||||
Important: Kernel should support GPT in order to partition using GPT format. By default RHEL/CentOS have Kernel with GPT support, but for Debian/Ubuntu you need to recompile the kernel after changing the config.
|
||||
|
||||
That’s it! In this article, we have shown you how to use the parted command. Share your comments and feedback with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I work on various platforms including IBM-AIX, Solaris, HP-UX, and storage technologies ONTAP and OneFS and have hands on experience on Oracle Database.
|
||||
|
||||
-----------------------
|
||||
|
||||
via: http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
||||
|
||||
作者:[Lakshmi Dhandapani][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/lakshmi/
|
||||
|
||||
[1]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/04/List-Linux-Partition-Table.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/04/List-New-Partition-Table.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/04/Delete-Linux-Partition.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/04/Create-Partition-using-Parted.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/04/Verify-Partition-Details.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/04/Format-Linux-Partition.png
|
||||
[8]:http://www.tecmint.com/author/lakshmi/
|
||||
[9]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[10]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,213 @@
|
||||
(翻译中 by runningwater)
|
||||
FreeFileSync – Compare and Synchronize Files in Ubuntu
|
||||
============================================================
|
||||
|
||||
|
||||
FreeFileSync is a free, open source and cross platform folder comparison and synchronization software, which helps you [synchronize files and folders on Linux][2], Windows and Mac OS.
|
||||
|
||||
It is portable and can also be installed locally on a system, it’s feature-rich and is intended to save time in setting up and executing backup operations while having attractive graphical interface as well.
|
||||
|
||||
#### FreeFileSync Features
|
||||
|
||||
Below are it’s key features:
|
||||
|
||||
1. It can synchronize network shares and local disks.
|
||||
2. It can synchronize MTP devices (Android, iPhone, tablet, digital camera).
|
||||
3. It can also synchronize via [SFTP (SSH File Transfer Protocol)][1].
|
||||
4. It can identify moved and renamed files and folders.
|
||||
5. Displays disk space usage with directory trees.
|
||||
6. Supports copying locked files (Volume Shadow Copy Service).
|
||||
7. Identifies conflicts and propagate deletions.
|
||||
8. Supports comparison of files by content.
|
||||
9. It can be configured to handle Symbolic Links.
|
||||
10. Supports automation of sync as a batch job.
|
||||
11. Enables processing of multiple folder pairs.
|
||||
12. Supports in-depth and detailed error reporting.
|
||||
13. Supports copying of NTFS extended attributes such as (compressed, encrypted, sparse).
|
||||
14. Also supports copying of NTFS security permissions and NTFS Alternate Data Streams.
|
||||
15. Support long file paths with more than 260 characters.
|
||||
16. Supports Fail-safe file copy prevents data corruption.
|
||||
17. Allows expanding of environment variables such as %UserProfile%.
|
||||
18. Supports accessing of variable drive letters by volume name (USB sticks).
|
||||
19. Supports managing of versions of deleted/updated files.
|
||||
20. Prevent disc space issues via optimal sync sequence.
|
||||
21. Supports full Unicode.
|
||||
22. Offers a highly optimized run time performance.
|
||||
23. Supports filters to include and exclude files plus lots more.
|
||||
|
||||
### How To Install FreeFileSync in Ubuntu Linux
|
||||
|
||||
We will add official FreeFileSync PPA, which is available for Ubuntu 14.04 and Ubuntu 15.10 only, then update the system repository list and install it like so:
|
||||
|
||||
```
|
||||
-------------- On Ubuntu 14.04 and 15.10 --------------
|
||||
$ sudo apt-add-repository ppa:freefilesync/ffs
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install freefilesync
|
||||
```
|
||||
|
||||
On Ubuntu 16.04 and newer version, go to the [FreeFileSync download page][3] and get the appropriate package file for Ubuntu and Debian Linux.
|
||||
|
||||
Next, move into the Download folder, extract the FreeFileSync_*.tar.gz into the /opt directory as follows:
|
||||
|
||||
```
|
||||
$ cd Downloads/
|
||||
$ sudo tar xvf FreeFileSync_*.tar.gz -C /opt/
|
||||
$ cd /opt/
|
||||
$ ls
|
||||
$ sudo unzip FreeFileSync/Resources.zip -d /opt/FreeFileSync/Resources/
|
||||
```
|
||||
|
||||
Now we will create an application launcher (.desktop file) using Gnome Panel. To view examples of `.desktop`files on your system, list the contents of the directory /usr/share/applications:
|
||||
|
||||
```
|
||||
$ ls /usr/share/applications
|
||||
```
|
||||
|
||||
In case you do not have Gnome Panel installed, type the command below to install it:
|
||||
|
||||
```
|
||||
$ sudo apt-get install --no-install-recommends gnome-panel
|
||||
```
|
||||
|
||||
Next, run the command below to create the application launcher:
|
||||
|
||||
```
|
||||
$ sudo gnome-desktop-item-edit /usr/share/applications/ --create-new
|
||||
```
|
||||
|
||||
And define the values below:
|
||||
|
||||
```
|
||||
Type: Application
|
||||
Name: FreeFileSync
|
||||
Command: /opt/FreeFileSync/FreeFileSync
|
||||
Comment: Folder Comparison and Synchronization
|
||||
```
|
||||
|
||||
To add an icon for the launcher, simply clicking on the spring icon to select it: /opt/FreeFileSync/Resources/FreeFileSync.png.
|
||||
|
||||
When you have set all the above, click OK create it.
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
Create Desktop Launcher
|
||||
|
||||
If you don’t want to create desktop launcher, you can start FreeFileSync from the directory itself.
|
||||
|
||||
```
|
||||
$ ./FreeFileSync
|
||||
```
|
||||
|
||||
### How to Use FreeFileSync in Ubuntu
|
||||
|
||||
In Ubuntu, search for FreeFileSync in the Unity Dash, whereas in Linux Mint, search for it in the System Menu, and click on the FreeFileSync icon to open it.
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
FreeFileSync
|
||||
|
||||
#### Compare Two Folders Using FreeFileSync
|
||||
|
||||
In the example below, we’ll use:
|
||||
|
||||
```
|
||||
Source Folder: /home/aaronkilik/bin
|
||||
Destination Folder: /media/aaronkilik/J_CPRA_X86F/scripts
|
||||
```
|
||||
|
||||
To compare the file time and size of the two folders (default setting), simply click on the Compare button.
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
Compare Two Folders in Linux
|
||||
|
||||
Press `F6` to change what to compare by default, in the two folders: file time and size, content or file size from the interface below. Note that the meaning of the each option you select is included as well.
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
File Comparison Settings
|
||||
|
||||
#### Synchronization Two Folders Using FreeFileSync
|
||||
|
||||
You can start by comparing the two folders, and then click on Synchronize button, to start the synchronization process; click Start from the dialog box the appears thereafter:
|
||||
|
||||
```
|
||||
Source Folder: /home/aaronkilik/Desktop/tecmint-files
|
||||
Destination Folder: /media/aaronkilik/Data/Tecmint
|
||||
```
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
Compare and Synchronize Two Folders
|
||||
|
||||
[
|
||||
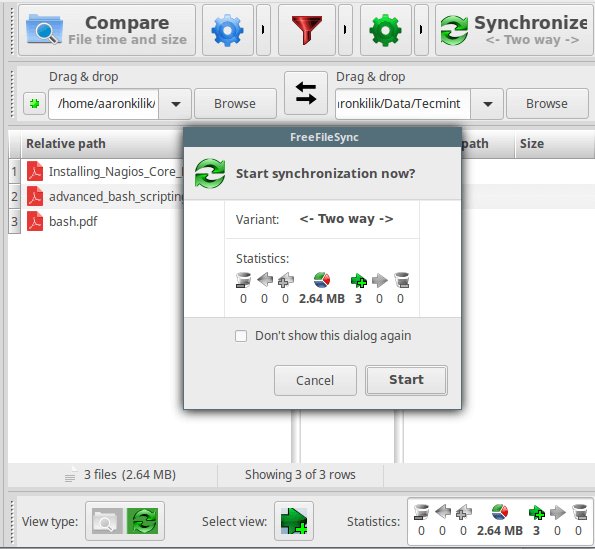
|
||||
][9]
|
||||
|
||||
Start File Synchronization
|
||||
|
||||
[
|
||||
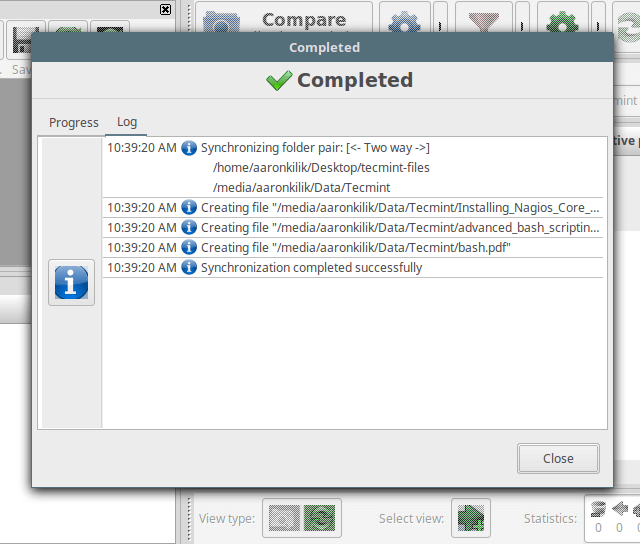
|
||||
][10]
|
||||
|
||||
File Synchronization Completed
|
||||
|
||||
To set the default synchronization option: two way, mirror, update or custom, from the following interface; press `F8`. The meaning of the each option is included there.
|
||||
|
||||
[
|
||||
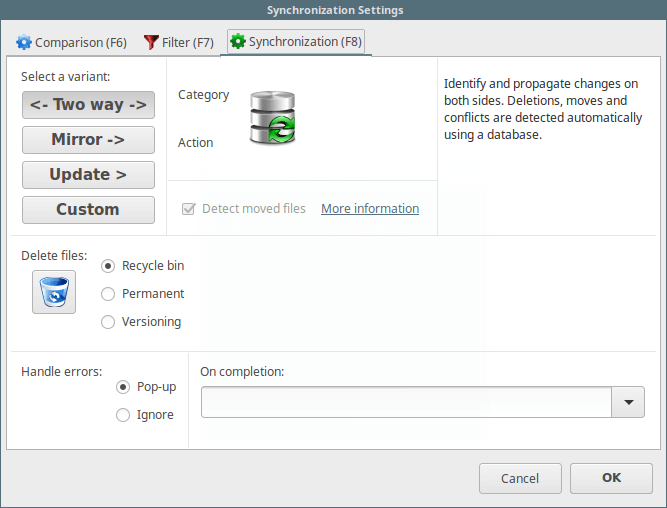
|
||||
][11]
|
||||
|
||||
File Synchronization Settings
|
||||
|
||||
For more information, visit FreeFileSync homepage at [http://www.freefilesync.org/][12]
|
||||
|
||||
That’s all! In this article, we showed you how to install FreeFileSync in Ubuntu and it’s derivatives such as Linux Mint, Kubuntu and many more. Drop your comments via the feedback section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I am Ravi Saive, creator of TecMint. A Computer Geek and Linux Guru who loves to share tricks and tips on Internet. Most Of My Servers runs on Open Source Platform called Linux. Follow Me: [Twitter][00], [Facebook][01] and [Google+][02]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/freefilesync-compare-synchronize-files-in-ubuntu/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[00]:https://twitter.com/ravisaive
|
||||
[01]:https://www.facebook.com/ravi.saive
|
||||
[02]:https://plus.google.com/u/0/+RaviSaive
|
||||
|
||||
[1]:http://www.tecmint.com/sftp-command-examples/
|
||||
[2]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[3]:http://www.freefilesync.org/download.php
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-Desktop-Launcher.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/FreeFileSync-launched.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/compare-two-folders.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/comparison-settings.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/compare-and-sychronize-two-folders.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/start-sychronization.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/synchronization-complete.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/synchronization-setttings.png
|
||||
[12]:http://www.freefilesync.org/
|
||||
[13]:http://www.tecmint.com/author/admin/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,167 @@
|
||||
Cpustat – Monitors CPU Utilization by Running Processes in Linux
|
||||
============================================================
|
||||
|
||||
Cpustat is a powerful system performance measure program for Linux, written using [Go programming language][3]. It attempts to reveal CPU utilization and saturation in an effective way, using The Utilization Saturation and Errors (USE) Method (a methodology for analyzing the performance of any system).
|
||||
|
||||
It extracts higher frequency samples of every process being executed on the system and then summarizes these samples at a lower frequency. For instance, it can measure every process every 200ms and summarize these samples every 5 seconds, including min/average/max values for certain metrics.
|
||||
|
||||
**Suggested Read:** [20 Command Line Tools to Monitor Linux Performance][4]
|
||||
|
||||
Cpustat outputs data in two possible ways: a pure text list of the summary interval and a colorful scrolling dashboard of each sample.
|
||||
|
||||
### How to Install Cpustat in Linux
|
||||
|
||||
You must have Go (GoLang) installed on your Linux system in order to use cpustat, click on the link below to follow the GoLang installation steps that is if you do not have it installed:
|
||||
|
||||
1. [Install GoLang (Go Programming Language) in Linux][1]
|
||||
|
||||
Once you have installed Go, type the go get command below to install it, this command will install the cpustat binary in your GOBIN variable:
|
||||
|
||||
```
|
||||
# go get github.com/uber-common/cpustat
|
||||
```
|
||||
|
||||
### How to Use Cpustat in Linux
|
||||
|
||||
When the installation process completes, run cpustat as follows with root privileges using the sudo command that is if your controlling the system as a non-root user, otherwise you’ll get the error as shown:
|
||||
|
||||
```
|
||||
$ $GOBIN/cpustat
|
||||
This program uses the netlink taskstats interface, so it must be run as root.
|
||||
```
|
||||
|
||||
Note: To run cpustat as well as all other Go programs you have installed on your system like any other commands, include GOBIN variable in your PATH environment variable. Open the link below to learn how to set the PATH variable in Linux.
|
||||
|
||||
1. [Learn How to Set Your $PATH Variables Permanently in Linux][2]
|
||||
|
||||
This is how cpustat works; the `/proc` directory is queried to get the current [list of process IDs][5] for every interval, and:
|
||||
|
||||
* for each PID, read /proc/pid/stat, then compute difference from previous sample.
|
||||
* in case it’s a new PID, read /proc/pid/cmdline.
|
||||
* for each PID, send a netlink message to fetch the taskstats, compute difference from previous sample.
|
||||
* fetch /proc/stat to get the overall system stats.
|
||||
|
||||
Again, each sleep interval is adjusted to account for the amount of time consumed fetching all of these stats. Furthermore, each sample also records the time it took to scale each measurement by the actual elapsed time between samples. This attempts to account for delays in cpustat itself.
|
||||
|
||||
When run without any arguments, cpustat will display the following by default: sampling interval: 200ms, summary interval: 2s (10 samples), [showing top 10 procs][6], user filter: all, pid filter: all as shown in the screenshot below:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Cpustat – Monitor Linux CPU Usage
|
||||
|
||||
From the output above, the following are the meanings of the system-wide summary metrics displayed before the fields:
|
||||
|
||||
* usr – min/avg/max user mode run time as a percentage of a CPU.
|
||||
* sys – min/avg/max system mode run time as a percentage of a CPU.
|
||||
* nice – min/avg/max user mode low priority run time as a percentage of a CPU.
|
||||
* idle – min/avg/max user mode run time as a percentage of a CPU.
|
||||
* iowait – min/avg/max delay time waiting for disk IO.
|
||||
* prun – min/avg/max count of processes in a runnable state (same as load average).
|
||||
* pblock – min/avg/max count of processes blocked on disk IO.
|
||||
* pstart – number of processes/threads started in this summary interval.
|
||||
|
||||
Still from the output above, for a given process, the different columns mean:
|
||||
|
||||
* name – common process name from /proc/pid/stat or /proc/pid/cmdline.
|
||||
* pid – process id, also referred to as “tgid”.
|
||||
* min – lowest sample of user+system time for the pid, measured from /proc/pid/stat. Scale is a percentage of a CPU.
|
||||
* max – highest sample of user+system time for this pid, also measured from /proc/pid/stat.
|
||||
* usr – average user time for the pid over the summary period, measured from /proc/pid/stat.
|
||||
* sys – average system time for the pid over the summary period, measured from /proc/pid/stat.
|
||||
* nice – indicates current “nice” value for the process, measured from /proc/pid/stat. Higher means “nicer”.
|
||||
* runq – time the process and all of its threads spent runnable but waiting to run, measured from taskstats via netlink. Scale is a percentage of a CPU.
|
||||
* iow – time the process and all of its threads spent blocked by disk IO, measured from taskstats via netlink. Scale is a percentage of a CPU, averaged over the summary interval.
|
||||
* swap – time the process and all of its threads spent waiting to be swapped in, measured from taskstats via netlink. Scale is a percentage of a CPU, averaged over the summary interval.
|
||||
* vcx and icx – total number of voluntary context switches by the process and all of its threads over the summary interval, measured from taskstats via netlink.
|
||||
* rss – current RSS value fetched from /proc/pid/stat. It is the amount of memory this process is using.
|
||||
* ctime – sum of user+sys CPU time consumed by waited for children that exited during this summary interval, measured from /proc/pid/stat.
|
||||
|
||||
Note that long running child processes can often confuse this measurement, because the time is reported only when the child process exits. However, this is useful for measuring the impact of frequent cron jobs and health checks where the CPU time is often consumed by many child processes.
|
||||
|
||||
* thrd – number of threads at the end of the summary interval, measured from /proc/pid/stat.
|
||||
* sam – number of samples for this process included in the summary interval. Processes that have recently started or exited may have been visible for fewer samples than the summary interval.
|
||||
|
||||
The following command displays the top 10 root user processes running on the system:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -u root
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Find Root User Running Processes
|
||||
|
||||
To display output in a fancy terminal mode, use the `-t` flag as follows:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -u roo -t
|
||||
```
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Running Process Usage of Root User
|
||||
|
||||
To view the [top x number of processes][10] (the default is 10), you can use the `-n` flag, the following command shows the [top 20 Linux processes running][11] on the system:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -n 20
|
||||
```
|
||||
|
||||
You can also write CPU profile to a file using the `-cpuprofile` option as follows and then use the [cat command][12] to view the file:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -cpuprofile cpuprof.txt
|
||||
$ cat cpuprof.txt
|
||||
```
|
||||
|
||||
To display help info, use the `-h` flag as follows:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -h
|
||||
```
|
||||
|
||||
Find additional info from the cpustat Github Repository: [https://github.com/uber-common/cpustat][13]
|
||||
|
||||
That’s all! In this article, we showed you how to install and use cpustat, a useful system performance measure tool for Linux. Share your thoughts with us via the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/cpustat-monitors-cpu-utilization-by-processes-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/install-go-in-linux/
|
||||
[2]:http://www.tecmint.com/set-path-variable-linux-permanently/
|
||||
[3]:http://www.tecmint.com/install-go-in-linux/
|
||||
[4]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[5]:http://www.tecmint.com/find-process-name-pid-number-linux/
|
||||
[6]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Cpustat-Monitor-Linux-CPU-Usage.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/show-root-user-processes.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Root-User-Runnng-Processes.png
|
||||
[10]:http://www.tecmint.com/find-processes-by-memory-usage-top-batch-mode/
|
||||
[11]:http://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||
[12]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[13]:https://github.com/uber-common/cpustat
|
||||
[14]:http://www.tecmint.com/author/aaronkili/
|
||||
[15]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[16]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,105 @@
|
||||
How to install Asterisk on the Raspberry Pi
|
||||
============================================================
|
||||
|
||||
> Are you looking for a phone system for your small business or home office?
|
||||
|
||||
|
||||

|
||||
>Image credits : Dwight Sipler on [Flickr][8]
|
||||
|
||||
Are you looking for a phone system for your small business or home office? I've been interested in a scalable VoIP (Voice over IP) solution, and that's when I came across an implementation of [Asterisk][9] on the Raspberry Pi.
|
||||
|
||||
My curiosity was piqued and I was determined to give it a try, so I [downloaded][10] the software from [Asterisk][11] and then set about building the server using my Raspberry Pi 3.
|
||||
|
||||
### Getting started
|
||||
|
||||
First, I burned the downloaded image onto a MicroSD card; the suggested minimum is 4GB. After transferring the image to the MicroSD card and inserting it into the appropriate slot on the Raspberry Pi, I connected an Ethernet cable to the Pi and to an Ethernet port on my home router.
|
||||
|
||||
More on Raspberry Pi
|
||||
|
||||
* [Our latest on Raspberry Pi][1]
|
||||
* [What is Raspberry Pi?][2]
|
||||
* [Getting started with Raspberry Pi][3]
|
||||
* [Send us your Raspberry Pi projects and tutorials][4]
|
||||
|
||||
Next, I opened a terminal on my Linux computer and entered **ssh root@192.168.1.8**, which is the IP address of my server. I was prompted to log in as root on the **raspbx**. The default password is "raspberry." (For security reasons, be sure to change your passwords from the default settings if you plan to do more than just try it out.)
|
||||
|
||||
Once I was logged into the shell on the **raspbx,** I then needed to prepare the server for use. Following the [documentation][12] provided on the site, I created new host keys as directed by entering **regen-hostkeys** at the shell prompt. Then, I configured the time zone for the server by entering **configure-timezone** at the shell prompt. I configured the locale setting by entering, **dpkg-reconfigure locales** at the prompt. I also installed [Fail2Ban][13] to provide security on my server.
|
||||
|
||||
Now I was ready to test my configuration.
|
||||
|
||||
### Testing
|
||||
|
||||
I logged out of the **raspbx** shell and then opened a browser and pointed it at the IP address of my server. Loading the server IP address into the browser, I was presented with a lovely login page.
|
||||
|
||||
[FreePBX][14] provides a very nice web-based, open source graphical user interface, which I used to control and configure Asterisk (find on [GitHub][15]). (FreePBX is licensed under the GPL.) I used it to complete the rest of the configuration. The default login for FreePBX is**username:admin;password:admin**.
|
||||
|
||||

|
||||
|
||||
Once in, I navigated to the Application Menu, which is located at the upper left of the display. I clicked on the menu link and selected the second option, which is Applications, and selected the fourth option, which is labeled Extensions. From there I created a **New Chan_Sip** extension.
|
||||
|
||||
|
||||
|
||||
I configured a **Sip** extension user with a password. Passwords are either automatically generated or you can elect to create your own.
|
||||
|
||||
Now that I had a functioning extension I was anxious to try out my new VoIP server. I downloaded and installed [Yate Client][16], which I discovered in the process of building the server. After installing [Yate][17], I wanted to test the connectivity with the server. I discovered that I could connect to the server for an echo test using Yate and entering ***43**. I was really excited when I heard the instructions through the client.
|
||||
|
||||
|
||||
|
||||
I decided to create another **Sip** extension so that I could test the voicemail capabilities of the system. Once I completed that I used the Yate client to call that extension and leave a brief voice message. Then using Yate again, I called that extension and entered ***97** and retrieved the voice message. Then I wanted to see if I could use my new server to call an outside line. Returning to the menu, I chose the Connectivity option and added a Google Voice line.
|
||||
|
||||

|
||||
|
||||
Then I returned to the Connectivity menu and added Google Voice to the Outbound routes.
|
||||
|
||||

|
||||
|
||||
### Completing a call
|
||||
|
||||
Returning to the Yate client, I entered an outside line and successfully completed that call.
|
||||
|
||||
I'm convinced that this particular VoIP solution could easily work for a small office. According to the [Frequently Asked Questions][18] section of the RasPBX website, a typical Raspberry Pi system could support up to 10 concurrent calls on a Raspberry Pi 1.
|
||||
|
||||
Asterisk has many nuances and the FreePBX software easily leveraged them.
|
||||
|
||||
_For more information about the Asterisk on Raspberry Pi project, follow their[blog][5]. You can find additional information about [FreePBX source code][6] on their website._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Don Watkins - Educator, education technology specialist, entrepreneur, open source advocate. M.A. in Educational Psychology, MSED in Educational Leadership, Linux system administrator, CCNA, virtualization using Virtual Box. Follow me at @Don_Watkins .
|
||||
|
||||
----------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/4/asterisk-raspberry-pi-3
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:http://www.raspberry-asterisk.org/blog/
|
||||
[6]:https://www.freepbx.org/development/source-code/
|
||||
[7]:https://opensource.com/article/17/4/asterisk-raspberry-pi-3?rate=zM9tOp0HEPyOUq31Np__W0QNnuAfWATkdkixOdSysDY
|
||||
[8]:http://www.flickr.com/photos/photofarmer/272567650/
|
||||
[9]:http://www.asterisk.org/
|
||||
[10]:http://download.raspberry-asterisk.org/raspbx-28-01-2017.zip
|
||||
[11]:http://www.raspberry-asterisk.org/downloads/
|
||||
[12]:http://www.raspberry-asterisk.org/documentation/
|
||||
[13]:http://www.raspberry-asterisk.org/documentation/#fail2ban
|
||||
[14]:https://www.freepbx.org/
|
||||
[15]:https://github.com/asterisk/asterisk/blob/master/LICENSE
|
||||
[16]:http://yateclient.yate.ro/index.php/Download/Download
|
||||
[17]:https://en.wikipedia.org/wiki/Yate_(telephony_engine)
|
||||
[18]:http://www.raspberry-asterisk.org/faq/
|
||||
[19]:https://opensource.com/user/15542/feed
|
||||
[20]:https://opensource.com/article/17/4/asterisk-raspberry-pi-3#comments
|
||||
[21]:https://opensource.com/users/don-watkins
|
||||
@ -1,139 +0,0 @@
|
||||
XYenChi is translating
|
||||
# 微软 Office 在线版变得更好 - linux上亦然
|
||||
|
||||
对于 linux 用户,影响 linux 使用体验的主要因素之一便是缺少微软 office 套装。如果你非得靠office 谋生,而它被绝大多数人使用,你可能不能承受使用开源产品的代价。理解矛盾之所在了吗?
|
||||
|
||||
的确, LibreOffice 是一个 [很棒的][1] 免费程序,但如果你的客户, 顾客或老板需要 Word 和 Excel 文件呢? 你确定能 [承担任何失误][2] 在转换这些文件从ODT或别的格式到DOCX之类时的错误或小问题 , 反之亦然。这是一系列难办的问题。 不幸的是,在技术在层面上对大多数人linux超出了能力范围。当然,不是绝对 。
|
||||
|
||||

|
||||
|
||||
### 加入微软 Office 在线, 加入 Linux
|
||||
|
||||
众所周知,微软拥有自己的云 office 服务多年。通过当今任何浏览器都可以使用使得它很棒且具有意义,这意味着 linux 也能使用!我前阵子刚测试了这个[方法][3]并且它表现出色。我能够轻松使用这个产品,以原本的格式保存文件或是转换我 ODF 格式的文件,这真的很棒。
|
||||
|
||||
我决定再次使用这个套装看看它在过去几年的进步以及是否依旧对 Linux 友好。我使用 [Fedora 25][4](一种操作系统)作为例子。我同时做这些去测试 [SoftMaker Office 2016][5]. 听起来有趣,也确实如此
|
||||
|
||||
### 第一印象
|
||||
|
||||
我得说我很高兴。office 不需要任何特别的插件。没有Silverlight 或 Flash 之类的东西。 单纯而大量的 HTML 和 Javascript 。 同时,交互界面反映及其迅速。唯一我不喜欢的就是 Word 文档的灰色背景,它让人很快感到疲劳。除了这个,整个套装工作流畅,没有延迟、奇怪之处及意料之外的错误。接下来让我们放慢脚步。
|
||||
|
||||
这个套装倒是需要你登录在线账户或者手机号——不必是 Live 或 Hotmail 邮箱。任何邮箱都可以。如果你有微软 [手机][6], 那么你可以用相同的账户并且可以同步你的数据。账户也会免费分配 5GB OneDrive 的储存空间。这很有条理,不是优秀或令人超级兴奋而是非常得当
|
||||
|
||||

|
||||
|
||||
你可以使用各种各样的程序, 包括必需的三件套 - Word, Excel 和 Powerpoint, bu并且其他的东西也供使用, 包括一些新奇事物.文档自动保存, 但你也可以下载备份和转换成其他格式,像PDF和ODF。
|
||||
|
||||
对我来说这简直完美。分享一个自己的小故事。我用 LibreOffice 写一本 [新奇的][7]书,之后当我需要将它们送去出版社编辑或者校对,我需要把它们转换成 DOCX 格式。唉,这需要微软 office。从我的 [Linux 问题解决大全][8]得知,我得一开始就使用Word,因为有一堆工作要与授权使用专有解决方案的编辑合作完成。没有任何情面可讲,只有出于对冷酷的金钱和商业的考量。错误是不容许接受的。
|
||||
|
||||

|
||||
|
||||
使用 office 在线版在特殊场合能给很多人自由空间。 偶尔使用Word、Excel等,不需要购买整个完整的套装。如果你是 LibreOffice 的忠实粉丝,也可以暗地里将微软 Office 当作消遣而不必感到愧疚。有人传给你一个 Word 或 PPT 文件,你可以上传然后在线操作它们,然后转换成所需要的。这样的话你就可以在线生成你的工作,发送给要求严格的人,同时自己留一个 ODF 格式的备份,有需要的话就用 LibreOffice 操作。虽然这种方法的灵活性很是实用,但这不应该成为你的主要手段。对于 Linux 用户,这给予了很多他们平时所没有的自由,毕竟即使你想用微软 Office 也不好安装。
|
||||
|
||||

|
||||
|
||||
### 特性, 选项, 工具
|
||||
|
||||
我开始琢磨一个文档——考虑到这其中各种细枝末节。用一种或三种风格写作,链接文本,嵌入图片,加上脚注,评论自己的文章甚至作为一个多重人格的极客巧妙地回复自己的评论。
|
||||
|
||||
除了灰色背景——我们得学会很好地完成一项无趣工作,即便是像臭鼬工厂那样的工作方式,因为浏览器里没有选项调整背景颜色——其实也还好。
|
||||
|
||||
Skype 也整合到了其中,你可以沟通合作。色相,非常整洁。鼠标右键可以选择一些快捷操作,包括链接、评论和翻译。改进的地方还有不少,它没有给我想要的,翻译有差错。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
你也可以加入图片——包括默认嵌入必应搜索筛选图片基于他们的监听和再分配权。这很棒,特别是当你想要创作而又想避免版权纷争时。
|
||||
|
||||

|
||||
|
||||
### 更多评论、追踪
|
||||
|
||||
说老实话,很实用,在线使用使得更改和编辑被默认追踪,所以你就有基本的版本控制功能。不过如果直接关闭不保存的话,阶段性的编辑会遗失。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
看到一个错误——如果你试着在 Linux 上编辑 Word 或 Excel 文件,会被提示你很调皮,因为这明显是个不支持的操作。
|
||||
|
||||

|
||||
|
||||
### Excel and friends
|
||||
|
||||
实际工作流程不止使用 Word。我也使用 Excel,众所周知,它包含了很多整齐有效的模板之类的。好用而且在更新单元格和公式时没有任何延迟,涵盖了你所需要的大多数功能。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### OneDrive
|
||||
|
||||
在这里你可以新建文件夹和文件、移动文件、给你的朋友(如果你有的话)和同事们分享文件。5 GB 免费,当然,收费增容。总的来说,做的不错。在更新和展示内容上会花费一定时间。打开了的文档不能被删除,这可能看起来像一个漏洞,但从计算机角度来看是完美的体验。
|
||||
|
||||

|
||||
|
||||
### 帮助
|
||||
|
||||
如果你感到疑惑——比如被人工智能戏耍,可以向 Redmond Borg ship 的云智囊团寻求帮助。 虽然这种方式不那么直接,但至少好用,结果往往也能令人满意T。
|
||||
|
||||

|
||||
|
||||
### 问题
|
||||
|
||||
在我三个小时的摸索中,我只遇到了两个小问题。一是文件编辑的时候浏览器会有警告(黄色三角),提醒我不安全的因素加载了建议使用 HTTPS 会话。二是创建 Excel 文件失败,只出现过一次。
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
微软 Office 在线版是一个优秀的产品,与我两年前测试相比较,它变得更好了。外观出色,表现良好,使用期间错误很少,完美兼容,甚至对于 Linux 用户,使之具有个人意义和商业价值。我不能说它是自 VHS (Video Home System,家用录像系统)最好的,但一定是很棒的,它架起了 Linux 用户与微软 Office 之间的桥梁,解决了 Linux 用户长期以来的问题,方便且很好的支持 ODF 。
|
||||
|
||||
现在我们来让事情变得更有趣些,如果你喜欢云概念的事物,那你可能对[Open365][9]感兴趣, 一个基于 LibreOfiice 的办公软件, 加上额外的邮件客户端和图像处理软件,还有 20 GB 的免费存储空间。最重要的是,你可以用浏览器同时完成这一切,只需要多开几个窗口。
|
||||
回到微软,如果你是 Linux 用户,如今可能确实需要微软 Office 产品。在线 Office 套装无疑是更方便的使用方法——或者至少不需要更改操作系统。它免费、优雅、透明度高。值得一提的是,你可以把思维游戏放在一边,享受你的云端生活。
|
||||
|
||||
干杯
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我的名字是 Igor Ljubuncic. 38 岁左右, 已婚已育.现在是一家云技术公司的首席工程师,一个新的领域。直到 2015 年初,我作为团队中的一名操作系统工程师就职于世界上最大的信息技术公司之一 。开发新的 Linux 解决方案、完善内核、入侵 linux 进程。在这之前,我是创新设计团队的技术指导,致力于高性能计算环境的创新解决方案。还有一些像系统专家、系统程序员之类的新奇的名字。这些全是我的爱好,直到2008年,变成了工作,还有什么能比这更令人满意呢?
|
||||
从 2004 到 2008,我作为物理学家在医学影像行业谋生。我专攻解决问题和发展算法,后来大量使用 Matlab 处理信号和图像。另外我认证了很多工程计算方法,包括 MEDIC Six Sigma Green Belt, 实验设计 和数据化工程。
|
||||
|
||||
我也开始写作,包括 Linux 上新鲜的技术性的工作。彼此包括。
|
||||
|
||||
请看我完整的开源项目清单、出版物、专利,下拉。
|
||||
|
||||
完整的奖励和提名请看那边。
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/office-online-linux-better.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.ocsmag.com/2015/02/16/libreoffice-4-4-review-finally-it-rocks/
|
||||
[2]:http://www.ocsmag.com/2014/03/14/libreoffice-vs-microsoft-office-part-deux/
|
||||
[3]:http://www.dedoimedo.com/computers/office-online-linux.html
|
||||
[4]:http://www.dedoimedo.com/computers/fedora-25-gnome.html
|
||||
[5]:http://www.ocsmag.com/2017/01/18/softmaker-office-2016-your-alternative-to-libreoffice/
|
||||
[6]:http://www.dedoimedo.com/computers/microsoft-lumia-640.html
|
||||
[7]:http://www.thelostwordsbooks.com/
|
||||
[8]:http://www.dedoimedo.com/computers/linux-problem-solving-book.html
|
||||
[9]:http://www.ocsmag.com/2016/08/17/open365/
|
||||
346
translated/tech/20110123 How debuggers work Part 1 - Basics.md
Normal file
346
translated/tech/20110123 How debuggers work Part 1 - Basics.md
Normal file
@ -0,0 +1,346 @@
|
||||
[调试器的工作原理:第一篇-基础][21]
|
||||
============================================================
|
||||
|
||||
这是调试器工作原理系列文章的第一篇,我不确定这个系列会有多少篇文章,会涉及多少话题,但我仍会从这篇基础开始。
|
||||
|
||||
### 这一篇会讲什么
|
||||
|
||||
我将为大家展示 Linux 中调试器的主要构成模块 - ptrace 系统调用。这篇文章所有代码都是基于 32 位 Ubuntu 操作系统.值得注意的是,尽管这些代码是平台相关的,将他们移植到其他平台应该并不困难。
|
||||
|
||||
### 缘由
|
||||
|
||||
为了理解我们要做什么,让我们先考虑下调试器为了完成调试都需要什么资源。调试器可以开始一个进程并调试这个进程,又或者将自己同某个已经存在的进程关联起来。调试器能够单步执行代码,设定断点并且将程序执行到断点,检查变量的值并追踪堆栈。许多调试器有着更高级的特性,例如在调试器的地址空间内执行表达式或者调用函数,甚至可以在进程执行过程中改变代码并观察效果。
|
||||
|
||||
尽管现代的调试器都十分的复杂 [[1]][13],但他们的工作的原理却是十分的简单。调试器的基础是操作系统与编译器 / 链接器提供的一些基础服务,其余的部分只是[简单的编程][14]。
|
||||
|
||||
### Linux 的调试 - ptrace
|
||||
|
||||
Linux 调试器中的瑞士军刀便是 ptrace 系统调用 [[2]][15]。这是一种复杂却强大的工具,可以允许一个进程控制另外一个进程并从内部替换被控制进程的内核镜像的值[[3]][16].。
|
||||
|
||||
接下来会深入分析。
|
||||
|
||||
### 执行进程的代码
|
||||
|
||||
我将编写一个示例,实现一个在“跟踪”模式下运行的进程。在这个模式下,我们将单步执行进程的代码,就像机器码(汇编代码)被 CPU 执行时一样。我将分段展示、讲解示例代码,在文章的末尾也有完整 c 文件的下载链接,你可以编译、执行或者随心所欲的更改。
|
||||
|
||||
更进一步的计划是实现一段代码,这段代码可以创建可执行用户自定义命令的子进程,同时父进程可以跟踪子进程。首先是主函数:
|
||||
|
||||
```
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
pid_t child_pid;
|
||||
|
||||
if (argc < 2) {
|
||||
fprintf(stderr, "Expected a program name as argument\n");
|
||||
return -1;
|
||||
}
|
||||
|
||||
child_pid = fork();
|
||||
if (child_pid == 0)
|
||||
run_target(argv[1]);
|
||||
else if (child_pid > 0)
|
||||
run_debugger(child_pid);
|
||||
else {
|
||||
perror("fork");
|
||||
return -1;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
看起来相当的简单:我们用 fork 命令创建了一个新的子进程。if 语句的分支执行子进程(这里称之为“target”),else if 的分支执行父进程(这里称之为“debugger”)。
|
||||
|
||||
下面是 target 进程的代码:
|
||||
|
||||
```
|
||||
void run_target(const char* programname)
|
||||
{
|
||||
procmsg("target started. will run '%s'\n", programname);
|
||||
|
||||
/* Allow tracing of this process */
|
||||
if (ptrace(PTRACE_TRACEME, 0, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Replace this process's image with the given program */
|
||||
execl(programname, programname, 0);
|
||||
}
|
||||
```
|
||||
|
||||
这段代码中最值得注意的是 ptrace 调用。在 "sys/ptrace.h" 中,ptrace 是如下定义的:
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
第一个参数是 _request_,这是许多预定义的 PTRACE_* 常量中的一个。第二个参数为请求分配进程 ID。第三个与第四个参数是地址与数据指针,用于操作内存。上面代码段中的ptrace调用发起了 PTRACE_TRACEME 请求,这意味着该子进程请求系统内核让其父进程跟踪自己。帮助页面上对于 request 的描述很清楚:
|
||||
|
||||
> 意味着该进程被其父进程跟踪。任何传递给该进程的信号(除了 SIGKILL)都将通过 wait() 方法阻塞该进程并通知其父进程。**此外,该进程的之后所有调用 exec() 动作都将导致 SIGTRAP 信号发送到此进程上,使得父进程在新的程序执行前得到取得控制权的机会**。如果一个进程并不需要它的的父进程跟踪它,那么这个进程不应该发送这个请求。(pid,addr 与 data 暂且不提)
|
||||
|
||||
我高亮了这个例子中我们需要注意的部分。在 ptrace 调用后,run_target 接下来要做的就是通过 execl 传参并调用。如同高亮部分所说明,这将导致系统内核在 execl 创建进程前暂时停止,并向父进程发送信号。
|
||||
|
||||
是时候看看父进程做什么了。
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
如前文所述,一旦子进程调用了 exec,子进程会停止并被发送 SIGTRAP 信号。父进程会等待该过程的发生并在第一个 wait() 处等待。一旦上述事件发生了,wait() 便会返回,由于子进程停止了父进程便会收到信号(如果子进程由于信号的发送停止了,WIFSTOPPED 就会返回 true)。
|
||||
|
||||
父进程接下来的动作就是整篇文章最需要关注的部分了。父进程会将 PTRACE_SINGLESTEP 与子进程ID作为参数调用 ptrace 方法。这就会告诉操作系统,“请恢复子进程,但在它执行下一条指令前阻塞”。周而复始地,父进程等待子进程阻塞,循环继续。当 wait() 中传出的信号不再是子进程的停止信号时,循环终止。在跟踪器(父进程)运行期间,这将会是被跟踪进程(子进程)传递给跟踪器的终止信号(如果子进程终止 WIFEXITED 将返回 true)。
|
||||
|
||||
icounter 存储了子进程执行指令的次数。这么看来我们小小的例子也完成了些有用的事情 - 在命令行中指定程序,它将执行该程序并记录它从开始到结束所需要的 cpu 指令数量。接下来就让我们这么做吧。
|
||||
|
||||
### 测试
|
||||
|
||||
我编译了下面这个简单的程序并利用跟踪器运行它:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
printf("Hello, world!\n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
令我惊讶的是,跟踪器花了相当长的时间,并报告整个执行过程共有超过 100,000 条指令执行。仅仅是一条输出语句?什么造成了这种情况?答案很有趣[[5]][18]。Linux 的 gcc 默认会动态的将程序与 c 的运行时库动态地链接。这就意味着任何程序运行前的第一件事是需要动态库加载器去查找程序运行所需要的共享库。这些代码的数量很大 - 别忘了我们的跟踪器要跟踪每一条指令,不仅仅是主函数的,而是“整个过程中的指令”。
|
||||
|
||||
所以当我将测试程序使用静态编译时(通过比较,可执行文件会多出 500 KB 左右的大小,这部分是 C 运行时库的静态链接),跟踪器提示只有大概 7000 条指令被执行。这个数目仍然不小,但是考虑到在主函数执行前 libc 的初始化以及主函数执行后的清除代码,这个数目已经是相当不错了。此外,printf 也是一个复杂的函数。
|
||||
|
||||
仍然不满意的话,我需要的是“可以测试”的东西 - 例如可以完整记录每一个指令运行的程序执行过程。这当然可以通过汇编代码完成。所以我找到了这个版本的“Hello, world!”并编译了它。
|
||||
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len
|
||||
mov ecx, msg
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
msg db 'Hello, world!', 0xa
|
||||
len equ $ - msg
|
||||
```
|
||||
|
||||
|
||||
当然,现在跟踪器提示 7 条指令被执行了,这样一来很容易区分他们。
|
||||
|
||||
|
||||
### 深入指令流
|
||||
|
||||
|
||||
上面那个汇编语言编写的程序使得我可以向你介绍 ptrace 的另外一个强大的用途 - 详细显示被跟踪进程的状态。下面是 run_debugger 函数的另一个版本:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
unsigned instr = ptrace(PTRACE_PEEKTEXT, child_pid, regs.eip, 0);
|
||||
|
||||
procmsg("icounter = %u. EIP = 0x%08x. instr = 0x%08x\n",
|
||||
icounter, regs.eip, instr);
|
||||
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
不同仅仅存在于 while 循环的开始几行。这个版本里增加了两个新的 ptrace 调用。第一条将进程的寄存器值读取进了一个结构体中。 sys/user.h 定义有 user_regs_struct。如果你查看头文件,头部的注释这么写到:
|
||||
|
||||
```
|
||||
/* The whole purpose of this file is for GDB and GDB only.
|
||||
Don't read too much into it. Don't use it for
|
||||
anything other than GDB unless know what you are
|
||||
doing. */
|
||||
```
|
||||
|
||||
```
|
||||
/* 这个文件只为了GDB而创建
|
||||
不用详细的阅读.如果你不知道你在干嘛,
|
||||
不要在除了 GDB 以外的任何地方使用此文件 */
|
||||
```
|
||||
|
||||
|
||||
不知道你做何感想,但这让我觉得我们找对地方了。回到例子中,一旦我们在 regs 变量中取得了寄存器的值,我们就可以通过将 PTRACE_PEEKTEXT 作为参数、 regs.eip(x86 上的扩展指令指针)作为地址,调用 ptrace ,读取当前进程的当前指令。下面是新跟踪器所展示出的调试效果:
|
||||
|
||||
```
|
||||
$ simple_tracer traced_helloworld
|
||||
[5700] debugger started
|
||||
[5701] target started. will run 'traced_helloworld'
|
||||
[5700] icounter = 1\. EIP = 0x08048080\. instr = 0x00000eba
|
||||
[5700] icounter = 2\. EIP = 0x08048085\. instr = 0x0490a0b9
|
||||
[5700] icounter = 3\. EIP = 0x0804808a. instr = 0x000001bb
|
||||
[5700] icounter = 4\. EIP = 0x0804808f. instr = 0x000004b8
|
||||
[5700] icounter = 5\. EIP = 0x08048094\. instr = 0x01b880cd
|
||||
Hello, world!
|
||||
[5700] icounter = 6\. EIP = 0x08048096\. instr = 0x000001b8
|
||||
[5700] icounter = 7\. EIP = 0x0804809b. instr = 0x000080cd
|
||||
[5700] the child executed 7 instructions
|
||||
```
|
||||
|
||||
|
||||
现在,除了 icounter,我们也可以观察到指令指针与它每一步所指向的指令。怎么来判断这个结果对不对呢?使用 objdump -d 处理可执行文件:
|
||||
|
||||
```
|
||||
$ objdump -d traced_helloworld
|
||||
|
||||
traced_helloworld: file format elf32-i386
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 0e 00 00 00 mov $0xe,%edx
|
||||
8048085: b9 a0 90 04 08 mov $0x80490a0,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: b8 01 00 00 00 mov $0x1,%eax
|
||||
804809b: cd 80 int $0x80
|
||||
```
|
||||
|
||||
|
||||
这个结果和我们跟踪器的结果就很容易比较了。
|
||||
|
||||
|
||||
### 将跟踪器关联到正在运行的进程
|
||||
|
||||
|
||||
如你所知,调试器也能关联到已经运行的进程。现在你应该不会惊讶,ptrace 通过 以PTRACE_ATTACH 为参数调用也可以完成这个过程。这里我不会展示示例代码,通过上文的示例代码应该很容易实现这个过程。出于学习目的,这里使用的方法更简便(因为我们在子进程刚开始就可以让它停止)。
|
||||
|
||||
|
||||
### 代码
|
||||
|
||||
|
||||
上文中的简单的跟踪器(更高级的,可以打印指令的版本)的完整c源代码可以在[这里][20]找到。它是通过 4.4 版本的 gcc 以 -Wall -pedantic --std=c99 编译的。
|
||||
|
||||
|
||||
### 结论与计划
|
||||
|
||||
|
||||
诚然,这篇文章并没有涉及很多内容 - 我们距离亲手完成一个实际的调试器还有很长的路要走。但我希望这篇文章至少可以使得调试这件事少一些神秘感。ptrace 是功能多样的系统调用,我们目前只展示了其中的一小部分。
|
||||
|
||||
|
||||
单步调试代码很有用,但也只是在一定程度上有用。上面我通过c的“Hello World!”做了示例。为了执行主函数,可能需要上万行代码来初始化c的运行环境。这并不是很方便。最理想的是在main函数入口处放置断点并从断点处开始分步执行。为此,在这个系列的下一篇,我打算展示怎么实现断点。
|
||||
|
||||
|
||||
|
||||
### 参考
|
||||
|
||||
|
||||
撰写此文时参考了如下文章
|
||||
|
||||
* [Playing with ptrace, Part I][11]
|
||||
* [How debugger works][12]
|
||||
|
||||
|
||||
|
||||
[1] 我没有检查,但我确信 gdb 的代码行数至少有六位数。
|
||||
|
||||
[2] 使用 man 2 ptrace 命令可以了解更多。
|
||||
|
||||
[3] Peek and poke 在系统编程中是很知名的叫法,指的是直接读写内存内容。
|
||||
|
||||
[4] 这篇文章假定读者有一定的 Unix/Linux 编程经验。我假定你知道(至少了解概念)fork,exec 族函数与 Unix 信号。
|
||||
|
||||
[5] 至少你同我一样痴迷与机器/汇编语言。
|
||||
|
||||
[6] 警告:如同我上面所说,文章很大程度上是平台相关的。我简化了一些设定 - 例如,x86指令集不需要调整到 4 字节(我的32位 Ubuntu unsigned int 是 4 字节)。事实上,许多平台都不需要。从内存中读取指令需要预先安装完整的反汇编器。我们这里没有,但实际的调试器是有的。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
译者:[译者ID](https://github.com/YYforymj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id1
|
||||
[2]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id2
|
||||
[3]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id3
|
||||
[4]:http://www.jargon.net/jargonfile/p/peek.html
|
||||
[5]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.linuxjournal.com/article/6100?page=0,1
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id7
|
||||
[14]:http://en.wikipedia.org/wiki/Small_matter_of_programming
|
||||
[15]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id8
|
||||
[16]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id9
|
||||
[17]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id10
|
||||
[18]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id11
|
||||
[19]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id12
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2011/simple_tracer.c
|
||||
[21]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
@ -1,37 +1,37 @@
|
||||
探索传统 JavaScript 基准测试
|
||||
============================================================
|
||||
|
||||
可以很公平地说,[JavaScript][22] 是当下软件工程最重要的技术。对于那些深入接触过编程语言、编译器和虚拟机的人来说,这仍然有点令人惊讶,因为在语言设计者看来,`JavaScript` 不是十分优雅;在编译器工程师看来,它没有多少可优化的地方;而且还没有一个伟大的标准库。取决于你和谁吐槽,`JavaScript` 的缺点你花上数周都枚举不完,不过你总会找到一些你从所未知的神奇的东西。尽管这看起来明显困难重重,不过 `JavaScript` 还是成为当今 web 的核心,并且还成为服务器端/云端的主导技术(通过 [Node.js][23]),甚至还开辟了进军物联网空间的道路。
|
||||
可以很公平地说,[JavaScript][22] 是当下软件工程最重要的技术。对于那些深入接触过编程语言、编译器和虚拟机的人来说,这仍然有点令人惊讶,因为在语言设计者看来,JavaScript 不是十分优雅;在编译器工程师看来,它没有多少可优化的地方;而且还没有一个伟大的标准库。这取决于你和谁吐槽,JavaScript 的缺点你花上数周都枚举不完,不过你总会找到一些你从所未知的神奇的东西。尽管这看起来明显困难重重,不过 JavaScript 还是成为当今 web 的核心,并且还成为服务器端/云端的主导技术(通过 [Node.js][23]),甚至还开辟了进军物联网空间的道路。
|
||||
|
||||
问题来了,为什么 `JavaScript` 如此受欢迎/成功?我知道没有一个很好的答案。如今我们有许多使用 `JavaScript` 的好理由,或许最重要的是围绕其构建的庞大的生态系统,以及今天大量可用的资源。但所有这一切实际上是发展到一定程度的后果。为什么 `JavaScript` 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 `JavaScript`。回顾过去,似乎第一波 `JavaScript` 浪潮爆发在上个年代的后半段。不出所料,那个时候 `JavaScript` 引擎在不同的负载下实现了巨大的加速,这可能让很多人对 `JavaScript` 刮目相看。
|
||||
问题来了,为什么 JavaScript 如此受欢迎?或者说如此成功?我知道没有一个很好的答案。如今我们有许多使用 JavaScript 的好理由,或许最重要的是围绕其构建的庞大的生态系统,以及今天大量可用的资源。但所有这一切实际上是发展到一定程度的后果。为什么 JavaScript 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 JavaScript。回顾过去,似乎第一波 JavaScript 浪潮爆发在上个年代的后半段。不出所料,那个时候 JavaScript 引擎加速了各种不同的任务的执行,这可能让很多人对 JavaScript 刮目相看。
|
||||
|
||||
回到过去那些日子,这些加速测试使用了现在所谓的传统 `JavaScript` 基准——从苹果的 [SunSpider 基准][24](JavaScript 微基准之母)到 Mozilla 的 [Kraken 基准][25] 和谷歌的 `V8` 基准。后来,`V8` 基准被 [Octane 基准][26] 取代,而苹果发布了新的 [JetStream 基准][27]。这些传统的 `JavaScript` 基准测试驱动了无数人的努力,使 `JavaScript` 的性能达到了本世纪初没人能预料到的水平。据报道加速达到了 1000 倍,一夜之间在网站使用 `<script>` 标签不再是魔鬼的舞蹈,做客户端不再仅仅是可能的了,甚至是被鼓励的。
|
||||
回到过去那些日子,这些加速测试使用了现在所谓的传统 JavaScript 基准——从苹果的 [SunSpider 基准][24](JavaScript 微基准之母)到 Mozilla 的 [Kraken 基准][25] 和谷歌的 V8 基准。后来,V8 基准被 [Octane 基准][26] 取代,而苹果发布了新的 [JetStream 基准][27]。这些传统的 JavaScript 基准测试驱动了无数人的努力,使 JavaScript 的性能达到了本世纪初没人能预料到的水平。据报道加速达到了 1000 倍,一夜之间在网站使用 `<script>` 标签不再是魔鬼的舞蹈,做客户端不再仅仅是可能的了,甚至是被鼓励的。
|
||||
|
||||
[][28]
|
||||
|
||||
现在是 2016 年,所有(相关的)`JavaScript` 引擎的性能都达到了一个令人难以置信的水平,web 应用可以像端应用(或者本地的应用)一样快。引擎配有复杂的优化编译器,通过收集过去关于类型/形状的反馈来推测某些操作(即属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数优化是由 `SunSpider` 或 `Kraken` 等微基准以及 `Octane` 和 `JetStream` 等静态测试套件驱动的。由于有像 [asm.js][29] 和 [Emscripten][30] 这样的 `JavaScript` 技术,我们甚至可以将大型 `C++` 应用程序编译成 `JavaScript`,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 [AngryBots][31],无需沙盒,而过去的 web 游戏需要安装一堆诸如 `Adobe Flash` 或 `Chrome PNaCl` 的插件。
|
||||
现在是 2016 年,所有(相关的)JavaScript 引擎的性能都达到了一个令人难以置信的水平,web 应用像原生应用一样快(或者能够像本地应用一样快)。引擎配有复杂的优化编译器,通过收集过去关于类型/形状的反馈来推测某些操作(例如属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数优化是由 SunSpider 或 Kraken 等微基准以及 Octane 和 JetStream 等静态测试套件驱动的。由于有像 [asm.js][29] 和 [Emscripten][30] 这样的 JavaScript 技术,我们甚至可以将大型 C++ 应用程序编译成 JavaScript,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 [AngryBots][31],无需沙盒,而过去的 web 游戏需要安装一堆诸如 Adobe Flash 或 Chrome PNaCl 的插件。
|
||||
|
||||
这些成就绝大多数都要归功于这些微基准和静态性能测试套件,以及这些传统 `JavaScript` 基准间至关重要的竞争。你可以对 `SunSpider` 表示不满,但很显然,没有 `SunSpider`,`JavaScript` 的性能可能达不到今天的高度。好吧,赞美到此为止。现在看看另一方面,所有静态性能测试——无论是微基准还是大型应用的宏基准,都注定要随着时间的推移变得不相关!为什么?因为在开始游戏前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般适用性将呈指数下降。例如,我们将 `Octane` 作为现实世界中 web 应用性能的代理,并且在相当长的一段时间里,它可能做得很不错,但是现在,`Octane` 与现实场景中的时间分布是截然不同的,因此即使眼下再优化 `Octane` 至超越自身,可能在现实世界中还是得不到任何显著的改进(无论是通用 web 还是 `Node.js` 的工作负载)。
|
||||
这些成就绝大多数都要归功于这些微基准和静态性能测试套件,以及这些传统 JavaScript 基准间至关重要的竞争。你可以对 SunSpider 表示不满,但很显然,没有 SunSpider,JavaScript 的性能可能达不到今天的高度。好吧,赞美到此为止。现在看看另一方面,所有静态性能测试——无论是微基准还是大型应用的宏基准,都注定要随着时间的推移变得不相关!为什么?因为在开始摆弄它之前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般适用性将呈指数下降。例如,我们将 Octane 作为现实世界中 web 应用性能的代理,并且在相当长的一段时间里,它可能做得很不错,但是现在,Octane 与现实场景中的时间分布是截然不同的,因此即使眼下再优化 Octane 乃至超越自身,可能在现实世界中还是得不到任何显著的改进(无论是通用 web 还是 Node.js 的工作负载)。
|
||||
|
||||
[][32]
|
||||
|
||||
由于传统 `JavaScript` 基准(包括最新版的 `JetStream` 和 `Octane`)可能已经超越其有用性变得越来越明显,我们开始调查新的方法来测量年初现实场景的性能,为 `V8` 和 `Chrome` 添加了大量新的性能追踪钩子。我们还特意添加一些机制来查看我们在浏览 web 时的时间开销,即是否是脚本执行、垃圾回收、编译等,并且这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 `Octane` 花费超过 70% 的时间执行 `JavaScript` 和回收垃圾,而浏览 web 的时候,通常执行 `JavaScript` 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。反而花费大量时间来解析和编译,这不像 `Octane` 的作风。因此,将更多的时间用在优化 `JavaScript` 执行上将提高你的 `Octane` 跑分,但不会对加载 [youtube.com][33] 有任何积极的影响。事实上,花费更多的时间来优化 `JavaScript` 执行甚至可能有损你现实场景的性能,因为编译器需要更多的时间,或者你需要跟踪更多的反馈,最终为编译、IC 和运行时桶开销更多的时间。
|
||||
由于传统 JavaScript 基准(包括最新版的 JetStream 和 Octane)可能已经超越其有用性变得越来越明显,我们开始调查新的方法来测量年初现实场景的性能,为 V8 和 `Chrome` 添加了大量新的性能追踪钩子。我们还特意添加一些机制来查看我们在浏览 web 时的时间开销,即是否是脚本执行、垃圾回收、编译等,并且这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 Octane 花费超过 70% 的时间执行 JavaScript 和回收垃圾,而浏览 web 的时候,通常执行 JavaScript 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。反而花费大量时间来解析和编译,这不像 Octane 的作风。因此,将更多的时间用在优化 JavaScript 执行上将提高你的 Octane 跑分,但不会对加载 [youtube.com][33] 有任何积极的影响。事实上,花费更多的时间来优化 JavaScript 执行甚至可能有损你现实场景的性能,因为编译器需要更多的时间,或者你需要跟踪更多的反馈,最终为编译、IC 和运行时桶开销更多的时间。
|
||||
|
||||
[][34]
|
||||
|
||||
还有另外一组基准测试用于测量浏览器整体性能(包括 `JavaScript` 和 `DOM` 性能),最新推出的是 [Speedometer 基准][35]。基准试图通过运行一个用不同的主流 web 框架实现的简单的 [TodoMVC][36] 应用(现在看来有点过时了,不过新版本正在研发中)以捕获真实性能。各种在 Octane 下的测试(Angular、Ember、React、Vanilla、Flight 和 Backbone)都罗列在幻灯片中,你可以看到这些测试似乎更好地代表了现在的性能指标。但是请注意,这些数据收集在本文撰写将近 6 个月以前,而且我们优化了更多的现实场景模式(例如我们正在重构 IC 系统以显著地降低开销,并且 [解析器也正在重新设计][37])。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不是现实场景中 `Node.js` 应用性能的一个好代理。
|
||||
还有另外一组基准测试用于测量浏览器整体性能(包括 JavaScript 和 `DOM` 性能),最新推出的是 [Speedometer 基准][35]。基准试图通过运行一个用不同的主流 web 框架实现的简单的 [TodoMVC][36] 应用(现在看来有点过时了,不过新版本正在研发中)以捕获真实性能。各种在 Octane 下的测试(Angular、Ember、React、Vanilla、Flight 和 Backbone)都罗列在幻灯片中,你可以看到这些测试似乎更好地代表了现在的性能指标。但是请注意,这些数据收集在本文撰写将近 6 个月以前,而且我们优化了更多的现实场景模式(例如我们正在重构 IC 系统以显著地降低开销,并且 [解析器也正在重新设计][37])。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不是现实场景中 Node.js 应用性能的一个好代理。
|
||||
|
||||
[][38]
|
||||
|
||||
所有这一切可能已经路人皆知了,因此我将用本文剩下的部分强调一些关于我为什么认为这不仅有用,而且对于 `JavaScript` 社区的健康(必须停止关注某一阔值的静态峰值性能基准测试)很关键的具体案例。让我通过一些例子说明 `JavaScript` 引擎怎样来玩弄基准。
|
||||
所有这一切可能已经路人皆知了,因此我将用本文剩下的部分强调一些关于我为什么认为这不仅有用,而且对于 JavaScript 社区的健康(必须停止关注某一阔值的静态峰值性能基准测试)很关键的具体案例。让我通过一些例子说明 JavaScript 引擎怎样来玩弄基准。
|
||||
|
||||
### 臭名昭著的 SunSpider 案例
|
||||
|
||||
一篇关于传统 `JavaScript` 基准测试的博客如果没有指出 `SunSpider` 明显的问题是不完整的。让我们从性能测试的最佳实践开始,它在现实场景中不是很适用:[`bitops-bitwise-and.js` 性能测试][39]
|
||||
一篇关于传统 JavaScript 基准测试的博客如果没有指出 SunSpider 明显的问题是不完整的。让我们从性能测试的最佳实践开始,它在现实场景中不是很适用:[`bitops-bitwise-and.js` 性能测试][39]
|
||||
|
||||
[][40]
|
||||
|
||||
有一些算法需要进行快速的位运算,特别是从 `C/C++` 转译成 `JavaScript` 的地方,所以快速执行按位操作确实有点意义。然而,现实场景中的网页可能不关心引擎是否可以执行位运算,并且能否在循环中比另一个引擎快两倍。但是再盯着这段代码几秒钟,你可能会注意到,在第一次循环迭代之后 `bitwiseAndValue` 将变成 `0`,并且在接下来的 599999 次迭代中将保持为 `0`。所以一旦你在此获得好性能,即在体面的硬件上所有测试均低于 5ms,在经过尝试之后意识到,只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 [loop peeling][41] 后面的死代码),现在你可以开始玩弄这个基准了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 `bitwiseAndValue` 是全局对象的常规属性还是在执行脚本之前不存在,全局对象或者它的原型上必须没有拦截器。但如果你真的想要赢得这个基准测试,并且你愿意全力以赴,那么你可以在不到 1ms 的时间内完成这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
|
||||
有一些算法需要进行快速的位运算,特别是从 `C/C++` 转译成 JavaScript 的地方,所以快速执行按位操作确实有点意义。然而,现实场景中的网页可能不关心引擎是否可以执行位运算,并且能否在循环中比另一个引擎快两倍。但是再盯着这段代码几秒钟,你可能会注意到,在第一次循环迭代之后 `bitwiseAndValue` 将变成 `0`,并且在接下来的 599999 次迭代中将保持为 `0`。所以一旦你在此获得好性能,即在体面的硬件上所有测试均低于 5ms,在经过尝试之后意识到,只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 [loop peeling][41] 后面的死代码),现在你可以开始玩弄这个基准了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 `bitwiseAndValue` 是全局对象的常规属性还是在执行脚本之前不存在,全局对象或者它的原型上必须没有拦截器。但如果你真的想要赢得这个基准测试,并且你愿意全力以赴,那么你可以在不到 1ms 的时间内完成这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
|
||||
|
||||
好吧,那么 [`bitops-bitwise-and.js`][42] 测试彻底肯定是微基准最失败的案例。让我们继续转移到 SunSpider 中更逼真的场景——[`string-tagcloud.js`][43] 测试,它的底层运行着一个较早版本的 `json.js polyfill`。该测试可以说看起来比位运算测试更合理,但是查看基准的配置之后立刻显示:大量的时间浪费在一条 `eval` 表达式(高达 20% 的总执行时间被用于解析和编译,再加上实际执行编译后代码的 10% 的时间)。
|
||||
|
||||
@ -77,7 +77,7 @@
|
||||
])
|
||||
```
|
||||
|
||||
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 `JSON` 并生成适当的对象图的开销将更加低廉。所以,加快这个基准测试的一个小把戏就是模拟 `eval`,并尝试总是将数据首先作为 `JSON` 解析,然后再回溯到真实的解析、编译、执行,直到尝试读取 `JSON` 失败(尽管需要一些额外的黑魔法来跳过括号)。早在 2007 年,这甚至不算是一个坏点子,因为没有 [`JSON.parse`][45],不过在 2017 年这只是 `JavaScript` 引擎的技术债,可能会让 `eval` 的合法使用遥遥无期。
|
||||
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 `JSON` 并生成适当的对象图的开销将更加低廉。所以,加快这个基准测试的一个小把戏就是模拟 `eval`,并尝试总是将数据首先作为 `JSON` 解析,然后再回溯到真实的解析、编译、执行,直到尝试读取 `JSON` 失败(尽管需要一些额外的黑魔法来跳过括号)。早在 2007 年,这甚至不算是一个坏点子,因为没有 [`JSON.parse`][45],不过在 2017 年这只是 JavaScript 引擎的技术债,可能会让 `eval` 的合法使用遥遥无期。
|
||||
|
||||
```
|
||||
--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
|
||||
@ -93,7 +93,7 @@
|
||||
}
|
||||
```
|
||||
|
||||
事实上,将基准测试更新到现代 `JavaScript` 会立刻提升性能,正如今天的 `V8 LKGR` 从 36ms 降到了 26ms,性能足足提升了 30%!
|
||||
事实上,将基准测试更新到现代 JavaScript 会立刻提升性能,正如今天的 `V8 LKGR` 从 36ms 降到了 26ms,性能足足提升了 30%!
|
||||
|
||||
```
|
||||
$ node string-tagcloud.js.ORIG
|
||||
@ -121,7 +121,7 @@ $
|
||||
* 0.05235987755982989,
|
||||
* 0.08726646259971647
|
||||
|
||||
显然,你可以在这里做的一件事情就是通过缓存以前的计算值来避免重复计算相同的正弦值和余弦值。事实上,这是 `V8` 以前的做法,而其它引擎例如 `SpiderMonkey` 仍然这样做。我们从 `V8` 中删除了所谓的超载缓存,因为缓存的开销在现实中的工作负载是不可忽视的,你不可能总是在一行代码中计算相同的值,这在其它地方倒不稀奇。当我们在 2013 和 2014 年移除这个特定的基准优化时,我们对 `SunSpider` 基准产生了强烈的冲击,但我们完全相信,优化基准并没有任何意义,同时以这种方式批判现实场景中的使用案例。
|
||||
显然,你可以在这里做的一件事情就是通过缓存以前的计算值来避免重复计算相同的正弦值和余弦值。事实上,这是 V8 以前的做法,而其它引擎例如 `SpiderMonkey` 仍然这样做。我们从 V8 中删除了所谓的超载缓存,因为缓存的开销在现实中的工作负载是不可忽视的,你不可能总是在一行代码中计算相同的值,这在其它地方倒不稀奇。当我们在 2013 和 2014 年移除这个特定的基准优化时,我们对 SunSpider 基准产生了强烈的冲击,但我们完全相信,优化基准并没有任何意义,同时以这种方式批判现实场景中的使用案例。
|
||||
|
||||
[][52]
|
||||
|
||||
@ -129,27 +129,27 @@ $
|
||||
|
||||
### 垃圾回收是有害的
|
||||
|
||||
除了这些非常具体的测试问题,`SunSpider` 还有一个根本的问题:总体执行时间。目前 `V8` 在体面的英特尔硬件上运行整个基准测试大概只需要 200ms(使用默认配置)。次要的 `GC` 在 1ms 到 25ms 之间(取决于新空间中的活对象和旧空间的碎片),而主 `GC` 暂停可以浪费掉 30ms(甚至不考虑增量标记的开销),这超过了 `SunSpider` 套件总体执行时间的 10%!因此,任何不想因 `GC` 循环而造成减速 10-20% 的引擎,必须用某种方式确保它在运行 `SunSpider` 时不会触发 `GC`。
|
||||
除了这些非常具体的测试问题,SunSpider 还有一个根本的问题:总体执行时间。目前 V8 在体面的英特尔硬件上运行整个基准测试大概只需要 200ms(使用默认配置)。次要的 `GC` 在 1ms 到 25ms 之间(取决于新空间中的活对象和旧空间的碎片),而主 `GC` 暂停可以浪费掉 30ms(甚至不考虑增量标记的开销),这超过了 SunSpider 套件总体执行时间的 10%!因此,任何不想因 `GC` 循环而造成减速 10-20% 的引擎,必须用某种方式确保它在运行 SunSpider 时不会触发 `GC`。
|
||||
|
||||
[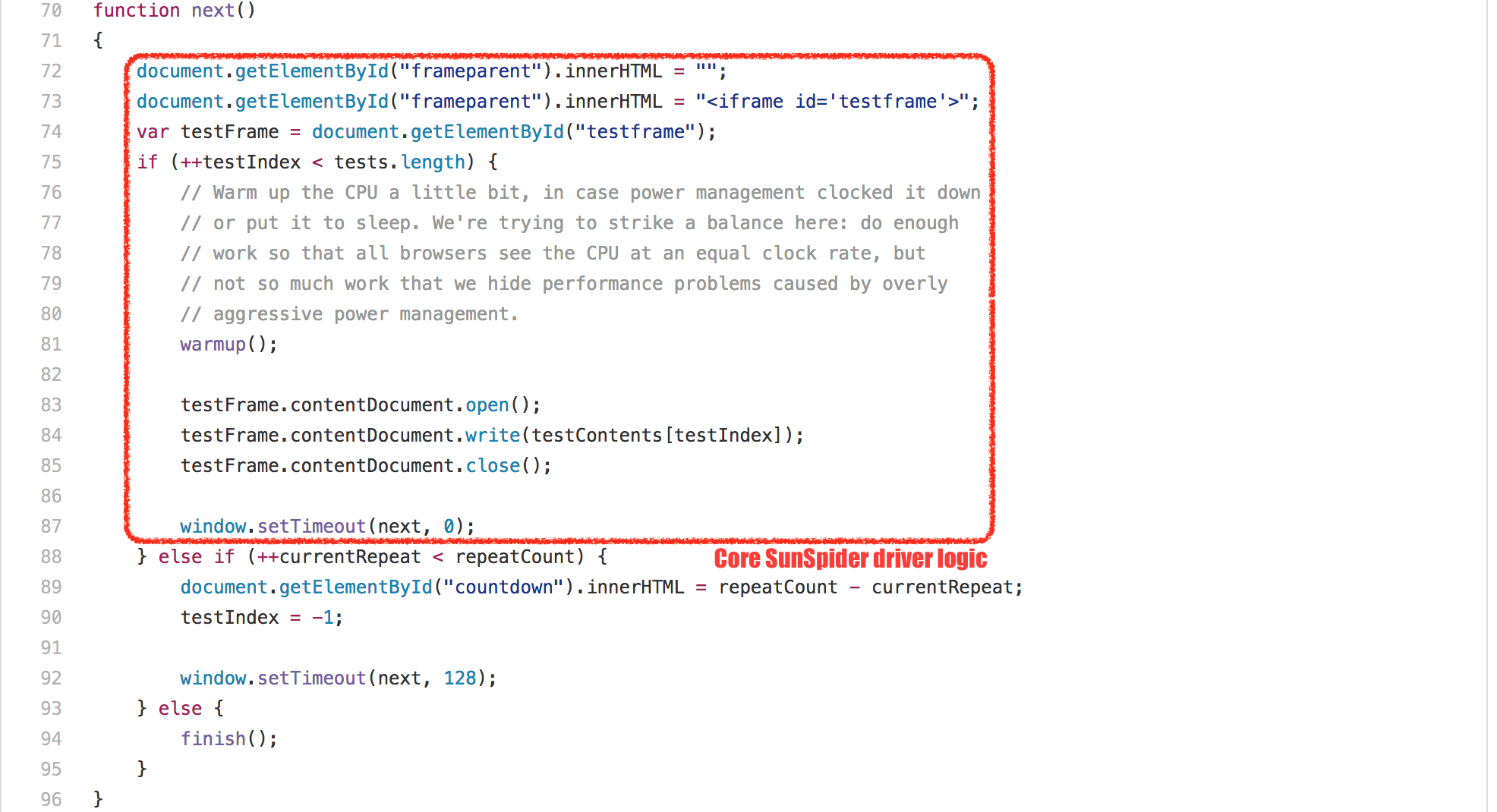][54]
|
||||
|
||||
就实现而言,有不同的方案,不过就我所知,没有一个在现实场景中产生了任何积极的影响。`V8` 使用了一个相当简单的技巧:由于每个 `SunSpider` 套件都运行在一个新的 `<iframe>` 中,这对应于 `V8` 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 `SunSpider` 测试花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们在实际运行测试的时候不会触发 `GC`。这个技巧很好,99.9% 的案例没有与实际用途冲突;除了每时每刻,无论你在做什么,都让你看起来像是 `V8` 的 `SunSpider` 测试驱动程序,那么你可能会遇到困难,或许你可以通过强制 `GC` 来解决,不过这对你的应用可能会有负面影响。所以紧记一点:**不要让你的应用看起来像 SunSpider!**
|
||||
就实现而言,有不同的方案,不过就我所知,没有一个在现实场景中产生了任何积极的影响。V8 使用了一个相当简单的技巧:由于每个 SunSpider 套件都运行在一个新的 `<iframe>` 中,这对应于 V8 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 SunSpider 测试花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们在实际运行测试的时候不会触发 `GC`。这个技巧很好,99.9% 的案例没有与实际用途冲突;除了每时每刻,无论你在做什么,都让你看起来像是 V8 的 SunSpider 测试驱动程序,那么你可能会遇到困难,或许你可以通过强制 `GC` 来解决,不过这对你的应用可能会有负面影响。所以紧记一点:**不要让你的应用看起来像 SunSpider!**
|
||||
|
||||
我可以继续展示更多 `SunSpider` 示例,但我不认为这非常有用。到目前为止,应该清楚的是,`SunSpider` 为刷新业绩而做的进一步优化在现实场景中没有带来任何好处。事实上,世界可能会因为没有 `SunSpider` 而更美好,因为引擎可以放弃只是用于 `SunSpider` 的奇淫技巧,甚至可以伤害到现实中的用例。不幸的是,SunSpider 仍然被(科技)媒体大量地用来比较他们眼中的浏览器性能,或者甚至用来比较手机!所以手机制造商和安卓制造商对于让 `SunSpider`(以及其它现在毫无意义的基准 `FWIW`) 上的 `Chrome` 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 `SunSpider` 中得分较高的旧版 `V8`,向他们的用户展示各种未修复的安全漏洞(在新版中早已被修复),并保护用户免受最新版本的 `V8` 的任何现实场景的性能优势!
|
||||
我可以继续展示更多 SunSpider 示例,但我不认为这非常有用。到目前为止,应该清楚的是,SunSpider 为刷新业绩而做的进一步优化在现实场景中没有带来任何好处。事实上,世界可能会因为没有 SunSpider 而更美好,因为引擎可以放弃只是用于 SunSpider 的奇淫技巧,甚至可以伤害到现实中的用例。不幸的是,SunSpider 仍然被(科技)媒体大量地用来比较他们眼中的浏览器性能,或者甚至用来比较手机!所以手机制造商和安卓制造商对于让 SunSpider(以及其它现在毫无意义的基准 `FWIW`) 上的 `Chrome` 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 SunSpider 中得分较高的旧版 V8,向他们的用户展示各种未修复的安全漏洞(在新版中早已被修复),并保护用户免受最新版本的 V8 的任何现实场景的性能优势!
|
||||
|
||||
[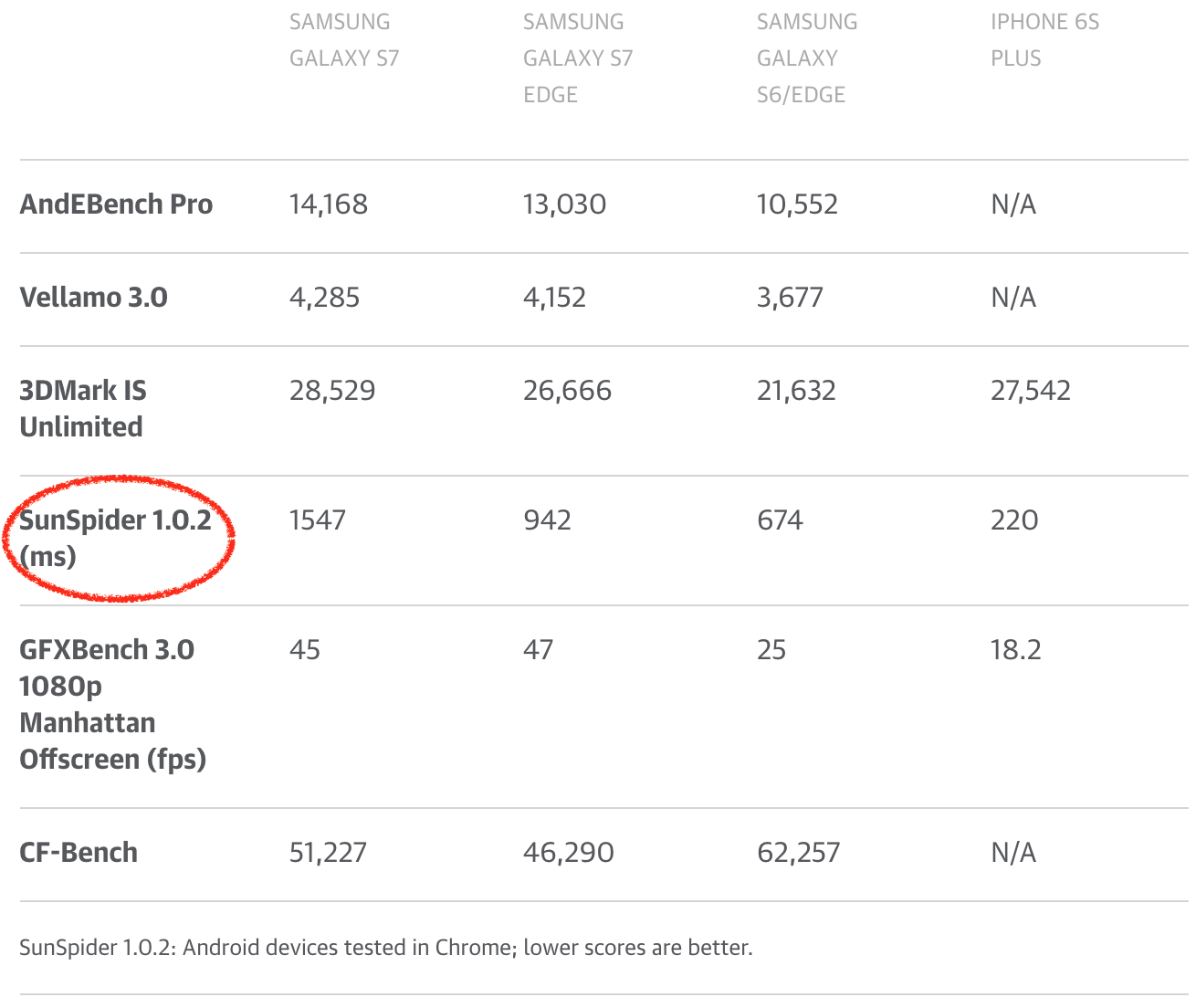][55]
|
||||
|
||||
作为 `JavaScript` 社区的一员,如果我们真的想认真对待 `JavaScript` 领域现实场景的性能,我们需要让各大技术媒体停止使用传统的 `JavaScript` 基准来比较浏览器或手机。我看到的一个好处是能够在每个浏览器中运行一个基准测试,并比较它的得分,但是请使用一个与当今世界相关的基准,例如真实的 `web` 页面;如果你觉得需要通过浏览器基准来比较两部手机,请至少考虑使用 [Speedometer][56]。
|
||||
作为 JavaScript 社区的一员,如果我们真的想认真对待 JavaScript 领域现实场景的性能,我们需要让各大技术媒体停止使用传统的 JavaScript 基准来比较浏览器或手机。我看到的一个好处是能够在每个浏览器中运行一个基准测试,并比较它的得分,但是请使用一个与当今世界相关的基准,例如真实的 `web` 页面;如果你觉得需要通过浏览器基准来比较两部手机,请至少考虑使用 [Speedometer][56]。
|
||||
|
||||
### 轻松一刻
|
||||
|
||||

|
||||
|
||||
我一直很喜欢这个 [Myles Borins][57] 谈话,所以我不得不无耻地向他偷师。现在我们从 `SunSpider` 的谴责中回过头来,让我们继续检查其它经典基准。
|
||||
我一直很喜欢这个 [Myles Borins][57] 谈话,所以我不得不无耻地向他偷师。现在我们从 SunSpider 的谴责中回过头来,让我们继续检查其它经典基准。
|
||||
|
||||
### 不是那么详细的 Kraken 案例
|
||||
|
||||
`Kraken` 基准是 [Mozilla 于 2010 年 9 月 发布的][58],据说它包含了现实场景应用的片段/内核,并且与 `SunSpider` 相比少了一个微基准。我不想花太多时间在 `Kraken` 上,因为我认为它不像 `SunSpider` 和 `Octane` 一样对 `JavaScript` 性能有着深远的影响,所以我将强调一个特别的案例——[`audio-oscillator.js`][59] 测试。
|
||||
Kraken 基准是 [Mozilla 于 2010 年 9 月 发布的][58],据说它包含了现实场景应用的片段/内核,并且与 SunSpider 相比少了一个微基准。我不想花太多时间在 Kraken 上,因为我认为它不像 SunSpider 和 Octane 一样对 JavaScript 性能有着深远的影响,所以我将强调一个特别的案例——[`audio-oscillator.js`][59] 测试。
|
||||
|
||||
[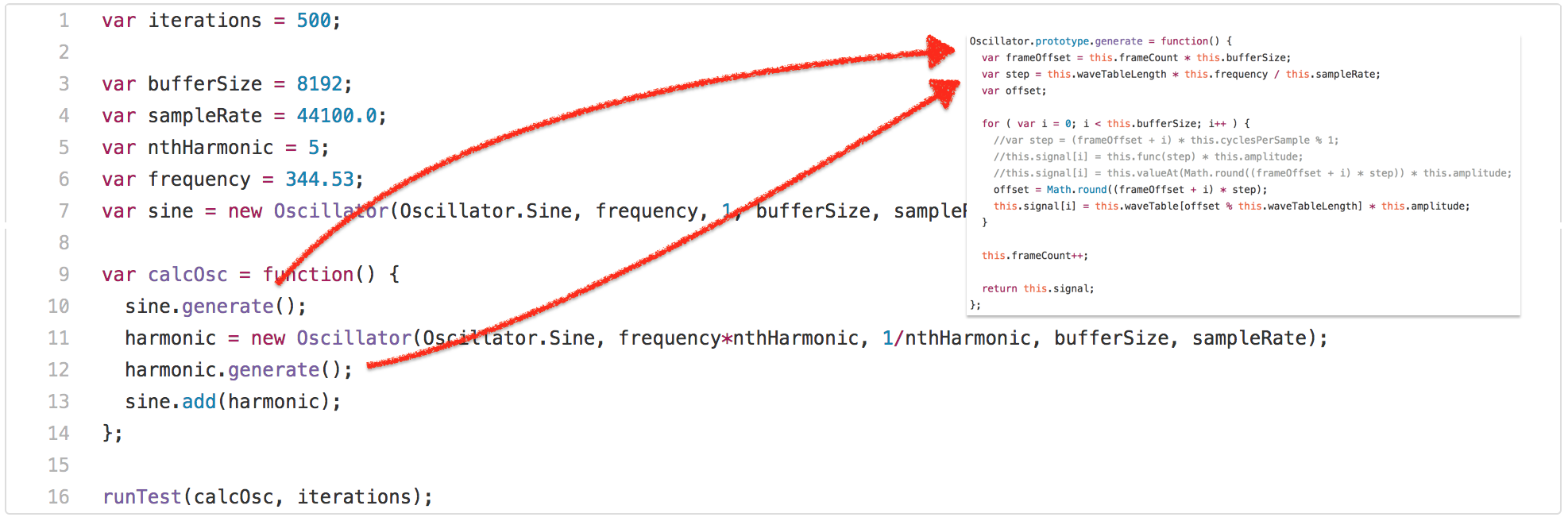][60]
|
||||
|
||||
@ -163,7 +163,7 @@ $
|
||||
|
||||
如果我们知道整数模数运算的右边是 2 的幂,我们可以生成[更好的代码][64],显然完全避免了英特尔上的 `idiv` 指令。所以我们需要获取一种信息使 `this.waveTableLength` 从 `Oscillator` 构造器到 `Oscillator.prototype.generate` 中的模运算都是 2048。一个显而易见的方法是尝试依赖于将所有内容内嵌到 `calcOsc` 函数,并让 `load/store` 消除为我们进行的常量传播,但这对于在 `calcOsc` 函数之外分配的正弦振荡器无效。
|
||||
|
||||
因此,我们所做的就是添加支持跟踪某些常数值作为模运算符的右侧反馈。这在 `V8` 中是有意义的,因为我们为诸如 `+`、`*` 和 `%` 的二进制操作跟踪类型反馈,这意味着操作者跟踪输入的类型和产生的输出类型(参见最近圆桌讨论关于[动态语言的快速运算][65]的幻灯片)。当然,用 `fullcodegen` 和 `Crankshaft` 挂接起来也是相当容易的,`MOD` 的 `BinaryOpIC` 也可以跟踪两个右边的已知权。
|
||||
因此,我们所做的就是添加支持跟踪某些常数值作为模运算符的右侧反馈。这在 V8 中是有意义的,因为我们为诸如 `+`、`*` 和 `%` 的二进制操作跟踪类型反馈,这意味着操作者跟踪输入的类型和产生的输出类型(参见最近圆桌讨论关于[动态语言的快速运算][65]的幻灯片)。当然,用 `fullcodegen` 和 `Crankshaft` 挂接起来也是相当容易的,`MOD` 的 `BinaryOpIC` 也可以跟踪两个右边的已知权。
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
@ -173,7 +173,7 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
$
|
||||
```
|
||||
|
||||
显示表明 `BinaryOpIC` 正在为模数的右侧拾取适当的恒定反馈,并正确跟踪左侧始终是一个小整数(`V8` 的 `Smi` 说),我们也总是产生一个小的整数结果 。 使用 `--print-opt-code -code-comments` 查看生成的代码,很快就显示出,`Crankshaft` 利用反馈在 `Oscillator.prototype.generate` 中为整数模数生成一个有效的代码序列:
|
||||
显示表明 `BinaryOpIC` 正在为模数的右侧拾取适当的恒定反馈,并正确跟踪左侧始终是一个小整数(V8 的 `Smi` 说),我们也总是产生一个小的整数结果 。 使用 `--print-opt-code -code-comments` 查看生成的代码,很快就显示出,`Crankshaft` 利用反馈在 `Oscillator.prototype.generate` 中为整数模数生成一个有效的代码序列:
|
||||
|
||||
```
|
||||
[...SNIP...]
|
||||
@ -230,7 +230,7 @@ $
|
||||
|
||||
这是一个非常可怕的性能悬崖的例子:假设开发人员为库编写代码,并使用某些样本输入值进行仔细的调整和优化,性能是体面的。现在,用户开始使用该库读取性能日志,但不知何故从性能悬崖下降,因为她/他正在以一种稍微不同的方式使用库,即以某种方式污染某种 `BinaryOpIC` 的类型反馈,并且遭受 20% 的减速(与该库作者的测量相比),该库的作者和用户都无法解释,这似乎是随机的。
|
||||
|
||||
现在这在 `JavaScript` 领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 `JavaScript` 的性能是基于乐观的假设和猜测的事实。我们已经花了 **大量** 时间和精力来试图找到避免这些性能悬崖的方法,不过依旧提供(几乎)相同的性能。事实证明,尽可能避免 `idiv` 是很有意义的,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 `TurboFan` 的做法有异于 `Crankshaft` 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化两个右手侧的(未知)权看起来像这样(在伪代码中):
|
||||
现在这在 JavaScript 领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 JavaScript 的性能是基于乐观的假设和猜测的事实。我们已经花了 **大量** 时间和精力来试图找到避免这些性能悬崖的方法,不过依旧提供(几乎)相同的性能。事实证明,尽可能避免 `idiv` 是很有意义的,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 `TurboFan` 的做法有异于 `Crankshaft` 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化两个右手侧的(未知)权看起来像这样(在伪代码中):
|
||||
|
||||
```
|
||||
if 0 < rhs then
|
||||
@ -259,21 +259,21 @@ Time (audio-oscillator-once): 69 ms.
|
||||
$
|
||||
```
|
||||
|
||||
基准和过度专业化的问题在于基准可以给你提示在哪里可以看看以及该怎么做,但它不告诉你你应该走多远,不能保护优化。例如,所有 `JavaScript` 引擎都使用基准来防止性能下降,但是运行 `Kraken` 不能保护我们在 `TurboFan` 中的一般方法,即我们可以将 `TurboFan` 中的模优化降级到过度专业版本的 `Crankshaft`,而基准不会告诉我们却在倒退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们做的相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不会任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度专业化将支配一切,你会有一个真正的、可接受的、巨大的性能悬崖线。
|
||||
基准和过度专业化的问题在于基准可以给你提示在哪里可以看看以及该怎么做,但它不告诉你你应该走多远,不能保护优化。例如,所有 JavaScript 引擎都使用基准来防止性能下降,但是运行 Kraken 不能保护我们在 `TurboFan` 中的一般方法,即我们可以将 `TurboFan` 中的模优化降级到过度专业版本的 `Crankshaft`,而基准不会告诉我们却在倒退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们做的相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不会任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度专业化将支配一切,你会有一个真正的、可接受的、巨大的性能悬崖线。
|
||||
|
||||
`Kraken` 测试还有许多其它的问题,不过现在让我们继续讨论过去五年中最有影响力的 `JavaScript` 基准测试—— `Octane` 测试。
|
||||
Kraken 测试还有许多其它的问题,不过现在让我们继续讨论过去五年中最有影响力的 JavaScript 基准测试—— Octane 测试。
|
||||
|
||||
### 深入接触 Octane
|
||||
|
||||
[Octane][66] 基准是 `V8` 基准的继承者,最初由[谷歌于 2012 年中期发布][67],目前的版本 `Octane` 2.0 [于 2013 年年底发布][68]。这个版本包含 15 个独立测试,其中对于 `Splay` 和 `Mandreel`,我们用来测试吞吐量和延迟。这些测试范围从 [微软 TypeScript 编译器][69] 编译自身到 `zlib` 测试测量原生的 [asm.js][70] 性能,再到 `RegExp` 引擎的性能测试、光线追踪器、2D 物理引擎等。有关各个基准测试项的详细概述,请参阅[说明书][71]。所有这些测试项目都经过仔细的筛选,以反映 `JavaScript` 性能的方方面面,我们认为这在 2012 年非常重要,或许预计在不久的将来会变得更加重要。
|
||||
[Octane][66] 基准是 V8 基准的继承者,最初由[谷歌于 2012 年中期发布][67],目前的版本 Octane 2.0 [于 2013 年年底发布][68]。这个版本包含 15 个独立测试,其中对于 `Splay` 和 `Mandreel`,我们用来测试吞吐量和延迟。这些测试范围从 [微软 TypeScript 编译器][69] 编译自身到 `zlib` 测试测量原生的 [asm.js][70] 性能,再到 `RegExp` 引擎的性能测试、光线追踪器、2D 物理引擎等。有关各个基准测试项的详细概述,请参阅[说明书][71]。所有这些测试项目都经过仔细的筛选,以反映 JavaScript 性能的方方面面,我们认为这在 2012 年非常重要,或许预计在不久的将来会变得更加重要。
|
||||
|
||||
在很大程度上 `Octane` 在实现其将 `JavaScript` 性能提高到更高水平的目标方面无比的成功,它在 2012 年和 2013 年引导了良性的竞争,`Octane` 创造了巨大的业绩和成就。但是现在将近 2017 年了,世界看起来与 2012 年真的迥然不同了。除了通常和经常被引用的批评,`Octane` 中的大多数项目基本上已经过时(例如,老版本的 `TypeScript`,`zlib` 通过老版本的 [Emscripten][72] 编译而成,`Mandreel` 甚至不再可用等等),某种更重要的方式影响了 `Octane` 的用途:
|
||||
在很大程度上 Octane 在实现其将 JavaScript 性能提高到更高水平的目标方面无比的成功,它在 2012 年和 2013 年引导了良性的竞争,Octane 创造了巨大的业绩和成就。但是现在将近 2017 年了,世界看起来与 2012 年真的迥然不同了。除了通常和经常被引用的批评,Octane 中的大多数项目基本上已经过时(例如,老版本的 `TypeScript`,`zlib` 通过老版本的 [Emscripten][72] 编译而成,`Mandreel` 甚至不再可用等等),某种更重要的方式影响了 Octane 的用途:
|
||||
|
||||
我们看到大型 web 框架赢得了 web 种族之争,尤其是像 [Ember][73] 和 [AngularJS][74] 这样的重型框架,它们使用了 `JavaScript` 执行模式,不过根本没有被 `Octane` 所反映,并且经常受到(我们)`Octane` 具体优化的损害。我们还看到 `JavaScript` 在服务器和工具前端获胜,这意味着有大规模的 `JavaScript` 应用现在通常运行上数星期,如果不是运行上数年都不会被 `Octane` 捕获。正如开篇所述,我们有硬数据表明 `Octane` 的执行和内存配置文件与我们每天在 web 上看到的截然不同。
|
||||
我们看到大型 web 框架赢得了 web 种族之争,尤其是像 [Ember][73] 和 [AngularJS][74] 这样的重型框架,它们使用了 JavaScript 执行模式,不过根本没有被 Octane 所反映,并且经常受到(我们)Octane 具体优化的损害。我们还看到 JavaScript 在服务器和工具前端获胜,这意味着有大规模的 JavaScript 应用现在通常运行上数星期,如果不是运行上数年都不会被 Octane 捕获。正如开篇所述,我们有硬数据表明 Octane 的执行和内存配置文件与我们每天在 web 上看到的截然不同。
|
||||
|
||||
让我们来看看今天一些玩弄 `Octane` 基准的具体例子,其中优化不再反映在现实场景。请注意,即使这可能听起来有点负面回顾,它绝对不意味着这样!正如我已经说过好几遍,`Octane` 是 `JavaScript` 性能故事中的重要一章,它发挥了至关重要的作用。在过去由 `Octane` 驱动的 `JavaScript` 引擎中的所有优化都是善意地添加的,因为 `Octane` 是现实场景性能的好代理!每个年代都有它的基准,而对于每一个基准都有一段时间你必须要放手!
|
||||
让我们来看看今天一些玩弄 Octane 基准的具体例子,其中优化不再反映在现实场景。请注意,即使这可能听起来有点负面回顾,它绝对不意味着这样!正如我已经说过好几遍,Octane 是 JavaScript 性能故事中的重要一章,它发挥了至关重要的作用。在过去由 Octane 驱动的 JavaScript 引擎中的所有优化都是善意地添加的,因为 Octane 是现实场景性能的好代理!每个年代都有它的基准,而对于每一个基准都有一段时间你必须要放手!
|
||||
|
||||
话虽如此,让我们在路上看这个节目,首先看看 `Box2D` 测试,它是基于 [Box2DWeb][75] (一个最初由 Erin Catto 编写的移植到 `JavaScript` 的流行的 2D 物理引擎)的。总的来说,很多浮点数学驱动了很多 `JavaScript` 引擎下很好的优化,但是,事实证明它包含一个可以肆意玩弄基准的漏洞(怪我,我发现了漏洞,并添加在这种情况下的漏洞)。在基准中有一个函数 `D.prototype.UpdatePairs`,看起来像这样:
|
||||
话虽如此,让我们在路上看这个节目,首先看看 `Box2D` 测试,它是基于 [Box2DWeb][75] (一个最初由 Erin Catto 编写的移植到 JavaScript 的流行的 2D 物理引擎)的。总的来说,很多浮点数学驱动了很多 JavaScript 引擎下很好的优化,但是,事实证明它包含一个可以肆意玩弄基准的漏洞(怪我,我发现了漏洞,并添加在这种情况下的漏洞)。在基准中有一个函数 `D.prototype.UpdatePairs`,看起来像这样:
|
||||
|
||||
```
|
||||
D.prototype.UpdatePairs = function(b) {
|
||||
@ -333,7 +333,7 @@ x.proxyA = t < m ? t : m;
|
||||
x.proxyB = t >= m ? t : m;
|
||||
```
|
||||
|
||||
所以这两行无辜的代码要负起 99% 的时间开销的责任!这怎么来的?好吧,与 `JavaScript` 中的许多东西一样,[抽象关系比较][79] 的直观用法不一定是正确的。在这个函数中,`t` 和 `m` 都是 `L` 的实例,它是这个应用的一个中心类,但不会覆盖 `Symbol.toPrimitive`、`“toString”`、`“valueOf”` 或 `Symbol.toStringTag` 属性,它们与抽象关系比较相关。所以如果你写 `t < m` 会发生什么呢?
|
||||
所以这两行无辜的代码要负起 99% 的时间开销的责任!这怎么来的?好吧,与 JavaScript 中的许多东西一样,[抽象关系比较][79] 的直观用法不一定是正确的。在这个函数中,`t` 和 `m` 都是 `L` 的实例,它是这个应用的一个中心类,但不会覆盖 `Symbol.toPrimitive`、`“toString”`、`“valueOf”` 或 `Symbol.toStringTag` 属性,它们与抽象关系比较相关。所以如果你写 `t < m` 会发生什么呢?
|
||||
|
||||
1. 调用 [ToPrimitive][12](`t`, `hint Number`)。
|
||||
2. 运行 [OrdinaryToPrimitive][13](`t`, `"number"`),因为这里没有 `Symbol.toPrimitive`。
|
||||
@ -373,7 +373,7 @@ Score (Box2D): 55359
|
||||
$
|
||||
```
|
||||
|
||||
那么我们是怎么做呢?事实证明,我们已经有一种用于跟踪比较对象的形状的机制,比较发生于 `CompareIC`,即所谓的已知接收器映射跟踪(其中的映射是 `V8` 的对象形状+原型),不过这是有限的抽象和严格相等比较。但是我可以很容易地扩展跟踪,并且收集反馈进行抽象的关系比较:
|
||||
那么我们是怎么做呢?事实证明,我们已经有一种用于跟踪比较对象的形状的机制,比较发生于 `CompareIC`,即所谓的已知接收器映射跟踪(其中的映射是 V8 的对象形状+原型),不过这是有限的抽象和严格相等比较。但是我可以很容易地扩展跟踪,并且收集反馈进行抽象的关系比较:
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
@ -384,7 +384,7 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
$
|
||||
```
|
||||
|
||||
这里基准代码中使用的 `CompareIC` 告诉我们,对于我们正在查看的函数中的 `LT`(小于)和 `GTE`(大于或等于)比较,到目前为止这只能看到 `RECEIVERs`(接收器,`V8` 的 `JavaScript` 对象),并且所有这些接收器具有相同的映射 `0x1d5a860493a1`,其对应于 `L` 实例的映射。因此,在优化的代码中,只要我们知道比较的两侧映射的结果都为 `0x1d5a860493a1`,并且没人混淆 `L` 的原型链(即 `Symbol.toPrimitive`、`"valueOf"` 和 `"toString"` 这些方法都是默认的,并且没人赋予过 `Symbol.toStringTag` 的访问权限),我们可以将这些操作分别常量折叠为 `false` 和 `true`。剩下的故事都是关于 `Crankshaft` 的黑魔法,有很多一部分都是由于初始化的时候忘记正确地检查 `Symbol.toStringTag` 属性:
|
||||
这里基准代码中使用的 `CompareIC` 告诉我们,对于我们正在查看的函数中的 `LT`(小于)和 `GTE`(大于或等于)比较,到目前为止这只能看到 `RECEIVERs`(接收器,V8 的 JavaScript 对象),并且所有这些接收器具有相同的映射 `0x1d5a860493a1`,其对应于 `L` 实例的映射。因此,在优化的代码中,只要我们知道比较的两侧映射的结果都为 `0x1d5a860493a1`,并且没人混淆 `L` 的原型链(即 `Symbol.toPrimitive`、`"valueOf"` 和 `"toString"` 这些方法都是默认的,并且没人赋予过 `Symbol.toStringTag` 的访问权限),我们可以将这些操作分别常量折叠为 `false` 和 `true`。剩下的故事都是关于 `Crankshaft` 的黑魔法,有很多一部分都是由于初始化的时候忘记正确地检查 `Symbol.toStringTag` 属性:
|
||||
|
||||
[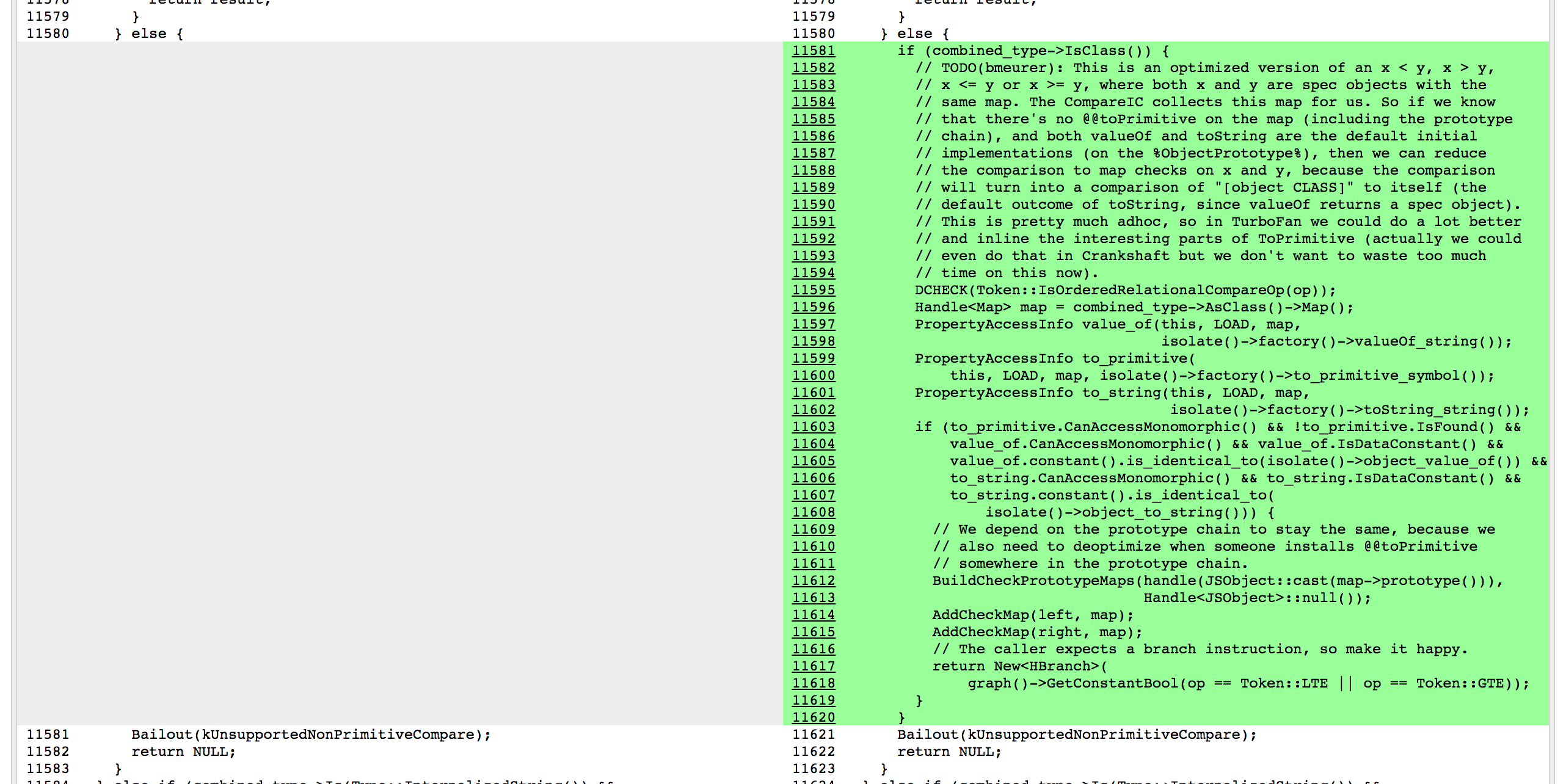][80]
|
||||
|
||||
@ -392,13 +392,13 @@ $
|
||||
|
||||
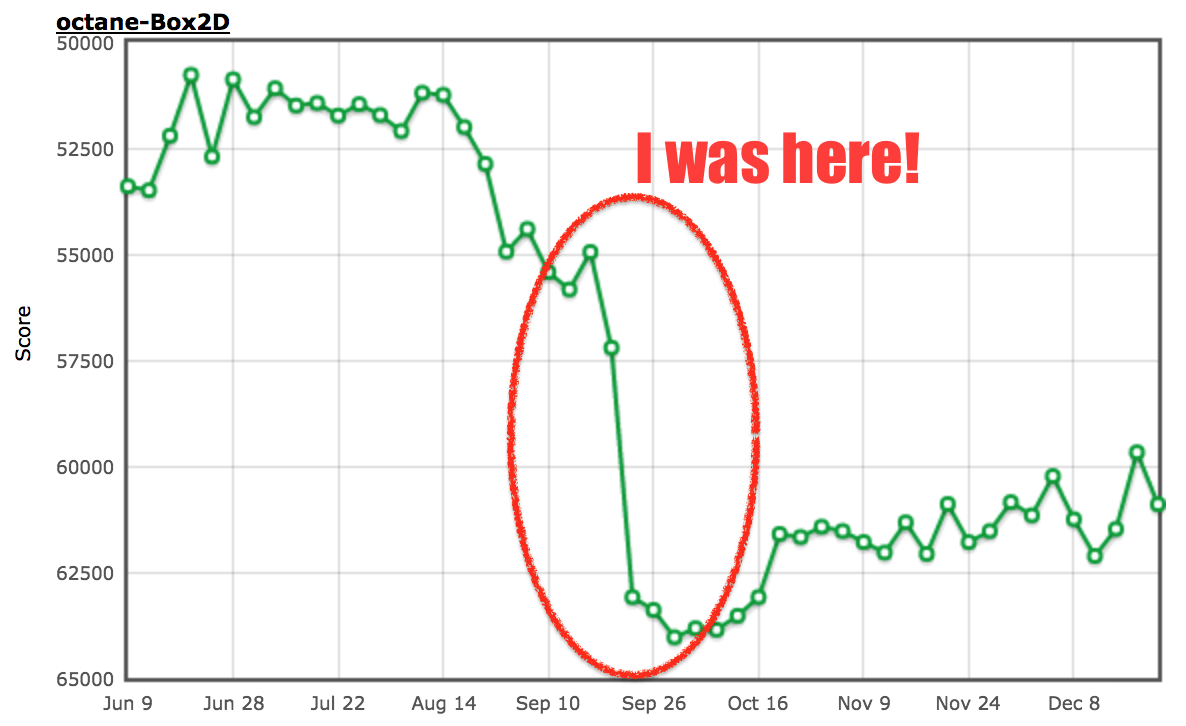
|
||||
|
||||
我要声明一下,当时我并不相信这个特定的行为总是指向源代码中的漏洞,所以我甚至期望外部代码经常会遇到这种情况,同时也因为我假设 `JavaScript` 开发人员不会总是关心这些种类的潜在错误。但是,我大错特错了,在此我马上悔改!我不得不承认,这个特殊的优化纯粹是一个基准测试的东西,并不会有助于任何真实代码(除非代码是为了从这个优化中获益而写,不过以后你可以在代码中直接写入 `true` 或 `false`,而不用再总是使用常量关系比较)。你可能想知道我们为什么在打补丁后又马上回滚了一下。这是我们整个团队投入到 `ES2015` 实施的非常时期,这才是真正的恶魔之舞,我们需要在没有严格的回归测试的情况下将所有新特性(`ES2015` 就是个怪兽)纳入传统基准。
|
||||
我要声明一下,当时我并不相信这个特定的行为总是指向源代码中的漏洞,所以我甚至期望外部代码经常会遇到这种情况,同时也因为我假设 JavaScript 开发人员不会总是关心这些种类的潜在错误。但是,我大错特错了,在此我马上悔改!我不得不承认,这个特殊的优化纯粹是一个基准测试的东西,并不会有助于任何真实代码(除非代码是为了从这个优化中获益而写,不过以后你可以在代码中直接写入 `true` 或 `false`,而不用再总是使用常量关系比较)。你可能想知道我们为什么在打补丁后又马上回滚了一下。这是我们整个团队投入到 `ES2015` 实施的非常时期,这才是真正的恶魔之舞,我们需要在没有严格的回归测试的情况下将所有新特性(`ES2015` 就是个怪兽)纳入传统基准。
|
||||
|
||||
关于 `Box2D` 点到为止了,让我们看看 `Mandreel` 基准。`Mandreel` 是一个用来将 `C/C++` 代码编译成 `JavaScript` 的编译器,它并没有用上新一代的 [Emscripten][82] 编译器所使用,并且已经被弃用(或多或少已经从互联网消失了)大约三年的 `JavaScript` 子集 [asm.js][81]。然而,`Octane` 仍然有一个通过 [Mandreel][84] 编译的[子弹物理引擎][83]。`MandreelLatency` 测试十分有趣,它测试 `Mandreel` 基准与频繁的时间测量检测点。有一种说法是,由于 `Mandreel` 强制使用虚拟机编译器,此测试提供了由编译器引入的延迟的指示,并且测量检测点之间的长时间停顿降低了最终得分。这听起来似乎合情合理,确实有一定的意义。然而,像往常一样,供应商找到了在这个基准上作弊的方法。
|
||||
关于 `Box2D` 点到为止了,让我们看看 `Mandreel` 基准。`Mandreel` 是一个用来将 `C/C++` 代码编译成 JavaScript 的编译器,它并没有用上新一代的 [Emscripten][82] 编译器所使用,并且已经被弃用(或多或少已经从互联网消失了)大约三年的 JavaScript 子集 [asm.js][81]。然而,Octane 仍然有一个通过 [Mandreel][84] 编译的[子弹物理引擎][83]。`MandreelLatency` 测试十分有趣,它测试 `Mandreel` 基准与频繁的时间测量检测点。有一种说法是,由于 `Mandreel` 强制使用虚拟机编译器,此测试提供了由编译器引入的延迟的指示,并且测量检测点之间的长时间停顿降低了最终得分。这听起来似乎合情合理,确实有一定的意义。然而,像往常一样,供应商找到了在这个基准上作弊的方法。
|
||||
|
||||
[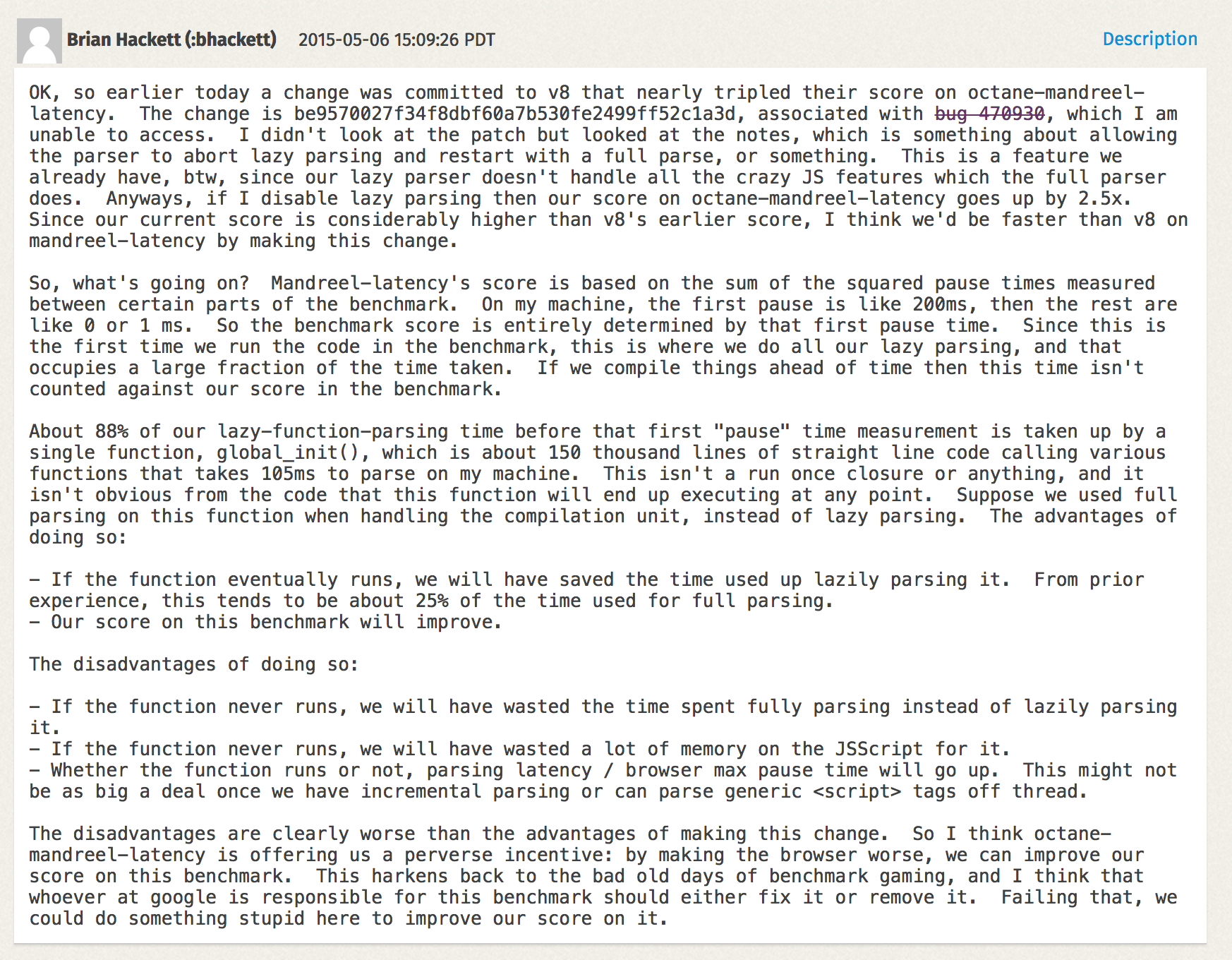][85]
|
||||
|
||||
`Mandreel` 自带一个重型初始化函数 `global_init`,光是解析这个函数并为其生成基线代码就花费了不可思议的时间。因为引擎通常在脚本中多次解析各种函数,一个所谓的预解析步骤用来发现脚本内的函数。然后作为函数第一次被调用完整的解析步骤以生成基线代码(或者说字节码)。这在 `V8` 中被称为[懒解析][86]。`V8` 有一些启发式检测函数,当预解析浪费时间的时候可以立刻调用,不过对于 `Mandreel` 基准的 `global_init` 函数就不太清楚了,于是我们将经历这个大家伙“预解析+解析+编译”的长时间停顿。所以我们[添加了一个额外的启发式函数][87]以避免 `global_init` 函数的预解析。
|
||||
`Mandreel` 自带一个重型初始化函数 `global_init`,光是解析这个函数并为其生成基线代码就花费了不可思议的时间。因为引擎通常在脚本中多次解析各种函数,一个所谓的预解析步骤用来发现脚本内的函数。然后作为函数第一次被调用完整的解析步骤以生成基线代码(或者说字节码)。这在 V8 中被称为[懒解析][86]。V8 有一些启发式检测函数,当预解析浪费时间的时候可以立刻调用,不过对于 `Mandreel` 基准的 `global_init` 函数就不太清楚了,于是我们将经历这个大家伙“预解析+解析+编译”的长时间停顿。所以我们[添加了一个额外的启发式函数][87]以避免 `global_init` 函数的预解析。
|
||||
|
||||
[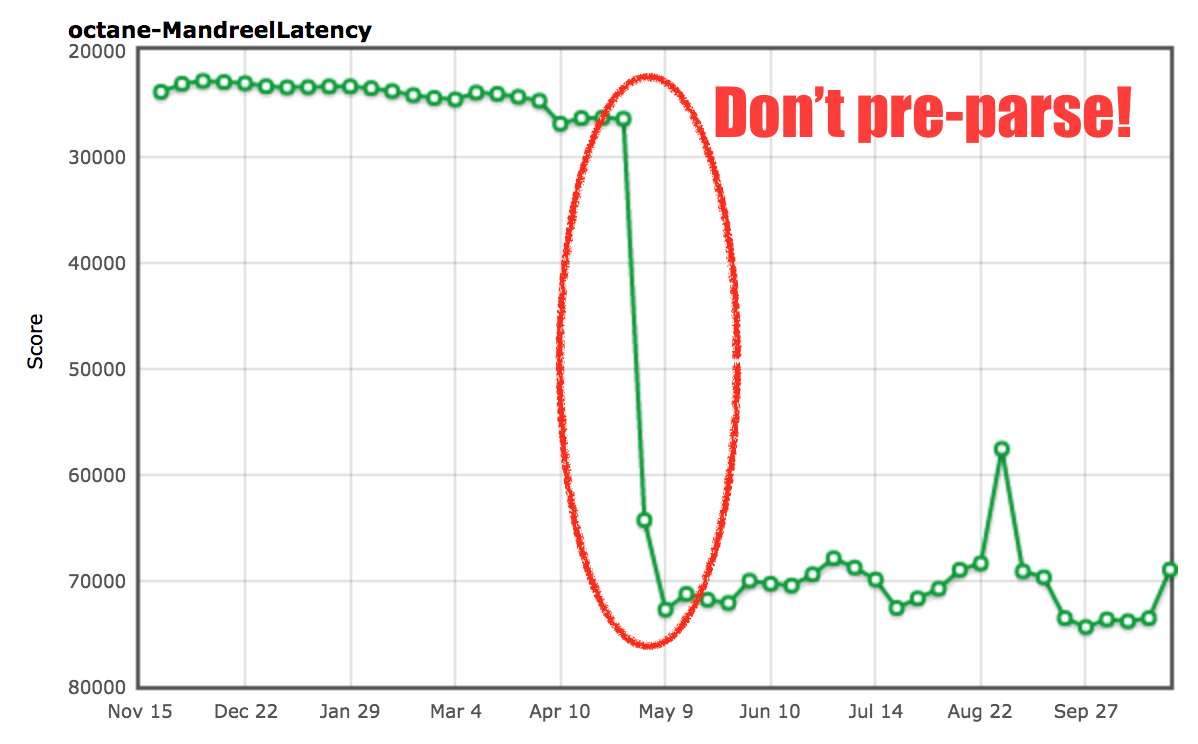][88]
|
||||
|
||||
@ -408,7 +408,7 @@ $
|
||||
|
||||
[][90]
|
||||
|
||||
这是伸展树结构的核心,尽管你可能想看完整的基准,不过这或多或少是 `SplayLatency` 得分的重要来源。怎么回事?实际上,基准测试是建立巨大的伸展树,尽可能保留所有节点,从而还原它原本的空间。使用像 `V8` 这样的代数垃圾回收器,如果程序违反了[代数假设][91],导致极端的时间停顿,从本质上看,将所有东西从新空间撤回到旧空间的开销是非常昂贵的。在旧配置中运行 `V8` 可以清楚地展示这个问题:
|
||||
这是伸展树结构的核心,尽管你可能想看完整的基准,不过这或多或少是 `SplayLatency` 得分的重要来源。怎么回事?实际上,基准测试是建立巨大的伸展树,尽可能保留所有节点,从而还原它原本的空间。使用像 V8 这样的代数垃圾回收器,如果程序违反了[代数假设][91],导致极端的时间停顿,从本质上看,将所有东西从新空间撤回到旧空间的开销是非常昂贵的。在旧配置中运行 V8 可以清楚地展示这个问题:
|
||||
|
||||
```
|
||||
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||
@ -534,7 +534,7 @@ $
|
||||
|
||||
喘口气。
|
||||
|
||||
好吧,我想这足以强调我的观点了。我可以继续指出更多的例子,其中 `Octane` 驱动的改进后来变成了一个坏主意,也许改天我会接着写下去。但是今天就到此为止了吧。
|
||||
好吧,我想这足以强调我的观点了。我可以继续指出更多的例子,其中 Octane 驱动的改进后来变成了一个坏主意,也许改天我会接着写下去。但是今天就到此为止了吧。
|
||||
|
||||
### 结论
|
||||
|
||||
@ -542,11 +542,11 @@ $
|
||||
|
||||
[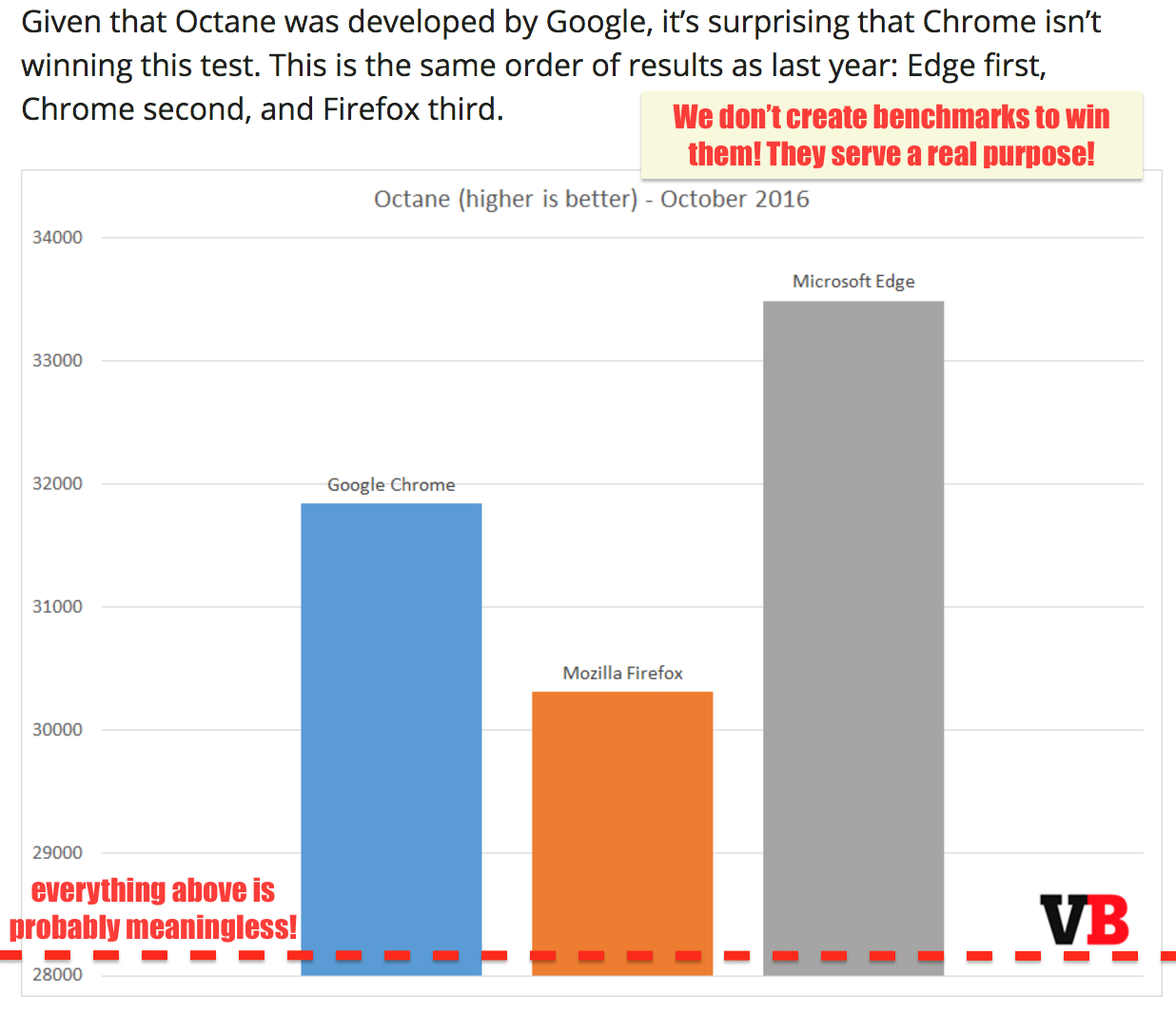][99]
|
||||
|
||||
没人害怕竞争,但是玩弄可能已经坏掉的基准不像是在合理使用工程时间。我们可以尽更大的努力,并把 JavaScript 提高到更高的水平。让我们开展有意义的性能测试,以便为最终用户和开发者带来有意思的领域竞争。此外,让我们再对服务器和运行在 `Node.js`(还有 `V8` 和 `ChakraCore`)中的工具代码做一些有意义的改进!
|
||||
没人害怕竞争,但是玩弄可能已经坏掉的基准不像是在合理使用工程时间。我们可以尽更大的努力,并把 JavaScript 提高到更高的水平。让我们开展有意义的性能测试,以便为最终用户和开发者带来有意思的领域竞争。此外,让我们再对服务器和运行在 Node.js(还有 V8 和 `ChakraCore`)中的工具代码做一些有意义的改进!
|
||||
|
||||

|
||||
|
||||
结束语:不要用传统的 `JavaScript` 基准来比较手机。这是真正最没用的事情,因为 `JavaScript` 的性能通常取决于软件,而不一定是硬件,并且 `Chrome` 每 6 周发布一个新版本,所以你在三月的测试结果到了四月就已经毫不相关了。如果在浏览器中发送一个数字都一部手机不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 [Speedometer 基准][100]。
|
||||
结束语:不要用传统的 JavaScript 基准来比较手机。这是真正最没用的事情,因为 JavaScript 的性能通常取决于软件,而不一定是硬件,并且 `Chrome` 每 6 周发布一个新版本,所以你在三月的测试结果到了四月就已经毫不相关了。如果在浏览器中发送一个数字都一部手机不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 [Speedometer 基准][100]。
|
||||
|
||||
感谢你花时间阅读!
|
||||
|
||||
|
||||
@ -0,0 +1,129 @@
|
||||
|
||||
安卓IoT能否像在移动终端一样成功?
|
||||
============================================================
|
||||
|
||||

|
||||
Android Things让IoT如虎添翼
|
||||
|
||||
###我在Android Things上的最初24小时
|
||||
正当我在开发一个基于Android的运行在树莓派3的物联网商业项目时,一些令人惊喜的事情发生了。谷歌发布了[Android Things] [1]的第一个预览版本,他们的SDK专门针对(最初)3个SBC(单板计算机) - 树莓派 3,英特尔Edison和恩智浦Pico。说我一直在挣扎似乎有些轻描淡写 - 没有成功的移植树莓派安卓可以参照,我们在理想丰满,但是实践漏洞百出的内测版本上叫苦不迭。其中一个问题,同时也是不可原谅的问题是,它不支持触摸屏,甚至连[Element14][2]官方销售的也不支持。曾经我认为安卓已经支持树莓派,更早时候[commi tto AOSP project from Google][3]提到过Pi曾让所有人兴奋不已。所以当2016年12月12日谷歌发布"Android Things"和其SDK的时候,我马上闭门谢客,全身心地去研究了……
|
||||
|
||||
### 问题?
|
||||
安卓扩展的工作和Pi上做过的一些项目,包括之前提到的,当前正在开发中的Pi项目,使我对谷歌安卓产生了许多问题。未来我会尝试解决它们,但是最重要的问题可以马上解答 - 有完整的Android Studio支持,Pi成为列表上的另一个常规的ADB可寻址设备。好极了。Android Atudio强大的,便利的,纯粹的易用的功能包括布局预览,调试系统,源码检查器,自动化测试等可以真正的应用在IoT硬件上。这些好处怎么说都不过分。到目前为止,我在Pi上的大部分工作都是在python中使用SSH运行在Pi上的编辑器(MC,如果你真的想知道)。这是有效的,毫无疑问硬核Pi / Python头可以指出更好的工作方式,而不是当前这种像极了80年代码农的软件开发模式。我的项目涉及到在控制Pi的手机上编写Android软件,这有点像在伤口狂妄地撒盐 - 我使用Android Studio做“真正的”Android工作,用SSH做剩下的。但是有了"Android Things"之后,一切都结束了。
|
||||
|
||||
所有的示例代码都适用于3个SBC,Pi 只是其中之一。 Build.DEVICE常量在运行时确定,所以你会看到很多如下代码:
|
||||
|
||||
```
|
||||
public static String getGPIOForButton() {
|
||||
switch (Build.DEVICE) {
|
||||
case DEVICE_EDISON_ARDUINO:
|
||||
return "IO12";
|
||||
case DEVICE_EDISON:
|
||||
return "GP44";
|
||||
case DEVICE_RPI3:
|
||||
return "BCM21";
|
||||
case DEVICE_NXP:
|
||||
return "GPIO4_IO20";
|
||||
default:
|
||||
throw new IllegalStateException(“Unknown Build.DEVICE “ + Build.DEVICE);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我对GPIO处理有浓厚的兴趣。 由于我只熟悉Pi,我只能假定其他SBC工作方式相同,GPIO只是一组引脚,可以定义为输入/输出,是连接物理外部世界的主要接口。 基于Pi Linux的操作系统发行版通过Python中的读取和写入方法提供了完整和便捷的支持,但对于Android,您必须使用NDK编写C ++驱动程序,并通过JNI在Java中与这些驱动程序对接。 不是那么困难,但需要在你的构建链中维护额外的一些东西。 Pi还为I2C指定了2个引脚,时钟和数据,因此需要额外的工作来处理它们。 I2C是真正酷的总线寻址系统,它通过串行化将许多独立的数据引脚转换成一个。 所以这里的优势是 - Android Things已经帮你完成了所有这一切。 你只需要_read()_和_write()_to /from你需要的任何GPIO引脚,I2C同样容易:
|
||||
|
||||
```
|
||||
public class HomeActivity extends Activity {
|
||||
// I2C Device Name
|
||||
private static final String I2C_DEVICE_NAME = ...;
|
||||
// I2C Slave Address
|
||||
private static final int I2C_ADDRESS = ...;
|
||||
|
||||
private I2cDevice mDevice;
|
||||
|
||||
@Override
|
||||
protected void onCreate(Bundle savedInstanceState) {
|
||||
super.onCreate(savedInstanceState);
|
||||
// Attempt to access the I2C device
|
||||
try {
|
||||
PeripheralManagerService manager = new PeripheralManagerService();
|
||||
mDevice = manager.openI2cDevice(I2C_DEVICE_NAME, I2C_ADDRESS)
|
||||
} catch (IOException e) {
|
||||
Log.w(TAG, "Unable to access I2C device", e);
|
||||
}
|
||||
}
|
||||
|
||||
@Override
|
||||
protected void onDestroy() {
|
||||
super.onDestroy();
|
||||
|
||||
if (mDevice != null) {
|
||||
try {
|
||||
mDevice.close();
|
||||
mDevice = null;
|
||||
} catch (IOException e) {
|
||||
Log.w(TAG, "Unable to close I2C device", e);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
### Android Things基于Android的哪个版本?
|
||||
看起来是Android 7.0,这样很好,因为我们可以继承Android以前的所有版本的文档,优化,安全加固等。它也提出了一个有趣的问题 - 与应用程序必须单独管理不同,未来的平台应如何更新升级?请记住,这些设备可能无法连接到互联网。我们可能不在蜂窝/ WiFi连接的舒适空间,虽然之前这些连接至少可用,即使有时不那么可靠。
|
||||
|
||||
另一个担心是,Android Things仅仅是一个名字不同的分支版本的Android,如何选择它们的共同特性,就像启动Arduino(已经发布的一个更像市场营销而不是操作系统的操作系统)这种简单特性。实际上,通过查看[samples] [4],一些功能可能永不再用 - 比如一个最近的Android创新,甚至使用SVG图形作为资源,而不是传统的基于位图的图形,当然Andorid Things也可以轻松处理。
|
||||
|
||||
不可避免地,与Android Things相比,普通的Android会抛出问题。例如,权限问题。因为Android Things为固定硬件设计,用户通常不会在这种设备上安装App,所以在一定程序上减轻了这个问题。另外,在没有图形界面的设备上请求权限通常不是问题,我们可以在安装时开放所有权限给App。 通常,这些设备只有一个应用程序,该应用程序从设备上电的那一刻就开始运行。
|
||||
|
||||

|
||||
|
||||
### Brillo怎么了?
|
||||
|
||||
Brillo是谷歌以前的IoT操作系统的代号,听起来很像Android的前身。 实际上现在你仍然能看到很多Brillo引用,特别是在GitHub Android Things源码的例子中。 然而,它已经不复存在了。新王已经登基!
|
||||
|
||||
### UI指南?
|
||||
Google针对Android智能手机和平板电脑应用发布了大量指南,例如屏幕按钮间距等。 当然,你最好在可行的情况下遵循这些,但这已经不是本文应该考虑的范畴了。 缺省情况下什么也没有- 应用程序作者决定一切。 这包括顶部状态栏,底部导航栏 - 绝对一切。 多年来谷歌一直叮咛Android应用程序作者不要去渲染屏幕上的返回按钮,因为平台将提供一个抛出异常,因为对于Android Things,[可能甚至不是一个UI!] [5]
|
||||
|
||||
### 多少智能手机上的服务可以期待?
|
||||
有些,但不是所有。第一个预览版本没有蓝牙支持。没有NFC,两者都对物联网革命有重大贡献。 SBC支持他们,所以我们应该不会等待太久。由于没有通知栏,因此不支持任何通知。没有地图。缺省没有软键盘,你必须自己安装一个。由于没有Play商店,你只能屈尊通过 ADB做这个和许多其他操作。
|
||||
|
||||
当开发Android Things时我试图和Pi使用同一个APK。这引发了一个错误,阻止它安装在除Android Things设备之外的任何设备:库“_com.google.android.things_”不存在。 Kinda有意义,因为只有Android Things设备需要这个,但它似乎是有限的,因为不仅智能手机或平板电脑不会出现,任何模拟器也不会。似乎只能在物理Android Things设备上运行和测试您的Android Things应用程序...直到Google在[G + Google的IoT开发人员社区] [6]组中回答了我的问题,并提供了规避方案。但是,躲过初一,躲不过十五 。
|
||||
|
||||
### 让我如何期待Android Thing生态演进?
|
||||
|
||||
我期望看到移植更多传统的基于Linux服务器的应用程序,这对Android只有智能手机和平板电脑没有意义。例如,Web服务器突然变得非常有用。一些已经存在,但没有像重量级的Apache,或Nginx。物联网设备可能没有本地UI,但通过浏览器管理它们当然是可行的,因此需要用这种方式呈现Web面板。类似的那些如雷贯耳的通讯应用程序 - 它需要的仅是一个麦克风和扬声器,在理论上对任何视频通话应用程序,如Duo,Skype,FB等都可行。这个演变能走多远目前只能猜测。会有Play商店吗?他们会展示广告吗?我们可以确定他们不会窥探我们,或让黑客控制他们?从消费者的角度来看,物联网应该是具有触摸屏的网络连接设备,因为每个人都已经习惯于通过智能手机工作。
|
||||
|
||||
我还期望看到硬件的迅速发展 - 特别是更多的SBC并且拥有更低的成本。看看惊人的5美元 树莓派0,不幸的是,由于其有限的CPU和RAM,几乎肯定不能运行Android Things。多久之后像这样的设备才能运行Android Things?这是很明显的,标杆已经设定,任何自重的SBC制造商将瞄准Android Things的兼容性,规模经济也将波及到外围设备,如23美元的触摸屏。没人购买不会播放YouTube的微波炉,你的洗碗机会在eBay上购买更多的粉末商品,因为它注意到你很少使用它……
|
||||
|
||||
然而,我不认为我们会失去掌控力。了解一点Android架构有助于将其视为一个包罗万象的物联网操作系统。它仍然使用Java,并几乎被其所有的垃圾回收机制导致的时序问题锤击致死。这仅仅是问题最少的部分。真正的实时操作系统依赖于可预测,准确和坚如磐石的时序,或者它不能被描述为“mission critical”。想想医疗应用程序,安全监视器,工业控制器等。使用Android,如果主机操作系统认为它需要,理论上可以在任何时候杀死您的活动/服务。在手机上不是那么糟糕 - 用户可以重新启动应用程序,杀死其他应用程序,或重新启动手机。心脏监视器完全是另一码事。如果前台Activity / Service正在监视一个GPIO引脚,并且信号没有被准确地处理,我们已经失败了。必须要做一些相当根本的改变让Android来支持这一点,到目前为止还没有迹象表明它已经在计划之中了。
|
||||
|
||||
###这24小时
|
||||
所以,回到我的项目。 我认为我会接管我已经完成和尽力能为的工作,等待不可避免的路障,并向G+社区寻求帮助。 除了一些在非Android Things上如何运行程序 的问题之外 ,没有其他问题。 它运行得很好! 这个项目也使用了一些奇怪的东西,自定义字体,高精定时器 - 所有这些都在Android Studio中完美地展现。对我而言,可以打满分 - 最后我可以开始给出实际原型,而不只是视频和截图。
|
||||
|
||||
### 蓝图
|
||||
今天的物联网操作系统环境看起来非常零碎。 显然没有市场领导者,尽管炒作之声沸反连天,物联网仍然在草创阶段。 谷歌Android物联网能否像它在移动端那样,现在Android在那里的主导地位非常接近90%? 我相信果真如此,Android Things的推出正是重要的一步。
|
||||
|
||||
记住所有的关于开放和封闭软件的战争,它们主要发生在从不授权的苹果和一直担心免费还不够充分的谷歌之间? 那个老梗又来了,因为让苹果推出一个免费的物联网操作系统的构想就像让他们免费赠送下一代iPhone一样遥不可及。
|
||||
|
||||
物联网操作系统游戏是开放的,大家机遇共享,不过这个时候,封闭派甚至不会公布它们的开发工具箱……
|
||||
|
||||
转到[Developer Preview] [7]网站,立即获取Android Things SDK的副本。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@carl.whalley/will-android-do-for-iot-what-it-did-for-mobile-c9ac79d06c#.hxva5aqi2
|
||||
|
||||
作者:[Carl Whalley][a]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@carl.whalley
|
||||
[1]:https://developer.android.com/things/index.html
|
||||
[2]:https://www.element14.com/community/docs/DOC-78156/l/raspberry-pi-7-touchscreen-display
|
||||
[3]:http://www.androidpolice.com/2016/05/24/google-is-preparing-to-add-the-raspberry-pi-3-to-aosp-it-will-apparently-become-an-officially-supported-device/
|
||||
[4]:https://github.com/androidthings/sample-simpleui/blob/master/app/src/main/res/drawable/pinout_board_vert.xml
|
||||
[5]:https://developer.android.com/things/sdk/index.html
|
||||
[6]:https://plus.google.com/+CarlWhalley/posts/4tF76pWEs1D
|
||||
[7]:https://developer.android.com/things/preview/index.html
|
||||
128
translated/tech/20170125 NMAP Common Scans – Part Two.md
Normal file
128
translated/tech/20170125 NMAP Common Scans – Part Two.md
Normal file
@ -0,0 +1,128 @@
|
||||
NMAP 常用扫描简介(二)
|
||||
=====================
|
||||
|
||||
|
||||
|
||||
在我们之前的 [NMAP 安装][1]一文中,列出了 10 种不同的 ZeNMAP 扫描模式,大多数的模式使用了不同的参数。各种不同参数代表执行不同的扫描模式。这篇文章将介绍最后剩下的两种常用扫描类型。
|
||||
|
||||
**四种通用扫描类型**
|
||||
|
||||
下面列出了最常用的四种扫描类型:
|
||||
|
||||
1. PING 扫描(-sP)
|
||||
2. TCP SYN 扫描(-sS)
|
||||
3. TCP Connect() 扫描(-sT)
|
||||
4. UDP 扫描(-sU)
|
||||
|
||||
当我们利用 NMAP 来执行扫描的时候,这四种扫描类型是我们需要熟练掌握的。更重要的是需要知道这些命令做了什么,并且需要知道这些命令是怎么做的。在这篇文章中将介绍两种 TCP 扫描 — TCP SYN 扫描和 TCP Connect() 扫描。
|
||||
|
||||
([阅读 NMAP 常用扫描简介(一)][2])
|
||||
|
||||
**TCP SYN 扫描 (-sS)**
|
||||
|
||||
TCP SYN 扫描是默认的 NMAP 扫描。为了运行 TCP SYN 扫描,你需要有 Root 权限。
|
||||
|
||||
TCP SYN 扫描的目的是找到被扫描系统上的已开启端口。使用 NMAP 扫描可以扫描在防火墙另一侧的系统。当扫描通过防火墙时,扫描时间会延长,因为数据包会变慢。
|
||||
|
||||
TCP SYN 扫描的工作方式是启动一个“三次握手”。正如在另一篇文章中所述,“三次握手”发生在两个系统之间。首先,源系统发送一个包到目标系统,这是一个同步(Sync)请求。然后,目标系统将通过同步/应答(SYN/ACK)响应。接下来,源系统将通过应答(ACK)来响应,从而建立起一个通信连接,然后,可以在两个系统之间传输数据。
|
||||
|
||||
TCP SYN 扫描通过执行下面的步骤来进行工作:
|
||||
|
||||
1. 源系统向目标系统发送一个同步请求,同时,一个端口号会被添加到请求中。
|
||||
2. 如果添加在上一步中的请求中的端口号是开启的,那么目标系统将通过同步/应答(SYN/ACK)来响应源系统。
|
||||
3. 源系统通过重置(RST)来响应目标系统,从而断开连接。
|
||||
4. 目标系统可以通过重置/应答(SYN/ACK)来响应源系统。
|
||||
|
||||
连接已经建立,所以这被认为是半开放连接。因为连接状态是由 NMAP 管理的,所以你需要有 Root 权限。
|
||||
|
||||
如果被扫描的端口是关闭的,那么将执行下面的步骤:
|
||||
|
||||
1. 源系统发送一个同步(SYN)请求到目标系统,同时一个端口号被添加到请求中。
|
||||
2. 目标系统通过重置(RST)响应源系统,因为该端口是关闭的。
|
||||
|
||||
如果目标系统被防火墙监控,那么 ICMP 传输或响应将会防火墙禁止,此时,会执行下面的步骤:
|
||||
|
||||
1. 源系统发送一个同步请求到目标系统,同时一个端口号被添加到请求中。
|
||||
2. 没有任何响应,因为请求被防火墙过滤了。
|
||||
|
||||
在这种情况下,端口可能是被过滤、或者可能打开、或者可能没打开。防火墙可以设置禁止指定端口所有包的传出。防火墙可以禁止所有传入某个指定端口的包,因此目标系统不会接收到请求。
|
||||
|
||||
**注:**无响应可能发生在一个启用了防火墙的系统上。即使在本地网络,你也可能会发现被过滤端口
|
||||
|
||||
我将向图片1那样执行对单一系统(10.0.0.2)的扫描和执行 TCP SYN 扫描。使用命令 `sudo nmap -sS <IP 地址>` 来执行扫描。`<IP 地址>`可以改为一个单一 IP 地址,像图片1那样,也可以使用一组 IP 地址。
|
||||
|
||||

|
||||
|
||||
**图片1**
|
||||
|
||||
你可以看到,状态为 997 的被过滤端口没有显示。NMAP 找到两个开启的端口:139 和 445 。
|
||||
|
||||
**注:**请记住,NMAP 只会扫描绝大多数熟知的 1000 多个端口。以后,我们会介绍可以扫描所有端口或者指定端口的其他扫描。
|
||||
|
||||
扫描会被 WireShark 俘获,正如图片2所展示的那样。在这儿,你可以看到目标系统的初始地址解析协议(ARP)请求。在 ARP 请求下面的是一长列到达目标系统端口的 TCP 请求。第 4 行是到达 `http-alt` 端口(8080)。源系统的端口号为 47128 。正如图片3展示的,许多 SYN 请求只有在做出响应以后才会发送。
|
||||
|
||||

|
||||
|
||||
**图片2**
|
||||
|
||||

|
||||
|
||||
**图片3**
|
||||
|
||||
在图片3的第 50 行和第 51 行,你可以看到,重置(RST)包被发送给了源系统。第 53 行和第 55 行显示 RST/ACK(重置/应答)。第 50 行是针对 ‘microsoft-ds’ 端口(445),第 51 行是针对 ‘netbios-ssn’ 端口(135),我们可以看到,这两个端口都是打开的。除了这些端口,没有其他 ACK(应答)是来自目标系统的。每一个请求均可发送超过 1000 次。
|
||||
|
||||
正如图片4所展示的,目标系统是 Windows 系统,我关闭了系统防火墙,然后再次执行扫描。现在,我们看到 997 端口不是被过滤端口,而是已关闭端口。目标系统上的 135 端口之前被防火墙禁止了,现在也是开启的。
|
||||
|
||||

|
||||
|
||||
**图片4**
|
||||
|
||||
**TCP Connect() 扫描 (-sT)**
|
||||
|
||||
尽管 TCP SYN 扫描需要 Root 权限,但 TCP Connect() 扫描并不需要。一个完整的“三次握手”会在这次扫描中执行。因为不需要 Root 权限,所以在无法获取 Root 权限的网络上,这种扫描非常有用。
|
||||
|
||||
TCP Connect 扫描的工作方式也是执行“三次握手”。正如上面描述过的,“三次握手”发生在两个系统之间。源系统发送一个同步(Sync)请求到目标系统。然后,目标系统将通过同步/应答(SYN/ACK)来响应。最后,源系统通过应答(ACK)来响应,从而建立起连接,然后便可在两个系统之间传输数据。
|
||||
|
||||
TCP Connect 扫描通过执行下面的步骤来工作:
|
||||
|
||||
1. 源系统发送一个同步(SYN)请求到目标系统,同时一个端口号被添加到请求中。
|
||||
2. 如果上一步添加到请求中的端口是开启的,那么目标系统将通过同步/应答(SYN/ACK)来响应源系统。
|
||||
3. 源系统通过应答(ACK)来响应目标系统从而结束会话。
|
||||
4. 然后,源系统向目标系统发送一个重置(RST)包来关闭会话。
|
||||
5. 目标系统可以通过同步/应答(SYN/ACK)来响应源系统。
|
||||
|
||||
若步骤 2 执行了,那么源系统就知道在步骤 1 中的指定端口是开启的。
|
||||
|
||||
如果端口是关闭的,那么会发生和 TCP SYN 扫描相同的事。在步骤 2 中,目标系统将会通过一个重置(RST)包来响应源系统。
|
||||
|
||||
可以使用命令 `nmap -sT <IP 地址>` 来执行扫描。`<IP 地址>`可以改为一个单一 IP 地址,像图片5那样,或者使用一组 IP 地址。
|
||||
|
||||
TCP Connect 扫描的结果可以在图片5中看到。在这儿,你可以看到,有两个已开启端口:139 和 445,这和 TCP SYN 扫描的发现一样。端口 80 是关闭的。剩下没有显示的端口是被过滤了的。
|
||||
|
||||

|
||||
|
||||
**图片5**
|
||||
|
||||
让我们关闭防火墙以后再重新扫描一次,扫描结果展示在图片6中。
|
||||
|
||||

|
||||
|
||||
**图片6**
|
||||
|
||||
关闭防火墙以后,我们可以看到,更多的端口被发现了。就和 TCP SYN 扫描一样,关闭防火墙以后,发现 139 端口和 445 端口是开启的。我们还发现,端口 2869 也是开启的。也发现端口 996 是关闭的。现在,端口 80 是 996 已关闭端口的一部分 — 不再被防火墙过滤。
|
||||
|
||||
在一些情况下, TCP Connect 扫描可以在一个更短的时间内完成。和 TCP SYN 扫描相比,TCP Connect 扫描也可以找到更多的已开启端口
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxforum.com/threads/nmap-common-scans-part-two.3879/
|
||||
|
||||
作者:[Jarret ][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||
[1]:https://www.linuxforum.com/threads/nmap-installation.3431/
|
||||
[2]:https://linux.cn/article-8346-1.html/
|
||||
@ -0,0 +1,97 @@
|
||||
使用 Cozy 搭建个人云
|
||||
============================================================
|
||||
|
||||

|
||||
>Image by : [Pixabay][2]. Modified by Opensource.com. [CC BY-SA 4.0][3]
|
||||
|
||||
我认识的大部分人为了他们的日历、电子邮件、文件存储等,都会使用一些基于 Web 的应用。但是,如果像我这样,对隐私感到担忧、或者只是希望将你自己的数字生活简单化为一个你所控制的地方呢? [Cozy][4] 就是一个朝着健壮的自主云平台方向发展的项目。你可以从 [GitHub][5] 上获取 Cozy 的源代码,它采用 AGPL 3.0 协议。
|
||||
|
||||
### 安装
|
||||
|
||||
安装 Cozy 非常快捷简单,这里有多种平台的 [简单易懂安装指令][6]。在我的测试中,我使用 64 位的 Debian 8 系统。安装需要几分钟时间,然后你只需要到服务器的 IP 地址注册一个账号,就会加载并准备好默认的应用程序集。
|
||||
|
||||
要注意的一点 - 安装假设没有正在运行任何其它 Web 服务,而且它会尝试安装 [Nginx web 服务器][7]。如果你的服务器已经有网站正在运行,配置可能就比较麻烦。我是在一个全新的 VPS(Virtual Private Server,虚拟个人服务器)上安装,因此比较简单。运行安装程序、启动 Nginx,然后你就可以访问云了。
|
||||
|
||||
Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序。有一些看起来非常有趣,例如 [Ghost 博客平台][9] 以及开源维基 [TiddlyWiki][10]。其中的目标,显然是允许把其它很多好的应用程序集成到这个平台。我认为你要看到很多其它流行的开源应用程序提供集成功能只是时间问题。此刻,已经支持 [Node.js][11],但是如何也支持其它应用层,你就可以看到很多其它很好的应用程序。
|
||||
|
||||
其中可能的一个功能是从安卓设备中使用免费的安卓应用程序访问你的信息。当前还没有 iOS 应用,但有计划要解决这个问题。
|
||||
|
||||
现在,Cozy 已经有很多核心的应用程序。
|
||||
|
||||

|
||||
|
||||
主要 Cozy 界面
|
||||
|
||||
### 文件
|
||||
|
||||
和很多分支一样,我使用 [Dropbox][12] 进行文件存储。事实上,由于我有很多东西需要存储,我需要花钱买 DropBox Pro。对我来说,如果它有我想要的功能,那么把我的文件移动到 Cozy 能为我节省很多开销。
|
||||
|
||||
我希望我能说这是真的,我确实做到了。我被 Cozy 应用程序内建的基于 web 的文件上传和文件管理工具所惊讶。拖拽功能正如你期望的那样,界面也很干净整洁。我在上传事例文件和目录、随处跳转、移动、删除以及重命名文件时都没有遇到问题。
|
||||
|
||||
如果你想要的就是基于 web 的云文件存储,那么你做到了。对我来说,它缺失的是 DropBox 具有的选择性文件目录同步功能。在 DropBox 中,如果你拖拽一个文件到目录中,它就会被拷贝到云,几分钟后该文件在你所有同步设备中都可以看到。实际上,[Cozy 正在研发该功能][13],但此时它还处于 beta 版,而且只支持 Linux 客户端。另外,我有一个称为 [Download to Dropbox][15] 的 [Chrome][14] 扩展,我时不时用它抓取图片和其它内容,但当前 Cozy 中还没有类似的工具。
|
||||
|
||||

|
||||
|
||||
文件管理界面
|
||||
|
||||
### 从 Google 导入数据
|
||||
|
||||
如果你正在使用 Google 日历和联系人,使用 Cozy 安装的应用程序很轻易的就可以导入它们。当你授权访问 Google 时,会给你一个 API 密钥,把它粘贴到 Cozy,它就会迅速高效地进行复制。两种情况下,内容都会被打上“从 Google 导入”的标签。对于我混乱的联系人,这可能是件好事情,因为它使得我有机会重新整理,把它们重新标记为更有意义的类别。“Google Calendar” 中所有的事件都导入了,但是我注意到其中一些事件的时间不对,可能是由于两端时区设置的影响。
|
||||
|
||||
### 联系人
|
||||
|
||||
联系人正如你期望的那样,界面也很像 Google 联系人。尽管如此,还是有一些不好的地方。和你(例如)智能手机的同步通过 [CardDAV][16] 完成,这是用于共享联系人数据的标准协议,但安卓手机并不原生支持该技术。为了把你的联系人同步到安卓设备,你需要在你的手机上安装一个应用。这对我来说是个很大的打击,因为我已经有很多类似这样的旧应用程序了(例如 work mail、Gmail以及其它 mail,我的天),我并不想安装一个不能和我智能手机原生联系人应用程序同步的软件。如果你正在使用 iPhone,你直接就能使用 CradDAV。
|
||||
|
||||
### 日历
|
||||
|
||||
对于日历用户来说好消息就是安卓设备支持这种类型数据的交换格式 [CalDAV][17]。正如我导入数据时提到的,我的一些日历时间的时间不对。在这之前我在和其它日历系统进行迁移时也遇到过这个问题,因此这对我并没有产生太大困扰。界面允许你创建和管理多个日历,就像 Google 那样,但是你不能订阅这个 Cozy 实例之外的其它日历。该应用程序另一个怪异的地方就是它的一周从周一开始,而且你不能更改。通常来说,我从周日开始我的一周,因此能更改从周一开始的功能对我来说非常有用。设置对话框并没有任何设置;它只是告诉你如何通过 CalDAV 连接的指令。再次说明,这个应用程序接近我想要的,但 Cozy 做的还不够好。
|
||||
|
||||
### 照片
|
||||
|
||||
照片应用让我印象深刻,它从文件应用程序借鉴了很多东西。你甚至可以把一个其它应用程序的照片文件添加到相册,或者直接通过拖拽上传。不幸的是,一旦上传后,我没有找到任何重拍和编辑照片的方法。你只能把它们从相册中删除。应用有一个通过令牌链接进行分享的工具,而且你可以指定一个或多个联系人。系统会给这些联系人发送邀请他们查看相册的电子邮件。当然还有很多比这个有更丰富功能的相册应用,但在 Cozy 平台中这算是一个好的起点。
|
||||
|
||||

|
||||
|
||||
Photos 界面
|
||||
|
||||
### 总结
|
||||
|
||||
Cozy 目标远大。他们尝试搭建你能部署任意你想要的基于云的服务的平台。它已经到了黄金时段吗?我并不认为。对于一些重度用户来说我之前提到的一些问题很严重,而且还没有 iOS 应用,这可能阻碍用户使用它。不管怎样,继续关注吧 - 随着研发的继续,Cozy 有一家代替很多应用程序的潜能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
D Ruth Bavousett - D Ruth Bavousett 作为系统管理员和软件开发者已经很长时间了,长期以来她都专注于 a VAX 11/780。(到目前为止)她花了很多时间服务于图书馆的技术需求,她从 2008 年就开始成为 Koha 开源图书馆自动化套件的贡献者。 Ruth 现在是 Houston cPanel 公司的 Perl 开发人员,同时还是两个孩子的母亲。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/cozy-personal-cloud
|
||||
|
||||
作者:[D Ruth Bavousett][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/druthb
|
||||
[1]:https://opensource.com/article/17/2/cozy-personal-cloud?rate=FEMc3av4LgYK-jeEscdiqPhSgHZkYNsNCINhOoVR9N8
|
||||
[2]:https://pixabay.com/en/tree-field-cornfield-nature-247122/
|
||||
[3]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[4]:https://cozy.io/
|
||||
[5]:https://github.com/cozy/cozy
|
||||
[6]:https://docs.cozy.io/en/host/install/
|
||||
[7]:https://www.nginx.com/
|
||||
[8]:https://cozy.io/en/apps/
|
||||
[9]:https://ghost.org/
|
||||
[10]:http://tiddlywiki.com/
|
||||
[11]:http://nodejs.org/
|
||||
[12]:https://www.dropbox.com/
|
||||
[13]:https://github.com/cozy-labs/cozy-desktop
|
||||
[14]:https://www.google.com/chrome/
|
||||
[15]:https://github.com/pwnall/dropship-chrome
|
||||
[16]:https://en.wikipedia.org/wiki/CardDAV
|
||||
[17]:https://en.wikipedia.org/wiki/CalDAV
|
||||
[18]:https://opensource.com/user/36051/feed
|
||||
[19]:https://opensource.com/article/17/2/cozy-personal-cloud#comments
|
||||
[20]:https://opensource.com/users/druthb
|
||||
@ -0,0 +1,296 @@
|
||||
在 Linux 如何用 ‘bash-support’ 插件将 Vim 编辑器打造成一个 Bash-IDE
|
||||
============================================================
|
||||
|
||||
IDE([集成开发环境][1])就是一个软件,它为了最大化程序员生产效率,提供了很多编程所需的设施和组件。 IDE 将所有开发集中到一个程序中,使得程序员可以编写、修改、编译、部署以及调试程序。
|
||||
|
||||
在这篇文章中,我们会介绍如何通过使用 bash-support vim 插件将[Vim 编辑器安装和配置][2] 为一个 Bash-IDE。
|
||||
|
||||
#### 什么是 bash-support.vim 插件?
|
||||
|
||||
bash-support 是一个高度定制化的 vim 插件,它允许你插入:文件头、补全语句、注释、函数、以及代码块。它也使你可以进行语法检查、使脚本可执行、通过一次按键启动调试器;完成所有的这些而不需要关闭编辑器。
|
||||
|
||||
它使用快捷键(映射),通过有组织、一致的文件内容编写/插入,使得 bash 脚本变得有趣和愉快。
|
||||
|
||||
插件当前版本是 4.3,版本 4.0 重写了版本 3.12.1,4.0 及之后的版本基于一个全新的、更强大的、和之前版本模板语法不同的模板系统。
|
||||
|
||||
### 如何在 Linux 中安装 Bash-support 插件
|
||||
|
||||
用下面的命令下载最新版本的 bash-support 插件:
|
||||
|
||||
```
|
||||
$ cd Downloads
|
||||
$ curl http://www.vim.org/scripts/download_script.php?src_id=24452 >bash-support.zip
|
||||
```
|
||||
|
||||
按照如下步骤安装;在你的主目录创建 `.vim` 目录(如果它不存在的话),进入该目录并提取 bash-support.zip 内容:
|
||||
|
||||
```
|
||||
$ mkdir ~/.vim
|
||||
$ cd .vim
|
||||
$ unzip ~/Downloads/bash-support.zip
|
||||
```
|
||||
|
||||
下一步,在 `.vimrc` 文件中激活它:
|
||||
|
||||
```
|
||||
$ vi ~/.vimrc
|
||||
```
|
||||
|
||||
通过插入下面一行:
|
||||
|
||||
```
|
||||
filetype plug-in on
|
||||
set number #optionally add this to show line numbers in vim
|
||||
```
|
||||
|
||||
### 如何在 Vim 编辑器中使用 Bash-support 插件
|
||||
|
||||
为了简化使用,通常使用的结构和特定操作可以分别通过键映射插入/执行。 ~/.vim/doc/bashsupport.txt 和 ~/.vim/bash-support/doc/bash-hotkeys.pdf 或者 ~/.vim/bash-support/doc/bash-hotkeys.tex 文件中介绍了映射。
|
||||
|
||||
##### 重要:
|
||||
|
||||
1. 所有映射(`(\)+charater(s)` 组合)都是针对特定文件类型的:为了避免和其它插件的映射冲突,它们只适用于 ‘sh’ 文件。
|
||||
2. 使用键映射的时候打字速度也有关系,引导符 `('\')` 和后面字符的组合要在特定短时间内才能识别出来(很可能少于 3 秒 - 基于假设)。
|
||||
|
||||
下面我们会介绍和学习使用这个插件一些显著的功能:
|
||||
|
||||
#### 如何为新脚本自动生成文件头
|
||||
|
||||
看下面的事例文件头,为了要在你所有的新脚本中自动创建该文件头,请按照以下步骤操作。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
脚本事例文件头选项
|
||||
|
||||
首先设置你的个人信息(作者名称、作者参考、组织、公司等)。在一个 Bash 缓冲区(像下面这样打开一个测试脚本)中使用映射 `\ntw` 启动模板设置向导。
|
||||
|
||||
选中选项(1)设置个性化文件,然后按回车键。
|
||||
|
||||
```
|
||||
$ vi test.sh
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
在脚本文件中设置个性化信息
|
||||
|
||||
之后,再次输入回车键。然后再一次选中选项(1)设置个性化文件的路径并输入回车。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
设置个性化文件路径
|
||||
|
||||
设置向导会把目标文件 .vim/bash-support/rc/personal.templates 拷贝到 .vim/templates/personal.templates,打开并编辑它,在这里你可以输入你的信息。
|
||||
|
||||
按 `i` 键像截图那样在一个单引号中插入合适的值。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
在脚本文件头添加信息
|
||||
|
||||
一旦你设置了正确的值,输入 `:wq` 保存并退出文件。关闭 Bash 测试脚本,打开另一个脚本来测试新的配置。现在文件头中应该有和下面截图类似的你的个人信息:
|
||||
|
||||
```
|
||||
$ test2.sh
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
自动添加文件头到脚本
|
||||
|
||||
#### 使 Bash-support 插件帮助信息可访问
|
||||
|
||||
为此,在 Vim 命令行输入下面的命令并按回车键,它会创建 .vim/doc/tags 文件:
|
||||
|
||||
```
|
||||
:helptags $HOME/.vim/doc/
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
在 Vi 编辑器添加插件帮助
|
||||
|
||||
#### 如何在 Shell 脚本中插入注释
|
||||
|
||||
要插入一个块注释,在普通模式下输入 `\cfr`:
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
添加注释到脚本
|
||||
|
||||
#### 如何在 Shell 脚本中插入语句
|
||||
|
||||
下面是一些用于插入语句的键映射(`n` – 普通模式, `i` – 插入模式):
|
||||
|
||||
1. `\sc` – case in … esac (n, I)
|
||||
2. `\sei` – elif then (n, I)
|
||||
3. `\sf` – for in do done (n, i, v)
|
||||
4. `\sfo` – for ((…)) do done (n, i, v)
|
||||
5. `\si` – if then fi (n, i, v)
|
||||
6. `\sie` – if then else fi (n, i, v)
|
||||
7. `\ss` – select in do done (n, i, v)
|
||||
8. `\su` – until do done (n, i, v)
|
||||
9. `\sw` – while do done (n, i, v)
|
||||
10. `\sfu` – function (n, i, v)
|
||||
11. `\se` – echo -e “…” (n, i, v)
|
||||
12. `\sp` – printf “…” (n, i, v)
|
||||
13. `\sa` – 数组元素, ${.[.]} (n, i, v) 和其它更多的数组功能。
|
||||
|
||||
#### 插入一个函数和函数头
|
||||
|
||||
输入 `\sfu` 添加一个新的空函数,然后添加函数名并按回车键创建它。之后,添加你的函数代码。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
在脚本中插入新函数
|
||||
|
||||
为了给上面的函数创建函数头,输入 `\cfu`,输入函数名称,按回车键并填入合适的值(名称、介绍、参数、返回值):
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
在脚本中创建函数头
|
||||
|
||||
#### 更多关于添加 Bash 语句的例子
|
||||
|
||||
下面是一个使用 `\si` 插入一条 if 语句的例子:
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
在脚本中插入语句
|
||||
|
||||
下面的例子显示使用 `\se` 添加一条 echo 语句:
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
在脚本中添加 echo 语句
|
||||
|
||||
#### 如何在 Vi 编辑器中使用运行操作
|
||||
|
||||
下面是一些运行操作键映射的列表:
|
||||
|
||||
1. `\rr` – 更新文件,运行脚本 (n, I)
|
||||
2. `\ra` – 设置脚本命令行参数 (n, I)
|
||||
3. `\rc` – 更新文件,检查语法 (n, I)
|
||||
4. `\rco` – 语法检查选项 (n, I)
|
||||
5. `\rd` – 启动调试器 (n, I)
|
||||
6. `\re` – 使脚本可/不可执行(*) (in)
|
||||
|
||||
#### 使脚本可执行
|
||||
|
||||
编写完脚本后,保存它然后输入 `\re` 和回车键使它可执行。
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
使脚本可执行
|
||||
|
||||
#### 如何在 Bash 脚本中使用预定义代码片段
|
||||
|
||||
预定义代码片段是为了特定目的包含了已写好代码的文件。为了添加代码段,输入 `\nr` 和 `\nw` 读/写预定义代码段。输入下面的命令列出默认的代码段:
|
||||
|
||||
```
|
||||
$ .vim/bash-support/codesnippets/
|
||||
```
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
代码段列表
|
||||
|
||||
为了使用代码段,例如 free-software-comment,输入 `\nr` 并使用自动补全功能选择它的名称,然后输入回车键:
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
添加代码段到脚本
|
||||
|
||||
#### 创建自定义预定义代码段
|
||||
|
||||
可以在 ~/.vim/bash-support/codesnippets/ 目录下编写你自己的代码段。另外,你还可以从你正常的脚本代码中创建你自己的代码段:
|
||||
|
||||
1. 选择你想作为代码段的部分代码,然后输入 `\nw` 并给它一个相近的文件名。
|
||||
2. 要读入它,只需要输入 `\nr` 然后使用文件名就可以添加你自定义的代码段。
|
||||
|
||||
#### 在当前光标处查看内建和命令帮助
|
||||
|
||||
要显示帮助,在普通模式下输入:
|
||||
|
||||
1. `\hh` – 内建帮助
|
||||
2. `\hm` – 命令帮助
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
查看内建命令帮助
|
||||
|
||||
更多参考资料,可以查看文件:
|
||||
|
||||
```
|
||||
~/.vim/doc/bashsupport.txt #copy of online documentation
|
||||
~/.vim/doc/tags
|
||||
```
|
||||
|
||||
访问 Bash-support 插件 GitHub 仓库:[https://github.com/WolfgangMehner/bash-support][18]
|
||||
在 Vim 网站访问 Bash-support 插件:[http://www.vim.org/scripts/script.php?script_id=365][19]
|
||||
|
||||
就是这些啦,在这篇文章中,我们介绍了在 Linux 中使用 Bash-support 插件安装和配置 Vim 为一个 Bash-IDE 的步骤。快去发现这个插件其它令人兴奋的功能吧,一定要在评论中和我们分享哦。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者、Linux 系统管理员、网络开发人员,现在也是 TecMint 的内容创作者,她喜欢和电脑一起工作,坚信共享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/best-linux-ide-editors-source-code-editors/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/02/Script-Header-Options.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Personalization-in-Scripts.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Personalization-File-Location.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Info-in-Script-Header.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Auto-Adds-Header-to-Script.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Plugin-Help-in-Vi-Editor.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Comments-to-Scripts.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/02/Insert-New-Function-in-Script.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/02/Create-Header-Function-in-Script.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Insert-Statement-to-Script.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-echo-Statement-to-Script.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/02/make-script-executable.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/02/list-of-code-snippets.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Code-Snippet-to-Script.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/02/View-Built-in-Command-Help.png
|
||||
[18]:https://github.com/WolfgangMehner/bash-support
|
||||
[19]:http://www.vim.org/scripts/script.php?script_id=365
|
||||
@ -0,0 +1,234 @@
|
||||
如何在 CentOS 7 中使用 SSL/TLS 加固 FTP 服务器进行安全文件传输
|
||||
============================================================
|
||||
|
||||
在一开始的设计中,FTP(文件传输协议)是不安全的,意味着它不会加密两台机器之间传输的数据以及用户的凭据。这使得数据和服务器安全面临很大威胁。
|
||||
|
||||
在这篇文章中,我们会介绍在 CentOS/RHEL 7 以及 Fedora 中如何在 FTP 服务器中手动启用数据加密服务;我们会介绍使用 SSL/TLS 证书保护 VSFTPD(Very Secure FTP Daemon)服务的各个步骤。
|
||||
|
||||
#### 前提条件:
|
||||
|
||||
1. 你必须已经[在 CentOS 7 中安装和配置 FTP 服务][1]
|
||||
|
||||
在我们开始之前,要注意本文中所有命令都以 root 用户运行,否则,如果现在你不是使用 root 用户控制服务器,你可以使用 [sudo 命令][2] 去获取 root 权限。
|
||||
|
||||
### 第一步:生成 SSL/TLS 证书和密钥
|
||||
|
||||
1. 我们首先要在 `/etc/ssl` 目录下创建用于保存 SSL/TLS 证书和密钥文件的子目录:
|
||||
|
||||
```
|
||||
# mkdir /etc/ssl/private
|
||||
```
|
||||
|
||||
2. 然后运行下面的命令为 vsftpd 创建证书和密钥并保存到一个文件中,下面会解析使用的每个标签。
|
||||
|
||||
1. req - 是 X.509 Certificate Signing Request (CSR,证书签名请求)管理的一个命令。
|
||||
2. x509 - X.509 证书数据管理。
|
||||
3. days - 定义证书的有效日期。
|
||||
4. newkey - 指定证书密钥处理器。
|
||||
5. rsa:2048 - RSA 密钥处理器,会生成一个 2048 位的密钥。
|
||||
6. keyout - 设置密钥存储文件。
|
||||
7. out - 设置证书存储文件,注意证书和密钥都保存在一个相同的文件:/etc/ssl/private/vsftpd.pem。
|
||||
|
||||
```
|
||||
# openssl req -x509 -nodes -keyout /etc/ssl/private/vsftpd.pem -out /etc/ssl/private/vsftpd.pem -days 365 -newkey rsa:2048
|
||||
```
|
||||
|
||||
上面的命令会让你回答以下的问题,记住使用你自己情况的值。
|
||||
|
||||
```
|
||||
Country Name (2 letter code) [XX]:IN
|
||||
State or Province Name (full name) []:Lower Parel
|
||||
Locality Name (eg, city) [Default City]:Mumbai
|
||||
Organization Name (eg, company) [Default Company Ltd]:TecMint.com
|
||||
Organizational Unit Name (eg, section) []:Linux and Open Source
|
||||
Common Name (eg, your name or your server's hostname) []:tecmint
|
||||
Email Address []:admin@tecmint.com
|
||||
```
|
||||
|
||||
### 第二步:配置 VSFTPD 使用 SSL/TLS
|
||||
|
||||
3. 在我们进行任何 VSFTPD 配置之前,首先开放 990 和 40000-50000 端口,以便在 VSFTPD 配置文件中分别定义 TLS 连接的端口和被动端口的端口范围:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=public --permanent --add-port=990/tcp
|
||||
# firewall-cmd --zone=public --permanent --add-port=40000-50000/tcp
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
4. 现在,打开 VSFTPD 配置文件并在文件中指定 SSL 的详细信息:
|
||||
|
||||
```
|
||||
# vi /etc/vsftpd/vsftpd.conf
|
||||
```
|
||||
|
||||
找到 `ssl_enable` 选项把它的值设置为 `YES` 激活使用 SSL,另外,由于 TSL 比 SSL 更安全,我们会使用 `ssl_tlsv1_2` 选项让 VSFTPD 使用更严格的 TLS:
|
||||
|
||||
```
|
||||
ssl_enable=YES
|
||||
ssl_tlsv1_2=YES
|
||||
ssl_sslv2=NO
|
||||
ssl_sslv3=NO
|
||||
```
|
||||
|
||||
5. 然后,添加下面的行定义 SSL 证书和密钥文件的位置:
|
||||
|
||||
```
|
||||
rsa_cert_file=/etc/ssl/private/vsftpd.pem
|
||||
rsa_private_key_file=/etc/ssl/private/vsftpd.pem
|
||||
```
|
||||
|
||||
6. 下面,我们要阻止匿名用户使用 SSL,然后强制所有非匿名用户登录使用安全的 SSL 连接进行数据传输和登录过程中的密码发送:
|
||||
|
||||
```
|
||||
allow_anon_ssl=NO
|
||||
force_local_data_ssl=YES
|
||||
force_local_logins_ssl=YES
|
||||
```
|
||||
|
||||
7. 另外,我们还可以添加下面的选项增强 FTP 服务器的安全性。当选项 `require_ssl_reuse` 被设置为 `YES` 时,要求所有 SSL 数据连接都显示 SSL 会话重用;表明它们知道与控制频道相同的主机密码。
|
||||
|
||||
因此,我们需要把它关闭。
|
||||
|
||||
```
|
||||
require_ssl_reuse=NO
|
||||
```
|
||||
|
||||
另外,我们还要用 `ssl_ciphers` 选项选择 VSFTPD 允许用于加密 SSL 连接的 SSL 密码。这可以大大限制尝试使用在漏洞中发现的特定密码的攻击者:
|
||||
|
||||
```
|
||||
ssl_ciphers=HIGH
|
||||
```
|
||||
|
||||
8. 现在,设置被动端口的端口范围(最小和最大端口)。
|
||||
```
|
||||
pasv_min_port=40000
|
||||
pasv_max_port=50000
|
||||
```
|
||||
|
||||
9. 选择性启用 `debug_ssl` 选项以允许 SSL 调试,意味着 OpenSSL 连接诊断会被记录到 VSFTPD 日志文件:
|
||||
|
||||
```
|
||||
debug_ssl=YES
|
||||
```
|
||||
|
||||
保存所有更改并关闭文件。然后让我们重启 VSFTPD 服务:
|
||||
|
||||
```
|
||||
# systemctl restart vsftpd
|
||||
```
|
||||
|
||||
### 第三步:用 SSL/TLS 连接测试 FTP 服务器
|
||||
|
||||
10. 完成上面的所有配置之后,像下面这样通过在命令行中尝试使用 FTP 测试 VSFTPD 是否使用 SSL/TLS 连接:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.10
|
||||
Connected to 192.168.56.10 (192.168.56.10).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.10:root) : ravi
|
||||
530 Non-anonymous sessions must use encryption.
|
||||
Login failed.
|
||||
421 Service not available, remote server has closed connection
|
||||
ftp>
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
验证 FTP SSL 安全连接
|
||||
|
||||
从上面的截图中,我们可以看到这里有个错误提示我们 VSFTPD 只允许用户从支持加密服务的客户端登录。
|
||||
|
||||
命令行并不会提供加密服务因此产生了这个错误。因此,为了安全地连接到服务器,我们需要一个支持 SSL/TLS 连接的 FTP 客户端,例如 FileZilla。
|
||||
|
||||
### 第四步:安装 FileZilla 以便安全地连接到 FTP 服务器
|
||||
|
||||
11. FileZilla 是一个时尚、流行且重要的交叉平台 FTP 客户端,它默认支持 SSL/TLS 连接。
|
||||
|
||||
要在 Linux 上安装 FileZilla,可以运行下面的命令:
|
||||
|
||||
```
|
||||
--------- On CentOS/RHEL/Fedora ---------
|
||||
# yum install epel-release filezilla
|
||||
--------- On Debian/Ubuntu ---------
|
||||
$ sudo apt-get install filezilla
|
||||
```
|
||||
|
||||
12. 当安装完成后(或者你已经安装了该软件),打开它,选择 File=>Sites Manager 或者按 `Ctrl + S` 打开 Site Manager 界面。
|
||||
|
||||
点击 New Site 按钮添加一个新的站点/主机连接详细信息。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
在 FileZilla 中添加新 FTP 站点
|
||||
|
||||
13. 下一步,像下面这样设置主机/站点名称、添加 IP 地址、定义使用的协议、加密和登录类型(使用你自己情况的值):
|
||||
|
||||
```
|
||||
Host: 192.168.56.10
|
||||
Protocol: FTP – File Transfer Protocol
|
||||
Encryption: Require explicit FTP over #recommended
|
||||
Logon Type: Ask for password #recommended
|
||||
User: username
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
在 Filezilla 中添加 FTP 服务器详细信息
|
||||
|
||||
14. 然后点击 Connect,再次输入密码,然后验证用于 SSL/TLS 连接的证书,再一次点击 `OK` 连接到 FTP 服务器:
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
验证 FTP SSL 证书
|
||||
|
||||
到了这里,我们应该使用 TLS 连接成功地登录到了 FTP 服务器,在下面的界面中检查连接状态部分获取更多信息。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
通过 TLS/SSL 连接到 FTP 服务器
|
||||
|
||||
15. 最后,在文件目录尝试 [从本地传输文件到 FTP 服务器][8],看 FileZilla 界面后面的部分查看文件传输相关的报告。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
使用 FTP 安全地传输文件
|
||||
|
||||
就是这些。记住 FTP 默认是不安全的,除非我们像上面介绍的那样配置它使用 SSL/TLS 连接。在下面的评论框中和我们分享你关于这篇文章/主题的想法吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 的爱好者,Linux 系统管理员,网络开发员,目前也是 TecMint 的内容创作者,他喜欢和电脑一起工作,并且坚信共享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/secure-vsftpd-using-ssl-tls-on-centos/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/install-ftp-server-in-centos-7/
|
||||
[2]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/02/Verify-FTP-Secure-Connection.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-New-FTP-Site-in-Filezilla.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-FTP-Server-Details-in-Filezilla.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/Verify-FTP-SSL-Certificate.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/connected-to-ftp-server-with-tls.png
|
||||
[8]:http://www.tecmint.com/sftp-command-examples/
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/Transfer-Files-Securely-Using-FTP.png
|
||||
@ -1,84 +0,0 @@
|
||||
|
||||
什么是 Linux VPS Hosting?
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
如果你有一个吞吐量很大的网站,或者至少,你想要增加你的网站吞吐量,那么你可以考虑使用 [Linux VPS hosting][6] 包 。你可以把它安装在网站所在的服务器上,如果你想要控制除此之外的很多事情,那么 Linux VPS hosting 包就是最好的选择之一。这里我会回答一些频繁被提及的关于 Linux VPS hosting 的问题。
|
||||
|
||||
|
||||
### Linux VPS 意味着什么?
|
||||
事实上, Linux VPS 就像一个运行在 Linux 系统上的虚拟专属服务器 。虚拟专属服务器是一个在物理服务器上的虚拟服务主机 。这种虚拟专属服务器运行在物理主机的内存里。物理主机可以轮流运行很多其他的虚拟专属服务器 。
|
||||
|
||||
### 我必须和其他用户共享服务器吗?
|
||||
一般是这样的。但这并不意味着下载时间变长或者服务器性能降低。每个虚拟服务器可以运行它自己的操作系统,这些系统之间可以相互独立的进行管理。一个虚拟专属服务器有它自己的操作系统、数据、应用程序;它们都与物理主机和其他虚拟服务器中的操作系统、应用程序、数据相互分离。
|
||||
|
||||
尽管必须和其他虚拟专属服务器共享物理主机,但是你却可以不需花费大价钱得到一个昂贵专用服务器的诸多好处。
|
||||
|
||||
### Linux VPS hosting 的优势是什么?
|
||||
使用 Linux VPS hosting 服务会有很多的优势,包括容易使用、安全性增加以及在更低的总体成本上提高可用性。然而,对于大多数网站管理者、程序员、设计者和开发者来说,使用 Linux VPS hosting 服务的最大的优势是它的灵活性。每个虚拟专属务器都和它自己的操作环境相互隔离,这意味着你可以容易且安全的安装一个你喜欢的或者迫切需要的操作系统,每当你想要安装操作系统的时候,你可以很容易的卸载或者安装软件及应用程序。
|
||||
|
||||
|
||||
你也可以更改你的 VPS 环境以适应你的性能需求,同样也可以提高你的网站用户或访客的体验。灵活性会是你超越对手的主要优势。
|
||||
|
||||
记住,一些 Linux VPS 提供商可能不会给你 root 权限。这样你的服务器性能就会受到限制。要确定你得到的是 [拥有 root 权限的 Linux VPS][7] ,这样你就可以做任何你想做的修改。
|
||||
|
||||
|
||||
### 任何人都可以使用 Linux VPS hosting 吗?
|
||||
当然,你甚至可以运行一个专门的个人兴趣博客,你可以从 Linux VPS hosting 包中受益。如果你为公司搭建开发一个网站,你也会获益匪浅。基本上,如果你想使你的网站更健壮并且增加它的网络吞吐量,那么 Linux VPS 就是为你而生。
|
||||
|
||||
|
||||
个人和企业在进行定制开发的时候都需要很大的灵活行,所以他们肯定会选择 Linux VPS ; 特别是那些正在寻找不使用专用服务器就能得到高性能服务的人们,专用服务器会消耗大量的网站运营成本。
|
||||
|
||||
|
||||
### 不会使用 Linux 也可以使用 Linux VPS 吗?
|
||||
当然,如果 Linux VPS 由你管理,你的 VPS 提供商会为你管理整个服务器。更有可能,他们将会为你安装、配置一切你想要运行在 Linux VPS 上的服务。如果你使用我们的 VPS,我们会全天候的为你看管 7 天,也会安装、配置 、优化一切服务。这些免费的服务都被包括在所有的我们的 [Linux VPS hosting 管理器][8] 包里。
|
||||
|
||||
如果你使用我们的主机服务,你会从 Linux VPS 中获益匪浅,并且不需要任何 Linux 工作经验。
|
||||
|
||||
另一个方面,对于使用 Linux VPS 的新手来说,得到一个 [带有控制面板的 VPS][9]、 [DirectAdmin][10] 或者任何 [其他的主机控制面板][11] 都是很容易的。如果你使用控制面板,就可以通过一个 GUI 管理你的服务器,尤其对于新手,它是很容易使用的。[使用命令行管理 Linux VPS][12] 很有趣,而且你还可以在实践中学到很多。
|
||||
|
||||
### Linux VPS 和专用服务器有什么不同?
|
||||
如前所述,一个虚拟专属服务器仅仅是在物理主机上的一个虚拟分区。物理服务器与很多虚拟服务器相互分离,这些虚拟服务器可以降低多个虚拟分区用户的网站维护成本和开销。这就是 Linux VPS 相比一个 [专用服务器][13] 更加便宜的原因,专用服务器的字面意思就是指只有一个用户专用。想要知道关于更多不同点的细节,可以查看 [物理服务器(专用的)vs 虚拟服务器(VPS) 比较][14]。
|
||||
|
||||
除了比专用服务器有更好的成本效益,Linux 虚拟专属服务器经常运行在主机上,所以它比专用服务器的性能更强大,同时它的容量也比专用服务器更大。
|
||||
|
||||
### 我可以把网站从共享主机环境迁移到到 Linux VPS 上吗?
|
||||
如果你当前使用 [共享主机服务][15],你可以很容易的迁移到 Linux VPS 上。一种做法就是 [让它自己完成迁移][16],但是迁移过程很复杂,不建议新手使用。最好的方法是找到一个提供 [免费网站迁移][17] 的主机,然后让它们帮你完成迁移。你还可以从一个带有控制面板的共享主机迁移到一个不带有控制面板的 Linux VPS 。
|
||||
|
||||
### 更多问题?
|
||||
随时在下面留下评论。
|
||||
如果你使用我们提供的 VPS,我们的 Linux 管理专家会帮助你完成需要在你的 Linux VPS 上的一切工作,并且会回答你的一切关于使用 Linux VPS 的问题。我们的管理员会一周全天候在线及时解决你的问题。
|
||||
|
||||
PS. 如果你喜欢这个专栏,请使用下面的按钮把它分享给你的网友,或者你也可以在下面的评论区写下你的答复。谢谢。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||
|
||||
作者:[https://www.rosehosting.com ][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||
[1]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||
[2]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/#comments
|
||||
[3]:https://www.rosehosting.com/blog/category/guides/
|
||||
[4]:https://plus.google.com/share?url=https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||
[5]:http://www.linkedin.com/shareArticle?mini=true&url=https://www.rosehosting.com/blog/what-is-linux-vps-hosting/&title=What%20is%20Linux%20VPS%20Hosting%3F&summary=If%20you%20have%20a%20site%20that%20gets%20a%20lot%20of%20traffic,%20or%20at%20least,%20is%20expected%20to%20generate%20a%20lot%20of%20traffic,%20then%20you%20might%20want%20to%20consider%20getting%20a%20Linux%20VPS%20hosting%20package.%20A%20Linux%20VPS%20hosting%20package%20is%20also%20one%20of%20your%20best%20options%20if%20you%20want%20more%20...
|
||||
[6]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
[7]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
[8]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
[9]:https://www.rosehosting.com/cpanel-hosting.html
|
||||
[10]:https://www.rosehosting.com/directadmin-hosting.html
|
||||
[11]:https://www.rosehosting.com/control-panel-hosting.html
|
||||
[12]:https://www.rosehosting.com/blog/basic-shell-commands-after-putty-ssh-logon/
|
||||
[13]:https://www.rosehosting.com/dedicated-servers.html
|
||||
[14]:https://www.rosehosting.com/blog/physical-server-vs-virtual-server-all-you-need-to-know/
|
||||
[15]:https://www.rosehosting.com/linux-shared-hosting.html
|
||||
[16]:https://www.rosehosting.com/blog/from-shared-to-vps-hosting/
|
||||
[17]:https://www.rosehosting.com/website-migration.html
|
||||
@ -38,7 +38,6 @@
|
||||
### 迁移
|
||||
|
||||
变更我们用户的内容堆栈以兼容 CommonMark 规范,并不同于转换我们用来解析 Markdown 的库那样容易:目前我们在遇到最根本的障碍就是由于一些不常用语法 (LCTT 译注:原文是 the Corner,作为名词的原意为角落、偏僻处、窘境,这应该是指那些不常用语法),CommonMark 规范 (以及有歧义的 Markdown 原文) 可能会以一种意想不到的方式来渲染一些老旧的 Markdown 内容。
|
||||
the fundamental roadblock we encountered here is that the corner cases that CommonMark specifies (and that the original Markdown documentation left ambiguous) could cause some old Markdown content to render in unexpected ways.
|
||||
|
||||
通过综合分析 GitHub 中大量的 Markdown 语料库,我们断定现存的用户内容只有不到 1% 会受到新版本实现的影响:我们是通过同时使用新 (`cmark`,兼容 CommonMark 规范) 旧 (Sundown) 版本的库来渲染大量的 Markdown 文档、标准化 HTML 结果、分析它们的不同点,最后才得到这一个数据的。
|
||||
|
||||
@ -56,11 +55,11 @@ the fundamental roadblock we encountered here is that the corner cases that Comm
|
||||
|
||||
除了转换之外,这还是一个高效的标准化过程,并且我们对此信心满满,毕竟完成这一任务的是我们在五年前就使用过的解析器。因此,所有的现存文档在保留其原始语意的情况下都能够进行明确的解析。
|
||||
|
||||
一旦升级 Sundown 来标准化输入文档并充分测试之后,我们就会做好开启转换进程的准备。最开始的一步,就是在新的 `cmark` 实现上为所有的用户内容进行反置转换,以便确保我们能有一个有限的分界点来进行过渡。我们将为网站上这几个月内所有 **新的** 用户评论启用 CommonMark,这一过程不会引起任何人注意的 —— 他们这是一个关于 CommonMark 团队出色工作的圣约,通过一个最具现实世界用法的方式来正式规范 Markdown 语言。
|
||||
一旦升级 Sundown 来标准化输入文档并充分测试之后,我们就会做好开启转换进程的准备。最开始的一步,就是在新的 `cmark` 实现上为所有新用户内容进行反置转换,以便确保我们能有一个有限的分界点来进行过渡。实际上,几个月前我们就为网站上所有 **新的** 用户评论启用了 CommonMark,这一过程几乎没有引起任何人注意 —— 这是关于 CommonMark 团队出色工作的证明,通过一个最具现实世界用法的方式来正式规范 Markdown 语言。
|
||||
|
||||
在后端,我们开启 MySQL 转换来升级替代用户的 Markdown 内容。在所有的评论进行标准化之后,在将其写回到数据库之前,我们将使用新实现来进行渲染并与旧实现的渲染结果进行对比,以确保 HTML 输出结果视觉可鉴以及用户数据在任何情况下都不被破坏。总而言之,只有不到 1% 的输入文档会受到表彰进程的修改,这符合我们的的期望,同时再次证明 CommonMark 规范能够呈现语言的真实用法。
|
||||
在后端,我们开启 MySQL 转换来升级替代所有 Markdown 用户内容。在所有的评论进行标准化之后,在将其写回到数据库之前,我们将使用新实现来进行渲染并与旧实现的渲染结果进行对比,以确保 HTML 输出结果视觉上感觉相同,并且用户数据在任何情况下都不会被破坏。总而言之,只有不到 1% 的输入文档会受到标准进程的修改,这符合我们的的期望,同时再次证明 CommonMark 规范能够呈现语言的真实用法。
|
||||
|
||||
整个过程会持续好几天,最后的结果是网站上所有的 Markdown 用户内容会得到全面升级以符合新的 Markdown 标准,同时确保所有的最终渲染输出效果都对用户视觉可辩。
|
||||
整个过程会持续好几天,最后的结果是网站上所有的 Markdown 用户内容会得到全面升级以符合新的 Markdown 标准,同时确保所有的最终渲染输出效果对用户视觉上感觉相同。
|
||||
|
||||
#### 结论
|
||||
|
||||
@ -68,11 +67,11 @@ the fundamental roadblock we encountered here is that the corner cases that Comm
|
||||
|
||||
能够让在 GitHub 上的所有 Markdown 内容符合一个动态变化且使用的标准,同时还可以为我的用户提供一个关于 GFM 如何进行解析和渲染 [清晰且权威的参考说明][19],我们是相当激动的。
|
||||
|
||||
我们还将致力于 CommonMark 规范,一直到在它正式发布之前消沉最后一个 bug。我们也希望 GitHub.com 在 1.0 规范发布之后可以进行完美兼容。
|
||||
我们还将致力于 CommonMark 规范,一直到在它正式发布之前消除最后一个 bug。我们也希望 GitHub.com 在 1.0 规范发布之后可以进行完美兼容。
|
||||
|
||||
作为结束,以下为想要学习 CommonMark 规范或则自己来编写实现的朋友提供一些有用的链接。
|
||||
|
||||
* [CommonMark 主页][1],可以了解该项目该多信息
|
||||
* [CommonMark 主页][1],可以了解本项目更多信息
|
||||
* [CommonMark 论坛讨论区][2],可以提出关于该规范的的问题和更改建议
|
||||
* [CommonMark 规范][3]
|
||||
* [使用 C 语言编写的参考实现][4]
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
Pyinotify - 在 Linux 中实时监控文件系统更改
|
||||
============================================================
|
||||
|
||||
Pyinotify 是一个简单而有用的 Python 模块,它可用于在 Linux 中实时[监控文件系统更改][1]。
|
||||
|
||||
作为一名系统管理员,你可以用它来监视你感兴趣的目录的更改,如 Web 目录或程序数据存储目录及其他目录。
|
||||
|
||||
**建议阅读:** [fswatch - 监控 Linux 中的文件和目录更改或修改][2]
|
||||
|
||||
它取决于 inotify(内核 2.6.13 中包含的 Linux 内核功能),它是一个事件驱动的通知程序,其通知通过三个系统调用从内核空间导出到用户空间。
|
||||
|
||||
pyinotiy 的目的是绑定这三个系统调用,并在其上提供了一个通用和抽象的方法来操作这些功能。
|
||||
|
||||
在本文中,我们将向你展示如何在 Linux 中安装并使用 pyinotify 来实时监控文件系统更改或修改。
|
||||
|
||||
#### 依赖
|
||||
|
||||
要使用 pyinotify,你的系统必须运行:
|
||||
|
||||
1. Linux kernel 2.6.13 或更高
|
||||
2. Python 2.4 或更高
|
||||
|
||||
### 如何在 Linux 中安装 Pyinotify
|
||||
|
||||
首先在系统中检查内核和 Python 的版本:
|
||||
|
||||
```
|
||||
# uname -r
|
||||
# python -V
|
||||
```
|
||||
|
||||
一旦依赖满足,我们会使用 pip 安装 pynotify。在大多数 Linux 发行版中,如果你使用的是 Python 2 >= 2.7.9 或者从 python.org 下载了 Python 3 >=3.4 的二进制,那么 pip 就已经安装了,否则,就按如下安装:
|
||||
|
||||
```
|
||||
# yum install python-pip [On CentOS based Distros]
|
||||
# apt-get install python-pip [On Debian based Distros]
|
||||
# dnf install python-pip [On Fedora 22+]
|
||||
```
|
||||
|
||||
现在安装 pyinotify:
|
||||
|
||||
```
|
||||
# pip install pyinotify
|
||||
```
|
||||
|
||||
它会从默认仓库安装可用的版本,如果你想要最新的稳定版,考虑按如下从 git 仓库 clone 下来:
|
||||
|
||||
```
|
||||
# git clone https://github.com/seb-m/pyinotify.git
|
||||
# cd pyinotify/
|
||||
# ls
|
||||
# python setup.py install
|
||||
```
|
||||
|
||||
### 如何在 Linux 中使用 pyinotify
|
||||
|
||||
在下面的例子中,我以 root 用户(通过 ssh 登录)监视了任何用户 tecmint 家目录(/home/tecmint)下的改变,如截图所示:
|
||||
|
||||
```
|
||||
# python -m pyinotify -v /home/tecmint
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
监视目录更改
|
||||
|
||||
接下来,我会观察到任何 web 目录 (/var/www/html/tecmint.com) 的更改:
|
||||
|
||||
```
|
||||
# python -m pyinotify -v /var/www/html/tecmint.com
|
||||
```
|
||||
|
||||
要退出程序,只要点击 `[Ctrl+C]`。
|
||||
|
||||
注意:当你在运行时没有指定要监视的目录是,`/tmp` 将作为默认目录。
|
||||
|
||||
在 Github 上了解更多 Pyinotify 信息:[https://github.com/seb-m/pyinotify][4]
|
||||
|
||||
就是这样了!在本文中,我们向你展示了如何安装及使用 pyinotify,一个有用的用于在 Linux 中监控文件系统更改的 Python 模块。
|
||||
|
||||
你有遇到类似的 Python 模块或者相关的[ Linux 工具/小程序][5]么?让我们在评论中了解,或许你也可以询问与这篇文章相关的问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux 系统管理员和网络开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/pyinotify-monitor-filesystem-directory-changes-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/fswatch-monitors-files-and-directory-changes-modifications-in-linux/
|
||||
[2]:http://www.tecmint.com/fswatch-monitors-files-and-directory-changes-modifications-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Monitor-Directory-File-Changes.png
|
||||
[4]:https://github.com/seb-m/pyinotify
|
||||
[5]:http://tecmint.com/tag/commandline-tools
|
||||
[6]:http://www.tecmint.com/author/aaronkili/
|
||||
[7]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[8]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
Loading…
Reference in New Issue
Block a user