mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
b808184cf7
@ -1,17 +1,21 @@
|
||||
怎样在桌面上安装 Docker CE?
|
||||
=====
|
||||
|
||||
[在上一篇文章中][1],我们学习了容器世界的一些基本术语。当我们运行命令并在后续文章中使用其中一些术语时,这些背景信息将会派上用场,包括这篇文章。本文将介绍在桌面 Linux, macOS 和 Windows 上安装 Docker,它适用于想要开始使用 Docker 容器的初学者。唯一的先决条件是你对命令行界面满意。
|
||||
> 按照这些简单的步骤在你的 Linux、Mac 或 Windows 桌面上安装 Docker CE。
|
||||
|
||||

|
||||
|
||||
[在上一篇文章中][1],我们学习了容器世界的一些基本术语。当我们运行命令并在后续文章中使用其中一些术语时,这些背景信息将会派上用场,包括这篇文章。本文将介绍在桌面 Linux、 macOS 和 Windows 上安装 Docker,它适用于想要开始使用 Docker 容器的初学者。唯一的先决条件是你对命令行界面满意。
|
||||
|
||||
### 为什么我在本地机器上需要 Docker CE?
|
||||
|
||||
作为一个新用户,你很可能想知道为什么你在本地系统上需要容器。难道它们不是作为微服务在云和服务器中运行吗?尽管容器长期以来一直是 Linux 世界的一部分,但 Docker 使它们真正可以使用它的工具和技术。(to 校正者:这句话它们意义似乎不明确)
|
||||
作为一个新用户,你很可能想知道为什么你在本地系统上需要容器。难道它们不是作为微服务在云和服务器中运行吗?尽管容器长期以来一直是 Linux 世界的一部分,但 Docker 才真正使容器的工具和技术步入使用。
|
||||
|
||||
Docker 容器最大的优点是可以使用本地机器进行开发和测试。你在本地系统上创建的容器映像可以在“任何位置”运行。就应用程序在开发系统上运行良好但生产环境中出现问题这一点,开发人员和操作人员之间不会起冲突。
|
||||
Docker 容器最大的优点是可以使用本地机器进行开发和测试。你在本地系统上创建的容器映像可以在“任何位置”运行。开发人员和操作人员之间不再会为应用程序在开发系统上运行良好但生产环境中出现问题而产生纷争。
|
||||
|
||||
关键是,为了创建容器化的应用程序,你必须能够在本地系统上运行和创建容器。
|
||||
而这个关键是,要创建容器化的应用程序,你必须能够在本地系统上运行和创建容器。
|
||||
|
||||
你可以使用以下三个平台中的任何一个 -- 桌面 Linux, Windows 或 macOS 作为容器的开发平台。一旦 Docker 在这些系统上成功运行,你将可以在不同的平台上使用相同的命令。因此,接下来你运行的操作系统无关紧要。
|
||||
你可以使用以下三个平台中的任何一个 —— 桌面 Linux、 Windows 或 macOS 作为容器的开发平台。一旦 Docker 在这些系统上成功运行,你将可以在不同的平台上使用相同的命令。因此,接下来你运行的操作系统无关紧要。
|
||||
|
||||
这就是 Docker 之美。
|
||||
|
||||
@ -21,149 +25,152 @@ Docker 容器最大的优点是可以使用本地机器进行开发和测试。
|
||||
|
||||
Docker CE 有两个版本:stable 和 edge。顾名思义,stable(稳定)版本会为你提供经过充分测试的季度更新,而 edge 版本每个月都会提供新的更新。经过进一步的测试之后,这些边缘特征将被添加到稳定版本中。我建议新用户使用 stable 版本。
|
||||
|
||||
Docker CE 支持 macOS, Windows 10, Ubuntu 14.04, 16.04, 17.04 和 17.10,以及 Debian 7.7, 8, 9 和 10, Fedora 25, 26, 27 和 centOS。虽然你可以下载 Docker CE 二进制文件并安装到桌面 Linux 上,但我建议添加仓库源以便继续获得修补程序和更新。
|
||||
Docker CE 支持 macOS、 Windows 10、 Ubuntu 14.04/16.04/17.04/17.10、 Debian 7.7/8/9/10、 Fedora 25/26/27 和 CentOS。虽然你可以下载 Docker CE 二进制文件并安装到桌面 Linux 上,但我建议添加仓库源以便继续获得修补程序和更新。
|
||||
|
||||
### 在桌面 Linux 上安装 Docker CE
|
||||
|
||||
你不需要一个完整的桌面 Linux 来运行 Docker,你也可以将它安装在最小的 Linux 服务器上,即你可以在一个虚拟机中运行。在本教程中,我将在我的主系统 Fedora 27 和 Ubuntu 17.04 上运行它(to 校正者:这句话搞不清主要是什么系统)。
|
||||
你不需要一个完整的桌面 Linux 来运行 Docker,你也可以将它安装在最小的 Linux 服务器上,即你可以在一个虚拟机中运行。在本教程中,我将在我的主系统的 Fedora 27 和 Ubuntu 17.04 上运行它。
|
||||
|
||||
### 在 Ubuntu 上安装
|
||||
|
||||
首先,运行系统更新,以便你的 Ubuntu 软件包完全更新:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
```
|
||||
|
||||
现在运行系统升级:
|
||||
|
||||
```
|
||||
$ sudo apt-get dist-upgrade
|
||||
|
||||
```
|
||||
|
||||
然后安装 Docker PGP 密钥:
|
||||
|
||||
```
|
||||
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
|
||||
|
||||
```
|
||||
```
|
||||
Update the repository info again:
|
||||
$ sudo apt-get update
|
||||
|
||||
```
|
||||
|
||||
现在安装 Docker CE:
|
||||
|
||||
```
|
||||
$ sudo apt-get install docker-ce
|
||||
|
||||
```
|
||||
|
||||
一旦安装,Docker CE 就会在基于 Ubuntu 的系统上自动运行,让我们来检查它是否在运行:
|
||||
一旦安装完成,Docker CE 就会在基于 Ubuntu 的系统上自动运行,让我们来检查它是否在运行:
|
||||
|
||||
```
|
||||
$ sudo systemctl status docker
|
||||
|
||||
```
|
||||
|
||||
你应该得到以下输出:
|
||||
|
||||
```
|
||||
docker.service - Docker Application Container Engine
|
||||
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Thu 2017-12-28 15:06:35 EST; 19min ago
|
||||
Docs: https://docs.docker.com
|
||||
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Thu 2017-12-28 15:06:35 EST; 19min ago
|
||||
Docs: https://docs.docker.com
|
||||
Main PID: 30539 (dockerd)
|
||||
|
||||
```
|
||||
|
||||
由于 Docker 安装在你的系统上,你现在可以使用 Docker CLI(命令行界面)运行 Docker 命令。像往常一样,我们运行 ‘Hello World’ 命令:
|
||||
|
||||
```
|
||||
$ sudo docker run hello-world
|
||||
|
||||
```
|
||||
|
||||
![YMChR_7xglpYBT91rtXnqQc6R1Hx9qMX_iO99vL8][2]
|
||||
|
||||
恭喜!在你的 Ubuntu 系统上正在运行着 Docker。
|
||||
|
||||
### 在 Fedora 上安装 Docker CE
|
||||
|
||||
Fedora 27 上的情况有些不同。在 Fedora 上,你首先需要安装 def-plugins-core 包,这将允许你从 CLI 管理你的 DNF 包。
|
||||
Fedora 27 上的情况有些不同。在 Fedora 上,你首先需要安装 `def-plugins-core` 包,这将允许你从 CLI 管理你的 DNF 包。
|
||||
|
||||
```
|
||||
$ sudo dnf -y install dnf-plugins-core
|
||||
|
||||
```
|
||||
|
||||
现在在你的系统上安装 Docker 仓库:
|
||||
|
||||
```
|
||||
$ sudo dnf config-manager \
|
||||
--add-repo \
|
||||
https://download.docker.com/linux/fedora/docker-ce.repo
|
||||
--add-repo \
|
||||
https://download.docker.com/linux/fedora/docker-ce.repo
|
||||
It’s time to install Docker CE:
|
||||
|
||||
$ sudo dnf install docker-ce
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
$ sudo dnf install docker-ce
|
||||
```
|
||||
与 Ubuntu 不同,Docker 不会在 Fedora 上自动启动。那么让我们启动它:
|
||||
|
||||
```
|
||||
$ sudo systemctl start docker
|
||||
|
||||
```
|
||||
|
||||
你必须在每次重新启动后手动启动 Docker,因此让我们将其配置为在重新启动后自动启动。$ systemctl enable docker 就行。现在该运行 Hello World 命令了:
|
||||
你必须在每次重新启动后手动启动 Docker,因此让我们将其配置为在重新启动后自动启动。`$ systemctl enable docker` 就行。现在该运行 Hello World 命令了:
|
||||
|
||||
```
|
||||
$ sudo docker run hello-world
|
||||
|
||||
```
|
||||
|
||||
恭喜,在你的 Fedora 27 系统上正在运行着 Docker。
|
||||
|
||||
### 解除 root
|
||||
|
||||
你可能已经注意到你必须使用 sudo 来运行 Docker 命令。这是因为 Docker 守护进程与 UNIX 套接字绑定,而不是 TCP 端口,套接字由 root 用户拥有。所以,你需要 sudo 权限才能运行 docker 命令。你可以将系统用户添加到 docker 组,这样它就不需要 sudo 了:
|
||||
你可能已经注意到你必须使用 `sudo` 来运行 `docker` 命令。这是因为 Docker 守护进程与 UNIX 套接字绑定,而不是 TCP 端口,套接字由 root 用户拥有。所以,你需要 `sudo` 权限才能运行 `docker` 命令。你可以将系统用户添加到 docker 组,这样它就不需要 `sudo` 了:
|
||||
|
||||
```
|
||||
$ sudo groupadd docker
|
||||
|
||||
```
|
||||
|
||||
在大多数情况下,在安装 Docker CE 时会自动创建 Docker 用户组,因此你只需将用户添加到该组中即可:
|
||||
|
||||
```
|
||||
$ sudo usermod -aG docker $USER
|
||||
|
||||
```
|
||||
|
||||
为了测试组是否已经成功添加,根据用户名运行 groups 命令:
|
||||
为了测试该组是否已经成功添加,根据用户名运行 `groups` 命令:
|
||||
|
||||
```
|
||||
$ groups swapnil
|
||||
|
||||
```
|
||||
|
||||
(这里,swapnil 是用户名。)
|
||||
(这里,`swapnil` 是用户名。)
|
||||
|
||||
这是在我系统上的输出:
|
||||
```
|
||||
$ swapnil : swapnil adm cdrom sudo dip plugdev lpadmin sambashare docker
|
||||
|
||||
```
|
||||
swapnil : swapnil adm cdrom sudo dip plugdev lpadmin sambashare docker
|
||||
```
|
||||
|
||||
你可以看到该用户也属于 docker 组。注销系统,这样组就会生效。一旦你再次登录,在不使用 sudo 的情况下试试 Hello World 命令:
|
||||
你可以看到该用户也属于 docker 组。注销系统,这样组就会生效。一旦你再次登录,在不使用 `sudo` 的情况下试试 Hello World 命令:
|
||||
|
||||
```
|
||||
$ docker run hello-world
|
||||
|
||||
```
|
||||
|
||||
你可以通过运行以下命令来查看关于 Docker 的安装版本以及更多系统信息:
|
||||
|
||||
```
|
||||
$ docker info
|
||||
|
||||
```
|
||||
|
||||
### 在 macOS 和 Windows 上安装 Docker CE
|
||||
|
||||
你可以在 macOS 和 Windows 上很轻松地安装 Docker CE(和 EE)。下载官方为 macOS 提供的 Docker 安装包,在 macOS 上安装应用程序的方式是只需将它们拖到 Applications 目录即可。一旦文件被复制,从 spotlight(译者注:mac 下的搜索)下打开 Docker 开始安装。一旦安装,Docker 将自动启动,你可以在 macOS 的顶部看到它。
|
||||
你可以在 macOS 和 Windows 上很轻松地安装 Docker CE(和 EE)。下载官方为 macOS 提供的 Docker 安装包,在 macOS 上安装应用程序的方式是只需将它们拖到 Applications 目录即可。一旦文件被复制,从 spotlight(LCTT 译注:mac 下的搜索功能)下打开 Docker 开始安装。一旦安装,Docker 将自动启动,你可以在 macOS 的顶部看到它。
|
||||
|
||||
![IEX23j65zYlF8mZ1c-T_vFw_i1B1T1hibw_AuhEA][3]
|
||||
|
||||
macOS 是类 UNIX,所以你可以简单地打开终端应用程序,并开始使用 Docker 命令。测试 hello world 应用:
|
||||
macOS 是类 UNIX 系统,所以你可以简单地打开终端应用程序,并开始使用 Docker 命令。测试 hello world 应用:
|
||||
|
||||
```
|
||||
$ docker run hello-world
|
||||
|
||||
```
|
||||
|
||||
恭喜,你已经在你的 macOS 上运行了 Docker。
|
||||
@ -173,9 +180,9 @@ $ docker run hello-world
|
||||
你需要最新版本的 Windows 10 Pro 或 Server 才能在它上面安装或运行 Docker。如果你没有完全更新,Windows 将不会安装 Docker。我在 Windows 10 系统上遇到了错误,必须运行系统更新。我的版本还很落后,我出现了[这个][14] bug。所以,如果你无法在 Windows 上安装 Docker,只要知道并不是只有你一个。仔细检查该 bug 以找到解决方案。
|
||||
|
||||
一旦你在 Windows 上安装 Docker 后,你可以通过 WSL 使用 bash shell,或者使用 PowerShell 来运行 Docker 命令。让我们在 PowerShell 中测试 “Hello World” 命令:
|
||||
|
||||
```
|
||||
PS C:\Users\swapnil> docker run hello-world
|
||||
|
||||
```
|
||||
|
||||
恭喜,你已经在 Windows 上运行了 Docker。
|
||||
@ -188,9 +195,9 @@ PS C:\Users\swapnil> docker run hello-world
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
DevOps 如何帮助你将很酷的应用交付给用户
|
||||
======
|
||||
|
||||
> 想要在今天的快节奏的商业环境中获得成功?要么选择 DevOps,要么死亡。
|
||||
|
||||

|
||||
|
||||
在很久之前,遥远的银河系中,在 DevOps 成为主流实践之前,软件开发的过程是极其缓慢、单调和按部就班的。当一个应用准备要部署的时候,就已经为下一个主要版本迭代积累了一长串的变更和修复。每次为新版本迭代所花费的准备时间都需要花费数个月的时间去回顾和贯穿整个开发周期。请记住这个过程将会在交付更新给用户的过程中不断的
|
||||
重复。
|
||||
|
||||
今天一切都是瞬间和实时完成的,这个概念似乎很原始。这场移动革命已经极大的改变了我们和软件之间的交互。那些早期采用 DevOps 的公司已经彻底改变了对软件开发和部署的期望。
|
||||
|
||||
让我们看看 Facebook:这个移动应用每两周更新和刷新一次,像钟表一样。这就是新的标准,因为现在的用户期望软件持续的被修复和更新。任何一家要花费一个月或者更多的时间来部署新的功能或者修复 bug 的公司将会逐渐走向没落。如果你不能交付用户所期待的,他们将会去寻找那些能够满足他们需求的。
|
||||
|
||||
Facebook,以及一些工业巨头如亚马逊、Netfix、谷歌以及其他公司,都已经强制要求企业变得更快速、更有效的来满足今天的顾客们的需求。
|
||||
|
||||
### 为什么是 DevOps?
|
||||
|
||||
敏捷和 DevOps 对于移动应用开发领域是相当重要的,因为开发周期正变得如闪电般的快。现在是一个密集、快节奏的环境,公司必须加紧步伐赶超,思考的更深入,运用策略来去完成,从而生存下去。在应用商店中,排名前十的应用平均能够保持的时间只有一个月左右。
|
||||
|
||||
为了说明老式的瀑布方法,回想一下你第一次学习驾驶。起先,你专注于每个独立的层面,使用一套方法论的过程:你上车;系上安全带;调整座椅、镜子,控制方向盘;发动汽车,将你的手放在 10 点和 2 点钟的方向,等等。完成一个换车道一样简单的任务需要付出艰苦的努力,以一个特定的顺序执行多个步骤。
|
||||
|
||||
DevOps,正好相反,是在你有了几年的经验之后如何去驾驶的。一切都是靠直觉同时发生的,你可以不用过多的思考就很平滑的从 A 点移动到 B 点。
|
||||
|
||||
移动 app 的世界对越老式的 app 开发环境来说太快节奏了。DevOps 被设计用来快速交付有效、稳定的 app,而不需要增加资源。然而你不能像购买一件普通的商品或者服务一样去购买 DevOps。DevOps 是用来指导改变团队如何一起工作的文化和活动的。
|
||||
|
||||
不是只有像亚马逊和 Facebook 这样的大公司才拥抱 DevOps 文化;小的移动应用公司也在很好的使用。“缩短迭代周期,同时保持生产事故处于一个较低水平,以及满足顾客追求的整体故障成本。”来自移动产品代理 [Reinvently][1]的工程部的负责人,Oleg Reshetnyak 说道。
|
||||
|
||||
### DevOps: 不是如果,而是什么时候
|
||||
|
||||
在今天的快节奏的商业环境中,选在了 DevOps 就像是选择了呼吸:要么去[做要么就死亡][2]。
|
||||
|
||||
根据[美国小企业管理局][3]的报道,现在只有 16% 的公司能够持续一代人的时间。不采用 DevOps 的移动应用公司将冒着逐渐走向灭绝的风险。而且,同样的研究表明采用 DevOps 的公司组织可能能够获得两倍的盈利能力、生产目标以及市场份额。
|
||||
|
||||
更快速、更安全的革新需要做到三点:云、自动化和 DevOps。根据你对 DevOps 的定义的不同,这三个要点之间的界限是不清晰的。然而,有一点是确定的:DevOps 围绕着更快、更少风险地交付高质量的软件的共同目标将组织内的每个人都统一起来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/devops-delivers-cool-apps-users
|
||||
|
||||
作者:[Stanislav Ivaschenko][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ilyadudkin
|
||||
[1]:https://reinvently.com/
|
||||
[2]:https://squadex.com/insights/devops-or-die/
|
||||
[3]:https://www.sba.gov/
|
||||
@ -0,0 +1,119 @@
|
||||
学习用 Thonny 写代码: 一个面向初学者的Python IDE
|
||||
======
|
||||
|
||||

|
||||
|
||||
学习编程很难。即使当你最终怎么正确使用你的冒号和括号,但仍然有很大的可能你的程序不会如果所想的工作。 通常,这意味着你忽略了某些东西或者误解了语言结构,你需要在代码中找到你的期望与现实存在分歧的地方。
|
||||
|
||||
程序员通常使用被叫做<ruby>调试器<rt>debugger</rt></ruby>的工具来处理这种情况,它允许一步一步地运行他们的程序。不幸的是,大多数调试器都针对专业用途进行了优化,并假设用户已经很好地了解了语言结构的语义(例如:函数调用)。
|
||||
|
||||
Thonny 是一个适合初学者的 Python IDE,由爱沙尼亚的 [Tartu 大学][1] 开发,它采用了不同的方法,因为它的调试器是专为学习和教学编程而设计的。
|
||||
|
||||
虽然 Thonny 适用于像小白一样的初学者,但这篇文章面向那些至少具有 Python 或其他命令式语言经验的读者。
|
||||
|
||||
### 开始
|
||||
|
||||
从第 Fedora 27 开始,Thonny 就被包含在 Fedora 软件库中。 使用 `sudo dnf install thonny` 或者你选择的图形工具(比如“<ruby>软件<rt>Software</rt></ruby>”)安装它。
|
||||
|
||||
当第一次启动 Thonny 时,它会做一些准备工作,然后呈现一个空白的编辑器和 Python shell 。将下列程序文本复制到编辑器中,并将其保存到文件中(`Ctrl+S`)。
|
||||
|
||||
```
|
||||
n = 1
|
||||
while n < 5:
|
||||
print(n * "*")
|
||||
n = n + 1
|
||||
```
|
||||
|
||||
我们首先运行该程序。 为此请按键盘上的 `F5` 键。 你应该看到一个由星号组成的三角形出现在 shell 窗格中。
|
||||
|
||||
![一个简单的 Thonny 程序][2]
|
||||
|
||||
Python 分析了你的代码并理解了你想打印一个三角形了吗?让我们看看!
|
||||
|
||||
首先从“<ruby>查看<rt>View</rt></ruby>”菜单中选择“<ruby>变量<rt>Variables</rt></ruby>”。这将打开一张表格,向我们展示 Python 是如何管理程序的变量的。现在通过按 `Ctrl + F5`(在 XFCE 中是 `Ctrl + Shift + F5`)以调试模式运行程序。在这种模式下,Thonny 使 Python 在每一步所需的步骤之前暂停。你应该看到程序的第一行被一个框包围。我们将这称为焦点,它表明 Python 将接下来要执行的部分代码。
|
||||
|
||||
![ Thonny 调试器焦点 ][3]
|
||||
|
||||
你在焦点框中看到的一段代码段被称为赋值语句。 对于这种声明,Python 应该计算右边的表达式,并将值存储在左边显示的名称下。按 `F7` 进行下一步。你将看到 Python 将重点放在语句的正确部分。在这个例子中,表达式实际上很简单,但是为了通用性,Thonny 提供了表达式计算框,它允许将表达式转换为值。再次按 `F7` 将文字 `1` 转换为值 `1`。现在 Python 已经准备好执行实际的赋值—再次按 `F7`,你应该会看到变量 `n` 的值为 `1` 的变量出现在变量表中。
|
||||
|
||||
![Thonny 变量表][4]
|
||||
|
||||
继续按 `F7` 并观察 Python 如何以非常小的步骤前进。它看起来像是理解你的代码的目的或者更像是一个愚蠢的遵循简单规则的机器?
|
||||
|
||||
### 函数调用
|
||||
|
||||
<ruby>函数调用<rt>Function Call</rt></ruby>是一种编程概念,它常常给初学者带来很大的困惑。从表面上看,没有什么复杂的事情——给代码命名,然后在代码中的其他地方引用它(调用它)。传统的调试器告诉我们,当你进入调用时,焦点跳转到函数定义中(然后稍后神奇地返回到原来的位置)。这是整件事吗?这需要我们关心吗?
|
||||
|
||||
结果证明,“跳转模型” 只对最简单的函数是足够的。理解参数传递、局部变量、返回和递归都得理解堆栈框架的概念。幸运的是,Thonny 可以直观地解释这个概念,而无需在厚厚的掩盖下搜索重要的细节。
|
||||
|
||||
将以下递归程序复制到 Thonny 并以调试模式(`Ctrl+F5` 或 `Ctrl+Shift+F5`)运行。
|
||||
|
||||
```
|
||||
def factorial(n):
|
||||
if n == 0:
|
||||
return 1
|
||||
else:
|
||||
return factorial(n-1) * n
|
||||
|
||||
print(factorial(4))
|
||||
```
|
||||
|
||||
重复按 `F7`,直到你在对话框中看到表达式 `factorial(4)`。 当你进行下一步时,你会看到 Thonny 打开一个包含了函数代码、另一个变量表和另一个焦点框的新窗口(移动窗口以查看旧的焦点框仍然存在)。
|
||||
|
||||
![通过递归函数的 Thonny][5]
|
||||
|
||||
此窗口表示堆栈帧,即用于解析函数调用的工作区。几个放在彼此顶部的这样的窗口称为<ruby>调用堆栈<rt>call stack</rt></ruby>。注意调用位置的参数 `4` 与 “局部变量” 表中的输入 `n` 之间的关系。继续按 `F7` 步进, 观察在每次调用时如何创建新窗口并在函数代码完成时被销毁,以及如何用返回值替换了调用位置。
|
||||
|
||||
### 值与参考
|
||||
|
||||
现在,让我们在 Python shell 中进行一个实验。首先输入下面屏幕截图中显示的语句:
|
||||
|
||||
![Thonny shell 显示列表突变][6]
|
||||
|
||||
正如你所看到的, 我们追加到列表 `b`, 但列表 `a` 也得到了更新。你可能知道为什么会发生这种情况, 但是对初学者来说,什么才是最好的解释呢?
|
||||
|
||||
当教我的学生列表时,我告诉他们我一直欺骗了他们关于 Python 内存模型。实际上,它并不像变量表所显示的那样简单。我告诉他们重新启动解释器(工具栏上的红色按钮),从“<ruby>查看<rt>View</rt></ruby>”菜单中选择“<ruby>堆<rt>Heap</rt></ruby>”,然后再次进行相同的实验。如果这样做,你就会发现变量表不再包含值——它们实际上位于另一个名为“<ruby>堆<rt>Heap</rt></ruby>”的表中。变量表的作用实际上是将变量名映射到地址(或称 ID),地址又指向了<ruby>堆<rt>Heap</rt></ruby>表中的行。由于赋值仅更改变量表,因此语句 `b = a` 只复制对列表的引用,而不是列表本身。这解释了为什么我们通过这两个变量看到了变化。
|
||||
|
||||
![在堆模式中的 Thonny][7]
|
||||
|
||||
(为什么我要在教列表的主题之前推迟说出内存模型的事实?Python 存储的列表是否有所不同?请继续使用 Thonny 的堆模式来找出结果!在评论中告诉我你认为怎么样!)
|
||||
|
||||
如果要更深入地了解参考系统, 请将以下程序通过打开堆表复制到 Thonny 并进行小步调试(`F7`) 中。
|
||||
|
||||
```
|
||||
def do_something(lst, x):
|
||||
lst.append(x)
|
||||
|
||||
a = [1,2,3]
|
||||
n = 4
|
||||
do_something(a, n)
|
||||
print(a)
|
||||
```
|
||||
|
||||
即使“堆模式”向我们显示真实的图片,但它使用起来也相当不方便。 因此,我建议你现在切换回普通模式(取消选择“<ruby>查看<rt>View</rt></ruby>”菜单中的“<ruby>堆<rt>Heap</rt></ruby>”),但请记住,真实模型包含变量、参考和值。
|
||||
|
||||
### 结语
|
||||
|
||||
我在这篇文章中提及到的特性是创建 Thonny 的主要原因。很容易对函数调用和引用形成错误的理解,但传统的调试器并不能真正帮助减少混淆。
|
||||
|
||||
除了这些显著的特性,Thonny 还提供了其他几个初学者友好的工具。 请查看 [Thonny的主页][8] 以了解更多信息!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-code-thonny-python-ide-beginners/
|
||||
|
||||
作者:[Aivar Annamaa][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/
|
||||
[1]:https://www.ut.ee/en
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2017/12/scr1.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr2.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr3.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr4.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr5.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr6.png
|
||||
[8]:http://thonny.org
|
||||
@ -1,8 +1,11 @@
|
||||
在 Linux 上用 DNS 实现简单的负载均衡
|
||||
======
|
||||
|
||||
> DNS 轮询将多个服务器映射到同一个主机名,并没有为这里展示的魔法做更多的工作。
|
||||
|
||||

|
||||
如果你的后端服务器是由多台服务器构成的,比如集群化或者镜像的 Web 或者文件服务器,通过一个负载均衡器提供了单一的入口点。业务繁忙的大型电商花费大量的资金在高端负载均衡器上,用它来执行各种各样的任务:代理、缓存、状况检查、SSL 处理、可配置的优先级、流量整形等很多任务。
|
||||
|
||||
如果你的后端服务器是由多台服务器构成的,比如集群化或者镜像的 Web 或者文件服务器,通过负载均衡器提供了单一的入口点。业务繁忙的大型电商在高端负载均衡器上花费了大量的资金,用它来执行各种各样的任务:代理、缓存、状况检查、SSL 处理、可配置的优先级、流量整形等很多任务。
|
||||
|
||||
但是你并不需要做那么多工作的负载均衡器。你需要的是一个跨服务器分发负载的简单方法,它能够提供故障切换,并且不太在意它是否高效和完美。DNS 轮询和使用轮询的子域委派是实现这个目标的两种简单方法。
|
||||
|
||||
@ -12,11 +15,12 @@ DNS 轮询是将多台服务器映射到同一个主机名上,当用户访问
|
||||
|
||||
### DNS 轮询
|
||||
|
||||
轮询和旅鸫鸟(robins)没有任何关系,据我喜欢的图书管理员说,它最初是一个法语短语,_`ruban rond`_、或者 `round ribbon`。很久以前,法国政府官员以不分级的圆形、波浪形、或者辐条形状去签署请愿书以掩盖请愿书的发起人。
|
||||
轮询和<ruby>旅鸫鸟<rt>robins</rt></ruby>没有任何关系,据我相熟的图书管理员说,它最初是一个法语短语,_ruban rond_、或者 _round ribbon_。很久以前,法国政府官员以不分级的圆形、波浪线、或者直线形状来在请愿书上签字,以盖住原来的发起人。
|
||||
|
||||
DNS 轮询也是不分级的,简单配置一个服务器列表,然后将请求转到每个服务器上。它并不做真正的负载均衡,因为它根本就不测量负载,也没有状况检查,因此如果一个服务器宕机,请求仍然会发送到那个宕机的服务器上。它的优点就是简单。如果你有一个小的文件或者 Web 服务器集群,想通过一个简单的方法在它们之间分散负载,那么 DNS 轮询很适合你。
|
||||
|
||||
你所做的全部配置就是创建多条 A 或者 AAAA 记录,映射多台服务器到单个的主机名。这个 BIND 示例同时使用了 IPv4 和 IPv6 私有地址类:
|
||||
|
||||
```
|
||||
fileserv.example.com. IN A 172.16.10.10
|
||||
fileserv.example.com. IN A 172.16.10.11
|
||||
@ -25,10 +29,10 @@ fileserv.example.com. IN A 172.16.10.12
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::10
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::11
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::12
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq 在 _/etc/hosts_ 文件中保存 A 和 AAAA 记录:
|
||||
Dnsmasq 在 `/etc/hosts` 文件中保存 A 和 AAAA 记录:
|
||||
|
||||
```
|
||||
172.16.1.10 fileserv fileserv.example.com
|
||||
172.16.1.11 fileserv fileserv.example.com
|
||||
@ -36,15 +40,14 @@ Dnsmasq 在 _/etc/hosts_ 文件中保存 A 和 AAAA 记录:
|
||||
fd02:faea:f561:8fa0:1::10 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::11 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::12 fileserv fileserv.example.com
|
||||
|
||||
```
|
||||
|
||||
请注意这些示例都是很简化的,解析完全合格域名有多种方法,因此,关于如何配置 DNS 请自行学习。
|
||||
|
||||
使用 `dig` 命令去检查你的配置能否按预期工作。将 `ns.example.com` 替换为你的域名服务器:
|
||||
|
||||
```
|
||||
$ dig @ns.example.com fileserv A fileserv AAA
|
||||
|
||||
```
|
||||
|
||||
它将同时显示出 IPv4 和 IPv6 的轮询记录。
|
||||
@ -56,6 +59,7 @@ $ dig @ns.example.com fileserv A fileserv AAA
|
||||
这种方法需要多台域名服务器。在最简化的场景中,你需要一台主域名服务器和两个子域,每个子域都有它们自己的域名服务器。在子域服务器上配置你的轮询记录,然后在你的主域名服务器上配置委派。
|
||||
|
||||
在主域名服务器上的 BIND 中,你至少需要两个额外的配置,一个区声明以及在区数据文件中的 A/AAAA 记录。主域名服务器中的委派应该像如下的内容:
|
||||
|
||||
```
|
||||
ns1.sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
@ -64,64 +68,65 @@ ns2.sub.example.com. IN AAA fd02:faea:f561:8fa0:1::21
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN NS ns2.sub.example.com.
|
||||
|
||||
```
|
||||
|
||||
接下来的每台子域服务器上有它们自己的区文件。在这里它的关键点是每个服务器去返回它**自己的** IP 地址。在 `named.conf` 中的区声明,所有的服务上都是一样的:
|
||||
|
||||
```
|
||||
zone "sub.example.com" {
|
||||
type master;
|
||||
file "db.sub.example.com";
|
||||
type master;
|
||||
file "db.sub.example.com";
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
然后数据文件也是相同的,除了那个 A/AAAA 记录使用的是各个服务器自己的 IP 地址。SOA 记录都指向到主域名服务器:
|
||||
|
||||
```
|
||||
; first subdomain name server
|
||||
$ORIGIN sub.example.com.
|
||||
$TTL 60
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018123456 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018123456 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
)
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
|
||||
sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
; second subdomain name server
|
||||
$ORIGIN sub.example.com.
|
||||
$TTL 60
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018234567 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018234567 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
)
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN A 172.16.1.21
|
||||
ns2.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::21
|
||||
|
||||
sub.example.com. IN A 172.16.1.21
|
||||
ns2.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::21
|
||||
```
|
||||
|
||||
接下来生成子域服务器上的轮询记录,方法和前面一样。现在你已经有了多个域名服务器来处理到你的子域的请求。再说一次,BIND 是很复杂的,做同一件事情它有多种方法,因此,给你留的家庭作业是找出适合你使用的最佳配置方法。
|
||||
|
||||
在 Dnsmasq 中做子域委派很容易。在你的主域名服务器上的 `dnsmasq.conf` 文件中添加如下的行,去指向到子域的域名服务器:
|
||||
|
||||
```
|
||||
server=/sub.example.com/172.16.1.20
|
||||
server=/sub.example.com/172.16.1.21
|
||||
server=/sub.example.com/fd02:faea:f561:8fa0:1::20
|
||||
server=/sub.example.com/fd02:faea:f561:8fa0:1::21
|
||||
|
||||
```
|
||||
|
||||
然后在子域的域名服务器上的 `/etc/hosts` 中配置轮询。
|
||||
|
||||
获取配置方法的详细内容和帮助,请参考这些资源:~~(致校对:这里的资源链接全部丢失了!!)~~
|
||||
获取配置方法的详细内容和帮助,请参考这些资源:
|
||||
|
||||
- [Dnsmasq][2]
|
||||
- [DNS and BIND, 5th Edition][3]
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][1] 学习更多 Linux 的知识。
|
||||
|
||||
@ -131,9 +136,11 @@ via: https://www.linux.com/learn/intro-to-linux/2018/3/simple-load-balancing-dns
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[2]:http://www.thekelleys.org.uk/dnsmasq/doc.html
|
||||
[3]:http://shop.oreilly.com/product/9780596100575.do
|
||||
@ -1,11 +1,15 @@
|
||||
可以考虑的 9 个开源 ERP 系统
|
||||
值得考虑的 9 个开源 ERP 系统
|
||||
======
|
||||
|
||||
> 有一些使用灵活、功能丰富而物有所值的开源 ERP 系统,这里有 9 个值得你看看。
|
||||
|
||||
|
||||
拥有一定数量员工的企业就需要大量的协调工作,包括价格、生产计划、帐务和财务、管理支出、管理存货等等。把一套截然不同的工具拼接到一起去处理这些工作,是一种粗制滥造和无价值的做法。
|
||||
|
||||
拥有一定数量员工的企业就需要大量的协调工作,包括制定价格、计划生产、会计和财务、管理支出、管理存货等等。把一套截然不同的工具拼接到一起去处理这些工作,是一种粗制滥造和无价值的做法。
|
||||
|
||||
那种方法没有任何弹性。并且那样在各种各样的自组织系统之间高效移动数据是非常困难的。同样,它也很难维护。
|
||||
|
||||
因此,大多数成长型企业都转而使用一个 [企业资源计划][1] (ERP) 系统。
|
||||
因此,大多数成长型企业都转而使用一个 [企业资源计划][1] (ERP)系统。
|
||||
|
||||
在这个行业中的大咖有 Oracle、SAP、以及 Microsoft Dynamics。它们都提供了一个综合的系统,但同时也很昂贵。如果你的企业支付不起如此昂贵的大系统,或者你仅需要一个简单的系统,怎么办呢?你可以使用开源的产品来作为替代。
|
||||
|
||||
@ -21,23 +25,23 @@
|
||||
|
||||
### ADempiere
|
||||
|
||||
像大多数其它开源 ERP 解决方案,[ADempiere][2] 的目标客户是中小企业。它已经存在一段时间了— 这个项目出现于 2006,它是 Compiere ERP 软件的一个分支。
|
||||
像大多数其它开源 ERP 解决方案,[ADempiere][2] 的目标客户是中小企业。它已经存在一段时间了 — 这个项目出现于 2006,它是 Compiere ERP 软件的一个分支。
|
||||
|
||||
它的意大利语名字的意思是“实现”或者“满足”,它“涉及多个方面”的 ERP 特性旨在帮企业去满足各种需求。它在 ERP 中增加了供应链管理(SCM)和客户关系管理(CRM)功能,能够让 ERP 套件在一个软件中去管理销售、采购、库存、以及帐务处理。它的最新版本是 v.3.9.0,更新了用户界面、销售点、人力资源、工资、以及其它的特性。
|
||||
它的意大利语名字的意思是“实现”或者“满足”,它“涉及多个方面”的 ERP 特性,旨在帮企业去满足各种需求。它在 ERP 中增加了供应链管理(SCM)和客户关系管理(CRM)功能,能够让该 ERP 套件在一个软件中去管理销售、采购、库存以及帐务处理。它的最新版本是 v.3.9.0,更新了用户界面、POS、人力资源、工资以及其它的特性。
|
||||
|
||||
因为是一个跨平台的、基于 Java 的云解决方案,ADempiere 可以运行在Linux、Unix、Windows、MacOS、智能手机、平板电脑上。它使用 [GPLv2][3] 授权。如果你想了解更多信息,这里有一个用于测试的 [demo][4],或者也可以在 GitHub 上查看它的 [源代码][5]。
|
||||
|
||||
### Apache OFBiz
|
||||
|
||||
[Apache OFBiz][6] 的业务相关的套件是构建在通用的架构上的,它允许企业根据自己的需要去定制 ERP。因此,它是有内部开发资源的大中型企业去修改和集成它到它们现有的 IT 和业务流程的最佳套件。
|
||||
[Apache OFBiz][6] 的业务相关的套件是构建在通用的架构上的,它允许企业根据自己的需要去定制 ERP。因此,它是有内部开发资源的大中型企业的最佳套件,可以去修改和集成它到它们现有的 IT 和业务流程。
|
||||
|
||||
OFBiz 是一个成熟的开源 ERP 系统;它的网站上说它是一个有十年历史的顶级 Apache 项目。可用的 [模块][7] 有帐务、生产制造、人力资源、存货管理、目录管理、客户关系管理、以及电子商务。你可以在它的 [demo 页面][8] 上试用电子商务的网上商店以及后端的 ERP 应用程序。
|
||||
OFBiz 是一个成熟的开源 ERP 系统;它的网站上说它是一个有十年历史的顶级 Apache 项目。可用的 [模块][7] 有会计、生产制造、人力资源、存货管理、目录管理、客户关系管理,以及电子商务。你可以在它的 [demo 页面][8] 上试用电子商务的网上商店以及后端的 ERP 应用程序。
|
||||
|
||||
Apache OFBiz 的源代码能够在它的 [项目仓库][9] 中找到。它是用 Java 写的,它在 [Apache 2.0 license][10] 下可用。
|
||||
|
||||
### Dolibarr
|
||||
|
||||
[Dolibarr][11] 提供了中小型企业端到端的业务管理,从发票跟踪、合同、存货、订单、以及支付,到文档管理和电子化 POS 系统支持。它的全部功能封装在一个清晰的界面中。
|
||||
[Dolibarr][11] 提供了中小型企业端到端的业务管理,从发票跟踪、合同、存货、订单,以及支付,到文档管理和电子化 POS 系统支持。它的全部功能封装在一个清晰的界面中。
|
||||
|
||||
如果你担心不会使用 Dolibarr,[这里有一些关于它的文档][12]。
|
||||
|
||||
@ -45,15 +49,15 @@ Apache OFBiz 的源代码能够在它的 [项目仓库][9] 中找到。它是用
|
||||
|
||||
### ERPNext
|
||||
|
||||
[ERPNext][17] 是这类开源项目中的其中一个;实际上它最初 [出现在 Opensource.com][18]。它被设计用于打破一个陈旧而昂贵的专用 ERP 系统的垄断局面。
|
||||
[ERPNext][17] 是这类开源项目中的其中一个;实际上它最初在 2014 年就被 [Opensource.com 推荐了][18]。它被设计用于打破一个陈旧而昂贵的专用 ERP 系统的垄断局面。
|
||||
|
||||
ERPNext 适合于中小型企业。它包含的模块有帐务、存货管理、销售、采购、以及项目管理。ERPNext 是表单驱动的应用程序 — 你可以在一组字段中填入信息,然后让应用程序去完成剩余部分。整个套件非常易用。
|
||||
ERPNext 适合于中小型企业。它包含的模块有会计、存货管理、销售、采购、以及项目管理。ERPNext 是表单驱动的应用程序 — 你可以在一组字段中填入信息,然后让应用程序去完成剩余部分。整个套件非常易用。
|
||||
|
||||
如果你感兴趣,在你考虑参与之前,你可以请求获取一个 [demo][19],去 [下载它][20] 或者在托管服务上 [购买一个订阅][21]。
|
||||
|
||||
### Metasfresh
|
||||
|
||||
[Metasfresh][22] 的名字表示它承诺软件的代码始终保持“新鲜”。它自 2015 年以来每周发行一个更新版本,那时,它的代码是由创始人从 ADempiere 项目中 fork 的。与 ADempiere 一样,它是一个基于 Java 的开源 ERP,目标客户是中小型企业。
|
||||
[Metasfresh][22] 的名字表示它承诺软件的代码始终保持“新鲜”。它自 2015 年以来每周发行一个更新版本,那时,它的代码是由创始人从 ADempiere 项目中分叉的。与 ADempiere 一样,它是一个基于 Java 的开源 ERP,目标客户是中小型企业。
|
||||
|
||||
虽然,相比在这里介绍的其它软件来说,它是一个很 “年青的” 项目,但是它早早就引起了一起人的注意,获得很多积极的评价,比如,被提名为“最佳开源”的 IT 创新奖入围者。
|
||||
|
||||
@ -71,7 +75,7 @@ Odoo 是基于 web 的工具。按单个模块来订阅的话,每个模块每
|
||||
|
||||
[Opentaps][30] 是专为大型业务设计的几个开源 ERP 解决方案之一,它的功能强大而灵活。这并不奇怪,因为它是在 Apache OFBiz 基础之上构建的。
|
||||
|
||||
你可以得到你所希望的模块组合,来帮你管理存货、生产制造、财务、以及采购。它也有分析功能,帮你去分析业务的各个方面。你可以借助这些信息让未来的计划做的更好。Opentaps 也包含一个强大的报表功能。
|
||||
你可以得到你所希望的模块组合,来帮你管理存货、生产制造、财务,以及采购。它也有分析功能,帮你去分析业务的各个方面。你可以借助这些信息让未来的计划做的更好。Opentaps 也包含一个强大的报表功能。
|
||||
|
||||
在它的基础之上,你还可以 [购买一些插件和附加模块][31] 去增强 Opentaps 的功能。包括与 Amazon Marketplace Services 和 FedEx 的集成等。在你 [下载 Opentaps][32] 之前,你可以到 [在线 demo][33] 上试用一下。它遵守 [GPLv3][34] 许可。
|
||||
|
||||
@ -87,7 +91,7 @@ WebERP 正在积极地进行开发,并且它有一个活跃的 [论坛][37],
|
||||
|
||||
如果你的生产制造、分销、电子商务业务已经从小规模业务成长起来了,并且正在寻找一个适合你的成长型企业的 ERP 系统,那么,你可以去了解一下 [xTuple PostBooks][41]。它是围绕核心 ERP 功能、帐务、以及可以添加存货、分销、采购、以及供应商报告等 CRM 功能构建的全面解决方案的系统。
|
||||
|
||||
xTuple 在通用公共属性许可证([CPAL][42])下使用,并且这个项目欢迎开发者去 fork 它,然后为基于存货的生产制造型企业开发其它的业务软件。它的基于 web 的核心是用 JavaScript 写的,它的 [源代码][43] 可以在 GitHub 上找到。你可以去在 xTuple 的网站上注册一个免费的 [demo][44] 去了解它。
|
||||
xTuple 在通用公共属性许可证([CPAL][42])下使用,并且这个项目欢迎开发者去分叉它,然后为基于存货的生产制造型企业开发其它的业务软件。它的基于 web 的核心是用 JavaScript 写的,它的 [源代码][43] 可以在 GitHub 上找到。你可以去在 xTuple 的网站上注册一个免费的 [demo][44] 去了解它。
|
||||
|
||||
还有许多其它的开源 ERP 可供你选择 — 另外你可以去了解的还有 [Tryton][45],它是用 Python 写的,并且使用的是 PostgreSQL 数据库引擎,或者基于 Java 的 [Axelor][46],它的好处是用户可以使用拖放界面来创建或者修改业务应用。如果还有在这里没有列出的你喜欢的开源 ERP 解决方案,请在下面的评论区共享出来。你也可以去查看我们的 [供应链管理工具][47] 榜单。
|
||||
|
||||
@ -98,9 +102,9 @@ xTuple 在通用公共属性许可证([CPAL][42])下使用,并且这个项
|
||||
via: https://opensource.com/tools/enterprise-resource-planning
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,83 +1,86 @@
|
||||
如何在 Linux 和 Windows 之间共享文件?
|
||||
如何在 Linux 和 Windows 之间共享文件?
|
||||
=====
|
||||
|
||||
> 用一些来自 Linux 社区的工具,在 Linux 和 Windows 之间共享文件是超容易的。让我们看看可以做这件事的两种不同方法。
|
||||
|
||||

|
||||
|
||||
现代很多人都在混合网络上工作,Linux 和 Windows 系统都扮演着重要的结束。在两者之间共享文件有时是非常关键的,并且使用正确的工具非常容易。只需很少的功夫,你就可以将文件从 Windows 复制到 Linux 或从 Linux 到 Windows。在这篇文章中,我们将讨论配置 Linux 和 Windows 系统所需的东西,以允许你轻松地将文件从一个操作系统转移到另一个。
|
||||
|
||||
### 在 Linux 和 Windows 之间复制文件
|
||||
|
||||
在 Windows 和 Linux 之间移动文件的第一步是下载并安装诸如 PuTTY 的 pscp 之类的工具。你可以从 [putty.org][1] 获得它,并轻松将其设置在 Windows 系统上。PuTTY 带有一个终端仿真器(putty)以及像 **pscp** 这样的工具,用于在 Linux 和 Windows 系统之间安全地复制文件。当你进入 PuTTY 站点时,你可以选择安装所有工具,或选择安装你想要的工具,也可以选择单个 .exe 文件。
|
||||
在 Windows 和 Linux 之间移动文件的第一步是下载并安装诸如 PuTTY 的 `pscp` 之类的工具。你可以从 [putty.org][1] 获得它(LCTT 译注:切记从官方网站下载,并最好对比其 md5/sha1 指纹),并轻松将其设置在 Windows 系统上。PuTTY 带有一个终端仿真器(`putty`)以及像 `pscp` 这样的工具,用于在 Linux 和 Windows 系统之间安全地复制文件。当你进入 PuTTY 站点时,你可以选择安装所有工具,或选择安装你想要的工具,也可以选择单个 .exe 文件。
|
||||
|
||||
你还需要在你的 Linux 系统上设置并运行 ssh 服务器。这允许它支持客户端(Windows 端)连接请求。如果你还没有安装 ssh 服务器,那么以下步骤可以在 Debian 系统上运行(包括 Ubuntu 等):
|
||||
|
||||
你还需要在你的 Linux 系统上设置并运行 ssh-server。这允许它支持客户端(Windows 端)连接请求。如果你还没有安装 ssh 服务器,那么以下步骤可以在 Debian 系统上运行(包括 Ubuntu 等):
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install ssh-server
|
||||
sudo service ssh start
|
||||
|
||||
```
|
||||
|
||||
对于 Red Hat 及其相关的 Linux 系统,使用类似的命令:
|
||||
|
||||
```
|
||||
sudo yum install openssh-server
|
||||
sudo systemctl start sshd
|
||||
|
||||
```
|
||||
注意,如果你正在运行防火墙(例如 ufw),则可能需要打开 22 端口以允许连接。
|
||||
|
||||
使用 **pscp** 命令,你可以将文件从 Windows 移到 Linux,反之亦然。它的 “copy from to” 命令的语法非常简单。
|
||||
使用 `pscp` 命令,你可以将文件从 Windows 移到 Linux,反之亦然。它的 “copy from to” 命令的语法非常简单。
|
||||
|
||||
#### 从 Windows 到 Linux
|
||||
|
||||
在下面显示的命令中,我们将 Windows 系统上用户账户中的文件复制到 Linux 系统下的 /tmp 目录。
|
||||
|
||||
```
|
||||
C:\Program Files\PuTTY>pscp \Users\shs\copy_me.txt shs@192.168.0.18:/tmp
|
||||
shs@192.168.0.18's password:
|
||||
copy_me.txt | 0 kB | 0.1 kB/s | ETA: 00:00:00 | 100%
|
||||
|
||||
```
|
||||
|
||||
#### 从 Linux 到 Windows
|
||||
|
||||
将文件从 Linux 转移到 Windows 也同样简单。只要反向参数即可。
|
||||
将文件从 Linux 转移到 Windows 也同样简单。只要颠倒参数即可。
|
||||
|
||||
```
|
||||
C:\Program Files\PuTTY>pscp shs@192.168.0.18:/tmp/copy_me.txt \Users\shs
|
||||
shs@192.168.0.18's password:
|
||||
copy_me.txt | 0 kB | 0.1 kB/s | ETA: 00:00:00 | 100%
|
||||
|
||||
```
|
||||
|
||||
如果 1) pscp 位于 Windows 搜索路径中,并且 2) 你的 Linux 系统在 Windows hosts 文件中,则该过程可以变得更加顺畅和轻松。(to 校正者:这句话不怎么明白)
|
||||
如果 1) `pscp` 位于 Windows 搜索路径中,并且 2) 你的 Linux 系统在 Windows 的 hosts 文件中,则该过程可以变得更加顺畅和轻松。
|
||||
|
||||
#### Windows 搜索路径
|
||||
|
||||
如果你使用 PuTTY 安装程序安装 PuTTY 工具,你可能会发现 **C:\Program files\PuTTY** 位于 Windows 搜索路径中。你可以通过在 Windows 命令提示符下键入 **echo %path%** 来检查是否属于这种情况(在搜索栏中键入 “cmd” 来打开命令提示符)。如果是这样,你不需要关心文件系统中相对于 pscp 可执行文件的位置。进入到包含你想要移动文件的文件夹可能会更容易。
|
||||
如果你使用 PuTTY 安装程序安装 PuTTY 工具,你可能会发现 `C:\Program files\PuTTY` 位于 Windows 搜索路径中。你可以通过在 Windows 命令提示符下键入 `echo %path%` 来检查是否属于这种情况(在搜索栏中键入 `cmd` 来打开命令提示符)。如果是这样,你不需要关心文件系统中相对于 `pscp` 可执行文件的位置。进入到包含你想要移动文件的文件夹可能会更容易。
|
||||
|
||||
```
|
||||
C:\Users\shs>pscp copy_me.txt shs@192.168.0.18:/tmp
|
||||
shs@192.168.0.18's password:
|
||||
copy_me.txt | 0 kB | 0.1 kB/s | ETA: 00:00:00 | 100%
|
||||
|
||||
```
|
||||
|
||||
#### 更新你的 Windows hosts 文件
|
||||
#### 更新你的 Windows 的 hosts 文件
|
||||
|
||||
这是另一个小修补。使用管理员权限,你可以将 Linux 系统添加到 Windows 的 hosts 文件中(`C:\Windows\System32\drivers\etc\hosts`),然后使用其主机名代替其 IP 地址。请记住,如果你的 Linux 系统的 IP 地址是动态分配的,那么它不会一直发挥作用。
|
||||
|
||||
这是另一个小修补。使用管理员权限,你可以将 Linux 系统添加到 Windows hosts 文件(C:\Windows\System32\drivers\etc\hosts),然后使用其主机名代替其 IP 地址。请记住,如果你的 Linux 系统的 IP 地址是动态分配的,那么它不会一直发挥作用。
|
||||
```
|
||||
C:\Users\shs>pscp copy_me.txt shs@stinkbug:/tmp
|
||||
shs@192.168.0.18's password:
|
||||
hosts | 0 kB | 0.8 kB/s | ETA: 00:00:00 | 100%
|
||||
|
||||
```
|
||||
|
||||
请注意,Windows hosts 文件与 Linux 系统上的 /etc/hosts 文件格式相同 -- IP 地址,空格,主机名。注释以 pound(to 校正者:这个符号是英镑符??) 符号来表示的。
|
||||
请注意,Windows 的 hosts 文件与 Linux 系统上的 `/etc/hosts` 文件格式相同 -- IP 地址、空格、主机名。注释以 `#` 符号来表示的。
|
||||
|
||||
```
|
||||
# Linux systems
|
||||
192.168.0.18 stinkbug
|
||||
|
||||
```
|
||||
|
||||
#### 讨厌的行结尾符
|
||||
|
||||
请记住,Windows 上文本文件中的行以回车符和换行符结束。pscp 工具不会删除回车符,使文件看起来像 Linux 文本文件。相反,它只是完整地复制文件。你可以考虑安装 **tofrodos** 包,这使你能够在 Linux 系统上使用 **fromdos** 和 **todos** 命令来调整在平台之间移动的文件。
|
||||
请记住,Windows 上文本文件中的行以回车符和换行符结束。`pscp` 工具不会删除回车符,以使文件看起来像 Linux 文本文件。相反,它只是完整地复制文件。你可以考虑安装 `tofrodos` 包,这使你能够在 Linux 系统上使用 `fromdos` 和 `todos` 命令来调整在平台之间移动的文件。
|
||||
|
||||
### 在 Windows 和 Linux 之间共享文件夹
|
||||
|
||||
@ -96,7 +99,7 @@ via: https://www.networkworld.com/article/3269189/linux/sharing-files-between-li
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,61 +1,56 @@
|
||||
# 在命令行中整理数据
|
||||
如何在命令行中整理数据
|
||||
=========
|
||||
|
||||
> 命令行审计不会影响数据库,因为它使用从数据库中释放的数据。
|
||||
|
||||

|
||||
|
||||
我兼职做数据审计。把我想象成一个校对者,处理数据表格而不是一页一页的文章。这些表是从关系数据库导出的,并且规模相当小:100,000 到 1,000,000条记录,50 到 200个字段。
|
||||
我兼职做数据审计。把我想象成一个校对者,校对的是数据表格而不是一页一页的文章。这些表是从关系数据库导出的,并且规模相当小:100,000 到 1,000,000条记录,50 到 200 个字段。
|
||||
|
||||
我从来没有见过没有错误的数据表。您可能认为,这种混乱并不局限于重复记录、拼写和格式错误以及放置在错误字段中的数据项。我还发现:
|
||||
我从来没有见过没有错误的数据表。如你所能想到的,这种混乱并不局限于重复记录、拼写和格式错误以及放置在错误字段中的数据项。我还发现:
|
||||
|
||||
* 损坏的记录分布在几行上,因为数据项具有内嵌的换行符
|
||||
* 损坏的记录分布在几行上,因为数据项具有内嵌的换行符
|
||||
* 在同一记录中一个字段中的数据项与另一个字段中的数据项不一致
|
||||
* 使用截断数据项的记录,通常是因为非常长的字符串被硬塞到具有50或100字符限制的字段中
|
||||
* 字符编码失败产生称为[乱码][1]
|
||||
* 使用截断数据项的记录,通常是因为非常长的字符串被硬塞到具有 50 或 100 字符限制的字段中
|
||||
* 字符编码失败产生称为[乱码][1]的垃圾
|
||||
* 不可见的[控制字符][2],其中一些会导致数据处理错误
|
||||
* 由上一个程序插入的[替换字符][3]和神秘的问号,这导致了不知道数据的编码是什么
|
||||
* 由上一个程序插入的[替换字符][3]和神秘的问号,这是由于不知道数据的编码是什么
|
||||
|
||||
解决这些问题并不困难,但找到它们存在非技术障碍。首先,每个人都不愿处理数据错误。在我看到表格之前,数据所有者或管理人员可能已经经历了数据悲伤的所有五个阶段:
|
||||
解决这些问题并不困难,但找到它们存在非技术障碍。首先,每个人都不愿处理数据错误。在我看到表格之前,数据所有者或管理人员可能已经经历了<ruby>数据悲伤<rt>Data Grief</rt></ruby>的所有五个阶段:
|
||||
|
||||
1. 我们的数据没有错误。
|
||||
2. 好吧,也许有一些错误,但它们并不重要。
|
||||
3. 好的,有很多错误;我们会让我们的内部人员处理它们。
|
||||
4. 我们已经开始修复一些错误,但这很耗时间;我们将在迁移到新的数据库软件时执行此操作。
|
||||
5. 移至新数据库时,我们没有时间整理数据; 我们需要一些帮助。
|
||||
|
||||
1. 好吧,也许有一些错误,但它们并不重要。
|
||||
2. 好的,有很多错误; 我们会让我们的内部人员处理它们。
|
||||
3. 我们已经开始修复一些错误,但这很耗时间; 我们将在迁移到新的数据库软件时执行此操作。
|
||||
4. 1.移至新数据库时,我们没有时间整理数据; 我们可以使用一些帮助。
|
||||
|
||||
第二个阻碍进展的是相信数据整理需要专用的应用程序——要么是昂贵的专有程序,要么是优秀的开源程序 [OpenRefine][4] 。为了解决专用应用程序无法解决的问题,数据管理人员可能会向程序员寻求帮助,比如擅长 [Python][5] 或 [R][6] 的人。
|
||||
第二个阻碍进展的是相信数据整理需要专用的应用程序——要么是昂贵的专有程序,要么是优秀的开源程序 [OpenRefine][4] 。为了解决专用应用程序无法解决的问题,数据管理人员可能会向程序员寻求帮助,比如擅长 [Python][5] 或 [R][6] 的人。
|
||||
|
||||
但是数据审计和整理通常不需要专用的应用程序。纯文本数据表已经存在了几十年,文本处理工具也是如此。打开 Bash shell,您将拥有一个工具箱,其中装载了强大的文本处理器,如 `grep`、`cut`、`paste`、`sort`、`uniq`、`tr` 和 `awk`。它们快速、可靠、易于使用。
|
||||
|
||||
我在命令行上执行所有的数据审计工作,并且在 “[cookbook][7]” 网站上发布了许多数据审计技巧。我经常将操作存储为函数和 shell 脚本(参见下面的示例)。
|
||||
|
||||
是的,命令行方法要求将要审计的数据从数据库中导出。 是的,审计结果需要稍后在数据库中进行编辑,或者(数据库允许)整理的数据项作为替换杂乱的数据项导入其中。
|
||||
是的,命令行方法要求将要审计的数据从数据库中导出。而且,审计结果需要稍后在数据库中进行编辑,或者(数据库允许)将整理的数据项导入其中,以替换杂乱的数据项。
|
||||
|
||||
但其优势是显著的。awk 将在普通的台式机或笔记本电脑上以几秒钟的时间处理数百万条记录。不复杂的正则表达式将找到您可以想象的所有数据错误。所有这些都将安全地发生在数据库结构之外:命令行审计不会影响数据库,因为它使用从数据库中释放的数据。
|
||||
|
||||
受过 Unix 培训的读者此时会沾沾自喜。他们还记得许多年前用这些方法操纵命令行上的数据。从那时起,计算机的处理能力和 RAM 得到了显著提高,标准命令行工具的效率大大提高。数据审计从来都不是更快或更容易的。现在微软的 Windows 10 可以运行 Bash 和 GNU/Linux 程序了,Windows 用户也可以用 Unix 和 Linux 的座右铭来处理混乱的数据:保持冷静,打开一个终端。
|
||||
受过 Unix 培训的读者此时会沾沾自喜。他们还记得许多年前用这些方法操纵命令行上的数据。从那时起,计算机的处理能力和 RAM 得到了显著提高,标准命令行工具的效率大大提高。数据审计从来没有这么快、这么容易过。现在微软的 Windows 10 可以运行 Bash 和 GNU/Linux 程序了,Windows 用户也可以用 Unix 和 Linux 的座右铭来处理混乱的数据:保持冷静,打开一个终端。
|
||||
|
||||
|
||||
![Tshirt, Keep Calm and Open A Terminal][9]
|
||||
|
||||
图片:Robert Mesibov,CC BY
|
||||
### 例子
|
||||
|
||||
### 例子:
|
||||
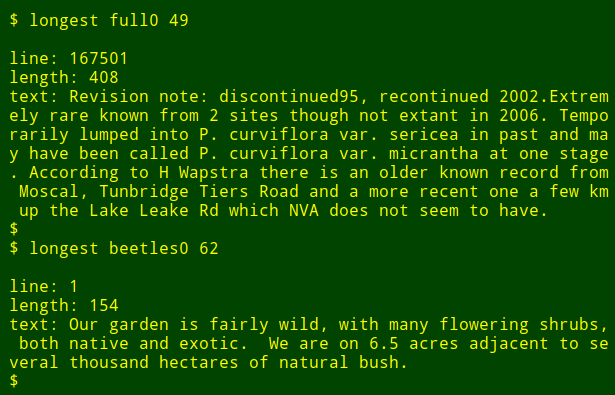
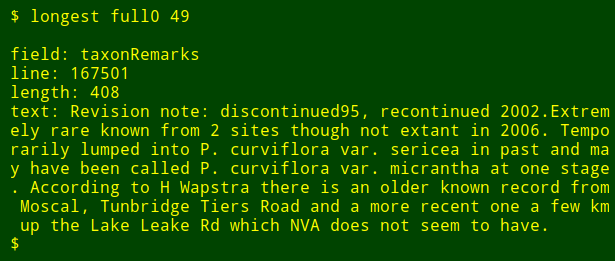
假设我想在一个大的表中的特定字段中找到最长的数据项。 这不是一个真正的数据审计任务,但它会显示 shell 工具的工作方式。 为了演示目的,我将使用制表符分隔的表 `full0` ,它有 1,122,023 条记录(加上一个标题行)和 49 个字段,我会查看 36 号字段。(我得到字段编号的函数在我的[网站][10]上有解释)
|
||||
|
||||
假设我想在一个大的表中的特定字段中找到最长的数据项。 这不是一个真正的数据审计任务,但它会显示 shell 工具的工作方式。 为了演示目的,我将使用制表符分隔的表 `full0` ,它有 1,122,023 条记录(加上一个标题行)和 49 个字段,我会查看 36 号字段.(我得到字段编号的函数在我的[网站][10]上有解释)
|
||||
|
||||
首先,使用 `tail` 命令从表 `full0` 移除标题行,结果管道至 `cut` 命令,截取第 36 个字段,接下来,管道至 `awk` ,这里有一个初始化为 0 的变量 `big` ,然后 `awk` 开始检测第一行数据项的长度,如果长度大于 0 , `awk` 将会设置 `big` 变量为新的长度,同时存储行数到变量 `line` 中。整个数据项存储在变量 `text` 中。然后 `awk` 开始轮流处理剩余的 1,122,022 记录项。同时,如果发现更长的数据项时,更新 3 个变量。最后,它打印出行号,数据项的长度,以及最长数据项的内容。(在下面的代码中,为了清晰起见,将代码分为几行)
|
||||
首先,使用 `tail` 命令从表 `full0` 移除标题行,结果管道至 `cut` 命令,截取第 36 个字段,接下来,管道至 `awk` ,这里有一个初始化为 0 的变量 `big` ,然后 `awk` 开始检测第一行数据项的长度,如果长度大于 0 ,`awk` 将会设置 `big` 变量为新的长度,同时存储行数到变量 `line` 中。整个数据项存储在变量 `text` 中。然后 `awk` 开始轮流处理剩余的 1,122,022 记录项。同时,如果发现更长的数据项时,更新 3 个变量。最后,它打印出行号、数据项的长度,以及最长数据项的内容。(在下面的代码中,为了清晰起见,将代码分为几行)
|
||||
|
||||
```
|
||||
<code>tail -n +2 full0 \
|
||||
|
||||
tail -n +2 full0 \
|
||||
> | cut -f36 \
|
||||
|
||||
> | awk 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
> {big=length($0);line=NR;text=$0} \
|
||||
|
||||
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
|
||||
|
||||
> END {print "\nline: "line"\nlength: "big"\ntext: "text}'
|
||||
```
|
||||
|
||||
大约花了多长时间?我的电脑大约用了 4 秒钟(core i5,8GB RAM);
|
||||
@ -66,25 +61,19 @@
|
||||
|
||||

|
||||
|
||||
现在,我重新运行这个命令,在另一个文件中找另一个字段中最长的数据项而不需要去记忆命令是如何写的:
|
||||
现在,我可以以函数的方式重新运行这个命令,在另一个文件中的另一个字段中找最长的数据项,而不需要去记忆这个命令是如何写的:
|
||||
|
||||
|
||||
|
||||
最后调整一下,我还可以输出我要查询字段的名称,我只需要使用 `head` 命令抽取表格第一行的标题行,然后将结果管道至 `tr` 命令,将制表位转换为换行,然后将结果管道至 `tail` 和 `head` 命令,打印出第二个参数在列表中名称,第二个参数就是字段号。字段的名字就存储到变量 `field` 中,然后将他传向 `awk` ,通过变量 `fld` 打印出来。(译者注:按照下面的代码,编号的方式应该是从右向左)
|
||||
最后调整一下,我还可以输出我要查询字段的名称,我只需要使用 `head` 命令抽取表格第一行的标题行,然后将结果管道至 `tr` 命令,将制表位转换为换行,然后将结果管道至 `tail` 和 `head` 命令,打印出第二个参数在列表中名称,第二个参数就是字段号。字段的名字就存储到变量 `field` 中,然后将它传向 `awk` ,通过变量 `fld` 打印出来。(LCTT 译注:按照下面的代码,编号的方式应该是从右向左)
|
||||
|
||||
```
|
||||
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
|
||||
|
||||
longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
|
||||
tail -n +2 "$1" \
|
||||
|
||||
| cut -f"$2" | \
|
||||
|
||||
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
{big=length($0);line=NR;text=$0}
|
||||
|
||||
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>
|
||||
|
||||
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }
|
||||
```
|
||||
|
||||
|
||||
@ -98,7 +87,7 @@ via: https://opensource.com/article/18/5/command-line-data-auditing
|
||||
作者:[Bob Mesibov][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
120
published/20180529 Copying and renaming files on Linux.md
Normal file
120
published/20180529 Copying and renaming files on Linux.md
Normal file
@ -0,0 +1,120 @@
|
||||
在 Linux 上复制和重命名文件
|
||||
======
|
||||
|
||||
> cp 和 mv 之外,在 Linux 上有更多的复制和重命名文件的命令。试试这些命令或许会惊艳到你,并能节省一些时间。
|
||||
|
||||

|
||||
|
||||
Linux 用户数十年来一直在使用简单的 `cp` 和 `mv` 命令来复制和重命名文件。这些命令是我们大多数人首先学到的,每天可能有数百万人在使用它们。但是还有其他技术、方便的方法和另外的命令,这些提供了一些独特的选项。
|
||||
|
||||
首先,我们来思考为什么你想要复制一个文件。你可能需要在另一个位置使用同一个文件,或者因为你要编辑该文件而需要一个副本,并且希望确保备有便利的备份以防万一需要恢复原始文件。这样做的显而易见的方式是使用像 `cp myfile myfile-orig` 这样的命令。
|
||||
|
||||
但是,如果你想复制大量的文件,那么这个策略可能就会变得很老。更好的选择是:
|
||||
|
||||
* 在开始编辑之前,使用 `tar` 创建所有要备份的文件的存档。
|
||||
* 使用 `for` 循环来使备份副本更容易。
|
||||
|
||||
使用 `tar` 的方式很简单。对于当前目录中的所有文件,你可以使用如下命令:
|
||||
|
||||
```
|
||||
$ tar cf myfiles.tar *
|
||||
```
|
||||
|
||||
对于一组可以用模式标识的文件,可以使用如下命令:
|
||||
|
||||
```
|
||||
$ tar cf myfiles.tar *.txt
|
||||
```
|
||||
|
||||
在每种情况下,最终都会生成一个 `myfiles.tar` 文件,其中包含目录中的所有文件或扩展名为 .txt 的所有文件。
|
||||
|
||||
一个简单的循环将允许你使用修改后的名称来制作备份副本:
|
||||
|
||||
```
|
||||
$ for file in *
|
||||
> do
|
||||
> cp $file $file-orig
|
||||
> done
|
||||
```
|
||||
|
||||
当你备份单个文件并且该文件恰好有一个长名称时,可以依靠使用 `tab` 来补全文件名(在输入足够的字母以便唯一标识该文件后点击 `Tab` 键)并使用像这样的语法将 `-orig` 附加到副本的名字后。
|
||||
|
||||
```
|
||||
$ cp file-with-a-very-long-name{,-orig}
|
||||
```
|
||||
|
||||
然后你有一个 `file-with-a-very-long-name` 和一个 `file-with-a-very-long-name-orig`。
|
||||
|
||||
### 在 Linux 上重命名文件
|
||||
|
||||
重命名文件的传统方法是使用 `mv` 命令。该命令将文件移动到不同的目录,或原地更改其名称,或者同时执行这两个操作。
|
||||
|
||||
```
|
||||
$ mv myfile /tmp
|
||||
$ mv myfile notmyfile
|
||||
$ mv myfile /tmp/notmyfile
|
||||
```
|
||||
|
||||
但我们也有 `rename` 命令来做重命名。使用 `rename` 命令的窍门是习惯它的语法,但是如果你了解一些 Perl,你可能发现它并不棘手。
|
||||
|
||||
有个非常有用的例子。假设你想重新命名一个目录中的文件,将所有的大写字母替换为小写字母。一般来说,你在 Unix 或 Linux 系统上找不到大量大写字母的文件,但你可以有。这里有一个简单的方法来重命名它们,而不必为它们中的每一个使用 `mv` 命令。 `/A-Z/a-z/` 告诉 `rename` 命令将范围 `A-Z` 中的任何字母更改为 `a-z` 中的相应字母。
|
||||
|
||||
```
|
||||
$ ls
|
||||
Agenda Group.JPG MyFile
|
||||
$ rename 'y/A-Z/a-z/' *
|
||||
$ ls
|
||||
agenda group.jpg myfile
|
||||
```
|
||||
|
||||
你也可以使用 `rename` 来删除文件扩展名。也许你厌倦了看到带有 .txt 扩展名的文本文件。简单删除这些扩展名 —— 用一个命令。
|
||||
|
||||
```
|
||||
$ ls
|
||||
agenda.txt notes.txt weekly.txt
|
||||
$ rename 's/.txt//' *
|
||||
$ ls
|
||||
agenda notes weekly
|
||||
```
|
||||
|
||||
现在让我们想象一下,你改变了心意,并希望把这些扩展名改回来。没问题。只需修改命令。窍门是理解第一个斜杠前的 `s` 意味着“替代”。前两个斜线之间的内容是我们想要改变的东西,第二个斜线和第三个斜线之间是改变后的东西。所以,`$` 表示文件名的结尾,我们将它改为 `.txt`。
|
||||
```
|
||||
$ ls
|
||||
agenda notes weekly
|
||||
$ rename 's/$/.txt/' *
|
||||
$ ls
|
||||
agenda.txt notes.txt weekly.txt
|
||||
```
|
||||
|
||||
你也可以更改文件名的其他部分。牢记 `s/旧内容/新内容/` 规则。
|
||||
|
||||
```
|
||||
$ ls
|
||||
draft-minutes-2018-03 draft-minutes-2018-04 draft-minutes-2018-05
|
||||
$ rename 's/draft/approved/' *minutes*
|
||||
$ ls
|
||||
approved-minutes-2018-03 approved-minutes-2018-04 approved-minutes-2018-05
|
||||
```
|
||||
|
||||
在上面的例子中注意到,当我们在 `s/old/new/` 中使用 `s` 时,我们用另一个名称替换名称的一部分。当我们使用 `y` 时,我们就是直译(将字符从一个范围替换为另一个范围)。
|
||||
|
||||
### 总结
|
||||
|
||||
现在有很多复制和重命名文件的方法。我希望其中的一些会让你在使用命令行时更愉快。
|
||||
|
||||
在 [Facebook][1] 和 [LinkedIn][2] 上加入 Network World 社区来对热门主题评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3276349/linux/copying-and-renaming-files-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -1,88 +1,63 @@
|
||||
如何在 Linux 中使用 history 命令
|
||||
======
|
||||
|
||||
> 用强大的 history 命令使你的命令行提示符更有效率。
|
||||
|
||||

|
||||
|
||||
随着我在终端中花费越来越多的时间,我感觉就像不断地寻找新的命令,使我的日常任务更加高效。GNU 的 `history` 命令是一个真正改变我日常工作的命令。
|
||||
随着我在终端中花费越来越多的时间,我感觉就像在不断地寻找新的命令,以使我的日常任务更加高效。GNU 的 `history` 命令是一个真正改变我日常工作的命令。
|
||||
|
||||
GNU `history` 命令保存了从该终端会话运行的所有其他命令的列表,然后允许你重放或者重用这些命令,而不用重新输入它们。如果你是一个老玩家,你知道 `history` 的力量,但对于我们这些半吊子或新手系统管理员来说, `history` 是一个立竿见影的生产力增益。
|
||||
|
||||
### History 101
|
||||
### 历史 101
|
||||
|
||||
要查看命令历史,请在 Linux 中打开终端程序,然后输入:
|
||||
|
||||
要查看 `history`,请在 Linux 中打开终端程序,然后输入:
|
||||
```
|
||||
$ history
|
||||
|
||||
```
|
||||
|
||||
这是我得到的响应:
|
||||
|
||||
```
|
||||
1 clear
|
||||
|
||||
|
||||
|
||||
2 ls -al
|
||||
|
||||
|
||||
|
||||
3 sudo dnf update -y
|
||||
|
||||
|
||||
|
||||
4 history
|
||||
|
||||
```
|
||||
|
||||
`history` 命令显示自开始会话后输入的命令列表。 `history` 有趣的地方是你可以使用以下命令重放任意一个命令:
|
||||
|
||||
```
|
||||
$ !3
|
||||
|
||||
```
|
||||
|
||||
提示符中的 `!3` 告诉 shell 重新运行历史列表中第 3 个命令。我还可以输入以下命令来使用:
|
||||
|
||||
```
|
||||
linuser@my_linux_box: !sudo dnf
|
||||
|
||||
```
|
||||
|
||||
`history` 将搜索与你提供的模式相匹配的最后一个命令并运行它。
|
||||
`history` 将搜索与你提供的模式相匹配的最后一个命令,并运行它。
|
||||
|
||||
### 搜索历史
|
||||
|
||||
你还可以输入 `!!` 重新运行 `history` 的最后一条命令。而且,通过与` grep` 配对,你可以搜索与文本模式相匹配的命令,或者通过与 `tail` 一起使用,你可以找到你最后几条执行的命令。例如:
|
||||
你还可以输入 `!!` 重新运行命令历史中的最后一条命令。而且,通过与` grep` 配对,你可以搜索与文本模式相匹配的命令,或者通过与 `tail` 一起使用,你可以找到你最后几条执行的命令。例如:
|
||||
|
||||
```
|
||||
$ history | grep dnf
|
||||
|
||||
|
||||
|
||||
3 sudo dnf update -y
|
||||
|
||||
|
||||
|
||||
5 history | grep dnf
|
||||
|
||||
|
||||
|
||||
$ history | tail -n 3
|
||||
|
||||
|
||||
|
||||
4 history
|
||||
|
||||
|
||||
|
||||
5 history | grep dnf
|
||||
|
||||
|
||||
|
||||
6 history | tail -n 3
|
||||
|
||||
```
|
||||
|
||||
另一种实现这个功能的方法是输入 `Ctrl-R` 来调用你的命令历史记录的递归搜索。输入后,提示变为:
|
||||
|
||||
```
|
||||
(reverse-i-search)`':
|
||||
|
||||
```
|
||||
|
||||
现在你可以开始输入一个命令,并且会显示匹配的命令,按回车键执行。
|
||||
@ -90,9 +65,9 @@ $ history | tail -n 3
|
||||
### 更改已执行的命令
|
||||
|
||||
`history` 还允许你使用不同的语法重新运行命令。例如,如果我想改变我以前的命令 `history | grep dnf` 成 `history | grep ssh`,我可以在提示符下执行以下命令:
|
||||
|
||||
```
|
||||
$ ^dnf^ssh^
|
||||
|
||||
```
|
||||
|
||||
`history` 将重新运行该命令,但用 `ssh` 替换 `dnf`,并执行它。
|
||||
@ -111,8 +86,6 @@ $ ^dnf^ssh^
|
||||
* 记录历史中每行的日期和时间
|
||||
* 防止某些命令被记录在历史记录中
|
||||
|
||||
|
||||
|
||||
有关 `history` 命令的更多信息和其他有趣的事情,请参考[ GNU Bash 手册][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -122,7 +95,7 @@ via: https://opensource.com/article/18/6/history-command
|
||||
作者:[Steve Morris][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,29 +1,32 @@
|
||||
不像 MySQL 的 MySQL:MySQL 文档存储介绍
|
||||
======
|
||||
|
||||
> MySQL 文档存储 可以跳过底层数据结构创建、数据规范化和其它使用传统数据库时需要做的工作,直接存储数据。
|
||||
|
||||

|
||||
|
||||
MySQL 可以提供 NoSQL JSON <ruby>文档存储<rt>Document Store</rt></ruby>了,这样开发者保存数据前无需<ruby>规范化<rt>normalize</rt></ruby>数据、创建数据库,也无需在开发之前就制定好数据样式。从 MySQL 5.7 版本和 MySQL 8.0 版本开始,开发者可以在表的一列中存储 JSON 文档。由于引入 X DevAPI,你可以从你的代码中移除令人不爽的结构化查询字符串,改为使用支持现代编程设计的 API 调用。
|
||||
|
||||
系统学习过结构化查询语言(SQL)、<ruby>关系理论<rt>relational theory</rt></ruby>和其它关系数据库底层理论的开发者并不多,但他们需要一个安全可靠的数据存储。如果数据库管理人员不足,事情很快就会变得一团糟,
|
||||
系统学习过结构化查询语言(SQL)、<ruby>关系理论<rt>relational theory</rt></ruby>、<ruby>集合<rt>set</rt></ruby>和其它关系数据库底层理论的开发者并不多,但他们需要一个安全可靠的数据存储。如果数据库管理人员不足,事情很快就会变得一团糟,
|
||||
|
||||
[MySQL 文档存储][1] 允许开发者跳过底层数据结构创建、数据规范化和其它使用传统数据库时需要做的工作,直接存储数据。只需创建一个 JSON <ruby>文档集合<rt>document collection</rt></ruby>,接着就可以使用了。
|
||||
|
||||
### JSON 数据类型
|
||||
|
||||
所有这一切都基于多年前 MySQL 5.7 引入的 JSON 数据类型。允许在表的一行中提供大约 1GB 的列。数据必须是有效的 JSON,否则服务器会报错;但开发者可以自由使用这些空间。
|
||||
所有这一切都基于多年前 MySQL 5.7 引入的 JSON 数据类型。它允许在表的一行中提供大约 1GB 大小的列。数据必须是有效的 JSON,否则服务器会报错;但开发者可以自由使用这些空间。
|
||||
|
||||
### X DevAPI
|
||||
|
||||
旧的 MySQL 协议已经历经差不多四分之一个世纪,已经显现出疲态,因此新的协议被开发出来,协议名为 [X DevAPI][2]。协议引入高级会话概念,允许代码从单台服务器扩展到多台,使用符合<ruby>通用主机编程语言样式<rt>common host-language programming patterns</rt></ruby>的非阻塞异步 I/O。需要关注的是如何遵循现代实践和编码风格,同时使用 CRUD (create, replace, update, delete) 样式。换句话说,你不再需要在你精美、淳朴的代码中嵌入丑陋的 SQL 语句字符串。
|
||||
旧的 MySQL 协议已经历经差不多四分之一个世纪,已经显现出疲态,因此新的协议被开发出来,协议名为 [X DevAPI][2]。协议引入高级会话概念,允许代码从单台服务器扩展到多台,使用符合<ruby>通用主机编程语言样式<rt>common host-language programming patterns</rt></ruby>的非阻塞异步 I/O。需要关注的是如何遵循现代实践和编码风格,同时使用 CRUD (Create、 Replace、 Update、 Delete)样式。换句话说,你不再需要在你精美、纯洁的代码中嵌入丑陋的 SQL 语句字符串。
|
||||
|
||||
一个新的 shell 支持这种新协议,即所谓的 [MySQL Shell][3]。该 shell 可用于设置<ruby>高可用集群<rt>high-availability cluster</rt></ruby>、检查服务器<ruby>升级就绪状态<rt>upgrade readiness</rt></ruby>以及与 MySQL 服务器交互。支持的交互方式有以下三种:JavaScript,Python 和 SQL。
|
||||
|
||||
### 代码示例
|
||||
|
||||
一个新的 shell 支持这种新协议,即所谓的 [MySQL Shell][3]。该 shell 可用于设置<ruby>高可用集群<rt>high-availability clusters</rt></ruby>、检查服务器<ruby>升级就绪状态<rt>upgrade readiness</rt></ruby>以及与 MySQL 服务器交互。支持的交互方式有以下三种:JavaScript,Python 和 SQL。
|
||||
|
||||
下面的代码示例基于 JavaScript 方式使用 MySQL Shell,可以从 `JS>` 提示符看出。
|
||||
|
||||
下面,我们将使用用户 `dstokes` 、密码 `password` 登录本地系统上的 `demo` 库。`db` 是一个指针,指向 demo 库。
|
||||
下面,我们将使用用户 `dstokes` 、密码 `password` 登录本地系统上的 `demo` 库。`db` 是一个指针,指向 `demo` 库。
|
||||
|
||||
```
|
||||
$ mysqlsh dstokes:password@localhost/demo
|
||||
JS> db.createCollection("example")
|
||||
@ -35,14 +38,14 @@ JS> db.example.add(
|
||||
}
|
||||
)
|
||||
JS>
|
||||
|
||||
```
|
||||
|
||||
在上面的示例中,我们登录服务器,连接到 `demo` 库,创建了一个名为 `example` 的集合,最后插入一条记录;整个过程无需创建表,也无需使用 SQL。只要你能想象的到,你可以使用甚至滥用这些数据。这不是一种代码对象与关系语句之间的映射器,因为并没有将代码映射为 SQL;新协议直接与服务器层打交道。
|
||||
|
||||
### Node.js 支持
|
||||
|
||||
新 shell 看起来挺不错,你可以用其完成很多工作;但你可能更希望使用你选用的编程语言。下面的例子使用 `world_x` 示例数据库,搜索 `_id` 字段匹配 "CAN." 的记录。我们指定数据库中的特定集合,使用特定参数调用 `find` 命令。同样地,操作也不涉及 SQL。
|
||||
新 shell 看起来挺不错,你可以用其完成很多工作;但你可能更希望使用你选用的编程语言。下面的例子使用 `world_x` 示例数据库,搜索 `_id` 字段匹配 `CAN.` 的记录。我们指定数据库中的特定集合,使用特定参数调用 `find` 命令。同样地,操作也不涉及 SQL。
|
||||
|
||||
```
|
||||
var mysqlx = require('@mysql/xdevapi');
|
||||
mysqlx.getSession({ //Auth to server
|
||||
@ -62,10 +65,10 @@ collection // Get row for 'CAN'
|
||||
|
||||
session.close();
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
下面例子使用 PHP,搜索 `_id` 字段匹配 "USA" 的记录:
|
||||
下面例子使用 PHP,搜索 `_id` 字段匹配 `USA` 的记录:
|
||||
|
||||
```
|
||||
<?PHP
|
||||
// Connection parameters
|
||||
@ -88,19 +91,16 @@ collection // Get row for 'CAN'
|
||||
$data = $result->fetchAll();
|
||||
var_dump($data);
|
||||
?>
|
||||
|
||||
```
|
||||
|
||||
可以看出,在上面两个使用不同编程语言的例子中,`find` 操作符的用法基本一致。这种一致性对跨语言编程的开发者有很大帮助,对试图降低新语言学习成本的开发者也不无裨益。
|
||||
|
||||
支持的语言还包括 C,Java,Python 和 JavaScript 等,未来还会有更多支持的语言。
|
||||
支持的语言还包括 C、Java、Python 和 JavaScript 等,未来还会有更多支持的语言。
|
||||
|
||||
### 从两种方式受益
|
||||
|
||||
我会告诉你使用 NoSQL 方式录入的数据也可以用 SQL 方式使用?换句话说,我会告诉你新引入的 NoSQL 方式可以访问旧式关系型表中的数据?现在使用 MySQL 服务器有多种方式,作为 SQL 服务器,作为 NoSQL 服务器或者同时作为两者。
|
||||
|
||||
Dave Stokes 将于 6 月 8-10 日在北卡罗来纳州 Charlotte 市举行的 [Southeast LinuxFest][4] 大会上做”不用 SQL 的 MySQL,我的天哪!“主题演讲。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/mysql-document-store
|
||||
@ -108,7 +108,7 @@ via: https://opensource.com/article/18/6/mysql-document-store
|
||||
作者:[Dave Stokes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
149
published/20180611 How to partition a disk in Linux.md
Normal file
149
published/20180611 How to partition a disk in Linux.md
Normal file
@ -0,0 +1,149 @@
|
||||
如何在 Linux 中使用 parted 对磁盘分区
|
||||
==========
|
||||
|
||||
> 学习如何在 Linux 中使用 parted 命令来对存储设备分区。
|
||||
|
||||

|
||||
|
||||
在 Linux 中创建和删除分区是一种常见的操作,因为存储设备(如硬盘驱动器和 USB 驱动器)在使用之前必须以某种方式进行结构化。在大多数情况下,大型存储设备被分为称为<ruby>分区<rt>partition</rt></ruby>的独立部分。分区操作允许您将硬盘分割成独立的部分,每个部分都像是一个硬盘驱动器一样。如果您运行多个操作系统,那么分区是非常有用的。
|
||||
|
||||
在 Linux 中有许多强大的工具可以创建、删除和操作磁盘分区。在本文中,我将解释如何使用 `parted` 命令,这对于大型磁盘设备和许多磁盘分区尤其有用。`parted` 与更常见的 `fdisk` 和 `cfdisk` 命令之间的区别包括:
|
||||
|
||||
* **GPT 格式:**`parted` 命令可以创建全局惟一的标识符分区表 [GPT][1],而 `fdisk` 和 `cfdisk` 则仅限于 DOS 分区表。
|
||||
* **更大的磁盘:** DOS 分区表可以格式化最多 2TB 的磁盘空间,尽管在某些情况下最多可以达到 16TB。然而,一个 GPT 分区表可以处理最多 8ZiB 的空间。
|
||||
* **更多的分区:** 使用主分区和扩展分区,DOS 分区表只允许 16 个分区。在 GPT 中,默认情况下您可以得到 128 个分区,并且可以选择更多的分区。
|
||||
* **可靠性:** 在 DOS 分区表中,只保存了一份分区表备份,在 GPT 中保留了两份分区表的备份(在磁盘的起始和结束部分),同时 GPT 还使用了 [CRC][2] 校验和来检查分区表的完整性,在 DOS 分区中并没有实现。
|
||||
|
||||
由于现在的磁盘更大,需要更灵活地使用它们,建议使用 `parted` 来处理磁盘分区。大多数时候,磁盘分区表是作为操作系统安装过程的一部分创建的。在向现有系统添加存储设备时,直接使用 `parted` 命令非常有用。
|
||||
|
||||
### 尝试一下 parted
|
||||
|
||||
下面解释了使用 `parted` 命令对存储设备进行分区的过程。为了尝试这些步骤,我强烈建议使用一块全新的存储设备或一种您不介意将其内容删除的设备。
|
||||
|
||||
#### 1、列出分区
|
||||
|
||||
使用 `parted -l` 来标识你要进行分区的设备。一般来说,第一个硬盘 (`/dev/sda` 或 `/dev/vda` )保存着操作系统, 因此要寻找另一个磁盘,以找到你想要分区的磁盘 (例如,`/dev/sdb`、`/dev/sdc`、 `/dev/vdb `、`/dev/vdc` 等)。
|
||||
|
||||
```
|
||||
$ sudo parted -l
|
||||
[sudo] password for daniel:
|
||||
Model: ATA RevuAhn_850X1TU5 (scsi)
|
||||
Disk /dev/vdc: 512GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 525MB 524MB primary ext4 boot
|
||||
2 525MB 512GB 512GB primary lvm
|
||||
```
|
||||
|
||||
#### 2、打开存储设备
|
||||
|
||||
使用 `parted` 选中您要分区的设备。在这里例子中,是虚拟系统上的第三个磁盘(`/dev/vdc`)。指明你要使用哪一个设备非常重要。 如果你仅仅输入了 `parted` 命令而没有指定设备名字, 它会**随机**选择一个设备进行操作。
|
||||
|
||||
```
|
||||
$ sudo parted /dev/vdc
|
||||
GNU Parted 3.2
|
||||
Using /dev/vdc
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted)
|
||||
```
|
||||
|
||||
#### 3、 设定分区表
|
||||
|
||||
设置分区表为 GPT ,然后输入 `Yes` 开始执行。
|
||||
|
||||
```
|
||||
(parted) mklabel gpt
|
||||
Warning: the existing disk label on /dev/vdc will be destroyed
|
||||
and all data on this disk will be lost. Do you want to continue?
|
||||
Yes/No? Yes
|
||||
```
|
||||
|
||||
`mklabel` 和 `mktable` 命令用于相同的目的(在存储设备上创建分区表)。支持的分区表有:aix、amiga、bsd、dvh、gpt、mac、ms-dos、pc98、sun 和 loop。记住 `mklabel` 不会创建一个分区,而是创建一个分区表。
|
||||
|
||||
#### 4、 检查分区表
|
||||
|
||||
查看存储设备信息:
|
||||
|
||||
```
|
||||
(parted) print
|
||||
Model: Virtio Block Device (virtblk)
|
||||
Disk /dev/vdc: 1396MB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: gpt
|
||||
Disk Flags:
|
||||
Number Start End Size File system Name Flags
|
||||
```
|
||||
|
||||
#### 5、 获取帮助
|
||||
|
||||
为了知道如何去创建一个新分区,输入: `(parted) help mkpart` 。
|
||||
|
||||
```
|
||||
(parted) help mkpart
|
||||
mkpart PART-TYPE [FS-TYPE] START END make a partition
|
||||
|
||||
PART-TYPE is one of: primary, logical, extended
|
||||
FS-TYPE is one of: btrfs, nilfs2, ext4, ext3, ext2, fat32, fat16, hfsx, hfs+, hfs, jfs, swsusp,
|
||||
linux-swap(v1), linux-swap(v0), ntfs, reiserfs, hp-ufs, sun-ufs, xfs, apfs2, apfs1, asfs, amufs5,
|
||||
amufs4, amufs3, amufs2, amufs1, amufs0, amufs, affs7, affs6, affs5, affs4, affs3, affs2, affs1,
|
||||
affs0, linux-swap, linux-swap(new), linux-swap(old)
|
||||
START and END are disk locations, such as 4GB or 10%. Negative values count from the end of the
|
||||
disk. For example, -1s specifies exactly the last sector.
|
||||
|
||||
'mkpart' makes a partition without creating a new file system on the partition. FS-TYPE may be
|
||||
specified to set an appropriate partition ID.
|
||||
```
|
||||
|
||||
#### 6、 创建分区
|
||||
|
||||
为了创建一个新分区(在这个例子中,分区 0 有 1396MB),输入下面的命令:
|
||||
|
||||
```
|
||||
(parted) mkpart primary 0 1396MB
|
||||
|
||||
Warning: The resulting partition is not properly aligned for best performance
|
||||
Ignore/Cancel? I
|
||||
|
||||
(parted) print
|
||||
Model: Virtio Block Device (virtblk)
|
||||
Disk /dev/vdc: 1396MB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: gpt
|
||||
Disk Flags:
|
||||
Number Start End Size File system Name Flags
|
||||
1 17.4kB 1396MB 1396MB primary
|
||||
```
|
||||
|
||||
文件系统类型(`fstype`)并不是在 `/dev/vdc1`上创建 ext4 文件系统。 DOS 分区表的分区类型是<ruby>主分区<rt>primary</rt></ruby>、<ruby>逻辑分区<rt>logical</rt></ruby>和<ruby>扩展分区<rt>extended</rt></ruby>。 在 GPT 分区表中,分区类型用作分区名称。 在 GPT 下必须提供分区名称;在上例中,`primary` 是分区名称,而不是分区类型。
|
||||
|
||||
#### 7、 保存退出
|
||||
|
||||
当你退出 `parted` 时,修改会自动保存。退出请输入如下命令:
|
||||
|
||||
```
|
||||
(parted) quit
|
||||
Information: You may need to update /etc/fstab.
|
||||
$
|
||||
```
|
||||
|
||||
### 谨记
|
||||
|
||||
当您添加新的存储设备时,请确保在开始更改其分区表之前确定正确的磁盘。如果您错误地更改了包含计算机操作系统的磁盘分区,会使您的系统无法启动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/how-partition-disk-linux
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/GUID_Partition_Table
|
||||
[2]:https://en.wikipedia.org/wiki/Cyclic_redundancy_check
|
||||
@ -0,0 +1,60 @@
|
||||
如何在 Ubuntu Linux 上挂载和使用 exFAT 驱动器
|
||||
======
|
||||
|
||||
> 简介:本教程将向你展示如何在 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版上启用 exFAT 文件系统支持。用此种方法在系统上挂载 exFAT 驱动器时,你将不会看到错误消息。
|
||||
|
||||
### 在 Ubuntu 上挂载 exFAT 磁盘时出现问题
|
||||
|
||||
有一天,我试图使用以 exFAT 格式化 的 U 盘,其中包含约为 10GB 大小的文件。只要我插入 U 盘,我的 Ubuntu 16.04 就会抛出一个错误说**无法挂载未知的文件系统类型 ‘exfat’**。
|
||||
|
||||
![Fix exfat drive mount error on Ubuntu Linux][1]
|
||||
|
||||
确切的错误信息是这样的:
|
||||
|
||||
```
|
||||
Error mounting /dev/sdb1 at /media/abhishek/SHADI DATA: Command-line `mount -t "exfat" -o "uhelper=udisks2,nodev,nosuid,uid=1001,gid=1001,iocharset=utf8,namecase=0,errors=remount-ro,umask=0077" "/dev/sdb1" "/media/abhishek/SHADI DATA"` exited with non-zero exit status 32: mount: unknown filesystem type 'exfat'
|
||||
```
|
||||
|
||||
### exFAT 挂载错误的原因
|
||||
|
||||
微软最喜欢的 [FAT 文件系统][2]仅限于最大 4GB 的文件。你不能将大于 4GB 的文件传输到 FAT 驱动器。为了克服 FAT 文件系统的限制,微软在 2006 年推出了 [exFAT][3] 文件系统。
|
||||
|
||||
由于大多数微软相关的东西都是专有的,exFAT 文件格式也不例外。Ubuntu 和许多其他 Linux 发行版默认不提供专有的 exFAT 文件支持。这就是你看到 exFAT 文件出现挂载错误的原因。
|
||||
|
||||
### 如何在 Ubuntu Linux 上挂载 exFAT 驱动器
|
||||
|
||||
![Fix exFAT mount error on Ubuntu Linux][4]
|
||||
|
||||
解决这个问题很简单。你只需启用 exFAT 支持即可。
|
||||
|
||||
我将展示在 Ubuntu 中的命令,但这应该适用于其他基于 Ubuntu 的发行版,例如 [Linux Mint][5]、elementary OS 等。
|
||||
|
||||
打开终端(Ubuntu 中 `Ctrl+Alt+T` 快捷键)并使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install exfat-fuse exfat-utils
|
||||
```
|
||||
|
||||
安装完这些软件包后,进入文件管理器并再次点击 U 盘来挂载它。无需重新插入 USB。它应该能直接挂载。
|
||||
|
||||
#### 这对你有帮助么
|
||||
|
||||
我希望这个提示可以帮助你修复 Linux 发行版的 exFAT 的挂载错误。如果你有任何其他问题、建议或感谢,请在评论中留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mount-exfat/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/exfat-mount-error-linux.jpeg
|
||||
[2]:http://www.ntfs.com/fat-systems.htm
|
||||
[3]:https://en.wikipedia.org/wiki/ExFAT
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/exfat-mount-error-featured-800x450.jpeg
|
||||
[5]:https://linuxmint.com/
|
||||
@ -1,3 +1,4 @@
|
||||
(translating by runningwater)
|
||||
A year as Android Engineer
|
||||
============================================================
|
||||
|
||||
@ -121,7 +122,7 @@ The engineer role isn't just coding, but rather a broad range of skills. I am s
|
||||
via: https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8
|
||||
|
||||
作者:[Lara Martín][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Let's migrate away from GitHub
|
||||
======
|
||||
As many of you heard today, [Microsoft is acquiring GitHub][1]. What this means for the future of GitHub is not yet clear, but [the folks at Gitlab][2] think Microsoft's end goal is to integrate GitHub in their Azure empire. To me, this makes a lot of sense.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
"Darsh8 Translating"
|
||||
10 Killer Tips To Speed Up Ubuntu Linux
|
||||
======
|
||||
**Brief** : Some practical **tips to speed up Ubuntu** Linux. Tips here are valid for most versions of Ubuntu and can also be applied in Linux Mint and other Ubuntu based distributions.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Record Everything You Do In Terminal
|
||||
======
|
||||

|
||||
|
||||
@ -1,167 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Token ERC Comparison for Fungible Tokens – Blockchainers
|
||||
======
|
||||
“The good thing about standards is that there are so many to choose from.” [_Andrew S. Tanenbaum_][1]
|
||||
|
||||
### Current State of Token Standards
|
||||
|
||||
The current state of Token standards on the Ethereum platform is surprisingly simple: ERC-20 Token Standard is the only accepted and adopted (as [EIP-20][2]) standard for a Token interface.
|
||||
|
||||
Proposed in 2015, it has finally been accepted at the end of 2017.
|
||||
|
||||
In the meantime, many Ethereum Requests for Comments (ERC) have been proposed which address shortcomings of the ERC-20, which partly were caused by changes in the Ethereum platform itself, eg. the fix for the re-entrancy bug with [EIP-150][3]. Other ERC propose enhancements to the ERC-20 Token model. These enhancements were identified by experiences gathered due to the broad adoption of the Ethereum blockchain and the ERC-20 Token standard. The actual usage of the ERC-20 Token interface resulted in new demands and requirements to address non-functional requirements like permissioning and operations.
|
||||
|
||||
This blogpost should give a superficial, but complete, overview of all proposals for Token(-like) standards on the Ethereum platform. This comparison tries to be objective but most certainly will fail in doing so.
|
||||
|
||||
### The Mother of all Token Standards: ERC-20
|
||||
|
||||
There are dozens of [very good][4] and detailed description of the ERC-20, which will not be repeated here. Just the core concepts relevant for comparing the proposals are mentioned in this post.
|
||||
|
||||
#### The Withdraw Pattern
|
||||
|
||||
Users trying to understand the ERC-20 interface and especially the usage pattern for _transfer_ ing Tokens _from_ one externally owned account (EOA), ie. an end-user (“Alice”), to a smart contract, have a hard time getting the approve/transferFrom pattern right.
|
||||
|
||||
![][5]
|
||||
|
||||
From a software engineering perspective, this withdraw pattern is very similar to the [Hollywood principle][6] (“Don’t call us, we’ll call you!”). The idea is that the call chain is reversed: during the ERC-20 Token transfer, the Token doesn’t call the contract, but the contract does the call transferFrom on the Token.
|
||||
|
||||
While the Hollywood Principle is often used to implement Separation-of-Concerns (SoC), in Ethereum it is a security pattern to avoid having the Token contract to call an unknown function on an external contract. This behaviour was necessary due to the [Call Depth Attack][7] until [EIP-150][3] was activated. After this hard fork, the re-entrancy bug was not possible anymore and the withdraw pattern did not provide any more security than calling the Token directly.
|
||||
|
||||
But why should it be a problem now, the usage might be somehow clumsy, but we can fix this in the DApp frontend, right?
|
||||
|
||||
So, let’s see what happens if a user used transfer to send Tokens to a smart contract. Alice calls transfer on the Token contract with the contract address
|
||||
|
||||
**….aaaaand it’s gone!**
|
||||
|
||||
That’s right, the Tokens are gone. Most likely, nobody will ever get the Tokens back. But Alice is not alone, as Dexaran, inventor of ERC-223, found out, about $400.000 in tokens (let’s just say _a lot_ due to the high volatility of ETH) are irretrievably lost for all of us due to users accidentally sending Tokens to smart contracts.
|
||||
|
||||
Even if the contract developer was extremely user friendly and altruistic, he couldn’t create the contract so that it could react to getting Tokens transferred to it and eg. return them, as the contract will never be notified of this transfer and the event is only emitted on the Token contract.
|
||||
|
||||
From a software engineering perspective that’s a severe shortcoming of ERC-20. If an event occurs (and for the sake of simplicity, we are now assuming Ethereum transactions are actually events), there should be a notification to the parties involved. However, there is an event, but it’s triggered in the Token smart contract which the receiving contract cannot know.
|
||||
|
||||
Currently, it’s not possible to prevent users sending Tokens to smart contracts and losing them forever using the unintuitive transfer on the ERC-20 Token contract.
|
||||
|
||||
### The Empire Strikes Back: ERC-223
|
||||
|
||||
The first attempt at fixing the problems of ERC-20 was proposed by [Dexaran][8]. The main issue solved by this proposal is the different handling of EOA and smart contract accounts.
|
||||
|
||||
The compelling strategy is to reverse the calling chain (and with [EIP-150][3] solved this is now possible) and use a pre-defined callback (tokenFallback) on the receiving smart contract. If this callback is not implemented, the transfer will fail (costing all gas for the sender, a common criticism for ERC-223).
|
||||
|
||||
![][9]
|
||||
|
||||
#### Pros:
|
||||
|
||||
* Establishes a new interface, intentionally being not compliant to ERC-20 with respect to the deprecated functions
|
||||
|
||||
* Allows contract developers to handle incoming tokens (eg. accept/reject) since event pattern is followed
|
||||
|
||||
* Uses one transaction instead of two (transfer vs. approve/transferFrom) and thus saves gas and Blockchain storage
|
||||
|
||||
|
||||
|
||||
|
||||
#### Cons:
|
||||
|
||||
* If tokenFallback doesn’t exist then the contract fallback function is executed, this might have unintended side-effects
|
||||
|
||||
* If contracts assume that transfer works with Tokens, eg. for sending Tokens to specific contracts like multi-sig wallets, this would fail with ERC-223 Tokens, making it impossible to move them (ie. they are lost)
|
||||
|
||||
|
||||
### The Pragmatic Programmer: ERC-677
|
||||
|
||||
The [ERC-667 transferAndCall Token Standard][10] tries to marriage the ERC-20 and ERC-223. The idea is to introduce a transferAndCall function to the ERC-20, but keep the standard as is. ERC-223 intentionally is not completely backwards compatible, since the approve/allowance pattern is not needed anymore and was therefore removed.
|
||||
|
||||
The main goal of ERC-667 is backward compatibility, providing a safe way for new contracts to transfer tokens to external contracts.
|
||||
|
||||
![][11]
|
||||
|
||||
#### Pros:
|
||||
|
||||
* Easy to adapt for new Tokens
|
||||
|
||||
* Compatible to ERC-20
|
||||
|
||||
* Adapter for ERC-20 to use ERC-20 safely
|
||||
|
||||
#### Cons:
|
||||
|
||||
* No real innovations. A compromise of ERC-20 and ERC-223
|
||||
|
||||
* Current implementation [is not finished][12]
|
||||
|
||||
|
||||
### The Reunion: ERC-777
|
||||
|
||||
[ERC-777 A New Advanced Token Standard][13] was introduced to establish an evolved Token standard which learned from misconceptions like approve() with a value and the aforementioned send-tokens-to-contract-issue.
|
||||
|
||||
Additionally, the ERC-777 uses the new standard [ERC-820: Pseudo-introspection using a registry contract][14] which allows for registering meta-data for contracts to provide a simple type of introspection. This allows for backwards compatibility and other functionality extensions, depending on the ITokenRecipient returned by a EIP-820 lookup on the to address, and the functions implemented by the target contract.
|
||||
|
||||
ERC-777 adds a lot of learnings from using ERC-20 Tokens, eg. white-listed operators, providing Ether-compliant interfaces with send(…), using the ERC-820 to override and adapt functionality for backwards compatibility.
|
||||
|
||||
![][15]
|
||||
|
||||
#### Pros:
|
||||
|
||||
* Well thought and evolved interface for tokens, learnings from ERC-20 usage
|
||||
|
||||
* Uses the new standard request ERC-820 for introspection, allowing for added functionality
|
||||
|
||||
* White-listed operators are very useful and are more necessary than approve/allowance , which was often left infinite
|
||||
|
||||
|
||||
#### Cons:
|
||||
|
||||
* Is just starting, complex construction with dependent contract calls
|
||||
|
||||
* Dependencies raise the probability of security issues: first security issues have been [identified (and solved)][16] not in the ERC-777, but in the even newer ERC-820
|
||||
|
||||
|
||||
|
||||
|
||||
### (Pure Subjective) Conclusion
|
||||
|
||||
For now, if you want to go with the “industry standard” you have to choose ERC-20. It is widely supported and well understood. However, it has its flaws, the biggest one being the risk of non-professional users actually losing money due to design and specification issues. ERC-223 is a very good and theoretically founded answer for the issues in ERC-20 and should be considered a good alternative standard. Implementing both interfaces in a new token is not complicated and allows for reduced gas usage.
|
||||
|
||||
A pragmatic solution to the event and money loss problem is ERC-677, however it doesn’t offer enough innovation to establish itself as a standard. It could however be a good candidate for an ERC-20 2.0.
|
||||
|
||||
ERC-777 is an advanced token standard which should be the legitimate successor to ERC-20, it offers great concepts which are needed on the matured Ethereum platform, like white-listed operators, and allows for extension in an elegant way. Due to its complexity and dependency on other new standards, it will take time till the first ERC-777 tokens will be on the Mainnet.
|
||||
|
||||
### Links
|
||||
|
||||
[1] Security Issues with approve/transferFrom-Pattern in ERC-20: <https://drive.google.com/file/d/0ByMtMw2hul0EN3NCaVFHSFdxRzA/view>
|
||||
|
||||
[2] No Event Handling in ERC-20: <https://docs.google.com/document/d/1Feh5sP6oQL1-1NHi-X1dbgT3ch2WdhbXRevDN681Jv4>
|
||||
|
||||
[3] Statement for ERC-20 failures and history: <https://github.com/ethereum/EIPs/issues/223#issuecomment-317979258>
|
||||
|
||||
[4] List of differences ERC-20/223: <https://ethereum.stackexchange.com/questions/17054/erc20-vs-erc223-list-of-differences>
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blockchainers.org/index.php/2018/02/08/token-erc-comparison-for-fungible-tokens/
|
||||
|
||||
作者:[Alexander Culum][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://blockchainers.org/index.php/author/alex/
|
||||
[1]:https://www.goodreads.com/quotes/589703-the-good-thing-about-standards-is-that-there-are-so
|
||||
[2]:https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20.md
|
||||
[3]:https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md
|
||||
[4]:https://medium.com/@jgm.orinoco/understanding-erc-20-token-contracts-a809a7310aa5
|
||||
[5]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-20-Token-Transfer-2.png
|
||||
[6]:http://matthewtmead.com/blog/hollywood-principle-dont-call-us-well-call-you-4/
|
||||
[7]:https://consensys.github.io/smart-contract-best-practices/known_attacks/
|
||||
[8]:https://github.com/Dexaran
|
||||
[9]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-223-Token-Transfer-1.png
|
||||
[10]:https://github.com/ethereum/EIPs/issues/677
|
||||
[11]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-677-Token-Transfer.png
|
||||
[12]:https://github.com/ethereum/EIPs/issues/677#issuecomment-353871138
|
||||
[13]:https://github.com/ethereum/EIPs/issues/777
|
||||
[14]:https://github.com/ethereum/EIPs/issues/820
|
||||
[15]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-777-Token-Transfer.png
|
||||
[16]:https://github.com/ethereum/EIPs/issues/820#issuecomment-362049573
|
||||
@ -1,72 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Python Debugging Tips
|
||||
======
|
||||
When it comes to debugging, there’s a lot of choices that you can make. It is hard to give generic advice that always works (other than “Have you tried turning it off and back on?”).
|
||||
|
||||
Here are a few of my favorite Python Debugging tips.
|
||||
|
||||
### Make a branch
|
||||
|
||||
Trust me on this. Even if you never intend to commit the changes back upstream, you will be glad your experiments are contained within their own branch.
|
||||
|
||||
If nothing else, it makes cleanup a lot easier!
|
||||
|
||||
### Install pdb++
|
||||
|
||||
Seriously. It makes you life easier if you are on the command line.
|
||||
|
||||
All that pdb++ does is replace the standard pdb module with 100% PURE AWESOMENESS. Here’s what you get when you `pip install pdbpp`:
|
||||
|
||||
* A Colorized prompt!
|
||||
* tab completion! (perfect for poking around!)
|
||||
* It slices! It dices!
|
||||
|
||||
|
||||
|
||||
Ok, maybe the last one is a little bit much… But in all seriousness, installing pdb++ is well worth your time.
|
||||
|
||||
### Poke around
|
||||
|
||||
Sometimes the best approach is to just mess around and see what happens. Put a break point in an “obvious” spot and make sure it gets hit. Pepper the code with `print()` and/or `logging.debug()` statements and see where the code execution goes.
|
||||
|
||||
Examine the arguments being passed into your functions. Check the versions of the libraries (if things are getting really desperate).
|
||||
|
||||
### Only change one thing at a time
|
||||
|
||||
Once you are poking around a bit you are going to get ideas on things you could do. But before you start slinging code, take a step back and think about what you could change, and then only change 1 thing.
|
||||
|
||||
Once you’ve made the change, then test and see if you are closer to resolving the issue. If not, change the thing back, and try something else.
|
||||
|
||||
Changing only one thing allows you to know what does and doesn’t work. Plus once you do get it working, your new commit is going to be much smaller (because there will be less changes).
|
||||
|
||||
This is pretty much what one does in the Scientific Process: only change one variable at a time. By allowing yourself to see and measure the results of one change you will save your sanity and arrive at a working solution faster.
|
||||
|
||||
### Assume nothing, ask questions
|
||||
|
||||
Occasionally a developer (not you of course!) will be in a hurry and whip out some questionable code. When you go through to debug this code you need to stop and make sure you understand what it is trying to accomplish.
|
||||
|
||||
Make no assumptions. Just because the code is in the `model.py` file doesn’t mean it won’t try to render some HTML.
|
||||
|
||||
Likewise, double check all of your external connections before you do anything destructive! Going to delete some configuration data? MAKE SURE YOU ARE NOT CONNECTED TO YOUR PRODUCTION SYSTEM.
|
||||
|
||||
### Be clever, but not too clever
|
||||
|
||||
Sometimes we write code that is so amazingly awesome it is not obvious how it does what it does.
|
||||
|
||||
While we might feel smart when we publish that code, more often than not we will wind up feeling dumb later on when the code breaks and we have to remember how it works to figure out why it isn’t working.
|
||||
|
||||
Keep an eye out for any sections of code that look either overly complicated and long, or extremely short. These could be places where complexity is hiding and causing your bugs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pythondebugging.com/articles/python-debugging-tips
|
||||
|
||||
作者:[PythonDebugging.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://pythondebugging.com
|
||||
@ -1,183 +0,0 @@
|
||||
4 tools for building embedded Linux systems
|
||||
======
|
||||

|
||||
|
||||
Linux is being deployed into a much wider array of devices than Linus Torvalds anticipated when he was working on it in his dorm room. The variety of supported chip architectures is astounding and has led to Linux in devices large and small; from [huge IBM mainframes][1] to [tiny devices][2] no bigger than their connection ports and everything in between. It is used in large enterprise data centers, internet infrastructure devices, and personal development systems. It also powers consumer electronics, mobile phones, and many Internet of Things devices.
|
||||
|
||||
When building Linux software for desktop and enterprise-class devices, developers typically use a desktop distribution such as [Ubuntu][3] on their build machines to have an environment as close as possible to the one where the software will be deployed. Tools such as [VirtualBox][4] and [Docker][5] allow even better alignment between development, testing, and productions environments.
|
||||
|
||||
### What is an embedded system?
|
||||
|
||||
Wikipedia defines an [embedded system][6] as: "A computer system with a dedicated function within a larger mechanical or electrical system, often with real-time computing constraints."
|
||||
|
||||
I find it simple enough to say that an embedded system is a computer that most people don't think of as a computer. Its primary role is to serve as an appliance of some sort, and it is not considered a general-purpose computing platform.
|
||||
|
||||
The development environment in embedded systems programming is usually very different from the testing and production environments. They may use different chip architectures, software stacks, and even operating systems. Development workflows are very different for embedded developers vs. desktop and web developers. Typically, the build output will consist of an entire software image for the target device, including the kernel, device drivers, libraries, and application software (and sometimes the bootloader).
|
||||
|
||||
In this article, I will present a survey of four commonly available options for building embedded Linux systems. I will give a flavor for what it's like to work with each and provide enough information to help readers decide which tool to use for their design. I won't teach you how to use any of them; there are plenty of in-depth online learning resources once you have narrowed your choices. No option is right for all use cases, and I hope to present enough details to direct your decision.
|
||||
|
||||
### Yocto
|
||||
|
||||
The [Yocto][7] project is [defined][8] as "an open source collaboration project that provides templates, tools, and methods to help you create custom Linux-based systems for embedded products regardless of the hardware architecture." It is a collection of recipes, configuration values, and dependencies used to create a custom Linux runtime image tailored to your specific needs.
|
||||
|
||||
Full disclosure: most of my work in embedded Linux has focused on the Yocto project, and my knowledge and bias to this system will likely be evident.
|
||||
|
||||
Yocto uses [Openembedded][9] as its build system. Technically the two are separate projects; in practice, however, users do not need to understand the distinction, and the project names are frequently used interchangeably.
|
||||
|
||||
The output of a Yocto project build consists broadly of three components:
|
||||
|
||||
* **Target run-time binaries:** These include the bootloader, kernel, kernel modules, root filesystem image. and any other auxiliary files needed to deploy Linux to the target platform.
|
||||
* **Package feed:** This is the collection of software packages available to be installed on your target. You can select the package format (e.g., deb, rpm, ipk) based on your needs. Some of them may be preinstalled in the target runtime binaries, however, it is possible to build packages for installation into a deployed system.
|
||||
* **Target SDK:** These are the collection of libraries and header files representing the software installed on your target. They are used by application developers when building their code to ensure they are linked with the appropriate libraries
|
||||
|
||||
|
||||
|
||||
#### Advantages
|
||||
|
||||
The Yocto project is widely used in the industry and has backing from many influential companies. Additionally, it has a large and vibrant developer [community][10] and [ecosystem][11] contributing to it. The combination of open source enthusiasts and corporate sponsors helps drive the Yocto project.
|
||||
|
||||
There are many options for getting support with Yocto. There are books and other training materials if you wish to do-it-yourself. Many engineers with experience in Yocto are available if you want to hire expertise. And many commercial organizations provide turnkey Yocto-based products or services-based implementation and customization for your design.
|
||||
|
||||
The Yocto project is easily expanded through [layers][12], which can be published independently to add additional functionality, to target platforms not available in the project releases, or to store customizations unique to your system. Layers can be added to your configuration to add unique features that are not specifically included in the stock releases; for example, the "[meta-browser][13]" layer contains recipes for web browsers, which can be easily built for your system. Because they are independently maintained, layers can be on a different release schedule (tuned to the layers' development velocity) than the standard Yocto releases.
|
||||
|
||||
Yocto has arguably the widest device support of any of the options discussed in this article. Due to support from many semiconductor and board manufacturers, it's likely Yocto will support any target platform you choose. The direct Yocto [releases][14] support only a few boards (to allow for proper testing and release cycles), however, a standard working model is to use external board support layers.
|
||||
|
||||
Finally, Yocto is extremely flexible and customizable. Customizations for your specific application can be stored in a layer for encapsulation and isolation. Customizations unique to a feature layer are generally stored as part of the layer itself, which allows the same settings to be applied simultaneously to multiple system configurations. Yocto also provides a well-defined layer priority and override capability. This allows you to define the order in which layers are applied and searched for metadata. It also enables you to override settings in layers with higher priority; for instance, many customizations to existing recipes will be added in your private layers, with the order precisely controlled by the priorities.
|
||||
|
||||
#### Disadvantages
|
||||
|
||||
The biggest disadvantage with the Yocto project is the learning curve. It takes significant time and effort to learn the system and truly understand it. Depending on your needs, this may be too large of an investment in technologies and competence that are not central to your application. In such cases, working with one of the commercial vendors may be a good option.
|
||||
|
||||
Development build times and resources are fairly high for Yocto project builds. The number of packages that need to be built, including the toolchain, kernel, and all target runtime components, is significant. Development workstations for Yocto developers tend to be large systems. Using a compact notebook is not recommended. This can be mitigated by using cloud-based build servers available from many providers. Additionally, Yocto has a built-in caching mechanism that allows it to reuse previously built components when it determines that the parameters for building a particular package have not changed.
|
||||
|
||||
#### Recommendation
|
||||
|
||||
Using the Yocto project for your next embedded Linux design is a strong choice. Of the options presented here, it is the most broadly applicable regardless of your target use case. The broad industry support, active community, and wide platform support make this a good choice for must designers.
|
||||
|
||||
### Buildroot
|
||||
|
||||
The [Buildroot][15] project is defined as "a simple, efficient, and easy-to-use tool to generate embedded Linux systems through cross-compilation." It shares many of the same objectives as the Yocto project, however it is focused on simplicity and minimalism. In general, Buildroot will disable all optional compile-time settings for all packages (with a few notable exceptions), resulting in the smallest possible system. It will be up to the system designer to enable the settings that are appropriate for a given device.
|
||||
|
||||
Buildroot builds all components from source but does not support on-target package management. As such, it is sometimes called a firmware generator since the images are largely fixed at build time. Applications can update the target filesystem, but there is no mechanism to install new packages into a running system.
|
||||
|
||||
The Buildroot output consists broadly of three components:
|
||||
|
||||
* The root filesystem image and any other auxiliary files needed to deploy Linux to the target platform
|
||||
* The kernel, boot-loader, and kernel modules appropriate for the target hardware
|
||||
* The toolchain used to build all the target binaries.
|
||||
|
||||
|
||||
|
||||
#### Advantages
|
||||
|
||||
Buildroot's focus on simplicity means that, in general, it is easier to learn than Yocto. The core build system is written in Make and is short enough to allow a developer to understand the entire system while being expandable enough to meet the needs of embedded Linux developers. The Buildroot core generally only handles common use cases, but it is expandable via scripting.
|
||||
|
||||
The Buildroot system uses normal Makefiles and the Kconfig language for its configuration. Kconfig was developed by the Linux kernel community and is widely used in open source projects, making it familiar to many developers.
|
||||
|
||||
Due to the design goal of disabling all optional build-time settings, Buildroot will generally produce the smallest possible images using the out-of-the-box configuration. The build times and build host resources will likewise be smaller, in general, than those of the Yocto project.
|
||||
|
||||
#### Disadvantages
|
||||
|
||||
The focus on simplicity and minimal enabled build options imply that you may need to do significant customization to configure a Buildroot build for your application. Additionally, all configuration options are stored in a single file, which means if you have multiple hardware platforms, you will need to make each of your customization changes for each platform.
|
||||
|
||||
Any change to the system configuration file requires a full rebuild of all packages. This is somewhat mitigated by the minimal image sizes and build times compared with Yocto, but it can result in long builds while you are tweaking your configuration.
|
||||
|
||||
Intermediate package state caching is not enabled by default and is not as thorough as the Yocto implementation. This means that, while the first build may be shorter than an equivalent Yocto build, subsequent builds may require rebuilding of many components.
|
||||
|
||||
#### Recommendation
|
||||
|
||||
Using Buildroot for your next embedded Linux design is a good choice for most applications. If your design requires multiple hardware types or other differences, you may want to reconsider due to the complexity of synchronizing multiple configurations, however, for a system consisting of a single setup, Buildroot will likely work well for you.
|
||||
|
||||
### OpenWRT/LEDE
|
||||
|
||||
The [OpenWRT][16] project was started to develop custom firmware for consumer routers. Many of the low-cost routers available at your local retailer are capable of running a Linux system, but maybe not out of the box. The manufacturers of these routers may not provide frequent updates to address new threats, and even if they do, the mechanisms to install updated images are difficult and error-prone. The OpenWRT project produces updated firmware images for many devices that have been abandoned by their manufacturers and gives these devices a new lease on life.
|
||||
|
||||
The OpenWRT project's primary deliverables are binary images for a large number of commercial devices. There are network-accessible package repositories that allow device end users to add new software to their systems. The OpenWRT build system is a general-purpose build system, which allows developers to create custom versions to meet their own requirements and add new packages, but its primary focus is target binaries.
|
||||
|
||||
#### Advantages
|
||||
|
||||
If you are looking for replacement firmware for a commercial device, OpenWRT should be on your list of options. It is well-maintained and may protect you from issues that the manufacturer's firmware cannot. You can add extra functionality as well, making your devices more useful.
|
||||
|
||||
If your embedded design is networking-focused, OpenWRT is a good choice. Networking applications are the primary use case for OpenWRT, and you will likely find many of those software packages available in it.
|
||||
|
||||
#### Disadvantages
|
||||
|
||||
OpenWRT imposes significant policy decisions on your design (vs. Yocto and Buildroot). If these decisions don't meet your design goals, you may have to do non-trivial modifications.
|
||||
|
||||
Allowing package-based updates in a fleet of deployed devices is difficult to manage. This, by definition, results in a different software load than what your QA team tested. Additionally, it is difficult to guarantee atomic installs with most package managers, and an ill-timed power cycle can leave your device in an unpredictable state.
|
||||
|
||||
#### Recommendation
|
||||
|
||||
OpenWRT is a good choice for hobbyist projects or for reusing commercial hardware. It is also a good choice for networking applications. If you need significant customization from the default setup, you may prefer Buildroot or Yocto.
|
||||
|
||||
### Desktop distros
|
||||
|
||||
A common approach to designing embedded Linux systems is to start with a desktop distribution, such as [Debian][17] or [Red Hat][18], and remove unneeded components until the installed image fits into the footprint of your target device. This is the approach taken for the popular [Raspbian][19] distribution for the [Raspberry Pi][20] platform.
|
||||
|
||||
#### Advantages
|
||||
|
||||
The primary advantage of this approach is familiarity. Often, embedded Linux developers are also desktop Linux users and are well-versed in their distro of choice. Using a similar environment on the target may allow developers to get started more quickly. Depending on the chosen distribution, many additional tools can be installed using standard packaging tools such as apt and yum.
|
||||
|
||||
It may be possible to attach a display and keyboard to your target device and do all your development directly there. For developers new to the embedded space, this is likely to be a more familiar environment and removes the need to configure and use a tricky cross-development setup.
|
||||
|
||||
The number of packages available for most desktop distributions is generally greater than that available for the embedded-specific builders discussed previously. Due to the larger user base and wider variety of use cases, you may be able to find all the runtime packages you need for your application already built and ready for use.
|
||||
|
||||
#### Disadvantages
|
||||
|
||||
Using the target as your primary development environment is likely to be slow. Running compiler tools is a resource-intensive operation and, depending on how much code you are building, may hinder your performance.
|
||||
|
||||
With some exceptions, desktop distributions are not designed to accommodate low-resource systems, and it may be difficult to adequately trim your target images. Similarly, the expected workflow in a desktop environment is not ideal for most embedded designs. Getting a reproducible environment in this fashion is difficult. Manually adding and deleting packages is error-prone. This can be scripted using distribution-specific tools, such as [debootstrap][21] for Debian-based systems. To further improve [reproducibility][21], you can use a configuration management tool, such as [CFEngine][22] (which, full disclosure, is made by my employer, [Mender.io][23]). However, you are still at the mercy of the distribution provider, who will update packages to meet their needs, not yours.
|
||||
|
||||
#### Recommendation
|
||||
|
||||
Be wary of this approach for a product you plan to take to market. This is a fine model for hobbyist applications; however, for products that need support, this approach is likely going to be trouble. While you may be able to get a faster start, it may cost you time and effort in the long run.
|
||||
|
||||
### Other considerations
|
||||
|
||||
This discussion has focused on build systems' functionality, but there are usually non-functional requirements that may affect your decision. If you have already selected your system-on-chip (SoC) or board, your choice will likely be dictated by the vendor. If your vendor provides a board support package (BSP) for a given system, using it will normally save quite a bit of time, but please research the BSP's quality to avoid issues later in your development cycle.
|
||||
|
||||
If your budget allows, you may want to consider using a commercial vendor for your target OS. There are companies that will provide a validated and supported configuration of many of the options discussed here, and, unless you have expertise in embedded Linux build systems, this is a good choice and will allow you to focus on your core competency.
|
||||
|
||||
As an alternative, you may consider commercial training for your development staff. This is likely to be cheaper than a commercial OS provider and will allow you to be more self-sufficient. This is a quick way to get over the learning curve for the basics of the build system you choose.
|
||||
|
||||
Finally, you may already have some developers with experience with one or more of the systems. If you have engineers who have a preference, it is certainly worth taking that into consideration as you make your decision.
|
||||
|
||||
### Summary
|
||||
|
||||
There are many choices available for building embedded Linux systems, each with advantages and disadvantages. It is crucial to prioritize this part of your design, as it is extremely costly to switch systems later in the process. In addition to these options, new systems are being developed all the time. Hopefully, this discussion will provide some context for reviewing new systems (and the ones mentioned here) and help you make a solid decision for your next project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/embedded-linux-build-tools
|
||||
|
||||
作者:[Drew Moseley][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drewmoseley
|
||||
[1]:https://en.wikipedia.org/wiki/Linux_on_z_Systems
|
||||
[2]:http://www.picotux.com/
|
||||
[3]:https://www.ubuntu.com/
|
||||
[4]:https://www.virtualbox.org/
|
||||
[5]:https://www.docker.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Embedded_system
|
||||
[7]:https://yoctoproject.org/
|
||||
[8]:https://www.yoctoproject.org/about/
|
||||
[9]:https://www.openembedded.org/
|
||||
[10]:https://www.yoctoproject.org/community/
|
||||
[11]:https://www.yoctoproject.org/ecosystem/participants/
|
||||
[12]:https://layers.openembedded.org/layerindex/branch/master/layers/
|
||||
[13]:https://layers.openembedded.org/layerindex/branch/master/layer/meta-browser/
|
||||
[14]:https://yoctoproject.org/downloads
|
||||
[15]:https://buildroot.org/
|
||||
[16]:https://openwrt.org/
|
||||
[17]:https://www.debian.org/
|
||||
[18]:https://www.redhat.com/
|
||||
[19]:https://www.raspbian.org/
|
||||
[20]:https://www.raspberrypi.org/
|
||||
[21]:https://wiki.debian.org/Debootstrap
|
||||
[22]:https://cfengine.com/
|
||||
[23]:http://Mender.io
|
||||
@ -1,59 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
BLUI: An easy way to create game UI
|
||||
======
|
||||
|
||||

|
||||
|
||||
Game development engines have become increasingly accessible in the last few years. Engines like Unity, which has always been free to use, and Unreal, which recently switched from a subscription-based service to a free service, allow independent developers access to the same industry-standard tools used by AAA publishers. While neither of these engines is open source, each has enabled the growth of open source ecosystems around it.
|
||||
|
||||
Within these engines are plugins that allow developers to enhance the base capabilities of the engine by adding specific applications. These apps can range from simple asset packs to more complicated things, like artificial intelligence (AI) integrations. These plugins widely vary across creators. Some are offered by the engine development studios and others by individuals. Many of the latter are open source plugins.
|
||||
|
||||
### What is BLUI?
|
||||
|
||||
As part of an indie game development studio, I've experienced the perks of using open source plugins on proprietary game engines. One open source plugin, [BLUI][1] by Aaron Shea, has been instrumental in our team's development process. It allows us to create user interface (UI) components using web-based programming like HTML/CSS and JavaScript. We chose to use this open source plugin, even though Unreal Engine (our engine of choice) has a built-in UI editor that achieves a similar purpose. We chose to use open source alternatives for three main reasons: their accessibility, their ease of implementation, and the active, supportive online communities that accompany open source programs.
|
||||
|
||||
In Unreal Engine's earliest versions, the only means we had of creating UI in the game was either through the engine's native UI integration, by using Autodesk's Scaleform application, or via a few select subscription-based Unreal integrations spread throughout the Unreal community. In all those cases, the solutions were either incapable of providing a competitive UI solution for indie developers, too expensive for small teams, or exclusively for large-scale teams and AAA developers.
|
||||
|
||||
After commercial products and Unreal's native integration failed us, we looked to the indie community for solutions. There we discovered BLUI. It not only integrates with Unreal Engine seamlessly but also maintains a robust and active community that frequently pushes updates and ensures the documentation is easily accessible for indie developers. BLUI gives developers the ability to import HTML files into the Unreal Engine and program them even further while inside the program. This allows UI created through web languages to integrate with the game's code, assets, and other elements with the full power of HTML, CSS, JavaScript, and other web languages. It also provides full support for the open source [Chromium Embedded Framework][2].
|
||||
|
||||
### Installing and using BLUI
|
||||
|
||||
The basic process for using BLUI involves first creating the UI via HTML. Developers may use any tool at their disposal to achieve this, including bootstrapped JavaScript code, external APIs, or any database code. Once this HTML page is ready, you can install the plugin the same way you would install any Unreal plugin and load or create a project. Once the project is loaded, you can place a BLUI function anywhere within an Unreal UI blueprint or hardcoded via C++. Developers can call functions from within their HTML page or change variables easily using BLUI's internal functions.
|
||||
|
||||
![Integrating BLUI into Unreal Engine 4 blueprints][4]
|
||||
|
||||
Integrating BLUI into Unreal Engine 4 blueprints.
|
||||
|
||||
In our current project, we use BLUI to sync UI elements with the in-game soundtrack to provide visual feedback to the rhythm aspects of the game mechanics. It's easy to integrate custom engine programming with the BLUI plugin.
|
||||
|
||||
![Using BLUI to sync UI elements with the soundtrack.][6]
|
||||
|
||||
Using BLUI to sync UI elements with the soundtrack.
|
||||
|
||||
Implementing BLUI into Unreal Engine 4 is a trivial process thanks to the [documentation][7] on the BLUI GitHub page. There is also [a forum][8] populated with supportive Unreal Engine developers eager to both ask and answer questions regarding the plugin and any issues that appear when implementing the tool.
|
||||
|
||||
### Open source advantages
|
||||
|
||||
Open source plugins enable expanded creativity within the confines of proprietary game engines. They continue to lower the barrier of entry into game development and can produce in-game mechanics and assets no one has seen before. As access to proprietary game development engines continues to grow, the open source plugin community will become more important. Rising creativity will inevitably outpace proprietary software, and open source will be there to fill the gaps and facilitate the development of truly unique games. And that novelty is exactly what makes indie games so great!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blui-game-development-plugin
|
||||
|
||||
作者:[Uwana lkaiddi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/uwikaiddi
|
||||
[1]:https://github.com/AaronShea/BLUI
|
||||
[2]:https://bitbucket.org/chromiumembedded/cef
|
||||
[3]:/file/400616
|
||||
[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
|
||||
[5]:/file/400621
|
||||
[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
|
||||
[7]:https://github.com/AaronShea/BLUI/wiki
|
||||
[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
|
||||
@ -1,58 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
How to Mount and Use an exFAT Drive on Ubuntu Linux
|
||||
======
|
||||
**Brief: This quick tutorial shows you how to enable exFAT file system support on Ubuntu and other Ubuntu-based Linux distributions. This way you won’t see any error while mounting exFAT drives on your system.**
|
||||
|
||||
### Problem mounting exFAT disk on Ubuntu
|
||||
|
||||
The other day, I tried to use an external USB key formatted in exFAT format that contained a file of around 10 GB in size. As soon as I plugged the USB key, my Ubuntu 16.04 throw an error complaining that it **cannot mount unknown filesystem type ‘exfat’**.
|
||||
|
||||
![Fix exfat drive mount error on Ubuntu Linux][1]
|
||||
|
||||
The exact error message was this:
|
||||
**Error mounting /dev/sdb1 at /media/abhishek/SHADI DATA: Command-line `mount -t “exfat” -o “uhelper=udisks2,nodev,nosuid,uid=1001,gid=1001,iocharset=utf8,namecase=0,errors=remount-ro,umask=0077” “/dev/sdb1” “/media/abhishek/SHADI DATA”‘ exited with non-zero exit status 32: mount: unknown filesystem type ‘exfat’**
|
||||
|
||||
### The reason behind this exFAT mount error
|
||||
|
||||
Microsoft’s favorite [FAT file system][2] is limited to files up to 4GB in size. You cannot transfer a file bigger than 4 GB in size to a FAT drive. To overcome the limitations of the FAT filesystem, Microsoft introduced [exFAT][3] file system in 2006.
|
||||
|
||||
As most of the Microsoft related stuff are proprietary, exFAT file format is no exception to that. Ubuntu and many other Linux distributions don’t provide the proprietary exFAT file support by default. This is the reason why you see the mount error with exFAT files.
|
||||
|
||||
### How to mount exFAT drive on Ubuntu Linux
|
||||
|
||||
![Fix exFAT mount error on Ubuntu Linux][4]
|
||||
|
||||
The solution to this problem is simple. All you need to do is to enable exFAT support.
|
||||
|
||||
I am going to show the commands for Ubuntu but this should be applicable to other Ubuntu-based distributions such as [Linux Mint][5], elementary OS etc.
|
||||
|
||||
Open a terminal (Ctrl+Alt+T shortcut in Ubuntu) and use the following command:
|
||||
```
|
||||
sudo apt install exfat-fuse exfat-utils
|
||||
|
||||
```
|
||||
|
||||
Once you have installed these packages, go to file manager and click on the USB disk again to mount it. There is no need to replug the USB. It should be mounted straightaway.
|
||||
|
||||
#### Did it help you?
|
||||
|
||||
I hope this quick tip helped you to fix the exFAT mount error for your Linux distribution. If you have any further questions, suggestions or a simple thanks, please use the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mount-exfat/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/exfat-mount-error-linux.jpeg
|
||||
[2]:http://www.ntfs.com/fat-systems.htm
|
||||
[3]:https://en.wikipedia.org/wiki/ExFAT
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/exfat-mount-error-featured-800x450.jpeg
|
||||
[5]:https://linuxmint.com/
|
||||
@ -1,95 +0,0 @@
|
||||
Use this vi setup to keep and organize your notes
|
||||
======
|
||||
|
||||

|
||||
|
||||
The idea of using vi to manage a wiki for your notes may seem unconventional, but when you're using vi in your daily work, it makes a lot of sense.
|
||||
|
||||
As a software developer, it’s just easier to write my notes in the same tool I use to code. I want my notes to be only an editor command away, available wherever I am, and managed the same way I handle my code. That's why I created a vi-based setup for my personal knowledge base. In a nutshell: I use the vi plugin [Vimwiki][1] to manage my wiki locally on my laptop, I use Git to version it (and keep a central, updated version), and I use GitLab for online editing (for example, on my mobile device).
|
||||
|
||||
### Why it makes sense to use a wiki for note-keeping
|
||||
|
||||
I've tried many different tools to keep track of notes, write down fleeting thoughts, and structure tasks I shouldn’t forget. These include offline notebooks (yes, that involves paper), special note-keeping software, and mind-mapping software.
|
||||
|
||||
All these solutions have positives, but none fit all of my needs. For example, [mind maps][2] are a great way to visualize what’s in your mind (hence the name), but the tools I tried provided poor searching functionality. (The same thing is true for paper notes.) Also, it’s often hard to read mind maps after time passes, so they don’t work very well for long-term note keeping.
|
||||
|
||||
One day while setting up a [DokuWiki][3] for a collaboration project, I found that the wiki structure fits most of my requirements. With a wiki, you can create notes (like you would in any text editor) and create links between your notes. If a link points to a non-existent page (maybe because you wanted a piece of information to be on its own page but haven’t set it up yet), the wiki will create that page for you. These features make a wiki a good fit for quickly writing things as they come to your mind, while still keeping your notes in a page structure that is easy to browse and search for keywords.
|
||||
|
||||
While this sounds promising, and setting up DokuWiki is not difficult, I found it a bit too much work to set up a whole wiki just for keeping track of my notes. After some research, I found Vimwiki, a Vi plugin that does what I want. Since I use Vi every day, keeping notes is very similar to editing code. Also, it’s even easier to create a page in Vimwiki than DokuWiki—all you have to do is press Enter while your cursor hovers over a word. If there isn’t already a page with that name, Vimwiki will create it for you.
|
||||
|
||||
To take my plan to use my everyday tools for note-keeping a step further, I’m not only using my favorite IDE to write notes but also my favorite code management tools—Git and GitLab—to distribute notes across my various machines and be able to access them online. I’m also using Markdown syntax in GitLab's online Markdown editor to write this article.
|
||||
|
||||
### Setting up Vimwiki
|
||||
|
||||
Installing Vimwiki is easy using your existing plugin manager: Just add `vimwiki/vimwiki` to your plugins. In my preferred plugin manager, Vundle, you just add the line `Plugin 'vimwiki/vimwiki'` in your `~/.vimrc` followed by a `:source ~/.vimrc|PluginInstall`.
|
||||
|
||||
Following is a piece of my `~.vimrc` showing a bit of Vimwiki configuration. You can learn more about installing and using this tool on the [Vimwiki page][1].
|
||||
```
|
||||
let wiki_1 = {}
|
||||
let wiki_1.path = '~/vimwiki_work_md/'
|
||||
let wiki_1.syntax = 'markdown'
|
||||
let wiki_1.ext = '.md'
|
||||
|
||||
let wiki_2 = {}
|
||||
let wiki_2.path = '~/vimwiki_personal_md/'
|
||||
let wiki_2.syntax = 'markdown'
|
||||
let wiki_2.ext = '.md'
|
||||
|
||||
let g:vimwiki_list = [wiki_1, wiki_2]
|
||||
let g:vimwiki_ext2syntax = {'.md': 'markdown', '.markdown': 'markdown', '.mdown': 'markdown'}
|
||||
```
|
||||
|
||||
Another advantage of my approach, which you can see in the configuration, is that I can easily divide my personal and work-related notes without switching the note-keeping software. I want my personal notes accessible everywhere, but I don’t want to sync my work-related notes to my private GitLab and computer. This was easier to set up in Vimwiki compared to the other software I tried.
|
||||
|
||||
The configuration tells Vimwiki there are two different wikis and I want to use Markdown syntax in both (again, because I’m used to Markdown from my daily work). It also tells Vimwiki the folders where to store the wiki pages.
|
||||
|
||||
If you navigate to the folders where the wiki pages are stored, you will find your wiki’s flat Markdown pages without any special Vimwiki context. That makes it easy to initialize a Git repository and sync your wiki to a central repository.
|
||||
|
||||
### Synchronizing your wiki to GitLab
|
||||
|
||||
The steps to check out a GitLab project to your local Vimwiki folder are nearly the same as you’d use for any GitHub repository. I just prefer to keep my notes in a private GitLab repository, so I keep a GitLab instance running for my personal projects.
|
||||
|
||||
GitLab has a wiki functionality that allows you to create wiki pages for your projects. Those wikis are Git repositories themselves. And they use Markdown syntax. You get where this is leading.
|
||||
|
||||
Just initialize the wiki you want to synchronize with the wiki of a project you created for your notes:
|
||||
```
|
||||
cd ~/vimwiki_personal_md/
|
||||
git init
|
||||
git remote add origin git@your.gitlab.com:your_user/vimwiki_personal_md.wiki
|
||||
git add .
|
||||
git commit -m "Initial commit"
|
||||
git push -u origin master
|
||||
```
|
||||
|
||||
These steps can be copied from the page where you land after creating a new project on GitLab. The only thing to change is the `.wiki` at the end of the repository URL (instead of `.git`), which tells it to clone the wiki repository instead of the project itself.
|
||||
|
||||
That’s it! Now you can manage your notes with Git and edit them in GitLab’s wiki user interface.
|
||||
|
||||
But maybe (like me) you don’t want to manually create commits for every note you add to your notebook. To solve this problem, I use the Vim plugin [chazy/dirsettings][4]. I added a `.vimdir` file with the following content to `~/vimwiki_personal_md`:
|
||||
```
|
||||
:cd %:p:h
|
||||
silent! !git pull > /dev/null
|
||||
:e!
|
||||
autocmd! BufWritePost * silent! !git add .;git commit -m "vim autocommit" > /dev/null; git push > /dev/null&
|
||||
```
|
||||
|
||||
This pulls the latest version of my wiki every time I open a wiki file and publishes my changes after every `:w` command. Doing this should keep your local copy in sync with the central repo. If you have merge conflicts, you may need to resolve them (as usual).
|
||||
|
||||
For now, this is the way I interact with my knowledge base, and I’m quite happy with it. Please let me know what you think about this approach. And please share in the comments your favorite way to keep track of your notes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/vimwiki-gitlab-notes
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:http://vimwiki.github.io/
|
||||
[2]:https://opensource.com/article/17/8/mind-maps-creative-dashboard
|
||||
[3]:https://www.dokuwiki.org/dokuwiki
|
||||
[4]:https://github.com/chazy/dirsettings
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Stop merging your pull requests manually
|
||||
======
|
||||
|
||||
|
||||
@ -1,51 +0,0 @@
|
||||
|
||||
DevOps如何帮助你将很酷的应用交付给用户
|
||||
======
|
||||
|
||||

|
||||
|
||||
在很久之前,在DevOps成为主流实践之前,软件开放的过程是极其缓慢,单调和系统性的。当一个应用准备要部署的时候,一长串为下次主要的版本迭代的工具变更已经积累起来了。每次的新版本迭代的准备都将花费数月的时间去追溯以及贯穿整个开发周期的工作。请记住这个过程将会在交付更新给用户的过程中不断的
|
||||
重复。
|
||||
|
||||
今天一切都是瞬间和实时完成的,这个概念似乎很原始。这场移动革命已经极大的改变了我们和软件之间的交互。那些早期采用DevOps的公司已经彻底改变了对
|
||||
软件开发和部署的期望。
|
||||
|
||||
考虑到脸书:脸书这个移动应用每两周更新和刷新一次,像钟表一样,这就是新的标准因为现在的用户期望软件持续的被修复和更新。任何一家要花费一个月或者更多的
|
||||
时间来部署新的功能或者修复bug的公司将会逐渐走向没落。如果你不能交付用户所期待的,他们将会去寻找那些能够满足他们需求的。
|
||||
|
||||
Facebook,以及一些工业巨头如亚马逊,Netfix,谷歌以及其他的都已经强制要求企业变得更快速更有效的来满足如天的顾客们的需求。
|
||||
|
||||
### 为什么是DevOps?
|
||||
|
||||
敏捷和DevOps在移动应用开发领域是相当重要的因为开发周期正变得越来越快。现在是一个密集快节奏的环境,公司必须加紧步伐赶超,思考的更深入,运用策略来去完成从而生存下去。在应用商店中,排名前十的应用平均能够保持的时间只有一个月左右。
|
||||
|
||||
为了说明老式的瀑布方法,回想一下你第一次学习驾驶。起先,你专注于每个独立的层面,使用一套方法论的过程:你上车;系上安全带;调整座椅,镜子,控制方向盘,发动汽车,将你的手放在10点和2点钟的方向,等等。完成一个简单的任务就像是换车道一样需要付出艰苦的努力,在一个特定的顺序下执行多个步骤。
|
||||
|
||||
DevOps,正好相反,是在你有了几年的经验之后如何去驾驶的。一切都是靠直觉同时发生的,你可以不用过多的思考就很平滑的从A移动到B。
|
||||
|
||||
移动APP的世界对越老式的APP开发环境来说太快节奏了。DevOps被设计用来有效,稳定快速的在不需要增加资源的情况下交付应用。然而你不能像购买一件普通的商品或者服务一样去购买DevOps.DevOps是用来指导改变团队如何一起工作的文化和活动的。
|
||||
|
||||
不是只有像亚马逊和脸书这样的大公司拥抱DevOps文化;小的移动应用公司也在很好的使用。“在保持生产事故处于一个较低水平的同时速度啊迭代周期以及满足顾客最求的整体的失败成本。”来自移产品代理[Reinvently][1]的工程部的负责人,Oleg Reshetnyak说道。
|
||||
|
||||
### DevOps: 不是如果,而是什么时候
|
||||
|
||||
在今天的快节奏的商业环境中,选在了DevOps就像是选择了呼吸:要么去做要么就死亡。[2]
|
||||
|
||||
根据美国小企业管理的报道,现在只有16% 的公司能够持续一代人的时间。不采用DevOps的移动应用公司将冒着逐渐走向灭绝的风险。而且,同样的研究表明采用DevOps的公司组织可能能够超过盈利能力,生产目标以及市场份额。
|
||||
|
||||
更快速更安全的革新需要做到三点:云,自动化和DevOps, 根据你对DevOps的定义的不同,这三个要点之间的界限是不清晰的。然而,有一点是确定的:DevOps围绕着更快更少风险的交付高质量的软件的共同目标将组织额内的每个人都统一起来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/devops-delivers-cool-apps-users
|
||||
|
||||
作者:[Stanislav Ivaschenko][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ilyadudkin
|
||||
[1]:https://reinvently.com/
|
||||
[2]:https://squadex.com/insights/devops-or-die/
|
||||
[3]:https://www.sba.gov/
|
||||
@ -1,41 +1,40 @@
|
||||
Translating by qhwdw
|
||||
Learn Blockchains by Building One
|
||||
通过构建一个区块链来学习区块链技术
|
||||
======
|
||||
|
||||

|
||||
You’re here because, like me, you’re psyched about the rise of Cryptocurrencies. And you want to know how Blockchains work—the fundamental technology behind them.
|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术是什么。
|
||||
|
||||
But understanding Blockchains isn’t easy—or at least wasn’t for me. I trudged through dense videos, followed porous tutorials, and dealt with the amplified frustration of too few examples.
|
||||
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
|
||||
|
||||
I like learning by doing. It forces me to deal with the subject matter at a code level, which gets it sticking. If you do the same, at the end of this guide you’ll have a functioning Blockchain with a solid grasp of how they work.
|
||||
我喜欢在实践中学习。这迫使我去处理被卡在代码级别上的难题。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
|
||||
### Before you get started…
|
||||
### 开始之前 …
|
||||
|
||||
Remember that a blockchain is an _immutable, sequential_ chain of records called Blocks. They can contain transactions, files or any data you like, really. But the important thing is that they’re _chained_ together using _hashes_ .
|
||||
记住,区块链是一个 _不可更改的、有序的_ 被称为区块的记录链。它们可以包括事务~~(交易???校对确认一下,下同)~~、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
|
||||
If you aren’t sure what a hash is, [here’s an explanation][1].
|
||||
如果你不知道哈希是什么,[这里有解释][1]。
|
||||
|
||||
**_Who is this guide aimed at?_** You should be comfy reading and writing some basic Python, as well as have some understanding of how HTTP requests work, since we’ll be talking to our Blockchain over HTTP.
|
||||
**_本指南的目标读者是谁?_** 你应该能很容易地读和写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
|
||||
**_What do I need?_** Make sure that [Python 3.6][2]+ (along with `pip`) is installed. You’ll also need to install Flask and the wonderful Requests library:
|
||||
**_我需要做什么?_** 确保安装了 [Python 3.6][2]+(以及 `pip`),还需要去安装 Flask 和非常好用的 Requests 库:
|
||||
|
||||
```
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
```
|
||||
|
||||
Oh, you’ll also need an HTTP Client, like [Postman][3] or cURL. But anything will do.
|
||||
当然,你也需要一个 HTTP 客户端,像 [Postman][3] 或者 cURL。哪个都行。
|
||||
|
||||
**_Where’s the final code?_** The source code is [available here][4].
|
||||
**_最终的代码在哪里可以找到?_** 源代码在 [这里][4]。
|
||||
|
||||
* * *
|
||||
|
||||
### Step 1: Building a Blockchain
|
||||
### 第 1 步:构建一个区块链
|
||||
|
||||
Open up your favourite text editor or IDE, personally I ❤️ [PyCharm][5]. Create a new file, called `blockchain.py`. We’ll only use a single file, but if you get lost, you can always refer to the [source code][6].
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人 ❤️ [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将使用一个单个的文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
|
||||
#### Representing a Blockchain
|
||||
#### 描述一个区块链
|
||||
|
||||
We’ll create a `Blockchain` class whose constructor creates an initial empty list (to store our blockchain), and another to store transactions. Here’s the blueprint for our class:
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存事务。下面是我们的类规划:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -63,13 +62,13 @@ pass
|
||||
```
|
||||
|
||||
|
||||
Our Blockchain class is responsible for managing the chain. It will store transactions and have some helper methods for adding new blocks to the chain. Let’s start fleshing out some methods.
|
||||
我们的区块链类负责管理链。它将存储事务并且有一些为链中增加新区块的助理性质的方法。现在我们开始去充实一些类的方法。
|
||||
|
||||
#### What does a Block look like?
|
||||
#### 一个区块是什么样子的?
|
||||
|
||||
Each Block has an index, a timestamp (in Unix time), a list of transactions, a proof (more on that later), and the hash of the previous Block.
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个事务的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
|
||||
Here’s an example of what a single Block looks like:
|
||||
单个区块的示例应该是下面的样子:
|
||||
|
||||
```
|
||||
block = {
|
||||
@ -87,13 +86,13 @@ block = {
|
||||
}
|
||||
```
|
||||
|
||||
At this point, the idea of a chain should be apparent—each new block contains within itself, the hash of the previous Block. This is crucial because it’s what gives blockchains immutability: If an attacker corrupted an earlier Block in the chain then all subsequent blocks will contain incorrect hashes.
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。这一点非常重要,因为这就是区块链不可更改的原因:如果攻击者修改了一个早期的区块,那么所有的后续区块将包含错误的哈希。
|
||||
|
||||
Does this make sense? If it doesn’t, take some time to let it sink in—it’s the core idea behind blockchains.
|
||||
这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。
|
||||
|
||||
#### Adding Transactions to a Block
|
||||
#### 添加事务到一个区块
|
||||
|
||||
We’ll need a way of adding transactions to a Block. Our new_transaction() method is responsible for this, and it’s pretty straight-forward:
|
||||
我们将需要一种区块中添加事务的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -117,13 +116,13 @@ class Blockchain(object):
|
||||
return self.last_block['index'] + 1
|
||||
```
|
||||
|
||||
After new_transaction() adds a transaction to the list, it returns the index of the block which the transaction will be added to—the next one to be mined. This will be useful later on, to the user submitting the transaction.
|
||||
在 `new_transaction()` 运行后将在列表中添加一个事务,它返回添加事务后的那个区块的索引 —— 那个区块接下来将被挖矿。提交事务的用户后面会用到这些。
|
||||
|
||||
#### Creating new Blocks
|
||||
#### 创建新区块
|
||||
|
||||
When our Blockchain is instantiated we’ll need to seed it with a genesis block—a block with no predecessors. We’ll also need to add a “proof” to our genesis block which is the result of mining (or proof of work). We’ll talk more about mining later.
|
||||
当我们的区块链被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
|
||||
In addition to creating the genesis block in our constructor, we’ll also flesh out the methods for new_block(), new_transaction() and hash():
|
||||
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 `new_block()`、`new_transaction()` 以及 `hash()`:
|
||||
|
||||
```
|
||||
import hashlib
|
||||
@ -194,15 +193,15 @@ class Blockchain(object):
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
```
|
||||
|
||||
The above should be straight-forward—I’ve added some comments and docstrings to help keep it clear. We’re almost done with representing our blockchain. But at this point, you must be wondering how new blocks are created, forged or mined.
|
||||
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
|
||||
|
||||
#### Understanding Proof of Work
|
||||
#### 理解工作量证明
|
||||
|
||||
A Proof of Work algorithm (PoW) is how new Blocks are created or mined on the blockchain. The goal of PoW is to discover a number which solves a problem. The number must be difficult to find but easy to verify—computationally speaking—by anyone on the network. This is the core idea behind Proof of Work.
|
||||
一个工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
|
||||
We’ll look at a very simple example to help this sink in.
|
||||
我们来看一个非常简单的示例来帮助你了解它。
|
||||
|
||||
Let’s decide that the hash of some integer x multiplied by another y must end in 0\. So, hash(x * y) = ac23dc...0\. And for this simplified example, let’s fix x = 5\. Implementing this in Python:
|
||||
我们来解决一个问题,一些整数 x 乘以另外一个整数 y 的结果的哈希值必须以 0 结束。因此,hash(x * y) = ac23dc…0。为简单起见,我们先把 x = 5 固定下来。在 Python 中的实现如下:
|
||||
|
||||
```
|
||||
from hashlib import sha256
|
||||
@ -216,19 +215,19 @@ while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
|
||||
print(f'The solution is y = {y}')
|
||||
```
|
||||
|
||||
The solution here is y = 21\. Since, the produced hash ends in 0:
|
||||
在这里的答案是 y = 21。因为它产生的哈希值是以 0 结尾的:
|
||||
|
||||
```
|
||||
hash(5 * 21) = 1253e9373e...5e3600155e860
|
||||
```
|
||||
|
||||
The network is able to easily verify their solution.
|
||||
网络上的任何人都可以很容易地去核验它的答案。
|
||||
|
||||
#### Implementing basic Proof of Work
|
||||
#### 实现基本的 PoW
|
||||
|
||||
Let’s implement a similar algorithm for our blockchain. Our rule will be similar to the example above:
|
||||
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
|
||||
|
||||
> Find a number p that when hashed with the previous block’s solution a hash with 4 leading 0s is produced.
|
||||
> 找出一个数字 p,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 0 组成。
|
||||
|
||||
```
|
||||
import hashlib
|
||||
@ -270,27 +269,27 @@ class Blockchain(object):
|
||||
return guess_hash[:4] == "0000"
|
||||
```
|
||||
|
||||
To adjust the difficulty of the algorithm, we could modify the number of leading zeroes. But 4 is sufficient. You’ll find out that the addition of a single leading zero makes a mammoth difference to the time required to find a solution.
|
||||
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
|
||||
|
||||
Our class is almost complete and we’re ready to begin interacting with it using HTTP requests.
|
||||
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
|
||||
|
||||
* * *
|
||||
|
||||
### Step 2: Our Blockchain as an API
|
||||
### 第 2 步:以 API 方式去访问我们的区块链
|
||||
|
||||
We’re going to use the Python Flask Framework. It’s a micro-framework and it makes it easy to map endpoints to Python functions. This allows us talk to our blockchain over the web using HTTP requests.
|
||||
我们将去使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
|
||||
We’ll create three methods:
|
||||
我们将创建三个方法:
|
||||
|
||||
* `/transactions/new` to create a new transaction to a block
|
||||
* `/transactions/new` 在一个区块上创建一个新事务
|
||||
|
||||
* `/mine` to tell our server to mine a new block.
|
||||
* `/mine` 告诉我们的服务器去挖矿一个新区块
|
||||
|
||||
* `/chain` to return the full Blockchain.
|
||||
* `/chain` 返回完整的区块链
|
||||
|
||||
#### Setting up Flask
|
||||
#### 配置 Flask
|
||||
|
||||
Our “server” will form a single node in our blockchain network. Let’s create some boilerplate code:
|
||||
我们的 “服务器” 将在我们的区块链网络中产生一个单个的节点。我们来创建一些样板代码:
|
||||
|
||||
```
|
||||
import hashlib
|
||||
@ -336,25 +335,25 @@ if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
```
|
||||
|
||||
A brief explanation of what we’ve added above:
|
||||
对上面的代码,我们做添加一些详细的解释:
|
||||
|
||||
* Line 15: Instantiates our Node. Read more about Flask [here][7].
|
||||
* Line 15:实例化我们的节点。更多关于 Flask 的知识读 [这里][7]。
|
||||
|
||||
* Line 18: Create a random name for our node.
|
||||
* Line 18:为我们的节点创建一个随机的名字。
|
||||
|
||||
* Line 21: Instantiate our Blockchain class.
|
||||
* Line 21:实例化我们的区块链类。
|
||||
|
||||
* Line 24–26: Create the /mine endpoint, which is a GET request.
|
||||
* Line 24–26:创建 /mine 端点,这是一个 GET 请求。
|
||||
|
||||
* Line 28–30: Create the /transactions/new endpoint, which is a POST request, since we’ll be sending data to it.
|
||||
* Line 28–30:创建 /transactions/new 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
|
||||
* Line 32–38: Create the /chain endpoint, which returns the full Blockchain.
|
||||
* Line 32–38:创建 /chain 端点,它返回全部区块链。
|
||||
|
||||
* Line 40–41: Runs the server on port 5000.
|
||||
* Line 40–41:在 5000 端口上运行服务器。
|
||||
|
||||
#### The Transactions Endpoint
|
||||
#### 事务端点
|
||||
|
||||
This is what the request for a transaction will look like. It’s what the user sends to the server:
|
||||
这就是对一个事务的请求,它是用户发送给服务器的:
|
||||
|
||||
```
|
||||
{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
|
||||
@ -386,17 +385,17 @@ def new_transaction():
|
||||
response = {'message': f'Transaction will be added to Block {index}'}
|
||||
return jsonify(response), 201
|
||||
```
|
||||
A method for creating Transactions
|
||||
创建事务的方法
|
||||
|
||||
#### The Mining Endpoint
|
||||
#### 挖矿端点
|
||||
|
||||
Our mining endpoint is where the magic happens, and it’s easy. It has to do three things:
|
||||
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
|
||||
|
||||
1. Calculate the Proof of Work
|
||||
1. 计算工作量证明
|
||||
|
||||
2. Reward the miner (us) by adding a transaction granting us 1 coin
|
||||
2. 因为矿工(我们)添加一个事务而获得报酬,奖励矿工(我们) 1 个硬币
|
||||
|
||||
3. Forge the new Block by adding it to the chain
|
||||
3. 通过将它添加到链上而打造一个新区块
|
||||
|
||||
```
|
||||
import hashlib
|
||||
@ -438,34 +437,34 @@ def mine():
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
Note that the recipient of the mined block is the address of our node. And most of what we’ve done here is just interact with the methods on our Blockchain class. At this point, we’re done, and can start interacting with our blockchain.
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的区块链类的方法进行交互的。到目前为止,我们已经做到了,现在开始与我们的区块链去交互。
|
||||
|
||||
### Step 3: Interacting with our Blockchain
|
||||
### 第 3 步:与我们的区块链去交互
|
||||
|
||||
You can use plain old cURL or Postman to interact with our API over a network.
|
||||
你可以使用简单的 cURL 或者 Postman 通过网络与我们的 API 去交互。
|
||||
|
||||
Fire up the server:
|
||||
启动服务器:
|
||||
|
||||
```
|
||||
$ python blockchain.py
|
||||
```
|
||||
|
||||
Let’s try mining a block by making a GET request to http://localhost:5000/mine:
|
||||
我们通过生成一个 GET 请求到 http://localhost:5000/mine 去尝试挖一个区块:
|
||||
|
||||
|
||||
Using Postman to make a GET request
|
||||
使用 Postman 去生成一个 GET 请求
|
||||
|
||||
Let’s create a new transaction by making a POST request tohttp://localhost:5000/transactions/new with a body containing our transaction structure:
|
||||
我们通过生成一个 POST 请求到 http://localhost:5000/transactions/new 去创建一个区块,它带有一个包含我们的事务结构的 `Body`:
|
||||
|
||||
|
||||
Using Postman to make a POST request
|
||||
使用 Postman 去生成一个 POST 请求
|
||||
|
||||
If you aren’t using Postman, then you can make the equivalent request using cURL:
|
||||
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
|
||||
|
||||
```
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
|
||||
```
|
||||
I restarted my server, and mined two blocks, to give 3 in total. Let’s inspect the full chain by requesting http://localhost:5000/chain:
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了3 个区块。我们通过请求 http://localhost:5000/chain 来检查整个区块链:
|
||||
```
|
||||
{
|
||||
"chain": [
|
||||
@ -505,19 +504,19 @@ I restarted my server, and mined two blocks, to give 3 in total. Let’s inspect
|
||||
],
|
||||
"length": 3
|
||||
```
|
||||
### Step 4: Consensus
|
||||
### 第 4 步:共识
|
||||
|
||||
This is very cool. We’ve got a basic Blockchain that accepts transactions and allows us to mine new Blocks. But the whole point of Blockchains is that they should be decentralized. And if they’re decentralized, how on earth do we ensure that they all reflect the same chain? This is called the problem of Consensus, and we’ll have to implement a Consensus Algorithm if we want more than one node in our network.
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收事务并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
|
||||
#### Registering new Nodes
|
||||
#### 注册新节点
|
||||
|
||||
Before we can implement a Consensus Algorithm, we need a way to let a node know about neighbouring nodes on the network. Each node on our network should keep a registry of other nodes on the network. Thus, we’ll need some more endpoints:
|
||||
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
|
||||
|
||||
1. /nodes/register to accept a list of new nodes in the form of URLs.
|
||||
1. /nodes/register 以 URLs 的形式去接受一个新节点列表
|
||||
|
||||
2. /nodes/resolve to implement our Consensus Algorithm, which resolves any conflicts—to ensure a node has the correct chain.
|
||||
2. /nodes/resolve 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
|
||||
We’ll need to modify our Blockchain’s constructor and provide a method for registering nodes:
|
||||
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
|
||||
|
||||
```
|
||||
...
|
||||
@ -541,13 +540,13 @@ class Blockchain(object):
|
||||
parsed_url = urlparse(address)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
```
|
||||
A method for adding neighbouring nodes to our Network
|
||||
一个添加邻居节点到我们的网络的方法
|
||||
|
||||
Note that we’ve used a set() to hold the list of nodes. This is a cheap way of ensuring that the addition of new nodes is idempotent—meaning that no matter how many times we add a specific node, it appears exactly once.
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的内容是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
|
||||
#### Implementing the Consensus Algorithm
|
||||
#### 实现共识算法
|
||||
|
||||
As mentioned, a conflict is when one node has a different chain to another node. To resolve this, we’ll make the rule that the longest valid chain is authoritative. In other words, the longest chain on the network is the de-facto one. Using this algorithm, we reach Consensus amongst the nodes in our network.
|
||||
正如前面提到的,当一个节点与另一个节点有不同的链时就会产生冲突。为解决冲突,我们制定一个规则,即最长的有效的链才是权威的链。换句话说就是,网络上最长的链就是事实上的区块链。使用这个算法,可以在我们的网络上节点之间达到共识。
|
||||
|
||||
```
|
||||
...
|
||||
@ -619,11 +618,11 @@ class Blockchain(object)
|
||||
return False
|
||||
```
|
||||
|
||||
The first method valid_chain() is responsible for checking if a chain is valid by looping through each block and verifying both the hash and the proof.
|
||||
第一个方法 `valid_chain()` 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
|
||||
|
||||
resolve_conflicts() is a method which loops through all our neighbouring nodes, downloads their chains and verifies them using the above method. If a valid chain is found, whose length is greater than ours, we replace ours.
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。
|
||||
|
||||
Let’s register the two endpoints to our API, one for adding neighbouring nodes and the another for resolving conflicts:
|
||||
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
|
||||
|
||||
```
|
||||
@app.route('/nodes/register', methods=['POST'])
|
||||
@ -662,31 +661,30 @@ def consensus():
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
At this point you can grab a different machine if you like, and spin up different nodes on your network. Or spin up processes using different ports on the same machine. I spun up another node on my machine, on a different port, and registered it with my current node. Thus, I have two nodes: [http://localhost:5000][9] and http://localhost:5001.
|
||||
这种情况下,如果你愿意可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:[http://localhost:5000][9] 和 http://localhost:5001。
|
||||
|
||||
|
||||
Registering a new Node
|
||||
注册一个新节点
|
||||
|
||||
I then mined some new Blocks on node 2, to ensure the chain was longer. Afterward, I called GET /nodes/resolve on node 1, where the chain was replaced by the Consensus Algorithm:
|
||||
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 `GET` 方式调用了 `/nodes/resolve`,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:
|
||||
|
||||
|
||||
Consensus Algorithm at Work
|
||||
工作中的共识算法
|
||||
|
||||
And that’s a wrap... Go get some friends together to help test out your Blockchain.
|
||||
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
|
||||
|
||||
* * *
|
||||
|
||||
I hope that this has inspired you to create something new. I’m ecstatic about Cryptocurrencies because I believe that Blockchains will rapidly change the way we think about economies, governments and record-keeping.
|
||||
|
||||
**Update:** I’m planning on following up with a Part 2, where we’ll extend our Blockchain to have a Transaction Validation Mechanism as well as discuss some ways in which you can productionize your Blockchain.
|
||||
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
|
||||
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备事务验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
|
||||
作者:[Daniel van Flymen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,165 @@
|
||||
对可互换通证的通证 ERC 的比较 – Blockchainers
|
||||
======
|
||||
“对于标准来说,最好的事情莫过于大量的人都去选择使用它。“ [_Andrew S. Tanenbaum_][1]
|
||||
|
||||
### 通证标准的现状
|
||||
|
||||
在以太坊平台上,通证标准的现状出奇的简单:ERC-20 通证标准是通证接口中唯一被采用( [EIP-20][2])和接受的通证标准。
|
||||
|
||||
它在 2015 年被提出,最终接受是在 2017 年末。
|
||||
|
||||
在此期间,提出了许多解决 ERC-20 缺点的以太坊意见征集(ERC),其中的一部分是因为以太坊平台自身变更所导致的,比如,由 [EIP-150][3] 修复的重入(re-entrancy) bug。其它 ERC 提出的对 ERC-20 通证模型的强化。这些强化是通过采集大量的以太坊区块链和 ERC-20 通证标准的使用经验所确定的。ERC-20 通证接口的实际应用产生了新的要求和需要,比如像权限和操作方面的非功能性需求。
|
||||
|
||||
这篇文章将浅显但完整地对以太坊平台上提出的所有通证(类)标准进行简单概述。我将尽可能客观地去做比较,但不可避免地仍有一些不客观的地方。
|
||||
|
||||
### 通证标准之母:ERC-20
|
||||
|
||||
有成打的 [非常好的][4] 关于 ERC-20 的详细描述,在这里就不一一列出了。只对在文章中提到的相关核心概念做个比较。
|
||||
|
||||
#### 提取模式
|
||||
|
||||
用户们尽可能地去理解 ERC-20 接口,尤其是从一个外部所有者帐户(EOA)_转账_ 通证的模式,即一个终端用户(“Alice”)到一个智能合约,很难去获得 approve/transferFrom 模式权利。
|
||||
|
||||
![][5]
|
||||
|
||||
从软件工程师的角度看,这个提取模式非常类似于 [好莱坞原则][6] (“不要给我们打电话,我们会给你打电话的!”)。那个调用链的创意正好相反:在 ERC-20 通证转账中,通证不能调用合约,但是合约可以调用通证上的 `transferFrom`。
|
||||
|
||||
虽然好莱坞原则经常用于去实现关注点分离(SoC),但在以太坊中它是一个安全模式,目的是为了防止通证合约去调用外部合约上的未知的函数。这种行为是非常有必要的,因为 [Call Depth Attack][7] 直到 [EIP-150][3] 才被启用。在硬分叉之后,这个重入bug 将不再可能出现了,并且提取模式不提供任何比直接通证调用更好的安全性了。
|
||||
|
||||
但是,为什么现在它成了一个问题呢?可能是由于某些原因,它的用法设计有些欠佳,但是我们可以通过前端的 DApp 来修复这个问题,对吗?
|
||||
|
||||
因此,我们来看一看,如果一个用户使用 `transfer` 去转账一些通证到智能合约会发生什么事情。Alice 在带合约地址的通证合约上调用 `transfer`
|
||||
|
||||
**….aaaaand 它不见了!**
|
||||
|
||||
是的,通证没有了。很有可能,没有任何人再能拿回通证了。但是像 Alice 的这种做法并不鲜见,正如 ERC-223 的发明者 Dexaran 所发现的,大约有 $400.000 的通证(由于 ETH 波动很大,我们只能说很多)是由于用户意外发送到智能合约中,并因此而丢失。
|
||||
|
||||
即便合约开发者是一个非常友好和无私的用户,他也不能创建一个合约以便将它收到的通证返还给你。因为合约并不会提示这类转账,并且事件仅在通证合约上发出。
|
||||
|
||||
从软件工程师的角度来看,那就是 ERC-20 的重大缺点。如果发生一个事件(为简单起见,我们现在假设以太坊交易是真实事件),对参与的当事人将有一个提示。但是,这个事件是在通证智能合约中触发的,合约接收方是无法知道它的。
|
||||
|
||||
目前,还不能做到防止用户向智能合约发送通证,并且在 ERC-20 通证合约上使用不直观转账将导致这些发送的通证永远丢失。
|
||||
|
||||
### 帝国反击战:ERC-223
|
||||
|
||||
[Dexaran][8] 第一个提出尝试去修复 ERC-20 的问题。这个提议通过将 EOA 和智能合约账户做不同的处理的方式来解决这个问题。
|
||||
|
||||
强制的策略是去反转调用链(并且使用 [EIP-150][3] 解决它现在能做到了),并且在正接收的智能合约上使用一个预定义的回调(tokenFallback)。如果回调没有实现,转账将失败(将消耗掉发送方的汽油,这是 ERC-223 被批的最常见的一个地方)。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 好处:
|
||||
|
||||
* 创建一个新接口,有意不遵守 ERC-20 关于弃权的功能
|
||||
|
||||
* 允许合约开发者去处理收到的通证(即:接受/拒绝)并因此遵守事件模式
|
||||
|
||||
* 用一个交易来代替两个交易(transfer vs. approve/transferFrom)并且节省了汽油和区域链的存储空间
|
||||
|
||||
|
||||
|
||||
|
||||
#### 坏处:
|
||||
|
||||
* 如果 `tokenFallback` 不存在,那么合约的 `fallback` 功能将运行,这可能会产生意料之外的副作用
|
||||
|
||||
* 如果合约假设使用通证转账,比如,发送通证到一个特定的像多签名钱包一样的账户,这将使 ERC-223 通证失败,它将不能转移(即它们会丢失)。
|
||||
|
||||
|
||||
### 程序员修练之道:ERC-677
|
||||
|
||||
[ERC-667 transferAndCall 通证标准][10] 尝试将 ERC-20 和 ERC-223 结合起来。这个创意是在 ERC-20 中引入一个 `transferAndCall` 函数,并保持标准不变。ERC-223 有意不完全向后兼容,由于不再需要 approve/allowance 模式,并因此将它删除。
|
||||
|
||||
ERC-667 的主要目标是向后兼容,为新合约向外部合约转账提供一个安全的方法。
|
||||
|
||||
![][11]
|
||||
|
||||
#### 好处:
|
||||
|
||||
* 容易适用新的通证
|
||||
|
||||
* 兼容 ERC-20
|
||||
|
||||
* 为 ERC-20 设计的适配器用于安全使用 ERC-20
|
||||
|
||||
#### 坏处:
|
||||
|
||||
* 不是真正的新方法。只是一个 ERC-20 和 ERC-223 的折衷
|
||||
|
||||
* 目前实现 [尚未完成][12]
|
||||
|
||||
|
||||
### 重逢:ERC-777
|
||||
|
||||
[ERC-777 一个新的先进的通证标准][13],引入它是为了建立一个演进的通证标准,它是吸取了像带值的 `approve()` 以及上面提到的将通证发送到合约这样的错误观念的教训之后得来的演进后标准。
|
||||
|
||||
另外,ERC-777 使用了新标准 [ERC-820:使用一个注册合约的伪内省][14],它允许为合约注册元数据以提供一个简单的内省类型。并考虑到了向后兼容和其它的功能扩展,这些取决于由一个 EIP-820 查找到的地址返回的 `ITokenRecipient`,和由目标合约实现的函数。
|
||||
|
||||
ERC-777 增加了许多使用 ERC-20 通证的经验,比如,白名单操作者、提供带 send(…) 的以太兼容的接口,为了向后兼容而使用 ERC-820 去覆盖和调整功能。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 好处:
|
||||
|
||||
* 从 ERC-20 的使用经验上得来的、经过深思熟虑的、进化的通证接口
|
||||
|
||||
* 为内省要求 ERC-820 使用新标准,接受了增加的功能
|
||||
|
||||
* 白名单操作者非常有用,而且比 approve/allowance 更有必要,它经常是无限的
|
||||
|
||||
|
||||
#### 坏处:
|
||||
|
||||
* 刚刚才开始,复杂的依赖合约调用的结构
|
||||
|
||||
* 依赖导致出现安全问题的可能性增加:第一个安全问题并不是在 ERC-777 中 [确认(并解决的)][16],而是在最新的 ERC-820 中
|
||||
|
||||
|
||||
|
||||
|
||||
### (纯主观的)结论(轻喷)
|
||||
|
||||
目前为止,如果你想遵循 “行业标准”,你只能选择 ERC-20。它获得了最广泛的理解与支持。但是,它还是有缺陷的,最大的一个缺陷是因为非专业用户设计和规范问题导致的用户真实地损失金钱的问题。ERC-223 是非常好的,并且在理论上找到了 ERC-20 中这个问题的答案了,它应该被考虑为 ERC-20 的一个很好的替代标准。在一个新通证中实现这两个接口并不复杂,并且可以降低汽油的使用。
|
||||
|
||||
ERC-677 是事件和金钱丢失问题的一个务实的解决方案,但是它并没能提供足够多的新方法,以促使它成为一个标准。但是它可能是 ERC-20 2.0 的一个很好的候选者。
|
||||
|
||||
ERC-777 是一个更先进的通证标准,它应该成为 ERC-20 的合法继任者,它提供了以太坊平台所需要的非常好的成熟概念,像白名单操作者,并允许以优雅的方式进行扩展。由于它的复杂性和对其它新标准的依赖,在主链上出现第一个 ERC-777 标准的通证还需要些时日。
|
||||
|
||||
### 链接
|
||||
|
||||
[1] 在 ERC-20 中使用 approve/transferFrom-Pattern 的安全问题: <https://drive.google.com/file/d/0ByMtMw2hul0EN3NCaVFHSFdxRzA/view>
|
||||
|
||||
[2] ERC-20 中的无事件操作:<https://docs.google.com/document/d/1Feh5sP6oQL1-1NHi-X1dbgT3ch2WdhbXRevDN681Jv4>
|
||||
|
||||
[3] ERC-20 的故障及历史:<https://github.com/ethereum/EIPs/issues/223#issuecomment-317979258>
|
||||
|
||||
[4] ERC-20/223 的不同之处:<https://ethereum.stackexchange.com/questions/17054/erc20-vs-erc223-list-of-differences>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blockchainers.org/index.php/2018/02/08/token-erc-comparison-for-fungible-tokens/
|
||||
|
||||
作者:[Alexander Culum][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://blockchainers.org/index.php/author/alex/
|
||||
[1]:https://www.goodreads.com/quotes/589703-the-good-thing-about-standards-is-that-there-are-so
|
||||
[2]:https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20.md
|
||||
[3]:https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md
|
||||
[4]:https://medium.com/@jgm.orinoco/understanding-erc-20-token-contracts-a809a7310aa5
|
||||
[5]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-20-Token-Transfer-2.png
|
||||
[6]:http://matthewtmead.com/blog/hollywood-principle-dont-call-us-well-call-you-4/
|
||||
[7]:https://consensys.github.io/smart-contract-best-practices/known_attacks/
|
||||
[8]:https://github.com/Dexaran
|
||||
[9]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-223-Token-Transfer-1.png
|
||||
[10]:https://github.com/ethereum/EIPs/issues/677
|
||||
[11]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-677-Token-Transfer.png
|
||||
[12]:https://github.com/ethereum/EIPs/issues/677#issuecomment-353871138
|
||||
[13]:https://github.com/ethereum/EIPs/issues/777
|
||||
[14]:https://github.com/ethereum/EIPs/issues/820
|
||||
[15]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-777-Token-Transfer.png
|
||||
[16]:https://github.com/ethereum/EIPs/issues/820#issuecomment-362049573
|
||||
@ -1,120 +0,0 @@
|
||||
学习用 Thonny 写代码 — 一个面向初学者的PythonIDE
|
||||
======
|
||||
|
||||

|
||||
学习编程很难。即使当你最终得到了你的冒号和括号是正确的,但仍然有很大的机会,程序不会做你想做的事情。 通常,这意味着你忽略了某些东西或者误解了语言结构,你需要在代码中找到你的期望与现实存在分歧的地方。
|
||||
|
||||
程序员通常使用被叫做调试器的工具来处理这种情况,它允许一步一步地运行他们的程序。不幸的是,大多数调试器都针对专业用途进行了优化,并假设用户已经很好地了解了语言结构的语义(例如:函数调用)。
|
||||
|
||||
Thonny 是一个适合初学者的 Python IDE,由爱沙尼亚的 [Tartu大学][1] 开发,它采用了不同的方法,因为它的调试器是专为学习和教学编程而设计的。
|
||||
|
||||
虽然Thonny 适用于像小白一样的初学者,但这篇文章面向那些至少具有 Python 或其他命令式语言经验的读者。
|
||||
|
||||
### 开始
|
||||
|
||||
从第27版开始,Thonny 就被包含在 Fedora 软件库中。 使用 sudo dnf 安装 thonny 或者你选择的图形工具(比如软件)安装它。
|
||||
|
||||
当第一次启动 Thonny 时,它会做一些准备工作,然后呈现一个空编辑器和 Pythonshell 。将下列程序文本复制到编辑器中,并将其保存到文件中(Ctrl+S)。
|
||||
```
|
||||
n = 1
|
||||
while n < 5:
|
||||
print(n * "*")
|
||||
n = n + 1
|
||||
|
||||
```
|
||||
我们首先运行该程序。 为此请按键盘上的 F5 键。 你应该看到一个由周期组成的三角形出现在外壳窗格中。
|
||||
|
||||
![一个简单的 Thonny 程序][2]
|
||||
|
||||
Python 只是分析了你的代码并理解了你想打印一个三角形吗?让我们看看!
|
||||
|
||||
首先从“查看”菜单中选择“变量”。这将打开一张表格,向我们展示 Python 是如何管理程序的变量的。现在通过按 Ctrl + F5(或 XFCE 中的 Ctrl + Shift + F5)以调试模式运行程序。在这种模式下,Thonny 使 Python 在每一步所需的步骤之前暂停。你应该看到程序的第一行被一个框包围。我们将这称为焦点,它表明 Python 将接下来要执行的部分代码。
|
||||
|
||||
|
||||
![ Thonny 调试器焦点 ][3]
|
||||
|
||||
你在焦点框中看到的一段代码段被称为赋值语句。 对于这种声明,Python 应该计算右边的表达式,并将值存储在左边显示的名称下。按 F7 进行下一步。你将看到 Python 将重点放在语句的正确部分。在这种情况下,表达式实际上很简单,但是为了通用性,Thonny 提供了表达式计算框,它允许将表达式转换为值。再次按 F7 将文字 1 转换为值 1。现在 Python 已经准备好执行实际的赋值—再次按 F7,你应该会看到变量 n 的值为 1 的变量出现在变量表中。
|
||||
|
||||
![Thonny 变量表][4]
|
||||
|
||||
继续按 F7 并观察 Python 如何以非常小的步骤前进。它看起来像是理解你的代码的目的或者更像是一个愚蠢的遵循简单规则的机器?
|
||||
|
||||
### 函数调用
|
||||
|
||||
函数调用(FunctionCall)是一种编程概念,它常常给初学者带来很大的困惑。从表面上看,没有什么复杂的事情--给代码命名,然后在代码中的其他地方引用它(调用它)。传统的调试器告诉我们,当你进入调用时,焦点跳转到函数定义中(然后神奇地返回到原来的位置)。这是整件事吗?这需要我们关心吗?
|
||||
|
||||
结果证明,“跳转模型” 只对最简单的函数是足够的。理解参数传递、局部变量、返回和递归都得益于堆栈框架的概念。幸运的是,Thonny 可以直观地解释这个概念,而无需在厚厚的一层下搜索重要的细节。
|
||||
|
||||
将以下递归程序复制到 Thonny 并以调试模式(Ctrl+F5 或 Ctrl+Shift+F5)运行。
|
||||
```
|
||||
def factorial(n):
|
||||
if n == 0:
|
||||
return 1
|
||||
else:
|
||||
return factorial(n-1) * n
|
||||
|
||||
print(factorial(4))
|
||||
|
||||
```
|
||||
|
||||
重复按 F7,直到你在对话框中看到表达式因式(4)。 当你进行下一步时,你会看到 Thonny 打开一个包含功能代码,另一个变量表和另一个焦点框的新窗口(移动窗口以查看旧的焦点框仍然存在)。
|
||||
|
||||
![通过递归函数的 Thonny][5]
|
||||
|
||||
此窗口表示堆栈帧, 即用于解析函数调用的工作区。在彼此顶部的几个这样的窗口称为调用堆栈。注意调用站点上的参数4与 "局部变量" 表中的输入 n 之间的关系。继续按 F7步进, 观察在每次调用时如何创建新窗口并在函数代码完成时被销毁, 以及如何用返回值替换调用站点。
|
||||
|
||||
|
||||
### 值与参考
|
||||
|
||||
现在,让我们在 Pythonshell 中进行一个实验。首先输入下面屏幕截图中显示的语句:
|
||||
|
||||
![Thonny 壳显示列表突变][6]
|
||||
|
||||
正如你所看到的, 我们追加到列表 b, 但列表 a 也得到了更新。你可能知道为什么会发生这种情况, 但是对初学者来说,什么才是最好的解释呢?
|
||||
|
||||
当教我的学生列表时,我告诉他们我一直在骗他们关于 Python 内存模型。实际上,它并不像变量表所显示的那样简单。我告诉他们重新启动解释器(工具栏上的红色按钮),从“视图”菜单中选择“堆”,然后再次进行相同的实验。如果这样做,你就会发现变量表不再包含值-它们实际上位于另一个名为“Heap”的表中。变量表的作用实际上是将变量名映射到地址(或ID-s),地址(或ID-s)引用堆表中的行。由于赋值仅更改变量表,因此语句 b = a 只复制对列表的引用,而不是列表本身。这解释了为什么我们通过这两个变量看到了变化。
|
||||
|
||||
|
||||
![在堆模式中的 Thonny][7]
|
||||
|
||||
(为什么我要在教列表的主题之前推迟说出内存模型的事实?Python存储的列表是否有所不同?请继续使用Thonny的堆模式来找出结果!在评论中告诉我你认为怎么样!)
|
||||
|
||||
如果要更深入地了解参考系统, 请将以下程序通过打开堆表复制到 Thonny 和小步骤 (F7) 中。
|
||||
```
|
||||
def do_something(lst, x):
|
||||
lst.append(x)
|
||||
|
||||
a = [1,2,3]
|
||||
n = 4
|
||||
do_something(a, n)
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
即使“堆模式”向我们显示真实的图片,但它使用起来也相当不方便。 因此,我建议你现在切换回普通模式(取消选择“查看”菜单中的“堆”),但请记住,真实模型包含变量,参考和值。
|
||||
|
||||
### 结语
|
||||
|
||||
我在这篇文章中提及到的特性是创建 Thonny 的主要原因。这很容易对函数调用和引用形成错误的理解,但传统的调试器并不能真正帮助减少混淆。
|
||||
|
||||
除了这些显著的特性,Thonny 还提供了其他几个初学者友好的工具。 请查看 [Thonny的主页][8] 以了解更多信息!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-code-thonny-python-ide-beginners/
|
||||
|
||||
作者:[Aivar Annamaa][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/
|
||||
[1]:https://www.ut.ee/en
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2017/12/scr1.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr2.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr3.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr4.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr5.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr6.png
|
||||
[8]:http://thonny.org
|
||||
@ -1,28 +1,27 @@
|
||||
Translating by qhwdw
|
||||
Passwordless Auth: Client
|
||||
无密码验证:客户端
|
||||
======
|
||||
Time to continue with the [passwordless auth][1] posts. Previously, we wrote an HTTP service in Go that provided with a passwordless authentication API. Now, we are gonna code a JavaScript client for it.
|
||||
我们继续 [无密码验证][1] 的文章。上一篇文章中,我们用 Go 写了一个 HTTP 服务,用这个服务来做无密码验证 API。今天,我们为它再写一个 JavaScript 客户端。
|
||||
|
||||
We’ll go with a single page application (SPA) using the technique I showed [here][2]. Read it first if you haven’t yet.
|
||||
我们将使用 [这里的][2] 这个单页面应用程序(SPA)来展示使用的技术。如果你还没有读过它,请先读它。
|
||||
|
||||
For the root URL (`/`) we’ll show two different pages depending on the auth state: a page with an access form or a page greeting the authenticated user. Another page is for the auth callback redirect.
|
||||
我们将根据验证的状态分别使用两个不同的根 URL(`/`):一个是访问状态的页面或者是欢迎已验证用户的页面。另一个页面是验证失败后重定向到验证页面。
|
||||
|
||||
### Serving
|
||||
|
||||
I’ll serve the client with the same Go server, so let’s add some routes to the previous `main.go`:
|
||||
我们将使用相同的 Go 服务器来为客户端提供服务,因此,在我们前面的 `main.go` 中添加一些路由:
|
||||
```
|
||||
router.Handle("GET", "/js/", http.FileServer(http.Dir("static")))
|
||||
router.HandleFunc("GET", "/...", serveFile("static/index.html"))
|
||||
|
||||
```
|
||||
|
||||
This serves files under `static/js`, and `static/index.html` is served for everything else.
|
||||
这个伺服文件在 `static/js` 下,而 `static/index.html` 文件是为所有的访问提供服务的。
|
||||
|
||||
You can use your own server apart, but you’ll have to enable [CORS][3] on the server.
|
||||
你可以使用你自己的服务器,但是你得在服务器上启用 [CORS][3]。
|
||||
|
||||
### HTML
|
||||
|
||||
Let’s see that `static/index.html`.
|
||||
我们来看一下那个 `static/index.html` 文件。
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
@ -38,13 +37,13 @@ Let’s see that `static/index.html`.
|
||||
|
||||
```
|
||||
|
||||
Single page application left all the rendering to JavaScript, so we have an empty body and a `main.js` file.
|
||||
单页面应用程序剩余的渲染由 JavaScript 来完成,因此,我们使用了一个空的 body 部分和一个 `main.js` 文件。
|
||||
|
||||
I’ll user the Router from the [last post][2].
|
||||
我们将使用 [上篇文章][2] 中的 Router。
|
||||
|
||||
### Rendering
|
||||
|
||||
Now, create a `static/js/main.js` file with the following content:
|
||||
现在,我们使用下面的内容来创建一个 `static/js/main.js` 文件:
|
||||
```
|
||||
import Router from 'https://unpkg.com/@nicolasparada/router'
|
||||
import { isAuthenticated } from './auth.js'
|
||||
@ -73,11 +72,11 @@ function guard(fn1, fn2 = view('welcome')) {
|
||||
|
||||
```
|
||||
|
||||
Differing from the last post, we implement an `isAuthenticated()` function and a `guard()` function that uses it to render one or another page. So when a user visits `/` it will show the home or welcome page whether the user is authenticated or not.
|
||||
与上篇文章不同的是,我们实现了一个 `isAuthenticated()` 函数和一个 `guard()` 函数,使用它去渲染两种验证状态的页面。因此,当用户访问 `/` 时,它将根据用户是否通过了验证来展示 home 页面或者是欢迎页面。
|
||||
|
||||
### Auth
|
||||
|
||||
Now, let’s write that `isAuthenticated()` function. Create a `static/js/auth.js` file with the following content:
|
||||
现在,我们来编写 `isAuthenticated()` 函数。使用下面的内容来创建一个 `static/js/auth.js` 文件:
|
||||
```
|
||||
export function getAuthUser() {
|
||||
const authUserItem = localStorage.getItem('auth_user')
|
||||
@ -102,18 +101,18 @@ export function isAuthenticated() {
|
||||
|
||||
```
|
||||
|
||||
When someone login, we save the JSON web token, expiration date of it and the current authenticated user on `localStorage`. This module uses that.
|
||||
当有人登入时,我们将保存 JSON 格式的 web 令牌、过期日期、以及在 `localStorage` 上的当前已验证用户。这个模块就是这个用处。
|
||||
|
||||
* `getAuthUser()` gets the authenticated user from `localStorage` making sure the JSON Web Token hasn’t expired yet.
|
||||
* `isAuthenticated()` makes use of the previous function to check whether it doesn’t return `null`.
|
||||
* `getAuthUser()` 用于从 `localStorage` 获取已认证的用户,以确认 JSON 格式的 Web 令牌没有过期。
|
||||
* `isAuthenticated()` 在前面的函数中用于去检查它是否返回了 `null`。
|
||||
|
||||
|
||||
|
||||
### Fetch
|
||||
|
||||
Before continuing with the pages, I’ll code some HTTP utilities to work with the server API.
|
||||
在继续这个页面之前,我将写一些与服务器 API 一起使用的 HTTP 工具。
|
||||
|
||||
Let’s create a `static/js/http.js` file with the following content:
|
||||
我们使用以下的内容去创建一个 `static/js/http.js` 文件:
|
||||
```
|
||||
import { isAuthenticated } from './auth.js'
|
||||
|
||||
@ -160,11 +159,11 @@ export default {
|
||||
|
||||
```
|
||||
|
||||
This module exports `get()` and `post()` functions. They are wrappers around the `fetch` API. Both functions inject an `Authorization: Bearer <token_here>` header to the request when the user is authenticated; that way the server can authenticate us.
|
||||
这个模块导出了 `get()` 和 `post()` 函数。它们是 `fetch` API 的封装。当用户是已验证的,这二个函数注入一个 `Authorization: Bearer <token_here>` 头到请求中;这样服务器就能对我们进行身份验证。
|
||||
|
||||
### Welcome Page
|
||||
|
||||
Let’s move to the welcome page. Create a `static/js/pages/welcome-page.js` file with the following content:
|
||||
我们现在来到欢迎页面。用如下的内容创建一个 `static/js/pages/welcome-page.js` 文件:
|
||||
```
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
@ -187,11 +186,11 @@ export default function welcomePage() {
|
||||
|
||||
```
|
||||
|
||||
This page uses an `HTMLTemplateElement` for the view. It is just a simple form to enter the user’s email.
|
||||
正如你所见,这个页面使用一个 `HTMLTemplateElement`。这是一个只输入用户 email 的简单表格。
|
||||
|
||||
To not make this boring, I’ll skip error handling and just log them to console.
|
||||
为了不让代码太乏味,我将跳过错误处理部分,只是将它们输出到控制台上。
|
||||
|
||||
Now, let’s code that `onAccessFormSubmit()` function.
|
||||
现在,我们来写 `onAccessFormSubmit()` 函数。
|
||||
```
|
||||
import http from '../http.js'
|
||||
|
||||
@ -225,7 +224,7 @@ function wantToCreateAccount() {
|
||||
|
||||
```
|
||||
|
||||
It does a `POST` request to `/api/passwordless/start` with the email and redirectUri in the body. In case it returns with `404 Not Found` status code, we’ll create a user.
|
||||
它使用 email 做了一个 `POST` 请求到 `/api/passwordless/start`,然后在 body 中做了 URI 转向。在本例中使用 `404 Not Found` 状态码返回,我们将创建一个用户。
|
||||
```
|
||||
function runCreateUserProgram(email) {
|
||||
const username = prompt("Enter username")
|
||||
@ -239,11 +238,11 @@ function runCreateUserProgram(email) {
|
||||
|
||||
```
|
||||
|
||||
The user creation program, first, ask for username and does a `POST` request to `/api/users` with the email and username in the body. On success, it sends a magic link for the user created.
|
||||
这个用户创建程序,首先询问用户名,然后使用 email 和用户名,在 body 中做一个 `POST` 请求到 `/api/users`。成功之后,给创建的用户发送一个魔法链接。
|
||||
|
||||
### Callback Page
|
||||
|
||||
That was all the functionality for the access form, let’s move to the callback page. Create a `static/js/pages/callback-page.js` file with the following content:
|
||||
这就是访问表格的所有功能,现在我们来做回调页面。使用如下的内容来创建一个 `static/js/pages/callback-page.js` 文件:
|
||||
```
|
||||
import http from '../http.js'
|
||||
|
||||
@ -279,13 +278,13 @@ export default function callbackPage() {
|
||||
|
||||
```
|
||||
|
||||
To remember… when clicking the magic link, we go to `/api/passwordless/verify_redirect` which redirect us to the redirect URI we pass (`/callback`) with the JWT and expiration date in the URL hash.
|
||||
请记住 … 当点击魔法链接时,我们来到 `/api/passwordless/verify_redirect`,我们通过 (`/callback`)在 URL 的哈希中传递 JWT 和过期日期,将我们转向到重定向 URI。
|
||||
|
||||
The callback page decodes the hash from the URL to extract those parameters to do a `GET` request to `/api/auth_user` with the JWT saving all the data to `localStorage`. Finally, it just redirects to home.
|
||||
回调页面解码 URL 中的哈希,提取这些参数去做一个 `GET` 请求到 `/api/auth_user`,用 JWT 保存所有数据到 `localStorage` 中。最后,重定向到主页面。
|
||||
|
||||
### Home Page
|
||||
|
||||
Create a `static/pages/home-page.js` file with the following content:
|
||||
创建如下内容的 `static/pages/home-page.js` 文件:
|
||||
```
|
||||
import { getAuthUser } from '../auth.js'
|
||||
|
||||
@ -314,9 +313,9 @@ function logout() {
|
||||
|
||||
```
|
||||
|
||||
This page greets the authenticated user and also has a logout button. The `logout()` function just clears `localStorage` and reloads the page.
|
||||
这个页面欢迎已验证用户,同时也有一个登出按钮。`logout()` 函数的功能只是清理掉 `localStorage` 并重载这个页面。
|
||||
|
||||
There is it. I bet you already saw the [demo][4] before. Also, the source code is in the same [repository][5].
|
||||
这就是全部内容了。我敢说你在此之前已经看过这个 [demo][4] 了。当然,这些源代码也在同一个 [仓库][5] 中。
|
||||
|
||||
👋👋👋
|
||||
|
||||
@ -326,7 +325,7 @@ via: https://nicolasparada.netlify.com/posts/passwordless-auth-client/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
70
translated/tech/20180519 Python Debugging Tips.md
Normal file
70
translated/tech/20180519 Python Debugging Tips.md
Normal file
@ -0,0 +1,70 @@
|
||||
Python 调试技巧
|
||||
======
|
||||
当涉及到调试时,你可以做出很多选择。很难提供总是有效的通用建议(除了“你试过关闭再打开么?”)。
|
||||
|
||||
这里有一些我最喜欢的 Python 调试技巧。
|
||||
|
||||
### 建立一个分支
|
||||
|
||||
请相信我。即使你从来没有打算将修改提交回上游,你也会乐意你的实验被包含在它们自己的分支中。
|
||||
|
||||
如果没有其他的东西,它会使清理更容易!
|
||||
|
||||
### 安装 pdb++
|
||||
|
||||
认真地说,如果你使用命令行,它会让你的生活更轻松。
|
||||
|
||||
pdb++ 所做的一切就是用更好的模块替换标准的 pdb 模块。以下是你在 `pip install pdbpp` 会看到的:
|
||||
|
||||
* 彩色提示!
|
||||
* tab补全!(非常适合探索!)
|
||||
* 支持切分!
|
||||
|
||||
|
||||
|
||||
好的,也许最后一个是有点多余......但是非常认真地说,安装 pdb++ 非常值得。
|
||||
|
||||
### 探索
|
||||
|
||||
有时候最好的办法就是搞乱,然后看看会发生什么。在“明显”的位置放置一个断点并确保它被击中。在代码中加入 `print()` 和/或 `logging.debug()` 语句,并查看代码执行的位置。
|
||||
|
||||
检查传递给你的函数的参数。检查库的版本(如果事情变得非常绝望)。
|
||||
|
||||
### 一次只能改变一件事
|
||||
|
||||
在你在探索一下后,你将会对你可以做的事情有所了解。但在你开始使用代码之前,先退一步,考虑一下你可以改变什么,然后只改变一件事。
|
||||
|
||||
做出改变后,然后测试一下,看看你是否接近解决问题。如果没有,请将它改回来,然后尝试其他方法。
|
||||
|
||||
只更改一件事就可以让你知道什么工作,哪些不工作。另外,一旦工作后,你的新提交将会小得多(因为将有更少的变化)。
|
||||
|
||||
这几乎是科学过程中所做的事情:一次只更改一个变量。通过让自己看到并衡量一次更改的结果,你可以节省你的理智,并更快地找到解决方案。
|
||||
|
||||
### 不要假设,提出问题
|
||||
|
||||
偶尔一个开发人员(当然不是你!)会匆忙提交一些有问题的代码。当你去调试这段代码时,你需要停下来,并确保你明白它想要完成什么。
|
||||
|
||||
不要做任何假设。仅仅因为代码在 `model.py` 中并不意味着它不会尝试渲染一些 HTML。
|
||||
|
||||
同样,在做任何破坏性的事情之前,仔细检查你的所有外部连接。要删除一些配置数据?请确保你没有连接到你的生产系统。
|
||||
|
||||
### 聪明,但不太聪明
|
||||
|
||||
有时候我们编写的代码非常棒,不知道它是如何做的。
|
||||
|
||||
当我们发布代码时,我们可能会觉得很聪明,但当代码崩溃时,我们往往会感到愚蠢,我们必须记住它是如何工作的,以便弄清楚它为什么不起作用。
|
||||
|
||||
留意任何看起来过于复杂,冗长或极短的代码段。这些可能是隐藏复杂并导致错误的地方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pythondebugging.com/articles/python-debugging-tips
|
||||
|
||||
作者:[PythonDebugging.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://pythondebugging.com
|
||||
@ -1,119 +0,0 @@
|
||||
在 Linux 上复制和重命名文件
|
||||
======
|
||||

|
||||
Linux 用户数十年来一直在使用简单的 cp 和 mv 命令来复制和重命名文件。这些命令是我们大多数人第一次了解并且每天可能由数百万人使用的一些命令。但是还有其他技术、方便的方法和另外的命令,这些提供了一些独特的选项。
|
||||
|
||||
首先,我们来思考为什么你想要复制一个文件。你可能需要在另一个位置使用同一个文件,或者因为你要编辑该文件而需要一个副本,并且希望确保备有便利的备份以防万一需要恢复原始文件。这样做的显而易见的方式是使用像 “cp myfile myfile-orig” 这样的命令。
|
||||
|
||||
但是,如果你想复制大量的文件,那么这个策略可能就会变得很老。更好的选择是:
|
||||
|
||||
* 在开始编辑之前,使用 tar 创建所有要备份的文件的存档。
|
||||
* 使用 for 循环来使备份副本更容易。
|
||||
|
||||
|
||||
|
||||
使用 tar 的方式很简单。对于当前目录中的所有文件,你可以使用如下命令:
|
||||
```
|
||||
$ tar cf myfiles.tar *
|
||||
|
||||
```
|
||||
|
||||
对于一组可以用模式标识的文件,可以使用如下命令:
|
||||
```
|
||||
$ tar cf myfiles.tar *.txt
|
||||
|
||||
```
|
||||
|
||||
在每种情况下,最终都会生成一个 myfiles.tar 文件,其中包含目录中的所有文件或扩展名为 .txt 的所有文件。
|
||||
|
||||
一个简单的循环将允许你使用修改后的名称制作备份副本:
|
||||
```
|
||||
$ for file in *
|
||||
> do
|
||||
> cp $file $file-orig
|
||||
> done
|
||||
|
||||
```
|
||||
|
||||
当你备份单个文件并且该文件恰好有一个长名称时,可以依靠使用 tab来补全文件名(在输入足够的字母以便唯一标识该文件后点击 Tab 键)并使用像这样的语法将 “-orig” 附加到副本。
|
||||
```
|
||||
$ cp file-with-a-very-long-name{,-orig}
|
||||
|
||||
```
|
||||
|
||||
然后你有一个 file-with-a-very-long-name 和一个 file-with-a-very-long-name file-with-a-very-long-name-orig。
|
||||
|
||||
### 在Linux上重命名文件
|
||||
|
||||
重命名文件的传统方法是使用 mv 命令。该命令将文件移动到不同的目录,更改其名称并保留在原位置,或者同时执行这两个操作。
|
||||
```
|
||||
$ mv myfile /tmp
|
||||
$ mv myfile notmyfile
|
||||
$ mv myfile /tmp/notmyfile
|
||||
|
||||
```
|
||||
|
||||
但我们也有 rename 命令来做重命名。使用 rename 命令的窍门是习惯它的语法,但是如果你了解一些 perl,你可能发现它并不棘手。
|
||||
|
||||
有个非常有用的例子。假设你想重新命名一个目录中的文件,将所有的大写字母替换为小写字母。一般来说,你在 Unix 或 Linux 系统上找不到大量大写字母的文件,但你可以。这里有一个简单的方法来重命名它们,而不必为它们中的每一个使用 mv 命令。 /A-Z/a-z/ 告诉 rename 命令将范围 A-Z 中的任何字母更改为 a-z 中的相应字母。
|
||||
```
|
||||
$ ls
|
||||
Agenda Group.JPG MyFile
|
||||
$ rename 'y/A-Z/a-z/' *
|
||||
$ ls
|
||||
agenda group.jpg myfile
|
||||
|
||||
```
|
||||
|
||||
你也可以使用 rename 来删除文件扩展名。也许你厌倦了看到带有 .txt 扩展名的文本文件。简单删除它们 - 并用一个命令。
|
||||
```
|
||||
$ ls
|
||||
agenda.txt notes.txt weekly.txt
|
||||
$ rename 's/.txt//' *
|
||||
$ ls
|
||||
agenda notes weekly
|
||||
|
||||
```
|
||||
|
||||
现在让我们想象一下,你改变了心意,并希望把这些扩展名改回来。没问题。只需修改命令。窍门是理解第一个斜杠前的 “s” 意味着“替代”。前两个斜线之间的内容是我们想要改变的东西,第二个斜线和第三个斜线之间是改变后的东西。所以,$ 表示文件名的结尾,我们将它改为 “.txt”。
|
||||
```
|
||||
$ ls
|
||||
agenda notes weekly
|
||||
$ rename 's/$/.txt/' *
|
||||
$ ls
|
||||
agenda.txt notes.txt weekly.txt
|
||||
|
||||
```
|
||||
|
||||
你也可以更改文件名的其他部分。牢记 **s/旧内容/新内容/** 规则。
|
||||
```
|
||||
$ ls
|
||||
draft-minutes-2018-03 draft-minutes-2018-04 draft-minutes-2018-05
|
||||
$ rename 's/draft/approved/' *minutes*
|
||||
$ ls
|
||||
approved-minutes-2018-03 approved-minutes-2018-04 approved-minutes-2018-05
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中注意到,当我们在 “ **s** /old/new/” 中使用 **s** 时,我们用另一个名称替换名称的一部分。当我们使用 **y** 时,我们就是直译(将字符从一个范围替换为另一个范围)。
|
||||
|
||||
### 总结
|
||||
|
||||
现在有很多复制和重命名文件的方法。我希望其中的一些会让你在使用命令行时更愉快。
|
||||
|
||||
在 [Facebook][1] 和 [LinkedIn][2] 上加入 Network World 社区来对热门主题评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3276349/linux/copying-and-renaming-files-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -1,190 +0,0 @@
|
||||
# Linux 磁盘分区
|
||||
|
||||

|
||||
|
||||
在 Linux 中创建和删除分区是一种常见的操作,因为存储设备(如硬盘驱动器和USB驱动器)在使用之前必须以某种方式进行结构化。在大多数情况下,大型存储设备被分为称为分区的独立部分。分区还允许您将硬盘分割成独立的部分,每个部分都作为自己的硬盘驱动器。如果您运行多个操作系统,那么分区是非常有用的。
|
||||
|
||||
在 Linux 中有许多强大的工具可以创建、删除和操作磁盘分区。在本文中,我将解释如何使用 `parted` 命令,这对于大型磁盘设备和许多磁盘分区尤其有用。`parted` 与更常见的 `fdisk` 和 `cfdisk` 命令之间的区别包括:
|
||||
|
||||
* **GPT 格式:**`parted` 命令可以创建全局惟一的标识符分区表 [GPT][1],而 `fdisk` 和 `cfdisk` 则仅限于 DOS 分区表。
|
||||
* **更大的磁盘:** DOS 分区表可以格式化最多 2TB 的磁盘空间,尽管在某些情况下最多可以达到 16TB。然而,一个 GPT 分区表可以处理最多 8ZiB 的空间。
|
||||
* **更多的分区:** 使用主分区和扩展分区,DOS 分区表只允许 16 个分区。在 GPT 中,默认情况下您可以得到 128 个分区,并且可以选择更多的分区。
|
||||
* **可靠性:** 在 DOS 分区表中,只保存了一份分区表备份,在 GPT 中保留了两份分区表的备份(在磁盘的起始和结束部分),同时 GPT 还使用了 [CRC][2] 校验和来检查分区表的完整性,在 DOS 分区中并没有实现。
|
||||
|
||||
由于现在的磁盘更大,需要更灵活地使用它们,建议使用 `parted` 来处理磁盘分区。大多数时候,磁盘分区表是作为操作系统安装过程的一部分创建的。在向现有系统添加存储设备时,直接使用parted命令非常有用。
|
||||
|
||||
### 尝试一下 parted
|
||||
|
||||
`parted` 命令。为了尝试这些步骤,我强烈建议使用一种全新的存储设备或一种您不介意将内容删除的设备。
|
||||
|
||||
下面解释了使用该命令对存储设备进行分区的过程。为了尝试这些步骤,我强烈建议使用一种全新的存储设备或一种您不介意将内容删除的设备。
|
||||
|
||||
**1\. 列出分区:** 使用 `parted -l` 来标识你要进行分区的设备。一般来说,第一个硬盘 (`/dev/sda` 或 `/dev/vda` )保存着操作系统, 因此寻找另一个磁盘,以找到你想要分区的磁盘 (例如, `/dev/sdb`, `/dev/sdc`, `/dev/vdb `,`/dev/vdc`, 等。)。
|
||||
|
||||
```
|
||||
$ sudo parted -l
|
||||
|
||||
[sudo] password for daniel:
|
||||
|
||||
Model: ATA RevuAhn_850X1TU5 (scsi)
|
||||
|
||||
Disk /dev/vdc: 512GB
|
||||
|
||||
Sector size (logical/physical): 512B/512B
|
||||
|
||||
Partition Table: msdos
|
||||
|
||||
Disk Flags:
|
||||
|
||||
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
|
||||
1 1049kB 525MB 524MB primary ext4 boot
|
||||
|
||||
2 525MB 512GB 512GB primary lvm
|
||||
|
||||
```
|
||||
|
||||
**2\. 打开存储设备:** 使用 `parted` 选中您要分区的设备。在这里例子中,是虚拟系统上的第三个磁盘(`/dev/vdc`)。指明你要使用哪一个设备非常重要。 如果你仅仅输入了 `parted` 命令而没有指定设备名字, 它会随机选择一个设备进行操作。
|
||||
|
||||
```
|
||||
$ sudo parted /dev/vdc
|
||||
|
||||
GNU Parted 3.2
|
||||
|
||||
Using /dev/vdc
|
||||
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
|
||||
(parted)
|
||||
|
||||
```
|
||||
|
||||
**3\. 设定分区表:** 设置分区表为 GPT ,然后输入 "Yes" 开始执行
|
||||
|
||||
```
|
||||
(parted) mklabel gpt
|
||||
|
||||
Warning: the existing disk label on /dev/vdc will be destroyed
|
||||
|
||||
and all data on this disk will be lost. Do you want to continue?
|
||||
|
||||
Yes/No? Yes
|
||||
|
||||
```
|
||||
|
||||
`mklabel` 和 `mktable` 命令用于相同的目的(在存储设备上创建分区表)。支持的分区表有:aix、amiga、bsd、dvh、gpt、mac、ms-dos、pc98、sun 和 loop。记住 `mklabel` 不会创建一个分区,而是创建一个分区表。
|
||||
|
||||
**4\. 检查分区表:** 查看存储设备信息
|
||||
|
||||
```
|
||||
(parted) print
|
||||
|
||||
Model: Virtio Block Device (virtblk)
|
||||
|
||||
Disk /dev/vdc: 1396MB
|
||||
|
||||
Sector size (logical/physical): 512B/512B
|
||||
|
||||
Partition Table: gpt
|
||||
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size File system Name Flags
|
||||
|
||||
```
|
||||
|
||||
**5\.获取帮助:** 为了知道如何去创建一个新分区,输入: `(parted) help mkpart` 。
|
||||
|
||||
```
|
||||
(parted) help mkpart
|
||||
|
||||
mkpart PART-TYPE [FS-TYPE] START END make a partition
|
||||
|
||||
|
||||
|
||||
PART-TYPE is one of: primary, logical, extended
|
||||
|
||||
FS-TYPE is one of: btrfs, nilfs2, ext4, ext3, ext2, fat32, fat16, hfsx, hfs+, hfs, jfs, swsusp,
|
||||
|
||||
linux-swap(v1), linux-swap(v0), ntfs, reiserfs, hp-ufs, sun-ufs, xfs, apfs2, apfs1, asfs, amufs5,
|
||||
|
||||
amufs4, amufs3, amufs2, amufs1, amufs0, amufs, affs7, affs6, affs5, affs4, affs3, affs2, affs1,
|
||||
|
||||
affs0, linux-swap, linux-swap(new), linux-swap(old)
|
||||
|
||||
START and END are disk locations, such as 4GB or 10%. Negative values count from the end of the
|
||||
|
||||
disk. For example, -1s specifies exactly the last sector.
|
||||
|
||||
|
||||
|
||||
'mkpart' makes a partition without creating a new file system on the partition. FS-TYPE may be
|
||||
|
||||
specified to set an appropriate partition ID.
|
||||
|
||||
```
|
||||
|
||||
**6\. 创建分区:** 为了创建一个新分区(在这个例子中,分区 0 有 1396MB),输入下面的命令:
|
||||
|
||||
```
|
||||
(parted) mkpart primary 0 1396MB
|
||||
|
||||
|
||||
|
||||
Warning: The resulting partition is not properly aligned for best performance
|
||||
|
||||
Ignore/Cancel? I
|
||||
|
||||
|
||||
|
||||
(parted) print
|
||||
|
||||
Model: Virtio Block Device (virtblk)
|
||||
|
||||
Disk /dev/vdc: 1396MB
|
||||
|
||||
Sector size (logical/physical): 512B/512B
|
||||
|
||||
Partition Table: gpt
|
||||
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size File system Name Flags
|
||||
|
||||
1 17.4kB 1396MB 1396MB primary
|
||||
|
||||
```
|
||||
|
||||
文件系统类型(fstype)不会在 `/dev/vdc1`上创建 ext4 文件系统。 DOS 分区表的分区类型是主分区,逻辑分区和扩展分区。 在 GPT 分区表中,分区类型用作分区名称。 在 GPT 下提供分区名称是必须的;在上例中,primary 是名称,而不是分区类型。
|
||||
|
||||
**7\. 保存推出:** 当你退出 `parted` 时,修改会自动保存。退出请输入如下命令:
|
||||
|
||||
```
|
||||
(parted) quit
|
||||
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
$
|
||||
|
||||
```
|
||||
|
||||
### 谨记
|
||||
|
||||
当您添加新的存储设备时,请确保在开始更改其分区表之前确定正确的磁盘。如果您错误地更改包含计算机操作系统的磁盘分区,您可以使您的系统无法启动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/how-partition-disk-linux
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/GUID_Partition_Table
|
||||
[2]:https://en.wikipedia.org/wiki/Cyclic_redundancy_check
|
||||
@ -0,0 +1,212 @@
|
||||
4种用于构建嵌入式Linux系统的工具
|
||||
======
|
||||

|
||||
|
||||
|
||||
Linux被部署到比Linus Torvalds在他的宿舍里工作时所预期的更广泛的设备。对各种芯片的支持是令人震惊的,使得Linux应用在大大小小的设备上:
|
||||
从[IBM的巨型机][1]到[微型设备][2],没有比他们的连接端口和其间的任何东西都大。它被用于大型企业数据中心,互联网基础设施设备和个人开发系统。
|
||||
它还为消费电子产品、移动电话和许多物联网设备提供动力。
|
||||
|
||||
在为桌面和企业级设备构建Linux软件时,开发者典型的在他们的构建机器上使用桌面发行版,如[Ubuntu][3] 以便尽可能与被部署的机器相似。工具
|
||||
如[VirtualBox][4] and [Docker][5]使得开发测试和生成环境更好的保持一致
|
||||
|
||||
### 什么是嵌入式系统?
|
||||
|
||||
维基百科将[嵌入式系统] [6]定义为:“在更大的机械或电气系统中具有专用功能的计算机系统,往往伴随着实时计算限制。
|
||||
我觉得很简单,可以说嵌入式系统是大多数人不认为是计算机的计算机。它的主要作用是作为某种设备,它不被视为通用计算平台。
|
||||
|
||||
嵌入式系统编程中的开发环境通常与测试和生产环境大不相同。他们可能会使用不同的芯片架构,软件堆栈甚至操作系统。开发工作流程对于嵌入式开发
|
||||
人员与桌面和Web开发人员来说是非常不同通常,构建输出将包含目标设备的整个软件映像,包括内核,设备驱动程序,库和应用程序软件(有时也包括引导
|
||||
加载程序)。
|
||||
|
||||
在本文中,我将对构建嵌入式Linux系统的四种常用选项进行纵览。我将介绍一下每种产品的工作原理,并提供足够的信息来帮助读者确定使用哪种工具
|
||||
进行设计。我不会教你如何使用它们中的任何一个;一旦缩小了选择范围,就有大量深入的在线学习资源。没有任何选择适用于所有用例,我希望提供足够的
|
||||
细节来指导您的决定。
|
||||
### Yocto
|
||||
|
||||
[Yocto] [7]项目[定义] [8]是:一个开源协作项目,提供模板,工具和方法,帮助您为嵌入式产品创建定制的基于Linux的系统,而不管硬件架构如何。
|
||||
它是用于创建定制的Linux运行时映像的配方,配置值和依赖关系的集合,可根据您的特定需求进行定制。
|
||||
完全公开:我在嵌入式Linux中的大部分工作都集中在Yocto项目上,而且我对这个系统的认识和偏见可能很明显。
|
||||
Yocto使用[Openembedded] [9]作为其构建系统。从技术上讲,这两个是独立的项目;然而,在实践中,用户不需要了解区别,项目名称经常可以互换使用。
|
||||
|
||||
Yocto项目的输出大致由三部分组成:
|
||||
|
||||
* **目标运行时二进制文件:**这些包括引导加载程序,内核,内核模块,根文件系统映像。以及将Linux部署到目标平台所需的任何其他辅助文件。
|
||||
* **包流:**这是可以安装在目标上的软件包集合。您可以根据需要选择软件包格式(例如,deb,rpm,ipk)。其中一些可能预先安装在目标运行时
|
||||
二进制文件中,但可以构建用于安装到已部署系统的软件包。
|
||||
* **目标SDK:**这些是表示安装在目标上的软件的库和头文件的集合。应用程序开发人员在构建代码时使用它们,以确保它们与适当的库链接
|
||||
|
||||
#### 优点
|
||||
|
||||
Yocto项目在行业中得到广泛应用,并得到许多有影响力的公司的支持。此外,它还拥有一个庞大且充满活力的开发人员[社区] [10]和[生态系统] [11]。
|
||||
开源爱好者和企业赞助商的结合有助于推动Yocto项目。
|
||||
Yocto获得支持有很多选择。如果您想自己动手,还有书籍和其他培训材料。如果您想获得专业知识,许多有Yocto经验的工程师都可以使用。许多商业组
|
||||
织为您的设计提供基于Yocto的Turnkey产品或基于服务的实施和定制。
|
||||
Yocto项目很容易通过[layer] [12]进行扩展,它可以独立发布以添加额外的功能,将目标平台定位到项目发布中不可用的平台,或存储系统特有的自定义项。
|
||||
layer可以添加到您的配置中,以添加未特别包含在市面上版本中的独特功能;例如,[meta-browser] [13] layer包含Web浏览器的清单,可以轻松为您
|
||||
的系统进行构建。因为它们是独立维护的,所以layer可以在不同的发布时间安排上(根据layer的开发速度)而不是标准的Yocto版本。
|
||||
|
||||
Yocto可以说是本文讨论的任何选项中最广泛的设备支持。由于许多半导体和电路板制造商的支持,Yocto很可能会支持您选择的任何目标平台。
|
||||
主版本Yocto [分支] [14]仅支持少数几块主板(以便进行正确的测试和发布周期),但是,标准工作模式是使用外部主板支持layer。
|
||||
|
||||
最后,Yocto非常灵活和可定制。您的特定应用程序的自定义可以存储在一个layer进行封装和隔离。通常将要素layer特有的自定义项存储为layer本身
|
||||
的一部分,这可以将相同的设置同时应用于多个系统配置。 Yocto还提供了一个定义良好的layer优先和覆盖功能。这使您可以定义layer应用和搜索元数
|
||||
据的顺序。它还使您可以覆盖具有更高优先级的layer的设置;例如,现有清单的许多自定义功能都将保留
|
||||
|
||||
#### 缺点
|
||||
|
||||
Yocto项目最大的缺点是学习曲线。 学习系统并真正理解系统需要花费大量的时间和精力。 根据您的需求,这可能对您的应用程序不重要的技术和能力
|
||||
投入太大。 在这种情况下,与其中一家商业供应商合作可能是一个不错的选择。
|
||||
|
||||
Yocto项目的开发时间和资源相当高。 需要构建的包(包括工具链,内核和所有目标运行时组件)的数量非常重要。 Yocto开发人员的开发工作站往往是
|
||||
大型系统。 不建议使用小型笔记本电脑。 这可以通过使用许多提供商提供的基于云的构建服务器来缓解。 另外,Yocto有一个内置的缓存机制,当它确定
|
||||
用于构建特定包的参数没有改变时,它允许它重新使用先前构建的组件。
|
||||
|
||||
#### 建议
|
||||
|
||||
为您的下一个嵌入式Linux设计使用Yocto项目是一个强有力的选择。 在这里介绍的选项中,无论您的目标用例如何,它都是最广泛适用的。 广泛的行业
|
||||
支持,积极的社区和广泛的平台支持使其成为必须设计师的不错选择。
|
||||
|
||||
### Buildroot
|
||||
|
||||
[Buildroot] [15]项目被定义为:通过交叉编译生成嵌入式Linux系统的简单,高效且易于使用的工具。它与Yocto项目具有许多相同的目标,但它注重
|
||||
简单性和简约性。一般来说,Buildroot会禁用所有软件包的所有可选编译时设置(有一些值得注意的例外),从而导致尽可能小的系统。系统设计人员需要
|
||||
启用适用于给定设备的设置。
|
||||
|
||||
Buildroot从源代码构建所有组件,但不支持按目标包管理。因此,它有时称为固件生成器,因为镜像在构建时大部分是固定的。应用程序可以更新目标
|
||||
文件系统,但是没有机制将新软件包安装到正在运行的系统中。
|
||||
Buildroot输出主要由三部分组成:
|
||||
|
||||
*将Linux部署到目标平台所需的根文件系统映像和任何其他辅助文件
|
||||
*适用于目标硬件的内核,引导加载程序和内核模块
|
||||
*用于构建所有目标二进制文件的工具链。
|
||||
|
||||
### 优点
|
||||
|
||||
Buildroot对简单性的关注意味着,一般来说,它比Yocto更容易学习。核心构建系统用Make编写,并且足够短以允许开发人员了解整个系统,同时可扩展
|
||||
到足以满足嵌入式Linux开发人员的需求。 Buildroot核心通常只处理常见用例,但它可以通过脚本进行扩展。Buildroot系统使用普通的Makefile和Kconfig
|
||||
语言来进行配置。 Kconfig由Linux内核社区开发,广泛用于开源项目,使得许多开发人员都熟悉它。
|
||||
由于禁用所有可选构建时间设置的设计目标,Buildroot通常会使用开箱即用的配置生成尽可能最小的镜像。一般来说,构建时间和构建主机资源的规模
|
||||
将比Yocto项目的规模更小。
|
||||
|
||||
####缺点
|
||||
|
||||
关注简单性和最小化启用的构建选项意味着您可能需要执行重要的自定义来为应用程序配置Buildroot构建。此外,所有配置选项都存储在单个文件中,
|
||||
这意味着如果您有多个硬件平台,则需要为每个平台进行每个定制更改。对系统配置文件的任何更改都需要全部重新构建所有软件包。与Yocto相比,这可以
|
||||
通过最小的镜像大小和构建时间进行缓解,但在您调整配置时可能会导致构建时间过长。
|
||||
|
||||
中间软件包状态缓存默认情况下未启用,并且不像Yocto实施那么彻底。这意味着,虽然第一次构建可能比等效的Yocto构建短,但后续构建可能需要重建
|
||||
许多组件。
|
||||
|
||||
####建议
|
||||
|
||||
对于大多数应用程序,使用Buildroot进行下一个嵌入式Linux设计是一个不错的选择。如果您的设计需要多种硬件类型或其他差异,但由于同步多个配置
|
||||
的复杂性,您可能需要重新考虑,但对于由单一设置组成的系统,Buildroot可能适合您。
|
||||
|
||||
[OpenWRT] [16]项目开始为消费者路由器开发定制固件。您当地零售商提供的许多低成本路由器都可以运行Linux系统,但可能无法使用。这些路由器的
|
||||
制造商可能无法提供频繁的更新来解决新的威胁,即使他们这样做,安装更新镜像的机制也很困难且容易出错。 OpenWRT项目为许多已被其制造商放弃的
|
||||
设备生成更新的固件镜像,并让这些设备更加有效。
|
||||
|
||||
OpenWRT项目的主要交付物是大量商业设备的二进制镜像。有网络可访问的软件包存储库,允许设备最终用户将新软件添加到他们的系统中。 OpenWRT构建
|
||||
系统是一个通用构建系统,它允许开发人员创建自定义版本以满足他们自己的需求并添加新软件包,但其主要重点是目标二进制文件。
|
||||
|
||||
#### 优点
|
||||
|
||||
如果您正在寻找商业设备的替代固件,则OpenWRT应位于您的选项列表中。它的维护良好,可以保护您免受制造商固件无法解决的问题。您也可以添加额外的功能,使您的设备更有用。
|
||||
|
||||
如果您的嵌入式设计专注于网络,则OpenWRT是一个不错的选择。网络应用程序是OpenWRT的主要用例,您可能会发现许多可用的软件包。
|
||||
|
||||
####缺点
|
||||
|
||||
OpenWRT对您的设计施加重大决策(与Yocto和Buildroot相比)。如果这些决定不符合您的设计目标,则可能需要进行非平凡的修改。
|
||||
|
||||
在部署的设备中允许基于软件包的更新很难管理。按照定义,这会导致与您的QA团队测试的软件负载不同。此外,很难保证大多数软件包管理器的原子安装,
|
||||
以及错误的电源循环可能会使您的设备处于不可预知的状态。
|
||||
|
||||
####建议
|
||||
|
||||
OpenWRT是爱好者项目或重复使用商用硬件的不错选择。它也是网络应用程序的不错选择。如果您需要从默认设置进行大量定制,您可能更喜欢Buildroot或Yocto
|
||||
|
||||
### Desktop distros
|
||||
|
||||
设计嵌入式Linux系统的一种常见方法是从桌面发行版开始,例如[Debian] [17]或[Red Hat] [18],并在安装的镜像符合目标设备的占用空间之前删除
|
||||
不需要的组件。这是[Raspberry Pi] [20]平台流行的[Raspbian] [19]分发方法。
|
||||
|
||||
### 优点
|
||||
|
||||
这种方法的主要优点是熟悉。通常,嵌入式Linux开发人员也是桌面Linux用户,并且精通他们的选择发行版。在目标上使用类似的环境可能会让开发人员
|
||||
更快地入门。根据所选的分布,可以使用apt和yum等标准封装工具安装许多其他工具。
|
||||
|
||||
可以将显示器和键盘连接到目标设备,并直接在那里进行所有的开发。对于不熟悉嵌入式空间的开发人员来说,这可能是一个更为熟悉的环境,无需配置和
|
||||
使用棘手的跨开发设置。
|
||||
|
||||
大多数桌面发行版可用的软件包数量通常大于前面讨论的嵌入式特定的构建器可用软件包数量。由于较大的用户群和更广泛的用例,您可能能够找到您的
|
||||
应用程序所需的所有运行时包,这些包已经构建并可供使用。
|
||||
|
||||
####缺点
|
||||
|
||||
将目标作为您的主要开发环境可能会很慢。运行编译器工具是一项资源密集型操作,根据您构建的代码的多少,可能会妨碍您的性能。
|
||||
|
||||
除了一些例外情况,桌面分布的设计并不适合低资源系统,并且可能难以充分修剪目标图像。同样,桌面环境中的预期工作流程对于大多数嵌入式设计来说
|
||||
都不理想。以这种方式获得可重复的环境很困难。手动添加和删除软件包很容易出错。这可以使用特定于发行版的工具进行脚本化,例如基于Debian系统
|
||||
的[debootstrap] [21]。为了进一步提高[可重复性] [21],您可以使用配置管理工具,如[CFEngine] [22](我的雇主[Mender.io] [23]完整披露了
|
||||
这一工具)。但是,您仍然受分发提供商的支配,他们将更新软件包以满足他们的需求,而不是您的需求。
|
||||
|
||||
####建议
|
||||
|
||||
对于您打算推向市场的产品,请谨慎使用此方法。这对于爱好者应用程序来说是一个很好的模型;但是,对于需要支持的产品,这种方法很可能会遇到麻烦。
|
||||
虽然您可能能够获得更快的起步,但从长远来看,您可能会花费您的时间和精力。
|
||||
|
||||
###其他考虑
|
||||
|
||||
这个讨论集中在构建系统的功能上,但通常有非功能性需求可能会影响您的决定。如果您已经选择了片上系统(SoC)或电路板,则您的选择很可能由供应商
|
||||
决定。如果您的供应商为特定系统提供板级支持包(BSP),使用它通常会节省相当多的时间,但请研究BSP的质量以避免在开发周期后期发生问题。
|
||||
|
||||
如果您的预算允许,您可能需要考虑为目标操作系统使用商业供应商。有些公司会为这里讨论的许多选项提供经过验证和支持的配置,除非您拥有嵌入式
|
||||
Linux构建系统方面的专业知识,否则这是一个不错的选择,可以让您专注于核心能力。
|
||||
|
||||
作为替代,您可以考虑为您的开发人员进行商业培训。这可能比商业OS提供商便宜,并且可以让你更加自给自足。这是快速找到您选择的构建系统基础知识
|
||||
的学习曲线。
|
||||
|
||||
最后,您可能已经有一些开发人员拥有一个或多个系统的经验。如果你有工程师有偏好,当你做出决定时,肯定值得考虑。
|
||||
|
||||
###总结
|
||||
|
||||
构建嵌入式Linux系统有多种选择,每种都有优点和缺点。将这部分设计放在优先位置至关重要,因为在以后的过程中切换系统的成本非常高。除了这些
|
||||
选择之外,新系统一直在开发中。希望这次讨论能够为审查新系统(以及这里提到的系统)提供一些背景,并帮助您为下一个项目做出坚实的决定。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/embedded-linux-build-tools
|
||||
|
||||
作者:[Drew Moseley][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LHRChina](https://github.com/LHRChina)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drewmoseley
|
||||
[1]:https://en.wikipedia.org/wiki/Linux_on_z_Systems
|
||||
[2]:http://www.picotux.com/
|
||||
[3]:https://www.ubuntu.com/
|
||||
[4]:https://www.virtualbox.org/
|
||||
[5]:https://www.docker.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Embedded_system
|
||||
[7]:https://yoctoproject.org/
|
||||
[8]:https://www.yoctoproject.org/about/
|
||||
[9]:https://www.openembedded.org/
|
||||
[10]:https://www.yoctoproject.org/community/
|
||||
[11]:https://www.yoctoproject.org/ecosystem/participants/
|
||||
[12]:https://layers.openembedded.org/layerindex/branch/master/layers/
|
||||
[13]:https://layers.openembedded.org/layerindex/branch/master/layer/meta-browser/
|
||||
[14]:https://yoctoproject.org/downloads
|
||||
[15]:https://buildroot.org/
|
||||
[16]:https://openwrt.org/
|
||||
[17]:https://www.debian.org/
|
||||
[18]:https://www.redhat.com/
|
||||
[19]:https://www.raspbian.org/
|
||||
[20]:https://www.raspberrypi.org/
|
||||
[21]:https://wiki.debian.org/Debootstrap
|
||||
[22]:https://cfengine.com/
|
||||
[23]:http://Mender.io
|
||||
@ -0,0 +1,57 @@
|
||||
BLUI:创建游戏 UI 的简单方法
|
||||
======
|
||||
|
||||

|
||||
|
||||
游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的 Unreal,允许独立开发者使用 AAA 发布商使用的相同行业标准工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
|
||||
|
||||
这些引擎中包含的插件允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
|
||||
|
||||
### 什么是 BLUI?
|
||||
|
||||
作为独立游戏开发工作室的一部分,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI][1] 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管虚幻引擎(我们选择的引擎)有一个内置的 UI 编辑器实现了类似目的,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
|
||||
|
||||
在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的 Unreal 集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,要么对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
|
||||
|
||||
在商业产品和 Unreal 的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过网络语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework][2] 提供全面支持。
|
||||
|
||||
### 安装和使用 BLUI
|
||||
|
||||
使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括自举 JavaScript 代码,外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何 Unreal 插件那样安装它并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在 Unreal UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。
|
||||
|
||||
![Integrating BLUI into Unreal Engine 4 blueprints][4]
|
||||
|
||||
将 BLUI 集成到虚幻 4 图纸中。
|
||||
|
||||
在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。
|
||||
|
||||
![Using BLUI to sync UI elements with the soundtrack.][6]
|
||||
|
||||
使用 BLUI 将 UI 元素与音轨同步。
|
||||
|
||||
通过 BLUI GitHub 页面上的[文档][7],将 BLUI 集成到虚幻 4 中是一个微不足道的过程。还有一个由支援虚幻引擎开发人员组成的[论坛][8],他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
|
||||
|
||||
### 开源优势
|
||||
|
||||
开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blui-game-development-plugin
|
||||
|
||||
作者:[Uwana lkaiddi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/uwikaiddi
|
||||
[1]:https://github.com/AaronShea/BLUI
|
||||
[2]:https://bitbucket.org/chromiumembedded/cef
|
||||
[3]:/file/400616
|
||||
[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
|
||||
[5]:/file/400621
|
||||
[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
|
||||
[7]:https://github.com/AaronShea/BLUI/wiki
|
||||
[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
|
||||
@ -0,0 +1,94 @@
|
||||
# 用这样的 VI 配置来保存和组织你的笔记
|
||||
|
||||
![1][]
|
||||
|
||||
用 vi 来管理 wiki 笔记 , 这听起来不像是一个符合常规的主意 ; 但当你的日常工作都会用到 vi , 那它是有意义的 ;
|
||||
|
||||
作为一个软件开发人员 , 用编码工具来写笔记会更加简单 ; 我想将我的笔记变成一种编辑器命令 , 无论我在哪 , 都能够用管理我代码的方法来管理我的笔记 , 这便是我在我知识基础上建立这个 vi 配置的原因 ; 简单概括起来 ,在笔记本上我用 vi 插件 [Viwiki][2] 来管理我的本地百科 ; 用 GIT 来进行版本控制 ( 保持中心节点和更新版本 ) ; 用 Gitlab 来进行在线修改 ( 例如在我的手机上 ) .
|
||||
|
||||
## 为什么用百科来进行笔记保存是有意义
|
||||
|
||||
我尝试过许多不同的工具来持续的追踪我的笔记 , 笔记里保存着我的灵感以及不应该被忘记的任务模型 . 这包括离线笔记本 ( 是的 , 包含纸质笔记本 ) , 特殊的笔记软件 , 以及思维导图软件 .
|
||||
|
||||
但每种方案都有不好一面 , 没有一个能够满足我所有的需求 . 例如思维导图 , 能够很好的形象化你的想法 ( 因此得名 ) . 我尝试提供一些简单的搜索方法 ( 和纸质笔记一样 ) ; 但当一段时间过去 , 思维导图会变得很难阅读 , 所以思维导图不适合长时间保存的笔记 .
|
||||
|
||||
我为一个合作项目配置 [DokuWiki][2] , 我发现这个 wiki 模型符合了我大多数的需求 . 在百科上 , 你能够创建一个文件 ( 和你在文本编辑器中所作的一样 ) , 创建一个笔记的链接 . 如果一个链接指向一个不存在的页面 ( 你想让本页面添加一条还没有创建的信息 ) , wiki 会为你建立这个页面 . 这个特性使得 wiki 很好的适应了那些需要快速写下心中所想的人的需求 . 然而笔记页面仍保持在能够容易浏览和搜索关键字的界面 .
|
||||
|
||||
这看起来很有希望 , 并且配置 DokuWiki 也很容易 , 但我发现配置整个 wiki 太复杂 , 而仅仅只是为了追踪笔记 . 在一番搜索后 , 我发现了 Vimwiki , 我想要的 vi 插件 . 自从我每天使用 vi , 做笔记和修改代码一样简单 . 创建一个界面 , vimwiki 比 Dokuwiki 简单 . 你只需要在光标下的单词按下 Enter 键 , 如果本地没有文件是这个名字 , vimwiki 会为你创建一个 . 为了更一步的实现用每天都会使用的工具来做笔记的计划 , 我不仅用我最爱的 IDE 来写笔记 , 而且用 GIT - 我最爱的代码管理工具 , Gilab - 发布我的笔记并且在线访问 . 我也在 Gitlab markdown 在线工具上用 markdown 语法来写这篇文章 .
|
||||
|
||||
## 配置 vimwiki
|
||||
|
||||
用存在的插件管理工具来安装 vimwiki 很简单 , 只需要添加 vimwiki/vimwiki 到你的插件 . 对于我的喜爱的插件管理器 , Vundle , 你只需要在 /.vimrc 中添加 "plugin vimwiki/vimwiki " 这一行 . 然后执行 :source ~/.vimrc | PluginInstall .
|
||||
|
||||
下面是我的文件 .vimrc 的一部分 , 展示一些 vimwiki 配置 . 你能在 [vimwiki][2] 页面学到更多的配置和使用的的信息 .
|
||||
|
||||
```code
|
||||
let wiki_1 = {}
|
||||
let wiki_1.path = '~/vimwiki_work_md/'
|
||||
let wiki_1.syntax = 'markdown'
|
||||
let wiki_1.ext = '.md'
|
||||
|
||||
let wiki_2 = {}
|
||||
let wiki_2.path = '~/vimwiki_personal_md/'
|
||||
let wiki_2.syntax = 'markdown'
|
||||
let wiki_2.ext = '.md'
|
||||
|
||||
let g:vimwiki_list = [wiki_1, wiki_2]
|
||||
let g:vimwiki_ext2syntax = {'.md': 'markdown', '.markdown': 'markdown', '.mdown': 'markdown'}
|
||||
|
||||
```
|
||||
|
||||
我的配置有一个优点 , 你能简单的区分个人和工作相关的文件 , 而不用切换笔记软件 . 我想能随时随地访问我的个人笔记 , 而不想我的工作笔记同步到我私人的 GitLab 和 电脑 . 这样配置对于 vimwiki 要比其他软件简单 . 这个配置告诉 vimwiki 有两个不同 Wiki , 两个 wiki 都使用 markdown 语法 ( 我用 markdown 语法在每天的工作 ) . 同样的告诉 Vimwiki wiki 页面存储到那个文件夹 .
|
||||
|
||||
如果你操作 wiki 页面存储的文件夹 , 你会你的单一的 wiki 的 markdown 页面文件而没有其他特殊的 Vimwiki 内容 , 这使得很容易的初始化 GIT 仓库和同步你的 wiki 到中心仓库 .
|
||||
|
||||
## 同步你的 wiki 到 GitLab
|
||||
|
||||
这一步检查 GitLab 工程到本地的 VimWiki 文件夹 , 这步操作和你操作任何 GitHub 的仓库相同 . 只是我更喜欢保存我的笔记到我的私人 GitLab 仓库 , 所以我为我个人的工程保持运行 GitLab .
|
||||
|
||||
你可以使用 GitLab 的 wiki 功能来为你的工程创建 wiki 页面 . 这些 wiki 是 GIT 仓库本身 , 用 markdown 语法 , 你到主要的地址 .
|
||||
|
||||
只需要初始化你想要的笔记 , 那些你为你的笔记所创建的 wiki 工程 :
|
||||
|
||||
```codecd ~/vimwiki_personal_md/
|
||||
git init
|
||||
git remote add origin git@your.gitlab.com:your_user/vimwiki_personal_md.wiki
|
||||
git add .
|
||||
git commit -m "Initial commit"
|
||||
git push -u origin master
|
||||
```
|
||||
|
||||
能够在 GitLab 创建一个新的工程后 , 这些步骤能复制到你导入的界面到新的工程 . 唯一的改变是仓库地址结尾是 .wiki ( 而不是 .git ) . 告诉 git 拷贝 wiki 仓库而不是工程本身 .
|
||||
|
||||
就是这样 ! 现在你能够通过 git 来管理你的笔记 , 通过 GitLab wiki 用户接口来修改笔记 .
|
||||
|
||||
你可能不想手动的为每个添加到笔记本的笔记创建提交 , 为了解决这个问题 , 我使用 Vim 插件 [chazy/dirsetting][4] , 我添加一个 .vimaddr 文件 , 通过下面的内容 :
|
||||
|
||||
```code
|
||||
:cd %:p:h
|
||||
silent! !git pull > /dev/null
|
||||
:e!
|
||||
autocmd! BufWritePost * silent! !git add .;git commit -m "vim autocommit" > /dev/null; git push > /dev/null&
|
||||
```
|
||||
|
||||
当我打开 Wiki 文件时会更新到最新的版本 , 没一次的写入命令 ( :w ) 都会提交 ; 这样做会同步你的本地文件到中心仓库 . 如果你有合并冲突 ,通常你需要解决它们 .
|
||||
|
||||
目前 , 这就是以我的知识基础来互动的方法 , 我很喜欢这方法 ; 请告诉我你对于这个方法的想法 , 可以在评论区分享你最爱的方法 , 对于如何追踪笔记 .
|
||||
|
||||
-----------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/vimwiki-gitlab-notes
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[octopus][5]
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]:https://camo.githubusercontent.com/9901c750dce2008ea7a459201121077c355fc257/68747470733a2f2f6f70656e736f757263652e636f6d2f73697465732f64656661756c742f66696c65732f7374796c65732f696d6167652d66756c6c2d73697a652f7075626c69632f6c6561642d696d616765732f636865636b6c6973745f68616e64735f7465616d5f636f6c6c61626f726174696f6e2e706e673f69746f6b3d753832516570506b
|
||||
[2]:https://vimwiki.github.io/
|
||||
[3]:https://www.dokuwiki.org/dokuwiki
|
||||
[4]:https://github.com/chazy/dirsettings
|
||||
[5]:https://github.com/singledo
|
||||
Loading…
Reference in New Issue
Block a user